
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
15,733 | 使用这个开源工具轻松同步数据库 | https://opensource.com/article/23/3/synchronize-databases-apache-seatunnel | 2023-04-18T17:36:22 | [
"SeaTunnel",
"数据库"
] | https://linux.cn/article-15733-1.html | 
>
> 开源的 Apache SeaTunnel 项目是一个数据整合平台,可以很容易地实现数据同步。
>
>
>
<ruby> 变更数据捕获 <rt> Change Data Capture </rt></ruby>(CDC)使用服务端代理来记录、添加、更新和删除对数据表的各种操作。它以一种易用的关系型格式提供了数据变化的细节信息。它可以捕获将更改应用于目标环境中的已修改行所需的列信息和元数据。这些信息保存在一个与被跟踪的源表的列结构相对应的变化表内。
捕获变更的数据可不是一件容易的事。不过,有一个开源项目 —— [Apache SeaTunnel](https://seatunnel.apache.org/),它是一个数据整合平台,它提供的 CDC 功能的设计理念和功能集使这些捕获成为可能,其功能包括上文提到的,超越了现有产品的解决方案。
### 使用场景
CDC 的经典应用是异质数据库之间的数据同步或备份。你可以在 [MySQL](https://opensource.com/downloads/mariadb-mysql-cheat-sheet)、PostgreSQL、MariaDB 和类似的数据库间进行数据同步。另外一个例子,你也可以将数据同步到应该全文搜索引擎。借助 CDC,你可以基于 CDC 捕获的数据创建备份。
如果设计得当,数据分析系统通过订阅目标数据表的变化情况获取需要处理的数据,而不需要将分析过程嵌入已有系统。
### 在微服务间共享数据状态
微服务现在很流行,但是在微服务间共享信息往往是一件复杂的事。CDC 是一个可能的解决方案。微服务可以使用 CDC 来获取其他微服务的数据库变化,获取数据状态更新,以及执行相应逻辑。
### 更新缓存
<ruby> 命令查询责任隔离 <rt> Command Query Responsibility Segregation </rt></ruby>([CQRS](https://www.redhat.com/architect/illustrated-cqrs))的概念是将命令活动与查询活动分开。这两者有本质上的不同:
* 命令向数据源写入数据。
* 查询从数据源读取数据。
问题是,读事件发生的时间与写事件发生的时间有关,以及这些事件的发生是由谁来承担责任的?
更新缓存可能很困难。你可以使用 CDC 从数据库获取数据更新事件,让它控制缓存的更新或失效。
CQRS 设计通常使用两种不同的存储实例来支持业务查询和变更操作。为了保证数据的一致性,我们可以使用分布式事务来保证强大的数据一致性,代价是可用性、性能和扩展性。你也可以使用 CDC 来确保最终的数据一致性,它的性能和伸缩性较好,但其代价是数据延迟,目前业界可以保持在毫秒范围内。
例如,你可以使用 CDC 把 MySQL 中的数据同步到你的全文搜索引擎(比如ElasticSearch)。在这种架构中,ElasticSearch 搜索了所有的查询,但是当你需要修改数据时,你不能直接操作 ElasticSearch 的,你需要修改上游的 MySQL 数据,因而生成了一个更新事件。当 ElasticSearch 监视数据库时,这个事件就被系统获取了,并在 ElasticSearch 中提示更新。
在一些 CQRS 系统中,也可以用类似的方法更新查询视图。
### 痛点
CDC 不是一个新概念,很多现有的项目已经实现了它。但是对很多用户来说,已有解决方案存在一些不足。
#### 单数据表配置
当你使用一些 CDC 软件时,你必须分别配置每个表。例如,为了同步十张表,你需要写十条 源 SQL 和 <ruby> 汇聚 <rt> Sink </rt></ruby> SQL 语句。为了进行转换操作,你也需要写与转换相关的 SQL 语句。
有时候,对于一张表来说可以手写,但只对数据量小的情况适用。当数据量大时,会发生类型映射或参数配置的错误,进而导致较高的操作和维护成本。
SeaTunnel 是一个易用的数据集成平台,有望解决这个问题。
#### 不支持模式演化
一些 CDC 解决方案支持 DDL 事件传递,但不支持传递到 <ruby> 汇聚节点 <rt> Sink </rt></ruby>,以便它能进行同步变更。由于无法根据 DDL 事件改变转换的类型信息,所以即使一个能获取事件的 CDC 也不一定可以将它发送至引擎(所以汇聚节点不能遵循 DDL 事件来进行变更)。
#### 太多的链接
在一些 CDC 平台上,当有多个表时,如果一张表被同步了,就必须使用一个链接来代表一张表。当存在多个表时,也需要很多链接。这就给源 JDBC 数据库带来了压力,同时导致binlog 过多,还会导致重复的日志解析。
### SeaTunnel CDC 架构的目标
Apache SeaTunnel 是一个开源、高效、分布式、大规模的数据集成框架。为了解决现有数据集成工具解决不了的问题,开发者社区“重新造轮子”,开发了一种具有独特功能的 CDC 平台。它的架构设计吸收了现有工具的优点,消除了相应的缺点。
Apache Seatunnel 支持:
* 以无锁并行的方式快照历史数据。
* 日志心跳检测和动态添加数据表。
* 读取子数据库、子表和多结构表。
* 模式演进。
* 所有基础的 CDC 功能。
它降低了用户的操作和维护成本,并且支持动态添加数据表。
例如,当你要同步整个数据库,并在稍后需要添加一个新表,你不必手动维护、改变配置或重启当前作业。
另外,Apache SeaTunnel 也支持并行读取子数据库、子表和多结构表。还支持模式演进、DDL 转换,以及在引擎内改变支持的模式,这些可以变为 <ruby> 转换器 <rt> Transform </rt></ruby>和 <ruby> 汇聚节点 <rt> Sink </rt></ruby>。
### SeaTunnel CDC 现状
如今,CDC 拥有支持增量和快照阶段的基本能力。它也支持 MySQL 实时和离线使用。MySQL 实时测试已完成,即将进行离线测试。因为它涉及对转换器和汇聚节点的更改,目前还不支持模式。不支持动态发现新增表,已预留了一些支持多结构表的接口。
### 项目展望
作为 Apache 孵化的项目,Apache SeaTunnel 的社区正快速发展起来。下一届社区计划会议的主要目标有:
#### 1、发展并改进连接器和目录生态
我们正努力改善连接器和目录功能,包括:
* 支持连接更多数据库,包括 TiDB、Doris 和 Stripe。
* 改善现有的连接器的易用性和性能。
* 支持 CDC 连接器用于实时、增量同步场景。
任何对连接器感兴趣者都可以查看 [Umbrella](https://github.com/apache/incubator-seatunnel/issues/1946)。
#### 2、支持更多数据集成场景(SeaTunnel 引擎)
现有的引擎仍然存在一些解决不了的痛点,例如对整个数据库的同步,表结构变化的同步以及任务失败的大粒度。
我们正努力解决这些问题,对此感兴趣者可以查看 [#2272 议题](https://github.com/apache/incubator-seatunnel/issues/2272)。
#### 3、更易使用(Web 版)
我们正努力提供 Web 界面,令操作更简便。通过 Web 界面,我们将实现以 DAG/SQL 的形式查看目录、连接器、任务和相关信息。我们也会给予用户访问调度平台的权限,以便更方便地进行任务管理。
欲了解更多关于 Web 版的信息,请访问 [Web 平台子项目](https://github.com/apache/incubator-seatunnel-web)。
### 总结
数据库活动通常必须被仔细跟踪,才能对数据的更新、删除或添加操作进行管理。CDC 提供了这种功能。Apache SeaTunnel 是一个开源解决方案,能满足这些需求,它将持续迭代更新,从而提供更多功能。该项目和社区也很活跃,欢迎你的加入。
*(题图:MJ:database connections illustration in high resolution, very detailed, 8k)*
---
via: <https://opensource.com/article/23/3/synchronize-databases-apache-seatunnel>
作者:[Li Zongwen](https://opensource.com/users/li-zongwen) 选题:[lkxed](https://github.com/lkxed/) 译者:[cool-summer-021](https://github.com/cool-summer-021) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Change Data Capture (CDC) uses Server Agents to record, insert, update, and delete activity applied to database tables. CDC provides details on changes in an easy-to-use relational format. It captures column information and metadata needed to apply the changes to the target environment for modified rows. A changing table that mirrors the column structure of the tracked source table stores this information.
Capturing change data is no easy feat. However, the open source [Apache SeaTunnel project](https://seatunnel.apache.org/) i is a data integration platform provides CDC function with a design philosophy and feature set that makes these captures possible, with features above and beyond existing solutions.
## CDC usage scenarios
Classic use cases for CDC is data synchronization or backups between heterogeneous databases. You may synchronize data between [MySQL](https://opensource.com/downloads/mariadb-mysql-cheat-sheet), PostgreSQL, MariaDB, and similar databases in one scenario. You could synchronize the data to a full-text search engine in a different example. With CDC, you can create backups of data based on what CDC has captured.
When designed well, the data analysis system obtains data for processing by subscribing to changes in the target data tables. There's no need to embed the analysis process into the existing system.
## Sharing data state between microservices
[Microservices](https://www.redhat.com/en/topics/microservices?intcmp=7013a000002qLH8AAM) are popular, but sharing information between them is often complicated. CDC is a possible solution. Microservices can use CDC to obtain changes in other microservice databases, acquire data status updates, and execute the corresponding logic.
## Update cache
The concept of [Command Query Responsibility Segregation (CQRS)](https://www.redhat.com/architect/illustrated-cqrs) is the separation of command activity from query activity. The two are fundamentally different:
- A command writes data to a data source.
- A query reads data from a data source.
The problem is, when does a read event happen in relation to when a write event happened, and what bears the burden of making those events occur?
It can be difficult to update a cache. You can use CDC to obtain data update events from a database and let that control the refresh or invalidation of the cache.
CQRS design usually uses two different storage instances to support business query and change operations. Because of the use of two stores, in order to ensure data consistency, we can use distributed transactions to ensure strong data consistency, at the cost of availability, performance, and scalability. You can also use CDC to ensure final consistency of data, which has better performance and scalability, but at the cost of data latency, which can currently be kept in the range of millisecond in the industry.
For example, you could use CDC to synchronize MySQL data to your full-text search engine, such as ElasticSearch. In this architecture, ElasticSearch searches all queries, but when you want to modify data, you don't directly change ElasticSearch. Instead, you modify the upstream MySQL data, which generates a data update event. This event is consumed by the ElasticSearch system as it monitors the database, and the event prompts an update within ElasticSearch.
In some CQRS systems, a similar method can be used to update the query view.
## Pain points
CDC isn't a new concept and various existing projects implement it. For many users, though, there are some disadvantages to the existing solutions.
### Single table configuration
With some CDC software, you must configure each table separately. For example, to synchronize ten tables, you need to write ten source SQLs and Sink SQLs. To perform a transform, you also need to write the transform SQL.
Sometimes, a table can be written by hand, but only when the volume is small. When the volume is large, type mapping or parameter configuration errors may occur, resulting in high operation and maintenance costs.
Apache SeaTunnel is an easy-to-use data integration platform hoping to solve this problem.
### Schema evolution is not supported
Some CDC solutions support DDL event sending but do not support sending to Sink so that it can make synchronous changes. Even a CDC that can get an event may not be able to send it to the engine because it cannot change the Type information of the transform based on the DDL event (so the Sink cannot follow the DDL event to change it).
### Too many links
On some CDC platforms, when there are several tables, a link must be used to represent each table while one is synchronized. When there are many tables, a lot of links are required. This puts pressure on the source JDBC database and causes too many Binlogs, which may result in repeated log parsing.
## SeaTunnel CDC architecture goals
Apache SeaTunnel is an open source high-performance, distributed, and massive data integration framework. To tackle the problems the existing data integration tool's CDC functions cannot solve, the community "reinvents the wheel" to develop a CDC platform with unique features. This architectural design is based on the strengths and weaknesses of existing CDC tools.
Apache Seatunnel supports:
- Lock-free parallel snapshot history data.
- Log heartbeat detection and dynamic table addition.
- Sub-database, sub-table, and multi-structure table reading.
- Schema evolution.
- All the basic CDC functions.
The Apache SeaTunnel reduces the operations and maintenance costs for users and can dynamically add tables.
For example, when you want to synchronize the entire database and add a new table later, you don't need to maintain it manually, change the job configuration, or stop and restart jobs.
Additionally, Apache SeaTunnel supports reading sub-databases, sub-tables, and multi-structure tables in parallel. It also allows schema evolution, DDL transmission, and changes supporting schema evolution in the engine, which can be changed to Transform and Sink.
## SeaTunnel CDC current status
Currently, CDC has the basic capabilities to support incremental and snapshot phases. It also supports MySQL for real-time and offline use. The MySQL real-time test is complete, and the offline test is coming. The schema is not supported yet because it involves changes to Transform and Sink. The dynamic discovery of new tables is not yet supported, and some interfaces have been reserved for multi-structure tables.
## Project outlook
As an Apache incubation project, the Apache SeaTunnel community is developing rapidly. The next community planning session has these main directions:
### 1. Expand and improve connector and catalog ecology
We're working to enhance many connector and catalog features, including:
- Support more connectors, including TiDB, Doris, and Stripe.
- Improving existing connectors in terms of usability and performance.
- Support CDC connectors for real-time, incremental synchronization scenarios.
Anyone interested in connectors can review [Umbrella](https://github.com/apache/incubator-seatunnel/issues/1946).
### 2. Support for more data integration scenarios (SeaTunnel Engine)
There are pain points that existing engines cannot solve, such as the synchronization of an entire database, the synchronization of table structure changes, and the large granularity of task failure.
We're working to solve those issues. Anyone interested in the CDC engine should look at [issue 2272](https://github.com/apache/incubator-seatunnel/issues/2272).
### 3. Easier to use (SeaTunnel Web)
We're working to provide a web interface to make operations easier and more intuitive. Through a web interface, we will make it possible to display Catalog, Connector, Job, and related information, in the form of DAG/SQL. We're also giving users access to the scheduling platform to easily tackle task management.
Visit the [web sub-project](https://github.com/apache/incubator-seatunnel-web) for more information on the web UI.
## Wrap up
Database activity often must be carefully tracked to manage changes based on activities such as record updates, deletions, or insertions. Change Data Capture provides this capability. Apache SeaTunnel is an open source solution that addresses these needs and continues to evolve to offer more features. The project and community are active and your participation is welcome.
## Comments are closed. |
15,735 | 开源领域中姐妹情谊和盟友关系的力量 | https://opensource.com/article/23/3/power-sisterhood-allyship-open-source | 2023-04-18T23:49:00 | [
"开源",
"女性"
] | /article-15735-1.html | 
>
> “站在巨人的肩膀上”不仅是指开源,而且是指通过承认女性先驱和领导者在该领域的作用,在技术中建立姐妹情谊的基础。
>
>
>
两年多前,我从艺术家转职成为一名 [软件开发人员](https://enterprisersproject.com/article/2022/9/software-developer-day-life?intcmp=7013a000002qLH8AAM)。我不是单凭一己之力做到的。 我得到了 PyLadies Berlin 的支持,PyLadies Berlin 是一个国际志愿者团体的柏林本地分会,旨在支持女性从事技术工作。
我们习惯了“职业变化”这个词,就好像它是一个轨迹的中断。但根据我的经验,事实并非如此。一个人无法抹去自己过去的点点滴滴,而多样化背景带来的丰富性可以造就爆发点。个体的人生旅程虽然通常与计算机科学毫无相关,却担起了令科技对社会有所影响的职责,并为技术行业带来丰富性和创造力。
作为一名艺术家,我得到了自由,并打开了探索从建筑到科学等多个领域的大门。我大部分的艺术经历发生在巴西的黑客空间里,这里充斥着<ruby> 自由及开源软件 <rt> Free/Libre Open Source Software </rt></ruby>(FLOSS)的思想,即开放的自由共享文化。如今,由于一些不属于本文讨论范围的意识形态和实践原因,最常见的术语是“开源”。对我来说幸运的是,我的职业转变始于一次在 <ruby> 开源项目办公室 <rt> Open Source Program Office </rt></ruby>(OSPO)的实习,它让我的转变经历感觉——几乎可以说——像回家一样。
### 放在巨人的肩膀上
我们都受益于开源。无论你是否编码,你所使用的软件都依赖于它。由于这是一种开放的文化,一切都建立在他人的工作之上,所以经常听到“站在巨人的肩膀上”这个表述,指的是我们的进步都建立在前人的工作和贡献之上。 这突出了从他人的经验和成就中学习的重要性。
这篇文章旨在揭示我站在谁的肩膀上。这不仅是为了表达我对他们的感激之情,也是为了回答我在接受 JSParty 的 Kevin Ball 和 Christopher Hiller 采访时被问到的一个问题:你能做些什么来改善周围环境的多样性?
“站在巨人的肩膀上”不仅是指开源,而且是指通过承认女性先驱和领导者在该领域的作用,在技术中建立姐妹情谊的基础。通过承认在我们之前的女性所做的贡献,我们可以从她们所面临的挑战中获得灵感和洞察力,并从她们挣脱束缚的经验中学习。通过这种方式,我们“站在巨人的肩膀上”,以她们的工作为基础,为女性和 [被低估的](https://www.if-me.org/) 技术人员创造更具包容性和支持性的环境。
通过相互支持,认识到从他人经验中学习的重要性,并形成一个支持网络,我们可以共同努力克服挑战,通过创造更公平的环境,为所有人建设更美好的未来。通过这样做,我们正在创造新的巨人,供其他人在未来立足。
### 组织一个当地社区: Meili Triantafyllidi 和 Jessica Greene
我加入了 PyLadies Berlin,它由 Meili 于 2013 年创立。Jessica 是组织者之一,她是 Ecosia 的一名初级软件工程师。成为社区组织者意味着利用你个人的空闲时间和热情,尽力创建一个安全的、支持性的网络和学习空间。这些工作包括寻找举办地点、宣传活动、策划主题、寻找演讲者,最重要的是,倾听社区的需求。
作为多元文化城市的新人并试图在城市中找到自己的位置,我感到 PyLadies 与其说是一个学习 Python 的地方,不如说是一个让我感受到被欢迎和被理解的中心。
根据我们常常听到的叙述,科技领域是每个人都在前往的新希望之地,有无限的岗位需求、切换国家的自由和高薪的职业。其他行业没有提供这种服务,或者至少没有达到这种规模。专注于带来多样性空间的社区提供了使这对每个人都成为现实的可能性。
每个活动都以社区公告、包含议程的简单幻灯片以及类似活动的宣传开始。当时我听闻的两个活动引导我走上了我的职业道路:Rail Girls Summer of Code 计划和 FrauenLoop。因为感觉有必要回馈当初给予了我支持的社区,我成为了共同组织者之一。
### 搭建人际关系网和学习专业知识: FrauenLoop
FrauenLoop 由 Nakeema Stefflbauer 博士于 2016 年创立,致力于改变欧盟科技公司的面貌。该项目分为 3 个月的周期,由每周的晚间课程和周末研讨会组成,以培训在科技行业里没有人际关系网的女性。
学习课程是围绕女性的专业需求开发的,从以技术行业为重点的课程到女性举办的关于科技行业如何真正运作以及如何成功立足的研讨会。一些常见的话题包括薪资谈判和练习技术面试。最近,为了应对裁员,柏林技术工人联盟举办了一场研讨会,揭开如何对公司解雇流程提出质疑的神秘面纱。
研讨会聚焦于女性,尤其是移民群体,她们正处于家庭状况和职业转变的阶段,真正准备好去寻找工作了。
和 Nakeema 在一起本身就给我带来了灵感。该项目提供了理解编程和学习网页开发基础知识的起点。但最重要的是,你与项目中的其他人建立了联系,他们是 PyLadies 未来的共同组织者、演讲者、业余项目的导师和朋友。
FrauenLoop 还为其学生提供了回去担任导师的机会。对我来说,这是决定我前进道路的转折点。做了一年多的导师,增强了我对自己的信心,也巩固了我自己的学习。受到帮助他人学习这一责任的挑战,你不可避免要一直学习。
在那里我遇到了 Victoria Hodder,她是我申请 Rail Girls Summer of Code 时的搭档。
### 多元化项目:从 Rail Girls Summer of Code 到 Ecosia Summer of Code
Rail Girls Summer of Code 是一项面向女性和非二元性别程序员的全球奖学金计划,入选的申请者将获得为期三个月的奖学金,以从事现有的开源项目。该计划活跃于 2013 年到 2020 年。
申请以一个团队为单位进行提交,即来自同一个城市的两个人。虽然这是一个远程项目,但有一个本地同行确保了问责制和相互支持。
除了同伴,项目还需要有一个办公的地方,一个适合工作三个月的环境。这个地方可以是你的家、联合办公空间、工作办公室,或者最好的情况下是培训公司。虽然培训公司除了提供工作空间外没有其他义务,但它让我们与当地公司联系起来,并为我们提供了一个空间,让我们能够与我们想进入的行业内的人建立知名度和关系网。
我在 PyLadies Berlin 的联合组织者 Jessica 通过该项目开启了她在科技领域的职业生涯。她提议 Ecosia(她当时也是现在所任职的公司)担任两个团队的指导工作,其中一个是我和 Victoria 的团队(我们专注于网络开发),另一个是 Taciana Cruz 和 Karina Cordeiro 的团队(他们专注于数据)。
在三个月的申请期内,大流行来势汹汹。在参与 [if-me](https://www.if-me.org/) 项目后,我和维多利亚被 *某种程度上* 选入了 the Rail Girls 项目。因为是 *某种程度上* 被选中的,我们与 Rail Girls 的沟通在选拔后期变得非常混乱,最终他们在最后一刻取消了项目。
我们当时都崩溃了。大流行的重压给我们带来了沉重打击,它不仅粉碎了我们获得一份有偿工作的机会,而且粉碎了长期以来养成的开始新职业的梦想。
当时还是初级软件开发人员的 Jessica懂我们的处境,因此她挺身而出,她没有感到无能为力,而是站出来表明自己的立场。除了为适应个人新角色所付出的努力,她还给自己安排了更多工作,并创建了 [Ecosia Summer of Code](https://blog.ecosia.org/ecosia-summer-of-code-mentoring/) 这一项目。
Ecosia 无法支付奖学金,但 Jessica 开发了一个导师计划。该计划利用公司的可用资源,提供高素质专业人士的指导,以填补我们的知识空白。由于 Victoria 和 Karina 因为需要有报酬的工作而放弃了项目,Taciana 和我设法继续进行个人项目。我们找到了可以一起努力并相互支持的共同主题。
大约一年后,其中一位导师 Jakiub Fialla 邀请我去她的公司聊聊开源。我与其他一些人依然保持着联系,时不时地,当他们举办 PyLadies Berlin 活动时,我会顺便过去见见他们。如此甜蜜。
### 赞助多样性: Coyotiv 项目和它的创始人 Armagan Amcalar
当 Rail Girls 项目被取消时,我在 Instagram 上看到一篇关于训练营的帖子,该训练营提供全栈网络开发计划奖学金。
申请流程很简单,所以我就申请了。我很快收到了一份自发的面试邀请。当时的我感到沮丧、凌乱又绝望,没有任何准备就参加了面试,所以我全程非常诚实。整个面试的谈话同样坦诚,对此我深表感激。
面试官是 [Coyotiv 软件工程学院](https://www.coyotiv.com/) 的创始人 Armagan Amcalar。具有音乐背景的Armagan 富有创造力,对周围的世界有着批判性的思考。这所学校是在他为柏林的 Women Techmakers 提供免费速成课程三年后创办的。他没有死记硬背多样性演讲,而是根据它采取行动,为所有全职参与者提供奖学金。
我获得了奖学金,并与其他四个人(其中 3 名女性)一起组成了第一批学生。训练营持续了高强度的 17 周。它对改变我对代码的看法极为重要。与我尝试学习的其他地方不同,Armagan 并不关心我们选择什么编程框架。相反,这一切都是为了理解我们在做什么,并将软件工程视为一种创造性的、强大的工具来塑造我们生活的世界。我得到的不仅仅是奖学金,我还收获了一个朋友和终身导师,他为我提供华丽转身的机会,打开了一扇通往美好生活的大门。
你是不是觉得我的反应太夸张了?你可以问问我身边的人。我的搭档此时已经认识我大约 14 年了,他是这样评价我的变化的:我变得纪律严明,充满活力,一路走来我对学到的东西感到高兴,就软件及其相关的事物进行深入对话,不再困惑矛盾,我放弃了终生的艺术事业,转而找到了人生的目标。由于我的变化实在惊人,他参加了我后面的几届训练营项目。
学校为我提供了技术知识、面试培训、简历支持和公开演讲培训。毕业不仅仅要求开发个人的全栈项目,还必须通过在 npm 上发布一个库来回馈开源,因为有如此多的软件是基于开源构建的。Node 包管理器(npm)是一个 JavaScript 包存储库,允许你通过在基于 Javascript 的项目中轻松安装代码来重用代码。尽管我参与自由软件运动和开源已经十多年了,但我从没想过我可以用实际代码回馈它。
### 我的贡献
[彩虹企鹅](https://www.npmjs.com/package/rainbow-penguin) 就这样诞生了。它是一个 npm 库,可以在开发人员敲代码时发送激励信息。 也许它不是一个非常实用的工具。但对我来说它依然是个必要的工具,这基于我个人的经历——我经历过学习编码的挫折,为 if-me 项目做出贡献,而且从其他学习者那里听到了许多类似的故事。
通过我在这些编程社区的经历,我了解到编程远不止一行行的代码,拥有盟友是多么强大和有必要。无论你是谁或你自认为了解什么,自由和开源软件社区中都有机会。你的参与不一定要是大动作,因为盟友们的小小贡献加起来远大于一个人贡献的总和。迈出第一步。在开源领域中找到你的盟友。
*(题图:MJ:tech woman illustration in high resolution, very detailed, 8k)*
---
via: <https://opensource.com/article/23/3/power-sisterhood-allyship-open-source>
作者:[Paloma Oliveira](https://opensource.com/users/discombobulateme) 选题:[lkxed](https://github.com/lkxed/) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,736 | 搜索知识共享内容的搜索引擎 | https://opensource.com/article/23/4/search-engine-creative-commons-openverse | 2023-04-19T18:44:52 | [
"知识共享"
] | https://linux.cn/article-15736-1.html | 
>
> 寻找具有开放许可的图像和音频。
>
>
>
你是否正在寻找可以重复使用的公开许可的内容?那么你可能会对 [Openverse](https://openverse.org/) 感兴趣。Openverse 是一个创新工具,可从不同数据库的集合中对多达 3 亿张图片进行搜索。它不仅仅可以搜索图像,还允许用户访问由机器学习模型创建的标签,并可以一键设置归属。由于可以搜索大量的视觉效果,用户可以找到完美的图像,使他们的项目更具吸引力。这些内容来自各种来源,包括史密森尼博物馆、克利夫兰艺术博物馆、美国宇航局和纽约公共图书馆。
2019 年,<ruby> 知识共享 <rt> Creative Commons </rt></ruby>(CC)站点提供的 CC Search 工具被 WordPress 项目采用。Openverse 是 CC Search 的新化身。
目前,Openverse 仅索引了图像和视听内容。视频的搜索可以从外部来源获得。他们计划增加更多的开放性文本、3D 模型等形式。他们有一个共同的目标:让人们可以使用 [知识共享](https://opensource.com/article/20/1/what-creative-commons) 许可和在线公共领域作品,这些估计有 25 亿之多。他们所使用的代码都是开源的。
请注意,Openverse 不保证视觉资料已正确提供了知识共享许可,也不保证所收集的归属信息和任何其他相关许可信息准确完整。为了安全起见,请在重新使用材料之前仔细检查版权状态和归属信息。要了解更多信息,请阅读 [Openverse](https://creativecommons.org/terms/) 中的使用条款。
### Openverse 搜索
使用 Openverse 很容易。在**搜索内容**字段中输入你的搜索词,然后按**回车**。我对“尼亚加拉大瀑布”进行了简单搜索,收到了超过 [10,000 个结果](https://openverse.org/search/?q=niagara%20falls) 的图像和两个音频结果。在显示屏的最右侧是一个对话框,用于检查可用于商业用途的内容,另一个用于检查允许修改和改编的内容。
此外,第二个复选框允许你指定要使用或重复使用的知识共享许可,包括 CC0(公共领域)、[CC-BY](https://creativecommons.org/licenses/by/4.0/)、[CC-BY-SA](https://creativecommons.org/licenses/by-sa/4.0/)、所有 [CC-BY-NC-ND](https://creativecommons.org/licenses/by-nc-nd/4.0/) 的方式。
### 有功者受禄
在使用公开许可的内容时,重要的是确保你提供适当的归属,并遵守内容原创作者所规定的许可条款。关于知识共享协议的更多信息,请查阅 [知识共享网站](https://creativecommons.org/about/cclicenses/)。
Openverse 是一个 [开源](https://github.com/WordPress/openverse) 项目,这意味着你可以托管自己的副本或为该项目做出贡献。该项目有一个 [贡献者指南](https://make.wordpress.org/openverse/handbook/new-contributor-guide/),供想要参与的人使用。该项目还欢迎你对新特性和功能提出 [建议](https://github.com/WordPress/openverse/tree/main/rfcs)。
*(题图:MJ:Creative Commons" shared illustration:: blueprint drawing::1 blue::1)*
---
via: <https://opensource.com/article/23/4/search-engine-creative-commons-openverse>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Are you looking for content that is openly licensed that you can reuse? Then you might be interested in [Openverse](https://openverse.org/). Openverse is an innovative tool that searches over 300 million pictures from an aggregation of different databases. It goes beyond just searching for an image by giving users access to tags created by machine learning models and one-click attribution. With so many visuals to explore, users can find the perfect image to make their project more engaging. The content comes from a variety of sources, including the Smithsonian, Cleveland Museum of Art, NASA, and the New York Public Library.
In 2019, the CC Search tool provided by the Creative Commons site was adopted by the WordPress project. Openverse is the new incarnation of CC Search.
Currently, Openverse only indexes images and audio-visual content. Searches for video are available from external sources. Plans are in place to add additional representations of open-access texts, 3D models, and more. They have one common goal: Grant access to the estimated 2.5 billion [Creative Commons](https://opensource.com/article/20/1/what-creative-commons) licenses and public domain works available online. All the code utilized is open source.
Please be aware that Openverse does not guarantee that the visuals have been correctly provided with a Creative Commons license or that the attribution and any other related licensing information collected are precise and complete. To be safe, please double-check the copyright status and attribution information before reusing the material. To find out more, please read the terms of use in [Openverse](https://creativecommons.org/terms/).
## Openverse search
Using Openverse is easy. Enter your search term in the **Search for Content** field and press **Enter**. I did a simple search for "Niagara Falls" and received over [10,000 results](https://openverse.org/search/?q=niagara%20falls) for images and two results for audio. On the display's far right is a dialog box to check for content that can be used commercially and another for content that allows modification and adaptation.
In addition, a second checkbox allows you to specify which Creative Commons license you want to use or reuse, including CC0 (Public domain), [CC-BY](https://creativecommons.org/licenses/by/4.0/), [CC-BY-SA](https://creativecommons.org/licenses/by-sa/4.0/), all the way to [CC-BY-NC-ND](https://creativecommons.org/licenses/by-nc-nd/4.0/).
## Credit where credit is due
When using openly licensed content, it's important to make sure that you provide proper attribution and comply with the license terms that have been stipulated by the original creator of the content. For more information about Creative Commons licenses, consult the [Creative Commons website](https://creativecommons.org/about/cclicenses/).
Openverse is an [open source ](https://github.com/WordPress/openverse)project which means you can host your own copy or contribute to the project. The project has a [contributor guide](https://make.wordpress.org/openverse/handbook/new-contributor-guide/) for folks who want to get involved. The project also welcomes your [proposals](https://github.com/WordPress/openverse/tree/main/rfcs) for new features and functionality.
## 1 Comment |
15,738 | 开源设计系统 PatternFly 的 5 个最佳实践 | https://opensource.com/article/23/4/open-source-design-system-patternfly | 2023-04-20T11:20:42 | [
"开源设计"
] | https://linux.cn/article-15738-1.html | 
>
> PatternFly 是一个开源、开放社区的设计系统。
>
>
>
你是否曾欣赏过宝石的切面?这些角度和倾斜是一件美丽的事情。你可以看到多面宝石比平面宝石更亮。在分析一个多面体设计系统时,你也可能会看到这种美。设计系统是用于创建一致且统一的用户界面(UI)的准则、标准和资源的集合。就像钻石的各个切面一样,一个富含不同贡献和社区参与的开源设计系统最终会带来更好的产品体验。
[PatternFly](https://www.patternfly.org/v4/) 项目是一个用于红帽产品的开源设计系统。但开源并没有以 PatternFly 的代码为终点。PatternFly 的背后是一群完全公开创作设计的人。从设计师和开发人员到研究人员和作家,我们作为一个开源社区共同努力。
我们的秘密?我们没有秘密 —— 我们在开放中工作,记得吗?然而,我们使用了这五个最佳实践。我将在这里分享它们,这样你也可以使用开源来支持你自己的设计系统。
### 1、集体贡献
我们有一个核心的 PatternFly 设计团队来设计、维护和发展设计系统。但我们鼓励并欢迎所有人的贡献。如果你对协作充满热情并且擅长用户体验(UX),[PatternFly 希望收到你的反馈](https://www.patternfly.org/v4/contribute/about)。
### 2、建立社区
在孤岛中创建的任何内容都无法进入 PatternFly。我们相信开放的设计更好。这就是我们将社区纳入所有更新、更改和添加的原因。我们收集来自设计和开发人员对贡献的反馈,以便每个人都对实施的内容有发言权。我们还寻求多个 [设计学科](https://design.redhat.com/?intcmp=7013a000002qLH8AAM) 的人们的意见和协作。这样做是为了摆脱任何偏见或假设。这种开放的设计让我们的设计体系更加强大。它还加强了我们蓬勃发展的社区,该社区由参与 PatternFly 或为之做出贡献的人们组成(我们亲切地称他们为 “飞人”)。
### 3、在每个人中循环
如果你发现与他人集思广益的想法产生的解决方案比任何一个人梦寐以求的都要好,那么你已经像“飞人”一样思考了。我们定期举行设计会议,供贡献者在小组环境中展示他们的想法并讨论设计方法。这使我们能够保持我们的想法协作,并从各个角度考虑设计。此外,我们每月举办社区会议,以便我们可以与来自全球各地的“飞人”们联系并分享最新动态。你可以在我们的 [PatternFly YouTube 频道](https://www.youtube.com/channel/UCqLT0IEvYmb8z__9IFLSVyQ) 上观看我们过去的所有会议记录。
### 4、倾听用户
作为一个社区,我们的目标是让 PatternFly 的所有贡献都能在不同的环境中带来功能性和美观的产品体验。为了实现这一目标,我们要求自己打破自己的泡沫并与用户互动。我们与 UX 研究人员合作,与用户一起测试更新、更改和添加(例如视觉主题和交互),以确保我们创建的设计、资源和体验能够为每个人解决问题,而不仅仅是像我们这样的人。
### 5、创建连接
PatternFly 是贯穿红帽公司产品的一致性的主线。每个人都有创造的自由,来构建最适合他们用户的东西。但我们作为一个团队,通过设计系统连接产品组,以获得更统一的用户体验。PatternFly 的资源很容易获得,并向所有人开放。这有助于我们建立联系,压制孤岛。
### 与我们一起开放设计
无论你是一个由 1 人还是 100 人组成的团队,或者你的设计系统是否是开源的,在我们所做的每一件事中,总有一点协作和社区的空间。联系 [PatternFly 社区](https://www.patternfly.org/v4/community),告诉我们你的结果如何。我们迫不及待地想收到你的来信。
*(题图:MJ:open source design community:: blueprint drawing::1 moonlight::1 ultra wide angle lens::1 green::1)*
---
via: <https://opensource.com/article/23/4/open-source-design-system-patternfly>
作者:[Abigael Donahue](https://opensource.com/users/abigaeljamie) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Have you ever admired the facets of a gemstone? The angles and slants are a thing of beauty. You can see that a multi-faceted gemstone shines brighter than a flat one. You may also see this kind of beauty when analyzing a multi-faceted design system. A design system is a collection of guidelines, standards, and resources for creating consistent and unified user interfaces (UI). Like the facets of a diamond, an open source design system rich with diverse contributions and community engagement ultimately leads to better product experiences.
The [PatternFly](https://www.patternfly.org/v4/) project is an open source design system for Red Hat products. But open source doesn't end with PatternFly's code. Behind PatternFly is a team of people who create designs completely in the open. From designers and developers to researchers and writers, we work together to operate as an open source community.
Our secret? We don't have one — we work in the open, remember? However, we use these five best practices. I'll share them here so that you too can power your own design system with open source.
## 1. Contribute collectively
We have a core PatternFly design team to design, maintain, and evolve the design system. But we encourage and welcome contributions from everyone. If you have a passion for collaboration and a knack for user experience (UX), [PatternFly wants to hear from you](https://www.patternfly.org/v4/contribute/about).
## 2. Build community
Nothing created in a silo makes its way to PatternFly. We believe design is better in the open. This is why we include the community in all updates, changes, and additions. We collect feedback on contributions from people across design and development so that everyone has a say in what gets implemented. We also seek input and collaboration from people across multiple [design disciplines](https://design.redhat.com/?intcmp=7013a000002qLH8AAM). This is done to break free from any bias or assumption. This kind of open design makes our design system stronger. It also strengthens our blossoming community of people who engage with or contribute to PatternFly (we lovingly refer to them as Flyers).
## 3. Loop in everyone
If you find that brainstorming ideas with others results in solutions better than any one person would have dreamed of, then you already think like a Flyer. We have regular design meetings where contributors present their ideas and discuss design approaches in a group setting. This enables us to keep our ideas collaborative and consider designs from all angles. Additionally, we host monthly community meetings so that we can connect with Flyers from across the globe and share the latest updates. You can catch all of our past meeting recordings on our [PatternFly YouTube channel](https://www.youtube.com/channel/UCqLT0IEvYmb8z__9IFLSVyQ).
## 4. Listen to users
As a community, we aim to have all PatternFly contributions lead to functional and beautiful product experiences across different contexts. To make that a reality, we hold ourselves accountable to break out of our own bubbles and engage with users. We work with UX researchers to test updates, changes, and additions with users — such as visual themes and interactions — to ensure that we're creating designs, resources, and experiences that solve for everyone, not just people like us.
## 5. Create connections
PatternFly is the thread of consistency through products across Red Hat's portfolio. Everyone has the creative freedom to build what best serves their users. But we work as a team to connect product groups through the design system for a more unified user experience. PatternFly resources are easy to access and open to all. This helps us create connections and squash silos.
## Come design in the open with us
Whether you're a team of 1 or 100, or whether your design system is open source or not — there's always room for a little collaboration and community in everything we do. Tell us how things turn out for you by connecting with the [PatternFly community](https://www.patternfly.org/v4/community). We can't wait to hear from you.
## Comments are closed. |
15,739 | 在 FreeDOS 上如何使用 C 语言编程 | https://opensource.com/article/21/6/program-c-freedos | 2023-04-20T15:31:09 | [
"C 语言"
] | https://linux.cn/article-15739-1.html | 
>
> 在 FreeDOS 上使用 C 语言编程与在 Linux 上使用 C 语言编程非常类似。
>
>
>
当我第一次开始使用 DOS 时,我喜欢 DOS 自带的 BASIC 来编写游戏和其它一些有趣的程序。很长时间后,我才学习 C 编程语言。
我马上爱上了使用 C 语言做开发!它是一种简单易懂的编程语言,在编写有用的程序时,这给予我很大的灵活性。实际上,很多 FreeDOS 的核心实用程序都是使用 C 语言和汇编语言编写的。
因此,FreeDOS 的 1.3 RC4 包含一个 C 语言可能并不出人意料,此外还有其它编程语言的编译器。FreeDOS 的 1.3 RC4 LiveCD 包含两个 C 编译器:Bruce's C 编译器(一个简单的 C 编译器)和 OpenWatcom C 编译器 。在 Bonus CD 上,你也可以找到 DJGPP(一款基于 GNU 的 GCC 的 32 位 C 编译器)和 GCC 的 IA-16 移植(需要 386 或更好的 CPU 来编译,但是,生成的程序可以在低端系统上运行)。
在 FreeDOS 上使用 C 语言编程与在 Linux 上使用 C 语言编程非常类似,但是有两个例外:
1. **你需要知道你使用了多少内存。** Linux 允许程序使用很多内存,但是 FreeDOS 有很多限制。DOS 程序只使用四种 [内存模式](https://devblogs.microsoft.com/oldnewthing/20200728-00/?p=104012)(大、中、紧凑和小)中的其中一种,具体取决于它们需要多少内存。
2. **你可以直接访问控制台终端。** 在 Linux 上,你可以创建 *文本模式* 的程序,使用一个诸如 ncurses 之类的库来绘制终端屏幕。但是,DOS 允许程序访问控制台终端和视频硬件。这为编写更有趣的程序提供了极大的灵活性。
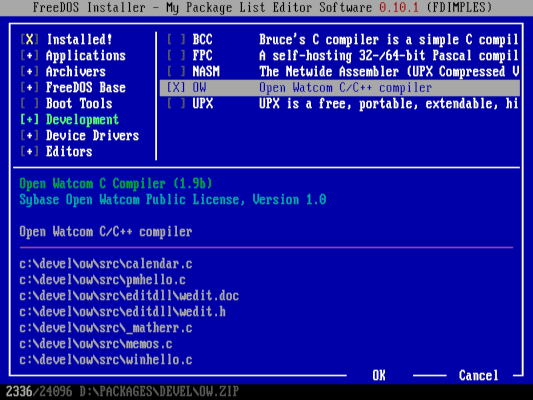
我喜欢在 GCC 的 IA-16 移植或 OpenWatcom 中编写我的 C 程序,具体取决于我正在编写的是哪种程序。OpenWatcom C 编译器更容易安装,因为它只是个单一的软件包。这就是为什么我们在 FreeDOS 的 LiveCD 中提供 OpenWatcom 的原因, 在你安装 FreeDOS 的 1.3 RC4 时,如果你选择 “<ruby> 完全的安装(包括安装应用程序和游戏) <rt> Full installation including applications and games </rt></ruby>”,那么你也自动地安装 OpenWatcom。如果你选择安装 “<ruby> 纯 DOS 系统 <rt> Plain DOS system </rt></ruby>”,那么,你将需要使用 FDIMPLES 软件包管理器来安装 OpenWatcom C 编译器。

*在 FreeDOS 1.3 RC4 上安装 OpenWatcom*
### 在 DOS 上使用 C 语言编程
你可以在 [OpenWatcom 项目网站](http://openwatcom.org/) 找到文档和库指南,以学习 OpenWatcom C 编译器所提供的独特的关于 DOS 的 C 语言编程库。简单描述几个最有用的函数:
来自 `conio.h` 头文件:
* `int getch(void)`:从键盘上获取一个按下的单个按键
* `int getche(void)`:从键盘上获取一个按下的单个按键,并回显该按键
来自 `graph.h` 头文件:
* `_settextcolor(short color)`:设置打印文本时的颜色
* `_setbkcolor(short color)`:设置打印文本时的背景颜色
* `_settextposition(short y, short x)`:移动光标到行 `y` 和 列 `x`
* `_outtext(char _FAR *string)`:从当前光标位置开始,直接将一串字符打印到屏幕
DOS 只支持 [16 种文本颜色](https://opensource.com/article/21/6/freedos-sixteen-colors) 和 8 种背景颜色。你可以使用值 0(黑色)到 15(亮白色)来具体指定文本颜色,以及使用值 0(黑色)到 7(白色)来具体指定背景颜色:
* `0`:黑色
* `1`:蓝色
* `2`:绿色
* `3`:品蓝色
* `4`:红色
* `5`:品红色
* `6`:棕色
* `7`:白色
* `8`:亮黑色
* `9`:亮蓝色
* `10`:亮绿色
* `11`:亮品蓝色
* `12`:亮红色
* `13`:亮品红色
* `14`:黄色
* `15`:亮白色
### 一个花哨的 “Hello world” 程序
很多新开发者学习编写的第一个程序是为用户打印 “Hello world” 。我们可以使用 DOS 的 `conio` 和 `graphics` 库来制作一个更有趣的程序,并使用彩虹般的颜色打印 “Hello world” 。
在这个实例中,我们将遍历每种文本颜色,从 0(黑色)到 15(亮白色)。随着我们打印每一行,我们都将为下一行缩进一个空格。在我们完成后,我们将等待用户按下任意按键,然后,我们将重置屏幕并退出。
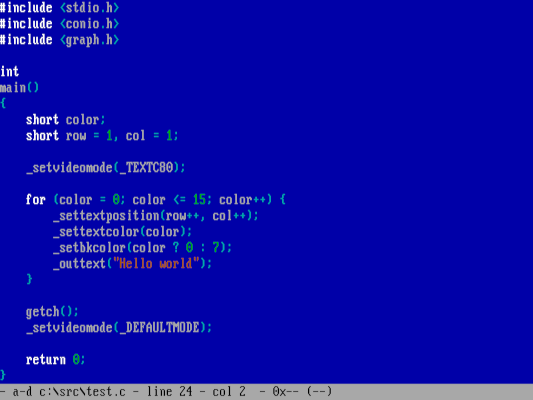
你可以使用任何文本编辑器来编写你的 C 源文件代码。我喜欢使用一些与众不同的编辑器,如 [FreeDOS Edit](https://opensource.com/article/21/6/freedos-text-editor) 和 [Freemacs](https://opensource.com/article/21/6/freemacs),但是,我最近一直在使用 [FED editor](https://opensource.com/article/21/1/fed-editor) ,因为它提供 *语法高亮* 功能,使其很容易在我的程序源文件代码中看到关键字、字符串(LCCT 译注:C 语言中没有字符串)、变量。

*使用 C 语言编写一个简单的测试程序*
在你使用 OpenWatcom 编译前,你将需要设置 DOS 的 [环境变量](https://opensource.com/article/21/6/freedos-environment-variables),以便 OpenWatcom 可以找到它的支持文件。OpenWatcom C 编译器软件包中包含了一个为你做这件事的设置 [批处理文件](https://opensource.com/article/21/6/automate-tasks-bat-files-freedos):`\DEVEL\OW\OWSETENV.BAT`。运行这个批处理文件可以自动为你的 OpenWatcom 设置环境变量。
在你的开发环境准备好后,你可以使用 OpenWatcom 编译器来编译这个 “Hello world” 程序。我已经将我的 C 源文件文件保存为 `TEST.C` ,因此,我可以输入 `WCL TEST.C` 来编译和连接该程序为一个名称为 `TEST.EXE` 的 DOS 可执行文件。在 OpenWatcom 的输出信息中,你将看到 `WCL` 实际上调用 OpenWatcom C 编译器(`WCC`)来编译,并调用 OpenWatcom 链接器(`WLINK`)来执行 <ruby> 对象/目标 <rt> object </rt></ruby> 链接阶段:

*使用 OpenWatcom 编译测试文件*
OpenWatcom 会打印一些无关的输出信息,这可能会使发现错误和警告变得困难。为了告诉编译器来抑制这些大量的额外信息,请在编译时使用 `/Q`(“Quiet”)选项:
 option to make OpenWatcom print less output")
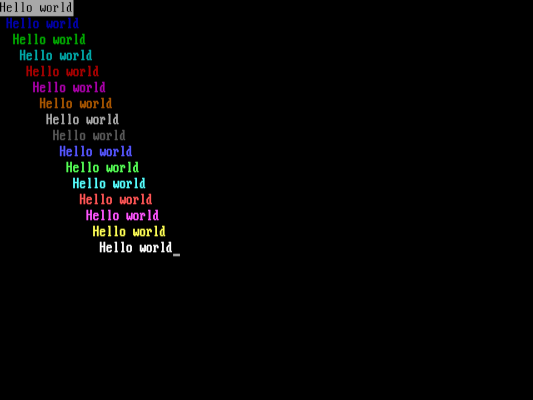
在编译 C 源文件文件时,如果你没有看到任何错误信息,那么你现在就可以运行你的 DOS 程序了。这个 “Hello World” 示例的程序名称是 `TEST.EXE` 。在 DOS 命令行中输入 `TEST` 来运行新的程序,你应该会看到这个非常漂亮的输出:

C 语言是一种非常高效的编程语言,在像 DOS 之类的资源有限的系统上进行编程也可以很好的工作。在 DOS 上,你可以使用 C 语言来做更多的事。如果你是 C 语言的初学者,那么,你可以跟随我们在 FreeDOS 网站上的 《[使用 C 语言编写 FreeDOS 程序](https://www.freedos.org/books/cprogramming/)》 的自学电子书,以及在 [FreeDOS YouTube 频道](https://www.youtube.com/freedosproject) 上的配套的 <ruby> 入门指南 <rt> how-to </rt></ruby> 系列视频,来自主学习 C 语言。
*(题图:MJ:Legacy sci-fi computer programming::1.7 celestial::1 edison bulb::1 satellite imagery::1 wooden::1 in high resolution, very detailed, 8k)*
---
via: <https://opensource.com/article/21/6/program-c-freedos>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When I first started using DOS, I enjoyed writing games and other interesting programs using BASIC, which DOS included. Much later, I learned the C programming language.
I immediately loved working in C! It was a straightforward programming language that gave me a ton of flexibility for writing useful programs. In fact, much of the FreeDOS core utilities are written in C and Assembly.
So it's probably not surprising that FreeDOS 1.3 RC4 includes a C compiler—along with other programming languages. The FreeDOS 1.3 RC4 LiveCD includes two C compilers—Bruce's C compiler (a simple C compiler) and the OpenWatcom C compiler. On the Bonus CD, you can also find DJGPP (a 32-bit C compiler based on GNU GCC) and the IA-16 port of GCC (requires a '386 or better CPU to compile, but the generated programs can run on low-end systems).
Programming in C on FreeDOS is basically the same as C programming on Linux, with two exceptions:
**You need to remain aware of how much memory you use.**Linux allows programs to use lots of memory, but FreeDOS is more limited. Thus, DOS programs used one of four[memory models](https://devblogs.microsoft.com/oldnewthing/20200728-00/?p=104012)(large, medium, compact, and small) depending on how much memory they needed.**You can directly access the console.**On Linux, you can create*text-mode*mode programs that draw to the terminal screen using a library like*ncurses*. But DOS allows programs to access the console and video hardware. This provides a great deal of flexibility in writing more interesting programs.
I like to write my C programs in the IA-16 port of GCC, or OpenWatcom, depending on what program I am working on. The OpenWatcom C compiler is easier to install since it's only a single package. That's why we provide OpenWatcom on the FreeDOS LiveCD, so you can install it automatically if you choose to do a "Full installation including applications and games" when you install FreeDOS 1.3 RC4. If you opted to install a "Plain DOS system," then you'll need to install the OpenWatcom C compiler afterward, using the FDIMPLES package manager.
opensource.com
## DOS C programming
You can find documentation and library guides on the [OpenWatcom project website](http://openwatcom.org/) to learn all about the unique DOS C programming libraries provided by the OpenWatcom C compiler. To briefly describe a few of the most useful functions:
From `conio.h`
:
`int getch(void)—`
Get a single keystroke from the keyboard`int getche(void)—`
Get a single keystroke from the keyboard, and echo it
From `graph.h`
:
`_settextcolor(short color)—`
Sets the color when printing text`_setbkcolor(short color)—`
Sets the background color when printing text`_settextposition(short y, short x)—`
Move the cursor to row`y`
and column`x`
`_outtext(char _FAR *string)—`
Print a string directly to the screen, starting at the current cursor location
DOS only supports [sixteen text colors](https://opensource.com/article/21/6/freedos-sixteen-colors) and eight background colors. You can use the values 0 (Black) to 15 (Bright White) to specify the text colors, and 0 (Black) to 7 (White) for the background colors:
**0**—Black**1**—Blue**2**—Green**3**—Cyan**4**—Red**5**—Magenta**6**—Brown**7**—White**8**—Bright Black**9**—Bright Blue**10**—Bright Green**11**—Bright Cyan**12**—Bright Red**13**—Bright Magenta**14**—Yellow**15**—Bright White
## A fancy "Hello world" program
The first program many new developers learn to write is a program that just prints "Hello world" to the user. We can use the DOS "conio" and "graphics" libraries to make this a more interesting program and print "Hello world" in a rainbow of colors.
In this case, we'll iterate through each of the text colors, from 0 (Black) to 15 (Bright White). As we print each line, we'll indent the next line by one space. When we're done, we'll wait for the user to press any key, then we'll reset the screen and exit.
You can use any text editor to write your C source code. I like using a few different editors, including [FreeDOS Edit](https://opensource.com/article/21/6/freedos-text-editor)** **and [Freemacs](https://opensource.com/article/21/6/freemacs), but more recently I've been using the [FED editor](https://opensource.com/article/21/1/fed-editor) because it provides *syntax highlighting*, making it easier to see keywords, strings, and variables in my program source code.
Before you can compile using OpenWatcom, you'll need to set up the DOS [environment variables](https://opensource.com/article/21/6/freedos-environment-variables)** **so OpenWatcom can find its support files. The OpenWatcom C compiler package includes a setup [batch file](https://opensource.com/article/21/6/automate-tasks-bat-files-freedos) that does this for you, as `\DEVEL\OW\OWSETENV.BAT`
. Run this batch file to automatically set up your environment for OpenWatcom.
Once your environment is ready, you can use the OpenWatcom compiler to compile this "Hello world" program. I've saved my C source file as `TEST.C`
, so I can type `WCL TEST.C`
to compile and link the program into a DOS executable, called `TEST.EXE`
. In the output messages from OpenWatcom, you can see that `WCL`
actually calls the OpenWatcom C Compiler (`WCC`
) to compile, and the OpenWatcom Linker (`WLINK`
) to perform the object linking stage:

OpenWatcom prints some extraneous output that may make it difficult to spot errors or warnings. To tell the compiler to suppress most of these extra messages, use the `/Q`
("Quiet") option when compiling:

If you don't see any error messages when compiling the C source file, you can now run your DOS program. This "Hello world" example is `TEST.EXE`
. Enter `TEST`
on the DOS command line to run the new program, and you should see this very pretty output:
C is a very efficient programming language that works well for writing programs on limited-resource systems like DOS. There's lots more that you can do by programming in C on DOS. If you're new to the C language, you can learn C yourself by following along in our [Writing FreeDOS Programs in C](https://www.freedos.org/books/cprogramming/) self-paced ebook on the FreeDOS website, and the accompanying "how-to" video series on the [FreeDOS YouTube channel](https://www.youtube.com/freedosproject).
## 1 Comment |
15,741 | Fedora 38 正式发布 | https://debugpointnews.com/fedora-38-release/ | 2023-04-21T09:49:00 | [
"Fedora"
] | /article-15741-1.html | 
>
> Fedora Linux 的最新版本 Fedora 38 已经发布,带来了一系列令人兴奋的新功能和更新。以下是其中的一些亮点。
>
>
>
Fedora Linux 是一个流行的发行版,提供最新的软件包和技术。它是一个由红帽公司赞助的社区驱动的项目,是在主流 Linux 发行版之前领先采用新技术和功能的先驱。
它的 2023 年的第一个版本现在已经可以下载和升级。虽然我在我的文章中介绍过了它的功能亮点,但让我给你再摘要介绍一下。

### Fedora 38 工作站的新内容
让我们从 Fedora 38 工作站版开始,它默认提供的是 GNOME 桌面。Fedora 38 工作站采用 GNOME 44 版本的桌面环境,为用户提供了正宗的 GNOME 体验,因为 Fedora Linux 工作站搭载的是原汁原味的 GNOME。
在 GNOME 44 中最重要的更新之一是系统托盘菜单中的后台应用程序功能。这个功能在主应用程序窗口不可见时非常有用,许多应用程序和用户都借助了该功能。Fedora 38 还包括了 “<ruby> 文件 <rt> Files </rt></ruby>”(即 Nautilus)应用程序中的扩展文件夹视图,现在它可以在列表视图中使用。

此外,Fedora 38 还改进了文件打开对话框,可以在网格视图布局中显示图像预览,这个功能人们已经等待了十年之久。这些变化和改进之外,[GNOME 44](https://www.debugpoint.com/gnome-44/) 中还有许多其他较小的改进。
除了 GNOME,Fedora 38 还有作为 “<ruby> 定制版 <rt> Spin </rt></ruby>” 的其他桌面环境,比如 KDE Plasma、Xfce、LXQt 和 MATE。
KDE Plasma 版的 Fedora 38 采用了 [Plasma 5.27](https://www.debugpoint.com/kde-plasma-5-27/) 桌面版本,其中包括平铺窗口功能、多显示器显示的强大设置、Wayland 更新以及一个全新的欢迎屏幕。
Fedora 38 Xfce 版中包含了 Xfce 4.18 的桌面。经过近两年的时间,这是一个功能方面的大规模发布,包括了重新打造的 Thunar 文件管理器,它带有分割视图、图像预览、强大的 FTP 设置和更多面板调整。

其他风格的桌面,如 [LXQt 1.2.0](https://www.debugpoint.com/lxqt-1-2-0-features/) 和 MATE 1.26 在 Fedora 38 也是最新的版本。Fedora LXQt 定制版正在为用户引入一个 Arch64 ISO 镜像。
由于 i3 窗口管理器定制版的流行,Fedora 在 Fedora 38 中引入了一个官方的 Sway 定制版。喜欢低内存占用的精简桌面的用户现在可以享受 Sway 了,它带来了出色的 Wayland 支持。
经过几个月的开发,一个官方的 Fedora Budgie 定制版在 Fedora 38 中首次出现。它由 Solus 项目开发的,是一个轻量级但功能丰富的桌面环境,看起来很专业,并为菜单/图标驱动的桌面提供了一种替代。这个版本带来了 Budgie 桌面 10.7.2 版本中令人兴奋的功能更新。
Fedora 38 现在可以不受限制地使用 Flathub 的软件包,这是一个最广泛的 Flatpak 应用集合。以前,用户必须改变过滤器才能从“软件”应用中访问 Flathub 软件包。然而,现在所有的 Flathub 软件包都可以在“软件”应用中使用,其中优先考虑 Fedora 核心软件包。
Fedora 38 中默认的 systemd 单元关机计时器从 2 分钟变为 45 秒。这一改变解决了一个有问题的服务会导致系统关闭过程停滞 2 分钟,给用户带来不必要的等待的问题。团队将观察实际的反馈和用户体验,并可能在未来的版本中将其减少到 15 秒。
出于安全考虑,现在默认情况下,从一个大端架构(s390x)以外的不同的大小端系统连接到 X 服务器([X.Org](http://X.Org) 或 XWayland)是禁用的。然而,用户可以创建自定义配置来允许它。
所以,这就是关于 Fedora 38 的主要亮点。你可以在我的重要专题 [文章](https://www.debugpoint.com/fedora-38/) 中了解更多细节。
### 如何升级到 Fedora 38
你可以依次运行以下命令来升级到最新版本。详细的升级指南 [放在这里](https://www.debugpoint.com/upgrade-fedora-38-from-fedora-37/)。
```
sudo dnf update
sudo dnf upgrade --refresh
sudo dnf install dnf-plugin-system-upgrade
sudo dnf system-upgrade download --releasever=38
sudo dnf system-upgrade reboot
```
### 下载新鲜出炉的 Fedora 38
你可以使用下面网页上的种子文件下载 Fedora 38 工作站和所有的定制版。
>
> **[下载 Fedora 38(种子)](https://torrent.fedoraproject.org/)**
>
>
>
>
> **[下载 Fedora 38 ISO](https://fedoraproject.org/workstation/download/)**
>
>
>
参考自官方 [变更日志](https://fedoraproject.org/wiki/Releases/38/ChangeSet) 和 [公告](https://fedoramagazine.org/whats-new-fedora-38-workstation/)。
---
via: <https://debugpointnews.com/fedora-38-release/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,743 | 编写对社区真正有用的文档 | https://opensource.com/article/23/3/community-documentation | 2023-04-22T17:28:00 | [
"文档"
] | https://linux.cn/article-15743-1.html | 
>
> 建立良好的文档可能是困难的,但它对有效的沟通至关重要。遵循这个框架来编写并与正确的人分享文档。
>
>
>
成功和可持续的项目,与那些消失无踪的项目有什么不同?答案是 —— 社区。社区是开源项目的发展动力,而文档是构建社区的基石之一。也就是说,文档的意义不仅仅在于文档本身。
建立好的文档可能很困难。用户不愿意阅读文档,因为它不易查找,它很快就过时了,它冗长,或者它不全面。
开发团队不写文档,因为他们陷入了“对我来说显而易见,所以对所有人都显而易见”的陷阱。他们不写,因为他们忙于开发项目。要么是需求变化太快了,要么是开发得还不够快。
但是好的文档仍然是团队和项目之间最好的沟通工具。考虑到项目随着时间的推移往往会变得更大,这一点尤其重要。
文档可以是团队或公司内部的唯一真理。这在协调人们朝着共同的目标前进,以及在人们转移到不同的项目时保留知识方面非常重要。
那么,要如何为一个项目写出合适的文档,并与正确的人分享呢?
### 什么是成功的社区文档?
要想在你的社区文档编写中取得成功,你需要:
* 规划你的路径
* 使其清晰简单
* 灵活变通,根据具体情况调整路径
* 做版本控制

灵活并不意味着混乱。许多项目之所以成功,就是因为它们组织得很好。
James Clear(《<ruby> 原子习惯 <rt> Atomic Habits </rt></ruby>》一书的作者)写道:“你并不是提升到了你目标所在的水平,而是降低到你整个系统所在的水平。”一定要组织好过程,使水平足够高,才能取得成功。
### 设计流程
文档本身就是一个项目。你可以把写文档当作写代码一样。事实上,文档可以是一个产品,而且是一个非常有价值的产品。
这就意味着你可以采用与软件开发相同的流程:分析、获取需求、设计、实现和维护,把文档作为你的一个流程对待。
在设计流程时,要从不同的角度考虑。不是所有的文档都适用于所有人。
大多数用户只需要一个了解项目概况的文档,而 API 文档则是留给开发者或高级用户的。
开发者需要了解库和函数的文档。用户则更需要看到示例、操作指南,和项目与其他软件相配合的架构概述。

总之,在创建任何流程之前,你必须确定你需要什么:
* **关注的群体:** 包括开发者、集成商、管理员、用户、销售、运营、高管
* **专业水平:** 要考虑到初级、中级和高级用户
* **详细程度:** 既要有高层级的概述,也要有技术细节,所以要考虑如何呈现这些内容
* **路径和入口:** 人们如何找到文档,如何使用文档
当你思考这些问题时,它可以帮助你构建你想通过文档传达的信息的结构。它定义了文档中必须包含的内容的清晰指标。
下面是如何围绕文档建立一个流程的方法。
### 编码约定
代码本身应该有意义。文档应通过良好的类名、文件名等来表达出来。通过思考以下内容,创建通用的编码标准和自我注解的编码过程:
* 变量命名约定
* 通过使用类、函数命名方案使名称易于理解
* 避免深度嵌套,或 [根本不嵌套](https://opensource.com/article/20/2/java-streams)
* 不要简单地复制和粘贴代码
* 不应使用长方法
* 避免使用幻数(改用常量)
* 使用提取的方法、变量等
* 使用有意义的目录结构、模块、包和文件名
### 开发时测试
测试不仅仅是关于代码应该如何工作。它还涉及如何使用 API、函数、方法等。编写良好的测试可以揭示基本用例和边缘用例。甚至还有一种 [测试驱动开发](https://opensource.com/article/20/1/test-driven-development) 的实践,专注于在代码开发之前创建测试用例(应该测试什么以及如何测试的分步场景)。
### 版本控制
版本控制(即使是对文档进行版本控制)可以帮助你跟踪更改的逻辑。它可以帮助你回答为什么这么修改。
确保提交期间的注释能解释为什么进行更改,而不是进行了哪些更改。
编写文档过程越吸引人,就会有更多的人参与其中,为它添加创造力和乐趣。你应该通过以下方式考虑文档的可读性:
* 软件代码约定
* 图表和图形(也通过文字进行解释)
* 思维导图
* 概念图
* 信息图表
* 图片(突出显示重要的部分)
* 短视频
通过使用不同的交流方式,你可以提供更多的方式来参与文档。这有助于防止误解(不同的语言,不同的含义)和有助于通过不同的学习方式进行学习。
以下是一些用于创建文档的软件工具:
* **Javadoc、Doxygen、JsDoc 等:** 许多语言都有自动化的文档工具,以帮助捕获代码中的主要功能
* **Web 钩子和 CI/CD 引擎:** 允许持续发布文档
* **Restructured Text、Markdown、Asciidoc:** 文件格式和处理引擎,帮助你从纯文本文件中生成美观且实用的文档
* **ReadTheDocs:** 是一个可以和公共 Git 存储库联动的文档托管主机
* **[Draw.io](http://Draw.io)、LibreOffice Draw、Dia:** 制作图表、图形、思维导图、路线图、计划、标准和指标等
* **Peek、Asciinema:** 记录终端命令操作
* **VokoscreenNG:** 录制屏幕和鼠标点击操作
### 文档很重要
编写文档的过程和协议与项目本身同样重要。最重要的是,它把项目的信息和项目的创造传达到位,更加令人兴奋。
快速进入项目和流程,以及了解一切是如何工作的,是文档一个重要的功能。它有助于确保众人持续参与。通过在团队中构建一种“语言”,可以简化流程,更清晰地理解所要做的事情。
文档旨在传达价值,即无论是通过团队成员还是通过应用程序的用户的言行,来展示出某些东西。
要将这个过程视为一个连续的整体,并在其中融合使用沟通、流程和文档的方式。

文档是一种沟通手段。
(题图:MJ:**document development illustration in high resolution, very detailed**)
---
via: <https://opensource.com/article/23/3/community-documentation>
作者:[Olga Merkulova](https://opensource.com/users/olga-merkulova) 选题:[lkxed](https://github.com/lkxed/) 译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | What distinguishes successful and sustainable projects from those that disappeared into the void? Spoiler — it's community. Community is what drives an open source project, and documentation is one of the foundational blocks for building a community. In other words, documentation isn't only about documentation.
Establishing good documentation can be difficult, though. Users don't read documentation because it's inconvenient, it goes out of date very quickly, there's too much, or there's not enough.
The development team doesn't write documentation because of the "it's obvious for me, so it's obvious to everyone" trap. They don't write because they are too busy making the project exist. Things are developing too fast, or they're not developing fast enough.
But good documentation remains the best communication tool for groups and projects. This is especially true considering that projects tend to get bigger over time.
Documentation can be a single source of truth within a group or a company. This is important when coordinating people toward a common goal and preserving knowledge as people move on to different projects.
So how do you write appropriate documentation for a project and share it with the right people?
## What is successful community documentation?
To succeed in writing documentation in your community:
-
Organize your routine
-
Make it clear and straightforward
-
Be flexible, make changes to the routine according to a specific situation
-
Do version control

(Olga Merkulova, CC BY-SA 4.0)
Being flexible doesn't mean being chaotic. Many projects have succeeded just because they are well-organized.
James Clear (author of *Atomic Habits*) wrote, "You do not rise to the level of your goals. You fall to the level of your systems." Be sure to organize the process so that the level is high enough to achieve success.
## Design the process
Documentation is a project. Think of writing docs as writing code. In fact, documentation can be a product and a very useful one at that.
This means you can use the same processes as in software development: analysis, capturing requirements, design, implementation, and maintenance. Make documentation one of your processes.
Think about it from different perspectives while designing the process. Not all documentation is the right documentation for everyone.
Most users only need a high-level overview of a project, while API documentation is probably best reserved for developers or advanced users.
Developers need library and function documentation. Users are better served by example use cases, step-by-step guides, and an architectural overview of how a project fits in with the other software they use.
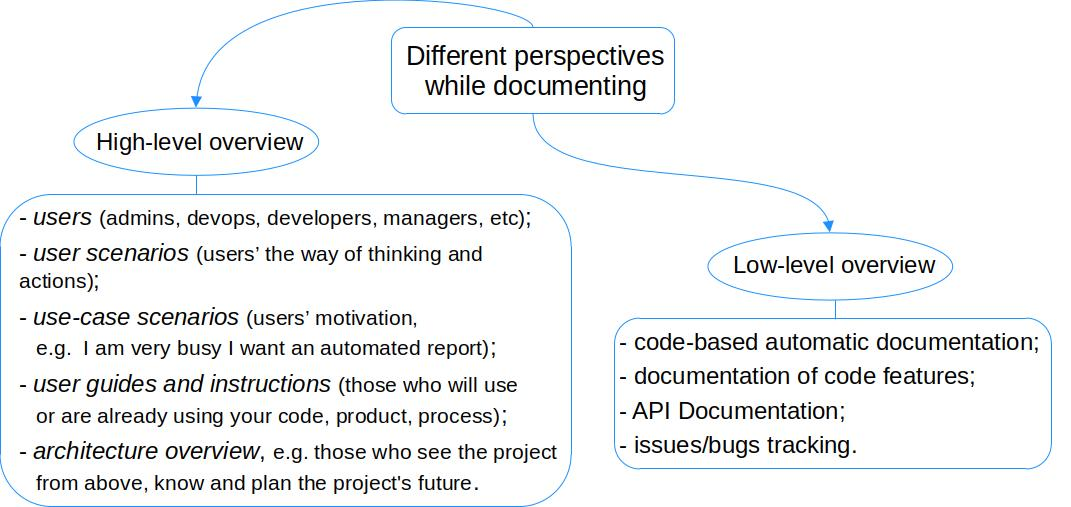
(Olga Merkulova, CC BY-SA 4.0)
Ultimately, before creating any process, you must determine what you need:
-
**Focus groups:**this includes developers, integrators, administrators, users, sales, operations, executives -
**Level of expertise**: Keep in mind the beginner, intermediate, and advanced users -
**Level of detail**: There's room for a high-level overview as well as technical detail, so consider how you want these to be presented -
**Journeys and entry points**: How do people find the documentation, how they use it
When you ponder these questions, it helps you structure information you want to communicate through documentation. It defines clear metrics on what has to be in the documentation.
Here's how to approach building a process around documentation.
## Coding conventions
The code itself should make sense. Documentation should be expressed through good class names, file names, and so on. Create common coding standards and make a self-documented code process by thinking about:
-
Variable naming conventions
-
Make names understandable by using class, function naming schemes
-
Avoid deep nesting, or
[don't nest at all](https://opensource.com/article/20/2/java-streams) -
Do not simply copy-and-paste code
-
No long methods should be used
-
Avoid using magic numbers (use const instead)
-
Use extract methods, variables, and so on
-
Use meaningful directory structures, modules, packages, and files
## Testing along with engineering
Testing isn't only about how code should behave. It's also about how to use an API, functions, methods, and so on. Well-written tests can reveal base and edge case scenarios. There's even a [test-driven development](https://opensource.com/article/20/1/test-driven-development) practice that focuses on creating test cases (step by step scenarios of what should be tested and how) before code development.
## Version control
Version control, even for your documentation, helps you track the logic of your changes. It can help you answer why a change was made.
Make sure comments during commits explain WHY a change was made, not WHAT change was made.
The more engaging the documentation process is, the more people will get into it. Add creativity and fun to it. You should think about readability of documentation by using:
-
software code conventions
-
diagrams and graphs (that are also explained in text)
-
mind maps
-
concept maps
-
infographics
-
images (highlight important parts)
-
short videos
By using different ways of communication, you offer more ways to engage with your documentation. This can help forestall misunderstanding (different languages, different meanings), and different learning styles.
Here are some software tools for creating documentation:
**Javadoc, Doxygen, JsDoc, and so on**: Many languages have automated documentation tools to help capture major features in code**Web hooks and CI/CD engines**: Allows continuous publication of your documentation**Restructured Text, Markdown, Asciidoc**: File formats and processing engines help you produce beautiful and usable documentation out of plain text files**ReadTheDocs***:*Is a documentation host that can be attached to a public Git repository**Draw.io**: Produce diagrams, graphs, mind-maps, roadmaps, planning, standards, and metrics*,**LibreOffice Draw,**Dia***Peek**: Use commands for recording your terminal*,*Asciinema**VokoscreenNG**: Use mouse clicks and screen capture
## Documentation is vital
Documenting processes and protocols are just as important as documenting your project itself. Most importantly, make information about your project and creation of your project exciting.
The speed of entering into a project and process, and understanding how everything works, is an important feature. It helps ensure continued engagement. Simple processes and a clear understanding of what needs to be done is obtained by building one "language" in the team.
Documentation is designed to convey value, which means demonstrating something through words and deeds. It doesn't matter whether it's a member of your team or a user of your application.
Think about the process as a continuum and use means of communication, processes, and documentation.
(Olga Merkulova, CC BY-SA 4.0)
Documentation is a means of communication.
## Comments are closed. |
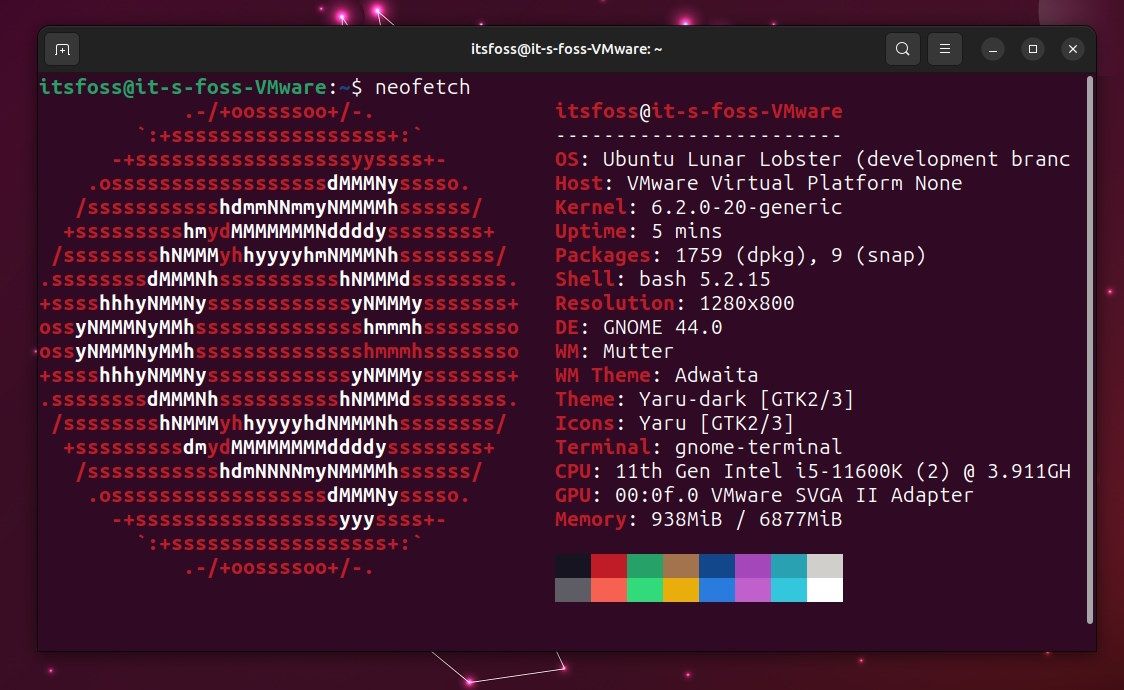
15,744 | Ubuntu 23.04 发布:新安装程序、新风味版和 GNOME 44 | https://news.itsfoss.com/ubuntu-23-04-release/ | 2023-04-22T18:26:22 | [
"Ubuntu"
] | https://linux.cn/article-15744-1.html |
>
> Ubuntu 23.04 增加了 GNOME 44 的魔力,并有一些自己的调整和改进。请看下文。
>
>
>

每年的这个时候,都会有新的 Ubuntu 版本发布:**Ubuntu 23.04** 来了。
然而,这并不是一个 [长期支持版本](https://itsfoss.com/long-term-support-lts/?ref=news.itsfoss.com)。所以,代号为 <ruby> 月球龙虾 <rt> Lunar Lobster </rt></ruby> 的 Ubuntu 23.04 并不适合所有人。
如果你想要最新和最棒的发行版,并且不介意在一年内再次升级你的系统,那么这个版本适合你。而如果你想在几年内坚持使用一个版本,你应该继续使用 [Ubuntu 20.04 LTS](https://itsfoss.com/things-to-do-after-installing-ubuntu-20-04/?ref=news.itsfoss.com) 或 [Ubuntu 22.04 LTS](https://itsfoss.com/ubuntu-22-04-release-features/?ref=news.itsfoss.com)。
现在,继续说说 Ubuntu 23.04 的亮点:
>
> ? Ubuntu 23.04 将被支持 **九个月**,直到 **2024 年 1 月**。如果你想在其寿命结束后得到一个最新的安全系统,你可以升级到 Ubuntu 23.10(即将推出的版本)。
>
>
>
### ⭐ Ubuntu 23.04:有什么新内容?

该版本最重要的改进包括以下内容:
* 新的现代化安装程序
* Steam Snap 晋升为稳定版
* GNOME 44
* 文件管理器的改进
* Linux 内核 6.2
* 传统和最小化 ISO
* 新的 Cinnamon 风味版
>
> ? 这 **不是** 一个 [长期支持](https://itsfoss.com/long-term-support-lts/?ref=news.itsfoss.com) 版本。因此,对于大多数人来说,你不需要升级。只有当你想要最新的和最棒的 Linux 发行版,同时愿意在一年内再次升级的时候,它才是你要的。
>
>
>
#### 基于 Flutter 的默认安装程序

Canonical 一直在开发一个由 [Subiquity](https://github.com/canonical/subiquity?ref=news.itsfoss.com) 支持的现代化的安装程序,它的外观感觉看起来不错。
这个安装程序被打包成了一个 Snap 包,而最小化的安装方式在这个新改造下也变得更快。
这个新的安装程序还旨在向新用户提供有意义的信息,同时改善用户体验。一些幻灯片、动画和加载屏幕将看起来完全不同。
总体而言,安装体验应该更快、更直观。
#### Steam Snap 现已晋升为稳定版
上个月,我们 [报道](https://news.itsfoss.com/ubuntu-steam-snap/) 了 Canonical 正在寻找用户来测试 Ubuntu 的 Steam Snap 应用。

随着 Ubuntu 23.04 的到来,等待已经结束了!Steam Snap 应用现在被推广到了稳定频道。
所以,现在你可以在 Steam 新 Snap 应用的帮助下无忧无虑地运行新老游戏了。虽然这是为 Ubuntu 量身定做的,但你也可以用其他任何发行版来尝试,通过 Steam 改善你的游戏体验。
你可以查看我们的 [Linux 游戏指南](https://itsfoss.com/linux-gaming-guide/?ref=news.itsfoss.com) 以获得进一步的帮助。
#### GNOME 44

[GNOME 44](https://news.itsfoss.com/gnome-44/),从其核心上分为你带来了一些根本变化,比如一个具有新能力的、更加互动的快速菜单。
比如说:
* 快速蓝牙切换可以查看/管理设备,而无需进入设置页面
* 监控后台应用程序
当然,Canonical 调整了原本的 GNOME 44 体验,不像你在 [Fedora 38](https://news.itsfoss.com/fedora-38/) 中发现的那样原汁原味。但是你可以在这里探索 GNOME 44 的详细变化:
>
> **[7 个值得关注的 GNOME 44 功能](https://news.itsfoss.com/gnome-44/)**
>
>
>
#### 传统的和最小化 ISO
Ubuntu 将首次单独提供一个最小化 ISO,它需要互联网连接才能在机器上成功安装 Ubuntu 23.04。

还有一个传统的 ISO 提供了旧的安装程序,供那些适应它的用户使用。
#### 新的 Cinnamon 风味版和 Edubuntu 的复活
当然,每一个 Ubuntu 风味版都会随着新的 23.04 版本的发布而得到升级。

Cinnamon 风味版是随着这个版本的发布而新增加的。因此,如果你喜欢使用 Cinnamon 桌面而不是 GNOME,你可以下载 Ubuntu Cinnamon 风味版。
此外,以前的 Ubuntu 的一个官方版本,**Edubuntu**,现在已经复活了。

你可以在 [Ubuntu 的网站](https://ubuntu.com/desktop/flavours?ref=news.itsfoss.com) 上找到列出的官方风味版。
#### 文件管理器的改进

作为 GNOME 44 改进的一部分,文件管理器(Nautilus)已经得到了改进。
你可以期待更好的性能和打开可展开文件夹的能力(是的,这个功能在 Ubuntu 22.10 中被放弃后又回来了)。
#### Linux 内核 6.2

为了帮助你跟上最新的硬件兼容性和改进,Ubuntu 23.04 配备了 Linux 内核 6.2。
这个内核版本增加了对英特尔 Arc 图形卡的全面支持、Nouveau 驱动更新,以及其他增强功能。
#### ?️ 其他变化
此外,一些细微的变化可以提升 Ubuntu 的体验。其中一些包括以下内容:
* 在软件中心搜索 Snap 时支持分类
* Ubuntu 字体更新
* Telegram 应用程序以 Snap 提供,不再有 Deb 包
* 固件更新器作为一个单独的应用程序加入到 Snap 商店中
* PostgreSQL 15、Rclone 1.60.1、NetworkManager 1.42、Ruby 3.1
* Qemu v7.2.0,支持 RISC-V
* 更新的应用程序: Firefox 111、LibreOffice 7.5.2、Thunderbird 102.9
你可以参考 [官方发布说明](https://discourse.ubuntu.com/t/lunar-lobster-release-notes/31910?ref=news.itsfoss.com),了解更多关于 Ubuntu 服务器和物联网版变化的细节。
### ? 下载 Ubuntu 23.04
前往 [官方网站](https://releases.ubuntu.com/lunar/?ref=news.itsfoss.com) 获取最新的 ISO,或者使用 [Ubuntu 镜像库](https://cdimage.ubuntu.com/ubuntu/releases/23.04/?ref=news.itsfoss.com) 来获取它。
>
> **[Ubuntu 23.04](https://ubuntu.com/download/desktop?ref=news.itsfoss.com)**
>
>
>
如果你已经是一个 **Ubuntu 用户**,你可以按照我们的指南 [升级到 Ubuntu 23.04](https://itsfoss.com/upgrade-ubuntu-to-newer-version/?ref=news.itsfoss.com)。
?你对 Ubuntu 23.04 有什么看法?请在下面的评论中分享你的想法。
---
via: <https://news.itsfoss.com/ubuntu-23-04-release/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It is that time of year, a new Ubuntu release! **Ubuntu 23.04**.
However, it is not a [Long-Term Support version](https://itsfoss.com/long-term-support-lts/?ref=news.itsfoss.com). So, Ubuntu 23.04, codenamed **Lunar Lobster** is not everyone.
If you want the latest and greatest and do not mind upgrading your system within a year, this release is for you. And if you want to stick to one version for a few years, you should continue with [Ubuntu 20.04 LTS](https://itsfoss.com/things-to-do-after-installing-ubuntu-20-04/?ref=news.itsfoss.com) or [Ubuntu 22.04 LTS](https://itsfoss.com/ubuntu-22-04-release-features/?ref=news.itsfoss.com).
Now, moving on to the highlights of Ubuntu 23.04.
**nine**months until
**January 2024**. You can upgrade to Ubuntu 23.10 (upcoming version) if you want an up-to-date and secure system after its end of life.
## ⭐ Ubuntu 23.04: What's New?
The most significant improvements with the release include the following:
**New modern installer****Steam snap promoted to Stable****GNOME 44****File manager improvements****Linux Kernel 6.2****Legacy and Minimal ISO****New Cinnamon Flavour**
**not**a
[Long-Term Support](https://itsfoss.com/long-term-support-lts/?ref=news.itsfoss.com)version. So, for most, you do not need to upgrade. Go ahead only if you want the latest and greatest while willing to upgrade again soon under a year.
### Flutter-based Installer by Default
Canonical has been working on a modernized installer backed by [Subiquity](https://github.com/canonical/subiquity?ref=news.itsfoss.com) that looks and feels good.
The installer is packaged as a snap and the minimal install option is now faster with the new makeover.
The new installer also aims to provide meaningful information to new users while improving the user experience. Some slides, animations, and loading screens will seem entirely different.
Overall, the installation experience should be faster and more intuitive.
### Steam Snap is Now Promoted to Stable
Last month, we [reported](https://news.itsfoss.com/ubuntu-steam-snap/) that Canonical is looking for users to test the Steam's snap app for Ubuntu.
With Ubuntu 23.04, the wait is over! The steam snap app is now promoted to the stable channel.
So, now you can run old and new games hassle-free with the help of Steam's new snap app. While it would be tailored for Ubuntu, you can try it with any other distro to improve your gaming experience through Steam.
You can check out our [Linux gaming guide](https://itsfoss.com/linux-gaming-guide/?ref=news.itsfoss.com) for further help.
**Suggested Read **📖
[Gaming On Linux: All You Need To KnowCan I play games on Linux? What are the games available for Linux? Where to find Linux games? This comprehensive article answers all your questions on Linux gaming.](https://itsfoss.com/linux-gaming-guide/?ref=news.itsfoss.com)

### GNOME 44
[GNOME 44](https://news.itsfoss.com/gnome-44/), at its core, brings you some essential changes like a more interactive quick menu with new abilities.
For instance:
- Quick Bluetooth toggle to view/manage devices without heading to the settings
- Monitor background apps
Of course, Canonical tweaks the stock GNOME 44 experience, like you would find with [Fedora 38](https://news.itsfoss.com/fedora-38/). But you can explore the detailed changes with GNOME 44 here:
[7 Cool GNOME 44 Features To Watch Out ForGNOME 44 is around the corner. Learn more about the features arriving with GNOME 44 release.](https://news.itsfoss.com/gnome-44/)

### Legacy and Minimal ISO
For the first time, Ubuntu will offer a separate minimal ISO requiring an internet connection to install Ubuntu 23.04 on a machine successfully.
And a legacy ISO features the old installer for users who are comfortable with it.
### New Cinnamon Flavour & Edubuntu Revival
Of course, every other Ubuntu flavour will receive upgrades with a new 23.04 version release.

The Cinnamon flavour is a new addition along with this release. So, if you prefer using Cinnamon desktop over GNOME, you can download Ubuntu Cinnamon.
In addition, **Edubuntu**, which was previously an official flavor of Ubuntu, has been revived.
You can find the official flavours listed on [Ubuntu's website](https://ubuntu.com/desktop/flavours?ref=news.itsfoss.com).
### File Manager Improvements
File Manager, Nautilus, has received improvements as part of GNOME 44 refinements.
You can expect better performance and the ability to toggle expandable folders (yes, the feature is back again after being dropped with Ubuntu 22.10).
### Linux Kernel 6.2
To help you keep up with the latest hardware compatibility and improvements, Ubuntu 23.04 comes with Linux Kernel 6.2.
This kernel version adds full Intel Arc graphics support, nouveau driver update, and other enhancements.
### 🛠️ Other Changes
In addition, several subtle changes can elevate the Ubuntu experience. Some of them include the following:
**Support for categories when searching for snaps in the software center****Ubuntu font updated****Telegram app as a snap, no more deb.****Firmware updater added as a separate app within the Snap store****PostgreSQL 15, Rclone 1.60.1, NetworkManager 1.42, Ruby 3.1****Qemu v7.2.0 with Risc-V support****Updated applications: Firefox 111, LibreOffice 7.5.2, Thunderbird 102.9**
You can refer to the [official release notes](https://discourse.ubuntu.com/t/lunar-lobster-release-notes/31910?ref=news.itsfoss.com) for more details on the Ubuntu server and IoT changes.
## 📥 Download Ubuntu 23.04
Head to the [official site](https://releases.ubuntu.com/lunar/?ref=news.itsfoss.com) for the latest ISO, or use [Ubuntu's image repository](https://cdimage.ubuntu.com/ubuntu/releases/23.04/?ref=news.itsfoss.com) to get it.
If you are an **existing user**, you can follow our guide to [upgrade to Ubuntu 23.04](https://itsfoss.com/upgrade-ubuntu-to-newer-version/?ref=news.itsfoss.com).
[How to Upgrade to Ubuntu 23.04 Right NowUbuntu 23.04 ‘Lunar Lobster’ has just been released. If you are using Ubuntu 22.04 or 22.10, here’s how you can upgrade to Ubuntu 23.04 right away.](https://itsfoss.com/upgrade-ubuntu-to-newer-version/?ref=news.itsfoss.com)

💬*What do you think of Ubuntu 23.04? Share your thoughts in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,746 | 开源项目领导者可以如何营造包容的环境 | https://opensource.com/article/23/2/open-source-leaders-inclusive-environment | 2023-04-22T23:43:44 | [
"开源社区"
] | https://linux.cn/article-15746-1.html | 
>
> 那些被你领入社区的人,有一天也会向其他人伸出援手。
>
>
>
开源领导者可以通过创造归属感、提供机会和表示支持来为新来者创造包容性社区。他们了解提交代码和与其他社区成员建立联系的复杂性。创造包容性社区可以建立信誉并获得影响力。这种经验对于想要参与但不知道从哪里开始的贡献者来说是无价的。
几年前,当我开始管理一个活跃于 Linux 内核社区的团队时,我发现自己因为没有任何内核经验而感到处境困难。复杂的代码库、庞大的电子邮件归档和高风险的交流让我感到害怕。当我团队中的新内核开发人员表达了类似的感受时,我意识到我的感觉在团队里普遍存在。对于那些支持贡献者或想自己做出贡献的人来说,入门的道路并不总是清晰的,甚至可能感觉遥不可及。
### 4 个策略建立包容性领导力
开源领导者可以通过为那些希望融入社区的人创造途径来发挥自己的影响力。本文涵盖的策略可应用于正式的 [指导](https://opensource.com/article/22/8/mentoring-power-multiplier) 或 [辅导](https://enterprisersproject.com/article/2021/4/it-leadership-how-to-coach?intcmp=7013a000002qLH8AAM) 关系,但同样适用于日常互动。在培养环境的包容性时,看似微不足道的交流往往会产生最重要的影响。
#### 怀着好奇心接近了解新人
经验较少或来自非传统背景的人可能会以意想不到或不同的方式解决问题。在应对这些差异时,如果用妄加评论或批评的方式,可能会在知识曲线通常很陡峭的社区中创造一个不安全的学习环境。例如,Linux 内核的长期贡献者了解社区丰富的历史,这意味着他们不需要明说就能理解社区的决策和反应。新的贡献者必须积累这方面的知识,但只有当他们感到安全,并愿意冒必要的风险来发展自己的技能时,他们才能有效地做到这一点。
开源领导者可以通过带着好奇心去接近新人来支持他们学习。你可以问他们这样的问题,“你能帮我理解一下你为什么采用这种方法吗?”而不是直接宣布提议的解决方案“对或错”。问题打开了一个继续学习的对话,而不是关闭那些值得探索的重要方面的想法。这个过程也拓宽了领导者的视野,他们可以通过考虑新的观点来学习。
#### 发现并分享学习机会
开源领导者可以确定适合其他人的项目,使他们可以获得技术专长和学习社区流程。在为他人创造机会的同时,领导者也为自己创造了更多机会。这是因为他们有更多时间探索新的尝试,同时通过分派任务继续推进他们的工作。随着领导者的成长,他们帮助周围的人取得成功的能力变得与他们的直接贡献一样重要。
要知道 [失败](https://opensource.com/article/20/11/normalize-failure) 是学习的一部分,因此你要考虑找一些新手失败后不会造成严重后果的项目。例如,在 Linux 内核中,代码库的某些部分的小改动可能会造成灾难性的后果。考虑可以实现小小的胜利的项目,以帮助新来者在没有高风险的情况下建立信心并感到掌控感。通过会议、电子邮件论坛或任何涉及如何参与到社区里的宣传活动分享这些想法,让人们更容易获取到这些信息。
#### 展现你脆弱的一面
拥有更多的经验并不意味着你知道一切。通常情况下,即使是与我共事过的最有经验的 Linux 内核贡献者也会被未知子系统中的新挑战击败。经验不足的社区成员通常会认为经验丰富的社区成员已经了解了一切。但是,经验就是要善于找出你不知道的东西。如果你处于权威地位或者被认为是专家,你可以通过分享个人挣扎和坚持的经验来表现你脆弱的一面,这样做可以鼓励那些和你有着类似感受的人。
#### 为他人做担保
向你的人脉介绍新来的成员。在激发他们兴趣的领域里,让新成员和在这个领域内具有专业知识的社区成员建立联系。在公共论坛上说出他们的名字,并称赞他们所做的出色工作。作为受人尊敬的领导者,你的支持可以帮助他们在社区内建立联系和信任。
通过树立社区包容性,我们可以拥有丰富多样的社区。我希望开源领导者会考虑这些建议,因为你提拔到社区的人未来的某天也会同样向别人伸出援手。
(题图:MJ:**inclusive environment community illustration in high resolution, very detailed**)
---
via: <https://opensource.com/article/23/2/open-source-leaders-inclusive-environment>
作者:[Kate Carcia Poulin](https://opensource.com/users/kcarcia) 选题:[lkxed](https://github.com/lkxed) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Open source leaders can foster inclusive communities for newcomers by creating belonging, providing opportunities, and showing support. They understand the intricacies of submitting code and making connections with other community members. In doing so, they build credibility and gain influence. This experience is invaluable to contributors who want to participate but don't know where to start.
A few years ago, I found myself in this daunting position when I began managing a team active in the Linux kernel community without any experience in kernel myself. The complex code base, expansive email archives, and high-stakes communications intimidated me. When new kernel developers on my team expressed similar feelings, I realized my experience was ubiquitous. For those supporting contributors or those seeking to contribute themselves, the path to entry is not always clear and can feel unattainable.
## 4 strategies for inclusive leadership
Open source leaders can have an impact by creating pathways for those looking to integrate into the community. The strategies covered in this article can be applied in formal [mentoring](https://opensource.com/article/22/8/mentoring-power-multiplier) or [coaching](https://enterprisersproject.com/article/2021/4/it-leadership-how-to-coach?intcmp=7013a000002qLH8AAM) relationships but are just as applicable in day-to-day interactions. Seemingly minor exchanges often have the most significant impacts when fostering inclusivity in an environment.
## Approach with curiosity
Someone with less experience or coming from a non-traditional background may solve problems in unexpected or different ways. Reacting to those differences with judgment or criticism can create an unsafe environment for learning in communities that often have a steep knowledge curve. For example, long-time contributors to the Linux kernel understand its rich history. This means they have an implied understanding of community decisions and reactions. New contributors must build this knowledge but can only effectively do so if they feel safe taking necessary risks to grow their skill set.
Open source leaders can support newcomers as they learn by approaching them with curiosity. Consider asking questions like, "Can you help me understand why you took this approach?" rather than declaring proposed solutions "right or wrong". Questions open a dialog for continued learning rather than shutting down ideas that are an important aspect of exploration. This process also broadens the leader's viewpoint, who can learn by considering fresh perspectives.
## Identify and share learning opportunities
Open source leaders can identify projects suitable for others to gain technical expertise and learn community processes. In creating opportunities for others, leaders also create more opportunities for themselves. This is because they make more time to explore new endeavors while continuing to advance their work through delegation. As leaders grow, their ability to enable others around them to succeed becomes just as critical as their direct contributions.
Knowing that [failure](https://opensource.com/article/20/11/normalize-failure) is a part of learning, think about identifying projects where newcomers can safely fail without drastic consequences. In the Linux kernel, for example, there are certain parts of the code base where small changes can have disastrous consequences. Consider projects where small wins are achievable to help newcomers build confidence and feel empowered without high stakes. Make these ideas accessible by sharing them at conferences, in email forums, or in any way your community advertises how to become involved.
## Demonstrate vulnerability
Having more experience doesn't mean you know everything. More often than not, even the most experienced Linux kernel contributors I've worked with are humbled by new challenges in uncharted subsystems. It's common for community members with less experience to view more experienced community members as having it all figured out. But having experience is about being adept at figuring out what you don't know. If you are in a position of authority and regarded as an expert, demonstrating vulnerability by sharing personal experiences of struggle and perseverance can be encouraging to those dealing with similar feelings.
## Vouch for others
Introduce newcomers to your network. Connect them with community members with expertise in areas that pique their interests. Say their name in public forums and call out the excellent work they are doing. As a respected leader, your endorsement can help them build connections and trust within the community.
We can have rich and diverse communities by building in inclusivity. It is my hope that open source leaders will consider these suggestions because those you lift into the community will someday be able to extend a hand to others.
## Comments are closed. |
15,747 | Kubuntu 23.04 来了! | https://news.itsfoss.com/kubuntu-23-04/ | 2023-04-23T18:06:19 | [
"Kubuntu"
] | https://linux.cn/article-15747-1.html | 
>
> Kubuntu 23.04 已经到达,并带有 KDE Plasma 5.27。
>
>
>
如果你正在寻找一个基于 KDE 的发行版,毋庸置疑 Kubuntu 作为 Ubuntu 的官方风味版就是其中一个。
在 Kubuntu 23.04 中,你可以期待增强的 KDE 体验和其他一些改进。
让我带你了解一下 Kubuntu 23.04 版本的亮点。
>
> ? Kubuntu 23.04 将被支持 **九个月**,直到 **2024 年 1 月**。如果你想要在其寿命结束后得到一个最新的、安全的系统,你可以升级到 Kubuntu 23.10(即将发布)。
>
>
>
### ? Kubuntu 23.04:有什么新内容?

Kubuntu 23.04 版本中的一些特色部分包括:
* KDE Plasma 5.27
* Flatpak 被移除
* Discover 的改进
* Plasma Wayland 会话(测试)
* 默认采用 Pipewire
* KDE 应用程序更新
>
> ? 这 \**不是* 一个 [长期支持](https://itsfoss.com/long-term-support-lts/?ref=news.itsfoss.com) 版本。所以,对于大多数人来说,不需要升级。只有当你想要最新和最好的 Linux 发行版,同时愿意在一年内再次升级的时候,才该选择它。
>
>
>
#### KDE Plasma 5.27 LTS
KDE Plasma 5.27 是 KDE 6 到来之前最后一个 5.x 系列的版本。
因此,随着最新的 KDE Plasma 桌面的到来,你可以期待所有的改进都已就绪。比如说,增强的多显示器支持、新的欢迎屏幕,以及其他用户界面的改进,其中一些我将单独提及。
如果你想了解关于 [KDE Plasma 5.27](https://news.itsfoss.com/kde-plasma-5-27-release/) 的所有内容,我们的之前的报道应该能给你更好的介绍:
>
> **[给 KDE 用户的情人节礼物:Plasma 5.27](https://news.itsfoss.com/kde-plasma-5-27-release/)**
>
>
>
#### Flatpak 支持被移除
Kubuntu 默认包括 Flatpak。然而,最近 Canonical 决定 [对所有 Ubuntu 风味版默认放弃 Flatpak 支持](https://news.itsfoss.com/ubuntu-flavor-drops-flatpak/),Kubuntu 23.04 也不例外。

你可以手动 [添加 Flatpak](https://itsfoss.com/flatpak-guide/?ref=news.itsfoss.com),但你会发现它不是开箱即用的了。
#### “发现”应用的增强
作为 KDE Plasma 5.27 的一部分,“<ruby> 发现 <rt> Discover </rt></ruby>” 应用在列出应用和程序的方式上进行了重大改革。“发现”应用的商店看起来更有活力和更有价值,有了编辑选择区和流行应用区。

此外,你可以通过“发现”应用访问 Flatpak 应用程序的更多权限,并在手动启用后轻松地将 Flatpak 应用程序直接整合到“发现”应用中。

#### Plasma Wayland 会话(测试)
你现在可以在 Kubuntu 23.04 的登录屏幕上尝试 Wayland 会话。
然而,这只是测试,并不完全支持。
#### KDE 应用程序更新
KDE 套件的每个部分都收到了版本升级,包括文件管理器、Krunner 和其他。

Krunner,这个启动器现在如果没有找到与你要找的东西相匹配的东西,就会提示进行互联网搜索,如下面的截图所示。

#### 其他完善的功能
你会发现一个新的 [Linux 内核 6.2](https://news.itsfoss.com/linux-kernel-6-2-release/)、功能和其他细微的变化。值得一提的亮点包括以下内容:
* Pipewire 作为默认的音频服务器
* LibreOffice 7.5
* Firefox 111 Snap
* Qt 5.15.8
你可以参考 [发行说明](https://kubuntu.org/news/kubuntu-23-04-lunar-lobster-released/?ref=news.itsfoss.com) 了解更多技术细节。
### ? 下载 Kubuntu 23.04
前往 [官方网站](https://kubuntu.org/getkubuntu/?ref=news.itsfoss.com) 获取最新的 ISO,或者使用 [Ubuntu 镜像库](https://cdimage.ubuntu.com/kubuntu/releases/23.04/?ref=news.itsfoss.com) 来获取它。
>
> **[Kubuntu 23.04](https://kubuntu.org/getkubuntu/?ref=news.itsfoss.com)**
>
>
>
如果你已经是 Ubnutu 用户,你可以按照 [官方指南](https://help.ubuntu.com/community/KineticUpgrades/Kubuntu?ref=news.itsfoss.com) 来升级。
---
via: <https://news.itsfoss.com/kubuntu-23-04/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you are looking for a KDE-based distribution, Kubuntu is a no-brainer as an official Ubuntu flavour.
With Kubuntu 23.04, you can expect an enhanced KDE experience and several other improvements.
Let me take you through the highlights of the Kubuntu 23.04 release.
**nine**months until
**January 2024**. You can upgrade to Kubuntu 23.10 (upcoming version) if you want an up-to-date and secure system after its end of life.
## 🆕 Kubuntu 23.04: What's New?
Some of the best bits of the Kubuntu 23.04 release include:
**KDE Plasma 5.27****Flatpak Removed****Discover Improvements****Plasma Wayland Session for testing****Pipewire default****KDE Application updates**
**not**a
[Long-Term Support](https://itsfoss.com/long-term-support-lts/?ref=news.itsfoss.com)version. So, for most, you do not need to upgrade. Go ahead only if you want the latest and greatest while willing to upgrade again soon under a year.
### KDE Plasma 5.27 LTS
KDE Plasma 5.27 is the last 5. x series release before KDE 6 arrives.
So, with the latest KDE Plasma desktop onboard, you can expect all the improvements on the table. Things like enhanced multi-monitor support, a new welcome screen, and other user interface refinements, some of which I shall mention separately.
If you want to explore all about [KDE Plasma 5.27](https://news.itsfoss.com/kde-plasma-5-27-release/), our original coverage should give you better insights:
[💕Valentine’s Gift for KDE Users Arrive in the Form of Plasma 5.27 ReleaseKDE Plasma 5.27 has landed with plenty of improvements.](https://news.itsfoss.com/kde-plasma-5-27-release/)

### Flatpak Support Removed
Kubuntu included Flatpak by default. However, with the recent Canonical decision to [drop Flatpak support by default](https://news.itsfoss.com/ubuntu-flavor-drops-flatpak/) for all Ubuntu flavors, Kubuntu 23.04 is no exception.
You can manually [add Flatpak](https://itsfoss.com/flatpak-guide/?ref=news.itsfoss.com), but you will no longer find it out-of-the-box.
### Discover Enhancements
As part of KDE Plasma 5.27, Discover has received a significant overhaul for how it lists apps and programs. The Discover store looks more alive and valuable with the editor's choice and popular options.
Additionally, you can access more permissions for Flatpak apps through Discover and easily integrate Flatpak apps to Discover right after manually enabling them.
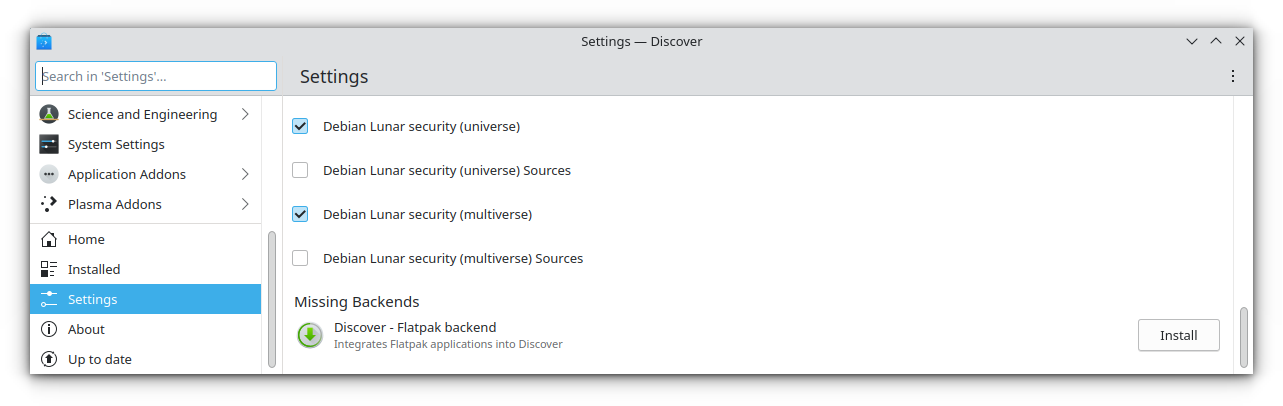
### Plasma Wayland Session (Testing)
You can now try the Wayland session from the login screen of Kubuntu 23.04.
However, it is only meant for testing and is not fully supported.
### KDE Application Updates
Every part of the KDE suite has received a version bump, including the file manager, Krunner, and others.
Krunner, the launcher now prompts for an internet search if it does not find anything matching what you are looking for, as shown in the screenshot below.
### Other Refinements
You will find a new [Linux Kernel 6.2](https://news.itsfoss.com/linux-kernel-6-2-release/), features, and other subtle changes. The highlights worth mentioning include the following:
**Pipewire as the default audio server****LibreOffice 7.5****Firefox 111 snap****Qt 5.15.8**
You can refer to the [release notes](https://kubuntu.org/news/kubuntu-23-04-lunar-lobster-released/?ref=news.itsfoss.com) for more technical details.
## 📥 Download Kubuntu 23.04
Head to the [official site](https://kubuntu.org/getkubuntu/?ref=news.itsfoss.com) for the latest ISO, or use [Ubuntu's image repository](https://cdimage.ubuntu.com/kubuntu/releases/23.04/?ref=news.itsfoss.com) to get it.
If you are an **existing user**, you can follow the [official guide](https://help.ubuntu.com/community/KineticUpgrades/Kubuntu?ref=news.itsfoss.com) to get the upgrade.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,749 | Valve 发布 Proton 8.0 | https://news.itsfoss.com/proton-8-0-release/ | 2023-04-24T11:32:00 | [
"游戏",
"Proton"
] | https://linux.cn/article-15749-1.html |
>
> Proton 8.0 已经到来,带来了一些改进,以提升 Linux 游戏体验。
>
>
>
Proton 8.0 的到来改进了 Linux 游戏体验。
(LCTT 译注:Proton 是 V 社开发的兼容层,可以让 Windows 游戏在 Linux 上运行。它是一个软件集合,扩展了流行的 API 翻译层 Wine,提供高性能和低开销的 Vulkan API。)

Proton 一直是 Linux 游戏玩家的福音,它使 Steam 客户端能够在 Linux 上运行 Windows 生态系统独有的游戏。
基于流行的 [Wine](https://www.winehq.org/?ref=news.itsfoss.com) 兼容层,Valve 多年来一直为 Proton 提供更新。
Proton 8.0 的发布带来了一些令人印象深刻的升级,标志着 Linux 游戏又迈出了重要一步。
让我们一起来一探究竟。
**Proton 8.0 有啥新鲜事儿:** Proton 的新版本增加了对许多**新游戏**的**兼容支持**和对现有游戏的**错误修复**。
例如,一些现有游戏,如 《<ruby> 极限竞速:地平线 5 <rt> Forza Horizon 5 </rt></ruby>》、《<ruby> 车祸模拟器 <rt> BeamNG </rt></ruby>》、《<ruby> 真人快打 X <rt> Mortal Combat X </rt></ruby>》、《<ruby> 最终幻想 14 <rt> Final Fantasy XIV Online </rt></ruby>》、《<ruby> 汤姆·克兰西的细胞分裂 <rt> Tom Clancy's Splinter Cell </rt></ruby>》都得到了不同程度的修复,使它们比之前表现更好。
**刚刚提到的新支持的游戏呢?**

最具期待的一些游戏包括:
* 《<ruby> 仁王 2 完整版 <rt> Nioh 2 – The Complete Edition </rt></ruby>》
* 《<ruby> 海贼无双 4 <rt> One Piece: Pirate Warriors 4 </rt></ruby>》
* 《<ruby> 死亡空间 2023 <rt> Dead Space (2023) </rt></ruby>》
* 《<ruby> 魔咒之地 <rt> Forspoken </rt></ruby>》
* 《<ruby> 无双大蛇 3 终极版 <rt> WARRIORS OROCHI 3 Ultimate Definitive Edition </rt></ruby>》
此外,还有一些改进会对 Steam Deck 用户有所帮助,包括:
* 改进了 Steam Deck 上 《<ruby> 小缇娜的奇幻之地 <rt> Tiny Tina's Wonderland </rt></ruby>》 的睡眠/恢复功能
* 改进了多点触控支持
**对技术细节更感兴趣?**
Proton 8.0 基于最近发布的 **Wine 8.0**,它可以提供**更好的 WoW64 32 位支持**、**提升了 Direct3D 性能**、**增强了对游戏控制器及方向盘的支持**等等。
你可以查看我们的报道以深入了解。
除此之外,此版本还引入了针对 GNOME 43 上的 **Alt+Tab 问题**、**为游戏启用了英伟达 API**、附带的 **dxvk v2.1-4-gcaf31033** 等的修复程序。
你或许想通过 [发行说明](https://github.com/ValveSoftware/Proton/releases/tag/proton-8.0-1c?ref=news.itsfoss.com) 来探索随 Proton 8.0 一起提供的**有关技术变更和游戏的详细列表**。
**想上手试试?**

如果你使用 Steam,你可以按照我们的指南了解如何在 Linux 上设置 Steam Play (Proton)并开始 [在 Linux 上玩游戏](https://itsfoss.com/linux-gaming-guide/?ref=news.itsfoss.com)。
不过,需要注意的是,随着 Proton 8.0 的发布,要想顺利运行系统需要 **至少支持 Vulkan 1.3 的 GPU**。
你还可以查看 [GitHub 代码库](https://github.com/ValveSoftware/Proton?ref=news.itsfoss.com),了解如何从源代码手动安装它。
*(题图:MJ/linux game illustration in high resolution, very detailed, 8k)*
---
via: <https://news.itsfoss.com/proton-8-0-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Proton has been a boon for the Linux gamers out there that enables the Steam client to run games exclusive to the Windows ecosystem on Linux.
Based on the popular [Wine](https://www.winehq.org/?ref=news.itsfoss.com) compatibility layer, Proton has been receiving many updates over the years thanks to Valve.
Proton 8.0 has been released with some impressive upgrades, marking yet another major step for Linux gaming.
Let's dig in to know more about it.
**Suggested Read **📖
[Gaming On Linux: All You Need To KnowCan I play games on Linux? What are the games available for Linux? Where to find Linux games? This comprehensive article answers all your questions on Linux gaming.](https://itsfoss.com/linux-gaming-guide/?ref=news.itsfoss.com)

**What's happening?: **The new version of Proton adds **compatibility** for a host of **new games** and **bug fixes** for the existing games.
For instance, existing games such as Forza Horizon 5, BeamNG, Mortal Combat X, Final Fantasy XIV Online, Tom Clancy's Splinter Cell have received various fixes that now allow them to perform better than before.
**What about the newly supported games I just mentioned?**

Some of the biggest highlights among the games include:
**Nioh 2 – The Complete Edition****One Piece: Pirate Warriors 4****Dead Space (2023)****Forspoken****WARRIORS OROCHI 3 Ultimate Definitive Edition**
Additionally, there are improvements that should help Steam Deck users, including:
- Improved sleep/resume functionality on Steam Deck for Tiny Tina's Wonderland.
- Improved multitouch support
**Interested in the technical bits?**
Proton 8.0 is based on the recently released **Wine 8.0** that allows it to take advantage of the **better WoW64 32-bit support**, **Direct3D performance boosts**,** enhanced controller/driving wheel support** and more.
You may check out our coverage on the same to dive deeper.
[Wine 8.0 Stable Release is Here!It gets better to run Windows applications on Linux with Wine 8.0!](https://news.itsfoss.com/wine-8-0-release/)

Other than that, this release has also introduces fixes for the **Alt+Tab issue on GNOME 43**,** enabled NVIDIA API for games**, ships with **dxvk v2.1-4-gcaf31033 **and more.
You may want to go through the [release notes](https://github.com/ValveSoftware/Proton/releases/tag/proton-8.0-1c?ref=news.itsfoss.com) to explore the **detailed list of technical changes and games** that have arrived with Proton 8.0.
**Want to try it?**
If you use Steam, you may follow our guide on how to set up Steam Play (Proton) on Linux and start [gaming on Linux](https://itsfoss.com/linux-gaming-guide/?ref=news.itsfoss.com).
[How to Play Windows-only Games on Linux with Steam PlaySteam Play (proton) lets you play Window-only games on Linux. Here’s how to get started.](https://itsfoss.com/steam-play/?ref=news.itsfoss.com)

Though, keep in mind that with the release of Proton 8.0, a **GPU with at least Vulkan 1.3 support** is required to run it smoothly.
You can also check out the [GitHub repo](https://github.com/ValveSoftware/Proton?ref=news.itsfoss.com) on how to build it manually from the source code.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,750 | 详解:如何将 GitHub 连接到 VS Code | https://itsfoss.com/vs-code-github/ | 2023-04-24T16:00:00 | [
"GitHub",
"VS Code"
] | https://linux.cn/article-15750-1.html | 
VS Code 无疑是最受欢迎的代码编辑器之一。同样,GitHub 是编码人员中最受欢迎的平台。
两种微软产品可以很好地融合在一起。你可以在 VS Code 中无缝编码并将更改推送到你的 GitHub 仓库。从同一个应用界面完成所有这些工作让生活变得如此轻松。
如何将 GitHub 添加到 VS Code? 其实很容易。
在本教程中,我将展示:
* 如何将你的 GitHub 帐户集成到 VS Code 中
* 如何将仓库从 GitHub 克隆到 VS Code 中
* 如何将你的更改从 VS Code 推送到 GitHub
听起来不错?让我们看看如何去做。
### 先决条件
请确保你的计算机上安装了 Git。怎么做?
一种方法是转到 VS Code 中的源代码管理视图。如果未安装 Git,它会要求你下载它。

另一件事是你**需要配置 Git 用户名和电子邮件**。
### 将 GitHub 添加到 VS Code
VS Code 内置了 GitHub 集成。你不需要安装任何扩展来克隆仓库和推送你的更改。
从左侧边栏转到源代码选项卡。你应该看到 “<ruby> 克隆仓库 <rt> Clone Repository </rt></ruby>” 或 “<ruby> 发布到 GitHub <rt> Publish to GitHub </rt></ruby>”(如果你已经打开了一个文件夹)选项。单击 “<ruby> 克隆仓库 <rt> Clone Repository </rt></ruby>” 并为其提供 GitHub 仓库链接或单击 “<ruby> 从 GitHub 克隆 <rt> Clone from GitHub </rt></ruby>”。

然后它会显示一条消息,要求你登录 GitHub。

你单击“<ruby> 允许 <rt> Allow </rt></ruby>”按钮,它将打开 GitHub 登录页面。

如果你尝试克隆一个仓库,你应该会看到这样的消息并单击 “<ruby> 打开 <rt> Open </rt></ruby>”。

这应该需要几秒钟,你就会登录到你的 GitHub 帐户。
#### 你怎么知道你已经使用 VS Code 登录到 GitHub?
好吧,它将开始在顶部视图中显示你的 GitHub 仓库(如果有的话)(如果你之前按下了“克隆存储库”)。

或者,你可以单击左下角的配置文件图标,查看它是否显示你已登录到你的 GitHub 帐户。

### 在 GitHub 中克隆一个 GitHub 仓库
如果你已经在 GitHub 中打开了一个项目,想要克隆另一个 GitHub 仓库,有几种方法可以做到。
你可以**使用 Git 命令将仓库克隆到磁盘上**,然后在 VS Code 中打开此仓库文件夹。
或者,如果你不想使用命令行,则可以坚持使用 VS Code。
这很简单。在 VS Code 中打开一个新窗口。

这将为你提供一个全新、干净的编辑器。**如果看到欢迎屏幕**,你可以从那里单击 “克隆存储库” 的快速链接。
否则,从左侧边栏转到“<ruby> 源码管理 <rt> Source Control </rt></ruby>”选项卡,然后单击“<ruby> 克隆仓库 <rt> Clone Repository </rt></ruby>”按钮。
它将在顶部打开一个视图。你可以**直接复制 GitHub 仓库的 URL**。它可以自动从中获取克隆链接。

它会问你把克隆的仓库放在哪里。

它会询问你是否要将克隆的仓库在 VS Code 中打开。如果你想立即处理它,那就去做吧。

不仅仅是克隆的存储库,VS Code 会询问你是否信任你添加到其中的任何文件夹的作者。

好了,你已经在 VS Code 中克隆了一个 GitHub 仓库。让我们看看如何修改并将更改推送到 GitHub。
### 从 VS Code 推送更改到 GitHub
现在假设你对代码进行了一些更改并希望将提交推送到你的仓库。
当你将更改保存到文件中,**VS Code 就会开始用 “M” 指示修改后的文件**。对于新文件,符号为 “U”(未跟踪)。
从左侧进入“源码控制”,输入提交消息,然后单击提交旁边的按钮并选择 “<ruby> 提交并推送 <rt> Commit & Push </rt></ruby>”。

如果你没有配置 Git 用户名和电子邮件,你将看到如下错误。

你可以 [在全局或仓库级别设置用户名和电子邮件](https://git-scm.com/book/en/v2/Getting-Started-First-Time-Git-Setup?ref=itsfoss.com)。完全根据你自己的选择。
>
> ? 对于成功的提交和推送,你不会看到任何错误。已修改文件或新文件旁边的 “M” 或 “U” 符号将消失。
>
>
>
**你可以通过进入 GitHub 上的仓库来验证你的推送是否成功。**
你可以选择在本地提交更改而不推送它们。你也可以在这里使用 `git` 命令执行所有你以前使用过的操作。有用于创建拉取请求、刷新等等的选项。

### 通过 GitHub 官方扩展将其提升到一个新的水平
有一个专用的官方扩展,让你还可以**管理其他人对你的仓库的拉取请求并合并它们**。你还可以在此处查看在你的仓库中打开中的问题。这是将 GitHub 与 VS Code 集成的更好方法。
打开 VS Code,然后转到左侧栏中的扩展选项卡。在这里**搜索 “GitHub Pull Requests and Issues”**。它是 GitHub 本身的官方插件。你可以看到已验证的勾选。
单击安装按钮并在你的编辑器上安装 [扩展](https://itsfoss.com/install-vs-code-extensions/)。

使用此扩展,如果其他人正在协作,你可以管理你的存储库。
在 VS Code 中完全集成 Git 和 GitHub 是件好事。不喜欢命令行的人肯定会喜欢这种集成。
我希望本教程能帮助你将 GitHub 无缝添加到 VS Code。如果你仍然遇到任何问题,请告诉我。
*(题图:MJ/GitHub VS Code develop illustration in high resolution, very detailed, 8k)*
---
via: <https://itsfoss.com/vs-code-github/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

VS Code is undoubtedly one of the most popular code editors. Similarly, GitHub is the most popular platform among coders.
Both Microsoft products gel quite well. You can seamlessly code in VS Code and push changes to your GitHub repo. It makes life so much easier to do all of it from the same application interface.
How to add GitHub to VS Code? It's quite easy actually.
In this tutorial, I'll show:
- How to integrate your GitHub account into VS Code
- How to clone repositories from GitHub into VS Code
- How to push your changes to GitHub from VS Code
Sounds good? Let's see how to do it.
## Prerequisite
Please ensure that Git is installed on your computer. How to do that?
One way would be to go to the Source Control view in VS Code. If Git is not installed, it will ask you to download it.
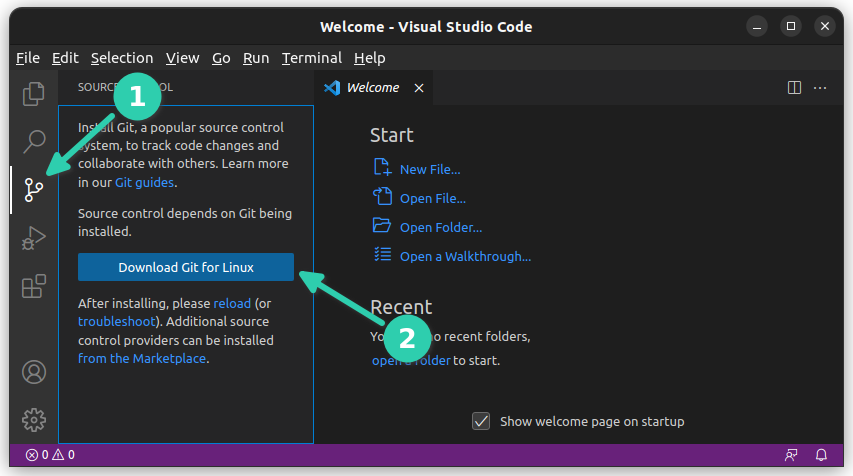
Another thing is that you **should have the Git username and email configured**.
## Adding GitHub to VS Code
VS Code comes builtin with GitHub integration. You should not need to install any extension for cloning repos and pushing your changes.
Go to the source code tab from the left sidebar. You should see a '**Clone Repository**' or '**Publish to GitHub**' (if you have opened a folder already) option. Click on the **Clone Repository** and give it a GitHub repo link or click on '**Clone from GitHub**'.
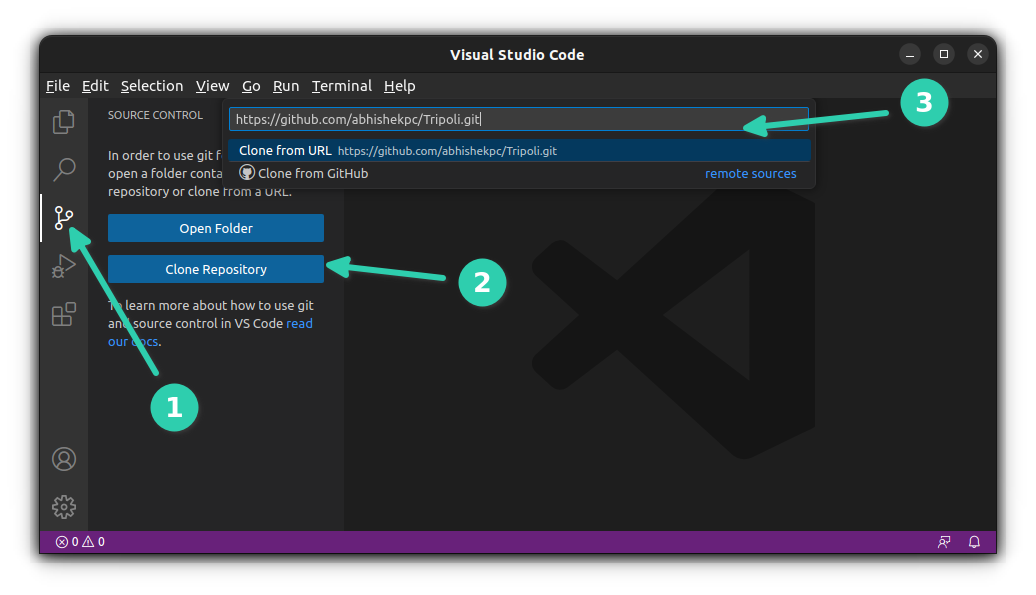
It will then show you a message that asks you to sign in to GitHub.
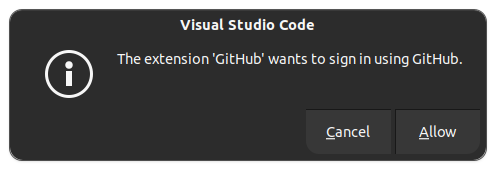
You click on Allow button and it will open a browser tab with a GitHub login page.
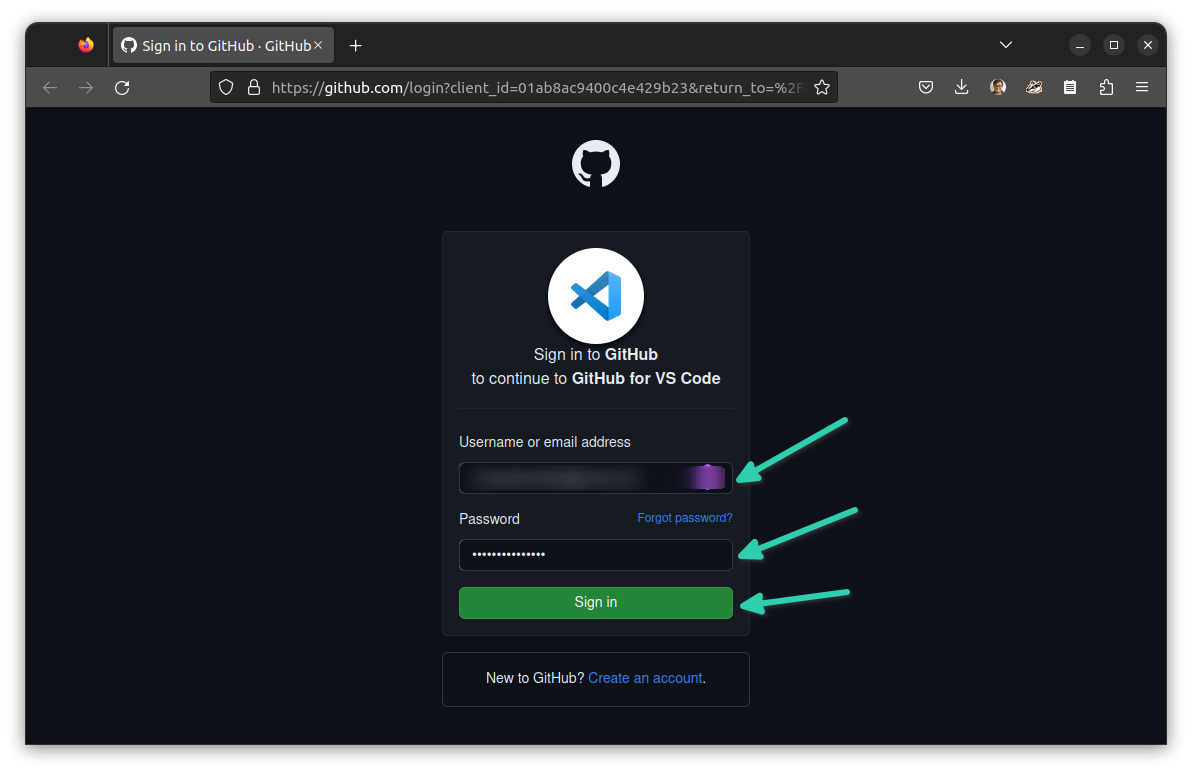
If you were trying to clone a repo, you should see a message like this and click **Open**.
It should take a couple of seconds and you should be signed into your GitHub account.
### How do you know you are logged into GitHub with VS Code?
Well, it will start showing your GitHub repositories (if you have any) in the top viewlet (if you pressed clone repository earlier).
Alternatively, you can click on the Profile icon at the bottom left corner to see if it says you are logged in to your GitHub account.
## Clone a GitHub repository in GitHub
If you have already opened a project in GitHub bit want to clone another GitHub repository, there are several ways to do that.
You can **use the Git commands to clone the repo on your disk** and then open this repo folder in VS Code.
Alternatively, if you don't want to use the command line, you can stick with VS Code.
It's simple. Open a new window in VS Code.
This will give you a fresh, clean editor. **If you have the welcome screen running**, you can click on the 'Clone Git Repository' quick link from there.
Otherwise, go to the Source Control tab from the left sidebar and click the Clone Repository button.
It will open a viewlet on the top. You can **simply copy the URL of the GitHub repo**. It can automatically get the clone link from it.
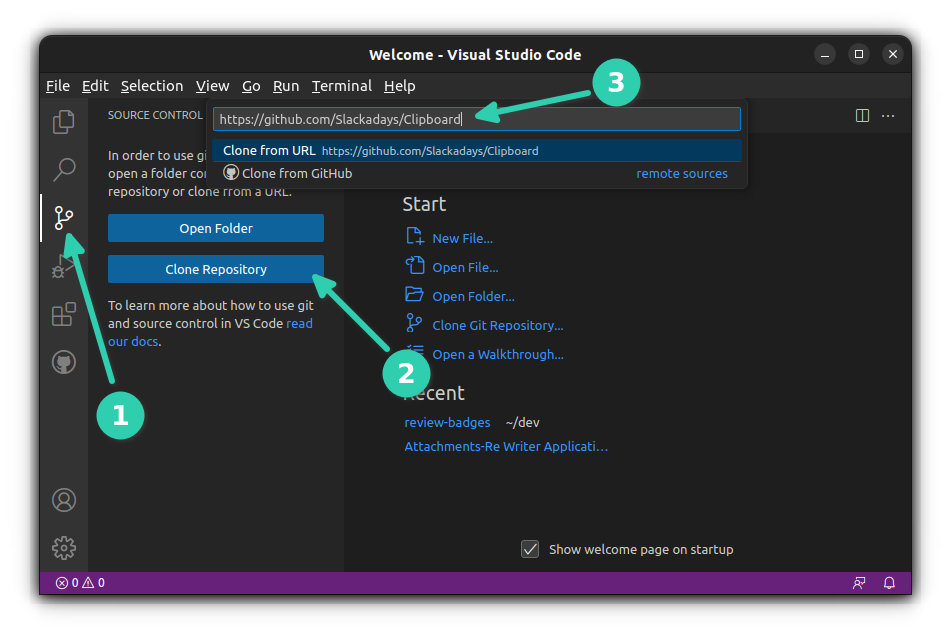
It will ask you where to place the cloned repo.
It will ask if you want to open the cloned repo into VS Code. Go for it if you want to work on it immediately.
Not just for a cloned repo, VS Code asks you if you trust the author for any folder you add to it.
Well, you have cloned a GitHub repo in VS Code. Let's see how to modify and push your changes to GitHub.
## Push changes to GitHub from VS Code
Now let's say you made some changes to the code and want to push the commit to your repo.
As soon as you save your changes to a file, **VS Code starts indicating the modified files with an M**. For new files, the symbol is U (untracked).
Go to Source Control from the left-hand side, type a commit message and then click on the carrot button beside Commit and choose Commit & Push.
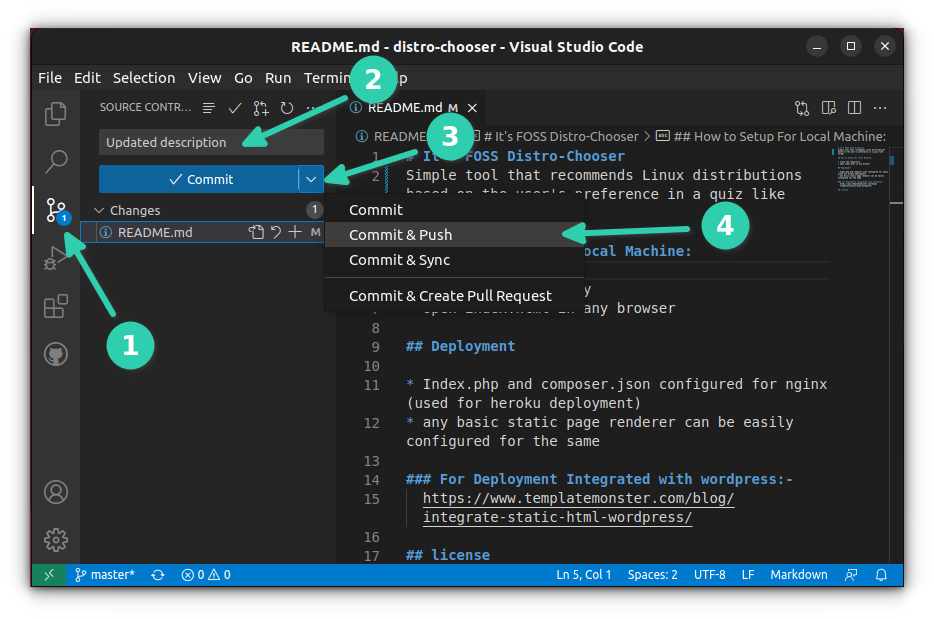
*If you don't have your Git username and email configured, you'll see this error.*
You can [set username and email at global level](https://git-scm.com/book/en/v2/Getting-Started-First-Time-Git-Setup) or repo level. Your choice, really.
**You can verify that your push was successful by going to the repo on GitHub.**
You may choose to commit your changes locally without pushing them. You can do all the things you used to do with git commands here as well. There are options for creating pull requests, refreshing and whatnot.
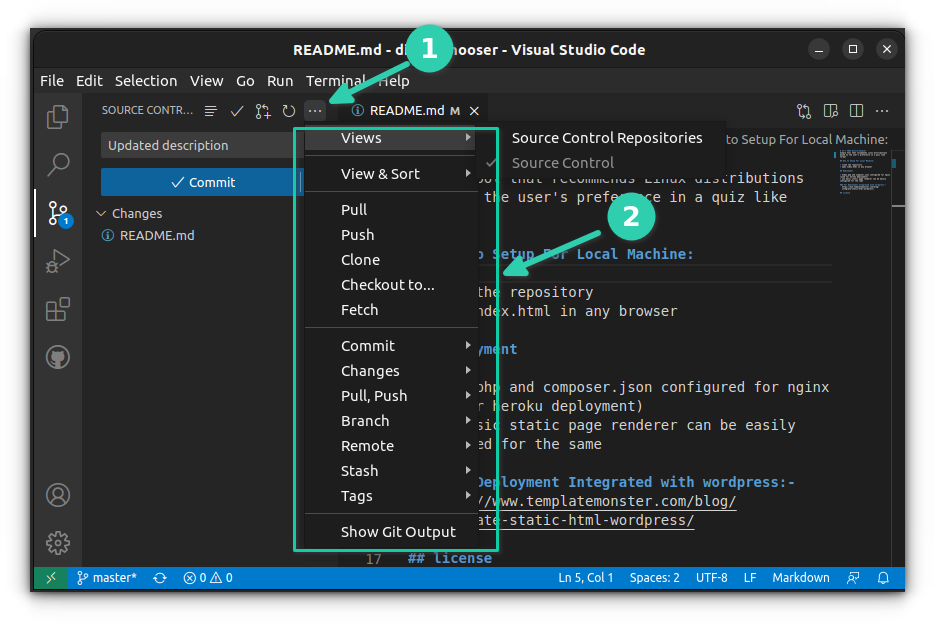
## Take it to the next level with GitHub official extension
There is a dedicated, official extension that lets you also **manage pull requests to your repos from other people and merge them**. You can also see issues opened on your repository here. This is a much better way to integrate GitHub with VS Code.
Open VS Code and go to the Extensions tab from the left sidebar. Here **search for GitHub Pull Requests and Issues**. It's an official plugin from GitHub itself. You can see the verified checkmark.
Click on the Install button and have the [extension installed](https://itsfoss.com/install-vs-code-extensions/) on your editor.
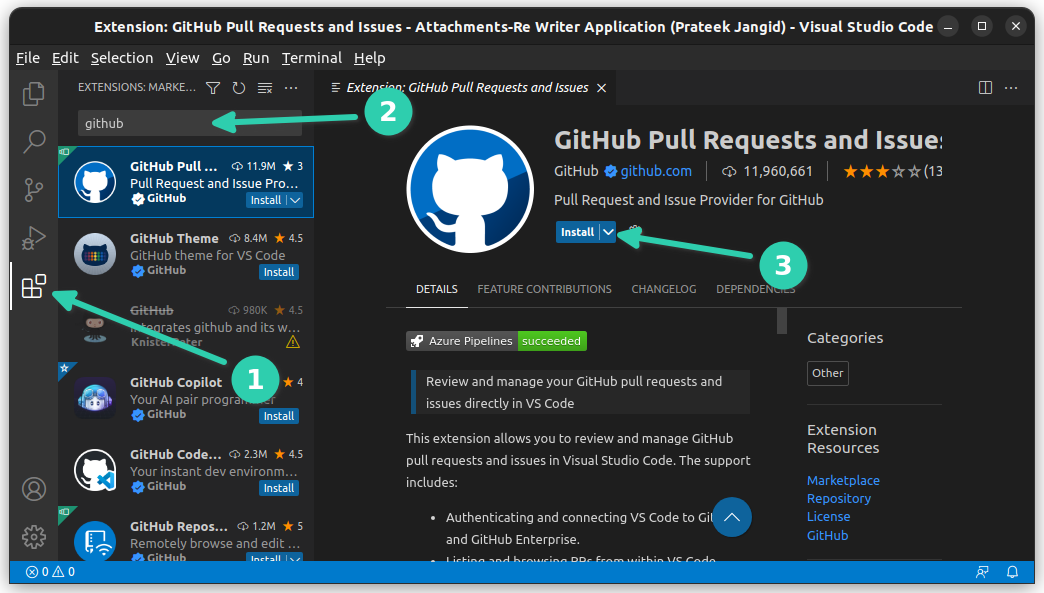
With this extension, you can manage your repository if others are collaborating on it.
It is good to have complete Git and GitHub integration in VS Code. People who don't like the command line surely enjoy this integration.
I hope this tutorial helped you add GitHub to VS Code seamlessly. Let me know if you still face any issues. |
15,752 | Linux Mint 的发行周期 | https://itsfoss.com/linux-mint-release-cycle/ | 2023-04-24T23:11:01 | [
"Linux Mint"
] | https://linux.cn/article-15752-1.html | 
你可能知道,Linux Mint 是一个基于 Ubuntu 的发行版。
Ubuntu 每六个月发布一个新版本,但 Linux Mint 并不遵循六个月一次的发行模式。
Linux Mint 以 Ubuntu LTS(<ruby> <a href="https://itsfoss.com/long-term-support-lts/"> 长期支持 </a> <rt> long term support </rt></ruby>)版本作为其基础。Ubuntu 的 LTS 版本每两年发布一次,所以 **你也会每两年得到一个 Mint 的大版本更新**(比如 Mint 19, 20, 21 等)。
与 Ubuntu LTS 版本一样,Linux Mint 的大版本也被支持五年。虽然在这期间有**三个小更新版本**(比如 Mint 20.1、20.2、20.3)。
与 Ubuntu 相比,多久能得到一次 Linux Mint 的升级?你应该在什么时候等待 Linux Mint 的升级?当有新版本的时候,你应该升级到新版本吗?
在这里,让我重点介绍一下这些 Linux Mint 的发行周期的重要细节。
### Linux Mint 的发行周期
Ubuntu 每两年发布一个长期支持版本。之后很快就会有一个 Mint 版本出现。换句话说,你每两年就会得到一个新的 Mint 版本。
所以,Linux Mint 20 是在 2020 年基于 Ubuntu 20.04 发行的,Mint 21 是在 2022 年基于 Ubuntu 22.04 发行的。
与 Ubuntu 不同,Mint 没有严格的发行时间表。没有事先确定的发行日期。新版本在其开发者认为准备好的时候就会到来。
#### 小版本
在 Mint 的两个大版本发布之间,有三个小版本,每隔 6 个月发布一次。
即 Mint 20(即 20.0)是在 2020 年 6 月发布的。Mint 20.1 在 2020 年 12 月,Mint 20.2 在 2021 年 6 月,Mint 20.3 在 2021 年 12 月。在这之后,Mint 团队将致力于开发下一个大版本。
这些小版本会更新什么?比如,一个新版本的桌面环境,主要包含用户图形界面的视觉变化。它有时也可能提供新的应用程序。
升级到小版本是可选的。你可以选择继续使用 20.1,而不升级到 20.2 和 20.3。这是那些不喜欢频繁(在图形界面上)改变他们系统的人的首选。
在最后一个消版本发布(XX.03)之后,你的系统将只得到已安装软件的安全和维护更新。你不会得到桌面环境和其他一些软件(如 GIMP 或 LibreOffice)的新的大版本更新。
#### 支持周期
并非所有基于 Ubuntu 的发行版都能为你提供与 Canonical 的 Ubuntu 相同的周期性更新优势。许多基于 Ubuntu 的发行版和 [官方的衍生版本](https://itsfoss.com/which-ubuntu-install/) 提供了最长 3 年的支持。
幸运的是,对于 **Linux Mint** 来说,你可以得到和 Ubuntu 一样的更新福利。
**每个 Linux Mint 版本的支持期为 5 年**,在此之后,你必须升级到下一个版本,或者重新安装较新的版本。
例如,Mint 20 是在 2020 年发布的,比 Ubuntu 20.04 晚几个月。Ubuntu 20.04 LTS 被支持到 2025 年,因此 Mint 20 系列也被支持到 2025 年。
一个系列的所有小版本都支持到同一日期。Mint 20.1、20.2 和 20.3 都将被支持到 2025 年。
同样地,Ubuntu 22.04 LTS 将被支持到 2027 年 4 月。你可以期待 Linux Mint 21 系列(它基于 Ubuntu 22.04)的更新周期到相同的时间线。
**总结一下:**
* 你每两年得到一个新的 Linux Mint 大版本
* 每个大版本的支持周期为 5 年
* 每个大版本(XX 版)在下一个大版本之前都会有三个小版本(XX.1、XX.2、XX.3)
* 小版本(XX.1,XX.2,XX.3)与大版本(XX)的支持时间相同
### 你什么时候应该升级 Linux Mint?
这完全取决于你,
每两年会有一个新的大版本。你可以选择在那时升级它,或者你可以在整个五年的生命周期内保持你目前的版本。
除非你想获得最新的功能和改进,你可以选择不把你的 Linux Mint 安装升级到另一个大版本。
对于小版本,你可以选择更新,也可以不更新。比如,20 到 20.1 或 20.1 到 20.2。即使你不使用最新的小版本,你仍然会得到重要的安全和维护更新。
你可以参考我们的 [Linux Mint 升级指南](https://itsfoss.com/upgrade-linux-mint-version/) 以寻求帮助。
### Linux Mint 的版本划分和命名
与 Ubuntu 发行版不同,Linux Mint 有一个不同的编号方案。Linux Mint 喜欢在每一个 Ubuntu LTS 版本中提升编号。
换句话说:
Linux Mint 19 → **Ubuntu 18.04 LTS**
Linux Mint 20 → **Ubuntu 20.04 LTS**
Linux Mint 21 → **Ubuntu 22.04 LTS**
所以,你应该避开以下的混淆:
*Linux Mint 20 基于 Ubuntu 20.04 并不意味着 Linux Mint 21 将基于 Ubuntu 21.04。*
此外,每个版本都有**三个小版本**,带有内核的小更新和一些 Linux Mint 应用程序的潜在升级。
现在,来看看它的**命名方案**:
每个 Linux Mint 版本,无论是小的还是大的,都有一个代号。通常,它是一个女性的名字,通常源自希腊或拉丁语。
和 Ubuntu 一样,代号也有一个模式。大版本的代号是按字母顺序递增的。当涉及到小版本时,你会发现新的名字会以相同的字母开头。
例如,Mint 20 被称为 **Ulyana**,20.1 为 **Ulyssa**,20.2 为 **Uma**,而 20.3 为 **Una**。同样地,Mint 19 系列的代号以 T 开头。
在写这篇文章的时候,Mint 21(最新版本)的代号以 **V** 开头,21 系列的第一个版本叫 **Vanessa**。
在 Mint 21 系列中至少还会有三个小版本,它们将每六个月发布一次,直到 2024 年的下一个 Mint 大版本。而它们都将有一个以字母 V 开头的代号。
### 薄荷留香
我希望这篇文章能消除对 Linux Mint 升级的各种困惑,并让你更多地了解 Linux Mint 的发布和更新周期。
*(题图:MJ/mint cinamon plain dark background in high resolution, very detailed, 8k)*
---
via: <https://itsfoss.com/linux-mint-release-cycle/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:[chris000132](https://github.com/chris000132) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux Mint is an Ubuntu-based distribution. You probably already know that.
Ubuntu releases a new version every six months but Linux Mint doesn’t follow the six-monthly release pattern.
Linux Mint uses the Ubuntu LTS ([long term support](https://itsfoss.com/long-term-support-lts/)) version as its base. An LTS version of Ubuntu is released every two years and hence **you also get a major Mint version every two years** (Mint 19, 20, 21, etc).
Like the Ubuntu LTS versions, a major Linux Mint version is also supported for five years. Although, there are **three point releases in between** (Mint 20.1, 20.2, 20.3).
Compared to Ubuntu, how long does Linux Mint receive updates? When should you expect an upgrade for Linux Mint? Should you upgrade when a new version is available?
Here, let me highlight all these necessary details regarding the release cycle of Linux Mint.
## Release Cycle of Linux Mint
Ubuntu releases a long-term support release every two years. A Mint version is followed soon after. In other words, you get a new Mint version every two years.
So, the Linux Mint 20 was released in 2020 based on Ubuntu 20.04, Mint 21 came in 2022 based on Ubuntu 22.04.
Unlike Ubuntu, there is no strict release schedule for Mint. There is no predefined release date. The new version arrives when it is deemed ready by its developers.
### Point Releases
In between the two (major) version releases of Mint, there are three point releases that arrive at an interval of six months.
So, Mint 20 (or 20.0) was released in June ’20. Mint 20.1 came in December’20, Mint 20.2 in June’21 and Mint 20.3 in December’21. After that, the Mint team works on developing the next major release.
What do these point releases have? A new version of the desktop environment, containing mostly visual changes in the UI. It may also feature new applications sometimes.
The upgrade to the point release is optional. You can choose to stay with 20.1 and not upgrade it to 20.2 and 20.3. This is preferred by people who don’t like frequent (visual) changes to their systems.
After the last point release (XX.03), your system will only get security and maintenance updates for installed software. You won’t get new major versions of the desktop environment and some other software like GIMP or LibreOffice.
### Support Cycle
Not all Ubuntu-based distributions give you the same update cycle benefit as Canonical’s Ubuntu. Many Ubuntu-based distributions and the [official flavours](https://itsfoss.com/which-ubuntu-install/) provide support for up to 3 years.
Fortunately, for **Linux Mint**, you get the same update perks as Ubuntu.
**Each Linux Mint release is supported for five years**. After that, you must upgrade to the next version or install the newer version afresh.
For example, Mint 20 was released in 2020, a few months after Ubuntu 20.04. Ubuntu 20.04 LTS is supported till 2025 and thus Mint 20 series is also supported till 2025.
All point releases of a series are supported till the same date. Mint 20.1, 20.2, and 20.3 will all be supported till 2025.
Similarly, Ubuntu 22.04 LTS will be supported until April 2027. You can expect the update cycle for Linux Mint 21 series (based on Ubuntu 22.04) until the same timeline.
**To summarize:**
- You get a new major version of Linux Mint every two years
- Each major version is supported for five years
- Each major release (version XX) is followed by three point releases (XX.1, XX.2, XX.3) before the next major release
- The point releases (XX.1, XX.2, XX.3) are supported till the same time as their major version (XX)
## When Should You Upgrade Linux Mint?
That totally depends on you.
A new major version comes every two years. If you can choose to upgrade it then or you can stay with your current version for its entire lifecycle of five years.
Unless you want access to the latest features and improvements, you can choose not to upgrade your Linux Mint installation to another major version.
For point releases, you may or may not choose to update. Like, 20 to 20.1 or 20.1 to 20.2. You will still get important security and maintenance updates even if you are not using the latest point release.
You can refer to our [Linux Mint upgrade guide](https://itsfoss.com/upgrade-linux-mint-version/) for help.
## Linux Mint Versioning and Naming
Unlike Ubuntu’s flavours, Linux Mint has a different numbering scheme. Linux Mint likes to bump up the number with every Ubuntu LTS release.
In other words:
Linux Mint 19 → **Ubuntu 18.04 LTS**
Linux Mint 20 → **Ubuntu 20.04 LTS**
Linux Mint 21 → **Ubuntu 22.04 LTS**
So, you should steer clear of the following confusion:
*Linux Mint 20 was based on Ubuntu 20.04 does not mean that Linux Mint 21 will be based on Ubuntu 21.04.*
Furthermore, every release has **three-point releases**, with minor updates to the core and potential upgrades to some Linux Mint applications.
Now, coming to its **naming scheme**:
Every Linux Mint release, be it minor or major, has a codename. Usually, it is a female name, normally of Greek or Latin origin.
Like Ubuntu, there is a pattern in the codename as well. The codenames are in alphabetically increasing order for the major releases. When it comes to point releases, you will find a new name starting with the same alphabet.
For example, Mint 20 was called **Ulyana**, with 20.1 as **Ulyssa**, 20.2 as **Uma**, and 20.3 **Una**. Similarly, Mint 19 series had codenames starting with T.
At the time of writing this, Mint 21 (the latest release) codename starts with **V,** and the first release of the 21 series is called **Vanessa**.
There will be at least three more minor releases in the Mint 21 series, and they will be released every six months until the next Mint major release in 2024. And they all will have a codename starting with the letter V.
## Keep it Minty
I hope this article clears any confusion with Linux Mint upgrades and educates you more about the release and update cycle on Linux Mint. |
15,753 | 什么是开源布道师? | https://opensource.com/article/21/1/open-source-evangelist | 2023-04-25T09:09:11 | [
"布道师"
] | /article-15753-1.html |
>
> 了解如何成为产品用户和开发人员之间的桥梁。
>
>
>

当人们得知我是位(专注于 [syslog-ng](https://www.syslog-ng.com/) 和 [sudo](https://www.sudo.ws/) 的)开源布道师的时候,他们经常问我为 Linux 世界中如此知名的软件“代言”是什么感觉。我的回答非常简短:非常棒!
我是整个研发环节的一部分,所以我不会觉得自己可有可无。当人们实践我教他们的东西,以及当我收集到的用户反馈影响产品开发的时候,我感觉我很有意义。
### 什么是布道师?
我将布道师定义为软件(或其他产品)的用户和开发人员之间的桥梁。布道师不仅仅将好消息分享给用户,还要从他们那里收集反馈。
布道师们有着各式各样的背景:有些人具有市场营销背景,对技术有着浓厚的兴趣;有些人是喜欢和用户交流的开发人员。我属于第三类——“资深用户”,即从用户视角对软件产品有深入了解的人。
我要和非常多的用户打交道。syslog-ng 的用户群体非常庞大,它可以用在大多数 Linux 发行版和 BSD 变体上。数以亿计的设备运行着 syslog-ng,其中包括 BMW i3 和 Kindle。大多数基于 BSD 的设备,譬如 FreeNAS,使用 syslog-ng 记录日志,而 Synology 和 QNAP 的基于 Linux 的<ruby> 网络附属存储 <rt> Network Attached Storage </rt></ruby>(NAS)也是如此。就算 syslog-ng 运行在太空的某处,我也不会感到惊讶。
大多数 Linux 和 Unix 用户使用 sudo,因为它几乎被安装在每一台 Linux 设备上。它的社区很大,有几千万人。人们经常问我是如何和那么多用户打交道的,但这并不困难。
### 我是如何成为一名布道师的
我成为布道师的旅程是一个跨越了近 20 年的进化过程。它始于许多年前,那时候我在大学教书。之后是和 POWER/PowerPC 的 Linux 用户、开发人员合作。最后,我在 [Balabit](https://en.wikipedia.org/wiki/Balabit) 的工作中开始使用 syslog-ng,再后来我开始接触 sudo。
我在 Balabit 的第一份工作是帮助 Linux 发行版将它们的 syslog-ng 包升级到上游的最新版本。随着我越来越多地了解 syslog-ng 的细节,我开始帮助它的用户。一年后,我在匈牙利和国际会议上发表关于 syslog-ng 的演说。不久之后,我从用户那里收集到的反馈开始对产品开发产生影响。
八年后,也就是 2018 年,Balabit 被 [One Identity](https://www.oneidentity.com/) 收购,sudo 的维护者 [Todd Miller](https://www.linkedin.com/in/millert/) 成为了我的同事。在那之前我只是了解一些基本的 sudo 功能,但我变得对 sudo 更感兴趣,并开始了解它的高级功能。很快,我开始为 sudo 布道,从一名 syslog-ng 布道师进化为一个更广泛意义上的开源布道师。
### 技术布道的四大支柱
技术布道师做很多事情,大致可以分为四类:开发人员、支持人员、技术产品营销和产品经理。我将更详细地介绍这四个支柱。
#### 开发人员
我不是开发人员,但我做了很多开发人员的工作,例如为各式各样的 Linux 发行版和 FreeBSD 打包 syslog-ng,做很多测试,将 syslog-ng 集成到其他软件中,并在异构平台上测试。我做的开发者任务有助于社区,并帮助我更好地了解社区需求。
#### 支持人员
关注错误追踪器,在 Google Alerts 和 Twitter 上查看 syslog-ng 关键词,以及阅读邮件列表,都能让我更好地帮助我们的用户群体。通过帮助他人,我也能能更好地理解他们的问题所在。
#### 技术产品营销
我真的不喜欢“营销”这个词,但是写博客和在会议上演说 *确实是* 营销。作为一名前系统管理员,我了解我的听众,我们有共同的声音。除了我自己的 Twitter 账号 [@PCzanik](https://twitter.com/PCzanik) 之外,我还在 [@sngOSE](https://twitter.com/sngose) (syslog-ng 开源版)和 [@SudoProject](https://twitter.com/SudoProject) (sudo)账号下发帖。
Twitter 是个收集和分享技术新闻的绝佳平台。即使营销只是我工作的一个方面,它仍是我布道工作中最引人注目的部分:
* **给内向者的社交场合生存技巧:** 当人们得知我是一个内向的人,而仍然从事了这份工作之后,就经常问我是如何做到的。发表演讲或在会议展位上工作一整天是很困难的:有太多的人、太多的噪音了。我在这里针对这种场合给出一些生存技巧:
+ 专注于结果。活动是从用户那里收集反馈的绝佳机会。等你演讲完,可以随地开始一场好的讨论,甚至在展台或走廊上。在活动中,用户会给出很多现实生活中的反馈,记住她们的意见会有很多帮助。
+ 知道活动何时结束。请记住在嘈杂的环境中只能待上一段时间,这对你会有很大的帮助。
+ 与你志同道合的人尽情交谈,他们和你一样害羞、和你一样有不安全感、和你有着相同的技术兴趣。
* **疫情期间的营销技巧:** 许多人问我 COVID-19 是如何影响我的工作的,因为我从 2020 年开始就不能出行。我刚从 [RSA 大会](https://www.rsaconference.com/usa/us-2020) 和 [南加州 Linux 博览会](https://www.socallinuxexpo.org/scale/18x) 上回来,两天后航班就暂停了、边境也关闭了(LCTT 校注:本文原文发表于 2021 年)。即使现在也在开虚拟会议,我仍可以做有关 sudo 和 syslog-ng 的演说,但这样反馈就会减少,甚至没有反馈——没有让我和用户见面的走廊,也没有供演讲者讨论最新、最好的技术的晚宴。会议上注意力比以往更不集中,因为在家里工作总有各种各样的干扰因素。我看到了许多不同的方法试图解决这个问题,每一项都有其优缺点:
+ 全局聊天室适合举办小型活动。但当活动有超过几十个人时,它将会变成一连串的“大家好,我来自马萨诸塞州,波士顿” 或者类似的无用的消息,从而没有机会进行一些有意义的讨论。
+ 如果活动有多个<ruby> 专题 <rt> track </rt></ruby>,给每个专题讨论一个单独的聊天室是很有用的。演讲者和用户都可以从聊天中发布的问题和评论中学到很多东西。如果有一个主持人,这将成倍地有用。始终记得将讨论限制在主题上,并确保在问答环节中产生的问题传达到演讲者耳中。
+ <ruby> 随机聊天 <rt> chat roulette </rt></ruby>是个随机联系陌生人的好方法,并且能产生好的讨论。不过这种方法对于演讲者来说随机性太高了。
+ <ruby> 针对性聊天 <rt> Tracking chats </rt></ruby>很好,不过许多人不喜欢公开提问或分享经验。直接与演讲者聊天可以解决这个问题。
#### 产品经理
我不是产品经理,尽管有时候我希望自己收集到的反馈可以直接转化为功能,但我定期与开发者和产品经理分享用户反馈。在内部讨论中,我总是代表用户一方,而不是考虑开发者如何用用最简单的方法推进产品,或者如何产生最多收益。
### 为什么要布道广为人知、广泛使用的软件?
每个 Linux 用户都知道 sudo,他们中的许多人也知道 syslog-ng。那我们为什么要布道它们呢?这是因为许多人只知道这些程序的基础知识,这也是他们刚开始使用 Linux 时学到的。但这两款软件都不是简单的、几十年来处于维护模式的工具序,两者都是仍在持续开发中的有生命力的程序。
大多数人对 syslog-ng 的了解仅限于它收集日志消息并把消息存储在文本文件中。但 syslog-ng 还有许多 [其他功能](https://www.syslog-ng.com/community/b/blog/posts/building-blocks-of-syslog-ng),包括解析消息、使用地理信息丰富消息、精确的消息路径(过滤)和把消息存储在数据库、Hadoop 或消息队列中。
sudo 通常被认为是管理员命令的前缀,但它可以做许多其他事情。sudo 可以记录在里面运行的会话,允许你检查用户通过 sudo 使用超级权限做了什么事情。你也可以使用插件扩展 sudo。从 [sudo 的 1.9 版本](https://opensource.com/article/20/10/sudo-19) 开始,你甚至可以用 Python 扩展 sudo,这使得扩展它变得容易得多。
### 总结
成为一名开源布道师是个非常有趣的工作,即使是在 COVID-19 时代,虽然确实增加了我的工作难度。如果你对于这个角色有其他问题,或者有关于技术布道师或者开发大使则如何帮助你的故事,请在评论里分享。
*(题图:MJ/sci-fi evangelist in high resolution, very detailed, 8k)*
---
via: <https://opensource.com/article/21/1/open-source-evangelist>
作者:[Peter Czanik](https://opensource.com/users/czanik) 选题:[lujun9972](https://github.com/lujun9972) 译者:[rsqrt2b](https://github.com/rsqrt2b) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,755 | 在 Linux 中验证 ISO 文件的初学者指南 | https://www.debugpoint.com/verify-iso-files-linux/ | 2023-04-25T21:28:00 | [
"ISO"
] | /article-15755-1.html | 
>
> 这篇简单指南演示了在 Ubuntu 和其他 Linux 发行版中验证 ISO 文件过程。
>
>
>
从互联网下载操作系统镜像文件或软件有时会带来安全风险,因为恶意行为者可能会损坏或修改文件。为保证下载文件的真实性和完整性,需要对其进行校验。在本初学者指南中,我们将引导你在 Linux 中验证 ISO 文件。
### 什么是 ISO 文件?
ISO 文件通常用于创建可启动媒体、安装软件和创建备份。ISO 文件包含压缩格式的所有原始应用/光盘数据,可以轻松下载并通过互联网共享。
例如,如果你下载 Ubuntu 桌面、服务器或任何其他 Linux 操作系统,你一定遇到过扩展名为 .iso 的文件。它还用于应用或其他操作系统,例如 Windows。
### 为什么要验证 ISO 文件?
验证 ISO 文件对于确保下载的文件真实且未被修改至关重要。修改后的 ISO 文件可能包含可能损害你系统的恶意软件或病毒。验证 ISO 文件可确保下载的文件与开发人员创建的文件相同且未被篡改。
例如,几年前 [Linux Mint 服务器被黑](https://blog.linuxmint.com/?p=2994) 并且官方 ISO 文件被修改。由于你是从官方网站下载的,你可能会认为这些文件是真实的,但它们不一定是。
因此,在使用 ISO 文件安装到你的笔记本电脑/台式机之前,始终验证 ISO 文件非常重要。
### 在 Linux 中验证 ISO 文件的方法
Linux 中校验 ISO 文件的常用方法有两种:
* 使用 SHA-256 校验和
* 使用 GPG 签名
#### 使用 SHA-256 校验和
[SHA-256](https://en.wikipedia.org/wiki/SHA-2) 是一种加密哈希函数,可为文件生成唯一的哈希值。校验和是将 SHA-256 算法应用于文件的结果。校验和是一个唯一的字符串,可用于验证文件的完整性。
要使用 SHA-256 校验和验证 ISO 文件,请从开发者网站下载 SHA-256 校验和。SHA-256 校验和文件将包含 ISO 文件的校验和值。你需要生成下载的 ISO 文件的校验和值,并将其与 SHA-256 校验和文件中的校验和值进行比较。如果两个值匹配,则下载的 ISO 文件是真实的且未被修改。
#### 使用 GPG 签名
[GPG](https://gnupg.org/)(GNU Privacy Guard)是一种加密软件,可用于对文件进行签名和验证。GPG 签名是一种数字签名,可确保文件的真实性和完整性。开发者使用他们的私钥签署 ISO 文件,用户使用开发者的公钥验证签名。
要使用 GPG 签名验证 ISO 文件,你需要从开发者网站下载 GPG 签名文件。GPG 签名文件将包含开发者的公钥和 ISO 文件的签名。你需要导入开发者公钥,下载 ISO 文件和 GPG 签名文件,并使用开发者公钥对 ISO 文件进行签名验证。如果签名有效,则 ISO 文件是真实的并且未被修改。
### 如何在 Linux 中验证 ISO 文件:示例
让我们看一下上述在 Linux 中使用 SHA-256 校验和及 GPG 签名验证 ISO 文件的方法的一些示例。
#### 使用 SHA-256 校验和验证 ISO 文件

* 我已经从 [官方网站](https://linuxmint.com/edition.php?id=302) 下载了 Linux Mint 21.1 ISO 文件。
* 此外,我还下载了包含 ISO 文件校验和的 SHA-256 文本文件(见上图)。
* 现在,打开终端并转到 ISO 和 SHA-256 校验和文件所在的目录。
* 在终端中使用 `sha256sum` 命令生成 ISO 文件的 SHA-256 校验和值。例如,要生成上述名为 linuxmint-21.1-cinnamon-64bit.iso 的 ISO 文件的校验和值,请运行以下命令:
```
sha256sum linuxmint-21.1-cinnamon-64bit.iso
```
* 将生成的校验和值与 SHA-256 校验和文件中的校验和值进行比较。如果两个值匹配,则 ISO 文件是真实的并且未被修改。
* 这是上述 ISO 文件的并排比较。

如果校验和匹配,你可以确信该文件是真实的并且没有被篡改。你可以对任何其他 ISO 文件和校验和使用相同的命令进行验证。
现在,让我们看看如何使用 GPG 密钥进行验证。
#### 使用 GPG 签名验证 ISO 文件
对于上面的示例,我已经从官方网站下载了 .gpg 文件和 ISO 文件。
下一步是下载并导入开发者的公钥。你可以从开发者的网站或密钥服务器下载公钥。
我使用下面的命令为这个例子下载了 Linux Mint 的公钥。因此,对于相应 Linux 发行版文件的 ISO 文件,请查看下载页面以找出公钥。
```
gpg --keyserver hkp://keyserver.ubuntu.com:80 --recv-key "27DE B156 44C6 B3CF 3BD7 D291 300F 846B A25B AE09"
```
**注意**:你还可以下载公钥 `.asc` 文件(如果有),然后使用命令 `gpg --import developer_key_file.asc` 将其导入你的系统。
完成后,运行下面的 gpg 命令来验证文件。
```
gpg --verify sha256sum.txt.gpg sha256sum.txt
```

如果文件是真实的,你应该会在上述命令的输出中看到 “Good signature” 消息。此外,你可以匹配公钥的最后 8 个字节。“Warning” 是一条通用消息,你可以忽略它。
### 总结
验证 ISO 文件是确保下载文件的真实性和完整性的重要步骤。在本初学者指南中,我介绍了在 Linux 中使用 SHA-256 校验和和 GPG 签名验证 ISO 文件的方法和步骤。通过执行这些步骤,你可以自信地下载和使用 ISO 文件,知道它们没有被修改并且可以安全使用。
请记住,即使你是从官方网站下载的,在你验证之前你永远不会知道 ISO 文件是否真实。因此,请将此作为最佳实践。
>
> **[参考信息](https://linuxmint-installation-guide.readthedocs.io/en/latest/verify.html)**
>
>
>
*(题图:MJ/iso cd image illustration in high resolution, very detailed, 8k)*
---
via: <https://www.debugpoint.com/verify-iso-files-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,758 | Xubuntu 23.04 发布:带来了 Xfce 4.18 和 Pipewire | https://news.itsfoss.com/xubuntu-23-04/ | 2023-04-27T06:55:14 | [
"Xubuntu",
"Ubuntu"
] | https://linux.cn/article-15758-1.html | 
>
> Xubuntu 23.04 版本带来了 Xfce 4.18 和必要的修复,以获得更好的体验。
>
>
>
Xubuntu 是最受欢迎的 Ubuntu 风味版之一,提供了极简版的 Xfce 桌面环境。
从去年这个时候 [Xubuntu 22.04 LTS](https://news.itsfoss.com/xubuntu-22-04-release/) 发布以来,Ubuntu 的 Xfce 风味版已经有了很多改进。
让我们来看看新版本提供了什么。
>
> ? Xubuntu 23.04 将被支持 **9 个月** 直到 **2024 年 1 月**。如果你想在它的生命周期结束后得到一个最新的、安全的系统,你可以升级到 Xubuntu 23.10(即将推出的版本)。
>
>
>
### ? Xubuntu 23.04:有什么新内容?

它基于 Ubuntu 23.04 “<ruby> 月球龙虾 <rt> Lunar Lobster </rt></ruby>”,这是一个包含许多重要更新的版本。值得注意的亮点包括以下内容:
* 桌面环境升级
* 删除默认的 Flatpak 支持
* Xubuntu 极简版
* 加入 PipeWire
>
> ? 这**不是**一个 [长期支持版本](https://itsfoss.com/long-term-support-lts/?ref=news.itsfoss.com)。因此,对于大多数人来说,你不是必须升级。只有当你想体验最新和最好的版本,同时愿意在一年内再次升级的时候,再去进行这一操作。
>
>
>
#### 桌面环境升级

在这个版本中,你会注意到最重要的变化是加入了 Xfce 4.18,它带来了许多新的改进,使其比前代产品更加完善。
其中一些改进包括:**Thunar 文件管理器增加了重大功能**、**Xfce 面板的更新**、**新的壁纸**、**初步的 Wayland 支持** 等等。
你可以通过我们的报道来了解更多:
>
> **[XFCE 4.18 发布先窥](https://news.itsfoss.com/xfce-4-18-release/)**
>
>
>
#### 移除默认的 Flatpak 支持
是的,你没看错!
由于 Xubuntu 是 Ubuntu 的一个版本,Flatpak 支持不再是一个默认的选项,Snap 才是。
你仍然可以通过在终端运行几行代码,[在几分钟内设置好 Flatpak](https://itsfoss.com/flatpak-guide/?ref=news.itsfoss.com)。
#### 最小化 ISO 的引入
与 Ubuntu [类似](https://news.itsfoss.com/ubuntu-mini-iso/), 你现在可以使用 **Xubuntu 的最小化的 ISO**,尽管它不像为 Ubuntu 设计的那样小,但它与标准 ISO 相比仍然很小。
这个最小的ISO只有 **1.7 GB** 大小,带有一套最小化的 **应用程序**:终端、文件管理器、系统设置应用程序、Snap 软件包管理器和屏幕截图应用程序。
正因为如此,它所 **占用的存储空间** 也比标准安装要少。
#### 加入 PipeWire
Xubuntu 现在终于有了 [PipeWire](https://pipewire.org/?ref=news.itsfoss.com)。这应该会为整个系统**加强对音频和视频的处理**。
它还将有助于以极小的延迟和实时处理来捕获和播放音频/视频。
#### ?️ 其他改进措施
除了上述提到的之外,这里还有一些值得了解的应用更新:
* [Linux 内核 6.2](https://news.itsfoss.com/linux-kernel-6-2-release/)
* Firefox 111.0(Snap
* GIMP 2.10.34
* LibreOffice 7.5.2
* Pipewire 0.3.65
* Snapd 2.58.3
* [Thunderbird 102.9.0](https://news.itsfoss.com/thunderbird-102-release/)
* 由于对系统托盘插件的图标大小进行了“自动调整”,托盘图标和系统状态图标现在有了一个更一致的外观
* 为了提高可读性,终端的默认字体大小从 9 号增加到了 10 号
你也可以查看 [发行说明](https://wiki.xubuntu.org/releases/23.04/release-notes?ref=news.itsfoss.com) 来深入了解技术上的变化。
### ? 下载 Xubuntu 23.04
前往 [官方网站](https://xubuntu.org/download/?ref=news.itsfoss.com) 获取最新的 ISO 镜像, 或者使用 [Ubuntu 镜像库](https://cdimage.ubuntu.com/xubuntu/releases/23.04/?ref=news.itsfoss.com) 来获取它。
>
> **[Xubuntu 23.04](https://xubuntu.org/download/?ref=news.itsfoss.com)**
>
>
>
如果你已经是一个 \*\* Ubuntu 用户\*\*,你可以按照 [官方指南](https://docs.xubuntu.org/latest/user/C/migrating-upgrading.html?ref=news.itsfoss.com) 来进行升级。
---
via: <https://news.itsfoss.com/xubuntu-23-04/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[chris000132](https://github.com/chris000132) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Xubuntu is one of the most popular Ubuntu flavors with minimal Xfce desktop environment.
Since the arrival of [Xubuntu 22.04 LTS](https://news.itsfoss.com/xubuntu-22-04-release/), around this time last year, there have been a lot of refinements to the XFCE experience on Ubuntu.
Let's take a look at what it has to offer.
**nine**months until
**January 2024**. You can upgrade to Xubuntu 23.10 (upcoming version) if you want an up-to-date and secure system after its end of life.
## 🆕 Xubuntu 23.04: What’s New?
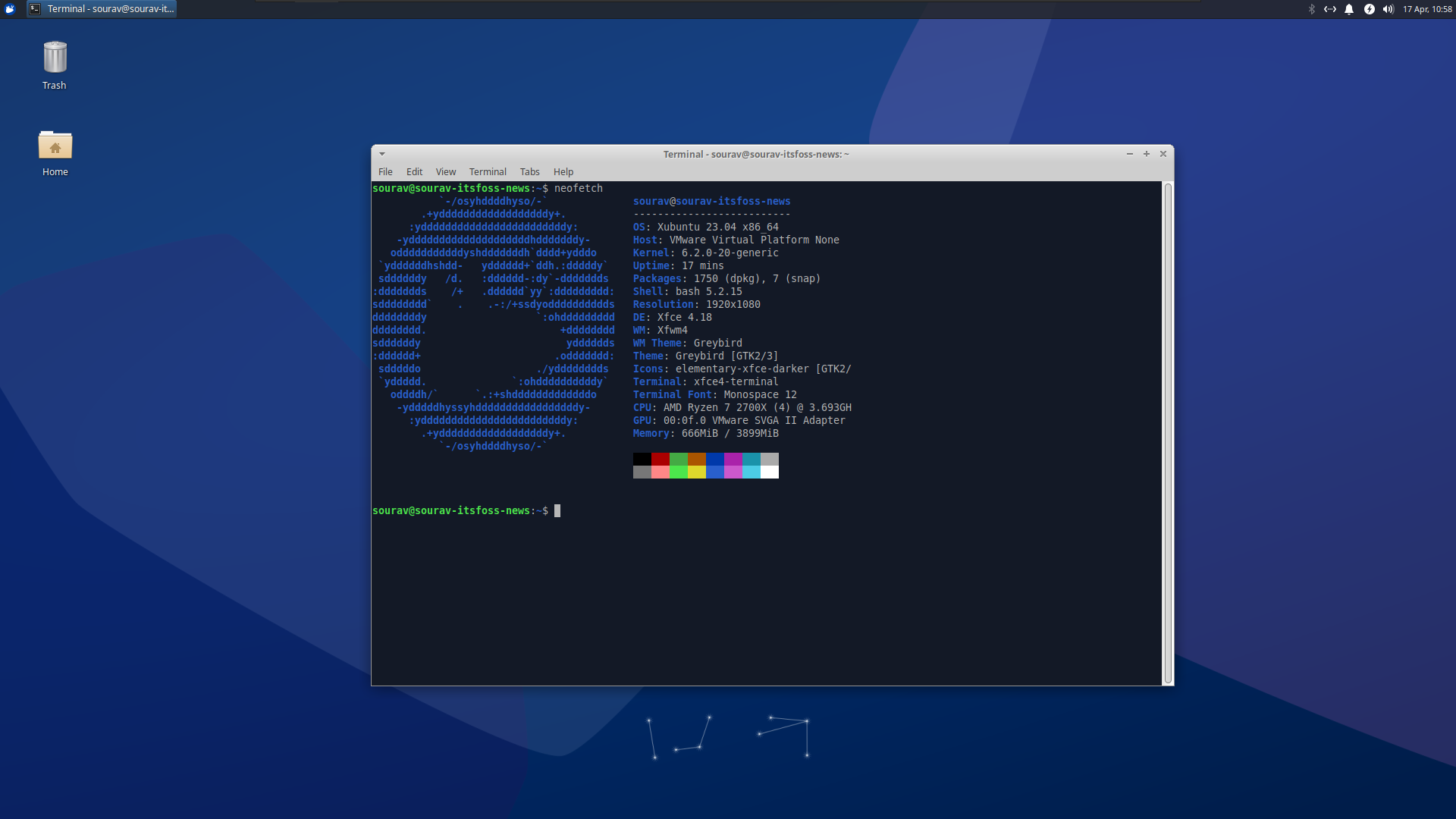
Based on **Ubuntu 23.04 'Lunar Lobster'**, this is a packed release with many important updates. The notable highlights include the following:
**Desktop Environment Upgrade****Removal Of Default Flatpak Support****Xubuntu Minimal****Inclusion of PipeWire**
**not**a
[Long-Term Support](https://itsfoss.com/long-term-support-lts/?ref=news.itsfoss.com)version. So, for most, you do not need to upgrade. Go ahead only if you want the latest and greatest while willing to upgrade again soon under a year.
### Desktop Environment Upgrades
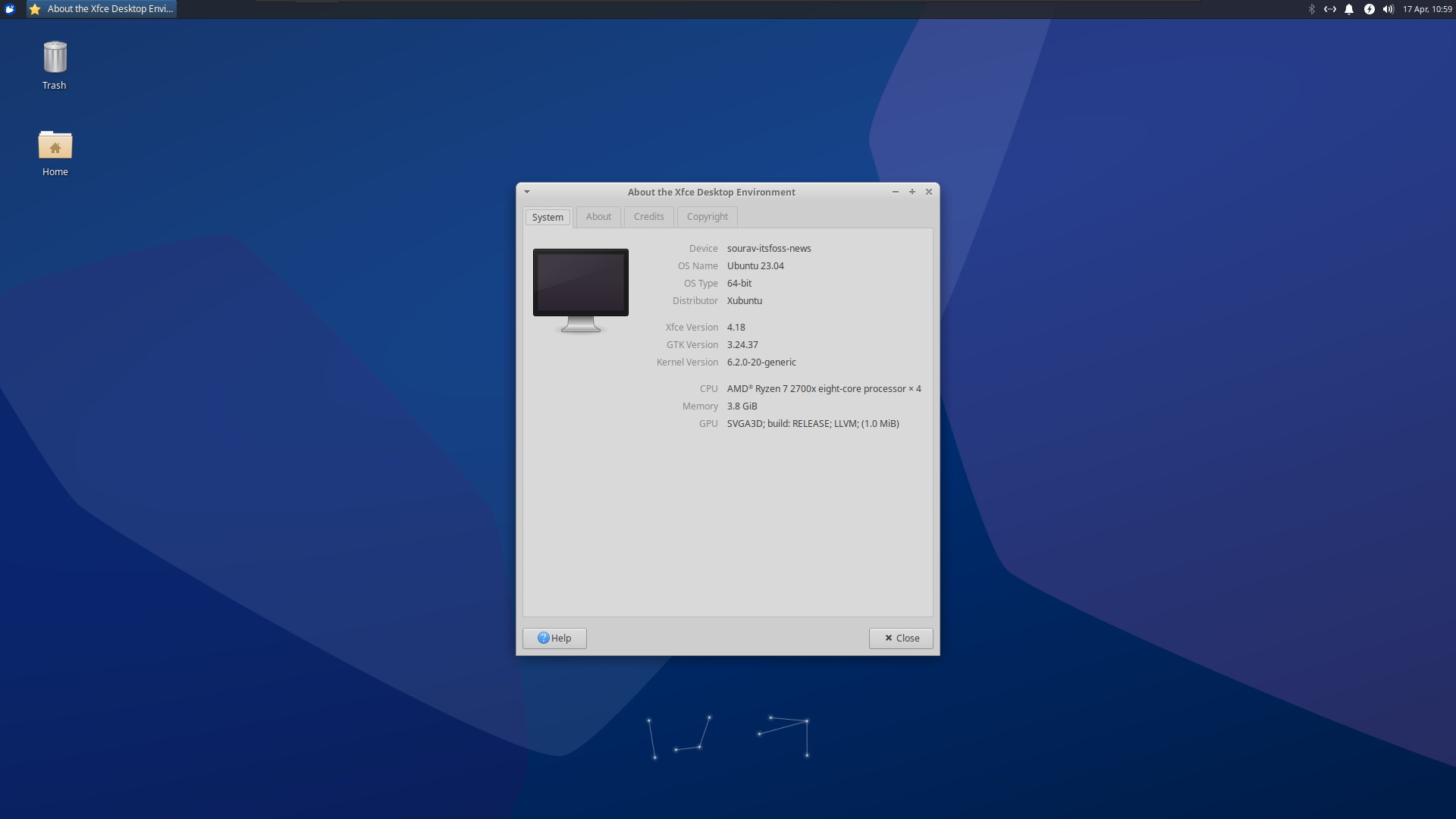
The most significant change you will notice with this release is the **inclusion of Xfce 4.18** which features many new improvements that have made it much more refined over its predecessor.
Some of those improvements include **major feature additions to the Thunar file manager**, **updates to the XFCE panel**, **new wallpapers**, **initial Wayland support**, and more.
You can go through our coverage on the same to learn more.
[XFCE 4.18 Release Looks Impressive!Xfce 4.18 is here with interesting feature additions and subtle changes.](https://news.itsfoss.com/xfce-4-18-release/)

### Removal Of Default Flatpak Support
Yes, you read that right.
As Xubuntu is an Ubuntu flavor, Flatpak support out-of-the-box is no longer an option by default.** **So, snap it is.
You can still [set up Flatpak in a matter of minutes](https://itsfoss.com/flatpak-guide/?ref=news.itsfoss.com) by running a few lines of code in the terminal.
**Suggested Read **📖
[Snapped! Ubuntu Cracks Down on Default Flatpak Support for its FlavorsUbuntu flavors will no longer include Flatpak support out-of-the-box. Why is that? Let’s find out.](https://news.itsfoss.com/ubuntu-flavor-drops-flatpak/)

### Introduction of Minimal ISO
In a [similar fashion](https://news.itsfoss.com/ubuntu-mini-iso/) to Ubuntu, you can now make use of a **minimal ISO for Xubuntu**. Though it's not as small as the one planned for Ubuntu, it still measures up well against the standard ISO.
The minimal ISO comes in at a smaller **1.7 GB** size with a minimal** set of applications**: The terminal, file manager, system settings apps, Snap package manager, and screenshot app.
Thanks to that, it also** takes up less storage space** than a standard installation.
### Inclusion of PipeWire
Xubuntu now finally ships with [PipeWire](https://pipewire.org/?ref=news.itsfoss.com); this should allow for **enhanced handling of audio and video** across the system.
It will also facilitate the capture and playback of audio/video with very little latency and real-time processing.
### 🛠️ Other Improvements
Other than the above mentioned, here are a few application updates that are worth knowing about:
[Linux Kernel 6.2](https://news.itsfoss.com/linux-kernel-6-2-release/)**Firefox 111.0 (snap)****GIMP 2.10.34****LibreOffice 7.5.2****Pipewire 0.3.65****Snapd 2.58.3**[Thunderbird 102.9.0](https://news.itsfoss.com/thunderbird-102-release/)- Tray icons and indicators now have a more consistent look thanks to an 'automatic' icon size tweak to the systray plugin.
- The default font size of the Terminal has been increased from 9 to 10 for better readability.
You may also review the [release notes](https://wiki.xubuntu.org/releases/23.04/release-notes?ref=news.itsfoss.com) to dig deeper into the technical changes.
## 📥 Download Xubuntu 23.04
Head to the [official site](https://xubuntu.org/download/?ref=news.itsfoss.com) for the latest ISO, or use [Ubuntu's image repository](https://cdimage.ubuntu.com/xubuntu/releases/23.04/?ref=news.itsfoss.com) to get it.
If you are an **existing user**, you can follow the [official guide](https://docs.xubuntu.org/latest/user/C/migrating-upgrading.html?ref=news.itsfoss.com) to get the upgrade.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,759 | 充分利用你的下一次技术会议的 7 个技巧 | https://opensource.com/article/23/4/tips-tech-conference | 2023-04-27T07:42:17 | [
"会议"
] | https://linux.cn/article-15759-1.html | 
>
> 会议是科技行业的福利之一。以下是如何充分利用你所参加的会议的方法。
>
>
>
我在 2023 年 2 月参加了两个针对开源软件的技术会议。我是比利时根特举办的 [Config Management Camp](https://cfgmgmtcamp.eu/ghent2023/) 的演讲者,也是比利时布鲁塞尔 [FOSDEM](https://fosdem.org/2023/) 的与会者。本文旨在着重讲述我在会议上的经验,并为你提供一些如何充分利用这种机会的建议。
### 保持目的性
不同的人参加会议有不同的原因。有些人是某个主题、知识或兴趣领域的演讲者。另外一些人是希望从这些讲座中获得知识并与其他志同道合的人建立联系的与会者。也有一些代表他们公司的与会者。你很可能属于其中的一类。明确你希望从会议中获得什么,这是进行一次成功会议访问的第一步。如果你是一个演讲者,这意味着你要熟练掌握你所演讲的东西。如果你是一个与会者,你应该对你想从会议中获得什么有一个认识。
### 了解场地和会议日程
FOSDEM 是一个非常大的会议,在两天的时间里至少有六千人参加。对于一个参加这样一个大型的会议的与会者来说,由于许多演讲会在同一时间举行,无法参加所有你感兴趣的会议并不奇怪。通常,这样的大型会议在大学或会议中心等宽敞的场地举行。由于面积非常大,会议会根据特定的主题分散在整个会场。这些会议会有一个固定的日程,所以有时你可能必须迅速地从场地的一边跑到另一边。场馆地图可以在场馆网站上轻松获取。在第一天早点到达会场并熟悉它是非常有用的。这有助于节省你在一个演讲结束时匆忙赶往另一个演讲的时间。
### 记些笔记
在现场集中注意力和专注于演讲当然很好。然而,你的头脑只能记住这么多。当然,有些人会试着尽可能地利用他们的手机拍摄正在演示的幻灯片(顺着演讲者的演讲节奏)。如果你想在社交媒体上快速更新你正在参加的会议信息,这是很好的。但是它不是很有效的笔记。通常幻灯片上的有效信息是最少的。但是如果演讲者在台上深入地解释了一些东西,你可能会错过这些解释。我建议你随身携带一个记事本和一支笔。你甚至可以带上笔记本电脑做笔记。这个做法的目的是在于通过在演讲中对有趣的花絮做一个简短的笔记,以便你可以在以后重温它们。而且它让你总是能在演讲快结束时回想起要向演讲者提问的问题。
### 建立关系和促成协作
会议可能是与志同道合的人彼此交往的最佳场所。他们和你一样对同样的话题感兴趣。最好利用这段时间来了解在感兴趣的话题上正在发生什么,看看人们如何解决令人感兴趣的问题,他们如何处理事情,并掌握整个行业的脉搏。你在会议上的时间有限,所以一定要把你介绍给那些从事与你有关的工作的人。这是一个收集信息的好机会,以便以后与他们沟通。你可以通过电子邮件、Mastodon、领英等方式交换个人信息。
### 腾出时间看展位和礼品
大多数技术会议都有来自各种公司或上游项目的展位,希望推销他们的产品和服务。为了吸引更多参展的人,展位上经常会有各种各样的免费的礼品(在大多数情况下)。这些礼品通常是贴纸、凉水瓶、有趣的小玩意、毛绒玩具、笔之类。一定要把它们收集起来,这样你就有东西送给你的同事和朋友了。参观展位不应该只是为了礼品。你应该利用这个机会与来自不同公司的人交谈(即使他们是竞争对手),以了解他们能提供什么。谁没准你就会得到以后的项目知识!
### 放松
参加会议不应该只是为了工作。这也让你你从平时忙碌的日程中休息一下,放松一下。很有可能你正在前往一个你还没有访问过的不同的国家或城市。会议、会谈和技术讨论都很重要。但这只是整个体验的一部分。另一半的经验是旅行,它可以使人了解另一个国家、它的文化、它的人民、食物、语言和不同的生活方式。退一步讲,享受所有这些经历,留下终生的回忆。我建议你在住宿的地方找一些著名的地标兼做。你也应该尝试当地的美食,或者你可以和当地人聊天。最后,你会发现你认为从来没有存在过的自己的另一面。
### 写下你的经历
一旦你从会议回来,不要只是忘记它然后回到你的日常生活,就好像什么都没发生一样。利用这个机会写下你的经历,并分享你认为最好的演讲以及原因。会议和旅行的主要收获是什么?你应该记录你学到的东西。你应该主动联系你在会议上遇到的人。你也可以在社交媒体上关注你可能错过的事情。
### 总结
会议是科技行业的福利之一。我建议每个人在职业生涯中的某个时候都去一次。我希望这篇文章能帮助你了解如何在参加技术会议时最大限度地利用会议。
*(题图:MJ/conference illustration talk meetup in high resolution, very detailed, 8k)*
---
via: <https://opensource.com/article/23/4/tips-tech-conference>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lkxed](https://github.com/lkxed/) 译者:[Taivas Jumala](https://github.com/TaivasJumala) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recently had the opportunity to visit two technical conferences in February 2023, both geared towards open source software. I was a presenter at [Config Management Camp](https://cfgmgmtcamp.eu/ghent2023/), in Ghent, Belgium, and an attendee at [FOSDEM](https://fosdem.org/2023/) in Brussels, Belgium. This article aims to highlight my experiences at the conferences and to provide you with some tips on how to make the most of such an opportunity whenever it arises.
## Have a purpose
Different people attend conferences for different reasons. Some people are presenters of a certain topic or area of knowledge or interest. Other people are attendees that want to gain knowledge from these talks and to network with other like-minded individuals. There are also attendees that are representing their companies. You most likely fall into one of these categories. Knowing what you wish to gain out of a conference is the first step to a successful conference visit. If you are a presenter, it means being proficient in whatever it is you are presenting. If you are an attendee, you should have a sense of what you want out of the conference.
## Know the venue and schedule
FOSDEM is a huge conference with at least six thousand people attending it in a span of two days. Not surprisingly, for a conference catering to such an audience, a number of talks happen at the same time. It is next to impossible to attend all talks that are of interest to you. Usually, such large conferences are hosted at a spacious venue like a university or a conference center. Because the area is so huge, the talks are spread across the venue based on specific topics. The talks have a fixed schedule, so you might have to move quickly from one side of the venue to another. The map of the venue is easily available on the venue's website. It makes sense to arrive at the venue a bit early on the first day and familiarize yourself with it. This helps save time when you are rushing out at the end of one talk to rush to another.
## Take notes
It's one thing to focus and enjoy the talk while it's happening live. However, your mind can only retain so much. Sure, folks try to use their phones to the fullest by taking pictures of the slides that are being presented (along with the speaker). This is good if you wish to quickly update on social media about the talk that you are attending. However, it's not very effective for note-taking. Usually, the material on the slides is minimal. But if the speaker explains something in depth on the stage, you might miss out on the explanation. I recommend carrying a notepad and a pen with you at all times. You can even bring your laptop for note-taking. The idea is to make quick one-liner notes about interesting tidbits during the talk so you can revisit them later. You can always ask the speaker questions toward the end.
## Network and collaborate
A conference is probably the best place to hang out with like-minded individuals. They are interested in the same topics as you. It's best to make use of this time to understand what work is being done on the topic of interest, see how folks solve interesting problems, how they approach things, and get a pulse of the industry in general. You are at the conference for a limited time, so make sure to get introduced to folks working on things that matter to you. This is a good opportunity to gather information for communicating with them later. You can exchange personal information such as email, Mastodon, LinkedIn, and so on.
## Make time for booths and swag
Most technical conferences have booths from different companies or upstream projects wanting to market their products and services. To attract more walk-ins at the booths, a variety of swag items are often kept as an attraction available for free (in most cases). These goodies are usually stickers, cool water bottles, fun gadgets, soft toys, pens, and so on. Be sure to collect them so you have something for your co-workers and friends back home. Visiting booths shouldn't be just about the swag. You should use this opportunity to talk to people from different companies (even if they are competitors) to understand what they have to offer. Who knows, you might get knowledge of future projects!
## Relax
Traveling for a conference shouldn't be just about work. It is also about taking a break from your usual busy schedule and relaxing. Chances are you are traveling to a different country or city that you haven't visited before. The conference, talks, and technical discussions are all important. However, they are only part of the whole experience. The other half of the experience is the travel which opens one up to another country, its culture, its people, the food, the language, and a different way of life. Take a step back and enjoy all these experiences and make lifelong memories. I recommend finding some famous landmarks to visit at the place of your stay. You should also try the local cuisine, or you can just chat with the locals. In the end, you will discover another part of yourself that you thought never existed.
## Write about your experience
Once you are back from the conference, don't just forget about it and go back to your regular schedule as if nothing happened. Use this opportunity to write about your experiences, and share which talks you found the best and why. What are the key takeaways from the conference and the travel? You should document what you learned. You should reach out to the people you met at the conference. You can also follow social media posts on things that you might have missed out on.
## Conclusion
Conferences are one of the perks of the tech industry. I suggest everyone go to one sometime during their career. I hope this article helped shed some light on how to make the most when visiting a technical conference.
## Comments are closed. |
15,761 | 官方的 Ubuntu 精简 ISO 真的“精简”吗? | https://debugpointnews.com/ubuntu-minimal-test-drive/ | 2023-04-27T21:35:00 | [
"Ubuntu",
"精简版"
] | /article-15761-1.html | 
>
> Ubuntu 23.04 “Lunar Lobster” 新推出的精简安装程序到底有多精简呢?一起来看看吧。
>
>
>
几周前,Canonical/Ubuntu 开发者 [确认了](/article-15588-1.html) Ubuntu 23.04 Lunar Lobster 将引入官方的精简版安装程序。对于那些等待 Ubuntu Linux 官方精简安装程序的用户来说,这是个好消息,因为 Canonical/Ubuntu 此前从未对任何精简 ISO 镜像提供官方支持。
虽然在 Ubuntu 18.04 时期有一些非官方性质的旧版精简 ISO 镜像,但它们都已经停止维护。鉴于 Ubuntu Linux 的热门程度,这种无法获取精简安装程序的情况已阻碍部分用户的选择。
正如公告所言,Canonical 现在已经为 Ubuntu 23.04 Lunar Lobster 版本推出了官方精简安装程序,这也意味着那些希望安装轻量版本 Ubuntu Linux 用户的等待终于结束了。
我试运行了该 **测试版** ISO 镜像(LCTT 校注:本文原文发布于 Ubuntu 23.04 正式版发布之前)。下面是我发现的一些东西。
在最新的 Beta 版本中,官方的 Ubuntu 精简版 ISO 安装程序现已提供试用。“Lunar Lobster”版本的官方 ISO 镜像大小为 113 MB,这确实很小。
当你首次启动该精简 ISO 时,你将可以选择两个主要选项 —— 针对服务器版本和桌面版本的安装选项。目前我用于试运行的测试版精简 ISO 显示了 Ubuntu 22.04 LTS 和 Ubuntu 22.10 Kinetic Kudu —— 于去年发布。不过,先暂时忽略这些文本标识吧。

我首先尝试安装桌面版本。令人惊讶的是,它运行了一个下载器,以获取用于标准桌面安装的所有软件包。精简桌面版的选项需要从互联网下载超过 3GB 的软件包,而且用时很长。考虑到我的位置与 Ubuntu 服务器状态,我的下载测试花费了大量时间。

如果你将使用精简 Ubuntu ISO 安装桌面所需的时间与精力与常规下载进行比较,那精简版反而慢许多,并占用大量系统资源。举个例子,在安装程序运行时,下载的完整 Ubuntu 桌面版也同时存储于内存当中。
因此,精简版的最小内存大小要求为 8GB。如果你没有 8GB 内存,你就无法运行该安装程序。而另一边,如果你借助标准的 torrent 文件下载 Ubuntu 桌面版,那么用于启动安装程序的最小内存要求则为 4GB。

下载完成后,安装程序将启动<ruby> 立付 <rt> Live </rt></ruby> Ubuntu 系统,在这里,你将可以和平常一样安装带有 GNOME 桌面的 Ubuntu 桌面版。这根本没有区别。
来到服务器选项,我在精简安装程序里选择了 Ubuntu 22.04 LTS 服务器版本。令我惊讶的是,服务器安装选项也需要至少 8GB 内存才能开始安装。基于该版本,它下载了约 1.8GB 的软件包。之后,它启动了正常的 Ubuntu 服务器版安装程序。这与常规的服务器版安装过程也是毫无区别。


综上可知,精简版桌面安装程序仅仅只是一个下载完整桌面版或服务器版镜像的 CLI 前端界面,仅此而已。这款安装程序的主要用途可能是 Ubuntu 桌面版或服务器版的联网安装。但,再次强调,你需要稳定的网络连接,以便下载所需内容。
与之相似的是,Xubuntu 团队在几周前 [提供了](https://www.debugpoint.com/xubuntu-minimal/) 精简版 ISO,它只包含基本的 Ubuntu,以及不含任何额外程序的原生 Xfce 桌面。
也就是说,这款安装程序恐怕和你从名字里所想的不太一样。如果他们能提供一款仅包含必要的 Ubuntu 组件,且不含桌面环境、Snap 等要素的“真·精简 ISO”,那会更好;就像不含任何桌面组件的原生 Arch 安装那样。
你可以从 [该页面](https://cdimages.ubuntu.com/ubuntu-mini-iso/daily-live/current/) 下载精简 ISO。
---
via: <https://debugpointnews.com/ubuntu-minimal-test-drive/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,762 | 使用 Linux 命令从图像中删除背景 | https://opensource.com/article/23/4/image-editing-linux-python | 2023-04-27T22:54:00 | [
"图像编辑"
] | https://linux.cn/article-15762-1.html | 
>
> Python 的力量使 Linux 上的图像编辑变得简单。
>
>
>
你有一张很棒的自己的照片,并想将其用于你的社交媒体资料,但背景让人分心。而另一张图片为你的个人资料图片提供了完美的背景。你如何将两者结合起来?一些智能手机应用可以进行这种照片处理,但价格太贵或充斥着广告软件。而且它们不是开源的。
[Rembg](https://github.com/danielgatis/rembg) 正适合于此。
Rembg 是用 Python 编写的,因此请在你的计算机上安装 Python 3。大多数 Linux 发行版默认包含 Python 3。你可以使用这个简单的命令检查你的版本:
```
$ python3 --version
```
Rembg 至少需要 Python 3.7 且不高于 Python 3.11。就我而言,我安装了 Python 3.10.6。
### 在 Linux 上安装 Rembg
我在我的 Linux 笔记本电脑上创建了一个名为 `PythonCoding` 的目录,然后创建了一个 Python 虚拟环境:
```
$ python3 -m venv /home/don/PythonCoding
```
接下来,我使用 `pip` 安装 `rembg`:
```
$ python3 -m pip install rembg
```
### 合并图像
是时候施展魔法了。首先,我选择了 2019 年在 All Things Open 拍摄的照片。

为了方便起见,我运行了以下 `rembg` 命令以使用较短的文件名重命名它:
```
$ rembg i dgw_ato.jpeg dgw_noback.jpg
```
第一次运行 `rembg` 时,它会下载一个开源 [模式识别模型](https://github.com/xuebinqin/U-2-Net)。这可能超过 100 MB,并且 `rembg` 将它保存到 `~/.u2net/u2net.onnx` 的用户目录中。该模型是 U-2-Net,并使用 Apache 2.0 许可证。有关模式识别模型的更多信息(包括如何训练你自己的模型),请阅读 Rembg 文档。
它在大约十秒钟内创建了我没有背景的新照片。我有一个带有 16 GB 内存的 Ryzen 7。你的体验可能因硬件而异。

过去我曾使用 [GIMP](https://opensource.com/content/cheat-sheet-gimp) 删除背景,但 `rembg` 比我使用 GIMP 时更快更彻底。
这就是删除背景的全部内容。如果添加一个新的呢?
### 添加新背景
接下来,我想给图片添加一个新的背景。有不同的方法可以做到这一点。例如,你可以使用 [ImageMagick](https://opensource.com/article/17/8/imagemagick) 组合图像,但获得正确的帧大小可能很复杂。最简单的方法是使用 GIMP 或 [Krita](https://opensource.com/article/21/12/open-source-photo-editing-krita)。
我使用 GIMP。首先,打开新创建的图像(在我的例子中是 `ato_image.jpg`)。现在转到 “<ruby> 文件 <rt> File </rt></ruby>” 菜单并选择 “<ruby> 打开为图层 <rt> Open as layers </rt></ruby>”。选择不同的背景图像。此图像作为现有照片的叠加层打开。
我想将新背景移到我的肖像下方。在 GIMP 窗口的右侧有两个缩略图,每个图像层一个。背景层在上面。我将背景层拖到肖像图像下方,结果如下:

这对我的个人资料照片来说是一个更好的设置!
### 尝试 Rembg
Rembg 有三个子命令,你可以在 `--help` 菜单中查看:
```
$ rembg --help
```
他们是:
* `rembg i` 用于文件
* `rembg p` 用于文件夹
* `rembg s` 用于 HTTP 服务器
Rembg 使用 [MIT](https://github.com/danielgatis/rembg/blob/main/LICENSE.txt) 许可证发布。下次你需要从图像中删除背景时试试看。
*(题图:MJ/blur background image lens in high resolution, very detailed, 8k)*
---
via: <https://opensource.com/article/23/4/image-editing-linux-python>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You have a great picture of yourself and want to use it for your social media profile, but the background is distracting. Another picture has a perfect background for your profile picture. How do you combine the two? Some smartphone apps that do this kind of photo manipulation but are too expensive or are riddled with ad-ware. And they aren't open source. [Rembg](https://github.com/danielgatis/rembg) is up to the challenge!
Rembg is written in Python, so install Python 3 on your computer. Most Linux distributions include Python 3 by default. You can check your version with this simple command:
```
````$ python3 --version`
Rembg requires at least Python 3.7 and no greater than Python 3.11. In my case, I have Python 3.10.6 installed.
## Install Rembg on Linux
I created a directory called `PythonCoding`
on my Linux laptop and then made a Python virtual environment:
```
````$ python3 -m venv /home/don/PythonCoding`
Next, I installed `rembg`
using `pip`
:
```
````$ python3 -m pip install rembg`
## Combine images
Time to work some magic. First, I chose the image containing a picture taken at All Things Open in 2019.

(Don Watkins, CC BY-SA 4.0)
I ran the following `rembg`
command to rename it with a shorter filename for convenience:
```
````$ rembg i dgw_ato.jpeg dgw_noback.jpg`
The first time you run `rembg`
, it downloads an open source [pattern recognition model](https://github.com/xuebinqin/U-2-Net). This can be over 100 MB and `rembg`
saves it in your user directory as `~/.u2net/u2net.onnx`
. The model is the U-2-Net and uses the Apache 2.0 license. For more information about the pattern recognition models (including how to train your own), read the Rembg documentation.
It created my new photo without the background in about ten seconds. I have a Ryzen 7 with 16 GB of RAM. Your experience may vary depending on your hardware.

(Don Watkins, CC BY-SA 4.0)
I have used [GIMP](https://opensource.com/content/cheat-sheet-gimp) to remove backgrounds in the past, but `rembg`
does it quicker and more completely than I have experienced with GIMP.
That's all there is to removing a background. What about adding a new one?
## Add a new background
Next, I want to add a new background to the picture. There are different ways to do that. You can, for instance, combine images with [ImageMagick](https://opensource.com/article/17/8/imagemagick), but getting the frame size right can be complex. The easiest way is to use GIMP or [Krita](https://opensource.com/article/21/12/open-source-photo-editing-krita).
I used GIMP. First, open the newly created image (`ato_image.jpg`
in my case). Now go to the **File** menu and select **Open as layers**. Choose a different image for the background. This image opens as an overlay above the existing photo.
I wanted to move the new background below my portrait. On the right of the GIMP window are two thumbnails, one for each image layer. The background layer is on top. I dragged the background layer beneath my portrait image, and here's the result:

(Don Watkins, CC BY-SA 4.0)
That's a much nicer setting for my profile picture!
## Try Rembg
Rembg has three subcommands you can review in the `--help`
menu:
```
````$ rembg --help`
They are:
`rembg i`
for files`rembg p`
for folders`rembg s`
for HTTP server
Rembg is released with an [MIT](https://github.com/danielgatis/rembg/blob/main/LICENSE.txt) license. Try it the next time you need a background removed from an image.
## 3 Comments |
15,764 | 使用 ChatGPT AI 从英文文本生成 Linux 命令 | https://itsfoss.com/linux-terminal-ai/ | 2023-04-29T11:18:20 | [
"Linux",
"命令",
"AI"
] | https://linux.cn/article-15764-1.html | 
即使是专家级的 Linux 用户也不记得所有的 Linux 命令和它们的选项。这对我们人类来说是不可能的。
但是机器呢?尤其是人工智能驱动的机器?
想象一下,如果你可以“命令”你的终端“显示过去 12 小时内修改过的所有小于 100 MB 的文件”。当然,你可以使用 Linux 命令“命令”它,但是用普通的英语进行交互呢?
由于人工智能的进步,这实际上是可能的。下面是自动生成 Linux 命令以显示当前目录中所有小于 10 KB 的文件的示例。

我使用的工具叫做 [Shell Genie](https://github.com/dylanjcastillo/shell-genie?ref=itsfoss.com)。它是一个命令行工具,可让你以普通的英语与终端进行交互。
它可以生成命令、运行命令(如果需要),还可以向你解释生成的命令。

### Shell-Genie 的特点
* 将普通英语转换为 Linux 命令。
* 提供了一个需要 openAI 的 API 密钥的 openAI gpt3 后端,和一个可以免费使用的 free-genie 后端。
* 提示一个选项以运行你要求的命令。
* 解释生成的命令。
### 安装 Shell Genie
Shell-genie 在任何发行版的默认仓库中都不可用。你可以使用 `pipx` 安装它。
要安装它,你需要安装 Python 3.10+ 和 Pip。你可以参考我们关于 [如何在 Ubuntu 和其他 Linux 发行版中安装 pip](https://itsfoss.com/install-pip-ubuntu/) 的文章。
安装 `pip` 后,使用以下命令安装 `pipx`:
```
python3 -m pip install --user pipx
python3 -m pipx ensurepath
```

现在,重启终端并运行以下命令安装 shell-genie:
```
pipx install shell-genie
```
这可能显示错误或需要依赖项。

运行提示的命令来安装所需的依赖。在我的例子中:
```
sudo apt install python3.10-venv
```
之后,再次运行 `shell-genie` 安装命令,就可以安装了。

安装完成后,运行以下命令:
```
shell-genie init
```
这将要求你选择后端,openAI 或 free-genie。如果你有 [openAI API](https://openai.com/product?ref=itsfoss.com),你可以选择它或继续使用 free-genie。
>
> ? free-genie 后端可能并不总是工作,因为它是由开发者托管的,他警告说可能会出现中断。
>
>
>
然后它将请求允许报告反馈。用 `y/n` 来决定。

现在就可以使用了。
### 使用 Shell-genie
>
> ? 如果你要进行实验,请尽量不要使用带有 `sudo` 或删除文件的命令。不要将你的机器交到机器手中。
>
>
>
如上所述,shell-genie 提供了两种工作模式:
* 从普通的英语获取命令
* 获取命令解释
#### 从普通英语中获取 Linux 命令
你可以使用 shell-genie 的 `ask` 选项从普通的英语中获取命令。例如:
```
shell-genie ask "Display only the folders of this directory"
```
这将显示正确的命令,并提示我们是否运行该命令。

#### 获取带解释的 Linux 命令
你可以使用 shell genie 来解释你要运行的一些命令。
```
shell-genie ask "display all files smaller than 10kb in here" --explain
```
上面的命令首先会显示需要的命令并进行解释,然后提示用户是否执行。

### 总结
有像 [Explain Shell](https://explainshell.com/?ref=itsfoss.com) 这样的工具(试图)解释 Linux 命令。但是这个 Shell genie 通过从普通的英语生成命令将它提升到一个新的水平。
当然,不能一味依赖人工智能。如果你对 Linux 命令有一定的了解,可以使用 Shell Genie 生成适合你的命令。你不必为手册页或各种网站而苦恼。
它可以帮助你在终端中更快地做事,也可以减少你的知识储备。为什么? 因为你越依赖它,你自己学的就越少。
这就是我所想的。 无论你同意或不同意我的观点,都可以在评论中发表你的看法。
*(题图:MJ/chatgpt commands linux cli illustration in high resolution, very detailed, 8k)*
---
via: <https://itsfoss.com/linux-terminal-ai/>
作者:[Sreenath](https://itsfoss.com/author/sreenath/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Even expert Linux users don't remember all the Linux commands and their options. It's not possible for us humans.
But what about the machine? Especially the AI-powered machine?
Imagine if you could 'order' your terminal to 'show all files under 100 MB in size that were modified in last 12 hours'. Sure, you can 'order' it using the Linux commands but what about interacting with in plain English?
Thanks to the advancement of AI, it is actually possible. Here's an example of automatically generating the Linux command to show all the files smaller than 10 KB in the present directory.
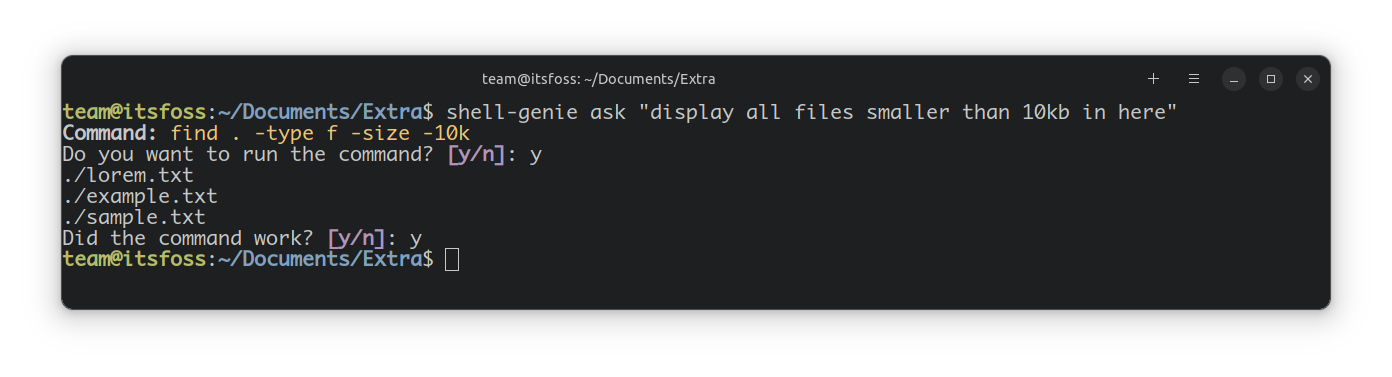
The tool I am using is called [Shell Genie](https://github.com/dylanjcastillo/shell-genie). It is a command-line tool that lets you interact with the terminal in plain English.
It can generate commands, run the commands (if you want to), and it can also explain the generated commands to you.
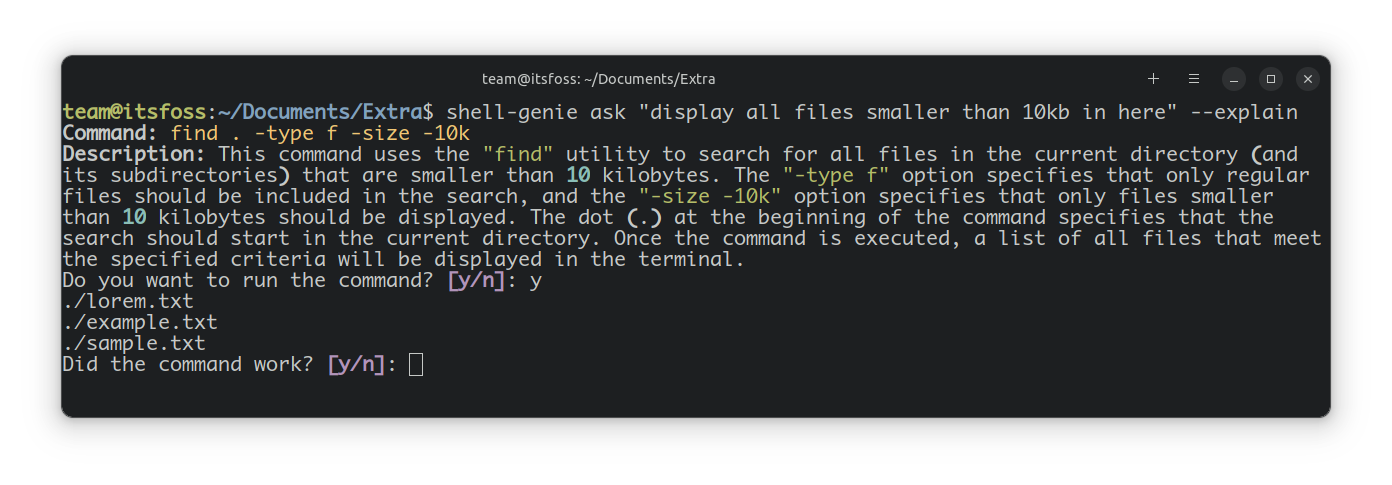
## Features of Shell-Genie
- Convert plain English to Linux Commands.
- Provides an openAI gpt3 backend that requires an API key from openAI and a free-genie backend that is free to use.
- Prompt with an option to run the command you asked for.
- Explains the generated commands.
## Install Shell Genie
Shell-genie is not available in the default repositories of any distro. You can install it [using pipx](https://itsfoss.com/install-pipx-ubuntu/).
In order to install, you need to have Python 3.10+ and Pip installed. You can refer to our article on [how to install pip in Ubuntu and other Linux distributions](https://itsfoss.com/install-pip-ubuntu/).
Once `pip`
is installed, install `pipx`
with the following command:
```
python3 -m pip install --user pipx
python3 -m pipx ensurepath
```
`pipx`
Now, restart the terminal and install shell-genie by running:
```
pipx install shell-genie
```
This may show an error or the need for a dependency.
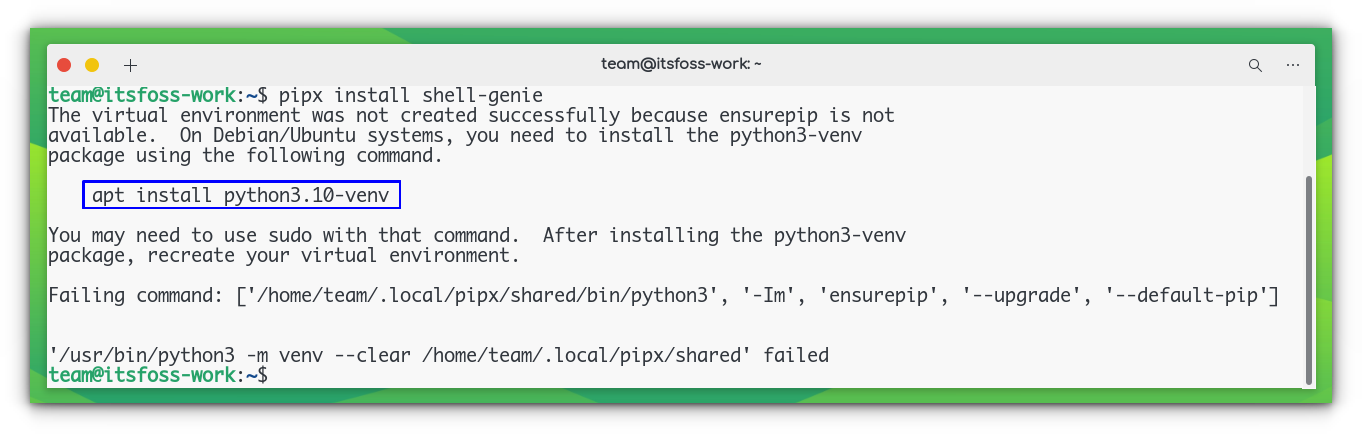
Run the command that is prompted to install the required dependency. In my case:
```
sudo apt install python3.10-venv
```
After this, run the `shell-genie`
install command once more, and it will be installed.
Once installation is complete, run the following:
`shell-genie init`
This will ask you to select the backend, either openAI or free-genie. If you have [openAI API](https://openai.com/product), you can choose that or stay with the free-genie.
It will then ask permission to report feedback. Decide on that with a `y/n`
.
You are ready to go now.
## Working with Shell-genie
As said above, shell-genie provides two modes for working.
- Get command from plain English
- Get command explanation
### Get Linux commands from plain English
You can use shell-genie's `ask`
option to get commands from plain English. For eg.
```
shell-genie ask "Display only the folders of this directory"
```
This will display the proper command, and prompt us to run the command or not.
### Get Linux commands with explanation
You can use shell genie to explain some commands that you want to run.
```
shell-genie ask "display all files smaller than 10kb in here" --explain
```
The above command will first display the required command and explains it and then prompts the user to execute it or not.
## Wrapping Up
There are tools like [Explain Shell](https://explainshell.com/) that (try to) explain the Linux commands. But this Shell genie takes it to the next level by generating commands from plain English.
Of course, you cannot rely on artificial intelligence blindly. If you are familiar with the Linux commands a little, you can use Shell Genie to generate commands for your purpose. You won't have to struggle with the man pages or various websites.
It sorts of helps you do things faster in the terminal and also makes you less knowledgeable. Why? Because the more you rely on it, the less you will learn on your own.
That's what I think. Feel free to agree or disagree with me in the comments. |
15,765 | HuggingChat:第一个面向所有人使用的 ChatGPT 开源替代方案 | https://news.itsfoss.com/huggingchat-chatgpt/ | 2023-04-29T20:16:49 | [
"ChatGPT"
] | https://linux.cn/article-15765-1.html |
>
> 忘了 ChatGPT 吧,我们一起来看看 HuggingChat,一个开源的项目。
>
>
>

新 AI 聊天机器人的浪潮看起来短时间内势不可挡;而新的一个竞争者已经加入与 ChatGPT 抗衡的比赛中。
这个竞争者最近刚发布,它就是“**HuggingChat**”。 这个聊天机器人的主要重点是提供一个比 ChatGPT 更**透明**、**包容**和**负责**的替代方案。
不要误会我的意思,HuggingChat 并不是 ChatGPT 的第一个开源替代品。 我们之前也介绍了挑战 ChatGPT 江湖地位的开源项目。
? 然而,**HugginChat 似乎是第一个可以访问的类似于 ChatGPT 的平台**。
因此,你在使用的不只是一个演示版,你正在用的版本已经拥有它本应具有的外观设计和性能表现 —— 只有后端会在你测试或者使用这个应用时得到升级。
让我们一起来看看 HuggingChat 是什么。
**它是什么:**
基本上呢,在当前状态下,HuggingChat 充当了用户界面的角色,促进用户与 **Open Assistant 支持的后端** 的交互,从而实现聊天机器人功能。
>
> ? [Open Assistant](https://open-assistant.io/?ref=news.itsfoss.com) 是一个旨在为大众提供可行的基于聊天的大语言模型(LLM)的项目。
>
>
>

HuggingChat 由 Open Assistant 最新的 [基于 LLaMA 的模型](https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor?ref=news.itsfoss.com) 提供支持,据说这是目前市场上最好的开源聊天模型之一。
但是在 HuggingChat 中使用该模型有一个问题。
你看,[LLaMA 模型](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/?ref=news.itsfoss.com) 是 **Meta AI** 的作品,他们限制了对其模型的任何商业使用。
因此,LLaMA 模型仅为暂时使用,**开发人员打算在未来增加对更多模型的支持**,为不同的使用场景甚至企业使用案例铺平道路。
除此之外,这个聊天机器人正在一个被 [Hugging Face](https://huggingface.co/?ref=news.itsfoss.com)(HuggingChat 的创建者)的人们称为“[Space](https://huggingface.co/docs/hub/spaces-overview?ref=news.itsfoss.com)”的地方运行。其推理后端还在其推理 API 基础设施上运行 [text-generation-inference](https://github.com/huggingface/text-generation-inference?ref=news.itsfoss.com)。
他们还开放了 HuggingChat 的用户界面代码。你可以在此处 [查看](https://huggingface.co/spaces/huggingchat/chat-ui/tree/main?ref=news.itsfoss.com)。
**它能行吗?**
额,部分能行吧。
由于它处于 **非常早期的开发阶段(版本 0)**,因此缺少一些关键功能,例如在浏览器重启或切换浏览器时保存对话。
然后就是熟悉的“*流量太大,请稍后再试*”错误,会在运行聊天命令时弹出。
当我可以运行命令时,我向 HuggingChat 询问了它的后端。它为我提供了相当不错的关于它自己的信息。

最后,总结一下吧!
Hugging Chat 还远没有达到 ChatGPT 的水平,但是 **拥有像这样的替代方案是当务之急**。我们都知道当一项服务在特定领域占据统治地位时会发生什么。
[OpenChatKit](https://news.itsfoss.com/open-source-chatgpt/) 和 [Dolly](https://news.itsfoss.com/open-source-model-dolly/) 也是一些值得了解的选择。
但目前我们能做的只有等待。这些开源替代品需要一些时间成长,但总有一天它们可能会与 ChatGPT 媲美甚至更好;谁知道呢? ?
**想试试吗?**
你可以通过访问其 [聊天页面](https://huggingface.co/chat/?ref=news.itsfoss.com) 来运行 HuggingChat;也可以在 [官方网站](https://huggingface.co/spaces?ref=news.itsfoss.com) 上查看它运行的代码。
>
> **[HuggingChat](https://huggingface.co/chat?ref=news.itsfoss.com)**
>
>
>
*(题图:MJ/ai chatting illustration in high resolution, very detailed, 8k)*
---
via: <https://news.itsfoss.com/huggingchat-chatgpt/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The wave of new AI chatbots is not stopping anytime soon; another contender has jumped into the ring with ChatGPT.
Released recently, it's called '**HuggingChat**.' The main focus of this chatbot is to provide a more **transparent**, **inclusive,** and **accountable** **alternative to ChatGPT**.
Don't get me wrong, HuggingChat is not the first open-source alternative to ChatGPT. We have covered open-source projects challenging ChatGPT.
[ChatGPT but Open Source: That’s What This Project is Aiming ForWill we finally have a working open-source alternative to ChatGPT? This looks promising!](https://news.itsfoss.com/open-source-chatgpt/)

⭐ However, **HugginChat seems to be the first one available to access as a platform that appears similar to ChatGPT**.
So, you are not using just a demo, you are already using what it is supposed to look and behave like - only the backend will get an upgrade as you test/use it.
Let's see what HuggingChat is all about.
**What is it: **So, basically in its current state, HuggingChat acts as a user interface that facilitates interaction with the **Open Assistant-powered back-end** allowing for chatbot functionality.
[Open Assistant](https://open-assistant.io/?ref=news.itsfoss.com)is a project that aims to provide the masses with a feasible chat-based large language model (LLM).
HuggingChat is powered by Open Assistant's latest [LLaMA-based model](https://huggingface.co/OpenAssistant/oasst-sft-6-llama-30b-xor?ref=news.itsfoss.com) which is said to be one of the best open-source chat models available in the market right now.
But there's a catch to that model's usage in HuggingChat.
You see, the [LLaMA model](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/?ref=news.itsfoss.com) is the work of **Meta AI**, and they have restricted any commercial use of their model.
So, the LLaMA model will be used for now, and the **developers intend to add support for more models** in the future, paving the way for varying usage scenarios and even enterprise use cases.
Besides that, the chatbot is running in what the folks over at [Hugging Face](https://huggingface.co/?ref=news.itsfoss.com) (the creators of HuggingChat) call '[Space](https://huggingface.co/docs/hub/spaces-overview?ref=news.itsfoss.com)'. The inference backend is also running [text-generation-inference](https://github.com/huggingface/text-generation-inference?ref=news.itsfoss.com) on their Inference API infrastructure.
They have also open-sourced the user interface of HuggingChat. You can take a [look](https://huggingface.co/spaces/huggingchat/chat-ui/tree/main?ref=news.itsfoss.com) here.
**Does it work?**
Well, sort of.
As it is in a **very early development stage (version 0)**, a few key features are missing, such as saving the conversation over a browser restart or when switching browsers.
Then there are familiar “*Too much traffic, try again later*” errors that pop up while running chat commands.
When I could run a command, I asked HuggingChat about its back end. It provided me with decent info about itself.
So, wrapping up.
Hugging Chat is not yet close to the levels of ChatGPT, but **alternatives like these are the need of the hour; we** all know what happens when one service dominates a specific niche.
[OpenChatKit](https://news.itsfoss.com/open-source-chatgpt/) or [Dolly](https://news.itsfoss.com/open-source-model-dolly/) can be some other options that you can look at.
But for now, all we can do is wait. These open-source alternatives will need some time, but someday they might be on par with ChatGPT or even better; who knows? 😲
**Want to try it?**
You can take HuggingChat for a run by visiting the [chat page](https://huggingface.co/chat/?ref=news.itsfoss.com); also look at the code that makes it run on the [official website](https://huggingface.co/spaces?ref=news.itsfoss.com).
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,767 | 7 个使你的 Drupal 网站无障碍访问的开源模块 | https://opensource.com/article/23/4/drupal-modules-website-accessibility | 2023-04-30T16:23:39 | [
"Drupal",
"无障碍访问"
] | https://linux.cn/article-15767-1.html | 
>
> 使用这些 Drupal 模块,使你的网站对每个人都可以无障碍访问。
>
>
>
随着网站的 <ruby> 无障碍访问 <rt> accessibility </rt></ruby> 继续成为人们日益关注的问题,网站所有者和开发人员需要确保他们的网站符合[美国残疾人法案](https://www.dol.gov/general/topic/disability/ada)(ADA)。Drupal 是一种流行的开源内容管理系统(CMS),它提供各种工具和模块以确保所有用户都可以访问你的网站,而无论他们的能力如何。本文讨论了网站无障碍访问的重要性、ADA 合规性的基本要求,以及 [Drupal](https://opensource.com/article/23/3/create-accessible-websites-drupal) 如何帮助你实现合规性。
### 为什么网站无障碍访问很重要
出于多种原因,网站无障碍访问很重要。首先,它确保残障人士可以访问和使用你的网站。这包括有视觉、听觉、身体和认知障碍的人。通过使你的网站可以无障碍访问,你不仅遵守了法律,而且还为所有用户提供了更好的体验。
此外,网站无障碍访问可以改善你网站的搜索引擎优化(SEO)并提高网站的可用性。搜索引擎优先考虑无障碍的网站,如果易于使用,用户更有可能在你的网站上停留更长时间并与你互动。
### ADA 合规性的基本要求
ADA 要求所有网站和数字内容都可供残障人士访问。ADA 合规性的一些基本要求包括:
* 为所有图像和非文本内容提供替代文本描述。
* 确保所有视频都有字幕和文字说明。
* 使用颜色对比和其他设计元素使你的网站更具可读性。
* 提供访问内容的替代方式,例如音频描述和键盘导航。
* 确保你的网站与辅助技术兼容,例如屏幕阅读器和盲文显示器。
### Drupal 如何帮助你实现合规性
Drupal 提供各种工具和模块来帮助你实现网站的无障碍和 ADA 合规性。以下是我认为最有用的七个:
* [无障碍访问检查器](https://www.drupal.org/project/editoria11y):扫描你的网站以查找常见的无障碍访问问题并提出改进建议。
* [颜色对比分析器](https://www.drupal.org/project/high_contrast):分析你网站的颜色对比度并做出改变以提高可读性。
* [块元素 ARIA 地标角色](https://www.drupal.org/project/block_aria_landmark_roles):增强 WAI-ARIA 在站点标记中的使用。此模块允许你通过块配置表单将 ARIA 地标角色和/或 ARIA 标签直接分配给站点布局中的每个块元素。
* [Civic 无障碍访问工具栏](https://www.drupal.org/project/civic_accessibility_toolbar):提供辅助工具以帮助残障用户浏览网站并与之交互。
* [htmLawed](https://www.drupal.org/project/htmlawed):通过限制和净化 HTML 确保符合 Web 标准和管理策略。
* [调整文本大小](https://www.drupal.org/project/textsize):通过在页面上显示可调整的文本大小更改器或缩放功能来增强 Web 无障碍。
* [自动替代文本](https://www.drupal.org/project/auto_alter):利用 [微软 Azure Cognitive Services API](https://www.microsoft.com/cognitive-services) 在没有替代文本时创建图像标题。
### 总结
出于法律原因和为所有用户提供更好的用户体验,确保网站无障碍访问和 ADA 合规性非常重要。从无障碍访问检查器到颜色对比分析器,Drupal 提供了多种方法来确保你的网站符合 ADA 标准。使用 Drupal 的工具和模块,你可以让每个人都可以访问你的网站,无论他们的能力如何,并提供更好的用户体验。
---
via: <https://opensource.com/article/23/4/drupal-modules-website-accessibility>
作者:[Neeraj Kumar](https://opensource.com/users/neerajskydiver) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As website accessibility continues to be a growing concern, website owners and developers need to ensure that their websites comply with the [Americans with Disabilities Act](https://www.dol.gov/general/topic/disability/ada) (ADA). Drupal, a popular open source content management system (CMS), offers various tools and modules to ensure your website is accessible to all users, regardless of their abilities. This article discusses the importance of website accessibility, the basic requirements of ADA compliance, and how [Drupal](https://opensource.com/article/23/3/create-accessible-websites-drupal) can help you achieve compliance.
## Why website accessibility is important
Website accessibility is important for several reasons. First, it ensures that people with disabilities can access and use your website. This includes people with visual, auditory, physical, and cognitive disabilities. By making your website accessible, you are not only complying with the law but also providing a better experience for all users.
In addition, website accessibility can improve your website's search engine optimization (SEO) and increase your website's usability. Search engines prioritize websites that are accessible, and users are more likely to stay on your website longer and engage with your content if it is easy to use.
## Basic requirements for ADA compliance
The ADA requires all websites and digital content to be accessible to people with disabilities. Some of the basic requirements for ADA compliance include the following:
- Providing alternative text descriptions for all images and non-text content.
- Ensuring that all videos have captions and transcripts.
- Using color contrast and other design elements to make your website more readable.
- Providing alternative ways to access content, such as audio descriptions and keyboard navigation.
- Ensuring that your website is compatible with assistive technologies, such as screen readers and braille displays.
## How Drupal can help you achieve compliance
Drupal offers various tools and modules to help you achieve website accessibility and ADA compliance. Here are the seven I find most useful:
-
[Accessibility Checker](https://www.drupal.org/project/editoria11y): Scans your website for common accessibility issues and suggests improvements. -
[Color Contrast Analyzer](https://www.drupal.org/project/high_contrast): Analyzes the color contrast of your website and makes changes to improve readability. -
[Block ARIA Landmark Roles](https://www.drupal.org/project/block_aria_landmark_roles): Enhances WAI-ARIA use in your site's markup. This module allows you to assign ARIA landmark roles and/or ARIA labels directly to every block in your site's layout through the block configuration form. -
[Civic Accessibility Toolbar](https://www.drupal.org/project/civic_accessibility_toolbar): Provides accessibility tools to help users with disabilities navigate and interact with websites. -
[htmLawed](https://www.drupal.org/project/htmlawed): Ensures compliance with web standards and admin policies by limiting and purifying HTML. -
[Text Resize](https://www.drupal.org/project/textsize): Enhances web accessibility by displaying an adjustable text size changer or a zoom function on the page. -
[Automatic Alternative Text](https://www.drupal.org/project/auto_alter): Leverages the[Microsoft Azure Cognitive Services API](https://www.microsoft.com/cognitive-services)to create an image caption when there's no Alternative Text (alt text).
## Wrap up
Ensuring website accessibility and ADA compliance is important for legal reasons and for providing a better user experience for all users. From the Accessibility Checker to the Color Contrast Analyzer, Drupal offers various ways to ensure your website is ADA-compliant. Using Drupal's tools and modules, you can make your website accessible to everyone, regardless of their abilities, and offer a better user experience.
## Comments are closed. |
15,768 | LXQt 1.3.0 发布:探索轻量级桌面的升级 | https://www.debugpoint.com/lxqt-1-3-0/ | 2023-04-30T16:54:00 | [
"LXQt"
] | /article-15768-1.html |
>
> 流行的轻量级桌面环境 LXQt 1.3.0 的新版本现已发布。以下是它的新功能。
>
>
>

轻量级桌面环境 LXQt 发布了 1.3.0 版本,其中包含许多改进和新功能。让我们深入了解细节。

### LXQt 1.3.0:主要功能
最新版本的 LXQt 仍然基于 Qt 5.15,即 Qt5 的最后一个 LTS 版本。该团队已经开始支持 Qt6,但由于缺乏稳定的 [KF6](https://phabricator.kde.org/project/profile/310/) 而无法发布。但是,该团队显著改进了文件管理器及其库。整个 KF6 API/库目前进行 Qt6 迁移,以供 KDE 和其他桌面使用。
#### LibFM-Qt / PCManFM-Qt
默认文件管理器 PCManFM-Qt 修复了一个问题,即在配置更改时防止桌面项目抖动。此外,最新版本增加了一个桌面标题,这有助于在某些 Wayland 合成器下设置窗口管理器(WM)规则。
此外,现在所有的视图模式都可以禁用平滑滚动,而之前仅适用于列表和紧凑模式。此外,现在已修复了使用可执行类型打开非可执行文件的问题,并使用 `New file` 作为新文件的默认名称(特别是在 GLib 2.75.1 不再将空文件视为文本/纯文本之后)。

#### LXQt 面板和 QTerminal
现在 LXQt 面板在编译时默认启用 DOM 插件。
新版 QTerminal 修复了深浅配色切换的问题。它还保证了上下文菜单在 Wayland 下的正确定位。
#### LXQt 会话
主要的 LXQt 会话现在添加了对 procps-ng >= 4.0.0 的支持。此外,它还有更好的方法来检测窗口管理器和系统托盘。在 Wayland 上,现在禁用了所有潜在的崩溃调用。
这是关于此版本的主要亮点。考虑到这是一个次要版本,亮点并不多。你可以在详细的 [变更日志](https://github.com/lxqt/lxqt/releases/tag/1.3.0) 中了解更多信息。
### LXQt 1.3.0 的 Linux 发行版可用性
[Lubuntu 23.04 “Lunar Lobster”](https://www.debugpoint.com/lubuntu-23-04/) 由于计划不匹配,将不会包含此版本。因此,你可以在 2023 年 10 月发布的 Lubuntu 上收到此更新。
到 2023 年底,Fedora 39 将把这个版本作为 Fedora LXQt 的一部分。
Arch Linux 用户可以在通过测试后立即安装此桌面。截至发布时,[当前](https://archlinux.org/packages/?sort=&q=lxqt&maintainer=&flagged=) 它在社区测试仓库中。你可能需要使用 [本指南](https://www.debugpoint.com/lxqt-arch-linux-install/) 进行安装。
或者,你可以编辑 `/etc/pacman.conf`,启用 `community-testing` 仓库,然后立即安装。[此处](https://www.debugpoint.com/lxqt-arch-linux-install/) 提供了一组示例命令。
其他基于 Arch 的发行版,例如 [Manjaro](https://www.debugpoint.com/manjaro-linux-review-2022/) 和 [Endeavour OS](https://www.debugpoint.com/endeavouros-review/),将在稳定后的几周内采用此版本。
### 总结
总之,LXQt 1.3.0 是一个重要的版本,包含许多新的改进和错误修复。用户现在可以通过 LXQt 桌面享受更稳定、超快、高效的体验。今天就试试吧!
*(题图:MJ/d96d5eb2-290d-4fe4-a9a6-1e51dff8e1d2)*
---
via: <https://www.debugpoint.com/lxqt-1-3-0/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,770 | GNOME 44 发布后的对该团队采访 | https://opensource.com/article/23/4/linux-gnome-44-features | 2023-05-01T12:33:10 | [
"GNOME"
] | https://linux.cn/article-15770-1.html | 
>
> GNOME Linux 桌面环境的最新版本现已推出。了解 GNOME 44 中新的和改进的蓝牙、用户界面、应用程序和其他功能。
>
>
>
我在家使用的 Linux PC 上采用 GNOME 作为我主要的桌面环境。GNOME 提供了方便易用的图形化桌面,不仅具备我所需的灵活性,而且在我专注工作时不会妨碍我的操作。
最近 GNOME 发布了 GNOME 44,引入了许多新功能。我联系了 GNOME 团队,咨询了最新版本的新特性和改进。以下是品牌经理 Caroline Henriksen、GNOME 开发者和发布团队成员 Matthias Clasen,以及设计团队成员 Allan Day 分享的信息。
### GNOME 的新特性
**Jim Hall:** 在 GNOME 44 中,有哪些令你们最为兴奋的新功能和更新的功能?
**GNOME 团队:** 我们非常期待全新的、现代化的用户界面设计,这不仅体现在核心应用如 “<ruby> <a href="https://opensource.com/article/22/12/linux-file-manager-gnome"> 文件 </a> <rt> Files </rt></ruby>”应用(文件管理器,即 Nautilus),还包括 “<ruby> 设置 <rt> Settings </rt></ruby>” 应用,在上一个开发循环中我们对其中的很多面板做了大量改进。如果你有机会,欢迎试用全新的 “<ruby> 鼠标和触控板 <rt> Mouse & Touchpad </rt></ruby>” 设置面板,享受其中的动态插图。
GNOME 44 中有很多让人惊喜的功能。比如,文件选择器中全新的网格视图一定会让很多人感到惊喜,同时你也可以通过快速设置中的全新蓝牙菜单轻松地连接设备。
**Jim**:发布说明提到了 GNOME Circle,同时增加了几个新应用程序。请问 GNOME Circle 是什么?
**团队**:GNOME Circle 是一组优秀的应用程序,它们使用了 GNOME 平台。GNOME Circle 是 GNOME 推广使用我们技术的最佳应用程序,并支持应用程序开发人员的一个项目。
为了被纳入 GNOME Circle,一个应用程序必须满足一组要求。一旦满足要求,开发人员就可以获得额外的公众宣传、GNOME 基金会会员资格,以及访问其他基础设施和旅行赞助支持。有关详细信息和如何申请,请参阅 [GNOME Circle](https://circle.gnome.org/) 页面。
我们非常高兴看到 GNOME Circle 取得了巨大的成功。目前,它已经包含了超过 50 个应用程序!我特别喜欢其中不是所有的应用程序都与计算机有关,你可以找到健康跟踪器、节拍器或象棋钟等应用程序。
**Jim**:GNOME 是几个 Linux 发行版的标准桌面环境。我们可以在哪里看到 GNOME 44?
**团队**:已经发布的 Fedora 38 版本包含 GNOME 44。Ubuntu 23.04 也包含 GNOME 44。而且,GNOME 44 构建已经在一些主要的发行版中出现,例如 openSUSE 的 Tumbleweed 和 MicroOS 等。
### GNOME 社区
**Jim:** GNOME 44 的发布名称是 Kuala Lumpur,请问这个名字的来源是什么?
**团队:** GNOME 每年都有两个重要的大型会议,[GUADEC](https://events.gnome.org/event/101/) 是在年中举办的(下一届会议将于 2023 年 7 月在拉脱维亚举行),[GNOME Asia](https://events.gnome.org/event/100/) 则在年末举行。我们非常感谢马来西亚的本地团队在 <ruby> 吉隆坡 <rt> Kuala Lumpur </rt></ruby> 为我们举办 2022 年的 GNOME Asia 活动。
组织这些活动需要 GNOME 的工作人员和当地团队投入大量的精力和承诺。作为对他们的感激之意,我们会将 GNOME 的发布版本以最近大会的地点命名。这个命名方案是几年前引入的。GNOME 3.18 的发布名称 <ruby> 哥德堡 <rt> Gothenburg </rt></ruby> 就是第一个采用这种方式命名的版本。
**Jim:** GNOME 拥有一个充满活力的用户社区,有很多积极的成员。那么,GNOME 是如何保持社区的积极参与的呢?
**团队:** GNOME 一直以来都是一个以社区为驱动的项目,具有强烈的协作和包容性。这也是成为 GNOME 贡献者和用户的回报之一。成为 GNOME 社区的一员,意味着你可以与来自全世界的人进行互动,共同实现目标并交流想法。这是一种丰富而鼓舞人心的体验,这也是我们的社区保持热情和积极性的原因之一。
我们提高社区参与度的一个重要手段是,尽可能地满足社区用户的需求,使我们的活动对世界各地的人来说更易于参加。例如,我们的旗舰会议 GUADEC 去年在墨西哥的 <ruby> 瓜达拉哈拉 <rt> Guadalajara </rt></ruby> 举行,这是自欧洲以外的地方举办的第一个 GUADEC 会议,这有助于增加拉丁美洲的 GNOME 用户和贡献者的参与度。
此外,我们还努力不仅在我们自己的会议和活动中,而且在其他活动如 Linux Application Summit、FOSDEM 或 [SCaLE](https://opensource.com/tags/scale) 中与我们的社区成员见面。如果你在这些活动中看到 GNOME 的展台,请过来打个招呼。通常你会发现,开发人员、设计师、基金会工作人员以及理事会成员都很乐意聊天和回答问题。
### 如何参与 GNOME
**Jim:** 如何开始编写自己的 GNOME 应用程序呢?如果我想学习如何编写我的第一个 GNOME “Hello World” 应用程序,有没有可以供我参考的教程?
**团队:** [开始为 GNOME 开发应用程序](https://developer.gnome.org/) 网站包括一系列教程,其中包括快速创建你的第一个应用程序的指南。随着 [Flatpak](https://opensource.com/article/21/5/launch-flatpaks-linux-terminal) 和 GNOME Builder 等新技术的出现,如今创建自己的应用程序变得非常容易。打开 Builder,单击 “<ruby> 新项目 <rt> new project </rt></ruby>”,填写一些细节,就可以拥有自己的运行中的 GNOME 应用程序。确实如此简单。
**Jim:** 参与者可以通过哪些方式做出贡献呢?
**团队:** 如果有人对 GNOME 产生了兴趣,并有动力参与其中,那么他们可以做很多事情来帮助我们。如果你是初学者,参与我们 Discourse 实例上的讨论或报告问题是一个很好的开始。还有很多非技术性工作需要完成,比如帮助我们的文档、将 GNOME 翻译成不同的语言,甚至帮助组织我们的年度会议。许多这些活动都有友好的团队进行协作,他们会帮助你入门。
或者,如果你有编码经验,你可以浏览我们的 [“新手”任务](https://gitlab.gnome.org/dashboard/issues?scope=all&state=opened&label_name%5B%5D=4.%20Newcomers),寻找你感兴趣的任务。
另一个贡献的方式是通过对 GNOME 的 [捐赠](https://www.gnome.org/donate/)。作为一个开源项目和非营利基金会,定期的捐赠可以帮助我们继续建设 GNOME,提供必要的基础设施,以及支持新的倡议。
*(题图:MJ/addea707-a20a-4469-9131-cf958b942e7b)*
---
via: <https://opensource.com/article/23/4/linux-gnome-44-features>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I use GNOME as my primary desktop environment on my Linux PC at home. GNOME gives me an easy-to-use graphical desktop that provides the flexibility I need yet doesn't get in my way when I focus on my work.
GNOME recently released GNOME 44 with a bunch of new features. I reached out to the GNOME team to ask about the latest version and what was in it. Here's what team members Caroline Henriksen (brand manager), Matthias Clasen (GNOME developer and release team member), and Allan Day (design team) had to share.
## New GNOME features
**Jim Hall:** What are some of the new and updated features in GNOME 44 that you're most excited about?
**GNOME Team:** I am very excited to see how fresh and modern our user interfaces look. Not just in the core apps like [Files](https://opensource.com/article/22/12/linux-file-manager-gnome) (the file manager, Nautilus) but also in our Settings, which have seen a lot of work in the last cycle—many Settings panels have been improved. If you have a chance, you should try the new Mouse & Touchpad panel and enjoy the animated illustrations.
There's a lot to like in GNOME 44. For example, I think that a lot of people are going to be really happy about the new grid view in the file chooser, as well as being able to easily connect devices from the new Bluetooth menu in the quick settings.
**Jim:** The release notes mention GNOME Circle and that a few new apps have been added. What is GNOME Circle?
**Team:** GNOME Circle is a collection of fantastic apps that use the GNOME platform. It's GNOME's way of promoting the best apps that use our technologies and supporting app developers.
To be included in GNOME Circle, an app has to meet a set of requirements. Once it does, the developers get things like extra publicity and GNOME Foundation membership. That, in turn, gives them access to additional infrastructure and travel sponsorship. More information and how to apply can be found on the [GNOME Circle](https://circle.gnome.org/) page.
We're thrilled with how successful GNOME Circle has been. It contains more than 50 apps now! I particularly like that not all of these apps revolve around computing. You can find apps like a health tracker, a metronome, or a chess clock.
**Jim:** GNOME is the standard desktop in several Linux distributions. Where can we expect to see GNOME 44?
**Team:** The upcoming Fedora 38 release will include GNOME 44 and should be out sometime in April, as will Ubuntu 23.04. And GNOME 44 builds have already landed in openSUSE's Tumbleweed and MicroOS, to name just a few of the major distros.
## The GNOME community
**Jim:** The release name for GNOME 44 is Kuala Lumpur. Where does this name come from?
**Team:** GNOME has two major yearly conferences, [GUADEC](https://events.gnome.org/event/101/) in the middle of the year (the next conference will take place in Latvia in July 2023) and [GNOME Asia](https://events.gnome.org/event/100/) towards the end of the year. We are very thankful to the local team in Malaysia who welcomed us for GNOME Asia 2022 in Kuala Lumpur.
Organizing these events takes a lot of effort and commitment from the GNOME staff and the local teams. As a small sign of our appreciation, GNOME releases are named after the location of the most recent conference. This naming scheme was introduced a number of years ago. GNOME 3.18, Gothenburg, was the first.
**Jim:** GNOME has a strong user community with active members. How does GNOME keep the community so engaged?
**Team:** GNOME has always been a community-driven project with a strong sense of collaboration and inclusivity. That's part of what makes being a GNOME contributor and user so rewarding. Being a member of the GNOME community means that you get to interact with people from all over the world to work on common goals and exchange ideas. It is an enriching and inspiring experience, and I think that is what helps keep our community excited and engaged.
One important aspect of fostering that engagement is meeting our community where they're at and making our events more accessible to people from all over the world. For example, our flagship conference, GUADEC, was hosted in Guadalajara, Mexico, last year. This was the first time GUADEC happened outside of Europe, and this helped make it easier for GNOME users and contributors in Latin America to attend.
We also make an effort to meet our community members not just online and at our own conferences but at other events such as Linux Application Summit, FOSDEM, or [SCaLE](https://opensource.com/tags/scale). If you see a GNOME booth at any of these events, please stop by and say hi. You'll often find developers, designers, foundation staff, and board members all happy to chat and answer questions.
## Get involved with GNOME
**Jim:** How can folks get started with writing their own apps for GNOME? If I wanted to learn how to write my first "hello world" app for GNOME, is there a tutorial I can follow?
**Team:** The [Get started developing for GNOME](https://developer.gnome.org/) site includes a collection of tutorials, including a guide on quickly creating your first app. With new technologies like [Flatpak](https://opensource.com/article/21/5/launch-flatpaks-linux-terminal) and GNOME Builder, it's amazing just how easy it is to create your own app nowadays. Fire up Builder, click "new project," fill in some details, and you'll have your own running GNOME app. It really is that easy.
**Jim:** What are some ways that people can contribute?
**Team:** If someone is interested in GNOME and is motivated to get involved, there are definitely things they can do to help. Participating in discussions on our Discourse instance or reporting issues is a great place to start if you're a beginner. There are also lots of non-technical jobs that need doing, like helping with our documentation, translating GNOME into different languages, or even helping organize our annual conferences. A lot of these activities have friendly teams working on them who will help you to get started.
Alternatively, if you have coding experience, you can browse our ["newcomer" tickets](https://gitlab.gnome.org/dashboard/issues?scope=all&state=opened&label_name%5B%5D=4.%20Newcomers) for tasks that might interest you.
Another way to contribute is through [donating to GNOME](https://www.gnome.org/donate/). As an open source project and a non-profit foundation, regular donations help us continue to build up GNOME, provide necessary infrastructure, and power new initiatives.
**[ Get the guide to installing applications on Linux ]**
## Comments are closed. |
15,771 | Rust 基础系列 #2: 在 Rust 程序中使用变量和常量 | https://itsfoss.com/rust-variables/ | 2023-05-01T14:50:31 | [
"Rust"
] | https://linux.cn/article-15771-1.html | 
>
> 推进你的 Rust 学习,熟悉 Rust 程序的变量和常量。
>
>
>
在 [该系列的第一章](/article-15709-1.html)中,我讲述了为什么 Rust 是一门越来越流行的编程语言。我还展示了如何 [在 Rust 中编写 Hello World 程序](/article-15709-1.html)。
让我们继续 Rust 之旅。在本文中,我将向你介绍 Rust 编程语言中的变量和常量。
此外,我还将讲解一个称为“<ruby> 遮蔽 <rt> shadowing </rt></ruby>”的新编程概念。
### Rust 变量的独特之处
在编程语言中,变量是指 *存储某些数据的内存地址的一个别名* 。
对 Rust 语言来讲也是如此。但是 Rust 有一个独特的“特性”。每个你声明的变量都是 **默认 <ruby> 不可变的 <rt> immutable </rt></ruby>** 。这意味着一旦给变量赋值,就不能再改变它的值。
这个决定是为了确保默认情况下,你不需要使用 <ruby> 自旋锁 <rt> spin lock </rt></ruby> 或 <ruby> 互斥锁 <rt> mutex </rt></ruby> 等特殊机制来引入多线程。Rust **会保证** 安全的并发。由于所有变量(默认情况下)都是不可变的,因此你不需要担心线程会无意中更改变量值。
这并不是在说 Rust 中的变量就像常量一样,因为它们确实不是常量。变量可以被显式地定义为可变的。这样的变量称为 **可变变量** 。
这是在 Rust 中声明变量的语法:
```
// 默认情况下不可变
// 初始化值是**唯一**的值
let variable_name = value;
// 使用 'mut' 关键字定义可变变量
// 初始化值可以被改变
let mut variable_name = value;
```
>
> ? 尽管你可以改变可变变量的值,但你不能将另一种数据类型的值赋值给它。
>
>
> 这意味着,如果你有一个可变的浮点型变量,你不能在后面将一个字符赋值给它。
>
>
>
### Rust 数据类型概观
在上一篇文章中,你可能注意到了我提到 Rust 是一种强类型语言。但是在定义变量时,你不需要指定数据类型,而是使用一个通用的关键字 `let`。
Rust 编译器可以根据赋值给变量的值推断出变量的数据类型。但是如果你仍然希望明确指定数据类型并希望注释类型,那么可以这样做。以下是语法:
```
let variable_name: data_type = value;
```
下面是 Rust 编程语言中一些常见的数据类型:
* **整数类型**:分别用于有符号和无符号的 32 位整数的 `i32` 和 `u32`
* **浮点类型**:分别用于 32 位和 64 位浮点数的 `f32` 和 `f64`
* **布尔类型**:`bool`
* **字符类型**:`char`
我会在下一篇文章中更详细地介绍 Rust 的数据类型。现在,这应该足够了。
>
> ? Rust 并不支持隐式类型转换。因此,如果你将值 `8` 赋给一个浮点型变量,你将会遇到编译时错误。你应该赋的值是 `8.` 或 `8.0`。
>
>
>
Rust 还强制要求在读取存储在其中的值之前初始化变量。
```
{ // 该代码块不会被编译
let a;
println!("{}", a); // 本行报错
// 读取一个**未初始化**变量的值是一个编译时错误
}
{ // 该代码块会被编译
let a;
a = 128;
println!("{}", a); // 本行不会报错
// 变量 'a' 有一个初始值
}
```
如果你在不初始化的情况下声明一个变量,并在给它赋值之前使用它,Rust 编译器将会抛出一个 **编译时错误** 。
虽然错误很烦人,但在这种情况下,Rust 编译器强制你不要犯写代码时常见的错误之一:未初始化的变量。
### Rust 编译器的错误信息
来写几个程序,你将
* 通过执行“正常”的任务来理解 Rust 的设计,这些任务实际上是内存相关问题的主要原因
* 阅读和理解 Rust 编译器的错误/警告信息
#### 测试变量的不可变性
让我们故意写一个试图修改不可变变量的程序,看看接下来会发生什么。
```
fn main() {
let mut a = 172;
let b = 273;
println!("a: {a}, b: {b}");
a = 380;
b = 420;
println!("a: {}, b: {}", a, b);
}
```
直到第 4 行看起来都是一个简单的程序。但是在第 7 行,变量 `b` —— 一个不可变变量 —— 的值被修改了。
注意打印 Rust 变量值的两种方法。在第 4 行,我将变量括在花括号中,以便打印它们的值。在第 8 行,我保持括号为空,并使用 C 的风格将变量作为参数。这两种方法都是有效的。(除了修改不可变变量的值,这个程序中的所有内容都是正确的。)
来编译一下!如果你按照上一章的步骤做了,你已经知道该怎么做了。
```
$ rustc main.rs
error[E0384]: cannot assign twice to immutable variable `b`
--> main.rs:7:5
|
3 | let b = 273;
| -
| |
| first assignment to `b`
| help: consider making this binding mutable: `mut b`
...
7 | b = 420;
| ^^^^^^^ cannot assign twice to immutable variable
error: aborting due to previous error
For more information about this error, try `rustc --explain E0384`.
```
>
> ? “binding” 一词是指变量名。但这只是一个简单的解释。
>
>
>
这很好的展示了 Rust 强大的错误检查和信息丰富的错误信息。第一行展示了阻止上述代码编译的错误信息:
```
error[E0384]: cannot assign twice to immutable variable b
```
这意味着,Rust 编译器注意到我试图给变量 `b` 重新赋值,但变量 `b` 是一个不可变变量。所以这就是导致这个错误的原因。
编译器甚至可以识别出错误发生的确切行和列号。
在显示 `first assignment to b` 的行下面,是提供帮助的行。因为我正在改变不可变变量 `b` 的值,所以我被告知使用 `mut` 关键字将变量 `b` 声明为可变变量。
>
> ?️ 自己实现一个修复来更好地理解手头的问题。
>
>
>
#### 使用未初始化的变量
现在,让我们看看当我们尝试读取未初始化变量的值时,Rust 编译器会做什么。
```
fn main() {
let a: i32;
a = 123;
println!("a: {a}");
let b: i32;
println!("b: {b}");
b = 123;
}
```
这里,我有两个不可变变量 `a` 和 `b`,在声明时都没有初始化。变量 `a` 在其值被读取之前被赋予了一个值。但是变量 `b` 的值在被赋予初始值之前被读取了。
来编译一下,看看结果。
```
$ rustc main.rs
warning: value assigned to `b` is never read
--> main.rs:8:5
|
8 | b = 123;
| ^
|
= help: maybe it is overwritten before being read?
= note: `#[warn(unused_assignments)]` on by default
error[E0381]: used binding `b` is possibly-uninitialized
--> main.rs:7:19
|
6 | let b: i32;
| - binding declared here but left uninitialized
7 | println!("b: {b}");
| ^ `b` used here but it is possibly-uninitialized
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
error: aborting due to previous error; 1 warning emitted
For more information about this error, try `rustc --explain E0381`.
```
这里,Rust 编译器抛出了一个编译时错误和一个警告。警告说变量 `b` 的值从来没有被读取过。
但是这是荒谬的!变量 `b` 的值在第 7 行被访问了。但是仔细看;警告是关于第 8 行的。这很令人困惑;让我们暂时跳过这个警告,继续看错误。
这个错误信息说 `used binding b is possibly-uninitialized`。和之前的例子一样,Rust 编译器指出错误是由于尝试在第 7 行读取变量 `b` 的值而引起的。读取变量 `b` 的值是错误的原因是它的值没有初始化。在 Rust 编程语言中,这是非法的。因此编译时错误出现。
>
> ?️ 这个错误可以很容易地通过交换第 7 和第 8 行的代码来解决。试一下,看看错误是否消失了。
>
>
>
### 示例程序:交换数字
现在你已经熟悉了常见的变量相关问题,让我们来看一个交换两个变量值的程序。
```
fn main() {
let mut a = 7186932;
let mut b = 1276561;
println!("a: {a}, b: {b}");
// 交换变量值
let temp = a;
a = b;
b = temp;
println!("a: {}, b: {}", a, b);
}
```
我在这里声明了两个变量 `a` 和 `b`。这两个变量都是可变的,因为我希望在后面改变它们的值。我赋予了一些随机值。最初,我打印了这些变量的值。
然后,在第 8 行,我创建了一个名为 `temp` 的不可变变量,并将存储在 `a` 中的值赋给它。之所以这个变量是不可变的,是因为 `temp` 的值不会改变。
要交换值,我将变量 `b` 的值赋给变量 `a`,在下一行,我将 `temp` 的值(它包含 `a` 的值)赋给变量 `b`。现在值已经交换了,我打印了变量 `a` 和 `b` 的值。
在编译并执行上面的代码后,我得到了以下输出:
```
a: 7186932, b: 1276561
a: 1276561, b: 7186932
```
正如你所见,值已经交换了。完美。
### 使用未使用的变量
当你声明了一些变量,打算在后面使用它们,但是还没有使用它们,然后编译你的 Rust 代码来检查一些东西时,Rust 编译器会警告你。
原因是显而易见的。不会被使用的变量占用了不必要的初始化时间(CPU 周期)和内存空间。如果不会被使用,为什么要在程序写上它呢?尽管编译器确实会优化这一点。但是它仍然是一个问题,因为它会以多余的代码的形式影响可读性。
但是,有的时候,你可能会面对这样的情况:创建一个变量与否不在你的控制之下。比如说,当一个函数返回多个值,而你只需要其中的一些值时。在这种情况下,你不能要求库维护者根据你的需要调整他们的函数。
所以,在这种情况下,你可以写一个以下划线开头的变量,Rust 编译器将不再显示这样的警告。如果你真的不需要使用存储在该未使用变量中的值,你可以简单地将其命名为 `_`(下划线),Rust 编译器也会忽略它!
接下来的程序不仅不会生成任何输出,而且也不会生成任何警告和/或错误消息:
```
fn main() {
let _unnecessary_var = 0; // 没有警告
let _ = 0.0; // 完全忽略
}
```
### 算术运算
数学就是数学,Rust 并没有在这方面创新。你可以使用在其他编程语言(如 C、C++ 和/或 Java)中使用过的所有算术运算符。
包含可以在 Rust 编程语言中使用的所有运算符和它们的含义的完整列表可以在 [这里](https://doc.rust-lang.org/book/appendix-02-operators.html?ref=itsfoss.com#operators) 找到。
#### 示例程序:一个生锈的温度计
(LCTT 译注:这里的温度计“生锈”了是因为它是使用 Rust(生锈)编写的,原作者在这里玩了一个双关。)
接下来是一个典型的程序,它将华氏度转换为摄氏度,反之亦然。
```
fn main() {
let boiling_water_f: f64 = 212.0;
let frozen_water_c: f64 = 0.0;
let boiling_water_c = (boiling_water_f - 32.0) * (5.0 / 9.0);
let frozen_water_f = (frozen_water_c * (9.0 / 5.0)) + 32.0;
println!(
"Water starts boiling at {}°C (or {}°F).",
boiling_water_c, boiling_water_f
);
println!(
"Water starts freezing at {}°C (or {}°F).",
frozen_water_c, frozen_water_f
);
}
```
没什么大不了的……华氏温度转换为摄氏温度,反之亦然。
正如你在这里看到的,由于 Rust 不允许自动类型转换,我不得不在整数 32、9 和 5 后放一个小数点。除此之外,这与你在 C、C++ 和/或 Java 中所做的类似。
作为练习,尝试编写一个程序,找出给定数中有多少位数字。
### 常量
如果你有一些编程知识,你可能知道这意味着什么。常量是一种特殊类型的变量,它的值**永远不会改变**。*它保持不变*。
在 Rust 编程语言中,使用以下语法声明常量:
```
const CONSTANT_NAME: data_type = value;
```
如你所见,声明常量的语法与我们在 Rust 中看到的变量声明非常相似。但是有两个不同之处:
* 常量的名字需要像 `SCREAMING_SNAKE_CASE` 这样。所有的大写字母和单词之间用下划线分隔。
* 常量的数据类型**必须**被显性定义。
#### 变量与常量的对比
你可能在想,既然变量默认是不可变的,为什么语言还要包含常量呢?
接下来这个表格应该可以帮助你消除疑虑。(如果你好奇并且想更好地理解这些区别,你可以看看[我的博客](https://blog.thefossguy.com/posts/immutable-vars-vs-constants-rs.md?ref=itsfoss.com),它详细地展示了这些区别。)

#### 使用常量的示例程序:计算圆的面积
这是一个很直接的关于 Rust 中常量的简单程序。它计算圆的面积和周长。
```
fn main() {
const PI: f64 = 3.14;
let radius: f64 = 50.0;
let circle_area = PI * (radius * radius);
let circle_perimeter = 2.0 * PI * radius;
println!("有一个周长为 {radius} 厘米的圆");
println!("它的面积是 {} 平方厘米", circle_area);
println!(
"以及它的周长是 {} 厘米",
circle_perimeter
);
}
```
如果运行代码,将产生以下输出:
```
有一个周长为 50 厘米的圆
它的面积是 7850 平方厘米
以及它的周长是 314 厘米
```
### Rust 中的变量遮蔽
如果你是一个 C++ 程序员,你可能已经知道我在说什么了。当程序员**声明**一个与已经声明的变量同名的新变量时,这就是变量遮蔽。
与 C++ 不同,Rust 允许你在同一作用域中执行变量遮蔽!
>
> ? 当程序员遮蔽一个已经存在的变量时,新变量会被分配一个新的内存地址,但是使用与现有变量相同的名称引用。
>
>
>
来看看它在 Rust 中是如何工作的。
```
fn main() {
let a = 108;
println!("a 的地址: {:p}, a 的值 {a}", &a);
let a = 56;
println!("a 的地址: {:p}, a 的值: {a} // 遮蔽后", &a);
let mut b = 82;
println!("\nb 的地址: {:p}, b 的值: {b}", &b);
let mut b = 120;
println!("b的地址: {:p}, b的值: {b} // 遮蔽后", &b);
let mut c = 18;
println!("\nc 的地址: {:p}, c的值: {c}", &c);
c = 29;
println!("c 的地址: {:p}, c的值: {c} // 遮蔽后", &c);
}
```
`println` 语句中花括号内的 `:p` 与 C 中的 `%p` 类似。它指定值的格式为内存地址(指针)。
我在这里使用了 3 个变量。变量 `a` 是不可变的,并且在第 4 行被遮蔽。变量 `b` 是可变的,并且在第 9 行也被遮蔽。变量 `c` 是可变的,但是在第 14 行,只有它的值被改变了。它没有被遮蔽。
现在,让我们看看输出。
```
a 的地址: 0x7ffe954bf614, a 的值 108
a 的地址: 0x7ffe954bf674, a 的值: 56 // 遮蔽后
b 的地址: 0x7ffe954bf6d4, b 的值: 82
b 的地址: 0x7ffe954bf734, b 的值: 120 // 遮蔽后
c 的地址: 0x7ffe954bf734, c 的值: 18
c 的地址: 0x7ffe954bf734, c 的值: 29 // 遮蔽后
```
来看看输出,你会发现不仅所有三个变量的值都改变了,而且被遮蔽的变量的地址也不同(检查十六进制的最后几个字符)。
变量 `a` 和 `b` 的内存地址改变了。这意味着变量的可变性或不可变性并不是遮蔽变量的限制。
### 总结
本文介绍了 Rust 编程语言中的变量和常量。还介绍了算术运算。
做个总结:
* Rust 中的变量默认是不可变的,但是可以引入可变性。
* 程序员需要显式地指定变量的可变性。
* 常量总是不可变的,无论如何都需要类型注释。
* 变量遮蔽是指使用与现有变量相同的名称声明一个 *新* 变量。
很好!我相信和 Rust 一起的进展不错。在下一章中,我将讨论 Rust 中的数据类型。敬请关注。
与此同时,如果你有任何问题,请告诉我。
*(题图:MJ/7c5366b8-f926-487e-9153-0a877145ca5)*
---
via: <https://itsfoss.com/rust-variables/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Rust Basics Series #2: Using Variables and Constants in Rust Programs
Move ahead with your Rust learning and familiarize yourself with Rust programs' variables and constants.
In the [first chapter of the series](https://itsfoss.com/rust-introduction/), I shared my thoughts on why Rust is an increasingly popular programming language. I also showed how to [write Hello World program in Rust](https://itsfoss.com/rust-introduction/).
Let's continue this Rust journey. In this article, I shall introduce you to variables and constants in the Rust programming language.
On top of that, I will also cover a new programming concept called "shadowing".
## The uniqueness of Rust's variables
A variable in the context of a programming language (like Rust) is known as *an alias to the memory address in which some data is stored*.
This is true for the Rust programming language too. But Rust has one unique "feature" compared to most other popular programming languages. Every variable that you declare is **immutable by default**. This means that once a value is assigned to the variable, it can not be changed.
This decision was made to ensure that, by default, you don't have to make special provisions like *spin locks* or *mutexes* to introduce multi-threading. Rust **guarantees** safe concurrency. Since all variables (by default) are immutable, you do not need to worry about a thread changing a value unknowingly.
This is not to say that variables in Rust are like constants because they are not. Variables can be explicitly defined to allow mutation. Such a variable is called a **mutable variable**.
Following is the syntax to declare a variable in Rust:
```
// immutability by default
// the initialized value is the **only** value
let variable_name = value;
// mutable variable defined by the use of 'mut' keyword
// the initial value can be changed to something else
let mut variable_name = value;
```
Meaning, if you have a mutable variable of type float, you can not assign a character to it down the road.
## High-level overview of Rust's data types
In the previous article, you might have noticed that I mentioned that Rust is a strongly typed language. But to define a variable, you don't specify the data type, instead, you use a generic keyword `let`
.
The Rust compiler can infer the data type of a variable based on the value assigned to it. But it can be done if you still wish to be explicit with data types and want to annotate the type. Following is the syntax:
`let variable_name: data_type = value;`
Some of the common data types in the Rust programming language are as follows:
**Integer type**:`i32`
and`u32`
for signed and unsigned, 32-bit integers, respectively**Floating point type**:`f32`
and`f64`
, 32-bit and 64-bit floating point numbers**Boolean type**:`bool`
**Character type**:`char`
I will cover Rust's data types in more detail in the next article. For now, this should be sufficient.
**to a variable with a floating point data type, you will face a compile time error. What you should assign instead is the value**
**8****or**
**8.****.**
**8.0**Rust also enforces that a variable be initialized before the value stored in it is read.
```
{ // this block won't compile
let a;
println!("{}", a); // error on this line
// reading the value of an **uninitialized** variable is a compile-time error
}
{ // this block will compile
let a;
a = 128;
println!("{}", a); // no error here
// variable 'a' has an initial value
}
```
If you declare a variable without an initial value and use it before assigning it some initial value, the Rust compiler will throw a **compile time error**.
Though errors are annoying. In this case, the Rust compiler is forcing you not to make one of the very common mistakes one makes when writing code: un-initialized variables.
## Rust compiler's error messages
Let's write a few programs where you
- Understand Rust's design by performing "normal" tasks, which are actually a major cause of memory-related issues
- Read and understand the Rust compiler's error/warning messages
#### Testing variable immutability
Let us deliberately write a program that tries to modify a mutable variable and see what happens next.
```
fn main() {
let mut a = 172;
let b = 273;
println!("a: {a}, b: {b}");
a = 380;
b = 420;
println!("a: {}, b: {}", a, b);
}
```
Looks like a simple program so far until line 4. But on line 7, the variable `b`
--an immutable variable--gets its value modified.
Notice the two methods of printing the values of variables in Rust. On line 4, I enclosed the variables between curly brackets so that their values will be printed. On line 8, I keep the brackets empty and provide the variables as arguments, C style. Both approaches are valid. (Except for modifying the immutable variable's value, everyting in this program is correct.)
Let's compile! You already know how to do that if you followed the previous chapter.
```
$ rustc main.rs
error[E0384]: cannot assign twice to immutable variable `b`
--> main.rs:7:5
|
3 | let b = 273;
| -
| |
| first assignment to `b`
| help: consider making this binding mutable: `mut b`
...
7 | b = 420;
| ^^^^^^^ cannot assign twice to immutable variable
error: aborting due to previous error
For more information about this error, try `rustc --explain E0384`.
```
This perfectly demonstrates Rust's robust error checking and informative error messages. The first line reads out the error message that prevents the compilation of the above code:
`error[E0384]: cannot assign twice to immutable variable b`
It means that the Rust compiler noticed that I was trying to re-assign a new value to the variable `b`
but the variable `b`
is an immutable variable. So that is causing this error.
The compiler even identifies the exact line and column numbers where this error is found.
Under the line that says `first assignment to `b``
is the line that provides help. Since I am mutating the value of the immutable variable `b`
, I am told to declare the variable `b`
as a mutable variable using the `mut`
keyword.
#### Playing with uninitialized variables
Now, let's look at what the Rust compiler does when an uninitialized variable's value is read.
```
fn main() {
let a: i32;
a = 123;
println!("a: {a}");
let b: i32;
println!("b: {b}");
b = 123;
}
```
Here, I have two immutable variables `a`
and `b`
and both are uninitialized at the time of declaration. The variable `a`
gets a value assigned before its value is read. But the variable `b`
's value is read before it is assigned an initial value.
Let's compile and see the result.
```
$ rustc main.rs
warning: value assigned to `b` is never read
--> main.rs:8:5
|
8 | b = 123;
| ^
|
= help: maybe it is overwritten before being read?
= note: `#[warn(unused_assignments)]` on by default
error[E0381]: used binding `b` is possibly-uninitialized
--> main.rs:7:19
|
6 | let b: i32;
| - binding declared here but left uninitialized
7 | println!("b: {b}");
| ^ `b` used here but it is possibly-uninitialized
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
error: aborting due to previous error; 1 warning emitted
For more information about this error, try `rustc --explain E0381`.
```
Here, the Rust compiler throws a compile time error and a warning. The warning says that the variable `b`
's value is never being read.
But that's preposterous! The value of variable `b`
is being accessed on line 7. But look closely; the warning is regarding line 8. This is confusing; let's temporarily skip this warning and move on to the error.
The error message reads that `used binding `b` is possibly-uninitialized`
. Like in the previous example, the Rust compiler is pointing out that the error is caused by reading the value of the variable `b`
on line 7. The reason why reading the value of the variable `b`
is an error is that its value is uninitialized. In the Rust programming language, that is illegal. Hence the compile time error.
## Example program: Swap numbers
Now that you are familiar with the common variable-related issues, let's look at a program that swaps the values of two variables.
```
fn main() {
let mut a = 7186932;
let mut b = 1276561;
println!("a: {a}, b: {b}");
// swap the values
let temp = a;
a = b;
b = temp;
println!("a: {}, b: {}", a, b);
}
```
Here, I have declared two variables, `a`
and `b`
. Both variables are mutable because I wish to change their values down the road. I assigned some random values. Initially, I print the values of these variables.
Then, on line 8, I create an immutable variable called `temp`
and assign it the value stored in `a`
. The reason why this variable is immutable is because `temp`
's value will not be changed.
To swap values, I assign the value of variable `b`
to variable `a`
and on the next line I assign the value of `temp`
(which contains value of `a`
) to variable `b`
. Now that the values are swapped, I print values of variables `a`
and `b`
.
When the above code is compiled and executed, I get the following output:
```
a: 7186932, b: 1276561
a: 1276561, b: 7186932
```
As you can see, the values are swapped. Perfect.
## Using Unused variables
When you have declared some variables you intend to use down the line but have not used them yet, and compile your Rust code to check something, the Rust compiler will warn you about it.
The reason for this is obvious. Variables that will not be used take up unnecessary initialization time (CPU cycle) and memory space. If it will not be used, why have it in your program in the first place? Though, the compiler does optimize this away. But it still remains an issue in terms of readability in form of excess code.
But sometimes, you might be in a situation where creating a variable might not be in your hands. Say when a function returns more than one value and you only need a few values. In that case, you can't tell the library maintainer to adjust their function according to your needs.
So, in times like that, you can have a variable that begins with an underscore and the Rust compiler will no longer give you such warnings. And if you really do not need to even use the value stored in said unused variable, you can simply name it `_`
(underscore) and the Rust compiler will ignore it too!
The following program will not only not generate any output, but it will also not generate any warnings and/or error messages:
```
fn main() {
let _unnecessary_var = 0; // no warnings
let _ = 0.0; // ignored completely
}
```
## Arithmetic operations
Since math is math, Rust doesn't innovate on it. You can use all of the arithmetic operators you might have used in other programming languages like C, C++ and/or Java.
A complete list of all the operations in the Rust programming language, along with their meaning, can be found [here](https://doc.rust-lang.org/book/appendix-02-operators.html#operators).
### Example Program: A Rusty thermometer
Following is a typical program that converts Fahrenheit to Celsius and vice a versa.
```
fn main() {
let boiling_water_f: f64 = 212.0;
let frozen_water_c: f64 = 0.0;
let boiling_water_c = (boiling_water_f - 32.0) * (5.0 / 9.0);
let frozen_water_f = (frozen_water_c * (9.0 / 5.0)) + 32.0;
println!(
"Water starts boiling at {}°C (or {}°F).",
boiling_water_c, boiling_water_f
);
println!(
"Water starts freezing at {}°C (or {}°F).",
frozen_water_c, frozen_water_f
);
}
```
Not much is going on here... The Fahrenheit temperature is converted to Celsius and vice a versa for the temperature in Celsius.
As you can see here, since Rust does not allow automatic type casting, I had to introduce a decimal point to the whole numbers 32, 9 and 5. Other than that, this is similar to what you would do in C, C++ and/or Java.
As a learning exercise, try writing a program that finds out how many digits are in a given number.
## Constants
With some programming knowledge, you might know what this means. A constant is a special type of variable whose value **never changes**. *It stays constant*.
In the Rust programming language, a constant is declared using the following syntax:
`const CONSTANT_NAME: data_type = value;`
As you can see, the syntax to declare a constant is very similar to what we saw in declaring a variable in Rust. There are two differences though:
- A constant name should be in
`SCREAMING_SNAKE_CASE`
. All uppercase characters and words separated by an undercase. - Annotating the data type of the constant is
**necessary**.
### Variables vs Constants
You might be wondering, since the variables are immutable by default, why would the language also include constants?
The following table should help alleviate your doubts. (If you are curious and want to better understand these differences, you can look at [my blog](https://blog.thefossguy.com/posts/immutable-vars-vs-constants-rs.md) which shows these differences in detail.)

### Example program using constants: Calculate area of circle
Following is a straightforward program about constants in Rust. It calculates the area and the perimeter of a circle.
```
fn main() {
const PI: f64 = 3.14;
let radius: f64 = 50.0;
let circle_area = PI * (radius * radius);
let circle_perimeter = 2.0 * PI * radius;
println!("There is a circle with the radius of {radius} centimetres.");
println!("Its area is {} centimetre square.", circle_area);
println!(
"And it has circumference of {} centimetres.",
circle_perimeter
);
}
```
And upon running the code, the following output is produced:
```
There is a circle with the radius of 50 centimetres.
Its area is 7850 centimetre square.
And it has circumference of 314 centimetres.
```
## Variable shadowing in Rust
If you are a C++ programmer, you already sort of know what I am referring to. When the programmer **declares** a new variable with the same name as an already declared variable, it is known as variable shadowing.
Unlike C++, Rust allows you to perform variable shadowing in the same scope too!
Let us take a look at how it works in Rust.
```
fn main() {
let a = 108;
println!("addr of a: {:p}, value of a: {a}", &a);
let a = 56;
println!("addr of a: {:p}, value of a: {a} // post shadowing", &a);
let mut b = 82;
println!("\naddr of b: {:p}, value of b: {b}", &b);
let mut b = 120;
println!("addr of b: {:p}, value of b: {b} // post shadowing", &b);
let mut c = 18;
println!("\naddr of c: {:p}, value of c: {c}", &c);
c = 29;
println!("addr of c: {:p}, value of c: {c} // post shadowing", &c);
}
```
The `:p`
inside curly brackets in the `println`
statement is similar to using `%p`
in C. It specifies that the value is in the format of a memory address (pointer).
I take 3 variables here. Variable `a`
is immutable and is shadowed on line 4. Variable `b`
is mutable and is also shadowed on line 9. Variable `c`
is mutable but on line 14, only it's value is mutated. It is not shadowed.
Now, let's look at the output.
```
addr of a: 0x7ffe954bf614, value of a: 108
addr of a: 0x7ffe954bf674, value of a: 56 // post shadowing
addr of b: 0x7ffe954bf6d4, value of b: 82
addr of b: 0x7ffe954bf734, value of b: 120 // post shadowing
addr of c: 0x7ffcfcd16b54, value of c: 18
addr of c: 0x7ffcfcd16b54, value of c: 29 // post shadowing
```
Looking at the output, you can see that not only the values of all three variables have changed, but the addresses of variables that were shadowed are are also different (check the last few hex characters).
The memory address for the variables `a`
and `b`
changed. This means that mutability, or lack thereof, of a variable is not a restriction when shadowing a variable.
## Conclusion
This article covers variables and constants in the Rust programming language. Arithmetic operations are also covered.
As a recap:
- Variables in Rust are immutable by default but mutability can be introduced.
- Programmer needs to explicitly specify variable mutability.
- Constants are always immutable no matter what and require type annotation.
- Variable shadowing is declaring a
*new*variable with the same name as an existing variable.
Awesome! Good going with Rust, I believe. In the next chapter, I discuss [data types in Rust](https://itsfoss.com/rust-data-types/). Stay Tuned.
[Rust Basics Series #3: Data Types in RustIn the third chapter of this series, learn about Integers, Floats, Characters and Boolean data types in Rust programming language.](https://itsfoss.com/rust-data-types/)

Meanwhile, if you have any questions, please let me know. |
15,773 | KDE 团队正在开发新的电子书管理应用:Arianna | https://debugpointnews.com/kde-app-arinna/ | 2023-05-02T14:43:00 | [
"电子书"
] | /article-15773-1.html | 
>
> KDE 引入了 Arianna,这是一款基于 Qt 和 Kirigami 构建的新 ePub 阅读器应用,集成了 Baloo,可轻松组织和浏览文件。
>
>
>
著名的国际自由软件社区 KDE 正在开发新的 ePub 阅读器应用 Arianna。该应用程序建立在 Qt 和 Kirigami 之上,提供时尚现代的用户界面。
Arianna 既是 ePub 查看器,也是库管理应用。该应用利用 KDE 的文件索引和搜索框架 Baloo 来查找和分类用户设备上的现有 ePub 文件。
Arianna 的库视图会跟踪用户的阅读进度,并在新书下载后立即更新。对于那些拥有较大库的人,Arianna 提供内部搜索功能以及按体裁、出版商或作者浏览书籍的能力。
Arianna 的实际阅读界面很简单,唯一的目的就是展示书的内容。但是,该应用确实有有用的功能,例如用于跟踪用户阅读进度的进度条和键盘导航功能。它还允许用户在书中搜索特定单词。
以下是来自公告的一些截图:



该应用在 Flathub 中以 Flatpak 的形式提供。你需要使用[本指南](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/)为你的 Linux 发行版设置 Flatpak/Flathub。并使用以下命令安装它。
```
flatpak install flathub org.kde.arianna
```
尽管它具有令人印象深刻的功能,但人们可能会质疑是否需要另一个 ePub 管理应用,因为已经有了 [Calibre](https://calibre-ebook.com/),这是一个自由开源的替代方案。然而,Arianna 现代而直观的设计,以及与 KDE 生态系统的无缝集成,使其成为 ePub 阅读器领域的有力竞争者。
总之,Arianna 是 KDE 大量应用中令人兴奋的新成员。它提供时尚现代的设计以及用于管理和阅读 ePub 文件的实用功能。随着它的不断发展,用户可以期待在未来有更多的改进和增强。
>
> 来自 [Carl 的博客](https://carlschwan.eu/2023/04/13/announcing-arianna-1.0/)
>
>
>
*(题图:MJ/665fb955-deb5-4519-9259-afa983b616cc)*
---
via: <https://debugpointnews.com/kde-app-arinna/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,774 | 在 MySQL 中处理时间 | https://opensource.com/article/23/2/temporal-values-mysql | 2023-05-02T17:10:00 | [
"MySQL",
"时间"
] | /article-15774-1.html | 
>
> 这篇关于 MySQL 中日期和时间的概述将帮助你在数据库表中处理时间值。
>
>
>
流行数据库系统 MySQL 的新老用户常常会对数据库处理时间值的方式感到困惑。有时用户不会费心去了解时间值的数据类型。这可能是因为他们觉得本身也没有什么好了解的。日期就是日期,对吧?好吧,并非总是如此。花几分钟时间了解 MySQL 如何存储和显示日期和时间是有益的。学习如何最好地利用数据库表中的时间值可以帮助你成为更好的编码者。
### MySQL 时间值类型
当你在 MySQL 中新建表时,选择合适的数据类型(`INT`、`FLOAT`、`CHAR` 等)高效地保存插入到表中的数据。MySQL 为时间值提供了五种数据类型。它们是 `DATE`、`TIME`、`DATETIME`、`TIMESTAMP` 和 `YEAR`。
MySQL 使用 `ISO 8601` 格式来存储以下格式的值(LCTT 译注:国际标准 ISO 8601,是国际标准化组织的日期和时间的表示方法,全称为《数据存储和交换形式·信息交换·日期和时间的表示方法》):
* `DATE`:`YYYY-MM-DD`
* `TIME`:`HH:MM:SS`
* `TIMESTAMP`:`YYYY-MM-DD HH:MM:SS`
* `YEAR`:`YYYY`
### DATETIME 与 TIMESTAMP 的比较
你可能已经注意到 <ruby> 日期时间 <rt> DATETIME </rt></ruby> 和 <ruby> 时间戳 <rt> TIMESTAMP </rt></ruby> 数据类型存有相同的数据。你可能想知道这两者之间是否有差异。答案是:有。
首先,可以使用的日期范围不同。`DATETIME` 可以保存 1000-01-01 00:00:00 和 9999-12-31 23:59:59 之间的日期,而 `TIMESTAMP` 的范围更有限,从 1970-01-01 00:00:01 到 2038-01-19 03:14:07 UTC。
其次,虽然两种数据类型都允许你 <ruby> 自动初始化 <rt> auto_initialize </rt></ruby> 或 <ruby> 自动更新 <rt> auto_update </rt></ruby> 它们各自的值(分别用 `DEFAULT CURRENT_TIMESTAMP` 和 `ON UPDATE CURRENT_TIMESTAMP`),但在 5.6.5 版本之前,对 `DATETIME` 值不能这样操作。如果你要用 `DATETIME`,你可以使用 `CURRENT_TIMESTAMP` 的 MySQL 同义词之一,例如 `NOW()` 或 `LOCALTIME()`。
如果你对一个 `DATETIME` 值使用 `ON UPDATE CURENT_TIMESTAMP`(或其同义词之一),但没有使用 `DEFAULT CURRENT_TIMESTAMP` 子句,那么这个列的默认值为 `NULL`。除非你在表的定义中包含 `NOT NULL`,在这种情况下,它默认为 0。
另一件需要记住的重要事情是,尽管通常情况下,除非你声明一个默认值,否则 `DATETIME` 和 `TIMESTAMP` 列都没有一个默认值,但这个规则有一个例外。如果没有指定 `DEFAULT CURRENT_TIMESTAMP` 和 `ON UPDATE CURRENT_TIMESTAMP` 这两个子句,并且禁用 `explicit_defaults_for_timestamp` 这个变量,那么你表中的第一个 `TIMESTAMP` 列将被隐式创建。
要检查这个变量的状态,请运行:
```
mysql> show variables like 'explicit_default%';
```
如果你想打开或关闭它,运行这段代码(用 0 表示关闭,用 1 表示打开):
```
mysql> set explicit_defaults_for_timestamp = 0;
```
### TIME
MySQL 的 <ruby> 时间 <rt> TIME </rt></ruby> 数据类型可能看起来很简单,但有几件事是一个优秀的程序员应该牢记的。
首先要注意的是,虽然 `TIME` 经常被认为是一天中的时间,但它实际上是经过的时间。换句话说,它可以是一个负值,或者可以大于 23:59:59。在 MySQL 中,一个 `TIME` 值的范围可以是 -838:59:59 到 838:59:59。
另外,如果你缩写一个时间值,MySQL 会因你是否使用冒号作出不同解释。例如,10:34 这个值被 MySQL 看作是 10:34:00。也就是说,十点过后的 34 分钟。但是,如果你不使用冒号写作 `1034`,MySQL 将其视为 00:10:34,意思是 10 分钟 34 秒。
最后,你应该知道 `TIME` 值(以及 `DATETIME` 和 `TIMESTAMP` 字段的时间部分)从 5.6.4 版本开始,可以取一个小数部分。要使用它,请在数据类型定义的结尾处添加一个整数(最大值为 6)的圆括号。
```
time_column TIME(2)
```
### 时区
时区变化不仅在现实世界中产生混乱和疲劳,而且也会在数据库系统中制造麻烦。地球被划分为 24 个独立的时区,通常每隔 15 度经度就会发生变化。我说通常是因为一些国家行事方式不同。例如中国只在一个时区运作,而不是预期的五个时区。
你如何处理处于不同时区的数据库系统的用户就成了一个问题。幸运的是,MySQL 并没有使这个问题变得太困难。
要检查你的会话时区,请运行:
```
mysql> select @@session.time_zone;
```
如果结果显示 `System`,这意味着它正在使用你的 `my.cnf` 配置文件中设置的时区。如果你在本地计算机上运行你的 MySQL 服务器,这可能就是你会得到的,你不需要做任何改变。
如果你想改变你的会话的时区,请运行如下命令:
```
mysql> set time_zone = '-05:00';
```
这将你的时区设置为 <ruby> 美国/东部 <rt> US/Eastern </rt></ruby>,比 <ruby> 协调世界时 <rt> UTC </rt></ruby> 晚五个小时。
### 获得一周的日期
为了跟上本教程后面部分的代码,你应该在你的系统中创建一个带有日期值类型的表。比如:
```
mysql> create table test
( row_id smallint not null auto_increment primary key,
the_date date not null);
```
然后使用 ISO 8601 格式在表中插入一些随机日期,如
```
mysql> insert into test (the_date) VALUES ('2022-01-05');
```
我在我的 `test` 表中插入了四行日期值,你插入多少行都可以。
有时你可能想知道某一天是星期几。MySQL 给了你几种实现方法。
第一种,也是最显而易见的方法,是使用 `DAYNAME()` 函数。如下示例表所展示,`DAYNAME()` 函数可以告诉你每个日期是星期几:
```
mysql> SELECT the_date, DAYNAME(the_date) FROM test;
+------------+-------------------------------+
| the_date | DAYNAME(the_date) |
+------------+-------------------------------+
| 2021-11-02 | Tuesday |
| 2022-01-05 | Wednesday |
| 2022-05-03 | Tuesday |
| 2023-01-13 | Friday |
+------------+-------------------------------+
4 rows in set (0.00 sec)
```
另外两种获取星期几的方法是返回整数值,而不是星期几的名称,分别是 `WEEKDAY()` 和 `DAYOFWEEK()`。他们都返回数字,却又各不相同。`WEEKDAY()` 函数返回从 0 到 6 的数字,其中 0 代表星期一,6 代表星期日。而 `DAYOFWEEK()` 则返回从 1 到 7 的数字,其中 1 代表星期日,7 代表星期六。
```
mysql> SELECT the_date, DAYNAME(the_date),
WEEKDAY(the_date), DAYOFWEEK(the_date) FROM test;
+------------+------------------+------------------+--------------------+
| the_date | DAYNAME(the_date)| WEEKDAY(the_date)| DAYOFWEEK(the_date)|
| 2021-11-02 | Tuesday | 1 | 3 |
| 2022-01-05 | Wednesday | 2 | 4 |
| 2022-05-03 | Tuesday | 1 | 3 |
| 2023-01-13 | Friday | 4 | 6 |
+------------+------------------+------------------+--------------------+
4 rows in set (0.00 sec)
```
### 当你只想获取日期的一部分时
有时你可能在 MySQL 表中存储了一个日期,但是你只想获取日期的一部分。这并不是问题。
MySQL 中有几个顾名思义的函数,可以轻松获取日期对象的特定部分。以下是一些示例:
```
mysql> SELECT the_date, YEAR(the_date), MONTHNAME(the_date),
DAYOFMONTH(the_date) FROM test ;
+-----------+---------------+-------------------+---------------------+
| the_date | YEAR(the_date)|MONTHNAME(the_date)| DAYOFMONTH(the_date)|
+-----------+---------------+-------------------+---------------------+
| 2021-11-02| 2021 | November | 2 |
| 2022-01-05| 2022 | January | 5 |
| 2022-05-03| 2022 | May | 3 |
| 2023-01-13| 2023 | January | 13 |
+-----------+---------------+-------------------+---------------------+
4 rows in set (0.00 sec)
```
MySQL 也允许你使用 `EXTRACT()` 函数来获取日期的一部分。你提供给函数的参数是一个单位说明符(确保是单数形式)、`FROM` 和列名。因此,为了从我们的 test 表中仅获取年份,你可以写:
```
mysql> SELECT EXTRACT(YEAR FROM the_date) FROM test;
+----------------------------------------------+
| EXTRACT(YEAR FROM the_date) |
+----------------------------------------------+
| 2021 |
| 2022 |
| 2022 |
| 2023 |
+----------------------------------------------+
4 rows in set (0.01 sec)
```
### 插入和读取不同格式的日期
正如之前提到的,MySQL 使用 `ISO 8601` 格式存储日期和时间值。但是如果你想以另一种方式存储日期和时间值,例如 `MM-DD-YYYY` 格式,怎么办?首先,不要尝试这样做。MySQL 以 8601 格式存储日期和时间,就是这样。不要尝试更改它。但是,这并不意味着你必须在将数据输入到数据库之前将数据转换为特定的格式,或者你不能以任何你想要的格式展示数据。
如果你想要将非 ISO 的格式的日期输入到表中,你可以使用 `STR_TO_DATE()` 函数。第一个参数是你想要存储在数据库中的日期的字符串值。第二个参数是格式化字符串,它让 MySQL 知道日期的组织方式。让我们看一个简单的例子,然后我将更深入地研究这个看起来很奇怪的格式化字符串是什么。
```
mysql> insert into test (the_date) values (str_to_date('January 13, 2023','%M %d, %Y'));
Query OK, 1 row affected (0.00 sec)
```
你将格式化字符串放在引号中,并在每个特殊字符前加上百分号。上面代码中的格式序列告诉 MySQL 我的日期由一个完整的月份名称 `%M`,后跟一个两位数的日期`%d`,然后是一个逗号,最后由一个四位数的年份 `%Y` 组成。请注意,大写很重要。
一些其他常用的格式化字符串字符是:
* `%b` 缩写月份的名称(例如: `Jan`)
* `%c` 数字月份(例如: 1)
* `%W` 星期名称(例如: `Saturday)
* `%a` 星期名称的缩写(例如: `Sat`)
* `%T` 24 小时制的时间(例如: `22:01:22`)
* `%r` 带 AM/PM 的 12 小时制的时间(例如: `10:01:22 PM`)
* `%y` 两位数的年份(例如: 23)
请注意,对于两位数年份 `%y`,年份范围是 1970 到 2069。因此,从 70 到 99 的数字被假定为 20 世纪,而从 00 到 69 的数字被假定为 21 世纪。
如果你有一个日期存储在你的数据库中,你想用不同的格式显示它,你可以使用这个 `DATE_FORMAT()` 函数:
```
mysql> SELECT DATE_FORMAT(the_date, '%W, %b. %d, %y') FROM test;
+-----------------------------------------+
| DATE_FORMAT(the_date, '%W, %b. %d, %y') |
+-----------------------------------------+
| Tuesday, Nov. 02, 21 |
| Wednesday, Jan. 05, 22 |
| Tuesday, May. 03, 22 |
| Friday, Jan. 13, 23 |
+-----------------------------------------+
4 rows in set (0.00 sec)
```
### 总结
本教程应该为你提供了一个关于 MySQL 中的日期和时间值的有用的概述。我希望本文教会了您一些新知识,使您能够更好地控制和理解 MySQL 数据库如何处理时间值。
*(题图:MJ/76b6481a-a271-4e81-bc17-dd7fbe08a240)*
---
via: <https://opensource.com/article/23/2/temporal-values-mysql>
作者:[Hunter Coleman](https://opensource.com/users/hunterc) 选题:[lkxed](https://github.com/lkxed/) 译者:[hanszhao80](https://github.com/hanszhao80) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,776 | Debian 12 “Bookworm” 的新特性和发布日期 | https://news.itsfoss.com/debian-12-features/ | 2023-05-03T00:17:00 | [
"Debian"
] | https://linux.cn/article-15776-1.html |
>
> Debian 12 即将发布。了解一下更多关于其新特性和发布日期的相关信息。
>
>
>

Debian 即将发布系统代号为 “<ruby> 书虫 <rt> Bookworm </rt></ruby>” 的新版本。与 [Debian 11 “Bullseye”](https://news.itsfoss.com/debian-11-feature/) 相比,有许多改进和新功能。
Debian 12 “Bookworm” **包含了超过 11200 个新软件包**,软件包总数 **超过了 59000 个**!
Debian 所包含的大多数软件都已更新,**超过 9500 个软件包** 因陈旧或过时而被删除。
你期盼吗?让我们来看看 Debian 12 的新内容。
>
> ? 除非有任何意外的延误,Debian 12 的发布日期 [已经确定](https://lists.debian.org/debian-devel-announce/2023/04/msg00007.html?ref=news.itsfoss.com) 为 **2023 年 6 月 10 日**。
>
>
>
### 1、更新的安装程序

Debian 的安装程序得到了一些改进,从而改善了硬件支持,并带来一些令人兴奋的新功能。
例如,改进了对硬件专有固件(非自由软件)的处理,现在已经可以直接从安装程序中加载此类固件。
这要归功于 **Debian APT 2.6** 的加入,它允许在 Debian 上更好地处理非自由固件。

因此,现在当确定需要非自由固件二进制文件时,将默认启用这些文件。
这些变化将使得其**更好地支持在非自由固件上运行的各种硬件**, 特别是显卡和无线网卡控制器。
### 2、Linux 内核 6.1

Debian 12 “Bookworm” 由 [最近获得 LTS 批准的](https://news.itsfoss.com/linux-kernel-6-1-is-now-an-lts-version/) Linux 内核 6.1 驱动,该内核具有**对 Rust 的实验性支持**、**对英特尔 Meteor Lake 的支持**、**对 ARM SoC 的改进支持**等等。
你可能想通过我们的报道来深入了解:
>
> **[Linux 内核 6.1 发布,包含初始 Rust 代码](https://news.itsfoss.com/linux-kernel-6-1-release/)**
>
>
>
### 3、更新的软件套件
这个 Debian 版本还提供了一套更新的软件,包括:
* GNOME 43
* KDE Plasma 5.27
* Xfce 4.18
* LXDE 11
* LXQt 1.2.0
* MATE 1.26
* LibreOffice 7.4
* Inkscape 1.2.2
* GIMP 2.10.34
* Vim 9.0
>
> ? 因为 [GNOME 44](https://news.itsfoss.com/gnome-44-release/) 是在三月底发布的,由于日程冲突,它无法进入 Debian 12。
>
>
>
桌面环境的升级听起来不错,除此之外还有必要的应用程序更新。
### 4、默认的 PipeWire

对于 [PipeWire](https://pipewire.org/?ref=news.itsfoss.com) 支持者来说是个好消息!
Debian 12 现在与其他领先的发行版,如 Ubuntu、Fedora、Pop!\_OS 等看齐,提供对 PipeWire 的开箱即用支持。
它取代了老旧的 [PulseAudio](https://en.wikipedia.org/wiki/PulseAudio?ref=news.itsfoss.com),整个系统的音频和视频处理性能得到极大的改善。
### 5、新壁纸

每个新的 Debian 版本都会带来新的壁纸和主题更新。
新壁纸被称为 “Emerald”,这是一种看起来非常干净的艺术作品风格,似乎在说明宝石的特性,“优雅的抛光和凿刻”。
如上面的截图所示,默认主题、安装程序的横幅等都采用了这种艺术作品风格。
你可以查看 Emerald [图集](https://wiki.debian.org/DebianArt/Themes/Emerald?ref=news.itsfoss.com),以了解更多。
### ?️ 其他更改和提高
上面提到的并不是唯一的变化,下面同样是一些值得一提的变化:
* 非自由固件包现在由存档区的一个名为 `non-free-firmware` 的专门组件处理。
* 基于 Go 的软件包具有有限的安全支持。
* 超过 9519 个软件包被移除,因为它们是过时的。
* Debian 12 现在可以在双启动设置中检测到 Windows 11。
* 增加了对新的 ARM 设备的支持。
所以,总结一下:
这个版本的 Debian 打造的相当好,有许多改进和功能的增加。
你对 Debian 12 有什么期待?请在下面的评论中分享你的想法。
---
via: <https://news.itsfoss.com/debian-12-features/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[chris000132](https://github.com/chris000132) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Debian's upcoming release code-named '**Bookworm**' is almost here, with many improvements and new features over [Debian 11 Bullseye](https://news.itsfoss.com/debian-11-feature/).
Debian 12 'Bookworm' **contains over 11200 new packages, **bringing the total to **over 59000 packages**!
Most software included with Debian has been updated, with **9500+ packages being removed** for being old or obsolete.
Are you excited? Let's see what's new in Debian 12.
[has been set](https://lists.debian.org/debian-devel-announce/2023/04/msg00007.html?ref=news.itsfoss.com)to
**June 10, 2023**, barring any unforeseen delays.
## 1. Updated Installer
The installer on Debian has received various improvements that have resulted in improved hardware support and some exciting new features.
Take, for instance, the improved handling of proprietary firmware (non-free) for hardware, which has now made it straightforward to load up such firmware from within the installer.
This was made possible thanks to the inclusion of **Debian APT 2.6** which allows for better handling of non-free firmware on Debian.
So, now the non-free firmware binaries will be enabled by default when it is ascertained that they are required.
These changes will enable** better support for different hardware running on non-free firmware**, especially GPUs and Wi-Fi adapters.
## 2. Linux Kernel 6.1
Debian 12 'Bookworm' is powered by the [recently LTS-approved](https://news.itsfoss.com/linux-kernel-6-1-is-now-an-lts-version/) Linux Kernel 6.1 that features **experimental support for Rust**, **enablement of Intel Meteor Lake**, **improved ARM SoC support,** and more.
You may want to go through our coverage to dive deeper.
[Linux Kernel 6.1 Released With Initial Rust CodeLinux Kernel 6.1 is now available! Potentially an LTS version considering it is the last stable release of the year.](https://news.itsfoss.com/linux-kernel-6-1-release/)

## 3. Updated Software Suite
This Debian release also features an updated set of software that includes:
- GNOME 43
- KDE Plasma 5.27
- Xfce 4.18
- LXDE 11
- LXQt 1.2.0
- MATE 1.26
- LibreOffice 7.4
- Inkscape 1.2.2
- GIMP 2.10.34
- Vim 9.0
[GNOME 44](https://news.itsfoss.com/gnome-44-release/)was released at the end of March, it could not make it into Debian 12 due to schedule conflicts.
The desktop environment upgrades sound good along with necessary application updates.
## 4. PipeWire by Default
Great news for the [PipeWire](https://pipewire.org/?ref=news.itsfoss.com) enthusiasts out there!
Debian 12 is now at par with other leading distros, such as Ubuntu, Fedora, Pop!_OS, etc., by providing support for PipeWire out-of-the-box.
It replaces the aging [PulseAudio](https://en.wikipedia.org/wiki/PulseAudio?ref=news.itsfoss.com), allowing greatly improved handling of audio and video across the system.
## 5. New Wallpaper
Any new release of Debian also means the inclusion of new wallpaper and theming updates.
Called '**Emerald**', this is a very clean-looking artwork style that seems to illustrate the properties of a gemstone, “*Elegantly polished and chiseled*.”
The default theme, installer banners, and more feature this artwork style, as demonstrated in the screenshots above.
You can check out its [gallery](https://wiki.debian.org/DebianArt/Themes/Emerald?ref=news.itsfoss.com) for Emerald to know more.
## 🛠️ Other Changes and Improvements
The above-mentioned are not the only changes; here are some that are worth mentioning:
- Non-free firmware packages are now handled with a dedicated component called 'non-free-firmware' in the Archive areas.
- Go-based packages have limited security support.
- Over 9519 packages were removed because they were old/obsolete.
- Debian 12 can now detect Windows 11 in a dual-boot setup.
- Added support for new ARM devices.
So, wrapping up.
This release of Debian is shaping up quite well, with many improvements and feature additions.
*What are you excited about with Debian 12? Let me know your thoughts in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,777 | 使用开源人工智能 Upscayl 放大你的老照片 | https://opensource.com/article/23/4/edit-photos-open-source-ai | 2023-05-03T08:52:00 | [
"照片",
"AI"
] | https://linux.cn/article-15777-1.html | 
>
> Upscayl 是一个自由开源的程序,它使用开源人工智能来提升低分辨率的图像。
>
>
>
自从我小时候使用了我父亲的柯达 620 相机以来,我就一直对摄影很感兴趣。我用它来拍摄我们附近的动植物。出于对摄影的热爱,我在高中时购买了一台 Instamatic 相机,并最终在 1990 年代后期购买了一台刚刚进入市场的数码相机。早期的数码相机便于携带,能够快速捕捉图像并轻松地在互联网上共享图像。但它们在质量和复杂性上不如最好的胶片摄影。当然,从那时起,数码相机有了很大的改进。但我这么多年的数码照片看起来有点小,嗯,是在现代设备上看起来比较*小*。
直到最近,我用于提升数字图像的首选工具一直都是 [GIMP](https://opensource.com/tags/gimp)。几年前,我尝试使用 GIMP 放大我父亲在 1940 年代中期拍摄的“小”图。不过虽然放大了,但照片缺乏我想要的细节、深度和清晰度。
自从我知道了 [Upscayl](https://github.com/upscayl/upscayl),这一切都发生了变化。这是一个自由开源的程序,它使用了 <ruby> <a href="https://opensource.com/article/22/10/defining-open-source-ai"> 开源人工智能 </a> <rt> open source artificial intelligence </rt></ruby> 来升级低分辨率图像,
### Upscayl
Upscayl 适用于 Linux、Windows 和 macOS。
无论你的系统使用 RPM 还是 DEB 包,在 Linux 上安装都很容易,它的网站也包含一个通用的 Linux [AppImage](https://appimage.github.io/Upscayl/)。
对于 macOS 和 Windows,你可以从项目的网站下载安装程序。Upscayl 使用 [AGPL](https://github.com/upscayl/upscayl/blob/main/LICENSE) 许可证发布。
### 开始使用 Upscayl
安装后,你可以用它放大图像了。GUI 软件非常易于使用。该软件使你的旧图像看起来像昨天拍摄的,图像分辨率远远超过原件。此外,你可以批量缩放整个文件夹和图像相册,并一次对它们进行提升。

启动软件并单击 “<ruby> 选择图像 <rt> Select Image </rt></ruby>” 按钮。找到要放大的图像或图像文件夹。
加载图像后,选择要尝试的放大类型。默认值为 Real-ESRGAN,这是一个很好的起点。有六个选项可供选择,包括数字艺术的选择:
* 使用 [Real-ESRGAN](https://github.com/xinntao/Real-ESRGAN) 放大普通照片
* 使用 [remacri](https://upscale.wiki/wiki/Model_Database) 放大普通照片
* 使用 [ultramix balanced](https://upscale.wiki/wiki/Model_Database) 放大普通照片
* 使用 [ultrasharp](https://upscale.wiki/wiki/Model_Database) 放大普通照片
* 数字艺术
* 锐化图像
接下来,选择要保存放大图像的输出目录。
最后,单击 “Upscayl” 按钮开始放大过程。转换速度取决于你的 GPU 和你选择的图像输出方式。
这是一张测试图像,左侧是低分辨率图像,右侧是 Upscayl 版本:

### 是时候为你的图像尝试 Upscayl 了
Upscayl 是我最喜欢的放大应用之一。它确实在很大程度上取决于你的 GPU,因此它可能无法在旧计算机或显卡特别弱的计算机上运行。但是尝试一下也没有坏处。所以下载并尝试一下。我想你会对结果印象深刻。
*(题图:MJ/4ccffdf1-f17a-49ab-81a8-ce20c63d0da1)*
---
via: <https://opensource.com/article/23/4/edit-photos-open-source-ai>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I've been interested in photography ever since I co-opted my father's Kodak 620 camera as a young boy. I used it to take pictures of the flora and fauna of our neighborhood. My love of photography led me to an Instamatic camera in high school, and eventually to digital cameras as they entered the marketplace in the late 1990s. Early digital cameras provided portability and the ability to quickly capture and easily share images on the internet. But they lacked the quality and complexity of the best of film photography. Of course digital cameras have improved a lot since then. But I have years of digital photographs that just look a little, well, *little* on modern devices.
Until recently, my go-to tool for upscaling digital images has been [GIMP](https://opensource.com/tags/gimp). A couple of years ago, I tried to use GIMP to upscale a thumbnail image of my father that was taken in the mid-1940s. It worked, but the photo lacked the detail, depth, and clarity that I wanted.
That's all changed since I learned about [Upscayl](https://github.com/upscayl/upscayl), a free and open source program that uses [open source artificial intelligence](https://opensource.com/article/22/10/defining-open-source-ai) to upscale low-resolution images.
## Upscayl
Upscayl works on Linux, Windows, and macOS.
It's easy to install on Linux whether your system uses RPM or DEB packages, and its website contains a universal Linux [AppImage](https://appimage.github.io/Upscayl/) too.
For macOS and Windows, you can download installers from the project's website. Upscayl is released with an [AGPL](https://github.com/upscayl/upscayl/blob/main/LICENSE) license.
## Get started with Upscayl
Once installed, you can begin upscaling your images. The GUI software is very easy to use. The software makes your old images look like they were taken yesterday with image resolutions that far exceed the originals. In addition, you can batch scale entire folders and photo albums of images and upscale them all at once.
(Don Watkins, CC BY-SA 4.0)
Launch the software and click the **Select Image** button. Find the image or folder of images you want to upscale.
Once the image is loaded, select the type of upscaling you want to try. The default is Real-ESRGAN, and that's a good place to start. There are six options to choose from, including a selection for digital art.
- General photo with
[Real-ESRGAN](https://github.com/xinntao/Real-ESRGAN) - General photo with
[remacri](https://upscale.wiki/wiki/Model_Database) - General photo with
[ultramix balanced](https://upscale.wiki/wiki/Model_Database) - General photo with
[ultrasharp](https://upscale.wiki/wiki/Model_Database) - Digital Art
- Sharpen Image
Next, select the output directory where you want your upscaled images to be saved.
And finally, click the **Upscayl** button to begin the upscaling process. The speed of conversion depends on your GPU and the image output choice you make.
Here's a test image, with the low-resolution image on the left and the Upscayl version on the right:

(Derived from [Jurica Koletić](https://unsplash.com/@juricakoletic?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText), [Unsplash License](https://unsplash.com/s/photos/portrait?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText))
## Time to try Upscayl for your images
Upscayl is one of my favorite upscaling applications. It does depend heavily on your GPU, so it may not work on an old computer or one with an especially weak graphics card. But there's no harm in giving it a try. So download it and try it. I think you'll be impressed with the results.
## Comments are closed. |
15,779 | Opera 重新设计的全新网页浏览器也可在 Linux 上使用了! | https://news.itsfoss.com/opera-one-browser/ | 2023-05-04T14:58:14 | [
"Opera"
] | https://linux.cn/article-15779-1.html |
>
> 对对对,这不是一个自由和开源软件,但拥有另一个可用于 Linux,且功能丰富的浏览器也不是一件坏事嘛。
>
>
>

Opera 是一个以 Chromium 为核心的跨平台网站浏览器。
它以其独特的功能和制作精良的界面与其他基于 Chromium 的浏览器区分开来。别忘了它的游戏浏览器 [Opera GX](https://itsfoss.com/best-browsers-ubuntu-linux/?ref=news.itsfoss.com),它也是其独特的产品之一,可以作为在 Linux 上首次亮相的卖点。
在最新发布的公告中,Opera 的团队**介绍了这个颇受欢迎的网页浏览器的最新进化版本**,即**Opera One**。
>
> ✋ Opera One 不是开源网络浏览器。我们在这里介绍它是因为它在 Linux 上使用。
>
>
>
### 它是什么?
“**Opera One**” 是它的名字,它对原版进行完全重新设计,**旨在逐步淘汰现有的 Opera 浏览器**,其浏览器的整体设计采用模块化方法。

为实现这一目标,这次重新设计**采用了一个新的多线程合成器**,使 Opera One 的界面更加灵活。
>
> ? Opera One 目前仅提供开发者预览版。稳定版本的出现还需要再等几个月。
>
>
>
### 它是如何运作的?
它通过将任务卸载到专用的合成器线程来更有效地处理用户界面,类似于网页渲染器的工作方式。
此外,他们已经切换到基于图层的动画,绕过了涉及用户界面线程的需要,从而带来更流畅的浏览体验。
这个新特点很酷,值得被更多的浏览器采用。你可以在 Opera 的 [博客](https://blogs.opera.com/desktop/2023/04/opera-one-multithreaded-compositor/?ref=news.itsfoss.com) 上阅读有关其技术细节的更多信息。
### 那么,这对 Opera One 有何帮助
首先,图形密集型网站将比以前运行得更流畅,不会出现被其他浏览器进程的滞后或中断。
其次是模块化功能的实现。
本次发布引入的其中一个特色功能是“<ruby> 标签岛 <rt> Tab Islands </rt></ruby>”功能,它可以自动对相关标签进行分组。标签岛用彩色丝带区分,单击时展开。
在我看来,它的设计确实看起来很整洁。
**当我在我的 Linux 系统上测试它时**,它似乎没有自动分类标签岛;我必须通过按住 `Ctrl` 键并右键单击标签页来手动创建标签岛。

提个醒 —— 我测试的是**早期开发者预览版**,所以这个问题应该会在正式发布时得到修复。
Opera 还透露了集成内部 AI 引擎的计划,该引擎将在未来几个月内随 Opera One 一起面世。
你可以浏览 Opera 的 [公告博客](https://blogs.opera.com/news/2023/04/opera-one-developer/?ref=news.itsfoss.com) 进行深入了解。
### 现在就试试
你是不是迫不及待地想在实际发布之前试一下? 来吧,你可以前往 [官方网站](https://www.opera.com/one?ref=news.itsfoss.com) 获取你想要的预览包。
Opera One 适用于 **Linux**、**Windows** 和 **macOS**。
>
> **[Opera One](https://www.opera.com/one?ref=news.itsfoss.com)**
>
>
>
Opera One 似乎有意与功能丰富的 [Vivaldi](https://news.itsfoss.com/vivaldi-6-0/) 进行竞争,提供类似但存在一些差异的产品。让我们拭目以待结果吧。
---
via: <https://news.itsfoss.com/opera-one-browser/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Opera is a cross-platform web browser that uses Chromium at its core.
It can distinguish itself from other Chromium-based browsers with its unique features and a well-made interface. Not to forget, its gaming browser, [Opera GX](https://itsfoss.com/best-browsers-ubuntu-linux/?ref=news.itsfoss.com), is one of its unique offerings that could use a debut on Linux.
With a recent announcement, the folks at Opera have **introduced the latest evolution** of the popular web browser, i.e., **Opera One**.
**What is it: **Called the '**Opera One**,' it is a complete redesign that **aims to phase out the existing Opera browser** with its modular approach for the overall design of the browser.
To achieve that, this redesign **features a new multithreaded compositor** that enables Opera One to be more flexible with its interface.
**stable release.**
**How does that work?**
It makes a more efficient way to handle the user interface by offloading the task to a dedicated compositor thread, similar to how a webpage renderer works.
Furthermore, they have switched to layer-based animations, bypassing the need to involve the user interface thread, resulting in a smoother browsing experience.
It is quite a cool feature that more browsers should adopt. You can read more about its technicalities on Opera's [blog](https://blogs.opera.com/desktop/2023/04/opera-one-multithreaded-compositor/?ref=news.itsfoss.com).
**Suggested Read **📖
[Top 10 Best Browsers for Ubuntu LinuxWhat are your options when it comes to web browsers for Linux? Here are the best web browsers you can pick for Ubuntu and other Linux distros.](https://itsfoss.com/best-browsers-ubuntu-linux/?ref=news.itsfoss.com)

**So, how does this help Opera One?**
For starters, graphically intensive websites will run much smoother than before, without lags or interruptions by other browser processes.
Then, there's the implementation of modular features.
One such feature they have introduced is the '**Tab Islands**' feature that automatically groups related tabs. The tab islands are differentiated with a colored ribbon that expands the islands when clicked upon.
It does look quite neat, in my opinion.
**When I tested it out on my Linux system**, it didn't seem to sort them into tab islands automatically; I had to manually make them into tab islands by holding the 'Ctrl' key and right-clicking on them.
Mind you; I tested an **early developer preview build**, so expect this bug to be fixed by the time in the latest stable build.
Opera has also revealed plans to integrate an in-house AI engine that will be shipped with Opera One in the coming months.
You may go through the [announcement blog](https://blogs.opera.com/news/2023/04/opera-one-developer/?ref=news.itsfoss.com) to dive deeper.
**Try it now: **Head to the [official website](https://www.opera.com/one?ref=news.itsfoss.com) to grab the package of your choice.
It is available for **Linux**, **Windows**, and **macOS**.
*Opera One might seem inclined towards competing with the feature-rich **Vivaldi **offers with some differences. Let us see how that works out.*
**Suggested Read **📖
[Vivaldi 6.0 Introduces Workspaces and Custom IconsVivaldi 6.0 has a new feature to help you multitask more efficiently. Learn more.](https://news.itsfoss.com/vivaldi-6-0/)

## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,780 | 使用 Lens Desktop 监控和调试 Kubernetes | https://www.opensourceforu.com/2022/09/monitoring-and-debugging-kubernetes-with-lens-desktop/ | 2023-05-04T19:36:00 | [
"Kubernetes"
] | https://linux.cn/article-15780-1.html | 
>
> Lens Desktop 是一个令人兴奋的 Kubernetes 工作平台。它是基于 OpenLens 资源库的一个定制化发行版本。通过本文来了解下 Lens Desktop 能做什么以及它是如何工作的。
>
>
>
Lens Desktop 是免费的。你可以查看 <https://app.k8slens.dev/subscribe> 来了解更多内容。Lens Desktop 有如下优势:
* 简单高效 —— 你无需学习 `kubectl` 命令
* 可视化已有的 Kubernetes 资源
* 基于开源代码构建
* 可观测性 —— 实时的统计数据、事件和日志流
* 错误和警告可以直接在 Lens 仪表盘上看到
* 支持 EKS、AKS、GKE、Minikube、Rancher、k0s、k3s、OpenShift
* 强大的社区支持 —— 有 450000 用户,在 GitHub 上共获得 17000 星
### Minikube 安装
Minikube 是一个用于本地运行 Kubernetes 的工具。它运行一个单节点的 Kubernetes 集群,这样就可以在 Kubernetes 上进行日常软件开发的实践工作。
我们将使用 Minikube 并验证 Lens 的用法。首先让我们在基于 Windows 的系统上安装 Minikube。你也可以把它安装在其他操作系统、虚拟机或笔记本电脑上。
* 2 核以上 CPU
* 2GB RAM
* 20GB 空闲硬盘空间
* 能连接网络
* 容器或虚拟机管理器,如 Docker、VirtualBox
在终端或命令提示符处,运行 `minikube start` 命令:
```
minikube start --driver=virtualbox
* minikube v1.12.3 on Microsoft Windows 10 Home Single Language 10.0.19044 Build 19044
* Using the virtualbox driver based on existing profile
* minikube 1.26.0 is available! Download it: https://github.com/kubernetes/minikube/releases/tag/v1.26.0
* To disable this notice, run: ‘minikube config set WantUpdateNotification false’
* Starting control plane node minikube in cluster minikube
* virtualbox “minikube” VM is missing, will recreate.
* Creating virtualbox VM (CPUs=2, Memory=3000MB, Disk=20000MB) ...
! This VM is having trouble accessing https://k8s.gcr.io
* To pull new external images, you may need to configure a proxy: https://minikube.sigs.k8s.io/docs/reference/networking/proxy/
* Preparing Kubernetes v1.18.3 on Docker 19.03.12 ...
* Verifying Kubernetes components...
* Enabled addons: default-storageclass, storage-provisioner
* Done! kubectl is now configured to use “minikube”
```
进入你的 VirtualBox,并验证刚安装的 Minikube 虚拟机功能正常(图 1)。

使用 `minikube status` 命令,查看状态是否与下面的输出一致:
```
C:\>minikube status
minikube
type: Control Plane
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
```
然后,使用 `kubectl cluster-info` 命令查看 KubeDNS 详情:
```
kubectl cluster-info
Kubernetes master is running at https://192.168.99.103:8443
KubeDNS is running at https://192.168.99.103:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
```
你可以使用 `kubectl cluster-info dump` 命令来调试和诊断集群问题。
当 Minikube 安装完成后,安装 `kubectl`(<https://kubernetes.io/docs/tasks/tools/>)。它是一个命令行集群,用于对 Kubernetes 集群和 Minikube 执行命令。

执行 `kubectl get nodes` 命令获取所有 <ruby> 节点 <rt> node </rt></ruby> 的详情,在本例中是获取 Minikube 的详情:
```
C:\>kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready master 7m57s v1.18.3
```
使用 `kubectl get all` 命令获取默认命名空间下的所有详情:
```
C:\>kubectl get all
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7m58s
```
我们现在已经有一个 Minikube 集群,并准备好了 Kubectl。下一步是安装和配置 Lens,并用示例应用程序来验证。
### Lens 的安装和配置
打开 <https://k8slens.dev/> ,下载与你的操作系统匹配的安装包。
然后,参照屏幕上的教程来安装 Lens,安装完成后打开 Lens。你会发现在目录中有一个 `minikube`(图 3)。

点击 “minikube” 后,你就进入了 Minikube 的世界,你会爱上它的。
点击 <ruby> 节点 <rt> node </rt></ruby> 获取有关 `kubectl get nodes` 命令输出的 <ruby> 节点 <rt> node </rt></ruby> 详情。
现在,你可以使用 Lens 了。

我们现在部署 <https://github.com/GoogleCloudPlatform/microservices-demo>,这是一个云原生微服务演示应用程序。它有 11 层的微服务应用,是一个基于网络的电子商务应用。
下载这个应用程序,把它解压到与 Minikube 相同的目录。
进入 `release` 目录,执行以下命令。
```
kubectl apply -f kubernetes-manifests.yaml
deployment.apps/emailservice created
service/emailservice created
deployment.apps/checkoutservice created
service/checkoutservice created
deployment.apps/recommendationservice created
service/recommendationservice created
deployment.apps/frontend created
service/frontend created
service/frontend-external created
deployment.apps/paymentservice created
service/paymentservice created
deployment.apps/productcatalogservice created
service/productcatalogservice created
deployment.apps/cartservice created
service/cartservice created
deployment.apps/loadgenerator created
deployment.apps/currencyservice created
service/currencyservice created
deployment.apps/shippingservice created
service/shippingservice created
deployment.apps/redis-cart created
service/redis-cart created
deployment.apps/adservice created
service/adservice created
```
安装过程现在应该已经开始了,不过它需要一些时间来反映出我们使用了 `kubectl` 命令。

```
kubectl get pods
NAME READY STATUS RESTARTS AGE
adservice-775d8b9bf5-cp7jr 0/1 Pending 0 8h
cartservice-79749895f5-jrq4d 1/1 Running 0 8h
checkoutservice-5645bf9c65-882m4 1/1 Running 0 8h
currencyservice-545c79d477-8rhg7 1/1 Running 0 8h
emailservice-7cc5c74b4f-hk74s 1/1 Running 0 8h
frontend-9cdf787f5-klfkh 1/1 Running 1 8h
loadgenerator-7b6874cb4c-645v9 1/1 Running 0 8h
paymentservice-5f74bc7b87-l4248 1/1 Running 0 8h
productcatalogservice-6846f59899-v4q4w 1/1 Running 0 8h
recommendationservice-d9c6c8b55-m2x9k 1/1 Running 0 8h
redis-cart-57bd646894-v7kfr 0/1 Pending 0 8h
shippingservice-8685dd9855-pmgjm 1/1 Running 0 8h
```
表 1 列出了你可以通过 `kubectl` 来获取信息的几个命令。

| 描述 | 命令 |
| --- | --- |
| 列出节点 | `kubectl get node` |
| 列出集群中的所有资源 | `kubectl get all –all-namespaces` |
| 列出部署 | `kubectl get deployment` |
| 显示部署的完整状态 | `kubectl describe deployment <deployment_name>` |
| 修改集群上的部署 | `kubectl edit deployment <deployment_name>` |
| 删除部署 | `kubectl delete deployment <deployment_name>` |
| 列出容器荚 | `kubectl get pod` |
| 删除容器荚 | `kubectl delete pod <pod_name>` |
| 显示容器荚的完整状态 | `kubectl describe pod <pod_name>` |
| 在 Shell 中运行一个单容器荚 | `kubectl exec -it <pod_name> /bin/bash` |
| 列出机密信息 | `kubectl get secrets` |
| 列出服务 | `kubectl get services` |
| 列出服务的完整状态 | `kubectl describe services` |
| 修改集群中的服务 | `kubectl edit services / kubectl edit deployment <deployment_name>` |
| 列出命名空间 | `kubectl get namespace <namespace_name>` |
| 打印容器荚日志 | `kubectl logs <pod_name>` |
| 打印容器荚中特定容器的日志 | `kubectl logs -c <container_name> <pod_name>` |
Lens 不仅可以帮你获取表 1 中列出的所有信息,它还可以获取指定集群的信息。我们还能用 Lens 来对 Kubernetes 资源进行编辑和删除操作。

我们来看下是如何操作的。在 <ruby> 工作负载 <rt> Workloads </rt></ruby> 部分选择 <ruby> 容器荚 <rt> Pod </rt></ruby>(图 6),我们能通过 Lens 来编辑、删除、查看日志、访问 <ruby> 容器荚 <rt> Pod </rt></ruby> 的终端,这是不是很酷?

你可以验证 <ruby> 工作负载 <rt> Workloads </rt></ruby> 区域中所有 <ruby> 部署 <rt> deployments </rt></ruby>(图 7),<ruby> 工作负载 <rt> Workloads </rt></ruby> 区域中所有 <ruby> 副本 <rt> Replicasets </rt></ruby> (图 8),<ruby> 配置 <rt> Config </rt></ruby> 区域中所有 <ruby> 密钥 <rt> Secrets </rt></ruby> (图 9),以及 <ruby> 网络 <rt> Network </rt></ruby> 区域中所有 <ruby> 服务 <rt> Services </rt></ruby> 是否都正常(图 10),

你可以看到,跳转到所有的资源以及在一个地方高效地查看所有资源就是如此轻松。我们可以用 Lens 修改 YAML 文件,在运行时应用它来查看变更。

对于配置在不同的云服务商部署的多个集群,我们仍可以用 Lens 来进行观察和故障处理。
*(题图:MJ/069da8c5-9043-46b3-9b14-87a0ffc6bb35)*
---
via: <https://www.opensourceforu.com/2022/09/monitoring-and-debugging-kubernetes-with-lens-desktop/>
作者:[Mitesh Soni](https://www.opensourceforu.com/author/mitesh_soni/) 选题:[lkxed](https://github.com/lkxed) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Lens Desktop is an exciting platform for working with Kubernetes. It is a distribution of the OpenLens repository with specific customisations. In this article we will see what Lens Desktop can do and how it works.*
Lens Desktop is free of charge. For more details, you can visit *https://k8slens.dev/pricing.html.* A few benefits of using Lens Desktop are:
- Simplicity and increased productivity – no need to learn kubectl commands
- Visibility in existing Kubernetes resources
- Built on open source
- Observability — live statistics, events, and log streams in real-time
- Errors and warnings are directly available on the Lens dashboard
- Supports EKS, AKS, GKE, Minikube, Rancher, k0s, k3s, OpenShift
- Huge community support — 450,000 users and 17,000 stars on GitHub
## Minikube installation
Minikube is a tool that is used to run Kubernetes locally. It runs a single-node Kubernetes cluster so that hands-on work can be done on Kubernetes for daily software development.
We will use minikube and verify the usage of Lens. Let’s install minikube on a Windows based system first. You can also install it on other operating systems, virtual machines or laptops.
- Two or more CPUs
- 2GB of RAM
- 20GB of free disk space
- Internet connectivity
- Container or virtual machine manager such as Docker or VirtualBox
From a terminal or command prompt, execute the minikube start command.
minikube start --driver=virtualbox * minikube v1.12.3 on Microsoft Windows 10 Home Single Language 10.0.19044 Build 19044 * Using the virtualbox driver based on existing profile * minikube 1.26.0 is available! Download it: https://github.com/kubernetes/minikube/releases/tag/v1.26.0 * To disable this notice, run: ‘minikube config set WantUpdateNotification false’ * Starting control plane node minikube in cluster minikube * virtualbox “minikube” VM is missing, will recreate. * Creating virtualbox VM (CPUs=2, Memory=3000MB, Disk=20000MB) ... ! This VM is having trouble accessing https://k8s.gcr.io * To pull new external images, you may need to configure a proxy: https://minikube.sigs.k8s.io/docs/reference/networking/proxy/ * Preparing Kubernetes v1.18.3 on Docker 19.03.12 ... * Verifying Kubernetes components... * Enabled addons: default-storageclass, storage-provisioner * Done! kubectl is now configured to use “minikube”
Go to your virtual box and verify the newly created minikube virtual machine (Figure 1).

Now verify the existing status of minikube using the *minikube* status command.
C:\>minikube status minikube type: Control Plane host: Running kubelet: Running apiserver: Running kubeconfig: Configured
Next, use the *kubectl cluster-info* command to get details about kubeDNS.
kubectl cluster-info Kubernetes master is running at https://192.168.99.103:8443 KubeDNS is running at https://192.168.99.103:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To get more details on debugging and to diagnose cluster problems, use the *kubectl cluster-info* dump command.
Once minikube is ready, install kubectl *( https://kubernetes.io/docs/tasks/tools/)*. It is a command line cluster that is used to run commands against Kubernetes clusters and minikube as well.

Execute the *kubectl get* *nodes* command to get details on all nodes and, in this case, minikube.
C:\>kubectl get nodes NAME STATUS ROLES AGE VERSION minikube Ready master 7m57s v1.18.3
Use the *kubectl get all* command to get all details for the default name space.
C:\>kubectl get all NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7m58s
We now have a minikube cluster ready with kubectl. The next step is to install and configure Lens and verify the sample applications.
## Lens installation and configuration
Go to *https://k8slens.dev/* and download an installable package based on the operating system you have.
Next, install Lens as per the instruction displayed on the screen. Open Lens after successful installation. You will find a minikube in the catalogue (Figure 3).

Click on *minikube* and you will enter the world of minikube clusters, which you will love forever.
Click on *Nodes* and get the node details that you got after executing the kubectl get nodes commands.
Now, Lens is ready to use.

Let’s deploy [ https://github.com/GoogleCloudPlatform/microservices-demo](https://github.com/GoogleCloudPlatform/microservices-demo), which is a cloud-native microservices demo application. It has 11-tier microservices applications, and is a Web based e-commerce app.
Download the application and extract it locally in the system where you have downloaded and configured minikube.
Go to the *release* directory and execute the following command.
kubectl apply -f kubernetes-manifests.yaml deployment.apps/emailservice created service/emailservice created deployment.apps/checkoutservice created service/checkoutservice created deployment.apps/recommendationservice created service/recommendationservice created deployment.apps/frontend created service/frontend created service/frontend-external created deployment.apps/paymentservice created service/paymentservice created deployment.apps/productcatalogservice created service/productcatalogservice created deployment.apps/cartservice created service/cartservice created deployment.apps/loadgenerator created deployment.apps/currencyservice created service/currencyservice created deployment.apps/shippingservice created service/shippingservice created deployment.apps/redis-cart created service/redis-cart created deployment.apps/adservice created service/adservice created
The installation of the app will start now, but it will take some time to reflect that we have used kubectl commands.

kubectl get pods NAME READY STATUS RESTARTS AGE adservice-775d8b9bf5-cp7jr 0/1 Pending 0 8h cartservice-79749895f5-jrq4d 1/1 Running 0 8h checkoutservice-5645bf9c65-882m4 1/1 Running 0 8h currencyservice-545c79d477-8rhg7 1/1 Running 0 8h emailservice-7cc5c74b4f-hk74s 1/1 Running 0 8h frontend-9cdf787f5-klfkh 1/1 Running 1 8h loadgenerator-7b6874cb4c-645v9 1/1 Running 0 8h paymentservice-5f74bc7b87-l4248 1/1 Running 0 8h productcatalogservice-6846f59899-v4q4w 1/1 Running 0 8h recommendationservice-d9c6c8b55-m2x9k 1/1 Running 0 8h redis-cart-57bd646894-v7kfr 0/1 Pending 0 8h shippingservice-8685dd9855-pmgjm 1/1 Running 0 8h
Table 1 lists a few commands that you can use to get information from kubectl.
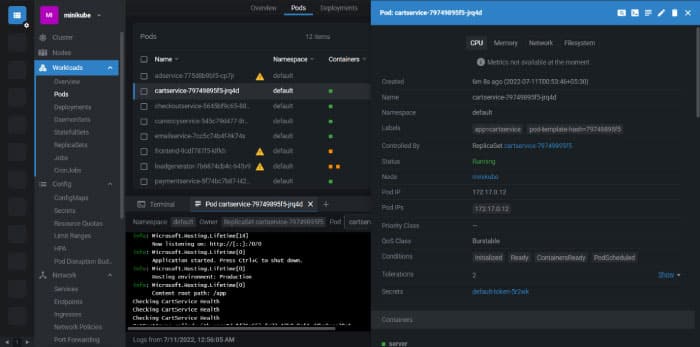

Description |
Command |
List one or more nodes | kubectl get node |
List all resources in the cluster | kubectl get all –all-namespaces |
List one or more deployments | kubectl get deployment |
Display the complete state of one or more deployments | kubectl describe deployment <deployment_name> |
Edit and update one or more deployments on the cluster | kubectl edit deployment <deployment_name> |
Delete deployments | kubectl delete deployment <deployment_name> |
List one or more pods | kubectl get pod |
Delete a pod | kubectl delete pod <pod_name> |
Display the complete state of a pod | kubectl describe pod <pod_name> |
Get a shell to a running single-container pod | kubectl exec -it <pod_name> /bin/bash |
List secrets | kubectl get secrets |
List one or more services | kubectl get services |
Display the complete state of a service | kubectl describe services |
Edit and update one or more services on the cluster | kubectl edit services / kubectl edit deployment <deployment_name> |
List one or more namespaces | kubectl get namespace <namespace_name> |
Print the logs for a pod | kubectl logs <pod_name> |
Print the logs for a specific container in a pod | kubectl logs -c <container_name> <pod_name> |
Lens can help you get all the information listed in Table 1 and more for a specific cluster. We can also perform edit and delete actions on Kubernetes resources using Lens.
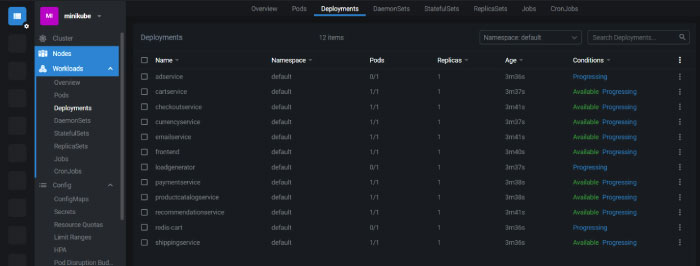

Let’s see how this works. Select *Pods* in the Workloads section (Figure 6). We can edit, delete, access logs, access terminals of pod from Lens itself. Cool, right?
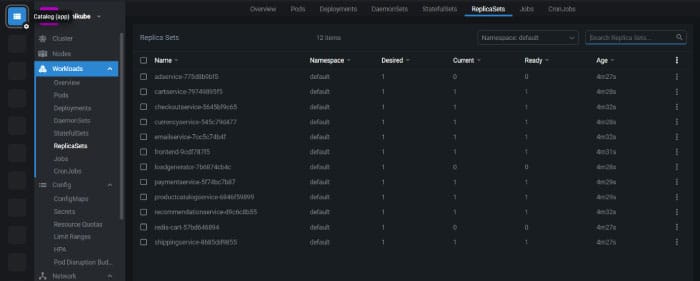

You can verify all *deployments* in the *Workloads* section (Figure 7), verify all *Replicasets* in the *Workloads* section (Figure 8), all *Secrets* in the *Config* section (Figure 9) and all *Services* in the *Network* section (Figure 10).
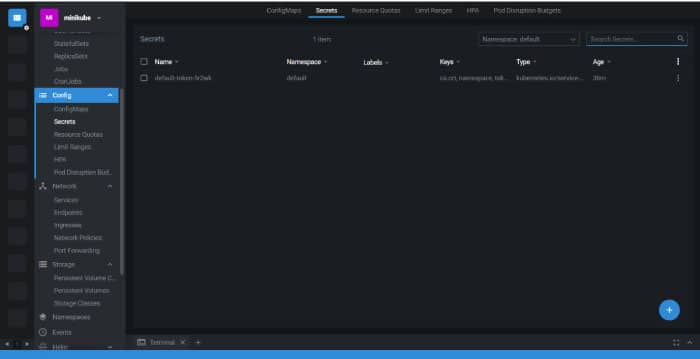

You can see how easy it is to navigate to all resources, and effectively find all Kubernetes resources from a single place quickly. We can edit YAML files in Lens and apply it at runtime to see the change.

We can also configure multiple clusters deployed by multiple cloud service providers and use Lens for visibility and troubleshooting. |
15,782 | 开源的项目的运行离不开非代码贡献 | https://opensource.com/article/22/8/non-code-contribution-powers-open-source | 2023-05-05T15:42:03 | [
"开源贡献",
"非代码贡献"
] | https://linux.cn/article-15782-1.html | 
>
> 有时成为开源贡献者最困难的是意识到自己能够做出多大的贡献。
>
>
>
在今年的北美 DrupalCon 上,EPAM 解决方案架构师 John Picozzi 发表了关于非代码贡献重要性的演讲。他谈到每个人可以参与非代码贡献,以及为什么他认为这个话题很重要。本文是 John 演讲的文本改编;在下方可以找到在 DrupalCon 上完整演讲视频的链接。
什么是非代码贡献?我问了谷歌这个问题并得到了以下答案:“任何有助于开源项目但不涉及编写代码的贡献。”谷歌,听我说谢谢你,但这点我早就懂了。如果你要我深入挖掘,我会说非代码贡献意味着你提供个人的时间、技能和资源来使项目受益。
### 谁能成为开源贡献者?
早期,“贡献”意味着编写代码。 最初,Drupal 的运行模式是“由开发者构建,为开发者服务”。然而,多年来,Drupal 社区已经转变了这种思维方式。我们的社区已经学会像重视代码一样重视非代码贡献:任何贡献都是贡献。
开源是在聚会、训练营和大会中建立的;它是由社区建立的,建立于社区之中。事实上,这些活动中的大部分贡献都与编程无关。要举办这些活动,你需要的是参与者、演讲者、培训师和组织者。不要误会我的意思:当然,开源社区仍然需要编写代码的人,但这并不是唯一需要的东西。如果你参与社区,分享想法、提出问题或提供帮助——恭喜你,你已经在做出贡献了!
“贡献者”是自我称号(“我是贡献者”)还是社区赋予(“我们说你是贡献者”)?可以肯定地说,每个人都是贡献者:会议参加者、创建 UI 和模块徽标的设计师、帮助市场推广模块或活动的营销人员等等。不要等待别人给你那个称号。你可以参与其中,并自信地告诉其他人你是贡献者。
有很多方法可以激励别人(或你自己)做出贡献。金钱并不总是最重要的激励因素。但是,有时贡献可以是有偿工作。许多人做出贡献只是因为他们想回馈社区。
当被问及为什么做出贡献时,每个人可能会给出与同伴不同的答案,但以下是一些最常见的回答:
* 它让你感觉良好
* 建立和提高技能
* 职业发展
* 建立人际关系/网络
这个列表无穷无尽,并且与贡献者本身一样多样化。每个贡献者都有自己的理由,没有正确或错误的回答。

### 为什么非代码贡献对开源很重要?
对于项目的健康运转,非代码贡献与编写代码一样有价值。它有助于让更多具有各种技能的人参与社区。每个人都可以提供一些东西,也可以分享一套独特的技能。
所有项目都有非代码要求,并不是每个人都是开发人员或编码人员。此外,不同的观点都应该得到表达。例如,营销人员可能与开发人员有不同的经验和观点。每一项努力都以某种方式推动开源向前发展——这就是为什么非代码贡献是必不可少的原因。
#### 常见的挑战
贡献的定义可能听起来很简单:只需分享你的知识、表达你的想法并帮助社区即可。然而,贡献者面临着一些挑战。最常见的一种是“<ruby> 冒名顶替综合症 <rt> imposter syndrome </rt></ruby>”(自我怀疑情绪)。不太有经验的贡献者可能会担心他们的贡献没有价值或没有帮助。你可以通过专注于自己的特定技能和热情来克服这种感觉。例如,如果你有组织活动的经验,你可以利用这个经验专注于组织活动和在活动中帮忙。
为了克服这些消极的想法,你可以将贡献转化为一种积极的体验。工作/生活/贡献的平衡很重要。贡献应该是愉快的,而不只是另一份工作。如果可以,请把你的贡献成果用在你的日常工作中。 许多雇主鼓励你做出贡献并从中受益,你甚至有可能基于自己做出的贡献建立职业。
不要让自己筋疲力尽,不停在晚上和周末做出贡献。你只需要在一天的开始或结束时增加 30 分钟的贡献时间,或者如果可能的话,将贡献纳入你日常工作中即可。
### 如何做出你的第一个非代码贡献?
看到这里,我希望你已经开始思考,“好的,我准备好了。我要做些什么?” 你该如何参与?去做就对了!你只需要开始:例如,开始在 Drupal 社区中做出贡献,去 [问题队列](https://www.drupal.org/project/issues/drupal?categories=All) 或 [Drupal 聊天](https://www.drupal.org/community/contributor-guide/reference-information/talk/tools/slack) 那儿提问,或者联系活动组织者寻求建议。整个社区都在等着支持你呢。

请记住遵从自己的技能和兴趣。你已经拥有了技能和兴趣,请用它们来激发你的贡献。你的兴趣可能和你的技能不同:有些事情可能你几乎没有经验但却一直想了解更多,你也可以决定为此做出贡献。单纯地与人交谈、分享知识、提出问题、参加聚会或线下见面,并做出贡献。
我想引用玛格丽特·米德(美国人类学家)的话来结束对我的开源贡献的完美描述:“永远不要怀疑一小群有思想、有奉献精神的公民可以改变世界。事实上,世界的改变只能依靠这个了。” 米德博士并没有说“一小群代码编写者或开发人员”。 她说,这是一群有思想、有奉献精神的公民——他们有着极大的热情和许多不同的技能。这就是开源的动力,也是 Drupal 的动力。
完整视频可以在 [YouTube](https://www.youtube.com/watch?v=NwNqfpISMPM) 上观看。
*(题图:MJ/2d680e28-3cb4-4644-896b-a406ba3b596e)*
---
via: <https://opensource.com/article/22/8/non-code-contribution-powers-open-source>
作者:[John E. Picozzi](https://opensource.com/users/johnpicozzi) 选题:[lkxed](https://github.com/lkxed) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *At this year's DrupalCon North America, EPAM Solution Architect John Picozzi presented a talk about the importance of non-code contribution. He talked about how everyone can get involved and why he believes this is an important topic. This article is a text adaptation of John's talk; find a link below to a video recording of the complete presentation at DrupalCon.*
What is non-code contribution? I asked Google this question and got the following answer: "Any contribution that helps an open source project that does not involve writing code." Thanks, Google, but I already figured that out. If you asked me to dig deeper, I'd say it's about providing your time, skills, and resources to benefit a project.
## Who is an open source contributor?
Early on, "contribution" implied writing code. Originally, Drupal's model was "Built by developers, for developers." Over the years, however, the Drupal community has shifted away from that mindset. Our community has learned to value non-code contributions just as much as code: Any contribution is contribution.
Open source is built in meetups, camps, and cons; it's built-in and by the community. In fact, most of the contributions at those events have very little to do with coding. To have those events, you need attendees, speakers, trainers, and organizers. Don't get me wrong: Of course, open source communities still need people who write code, but that's not the only thing they need. If you participate in the community and share ideas, ask questions, or provide help—congratulations, you're already contributing!
Is *contributor* a self-designation ("I'm a contributor") or a community designation ("We say you're a contributor")? It's safe to say that everyone is a contributor: conference attendees, designers who create UI and module logos, marketing folks who help market modules or events, and many more. Don't wait for someone else to give you that designation. You can get involved and feel confident telling others you're a contributor.
There are many ways to motivate someone (or yourself) to contribute. Money is not always the top motivator. However, sometimes contribution can be paid work. Many people contribute simply because they want to give back to the community.
Everyone would probably give a different answer from their peers when asked why they contribute, but here are some of the most common responses:
- It makes you feel good
- Building and improving skills
- Career development
- Making connections/networking
The list is endless and as varied as the contributors themselves. Each contributor has their own reasons, and there are no right or wrong answers.
(John Picozzi, CC BY-SA 4.0)
## Why non-code contribution is important to open source
Non-code contribution is as valuable to the health of a project as writing code. It helps to get more people with a wide variety of skills involved in the community. Everyone has something to offer and a unique skill set to share.
There are non-code requirements for all projects, and not everyone is a developer or coder. Moreover, different points of view need to be represented. For example a marketing person will likely have different experiences and perspectives than a developer. Every effort moves open source forward in some way—that's why non-code contribution is essential.
### Common challenges
This definition of contribution may make it sound very simple: Just share your knowledge, express your thoughts, and help the community. However, contributors face several challenges. One of the most common is imposter syndrome. Less experienced contributors may worry that their contribution isn't valuable or helpful. You can combat that feeling by focusing on your specific skills and passions. For example, if you have event organizing experience, you can lean into that and focus on organizing and helping with those activities.
To combat these negative thoughts, make contributing a positive experience. Work/life/contribution balance is important. Contribution should be enjoyable, not just another job. If you can, implement contribution into your work. Many employers encourage and benefit from your contribution, and it's possible to build a career based on contribution.
Don't burn out and contribute nonstop during nights and weekends. Just add 30 minutes to the start or end of your day, or incorporate contribution into your regular workday if possible.
## How to make your first non-code contribution
At this point in the article, I hope you're thinking, "OK, I'm ready. What do I do?" How do you get involved? Just do it! You only need to get started: For example, to start contributing in the Drupal community, ask in [the issue queue](https://www.drupal.org/project/issues/drupal?categories=All) or [Drupal chat](https://www.drupal.org/community/contributor-guide/reference-information/talk/tools/slack) or reach out to camp organizers for recommendations. A whole community is waiting to support you.

(John Picozzi, CC BY-SA 4.0)
Remember to follow your skills and interests. You have them, so use them to inspire your contributions. Your interests may differ from your skills: You could decide to contribute to something you have little experience with but always wanted to know more about. Simply talk to people, share knowledge, ask questions, go to a camp or a meetup, and contribute.
I want to close with a quote by Margaret Mead (an American anthropologist) that perfectly describes open source contribution to me: "Never doubt that a small group of thoughtful, committed citizens can change the world. Indeed, it is the only thing that ever has." Dr. Mead doesn't say "a small group of code writers or developers." She says a thoughtful, committed group of citizens—citizens with great passion and many different skills. That's what powers open source, and that's what powers Drupal.
Watch the talk below or [on YouTube](https://www.youtube.com/watch?v=NwNqfpISMPM).
## 2 Comments |
15,783 | 如何在 RHEL 8 上安装 FreeIPA 服务器 | https://www.linuxtechi.com/install-freeipa-rhel-rocky-almalinux/ | 2023-05-05T16:03:00 | [
"FreeIPA"
] | https://linux.cn/article-15783-1.html | 
你是否正在寻找有关如何在 Linux 上安装 FreeIPA 服务器的简单指南?
此页面上的分步指南将展示如何在 RHEL 8、Rocky Linux 8 和 AlmaLinux 8 上安装 FreeIPA 服务器。
[FreeIPA](https://www.freeipa.org/page/Main_Page) 是一个自由开源的基于 Linux 系统的集中式身份和访问管理工具,它是 Red Hat 身份管理器的上游项目。使用 FreeIPA,我们可以轻松地管理集中式身份验证以及帐户管理、策略(基于主机的访问控制)和审计。
FreeIPA 基于以下开源项目:
* LDAP 服务器 – 基于 389 项目
* KDC – 基于 MIT Kerberos 实现
* 基于 Dogtag 项目的 PKI
* 用于活动目录集成的 Samba 库
* 基于 BIND 和 Bind-DynDB-LDAP 插件的 DNS 服务器
* NTP
### 先决条件
* 预装 RHEL 8 或 Rocky Linux 8 或 AlmaLinux 8
* 具有管理员权限的 Sudo 用户
* 内存 = 2 GB
* CPU = 2 个 vCPU
* 磁盘 = 根目录有 12GB 可用空间
* 互联网连接
### FreeIPA 的实验室详细信息
* IP 地址 = 192.168.1.102
* Hostanme = ipa.linuxtechi.lan
* 操作系统:RHEL 8 或 Rocky Linux 8 或 AlmaLinux 8
事不宜迟,让我们深入了解 FreeIPA 安装步骤。
### 1、设置主机名并安装更新
打开服务器的终端并使用 `hostnamectl` 命令设置主机名:
```
$ sudo hostnamectl set-hostname "ipa.linuxtechi.lan"
$ exec bash
```
使用 `yum`/`dnf` 命令安装更新,然后重新启动:
```
$ sudo dnf update -y
$ sudo reboot
```
### 2、更新主机文件并将 SELinux 设置为许可
运行以下 `tee` 命令更新 `/etc/hosts` 文件,根据你的设置替换 IP 地址和主机名。
```
$ echo -e "192.168.1.102\tipa.linuxtechi.lan\t ipa" | sudo tee -a /etc/hosts
```
将 SELinux 设置为许可,运行以下命令:
```
$ sudo setenforce 0
$ sudo sed -i 's/^SELINUX=.*/SELINUX=permissive/g' /etc/selinux/config
$ getenforce
Permissive
```
### 3、安装 FreeIPA 及其组件
Appstream 包仓库中提供了 FreeIPA 包及其依赖项。由于我们计划安装集成 DNS 的 FreeIPA,因此我们还将安装 `ipa-server-dns` 和 `bind-dyndb-ldap`。
运行以下命令安装 FreeIPA 及其依赖项:
```
$ sudo dnf -y install @idm:DL1
$ sudo dnf install freeipa-server ipa-server-dns bind-dyndb-ldap -y
```
### 4、开始安装 FreeIPA
成功安装 FreeIPA 包及其依赖项后,使用以下命令启动 FreeIPA 安装设置。
它将提示几件事,例如配置集成 DNS、主机名、域名和领域名。
```
$ sudo ipa-server-install
```
上述命令的输出如下所示:


在上面的窗口中输入 “yes” 后,需要一些时间来配置你的 FreeIPA 服务器,设置成功后,我们将得到下面的输出:

以上输出确认 FreeIPA 已成功安装。
### 5、在防火墙中允许 FreeIPA 端口
如果正在你的服务器上运行系统防火墙,那么运行如下 `firewall-cmd` 命令以允许 FreeIPA 端口:
```
$ sudo firewall-cmd --add-service={http,https,dns,ntp,freeipa-ldap,freeipa-ldaps} --permanent
$ sudo firewall-cmd --reload
```
### 6、访问 FreeIPA 管理门户
执行下面的 `ipactl` 命令查看 FreeIPA 的所有服务是否都在运行:
```
$ ipactl status
You must be root to run ipactl.
$ sudo ipactl status
Directory Service: RUNNING
krb5kdc Service: RUNNING
kadmin Service: RUNNING
named Service: RUNNING
httpd Service: RUNNING
ipa-custodia Service: RUNNING
pki-tomcatd Service: RUNNING
ipa-otpd Service: RUNNING
ipa-dnskeysyncd Service: RUNNING
ipa: INFO: The ipactl command was successful
$
```
让我们使用 `kinit` 命令验证管理员用户是否会通过 Kerberos 获取令牌,使用我们在 FreeIPA 安装期间提供的相同管理员用户密码。
```
$ kinit admin
$ klist
```
以上命令的输出:

完美,上面的输出确认管理员获得了令牌。现在,尝试访问 FreeIPA Web 控制台,在网络浏览器上输入以下 URL:
```
https://ipa.linuxtechi.lan/ipa/ui
```
或者
```
https://<Server-IPAddress>/ipa/ui
```
使用我们在安装过程中指定的用户名 `admin` 和密码。

对于 FreeIPA Web 控制台,使用自签名 SSL 证书,这就是我们看到此窗口的原因,因此单击“<ruby> 接受风险并继续 <rt> Accept the Risk and Continue </rt></ruby>”。

输入凭据后,单击“<ruby> 登录 <rt> Log in </rt></ruby>”。

这证实我们已在 RHEL 8/Rocky Linux 8 / AlmaLinux8 上成功设置 FreeIPA。
这就是全部,我希望你觉得它提供了很多信息。请在下面的评论部分中发表你的疑问和反馈。
*(题图:MJ/9df57ea0-b5a0-48f9-a323-853a28ca6162)*
---
via: <https://www.linuxtechi.com/install-freeipa-rhel-rocky-almalinux/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Are you looking for an easy guide on how to install FreeIPA server on Linux ?
The step-by-step guide on this page will show how to install FreeIPA server on RHEL 8 , Rocky Linux 8 and AlmaLinux 8.
[FreeIPA ](https://www.freeipa.org/page/Main_Page)is a free and open source centralized identity and access management tool for Linux-based systems, it is the upstream project for Red Hat identity manager. Using FreeIPA, we can easily manage centralized authentication along with account management, policy (host-based access control) and audit.
FreeIPA is based on the following Open Source projects,
- LDAP Server – based on the 389 project
- KDC – based on MIT Kerberos implementation
- PKI based on Dogtag project
- Samba libraries for Active Directory integration
- DNS Server based on BIND and the Bind-DynDB-LDAP plugin
- NTP
#### Prerequisites
- Pre Installed RHEL 8 or Rocky Linux 8 or AlmaLinux 8
- Sudo User with admin rights
- RAM = 2 GB
- CPU =2 vCPU
- Disk = 12 GB free space on /
- Internet connectivity
#### Lab Details for FreeIPA
- IP Address = 192.168.1.102
- Hostanme = ipa.linuxtechi.lan
- OS: RHEL 8 or Rocky Linux 8 or AlmaLinux 8
Without further ado, let’s deep dive into FreeIPA installation steps,
## 1) Set Hostname and Install Updates
Open the terminal of your server and set the hostname using [hostnamectl](https://www.linuxtechi.com/change-hostname-rhel-centos/) command,
$ sudo hostnamectl set-hostname "ipa.linuxtechi.lan" $ exec bash
Install updates using yum/dnf command and then reboot it
$ sudo dnf update -y $ sudo reboot
## 2) Update the hosts file & Set SELinux as Permissive
Run the below [tee command](https://www.linuxtechi.com/tee-command-examples-in-linux/) to update /etc/hosts file, replace the ip address and hostname as per your setup.
$ echo -e "192.168.1.102\tipa.linuxtechi.lan\t ipa" | sudo tee -a /etc/hosts
Set the selinux as permissive, run following commands,
$ sudo setenforce 0 $ sudo sed -i 's/^SELINUX=.*/SELINUX=permissive/g' /etc/selinux/config ]$ getenforce Permissive $
## 3) Install FreeIPA and its Components
FreeIPA packages and its dependencies are available in the Appstream package repositories. As we are planning to install integrated DNS of FreeIPA, so we will also install “ipa-server-dns & bind-dyndb-ldap”
Run the below command to install FreeIPA and its dependencies
$ sudo dnf -y install @idm:DL1 $ sudo dnf install freeipa-server ipa-server-dns bind-dyndb-ldap -y
## 4) Start FreeIPA Installation
Once FreeIPA package and it’s dependencies are installed successfully then use the below command to start the freeipa installation setup,
It will prompt couple of things like to configure Integrated DNS, Host name, Domain Name and Realm Name.
$ sudo ipa-server-install
Output of above command would be something like below
After pressing yes in above window, it will take some time to configure your FreeIPA server and once it has been setup successfully then we will get output something like below,
Above output confirms that FreeIPA has been installed successfully.
## 5) Allow FreeIPA ports in Firewall
In case OS firewall is running on your server then run beneath firewall-cmd commands to allow FreeIPA ports,
$ sudo firewall-cmd --add-service={http,https,dns,ntp,freeipa-ldap,freeipa-ldaps} --permanent $ sudo firewall-cmd --reload
## 6) Access FreeIPA admin portal
Execute the below ipactl command to check whether all services of FreeIPA are running or not
[sysops@ipa ~]$ ipactl status You must be root to run ipactl. [sysops@ipa ~]$ sudo ipactl status Directory Service: RUNNING krb5kdc Service: RUNNING kadmin Service: RUNNING named Service: RUNNING httpd Service: RUNNING ipa-custodia Service: RUNNING pki-tomcatd Service: RUNNING ipa-otpd Service: RUNNING ipa-dnskeysyncd Service: RUNNING ipa: INFO: The ipactl command was successful [sysops@ipa ~]$
Let’s verify whether admin user will get token via Kerberos using the kinit command, use the same password of admin user that we supplied during FreeIPA installation.
$ kinit admin $ klist
Output of above commands,
Perfect, output above confirms that admin gets the token. Now, try to access FreeIPA Web Console, type following url on web browser,
https://ipa.linuxtechi.lan/ipa/ui
or
https://<Server-IPAddress>/ipa/ui
Use the user name as admin and the password that we specify during the installation.
For FreeIPA web console, self-signed ssl certificates are used that’s why we got this window, so click on “Accept the Risk and Continue”
After entering the credentials, click on ‘Log in‘
This confirms that we have successfully setup FreeIPA on RHEL 8/Rocky Linux 8 / AlmaLinux8.
That’s all from this, I hope you have found it informative. Kindly do post your queries and feedback in below comments section.
Read Also : [How to Install FreeIPA Client on RHEL | Rocky Linux | AlmaLinux](https://www.linuxtechi.com/install-freeipa-client-on-rhel-rockylinux-almalinux/)
yunusThanks for correct steps
GauravNot able to access the web UI, FreeIPA is installed successfully. error “DNS_PROBE_FINISHED_NXDOMAIN”
BobHello Gauray. Do you solve it .I found the same problem
Gaurav AgnihoriDo you have DNS setup? If not add in the /etc/hosts file like- 10.103.x.x ipa.linuxtechi.lan
DaveThanks for this,it really helped me a lot.
Is there a way this can be installed on a system with no internet connection. All i have is a Basic Server with a GUI. Can this be done and if so how?
Thanks
JohnDave,
Ultimately the answer is “no”. The free-ipa package has a LOT of dependencies (~250) that you would need to download and make available to your target system.
For me, the solution was to create a CentOS repository on a machine connected to the Internet, move it to my closed network, and install my Identity Manager from this repository.
I also have a requirement to install CentOS Identity Manager clients from the repository, so the solution works for me.
AamirCreate a local yum repos! Copy all the packages or mount iso staright and point your local repos to that mount point. It will be achievable. As admin mention ipa does need packages/dependencies so local repos would be perfect solution if you don’t have internet connection!
Ajad Kumar GautamThis is good article, Thank you so much for writing step by step article
AnilCan we setup FreeIPA on CentOS 8.2 also?
Mac T Mohanshowing this error
ipa.ipapython.install.cli.install_tool(Server): ERROR Integrated DNS requires ‘ipa-server-dns’ package
Bobcan i use ipa on centos 7 as a website hosting server for my own websites? i ask because it doesn’t really mention anything about being a hosting server and i have been 3 years trying to turn my home desktop into a private website server for my wife and i.
ArvindDear Support Team,
I am unable to start httpd service of freeipa .how to resolved it.
Sivai am getting below error, please advise, where do i need to check this DNS entry ?
Checking DNS domain byuprod.cxos.tech., please wait …
DNS zone byuprod.cxos.tech. already exists in DNS and is handled by server(s): [‘ns-1536.awsdns-00.co.uk.’, ‘ns-512.awsdns-00.net.’, ‘ns-0.awsdns-00.com.’, ‘ns-1024.awsdns-00.org.’]
The ipa-server-install command failed. See /var/log/ipaserver-install.log for more information |
15,785 | 为什么开源对于数据分析很重要? | https://opensource.com/article/22/9/open-source-data-analytics | 2023-05-06T09:39:40 | [
"开源"
] | https://linux.cn/article-15785-1.html | 
>
> 开源对于数据分析非常重要,它能为用户、社区成员和公司带来长远利益。
>
>
>
我曾经写过介绍 Cube 社区的文章,至今已过去了一年多。随着和社区会员以及其他供应商在一起工作,我更坚信开源对于数据分析工作是很有好处的。我也认为,需要不断思考开源为什么重要,以及开源是如何为人们带来长远利益的。
### 开源对于用户和客户的好处
我从 Cube 社区听说的第一件事就是:他们经常可以从与其他社区成员的交流中得到技术支持,这种支持往往好于使用需要付费的专有软件获得的支持。在很多开源社区中,我发现,社区成员很乐意帮助别人(特别是帮助新手),并且把这种帮助看作回报开源社区的方式。
在开源社区,你不需要获得许可就可以加入。一个好的开源社区不但服务于开发者,而且令人们感觉到有一种信任的文化,认为与他人在聊天室、论坛和问题跟踪工具进行开放式讨论是一件愉快的事。这对于诸如数据工程师或数据分析师之类的非开发者来说也很重要。
当然,借助开源软件,还可以直接查看代码、修复错误或为项目添加新功能。以 Cube 社区为例,对于 GraphQL 的支持就是我们去年的亮点,我们的社区成员为项目 [贡献了这些功能](https://github.com/cube-js/cube.js/pull/3555)。
对一个活跃的社区来说,也是很有好处的。即使当供应商不能及时地发布修复版本,你仍然可以自行修改,并可以在等待官方修复版的这段时间内使用修改后的版本。社区成员和用户也不愿意被供应商的奇思妙想所束缚,而且使用开源软件时也不存在升级的压力。
开源社区在 GitLab、GitHub、Codeberg、YouTube 等各种地方留下了很多“面包屑”,这令衡量活跃程度和社区参与度更容易,也可以衡量社区参与和文化的水平。所以,即使在试用软件前,你也可以在做决定之前了解到它的社区(以及公司)的一些情况。
### 开源对公司的好处
没有其他办法比开源更能降低使用软件的障碍了。在早期,开源可以提高技术受众的认知度。早期的使用者往往后来会成为你的最忠实的粉丝。
早期的使用者也是加速产品发展的催化剂。他们对于产品的反馈和功能需求(例如对问题的追踪)能实现对真实用例的洞察。另外,很多开源爱好者可以合作开发(比如通过代码仓库)新功能和进行 BUG 修复。不用说,这对于创业早期的公司来说是很重要的,因为当时缺少开发和产品相关的资源。
你对社区的关注会令它发展壮大,并且呈现多样化趋势。多样化不仅体现在人数和地域方面。你需要来自新兴行业的用户或从事各种职业的用户。以 Cube 社区为例,在一年前我常常会跟一些开发者交流,但一年后与我交流得更多的是那些数据使用者和用户。
在良好的开源社区里,合作文化降低了准入门槛,不仅对于开发者,对于其他提问者、分享观点者或愿意作出非技术性贡献的人们来说都是如此。随着公司和社区的发展,你可以更好地接触到不同的观点。
对包括社区成员在内的广大人群来说,开源使合作变得更容易。例如,你需要跟其他贡献者在同一个数据库驱动或集成上进行合作,如果可以通过开源仓库进行合作,就很方便了。
### 关于社区
以上这些好处都降低了使用软件和协作开发的门槛。开源模型不仅对单个软件或公司有帮助,它还能令整个生态和行业加速发展。我希望在数据分析领域看到更多开源的公司和社区,同时希望人们持续关注开源产品。
*(题图:MJ/50a877f5-e0e1-4f66-91bf-f1f60b4a9023)*
---
via: <https://opensource.com/article/22/9/open-source-data-analytics>
作者:[Ray Paik](https://opensource.com/users/rpaik) 选题:[lkxed](https://github.com/lkxed) 译者:[cool-summer-021](https://github.com/cool-summer-021) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's been a little over a year since I wrote my article on Opensource.com, [introducing the Cube community](https://opensource.com/article/21/6/cubejs). As I worked with our community members and other vendors, I've become more convinced of the benefits of open source in data analytics. I also think it's good to remind ourselves periodically why open source matters and how it provides long-term benefits for everyone.
## Benefits of open source for users and customers
One of the first things I heard from the Cube community was that they often received better support in chat from other community members than they did with proprietary software and a paid support plan. Across many open source communities, I find people who are motivated to help other (especially new) community members and see it as a way of giving back to the community.
You don't need permission to participate in open source communities. A good open source community isn't for developers only, and people feel there's a culture of trust and feel comfortable enough to have open discussions on chat platforms, forums, and issue trackers. This is especially important for non-developers, such as data engineers or analysts in the data analytics space.
Of course, with open source software, there's the ability to see and contribute directly to the codebase to fix bugs or add new features. Using an example from the Cube community, GraphQL support was one of our highlights last year, and our community members [contributed to this feature](https://github.com/cube-js/cube.js/pull/3555).
There are plenty of benefits to an active community. Even in cases where the vendor cannot release a fix in a timely manner, you can still make the changes yourself and own the runtime while you wait for an "official" fix. Community members and users also don't like being locked in to a vendor's whims, and there's no pressure to upgrade when using open source software.
Open source communities leave many "bread crumbs" in different tools like GitLab, GitHub, Codeberg, YouTube, and so on, making it a lot easier to gauge not just the volume of activities but also the level of community engagement and culture. So even before trying out the software, you can get a good sense of the community's health (and, by extension, the company) before deciding if this is a technology you want to invest in.
**[ Related read How we track the community health of our open source project ]**
## Benefits of open source for the company
There's no better way to lower the barrier to adoption of your software than being open source. Early on, this helps grow adoption among the technical audience. Early adopters then often become some of your most loyal fans for years to come.
Early adopters are also catalysts for speeding up your development. Their feedback on your product and feature requests (for instance on your issue trackers) will provide insight into real-world use cases. In addition, many of the open source enthusiasts participate in co-development efforts (for example, on your repositories) for new features or bug fixes. Needless to say, this is precious for companies in the early days when there is a shortage of resources in development and product teams.
As you tend to your community, you will help it grow and diversify. Increased diversity isn't just in demographics or geography. You want users from new industries, or users with different job titles. Using the Cube community as an example, I mostly talked to application developers a year ago, but now I’m meeting with more people that are data consumers or users.
The collaborative culture in good open source communities lowers the barrier to entry not just for developers but also for others who want to ask questions, share their ideas or make other [non-technical contributions](https://opensource.com/article/22/8/non-code-contribution-powers-open-source). You get better access to diverse perspectives as your company and community grows.
Being open source makes it easy to collaborate with other vendors and communities, not just with individual community members. For example, if you want to work with another vendor on a database driver or integration, it's a lot simpler when you can just collaborate across open source repositories.
## Community matters
All these benefits lead to lowering the barriers to entry for using your software and collaboration. The open source model will not only help individual software or companies, but it can help accelerate the growth of our entire ecosystem and the industry. I hope to see more open source companies and communities in the data analytics space and for all of us to continue this journey.
## 1 Comment |
15,786 | 使用这些 Python 工具可视化地探索数据 | https://opensource.com/article/23/4/data-visualization-pygwalker-jupyter-notebook | 2023-05-06T10:15:00 | [
"数据可视化"
] | https://linux.cn/article-15786-1.html | 
>
> 结合 Python、Pygwalker、Pandas 和 Jupyter Notebook,为你的数据提供一个动态的可视化界面。
>
>
>
开源工具在推动技术进步和使其更加普及方面发挥了重要作用。数据分析也不例外。随着数据变得越来越丰富和复杂,[数据科学家](https://enterprisersproject.com/article/2022/9/data-scientist-day-life?intcmp=7013a000002qLH8AAM) 始终在寻找简化工作流程并创建交互式和吸引人的可视化的方式。PyGWalker 就是为解决此类问题而设计的。
[PyGWalker](https://github.com/Kanaries/pygwalker)(Graphic Walker 的 Python 绑定)将 Python Jupyter Notebook 的工作环境连接到 [Graphic Walker](https://github.com/Kanaries/graphic-walker),以创建开源数据可视化工具。你可以通过简单的拖放操作将 [Pandas 数据帧](https://opensource.com/article/20/6/pandas-python) 转化为精美的数据可视化。

### 开始使用 PyGWalker
使用 `pip` 安装 PyGWalker:
```
$ python3 -m pip install pygwalker
```
导入 `pygwalker` 和 `pandas` 以在项目中使用它:
```
import pandas as pd
import pygwalker as pyg
```
将数据加载到 Pandas 数据报中并调用 PyGWalker:
```
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)
```
你现在有一个图形用户界面来探索和可视化你的 Pandas 数据帧!
### 使用 Graphic Walker 探索数据
Graphic Walker 的主要功能之一是能够更改标记类型以创建不同类型的图表。例如,通过将标记类型更改为折线来创建折线图。

你还可以通过创建 concat 视图来比较不同的度量,该视图将多个度量添加到行和列中。

将维度放入行或列中,以创建一个 facet 视图,这个视图包含多个子视图,这些子视图由一个维度中的值分隔开。

在 <ruby> 数据 <rt> Data </rt></ruby> 选项卡中,你可以在表格中查看数据帧并配置分析和语义类型。

### 使用 PyGWalker 进行数据探索
你可以使用 PyGWalker 将 Pandas 数据转换为高度可定制的图形图表。你也可以使用 PyGWalker 作为探索数据的强大工具,以发现潜在的模式、趋势和洞察力。
数据探索选项可以在“<ruby> 探索模式 <rt> Exploration Mode </rt></ruby>”选项(工具栏中)中找到。它们可以设置为**点模式**或**刷模式**。
* **点模式**:通过将你的鼠标光标指向数据的一个特定部分来探索数据。
* **刷模式**:通过在数据范围周围画一个选择框来探索数据,然后拖动选择框来查看生成的报告。
### 试试看你的数据
你可以在这些云演示中试用 PyGWalker:[Google Colab](https://colab.research.google.com/drive/171QUQeq-uTLgSj1u-P9DQig7Md1kpXQ2?usp=sharing)、[Binder](https://mybinder.org/v2/gh/Kanaries/pygwalker/main?labpath=tests%2Fmain.ipynb) 或 [Graphic Walker Online Demo](https://graphic-walker.kanaries.net/)。
PyGWalker 是一个用于简化数据分析和可视化工作流程的优秀工具,特别是对于那些想要使用 Pandas 进行界面可视化的人。借助 PyGWalker 和 Graphic Walker,数据科学家可以在 [Jupyter Notebook](https://opensource.com/downloads/jupyter-guide) 中通过简单的拖放操作轻松创建令人惊叹的可视化效果。请查看 PyGWalker Git 仓库获取源代码。
对于寻求自动化数据探索和高级增强分析的开源解决方案的数据科学家,该项目还适用于 [RATH](https://kanaries.net/),这是一种开源自动 EDA、人工智能支持的数据探索和可视化工具。你还可以查看 [RATH Git 仓库](https://github.com/Kanaries/Rath) 获取源代码和活跃的社区。
*(题图:MJ/21c21716-b900-4466-98a9-51268960c9b8)*
---
via: <https://opensource.com/article/23/4/data-visualization-pygwalker-jupyter-notebook>
作者:[Bill Wang](https://opensource.com/users/bill-wang) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Open source tools have been instrumental in advancing technology and making it more accessible to everyone. Data analysis is no exception. As data becomes more abundant and complex, [data scientists](https://enterprisersproject.com/article/2022/9/data-scientist-day-life?intcmp=7013a000002qLH8AAM) always look for ways to simplify their workflow and create interactive and engaging visualizations. PyGWalker is designed to solve such problems.
[PyGWalker](https://github.com/Kanaries/pygwalker) (Python binding of Graphic Walker) connects a working environment of Python Jupyter Notebook to [Graphic Walker](https://github.com/Kanaries/graphic-walker) to create an open source data visualization tool. You can turn your [Pandas dataframe](https://opensource.com/article/20/6/pandas-python) into a beautifully crafted data visualization with simple drag-and-drop operations.
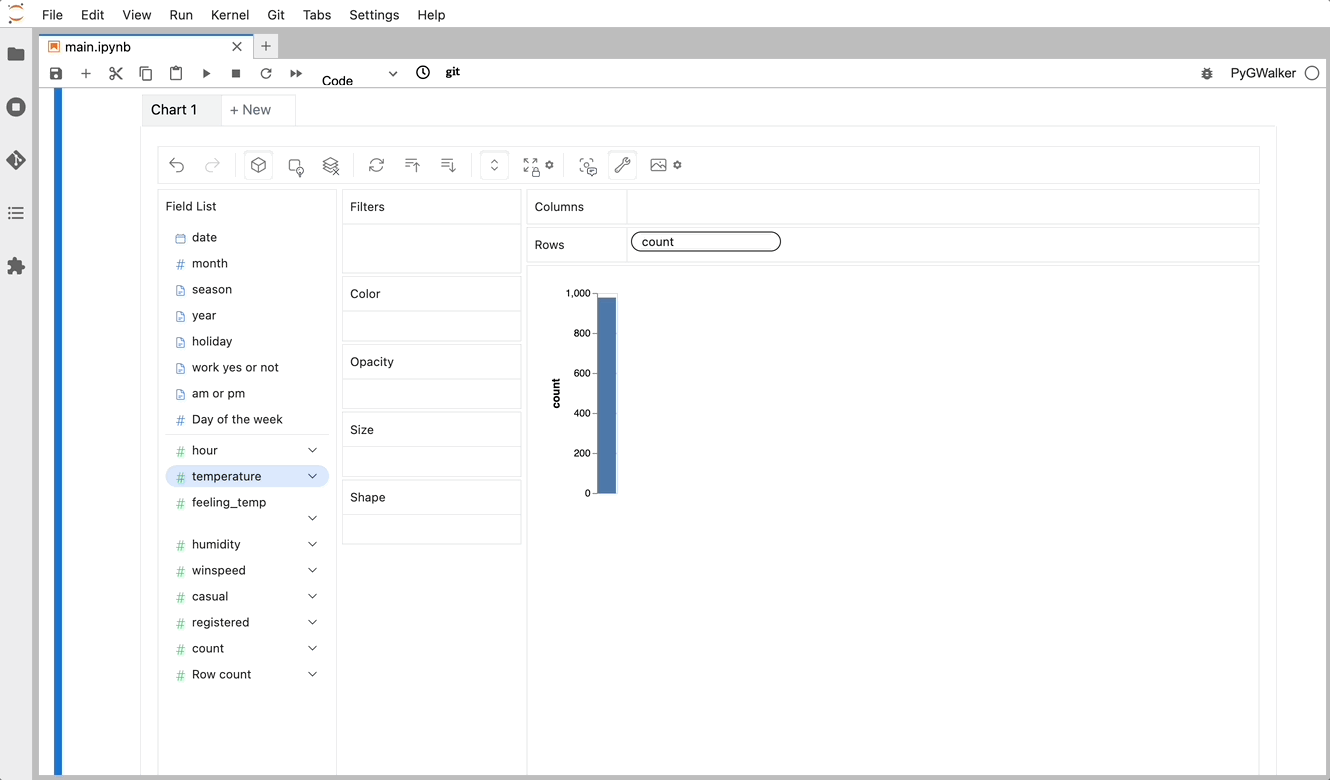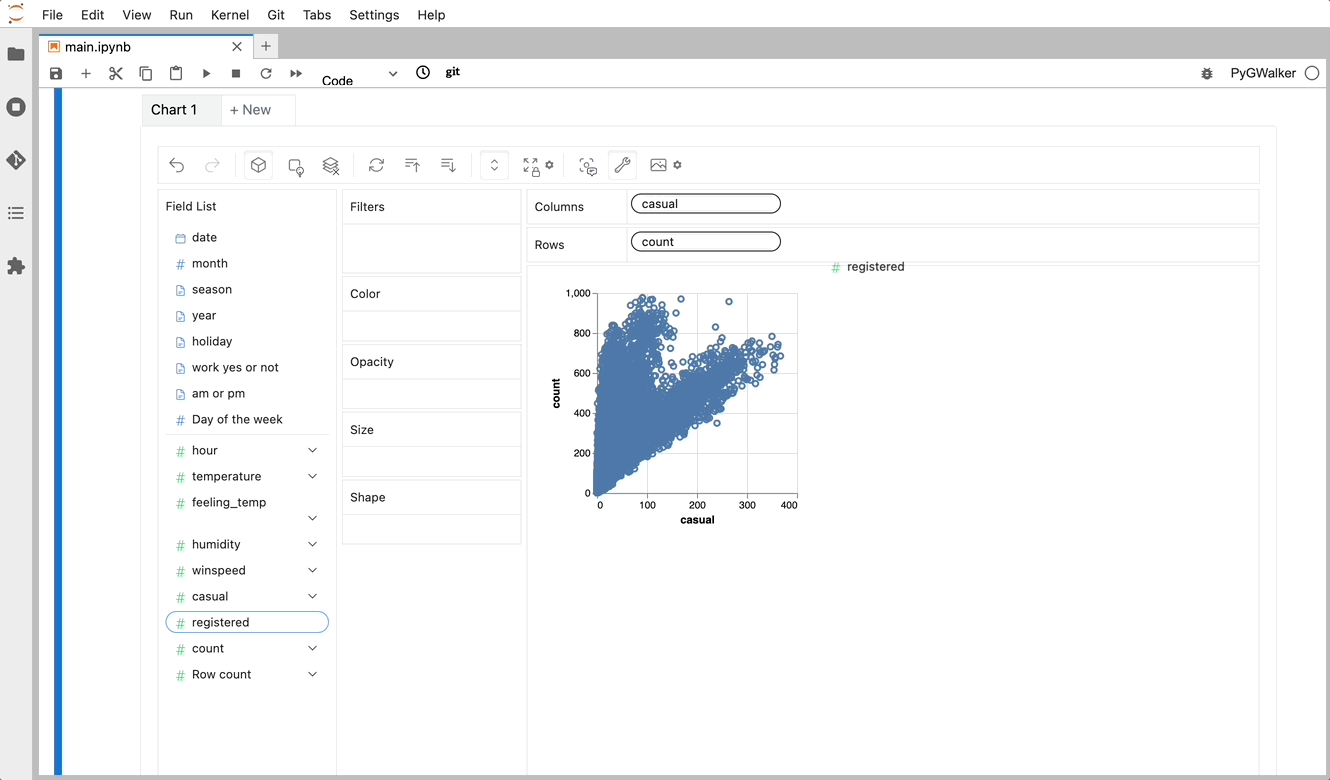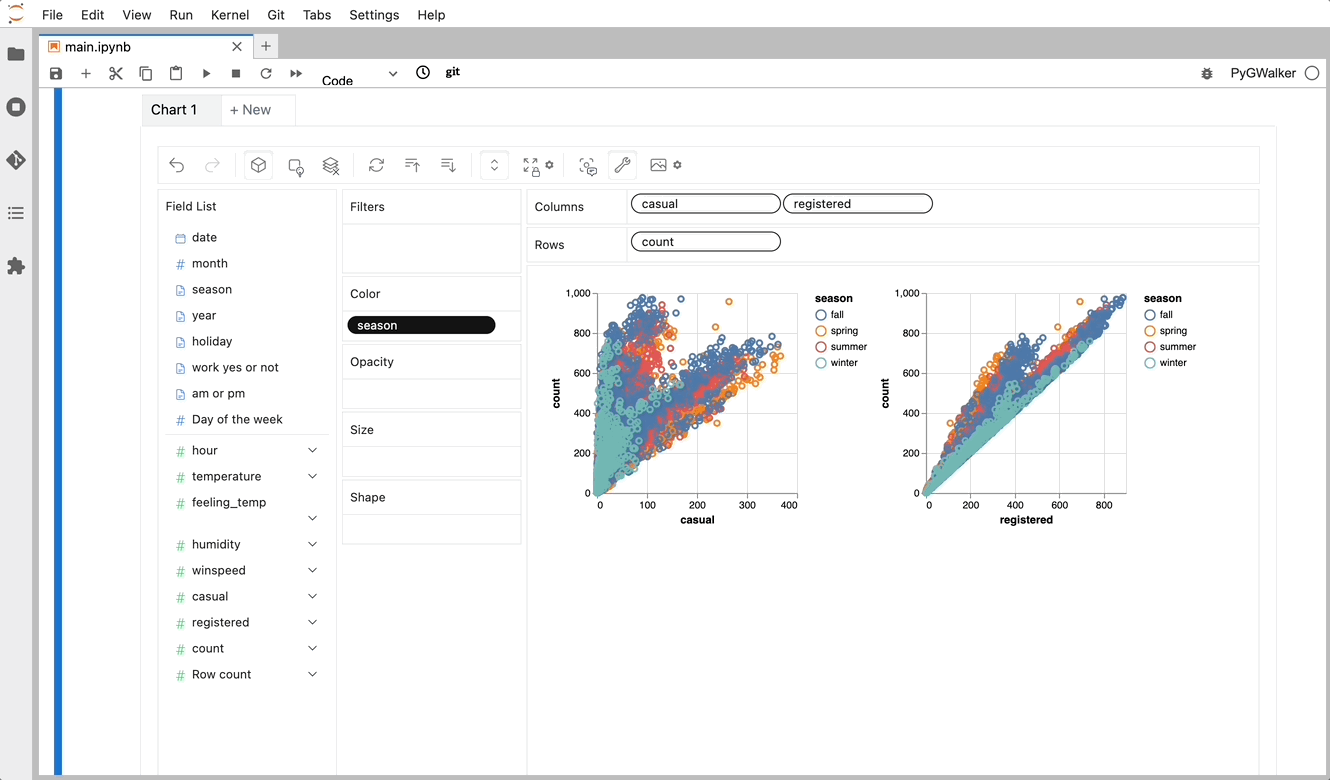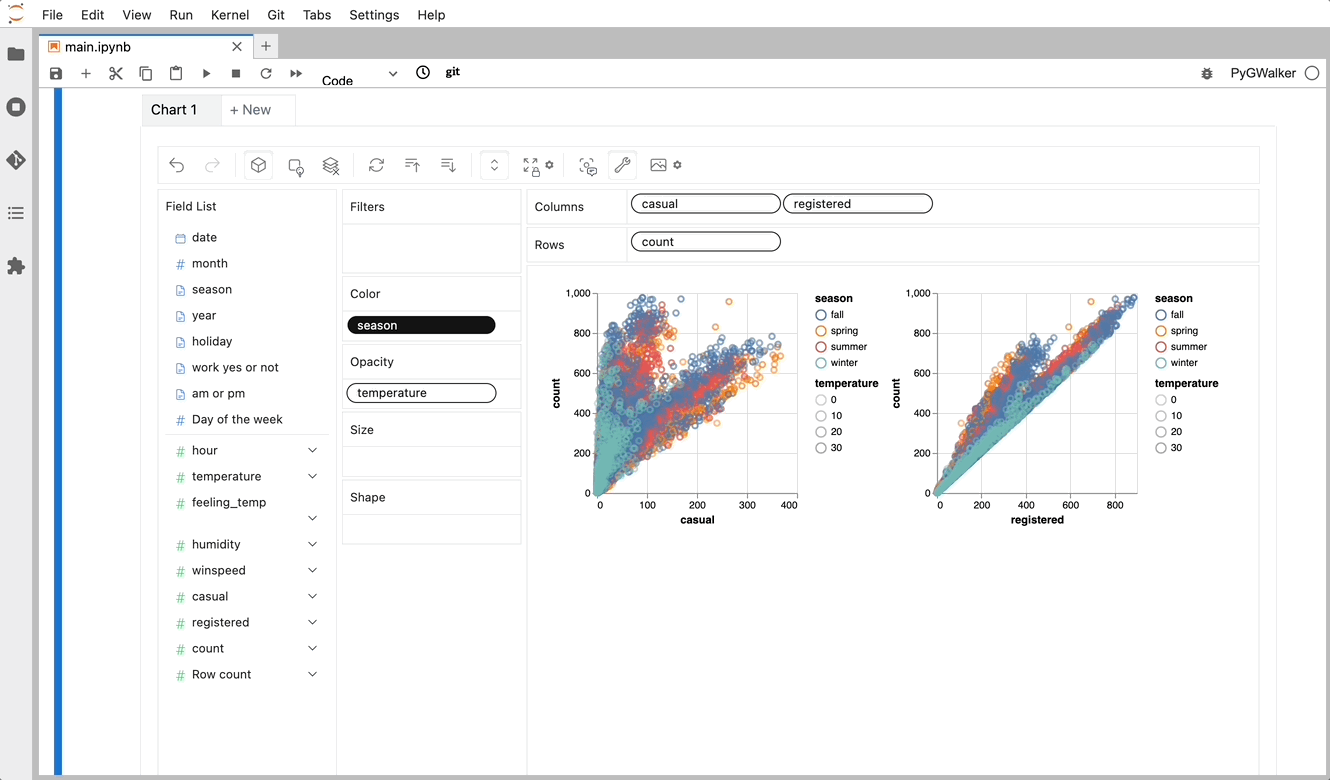
(Bill Wang, CC BY-SA 4.0)
## Get started with PyGWalker
Use `pip`
to install PyGWalker:
```
````$ python3 -m pip install pygwalker`
Import `pygwalker`
and `pandas`
to use it in a project:
```
``````
import pandas as pd
import pygwalker as pyg
```
Load data into a Pandas datagram and call PyGWalker:
```
``````
df = pd.read\_csv('./bike\_sharing\_dc.csv', parse\_dates=\['date'\])
gwalker = pyg.walk(df)
```
You now have a graphical UI to explore and visualize your Pandas dataframe!
## Explore data with Graphic Walker
One of the key features of Graphic Walker is the ability to change mark types to create different kinds of charts. For example, create a line chart by changing the **mark** type to a line.
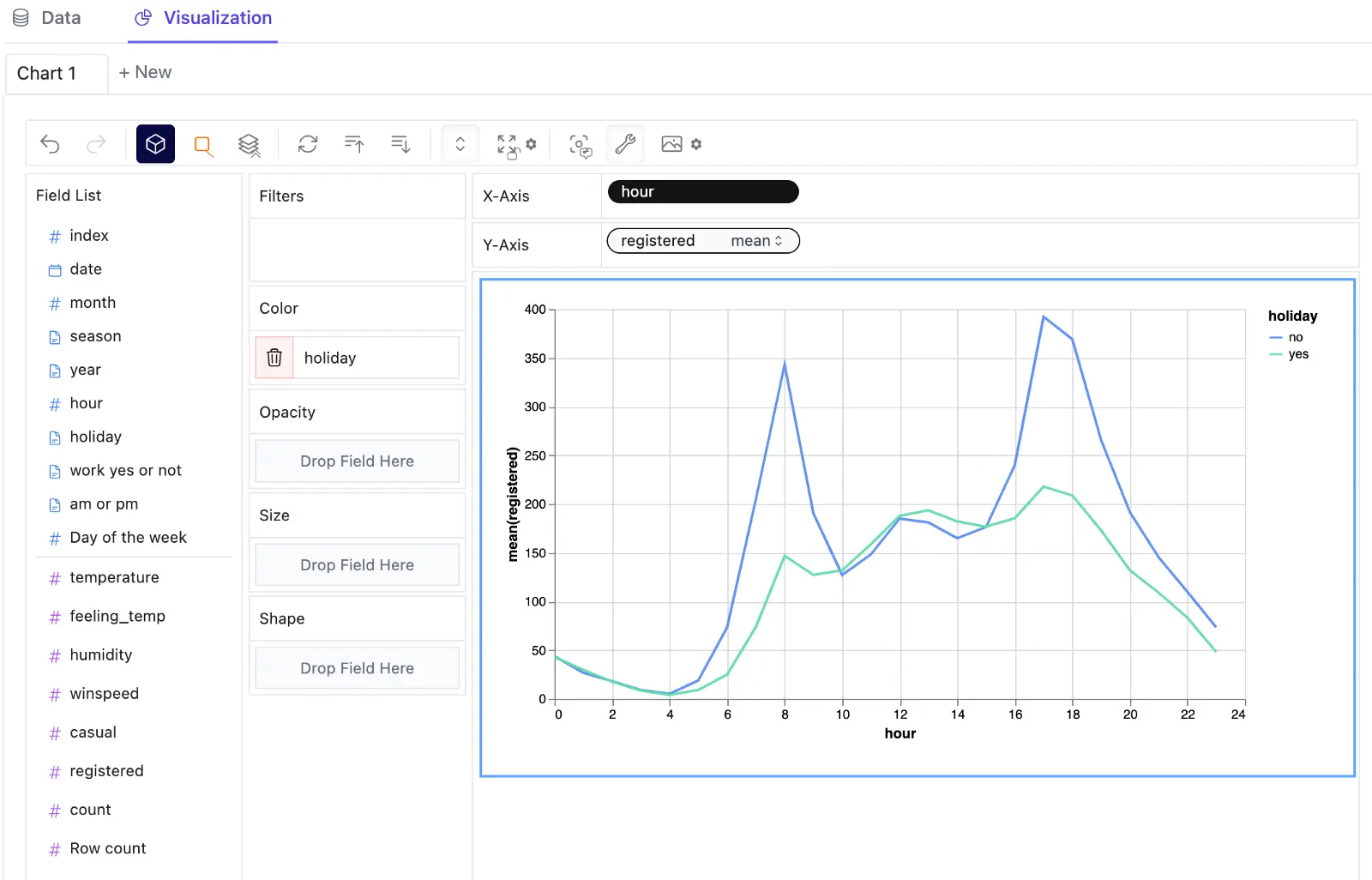
(Bill Wang, CC BY-SA 4.0)
You can also compare different measures by creating a **concat** view, which adds more than one measure into rows and columns.
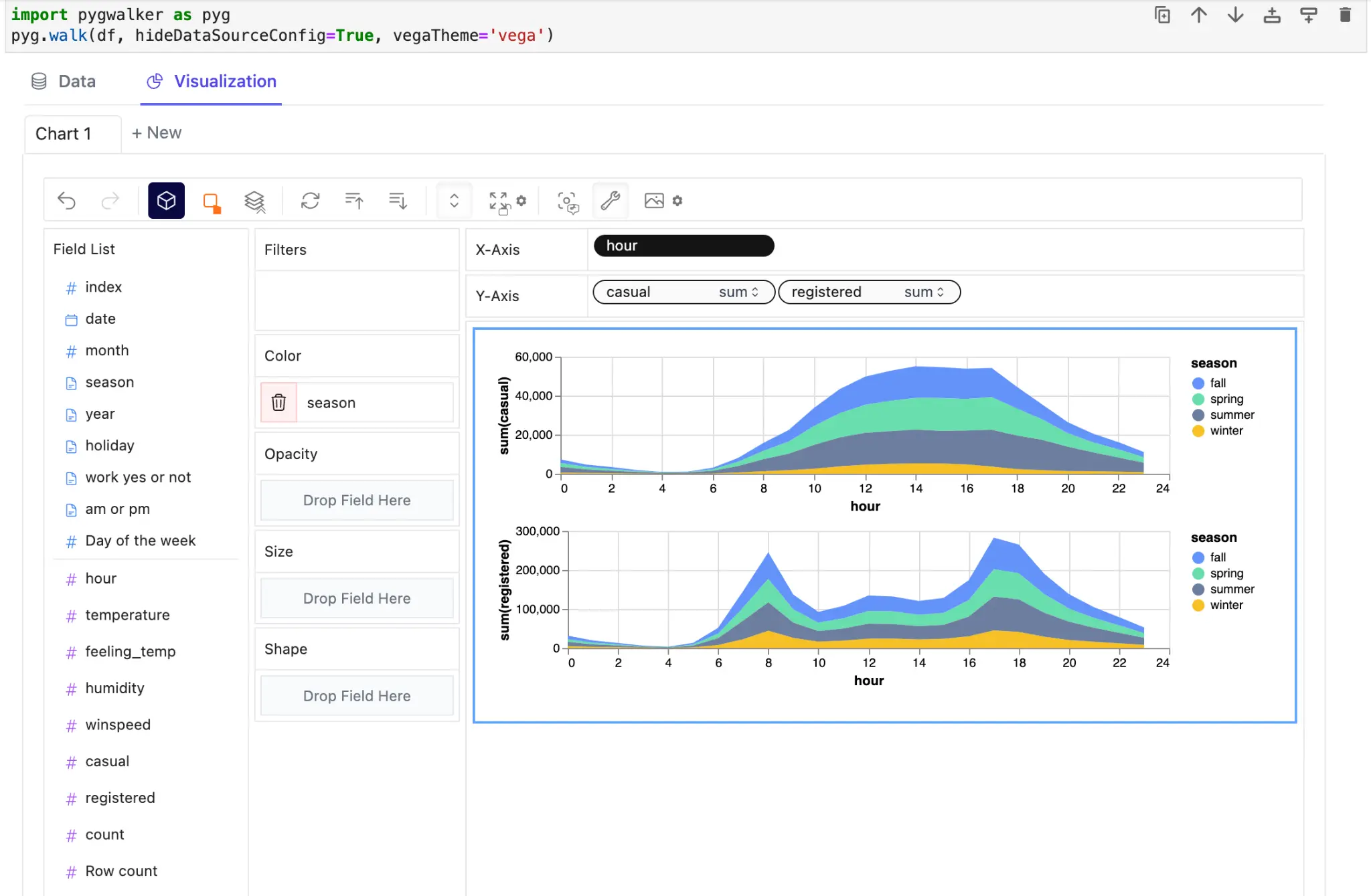
(Bill Wang, CC BY-SA 4.0)
Put dimensions into rows or columns to create a **facet** view of several subviews divided by the value in a dimension.
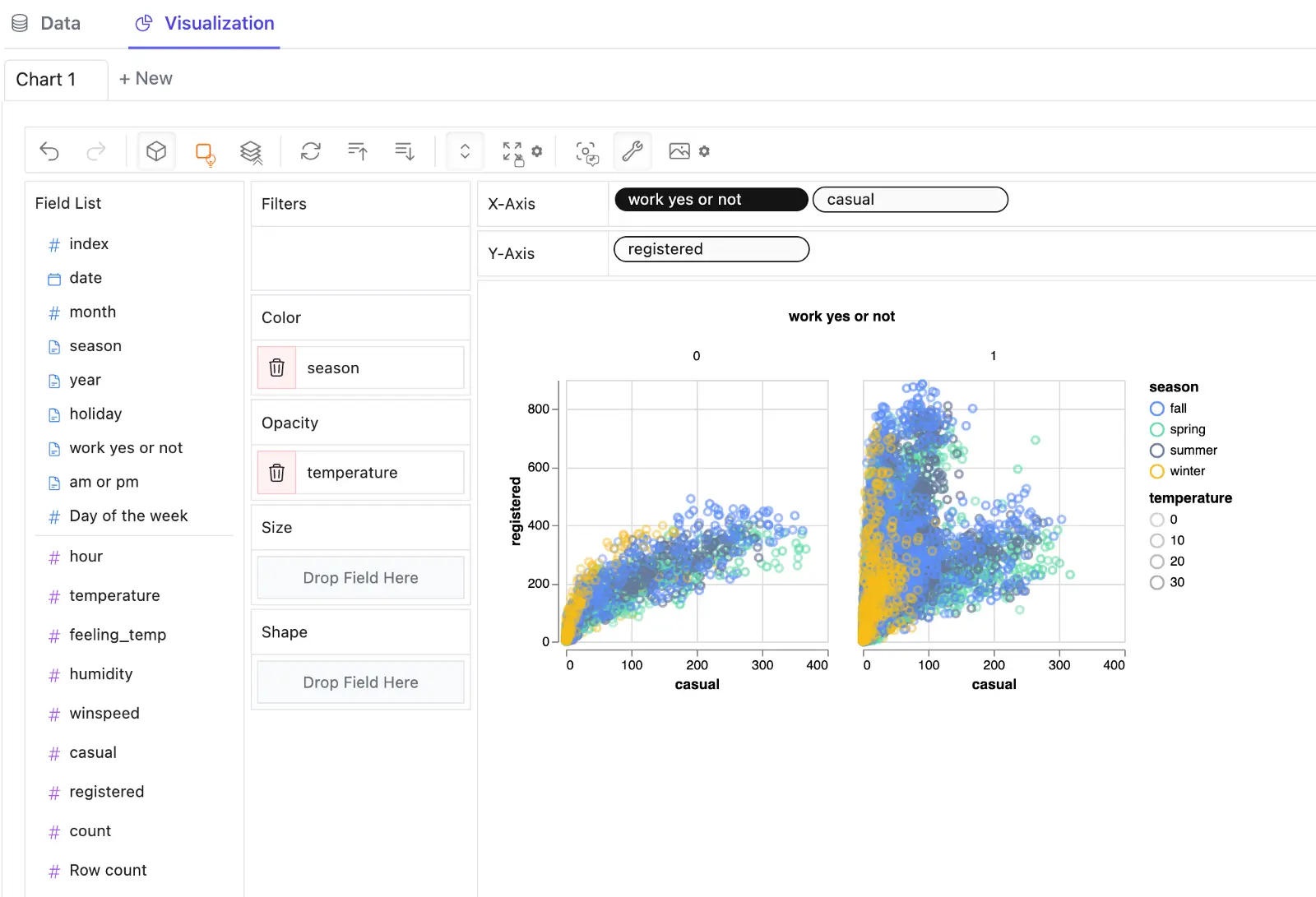
(Bill Wang, CC BY-SA 4.0)
In the **Data** tab, you can view the data frame in a table and configure the analytic and semantic types.
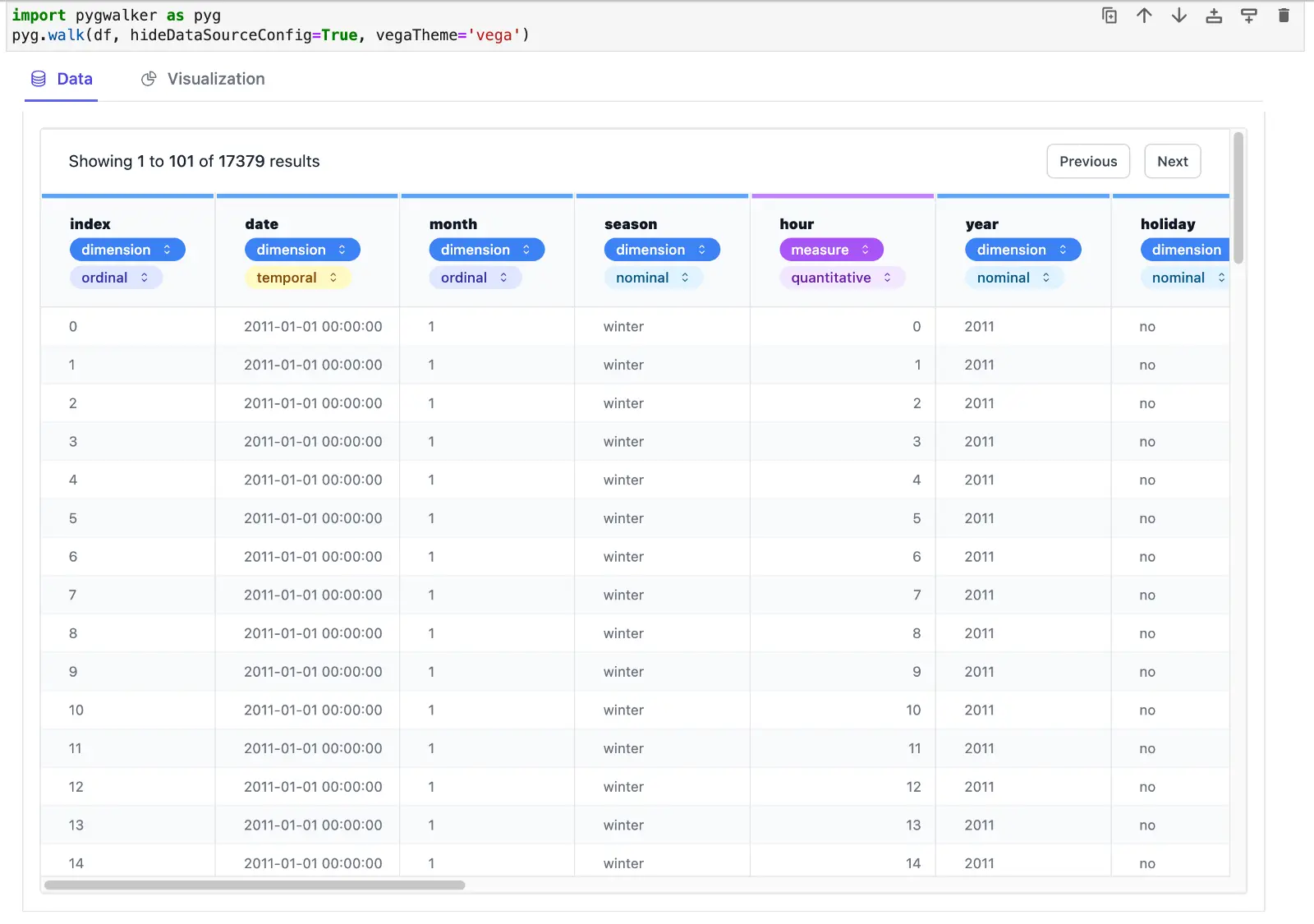
(Bill Wang, CC BY-SA 4.0)
## Data exploration with PyGWalker
You can turn your Pandas data into graphical and highly-customizable charts with PyGWalker. You can also use PyGWalker as a powerful tool for exploring data to uncover underlying patterns, trends, and insights.
Data exploration options are available in the **Exploration Mode** option (in the toolbar). They can be set to either **Point Mode** or **Brush Mode**.
**Point Mode**: Explore data by pointing your mouse cursor at a specific segment of the data.**Brush Mode**: Explore data by drawing a selection box around a range of data and then drag it to see generated insights.
## Try this to see your data
You can try PyGWalker on these cloud demos: [Google Colab](https://colab.research.google.com/drive/171QUQeq-uTLgSj1u-P9DQig7Md1kpXQ2?usp=sharing), [Binder](https://mybinder.org/v2/gh/Kanaries/pygwalker/main?labpath=tests%2Fmain.ipynb), or [Graphic Walker Online Demo](https://graphic-walker.kanaries.net/).
PyGWalker is an excellent tool for simplifying data analysis and visualization workflows, particularly for those who want a visual interface for Pandas. With PyGWalker and Graphic Walker, data scientists can easily create stunning visualizations with simple drag-and-drop operations in [Jupyter Notebook](https://opensource.com/downloads/jupyter-guide). Check out the PyGWalker Git repository for the source code.
For data scientists who seek an open source solution to automated data exploration and advanced augmented analytics, the project also works on [RATH](https://kanaries.net/), an open source auto-EDA, AI-empowered data exploration and visualization tool. You can also check out the [RATH Git repository](https://github.com/Kanaries/Rath) for the source code and an active community.
## Comments are closed. |
15,787 | Ubuntu 23.10 公布代号:“Mantic Minotaur” | https://debugpointnews.com/ubuntu-23-10-codename/ | 2023-05-06T15:20:00 | [
"Ubuntu"
] | /article-15787-1.html | 
>
> Ubuntu 操作系统背后的团队已经公布了下一个版本的代号,令人兴奋的是,它是 “Mantic Minotaur”。
>
>
>
根据 Ubuntu 开发平台 [Launchpad](https://launchpad.net/ubuntu/mantic) 的信息,Ubuntu 23.10 将被称为 “<ruby> Mantic Minotaur <rt> 预言牛头怪 </rt></ruby>”。虽然这个名称可能没有任何深层含义,但它确实听起来很不错。(LCTT 译注:尬吹)
这个名称由两个单词组成:“Mantic” 和 “Minotaur”。“Mantic” 指占卜或预言,而 “Minotaur” 是希腊神话中的半人半牛的生物。虽然这两个单词的组合可能没有任何隐藏的含义,但它确实是一个有趣的代号。
过去,Ubuntu 发行版的代号通常具有神秘的涵义,或传递着版本发布的某种特定信息。然而,最近的几个版本的代号变得更加轻松、有趣和古怪。从“<ruby> Disco Dingo <rt> 迪斯科丁格狗 </rt></ruby>”到“<ruby> Hirsute Hippo <rt> 有长发的河马 </rt></ruby>”,这些代号之所以被选择,是因为它们有趣而好玩。
虽然“Mantic Minotaur”可能不符合哺乳类动物作为 Linux 发行版的吉祥物的模式,但并不是第一个用作 Ubuntu 发行版代号的神话生物。在过去,该团队也曾使用过一些其他的神话生物作为代号,例如“<ruby> Wily Werewolf <rt> 狡猾的狼人 </rt></ruby>”和“<ruby> Jaunty Jackalope <rt> 神奇的沙漠兔角兽 </rt></ruby>”。
Ubuntu 23.10 的预计发布日期为 2023 年 10 月 12 日。虽然该团队尚未透露该版本具体的更新内容,但我们可以猜测该版本将包含一个新的 Linux 内核和更新的图形驱动程序。此外,我们也可以期待看到 GNOME 45 和基于 Flutter 的安装程序进一步开发的草稿。
你对新的代号有什么想法?你对即将到来的版本有什么期待?请在评论中与我们分享。
*(题图:MJ:/38b23fa4-f583-4b14-9b9e-478790bbdb49)*
---
via: <https://debugpointnews.com/ubuntu-23-10-codename/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,789 | “茄子”的未来:GNOME 的下一代照相应用程序“快照”应用 | https://news.itsfoss.com/gnome-snapshot/ | 2023-05-06T22:54:08 | [
"GNOME",
"照相"
] | https://linux.cn/article-15789-1.html |
>
> GNOME 的下一代照相应用程序 “<ruby> 快照 <rt> Snapshot </rt></ruby>” 应用正式启用,用以替代现有的经典 “<ruby> 茄子 <rt> Cheese </rt></ruby>” 工具。
>
>
>

一个新的应用程序已被接受进入 [GNOME 的孵化器组](https://gitlab.gnome.org/Incubator/?ref=news.itsfoss.com):“<ruby> 快照 <rt> Snapshot </rt></ruby>”。
“快照” 应用的第一个预览版本已经发布,这使它成为取代 “<ruby> <a href="https://wiki.gnome.org/Apps/Cheese?ref=news.itsfoss.com"> 茄子 </a> <rt> Cheese </rt></ruby>” 应用的卓越候选者,“茄子” 应用是 Linux 用户当前使用的 GNOME 网络摄像头应用程序。
让我们快速看一下它。
>
> ? “[孵化器](https://gitlab.gnome.org/Incubator?ref=news.itsfoss.com)” 组包含那些将成为 GNOME 核心和 GNOME 开发工具一部分的项目,这意味着 **它可能会有一天被纳入 GNOME 的发布版本**。
>
>
>
### ? “快照” 应用是什么?

正如我前面提到的那样,它是 GNOME 的一款照相应用程序。它是使用内存安全的 Rust 编程语言编写的,提供了非常简洁的功能集。
“快照” 应用的用户界面非常简洁,既适用于移动设备,也适用于传统的桌面/笔记本电脑。
功能方面,它几乎拥有你对此类应用程序的所有期望。
它有一个 “倒计时” 功能,允许你设置拍照或录像的定时器,并提供几个计时选项。

此外,你可以通过进入偏好设置菜单,在这个应用程序中禁用相机快门的声音。

“快照” 应用程序还带有一个相当不错的画廊视图,让你查看拍摄的照片/视频,并使用不同的程序共享或访问它们。
**你觉得 “快照” 应用的功能很少吗?**
我不知道你怎么看,但我觉得很少。
不过,**有时候,简单更好**。对于 GNOME 应用程序来说,通常是这样。
它不会很快取代 GNOME 现有的相机应用程序 “[茄子](https://wiki.gnome.org/Apps/Cheese?ref=news.itsfoss.com)”。但随着开发的进展,他们可能会添加一些令人兴奋的功能。
如果想要了解更多信息,可以关注 [本周 GNOME](https://thisweek.gnome.org/posts/2023/04/twig-93/?ref=news.itsfoss.com) 博客以查看 “快照” 应用和其他 GNOME 应用程序的开发更新。
### ? 获取 “快照” 应用
你可以从 [Flathub 商店](https://flathub.org/apps/org.gnome.Snapshot?ref=news.itsfoss.com) 获取该应用程序,并在 [GitLab](https://gitlab.gnome.org/Incubator/snapshot?ref=news.itsfoss.com) 上探索其源代码。
>
> **[Snapshot(Flathub)](https://flathub.org/apps/org.gnome.Snapshot?ref=news.itsfoss.com)**
>
>
>
? 你觉得呢?“快照” 能否取代 “茄子” 成为你在 GNOME 上的默认相机应用程序?
---
via: <https://news.itsfoss.com/gnome-snapshot/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

A new app has been accepted into [GNOME's Incubator Group](https://gitlab.gnome.org/Incubator/?ref=news.itsfoss.com), i.e., **Snapshot.**
The first preview release for Snapshot is out, making it an excellent candidate to replace [Cheese](https://wiki.gnome.org/Apps/Cheese?ref=news.itsfoss.com), the current GNOME webcam app for Linux users.
Let's take a quick look at it.
[Incubator](https://gitlab.gnome.org/Incubator?ref=news.itsfoss.com)' group contains projects set to be part of GNOME Core and GNOME Development tools, signifying that
**this might someday make it into a GNOME release**.
## 🆕 Snapshot: What is it?
As I mentioned earlier, it is a camera app for GNOME. **Written in the memory-safe Rust programming language**, it offers a very minimal set of features.
Designed with mobile devices and traditional desktops/laptops in mind, Snapshot has **a neat user interface** with all the valuable options.
As for the features, it has just about what you would expect from such an app.
It has a '**Countdown**' feature allowing you to set a timer for clicking photos or videos, with a few timing choices.
Then there is the ability to disable the shutter sounds in the app by heading over to the preferences menu.
Snapshot also has a decent gallery view inside the app, letting you view the clicked photos/videos and share or access them using different programs.
**Did you find Snapshot very feature-lacking?**
I don't know about you, but I did.
But, of course, **sometimes, simple is better**. With **GNOME apps, it is usually the case. **
It won't replace GNOME's existing camera app, '[Cheese](https://wiki.gnome.org/Apps/Cheese?ref=news.itsfoss.com)' anytime soon. But as the development progresses, they might add some exciting features.
To know more, you can keep an eye on [This Week in GNOME](https://thisweek.gnome.org/posts/2023/04/twig-93/?ref=news.itsfoss.com) blog to check the development updates on Snapshot and other GNOME apps.
## 📥 Get Snapshot
You can get the app from the [Flathub store](https://flathub.org/apps/org.gnome.Snapshot?ref=news.itsfoss.com), and explore its source code on [GitLab](https://gitlab.gnome.org/Incubator/snapshot?ref=news.itsfoss.com).
*💬 What do you think? Will Snapshot replace Cheese as the default camera app on GNOME for you?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,790 | 在 OBS 中将摄像头锁定到特定的 USB 端口 | https://opensource.com/article/22/1/cameras-usb-ports-obs | 2023-05-06T23:31:05 | [
"摄像头"
] | https://linux.cn/article-15790-1.html |
>
> 为了使复杂的摄像头设置标准化,你可以对 Linux 文件系统中摄像头的位置分配施加一些特殊规则。
>
>
>

如果在 Linux 上用多个摄像头 [使用 OBS 进行直播](https://opensource.com/life/15/12/real-time-linux-video-editing-with-obs-studio),你可能会注意到摄像头会在开机时按照它们被检测到的顺序加载。通常情况下你不需要特别在意,但如果你有一个固定的直播设置和复杂的 OBS 模板,你需要知道现实世界中哪个摄像头将会显示在虚拟世界的哪个屏幕上。换句话说,你不希望今天将一个设备分配为“摄像头 A”,而明天它却成为“摄像头 B”。
为了使复杂的摄像头设置标准化,你可以对 Linux 文件系统中摄像头的位置分配施加一些特殊规则。
### udev 子系统
在 Linux 上处理硬件外设的系统称为 udev。它检测和管理你接入计算机的所有设备。你可能没有意识到它的存在,因为它不会吸引太多注意力。尽管当你插入 USB 闪存驱动器以在桌面上打开它或连接打印机时,你肯定与它交互过。
### 硬件检测
假设你有两个 USB 摄像头:一个在电脑左侧,另一个在右侧。左侧摄像头拍摄近景,右侧摄像头拍摄远景,并且在直播过程中你需要切换两个摄像头。在 OBS 中,你将每个摄像头添加到 <ruby> 源 <rt> Sources </rt></ruby> 面板中,并直观地将它们命名为 “camLEFT” 和 “camRIGHT”。
设想一种最坏的场景,你有两个 *相同的* 摄像头:它们是同一品牌、同一型号。这是最坏的情况,因为当两个硬件设备完全相同时,它们几乎不可能有任何独特的 ID,以便你的电脑能够将它们区分开来。
不过,这个难题有解决办法,只需要一些简单的终端命令进行一些调查。
#### 1、获取厂商和产品 ID
首先,将一个摄像头插入你想要它分配到的 USB 端口。然后输入以下命令:
```
$ lsusb
Bus 006 Device 002: ID 0951:1666 Kingston Technology DataTraveler G4
Bus 005 Device 003: ID 03f0:3817 Hewlett-Packard LaserJet P2015 series
Bus 003 Device 006: ID 045e:0779 Microsoft Corp. LifeCam HD-3000
Bus 003 Device 002: ID 8087:0025 Intel Corp.
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 003: ID 046d:c216 Logitech, Inc. Dual Action Gamepad
Bus 001 Device 002: ID 048d:5702 Integrated Technology Express, Inc.
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
[...]
```
你通常可以专门搜索字符串 `cam` 以缩小结果范围,因为大多数(但不是所有)摄像头都会报告为 “camera”。
```
$ lsusb | grep -i cam
Bus 003 Device 006: ID 045e:0779 Microsoft Corp. LifeCam HD-3000
```
这里有很多信息。ID 被列为 `045e:0779`。第一个数字是供应商 ID,第二个数字是产品 ID。把它们写下来,因为稍后你会需要它们。
#### 2、获取 USB 标识符
你还获取了摄像头的设备路径:总线 3,设备 6。在 Linux 中有一句话:“一切皆文件”,实际上,USB 设备被描述为以 `/dev/bus/usb/` 开始,以总线(本例中为 003)和设备(本例中为 006)结尾的文件路径。查看 `lsusb` 输出中的总线和设备号。它们告诉你该摄像头位于 `/dev/bus/usb/003/006`。
你可以使用 `udevadm` 命令获取此 USB 设备的内核代号:
```
$ sudo udevadm info --attribute-walk /dev/bus/usb/003/006 | grep "KERNEL="
KERNEL=="3-6.2.1"
```
这个例子中的内核 USB 标识符是 `3-6.2.1`。把你系统中的标识符记下来,因为之后也会用到它。
#### 3、为每个摄像头重复该过程
将另一个摄像头(如果你有多个摄像头,则为每个摄像头)连接到要分配给它的 USB 端口。这与你用于另一个摄像头的 USB 端口是不同的!
重复该过程,获取供应商和产品 ID(如果摄像头是相同的品牌和型号,则应与第一个摄像头相同)以及内核 USB 标识符。
```
$ lsusb | grep -i cam
Bus 001 Device 004: ID 045e:0779 Microsoft Corp. LifeCam HD-3000
$ sudo udevadm info --attribute-walk dev/bus/usb/001/004 | grep "KERNEL="
KERNEL=="1-6"
```
在这个例子中,我已经确定我的摄像头连接到了 1-6 和 3-6.2.1(第一个是我的机器上的 USB 端口,另一个是插在我的机器上的显示器插口的集线器,这就是为什么一个比另一个更复杂的原因)。
### 编写一个 udev 规则
你已经有了所需的一切,因此现在可以编写一个规则,告诉 udev 在特定的 USB 端口找到一个摄像头时给它一个一致的标识符。
创建并打开一个名为 `/etc/udev/rules.d/50-camera.conf` 的文件,并输入这两个规则,使用适合你自己系统的厂商和产品 ID 和内核标识符:
```
SUBSYSTEM=="usb", KERNEL=="1-6", ATTR{idVendor}=="045e", ATTR{idProduct}=="0779", SYMLINK+="video100"
SUBSYSTEM=="usb", KERNEL=="3-6.2.1", ATTR{idVendor}=="045e", ATTR{idProduct}=="0779", SYMLINK+="video101"
```
这些规则告诉 udev,当在特定的 USB 位置找到与特定供应商和产品 ID 匹配的设备时,创建一个名为 `video100` 和 `video101` 的符号链接(有时也称为“别名”)。符号链接大多是任意的。我使用较大的数字,这样它们就容易被发现,并且数字不能与现有设备冲突。如果实际上有超过 101 个摄像头连接到计算机上,请使用 `video200` 和 `video201` 以确保安全(记得联系我!我很想了解 *该* 项目的情况)。
### 重启
重新启动计算机。你现在可以让摄像头保持连接在计算机上,但实际上这并不重要。一旦 udev 加载了规则,它就会遵循这些规则,无论设备是否在启动期间附加或稍后插入。
许多人说 Linux 从不需要重启,但是 udev 在引导期间加载其规则,而且此外,你想保证你的 udev 规则在重新启动时也起作用。
计算机重新启动后,请查看摄像头注册的 `/dev/video` 目录:
```
$ ls -1 /dev/video*
/dev/video0
/dev/video1
/dev/video100
/dev/video101
/dev/video2
/dev/video3
```
正如你所看到的,在 `video100` 和 `video101` 有条目。今天,这些是指向 `/dev/video2` 和 `/dev/video3` 的符号链接,但明天它们可能是指向 `/dev/video1` 和 `/dev/video2` 或任何其他基于 Linux 检测和分配文件的组合。

你可以在 OBS 中使用这些符号链接,这样 camLEFT 始终是 camLEFT,camRIGHT 始终是 camRIGHT。
*(题图:MJ/9bb70b6d-9f49-493a-8daf-5546d207781f)*
---
via: <https://opensource.com/article/22/1/cameras-usb-ports-obs>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hanszhao80](https://github.com/hanszhao80) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you [stream with OBS](https://opensource.com/life/15/12/real-time-linux-video-editing-with-obs-studio) with multiple cameras on Linux, you might notice that cameras are loaded as they are detected during boot. You probably don't give it much thought, normally, but if you have a permanent streaming setup with complex OBS templates, you need to know which camera in the physical world is going to show up in which screen in the virtual one. In other words, you don't want to assign one device as Camera A today only to have it end up as Camera B tomorrow.
To standardize a complex camera setup, you can impose some special rules on how cameras get assigned to locations in the Linux filesystem.
## The udev subsystem
The system dealing with hardware peripherals on Linux is called udev. It detects and manages all devices you plug into your computer. You're probably not aware of it because it doesn't draw too much attention to itself, although you've certainly interacted with it when you plug in a USB thumb drive to open on your desktop or attached a printer.
## Hardware detection
Assume you have two USB cameras: One on the left of your computer and one on the right. The left camera is shooting a close-up, the right camera is shooting a long shot, and you switch between the two during your stream. In OBS, you add each camera to your **Sources** panel and, intuitively, call one **camLEFT** and the other **camRIGHT**.
Assuming the worst-case scenario, say you have two of the *same* cameras: They're the same brand and the same model number. This is the worst-case scenario because when two pieces of hardware are identical, there's little chance each one has any kind of unique ID for your computer to differentiate them from one another.
There's a solution to this puzzle, though, and it just requires a little investigation using some simple terminal commands.
### 1. Get the vendor and product IDs
First, plugin just one camera into the USB port you want it assigned to. Then issue this command:
```
$ lsusb
Bus 006 Device 002: ID 0951:1666 Kingston Technology DataTraveler G4
Bus 005 Device 003: ID 03f0:3817 Hewlett-Packard LaserJet P2015 series
Bus 003 Device 006: ID 045e:0779 Microsoft Corp. LifeCam HD-3000
Bus 003 Device 002: ID 8087:0025 Intel Corp.
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 003: ID 046d:c216 Logitech, Inc. Dual Action Gamepad
Bus 001 Device 002: ID 048d:5702 Integrated Technology Express, Inc.
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
[...]
```
You can usually search specifically for the string "cam" to narrow down the results because most (but not all) cameras report as a camera.
```
$ lsusb | grep -i cam
Bus 003 Device 006: ID 045e:0779 Microsoft Corp. LifeCam HD-3000
```
There's a lot of information here. The ID is listed as `045e:0779`
. The first number is the vendor ID, and the second is the product ID. Write those down because you'll need them later.
### 2. Get the USB identifier
You've also obtained the device path to the camera: bus 3, device 6. There's a saying in Linux that "everything is a file," and indeed USB devices are described to udev as a file path starting with `/dev/bus/usb/`
and ending with the bus (003 in this case) and the device (006 in this case). Look at the bus and device numbers in the `lsusb`
output. They tell you that this camera is located on `/dev/bus/usb/003/006`
.
You can use the `udevadm`
command to obtain the kernel's designator for this USB device:
```
$ sudo udevadm info \
--attribute-walk \
/dev/bus/usb/003/006 | grep "KERNEL="
KERNEL=="3-6.2.1"
```
The kernel USB identifier in this example is `3-6.2.1`
. Write down the identifier for your system because you'll also need it later.
### 3. Repeat for each camera
Attach the other camera (or cameras, if you have more than two) to the USB port you want it assigned to. This is *different* than the USB port you used for the other camera!
Repeat the process, obtaining the vendor and product ID (if the cameras are the same make and model, these should be the same as the first one) and the kernel USB identifier.
```
$ lsusb | grep -i cam
Bus 001 Device 004: ID 045e:0779 Microsoft Corp. LifeCam HD-3000
$ sudo udevadm info \
--attribute-walk \
/dev/bus/usb/001/004 | grep "KERNEL="
KERNEL=="1-6"
```
In this example, I've determined that I have my cameras attached to 1-6 and 3-6.2.1 (the first one is a USB port on my machine, the other one is a hub plugged into the monitor plugged into my machine, which is why one is more complex than the other.)
## Write a udev rule
You have everything you need, so now you can write a rule to tell udev to give each camera a consistent identifier when one is found at a specific USB port.
Create and open a file called `/etc/udev/rules.d/50-camera.conf`
, and enter these two rules, using the vendor and product IDs and kernel identifiers appropriate for your own system:
```
SUBSYSTEM=="usb", KERNEL=="1-6", ATTR{idVendor}=="045e", ATTR{idProduct}=="0779", SYMLINK+="video100"
SUBSYSTEM=="usb", KERNEL=="3-6.2.1", ATTR{idVendor}=="045e", ATTR{idProduct}=="0779", SYMLINK+="video101"
```
These rules tell udev that when it finds a device matching a specific vendor and product ID at those specific USB locations, to create a symlink (sometimes also called an "alias") named `video100`
and `video101`
. The symlinks are mostly arbitrary. I give them high numbers, so they're easy to spot and because the number must not clash with existing devices. If you actually do have more than 101 cameras attached to your computer, use `video200`
and
just to be safe (and get in contact! I'd love to learn more about `video201`*that* project).
## Reboot
Reboot your computer. You can leave the cameras attached for now, but it doesn't actually matter. Once udev has a rule loaded, it follows those rules whether a device was attached during boot or is plugged in later.
Many people say that Linux never needs to reboot, but udev loads its rules during boot, and besides, you want to prove that your udev rules are working across reboots.
Once your computer is back up and running, take a look in `/dev/video`
, where cameras are registered:
```
$ ls -1 /dev/video*
/dev/video0
/dev/video1
/dev/video100
/dev/video101
/dev/video2
/dev/video3
```
As you can see, there are entries at `video100`
and `video101`
. Today, these are symlinks to `/dev/video2`
and `/dev/video3`
, but tomorrow they may be symlinks to `/dev/video1`
and `/dev/video2`
, or any other combination based on when Linux detected and assigned them a file.
(Photo by Jeff Siepman)
You can use the symlinks in OBS, though, so that camLEFT is always camLEFT, and camRIGHT is always camRIGHT.
## Comments are closed. |
15,792 | Ubuntu 18.04 即将停止更新,你该怎么办? | https://news.itsfoss.com/ubuntu-18-04-eol/ | 2023-05-07T19:41:00 | [
"Ubuntu"
] | https://linux.cn/article-15792-1.html |
>
> Ubuntu 18.04 即将停止更新,以下是你需要了解的信息。
>
>
>

标志性的 Ubuntu 18.04 “Bionic Beaver” 带来了许多改进和新增功能。但就像大多数优秀的产品一样,该版本也已经走到了尽头(对大多数用户而言)。
**那么,现在发生了什么呢?**
在三月份,Canonical 宣布 Ubuntu 18.04 将于 2023 年 5 月 31 日到达其计划更新周期的五年截止期。
这一天正在迅速到来,只剩下了几个星期的时间。
### EOL 意味着什么呢?
对于 [长期支持版本](https://itsfoss.com/long-term-support-lts/) 的 Ubuntu 发行版,它将停止获得维护更新和安全修补。
### 检查你是否正在使用 Ubuntu 18.04
如果你不知道你正在使用 Ubuntu 的哪个版本,可以检查一下。
打开终端并使用如下命令:
```
lsb_release -a
```
如果你在输出中看到 “18.04” 或 “bionic”,那么你正在使用 Ubuntu 18.04:
```
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04.5 LTS
Release: 18.04
Codename: bionic
```
### 现在应该怎么做呢?
如果你是企业用户或想继续使用 Ubuntu 18.04,Canonical 建议你选择 [Ubuntu Pro](https://ubuntu.com/pro) 服务,将支持扩展至 2028 年 4 月份。
>
> ? 请注意,Ubuntu Pro 仅支持 x86、x64 和 arm64 架构。
>
>
>
Ubuntu Pro 包含可扩展安全维护(ESM)的全套安全补丁,以及 24 小时的电话和支持工单。
如果你需要个人或非商业使用,还有一个 [免费的 Ubuntu Pro 计划](https://news.itsfoss.com/ubuntu-pro-free/),从其最初发布日期起,可为你提供 **10 年的安全更新**。换句话说,使用 Ubuntu Pro 将可以获得五年额外的支持期限。
>
> ⚠️ 但请注意,Ubuntu Pro 不会提供 “功能更新”,也不会从 Ubuntu 软件源获取最新版本的软件。它将通过提供安全和维护更新,使你的系统继续运行。
>
>
>
无论哪种情况,你都可以升级至 [Ubuntu 20.04 LTS](https://itsfoss.com/download-ubuntu-20-04/) 版本或全新安装 [Ubuntu 22.04 LTS](https://news.itsfoss.com/ubuntu-22-04-release/) 版本来获取最新和最棒的 Ubuntu LTS 发行版。
以下是一份实用的指南,可帮助你完成升级/重新安装。
>
> **[如何从 Ubuntu 20.04 LTS 或 21.10 升级到 22.04 LTS](https://itsfoss.com/upgrade-ubuntu-version/)**
>
>
>
如果你没有 Ubuntu Pro 且未获得扩展维护更新,那么应尽快升级,否则你的系统将面临安全风险。
### 总结
* Ubuntu 18.04 将于 2023 年 5 月 31 日到达生命周期结束。
* 现有的 Ubuntu 18.04 用户可以选择免费订阅 Ubuntu Pro 以继续使用。
* 现有用户也可以选择升级至新的 LTS 版本 20.04。
* 还有一个重新安装全新的 22.04 版本的方式,但这将格式化你的数据。
? 你会选择升级还是订阅 Ubuntu Pro 以获得扩展更新?
*(题图:MJ/a1402ad8-d260-42b3-9b92-e3935c9238ad)*
---
via: <https://news.itsfoss.com/ubuntu-18-04-eol/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The iconic Ubuntu 18.04 'Bionic Beaver' was a release that offered many improvements and features. First LTS to feature GNOME instead of Unity.
But like most good things, this, too, has reached an end (for most).
**What's Happening: **On **31 May 2023, Ubuntu 18.04 completed its five-year** planned update cycle.
In other words, Ubuntu 18.04 LTS has now reached end-of-life (EOL).
## What does EOL mean?
For a [Long-Term Version](https://itsfoss.com/long-term-support-lts/?ref=news.itsfoss.com) Ubuntu release, it will stop** getting maintenance updates and security fixes.**
**Suggested Read **📖
[What is End of Life in Ubuntu? Everything You Should Know About itIf you have been following It’s FOSS for some time, you might have noticed that I publish news articles like Ubuntu XYZ version has reached end of life (EoL). This end of life is one of those essential concepts that every Ubuntu user should be aware of. This is](https://itsfoss.com/end-of-life-ubuntu/?ref=news.itsfoss.com)

## Check if you are using Ubuntu 18.04
If you don't know [which Ubuntu version you are using](https://itsfoss.com/how-to-know-ubuntu-unity-version/?ref=news.itsfoss.com), it's time to check it.
Open a terminal and use the following command:
`lsb_release -a`
If you see 18.04 or bionic in the output, you are using Ubuntu 18.04:
```
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04.5 LTS
Release: 18.04
Codename: bionic
```
## What should you do now?
If you want to stick to Ubuntu 18.04, Canonical suggests you opt for [Ubuntu Pro](https://ubuntu.com/pro?ref=news.itsfoss.com), which will **extend support for Ubuntu 18.04 until April 2028**.
Ubuntu Pro includes the full security patching treatment thanks to Expanded Security Maintenance (ESM) with 24/7 phone and ticket support.
Fret not; there is a [free plan for Ubuntu Pro](https://news.itsfoss.com/ubuntu-pro-free/) if you need it for personal or non-commercial use, giving you **10 years of security updates** from the date of its original release. In other words, you get five more years.
Otherwise, you could upgrade to the [Ubuntu 20.04](https://itsfoss.com/download-ubuntu-20-04/?ref=news.itsfoss.com) LTS release or do a fresh install of [Ubuntu 22.04](https://news.itsfoss.com/ubuntu-22-04-release/) LTS if you want the latest and greatest Ubuntu LTS release,
Here's a handy guide to help you on your upgrade/reinstall journey.
[How to Upgrade to Ubuntu 22.04 LTS from Ubuntu 20.04 LTS and 21.10This tutorial demonstrates the steps for upgrading to Ubuntu 22.04 from Ubuntu 21.10 and 20.04. You can use the same steps to upgrade from any other supported Ubuntu version. There are plenty of new features in Ubuntu 22.04 LTS. As an ardent Ubuntu user, it is](https://itsfoss.com/upgrade-ubuntu-version/?ref=news.itsfoss.com)

If you do not have Ubuntu Pro and do not get extended maintenance updates, you should upgrade as soon as possible, else your system will remain vulnerable to security issues.
**To summarize:**
- Ubuntu 18.04 is reaching end of life by 31st May 2023
- Existing Ubuntu 18.04 users can stay with it by opting for free Ubuntu Pro subscription
- Existing users may also upgrade to the next LTS, 20.04
- The option to reinstall a fresh 22.04 version is also there but it will format your data
*💬 Will you be upgrading or opting for a Ubuntu Pro subscription to get extended updates?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,793 | 使用开源 Python API 封装器与你的集群对话 | https://opensource.com/article/23/4/cluster-open-source-python-api-wrapper | 2023-05-07T23:26:29 | [
"API"
] | https://linux.cn/article-15793-1.html | 
>
> 结合开放的 API 和 Python 编程语言的力量。
>
>
>
围绕 API 创建封装器的开源项目正变得越来越流行。这些项目使开发人员更容易与 API 交互并在他们的应用中使用它们。`openshift-python-wrapper` 项目是 [openshift-restclient-python](https://github.com/openshift/openshift-restclient-python) 的封装器。最初是一个帮助我们的团队使用 OpenShift API 的内部包,后来变成了一个[开源项目](https://github.com/RedHatQE/openshift-python-wrapper)(Apache 许可证 2.0)。
本文讨论了什么是 API 封装器,为什么它很有用,以及封装器的一些例子。
### 为什么要使用 API 封装器?
API 封装器是位于应用和 API 之间的一层代码。它通过将一些涉及发出请求和解析响应的复杂性抽象出来,以简化 API 访问过程。封装器还可以提供 API 本身提供的功能之外的附加功能,例如缓存或错误处理。
使用 API 封装器使代码更加模块化并且更易于维护。无需为每个 API 编写自定义代码,你可以使用封装器来提供与 API 交互的一致接口。它可以节省时间,避免代码重复,并减少出错的机会。
使用 API 封装器的另一个好处是它可以保护你的代码免受 API 变化的影响。如果 API 更改了它的接口,你可以更新封装器代码而无需修改你的应用程序代码。随着时间的推移,这可以减少维护应用程序所需的工作。
### 安装
该应用位于 [PyPi](https://pypi.org/project/openshift-python-wrapper/) 上,因此使用 [pip 命令](https://opensource.com/downloads/pip-cheat-sheet) 安装 `openshift-python-wrapper`:
```
$ python3 -m pip install openshift-python-wrapper
```
### Python 封装器
[OpenShift REST API](https://access.redhat.com/documentation/en-us/openshift_container_platform/3.5/html-single/using_the_openshift_rest_api/index?intcmp=7013a000002qLH8AAM) 提供对 OpenShift 平台的许多功能的编程访问。封装器提供了一个简单直观的界面,用于使用 `openshift-restclient-python` 库与 API 进行交互。它标准化了如何使用集群资源,并提供了统一的资源 CRUD(创建、读取、更新和删除)流程。它还提供额外的功能,例如需要由用户实现的特定于资源的功能。随着时间的推移,封装器使代码更易于阅读和维护。
简化用法的一个示例是与容器交互。在容器内运行命令需要使用 Kubernetes 流、处理错误等。封装器处理这一切并提供 [简单直观的功能](https://github.com/RedHatQE/openshift-python-wrapper/blob/main/ocp_resources/pod.py#L72)。
```
>>> from ocp_resources.pod import Pod
>>> from ocp_utilities.infra import get_client
>>> client = get_client()
ocp_utilities.infra INFO Trying to get
client via new_client_from_config
>>> pod = Pod(client=client, name="nginx-deployment-7fb96c846b-b48mv", namespace="default")
>>> pod.execute("ls")
ocp_resources Pod INFO Execute ls on
nginx-deployment-7fb96c846b-b48mv (ip-10-0-155-108.ec2.internal)
'bin\nboot\ndev\netc\nhome\nlib\nlib64\nmedia\nmnt\nopt\nproc\nroot\nrun\nsbin\nsrv\nsys\ntmp\nusr\nvar\n'
```
开发人员或测试人员可以使用这个封装器,我们的团队在编写代码的同时牢记测试。使用 Python 的上下文管理器可以提供开箱即用的资源创建和删除,并且可以使用继承来扩展特定场景的功能。Pytest fixtures 可以使用代码进行设置和拆卸,不留任何遗留物。甚至可以保存资源用于调试。可以轻松收集资源清单和日志。
这是上下文管理器的示例:
```
@pytest.fixture(scope="module")
def namespace():
admin_client = get_client()
with Namespace(client=admin_client, name="test-ns",) as ns:
ns.wait_for_status(status=Namespace.Status.ACTIVE, timeout=240)
yield ns
def test_ns(namespace):
print(namespace.name)
```
生成器遍历资源,如下所示:
```
>>> from ocp_resources.node import Node
>>> from ocp_utilities.infra import get_client
>>> admin_client = get_client()
# This returns a generator
>>> for node in Node.get(dyn_client=admin_client):
print(node.name)
ip-10-0-128-213.ec2.internal
```
### 开源社区的开源代码
套用一句流行的说法,“如果你热爱你的代码,就应该让它自由。” `openshift-python-wrapper` 项目最初是作为 [OpenShift 虚拟化](https://www.redhat.com/en/technologies/cloud-computing/openshift/virtualization?intcmp=7013a000002qLH8AAM) 的实用模块。随着越来越多的项目从代码中受益,我们决定将这些程序提取到一个单独的仓库中并将其开源。套用另一句俗语,“如果代码不回到你这里,那就意味着它从未属于你。” 一旦这种情况发生,它就真正成为了开源。
更多的贡献者和维护者意味着代码属于社区。欢迎大家贡献。
*(题图:MJ/5ca32a4a-2194-4b36-ade9-053433e79201)*
---
via: <https://opensource.com/article/23/4/cluster-open-source-python-api-wrapper>
作者:[Ruth Netser](https://opensource.com/users/rnetser1) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Open source projects that create a wrapper around an API are becoming increasingly popular. These projects make it easier for developers to interact with APIs and use them in their applications. The `openshift-python-wrapper`
project is a wrapper around [openshift-restclient-python](https://github.com/openshift/openshift-restclient-python). What began as an internal package to help our team work with the OpenShift API became an [open source project](https://github.com/RedHatQE/openshift-python-wrapper) (Apache License 2.0).
This article discusses what an API wrapper is, why it's useful, and some examples from the wrapper.
## Why use an API wrapper?
An API wrapper is a layer of code that sits between an application and an API. It simplifies the API access process by abstracting away some of the complexities involved in making requests and parsing responses. A wrapper can also provide additional functionality beyond what the API itself offers, such as caching or error handling.
Using an API wrapper makes the code more modular and easier to maintain. Instead of writing custom code for every API, you can use a wrapper that provides a consistent interface for interacting with APIs. It saves time, avoids code duplications, and reduces the chance of errors.
Another benefit of using an API wrapper is that it can shield your code from changes to the API. If an API changes its interface, you can update the wrapper code without modifying your application code. This can reduce the work required to maintain your application over time.
## Install
The application is on [PyPi](https://pypi.org/project/openshift-python-wrapper/), so install `openshift-python-wrapper`
using the [pip command](https://opensource.com/downloads/pip-cheat-sheet):
```
````$ python3 -m pip install openshift-python-wrapper`
## Python wrapper
The [OpenShift REST API](https://access.redhat.com/documentation/en-us/openshift_container_platform/3.5/html-single/using_the_openshift_rest_api/index?intcmp=7013a000002qLH8AAM) provides programmatic access to many of the features of the OpenShift platform. The wrapper offers a simple and intuitive interface for interacting with the API using the `openshift-restclient-python`
library. It standardizes how to work with cluster resources and offers unified resource CRUD (Create, Read, Update, and Delete) flows. It also provides additional capabilities, such as resource-specific functionality that otherwise needs to be implemented by users. The wrapper makes code easier to read and maintain over time.
One example of simplified usage is interacting with a container. Running a command inside a container requires using Kubernetes stream, handling errors, and more. The wrapper handles it all and provides [simple and intuitive functionality](https://github.com/RedHatQE/openshift-python-wrapper/blob/main/ocp_resources/pod.py#L72).
```
``````
>>> from ocp_resources.pod import Pod
>>> from ocp_utilities.infra import get_client
>>> client = get_client()
ocp_utilities.infra INFO Trying to get
client via new_client_from_config
>>> pod = Pod(client=client, name="nginx-deployment-7fb96c846b-b48mv", namespace="default")
>>> pod.execute("ls")
ocp_resources Pod INFO Execute ls on
nginx-deployment-7fb96c846b-b48mv (ip-10-0-155-108.ec2.internal)
'bin\nboot\ndev\netc\nhome\nlib\nlib64\nmedia\nmnt\nopt\nproc\nroot\nrun\nsbin\nsrv\nsys\ntmp\nusr\nvar\n'
```
Developers or testers can use this wrapper—our team wrote the code while keeping testing in mind. Using Python capabilities, context managers can provide out-of-the-box resource creation and deletion, and inheritance can be used to extend functionality for specific use cases. Pytest fixtures can utilize the code for setup and teardown, leaving no leftovers. Resources can even be saved for debugging. Resource manifests and logs can be easily collected.
Here's an example of a context manager:
```
``````
@pytest.fixture(scope="module")
def namespace():
admin_client = get_client()
with Namespace(client=admin_client, name="test-ns",) as ns:
ns.wait_for_status(status=Namespace.Status.ACTIVE, timeout=240)
yield ns
def test_ns(namespace):
print(namespace.name)
```
Generators iterate over resources, as seen below:
```
``````
>>> from ocp_resources.node import Node
>>> from ocp_utilities.infra import get_client
>>> admin_client = get_client()
# This returns a generator
>>> for node in Node.get(dyn_client=admin_client):
print(node.name)
ip-10-0-128-213.ec2.internal
```
## Open source code for open source communities
To paraphrase a popular saying, "If you love your code, set it free." The `openshift-python-wrapper`
project started as utility modules for [OpenShift Virtualization](https://www.redhat.com/en/technologies/cloud-computing/openshift/virtualization?intcmp=7013a000002qLH8AAM). As more and more projects benefitted from the code, we decided to extract those utilities into a separate repository and have it open sourced. To paraphrase another common saying, "If the code does not return to you, it means it was never yours." We like saying that once that happens, it's truly open source.
More contributors and maintainers mean that the code belongs to the community. Everyone is welcome to contribute.
## Comments are closed. |
15,795 | Apache 软件基金会如何选择开源项目 | https://opensource.com/article/21/6/apache-software-foundation | 2023-05-09T10:41:15 | [
"Apache 软件基金会",
"ASF"
] | https://linux.cn/article-15795-1.html |
>
> Apache 软件基金会(ASF)围绕一套独特的流程和价值观构建,以确保其开放性。
>
>
>

作为 <ruby> <a href="https://www.apache.org/"> Apache 软件基金会 </a> <rt> Apache Software Foundation </rt></ruby>(ASF) 的长期志愿者和导师(以及现任董事会成员)和 Apache 孵化器的副总裁,我很自豪能够提供我对 ASF 运营的独特流程和价值观的见解。
ASF 以开源 [Apache 许可证](https://www.apache.org/licenses/LICENSE-2.0) 为中心,采用开放而务实的方式运作,与许多其他基金会不同,是一个为公共利益而建立的慈善组织。例如,ASF 董事会由成员选举产生。没有人可以购买董事会席位,ASF 的联属关系是与个人建立的,而不是与公司建立的。一般来说,参与 ASF 的任何个人的公司隶属关系都不会被说明,这并不重要。结果是,ASF 营造了一个供应商中立的环境,公司可以在其中舒适地协作构建有价值的项目。
让我们看一下 ASF 如何选择其项目、开源许可证的现状以及你对 ASF 未来的展望。
### Apache 孵化器流程和 “Apache 之道”
潜在的 Apache 项目始于 <ruby> <a href="https://incubator.apache.org/"> Apache 孵化器 </a> <rt> Apache Incubator </rt></ruby>,在那里它们接受帮助和指导,以期望能够毕业成为顶级的 Apache 项目。任何人都可以为孵化器制定项目提案(他们只需要找到 ASF 内部愿意帮助支持它的人)。在审查潜在的项目时,ASF 更愿意看到涉及到的人和实体的多样性,而不仅仅是一个单一的法人团体。我们发现,这种更广泛的多样性会导致项目被更广泛地使用并具有更长久的生命力。
孵化器的主要目的是帮助项目学习并按照我们所说的 <ruby> <a href="https://apache.org/theapacheway/"> Apache 之道 </a> <rt> The Apache Way </rt></ruby> 运作。这是一套为社区主导的发展提供最佳实践的价值观。“Apache 之道”的最重要方面包括严格的供应商中立性优先考虑社区,甚至优先于项目代码。开放和透明的交流也是至关重要的:ASF 要求所有项目交流都是公开可访问的,并永久归档以支持异步协作。此外,开源的 Apache 许可证附加在所有被接受的项目上,确保所有源代码也是公开可用的。
在孵化器中,我们首先会根据项目与 Apache 价值观的一致程度来考察项目是否适合。不需要百分之百的一致,但项目需要愿意适应。还将从许可证的角度讨论确保项目与 Apache 完全兼容,在某些情况下,将根据需要删除或替换依赖项。“Apache 之道”会朝构建自我维持的社区方向做准备。尽管如此,对于一些项目来说,建立社区可能很困难,有些项目无法通过孵化器。
“Apache 之道”对繁荣社区至关重要的另一个关键元素,是基于共识做出决策。根据我们的经验,开放讨论和避免单个项目负责人对该流程至关重要。我们曾经有过一些孵化项目,有一个试图保持控制权的强势人物,由于这个原因,这些项目没有成功。
### 开源和 Apache 许可证
开源项目有很多种。同时,使用开源许可证不会自动使项目开源。项目的社区才是释放开源的益处,并促进更大的开放和透明度的关键。
一些公司高调地从 Apache 许可转向不太宽松的许可。如果你的公司从开源许可证更改为非开源许可证,我不得不质疑你们当初为什么要选择开源许可证。这可能意味着商业模式不适合开源。我认为,企业改变开源许可证,对他们的社区和用户造成了巨大的伤害。
正如我所说,ASF 是一个非营利性慈善组织,致力于为公共利益而开发软件。这就是宽松的 Apache 许可证的目的。从软件中赚钱很好,但这不是 Apache 许可证的目的。作为一个规则,ASF 不允许任何使用领域限制。*任何人* 都可以以任何理由使用 Apache 项目。真正开源背后的理念是一些使用项目的人会回馈它,但绝对不能强制要求贡献。那些似乎困扰于这一点的公司需要明白,这不是开源的运作方式,也不是它应该的运作方式。
### 开源和 ASF 的未来
在过去的五到十年里,开源无疑得到了广泛的采用,尤其是在企业中加速采用。我可以肯定地说,地球上几乎没有哪个软件不包含或不依赖某种方式的开源项目。这种采用率只会增长。
与某些基金会不同,ASF 在项目招募方面相当放手。期待 ASF 能一如既往地坚持下去,并与那些看到 ASF 方式的价值的项目一同,阐明 “Apache 之道”的价值。随着 ASF 项目在重大行业变革中处于领先地位(最初是 Web 服务器,最近是通过 Apache Hadoop 和 Spark、Cassandra 和 Kafka 等大数据项目),这种放手的做法已被证明是成功和可持续的。
下一步,ASF 有几个大型的人工智能和机器学习项目。此外,一些物联网项目也通过了 Apache 孵化器,其中几个可能会变得相当有影响力。展望未来,期待 ASF 将一如既往,推出一些主要行业参与者使用的非常成功的开源项目,以及其他小型项目,提供至关重要的(如果有更多的利基市场的话)吸引力。
*(选题:MJ/05f6689e-49df-47db-ba00-924d4fc612fd)*
---
via: <https://opensource.com/article/21/6/apache-software-foundation>
作者:[Justin Mclean](https://opensource.com/users/justin-mclean) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hanszhao80](https://github.com/hanszhao80) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As a longtime volunteer and mentor (and current board member) at the [Apache Software Foundation](https://www.apache.org/) (ASF) and vice president of the Apache Incubator, I'm proud to offer my insights into the unique processes and values with which the ASF operates.
Centered upon the permissive and pragmatic open source [Apache License](https://www.apache.org/licenses/LICENSE-2.0), the ASF conducts itself differently from many other foundations simply because it is a charitable organization constructed for the public good. For example, the ASF board is elected by members. No one can buy a seat on the board, and the ASF's affiliations are with individuals, not companies. Generally, the corporate affiliation of any individual involved with ASF goes unstated, and it doesn't matter. As an outcome, the ASF has fostered a vendor-neutral environment where companies can comfortably collaborate on building valuable projects.
Let's take a look at how the ASF selects its projects, the state of open source licensing today, and what you can expect from the ASF heading into the future.
## The Apache Incubator process and 'The Apache Way'
Potential Apache projects begin in the [Apache Incubator](https://incubator.apache.org/), where they receive assistance and mentoring toward their hopeful graduation as top-level Apache projects. Anyone is welcome to put together a project proposal for the Incubator (they simply need to find someone inside the ASF who's willing to help champion it). When vetting a potential project, the ASF prefers to see a diversity of people and entities involved—and certainly not just a singular corporate body. We've found this greater diversity results in projects that are more widely used and longer lasting.
The central purpose of the Incubator is to help projects learn and operate in alignment with what we call [The Apache Way](https://apache.org/theapacheway/). It is a set of values that inform best practices for community-led development. The most important aspects of The Apache Way include strict vendor-neutral independence and prioritization of a strong community, even over the strength of a project's code. Open and transparent communication is crucial as well: The ASF requires that all project communication is publicly accessible and permanently archived to enable asynchronous collaboration. In addition, the open source Apache License is attached to all accepted projects, ensuring that all source code is publicly available as well.
At the Incubator, we initially look at whether a project is a good fit in terms of how it aligns with these Apache values. It isn't necessary to have 100% alignment, but the project needs to be willing to adapt. There will also be a discussion around ensuring that the project is fully compatible with Apache from a licensing perspective—in some scenarios, dependencies will be removed or replaced as needed. The Apache Way prepares projects to build communities that are self-sustaining. That said, it can be difficult for some projects to build a community, and some don't make it through the incubator.
Another key element of The Apache Way—one essential to thriving communities—is making decisions based on consensus. In our experience, open discussions and avoiding a single individual project leader are mission-critical to that process. We have had a couple of incubating projects that included a strong personality trying to retain control, and well, those projects didn't succeed for that reason.
## Open source and the Apache License
Open source projects come in many varieties. At the same time, using an open source license doesn't automatically make a project open source. It's a project's community that unlocks open source benefits and whose contributions precipitate greater openness and transparency.
Recently, some companies have made high-profile moves away from the Apache License to less-permissive licensing. If your company changes from an open source to a non-open source license, I have to question why you had that open source license in the first place. It probably meant that the business model didn't fit open source. I believe that by changing away from open source licenses, companies are doing a huge disservice to their communities and their users.
As I said, the ASF is a non-profit, charitable organization that creates software for the public good. That's the purpose of the permissive Apache License. Making money off that software is fine, but that's not what the Apache License is about. As a rule, ASF disallows any field-of-use restrictions. *Anyone* can use Apache projects for any reason. The idea behind true open source is that some people who use a project will give back to it, but contributions absolutely cannot be required. The companies that seem so hung up on that point need to understand that isn't how open source works, and that isn't how it should work.
## The future of open source and the ASF
Open source has certainly seen outsized adoption in the last five to 10 years and particular acceleration among enterprises. I think it's safe to say that there's hardly any software on the planet that doesn't include or rely upon open source projects in some way. That adoption is only going to grow.
Unlike some foundations, the ASF is fairly hands-off in terms of project recruitment. Expect the ASF to continue as it has, stating the values of The Apache Way and working with those projects that see value in the ASF's approach. With ASF projects leading at the forefront of major industry shifts—initially with web servers and more recently with big data through projects like Apache Hadoop and Spark, Cassandra, and Kafka—the hands-off stance has shown to be successful and sustainable.
When it comes to what's next, the ASF has several large and buzzed-about artificial intelligence and machine learning projects. In addition, several Internet of Things (IoT) projects have also been passing through the Apache Incubator, some of which will likely become quite influential. Looking forward, expect the ASF to continue as it has, introducing some hugely successful open source projects used by major industry players, with other smaller projects providing vital—if more niche—appeal.
## Comments are closed. |
15,796 | 11 种提高隐私保护的方法 | https://itsfoss.com/improve-privacy/ | 2023-05-09T17:42:06 | [
"隐私"
] | https://linux.cn/article-15796-1.html | 
>
> 不管你是否使用 Linux,都可以采用以下提示来提高在线隐私保护水平,为安全保障带来最佳表现!
>
>
>
渐渐地,用户转向注重隐私,而非便利的解决方案。
为什么?简单来说就是,越来越多的人意识到他们个人数据的价值。
当然,保护隐私并不意味着保持匿名。而是你不会向未经授权的第三方共享重要信息,同时保护个人敏感数据的隐私。
你可以在你使用的各种设备上改善隐私水平。以下是一些行之有效的增强隐私的方法。
>
> ? 以下方法不只限于 Linux 系统,其它各种设备和操作系统同样适用。你不需要必须遵循每一条。这些只是提供的建议。看看哪些方法适合你。
>
>
>
### 1、保护和隐藏你的电子邮件
你的电子邮件会出现在包括从银行到云存储平台等各种在线平台中。
如果你的电子邮件保持私密,你将会收到更少的垃圾邮件和更少的企图接管你的帐户或欺骗你从电子邮件中下载恶意文件的恶意链接。
我想你明白我的意思?
但是,你通常会和每一个你使用的重要应用/服务共享你的电子邮箱地址。
**那么,如何才能做到不共享邮箱也能使用这些应用/服务呢?**
你可以使用**电子邮件别名**来保持你的实际电子邮件地址的私密性。我们提供了 [一系列工具来帮助你保护电子邮件地址](https://itsfoss.com/protect-email-address/)。选择任何一个,如 SimpleLogin,或使用你的电子邮件提供商允许创建的电子邮件别名地址。
此外,尝试使用 Tutanota 或 [ProtonMail](https://itsfoss.click/protonmail?ref=itsfoss.com) 等 [安全电子邮件服务](https://itsfoss.com/secure-private-email-services/) 以获得最佳体验。
>
> ? 本文包括受益链接,如果你购买 Proton VPN 等某些服务,这些链接会给原文作者一小笔佣金,但不会额外收取你的费用。
>
>
>
### 2、保护你的互联网
如果你的互联网连接是暴露的或不安全的,攻击者可以窥探你的网络活动,并可能使用它来获取重要信息或影响你的设备数据。
因此,确保你的互联网安全至关重要。
为此,你可以执行以下操作:
* 使用安全或加密的 DNS,如 [NextDNS](https://nextdns.io/?ref=itsfoss.com) 或 [ControlD](https://controld.com/?ref=itsfoss.com)
* 使用 VPN 加密你的互联网连接
[ProtonVPN](https://go.getproton.me/aff_c?offer_id=10&aff_id=1173&ref=news.itsfoss.com) 和 Mullvad VPN 将是两个很好的选择,提供开源的客户端和 Linux 支持。
### 3、保护你的搜索行为
每个人都利用搜索引擎来查找他们需要的内容。
大多数人会选择谷歌,到目前为止,它是地球上最受欢迎的网站。
但是,它会收集你的一些数据以提高其可搜索可用性,并且还可能根据你的喜好和其他因素个性化搜索结果。
如果你想要完全私密的搜索体验和非个性化结果,[隐私友好的搜索引擎](https://itsfoss.com/privacy-search-engines/) 应该会有所帮助。
### 4、使用注重隐私的浏览器
就像你使用搜索引擎一样,浏览器是交互过程的重要手段。
就个人而言,我向你推荐 Vivaldi、Firefox 和 Brave。如果你想了解更多,请查看我们的 Linux 最佳浏览器列表。
>
> **[10 个最佳的支持 Linux 的浏览器](https://itsfoss.com/best-browsers-ubuntu-linux/)**
>
>
>
### 5、不要安装未知程序
无论你使用 Linux 还是任何其他操作系统,都不应安装未知的应用。并非所有程序都有隐私保护。
有些根本不收集任何数据,有些则会收集。
在选择要安装新的软件之前,你可以寻找绿色软件特征。其中包括:
* 它有大量的用户(不仅仅是新用户)。
* 它非常受欢迎。
* 它是开源的,并且具有稳定的版本。
还有一些值得你注意的点:
* 即使该软件是专有的, 你也应该查看其受欢迎程度和隐私政策。
* 通常,最好避免使用新的软件工具。
* 请勿下载未验证的电子邮件附件。
* 从其官方渠道下载软件。不要使用第三方分发网站下载软件包,除非官方推荐。
### 6、设置所有隐私调整选项
你使用的每个应用程序、每个操作系统和每项服务都提供一定程度的隐私控制。
例如,你可以向公众隐藏你的 Instagram 帐户,并且只对你想分享的人和关注者开放。
我建议你点开手机、Linux 桌面和其他应用的“隐私设置”页面。

它可以是各种形式,删除旧文件、禁用诊断信息共享等。如果你觉得可行,请使用可用的选项来获得你的最佳体验。
### 7、使用安全的密码管理器
密码和凭据是一切的核心。如果你需要确保它们受到良好的保护和组织,请使用优秀的密码管理器。
我通常为所有类型的用户推荐 [Bitwarden](https://bitwarden.com/?ref=itsfoss.com) 和 KeePassXC。
如果你更想要离线使用,[KeePassXC](https://keepassxc.org/?ref=itsfoss.com) 可以跨平台使用。如果你想要基于云的解决方案,Bitwarden 不失为一个好选择。
你还可以了解一些 [面向 Linux 用户的密码管理器](https://itsfoss.com/password-managers-linux/)。
### 8、确保笔记安全
记录笔记对于很多人来说是一种习惯,这习惯可能好也可能不好。
为什么这么说呢?嗯,便签通常有敏感信息,有时是密码或 PIN。
所以,如果你确保你的笔记是安全的,这是提高隐私保护的最简单方法之一。
建议使用 [Standard Notes](https://standardnotes.com/?ref=itsfoss.com) 和 [CryptPad](https://cryptpad.fr/?ref=itsfoss.com)。你可以了解一下具有端到端加密或各种功能的其它选择:
>
> **[想在 Linux 上寻找一些好的笔记应用程序](https://itsfoss.com/note-taking-apps-linux/)**
>
>
>
### 9、在私有云平台上存储或备份
不是每个人都有时间或耐心来维护/配置 RAID 设置以在家中存储/备份数据。
因此,云存储服务是通用解决方案。
我个人的建议包括 [Mega](https://mega.nz/aff=cGWF0mqjBJ0?ref=itsfoss.com)(端到端加密)和 [pCloud](https://partner.pcloud.com/r/1935?ref=itsfoss.com)。你还可以查看我们的云存储服务清单以寻求更好的选择。
>
> **[10 个支持 Linux 的最好的免费云存储服务](https://itsfoss.com/cloud-services-linux/)**
>
>
>
此外,借助 [Cryptomator](https://cryptomator.org/?ref=itsfoss.com) 等解决方案,你可以在将文件上传到云之前对其进行加密。
### 10、使用私人通讯软件
你可以使用开源加密软件如 [Signal](https://www.signal.org/?ref=itsfoss.com)(跨平台)来保护你的通讯。
有 [多个 WhatsApp 替代品](https://itsfoss.com/private-whatsapp-alternatives/) 可供个人使用。
如果要商用,可以考虑 [开源的 Slack 替代方案](https://itsfoss.com/open-source-slack-alternative/)。
### 11、专用发行版
如果你对新鲜事物充满了兴趣,尝试量身定制的操作系统,比如 [Tails OS](https://tails.boum.org/?ref=itsfoss.com)、 [Whonix](https://www.whonix.org/?ref=itsfoss.com) 等。
这些系统有的会在你完成操作后立即清除你的活动记录,有的具有特殊的安全功能,完全能满足你的日常使用。
如果你感兴趣,可以试试 [注重隐私的 Linux 发行版](https://itsfoss.com/privacy-focused-linux-distributions/)。
? **仍然不知道该如何做?**
我有一篇专栏,列出了一些针对注重隐私的浏览器、VPN、通讯软件等。如果你无法决定要选择什么来掌控你的隐私,你可以随时参考它。
>
> **[12 个保护隐私的简单工具](https://itsfoss.com/privacy-tools)**
>
>
>
*(题图:MJ/b4ffbfa6-432b-4a15-adb9-d1089f20d4ab)*
---
via: <https://itsfoss.com/improve-privacy/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Dangal2018](https://github.com/Dangal2018) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Slowly, users are moving to privacy-focused solutions instead of convenient options.
Why? Simply because many have realized the worth of their personal data.
Of course, protecting your privacy does not mean staying anonymous. But, taking control of privacy means that you do not share essential information with unauthorized parties while keeping your sensitive data private from everyone.
You can improve privacy on all kinds of devices you use. Here, I shall provide some proven methods to enhance privacy easily.
## 1. Secure & Hide Your Email
Your email address is connected to everything online, whether banking or a cloud storage platform.
If your email remains private, you get less spam and fewer attempts to take over your account or trick you into downloading a malicious file from your email.
I think you get what I mean 🙃
But… you share your email address with every essential app/service you use.
**So, how can you not share them but still use them?**
You can use **email aliases** to keep your actual email address private. We have a list of [tools to help protect your email address](https://itsfoss.com/protect-email-address/). Choose any options like SimpleLogin or use the email alias addresses your email provider allows creating.
Also, try using [secure email services](https://itsfoss.com/secure-private-email-services/) like Tutanota or [ProtonMail](https://itsfoss.click/protonmail) for the best experience.
**Suggested Read 📖**
[Best Secure Email Services For Privacy Concerned PeopleCan you call Gmail, Outlook, YahooMail etc secure email services? Well, they’re definitely secure in the way that your data is (usually) safe from outside attackers. But when we talk of secure email service, the focus is on data security and privacy. Most of these free email services snoop](https://itsfoss.com/secure-private-email-services/)

## 2. Secure Your Internet
With an exposed or insecure internet connection, an attacker can snoop on your web activity and potentially use it to gain vital information or affect your device data.
So, it is essential to keep your internet secure.
To achieve that, you can do a few things like:
[ProtonVPN](https://go.getproton.me/aff_c?offer_id=10&aff_id=1173&ref=news.itsfoss.com), Mullvad VPN and [Surfshark](https://get.surfshark.net/aff_c?offer_id=926&aff_id=13591) would be some excellent options, offering open-source clients and Linux support.
[Best VPN Services for Privacy Minded Linux UsersNo matter whether you use Linux or Windows, ISPs spy all the time. Also, it is often your Internet Service Provider who enforces annoying restrictions, and throttles speed while tracking your online activity. I’m not sure what might be the cause of a privacy breach for you – but when](https://itsfoss.com/best-vpn-linux/)

## 3. Secure Your Search Activity
Everyone utilizes a search engine to find what they are looking for.
For most of them, it is Google. It is the most popular website on the planet as of now.
But, it collects some of your data to improve its searchability and may also personalize the search results per your likes and other factors.
However, if you want an entirely private search experience and non-personalized results, [privacy-friendly search engines](https://itsfoss.com/privacy-search-engines/) should be helpful.
[10 Privacy Oriented Alternative Search Engines To GoogleBrief: In this age of the internet, you can never be too careful with your privacy. Use these alternative search engines that do not track you. Google — unquestionably the best search engine out there (for most)- uses powerful and intelligent algorithms (including A.I. implementations) to let u…](https://itsfoss.com/privacy-search-engines/)

## 4. Use a Privacy-Focused Browser
Just like you use search engines, the browser is a vital means of the interaction process.
A browser with solid privacy and security features should help you enhance your browsing experience.
Personally, I could point you to **Vivaldi, Firefox, and Brave**. If you are keen to explore more options, look at our list of the [best browsers for Linux](https://itsfoss.com/best-browsers-ubuntu-linux/).
[Top 10 Best Browsers for Ubuntu LinuxWhat are your options when it comes to web browsers for Linux? Here are the best web browsers you can pick for Ubuntu and other Linux distros.](https://itsfoss.com/best-browsers-ubuntu-linux/)

## 5. Do Not Install a Program You Don't Know
Whether you use Linux or any other operating system, you should not install anything you are unaware of. Not all programs are privacy-friendly.
Some do not collect any data at all, and some do.
Yes, there are certain green flags that you can look for before picking a new software to install. Some of them include:
- It has a decent number of users (not entirely new).
- It is incredibly popular.
- It is open source and has a stable release.
Some other pointers that you can keep in mind:
- Even if the program is proprietary, you should check out its popularity and privacy policy.
- Usually, best to avoid new software tools.
- Do not download email attachments without separately verifying them.
- Download software from its official channels. Do not use third-party distribution websites to download packages unless they officially recommend it.
## 6. Utilize All Privacy Tweaks and Options
Every app, every operating system, and every service that you use provides some amount of privacy control.
For instance, you can hide your Instagram account from the public and only accept followers you know/want.
Similarly, when possible, I recommend you head to “**Privacy settings**” on your mobile phone, Linux desktop, and everything else.
It can be anything, deleting your old files, disabling diagnostics information sharing, and so on. If it sounds feasible to you, use the available option to your advantage.
## 7. Use Secure Password Managers
Passwords and credentials are at the center of everything. If you need to ensure they are well-protected and organized, use a good password manager.
I usually suggest [Bitwarden](https://bitwarden.com) and KeePassXC for all kinds of users.
If you prefer keeping things offline, [KeePassXC](https://keepassxc.org/?ref=itsfoss.com) is available cross-platform. And, if you want a cloud-based solution, Bitwarden should not disappoint.
You can also explore some [password managers for Linux users](https://itsfoss.com/password-managers-linux/).
## 8. Keep Your Notes Secure
Taking notes can be a habit for some, and it can be a good/bad one.
Why do I say that? Well, notes often have sensitive information, sometimes passwords or PINs.
So, if you make sure that your notes are secure, it is one of the easiest ways to boost your privacy game.
Recommendations will include [Standard Notes](https://standardnotes.com) and [CryptPad](https://cryptpad.fr). You can explore other options with end-to-end encryption or a variety of features:
[Looking for Some Good Note Taking Apps on Linux? Here are the Best Notes Apps we Found for YouNo matter what you do — taking notes is always a good habit. Yes, there are a lot of note taking apps to help you achieve that. But, what about some open-source note taking apps for Linux? Fret not, you don’t need to endlessly search the Internet to find the](https://itsfoss.com/note-taking-apps-linux/)

## 9. Store or Backup on a Private Cloud Platform
Not everyone has the time or patience to maintain/configure a RAID setup to store/backup data at home.
So, cloud storage services are the usual solution.
My personal recommendations include [Mega](https://mega.nz/aff=cGWF0mqjBJ0?ref=itsfoss.com) (end-to-end encryption), and [pCloud](https://partner.pcloud.com/r/1935?ref=itsfoss.com). But I suggest you check out our [list of cloud storage services](https://itsfoss.com/cloud-services-linux/) to explore better options.
Additionally, you can encrypt your files before uploading them to the cloud thanks to solutions like [Cryptomator](https://cryptomator.org).
[Top 10 Best Free Cloud Storage Services for LinuxWhich cloud service is the best for Linux? Check out this list of free cloud storage services that you can use in Linux.](https://itsfoss.com/cloud-services-linux/)

## 10. Use Private Messengers
You can always utilize open-source and encrypted messengers like [Signal](https://www.signal.org) (cross-platform) to secure your communications.
There are [multiple WhatsApp alternatives](https://itsfoss.com/private-whatsapp-alternatives/) that you can explore for personal use.
If it is for your business, [open source Slack alternatives](https://itsfoss.com/open-source-slack-alternative/) should help.
**Suggested Read 📖**
[9 Best Matrix Clients for Decentralized MessagingMatrix is an open network standard tailored for secure decentralized real-time communication. It is published and maintained by a non-profit, Matrix.org Foundation. They aim to create an open, independent, and evolving communication platform. If an application supports the Matrix protocol,…](https://itsfoss.com/best-matrix-clients/)

## 11. Specialized Distributions
If you are adventurous and want to try an entirely different operating system tailored to give you a private experience, you can pick [Tails OS](https://tails.boum.org/?ref=itsfoss.com), [Whonix](https://www.whonix.org), and similar options.
Some are built to erase your activity as soon as you finish it. And some of them feature special security features, which could be overwhelming for daily usage.
If you are curious, explore the [best privacy-focused Linux distributions](https://itsfoss.com/privacy-focused-linux-distributions/).
🤨 **Still, confused about what you want to do? **
I have a separate article listing some of the best browsers, VPNs, messengers, etc., for privacy-focused users. You can always refer to that if you cannot decide what you want to pick to take control of your privacy.
[12 Simple Tools to Protect Your PrivacyQuick ways to enhance online privacy? Use these simple tools to take control of your data easily.](https://itsfoss.com/privacy-tools)
 |
15,798 | 服务器推送事件:一种从服务器流式推送事件的简易方法 | https://jvns.ca/blog/2021/01/12/day-36--server-sent-events-are-cool--and-a-fun-bug/ | 2023-05-10T08:58:55 | [
"服务器推送事件"
] | https://linux.cn/article-15798-1.html | 
哈喽!昨天我见识到了一种我以前从没见过的从服务器推送事件的炫酷方法:<ruby> <a href="https://html.spec.whatwg.org/multipage/server-sent-events.html"> 服务器推送事件 </a> <rt> server-sent events </rt></ruby>!如果你只需要让服务器发送事件,相较于 Websockets,它们或许是一个更简便的选择。
我会聊一聊它们的用途、运作原理,以及我昨日在试着运行它们的过程中遇到的几个错误。
### 问题:从服务器流式推送更新
现在,我有一个启动虚拟机的 Web 服务,客户端轮询服务器,直到虚拟机启动。但我并不想使用轮询方式。
相反,我想让服务器流式推送更新。我跟 Kamal 说我要用 Websockets 来实现它,而他建议使用服务器推送事件不失为一个更简便的选择!
我登时就愣住了——那什么玩意???听起来像是些我从来没见过的稀罕玩意儿。于是乎我就查了查。
### 服务器推送事件就是个 HTTP 请求协议
下文便是服务器推送事件的运作流程。我-很-高-兴-地了解到它们就是个 HTTP 请求协议。
1.客户端提出一个 GET 请求(举个例子)`https://yoursite.com/events` 2.客户端设置 `Connection: keep-alive`,这样我们就能有一个长连接 3.服务器设置设置一个 `Content-Type: text/event-stream` 响应头 4.服务器开始推送事件,就比如下文这样:
```
event: status
data: one
```
举个例子,这里是当我借助 `curl` 发送请求时,一些服务器推送事件的样子:
```
$ curl -N 'http://localhost:3000/sessions/15/stream'
event: panda
data: one
event: panda
data: two
event: panda
data: three
event: elephant
data: four
```
服务器可以根据时间推移缓慢推送事件,并且客户端也能够在它们到来时读取它们。你也可以将 JSON 或任何你想要的东西放在事件当中,就比如 `data: {'name': 'ahmed'}`。
线路协议真的很简单(只需要设置 `event:` 和 `data:`,或者如果你愿意,可设置为 `id:` 和 `retry:`),所以你并不需要任何花里胡哨的服务器库来实现服务器推送事件。
### JavaScript 的代码也超级简单(仅使用 EventSource)
以下是用于流式服务器推送事件的浏览器 JavaScript 的代码。(我从 [服务器推送事件的 MND 页面](https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events/Using_server-sent_events) 得到的这个范例)
你可以订阅所有事件,也可以为不同类型的事件使用不同的处理程序。这里我有一个只接受类型为 `panda` 的事件的处理程序(就像我们的服务器在上一节中推送的那样)。
```
const evtSource = new EventSource("/sessions/15/stream", { withCredentials: true })
evtSource.addEventListener("panda", function(event) {
console.log("status", event)
});
```
### 客户端在中途不能推送更新
不同于 Websockets,服务器推送事件不允许大量的来回事件通讯。(这体现在它的字眼中 —— **服务器** 推送所有事件)。初始的时候客户端发出一个请求,然后服务器发出一连串响应。
### 如果 HTTP 连接结束,它会自动重连
使用 `EventSource` 发出的 HTTP 请求和常规 HTTP 请求有一个很大的区别,MDN 文档中对此有所说明:
>
> 默认情况下,如果客户端和服务器之间的连接断开,则连接会重启。请使用 `.close()` 方法来终止连接。
>
>
>
很奇怪,一开始我真的被它吓到了:我打开了一个连接,然后在服务器端将其关闭,然后两秒过后客户端向我的传送终端发送了另一条请求!
我觉得这里可能是因为连接在完成之前意外断开了,所以客户端自动重新打开了它以防止类似情况再发生。
所以如果你不想让客户端继续重试,你就得通过调用 `.close()` 直截了当地关闭连接。
### 这里还有些其它特性
你还能在服务器推送事件中设置 `id:` 和 `retry:` 字段。似乎,如果你在服务器推送事件上设置,那么当重新连接时,客户端将发送一个 `Last-Event-ID` 响应头,带有它收到的最后一个 ID。酷!
我发现 [W3C 的服务器推送事件页面](https://html.spec.whatwg.org/multipage/server-sent-events.html#event-stream-interpretation) 令人惊讶地容易理解。
### 在设置服务器推送事件的时候我遇到了两个错误
我在 Rails 中使用服务器推送事件时遇到了几个问题,我认为这些问题挺有趣的。其中一个缘于 Nginx,另一个是由 Rails 引起的。
**问题一:我不能在事件推送的过程中暂停**
这个奇怪的错误是在我做以下操作时出现的:
```
def handler
# SSE is Rails' built in server-sent events thing
sse = SSE.new(response.stream, event: "status")
sse.write('event')
sleep 1
sse.write('another event')
end
```
它会写入第一个事件,但不能写入第二个事件。我对此-非-常-困-惑,然后放开脑洞,试着理解 Ruby 中的 `sleep` 是如何运作的。但是 Cass 将我引领到一个与我有着相同困惑的 [Stack Overflow 问答帖](https://stackoverflow.com/questions/25660399/sse-eventsource-closes-after-first-chunk-of-data-rails-4-puma-nginx),而这里包含了让我为之震惊的回答!
事实证明,问题出在我的 Rails 服务器位于 Nginx 之后,似乎 Nginx 默认使用 HTTP/1.0 向上游服务器发起请求(为啥?都 2021 年了,还这么干?我相信这其中一定有合乎情理的解释,也许是为了向下兼容之类的)。
所以客户端(Nginx)会在服务器推送第一个事件之后直接关闭连接。我觉得如果在我推送第二个事件的过程中 *没有* 暂停,它继续正常工作,基本上就是服务器在连接关闭之前和客户端在争速度,争着推送第二部分响应,如果我这边推送速度足够快,那么服务器就会赢得比赛。
我不确定为什么使用 HTTP/1.0 会使客户端的连接关闭(可能是因为服务器在每个事件结尾写入了两个换行符?),但因为服务器推送事件是一个比较新的玩意儿,HTTP/1.0 (这种老旧协议)不支持它一点都会不意外。
设置 `proxy_http_version 1.1` 从而解决那个麻烦。好欸!
**问题二:事件被缓冲**
这个事情解决完,第二个麻烦接踵而至。不过这个问题实际上非常好解决,因为 Cass 已经建议将 [stackoverflow 里另一篇帖的回答](https://stackoverflow.com/questions/63432012/server-sent-events-in-rails-not-delivered-asynchronously/65127528#65127528) 作为前一个问题的解决方案,虽然它并没有是导致问题一出现的源头,但它-确-实-解-释-了问题二。
问题在这个示例代码中:
```
def handler
response.headers['Content-Type'] = 'text/event-stream'
# Turn off buffering in nginx
response.headers['X-Accel-Buffering'] = 'no'
sse = SSE.new(response.stream, event: "status")
10.times do
sse.write('event')
sleep 1
end
end
```
我本来期望它每秒返回 1 个事件,持续 10 秒,但实际上它等了 10 秒才把 10 个事件一起返回。这不是我们想要的流式传输方式!
原来这是因为 Rack ETag 中间件想要计算 ETag(响应的哈希值),为此它需要整个响应为它服务。因此,我需要禁用 ETag 生成。
Stack Overflow 的回答建议完全禁用 Rack ETag 中间件,但我不想这样做,于是我去看了 [链接至 GitHub 上的议题](https://github.com/rack/rack/issues/1619)。
那个 GitHub 议题建议我可以针对仅流式传输终端应用一个解决方法,即 `Last-Modified` 响应头,显然,这么做可以绕过 ETag 中间件。
所以我设置为:
```
headers['Last-Modified'] = Time.now.httpdate
```
然后它起作用了!!!
我还通过设置响应头 `X-Accel-Buffering: no` 关闭了位于 Nginx 中的缓冲区。我并没有百分百确定我要那样做,但这么做似乎更安全。
### Stack Overflow 很棒
起初,我全身心致力于从头开始调试这两个错误。Cass 为我指向了那两个 Stack Overflow 帖子,一开始我对那些帖下提出的解决方案持怀疑态度(我想:“我没有使用 HTTP/1.0 啊!ETag 响应头什么玩意,跟这一切有关系吗??”)。
但结果证明,我确实无意中使用 *了* HTTP/1.0,并且 Rack ETag 中间件确实给我带来了问题。
因此,也许这个故事告诉我,有时候计算机就是会以奇怪的方式相互作用,其它人在过去也遇到过计算机以完全相同的奇怪方式相互作用的问题,而 Stack Overflow 有时会提供关于为什么会发生这些情况的答案 : )
我认为重要的是不要随意从 Stack Overflow 中尝试各种解决方案(当然,在这种情况下不会有人建议这样做!)。对于这两个问题,我确实需要去仔细思考,了解发生了什么,还有为什么更改这些设置会起作用。
### 就是这样!
今天我要继续着手实现服务器推送事件,因为昨天一整天我都沉浸在上述这些错误里。好在我学到了一个以前从未听说过的易学易用的网络技术,心里还是很高兴的。
*(题图:MJ/4c08a193-086e-4efe-a662-00401c928c41)*
---
via: <https://jvns.ca/blog/2021/01/12/day-36--server-sent-events-are-cool--and-a-fun-bug/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Drwhooooo](https://github.com/Drwhooooo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
15,799 | 7 个超轻量级 Linux 发行版 | https://itsfoss.com/super-lightweight-distros/ | 2023-05-10T17:37:00 | [
"发行版",
"轻量级"
] | https://linux.cn/article-15799-1.html | 
>
> 值得试一试这些超级小的、轻量级的 Linux 发行版。
>
>
>
Linux 发行版的多样性不是缺点,而是有益的特性。
无论你的需求是在旧硬件或者存储空间有限的系统上运行 Linux,还是需要占用最少磁盘空间同时又能处理特定任务,在这里都可以找到适合你的选项。
因此,让我重点介绍一些用于此类场景的超轻量级 Linux 发行版。
>
> ? 需要注意的是,对系统要求较低和占用存储空间较小的发行版可能无法为所有人提供便利的桌面体验,你可能需要做一些调整。
>
>
>
### 1、Tiny Core

[Tiny Core](http://tinycorelinux.net/?ref=itsfoss.com),又名 The Core x86 Project,是一款模块化的 Linux 发行版,提供了几种变体的超小型 ISO 文件。
其中最小的是 “**Core**” 版(**17 MB**),只提供命令行界面和一些工具,没有任何图形桌面环境。其次是 **TinyCore**(**23 MB**),它包括基本系统和图形桌面环境的 GUI 扩展。
最后一个,**CorePlus ISO**(**248 MB**)是为新用户量身定制的,它支持无线网络、提供可选的多种窗口管理器,以及一些来帮助安装发行版的其他 GUI 工具。
该发行版的大小多年来一直在增长。但是,它仍然令人印象深刻。
### 2、Puppy Linux

[Puppy Linux](https://puppylinux-woof-ce.github.io/?ref=itsfoss.com) 是一个因其文件大小极小和易用性而广受欢迎的 Linux 发行版。它是本列表中最古老的选项,起源可以追溯到 **2003** 年。
其 ISO 文件大小为 300-400 MB,具体取决于你选择的变体。
是的,Puppy Linux 不是单个 Linux 发行版。该项目使用其他发行版,并使用其系统构建器重建它们,添加其应用并进行配置,以使 ISO 最终的大小通常小于 500 MB。
你能找到 **Ubuntu、Raspbian 和 Slackware 的 Puppy Linux 变体,包括 32 位和 64 位版本。**
### 3、SliTaz

[SliTaz](https://www.slitaz.org/en/?ref=itsfoss.com) 是一款有趣的 [滚动发布的发行版](https://itsfoss.com/rolling-release/),提供了所有必要的内容,以获得可用的桌面体验。
而所有这些都放在只有 **43MB** 的 ISO 中。令人惊讶,对吧!与 TinyCore 不同,你可以得到图形用户界面,同时节省大量存储空间。
SliTaz 完全是从头开始构建的,因此它一款独立发行版。它可能不适合初学者,但它确实包含一些实用程序,可帮助你安装必备软件,并以最小的学习曲线入门。
### 4、Bodhi Linux

[Bodhi Linux](https://www.bodhilinux.com/?ref=itsfoss.com) 是基于 Ubuntu 的流行的 [轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/) 之一。如果你想要一个轻量级的选择和便捷的用户体验,搭载 Moksha 桌面的 Bodhi Linux 就是答案。
其 ISO 文件的大小小于 900 MB。因此,是的,它可能不是各种替代方案中最轻量级的,但如果你不想牺牲使用体验,那么选择它一定不会错。
### 5、AntiX Linux

[AntiX Linux](https://antixlinux.com/?ref=itsfoss.com) 基于 Debian 稳定分支构建。它是 [支持 32 位系统的发行版](https://itsfoss.com/32-bit-linux-distributions/) 之一。
它提供了多个变体,包括:**Full、Base、Core 和 net**。Full 版略大于 1GB,包含许多预装的应用。带有 GUI(窗口管理器)的 Base 大约为 800 MB。
其他版本不提供 GUI,ISO 文件小于 500 MB。
如果你不知道,AntiX Linux 支持两种不同的初始化系统 SysVinit 或 runit。因此,AntiX Linux 也是 [无 Systemd 发行版](https://itsfoss.com/systemd-free-distros/) 之一。
### 6、Porteus Linux

[Porteus Linux](http://www.porteus.org/?ref=itsfoss.com) 是一款针对最小硬件优化的发行版,其 ISO 镜像大小不到 300 MB。
它支持 32 位和 64 位系统。Porteus 基于 Slackware,提供了两个版本,一个用于桌面,另一个用于信息亭(网络终端)。
你可以使用 Porteus 携带的多种桌面环境,包括 GNOME 和 KDE,在这么小的包中获得熟悉的桌面体验。
### 7、ArchBang Linux

[ArchBang](https://archbang.org/?ref=itsfoss.com) 是一款基于 Arch 的发行版,它使用 i3 窗口管理器,不到 1GB ISO 文件提供了轻量级体验。
如果您想使用一种带有某些额外便利的极简 Arch Linux 体验,那么 ArchBang 是一个不错的选择。
你可以参照我们的 [ArchBang 安装指南](https://itsfoss.com/install-archbang/) 开始使用。
此外,如果你想自定义 ArchBang Linux 的外观,可以参考我们的 [i3 自定义指南](https://itsfoss.com/i3-customization/)。
### 节省你的系统资源以获得快速体验
如果你想节省系统资源并仍然能够执行基本任务,那么这些发行版是你安装的最佳选择。
考虑到缺少预安装的应用和实用程序,你可能无法在其中一些发行版上完成所有操作。但是,我们精心挑选的选择应该可以为你提供可用的桌面体验。
你曾经使用过这些发行版么?你的使用经验如何?
*(题图:MJ/3605b6f0-811f-419a-b3b8-9da0046586b3)*
---
via: <https://itsfoss.com/super-lightweight-distros/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The variety of Linux distributions available is not a disadvantage but a helpful trait.
There is something for everyone. And here, we want to address the options tailored for users who wish to run Linux on dated hardware and systems with shallow storage space.
Or maybe, you want the operating system to occupy the least space while you can carry out specific tasks on your computer?
So, let me highlight some super lightweight Linux distros for such use cases.
## 1. Tiny Core
[Tiny Core](http://tinycorelinux.net), aka The Core x86 Project, is a modular Linux distribution offering different super small ISO files featuring the distro variants.
The smallest is the "**Core**" edition (**17 MB**), which provides a command line interface and some tools without any graphical desktop environment. The second is **TinyCore** (**23 MB**), which includes the base system and GUI extensions for a graphical desktop environment.
Ultimately, a **CorePlus ISO** (**248 MB**) is tailored for new users, with support for wireless networks, a choice for window managers, and some other GUI tools to help install the distro.
The size of the distro has grown over the years. However, it is still something impressive.
## 2. Puppy Linux
[Puppy Linux](https://puppylinux-woof-ce.github.io) is a popular name known for its minimal file size and ease of use. It is the oldest option in this list here, all the way back from **2003**.
The ISO file sizes range from 300-400 MB, depending on your chosen variant.
Yes, Puppy Linux is not a single Linux distro. The project uses other distros and rebuilds them using its system builder, adds its applications, and configures so that the ISO usually ends up less than 500 MB in size.
You can find puppy variants of **Ubuntu, Raspbian, and Slackware in 32-bit and 64-bit editions.**
## 3. SliTaz
[SliTaz](https://www.slitaz.org/en/) is an interesting [rolling-release distribution](https://itsfoss.com/rolling-release/) with all the essentials for a usable desktop experience.
All of this is in just **43 MB** ISO. Surprising, isn't it? Unlike TinyCore, you get a GUI while saving much storage space.
It is entirely built from scratch, making it an independent distribution. SliTaz may not be suitable for beginners, but it does include utilities that help you install the essentials and get started with a minimal learning curve.
**Suggested Read 📖**
[13 Independent Linux Distros That are Built From ScratchUnique and independent Linux distributions that are totally built from scratch. Sounds interesting? Check out the list here.](https://itsfoss.com/independent-linux-distros/)

## 4. Bodhi Linux
[Bodhi Linux](https://www.bodhilinux.com) is one of the popular [lightweight Linux distributions](https://itsfoss.com/lightweight-linux-beginners/) based on Ubuntu. If you want a lightweight option and a convenient user experience, Bodhi Linux, with its Moksha desktop, is the answer.
The ISO size is less than 900 MB. So, yes, it may not be the lightest among the alternatives, but you cannot go wrong if you do not want to compromise your experience.
## 5. AntiX Linux
[AntiX Linux](https://antixlinux.com) is built on top of Debian's stable branch. It is one of the [distros that support 32-bit systems](https://itsfoss.com/32-bit-linux-distributions/).
It offers different variants that include: **Full, Base, Core, and net**. The full version is a little over 1 GB, packed with many pre-installed applications. The base is around 800 MB with a GUI (window manager).
The other editions do not offer a GUI, which is less than 500 MB.
If you did not know, AntiX Linux supports two different init systems SysVinit or runit. So, AntiX Linux is one of the [Systemd-free distros](https://itsfoss.com/systemd-free-distros/) as well.
**Suggested Read 📖**
[Top 15 Linux Distros That Still Support 32 Bit SystemsIf you have vintage hardware with 32-bit processor and you would like to keep on using it, here are the best choices of Linux distros with 32-bit support.](https://itsfoss.com/32-bit-linux-distributions/)

## 6. Porteus
[Porteus Linux](http://www.porteus.org) is a distro optimized for minimal hardware featuring an ISO image less than 300 MB in size.
It supports both 32-bit and 64-bit systems. Porteus is based on Slackware and offers two editions, one for desktops and the other for kiosks (web terminals).
You get different desktop flavors with Porteus that include GNOME and KDE. So, you can have a familiar desktop experience in such a tiny package.
## 7. ArchBang Linux

[ArchBang](https://archbang.org) is an Arch-based distro that uses the i3 window manager to offer a lightweight experience under a 1 GB ISO file size.
If you want to use a minimal Arch Linux experience with some added convenience, ArchBang is a good option.
You can follow our [ArchBang installation guide](https://itsfoss.com/install-archbang/) to get started.
Additionally, you can refer to our [i3 customization guide](https://itsfoss.com/i3-customization/) if you want to customize the look of ArchBang Linux.
**Suggested Read 📖**
[The Ultimate Guide to i3 Customization in LinuxLearn about customizing your system’s look and feel with i3 window manager in this super-detailed guide.](https://itsfoss.com/i3-customization/)

## Save Your System Resources for a Fast Experience
These distributions are some of your best options to install if you want to save system resources and still be able to carry out basic tasks.
Considering the lack of pre-installed applications and utilities, you may not be able to do everything on some of these distros. However, our handpicked choices should give you a usable desktop experience.
**Recommended Read 📖**
[16 Best Lightweight Linux Distributions for Older ComputersDon’t throw your old computer just yet. Use a lightweight Linux distro and revive that decades-old system.](https://itsfoss.com/lightweight-linux-beginners/)

Have you ever used such a distribution? How's your experience with it? |
15,801 | 在 Linux 上用 Kdenlive 编辑视频 | https://opensource.com/article/21/12/kdenlive-linux-creative-app | 2023-05-11T11:58:32 | [
"视频编辑",
"Kdenlive"
] | /article-15801-1.html |
>
> 尝试用这个 KDE 程序做专业的视频编辑。
>
>
>

无论是雪日、季节性假期,或是任何假期,都是在你电脑前专心发挥创造力的好时候。我最喜欢的一种消遣就是剪视频。有时,我为了讲个故事来剪;其他时候,我则是为了表达我的心情、观点、为我发现或创作的音乐提供视觉效果。也许这是因为我在学校为从事这一领域的职业学习了剪视频,或就只是因为我喜欢强大的开源工具。至今,我最喜欢的视频剪辑程序是优秀的 Kdenlive,这是一个强大而专业的剪辑工具,提供了直观的工作流、大量的特效和转场。
### 在 Linux 上安装 Kdenlive
Kdenlive 可以通过大部分的 Linux 发行版的包管理器安装。在 Fedora、Mageia 或类似的发行版:
```
$ sudo dnf install kdenlive
```
在 Elementary、Mine 或其他基于 Debian 的发行版:
```
$ sudo apt install kdenlive
```
不过,我用 [Flatpak](https://opensource.com/article/21/11/install-flatpak-linux) 来安装 Kdenlive。
### 如何籍视频讲故事
到底“编辑”视频是什么意思?
剪辑视频有些夸张的误解。当然,它是使鸿篇巨制的大片影响全世界数百万人的过程,但当你在你的笔记本前坐下时,你不必那样想。剪辑视频就是一个十分简单的,移除“坏的”部分,直到只剩下“好的”部分的工作。
什么是“好”镜头还是“坏”镜头,完全取决于你自己的品味,甚至可能根据你想用你的创作 “说” 的内容而改变。如果你在剪辑你在后院发现的野生动物的镜头,你可能会剪掉那些突出你的垃圾桶或你踩着耙子的镜头。剩下的部分肯定会使你的后院看起来像一个神奇的秘密花园,里面有蜂鸟、蝴蝶、好奇的兔子和一只俏皮的狗。另一方面,留下这些 “坏” 镜头,你就可以创造一部喜剧,讲述一个郊区人在清理垃圾时,踩到了耙子上,把所有的动物都吓跑了,总之是在捣乱。这没有对错之分。无论你切掉什么,没有人知道曾经存在过。无论你保留什么,都会有一个故事。
### 导入镜头
当你启动 Kdenlive,你会有个空项目。Kdenlive 窗口包括在左上角 <ruby> 项目箱 <rt> Project Bin </rt></ruby>、一个在中间的信息框,以及一个在右上的 <ruby> 项目监视器 <rt> Project Monitor </rt></ruby>。在下面的是十分重要的部分—— <ruby> 时间轴 <rt> Timeline </rt></ruby>。时间轴是创建你的故事的地方。在你的项目结束时,时间轴中的所有内容都是你的观众所看到的。这就是你的影片。
在你开始在你的时间轴上构建故事前,你需要一些素材。假设你已经从相机或手机上获得了一些视频,你必须在项目箱中增加一些素材。右键点击项目箱面板的空位置,然后选择 <ruby> 添加素材或文件夹 <rt> Add Clip or Folder </rt></ruby>。

### 裁剪镜头
Kdenlive 中有许多方式来裁剪视频镜头。
#### 三点式编辑
以前,创建素材的正式方式是“三点式编辑”,包括如下几点:
1. 在 <ruby> 素材监视器 <rt> Clip Monitor </rt></ruby> 中打开一个视频素材,找到你希望视频开始的点,然后点键盘上的 `l` 来标记 *开始*。
2. 然后找你想让视频停止的点,并按 `O` 来标记 *结束*。
3. 从素材监视器拖动视频素材到 Kdenlive 窗口底部的时间轴上的某一个位置。

这个方法依然在某些环境中保有重要地位,但对于很多用户来说太“书面化”了。
#### 轴内编辑
另一个编辑的方法是拖动切片到 Kdenlive 的时间轴面板,并拖动切片的边缘,直到只留下好的部分。

### 离切的艺术
另一种编辑技巧是 <ruby> <rt> 离切 </rt> cut-away</ruby>。这是个重要的技巧,它不只帮助你跳过视频切片中的坏的部分,而且可以为你的观众增加背景信息。在电影和电视中,你已经见过了许多离切,即使你不理解它。每当荧幕上的人看惊讶地抬头,然后你就能看到他们的视角,这就是离切。当一个新闻主播提到你们城市中的一处地方,然后那个地方的镜头跟随其后,这也是离切。
你可以轻易的在 Kdenlive 中完成离切操作,因为 Kdenlive 时间轴是叠层式的。默认情况下,Kdenlive 中有四个 “<ruby> 轨道 <rt> track </rt></ruby>” ——最上面的两个分给视频,而下面的两个给伴奏的音频。当你在时间轴上放置视频素材,放在较高的视频轨道上的优先于放在下面的轨道。这意味着你可以在功能上编辑掉视频轨道的镜头,只需要通过在较高的轨道上放些更好的素材就行。

### 导出你的电影
当你的编辑都完成后,你可以导出你的电影,然后来把它发布到网上,让其他人看到。要做到这一点,点击在 Kdenlive 窗口顶端工具栏上的 <ruby> 渲染 <rt> Render </rt></ruby> 按钮。在显现的 <ruby> 渲染 <rt> Rendering </rt></ruby> 窗口中,选择你的视频托管服务支持的格式。WEBM 格式是近日很普遍的一种格式,除了是开源的,它也是可用于分发和存档的最佳格式之一。它能支持 4K、立体图像、广色域等更多的特性。而且所有的主流浏览器都可以播放它。
渲染需要时间,这取决于你的项目长度、你作出了多少编辑、以及你电脑的性能。
### 一个长效的解决方案
当我写这篇文章的时候,正好在十年前的今天,我发表了 [关于 Kdenlive 的六篇介绍文章](https://opensource.com/life/11/11/introduction-kdenlive) 。令我惊讶的是,这意味着我成为 Kdenlive 用户的时间比我在电影学院学习的专有编辑器的时间还要长。这是令人印象深刻的长寿,而且我今天仍然在使用它,因为它的灵活性和可靠性是其他编辑器无法比拟的。糟糕的是,我所学过的专有视频编辑器甚至都不存在了,至少不再以同样的形式存在(这让我希望我在一个开源平台上学习编辑!)。
Kdenlive 是一个功能强大的编辑器,有很多功能,但不要让这些吓倒你。我的介绍系列在今天和十年前一样相关而准确,在我看来,这是一个真正可靠的应用程序的特征。如果你想选择 Kdenlive 作为视频编辑器,一定要下载我们的 [速查表](https://opensource.com/downloads/kdenlive-cheat-sheet),这样你就可以熟练使用键盘快捷键,减少点击次数,使编辑过程无缝进行。
现在去讲你的故事吧!
*(题图:MJ/028511ed-687f-4894-b4aa-cf3f6c108a1a)*
---
via: <https://opensource.com/article/21/12/kdenlive-linux-creative-app>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[yjacks](https://github.com/yjacks) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,802 | Firefox 浏览器 113 版推出,带来了更好的画中画功能 | https://debugpointnews.com/firefox-113/ | 2023-05-11T16:34:00 | [
"Firefox"
] | /article-15802-1.html | 
>
> Firefox 113 版本引入了增强的画中画,提高了密码安全性,同时支持 AV1 图像格式文件,以下是具体更新内容:
>
>
>
Firefox 113 版本现已推出,搭载了多个新功能、增强功能和错误修复。其中最显著的新功能之一是改进的 <ruby> 画中画 <rt> Picture-in-Picture </rt></ruby>(PIP),使用户可以轻松在网络上最受欢迎的视频网站上倒带、查看视频长度并切换到全屏模式。
此外,Firefox 还在密码生成器中增加了特殊字符,使其更加安全。同时,从 Safari 或基于 Chrome 的浏览器导入书签也变得更加简单,因为默认会导入这些书签上的网站图标。
Firefox 113 还加强了 Windows GPU 沙盒,该功能在 Firefox 110 中首次引入,提供更强的安全保障。此更新还实现了一个 13 年前被请求的功能:允许用户直接从微软 Outlook 拖放文件。

Mac 用户现在可以直接从上下文菜单中访问 macOS “服务”,而在 Windows 上,默认已启用弹性滚动效果,当滚动超出滚动容器的边缘时提供反弹动画。
Firefox 113 还增加了对包含动画的 AV1 图像格式文件(AVIS)的支持,并允许使用 `window.print()` 的网站在安卓上的 Firefox 中打印。安卓版 Firefox 默认支持硬件加速的 AV1 视频解码,也默认启用了 GPU 加速的 Canvas2D,这是继 Firefox 110 中已在 macOS 和 Linux 上发布的工作之后的进一步工作。
开发人员也会高兴地得知,Firefox 113 增加了对许多 WebRTC 功能的支持,包括 `RTCMediaSourceStats`、`RTCPeerConnectionState`、`RTCPeerConnectionStats`(“peer-connection” RTCStatsType)、`RTCRtpSender.setStreams()` 和 `RTCSctpTransport`。模块脚本现在可以在 Worklets 中导入其他 ES 模块脚本,Firefox 现在支持四级颜色规范中的颜色函数,包括 `lab()`、`lch()`、`oklab()`、`oklch()` 和 `color()` 函数。
Firefox 113 还引入了重新设计的无障碍引擎,显著提高了 Firefox 对屏幕阅读器和某些其他辅助功能软件用户的速度、响应性和稳定性。
此外,Awesomebar 搜索结果菜单现在已启用,允许你删除历史记录结果和关闭赞助的 Firefox Suggest 结果。
虽然 Firefox 113 带来了许多令人兴奋的新功能和增强,但它也删除了长期弃用的 `mozRTCPeerConnection`、`mozRTCIceCandidate` 和 `mozRTCSessionDescription` 类型,网站应该使用其非前缀变体。安卓版 Firefox 还改进了内置 PDF 阅读器的用户界面,使直接保存 PDF 文件变得更加容易。
### 下载
该版本现已正式发布,并可以从以下 FTP 网站下载。
>
> **[下载 Firefox 113](https://ftp.mozilla.org/pub/firefox/releases/113.0/)**
>
>
>
主要的 Linux 发行版将在未来几天内将其打包到他们的软件库中,并且你应该可以通过常规操作系统更新获得此版本。
* [113 发布说明](https://www.mozilla.org/en-US/firefox/113.0/releasenotes/)
*(题图:MJ/5ba4d222-516a-476f-8231-968ac3dba38e)*
---
via: <https://debugpointnews.com/firefox-113/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,803 | Ubuntu MATE 23.04:最佳功能和更新 | https://www.debugpoint.com/ubuntu-mate-23-04/ | 2023-05-11T17:17:00 | [
"Ubuntu MATE"
] | /article-15803-1.html | 
>
> Ubuntu MATE 23.04 “Lunar Lobster” 已发布,让我们来了解一下这个以 MATE 桌面为特色的官方 Ubuntu 版本。
>
>
>
代号 “<ruby> 月球龙虾 <rt> Lunar Lobster </rt></ruby>” 的 Ubuntu MATE 23.04 已于 2023 年 4 月 20 日发布。最新版本的 Ubuntu MATE 23.04 是 2023 年的第一个短期版本,将获得为期 9 个月的支持,直至 2024 年 1月。它是具有超轻量级 MATE 桌面的官方 Ubuntu 版本,它包含一些增强功能,对于那些想要 GNOME 的传统桌面外观的人来说值得考虑。

### Ubuntu MATE 23.04:最佳功能
Ubuntu MATE 23.04 与它的前身 Ubuntu MATE 22.10 看起来可能没有太大区别,但也包含了一些明显的变化。
MATE 桌面和 Ayatana 指示器跳跃了一些版本,修复了一系列小错误,而 AI 生成的壁纸为桌面增添了一丝优雅。
此版本具有 MATE Desktop 1.26.1(但是,我没有在测试安装中看到这个次要版本),它带来了自 1.26 主要版本以来的一些更新。
也许你注意到的主要区别是 Flatpak 安装,它在 Ubuntu MATE 22.10 之前默认安装。从这个版本开始,Flatpak 不再默认安装,但如果你想使用它,你仍然可以安装它。我们在这里有一个专门的指南,介绍 [如何安装 Flatpak](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/)。或者,你可以使用以下命令安装它:
```
sudo apt install flatpakflatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakreporeboot
```
在 Ubuntu MATE 22.10 中已经是默认安装的 PipeWire,已在 Ubuntu 中更新修订包。此外,此版本中包含的 LibreOffice 7.5 具有改进的 Writer 书签模块、Calc 电子表格中的新数字格式、Impress 中的新表格设计样式等等。默认网络浏览器是 Firefox 112 (Snap)。
默认文件管理器 Caja 已更新至 1.26.1,它是唯一获得小更新的应用。其余的仍然是他们以前的版本,如下所示:
* Caja 文件管理器 1.26.1
* 磁盘使用分析器 1.26.0
* MATE 终端 1.26.0
* Eye of MATE 1.26.0
* MATE Tweak 工具 1.26.0

最新的 Ubuntu “Lunar Lobster” 版本用新的 [基于 Flutter 的安装程序](https://www.debugpoint.com/new-ubuntu-installer/) 替换了 Ubuntu 23.04 中的默认安装程序。但是 Ubuntu MATE 仍然使用旧的 Ubiquity 安装程序,以便为其用户群保持简单明了。
在核心方面,Ubuntu MATE 23.04 默认包含的 [Linux 内核 6.2](https://www.debugpoint.com/linux-kernel-6-2/) 改进了对 GPU、CPU、端口和 Rust 更新的支持。它增强了操作系统的性能和稳定性,确保为用户提供流畅可靠的体验。
遵循传统,Ubuntu MATE 有一些 AI 生成的“龙虾”主题壁纸,在桌面上看起来很棒!

总的来说,Ubuntu MATE 23.04 是一个小更新,给用户带来的改进很少。它的简单性和用户友好性使其成为那些喜欢旧式 GNOME 桌面外观和感觉的人的不二之选。
你可以从 [此页面](https://ubuntu-mate.org/download/) 下载 Ubuntu MATE 23.04。
*(题图:MJ/b8450f09-cc50-48a6-9799-234975e18625)*
---
via: <https://www.debugpoint.com/ubuntu-mate-23-04/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,805 | Ubuntu 现已在世界上第一款具备 GPU 的高性能 RISC-V SBC 上运行 | https://news.itsfoss.com/ubuntu-riscv-visionfive-2/ | 2023-05-11T23:47:31 | [
"VisionFive",
"RISC-V"
] | https://linux.cn/article-15805-1.html |
>
> 受益于最新的 Ubuntu 发行版,赛昉科技的 RISC-V 开发板 VisionFive 2 的体验得以提高。
>
>
>

自树莓派和 Arduino 等问世以来,单板计算机(SBC)因其相对紧凑的体积和各种不同的处理能力水平,而受到越来越多创客和爱好者的青睐。
现在,Canonical 宣布,在世界上第一款具备 GPU 的高性能 RISC-V SBC **赛昉 VisionFive 2** 上,**已经可以运行 Ubuntu**。
让我们深入了解更多细节。
**最新消息:** 在 Canonical 公司 [最近的一份声明](https://ubuntu.com//blog/canonical-enables-ubuntu-on-starfive-visionfive2-risc-v-board?ref=news.itsfoss.com) 中,该公司公布了与 [赛昉科技](https://www.starfivetech.com/en?ref=news.itsfoss.com) 合作的最新结果,这是一家专注于 **RISC-V 软件和硬件** 的中国高科技公司。
由此产生的结果是,其最新旗舰产品赛昉 VisionFive 2 可以运行 Ubuntu。这是一款由 RISC-V 驱动的 SBC,可实现强大的功能,而且还配备了一块 GPU,以支持 3D 任务。

这将为 RISC-V SBC 计算打开新的渠道,用户可以在各种项目中实施它。
此外,由于有了 Ubuntu,即使是在企业使用情况下,也可以在大规模部署它。
**对技术细节感兴趣吗?**
VisionFive 2 由一颗 **赛昉 JH7110 64 位 SoC** 驱动,其中包含一颗 **RISC-V RV64GC 处理器**,最高可达 1.5 GHz 时钟速度。
你可以选择 **2GB/4GB/8GB** 内存变种。其具有一个用于存储的 TransFlash 卡槽,同时可以支持 **HDMI 2.0** 和 **MIPI-DSI** 视频输出。
你可以在 [此处](https://www.starfivetech.com/en/site/boards?ref=news.itsfoss.com) 深入了解规格。
Canonical 的这项举措应该能够让更多的 SBC 爱好者轻松地切换到 Ubuntu,特别是在拥有如此强大的 RISC-V 驱动的 SBC 的情况下。
**想要试一试吗?**
你可以前往 Ubuntu [官方网站](https://ubuntu.com/download/risc-v?ref=news.itsfoss.com),获取专为 VisionFive 2 优化过 Ubuntu 23.04 预装镜像。
>
> **[Ubuntu for RISC-V](https://ubuntu.com/download/risc-v?ref=news.itsfoss.com)**
>
>
>
? 看起来,我们可能需要将赛昉 VisionFive 2 添加到我们的 [树莓派替代方案](https://itsfoss.com/raspberry-pi-alternatives/?ref=news.itsfoss.com) 列表中。你觉得怎样?
*(题图:MJ/b9ad4ba4-d330-40ad-9502-8df6787c0d0e)*
---
via: <https://news.itsfoss.com/ubuntu-riscv-visionfive-2/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Single-board computers (SBC) have been rising in popularity ever since the likes of **Raspberry Pi**, and **Arduino **came into the spotlight.
These boards are relatively compact and have varying levels of processing power that both tinkerers and hobbyists alike enjoy exploring.
And now.
Canonical has announced that **Ubuntu is available** on the World's first high-performance RISC-V SBC with an integrated GPU, called the **StarFive VisionFive 2.**
Let's dive in and take a look at more details.
**What's Happening: **In a [recent announcement](https://ubuntu.com//blog/canonical-enables-ubuntu-on-starfive-visionfive2-risc-v-board?ref=news.itsfoss.com), Canonical revealed the end result of their collaboration with [StarFive](https://www.starfivetech.com/en?ref=news.itsfoss.com), a Chinese high-tech company specializing **in RISC-V software and hardware**.
The result of this is the **availability of Ubuntu on their latest flagship**, the **StarFive VisionFive 2**, a powerful piece of RISC-V-powered SBC that features an onboard GPU for powering 3D tasks.

This will open up new avenues for RISC-V SBC computing, with users able to implement this in various projects.
Moreover, even in enterprise use cases, these can now be deployed at a large-scale, thanks to Ubuntu.
**Suggested Read **📖
[36 Raspberry Pi Projects Anyone Can Follow [2023]Here we list some of the cool Raspberry Pi projects and ideas. The projects have been divided into easy, intermediate, and advanced categories.](https://itsfoss.com/raspberry-pi-projects/?ref=news.itsfoss.com)

**Interested in the technical bits?**
The VisionFive 2 is powered by a **StarFive JH7110 64-bit SoC** with a **RISC-V RV64GC processor** with up to 1.5 GHz clock speeds.
You can choose between **2GB/4GB/8GB** memory variants. It has a **TransFlash card slot** for storage purposes, and for video output support, it can handle **HDMI 2.0** and **MIPI-DSI**.
You can dive deeper into the specifications [here](https://www.starfivetech.com/en/site/boards?ref=news.itsfoss.com).
This move by Canonical should help more SBC enthusiasts easily switch to Ubuntu, especially with such a powerful RISC-V-powered SBC.
**Want to try it out?**
You can head to the [official website](https://ubuntu.com/download/risc-v?ref=news.itsfoss.com) to grab a preinstalled image of the Ubuntu 23.04 release optimized for VisionFive 2.
*💬 Looking at how things are progressing, we might need to add StarFive VisionFive 2 to our Raspberry Pi alternatives list. What do you think of that?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,806 | 如何在 RHEL 8 上安装 FreeIPA 客户端 | https://www.linuxtechi.com/install-freeipa-client-on-rhel-rockylinux-almalinux/ | 2023-05-12T18:27:00 | [
"FreeIPA"
] | https://linux.cn/article-15806-1.html | 
>
> 在本文中,我们将向你展示如何在 RHEL、Rocky Linux 或 AlmaLinux 上安装和配置 FreeIPA 客户端。
>
>
>
为了演示,我们在 RHEL 系统上集成了 [FreeIPA 服务器](/article-15783-1.html),使用 FreeIPA 进行集中认证。
FreeIPA 服务器是一个开源的身份管理解决方案,为 Linux 系统提供集中的身份验证、授权和帐户信息。
### 先决条件
* 已预装 RHEL 9/8 或 Rocky Linux 9/8 或 AlmaLinux 9/8
* 具有 sudo 权限的普通用户
* RHEL 系统的有效订阅。
* 互联网连接
事不宜迟,让我们深入了解 FreeIPA 客户端安装和配置步骤,
### 1、在 FreeIPA 服务器上创建一个用户
登录到 FreeIPA 服务器并创建一个用户以进行集中身份验证,这里我使用以下命令使用创建了一个用户 `opsadm`:
```
$ sudo kinit admin
$ sudo ipa user-add opsadm --first=Ops --last=Admin --password
Password:
Enter Password again to verify:
-------------------
Added user "opsadm"
-------------------
User login: opsadm
First name: Ops
Last name: Admin
Full name: Ops Admin
Display name: Ops Admin
Initials: OA
Home directory: /home/opsadm
GECOS: Ops Admin
Login shell: /bin/bash
Principal name: [email protected]
Principal alias: [email protected]
User password expiration: 20230502010113Z
Email address: [email protected]
UID: 464600004
GID: 464600004
Password: True
Member of groups: ipausers
Kerberos keys available: True
$
```
### 2、为 RHEL、Rocky Linux 或 AlmaLinux 添加 DNS 记录
下一步是为我们想要与 FreeIPA 服务器集成以集中身份验证的机器添加 DNS 记录。在 FreeIPA 服务器上,运行以下命令:
```
$ sudo ipa dnsrecord-add linuxtechi.lan rhel.linuxtechi.lan --a-rec 192.168.1.2
```
注意:在上述命令中**替换**为你自己的 IP 地址和主机名。

现在登录到 RHEL 客户端并在 `/etc/hosts` 文件中添加以下条目:
```
192.168.1.102 ipa.linuxtechi.lan ipa
192.168.1.2 rhel.linuxtechi.lan rhel
```
保存并退出文件。
### 3、在 RHEL、RockyLinux 和 AlmaLinux 上安装和配置 FreeIPA 客户端
FreeIPA 客户端及其依赖项在默认软件包仓库(AppStream 和 BaseOS)中可用,因此要安装 FreeIPA 客户端,请运行:
```
$ sudo dnf install freeipa-client -y
```

安装完成后,配置 FreeIPA 客户端,运行以下命令:
```
$ sudo ipa-client-install --hostname=`hostname -f` --mkhomedir --server=ipa.linuxtechi.lan --domain linuxtechi.lan --realm LINUXTECHI.LAN
```
根据你的设置**替换** FreeIPA 服务器的主机名、域名和领域。
输出:

完美,上面的输出确认 `freeipa-client` 命令已成功执行。要测试 FreeIPA 客户端集成,请从当前用户注销并尝试以我们在 IPA 服务器上创建的 `opsadm` 用户身份登录。
### 4、测试 FreeIPA 客户端
试着在你刚刚配置了 FreeIPA 客户端的 RHEL 系统上使用 `opsadm` 用户通过 SSH 登录。
```
$ ssh opsadm@<IPAddress-RHEL>
```

当我们第一次登录系统时,由于密码过期政策,它会提示你设置新密码。
修改密码后,再次尝试登录。这次你应该可以登录了。

很好,上面的输出确认我们可以使用 `opsadm` 用户登录。这确认 FreeIPA 客户端安装和配置成功。
以上就是这篇文章的全部内容,希望你发现它提供了丰富的信息,请在下面的评论部分中发表你的疑问和反馈。
*(题图:MJ/583ee400-3bad-4036-a725-f9d2078d69ab)*
---
via: <https://www.linuxtechi.com/install-freeipa-client-on-rhel-rockylinux-almalinux/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this post, we will show you how to install and configure FreeIPA client on RHEL, Rocky Linux or AlmaLinux.
For the demonstration purpose, we will integrate a RHEL system with FreeIPA server using FreeIPA client for centralize authentication.
FreeIPA server is an open-source identity management solution that provides centralized authentication, authorization, and account information for Linux systems.
#### Prerequisites
- Pre-Installed RHEL-9/8 or Rocky Linux9/8 or AlmaLinux 9/8
- Regular user with sudo rights
- Valid subscription for RHEL system.
- Internet Connectivity
Also Read: [How to Install FreeIPA Server on RHEL 8 | Rocky Linux 8 | AlmaLinux 8](https://www.linuxtechi.com/install-freeipa-rhel-rocky-almalinux/)
Without any delay, let’s deep dive into FreeIPA client installation and configuration steps,
## 1) Create a User on FreeIPA Server
Login to FreeIPA server and create a user for centralize authentication, here I am creating a user with opsadm using following command.
$ sudo kinit admin $ sudo ipa user-add opsadm --first=Ops --last=Admin --password Password: Enter Password again to verify: ------------------- Added user "opsadm" ------------------- User login: opsadm First name: Ops Last name: Admin Full name: Ops Admin Display name: Ops Admin Initials: OA Home directory: /home/opsadm GECOS: Ops Admin Login shell: /bin/bash Principal name:[[email protected]]Principal alias:[[email protected]]User password expiration: 20230502010113Z Email address:[[email protected]]UID: 464600004 GID: 464600004 Password: True Member of groups: ipausers Kerberos keys available: True $
## 2) Add DNS Record for RHEL, Rocky Linux or AlmaLinux
Next step is to add DNS record for machine which we want to integrate with FreeIPA server for centralize authentication. On FreeIPA Server, run following command
$ sudo ipa dnsrecord-add linuxtechi.lan rhel.linuxtechi.lan --a-rec 192.168.1.2
Note: Replace IP address and hostname in above commands that suits to your setup.
Now login to RHEL client and add following entries in /etc/hosts file
192.168.1.102 ipa.linuxtechi.lan ipa 192.168.1.2 rhel.linuxtechi.lan rhel
Save and exit the file.
## 3) Install and configure FreeIPA client on RHEL, RockyLinux & AlmaLinux
FreeIPA client and its dependencies are available in the default package repositories (AppStream and BaseOS), so to install freeipa client, run
$ sudo dnf install freeipa-client -y
After the installation, configure the FreeIPA client, run following command
$ sudo ipa-client-install --hostname=`hostname -f` --mkhomedir --server=ipa.linuxtechi.lan --domain linuxtechi.lan --realm LINUXTECHI.LAN
// Replace freeipa server’s hostname, domain name and realm according to your setup.
Output ,
Perfect, output above confirms that freeipa-client command has been executed successfully. To test the freeipa client integration, logout from the current user and try to login as opsadm user that we had created on IPA server.
## 4) Test FreeIPA Client
Try to ssh the rhel system on which you have just configured FreeIPA client using opsadm user,
$ ssh opsadm@<IPAddress-RHEL>
When we login to the system first time then it will prompt you to set new password because of password expiry policy.
After changing the password, try to login again. This time you should be able to login
$ ssh[[email protected]]
Great, output above confirms that we can login using opsadm user. This confirms that FreeIPA client installation and configuration is successful.
That’s all from this post, I hope you have found it informative, please do post your queries and feedback in below comments section. |
15,808 | ZOMBIES:我的软件开发和测试简便指南(一) | https://opensource.com/article/21/2/development-guide | 2023-05-13T13:52:10 | [
"软件测试"
] | /article-15808-1.html |
>
> 编程过程有时候就像一场与丧尸群之间的战斗。在这个系列文章中,我将带你了解怎样将 ZOMBIES 方法应用到实际工作中。
>
>
>

很久以前,在我还是一个萌新程序员的时候,我们曾经被分配一大批工作。我们每个人都被分配了一个编程任务,然后回到自己的小隔间里噼里啪啦地敲键盘。我记得团队里的成员在自己的小隔间里一呆就是几个小时,为打造无缺陷的程序而奋斗。当时流行的思想是:能一次性做得越多,能力越强。
对于我来说,能够长时间编写或者修改代码而不用中途停下来检验这些代码是否有效,就像荣誉勋章一样。那个时候我们都认为停下来检验代码是否工作是能力不足的表现,菜鸟才这么干。一个“真正的开发者”应该能一口气构建起整个程序,中途不用停下来检查任何东西!
然而事与愿违,当我停止在开发过程中测试自己的代码之后,来自现实的检验狠狠地打了我的脸。我的代码要么无法通过编译,要么构建失败,要么无法运行,或者不能按预期处理数据。我不得不在绝望中挣扎着解决这些烦人的问题。
### 避开丧尸群
如果你觉得旧的工作方式听起来很混乱,那是因为它确实是这样的。我们一次性处理所有的任务,在问题堆里左砍右杀,结果只是引出更多的问题。着就像是跟一大群丧尸间的战斗。
如今我们已经学会了避免一次性做太多的事情。在最初听到一些专家推崇避免大批量地开发的好处时,我觉得这很反直觉,但我已经从过去的犯错中吸取了教训。我使用被 [James Grenning](https://www.agilealliance.org/resources/speakers/james-grenning/) 称为 **ZOMBIES** 的方法来指导我的软件开发工作。
### ZOMBIES 方法来救援!
ZOMBIES 表示以下首字母缩写:
* **Z** – 最简场景(Zero)
* **O** – 单元素场景(One)
* **M** – 多元素场景(Many or more complex)
* **B** – 边界行为(Boundary behaviors)
* **I** – 接口定义(Interface definition)
* **E** – 处理特殊行为(Exercise exceptional behavior)
* **S** – 简单场景用简单的解决方案(Simple scenarios, simple solutions)
我将在本系列文章中对它们进行分析讲解。
### 最简场景
最简场景指可能出现的最简单的情况。
人们倾向于最开始的时候使用硬编码值,因为这是最简单的方式。通过在编码活动中使用硬编码值,可以快速构建出一个能即时反馈的解决方案。不需要几分钟,更不用几个小时,使用硬编码值让你能够马上与正在构建的系统进行交互。如果你喜欢这个交互,就朝这个方向继续做下去。如果你发现不喜欢这种交互,你可以很容易抛弃它,根本没有什么可损失。
本系列文章将以构建一个简易的购物系统的后端 API 为例进行介绍。该服务提供的 API 允许用户创建购物筐、向购物筐添加商品、从购物筐移除商品、计算商品总价。
首先,创建项目的基本结构(将购物程序的代码和测试代码分别放到 `app` 和 `tests` 目录下)。我们的例子中使用开源的 [xUnit](https://xunit.net/) 测试框架。
现在撸起你的袖子,在实践中了解最简场景吧!
```
[Fact]
public void NewlyCreatedBasketHas0Items() {
var expectedNoOfItems = 0;
var actualNoOfItems = 1;
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
```
这是一个伪测试,它测试的是硬编码值。新创建的购物筐是空的,所以购物筐中预期的商品数是 0。通过比较期望值和实际值是否相等,这个预期被表示成一个测试(或者称为断言)。
运行该测试,输出结果如下:
```
Starting test execution, please wait...
A total of 1 test files matched the specified pattern.
[xUnit.net 00:00:00.57] tests.UnitTest1.NewlyCreatedBasketHas0Items [FAIL]
X tests.UnitTest1.NewlyCreatedBasketHas0Items [4ms]
Error Message:
Assert.Equal() Failure
Expected: 0
Actual: 1
[...]
```
这个测试显然无法通过:期望商品数是 0,但是实际值被硬编码为了 1。
当然,你可以马上把硬编码的值从 1 改成 0,这样测试就能通过了:
```
[Fact]
public void NewlyCreatedBasketHas0Items() {
var expectedNoOfItems = 0;
var actualNoOfItems = 0;
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
```
与预想的一样,运行测试,测试通过:
```
Starting test execution, please wait...
A total of 1 test files matched the specified pattern.
Test Run Successful.
Total tests: 1
Passed: 1
Total time: 1.0950 Seconds
```
你也许会认为执行一个被强迫失败的测试完全没有意义,但是不管一个测试多么简单,确保它的可失败性是绝对有必要的。只有这样才能够保证如果在后续工作中不小心破坏了程序的处理逻辑时该测试能够给你相应的警告。
现在停止伪造数据,将硬编码的值替换成从 API 中获取的值。我们已经构造了一个能够可靠地失败的测试,它期望一个空的购物筐中有 0 个商品,现在是时候编写一些应用程序代码了。
就跟常见的软件建模活动一样,我们先从构造一个简单的接口开始。在 `app` 目录下新建文件 `IShoppingAPI.cs`(习惯上接口名一般以大写 I 开头)。在该接口中声明一个名为 `NoOfItems()` 的方法,它以 `int` 类型返回商品的数量。下面是接口的代码:
```
using System;
namespace app {
public interface IShoppingAPI {
int NoOfItems();
}
}
```
当然这个接口什么事也做不了,在你需要实现它。在 `app` 目录下创建另一个文件 `ShoppingAPI`。在其中将 `ShoppingAPI` 声明为一个实现了 `IShoppingAPI` 的公有类。在类中定义方法 `NoOfItems` 返回整数 1:
```
using System;
namespace app {
public class ShoppingAPI : IShoppingAPI {
public int NoOfItems() {
return 1;
}
}
}
```
从上面代码中你发现自己又在通过返回硬编码值 1 的方式来伪造代码逻辑。现阶段这是一件好事,因为你需要保持一切超级无敌简单。现在还不是仔细构想如何实现购物筐的处理逻辑时候。这些工作后续再做!到目前为止,你只是通过构建最简场景来检验自己是否满意现在的设计。
为了确定这一点,将硬编码值换成这个 API 在运行中收到请求时应该返回的值。你需要通过 `using app;` 声明来告诉测试你使用的购物逻辑代码在哪里。
接下来,你需要 <ruby> 实例化 <rt> instantiate </rt></ruby> `IShoppingAPI` 接口:
```
IShoppingAPI shoppingAPI = new ShoppingAPI();
```
这个实例用来发送请求并接收返回的值。
现在,代码变成了这样:
```
using System;
using Xunit;
using app;
namespace tests {
public class ShoppingAPITests {
IShoppingAPI shoppingAPI = [new][3] ShoppingAPI();
[Fact]
public void NewlyCreatedBasketHas0Items() {
var expectedNoOfItems = 0;
var actualNoOfItems = shoppingAPI.NoOfItems();
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
}
}
```
显然执行这个测试的结果是失败,因为你硬编码了一个错误的返回值(期望值是 0,但是返回的是 1)。
同样的,你也可以通过将硬编码的值从 1 改成 0 来让测试通过,但是现在做这个是在浪费时间。现在设计的接口已经跟测试关联上了,你剩下的职责就是编写代码实现预期的行为逻辑。
在编写应用程序代码时,你得决定用来表示购物筐得数据结构。为了保持设计的简单,尽量选择 C# 中表示集合的最简单类型。第一个想到的就是 `ArrayList`。它非常适合目前的使用场景——可以保存不定个数的元素,并且易于遍历访问。
因为 `ArrayList` 是 `System.Collections` 包的一部分,在你的代码中需要声明:
```
using System.Collections;
```
然后 `basket` 的声明就变成这样了:
```
ArrayList basket = new ArrayList();
```
最后将 `NoOfItems()` 中的因编码值换成实际的代码:
```
public int NoOfItems() {
return basket.Count;
}
```
这次测试能够通过了,因为最初购物筐是空的,`basket.Count` 返回 0。
这也是你的第一个最简场景测试要做的事情。
### 更多案例
目前的课后作业是处理一个丧尸,也就是第 0 个丧尸。在下一篇文章中,我将带你了解单元素场景和多元素场景。不要错过哦!
*(题图:MJ/7917bc47-5325-4c0f-a2dd-4e444f57a46c)*
---
via: <https://opensource.com/article/21/2/development-guide>
作者:[Alex Bunardzic](https://opensource.com/users/alex-bunardzic) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,809 | 终端基础:在 Linux 中删除文件和文件夹 | https://itsfoss.com/delete-files-folders-linux/ | 2023-05-13T14:07:25 | [
"终端基础"
] | https://linux.cn/article-15809-1.html | 
>
> 你已经学会了创建文件和目录。现在是时候学习如何在命令行中删除文件和文件夹了。
>
>
>
在终端基础系列的前几章中,你学习了 [创建新文件](/article-15643-1.html) 和 [目录](/article-15595-1.html)(文件夹)。
现在让我们看看如何在 Linux 终端中删除文件和文件夹。
### 删除文件
要删除文件,你可以按以下方式使用 `rm` 命令:
```
rm filename_or_path
```
如果文件已成功删除,你将看不到任何输出。
这是一个示例,其中我删除了一个名为 `new_file` 的文件。当我列出目录内容时,你可以看到 `new_file` 不再存在。

你还可以在同一命令中删除多个文件:
```
rm file1 file2 file3
```
让我展示一个在单条命令中删除两个文件的示例。

#### ?️练习文件删除
让我们练习一下刚刚学到的东西。创建一个名为 `practice_delete` 的目录并切换到该目录:
```
mkdir practice_delete && cd practice_delete
```
现在创建一些空文件:
```
touch file1 file2 file3
```
删除 `file3`:
```
rm file3
```
现在,让我们做一些额外的事情。运行此命令并更改 `file2` 的权限:
```
chmod u-w file1 file2
```
现在尝试删除 `file2`:
```
rm file2
```
你是否看到消息 “**remove write protected file**”? 那是因为你从这个文件中删除了写权限(用于修改)。
你可以**按 `Y` 或回车键确认删除或按 `N` 拒绝删除。**
如果你不想看到这条消息并仍然删除它,你可以使用强制删除选项 `-f`。通过删除 `file1` 试试:
```
rm -f file1
```
以下是上述所有示例的重放:

>
> ? Linux 命令行中没有垃圾桶。一旦文件被删除,你就无法像在图形文件管理器中那样撤消将其从垃圾箱中取回的操作。因此,删除文件时要格外小心。
>
>
>
#### 小心删除
缺少垃圾桶使删除成为一种永久性的工作。这就是为什么你应该注意要删除的文件的原因。
有一个带 `-i` 选项的交互模式。有了这个,你会被要求确认删除。
```
rm -i filename
```
当你根据特定模式删除多个文件时,这很有用。
这是一个示例,其中我以交互方式删除名称中匹配 `file_` 模式的所有文件。我删除了一些并在交互模式下保留了一些。

>
> ? 我建议切换到文件所在的目录,然后删除它们。这有助于减少由文件路径中的拼写错误引起的任何可能性。
>
>
>
### 删除目录
在 Linux 中有专门的 `rmdir` 命令来删除目录。
```
rmdir dir_name
```
但是,它只能删除空目录。如果目录中有任何文件或子目录,`rmdir` 命令将抛出错误。
```
$ rmdir dir2
rmdir: failed to remove 'dir2': Directory not empty
```
这使得它在大多数情况下用处不大。
那么,如何删除非空文件夹呢? 好吧,使用与之前删除文件相同的 `rm` 命令。
是的,相同的 `rm` 命令,但带有递归选项 `-r`:
```
rm -r dir_name
```
#### ?️练习文件夹删除
让我们练习你学到的东西。
如果你还没有,请切换到 `practice_delete` 文件夹。现在,创建两个目录 `dir1` 和 `dir2`。
```
mkdir dir1 dir2
```
在 `dir2` 中创建一个文件:
```
touch dir2/file
```
现在尝试使用 `rmdir` 命令删除目录:
```
rmdir dir1
```
```
rmdir dir2
```
由于 `dir2` 不为空,`rmdir` 命令将失败。相反,使用带有递归选项的 `rm` 命令:
```
rm -r dir2
```
以下是上述所有命令示例的重放:

>
> ? 交互式删除模式在使用 `rm` 命令的递归选项删除目录时更有帮助:
>
>
>
```
rm-ri dir_name
```
因此,你学会了使用 Linux 命令删除文件和文件夹。是时候多练习了。
### 测试你的知识
准备一个如下所示的目录树:
```
.
├── dir1
│ ├── file1
│ ├── file2
│ └── file3
├── dir2
├── dir3
└── file
```
基本上,你在当前目录(`practice_delete`)中创建一个名为 `file` 的文件和三个目录 `dir1`、`dir2` 和 `dir3`。然后在 `dir1` 中创建文件 `file1`、`file2` 和 `file3`。
现在执行以下操作:
* 删除 `file2`。
* 切换到 `dir3` 并强制删除上层目录中名为 `file` 的文件。
* 删除 dir1 的所有内容,但不删除目录本身。
* 列出 `dir` 的内容。
一切进展顺利。你已经学习了一些基本知识,例如切换目录、检查目录内容、创建和删除文件和目录。在下一章中,你将学习如何在终端中复制文件和文件夹。敬请关注!
---
via: <https://itsfoss.com/delete-files-folders-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter 6: Delete Files and Folders in Linux
You have learned to create files and directories. Now it is time to learn about deleting files and folders in the command line.
In the earlier chapters of the Terminal Basics series, you learned to [create new files](https://itsfoss.com/create-files/) and directories (folders).
Let's now see how you can delete files and folders in the Linux terminal.
## Deleting files
To remove files, you can use the rm command in the following fashion:
`rm filename_or_path`
You won't see any output if the file is successfully deleted.
Here's an example where I removed one of the files named `new_file`
. When I list the directory contents, you can see that `new_file`
no longer exists.
You can also remove multiple files in the same command:
`rm file1 file2 file3`
Let me show an example of deleting two files in a single command.
### 🏋️ Exercise file deletion
Let's practice what you just learned. Create a directory named practice_delete and switch to it:
`mkdir practice_delete && cd practice_delete`
Now create a few empty files:
`touch file1 file2 file3`
Delete the file3:
`rm file3`
Now, let's do something extra. Run this command and change the permission on file2:
`chmod u-w file1 file2`
Try deleting file2 now:
`rm file2`
Do you see a message '**remove write protected file**'? That's because you removed the write permission (for modification) from this file.
You can **press Y or enter key to confirm the deletion or N to deny the removal.**
If you don't want to see this message and still delete it, you can use the force delete option `-f`
. Try it by deleting `file1`
:
`rm -f file1`
Here's a replay of all the above examples to help you:
### Remove but with caution
The lack of trash bin makes the deletion a permanent jobs of sort. This is why you should be careful about what files are you deleting.
There is an interactive mode with option `-i`
. With this, you'll be asked to confirm the deletion.
`rm -i filename`
This is helpful when you are deleting several files based on a certain pattern.
Here's an example where I am interactively deleting all the files that match file_ pattern in their name. I delete some and keep some in the interactive mode.
## Deleting directories
There is a dedicated rmdir command to remove directories in Linux.
`rmdir dir_name`
However, it can only delete empty directories. If the directory has any files or subdirectories in it, the rmdir command will throw error.
```
abhishek@itsfoss:~/practice_delete$ rmdir dir2
rmdir: failed to remove 'dir2': Directory not empty
```
And that makes it less useful in most cases.
So, how do you delete a non-empty folder then? Well, you use the same rm command that you used earlier for removing files.
Yes, the same rm command but with the recursive option `-r`
:
`rm -r dir_name`
### 🏋️ Exercise folder deletion
Let's practice what you learned.
Switch to practice_delete folder if you are not already there. Now, create two directories dir1 and dir2.
`mkdir dir1 dir2`
Create a file in dir2:
`touch dir2/file`
Now try deleting the directories using the rmdir command:
`rmdir dir1`
`rmdir dir2`
Since the dir2 is not empty, rmdir command will fail. Instead, use the rm command with recursive option:
`rm -r dir2`
Here's a replay of all the above command examples to help you out:
`rm-ri dir_name`
So, you learned to delete files and folders both using Linux commands. It's time to practice some more.
## 📝 Test your knowledge
Prepare a directory tree that looks like this:
```
.
├── dir1
│ ├── file1
│ ├── file2
│ └── file3
├── dir2
├── dir3
└── file
```
Basically, you create a file named file and three directories dir1, dir2 and dir3 in the current directory (practice_delete). And then you create files file1, file2 and file3 in dir1.
Now do the following:
- Delete
`file2`
. - Switch to the
`dir3`
and force delete the file named`file`
in the upper directory. - Delete all the contents of dir1 but not the directory itself.
- List the contents of the
`dir`
.
I encourage you to discuss the practice questions in the [It's FOSS community forum](https://itsfoss.community/).
This is going good. You have learned several basic things like switching directories, checking the contents of a directory, and creating and deleting files and directories.
In the next chapter, you'll learn about copying files and folders in the terminal. Stay tuned! |
15,811 | Rust 基础系列 #3: Rust 中的数据类型 | https://itsfoss.com/rust-data-types/ | 2023-05-13T21:53:36 | [
"Rust"
] | https://linux.cn/article-15811-1.html | 
在 [上一篇](/article-15771-1.html) 关于 Rust 编程语言的文章中,我们提到了变量、常量和 <ruby> 遮蔽 <rt> shadowing </rt></ruby> 。
现在来讲解数据类型是再自然不过的了。
### 数据类型是什么?
将这个词汇展开些单词的顺序改变一下你就会得到答案了;“数据类型” -> “数据的类型”。
计算机使用 `0` 和 `1` 来存储数据,但是为了让数据在读取时有意义,我们使用数据类型来表示这些 `0` 和 `1` 的含义。
Rust 有两种数据类型:
* **标量数据类型**:只能存储单个值的类型。
* **复合数据类型**:可以存储多个值,甚至是不同类型的值。
在本文中,我将讲解标量数据类型。我将在下一篇文章中讲解第二类数据类型。
接下来是 Rust 中四种主要标量数据类型的简要概述:
* **整型**:存储整数。有每种特定情况下使用的子类型。
* **浮点数**:存储带有小数部分的数字。有两种基于大小的子类型。
* **字符**:使用 UTF-8 编码存储单个字符。(是的,你可以在字符中存储表情符号\*。)
* **布尔值**: 存储 `true` 或 `false`。(给那些无法就 `0` 是 `true` 还是 `0` 是 `false` 达成一致的开发者。)
### 整型
在编程语言中,整型指的是一个整数。Rust 中的整型要么是**有符号**的,要么是**无符号**的。无符号整型只能存储 0 和正数,而有符号整型可以存储负数、0 和正数。
>
> ? 一个有符号整型的范围从 `-(2<sup> n-1</sup>)` 开始,以 `(2<sup> n-1</sup>)-1` 结束。同样,无符号整型的范围从 `0` 开始,以 `(2<sup> n</sup>)-1` 结束。
>
>
>
这是根据符号和长度可用的整型:

正如你所见,Rust 有 8、16、32、64 甚至 128 位的有符号和无符号整型!
使用 `*size` 的整型根据计算机的架构而变化。在 8 位微控制器上,它是 `*8`,在 32 位的旧计算机上,它是 `*32`,在现代 64 位系统上,它是 `*64`。
使用 `*size` 是为了存储与内存(这与裸机相关)有关的数据,比如指针、偏移量等。
>
> ? 当你没有显式地指定整型的子类型时,Rust 编译器会默认推断为 `i32`。显然,如果值比 `i32` 能存储的值大或小,Rust 编译器会礼貌地报错并要求你手动指定类型。
>
>
>
Rust 不仅允许你以十进制形式存储整数,还允许你以二进制、八进制和十六进制形式存储整数。
为了更好的可读性,你可以使用下划线 `_` 来代替逗号来书写/读取大数。
```
fn main() {
let bin_value = 0b100_0101; // 使用前缀“0b”表示二进制
let oct_value = 0o105; // 使用前缀“0o”表示八进制
let hex_value = 0x45; // 使用前缀“0x”表示十六进制
let dec_value = 1_00_00_000; // 和写一克若(1,00,00,000)一样
println!("二进制值: {bin_value}");
println!("八进制值: {oct_value}");
println!("十六进制值: {hex_value}");
println!("十进制值: {dec_value}");
}
```
我使用二进制、八进制和十六进制分别将十进制数 69 存储在变量 `bin_value`、`oct_value` 和 `hex_value` 中。在变量 `dec_value` 中,我存储了数字 <ruby> <a href="https://zh.wikipedia.org/zh-cn/%E5%85%8B%E8%8B%A5"> 1 克若 </a> <rt> 1 Crore </rt></ruby>(一千万),并且使用了下划线替代逗号,这是印度的书写系统。对于那些更熟悉国际计数系统的人来说,你可以将其写成 `10_000_000`。
在编译并运行这个二进制文件后,我得到了如下输出:
```
二进制值: 69
八进制值: 69
十六进制值: 69
十进制值: 10000000
```
### 浮点数
浮点数是一种存储带有小数部分的数字的数据类型。
与 Rust 中的整型不同,浮点数只有两种子类型:
* `f32`: 单精度浮点数类型
* `f64`: 双精度浮点数类型
和 Rust 中的整型一样,当 Rust 推断一个变量的类型时,如果它看起来像一个浮点数,那么它就会被赋予 `f64` 类型。这是因为 `f64` 类型比 `f32` 类型有更高的精度,并且在大多数计算操作中几乎和 `f32` 类型一样快。请注意,*浮点数据类型(`f32` 和 `f64`)都是**有符号**的*。
>
> ? Rust 编程语言按照 [IEEE 754](https://zh.wikipedia.org/zh-cn/IEEE_754) 二进制浮点数表示与算术标准存储浮点数。
>
>
>
```
fn main() {
let pi: f32 = 3.1400; // f32
let golden_ratio = 1.610000; // f64
let five = 5.00; // 小数点表示它必须被推断为浮点数
let six: f64 = 6.; // 尽管类型说明被显式的添加了,小数点也是**必须**的
println!("pi: {pi}");
println!("黄金比例: {golden_ratio}");
println!("五: {five}");
println!("六: {six}");
}
```
仔细看第 5 行。尽管我已经为变量 `six` 指定了类型,但我**必须**至少加上一个小数点。小数点之后有什么就由你决定了。
程序的输出是相当可预测的... 吗?
```
pi: 3.14
黄金比例: 1.61
五: 5
六: 6
```
在上面的输出中,你可能已经注意到,当显示变量 `pi`、`golden_ratio` 和 `five` 中存储的值时,我在变量声明时在结尾增加的零已经消失了。
就算这些零没有被 *移除*,它们也会在通过 `println` 宏输出值时被省略。所以,不,Rust 没有篡改你的变量值。
### 字符
你可以在一个变量中存储一个字符,类型是 `char`。像 80 年代的传统编程语言一样,你可以存储一个 [ASCII](https://www.ascii-code.com/?ref=itsfoss.com) 字符。但是 Rust 还扩展了字符类型,以存储一个有效的 UTF-8 字符。这意味着你可以在一个字符中存储一个表情符号 ?
>
> ? 一些表情符号实际上是两个已有表情符号的组合。一个很好的例子是“燃烧的心”表情符号:❤️?。这个表情符号是通过使用 [零宽度连接器](https://unicode-table.com/en/200D/?ref=itsfoss.com) 来组合两个表情符号构成的:❤️ + ? = ❤️?
>
>
> Rust 的字符类型无法存储这样的表情符号。
>
>
>
```
fn main() {
let a = 'a';
let p: char = 'p'; // 带有显性类型说明
let crab = '?';
println!("Oh look, {} {}! :{}", a, crab, p);
}
```
正如你所见,我已经将 ASCII 字符 'a' 和 'p' 存储在变量 `a` 和 `p` 中。我还在变量 `crab` 中存储了一个有效的 UTF-8 字符,即螃蟹表情符号。然后我打印了存储在每个变量中的字符。
这是输出:
```
Oh look, a ?! :p
```
### 布尔值
在 Rust 中,布尔值类型只存储两个可能的值之一:`true` 或 `false`。如果你想显性指定类型,请使用 `bool`。
```
fn main() {
let val_t: bool = true;
let val_f = false;
println!("val_t: {val_t}");
println!("val_f: {val_f}");
}
```
编译并执行上述代码后,结果如下:
```
val_t: true
val_f: false
```
### 额外内容:显性类型转换
在上一篇讲述 Rust 编程语言中的变量的文章中,我展示了一个非常基础的 [温度转换程序](/article-15771-1.html)。在那里,我提到 Rust 不允许隐式类型转换。
但这不代表 Rust 也不允许 *显性* 类型转换 ; )
要进行显性类型转换,使用 `as` 关键字,后面跟着要转换的数据类型。
这是一个示例程序:
```
fn main() {
let a = 3 as f64; // f64
let b = 3.14159265359 as i32; // i32
println!("a: {a}");
println!("b: {b}");
}
```
在第二行,我没有使用 `3.0`,而是在 `3` 后面写上 `as f64`,以表示我希望编译器将 `3`(一个整数)转换为 64 位浮点数的类型转换。第三行也是一样。但是这里,类型转换是**有损的**。这意味着小数部分 *完全消失*。它不是存储为 `3.14159265359`,而是存储为简单的 `3`。
程序的输出可以验证这一点:
```
a: 3
b: 3
```
### 总结
本文介绍了 Rust 中的原始/标量数据类型。主要有四种这样的数据类型:整型、浮点数、字符和布尔值。
整型用于存储整数,它们有几种子类型,基于它们是有符号还是无符号以及长度。浮点数用于存储带有小数的数字,根据长度有两种子类型。字符数据类型用于存储单个有效的 UTF-8 编码字符。最后,布尔值用于存储 `true` 或 `false` 值。
在下一章中,我将讨论数组和元组等复合数据类型。敬请关注。
*(题图:MJ/c0c49e15-cc9d-4eef-8e52-2f0d62294965)*
---
via: <https://itsfoss.com/rust-data-types/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Rust Basics Series #3: Data Types in Rust
In the third chapter of this series, learn about Integers, Floats, Characters and Boolean data types in Rust programming language.
In the [previous post](https://itsfoss.com/rust-variables) about the Rust programming language, we looked at variables, constants and shadowing.
It is only natural to cover data types now.
## What are data types?
Change the order of these words and you get your answer; "data types" -> "type of data".
The computer stores data as `0`
s and `1`
s but to make sense of it when reading, we use data type to say what those `0`
s and `1`
s mean.
Rust has two types of data types:
**Scalar data type**: Types that store only a single value.**Compound data type**: Types that store multiple values, even values of different types.
In this article, I shall cover scalar data types. I will go through the second category in the next article.
Following is a brief overview of the four main categories of Scalar data types in Rust:
**Integers**: Stores whole numbers. Has sub-types for each specific use case.**Floats**: Stores numbers with a fractional value. Has two sub-types based on size.**Characters**: Stores a single character of UTF-8 encoding. (Yes, you can store an emoji* in a character.)**Booleans**: Stores either a`true`
or a`false`
. (For developers who can't agree if`0`
is`true`
or if`0`
means`false`
.)
## Integers
An integer in the context of a programming language refers to whole numbers. Integers in Rust are either **Signed** or **Unsigned**. Unsigned integers store only 0 and positive numbers, while Signed integers can store negative numbers, 0 and positive numbers.
Following are the available Integer types based on the sign and length:

As you can see, Rust has Signed and Unsigned integers of length 8, 16, 32, 64 and even 128!
The integers with `*size`
vary based on the architecture of the computer. On 8-bit micro-controllers, it is `*8`
, on 32-bit legacy computers, it is `*32`
and on modern 64-bit systems, it is `*64`
.
The use of `*size`
is to store data that is mostly related to memory (which is machine dependent), like pointers, offsets, etc.
Rust not only allows you to store integers in their decimal form but also in the binary, octal and hex forms too.
For better readability, you can use underscore `_`
as a replacement for commas in writing/reading big numbers.
```
fn main() {
let bin_value = 0b100_0101; // use prefix '0b' for Binary representation
let oct_value = 0o105; // use prefix '0o' for Octals
let hex_value = 0x45; // use prefix '0x' for Hexadecimals
let dec_value = 1_00_00_000; // same as writing 1 Crore (1,00,00,000)
println!("bin_value: {bin_value}");
println!("oct_value: {oct_value}");
println!("hex_value: {hex_value}");
println!("dec_value: {dec_value}");
}
```
I have stored the decimal number 69 in binary form, octal form and hexadecimal form in the variables `bin_value`
, `oct_value`
and `hex_value`
respectively. In the variable `dec_value`
, I have stored the number [1 Crore](https://en.wikipedia.org/wiki/Crore) (10 million) and have commas with underscores, as per the Indian numbering system. For those more familiar with the International numbering system, you may write this as `10_000_000`
.
Upon compiling and running this binary, I get the following output:
```
bin_value: 69
oct_value: 69
hex_value: 69
dec_value: 10000000
```
## Floating point numbers
Floating point numbers, or more commonly known as "float(s)" is a data type that holds numbers that have a fractional value (something after the decimal point).
Unlike the Integer type in Rust, Floating point numbers have only two subset types:
`f32`
: Single precision floating point type`f64`
: Double precision floating point type
Like the Integer type in Rust, when Rust infers the type of a variable that seems like a float, it is assigned the `f64`
type. This is because the `f64`
type has more precision than the `f32`
type and is almost as fast as the `f32`
type in most computational operations. Please note that *both the floating point data types ( f32 and f64) are *.
**Signed**
[IEEE 754](https://en.wikipedia.org/wiki/IEEE_754)standard of floating point number representation and arithmetic.
```
fn main() {
let pi: f32 = 3.1400; // f32
let golden_ratio = 1.610000; // f64
let five = 5.00; // decimal point indicates that it must be inferred as a float
let six: f64 = 6.; // even the though type is annotated, a decimal point is still
// **necessary**
println!("pi: {pi}");
println!("golden_ratio: {golden_ratio}");
println!("five: {five}");
println!("six: {six}");
}
```
Look closely at the 5th line. Even though I have annotated the type for the variable `six`
, I **need **to at least use the decimal point. If you have something *after* the decimal point is up to you.
The output of this program is pretty predictable... Or is it?
```
pi: 3.14
golden_ratio: 1.61
five: 5
six: 6
```
In the above output, you might have noticed that while displaying the value stored inside variables `pi`
, `golden_ratio`
and `five`
, the trailing zeros that I specified at the time of variable declaration, are missing.
While those zeros are not *removed*, they are omitted while outputting the values via the `println`
macro. So no, Rust did not tamper with your variable's values.
## Characters
You can store a single character in a variable and the type is simply `char`
. Like traditional programming languages of the '80s, you can store an [ASCII](https://www.ascii-code.com/) character. But Rust also extends the character type to store a valid UTF-8 character. This means that you can store an emoji in a single character 😉
[zero width joiner](https://unicode-table.com/en/200D/): ❤️ + 🔥 = ❤️🔥
Storing such emojis in a single Rust variable of the character type is not possible.
```
fn main() {
let a = 'a';
let p: char = 'p'; // with explicit type annotation
let crab = '🦀';
println!("Oh look, {} {}! :{}", a, crab, p);
}
```
As you can see, I have stored the ASCII characters 'a' and 'p' inside variables `a`
and `p`
. I also store a valid UTF-8 character, the crab emoji, in the variable `crab`
. I then print the characters stored in each of these variables.
Following is the output:
`Oh look, a 🦀! :p`
## Booleans
The boolean type in Rust stores only one of two possible values: either `true`
or `false`
. If you wish to annotate the type, use `bool`
to indicate the type.
```
fn main() {
let val_t: bool = true;
let val_f = false;
println!("val_t: {val_t}");
println!("val_f: {val_f}");
}
```
The above code, when compiled and executed results in the following output:
```
val_t: true
val_f: false
```
## Bonus: Explicit typecasting
In the previous article about Variables in the Rust programming language, I showed a very basic [temperature conversion program](https://itsfoss.com/rust-variables/#a-rusty-thermometer). In there, I mentioned that Rust does not allow implicit typecasting.
But that doesn't mean that Rust does not allow *explicit* typecasting either ;)
To perform explicit type casting, the `as`
keyword is used and followed by the data type to which the value should be cast in.
Following is a demo program:
```
fn main() {
let a = 3 as f64; // f64
let b = 3.14159265359 as i32; // i32
println!("a: {a}");
println!("b: {b}");
}
```
On line 2, instead of using '3.0', I follow the '3' with `as f64`
to denote that I want the compiler to handle type casting of '3' (an Integer) into a 64-bit float. Same with the 3rd line. But here, the type casting is **lossy**. Meaning, that the fractional element is *completely gone*. Instead of storing `3.14159265359`
, it is stored as simply `3`
.
This can be verified from the program's output:
```
a: 3
b: 3
```
## Conclusion
This article covers the Primitive/Scalar data types in Rust. There are primarily four such data types: Integers, Floating point numbers, Characters and Booleans.
Integers are used to store whole numbers and they have several sub-types based on either they are signed or unsigned and the length. Floating point numbers are used to store numbers with some fractional values and have two sub-types based on length. The character data type is used to store a single, valid UTF-8 encoded character. Finally, booleans are used to store either a `true`
or `false`
value.
In the next chapter, I discuss [compound data types like arrays and tuples](https://itsfoss.com/rust-arrays-tuples/).
[Rust Basics Series #4: Arrays and Tuples in RustIn the fourth chapter of the Rust series, learn about compound data types, Arrays and Tuples.](https://itsfoss.com/rust-arrays-tuples/)

Stay tuned. |
15,812 | Alpine Linux 3.18 发布 | https://debugpointnews.com/alpine-linux-3-18/ | 2023-05-13T22:54:00 | [
"Alpine"
] | /article-15812-1.html | 
>
> Alpine Linux 3.18 发布,其内核版本升级至 6.1,同时更新了 GNOME 44。
>
>
>
Alpine Linux 是一款注重轻量化和安全性的发行版,最新版本 Alpine Linux 3.18.0 的发布标志着正式推出 v3.18 稳定版系列。该版本包含了许多令人兴奋的更新和改进,为用户带来了许多新功能、功能增强以及流行软件组件的最新版本。
此次 Alpine Linux 3.18 的一个重要亮点是引入了 [Linux 内核 6.1](https://www.debugpoint.com/linux-kernel-6-1/),该版本自带初步的 Rust 支持和最新的 GPU 和 CPU 更新。此外,Alpine Linux 3.18.0 还通过验证模块的真实性和完整性来增强系统安全性。但需要注意的是,默认情况下模块验证并未强制执行,因此支持具有 AKMS 的第三方模块无缝运行。

除了升级的内核,Alpine Linux 3.18 还配备了 musl libc 1.2.4,在 DNS 解析器中包含了 TCP 回退功能。此功能增强了网络通信的鲁棒性,并确保在有挑战性的网络环境中实现可靠的 DNS 解析。
开发人员将会很高兴地发现,此版本还更新了流行编程语言的版本。包括 Python 3.11、Ruby 3.2、和 Node.js (current) 20.1,提供了强大的工具包,用于创建各种应用,这些语言版本的更新带来了各种性能改进、错误修复以及新功能,丰富了开发体验。
图形桌面环境 GNOME 在 Alpine Linux 3.18 中也得到了显著升级,升级到了 GNOME 44。此版本的 GNOME 引入了本地后台应用、“文件”应用中一直被期待的图像预览功能,以及其他一些更新,你可以在我详细的 [功能概览页面](https://www.debugpoint.com/gnome-44/) 中了解。
Alpine Linux 3.18 中其他值得一提的更新还包括添加了 Go 1.20、KDE Plasma 5.27 和 Rust 1.69。这些的更新确保开发人员可访问最新的工具和框架,以创建前沿的应用。
Alpine Linux 3.18 还通过 tiny-cloud 引入了实验性的无人值守安装支持。该功能允许自动化且精简的部署,使系统管理员能够更轻松地在多台机器上设置和配置 Alpine Linux。tiny-cloud 功能为云和虚拟化环境中的高效和可扩展的部署打开了新的可能性。
此外,Alpine Linux 3.18 在软件包大小方面做出了显著优化。所有 ppc64le、x86 和x86\_64 的软件包都与 DT\_RELR 链接,从而减小了已编译二进制文件的大小。此优化有助于节省存储空间,并有助于更快的软件包安装和低资源消耗。
为了进一步优化安装过程,Alpine Linux 3.18 现在提供了单独的 Python 预编译文件(`pyc`)软件包。这意味着用户可以选择仅安装必要的组件,通过排除 `pyc` 文件节省宝贵的磁盘空间。
你可以从下面的页面下载 Alpine Linux 3.18:
>
> **[下载 Alpine Linux 3.18](https://dl-cdn.alpinelinux.org/alpine/v3.18/releases/x86_64/alpine-extended-3.18.0-x86_64.iso)**
>
>
>
来源:[变更日志](https://alpinelinux.org/posts/Alpine-3.18.0-released.html)
*(题图:MJ/228bb6eb-6247-439a-b41c-9a44dff8ad55)*
---
via: <https://debugpointnews.com/alpine-linux-3-18/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,814 | 10 种漂亮的 Linux 终端字体 | https://itsfoss.com/fonts-linux-terminal/ | 2023-05-15T18:25:04 | [
"终端",
"字体"
] | https://linux.cn/article-15814-1.html | 
>
> 为你的终端安装最好的字体,以改善外观和可读性,并让你的终端体验变得有趣。
>
>
>
选择完美的字体对很多事情都至关重要,无论你是程序员、系统管理员,还是喜欢终端的 Linux 用户。
[更改终端字体](https://itsfoss.com/change-terminal-font-ubuntu/) 可帮助你实现以下目标:
* **美观的终端外观**
* **增强可读性**
* **减少眼睛疲劳**
听起来不错。但是如何选择完美的字体呢?这里有成百上千种选择。
对于初学者,你可以选择 **针对技术文档或编码优化的字体**,因为它们具有良好的可读性。接下来,你可以筛选出 **FOSS 项目**(如果这对你很重要)并检查这些 **字体是否可以在高分辨率显示器上很好地缩放**(根据你的需求)。
不要担心,为了让你有一个良好的开端,我们选择了一些最适合编码的字体,提供良好的可读性,同时看起来也不错。
### 1、Cascadia

[Cascadia](https://github.com/microsoft/cascadia-code) 是微软提供的一种字体,默认用于 [最好的开源编辑器](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) 之一 VSCode。
它包括编码连字支持,并提供三种变体:标准、等宽和支持嵌入式 PowerLine 符号的版本。
### 2、Fira Code

[Fira Code](https://github.com/tonsky/FiraCode) 是一种等宽字体,具有编码连字和 ASCII 支持。
它会定期进行微调以支持字母对和更好的标点符号输出。
### 3、Hack

[Hack](https://github.com/source-foundry/Hack) 是另一种为源代码量身定制的等宽字体。
你可以获得 ASCII、PowerLine 支持以及**粗体、斜体和粗斜体等常用样式**。
如果你注意到它的 GitHub 页面,它们为某些 Linux 发行版提供了改进字体渲染的说明。
### 4、Inconsolata

[Inconsolata](https://fonts.google.com/specimen/Inconsolata) 是一种清晰的等宽字体,具有出色的可读性。它是谷歌字体系列之一。
对于 [终端仿真器](https://itsfoss.com/linux-terminal-emulators/) 和编码用途,该字体提供了几种有用的样式。
### 5、Iosevka

[Iosevka](https://github.com/be5invis/Iosevka) 是一种外观简洁的多功能开源字体,用于编写代码并在终端和技术文档中使用。
你可以从它的 GitHub 页面获取其他平台(包括 Linux)的安装说明。
### 6、JetBrains Mono

[JetBrains Mono](https://github.com/JetBrains/JetBrainsMono) 是专为开发人员量身定制的自由开源字体。
顾名思义,它是流行的开发者工具 [JetBrains](https://www.jetbrains.com/) 使用的默认字体。
### 7、Meslo NF

Meslo NF 是一种可以在终端中很好地支持 ASCII 和图标的字体。
作为 GitHub 上 [Nerd Fonts](https://github.com/ryanoasis/nerd-fonts/) 集的一部分,它提供了用于编码和终端的漂亮字体。你可以在它的 [GitHub 发布页](https://github.com/ryanoasis/nerd-fonts/releases/tag/v3.0.0) 的资源列表中找到该字体。
它在 Zsh、Fish 和其他 Shell 中看起来很棒。
### 8、Monoid

[Monoid](https://larsenwork.com/monoid/) 是另一种旨在用于编码的开源字体。有通常的连字支持和深色浅色变体,它应该是终端的不错选择。
### 9、Ubuntu Monospace

我们都喜欢 Ubuntu 的默认字体 [Ubuntu Monospace](https://design.ubuntu.com/font)。它针对多种语言、高分辨率屏幕和良好的可读性进行了优化。
如果你已经使用 Ubuntu,则无需单独安装它。
### 10、SourceCode Pro

[Source Code Pro](https://github.com/adobe-fonts/source-code-pro) 很好地融合了一切需求。虽然它针对编码环境进行了优化,并由 Adobe 开发,但它也为终端提供了具体良好可读性和美观性。
### 如何安装这些字体?
你可以通过下载 TTF 或 OTF 文件轻松安装字体,然后双击它们以使用字体查看器打开它进行安装。

要同时安装多种字体,你可以在主目录中新建一个 `.fonts` 文件夹,并将字体文件放在那里。你可以查看我们关于 [安装新字体](https://itsfoss.com/install-fonts-ubuntu/) 的指南,了解更多详细信息。
### 更多自定义终端的方法
这里有一些自定义终端外观的 [方法](https://itsfoss.com/customize-linux-terminal/)。
还有一个有趣的 [工具](https://itsfoss.com/pywal/),可以根据你的桌面墙纸自动更改终端的配色方案。多么酷啊!
? 名单上你最喜欢的是什么?你使用什么终端字体?
*(题图:MJ/e5ae0ee3-9ea2-4136-a000-8fe681480356)*
---
via: <https://itsfoss.com/fonts-linux-terminal/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Picking the perfect font is crucial for many things, whether you are a programmer, system administrator, or a Linux user fond of the terminal.
[Changing the terminal font](https://itsfoss.com/change-terminal-font-ubuntu/) helps you achieve the following:
**An aesthetically pleasing look of your terminal****Enhances readability****Reduces eye strain**
Sounds good. But how can you choose the perfect font? There are hundreds and thousands of options out there.
For starters, you can select a **font optimized for technical documents or coding** because those have good readability. Next, you can filter **foss projects** (if that matters to you) and check if those **fonts scale well** with high-resolution monitors (per your requirements).
Fret not; to give you a head start, we have picked some of the best fonts fit for coding, offering good readability while also looking good at the same time.
## 1. Cascadia
[Cascadia](https://github.com/microsoft/cascadia-code) is a font by Microsoft, used by default for Visual Studio Code, one of the [best open-source code editors](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/).
It includes coding ligature support and offers three variants: standard, mono, and a version supporting embedded powerline symbols.
## 2. Fira Code
[Fira Code](https://github.com/tonsky/FiraCode) is a monospaced font with programming ligature and ASCII support.
It is regularly fine-tuned to support letter pairs and better punctuation output.
## 3. Hack
[Hack](https://github.com/source-foundry/Hack) is another monospaced font tailored for source codes.
You get ASCII, powerline support, and the usual styles for **bold, italic, and bold italic.**
If you notice its GitHub page, they provide instructions to improve the font rendering for certain Linux distributions.
## 4. Inconsolata
[Inconsolata](https://fonts.google.com/specimen/Inconsolata) is a clear monospace font tailored for great readability. You can find it as one of the options in the Google Font family.
The font offers several styles useful for [terminal emulators](https://itsfoss.com/linux-terminal-emulators/) and coding purposes.
## 5. Iosevka
[Iosevka](https://github.com/be5invis/Iosevka) is a clean-looking versatile open-source font built to write code and use in terminals and technical documents.
You can get installation instructions from its GitHub page for other platforms, including Linux.
## 6. JetBrains mono
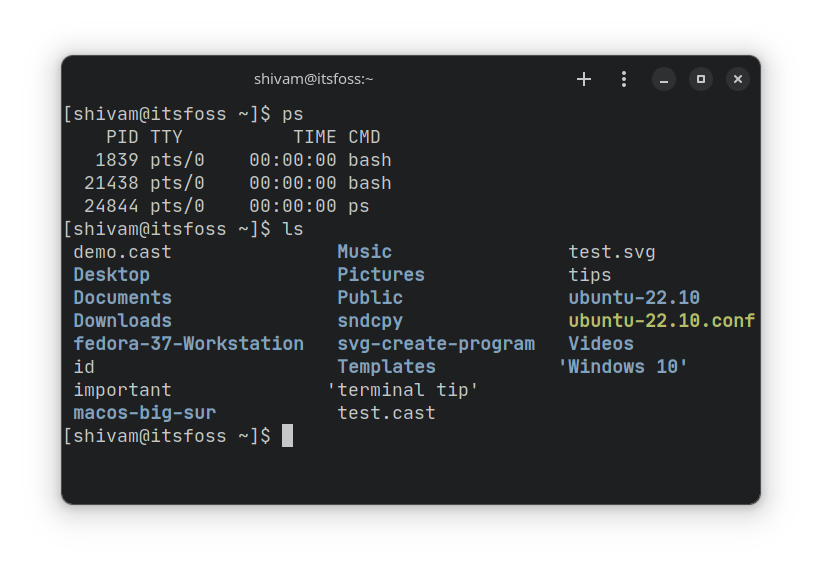
The free and open-source typeface is tailored for developers, i.e., [JetBrains Mono](https://github.com/JetBrains/JetBrainsMono).
As the name suggests, it is the default font used by the popular developer tools under [JetBrains](https://www.jetbrains.com).
## 7. Meslo NF
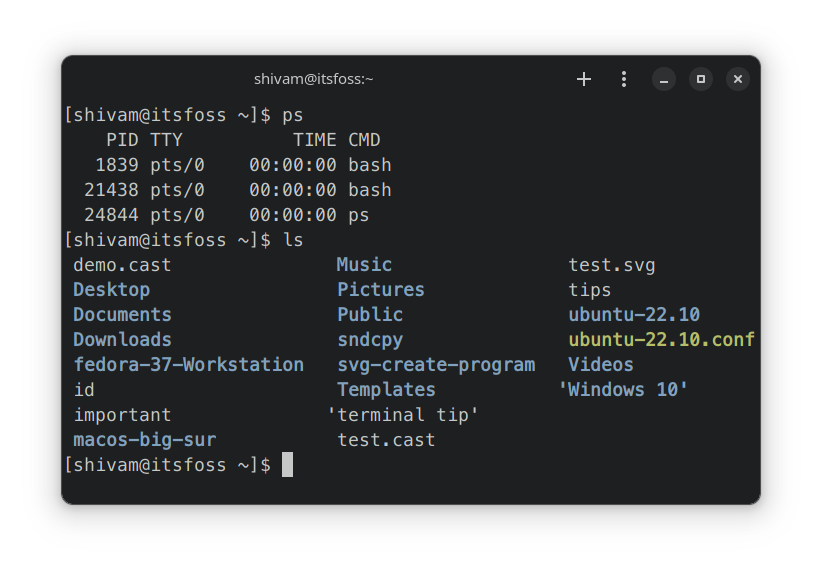
Meslo NF is a font that supports ASCII and icons well in the terminal.
A part of "[Nerd Fonts](https://github.com/ryanoasis/nerd-fonts/)" collection on GitHub, which features good-looking fonts for coding and terminal. You can find the font among the assets in its [GitHub releases](https://github.com/ryanoasis/nerd-fonts/releases/tag/v3.0.0) section.
It looks excellent in shells like Zsh, fish, and others. You can check out our article on lesser-known [Linux shells](https://itsfoss.com/shells-linux/) to explore others.
**Suggested Read 📖**
[Beyond Bash: 9 Lesser-Known Linux Shells and Their CapabilitiesYou probably already know about the popular shells like bash and zsh. Let us explore some interesting and unique shells.](https://itsfoss.com/shells-linux/)

## 8. Monoid
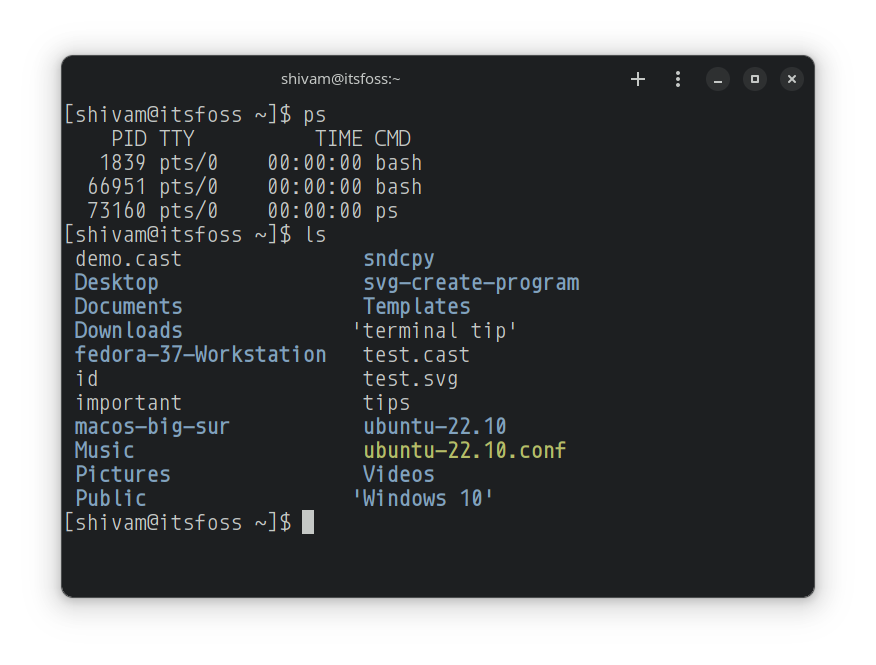
[Monoid](https://larsenwork.com/monoid/) is another open-source font that aims to be useful for coding. With the usual ligature support and light-dark variants, it should be a nice choice for terminals.
## 9. Ubuntu Monospace
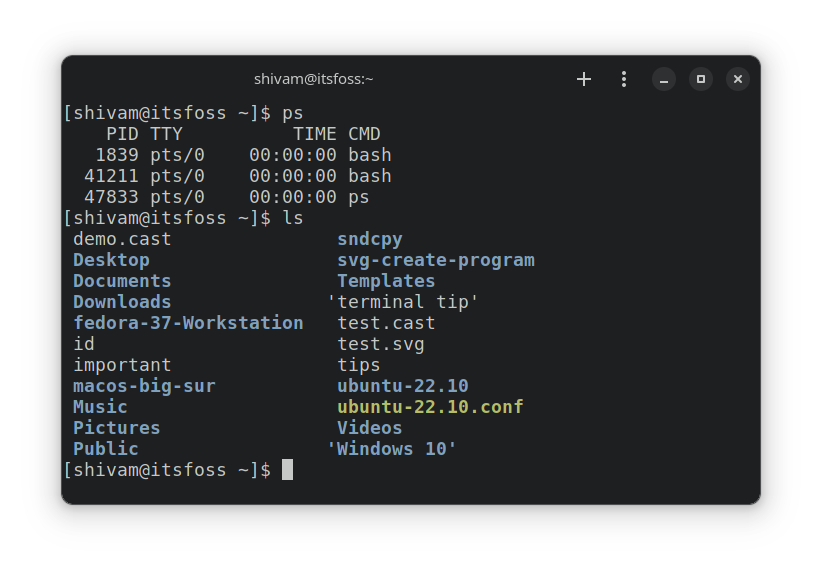
We all love Ubuntu's default font, i.e., [Ubuntu Monospace](https://design.ubuntu.com/font). It is optimized for many languages, high-resolution screens, and good readability.
You do not need to install it if you already use Ubuntu.
## 10. SourceCode Pro
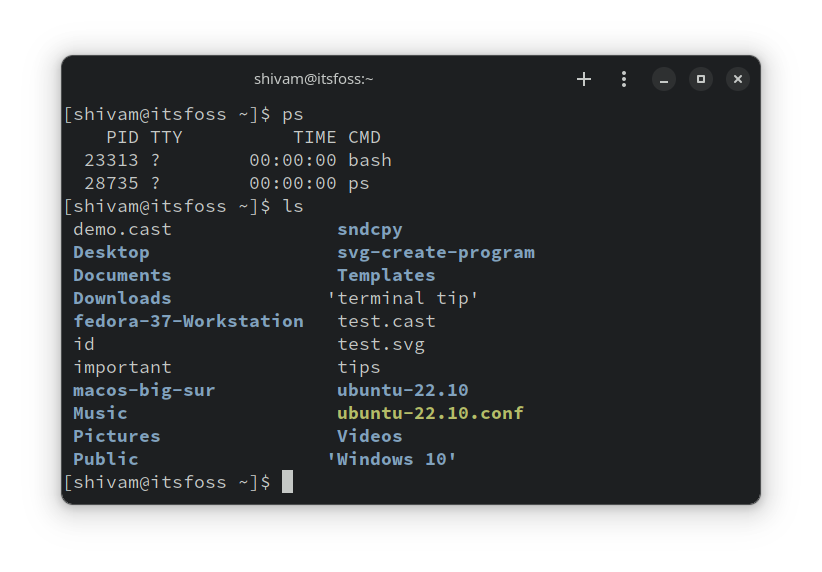
[Source Code Pro](https://github.com/adobe-fonts/source-code-pro) is a good mix of everything. While it is optimized for coding environments and developed by Adobe, it offers good readability and look-for terminals.
**Recommended Read 📖**
[Top 14 Terminal Emulators for Linux (With Extra Features or Amazing Looks)Want a terminal that looks cool or has extra features? Here are the best Linux terminal emulators you can get.](https://itsfoss.com/linux-terminal-emulators/)

## How to Install These Fonts?
You can easily install a font by downloading the TTF or OTF file and then double-clicking on them to open it using Font Viewer to install.
To install multiple fonts simultaneously, you can make a new `.fonts`
folder in the home directory and put the font files there. You can check out our guide on [ installing new fonts](https://itsfoss.com/install-fonts-ubuntu/) for more detailed information.
[How to Install New Fonts in Ubuntu and Other Linux DistrosWondering how to install additional fonts in Ubuntu Linux? Here is a screenshot tutorial to show you how to easily install new fonts.](https://itsfoss.com/install-fonts-ubuntu/)

## More ways to customize terminal
Here are a few more ways to customize the look and feel of your terminal.
[5 Tweaks to Customize the Look of Your Linux TerminalWant a beautiful-looking Linux terminal? Here are several ways to tweak the look and feel of your current terminal and make it look beautiful.](https://itsfoss.com/customize-linux-terminal/)

Another interesting tool that automatically changes the color scheme of the terminal based on your desktop wallpaper. How cool is that!
[Automatically Change Color Scheme of Your Linux Terminal Based on Your WallpaperIf you are It’s FOSS newsletter subscriber, you already know that we have started a new ‘Terminal Tuesday’ series. In this, you’ll get to read about command line tools or tips/tricks to help you in the terminal. Terminal is not all about serious work, it can be](https://itsfoss.com/pywal/)

💬*What is your favorite on the list? Do you have better suggestions? Do share your thoughts in the comments below.* |
15,815 | 如何为 APT 命令设置代理 | https://www.linuxtechi.com/set-proxy-settings-for-apt-command/ | 2023-05-15T18:45:00 | [
"代理",
"apt"
] | https://linux.cn/article-15815-1.html | 
>
> 在本指南中,你将了解如何在 Ubuntu/Debian Linux 发行版中为 `apt` 命令设置代理。
>
>
>
代理服务器是位于请求资源的客户端系统或最终用户与资源本身之间的中间服务器。在大多数情况下,代理服务器充当最终用户和互联网之间的网关。
对于组织和企业环境,代理服务器提供了许多好处。它通过阻止被认为会影响员工工作效率的网站来控制互联网的使用。它还通过数据加密增强隐私并提高组织的安全性。
有几种方法可以为 `apt` 命令设置代理,让我们直接进入。
注意:为了演示,我们将使用 Ubuntu 22.04。
### 使用代理文件为 APT 配置代理
为 `apt` 命令配置代理的最简单方法是创建一个 `proxy.conf` 文件,如下:
```
$ sudo vi /etc/apt/apt.conf.d/proxy.conf
```
对于没有用户名和密码的代理服务器,添加以下条目,如下:
对于 HTTP 代理,添加以下条目:
```
Acquire::http::Proxy "http://proxy-IP-address:proxyport/";
```
对 HTTPS 代理执行相同的操作:
```
Acquire::https::Proxy "http://proxy-IP-address:proxyport/";
```
例子:
```
$ cat /etc/apt/apt.conf.d/proxy.conf
Acquire::http::Proxy "http://192.168.56.102:3128/";
Acquire::https::Proxy "http://192.168.56.102:3128/";
```
如果你的代理服务器需要用户名和密码详细信息,请按以下方式添加:
```
Acquire::http::Proxy "http://username:password@proxy-IP-address:proxyport";
Acquire::https::Proxy "http://username:password@proxy-IP-address:proxyport";
```
例子:
```
$ cat /etc/apt/apt.conf.d/proxy.conf
Acquire::http::Proxy "http://init@PassW0rd321#@192.168.56.102:3128/";
Acquire::https::Proxy "http://init@PassW0rd321#@192.168.56.102:3128/";
```
完成后,保存更改并退出配置文件。代理设置将在你下次运行 APT 包管理器时生效。
例如,你可以更新本地包索引,然后安装 `net-tools` 包:
```
$ sudo apt update
$ sudo apt install net-tools -y
```

验证代理服务器日志以确认 `apt` 命令正在使用代理服务器下载包。在代理服务器运行时:
```
# tail -f /var/log/squid/access.log | grep -i 192.168.56.240
```
这里 `192.168.56.240` 是我们 Ubuntu 机器的 IP 地址。

完美,上面的输出确认我们的 Ubuntu 系统的 `apt` 命令正在通过代理服务器(192.168.56.102)下载包。
### 另一种指定代理详细信息的方法
除了第一种方法,你还可以用更简单的方式指定代理详细信息。再次创建一个 `proxy.conf` 文件,如下所示。
```
$ sudo vi /etc/apt/apt.conf.d/proxy.conf
```
对于没有用户名和密码的代理服务器,如图所示进行定义。
```
Acquire {
http::Proxy "http://proxy-IP-address:proxyport/";
https::Proxy "http://proxy-IP-address:proxyport/";
}
```
示例文件如下所示:
```
$ sudo vi /etc/apt/apt.conf.d/proxy.conf
```

对于具有用户名和登录详细信息的代理服务器:
```
Acquire {
http::Proxy "http://username:password@proxy-IP-address:proxyport/";
https::Proxy "http://username:password@proxy-IP-address:proxyport/";
}
```
保存更改并退出配置文件。提醒一下,当你开始使用 APT 包管理器,这些设置就会立即生效。
### 总结
本指南到此结束。在本教程中,我们演示了如何为 Debian/Ubuntu Linux 发行版中使用的 APT 包管理器配置代理设置。本文就到这里了。
(题图:MJ/dfb4d5a0-9150-47bd-9f54-c120ddd77046)
---
via: <https://www.linuxtechi.com/set-proxy-settings-for-apt-command/>
作者:[James Kiarie](https://www.linuxtechi.com/author/james/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this guide, you will learn how to set proxy settings for the APT command in Ubuntu/Debian Linux distributions.
A proxy server is an intermediary server that sits between a client system or end user requesting the resource and the resource itself. In most cases, a proxy server acts as a gateway between end users and the internet.
For organizations and enterprise environments, a proxy server provides a number of benefits. It controls internet usage by blocking sites that are deemed to impact employees’ productivity. It also enhances privacy and improves the organization’s security through data encryption.
There are several ways to set proxy settings for apt command, so let’s jump right in.
Note: For demonstration, we will use Ubuntu 22.04.
## Configure Proxy Setting For APT Using A Proxy file
The easiest way to configure proxy settings for the APT command is by creating a proxy.conf file as shown.
$ sudo vi /etc/apt/apt.conf.d/proxy.conf
For a proxy server without a username and password, add the following entries as shown
For the HTTP Proxy, add the following entry:
Acquire::http::Proxy "http://proxy-IP-address:proxyport/";
Do the same for the HTTPS Proxy:
Acquire::https::Proxy "http://proxy-IP-address:proxyport/";
Example:
$ cat /etc/apt/apt.conf.d/proxy.conf Acquire::http::Proxy "http://192.168.56.102:3128/"; Acquire::https::Proxy "http://192.168.56.102:3128/";
If your Proxy server requires a username and password details, add them as follows
Acquire::http::Proxy "http://username:password@proxy-IP-address:proxyport"; Acquire::https::Proxy "http://username:password@proxy-IP-address:proxyport";
Example:
$ cat /etc/apt/apt.conf.d/proxy.conf Acquire::http::Proxy "http://init@PassW0rd321#@192.168.56.102:3128/"; Acquire::https::Proxy "http://init@PassW0rd321#@192.168.56.102:3128/";
Once you are done, Save the changes and exit the configuration file. The Proxy settings will come into action the next time you run the APT package manager.
For example, you can update the local package index and then install net-tools package
$ sudo apt update $ sudo apt install net-tools -y
Verify the proxy server logs to confirm that [apt command](https://www.linuxtechi.com/apt-command-ubuntu-debian-linux/) is using proxy server for downloading packages. On the proxy server run,
# tail -f /var/log/squid/access.log | grep -i 192.168.56.240
Here ‘192.168.56.240’ is the IP address of our Ubuntu machine,
Perfect, output above confirms that apt command of our ubuntu system is downloading the packages via proxy server (192.168.56.102)
## An Alternative Way of Specifying Proxy Details
Apart from the first approach, you can specify the proxy details in a much simpler way. Once again, create a proxy.conf file as follows.
$ sudo vi /etc/apt/apt.conf.d/proxy.conf
For a Proxy server without a username and password, define it as shown.
Acquire { http::Proxy "http://proxy-IP-address:proxyport/"; https::Proxy "http://proxy-IP-address:proxyport/"; }
Sample example file would look like below,
$ sudo vi /etc/apt/apt.conf.d/proxy.conf
For a Proxy server with username and login details:
Acquire { http::Proxy "http://username:password@proxy-IP-address:proxyport/"; https::Proxy "http://username:password@proxy-IP-address:proxyport/"; }
Save the changes and exit the configuration file. Just a reminder that these settings take immediate effect once you start using the APT package manager.
#### Conclusion
This concludes this guide. In this tutorial, we have demonstrated how you can configure proxy settings for the APT package manager which is used in Debian/Ubuntu Linux distributions. That’s all for now. Keep it Linuxechi!
Also Read: [How to Install Go (Golang) on Ubuntu Linux Step-by-Step](https://www.linuxtechi.com/install-go-golang-on-ubuntu-linux/) |
15,817 | ZOMBIES:软件开发和测试中的构建与拓展(二) | https://opensource.com/article/21/2/build-expand-software | 2023-05-16T15:50:41 | [
"测试"
] | /article-15817-1.html |
>
> 在开发初期只对单个元素进行编码和测试,之后再拓展到多个元素上。
>
>
>

在 [上一篇文章](/article-15808-1.html) 中我已经解释了为什么把所有编程问题当作一群丧尸一次性处理是错误的。我也解释了 ZOMBIES 方法中的第一条:最简场景。本文中我将进一步介绍接下来的两条:单元素场景和多元素场景。
ZOMBIES 表示以下首字母缩写:
* **Z** – 最简场景(Zero)
* **O** – 单元素场景(One)
* **M** – 多元素场景(Many or more complex)
* **B** – 边界行为(Boundary behaviors)
* **I** – 接口定义(Interface definition)
* **E** – 处理特殊行为(Exercise exceptional behavior)
* **S** – 简单场景用简单的解决方案(Simple scenarios, simple solutions)
在上一篇文章中,通过应用了最简场景,你在代码里构建了一条最简可行通路。这个代码里没有任何业务处理逻辑。现在是时候向系统中添加一个元素了。
最简场景表示系统中什么也没有,这是一个空的用例,我们什么也不用关心。单元素场景代表我们有一个元素需要关心考虑。这个单一元素可能是集合中的一个元素、一个访问着或者一个需要处理的事件。
对于多元素场景,我们需要处理更复杂的情况,比如两个或更多的集合元素或事件。
### 单元素场景
在上一篇文章的代码基础上,向虚拟购物筐里添加一些商品。首先,写一个伪测试:
```
[Fact]
public void Add1ItemBasketHas1Item() {
var expectedNoOfItems = 1;
var actualNoOfItems = 0;
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
```
不出所料,这个测试失败了,因为硬编码了一个错误的值:
```
Starting test execution, please wait...
A total of 1 test files matched the specified pattern.
[xUnit.net 00:00:00.57] tests.UnitTest1.NewlyCreatedBasketHas0Items [FAIL]
X tests.UnitTest1.NewlyCreatedBasketHas0Items [4ms]
Error Message:
Assert.Equal() Failure
Expected: 0
Actual: 1
[...]
```
现在是时候停止伪造了。现在你已经用 `ArrayList` 实现了购物筐。那么应该怎么实现*商品*呢?
简洁性应该一直是你的指导原则。在不了解商品的太多信息的情况下,你可以先用另一个集合来实现它。这个表示商品的集合应该包含些什么呢?由于你多半会关心计算购物筐中的商品总价,所以对商品的表示至少需要包含价格(可以是任意货币,为简单起见,不妨假设是人民币)。
(我们需要)一个简单的集合类型,它包含一个商品 ID(可以在系统中的其它地方使用 ID 来指向该商品)和这个商品的价格。
键值对类型的数据结构可以很容易满足这个需求。在 C# 中最先被想到的数据结构就是 `Hashtable`。
在购物应用的代码中给 `IShoppingAPI` 增加一个新功能:
```
int AddItem(Hashtable item);
```
这个新功能以一个用 `Hashtable` 表示的商品为输入,返回购物筐中的商品数量。
将测试代码中硬编码的值提替换为对接口的调用:
```
[Fact]
public void Add1ItemBasketHas1Item() {
var expectedNoOfItems = 1;
Hashtable item = [new][3] Hashtable();
var actualNoOfItems = shoppingAPI.AddItem(item);
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
```
在上面的代码中实例化了一个 `Hashtable` 并命名为 `item`,然后调用购物接口中的 `AddItem(item)` 方法,该方法会返回购物筐中实际的商品数量。
转到 `ShoppingAPI` 类中,实现这个方法:
```
public int AddItem(Hashtable item) {
return 0;
}
```
这里再次通过写假代码来检验测试的效果(测试是业务代码的第一个调用者)。如果测试失败,将硬编码值换成实际的代码:
```
public int AddItem(Hashtable item) {
basket.Add(item);
return basket.Count;
}
```
在上面的代码中,向购物筐里添加了一件商品,然后返回购物筐中的商品数量:
```
Test Run Successful.
Total tests: 2
Passed: 2
Total time: 1.0633 Seconds
```
到目前为止,你通过了两个测试,同时也基本里解了 ZOMBIES 方法中的最简场景和单元素场景两部分。
### 反思总结
回顾前面所做的工作,你会发现通过将注意力集中到处理最简场景和单元素场景上,你在构建接口的同时也定义了一些业务逻辑边界!这不是很棒吗?现在你已经部分地实现了最关键的抽象逻辑,并且能够处理什么也没有和只有一个元素的的情况。因为你正在构建的是一个电子交易 API,所以你不能对顾客的购物行为预设其它限制。总而言之,虚拟购物筐应该是无限大的。
ZOMBIES 提供的逐步优化思路的另一个重要方面(虽然不是很明显)是从大概思路到具体实现的阻力。你也许已经注意到了,要具体实现某个东西总是困难重重。倒不如先用硬编码值来构造一个伪实现。只有看到接口与测试之间以一种合理的方式交互之后,你才会愿意开始完善实现代码。
即便如此,你也应该采用简单直接的代码结构,尽可能避免条件逻辑分支。
### 多元素场景
通过定义顾客向购物筐里添加两件商品时的期望来拓展应用程序。首先构造一个伪测试。它的期望值为 2,但是现在将实际值硬编码为 0,强制让测试失败:
```
[Fact]
public void Add2ItemsBasketHas2Items() {
var expectedNoOfItems = 2;
var actualNoOfItems = 0;
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
```
执行测试,前两个测试用例通过了(针对最简场景和单元素场景的测试),而硬编码的测试不出所料地失败了:
```
A total of 1 test files matched the specified pattern.
[xUnit.net 00:00:00.57] tests.UnitTest1.Add2ItemsBasketHas2Items [FAIL]
X tests.UnitTest1.Add2ItemsBasketHas2Items [2ms]
Error Message:
Assert.Equal() Failure
Expected: 2
Actual: 0
Test Run Failed.
Tatal tests: 3
Passed: 2
Failed: 1
```
将硬编码值替换为实际的代码调用:
```
[Fact]
public void Add2ItemsBasketHas2Items() {
var expectedNoOfItems = 2;
Hashtable item = [new][3] Hashtable();
shoppingAPI.AddItem(item);
var actualNoOfItems = shoppingAPI.AddItem(item);
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
```
在这个测试中,你向购物筐中添加了两件商品(实际上是将同一件商品添加了两次),然后比较期望的商品数量和第二次添加商品后调用 `shoppingAPI` 返回的商品数量是否相等。
现在所有测试都能够通过!
### 敬请期待
现在你已经了解了最简场景、单元素场景和多元素场景。我将下一篇文章中介绍边界行为和接口定义。敬请期待!
(题图:MJ/e4679f1f-311a-4a41-80e8-8d2834b956f2)
---
via: <https://opensource.com/article/21/2/build-expand-software>
作者:[Alex Bunardzic](https://opensource.com/users/alex-bunardzic) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,818 | 为什么 0.1 + 0.2 = 0.30000000000000004? | https://jvns.ca/blog/2023/02/08/why-does-0-1-plus-0-2-equal-0-30000000000000004/ | 2023-05-16T16:31:00 | [
"浮点数"
] | https://linux.cn/article-15818-1.html | 
嗨!昨天我试着写点关于浮点数的东西,我发现自己对这个 64 位浮点数的计算方法很好奇:
```
>>> 0.1 + 0.2
0.30000000000000004
```
我意识到我并没有完全理解它是如何计算的。我的意思是,我知道浮点计算是不精确的,你不能精确地用二进制表示 `0.1`,但是:肯定有一个浮点数比 `0.30000000000000004` 更接近 0.3!那为什么答案是 `0.30000000000000004` 呢?
如果你不想阅读一大堆计算过程,那么简短的答案是: `0.1000000000000000055511151231257827021181583404541015625 + 0.200000000000000011102230246251565404236316680908203125` 正好位于两个浮点数之间,即 `0.299999999999999988897769753748434595763683319091796875` (通常打印为 `0.3`) 和 `0.3000000000000000444089209850062616169452667236328125`(通常打印为 `0.30000000000000004`)。答案是 `0.30000000000000004`,因为它的尾数是偶数。
#### 浮点加法是如何计算的
以下是浮点加法的简要计算原理:
* 把它们精确的数字加在一起
* 将结果四舍五入到最接近的浮点数
让我们用这些规则来计算 0.1 + 0.2。我昨天才刚了解浮点加法的计算原理,所以在这篇文章中我可能犯了一些错误,但最终我得到了期望的答案。
#### 第一步:0.1 和 0.2 到底是多少
首先,让我们用 Python 计算 `0.1` 和 `0.2` 的 64 位浮点值。
```
>>> f"{0.1:.80f}"
'0.10000000000000000555111512312578270211815834045410156250000000000000000000000000'
>>> f"{0.2:.80f}"
'0.20000000000000001110223024625156540423631668090820312500000000000000000000000000'
```
这确实很精确:因为浮点数是二进制的,你也可以使用十进制来精确的表示。但有时你只是需要一大堆数字:)
#### 第二步:相加
接下来,把它们加起来。我们可以将小数部分作为整数加起来得到确切的答案:
```
>>> 1000000000000000055511151231257827021181583404541015625 + 2000000000000000111022302462515654042363166809082031250
3000000000000000166533453693773481063544750213623046875
```
所以这两个浮点数的和是 `0.3000000000000000166533453693773481063544750213623046875`。
但这并不是最终答案,因为它不是一个 64 位浮点数。
#### 第三步:查找最接近的浮点数
现在,让我们看看接近 `0.3` 的浮点数。下面是最接近 `0.3` 的浮点数(它通常写为 `0.3`,尽管它不是确切值):
```
>>> f"{0.3:.80f}"
'0.29999999999999998889776975374843459576368331909179687500000000000000000000000000'
```
我们可以通过 `struct.pack` 将 `0.3` 序列化为 8 字节来计算出它之后的下一个浮点数,加上 1,然后使用 `struct.unpack`:
```
>>> struct.pack("!d", 0.3)
b'?\xd3333333'
# 手动加 1
>>> next_float = struct.unpack("!d", b'?\xd3333334')[0]
>>> next_float
0.30000000000000004
>>> f"{next_float:.80f}"
'0.30000000000000004440892098500626161694526672363281250000000000000000000000000000'
```
当然,你也可以用 `math.nextafter`:
```
>>> math.nextafter(0.3, math.inf)
0.30000000000000004
```
所以 `0.3` 附近的两个 64 位浮点数是 `0.299999999999999988897769753748434595763683319091796875` 和 `0.3000000000000000444089209850062616169452667236328125`。
#### 第四步:找出哪一个最接近
结果证明 `0.3000000000000000166533453693773481063544750213623046875` 正好在 `0.299999999999999988897769753748434595763683319091796875` 和 `0.3000000000000000444089209850062616169452667236328125` 的中间。
你可以通过以下计算看到:
```
>>> (3000000000000000444089209850062616169452667236328125000 + 2999999999999999888977697537484345957636833190917968750) // 2 == 3000000000000000166533453693773481063544750213623046875
True
```
所以它们都不是最接近的。
#### 如何知道四舍五入到哪一个?
在浮点数的二进制表示中,有一个数字称为“尾数”。这种情况下(结果正好在两个连续的浮点数之间),它将四舍五入到偶数尾数的那个。
在本例中为 `0.300000000000000044408920985006261616945266723632812500`。
我们之前就见到了这个数字的尾数:
* 0.30000000000000004 是 `struct.unpack('!d', b'?\xd3333334')` 的结果
* 0.3 是 `struct.unpack('!d', b'?\xd3333333')` 的结果
`0.30000000000000004` 的大端十六进制表示的最后一位数字是 `4`,它的尾数是偶数(因为尾数在末尾)。
#### 我们用二进制来算一下
之前我们都是使用十进制来计算的,这样读起来更直观。但是计算机并不会使用十进制,而是用 2 进制,所以我想知道它是如何计算的。
我不认为本文的二进制计算部分特别清晰,但它写出来对我很有帮助。有很多数字,读起来可能很糟糕。
#### 64 位浮点数如何计算:指数和尾数
64 位浮点数由 2 部分整数构成:**指数**和**尾数**,还有 1 比特 **符号位**.
以下是指数和尾数对应于实际数字的方程:

例如,如果指数是 `1`,尾数是 `2**51`,符号位是正的,那么就可以得到:

它等于 `2 * (1 + 0.5)`,即 3。
#### 步骤 1:获取 0.1 和 0.2 的指数和尾数
我用 Python 编写了一些低效的函数来获取正浮点数的指数和尾数:
```
def get_exponent(f):
# 获取前 52 个字节
bytestring = struct.pack('!d', f)
return int.from_bytes(bytestring, byteorder='big') >> 52
def get_significand(f):
# 获取后 52 个字节
bytestring = struct.pack('!d', f)
x = int.from_bytes(bytestring, byteorder='big')
exponent = get_exponent(f)
return x ^ (exponent << 52)
```
我忽略了符号位(第一位),因为我们只需要处理 0.1 和 0.2,它们都是正数。
首先,让我们获取 0.1 的指数和尾数。我们需要减去 1023 来得到实际的指数,因为浮点运算就是这么计算的。
```
>>> get_exponent(0.1) - 1023
-4
>>> get_significand(0.1)
2702159776422298
```
它们根据 `2**指数 + 尾数 / 2**(52 - 指数)` 这个公式得到 `0.1`。
下面是 Python 中的计算:
```
>>> 2**-4 + 2702159776422298 / 2**(52 + 4)
0.1
```
(你可能会担心这种计算的浮点精度问题,但在本例中,我很确定它没问题。因为根据定义,这些数字没有精度问题 -- 从 `2**-4` 开始的浮点数以 `1/2**(52 + 4)` 步长递增。)
`0.2` 也一样:
```
>>> get_exponent(0.2) - 1023
-3
>>> get_significand(0.2)
2702159776422298
```
它们共同工作得到 `0.2`:
```
>>> 2**-3 + 2702159776422298 / 2**(52 + 3)
0.2
```
(顺便说一下,0.1 和 0.2 具有相同的尾数并不是巧合 —— 因为 `x` 和 `2*x` 总是有相同的尾数。)
#### 步骤 2:重新计算 0.1 以获得更大的指数
`0.2` 的指数比 `0.1` 大 -- -3 大于 -4。
所以我们需要重新计算:
```
2**-4 + 2702159776422298 / 2**(52 + 4)
```
等于 `X / 2**(52 + 3)`
如果我们解出 `2**-4 + 2702159776422298 / 2**(52 + 4) = X / 2**(52 + 3)`,我们能得到:
`X = 2**51 + 2702159776422298 / 2`
在 Python 中,我们很容易得到:
```
>>> 2**51 + 2702159776422298 //2
3602879701896397
```
#### 步骤 3:添加符号位
现在我们试着做加法:
```
2**-3 + 2702159776422298 / 2**(52 + 3) + 3602879701896397 / 2**(52 + 3)
```
我们需要将 `2702159776422298` 和 `3602879701896397` 相加:
```
>>> 2702159776422298 + 3602879701896397
6305039478318695
```
棒。但是 `6305039478318695` 比 `2**52-1`(尾数的最大值)大,问题来了:
```
>>> 6305039478318695 > 2**52
True
```
#### 第四步:增加指数
目前结果是:
```
2**-3 + 6305039478318695 / 2**(52 + 3)
```
首先,它减去 2\*\*52:
```
2**-2 + 1801439850948199 / 2**(52 + 3)
```
完美,但最后的 `2**(52 + 3)` 需要改为 `2**(52 + 2)`。
我们需要将 `1801439850948199` 除以 2。这就是难题的地方 -- `1801439850948199` 是一个奇数!
```
>>> 1801439850948199 / 2
900719925474099.5
```
它正好在两个整数之间,所以我们四舍五入到最接近它的偶数(这是浮点运算规范要求的),所以最终的浮点结果是:
```
>>> 2**-2 + 900719925474100 / 2**(52 + 2)
0.30000000000000004
```
它就是我们预期的结果:
```
>>> 0.1 + 0.2
0.30000000000000004
```
#### 在硬件中它可能并不是这样工作的
在硬件中做浮点数加法,以上操作方式可能并不完全一模一样(例如,它并不是求解 “X”),我相信有很多有效的技巧,但我认为思想是类似的。
#### 打印浮点数是非常奇怪的
我们之前说过,浮点数 0.3 不等于 0.3。它实际上是:
```
>>> f"{0.3:.80f}"
'0.29999999999999998889776975374843459576368331909179687500000000000000000000000000'
```
但是当你打印它时,为什么会显示 `0.3`?
计算机实际上并没有打印出数字的精确值,而是打印出了*最短*的十进制数 `d`,其中 `f` 是最接近 `d` 的浮点数。
事实证明,有效做到这一点很不简单,有很多关于它的学术论文,比如 [快速且准确地打印浮点数](https://legacy.cs.indiana.edu/~dyb/pubs/FP-Printing-PLDI96.pdf)、[如何准确打印浮点数](https://lists.nongnu.org/archive/html/gcl-devel/2012-10/pdfkieTlklRzN.pdf) 等。
#### 如果计算机打印出浮点数的精确值,会不会更直观一些?
四舍五入到一个干净的十进制值很好,但在某种程度上,我觉得如果计算机只打印一个浮点数的精确值可能会更直观 -- 当你得到一个奇怪的结果时,它可能会让你看起来不那么惊讶。
对我来说,`0.1000000000000000055511151231257827021181583404541015625 + 0.200000000000000011102230246251565404236316680908203125 = 0.3000000000000000444089209850062616169452667236328125` 比 `0.1 + 0.2 = 0.30000000000000000004` 惊讶少一点。
这也许是一个坏主意,因为它肯定会占用大量的屏幕空间。
#### PHP 快速说明
有人在评论中指出在 PHP 中 `<?php echo (0.1 + 0.2 );?>` 会输出 `0.3`,这是否说明在 PHP 中浮点运算不一样?
非也 —— 我在 [这里](https://replit.com/languages/php_cli) 运行:
`<?php echo (0.1 + 0.2 )- 0.3);?>`,得到了与 Python 完全相同的答案:5.5511151231258E-17。因此,浮点运算的基本原理是一样的。
我认为在 PHP 中 `0.1 + 0.2` 输出 `0.3` 的原因是 PHP 显示浮点数的算法没有 Python 精确 —— 即使这个数字不是最接近 0.3 的浮点数,它也会显示 `0.3`。
#### 总结
我有点怀疑是否有人能耐心完成以上所有些算术,但它写出来对我很有帮助,所以我还是发表了这篇文章,希望它能有所帮助。
*(题图:MJ/53e9a241-14c6-4dc7-87d0-f9801cd2d7ab)*
---
via: <https://jvns.ca/blog/2023/02/08/why-does-0-1-plus-0-2-equal-0-30000000000000004/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lkxed](https://github.com/lkxed/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello! I was trying to write about floating point yesterday, and I found myself wondering about this calculation, with 64-bit floats:
```
>>> 0.1 + 0.2
0.30000000000000004
```
I realized that I didn’t understand exactly how it worked. I mean, I know
floating point calculations are inexact, and I know that you can’t exactly
represent `0.1`
in binary, but: there’s a floating point number that’s closer to
0.3 than `0.30000000000000004`
! So why do we get the answer
`0.30000000000000004`
?
If you don’t feel like reading this whole post with a bunch of calculations, the short answer is that
`0.1000000000000000055511151231257827021181583404541015625 + 0.200000000000000011102230246251565404236316680908203125`
lies exactly between
2 floating point numbers,
`0.299999999999999988897769753748434595763683319091796875`
(usually printed as `0.3`
) and
`0.3000000000000000444089209850062616169452667236328125`
(usually printed as `0.30000000000000004`
). The answer is
`0.30000000000000004`
(the second one) because its significand is even.
### how floating point addition works
This is roughly how floating point addition works:
- Add together the numbers (with extra precision)
- Round the result to the nearest floating point number
So let’s use these rules to calculate 0.1 + 0.2. I just learned how floating point addition works yesterday so it’s possible I’ve made some mistakes in this post, but I did get the answers I expected at the end.
### step 1: find out what 0.1 and 0.2 are
First, let’s use Python to figure out what the exact values of `0.1`
and `0.2`
are, as 64-bit floats.
```
>>> f"{0.1:.80f}"
'0.10000000000000000555111512312578270211815834045410156250000000000000000000000000'
>>> f"{0.2:.80f}"
'0.20000000000000001110223024625156540423631668090820312500000000000000000000000000'
```
These really are the exact values: because floating point numbers are in base 2, you can represent them all exactly in base 10. You just need a lot of digits sometimes :)
### step 2: add the numbers together
Next, let’s add those numbers together. We can add the fractional parts together as integers to get the exact answer:
```
>>> 1000000000000000055511151231257827021181583404541015625 + 2000000000000000111022302462515654042363166809082031250
3000000000000000166533453693773481063544750213623046875
```
So the exact sum of those two floating point numbers is `0.3000000000000000166533453693773481063544750213623046875`
This isn’t our final answer though because `0.3000000000000000166533453693773481063544750213623046875`
isn’t a 64-bit float.
### step 3: look at the nearest floating point numbers
Now, let’s look at the floating point numbers around `0.3`
. Here’s the closest floating point number to `0.3`
(usually written as just `0.3`
, even though that isn’t its exact value):
```
>>> f"{0.3:.80f}"
'0.29999999999999998889776975374843459576368331909179687500000000000000000000000000'
```
We can figure out the next floating point number after `0.3`
by serializing
`0.3`
to 8 bytes with `struct.pack`
, adding 1, and then using `struct.unpack`
:
```
>>> struct.pack("!d", 0.3)
b'?\xd3333333'
# manually add 1 to the last byte
>>> next_float = struct.unpack("!d", b'?\xd3333334')[0]
>>> next_float
0.30000000000000004
>>> f"{next_float:.80f}"
'0.30000000000000004440892098500626161694526672363281250000000000000000000000000000'
```
Apparently you can also do this with `math.nextafter`
:
```
>>> math.nextafter(0.3, math.inf)
0.30000000000000004
```
So the two 64-bit floats around
`0.3`
are
`0.299999999999999988897769753748434595763683319091796875`
and
`0.3000000000000000444089209850062616169452667236328125`
### step 4: find out which one is closest to our result
It turns out that `0.3000000000000000166533453693773481063544750213623046875`
is exactly in the middle of
`0.299999999999999988897769753748434595763683319091796875`
and
`0.3000000000000000444089209850062616169452667236328125`
.
You can see that with this calculation:
```
>>> (3000000000000000444089209850062616169452667236328125000 + 2999999999999999888977697537484345957636833190917968750) // 2 == 3000000000000000166533453693773481063544750213623046875
True
```
So neither of them is closest.
### how does it know which one to round to?
In the binary representation of a floating point number, there’s a number called the “significand”. In cases like this (where the result is exactly in between 2 successive floating point number, it’ll round to the one with the even significand.
In this case that’s `0.300000000000000044408920985006261616945266723632812500`
We actually saw the significand of this number a bit earlier:
- 0.30000000000000004 is
`struct.unpack('!d', b'?\xd3333334')`
- 0.3 is
`struct.unpack('!d', b'?\xd3333333')`
The last digit of the big endian hex representation of `0.30000000000000004`
is
`4`
, so that’s the one with the even significand (because the significand is at
the end).
### let’s also work out the whole calculation in binary
Above we did the calculation in decimal, because that’s a little more intuitive to read. But of course computers don’t do these calculations in decimal – they’re done in a base 2 representation. So I wanted to get an idea of how that worked too.
I don’t think this binary calculation part of the post is particularly clear but it was helpful for me to write out. There are a really a lot of numbers and it might be terrible to read.
### how 64-bit floats numbers work: exponent and significand
64-bit floating point numbers are represented with 2 integers: an **exponent** and the **significand** and a 1-bit **sign**.
Here’s the equation of how the exponent and significand correspond to an actual number
$$\text{sign} \times 2^\text{exponent} (1 + \frac{\text{significand}}{2^{52}})$$
For example if the exponent was `1`
the significand was `2**51`
, and the sign was positive, we’d get
$$2^{1} (1 + \frac{2^{51}}{2^{52}})$$
which is equal to `2 * (1 + 0.5)`
, or 3.
### step 1: get the exponent and significand for `0.1`
and `0.2`
I wrote some inefficient functions to get the exponent and significand of a positive float in Python:
```
def get_exponent(f):
# get the first 12 bytes
bytestring = struct.pack('!d', f)
return int.from_bytes(bytestring, byteorder='big') >> 52
def get_significand(f):
# get the last 52 bytes
bytestring = struct.pack('!d', f)
x = int.from_bytes(bytestring, byteorder='big')
exponent = get_exponent(f)
return x ^ (exponent << 52)
```
I’m ignoring the sign bit (the first bit) because we only need these functions to work on two numbers (0.1 and 0.2) and those two numbers are both positive.
First, let’s get the exponent and significand of 0.1. We need to subtract 1023 to get the actual exponent because that’s how floating point works.
```
>>> get_exponent(0.1) - 1023
-4
>>> get_significand(0.1)
2702159776422298
```
The way these numbers work together to get `0.1`
is `2**exponent + significand / 2**(52 - exponent)`
.
Here’s that calculation in Python:
```
>>> 2**-4 + 2702159776422298 / 2**(52 + 4)
0.1
```
(you might legitimately be worried about floating point accuracy issues with
this calculation, but in this case I’m pretty sure it’s fine because these
numbers by definition don’t have accuracy issues – the floating point numbers starting at `2**-4`
go up in steps of `1/2**(52 + 4)`
)
We can do the same thing for `0.2`
:
```
>>> get_exponent(0.2) - 1023
-3
>>> get_significand(0.2)
2702159776422298
```
And here’s how that exponent and significand work together to get `0.2`
:
```
>>> 2**-3 + 2702159776422298 / 2**(52 + 3)
0.2
```
(by the way, it’s not a coincidence that 0.1 and 0.2 have the same significand – it’s because `x`
and `2*x`
always have the same significand)
### step 2: rewrite `0.1`
to have a bigger exponent
`0.2`
has a bigger exponent than `0.1`
– -3 instead of -4.
So we need to rewrite
```
2**-4 + 2702159776422298 / 2**(52 + 4)
```
to be `X / (2**52 + 3)`
If we solve for X in `2**-4 + 2702159776422298 / 2**(52 + 4) = X / (2**52 + 3)`
, we get:
`X = 2**51 + 2702159776422298 /2`
We can calculate that in Python pretty easily:
```
>>> 2**51 + 2702159776422298 //2
3602879701896397
```
### step 3: add the significands
Now we’re trying to do this addition
```
2**-3 + 2702159776422298 / 2**(52 + 3) + 3602879701896397 / 2**(52 + 3)
```
So we need to add together `2702159776422298 `
and `3602879701896397`
```
>>> 2702159776422298 + 3602879701896397
6305039478318695
```
Cool. But `6305039478318695`
is more than 2**52 - 1 (the maximum value for a significand), so we have a problem:
```
>>> 6305039478318695 > 2**52
True
```
### step 4: increase the exponent
Right now our answer is
```
2**-3 + 6305039478318695 / 2**(52 + 3)
```
First, let’s subtract 2**52 to get
```
2**-2 + 1801439850948199 / 2**(52 + 3)
```
This is almost perfect, but the `2**(52 + 3)`
at the end there needs to be a `2**(52 + 2)`
.
So we need to divide 1801439850948199 by 2. This is where we run into inaccuracies – `1801439850948199`
is odd!
```
>>> 1801439850948199 / 2
900719925474099.5
```
It’s exactly in between two integers, so we round to the nearest even number (which is what the floating point specification says to do), so our final floating point number result is:
```
>>> 2**-2 + 900719925474100 / 2**(52 + 2)
0.30000000000000004
```
That’s the answer we expected:
```
>>> 0.1 + 0.2
0.30000000000000004
```
### this probably isn’t exactly how it works in hardware
The way I’ve described the operations here isn’t literally exactly what happens when you do floating point addition (it’s not “solving for X” for example), I’m sure there are a lot of efficient tricks. But I think it’s about the same idea.
### printing out floating point numbers is pretty weird
We said earlier that the floating point number 0.3 isn’t equal to 0.3. It’s actually this number:
```
>>> f"{0.3:.80f}"
'0.29999999999999998889776975374843459576368331909179687500000000000000000000000000'
```
So when you print out that number, why does it display `0.3`
?
The computer isn’t actually printing out the exact value of the number, instead
it’s printing out the *shortest* decimal number `d`
which has the property that
our floating point number `f`
is the closest floating point number to `d`
.
It turns out that doing this efficiently isn’t trivial at all, and there are a bunch of academic papers about it like [Printing Floating-Point Numbers Quickly and Accurately](https://legacy.cs.indiana.edu/~dyb/pubs/FP-Printing-PLDI96.pdf). or [How to print floating point numbers accurately](https://lists.nongnu.org/archive/html/gcl-devel/2012-10/pdfkieTlklRzN.pdf).
### would it be more intuitive if computers printed out the exact value of a float?
Rounding to a nice clean decimal value is nice, but in a way I feel like it might be more intuitive if computers just printed out the exact value of a floating point number – it might make it seem a lot less surprising when you get weird results.
To me, 0.1000000000000000055511151231257827021181583404541015625 + 0.200000000000000011102230246251565404236316680908203125 = 0.3000000000000000444089209850062616169452667236328125 feels less surprising than 0.1 + 0.2 = 0.30000000000000004.
Probably this is a bad idea, it would definitely use a lot of screen space.
### a quick note on PHP
Someone in the comments somewhere pointed out that `<?php echo (0.1 + 0.2 );?>`
prints out `0.3`
. Does that mean that floating point math is different in PHP?
I think the answer is no – if I run:
`<?php echo (0.1 + 0.2 )- 0.3);?>`
on [this
page](https://replit.com/languages/php_cli), I get the exact same answer as in
Python 5.5511151231258E-17. So it seems like the underlying floating point
math is the same.
I think the reason that `0.1 + 0.2`
prints out `0.3`
in PHP is that PHP’s
algorithm for displaying floating point numbers is less precise than Python’s
– it’ll display `0.3`
even if that number isn’t the closest floating point
number to 0.3.
### that’s all!
I kind of doubt that anyone had the patience to follow all of that arithmetic, but it was helpful for me to write down, so I’m publishing this post anyway. Hopefully some of this makes sense. |
15,820 | Voyager Linux 23.04:具有华丽外观且无 Snap 的 Ubuntu 体验 | https://www.debugpoint.com/voyager-linux-review-23-04/ | 2023-05-17T11:36:00 | [
"Voyager"
] | /article-15820-1.html | 
>
> 新版本的 Voyager Linux 23.04 已经来到,我率先试驾以了解更多信息。
>
>
>
在我去年年初上次 [测评](https://www.debugpoint.com/voyager-live-linux-review-2022/) 时,它还是一个崭露头角的发行版,提供了很棒的 Ubuntu LTS 体验。从那时起,这个发行版的方向发生了一些变化。因此,我觉得是时候进行另一轮试驾了。
顺便说一句,Voyager Linux 基于 Ubuntu Linux,针对 GNOME 桌面进行了出色的定制。之前,它只跟随 Ubuntu 长期支持(LTS)版本发布,但从去年开始,它也可跟随短期 Ubuntu 版本发布。
在 [Ubuntu 23.04 “Lunar Lobster”](https://www.debugpoint.com/ubuntu-23-04-features/) 发布后,Voyager 团队宣布发布了 Voyager 23.04。
### Voyager Linux 23.04 测评
与 Voyager 22.04 版本相比,此版本的 ISO 大小增加了约 30%。这可能主要是由于 Ubuntu 自己的软件包库。安装很顺利,但安装程序需要至少 24 GB 的存储空间(硬性要求)。但是,它使用旧的 Uniquity 安装程序,而不是新的基于 Flutter 的 Ubuntu 安装程序。
#### 外观及使用感受
如果你运行的是早期版本的 Voyager Linux,你首先会注意到新版的外观精美。GNOME 桌面现在更具个性化,使用了 “Kora” 主题和许多扩展程序。

在底部,你可以看到默认的程序坞,并通过 “Blur my shell” 扩展将其变成了透明的。此外,这一版本还预装了一系列扩展,并通过适当的设置启用,以便让 GNOME 桌面更好看。
值得重点一提的扩展是非常棒的 “Arc Menu”,可以下拉访问所有系统应用程序和资源。此外,“Dash to Dock”、“Blur my shell” 和 “Battery Indicator” 也是一些很有用的扩展应用。以下是 Voyager Linux 23.04 中预装的扩展列表:
* Arch menu
* Battery time
* Blur my shell
* Burn my windows
* Caffeine
* Clipboard history
* Compiz alike magic lamp effect
* Compiz windows effect
* Custom hot corners – Extended
* Dash to Dock
* Desktop Cube
* EasyScreenCast
* Gradient Top Bar
* Lock keys
* Replace Activities Label
* Screen Rotate
* SettingsCenter
* Simple net speed
* Space Bar
* Sur Clock
* Use Avatar in Quick Settings
所有这些都使桌面在美观的同时超级高效。

#### 应用、Snap 和 Flatpak
尽管 Voyager Linux 是基于 Ubuntu 的,但默认情况下完全不包含 Snap。此外,Voyager Linux 23.04 也没有支持 Ubuntu 从该版本开始删除 Flatpak 的决定。因此,总而言之,Voyager Linux 23.04 中默认支持的是 Flatpak,而没有任何 Snap 的痕迹。不仅如此,Firefox 网络浏览器是由原生 deb 模块打包的,而不是 Snap 版本。

应用程序列表很庞大且健全。主要应用程序包括 Gedit 文本编辑器、“文件”应用、Firefox 网络浏览器、GIMP 和 LibreOffice 套件。还包括 Thunderbird 电子邮件客户端、Remmina 远程连接应用程序、Transmission Torrent 客户端和 Pidgin 通讯软件。
Voyager 包括 Pitivi、MPV 和 Rhythmbox,均可用于播放视频和音乐。对于工作和文档处理,它提供了地图、日历、Foliate 阅读器应用程序、KeePassXC 和 Scrcpy 安卓屏幕镜像工具。
由于主 ISO 文件包括了 Xfce 和 GNOME 桌面,因此你也可以体验一些原生 Xfce 应用程序。

#### Box Voyager
Voyager Linux 带有自己的很棒的小应用,称为 “Box Voyager”,它让你可以一键访问所有桌面自定义设置。它有一个配置项列表,你可以直接使用此应用程序启动相应的设置。
此外,要进行更多自定义设置,你可以使用 Voyager Linux 中预装的多个 Conky 主题。 无需面对安装和配置 Conky 的麻烦。(LCTT 译注:Conky 是一个应用于桌面环境的系统监视软件,可以在桌面上监控系统运行状态、网络状态等一系列参数,而且可自由定制。)

#### 性能表现
安装了所有定制和扩展后,其性能表现令人印象深刻。它在闲置时占用 1.3 GB 的内存,CPU 使用率为 1%。但是,随着你安装和打开更多应用程序,性能指标可能会上升。
然而,由于预装了许多应用程序和 Xfce 桌面,它的安装需要大约 14 GB 的磁盘空间。另外,正如我之前提到的,整个安装需要 24 GB 的可用磁盘空间。

### 总结
在测评了 Voyager Linux 23.04 之后,我相信它是一个理想的、可以日常使用的非 Snap Ubuntu 变体。如果你不喜欢 Ubuntu GNOME 的默认外观,并且正在寻找具有稳定的 Ubuntu 长期支持/短期基础,且设计吸引人的预配置发行版,那么 Voyager Linux 可能是你的完美选择。
此外,最棒的是在同样的 Ubuntu 基础上还有一个 Xfce 桌面可以选择。试一试吧。
你可以在其 [官方网站](https://voyagerlive.org/) 下载 Voyager Linux。
*(题图:MJ/2deebcdf-7e04-43bc-beaf-7059e80b8057)*
---
via: <https://www.debugpoint.com/voyager-linux-review-23-04/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,821 | KDE Plasma 6 计划公布:5 种新的令人兴奋的默认设置 | https://news.itsfoss.com/kde-plasma-6-dev/ | 2023-05-17T15:40:33 | [
"KDE"
] | https://linux.cn/article-15821-1.html |
>
> KDE Plasma 6 的计划听起来很不错。了解一下将要带来的变化吧。
>
>
>

[KDE Plasma 5.27](https://news.itsfoss.com/kde-plasma-5-27-release/) 是一个值得关注的版本,它标志着 5.x 系列的终结。
我们非常期待 KDE Plasma 6,但是我们还没有关于它的确切信息。
现在有一些新的消息了。
在 **2023 年 Plasma Sprint 活动** 之后,KDE 的 *Nate Graham* 在他的博客上分享了 KDE Plasma 6 的一些重要亮点。
*Nate?* 英雄并非都穿着斗篷,对吧???
那么,让我分享他博客中的重要内容。
### KDE Plasma 6: 改变默认设置的最佳时机 ⭐
在重要版本升级时,用户应该期望会有重大变化,从而改善开箱即用的用户体验。
而其中一个关键因素就是 **改变默认设置**。
你可以期待更改哪些设置呢?
#### 1、默认采用 Wayland
在 KDE Plasma 6 中,**Wayland 会成为默认首选项**。
X11 会话不会消失。因此,Linux 发行版仍然可以覆盖这个默认设置,将 X11 保留为默认设置。
开发人员正在 [解决](https://invent.kde.org/plasma/plasma-workspace/-/merge_requests/2188?ref=news.itsfoss.com#note_676355) 某些问题以及几个和英伟达有关的问题。一旦这些问题解决,他们就可以按照他们的目标前进了。
#### 2、默认双击打开文件
为了改善从其他平台迁移过来的新用户的体验,双击打开文件/文件夹将成为新的默认设置。
#### 3、默认采用浮动面板

尽管 Windows 11 最初从 KDE 复制了(或许是灵感来自于)浮动面板,但浮动面板在 KDE Plasma 中是可选的特性。
因此,为了给用户带来新的开箱即用的体验,浮动面板现在成为了 KDE Plasma 默认外观的一部分。
#### 4、使用强调色调节窗口标题栏区域以区分活动窗口
为了帮助你更好地区分和识别活动窗口,你将会发现工作窗口的标题栏区域使用你设置的强调色装饰。

这样,窗口就会有一些微妙的视觉差异,告诉你哪个窗口是活动窗口。
你可以在 Plasma 桌面的 [GitLab 页面](https://invent.kde.org/plasma/plasma-desktop/-/issues/78?ref=news.itsfoss.com) 上探索其技术细节。
#### 5、新任务切换器
任务切换器极大影响了多任务用户的用户体验。在 KDE Plasma 6 中,他们决定使用“缩略图网格”任务切换器,其中包括图标和缩略图,为不同用户提供快速的视觉提示。
这是它的样子:

此外,[Nate 的博客文章](https://pointieststick.com/2023/05/11/plasma-6-better-defaults/?ref=news.itsfoss.com) 上列出了许多其他应该有助于增强 KDE Plasma 6 体验的内容,比如:
* 单击滚动条以跳跃导航
* 更慢一些的发布周期(可能是每年两次),以便于发行版提供更新的软件
* 系统设置中的壁纸页面
? 总的来说,这些计划看起来相当有前途。你觉得呢?
---
via: <https://news.itsfoss.com/kde-plasma-6-dev/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[KDE Plasma 5.27](https://news.itsfoss.com/kde-plasma-5-27-release/) was an interesting release, marking the end of the 5.x series.
However, we were eagerly awaiting the KDE Plasma 6 release, and didn't know what to expect a few months back.
But, that has now changed.
With the release of **KDE Plasma beta 1**, we now have a better look at this release than ever before, and guess what?, we also have a final release date; **KDE Plasma 6 will be released on February 28, 2024**.
A special shout out to *Nate Graham* from KDE, who has been sharing important highlights of the KDE Plasma 6 release on [his blog](https://pointieststick.com/?ref=news.itsfoss.com) as always!
So, allow me to share the important bits.
## KDE Plasma 6: The Best Time to Change Defaults ⭐
With a major version bump, users should expect **major changes that improve the out-of-the-box user experience**.
And one of the crucial things that will let them do that is **far more flexibility with the default settings**. Let's dive in and see what's in store.
### 1. Wayland by Default

With KDE Plasma 6, the **Wayland session will be the preferred default option**.
The **X11 session will not be going away**. So, you or the developers of distributions can still override the default and have X11 remain the default.
The developers have had to [iron out](https://invent.kde.org/plasma/plasma-workspace/-/merge_requests/2188?ref=news.itsfoss.com#note_676355) certain issues and several NVIDIA-specific problems. But, those are now ready, you can expect a really neat Wayland experience when the final release comes out.
### 2. Improved Discover
When Flatpak or Snap is set as the default app sourcing backend, Discover will now show a “** Newly Published & Recently Updated**” section on the homepage. According to Nate, this has been done in a bid to “make the Linux app ecosystem feel more alive”.


### 3. Floating Panel by Default
While Windows 11 originally copied (or maybe got inspired? 👀) the design from KDE for the floating panel, it was an optional feature with KDE Plasma.
So, to give users something new out-of-the-box, the **floating panel is now in the default look of KDE Plasma**. With what I saw during my usage, it feels and works pretty well.
### 4. Accent-color-tinted header area to distinguish active windows
To help you **better differentiate and identify an active window**, you will find the header area of the working window tinted with your accent color set.
This way, the open windows get a subtle visual difference, telling you which one's the active one. You can explore the technical details of this implementation on the Plasma Desktop [GitLab page](https://invent.kde.org/plasma/plasma-desktop/-/issues/78?ref=news.itsfoss.com).
### 5. New Task Switcher
A Task switcher greatly influences the user experience for multitaskers. With KDE Plasma 6, **they decided to use a “Thumbnail Grid” task switcher**, which includes the icon, and a thumbnail, giving quick visual cues for different users.
### 6. Wallpaper Menu in Settings
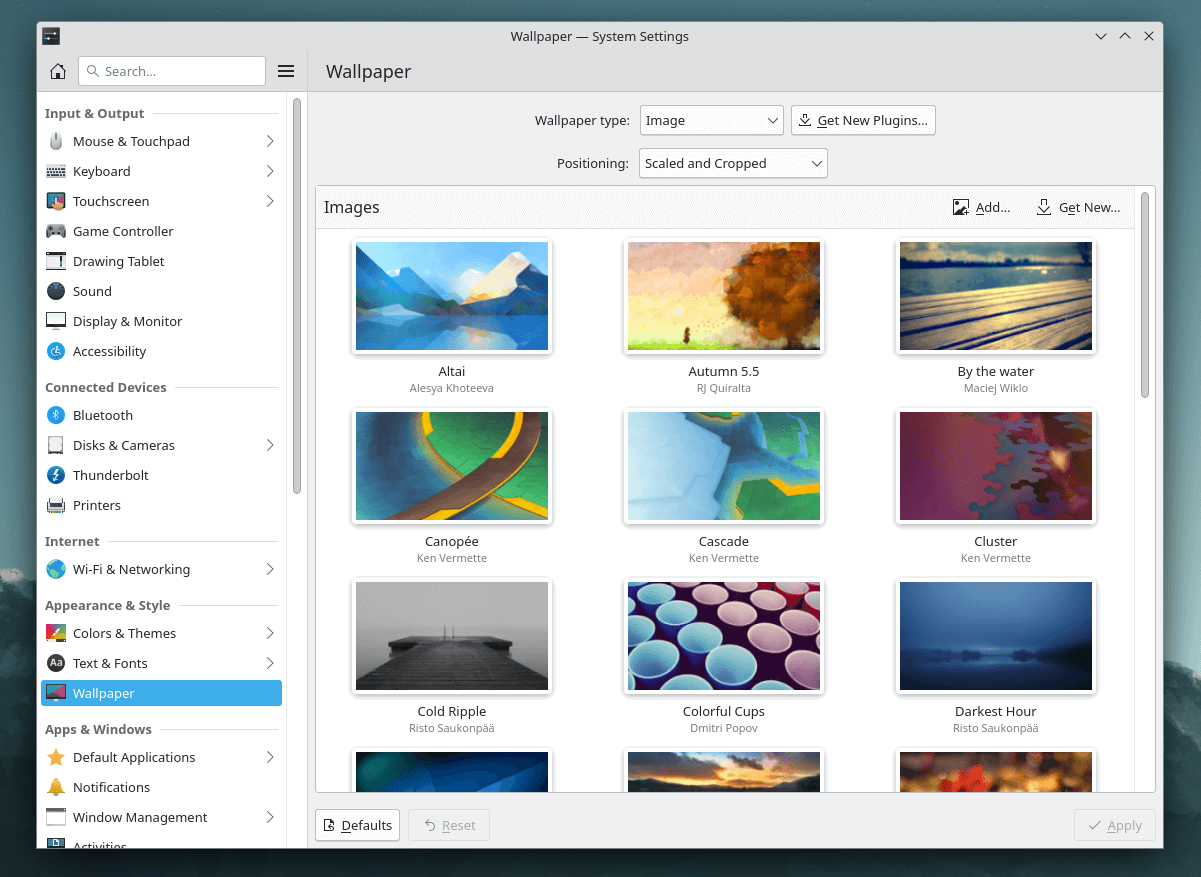
This is something that many desktop environments out there feature,** it was weird to see Plasma not having a dedicated Wallpaper page in the Settings menu** for changing the wallpaper and related settings. But finally, it is here.
### 6. Better Night Light
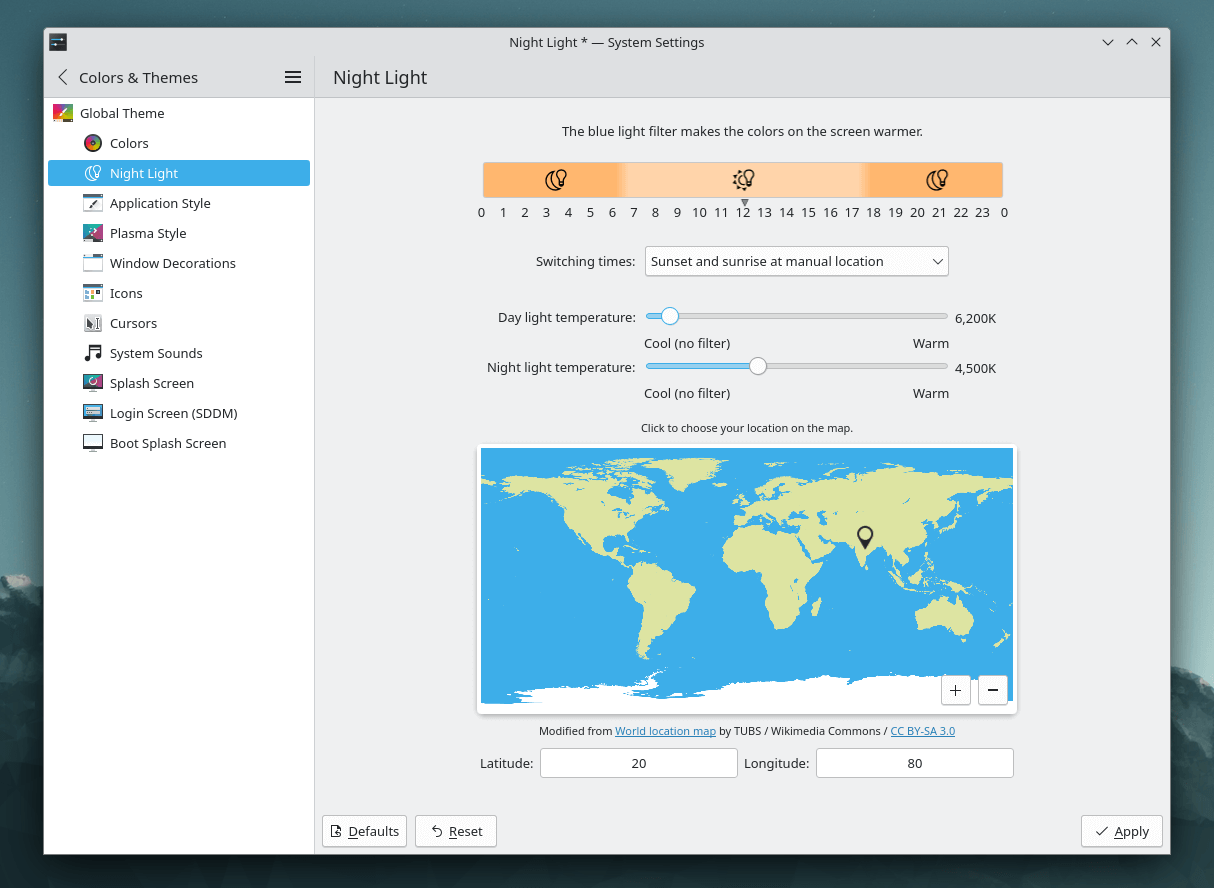
The Night Light page has also been improved, it now **shows a very handy graphical representation** of the active/inactive periods, alongside the transitions times.
### 🛠️ Other Changes and Improvements
There are plenty of miscellaneous changes too, here are some highlights:
- Support for
**hardware cursors on NVIDIA GPUs**. - Double-Clicking to open files/folders is the
**new default behavior**. - Ark, the file archiver now has a new “
**Extract here and delete archive**” option. - Auto-Hide panels now
**follows the user-set delay setting**that is used for other screen edge effects. - KRunner and other searches based on it
**now feature proper visual click feedback**when clicking on a search result. - A bug fix for Dolphin that
**fixes a common crash**that could happen during large file transfers to other locations.
You can go through the other changes listed on [Nate's blog post](https://pointieststick.com/2023/12/01/this-week-in-kde-changing-the-wallpaper-from-within-system-settings/?ref=news.itsfoss.com) to explore technical details about the KDE Plasma 6 release.
## How to Get KDE Plasma 6?
You can expect KDE Plasma 6 with future Fedora 40 spin (Kinoite variant) release.
Other than that, there are no other confirmed distributions to feature KDE Plasma 6 after its release.
If you are willing to experiment, and aren't concerned about stability, you can try [KDE Neon](https://neon.kde.org/?ref=news.itsfoss.com)'s Unstable edition to get your hands on KDE Plasma 6.
*💬* *I can't wait to get my hands on the KDE Plasma 6 release. The overall progress looks quite promising to me. What do you think?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,823 | Ubuntu 23.10 将引入安全增强的 PPA | https://news.itsfoss.com/ubuntu-23-10-set-to-let-you-easily-manage-ppas-while-enhancing-security/ | 2023-05-17T22:53:25 | [
"Ubuntu",
"PPA"
] | https://linux.cn/article-15823-1.html |
>
> Ubuntu 23.10 正在修改 PPA 的管理方式。
>
>
>

Ubuntu 的升级不断地增强功能并添加安全修复程序。但是,很少见到一些核心机制的更改。
在 Ubuntu 23.10 中,PPA 的功能得到了改进。至少,你在终端中看到警告会更少。
这是什么意思呢?让我详细说明一下。
### GPG 密钥问题
传统上,PPA 和其他外部存储库是通过 `/etc/apt/sources.list.d/` 中的 `.list` 来源列表文件进行管理的。此外,还有一个关联的 GPG 密钥环被放在 `/etc/apt/trusted.gpg.d` 中。
这被认为是一个潜在的安全问题,因为 GPG 密钥是在系统级别上添加的。
怎么回事?想象一下,你为存储库 A 添加密钥以获取包 AA,并从存储库 B 获取包 BB。你的系统将很乐意接受用存储库 A 的密钥签名的 BB 包。因为它无法将密钥与其各自的包关联起来。
这是个问题,对吧?这种旧机制正在逐步淘汰。现在,GPG 密钥信息将添加到外部存储库本身的 `sources.list` 中。这样,GPG 密钥将只接受其对应存储库的软件包。
现有的 Ubuntu 用户可能已经遇到了使用 `/etc/apt/trusted.gpg.d` 中的旧方法添加 GPG 密钥时出现的 `apt-key is deprecated` 警告。
以下是旧的 [添加外部存储库](https://itsfoss.com/adding-external-repositories-ubuntu/?ref=news.itsfoss.com) 的方法的示例:
```
sudo apt install apt-transport-https curl
curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
sudo sh -c 'echo "deb https://dl.yarnpkg.com/debian/ stable main" >> /etc/apt/sources.list.d/yarn.list'
sudo apt update && sudo apt install yarn
```
### PPA 将使用新的 GPG 密钥机制
现在,PPA 与添加外部存储库略有不同。在这里,你不需要手动导入 GPG 密钥并将其添加到 `/etc/apt/trusted.gpg.d` 目录中。
```
sudo add-apt-repository ppa:dr-akulavich/lighttable
sudo apt-get update
sudo apt-get install lighttable-installer
```
**直到现在**,所有事情都由 PPA 机制自己处理,与 PPA 相关联的 GPG 密钥会自动添加到 `/etc/apt/trusted.gpg.d` 目录中。用户在这里不需要做任何事情。
在 Ubuntu 23.10 中,引入了一种新的方法。
现在,PPA 将作为 deb822 格式的 `.sources` 文件添加,其中密钥直接嵌入文件的 `Signed-By` 字段中。
使用这种方法,可以获得以下一些优点:
* 当删除存储库时,相关的密钥也会被删除。
* PPA 与其密钥之间一一对应。没有安全问题。
在揭示这一消息的邮件列表中也提到:
>
> 该密钥专门用于特定的 PPA,无法用于其他存储库(与旧的存放所有存储库的源列表的 `trusted.gpg.d` 不同)。其他密钥不能用于签署该 PPA。
>
>
>
总的来说,新的 PPA 版本将减少 “Key is stored in legacy trusted.gpg keyring” 和 “Manage keyring files in trusted.gpg.d instead” 警告。
我认为 Ubuntu 应该早些时候就引入这个改变,但迟到总比没有好。 ?
你对 Ubuntu 处理 PPA 的这个新改变有什么想法?请让我知道你的想法。
---
via: <https://news.itsfoss.com/ubuntu-23-10-set-to-let-you-easily-manage-ppas-while-enhancing-security/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
15,824 | 安装 Arch Linux 后需要做的十件事 | https://www.debugpoint.com/things-to-do-arch-linux/ | 2023-05-18T13:39:00 | [
"Arch Linux"
] | /article-15824-1.html | 
>
> 在你的系统中完成安装基本的 Arch Linux 后,有几件事要做。
>
>
>
Arch Linux 为你建立自己的自定义 Linux 发行版打下了坚实的基础。如果你已经用 [archinstall](https://www.debugpoint.com/archinstall-guide/) 或其他脚本安装了一个非常基本的 Arch Linux,那么就该执行一些安装后的步骤来定制你的系统了。本文假设你的基本 Arch Linux 系统中没有安装 GUI 或桌面环境,所以这些步骤可以适用于大多数用户。

### 安装 Arch Linux 后需要做的十件事
#### 更新你的系统
安装 Arch Linux 后,你应该做的第一件事显然是更新你的系统。这可以确保你有最新的滚动发布包。这可以通过 `pacman` 命令轻松完成。在终端窗口中,运行以下命令:
```
sudo pacman -Syu
```
#### 选择最快的 pacman 镜像
Pacman 在下载软件包时有时会有点慢。如果你对它进行适当的配置,选择适当的镜像,你可以达到更快的下载速度。出现这种情况有几个原因,比如过时的镜像,pacman 服务器问题等等。
配置文件存储在文件 `/etc/pacman.d/mirrorlist` 中。有几个程序可以自动更新这个列表,根据你的位置提供更快的镜像。
其中之一是 `reflector` ,它是一个 Python 脚本。要安装它,请从终端运行以下程序:
```
sudo pacman -S reflector
```
然后在运行它之前对当前列表进行备份:
```
cp /etc/pacman.d/mirrorlist /etc/pacman.d/mirrorlist.bkp
```
然后从终端,更改你的国家或地区后运行以下命令。
```
sudo reflector --country 'India' --latest 5 --age 2 --fastest 5 --protocol https --sort rate --save /etc/pacman.d/mirrorlist
```
获取更多细节,[请访问我关于 reflector 的详细教程](https://www.debugpoint.com/slow-download-pacman-arch/)。
#### 安装显示管理器和 [X.Org](http://X.Org)
如果你想要一个图形化的桌面环境,那么你需要设置一个显示服务器、显示管理器与桌面环境。显示服务器的最佳选择是 [X.Org](http://X.Org),你可以用下面的命令来安装:
```
sudo pacman -S xorg
```
一旦你安装了显示服务器,你需要一个显示管理器来使你能够登录到你的桌面。有几个轻量级的显示管理器可用,你可以从中选择。
* [GDM](https://wiki.archlinux.org/title/GDM)
* [SDDM](https://wiki.archlinux.org/title/SDDM)
* [LightDM](https://wiki.archlinux.org/title/LightDM)
我推荐它们中的任何一个。你可以运行以下命令来安装它们中的任何一个:
```
sudo pacman -S lightdm lightdm-gtk-greeter lightdm-gtk-greeter-settings
```
不要忘记在安装完成后启用显示管理器服务:
```
sudo systemctl enable lightdm
```
#### 安装桌面环境
一旦你完成了显示服务器和显示管理器的设置,就该安装你喜欢的 Linux 桌面环境了。所有的桌面环境都可以在 Arch Linux 中安装。
例如,如果你想安装 Xfce 桌面环境,你可以运行以下命令:
```
sudo pacman -S --needed xfce4-goodies file-roller network-manager-applet leafpad epdfview galculator lightdm lightdm-gtk-greeter lightdm-gtk-greeter-settings capitaine-cursors arc-gtk-theme xdg-user-dirs-gtk
```
或者,你可以参考以下指南来安装其他桌面:
* [GNOME](https://www.debugpoint.com/gnome-arch-linux-install/)
* [KDE Plasma](https://www.debugpoint.com/kde-plasma-arch-linux-install/)
* [LXQt](https://www.debugpoint.com/lxqt-arch-linux-install/)
* [Pantheon](https://www.debugpoint.com/pantheon-arch-linux-install/)
#### 选择基本应用程序
由于你正在从头开始设置你的系统,你可以选择你想要的应用程序。应用程序列表可能包括网络浏览器、文本编辑器、图像浏览器、文件管理器等。
这里有一个基本应用程序的列表,你可以使用下面的命令来安装:
```
sudo pacman -S --needed firefox nemo leafpad evince ksnip lximage-qt
```
* Firefox 浏览器
* Nemo 文件管理器
* Leafpad 文本编辑器
* Evince PDF 阅读器
* Ksnip 截屏工具
* LXImage 图片查看器
#### 安装 AUR 辅助工具
标准的 Arch 软件库包含了成千上万的软件包。然而,[Arch 用户存储库](https://aur.archlinux.org/)(AUR)包含了数千个用户提交的应用程序和软件包,你可以使用它们。
不过,要从 AUR 安装,最好使用 Yay、paru 或 pikaur 等辅助程序。
我推荐使用 [Yay 辅助工具](https://www.debugpoint.com/install-yay-arch/),你可以用以下命令来安装:
```
sudo git clone https://aur.archlinux.org/yay.git
sudo chown -R <user-name>:users ./yay
cd yay
makepkg -si
```
一旦安装完毕,你可以在 AUR 存储库中搜索软件包,并使用简单的命令进行安装,例如::
```
yay -S <app-name>
```
#### 电源管理
优化电源管理设置,最大限度地提高笔记本电脑的电池寿命或减少台式机的功耗。通过你的桌面环境或窗口管理器的电源管理工具调整设置。
然而,如果你没有通过 GUI 在桌面上进行设置,你可以使用高级 powertop 工具。用以下方法安装它:
```
sudo pacman -S powertop
```
一旦安装完毕,使用命令运行它:
```
sudo powertop --auto-tune
```
你也可以启用 systemd 服务,使其在你每次打开系统时都能运行。更多细节,请访问 [此文档](https://wiki.archlinux.org/title/Powertop)。
#### 安装打印机
在 Linux 中配置打印机是非常容易的,这要感谢 CUPS。它可以处理很多麻烦,并为最常见的打印机提供所有必要的软件包。要在 Arch Linux 中设置打印机,你可以使用以下一组命令。第一个命令是安装 CUPS 软件包,然后启用/启动服务。
```
sudo pacman -S cupssudo systemctl enable cups.servicesudo systemctl start cups.service
```
#### 安装自定义内核
Arch Linux 提供了一个简单的方法来安装自定义 Linux 内核,带来额外的硬件支持和更新。尽管这可能并不适合所有人,但对于资深用户,可以利用自定义内核的优势。除了默认的主线内核外,重要的有:
* Linux LTS 内核
* Linux Hardened 内核
* Linux Zen 内核
你可以用以下命令来安装它们。在运行这些命令之前,请确保你知道你在做什么。
```
sudo pacman -S linux-lts linux-lts-headers
```
```
sudo pacman -S linux-hardened linux-hardened-headers
```
```
sudo pacman -S linux-zen linux-zen-headers
```
#### 安装 Plymouth
当你安装原装的 Arch Linux 时,初始的动画 Plymouth 默认是不安装的。因此,你可能会在屏幕上看到操作系统的输出。如果你想安装一个漂亮的动画启动画面,你可以阅读我下面的指南。[在 Arch Linux 中安装动画启动程序](https://www.debugpoint.com/install-plymouth-arch-linux/)。
### 结语
我希望这篇文章为你提供了一些入门的技巧和指导,让你在 Arch Linux 中获得最佳体验。上面的提示可能并不适用所有的人,但它们可以作为你定制的 Arch 安装的一个好的起点。
拥抱 Arch Linux 提供的自由和无尽的可能性,享受探索和掌握 Arch Linux 系统的旅程。
*(题图:MJ/88a0ea39-d673-4efc-b720-9c0fec7599a7)*
---
via: <https://www.debugpoint.com/things-to-do-arch-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[chris000132](https://github.com/chris000132) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,826 | risiOS:一个易于使用的基于 Fedora 的 Linux 发行版 | https://news.itsfoss.com/risi-os/ | 2023-05-18T22:39:22 | [
"Fedora"
] | https://linux.cn/article-15826-1.html |
>
> 你是 Fedora 的粉丝吗?那你可能会喜欢 risiOS 的调整和开箱即用的工具。
>
>
>

我们已经介绍了大量基于 Arch 和 Ubuntu 的发行版。
基于 Fedora 的发行版怎么样?为什么你还需要它呢?
好吧,risiOS 是 [最好的基于 Fedora 的发行版](https://itsfoss.com/best-fedora-linux-distributions/?ref=news.itsfoss.com) 之一,旨在让体验更轻松。虽然 Fedora 不是最复杂的发行版,但在首次设置时,一些细微差别可能会成为麻烦。
### risiOS:概述 ⭐

与 Fedora 相比,你不应该期望有很大的变化。
相反,risiOS 主要 **专注于使用某些 GUI 工具和功能来简化用户体验**。
例如,你会看到一个带有 risiOS 的欢迎屏幕,通知你基本的 [安装 Fedora 后应该做的事情](https://itsfoss.com/things-to-do-after-installing-fedora/?ref=news.itsfoss.com)。不仅仅是信息,它还有助于在首次安装 Fedora 后自动执行一些重要的第一步。
当然,你会注意区别于原生 Fedora 的不同的品牌、强调色和新的默认墙纸。
**risiOS 还有什么不同之处?** 让我强调其余的优点:
* 具有快速操作(使用 risiScripts)的欢迎应用以便可以轻松设置
* 用于自定义 GNOME 体验的 risiTweaks 应用
* Chromium 网络浏览器而不是 Firefox
* OnlyOffice 桌面编辑器
* 源自 Linux Mint 的 Web 应用功能
>
> ? risiOS 是一个相当新的发行版。无论你是想试用它还是将其日常使用都取决于你。
>
>
>
### 初步印象
请记住,你正在安装 Fedora,它带有一些开箱即用的实用程序,可帮助你快速进行设置。
因此,在你安装 risiOS 之后,你将看到相同的 Fedora 初始步骤来选择用户名和调整隐私设置。
通过后,你会注意到 “risiWelcome” 应用弹出窗口。

它列出了你只需单击一下即可执行的所有重要操作。
为了实现这一目标,该发行版依赖于其特色之一 “risiScripts”。

因此,每当你单击一个操作来设置 Flathub 或 RPMFusion 时,它都会提示你运行脚本。随着你的继续,这个过程变得自动化,你可以毫不费力地实现你的目标。
同样,你可以向下滚动以探索其他选项,例如使用 “risiTweaks” 调整用户体验:

你可以使用此应用控制要自定义的内容,包括动画设置、强调色、主题调整、字体、背景徽标定制等。
正如你所注意到的,risiOS 内置了一些 [GNOME 扩展](https://itsfoss.com/best-gnome-extensions/?ref=news.itsfoss.com)。你可以在此处使用相同的应用禁用或配置它们。

如果你探索 risiScript 菜单,你会找到安装程序来帮助你安装 Brave、Edge、Chrome、Opera 或 Vivaldi 浏览器。
默认情况下,你会通过 risiOS 获得 Chromium。
此外,如果你是一个动手达人,你可以用 [Fedora Nobara](https://nobaraproject.org/?ref=news.itsfoss.com)(游戏发行版)附带的 Fsync 内核替换原装内核。
因此,risiOS 对于所有类型的用户来说似乎都是一个有趣的选择。
最重要的是,risiOS 包含一些可能会增强你的用户体验的额外功能:
* 预装 ONLYOFFICE 桌面编辑器
* 来自 Linux Mint 的 Web 应用
当然,如果你喜欢 ONLYOFFICE 作为你的文档编辑器,risiOS 已经为你准备好了。
然而,Linux Mint 中的 “Web 应用”对于用户是个不错选择,可以将网站作为应用运行,并可以在其发行版中默认使用相同应用。

对于坚持使用网络应用,并且主要使用云来完成所有任务的用户来说,这是一个很好的补充。
### ? 尝试 risiOS
你可以前往其官方网站下载可用的最新 ISO。
我们建议你先 [在虚拟机或备用系统上尝试新发行版](https://itsfoss.com/why-linux-virtual-machine/?ref=news.itsfoss.com),然后再将它们安装到主系统上。
目前,它基于 [Fedora 37](https://news.itsfoss.com/fedora-37-features/)。你可以期待他们接下来发布基于 Fedora 38 的 ISO。
>
> **[risiOS](https://risi.io/?ref=news.itsfoss.com)**
>
>
>
?你如何看待 risiOS? 在评论区分享你的观点。
*(题图:MJ/d7d43199-e459-4ed7-852e-80d4e256fb07)*
---
via: <https://news.itsfoss.com/risi-os/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

We have covered plenty of Arch and Ubuntu-based distros.
What about a distro based on Fedora? And why would you even need that?
Well, risiOS is one of the [best Fedora-based distros](https://itsfoss.com/best-fedora-linux-distributions/?ref=news.itsfoss.com) that aims to make the experience easier. While Fedora is not the most complex distribution, some nuances could become a hassle when setting it up for the first time.
## risiOS: Overview ⭐

You should not expect a big set of changes when compared to Fedora.
Instead, risiOS mostly **focuses on easing the user experience** using certain GUI tools and capabilities.
For instance, you get a welcome screen with risiOS informing you of the essential [things you should do after installing Fedora](https://itsfoss.com/things-to-do-after-installing-fedora/?ref=news.itsfoss.com). Not just the information; it also helps automate some of the important first steps after installing Fedora for the first time.
Of course, you can notice a different branding, color accent, and a new default wallpaper, differentiating itself from vanilla Fedora installation.
**What else is different with risiOS? **Let me highlight the rest of the good parts:
- Welcome app with quick actions (with risiScripts) to set things up easily
- risiTweaks app to customize the GNOME experience
- Chromium web browser instead of Firefox
- OnlyOffice Desktop editors
- Web Apps functionality derived from Linux Mint
## Initial Impressions
Remember that you are installing Fedora, with some out-of-the-box utilities that help you set up things quickly.
So, after you install risiOS, you will be greeted with the same Fedora initial steps to pick a username and tweak privacy settings.
Once past that, you will notice the "**risiWelcome**" app pop-up.
It lists all the important actions you can do in a single click.
To make this happen, the distro relies on one of its specialties, "**risiScripts.**"
So, whenever you click on an action to set up Flathub or RPMFusion, it prompts you to run the script; as you proceed, the process becomes automated, and you achieve what you want effortlessly.
Similarly, you can scroll down to explore other options, such as tweaking the user experience with **risiTweaks**:
You can control what you want to customize using this app, including animation settings, accent color, theme tweaks, fonts, background logo customization, and more.
As you can notice, risiOS comes with some [GNOME extensions](https://itsfoss.com/best-gnome-extensions/?ref=news.itsfoss.com) built-in. You can disable them or configure them using the same app here.
If you explore the risiScript menu, you will find installers to help you install Brave, Edge, Chrome, Opera, or Vivaldi browser.
By default, you get Chromium with risiOS.
Additionally, if you are a tinkerer, you can replace the stock kernel with the Fsync kernel that comes with [Fedora Nobara](https://nobaraproject.org/?ref=news.itsfoss.com) (the gaming distro).
**Suggested Read **📖
[Install the Latest Mainline Linux Kernel Version in UbuntuThis article shows you how to upgrade to the latest Linux kernel in Ubuntu. There are two methods discussed. One is manually installing a new kernel and the other uses a GUI tool providing even easier way.](https://itsfoss.com/upgrade-linux-kernel-ubuntu/?ref=news.itsfoss.com)

So, risiOS seems like an interesting choice for all kinds of users.
To top it all, risiOS includes some more extras that might enhance your user experience:
**ONLYOFFICE Desktop editor pre-installed****Web Apps from Linux Mint**
Of course, if you like ONLYOFFICE as your document editor, risiOS is already taking care of it for you.
However, including "**Web Apps**" from Linux Mint makes it a nice choice for users who run websites as apps and want support for the same by default on their distro.
This is a good addition for users sticking to web apps and mostly using the cloud for all their tasks.
**Suggested Read **📖
[7 Best Distributions Based on Fedora LinuxThere are dozens of Ubuntu-based distributions available out there. Ranging from distributions for beginners to beautiful ones, Ubuntu dominates the Linux desktop space. You will also find some weird Ubuntu-based distributions if general distributions weren’t enough already. I am not going…](https://itsfoss.com/best-fedora-linux-distributions/?ref=news.itsfoss.com)

## 📥 Try risiOS
You can head to its official website to download the latest ISO available.
We recommend you try [new distros on a virtual machine](https://itsfoss.com/why-linux-virtual-machine/?ref=news.itsfoss.com) or a spare system before installing them on your main system.
At the moment, it is based on ** Fedora 37**. You can expect them to release a Fedora 38-based ISO next.
*💬 What do you think about risiOS? Share your thoughts in the comments.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,827 | 8 款最佳的 Linux 远程桌面工具 | https://itsfoss.com/remote-desktop-tools/ | 2023-05-19T08:15:14 | [
"远程桌面"
] | https://linux.cn/article-15827-1.html | 
>
> 在这里,我们列出了最好的 Linux 远程桌面工具,以及它们的优点和缺点。
>
>
>
远程连接计算机有诸多好处。也许你想帮助朋友在其台式机上解决问题,或者可能需要远程使用另一个桌面会话进行工作。
无论你是什么场景,Linux 上的远程桌面工具可以让你轻松连接。当然,这里列出的每个工具都是独立开发的。因此,你可以选择最适合你个人或专业需求的工具。
>
> ✋ **非自由软件警告!** 这里提到的某些应用程序不是开源的,但出于 Linux 的应用场景,它们也被包含在内。此类应用程序已经做了相应标注。
>
>
>
以下是适用于 Linux 的 8 款最佳远程桌面工具:
### 1、Remmina

[Remmina](https://remmina.org/) 是一款功能强大的自由开源的远程桌面客户端,支持多种协议,包括 RDP、VNC、SPICE、X2GO、SSH 和 HTTP(S)。
如果你需要一款功能全面的开源远程桌面工具,Remmina 是一个不错的选择。
除了各种协议的支持外,它还具有一些功能,比如轻松截图、恢复连接、缩放质量、配置分辨率等等,并且这些功能可以通过插件进行扩展。
优点:
* 使用 GTK 编写,原生支持 Linux。
* 通过服务器地址设置快速连接。
* 可以保存连接配置。
* 支持多种协议。
* 使用插件扩展功能,如信息亭模式、代理支持、终端仿真器等等。
缺点:
* 仅支持 Linux。
* 对新用户来说可能使用起来不太容易。
#### 安装 ?
Remminna 可以在大多数发行版的存储库中获取。但是,为了保证你获得最新版本,你可以通过 [Flatpak](https://flathub.org/apps/org.remmina.Remmina)(如果不使用“软件中心”)或 Snap 安装它,具体安装方法可以参考我们的 [Flatpak 指南](https://itsfoss.com/flatpak-guide/)。
对于 Flatpak,你可以使用以下命令进行安装:
```
flatpak install flathub org.remmina.Remmina
```
### 2、GNOME “连接”应用

[GNOME “连接”应用](https://apps.gnome.org/en-GB/app/org.gnome.Connections/) 是一款简单易用的应用程序,可以使用 RDP/VNC 协议快速连接到远程桌面。
它不支持其他协议,也没有高级功能。你只需要简单地单击该应用程序,就可以使用缩放、带宽调整和一些其他选项。
优点:
* 简单易用。
* 专为 GNOME 定制而设计,但也可以在其他桌面环境上使用。
缺点:
* 它不支持多种协议。
* 对大多数用户来说,可能没有其他功能,也不支持插件扩展。
#### 安装 ?
你可以通过 [Flathub](https://flathub.org/apps/org.gnome.Connections) 安装 GNOME “连接”应用,这适用于你选择的任何发行版。
如果你已经安装了 Flatpak,则可以使用以下命令通过终端安装它:
```
flatpak install flathub org.gnome.Connections
```
### 3、X2Go

[X2Go](https://wiki.x2go.org/doku.php/start) 是一款开源的跨平台远程桌面客户端,采用客户端-服务器架构。远程计算机必须安装 X2Go 服务器,这一般是一个 Linux 系统。然后,你可以在你选择的任何平台上安装 X2Go 客户端,然后使用它连接到 Linux 远程系统。
你也可以使用客户端软件连接到 Windows,其他平台没有可供安装的服务器。
因此,对于频繁连接到 Linux 计算机的用户来说,X2Go 是一个很好的选择。
优点:
* 支持 Linux 服务器。
* 支持跨平台客户端。
* 支持 SSH 访问、打印机共享、剪贴板模式和音频。
缺点:
* 它使用修改过的 [NX 3 协议](https://en.wikipedia.org/wiki/NX_technology),不支持其他协议。
#### 安装 ?
X2Go 客户端在 Ubuntu 的 “软件中心” 中可用。或者,你可以在基于 Debian 的 Linux 发行版中使用以下命令:
```
sudo get install x2goclient
```
要安装 X2Go 服务器,请使用以下命令:
```
sudo add-apt-repository ppa:x2go/stable
sudo apt update
sudo apt install x2goserver x2goserver-xsession
```
你可以在其 [官方文档](https://wiki.x2go.org/doku.php/doc:installation:x2goserver) 中了解更多信息。
### 4、KRDC

[KRDC](https://apps.kde.org/krdc/) 是一款由 KDE 开发的自由开源的远程桌面工具。你可以在一些采用 KDE 的发行版中找到它的预安装版本,也可以在任何发行版上安装它。
它支持两种协议,包括 RDP 和 VNC。你拥有缩放和远程会话管理等所有基本选项。
优点:
* 简单易用。
* 可以记忆连接历史记录。
* Linux 原生支持。
* 缩放支持。
缺点:
* 没有跨平台可用性,仅限于 Linux。
#### 安装 ?
你可以在 KDE 的 “发现” 应用中找到 KRDC ,也可以使用 [Flathub](https://flathub.org/apps/org.kde.krdc) 或 Snap 安装它。
如果你想要通过终端安装 Flatpak,请使用以下命令:
```
flatpak install flathub org.kde.krdc
```
### 5、TigerVNC

TigerVNC 是一款自由而开源的远程计算机连接工具,采用客户端-服务器架构。
换句话说,你需要在远程计算机上安装服务器,并安装客户端程序进行连接。
客户端程序非常简单,提供诸如显示设置和多种压缩调整的基本选项。与其他选择相比,TigerVNC 可以为你提供**快速的远程连接体验**。
优点:
* 跨平台。
* 快速的性能。
缺点:
* GUI 外观陈旧。
* 它不支持多种协议。
#### 安装 ?
你可以从 [GitHub 的发布区](https://github.com/TigerVNC/tigervnc/releases) 找到 TigerVNC 的软件包,或者在 [SourceForge](https://sourceforge.net/projects/tigervnc/files/stable/1.13.1/) 上下载二进制文件。如果需要帮助,可以参考我们的 [deb 文件安装](https://itsfoss.com/install-deb-files-ubuntu/) 文章。
### 6、TeamViewer(非 FOSS)

[TeamViewer](https://www.teamviewer.com/en/products/teamviewer/) 是一款跨平台的**流行工具**,甚至可以通过移动设备进行连接。有趣的是,它还提供了一个 Web 客户端。因此,要连接到其他系统,你不需要在计算机上安装客户端。
它是可以找到的最古老的远程桌面共享工具之一。虽然它提到**存在实验性的 Wayland 支持,但 TeamViewer 建议使用 Xorg 会话**。
人们经常使用 TeamViewer 进行远程支持和协作。虽然个人用途可以免费使用,但企业和大型组织需要商业许可证。
与其他一些软件不同,你不需要 IP 地址。只需在远程计算机上安装 TeamViewer,你就可以获得一个**唯一 ID**,将其共享给你想要授权远程连接的用户,就可以了!
优点:
* 直观的用户体验。
* 适合初学者。
* 支持移动端。
缺点:
* 需要创建帐户才能启用桌面共享。
* 不是轻量级工具。
* 非开源软件。
#### 安装 ?
TeamViewer 为 Linux 发行版提供了二进制文件以进行轻松安装。你可以获取 Ubuntu 的 .deb 包或参考我们的 [TeamViewer 指南](https://itsfoss.com/teamviewer-linux/) 获取帮助。
### 7、AnyDesk(非 FOSS)

[AnyDesk](https://anydesk.com/) 是业界领先的远程桌面工具之一,具有完整的功能集和安全访问。
它支持安卓和 iOS 平台的移动端。你可以免费使用它,但你需要购买许可证以解锁其所有功能。
优点:
* 跨平台支持。
* 移动支持。
缺点:
* 免费的功能有限。
* 非开源软件。
#### 安装 ?
你可以在其 [下载页面](https://anydesk.com/en/downloads/linux) 上找到适用于各种 Linux 发行版的二进制文件,支持 Ubuntu、openSUSE 和 RHEL。
### 8、Apache Guacamole
[Apache Guacamole](https://guacamole.apache.org/) 是一款用于云系统(或服务器)的特殊远程桌面工具。
你可以在服务器上安装 Apache Guacamole,并通过 Web 浏览器从任何其他平台访问。因此,它自称为无客户端远程桌面网关。
优点:
* 专为云计算设计。
* 自由而开源。
缺点:
* 一种特殊的工具,不适合所有人。
### 总结
还有一些其他的开源选项,如 [FreeRDP](https://www.freerdp.com/) 和 [XRDP](http://www.xrdp.org/)。FreeRDP 我没有运行成功,但它有活跃的维护。所以,你可以尝试一下。
XRDP 需要从源代码安装。如果你想要从 [源代码编译](https://itsfoss.com/install-software-from-source-code/),可以参考它。
? 告诉我们你更喜欢列表中的哪个或者你有其他建议。我们可能会更新列表以包含你的建议。
*(题图:MJ/bf5f2b07-db9a-416f-b5d7-857d3b8e5b1a)*
---
via: <https://itsfoss.com/remote-desktop-tools/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Remotely connecting to a computer has several advantages. Maybe you want to help troubleshoot an issue on your friend's desktop, or maybe you want to use another desktop session remotely for work.
Whatever your use case is, remote desktop tools on Linux allow you to connect easily. Of course, every tool is built differently. So, you can pick the one that suits your personal or professional requirements.
**Non-FOSS Warning!**Some applications mentioned here are not open source. They have been included in the context of Linux usage. Such applications are duly marked.
Here are the best remote desktop tools for Linux:
## 1. Remmina
[Remmina](https://remmina.org/) is a versatile free and open-source remote desktop client with **support for various protocols** that include RDP, VNC, SPICE, X2GO, SSH, and HTTP(S).
If you want a capable open-source remote desktop tool, you cannot go wrong with it.
Along with the protocol support, it has features to let you easily take screenshots, resume connection, scale quality, configure resolutions, and more.
Moreover, the features can be extended with the help of plugins.
**Pros:**
- Written in GTK, providing native support to Linux distributions.
- Quick connections are set up through the server address.
- Ability to save connection profiles
- Support for multiple protocols
- Plugin to extend functionalities like Kiosk mode, Proxy support, terminal emulator, and more.
**Cons:**
- Available only for Linux
- It may not be very easy to use for new users
**Installation **📥
Reminna is available in most of the distribution repositories. However, to ensure you get the latest version, you can install it as a Flatpak via [Flathub](https://flathub.org/apps/org.remmina.Remmina) or Snap, as you prefer.
For Flatpak, you can use the following command (if not using the software center) or follow our [Flatpak guide](https://itsfoss.com/flatpak-guide/) to set it up.
`flatpak install flathub org.remmina.Remmina`
**Suggested Read 📖**
[Complete Guide to Configuring SSH in UbuntuSSH has become the default method of accessing a remote Linux server these days. SSH stands for Secure Shell and it’s a powerful, efficient, and popular network protocol used to establish communication between two computers in a remote fashion. And let’s not forget the secure part of its](https://itsfoss.com/set-up-ssh-ubuntu/)

## 2. GNOME Connections
[GNOME Connections](https://apps.gnome.org/en-GB/app/org.gnome.Connections/) is a **straightforward app** that lets you quickly connect to a remote desktop using RDP/VNC protocol.
It does not support other protocols or any fancy features. You get a simple one-click app with support for scaling, bandwidth tweaks, and a couple more options.
**Pros:**
- Easy to use and simple
- Tailored for GNOME but can work on other desktop environments
**Cons:**
- It does not support many protocols
- It may not offer all kinds of functionalities for most, and no plugin support
**Installation **📥
You can install GNOME Connections through [Flathub](https://flathub.org/apps/org.gnome.Connections) on any distro of your choice.
If you already have Flatpak setup, use the command below to install it via the terminal:
`flatpak install flathub org.gnome.Connections`
## 3. RustDesk
[RustDesk](https://rustdesk.com) is a Rust-based remote desktop software that works out-of-the-box without the need for much configuration. It also allows for self-hosting, to further enhance the security of your remote connection.
**Pros:**
- P2P connection with end-to-end encryption based on NaCl.
- Supports many hardware/software codecs.
- Cross-platform.
**Cons:**
- Not available on Software Center or Store apps.
** Installation **📥
It is offered in various package formats such as ** .deb**,
**,**
**.rpm****, and more. You can find these packages from its GitHub**
**AppImage**[releases section](https://github.com/rustdesk/rustdesk/releases).
## 4. X2Go
[X2Go](https://wiki.x2go.org/doku.php/start) is an open-source, cross-platform remote desktop client with a client-server architecture. The remote machine must have an X2Go server installed, which should be a Linux system. And you can have X2Go client installed on any platform of your choice and then connect using it to the Linux remote system.
You can connect to Windows as well, using the client software, because you do not have the server available to be installed for other platforms.
So, X2Go is an excellent choice for users frequently connecting to Linux computers.
**Pros:**
- Linux server support
- Cross-platform clients
- SSH access, printer sharing, clipboard mode, and sound support
**Cons:**
- It uses a modified
[NX 3 protocol](https://en.wikipedia.org/wiki/NX_technology)and does not support other protocols
**Installation **📥
X2Go client is available in the software center for Ubuntu. Alternatively, you can use the below command in Debian-based Linux distribution.
`sudo get install x2goclient`
To install the x2go server, use the below command:
```
sudo add-apt-repository ppa:x2go/stable
sudo apt update
sudo apt install x2goserver x2goserver-xsession
```
You can explore more on its [official documentation](https://wiki.x2go.org/doku.php/doc:installation:x2goserver).
**Suggested Read 📖**
[11 Ways to Improve Your PrivacyBring your A game to improve your privacy online, whether you are a Linux user or not. Follow these tips for a secure experience!](https://itsfoss.com/improve-privacy/)

## 5. KRDC
[KRDC](https://apps.kde.org/krdc/) is a **free and open-source remote desktop tool built by KDE**. You can find it pre-installed in some KDE-powered distributions and install it on any distribution.
It supports two protocols that include RDP and VNC. You have all the essential options like scaling and remote session management.
**Pros:**
- Easy to use
- Remember connection history
- Native Linux support
- Scaling support
**Cons:**
- No cross-platform availability; Linux only
**Installation **📥
You can find KRDC from KDE's Discover Center or install it using [Flathub](https://flathub.org/apps/org.kde.krdc) or Snap.
If you want to install the Flatpak via the terminal, use the command below:
`flatpak install flathub org.kde.krdc`
## 6. TigerVNC
TigerVNC is a free and open-source remote computer connection tool with a client-server architecture.
In other words, you need to install the server on the remote computer and the client program to connect from.
The client program is pretty simple, with essential options like display settings and multiple tweaks for compression. TigerVNC manages to **provide you with a fast experience** for the remote connection compared to some other options.
**Pros:**
- Cross-platform
- Fast performance
**Cons:**
- GUI feels dated
- It does not support multiple protocols
**Installation **📥
You can find packages from its [GitHub releases section](https://github.com/TigerVNC/tigervnc/releases) or grab the binaries on [SourceForge](https://sourceforge.net/projects/tigervnc/files/stable/1.13.1/). Refer to our [deb file installation](https://itsfoss.com/install-deb-files-ubuntu/) article if you need help with it.
## 7. TeamViewer (Not FOSS)
[TeamViewer](https://www.teamviewer.com/en/products/teamviewer/) is a **popular tool **available cross-platform, even with the option to connect through mobile devices. Interestingly, there's **a web client available. So, to connect to other systems, you do not need the client installed on your computer.**
It is one of the oldest remote desktop-sharing tools out there. While it mentions **experimental Wayland support exists, TeamViewer recommends an Xorg session**.
Users frequently use TeamViewer for remote support and collaboration. While it is free for personal use cases, it needs a commercial license for businesses and enterprises.
Unlike some other options, you do not need an IP address. With TeamViewer installed on the remote computer, you get a **unique ID**, share it with the user you want to authorize connecting remotely, and that's it!
**Pros:**
- Intuitive user experience
- Good for beginners
- Mobile support
**Cons:**
- Need to create an account to enable desktop sharing
- Not a lightweight tool
- Not open-source
**Installation **📥
TeamViewer provides binaries for Linux distributions for easy installation. You can grab the .deb package for Ubuntu or refer to our [TeamViewer guide](https://itsfoss.com/teamviewer-linux/) for help.
[How to Install and Use TeamViewer on Linux [Complete Guide]Brief: Step-by-step beginner’s guide to installing TeamViewer on Linux. It also explains how to use TeamViewer on Linux. TeamViewer is a remote desktop application primarily used to connect to a different system quickly and securely. It lets you remotely connect to someone’s desktop, transfer f…](https://itsfoss.com/teamviewer-linux/)

## 8. AnyDesk (Not FOSS)
[AnyDesk](https://anydesk.com/) is one of the industry-leading remote desktop tools with a nice feature set and secure access.
You can use it for free, along with mobile support for Android and iOS. You will need to purchase a license to unlock all of its features.
**Pros:**
- Cross-platform support
- Mobile support
**Cons:**
- Limited functionality for free
- Not open-source
**Installation **📥
You can find binaries for all kinds of Linux distributions on its [download page](https://anydesk.com/en/downloads/linux), supporting Ubuntu, openSUSE, and RHEL.
## 9. Apache Guacamole
[Apache Guacamole](https://guacamole.apache.org) is a special remote desktop tool for cloud systems (or servers).
If your server runs an operating system, you can install Apache Guacamole and access it from any other platform via the web browser. Hence, it pitches itself as a clientless remote desktop gateway.
**Pros:**
- Tailored for cloud computing
- Free and open-source
**Cons:**
- A specialized tool not fit for everyone
**Recommended Read 📖**
[Best Linux Software: 39 Essential Linux Apps [2023]What are the must-have applications for Linux? The answer is subjective. Here, we’ve listed some of the best options.](https://itsfoss.com/essential-linux-applications/)

## Wrapping Up
There are some more open-source options like [FreeRDP](https://www.freerdp.com) and [XRDP](http://www.xrdp.org). FreeRDP did not work for me, but it is actively maintained. So, you can give it a try.
XRDP needs to be installed from the source. Feel free to look at it if you want to go through the hassle of [compiling from source](https://itsfoss.com/install-software-from-source-code/).
**🗨 Let us know which one prefer from the list or if you have something else to suggest. We might update the list with your suggestion.** |
15,829 | 如何从 Fedora 37 工作站升级到 Fedora 38(GUI 和 CLI) | https://www.debugpoint.com/upgrade-fedora-38-from-fedora-37/ | 2023-05-19T22:58:00 | [
"Fedora"
] | /article-15829-1.html | 
>
> 使用 GUI 和 CLI 方法从 Fedora 37 工作站版升级到 Fedora 38 的完整步骤。
>
>
>
Fedora 38 已发布,没有任何延误。此版本带来了令人惊叹的 GNOME 44 工作站版桌面、KDE Plasma 5.27(最后一个 Plasma 5 系列)等。你可以在 [此页面](https://www.debugpoint.com/fedora-38/) 上阅读我写的 Fedora 38 功能指南。
如果你尝试从 Fedora 37 升级到 Fedora 38,请遵循以下推荐步骤。
**注意**:如果你运行的是 Fedora 38 **beta** 版本,则无需按照以下步骤进行升级。你可以从终端运行 `sudo dnf update && sudo dnf upgrade 以获取正式版本。
如果你运行的是旧版本的 Fedora,例如 36 或 35,你**不应该跳版本**直接升级到 38。你可以先升级到 37,然后再升级到 38; 或者进行全新安装。根据我的经验,如果你在升级期间跳过版本,一些应用和扩展程序会崩溃,还包括内核相关问题。
### 升级到 Fedora 38
在你进入更新之前,这里有一些你应该做的事情。以防你遇到问题。我们总是建议这么做。
#### 升级到 Fedora 38 之前要遵循的步骤
首先,打开 GNOME “软件” 应用并检查是否有任何待处理的更新。或者,打开终端并运行以下命令以确保你的系统是最新的。
```
sudo dnf update
```
完成上述命令后,重新启动系统以确保应用所有更新。
其次,将你的重要文件(例如图片、文档或视频)从主目录备份到安全的地方(可能是单独的分区或 U 盘)。Fedora 升级过程不会失败,但如果你使用英伟达或任何具有双引导系统的特定硬件,我建议你进行备份。
第三,安装 [Extensions Flatpak 应用](https://flathub.org/apps/details/org.gnome.Extensions) 并禁用所有 GNOME 扩展(用于 GNOME 桌面)。主要原因是并非所有扩展都已移植到 GNOME 44。因此在升级之前禁用所有扩展是安全的。你可以稍后在完成升级过程后启用它们。
此外,看看官方论坛,看看 Fedora 38 任何可能影响升级过程的 [已知的重要问题](https://discussion.fedoraproject.org/tags/c/ask/common-issues/82/none/f38)。不要在这上面花太多时间。
最后,升级过程需要一些时间(以小时为单位),因此请确保你有足够的时间和稳定的互联网连接。
#### 如何升级到 Fedora 38 工作站
##### 图形化方法(GUI)
在 Fedora 38 正式发布后,你应该会在 GNOME “软件” 应用中看到有升级可用的通知。如果你没有看到任何通知,请不要担心。等一两天,你应该就可以了。

此外,你可以访问 GNOME “软件” 应用中的更新选项卡,看看它是否可用。
单击该通知并单击 <ruby> 下载 <rt> Download </rt></ruby> 以开始升级过程。升级程序将下载所需的软件包并提示你重新启动。点击重新启动以继续升级过程。
Fedora 将在重启期间应用升级。
##### 命令行方法(CLI)
如果你熟悉命令行,则可以使用 `dnf upgrade` 命令来执行升级过程。
打开终端并运行以下命令:
```
sudo dnf upgrade --refresh
```
此命令将刷新为 Fedora 38 准备的新升级软件包。
接下来,通过运行以下命令安装 DNF 升级插件。这是升级过程所必需的。
```
sudo dnf install dnf-plugin-system-upgrade
```
通过运行以下命令并安装任何必要的待定更新来确保你的系统是最新的。再做一次(如果你已经通过升级前的步骤完成了)。
```
sudo dnf --refresh upgrade
```
通过运行以下命令启动下载过程。此命令将获取所有必需的包并在升级前将它们保存在本地。
```
sudo dnf system-upgrade download --releasever=38
```
如果你手动安装了许多软件包和应用,并且不确定 Fedora 38 是否正确支持它们,请使用 `--allowerasing` 标志运行上述命令。当你提供此选项时,`dnf` 将删除阻止系统升级的软件包。
上面的命令显示将被替换、更新、升级或降级的内容。如果你想查看列表,请仔细浏览列表。或者,你可以检查红色标记的项目并开始升级过程,如下图所示。


请记住,下载大小一般以 GB 为单位,因此根据你的网速可能需要一些时间。
上述命令完成后,运行以下命令开始升级。
```
sudo dnf system-upgrade reboot
```
系统将自动重启,并等待整个升级过程的完成。正如我前面提到的,这可能需要几个小时的时间,这取决于你的系统硬件。因此要有耐心。
如果一切顺利,迎接你的将是一个全新的 Fedora 38 系统。
祝你好运!
*(题图:MJ/1fbeb9e2-ba9c-48ec-912f-78be9cfefcf3)*
---
via: <https://www.debugpoint.com/upgrade-fedora-38-from-fedora-37/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,830 | 如何入门 Linux Shell 脚本编写 | https://www.linuxtechi.com/get-started-shell-scripting-linux/ | 2023-05-19T23:58:00 | [
"脚本"
] | https://linux.cn/article-15830-1.html | 
>
> 各位读者,我们将在本文中介绍如何在 Linux 或 UNIX 系统中入门 Shell 脚本编写。
>
>
>
### 什么是 Shell 呢?
Shell(交互界面)是类 UNIX/Linux 操作系统中的一个解释器。它将用户输入的命令解释成操作系统的系统调用来执行这些命令。简单来说,Shell 形式上是操作系统的包装。比如,你可能使用 Shell 命令来列出目录中的文件,如 [ls](https://www.linuxtechi.com/linux-ls-command-examples-beginners/) 命令,或使用命令复制,如 `cp` 命令。
```
$ ls
Desktop Documents Downloads Music Pictures playbook.yaml Public snap Templates test5 Videos
```
在上方的例子中,当你输入 `ls` 并按下回车键。`$` 符号是 Shell 的提示符,意味着 Shell 等着命令的输入。下面的一行就是当前目录下的文件名。
### 什么是 Shell 提示符?
提示符,即 `$`,被称作命令提示符,是由 Shell 发出的(LCTT 译注:这个概念,可能有误。请参看:<https://www.gnu.org/savannah-checkouts/gnu/bash/manual/bash.html#Controlling-the-Prompt> )。当提示符出现后(LCTT 译注:此处提示符并不特指 `$` 符号),你就可以输入命令了。Shell 将会在你按下回车键后读取你的输入。它会通过查看你输入的第一个单词来确定你希望执行的命令。“单词”指的是一组连续的字符。空格和制表符作为分割单词的标志。
### 不同类型的 Shell
由于没有限制只能有一个 Shell,你可以按照自己的意愿来自由选择运行任何一种 Shell。这当然挺好的,但是在不清楚其它替代方案的情况下选择一种 Shell 没有多大益处。下面列出了一些 UNIx/Linux 下常见的 Shell。
#### Sh(Bourne Shell)
最初的 Unix Shell 通常被称作 Sh,是 Shell(或 Bourne Shell)的简写,以其作者 Steven Bourne 命名。它在几乎所有的类 UNIX 操作系统下都可以找到。基本的 Bourne Shell 仅支持相当有限的命令行编辑。你可以输入字符,使用退格键删除字符,还有就是按下回车键来执行命令。当命令行出现异常了,你可以按下 `Ctrl-C` 组合键来终止整个命令。
#### Csh(C Shell)
它是由加利福尼亚大学伯克利分校的 Bill Joy 设计的,由于它的语法和 C 语言相似,所以被命名为 C Shell。这种 Shell 在 Bourne shell 的基础上增加了一些实用功能,尤其是可以重用之前的命令来帮助创建之后要执行的命令。当你去完成一项专门任务的时候,大多数的情况下需要执行不止一条命令,这样 C shell 的能力就相当有用了。
#### Ksh(Korn Shell)
它是由贝尔实验室的 David Korn 创造的,Korn Shell 提供了和 C Shell 相同的增强,其中有一项重要的不同:Korn Shell 提供了对旧的 Bourne Shell 语法的向后兼容。在 Unix 下,如 AIX & HP-UX 上,Korn Shell 是默认 Shell。
#### Bash(Bourne Again Shell)
Bash 提供了像 Korn Shell 一样的命令行编辑,像 C Shell 一样的文件名补全和许多其它的高级功能。许多用户认为 Bash 集 Korn Shell 和 C Shell 的优点于一身。在 Linux 和 Mac OS X 系统下,Bash 是默认的 Shell。
#### Tcsh(T C Shell)
Linux 系统推广了 Tcsh。Tcsh 扩展了传统的 csh,增加了命令行编辑、文件名补全和其它功能。例如,当你按下 `Tab` 键后,Tcsh 会补全文件和目录名(与 Bash 中的按键相同)。旧的 C Shell 不支持这项功能。
### 什么是 Shell 脚本呢?
Shell 脚本是包含一条或多条命令的文本文件。在 Shell 脚本中,Shell 程序假定文本文件的每一行是一条不同的命令。这些命令的大部分就和你在 Shell 窗口手动输入的一样。
#### 为什么要使用 Shell 脚本呢?
Shell 脚本被用来自动化管理任务、简化复杂的配置细节,并且充分运用操作系统的性能。有了组合不同命令的能力就可以创造新命令了,从而增加操作系统的价值。此外,结合使用 Shell 与图形化桌面环境,可以兼得二者之长。
从系统管理员的角度看,日复一日的重复工作可以使用 Shell 脚本来实现自动处理,那就可以节约时间从事其它高质量的工作。
### 创建第一个 Shell 脚本
在当前工作目录下创建一个名为 `myscript.sh` 的文本文件,所有的 Shell 脚本都有 `.sh` 的扩展名(LCTT 译注:Linux 下根本没有扩展名一说,没有这个扩展一样是可以执行的)。脚本的第一行是 `#!/bin/sh` 或 `#!/bin/bash`,因为 `#` 符号被称作 “hash” 并且 `!` 符号被称作 “bang” 故被称为 shebang(释伴)。至于 `/bin/sh` 和 `/bin/bash` 则指出了命令将被 Sh 还是 Bash shell 执行。
以下就是 `myscript.sh` 的内容:
```
#!/bin/bash
# Written by LinuxTechi
echo
echo "Current Working Directory: $(pwd)"
echo
echo "Today' Date & Time: $(date)"
DISK=$(df -Th)
echo
echo "Disk Space on System:"
echo "$DISK"
```
上方的脚本将会展示当前工作目录、今天的日期与时间,还有磁盘空间。我们需要用到 [echo 命令](https://www.linuxtechi.com/echo-command-examples-in-linux/) 和其它 [Linux 命令](https://www.linuxtechi.com/20-linux-commands-interview-questions-answers/) 来实现这个脚本。
使用如下的 [chmod 命令](https://www.linuxtechi.com/chmod-command-examples-in-linux/) 来给文件增加执行权限:
```
$ chmod a+x myscript.sh
```
现在来执行脚本:
```
$ sh myscript.sh
或
$ ./myscript.sh
```
注意:在当前目录下执行当前目录下的 Shell 脚本,须使用 `./<脚本名>` 方式,如下所示:

#### 在 Shell 脚本中获取用户输入
`read` 命令用来获取用户的键盘输入,并且将之赋值给一个变量。`echo` 命令用来展示内容。
让我们更改上方的脚本以使之获取输入:
```
#!/bin/bash
# Written by LinuxTechi
read -p "Your Name: " NAME
echo
echo "Today' Date & Time: $(date)"
echo
read -p "Enter the file system:" DISK
echo "$(df -Th $DISK)""
```
现在,再执行脚本试试,这回应该会有输入信息的提醒:
```
$ ./myscript.sh
Your Name: Pradeep Kumar
Today' Date & Time: Sat 15 Oct 05:32:38 BST 2022
Enter the file system:/mnt/data
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/volgrp01-lv01 ext4 14G 24K 13G 1% /mnt/data
```

完美,上方的输出表明脚本有输入提醒,并加工处理了相应的数据。
本文结束。希望对你是有用的。非常欢迎任何的疑问、反馈。
*(题图:MJ/f83b771e-a70d-4c62-a169-ec42e9004a14)*
---
via: <https://www.linuxtechi.com/get-started-shell-scripting-linux/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed) 译者:[cyberwaddle](https://github.com/cyberwaddle) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello readers, In this post, we will cover how to get started with shell scripting in Linux or UNIX systems.
#### What is a Shell?
A shell is an interpreter in UNIX/Linux like operating systems. It takes commands typed by the user and calls the operating system to run those commands. In simple terms a shell acts as form of wrapper around the OS. For example , you may use the shell to enter a command to list the files in a directory , such as [ls command](https://www.linuxtechi.com/linux-ls-command-examples-beginners/) , or a command to copy ,such as cp.
$ ls Desktop Documents Downloads Music Pictures playbook.yaml Public snap Templates test5 Videos $
In this example , when you simply type ls and press enter . The $ is the shell prompt , which tells you the the shell awaits your commands.The remaining lines are the names of the files in the current directory.
#### What is Shell Prompt?
The prompt, $, which is called command prompt, is issued by the shell. While the prompt is displayed, you can type a command. The shell reads your input after you press Enter. It determines the command you want executed by looking at the first word of your input. A word is an unbroken set of characters. Spaces and tabs separate words.
## What are different types of Shells
since there is no monopoly of shells , you are free to run any shell as you wish. That’s all well and good , but choosing a shell without knowing the alternative is not very helpful. Below are lists of shells available in UNIX/Linux.
#### The Bourne Shell
The Original Unix Shell is known as sh , short for shell or the Bourne shell , named for steven Bourne , the creator of sh. This is available on almost all the UNIX like operating system. The Basic bourne shell supports only the most limited command line editing, You can type the Characters,remove characters one at a time with the Backspace key and Press enter to execute the command. If command line gets messed up , you can press Ctrl-C to cancel the whole command.
#### The C Shell
It is desgined by Bill Joy at the university of california at Berkeley , the C shell was so named because much of its syntax parallels that of C programming language. This shell adds some neat features to the Bourne shell,especially the ability to recall previous commands to help create future commands.Because it is very likely you will need to execute more than one command to perform a particular task,this C shell capability is very useful.
#### The Korn Shell
It is created by David Korn at AT&T Bell laboratories , the korn shell or ksh offers the same kind of enhancements offers by the C Shell , with one important difference: The korn shell is backward compatible with the older Bourne shell Synatx. In UNIX like AIX & HP-UX korn shell is the default shell.
#### Bash (The Bourne Again Shell)
Bash offers command-line editing like the korn shell,file name completion like the C shell and a lot of other advance features. Many Users view bash as having the best of the Korn and C shells in one shell. In Linux and Mac OS X system , bash is the default shell.
#### tcsh ( The T C Shell)
Linux systems popularized the T C shell ot Tcsh. Tcsh extends the traditional csh to add command line editing,file name completion and more. For example , tcsh will complete the file and directory names when you press Tab key(the same key used in bash). The older C shell did not support this feature.
## What is a Shell Script?
A Shell Script is a text file that contains one or more commands. In a shell script, the shell assumes each line of text file holds a separate command. These Commands appear for most parts as if you have typed them in at a shell windows.
#### Why to use Shell Script ?
Shell scripts are used to automate administrative tasks,encapsulate complex configuration details and get at the full power of the operating system.The ability to combine commands allows you to create new commands ,thereby adding value to your operating system.Furthermore ,combining a shell with graphical desktop environment allows you to get the best of both worlds.
In Linux system admin profile, day to day repeated tasks can be automated using shell script which saves time and allow admins to work on quality work.
#### Creating first shell script
Create a text file in your current working directory with a name myscript.sh , all the shell scripts have an “.sh” extension. First line of a shell script is either #!/bin/sh or #!/bin/bash , it is known as shebang because # symbol is called hash and ! Symbol is called a bang. Where as /bin/sh & /bin/bash shows that commands to be executed either sh or bash shell.
Below are the content of myscript.sh
#!/bin/bash # Written by LinuxTechi echo echo "Current Working Directory: $(pwd)" echo echo "Today' Date & Time: $(date)" DISK=$(df -Th) echo echo "Disk Space on System:" echo "$DISK"
Above shell script will display the current working , today’s date & time along with file system disk space. We have used [echo command](https://www.linuxtechi.com/echo-command-examples-in-linux/) and other [linux commands](https://www.linuxtechi.com/20-linux-commands-interview-questions-answers/) to build this script.
Assign the executable permissions using below [chmod command](https://www.linuxtechi.com/chmod-command-examples-in-linux/)
$ chmod a+x myscript.sh
Now execute the script.
$ sh myscript.sh or $ ./myscript.sh
Note: To execute any shell script available in current directory, use ./<script-name> as shown below,
output,
#### Taking Input from the user in shell script
Read command is used to take inputs from user via keyboard and assign the value to a variable. echo command is used to display the contents.
Let’s modify above script so that it starts taking input,
#!/bin/bash # Written by LinuxTechi read -p "Your Name: " NAME echo echo "Today' Date & Time: $(date)" echo read -p "Enter the file system:" DISK echo "$(df -Th $DISK)"
Now, try to execute the script this time it should prompt to enter details.
$ ./myscript.sh Your Name: Pradeep Kumar Today' Date & Time: Sat 15 Oct 05:32:38 BST 2022 Enter the file system:/mnt/data Filesystem Type Size Used Avail Use% Mounted on /dev/mapper/volgrp01-lv01 ext4 14G 24K 13G 1% /mnt/data $
Perfect, above output confirms that scripting is prompting for input and processing data.
That’s conclude the post. I hope you have found it informative. Kindly do post your queries and feedback in below comments section.
Read Also: [How to Debug a Bash Shell Script in Linux](https://www.linuxtechi.com/debugging-shell-scripts-in-linux/) |
15,832 | 你的第一门编程语言是什么? | https://opensource.com/article/21/8/first-programming-language | 2023-05-21T17:36:02 | [
"编程语言"
] | https://linux.cn/article-15832-1.html | 
>
> 以下是 24 位开源技术专家分享了他们开始编程之旅的故事。
>
>
>
我向我们的贡献者提问了这个问题:“你的第一门编程语言是什么?”不过这个问题并不像看上去那样简单。下面的故事谈到了是谁向你建议了第一门编程语言,是什么促使你学习它。如果你是付费学习的,接下来又发生了什么。这里还涉及到你所在的阶段以及这个世界上正在发生的事情。
让我们倾听这 24 位技术专家的故事吧。
---
*你的第一门编程语言是什么?*
BASIC。
*你花钱学习的吗?*
并不是。
*你是自己选择它的吗?*
不尽然。
*为什么这么说?*
那是 1979 年的圣诞节,我的父母(他们分别是学校的一名维护人员和一名公共卫生护士)省吃俭用地攒下了惊人的 1000 美元买下了一台 Tandy/Radio Shack TRS-80。它随附了一份涵盖了完整的 BASIC 编程语言的活页夹。我的父亲认为让我学习开发计算机软件是一个很好的将我从困境中解脱出来的方式。
*接下来发生了什么?*
我的父母给我和我的兄弟买了与“自学编程”相关的书籍,也订阅了相关的流行杂志。这些资源中提供了许多游戏的打印版的源代码。我们每个星期都花费大量的时间编写程序,然后一行一行地使用电脑自带的检查程序找出我们的打字错误并调试程序。当我们厌倦了游戏以后,我们开始修改它们。我们一开始只是简单地修改零零散散的字符串将一个罗马战斗策略游戏修改为一个太空战斗策略游戏。不过后来随着我们所做修改的复杂度的增加,我们最后开始开发我们自己的恐怖游戏。此后不久,我们开始通过信件分享我们的游戏磁盘,后来也通过当时仅 110bps 网速的电子公告板(BBS)分享我们的游戏。
40 年之后,我可以同全世界共同创作,家庭网络连接性能提升了七个数量级以上,但是我仍然时常怀念那个周六,那一天,在我和我的兄弟共同创造的真实的恐怖游戏当中,我被我的弟弟击败。
—— [Jeremy Stanley](https://opensource.com/users/fungi)
---
*你的第一门编程语言是什么?*
我的第一们编程语言是 BASIC,我在 7 年级的时候开始接触它。
*你是花钱学习的吗?*
如果你认为允许在午餐时间在计算机实验室里玩 《<ruby> 德军总部 3D <rt> Wolfenstein 3D </rt></ruby>》、《<ruby> 我的世界 <rt> Minecraft </rt></ruby>》、《<ruby> 模拟城市 <rt> Sim City </rt></ruby>》这些游戏,是对计算机科学足够感兴趣并学习 BASIC 语言的的花费的话,那就算是吧。
*你是自己选择它的吗?*
我不认为我当时曾确切地认识到还有第二选择。这是当时计算机实验室中仅有的内容,而且一些学长对它的介绍足以让我参与其中。我记得它不是计算机科学课程的一部分。
*为什么这么说?*
当时,我学习 BASIC 仅仅是因为乐趣。我仅仅用它来创造基于文本的“选择你自己的探险之旅”风格的游戏。从源代码创建一些兼具艺术性与趣味性的东西并让计算机运行它们这件事极大地吸引了我。我此前也使用过计算机,但这是我头一次让它为我做一些事情。
*接下来发生了什么?*
或许并不是巧合,我后来使用“选择你自己的探险之旅”风格的游戏来学习我后来接触到的每一种编程语言。
这一经历以及在计算机游戏中的首次探索(既有商业游戏也有我自创的游戏)开始了我进一步深入计算机领域的旅程,一直到我 11 年级时我的父母买回了我们家的第一台电脑。三年后,我将这一段旅程转化为了我的第一份计算机领域的工作,我成为了一家研究公司的实习生,这家公司最终录用了我为他们的 IT 支持组的一员,这是我大学毕业后的第一份“真正意义上”的工作。
将近 30 年后,我坚信是 BASIC(以及《模拟城市》)开启了我现在成为 SRE 的旅程,每天编写代码,与计算机集群为伍。
—— [Chris Collins](https://opensource.com/users/clcollins)
---
*你的第一门编程语言是什么?*
我玩过 BASIC 语言,但是我的第一门正式入门语言是 PL/I。我在我大学时的第一次编程课上学习它的。
—— [Heidi Ellis](https://opensource.com/users/heidi-jc-ellis)
---
*你的第一门编程语言是什么?*
我的第一门编程语言是 BASIC 语言。那是在 1981 年。我学习它是因为我买了一台能够启动进入 BASIC 编辑器的家用电脑,一台 TRS-80 彩色计算机。它拥有相当出众的 4K 容量的内存(没写错),而且它还可以在盒式磁带上存储程序。我希望让电脑做一些事情,因此我开始学习如何使用它能够理解的语言向它下达指令。一旦你第一次体验到程序成功运行的欣喜若狂的感受,你会发现我还想再次体验这种感觉。你还需要知道的是,如今已经过去 40 多年了。
—— [Matthew Helmke](https://opensource.com/users/matthew-helmke)
---
*你的第一门编程语言是什么?*
我的第一门编程语言是 BASIC。它是 1977 年大学第一学期中我的计算机科学课程的一部分,因此我既没有自己花钱学习它,也不是自己选的它。不过我始终认为这是非常重大的第一步,因为它使我学会了如何像计算机一样思考(我有一个好老师)。随着我从经济学院毕业,这门课程并没有立即促成一些事情。不过,多年之后,我成为了一名 IT 项目经理。所以我没有做过程序员,不过我管理过一些。
—— [Kevin O'Brien](https://opensource.com/users/ahuka)
---
*你的第一门编程语言是什么?*
BASIC
*你花钱学习的吗?*
不是。
*你是自己选择它的吗?*
它是内置在 Apple ][ 计算机里的,这台计算机是我母亲在暑假带回来的,我的选择很有限。
*为什么这么说?*
这台计算机里只有 BASIC 语言和 6502 汇编语言。显然,BASIC 语言看上去对六年级的我更具吸引力。
*接下来发生了什么?*
我去公共图书馆,找出了所有刊载了 Apple ][ 程序的源代码清单的往期的《Byte》杂志。我花了很多时间输入这些我几乎无法理解的程序,并享受调试其他人代码的乐趣(好吧,我更确定的是,大部分错误都是我带来)。我简直入迷了。几年以后,在高中毕业班的时候,当我知道可以主修某种称作“计算机科学”的课程的时候,我既惊讶又激动。剩下的就是历史了。
—— [Erik O'Shaughnessy](https://opensource.com/users/jnyjny)
---
*你的第一门编程语言是什么?*
Fortran IV,你应该已经知道这是多少年前的事情了。
*你花钱学习的吗?*
不是,这是我大学的计算机科学课程的一部分,因此我想也可以认为我是花钱学习它的。这是在大型机上,因此你在纸上写好你的程序以后,你需要带上空白的 IBM 穿孔卡,然后坐在一台键控打孔机前把你的程序打孔出来,然后将你的穿孔卡片集作为一项“作业”提交上去。然后第二天你就可以拿回你的穿孔卡片,上面带有行式打印机输出结果。如果你的程序没有成功运行,你得不到任何输出,或者如果你制造了某种死循环,你则可能拿到一页又一页的结果。
*接下来发生了什么?*
在我的大学生涯快结束的时候,学校开始使用 watfor 编译器,这是一款来自加拿大的滑铁卢大学的 Fortran 版本。它的优势在于你可以在终端中使用它,并在大型机中保存你的程序,而不需要使用我们曾经非常喜爱的穿孔卡。因此你可以自行运行你的程序,也可以立即创造死循环的程序。欧耶!
Fortran 之后,吸引了我的眼球的另一门编程语言是 BASIC,它与 Fortran 有很多相似之处,不过能够更好的处理字符串。Fortran 在字符串处理方面太糟糕了。我主要是在 Amiga 计算机上做这些事情的。
在转向 Linux 后,我接下来接触的语言是 Perl,奇怪的是,似乎很容易从 BASIC 语言过渡到 Perl。接着 Perl 之后,就是 Python,一门在语法上更加灵活的语言。
—— [Gregory Pittman](https://opensource.com/users/greg-p)
---
*你的第一门编程语言是什么?*
我 1974/1975 年学习的 Waterloo Fortran IV,这是入学第二年时我上的第一门计算机科学课程,当时我几乎确信我想要主修计算机科学了。这一年的稍晚时间,我们还学习了一些有关 IBM 360/370 汇编器的内容。在那段时间里,在英属哥伦比亚大学的低年级课程中我们使用的是打孔机,我们可以使用一个“学生终端”来连接我们的卡片盒,并得到一张供我们的卡片盒运行一次的“蓝色凭证”,然后走到 IBM 行式打印机后面拿回我们的程序输出。即使旁边明明写了一张提示“不要将你的卡片盒放在打印机上,以免打印机(上盖)开启”,不过如果你还是不注意,将你的卡片盒放到了打印机的上面。此刻,打印机可能刚好用完了纸或者发生了卡纸,于是主动打开了上盖,你的卡片盒将会掉到地上变成一团糟。
在我主修计算机科学的第三学年,我选了一系列的课程 —— 以 PL/I 为特色的第三年主流课程、一学期的 360/370 汇编器课程、两门关于计算机理论的荣誉课程、一门数值分析课程、“密歇根终端系统上的十二种编程语言”,以及一系列数学课。
在我的第四学年,我被应用数学研究所聘为研究助理。此时,我主要为一小群主要对求解微分方程的感兴趣的数学家们编写 Fortran 程序来获取报酬。同时,也是从那时开始,我意识到计算机科学并非我的最爱,我开始转向数学。我仍然继续学习了一些计算机科学课程 —— 优化课程以及更多的数值分析课程。回过头看,这是我走上数据科学之路的第一步。
我毕业之后的第一份工作还是编程,主要是使用 Fortran、PL/I 以及 SPSS 编程,SPSS 是一种统计编程语言。此外,我也学会了如何使用 MPSX(LCTT 译注:<ruby> 拓展数学编程系统 <rt> Mathematical Programming System Extended </rt></ruby>),这是 IBM 的一种线性规划通用语言。
—— [Chris Hermansen](https://opensource.com/users/clhermansen)
---
*你的第一门编程语言是什么?*
在我高中的时候,作为一项实验,让一位没有任何计算机经验的教师教我们计算机编程。我的学校之前从来没有尝试过这类课程。施乐公司给我们提供了一台 Model-33 型电传打字机和一台 110 波特的声耦调制解调器,这使得我们可以访问他们运行 CP-5 分时系统的 XDS Sigma 7大型机。BASIC 是当时的主流。
*你花钱学习的吗?*
上学算吗?
*接下来发生了什么?*
一些学生开始尝试在这台机器上 “瞎戳”,看看如果我们不在提示符位置输入 “BASIC” 会发生什么,这使我们发现这台机器上还内置了 *其他的* 编程语言!还有其它的东西!如果我没有记错的话,这台机器上至少还有三个独立的 Fortran 编译器 —— Fortran、FLAG(Fortran Load And Go —— FLAG 的编译速度在当时称得上“快”了,简直是快如闪电)。剩下的编译器 EFFORT 则是另一个极端 —— 也可能是 EFORT,只是发 “effort” 的读音,它的编译速度—相—当—慢,不过在我们眼里,它的确看上去拥有极致的代码优化。除此之外,我也短暂尝试过 APL 编程语言(LCTT 译注:这种编程语言的全称是:[A Programming Language](https://link.springer.com/chapter/10.1007/978-1-349-08004-5_6) ?)以及(用于 APL 语言编程的有各种符号的“怪异”键盘)。在 APL 语言中,退格键不是用来删除已经输入的内容,反而是重写该操作符为其他的操作符。
—— [Kevin Cole](https://opensource.com/users/kjcole)
---
*你的第一门编程语言是什么?*
雅达利 PILOT 语言以及雅达利 BASIC 语言(LCTT 译注:<ruby> 雅达利 <rt> Atari </rt></ruby>)。我的父母给孩童时期的我买了一台雅达利 1200XL 计算机,我开始只是用他们来玩游戏或者完成一些艺术课程。家里有两盒卡带,我父亲告诉我它们是“适合成人使用的,因为不是为小孩子设计的,我不会对他们感兴趣”。所以,显然我无比好奇。终于有一天我禁不住找出并装载了它们。刚开始的时候我一头雾水,直到我找到一本我父亲买的有关这两盒卡带的书籍。我输入了书上的样例,发现能够实现一些事情的感觉是相当酷的。我当时还不能完全独立地编写程序,不过我可以拿来书中的样例,然后仅仅更改其中的部分内容,直到我能让它完成一些其他的事情或者使之崩溃进而只能撤销这些更改。我曾经计划再次尝试一遍,看看我还能记得多少,不过我一直都没有抽出时间(来做这件事)。
—— [JT Pennington](https://opensource.com/users/jtpennington)
---
*你的第一门编程语言是什么?*
ELAN。这是那一时期相当优秀的编程语言。尤其需要重点说明的是它是与 EUMEL 系统紧密结合的,可以用它做并行计算。
*你花钱学习的吗?*
它是一项课后活动。
*你是自己选择它的吗?*
不是。
*为什么这么说?*
我想学习弹钢琴,我的父母跟我说如果我愿意参加打字课的话我就可以得到一台钢琴。打字课的隔壁就是课后计算机俱乐部,我觉得那有趣多了。不幸地是,时至今日我也不会弹钢琴,计算机使我一直忙到了现在。
*接下来发生了什么?*
当我上大学的时候,他们还在使用打孔卡和 Fortran。我很庆幸我的高中老师允许我使用学校的并行机编程。此间,我也尝试了 BASIC 语言,但这比不上我学习的 ELAN,而且很枯燥。后来我转向 Pascal,Pascal 也比不上 ELAN。再后来就是 C 语言、Modula-2 语言和 Ada 语言,我最后发现了 Occam,并且使用它在 <ruby> 晶体电脑 <rt> transputer </rt></ruby> 上完成了很多任务。这是相当激动人心的,因为我们可以做更多的并行计算。能够使用 64 台晶体电脑是一件相当酷的事情。同时,接入各种网络配置也令人兴奋。这是几十年前的事情了。我看到了往日的高中生与今日的高中生的不同点。我们当时几乎没有资源(我直到大四的时候才买得起一台电脑),而今天电脑已经习以为常了。而且,电脑与类似 FLL(FIRST Lego League)这样的机器人使得降低编程的门槛成为可能。然而,今天的学生们也被随处可及的电子游戏以及其中炫酷的图像所分心。现成产品(像电子游戏、手机以及平板电脑等)使得今天的学生能够从闲暇时间中抽出用来学习机算机科学的时间很有限。我必须承认,如果在我长大之后也接触到了今天这样的电子游戏,我可能对计算机科学拥有完全不同的看法,并且也不会被我的同学们视作“书呆子”,而是成为一个游戏玩家。
不幸的是,我没有时间玩游戏,我的 RTX3090 显卡在运行人工智能算法。我真正想要的玩具是一台 [A100 GPU](http://nvidia.zhidx.com/product-11.html) 以及一套我现在远程使用的 [DGX 系统](http://nvidia.zhidx.com/product-11.html)。我认为由于 [Google colab](https://colab.research.google.com/) 以及其通过 Jupyter 可访问的特点,对人工智能的接触可以下放到高中水平。然而这一切都取决于带领你入门的高中教师。如果你的编程老师只是教你乐高机器人上的块编程,而不是 Python,或者只是教你使用 Scratch 而不是 Google colab。那么我们就没有利用那些学生早年间的潜力,也没有利用这些出众的基础设施。
—— [Gregor von Laszewski](https://opensource.com/users/laszewski)
---
*你的第一门编程语言是什么?*
我在一台 Apple 电脑上接触到了 Logo 编程语言。它由麻省理工的 <ruby> 西蒙· 佩珀特 <rt> Seymour Papert </rt></ruby> 等人在 1967 年开发。这是一种为了教育目的开发的编程语言,是 Lisp 语言的一个子集。
我学习它是当时我参与的一项毕业教育项目的一部分。作为该项目的一部分,我使用 Logo 教一名五年级学生的几何学。在教这名学生 Logo 编程语言和这门课程的时候,我发现我在数学上的麻烦与无助在于无法可视化这些材料。在完成我的研究生课程以后,我使用 Logo 语言继续以相同的课程与编程语言教其他学生们几何与数学。学生们和我在这个过程中学习了数学,并开发了一些优美的图形,我们实际上是为一个“乌龟”机器人编程,在需要放在教室地板上的巨幅纸张上绘制我们的图像。我的编程经历让我开始寻找其他的方式来将数学带入学生的生活中,这让我开始接触 Python 以及 Python 中的“乌龟”模块。后来,我开始教学生们写 Python 程序,这些程序的特点是“屏幕上的”乌龟机器人可以创建优美的图像。与此同时,我也开始向这些学生介绍 Python 编程语言与逻辑思考能力。
—— [Donald Watkins](https://opensource.com/users/don-watkins)
---
*你的第一门编程语言是什么?*
ZX81 BASIC。
我还在上小学的时候,大概 10 岁或者 11 岁的样子,我的一个朋友得到了一台 ZX81 计算机。于是我自学了 BASIC 并编写了一些简单的程序尝试在他的机器上运行。1982 年的圣诞节,我得到了属于我自己的 ZX81 计算机,此后不久,ZX81 的硬件跟不上硬件发展了,我于 1993 年晚些时候转向了 ZX Spectrum ,自此之后,我也使用 Z80 汇编语言编写了一些程序。
多年以后,我偶然得到一款早期型的卡西欧掌上型计算器,它可以执行 BASIC 程序。这是 PB 系列的一款设备,有可能是 PB-200,不过我已经记不清具体的型号了。16 岁时在英国,我设法说服了我的老师允许我在我的 [数学普通等级考试中](https://en.wikipedia.org/wiki/GCE_Ordinary_Level_(United_Kingdom)) 使用它。我也关注过其他的编程语言,不过直到我在大学开始学习 Ada 之前,我都没有真正学过其他的编程语言。
—— [Steven Ellis](https://opensource.com/users/steven-ellis)
---
*你的第一门编程语言是什么?*
我的第一门编程语言是 BASIC,那是在 80 年代早期的事了。
我的一个亲戚给他们的孩子买了一台 C64 计算机用来让他们学习计算机。他们只用这台计算机玩游戏,我也被邀请一起玩。不过他们还有一本关于 BASIC 语言的书,我非常好奇并做了尝试。我写了一些简短的代码,我甚至都不知道怎么保存它,不过当我看到计算机如我告诉它的那样工作的时候那仍然令人十分兴奋。这也说明我不是花钱来学习 BASIC 编程的,也不是我的选择,它是我当时能接触到的语言。几年后当我得到我的第一台计算机,一台 XT 兼容机后,我首先用 GW-BASIC 语言写了一些代码,GW-BASIC 是 BASIC 语言在 DOS 系统下的一种方言。
*接下来发生了什么?*
我第一次真正选择的编程语言是 Pascal。我问了一圈,又查了一些书籍,它看上去是在功能与难度之间的一个挺好的妥协。一开始,我用的是 Turbo Pascal,我用它编写了各种简单的游戏与图形。我热爱 Pascal,因此在上大学的时候,我甚至还在用它(FreePascal 和 Lazarus)来进完成测量自动化与地下水污染分布的建模。
—— [Peter Czanik](https://opensource.com/users/czanik)
---
*你的第一门编程语言是什么?*
卡西欧 fx-7200G 的编程语言的 [一个变体](https://en.wikipedia.org/wiki/Casio_fx-7000G),我想它可能没有自己的名字。
*你花钱学习的吗?*
不是。
*你是自己选择它的吗?*
也不是。
*为什么这么说?*
我在 13 岁生日时得到了一台可编程计算器(包装盒上说它是“计算机”……)。
*接下来发生了什么?*
一年后,上高一的时候,我在甚至没有一本教科书的情况下学习了 Pascal 语言 —— 我们的老师推荐的主要的学习 Pascal 的教材还是大学程度的,他认为这些教材对我们而言还是太难了 —— 因此我们用来理论教学与练习的课程实际上都是使用 BASIC 语言的,因此我也学了一些 BASIC 语言(虽然是无意的,但是从老师的角度来看的确是这样)。
我认为我是一名后来者 —— 一些我的同班同学在家里拥有一台内置了 BASIC 的计算机(Commodore 64、Spectrum Sinclair、Amstrad 等等)。上高中之前我已经对 BASIC 有所了解,高一的一年里,我和那些对 BASIC 有点了解又无法欣赏 Pascal 的优点的学生之间关系有点紧张。
后来,我上大学了(方向是数学与计算机科学),我们这些学生可以使用 DOS 电脑或者一些苹果公司的 Macintosh,或者是主要连接到 SunOS 4 共享机的一些终端机(文本终端,如果你幸运的话,有 X 终端)。我大二的时候(1993 年),某位朋友向我介绍了 Linux,它可以在家用机器上运行。我已经给自己买了一台新电脑(一台 AMD 386SX 兼容机,直到 8 年后它退役是,我才意识到它是 AMD 的,而不是我之前一直以为的英特尔 386 机器)。得知我的 8088 电脑不适合运行更现代的系统之后,我尝试使用 Linux 系统,在仅有 2MB 内存的情况下安装好 Linux 花了我几个月的时间。此后不久,我升级到了 4MB 内存,我也几乎不再进入 DOS 系统(虽然我仍然将它作为我的第二启动项保留了好几年)。我至今仍然记得当我能够完全在家里运行一个类 UNIX 系统时我的惊讶与激动之情,即便只是 X Window(在升级到 4MB 内存以后)。
回到编程语言,在我大学期间,我们学习/使用了 Pascal 语言(第一门入门课程),C 语言(系统编程入门课程)以及一些课程专用的语言,Eiffel 语言(在面向对象课程中学习的),Matlab 语言(为了我的一项研究),等等。
我的第一份真正的工作是参与一个基于 Unix 的项目(我们主要使用运行 Ultrix 系统的 DECstation 工作站),我主要是使用 Lisp 语言(Lucid Common Lisp)和 C 语言。我就是在这时学习的 Lisp 语言,虽然我后来没有再使用过它,而且这段经历也给我留下了很多美好回忆。作为一个个人项目,我设法使该项目运行在 Linux 系统的个人电脑上,通过使用一个用于 SCO Unix 的 LCL 副本。我设法使之能在 Linux 下工作,主要是通过 `ibcs2` 组件,和用交叉编译器工具链重新编译的 GNU `libc` 库实现的(在 Linux 上使用 `gcc`/`as`/`ld` 生成用于 SCO 的 COFF 库)。我非常自豪地向我的领导演示这一应用,通常需要一台价值约 3 万美元的工作站,却可以在一台 5 千美元的电脑上运行。然而它从来没有被投入到生产环境中过。
—— [Yedidyah Bar David](https://opensource.com/users/didib)
---
*你的第一门编程语言是什么?*
TI-BASIC。
*你花钱学习的吗?*
不是,不过我那时才 10 岁。
*你是自己选择它的吗?*
不是。
*为什么这么说?*
这是 TI-99/4A 计算机上仅有的编程语言了!嗯,这台计算机上也有 “Extended Basic” 语言,不过这只是 BASIC 的一个拓展指令集。你实际上可以在 16Kb 内存中编写像样的游戏。
*接下来发生了什么?*
下一步就是输入通过纸质杂志上的程序并把它们记录到录音带上。不过我与我哥哥在这一步上做得更加深入 —— 我们通过将结果的声音通过电台广播的方式让别人录制下来!由于清晰的录音和足够的纠错,在 1985 年就实现了通过无线方式分发和下载程序。
—— [Thierry Carrez](https://opensource.com/users/thierry-carrez)
---
*你的第一门编程语言是什么?*
GW-BASIC。
*你是自己选择它的吗?*
不是。
*为什么这么说?*
它是针对初学者的标准教学内容。
*接下来发生了什么?*
我开始在一家公司里做计算机硬件专家。
—— [Hüseyin GÜÇ](https://opensource.com/users/hguc)
---
*你的第一门编程语言是什么?*
BASIC,在 VIC-20 机器上。
*你花钱学习的吗?*
不是。
*你是自己选择它的吗?*
我只是选择了那台电脑。
*为什么这么说?*
我发现 VIC 计算机至少是跟我在学校里见到的 PET 机器最兼容的机器了。而且它有一个好看的键盘。
*接下来发生了什么?*
接下来就是编程时间了,因为这台机器也没有其他事情可以做了——我学到了很多。
—— [Bob Murphy](https://opensource.com/users/murph)
---
*你的第一门编程语言是什么?*
如果我没有记错的话,那是 2004 年还是 2005 年。我还在上学,可能是 5 年级,我接触到了 BASIC。此前,我还学了有关 “Window Logo” 的一些知识。
*你花钱学习的吗?*
我父母花钱供我上学了。
*你是自己选择它的吗?*
根本不是。
*为什么这么说?*
这是由我学校学习的课程决定的。
*接下来发生了什么?*
它彻底燃起了我对编程的兴趣,我继续在课外学习班中学习了 C/C++ 语言。我的父母非常鼓励我,并且在设法给我提供了额外的费用。我经常是整个计算机补习机构里最后仅剩的那个“孩子”。我是唯一一个学习编程语言的人,而其他人大多学习 MS Office 或 PhotoShop 等。哈哈。好了,剩下的就是历史了。
—— [Kedar Vijay Kulkarni](https://opensource.com/users/kkulkarn)
---
*你的第一门编程语言是什么?*
Fortran,因为那是很久之前的事了。
*你花钱学习的吗?*
不是的,我是通过上计算机课程学习的它。
*你是自己选择它的吗?*
不,那是仅有的选择。我很幸运我用的是终端而不是打孔卡片,我可怜的丈夫在学习 Fortran 程序的时候用的还是打孔卡片。
*为什么这么说?*
我是人文专业毕业(英语与人类学双专业),我临毕业的时候实际上必须找一份工作。我想,学一门计算机课会让找工作容易一些。事实证明,就市场需要的技能而言,这一门编程课程是我学到的最有价值的课程。它给我在后续的学习 Python、理解 Git 以及为 Red Hat 撰写和编辑文档时提供了一个很好的基础。
*接下来发生了什么?*
我回家后在一台我父母购买的 TI-99 计算机上自学了 BASIC 语言(我不确定他们为什么买了它,或许是为了我的弟弟)。早些年的 Fortran 基础让我在 Windows 出现之前能够更加容易使用早期个人电脑,因为我能够搞懂 DOS。这显然是一个简陋的开始。
—— [Ingrid Towey](https://opensource.com/users/i-towey)
---
*你的第一门编程语言是什么?*
2001 年,我通过阅读艾迪生-韦斯利出版社的 《Goto Java》 这本书学习了 Java SE 1.2。
*你是花钱学习的吗?*
没有,我当时还在学校里。
*你是自己选择它的吗?*
是的。
*为什么这么说?*
我想要使用 Java Applets 制作交互式网页。
*接下来发生了什么?*
我上大学了,接触到了自由和开源软件(FOSS),并且学习了 ANSI C 语言。
—— [Joël Krähemann](https://opensource.com/users/joel2001k)
---
*你的第一门编程语言是什么?*
我准备就此写一篇文章,不过我已经写了这篇了:《[参与开源软件并不必须要计算机科学学位(2020 年 8 月 6 日)](https://opensource.com/article/20/8/learn-open-source)》。
这篇文章中的重点如下:
我的父母买了一台 Apple II+ 的克隆版,名为 Franklin ACE 1000。我和我的兄弟自学了如何使用 AppleSoft BASIC 编程。我的父母给我们买了一些书,我们如饥似渴地吸收了这些书籍。我通过阅读书上的内容学会了 BASIC 语言的各个方面,然后写了一个练习程序。我最喜欢的娱乐就是编写游戏和仿真程序。
我停留在 BASIC 语言上很长时间。但是当我上了大学以后,我开始学习其他的编程语言。我是物理学系的一名学生,作为学习数值分析的先导条件,我们必须学习 Fortran 语言。因为已经学过了 BASIC 语言,我觉得 Fortran 相当容易学习。Fortran 与 BASIC 是非常相似的,尽管根据我的经验,Fortran 的局限性更大。
我的哥哥在另一所大学里主修计算机科学,他给我介绍了 C 语言,我立马就爱上了用 C 语言编程!它是一种简明直接的语言,给了我相当大的灵活性,让我能够编写有用的程序。但是我的学位计划里没有足够的空间让我选择一门不适用于我所选择的物理学专业的课程。为此,我转而通过读书结合图书馆的参考指南来自学 C 语言。每当我希望学习新的主题的时候,我就在参考指南中寻找相应的内容,然后实践编写一个相应的程序来锻炼我的新知识。
随着时间的推移,我利用我所学的内容来学习其它的编程语言。我编写了大量 Unix Korn 命令行脚本、Linux Bash 脚本和 AWK 脚本。我还用 Perl 写些实用小工具,后来也用 Perl CGI 以及 PHP 做网站开发。我学习了够用的 LISP 语言来调整我的 GNU Emacs 副本,也学习了够用的 Scheme 来参与一个使用 GNU Guile 的项目。
—— [Jim Hall](https://opensource.com/users/jim-hall)
---
*你的第一门编程语言是什么?*
我的第一门编程是 BASIC,准确地说是<ruby> 雅达利 <rt> Atari </rt></ruby> BASIC 语言。
20 世纪 80 年代,我家买了一台雅达利 400 家用计算机。我用它来玩游戏,不过它也自带了一盘 BASIC 语言的卡带。它还包括一个盒式录音机(雅达利 1010)。那些年,程序可以存储在标准的录音带上。雅达利 400 没有内部存储空间,因此我也学会了如何将我的程序保存到录音带上,以及随后如何重新加载它们。除了常见的“Hello World”的程序,我还写了一些可以用操作杆来控制声音与图形的程序。我现在还记得用来设置和读取某些设置属性的 `PEEK` 和 `POKE` 命令,比如颜色或声音设置。
*你花钱学习的吗?*
不是。
*你是自己选择它的吗?*
是的,它是雅达利中内置的编程语言,因此我确定尝试一下——我非常喜欢用它编程。
*接下来发生了什么?*
一段时间之后,我可能对雅达利以及电子游戏失去了兴趣。直到 90 年代中期,当我参加计算机课程以辅修计算机科学时,我才重新对计算机和编程重新感兴趣。这些课程教会了我 C 语言、汇编语言以及很多其他的通用计算机与网络技术。作为我的硕士学位的一部分,我后来又学习了 Java。在我的职业生涯中我只进行过数量不多的正式编程工作,主要是在本世纪 10 年代中期时在 ColdFusion 环境下使用 Java 语言。从编程方面来说,命令行脚本是我的主要领域,主要是在 Bash 与 Windows 瞎,不过只要有需要,我也会进行特定目标的编程。我使用过 <ruby> 工作控制语言 <rt> Job Control Language </rt></ruby>(JCL)用来在大型机系统之间进行自动文件传输。我也使用过 Python 用来将 REST API 的查询结果返回给企业的监控面板。我仍然认为我早期的 BASIC 编程经历是值得的,因为我获得了对软件和编程的尊重。
—— [Alan Formy-Duval](https://opensource.com/users/alanfdoss)
*(题图:MJ/0cf8b9b0-fb92-4131-ab89-ee0880c1b4a9)*
---
via: <https://opensource.com/article/21/8/first-programming-language>
作者:[Jen Wike Huger](https://opensource.com/users/jen-wike) 选题:[lujun9972](https://github.com/lujun9972) 译者:[CanYellow](https://github.com/CanYellow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We asked our contributors *What was your first programming language?* but the question goes much deeper than that. There are stories to tell about who suggested it or what prompted you to learn it. If you were paid to do so, and what happened next. Then there's a lot it says about your age and what was going on in the world.
Let's hear a little bit about these 24 technologists' stories.
*What was your first programming language? *BASIC
*Were you paid to learn it? *Nope.
*Did you choose it? *Not really.
*Why? *It was Christmas of 1979, my parents (a school maintenance worker and a public health nurse) scrimped and saved the staggering US$1000 to buy a Tandy/Radio Shack TRS-80. It came with a ring binder that covered the complete BASIC programming language, and my Dad figured getting me to learn to write computer software would be a good way to keep me out of trouble.
*What happened next? *Mom and Dad would buy me and my younger brother books or subscriptions to popular magazines about "home computing," which included printed source code for a variety of games. We spent hours every weekend painstakingly typing and then debugging line by line with the accompanying checksums to find our typos. When the games got boring, we'd modify them... trivially at first just tweaking strings here and there to turn, say, a roman battle strategy game into a space battle strategy game; but later increasing the complexity of our changes and eventually starting to write terrible games of our own. Soon after that, we were sharing disks by mail and then over BBSes at 110bps.
Four decades later, I can collaborate on creations with the entire world and home connectivity has increased 7+ orders of magnitude, but part of me still misses those Saturday afternoons hunched over the keyboard, getting thoroughly trounced by my little brother at something truly terrible we created together. —[Jeremy Stanley](https://opensource.com/users/fungi)
*What was your first programming language? *My first language was BASIC, which I learned in 7th grade.
*Were you paid to learn it? *Not unless you count being allowed to play Wolfenstein 3D, Minecraft, and Sim City in the computer lab at lunch as a perk for being interested enough in computer science to learn BASIC for fun.
*Did you choose it? *I don't think I was aware enough at the time to realize there might have been alternatives. This was what was available in the computer lab, and some older students knew enough about it to get me into it. I don't remember it even being part of the computer science class curriculum.
*Why? *At the time, it was just for fun. I used it exclusively to create text-based "Choose Your Own Adventure"-style games. Something about creating something artistic and fun from code and having the computer run it appealed to me. I'd used computers before, but this was the first time I made it do something for me.
*What happened next? *Perhaps not-so-coincidentally, I've used "Choose Your Own Adventure"-style games to teach myself every one of the programming languages I've learned the rest of my life.
This experience and the first exploration of computer games (both commercial and self-written) started me down a path toward getting involved in computers more deeply, always at school until my family bought our first computer when I was in 11th grade. Three years later, I translated this exploration into my first computer job as an intern for a research company that eventually hired me for my first "real" job out of college—working in their IT Support group.
I credit BASIC (and Sim City) with starting me down the path toward where I am now as an SRE, writing code and running clusters daily, some 30 years later. —[Chris Collins](https://opensource.com/users/clcollins)
*What was your first programming language? *I played with BASIC, but my first formal introduction was PL/I—learned it in my first programming course in college. —[Heidi Ellis](https://opensource.com/users/heidi-jc-ellis)
*What was your first programming language? *My first programming language was BASIC. This was in 1981. I learned it because I bought a home computer that booted into a BASIC editor, a TRS-80 Color Computer. It had a whopping 4K of RAM (not a typo) and could store programs on a cassette tape. I wanted to make the computer do things, so I learned how to instruct it using language it understood. Once you tap, for the first time, into that feeling of joy when your program runs successfully, the elation takes over, and you find yourself wanting to experience it again. Next thing you know, 40 years have passed. —[Matthew Helmke](https://opensource.com/users/matthew-helmke)
*What was your first programming language? *My first programming language was BASIC. It was part of a computer science class I took in my first semester of college in 1977, so I was not paid to learn it nor did I choose it. But I always thought it was a great first step since it taught me how to think like a computer (and I had a good teacher). It didn't lead to anything right away as I went to graduate school in Economics, but years later I was an IT Project Manager. So I never was a coder, but I managed a few. —[Kevin O'Brien](https://opensource.com/users/ahuka)
*What was your first programming language? *BASIC
*Were you paid to learn it? *No.
*Did you choose it? *It was built into the Apple ][ computer my Mom brought home for the summer, and my choices were limited.
*Why? *It was either BASIC or 6502 Assembly, and BASIC seemed more attainable to sixth-grade-me.
*What happened next? *I went to the public library and found all the back issues of "Byte" magazine with source listings for Apple ][ programs. I spent a lot of time typing in programs that I could barely follow and learning the joys of debugging someone else's code (ok, I'm pretty sure I introduced most of the bugs). I was hooked. Several years later, senior-in-high-school me was very surprised and excited to learn that you could major in something called "computer science." The rest was history. —[Erik O'Shaughnessy](https://opensource.com/users/jnyjny)
*What was your first programming language? *Fortran IV—tells you something about how long ago this was.
*Were you paid to learn it? *No, this was part of my first computer science course in college, so I guess that means I paid to learn it. This was on a mainframe, so after writing your program on paper, you bought your blank IBM punchcards, sat down at a keypunch to punch them out, then had to submit your collection of punchcards as a "job." Then the next day, you got your cards back with a printout from a line printer. If your program didn't run, you got nothing, or you might get pages and pages if you managed to create some sort of never-ending loop.
*What happened next? *At the tail end of college, they began using *Watfor*, a Fortran implementation from the University of Waterloo in Canada. Its advantage was that you could use it on a terminal, saving your programs on the central system, rather than the punchcards we loved so well. So you could run your program yourself and create your never-ending loops right away. Whoopee!
After Fortran, the next language that caught my eye was BASIC, which was a lot like Fortran, but handled strings much better. Fortran was awful with strings. This was mostly on an Amiga.
After switching to Linux, my next language was Perl, which oddly enough seemed like a fairly easy transition from BASIC. After Perl, came Python, a language less stiff with syntax. —[Gregory Pittman](https://opensource.com/users/greg-p)
*What was your first programming language? *Waterloo Fortran IV in 1974-5, my first computer science course—taken in the second year—back when I was sorta sure I wanted to major in computer science. We also learned a bit about IBM 360/370 assembler later in the year. Back in those days, the lower-year courses at UBC used keypunches, and there was a "student terminal" where you would cue up with your deck of cards and exchange a "blue ticket" for a run of your deck, then walk around behind the IBM line printer to pick up your output. If you were careless or distracted you might put your deck on top of the printer—even though there was a sign saying "don't put your card deck on top of the printer, in case it opens"—and of course if you did, the printer would that very moment run out of paper or have a jam and obligingly raise its lid, which caused your card deck to spill to the floor and become an unorganized mess.
In my third year, still in computer science, I took a bunch of courses—the mainstream third-year course featuring PL/I, a one-semester 360/370 Assembler course, the two honors courses on computational theory, a numerical analysis course, "the twelve languages of MTS," and a bunch of math courses.
In my fourth year, I was hired by the applied math institute as a research assistant. At that point, I was getting paid for writing Fortran programs for a small group of mathematicians mostly interested in solving differential equations. Also, by then, I realized that computer science wasn't for me, and I had switched to math. I did continue to take some computer science courses—optimization, more numerical analysis. Looking back, those were my first steps down the data science pathway.
My first post-university job was programming, mostly in Fortran and in PL/I and SPSS, a statistics language. As well, I learned how to use MPSX, an IBM linear programming utility. —[Chris Hermansen](https://opensource.com/users/clhermansen)
*What was your first programming language? *In high school, a teacher who had zero experience with computers was asked to teach computer programming as part of an experiment: My school had not tried this before. Xerox Corp. provided the school with a Model-33 teletype and a 110-baud acoustic coupled modem, which gave us access to their XDS Sigma 7 mainframe running the CP-5 time-sharing system. BASIC was the order of the day.
*Were you paid to learn it? *Do grades count?
*What happened next? *A few of us started "poking a stick" at the machine to see what would happen if we didn't type "BASIC" at the prompt... which lead us to discover that there were *other *languages! And other stuff too! If I recall, there were (at least) three separate Fortran compilers—Fortran, FLAG (Fortran Load And Go—which compiled lightning-quick, or what passed for "quick" in the day), and at the opposite end EFFORT—or possibly EFORT, but pronounced "effort." S-L-O-W to compile, but it did what appeared to be, to our young eyes, amazing optimization of the code. Also, a brief foray with a "weird" keyboard with all sorts of symbols, and APL, where backspace was not used to erase anything but to overstrike operators to make other operators. —[Kevin Cole](https://opensource.com/users/kjcole)
*What was your first programming language? *Atari PILOT and Atari BASIC. My family bought an Atari 1200XL when I was a kid, and while I started out just using it for games and some art programs, there were two cartridges that my Dad said were "for adults" and "I wouldn't like them because they're not for kids." So obviously, I was incredibly curious. One day I decided to check them out. I was totally confused at first but then found the book that he had about them, and I typed in the sample code and thought it was really cool that I could make things happen. I never was able to write anything entirely on my own, but I took the sample code and just changed parts until I either got it to do something else or broke it and had to undo those changes. I've been meaning to try it out again and see how much I remember, but I just haven't had the time. —[JT Pennington](https://opensource.com/users/jtpennington)
*What was your first programming language? *ELAN. It was a superb language for the time. It is important to note it was tightly coupled with the OS EUMEL so we could do parallel computing.
*Were you paid to learn it? *It was an after-school activity.
*Did you choose it? *No.
*Why? *I wanted to learn piano, and my parents said I would get one if I take a typewriter course. Next door was the after-school computer club. I thought that was more interesting. Unfortunately, I still don't know how to play the piano as computers kept me busy till today.
*What happened next? *When I started at the university, they still had punch cards and Fortran. I was lucky as the high school teacher allowed me to use the parallel computer at the high school for programming. In between, I also tried BASIC, but that was just inferior and boring. I then looked at Pascal, which was not any better than ELAN. After C, Modula-2, and Ada, I finally found Occam and did lots of stuff in Occam on transputers. That was exciting as we could do more parallel computing. Having access to 64 of them was pretty cool. Also, plugging in various network configurations was exciting. This was decades ago. I see a difference between yesteryear's high school students and today's. While we initially had few resources (I could not afford a computer till I was in my fourth year at university), today's computers are commodities. Furthermore, the combination of computers and robotics such as FLL (FIRST Lego League) makes it possible to lower the entry barrier. However, today also students are distracted by accessibility to video games and access to very cool graphics. Ready-made products (videogames, cell phones, tablets) may limit the available "time" today's students have to learn computer science in their free time. I have to admit that if I would have been offered today's video games when I grew up, I may have had a very different outlook on computer science and may not have been labeled by my high schoolmates "nerd," but the video gamer.
Unfortunately, I have no time to do video games as my RTX3090 plays AI algorithms … The toy I really want for me is an A100 and a DGX which I use now remotely. I would argue that due to Google colab and accessibility via Jupyter, access to AI can be lowered to the high school level. However, this all depends on the high school teacher that introduces you to it. If you just have one that teaches you block-programming instead of, for example, Python on the lego robots or one that uses scratch instead of Google colab, then we do not leverage the potential that these students have in their early years and can leverage this superb infrastructure. —[Gregor von Laszewski](https://opensource.com/users/laszewski)
*What was your first programming language? *I got into Logo on an Apple, a computer language developed at MIT by Seymour Papert and others in 1967. It was a language designed for education. It's a subset of Lisp.
I learned it as part of a graduate education program I was involved with at the time. As part of that program, I taught geometry to a fifth-grade student using the Logo programming language. While teaching this student the computer language and the curriculum, I discovered that my own trouble and learned helplessness with mathematics came from an inability to visualize the material. After completing the graduate course, I used the Logo language to teach other students geometry and mathematics using the same curriculum and programming language. The students and I learned math and developed some beautiful graphics in the process, and we actually programmed a 'turtle' robot that drew our images on large pieces of paper on the classroom floor. My experience with programming led me to look for other ways to bring mathematics to life for students, which led me to Python and the "turtle' module. Lately, I've been teaching students how to write Python programs that feature an 'on-screen' turtle robot that can create beautiful graphics while at the same time introducing those students to the Python language and logical thinking skills. —[Donald Watkins](https://opensource.com/users/don-watkins)
*What was your first programming language? *ZX81 BASIC.
I was still at school, probably aged 10 or 11, when a friend got a ZX81—so I taught myself BASIC and wrote a couple of simple programs I could try out on his machine. Christmas 1982, I got my own ZX81 and pretty soon outgrew the hardware and moved onto a ZX Spectrum in late 1993, by which time I was also programming a little in Z80 assembly.
A couple of years later, I also picked up an early CASIO handheld that ran BASIC. It was one of the PB series, possibly the PB-200, but I can't remember the exact model version. I managed to convince my teachers to let me use it for my O-Level math exam at the age of 16 in the UK. I did take a look at some other languages but didn't really learn any until I started on Ada at university. —[Steven Ellis](https://opensource.com/users/steven-ellis)
*What was your first programming language? *My first ever programming language was BASIC in the early eighties.
One of my relatives bought a C64 for their kids to get started with learning computers. They only used it for gaming, and I was also invited. But they also had a book about BASIC, and I was curious and gave it a try. I wrote some shortcode, I did not even know how to save it, but it was exciting to see that the computer does what I say to it. This means that I was not paid to learn it, and it was not my choice. It was the language available to me. Obviously, when I got my first computer a few years later, an XT compatible box, I first wrote some code in GW-BASIC, the dialect of BASIC available with DOS.
*What happened next? *The first time I really choose a programming language was Pascal. I asked around, checked some books, and it seemed to be a good compromise between features and difficulty. First, it was Turbo Pascal, and I coded all kinds of simple games and graphics in it. I loved Pascal, so in my university years, I even used it (well, FreePascal and Lazarus) for measurement automation and modeling how pollution spreads in groundwater. —[Peter Czanik](https://opensource.com/users/czanik)
*What was your first programming language? *The language of the Casio fx-7200G ([a variant of](https://en.wikipedia.org/wiki/Casio_fx-7000G)). I don't think it has its own name.
*Were you paid to learn it? *No.
*Did you choose it? *No.
*Why? *I got this programmable calculator (the box said "computer"...) for my 13th birthday.
*What happened next? *A year later, first high-school year, I studied their Pascal, even though we didn't have books for it—the main Pascal book our teacher recommended was university-level, considered by him to be a bit too hard for us—and the main text we used for theory and exercises was actually using BASIC, so I also learned some BASIC (unintentionally, at least from the teacher's POV).
I considered myself a latecomer—some kids in my class had computers with BASIC (commodore 64, Spectrum Sinclair, Amstrad) at home, and I already knew a bit of BASIC before high school, and along the first years, there was a semi-tension between us—me, and those who knew BASIC and didn't appreciate the advantages of Pascal.
Later on, I went to university (math and computer science), where students could use DOS PCs or a few Macintoshes, or terminals (text ones, X Terminals if you were lucky and one was available), mainly to connect to shared SunOS 4 machines. In my second year (in 1993), someone told me about Linux, which I could run at home. I already bought myself a newer PC (an AMD 386SX-compatible. Only after I "decommissioned" it, ~ 8 years later, I realized it was AMD and not an Intel 386, which is what I thought I was buying) before knowing about Linux, learning my 8088 PC isn't suitable for running more modern OSes, and so I tried Linux, which it took me several months to get installed with only 2MB RAM—soon after that, I upgraded to 4MB and then seldom rebooted to DOS (which I kept as a dual-boot option for several years). I still remember my astonishment and excitement at being able to run a UNIX-like OS, even with X windows (after upgrading to 4MB RAM), all at home.
In terms of languages, in the university, we studied/used Pascal (first intro course), C (intro to systems programming course), and then some course-specific ones—Eiffel (in the OOP course), MatLab (for a workshop), etc.
My first real job was in a project written on Unix (we used mainly DECstation machines with Ultrix), mainly in Lisp (Lucid Common Lisp) and C, where I studied Lisp, and from which I still have very good memories, even though I never used it later. I managed to make the project semi-work on a PC with Linux, as a personal side project, using a copy of LCL for SCO Unix, which I managed to make work on Linux with the `ibcs2`
module and recompiling GNU `libc`
with a cross-compiler toolchain (`GCC/as/ld`
on Linux to generate COFF binaries for SCO). I was quite proud to demonstrate the application to my manager—something which normally needed a workstation costing ~ $30K, running on a $5K PC. But this never went to production. —[Yedidyah Bar David](https://opensource.com/users/didib)
*What was your first programming language? *TI-BASIC
*Were you paid to learn it? *No, but then, I was 10.
*Did you choose it? *No.
*Why? *It was the only language available on the TI-99/4A! Well, there was the "Extended Basic," too, but that was just an extended instruction set. You could actually write decent games in 16Kb of RAM.
*What happened next? *The next step was to type in programs that were shipped in print magazines and record them on audio cassette tapes. But with my brother, we took that one step further—we went live on radio to broadcast the resulting sound for others to record! With a clear recording and enough error correction, you could distribute and download programs wirelessly back in 1985. —[Thierry Carrez](https://opensource.com/users/thierry-carrez)
*What was your first programming language? *GW-BASIC
*Did you choose it? *No.
*Why? *It was standard education for beginners.
*What happened next? *I started in a company for computer hardware specialist. —[Hüseyin GÜÇ](https://opensource.com/users/hguc)
*What was your first programming language? *BASIC, on the VIC-20.
*Were you paid to learn it? *Nope.
*Did you choose it? *Only insofar as I chose the computer.
*Why? *I figured that the VIC would be at least mostly compatible with the PET I had seen in school. Also, it had a decent keyboard.
*What happened next? *Those were the days of programming because there was no other way to do anything with it—learned a lot. —[Bob Murphy](https://opensource.com/users/murph)
*What was your first programming language? *It was the year 2004-05 if I recall. I was in school, maybe a fifth-grader, I was introduced to BASIC. Before that, I had learned a little bit of something called "Window Logo."
*Were you paid to learn it? *My parents paid for my school.
*Did you choose it? *Not at all.
*Why? *Part of the curriculum my school decided on.
*What happened next? *It definitely piqued my interest in programming, and I went on to learn C/C++ through extra-curricular courses outside of my school. My parents encouraged it and managed to pay extra fees somehow. I often ended up as the only "kid" in the entire computer institute. I was the only one learning a programming language while others mostly learned MS Office or PhotoShop etc. LOL. Well, the rest is history. —[Kedar Vijay Kulkarni](https://opensource.com/users/kkulkarn)
*What was your first programming language? *Fortran, because I'm old.
*Were you paid to learn it? *No, I paid to learn it by taking a computer science class.
*Did you choose it? *No, it was the only choice. I was lucky that we had terminals to work on instead of the punchcards that my poor husband used when he learned how to program in Fortran.
*Why? *I was a humanities major (English and Anthropology double major), and I was getting close to graduation and actually having to find a JOB. I figured a computer class might make that possible. As it has turned out, that particular programming class was one of the more valuable ones that I took in terms of marketable skills. It provided a good foundation for learning Python, understanding Git, and editing and writing documentation for Red Hat.
*What happened next? *I went home and taught myself BASIC on the TI-99 that my parents had bought (I'm not sure why they bought it, though—maybe for my little brother?). That early foundation in Fortran (of all things) made it easier to use the early PCs before Windows existed because I could figure out DOS. A humble beginning for sure. —[Ingrid Towey](https://opensource.com/users/i-towey)
*What was your first programming language? *In 2001, I learned Java SE 1.2 by reading the book *Goto Java* from Addison-Wesley.
*Were you paid to learn it? *No, I was still in school.
*Did you choose it? *Yes.
*Why? *I wanted to create interactive websites with Java Applets.
*What happened next? *I went to college and got in touch with FOSS and learned ANSI C. —[Joël Krähemann](https://opensource.com/users/joel2001k)
*What was your first programming language? *
I was going to write an article for this, but I already wrote that one: [You don't need a computer science degree to work with open source software (6 Aug 2020)](https://opensource.com/article/20/8/learn-open-source).
Highlights from that article:
Our parents bought an Apple II+ clone called the Franklin ACE 1000. My brother and I taught ourselves how to program in AppleSoft BASIC. Our parents bought us books, and we devoured them. I learned every corner of BASIC by reading about something in the book, then writing a practice program. My favorite pastime was writing simulations and games.
I stayed with BASIC for a long time. But I began to learn other programming languages when I entered university. I was a physics student, and as part of our numerical analysis prerequisite, we had to learn Fortran. Having already learned BASIC, I thought Fortran was pretty easy to pick up. Fortran and BASIC were very similar, although Fortran was more limited in my experience.
My brother was a computer science major at a different university, and he introduced me to the C programming language. I immediately loved working in C! It was a straightforward programming language that gave me a ton of flexibility for writing useful programs. But I didn't have room in my degree program to take a class that didn't apply to my physics major. So, instead, I taught myself C by reading books and combing through the library reference guide. Each time I wanted to learn a new topic, I looked it up in the reference guide and wrote a practice program to exercise my new knowledge.
Over time, I leveraged what I'd learned to pick up other programming languages. I wrote a ton of Unix Korn shell scripts, Linux Bash scripts, and AWK scripts. I wrote small utilities in Perl, and later wrote Perl CGI and PHP pages for websites. I learned enough LISP to tweak my copy of GNU Emacs, and enough Scheme to work on a project that used GNU Guile. —[Jim Hall](https://opensource.com/users/jim-hall)
*What was your first programming language? *My first programming language was BASIC, Atari BASIC to be exact.
My family had an Atari 400 home computer in the early 1980s. I played games on it, but it also came with a cartridge for the BASIC language. It included a cassette recorder (Atari 1010). In those days, programs could be stored on standard audio cassette tapes. The Atari 400 didn't have internal storage, so I learned how to save my programs to cassette and later reload them. In addition to the usual "Hello World" programs, I wrote some that allowed for controlling sound and graphics using a joystick. I still remember the PEEK and POKE commands needed for setting and retrieving certain settings, such as a color or a sound setting.
*Were you paid to learn it? *No.
*Did you choose it? *Yes, it was the one language included with the Atari, so I decided to give it a try—and I did enjoy programming it.
*What happened next? *After a while, I guess I lost interest in Atari and computer gaming altogether. It wasn't until the mid-nineties that I became interested in computers and programming again when I attended computer science classes to earn a minor in CS. Those courses taught me languages such as C and Assembly and many general computer and networking skills. I later learned Java as part of my Master's degree. I have only done a small amount of formal coding during my career, mostly a little Java in a ColdFusion environment in the mid-2000s. In terms of coding, shell scripting has been my mainstay, mostly BASH and Windows, but I have coded for specific purposes whenever needed. I've used Job Control Language (JCL) for automating file transfers between mainframe systems. I've also used Python to feed REST API query results back to an enterprise monitoring dashboard. I still think that early experience with BASIC was valuable because I gained a respect for software and programming. —[Alan Formy-Duval](https://opensource.com/users/alanfdoss)
## 7 Comments |
15,834 | 在 Ubuntu 上安装和使用 Qemu | https://itsfoss.com/qemu-ubuntu/ | 2023-05-22T11:00:00 | [
"Qemu"
] | https://linux.cn/article-15834-1.html | 
>
> 学习如何在 Ubuntu 中正确安装 Qemu,然后在虚拟机中配置 Linux 发行版。
>
>
>
如果你需要运行 Linux 虚拟机,Qemu 是目前最快的管理程序之一,甚至没有“之一”。
除了速度之外,你还可以获得出色的配置选项。即使你不是一个资深用户,它也给你足够的调整空间。
在本教程中,我将引导你完成:
* 在 Ubuntu 上安装 Qemu 和 KVM
* 在 Qemu 上安装另一个发行版
* 在 Qemu 中启用共享文件夹、自动调整大小和复制粘贴(可选,但会使你的虚拟机体验更顺畅)。
那么让我们从安装开始吧。
### 在 Ubuntu 上安装 Qemu 和 KVM
>
> ✋ 在开始安装之前,让我们检查一下你的机器是否支持虚拟化。
>
>
>
要做到这一点,请使用以下命令:
```
LC_ALL=C lscpu | grep Virtualization
```
如果你有一个英特尔处理器,它应该带来以下输出:

如果你有一个 AMD 处理器,它应该得到以下输出:
```
Virtualization: AMD-V
```
另外,[确保你的系统有多个处理器核心](https://linuxhandbook.com/check-cpu-info-linux/?ref=itsfoss.com),这样你可以分配一些给你的虚拟机,并且仍然有足够的处理能力提供给宿主机。
如果你不确定,使用下面的命令,**输出应该大于零**:
```
egrep -c '(vmx|svm)' /proc/cpuinfo
```

一旦你都准备好了,你就可以用以下命令在 Ubuntu 上安装 Qemu 和 KVM:
```
sudo apt install qemu qemu-kvm virt-manager bridge-utils
```
安装结束后,**重新启动你的系统**。
#### 将用户添加到适当的组中
为了使 Qemu 工作,你必须 [将你的用户加入两个组](https://learnubuntu.com/add-user-group/?ref=itsfoss.com):`libvirt-kvm` 和 `libvirt`。
要做到这一点,请逐一使用以下命令:
```
sudo useradd -g $USER libvirt
sudo useradd -g $USER libvirt-kvm
```
接下来,启用并启动 `libvirt` 服务:
```
sudo systemctl enable libvirtd.service && sudo systemctl start libvirtd.service
```
这就行了!Qemu 的安装已经完成。
### 用 Qemu 安装另一个 Linux 虚拟机
>
> ? 请下载你想在 Qemu 虚拟机中安装的 Linux 发行版的 ISO 文件。
>
>
>
首先,从系统菜单中打开 <ruby> 虚拟机管理器 <rt> Virtual Machine Manager </rt></ruby>:

接下来,点击 “<ruby> 文件 <rt> File </rt></ruby>” 菜单,选择 “<ruby> 新建虚拟机 <rt> New Virtual Machine </rt></ruby>” 选项:

从这里,选择第一个选项 “<ruby> 本地安装介质 <rt> Local install media </rt></ruby>”,这将允许你从文件管理器中选择 ISO:

接下来,你将被要求添加 ISO 文件。在这里,点击 “<ruby> 浏览 <rt> Browse </rt></ruby>” 按钮;它将打开一个新的提示窗口,在那里,点击 “<ruby> 浏览本地 <rt> Browse Local </rt></ruby>”。
它将打开文件管理器,从那里选择 ISO 文件:

**在大多数情况下,ISO 文件会被检测到,但如果你发现它没有自动检测到,请按照以下步骤操作:**
* 取消勾选 “<ruby> 自动从安装介质/源检测 <rt> Automatically detect from the installtion media / source </rt></ruby>” 选项
* 选择 “<ruby> 常见的 Linux <rt> Generic Linux </rt></ruby>” 选项

接下来,你将被要求根据你的需要分配内存和存储。我建议桌面版至少要有 2 个核心、4GB 内存和 25GB 的存储空间:

>
> ? 除了磁盘空间,CPU 和内存等系统资源只在 VM 中运行操作系统时使用。
>
>
>
最后,给你的虚拟机起一个合适的名字;完成后,点击 “<ruby> 完成 <rt> Finish </rt></ruby>” 按钮:

它将加载 ISO,所以你可以从这里开始安装。
这就完成了。你可能会觉得这已经很不错了,但如果你启用共享文件夹、剪贴板共享等,你会更喜欢它。下面的几节将介绍如何做到这一点。
### 在 Qemu 中启用共享文件夹(可选)
在本节中,我将向你展示如何将宿主机的现有目录与虚拟机共享。
要做到这一点,你必须执行以下步骤:
* 通过 Qemu 中的虚拟机设置添加一个共享文件系统
* 在虚拟机中挂载文件系统
因此,首先从系统菜单中打开虚拟机管理器,选择虚拟机,并点击 “<ruby> 打开 <rt> Open </rt></ruby>” 按钮来管理控制台:

现在,点击 “<ruby> 信息 <rt> Info </rt></ruby>” 按钮,选择 “<ruby> 内存 <rt> Memory </rt></ruby>” 并启用共享内存:

接下来,点击 “<ruby> 添加硬件 <rt> Add Hardware </rt></ruby>” 按钮,选择 “<ruby> 文件系统 <rt> Filesystem </rt></ruby>” 选项。
在这里,你必须做以下工作:
* 在 “<ruby> 源路径 <rt> Source Path </rt></ruby>” 部分添加一个你想共享的目录的路径
* 在 “<ruby> 目标路径 <rt> Target Path </rt></ruby>” 部分添加该目录的名称

完成后,点击 “<ruby> 完成 <rt> Finish </rt></ruby>” 按钮,启动虚拟机。
在虚拟机中,打开终端,使用下面的语法来挂载共享目录:
```
sudo mount -t virtiofs sharename path/to/shared/directory
```
在我的例子中,它是 `Downloads` 目录,所以我将使用下面的方式:
```
sudo mount -t virtiofs Downloads /home/sagar/Downloads
```

这就行了。
**但这是一个临时的解决方案。**
要使它成为永久性的,你必须在虚拟机的 `/etc/fstab` 中创建一个条目。
要这样做,首先,用下面的方法打开 `/etc/fstab` 配置文件:
```
sudo nano /etc/fstab
```
按下`Alt + /`,[在 nano 文本编辑器中转到文件的末尾](https://linuxhandbook.com/beginning-end-file-nano/?ref=itsfoss.com) ,并使用以下语法创建一个条目:
```
sharename path/to/shared/directory virtiofs defaults 0 0
```
这是我的配置,看起来像这样:

一旦完成,[保存更改并退出 nano](https://linuxhandbook.com/nano-save-exit/?ref=itsfoss.com) 文本编辑器。
这里我展示了我是如何在主机上的 `Downloads` 目录下创建一个新文件,并且这些变化反映在我的虚拟机上:

因此,现在你可以使用这个共享文件夹在主机和虚拟机之间传输文件,没有任何问题了!
### 在 Qemu 中启用共享剪贴板(可选)
要启用共享剪贴板,你所要做的就是在虚拟机中安装 `spice-vdagent` 工具。
因此,如果你的虚拟机是基于 Ubuntu/Debian 的,你可以使用以下方法:
```
sudo apt install spice-vdagent
```
对于基于 Arch 的发行版:
```
sudo pacman -S spice-vdagent
```
对于基于 Fedora 的发行版:
```
sudo yum install spice-vdagent
```
一旦你完成了安装,**重启你的虚拟机**,剪贴板应该可以如期工作了。
### 在 Qemu 中启用自动调整大小(可选)
自动调整大小的功能没什么,但当你调整虚拟机窗口的大小时,虚拟机的显示会立即适应大小的变化:

要启用 Qemu 中的自动调整大小功能,你必须遵循 2 个简单的步骤:
* 点击 “<ruby> 视图 <rt> View </rt></ruby>”(从顶部菜单栏)。
* 选择 “<ruby> 缩放显示 <rt> Scale Display </rt></ruby>” 并选择 “<ruby> 总是 <rt> Always </rt></ruby>” 选项。

这就是我这边看到的情况了。
### 想要使用 Qemu 的即插即用版本?
在本教程中,我介绍了如何在 Qemu 中手动安装虚拟机,但如果我告诉你,你可以自动完成整个过程,如分配存储空间、内存等步骤呢?
是的,它提供了同样的效率,但当你想尽快创建一个新的虚拟机时,它就会派上用场!这个工具叫 Quickgui,我们有一个专门的安装教程:
>
> **[用基于 Qemu 的 Quickgui 轻松地创建虚拟机](https://itsfoss.com/quickgui/)**
>
>
>
我希望你会发现这个指南对你有帮助。如果你有任何疑问,欢迎在评论中提问。
*(题图:MJ/b3c4d5b2-e727-4b70-9bb8-e864941eef9a)*
---
via: <https://itsfoss.com/qemu-ubuntu/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you need to run Linux virtual machines, Qemu is one of the fastest hypervisors out there, if not the fastest.
Along with the speed, you also get excellent configuration options. Even if you are not an advanced user, it gives you enough room for tweaks.
In this tutorial, I will walk you through:
- Installing Qemu and KVM on Ubuntu
- Installing another distro on Qemu
- Enabling shared folder, auto-resize, and copy-paste in Qemu (optional but makes your VM experience smoother)
So let's start with the installation.
## Installing Qemu and KVM on Ubuntu
To do so, use the following command:
`LC_ALL=C lscpu | grep Virtualization`
If you have an intel processor, it should bring the following output:

And if you have an AMD processor, it should get you the following output:
`Virtualization: AMD-V`
Also, [make sure your system has multiple cores](https://linuxhandbook.com/check-cpu-info-linux/) so that you can allocate some to your VM and still have enough to power the host machine.
And if you're not sure, use the following command and the** output should be more than zero:**
`egrep -c '(vmx|svm)' /proc/cpuinfo`

Once you are all set, you can install Qemu and KVM on Ubuntu using the following command:
`sudo apt install qemu qemu-kvm virt-manager bridge-utils`
**Reboot your system **once the installation is over.
### Add user to appropriate groups
To make Qemu work, you'd have to [add your user to two groups](https://learnubuntu.com/add-user-group/): `libvirt-kvm`
and `libvirt`
.
To do so, use the following commands one by one:
`sudo useradd -g $USER libvirt`
`sudo useradd -g $USER libvirt-kvm`
Next, enable and start the `libvirt`
service:
`sudo systemctl enable libvirtd.service && sudo systemctl start libvirtd.service`
That's it! The installation of Qemu is done.
## Installing another Linux virtually with Qemu
First, open the Virtual Machine Manager from the system menu:
Next, click on the File menu and choose the `New Virtual Machine`
option:
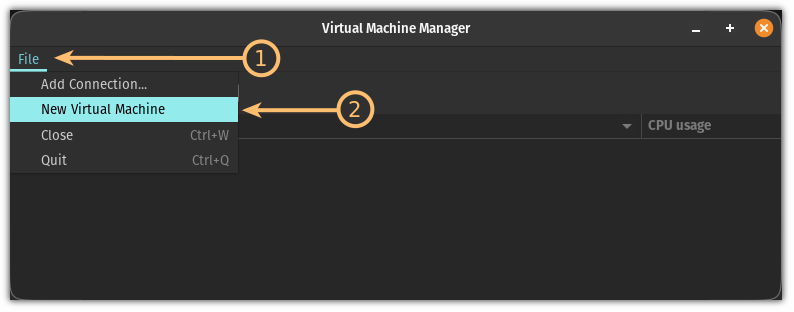
From here, choose the first option `Local install media`
which will allow you to choose the ISO from your file manager:
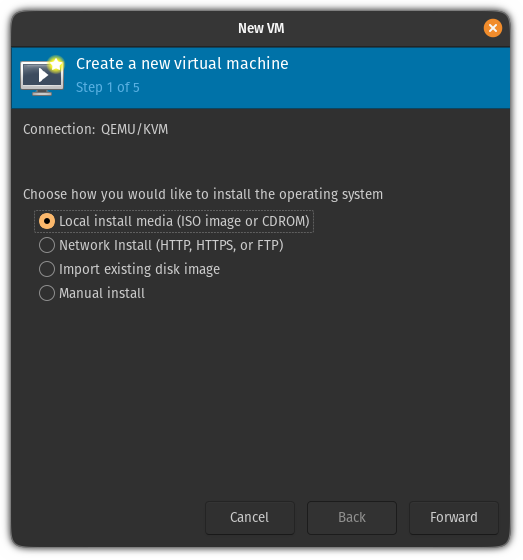
Next, you will be asked to add the ISO file. Here, **click on the Browse button; it** will open a new prompt, and there, **click on the browse local.**
It will open the file manager and from there, select the ISO file:
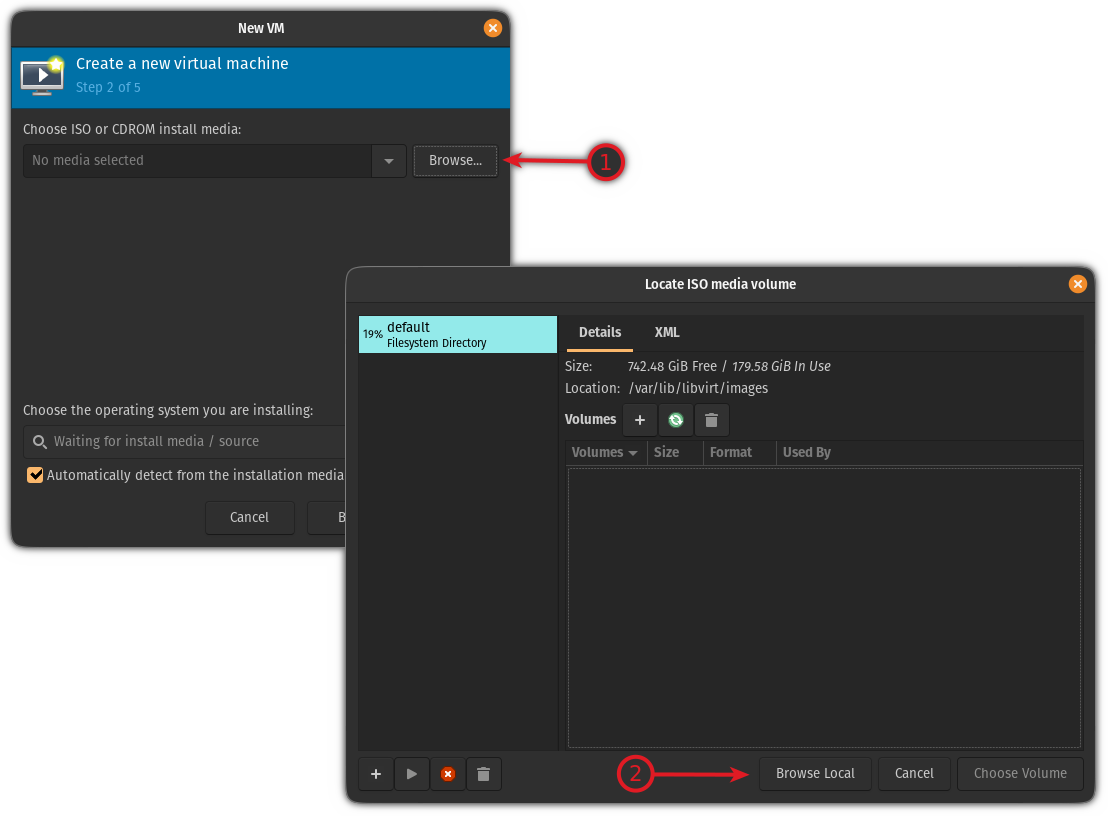
**In most cases, the ISO file will be detected but if you find a situation where it does not detect it automatically, follow the given steps:**
- Uncheck the Automatically detect from the source option
- Choose the
`Generic Linux`
option
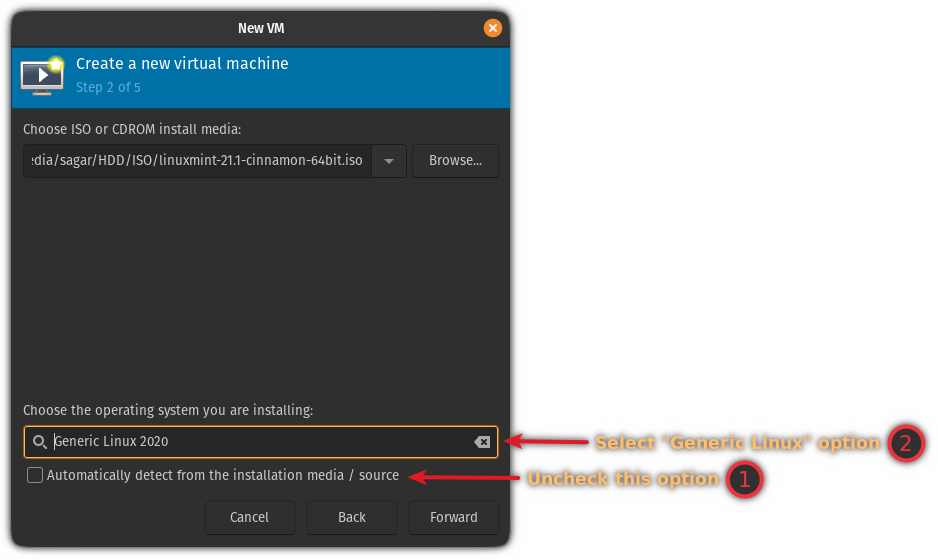
Next, you will be asked to allocate memory and storage as per your needs. I would recommend going with a minimum of 2 cores, 4 GB of RAM, and 25 GB of storage for the desktop version:
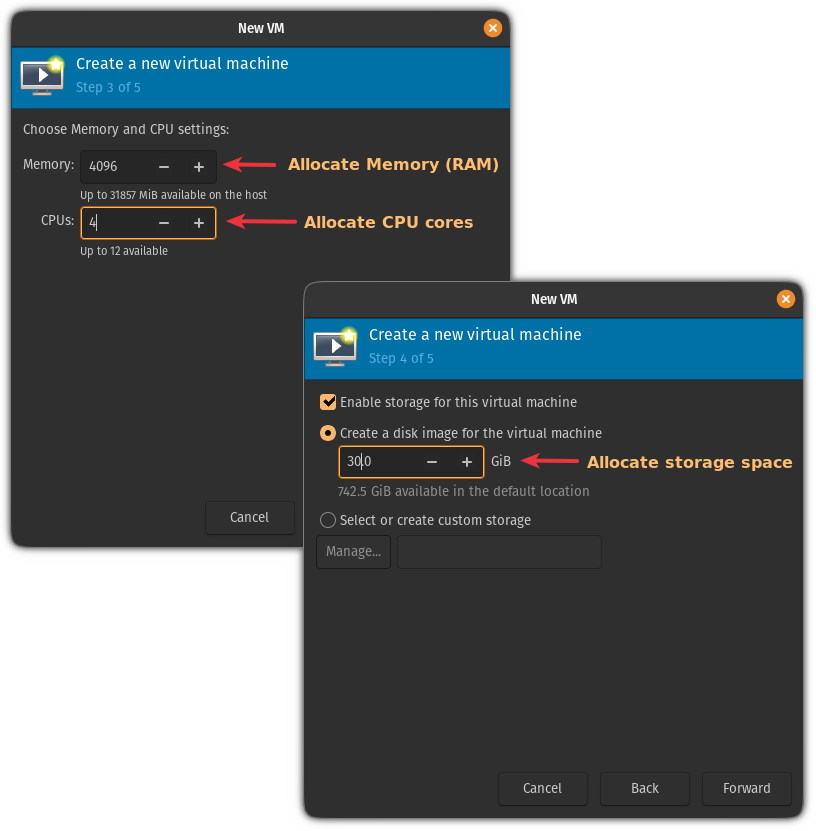
And finally, give the appropriate name to your VM; once done, click on the finish button:
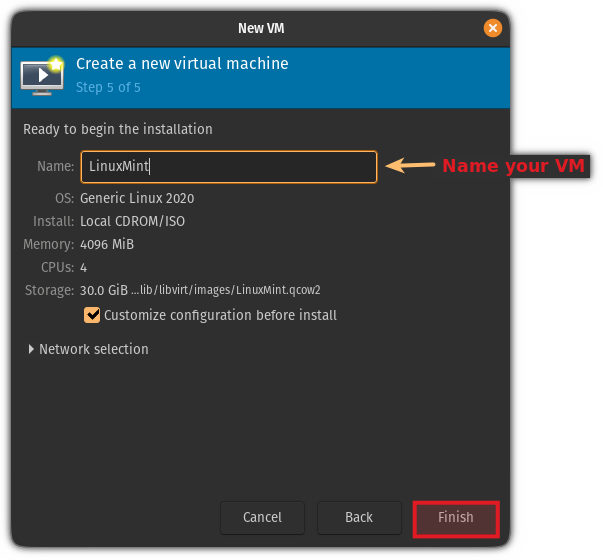
It will load the ISO, so you can start the installation from here.
That's done. You may enjoy your VM but you'll even enjoy it better if you enable shared folder, clipboard sharing, etc. The following few sections show how to do that.
## Enabling shared folders in Qemu (optional)
In this section, I will show you how you can share the existing directory of the host machine with the VM.
To do so, you'd have to perform the following:
- Adding a shared filesystem through VM settings in Qemu
- Mounting the FS in the VM
So first, open the Virtual Machine Manager from the system menu, select the VM, and click the `Open`
button to manage the console:
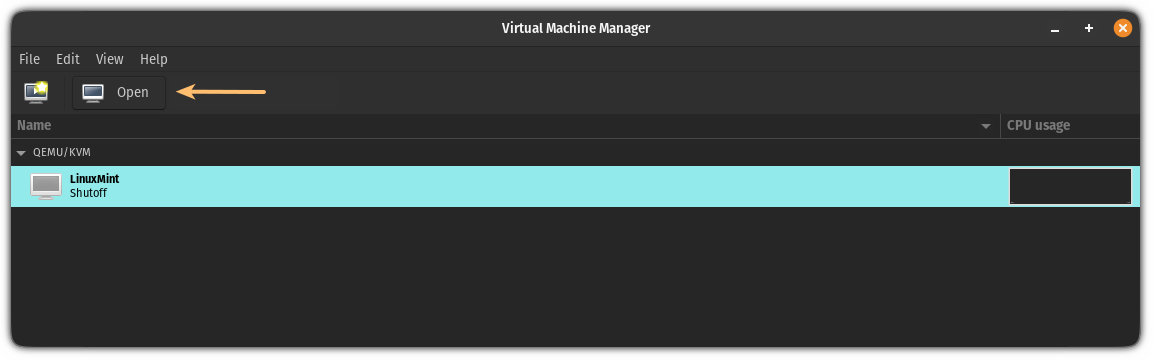
Now, click on the info button, select the `Memory`
and enable the shared memory:
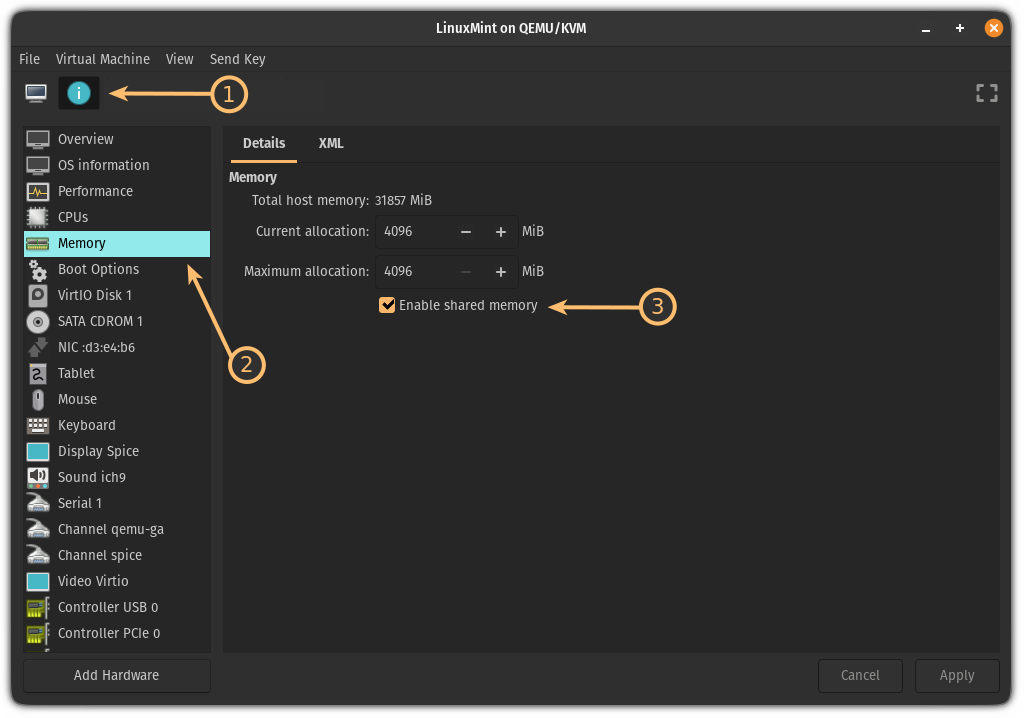
Next, click on the `Add Hardware`
button, select the `Filesystem`
option.
Here, you'd have to do the following:
- Add a path to the directory you want to share in the
`Source path`
section - Add the name of the directory in the
`Target path`
section
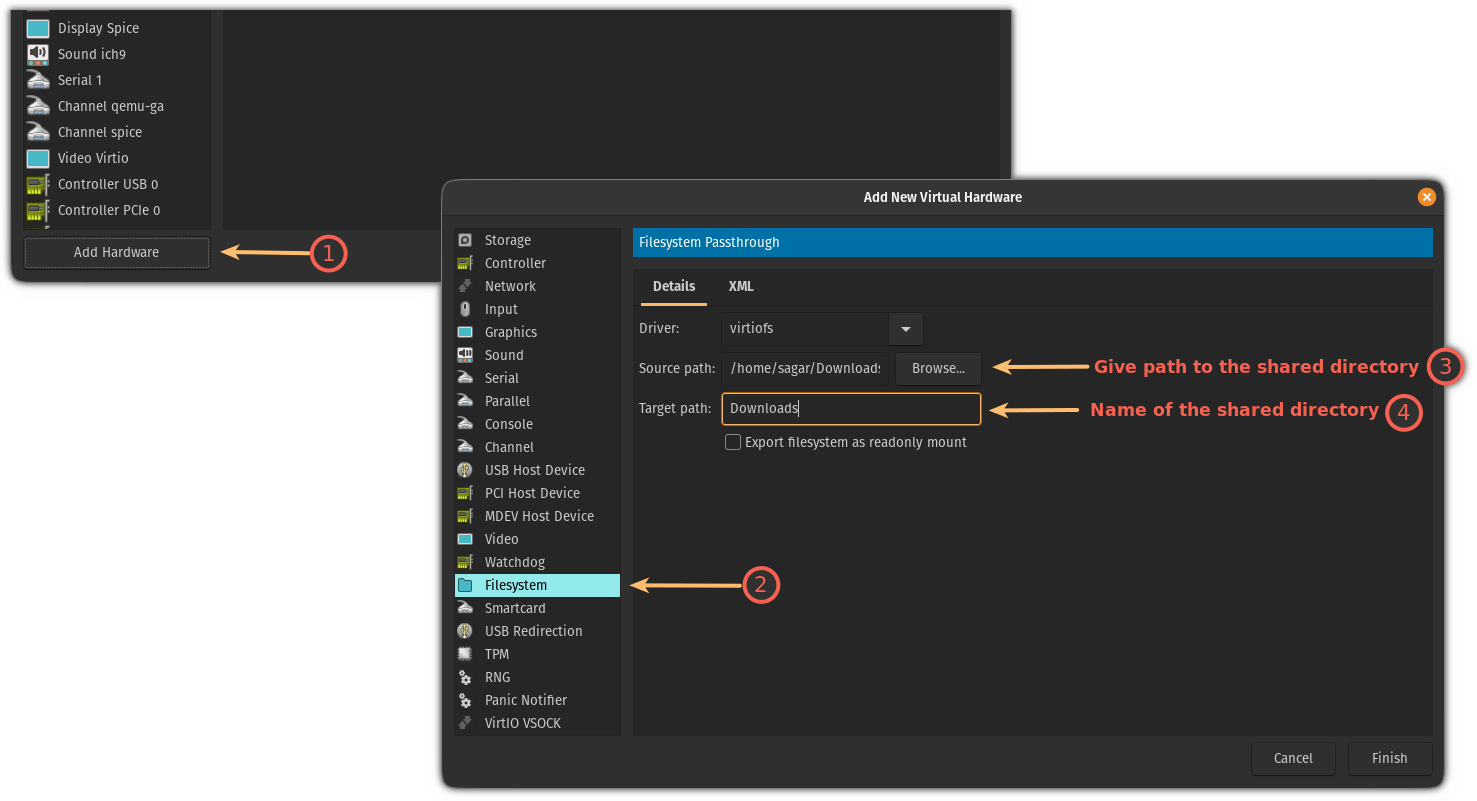
Once done, click on the Finish button and start the VM. [Create a directory](https://itsfoss.com/make-directories/) in the same location with the same name and location in the VM
In VM, open the terminal and use the following syntax to mount the shared directory:
`sudo mount -t virtiofs sharename path/to/shared/directory`
In my case, it was the `Downloads`
directory, so I will be using the following:
`sudo mount -t virtiofs Downloads /home/sagar/Downloads`

That's it!
**But that's a temporary solution.**
To make it permanent, you'd have to make create an entry in `/etc/fstab`
In the VM.
To do so, first, open the `/etc/fstab`
config file using the following:
`sudo nano /etc/fstab`
[Go to the end of the file in the nano text editor](https://linuxhandbook.com/beginning-end-file-nano/) using `Alt + /`
and use the following syntax to create an entry:
`sharename path/to/shared/directory virtiofs defaults 0 0`
Here's what my config looks like:
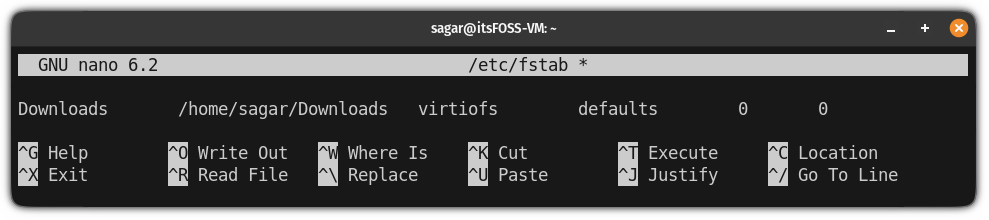
Once done, [save changes and exit from the nano](https://linuxhandbook.com/nano-save-exit/) text editor.
Here I've shown how I created a new file in my host machine in the `Downloads`
directory and the changes were reflected in my VM:
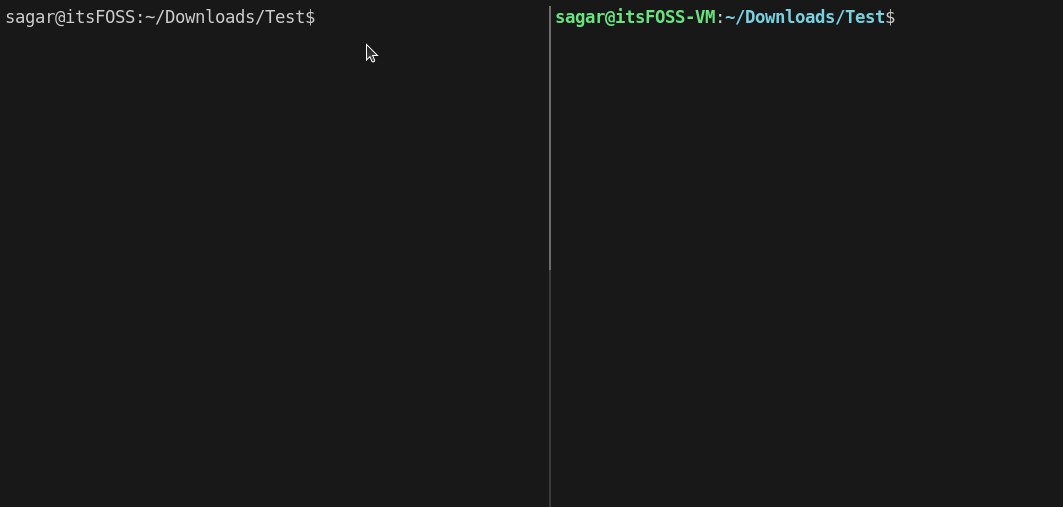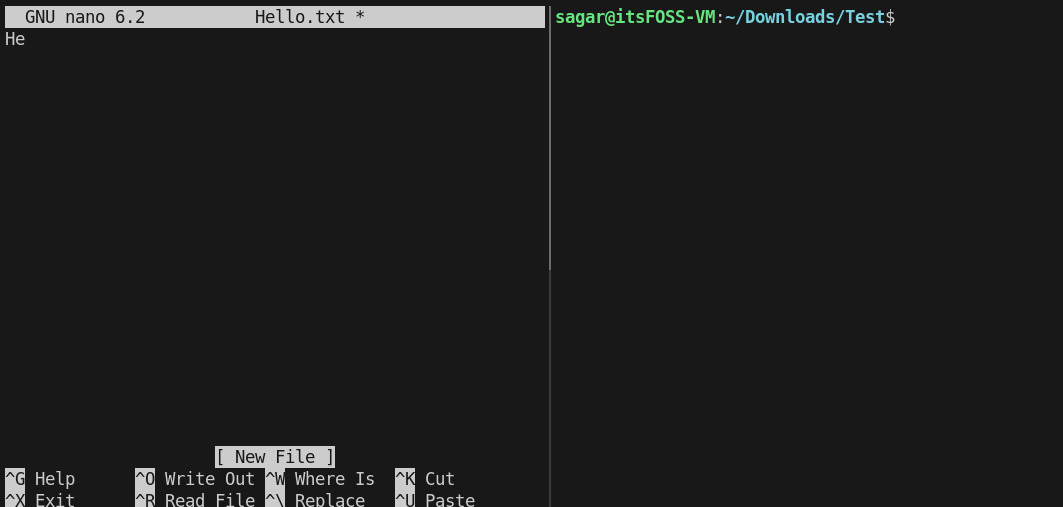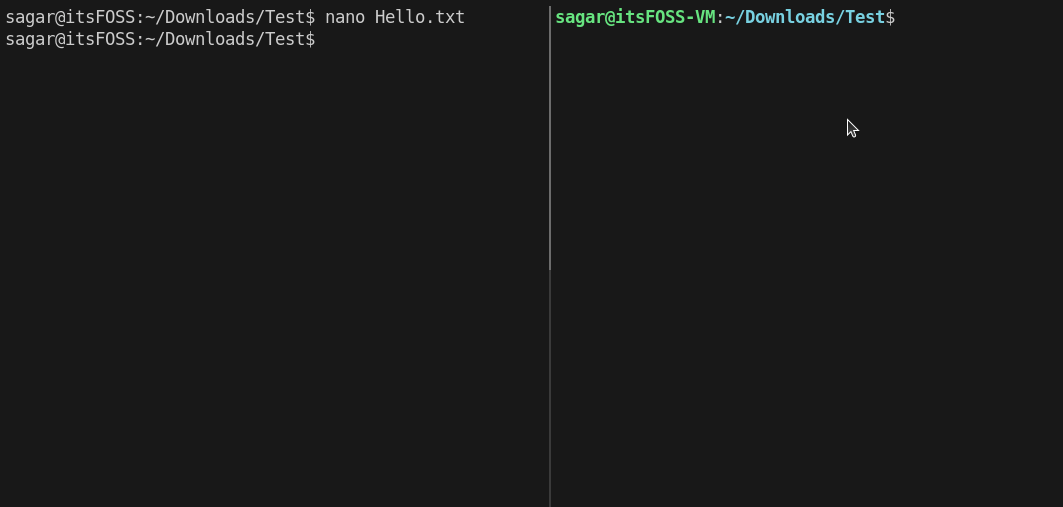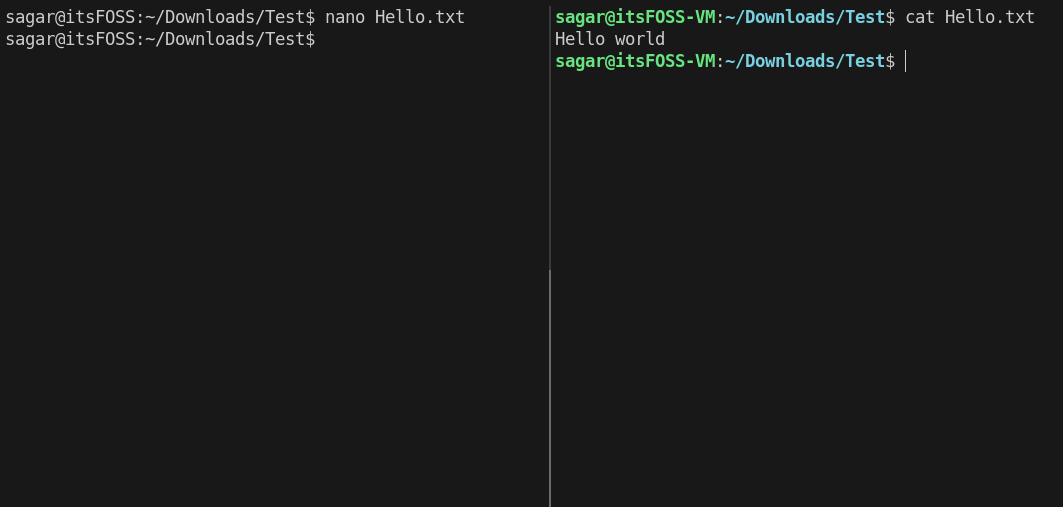
So now you can use this shared folder to transfer files between the host and VM without any issues!
## Enabling shared clipboard in Qemu (optional)
To enable the shared clipboard, all you have to do is install the `spice-vdagent`
utility in the VM.
So if your VM is Ubuntu/Debian based, you can use the following:
`sudo apt install spice-vdagent`
For Arch base:
`sudo pacman -S spice-vdagent`
For Fedora-based distros:
`sudo yum install spice-vdagent`
Once you are done with the installation, **reboot your VM**, and the clipboard should work as intended!
## Enabling auto-resize in Qemu (optional)
The auto-resize feature is nothing but when you resize the VM window, the VM display will adapt to the change in size immediately:
To enable the auto-resize in Qemu, you will have to follow 2 simple steps:
- Click on the
`View`
(from top menubar) - Select the
`Scale Display`
option and choose the`Always`
option

That's it from my side.
## Want to use a plug-and-play version of Qemu?
In this tutorial, I went through how you can manually install a VM in Qemu but what if I tell you that you can automate the whole process, like allocating storage, RAM, etc?
Yes, it gives the same efficiency but comes in handy when you want to create a new VM ASAP! The tool is called Quickgui and we have a dedicated tutorial for the installation:
[Create Virtual Machines Easily With QEMU-based QuickguiQuickgui aims to be a simpler alternative to VirtualBox and help create virtual machines quickly. Let us take a look at it.](https://itsfoss.com/quickgui/)

I hope you will find this guide helpful. And if you have any queries, feel free to ask in the comments. |
15,835 | Pano 剪贴板管理器是你需要的一个很棒的 GNOME 扩展 | https://news.itsfoss.com/pano-clipboard-manager/ | 2023-05-22T15:23:19 | [
"剪贴板"
] | https://linux.cn/article-15835-1.html |
>
> 一个灵巧的剪贴板管理器,提供视觉丰富的界面和有价值的选项。
>
>
>

你知道,有一种比 `Ctrl+C`/`Ctrl-V` 更好的方法来处理剪贴板文本。不,我不是在谈论使用右键单击菜单。
我是指使用一个**合适的剪贴板管理器**。而且,不仅仅是一个普通的剪贴板管理器,而是一个非常有用的东西。如果你喜欢,我相信它将成为 [Linux 上必不可少的应用程序](https://itsfoss.com/essential-linux-applications/?ref=news.itsfoss.com) 之一。
认识 Pano 剪贴板管理器。让我告诉你它能做什么。
### Pano 剪贴板管理器:概述 ⭐

Pano 是一个**易于使用且高度可定制的剪贴板应用**,它在一个非常紧凑的包中提供了一些很好的实用程序(以 GNOME 扩展的形式)。
它可以让你存储任何东西,从文本和表情符号,一直到颜色。
正如你在上面看到的,**复制的内容根据其类型进行分类,并在界面中整齐排列。**
除此之外,当你复制某些内容时,它会显示一个漂亮的通知,其中包含复制内容的简短预览。

该扩展**最近进行了更新**,进行了全面的视觉改造,并重新设计了托盘图标、占位符图像等。
你现在可以在配置菜单中调整 Pano 的高度,以及自定义背景颜色和不透明度、调整内容类型、字体大小等。

但是,当我的同事 Shivam 试用 Pano 时,他发现它**还会将密码从 Bitwarden** 复制到剪贴板。
我必须说,这是 Pano 的一个失误。它应该有排除特定应用的选项,如密码管理器。尽管如此,你应该是安全的,因为它没有云同步连接。
除此之外,这里有一些快捷方式可以在使用 Pano 时派上用场:
* 使用 `super+shift+V` 来切换 Pano。
* 使用 `ctrl+super+shift+V` 来进入隐身模式,以处理那些隐私剪贴板文本。
* 使用 `←` 和 `→` 箭头键在项目之间导航。
* 使用 `↑` 和 `↓` 箭头键将焦点放在搜索框和项目上。
* 使用 `Ctrl+S` 将处于输入焦点的项目添加到收藏夹。
对于更多这样的快捷方式,你可以参考它的 [GitHub 仓库](https://github.com/oae/gnome-shell-pano?ref=news.itsfoss.com)。
让我们继续。
Linux 和 GNOME 有类似的应用可以提供此类功能,比如 [CopyQ](https://itsfoss.com/copyq-clipboard-manager/?ref=news.itsfoss.com)。
但 Pano 提供的功能**有点不同**,尤其是在如此紧凑的包中。
### ? 获取 Pano 剪贴板管理器
你可以从 [Gnome 扩展网站](https://extensions.gnome.org/extension/5278/pano/?ref=news.itsfoss.com) 获取 Pano,或单击下面的下载按钮获取它:
>
> **[Pano 剪贴板管理器](https://extensions.gnome.org/extension/5278/pano/?ref=news.itsfoss.com)**
>
>
>
请记住,它需要两个依赖项,[libgda](https://gitlab.gnome.org/GNOME/libgda?ref=news.itsfoss.com) 和 [gsound](https://wiki.gnome.org/Projects/GSound?ref=news.itsfoss.com) 才能工作,这可以使用以下命令完成:
```
sudo apt install gir1.2-gda-5.0 gir1.2-gsound-1.0
```
你还可以参考我们关于 [使用 GNOME 扩展](https://itsfoss.com/best-gnome-extensions/?ref=news.itsfoss.com) 的指南来启用它。
---
via: <https://news.itsfoss.com/pano-clipboard-manager/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You know, there's a better way to handle clipboard text than just Ctrl+C/Ctrl-V. No, I am not talking about using the right-click menu, either.
But using a **proper clipboard manager** instead. And, not just any clipboard manager, something incredibly useful. I am sure it would become one of the [essential apps to have on Linux](https://itsfoss.com/essential-linux-applications/?ref=news.itsfoss.com) if you like it.
Meet Pano Clipboard Manager. Let me show you what it can do.
## Pano Clipboard Manager: Overview ⭐
Pano is an **easy-to-use and highly customizable clipboard app** that offers some good utility in a very compact package (in the form of a GNOME extension).
It lets you store anything, starting from text, and emoji, all the way to colors.
As you can see above, the **copied content is categorized according to its type and arranged neatly in its interface.**
In addition to that, when you copy something, it shows a nice little notification with a short preview of the copied content.
The extension was **recently updated** with a complete visual overhaul and redesigned tray icons, placeholder images, and more.
You can now adjust the height of Pano, as well as customize the background color, and opacity, tweak content types, font size, etc., in the configuration menu.
But, when my colleague Shivam tried out Pano, he discovered it **would also copy passwords from Bitwarden** to the clipboard.
I must say, that is an oopsie on Pano's part. It should have the option to exclude specific applications, such as password manager. Nevertheless, you should be safe because it has no cloud sync connection.
Other than that, here are a few shortcuts that can come in handy while using Pano:
- Use 'super' + 'shift' + 'V' to toggle Pano.
- Use 'Ctrl' + 'super' + 'shift' + 'V' to enter incognito mode for those spicy clipboard texts.
- Use the left and right arrow keys to navigate between items.
- Use the up and down arrow keys to focus on the search box and items.
- Use 'Ctrl' + 'S' to add a focused item to favorites.
For more shortcuts like this, you can refer to its [GitHub repo](https://github.com/oae/gnome-shell-pano?ref=news.itsfoss.com).
So, moving on.
There are similar apps available for Linux and GNOME that offer such functionality; take, for example, [CopyQ](https://itsfoss.com/copyq-clipboard-manager/?ref=news.itsfoss.com).
But Pano is a **bit different in what it offers**, especially in such a compact package.
**Suggested Read **📖
[CopyQ Clipboard Manager for Keeping a Track of Clipboard HistoryHow do you copy-paste text? Let me guess. You either use the right click menu to copy-paste or use Ctrl+C to copy a text and Ctrl+V to paste the text. The text copied this way is saved to ‘clipboard’. The clipboard is a special location in the memory](https://itsfoss.com/copyq-clipboard-manager/?ref=news.itsfoss.com)

## 📥 Get Pano Clipboard Manager
You can get Pano from the Gnome Extensions [site](https://extensions.gnome.org/extension/5278/pano/?ref=news.itsfoss.com), or click on the download button below to get it:
Do keep in mind that it requires two dependencies, '[libgda](https://gitlab.gnome.org/GNOME/libgda?ref=news.itsfoss.com)' and '[gsound](https://wiki.gnome.org/Projects/GSound?ref=news.itsfoss.com)' to work, which can be done using the following command:
`sudo apt install gir1.2-gda-5.0 gir1.2-gsound-1.0`
You can also refer to our guide on [using GNOME extensions](https://itsfoss.com/best-gnome-extensions/?ref=news.itsfoss.com) to enable it.
**Suggested Read **📖
[Top 20 GNOME Extensions to Enhance Your ExperienceYou can enhance the capacity of your GNOME desktop with extensions. Here, we list the best GNOME shell extensions to save you the trouble of finding them on your own.](https://itsfoss.com/best-gnome-extensions/?ref=news.itsfoss.com)

## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,837 | Rust 基础系列 #4: Rust 中的数组和元组 | https://itsfoss.com/rust-arrays-tuples/ | 2023-05-23T16:57:19 | [
"Rust"
] | https://linux.cn/article-15837-1.html | 
>
> 在 Rust 系列的第四篇中,学习复合数据类型、数组和元组。
>
>
>
在上一篇文章中,你学习到了 Rust 中的 [标量数据类型](/article-15811-1.html)。它们是整型、浮点数、字符和布尔值。
在本文中,我们将会看看 Rust 编程语言中的复合数据类型。
### Rust 中的复合数据类型是什么?
复合数据类型可以在一个变量中存储多个值。这些值可以是相同的标量数据类型,也可以是不同的标量数据类型。
Rust 编程语言中有两种这样的数据类型:
* <ruby> 数组 <rt> Array </rt></ruby>:存储相同类型的多个值。
* <ruby> 元组 <rt> Tuple </rt></ruby>:存储多个值,可以是相同的类型,也可以是不同的类型。
让我们了解一下它们吧!
### Rust 中的数组
Rust 编程语言中的数组具有以下特性:
* 每一个元素都必须是相同的类型
* 数组有一个固定的长度
* 数组存储在堆栈中,即其中存储的数据可以被 *迅速* 访问
创建数组的语法如下:
```
// 无类型声明
let variable_name = [element1, element2, ..., elementn];
// 有类型声明
let variable_name: [data_type; array_length] = [element1, element2, ..., elementn];
```
数组中的元素是在方括号中声明的。要访问数组的元素,需要在方括号中指定要访问的索引。
来让我们看一个例子来更好地理解这个。
```
fn main() {
// 无类型声明
let greeting = ['H', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!'];
// 有类型声明
let pi: [i32; 10] = [1, 4, 1, 5, 9, 2, 6, 5, 3, 5];
for character in greeting {
print!("{}", character);
}
println!("\nPi: 3.1{}{}{}{}", pi[0], pi[1], pi[2], pi[3]);
}
```
这里,我定义了一个字符数组和另一个存储 `i32` 类型的值的数组。`greeting` 数组以单独字符的形式存储了字符串 `"Hello world!"` 的字符。`pi` 数组以单独数字的形式存储了圆周率小数点后的前 10 位数字。
然后,我使用 `for` 循环打印了 `greeting` 数组的每个字符。(我很快就会讲到循环。)然后,我打印了 `pi` 数组的前 4 个值。
```
Hello world!
Pi: 3.11415
```
如果你想创建一个数组,其中每个元素都是 *y*,并且出现 *x* 次,你可以使用以下快捷方式在 Rust 中实现:
```
let variable_name = [y; x];
```
来看一个演示……
```
fn main() {
let a = [10; 5];
for i in a {
print!("{i} ");
}
println!("");
}
```
我创建了一个变量 `a`,它的长度为 5。数组中的每个元素都是 '10'。我通过使用 `for` 循环打印数组的每个元素来验证这一点。
它的输出如下:
```
10 10 10 10 10
```
>
> ? 作为练习,尝试创建一个长度为 *x* 的数组,然后尝试访问数组的第 *x+1* 个元素。看看会发生什么。
>
>
>
### Rust 中的元组
Rust 中的元组具有以下特性:
* 就像数组一样,元组的长度是固定的
* 元素可以是相同的/不同的标量数据类型
* 元组存储在堆栈中,所以访问速度更快
创建元组的语法如下:
```
// 无类型声明
let variable_name = (element1, element2, ..., element3);
// 有类型声明
let variable_name: (data_type, ..., data_type) = (element1, element2, ..., element3);
```
元组的元素写在圆括号中。要访问元素,使用点运算符,后跟该元素的索引。
```
fn main() {
let a = (38, 923.329, true);
let b: (char, i32, f64, bool) = ('r', 43, 3.14, false);
println!("a.0: {}, a.1: {}, a.2: {}", a.0, a.1, a.2);
println!("b.0: {}, b.1: {}, b.2: {}, b.3: {}", b.0, b.1, b.2, b.3);
// 元组解构
let pixel = (50, 0, 200);
let (red, green, blue) = pixel;
println!("red: {}, green: {}, blue: {}", red, green, blue);
}
```
在上面的代码中,我在第 2 行和第 3 行声明了两个元组。它们只包含我当时想到的随机值。但是仔细看,两个元组中每个元素的数据类型都不同。然后,在第 5 行和第 6 行,我打印了两个元组的每个元素。
在第 9 行,我声明了一个名为 `pixel` 的元组,它有 3 个元素。每个元素都是组成像素的颜色红色、绿色和蓝色的亮度值。这个范围是从 0 到 255。所以,理想情况下,我会声明类型为 `(u8, u8, u8)`,但是在学习代码时不需要这样优化 ; )
然后,在第 10 行,我“解构”了 `pixel` 元组的每个值,并将其存储在单独的变量 `red`、`green` 和 `blue` 中。然后,我打印了 `red`、`green` 和 `blue` 变量的值,而不是 `pixel` 元组的值。
让我们看看输出……
```
a.0: 38, a.1: 923.329, a.2: true
b.0: r, b.1: 43, b.2: 3.14, b.3: false
red: 50, green: 0, blue: 200
```
看起来不错 : )
### 额外内容:切片
准确的来说,<ruby> 切片 <rt> Slice </rt></ruby> 不是 Rust 中的复合数据类型。相反,切片是现有复合数据类型的 “切片”。
一个切片由三个元素组成:
* 一个初始索引
* 切片运算符(`..` 或 `..=`)
* 一个结束索引
接下来是数组切片的一个示例:
```
fn main() {
let my_array = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
let my_slice = &my_array[0..4];
for element in my_slice {
println!("{element}");
}
}
```
就像 C 和 C++ 一样,`&` 用于存储变量的引用(而不是原始指针)。所以 `&my_array` 意味着对变量 `my_array` 的引用。
然后,来看看切片。切片由 `[0..4]` 表示。这里,`0` 是切片开始的索引。而 `4` 是切片结束的索引。这里的 4 是一个非包含索引。
这是程序输出,以更好地理解正在发生的事情:
```
0
1
2
3
```
如果你想要一个 *包含* 范围,你可以使用 `..=` 作为包含范围的切片运算符。
```
fn main() {
let my_array = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
let my_slice = &my_array[0..=4];
for element in my_slice {
println!("{element}");
}
}
```
现在,这个范围是从第 0 个元素到第 4 个元素,下面是输出来证明这一点:
```
0
1
2
3
4
```
### 总结
本文讲到了 Rust 编程语言中的复合数据类型。你学习了如何声明和访问存储在数组和元组类型中的值。此外,你还了解了切片“类型”,以及如何解构元组。
在下一章中,你将学习如何在 Rust 程序中使用函数。敬请关注。
*(题图:MJ/22a0d143-2216-439f-8e1d-abd94cdfdbd0)*
---
via: <https://itsfoss.com/rust-arrays-tuples/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Rust Basics Series #4: Arrays and Tuples in Rust
In the fourth chapter of the Rust series, learn about compound data types, Arrays and Tuples.
In the previous post, you learned about the [Scalar data types in Rust](https://itsfoss.com/rust-data-types/). They are integers, floating points, characters and booleans.
In this article, we shall look at the Compound data types in the Rust programming language.
## What is compound data type in Rust?
Compound data types consist can store multiple values in a variable. These values may either be of the same scalar data type, or maybe of different scalar types.
The Rust programming language has two such data types:
**Arrays**: Stores multiple values of the same type.**Tuples**: Stores multiple values, either of the same type or even of different types.
So let's look at them!
## Arrays in Rust
Arrays in the Rust programming language have the following properties:
- Every element must have the same type
- Arrays have a fixed length
- Arrays are stored in the stack i.e., data stored in it can be accessed
*swiftly*
The syntax to create an array is as follows:
```
// without type annotation
let variable_name = [element1, element2, ..., elementn];
// with type annotation
let variable_name: [data_type; array_length] = [element1, element2, ..., elementn];
```
The elements of an array are declared inside square brackets. To access an element of an array, the index to be accessed is specified inside square brackets.
Let's look at an example program to understand this better.
```
fn main() {
// without type annotation
let greeting = ['H', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!'];
// with type annotation
let pi: [i32; 10] = [1, 4, 1, 5, 9, 2, 6, 5, 3, 5];
for character in greeting {
print!("{}", character);
}
println!("\nPi: 3.1{}{}{}{}", pi[0], pi[1], pi[2], pi[3]);
}
```
Here, I define one character array and another array that stores `i32`
types in it. The `greeting`
array has the characters of the string "Hello world!" stored in it as individual characters. The array `pi`
has the first 10 values of Pi after the decimal values stored in it as individual numbers.
I then print every character of the `greeting`
array using the `for`
loop. (I will get into loops very soon.) Then, I print the first 4 values of the `pi`
array.
```
Hello world!
Pi: 3.11415
```
If you wish to create an array where every element is *y* and occours *x* number of times, you can do this in Rust with the following shortcut:
`let variable_name = [y; x];`
Let's look at a demonstration...
```
fn main() {
let a = [10; 5];
for i in a {
print!("{i} ");
}
println!("");
}
```
I create a variable `a`
which will be of length 5. Each element in that array will be '10'. I verify this by printing every element of the array using the `for`
loop.
It has the following output:
`10 10 10 10 10`
*and access the*
*x*
*x+1**element of the array. See what happens.*
*st*## Tuples in Rust
A Tuple in the Rust programming language has the following properties:
- Tuples, like Arrays have a fixed length
- Elements can be of same/different Scalar data types
- The Tuple is stored on the stack i.e. faster access
The syntax to create a tuple is as following:
```
// without type annotation
let variable_name = (element1, element2, ..., element3);
// with type annotation
let variable_name: (data_type, ..., data_type) = (element1, element2, ..., element3);
```
The elements of a tuple are written inside the round brackets. To access an element, the dot operator is used and is followed by the index of said element.
```
fn main() {
let a = (38, 923.329, true);
let b: (char, i32, f64, bool) = ('r', 43, 3.14, false);
println!("a.0: {}, a.1: {}, a.2: {}", a.0, a.1, a.2);
println!("b.0: {}, b.1: {}, b.2: {}, b.3: {}", b.0, b.1, b.2, b.3);
// destructuring a tuple
let pixel = (50, 0, 200);
let (red, green, blue) = pixel;
println!("red: {}, green: {}, blue: {}", red, green, blue);
}
```
In the above code, on line 2 and 3 I declare two tuples. These just contain random values that I made up on the spot. But look closely, the data type of each element in both tuples is different. Then, on line 5 and 6, I print each element of both tuples.
On line 9, I declare a tuple called `pixel`
which has 3 elements. Each element is the magnitude of colors red, green and blue to make up a pixel. This ranges from 0 to 255. So, ideally, I would annotate the type to be `(u8, u8, u8)`
but that optimization is not required when learning ;)
Then, on line 10, I "de-structure" each value of the `pixel`
tuple and store it in individual variables `red`
, `green`
and `blue`
. Then, instead of printing the values of the `pixel`
tuple, I print the values of the `red`
, `green`
and `blue`
variables.
Let's see the output...
```
a.0: 38, a.1: 923.329, a.2: true
b.0: r, b.1: 43, b.2: 3.14, b.3: false
red: 50, green: 0, blue: 200
```
Looks good to me :)
## Bonus: Slices
Strictly speaking, slices aren't a type of compound data type in Rust. Rather, a slice is... a *slice* of an existing compound data type.
A slice consists of three elements:
- A starting index
- The slice operator (
`..`
or`..=`
) - An ending index
Following is an example of using a slice of an Array.
```
fn main() {
let my_array = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
let my_slice = &my_array[0..4];
for element in my_slice {
println!("{element}");
}
}
```
Like C and C++, the ampersand is used to store the reference (instead of a raw pointer) of a variable. So `&my_array`
means a reference to the variable `my_array`
.
Now, coming to the slice. The slice is denoted by the `[0..4]`
. Here, `0`
is the index of where to start the slice. And `4`
is where the slice ends. The 4 here is a non-inclusive index.
Following is the program output to better understand what is happening:
```
0
1
2
3
```
If you want an *inclusive* range, you can instead use `..=`
as the slice operator for an inclusive range.
```
fn main() {
let my_array = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
let my_slice = &my_array[0..=4];
for element in my_slice {
println!("{element}");
}
}
```
Now, this range is from the 0th element to the 4th element and below is the output to prove that:
```
0
1
2
3
4
```
## Conclusion
This article about the Rust programming language covers the compound data types in some depth. You learned to declare and access values stored in the Array and Tuple types. Additionally, you looked at the Slice "type" and also how to de-structure a tuple.
In the next chapter, you'll learn about using functions in Rust programs.
[Rust Basics Series #5: Functions in RustIn this chapter of the Rust Basics series, learn to use functions and return values from them with the help of examples.](https://itsfoss.com/rust-functions/)

Stay tuned. |
15,838 | 编程语言比较:C 和 Go | https://opensource.com/article/23/4/c-vs-go-programming-languages | 2023-05-23T18:20:10 | [
"Go 语言",
"C 语言"
] | https://linux.cn/article-15838-1.html | 
>
> 使用一个简单的计数程序比较古老的 C 语言和现代的 Go 语言。
>
>
>
Go 是一种现代编程语言,它很大程度上源自于 C 编程语言。因此,对于写 C 程序的程序员来说,Go 应该会感觉很熟悉。[Go 让编写新程序变得容易](https://opensource.com/article/17/6/getting-started-go),同时让 C 程序员感觉熟悉,但避免了 C 编程语言的许多常见陷阱。
本文比较了一个简单的 C 和 Go 程序,该程序将数字从一相加到十。由于这个程序只使用了小的数值,所以结果不会变得太大,因此只使用了普通的整数变量。像这样的循环在编程中非常常见,所以这个简单的程序很容易比较 C 和 Go。
### 如何在 C 中执行循环
C 语言中最基本的循环是 `for` 循环,它允许你对一组值进行迭代。`for` 循环的基本语法是:
```
for (起始条件 ; 结束条件 ; 每次迭代后执行的操作) { 循环内要执行的内容 ; }
```
你可以编写一个 `for` 循环,以打印从 1 到 10 的数字,将起始条件设置为 `count = 1`,将结束条件设置为 `count <= 10`。这样就以 `count` 变量等于 1 时开始循环。结束条件意味着只要 `count` 变量小于或等于 10 ,循环就会继续。
每次迭代之后,你使用 `count = count + 1` 将 `count` 变量的值增加 1。在循环内部,你可以使用 `printf` 打印 `count` 变量的值:
```
for (count = 1; count <= 10; count = count + 1) {
printf("%d\n", count);
}
```
C 程序中常见的惯例是 `++`,它表示 “将某个值加一”。如果你写 `count++`,那就相当于 `count = count + 1`。大多数 C 程序员会使用 `count++` 来编写 `for` 循环中每次迭代后要执行的操作,像这样:
```
for (count = 1; count <= 10; count++) {
printf("%d\n", count);
}
```
这是一个示例程序,将从 1 到 10 的数字相加,然后打印结果。使用 `for` 循环对数字进行迭代,但不要打印数字,而是将数字添加到 `sum` 变量中:
```
#include <stdio.h>
int main() {
int sum;
int count;
puts("adding 1 to 10 ..");
sum = 0;
for (count = 1; count <= 10; count++) {
sum = sum + count;
}
```
这个程序使用了两个不同的 C 函数来向用户打印结果。`puts` 函数打印引号中的字符串。如果你需要打印纯文本,使用 `puts` 是个不错的选择。
`printf` [函数](https://www.redhat.com/sysadmin/command-basics-printf?intcmp=7013a000002qLH8AAM) 使用特殊字符在格式字符串中打印格式化的输出。`printf` 函数可以打印许多不同种类的值。关键字 `%d` 打印十进制(整数)值。
如果你编译并运行这个程序,你会看到这个输出:
```
adding 1 to 10 ..
The sum is 55
```
### 如何在 Go 中执行循环
Go 提供了与 C 中非常相似的 `for` 循环。C 程序中的 `for` 循环可以直接转换为 Go 的 `for` 循环,并具有相似的表示形式:
```
for count = 1; count <= 10; count++ {
fmt.Printf("%d\n", count)
}
```
使用这个循环,你可以直接转换为 Go 的示例程序:
```
package main
import "fmt"
func main() {
var sum, count int
fmt.Println("adding 1 to 10 ..")
for count = 1; count <= 10; count++ {
sum = sum + count
}
fmt.Printf("The sum is %d\n", sum)
}
```
虽然上述方式在 Go 中是正确的,但它并不是最常用的 Go 写法。采用惯例是“使用与本地语言为人所知的表达方式”。任何语言的目标都是高效的沟通,编程语言也不例外。在不同的编程语言之间进行转换时,重要的是意识到尽管物似而意不同,一种编程语言中的典型写法在另一种编程语言中可能不完全相同。
为使用更符合惯例的 Go,你可以进行几个小修改:
* 通过使用 `+=` 操作符来将 `sum = sum + count` 更简洁地表达为 `sum += count`。
* 通过使用 [分配并推断类型运算符](https://go.dev/ref/spec#Short_variable_declarations) 来表达 `count := 1` 而不是 `var count int` 跟着 `count = 1`。`:=` 语法同时定义并初始化 `count` 变量。
* 将 `count` 的声明移到 `for` 循环的头中。这减少了一些认知负担,也通过减少程序员在任何时候都必须心里记着的变量数目来提高可读性。这个更改还通过在最接近其使用的地方和最小的范围中声明变量来增加安全性,从而减少了在代码不断演进的过程中对变量进行意外操作的可能性。
上述改动的组合将产生以下代码:
```
package main
import "fmt"
func main() {
fmt.Println("adding 1 to 10 ..")
var sum int
for count := 1; count <= 10; count++ {
sum += count
}
fmt.Printf("The sum is %d\n", sum)
}
```
你可以使用这个 Go.dev 的 [链接](https://go.dev/play/p/pt5mfRDR0rh) 在 Go 试验场中尝试这个示例程序。
### C 和 Go 相似但不同
通过在两种编程语言中编写相同的程序,你可以看到 C 和 Go 这两种语言虽然相似但仍然不同。将从 C 转换到 Go 时需要注意以下几点:
* 在 C 中,每个程序指令都必须以分号结尾。这告诉编译器一个语句在哪里结束,下一个在哪里开始。在 Go 中,分号是有效的,但几乎总是可以推断出来。
* 虽然大多数现代 C 编译器会为你将变量初始化为零值,但 C 语言规范指出,变量得到的是内存中的任意值。Go 值总是初始化为其零值。这有助于使 Go 成为一种更具内存安全的语言。这种差异在使用指针时变得更加有趣。
* 注意 Go 程序包对导入标识符的使用方式。例如,`fmt` 是一个实现格式化输入和输出的函数,类似于 C 中的 `stdio.h` 中的 `printf` 和 `scanf`。`fmt` 程序包在 [pkg.go.dev/fmt](https://pkg.go.dev/fmt) 中有文档描述。
* 在 Go 中,`main` 函数总是以退出代码 0 返回。如果你希望返回其他值,你必须调用 `os.Exit(n)`,其中 `n` 通常为 1 以表示错误。这可以从任何地方调用,不仅仅是 `main` 函数,来终止程序。你可以在 C 中使用在 `stdlib.h` 中定义的 `exit(n)` 函数来实现相同的效果。
*(题图:MJ/8f731484-2dc3-4bac-b895-cbc92a63b48b)*
---
via: <https://opensource.com/article/23/4/c-vs-go-programming-languages>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Go is a modern programming language that derives much of its history from the C programming language. As such, Go is likely to feel familiar to anyone who writes programs in C. [Go makes it easy to write new programs](https://opensource.com/article/17/6/getting-started-go) while feeling familiar to C programmers but avoiding many of the common pitfalls of the C programming language.
This article compares a simple C and Go program that adds the numbers from one to ten. Because this program uses only small values, the numbers won't grow to be too big, so they only use plain integer variables. Loops like this are very common in programming, so this simple program makes it easy to compare C and Go.
## How to do loops in C
The basic loop in C is the `for`
loop, which allows you to iterate through a set of values. The basic syntax of the `for`
loop is:
for (
start condition;end condition;action after each iteration) {things to do inside the loop; }
You can write a `for`
loop that prints the numbers from one to ten by setting the starting condition to `count = 1`
and the ending condition to `count <= 10`
. That starts the loop with the `count`
variable equal to one. The ending condition means the loop continues as long as the `count`
variable is less than or equal to ten.
After each iteration, you use `count = count + 1`
to increment the value of the `count`
variable by one. Inside the loop, you can use `printf`
to print the value of the `count`
variable:
```
``````
for (count = 1; count <= 10; count = count + 1) {
printf("%d\n", count);
}
```
A common convention in C programming is `++`
, which means "add one to something." If you write `count++`
, that's the same as `count = count + 1`
. Most C programmers would use this to write the `for`
loop using `count++`
for the action after each iteration, like this:
```
``````
for (count = 1; count <= 10; count++) {
printf("%d\n", count);
}
```
Here's a sample program that adds the numbers from one to ten, then prints the result. Use the `for`
loop to iterate through the numbers, but instead of printing the number, add the numbers to the `sum`
variable:
```
``````
#include <stdio.h>
int main() {
int sum;
int count;
puts("adding 1 to 10 ..");
sum = 0;
for (count = 1; count <= 10; count++) {
sum = sum + count;
}
```
This program uses two different C functions to print results to the user. The `puts`
function prints a string that's inside quotes. If you need to print plain text, `puts`
is a good way to do it.
The `printf `
[function](https://www.redhat.com/sysadmin/command-basics-printf?intcmp=7013a000002qLH8AAM) prints formatted output using special characters in a format string. The `printf`
function can print lots of different kinds of values. The keyword `%d`
prints a decimal (or integer) value.
If you compile and run this program, you see this output:
```
``````
adding 1 to 10 ..
The sum is 55
```
## How to do loops in Go
Go provides `for`
loops that are very similar to C `for`
loops. The for loop from the C program can be directly translated to a Go `for`
loop with a similar representation:
```
``````
for count = 1; count <= 10; count++ {
fmt.Printf("%d\n", count)
}
```
With this loop, you can write a direct transition to Go of the sample program:
```
``````
package main
import "fmt"
func main() {
var sum, count int
fmt.Println("adding 1 to 10 ..")
for count = 1; count <= 10; count++ {
sum = sum + count
}
fmt.Printf("The sum is %d\n", sum)
}
```
While the above is certainly a valid and correct Go, it's not the most idiomatic Go. To be idiomatic is *to use expressions that are natural to a native speaker*. A goal of any language is effective communication, this includes programming languages. When transitioning between programming languages, it is also important to recognize that what is typical in one programming language may not be exactly so in another, despite any outward similarities.
To update the above program using the more idiomatic Go, you can make a couple of small modifications:
-
Use the
`+=`
*add-to-self*operator to write`sum = sum + count`
more succinctly as`sum += count`
. C can use this style, as well. -
Use the
[assign-and-infer-type operator](https://go.dev/ref/spec#Short_variable_declarations)to say`count := 1`
rather than`var count int`
followed by`count = 1`
. The`:=`
syntax both defines and initializes the count variable. -
Move the declaration of
`count`
into the`for`
loop header itself. This reduces a bit of cognitive overhead, and increases readability by reducing the number of variables the programmer must mentally account for at any time. This change also increases safety by declaring variables as close as possible to their use and in the smallest scope possible. This reduces the likelihood of accidental manipulation as the code evolves.
The combination of the changes described above results in:
```
``````
package main
import "fmt"
func main() {
fmt.Println("adding 1 to 10 ..")
var sum int
for count := 1; count <= 10; count++ {
sum += count
}
fmt.Printf("The sum is %d\n", sum)
}
```
You can experiment with this sample program in the Go playground [with this link to go.dev](https://go.dev/play/p/pt5mfRDR0rh).
## C and Go are similar, but different
By writing the same program in two programming languages, you can see that C and Go are similar, but different. Here are a few important tips to keep in mind when transitioning from C to Go:
-
In C, every programming instruction must end with a semicolon. This tells the compiler where one statement ends and the next one begins. In Go, semicolons are valid but almost always inferred.
-
While most modern C compilers initialize variables to a zero value for you, the C specification says that variables get whatever value was in memory at the time. Go values are always initialized to their zero value. This helps make Go a more memory safe language. This distinction becomes even more interesting with pointers.
-
Note the use of the Go package specifier on imported identifiers. For example,
`fmt`
for functions that implement formatted input and output, similar to C's`printf`
and`scanf`
from`stdio.h`
. The`fmt`
package is documented in[pkg.go.dev/fmt](https://pkg.go.dev/fmt). -
In Go, the
`main`
function always returns with an exit code of 0. If you wish to return some other value, you must call`os.Exit(n)`
where*n*is typically 1 to indicate an error. This can be called from anywhere, not just`main`
, to terminate the program. You can do the same in C using the`exit(n)`
function, defined in`stdlib.h`
.
## Comments are closed. |
15,840 | 如何在 RHEL 9 上配置 DHCP 服务器 | https://www.linuxtechi.com/configure-dhcp-server-on-rhel-rockylinux/ | 2023-05-24T11:38:00 | [
"DHCP"
] | https://linux.cn/article-15840-1.html | 
DHCP 是 “<ruby> 动态主机配置协议 <rt> Dynamic Host Configuration Protocol </rt></ruby>” 的首字母缩写词,它是一种网络协议,可自动为计算机网络中的客户端系统分配 IP 地址。它从 DHCP 池或在其配置中指定的 IP 地址范围分配客户端。虽然你可以手动为客户端系统分配静态 IP,但 DHCP 服务器简化了这一过程,并为网络上的客户端系统动态分配 IP 地址。
在本文中,我们将演示如何在 RHEL 9 / Rocky Linux 9 上安装和配置 DHCP 服务器。
### 先决条件
* 预装 RHEL 9 或 Rocky Linux 9
* 具有 sudo 管理权限的普通用户
* 本地配置的 YUM/DNF 仓库或 RHEL 9 的 Red Hat 订阅
* 互联网连接
事不宜迟,让我们进入 DHCP 服务器安装步骤。
### 1、在 RHEL 9 / Rocky Linux 9 上配置静态 IP 地址
开始时,必须在 RHEL 或 Rocky Linux 系统上设置静态 IP 地址。有多种方法可以执行此操作,但最简单和最直观的方法是使用 `nmtui` 或 `nmcli` 实用程序。
要确认你的 Linux 系统的 IP 地址,请运行以下 `ip` 命令:
```
$ ip a
```

### 2、安装和配置 DHCP 服务器
配置静态 IP 后,下一步就是安装 DHCP 服务器。RHEL 9 或 Rocky Linux 9 仓库 (BaseOS) 默认提供 `dhcp-server` 包,你可以如图所示安装它:
```
$ sudo dnf install dhcp-server -y
```

安装 dhcp 服务器后,我们需要进一步并配置设置。因此,打开 DHCP 配置文件:
```
$ sudo vi /etc/dhcp/dhcpd.conf
```
将以下代码行粘贴到配置文件中。请务必将子网配置为你的首选值:
```
default-lease-time 3600;
max-lease-time 86400;
authoritative;
subnet 192.168.10.0 netmask 255.255.255.0 {
range 192.168.10.100 192.168.10.200;
option routers 192.168.10.1;
option subnet-mask 255.255.255.0;
option domain-name-servers 192.168.10.1;
}
```
保存并关闭文件。

让我们看一下其中的一些值:
* `default-lease-time` 值指定 DHCP 服务器将地址租给客户端的时间。在这种情况下,默认租用时间值为 3600 秒或 1 小时。
* `max-lease-time` 是将 IP 租给客户端的最长持续时间。在我们的例子中,这被设置为 86400 秒或 24 小时。
* 下一部分是子网配置。在此设置中,`192.168.10.0` 是子网,`255.255.255.0` 是子网掩码。IP 地址范围从 `192.168.10.100` 一直到 `192.168.10.200`。
* `router` 选项定义默认网关。在本例中为 `192.168.10.1`。
* `subnet-mask` 选项确定分配给每个客户端或主机的子网掩码。在本例中为 `255.255.255.0`。
* 最后,`domain-name-servers` 选项指定 DNS 服务器。在本例中为 `192.168.10.1`。
完成后,保存更改并退出。然后启用并启动 DHCP 服务。
```
$ sudo systemctl enable --now dhcpd
$ sudo systemctl status dhcpd
```

请注意:
此时,DHCP 服务应该分发 IP 地址。如果你的 LAN 中有另一个 DHCP 服务器或路由器,关闭它以防止 IP 地址分配冲突是明智的。这将导致一些客户端从 RHEL 或 Rocky Linux 服务器上的 DHCP 服务器获得 IP 分配,而其余的则从路由器获得 IP 分配,这当然不是你想要发生的事情。因此,请记住关闭 LAN 设置中的任何其他 DHCP 服务器。
### 3、测试 DHCP 服务器安装
在我们模拟的 LAN 设置中,你可以看到 Ubuntu 系统已经从 RHEL 或 Rocky Linux DHCP 服务器中选择了一个 IP。

回到我们的 DHCP 服务器并在 `/var/log/message` 文件中搜索 Ubuntu 机器的 IP 地址:
```
$ sudo tail -50 /var/log/messages | grep -i 192.168.10.100
```

完美,上面的输出确认 Ubuntu 机器从我们的 DHCP 服务器获得了 IP 服务器。
### 结论
这篇文章到此结束。在本指南中,你学习了如何在 RHEL 9 / Rocky Linux 9 上安装和配置 DHCP 服务器。请在下面的评论部分发表你的疑问和反馈。
(题图:MJ/d396485d-963c-4d17-8c4b-f3c8e11dcc5d)
---
via: <https://www.linuxtechi.com/configure-dhcp-server-on-rhel-rockylinux/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | DHCP, an acronym for Dynamic Host Configuration Protocol, is a network protocol that auto-assigns IP addresses to client systems in a computer network. It assigns clients from a DHCP pool or range of IP addresses specified in its configuration. While you can manually assign a static IP to client systems, a DHCP server simplifies this and dynamically assigns IP addresses to the client systems on your network.
In this post, we will demonstrate how to install and configure DHCP Server on RHEL 9 / Rocky Linux 9
#### Prerequisites
- Pre-Installed RHEL 9 or Rocky Linux 9
- Regular User with sudo sdmin rights
- Locally Configured YUM/DNF Repo or Red Hat Subscription for RHEL 9
- Internet Connectivity
Without any further delay, let’s jump into DHCP server installation steps.
## 1) Configure Static IP address on RHEL 9 / Rocky Linux 9
As you get started, it’s imperative to set a static IP address on your RHEL or Rocky Linux system. There are various ways of doing this, but the easiest and most intuitive one is using the nmtui or nmcli utility.
Read Also : [How to Set Static IP Address on RHEL 9](https://www.linuxtechi.com/set-static-ip-address-on-rhel-9/)
To confirm the IP address of your linux system, run below [ip command](https://www.linuxtechi.com/ip-command-examples-for-linux-users/)
$ ip a
## 2) Install and Configure DHCP Server
Once you have configured a static IP, the next course of action is to install a DHCP server. RHEL 9 or Rocky Linux 9 repositories (BaseOS) provide the dhcp-server package by default and you can install it as shown.
$ sudo dnf install dhcp-server -y
Post dhcp server installation, we need to go a step further and configure the settings. So, open the DHCP configuration file.
$ sudo vi /etc/dhcp/dhcpd.conf
Paste the following lines of code into the configuration file. Be sure to configure the subnet to your preferred values.
default-lease-time 3600; max-lease-time 86400; authoritative; subnet 192.168.10.0 netmask 255.255.255.0 { range 192.168.10.100 192.168.10.200; option routers 192.168.10.1; option subnet-mask 255.255.255.0; option domain-name-servers 192.168.10.1; }
Save & close the file.
Let’s take a look at some of these values:
- The default-lease-time value specifies how long the DHCP server will lease an address to a client. In this case, the default-lease-time value is 3600 seconds or 1 hour. The max-lease-time is the maximum duration that the IP will be leased to a client. In our case, this is set to 86400 seconds or 24 hours.
- The next section is the subnet configuration. In this setup, 192.168.10.0, is the subnet and 255.255.255.0 is the subnet mask. The IP address range starts from 192.168.10.100 right through 192.168.10.200.
- The option router option defines the default gateway. In this case, 192.168.10.1.
- The option subnet-mask option determines the subnet-mask assignment to each client or host. In this case, 255.255.255.0.
- Lastly, domain-name-servers specifies the DNS servers. In this case 192.168.10.1.
Once done, save the changes and exit. Then enable and start the DHCP service.
$ sudo systemctl enable --now dhcpd $ sudo systemctl status dhcpd
#### PLEASE NOTE
At this point, the DHCP service should be dishing out IP addresses. In case you have another DHCP server or router in your LAN, it’s prudent to turn it off to prevent a conflict of IP address assignment. This would lead to some clients getting the IP assignment from the RHEL or Rocky Linux server and the rest from the router which is certainly not what you want to happen. So, remember to turn off any other DHCP server in your LAN setup.
## 3) Test DHCP Server installation
In our simulated LAN setup, you can see that Ubuntu system has already picked an IP from the RHEL or Rocky Linux DHCP server.
Head back to our dhcp server and search the Ubuntu machine ip address in /var/log/message file
$ sudo tail -50 /var/log/messages | grep -i 192.168.10.100
Perfect, output above confirms that Ubuntu machine got the IP server from our DHCP server.
#### Conclusion
This draws this post to a close. In this guide, you have learned how to install and configure the DHCP server on RHEL 9 / Rocky Linux 9. Kindly do post your queries and feedback in below comments section. |
15,841 | 11 个不可变 Linux 发行版,适合那些想要拥抱未来的人们 | https://itsfoss.com/immutable-linux-distros/ | 2023-05-24T18:49:00 | [
"不可变",
"Linux 发行版"
] | https://linux.cn/article-15841-1.html | 
>
> 不可变性是一种时下流行的概念。看看有哪些适合你的不可变 Linux 发行版。
>
>
>
每个发行版都是根据一系列目的而定制的。一些配置适用于 [旧计算机](https://itsfoss.com/lightweight-linux-beginners/),一些旨在提供 [优质的用户体验](https://itsfoss.com/beautiful-linux-distributions/),而一些则专注于安全性。
几年前,不可变发行版不是用户想要的。但是,最近越来越多的项目正在将不可变性作为 Linux 发行版的核心特征。
为什么会这样?有哪些可供选择?在你查看此列表之前,让我简要地向你介绍不可变性的更多内容:
### 什么是不可变 Linux 发行版?
不可变发行版确保操作系统的核心保持不变。对于不可变发行版来说,根文件系统保持为只读状态使得它可以在多个实例中保持相同。当然,如果你希望更改某些内容,则仍可以进行更改。但默认情况下该能力会被禁用。
它有什么用处?
传统上,不可变发行版存在的目的是为了方便测试和基于容器的软件开发。此外,不可变性为你的操作系统提供了更好的安全性和可靠的更新。
早期,这种特性的关注点主要集中在针对专业人士和开发人员的发行版上。现在,它开始应用于日常桌面用户。
>
> ? 以下列表并没有按照任何特定的排名顺序列出,并且某些发行版仍处于早期开发阶段。
>
>
>
### 1、carbonOS

在写这篇文章时,[carbonOS](https://carbon.sh/) 是一款仍未推出的独立 Linux 发行版。它专注于提供强大的技术和流畅的用户体验。
它采用 Flatpak 优先和容器优先的方法。carbonOS 还旨在提供安全的系统更新,并提供一些不是所有原子发行版都具备的功能,如经过验证的启动。
除了其独特的特点外,它还希望专注于为用户提供出色的 GNOME 桌面体验。
### 2、Fedora Silverblue

[Silverblue](https://silverblue.fedoraproject.org/) 是具有不可变性的 Fedora Workstation 的变种,是最受欢迎的不可变发行版之一。
用户界面和体验与普通的 Fedora Workstation 发行版保持一致。每当有新的 Fedora 版本发布时,也会有一个新的 Silverblue 版本。
Fedora Silverblue 旨在提供稳定的体验,适用于测试和基于容器的软件开发。如果更新后出现问题,你总是可以回滚到该操作系统的先前版本。
### 3、Flatcar Container Linux

正如名字所示,这是一个专门针对容器工作负载而定制的社区构建版 Linux 发行版。
你将获得一个最小化的操作系统镜像,其中仅包括运行容器所需的工具,没有包管理器,也无需配置。
如果你想为你的容器提供可靠的底层,那么 [Flatcar](https://www.flatcar.org/) 可能是一个不错的选择,因为它同时具有可伸缩性、安全性和简单性。请在其 [GitHub 页面](https://github.com/flatcar/Flatcar) 上了解更多信息。
### 4、openSUSE MicroOS

[openSUSE MicroOS](https://microos.opensuse.org/) 是为需要部署容器或处理自动化工作流程的服务器而构建的。
它依赖于事务性更新(使用 Btrfs 进行快照),这有助于保存文件系统的历史记录而不占用太多存储空间。
总的来说,MicroOS 是服务器用户的一个可扩展、可靠和安全的选项。
### 5、Vanilla OS

[Vanilla OS](https://vanillaos.org/) 是不可变性领域中的一个相对较新的参与者。但是,它在发布后成功引起了轰动,并在第一个稳定版发布后切换到了以 Debian 为基础,放弃了 Ubuntu。
它旨在提供易于使用的桌面体验,同时具备可靠性和不可变性特征。
### 6、Bottlerocket
[Bottlerocket](https://aws.amazon.com/bottlerocket/) 是由 AWS 构建的基于 Linux 的开源操作系统,旨在在其平台上运行容器。
与其他选项不同,它的使用仅限于 AWS。
它确保使用 AWS 服务的客户具有最少的维护开销,并且可以无缝地自动化其工作流程。创建 EC2(<ruby> 亚马逊弹性计算云 <rt> Amazon Elastic Compute Cloud </rt></ruby>)时,你只能将其用作 AMI(<ruby> 亚马逊机器镜像 <rt> Amazon Machine Image </rt></ruby>) 使用。
### 7、blendOS

[blendOS](https://blendos.co/) 是一个正在开发中的有趣发行版,旨在提供其他发行版的各种优点。
换句话说,你可以在发行版上安装任何类型的软件包(RPM、DEB 等),同时获得所期望的不可变性和更新可靠性。
### 8、Talos Linux

另一个独特的 Linux 发行版,专为 Kubernetes 设计。[Talos Linux](https://www.talos.dev/) 对于云用户/开发人员来说是一个有趣的选择。
它是安全、不可变的,是支持云平台、裸机和虚拟化平台的最小化选择之一。你还可以在 Docker 中轻松启动 Talos 集群。
该操作系统从 [SquashFS](https://en.wikipedia.org/wiki/SquashFS) 中运行在内存中,这样整个主磁盘都可以留给 Kubernetes。
### 9、NixOS

[NixOS](https://nixos.org/) 是当前 [最先进的 Linux 发行版](https://itsfoss.com/advanced-linux-distros/) 之一。如果你想要不可变性以及易于恢复、强大的软件包管理器等诸多好处,那么 NixOS 将是一个很好的选择。
如果你还不了解 NixOS,也不用担心,可以浏览我们的 [NixOS 系列文章](https://itsfoss.com/tag/nix-os/) 来学习并进行设置。
### 10、GUIX

[GUIX](https://guix.gnu.org/) 类似于 NixOS(某种程度上),并且专为希望获得可靠升级和良好系统控制的高级用户而设计。
如果你是一名新的 Linux 用户,不应将其视为你的日常操作系统。因此,你可能需要查阅 [文档](https://guix.gnu.org/en/help/) 以便浏览并开始使用。
### 11、Endless OS

[Endless OS](https://endlessos.com/) 是一个基于 Debian 的 Linux 发行版。
与其它基于 Debian 的发行版(例如 Ubuntu)不同,Endless OS 采用了健壮的设计,在其核心实现了不可变性,以确保更新一个软件包不会破坏系统。
? 你对不可变的 Linux 发行版有何看法?你需要它们吗?你是否想在未来将你系统上的流行选项替换为其中任何一个?
*(题图:MJ/6c0169a0-9820-4bf7-b9fb-f0cd2c45d7bf)*
---
via: <https://itsfoss.com/immutable-linux-distros/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Every distro is tailored for a range of purposes. Some are configured to work on [old computers](https://itsfoss.com/lightweight-linux-beginners/), some aim to [great user experience](https://itsfoss.com/beautiful-linux-distributions/) and some focus on security.
Immutable distributions were not what users wanted a couple of years back. But, recently, more projects are focusing on the immutability aspect as a core feature of the Linux distribution.
Why is that? And, what are all the options available? Before you get to the list, let me briefly tell you more about immutability:
## What is an immutable Linux distro?
An immutable distro ensures that the operating system's core remains unchanged. The root file system for an immutable distro remains read-only, making it possible to stay the same across multiple instances. Of course, you can change things if you would like to. But, the ability remains disabled by default.
How is it useful?
Traditionally, immutable distributions existed to allow for easier testing and container-based software development. Furthermore, immutability provides you with better security and reliable updates for your operating system.
Back then, the focus on such features was limited to distros aimed for professionals and developers. Now, it is being incorporated for daily desktop users.
## 1. carbonOS
[carbonOS](https://carbon.sh/) is an upcoming independent Linux distro (at the time of writing this). It focuses on providing a seamless user experience with robust tech at its core.
It takes a Flatpak-first and container-first approach. carbonOS also aims to provide safe system updates, and verified boot as some features that not all atomic distros offer.
In addition to its unique traits, it also wants to focus on providing an excellent GNOME desktop experience to users.
**Suggested Read 📖**
[carbonOS: This Upcoming Independent Distro is All About UX and Robust ExperiencecarbonOS is a new upcoming distro on the radar. Explore more about it here.](https://news.itsfoss.com/carbonos/)

## 2. Fedora Silverblue
[Silverblue](https://silverblue.fedoraproject.org) is a variant of Fedora Workstation with immutability. It is one of the most popular immutable distributions out there.
The user interface and the experience remains unchanged from a typical Fedora Workstation release. Whenever you have a new Fedora release, expect a new Silverblue release as well.
Fedora Silverblue aims to offer a stable experience which is useful for testing and container-based software development. You can always roll back to the previous version of the operating system if something goes wrong after an update.
## 3. Flatcar Container Linux

A community-built Linux distribution tailored for container workloads, as the name suggests.
You get a minimal OS image that includes only the tools needed to run containers, no package manager, and no configuration hassle.
If you want to have a reliable infrastructure for your containers, [Flatcar](https://www.flatcar.org) can be a nice option that is scalable, secure, and simple at the same time. Explore more about it on its [GitHub page](https://github.com/flatcar/Flatcar).
## 4. NixOS

[NixOS](https://nixos.org) is one of the most [advanced Linux distributions](https://itsfoss.com/advanced-linux-distros/) available. But if you want immutability and a bunch of perks like easy recovery, robust package manager, etc., NixOS should be a great pick.
Fret not, if you do not know about NixOS, you can explore our [NixOS series](https://itsfoss.com/tag/nix-os/) to learn and set it up.
[Getting Started With NixOS LinuxA tutorial series to help you get familiar with the immutable NixOS Linux distribution.](https://itsfoss.com/tag/nix-os/)

## 5. GUIX
[GUIX](https://guix.gnu.org) is similar to NixOS (kind of) and tailored for advanced users wanting reliable upgrades and good control over their systems.
If you are a new Linux user, you should not expect it to be your daily driver. So, you might want to go through its [documentation](https://guix.gnu.org/en/help/) to explore and get started.
## 6. openSUSE MicroOS

[openSUSE MicroOS](https://microos.opensuse.org) is built for servers where one needs to deploy containers or work with automated workflows.
It relies on transactional updates utilizing btrfs with snapshots, that helps save the file system's history without occupying much storage space.
Overall, MicroOS is a scalable, reliable, and secure option for server users.
## 7. Vanilla OS
[Vanilla OS](https://vanillaos.org) is a fairly new entrant to the immutability space. However, it managed to make waves with its release, and then switching to a Debian base, ditching Ubuntu right after its first stable release.
It aims to provide an easy-to-use desktop experience with reliability and immutable features.
## 8. Bottlerocket
[Bottlerocket](https://aws.amazon.com/bottlerocket/) is a Linux-based open-source OS built by Amazon Web Services to run containers on its platform.
Unlike other options, its usage is limited to AWS.
It ensures that the customers using AWS services have minimal maintenance overhead and get to automate their workflows seamlessly. You can only use it as an Amazon Machine Image (AMI) when you create an Amazon Elastic Compute Cloud (EC2).
## 9. blendOS
[blendOS](https://blendos.co) is an interesting distro in development which aims to provide all the good things from other distributions.
In other words, you can install any package on the distro (RPM, DEB, etc.) while getting the immutability and update reliability as one would expect.
**Suggested Read 📖**
[blendOS Aims to Replace All Linux DistributionsUbuntu Unity’s lead has come up with a new distro that sounds like something everyone might want to keep an eye on.](https://news.itsfoss.com/blendos/)

## 10. Talos Linux

Yet another unique Linux distribution, designed for Kubernetes. [Talos Linux](https://www.talos.dev) is an intriguing option for cloud users/developers.
It is secure, immutable, and a minimal option that supports cloud platforms, bare metal, and virtualization platforms. You can easily launch a Talos cluster inside Docker too.
The OS runs in memory from a [SquashFS](https://en.wikipedia.org/wiki/SquashFS), which leaves the entire primary disk to Kubernetes.
## 11. Endless OS
[Endless OS](https://endlessos.com) is a Linux distribution based on Debian.
Unlike any other Debian-based distro (say, Ubuntu), Endless OS features a robust design with immutability at its heart to ensure updating a package does not break the system.
## 12. Nitrux
[Nitrux](https://nxos.org) is a Debian-based distribution with a unique approach to things, along with the support for atomic upgrades (making it an immutable option).
It features KDE Plasma as its desktop, and aims to provide a good user experience with all of its custom tweaks.
*💬 What do you think about immutable Linux distros? Do you need them? Do you want to replace the popular options on your system with any of these in the future?* |
15,843 | 如何在 Rocky Linux 9 / AlmaLinux 9 上安装 KVM | https://www.linuxtechi.com/install-kvm-on-rocky-linux-almalinux/ | 2023-05-25T15:59:00 | [
"KVM"
] | https://linux.cn/article-15843-1.html | 
>
> 在本指南中,我们演示了如何在 Rocky Linux 9 / Alma Linux 9 上安装 KVM。
>
>
>
KVM 是 <ruby> 内核虚拟机 <rt> Kernel Virtualization Machine </rt></ruby> 的简称,是一个为 Linux 内核设计的开源虚拟化平台。它是一种 1 类管理程序,或通常称为裸机管理程序。它允许用户创建和管理多台客户机,这些可以在 Linux 或 Windows 操作系统中创建。
与大多数虚拟化平台一样,它将硬件资源(如 CPU、内存、存储、网络、图形等)抽象化,并将它们分配给独立于宿主机运行的客户机。
### 先决条件
* 预装 Rocky Linux 9 / AlmaLinux 9
* 具有管理员权限的 sudo 用户
* 互联网连接
### 1、验证是否启用了硬件虚拟化
首先,你需要验证你的系统是否启用了虚拟化功能。在大多数现代系统上,此功能已在 BIOS 中启用。但可以肯定的是,你可以验证是否如图所示启用了虚拟化。
该命令探测是否存在 VMX(<ruby> 虚拟机扩展 <rt> Virtual Machine Extension </rt></ruby>),它是英特尔硬件虚拟化的 CPU 标志,或 SVM,它是 AMD 硬件虚拟化的标志。
```
$ cat /proc/cpuinfo | egrep "vmx|svm"
```
从以下输出中,你可以看到我们的系统启用了英特尔硬件虚拟化:

### 2、在 Rocky Linux 9 / AlmaLinux 9 上安装 KVM
确保启用虚拟化后,下一步就是安装 KVM 和管理工具。为此,请运行以下 `dnf` 命令。
```
$ sudo dnf install qemu-kvm virt-manager libvirt virt-install virt-viewer virt-top bridge-utils bridge-utils virt-top libguestfs-tools -y
```

安装完成后,运行以下命令检查是否已加载所需的 KVM 模块。
```
$ lsmod | grep kvm
```
你应该得到以下输出以确认已加载必要的模块:

### 3、启动并启用 libvirtd 守护进程
在下一步中,一定要启动 libvirtd 守护进程。这是一个服务器端守护程序组件,可在虚拟化的客户机上运行和管理任务。它用于管理虚拟化技术,例如 Xen、KVM 和 ESXi 等等。
要启动 libvirtd 守护进程,请运行以下命令:
```
$ sudo systemctl start libvirtd
```
请务必启用该服务以在引导时启动:
```
$ sudo systemctl enable --now libvirtd
```
验证 libvirtd 守护进程是否正在运行,如下所示:
```
$ sudo systemctl status libvirtd
```

### 4、设置桥接接口
到目前为止,我们已经安装了 KVM 和所有管理工具,事实上,我们可以继续启动虚拟机。但是,如果我们可以从管理程序网络外部访问虚拟机,那就太好了。为此,我们需要创建一个桥接接口。
首先,确定系统上的网络接口。
```
$ sudo nmcli connection show
```
从输出来看,`ens160` 是活动的网络接口,请务必注意你的情况下的接口,因为你将一路使用它。

要开始创建网桥,首先,使用以下语法用其 UUID 删除连接:
```
$ sudo nmcli connection delete UUID
```
在我们的例子中,命令将是:
```
$ sudo nmcli connection delete 19e98123-9a84-30a6-bc59-a7134446bb26
```
你将收到连接已成功删除的确认信息。

在继续进行之前,最好准备好以下详细信息:
* 网桥名称 – 新网桥的首选名称(例如 `br1`)
* 设备名称 – 这是你的网络接口的名称。它将作为网桥的从属设备(例如,`ens160`)
* IP 地址/子网 – 桥接网络的 IP 地址和子网(例如 `192.168.2.50/24`)。请注意,这应该与你的网络子网和 IP 地址相对应。
* 网关 – 你网络的默认网关地址(例如 `192.168.2.1`)
* DNS1 和 DNS2 – 首选 DNS 地址(例如 `8.8.8.8` 和 `8.8.4.4`)
继续,使用以下语法创建一个新的桥接接口。
```
$ sudo nmcli connection add type bridge autoconnect yes con-name BRIDGE NAME ifname BRIDGE NAME
```
在我们的例子中,`br1` 是首选的网桥接口名称。因此,命令将如图所示:
```
$ sudo nmcli connection add type bridge autoconnect yes con-name br1 ifname br1
```

在接下来的步骤中,你将通过指定 IP 子网、网关和 DNS 值来修改网桥。
首先使用以下语法指定 IP 子网:
```
$ sudo nmcli connection modify BRIDGE NAME ipv4.addresses IP ADDRESS/SUBNET ipv4.method manual
```
根据我们的设置,命令将是:
```
$ sudo nmcli connection modify br1 ipv4.addresses 192.168.2.150/24 ipv4.method manual
```
接下来,使用以下语法指定网关地址:
```
$ sudo nmcli connection modify BRIDGE NAME ipv4.gateway GATEWAY
```
根据我们的网络,该命令采用以下格式:
```
$ sudo nmcli connection modify br1 ipv4.gateway 192.168.2.1
```
DNS 地址的语法如下:
```
$ sudo nmcli connection modify BRIDGE NAME ipv4.dns DNS1 +ipv4.dns DNS2
```
该命令采用以下格式:
```
$ sudo nmcli connection modify br1 ipv4.dns 8.8.8.8 +ipv4.dns 8.8.4.4
```

此后,使用以下命令添加网桥从属设备:
```
$ sudo nmcli connection add type bridge-slave autoconnect yes con-name DEVICE NAME ifname DEVICE NAME master BRIDGE NAME
```
使用我们的值,命令如图所示:
```
$ sudo nmcli connection add type bridge-slave autoconnect yes con-name ens160 ifname ens160 master br1
```
你将收到以下确认信息,表明已成功添加网桥从属设备。请记住,桥接从属设备是你的网络接口或适配器。

要确认网桥已创建,请运行以下命令:
```
$ sudo nmcli connection show
```
从输出中,你可以看到列出了网桥接口。

激要活它,请运行以下命令:
```
$ sudo nmcli connection up br1
```

此外,你可以使用 `ip addr` 命令验证:
```
$ ip addr | grep br1
```

最后,编辑网桥配置文件。
```
$ sudo vi /etc/qemu-kvm/bridge.conf
```
添加以下行:
```
allow all
```
然后重新启动虚拟化守护进程以应用更改
```
$ sudo systemctl restart libvirtd
```
### 5、创建虚拟机
安装 KVM 并配置桥接连接后,现在让我们创建一个虚拟机。在执行之前,为登录用户分配必要的所有权,以便在不切换到 root 的情况下运行命令。
```
$ sudo chown -R $USER:libvirt /var/lib/libvirt/
```
在命令行上,我们将使用以下语法使用 Ubuntu 20.04 ISO 镜像创建虚拟机。
```
$ virt-install \
--name Ubuntu \
--ram 2048 \
--vcpus 2 \
--disk path=/var/lib/libvirt/images/ubuntu-20.04.img,size=15 \
--os-variant ubuntu20.04 \
--network bridge=br1,model=virtio \
--graphics vnc,listen=0.0.0.0 \
--console pty,target_type=serial \
--cdrom /home/linuxtechi/Downloads/ubuntu-20.04.4-desktop-amd64.iso
```

执行该命令后,将启动图形屏幕会话,并开始安装客户操作系统。


### 总结
我们关于如何在 Rocky Linux 9 / AlmaLinux 9 上安装 KVM 的文章到此结束,非常欢迎你提供反馈。
*(题图:MJ/a364d6e3-0c59-4be8-bf02-5df078359429)*
---
via: <https://www.linuxtechi.com/install-kvm-on-rocky-linux-almalinux/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this guide, we demonstrate how to install KVM on Rocky Linux 9 / Alma Linux 9.
[KVM](https://www.linux-kvm.org/page/Main_Page), short for Kernel Virtualization Machine, is an opensource virtualization platform designed for the Linux kernel. It’s a type 1 hypervisor, or commonly referred to as a bare metal hypervisor. It allows users to create and manage multiple guest machines which can be spun from either Linux or Windows operating systems.
Like most virtualization platforms, it abstracts hardware resources such as CPU, memory, storage, network, graphics etc. and allocates them to guest machines which run independently of the host.
#### Prerequisites
- Pre Installed Rocky Linux 9 / AlmaLinux 9
[Sudo User](https://www.linuxtechi.com/create-sudo-user-on-rhel-rocky-linux-almalinux/)with admin rights- Internet Connectivity
## 1) Verify if hardware Virtualization is Enabled
To start off, you need to verify if your system has the virtualization feature enabled. On most modern systems, this feature comes already enabled in the BIOS. But just to be sure, you can verify if virtualization is enabled as shown.
The command probes for the presence of vmx (Virtual Machine Extension) which is a CPU flag for Intel hardware virtualization or svm which is the flag for AMD hardware virtualization.
$ cat /proc/cpuinfo | egrep "vmx|svm"
From the following output, you can see that our system has Intel Hardware virtualization enabled.
## 2) Install KVM on Rocky Linux 9 / AlmaLinux 9
Once you have ensured that virtualization is enabled, the next step is to install KVM and management tools. To do so, run the following dnf command.
$ sudo dnf install qemu-kvm virt-manager libvirt virt-install virt-viewer virt-top bridge-utils bridge-utils virt-top libguestfs-tools -y
Once the installation is complete, run the following command to check if the required KVM modules have been loaded.
$ lsmod | grep kvm
You should get the following output to confirm that the necessary modules have been loaded.
## 3) Start and Enable the libvirtd daemon
In the next step, be sure to start the libvirtd daemon. This is a server-side daemon component that runs and manages tasks on virtualized guests. It is used to manage virtualization technologies such as Xen, KVM, and ESXi to mention a few.
To start the libvirtd daemon, run the command:
$ sudo systemctl start libvirtd
Be sure to enable the service to start on boot time.
$ sudo systemctl enable --now libvirtd
Verify that the libvirtd daemon is running as follows.
$ sudo systemctl status libvirtd
## 4) Setup the Bridge Interface
So far, we have installed KVM, and all the management tools and we can, in fact, proceed to spin up a virtual machine. However, it would be nice if we can access the VMs from outside the hypervisor network. To accomplish this, we need to create a bridge interface.
First, identify the network interfaces on your system.
$ sudo nmcli connection show
From the output, ens160 is the active network interface, be sure to take note of the interface in your case as you will use it along the way.
To begin creating the bridge, first, delete the connection using its UUID in the following syntax.
$ sudo nmcli connection delete UUID
In our case, the command will be:
$ sudo nmcli connection delete 19e98123-9a84-30a6-bc59-a7134446bb26
You will get a confirmation that the connection has successfully been deleted.
Before proceeding any further, it would be prudent to have the following details at hand:
- BRIDGE NAME – Preferred name of the new bridge (e.g. “br1”)
- DEVICE NAME – This is the name of your network interface. This will serve as the bridge slave (e.g., “ens160”)
- IP ADDRESS/SUBNET – The IP address and subnet for the bridge network (e.g., “192.168.2.50/24”). Note that this should correspond with your network subnet and IP addressing.
- GATEWAY – Default gateway address of your network (e.g. “192.168.2.1”)
- DNS1 and DNS2 – Preferred DNS addresses (e.g. “8.8.8.8” and “8.8.4.4”)
Moving on, create a new bridge interface using the following syntax.
$ sudo nmcli connection add type bridge autoconnect yes con-name BRIDGE NAME ifname BRIDGE NAME
In our case, br1 is the preferred bridge interface name. Therefore, the command will be as shown.
$ sudo nmcli connection add type bridge autoconnect yes con-name br1 ifname br1
In the next steps, you will modify the bridge by specifying the IP subnet, Gateway, and DNS values.
Start off by specifying the IP subnet using the following syntax.
$ sudo nmcli connection modify BRIDGE NAME ipv4.addresses IP ADDRESS/SUBNET ipv4.method manual
According to our setup, the command will be.
$ sudo nmcli connection modify br1 ipv4.addresses 192.168.2.150/24 ipv4.method manual
Next, specify the gateway address using the following syntax
$ sudo nmcli connection modify BRIDGE NAME ipv4.gateway GATEWAY
According to our network, the command takes the following format.
$ sudo nmcli connection modify br1 ipv4.gateway 192.168.2.1
The syntax for the DNS address is as follows.
$ sudo nmcli connection modify BRIDGE NAME ipv4.dns DNS1 +ipv4.dns DNS2
And the command takes the following format.
$ sudo nmcli connection modify br1 ipv4.dns 8.8.8.8 +ipv4.dns 8.8.4.4
Thereafter, use the following command to add the bridge slave.
$ sudo nmcli connection add type bridge-slave autoconnect yes con-name DEVICE NAME ifname DEVICE NAME master BRIDGE NAME
Using our values, the command is as shown.
$ sudo nmcli connection add type bridge-slave autoconnect yes con-name ens160 ifname ens160 master br1
You will get the following confirmation that the bridge slave was successfully added. Keep in mind that the bridge slave is your network interface or adapter.
To confirm that the bridge was created, run the following command:
$ sudo nmcli connection show
From the output, you can see that the bridge interface is listed.
To activate it, run the command:
$ sudo nmcli connection up br1
In addition, you can verify this using the [ip addr ](https://www.linuxtechi.com/ip-command-examples-for-linux-users/)command.
$ ip addr | grep br1
Lastly, edit the bridge configuration file.
$ sudo vi /etc/qemu-kvm/bridge.conf
Add the following line.
allow all
Then restart the virtualization daemon to apply the change
$ sudo systemctl restart libvirtd
## 5) Create a Virtual Machine
With KVM installed and the bridge connection configured, let’s now create a virtual machine. Before doing, assign the necessary ownership right to the logged-in user in order to run commands without switching to root.
$ sudo chown -R $USER:libvirt /var/lib/libvirt/
On the command line, we will create a virtual machine using Ubuntu 20.04 ISO image using the following syntax.
$ virt-install \ --name Ubuntu \ --ram 2048 \ --vcpus 2 \ --disk path=/var/lib/libvirt/images/ubuntu-20.04.img,size=15 \ --os-variant ubuntu20.04 \ --network bridge=br1,model=virtio \ --graphics vnc,listen=0.0.0.0 \ --console pty,target_type=serial \ --cdrom /home/linuxtechi/Downloads/ubuntu-20.04.4-desktop-amd64.iso
Once the command is executed, the graphical screen session will be launched, and the installation of the guest operating system will commence.
#### Conclusion
This concludes our article on how to install KVM on Rocky Linux 9 / AlmaLinux 9 Your feedback s highly welcome.
Also Read: [How to Manage KVM Virtual Machines with Cockpit Web Console](https://www.linuxtechi.com/manage-virtual-machines-cockpit-console/) |
15,844 | 测评适用于 Linux 中 Wayland 的最佳屏幕录制软件 | https://www.debugpoint.com/screen-recorders-linux-wayland/ | 2023-05-25T17:21:00 | [
"Wayland"
] | /article-15844-1.html | 
>
> 下面是适用于大多数现代 Linux 发行版中的 Wayland 的屏幕录制软件列表。
>
>
>
大多数主流 Linux 发行版(例如 Ubuntu 和 Fedora)中都默认使用现代的 Wayland 协议。然而,作为 [X.Org](http://X.Org) 的继任者,Wayland 更加安全并且遵循现代标准,但这需要开发人员针对 Wayland 重新开发应用程序。
基于 [X.Org](http://X.Org) 开发的 Linux 传统应用程序在大多数情况下都无法在 Wayland 上正常工作,除非进行修改。屏幕录制软件也属于这个范畴。许多广受欢迎的屏幕录制软件是为 [X.Org](http://X.Org) 开发的,并且在 Wayland 中已无法工作。
但是有些仍然可以工作。在本文中,我将向你介绍我在 Wayland 会话中测试过,并且运行良好的一些屏幕录制软件。
### 适用于 Linux 发行版下 Wayland 的最佳屏幕录制软件应用
#### 1、Kooha
首先介绍的是 Kooha,这是一款使用 GTK 编写的屏幕录制软件,支持 X11 和 Wayland。它是 GNOME 桌面环境下最快速、最简单的屏幕录制软件之一。该应用程序是提供顺畅录制体验的最佳 GNOME 应用之一。此实用工具支持硬件加速、定时器、多种输入源以及许多先进功能。主要功能如下:
* 在多显示器环境中,能够选择显示端口和窗口
* 硬件加速编码(默认禁用,但可以在设置中启用)
* 能够记录屏幕的特定区域
* 可以同时录制电脑声音和麦克风声音
* 指定制作录屏视频前的延时秒数
* 支持选择帧速率
* 支持多种媒体文件类型,包括:WebM、mp4、gif、Mkv 等


使用 Flatpak 安装 Kooha 非常容易。 [为你的系统设置 Flatpak 和 Flathub](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/),并运行以下命令进行安装:
```
flatpak install io.github.seadve.Kooha
```
我们在使用 Wayland 会话的最新版 Ubuntu 22.10 和 Fedora 37 中测试过,并且工作流程非常顺畅。
更多有关 Kooha 的详细信息:
* [主页](https://apps.gnome.org/app/io.github.seadve.Kooha/)
* [源代码](https://github.com/SeaDve/Kooha)
#### 2、GNOME 屏幕录制软件
在列表中的第二个是 GNOME Shell 内置的屏幕录制软件。它是 GNOME 新的截图实用程序的一部分,你可以在应用程序菜单中搜索 “<ruby> 截图 <rt> screenshot </rt></ruby>” 来启动它。
GNOME 屏幕录制软件提供了记录整个屏幕或矩形选区的选项。此外,你还可以选择将光标一并录制下来。
但是,它只支持 WebM 格式的录制,而且无法延迟录制。
你无需额外安装任何软件即可使用此功能,因为它默认随 GNOME 桌面环境一起安装。
使用键盘快捷键 `CTRL+SHIFT+ALT+R` 启动它。然后选择你需要的选项,最后点击录制按钮即可。
录制好的视频保存在 `~/Videos/Screencasts` 文件夹下。

#### 3、OBS Studio
流行的自由开源的直播应用程序 OBS Studio 最近开始支持 Wayland。虽然它主要用于实时流媒体,但实际上它的屏幕录制功能在 Wayland 中也可以使用。
由于它是专业级软件,你可以利用其强大的音频录制功能。此外,你还可以同时录制系统麦克风的声音。
通过 Flatpak 安装 OBS Studio 很容易。[为你的系统设置 Flathub](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/),然后使用以下命令安装它:
```
flatpak install com.obsproject.Studio
```
注意:OBS Studio 需要 FFmpeg 来运行。如果你想安装 FFmpeg,请参阅我们的 [此篇文章](https://www.debugpoint.com/install-ffmpeg-ubuntu/)。
启动 OBS Studio 后,在 “<ruby> 输入源 <rt> Sources </rt></ruby>” 下单击 “+” 号以添加源。然后选择 “<ruby> 屏幕捕捉… <rt> Screen capture... </rt></ruby>”。然后单击 “<ruby> 确定 <rt> Ok </rt></ruby>”。


停止录制后,录制文件会保存在你的用户主目录文件夹下。
更多有关 OBS Studio 的详细信息:
* [主页](https://obsproject.com/)
* [源代码](https://github.com/obsproject/obs-studio)
#### 4、vokoscreenNG
vokoscreenNG 是一款非常不同的屏幕录制软件,完全被低估了。它是一款老应用程序,并支持窗口捕捉、矩形捕捉。此外,它还支持与屏幕一起捕获音频、系统托盘控制、放大镜、倒计时、计时器和许多其他有趣的功能。
最近,它加入了实验性的 Wayland 支持,可供尝试。它运行得相当不错。目前,它支持 WebM、M4、Mkv、Mov 和 Avi 格式的 Wayland。但是,Wayland 会话的音频记录尚不可用。
你可以从以下链接下载适用于 Linux 发行版的预编译可执行文件,无需安装即可运行:
>
> **[下载链接](https://linuxecke.volkoh.de/vokoscreen/vokoscreen-download.html)**
>
>
>

更多有关 vokoscreenNG 的详细信息:
* [主页](https://linuxecke.volkoh.de/vokoscreen)
#### 5、Wayfarer
这个列表中的最后一个屏幕录制软件是 Wayfarer,它是基于 GTK4 的。它目前支持各种现代协议,如 Wayland、Pipewire 和 wireplumber。其简单的用户界面支持屏幕录制和音频捕捉。你还可以选择你的桌面的一部分或整个屏幕进行录制。
此外,你可以选择帧速率、鼠标捕捉,并具有延迟录制的功能。目前,它支持 webm、mp4 和 mkv 格式。

不过,它目前仅在 Arch Linux 的 Arch 用户仓库(AUR)中提供。你可以设置任何 AUR 辅助程序(例如 Yay)并使用以下命令进行安装:
```
yay -S wayfarer-git
```
更多有关 Wayfarer 的详细信息:
* [主页和源代码](https://github.com/stronnag/wayfarer)
### 其他目前无法在 Wayland 上正常使用的优秀屏幕录制软件
除了上面的列表之外,在 [X.Org](http://X.Org) 上有一些优秀的屏幕录制软件,目前在 Wayland 上不可用。根据我在 Ubuntu 22.10 和 Fedora 37 Wayland 会话中的测试,在录制文件中只会看到黑屏。希望它们能在未来被修复,并与 Wayland 兼容。
* [Peek](https://github.com/phw/peek)(可能支持 XWayland 后端)
* [Simple screen recorder](https://www.maartenbaert.be/simplescreenrecorder/)
* [Blue Recorder](https://github.com/xlmnxp/blue-recorder)(支持 Wayland,但目前有问题)
### 总结
根据我的个人经验,Wayland 更快、更好。由于许多现代发行版正在向 Wayland 转移,你必须使用替代应用程序来改变你的工作流程。我希望这个 Wayland 屏幕录制软件列表可以帮助你选择最适合自己的一个。
如果你知道其他类似的应用程序,并能在 Wayland 上正常使用,欢迎告诉我。
*(题图:MJ/9f04998c-0d4c-4651-b038-e595ca1f6bb6)*
---
via: <https://www.debugpoint.com/screen-recorders-linux-wayland/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,846 | 结合使用 Python 和 Rust | https://opensource.com/article/23/3/python-loves-rust | 2023-05-26T16:34:24 | [
"Rust",
"Python"
] | https://linux.cn/article-15846-1.html | 
>
> Rust 和 Python 的优势互补。可以使用 Python 进行原型设计,然后将性能瓶颈转移到 Rust 上。
>
>
>
Python 和 Rust 是非常不同的语言,但它们实际上非常搭配。但在讨论如何将 Python 与 Rust 结合之前,我想先介绍一下 Rust 本身。你可能已经听说了这种语言,但可能还没有了解过它的细节。
### 什么是 Rust?
Rust 是一种低级语言,这意味着程序员所处理的东西接近于计算机的 “真实” 运行方式。
例如,整数类型由字节大小定义,与 CPU 支持的类型相对应。虽然我们很想简单地说 Rust 中的 `a+b` 对应于一条机器指令,但实际上并不完全是这样!
Rust 编译器链非常复杂。作为第一种近似的方法,将这样的语句视为 “有点” 真实是有用的。
Rust 旨在实现零成本抽象,这意味着许多语言级别可用的抽象在运行时环境中会被编译去掉。
例如,除非明确要求,对象会在堆栈上分配。结果是,在 Rust 中创建本地对象没有运行时成本(尽管可能需要进行初始化)。
最后,Rust 是一种内存安全的语言。也有其他内存安全的语言和其他支持零成本抽象的语言。但通常这些是两类不同的语言。
内存安全并不意味着不可能在 Rust 中出现内存违规。它确实意味着只有两种方式可能导致内存违规:
* 编译器的错误。
* 显式声明为不安全(`unsafe`)的代码。
Rust 标准库代码有很多被标记为不安全的代码,虽然比许多人预期的少。这并不意味着该语句无意义。除了需要自己编写不安全代码的(罕见的)情况外,内存违规通常是由基础设施造成的。
### 为什么会有 Rust 出现?
为什么人们要创建 Rust?是哪些问题没有被现有编程语言解决吗?
Rust 被设计成既能高效运行,又保证内存安全。在现代的联网世界中,这是一个越来越重要的问题。
Rust 的典型应用场景是协议的低级解析。待解析的数据通常来自不受信任的来源,并且需要通过高效的方式进行解析。
如果你认为这听起来像 Web 浏览器所做的事情,那不是巧合。Rust 最初起源于 Mozilla 基金会,它是为了改进 Firefox 浏览器而设计的。
如今,需要保证安全和速度的不仅仅是浏览器。即使是常见的微服务架构也必须能够快速解析不受信任的数据,同时保证安全。
### 现实示例:统计字符
为了理解 “封装 Rust” 的例子,需要解决一个问题。这个问题需要满足以下要求:
* 足够容易解决。
* 能够写高性能循环来优化。
* 有一定的现实意义。
这个玩具问题的例子是判断一个字符在一个字符串中是否出现超过了 X 次。这个问题不容易通过高效的正则表达式解决。即使是专门的 Numpy 代码也可能不够快,因为通常没有必要扫描整个字符串。
你可以想象一些 Python 库和技巧的组合来解决这个问题。然而,如果在低级别的语言中实现直接的算法,它会非常快,并且更易于阅读。
为了使问题稍微有趣一些,以演示 Rust 的一些有趣部分,这个问题增加了一些变化。该算法支持在换行符处重置计数(意即:字符是否在一行中出现了超过 X 次?)或在空格处重置计数(意即:字符是否在单词中出现了超过 X 次?)。
这是唯一与 “现实性” 相关的部分。过多的现实性将使这个示例在教育上不再有用。
#### 支持枚举
Rust 支持使用枚举(`enum`)。你可以使用枚举做很多有趣的事情。
目前,只使用了一个简单的三选一的枚举,并没有其他的变形。这个枚举编码了哪种字符重置计数。
```
#[derive(Copy)]
enum Reset {
NewlinesReset,
SpacesReset,
NoReset,
}
```
#### 支持结构
接下来的 Rust 组件更大一些:这是一个结构(`struct`)。Rust 的结构与 Python 的 `dataclass` 有些相似。同样,你可以用结构做更复杂的事情。
```
#[pyclass]
struct Counter {
what: char,
min_number: u64,
reset: Reset,
}
```
#### 实现块
你可以在 Rust 中使用一个单独的块,称为实现(`impl`)块,为结构添加一个方法。但具体细节超出了本文的范围。
在这个示例中,该方法调用了一个外部函数。这主要是为了分解代码。更复杂的用例将指示 Rust 编译器内联该函数,以便在不产生任何运行时成本的情况下提高可读性。
```
#[pymethods]
impl Counter {
#[new]
fn new(what: char, min_number: u64, reset: Reset) -> Self {
Counter{what: what, min_number: min_number, reset: reset}
}
fn has_count(
&self,
data: &str,
) -> bool {
has_count(self, data.chars())
}
}
```
#### 函数
默认情况下,Rust 变量是常量。由于当前的计数(`current_count`)必须更改,因此它被声明为可变变量。
```
fn has_count(cntr: &Counter, chars: std::str::Chars) -> bool {
let mut current_count : u64 = 0;
for c in chars {
if got_count(cntr, c, &mut current_count) {
return true;
}
}
false
}
```
该循环遍历字符并调用 `got_count` 函数。再次强调,这是为了将代码分解成幻灯片展示。它展示了如何向函数发送可变引用。
尽管 `current_count` 是可变的,但发送和接收站点都显式标记该引用为可变。这可以清楚地表明哪些函数可能修改一个值。
#### 计数
`got_count` 函数重置计数器,将其递增,然后检查它。Rust 的冒号分隔的表达式序列评估最后一个表达式的结果,即是否达到了指定的阈值。
```
fn got_count(cntr: &Counter, c: char, current_count: &mut u64) -> bool {
maybe_reset(cntr, c, current_count);
maybe_incr(cntr, c, current_count);
*current_count >= cntr.min_number
}
```
#### 重置代码
`reset` 的代码展示了 Rust 中另一个有用的功能:模式匹配。对 Rust 中匹配的完整描述需要一个学期级别的课程,不适合在一个无关的演讲中讲解。这个示例匹配了该元组的两个选项之一。
```
fn maybe_reset(cntr: &Counter, c: char, current_count: &mut u64) -> () {
match (c, cntr.reset) {
('\n', Reset::NewlinesReset) | (' ', Reset::SpacesReset)=> {
*current_count = 0;
}
_ => {}
};
}
```
#### 增量支持
增量将字符与所需字符进行比较,并在匹配时增加计数。
```
fn maybe_incr(cntr: &Counter, c: char, current_count: &mut u64) -> (){
if c == cntr.what {
*current_count += 1;
};
}
```
请注意,我在本文中优化了代码以适合幻灯片。这不一定是 Rust 代码的最佳实践示例,也不是如何设计良好的 API 的示例。
### 为 Python 封装 Rust 代码
为了将 Rust 代码封装到 Python 中,你可以使用 PyO3。PyO3 Rust “crate”(即库)允许内联提示将 Rust 代码包装为 Python,使得修改两者更容易。
#### 包含 PyO3 crate 原语
首先,你必须包含 PyO3 crate 原语。
```
use pyo3::prelude::*;
```
#### 封装枚举
枚举需要被封装。`derive` 从句对于将枚举封装为 PyO3 是必需的,因为它们允许类被复制和克隆,使它们更容易在 Python 中使用。
```
#[pyclass]
#[derive(Clone)]
#[derive(Copy)]
enum Reset {
/* ... */
}
```
#### 封装结构
结构同样需要被封装。在 Rust 中,这些被称为 “宏”,它们会生成所需的接口位。
```
#[pyclass]
struct Counter {
/* ... */
}
```
#### 封装实现
封装实现(`impl`)更有趣。增加了另一个名为 `new` 的宏。此方法被标记为 `#[new]`,让 PyO3 知道如何为内置对象公开构造函数。
```
#[pymethods]
impl Counter {
#[new]
fn new(what: char, min_number: u64,
reset: Reset) -> Self {
Counter{what: what,
min_number: min_number, reset: reset}
}
/* ... */
}
```
#### 定义模块
最后,定义一个初始化模块的函数。此函数具有特定的签名,必须与模块同名,并用 `#[pymodule]` 修饰。
```
#[pymodule]
fn counter(_py: Python, m: &PyModule
) -> PyResult<()> {
m.add_class::<Counter>()?;
m.add_class::<Reset>()?;
Ok(())
}
```
`?` 显示此函数可能失败(例如,如果类没有正确配置)。 `PyResult` 在导入时转换为 Python 异常。
#### Maturin 开发
为了快速检查,用 `maturin develop` 构建并将库安装到当前虚拟环境中。这有助于快速迭代。
```
$ maturin develop
```
#### Maturin 构建
`maturin build` 命令构建一个 `manylinux` 轮子,它可以上传到 PyPI。轮子是特定于 CPU 架构的。
#### Python 库
从 Python 中使用库是最简单的部分。没有任何东西表明这与在 Python 中编写代码有什么区别。这其中的一个有用方面是,如果你优化了已经有单元测试的 Python 中的现有库,你可以使用 Python 单元测试来测试 Rust 库。
#### 导入
无论你是使用 `maturin develop` 还是 `pip install` 来安装它,导入库都是使用 `import` 完成的。
```
import counter
```
#### 构造函数
构造函数的定义正好使对象可以从 Python 构建。这并不总是如此。有时仅从更复杂的函数返回对象。
```
cntr = counter.Counter(
'c',
3,
counter.Reset.NewlinesReset,
)
```
#### 调用函数
最终的收益终于来了。检查这个字符串是否至少有三个 “c” 字符:
```
>>> cntr.has_count("hello-c-c-c-goodbye")
True
```
添加一个换行符会触发剩余操作,这里没有插入换行符的三个 “c” 字符:
```
>>> cntr.has_count("hello-c-c-\nc-goodbye")
False
```
### 使用 Rust 和 Python 很容易
我的目标是让你相信将 Rust 和 Python 结合起来很简单。我编写了一些“粘合剂”代码。Rust 和 Python 具有互补的优点和缺点。
Rust 非常适合高性能、安全的代码。Rust 具有陡峭的学习曲线,对于快速原型解决方案而言可能有些笨拙。
Python 很容易入手,并支持非常紧密的迭代循环。Python 确实有一个“速度上限”。超过一定程度后,从 Python 中获得更好的性能就更难了。
将它们结合起来完美无缝。在 Python 中进行原型设计,并将性能瓶颈移至 Rust 中。
使用 Maturin,你的开发和部署流程更容易进行。开发、构建并享受这一组合吧!
---
via: <https://opensource.com/article/23/3/python-loves-rust>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python and Rust are very different languages, but they actually go together rather well. But before discussing how to combine Python with Rust, I want to introduce Rust itself. You've likely heard of the language but may not have heard details about how it works.
## What is Rust?
Rust is a low-level language. This means that the things the programmers deal with are close to the way computers "really" work.
For example, integer types are defined by bit size and correspond to CPU-supported types. While it is tempting to say that this means `a+b`
in Rust corresponds to one machine instruction, it does not mean quite that!
Rust's compiler's chain is non-trivial. It is useful as a first approximation to treat statements like that as "kind of" true.
Rust is designed for zero-cost abstraction, meaning many of the abstractions available at the language level are compiled away at runtime.
For example, objects are allocated on the stack unless explicitly asked for. The result is that creating a local object in Rust has no runtime cost (though initialization might).
Finally, Rust is a memory-safe language. There are other memory-safe languages and other zero-cost abstraction languages. Usually, those are different languages.
Memory safety does not mean it is impossible to have memory violations in Rust. It does mean that there are only two ways that memory violations can happen:
- A bug in the compiler.
- Code that's explicitly declared unsafe.
Rust standard library code has quite a bit of code that is marked unsafe, though less than what many assume. This does not make the statement vacuous though. With the (rare) exception of needing to write unsafe code yourself, memory violations result from the underlying infrastructure.
## Why does Rust exist?
Why did people create Rust? What problem was not addressed by existing languages?
Rust was designed as a language to achieve a combination of high-performance code that is memory safe. This concern is increasingly important in a networked world.
The quintessential use case for Rust is low-level parsing of protocols. The data to be parsed often comes from untrusted sources and may need to be parsed in a performant way.
If this sounds like what a web browser does, it is no coincidence. Rust originated from the Mozilla Foundation as a way to improve the Firefox browser.
In the modern world, browsers are no longer the only things on which there is pressure to be safe and fast. Even the common microservice architecture, combined with defense-in-depth principles, must be able to unpack untrusted data quickly.
## Counting characters
To understand a "wrapping in Rust" example, there needs to be a problem to solve. Not just any problem will do. The issue needs to be:
- Easy enough to solve
- Be helped by the ability to write high-performance loops
- Somewhat realistic
The toy problem in this case is whether a character appears more than X times in a string. This is something that's not easily amenable to performant regular expressions. Even dedicated Numpy code can be slower than necessary because often there is no need to scan the entire string.
You can imagine some combination of Python libraries and tricks that make this possible. However, the obvious algorithm is pretty fast if implemented in a low-level language and makes things more readable.
A twist is added to make the problem slightly more interesting and demonstrate some fun parts of Rust. The algorithm supports resetting the count on a newline (does the character appear more than X times in a line?) or on a space (does the character appear more than X times in a word?).
This is the only nod given to "realism." Any more realism will make the example not useful pedagogically.
### Enum support
Rust supports enumeration (`enums`
). You can do many interesting things with `enums`
.
For now, a three-way `enum`
without any other twirls is used. The `enum`
encodes what character resets the count.
```
``````
#[derive(Copy)]
enum Reset {
NewlinesReset,
SpacesReset,
NoReset,
}
```
### Struct support
The next Rust component is a bit more substantial: a `struct`
. A Rust `struct`
is somewhat close to a Python `dataclass`
. Again, you can do more sophisticated things with a `struct`
.
```
``````
#[pyclass]
struct Counter {
what: char,
min_number: u64,
reset: Reset,
}
```
### Implementation blocks
You add a method to a `struct`
in a separate block in Rust: the `impl`
block. The details are outside the scope of this article.
In this example, the method calls an external function. This is mostly done to break up the code. A more sophisticated use would instruct the Rust compiler to inline the function to allow readability without any runtime cost.
```
``````
#[pymethods]
impl Counter {
#[new]
fn new(what: char, min_number: u64, reset: Reset) -> Self {
Counter{what: what, min_number: min_number, reset: reset}
}
fn has_count(
&self,
data: &str,
) -> bool {
has_count(self, data.chars())
}
}
```
### Function
By default, Rust variables are constant. Because the current count has to change, it is declared as a mutable variable.
```
``````
fn has_count(cntr: &Counter, chars: std::str::Chars) -> bool {
let mut current_count : u64 = 0;
for c in chars {
if got_count(cntr, c, &mut current_count) {
return true;
}
}
false
}
```
The loop goes over the characters and calls the function `got_count`
. Again, this is done to break the code into slides. It does show how to send a mutable borrow reference to a function.
Even though `current_count`
is mutable, both the sending and receiving sites explicitly mark the reference as mutable. This makes it clear which functions might modify a value.
### Counting
The `got_count`
resets the counter, increments it, and then checks it. Rust's colon-separated sequence of expressions evaluates to the result of the last expression, in this case, whether the threshold was met.
```
``````
fn got_count(cntr: &Counter, c: char, current_count: &mut u64) -> bool {
maybe_reset(cntr, c, current_count);
maybe_incr(cntr, c, current_count);
*current_count >= cntr.min_number
}
```
### Reset code
The `reset`
code shows another useful thing in Rust: matching. A complete description of the matching abilities in Rust would be a semester-level class, not two minutes in an unrelated talk, but this example matches on a tuple matching one of two options.
```
``````
fn maybe_reset(cntr: &Counter, c: char, current_count: &mut u64) -> () {
match (c, cntr.reset) {
('\n', Reset::NewlinesReset) | (' ', Reset::SpacesReset)=> {
*current_count = 0;
}
_ => {}
};
}
```
### Increment support
The increment compares the character to the desired one and, if matched, increments the count.
```
``````
fn maybe_incr(cntr: &Counter, c: char, current_count: &mut u64) -> (){
if c == cntr.what {
*current_count += 1;
};
}
```
Note that I optimized the code in this article for slides. It is not necessarily a best-practice example of Rust code or how to design a good API.
## Wrap Rust code for Python
To wrap Rust code for Python, you can use PyO3. The PyO3 Rust "crate" (or library) allows inline hints for wrapping Rust code into Python, making it easier to modify both together.
### Include PyO3 crate primitives
First, you must include the PyO3 crate primitives.
```
````use pyo3::prelude::*;`
### Wrap enum
The `enum`
needs to be wrapped. The `derive`
clauses are necessary for wrapping the `enum`
for PyO3, because they allow the class to be copied and cloned, making them easier to use from Python.
```
``````
#[pyclass]
#[derive(Clone)]
#[derive(Copy)]
enum Reset {
/* ... */
}
```
### Wrap struct
The `struct`
is similarly wrapped. These call "macros" in Rust, which generate the needed interface bits.
```
``````
#[pyclass]
struct Counter {
/* ... */
}
```
### Wrap impl
Wrapping the `impl`
is more interesting. Another macro is added called `new`
. This method is marked as `#[new]`
, letting PyO3 know how to expose a constructor for the built-in object.
```
``````
#[pymethods]
impl Counter {
#[new]
fn new(what: char, min_number: u64,
reset: Reset) -> Self {
Counter{what: what,
min_number: min_number, reset: reset}
}
/* ... */
}
```
### Define module
Finally, define a function that initializes the module. This function has a specific signature, must be named the same as the module, and decorated with `#[pymodule]`
.
```
``````
#[pymodule]
fn counter(_py: Python, m: &PyModule
) -> PyResult<()> {
m.add_class::<Counter>()?;
m.add_class::<Reset>()?;
Ok(())
}
```
The `?`
shows that this function can fail (for example, if the class was not appropriately configured). The `PyResult`
is translated into a Python exception at import time.
### Maturin develop
For quick checking, `maturin develop`
builds and installs the library into the current virtual environment. This helps iterate quickly.
```
````$ maturin develop`
### Maturin build
The `maturin build`
command builds a `manylinux`
wheel, which can be uploaded to PyPI. The wheel is specific to the CPU architecture.
### Python library
Using the library from Python is the nice part. Nothing indicates a difference between this and writing the code in Python. One useful aspect of this is that if you optimize an existing library in Python that already has unit tests, you can use the Python unit tests for the Rust library.
### Import
Whether you used `maturin develop`
or `pip install`
to install it, importing the library is done with `import`
.
```
````import counter`
### Construct
The constructor was defined exactly so the object could be built from Python. This is not always the case. Sometimes objects are only returned from more sophisticated functions.
```
``````
cntr = counter.Counter(
'c',
3,
counter.Reset.NewlinesReset,
)
```
### Call
The final pay-off is here at last. Check whether this string has at least three "c" characters:
```
``````
>>> cntr.has_count("hello-c-c-c-goodbye")
True
```
Adding a newline causes the rest to happen, and there aren't three "c" characters without an intervening newline:
```
``````
>>> cntr.has_count("hello-c-c-\nc-goodbye")
False
```
## Using Rust and Python is easy
My goal is to convince you that combining Rust and Python is easy. I wrote little code to "glue" them. Rust and Python have complementary strengths and weaknesses.
Rust is great for high-performance, safe code. Rust has a steep learning curve and can be awkward for quickly prototyping a solution.
Python is easy to get started with and supports incredibly tight iteration loops. Python does have a "speed cap." Beyond a certain level it is harder to get better performance from Python.
Combining them is perfect. Prototype in Python and move performance bottlenecks to Rust.
With `maturin`
, your development and deployment pipelines are easier to make. Develop, build, and enjoy the combo!
## Comments are closed. |
15,849 | 如何在 Ubuntu 22.04 / 20.04 上配置 FreeIPA 客户端 | https://www.linuxtechi.com/configure-freeipa-client-on-ubuntu/ | 2023-05-27T15:49:00 | [
"FreeIPA"
] | https://linux.cn/article-15849-1.html | 
FreeIPA 是一个强大的开源身份管理系统,提供集中的身份验证、授权和计费服务。在本文中,我们将逐步介绍在 Ubuntu 22.04 / 20.04 上配置 FreeIPA 客户端的步骤。配置 FreeIPA 客户端后,我们将尝试使用在 FreeIPA 服务器上创建的用户登录。
在我们之前的帖子中,我们已经讨论了 FreeIPA 服务器在 RHEL8/Rokcy Linux 8/ AlmaLinux 8 上的安装步骤。
### 在 FreeIPA 服务器上创建用户进行集中认证
登录到你的 FreeIPA 服务器并创建一个名为 `sysadm` 的用户,运行以下命令:
```
$ sudo kinit admin
Password for [email protected]:
$
$ sudo ipa config-mod --defaultshell=/bin/bash
$ sudo ipa user-add sysadm --first=System --last=Admin --password
Password:
Enter Password again to verify:
-------------------
Added user "sysadm"
-------------------
User login: sysadm
First name: System
Last name: Admin
Full name: System Admin
Display name: System Admin
Initials: SA
Home directory: /home/sysadm
GECOS: System Admin
Login shell: /bin/bash
Principal name: [email protected]
Principal alias: [email protected]
User password expiration: 20230415073041Z
Email address: [email protected]
UID: 464600003
GID: 464600003
Password: True
Member of groups: ipausers
Kerberos keys available: True
$
```
第一个命令是获取 Kerberos 凭证,第二个命令将所有用户的默认登录 shell 设置为 `/bin/bash`,第三个命令用于创建名为 `sysadm` 的用户。
### 在 Ubuntu 22.04 /20.04 上配置 FreeIPA 客户端的步骤
执行以下步骤来配置 FreeIPA 客户端以进行集中身份验证。
#### 1、在 FreeIPA 服务器上添加 Ubuntu 系统的 DNS 记录
登录到你的 FreeIPA 服务器并运行以下命令为 FreeIPA 客户端(即 Ubuntu 22.04/20.04)添加 DNS 记录:
```
$ sudo ipa dnsrecord-add linuxtechi.lan app01.linuxtechi.lan --a-rec 192.168.1.106
Record name: app01.linuxtechi.lan
A record: 192.168.1.106
$
```
在上面的命令中,`app01.linuxtechi.lan` 是我的 Ubuntu 系统,IP 地址为 `192.168.1.106`。
注意:确保你的 FreeIPA 服务器和客户端处于同一时区并从 NTP 服务器获取时间。
#### 2、安装 FreeIPA 客户端包
从你的 Ubuntu 系统运行以下命令以安装 `freeipa-client` 以及依赖项:
```
$ sudo apt install freeipa-client oddjob-mkhomedir -y
```
在安装 `freeipa-client` 时,我们将看到以下页面,选择确定并回车。

在下一个屏幕中,按回车键跳过。

#### 3、在主机文件中添加 FreeIPA 服务器 IP 和主机名
在 `/etc/hosts` 文件中添加以下 FreeIPA 服务器条目:
```
$ echo "192.168.1.102 ipa.linuxtechi.lan ipa" | sudo tee -a /etc/hosts
$ echo "192.168.1.106 app01.linuxtechi.lan app01" | sudo tee -a /etc/hosts
```
更改适合你的设置的 IP 地址和主机名。
#### 4、使用 ipa-client-install 配置 FreeIPA 客户端
现在运行以下 `ipa-client-install` 命令在你的 Ubuntu 系统上配置 FreeIPA 客户端:
```
$ sudo ipa-client-install --hostname=`hostname -f` --mkhomedir --server=ipa.linuxtechi.lan --domain linuxtechi.lan --realm LINUXTECHI.LAN
```
更改适合你设置的 FreeIPA 服务器地址、域名和领域。
上述命令的输出如下所示:

完美,上面的输出确认 FreeIPA 客户端安装成功。
现在允许在用户首次使用 FreeIPA 服务器进行身份验证时自动创建用户的主目录。
在文件 `/usr/share/pam-configs/mkhomedir` 中添加以下行:
```
required pam_mkhomedir.so umask=0022 skel=/etc/skel
```
```
$ echo "required pam_mkhomedir.so umask=0022 skel=/etc/skel" | sudo tee -a /usr/share/pam-configs/mkhomedir
```
要使上述更改生效,请运行以下命令:
```
$ sudo pam-auth-update
```

选择确定,然后按回车键。
#### 5、尝试使用 sysadm 用户登录到你的 Ubuntu 系统
尝试使用 `sysadm` 用户通过 SSH 登录到你的 Ubuntu 系统,
```
$ ssh [email protected]
```

正如你在上面看到的,当我们第一次登录时,它说密码已过期。它将提示我们设置新密码并断开会话。
更新密码后,尝试 SSH 登录 Ubuntu 系统,这次我们应该可以登录了。
```
$ ssh [email protected]
```
输出:

太好了,上面的输出确认我们已经使用集中用户成功登录到我们的 Ubuntu 系统。这也说明我们已经成功配置了 FreeIPA 客户端。
如果你想从 ubuntu 系统中卸载 FreeIPA,然后运行以下命令集:
```
$ sudo ipa-client-install --uninstall
$ sudo rm -rf /var/lib/sss/db/*
$ sudo systemctl restart sssd.service
```
以上就是这篇文章的全部内容,我相信你已经发现它提供了很多信息。请在下面发表你的疑问和反馈。
*(题图:MJ/bd5b7777-f70a-4367-ac78-d026792b855a)*
---
via: <https://www.linuxtechi.com/configure-freeipa-client-on-ubuntu/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | FreeIPA is a powerful open-source identity management system that provides centralized authentication, authorization, and accounting services. In this post, we will walk through the steps to configure FreeIPA client on Ubuntu 22.04 / 20.04. After configuring the freeipa client then we will try to login with the user created on FreeIPA server.
In our previous post, we had already discussed FreeIPA Server installation steps on RHEL8/Rokcy Linux 8/ AlmaLinux 8.
Also Read: [How to Install FreeIPA Server on RHEL 8 | Rocky Linux 8 | AlmaLinux 8](https://www.linuxtechi.com/install-freeipa-rhel-rocky-almalinux/)
#### Creating User on FreeIPA Server for Centralization Authentication
Login to your freeipa server and create a user with name “sysadm”, run the following commands
$ sudo kinit admin Password for[[email protected]]: $ $ sudo ipa config-mod --defaultshell=/bin/bash $ sudo ipa user-add sysadm --first=System --last=Admin --password Password: Enter Password again to verify: ------------------- Added user "sysadm" ------------------- User login: sysadm First name: System Last name: Admin Full name: System Admin Display name: System Admin Initials: SA Home directory: /home/sysadm GECOS: System Admin Login shell: /bin/bash Principal name:[[email protected]]Principal alias:[[email protected]]User password expiration: 20230415073041Z Email address:[[email protected]]UID: 464600003 GID: 464600003 Password: True Member of groups: ipausers Kerberos keys available: True $
First command is to get Kerberos credentials and second command to set default login shell for all users as “/bin/bash” and third command used for creating the user with name “sysadm”
## Steps to configure FreeIPA Client on Ubuntu 22.04 /20.04
Perform the following steps to configure FreeIPA client for centralize authentication.
#### 1) Add DNS record of Ubuntu System on FreeIPA Server
Login to your FreeIPA Server and run the beneath command to add dns record for FreeIPA client (i.e Ubuntu 22.04/20.04)
$ sudo ipa dnsrecord-add linuxtechi.lan app01.linuxtechi.lan --a-rec 192.168.1.106 Record name: app01.linuxtechi.lan A record: 192.168.1.106 $
In the above command app01.linuxtechi.lan is my Ubuntu system with IP address 192.168.1.106.
Note: Make sure your FreeIPA Server and Clients are on the same timezone and getting the time from NTP Servers.
#### 2) Install FreeIPA client Package
Run the below command from your Ubuntu system to install freeipa-client along with the dependencies,
$ sudo apt install freeipa-client oddjob-mkhomedir -y
While installing freeipa-client, we will get following screen, Choose OK and hit enter
In the next screen, Hit enter to skip,
#### 3) Add FreeIPA Server IP & hostname in hosts file
Add below entries of your FreeIPA Server in /etc/hosts file
$ echo "192.168.1.102 ipa.linuxtechi.lan ipa" | sudo tee -a /etc/hosts $ echo "192.168.1.106 app01.linuxtechi.lan app01" | sudo tee -a /etc/hosts
Change IP address and hostname that suits to your setup.
#### 4) Configure FreeIPA client using ipa-client-install
Now run following “ipa-client-install” command to configure freeipa-client on your Ubuntu system,
$ sudo ipa-client-install --hostname=`hostname -f` --mkhomedir --server=ipa.linuxtechi.lan --domain linuxtechi.lan --realm LINUXTECHI.LAN
Change the FreeIPA Server address, domain name and realm that suits to your setup.
Output of above command would be something like below :
Perfect, output above confirms that ipa-client installation was successful.
Now allow user’s home directory to be created automatically when they first time authenticated with FreeIPA Server.
Append the following line in the file “/usr/share/pam-configs/mkhomedir”
required pam_mkhomedir.so umask=0022 skel=/etc/skel
$ echo "required pam_mkhomedir.so umask=0022 skel=/etc/skel" | sudo tee -a /usr/share/pam-configs/mkhomedir
To make above changes into affect, run following command
$ sudo pam-auth-update
Select OK and then hit enter.
#### 5) Try to Login to your Ubuntu System with sysadm user
Try to ssh or login to your Ubuntu system using the sysadm user,
$ ssh[[email protected]]
As you can see above, when we first time to login, it says password expired. It will prompt us to set new password and will disconnect the session.
After updating the password, try to ssh ubuntu system and this time we should able to login.
$ ssh[[email protected]]
Output,
Great, output above confirms that we have successfully login to our Ubuntu system using a centralize user. This also shows that we have successfully configured FreeIPA client.
In case, you want to uninstall freeipa from your ubuntu system then run following set of commands,
$ sudo ipa-client-install --uninstall $ sudo rm -rf /var/lib/sss/db/* $ sudo systemctl restart sssd.service
That’s all from this post, I believe you have found it informative. Kindly do post your queries and feedback in below comments section.
Bruce C.Very nice article but is there a command not listed in the article right after “Apply the above changes using following command,”
Pradeep KumarHi Bruce,
Thanks for notifying the missing command, now i have updated the article with correct suggested “pam-auth-update” command.
Myles P.Excellent, thank you for a concise, quality guide.
VysakhI’m encountering an issue with the sudo command in an IPA AD-trust environment. Specifically while logging in with Active Directory (AD) credentials works, the sudo command fails on Ubuntu versions 22.04 and 24.04. This problem does not occur on other Ubuntu flavors, CentOS or Red Hat-based distributions.
$ sudo su
sudo: PAM account management error: Permission denied
sudo: a password is required |
15,850 | Kali Linux 简介:你需要了解的一切 | https://www.debugpoint.com/kali-linux-introduction/ | 2023-05-27T16:55:00 | [
"Kali Linux",
"网络安全"
] | /article-15850-1.html | 
>
> 如果你计划开始你的 Kali Linux 之旅,那么你应该知道一些基本信息。以下是一个概述。
>
>
>
>
> **免责声明:** Kali Linux 是安全专家和以及网络安全爱好者所使用的工具,你不应该也不允许使用它来对他人的计算机系统进行未经允许的任何活动。任何使用它带来的法律后果和损失,将由使用者自行承担。我们之所以推荐 Kali Linux,是希望有更多的人来保护计算机设施和发现其中的缺陷并提前防范。
>
>
>
Kali Linux 是一个流行的 Linux 发行版,广泛应用于网络安全领域。它以其强大的工具和功能而闻名,是安全专业人士、道德黑客(白帽子)和网络安全研究人员的绝佳选择。
### Kali Linux 简介

在核心层面上,Kali Linux 是基于 [Debian-testing](https://www.debugpoint.com/debian-stable-to-testing/) 分支构建的,专门为网络分析师、渗透测试人员和网络安全专业人员设计。Kali Linux 是由 Offensive Security 维护、Mati Aharoni 和 Devon Kearns 开发的 Debian Linux 衍生发行版。
它带有全面的预安装工具集,用于各种安全测试目的。它是一个开源操作系统,可以免费下载并使用。
### 历史
Kali Linux 最初发布于 2013 年 3 月,是 BackTrack Linux 的继任者。BackTrack 是一种流行的 Linux 发行版,广泛用于渗透测试和数字取证。它由 Offensive Security 创建,这是一家专门从事信息安全培训和渗透测试服务的网络安全公司。自其最初发布以来,Kali Linux 经过了许多更新和改进,成为最流行的用于安全工作负载的 Linux 发行版。

### 功能及何时使用 Kali Linux
Kali Linux 具有许多预安装的工具,对于安全专业人员、道德黑客和网络安全研究人员至关重要。它具有用户友好的界面,即使对于初学者也很容易使用。该操作系统可以高度定制,以满足用户的需求。它也与各种硬件兼容,使它成为桌面、笔记本电脑甚至像树莓派等小型设备的通用操作系统。
它还带有一个特定的变体,称为 [Kali NetHunter](https://www.kali.org/docs/nethunter/),主要为安卓操作系统提供工具。
### 安装过程
有多种方式可以使用 Kali Linux。因此,安装方式可能会有所不同。进行渗透测试或安全测试的常规方法是使用 <ruby> 立付 <rt> Live </rt></ruby> 介质。Kali Linux 和其工具被配置为可以通过 USB 存储器在受感染或易受攻击的系统上运行。
此外,Kali Linux 也可以安装在虚拟机或物理机中。安装过程简单,只需几分钟即可完成。Offensive Security 在其网站上提供了详细的 Kali Linux 安装说明。
如果你身在 Windows 系统中,并想在虚拟机中尝试 Kali Linux,可以阅读以下教程:
>
> **[如何在 Windows 上安装 Kali Linux](https://www.debugpoint.com/install-kali-linux-virtualbox-windows/)**
>
>
>
### 开始使用 Kali Linux
一旦你安装了 Kali Linux 或从中启动,你需要熟悉它的界面和功能。如果你是第一次使用它很重要。理想情况下,如果你是 Linux 的新手,你不应该把 Kali Linux 作为第一次尝试 Linux 的机会。你应该首先熟悉 Linux 及其命令。因此,最好的方法是安装易于使用的 Linux 发行版,如 [Linux Mint](https://www.debugpoint.com/linux-mint),然后再尝试 Kali Linux。
Kali Linux 使用轻量级和快速的 Xfce 桌面环境,有传统的菜单和图标驱动的桌面。主应用程序菜单将所有工具分类,以便更轻松地使用。
### 了解工具
Kali Linux 自带了对于安全测试是必不可少的丰富的基本工具,包括网络扫描、漏洞评估、密码破解和取证分析。Kali Linux 中一些最流行的工具有 Nmap、Metasploit、Aircrack-ng 和 John the Ripper 等等。
Kali Linux 中一些最流行的高级工具包括 Burp Suite、OWASP ZAP、Social Engineering Toolkit(SET)和 Wireshark 等等。这些工具非常复杂,需要高级技能才能有效使用。但是,它们对于进行全面的安全测试是必不可少的,被全球的安全专业人员广泛使用。

你可以在主应用程序菜单中按类别查找工具(如上图所示)。
### Kali Linux 与其他安全工具的区别
Kali Linux 及其工具箱并不是在网络安全领域中唯一的工具集合。其他安全工具,如 [Metasploit](https://www.metasploit.com/)、[Nessus](https://www.tenable.com/products/nessus) 和 [OpenVAS](https://openvas.org/) 也广泛用于安全测试。然而,Kali Linux 和这些工具相比有几个优点。
首先,它是一个 all-in-one 平台,具有全面的预安装工具,使其成为安全专业人员的方便选择。
其次,Kali Linux 是一个开源平台,这意味着它可以免费下载和使用,对于小型企业和创业公司来说是一种具有成本效益的选择。更不用说,Kali 团队提供了全面的文档,你可以免费培训学生和新员工,成本为零。
最后,Kali Linux 拥有庞大、活跃的开发者和用户社区,他们定期为其开发做出贡献,并为用户提供支持。
### Kali Linux 的应用
Kali Linux 广泛应用于渗透测试,渗透测试是测试计算机系统、网络或 Web 应用程序以确定攻击者可以利用的漏洞和弱点的过程。使用情况可能基于你或你的组织的需求而有所不同。
渗透测试是网络安全的重要组成部分,由安全专业人员用于评估组织的安全姿态。由于其全面的工具和功能集,Kali Linux 是进行安全测试的有效平台,因此成为渗透测试的流行选择。
除了渗透测试,Kali Linux 还具有多个安全应用程序。它可以用于数字取证,事件响应和恶意软件分析。Kali Linux 带有这些应用程序的预安装工具,其中包括文件刻录工具、内存分析工具和网络取证工具。
以下是在 Kali Linux 中预先安装的(开源)应用程序的的类别概述:
* 信息搜集
* 漏洞分析
* Web 应用程序分析
* 数据库评估
* 密码攻击
* 无线攻击
* 逆向工程
* 利用工具
* 嗅探和欺骗
* 后渗透
* 取证
* 报告工具
* 社交工程工具
想要了解更多关于这些应用程序的详细信息,你需要安装 Kali Linux 并尝试使用它们。
### Kali Linux 的更新和支持
Kali Linux 会定期接收更新和补丁,以解决安全漏洞并提高操作系统的性能。Offensive Security 在其网站上提供了详细的 Kali Linux 更新说明。除了更新之外,Kali Linux 还有庞大、活跃的开发者和用户社区,定期为其开发做出贡献,并为用户提供支持。
### 有效使用 Kali Linux 的提示
为了有效地使用 Kali Linux 或从基础开始学习 Kali Linux,用户应遵循以下几个提示和最佳实践:
* 熟悉操作系统和其功能
* 用备用机器或 USB 存储器,将 Kali Linux 安装在其中
* 有效和高效地使用预安装工具
* 定期使用更新和补丁保持操作系统最新
* 加入 Kali Linux 社区以获取支持和分享知识
* 负责任地和道德地使用 Kali Linux
### 结论
Kali Linux 是一个功能强大、多才多艺的 Linux 发行版,广泛用于网络安全社区。它具有全面的预安装工具和功能集,使其成为安全测试、数字取证、事件响应和恶意软件分析的有效平台。虽然 Kali Linux 需要高级技能才能有效使用,但它拥有庞大、活跃的开发者和用户社区,为用户提供支持和知识分享。
总之,如果你是网络安全专业人士、道德黑客或对网络安全感兴趣的人,那么 Kali Linux 是你必须熟悉的必备工具。凭借其先进的工具、开源平台和活跃的社区,Kali Linux 是进行安全测试和研究的强大平台。
### 关于 Kali Linux 的一些常见问题
**Kali Linux 和其他 Linux 发行版有什么区别?**
虽然 Kali Linux 是一个 Linux 发行版,但它是专门设计用于渗透测试和网络安全的。与其他发行版不同,Kali Linux 具有全面的预安装工具和功能,这些工具和功能在进行安全测试和研究时不可或缺。
**我能在我的个人电脑上使用 Kali Linux 吗?**
是的,你可以在你的个人电脑上使用 Kali Linux。它可以作为虚拟机或与现有操作系统双重启动进行安装。
**使用 Kali Linux 是否合法?**
是的,使用 Kali Linux 是合法的。但是,它应该只用于进行安全测试和研究目的,道德和负责任的用途。
**我可以自定义 Kali Linux,添加或删除工具吗?**
是的,你可以自定义 Kali Linux,添加或删除工具。Kali Linux 是一个开源平台,用户可以根据需要修改和自定义它。
**我怎样才能获得 Kali Linux 的支持?**
Kali Linux 拥有庞大、活跃的开发者和用户社区,他们提供支持和知识分享。几个在线资源,包括论坛、博客和文档,提供解决常见问题和错误的解决方案。Kali Linux 的开发者 Offensive Security 在他们的网站上也提供支持。
### 更多资源
* [Kali Linux 网站](https://www.kali.org/)
* [论坛](https://forums.kali.org/) 和 [Discord](https://discord.kali.org/)
* [下载](https://www.kali.org/get-kali/)
* [Kali Linux 文档](https://www.kali.org/docs/)
* [Kali 工具文档](https://www.kali.org/tools/)
---
via: <https://www.debugpoint.com/kali-linux-introduction/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,852 | Reminders:一个漂亮的开源 Linux 应用,可帮助你完成工作 | https://news.itsfoss.com/reminders/ | 2023-05-27T20:02:15 | [
"提醒",
"Todo"
] | https://linux.cn/article-15852-1.html |
>
> 你已尽力而为,但提醒仍然有帮助!
>
>
>

你经常忘记事情吗? 需要一点帮助来记住你的任务吗? ?
虽然你可以使用 [Linux 的笔记应用](https://itsfoss.com/note-taking-apps-linux/),但它们可能无法有效地提醒你任务和事情。
“Reminders” 应用可以成为你的小帮手,提醒你未完成的工作。
让我们看看它能为你做些什么。
### Reminders:概述 ⭐
Reminders 是一个**简单的 Linux 开源提醒应用**,主要使用 Python 编写。它在一个紧凑的包中包含了一些很好的特性。
你也可以将其用作 [待办事项列表应用](https://itsfoss.com/to-do-list-apps-linux/) 之一。
当你启动该应用时,你会看到一个精简的主屏幕,所有提醒都井井有条。
当然,我创建了一些你可能想要关注的有趣任务!?

>
> ? 默认情况下,你所有的提醒都按时间排序; 你可以使用左上角的切换按钮更改它。
>
>
>
你可以使用右下角的加号按钮创建新提醒。你可以给它起一个名字、一个简短的描述、将它设置为一个重要的提醒,并设置日期/时间。
你还可以将其设置为以特定的时间间隔重复,例如分钟、小时、天和周。
当提醒时间到了时,它会向你显示通知并播放声音通知你。

**犯了一个错误?**
你可以通过选择现有提醒并单击 “<ruby> 编辑 <rt> Edit </rt></ruby>” 按钮来编辑它们。

你还可以进入“<ruby> 即将到来的提醒 <rt> Upcoming Reminders </rt></ruby>”类别以查看已安排的提醒。

同样,你可以通过进入特定类别来查看过去的提醒和已完成的提醒:“<ruby> 过去的提醒 <rt> Past Reminders </rt></ruby>” 和 “<ruby> 已完成的提醒 <rt> Completed Reminders </rt></ruby>”。

Reminders 还**支持自定义列表**,可以整齐地组织提醒事项,以便快速轻松地访问。
**请允许我向你展示如何创建列表。**
首先,你必须创建一个自定义列表,方法是单击边栏中的 “<ruby> 编辑列表 <rt> Edit Lists </rt></ruby>” 按钮创建一个。

然后,在创建新提醒时,在 “<ruby> 位置 <rt> Location </rt></ruby>” 选项下,选择你刚刚创建的列表。
>
> ? 你还可以在编辑现有提醒时选择列表。
>
>
>

现在,单击侧边栏菜单中的列表以查看其下方的提醒。

>
> ? 这让我印象深刻。Reminders 有**可选支持,链接一个人的微软帐户以与他们的微软 To Do 列表同步**。
>
>
>
这是一个非常简单的链接过程,能够调整获取待办事项的自动刷新频率。

Reminders 在一个非常紧凑的包中提供了一些很棒的功能,[微软 To Do](https://todo.microsoft.com/) 集成可能会吸引正在寻找具有此类功能的 Linux 应用的用户。
最接近的替代方案是 “[Go For It!](https://itsfoss.com/go-for-it-to-do-app-in-linux/)”,这是另一个提供类似用户体验的 Linux 待办事项应用(未活跃维护,但足够好)。
### ? 获取 Reminders
你可以从 [Flathub](https://flathub.org/apps/io.github.dgsasha.Remembrance) 下载 Reminders 应用或使用 [GitHub](https://github.com/dgsasha/remembrance) 上的源代码构建它。
他们有将其移植到 Windows 的计划,但它可能发生也可能不会发生。
如果你已经安装了 [Flatpak](https://itsfoss.com/flatpak-guide/),你可以在终端输入以下命令来安装它:
```
flatpak install flathub io.github.dgsasha.Remembrance
```
>
> **[下载 Reminders(Flathub)](https://flathub.org/apps/io.github.dgsasha.Remembrance)**
>
>
>
? 你使用什么待办事项或提醒应用来跟踪你想做的事情? 在下面的评论中分享你的选择。
---
via: <https://news.itsfoss.com/reminders/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Are you often forgetting things? Want a little help remembering your tasks? 🤔
While you can always use [note-taking apps for Linux](https://itsfoss.com/note-taking-apps-linux/?ref=news.itsfoss.com), they may not effectively remind you of tasks and things.
The 'Reminders' app can be your little helper, reminding you of your pending work.
Let's see what it can do for you.
## Reminders: Overview ⭐
Reminders is a **simple open-source reminder app for Linux** written primarily using Python. It packs some good features in a compact package.
You can use it as one of the [to-do list apps](https://itsfoss.com/to-do-list-apps-linux/?ref=news.itsfoss.com) as well.
When you launch the app, you are greeted with a minimal home screen with all your reminders organized neatly.
Of course, I created some interesting tasks that you might want to follow!👀
You can use the plus button at the bottom right to create a new reminder. You can give it a name, a brief description, set it as an important reminder, and set the date/time.
You can also set it to repeat at specific intervals like minutes, hours, days, and weeks.
When the time comes for your reminder, it will show you a notification and play a sound to notify you.
**Made a mistake? **
You can edit existing reminders by selecting them and clicking the '**Edit**' button.
You can also go to the '**Upcoming Reminders**' category to see the reminders that have been scheduled.
Similarly, you can check your past reminders and the completed ones by going to the specific categories: '**Past Reminders**' & '**Completed Reminders**.'
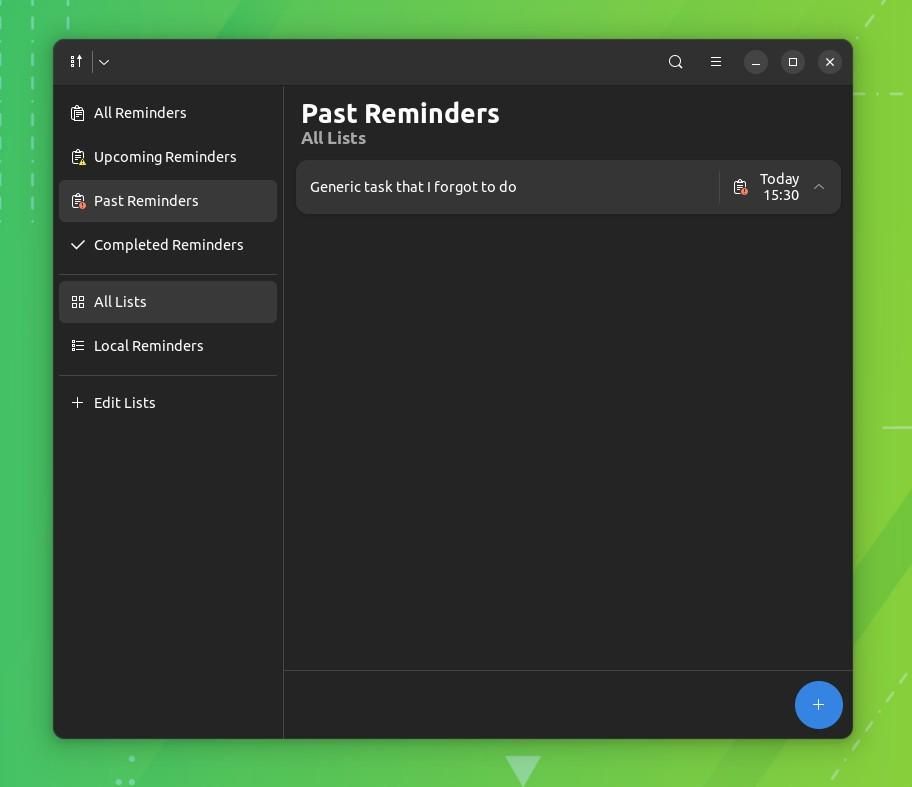
Reminders also **support custom lists** that organize reminders neatly for quick and easy access.
**Allow me to show you how to create a list.**
First, you must create a custom list by clicking on the 'Edit Lists' button in the sidebar and creating one.
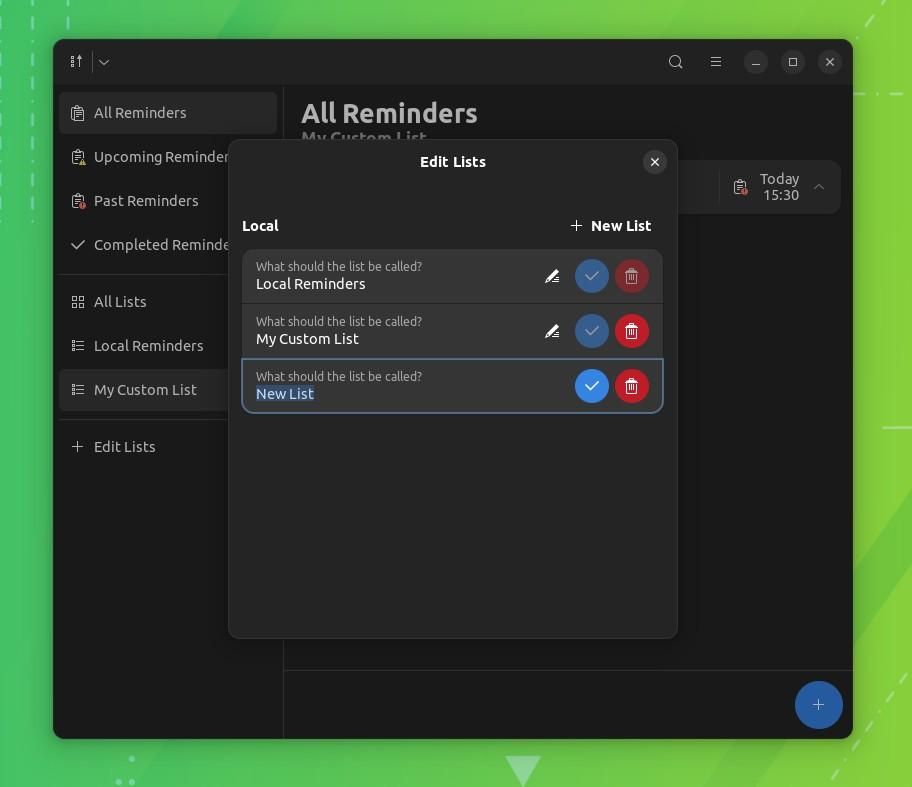
**Suggested Read **📖
[Free and Open-Source Alternatives to Microsoft PlannerLooking for free and open-source tools to replace Microsoft Planner? Here are some options!](https://itsfoss.com/microsoft-planner-alternatives/?ref=news.itsfoss.com)

Then, when creating a new reminder, under the 'Location' options, select the list you just created.
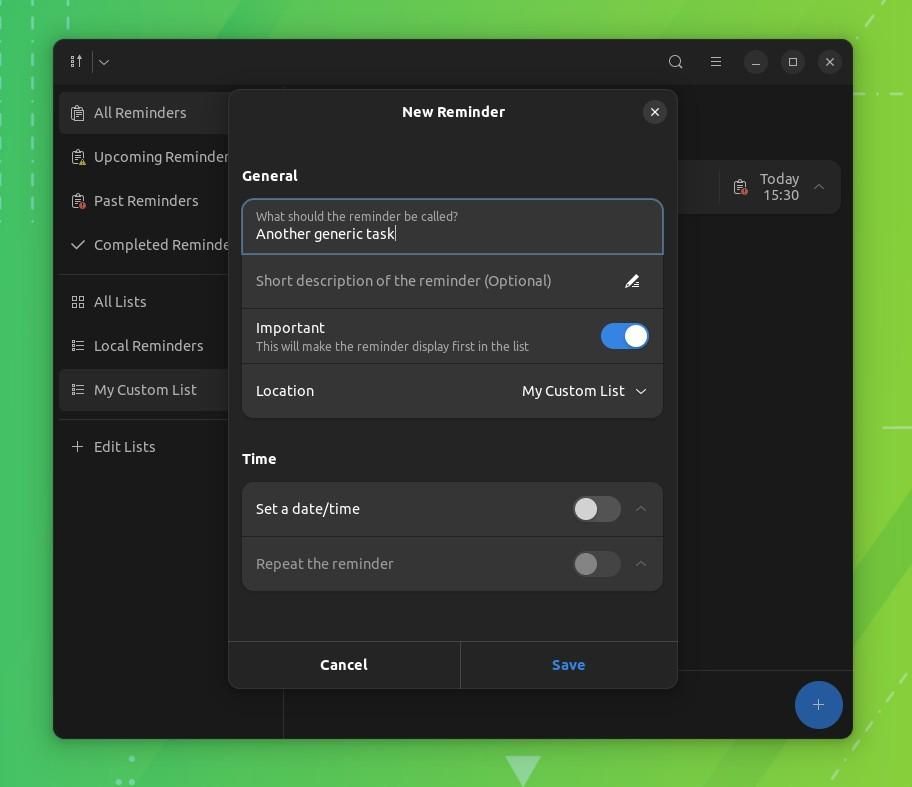
Now, click on the list from the sidebar menu to view the reminders under it.
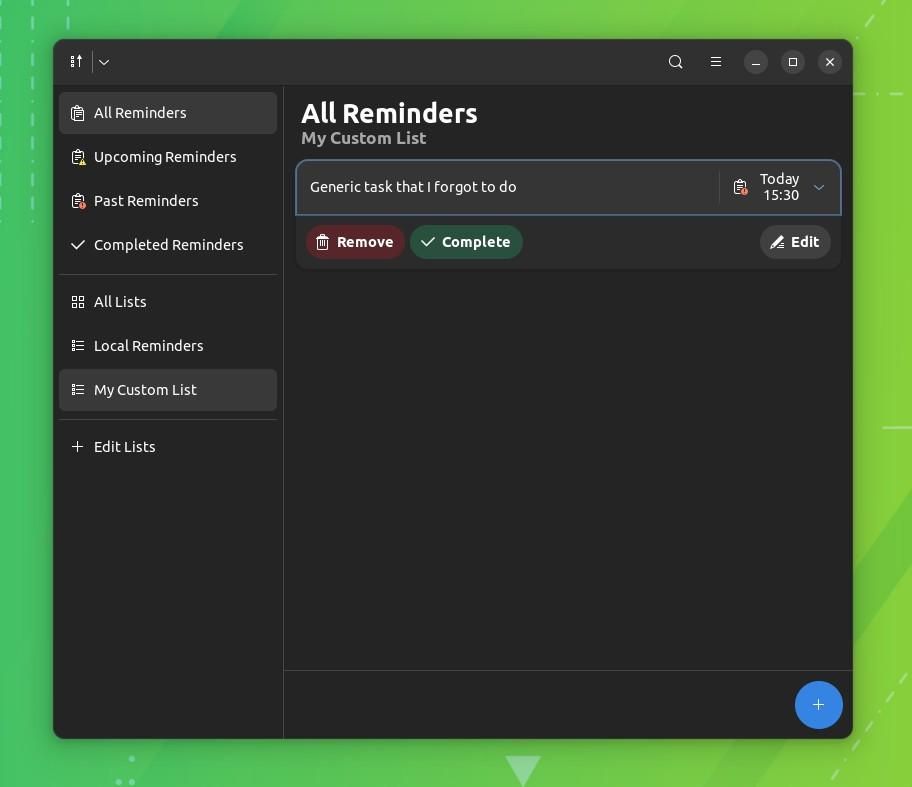
💡 This impressed me; Reminders has **optional support for linking one's Microsoft account to sync up with their Microsoft To Do lists**.
It's quite a straightforward linking process, with the ability to tweak the auto-refresh frequency of fetching the to-dos.
Reminders offer some great functionality in a very compact package, and the [Microsoft To Do](https://todo.microsoft.com/?ref=news.itsfoss.com) integration might appeal to users who are looking for a Linux app with such functionality.
The closest alternative to this would be '[Go For It](https://itsfoss.com/go-for-it-to-do-app-in-linux/?ref=news.itsfoss.com)!', another to-do app for Linux that provides a similar user experience (not actively maintained, but good enough).
**Recommended Read **📖
[7 Best To Do List Apps for Linux Desktop [2023]A good to-do list app helps you organize your work and be more productive by focusing on meaningful work. Here are the best to-do list apps for Linux desktop.](https://itsfoss.com/to-do-list-apps-linux/?ref=news.itsfoss.com)

## 📥 Get Reminders
You can download the Reminders app from [Flathub](https://flathub.org/apps/io.github.dgsasha.Remembrance?ref=news.itsfoss.com) or build it using its source code found on [GitHub](https://github.com/dgsasha/remembrance?ref=news.itsfoss.com).
They have plans for porting it for Windows, but it may or may not happen.
If you already have [Flatpak setup](https://itsfoss.com/flatpak-guide/?ref=news.itsfoss.com), you can type in the following command to install it via the terminal:
`flatpak install flathub io.github.dgsasha.Remembrance`
*💬 What to-do list or reminder app do you use to track what you want to do? Share your options in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,853 | 我如何使用内疚作为做好事的动力 | https://opensource.com/article/23/4/guilt-motivation | 2023-05-27T20:17:20 | [
"内疚"
] | https://linux.cn/article-15853-1.html | 
>
> 内疚通常被认为是一种消极的情绪,但通过很好地引导它,你可以取得令人惊讶的成功。
>
>
>
最近,一位朋友兼同事问我是否有兴趣一起在会议上发言。我很惊喜,因为我对他们展示的项目贡献不大,但我表达了兴趣。我们开会讨论演讲内容,那时我才知道我被邀请参加的真正原因:会议的 [多样性、公平性和包容性(DEI)](https://opensource.com/tags/diversity-and-inclusion) 倡议要求至少有一名发言人不是男性。我被冒犯了。感觉我被邀请参加会议只是因为我的性别,而不是基于我的能力。
我的朋友向我保证,这并不是邀请我的唯一原因。他们需要新的贡献者,因为有很多工作要做,他们希望我可以帮助填补这一空白。
我考虑了一下,并试图理解为什么会有 DEI 的举措。我还想到了硬币的另一面,想做演讲的人不能做演讲,除非他们找到一个来自少数群体的人和他们一起演讲。
当我想到大局和这个机会将给我带来的好处时,我决定放弃我的自我伤害。一旦我放下被冒犯的感觉,我就意识到,我在介绍我没有直接贡献的东西时也感到非常不舒服。我的道德观并不认同这一点。我怎么可能踏上舞台,充当我没有努力过的东西的代言人?
### 决心提供更多帮助
我对这个项目做了一些研究。这项技术对我来说并不完全陌生,而且我很好地掌握了它所要实现的基本原理。事实上,它的总体目标让我感到很兴奋,可以做出贡献。如果做得好,它对用户来说将是超级有用的。
我下定决心,只有当我有机会十倍地回馈社区并成为一个关键的贡献者时,我才会继续这个演讲机会。我的朋友非常愿意帮助我走上这条道路。
带着这个决心,我们提交了我们的演讲。我的共同演讲者都很支持我,让我感到很受欢迎。他们说,只要我对这个项目有兴趣,有热情,其他都不重要。
参加这次会议是一个巨大的机会,它对我产生了如此 [积极的影响](https://opensource.com/article/23/4/tips-tech-conference)。我遇到了很多开源社区的有经验的人,我感到很受鼓舞!我学到了很多新的东西!我从会议上的人和各种小组、会议和讨论中学到了 *很多* 新东西。我们的演讲很顺利,我认为在这样一个大型会议上发表演讲是一个相当大的成就。
然而,会议一结束,我的 *内疚感* 就开始发作了。
### 内疚是一种动力
我觉得我欠这个社区和那些给我这个机会的人。我想专注于我所做的承诺,但在其他更优先的事情的阻碍下,这很难。每当我偏离我的计划时,内疚感就会让我坚持下去。它提醒我,我必须回馈给我这样一个好机会的社区。经过几个月的挣扎和折腾,我可以自豪地说,我没有放弃。今天,我是这个项目的一个积极贡献者。
我喜欢它带来的挑战,我喜欢解决项目领域中的一些关键问题。我还能够带头在我们的下游生态系统中实施这个上游项目。作为锦上添花,我再次被邀请与团队一起展示,并向社区介绍项目的最新情况。这一次,不是因为 DEI 的倡议,因为比例已经平衡了。
感到内疚毕竟不是那么糟糕!
我很高兴我抓住了这个机会,我也很高兴这对每个参与者来说都是一个双赢的局面。如果没有人找我做共同主持人,我可能永远也不会参与这个项目,那将是多么大的失误啊!我很感激这些人!我很感谢那些给我这个机会并支持我的人。
我可能不是唯一面临这种情况的女性。我想告诉所有的女性,如果这样的机会出现,没有必要感到内疚,或者你“欠”别人的,或者任何形式的压力。如果你确实感到这种压力,那么就把这种情绪变成一种武器,用它来做好事!
这样就和标题联系起来了吗?因为我说的是我如何把这种内疚感作为一种动力,但也说首先不要感到任何内疚、
另一方面,不确定我们是否应该将文章的标题改为“DEI 机会在开始时可能不舒服,但有优势”之类的东西?无论如何,我对这篇文章总体上是满意的!
*(题图:MJ/19d2ee02-eaf1-4cd7-8bd2-0be83466b2fc)*
---
via: <https://opensource.com/article/23/4/guilt-motivation>
作者:[Surya Seetharaman](https://opensource.com/users/its-surya) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently, I was asked by a friend and colleague if I were interested in speaking together at a conference. I was pleasantly surprised because I hadn't contributed much to the project they were presenting, but I expressed interest. We met to discuss the presentation, and that's when I learned the real reason I was asked to participate: The conference's [diversity, equity, and inclusion (DEI)](https://opensource.com/tags/diversity-and-inclusion) initiatives required there to be at least one speaker that does not identify as a man. I was offended; it felt like I was approached only because of my gender, not based on merit.
My friend assured me that wasn't the only reason I'd been asked. They needed new contributors to the project because there was a lot of work to be done, and they were hoping I could help fill that gap.
**[ Want to create your own event? Read the 10-step guide for a successful hackathon ]**
I gave it some thought and tried to understand why the DEI initiatives were in place. I also thought about the other side of the coin, where the people who wanted to present couldn't, unless they found someone from a minority group to present alongside them.
As I thought about the bigger picture and the benefits this opportunity would bring to me, I decided to forego my ego being hurt. Once I let go of feeling offended, I realized that I was also feeling very uncomfortable presenting something that I hadn't contributed directly to. My ethics didn't agree with that. How could I possibly step onto a stage and act as the face of something I hadn't worked on?
## Resolving to help more
I did some research on the project. The technology was not totally alien to me, and I had a good grasp of the fundamentals it was trying to achieve. In fact, its overall goal made me feel excited to contribute. If done well, it would be super useful to users.
I made a resolution that I would go ahead with this speaking opportunity only if I got the opportunity to give back to the community tenfold and become a key contributor. My friend was more than willing to help me on that journey.
With that resolve, we submitted our talk. My co-presenters were supportive and made me feel welcome. They said that as long as I was interested and had a passion for the project, nothing else mattered.
**[ Also read How I returned to open source after facing grief ]**
Participating in the conference was a huge opportunity, and it had such a [positive impact](https://opensource.com/article/23/4/tips-tech-conference) on me. I met a lot of experienced people across the open source community and I felt inspired! I learned a *lot* of new things from the people and the various panels, sessions, and discussions at the conference. Our presentation went well, and I consider giving a talk at such a big conference quite an achievement.
However, once the conference was over the *guilt* started kicking in.
## Guilt as a motivator
I felt like I owed the community and the people who had given me this chance. I wanted to focus on the promise I'd made, but it was hard with other higher-priority things getting in the way. Whenever I deviated from my plan, the guilt kept me on track. It reminded me that I had to give back to the community that had given me such a good opportunity. After a few months of struggling and juggling, I can proudly say that I didn't give up. Today, I'm an active contributor to that project.
I love the challenges it presents, and I enjoy solving some of the key issues in the project's area. I also have been able to take the lead in implementing this upstream project in our downstream ecosystem. As icing on the cake, I was again invited to present with the team and give the community updates for the project. This time, it was not because of a DEI initiative, as the ratio was already balanced.
Feeling guilt isn't so bad after all!
I'm glad that I took the opportunity, and I'm glad it turned out to be a win-win situation for everyone involved. If I hadn't been approached about being a co-presenter, I probably would have never gotten involved in this project, and that would have been such a miss! I'm grateful to the people who gave me this chance and supported me.
I'm probably not the only woman who has faced this. I want to tell all the women out there if such an opportunity presents itself, there's no need to feel guilt, or that you "owe" anyone or any kind of pressure. If you feel such pressure, turn that emotion into a weapon and do good with it! I encourage you to take the opportunity if it will benefit you and make the most out of it. Later on, if you can do the same for another person and uplift them, that’s how you can really pay back to the community. After all, this is what open source community is all about. It's as much about the people as is about the technology being built!
**[ Ready to level up your communication skills? Get advice from IT leaders. Download 10 resources to make you a better communicator. ]**
## Comments are closed. |
15,855 | Rust 基础系列 #5: Rust 中的函数 | https://itsfoss.com/rust-functions/ | 2023-05-29T15:06:30 | [
"Rust"
] | https://linux.cn/article-15855-1.html | 
>
> 在这一章中,在实例的帮助下,学习如何使用函数并从中返回值。
>
>
>
就跟任何现代编程语言一样,Rust 也有函数。
你已经熟悉的函数是 `main` 函数。这个函数在程序启动时被调用。
但是其他函数呢?在本文中,你将学习如何在 Rust 程序中使用函数。
### 函数的基本语法
你可能已经在我们声明 `main` 函数时知道了这一点,不管怎么样,还是让我们看一下声明函数的语法。
```
// 声明函数
fn function_name() {
<statement(s)>;
}
// 调用函数
function_name();
```
来让我们看一个简单的函数,它将字符串 `"Hi there!"` 打印到标准输出。
```
fn main() {
greet();
}
fn greet() {
println!("Hi there!");
}
```
>
> ? 与 C 不一样的是,不管你是否要在声明或定义之前调用函数都没有关系。只要这个函数在 *某个地方* 被声明了,Rust 就会处理它。
>
>
>
正如预期,它的输出如下:
```
Hi there!
```
这挺简单的。让我们把它提升到下一个级别。让我们创建一个接受参数并返回值的函数。有没有参数和有没有返回值这两者之间无关。
### 使用函数接受参数
声明一个接受参数的函数的语法如下:
```
// 声明函数
fn function_name(variable_name: type) {
<statement(s)>;
}
// 调用函数
function_name(value);
```
你可以把函数参数想象成一个传递给函数的 [元组](/article-15837-1.html)。它可以接受多种数据类型的参数,而且你可以接受任意多个参数。所以,你不必局限于接受相同类型的参数。
与某些语言不同的是,Rust 没有 *默认参数*。**在调用函数时填充所有参数是强制性的**。
#### 示例:饥饿函数
来让我们看一个程序来更好地理解这个。
```
fn main() {
food(2, 4);
}
fn food(theplas: i32, rotis: i32) {
println!(
"我饿了... 我需要 {} 个葫芦巴叶饼和 {} 个罗提!",
theplas, rotis
);
}
```
在第 5 行,我声明了一个名为 `food` 的函数。这个函数接受 2 个参数:`theplas` 和 `rotis`(印度食物的名字)。然后我打印了这些变量的内容。
对于 `main` 函数,我使用参数 `2` 和 `4` 调用 `food` 函数。这意味着 `theplas` 被赋值为 `2`,`rotis` 被赋值为 `4`。
来让我们看一下程序的输出:
```
我饿了... 我需要 2 个葫芦巴叶饼和 4 个罗提!
```
我现在真的饿了... ?
### 从函数返回值
就像函数可以接受参数一样,函数也可以返回一个或多个值。这样的函数的语法如下:
```
// 声明函数
fn function_name() -> data_type {
<statement(s)>;
}
// 调用函数
let x = function_name();
```
函数可以使用 `return` 关键字或者使用表达式而不是语句来返回一个值。
等等!什么是表达式?
#### 在进一步之前:语句与表达式
在讲解 Rust 函数的例子中提起这个可能不太合适,但是你应该理解 Rust 和其他编程语言中语句和表达式的区别。
语句是以分号结尾且 *不会计算出某个值* 的代码行。另一方面,表达式是一行不以分号结尾且计算出某个值的代码行。
来让我们用一个例子来理解:
```
fn main() {
let a = 873;
let b = {
// 语句
println!("Assigning some value to b...");
// 表达式
a * 10
};
println!("b: {b}");
}
```
在第 3 行,我开始了一个代码块,在这个代码块中我有一个语句和一个表达式。注释标明了哪个是哪个。
在第 5 行的代码不会计算出某个值,因此需要以分号结尾。这是一个语句。
第 8 行的代码计算出了一个值。它是 `a * 10`(`873 * 10`),并计算出了 `8730`。因为这一行没有以分号结尾,所以这是一个表达式。
>
> ? 使用表达式是从代码块中返回某些东西的一种方便的方法。因此,当返回一个值时,它是 `return` 关键字的替代方案。表达式不仅仅用于从函数中 “返回” 一个值。正如你刚刚看到的,`a * 10` 的值是从内部作用域 “返回” 到外部作用域,并赋值给变量 `b`。一个简单的作用域不是一个函数,但表达式的值仍然被 “返回” 了。
>
>
>
#### 示例:购买腐烂的水果
来让我们看一个演示以理解函数如何返回一个值:
```
fn main() {
println!(
"如果我从水果摊买了 2 公斤苹果,我必须付给他们 {} 印度卢比。",
retail_price(2.0)
);
println!(
"但是,如果我从水果摊买了 30 公斤苹果,我就要付给他们 {} 印度卢比。",
wholesale_price(30.0)
);
}
fn retail_price(weight: f64) -> f64 {
return weight * 500.0;
}
fn wholesale_price(weight: f64) -> f64 {
weight * 400.0
}
```
我在上述代码中有两个函数:`retail_price` 和 `wholesale_price`。两个函数都接受一个参数并将值存储在 `weight` 变量中。这个变量的类型是 `f64`,函数签名表示最终函数返回一个 `f64` 值。
这两个函数都将购买的苹果的重量乘以一个数字。这个数字表示苹果的当前每公斤价格。由于批发商有大量订单,物流在某种程度上更容易,价格可以降低一点。
除了每公斤价格之外,这两个函数还有一个区别。那就是,`retail_price` 函数使用 `return` 关键字返回乘积。而 `wholesale_price` 函数使用表达式返回乘积。
```
如果我从水果摊买了 2 公斤苹果,我必须付给他们 1000 印度卢比。
但是,如果我从水果摊买了 30 公斤苹果,我就要付给他们 12000 印度卢比。
```
输出显示,从函数返回值的两种方法都按预期工作。
#### 返回多个值
你可以有一个返回不同类型的多个值的函数。你有很多选择,但返回一个元组是最简单的。
接下来是一个示例:
```
fn main() {
let (maths, english, science, sanskrit) = tuple_func();
println!("数学考试得分: {maths}");
println!("英语考试得分: {english}");
println!("科学考试得分: {science}");
println!("梵语考试得分: {sanskrit}");
}
fn tuple_func() -> (f64, f64, f64, f64) {
// return marks for a student
let maths = 84.50;
let english = 85.00;
let science = 75.00;
let sanskrit = 67.25;
(maths, english, science, sanskrit)
}
```
函数 `tuple_func` 返回 4 个封装在一个元组中的 `f64` 值。这些值是一个学生在四门科目(满分 100 分)中获得的分数。
当函数被调用时,这个元组被返回。我可以使用 `tuple_name.0` 方案打印这些值,但我认为最好先解构元组,这样可以帮助我们搞清楚值对应的是什么。然后我使用了包含被解构的元组的值的变量来打印分数。
这是我得到的输出:
```
数学考试得分: 84.5
英语考试得分: 85
科学考试得分: 75
梵语考试得分: 67.25
```
### 总结
本文介绍了 Rust 编程语言中的函数。这些是函数的 “类型”:
* 不接受任何参数也不返回任何值的函数
* 接收一个或多个参数的函数
* 给调用者返回一个或多个值的函数
你知道接下来是什么吗?Rust 中的条件语句,也就是 if-else。请继续关注并享受学习 Rust 的过程。
*(题图:MJ/5a07503b-c691-4276-83b2-bb42f5fda347)*
---
via: <https://itsfoss.com/rust-functions/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Rust Basics Series #5: Functions in the Rust Programming Language
In this chapter of the Rust Basics series, learn to use functions and return values from them with the help of examples.
Like any modern programming language, Rust too has functions.
The function that you are already familiar with is the `main`
function. This function gets called when the program is launched.
But what about other functions? In this article, you'll learn to use functions in Rust programs.
## The basic syntax of a function
You may already know this based on how we declare the `main`
function, but let's look at the syntax of declaring a function nonetheless.
```
// declaring the function
fn function_name() {
<statement(s)>;
}
// calling the function
function_name();
```
Let's look at a simple function that prints the string "Hi there!" to the standard output.
```
fn main() {
greet();
}
fn greet() {
println!("Hi there!");
}
```
*, Rust will handle it.*
*somewhere*And as expected, it has the following output:
`Hi there!`
That was simple. Let's take it to the next level. Let's create functions that accept parameter(s) and return value(s). Neither are mutually exclusive or inclusive.
## Accepting parameters with functions
The syntax for a function that accepts the parameter is as follows:
```
// declaring the function
fn function_name(variable_name: type) {
<statement(s)>;
}
// calling the function
function_name(value);
```
You can think of the function parameters as a [tuple](https://itsfoss.com/rust-arrays-tuples/) that is passed to the function. It can accept parameters of multiple data types and as many as you wish. So, you are not restricted to accepting parameters of the same type.
Unlike some languages, Rust does not have *default arguments*. **Populating all parameters when calling the function is compulsory**.
### Example: Famished function
Let's look at a program to understand this better.
```
fn main() {
food(2, 4);
}
fn food(theplas: i32, rotis: i32) {
println!(
"I am hungry... I need {} theplas and {} rotis!",
theplas, rotis
);
}
```
On line 5, I declare a function called `food`
. This function takes in 2 parameters: `theplas`
and `rotis`
(Names of Indian food items). I then print the contents of these variables.
From the `main`
function, I call the `food`
function with parameters '2' and '4'. This means that `theplas`
gets assigned the value '2' and `rotis`
get assigned the value '4'.
Let's look at the program output:
`I am hungry... I need 2 theplas and 4 rotis!`
And now I'm actually hungry... 😋
## Returning values from a function
Just as a function can accept values in the form of parameters, a function can also return one or more values. The syntax for such a function is as follows:
```
// declaring the function
fn function_name() -> data_type {
<statement(s)>;
}
// calling the function
let x = function_name();
```
The function can return a value using either the `return`
keyword or by using an expression instead of a statement.
Wait! Expression what?
### Before you go further: Statements vs Expressions
It may not fit in the flow of the Rust function examples but you should understand the difference between statements and expressions in Rust and other programming languages.
A statement is a line of code that ends with a semi-colon and *does not evaluate to some value*. An expression, on the other hand, is a line of code that does not end with a semi-colon and evaluates to some value.
Let's understand that with an example:
```
fn main() {
let a = 873;
let b = {
// statement
println!("Assigning some value to a...");
// expression
a * 10
};
println!("a: {a}");
}
```
On line 3, I open a code block, inside which I have a statement and an expression. The comments highlight which one is which.
The code on the 5th line does not evaluate to a value and hence needs to be ended with a semi-colon. This is a statement.
The code on the 8th line evaluates to a value. It is `b * 10`
which is `873 * 10`
and it evaluates to `8730`
. Since this line does not end with a semi-colon, this is an expression.
The expressions are not only used to "return" a value from a function. As you just saw, the value of `b * 10` was "returned" from the inner scope to the outer scope and it was assigned to the variable `b`. A simple scope isn't a function and the value of the expression was still "returned".
### Example: Buying rusted fruits
Let's understand how a function returns a value using a demonstration.
```
fn main() {
println!(
"If I buy 2 Kilograms of apples from a fruit vendor, I have to pay {} rupees to them.",
retail_price(2.0)
);
println!(
"But, if I buy 30 Kilograms of apples from a fruit vendor, I have to pay {} rupees to them.",
wholesale_price(30.0)
);
}
fn retail_price(weight: f64) -> f64 {
return weight * 500.0;
}
fn wholesale_price(weight: f64) -> f64 {
weight * 400.0
}
```
Above I have two functions: `retail_price`
and `wholesale_price`
. Both functions accept one parameter and store the value inside the `weight`
variable. This variable is of type `f64`
and the function signature denotes that an `f64`
value is ultimately returned by the function.
Both of these functions multiply the weight of apples purchased by a number. This number represents the current price per Kilogram for apples. Since wholesale purchasers have big orders, logistics are easier in a way, the price can be eased a bit.
Other than the price per Kilogram, the functions have one more difference. That is, the `retail_price`
function returns the product using the `return`
keyword. Whereas, the `wholesale_price`
function returns the product using an expression.
```
If I buy 2 Kilograms of apples from a fruit vendor, I have to pay 1000 rupees to them.
But, if I buy 30 Kilograms of apples from a fruit vendor, I have to pay 12000 rupees to them.
```
The output shows that both methods of returning a value from a function work as intended.
### Returning multiple values
You can have a function that returns multiple values of different types. You have many options, but returning a tuple is the easiest.
Following is an example:
```
fn main() {
let (maths, english, science, sanskrit) = tuple_func();
println!("Marks obtained in Maths: {maths}");
println!("Marks obtained in English: {english}");
println!("Marks obtained in Science: {science}");
println!("Marks obtained in Sanskrit: {sanskrit}");
}
fn tuple_func() -> (f64, f64, f64, f64) {
// return marks for a student
let maths = 84.50;
let english = 85.00;
let science = 75.00;
let sanskrit = 67.25;
(maths, english, science, sanskrit)
}
```
The `tuple_func`
returns four `f64`
values, enclosed in a tuple. These values are the marks obtained by a student in four subjects (out of 100).
When the function is called, this tuple is returned. I can either print the values using `tuple_name.0`
scheme, but I thought it best to destruct the tuple first. That will ease the confusion of which value is which. And I print the marks using the variables that contain values from the destructured tuple.
Following is the output I get:
```
Marks obtained in Maths: 84.5
Marks obtained in English: 85
Marks obtained in Science: 75
Marks obtained in Sanskrit: 67.25
```
## Conclusion
This article covers functions in the Rust programming language. The "types" of functions are covered here:
- Functions that do not accept any parameter(s) nor return value(s)
- Functions that accept one or more parameters
- Functions that return one or more values back to the caller
You know what comes next? Conditional statements, aka [if-else in Rest](https://itsfoss.com/rust-if-else/).
[Rust Basics Series #6: Using If ElseYou can control the flow of your program by using conditional statements. Learn to use if-else in Rust.](https://itsfoss.com/rust-if-else/)

Stay tuned and enjoy learning Rust with It's FOSS. |
15,856 | 如何在 RHEL 9/8 上设置高可用性 Apache(HTTP)集群 | https://www.linuxtechi.com/high-availability-apache-cluster-on-rhel/ | 2023-05-29T17:28:00 | [
"集群",
"Pacemaker"
] | https://linux.cn/article-15856-1.html | 
>
> 在本文中,我们将介绍如何在 RHEL 9/8 上使用 Pacemaker 设置两节点高可用性 Apache 集群。
>
>
>
Pacemaker 是适用于类 Linux 操作系统的高可用性集群软件。Pacemaker 被称为“集群资源管理器”,它通过在集群节点之间进行资源故障转移来提供集群资源的最大可用性。Pacemaker 使用 Corosync 进行集群组件之间的心跳和内部通信,Corosync 还负责集群中的投票选举(Quorum)。
### 先决条件
在我们开始之前,请确保你拥有以下内容:
* 两台 RHEL 9/8 服务器
* Red Hat 订阅或本地配置的仓库
* 通过 SSH 访问两台服务器
* root 或 sudo 权限
* 互联网连接
### 实验室详情:
* 服务器 1:[node1.example.com](http://node1.example.com)(192.168.1.6)
* 服务器 2:[node2.exaple.com](http://node2.exaple.com)(192.168.1.7)
* VIP:192.168.1.81
* 共享磁盘:`/dev/sdb`(2GB)
事不宜迟,让我们深入了解这些步骤。
### 1、更新 /etc/hosts 文件
在两个节点上的 `/etc/hosts` 文件中添加以下条目:
```
192.168.1.6 node1.example.com
192.168.1.7 node2.example.com
```
### 2、安装高可用包 Pacemaker
Pacemaker 和其他必需的包在 RHEL 9/8 的默认包仓库中不可用。因此,我们必须启用高可用仓库。在两个节点上运行以下订阅管理器命令。
对于 RHEL 9 服务器:
```
$ sudo subscription-manager repos --enable=rhel-9-for-x86_64-highavailability-rpms
```
对于 RHEL 8 服务器:
```
$ sudo subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms
```
启用仓库后,运行命令在两个节点上安装 `pacemaker` 包:
```
$ sudo dnf install pcs pacemaker fence-agents-all -y
```

### 3、在防火墙中允许高可用端口
要允许防火墙中的高可用端口,请在每个节点上运行以下命令:
```
$ sudo firewall-cmd --permanent --add-service=high-availability
$ sudo firewall-cmd --reload
```
### 4、为 hacluster 用户设置密码并启动 pcsd 服务
在两台服务器上为 `hacluster` 用户设置密码,运行以下 `echo` 命令:
```
$ echo "<Enter-Password>" | sudo passwd --stdin hacluster
```
执行以下命令在两台服务器上启动并启用集群服务:
```
$ sudo systemctl start pcsd.service
$ sudo systemctl enable pcsd.service
```
### 5、创建高可用集群
使用 `pcs` 命令对两个节点进行身份验证,从任何节点运行以下命令。在我的例子中,我在 `node1` 上运行它:
```
$ sudo pcs host auth node1.example.com node2.example.com
```
使用 `hacluster` 用户进行身份验证。

使用下面的 `pcs cluster setup` 命令将两个节点添加到集群,这里我使用的集群名称为 `http_cluster`。仅在 `node1` 上运行命令:
```
$ sudo pcs cluster setup http_cluster --start node1.example.com node2.example.com
$ sudo pcs cluster enable --all
```
这两个命令的输出如下所示:

从任何节点验证初始集群状态:
```
$ sudo pcs cluster status
```

注意:在我们的实验室中,我们没有任何防护设备,因此我们将其禁用。但在生产环境中,强烈建议配置防护。
```
$ sudo pcs property set stonith-enabled=false
$ sudo pcs property set no-quorum-policy=ignore
```
### 6、为集群配置共享卷
在服务器上,挂载了一个大小为 2GB 的共享磁盘(`/dev/sdb`)。因此,我们将其配置为 LVM 卷并将其格式化为 XFS 文件系统。
在开始创建 LVM 卷之前,编辑两个节点上的 `/etc/lvm/lvm.conf` 文件。
将参数 `#system_id_source = "none"` 更改为 `system_id_source = "uname"`:
```
$ sudo sed -i 's/# system_id_source = "none"/ system_id_source = "uname"/g' /etc/lvm/lvm.conf
```
在 `node1` 上依次执行以下一组命令创建 LVM 卷:
```
$ sudo pvcreate /dev/sdb
$ sudo vgcreate --setautoactivation n vg01 /dev/sdb
$ sudo lvcreate -L1.99G -n lv01 vg01
$ sudo lvs /dev/vg01/lv01
$ sudo mkfs.xfs /dev/vg01/lv01
```

将共享设备添加到集群第二个节点(`node2.example.com`)上的 LVM 设备文件中,仅在 `node2` 上运行以下命令:
```
[sysops@node2 ~]$ sudo lvmdevices --adddev /dev/sdb
```
### 7、安装和配置 Apache Web 服务器(httpd)
在两台服务器上安装 Apache web 服务器(httpd),运行以下 `dnf` 命令:
```
$ sudo dnf install -y httpd wget
```
并允许防火墙中的 Apache 端口,在两台服务器上运行以下 `firewall-cmd` 命令:
```
$ sudo firewall-cmd --permanent --zone=public --add-service=http
$ sudo firewall-cmd --permanent --zone=public --add-service=https
$ sudo firewall-cmd --reload
```
在两个节点上创建 `status.conf` 文件,以便 Apache 资源代理获取 Apache 的状态:
```
$ sudo bash -c 'cat <<-END > /etc/httpd/conf.d/status.conf
<Location /server-status>
SetHandler server-status
Require local
</Location>
END'
$
```
修改两个节点上的 `/etc/logrotate.d/httpd`:
替换下面的行
```
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
```
为
```
/usr/bin/test -f /run/httpd.pid >/dev/null 2>/dev/null &&
/usr/bin/ps -q $(/usr/bin/cat /run/httpd.pid) >/dev/null 2>/dev/null &&
/usr/sbin/httpd -f /etc/httpd/conf/httpd.conf \
-c "PidFile /run/httpd.pid" -k graceful > /dev/null 2>/dev/null || true
```
保存并退出文件。

### 8、为 Apache 创建一个示例网页
仅在 `node1` 上执行以下命令:
```
$ sudo lvchange -ay vg01/lv01
$ sudo mount /dev/vg01/lv01 /var/www/
$ sudo mkdir /var/www/html
$ sudo mkdir /var/www/cgi-bin
$ sudo mkdir /var/www/error
$ sudo bash -c ' cat <<-END >/var/www/html/index.html
<html>
<body>High Availability Apache Cluster - Test Page </body>
</html>
END'
$
$ sudo umount /var/www
```
注意:如果启用了 SElinux,则在两台服务器上运行以下命令:
```
$ sudo restorecon -R /var/www
```
### 9、创建集群资源和资源组
为集群定义资源组和集群资源。在我的例子中,我们使用 `webgroup` 作为资源组。
* `web_lvm` 是共享 LVM 卷的资源名称(`/dev/vg01/lv01`)
* `web_fs` 是将挂载在 `/var/www` 上的文件系统资源的名称
* `VirtualIP` 是网卡 `enp0s3` 的 VIP(`IPadd2`)资源
* `Website` 是 Apache 配置文件的资源。
从任何节点执行以下命令集。
```
$ sudo pcs resource create web_lvm ocf:heartbeat:LVM-activate vgname=vg01 vg_access_mode=system_id --group webgroup
$ sudo pcs resource create web_fs Filesystem device="/dev/vg01/lv01" directory="/var/www" fstype="xfs" --group webgroup
$ sudo pcs resource create VirtualIP IPaddr2 ip=192.168.1.81 cidr_netmask=24 nic=enp0s3 --group webgroup
$ sudo pcs resource create Website apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group webgroup
```

现在验证集群资源状态,运行:
```
$ sudo pcs status
```

很好,上面的输出显示所有资源都在 `node1` 上启动。
### 10、测试 Apache 集群
尝试使用 VIP(192.168.1.81)访问网页。
使用 `curl` 命令或网络浏览器访问网页:
```
$ curl http://192.168.1.81
```

或者

完美!以上输出确认我们能够访问我们高可用 Apache 集群的网页。
让我们尝试将集群资源从 `node1` 移动到 `node2`,运行:
```
$ sudo pcs node standby node1.example.com
$ sudo pcs status
```

完美,以上输出确认集群资源已从 `node1` 迁移到 `node2`。
要从备用节点(`node1.example.com`)中删除节点,运行以下命令:
```
$ sudo pcs node unstandby node1.example.com
```

以上就是这篇文章的全部内容,我希望你发现它提供了丰富的信息,请在下面的评论部分中发表你的疑问和反馈。
*(题图:MJ/3bf8c775-72ed-4e44-a28d-c872c7c8632f)*
---
via: <https://www.linuxtechi.com/high-availability-apache-cluster-on-rhel/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this post, we will cover how to setup two node high availability Apache cluster using pacemaker on RHEL 9/8
Pacemaker is a High Availability cluster Software for Linux like Operating System. Pacemaker is known as ‘Cluster Resource Manager ‘, It provides maximum availability of the cluster resources by doing fail over of resources between the cluster nodes. Pacemaker use corosync for heartbeat and internal communication among cluster components, Corosync also take care of Quorum in cluster.
#### Prerequisites
Before we begin, make sure you have the following:
- Two RHEL 9/8 servers
- Red Hat Subscription or Locally Configured Repositories
- SSH access to both servers
- Root or sudo privileges
- Internet connectivity
#### Lab Details:
- Server 1: node1.example.com (192.168.1.6)
- Server 2: node2.exaple.com (192.168.1.7)
- VIP: 192.168.1.81
- Shared Disk: /dev/sdb (2GB)
Without any further delay, let’s deep dive into the steps,
## 1) Update /etc/hosts file
Add the following entries in /etc/hosts file on both the nodes,
192.168.1.6 node1.example.com 192.168.1.7 node2.example.com
## 2) Install high availability (pacemaker) package
Pacemaker and other required packages are not available in default packages repositories of RHEL 9/8. So, we must enable high availability repository. Run following subscription manager command on both nodes.
For RHEL 9 Servers
$ sudo subscription-manager repos --enable=rhel-9-for-x86_64-highavailability-rpms
For RHEL 8 Servers
$ sudo subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms
After enabling the repository, run beneath command to install pacemaker packages on both the nodes,
$ sudo dnf install pcs pacemaker fence-agents-all -y
## 3) Allow high availability ports in firewall
To allow high availability ports in the firewall, run beneath commands on each node,
$ sudo firewall-cmd --permanent --add-service=high-availability $ sudo firewall-cmd --reload
## 4) Set password to hacluster and start pcsd service
Set password to hacluster user on both servers, run following [echo command](https://www.linuxtechi.com/echo-command-examples-in-linux/)
$ echo "<Enter-Password>" | sudo passwd --stdin hacluster
Execute the following command to start and enable cluster service on both servers
$ sudo systemctl start pcsd.service $ sudo systemctl enable pcsd.service
## 5) Create high availability cluster
Authenticate both the nodes using pcs command, run the below command from any node. In my case I am running it on node1,
$ sudo pcs host auth node1.example.com node2.example.com
Use hacluster user to authenticate,
Add both nodes to the cluster using following “pcs cluster setup” command , here I am using the cluster name as http_cluster . Run beneath commands only on node1,
$ sudo pcs cluster setup http_cluster --start node1.example.com node2.example.com $ sudo pcs cluster enable --all
Output of both the commands would look like below,
Verify initial cluster status from any node,
$ sudo pcs cluster status
Note : In our lab, we don’t have any fencing device, so we are disabling it. But in production environment it is highly recommended to configure the fencing.
$ sudo pcs property set stonith-enabled=false $ sudo pcs property set no-quorum-policy=ignore
## 6) Configure shared Volume for the cluster
On the servers, a shared disk (/dev/sdb) of size 2GB is attached. So, we will configure it as LVM volume and format it as xfs file system.
Before start creating lvm volume, edit /etc/lvm/lvm.conf file on both the nodes.
Change the parameter “# system_id_source = “none”” to system_id_source = “uname”
$ sudo sed -i 's/# system_id_source = "none"/ system_id_source = "uname"/g' /etc/lvm/lvm.conf
Execute following set of commands one after the another on node1 to create lvm volume
$ sudo pvcreate /dev/sdb $ sudo vgcreate --setautoactivation n vg01 /dev/sdb $ sudo lvcreate -L1.99G -n lv01 vg01 $ sudo lvs /dev/vg01/lv01 $ sudo mkfs.xfs /dev/vg01/lv01
Add the shared device to the LVM devices file on the second node (node2.example.com) of the cluster, run below command on node2 only,
[sysops@node2 ~]$ sudo lvmdevices --adddev /dev/sdb [sysops@node2 ~]$
## 7) Install and Configure Apache Web Server (HTTP)
Install apache web server (httpd) on both the servers, run following dnf command
$ sudo dnf install -y httpd wget
Also allow Apache ports in firewall, run following firewall-cmd command on both servers
$ sudo firewall-cmd --permanent --zone=public --add-service=http $ sudo firewall-cmd --permanent --zone=public --add-service=https $ sudo firewall-cmd --reload
Create status.conf file on both the nodes in order for the Apache resource agent to get the status of Apache
$ sudo bash -c 'cat <<-END > /etc/httpd/conf.d/status.conf <Location /server-status> SetHandler server-status Require local </Location> END' $
Modify /etc/logrotate.d/httpd on both the nodes
Replace the below line
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
With three lines
/usr/bin/test -f /run/httpd.pid >/dev/null 2>/dev/null && /usr/bin/ps -q $(/usr/bin/cat /run/httpd.pid) >/dev/null 2>/dev/null && /usr/sbin/httpd -f /etc/httpd/conf/httpd.conf \ -c "PidFile /run/httpd.pid" -k graceful > /dev/null 2>/dev/null || true
Save and exit the file.
## 8) Create a sample web page for Apache
Perform the following commands only on node1,
$ sudo lvchange -ay vg01/lv01 $ sudo mount /dev/vg01/lv01 /var/www/ $ sudo mkdir /var/www/html $ sudo mkdir /var/www/cgi-bin $ sudo mkdir /var/www/error $ sudo bash -c ' cat <<-END >/var/www/html/index.html <html> <body>High Availability Apache Cluster - Test Page </body> </html> END' $ $ sudo umount /var/www
Note: If SElinux is enable, then run following on both the servers,
$ sudo restorecon -R /var/www
## 9) Create cluster resources and resource group
Define resource group and cluster resources for clusters. In my case, we are using “webgroup” as resource group.
- web_lvm is name of resource for shared lvm volume (/dev/vg01/lv01)
- web_fs is name of filesystem resource which will be mounted on /var/www
- VirtualIP is the resource for VIP (IPadd2) for nic enp0s3
- Website is the resource of Apache config file.
Execute following set of commands from any node.
$ sudo pcs resource create web_lvm ocf:heartbeat:LVM-activate vgname=vg01 vg_access_mode=system_id --group webgroup $ sudo pcs resource create web_fs Filesystem device="/dev/vg01/lv01" directory="/var/www" fstype="xfs" --group webgroup $ sudo pcs resource create VirtualIP IPaddr2 ip=192.168.1.81 cidr_netmask=24 nic=enp0s3 --group webgroup $ sudo pcs resource create Website apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group webgroup
Now verify the cluster resources status, run
$ sudo pcs status
Great, output above shows that all the resources are started on node1.
## 10) Test Apache Cluster
Try to access web page using VIP – 192.168.1.81
Either use curl command or web browser to access web page
$ curl http://192.168.1.81
or
Perfect, above output confirms that we are able access the web page of our highly available Apache cluster.
Let’s try to move cluster resources from node1 to node2, run
$ sudo pcs node standby node1.example.com $ sudo pcs status
Perfect, above output confirms that cluster resources are migrated from node1 to node2.
To remove the node (node1.example.com) from standby, run beneath command
$ sudo pcs node unstandby node1.example.com
That’s all from this post, I hope you have found it informative, kindly do post your queries and feedback in below comments section.
RoanHi, I followed your guide and it works well for the most part. However I was wondering how you can change the html content after you make a resource of it in pacemaker. Thanks.
anonymousHi, nice guide, but I have a small problem. I am totally followed your guide, but in the end, node 2 doesn’t have partition storage part1, how to fix this problem? hope somebody can help me.
thanks
Bruce MalaudziHi, Your question has much info to help troubleshot. Please provide info, such command out. For example:
# lvdisplay /dev/sdb
# lvs
# blkid
# ls -lh /dev/mapper
Bruce MalaudziSorry for the typos. I meant to say that please provide us with enough information as you have not provided adequate info in the initial question.
LeandroBeautiful guide. But if I need to extend the disk dynamically I will not have it. Because the disk you are with fixed size and not in lvm how to solve this
Pradeep KumarHi Leandro,
It is recommended to use LVM on shared storage in cluster setup. You can’t extend the disk dynamically unless and until it is on LVM
EvanThis was a very well written guide that worked for me. Thanks for making it!
nawazpcs stonith show
scsi_fecing_device (stonith:fence_scsi): Stopped
Iris LamesHi Padeep Kumar, a job well done. I followed your instructions and I was able to setup my cluster. Cluster resource manages my httpd service. My question is, how do I restart the httpd service everytime I do changes on the configuration?
santhoshHi Pradeep,
We are planning to purchase SSL certificate for Apache Webserver which is running in cluster. How to use SSL certificate for Virtaul IP, While generating CSR file CN should be Virtual IP or fqdn?
Pradeep KumarHi Santosh,
It should be FQDN not the Virtual IP.
Takinif the website is on CPanel / WHM , how could i get it done ? |
15,858 | 如何解决 Git 合并冲突 | https://opensource.com/article/23/4/resolve-git-merge-conflicts | 2023-05-30T09:03:05 | [
"Git"
] | https://linux.cn/article-15858-1.html | 
>
> 在遇到合并冲突时,请不要惊慌。通过一些娴熟的技巧协商,你可以解决任何冲突。
>
>
>
假设你和我正在共同编辑同一个名称为 `index.html` 的文件。我对文件进行了修改,进行了提交,并将更改推送到 Git 远程仓库。你也对同一个文件进行了修改,进行了提交,并开始将更改推送到同一个 Git 仓库。然而,Git 检测到一个冲突,因为你所做的更改与我所做的更改冲突。
以下是你可以解决冲突的方法:
1、从远程仓库获取并合并最新更改:
```
$ git pull
```
2、识别一个或多个有冲突的文件:
```
$ git status
```
3、使用文本编辑器打开冲突文件:
```
$ vim index.html
```
4、解决冲突。冲突的修改会被标记为 `<<<<<<< HEAD` 和 `>>>>>>>`。你需要选择要保留和放弃哪些修改,并手动编辑文件以合并冲突的修改。
以下是一个示例:
```
<<<<<<< HEAD
<div class="header">
<h1>Sample text 1</h1>
</div>
=======
<div class="header">
<h1>Sample text 2</h1>
</div>
>>>>>>> feature-branch
```
在这个例子中,我将网站标题更改为 `Sample text 1`,而你将标题更改为 `Sample text 2`。两种更改都已添加到文件中。现在你可以决定保留哪一个标题,或者编辑文件以合并更改。在任一情况下,删除指示更改开始和结束的标记,只留下你想要的代码:
```
<div class="header">
<h1>Sample text 2</h1>
</div>
```
5、保存所有更改,并关闭编辑器。
6、将文件添加到暂存区:
```
$ git add index.html
```
7、提交更改:
```
$ git commit -m "Updated h1 in index.html"
```
此命令使用消息 `Resolved merge conflict` 提交更改。
8、将更改推送到远程仓库:
```
$ git push
```
### 结论
合并冲突是将注意力集中于代码的好理由。你在文件中进行的更改越多,就越容易产生冲突。你应该进行更多的提交,每个提交更改应该更少。你应该避免进行包含多个特性增强或错误修复的单片巨大更改。你的项目经理也会感谢你,因为具有清晰意图的提交更容易追踪。在最初遇到 Git 合并冲突时可能会感到吓人,但是现在你知道如何解决它,你会发现它很容易解决。
*(题图:MJ/f432c41a-eb4f-4de0-b2da-f3d8d7a86e26)*
---
via: <https://opensource.com/article/23/4/resolve-git-merge-conflicts>
作者:[Agil Antony](https://opensource.com/users/agantony) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Suppose you and I are working on the same file called **index.html**. I make some changes to the file, commit them, and push the changes to the remote Git repository. You also make some changes to the same file, commit them, and start pushing the changes to the same Git repository. However, Git detects a conflict because the changes you made conflict with the changes I made.
Here's how you can resolve the conflict:
-
Fetch and merge the latest changes from the remote repository:
`$ git pull`
-
Identify the one or more conflicting files:
`$ git status`
-
Open the conflicting file using a text editor:
`$ vim index.html`
-
Resolve the conflict. The conflicting changes are marked by
`<<<<<<< HEAD`
and`>>>>>>>`
. You need to choose which changes to keep and which to discard. Manually edit the file to combine the conflicting changes.Here's an example:
`<<<<<<< HEAD <div class="header"> <h1>Sample text 1</h1> </div> ======= <div class="header"> <h1>Sample text 2</h1> </div> >>>>>>> feature-branch`
In this example, I changed the website heading to
`Sample text 1`
, while you have changed the heading to`Sample text 2`
. Both changes have been added to the file. You can now decide which heading to keep or edit the file to combine the changes. In either case, remove the markers that indicate the beginning and end of the changes, leaving only the code you want:`<div class="header"> <h1>Sample text 2</h1> </div>`
-
Save all of your changes, and close your editor.
-
Add the file to the staging area:
`$ git add index.html`
-
Commit the changes:
`$ git commit -m "Updated h1 in index.html"`
This command commits the changes with the message
`Resolved merge conflict`
. -
Push the changes to the remote repository:
`$ git push`
## Resolution
Merge conflicts are a good reason to focus your changes on code. The more you change in a file, the greater the potential for conflict. You should make more commits with fewer changes each. You should avoid making a monolithic change that combines multiple feature enhancements or bug fixes into one. Your project manager will thank you, too, because commits with clear intent are easier to track. A Git merge conflict may seem intimidating at first, but now that you know how to do it, you'll see that it's easily resolved.
## 2 Comments |
15,859 | ZOMBIES:在软件开发中定义边界和接口(三) | https://opensource.com/article/21/2/boundaries-interfaces | 2023-05-30T09:22:00 | [
"测试"
] | https://linux.cn/article-15859-1.html | 
>
> 丧尸是没有边界感的,需要为你的软件设定限制和期望。
>
>
>
丧尸没有边界感。它们踩倒栅栏,推倒围墙,进入不属于它们的地盘。在前面的文章中,我已经解释了为什么把所有编程问题当作一群丧尸一次性处理是错误的。
ZOMBIES 代表首字母缩写:
* **Z** – 最简场景(Zero)
* **O** – 单个元素场景(One)
* **M** – 多个元素场景(Many or more complex)
* **B** – 边界行为(Boundary behaviors)
* **I** – 接口定义(Interface definition)
* **E** – 处理特殊行为(Exercise exceptional behavior)
* **S** – 简单场景用简单的解决方案(Simple scenarios, simple solutions)
在本系列的前面两篇文章中,我演示了 ZOMBIES 方法的前三部分:最简场景、单元素场景和多元素场景。第一篇文章 [实现了最简场景](/article-15808-1.html),它提供了代码中的最简可行路径。第二篇文章中针对单元素场景和多元素场景 [运行测试](/article-15817-1.html)。在这篇文章中,我将带你了解边界和接口。
### 回到单元素场景
要想处理边界,你需要绕回来(迭代)。
首先思考下面的问题:电子商务的边界是什么?我需要限制购物框的大小吗?(事实上,我不认为这有任何意义。)
目前唯一合理的边界条件是确保购物框里的商品数量不能为负数。将这个限制表示成可运行的期望:
```
[Fact]
public void Add1ItemRemoveItemRemoveAgainHas0Items() {
var expectedNoOfItems = 0;
var actualNoOfItems = -1;
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
```
这就是说,如果你向购物框里添加一件商品,然后将这个商品移除两次,`shoppingAPI` 的实例应该告诉你购物框里有零个商品。
当然这个可运行期望(微测试)不出意料地会失败。想要这个微测试能够通过,最小改动是什么呢?
```
[Fact]
public void Add1ItemRemoveItemRemoveAgainHas0Items() {
var expectedNoOfItems = 0;
Hashtable item = new Hashtable();
shoppingAPI.AddItem(item);
shoppingAPI.RemoveItem(item);
var actualNoOfItems = shoppingAPI.RemoveItem(item);
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
```
这个期望测试依赖于 `RemoveItem(item)` 功能。目前的 `shippingAPI` 还不具备该功能,你需要增加该功能。
回到 `app` 文件夹,打开 `IShippingAPI.cs` 文件,新增以下声明:
```
int RemoveItem(Hashtable item);
```
到 `ShippingAPI.cs` 中实现该功能:
```
public int RemoveItem(Hashtable item) {
basket.RemoveAt(basket.IndexOf(item));
return basket.Count;
}
```
运行,然后你会得到如下错误:

系统在移除一个不在购物框的商品,这导致了系统崩溃。加一点点 <ruby> 防御式编程defensive programming</ruby>:
```
public int RemoveItem(Hashtable item) {
if(basket.IndexOf(item) >= 0) {
basket.RemoveAt(basket.IndexOf(item));
}
return basket.Count;
}
```
在移除商品之前先检查它是否在购物框中。(你可能试过用捕获异常的方式来处理,但是我认为上面的处理方式更具可读性。)
### 更多具体的期望
在讲更多具体的期望之前,让我们先探讨一下什么是接口。在软件工程中,接口表示一种规范,或者对能力的描述。从某种程度上来说,接口类似于菜谱。它罗列出了制作蛋糕的原材料,但它本身并不能吃。我们只是按照菜谱上的说明来烤蛋糕。
与此类似,我们首先通过说明这个服务能做什么的方式来定义我们的服务。这个描述说明就是所谓的接口。但是接口本身并不能向我们提供任何功能。它只是指导我们实现指定功能的蓝图而已。
到目前为止,我们已经实现了接口(只是某部分实现了,稍后还会增加新功能)和业务处理边界(也就是购物框里的商品不能是负数)。你指导了 `shoppingAPI` 怎么向购物框添加商品,并通过 `Add2ItemsBasketHas2Items` 测试验证了该功能的有效性。
然而仅仅具备向购物框添加商品的功能还不足以使其成为一个网购应用程序。它还需要能够计算购物框里的商品的总价。现在需要增加另一个期望。
按照惯例,从最直接明了的期望开始。当你向购物框里加入一件价值 ¥10 的商品时,你希望这个购物 API 能正确地计算出总价为 ¥10。
第五个测试(伪造版)如下:
```
[Fact]
public void Add1ItemPrice10GrandTotal10() {
var expectedTotal = 10.00;
var actualTotal = 0.00;
Assert.Equal(expectedTotal, actualTotal);
}
```
还是一样的老把戏,通过硬编码一个错误的值让 `Add1ItemPrice10GrandTotal10` 测试失败。当然前三个测试成功通过,但第四个新增的测试失败了:
```
A total of 1 test files matched the specified pattern.
[xUnit.net 00:00:00.57] tests.UnitTest1.Add1ItemPrice10GrandTotal10 [FAIL]
X tests.UnitTest1.Add1ItemPrice10GrandTotal10 [4ms]
Error Message:
Assert.Equal() Failure
Expected: 10
Actual: 0
Test Run Failed.
Total tests: 4
Passed: 3
Failed: 1
Total time: 1.0320 Seconds
```
将硬编码值换成实际的处理代码。首先,检查接口是否具备计算订单总价的功能。根本没有这种东西。目前为止接口中只声明了三个功能:
1. `int NoOfItems();`
2. `int AddItem(Hashtable item);`
3. `int RemoveItem(Hashtable item);`
它们都不具备计算总价的能力。所以需要声明一个新功能:
```
double CalculateGrandTotal();
```
这个新功能应该让 `shoppingAPI` 具备计算总价的能力。这是通过遍历购物框中的商品并把它们的价格累加起来实现的。
修改第五个测试:
```
[Fact]
public void Add1ItemPrice10GrandTotal10() {
var expectedGrandTotal = 10.00;
Hashtable item = new Hashtable();
item.Add("00000001", 10.00);
shoppingAPI.AddItem(item);
var actualGrandTotal = shoppingAPI.CalculateGrandTotal();
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
这个测试表明了这样的期望:如果向购物框里加入一件价格 ¥10 的商品,然后调用 `CalculateGrandTotal()` 方法,它会返回商品总价 ¥10。这是一个完全合理的期望,它完全符合商品总价计算的逻辑。
那么怎么实现这个功能呢?就像以前一样,先写一个假的实现。回到 `ShippingAPI` 类中,实现在接口中声明的 `CalculateGrandTotal()` 方法:
```
public double CalculateGrandTotal() {
return 0.00;
}
```
现在先将返回值硬编码为 `0.00`,只是为了检验这个测试能否正常运行,并确认它是能够失败的。事实上,它能够运行,并且如预期一样失败。接下来的工作就是正确实现计算商品总价的处理逻辑:
```
public double CalculateGrandTotal() {
double grandTotal = 0.00;
foreach(var product in basket) {
Hashtable item = product as Hashtable;
foreach(var value in item.Values) {
grandTotal += Double.Parse(value.ToString());
}
}
return grandTotal;
}
```
运行,五个测试全部通过!
### 从单元素场景到多元素场景
现在是时候进入下一轮迭代了。你已经通过处理最简场景、单元素场景和边界场景迭代地构建了系统,现在需要处理稍复杂的多元素场景了。
快捷提示:由于我们一直在针对单个元素场景、多元素场景和边界行为这三点上对软件进行迭代改进,一些读者可能会认为我们同样应该对接口进行改进。我们稍后就会发现,接口已经完全满足需要了,目前没有新增功能的必要。请记住,应该保持接口的简洁。(盲目地)扩增接口不会带来任何好处,只会引入噪音。我们要遵循 <ruby> 奥卡姆剃刀 <rt> Occam's Razor </rt></ruby> 原则:**如无必要,勿增实体。** 现在我们已经基本完成了接口功能描述的工作,是时候改进实现了。
通过上一轮的迭代,系统已经能够处理购物框里有超过一件商品的情况了。现在我么来让系统具备购物框里有超过一件商品时计算总价的能力。首先写可执行期望:
```
[Fact]
public void Add2ItemsGrandTotal30() {
var expectedGrandTotal = 30.00;
var actualGrandTotal = 0.00;
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
硬编码所有值,尽量让期望测试失败。
测试确实失败了,现在得想办法让它通过。向购物框添加两件商品,然后调用 `CalculateGrandTotal()` 方法:
```
[Fact]
public void Add2ItemsGrandTotal30() {
var expectedGrandTotal = 30.00;
Hashtable item = new Hashtable();
item.Add("00000001", 10.00);
shoppingAPI.AddItem(item);
Hashtable item2 = new Hashtable();
item2.Add("00000002", 20.00);
shoppingAPI.AddItem(item2);
var actualGrandTotal = shoppingAPI.CalculateGrandTotal();
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
测试通过。现在共有六个可以通过的微测试,系统回到了稳态。
### 设定期望
作为一个认真负责的工程师,你希望确保当用户向购物框添加一些商品然后又移除一些商品后系统仍然能够计算出正确出总价。下面是这个新的期望:
```
[Fact]
public void Add2ItemsRemoveFirstItemGrandTotal200() {
var expectedGrandTotal = 200.00;
var actualGrandTotal = 0.00;
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
这个期望表示将两件商品加入到购物框,然后移除第一件后期望的总价是 ¥200。硬编码行为失败了。现在设计更具体的正面测试样例,然后运行代码:
```
[Fact]
public void Add2ItemsRemoveFirstItemGrandTotal200() {
var expectedGrandTotal = 200.00;
Hashtable item = new Hashtable();
item.Add("00000001", 100.00);
shoppingAPI.AddItem(item);
Hashtable item2 = new Hashtable();
item2.Add("00000002", 200.00);
shoppingAPI.AddItem(item2);
shoppingAPI.RemoveItem(item);
var actualGrandTotal = shoppingAPI.CalculateGrandTotal();
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
在这个正面测试样例中,先向购物框加入第一件商品(编号为 00000001,价格为 ¥100),再加入第二件商品(编号为 00000002,价格为 ¥200)。然后将第一件商品移除,计算总价,比较计算值与期望值是否相等。
运行期望测试,系统正确地计算出了总价,满足这个期望测试。现在有七个能顺利通过的测试了。系统运行良好,无异常!
```
Test Run Successful.
Total tests: 7
Passed: 7
Total time: 0.9544 Seconds
```
### 敬请期待
现在你已经学习了 ZOMBIES 方法中的 ZOMBI 部分,下一篇文章将介绍处理特殊行为。到那个时候,你可以试试自己的测试!
*(题图:MJ/c4eb23b5-84aa-4477-a6b9-7d2a6d1aeee4)*
---
via: <https://opensource.com/article/21/2/boundaries-interfaces>
作者:[Alex Bunardzic](https://opensource.com/users/alex-bunardzic) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Zombies are bad at understanding boundaries. They trample over fences, tear down walls, and generally get into places they don't belong. In the previous articles in this series, I explained why tackling coding problems all at once, as if they were hordes of zombies, is a mistake.
**ZOMBIES** is an acronym that stands for:
**Z** – Zero
**O** – One
**M** – Many (or more complex)
**B** – Boundary behaviors
**I** – Interface definition
**E** – Exercise exceptional behavior
**S** – Simple scenarios, simple solutions
In the first two articles in this series, I demonstrated the first three **ZOMBIES** principles of **Zero**, **One**, and **Many**. The first article [implemented Zero](https://opensource.com/article/21/1/zombies-zero), which provides the simplest possible path through your code. The second article
[performed tests](https://opensource.com/article/21/1/zombies-2-one-many)with
**O**ne and
**M**any samples. In this third article, I'll take a look at
**B**oundaries and
**I**nterfaces.
## Back to One
Before you can tackle **B**oundaries, you need to circle back (iterate).
Begin by asking yourself: What are the boundaries in e-commerce? Do I need or want to limit the size of a shopping basket? (I don't think that would make any sense, actually).
The only reasonable boundary at this point would be to make sure the shopping basket never contains a negative number of items. Write an executable expectation that expresses this limitation:
```
[Fact]
public void Add1ItemRemoveItemRemoveAgainHas0Items() {
var expectedNoOfItems = 0;
var actualNoOfItems = -1;
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
```
This says that if you add one item to the basket, remove that item, and remove it again, the `shoppingAPI`
instance should say that you have zero items in the basket.
Of course, this executable expectation (microtest) fails, as expected. What is the bare minimum modification you need to make to get this microtest to pass?
```
[Fact]
public void Add1ItemRemoveItemRemoveAgainHas0Items() {
var expectedNoOfItems = 0;
Hashtable item = new Hashtable();
shoppingAPI.AddItem(item);
shoppingAPI.RemoveItem(item);
var actualNoOfItems = shoppingAPI.RemoveItem(item);
Assert.Equal(expectedNoOfItems, actualNoOfItems);
}
```
This encodes an expectation that depends on the `RemoveItem(item)`
capability. And because that capability is not in your `shippingAPI`
, you need to add it.
Flip over to the `app`
folder, open `IShippingAPI.cs`
and add the new declaration:
`int RemoveItem(Hashtable item);`
Go to the implementation class (`ShippingAPI.cs`
), and implement the declared capability:
```
public int RemoveItem(Hashtable item) {
basket.RemoveAt(basket.IndexOf(item));
return basket.Count;
}
```
Run the system, and you get an error:

(Alex Bunardzic, CC BY-SA 4.0)
The system is trying to remove an item that does not exist in the basket, and it crashes. Add a little bit of defensive programming:
```
public int RemoveItem(Hashtable item) {
if(basket.IndexOf(item) >= 0) {
basket.RemoveAt(basket.IndexOf(item));
}
return basket.Count;
}
```
Before you try to remove the item from the basket, check if it is in the basket. (You could've tried by catching the exception, but I feel the above logic is easier to read and follow.)
## More specific expectations
Before we move to more specific expectations, let's pause for a second and examine what is meant by interfaces. In software engineering, an interface denotes a specification, or a description of some capability. In a way, interface in software is similar to a recipe in cooking. It lists the ingredients that make the cake but it is not actually edible. We follow the specified description in the recipe in order to bake the cake.
Similarly here, we define our service by first specifying what is this service capable of. That specification is what we call interface. But interface itself cannot provide any services to us. It is a mere blueprint which we then use and follow in order to implement specified capabilities.
So far, you have implemented the interface (partially; more capabilities will be added later) and the processing boundaries (you cannot have a negative number of items in the shopping basket). You instructed the `shoppingAPI`
how to add items to the shopping basket and confirmed that the addition works by running the `Add2ItemsBasketHas2Items`
test.
However, just adding items to the basket does not an e-commerce app make. You need to be able to calculate the total of the items added to the basket—time to add another expectation.
As is the norm by now (hopefully), start with the most straightforward expectation. When you add one item to the basket and the item price is $10, you expect the shopping API to correctly calculate the total as $10.
Your fifth test (the fake version):
```
[Fact]
public void Add1ItemPrice10GrandTotal10() {
var expectedTotal = 10.00;
var actualTotal = 0.00;
Assert.Equal(expectedTotal, actualTotal);
}
```
Make the `Add1ItemPrice10GrandTotal10`
test fail by using the good old trick: hard-coding an incorrect actual value. Of course, your previous three tests succeed, but the new fourth test fails:
```
A total of 1 test files matched the specified pattern.
[xUnit.net 00:00:00.57] tests.UnitTest1.Add1ItemPrice10GrandTotal10 [FAIL]
X tests.UnitTest1.Add1ItemPrice10GrandTotal10 [4ms]
Error Message:
Assert.Equal() Failure
Expected: 10
Actual: 0
Test Run Failed.
Total tests: 4
Passed: 3
Failed: 1
Total time: 1.0320 Seconds
```
Replace the hard-coded value with real processing. First, see if you have any such capability in your interface that would enable it to calculate order totals. Nope, no such thing. So far, you have declared only three capabilities in your interface:
`int NoOfItems();`
`int AddItem(Hashtable item);`
`int RemoveItem(Hashtable item);`
None of those indicates any ability to calculate totals. You need to declare a new capability:
`double CalculateGrandTotal();`
This new capability should enable your `shoppingAPI`
to calculate the total amount by traversing the collection of items it finds in the shopping basket and adding up the item prices.
Flip over to your tests and change the fifth test:
```
[Fact]
public void Add1ItemPrice10GrandTotal10() {
var expectedGrandTotal = 10.00;
Hashtable item = new Hashtable();
item.Add("00000001", 10.00);
shoppingAPI.AddItem(item);
var actualGrandTotal = shoppingAPI.CalculateGrandTotal();
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
This test declares your expectation that if you add an item priced at $10 and then call the `CalculateGrandTotal()`
method on the shopping API, it will return a grand total of $10. Which is a perfectly reasonable expectation since that's how the API should calculate.
How do you implement this capability? As always, fake it first. Flip over to the `ShippingAPI`
class and implement the `CalculateGrandTotal()`
method, as declared in the interface:
```
public double CalculateGrandTotal() {
return 0.00;
}
```
You're hard-coding the return value as 0.00, just to see if the test (your first customer) will be able to run it and whether it will fail. Indeed, it does run fine and fails, so now you must implement processing logic to calculate the grand total of the items in the shopping basket properly:
```
public double CalculateGrandTotal() {
double grandTotal = 0.00;
foreach(var product in basket) {
Hashtable item = product as Hashtable;
foreach(var value in item.Values) {
grandTotal += Double.Parse(value.ToString());
}
}
return grandTotal;
}
```
Run the system. All five tests succeed!
## From One to Many
Time for another iteration. Now that you have built the system by iterating to handle the **Z**ero, **O**ne (both very simple and a bit more elaborate scenarios), and **B**oundary scenarios (no negative number of items in the basket), you must handle a bit more elaborate scenario for **M**any.
A quick note: as we keep iterating and returning back to the concerns related to **O**ne, **M**any, and **B**oundaries (we are refining our implementation), some readers may expect that we should also rework the **I**nterface. As we will see later on, our interface is already fully fleshed out, and we see no need to add more capabilities at this point. Keep in mind that interfaces should be kept lean and simple; there is not much advantage in proliferating interfaces, as that only adds more noise to the signal. Here, we are following the principle of Occam's Razor, which states that entities should not multiply without a very good reason. For now, we are pretty much done with describing the expected capabilities of our API. We're now rolling up our sleeves and refining the implementation.
The previous iteration enabled the system to handle more than one item placed in the basket. Now, enable the system to calculate the grand total for more than one item in the basket. First things first; write the executable expectation:
```
[Fact]
public void Add2ItemsGrandTotal30() {
var expectedGrandTotal = 30.00;
var actualGrandTotal = 0.00;
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
You "cheat" by hard-coding all values first and then do your best to make sure the expectation fails.
And it does, so now is the time to make it pass. Modify your expectation by adding two items to the basket and then running the `CalculateGrandTotal()`
method:
```
[Fact]
public void Add2ItemsGrandTotal30() {
var expectedGrandTotal = 30.00;
Hashtable item = new Hashtable();
item.Add("00000001", 10.00);
shoppingAPI.AddItem(item);
Hashtable item2 = new Hashtable();
item2.Add("00000002", 20.00);
shoppingAPI.AddItem(item2);
var actualGrandTotal = shoppingAPI.CalculateGrandTotal();
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
And it passes. You now have six microtests pass successfuly; the system is back to steady-state!
## Setting expectations
As a conscientious engineer, you want to make sure that the expected acrobatics when users add items to the basket and then remove some items from the basket always calculate the correct grand total. Here comes the new expectation:
```
[Fact]
public void Add2ItemsRemoveFirstItemGrandTotal200() {
var expectedGrandTotal = 200.00;
var actualGrandTotal = 0.00;
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
This says that when someone adds two items to the basket and then removes the first item, the expected grand total is $200.00. The hard-coded behavior fails, and now you can elaborate with more specific confirmation examples and running the code:
```
[Fact]
public void Add2ItemsRemoveFirstItemGrandTotal200() {
var expectedGrandTotal = 200.00;
Hashtable item = new Hashtable();
item.Add("00000001", 100.00);
shoppingAPI.AddItem(item);
Hashtable item2 = new Hashtable();
item2.Add("00000002", 200.00);
shoppingAPI.AddItem(item2);
shoppingAPI.RemoveItem(item);
var actualGrandTotal = shoppingAPI.CalculateGrandTotal();
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
Your confirmation example, coded as the expectation, adds the first item (ID "00000001" with item price $100.00) and then adds the second item (ID "00000002" with item price $200.00). You then remove the first item from the basket, calculate the grand total, and assert if it is equal to the expected value.
When this executable expectation runs, the system meets the expectation by correctly calculating the grand total. You now have seven tests passing! The system is working; nothing is broken!
```
Test Run Successful.
Total tests: 7
Passed: 7
Total time: 0.9544 Seconds
```
## More to come
You're up to **ZOMBI** now, so in the next article, I'll cover **E**. Until then, try your hand at some tests of your own!
## Comments are closed. |
15,860 | ZOMBIES:如何在软件开发中实现业务需求(四) | https://opensource.com/article/21/2/exceptional-behavior | 2023-05-30T09:43:56 | [
"测试"
] | https://linux.cn/article-15860-1.html | 
>
> 完善你的电商应用,使它能够正确处理业务规则。
>
>
>
在前面的文章中,我已经解释了为什么将编程问题看作一整群丧尸来处理是错误的。我用 ZOMBIES 方法来解释为什么循序渐进地处理问题更好。
ZOMBIES 表示以下首字母缩写:
* **Z** – 最简场景(Zero)
* **O** – 单元素场景(One)
* **M** – 多元素场景(Many or more complex)
* **B** – 边界行为(Boundary behaviors)
* **I** – 接口定义(Interface definition)
* **E** – 处理特殊行为(Exercise exceptional behavior)
* **S** – 简单场景用简单的解决方案(Simple scenarios, simple solutions)
在系列的前三篇文章中,我展示了 ZOMBIES 方法的前五项。第一篇中 [实现了最简场景](/article-15808-1.html),它为代码提供了最简可行路径。第二篇文章中执行了 [单元素场景和多元素场景上的测试](/article-15817-1.html)。第三篇中介绍了 [边界和接口](/article-15859-1.html)。在本文中,我将带你了解倒数第二个方法:处理特殊行为。
### 处理特殊行为
在开发一个电子购物应用时,你需要从产品负责人或赞助商那里了解需要采用什么销售策略。
毫无疑问,与任何电子商业活动一样,你需要通过制定销售策略来诱导顾客进行消费。假设有如下的销售策略:订单金额超过 ¥500 时可以享受一定的折扣优惠。
现在将这个销售策略转换为可运行期望:
```
[Fact]
public void Add2ItemsTotal600GrandTotal540() {
var expectedGrandTotal = 540.00;
var actualGrandTotal = 0.00;
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
这个正面样例表示的销售策略是,如果订单总额为 ¥600.00,那么 `shoppingAPI` 会将其减价为 ¥540.00。上面的代码伪造了一个失败验证用例。现在修改它,让它能够通过测试:
```
[Fact]
public void Add2ItemsTotal600GrandTotal540() {
var expectedGrandTotal = 540.00;
Hashtable item = new Hashtable();
item.Add("00000001", 200.00);
shoppingAPI.AddItem(item);
Hashtable item2 = new Hashtable();
item2.Add("00000002", 400.00);
shoppingAPI.AddItem(item2);
var actualGrandTotal = shoppingAPI.CalculateGrandTotal();
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
在这个正样例中,你向购物框加入一件价值 ¥200 的商品和一件价值 ¥400 的商品,使总价达到 ¥600 。当调用 `CalculateGrandTotal()` 方法时,你期望总价是 ¥540。
这个微测试能够通过吗?
```
[xUnit.net 00:00:00.57] tests.UnitTest1.Add2ItemsTotal600GrandTotal540 [FAIL]
X tests.UnitTest1.Add2ItemsTotal600GrandTotal540 [2ms]
Error Message:
Assert.Equal() Failure
Expected: 540
Actual: 600
[...]
```
很可惜,它失败了。你期望的结果是 ¥540,但计算结果为 ¥600。为什么会这样呢?那是因为你还没有告诉系统在订单总价大于 ¥500 时怎么进行折扣计算。
现在来实现折扣计算逻辑。根据上面的正样例可知,当订单总价为 ¥600(超过了营销策略的阈值 ¥500)时,期望的最终总价为 ¥540。也就是说系统需要从订单总额中减去 ¥60。刚好是是原订单总价的 10%。因此该销售规则就是当订单总额超过 ¥500 时享受九折优惠。
在 `ShippingAPI` 类中实现该处理逻辑:
```
private double Calculate10PercentDiscount(double total) {
double discount = 0.00;
if(total > 500.00) {
discount = (total/100) * 10;
}
return discount;
}
```
首先,检查订单总额是否大于 ¥500 。如果是,则计算出总额的 10%。
你还需要告诉系统怎么从订单总额中减去 10%。改动非常直接:
```
return grandTotal - Calculate10PercentDiscount(grandTotal);
```
到此,所有测试都能够通过。你又一次享受到系统处于稳态的欢愉。你的代码通过处理特殊行为实现了需要的销售策略。
### 最后一步
现在我已经介绍完 ZOMBIE 了,只剩下 S 了。我将会在最后一篇中介绍它。
*(题图:MJ/7f8bf5d2-54ce-4d6e-9dbf-13abf6df966a)*
---
via: <https://opensource.com/article/21/2/exceptional-behavior>
作者:[Alex Bunardzic](https://opensource.com/users/alex-bunardzic) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my previous articles in this series, I explained why tackling coding problems all at once, as if they were hordes of zombies, is a mistake. I'm using a helpful acronym to explain why it's better to approach problems incrementally. **ZOMBIES** stands for:
**Z** – Zero
**O** – One
**M** – Many (or more complex)
**B** – Boundary behaviors
**I** – Interface definition
**E** – Exercise exceptional behavior
**S** – Simple scenarios, simple solutions
In the first three articles in this series, I demonstrated the first five **ZOMBIES** principles. The first article [implemented Zero](https://opensource.com/article/21/1/zombies-zero), which provides the simplest possible path through your code. The second article performed
[tests with](https://opensource.com/article/21/1/zombies-2-one-many)samples, and the third article looked at
**O**ne and**M**any[. In this article, I'll take a look at the penultimate letter in our acronym:](https://opensource.com/article/21/1/zombies-3-boundaries-interface)
**B**oundaries and**I**nterfaces**E**, which stands for "exercise exceptional behavior."
## Exceptional behavior in action
When you write an app like the e-commerce tool in this example, you need to contact product owners or business sponsors to learn if there are any specific business policy rules that need to be implemented.
Sure enough, as with any e-commerce operation, you want to put business policy rules in place to entice customers to keep buying. Suppose a business policy rule has been communicated that any order with a grand total greater than $500 gets a percentage discount.
OK, time to roll up your sleeves and craft the executable expectation for this business policy rule:
```
[Fact]
public void Add2ItemsTotal600GrandTotal540() {
var expectedGrandTotal = 540.00;
var actualGrandTotal = 0.00;
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
The confirmation example that encodes the business policy rule states that if the order total is $600.00, the `shoppingAPI`
will calculate the grand total to discount it to $540.00. The script above fakes the expectation just to see it fail. Now, make it pass:
```
[Fact]
public void Add2ItemsTotal600GrandTotal540() {
var expectedGrandTotal = 540.00;
Hashtable item = new Hashtable();
item.Add("00000001", 200.00);
shoppingAPI.AddItem(item);
Hashtable item2 = new Hashtable();
item2.Add("00000002", 400.00);
shoppingAPI.AddItem(item2);
var actualGrandTotal = shoppingAPI.CalculateGrandTotal();
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
In the confirmation example, you are adding one item priced at $200 and another item priced at $400 for a total of $600 for the order. When you call the `CalculateGrandTotal()`
method, you expect to get a total of $540.
Will this microtest pass?
```
[xUnit.net 00:00:00.57] tests.UnitTest1.Add2ItemsTotal600GrandTotal540 [FAIL]
X tests.UnitTest1.Add2ItemsTotal600GrandTotal540 [2ms]
Error Message:
Assert.Equal() Failure
Expected: 540
Actual: 600
[...]
```
Well, it fails miserably. You were expecting $540, but the system calculates $600. Why the error? It's because you haven't taught the system how to calculate the discount on order totals larger than $500 and then subtract that discount from the grand total.
Implement that processing logic. Judging from the confirmation example above, when the order total is $600.00 (which is greater than the business rule threshold of an order totaling $500), the expected grand total is $540. This means the system needs to subtract $60 from the grand total. And $60 is precisely 10% of $600. So the business policy rule that deals with discounts expects a 10% discount on all order totals greater than $500.
Implement this processing logic in the `ShippingAPI`
class:
```
private double Calculate10PercentDiscount(double total) {
double discount = 0.00;
if(total > 500.00) {
discount = (total/100) * 10;
}
return discount;
}
```
First, check to see if the order total is greater than $500. If it is, then calculate 10% of the order total.
You also need to teach the system how to subtract the calculated 10% from the order grand total. That's a very straightforward change:
`return grandTotal - Calculate10PercentDiscount(grandTotal);`
Now all tests pass, and you're again enjoying steady success. Your script **Exercises exceptional behavior** to implement the required business policy rules.
## One more to go
I've taken us to **ZOMBIE** now, so there's just **S** remaining. I'll cover that in the exciting series finale.
## 2 Comments |
15,861 | 为什么计算机采用 8 位字节 | https://jvns.ca/blog/2023/03/06/possible-reasons-8-bit-bytes/ | 2023-05-30T11:54:13 | [
"字节",
"架构"
] | https://linux.cn/article-15861-1.html | 
我正在制作一份有关计算机以二进制表示事物的小册子,有人问我一个问题 - 为什么 x86 架构使用 8 位字节?为什么不能是其他大小呢?
对于类似这样的问题,我认为有两种可能性:
* 这是历史原因造成的,其他尺寸(如 4、6 或 16 位)同样有效。
* 8 位是客观上的最佳选择,即使历史发展不同,我们仍然会使用 8 位字节。
* 一些混合 1 和 2 的因素。
我对计算机历史并不是非常着迷(与阅读计算机文献相比,我更喜欢使用计算机),但我总是很好奇计算机事物今天的方式是否存在本质原因,或者它们大多是历史偶然的结果。因此,我们将谈论一些计算机历史。
作为历史偶然性的一个例子:DNS 有一个 `class` 字段,它有 5 种可能的值(`internet`、`chaos`、`hesiod`、`none` 和 `any`)。 对我来说,这是一个明显的历史意外的例子 - 如果我们今天重新设计 DNS 而不必担心向后兼容性,我无法想象我们会以相同的方式定义类字段。我不确定我们是否会使用 `class` 字段!
这篇文章没有明确的答案,但我在 [Mastodon](https://social.jvns.ca/@b0rk/109976810279702728) 上提问,并找到了一些潜在的 8 位字节原因。我认为答案是这些原因的某种组合。
#### 字节和字有什么区别?
首先,本文中经常提到 “<ruby> 字节 <rt> byte </rt></ruby>” 和 “<ruby> 字 <rt> word </rt></ruby>”。它们有什么区别?我的理解是:
* **字节的大小** 是你可以寻址的最小单元。例如,在我的计算机上,程序中的 `0x20aa87c68` 可能是一个字节的地址,然后 `0x20aa87c69` 是下一个字节的地址。
* **字的大小** 是字节大小的某个倍数。我对此困惑了多年,维基百科的定义非常模糊(“字是特定处理器设计使用的自然数据单元”)。我最初认为字大小与寄存器大小相同(在 x86-64 上为 64 位)。但是根据 [英特尔架构手册](https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html) 的第 4.1 节(“基本数据类型”),在 x86 上,虽然寄存器是 64 位的,但一个字是 16 位的。因此我困惑了 —— 在 x86 上,一个字是 16 位还是 64 位?它可以根据上下文而有不同的含义吗?这是怎么回事?
现在让我们来讨论一些使用 8 位字节的可能原因!
#### 原因 1:将英文字母适配到 1 字节中
[维基百科文章](https://en.wikipedia.org/wiki/IBM_System/360) 表示 IBM System/360 于 1964 年引入了 8 位字节。
在管理该项目的 Fred Brooks 的一段 [视频采访](https://www.youtube.com/watch?v=9oOCrAePJMs&t=140s) 中,他讲述了原因。以下是我转录的一些内容:
>
> …… 6 位字节在科学计算中确实更好,而 8 位字节则更适合商业计算,每个字节都可以针对另一个字节进行调整,以使两种字节互相使用。
>
>
> 因此,这变成了一个高管决策,我决定根据 Jerry 的建议采用 8 位字节。
>
>
> ……
>
>
> 我在我的 IBM 职业生涯中做出的最重要的技术决策是为 360 选择 8 位字节。
>
>
> 我相信字符处理将变得重要,而不是十进制数字。
>
>
>
使用 8 位字节处理文本很有道理:2<sup> 6</sup> 为 64,因此 6 位不足以表示小写字母、大写字母和符号。
为了使用 8 位字节,System/360 还引入了 [EBCDIC 编码](https://en.wikipedia.org/wiki/EBCDIC),这是一种 8 位字符编码。
接下来在 8 位字节历史上重要的机器似乎是 [英特尔 8008](https://en.wikipedia.org/wiki/Intel_8008),它设计用于计算机终端(Datapoint 2200)。终端需要能够表示字母以及终端控制代码,因此使用 8 位字节对其来说很有意义。[计算机历史博物馆上的 Datapoint 2200 手册](https://archive.computerhistory.org/resources/text/2009/102683240.05.02.acc.pdf) 在第 7 页上说 Datapoint 2200 支持 ASCII(7 位)和 EBCDIC(8 位)。
#### 为什么 6 位字节在科学计算中更好?
我对这条 “6 位字节在科学计算中更好” 的评论很好奇。以下是 [Gene Amdahl 的一段采访摘录](https://archive.computerhistory.org/resources/access/text/2013/05/102702492-05-01-acc.pdf):
>
> 我原本希望采用 24 和 48 而非 32 和 64,因为这将为我提供一个更合理的浮点系统。因为在浮点运算中,使用 32 位字大小时,你必须将指数保持在 8 位中用于指数符号,并且要使其在数字范围上合理,你必须每次调整 4 个位而不是单个位。因此,这将导致你比使用二进制移位更快地失去一些信息。
>
>
>
我完全不理解这条评论 - 如果你使用 32 位字大小,为什么指数必须是 8 位?如果你想要,为什么不能使用 9 位或 10 位?但这是我在快速搜索中找到的全部内容。
#### 为什么大型机使用 36 位?
与 6 位字节相关的问题是:许多大型机使用 36 位字大小。为什么?在维基百科的 [36 位计算](https://en.wikipedia.org/wiki/36-bit_computing) 文章中有一个很好的解释:
>
> 在计算机问世之前,即需要高精度科学和工程运算的领域,使用的是十位数码电动机械计算器……这些计算器每位数码均有一个专用按键,操作人员在输入数字时需要用到所有手指,因此,虽然有些专业计算器有更多位数码,但这种情况是个实际的限制。
>
>
> 因此,早期针对相同市场的二进制计算机通常使用 36 位字长度。这足以表示正负整数最高精度到十位数字(最小应为 35 位)。
>
>
>
因此,这种 36 位大小似乎是基于

的,它等于 34.2。嗯。
我猜这个原因是在 50 年代,计算机非常昂贵。因此,如果您想要你的计算机支持十位十进制数字,你将设计它恰好具有足够的位来执行此操作,而不会更多。
现在计算机更快更便宜,因此,如果您想要出于某种原因表示十位十进制数字,你只需使用 64 位即可 - 浪费一点空间通常并不会有太大问题。
还有人提到,一些具有 36 位字大小的计算机可以让你选择字节大小 - 根据上下文,你可以使用 5 或 6 或 7 或 8 位字节。
#### 原因 2:与二进制编码的十进制一起工作
20 世纪 60 年代,有一种流行的整数编码叫做 <ruby> 二进制编码的十进制 <rt> binary-coded decimal </rt></ruby>(缩写为 [BCD](https://en.wikipedia.org/wiki/Binary-coded_decimal)),它将每个十进制数字编码为 4 位。
例如,如果你想要编码数字 `1234`,在 BCD 中,它会是这样的:
```
0001 0010 0011 0100
```
因此,如果你想要能够轻松地与二进制编码的十进制一起工作,你的字节大小应该是 4 位的倍数,比如 8 位!
#### 为什么 BCD 很流行?
这个整数表示方法对我来说真的很奇怪 —— 为什么不用更有效率的二进制来存储整数呢?在早期的计算机中,效率非常重要!
我最好的猜测是,早期的计算机没有像我们现在这样的显示器,所以一个字节的内容被直接映射到开关灯上。
这是来自维基百科一个带有一些亮灯的 IBM 650 显示器的图片([CC BY-SA 3.0](http://creativecommons.org/licenses/by-sa/3.0/) 许可):

因此,如果你想让人们能够相对容易地从二进制表示中读取十进制数,这样做就更有意义了。我认为,今天 BCD 已经过时了,因为我们拥有显示器,并且我们的计算机可以将用二进制表示的数字转换为十进制,并显示它们。
此外,我想知道,“<ruby> 四位 <rt> nibble </rt></ruby>”(意为 “4 位”)这个词是不是来自 BCD 的。在 BCD 的上下文中,你经常会引用半个字节(因为每个十进制数字是 4 位)。所以有一个 “4 位” 的词语是有意义的,人们称 4 个位为 “<ruby> 四位 <rt> nibble </rt></ruby>”。今天,“四位” 对我来说感觉像是一个古老的词汇,除了作为一个趣闻我肯定从未使用过它(它是一个很有趣的词!)。维基百科关于 “[四位](https://en.wikipedia.org/wiki/Nibble)” 的文章支持了这个理论:
>
> “四位” 用来描述存储在 IBM 大型计算机中打包的十进制格式(BCD)中数字的位数。
>
>
>
还有一个人提到 BCD 的另一个原因是 **金融计算**。今天,如果你想存储美元金额,你通常只需使用整数的分数,然后在需要美元部分时除以 100。这没什么大不了的,除法很快。但显然,在 70 年代,将一个用二进制表示的整数除以一个 100 是非常慢的,所以重新设计如何表示整数,以避免除以 100 是值得的。
好了,关于 BCD 就说这么多。
#### 原因 3:8 是 2 的幂?
许多人说,CPU 的字节大小是 2 的幂次方很重要。我无法确定这是真的还是假的,而且我对 “计算机使用二进制,所以 2 的幂次方很好” 这种解释感到不满意。这似乎非常合理,但我想深入探讨一下。而且从历史上看,肯定有很多使用字节大小不是 2 的幂次方的机器,例如(来自这个来自 Stack Exchange 上复古计算版块的 [帖子](https://retrocomputing.stackexchange.com/questions/7937/last-computer-not-to-use-octets-8-bit-bytes)):
* Cyber 180 大型机使用 6 位字节
* Univac 1100/2200 系列使用 36 位字长
* PDP-8 是一台 12 位计算机
一些我听到的关于 2 的幂次方很好的原因我还没有理解:
* 一个单词中的每个位都需要一个总线,而你希望总线数量是 2 的幂次方(为什么?)
* 很多电路逻辑容易针对分而治之的技术(我需要一个例子来理解这个)
对我更有意义的原因是:
* 它使设计“时钟分频器”更容易,这些分频器可以测量“在这条线路上发送了 8 位”,分别基于减半进行操作 - 你可以将 3 个减半时钟分频器串联起来。[Graham Sutherland](https://poly.nomial.co.uk/) 告诉我这个,他制作了这个非常酷的 [分频器模拟器](https://www.falstad.com/circuit/circuitjs.html?ctz=CQAgjCAMB0l3BWcMBMcUHYMGZIA4UA2ATmIxAUgpABZsKBTAWjDACgwEknsUQ08tQQKgU2AdxA8+I6eAyEoEqb3mK8VMAqWSNakHsx9Iywxj6Ea-c0oBKUy-xpUWYGc-D9kcftCQo-URgEZRQERSMnKkiTSTDFLQjw62NlMBorRP5krNjwDP58fMztE04kdKsRFBQqoqoQyUcRVhl6tLdCwVaonXBO2s0Cwb6UPGEPXmiPPLHhIrne2Y9q8a6lcpAp9edo+r7tkW3c5WPtOj4TyQv9G5jlO5saMAibPOeIoppm9oAPEEU2C0-EBaFoThAAHoUGx-mA8FYgfNESgIFUrNDYVtCBBttg8LiUPR0VCYWhyD0Wp0slYACIASQAamTIORFqtuucQAzGTQ2OTaD9BN8Soo6Uy8PzWQ46oImI4aSB6QA5ZTy9EuVQjPLq3q6kQmAD21Beome0qQMHgkDIhHCYVEfCQ9BVbGNRHAiio5vIltg8Ft9stXg99B5MPdFK9tDAFqg-rggcIDui1i23KZfPd3WjPuoVoDCiDjv4gjDErYQA),展示了这些分频器的工作原理。该网站(Falstad)还有很多其他示例电路,似乎是制作电路模拟器的一个非常酷的方式。
* 如果你有一个指令可以将字节中的特定位清零,则如果你的字节大小为 8(2 的 3 次方),你可以只使用 3 位指令来指示哪一位。x86 似乎没有这样做,但 [Z80 的位测试指令](http://www.chebucto.ns.ca/~af380/z-80-h.htm) 是这样做的。
* 有人提到一些处理器使用 [进位前瞻加法器](https://en.wikipedia.org/wiki/Carry-lookahead_adder),它们按 4 位分组。经过一些快速的谷歌搜索,似乎有各种各样的加法器电路。
* **位图**:你计算机的内存被组织成页(通常大小为 2 的 n 次方)。它需要跟踪每一页是否空闲。操作系统使用位图来完成这项工作,其中每个位对应一页,并且根据页面是空闲还是占用,值为 0 或 1。如果你有一个 9 位的字节,你需要除以 9 来在位图中找到你要查找的页面。除以 9 的速度比除以 8 慢,因为除以 2 的幂次方总是最快的。
我可能很糟糕地扭曲了其中一些解释:在这里,我非常超出了自己的知识领域。我们继续前进吧。
#### 原因 4:小字节大小很好
你可能会想:好吧,如果 8 位字节比 4 位字节更好,为什么不继续增加字节大小呢?我们可以有 16 位字节啊!
有几个保持字节大小较小的理由:
* 它是一种空间浪费 —— 字节是你可以寻址的最小单位,如果你的计算机存储了大量的 ASCII 文本(只需要 7 位),那么每个字符分配 12 或 16 个位相当浪费,而你可以使用 8 个位代替。
* 随着字节变得越来越大,你的 CPU 需要变得更复杂。例如,你需要每个位线路一条总线线路。因此,我想简单总是更好。
我对 CPU 架构的理解非常薄弱,所以就说到这里吧。对我来说,“这是一种空间浪费” 的理由似乎相当有说服力。
#### 原因 5:兼容性
英特尔 8008(1972 年)是 8080(1974 年)的前身,8080 是第一款 x86 处理器 8086(1976 年)的前身。似乎 8080 和 8086 很受欢迎,这就是我们现代 x86 计算机的来源。
我认为这里有一个 “如果它好好的就不要动它” 的问题 - 我假设 8 位字节功能良好,因此英特尔看不到需要更改设计的必要性。如果你保持相同的 8 位字节,那么你可以重复使用更多指令集。
此外,80 年代左右我们开始出现像 TCP 这样的网络协议,它们使用 8 位字节(通常称为“<ruby> 八位组 <rt> octet </rt></ruby>”),如果你要实现网络协议,你可能希望使用 8 位字节。
#### 就这些!
在我看来,8 位字节的主要原因是:
* 很多早期的电脑公司都是美国的,美国使用最广泛的语言是英语
* 这些人希望计算机擅长文本处理
* 较小的字节大小通常更好
* 7 位是你可以用来容纳所有英文字母和标点符号的最小尺寸
* 8 比 7 更好(因为它是 2 的幂次方)
* 一旦有得到成功应用的受欢迎的 8 位计算机,你希望保持相同的设计以实现兼容性。
有人指出 [这本 1962 年的书](https://web.archive.org/web/20170403014651/http://archive.computerhistory.org/resources/text/IBM/Stretch/pdfs/Buchholz_102636426.pdf) 第 65 页谈到了 IBM 选择 8 位字节的原因,基本上说了相同的内容:
>
> 1. 其完整的 256 个字符的容量被认为足以满足绝大多数应用程序的需要。
> 2. 在该容量范围内,单个字符由单个字节表示,因此任何特定记录的长度并不因该记录中字符而异。
> 3. 8 位字节在存储空间上是相当经济的。
> 4. 对于纯数字工作,一个十进制数字只需要 4 个比特表示,两个这样的 4 位字节可以打包成一个 8 位字节。尽管这种数字数据包装不是必需的,但为了提高速度和存储效率,它是一种常见做法。严格来说,4 位字节属于不同的代码,但与 4 位及 8 位方案相比,它们的简单性导致了更简单的机器设计和更清晰的寻址逻辑。
> 5. 4 位和 8 位的字节大小,作为 2 的幂次方,允许计算机设计师利用二进制寻址和位级索引的强大功能(见第 4 章和第 5 章)。
>
>
>
总的来说,如果你在英语国家设计二进制计算机,选择 8 位字节似乎是一个非常自然的选择。
*(题图:MJ/3526a0d5-bee5-4678-8637-e96e9843b53c)*
---
via: <https://jvns.ca/blog/2023/03/06/possible-reasons-8-bit-bytes/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
15,864 | 帮助 UX 设计师和开发人员更好地合作的 5 种开放方式 | https://opensource.com/article/23/4/designers-developers-collaborate | 2023-05-31T23:03:00 | [
"合作",
"开放决策框架"
] | https://linux.cn/article-15864-1.html | 
>
> 用开放的决策进行设计可以帮助增加用户体验和开发团队之间的合作。
>
>
>
理想情况下,设计师与他们的产品团队和用户有良好的关系。然而,设计师和开发者之间的关系更难建立和维持。缺乏密切的关系使得问题的解决或改进变得困难。
根据我的经验,开源的 <ruby> <a href="https://opensource.com/open-organization/resources/open-decision-framework"> 开放决策框架 </a> <rt> Open Decision Framework </rt></ruby> 可以克服许多这样的障碍。
开放决策框架宣称,[开放式决策](https://opensource.com/open-organization/20/6/open-management-practices) 是透明的、包容的、以客户为中心的。它包括与受影响的各方清楚地分享问题、要求和限制。它能够与多个利益相关者合作,以确保不同的意见和全面的反馈。最重要的是,它能在相互竞争的需求和优先事项之间管理关系和期望。
这些原则可能会引起任何参与设计产品、功能或服务的决策的人的共鸣。对于一个设计师来说,开发人员是做出最佳设计决策的关键利益相关者。如果你是一个设计师,现在是时候接受获得不同意见的机会了。
### 后台和用户体验
开发人员是关键的利益相关者,因为用户的产品或服务体验不仅仅是屏幕上的像素或工作流程的设计。它包含了服务的性能、[API](https://www.redhat.com/en/topics/api/what-are-application-programming-interfaces?intcmp=7013a000002qLH8AAM) 调用的速度、处理用户数据的方式,甚至是数据的可扩展性设计。当他们被认为是设计中的完全利益相关者时,开发者可以贡献他们在服务的后端和架构方面的专业知识,以协助整体的体验设计。
用户体验(UX)设计师是开发团队所负责的项目的利益相关者。性能上的不足,或者架构对可用数据的影响,都会阻碍用户体验。一个开放的、[开发和设计之间的合作关系](https://www.redhat.com/architect/keycloak-ui-architecture?intcmp=7013a000002qLH8AAM) 允许在所有领域的信任和透明。
### 为合作留出空间
开发者和设计之间的开放和透明的关系并不像它应该的那样普遍。这种工作方式对双方来说可能都是新的。以下是我为使合作成功而提出的五大建议:
1. **建立一个经常性的合作时间**:为设计和开发建立一个经常性的时间,在每周到每月一次之间进行会面。邀请的对象至少应该包括 UX、主导工程和质量工程。理想情况下,如果日程安排允许,团队中的所有开发人员都应该被邀请参加。
2. **使分享成为主要议程:** UX 应该分享他们目前正在进行的用例和功能,以及任何相关的用户研究数据。UX 设计师应该向开发团队展示工作流程设计、线框图和高保真模拟图。开发应该分享他们这边做出的任何可能影响用户体验的设计决定。
3. **鼓励提问:** 合作是最理想的情况。鼓励所有与会者提出问题并给予反馈。对问题的回答和对反馈的回应是讨论设计和方向的机会,也是一个相互学习的机会。
4. **拥抱学习的心态**:避免说教或“告诉”。相反,目的是互相学习。利用彼此的专业知识,为用户和客户设计和建立一个良好的体验。要求对不熟悉的技术或概念进行解释。
5. **考虑正式学习**:当群体说着相同的语言时,合作关系会更容易。考虑正式的学习途径,例如:
* **设计人员**:编码基础课程,如开源的 [Odin 项目](https://www.theodinproject.com/),对于学习服务的构造和构建的基本原理是有帮助的。
* **开发人员**:对 UX 原则的理解可以帮助指导问题和反馈。你可以在 UX 设计原则或各种书籍和文章中找到一个很好的概述。
### 一个开放合作的例子
在与我团队中的一个开发人员进行的早期设计审查中,我展示了一个具体的交互,以显示关于一个物体的更多数据。我传达了用户的需求并演示了这个交互,这时开发者问道:“是否需要完全以这种方式来完成?”
他提到,只要在设计上稍加改动,开发的工作量就会大大降低。我们同意,这些改变不会对用户体验产生负面影响,而且用户仍然能够实现他们的目标。
这种反馈节省了开发团队的时间,留下了更多的机会来解决错误,建立额外的功能,并保持健康的工作和生活的平衡。用户体验依然强劲,而团队则更加强大。如果没有一个与我有深厚工作关系的开发者的早期反馈,这个结果是不可能的。
### 你的下一步
建立体验是由一个合作的团队做出的一系列决定。产品、设计和开发需要作为各自领域的专家和其他人的利益相关者一起工作。我鼓励你让开发和设计参与进来,以获得更多的合作反馈,并一起努力创造出具有最佳用户体验的最佳产品。
(题图:MJ/f8f89c47-821a-4327-aa18-9483633aef50)
---
via: <https://opensource.com/article/23/4/designers-developers-collaborate>
作者:[Katie Riker](https://opensource.com/users/kriker) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Ideally, designers have a good relationship with their product team and users. However, the relationship between designers and developers is more difficult to build and maintain. The lack of a close relationship makes it difficult to solve problems or improve.
In my experience, the open source [Open Decision Framework](https://opensource.com/open-organization/resources/open-decision-framework) can overcome many of these obstacles.
The Open Decision Framework asserts that [open decision-making](https://opensource.com/open-organization/20/6/open-management-practices) is transparent, inclusive, and customer-centric. It involves clearly sharing problems, requirements, and constraints with affected parties. It enables collaboration with multiple stakeholders to secure diverse opinions and comprehensive feedback. Most importantly, it manages relationships and expectations across competing needs and priorities.
These principles probably resonate with anyone involved in the many decisions around designing a product, feature, or service. For a designer, developers are key stakeholders in making the best design decisions. If you're a designer, it's time to embrace the opportunity to get diverse opinions.
## The backend and the user experience
Developers are key stakeholders because a user's product or service experience is more than just the pixels on the screen or the workflow designs. It encompasses the service's performance, the speediness of [API](https://www.redhat.com/en/topics/api/what-are-application-programming-interfaces?intcmp=7013a000002qLH8AAM) calls, the way user data is treated, and even the design of the data for scalability. When they're considered full stakeholders in the design, developers can contribute their expertise on the backend and architecture of services to assist the overall design of the experience.
A user experience (UX) designer is a stakeholder for the items the dev team is responsible for. A performance deficit, or the effects of an architecture on what data is available, can hinder the user experience. An open, [collaborative relationship between dev and design](https://www.redhat.com/architect/keycloak-ui-architecture?intcmp=7013a000002qLH8AAM) allows for trust and transparency in all areas.
## Make space for collaboration
An open and transparent relationship between developers and design is not as common as it should be. This way of working may be new to both sides. Here are my top five tips for making collaboration a success:
-
**Set up a recurring time to collaborate**: Establish a recurring time for design and development to meet between once a week and once a month. The invitation should at least include UX, lead engineering, and quality engineering. Ideally, all developers on the team should be invited to attend as schedules permit. -
**Make sharing the main agenda:**UX should share the current use cases and features they are working on, along with any relevant user research data. UX designers should demonstrate workflow designs, wireframes, and high-fidelity mockups to the development team. Development should share any design decisions made on their side that may affect how the user experience works. -
**Encourage questions:**Collaboration is the ideal scenario. Encourage all attendees to ask questions and give feedback. Answers to questions and responses to feedback are opportunities to discuss design and direction, as well as a chance to learn from one another. -
**Embrace a learning mindset**: Avoid lecturing or "telling." Instead, aim to learn from each other. Use mutual expertise to design and build a great experience for users and customers. Ask for explanations of unfamiliar technology or concepts. -
**Consider formal learning**: A collaborative relationship can be easier when groups speak the same language. Consider formal learning paths, such as:**Designers**: A coding foundations course, such as the open source[Odin Project](https://www.theodinproject.com/), can be helpful for learning the fundamentals of how a service is constructed and built.**Developers**: An understanding of UX principles can help guide questions and feedback. You can find a good overview at UX design principles or in various books and articles.
## An example of open collaboration
In an early design review with a developer on my team, I showed a specific interaction for displaying more data about an object. I communicated the user's need and demonstrated the interaction when the developer asked, "Does it need to be done in exactly this way?"
He mentioned that with a few minor design changes, the effort to develop it would be significantly lower. We agreed that the changes would not negatively affect the user experience, and the user would still be able to achieve their goals.
This feedback saved the development team time, leaving more opportunity to address bugs, build additional features, and preserve a healthy work-life balance. The user experience remained strong, and the team was even stronger. This result would not have been possible without the early feedback from a developer with whom I had a strong working relationship.
## Your next steps
Creating an experience is a series of decisions made by a collaborative team. Product, design, and development need to work together as experts in their respective fields and stakeholders in the others. I encourage you to engage development and design for more collaborative feedback and work together to create the best product with the best user experience.
## Comments are closed. |
15,865 | 创建你的第一个使用 OpenAI ChatGPT API 的程序 | https://www.debugpoint.com/openai-chatgpt-api-python | 2023-06-01T07:13:00 | [
"OpenAI",
"ChatGPT"
] | /article-15865-1.html | 
>
> 以下是如何使用 OpenAI ChatGPT AI 创建聊天助手的 Python 程序的方法。
>
>
>
易于使用的 AI “ChatGPT” 已经以 API [提供](https://openai.com/blog/introducing-chatgpt-and-whisper-apis)。ChatGPT 的创造者 OpenAI 宣布,模型('gpt-3.5-turbo')现在适用于自定义产品和解决方案。而且成本也非常实惠。目前的价格为每 1000 个令牌 0.002 美元。
该模型目前与 Whisper API 一起提供,后者也用于文本到语音解决方案。该 API 目前具备以下功能:
* 创建自定义的对话代理和机器人
* 为你编写 Python 代码
* 起草电子邮件或任何你想要的文档
* 你可以将自然语言界面集成到你当前的产品/应用/服务或软件中,为你的消费者提供服务
* 语言翻译服务
* 成为许多科目的导师
* 模拟视频游戏角色
正如你所见,机会无限。
如果你计划尝试该 API 并开始使用它,这里有一个简单的指南,为你提供逐步指导。
### OpenAI ChatGPT API: 入门指南
#### 先决条件
确保你拥有一个 OpenAI 账户。如果你没有,[访问此页面](https://chat.openai.com/) 并创建一个账户。你也可以使用你的谷歌或微软账号。
创建一个账户后,生成一个专属于你的 API 密钥。访问 [此页面](https://platform.openai.com/account/api-keys) 并创建一个新的秘密密钥。

记录该密钥或在安全的地方保存它。基于安全原因,它将不会从 OpenAI 账户部分再次可见。而且不要与任何人分享此密钥。如果你计划使用企业解决方案,请向你的组织查询 API 密钥。由于该密钥与你的付费 OpenAI 计划相关,因此请谨慎使用。
### 设置环境
#### 安装 Python 和 pip
本指南使用 Python 编程语言来调用 OpenAI API 密钥。你可以使用 Java 或其他任何语言来调用它。
首先,请确保你在 Linux 或 Windows 中已经安装了 Python。如果没有,请按照以下指南安装 Python。如果你使用现代 Linux 发行版(例如 Ubuntu),Python 应该已经安装好了。
* [如何在 Windows 上安装 Python](https://www.debugpoint.com/install-python-windows/)
* [如何在 Ubuntu 及其他 Linux 上安装最新版 Python](https://www.debugpoint.com/install-python-3-11-ubuntu/)
在安装 Python 后,确保 `pip` 在 Linux 发行版中可用。运行以下命令进行安装。对于 Windows,你应该已经在 Python 安装的一部分中安装了它。
Ubuntu、Debian 和其他基于 Debian 的发行版:
```
sudo apt install python3-pip
```
Fedora、RHEL、CentOS 等:
```
sudo dnf install python3-pip
```
Arch Linux:
```
sudo pacman -S python-pip
```
#### 将 OpenAI API 密钥设置为环境变量
上述步骤中创建的 API 密钥,你可以直接在程序中使用。但这并不是最佳实践。
最佳实践是从文件或你系统的环境变量中调用它。
对于 Windows,请设置一个任何名字的环境变量,例如 `API-KEY`。并添加密钥值。
对于 Linux,请使用超级用户权限打开 `/etc/environment` 文件并添加密钥。例如:
```
API-KEY="<你的密钥>"
```
对于基于文件的密钥访问,请在你的代码中使用以下语句:
```
openai.api_key_path = <你的 API 密钥路径>
```
对于直接在代码中访问(不建议),你可以在你的代码中使用以下语句:
```
openai.api_key = "你的密钥"
```
**注意**:如果验证失败,OpenAI API 将抛出以下错误。你需要验证你的密钥值、路径和其他参数以进行更正:`openai.error.AuthenticationError: No API key provided`。
#### 安装 OpenAI API
最后一步是安装 OpenAI 的 Python 库。打开终端或命令窗口,使用以下命令安装 OpenAI API。
```
pip install openai
```
在此阶段,你已经准备好撰写你的第一个程序了!
### 编写助手程序(逐步)
OpenAI API 提供了各种接口模式。例如“聊天补完”、“代码补完”、“图像生成”等。在本指南中,我将使用 API 的“聊天补完”功能。使用此功能,我们可以创建一个简单的对话聊天机器人。
首先,你需要导入 OpenAI 库。你可以使用以下语句在你的 Python 程序中完成:
```
import openai
```
在这个语句之后,你应该确保启用你的 API 密钥。你可以使用上面解释的任何方法来完成。
```
openai.api_key="your key here"
```
```
openai.api_key="your environment variable"
```
```
openai.api_key_path = <your path to API key>
```
OpenAI 聊天 API 的基本功能如下所示。`openai.ChatCompletion.create` 函数以 JSON 格式接受多个参数。这些参数的形式是 “角色”(`role`) 和 “内容”(`content`):
```
openai.ChatCompletion.create(
model = "gpt-3.5-turbo",
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
```
**说明:**
`role`: 有效的值为 `system`、`user`、`assistant`
* `system`: 指示 API 如何行动。基本上,它是 OpenAI 的主提示。
* `user`: 你要问的问题。这是单个或多个会话中的用户输入。它可以是多行文本。
* `assistant`: 当你编写对话时,你需要使用此角色来添加响应。这样,API 就会记住讨论的内容。
**注意**:在一个单一的消息中,你可以发送多个角色。如上述代码片段所示的行为、你的问题和历史记录。
让我们定义一个数组来保存 OpenAI 的完整消息。然后向用户展示提示并接受 `system` 指令。
```
messages = []
system_message = input("What type of chatbot you want me to be?")
messages.append({"role":"system","content":system_message})
```
一旦设置好了,再次提示用户进行关于对话的进一步提问。你可以使用 Python 的 `input` 函数(或任何其他文件输入方法),并为角色 `user` 设置 `content`。
```
print("Alright! I am ready to be your friendly chatbot" + "\n" + "You can now type your messages.")
message = input("")
messages.append({"role":"user","content": message})
```
现在,你已经准备好了具有基本 JSON 输入的数组,用于调用“聊天补完”服务的 `create` 函数。
```
response=openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=messages)
```
现在,你可以对其进行适当的格式化,要么打印响应,要么解析响应。响应是以 JSON 格式提供的。输出响应提供了 `choices` 数组。响应在 `message` JSON 对象下提供,其中包括 `content` 值。
对于此示例,我们可以读取 `choices` 数组中的第一个对象并读取其 `content`。
```
reply = response["choices"][0]["message"]["content"]
print(reply)
```
最后,它将为你提供来自 API 的输出。
### 运行代码
你可以从你的 [喜好的 Python IDE](https://www.debugpoint.com/5-best-python-ide-code-editor/) 或直接从命令行运行代码。
```
python OpenAIDemo2.py
```
#### 未格式化的 JSON 输出
以下是使用未格式化的 JSON 输出运行上述程序供你参考。正如你所看到的,响应在 `choices` 数组下具有 `content`。
```
[debugpoint@fedora python]$ python OpenAIDemo2.py
What type of chatbot you want me to be?a friendly friend
Alright! I am ready to be your friendly chatbot
You can now type your messages.
what do you think about kindness?
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "As an AI language model, I don't have personal opinions, but I can tell you that kindness is a very positive and essential trait to have. Kindness is about being considerate and compassionate towards others, which creates positive emotions and reduces negativity. People who are kind towards others are more likely to inspire kindness and compassion in return. It is an important quality that helps to build positive relationships, promote cooperation, and create a more peaceful world.",
"role": "assistant"
}
}
],
"created": <removed>,
"id": "chatcmpl-<removed>",
"model": "gpt-3.5-turbo-0301",
"object": "chat.completion",
"usage": {
"completion_tokens": 91,
"prompt_tokens": 22,
"total_tokens": 113
}
}
```
#### 格式化的输出
这是一个适当的对话式输出。
```
[debugpoint@fedora python]$ python OpenAIDemo2.py
What type of chatbot you want me to be?a friendly friend
Alright! I am ready to be your friendly chatbot
You can now type your messages.
what do you think about artificial general intelligence?
```
```
As an AI language model, I am programmed to be neutral and not have personal opinions. However, artificial general intelligence (AGI) is a fascinating field of study. AGI refers to the development of machines and algorithms that can perform any intellectual task that a human being can. The potential benefits and risks of AGI are still widely debated, with some experts worried about the implications of machines reaching human-like intelligence. However, many believe that AGI has the potential to revolutionize fields such as healthcare, education, and transportation. The key is to ensure that AGI is developed in a responsible and ethical manner.
```
### 完整代码
这是上面演示中使用的完整代码。
```
import openai
openai.api_key = "<your key>"
messages = []
system_message = input("What type of chatbot you want me to be?")
messages.append({"role":"system","content":system_message})
print("Alright! I am ready to be your friendly chatbot" + "\n" + "You can now type your messages.")
message = input("")
messages.append({"role":"user","content": message})
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
reply = response["choices"][0]["message"]["content"]
print(reply)
```
### 总结
希望这篇简单的指南能让你开始尝试 OpenAI CharGPT API。你可以将上述步骤扩展到更复杂的会话式聊天机器人。此外,你还可以使用 OpenAI 的其他产品。
请不要错过我后续的教程,我将会实验和分享给大家。最后,请不要忘记关注我们,以便及时获取我们的文章。
如果上述步骤对你有帮助,请在评论框中告诉我。
干杯!
>
> **[参考资料](https://platform.openai.com/docs/guides/chat/introduction)**
>
>
>
*(题图:MJ/b206dd48-f698-4800-bccc-19ea11a17ea6)*
---
via: <https://www.debugpoint.com/openai-chatgpt-api-python>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,868 | 为你的开源项目举办一场文档马拉松 | https://opensource.com/article/23/4/open-source-docathon | 2023-06-02T00:11:17 | [
"文档马拉松"
] | https://linux.cn/article-15868-1.html | 
>
> 文档马拉松是为你的开源项目制作或改进文档的一个好方法。
>
>
>
你的开源项目的文档对你的客户至关重要。你的目标受众必须了解你的项目的目的和如何使用它,而文档是弥合这一差距的工具。一个项目很少有真正完成的时候,所以随着你项目的不断改进,资源的维护和更新同样重要。
但是,当你有大量的文档需要维护,但又缺乏资源来保持它的时效性时,会发生什么?答案很简单:举办一个 <ruby> 文档马拉松 <rt> docathon </rt></ruby>!
### 什么是文档马拉松?
文档马拉松就像 <ruby> 黑客马拉松 <rt> hackathon </rt></ruby>。黑客马拉松是工程师和社区领袖聚集在一起改进或添加新功能到一个现有的应用的活动。在一个文档马拉松中,同样的合作集中在改进文档上。
文档马拉松可以填补内容上的空白,重组大型文档集,修复失效的链接,或者只是纠正错别字。举办文档马拉松的目的是为了在相对短的时间内改进大量的文档。
一些产品文档的例子包括:
* 培训手册
* 用户手册
* 安装指南
* 故障排除指南
* 快速入门指南
* [API](https://www.redhat.com/en/topics/api/what-are-application-programming-interfaces?intcmp=7013a000002qLH8AAM) 文档
* 教程
在我的组织里,我们的文档团队举办了一次文档马拉松,成功地修改了 102 页的安装指南。这次文档马拉松使我们能够专注于项目的范围,即重新组织简化,删除重复的内容,并遵循客户旅程。举办文档马拉松给我的团队留下了深刻的印象,并提高了客户的成功率。
### 3 件你可以通过文档马拉松实现的事情
以下是我举办文档马拉松的三大理由:
#### 1、减少积压
大多数文档必须随着它所支持的产品的发展而发展。随着产品的变化或更新,文档也必须如此。在某些情况下,文档团队与工程团队的发布周期一起发布新版本的文档。随着团队内优先级的改变和 [GA 发布](https://opensource.com/article/19/7/what-golden-image) 的继续,文档团队面临着跟上新功能、错误修复和任务完成的挑战。被遗弃的变化成为积压的一部分,一种需要在以后完成的工作的积累。
>
> **提示:** 在文档马拉松期间,参与者可以对积压的项目进行分流,并在列表中完成它们。非技术性的参与者可以从事与错别字、失效的链接和其他文本相关问题的修复工作。
>
>
>
#### 2、改造大型指南
当你的文档团队意识到是时候修改指南的时候,它可能已经有好几章,好几百页了。一旦制定了内容计划,重组的复杂性就开始了。重组大量的文档并不适合胆小的人。
>
> **提示:** 组建一个团队来领导文档马拉松,并为不同团队或部门的全组织参与提供奖励。根据工作范围和时间限制,你的团队可以在比你预期更短的时间内成功重组整个指南。
>
>
>
#### 3、跨职能团队之间的合作
一个组织内的不同小组孤立地工作是很常见的。工程、产品、客户支持、营销和文档团队可能没有像他们应该的那样经常在项目上进行协作。
想象一下,举办一次活动,每个团队成员都可以利用他们的专业知识来改善产品文档。文档马拉松促进了主题专家(SME)的多样性、实时协作和沟通。它们还允许一个包容性的环境,居住在不同地理位置的人可以亲自或远程参与。你的文件会得到具有不同观点和专业的专家的关注,最大限度地减少孤立的孤岛、无意识的偏见和倦怠。
>
> **提示:** 使跨职能的团队为了一个共同的事业走到一起。
>
>
>
### 文档马拉松
下一次,当你的团队有一个似乎无法克服的积压工作,或者被赋予重组一个巨大的文档项目的任务时,考虑举办一个文档马拉松。这很容易,而且它的生产力可能会让你吃惊。关于举办这样的活动的更多信息,请阅读 Tiffany Long 写的很棒的 [举办黑客马拉松的 10 步指南](https://opensource.com/downloads/hackathon-guide?intcmp=7013a000002qLH8AAM)。
*(题图:MJ/1284f6fb-91e9-4799-8773-ee7f51fd87c9)*
---
via: <https://opensource.com/article/23/4/open-source-docathon>
作者:[Lydie Modé-Malivert](https://opensource.com/users/lmalivert) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Your open source project's documentation is essential to your customers. Your target audience must understand the purpose of your project and how to use it, and documentation is what bridges that gap. A project is rarely ever truly done, so it's equally important for resources to be maintained and updated with your project's continuous improvement.
But what happens when you have lots of documentation to maintain but lack the resources to keep it current? The answer is pretty simple: Host a docathon!
## What is a docathon?
A docathon is like a hackathon. A hackathon is an event where engineers and community leaders gather to improve or add new features to an existing application. In a docathon, the same kind of collaboration focuses on improving documentation.
**[ Learn about writing Docs as Code. ]**
A docathon can fill gaps within content, restructure large documentation sets, fix broken links, or just correct typos. The intent behind hosting a docathon is to improve a large amount of documentation in a relatively brief timeframe.
Some examples of product documentation include:
- Training manuals
- User manuals
- Installation guides
- Troubleshooting guides
- Quickstart guides
[API](https://www.redhat.com/en/topics/api/what-are-application-programming-interfaces?intcmp=7013a000002qLH8AAM)documentation- Tutorials
At my organization, our documentation team hosted a docathon and successfully revamped a 102-page installation guide. The docathon enabled us to focus on the project's scope, which was reorganizing for simplicity, removing duplicate content, and following the customer journey. Hosting a docathon left a lasting impression on my team and improved customer success.
**[ Read Write documentation that actually works for your community ]**
## 3 things you can achieve with a docathon
Here are my top three reasons to host a docathon:
### 1. No more backlog
Most documentation must evolve along with the product it supports. As the product changes or updates, so must the documentation. In some cases, documentation teams release new versions of their documentation alongside the engineering team's release cycle. As priorities within a team change and [GA releases](https://opensource.com/article/19/7/what-golden-image) continue, documentation teams face the challenge of keeping up with new features, bug fixes, and tasks to complete. The changes that get left behind become part of a backlog—an accumulation of work that needs to be completed at a later time.
Docathon tip:During a docathon, participants can triage backlog items and complete them as they progress through the list. Non-technical participants can work on fixes related to typos, broken links, and other text-related issues.
### 2. Revamp large-scale guides
By the time your documentation team realizes it's time to revamp a guide, it's probably several chapters in and hundreds of pages deep. Once the content plan has been developed, the complexity of restructuring begins. Restructuring a large amount of documentation is not for the faint of heart.
Docathon tip:Assemble a team to lead the docathon and provide incentives for organization-wide participation from different teams or departments. Depending on the scope of work and time constraints, your team can successfully restructure an entire guide in less time than you probably expect.
### 3. Collaboration between cross-functional teams
It is common for different groups within an organization to work in isolation. Engineering, product, customer support, marketing, and documentation teams may not collaborate on projects as often as they should.
Imagine hosting an event where each team member can use their expertise to improve product documentation. Docathons foster subject matter expert (SME) diversity, real-time collaboration, and communication. They also allow for an inclusive environment where individuals residing in different geographical locations can participate in person or remotely. Your documentation receives the undivided attention of experts with different viewpoints and specializations, minimizing isolated siloes, unconscious bias, and burnout.
Docathon tip:Enable cross-functional teams to come together for a common cause.
**[ Learn what it takes to build a resilient IT culture ]**
## Documentation marathon
The next time your team has a seemingly insurmountable backlog or is tasked with restructuring a huge documentation project, consider hosting a docathon. It's easy, and its productivity may surprise you. For more information on hosting an event like this, read Tiffany Long's excellent [10-step guide to hosting a hackathon](https://opensource.com/downloads/hackathon-guide?intcmp=7013a000002qLH8AAM).
## Comments are closed. |
15,869 | Fedora 36 到达生命终点(EOL),升级到 Fedora 37/38 | https://debugpointnews.com/fedora-36-eol/ | 2023-06-02T16:20:43 | [
"Fedora"
] | /article-15869-1.html | 
>
> 根据官方说明,Fedora 36 已经到了生命的尽头。你应该升级到 Fedora 37。
>
>
>
发布于 2022 年 5 月 10 日的 [Fedora Linux 36](https://www.debugpoint.com/fedora-36/),于 2023 年 5 月 16 日达到生命终点。这意味着在此日期之后,Fedora Linux 36 将不再有任何形式的更新,包括安全更新或安全公告。所有被推送到稳定版的 Fedora Linux 36 的更新也将被停止。
[Fedora Linux 37](https://www.debugpoint.com/fedora-37/),于 2022 年 11 月 15 日发布,将继续接收更新,直到 Fedora Linux 39 发布后大约一个月,即 2023 年 11 月 14 日左右。
我们鼓励 Fedora Linux 36 的用户尽快升级到 Fedora Linux 37,以确保他们继续接收安全更新和错误修复。要升级,你可以按照我下面的详细升级指南进行:
>
> **[如何从 Fedora 36 工作站升级到 Fedora 37(GUI 和 CLI 方法)](https://www.debugpoint.com/upgrade-fedora-37-from-fedora-36/)**
>
>
>
另外,[Fedora 38](https://www.debugpoint.com/fedora-38/) 是最新的版本,你可以尝试全新安装该版本。
Fedora 项目是一个社区支持的项目,开发和维护基于 Linux 内核的自由和开源的操作系统。Fedora 以其前沿的软件和对创新的承诺而闻名。
Fedora 项目每六个月发布一个新版本的 Fedora。每个新版本都是基于上一个版本,包括新功能、错误修复和安全更新。
对于那些想要一个前沿的、不断更新的操作系统的用户来说,Fedora 是一个受欢迎的选择。对于想参与开发自由和开源操作系统的用户来说,它也是一个不错的选择。
来自 [邮件列表公告](https://lists.fedoraproject.org/archives/list/[email protected]/thread/4GXBZJSGQ2PEKIBM2APCTLXBS6IDKSOP/),[EOL wiki](https://docs.fedoraproject.org/en-US/releases/eol/)
*(题图:MJ/11299909-932c-4740-b940-81c98d1d00db)*
---
via: <https://debugpointnews.com/fedora-36-eol/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,870 | 超越 Bash: 9 个不太知名的 Linux Shell 及其功能 | https://itsfoss.com/shells-linux/ | 2023-06-02T17:58:00 | [
"Shell"
] | https://linux.cn/article-15870-1.html | 
>
> 你可能已经知道像 Bash 和 Zsh 这样的流行 Shell。让我们来探索一些有趣和独特的 Shell。
>
>
>
Shell 通过解释命令为 Linux 和类 Unix 系统提供了一个接口,充当用户与操作系统的核心工作之间的中介。
毫无疑问,**Bash Shell 是最受欢迎的 Shell** 之一,但有些用户喜欢其他 Shell,比如在 macOS 上的默认 Shell——ZSH。但是除了这些流行的 Shell 之外,还存在许多 Shell,具有不同的功能和用途。
在本文中,我们将介绍一些被积极维护并提供不同用户体验的不太常见的 Shell。
### 1、Fish Shell
谈到除了 Bash、Zsh 之外的 Shell,第一个想到的就是 Fish Shell。
Fish 是一个智能的、用户友好的命令行 Shell,主要适用于类 Unix 操作系统。

Fish Shell 的特点:
* 根据历史记录提供命令自动建议和补全。
* 支持 24 位真彩。
* 支持语法高亮,所有特性都可以开箱即用。
安装 Fish:
Fish 可在几乎所有 Linux 发行版的官方仓库中获得。在 Ubuntu 中,你可以通过以下命令来安装:
```
sudo apt install fish
```
Ubuntu 仓库中的版本有点旧。如果你想安装最新版本,可以使用该团队提供的官方 PPA。
```
sudo apt-add-repository ppa:fish-shell/release-3
sudo apt update
sudo apt install fish
```
>
> **[Fish Shell](https://fishshell.com/)**
>
>
>
### 2、Nushell
Nushell(Nu)是一种新型的 Shell,可以在 Linux、macOS、Windows、BSD 等系统上使用。它的哲学和灵感来自于类似于 [PowerShell](https://itsfoss.com/microsoft-open-sources-powershell/)、函数式编程语言和现代 [CLI](https://itsfoss.com/gui-cli-tui/) 工具等项目。

Nushell 的特点:
* 一切皆数据:Nu 管道使用结构化数据,因此你每次都可以使用同样的方式安全地选择、过滤和排序。
* 强大的插件:可以使用强大的插件系统轻松扩展 Nu。
* 易读的错误消息:Nu 操作的是类型化的数据,因此它能够检测其他 Shell 无法检测到的错误。当出现问题时,Nu 会准确指出问题所在和原因。
* 干净的 IDE 支持。
安装 Nushell:
如果你使用的是 Ubuntu,是无法找到一个 Apt 存储库来安装 Nushell 的。但是,根据其在 [GitHub 上的说明](https://github.com/nushell/nushell),你可以通过安装所需的依赖项来构建它。
幸运的是,还有一种方法可以使用 Homebrew 在任何发行版上安装它。你可以参考我们的教程 [在 Linux 上安装并使用 Homebrew 软件包管理器](https://itsfoss.com/homebrew-linux/),成功在 Linux 上安装后,你需要输入以下命令来安装 Nushell:
```
brew install nushell
```
请访问其官方网站以查看更多安装方式。
>
> **[Nushell](https://www.nushell.sh/)**
>
>
>
### 3、Dune
该项目的创建者将 **Dune** 描述为海滩上的一个 “贝壳”。Dune 是一个快速、实用且美观的 Shell,提供了一些特殊的元编程功能,比如引用。

Dune Shell 的特点:
* 在进入交互模式之前,Dune 执行存储在主目录中的“预载”启动文件。
* Dune 的 REPL 是完全可定制的。
* 可以通过将变量分配给程序名称来定义别名。
* 使用宏来编写修改 Shell 环境的函数,就像命令或程序一样。
* Dune 提供了丰富的标准库,并提供漂亮的界面来查看每个模块中可用的所有函数。
安装 Dune Shell:
Dune shell 可在 Arch Linux 存储库中以 `dunesh` 的名字获得。
对于其他用户,Dune shell 可以通过 `cargo` 安装。所以,首先需要 [安装最新版本的 Rust](https://fishshell.com/)。如果已经安装了 Rust,请确保你有最新的版本,然后继续安装 Dune。
```
cargo install -f dune
```
安装完成后,可以通过输入以下命令访问 Shell:
```
dunesh
```
>
> **[Dune Shell](https://github.com/adam-mcdaniel/dune)**
>
>
>
### 4、Xonsh
Xonsh 是一个用 Python 编写的,跨平台 Shell 和命令提示符。它结合了 Python 和 Bash Shell,用户可以直接在 Shell 中运行 Python 命令。甚至可以结合使用 Python 和 Shell 命令。

如果你想了解更多,请阅读我们的 Xonsh 文章:
>
> **[Xonsh Shell:结合 Bash Shell 和 Python 最佳特点的 Shell](https://itsfoss.com/xonsh-shell/)**
>
>
>
Xonsh Shell 的特点:
* Xonsh 语言具有 Bash 中常用的 Shell 原语。
* 在 Python 中准备环境变量和参数,然后在 Shell 命令中使用它们。
* 第三方扩展系统 Xontribs。
* 可自定义的标签补全、键绑定、颜色样式。
* 丰富的界面,方便查看历史记录。
安装 Xonsh Shell:
Xonsh 可在许多 Linux 发行版的仓库中获得,如 Ubuntu、Fedora 等。因此,要在 Ubuntu 上安装它,请运行:
```
sudo apt install xonsh
```
Xonsh 还提供了一个 AppImage 包,可以从它们的下载页面下载。如果你不熟悉这种文件格式,请参考我们的 [AppImage 指南](https://itsfoss.com/use-appimage-linux/)。
>
> **[Xonsh](https://xon.sh/)**
>
>
>
### 5、Hilbish
Hilbish 是一个可扩展 Shell,可通过 Lua 编程语言进行定制。该 Shell 面向普通用户和高级用户。

Hilbish 的特点:
* 简单易用的脚本编写。
* 历史和补全菜单:为用户提供正确的补全和历史搜索菜单。
* 通过 Lua API 可以进行语法高亮和提示。
* 它可以在 Unix 系统和 Windows 上运行,但在 Windows 上可能会遇到问题。
安装 Hilbish:
Hilbish 在 Ubuntu 的包仓库中不可用。因此,需要从源代码构建安装。
要安装它,需要安装 **Go** 和 **task**。
```
sudo apt install golang-go
sudo snap install task --classic
```
安装完依赖项后,运行以下命令来安装 Hilbish shell:
```
git clone --recursive https://github.com/Rosettea/Hilbish
cd Hilbish
go get -d ./...
```
如果要使用稳定版,请运行以下命令:
```
git checkout $(git describe --tags `git rev-list --tags --max-count=1`)
task build
sudo task install
```
>
> **[Hilbish](https://rosettea.github.io/Hilbish/)**
>
>
>
### 6、Elvish
Elvish 是一种丰富的编程语言和多功能交互式 Shell。它可以在 Linux、Mac 和 Windows 上运行。即使版本 v1.0 尚未发布,它已经适合大多数日常交互使用。

Elvish 的特点:
* 强大的管道:Elvish 中的管道可以携带结构化数据,而不仅仅是文本。你可以通过管道传输列表、映射甚至函数。
* 直观的控制结构。
* 目录历史:Elvish 记住了你访问过的所有目录。你可以通过按 `CTRL+L` 访问它。
* 命令历史。
* 内置文件管理器:通过按 `CTRL + N` 访问。
安装 Elvish:
Elvish Shell 可在 Ubuntu 和 Arch Linux 的包管理器中获得。因此,要安装它,请打开终端并键入:
```
sudo apt install elvish
```
或者
```
sudo pacman -S elvish
```
要了解有关 Elvish 的更多信息,请访问 Elvish 的官方网站。
>
> **[Elvish](https://elv.sh/)**
>
>
>
### 7、Oh
据其开发者称,Oh 是 Unix shell 的重新设计。
它旨在成为现代 Shell 的更强大、更稳健的替代品,同时尊重 Unix shell 在过去半个世纪中建立的惯例。

Oh Shell 的特点:
* 一流的频道、管道、环境和函数。
* 适用于标准 Shell 构造的丰富返回值。
* 支持模块化。
* 简化的评估和引用规则。
* 语法尽可能少地偏离已有的惯例。
安装 Oh:
Oh 提供了一个预编译的二进制文件。你需要从它们的 [官方 GitHub 页面](https://github.com/michaelmacinnis/oh#linux) 下载它。
你需要使用以下命令为文件授予执行权限:
```
chmod +x oh
```
运行以下命令以在你的系统上安装它:
```
sudo mv oh /usr/local/bin/
```
现在,你可以通过以下命令启动 Oh:
```
oh
```
要了解有关 Oh 的详细信息,请查阅其文档。
>
> **[Oh](https://github.com/michaelmacinnis/oh)**
>
>
>
### 8、Solidity
Solidity 是一个带有轻量级会话记录和远程编译器支持的交互式 Shell。当你更改指示/语言时,它会自动获取匹配的远程编译器。

Solidity 的特点:
* `pragma solidity <version>` 会尝试动态加载所选的编译器版本。
* 可以使用 `.session` 命令保存和恢复会话。
* 设置在退出时保存(在运行并发 shell 时不安全)。
* `$_` 是上一个已知结果的占位符。
* 特殊命令是具有点前缀。其他所有都将被视为 Solidity 代码进行评估。
安装 Solidity:
你可以通过 `npm` 安装 Solidity shell。
[确保你安装了最新版本的 nodejs](https://itsfoss.com/install-nodejs-ubuntu/) 和 `npm`,然后输入以下命令:
```
npm install -g solidity-shell
```
安装完成后,运行 `solidity-shell` 来开始会话。
>
> **[Solidity Shell](https://github.com/tintinweb/solidity-shell)**
>
>
>
### 9、Yash
Yash(Yet another shell)是一个遵循 POSIX 标准的命令行 Shell,使用 C99(ISO/IEC 9899:1999)编写。它具有适用于日常交互和脚本使用的功能。

Yash Shell 的特点:
* 全局别名。
* 套接字重定向、管道重定向和进程重定向。
* 提示符命令和未找到命令的处理程序。
* 带有预定义补全脚本的命令行补全,覆盖了 100 多个命令。
* 基于命令历史记录的命令行预测。
安装 Yash Shell:
要安装该 Shell,你需要转到它们的 [GitHub 发布](https://github.com/magicant/yash/releases/tag/2.53) 页面下载 tar 文件。解压 tar 文件;在其中,你将找到一个包含安装说明的 `INSTALL` 文件。
通常,你应该在提取的文件夹中执行以下命令:
```
./configure
make
sudo make install
```
要了解有关 Yash Shell 的详细信息,请查看其手册页面。
>
> **[Yash](https://yash.osdn.jp/index.html.en)**
>
>
>
### 顺便提及
* Ion:[Ion Shell](https://gitlab.redox-os.org/redox-os/ion) 是用 Rust 编写的一种现代系统 Shell,主要用于 RedoxOS。它仍然是一个正在开发中的工作,用户应该对语法会变化有所预料。
* Closh:[Closh](https://github.com/dundalek/closh) 是一种类似 Bash 的 Shell,将传统的 UNIX Shell 与 [Clojure](https://clojure.org/) 的强大功能相结合。它旨在成为 Bash 的现代替代品。它也是在开发的早期阶段。
* Dash:[Dash](https://linuxhandbook.com/dash-shell/) 是来自 Debian 的符合 POSIX 标准、快速轻量级的 Shell。
? 你对这些列出的 Shell 有何看法?你是否会尝试将默认 Shell 更改为这里的某些选项?你最喜欢的是哪一个?在下面的评论框中分享你的想法。
*(题图:MJ/a84a1625-4dd1-4589-aabb-ce3f37090f32)*
---
via: <https://itsfoss.com/shells-linux/>
作者:[Sreenath](https://itsfoss.com/author/sreenath/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

A Shell provides an interface to Linux and Unix-like systems by interpreting commands and acts as an intermediary between the user and the core workings of the operating system.
Undoubtedly, the **bash shell is the most popular one**, and some users prefer other shells like ZSH, which is the default shell in macOS. But many shells exist other than these popular ones, with different features and use cases.
In this article, we will take a look at some less popular shells that are actively maintained and provide a different user experience.
[Learn Linux Quickly - Linux Commands for BeginnersLearn Linux Quickly doesn’t assume any prior Linux knowledge, which makes it a perfect fit for beginners. Nevertheless, intermediate and advanced Linux users will still find this book very useful as it goes through a wide range of topics. Learn Linux Quickly will teach you the following topics:Insta…](https://linuxhandbook.gumroad.com/l/mEsrwA)
## 1. Fish Shell
When talking about shells other than bash/zsh, the first name coming to our mind is the fish shell.
Fish is a **smart, user-friendly command line shell** primarily for UNIX-like operating systems.
**Features of Fish Shell**
- Autosuggestion of commands based on history and completions.
- Supports 24-bit color.
- It supports syntax highlighting, and all features work out of the box.
**Install Fish**
Fish is available in the official repos of almost all Linux distributions. In Ubuntu, you can install it by:
`sudo apt install fish`
The version in the Ubuntu repos is a bit old. If you want to install the latest version, you can use the official PPA provided by the team.
```
sudo apt-add-repository ppa:fish-shell/release-3
sudo apt update
sudo apt install fish
```
**Suggested Read 📖**
[How to Find Which Shell am I Using in Linux [4 Methods]Here are four simple commands to find out which shell are you using in Linux.](https://linuxhandbook.com/shell-using/)

## 2. Nushell
Nushell is a new type of shell that works in **Linux, macOS, Windows, BSD**, etc. **Nu**, as it’s also called, it takes its philosophy and inspiration from projects like [PowerShell](https://itsfoss.com/microsoft-open-sources-powershell/), functional programming languages, and modern [CLI](https://itsfoss.com/gui-cli-tui/) tools.
**Features of Nushell**
Nu pipelines use structured data so you can safely select, filter, and sort the same way every time.**Everything is data:**It's easy to extend Nu using a powerful plugin system.**Powerful plugins:****Easy to read error messages.**Nu operates on typed data, so it catches bugs that other shells don’t. And when things break, Nu tells you exactly where and why.- Clean IDE support.
**Install Nushell**
If you’re on Ubuntu, you won’t find an apt repository to install Nushell. But you can build it by installing the required dependencies, as per its [instructions on GitHub](https://github.com/nushell/nushell).
Fortunately, there is a way to install it on any distro using **Homebrew**. You can refer to our tutorial on [installing and using Homebrew Package Manager on Linux](https://itsfoss.com/homebrew-linux/).
Once you successfully set it up on Linux, you need to type in the following command to install Nushell:
`brew install nushell`
Head to its official website to explore more installation options.
## 3. Dune
The project's creator describes **Dune** as a shell by the beach. Dune is a **fast, useful and pretty shell**, offering a few niche metaprogramming features such as quoting.
**Features of Dune Shell**
- Before entering the interactive mode, Dune executes
*the prelude,*a startup file stored in the home directory. - Dune's REPL is entirely customizable
- You can define aliases by assigning a variable to a program's name
- Use a macro to write functions that modify your shell's environment and act like commands or programs
- Dune offers an extensive standard library and also provides a pretty interface to see all the functions available in each module.
**Install Dune Shell**
Dune shell is available in the Arch Linux repository as **dunesh**.
For all other users, the Dune shell can be installed with cargo. So first, you need to [install the latest version of rust](https://itsfoss.com/install-rust-cargo-ubuntu-linux/). If you already have rust installed, ensure you have the latest version and then proceed to install Dune.
`cargo install -f dune`
Once installed, you can access the shell by entering the following:
`dunesh`
**Suggested Read 📖**
[How to Change Shell in LinuxThis quick tutorial shows how to check the running shell, available shell in the system and how to change the default shell in Linux.](https://linuxhandbook.com/change-shell-linux/)

## 4. Xonsh
Xonsh is a **Python-powered, cross-platform shell **and command prompt. It combines Python and bash shell so that you can run Python commands directly in the shell. You can even combine Python and shell commands.
We had a separate article on Xonsh if you are curious to learn more:
[Xonsh Shell Combines the Best of Bash Shell and Python in Linux TerminalWhich is the most popular shell? I guess you’ll say bash or perhaps zsh and you are right about that. There are several shells available for UNIX and Linux systems. bash, ksh, zsh, fish and more. Recently, I came across another shell which offers a unique twist of combining](https://itsfoss.com/xonsh-shell/)

**Features of Xon**s
**h Shell**- The Xonsh language has shell primitives that you are used to from Bash
- Prepare environment variables and arguments in Python and use them in shell commands
- Xontribs is a 3rd-party extension system
- Customizable tab completion, key bindings, color styles
- Rich interface to discover history
**Installing Xonsh Shell**
Xonsh is available in the repos of many Linux distributions like Ubuntu, Fedora, etc. So, to install it on Ubuntu, run:
`sudo apt install xonsh`
Xonsh also provides an AppImage package, which can be downloaded from their download page. You may refer to our [AppImage guide](https://itsfoss.com/use-appimage-linux/) if you are new to the file format.
## 5. Hilbish
Hilbish is an **extensible shell** that is very customizable via the Lua programming language. The shell is aimed at both casual users and power users.
**Features of Hilbish**
- Simple and Easy Scripting
- History and Completion Menus: Provides the user with proper menus for completions and history searching
- Syntax highlighting and hinting are available via the Lua API
- It works on Unix systems and Windows, but on Windows, there may encounter issues.
**Installing Hilbish**
Hilbish is not available in the package repositories of Ubuntu. So, you will be building it from the source.
To install it, you need **Go and task** installed.
```
sudo apt install golang-go
sudo snap install task --classic
```
Once the dependencies are installed, run the following commands to install Hilbish shell:
```
git clone --recursive https://github.com/Rosettea/Hilbish
cd Hilbish
go get -d ./...
```
If you want a stable branch, run these commands:
```
git checkout $(git describe --tags `git rev-list --tags --max-count=1`)
task build
sudo task install
```
## 6. Elvish
Elvish is an expressive programming language and a versatile interactive shell. It runs on Linux, Mac, and Windows. Even if **v1.0** has not been released, it is already suitable for most daily interactive use.
**Features of Elvish**
Pipelines in Elvish can carry structured data, not just text. You can stream lists, maps, and even functions through the pipeline.**Powerful Pipelines:****Intuitive Control Structures**Elvish remembers all the directories you have been to. You can access it by pressing**Directory History:**`CTRL+L`
.**Command History**Accessible by pressing CTRL + N**Built-in File Manager:**
**Install Elvish**
Elvish shell is available in Ubuntu and Arch Linux package managers. So to install it, open a terminal and run:
`sudo apt install elvish`
## 7. Oh
According to its developers, Oh is a reimagining of the Unix shell.
It aims to become a more powerful and robust replacement to modern options while respecting the conventions established by the Unix shell over the last half-century.
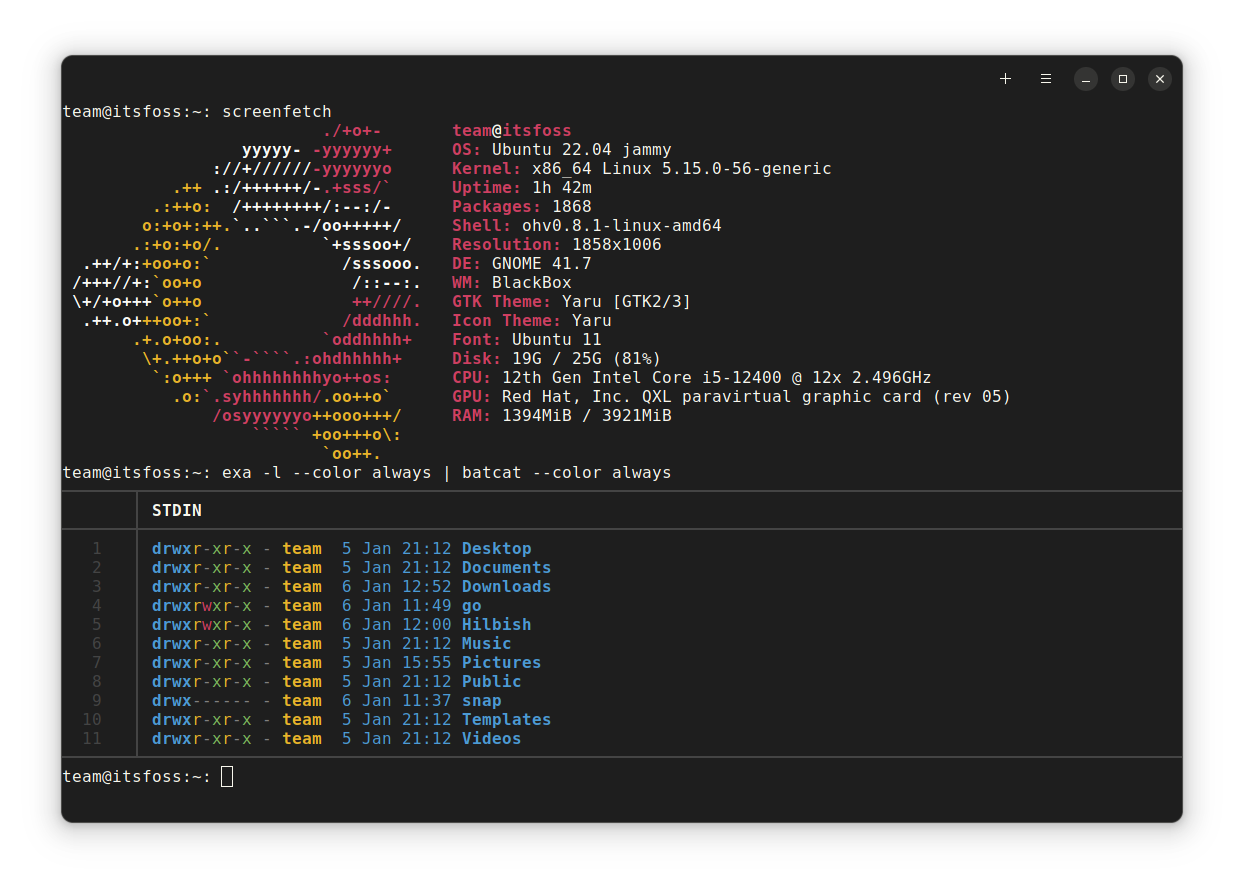
**Features of Oh Shell**
- First-class channels, pipes, environments, and functions
- Rich return values that work with standard shell constructs
- Support for modularity.
- A simplified set of evaluation and quoting rules.
- A syntax that deviates as little as possible from established conventions;
**Installing Oh**
Oh provides a pre-compiled binary. You need to download it from their [official GitHub page](https://github.com/michaelmacinnis/oh#linux).
You need to give execution permission to the file using the command:
`chmod +x filename`
Now, you can run it by :
`./<name of binary file>`
**Suggested Read 📖**
[How to Run a Shell Script in Linux [Essentials Explained for Beginners]There are two ways to run a shell script in Linux. You can use: bash script.sh Or you can execute the shell script like this: ./script.sh That maybe simple, but it doesn’t explain a lot. Don’t worry, I’ll do the necessary explaining with examples so](https://itsfoss.com/run-shell-script-linux/)

## 8. Solidity
Solidity is an interactive shell with lightweight session recording and remote compiler support. When you change the solidity pragma/language, it automatically fetches a matching remote compiler.
**Features of Solidity**
`pragma solidity <version>`
attempts to dynamically load the selected compiler version- Sessions can be saved and restored using the
`.session`
command. - Settings are saved on exit (not safe when running concurrent shells).
`$_`
is a placeholder for the last known result.- Special commands are dot-prefixed. Everything else is evaluated as Solidity code.
**Install Solidity**
You can install solidity shell through npm.
[Ensure you have the latest version of nodejs](https://itsfoss.com/install-nodejs-ubuntu/) and npm installed, then type the following command:
`npm install -g solidity-shell`
Once installed, run **solidity-shell **to start the session.
## 9. Yash
Yash, or yet another shell is a POSIX-compliant command line shell written in C99 (ISO/IEC 9899:1999). It has features for daily interactive and scripting use.
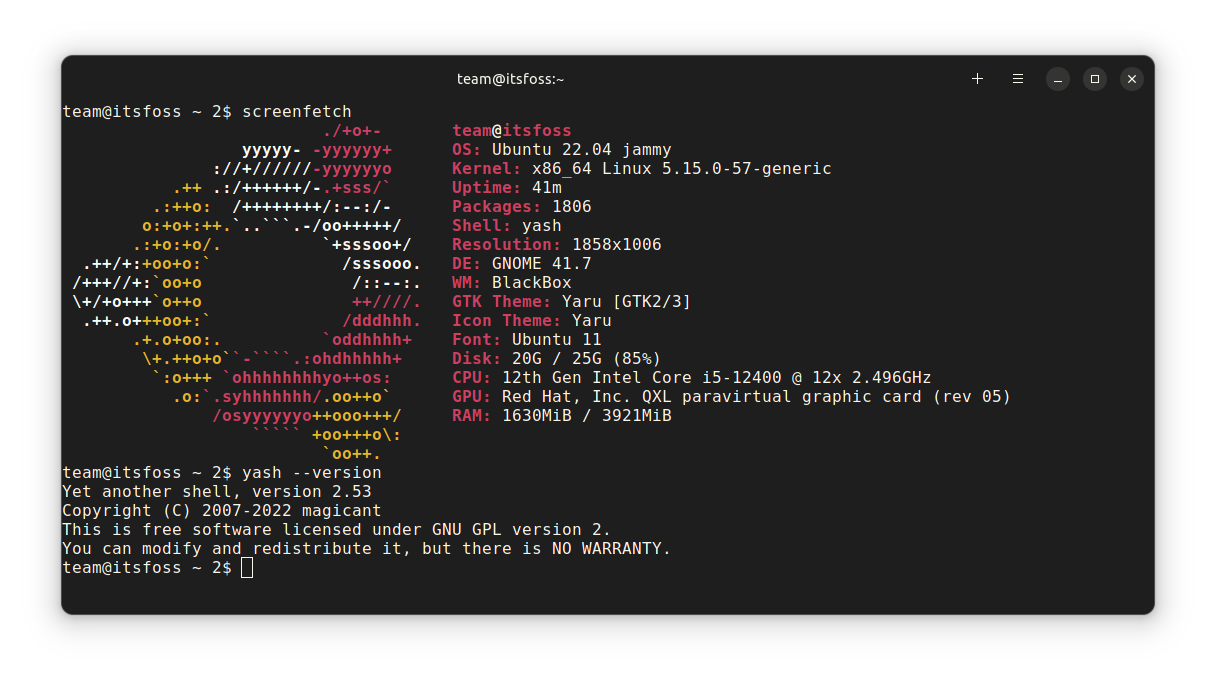
**Features of Yash Shell**
- Global aliases
- Socket redirection, pipeline redirection, and process redirection
- Prompt command and command-not-found handler
- Command line completion with predefined completion scripts for more than 100 commands
- Command line prediction based on command history
**Installing Yash Shell**
To install the shell, you need to go to their [GitHub releases](https://github.com/magicant/yash/releases/tag/2.53) page and download the tar file. Now extract the tar file; inside it, you will find an INSTALL file with instructions to install it.
Typically, you should execute the below command inside the extracted folder.
`./configure && make && sudo make install`
## Honorable Mentions
**Ion:**[Ion Shell](https://gitlab.redox-os.org/redox-os/ion)is a modern system shell written in Rust, primarily for**RedoxOS**. It is still a work in progress, and users should expect syntax changes.**Closh:**[Closh](https://github.com/dundalek/closh)is a bash-like shell that combines the best of traditional UNIX shells with the power of[Clojure](https://clojure.org/). It aims to be a modern alternative to bash. This, too, is in the early stages of development.- Dash:
[Dash](https://linuxhandbook.com/dash-shell/)is a POSIX-compliant, fast and lightweight shell from Debian.
💬 *What do you think about these shells listed? Would you experiment by changing the default shell to some of the options here? What's your favorite one? Share your thoughts in the comments box below.* |
15,872 | 10 个最好的开源 Discord 机器人 | https://itsfoss.com/open-source-discord-bots/ | 2023-06-03T09:36:51 | [
"Discord"
] | https://linux.cn/article-15872-1.html | 
>
> 想要一个开源的 Discord 机器人来增强你的 Discord 服务器功能吗?我们为你筛选了以下列表。
>
>
>
[Discord](https://discord.com/company) 最初是一个玩家和朋友们聚会的平台。截至 2022 年,Discord 拥有超过 1.5 亿用户,甚至在 [拒绝](https://www.bloomberg.com/news/articles/2021-04-20/chat-app-discord-is-said-to-end-takeover-talks-with-microsoft) 微软 120 亿美元的收购提案之后仍然如此。
如果你是第一次听说 Discord,请将其视为类似 Slack 的东西,但是有无数有趣的功能可以创建社区(即“服务器”)。
在所有功能中,Discord 机器人允许自动化某些事情或增添服务器的趣味性。但是大多数机器人是专有的。因此,在这个列表中,我推荐一些最好的开源 Discord 机器人。
**注意:** 机器人可能会传播恶意软件并影响整个 Discord 服务器。你必须确保不添加你不了解的机器人。这就是为什么你可能希望信任开源的 Discord 机器人而不是其他选择的原因。
### 1、MonitoRSS

亮点:
* RSS 源
* 过滤器和订阅
* 托管
[MonitoRSS](https://monitorss.xyz) 是一个有用的 Discord 机器人,可以使你的社区从支持 RSS 的任何来源接收新闻。
它是一个相当受欢迎的机器人,能够按预期工作。你可以将其添加到特定的频道,自定义其外观,并在 Discord 服务器上获取新闻更新。
它还可以让你过滤 RSS 内容,允许用户根据自己的喜好订阅。这可以使用 Web 接口控制面板进行管理和自定义。
可以在其 [GitHub 页面](https://github.com/synzen/MonitoRSS) 上了解更多信息。
### 2、ModMail

亮点:
* 允许用户联系服务器的官方成员
* 可以自行托管
* 托管版本
* 可选高级功能
[ModMail](https://modmail.xyz/) 是一个简单的开源 Discord 机器人,可以让用户顺滑地联系 Discord 频道的工作人员/管理员/版主。
传统上,你必须通过私信(DM)与很多人联系以获得你想要的帮助。但是,有些服务器有很多用户,因此服务器工作人员可能很难回复你。
当你向该机器人发送消息时,ModMail 会创建一个单独的频道。这个频道作为所有管理员、版主和你的共享收件箱。

它不仅可以轻松发送消息,还可以帮助服务器工作人员轻松地阅读过去的记录、启用自动回复、保存片段、匿名回复等等。其中有些功能是收费的。
你可以访问其 [官方网站](https://modmail.xyz/premium) 和 [GitHub 页面](https://github.com/chamburr/modmail) 了解更多信息。它还提供了自行托管所需的所有必要信息。
### 3、Red Discord Bot(自行托管)

亮点:
* 高度可定制
* 管理任务
* 良好的文档
* 多用途
[Red](https://github.com/Cog-Creators/Red-DiscordBot) 是一个完全模块化的机器人,为你提供许多功能,包括音乐、管理、问答游戏、流媒体警报等等。
无论你是想要它发送欢迎消息,还是帮助管理服务器,Red 应该都可以派上用场。
与其他一些机器人不同的是,你不能直接将机器人添加到你的服务器。你需要自行托管它、配置它,然后才能将其添加到你的服务器中。
安装不需要进行任何编码,你只需要按照 [文档](https://docs.discord.red/en/stable/) 的说明进行操作即可。
### 4、Discord Music Bot(自行托管)

亮点:
* 支持 Spotify、SoundCloud 和 YouTube
* 提供随机播放、音量控制和 Web 仪表板来管理它们
[Discord Music Bot](https://github.com/SudhanPlayz/Discord-MusicBot)(我知道它并不是一个独特的名称)是一个相当受欢迎的 Discord 机器人,你可以自行托管。
它支持 Spotify、SoundCloud 和 YouTube。一些功能包括随机播放、音量控制和 Web 仪表板。
你可以按照其 [GitHub 页面](https://github.com/SudhanPlayz/Discord-MusicBot) 上的说明为你的服务器安装并配置它。
### 5、Discord Tickets(自行托管)

亮点:
* 工单管理
* 免费添加自定义品牌标识
你在 Discord 上为你的服务/产品拥有客户吗?你可以使用 [Discord Tickets](https://discordtickets.app) 管理/创建工单,并免费添加自定义品牌标识。
大多数 Discord 流行的工单管理机器人都是专有的,并需要订阅高级服务才能添加品牌标识。
通过 Discord Tickets,你可以自行托管并按照自己的要求进行自定义。在其 [GitHub 页面](https://github.com/discord-tickets/bot) 了解更多信息。
### 6、EvoBot(自行托管)

亮点:
* 高度可定制化
* 搜索音乐或使用 URL 播放
[EvoBot](https://github.com/eritislami/evobot) 是另一个具有许多自定义选项的开源音乐 Discord 机器人。
你可以使用其 URL 或搜索/播放来自 YouTube 和 SoundCloud 的音乐。
在其 [GitHub 页面](https://github.com/eritislami/evobot)上了解更多关于安装和配置的信息。
### 7、Atlanta Bot

亮点:
* 托管版本
* 可自行托管
* Web 仪表板
* 多用途
[AtlantaBot](https://github.com/Androz2091/AtlantaBot) 是另一个多合一的机器人,提供了管理、音乐、有趣的命令和其他功能。
此外,它的仪表盘提供各种有用的选项。你可以设置仪表板并通过它管理你的服务器/配置。你还可以使用该机器人执行有限的翻译。
它可以自行托管,但如果你不想付出努力,也可以使用托管版本的机器人。
### 8、YAGPDB(自行托管)

亮点:
* 自定义命令
* 自动版主
* Reddit/YouTube 订阅
* 管理任务
[YAGPDB](https://yagpdb.xyz) 代表 “Yet Another General Purpose Discord Bot”,即“又一个通用 Discord 机器人”。
使用此机器人,你可以快速执行一般的管理任务、添加自定义命令、创建自动版主、管理/创建角色以及提取 Reddit/YouTube 订阅。
它是可配置的。因此,你可以做更多的事情,而不仅仅是我刚才提到的。可以在其 [GitHub 页面](https://github.com/botlabs-gg/yagpdb) 上了解更多信息。
### 9、Loritta

亮点:
* 托管版本
* 可以自行托管
* 吸引和管理功能
如果你正在寻找一个具有有趣角色的多合一 Discord 机器人,[Loritta](https://loritta.website/us/) 是一个不错的选择。
它支持管理、娱乐和自动化功能。你可以自行托管它或使用托管版本。
开发人员将该机器人描述为一个女孩,她可以帮助你管理、娱乐和吸引你服务器的成员。此外,它还提供了一些额外的待遇的高级计划。
可以在其 [GitHub 页面](https://github.com/LorittaBot) 上了解更多信息。
### 10、Melijn

亮点:
* 托管版本
* 可以自行托管
* 管理功能
[Melijn](https://melijn.com) 是另一个多合一的 Discord 机器人。
你可以使用音频命令进行交互、管理、执行用户验证和创建角色组等等。
它提供托管版本,并允许你自行托管它,按照其 [GitHub 页面](https://github.com/ToxicMushroom/Melijn) 上的说明进行操作。
### 你喜欢的 Discord 机器人是什么?
如果你是 Discord 服务器的管理员或管理员,你喜欢使用哪个机器人来管理社区?
你是否专注于管理功能或参与功能?你在 Discord 机器人中寻找的标准功能是什么?
在下面的评论中分享你的想法。
*(题图:MJ/cf3b3ab7-48a9-4c5e-bba4-b68718af3dee)*
---
via: <https://itsfoss.com/open-source-discord-bots/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Discord started as a platform where gamers and friends could hang out. ** Discord has over 150 million users** in
**2022**, even after
[turning down](https://www.bloomberg.com/news/articles/2021-04-20/chat-app-discord-is-said-to-end-takeover-talks-with-microsoft)a
**$12 billion offer from Microsoft**.
If it is your first time hearing about it, consider it something like Slack, but with countless fun functionalities to create communities (i.e., servers).
Among all the features, Discord bots allow automating things or spice up your server. But most of them are proprietary. So, in this list, I suggest some of the **best open-source Discord bots**.
**Note: **Bots can spread malware and affect your entire Discord server. You must ensure that you do not add bots you do not know about. And this is why you might want to trust open-source Discord bots more than other options.
## 1. MonitoRSS
*Highlights:*
**RSS Feed****Filters and Subscriptions****Hosted**
[MonitoRSS](https://monitorss.xyz/) is a useful Discord bot that enables your community to receive news from any sources that support RSS.
It is a reasonably popular bot that works as expected. You can add it to a particular channel, customize its look, and start getting news updates on your Discord server.
It also lets you filter articles for your feed and allow users to subscribe to an article as per their liking. This can be managed and customized using a web interface control panel.
Explore more on its [GitHub page](https://github.com/synzen/MonitoRSS).
## 2. ModMail

*Highlights:*
**Enables users to contact server staff****Self-host****Hosted version****Optional premium**
[ModMail](https://modmail.xyz/) is a simple open-source Discord bot that seamlessly lets a user contact the staff/admins/moderators of a Discord channel.
Traditionally, you have to reach out to multiple people via DMs to expect help on something you want to know. However, some servers have many users, so it may be difficult for the server staff to get back to you.
ModMail creates a separate channel when you send a message to the bot. And this channel acts as a shared inbox to all the administrators, mods, and you.
Not only does easy messaging, but it also helps the server staff to conveniently read past transcripts, enable automated replies, save snippets of them, respond anonymously, and more. Some features are premium-only.
You can check out its [official website](https://modmail.xyz/premium) and [GitHub page](https://github.com/chamburr/modmail) for more info. It also gives you all the necessary information to self-host it.
## 3. Red Discord Bot (Self-Hosted)
*Highlights:*
**Highly Customizable****Moderation****tasks****Good documentation****Multipurpose**
[Red](https://github.com/Cog-Creators/Red-DiscordBot) is an entirely modular bot that provides you with many functions, including music, moderation, trivia, stream alerts, and more.
Red should be useful whether you want it to send welcome messages or help moderate the server.
Unlike some others, you cannot add the bot directly to your server. You will have to self-host it, configure it, and then get the ability to add it to your server.
The installation does not need any sort of coding; you have to follow the [documentation](https://docs.discord.red/en/stable/).
## 4. Discord Music Bot (Self-Hosted)
*Highlights:*
**It****supports Spotify, SoundCloud, and YouTube**.**It offers shuffling, volume control, and a web dashboard to manage it all**.
[Discord Music Bot](https://github.com/SudhanPlayz/Discord-MusicBot) (not a unique name, I know) is a pretty popular Discord bot that you can self-host.
It supports Spotify, SoundCloud, and YouTube. Some features include shuffling, volume control, and a web dashboard.
You can follow the instructions on its [GitHub page](https://github.com/SudhanPlayz/Discord-MusicBot) to install and configure it for your server.
## 5. Discord Tickets (Self-Hosted)
*Highlights:*
**Ticket management****Add custom branding for free**
Do you have customers for your services/products on Discord? You can use [Discord Tickets](https://discordtickets.app/) to manage/create tickets and add your branding for free.
Most of the Discord’s popular ticket management bots are proprietary and require a premium subscription to add your brand logo.
With Discord Tickets, you can self-host and customize as per your requirements. Explore more about it on its [GitHub page](https://github.com/discord-tickets/bot).
## 6. EvoBot (Self-Hosted)
*Highlights:*
**Highly customizable****Search for music or use a URL to play**
[EvoBot](https://github.com/eritislami/evobot) is yet another open-source music Discord bot with lots of customization options.
You can play music from YouTube and SoundCloud using its URL or search/play.
Explore more about its installation and configuration on its [GitHub page](https://github.com/eritislami/evobot).
## 7. Atlanta Bot
*Highlights:*
**Hosted version****Self-host option****Web dashboard****Multipurpose**
[AtlantaBot](https://github.com/Androz2091/AtlantaBot) is yet another all-in-one bot that provides functionalities for moderation, music, fun commands, and several commands.
Furthermore, it features its dashboard with valuable options. You can set up the dashboard and manage your server/configuration through it. You can also perform limited translations using the bot.
It can be self-hosted, but if you would rather not make an effort, you can invite a hosted version of the bot.
## 8. YAGPDB (Self-Hosted)
*Highlights:*
**Custom commands****Automatic moderator****Reddit/YouTube feed****Moderation****tasks**
[YAGPDB](https://yagpdb.xyz/) stands for **Yet Another General Purpose Discord Bot**.
With this bot, you can quickly perform general moderation tasks, add custom commands, create an automatic moderator, manage/create roles, and pull Reddit/YouTube feeds.
It is configurable. So, you can do more with it than what I just mentioned. Explore more about it on its [GitHub page](https://github.com/botlabs-gg/yagpdb).
## 9. Loritta
*Highlights:*
**Hosted version****Self-host option****Engagement and Moderation features.**
If you are looking for a multipurpose Discord bot with an interesting character, [Loritta](https://loritta.website/us/) would be a good pick.
It supports moderation, entertainment, and automation features. You can self-host it or use the hosted version.
The developer presents the bot as a girl who helps you moderate, entertain, and engage the members of your server. Additionally, it offers a premium plan for some extra perks.
Explore more about it on its [GitHub page](https://github.com/LorittaBot).
## 10. Melijn
*Highlights:*
**Hosted version****Self-host option****Moderation features.**
[Melijn](https://melijn.com/) is yet another multipurpose bot for Discord servers.
You can interact with audio commands, moderate, perform user verifications, and create role groups.
It offers a hosted version and lets you self-host it, following the instructions on its [GitHub page](https://github.com/ToxicMushroom/Melijn).
## What’s Your Favorite Discord Bot?
If you are a Discord server moderator or admin, what bot do you like to use for your community?
Do you focus on moderation features or engagement features? What are the standard features that you look for in a Discord bot?
Share your thoughts in the comments below. |
15,873 | 共享经济的真实案例 | https://opensource.com/article/23/4/sharing-economy-examples | 2023-06-03T18:13:50 | [
"共享经济"
] | https://linux.cn/article-15873-1.html | 
>
> 许多流行的在线市场 —— 以及一些你从未听说过的市场 —— 说明了基于社会关系的经济如何能够发挥作用。
>
>
>
一些最熟悉的网络共享经济的例子开始时规模很小。比如 Airbnb,它从三个 <ruby> 空气床 <rt> airbed </rt></ruby> 开始,在 2008 年成为 AirBed and Breakfast(Airbnb)。截至 2016 年,已有 7000 万客人通过 Airbnb 住进了陌生人的家。基于互联网的平台将拥有未使用资源(过剩空间)的人与可以使用它的其他人联系起来,并为他们提供建立信任的方式。这是共享业务模型的完美示例。
在 [先前的文章](https://opensource.com/article/23/4/sharing-economy-open-organization) 中,我介绍了基于社会联系的企业背后的原则,借鉴了 Arun Sundararajan 的书《[共享经济:就业的终结和人群资本主义的兴起](https://www.goodreads.com/book/show/27310516-the-sharing-economy)》。我将讨论共享业务的几个例子。
### 一个连接的市场
根据 Sundararajan 的说法,基于人群的资本主义的经济基础优于目前基于利润的商业模式,因为这种经济的原材料:空间、时间、物品和技能都是过剩的。因为它们已经存在,所以不会产生额外的成本来提供它们。你可以认为这是一种改进的资源利用保护、环境保护或可持续性经济的形式。
人际关系是共享经济的一个重要价值组成部分。例如,一些共享汽车运营商希望乘客坐在前排座位上,以产生对话和互动。这种服务是关于社会联系以及乘车共享的。由于许多司机都是兼职,作为一个小的副业,互动对他们来说可能和收到的费用一样有价值。
以下是传统出租车服务的两个弱点:
* 服务不周
* 由于业务结构(司机或公司的车辆所有权),占用率(利用率)差
使用数字技术应用程序的基于人群的公私合营可以利用友好的人拥有的去中心化过剩能力,而不是单一公司拥有的集中式系统。热情好客,并且没有额外的前期投资。有一些网站可以将杂货的购买和运送外包,有一个应用程序可以帮助代客泊车服务使用 GPS 定位汽车和停车位,还有邮件取件服务、洗衣取件、遛狗等等。
### 平台如何建立信任
eBay 始于 1995 年,它将邻里间的车库销售搬到了网上,并为孤立的书商和旧货店主提供了一种在当地社区之外扩大市场范围的方法。eBay 系统有许多保障措施,通过交易过程保护买家和卖家,所以即使买家和卖家之间有很大的地理距离,eBay 也能保持交易伙伴的信任。对于共享经济中提供的服务,地点更为重要。点对点服务市场可能更适合人口密集的城市地区。
建立供应商和用户的信任是共享经济成功的重要因素。要确定是否信任提供商,消费者必须考虑每个平台的审查过程。他们的评级系统质量如何?一些组织使用 Facebook 好友作为证明来确认可信赖的人。有的平台完全控制支付系统,支付有保障,有的则不然。
BlaBlaCar 的联合创始人 Frederic Mazzella 认为信任是其公司业务的核心,并且对信任的重要性充满热情。BlaBlaCar 的公司总部有一个真人大小的纸板剪裁 “Trust Man”,这是一个穿着斗篷的超级英雄,他的连身衣上印有 “T” 字样。 Mazzella 的信任概念基于他所谓的 [D.R.E.A.M.S. 框架](https://blog.blablacar.com/trust):声明的、评级的、参与的、基于活动的、适度的和社交的。该公司一直致力于加深对可信交换的理解。
### 协作和社区建设
OuiShare 组织协调活动以促进协作。2021 年 6 月,他们在为期三天的 OuiShare Fest 期间聚集了 600 多人,其中包括会议、研讨会、表演和表演。通过这次活动,OuiShare 渴望通过将来自不同背景的人聚集在一起来建立社交联系、项目和协作。参与者探讨了他们有什么多余的以及可能需要和共享的东西。该小组起源于法国,现在遍布欧洲 20 个国家,它提供了一个共享的实验平台,使连接者和成员能够访问知识、工具和国际网络,从中学习和汲取灵感。你可以将其称为未充分利用者的透明度。
服务平台为有知识、技能或才能的人提供业余时间。例如,一些平台为教师提供特定的知识和技能,以换取其他知识或多余的物质商品,而不是金钱。
本文是共享经济系列文章的一部分。 在 [第一篇](https://opensource.com/article/23/4/sharing-economy-open-organization) 中,我解释了共享商业模式及其价值。在这篇文章中,我给出了很多现在正在运行的平台的例子。 在以后的文章中,我将探讨共享商业模式将如何演变。
*(题图:MJ/6c006d2c-4031-4c39-aabb-30c4941f2968)*
---
via: <https://opensource.com/article/23/4/sharing-economy-examples>
作者:[Ron McFarland](https://opensource.com/users/ron-mcfarland) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some of the most familiar examples of the online sharing economy started small. Consider Airbnb, which started from three airbeds and became AirBed and Breakfast in 2008. As of 2016, 70 million guests have stayed in a stranger's home via Airbnb. The internet-based platform connects people who have a resource not used to capacity—excess space—with others who can use it and provides a means for them to establish trust. It's a perfect example of the sharing business model.
In an [earlier article](https://opensource.com/article/23/4/sharing-economy-open-organization), I introduced the principles behind businesses based on social connection, drawing from the book [The Sharing Economy: The End of Employment and the Rise of Crowd-Based Capitalism](https://www.goodreads.com/book/show/27310516-the-sharing-economy) by Arun Sundararajan. I will discuss several examples of the sharing business model in this article.
## A market for connections
According to Sundararajan, the economic fundamentals of crowd-based capitalism are superior to the current profit-based business model because the raw materials for this economy—space, time, items, and skills—are in excess. Because they already exist, they don't create additional costs to offer them. You could consider it a form of improved resource use conservation, environmental protection or the sustainability economy.
Human relations are a significant value component of the sharing economy. For example, some ride-sharing operators want passengers to sit in the front seat to generate conversation and interaction. The service is about social connection as well as ride-sharing. Since many drivers work part-time as a small side job, the interaction may be just as valuable to them as the fee received.
Here are two weaknesses of traditional taxi services:
- Poor hospitality
- Poor occupancy (utilization) rates because of the business structure (vehicle ownership by driver or company)
Crowd-based, public-private ownership using digital technology apps can tap into decentralized excess capacity that friendly people have rather than single company-owned centralized systems. Hospitality improves, and there is no additional up-front investment. There are sites to outsource the buying and delivery of your groceries, an app to help valet parking services locate cars and parking spaces with GPS, a mail pickup service, laundry pickup, dog walking, and much more.
## How platforms build trust
eBay started in 1995 by moving the neighborhood garage sale online and offering isolated booksellers and thrift shop owners a way to expand their market reach outside their local community. The eBay system has many safeguards that protect both buyers and sellers through the transaction processes, so eBay maintains trading partner trust even with great geographic distance between buyers and sellers. For services offered in the sharing economy, location is more important. Peer-to-peer service markets may be more suitable for densely populated urban areas.
Building provider and user trust is an essential factor in making the sharing economy successful. To determine whether or not to place trust in a provider, consumers must consider the vetting process of each platform. What is the quality of their rating system? Some organizations use Facebook friendships as testimonials to confirm trustworthy people. Some platforms completely control the payment system, so payment is assured, but others don't.
Frederic Mazzella, a cofounder of BlaBlaCar, believes trust is central to his company's business and is passionate about its importance. BlaBlaCar's corporate headquarters has a life-sized cardboard cutout of Trust Man, a cape-wearing superhero with a "T" emblazoned on his jumpsuit. Mazzella's conception of trust is based on what he calls the [D.R.E.A.M.S. framework](https://blog.blablacar.com/trust): Declared, Rated, Engaged, Activity-based, Moderated, and Social. The company is constantly working on deepening its understanding of trusted exchange.
## Collaboration and community building
The organization OuiShare coordinates activities to foster collaboration. In June 2021, they gathered more than 600 people over the three days of OuiShare Fest, which included conferences, workshops, performances, and shows. With this event, OuiShare aspired to create social connections, projects, and collaborations by bringing together people from different backgrounds. Participants explored what they have an excess of and what might be needed and shared. The group started in France and now exists in 20 countries in Europe, where it provides a shared platform for experimentation that gives connectors and members access to a commons of knowledge, tools, and an international network of people from whom to learn and draw inspiration. You could call it transparency of the underused.
Service platforms offer the spare time of people with knowledge, skills, or talent. For example, some platforms provide teachers with specific knowledge and skills in exchange for other knowledge or excess material goods, but not money.
This article is part of a series on the sharing economy. In the [first article](https://opensource.com/article/23/4/sharing-economy-open-organization), I explained the sharing business model and its value. In this article, I gave many examples of platforms in operation now. In a future article, I will explore how the sharing business model will evolve.
## Comments are closed. |
15,875 | 修复 Arch Linux 中的 “invalid or corrupted package (PGP signature)” 错误 | https://www.debugpoint.com/invalid-corrupted-package-arch/ | 2023-06-03T23:16:00 | [
"Arch"
] | /article-15875-1.html | 
>
> 修复 Arch Linux 中 “invalid or corrupted package” 错误的简单指南。
>
>
>
我在物理机和虚拟机中都安装有一些 Arch Linux 系统,我会在需要时访问它们。将近两个月后,当我尝试使用 `sudo pacman -Syu` 升级其中一个中的 Arch Linux 时,我遇到了数百个这样的错误:

问题是当你遇到上面的错误时,你无法升级/更新你的 Arch 系统。即使你同步镜像或获得更快的镜像。所以,如果你运行 `sudo pacman -Syyu`,错误仍然存在。这就造成了困难,因为在修复此问题之前你无法安装任何其他软件包。
### 原因
当你在 Arch Linux 系统上安装或升级软件包时,pacman 会根据 `archlinux-keyring` 软件包中的密钥检查软件包的数字签名。此验证过程可确保你下载和安装的软件包未经修改且来自受信任的来源。
它包含用于 [验证包的真实性和完整性](https://wiki.archlinux.org/title/Pacman/Package_signing) 和 pacman 中的密钥环。`archlinux-keyring` 包由 Arch Linux 开发人员定期更新,以包含新的可信密钥并撤销任何泄露的密钥。
如果你的 Arch Linux 系统很长时间没有更新,那么各种包的数字签名可能会不匹配。更改后的密钥可能与你系统中的密钥不匹配。
因此出现错误了。
### 修复
要修复 Arch Linux 中的 “invalid or corrupted package (PGP signature)” 错误,你需要从 `Core` 仓库安装/更新 `archlinux-keyring` 包。从终端运行以下命令:
```
sudo pacman -S archlinux-keyring
```
上述命令完成后,运行升级:
```
sudo pacman -Syu
```
这将解决问题,你可以在 Arch Linux 中继续你的正常活动。建议始终保持 `archlinux-keyring` 包为最新,以维护 Arch Linux 系统的安全性和完整性。
*(题图:MJ/7ed6d549-93c6-463d-823e-3a8c3957790f)*
---
via: <https://www.debugpoint.com/invalid-corrupted-package-arch/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,877 | ZOMBIES:为什么简洁性是交付健壮软件的关键(五) | https://opensource.com/article/21/2/simplicity | 2023-06-05T15:34:04 | [
"测试"
] | https://linux.cn/article-15877-1.html | 
>
> 当你坚持最简场景时,你最终会得到最简单的解决方案。
>
>
>
在前面的文章中,我已经解释了为什么将编程问题看作一整群丧尸来处理是错误的。我用 ZOMBIES 方法来解释为什么循序渐进地处理问题更好。
ZOMBIES 表示以下首字母缩写:
* **Z** – 最简场景(Zero)
* **O** – 单元素场景(One)
* **M** – 多元素场景(Many or more complex)
* **B** – 边界行为(Boundary behaviors)
* **I** – 接口定义(Interface definition)
* **E** – 处理特殊行为(Exercise exceptional behavior)
* **S** – 简单场景用简单的解决方案(Simple scenarios, simple solutions)
在系列的前四篇文章中,我展示了 ZOMBIES 方法的前六个原则(LCTT译注:原文为前五个,应为笔误)。
第一篇中 [实现了最简场景](/article-15808-1.html),它为代码提供了最简可行路径。第二篇文章中执行了 [单元素场景和多元素场景上的测试](/article-15817-1.html)。第三篇中介绍了 [边界和接口](/article-15859-1.html)。 第四篇中处理 [特殊行为](/article-15860-1.html)。在本文中,我将介绍最后一项:简单场景用简单的解决方案。
### 简单场景用简单的解决方案
回顾这个网购 API 的实现过程,你会发现总是有目的性地坚持考虑最简单的场景。在这个过程中,最终你会得到最简单的解决方案。
ZOMBIES 方法通过坚持简洁性来帮助你交付健壮优雅的解决方案。
### 胜利了吗?
似乎一切工作都结束了,一个不那么认真负责的工程师很可能会宣布胜利。但开明的工程师总是会探索得更深一点。
我一直推荐做 <ruby> <a href="https://opensource.com/article/19/9/mutation-testing-example-definition"> 变异测试 </a> <rt> mutation testing </rt></ruby>。在圆满结束这个练习项目,开始新的征程之前,用变异测试来敲打敲打你的解决方案是明智的。况且你也不得不承认,变异很适合对付丧尸的。
你可以在开源网站 [Stryker.NET](https://stryker-mutator.io/) 上进行变异测试。

看起来有一个存活的变异体。这可不是好兆头。
这意味着什么呢?当你自认为解决方案无懈可击的时候,[Stryker.NET](http://Stryker.NET) 却表示在你的地盘上并非一切安好。
让我们来看看这个存活下来的烦人变异体:

变异测试工具将
```
if(total > 500.00) {
```
变异为:
```
if(total >= 500.00) {
```
然后运行测试,结果对于这个变化没有一个测试失败。如果业务处理代码中发生了一处变动却没有任何一个测试失败,这就意味着你遇到一个存活的变异体。
### 为什么要在意变异体
为什么存活的变异体是麻烦的征兆呢?因为你写的业务处理逻辑代码控制着整个系统的行为。如果业务处理逻辑改变,系统的行为也应该随之改变。而系统行为的改变应该会导致测试表示的期望被违反。如果没有期望被违反,那就说明这些期望对系统行为的描述还不够准确。这也意味着你的业务处理逻辑中存在漏洞。
要解决这个问题,你需要干掉这个存活下来的变异体。要怎么做呢?一般来说,有存活的变异体意味着有期望被遗漏了。
仔细检查代码,梳理已定义的期望,看看漏掉了什么:
* 期望 0:新建购物框里有零个商品(这隐含了总价为 ¥0)。
* 期望 1:向购物框添加一件商品的结果是购物框里有一件商品,如果这件商品的价格是 ¥10,那么总价为 ¥10。
* 期望 2:向购物框添里加入一件价值 ¥10 的商品,再加入一件价值 ¥20 的商品,总价是 ¥30 。
* 期望 3:关于从购物框移除商品的期望。
* 期望 4:总价大于 ¥500 时打,享受九折优惠。
缺了什么呢?根据变异测试报告,你没有定义订单总价刚好为 ¥500 的销售策略。你已经定义订单总额大于 ¥500 和小于 ¥500 时的情况。
定义边界情况的期望:
```
[Fact]
public void Add2ItemsTotal500GrandTotal500() {
var expectedGrandTotal = 500.00;
var actualGrandTotal = 450;
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
第一步先写一个假的实现让测试失败。现在共有 9 个微测试。其中 8 个通过,第 9 个失败了:
```
[xUnit.net 00:00:00.57] tests.UnitTest1.Add2ItemsTotal500GrandTotal500 [FAIL]
X tests.UnitTest1.Add2ItemsTotal500GrandTotal500 [2ms]
Error Message:
Assert.Equal() Failure
Expected: 500
Actual: 450
[...]
Test Run Failed.
Total tests: 9
Passed: 8
Failed: 1
Total time: 1.5920 Seconds
```
将硬编码值替换成正样例的预期代码:
```
[Fact]
public void Add2ItemsTotal500GrandTotal500() {
var expectedGrandTotal = 500.00;
Hashtable item1 = new Hashtable();
item1.Add("0001", 400.00);
shoppingAPI.AddItem(item1);
Hashtable item2 = new Hashtable();
item2.Add("0002", 100.00);
shoppingAPI.AddItem(item2);
var actualGrandTotal = shoppingAPI.CalculateGrandTotal(); }
```
共添加了两件商品,一件价值 ¥400,另一件价值 ¥100,总价是 ¥500。调用计算总价的函数,期望的总价是 ¥500。
运行,9 个测试全部通过!
```
Total tests: 9
Passed: 9
Failed: 0
Total time: 1.0440 Seconds
```
现在是揭晓真相的时刻。这个新增的期望能够清理掉所有的变异体吗?运行变异测试来看看结果:

成功了!10 个变异体全都被干掉了。太棒了!现在你可以放心地发布这个 API 了。
### 结语
如果从这次练习中有什么收获的话,那就是 <ruby> 技术性拖延 <rt> skillful procrastination </rt></ruby> 这一概念的提出。这个是一个重要的概念,因为我们中的许多人往往会在客户描述完他们的问题之前,就盲目地去设想解决方案。
#### 主动拖延
拖延对于软件工程师来说并不是一件容易的事情。我们总是急于动手写代码。我们熟悉各种设计模式、反模式、编程原则和现成的解决方案。我们总是迫不及待想将它们应用到可执行的代码中,并且倾向于一次性做大量的工作。所以在行动之前仔细考虑每个步骤是一种美德。
这个练习说明 ZOMBIES 方法能够通过一系列深思熟虑的小步骤来帮你实现解决方案。但是有一点需要特别注意,根据 [Yagni](https://martinfowler.com/bliki/Yagni.html) 原则,这些深思熟虑常常会飞得太远,以至于最终形成一个大而全的系统。这会产生臃肿、紧密耦合的系统。
### 迭代式开发与增量式开发
在这次练习给我们的另一个重要收获是让我们意识到保持系统持续可用的唯一方法是采用迭代式的开发方法。你通过改造已有代码开发出整个购物 API。这种改造工作是在迭代优化解决方案的过程中不可避免的。
很多团队混淆了迭代和增量。这是两个完全不同的概念。
增量式方法是假设是你有完整清晰的需求,然后通过增量累加的方式来构建解方案。大体上来说,你一点点地构建各个部分,然后将所有的部分组装在一起。大功告成!解决方案已经准备好交付了!
相比之下,迭代式方法中,你并不很确定自己需要交付给客户的是什么。因为这个原因,你更加小心谨慎。你会小心翼翼地避免破坏能够运行的系统(也就是说系统处于稳态)。如果不得不扰动已有的平衡,你也会采取最小侵入性的方式。你专注于用尽可能小的工作量来快速完成每次得改动工作。你倾向于让系统尽快回到稳态。
这就是为什么迭代式方法在真正实现一个功能之前总是先提供一个假实现。你硬编码一系列的期望,以验证小的修改不会导致系统无法运行。然后进行必要的修改,用实际处理代码替换硬编码的值。
作为经验法则,在迭代方法中,你的目标是通过设计期望(微测试),对代码进行不断改进。每进行一次改进,你都要检验系统,以确保它处于工作状态。以这种方式不断前进,最终会达到满足所有期望的程度,并且此时代码已经被重构,没有任何存活的变异体了。
一旦达到了这种状态,你就可以相当自信地交付解决方案了。
由衷感谢 [Kent Beck](https://en.wikipedia.org/wiki/Kent_Beck)、 [Ron Jeffries](https://en.wikipedia.org/wiki/Ron_Jeffries) 和[GeePaw Hill](https://www.geepawhill.org/) 在我的软件工程学习道路的启发。
愿 ZOMBIES 方法在软件开发的征程上帮助到你。
*(题图:MJ/ca463fc6-021b-4818-ba3d-9cd3c8736577)*
---
via: <https://opensource.com/article/21/2/simplicity>
作者:[Alex Bunardzic](https://opensource.com/users/alex-bunardzic) 选题:[lkxed](https://github.com/lkxed/) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the previous articles in this series, I explained why tackling coding problems all at once, as if they were hordes of zombies, is a mistake. I'm using a helpful acronym explaining why it's better to approach problems incrementally. **ZOMBIES** stands for:
**Z** – Zero
**O** – One
**M** – Many (or more complex)
**B** – Boundary behaviors
**I** – Interface definition
**E** – Exercise exceptional behavior
**S** – Simple scenarios, simple solutions
In the first four articles in this series, I demonstrated the first five **ZOMBIES** principles. The first article [implemented Zero](https://opensource.com/article/21/1/zombies-zero), which provides the simplest possible path through your code. The second article performed
[tests with](https://opensource.com/article/21/1/zombies-2-one-many)samples, the third article looked at
**O**ne and**M**any[, and the fourth examined](https://opensource.com/article/21/1/zombies-3-boundaries-interface)
**B**oundaries and**I**nterfaces[. In this article, I'll take a look at the final letter in the acronym:](https://opensource.com/article/21/1/zombies-4-exceptional-behavior)
**E**xceptional behavior**S**, which stands for "simple scenarios, simple solutions."
## Simple scenarios, simple solutions in action
If you go back and examine all the steps taken to implement the shopping API in this series, you'll see a purposeful decision to always stick to the simplest possible scenarios. In the process, you end up with the simplest possible solutions.
There you have it: **ZOMBIES** help you deliver sturdy, elegant solutions by adhering to simplicity.
## Victory?
It might seem you're done here, and a less conscientious engineer would very likely declare victory. But enlightened engineers always probe a bit deeper.
One exercise I always recommend is [mutation testing](https://opensource.com/article/19/9/mutation-testing-example-definition). Before you wrap up this exercise and go on to fight new battles, it is wise to give your solution a good shakeout with mutation testing. And besides, you have to admit that *mutation* fits well in a battle against zombies.
Use the open source [Stryker.NET](https://stryker-mutator.io/) to run mutation tests.
(Alex Bunardzic, CC BY-SA 4.0)
It looks like you have one surviving mutant! That's not a good sign.
What does this mean? Just when you thought you had a rock-solid, sturdy solution, Stryker.NET is telling you that not everything is rosy in your neck of the woods.
Take a look at the pesky mutant who survived:
(Alex Bunardzic, CC BY-SA 4.0)
The mutation testing tool took the statement:
`if(total > 500.00) {`
and mutated it to:
`if(total >= 500.00) {`
Then it ran the tests and realized that none of the tests complained about the change. If there is a change in processing logic and none of the tests complain about the change, that means you have a surviving mutant.
## Why mutation matters
Why is a surviving mutant a sign of trouble? It's because the processing logic you craft governs the behavior of your system. If the processing logic changes, the behavior should change, too. And if the behavior changes, the expectations encoded in the tests should be violated. If these expectations are not violated, that means that the expectations are not precise enough. You have a loophole in your processing logic.
To fix this, you need to "kill" the surviving mutant. How do you do that? Typically, the fact that a mutant survived means at least one expectation is missing.
Look through your code to see what expectation, if any, is not there:
- You clearly defined the expectation that a newly created basket has zero items (and, by implication, has a $0 grand total).
- You also defined the expectation that adding one item will result in the basket having one item, and if the item price is $10, the grand total will be $10.
- Furthermore, you defined the expectation that adding two items to the basket, one item priced at $10 and the other at $20, results in a grand total of $30.
- You also declared expectations regarding the removal of items from the basket.
- Finally, you defined the expectation that any order total greater than $500 results in a price discount. The business policy rule dictates that in such a case, the discount is 10% of the order's total price.
What is missing? According to the mutation testing report, you never defined an expectation regarding what business policy rule applies when the order total is exactly $500. You defined what happens if the order total is greater than the $500 threshold and what happens when the order total is less than $500.
Define this edge-case expectation:
```
[Fact]
public void Add2ItemsTotal500GrandTotal500() {
var expectedGrandTotal = 500.00;
var actualGrandTotal = 450;
Assert.Equal(expectedGrandTotal, actualGrandTotal);
}
```
The first stab fakes the expectation to make it fail. You now have nine microtests; eight succeed, and the ninth test fails:
```
[xUnit.net 00:00:00.57] tests.UnitTest1.Add2ItemsTotal500GrandTotal500 [FAIL]
X tests.UnitTest1.Add2ItemsTotal500GrandTotal500 [2ms]
Error Message:
Assert.Equal() Failure
Expected: 500
Actual: 450
[...]
Test Run Failed.
Total tests: 9
Passed: 8
Failed: 1
Total time: 1.5920 Seconds
```
Replace hard-coded values with an expectation of a confirmation example:
```
[Fact]
public void Add2ItemsTotal500GrandTotal500() {
var expectedGrandTotal = 500.00;
Hashtable item1 = new Hashtable();
item1.Add("0001", 400.00);
shoppingAPI.AddItem(item1);
Hashtable item2 = new Hashtable();
item2.Add("0002", 100.00);
shoppingAPI.AddItem(item2);
var actualGrandTotal = shoppingAPI.CalculateGrandTotal(); }
```
You added two items, one priced at $400, the other at $100, totaling $500. After calculating the grand total, you expect that it will be $500.
Run the system. All nine tests pass!
```
Total tests: 9
Passed: 9
Failed: 0
Total time: 1.0440 Seconds
```
Now for the moment of truth. Will this new expectation remove all mutants? Run the mutation testing and check the results:
(Alex Bunardzic, CC BY-SA 4.0)
Success! All 10 mutants were killed. Great job; you can now ship this API with confidence.
## Epilogue
If there is one takeaway from this exercise, it's the emerging concept of *skillful procrastination*. It's an essential concept, knowing that many of us tend to rush mindlessly into envisioning the solution even before our customers have finished describing their problem.
### Positive procrastination
Procrastination doesn't come easily to software engineers. We're eager to get our hands dirty with the code. We know by heart numerous design patterns, anti-patterns, principles, and ready-made solutions. We're itching to put them into executable code, and we lean toward doing it in large batches. So it is indeed a virtue to *hold our horses* and carefully consider each and every step we make.
This exercise proves how **ZOMBIES** help you take many deliberate small steps toward solutions. It's one thing to be aware of and to agree with the [Yagni](https://martinfowler.com/bliki/Yagni.html) principle, but in the "heat of the battle," those deep considerations often fly out the window, and you end up throwing in everything and the kitchen sink. And that produces bloated, tightly coupled systems.
## Iteration and incrementation
Another essential takeaway from this exercise is the realization that the only way to keep a system working at all times is by adopting an *iterative approach*. You developed the shopping API by applying some *rework*, which is to say, you proceeded with coding by making changes to code that you already changed. This rework is unavoidable when iterating on a solution.
One of the problems many teams experience is confusion related to iteration and increments. These two concepts are fundamentally different.
An *incremental approach* is based on the idea that you hold a crisp set of requirements (or a *blueprint*) in your hand, and you go and build the solution by working incrementally. Basically, you build it piece-by-piece, and when all pieces have been assembled, you put them together, and *voila*! The solution is ready to be shipped!
In contrast, in an *iterative approach*, you are less certain that you know all that needs to be known to deliver the expected value to the paying customer. Because of that realization, you proceed gingerly. You're wary of breaking the system that already works (i.e., the system in a steady-state). If you disturb that balance, you always try to disturb it in the least intrusive, least invasive manner. You focus on taking the smallest imaginable batches, then quickly wrapping up your work on each batch. You prefer to have the system back to the steady-state in a matter of minutes, sometimes even seconds.
That's why an iterative approach so often adheres to "*fake it 'til you make it*." You hard-code many expectations so that you can verify that a tiny change does not disable the system from running. You then make the changes necessary to replace the hard-coded value with real processing.
As a rule of thumb, in an iterative approach, you aim to craft an expectation (a microtest) in such a way that it precipitates only one improvement to the code. You go one improvement by one improvement, and with each improvement, you exercise the system to make sure it is in a working state. As you proceed in that fashion, you eventually hit the stage where all the expectations have been met, and the code has been refactored in such a way that it leaves no surviving mutants.
Once you get to that state, you can be fairly confident that you can ship the solution.
Many thanks to inimitable [Kent Beck](https://en.wikipedia.org/wiki/Kent_Beck), [Ron Jeffries](https://en.wikipedia.org/wiki/Ron_Jeffries), and [GeePaw Hill](https://www.geepawhill.org/) for being a constant inspiration on my journey to software engineering apprenticeship.
And may *your* journey be filled with ZOMBIES.
## Comments are closed. |
15,878 | “联邦宇宙”的 5 分钟之旅 | https://opensource.com/article/23/3/tour-the-fediverse | 2023-06-05T17:30:00 | [
"Mastodon",
"联邦宇宙"
] | https://linux.cn/article-15878-1.html | 
>
> 一个快闪式的游览,介绍所有连接在一起形成开源社交网络世界的网站。
>
>
>
人们希望在互联网上像在现实生活中一样轻松地进行交流,并享有类似的保护,但可能具有更广泛的影响力。换句话说,人们希望能够与不在同一地理位置的一群人聊天,并仍然对谁拥有对话内容进行一定程度的控制。在当今世界,很多公司对你通过互联网发送和接收的数据拥有很多权利。大多数公司似乎认为他们有权管理你的通讯方式、你的信息覆盖范围等等。幸运的是,开源并不需要拥有你的社交生活,因此开源社交网络的开发者正在推出一款首先属于你的社交网络。
“Fediverse”(“联邦”和“宇宙”合成的词,译为“联邦宇宙”)是一组协议、服务器和用户,这些组成了可以相互通信的网络。用户可以通过这些网络交换短消息、博客文章、音乐和视频。你发布的内容是联邦式的,这意味着一旦一个网络知道了你的内容,它就可以将该内容传递给另一个网络,然后再传递给另一个网络,以此类推。
大多数平台由单个公司或组织运行,是一个唯一的数据封闭系统。与其他人分享内容的唯一方法是要求他们加入该服务。
联邦允许不同服务的用户互动,而无需为每个需要共享的资源创建一个帐户。
每个服务实例的管理员可以在存在严重问题的情况下阻止其他实例。用户也可以阻止其他用户或整个实例,以改善自己的体验。
### 联邦宇宙平台的例子
最近受到了很多关注的联邦宇宙平台是 Mastodon,它专注于微博客(类似于 Twitter)。然而 Mastodon 只是联邦宇宙的一个组成部分。还有更多:
* 微博客:Mastodon、Pleroma、Misskey
* 博客:[Write.as](http://Write.as)、[Read.as](http://Read.as)
* 视频托管:Peertube
* 音频托管:Funkwhale
* 图像托管:Pixelfed
* 链接聚合器:Lemmy
* 活动规划:mobilizon、gettogether.community
### 联邦宇宙的历史
在 2008 年,Evan Prodromou 创建了一个微博客服务,名为 [identi.ca](http://identi.ca),采用了 Ostatus 协议和 [status.net](http://status.net) 服务器软件。几年后,他更改了服务协议,采用了一种名为 [pump.io](http://pump.io) 的新协议。他将 Ostatus 协议发布给自由软件基金会,并导入了 GNU/social。以这种方式,联邦宇宙持续了几年。
2016 年 3 月,Eugen Rochco(Gargron)创建了 Mastodon,它使用 GNU/social,并采用了类似于流行的 Twitter 接口 Tweetdeck 的界面。这使得 Mastodon 得到一定的流行度。

2018 年,一种名为 ActivityPub 的新协议被 W3C 接受为标准化协议。大多数联邦宇宙平台都采用了它。它由 Evan Prodromou、Christine Lemmer-Weber 和其他人编写,并扩展了之前的服务,提供了更好和更灵活的协议。
### 联邦宇宙看起来像什么?
联邦宇宙由使用 ActivityPub 协议的任何应用程序组成,因此其外观非常多样化。你可以想象,微博客平台与视频共享服务有不同的要求。
然而,进入这个伟大而未知的领域可能令人望而生畏。这里有一些我最喜欢的联合服务的屏幕截图:
Mastodon 网页客户端有简化视图和高级视图。默认的简化视图显示首页信息流的一个单列,右侧有更多选项。

下面显示的高级 Web 界面有首页时间线、本地时间线、联邦时间线以及用户的个人资料。当用户第一次使用时,更易于使用的单列视图是默认的。

Pixelfed 的界面专注于图像和视频的显示:

Peertube 用于共享视频:

Mobilizon 是一个活动计划网站,计划与联邦宇宙集成:

### 切换到开源社交网络
准备好开始了吗?请查看 [fediverse.info](http://fediverse.info) ,了解有关联邦宇宙的视频解释和基于主题的方式来查找(自选的)其他用户。
请查看 fedi.tips ,获取有关如何入门、如何迁移数据和更多信息的详细指南。
Mastodon 有几个入口:
* [joinmastodon.org](http://joinmastodon.org):Mastodon 服务器的最大列表。
* joinfediverse.wiki:有关不同联邦宇宙服务和实例的详细信息。
* fedi.garden:良好策划的实例列表。
如果你需要帮助决定加入哪个实例(假设你还不想自己搭建服务器),请访问 fediverse.party/en/portal/servers。
你是数据迷吗?请访问 [the-federation.info](http://the-federation.info) 了解有关已知联邦宇宙的统计数据、监控服务以及基于数据的观察。
### 成为联邦一份子
联邦宇宙是使用社交媒体的一种个性化方式,可以选择一个满足你需求的群体的实例或运行自己的服务器,并使它成为你想要的样子。它避免了广告、算法和其他困扰许多社交网络的令人不愉快的问题。
如果你正在寻找比大型封闭服务更适合你需求的社区,不妨看看 Mastodon 和联邦宇宙,它们也许很适合你。成为联邦一份子吧!
你可以在联邦宇宙上找到我,用户名为 [@[email protected]](https://hackers.town/@murph)。
*(题图:MJ/65de601a-4c04-4fe7-a0b7-26076e29f512)*
---
via: <https://opensource.com/article/23/3/tour-the-fediverse>
作者:[Bob Murphy](https://opensource.com/users/murph) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | People want to communicate over the internet as easily as they do in real life, with similar protections but, potentially, farther reach. In other words, people want to be able to chat with a group of other people who aren't physically in the same location, and still maintain some control over who claims ownership of the conversation. In today's world, of course, a lot of companies have a lot to say about who owns the data you send back and forth over the world wide web. Most companies seem to feel they have the right to govern the way you communicate, how many people your message reaches, and so on. Open source, luckily, doesn't need to own your social life, and so appropriately it's open source developers who are delivering a social network that belongs, first and foremost, to you.
The "Fediverse" (a portmanteau of "federated" and "universe") is a collection of protocols, servers, and users. Together, these form networks that can communicate with one another. Users can exchange short messages, blog-style posts, music, and videos over these networks. Content you post is federated, meaning that once one network is aware of your content, it can pass that content to another network, which passes it to another, and so on.
Most platforms are run by a single company or organization, a single silo where your data is trapped. The only way to share with others is to have them join that service.
Federation allows users of different services to inter-operate with one another without creating an account for each shared resource.
Admins for each service instance can block other instances in case of egregious issues. Users can likewise block users or entire instances to improve their own experience.
## Examples of Fediverse platforms
Mastodon is a Fediverse platform that has gotten a lot of attention lately, and it's focused on microblogging (similar to [Twitter](https://opensource.com/article/22/11/switch-twitter-mastodon)). Mastodon is only one component of the Fediverse, though. There's much, much more.
- Microblogging: Mastodon, Pleroma, Misskey
- Blogging: Write.as, Read.as
- Video hosting: Peertube
- Audio hosting: Funkwhale
- Image hosting: Pixelfed
- Link aggregator: Lemmy
- Event planning: mobilizon, gettogether.community
## History of the Fediverse
In 2008, Evan Prodromou created a microblogging service called identi.ca using the Ostatus protocol and status.net server software. A few years later, he changed his service to use a new protocol, called pump.io. He released the Ostatus protocol to the Free Software Foundation, where it got incorporated into GNU/social. In this form, the fediverse continued along for several years.
In March 2016, Eugen Rochco (Gargron) created Mastodon, which used GNU/social with an interface similar to a popular Twitter interface called Tweetdeck. This gained some popularity.

(Robert Martinez, CC BY-SA)
In 2018, a new protocol called ActivityPub was accepted as a standardized protocol by the W3C. Most Fediverse platforms have adopted it. It was authored by Evan Prodromou, Christine Lemmer-Weber, and others, and it expanded upon the previous services to provide a better and more flexible protocol.
## What does the Fediverse look like?
The Fediverse, being made of any application using the ActivityPub protocol, is pretty diverse in appearance. As you might imagine, a microblogging platform has different requirements than a video sharing service.
It can be intimidating to wander into the great unknown, though. Here are some screenshots of my favorite federated services:
The Mastodon web client has a simplified view, as well as the advanced view, the simplified default view shows a single column of the Home feed, with options on the right to view more.
(Bob Murphy, CC BY-SA 4.0)
The Advanced Web Interface, shown below, has the home timeline, local timeline, federated timeline, as well as a user's profile. When users first start, the easier one-column view is the default.
(Bob Murphy, CC BY-SA 4.0)
Pixelfed has an interface focused around displaying images and videos:

(Bob Murphy, CC BY-SA 4.0)
Peertube is for sharing videos:
(Bob Murphy, CC BY-SA 4.0)
Mobilizon is an event planning site, with plans for Fediverse integration:
(Bob Murphy, CC BY-SA 4.0)
## Switch to open source social
Ready to start? Check out fediverse.info for a nice video explanation and a subject-based way to find (self-selected) other users.
Go to [fedi.tips](https://fedi.tips) for a comprehensive guide on how to get started, how to migrate your data, and more.
Mastodon has several great entry points:
[Joinmastodon.org](https://joinmastodon.org): The largest list of Mastodon servers[Joinfediverse.wiki](https://joinfediverse.wiki): Great information on different fediverse services and instances[Fedi.garden](https://fedi.garden): A well-curated list of instances
For help deciding which instance to join (assuming you don't want to spin up your own just yet), visit [fediverse.party/en/portal/servers](https://fediverse.party/en/portal/servers).
Are you a data nerd? Visit [the-federation.info](https://opensource.com/the-federation.info) for stats, monitoring service, and a data-driven look at the known Fediverse.
## Get federated
The Fediverse is a way to use the social media in an individualized way, either by choosing an instance with a community that suits your needs, or running your own server, and making it exactly the way you want. It avoids the advertising, algorithms, and other unpleasantries that plague many social networks.
If you are looking for a community that better suits your needs than the big silos, take a look, the Mastodon and the Fediverse may be a good fit for you. Get federated today.
You can find me at [@[email protected]](https://hackers.town/@murph) on the Fediverse.
## 1 Comment |
15,880 | 在 Linux 中如何对 CPU 进行压力测试 | https://itsfoss.com/stress-test-cpu-linux/ | 2023-06-06T15:55:23 | [
"压力测试",
"CPU"
] | https://linux.cn/article-15880-1.html | 
>
> 压力测试 CPU 是检查处理器在重负载下性能表现以及系统在此情况下的温度的最佳方法之一。
>
>
>
当你压力测试 CPU 时,可以监视系统资源,观察它们在最高工作负载下的表现。虽然性能不会改变,但如果处理器不具备良好散热能力,温度可能会影响其运作。
**对于发烧友来说,压力测试是建造新系统时必不可少的**,特别是如果你打算以后超频 CPU。
例如,在压力测试过程中,如果你的 CPU 很快变得太热,你需要通过更换 CPU 风扇、使用更好的通风机箱等方式来改进散热解决方案。
现在你已经了解到压力测试的好处,接下来我将为你介绍在 Linux 中压力测试 CPU 的以下两种方法:
* **使用 GtkStressTesting(图形界面方式)**
* **使用 stress 和 s-tui 实用程序(命令行方式)**
接下来,让我们从第一种方法开始。
### 使用图形界面方法压力测试 Linux CPU ?️
如果你更喜欢使用图形界面方法,而不是通过终端操作,我有一个最简单的方法来帮助你进行系统压力测试。
有一个名为 **GtkStressTesting** 的图形界面实用工具,可以帮助你进行压力测试和同时监视温度。它提供了多种预设来进行系统压力测试,并提供了选择在测试期间需要使用多少个内核的功能。
>
> ? 该工具在 [GitLab](https://gitlab.com:443/leinardi/gst) 上已不再积极维护。但是它仍能按预期工作。
>
>
>
GtkStressTesting 可以作为 Flatpak 安装,因此如果你尚未启用 Flatpak 支持,请参考我们的 [Flatpak 安装指南](https://itsfoss.com/flatpak-guide/)。
一旦你启用了 Flatpak 支持,可以通过终端(如果没有软件中心)使用以下命令来安装 GtkStressTesting 实用工具:
```
flatpak install flathub com.leinardi.gst
```
安装完成后,你可以从系统菜单中启动 GtkStressTesting 实用工具。
在这里,我建议你点击“<ruby> 读取全部 <rt> Read all </rt></ruby>”按钮,并输入 sudo 密码,以便工具可以获取你系统的全部信息:

从这里,你可以选择压力测试系统的时间(如果温度过高,随时可以停止进程),并在“<ruby> 工作线程:自动 <rt> Workers: Auto </rt></ruby>”下拉菜单中选择可用的的最大数量。
我选择了 **12 核心和 5 分钟的压力测试**:

完成后,单击“<ruby> 开始 <rt> Start </rt></ruby>”按钮,监视温度,如果超过 90 度,请停止压力测试。
在我的系统上,压力测试过程中最高温度为 85 度:

这是一种非常简便的压力测试 CPU 的方法,是不是很简单呢? ?
### 使用命令行终端压力测试 Linux CPU

使用命令行终端压力测试需要两个实用工具:[s-tui](https://itsfoss.com/stress-terminal-ui/) 和 `stress`。
你可以从默认软件仓库或 [使用 pip](https://itsfoss.com/install-pip-ubuntu/) 来安装这些工具。如果你可以接受使用旧版本的工具,使用默认软件仓库更容易。
以下是适用于流行 Linux 发行版的安装命令:
基于 Ubuntu/Debian 的发行版:
```
sudo apt install s-tui stress
```
Arch Linux:
```
sudo pacman -S s-tui stress
```
Fedora/RHEL:
```
sudo dnf install s-tui stress
```
**如果想要使用 pip 安装最新版本**,可以使用以下命令:
```
pip install s-tui --user
```
安装完成后,在终端中启动 `s-tui` 实用工具:
```
s-tui
```
你将会看到以下内容:

你可以使用鼠标或键盘箭头键浏览菜单,然后点击“<ruby> 压力选项 <rt> Stress options </rt></ruby>”,选择你想要压力测试系统的时间(以“秒”为单位):

最后,选择“<ruby> 压力 <rt> Stress </rt></ruby>”选项,它会在指定时间内开始压力测试:

如果温度失控,你可以点击“<ruby> 退出 <rt> Quit </rt></ruby>”按钮手动停止压力测试。另外,如果你想要将数据存储在 .csv 格式中,该工具也提供了相应的功能。
要存储数据,你只需要在启动 `s-tui` 实用工具时附加 `-c` 标记,如下所示:
```
s-tui -c
```
如果你想用自己喜欢的名称保存文件,则必须使用 `--csv-file` 标记,如下所示:
```
s-tui --csv-file <file 名称>.csv
```
例如,这里我将文件命名为 `Hello.scv`:
```
s-tui --csv-file Hello.scv
```
你可以在它的 [GitHub 页面](https://github.com:443/amanusk/s-tui) 上了解更多关于这个工具的信息。
### 系统快乐,人生快乐 ?
并非每个用户都意识到进行压力测试的好处。有时候它会让他们感到害怕,认为系统无缘无故地达到其极限。
但是,测试将帮助你快速评估和监视系统的状况。例如,温度异常上升和 CPU 无法处理现有负载等问题,可以帮助你及早识别硬件问题。
在任何情况下,如果你想在不进行压力测试的情况下 [保持 CPU 温度正常](https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/),可以参考我们提供的温度监控资源。
你还可以查看一些 Linux 的 [系统监控工具](https://itsfoss.com/linux-system-monitoring-tools/) 或 [htop 的替代品](https://itsfoss.com/htop-alternatives/),以监控系统资源的使用情况。
? 你对于在 Linux 中压力测试 CPU 有什么看法?你认为我们应该这样做吗?请在评论区分享你的想法。
*(题图:MJ/e5f3fc49-5e47-4f8a-8970-43a445849172)*
---
via: <https://itsfoss.com/stress-test-cpu-linux/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Stress testing your CPU is one of the best ways to check your processor's performance capabilities under heavy load and the system's temperature when that happens.
When you stress test the CPU, you can monitor the system's resources to see how they behave with the CPU at its peak workload. While the performance will not change compared to what the processor is capable of, the temperature may affect its operation if it is not well-equipped.
**Stress testing is essential for enthusiasts when building a new system**, especially if you plan to overclock the CPU later.
For instance, if your CPU gets too hot too quickly during the stress test. You need a better cooling solution by changing the CPU cooler, using a better airflow cabinet, etc.
Now that you have an idea about the benefits, I will walk you through the following ways to stress test the CPU in Linux:
**Using GtkStressTesting (GUI method)****Using stress and s-tui utility (CLI method)**
So let's start with the first one.
## Stress test Linux CPU using GUI method 🖥️
If you prefer using a GUI solution over the terminal, I have just the easiest method for you to stress-test your system.
There is a GUI utility **GtkStressTesting, **which helps you stress test and monitor temperature simultaneously. It provides various presets to stress-test the system and provides an ability to choose how many cores you want to work with during the test.
[GitLab](https://gitlab.com/leinardi/gst). But it works as expected.
GtkStressTesting is available as a Flatpak, so if you haven't already enabled Flatpak support, refer to our [Flatpak setup guide](https://itsfoss.com/flatpak-guide/).
Once you have enabled Flatpak support, the GtkStressTesting utility can be installed using the following via the terminal (if not software center)
`flatpak install flathub com.leinardi.gst`
After the installation, you can start the GtkStressTesting utility from the system menu.
Here, I would recommend you click on the `Read all`
button and enter the sudo password so the utility can fetch all the information of your system:
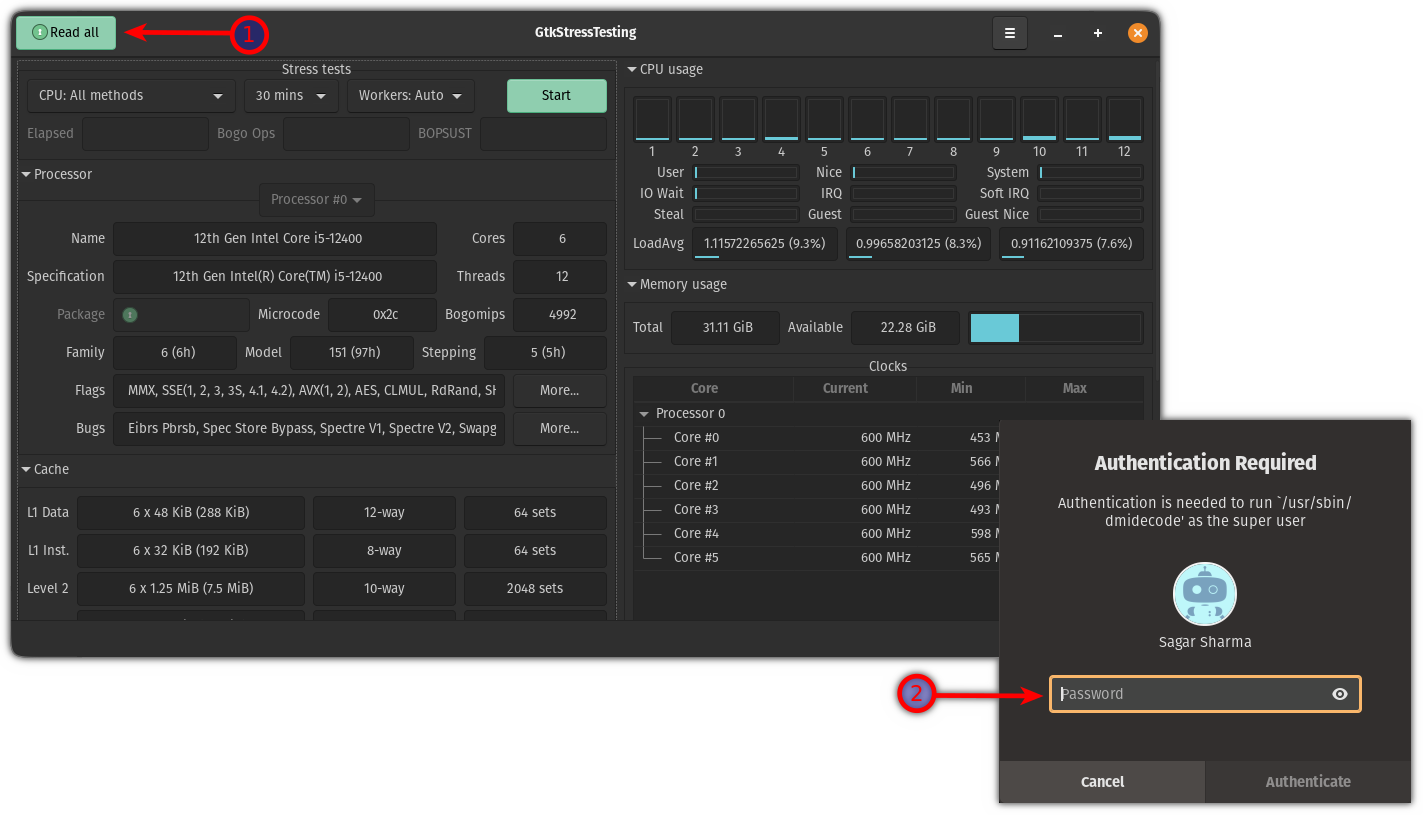
From here, you can choose how long you want to stress test your system (you can always stop the process if the temp gets too high) and choose the max number available in the `Workers: Auto`
.
I went for **12 cores and 5 mins of stress testing**:
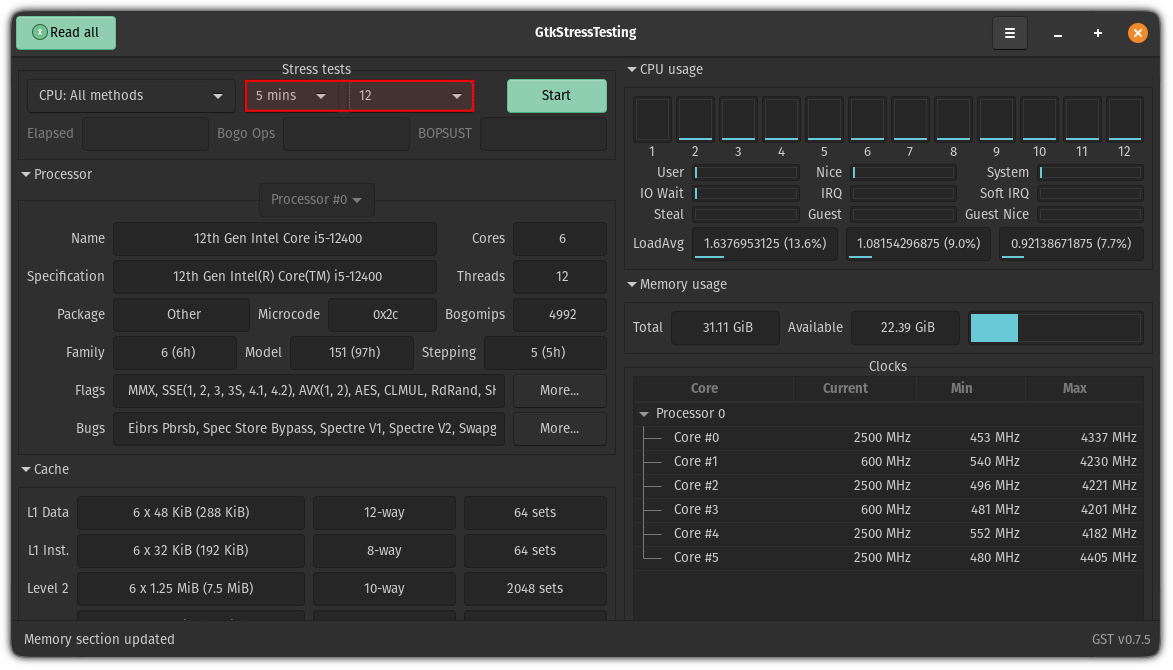
Once you are done, click on the start button and monitor the temperatures, and if they reach beyond 90, stop the stress testing.
My system went to 85 max during stress testing:
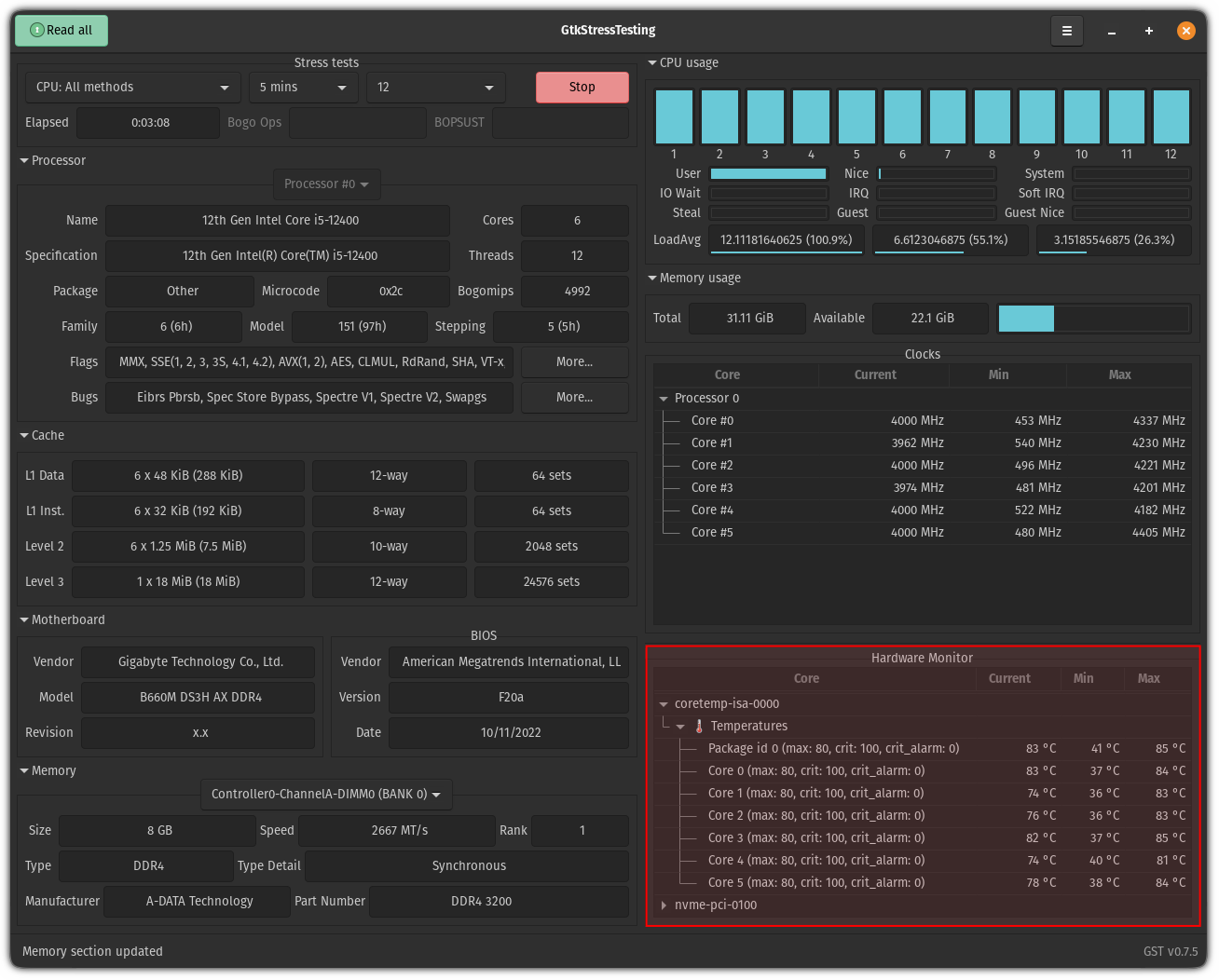
Pretty easy way to stress test the CPU. Isn't it? 😉
## Stress test Linux CPU using the Terminal
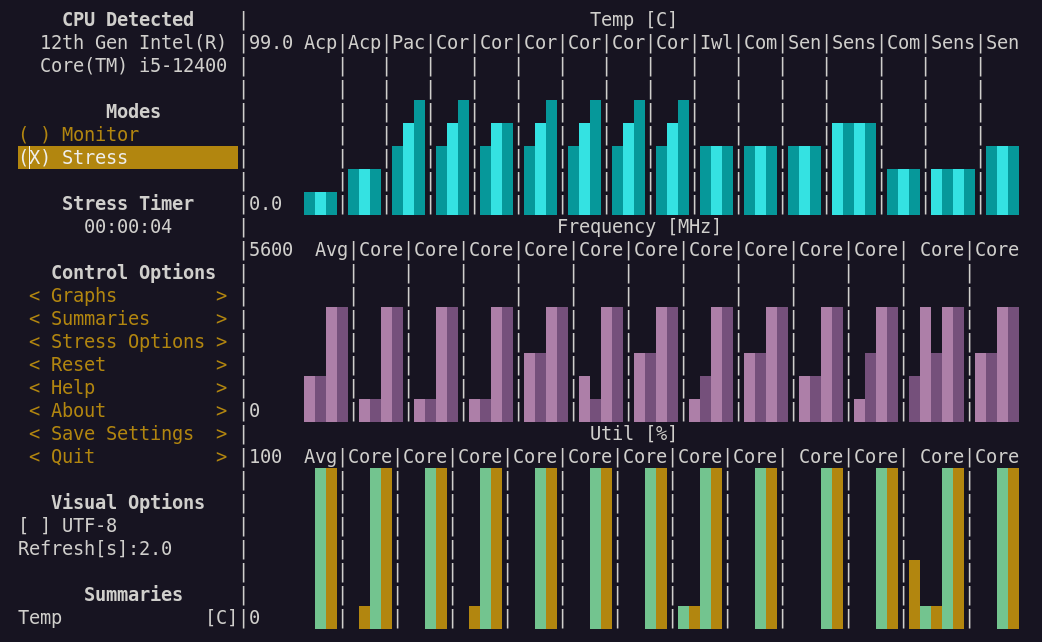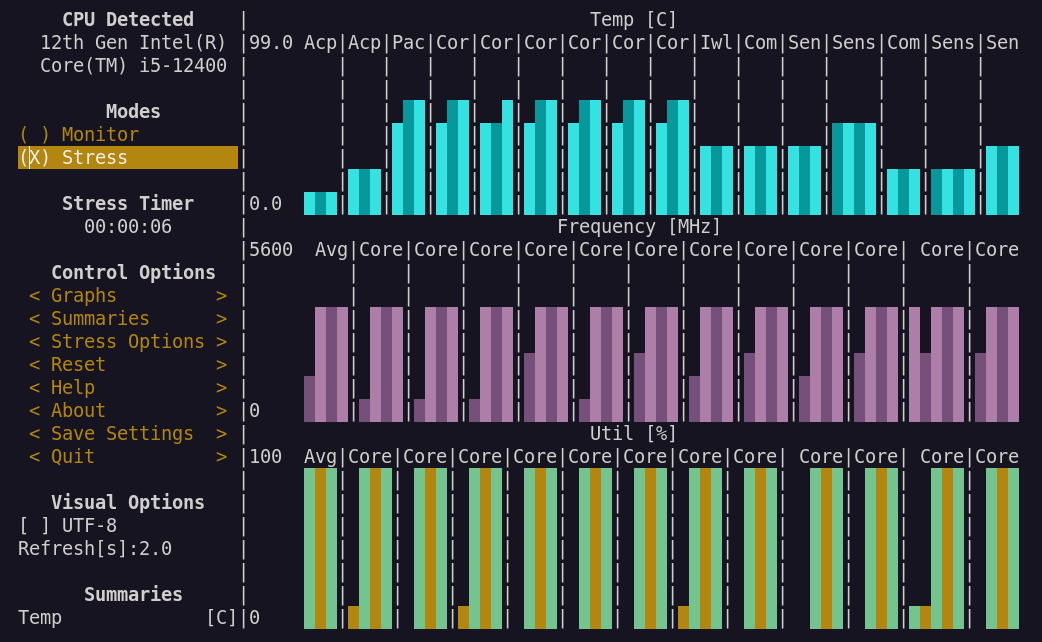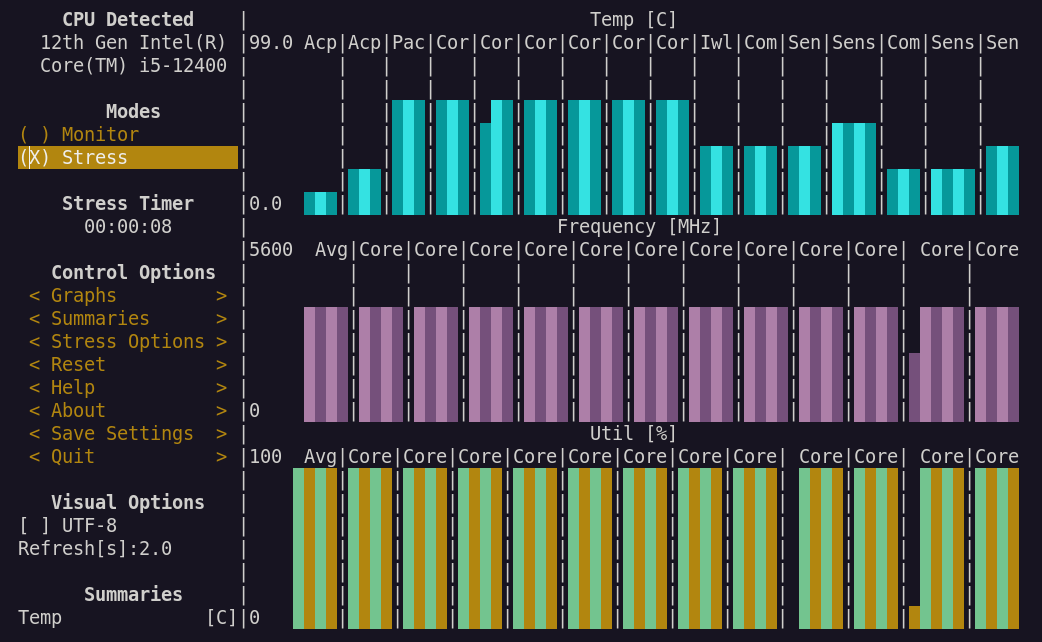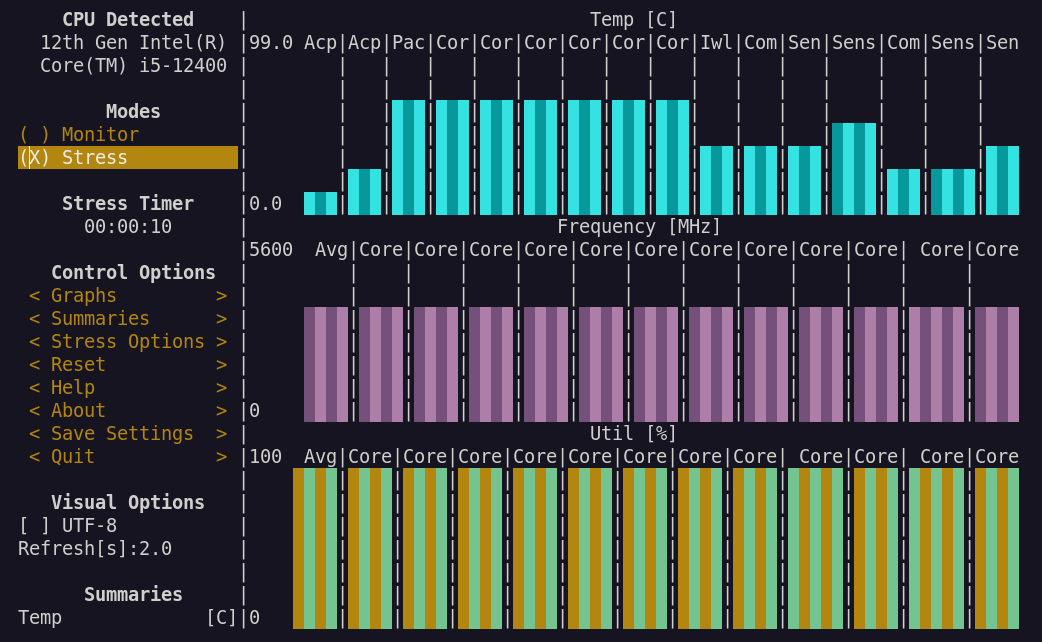
You'd need two utilities to stress test using a terminal: ** s-tui** and
**stress**.
You can get these tools installed from the default repositories or [using pip](https://itsfoss.com/install-pip-ubuntu/). It is easier with default repositories if you are okay with using an older version of the tool (a tad bit).
Here are the commands that will help you install them on popular Linux distros:
**For Ubuntu/Debian base:**
`sudo apt install s-tui stress `
**For Arch Linux:**
`sudo pacman -S s-tui stress`
**For Fedora/RHEL:**
`sudo dnf install s-tui stress`
**If you want to use pip **for the latest version, here is the command:
`pip install s-tui --user`
Once you are done with the installation, launch the s-tui utility in the terminal:
`s-tui`
And you would be met with the following:
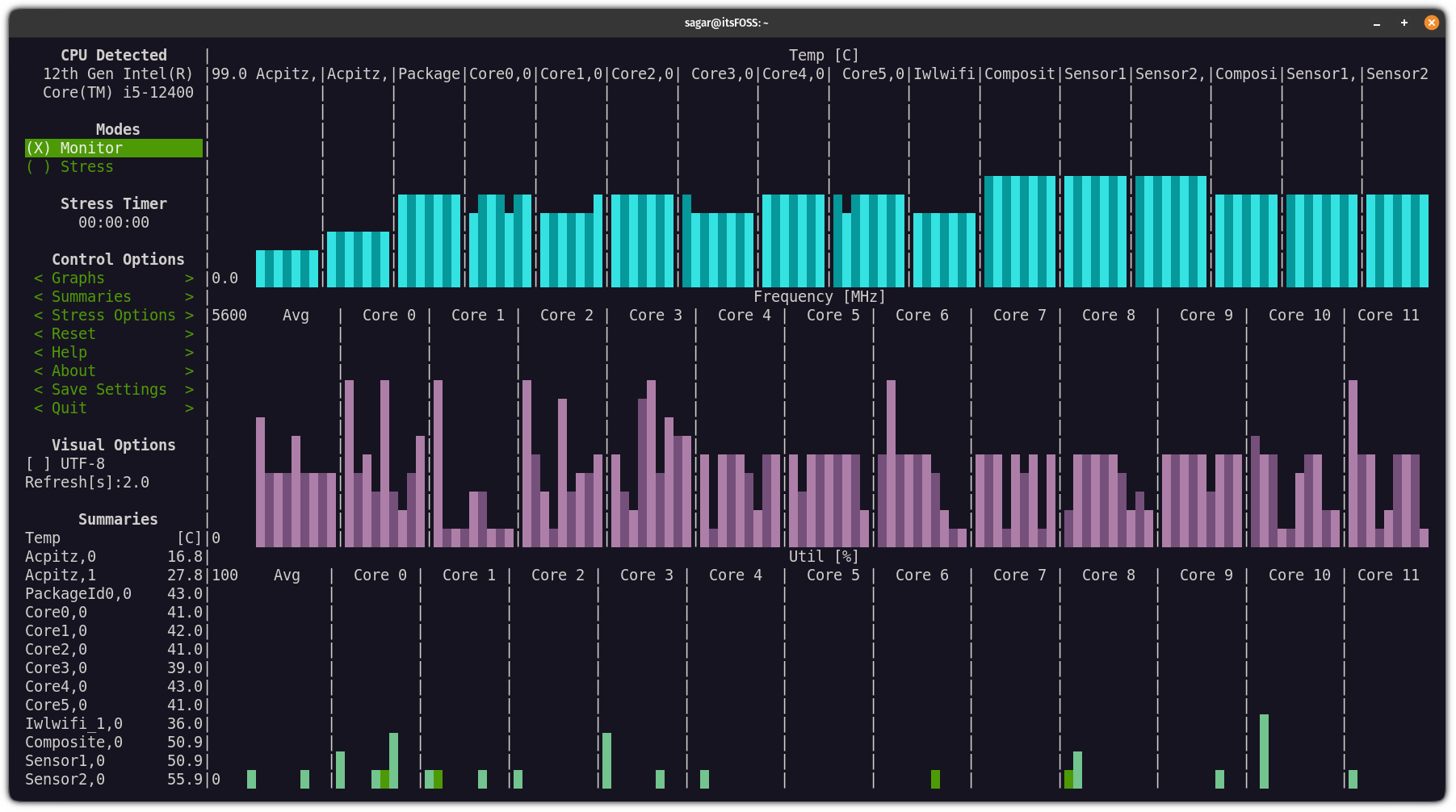
You can use the mouse or keyboard arrow keys to navigate through the menu, so click on the `Stres options`
and choose how long you want to stress test the system** (in seconds):**
And finally, select the `Stress`
option, and it will start the stress testing for a specified period:
And if the temperature gets out of control, you can click on the `Quit`
button to stop the stress test manually. Additionally, if you want to store the data in the `.csv`
format, the tool gives you the feature.
To store the data, all you have to do is append the `-c`
flag while starting the s-tui utility as shown:
`s-tui -c`
And if you want to save the file with a name to your liking, you'd have to use the `--csv-file`
flag as shown:
`s-tui --csv-file <name of file>.csv`
For example, here, I named the file `Hello.scv`
:
`s-tui --csv-file Hello.scv`
You can explore more about the tool on its [GitHub page](https://github.com/amanusk/s-tui).
**Suggested Read 📖**
[7 System Monitoring Tools for Linux That are Better Than TopTop command is good but there are better alternatives. Take a look at these system monitoring tools that are similar to top, but better than it.](https://itsfoss.com/linux-system-monitoring-tools/)

## Happy System, Happy Life 😁
Not every user realizes the benefits of a stress test. Sometimes it scares them off with the idea of their system reaching its limits for no reason.
However, the test will help you quickly evaluate and monitor your system's condition. Things like **abnormal temperature spikes** and CPU being unable to handle what it is should help you identify hardware issues early on.
In either case, you can refer to our temperature monitoring resource if you want to [keep your CPU monitor in check](https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/) without performing stress tests.
[How To Check CPU Temperature in Ubuntu LinuxThis quick tutorial shows you how to check the CPU temperature on Ubuntu and other Linux distributions with a help of a tool called Psensor. Overheating of laptops is a common issue one faces these days. Monitoring hardware temperature may help you diagnose why your laptop is getting overh…](https://itsfoss.com/check-laptop-cpu-temperature-ubuntu/)

You can also check out some of the [system monitoring tools](https://itsfoss.com/linux-system-monitoring-tools/) or [htop alternatives](https://itsfoss.com/htop-alternatives/) for Linux to keep an eye on your system resources.
💬 *What do you think about stress testing your CPU in Linux? Do you think we should do it? Share your thoughts on it in the comments below.* |
15,883 | Linux 爱好者线下沙龙:LLUG 2023 ,北京 · 开聚 | https://www.ceeting.com/login/2023oags/cn | 2023-06-06T19:41:00 | [
"LLUG"
] | https://linux.cn/article-15883-1.html | 
在 2021 年,[Linux 中国启动了线下聚会的活动](https://mp.weixin.qq.com/s/4pCLxaiR9v6zSNOEii7WSg),我们希望在疫情当下的时刻,仍能为大家提供面对面相互交流的机会。然而随着大流行病的发展,LLUG 仅仅组织了[两次活动](https://mp.weixin.qq.com/s/-hkwOZvXMaz0n6n3FXDyhA),便暂时按下了暂停键。
而今天,我们正式宣布,LLUG 2023 正式重新启动了,今年的 LLUG 活动主题是“**在一起,学技术**”,我们希望能够通过 LLUG 将大家重新聚集在线下,和我们一起聊聊天,看看最近又用到了什么不错的软件,有什么有趣的发行版,一起研究一下社区里的最新技术。
2023 年,我们将在全国的**多个城市**举办 LLUG 线下聚会,与我们的老朋友和新朋友们,在线下相见,重温人与人线下交流的温暖。同时,我们也要向大家介绍一下本次 LLUG 2023 的联合主办方 —— OpenAnolis 社区,来自 OpenAnolis 社区的贡献者们将和我们一起,在全国各地与大家相见。
>
> OpenAnolis 社区是国内的顶尖 Linux 发行版社区,我们希望在普及 Linux 知识的同时,也能让中国的 Linux 发行版,为更多人知晓,推动国产发行版的发展和进步。
>
>
>
**LLUG 2023 的第一站,将从北京开始。**
6 月 11 日 ~ 12 日,Linux 中国将在北京召开的**开放原子全球开放峰会现场**,组织 LLUG 2023 线下活动,与大家一同聊聊开源、聊聊 Linux ,聊聊社区当中的那些最新的技术。
我们将在 LLUG 2023 北京场和各位分享 Linux 中国在生成式 AI 上的新实践,以及我们对于通过开源推动 Linux 中国翻译组的持续发展的一些想法和探索。此外,我们还邀请到了 OpenAnolis社区的几位大咖来给大家分享他们在技术前沿的经验和总结。
具体议程如下:

*议程安排*
### 活动信息
活动主办方:Linux 中国
联合主办方:龙蜥社区(OpenAnolis)
活动支持:人民邮电出版社

**活动地点**:北人亦创国际会展中心 · 开放原子 2023 国际峰会 · 阿里云展台 · 龙蜥动手实验室
**活动时间**:2023 年 6 月 11 日、12 日,下午 13:00~16:00
报名方式:[点此链接](https://www.ceeting.com/login/2023oags/cn)或扫描下述二维码,**免费报名**参与开放原子 2023 国际峰会,即可来到现场和我们一起面对面沟通

*扫码报名*
如果你要来现场,不妨扫码加群,和我们更早的交流起来。到时候,咱们现场见!

*LLUG 2023 交流群*
### One More Thing
我们将会在活动现场举办线下抽奖,如果来到现场,别忘了参与互动,进行线下的抽奖哦~我们为大家准备了小米音箱、屏幕挂灯、背包、充电头等精选好物,期待在现场当中见到你哦~

除了北京,你还希望 LLUG 在哪里举办呢?在下方留言说出你的城市,说不定下一次,LLUG 就在你所在的城市举办~
| 303 | See Other | null |
15,884 | 使用 Docsify-This 从 Markdown 文件生成网页 | https://opensource.com/article/23/5/docsify-markdown-html | 2023-06-07T00:06:00 | [
"Markdown"
] | https://linux.cn/article-15884-1.html | 
>
> 这个开源工具可以轻松将 Markdown 转换为网页。
>
>
>
将 Markdown 文件直接变成网页,还无需搭建网站和生成过程,写完文档即可直接发布,你对这个内容感兴趣吗?你是否希望将 Markdown 或 HTML 自由地嵌入到多个平台(如内容管理系统或学习管理系统)中?由 [Docsify.js](https://docsify.js.org) 构建的开源项目 [Docsify-This](https://docsify-this.net) 提供了一种简单的方法来发布、分享和复用 Markdown 文件内容。
### Docsify-This 是什么?
使用 Docsify-This,你可以立即将任何 Markdown 文件转换为响应式的独立网页。你还可以将多个 Markdown 文件链接起来,以创建一个简单的网站。网页设计师可以简单地通过点击 Web 页面生成器界面或改变网页的地址参数(即 URL),来更改所显示页面的视觉外观。在创建自己的 Markdown 文件内容时,你还可以使用一组提供的 Markdown CSS 类。此外,如果你使用 Codeberg 或 GitHub 仓库存储 Markdown 文件的话,每个页面都会自动提供一个 “<ruby> 编辑此页面 <rt> Edit this Page </rt></ruby>” 的链接,以支持协同创作。
并且 Docsify-This 是开源的,因此你可以使用自定义域名托管 Docsify-This 实例,而不会有被平台锁定的风险。
### 使用 Docsify-This 网页生成器
要使用网页生成器,请先打开浏览器,导航到 [Docsify-This 网站](https://docsify-this.net) 或你在本地的实例。在 “<ruby> 网页生成器 <rt> Web Page Builder </rt></ruby>” 部分,输入 Codeberg 或 GitHub 上公共存储仓库中的一个 Markdown 文件的 URL(其他 Git 主机可以通过 Docsify-This URL 参数进行使用,但不能在网页生成器中使用),然后点击 “<ruby> 发布为独立网页 <rt> Publish as Standalone Web Page </rt></ruby>” 的按钮,如下图所示。

Markdown 文件将呈现为一个独立的网页,并生成一个可复制和共享的 URL。以下是一个示例 URL:
```
https://docsify-this.net/?basePath=https://raw.githubusercontent.com/hibbitts-design/docsify-this-one-page-article/main&homepage=home.md
```
Docsify-This 生成的网页非常适合嵌入,可以将 Docsify-This 页面的视觉样式调整到目标平台上去。

### 渲染同一存储库中的其他文件
你也可以通过直接编辑 Docsify-This URL 参数 `homepage` 来渲染同一存储库中的其他 Markdown 文件。例如:
```
https://docsify-this.net/?basePath=https://raw.githubusercontent.com/hibbitts-design/docsify-this-one-page-article/main&homepage=anotherfile.md
```
### 修改网页的外观
你可以使用 [URL 参数](https://docsify-this.net/#/?id=page-appearance-url-parameters) 更改 Docsify-This 中显示的任何 Markdown 文件的外观。例如,`font-family`(文本字体系列)、`font-size`(字体大小)、`link-color`(超链接颜色)和 `line-height`(行高)都是常见的 CSS 属性,同时也是 Docsify-This 中的有效参数:
```
https://docsify-this.net/?basePath=https://raw.githubusercontent.com/hibbitts-design/docsify-this-one-page-article/main&homepage=home.md&font-family=Open%20Sans,sans-serif
```
你也可以使用一组特殊的 [Markdown CSS 类](https://docsify-this.net/#/?id=supported-markdown-css-classes) 来改变网页的外观。例如,你可以为一个链接添加“按钮类”:
```
[Required Reading Quiz due Jun 4th](https://canvas.sfu.ca/courses/44038/quizzes/166553 ':class=button')
```
这将产生一个按钮,而不是一个文本链接:

除了 Docsify-This 支持的 Markdown CSS 类,你也可以在Markdown 文件中使用自定义类。例如:
```
<style>
.markdown-section .mybutton, .markdown-section .mybutton:hover {
cursor: pointer;
color: #CC0000;
height: auto;
display: inline-block;
border: 2px solid #CC0000;
border-radius: 4rem;
margin: 2px 0px 2px 0px;
padding: 8px 18px 8px 18px;
line-height: 1.2rem;
background-color: white;
font-family: -apple-system, "Segoe UI", "Helvetica Neue", sans-serif;
font-weight: bold;
text-decoration: none;
}
</style>
[Custom CSS Class Button](# ':class=mybutton')
```
使用这个自定义类将生成这样的按钮:

### 在 Markdown 文件中包含 HTML 片段
正如标准 Markdown 所支持的那样,你可以在 Markdown 文件中包括 HTML 片段。这允许你在你的 HTML 渲染中添加布局元素。例如:
```
<div class="row">
<div class="column">
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
</div>
<div class="column">
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
</div>
</div>
```
### 使用 iFrame 嵌入 Docsify-This 网页
你可以在几乎所有的平台上使用 iFrame 嵌入 Docsify-This 网页。你还可以使用 URL 参数来确保你的嵌入内容与你的目标平台相匹配:
```
<p><iframe style="overflow: hidden; border: 0px #ffffff none; margin-top: -26px; background: #ffffff;" src="https://docsify-this.net/?basePath=https://raw.githubusercontent.com/paulhibbitts/cmpt-363-222-pages/main&homepage=home.md&font-family=Lato%20Extended,Lato,Helvetica%20Neue,Helvetica,Arial,sans-serif&font-size=1&hide-credits=true" width="800px" height="950px" allowfullscreen="allowfullscreen"></iframe></p>
```

### 使用外部 URL 嵌入 Docsify-This
在某些学习管理系统中,包括开源的 [Moodle](https://opensource.com/article/21/3/moodle-plugins),或者专有的 [Canvas](https://github.com/instructure/canvas-lms),你可以将外部网页链接到课程导航菜单。例如,你可以使用 Canvas 中的重定向工具来显示 Docsify-This 网页。
```
url=https://docsify-this.net/?basePath=https://raw.githubusercontent.com/paulhibbitts/cmpt-363-222-pages/main&homepage=resources.md&edit-link=https://github.com/paulhibbitts/cmpt-363-222-pages/blob/main/resources.md&font-family=Lato%20Extended,Lato,Helvetica%20Neue, Helvetica,Arial,sans-serif&font-size=1&hide-credits=true
```
### 整合 Docsify-This 和 Git
为了充分利用版本控制的好处,并使用 “<ruby> 编辑此页面 <rt> Edit this Page </rt></ruby>” 的链接进行协同工作,请将你的 Docsify-This Markdown 文件存储在 Codeberg 或 GitHub 的 Git 存储库中。一些开源工具为 Git 提供了一个图形界面,包括 [GitHub Desktop](https://github.com/desktop/desktop)(最近已开源)、[Git-Cola](https://opensource.com/article/20/3/git-cola) 和 [SparkleShare](https://opensource.com/article/19/4/file-sharing-git)。文本编辑器 VSCode 和 Pulsar Edit(以前的 [Atom.io](https://opensource.com/article/20/12/atom))也都有整合 Git 的功能。
### 轻松实现 Markdown 文件在网页发布
由于 Docsify 的存在,每个人都能享受到 Markdown 文件的在网上发布的好处。而且由于 Docsify-This 的出现,这个工作变得很容易。不妨在 [Docsify-This 网站](https://docsify-this.net) 上试试吧。
*(题图:MJ/f38f0a40-002b-4e93-9697-e008205c1211)*
---
via: <https://opensource.com/article/23/5/docsify-markdown-html>
作者:[Paul Hibbitts](https://opensource.com/users/paulhibbitts) 选题:[lkxed](https://github.com/lkxed/) 译者:[chai001125](https://github.com/chai001125) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Are you interested in leveraging Markdown for online content without any website setup or build process? How about seamlessly embedding constraint-free Markdown or HTML into multiple platforms (such as a content management system or learning management system)? The open source project [Docsify-This](https://docsify-this.net), built with [Docsify.js](https://docsify.js.org), provides an easy way to publish, share, and reuse Markdown content.
**[ Get the Markdown cheat sheet ]**
## What is Docsify-This?
With Docsify-This, you can instantly turn any publicly available Markdown file into a responsive standalone web page. You can also link multiple Markdown files to create a simple website. Designers can alter the visual appearance of displayed pages with the point-and-click Web Page Builder interface or URL parameters. You can also use a set of provided Markdown CSS classes when creating your own Markdown content. In addition, if you use Codeberg or GitHub to store your Markdown files, an **Edit this Page** link can be automatically provided for each page to support collaborative authoring.
It's open source, so you can host a Docsify-This instance using your own custom domain without the risk of platform lock-in.
## Use the Docsify-This Web Page Builder
To use the Web Page Builder, open a browser and navigate to the [Docsify-This website](https://docsify-this.net) or your local instance. In the **Web Page Builder** section, enter the URL of a Markdown file in a public repo of Codeberg or GitHub (other Git hosts can also be used via Docsify-This URL parameters but not in the Web Page Builder), and then click the **Publish as Standalone Web Page** button.
(Paul Hibbitts, CC BY-A 4.0)
The Markdown file is rendered as a standalone web page with a URL you can copy and share. Here's an example URL:
```
````https://docsify-this.net/?basePath=https://raw.githubusercontent.com/hibbitts-design/docsify-this-one-page-article/main&homepage=home.md`
Docsify-This rendered web pages are perfect for embedding, with the ability to visually style Docsify-This pages to the destination platform.

(Paul Hibbitts, CC BY-A 4.0)
## Render other files in the same repository
You can render other Markdown files in the same repository by directly editing the Docsify-This URL parameter **homepage**. For example:
```
````https://docsify-this.net/?basePath=https://raw.githubusercontent.com/hibbitts-design/docsify-this-one-page-article/main&homepage=anotherfile.md`
## Modify the web page's appearance
You can change the appearance of any Markdown file displayed in Docsify-This by using [URL parameters](https://docsify-this.net/#/?id=page-appearance-url-parameters). For example, `font-family`
, `font-size`
, `link-color`
, and `line-height`
are all common CSS attributes and are valid parameters for Docsify-This:
```
````https://docsify-this.net/?basePath=https://raw.githubusercontent.com/hibbitts-design/docsify-this-one-page-article/main&homepage=home.md&font-family=Open%20Sans,sans-serif`
You can also alter the visual appearance using a set of special [Markdown CSS classes](https://docsify-this.net/#/?id=supported-markdown-css-classes). For example, you can add the `button`
class to a link:
```
````[Required Reading Quiz due Jun 4th](https://canvas.sfu.ca/courses/44038/quizzes/166553 ':class=button') `
This produces a button image instead of just a text link:

(Paul Hibbitts, CC BY-A 4.0)
In addition to the Markdown CSS classes supported by Docsify-This, you can define your own custom classes within your displayed Markdown files. For example:
```
``````
<style>
.markdown-section .mybutton, .markdown-section .mybutton:hover {
cursor: pointer;
color: #CC0000;
height: auto;
display: inline-block;
border: 2px solid #CC0000;
border-radius: 4rem;
margin: 2px 0px 2px 0px;
padding: 8px 18px 8px 18px;
line-height: 1.2rem;
background-color: white;
font-family: -apple-system, "Segoe UI", "Helvetica Neue", sans-serif;
font-weight: bold;
text-decoration: none;
}
</style>
[Custom CSS Class Button](# ':class=mybutton')
```
Produces this:

(Paul Hibbitts, CC BY-A 4.0)
## Include HTML snippets
As supported by standard Markdown, you can include HTML snippets. This allows you to add layout elements to your HTML render. For example:
```
``````
<div class="row">
<div class="column">
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
</div>
<div class="column">
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
</div>
</div>
```
## Embed Docsify-This as an iFrame
You can embed Docsify-This web pages using an iFrame in almost any platform. You can also use URL parameters to ensure your embedded content matches your destination platform:
```
````<p><iframe style="overflow: hidden; border: 0px #ffffff none; margin-top: -26px; background: #ffffff;" src="https://docsify-this.net/?basePath=https://raw.githubusercontent.com/paulhibbitts/cmpt-363-222-pages/main&homepage=home.md&font-family=Lato%20Extended,Lato,Helvetica%20Neue,Helvetica,Arial,sans-serif&font-size=1&hide-credits=true" width="800px" height="950px" allowfullscreen="allowfullscreen"></iframe></p>`
(Paul Hibbitts, CC BY-A 4.0)
## Embed Docsify-This with an external URL
In certain learning management systems (LMS), including the open source [Moodle](https://opensource.com/article/21/3/moodle-plugins) and even the proprietary [Canvas](https://github.com/instructure/canvas-lms), you can link external web pages to a course navigation menu and sometimes more. For example, you can use the Redirect Tool in Canvas to display Docsify-This web pages.
```
````url=https://docsify-this.net/?basePath=https://raw.githubusercontent.com/paulhibbitts/cmpt-363-222-pages/main&homepage=resources.md&edit-link=https://github.com/paulhibbitts/cmpt-363-222-pages/blob/main/resources.md&font-family=Lato%20Extended,Lato,Helvetica%20Neue, Helvetica,Arial,sans-serif&font-size=1&hide-credits=true`
## Integrate Docsify-This and Git
To fully leverage the benefits of version control and potentially collaboration using an optional **Edit this Page** link, store your Docsify-This Markdown pages in a Git repository on either Codeberg or GitHub. Several open source tools provide a graphical interface for Git, including [GitHub Desktop](https://github.com/desktop/desktop) (recently released as open source), [Git-Cola](https://opensource.com/article/20/3/git-cola), and [SparkleShare](https://opensource.com/article/19/4/file-sharing-git). The text editors VSCode and Pulsar Edit (formerly [Atom.io](https://opensource.com/article/20/12/atom)) both feature Git integration, too.
**[ Get the Git tips and tricks eBook ]**
## Markdown publishing made easy
The benefits of Markdown-based publishing are available to everyone, thanks to Docsify. And thanks to Docsify-This, it's easier than ever. Try it out at the [Docsify-This website](https://docsify-this.net).
## Comments are closed. |
15,885 | 5 个最漂亮的 Arch Linux 发行版 | https://www.debugpoint.com/beautiful-arch-linux/ | 2023-06-07T11:37:00 | [
"Arch Linux"
] | /article-15885-1.html | 
>
> 本文将介绍几个漂亮的 Arch Linux 发行版,这些发行版将设计的优雅之美与 Arch Linux 强大的底层框架相结合。
>
>
>
Arch Linux 提供滚动更新模型、强大的 pacman 软件包管理器,以及通过其软件仓库提供的成千上万的应用程序。它非常受欢迎,因为它允许你以 DIY 的方式创建定制的 Linux 发行版。它的优点之一是各种社区驱动的发行版,它们提供了预配置的设置和视觉上令人愉悦的界面。
本文将介绍其中一些,这些发行版的主要着眼点是它们的外观设计。
### 美观的 Arch Linux 发行版
让我们探索一些顶级美观的 Arch Linux 发行版,它们将美学与 Arch Linux 的核心功能相结合:
#### XeroLinux
XeroLinux 提供了一个视觉上惊艳的界面和流畅的设计。它预配置了 KDE Plasma 桌面环境,提供了一个整洁的工作区。这个发行版基于 Arch Linux,主要面向那些喜欢带有最新软件包和 KDE Plasma 的视觉效果的桌面环境,但又不想重新配置 Plasma 桌面环境的用户。XeroLinux 主要使用预配置的 Latte Dock 和 Kvantum 来为桌面环境带来独特的外观。

默认情况下,它使用 [Catppuccin 主题](https://catppuccin-website.vercel.app/),这是一个开源主题,旨在成为高对比度和低对比度主题之间的中间地带。Catppuccin 主题为 KDE Plasma 桌面环境提供了四种舒缓的温暖调色板,适用于各种用途,例如编码、休闲浏览或学习。
Plasma 桌面环境使用以下默认组件进行配置:
* 应用程序样式:Lightly
* Plasma 样式:Scratchy
* 图标:Tela circle drakula dark
* 光标:Catppuccin mocha dark
* 窗口装饰:Lightly
除上述外,KDE Plasma 顶部栏的应用程序全局菜单和终端的透明度提供了即插即用的视觉升华。

你可以阅读我的专题评论了解有关 XeroLinux 的性能、应用程序和其他方面的更多信息。可以使用以下链接下载 XeroLinux。
>
> **[下载 XeroLinux](https://xerolinux.xyz/)**
>
>
>
#### Mabox Linux
如果你是窗口管理器的粉丝,想要一个令人惊艳的 Arch Linux 发行版,试试 Mabox Linux 吧。Mabox Linux 专注于简单和优雅。它是 Manjaro Linux 的一个分支,主要环境使用 Openbox 窗口管理器。Openbox 直观的界面和视觉上令人愉悦的主题,创造了一个顺滑的、沉浸式的计算体验。

其默认外观包括顶部的 tint2 面板,它有两个部分。一些 Conky 项目在桌面上提供了非常必要的信息。右键单击菜单让你可以访问桌面上的所有应用程序和设置。
为了进一步定制,Mabox 提供了自己的控制中心,让你可以在一个地方自定义 OpenBox、Conky、面板和所有内容。

用户友好的安装过程,经过筛选的软件,对于那些想要使用窗口管理器的人来说,Mabox Linux 是一个极好的选择。
你可以在我的 [评论文章](https://www.debugpoint.com/mabox-linux-2022/) 中了解更多有关 Mabox Linux 的信息。你可以使用以下页面下载它。
>
> **[下载 Mabox Linux](https://maboxlinux.org/)**
>
>
>
#### Crystal Linux
本列表中的下一个发行版是新近推出的 Crystal Linux。Crystal Linux 默认采用自定义的 GNOME 桌面 “Onyx”,并提供了 GNOME、KDE Plasma、Xfce 和 i3 窗口管理器的选项。

我将其列入此列表的主要原因是,它是为 Arch Linux 打造的干净的 GNOME 外观的独特发行版之一。在定制方面,你将得到基本的 Adwaita GNOME 主题、漂亮的壁纸、底部固定式停靠区和 GNOME 快速设置。
然而,干净的 GNOME 桌面确实很美丽,你还可以进一步自定义它。Crystal Linux 还有其他优点,例如 Amethyst AUR 帮助程序、pacman 包管理器封装程序、Wayland 支持以及 [许多其他优点](https://getcryst.al/site/docs/amethyst/getting-started)。

你可以从以下页面下载 Crystal Linux。
>
> **[下载 Crystal Linux](https://getcryst.al/site)**
>
>
>
#### Archcraft OS
Archcraft OS 是另一个美丽的基于 Openbox 和 bspwm 窗口管理器的 Arch Linux。它旨在提供一个具有令人惊艳的外观的 “纯正” Arch Linux 体验。
Archcraft OS 的用户界面美观动人,带有预安装的 Openbox 主题和吸引人的壁纸。它通过预安装的设置管理器提供了 Openbox 的便捷配置选项。默认的窗口管理器主题,加上壁纸,创造了一个吸引人的视觉体验。

Archcraft OS 的默认面板包括工作区列表、时钟和日期显示、音量控制、电源选项、CPU、内存和磁盘使用指示器等基本组件。面板保持了干净和视觉上令人愉悦的外观。
Archcraft OS 预装了各种 Openbox 主题和样式,提供了深浅两种组合选项。这些样式包括 Beach、Forest、Grid、Manhattan、Slime、Spark 和 Wave。
它是漂亮的预配置 Arch Linux 发行版之一。你可以从以下页面下载它。
>
> **[下载 Archcraft Linux](https://archcraft.io/)**
>
>
>
#### Exodia OS
Exodia OS 是一种专门针对网络安全专业人员定制的 Arch Linux 发行版,即使你没有深入涉足网络安全领域,你也会欣赏 Exodia OS 的视觉上令人愉悦的界面和用户友好的工具。

Exodia OS 带有 BSPWM,这是一个平铺式窗口管理器,并提供了 20 个定制主题,以增强视觉体验。
以下是 Exodia OS 的一些关键优点:
* 它带有预安装的网络安全工具,涵盖了网络安全的所有方面。
* 目前有三个版本可用:Home、Predator 和 Wireless。
* 目前支持 BSPWM 和 DWM 两个窗口管理器,未来将计划支持更多桌面环境和窗口管理器。
你可以从以下页面下载 Exodia OS。
>
> **[下载 Exodia OS](https://exodia-os.github.io/exodia-website/)**
>
>
>
### 总结
总之,上述列出的顶级美观的 Arch Linux 发行版将 Arch Linux 的强大功能与令人愉悦的视觉界面相结合,为用户提供个性化和美学体验。本文列出的发行版涵盖了各种流行的桌面环境和窗口管理器。
这些发行版提供了可定制性、稳定性和轻量级性能。希望你可以选择一款令人惊艳的 Arch Linux 发行版来满足自己的口味。
*(题图:MJ/f0d52f3f-8ec4-491d-96bd-eb4376f2e8ea)*
---
via: <https://www.debugpoint.com/beautiful-arch-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,887 | GNOME 的新图像查看器应用 Loupe | https://news.itsfoss.com/loupe-image-viewer/ | 2023-06-08T16:28:00 | [
"GNOME"
] | https://linux.cn/article-15887-1.html |
>
> GNOME 的新图像查看器?看起来不错!
>
>
>

GNOME 的人们一直在忙碌着!
最近,你可能听说他们正在 [考虑](https://news.itsfoss.com/gnome-terminal-console/) 把终端应用带回来替代那个新的控制台应用,还有 [新的相机应用](https://news.itsfoss.com/gnome-snapshot/) 将在不久的将来替换 “<ruby> 茄子 <rt> Cheese </rt></ruby>” 应用。
你可能没注意到我们在这些核心 GNOME 应用更改中未涵盖的其他内容。
**一个名为 “Loupe” 的 GNOME 新图像查看器应用**,已被 GNOME 的 [孵化器](https://gitlab.gnome.org/GNOME/Incubator?ref=news.itsfoss.com) 接受。
请允许我带你了解一下。
>
> ? “孵化器”分组包含的项目属于 GNOME 核心和 GNOME 开发工具的一部分,这代表着 **可能有一天它们会进入 GNOME 的发布版本**。
>
>
>
### ? Loupe 是什么?

因此,正如我所说,这是一款适用于 GNOME 的新图像查看器应用,它 **用内存安全的 Rust 编程语言编写**,并提供一些很酷的功能。
例如,屏幕上的按钮可以切换各种照片、放大/缩小、进入全屏模式等等。
然后是元数据查看器,它已很好地集成到界面中,显示 **位置、大小、分辨率、创建日期** 等数据。

不止如此,Loupe 还支持键盘和触控板快捷键!你自己看。

这些键盘/触控板快捷方式和手势对笔记本电脑用户来说应该很方便。
这对于触摸屏来说很好 ?
另外,我怎么能忘记可以分别从功能区菜单和标题访问的 **复制到剪贴板**、**移动到垃圾箱**和 **打印图像** 选项?
这是实际操作:
很整洁,不是吗?
我必须说,Loupe 有一套漂亮的功能,我发现自己每天在浏览照片时都在使用它。
它旨在取代现有的 [Eye of GNOME(eog)](https://help.gnome.org/users/eog/stable/?ref=news.itsfoss.com)图片查看器,当然,除非有任何问题,否则可能会随着 GNOME 45 的发布而出现。
### ? 获取 Loupe
你可以从 [Flathub 商店](https://flathub.org/apps/org.gnome.Loupe?ref=news.itsfoss.com) 获取 Loupe,还可以在 [GitLab](https://gitlab.gnome.org/GNOME/Incubator/loupe?ref=news.itsfoss.com) 上探索其源代码。
>
> **[Loupe(Flathub)](https://flathub.org/apps/org.gnome.Loupe?ref=news.itsfoss.com)**
>
>
>
? 你怎么看? 作为 GNOME 上的默认图像查看器,Loupe 会是一个不错的选择吗?
---
via: <https://news.itsfoss.com/loupe-image-viewer/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The folks over at GNOME have been busy!
Recently, you might have heard that they are [considering](https://news.itsfoss.com/gnome-terminal-console/) bringing back the terminal app to replace the new console, then there's the [new camera app](https://news.itsfoss.com/gnome-snapshot/) set to replace Cheese in the near future.
You might have missed something else we did not cover among those core GNOME app changes.
**A new image viewer app for GNOME called 'Loupe'**. It has been accepted into GNOME's [Incubator Group](https://gitlab.gnome.org/GNOME/Incubator?ref=news.itsfoss.com).
Allow me to take you through this.
**this might someday make it into a GNOME release**.
## 🆕 Loupe: What is it?
So, as I was saying, this is a new image viewer app for GNOME, **written in the memory-safe Rust programming language,** and offers some cool features.
Take, for instance, the on-screen buttons to switch through various photos, zoom in/out, go into full-screen mode, and more.
Then there's the metadata viewer that has been integrated nicely into the interface, showing data such as the** location, size, resolution, date of creation,** etc.
That's not all; Loupe also supports keyboard and trackpad shortcuts! See for yourself.
These keyboard/trackpad shortcuts and gestures should be convenient for laptop users.
This is a nice touch 🤗
Also, how can I forget about the the **copy to clipboard**, **move to trash** and **print image** options that can be accessed from the ribbon-menu and the header, respectively?
Here's that in action:
It's neat, isn't it?
I must say, Loupe has a nifty set of features I see myself using daily while going through my photos.
It aims to replace the existing [Eye of GNOME](https://help.gnome.org/users/eog/stable/?ref=news.itsfoss.com) (eog) Image Viewer, maybe with the release of GNOME 45, barring any issues, of course.
**Suggested Read **📖
[Top 11 Image Viewers for Ubuntu and other LinuxIt is probably a good idea to stick with the default system image viewer unless you want a specific feature (that’s missing) or if you crave for better user experience. However, if you like to experiment, you may try out different image viewers. You could end up loving the](https://itsfoss.com/image-viewers-linux/?ref=news.itsfoss.com)

## 📥 Get Loupe
You can grab Loupe from the [Flathub store](https://flathub.org/apps/org.gnome.Loupe?ref=news.itsfoss.com), and also explore its source code on [GitLab](https://gitlab.gnome.org/GNOME/Incubator/loupe?ref=news.itsfoss.com).
*💬 What do you think? Will Loupe be a good choice as the default image viewer on GNOME for you?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.