
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
sequence | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
annahaz/xlm-roberta-base-misogyny-sexism-out-of-sample-test-opt | 1857909865ba72c35e85f562f442729b454821b1 | 2022-07-12T20:11:04.000Z | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
] | text-classification | false | annahaz | null | annahaz/xlm-roberta-base-misogyny-sexism-out-of-sample-test-opt | 4 | null | transformers | 20,400 | Entry not found |
wonkwonlee/distilbert-base-uncased-finetuned-cola | d0bb97be32c7cddaf63c6eb689f719f01f9fc063 | 2022-07-12T20:17:18.000Z | [
"pytorch",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | wonkwonlee | null | wonkwonlee/distilbert-base-uncased-finetuned-cola | 4 | null | transformers | 20,401 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5474713423103301
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5263
- Matthews Correlation: 0.5475
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5222 | 1.0 | 535 | 0.5384 | 0.4304 |
| 0.3494 | 2.0 | 1070 | 0.5128 | 0.4975 |
| 0.2381 | 3.0 | 1605 | 0.5263 | 0.5475 |
| 0.1753 | 4.0 | 2140 | 0.7498 | 0.5354 |
| 0.1243 | 5.0 | 2675 | 0.8013 | 0.5414 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cpu
- Datasets 2.3.2
- Tokenizers 0.12.1
|
dafraile/Clini-dialog-sum-T5 | d96a0bcf140735665f2766210fdf78c722aa8cd1 | 2022-07-19T02:00:14.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | dafraile | null | dafraile/Clini-dialog-sum-T5 | 4 | null | transformers | 20,402 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: tst-summarization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tst-summarization
This model is a fine-tuned version of [henryu-lin/t5-large-samsum-deepspeed](https://huggingface.co/henryu-lin/t5-large-samsum-deepspeed) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3922
- Rouge1: 54.905
- Rouge2: 26.6374
- Rougel: 40.4619
- Rougelsum: 52.3653
- Gen Len: 104.7241
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.10.0
- Datasets 1.18.4
- Tokenizers 0.11.6
|
cronous/wangchanberta-ner-2 | f21c9cea7d013433ddf1f2b2ab1d845266722f52 | 2022-07-13T05:17:16.000Z | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | cronous | null | cronous/wangchanberta-ner-2 | 4 | null | transformers | 20,403 | Entry not found |
linxi/tiny-bert-sst2-distilled | 443917c7acb27295a8441d0a8f2bdc45f3e6934d | 2022-07-13T07:43:29.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers"
] | text-classification | false | linxi | null | linxi/tiny-bert-sst2-distilled | 4 | null | transformers | 20,404 | Entry not found |
jordyvl/biobert-base-cased-v1.2_ncbi_disease-sm-all-ner | 4f03b5368c718280004fcf70235606f6a2712024 | 2022-07-13T11:14:23.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | jordyvl | null | jordyvl/biobert-base-cased-v1.2_ncbi_disease-sm-all-ner | 4 | null | transformers | 20,405 | Entry not found |
asahi417/lmqg-mt5_base-koquad | c7c3f77edc3ef62a65893f3c98a5c2d6d30df7c0 | 2022-07-13T12:26:20.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | asahi417 | null | asahi417/lmqg-mt5_base-koquad | 4 | null | transformers | 20,406 | Entry not found |
ghadeermobasher/Originalbiobert-BioRED-Chem-256-16-5 | dd2865c4167ab2aee954cb41665a90ab928c1c12 | 2022-07-13T13:54:03.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | ghadeermobasher | null | ghadeermobasher/Originalbiobert-BioRED-Chem-256-16-5 | 4 | null | transformers | 20,407 | Entry not found |
ghadeermobasher/Modified-biobertv1-BioRED-Chem-256-16-5 | 29bf13cfc4432f7737e061fdf2d6ceb50a733a9c | 2022-07-13T13:55:11.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | ghadeermobasher | null | ghadeermobasher/Modified-biobertv1-BioRED-Chem-256-16-5 | 4 | null | transformers | 20,408 | Entry not found |
fourthbrain-demo/bert_modelxcxcx_reddit_tslghja_tvcbracked | 018eb82a5b989916675a7d393c183a8eb1df0e47 | 2022-07-13T22:11:33.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | fourthbrain-demo | null | fourthbrain-demo/bert_modelxcxcx_reddit_tslghja_tvcbracked | 4 | null | transformers | 20,409 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert_modelxcxcx_reddit_tslghja_tvcbracked
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_modelxcxcx_reddit_tslghja_tvcbracked
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.19.4
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
fourthbrain-demo/alberta_base | d2b76c189c8e8bd714a6ccc4feda73bbea420603 | 2022-07-13T23:42:30.000Z | [
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | fourthbrain-demo | null | fourthbrain-demo/alberta_base | 4 | null | transformers | 20,410 | Entry not found |
Ali-fb/bert_model | f98125576e7a198b6297b240e4b7ed51011f49e8 | 2022-07-14T05:50:29.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | Ali-fb | null | Ali-fb/bert_model | 4 | null | transformers | 20,411 | Entry not found |
Ali-fb/alberta_base | e2402b670ccc23a9f7c8cad967f1a1136ba73102 | 2022-07-14T05:52:21.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | Ali-fb | null | Ali-fb/alberta_base | 4 | null | transformers | 20,412 | Entry not found |
gossminn/predict-perception-bertino-cause-object | 2871dc0e364b50fe6c65a40b655a1a79d30d4a76 | 2022-07-14T14:14:55.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | gossminn | null | gossminn/predict-perception-bertino-cause-object | 4 | null | transformers | 20,413 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: predict-perception-bertino-cause-object
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# predict-perception-bertino-cause-object
This model is a fine-tuned version of [indigo-ai/BERTino](https://huggingface.co/indigo-ai/BERTino) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0766
- R2: 0.8216
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 20
- eval_batch_size: 8
- seed: 1996
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 47
### Training results
| Training Loss | Epoch | Step | Validation Loss | R2 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.6807 | 1.0 | 14 | 0.4011 | 0.0652 |
| 0.3529 | 2.0 | 28 | 0.2304 | 0.4631 |
| 0.1539 | 3.0 | 42 | 0.0596 | 0.8611 |
| 0.0853 | 4.0 | 56 | 0.1600 | 0.6272 |
| 0.066 | 5.0 | 70 | 0.1596 | 0.6280 |
| 0.0563 | 6.0 | 84 | 0.1146 | 0.7330 |
| 0.0777 | 7.0 | 98 | 0.1010 | 0.7646 |
| 0.0299 | 8.0 | 112 | 0.0897 | 0.7910 |
| 0.0311 | 9.0 | 126 | 0.0832 | 0.8061 |
| 0.0274 | 10.0 | 140 | 0.0988 | 0.7697 |
| 0.0262 | 11.0 | 154 | 0.1048 | 0.7557 |
| 0.0204 | 12.0 | 168 | 0.0615 | 0.8566 |
| 0.0254 | 13.0 | 182 | 0.0742 | 0.8270 |
| 0.0251 | 14.0 | 196 | 0.0923 | 0.7850 |
| 0.0149 | 15.0 | 210 | 0.0663 | 0.8456 |
| 0.0141 | 16.0 | 224 | 0.0755 | 0.8241 |
| 0.0112 | 17.0 | 238 | 0.0905 | 0.7891 |
| 0.0108 | 18.0 | 252 | 0.0834 | 0.8057 |
| 0.0096 | 19.0 | 266 | 0.0823 | 0.8082 |
| 0.0073 | 20.0 | 280 | 0.0825 | 0.8078 |
| 0.0092 | 21.0 | 294 | 0.0869 | 0.7974 |
| 0.0075 | 22.0 | 308 | 0.0744 | 0.8266 |
| 0.0075 | 23.0 | 322 | 0.0825 | 0.8078 |
| 0.0062 | 24.0 | 336 | 0.0797 | 0.8144 |
| 0.0065 | 25.0 | 350 | 0.0793 | 0.8152 |
| 0.007 | 26.0 | 364 | 0.0840 | 0.8043 |
| 0.0067 | 27.0 | 378 | 0.0964 | 0.7753 |
| 0.0064 | 28.0 | 392 | 0.0869 | 0.7976 |
| 0.0063 | 29.0 | 406 | 0.0766 | 0.8215 |
| 0.0057 | 30.0 | 420 | 0.0764 | 0.8219 |
| 0.0057 | 31.0 | 434 | 0.0796 | 0.8145 |
| 0.0054 | 32.0 | 448 | 0.0853 | 0.8012 |
| 0.0044 | 33.0 | 462 | 0.0750 | 0.8253 |
| 0.0072 | 34.0 | 476 | 0.0782 | 0.8179 |
| 0.006 | 35.0 | 490 | 0.0867 | 0.7979 |
| 0.0054 | 36.0 | 504 | 0.0819 | 0.8092 |
| 0.0047 | 37.0 | 518 | 0.0839 | 0.8045 |
| 0.0043 | 38.0 | 532 | 0.0764 | 0.8221 |
| 0.0039 | 39.0 | 546 | 0.0728 | 0.8303 |
| 0.0041 | 40.0 | 560 | 0.0755 | 0.8241 |
| 0.0038 | 41.0 | 574 | 0.0729 | 0.8301 |
| 0.0034 | 42.0 | 588 | 0.0781 | 0.8180 |
| 0.0038 | 43.0 | 602 | 0.0762 | 0.8224 |
| 0.0032 | 44.0 | 616 | 0.0777 | 0.8189 |
| 0.0035 | 45.0 | 630 | 0.0776 | 0.8191 |
| 0.0037 | 46.0 | 644 | 0.0765 | 0.8217 |
| 0.0036 | 47.0 | 658 | 0.0766 | 0.8216 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu113
- Datasets 1.18.3
- Tokenizers 0.11.0
|
gossminn/predict-perception-bertino-cause-concept | 84c9683fb4bc837e36396b56b279bf9f90a5074e | 2022-07-14T14:22:13.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | gossminn | null | gossminn/predict-perception-bertino-cause-concept | 4 | null | transformers | 20,414 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: predict-perception-bertino-cause-concept
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# predict-perception-bertino-cause-concept
This model is a fine-tuned version of [indigo-ai/BERTino](https://huggingface.co/indigo-ai/BERTino) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2035
- R2: -0.3662
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 20
- eval_batch_size: 8
- seed: 1996
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 47
### Training results
| Training Loss | Epoch | Step | Validation Loss | R2 |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.3498 | 1.0 | 14 | 0.1845 | -0.2382 |
| 0.2442 | 2.0 | 28 | 0.1575 | -0.0573 |
| 0.1553 | 3.0 | 42 | 0.2216 | -0.4872 |
| 0.0726 | 4.0 | 56 | 0.1972 | -0.3234 |
| 0.0564 | 5.0 | 70 | 0.2832 | -0.9009 |
| 0.0525 | 6.0 | 84 | 0.1854 | -0.2444 |
| 0.0385 | 7.0 | 98 | 0.2816 | -0.8900 |
| 0.0257 | 8.0 | 112 | 0.1815 | -0.2183 |
| 0.03 | 9.0 | 126 | 0.3065 | -1.0576 |
| 0.0275 | 10.0 | 140 | 0.1991 | -0.3367 |
| 0.0175 | 11.0 | 154 | 0.2400 | -0.6110 |
| 0.017 | 12.0 | 168 | 0.1915 | -0.2856 |
| 0.0158 | 13.0 | 182 | 0.2008 | -0.3477 |
| 0.0127 | 14.0 | 196 | 0.1932 | -0.2968 |
| 0.009 | 15.0 | 210 | 0.2500 | -0.6783 |
| 0.0078 | 16.0 | 224 | 0.1969 | -0.3215 |
| 0.0075 | 17.0 | 238 | 0.1857 | -0.2463 |
| 0.0079 | 18.0 | 252 | 0.2405 | -0.6145 |
| 0.0089 | 19.0 | 266 | 0.1865 | -0.2517 |
| 0.0082 | 20.0 | 280 | 0.2275 | -0.5267 |
| 0.0078 | 21.0 | 294 | 0.1890 | -0.2687 |
| 0.0072 | 22.0 | 308 | 0.2230 | -0.4965 |
| 0.0064 | 23.0 | 322 | 0.2286 | -0.5346 |
| 0.0052 | 24.0 | 336 | 0.2154 | -0.4457 |
| 0.0049 | 25.0 | 350 | 0.1901 | -0.2757 |
| 0.0062 | 26.0 | 364 | 0.1917 | -0.2870 |
| 0.0043 | 27.0 | 378 | 0.2042 | -0.3704 |
| 0.0038 | 28.0 | 392 | 0.2251 | -0.5110 |
| 0.0049 | 29.0 | 406 | 0.2092 | -0.4040 |
| 0.0044 | 30.0 | 420 | 0.2119 | -0.4221 |
| 0.0041 | 31.0 | 434 | 0.2018 | -0.3542 |
| 0.0039 | 32.0 | 448 | 0.1875 | -0.2586 |
| 0.0038 | 33.0 | 462 | 0.1980 | -0.3291 |
| 0.0038 | 34.0 | 476 | 0.2071 | -0.3903 |
| 0.0043 | 35.0 | 490 | 0.1998 | -0.3412 |
| 0.0043 | 36.0 | 504 | 0.2052 | -0.3771 |
| 0.004 | 37.0 | 518 | 0.2143 | -0.4382 |
| 0.004 | 38.0 | 532 | 0.1977 | -0.3273 |
| 0.0039 | 39.0 | 546 | 0.2002 | -0.3439 |
| 0.0034 | 40.0 | 560 | 0.2035 | -0.3659 |
| 0.0036 | 41.0 | 574 | 0.1994 | -0.3387 |
| 0.0029 | 42.0 | 588 | 0.2036 | -0.3667 |
| 0.0032 | 43.0 | 602 | 0.2055 | -0.3797 |
| 0.0029 | 44.0 | 616 | 0.2025 | -0.3593 |
| 0.0027 | 45.0 | 630 | 0.2047 | -0.3743 |
| 0.0033 | 46.0 | 644 | 0.2067 | -0.3877 |
| 0.0027 | 47.0 | 658 | 0.2035 | -0.3662 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu113
- Datasets 1.18.3
- Tokenizers 0.11.0
|
gossminn/predict-perception-bertino-cause-none | 8c5deb7838c486280295d0aaa4e769fef969b7d7 | 2022-07-14T14:26:27.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | gossminn | null | gossminn/predict-perception-bertino-cause-none | 4 | null | transformers | 20,415 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: predict-perception-bertino-cause-none
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# predict-perception-bertino-cause-none
This model is a fine-tuned version of [indigo-ai/BERTino](https://huggingface.co/indigo-ai/BERTino) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1988
- R2: 0.4467
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 20
- eval_batch_size: 8
- seed: 1996
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 47
### Training results
| Training Loss | Epoch | Step | Validation Loss | R2 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.56 | 1.0 | 14 | 0.3460 | 0.0372 |
| 0.3752 | 2.0 | 28 | 0.3082 | 0.1423 |
| 0.147 | 3.0 | 42 | 0.2299 | 0.3603 |
| 0.0961 | 4.0 | 56 | 0.3254 | 0.0944 |
| 0.0859 | 5.0 | 70 | 0.2650 | 0.2625 |
| 0.0735 | 6.0 | 84 | 0.2430 | 0.3237 |
| 0.042 | 7.0 | 98 | 0.2567 | 0.2856 |
| 0.0328 | 8.0 | 112 | 0.2092 | 0.4180 |
| 0.028 | 9.0 | 126 | 0.2262 | 0.3706 |
| 0.0237 | 10.0 | 140 | 0.2170 | 0.3960 |
| 0.0235 | 11.0 | 154 | 0.2137 | 0.4054 |
| 0.0195 | 12.0 | 168 | 0.2009 | 0.4409 |
| 0.0217 | 13.0 | 182 | 0.2001 | 0.4431 |
| 0.0176 | 14.0 | 196 | 0.2123 | 0.4091 |
| 0.0226 | 15.0 | 210 | 0.2076 | 0.4224 |
| 0.019 | 16.0 | 224 | 0.1920 | 0.4657 |
| 0.0122 | 17.0 | 238 | 0.2301 | 0.3598 |
| 0.0121 | 18.0 | 252 | 0.2092 | 0.4178 |
| 0.0112 | 19.0 | 266 | 0.2038 | 0.4329 |
| 0.0081 | 20.0 | 280 | 0.2008 | 0.4411 |
| 0.0079 | 21.0 | 294 | 0.1930 | 0.4631 |
| 0.0083 | 22.0 | 308 | 0.2076 | 0.4222 |
| 0.0061 | 23.0 | 322 | 0.2036 | 0.4334 |
| 0.0057 | 24.0 | 336 | 0.1986 | 0.4472 |
| 0.0059 | 25.0 | 350 | 0.2079 | 0.4215 |
| 0.0082 | 26.0 | 364 | 0.2125 | 0.4087 |
| 0.0093 | 27.0 | 378 | 0.2096 | 0.4168 |
| 0.0061 | 28.0 | 392 | 0.2129 | 0.4076 |
| 0.005 | 29.0 | 406 | 0.2054 | 0.4284 |
| 0.0058 | 30.0 | 420 | 0.2024 | 0.4368 |
| 0.006 | 31.0 | 434 | 0.1999 | 0.4437 |
| 0.0047 | 32.0 | 448 | 0.1917 | 0.4666 |
| 0.0046 | 33.0 | 462 | 0.2000 | 0.4435 |
| 0.005 | 34.0 | 476 | 0.2003 | 0.4425 |
| 0.0041 | 35.0 | 490 | 0.2057 | 0.4276 |
| 0.0037 | 36.0 | 504 | 0.1985 | 0.4476 |
| 0.0049 | 37.0 | 518 | 0.2029 | 0.4353 |
| 0.0031 | 38.0 | 532 | 0.1963 | 0.4539 |
| 0.0031 | 39.0 | 546 | 0.1957 | 0.4554 |
| 0.0031 | 40.0 | 560 | 0.1962 | 0.4540 |
| 0.0029 | 41.0 | 574 | 0.2000 | 0.4433 |
| 0.0028 | 42.0 | 588 | 0.1986 | 0.4473 |
| 0.0035 | 43.0 | 602 | 0.1972 | 0.4514 |
| 0.0029 | 44.0 | 616 | 0.1984 | 0.4479 |
| 0.0036 | 45.0 | 630 | 0.2005 | 0.4422 |
| 0.0033 | 46.0 | 644 | 0.1994 | 0.4452 |
| 0.0029 | 47.0 | 658 | 0.1988 | 0.4467 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu113
- Datasets 1.18.3
- Tokenizers 0.11.0
|
gossminn/predict-perception-bertino-focus-assassin | 336a000136e017003f888a039b304341033ff24d | 2022-07-14T14:34:40.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | gossminn | null | gossminn/predict-perception-bertino-focus-assassin | 4 | null | transformers | 20,416 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: predict-perception-bertino-focus-assassin
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# predict-perception-bertino-focus-assassin
This model is a fine-tuned version of [indigo-ai/BERTino](https://huggingface.co/indigo-ai/BERTino) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3409
- R2: 0.3205
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 20
- eval_batch_size: 8
- seed: 1996
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 47
### Training results
| Training Loss | Epoch | Step | Validation Loss | R2 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.5573 | 1.0 | 14 | 0.4856 | 0.0321 |
| 0.1739 | 2.0 | 28 | 0.4735 | 0.0562 |
| 0.0813 | 3.0 | 42 | 0.3416 | 0.3191 |
| 0.0764 | 4.0 | 56 | 0.3613 | 0.2799 |
| 0.0516 | 5.0 | 70 | 0.3264 | 0.3495 |
| 0.0459 | 6.0 | 84 | 0.4193 | 0.1643 |
| 0.0414 | 7.0 | 98 | 0.3502 | 0.3019 |
| 0.028 | 8.0 | 112 | 0.3361 | 0.3301 |
| 0.0281 | 9.0 | 126 | 0.3610 | 0.2804 |
| 0.027 | 10.0 | 140 | 0.3523 | 0.2978 |
| 0.0216 | 11.0 | 154 | 0.3440 | 0.3143 |
| 0.0181 | 12.0 | 168 | 0.3506 | 0.3012 |
| 0.013 | 13.0 | 182 | 0.3299 | 0.3424 |
| 0.0116 | 14.0 | 196 | 0.3611 | 0.2803 |
| 0.0118 | 15.0 | 210 | 0.3505 | 0.3013 |
| 0.0139 | 16.0 | 224 | 0.3529 | 0.2967 |
| 0.0099 | 17.0 | 238 | 0.3536 | 0.2952 |
| 0.0096 | 18.0 | 252 | 0.3542 | 0.2941 |
| 0.0107 | 19.0 | 266 | 0.3770 | 0.2486 |
| 0.0088 | 20.0 | 280 | 0.3467 | 0.3091 |
| 0.0065 | 21.0 | 294 | 0.3327 | 0.3369 |
| 0.0073 | 22.0 | 308 | 0.3479 | 0.3066 |
| 0.0062 | 23.0 | 322 | 0.3566 | 0.2893 |
| 0.0063 | 24.0 | 336 | 0.3503 | 0.3019 |
| 0.0057 | 25.0 | 350 | 0.3371 | 0.3282 |
| 0.0049 | 26.0 | 364 | 0.3334 | 0.3355 |
| 0.0045 | 27.0 | 378 | 0.3399 | 0.3225 |
| 0.0049 | 28.0 | 392 | 0.3379 | 0.3266 |
| 0.0049 | 29.0 | 406 | 0.3377 | 0.3268 |
| 0.0055 | 30.0 | 420 | 0.3357 | 0.3309 |
| 0.005 | 31.0 | 434 | 0.3394 | 0.3235 |
| 0.0046 | 32.0 | 448 | 0.3432 | 0.3159 |
| 0.0048 | 33.0 | 462 | 0.3427 | 0.3169 |
| 0.0041 | 34.0 | 476 | 0.3450 | 0.3123 |
| 0.0041 | 35.0 | 490 | 0.3436 | 0.3151 |
| 0.0051 | 36.0 | 504 | 0.3394 | 0.3234 |
| 0.0037 | 37.0 | 518 | 0.3370 | 0.3283 |
| 0.004 | 38.0 | 532 | 0.3370 | 0.3284 |
| 0.0033 | 39.0 | 546 | 0.3339 | 0.3344 |
| 0.0034 | 40.0 | 560 | 0.3335 | 0.3352 |
| 0.003 | 41.0 | 574 | 0.3373 | 0.3276 |
| 0.0035 | 42.0 | 588 | 0.3380 | 0.3264 |
| 0.0032 | 43.0 | 602 | 0.3382 | 0.3259 |
| 0.0034 | 44.0 | 616 | 0.3432 | 0.3158 |
| 0.003 | 45.0 | 630 | 0.3421 | 0.3181 |
| 0.0027 | 46.0 | 644 | 0.3410 | 0.3203 |
| 0.0037 | 47.0 | 658 | 0.3409 | 0.3205 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu113
- Datasets 1.18.3
- Tokenizers 0.11.0
|
gossminn/predict-perception-bertino-focus-victim | 8b04135e124f9727a0fc892fdd2253fffef0a824 | 2022-07-14T14:42:05.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | gossminn | null | gossminn/predict-perception-bertino-focus-victim | 4 | null | transformers | 20,417 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: predict-perception-bertino-focus-victim
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# predict-perception-bertino-focus-victim
This model is a fine-tuned version of [indigo-ai/BERTino](https://huggingface.co/indigo-ai/BERTino) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2497
- R2: 0.6131
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 20
- eval_batch_size: 8
- seed: 1996
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 47
### Training results
| Training Loss | Epoch | Step | Validation Loss | R2 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.5438 | 1.0 | 14 | 0.4405 | 0.3175 |
| 0.2336 | 2.0 | 28 | 0.2070 | 0.6792 |
| 0.0986 | 3.0 | 42 | 0.2868 | 0.5555 |
| 0.0907 | 4.0 | 56 | 0.2916 | 0.5481 |
| 0.0652 | 5.0 | 70 | 0.2187 | 0.6611 |
| 0.0591 | 6.0 | 84 | 0.2320 | 0.6406 |
| 0.0478 | 7.0 | 98 | 0.2501 | 0.6125 |
| 0.0347 | 8.0 | 112 | 0.2425 | 0.6243 |
| 0.021 | 9.0 | 126 | 0.2670 | 0.5863 |
| 0.0214 | 10.0 | 140 | 0.2853 | 0.5580 |
| 0.0172 | 11.0 | 154 | 0.2726 | 0.5776 |
| 0.0177 | 12.0 | 168 | 0.2629 | 0.5927 |
| 0.0152 | 13.0 | 182 | 0.2396 | 0.6287 |
| 0.012 | 14.0 | 196 | 0.2574 | 0.6012 |
| 0.0119 | 15.0 | 210 | 0.2396 | 0.6288 |
| 0.0128 | 16.0 | 224 | 0.2517 | 0.6100 |
| 0.0109 | 17.0 | 238 | 0.2509 | 0.6112 |
| 0.008 | 18.0 | 252 | 0.2522 | 0.6092 |
| 0.0101 | 19.0 | 266 | 0.2503 | 0.6121 |
| 0.0075 | 20.0 | 280 | 0.2527 | 0.6084 |
| 0.0082 | 21.0 | 294 | 0.2544 | 0.6058 |
| 0.0061 | 22.0 | 308 | 0.2510 | 0.6111 |
| 0.006 | 23.0 | 322 | 0.2402 | 0.6279 |
| 0.005 | 24.0 | 336 | 0.2539 | 0.6066 |
| 0.0058 | 25.0 | 350 | 0.2438 | 0.6222 |
| 0.0051 | 26.0 | 364 | 0.2439 | 0.6221 |
| 0.006 | 27.0 | 378 | 0.2442 | 0.6216 |
| 0.0061 | 28.0 | 392 | 0.2416 | 0.6257 |
| 0.0053 | 29.0 | 406 | 0.2519 | 0.6097 |
| 0.0045 | 30.0 | 420 | 0.2526 | 0.6085 |
| 0.0034 | 31.0 | 434 | 0.2578 | 0.6006 |
| 0.0039 | 32.0 | 448 | 0.2557 | 0.6038 |
| 0.0043 | 33.0 | 462 | 0.2538 | 0.6068 |
| 0.0041 | 34.0 | 476 | 0.2535 | 0.6072 |
| 0.0042 | 35.0 | 490 | 0.2560 | 0.6033 |
| 0.0037 | 36.0 | 504 | 0.2576 | 0.6009 |
| 0.0036 | 37.0 | 518 | 0.2634 | 0.5919 |
| 0.0037 | 38.0 | 532 | 0.2582 | 0.5999 |
| 0.0038 | 39.0 | 546 | 0.2552 | 0.6045 |
| 0.0034 | 40.0 | 560 | 0.2563 | 0.6028 |
| 0.0033 | 41.0 | 574 | 0.2510 | 0.6110 |
| 0.0029 | 42.0 | 588 | 0.2515 | 0.6103 |
| 0.0033 | 43.0 | 602 | 0.2525 | 0.6088 |
| 0.0028 | 44.0 | 616 | 0.2522 | 0.6093 |
| 0.0028 | 45.0 | 630 | 0.2526 | 0.6085 |
| 0.0027 | 46.0 | 644 | 0.2494 | 0.6136 |
| 0.0024 | 47.0 | 658 | 0.2497 | 0.6131 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu113
- Datasets 1.18.3
- Tokenizers 0.11.0
|
gossminn/predict-perception-bertino-focus-object | 23284365f60e3c93e0b49f4fae65e42578110c18 | 2022-07-14T14:46:13.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-classification | false | gossminn | null | gossminn/predict-perception-bertino-focus-object | 4 | null | transformers | 20,418 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: predict-perception-bertino-focus-object
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# predict-perception-bertino-focus-object
This model is a fine-tuned version of [indigo-ai/BERTino](https://huggingface.co/indigo-ai/BERTino) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2766
- R2: 0.5460
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 20
- eval_batch_size: 8
- seed: 1996
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 47
### Training results
| Training Loss | Epoch | Step | Validation Loss | R2 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.4798 | 1.0 | 14 | 0.4519 | 0.2581 |
| 0.2481 | 2.0 | 28 | 0.3042 | 0.5007 |
| 0.12 | 3.0 | 42 | 0.3746 | 0.3851 |
| 0.0969 | 4.0 | 56 | 0.3186 | 0.4770 |
| 0.0907 | 5.0 | 70 | 0.3727 | 0.3882 |
| 0.0673 | 6.0 | 84 | 0.2847 | 0.5327 |
| 0.0457 | 7.0 | 98 | 0.3141 | 0.4844 |
| 0.0431 | 8.0 | 112 | 0.3369 | 0.4470 |
| 0.028 | 9.0 | 126 | 0.3039 | 0.5012 |
| 0.0244 | 10.0 | 140 | 0.2964 | 0.5135 |
| 0.0201 | 11.0 | 154 | 0.3072 | 0.4958 |
| 0.0153 | 12.0 | 168 | 0.3049 | 0.4995 |
| 0.0155 | 13.0 | 182 | 0.2924 | 0.5201 |
| 0.015 | 14.0 | 196 | 0.2585 | 0.5757 |
| 0.0181 | 15.0 | 210 | 0.3258 | 0.4652 |
| 0.0136 | 16.0 | 224 | 0.3142 | 0.4842 |
| 0.0105 | 17.0 | 238 | 0.2536 | 0.5837 |
| 0.0104 | 18.0 | 252 | 0.2407 | 0.6050 |
| 0.0107 | 19.0 | 266 | 0.2727 | 0.5524 |
| 0.0084 | 20.0 | 280 | 0.3117 | 0.4883 |
| 0.0102 | 21.0 | 294 | 0.2999 | 0.5078 |
| 0.0074 | 22.0 | 308 | 0.3018 | 0.5047 |
| 0.0068 | 23.0 | 322 | 0.2826 | 0.5361 |
| 0.0054 | 24.0 | 336 | 0.2804 | 0.5398 |
| 0.0044 | 25.0 | 350 | 0.2912 | 0.5220 |
| 0.0048 | 26.0 | 364 | 0.2813 | 0.5382 |
| 0.005 | 27.0 | 378 | 0.2933 | 0.5186 |
| 0.0046 | 28.0 | 392 | 0.2820 | 0.5371 |
| 0.004 | 29.0 | 406 | 0.2717 | 0.5541 |
| 0.0054 | 30.0 | 420 | 0.2717 | 0.5540 |
| 0.0042 | 31.0 | 434 | 0.2699 | 0.5570 |
| 0.0033 | 32.0 | 448 | 0.2630 | 0.5684 |
| 0.0038 | 33.0 | 462 | 0.2578 | 0.5767 |
| 0.0032 | 34.0 | 476 | 0.2687 | 0.5589 |
| 0.004 | 35.0 | 490 | 0.2737 | 0.5507 |
| 0.0031 | 36.0 | 504 | 0.2753 | 0.5481 |
| 0.0037 | 37.0 | 518 | 0.2819 | 0.5373 |
| 0.0034 | 38.0 | 532 | 0.2759 | 0.5471 |
| 0.0034 | 39.0 | 546 | 0.2835 | 0.5347 |
| 0.0029 | 40.0 | 560 | 0.2814 | 0.5381 |
| 0.0033 | 41.0 | 574 | 0.2801 | 0.5403 |
| 0.0025 | 42.0 | 588 | 0.2759 | 0.5472 |
| 0.0029 | 43.0 | 602 | 0.2790 | 0.5421 |
| 0.0028 | 44.0 | 616 | 0.2801 | 0.5401 |
| 0.003 | 45.0 | 630 | 0.2772 | 0.5451 |
| 0.0028 | 46.0 | 644 | 0.2764 | 0.5463 |
| 0.0026 | 47.0 | 658 | 0.2766 | 0.5460 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu113
- Datasets 1.18.3
- Tokenizers 0.11.0
|
yunbaree/distilbert-base-uncased-finetuned-emotion | 414e298d86f3079f8cb28f0d717b3c084ee24208 | 2022-07-14T16:27:55.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | yunbaree | null | yunbaree/distilbert-base-uncased-finetuned-emotion | 4 | null | transformers | 20,419 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.924
- name: F1
type: f1
value: 0.9240032665380036
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2244
- Accuracy: 0.924
- F1: 0.9240
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.843 | 1.0 | 250 | 0.3250 | 0.906 | 0.9041 |
| 0.254 | 2.0 | 500 | 0.2244 | 0.924 | 0.9240 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Team-PIXEL/pixel-base-finetuned-masakhaner-amh | 624a582333d5bedd10ddb7a74217b563c19a4451 | 2022-07-14T19:02:29.000Z | [
"pytorch",
"pixel",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | Team-PIXEL | null | Team-PIXEL/pixel-base-finetuned-masakhaner-amh | 4 | null | transformers | 20,420 | Entry not found |
Sayan01/tiny-bert-cola-128-distilled | b2030f0b212182e43bf7d30e7b7d3e5799118bd0 | 2022-07-14T23:59:38.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers"
] | text-classification | false | Sayan01 | null | Sayan01/tiny-bert-cola-128-distilled | 4 | null | transformers | 20,421 | Entry not found |
CennetOguz/bert-large-uncased-finetuned-youcook_1 | c9ab76b25cf229fa5085529e64160bf9200c674f | 2022-07-15T00:05:07.000Z | [
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | fill-mask | false | CennetOguz | null | CennetOguz/bert-large-uncased-finetuned-youcook_1 | 4 | null | transformers | 20,422 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-large-uncased-finetuned-youcook_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-uncased-finetuned-youcook_1
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9929
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.3915 | 1.0 | 206 | 2.1036 |
| 2.0412 | 2.0 | 412 | 2.2207 |
| 1.9062 | 3.0 | 618 | 1.7281 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0a0+17540c5
- Datasets 2.3.2
- Tokenizers 0.12.1
|
CennetOguz/bert-large-uncased-finetuned-youcook_4 | 52f949fd2f3153f727a4f8ce23069c728a6ce15e | 2022-07-15T00:43:32.000Z | [
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | fill-mask | false | CennetOguz | null | CennetOguz/bert-large-uncased-finetuned-youcook_4 | 4 | null | transformers | 20,423 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-large-uncased-finetuned-youcook_4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-uncased-finetuned-youcook_4
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9929
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.3915 | 1.0 | 206 | 2.1036 |
| 2.0412 | 2.0 | 412 | 2.2207 |
| 1.9062 | 3.0 | 618 | 1.7281 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0a0+17540c5
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Team-PIXEL/pixel-base-finetuned-mrpc | 8463f234ac9e2f2404c2051913ca5aede9267a6d | 2022-07-15T02:46:30.000Z | [
"pytorch",
"pixel",
"text-classification",
"en",
"dataset:glue",
"transformers",
"generated_from_trainer",
"model-index"
] | text-classification | false | Team-PIXEL | null | Team-PIXEL/pixel-base-finetuned-mrpc | 4 | null | transformers | 20,424 | ---
language:
- en
tags:
- generated_from_trainer
datasets:
- glue
model-index:
- name: pixel-base-finetuned-mrpc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pixel-base-finetuned-mrpc
This model is a fine-tuned version of [Team-PIXEL/pixel-base](https://huggingface.co/Team-PIXEL/pixel-base) on the GLUE MRPC dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 15000
- mixed_precision_training: Apex, opt level O1
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.12.1
|
ecnmchedsgn/distilbert-base-uncased-finetuned-emotion | 6171b643f0ec27af089a879cafebd27fe8c087b3 | 2022-07-15T03:04:52.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | ecnmchedsgn | null | ecnmchedsgn/distilbert-base-uncased-finetuned-emotion | 4 | null | transformers | 20,425 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.929
- name: F1
type: f1
value: 0.9289631525394138
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2237
- Accuracy: 0.929
- F1: 0.9290
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8466 | 1.0 | 250 | 0.3299 | 0.899 | 0.8944 |
| 0.2589 | 2.0 | 500 | 0.2237 | 0.929 | 0.9290 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Team-PIXEL/pixel-base-finetuned-qqp | a90d4dbf9bf438e9cd13766286fdbd0193a1c31d | 2022-07-15T02:56:49.000Z | [
"pytorch",
"pixel",
"text-classification",
"transformers"
] | text-classification | false | Team-PIXEL | null | Team-PIXEL/pixel-base-finetuned-qqp | 4 | null | transformers | 20,426 | Entry not found |
Team-PIXEL/pixel-base-finetuned-rte | 2e6b09812b1cdcc8c5bf6d508d5d5d89a6d1bfa0 | 2022-07-15T03:00:54.000Z | [
"pytorch",
"pixel",
"text-classification",
"en",
"dataset:glue",
"transformers",
"generated_from_trainer",
"model-index"
] | text-classification | false | Team-PIXEL | null | Team-PIXEL/pixel-base-finetuned-rte | 4 | null | transformers | 20,427 | ---
language:
- en
tags:
- generated_from_trainer
datasets:
- glue
model-index:
- name: pixel-base-finetuned-rte
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pixel-base-finetuned-rte
This model is a fine-tuned version of [Team-PIXEL/pixel-base](https://huggingface.co/Team-PIXEL/pixel-base) on the GLUE RTE dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 15000
- mixed_precision_training: Apex, opt level O1
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.12.1
|
asahi417/lmqg-mt5_base-itquad | 540123b1bd2fbac0a2f03e1f94eac39e3d3695b8 | 2022-07-15T05:11:58.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | asahi417 | null | asahi417/lmqg-mt5_base-itquad | 4 | null | transformers | 20,428 | Entry not found |
YNnnn/distilbert-base-uncased-finetuned-sst2 | afbc8e4663eb04f4363f745f9318294b6321c064 | 2022-07-15T12:20:56.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | YNnnn | null | YNnnn/distilbert-base-uncased-finetuned-sst2 | 4 | null | transformers | 20,429 | Entry not found |
jinwooChoi/hjw_base_25_48_1e-05 | 27993ea52cc8937dd014b48aa10baca852e07b4d | 2022-07-15T08:07:13.000Z | [
"pytorch",
"electra",
"text-classification",
"transformers"
] | text-classification | false | jinwooChoi | null | jinwooChoi/hjw_base_25_48_1e-05 | 4 | null | transformers | 20,430 | Entry not found |
darragh/swinunetr-btcv-small | f014e9c2ca59b45165bfb586f0da5002402f5d98 | 2022-07-15T21:00:57.000Z | [
"pytorch",
"en",
"dataset:BTCV",
"transformers",
"btcv",
"medical",
"swin",
"license:apache-2.0"
] | null | false | darragh | null | darragh/swinunetr-btcv-small | 4 | null | transformers | 20,431 | ---
language: en
tags:
- btcv
- medical
- swin
license: apache-2.0
datasets:
- BTCV
---
# Model Overview
This repository contains the code for Swin UNETR [1,2]. Swin UNETR is the state-of-the-art on Medical Segmentation
Decathlon (MSD) and Beyond the Cranial Vault (BTCV) Segmentation Challenge dataset. In [1], a novel methodology is devised for pre-training Swin UNETR backbone in a self-supervised
manner. We provide the option for training Swin UNETR by fine-tuning from pre-trained self-supervised weights or from scratch.
The source repository for the training of these models can be found [here](https://github.com/Project-MONAI/research-contributions/tree/main/SwinUNETR/BTCV).
# Installing Dependencies
Dependencies for training and inference can be installed using the model requirements :
``` bash
pip install -r requirements.txt
```
# Intended uses & limitations
You can use the raw model for dicom segmentation, but it's mostly intended to be fine-tuned on a downstream task.
Note that this model is primarily aimed at being fine-tuned on tasks which segment CAT scans or MRIs on images in dicom format. Dicom meta data mostly differs across medical facilities, so if applying to a new dataset, the model should be finetuned.
# How to use
To install necessary dependencies, run the below in bash.
```
git clone https://github.com/darraghdog/Project-MONAI-research-contributions pmrc
pip install -r pmrc/requirements.txt
cd pmrc/SwinUNETR/BTCV
```
To load the model from the hub.
```
>>> from swinunetr import SwinUnetrModelForInference
>>> model = SwinUnetrModelForInference.from_pretrained('darragh/swinunetr-btcv-tiny')
```
# Limitations and bias
The training data used for this model is specific to CAT scans from certain health facilities and machines. Data from other facilities may difffer in image distributions, and may require finetuning of the models for best performance.
# Evaluation results
We provide several pre-trained models on BTCV dataset in the following.
<table>
<tr>
<th>Name</th>
<th>Dice (overlap=0.7)</th>
<th>Dice (overlap=0.5)</th>
<th>Feature Size</th>
<th># params (M)</th>
<th>Self-Supervised Pre-trained </th>
</tr>
<tr>
<td>Swin UNETR/Base</td>
<td>82.25</td>
<td>81.86</td>
<td>48</td>
<td>62.1</td>
<td>Yes</td>
</tr>
<tr>
<td>Swin UNETR/Small</td>
<td>79.79</td>
<td>79.34</td>
<td>24</td>
<td>15.7</td>
<td>No</td>
</tr>
<tr>
<td>Swin UNETR/Tiny</td>
<td>72.05</td>
<td>70.35</td>
<td>12</td>
<td>4.0</td>
<td>No</td>
</tr>
</table>
# Data Preparation
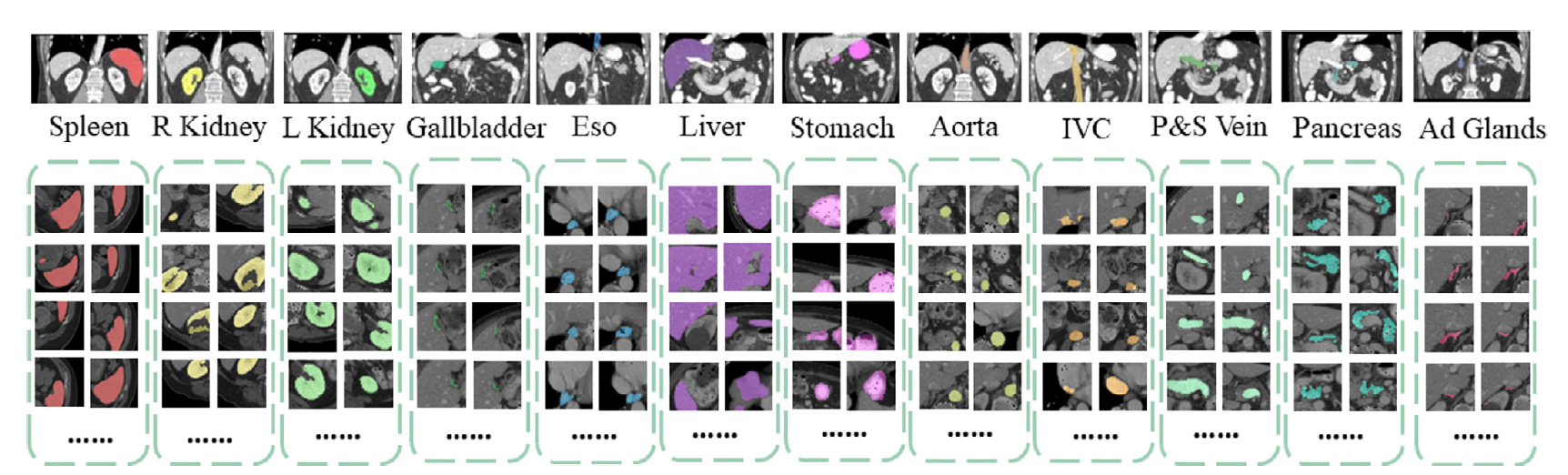
The training data is from the [BTCV challenge dataset](https://www.synapse.org/#!Synapse:syn3193805/wiki/217752).
- Target: 13 abdominal organs including 1. Spleen 2. Right Kidney 3. Left Kideny 4.Gallbladder 5.Esophagus 6. Liver 7. Stomach 8.Aorta 9. IVC 10. Portal and Splenic Veins 11. Pancreas 12.Right adrenal gland 13.Left adrenal gland.
- Task: Segmentation
- Modality: CT
- Size: 30 3D volumes (24 Training + 6 Testing)
# Training
See the source repository [here](https://github.com/Project-MONAI/research-contributions/tree/main/SwinUNETR/BTCV) for information on training.
# BibTeX entry and citation info
If you find this repository useful, please consider citing the following papers:
```
@inproceedings{tang2022self,
title={Self-supervised pre-training of swin transformers for 3d medical image analysis},
author={Tang, Yucheng and Yang, Dong and Li, Wenqi and Roth, Holger R and Landman, Bennett and Xu, Daguang and Nath, Vishwesh and Hatamizadeh, Ali},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={20730--20740},
year={2022}
}
@article{hatamizadeh2022swin,
title={Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images},
author={Hatamizadeh, Ali and Nath, Vishwesh and Tang, Yucheng and Yang, Dong and Roth, Holger and Xu, Daguang},
journal={arXiv preprint arXiv:2201.01266},
year={2022}
}
```
# References
[1]: Tang, Y., Yang, D., Li, W., Roth, H.R., Landman, B., Xu, D., Nath, V. and Hatamizadeh, A., 2022. Self-supervised pre-training of swin transformers for 3d medical image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 20730-20740).
[2]: Hatamizadeh, A., Nath, V., Tang, Y., Yang, D., Roth, H. and Xu, D., 2022. Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images. arXiv preprint arXiv:2201.01266.
|
asahi417/lmqg-mt5_base-dequad | 02ffc96c5b2034a6cf2c24068202c8e538ac1ae0 | 2022-07-15T14:01:22.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | asahi417 | null | asahi417/lmqg-mt5_base-dequad | 4 | null | transformers | 20,432 | Entry not found |
jhonparra18/bert-base-cased-cv-studio_name-pooler | cdbc3df68ba3705b9e19f946ef4b29457c719646 | 2022-07-15T16:38:17.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | jhonparra18 | null | jhonparra18/bert-base-cased-cv-studio_name-pooler | 4 | null | transformers | 20,433 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-base-cased-cv-studio_name-pooler
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-cv-studio_name-pooler
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9427
- Accuracy: 0.3881
- F1 Micro: 0.3881
- F1 Macro: 0.1563
- Precision Micro: 0.3881
- Recall Micro: 0.3881
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 20
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 Micro | F1 Macro | Precision Micro | Recall Micro |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:--------:|:--------:|:---------------:|:------------:|
| 2.3164 | 0.98 | 1000 | 2.2860 | 0.2556 | 0.2556 | 0.0327 | 0.2556 | 0.2556 |
| 2.2301 | 1.96 | 2000 | 2.1948 | 0.3052 | 0.3052 | 0.0791 | 0.3052 | 0.3052 |
| 2.1534 | 2.93 | 3000 | 2.1321 | 0.3179 | 0.3179 | 0.0811 | 0.3179 | 0.3179 |
| 2.092 | 3.91 | 4000 | 2.0889 | 0.3392 | 0.3392 | 0.1002 | 0.3392 | 0.3392 |
| 2.0748 | 4.89 | 5000 | 2.0511 | 0.3541 | 0.3541 | 0.1108 | 0.3541 | 0.3541 |
| 2.0555 | 5.87 | 6000 | 2.0292 | 0.3602 | 0.3602 | 0.1111 | 0.3602 | 0.3602 |
| 2.0416 | 6.84 | 7000 | 2.0080 | 0.3715 | 0.3715 | 0.1287 | 0.3715 | 0.3715 |
| 2.0162 | 7.82 | 8000 | 1.9921 | 0.3663 | 0.3663 | 0.1240 | 0.3663 | 0.3663 |
| 1.9931 | 8.8 | 9000 | 1.9805 | 0.3746 | 0.3746 | 0.1431 | 0.3746 | 0.3746 |
| 1.9644 | 9.78 | 10000 | 1.9660 | 0.3805 | 0.3805 | 0.1468 | 0.3805 | 0.3805 |
| 1.9664 | 10.75 | 11000 | 1.9573 | 0.3815 | 0.3815 | 0.1461 | 0.3815 | 0.3815 |
| 1.9606 | 11.73 | 12000 | 1.9508 | 0.3842 | 0.3842 | 0.1505 | 0.3842 | 0.3842 |
| 1.9666 | 12.71 | 13000 | 1.9489 | 0.3859 | 0.3859 | 0.1583 | 0.3859 | 0.3859 |
| 1.9507 | 13.69 | 14000 | 1.9435 | 0.3851 | 0.3851 | 0.1530 | 0.3851 | 0.3851 |
| 1.9522 | 14.66 | 15000 | 1.9427 | 0.3881 | 0.3881 | 0.1563 | 0.3881 | 0.3881 |
### Framework versions
- Transformers 4.19.0
- Pytorch 1.8.2+cu111
- Datasets 1.6.2
- Tokenizers 0.12.1
|
abdulmatinomotoso/testing_headline_generator | aa590468f437e487edf986db5ffcc2e5ea46bd70 | 2022-07-16T11:53:47.000Z | [
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | abdulmatinomotoso | null | abdulmatinomotoso/testing_headline_generator | 4 | null | transformers | 20,434 | ---
tags:
- generated_from_trainer
model-index:
- name: testing_headline_generator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# testing_headline_generator
This model is a fine-tuned version of [google/pegasus-multi_news](https://huggingface.co/google/pegasus-multi_news) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
nbolton04/bert_model | 1e756d60eb906eab8233b124427b662b3d0710c7 | 2022-07-16T23:24:19.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | nbolton04 | null | nbolton04/bert_model | 4 | null | transformers | 20,435 | Entry not found |
asahi417/lmqg-mt5_base-ruquad | cd373171a9be97472f6688dc86c6d6c955f2d528 | 2022-07-17T02:17:52.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | asahi417 | null | asahi417/lmqg-mt5_base-ruquad | 4 | null | transformers | 20,436 | Entry not found |
abdulmatinomotoso/testing_headline_generator_1 | e6314d1e09ebe77ad506f1c9b3cd2f89d283127e | 2022-07-17T09:55:19.000Z | [
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | abdulmatinomotoso | null | abdulmatinomotoso/testing_headline_generator_1 | 4 | null | transformers | 20,437 | ---
tags:
- generated_from_trainer
model-index:
- name: testing_headline_generator_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# testing_headline_generator_1
This model is a fine-tuned version of [google/pegasus-multi_news](https://huggingface.co/google/pegasus-multi_news) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Edresson/wav2vec2-large-100k-voxpopuli-ft-TTS-Dataset-russian | 42138f73d2a98116f4448be3b1c7d369e8d97e55 | 2022-07-17T17:36:19.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ru",
"dataset:Common Voice",
"arxiv:2204.00618",
"transformers",
"audio",
"speech",
"Russian-speech-corpus",
"PyTorch",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | Edresson | null | Edresson/wav2vec2-large-100k-voxpopuli-ft-TTS-Dataset-russian | 4 | null | transformers | 20,438 | ---
language: ru
datasets:
- Common Voice
metrics:
- wer
tags:
- audio
- speech
- wav2vec2
- Russian-speech-corpus
- automatic-speech-recognition
- speech
- PyTorch
license: apache-2.0
model-index:
- name: Edresson Casanova Wav2vec2 Large 100k Voxpopuli fine-tuned with a single-speaker dataset in Russian
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
metrics:
- name: Test Common Voice 7.0 WER
type: wer
value: 74.02
---
# Wav2vec2 Large 100k Voxpopuli fine-tuned with a single-speaker dataset in Russian
[Wav2vec2 Large 100k Voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) fine-tuned in Russian using a single-speaker dataset.
# Use this model
```python
from transformers import AutoTokenizer, Wav2Vec2ForCTC
tokenizer = AutoTokenizer.from_pretrained("Edresson/wav2vec2-large-100k-voxpopuli-ft-TTS-Dataset-russian")
model = Wav2Vec2ForCTC.from_pretrained("Edresson/wav2vec2-large-100k-voxpopuli-ft-TTS-Dataset-russian")
```
# Results
For the results check the [paper](https://arxiv.org/abs/2204.00618)
# Example test with Common Voice Dataset
```python
dataset = load_dataset("common_voice", "ru", split="test", data_dir="./cv-corpus-7.0-2021-07-21")
resampler = torchaudio.transforms.Resampl(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
```
```python
ds = dataset.map(map_to_array)
result = ds.map(map_to_pred, batched=True, batch_size=1, remove_columns=list(ds.features.keys()))
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
|
Edresson/wav2vec2-large-100k-voxpopuli-ft-TTS-Dataset-portuguese | 7406a887bc04ca9bac7dd1d72fe5dc591fae035b | 2022-07-17T17:37:08.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"pt",
"dataset:Common Voice",
"arxiv:2204.00618",
"transformers",
"audio",
"speech",
"portuguese-speech-corpus",
"PyTorch",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | Edresson | null | Edresson/wav2vec2-large-100k-voxpopuli-ft-TTS-Dataset-portuguese | 4 | null | transformers | 20,439 | ---
language: pt
datasets:
- Common Voice
metrics:
- wer
tags:
- audio
- speech
- wav2vec2
- pt
- portuguese-speech-corpus
- automatic-speech-recognition
- speech
- PyTorch
license: apache-2.0
model-index:
- name: Edresson Casanova Wav2vec2 Large 100k Voxpopuli fine-tuned with a single-speaker dataset in Portuguese
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
metrics:
- name: Test Common Voice 7.0 WER
type: wer
value: 63.90
---
# Wav2vec2 Large 100k Voxpopuli fine-tuned with a single-speaker dataset plus Data Augmentation in Portuguese
[Wav2vec2 Large 100k Voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) fine-tuned in Portuguese using a single-speaker dataset (TTS-Portuguese Corpus).
# Use this model
```python
from transformers import AutoTokenizer, Wav2Vec2ForCTC
tokenizer = AutoTokenizer.from_pretrained("Edresson/wav2vec2-large-100k-voxpopuli-ft-TTS-Dataset-portuguese")
model = Wav2Vec2ForCTC.from_pretrained("Edresson/wav2vec2-large-100k-voxpopuli-ft-TTS-Dataset-portuguese")
```
# Results
For the results check the [paper](https://arxiv.org/abs/2204.00618)
# Example test with Common Voice Dataset
```python
dataset = load_dataset("common_voice", "pt", split="test", data_dir="./cv-corpus-7.0-2021-07-21")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
```
```python
ds = dataset.map(map_to_array)
result = ds.map(map_to_pred, batched=True, batch_size=1, remove_columns=list(ds.features.keys()))
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
|
johnsonj561/distilbert-base-uncased-finetuned-emotion | 6f17c21e124e08fcebd8b14a2a929193d268918f | 2022-07-17T22:57:57.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | johnsonj561 | null | johnsonj561/distilbert-base-uncased-finetuned-emotion | 4 | null | transformers | 20,440 | Entry not found |
asahi417/lmqg-mt5_base-frquad | 3a246da792dc4b85f406d6feb9242c5bbc18151d | 2022-07-17T23:47:07.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | asahi417 | null | asahi417/lmqg-mt5_base-frquad | 4 | null | transformers | 20,441 | Entry not found |
uer/roberta-medium-wwm-chinese-cluecorpussmall | 3afe2405c5ab6a9b6a12877636af62fcb2b34078 | 2022-07-18T05:47:54.000Z | [
"pytorch",
"bert",
"fill-mask",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"arxiv:1908.08962",
"transformers",
"autotrain_compatible"
] | fill-mask | false | uer | null | uer/roberta-medium-wwm-chinese-cluecorpussmall | 4 | null | transformers | 20,442 | ---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "北京是[MASK]国的首都。"
---
# Chinese Whole Word Masking RoBERTa Miniatures
## Model description
This is the set of 6 Chinese Whole Word Masking RoBERTa models pre-trained by [UER-py](https://arxiv.org/abs/1909.05658).
[Turc et al.](https://arxiv.org/abs/1908.08962) have shown that the standard BERT recipe is effective on a wide range of model sizes. Following their paper, we released the 6 Chinese Whole Word Masking RoBERTa models. In order to facilitate users to reproduce the results, we used the publicly available corpus and word segmentation tool, and provided all training details.
You can download the 6 Chinese RoBERTa miniatures either from the [UER-py Github page](https://github.com/dbiir/UER-py/), or via HuggingFace from the links below:
| | Link |
| -------- | :-----------------------: |
| **Tiny** | [**2/128 (Tiny)**][2_128] |
| **Mini** | [**4/256 (Mini)**][4_256] |
| **Small** | [**4/512 (Small)**][4_512] |
| **Medium** | [**8/512 (Medium)**][8_512] |
| **Base** | [**12/768 (Base)**][12_768] |
| **Large** | [**24/1024 (Large)**][24_1024] |
Here are scores on the devlopment set of six Chinese tasks:
| Model | Score | douban | chnsenticorp | lcqmc | tnews(CLUE) | iflytek(CLUE) | ocnli(CLUE) |
| ------------------ | :---: | :----: | :----------: | :---: | :---------: | :-----------: | :---------: |
| RoBERTa-Tiny-WWM | 72.1 | 82.8 | 91.8 | 81.8 | 62.1 | 55.4 | 58.6 |
| RoBERTa-Mini-WWM | 76.1 | 84.9 | 93.0 | 86.8 | 64.4 | 58.7 | 68.8 |
| RoBERTa-Small-WWM | 77.3 | 86.8 | 93.8 | 87.2 | 65.2 | 59.6 | 71.4 |
| RoBERTa-Medium-WWM | 78.4 | 88.2 | 94.4 | 88.8 | 66.0 | 59.9 | 73.2 |
| RoBERTa-Base-WWM | 80.1 | 90.0 | 95.8 | 89.4 | 67.5 | 61.8 | 76.2 |
| RoBERTa-Large-WWM | 81.0 | 90.4 | 95.8 | 90.0 | 68.5 | 62.1 | 79.1 |
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained with the sequence length of 128:
- epochs: 3, 5, 8
- batch sizes: 32, 64
- learning rates: 3e-5, 1e-4, 3e-4
## How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='uer/roberta-tiny-wwm-chinese-cluecorpussmall')
>>> unmasker("北京是[MASK]国的首都。")
[
{'score': 0.294228732585907,
'token': 704,
'token_str': '中',
'sequence': '北 京 是 中 国 的 首 都 。'},
{'score': 0.19691626727581024,
'token': 1266,
'token_str': '北',
'sequence': '北 京 是 北 国 的 首 都 。'},
{'score': 0.1070084273815155,
'token': 7506,
'token_str': '韩',
'sequence': '北 京 是 韩 国 的 首 都 。'},
{'score': 0.031527262181043625,
'token': 2769,
'token_str': '我',
'sequence': '北 京 是 我 国 的 首 都 。'},
{'score': 0.023054633289575577,
'token': 1298,
'token_str': '南',
'sequence': '北 京 是 南 国 的 首 都 。'}
]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('uer/roberta-base-wwm-chinese-cluecorpussmall')
model = BertModel.from_pretrained("uer/roberta-base-wwm-chinese-cluecorpussmall")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('uer/roberta-base-wwm-chinese-cluecorpussmall')
model = TFBertModel.from_pretrained("uer/roberta-base-wwm-chinese-cluecorpussmall")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data.
## Training procedure
Models are pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 512. We use the same hyper-parameters on different model sizes.
[jieba](https://github.com/fxsjy/jieba) is used as word segmentation tool.
Taking the case of Whole Word Masking RoBERTa-Medium
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_seq128_dataset.pt \
--processes_num 32 --seq_length 128 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_word_seq128_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_wwm_roberta_medium_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-4 --batch_size 64 \
--whole_word_masking \
--data_processor mlm --target mlm
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_seq512_dataset.pt \
--processes_num 32 --seq_length 512 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_seq512_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--pretrained_model_path models/cluecorpussmall_wwm_roberta_medium_seq128_model.bin-1000000 \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_wwm_roberta_medium_seq512_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-5 --batch_size 16 \
--whole_word_masking \
--data_processor mlm --target mlm
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bert_from_uer_to_huggingface.py --input_model_path models/cluecorpussmall_wwm_roberta_medium_seq512_model.bin \
--output_model_path pytorch_model.bin \
--layers_num 8 --type mlm
```
### BibTeX entry and citation info
```
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
[2_128]:https://huggingface.co/uer/roberta-tiny-wwm-chinese-cluecorpussmall
[4_256]:https://huggingface.co/uer/roberta-mini-wwm-chinese-cluecorpussmall
[4_512]:https://huggingface.co/uer/roberta-small-wwm-chinese-cluecorpussmall
[8_512]:https://huggingface.co/uer/roberta-medium-wwm-chinese-cluecorpussmall
[12_768]:https://huggingface.co/uer/roberta-base-wwm-chinese-cluecorpussmall
[24_1024]:https://huggingface.co/uer/roberta-large-wwm-chinese-cluecorpussmall |
fumakurata/distilbert-base-uncased-finetuned-emotion | 6f86b9405c70aad220a464bb0a1c63d0c0dc4cbd | 2022-07-18T10:12:18.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | fumakurata | null | fumakurata/distilbert-base-uncased-finetuned-emotion | 4 | null | transformers | 20,443 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.834
- name: F1
type: f1
value: 0.8171742650957551
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5401
- Accuracy: 0.834
- F1: 0.8172
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 192
- eval_batch_size: 192
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 84 | 0.7993 | 0.74 | 0.6827 |
| No log | 2.0 | 168 | 0.5401 | 0.834 | 0.8172 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
jordyvl/bert-base-cased_conll2003-CRF-first-ner | ab398a731ad05f0f6e6a570ce10c63ab39f18e78 | 2022-07-18T16:48:55.000Z | [
"pytorch",
"tensorboard",
"bert",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | null | false | jordyvl | null | jordyvl/bert-base-cased_conll2003-CRF-first-ner | 4 | null | transformers | 20,444 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-cased_conll2003-CRF-first-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased_conll2003-CRF-first-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0546
- Precision: 0.6483
- Recall: 0.3940
- F1: 0.4902
- Accuracy: 0.9225
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.089 | 1.0 | 7021 | 0.0522 | 0.6315 | 0.3781 | 0.4730 | 0.9193 |
| 0.0203 | 2.0 | 14042 | 0.0481 | 0.6587 | 0.4044 | 0.5011 | 0.9233 |
| 0.0166 | 3.0 | 21063 | 0.0546 | 0.6483 | 0.3940 | 0.4902 | 0.9225 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.2+cu102
- Datasets 2.2.2
- Tokenizers 0.12.1
|
borjagomez/bert_model_2 | 916372de26193464a172dcae18bae74251931cd6 | 2022-07-19T10:43:04.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | borjagomez | null | borjagomez/bert_model_2 | 4 | null | transformers | 20,445 | Entry not found |
nbolton04/alberta_base | 67634aa6acf288f41ff338837013f31a08dea7cf | 2022-07-18T12:41:19.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | nbolton04 | null | nbolton04/alberta_base | 4 | null | transformers | 20,446 | Entry not found |
claudiovaliense/teste_claudio3 | 4153c0d360403e2554810bd90bc3ca37ae1be807 | 2022-07-18T15:31:14.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | claudiovaliense | null | claudiovaliense/teste_claudio3 | 4 | null | transformers | 20,447 | Entry not found |
borjagomez/alberta_base | c54ac87e0c7440df869263b319f9fdbbf68aa525 | 2022-07-19T14:05:51.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | borjagomez | null | borjagomez/alberta_base | 4 | null | transformers | 20,448 | Entry not found |
Kayvane/distilbert-base-uncased-wandb-week-3-complaints-classifier-1024 | c6cbee2e98de17860e660604867aed5229d8f460 | 2022-07-19T03:39:12.000Z | [
"pytorch",
"distilbert",
"text-classification",
"dataset:consumer-finance-complaints",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | Kayvane | null | Kayvane/distilbert-base-uncased-wandb-week-3-complaints-classifier-1024 | 4 | null | transformers | 20,449 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- consumer-finance-complaints
metrics:
- accuracy
- f1
- recall
- precision
model-index:
- name: distilbert-base-uncased-wandb-week-3-complaints-classifier-1024
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: consumer-finance-complaints
type: consumer-finance-complaints
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8166760103970236
- name: F1
type: f1
value: 0.8089132637288794
- name: Recall
type: recall
value: 0.8166760103970236
- name: Precision
type: precision
value: 0.810259366582512
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-wandb-week-3-complaints-classifier-1024
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the consumer-finance-complaints dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5664
- Accuracy: 0.8167
- F1: 0.8089
- Recall: 0.8167
- Precision: 0.8103
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.9291066722689668e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1024
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Recall | Precision |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:------:|:---------:|
| 0.7592 | 0.61 | 1500 | 0.6981 | 0.7776 | 0.7495 | 0.7776 | 0.7610 |
| 0.5859 | 1.22 | 3000 | 0.6082 | 0.8085 | 0.7990 | 0.8085 | 0.8005 |
| 0.5228 | 1.83 | 4500 | 0.5664 | 0.8167 | 0.8089 | 0.8167 | 0.8103 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
pnr-svc/Electra-Sentiment-Analysis-Turkish | b2f024b73a58b00e81796fad8fc5a852222a5797 | 2022-07-18T19:44:12.000Z | [
"pytorch",
"electra",
"text-classification",
"transformers"
] | text-classification | false | pnr-svc | null | pnr-svc/Electra-Sentiment-Analysis-Turkish | 4 | null | transformers | 20,450 | Entry not found |
rifkat/uzbert | dcd519f40a75247738c064ae3e8c8234408a5fa9 | 2022-07-20T19:14:28.000Z | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | rifkat | null | rifkat/uzbert | 4 | null | transformers | 20,451 | Entry not found |
domenicrosati/opus-mt-es-en-scielo | cd2401ceb4a330b252baedc549444421a0cc8df2 | 2022-07-18T22:14:58.000Z | [
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"dataset:scielo",
"transformers",
"translation",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | translation | false | domenicrosati | null | domenicrosati/opus-mt-es-en-scielo | 4 | null | transformers | 20,452 | ---
license: apache-2.0
tags:
- translation
- generated_from_trainer
datasets:
- scielo
metrics:
- bleu
model-index:
- name: opus-mt-es-en-scielo
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: scielo
type: scielo
args: en-es
metrics:
- name: Bleu
type: bleu
value: 40.87878888820179
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-es-en-scielo
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-es-en](https://huggingface.co/Helsinki-NLP/opus-mt-es-en) on the scielo dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2593
- Bleu: 40.8788
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|
| 1.4277 | 1.0 | 10001 | 1.3473 | 40.5849 |
| 1.2007 | 2.0 | 20002 | 1.3146 | 41.3308 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Kayvane/distilbert-base-uncased-wandb-week-3-complaints-classifier-512 | 096d99d9861678a8631880df5daec295fe1baa15 | 2022-07-18T21:55:04.000Z | [
"pytorch",
"distilbert",
"text-classification",
"dataset:consumer-finance-complaints",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | Kayvane | null | Kayvane/distilbert-base-uncased-wandb-week-3-complaints-classifier-512 | 4 | null | transformers | 20,453 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- consumer-finance-complaints
metrics:
- accuracy
- f1
- recall
- precision
model-index:
- name: distilbert-base-uncased-wandb-week-3-complaints-classifier-512
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: consumer-finance-complaints
type: consumer-finance-complaints
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6745323887671373
- name: F1
type: f1
value: 0.6355967633316707
- name: Recall
type: recall
value: 0.6745323887671373
- name: Precision
type: precision
value: 0.6122130681567332
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-wandb-week-3-complaints-classifier-512
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the consumer-finance-complaints dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0839
- Accuracy: 0.6745
- F1: 0.6356
- Recall: 0.6745
- Precision: 0.6122
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0007879237562376572
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 512
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Recall | Precision |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:------:|:---------:|
| 1.2707 | 0.61 | 1500 | 1.3009 | 0.6381 | 0.5848 | 0.6381 | 0.5503 |
| 1.1348 | 1.22 | 3000 | 1.1510 | 0.6610 | 0.6178 | 0.6610 | 0.5909 |
| 1.0649 | 1.83 | 4500 | 1.0839 | 0.6745 | 0.6356 | 0.6745 | 0.6122 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Mathissimo/bert_model | 4a3ea2eebdacb2e23d0a30748b9c8ab10db80775 | 2022-07-20T08:33:23.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | Mathissimo | null | Mathissimo/bert_model | 4 | null | transformers | 20,454 | Entry not found |
martomor/bert_model | df58d85012d8d2aafcac1f72441a8bf2f641dcca | 2022-07-19T18:14:56.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | martomor | null | martomor/bert_model | 4 | null | transformers | 20,455 | Entry not found |
danielhou13/bert-finetuned_papers | a6b85c9c5fe16f042d2abcc194e2974ff5f0a747 | 2022-07-19T02:57:15.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | danielhou13 | null | danielhou13/bert-finetuned_papers | 4 | null | transformers | 20,456 | Entry not found |
Kayvane/distilroberta-base-wandb-week-3-complaints-classifier-512 | 1eb20382810dc47f156472307f69f4d5d1362172 | 2022-07-19T05:04:51.000Z | [
"pytorch",
"roberta",
"text-classification",
"dataset:consumer-finance-complaints",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | Kayvane | null | Kayvane/distilroberta-base-wandb-week-3-complaints-classifier-512 | 4 | null | transformers | 20,457 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- consumer-finance-complaints
metrics:
- accuracy
- f1
- recall
- precision
model-index:
- name: distilroberta-base-wandb-week-3-complaints-classifier-512
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: consumer-finance-complaints
type: consumer-finance-complaints
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8038326283064064
- name: F1
type: f1
value: 0.791857014338201
- name: Recall
type: recall
value: 0.8038326283064064
- name: Precision
type: precision
value: 0.7922430702228043
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-wandb-week-3-complaints-classifier-512
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the consumer-finance-complaints dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6004
- Accuracy: 0.8038
- F1: 0.7919
- Recall: 0.8038
- Precision: 0.7922
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.7835312622444155e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 512
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Recall | Precision |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:------:|:---------:|
| 0.7559 | 0.61 | 1500 | 0.7307 | 0.7733 | 0.7411 | 0.7733 | 0.7286 |
| 0.6361 | 1.22 | 3000 | 0.6559 | 0.7846 | 0.7699 | 0.7846 | 0.7718 |
| 0.5774 | 1.83 | 4500 | 0.6004 | 0.8038 | 0.7919 | 0.8038 | 0.7922 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
danielhou13/bert-finetuned-news | 7266dda9f50e327440994ee318f4eef35aec501d | 2022-07-19T05:01:23.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | danielhou13 | null | danielhou13/bert-finetuned-news | 4 | null | transformers | 20,458 | Entry not found |
jordyvl/udpos28-en-sm-first-POS | e3a03227e7ed31535796280eb1b51f8586925155 | 2022-07-19T09:41:54.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | jordyvl | null | jordyvl/udpos28-en-sm-first-POS | 4 | null | transformers | 20,459 | Entry not found |
google/ddpm-bedroom-256 | 108e9fce884967ff7b4eac68c3cb2f56e30bbd5e | 2022-07-21T15:00:35.000Z | [
"diffusers",
"arxiv:2006.11239",
"pytorch",
"unconditional-image-generation",
"license:apache-2.0"
] | unconditional-image-generation | false | google | null | google/ddpm-bedroom-256 | 4 | null | diffusers | 20,460 | ---
license: apache-2.0
tags:
- pytorch
- diffusers
- unconditional-image-generation
---
# Denoising Diffusion Probabilistic Models (DDPM)
**Paper**: [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
**Authors**: Jonathan Ho, Ajay Jain, Pieter Abbeel
**Abstract**:
*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.*
## Inference
**DDPM** models can use *discrete noise schedulers* such as:
- [scheduling_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py)
- [scheduling_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [scheduling_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py)
for inference. Note that while the *ddpm* scheduler yields the highest quality, it also takes the longest.
For a good trade-off between quality and inference speed you might want to consider the *ddim* or *pndm* schedulers instead.
See the following code:
```python
# !pip install diffusers
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
model_id = "google/ddpm-bedroom-256"
# load model and scheduler
ddpm = DDPMPipeline.from_pretrained(model_id) # you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
# run pipeline in inference (sample random noise and denoise)
image = ddpm()["sample"]
# save image
image[0].save("ddpm_generated_image.png")
```
For more in-detail information, please have a look at the [official inference example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
## Training
If you want to train your own model, please have a look at the [official training example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
## Samples
1. 
2. 
3. 
4.  |
google/ddpm-ema-cat-256 | d6e79baae6343099116c4c96c0ef679c25169ab3 | 2022-07-21T15:00:10.000Z | [
"diffusers",
"arxiv:2006.11239",
"pytorch",
"unconditional-image-generation",
"license:apache-2.0"
] | unconditional-image-generation | false | google | null | google/ddpm-ema-cat-256 | 4 | null | diffusers | 20,461 | ---
license: apache-2.0
tags:
- pytorch
- diffusers
- unconditional-image-generation
---
# Denoising Diffusion Probabilistic Models (DDPM)
**Paper**: [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
**Authors**: Jonathan Ho, Ajay Jain, Pieter Abbeel
**Abstract**:
*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.*
## Inference
**DDPM** models can use *discrete noise schedulers* such as:
- [scheduling_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py)
- [scheduling_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [scheduling_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py)
for inference. Note that while the *ddpm* scheduler yields the highest quality, it also takes the longest.
For a good trade-off between quality and inference speed you might want to consider the *ddim* or *pndm* schedulers instead.
See the following code:
```python
# !pip install diffusers
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
model_id = "google/ddpm-ema-cat-256"
# load model and scheduler
ddpm = DDPMPipeline.from_pretrained(model_id) # you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
# run pipeline in inference (sample random noise and denoise)
image = ddpm()["sample"]
# save image
image[0].save("ddpm_generated_image.png")
```
For more in-detail information, please have a look at the [official inference example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
## Training
If you want to train your own model, please have a look at the [official training example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
## Samples
1. 
2. 
3. 
4.  |
Tahsin-Mayeesha/t5-end2end-questions-generation | 1b37dc835bd0193bced9d63b8d58130a93b2d7b1 | 2022-07-19T13:52:43.000Z | [
"pytorch",
"t5",
"text2text-generation",
"dataset:squad_modified_for_t5_qg",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | Tahsin-Mayeesha | null | Tahsin-Mayeesha/t5-end2end-questions-generation | 4 | null | transformers | 20,462 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_modified_for_t5_qg
model-index:
- name: t5-end2end-questions-generation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-end2end-questions-generation
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the squad_modified_for_t5_qg dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.6143
- eval_runtime: 96.0898
- eval_samples_per_second: 21.511
- eval_steps_per_second: 5.38
- epoch: 2.03
- step: 600
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
abdulmatinomotoso/testing_headline_generator_4 | 895431ae787a9dacdfbe95ebcf55896e8ee73892 | 2022-07-19T13:56:33.000Z | [
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | abdulmatinomotoso | null | abdulmatinomotoso/testing_headline_generator_4 | 4 | null | transformers | 20,463 | ---
tags:
- generated_from_trainer
model-index:
- name: testing_headline_generator_4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# testing_headline_generator_4
This model is a fine-tuned version of [google/pegasus-multi_news](https://huggingface.co/google/pegasus-multi_news) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 7.5919
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.7781 | 0.53 | 100 | 7.5919 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
jordyvl/bert-base-cased_conll2003-lowC-sm-first-ner | a3001fa798a3fb9b88a027b8a69f718585bf117f | 2022-07-19T13:59:35.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | jordyvl | null | jordyvl/bert-base-cased_conll2003-lowC-sm-first-ner | 4 | null | transformers | 20,464 | Entry not found |
jordyvl/bert-base-cased_conll2003-lowC-CRF-first-ner | 5ec9c0f4c9f7c62b3756eaef36df2b80e91cd03b | 2022-07-19T14:42:21.000Z | [
"pytorch",
"tensorboard",
"bert",
"transformers"
] | null | false | jordyvl | null | jordyvl/bert-base-cased_conll2003-lowC-CRF-first-ner | 4 | null | transformers | 20,465 | Entry not found |
jordyvl/bert-base-portuguese-cased_harem-selective-lowC-sm-first-ner | d4c8d644022b1a14b575d0241fc2bf01cce1eb0a | 2022-07-19T15:08:00.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"dataset:harem",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | token-classification | false | jordyvl | null | jordyvl/bert-base-portuguese-cased_harem-selective-lowC-sm-first-ner | 4 | null | transformers | 20,466 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- harem
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-portuguese-cased_harem-selective-lowC-sm-first-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: harem
type: harem
args: selective
metrics:
- name: Precision
type: precision
value: 0.8
- name: Recall
type: recall
value: 0.8764044943820225
- name: F1
type: f1
value: 0.8364611260053619
- name: Accuracy
type: accuracy
value: 0.9764089121887287
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-portuguese-cased_harem-selective-lowC-sm-first-ner
This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the harem dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1160
- Precision: 0.8
- Recall: 0.8764
- F1: 0.8365
- Accuracy: 0.9764
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.055 | 1.0 | 2517 | 0.0934 | 0.81 | 0.9101 | 0.8571 | 0.9699 |
| 0.0236 | 2.0 | 5034 | 0.0883 | 0.8307 | 0.8820 | 0.8556 | 0.9751 |
| 0.0129 | 3.0 | 7551 | 0.1160 | 0.8 | 0.8764 | 0.8365 | 0.9764 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.2+cu102
- Datasets 2.2.2
- Tokenizers 0.12.1
|
charles-go/distilbert-base-uncased-finetuned-emotion | d31787e2165ad06e16fb9c7e5a494334c24555ce | 2022-07-19T18:52:04.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | charles-go | null | charles-go/distilbert-base-uncased-finetuned-emotion | 4 | null | transformers | 20,467 | Entry not found |
Evelyn18/roberta-base-spanish-squades-modelo-robertav1b3 | f624b01bd18299924958e512f983f1077fb40d45 | 2022-07-19T18:51:05.000Z | [
"pytorch",
"tensorboard",
"roberta",
"question-answering",
"dataset:becasv3",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] | question-answering | false | Evelyn18 | null | Evelyn18/roberta-base-spanish-squades-modelo-robertav1b3 | 4 | null | transformers | 20,468 | ---
tags:
- generated_from_trainer
datasets:
- becasv3
model-index:
- name: roberta-base-spanish-squades-modelo-robertav1b3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-spanish-squades-modelo-robertav1b3
This model is a fine-tuned version of [IIC/roberta-base-spanish-squades](https://huggingface.co/IIC/roberta-base-spanish-squades) on the becasv3 dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3537
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 11
- eval_batch_size: 11
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 6 | 2.0804 |
| No log | 2.0 | 12 | 1.6591 |
| No log | 3.0 | 18 | 1.9973 |
| No log | 4.0 | 24 | 2.1109 |
| No log | 5.0 | 30 | 2.2085 |
| No log | 6.0 | 36 | 2.3537 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
martomor/alberta_base | f8ab56b4acccf0c577de04b762cf0e60ee2a3b44 | 2022-07-20T02:37:56.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | martomor | null | martomor/alberta_base | 4 | null | transformers | 20,469 | Entry not found |
Mathissimo/alberta_base | 916b661d3bd6946bfbdaa77f4f7cf14643abe4ed | 2022-07-20T20:20:14.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | Mathissimo | null | Mathissimo/alberta_base | 4 | null | transformers | 20,470 | Entry not found |
kalpeshk2011/rankgen-t5-large-all | 61c35e4cf8a254672de3ea6ed342acb8d9f5efa2 | 2022-07-23T16:20:48.000Z | [
"pytorch",
"t5",
"en",
"dataset:Wikipedia",
"dataset:PG19",
"dataset:Project Gutenberg",
"dataset:C4",
"dataset:relic",
"dataset:ChapterBreak",
"dataset:HellaSwag",
"dataset:ROCStories",
"transformers",
"contrastive learning",
"ranking",
"decoding",
"metric learning",
"text generation",
"retrieval",
"license:apache-2.0"
] | null | false | kalpeshk2011 | null | kalpeshk2011/rankgen-t5-large-all | 4 | null | transformers | 20,471 | ---
language:
- en
thumbnail: "https://pbs.twimg.com/media/FThx_rEWAAEoujW?format=jpg&name=medium"
tags:
- t5
- contrastive learning
- ranking
- decoding
- metric learning
- pytorch
- text generation
- retrieval
license: "apache-2.0"
datasets:
- Wikipedia
- PG19
- Project Gutenberg
- C4
- relic
- ChapterBreak
- HellaSwag
- ROCStories
metrics:
- MAUVE
- human
---
## Main repository
https://github.com/martiansideofthemoon/rankgen
## What is RankGen?
RankGen is a suite of encoder models (100M-1.2B parameters) which map prefixes and generations from any pretrained English language model to a shared vector space. RankGen can be used to rerank multiple full-length samples from an LM, and it can also be incorporated as a scoring function into beam search to significantly improve generation quality (0.85 vs 0.77 MAUVE, 75% preference according to humans annotators who are English writers). RankGen can also be used like a dense retriever, and achieves state-of-the-art performance on [literary retrieval](https://relic.cs.umass.edu/leaderboard.html).
## Setup
**Requirements** (`pip` will install these dependencies for you)
Python 3.7+, `torch` (CUDA recommended), `transformers`
**Installation**
```
python3.7 -m virtualenv rankgen-venv
source rankgen-venv/bin/activate
pip install rankgen
```
Get the data [here](https://drive.google.com/drive/folders/1DRG2ess7fK3apfB-6KoHb_azMuHbsIv4?usp=sharing) and place folder in root directory. Alternatively, use `gdown` as shown below,
```
gdown --folder https://drive.google.com/drive/folders/1DRG2ess7fK3apfB-6KoHb_azMuHbsIv4
```
Run the test script to make sure the RankGen checkpoint has loaded correctly,
```
python -m rankgen.test_rankgen_encoder --model_path kalpeshk2011/rankgen-t5-base-all
### Expected output
0.0009239262409127233
0.0011521980725477804
```
## Using RankGen
Loading RankGen is simple using the HuggingFace APIs (see Method-2 below), but we suggest using [`RankGenEncoder`](https://github.com/martiansideofthemoon/rankgen/blob/master/rankgen/rankgen_encoder.py), which is a small wrapper around the HuggingFace APIs for correctly preprocessing data and doing tokenization automatically. You can either download [our repository](https://github.com/martiansideofthemoon/rankgen) and install the API, or copy the implementation from [below](#rankgenencoder-implementation).
#### [SUGGESTED] Method-1: Loading the model with RankGenEncoder
```
from rankgen import RankGenEncoder, RankGenGenerator
rankgen_encoder = RankGenEncoder("kalpeshk2011/rankgen-t5-large-all")
# Encoding vectors
prefix_vectors = rankgen_encoder.encode(["This is a prefix sentence."], vectors_type="prefix")
suffix_vectors = rankgen_encoder.encode(["This is a suffix sentence."], vectors_type="suffix")
# Generating text
# use a HuggingFace compatible language model
generator = RankGenGenerator(rankgen_encoder=rankgen_encoder, language_model="gpt2-medium")
inputs = ["Whatever might be the nature of the tragedy it would be over with long before this, and those moving black spots away yonder to the west, that he had discerned from the bluff, were undoubtedly the departing raiders. There was nothing left for Keith to do except determine the fate of the unfortunates, and give their bodies decent burial. That any had escaped, or yet lived, was altogether unlikely, unless, perchance, women had been in the party, in which case they would have been borne away prisoners."]
# Baseline nucleus sampling
print(generator.generate_single(inputs, top_p=0.9)[0][0])
# Over-generate and re-rank
print(generator.overgenerate_rerank(inputs, top_p=0.9, num_samples=10)[0][0])
# Beam search
print(generator.beam_search(inputs, top_p=0.9, num_samples=10, beam_size=2)[0][0])
```
#### Method-2: Loading the model with HuggingFace APIs
```
from transformers import T5Tokenizer, AutoModel
tokenizer = T5Tokenizer.from_pretrained(f"google/t5-v1_1-large")
model = AutoModel.from_pretrained("kalpeshk2011/rankgen-t5-large-all", trust_remote_code=True)
```
### RankGenEncoder Implementation
```
import tqdm
from transformers import T5Tokenizer, T5EncoderModel, AutoModel
class RankGenEncoder():
def __init__(self, model_path, max_batch_size=32, model_size=None, cache_dir=None):
assert model_path in ["kalpeshk2011/rankgen-t5-xl-all", "kalpeshk2011/rankgen-t5-xl-pg19", "kalpeshk2011/rankgen-t5-base-all", "kalpeshk2011/rankgen-t5-large-all"]
self.max_batch_size = max_batch_size
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
if model_size is None:
if "t5-large" in model_path or "t5_large" in model_path:
self.model_size = "large"
elif "t5-xl" in model_path or "t5_xl" in model_path:
self.model_size = "xl"
else:
self.model_size = "base"
else:
self.model_size = model_size
self.tokenizer = T5Tokenizer.from_pretrained(f"google/t5-v1_1-{self.model_size}", cache_dir=cache_dir)
self.model = AutoModel.from_pretrained(model_path, trust_remote_code=True)
self.model.to(self.device)
self.model.eval()
def encode(self, inputs, vectors_type="prefix", verbose=False, return_input_ids=False):
tokenizer = self.tokenizer
max_batch_size = self.max_batch_size
if isinstance(inputs, str):
inputs = [inputs]
if vectors_type == 'prefix':
inputs = ['pre ' + input for input in inputs]
max_length = 512
else:
inputs = ['suffi ' + input for input in inputs]
max_length = 128
all_embeddings = []
all_input_ids = []
for i in tqdm.tqdm(range(0, len(inputs), max_batch_size), total=(len(inputs) // max_batch_size) + 1, disable=not verbose, desc=f"Encoding {vectors_type} inputs:"):
tokenized_inputs = tokenizer(inputs[i:i + max_batch_size], return_tensors="pt", padding=True)
for k, v in tokenized_inputs.items():
tokenized_inputs[k] = v[:, :max_length]
tokenized_inputs = tokenized_inputs.to(self.device)
with torch.inference_mode():
batch_embeddings = self.model(**tokenized_inputs)
all_embeddings.append(batch_embeddings)
if return_input_ids:
all_input_ids.extend(tokenized_inputs.input_ids.cpu().tolist())
return {
"embeddings": torch.cat(all_embeddings, dim=0),
"input_ids": all_input_ids
}
``` |
kalpeshk2011/rankgen-t5-xl-pg19 | ceab00d8723c2e35cc331dccd70a8cb3d83f16ce | 2022-07-23T16:20:58.000Z | [
"pytorch",
"t5",
"en",
"dataset:Wikipedia",
"dataset:PG19",
"dataset:Project Gutenberg",
"dataset:C4",
"dataset:relic",
"dataset:ChapterBreak",
"dataset:HellaSwag",
"dataset:ROCStories",
"transformers",
"contrastive learning",
"ranking",
"decoding",
"metric learning",
"text generation",
"retrieval",
"license:apache-2.0"
] | null | false | kalpeshk2011 | null | kalpeshk2011/rankgen-t5-xl-pg19 | 4 | 1 | transformers | 20,472 | ---
language:
- en
thumbnail: "https://pbs.twimg.com/media/FThx_rEWAAEoujW?format=jpg&name=medium"
tags:
- t5
- contrastive learning
- ranking
- decoding
- metric learning
- pytorch
- text generation
- retrieval
license: "apache-2.0"
datasets:
- Wikipedia
- PG19
- Project Gutenberg
- C4
- relic
- ChapterBreak
- HellaSwag
- ROCStories
metrics:
- MAUVE
- human
---
## Main repository
https://github.com/martiansideofthemoon/rankgen
## What is RankGen?
RankGen is a suite of encoder models (100M-1.2B parameters) which map prefixes and generations from any pretrained English language model to a shared vector space. RankGen can be used to rerank multiple full-length samples from an LM, and it can also be incorporated as a scoring function into beam search to significantly improve generation quality (0.85 vs 0.77 MAUVE, 75% preference according to humans annotators who are English writers). RankGen can also be used like a dense retriever, and achieves state-of-the-art performance on [literary retrieval](https://relic.cs.umass.edu/leaderboard.html).
## Setup
**Requirements** (`pip` will install these dependencies for you)
Python 3.7+, `torch` (CUDA recommended), `transformers`
**Installation**
```
python3.7 -m virtualenv rankgen-venv
source rankgen-venv/bin/activate
pip install rankgen
```
Get the data [here](https://drive.google.com/drive/folders/1DRG2ess7fK3apfB-6KoHb_azMuHbsIv4?usp=sharing) and place folder in root directory. Alternatively, use `gdown` as shown below,
```
gdown --folder https://drive.google.com/drive/folders/1DRG2ess7fK3apfB-6KoHb_azMuHbsIv4
```
Run the test script to make sure the RankGen checkpoint has loaded correctly,
```
python -m rankgen.test_rankgen_encoder --model_path kalpeshk2011/rankgen-t5-base-all
### Expected output
0.0009239262409127233
0.0011521980725477804
```
## Using RankGen
Loading RankGen is simple using the HuggingFace APIs (see Method-2 below), but we suggest using [`RankGenEncoder`](https://github.com/martiansideofthemoon/rankgen/blob/master/rankgen/rankgen_encoder.py), which is a small wrapper around the HuggingFace APIs for correctly preprocessing data and doing tokenization automatically. You can either download [our repository](https://github.com/martiansideofthemoon/rankgen) and install the API, or copy the implementation from [below](#rankgenencoder-implementation).
#### [SUGGESTED] Method-1: Loading the model with RankGenEncoder
```
from rankgen import RankGenEncoder, RankGenGenerator
rankgen_encoder = RankGenEncoder("kalpeshk2011/rankgen-t5-xl-pg19")
# Encoding vectors
prefix_vectors = rankgen_encoder.encode(["This is a prefix sentence."], vectors_type="prefix")
suffix_vectors = rankgen_encoder.encode(["This is a suffix sentence."], vectors_type="suffix")
# Generating text
# use a HuggingFace compatible language model
generator = RankGenGenerator(rankgen_encoder=rankgen_encoder, language_model="gpt2-medium")
inputs = ["Whatever might be the nature of the tragedy it would be over with long before this, and those moving black spots away yonder to the west, that he had discerned from the bluff, were undoubtedly the departing raiders. There was nothing left for Keith to do except determine the fate of the unfortunates, and give their bodies decent burial. That any had escaped, or yet lived, was altogether unlikely, unless, perchance, women had been in the party, in which case they would have been borne away prisoners."]
# Baseline nucleus sampling
print(generator.generate_single(inputs, top_p=0.9)[0][0])
# Over-generate and re-rank
print(generator.overgenerate_rerank(inputs, top_p=0.9, num_samples=10)[0][0])
# Beam search
print(generator.beam_search(inputs, top_p=0.9, num_samples=10, beam_size=2)[0][0])
```
#### Method-2: Loading the model with HuggingFace APIs
```
from transformers import T5Tokenizer, AutoModel
tokenizer = T5Tokenizer.from_pretrained(f"google/t5-v1_1-xl")
model = AutoModel.from_pretrained("kalpeshk2011/rankgen-t5-xl-pg19", trust_remote_code=True)
```
### RankGenEncoder Implementation
```
import tqdm
from transformers import T5Tokenizer, T5EncoderModel, AutoModel
class RankGenEncoder():
def __init__(self, model_path, max_batch_size=32, model_size=None, cache_dir=None):
assert model_path in ["kalpeshk2011/rankgen-t5-xl-all", "kalpeshk2011/rankgen-t5-xl-pg19", "kalpeshk2011/rankgen-t5-base-all", "kalpeshk2011/rankgen-t5-large-all"]
self.max_batch_size = max_batch_size
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
if model_size is None:
if "t5-large" in model_path or "t5_large" in model_path:
self.model_size = "large"
elif "t5-xl" in model_path or "t5_xl" in model_path:
self.model_size = "xl"
else:
self.model_size = "base"
else:
self.model_size = model_size
self.tokenizer = T5Tokenizer.from_pretrained(f"google/t5-v1_1-{self.model_size}", cache_dir=cache_dir)
self.model = AutoModel.from_pretrained(model_path, trust_remote_code=True)
self.model.to(self.device)
self.model.eval()
def encode(self, inputs, vectors_type="prefix", verbose=False, return_input_ids=False):
tokenizer = self.tokenizer
max_batch_size = self.max_batch_size
if isinstance(inputs, str):
inputs = [inputs]
if vectors_type == 'prefix':
inputs = ['pre ' + input for input in inputs]
max_length = 512
else:
inputs = ['suffi ' + input for input in inputs]
max_length = 128
all_embeddings = []
all_input_ids = []
for i in tqdm.tqdm(range(0, len(inputs), max_batch_size), total=(len(inputs) // max_batch_size) + 1, disable=not verbose, desc=f"Encoding {vectors_type} inputs:"):
tokenized_inputs = tokenizer(inputs[i:i + max_batch_size], return_tensors="pt", padding=True)
for k, v in tokenized_inputs.items():
tokenized_inputs[k] = v[:, :max_length]
tokenized_inputs = tokenized_inputs.to(self.device)
with torch.inference_mode():
batch_embeddings = self.model(**tokenized_inputs)
all_embeddings.append(batch_embeddings)
if return_input_ids:
all_input_ids.extend(tokenized_inputs.input_ids.cpu().tolist())
return {
"embeddings": torch.cat(all_embeddings, dim=0),
"input_ids": all_input_ids
}
``` |
johanna-k/pw-canine-ameps | 35e663fa99ef46194dff71ceb098193a0b81b91a | 2022-07-20T07:39:18.000Z | [
"pytorch",
"canine",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | johanna-k | null | johanna-k/pw-canine-ameps | 4 | null | transformers | 20,473 | Entry not found |
ManqingLiu/distilbert-base-uncased-finetuned-clinc | 84e7b4ff172a2a0a12669f97ecc9e97a95d79724 | 2022-07-20T21:02:46.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:clinc_oos",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | ManqingLiu | null | ManqingLiu/distilbert-base-uncased-finetuned-clinc | 4 | null | transformers | 20,474 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9170967741935484
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7755
- Accuracy: 0.9171
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.2892 | 1.0 | 318 | 3.2834 | 0.7394 |
| 2.6289 | 2.0 | 636 | 1.8732 | 0.8348 |
| 1.5479 | 3.0 | 954 | 1.1580 | 0.8903 |
| 1.0135 | 4.0 | 1272 | 0.8585 | 0.9077 |
| 0.7968 | 5.0 | 1590 | 0.7755 | 0.9171 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
egirones/distilbert-base-uncased-finetuned-emotion | a029701745848d5060393f087f4163d7655b540c | 2022-07-20T21:43:23.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | egirones | null | egirones/distilbert-base-uncased-finetuned-emotion | 4 | null | transformers | 20,475 | Entry not found |
trevorj/BART_reddit_advice_story | 9d5fe77312887bfe13d0e75a5c1a93c62b8be94d | 2022-07-21T05:35:30.000Z | [
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | trevorj | null | trevorj/BART_reddit_advice_story | 4 | null | transformers | 20,476 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: BART_reddit_advice_story
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BART_reddit_advice_story
This model is a fine-tuned version of [sshleifer/distilbart-xsum-6-6](https://huggingface.co/sshleifer/distilbart-xsum-6-6) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2552
- Rouge1: 21.9349
- Rouge2: 6.3417
- Rougel: 17.7133
- Rougelsum: 18.7199
- Gen Len: 21.092
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 3.3743 | 1.0 | 1875 | 3.2787 | 21.1275 | 5.9618 | 17.3772 | 18.317 | 20.447 |
| 3.025 | 2.0 | 3750 | 3.2466 | 21.8443 | 6.2351 | 17.6358 | 18.6259 | 21.506 |
| 2.7628 | 3.0 | 5625 | 3.2552 | 21.9349 | 6.3417 | 17.7133 | 18.7199 | 21.092 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
koanlp/bart-large-cnn-finetuned-news | 819928a5679b918ff5856999dcc289fb33021d6b | 2022-07-21T07:59:43.000Z | [
"pytorch",
"bart",
"text2text-generation",
"dataset:multi_news",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | koanlp | null | koanlp/bart-large-cnn-finetuned-news | 4 | null | transformers | 20,477 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- multi_news
model-index:
- name: bart-large-cnn-finetuned-news
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-finetuned-news
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on the multi_news dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
- label_smoothing_factor: 0.1
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
psato/distilbert-base-uncased-finetuned-squad | 20be0b161f2dd3e86fb1fae500801850ed871004 | 2022-07-25T17:07:29.000Z | [
"pytorch",
"distilbert",
"question-answering",
"dataset:squad",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | question-answering | false | psato | null | psato/distilbert-base-uncased-finetuned-squad | 4 | null | transformers | 20,478 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1552
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2264 | 1.0 | 5533 | 1.1785 |
| 0.9409 | 2.0 | 11066 | 1.0934 |
| 0.7492 | 3.0 | 16599 | 1.1552 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
rbiswas4/distilbert-base-uncased-finetuned-squad | 8e2b4bbb0cd07d3532f4024b20df74385bb086a7 | 2022-07-21T17:48:26.000Z | [
"pytorch",
"distilbert",
"question-answering",
"dataset:squad",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | question-answering | false | rbiswas4 | null | rbiswas4/distilbert-base-uncased-finetuned-squad | 4 | null | transformers | 20,479 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1542
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2137 | 1.0 | 5533 | 1.1516 |
| 0.9463 | 2.0 | 11066 | 1.1115 |
| 0.7665 | 3.0 | 16599 | 1.1542 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0
- Datasets 2.3.2
- Tokenizers 0.12.1
|
trevorj/BART_reddit_gaming | cf9a64b7339c66b2d202bd284547f5b7c8669293 | 2022-07-21T16:51:59.000Z | [
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | trevorj | null | trevorj/BART_reddit_gaming | 4 | null | transformers | 20,480 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: BART_reddit_gaming
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BART_reddit_gaming
This model is a fine-tuned version of [sshleifer/distilbart-xsum-6-6](https://huggingface.co/sshleifer/distilbart-xsum-6-6) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7373
- Rouge1: 18.1202
- Rouge2: 4.6045
- Rougel: 15.1273
- Rougelsum: 15.7601
- Gen Len: 18.208
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 3.864 | 1.0 | 1875 | 3.7752 | 17.3754 | 4.51 | 14.6763 | 15.22 | 16.944 |
| 3.4755 | 2.0 | 3750 | 3.7265 | 17.8066 | 4.4188 | 14.9432 | 15.5396 | 18.104 |
| 3.2629 | 3.0 | 5625 | 3.7373 | 18.1202 | 4.6045 | 15.1273 | 15.7601 | 18.208 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
trevorj/BART_reddit_other | 8663f90cb1b0971d35bcab471041eb0dfeb5f10f | 2022-07-21T18:56:10.000Z | [
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | trevorj | null | trevorj/BART_reddit_other | 4 | null | transformers | 20,481 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: BART_reddit_other
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BART_reddit_other
This model is a fine-tuned version of [sshleifer/distilbart-xsum-6-6](https://huggingface.co/sshleifer/distilbart-xsum-6-6) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5792
- Rouge1: 18.5705
- Rouge2: 5.0107
- Rougel: 15.2581
- Rougelsum: 16.082
- Gen Len: 19.402
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 3.7887 | 1.0 | 1875 | 3.6044 | 18.4668 | 5.182 | 15.359 | 16.169 | 19.341 |
| 3.3816 | 2.0 | 3750 | 3.5628 | 18.0998 | 4.8937 | 15.0179 | 15.7615 | 17.789 |
| 3.134 | 3.0 | 5625 | 3.5792 | 18.5705 | 5.0107 | 15.2581 | 16.082 | 19.402 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
NbAiLab/wav2vec2-large-voxrex-npsc-nst-bokmaal-fixed | a35227a84500a62d1df37401c3965564f9a6be75 | 2022-07-30T09:47:44.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers"
] | automatic-speech-recognition | false | NbAiLab | null | NbAiLab/wav2vec2-large-voxrex-npsc-nst-bokmaal-fixed | 4 | null | transformers | 20,482 | Entry not found |
maykcaldas/dummy-model-test | 6b6d7c5490ee88915797ec7d2801fb5528e9378e | 2022-07-22T19:53:05.000Z | [
"pytorch",
"camembert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | maykcaldas | null | maykcaldas/dummy-model-test | 4 | null | transformers | 20,483 | bla |
enoriega/rule_learning_margin_3mm_many_negatives_spanpred_attention | 0bf315b387ef5f8bc438dcb599e555746a3b4699 | 2022-07-25T21:21:23.000Z | [
"pytorch",
"tensorboard",
"bert",
"dataset:enoriega/odinsynth_dataset",
"transformers",
"generated_from_trainer",
"model-index"
] | null | false | enoriega | null | enoriega/rule_learning_margin_3mm_many_negatives_spanpred_attention | 4 | null | transformers | 20,484 | ---
tags:
- generated_from_trainer
datasets:
- enoriega/odinsynth_dataset
model-index:
- name: rule_learning_margin_3mm_many_negatives_spanpred_attention
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rule_learning_margin_3mm_many_negatives_spanpred_attention
This model is a fine-tuned version of [enoriega/rule_softmatching](https://huggingface.co/enoriega/rule_softmatching) on the enoriega/odinsynth_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2196
- Margin Accuracy: 0.8969
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2000
- total_train_batch_size: 8000
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Margin Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------------:|
| 0.3149 | 0.16 | 60 | 0.3098 | 0.8608 |
| 0.2754 | 0.32 | 120 | 0.2725 | 0.8733 |
| 0.2619 | 0.48 | 180 | 0.2512 | 0.8872 |
| 0.2378 | 0.64 | 240 | 0.2391 | 0.8925 |
| 0.2451 | 0.8 | 300 | 0.2305 | 0.8943 |
| 0.2357 | 0.96 | 360 | 0.2292 | 0.8949 |
| 0.2335 | 1.12 | 420 | 0.2269 | 0.8952 |
| 0.2403 | 1.28 | 480 | 0.2213 | 0.8957 |
| 0.2302 | 1.44 | 540 | 0.2227 | 0.8963 |
| 0.2353 | 1.6 | 600 | 0.2222 | 0.8961 |
| 0.2271 | 1.76 | 660 | 0.2207 | 0.8964 |
| 0.228 | 1.92 | 720 | 0.2218 | 0.8967 |
| 0.2231 | 2.08 | 780 | 0.2201 | 0.8967 |
| 0.2128 | 2.24 | 840 | 0.2219 | 0.8967 |
| 0.2186 | 2.4 | 900 | 0.2202 | 0.8967 |
| 0.2245 | 2.56 | 960 | 0.2205 | 0.8969 |
| 0.2158 | 2.72 | 1020 | 0.2196 | 0.8969 |
| 0.2106 | 2.88 | 1080 | 0.2192 | 0.8968 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.1
- Tokenizers 0.12.1
|
planhanasan/hana-model | 9fc435d2e72902e8dccf7d20af3d4159b13c55b5 | 2022-07-23T07:39:59.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | planhanasan | null | planhanasan/hana-model | 4 | null | transformers | 20,485 | Entry not found |
Ahmed007/google-mt5-small-ibn-Shaddad-v1 | 6a3af5e608ddfe3e2a066616af6da51c453f4590 | 2022-07-23T11:16:10.000Z | [
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"transformers",
"Poet",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | Ahmed007 | null | Ahmed007/google-mt5-small-ibn-Shaddad-v1 | 4 | null | transformers | 20,486 | ---
license: apache-2.0
tags:
- Poet
- generated_from_trainer
model-index:
- name: google-mt5-small-ibn-Shaddad-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# google-mt5-small-ibn-Shaddad-v1
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0015
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.8795 | 1.0 | 1067 | 0.0011 |
| 0.0505 | 2.0 | 2134 | 0.0015 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Sarmila/distilbert-base-uncased-distilled-squad | 3c4c73f36528ead2435197766bed054da270c1cd | 2022-07-24T18:46:37.000Z | [
"pytorch",
"distilbert",
"question-answering",
"en",
"transformers",
"Not available",
"autotrain_compatible"
] | question-answering | false | Sarmila | null | Sarmila/distilbert-base-uncased-distilled-squad | 4 | null | transformers | 20,487 | ---
language: en
tags: Not available
datasets: []
metrics: Not available
thumbnail: null
---
## Model description
PyTorch implementation containing all the modelling needed for your NLP task. Combines a language
model and a prediction head. Allows for gradient flow back to the language model component.
## Model Type
not defined
## Model Details ##
- version: 1
- device: cuda
- number of labels: not found
- number_of_parameters: 66364418
- base_model: this is a base model itself
## Training
No Information
## Evaluation
No Information
## quantitative_analyses
not filled yet
## ethical_considerations
not filled yet
## caveats_and_recommendations
not filled yet
|
relbert/relbert-roberta-large-semeval2012-average-prompt-e-nce | b82b8c221430b5cbd355c4acb30158fc5bb62c21 | 2022-07-25T18:35:07.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | relbert | null | relbert/relbert-roberta-large-semeval2012-average-prompt-e-nce | 4 | null | transformers | 20,488 | Entry not found |
jonatasgrosman/exp_w2v2r_de_vp-100k_gender_male-8_female-2_s564 | b2900f3dca361f4c80835f4f9604590fb12fb66c | 2022-07-25T04:48:13.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"de",
"dataset:mozilla-foundation/common_voice_7_0",
"transformers",
"license:apache-2.0"
] | automatic-speech-recognition | false | jonatasgrosman | null | jonatasgrosman/exp_w2v2r_de_vp-100k_gender_male-8_female-2_s564 | 4 | null | transformers | 20,489 | ---
language:
- de
license: apache-2.0
tags:
- automatic-speech-recognition
- de
datasets:
- mozilla-foundation/common_voice_7_0
---
# exp_w2v2r_de_vp-100k_gender_male-8_female-2_s564
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
amartyobanerjee/bert-finetuned-ner | 1a0606bf3bf673fc5fb371ed410f1c83649deb91 | 2022-07-25T08:27:35.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | token-classification | false | amartyobanerjee | null | amartyobanerjee/bert-finetuned-ner | 4 | null | transformers | 20,490 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9314097279472382
- name: Recall
type: recall
value: 0.9506900033658701
- name: F1
type: f1
value: 0.94095111185142
- name: Accuracy
type: accuracy
value: 0.9862541943839407
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0622
- Precision: 0.9314
- Recall: 0.9507
- F1: 0.9410
- Accuracy: 0.9863
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0821 | 1.0 | 1756 | 0.0639 | 0.9108 | 0.9371 | 0.9238 | 0.9834 |
| 0.0366 | 2.0 | 3512 | 0.0585 | 0.9310 | 0.9497 | 0.9403 | 0.9857 |
| 0.019 | 3.0 | 5268 | 0.0622 | 0.9314 | 0.9507 | 0.9410 | 0.9863 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
huggingtweets/bwahwtfbwah | 592a06db972eaa824fb7adbc4ff149c1e000bc81 | 2022-07-25T11:22:47.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] | text-generation | false | huggingtweets | null | huggingtweets/bwahwtfbwah | 4 | null | transformers | 20,491 | ---
language: en
thumbnail: http://www.huggingtweets.com/bwahwtfbwah/1658748163123/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1543387213370638338/Xn8bL7wJ_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">🤍🖤</div>
<div style="text-align: center; font-size: 14px;">@bwahwtfbwah</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 🤍🖤.
| Data | 🤍🖤 |
| --- | --- |
| Tweets downloaded | 3245 |
| Retweets | 501 |
| Short tweets | 655 |
| Tweets kept | 2089 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/p4n65kie/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @bwahwtfbwah's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3pyxv8zk) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3pyxv8zk/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/bwahwtfbwah')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
jinwooChoi/SKKU_AP_SA_KBT8 | 4660fb99253bcf42eee631ee8bcb9fca131cb062 | 2022-07-26T02:01:42.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | jinwooChoi | null | jinwooChoi/SKKU_AP_SA_KBT8 | 4 | null | transformers | 20,492 | Entry not found |
Frikallo/output | c5fde4c607cc6afc6c3c2c069de9c04dbe962151 | 2022-07-26T07:08:03.000Z | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-generation | false | Frikallo | null | Frikallo/output | 4 | null | transformers | 20,493 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001372
- train_batch_size: 1
- eval_batch_size: 8
- seed: 2811898863
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.9.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Frikallo/Dodo82J-vgdunkey | 1cf1840925ac4b963c3cac7db323f242b378a578 | 2022-07-26T07:21:52.000Z | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] | text-generation | false | Frikallo | null | Frikallo/Dodo82J-vgdunkey | 4 | null | transformers | 20,494 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: Dodo82J-vgdunkey
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Dodo82J-vgdunkey
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001372
- train_batch_size: 1
- eval_batch_size: 8
- seed: 2423377218
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.9.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
AykeeSalazar/vc-bantai-vit-withoutAMBI-adunest | b03019b40bffaf1f551f4977b04d0cbc84c0372f | 2022-07-27T02:12:37.000Z | [
"pytorch",
"tensorboard",
"vit",
"image-classification",
"dataset:imagefolder",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | image-classification | false | AykeeSalazar | null | AykeeSalazar/vc-bantai-vit-withoutAMBI-adunest | 4 | null | transformers | 20,495 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vc-bantai-vit-withoutAMBI-adunest
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
args: Violation-Classification---Raw-6
metrics:
- name: Accuracy
type: accuracy
value: 0.9388646288209607
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vc-bantai-vit-withoutAMBI-adunest
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1950
- Accuracy: 0.9389
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4821 | 0.11 | 100 | 0.7644 | 0.6714 |
| 0.7032 | 0.23 | 200 | 0.5568 | 0.75 |
| 0.5262 | 0.34 | 300 | 0.4440 | 0.7806 |
| 0.4719 | 0.45 | 400 | 0.3893 | 0.8144 |
| 0.5021 | 0.57 | 500 | 0.5129 | 0.8090 |
| 0.3123 | 0.68 | 600 | 0.4536 | 0.7980 |
| 0.3606 | 0.79 | 700 | 0.3679 | 0.8483 |
| 0.4081 | 0.91 | 800 | 0.3335 | 0.8559 |
| 0.3624 | 1.02 | 900 | 0.3149 | 0.8592 |
| 0.1903 | 1.14 | 1000 | 0.3296 | 0.8766 |
| 0.334 | 1.25 | 1100 | 0.2832 | 0.8897 |
| 0.2731 | 1.36 | 1200 | 0.2546 | 0.8930 |
| 0.311 | 1.48 | 1300 | 0.2585 | 0.8908 |
| 0.3209 | 1.59 | 1400 | 0.2701 | 0.8854 |
| 0.4005 | 1.7 | 1500 | 0.2643 | 0.8897 |
| 0.3128 | 1.82 | 1600 | 0.2864 | 0.8843 |
| 0.3376 | 1.93 | 1700 | 0.2882 | 0.8657 |
| 0.2698 | 2.04 | 1800 | 0.2876 | 0.9028 |
| 0.2347 | 2.16 | 1900 | 0.2405 | 0.8974 |
| 0.2436 | 2.27 | 2000 | 0.2804 | 0.8886 |
| 0.1764 | 2.38 | 2100 | 0.2852 | 0.8952 |
| 0.1197 | 2.5 | 2200 | 0.2312 | 0.9127 |
| 0.1082 | 2.61 | 2300 | 0.2133 | 0.9116 |
| 0.1245 | 2.72 | 2400 | 0.2677 | 0.8985 |
| 0.1335 | 2.84 | 2500 | 0.2098 | 0.9181 |
| 0.2194 | 2.95 | 2600 | 0.1911 | 0.9127 |
| 0.089 | 3.06 | 2700 | 0.2062 | 0.9181 |
| 0.0465 | 3.18 | 2800 | 0.2414 | 0.9247 |
| 0.0985 | 3.29 | 2900 | 0.1869 | 0.9389 |
| 0.1113 | 3.41 | 3000 | 0.1819 | 0.9323 |
| 0.1392 | 3.52 | 3100 | 0.2101 | 0.9312 |
| 0.0621 | 3.63 | 3200 | 0.2201 | 0.9367 |
| 0.1168 | 3.75 | 3300 | 0.1935 | 0.9389 |
| 0.059 | 3.86 | 3400 | 0.1946 | 0.9367 |
| 0.0513 | 3.97 | 3500 | 0.1950 | 0.9389 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
fourthbrain-demo/bert_model_reddit_tsla_tracked_actions | 48925fcbd0766f87dc2168551f3db5de510736eb | 2022-07-26T16:00:15.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | fourthbrain-demo | null | fourthbrain-demo/bert_model_reddit_tsla_tracked_actions | 4 | null | transformers | 20,496 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert_model_reddit_tsla_tracked_actions
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_model_reddit_tsla_tracked_actions
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Shenzy2/autotrain-tk-1181244086 | 0c8aa0eb31862583bdb1e0653c241ec68dc58bfe | 2022-07-26T13:03:18.000Z | [
"pytorch",
"bert",
"token-classification",
"en",
"dataset:Shenzy2/autotrain-data-tk",
"transformers",
"autotrain",
"co2_eq_emissions",
"autotrain_compatible"
] | token-classification | false | Shenzy2 | null | Shenzy2/autotrain-tk-1181244086 | 4 | null | transformers | 20,497 | ---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- Shenzy2/autotrain-data-tk
co2_eq_emissions: 0.004663044473485149
---
# Model Trained Using AutoTrain
- Problem type: Entity Extraction
- Model ID: 1181244086
- CO2 Emissions (in grams): 0.004663044473485149
## Validation Metrics
- Loss: 0.5532978773117065
- Accuracy: 0.8263097949886105
- Precision: 0.5104166666666666
- Recall: 0.4681528662420382
- F1: 0.4883720930232558
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/Shenzy2/autotrain-tk-1181244086
```
Or Python API:
```
from transformers import AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("Shenzy2/autotrain-tk-1181244086", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("Shenzy2/autotrain-tk-1181244086", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
``` |
swtx/ernie-3.0-medium-chinese | 190de263ddb59677b0c7e1216fe9ab53a7833a71 | 2022-07-26T15:08:03.000Z | [
"pytorch",
"transformers",
"license:apache-2.0"
] | null | false | swtx | null | swtx/ernie-3.0-medium-chinese | 4 | null | transformers | 20,498 | ---
license: apache-2.0
---
|
jperezv/bert-finetuned-ner | 0b5f2b521665b8a4e537fe46c182acffbf0d4960 | 2022-07-26T16:09:56.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | token-classification | false | jperezv | null | jperezv/bert-finetuned-ner | 4 | null | transformers | 20,499 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9389414302306288
- name: Recall
type: recall
value: 0.9523729384045776
- name: F1
type: f1
value: 0.9456094911855628
- name: Accuracy
type: accuracy
value: 0.9866074056631542
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0627
- Precision: 0.9389
- Recall: 0.9524
- F1: 0.9456
- Accuracy: 0.9866
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0835 | 1.0 | 1756 | 0.0711 | 0.9200 | 0.9334 | 0.9266 | 0.9825 |
| 0.0329 | 2.0 | 3512 | 0.0648 | 0.9308 | 0.9485 | 0.9396 | 0.9858 |
| 0.0179 | 3.0 | 5268 | 0.0627 | 0.9389 | 0.9524 | 0.9456 | 0.9866 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.