
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
15,888 | 用 Lua 控制你的树莓派 | https://opensource.com/article/23/3/control-your-raspberry-pi-lua | 2023-06-08T17:05:15 | [
"Lua",
"树莓派"
] | https://linux.cn/article-15888-1.html | 
>
> 学习如何使用 Lua 编程语言为物联网(IoT)设备编程,并与树莓派上的通用输入/输出(GPIO)引脚互动。
>
>
>
Lua 是一种有时会被误解的语言。它与 Python 等其他语言不同,但它是一种通用的扩展语言,广泛用于游戏引擎、框架等。总的来说,我发现 Lua 对开发人员来说是一个有价值的工具,可以让他们以一些强大的方式增强和扩展他们的项目。
你可以按照 Seth Kenlon 的文章《[Lua 值得学习吗?](https://opensource.com/article/22/11/lua-worth-learning)》的介绍下载并运行常用的 Lua,该文章中还包括了简单的 Lua 代码示例。但是,要充分利用 Lua,最好将它与采用该语言的框架一起使用。在本教程中,我演示了如何使用名为 Mako Server 的框架,该框架旨在使 Lua 程序员能够轻松地编写 IoT 和 Web 应用代码。我还向你展示了如何使用 API 扩展此框架以使用树莓派的 GPIO 引脚。
### 要求
在学习本教程之前,你需要一个可以登录的正在运行的树莓派。虽然我将在本教程中编译 C 代码,但你不需要任何 C 代码经验。但是,你需要一些使用 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 终端的经验。
### 安装
首先,在树莓派上打开一个终端窗口并安装以下工具,以使用 Git 下载代码和编译 C 代码:
```
$ sudo apt install git unzip gcc make
```
接下来,通过运行以下命令编译开源 Mako Server 代码和 lua-periphery 库(树莓派的 GPIO 库):
```
$ wget -O Mako-Server-Build.sh \
https://raw.githubusercontent.com/RealTimeLogic/BAS/main/RaspberryPiBuild.sh
```
查看脚本以了解它的作用,并在你觉得没问题后运行它:
```
$ sh ./Mako-Server-Build.sh
```
编译过程可能需要一些时间,尤其是在较旧的树莓派上。编译完成后,脚本会要求你将 Mako Server 和 lua-periphery 模块安装到 `/usr/local/bin/`。我建议安装它以简化软件的使用。别担心,如果你不再需要它,你可以卸载它:
```
$ cd /usr/local/bin/
$ sudo rm mako mako.zip periphery.so
```
要测试安装,请在终端中输入 `mako`。这将启动 Mako 服务器,并在你的终端中看到一些输出。你可以按 `CTRL+C` 停止服务器。
### IoT 和 Lua
现在 Mako 服务器已在你的树莓派上设置好,你可以开始对 IoT 和 Web 应用进行编程,并使用 Lua 操作树莓派的 GPIO 引脚。Mako Server 框架为 Lua 开发人员提供了一个强大而简单的 API 来创建物联网应用,而 lua-periphery 模块让 Lua 开发人员可以与树莓派的 GPIO 引脚和其他外围设备进行交互。
首先创建一个应用目录和一个 `.preload` 脚本,其中插入用于测试 GPIO 的 Lua 代码。`.preload` 脚本是一个 Mako 服务器扩展,在应用启动时作为 Lua 脚本加载和运行。
```
$ mkdir gpiotst
$ nano gpiotst/.preload
```
将以下内容复制到 [Nano 编辑器](https://opensource.com/article/20/12/gnu-nano) 中并保存文件:
```
-- Load periphery.so and access the LED interface
local LED = require('periphery').LED
local function doled()
local led = LED("led0") -- Open LED led0
trace"Turn LED on"
led:write(true) -- Turn on LED (set max brightness)
ba.sleep(3000) -- 3 seconds
trace"Turn LED off"
led:write(false) -- Turn off LED (set zero brightness)
led:close()
end
ba.thread.run(doled) -- Defer execution
-- to after Mako has started
```
上面的 Lua 代码使用你编译并包含在 Mako 服务器中的 Lua-periphery 库控制树莓派 LED。该脚本定义了一个名为 `doled` 的函数来控制 LED。该脚本首先使用 Lua `require` 函数加载 `periphery` 库(共享库 [periphery.so](http://periphery.so))。返回的数据是一个包含所有 GPIO API 函数的 [Lua 表](https://opensource.com/article/22/11/iterate-over-tables-lua)。但是,你只需要 LED API,你可以通过在调用 `require` 后附加 `.LED` 来直接访问它。接下来,代码定义了一个名为 `doled` 的函数,它执行以下操作:
* 通过调用 `periphery` 库中的 `LED` 函数,并将字符串 `led0` 传给它,打开树莓派主 LED,识别为 `led0`。
* 将消息 `Turn LED on` 打印到跟踪(控制台)。
* 通过调用 LED 对象上的 `write` 方法并将布尔值 `true` 传递给它来激活 LED,该值设置 LED 的最大亮度。
* 通过调用 `ba.sleep(3000)` 等待 3 秒。
* 将消息 `Turn LED off` 打印到跟踪。
* 通过调用 LED 对象上的 `write` 方法并将布尔值 `false` 传递给它来停用 LED,这会将 LED 的亮度设置为零。
* 通过调用 LED 对象上的 `close` 函数关闭 `LED`。
在 `.preload` 脚本的末尾,`doled` 函数作为参数传递给 `ba.thread.run` 函数。这允许将 `doled` 函数的执行推迟到 Mako 服务器启动之后。
要启动 `gpiotst` 应用,请按如下方式运行 Mako 服务器:
```
$ mako -l::gpiotst
```
控制台中打印以下文本:
```
Opening LED:
opening 'brightness': Permission denied.
```
访问 GPIO 需要 root 访问权限,因此按 `CTRL+C` 停止服务器并重新启动 Mako 服务器,如下所示:
```
$ sudo mako -l::gpiotst
```
现在树莓派 LED 亮起 3 秒。成功!
### Lua 解锁 IoT
在本入门教程中,你学习了如何编译 Mako 服务器,包括 GPIO Lua 模块,以及如何编写用于打开和关闭树莓派 LED 的基本 Lua 脚本。在以后的文章中,我将在本文的基础上进一步介绍 IoT 功能。
同时,你可以通过阅读它的 [文档](https://github.com/vsergeev/lua-periphery/tree/master/docs) 来更深入地研究 Lua-periphery GPIO 库,以了解有关功能以及如何将其与不同外设一起使用的更多信息。要充分利用本教程,请考虑关注 [交互式 Mako Server Lua 教程](https://tutorial.realtimelogic.com/Introduction.lsp) 以更好地了解 Lua、Web 和 IoT。编码愉快!
*(题图:MJ/4514210d-5697-4cd3-8c44-450bbe56be64)*
---
via: <https://opensource.com/article/23/3/control-your-raspberry-pi-lua>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Lua is a sometimes misunderstood language. It’s different from other languages, like Python, but it’s a versatile extension language that’s widely used in game engines, frameworks, and more. Overall, I find Lua to be a valuable tool for developers, letting them enhance and expand their projects in some powerful ways.
You can download and run stock Lua as Seth Kenlon explained in his article [Is Lua worth learning](https://opensource.com/article/22/11/lua-worth-learning), which includes simple Lua code examples. However, to get the most out of Lua, it’s best to use it with a framework that has already adopted the language. In this tutorial, I demonstrate how to use a framework called Mako Server, which is designed for enabling Lua programmers to easily code IoT and web applications. I also show you how to extend this framework with an API for working with the Raspberry Pi’s GPIO pins.
## Requirements
Before following this tutorial, you need a running Raspberry Pi that you can log into. While I will be compiling C code in this tutorial, you do not need any prior experience with C code. However, you do need some experience with a [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) terminal.
## Install
To start, open a terminal window on your Raspberry Pi and install the following tools for downloading code using Git and for compiling C code:
```
````$ sudo apt install git unzip gcc make`
Next, compile the open source Mako Server code and the Lua-periphery library (the Raspberry Pi GPIO library) by running the following command:
```
``````
$ wget -O Mako-Server-Build.sh \
https://raw.githubusercontent.com/RealTimeLogic/BAS/main/RaspberryPiBuild.sh
```
Review the script to see what it does, and run it once you’re comfortable with it:
```
````$ bash ./Mako-Server-Build.sh`
The compilation process may take some time, especially on an older Raspberry Pi. Once the compilation is complete, the script asks you to install the Mako Server and the lua-periphery module to `/usr/local/bin/`
. I recommend installing it to simplify using the software. Don’t worry, if you no longer need it, you can uninstall it:
```
``````
$ cd /usr/local/bin/
$ sudo rm mako mako.zip periphery.so
```
To test the installation, type `mako`
into your terminal. This starts the Mako Server, and see some output in your terminal. You can stop the server by pressing **CTRL+C**.
## IoT and Lua
Now that the Mako Server is set up on your Raspberry Pi, you can start programming IoT and web applications and working with the Raspberry Pi’s GPIO pins using Lua. The Mako Server framework provides a powerful and easy API for Lua developers to create IoT applications and the lua-periphery module lets Lua developers interact with the Raspberry Pi’s GPIO pins and other peripheral devices.
Start by creating an application directory and a `.preload`
script, which inserts Lua code for testing the GPIO. The `.preload`
script is a Mako Server extension that’s loaded and run as a Lua script when an application is started.
```
``````
$ mkdir gpiotst
$ nano gpiotst/.preload
```
Copy the following into the [Nano editor](https://opensource.com/article/20/12/gnu-nano) and save the file:
```
``````
-- Load periphery.so and access the LED interface
local LED = require('periphery').LED
local function doled()
local led = LED("led0") -- Open LED led0
trace"Turn LED on"
led:write(true) -- Turn on LED (set max brightness)
ba.sleep(3000) -- 3 seconds
trace"Turn LED off"
led:write(false) -- Turn off LED (set zero brightness)
led:close()
end
ba.thread.run(doled) -- Defer execution
-- to after Mako has started
```
The above Lua code controls the main Raspberry Pi LED using the Lua-periphery library you compiled and included with the Mako Server. The script defines a single function called `doled`
that controls the LED. The script begins by loading the `periphery`
library (the shared library periphery.so) using the Lua `require`
function. The returned data is a [Lua table](https://opensource.com/article/22/11/iterate-over-tables-lua) with all GPIO API functions. However, you only need the LED API, and you directly access that by appending `.LED`
after calling `require`
. Next, the code defines a function called `doled`
that does the following:
- Opens the Raspberry Pi main LED identified as
`led0`
by calling the`LED`
function from the`periphery`
library and by passing it the string`led0`
. - Prints the message
`Turn LED on`
to the trace (the console). - Activates the LED by calling the
`write`
method on the LED object and passing it the Boolean value`true`
, which sets the maximum brightness of the LED. - Waits for 3 seconds by calling
`ba.sleep(3000)`
. - Prints the message
`Turn LED off`
to the trace. - Deactivates the LED by calling the
`write`
method on the LED object and passing it the Boolean value`false`
, which sets zero brightness of the LED. - Closes the
`LED`
by calling the`close`
function on the LED object.
At the end of the `.preload`
script, the `doled`
function is passed in as argument to function `ba.thread.run`
. This allows the execution of the `doled`
function to be deferred until after Mako Server has started.
To start the `gpiotst`
application, run the Mako Server as follows:
```
````$ mako -l::gpiotst`
The following text is printed in the console:
```
``````
Opening LED:
opening 'brightness': Permission denied.
```
Accessing GPIO requires root access, so stop the server by pressing **CTRL+C** and restart the Mako Server as follows:
```
````$ sudo mako -l::gpiotst`
Now the Raspberry Pi LED turns on for 3 seconds. Success!
## Lua unlocks IoT
In this primer, you learned how to compile the Mako Server, including the GPIO Lua module, and how to write a basic Lua script for turning the Raspberry Pi LED on and off. I’ll cover further IoT functions, building upon this article, in future articles.
You may in the meantime delve deeper into the Lua-periphery GPIO library by reading its [documentation](https://github.com/vsergeev/lua-periphery/tree/master/docs) to understand more about its functions and how to use it with different peripherals. To get the most out of this tutorial, consider following the [interactive Mako Server Lua tutorial](https://tutorial.realtimelogic.com/Introduction.lsp) to get a better understanding of Lua, web, and IoT. Happy coding!
## Comments are closed. |
15,890 | 使用 Linux 让旧电脑焕发新颜 | https://opensource.com/article/23/3/refurbish-old-computer-linux | 2023-06-09T16:32:44 | [
"旧电脑"
] | https://linux.cn/article-15890-1.html | 
>
> 这份逐步指南教你如何将旧电脑重新翻新,使其继续发挥作用。
>
>
>
我们生活在一个激动人心的时代。不久之前,我们都被束缚在“升级跑步机”上,被迫每隔几年购买昂贵的新电脑。
今天,借助开源软件的好处,你可以打破这种循环。其中一种方法是 [翻新旧电脑](https://opensource.com/article/22/10/obsolete-computer-linux-opportunity),让它们继续发挥作用。本文告诉你如何实现。
### 1、找一台旧电脑
也许你的地下室或仓库里有一台闲置的旧电脑,为什么不利用一下呢?
或者你可以从朋友、家人或二手广告中得到一台旧机器。许多电子回收中心会让你四处翻找并带走一台你看上的被抛弃的机器。如果可以的话,务必多带回来几台,因为你可能需要从几台被弃置的电脑中获取零件来组装成一台好的电脑。
看看机器前面的贴纸,确保选择的是好的可供翻新的机器。带有 Windows 7 和 8 标志的电脑非常适合运行 Linux。对于 8.1,其扩展支持已于今年 1 月份结束,所以我看到很多这样的电脑被丢弃。
很多这些 Windows 电脑提供了完全良好的硬件。它们只是因为计划性过时而被丢弃了,因为它们不能运行 Windows 11。但是它们可以很好地运行开源软件。
### 2、确认并清洁所有零件
在打开你的“新”机器之前,确保通过触摸金属物品消除静电。有可能一点点的静电都会破坏精细的电路。
你需要马上查看是否缺失了零件。许多人在丢弃电脑之前会取出它们的硬盘或内存条。你要么需要获取多台机器来解决这一点,要么就需要购买一两个零件来使它完整。
在进一步操作之前,给机器做彻底的清洁非常重要。特别注意 CPU 的复杂结构、风扇和所有表面。请记住,你不能用抹布来清洁电子设备,否则会有损坏的风险,因此使用压缩空气来清洁。
### 3、确保所有硬件均正常工作
在安装任何软件之前,你需要验证所有硬件是否正常工作。不要省略测试!如果你在进行下一步操作之前只是短暂运行了内存测试,并在以后发现你的计算机存在内存错误,那么这将会浪费你很多的时间。我发现在夜间运行耗时的测试非常方便。
大多数计算机都有内置的硬件专用诊断程序。你通常可以通过启动时的 UEFI/BIOS 面板或在启动时按下功能键来访问这些诊断程序。如果你的机器没有测试工具,请尝试使用 [Ultimate Boot Disk](https://www.ultimatebootcd.com/),该工具提供了大量有用的测试工具。
确保你彻底测试了所有组件:
* 内存
* 磁盘
* CPU 和主板
* 外部设备(USB 端口、声音、麦克风、键盘、显示器、风扇等)
如果你发现问题,请下载我的免费 [快速修复硬件指南](http://rexxinfo.org/howard_fosdick_articles/quick_guide_to_fixing_pc_hardware/Quick_Guide_to_Fixing_Computer_Hardware.html)。这加上一些在线搜索可以让你修复几乎任何东西。
### 4、准备硬盘
你已经评估了你的硬件并使其正常工作。如果你的计算机配备了硬盘驱动器(HDD),下一步是将其准备好以供使用。
你需要完全擦除硬盘,因为它可能包含违法获取的电影、音乐或软件。为了彻底清除 HDD,请运行类似 [DBAN](https://sourceforge.net/projects/dban/) 的工具。运行完成后,你可以放心使用干净的硬盘。
如果你有一个固态硬盘(SSD),情况就会有点棘手。旨在清洁硬盘的磁盘擦除程序不能用于 SSD。你需要一个专用的“安全擦除”程序来清除 SSD。
一些计算机在其 UEFI/BIOS 中配备了“安全擦除”实用程序。你只需访问启动配置面板即可运行它。
另一个选择是访问硬盘制造商的网站。许多制造商为其 SSD 提供免费下载的安全擦除实用程序。
不幸的是,一些供应商并没有为其部分消费级驱动器提供安全擦除实用程序,而其他供应商仅提供一个 Windows 可执行文件。对于 SSD,[Parted Magic](https://partedmagic.com/) 的安全擦除功能是最佳选择。
### 5、引导、数据存储和备份
你的翻新计算机的硬盘策略必须解决三个需求:引导、数据存储和备份。
几年前,如果你的翻新机器包含存储设备,它肯定是硬盘。你可以使用 DBAN 清除它,然后安装你喜欢的 Linux 发行版,并将其用作引导和存储设备。问题解决了。
今天的技术提供了更好的选择。这些解决了之前使用旧设备总是存在的硬盘访问慢等问题。
一种选择是购买一款现有的低端 SSD。这些现在提供了与成熟计算机兼容的 SATA 和外部 USB 接口。
它的价格已经暴跌。我最近以 $25 的价格购买了一块 480GB 的 SSD/SATA 硬盘。这么便宜,即使你的旧计算机配备了硬盘,你可能仍然愿意购买一块新的 SSD。它引导和访问数据的速度比硬盘快得多。
轻巧的 2.5 英寸 SSD 也解决了旧台式机常常面临的安装困境。使用一个螺丝钉,你可以将它们连接到几乎任何地方。不再需要处理轨道、硬盘架和所有其他傻瓜专有部件,企业曾用于安装它们的笨重的 3.5 英寸硬盘。
另一种选择是通过 [USB 存储设备](https://opensource.com/article/20/4/first-linux-computer) 引导。如今,U 盘提供了足够的空间来托管你喜欢的任何操作系统,同时还为你的数据留下一些存储空间。除了速度,通过将系统安装在便携式设备上,你还获得了灵活性。
所以考虑安装操作系统到快速的 SSD 或 USB 上,并从其中引导和运行它。
那其他驱动器呢?我喜欢将任何随计算机附带的硬盘作为我的启动 SSD 的备份磁盘。或将其用作大规模存储。
我通常会拆卸旧台式机中的光驱。由于 USB 存储设备更快且可存储更多数据,几乎没有人再使用光盘。现在大多数人通过流媒体观看电影、音乐和软件程序,而不是把它们收集在光盘上。
拆卸光驱会腾出额外的一组磁盘连接器。它也会在机箱中留出大量的空间,并改善了空气流动。如果你正在处理小体积的台式机,如微型塔式机或超薄机箱,则这可以有很大的影响。
最后,花几分钟时间来确定备份策略。你需要备份两个不同的东西:你的数据和操作系统。
你会备份到 PC 内的第二个驱动器、可拆卸存储设备还是云服务?你的决定有助于确定你是否需要在翻新的计算机中再添加一个硬盘。
### 6、选择并安装软件
不同的人有不同的需求,这些需求驱动他们选择软件。以下是一些一般性的指南。
如果你的计算机配备了英特尔 i 系列处理器和至少 4GB 内存,它几乎可以舒适地运行任何 Linux 发行版和任何 [桌面环境(DE)](https://opensource.com/article/20/5/linux-desktops#default)。
如果内存为 2 到 4GB,请安装一个 [轻量级界面](https://opensource.com/article/20/5/linux-desktops#lightweight) 的 Linux 系统。因为高端显示图形会大量占用内存资源。我发现像 XFCE、LXDE 和 LXQt 等 DE 的 Linux 发行版效果不错。
如果只有 1GB 内存,请选择“超轻量级”的 Linux 发行版。如果你拥有旧的双核 CPU 或相当的 CPU,这也应该是你的选择。
我已经在这样最小配置的硬件上使用了 [Puppy Linux](https://puppylinux-woof-ce.github.io/) 和 [AntiX](https://antixlinux.com/) 实现了很好的效果。它们都采用轻量级的窗口管理器作为用户界面,而不是完整的桌面环境,并且都捆绑了特别选择的应用程序,以最小化资源使用。
### 7、高效地浏览网页
在过去的五年中,网页已经大幅增长。许多受欢迎网站所需的计算机资源的一半以上现在都被广告和追踪器消耗了。所以在浏览网页时,要阻止所有这些广告和追踪器。如果可以将广告拦截从浏览器转移到 VPN,那么就更理想了。不要让自动播放的视频在没有得到你明确许可的情况下运行。
寻找最适合你设备的浏览器。有些浏览器采用多线程思想设计,如果你的 PC 可以支持,那就很棒。其他浏览器尝试最小化整体资源使用。许多人不知道有 [相当多的](https://opensource.com/article/19/7/open%20source-browsers) 能够胜任的精简 Linux 浏览器可供选择。最终,选择最符合你设备和上网方式的浏览器。
### 8、玩得开心
不论你是想利用放在地下室的旧计算机,[延长计算机的生命周期](https://opensource.com/article/19/7/how-make-old-computer-useful-again) 来践行环保,还是只想找到一个免费的计算机,翻新都是一个值得追求的目标。
任何人都可以成功地实现翻新。除了投入你的时间,成本是很小的。在这个过程中,你肯定会学到一些技能。请在评论区中与大家分享你自己的翻新技巧。
*(题图:MJ/44ebfc73-72a3-43ef-afec-663bbbc1c14b)*
---
via: <https://opensource.com/article/23/3/refurbish-old-computer-linux>
作者:[Howard Fosdick](https://opensource.com/users/howtech) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We live in a remarkable era. It wasn't so long ago we were all chained to the "upgrade treadmill," forced to buy expensive new personal computers every few years.
Today, with the benefit of open source software, you can break out of that cycle. One way is to [refurbish old computers](https://opensource.com/article/22/10/obsolete-computer-linux-opportunity) and keep them in service. This article tells you how.
## 1. Grab an old PC
Maybe you have an old computer lying unused in the basement or garage. Why not put it to use?
Or you can get an old machine from a friend, family member, or Craigslist ad. Many electronics recycling centers will let you poke around and take a discarded machine if it fits your fancy. Be sure to grab more than one if you can, as you may need parts from a couple abandoned PCs to build one good one.
Look at the stickers on the front of the machines to make sure you're selecting good refurbishing candidates. Items with Window 7 and 8 logos run Linux quite well. Extended support ended for 8.1 this January, so I'm seeing a lot of those getting dumped.
Many of these Windows computers offer perfectly good hardware. They're only being trashed due to planned obsolescence because they can't run Windows 11. They run open source software just fine.
## 2. Identify and clean everything
Before you open up your "new" machine to see what you've got, be sure to ground yourself by touching something metal. Even a shock so slight you don't feel it can destroy delicate circuitry.
You'll instantly see if any parts are missing. Many people take out their disks or sometimes the memory before recycling a computer. You'll either have to acquire more than a single box to cover this, or you'll need to buy a part or two to make it whole.
Before proceeding further, it's important to give the machine a thorough cleaning. Pay special attention to the CPU complex, the fans, and all surfaces. Remember that you can't rub electronics without risking damage, so use compressed air for cleaning.
## 3. Ensure all hardware works
You'll want to verify that all hardware works prior to installing any software. Don't skimp on the testing! It's a huge waste of your time if you find out, for example, that your computer has a transient memory error at a later time because you ran only a short ram test before going to next steps. I find it convenient to run time-consuming tests overnight.
Most computers have hardware-specific diagnostics built in. You usually access these either through the boot-time UEFI/BIOS panels or by pressing a PF key while booting. If your machine doesn't include testing tools, try [Ultimate Boot Disk](https://www.ultimatebootcd.com/), which provides tons of useful testing utilities.
Be sure you test all components thoroughly:
- Memory
- Disk
- CPU and Motherboard
- Peripherals (USB ports, sound, microphone, keyboard, display, fans, etc)
If you find problems, download my free [Quick Guide to Fixing Hardware](http://rexxinfo.org/howard_fosdick_articles/quick_guide_to_fixing_pc_hardware/Quick_Guide_to_Fixing_Computer_Hardware.html). That plus some searching online enables you to fix just about anything.
## 4. Prepare the disk
You've assessed your hardware and have gotten it into good working order. If your computer came with a hard disk drive (HDD), the next step is to ready that for use.
You need to completely wipe the disk because it could contain illegally obtained movies, music, or software. To thoroughly wipe an HDD, run a tool like [DBAN](https://sourceforge.net/projects/dban/). After running that, you can rest assured the disk is completely clean.
If you have a solid state disk (SSD), the situation is a bit trickier. Disk-wipe programs designed to cleanse hard disks don't work with SSDs. You need a specialized *secure erase* program for an SSD.
Some computers come with an secure erase utility in their UEFI/BIOS. All you have to do is access the boot configuration panels to run it.
The other option is the website of the disk manufacturer. Many offer free downloads for secure erase utilities for their SSDs.
Unfortunately, some vendors don't provide a secure erase utility for some of their consumer drives, while others supply only a Windows executable. For an SSD, [Parted Magic's](https://partedmagic.com/) secure erase function is the best option.
## 5. Booting, data storage, and backups
Your disk strategy for your refurbished computer must address three needs: booting, data storage, and backups.
A few years ago, if your refurbishing candidate contained a disk, it was always a hard drive. You'd wipe it with DBAN, then install your favorite Linux distribution, and use it as both your boot and storage device. Problem solved.
Today's technology offers better options. These eliminate the slow hard disk access that was previously one of the downsides of using older equipment.
One option is to buy one of the new low-end SSDs that have become available. These now offer the SATA and external USB interfaces that work with mature computers.
Prices have plummeted. I recently bought a 480 gig SSD/SATA drive for $25. That's so inexpensive that, even if your old computer came with a hard drive included, you might prefer to buy a new SSD anyway. It boots and accesses data so much faster.
The lightweight 2.5" SSDs also solve the mounting dilemmas one sometimes faced with old desktops. With a single screw you can attach them almost anywhere. No more messing with rails, cages, and all the other goofy proprietary parts companies used to mount their heavy 3.5" hard drives.
An alternative to an SSD is to boot off a [USB memory stick](https://opensource.com/article/20/4/first-linux-computer). Thumb drives now offer enough space to host any operating system you prefer, while leaving some storage space for your data. Beyond speed, you gain flexibility by keeping your system on a portable device.
So consider installing your operating system to a fast SSD or USB and booting and running it from that.
What about other drives? I like to use any hard drive that came with the computer as a backup disk for my boot SSD. Or employ it as mass storage.
I usually remove the optical drives you find in old desktops. Since USB sticks are faster and hold more data, few people use them anymore. Most now stream their films, music, and software programs instead of collecting them on optical media.
Removing the optical drive frees up an extra set of disk connectors. It also opens up lots of space in the cabinet and improves air flow. This can make a big difference if you're dealing with small footprint desktops with slimline or mini-tower cases.
Finally, take a few minutes to decide on your backup strategy. You'll need to back up two separate things: your data and the operating system.
Will you back up to a second drive inside the PC, a detachable storage device, or cloud services? Your decision helps determine whether you'll need a second disk in your refurbished computer.
## 6. Select and install software
Different people have different needs that drive their software selection. Here are some general guidelines.
If your computer has an Intel i-series processor and at least 4 GB of memory, it can comfortably run nearly any Linux distribution with any [desktop environment (DE)](https://opensource.com/article/20/5/linux-desktops#default).
With between two and four gigabytes of memory, install a Linux with a [lightweight interface](https://opensource.com/article/20/5/linux-desktops#lightweight). This is because high-end display graphics is a big consumer of memory resources. I've found that Linux distros with a DE like XFCE, LXDE, and LXQt work well.
If you only have a gigabyte of memory, go for an "ultra-light" Linux distribution. This should probably also be your choice if you have an old dual-core CPU or equivalent.
I've used both [Puppy Linux](https://puppylinux-woof-ce.github.io/) and [AntiX](https://antixlinux.com/) with great results on such minimal hardware. Both employ lightweight windows managers for their user interface instead of full desktop environments. And both come bundled with apps selected specifically to minimize resource use.
## 7. Browse the web efficiently
Web pages have grown dramatically in the past five years. Over half the computer resource many popular websites require is now consumed by advertisements and trackers. So when web surfing, block all those ads and trackers. If you can off-load ad blocking from your browser to your VPN, that's ideal. And don't let those auto-run videos run without your explicit permission.
Look around to see what browser works best for your equipment. Some are designed with a multi-threading philosophy, which is great if your PC can support it. Others try to minimize overall resource usage. Many people aren't aware that there are [quite a few](https://opensource.com/article/19/7/open-source-browsers) capable yet minimalist Linux browsers available. In the end, pick the browser that best matches both your equipment and your web surfing style.
## 8. Have fun
Whether you want to make use of an old computer sitting in your basement, help the environment by [extending the computer life cycle](https://opensource.com/article/19/7/how-make-old-computer-useful-again), or just find a free computer, refurbishing is a worthy goal.
Anyone can succeed at this. Beyond investing your time, the cost is minimal. You're sure to learn a bit while having fun along the way. Please share your own refurbishing tips with everyone in the comments section.
## 2 Comments |
15,891 | 有助于组织治理的 5 项开源原则 | https://opensource.com/article/23/4/open-source-principals-organizational-governance | 2023-06-09T16:57:08 | [
"开放式领导"
] | /article-15891-1.html | 
>
> 采用基于开源原则的组织治理可以引导你的组织降低成本,降低技术债务,增加团队协作,促进创新,最重要的是,推动你的组织共同前进。
>
>
>
在我的职业生涯中,我很幸运地与许多不同规模的组织在各种项目上合作。所有这些项目的核心都是开源软件,而且大多数人都对开源社区做出了力所能及的回报。我最近在一个大型组织内从事一个使用开源软件的绿地项目。在项目的 MVP 阶段结束后,该组织的领导层很想知道是什么导致了项目的成功,以及他们如何将其应用到整个组织的其他团队中。经过思考,我发现我们团队的工作方式与开源社区和开发之间有相似之处。以下是对开源原则如何帮助组织节省资金、[减少技术债务](https://enterprisersproject.com/article/2020/6/technical-debt-explained-plain-english?intcmp=7013a000002qLH8AAM) 和打破内部孤岛的一些见解。
### 1、更好地使用预算
我最近在佛罗里达 Drupal 营地发表了关于 [无头全渠道网络平台](https://noti.st/johnpicozzi/thgcPs/think-locally-build-globally-how-drupal-is-powering-headless-omni-channel-web-platforms) 的演讲。演讲中强调的主要好处之一是如何通过实施这种网络平台来节省资金。这个想法来自于开源软件的开发。一个组织内的不同小组可以利用他们的预算来为一个核心软件或平台贡献特性或功能。他们还可以与其他小组合作,集中资金开发更复杂的功能。当功能开发完成后,它将被添加到核心软件或平台中,供所有人使用。使用这种开源原则可以为组织内的团体提供互利。允许共享特性和功能,并集体从彼此的支出中获益,可以改善软件或平台。
这种方法的另一个方面是可以节省开支,并允许持续改进,即对一个功能进行一次测试和开发,并重复使用它。在创建一个使用基于组件的设计系统作为起点的网络平台时,我们经常看到这种情况。该平台的用户可以重复使用其他用户开发的组件或功能。通常,这些都已经经过了无数次的测试,比如用户体验、可及性,甚至是安全测试。
这个简单的想法在许多组织中面临反对,因为个别团体觊觎和保护预算。团体不愿意放弃他们的预算来支持核心软件或平台。某些情况下,优先级和意见上的差异加剧了许多机构的孤岛化。
### 2、减少技术债务
许多机构努力减少技术债务。实施一个全面的核心软件或平台并使用开源原则,可以帮助减少技术债务。这可以通过允许开发团队充分考虑一个功能不仅对建立它的小组,而且对更广泛的组织有什么影响。这一点,加上与组织内其他小组的合作,可以帮助减少未来重建或增加功能的需要。
有时,由于内部竞争,组织在这种合作和思考方面会有困难。一些公司培养了一种文化,即第一个建立一个功能或提出一个想法会得到奖励。这可能会导致各小组不一起工作或分享想法,在组织内形成孤岛,大大阻碍了创新。
### 3、更快进入市场
我经常听到的一句话是“更快进入市场”。每个人都想更快、更容易地把他们的东西推出去。这通常是一个核心软件或平台的好处,因为内部团体可以重用现有的、经过测试和验证的特性和功能,而不是从头开始建立自己的功能。如果你的团队正在启动一个项目,而它可以从 80% 的完成度而不是 0% 的完成度开始,你会这样做吗?我想是的。现在再加上为其他用户增加所需功能的超级英雄感觉。这是一个双赢的结果!
### 4、发布兴奋点
另一个可以帮助你的组织的伟大的开源原则是建立兴奋的发布时间表。当你的组织实施一个核心软件或平台时,用户会对更新的时间进行投资。一个发布时间表和路线图可以向他们传达这一点。这两个工具可以帮助用户对新功能感到兴奋,并相应地规划他们自己的路线图。这也有助于建立对其他团队的欣赏,以及对建立新功能的团队的自豪感。这可以统一一个组织,让组织有团队合作和成就感,同时提供结构和未来的计划。
### 5、一个核心团队和管理
我发现你需要两个关键项目来克服上述障碍,并在你的组织内成功应用开源原则。这就是: 一个核心团队和坚实的组织管理。一个核心团队将允许一个小组来维护和管理你的组织的核心软件或平台。它将支持该解决方案,并确保明智地增加新的特性和功能。这个团队可以帮助减少内部团队的成本,并告知各组路线图的功能。核心团队需要得到强大的组织治理的支持。这种治理将为组织内的小组提供一个共同的方向和组织支持,以取得成功。这种组织治理可以在几个方面模仿开源的治理和原则。最基本和最高级别的原则是社区和为共同目标而工作的理念。
### 开放式领导
采用基于 [开源原则](https://opensource.com/article/23/4/open-leadership-through-change) 的组织治理可以引导你的组织降低成本,降低技术债务,增加团队协作,促进创新,最重要的是,推动你的组织共同前进。
(题图:MJ/be676bca-3cd3-4c21-9c6a-6cc5911c9c04)
---
via: <https://opensource.com/article/23/4/open-source-principals-organizational-governance>
作者:[John E. Picozzi](https://opensource.com/users/johnpicozzi) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,893 | Linus Torvalds:我是那些“清醒的共产主义者”之一 | https://news.itsfoss.com/linus-torvalds-woke-communists/ | 2023-06-10T16:07:00 | [
"Linus Torvalds"
] | https://linux.cn/article-15893-1.html |
>
> 又一次,Linus Torvalds 立场坚定地、咆哮地小小回复了某人。
>
>
>

Linus Torvalds 又发表了一篇热点看法(或争议?)?
一切都始于 Linus Torvalds 对《纽约时报》网页体验的看法。
在 `social.kernel.org` 上发布的一篇公开帖子中,Linus 抱怨了纽约时报网站上的广告和糟糕的用户体验。此外,他还感到烦恼的是,人们必须致电该网站团队才能取消订阅纽约时报。
下面是他的发帖:

但是,这与我们新闻标题毫不相关,是吗??
是有点无关,但这件事还有更多的内容。
实际上,Linus 在 [他的帖子](https://social.kernel.org:443/notice/AWSXomDbvdxKgOxVAm) 中继续向他的一些粉丝解释,他并不介意订阅纽约时报,但是由于令人讨厌的体验,这变成了一项不可接受的条件。
在他的帖子的一条评论中,一位用户还提到纽约时报不值得关注,并将其称为“清醒的共产主义宣传”。
以下是该用户的原文:

虽然这与最初讨论的上下文无关,但 Linus Torvalds 坚定的表明了他对这种观点的信仰。

他的回复如下:
>
> 我觉得你可能不应该关注我,因为你那个“清醒的共产主义宣传”的评论让我觉得你是一个一流的白痴。我强烈怀疑我**就是**你担心的那些“清醒的共产主义者”之一。但你可能无法解释**这两个**词的任何一个真正意思,对吧?
>
>
>
此外,他还分享了下面这段话:
>
> 我是一名持证的无神论者,我认为妇女的选择权非常重要,我认为“有组织的民兵”意味着应该仔细发放枪支许可证,而不是随便给予任何有脉搏的白痴,我一点也不在意你决定穿“错误”的衣服或者决定不为你出生时的性别所束缚。该死的,如果这些让我成为“清醒”的人,那么我认为使用这个词作为贬义词的任何人都是人类的耻辱。所以请立刻取消关注我吧。
>
>
>
虽然这只是社交媒体上的一次言论碰撞,但他的回复被一些人视为有争议,有些人将他标签为“左派”(不管这是什么意思)。
当然,还有其他人认为 Linus Torvalds 正确地表达了他想要说的话,这没有什么不对的。如果你了解 Linus Torvalds,你会知道他通常直言不讳地表达自己的观点。
就像他最近对 Linux 6.3 的 [一个糟糕的提交请求](https://news.itsfoss.com/linus-torvalds-pull-request/) 感到愤怒一样。
在这里,我们不讨论具体问题。当然,我们关注的是 Linux 和开源软件……还有 Linus Torvalds ?
但是,从回复中可以看出,Linus Torvalds 似乎不喜欢用“清醒”一词来贬低某些事物。他明显尊重其他人的选择,并且“*一点也不在意*”。
?你认为 Linus Torvalds 对“清醒的共产主义”意识形态的看法怎么样?请在下方评论区分享你的想法。
---
via: <https://news.itsfoss.com/linus-torvalds-woke-communists/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linus Torvalds is again back with a hot take (or controversy?) 🐧
So, it all starts with Linus Torvalds sharing his views on The New York Times web page experience.
With a public post on **social.kernel.org**, Linus complained about the advertisements and poor user experience on the New York Times website. Moreover, he was annoyed that one had to call the website's team to cancel the NYTimes subscription.
Here's what it looked like:
But wait, this looks entirely irrelevant to our news title, right? 😕
Kind of. There's more to it.
So, Linus [continued explaining](https://social.kernel.org/notice/AWSXomDbvdxKgOxVAm?ref=news.itsfoss.com) to some followers that he did not mind subscribing to the NYTimes, but with the annoying experience, it became a deal breaker.
In one of those comments to his post, a user also mentioned that The New York Times was not worth following and labeled the NYTimes as "*woke communist propaganda*."
Here's what the user had to say:
While this was irrelevant to the context of the original discussion, Linus Torvalds replied with a firm take on his belief in such opinions.
Here's what he mentioned:
I think you might want to make sure you don’t follow me.
Because your “woke communist propaganda” comment makes me think you’re a moron of the first order.
I strongly suspect Ione of those “woke communists” you worry about. But you probably couldn’t actually explain whatamof those words actually mean, could you?either
Furthermore, he also shared:
I’m a card-carrying atheist, I think a woman’s right to choose is very important, I think that “well regulated militia” means that guns should be carefully licensed and not just randomly given to any moron with a pulse, and I couldn’t care less if you decided to dress up in the “wrong” clothes or decided you’d rather live your life without feeling tied to whatever plumbing you were born with.
And dammit, if that all makes me “woke”, then I think anybody who uses that word as a pejorative is a f*cking disgrace to the human race. So please just unfollow me right now.
While this was an exchange of words on social media, his reply is being seen as controversial by some people, some labeling him as "leftist" (whatever that means).
Of course, others think Linus Torvalds correctly expressed what he wanted to say, and there was nothing wrong with it. If you know Linus Torvalds, he usually gets straightforward with what he wants to express.
Like he recently got furious about a [poorly executed pull request](https://news.itsfoss.com/linus-torvalds-pull-request/) for Linux 6.3.
[Linus Torvalds Reacts to Poorly-Executed Pull Requests for Linux 6.3You do not want to see the furious-side of Linus Torvalds. Do you?](https://news.itsfoss.com/linus-torvalds-pull-request/)

Here, we do not discuss the specifics. Of course, we are all about Linux and open source.. and Linus Torvalds, too 😉
But, as one can see from the replies, Linus Torvalds looks like someone who does not like the term "woke" used to demean something. He clearly respects what others choose to do and "*couldn't care less*" about it.
💬 *What do you think about Linus Torvald's take on the whole "woke communists" ideology? Share your thoughts in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,894 | 我是如何在面对悲痛后回归开源的 | https://opensource.com/article/23/3/open-source-after-grief | 2023-06-10T16:50:12 | [
"社区"
] | /article-15894-1.html | 
>
> 在失去亲人后为开源项目做贡献可能会让人感到畏惧。下面是我对如何重新加入社区的建议。
>
>
>
开源社区是一个奇妙的地方,在这里人们聚集在一起合作,分享知识,并建立令人惊奇的东西。我还记得 12 年前 [我在 Fedora 的第一次贡献](https://fedoraproject.org/wiki/User:Amsharma),从那时起,这就是一个奇妙的旅程。然而,生活有时会妨碍我们,导致我们从参与中抽身。COVID-19 大流行病以不同的方式影响了我们所有人,对一些人来说,这是一个巨大的损失和悲痛的时期。我在大流行期间失去了我的爱人,这是最难处理的生活事件。这也让我从 Fedora 社区休息了一段时间。对于那些因为失去亲人而不得不休息的开源社区成员来说,重新回到编码和为项目做贡献可能会让人感到畏惧。然而,通过一些思考和计划,有可能卷土重来,再次成为社区的积极成员。
首先,最重要的是照顾好自己,让自己有时间和空间去悲伤。悲伤是一种个人和独特的经历。没有正确或错误的方式去经历它。重要的是要善待自己。在你准备好之前,不要急于做事情。
当你准备好重新开始贡献,你可以做几件事来使你的复出尽可能顺利。
### 与其他贡献者联系
这是一个艰难的事实:没有什么东西会因为你而停止,技术正在以指数形式增长。当我最近重新加入 Fedora 的时候,我觉得世界在我身边变化得太快了。从 IRC 到 Telegram 再到 Signal 和 Matrix,从 IRC 会议 到谷歌会议,从 Pagure 到 GitLab,从邮件列表到讨论区,这个名单还在继续。如果你有一段时间没有在你的社区里活动,联系你在社区里的朋友,让他们知道你回来了,并准备再次做出贡献,这可能会有帮助。这可以帮助你与人们重新建立联系,并重新进入事情的轨道。他们可能有一些建议或机会让你参与其中。我很感谢我的 Fedora 朋友 [Justin W. Flory](https://opensource.com/users/jflory),他无私地帮助我,确保我找到了回到社区的方法。
### 从小事做起
过去,我曾担任 [Fedora 多样性、公平和包容(D.E.I.)顾问](https://docs.fedoraproject.org/en-US/diversity-inclusion/roles/council-advisor/),这是 [Fedora 理事会](https://docs.fedoraproject.org/en-US/council/) 成员职位之一。这是一个很大的工作。我认识到这一点,而且我知道如果我在休息后立即考虑做同样的工作,那么这将是一个负担,有可能导致 [早期倦怠](https://opensource.com/article/21/5/open-source-burnout)。放轻松是非常重要的。从小事做起。
如果你对重新投入一个大项目的想法感到不知所措,那就从小事做起。有大量的小任务和错误需要修复,解决其中的一个问题可以帮助你轻松地回到社区。
### 找一个导师
如果你对如何开始或将你的努力集中在哪里感到不确定,可以考虑找一个 [导师](https://enterprisersproject.com/article/2019/10/it-mentors-how-make-most-of-mentoring?intcmp=7013a000002qLH8AAM)。导师(就我而言,是 Justin W. Flory)可以在你复出时提供指导、建议和支持。
### 展示感激
开源社区是建立在许多人的贡献之上的。一个健康的社区会对你的贡献表示感谢。表达感激之情是使社区健康发展的一部分。对那些帮助你、指导你、给你反馈的人表示感谢。
### 封锁你的日历
最初,可能需要一些时间来恢复贡献的节奏。在你的日历中安排一些时间用于开源工作是有帮助的。它可以是每周/每两周一次,取决于你的可用性。记住,[每一个贡献都很重要](https://opensource.com/article/23/3/non-code-contribution-open-source),这就是开源世界的魅力所在。这个技巧将帮助你养成规律的作息习惯。
### 向前两步,向后一步
最后,重要的是要记住,如果你需要,退一步也没关系。悲伤不是一个线性过程。你可能会发现,你在未来需要再次休息一下。重要的是,要对自己和他人诚实,了解自己的需求。利用你需要的时间来照顾自己。
### 按照你自己的条件返回
在经历了一段时间的悲痛之后,回到开源社区可能是一种挑战。这也是一个与你所热衷的事物重新联系的机会,并对世界产生积极影响。随着时间的推移,你会发现你能够从你离开的地方拾起,并再次重新参与到社区中。
我把我的第一篇 [Opensource.com](http://Opensource.com) 文章献给我已故的弟弟 Nalin Sharma 先生,他在 2021 年因 COVID-19 而离开我们,年仅 32 岁。他是一个充满激情的工程师,充满了生命力。我希望他现在在一个更好的地方,我相信他将永远活在我的记忆中。
*(题图:MJ/6a42a5e7-47a7-45ac-8644-9f91d9b8516d)*
---
via: <https://opensource.com/article/23/3/open-source-after-grief>
作者:[Amita Sharma](https://opensource.com/users/amita) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,896 | Rust 基础系列 #6: 条件语句 | https://itsfoss.com/rust-if-else/ | 2023-06-11T09:49:25 | [
"Rust"
] | https://linux.cn/article-15896-1.html | 
在 [上一篇文章](/article-15855-1.html) 中,你学习了函数。在这篇文章中,我们将学习使用条件语句来管理 Rust 程序的控制流。
### 什么是条件语句?
在编写代码的时候,最常见的任务之一就是检查某些条件是否为 `true` 或 `false`。“如果温度高于 35°C,打开空调。”
通过使用 `if` 和 `else` 这样的关键字(有时候结合使用),程序员可以根据条件(例如提供的参数数量、从命令行传递的选项、文件名、错误发生等)改变程序的行为。
所以,对一个程序员来说,了解任何语言的控制流都是至关重要的,更不用说 Rust 了。
#### 条件运算符
下表列出了所有常用的单个条件运算符:
| 运算符 | 示例 | 解释 |
| --- | --- | --- |
| `>` | `a > b` | `a` **大于** `b` |
| `<` | `a < b` | `a` **小于** `b` |
| `==` | `a == b` | `a` **等于** `b` |
| `!=` | `a != b` | `a` **不等于** `b` |
| `>=` | `a >= b` | `a` **大于** 或 **等于** `b` |
| `<=` | `a <= b` | `a` **小于** 或 **等于** `b` |
以及下表是逻辑运算符,它们用于一个或多个条件之间:
| 运算符 | 示例 | 解释 |
| --- | --- | --- |
| `||` (逻辑或) | `条件1 || 条件2` | `条件1` 或 `条件2` 中至少有一个为 `true` |
| `&&` (逻辑与) | `条件1 && 条件2` | **所有** 条件都为 `true` |
| `!` (逻辑非) | `!条件` | `条件` 的布尔值的相反值 |
>
> ? 与数学相似,你可以使用圆括号来指定操作的优先级。
>
>
>
### 使用 if else
要控制 Rust 代码的基本流程,使用两个关键字:`if` 和 `else`。这可以根据提供的条件的状态创建两个“执行路径”。
一个简单的带有替代执行路径的 if 块的语法如下:
```
if 条件 {
<语句>;
} else {
<语句>;
}
```
>
> ? 当只有一个条件时,将其括在圆括号中并不是强制性的。根据语法,使用圆括号是可选的。你仍然应该使用它们来指定优先级并优化可读性。
>
>
>
来看看一个例子。
```
fn main() {
let a = 36;
let b = 25;
if a > b {
println!("a 大于 b");
} else {
println!("b 大于 a");
}
}
```
这里,我声明了两个整数变量 `a` 和 `b`,它们的值分别为 '36' 和 '25'。在第 5 行,我检查变量 `a` 中存储的值是否大于变量 `b` 中存储的值。如果条件计算结果为 `true`,则会执行第 6 行的代码。如果条件计算结果为 `false`,由于我们有一个 `else` 块(可选),第 8 行的代码将被执行。
来看看程序的输出。
```
a 大于 b
```
完美!
来修改一下变量 `a` 的值,使其小于变量 `b` 的值,看看会发生什么。我将把 `a` 的值改为 '10'。修改后的输出如下:
```
b 大于 a
```
但是,如果我将相同的值存储在变量 `a` 和 `b` 中呢?为了看到这一点,我将两个变量的值都设置为 '40'。修改后的输出如下:
```
b 大于 a
```
嗯?从逻辑上讲,这没有任何意义... :frowning:
但是这可以改进!我们继续。
### 使用 else if 条件
与其他任何编程语言一样,你可以使用 `else if` 块来提供多于两个的执行路径。语法如下:
```
if 条件 {
<语句>;
} else if 条件 {
<语句>;
} else {
<语句>;
}
```
现在,通过使用 `else if` 块,我可以改进程序的逻辑。下面是修改后的程序。
```
fn main() {
let a = 40;
let b = 40;
if a == b {
println!("a 与 b 是相等的");
} else if a > b {
println!("a 大于 b");
} else {
println!("b 大于 a");
}
}
```
现在,我的程序的逻辑是正确的。它已经处理了所有的边缘情况(我能想到的)。第 5 行处理了 `a` 等于 `b` 的情况。第 7 行处理了 `a` 可能大于 `b` 的情况。而 `a` 小于 `b` 的情况则由第 9 行的 `else` 块隐式处理。
现在,当我运行这段代码时,我得到了以下输出:
```
a 与 b 是相等的
```
现在这就完美了!
### 示例:找到最大值
我知道使用 `if` 和 `else` 很容易,但是让我们再看一个程序。这次,我们来比较三个数字。我还将在这个实例中使用逻辑运算符!
```
fn main() {
let a = 73;
let b = 56;
let c = 15;
if (a != b) && (a != c) && (b != c) {
if (a > b) && (a > c) {
println!("a 是最大的");
} else if (b > a) && (b > c) {
println!("b 是最大的");
} else {
println!("c 是最大的");
}
}
}
```
这个程序第一眼看上去可能很复杂,但是不要害怕,我会解释的!
最开始,我声明了三个变量 `a`、`b` 和 `c`,并赋予了我能想到的随机值。然后,在第 6 行,我检查了没有变量的值与其他变量相同的条件。首先,我检查 `a` 和 `b` 的值,然后是 `a` 和 `c`,最后是 `b` 和 `c`。这样我就可以确定没有变量中存储了重复的值。
然后,在第 7 行,我检查了变量 `a` 中存储的值是否是最大的。如果这个条件计算结果为 `true`,则会执行第 8 行的代码。否则,将检查第 9 行的执行路径。
在第 9 行,我检查了变量 `b` 中存储的值是否是最大的。如果这个条件计算结果为 `true`,则会执行第 10 行的代码。如果这个条件也是 `false`,那么只有一种可能。3 个变量中的最大值既不是 `a` 也不是 `b`。
所以,自然地,在 `else` 块中,我打印出变量 `c` 拥有最大值。
来看看程序的输出:
```
a 是最大的
```
这是预期的结果。尝试修改分配给每个变量的值,并自己测试一下! :smiley:
### 总结
你学习到了如何使用 `if` 和 `else` 语句。在你继续使用大量 `if` `else if` 语句制作自己的 AI 之前(哈哈),让我们在本系列的下一篇文章中学习 Rust 中的循环。
持续关注。
*(题图:MJ/3eea3bbb-b630-4470-ae21-391ab86cd5bf)*
---
via: <https://itsfoss.com/rust-if-else/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Rust Basics Series #6: Conditional Statements
You can control the flow of your program by using conditional statements. Learn to use if-else in Rust.
In the [previous article](https://itsfoss.com/rust-functions) in this series, you looked at Functions. In this article, let's look at managing the control flow of our Rust program using conditional statements.
## What are conditional statements?
When writing some code, one of the most common tasks is to perform a check for certain conditions to be `true`
or `false`
. "If the temperature is higher than 35°C, turn on the air conditioner."
By using keywords like `if`
and `else`
(sometimes in combination), a programmer can change what the program does based on conditions like the number of arguments provided, the options passed from the command line, the names of files, error occurrence, etc.
So it is critical for a programmer to know control flow in any language, let alone in Rust.
### Conditional operators
The following table shows all the frequently used operators for an individual condition:
Operator |
Example |
Interpretation |
---|---|---|
`>` |
`a > b` |
`a` is greater than `b` |
`<` |
`a < b` |
`a` is less than `b` |
`==` |
`a == b` |
`a` is equal to `b` |
`!=` |
`a != b` |
`a` is not equal to `b` |
`>=` |
`a >= b` |
`a` is greater than OR equal to `b` |
`<=` |
`a <= b` |
`a` is less than OR equal to `b` |
And following is the table for logical operators, they are used between one or more conditions:
Operator | Example | Interpretation |
---|---|---|
`||` (Logical OR) |
`COND1 || COND2` |
At least one of the condition `COND1` or `COND2` evaluates to `true` |
`&&` (Logical AND) |
`COND1 && COND2` |
All conditions evaluate to `true` |
`!` (Logical NOT) |
`!COND` |
Opposite boolean value of what `COND` evaluates to |
## Using if else
To handle the basic flow of Rust code, two keywords are used: `if`
and `else`
. This helps you create two "execution paths" based on the state of the provided condition.
The syntax of a simple if block with an alternative execution path is as follows:
```
if condition {
<statement(s)>;
} else {
<statement(s)>;
}
```
Let's look at an example.
```
fn main() {
let a = 36;
let b = 25;
if a > b {
println!("a is greater than b");
} else {
println!("b is greater than a");
}
}
```
Here, I have declared two integer variables `a`
and `b`
with the values '36' and '25'. On line 5, I check if the value stored in variable `a`
is greater than the value stored in variable `b`
. If the condition evaluates to `true`
, the code on line 6 will be executed. If the condition evaluates to `false`
, due to the fact that we have an `else`
block (which is optional), the code on line 8 will get executed.
Let's verify this by looking at the program output.
`a is greater than b`
Perfect!
Let's modify the value of variable `a`
to be less than value of variable `b`
and see what happens. I will change `a`
's value to '10'. Following is the output after this modification:
`b is greater than a`
But, what if I store the same value in variables `a`
and `b`
? To see this, I will set both variables' value to be '40'. Following is the output after this particular modification:
`b is greater than a`
Huh? Logically, this doesn't make any sense... :(
But this can be improved! Continue reading.
## Using 'else if' conditional
Like any other programming language, you can put an `else if`
block to provide more than two execution paths. The syntax is as follows:
```
if condition {
<statement(s)>;
} else if condition {
<statement(s)>;
} else {
<statement(s)>;
}
```
Now, with the use of an `else if`
block, I can improve the logic of my program. Following is the modified program.
```
fn main() {
let a = 40;
let b = 40;
if a == b {
println!("a and b are equal");
} else if a > b {
println!("a is greater than b");
} else {
println!("b is greater than a");
}
}
```
Now, the logic of my program is correct. It has handled all edge cases (that I can think of). The condition where `a`
is equal to `b`
is handled on line 5. The condition where `a`
might be greater than `b`
is handled on line 7. And, the condition where `a`
is less than `b`
is intrinsically handled by the `else`
block on line 9.
Now, when I run this code, I get the following output:
`a and b are equal`
Now that's perfect!
## Example: Find the greatest
I know that the use of `if`
and `else`
is easy, but let us look at one more program. This time, let's compare three numbers. I will also make use of a logical operator in this instance!
```
fn main() {
let a = 73;
let b = 56;
let c = 15;
if (a != b) && (a != c) && (b != c) {
if (a > b) && (a > c) {
println!("a is the greatest");
} else if (b > a) && (b > c) {
println!("b is the greatest");
} else {
println!("c is the greatest");
}
}
}
```
This might look complicated at first sight, but fear not; I shall explain this!
Initially, I declare three variables `a`
, `b`
and `c`
with random values that I could think of at that time. Then, on line 6, I check for the condition where no variable's value is same as any other variable. First, I check the values of `a`
and `b`
, then `a`
and `c`
and then `b`
and `c`
. This way I can be sure that there are no duplicate values stored in either variable.
Then, on line 7, I check if the value stored in variable `a`
is the greatest. If that condition evaluates to `true`
, code on line 8 gets executed. Otherwise the execution path on line 9 is checked.
On line 9, I check if the value stored in variable `b`
is the greatest. If this condition evaluates to `true`
, code on line 10 gets executed. If this condition is also `false`
, then it means only one thing. Neither variable `a`
, nor variable `b`
is the greatest among all 3.
So naturally, in the `else`
block, I print that the variable `c`
holds the greatest value.
Let's verify this with the program output:
`a is the greatest`
And this is as expected. Try and modify the values assigned to each variable and test it out yourself! :)
## Conclusion
You learned to use if and else statements. Before you go on making your own AI with lost of if else-if statements (haha), let' learn about loops in Rust in the next chapter of the series.
Stay tuned. |
15,897 | BASIC 与 FORTRAN 77:比较过去的编程语言 | https://opensource.com/article/23/4/basic-vs-fortran-77 | 2023-06-11T11:07:52 | [
"BASIC",
"FORTRAN"
] | /article-15897-1.html | 如果你和我一样,在 20 世纪七八十年代使用计算机长大,你可能学过一种常见的个人计算机编程语言,名为 BASIC(全称是 “<ruby> 初学者的通用符号指令代码 <rt> Beginner's All-purpose Symbolic Instruction Code </rt></ruby>”)。那个时期,包括 TRS-80、Apple II 和 IBM PC 在内的每台个人计算机都可以找到 BASIC 实现。当时,我是一个自学的 BASIC 程序员,在尝试了 Apple II 上的 AppleSoft BASIC 后,转向 IBM PC 上的 GW-BASIC,后来在 DOS 上学习了 QuickBASIC。
>
> 我通过编写一个示例程序来探索 BASIC 和 FORTRAN 77 中的 FOR 循环,以将数字列表从 1 加到 10。
>
>
>
但是曾经,一种在科学编程领域受欢迎的语言是 FORTRAN(即 “<ruby> 公式翻译 <rt> FORmula TRANslation </rt></ruby>”)。尽管在 1990 年对该语言进行的规范以后,该名称更常见的风格是 “Fortran”。
当我在 1990 年代初作为大学本科物理学生学习物理学时,我利用自己在 BASIC 上的经验学习了 FORTRAN 77。那时我意识到 BASIC 许多概念都来源于 FORTRAN。当然,FORTRAN 和 BASIC 在很多其他方面也存在差异,但我发现了解一点 BASIC 可以帮助我快速学习 FORTRAN 编程。
我想通过使用两种语言编写相同的程序,展示它们之间的一些相似之处。通过编写一个示例程序来探索 BASIC 和 FORTRAN 77 中的 `FOR` 循环,这个程序将把 1 到 10 之间的数字相加。
### Bywater BASIC
BASIC 存在许多种不同的版本,这取决于你的计算机,但该语言总体保持不变。我喜欢的一种 BASIC 版本是 [Bywater BASIC](https://sourceforge.net/projects/bwbasic/),这是一种开源的 BASIC 实现,适用于包括 Linux 和 DOS 在内的不同平台。
要在 FreeDOS 上使用 Bywater BASIC,你必须首先从 FreeDOS 1.3 Bonus CD 中 [安装该软件包](https://opensource.com/article/21/6/freedos-package-manager)。然后进入 `C:` 目录并输入 `bwbasic` 命令,这将启动 BASIC 解释器。你可以在这个提示符下输入程序:
```
bwBASIC:
```
Bywater BASIC 使用较早的 BASIC 编程标准,需要你在每个程序指令上编写一个行号。将行号视为索引。你可以使用行号轻松地引用程序中的任何指令。当你将程序键入 Bywater BASIC 解释器时,请在每个指令前添加行号:
```
bwBASIC: 10 print "Add the numbers from 1 to 10 ..."
bwBASIC: 20 sum = 0
bwBASIC: 30 for i = 1 to 10
bwBASIC: 40 sum = sum + i
bwBASIC: 50 next i
bwBASIC: 60 print sum
bwBASIC: 70 end
```
可以使用 `list` 命令查看你已经输入到解释器中的程序:
```
bwBASIC: list
10 print "Add the numbers from 1 to 10 ..."
20 sum = 0
30 for i = 1 to 10
40 sum = sum + i
50 next i
60 print sum
70 end
```
这个简短的程序演示了 BASIC 中的 `FOR` 循环。 `FOR` 是任何编程语言中最基本的循环构造,允许你迭代一组值。在 Bywater BASIC 中,`FOR` 循环的一般语法看起来像这样:
```
FOR 变量 = 起始值 TO 终止值
```
在这个示例程序中,指令 `for i = 1 to 10` 开始一个循环,迭代值为 1 到 10。在每个循环中,变量 `i` 被设置为新值。
在 BASIC 中,所有到 `next` 指令前的指令都将作为 `FOR` 循环的一部分执行。因为你可以将一个 `FOR` 循环放入另一个 `FOR` 循环中,Bywater BASIC 使用语法 `NEXT 变量` 来指定要迭代的循环变量。
在提示符下键入 `run` 来执行程序:
```
bwBASIC: run
Add the numbers from 1 to 10 ...
55
```
Bywater BASIC 被称为 BASIC 解释器,因为只能从 Bywater BASIC 环境中运行程序。这意味着解释器会处理与操作系统的交互的所有繁重工作,因此你的程序不需要自己完成这个工作。 这样做的代价是,程序在解释环境中运行会比它作为编译程序运行慢一些。
### FreeBASIC
另一个流行的 BASIC 实现是 [FreeBASIC](https://www.freebasic.net/),这是一个开源的 BASIC 编译器,适用于多个平台,包括 Linux 和 DOS。要使用 FreeBASIC,你需要从 FreeDOS 1.3 Bonus CD 安装 FreeBASIC 包,然后进入 `C:` 目录,你会在这里找到 FreeBASIC 程序。
FreeBASIC 是一个编译器,因此你首先需要创建一个包含程序指令的源文件,然后使用源代码运行编译器以创建一个可运行的程序。我编写了一个类似于“将 1 到 10 的数字相加”的程序版本,将其保存为 BASIC 文件,并命名为 `sum.bas`:
```
dim sum as integer
dim i as integer
print "Add the numbers from 1 to 10 ..."
sum = 0
for i = 1 to 10
sum = sum + i
next
print sum
end
```
如果你将这段代码与 Bywater BASIC 版本的程序进行比较,你可能会注意到 FreeBASIC 不需要行号。FreeBASIC 实现了一种更现代的 BASIC 版本,使得编写程序时不需要跟踪行号更容易。
另一个主要的区别是你必须在源代码中定义或声明变量。使用 `DIM` 指令在 FreeBASIC 中声明变量,例如 `dim sum as integer`,以定义一个名为 `sum` 的整数变量。
现在可以在命令行上使用 `fbc` 编译 BASIC 程序:
```
C:\DEVEL\FBC> fbc sum.bas
```
如果你的代码没有任何错误,编译器将生成一个可以运行的程序。例如,我的程序现在称为 `sum`。运行我的程序将从 1 加到 10:
```
C:\DEVEL\FBC> sum
Add the numbers from 1 to 10 ...
55
```
### FORTRAN 77
FORTRAN 编程语言类似于旧式和现代 BASIC 之间的混合体。FORTRAN 比 BASIC 更早出现,而 BASIC 显然从 FORTRAN 中汲取灵感,就像后来的 FORTRAN 版本从 BASIC 中获得启示一样。你可以将 FORTRAN 程序以源代码的形式写成文件,但并不需要在每个地方使用行号。但是,FORTRAN 77 在某些指令中使用行号(称为标签),包括 `FOR` 循环。在 FORTRAN 77 中,`FOR` 实际上被称为 `DO` 循环,它执行相同的功能并具有几乎相同的用法。
在 FORTRAN 77 中,`DO` 循环的语法如下:
```
DO 行号 变量 = 起始值, 终止值
```
这种情况是需要行号来指示 `DO` 循环结束位置的一种情况。你在 BASIC 中使用了 `NEXT` 指令,但 FORTRAN 需要一个行标签。通常,该行是一个 `CONTINUE` 指令。
查看这个示例 FORTRAN 程序,了解如何使用 `DO` 循环来循环一组数字。我将此源文件保存为 `sum.f`:
```
PROGRAM MAIN
INTEGER SUM,I
PRINT *, 'ADD THE NUMBERS FROM 1 TO 10 ...'
SUM = 0
DO 10 I = 1, 10
SUM = SUM + I
10 CONTINUE
PRINT *, SUM
END
```
在 FORTRAN 中,每个程序都需要以 `PROGRAM` 指令开始,并指定程序名称。你可能会将此程序命名为 `SUM`,但随后在程序中不能使用变量 `SUM`。当我学习 FORTRAN 时,我从 C 编程中借鉴了一些东西,并以 `PROGRAM MAIN` 开始了我的所有 FORTRAN 程序,做法类似于 C 程序中的 `main()` 函数,因为我不太可能使用名为 `MAIN` 的变量。
FORTRAN 中的 `DO` 循环类似于 BASIC 中的 `FOR` 循环。它迭代从 1 到 10 的值。变量 `I` 在每次循环中获取新值。这样可以将 1 到 10 的每个数字相加,并在完成时打印总和。
你可以在每个平台上找到适合的 FORTRAN 编译器,包括 Linux 和 DOS。FreeDOS 1.3 的 Bonus CD 中包括 OpenWatcom FORTRAN 编译器。在 Linux 上,你可能需要安装一个包来安装 GNU Fortran 支持(在 GNU 编译器集合(GCC)中)。在 Fedora Linux 上,你可以使用以下命令添加 GNU Fortran 支持:
```
$ sudo dnf install gcc-gfortran
```
然后你可以使用以下命令编译 `sum.f` 并运行程序:
```
$ gfortran -o sum sum.f
$ ./sum
ADD THE NUMBERS FROM 1 TO 10 ...
55
```
### 一点不同之处
我发现 FORTRAN 和 BASIC 非常相似,但也存在一些不同之处。这些语言的核心是不同的,但如果你了解一些 BASIC,你可以学习 FORTRAN,同样,如果你了解一些 FORTRAN,你也可以学习 BASIC。
如果你想探索这两种语言,有几点需要注意:
* **FORTRAN 77 使用全大写**,但后来的 FORTRAN 版本允许大小写混用,只要对变量、函数和子程序使用相同的大小写。大多数 BASIC 实现都不区分大小写,这意味着你可以自由地混合大小写字母。
* **有许多不同版本的 BASIC**,但它们通常做同样的事情。如果你学会了一种 BASIC 实现方式,很容易学会另一种。注意 BASIC 解释器或编译器的警告或错误信息,查阅手册了解差异。
* **某些 BASIC 实现需要使用行号**,例如 Bywater BASIC 和 GW-BASIC。更现代的 BASIC 版本允许你编写不使用行号的程序。FreeBASIC 需要使用 `-lang` 废弃选项编译带有行号的程序。
*(题图:MJ/dba28597-dd62-4ffe-bb4a-e38874a65239)*
---
via: <https://opensource.com/article/23/4/basic-vs-fortran-77>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,899 | 40 个最佳开源安卓应用程序 | https://itsfoss.com/open-source-android-apps/ | 2023-06-12T16:45:00 | [
"安卓"
] | https://linux.cn/article-15899-1.html | 
>
> 最好的开源安卓应用程序。替换专有应用,享受更好的体验!
>
>
>
无论是智能手机、桌面电脑还是物联网设备,开源软件在某种形式上无处不在。
虽然安卓是一个开源项目,但你可以在上面找到专有和开源的应用程序。**除了你可能已经使用的流行专有安卓应用程序,开源安卓应用程序可以作为更好的替代品,它尊重你的隐私。**
在这里,我为你精选了最好的开源安卓应用程序,可以作为日常使用的应用。
希望这个列表对你分享给他人时有所帮助!
>
> ? 列出的开源应用程序可以在谷歌 Play 商店、F-Droid 商店或开发者的官方网站/平台上找到。你应始终使用官方推荐源来下载和安装 APK。
>
>
>
### 键盘应用

当你发送短信或搜索信息时,键盘应用程序是你最常接触的应用程序。
当然,像 [SwiftKey](https://play.google.com/store/apps/details?id=com.touchtype.swiftkey) 这样的应用也许在以前还不错,但现在它们已经稍显普通了。此外,选择一个尊重你的隐私、符合预期(没有任何花哨的功能)的开源键盘应用程序才是明智的选择。一些最佳选项包括:
#### 1、Simple Keyboard
如其名称所示,Simple Keyboard 是一个 **极简的选项**,适合想要没有花哨功能的简单键盘应用程序的用户。它是谷歌默认键盘应用程序 [Gboard](https://play.google.com/store/apps/details?id=com.google.android.inputmethod.latin) 的出色替代品。
但如果你想要主题自定义和一些额外的控件,它可能会让你失望。
>
> **[? GitHub](https://github.com/rkkr/simple-keyboard)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/rkr.simplekeyboard.inputmethod/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=rkr.simplekeyboard.inputmethod)**
>
>
>
#### 2、AnySoftKeyboard
AnySoftKeyboard 是我的最爱,它拥有我需要的所有基本功能,包括 **主题自定义、快速文本和手势支持**。
如果你想要一个简单的键盘体验,它可以很简单;如果你要求更多的功能,它也可以是一个合适工具。
>
> **[? GitHub](https://github.com/AnySoftKeyboard/AnySoftKeyboard)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/com.menny.android.anysoftkeyboard/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.menny.android.anysoftkeyboard&pli=1)**
>
>
>
#### 3、OpenBoard
你可以将 OpenBoard 视为 **不依赖谷歌二进制文件的安卓默认键盘应用程序。**
因此,如果你喜欢 Gboard,但讨厌其与谷歌服务的关联,你可以使用 OpenBoard,它是一个简单而有效的键盘应用程序。
>
> **[? GitHub](https://github.com/openboard-team/openboard)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/org.dslul.openboard.inputmethod.latin/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=org.dslul.openboard.inputmethod.latin)**
>
>
>
### 文件管理器应用程序

每个智能手机制造商都会装载其自己品牌的文件管理器。根据你的智能手机,你可能已经有了三星的“**我的文件**”或小米的“**文件管理器**”。
不幸的是,默认的文件管理器应用程序(包括谷歌的“文件”)可能不是最好的选择。此外,它们收集了你可能不想共享的一些使用数据。
一些最佳的开源文件管理器选项包括:
#### 1、Amaze File Manager
Amaze File Manager 是一个不错的开源替代品,类似于 **Solid Explorer** 和 **EX 文件管理器**。
你可以得到 Material Design 的用户界面,以及剪切、复制、删除、压缩、解压等基本功能。此外,你还可以调整主题。
>
> **[? GitHub](https://github.com/TeamAmaze/AmazeFileManager)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/com.amaze.filemanager/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.amaze.filemanager)**
>
>
>
#### 2、Simple File Manager
Simple File Manager 是一个有用的应用程序,由一个专注于制作“**简单**”移动工具的开发团队开发。
它是一个轻巧而多功能的文件管理器,具有基本的文件管理功能。
>
> **[? GitHub](https://github.com/SimpleMobileTools/Simple-File-Manager)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/com.simplemobiletools.filemanager.pro/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.simplemobiletools.filemanager)**
>
>
>
#### 3、Little File Manager
只想要**一个浏览和访问文件的小应用**?Little 文件管理器应该是一个不错的选择,它让你能够像复制粘贴文件那样做基本操作。
>
> **[? GitHub](https://github.com/martinmimigames/little-file-explorer)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/com.martinmimigames.simplefileexplorer/)**
>
>
>
### 网页浏览器

想要使用隐私友好和开源的移动浏览器浏览网页吗?这些选项应该很适合:
#### 1、Firefox
Mozilla Firefox 可能是桌面和移动用户 **最喜欢的开源浏览器**。
在安卓上,他们做得很出色,让它成为一个令人愉悦、快速、隐私保护的体验。你也可以尝试 Firefox 的变体,比如 “**Firefox Focus**”,它是一个简单的应用程序,退出后会删除你的历史记录。
>
> **[? GitHub](https://github.com/mozilla-mobile/firefox-android)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=org.mozilla.firefox)**
>
>
>
#### 2、DuckDuckGo Private Browser
DuckDuckGo Private Browser 是由 [隐私友好的搜索引擎](https://itsfoss.com/privacy-search-engines/) 巨头开发的一个令人兴奋的选项。
你可以得到一个极简的用户体验,其中包含一些特殊的 DuckDuckGo 功能,比如 **应用程序追踪保护和电子邮件保护**。
>
> **[? GitHub](https://github.com/duckduckgo/Android)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/en/packages/com.duckduckgo.mobile.android/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.duckduckgo.mobile.android)**
>
>
>
#### 3、Bromite
Bromite 是一个安卓上的 Chromium 复刻,具有 **隐私增强和广告拦截功能。**
你可以从其官方网站或 GitHub 页面下载 APK。另外,你可以将其存储库添加到 F-Droid 中来安装和管理更新。
>
> **[? GitHub](https://github.com/bromite/bromite)**
>
>
>
>
> **[? F-Droid](https://www.bromite.org/fdroid)**
>
>
>
>
> **[? Website](https://www.bromite.org)**
>
>
>
#### 4、Tor 浏览器
Tor 浏览器基于 Firefox,但具有 **增强的安全性和隐私保护。**
它可能不会提供你最好的用户体验,但如果你想在浏览会话中获得最大的隐私保护,Tor 浏览器可能是一个不错的选择。
>
> **[? GitLab](https://gitlab.torproject.org/tpo/applications/tor-browser)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=org.torproject.torbrowser)**
>
>
>
### 多平台同步或文件共享应用

无论你想要同步通知、播放音乐,还是分享文件/剪贴板内容,你可能不想使用带有侵入式广告和差劲的隐私实践的文件共享应用,以下这些应用可能能够帮助你更好地完成这些任务:
#### 1、KDE Connect
KDE Connect 是一个流行的开源应用程序,可以让你连接跨设备,例如你的 Linux PC 和安卓手机,以共享剪贴板内容、文件、URL 和通知。
如果你使用 [基于 KDE 的发行版](https://itsfoss.com/best-kde-distributions/),则已经默认安装了此应用程序。
>
> **[? GitHub](https://github.com/KDE/kdeconnect-kde)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/en/packages/org.kde.kdeconnect_tp/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=org.kde.kdeconnect_tp)**
>
>
>
#### 2、LocalSend
LocalSend 帮助你将文件发送到附近设备(跨平台)。它是谷歌 Play 商店上几个 Shareit 克隆品的**简单、无广告的开源替代品**。
有趣的是,它还支持 macOS、Windows 和 Linux,对许多用户而言,这可以是共享文件的一站式解决方案。
>
> **[? GitHub](https://github.com/localsend/localsend)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/org.localsend.localsend_app/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=org.localsend.localsend_app)**
>
>
>
#### 3、Warpinator(非官方)
如果你想要一个移动端的 Linux Mint [Warpinator 工具](https://github.com/linuxmint/warpinator),可以试试这个。
即使 Linux Mint 开发人员也正式提到了它,但是请将其视为同名的非官方版本。
>
> **[? GitHub](https://github.com/slowscript/warpinator-android)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/en/packages/slowscript.warpinator/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=slowscript.warpinator)**
>
>
>
#### 4、Zorin Connect
如果你想要类似于 KDE Connect 但具有略微更好一些的用户体验的替代品,可以考虑使用 Zorin Connect。
它提供相同的功能,包括控制音乐和视频播放、发送文件、控制鼠标以及将手机用作幻灯片演示远程控制器。
>
> **[? GitHub](https://github.com/ZorinOS/zorin-connect-android)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/com.zorinos.zorin_connect/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.zorinos.zorin_connect)**
>
>
>
### 播客或有声读物播放器

如果你想要在没有任何干扰的情况下听播客,并拥有简单的用户体验,以下这些开源播客应用程序应该可以帮助你:
#### 1、AntennaPod
AntennaPod 是一个 **功能强大的开源播客管理器和播放器**,可以让你访问全球各种各样的播客。
你可以使用 RSS URL、iTunes 播客数据库或 OPML 文件很容易地添加(导入和导出)你的源。
>
> **[? GitHub](https://github.com/AntennaPod/AntennaPod)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/de.danoeh.antennapod/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=de.danoeh.antennapod)**
>
>
>
#### 2、Voice
Voice 是一个简单的播放器,可以让你轻松地播放和管理有声读物。它的 **用户体验简单且高效**,可以让你专注于听有声读物而不是其他功能。
>
> **[? GitHub](https://github.com/PaulWoitaschek/Voice)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/de.ph1b.audiobook/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=de.ph1b.audiobook)**
>
>
>
### RSS 阅读器

在网上获取所有信息或将其组织成列表可能很困难。不过,RSS 阅读器总是可以帮助你优雅地完成这个任务。
如果你已经厌倦了像 Feedly 或 Inoreader 等应用的付款方式,你可以简单地将你的 RSS 源添加/导入到以下这些应用程序中:
#### 1、Feeder
Feeder 是我最喜欢的安卓 RSS 阅读器应用程序,它提供了 **良好的用户体验和一些自定义选项** 来过滤/组织你的源。
它支持深色模式,所以你可以轻松地获取信息而不会累着眼睛。
>
> **[? GitLab](https://gitlab.com/spacecowboy/Feeder)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/com.nononsenseapps.feeder/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.nononsenseapps.feeder.play)**
>
>
>
#### 2、Read You
Read You 是一个相对较新加入 RSS 阅读器类别的应用程序,此外它遵循了谷歌的新 **Material You** UI 风格。
它具备你需要的 RSS 阅读器的所有基本功能,并提供愉悦的用户体验。
>
> **[? GitHub](https://github.com/Ashinch/ReadYou)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/me.ash.reader/)**
>
>
>
#### 3、NewsBlur
需要一个完整的开源新闻阅读器吗?NewsBlur 是一个非常有趣的解决方案,它具备一组基本功能,可以满足你的需求。
它旨在成为谷歌 Reader 的替代品。值得一试!
>
> **[? GitHub](https://github.com/samuelclay/NewsBlur)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/com.newsblur/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.newsblur)**
>
>
>
### vPN 应用程序

对于大多数 vPN 服务,你将不得不信任公司或服务来保护你的隐私。
然而,如果你使用开源 vPN 应用程序,则可以获得一定程度的透明度,了解客户端的工作方式。因此,与专有的 vPN 应用程序相比,开源 vPN 应用程序可能证明更好的选择。
#### 1、ProtonVPN
[ProtonVPN](http://proton.go2cloud.org/aff_c?offer_id=10&aff_id=1173) 是 **隐私关注的 vPN 服务中最受欢迎的选择之一**。与其他 vPN 应用程序相比,它提供有用的功能,如跟踪器阻止、安全核心服务器等,以提升隐私保护。
与其他一些 vPN 不同,Proton 的整个产品都是开源的,这使得它成为一个不错的选择。
>
> **[? GitHub](https://github.com/ProtonVPN/android-app)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/ch.protonvpn.android/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=ch.protonvpn.android)**
>
>
>
#### 2、Mullvad
[Mullvad](https://mullvad.net/en/) 是一个 **独特的 vPN 提供商**,不需要太多的个人信息。它生成一个独特的随机数字来分配给你一个帐户,你只需要使用你的付款信息来订阅。
Mullvad 的应用程序是开源的,对于不喜欢 ProtonVPN 的用户来说,它可能是一个很好的选择。
>
> **[? GitHub](https://github.com/mullvad/mullvadvpn-app)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/net.mullvad.mullvadvpn/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=net.mullvad.mullvadvpn)**
>
>
>
#### 3、IVPN
[IVPN](https://www.ivpn.net) 以其 **极度诚实的营销** 而闻名。在购买之前,它会告诉你是否需要购买 vPN。
该应用程序是开源的,提供基本功能和简单的用户体验。
>
> **[? GitHub](https://github.com/ivpn/android-app)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/net.ivpn.client/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=net.ivpn.client&hl=en_IN&gl=US)**
>
>
>
### 漫画阅读器

#### 1、Tachiyomi
Tachiyomi 是一款 **极受欢迎的自由开源的漫画阅读器**,适用于安卓。
你可以从各种来源浏览内容或阅读下载的漫画,同时能够使用分类来组织你的库。阅读器可以进行调整以符合你的体验,还支持浅色/深色主题。
>
> ? 你可以在 Tachiyomi 的 GitHub 发布区中找到最新的 APK。
>
>
>
>
> **[? GitHub](https://github.com/tachiyomiorg/tachiyomi)**
>
>
>
>
> **[? Website](https://tachiyomi.org/)**
>
>
>
#### 2、Kotatsu
Kotatsu 是另一个适用于 安卓 的开源漫画阅读器。你可以浏览在线目录、组织你阅读的漫画,并获得具有离线支持的优化阅读器。
它采用现代的 **Material You** 用户界面,可以提供更好的体验。
>
> **[? GitHub](https://github.com/KotatsuApp/Kotatsu)**
>
>
>
>
> **[? Website](https://itsfoss.comkotatsuapp.github.io)**
>
>
>
#### 3、Seeneva
需要一个智能的漫画书阅读器吗?Seeneva 是一个不太受欢迎但表现不错的选择。
它支持各种漫画书归档格式,如 CBZ、CBR、CB7 等。
>
> **[? GitHub](https://github.com/Seeneva/seeneva-reader-android)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/app.seeneva.reader/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=app.seeneva.reader)**
>
>
>
### 音乐播放器

从技术上讲,如果你只想播放音乐,那么默认的音乐播放器应该也可以胜任。但是,如果你想要组织你的库并且拥有一个简单的音乐播放体验,以下这些应用程序可能非常适合:
#### 1、Simple Music Player
Simple Music Player 是由开发 Simple File Manager 应用程序的同一团队开发的另一个实用程序。
虽然它提供了一个简单的体验,但它具有 **直观的用户界面**,可以选择分组文件、自定义颜色方案,并享受音乐。
>
> **[? GitHub](https://github.com/SimpleMobileTools/Simple-Music-Player)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/com.simplemobiletools.musicplayer/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.simplemobiletools.musicplayer)**
>
>
>
#### 2. Vanilla Music
Vanilla Music 是一个干净的开源音乐播放器,支持最常见的音频格式,并提供基本的功能。
>
> **[? GitHub](https://github.com/vanilla-music/vanilla)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/ch.blinkenlights.android.vanilla/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=ch.blinkenlights.android.vanilla)**
>
>
>
### 笔记应用

笔记可以是个人的或随手的记录。然而,使用一个严格保护隐私并为你提供更好的安全性的笔记应用是必要的。你可能会写一些敏感的内容,不应该在隐私控制做得很差的笔记应用中分享这些信息。
#### 1、Joplin
Joplin 是一款出色的开源笔记应用程序,也可用于桌面平台。
你可以将你的笔记存储在本地、加密、同步等等来组织它们。用户体验可能不是最直观的,但如果你想要一个开源的、功能丰富的笔记应用,Joplin 不会让你失望。
>
> **[? GitHub](https://github.com/laurent22/joplin)**
>
>
>
>
> **[? F-Droid](https://apt.izzysoft.de/fdroid/index/apk/net.cozic.joplin)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=net.cozic.joplin)**
>
>
>
#### 2、Standard Notes
Standard Notes 是一个 **方便的选项,提供了默认的端到端加密,并将你的数据存储在云端**。
你可以选择高级版来扩展其功能。不过,基本功能应该足够让你开始使用。
>
> **[? GitHub](https://github.com/standardnotes/app)**
>
>
>
>
> **[? F-Droid](https://apt.izzysoft.de/fdroid/index/apk/net.cozic.joplin)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.standardnotes)**
>
>
>
#### 3、Simplenote
Simplenote 是一款易于使用的笔记应用,由 WordPress 的开发公司 **Automattic** 开发。
如果你不想要花哨的功能或庞大的设置选项,这是最好的开源应用程序,可在多个设备之间同步笔记。
>
> **[? GitHub](https://github.com/Automattic/simplenote-android)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.automattic.simplenote)**
>
>
>
### 2FA 和密码应用程序

管理密码和双因素身份验证代码非常重要。特别是当我们看到类似 LastPass 的专有密码管理器经常出现安全漏洞时,你怎么能信任它们呢?
因此,你可以尝试使用开源选项,以获得更好的隐私和透明度,从而放心。
#### 1、KeePassDX
KeePassDX 是一个简单且强大的密码管理器,适用于不想将其数据与云同步的用户。
你可以创建数据库、导出/导入它们,并在任何地方管理你的密码。它与 [KeePassXC](https://itsfoss.com/keepassxc/) 兼容,后者是 [Linux 上最好的密码管理器之一](https://itsfoss.com/password-managers-linux/)。
>
> **[? GitHub](https://github.com/Kunzisoft/KeePassDX)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/com.kunzisoft.keepass.libre/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.kunzisoft.keepass.free)**
>
>
>
#### 2、Bitwarden
Bitwarden 是 **最受欢迎的开源密码管理器**,可以在设备和浏览器(带扩展)之间同步。你也可以在这里存储 2FA 令牌。
与上述密码管理器不同,它同步到云端。但是,它提供行业标准的保护措施和更高级的功能,以保护你的数据。此外,与其他专有密码管理器相比,Bitwarden 的高级套餐价格实惠。
>
> **[? GitHub](https://github.com/bitwarden)**
>
>
>
>
> **[? F-Droid](https://mobileapp.bitwarden.com/fdroid/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.x8bit.bitwarden)**
>
>
>
#### 3、Aegis Authenticator
需要一个 **开源的 Authy 替代品** 吗?Aegis Authenticator 可能是一个不错的解决方案,支持行业标准的 2FA 令牌。
>
> **[? GitHub](https://github.com/beemdevelopment/Aegis)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/en/packages/com.beemdevelopment.aegis/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.beemdevelopment.aegis)**
>
>
>
### 电子邮件

如果你正在寻找增强隐私和安全性的方法,开源电子邮件应用程序是必不可少的。我们的推荐包括以下应用程序:
#### 1、K-9 Mail(或 Thunderbird)
K-9 Mail 是一个在安卓上非常受欢迎的开源电子邮件客户端,具有所有基本功能。
在 2022 年,K-9 Mail 的项目维护者加入了 Thunderbird,利用 Mozilla 的资源和专业知识改进 K-9 体验。因此,K-9 Mail 最终将变成 **Thunderbird 的移动应用程序**。
>
> **[? GitHub](https://github.com/thundernest/k-9)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/com.fsck.k9/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=com.fsck.k9)**
>
>
>
#### 2、FairEmail
FairEmail 是另一个支持 Gmail、Outlook 等帐户的开源电子邮件客户端。
它提供一个简单的用户界面和许多实用功能。
>
> **[? GitHub](https://github.com/M66B/FairEmail)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/en/packages/eu.faircode.email/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=eu.faircode.email)**
>
>
>
#### 3、Tutanota
Tutanota 是一项 **加密电子邮件服务**。如果你想要增强隐私和安全性,你可以使用它的移动应用程序。
通过高级订阅,你可以解锁某些功能。否则,你可以免费使用它。
>
> **[? GitHub](https://github.com/tutao/tutanota)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/de.tutao.tutanota/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=de.tutao.tutanota)**
>
>
>
#### 4、Proton Mail
Proton Mail 是另一个 **受欢迎的加密电子邮件服务**。这可能提供更好的用户体验(这是我喜欢的)。
这两个选项都是隐私关注者的绝佳推荐。
>
> **[? GitHub](https://github.com/ProtonMail/proton-mail-android)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=ch.protonmail.android)**
>
>
>
### 视频播放器

如果你需要处理不同的文件格式在移动设备上观看媒体,那么开源视频播放器应该会很有用。尝试以下选项:
#### 1、VLC
VLC 可能不需要介绍。它是跨多个平台 **最好的开源视频/媒体播放器之一**。
它支持广泛的文件格式。
>
> **[? GitHub](https://github.com/videolan/vlc-android)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/en/packages/org.videolan.vlc/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=org.videolan.vlc)**
>
>
>
#### 2、Nova video player
Nova video player 是一个 **拥有良好功能集合的选项**,如果你需要一些不同的东西就可以选择它。
>
> **[? GitHub](https://github.com/videolan/vlc-android)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/packages/org.courville.nova/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=org.courville.nova)**
>
>
>
#### 3、mpv-android
想要一个 **超级简单的视频播放器**?Mpv-android 可能会是你的选择。
用户界面并不复杂,够用而已。
>
> **[? GitHub](https://github.com/mpv-android/mpv-android)**
>
>
>
>
> **[? F-Droid](https://f-droid.org/en/packages/is.xyz.mpv/)**
>
>
>
>
> **[? Play 商店](https://play.google.com/store/apps/details?id=is.xyz.mpv)**
>
>
>
### 想要更多的 FOSS 应用?
如果你喜欢实验、技术能力强,并且喜欢 DIY,你甚至可以选择其他安卓 ROM 来完全控制你的智能手机。
如果我们为所有类型的东西添加开源替代方案,例如相机、短信等,那这个列表将是无穷无尽的。
?如果你想要更多的开源应用程序,可以前往 [F-Droid 商店](https://f-droid.org),或查看 [此 GitHub 页面上的 FOSS 应用列表](https://github.com/offa/android-foss),以获得更多建议。
?你在这个列表中最喜欢的是什么?欢迎在评论区分享你的想法。
*(题图:MJ/5c0acc1e-4dee-4b86-85d4-d5f84c0cb02e)*
---
via: <https://itsfoss.com/open-source-android-apps/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Whether we talk about smartphones, desktops, or IoT devices, open-source software is omnipresent in some form.
While Android is already an open-source project, you can find proprietary and open-source applications.
And** open-source Android apps can act as better replacements that respect your privacy** than popular proprietary Android apps that you may already use.
Here, I have curated a list of the best open-source Android apps you can use as daily drivers.
I hope this list comes in handy for anyone you share it with!
**/platform. You should always use the officially recommended source to download and install APKs.**
**Google Play Store, F-Droid store, or the developer's official website**## Keyboard Apps

The keyboard app is what you interact with the most when texting or searching for something.
Sure, options like [SwiftKey](https://play.google.com/store/apps/details?id=com.touchtype.swiftkey) may have been good in the past, but they are not so impressive anymore. Moreover, it only makes sense to opt for an open-source keyboard app that respects your privacy and works as one would expect (without any fancy features). Some of the best options include:
### 1. Simple Keyboard
As the name suggests, Simple Keyboard is a **minimal option for users** who want a straightforward keyboard app with no frills. It is an excellent alternative to [Gboard](https://play.google.com/store/apps/details?id=com.google.android.inputmethod.latin), the default keyboard app by Google.
This may disappoint you if you want theme customizations and a few extra controls.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 2. AnySoftKeyboard
AnySoftKeyboard is my favorite, as it comes with all the essential features I need, including **theme customization, quick text, and gesture support.**
It can be a simple keyboard experience if you want or act as a tool you can do more with.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 3. OpenBoard
You can think of OpenBoard as **Android's default keyboard app without relying on Google binaries.**
So, if you like Gboard but hate its association with Google services, you can use OpenBoard, which is a simple and effective keyboard app
📥 **GitHub**** | ****F-Droid**** | ****Play Store**
## File Manager Apps

Every smartphone manufacturer loads up their native-branded file manager. Depending on your smartphone, you may already have a '**Samsung My Files**' or 'F**ile Manager by Mi**'.
Unfortunately, the default file manager applications (including **Files by Google**) may not work the best. Moreover, they collect some usage data you may not want to share.
Some of the best open-source file manager options are:
### 1. Amaze File Manager
Amaze File Manager is a nice open-source alternative to options like **Solid Explorer** and **EX File manager**.
You get a material design user interface and the essential features to cut, copy, delete, compress, extract, and more. Also, you get to tweak the theme.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 2. Fossify File Manager
Fossify File Manager is a helpful app from a developer team focused entirely on making '**easy-to-use**' tools for mobile.
It is a lightweight and versatile file manager with essential file management features.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 3. Little File Manager
Just want **a small app to explore and access files**? Little File Manager should be a good pick that lets you do the fundamentals like copy-pasting files.
## Web Browsers

Want to browse the web using a privacy-friendly and an open-source mobile browser? These options should suit well:
### 1. Firefox
Mozilla Firefox is probably the **favorite open-source browser for desktop and mobile users. **
With Android, they have stepped up the game well, making it a pleasing, fast, and private experience. You can also try variants of Firefox, like '**Firefox Focus**' which is a simple app that deletes your history once you exit.
**📥 ****GitHub**** | ****Play Store**
### 2. DuckDuckGo Private Browser
DuckDuckGo private browser is an exciting option developed by the [privacy-friendly search engine](https://itsfoss.com/privacy-search-engines/) giant.
You get a minimal user experience sprinkled with special DuckDuckGo features like **App Tracking Protection and Email Protection**.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
**Suggested Read 📖**
[Top 10 Best Browsers for Ubuntu LinuxWhat are your options when it comes to web browsers for Linux? Here are the best web browsers you can pick for Ubuntu and other Linux distros.](https://itsfoss.com/best-browsers-ubuntu-linux/)

### 3. Bromite
Bromite is a Chromium fork for Android that comes with **privacy enhancements and ad-blocking capabilities.**
You can download the APK from its official website or the GitHub page. Additionally, you can add its repository to F-Droid to install and manage updates.
### 4. Tor Browser
Tor Browser is based on Firefox but has **enhanced security and privacy protections.**
It may not provide you with the best user experience, but if you want maximum privacy during browsing sessions, the Tor browser can be a good choice.
**📥 ****GitLab**** | ****Play Store**
## Multi-Platform Sync or File-Sharing Apps

Whether you want to sync your notifications, control music, or share files/clipboard content, you may not want to use file-sharing apps with intrusive ads and poor privacy practices.
These apps can help you better:
### 1. KDE Connect
KDE Connect is a popular open-source application that lets you connect across devices like your Linux PC and Android mobile to share clipboard content, files, URLs, and notifications.
If you use [KDE-based distributions](https://itsfoss.com/best-kde-distributions/), it comes built-in with the desktop experience.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 2. LocalSend
LocalSend helps you send files to nearby devices (cross-platform). It is **a simple, ad-free open-source alternative** to several clones of Shareit on the Play Store.
Interestingly, along with iOS and Android, it also supports macOS, Microsoft Windows, and Linux. For many users, this can be a one-stop solution to share files safely across devices.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 3. Warpinator (unofficial)
If you want a mobile port to Linux Mint's [Warpinator tool](https://github.com/linuxmint/warpinator), you can try this out.
Even Linux Mint developers have given it a mention officially. However, consider it an unofficial build with the same name.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 4. Zorin Connect
Zorin Connect can be an alternative if you want something** similar to KDE Connect but with a slightly better user experience**.
It provides the same features to control music, and video playback, send files, control the mouse, and use your phone as a slideshow remote.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
## Podcast or Audio Book Players

If you want to listen to podcasts without any interruptions with a simple user experience, these foss podcast applications should help:
### 1. AntennaPod
AntennaPod is a **powerful open-source podcast manager** and player that gives you access to various podcasts across the globe.
You can easily add (import and export) your feeds from other apps using RSS URLs, iTunes podcast database, or OPML files.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 2. Voice
Voice is a straightforward player that lets you play/manage audiobooks with ease. The **user experience is minimal** but effective in letting you focus on listening to the audiobook instead of other functions.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
## RSS Readers

It can be tough to keep up with all the information online or have a list of it organized. However, RSS readers always help with the task gracefully.
If you are tired of paying for options like Feedly or Inoreader, you can simply add/import your RSS feeds to these apps:
### 1. Feeder
Feeder is my favorite RSS reader app for Android that provides a **good user experience and a few customization options** to filter/organize your feeds.
It does support a dark mode, so you can easily keep up with information without straining your eyes.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 2. Read You
Read You is a relatively new app to join the RSS reader category, considering it follows Google's new **Material You** UI style.
It ticks all the essential features you need with an RSS feed reader and provides a pleasant user experience.
### 3. NewsBlur
Need a full-fledged open-source news reader? NewsBlur is an exciting solution with a basic feature set to satisfy your needs.
It **aims to be a replacement for Google Reader**. Worth a try!
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
## VPN Apps

You will have to trust the company or service to protect your privacy for most VPN services.
However, if you use open-source VPN applications, you get a good amount of transparency of how the client-side of it works. So, open-source VPN apps may prove to be a better option than proprietary ones.
### 1. ProtonVPN
[ProtonVPN](http://proton.go2cloud.org/aff_c?offer_id=10&aff_id=1173) is a **popular option among privacy-focused VPN services**. It offers valuable features like tracker blocking, secure core servers, and more to enhance privacy compared to other VPN apps.
Unlike some others, Proton's entire offering is open-source, which makes it a good choice to pick.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
**Suggested Read 📖**
[Best VPN Services for Privacy Minded Linux UsersNo matter whether you use Linux or Windows, ISPs spy all the time. Also, it is often your Internet Service Provider who enforces annoying restrictions, and throttles speed while tracking your online activity. I’m not sure what might be the cause of a privacy breach for you – but when](https://itsfoss.com/best-vpn-linux/)

### 2. Mullvad
[Mullvad](https://mullvad.net/en/) is a **unique VPN offering** that does not need much personal information. It generates a unique random number to assign you an account that you use. You only have to use your payment information to subscribe.
Mullvad's app is open-source and can be a good alternative for users who do not prefer ProtonVPN.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 3. IVPN
[IVPN](https://www.ivpn.net) is **well-known for its brutally honest marketing**. It informs you whether you need a VPN or not before you opt to purchase it.
The app is open-source and offers essential features with a simple user experience.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
## Comics or Manga Reader

### 1. Tachiyomi
Tachiyomi is an **immensely popular free and open-source manga reader** for Android.
You can browse content from various source or read download manga while being able to organize the library using categories. The reading viewer can be tweaked to adjust your experience and it also supports light/dark themes.
### 2. Kotatsu
Kotatsu is yet another open source manga reader for Android. You can explore online catalogues, organize manga you read, and get an optimized reader with offline support.
It **features the modern Material You** user interface which could provide a better experience.
### 3. Seeneva
Need a smart comic book reader? Seeneva is a solid choice that may not be popular enough.
It supports various comic book archive formats like CBZ, CBR, CB7, and more.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
## Music Player

Technically, the default music player should do fine if you only want to play music. However, if you want the ability to organize a library and also have a minimal music playback experience, these applications should suit well:
### 1. Simple Music Player
Simple Music Player is another utility developed by the same team behind the Fossify File Manager app.
While it offers a simple experience, it features an** intuitive user interface** with options to group files, customize color schemes, and enjoy music.
**📥 ****GitHub**** | ****F-Droid (IzzyOnDroid Repo)**** **
### 2. Vanilla Music
Vanilla Music is a clean open-source music player that supports the most common audio formats and provides basic functionalities.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
## Note Taking

Notes can be personal or random scribbles. However, using a note-taking app that takes privacy seriously and gives you better security is essential. You might write something sensitive and should not share such information in a note-taking app with poor privacy practices.
### 1. Joplin
Joplin is a fantastic open-source note-taking app also available for desktop platforms.
You can store your notes locally, encrypt them, sync them, and do lots more to organize things. The user experience may not be the most intuitive thing, but if you want an open-source, feature-rich note app, Joplin will not disappoint.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 2. Standard Notes
Standard Notes is a** convenient option that offers end-to-end encryption** by default and stores your data in the cloud.
You can opt for the premium to extend its features. However, the basic functionalities should be enough for you to get started.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
**Suggested Read 📖**
[Looking for Some Good Note Taking Apps on Linux? Here are the Best Notes Apps we Found for YouNo matter what you do — taking notes is always a good habit. Yes, there are a lot of note taking apps to help you achieve that. But, what about some open-source note taking apps for Linux? Fret not, you don’t need to endlessly search the Internet to find the](https://itsfoss.com/note-taking-apps-linux/)

### 3. Simplenote
Simplenote is an easy-to-use note-taking app developed by **Automattic** (the company behind WordPress).
If you do not want fancy features or overwhelming options, this is the best open-source app to sync notes across multiple devices.
**📥 ****GitHub**** | ****Play Store**
## 2FA and Password Apps

Managing passwords and two-factor authentication codes are crucial. Especially when we see proprietary password managers like LastPass getting regular security breaches, how can you even trust them?
So, you can try going with open-source options that give you better privacy and transparency for peace of mind:
### 1. KeePassDX
KeePassDX is a simple and powerful password manager for users who do not want to sync their data with the cloud.
You can create a database, export/import them, and manage your passwords wherever you go. It is compatible with [KeePassXC](https://itsfoss.com/keepassxc/), one of the [best password managers on Linux](https://itsfoss.com/password-managers-linux/).
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 2. Bitwarden
Bitwarden is the **most popular open-source password manager** that syncs across devices and browsers (with extensions). You can also store 2FA tokens here.
Unlike the above, it syncs to the cloud. However, it does provide industry-standard protections and more advanced features to protect your data. In addition, the premium for Bitwarden is affordable compared to other proprietary password managers.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 3. Aegis Authenticator
Looking for an **open-source replacement for Authy**? Aegis Authenticator can be a good solution that supports industry-standard 2FA tokens.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**

If you are looking for enhanced privacy and security, open-source email applications are a must. Our recommendations include the following:
### 1. K-9 Mail (or Thunderbird)
K-9 mail is a popular open-source email client on Android with all the essential features.
In 2022, the K-9 mail's project maintainer joined Thunderbird to use Mozilla's resources and expertise to improve the K-9 experience. So, K-9 mail will eventually turn into **Thunderbird's mobile app**.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 2. FairEmail
FairEmail is yet another open-source email client that supports accounts like Gmail, Outlook, and more.
It offers a simple user interface with plenty of useful features.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 3. Tutanota
Tutanota is an **encrypted email service**. You can get started with its mobile app if you want to use it for enhanced privacy and security.
With a premium subscription, you unlock certain capabilities. Otherwise, you can use it for free.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 4. Proton Mail
Proton Mail is another **popular encrypted email service**. It may provide a better user experience (that's what I prefer).
Both of these options are excellent recommendations for privacy-focused users.
**📥 ****GitHub**** | ****Play Store**
## Video Player

An open-source video player should come in handy if you dabble with different file formats to watch media on your mobile. Try these out:
### 1. VLC
VLC probably needs no introduction. It is **among the best open-source video/media players** across multiple platforms.
It supports a wide range of file formats.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 2. Nova video player
The Nova video player is an option if you need something different for a change with a **good feature set**.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
### 3. mpv-android
Want a **super simple video player**? Mpv-android can be your pick.
The user interface does not get in your way and just works.
**📥 ****GitHub**** | ****F-Droid**** | ****Play Store**
## Want more FOSS with Android?
If you are experimental, technically competent and love the DIY stuff, you may even opt for other Android ROMs to take complete control of your smartphone.
[5 De-Googled Android-based Operating SystemsWith the ever-growing surveilling presence of advertisement giants like Google and Facebook on your personal devices (including smartphones), it is time you do something about it. One of the most effective ways to do that is by installing a privacy/security-focused Android ROM. You might be wonder…](https://itsfoss.com/android-distributions-roms/)

It will be an endless list if we add open-source alternatives for all kinds of things like cameras, SMS, and more.
🚀 To find more open-source applications, you can head to the [F-Droid store](https://f-droid.org) or check out a list of [foss applications on this GitHub page](https://github.com/offa/android-foss) to get more suggestions.
💬*What is your favorite on the list? Feel free to share your thoughts in the comments down below.* |
15,901 | Debian 12 “Bookworm” 已经推出 | https://news.itsfoss.com/debian-12-release/ | 2023-06-13T08:54:15 | [
"Debian"
] | https://linux.cn/article-15901-1.html |
>
> Debian 的下一个重要版本已经发布。
>
>
>

虽然没有固定的时间表,但每隔约两年 Debian 就会推出一个新的稳定版升级。
Debian 11 发布于 2021 年,现在是 2023 年,我们迎来了下一个主要版本 Debian 12。
要注意的是,正如发布说明中所提到的,**Debian 12 发布时已知存在约 100 个错误**。因此,在升级或安装之前,你可能需要详细阅读此版本的发布说明。
>
> ? 如果你不知道,每个 Debian 的稳定版本都可以得到 **至少三年的活动维护和支持**,此外,它也提供了 **两年的扩展 LTS** 支持作为商业服务。直到 **2028 年 6 月**,Debian 12 都将得到支持。你有一年的时间从 Debian 11 升级。
>
>
>
### Debian 12 有哪些新功能?
对于重大版本升级,肯定会更新一些软件包,而过时或老旧的软件会被删除。
与我们在 [Debian 12 功能列表](/article-15776-1.html) 中提到的类似,包括了以下增强功能:
* 更新的安装程序
* Linux 内核 6.1
* 默认启用 PipeWire 音频系统
* 全新壁纸
#### 安装程序升级

每个发行版都致力于改进新用户的安装体验,而 Debian 也不例外。
Debian 12 可以更好地处理非自由固件,这是可以提高新用户的入门体验的亮点之一。
此外,还有许多底层改进,包括硬件兼容性升级。
#### Linux 内核 6.1

Debian 12 带有 [LTS 版本的 Linux 内核 6.1](https://news.itsfoss.com/linux-kernel-6-1-is-now-an-lts-version/)。
该内核包含 Rust 的实验性支持、AMD 硬件优化和改进的 ARM 支持。
#### 桌面环境和软件升级
Debian 12 默认预装了 [GNOME 43](https://news.itsfoss.com/gnome-43-release/)、[KDE Plasma 5.27](https://news.itsfoss.com/kde-plasma-5-27-release/)、LXDE 11、LXQt 1.2.0、MATE 1.26 和 [XFCE 4.18](https://news.itsfoss.com/xfce-4-18-release/)。新的桌面环境版本应该会提升桌面体验,还有必要的应用程序更新,包括:
* GIMP 2.10.34
* Perl 5.36
* [Vim 9.0](https://news.itsfoss.com/vim-9-0-release/)
* OpenJDK 17

不要忘了还有一张新的 [壁纸](https://wiki.debian.org/DebianArt/Themes/Emerald),为所有那些神奇的软件更新增添了装饰。
### 其他变化

如果你需要了解完整的技术细节和升级信息,可以查看 [发行说明](https://www.debian.org:443/releases/bookworm/amd64/release-notes/) 或 [官方公告](https://www.debian.org:443/News/2023/20230610)。这里列出了一些重要的更新亮点:
* 默认启用 PipeWire 音频服务器
* 基于 Go 的软件包支持限制安全
* 删除了超过 9,519 个过时/陈旧的软件包
* Debian 12 现在可以检测到双引导系统中的 Windows 11。
* 已经重新引入了 ARM64 上的 Secure Boot 支持。
>
> **[下载 Debian 12](https://www.debian.org:443/distrib/)**
>
>
>
Debian 12 是一个不错的升级版本,但请注意 [某些问题](https://www.debian.org:443/releases/bookworm/amd64/release-notes/ch-information.en.html#systemd-resolved)。你已经升级了吗?请让我知道你的想法。
---
via: <https://news.itsfoss.com/debian-12-release/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

While there is no fixed schedule, a new stable Debian upgrade appears every two years or so.
Debian 11 was released in 2021, and now in 2023, we have the next major version bump, i.e.,** Debian 12**.
Interestingly, **Debian 12 has been released with about 100 known bugs**, as mentioned in the release notes. So, you might want to explore the release details before upgrading or installing it.
**at least three years.**And it offers a
**two-year extended LTS**support as a commercial offering.
Debian 12 will be supported until
**June 2028**. You have one year to upgrade from Debian 11.
## What's New in Debian 12?
Of course, with a major upgrade, you can expect package updates and obsolete/old software removed.
Similar to what we mentioned in our [Debian 12 feature list](https://news.itsfoss.com/debian-12-features/), the following enhancements are included:
**Updated Installer****Linux Kernel 6.1****PipeWire by default****New wallpaper**
**Suggested Read **📖
[Debian 12 ‘Bookworm’ New Features and Release DateDebian 12 is due for release soon. Learn more about its features and the release date.](https://news.itsfoss.com/debian-12-features/)

### Installer Upgrades
Every distro focuses on improving the installation experience for new users. And it was time Debian stepped up.
The better handling of non-free firmware on Debian 12 is one of the highlights that should improve the onboarding experience.
In addition, there are many under-the-hood improvements including hardware compatibility upgrades.
### Linux Kernel 6.1
Debian 12 features [Linux Kernel 6.1](https://news.itsfoss.com/linux-kernel-6-1-is-now-an-lts-version/), which is an LTS version.
The kernel comes baked in with Rust's experimental support, AMD hardware optimizations, and improved ARM support.
### Desktop Environment & Software Upgrades
Debian 12 ships with [GNOME 43](https://news.itsfoss.com/gnome-43-release/), [KDE Plasma 5.27](https://news.itsfoss.com/kde-plasma-5-27-release/), LXDE 11, LXQt 1.2.0, MATE 1.26, and [XFCE 4.18](https://news.itsfoss.com/xfce-4-18-release/).
The new desktop environment versions should improve the desktop experience along with the essential application updates that include:
- GIMP 2.10.34
- Perl 5.36
[Vim 9.0](https://news.itsfoss.com/vim-9-0-release/)- OpenJDK 17

Not to forget, you get a new wallpaper with all the magical software updates.
## Other Changes
While you can go through the [release notes](https://www.debian.org/releases/bookworm/amd64/release-notes/?ref=news.itsfoss.com) or the [announcement post](https://www.debian.org/News/2023/20230610?ref=news.itsfoss.com) for full technical details and upgrade information, some important highlights include:
- Pipewire audio server by default
- Go-based packages have limited security support.
- Over 9519 packages were removed because they were old/obsolete.
- Debian 12 can now detect Windows 11 in a dual-boot setup.
- Support for Secure Boot on ARM64 has been reintroduced.
*Debian 12 is a nice upgrade with some issues to be aware of. Have you upgraded already? Let me know your thoughts on the same.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,902 | 从 Debian 11 升级到 Debian 12 | https://www.debugpoint.com/upgrade-debian-12-from-debian-11/ | 2023-06-13T09:55:00 | [
"Debian"
] | /article-15902-1.html | 
>
> 以下是如何从 Debian 11 升级到 Debian 12 “Bookworm” 的步骤。
>
>
>
Debian 12 Bookworm 已经发布。如果你正在运行 Debian 11 “Bullseye”,你可以计划现在升级你的台式机或服务器。但是,建议你等待 Debian “Bookworm” 的第一个小版本,即 12.1 版本,再进行关键服务器升级。
话虽如此,如果你想了解 Debian 12 的新特性,可以查看 [这篇文章](/article-15776-1.html)。以下是详细的升级步骤:
### 从 Debian 11 升级到 Debian 12
无论你运行的是 Debian 服务器还是任何桌面版本,请确保备份关键数据。例如,你可能需要为桌面文档进行备份。如果是服务器,请记录正在运行的服务。你可以使用 `rsync` 或其他实用工具来完成此操作。
Debian 12 引入了一个名为 `non-free-firmware` 的新仓库,用于专有驱动程序和软件包。如果你使用任何“闭源”的网络、显示、图形或其他驱动程序,你可能需要在升级后进行配置。
对于网络驱动程序,请确保在某个地方安全地记录 `/etc/network/interfaces` 和 `/etc/resolv.conf` 文件的内容。如果在升级完成后失去了网络连接,可以 [按照这个指南](https://wiki.debian.org/NetworkConfiguration) 轻松设置它。
从命令提示符运行以下命令,以确保 Debian 11 更新了安全和其他软件包:
```
sudo apt update
sudo apt upgrade
sudo apt full-upgrade
sudo apt autoremove
```
完成上述命令后,重新启动 Debian 11 系统:
```
sudo systemctl reboot
```
记下关于 Debian 11 的几个信息。这对于服务器很重要。它们包括内核版本和 Debian 版本。这是因为升级后,你可以验证下面的相同命令以确保升级成功。
例如,我尝试升级的系统是 Debian 11.7,内核版本为 5.10。
```
uname -mr
```
示例输出:
```
5.10.0-23-amd64 x86_64
```
```
cat /etc/debian_version
```
示例输出:
```
11.7
```
将 APT 源文件备份到你选择的任何目录:
```
sudo cp -v /etc/apt/sources.list /home/arindam/
sudo cp -vr /etc/apt/sources.list.d/ /home/arindam/
```
打开 `/etc/apt/sources.list` 文件,并将 Debian 12 的代号 `bookworm` 添加到该文件中,替换 `bullseye`。
```
sudo nano /etc/apt/sources.list
```
以下是我测试系统中的 `/etc/apt/sources.list` 文件**更改之前**的内容作为参考:
```
deb http://deb.debian.org/debian/ bullseye main
deb-src http://deb.debian.org/debian/ bullseye main
deb http://security.debian.org/debian-security bullseye-security main
deb-src http://security.debian.org/debian-security bullseye-security main
deb http://deb.debian.org/debian/ bullseye-updates main
deb-src http://deb.debian.org/debian/ bullseye-updates main
```
以下是**更改后**的 `/etc/apt/sources.list` 文件。以下镜像网址是默认设置。如果你使用不同的 Debian 镜像,请不要更改它们:
```
deb http://deb.debian.org/debian/ bookworm main
deb-src http://deb.debian.org/debian/ bookworm main
deb http://security.debian.org/debian-security bookworm-security main
deb-src http://security.debian.org/debian-security bookworm-security main
deb http://deb.debian.org/debian/ bookworm-updates main
deb-src http://deb.debian.org/debian/ bookworm-updates main
deb http://deb.debian.org/debian bookworm non-free non-free-firmware
deb-src http://deb.debian.org/debian bookworm non-free non-free-firmware
deb http://deb.debian.org/debian-security bookworm-security non-free non-free-firmware
deb-src http://deb.debian.org/debian-security bookworm-security non-free non-free-firmware
deb http://deb.debian.org/debian bookworm-updates non-free non-free-firmware
deb-src http://deb.debian.org/debian bookworm-updates non-free non-free-firmware
```

**注意**:从 Debian 12 “Bookworm” 开始,Debian 团队创建了一个新的仓库 `non-free-firmware` 来打包非自由的软件包。因此,在上面的示例中最后三个部分中也包含了它们。
保存文件并退出。
打开终端并运行以下命令以开始升级过程:
```
sudo apt update
sudo apt full-upgrade
```


在升级过程中,安装程序可能会要求你重新启动几个服务。仔细阅读消息后点击 “Yes”。另外,如果你看到带有 `:` 的提示,请按 `q` 键退出该消息。

等待软件包下载和安装完成。
升级完成后,请重新启动你的 Debian 桌面或服务器:
```
sudo systemctl reboot
```
### 检查升级状态
重启后,请验证你是否正在运行 Debian 12。可以使用以下文件检查 Debian 版本:
```
cat /etc/debian_version
```
示例输出:

此外,如果你刚刚升级到 Debian 12 服务器,请确保验证正在运行的服务,例如 HTTP、SSH 等。你可以使用以下 [systemd 命令](https://www.debugpoint.com/systemd-systemctl-service/) 了解正在运行的服务:
```
systemctl list-units --type=service
```
### 总结和清理
在确认所有步骤都已完成后,你可能希望运行 `apt autoremove` 命令来清理不需要的软件包。但是,请在执行此操作时格外小心。
```
sudo apt --purge autoremove
```
这就是升级到 Debian 12 的简要步骤。希望你的升级顺利进行。如果你正在关键服务器上运行 Debian 11,请勿立即升级,请等到 Debian 12.1 发布。
有关 Debian 升级的更多信息,请访问 [官方文档](https://www.debian.org/releases/bookworm/amd64/release-notes/ch-upgrading.en.html)。
最后,请别忘了告诉我们你的升级情况。
---
via: <https://www.debugpoint.com/upgrade-debian-12-from-debian-11/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,904 | Sniffnet:任何人都可以使用的有趣的开源网络监控工具 | https://news.itsfoss.com/sniffnet/ | 2023-06-14T16:38:51 | [
"监控",
"嗅探"
] | https://linux.cn/article-15904-1.html |
>
> 使用这个方便的应用查看你的网络连接。
>
>
>

嗅探,嗅探,那是什么? ?
这是我在系统上看到的可疑网络连接吗? ?❌
你可能想知道我如何查看系统上的网络活动。 嗯,当然,一些 [系统监控工具](https://itsfoss.com:443/linux-system-monitoring-tools/) 应该有所帮助。但是,如果我想要更多详细信息怎么办?
好吧,我遇到了一个不错的工具 **Sniffnet**。 它是一个用于实时监控网络活动的简洁的**开源应用**,也是专有的 [GlassWire](https://www.glasswire.com:443/)(如 [Portmaster](https://news.itsfoss.com/portmaster-1-release/))的一个很好的替代品。
那么,让我们深入挖掘吧!
### Sniffnet:概述 ⭐

Sniffnet 是一个**基于 Rust 的**网络监控工具,可让你跟踪通过系统的所有互联网流量。 它提供了一些非常有用的功能,高级用户肯定会喜欢这些功能\*\*。
当你第一次启动 Sniffnet 时,你会看到一个菜单来选择**网络适配器、过滤器和应用协议**。
完成选择后,单击“火箭”按钮开始。

这是概览页的样子。它显示了所有当前的网络连接,以及一个方便的流量图,供你分析流量。
>
> ? 你可以选择将数据显示为字节或单个数据包。
>
>
>

要更深入地查看你的网络连接,你可以前往“<ruby> 检查 <rt> Inspect </rt></ruby>”选项卡。
在这里,你将看到一个包含所有重要信息的列表,例如 IP 地址、数据包数量、数据量、来源国家等等。
你可以单击各个连接获得更详细的情况。

#### 如果你想为更具体的目的过滤结果怎么办?
好吧,那么你可以使用“检查”选项卡下的过滤器选项根据你的需要过滤结果。
你可以通过以下方式过滤列表: 应用、国家、域名等。
这是它的样子:

Sniffnet 还可以向你显示可以以文本格式导出的连接的详细报告。
只需单击右下角带有页面/向右箭头的徽标即可开始。

#### 可定制性如何?
好吧,Sniffnet 有一组不错的设置供你调整。
第一个是“通知”选项卡,它允许你根据可以设置的各种阈值来设置通知的行为。

然后是可以通过“<ruby> 样式 <rt> Style </rt></ruby>”选项卡访问的主题。它提供四种选择,雪人之夜是我的最爱。

最后,“<ruby> 语言 <rt> Language </rt></ruby>”选项卡允许你设置你选择的界面语言。

好了,就此结束。
Sniffnet 是一个方便的工具,可以非常详细地了解系统上的网络活动。
你可以使用它来监控你的网络。
此外,与另一个网络监控工具 [Nutty](https://itsfoss.com:443/nutty-network-monitoring-tool/) 相比,在我看来,Sniffnet 的使用和设置要直观得多。
### ? 获取 Sniffnet
Sniffnet 可跨多个平台使用,包括 **Linux**、**Windows** 和 **macOS**。 你可以前往[官方网站](https://www.sniffnet.net:443/download/)获取你选择的安装包。
>
> **[Sniffnet](https://www.sniffnet.net:443/download/)**
>
>
>
如果愿意,你还可以在 [GitHub](https://github.com:443/GyulyVGC/sniffnet) 上仔细查看其源代码。
---
via: <https://news.itsfoss.com/sniffnet/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Sniff, sniff, what is that? 🤔
Is that a suspicious network connection I see on my system? 🚨❌
You might be wondering how I could see the network activity on my system. Well, of course, some of the [system monitoring tools](https://itsfoss.com/linux-system-monitoring-tools/?ref=news.itsfoss.com) should help. But, what if I want more details?
Well, I came across a nice tool **Sniffnet**. It is a neat **open-source app for monitoring network activity** in real-time, which also acts as a good alternative to the proprietary [GlassWire](https://www.glasswire.com/?ref=news.itsfoss.com) like [Portmaster](https://news.itsfoss.com/portmaster-1-release/).
So, let's dig in!
## Sniffnet: Overview ⭐
Sniffnet is a **Rust-based** network monitoring tool that lets you track all the internet traffic through your system. It offers some pretty **useful features that a power user will most definitely like**.
When you first launch Sniffnet, you are shown a menu to select the **network adapter, filters, and application protocol**.
After you are done selecting, click on the rocket button to get started.
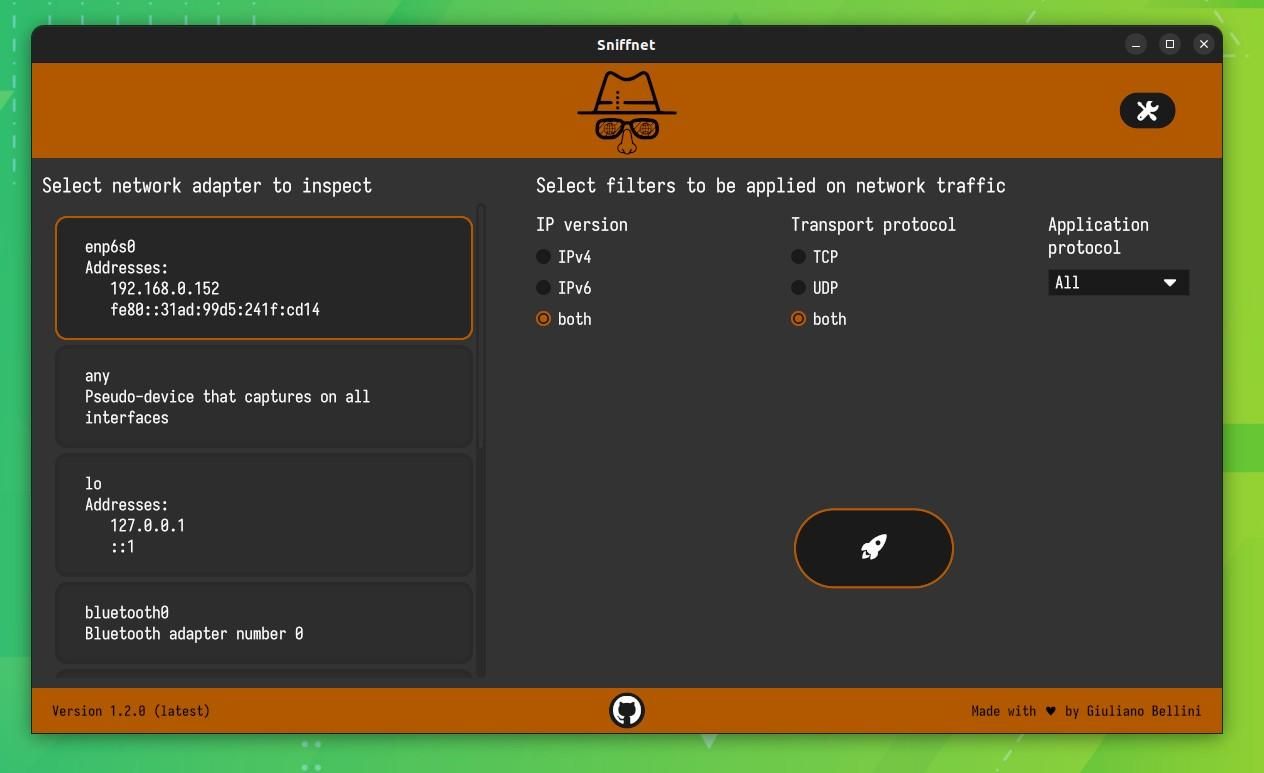
This is how the overview page looks; it shows all the current network connections, as well as a handy traffic rate graph for you to analyze the flow of traffic.
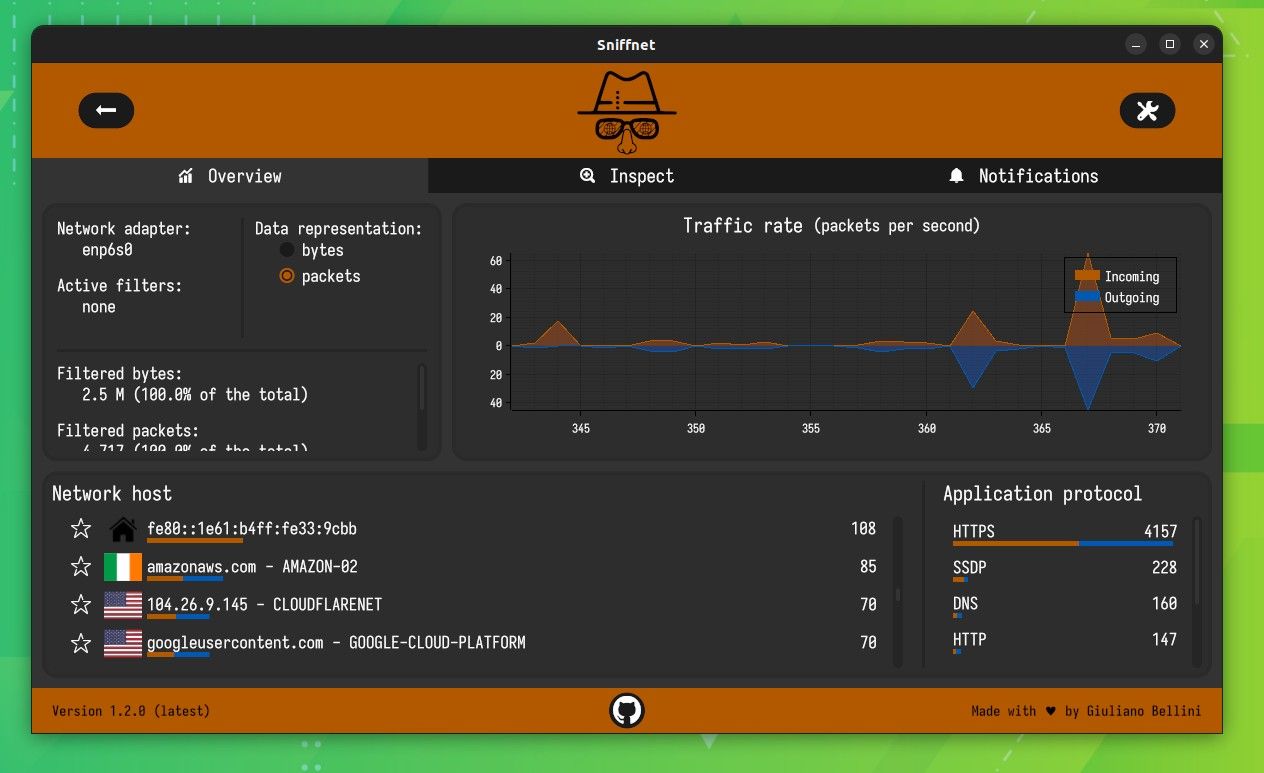
For a more in-depth look at your network connections, you can head to the '**Inspect**' tab.
Here you will be shown a list with all the important info, such as the IP address, number of packets, amount of data, the originating country, and more.
You can click on the individual connections to get a more detailed outlook.
**Suggested Read **📖
[Monitoring Network Bandwidth and Speed in LinuxBrief: In this article, we list some open source utilities to monitor the network traffic, bandwidth and internet speed in Linux. Monitoring internet speed can be a crucial step in understanding your connection and it can help you find possible problems. It will also help you troubleshoot any c…](https://itsfoss.com/network-speed-monitor-linux/?ref=news.itsfoss.com)

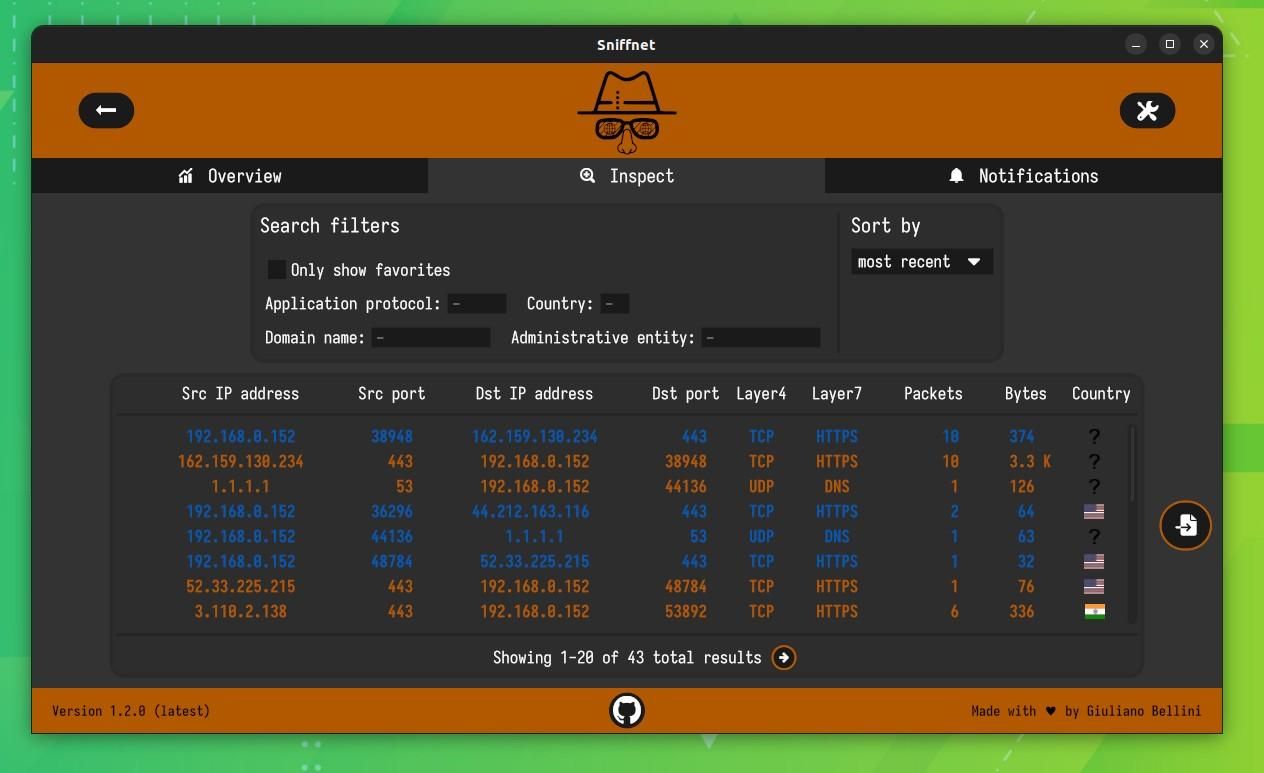
**What if you want to filter the results for a more specific purpose?**
Well, then you can use the filter options under the 'Inspect' tab to filter the results according to your needs.
You can filter the list by; application protocol, country, domain name, and more.
Here's what it looks like:
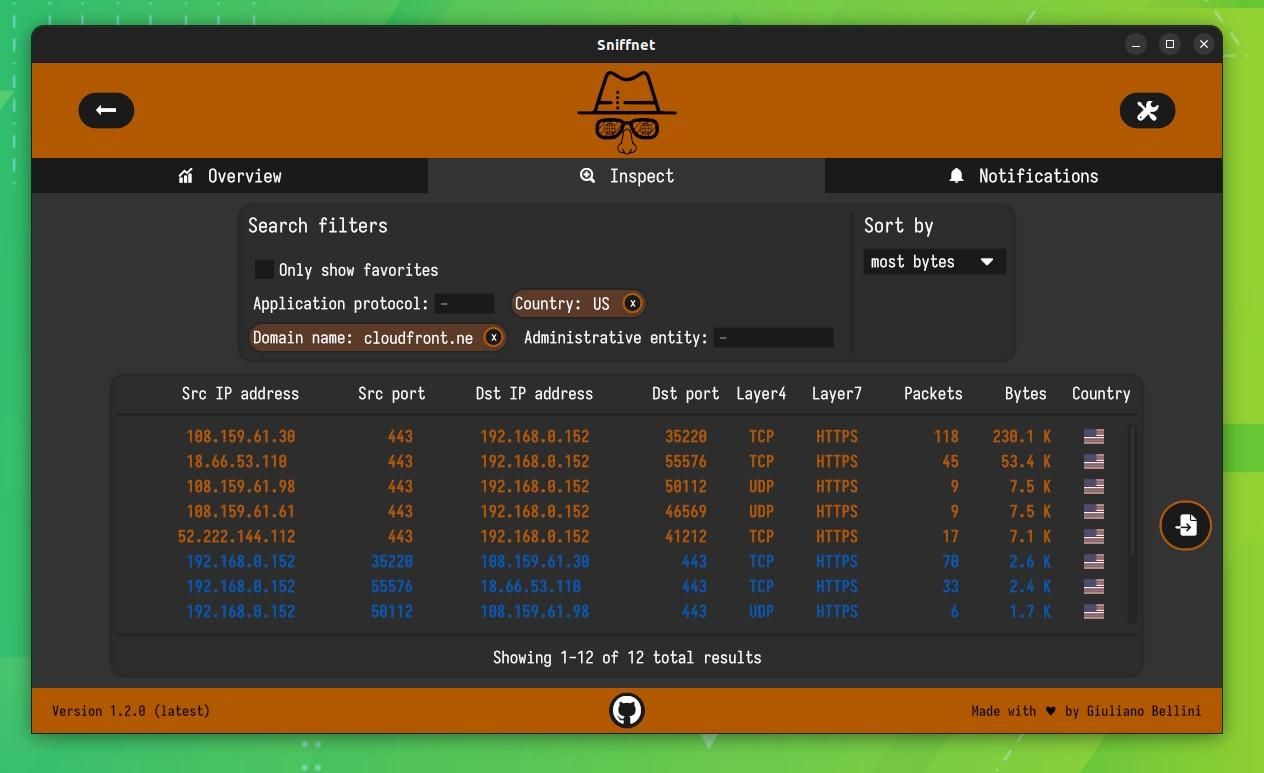
Sniffnet can also show you a detailed report of a connection that can be exported in text format.
Simply click on the logo with a page/right arrow at the bottom-right to get started.
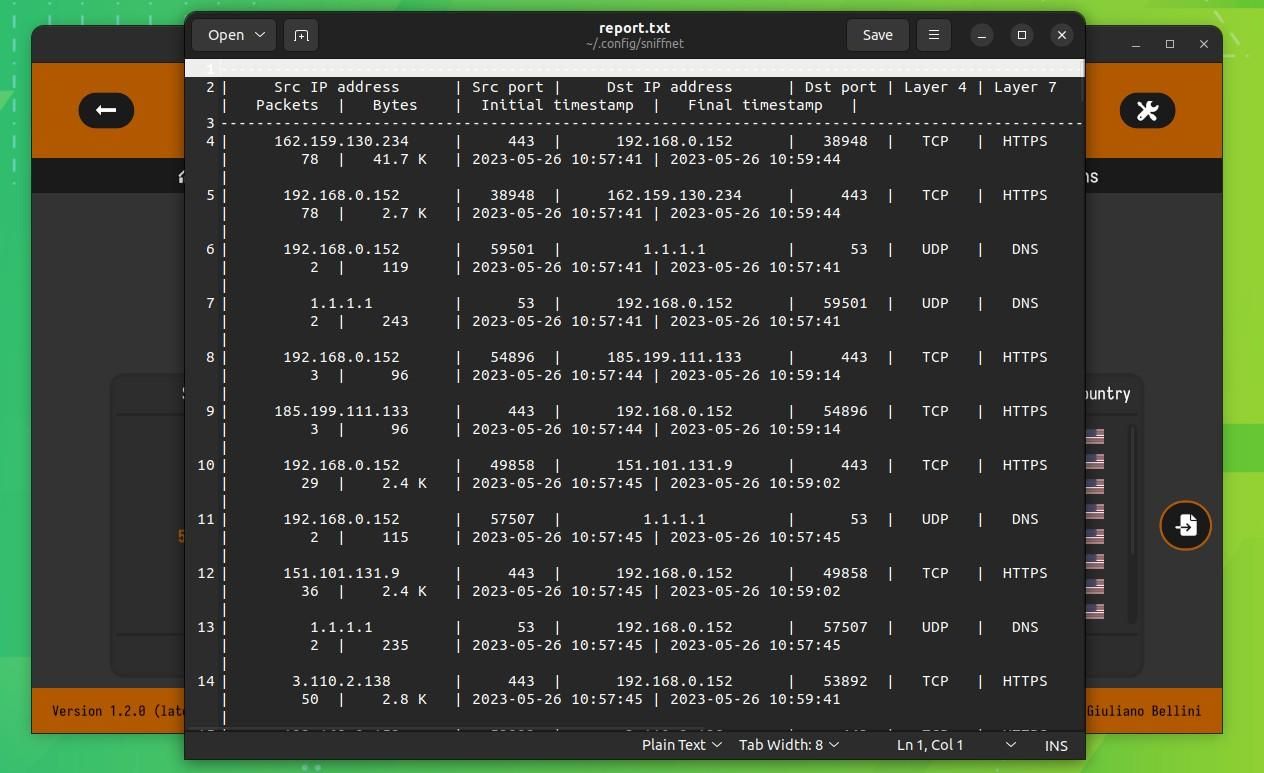
**What about the customizability?**
Well, Sniffnet has a decent set of settings for you to tweak.
The first one is the 'Notifications' tab, which allows you to set the behavior of notifications according to the various thresholds that can be set.
Then there are the themes that can be accessed via the 'Style' tab; Four options are on offer, with the Yeti Night being my favorite.
And finally, the 'Language' tab allows you to set an interface language of your choice.
So, wrapping up.
Sniffnet is a handy tool that gives a very detailed outlook of the network activity on a system.
You can use this to monitor your network.
Furthermore, compared to [Nutty](https://itsfoss.com/nutty-network-monitoring-tool/?ref=news.itsfoss.com), another network monitoring tool, Sniffnet is far more intuitive to use and set up in my opinion.
## 📥 Get Sniffnet
Sniffnet is available across multiple platforms including **Linux**, **Windows**, and **macOS**. You can head over to the [official website](https://www.sniffnet.net/download/?ref=news.itsfoss.com) to grab the package of your choice.
If you'd like, you can also look closely at its source code on [GitHub](https://github.com/GyulyVGC/sniffnet?ref=news.itsfoss.com).
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,905 | Debian 12 “Bookworm” 安装完成后需要做的 10 件事 | https://www.debugpoint.com/things-to-do-debian-12/ | 2023-06-14T17:18:47 | [
"Debian"
] | /article-15905-1.html | 
>
> 在安装完 Debian 12 “Bookworm”要做的一些事情。
>
>
>
我想你已经安装好了 Debian 12 “Bookworm” 或者 [准备升级](https://www.debugpoint.com/upgrade-debian-12-from-debian-11/) 了。Debian 12 经过一年多的开发,于 2023 年 6 月 10 日发布。它带来了最新的软件包、升级和替换一些关键模块。请在此查看 Debian 12 的一些新特性 [指南](https://www.debugpoint.com/debian-12-features/)。
如果你在笔记本电脑或台式机上使用 Debian,那么在安装或升级到 Debian 12 后,以下是你可能需要完成的一些步骤。
### Debian 12 安装后需要做的几件事情
#### 启用 sudo
如果你将 Debian 12 作为新安装的系统,那么你的用户账户可能没有超级用户访问权限。出于安全原因,Debian 在安装期间不允许任何选项给予用户账户 sudo 访问权限。以下是如何将用户添加到超级用户组。
打开终端并使用 root 密码进入 root 账户。
```
su
```
然后运行以下命令,将你的用户账户添加到 `sudo` 组。请将下面的用户名更改为你的账户。
```
/sbin/addgroup 用户名 sudo
```
现在,你可以注销并再次登录该账户。
#### 确保 Debian 已更新至最新版本
在开始工作或进行任何配置之前,确保 Debian 12 已更新至最新版本非常重要。从终端中按以下顺序运行以下命令以刷新 Debian 系统。
```
sudo apt update
sudo apt upgrade
```
#### Debian 12 中的非自由软件
Debian 12 中有一个关于管理“非自由”固件包的根本变化。Debian 创建了一个新的软件源,以便轻松访问那些专有包。因此,如果你想添加非自由软件包,需要确保在 APT 软件源文件 `/etc/apt/sources.list` 中添加以下行:
```
sudo nano /etc/apt/sources.list
```
```
deb http://deb.debian.org/debian bookworm non-free non-free-firmware
deb-src http://deb.debian.org/debian bookworm non-free non-free-firmware
deb http://deb.debian.org/debian-security bookworm-security non-free non-free-firmware
deb-src http://deb.debian.org/debian-security bookworm-security non-free non-free-firmware
deb http://deb.debian.org/debian bookworm-updates non-free non-free-firmware
deb-src http://deb.debian.org/debian bookworm-updates non-free non-free-firmware
```
保存并关闭文件。然后刷新 Debian 系统。完成后,你现在可以安装“非自由”软件包。
```
sudo apt update
```
#### 安装额外的桌面环境
Debian Linux 提供了所有主要的桌面环境包。如果你使用 Debian 的 Netinst ISO 文件(最小化 ISO 镜像)进行安装,那么你可能已经获得了默认的 Xfce 桌面环境。在 Debian 12 安装期间,你可以选择桌面环境。
如果你想安装任何额外的桌面环境,则可以使用各种软件包管理器进行安装。或者,获取专用的 ISO 文件。从 Debian 12 开始,团队为每个桌面提供单独的 ISO 文件。你可以在以下链接中获取它们。
* [amd64 – 种子](https://cdimage.debian.org/debian-cd/current-live/amd64/bt-hybrid/)(GNOME、KDE Plasma、Xfce、LXQt、LXDE、MATE 和 Cinnamon)
* [直接下载 ISO 文件](https://cdimage.debian.org/debian-cd/current-live/amd64/iso-hybrid/)(GNOME、KDE Plasma、Xfce、LXQt、LXDE、MATE 和 Cinnamon)
#### 设置 Flatpak 和 Flathub
你应该在 Debian 中 [设置 Flatpak](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/),以便从 Flathub 获取数百款最新的应用程序。要设置它,可以从终端中运行以下命令。
```
sudo apt install flatpak
```
如果你想通过浏览器安装 Flatpak 应用程序,则以下软件包是可选的。
```
sudo apt install gnome-software-plugin-flatpak
```
添加 Flathub 软件源库,其中包含所有 Flatpak 应用程序。从终端中运行以下命令。
```
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
重新启动 Debian 系统就可以使用 Flatpak 应用程序了。
#### 安装最新的 Firefox
Debian Linux 附带的是 Firefox ESR 版本,这个版本的功能略旧。不过它非常稳定和安全。如果你想 [安装最新版本的 Firefox](https://www.debugpoint.com/download-firefox/),可以从以下官方网站下载预编译的二进制文件,并执行 `firefox`。
>
> **[下载 Firefox](https://www.mozilla.org/en-US/firefox/new/)**
>
>
>
#### 安装额外的软件 – 图形界面
默认的 Debian 安装只有非常简洁的图形界面应用程序。为了配置你的工作站,你可以考虑安装以下一组应用程序。但是,以下列表非常基本,对于基本用例应该是足够的。
它们包括分区软件、BT 客户端、媒体播放器和图形实用工具。
```
sudo apt install gparted transmission-gtk vlc pavucontrol geany gimp inkscape audacity filezilla leafpad
```
#### 安装额外的软件 – 命令行界面
虽然上述图形界面应用程序是必要的,但是你应该始终安装一些超级重要的命令行实用工具。以下是我为你准备的列表。
```
sudo apt install ffmpeg default-jdk git wget nano vim htop locate p7zip p7zip-full unzip
```
#### Debian 12 中的替代包
如果你正在运行 Debian 服务器或桌面系统,你应该注意本版本中一些关键软件包已被替换。以下是其中的一些:
* 默认系统时钟现在由 `systemd-timesyncd` 管理,`ntp` 已被 `ntpsec` 替换。
* DNS 选项 `dnssec-enable` 已经过时。如果遇到无效选项错误,请在 `named.conf` 文件中注释该行(应该在 `/etc` 或 `/etc/bind9` 中)。
* 不会自动安装 `systemd-resolved` 包。你需要手动安装和启动它。
* `rsyslog` 包不会默认安装,因为 `journalctl` 接管了该功能。
#### 配置 Debian 多媒体仓库
由社区创建的流行 Debian 多媒体仓库已更新为 Bookworm 版本。你可以在 APT 软件源文件中添加以下行,并利用数百个多媒体软件包来完成你的项目。
```
deb https://www.deb-multimedia.org bookworm main non-free
```
你可以访问 [官方页面](https://deb-multimedia.org/) 以了解有关该软件源库的更多信息。
### 总结
以上是你可以利用的各种提示列表。它们只是指南,可能不适用于你的情况,但它们可以成为你开始 Debian 12 后安装旅程的起点。
在评论框中让我知道你最喜欢的 Debian 后安装提示是什么。
---
via: <https://www.debugpoint.com/things-to-do-debian-12/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,908 | Rust 基础系列 #7: 在 Rust 中使用循环 | https://itsfoss.com/rust-loops/ | 2023-06-15T16:42:19 | [
"Rust"
] | https://linux.cn/article-15908-1.html | 
在 Rust 系列的 [上一篇文章](/article-15896-1.html) 中,我介绍了如何使用 `if` 和 `else` 关键字来处理 Rust 程序的控制流。
这是处理程序控制流的一种方法。另一种方法是使用循环。因此,让我们在本文中看看循环。
### Rust 中可用的循环
Rust 编程语言有三种不同的循环,基于你想要实现什么以及可用的内容:
* `for`
* `while`
* `loop`
我假设你对 `for` 和 `while` 已经很熟悉了,但 `loop` 对你来说可能是个新概念。让我们先从熟悉的概念开始。
### for 循环
`for` 循环主要用于迭代一种称为迭代器的东西。
这个迭代器可以从任何东西中创建,从数组、向量(很快就会介绍!)、一系列值,或者任何自定义的东西。这里的可能性是无限的。
来看看 `for` 循环的语法。
```
for 迭代变量 in 迭代器 {
<语句>;
}
```
其中的 `迭代变量` 在大多数其他编程语言教程中通常被称为 `i` ; )
`迭代器` 可以是任何东西,只要它能告诉下一个值是什么,如果有的话。
来通过一个程序来理解这个。
```
fn main() {
let my_arr = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
println!("迭代数组");
for element in my_arr {
println!("{}", element);
}
println!("\n迭代一个真正的迭代器");
for element in my_arr.iter() {
println!("{}", element);
}
println!("\nPython 风格的范围");
for element in 0..10 {
println!("{}", element);
}
}
```
这里,我声明了一个数组,它包含从 0 到 9 的 10 个数字。在第 5 行的 `for` 循环中,我只是将这个数组指定为迭代器,Rust 会自动处理对这个数组的所有元素的迭代。不需要花哨的 `my_arr[i]` 魔法。
但是,在第 10 行,我调用了 `.iter()` 函数。这是一个明确的提及,它基于 `my_arr` 的值来获取一个迭代器。这个循环和第 5 行的循环之间唯一的区别是,这里你是通过在数组上调用 `.iter()` 函数来明确地调用它的。
*在这个上下文环境中*,在一个数据类型上调用 `.iter()` 函数不是必须的。因为这是一个数组,是语言本身提供的一种数据类型,Rust 已经知道如何处理它了。但是你 *需要* 在自定义数据类型中使用它。
最后,在第 15 行,我们有一个循环,它循环遍历一个范围。嗯,差不多是这样。如果你仔细看,这个范围看起来很像切片 “类型”。Rust 也知道这一点,并且 *为* 你处理了迭代(哈哈,明白了吗?)。
>
> LCTT 译注:此处的梗是,“为你处理了迭代” 的英文原文是 “handles iteration *for* you",其中的 “for” 与 “for 循环” 的 “for” 是同一个单词。
>
>
>
输出如下:
```
迭代数组
0
1
2
3
4
5
6
7
8
9
迭代一个真正的迭代器
0
1
2
3
4
5
6
7
8
9
Python 风格的范围
0
1
2
3
4
5
6
7
8
9
```
### while 循环
`while` 循环可以被认为是非常类似于 `if` 条件语句。使用 `if` 语句,只要用户提供的条件为 `true`,`if` 语句体中的代码就会被执行 *一次*。
但是,在 `while` 循环中,如果条件评估为 `true`,循环就会开始循环循环体。只要条件继续评估为 `true`,循环就会继续迭代。
`while` 循环只有在循环完成当前迭代中所有语句的执行并且在检查条件时,它的结果为 `false` 时才会停止。
来看看 `while` 循环的语法...
```
while 条件 {
<语句>;
}
```
看到了吗?和 `if` 条件语句非常相似!不过没有 `else` 块 ; )
来看一个程序来更好地理解这个。
```
fn main() {
let mut var = 0;
while var < 3 {
println!("{var}");
var += 1;
}
}
```
我有一个可变变量 `var`,它的初始值为 0。只要可变变量 `var` 中存储的值小于 3,`while` 循环就会执行。
在循环中,`var` 的值被打印出来,然后它的值被增加 1。
这是上面代码的输出:
```
0
1
2
```
### loop 循环
Rust 有一个无限循环。是的,一个没有开始条件和停止条件的循环。它只是一直循环,直到永远。当然,它有触发器来停止代码本身的循环执行。
无限循环的语法如下:
```
loop {
<语句>;
}
```
>
> ? 这些循环主要用于 GUI 软件,退出是一个 *显式* 操作。
>
>
>
在我给你一个例子之前,因为这个循环非常特殊,让我们先看看如何 *退出* 它 :p
要停止无限循环的执行,需要在循环内使用 `break` 关键字。
来看一个例子,只有 0 到 3 之间的整数(包括 0 和 3)才会被打印到程序输出。
```
fn main() {
let mut var = 0;
loop {
if var > 3 {
break;
}
println!("{}", var);
var += 1;
}
}
```
看待这个特定的例子的最好方法是将它看作是一个增加了一堆没有必要的东西的 `while` 循环 ; )
你有一个可变变量 `var`,它的初始值为 0,它被用作迭代器。无限循环从一个 `if` 条件开始,如果 `var` 的值大于 3,`break` 关键字就会被执行。后来,就像 `while` 循环的前一个例子一样,`var` 的值被打印到标准输出,然后它的值被增加 1。
它的输出如下:
```
0
1
2
3
```
### 标记循环
假设有两个无限循环,一个嵌套在另一个中。由于某种原因,退出条件在最内层循环中被检查,但这个退出条件是为了退出最外层循环。
在这种情况下,标记循环可能是有益的。
>
> ? `break` 和 `continue` 关键字并不仅仅用于无限循环。它们可以用于 Rust 语言提供的所有三种循环。
>
>
>
接下来是如何标记循环。
```
'标记: loop {}
```
要告诉编译器一个循环被标记了,从一个单引号字符开始,输入它的标签,然后跟着一个冒号。然后,继续使用你通常定义循环的方式。
当你需要退出某个循环时,只需像这样指定循环标签:
```
break '标记;
```
来看一个例子来更好地理解这个。
```
fn main() {
let mut a = 0;
let mut b = 0;
'parent: loop {
a += 1;
loop {
println!("a: {}, b: {}", a, b);
b += 1;
if a + b == 10 {
println!("\n{} + {} = 10", a, b);
break 'parent;
}
}
}
}
```
这里,我使用两个可变变量 `a` 和 `b`,它们的初始值都设置为 0。
然后,最外层的循环被标记为 `parent`。`parent` 循环将变量 `a` 的值增加 1,并有一个内部/子循环。
这个(在第 8 行的)子循环打印变量 `a` 和 `b` 的值。在这个循环内部,变量 `b` 的值增加了 1。退出条件是 `a + b == 10`。这意味着只要变量 `a` 和 `b` 中存储的值相加,结果为 10,`parent` 循环就会被打破。即使第 14 行的 `break` 条件“属于”内部循环,它也会打破 `parent` 循环。
来看看程序的输出。
```
a: 1, b: 0
a: 1, b: 1
a: 1, b: 2
a: 1, b: 3
a: 1, b: 4
a: 1, b: 5
a: 1, b: 6
a: 1, b: 7
a: 1, b: 8
1 + 9 = 10
```
就像从程序输出中可以看出的那样,循环在 `a` 和 `b` 分别具有值 1 和 9 时停止。
### continue 关键字
如果你已经在其他编程语言(如 C/C++/Java/Python)中使用过循环,你可能已经知道 `continue` 关键字的用法。
当 `break` 关键字用于完全停止循环执行时,`continue` 关键字用于“跳过”循环执行的 **当前迭代** 并从下一迭代开始(如果条件允许)。
来看一个例子来理解 `continue` 关键字的工作原理。
```
fn main() {
for i in 0..10 {
if i % 2 == 0 {
continue;
}
println!("{}", i)
}
}
```
在上面的代码中,我有一个 `for` 循环,它迭代了 0 到 9 之间的整数(包括 0 和 9)。一旦循环开始,我就设置了一个条件检查,看看这个数字是不是偶数。如果这个数字是偶数,`continue` 关键字就会被执行。
但是如果这个数字是奇数,这个数字就会被打印到程序输出。
来看看这个程序的输出。
```
1
3
5
7
9
```
正如你所看到的,循环似乎一直在“进行”,尽管 0 到 9 之间显然有偶数。但是因为我使用了 `continue` 关键字,当遇到这个关键字时,循环执行就会停止。
这个循环跳过了它下面的任何东西,并继续下一次迭代。这就是为什么偶数没有被打印出来,但是 0 到 9 之间的所有奇数都被打印到了程序输出中。
### 总结
要总结这篇长文,我演示了 3 种不同循环的用法:`for`、`while` 和 `loop`。我还讨论了两个关键字,它们影响这些循环的控制流:`break` 和 `continue`。
我希望你现在能理解每个循环的适当用例。如果你有任何问题,请告诉我。
*(题图:MJ/25579e09-ae1c-47d3-8266-3bd9a54456c0)*
---
via: <https://itsfoss.com/rust-loops/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Rust Basics Series #7: Using Loops in Rust
Loops are another way of handling control flow of your programs. Learn about for, while and 'loop' loops in Rust.
In the [previous article](https://itsfoss.com/rust-if-else/) of the Rust series, I went over the use of if and else keywords to handle the control flow of your Rust program.
That is one way of handling the control flow of your program. The other way you can do this is by using loops. So let us look at loops in this follow-up article.
## Loops available in Rust
The Rust programming language has three different loops based on what you want to achieve and what is available:
- for
- while
- loop
I presume that you are familiar with `for`
and `while`
but `loop`
might be new here. Let's start with familiar concepts first.
## The for loop
The `for`
loop is primarily used to iterate over something called an iterator.
This iterator can be made from anything, from an array, a vector (will be covered soon!), a range of values, or anything custom. The sky is the limit here.
Let us look at the syntax of the `for`
loop.
```
for iterating_variable in iterator {
<statement(s)>;
}
```
The `iterating_variable`
is more generally known as `i`
in most other programming language tutorials ;)
And an `iterator`
, as I said, can be really anything that tells what the next value is, if any.
Let's understand this using a program.
```
fn main() {
let my_arr = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
println!("iteration over an array");
for element in my_arr {
println!("{}", element);
}
println!("\niteration over a real iterator");
for element in my_arr.iter() {
println!("{}", element);
}
println!("\nPython-style range");
for element in 0..10 {
println!("{}", element);
}
}
```
Here, I have declared an array that holds 10 numbers, from 0 to 9. On the `for`
loop that is on line 5, I simply specify this array as the iterator and Rust automatically handles iteration over all the elements of this array for me. No fancy `my_arr[i]`
magic is needed.
But on line 10, I call the `.iter()`
function on the array. This is an explicit mention of getting an iterator based on the values that `my_arr`
consists of. The only difference between this loop and the loop on line 5 is that here you are being explicit by calling the `.iter()`
function on the array.
Calling the `.iter()`
function on a data type, *in this context,* isn't strictly necessary. Since this is an array, which is a data type provided by the language itself, Rust already knows how to handle it. But you *will* need it with custom data types.
Finally, on line 15, we have a for loop that loops over a range. Well sort of. If you look closely, this range will look very similar to the Slice "type". Rust knows about this too and handles iteration *for* you (haha, get it?).
The output looks like following:
```
iteration over an array
0
1
2
3
4
5
6
7
8
9
iteration over a real iterator
0
1
2
3
4
5
6
7
8
9
Python-style range
0
1
2
3
4
5
6
7
8
9
```
## The while loop
The `while`
loop can be thought to be very similar to an `if`
conditional statement. With the `if`
statement, provided that the user-provided condition evaluates to `true`
, the code in the `if`
statement's body is executed *once*.
But with the `while`
loop, if the condition evaluates to `true`
, the loop starts looping over the loop body. The loop will continue its iteration as long as the condition keeps on evaulating to `true`
.
The `while`
loop stops only when the loop has completed the execution of all statements in the current iteration and upon checking the condition, it evaluates to `false`
.
Let's look at the syntax of a while loop...
```
while condition {
<statement(s)>;
}
```
See? Very similar to an `if`
conditional statement! No `else`
blocks though ;)
Let's look at a program to understand this better.
```
fn main() {
let mut var = 0;
while var < 3 {
println!("{var}");
var += 1;
}
}
```
I have a mutable variable, `var`
, with an initial value of 0. The `while`
loop will loop as long as the value stored in the mutable variable `var`
is less than 3.
Inside the loop, `var`
's value gets printed and later on, its value gets incremented by 1.
Below is the output of the code written above:
```
0
1
2
```
## The loop
Rust has an infinite loop. Yes, one with no condition for starting and no condition to stop. It just continues looping over and over again till infinity. But of course, has triggers to stop the loop execution from the code itself.
The syntax for this infinite loop is as follows:
```
loop {
<statement(s)>;
}
```
*operation.*
*explicit*Before I even give you an example, since this loop is quite special, let's first look at how to *exit* it :p
To stop the execution of an infinite loop, the `break`
keyword is used inside the loop.
Let's look at an example where only whole numbers between 0 and 3 (inclusive) are printed to the program output.
```
fn main() {
let mut var = 0;
loop {
if var > 3 {
break;
}
println!("{}", var);
var += 1;
}
}
```
The best way to interpret this particular example is to look at it as an unnecessarily expanded form of a `while`
loop ;)
You have a mutable variable `var`
with an initial value of 0 that is used as an iterator, kind of. The infinite loop starts with an `if`
condition that *should var's value be greater than 3, the break keyword should be executed*. Later on, like the previous example of the
`while`
loop, `var`
's value is printed to the stdout and then its value is incremented by 1.It produces the following output:
```
0
1
2
3
```
## Labelled loops
Let's say there are two infinite loops, one nested in the other. For some reason, the exit condition is checked in the innermost loop but this exit condition is for exiting out of the outermost loop.
In such a case, labelling the loop(s) might be beneficial.
Following is how to label a loop.
`'label: loop {}`
To tell the compiler that a loop is being labelled, start with a single quote character, type the label for it, and follow it with a colon. Then, continue with how you regularly define a loop.
When you need to break certain loop, simply specify the loop label like so:
` break 'label;`
Let's take a look at an example to better understand this.
```
fn main() {
let mut a = 0;
let mut b = 0;
'parent: loop {
a += 1;
loop {
println!("a: {}, b: {}", a, b);
b += 1;
if a + b == 10 {
println!("\n{} + {} = 10", a, b);
break 'parent;
}
}
}
}
```
Here, I took two mutable variables `a`
and `b`
with the initial values set to 0 for both.
Later down, the outer-most loop is labelled `parent`
. The 'parent' loop increments the value of varaible `a`
by 1 and has an inner/child loop.
This child loop (on line 8) prints the values of variables `a`
and `b`
. Inside this loop, the value of `b`
gets incremented by 1. And the exit condition is that `a + b == 10`
. Meaning whenever the values stored in variables `a`
and `b`
, when added together, result in 10, the `parent`
loop is broken. Even though the `break`
condition on line 14 "belongs" to the inner loop, it breaks the `parent`
loop.
Let's look at the program output now.
```
a: 1, b: 0
a: 1, b: 1
a: 1, b: 2
a: 1, b: 3
a: 1, b: 4
a: 1, b: 5
a: 1, b: 6
a: 1, b: 7
a: 1, b: 8
1 + 9 = 10
```
As evident from the program output, the loop stops as soon as `a`
and `b`
have the values 1 and 9 respectively.
## The continue keyword
If you have already used loops in any other programming language like C/C++/Java/Python, you might already know the use of the `continue`
keyword.
While the `break`
keyword is to stop the loop execution completely, the `continue`
keyword is used to "skip" the **current iteration** of loop execution and start with the next iteration (if the conditions permit).
Let's look at an example to understand how the `continue`
keyword works.
```
fn main() {
for i in 0..10 {
if i % 2 == 0 {
continue;
}
println!("{}", i)
}
}
```
In the code above, I have a `for`
loop that iterates over whole numbers between 0 and 9 (inclusive). As soon as the loop starts, I put a conditional check to see if the number is even or not. If the number is even, the `continue`
keyword is executed.
But if the number is odd, the number gets printed to the program output.
Let's first look at the output of this program.
```
1
3
5
7
9
```
As you can see, the loop appears to have been "going on" even though there clearly are even numbers between 0 and 9. But because I used the `continue`
keyword, the loop execution stopped when that keyword was encountered.
The loop skipped whatever was under it and continued with the next iteration. That's why even numbers are not printed, but all odd numbers between 0 and 9 are printed to the proogram output.
## Conclusion
To conclude this long article, I demonstrated the use of 3 different loops: `for`
, `while`
and `loop`
. I also discussed two keywords that affect the control flow of these loops: `break`
and `continue`
.
I hope that you now understand the appropriate use case for each loop. Please let me know if you have any questions. |
15,909 | 开源的养家之道 | https://opensource.com/article/23/3/open-source-family | 2023-06-15T17:09:06 | [
"开放"
] | /article-15909-1.html | 
>
> 与你最亲近的人建立一种开放的文化,并带着它走遍天下。
>
>
>
作为 80 年代的叛逆少年,“因为我这么说”是我在家里经常听到的一句话。我并不是一个真正的叛逆者。我只是想让别人听到我的声音,把我看成是一个开始表达自己想法和情感的人。
我那种不被倾听/聆听的感觉让我相信,培养不害怕说话的孩子很重要,但他们也能学会适应。倾听他们的意见,与孩子们合作,也可以帮助他们发挥创造力,最终让他们成为成功组织的一部分。
### 孩子们如何解释信息
我并没有刻意鼓励孩子们的开放行为,也没有主动告诉孩子们要大声说话。尽管如此,在我大儿子上幼儿园的第一天,他的老师给我们打电话。她告诉我们,当她和全班同学一起讨论不打架、不推搡等规则时,我的孩子举手告诉她,他的父母允许他一直争论和辩论。
这是真的。我让我的孩子们表达自己的意见,并让他们听到。但我孩子的话让我感到惊讶。直到那时我才意识到,虽然我一直在做正确的事情,但事实上,我的孩子们的行为不应该只是对我们教育他们的方式的反应。我们也不应该让他们从二手语境中挑选东西。那一天对我来说是一个游戏规则的改变,践行开放的文化正式主动地进入我们的家庭。
### 为成长而开放
在我小的时候,父母和长辈是有知识的人。
作为一个孩子,要获得信息并不容易。虽然我被鼓励表达意见,但也只是到了一个规范的、“容易消化”的程度。今天,父母、老师和孩子都有同样的手段来获取数据。你如何处理它,完全取决于你。
例如,在用希伯来语玩 Scattergories 时,“病毒”一词通常是大多数人玩的唯一以 “V” 开头的生物。为了获得更多的分数,我们决定寻找其他符合条件的动物名称。不一会儿,我们就找到了不是一种而是三种新的生物(我孩子的老师认为“小袋鼠”(希伯来语中以 “V” 拼写)不是一种真实的东西,但这是另一个故事)。
我教我的孩子阅读字里行间的内容,决不要不加质疑地接受作为“事实”呈现给他们的东西。这使他们能够练习批判性思维。这也使他们能够质疑我,从而使我们进行公开和透明的讨论。
这些讨论容易吗?不是。我总是有精力进行这些讨论吗?绝对不是。
然而,为了帮助他们练习学会倾听的“肌肉”,这些对话是必须的。
偶尔,我们必须强迫自己找到时间,把注意力集中在家庭上。建立一个强大而开放的文化需要时间,随着人们的变化,你的家庭文化也在变化。你必须适应并努力保持它的活力。作为群体的领导者,我必须为我的孩子们提供一个安全的地方,一个他们可以公开分享自己想法的地方,一个他们有归属感的地方。
在一个家庭中,你们必须合作,共同解决问题。倾听不同的想法和解决问题的方法可以让你想出创造性的(但并不总是符合每个人的喜好)解决方案。
我家里的一个问题是玩电脑游戏时家里的噪音。这种情况大多发生在深夜和周末。我们一起坐下来,想出了一个商定的嘈杂游戏的时间段。从那时起,那些想玩的人知道他们什么时候可以玩,而那些寻求一些安静时间的人也知道这些时间会发生什么。随着孩子们的长大,决定和讨论的性质也发生了变化。
这是否意味着所有的决定都与孩子们分享?不。这是否意味着都是玫瑰花?绝对不是。
鼓励孩子们建立联系可能会以一个破花瓶告终,似乎没有人对此负责。这可能会导致“因为我这么说”来拜访。然而,进行具有挑战性但又具有包容性的对话、鼓励创新思维以及让孩子参与决策都是让他们为成年做好准备的方法。希望它也能让他们成为更好的人(到目前为止,以我的拙见,这运作良好)。
### 开放的家庭文化
实行开放的文化不是一次性的事情。它是一个旅程,也是一种心态。我相信它为我和我的孩子们提供了工具,使他们在屋内和屋外都能坚韧不拔、思想开放、宽容和充满好奇心。与你最亲近的人建立一种开放的文化,并带着它走遍天下。
*(题图:MJ/76568fbf-4e8a-4a9e-9ff1-d6a7e0922622)*
---
via: <https://opensource.com/article/23/3/open-source-family>
作者:[Ruth Netser](https://opensource.com/users/rnetser1) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,911 | 10 个最佳 Linux 虚拟化软件 | https://itsfoss.com/virtualization-software-linux/ | 2023-06-16T10:03:50 | [
"虚拟机"
] | https://linux.cn/article-15911-1.html | 
>
> 我们将介绍一些最佳的虚拟化程序,为用户创建/管理虚拟机提供便利。
>
>
>
虚拟化软件由于其用途和好处而广泛使用,你可以使用它来体验、测试或运行需要特定操作系统版本的软件。
虚拟化提供了一个抽象的计算机硬件概念,帮助你创建虚拟机(VM)、网络、存储等。其好处包括隔离性、安全性和自由度高,可以尽情测试各种事物。
不同类型的虚拟化软件分别适用于桌面用户、服务器管理员和企业用户。
在列出各种虚拟化软件的同时,我还会提到适用对象。
### 1、VirtualBox

[VirtualBox](https://www.virtualbox.org:443/) 是一款备受赞誉的开源虚拟机程序,适用于 Linux、Windows 和 macOS。
它适用于各种类型的用户,无论你只是想在虚拟机上运行 Linux,还是想创建一个用于测试的虚拟机,或者是企业需要一个虚拟机解决方案。
对大多数用户来说,它可以被视为一个全能解决方案。虽然它主要适用于桌面使用,但你可以尝试其<ruby> 无头 <rt> headless </rt></ruby>模式,通过查阅其 [文档](https://www.virtualbox.org:443/manual/ch07.html),将虚拟机作为远程桌面服务器运行。
主要亮点:
* 支持广泛的客户操作系统
* 简单的用户界面和快速的性能
* 定期更新
* 功能丰富
### 2、OpenVZ

想在服务器上创建隔离的 Linux 容器吗?[OpenVZ](https://openvz.org:443/) 可以帮助你。
你可以创建行为类似于独立服务器的容器。这些容器具备帮助你高效管理的所有基本功能。
由于 OpenVZ 是作为 Linux 发行版构建和分发的,因此容器仅运行于 Linux 上。
对于初学者来说,OpenVZ 是学习使用容器的绝佳选择,因为它易于配置和管理。此外,与其他一些方案相比,基于 OpenVZ 的 VPS 托管价格实惠。
主要亮点:
* 资源利用效率高
* 使用和管理简单
### 3、KVM
<ruby> 基于内核的虚拟机 <rt> Kernel-based Virtual Machine </rt></ruby>([KVM](https://www.linux-kvm.org:443/page/Main_Page))集成在 Linux 中,这是它最大的优势。你可以直接在 Linux 上使用 KVM 运行虚拟机。它是一种<ruby> 第一类 <rt> type-1 </rt></ruby> <ruby> 虚拟化管理程序 <rt> Hypervisor </rt></ruby>,也就是硬件级别的虚拟化。
KVM 可以将 Linux 主机转换为运行虚拟机的虚拟化管理程序,以实现与物理机相似的性能。
与 OpenVZ 不同,KVM 高度可定制,且已内置于 Linux 系统中,无需单独安装。考虑到 KVM 借助虚拟化管理程序实现硬件级别的虚拟化,它相对需要更多的内存和其他系统资源。
你可以使用 KVM 创建不同操作系统的虚拟机。要配置它,你可以参考 [Ubuntu 的官方博客文章](https://ubuntu.com:443/blog/kvm-hyphervisor) 关于 KVM 安装的内容。
主要亮点:
* 高度可定制且设置复杂
* 与 Linux 系统集成
>
> ? <ruby> <a href="https://linuxhandbook.com:443/what-is-hypervisor/"> 虚拟化管理程序 </a> <rt> Hypervisor </rt></ruby> 是一种创建和运行虚拟机(VM)的软件。
>
>
>
### 4、GNOME Boxes

GNOME Boxes 是最简单的虚拟化程序,适用于希望尽快下载和测试发行版的用户。
与其他一些解决方案相比,GNOME Boxes 可能不具备各种各样复杂的功能,但它包含了必需的功能。用户体验简单,新手也能轻松上手。
主要亮点:
* 现代化的用户界面
* 简单易用
### 5、VMware Workstation(非自由及开源软件)

[VMware](https://www.vmware.com:443/products/workstation-player.html) 是一款非常受欢迎的 Linux、Windows 和 macOS 虚拟机程序。
尽管它是一个专有解决方案,但它是个人用户和企业用户使用的行业领先选项之一。VMware 还提供了与云计算相关的几种其他产品。
因此,如果你需要一个桌面虚拟化程序,VMware Workstation Player 可以是一个很好的选择。对于其他用户,还有许多其他用于服务器和云服务提供商的版本。
主要亮点:
* 个人和企业服务器版本
* 易于使用
* 高级版带有更多功能
### 6、Xen
[Xen](https://xenproject.org:443/) 是最古老的虚拟化软件之一,亚马逊和红帽使用它。尽管大多数人已经转向使用 KVM,但 Xen 仍然是云基础设施的一个选项。
是的,Xen 更适合用于服务器而不是桌面虚拟化。它支持 Linux、Windows 和 FreeBSD。
主要亮点:
* 面向服务器基础设施
* 支持半虚拟化(大多数其他软件不支持)
### 7、oVirt

[oVirt](https://www.ovirt.org:443/) 是一个优秀的开源解决方案,适用于寻找管理服务器架构的社区和企业。它是一个利用 KVM 的管理工具。
你可以使用丰富的基于 Web 的用户界面来管理其中的一切,包括主机、存储和网络配置。它还支持虚拟机的实时迁移,以提供便利。
然而 oVirt 不支持 Windows 平台,它专为与 RHEL 和 CentOS Linux 配合使用而设计。
主要亮点:
* 针对企业市场
* 使用 KVM 虚拟化管理程序
* 分布式虚拟化解决方案
* 不适合初学者使用
### 8、Proxmox

[Proxmox](https://itsfoss.comproxmox.com/) 是另一个针对企业市场的开源虚拟化平台。
你需要订阅才能获得软件更新和技术支持。根据你的需求,你可以选择其中一个订阅方案。除了虚拟环境平台,他们还提供备份和电子邮件安全解决方案,以供你在企业基础设施中使用。
主要亮点:
* 安装设置简单
* 文档齐全
### 9、QEMU

[QEMU](https://www.qemu.org:443/) 是一个很棒的虚拟机程序(及模拟器),可在多个平台上运行。
它支持广泛的硬件架构和客户操作系统。你可以与 KVM 结合使用,以运行表现出色的虚拟机,因为 KVM 是硬件级别的虚拟化工具,而 QEMU 是软件级别的虚拟化程序。
从技术上讲,QEMU 是一种<ruby> 第二类 <rt> type-2 </rt></ruby>虚拟化软件。
如果你想要一个以 QEMU 为核心,并且方便初学者创建虚拟机的工具,你可以尝试 [Quickgui](https://itsfoss.com/quickgui/)。
主要亮点:
* 支持广泛的操作系统
* 在不依赖硬件的情况下提供灵活性
### 10、Hyper-V

[Hyper-V](https://learn.microsoft.com:443/en-us/windows-server/virtualization/hyper-v/hyper-v-technology-overview) 是一种与微软 Windows 操作系统捆绑在一起的虚拟化管理程序。
尽管它不适用于 Linux,但它支持将 Linux 作为客户操作系统运行。你可以在 Windows 上使用 Hyper-V 运行 Kali Linux 和 Ubuntu 等发行版。
Hyper-V 在 Windows 桌面版和服务器版上有一些功能差异。因此,根据你的用例,你可能需要查阅其 [官方文档](https://learn.microsoft.com:443/en-us/virtualization/hyper-v-on-windows/about/)。
主要亮点:
* 可用于 Windows 的第一类虚拟化软件
* 性能卓越
* 支持 Windows 和 Linux 操作系统
* 适用于桌面和服务器用户
### 这些工具让虚拟化变得简单
虚拟化是一种在十年前开始兴起的概念。现在几乎所有熟悉计算机的人都知道它。
用于实现虚拟化的程序易于使用,并提供了简化专业用户和家庭用户工作的功能。对于大多数用户来说,VirtualBox、GNOME Boxes 和 VMware 等解决方案应该是首选。
如果你是一个企业用户或技术爱好者,你可以根据你的需求寻找其他选项。
? 你在 Linux 上运行虚拟化软件时最喜欢使用哪个?你更喜欢使用虚拟机管理程序还是 Linux 或其他主机操作系统?在下方的评论中分享你的想法。
*(题图:MJ/c89ae6b4-c923-4219-b7cd-96ee7e37c84b)*
---
via: <https://itsfoss.com/virtualization-software-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Virtualization software is prevalent because of its use cases and benefits. You get to experiment, test, or run software that requires a specific OS version.
Virtualization provides an abstract concept of computer hardware to help you create virtual machines (VMs), networks, storage, and more. The benefits include isolation, security, and the freedom to test things to your heart's extent.
Different types of virtualization software cater to desktop users, server administrators, and enterprises.
While I list all kinds of virtualization software, I mention who it is for.
## 1. VirtualBox
[VirtualBox](https://www.virtualbox.org) is a top-rated open-source virtual machine program for Linux, Windows, and macOS.
It is suitable for all kinds of users, whether you are just someone who wants to [run Linux on a virtual machine](https://itsfoss.com/why-linux-virtual-machine/), a professional who wants to create a VM for testing or an enterprise that needs a VM solution.
You can consider it as an all-in-one solution for most users. Even though it is primarily fit for desktop usage, you can try its headless mode to run a virtual machine as a remote desktop server by exploring its [documentation](https://www.virtualbox.org/manual/ch07.html).
**Key Highlights:**
- It supports a wide range of guest operating systems
- Simple user interface and fast performance
- Regularly updated
- Feature-rich
## 2. OpenVZ

Want to create isolated Linux containers on servers? [OpenVZ](https://openvz.org) should help.
You can create containers that behave like a stand-alone server. The containers have all the essential functionalities to help you manage them efficiently.
The containers run on Linux only as OpenVZ is built and distributed as a Linux distribution.
OpenVZ is an excellent pick for new users learning to work with containers considering it is easy to configure and manage. Additionally, OpenVZ-powered VPS hosting is affordable compared to some others.
**Key Highlights:**
- Efficient resource usage
- Simple to use and manage
## 3. KVM
Kernel-based Virtual Machine ([KVM](https://www.linux-kvm.org/page/Main_Page)) is built into Linux, which is its biggest advantage. You can run VMs out of the box on Linux with KVM. It is a **type-1 hypervisor **i.e. hardware-based.
KVM converts the Linux host to a hypervisor to run virtual machines with bare metal like performance.
Unlike OpenVZ, KVM is highly customizable and baked into the Linux system without needing to install separately. Considering KVM provides hardware-level virtualization with the help of a hypervisor, it needs more memory and other system resources comparatively.
You can create guest/virtual machines of different operating systems with KVM. To set it up, you can explore [Ubuntu's official blog post](https://ubuntu.com/blog/kvm-hyphervisor) on KVM installation.
**Key Highlights:**
- Highly customizable and complex to setup
- Baked in with Linux
[Hypervisor](https://linuxhandbook.com/what-is-hypervisor/)is software that creates and runs virtual machines (VMs)
## 4. GNOME Boxes
**Key Highlights:**
- Modern UX
- Simple and easy to use
GNOME Boxes is the simplest virtualization program for users looking to download test distros as quickly as possible.
Compared to some other solutions, GNOME Boxes may not feature all kinds of features but the essentials. The user experience is simple, and it is easy to use for newbies.
## 5. VMware Workstation (Not FOSS)
**Key Highlights**
- Personal and enterprise server offerings
- Easy to use
- Premium edition with more features
[VMware](https://www.vmware.com/products/workstation-player.html) is an incredibly popular virtual machine program for Linux, Windows, and macOS.
While it is a proprietary solution, it is one of the industry-leading options used by personal users and enterprises. There are several other offerings by VMware related to cloud computing.
So, if you want a desktop virtualization program, VMware Workstation Player can be a good pick for you. For others, there are plenty of other editions for server and cloud providers.
## 6. Xen
[Xen](https://xenproject.org) is one of the oldest virtualization software used by Amazon And Red Hat. While most have switched to using KVM over Xen, it is still an option for cloud infrastructure.
Yes, Xen is tailored for more server usage than desktop virtualization. It supports Linux, Windows, and FreeBSD.
**Key Highlights:**
- Tailored for server infrastructure
- Supports para-virtualization (which most others don't)
## 7. oVirt
[oVirt](https://www.ovirt.org) is an excellent open-source solution for communities and enterprises looking for a tool to manage server architecture. It is a management tool that utilizes KVM.
You get a rich web-based user interface to manage everything in it, hosts, storage, and network configuration. It also supports live migration of virtual machines for convenience.
Considering it does not support the Windows platform, it is tailored to work with Red Hat Enterprise Linux (RHEL) and CentOS Linux.
**Key Highlights:**
- Enterprise-focused
- Uses KVM hypervisor
- Distributed virtualization solution
- Not suitable for beginners
## 8. Proxmox
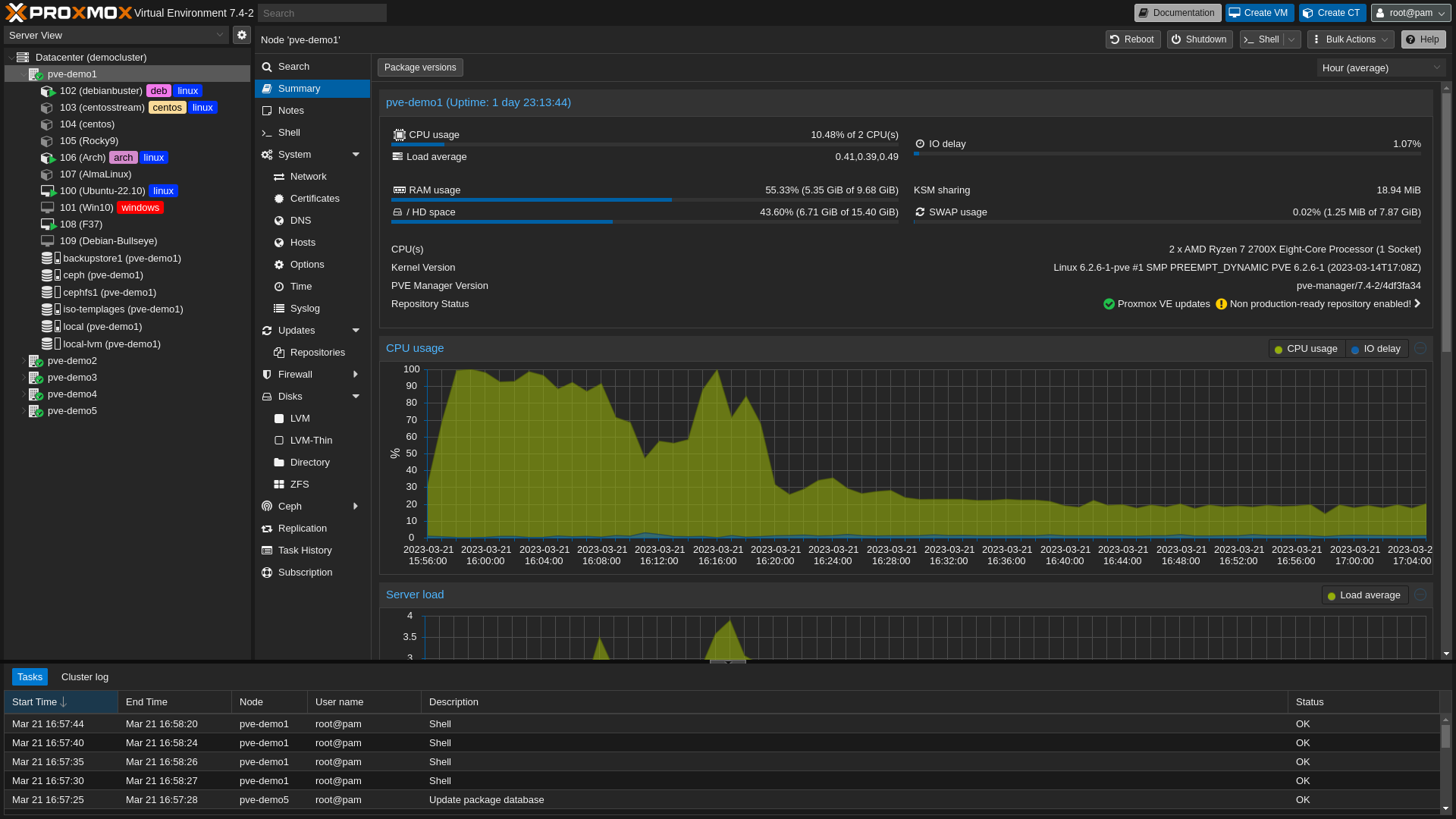
[Proxmox](proxmox.com/) is yet another open-source virtualization platform tailored for enterprises.
You need to get a subscription to receive software updates and technical help. As per your requirements, you can opt for one of them. Not just limited to virtual environment platforms, they also offer backup and email security solutions if you plan to explore for your enterprise infrastructure.
**Key Highlights:**
- Easy to setup
- Well documented
## 9. QEMU
[QEMU](https://www.qemu.org) is a nice virtual machine program (and emulator) available across multiple platforms.
It supports a wide range of hardware architectures and guest operating systems. You can couple it with KVM to run VMs that perform well because KVM is a hardware-level virtualization tool, and QEMU is a software-level virtualization program.
Technically, QEMU is a **type-2 hypervisor**.
If you want a tool that utilizes QEMU at its core and makes it easy for beginners to create virtual machines, you can explore [Quickgui](https://itsfoss.com/quickgui/).
**Key Highlights:**
- Wide range of operating system support
- It provides flexibility without depending on your hardware
## Extra: Hyper-V (for Linux VMs on Windows)
[Hyper-V](https://learn.microsoft.com/en-us/windows-server/virtualization/hyper-v/hyper-v-technology-overview) is a hypervisor that comes baked in with the Microsoft Windows operating system.
While it is not for Linux, it supports running Linux as a guest operating system. You can run distros like Kali Linux and Ubuntu with Hyper-V on Windows.
There are some feature differences with Hyper-V on Windows desktop edition and server. So, you might want to review its [official documentation](https://learn.microsoft.com/en-us/virtualization/hyper-v-on-windows/about/) per your use case.
**Key Highlights:**
- Available for Windows as a type 1 hypervisor
- Fast performance
- Supports Windows and Linux operating systems
- Works for desktop and server users
## Virtualization is Easy Because of These Tools
Virtualization was a concept starting to get ahead a decade back. Now almost everyone familiar with computing knows it.
The programs available to facilitate are easy to use and offer features that uncomplicate things for professionals and home users. For the most part, solutions like VirtualBox, GNOME Boxes, and VMware should be the pick for new users.
If you are an enterprise or a techie, you can look for other options per your requirements.
*💬 What is your favorite virtualization software to run on Linux? Do you prefer using hypervisors instead of Linux or another host operating system? Share your thoughts in the comments below.* |
15,912 | 如何在 Ubuntu 和其他 Linux 发行版中查看 AVIF 图像 | https://itsfoss.com/view-avif-images-linux/ | 2023-06-16T11:28:00 | [
"AVIF"
] | https://linux.cn/article-15912-1.html | 
>
> 在 Linux 中无法打开 AVIF 图片?AVIF 是一种新的网络图像文件格式,下面是在 Linux 桌面上查看 AVIF 图像的方法。
>
>
>
就质量而言,PNG 是最好的,但它们体积庞大,因此不适合用于网站。
JPEG 会减小文件大小,但会显着降低图像质量。
WebP 是一种相对较新的格式,可以生成尺寸更小、质量更好的图像。
现在,[AVIF](https://aomediacodec.github.io/av1-avif/) 是一种新的文件格式,可以在不牺牲质量的情况下压缩图像。对于相同的图像质量,它们比 WebP 更小。
最近 [Linux 已开始提供 WebP 支持](https://itsfoss.com/webp-ubuntu-linux/)。但是,许多发行版默认不支持 AVIF 图像格式。
如果你从网络上下载 AVIF 格式的图像,它不会显示缩略图。

如果你尝试使用默认图像查看器打开它,它很可能会显示“无法识别的图像文件格式”错误。

那么,解决方案是什么? 在 Linux 上根本看不了 AVIF 图像吗?
不,事实并非如此。对于 Linux,总有一种解决方法。
### 在 Linux 中查看 AVIF 图像文件
有一个名为 gThumb 的便捷 [图像查看器](https://itsfoss.com/image-viewers-linux/),可用于在 Linux 上打开 AVIF 图像。
如果不是全部的话,它应该在大多数 Linux 发行版的仓库中可用。
在 Ubuntu 和基于 Debian 的发行版上,使用以下命令安装 gThumb。
```
sudo apt install gthumb
```

安装后,选择一张 AVIF 图像,右键单击它并选择“<ruby> 打开方式 <rt> Open With </rt></ruby>”选项。在这里,选择 gThumb,将其设为 AVIF 图像的默认值并打开它。

gThumb 在打开的图像下以缩略图格式显示同一文件夹中的所有图像。

使用 gThumb 打开 AVIF 图像后,它们也应该以缩略图显示。

就是这样。你现在可以在 Linux 桌面上欣赏 AVIF 图像。
### 总结
gThumb 是一个用途极为广泛且功能强大的应用。这让我想知道为什么它不被用作 GNOME 或其他桌面环境和发行版中的默认图像查看器。
关于 Linux 中默认的 AVIF 支持,迟早会添加。目前,gThumb 完成了这项工作。
*(题图:MJ/a54d1f0d-ea92-42dd-bb31-de8097153cad)*
---
via: <https://itsfoss.com/view-avif-images-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

PNGs are the best when it comes to quality but they are huge in size and hence not ideal for websites.
JPEGs reduce the file size but they reduce the quality of the images significantly.
WebP is a relatively newer format that produces better-quality images with significantly smaller sizes.
Now, [AVIF](https://aomediacodec.github.io/av1-avif/) is a new file format that compresses images without sacrificing quality. They are smaller than WebP for the same image quality.
[Linux has started providing WebP support](https://itsfoss.com/webp-ubuntu-linux/) recently. However, AVIF image format is not yet supported by default in many distributions.
If you download an image in AVIF format from the web, it won’t display the thumbnail.
And if you try to open it with the default image viewer, it is likely to show ‘unrecognized image file format’ error.
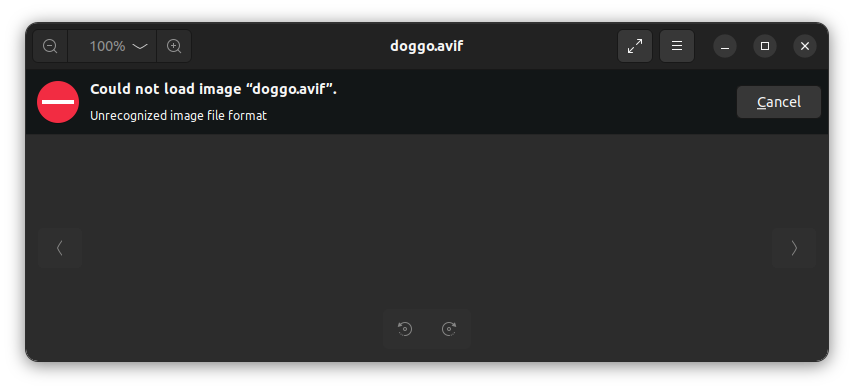
So, what’s the solution? Can you not view AVIF images on Linux at all?
Nope, that’s not the case. There is always a workaround when it comes to Linux.
## Viewing AVIF image files in Linux
There is a handy [image viewer](https://itsfoss.com/image-viewers-linux/) called gThumb that can be used for opening AVIF images on Linux.
It should be available in the repositories of most Linux distributions, if not all.
On Ubuntu and Debian-based distributions, use the following command to install gThumb.
`sudo apt install gthumb`
Once installed, select an AVIF image, right-click on it and select “Open With” option. Here, select gThumb, make it default for AVIF images and open it.
gThumb shows all the images from the same folder in thumbnail format under the opened image.
Once you open AVIF images with gThumb, they should also be displayed with thumbnails.
That’s it. You can now enjoy AVIF images on your Linux desktop.
## Conclusion
gThumb is an extremely versatile and capable application. It makes me wonder why it is not used as the default image viewer in GNOME or other desktop environments and distributions.
And about default AVIF support in Linux, sooner or later it will be added. For now, gThumb does the job. |
15,915 | 在 Linux 中安装和使用 pipx | https://itsfoss.com/install-pipx-ubuntu/ | 2023-06-17T15:15:10 | [
"pipx",
"pip"
] | https://linux.cn/article-15915-1.html | 
>
> `pipx` 解决了流行的 `pip` 工具的不足之处。学习在 Linux 中安装和使用 `pipx`。
>
>
>
`pip` 是一种流行的工具,用于从 [Python 包索引](https://pypi.org:443/) 中安装 Python 包和模块。
然而,在最近的发行版本中,`pip` 用户遇到了 [外部管理环境错误](https://itsfoss.com/externally-managed-environment/)。

这是为避免通过 [pip](https://itsfoss.com/install-pip-ubuntu/) 安装的 Python 包与本机包管理器之间发生冲突而添加的“功能”。Python 希望你使用单独的虚拟环境,而不是通过 `pip` 在全局安装包。
**这就是 `pipx` 发挥作用的地方**。它为你安装的每个应用创建一个新的虚拟环境,然后在全局级别的 `/bin` 中创建到本地二进制文件的链接。这一切都是自动的。它为你节省时间和精力。
让我们看看如何在 Ubuntu 和其他 Linux 发行版上安装和使用 `pipx`。
### 在 Ubuntu 和其他 Linux 上安装 pipx
安装很简单,可以在 Ubuntu 和 Debian 上使用以下命令安装:
```
sudo apt update && sudo apt install pipx
```
对于其他发行版,请使用你的包管理器并安装它。
完成安装后,[将其添加到 $PATH](https://itsfoss.com/add-directory-to-path-linux/) 以便可以从任何地方访问它:
```
pipx ensurepath
```

**关闭终端并重新启动它**。这就完成了! 现在,让我们看看如何使用它。
### 使用 pipx
包管理器的主要用途是什么? 软件包安装、更新和删除。
让我向你展示如何使用 `pipx` 执行以下操作:
* 搜索包
* 包安装
* 升级
* 包移除
让我们从安装开始。
#### 如何使用 pipx 安装包
要使用 `pipx` 安装包,你必须遵循一个简单的命令语法:
```
pipx install <package_name>
```
例如,在这里,我安装了一个非常有用的程序 Cowsay:
```
pipx install cowsay
```

同样,如果你想安装特定版本的包,你必须在 `==` 后跟上版本号,如下所示:
```
pipx install package==version
```
例如,在这里,我安装了 1.24.1 版本的 numpy:
```
pipx install numpy==1.24.1
```

#### 如何搜索包
`pipx` 程序没有搜索功能(因为 PyPI 的 API 使用限制)但这并不意味着你不能搜索 Python 包。
要搜索包,你需要安装 `pypisearch`:
```
pipx install pypisearch
```
完成后,你可以使用 `pypisearch` 命令搜索包:
```
pypisearch python_package_name
```
在这里,我搜索了 neofetch:

#### 如何使用 pipx 升级包
与任何其他现代包管理器一样,你可以一次升级所有包,也可以一次升级一个包。
要一次升级所有软件包,你只需执行以下命令:
```
pipx upgrade-all
```

如你所见,它将 numpy 升级到最新版本。
但是如果你想升级一个特定的包,你可以这样做:
```
pipx upgrade package-name
```
假设我想将 `cowsay` 包升级到最新版本,那么,我将使用以下命令:
```
pipx upgrade cowsay
```

#### 如何使用 pipx 卸载包
要删除包,你必须使用 `uninstall` 标志,如下所示:
```
pipx uninstall package_name
```
为了供你参考,在这里,我从我的系统中删除了 `numpy`:
```
pipx uninstall numpy
```

### pip 还是 pipx?
对 `pip` 的限制影响了最终用户对它的使用。值得庆幸的是,`pipx` 提供了急需的替代方案。它符合使用虚拟环境的 Python 准则,同时允许已安装的应用在全局范围内可用。
对于不是 Python 应用开发的最终用户,这提供了使用发行版仓库中不可用的 Python 应用的选项。
希望本教程对你有所帮助。如果你有任何问题或建议,请告诉我。
*(题图:MJ/fc6190e2-a412-443e-a83c-91fce1dcf695)*
---
via: <https://itsfoss.com/install-pipx-ubuntu/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Pip is a popular tool for installing Python packages and modules from [Python Package Index](https://pypi.org/).
However, in recent distribution versions, pip users are encountering an [externally-managed-environment error](https://itsfoss.com/externally-managed-environment/).
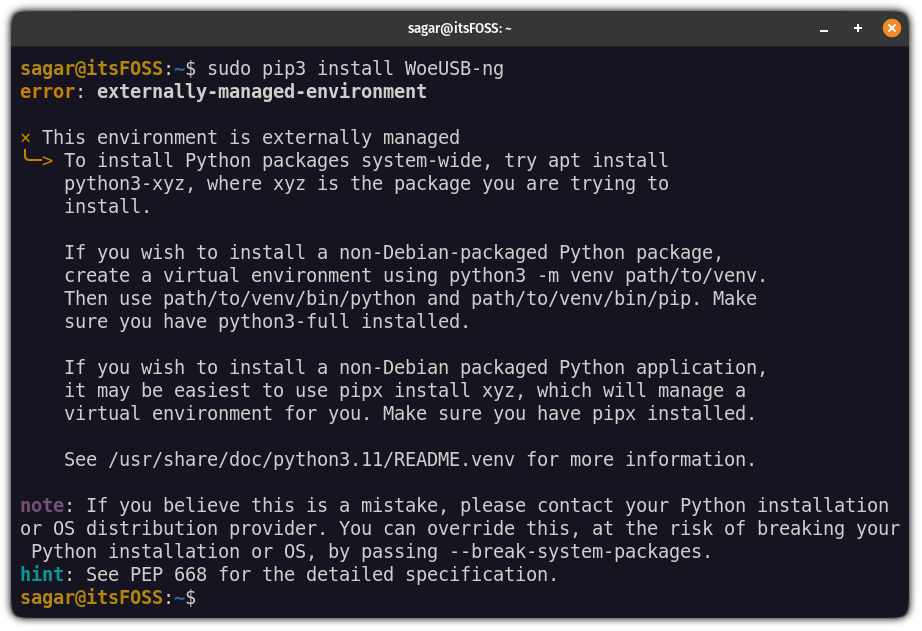
That's a 'feature' added to avoid conflicts between Python packages installed via [Pip](https://itsfoss.com/install-pip-ubuntu/) and the native package manager. Python wants you to use separate virtual environments instead of installing the package at the global level via Pip.
**This is where pipx comes into the picture**. It creates a new virtual environment for each application you install and then creates links to local binary in the /bin at the global level. All this is automatic. It saves time and effort for you.
Let's see how to install and use Pipx on Ubuntu and other Linux distributions.
## Install pipx on Ubuntu and other Linux
The installation is straightforward and can be installed using the following command on Ubuntu and Debian:
`sudo apt update && sudo apt install pipx`
For other distributions, please use your package manager and install it.
Once you are done with the installation, [add it to the $PATH](https://itsfoss.com/add-directory-to-path-linux/) so it can be accessed from everywhere:
`pipx ensurepath`
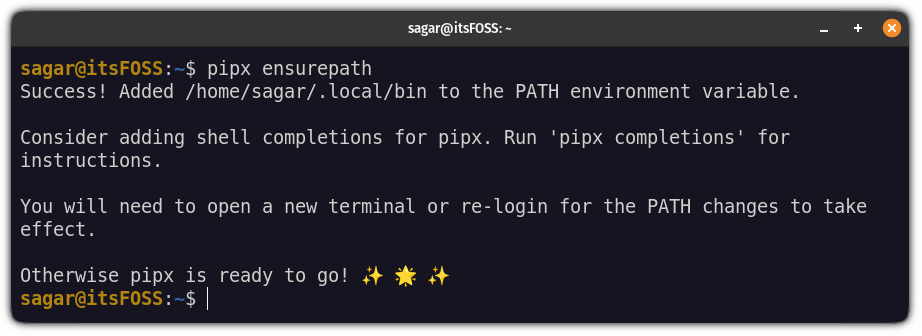
**Close the terminal and start it again**. That's it! Now, let's have a look at how to use it.
## Using pipx
What is the primary use of a package manager? Package installation, updation, and removal.
Let me show how you can do the following with pipx:
- Search packages
- Package installation
- Upgradation
- Package removal
Let's start with the installation.
### How to install packages using pipx
To install packages using pipx, you'd have to follow a simple command syntax:
`pipx install <package_name>`
For example, here, I installed a very useful program Cowsay:
`pipx install cowsay`
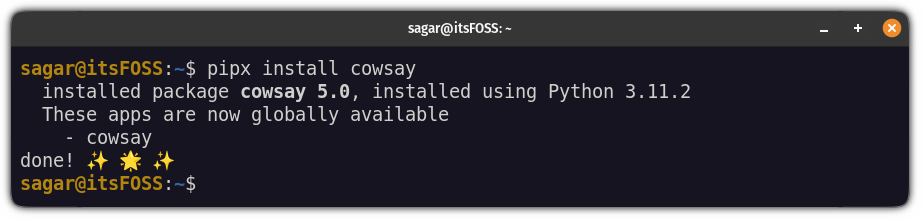
Similarly, if you want to install a specific version of the package, you'd have to insert the version number followed by `==`
as shown:
`pipx install package==version`
For example, here, I installed numpy version 1.24.1:
`pipx install numpy==1.24.1`
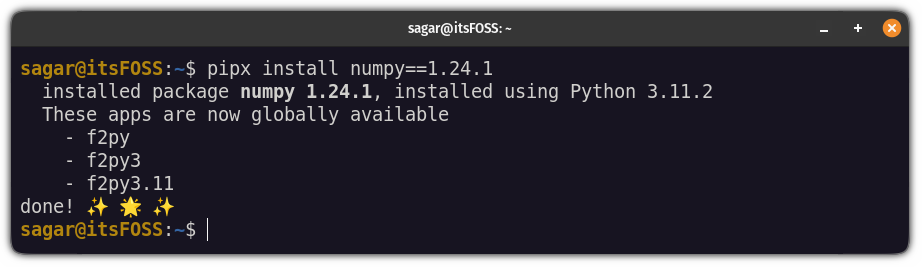
### How to search packages
The pipx utility does not have a search feature (because of limited API use of PyPI) but that doesn't mean you can't search Python packages.
To search packages, you'd have to install `pypisearch`
:
`pipx install pypisearch`
Once you do that, you can search the packages using the `pypisearch`
command:
`pypisearch python_package_name`
Here, I searched for neofetch:
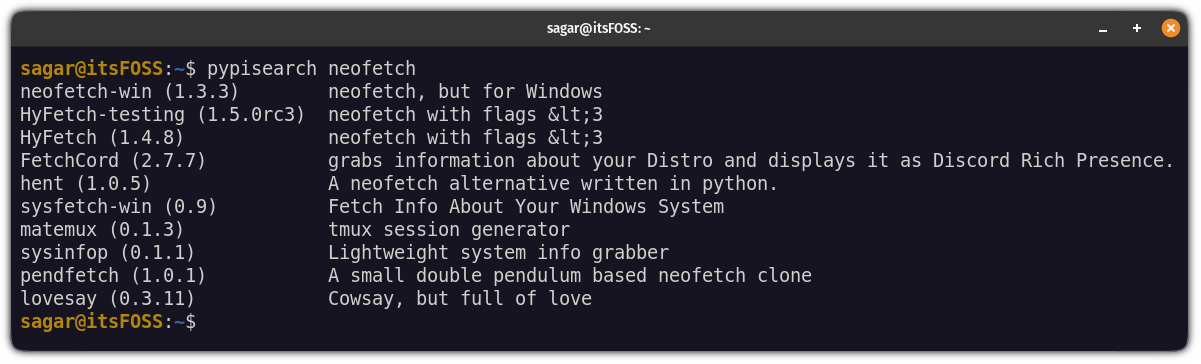
### How to upgrade packages using pipx
Like any other modern package manager, you can upgrade all packages at once or you can upgrade one package at a time.
To upgrade all the packages at once, all you have to do is execute the following command:
`pipx upgrade-all`

As you can see, it upgraded numpy to the latest version.
But if you want to upgrade a specific package, here's how you do it:
`pipx upgrade package-name`
Let's say I want to upgrade `cowsay`
package to the latest version, then, I will be using the following:
`pipx upgrade cowsay`

### How to uninstall packages using pipx
To remove packages, you'd have to use the `uninstall`
flag as shown:
`pipx uninstall package_name`
For your reference, here, I removed `numpy`
from my system:
`pipx uninstall numpy`

## Pip or Pipx?
The restrictions put on Pip have limited its use by the end users. Thankfully, Pipx provides the much-needed alternative. It meets the Python guidelines of using virtual environments and, at the same time, allows installed applications to be available at the global level.
For end users, who are not Python application developers, this gives the option to use Python applications unavailable in distribution repositories.
I hope you find this tutorial helpful. Let me know if you have questions or suggestions. |
15,916 | GitHub Copilot 之所以强大,是因为它盗窃了开源代码 | https://www.opensourceforu.com/2022/07/github-copilot-is-only-effective-because-it-steals-open-source-code/ | 2023-06-17T15:38:00 | [
"Copilot"
] | https://linux.cn/article-15916-1.html | 
<ruby> 软件自由保护协会 <rt> Software Freedom Conservancy </rt></ruby>(SFC)是一家由开源倡导者组成的非营利性社区。今天(本文原文发表于 2022 年 7 月 5 日),它发布了一篇抨击性的博文,宣布退出 GitHub,并请求其成员及支持者公开谴责该平台。SFC 与 GitHub 的如此纷争,源于这一颇受指责的举动:微软和 OpenAI 训练了一个名为 Copilot 的 AI 系统,而其训练数据的来源,是那些使用了开源许可证公开的代码。开源代码不是捐款箱,不是想拿多少就拿多少,想怎么用就怎么用的。
它更像是摄影作品。即便摄影师没有向你收取照片的使用费,你仍需要在该署名的地方进行署上来源。据 SFC 的一篇 [博文](https://sfconservancy.org/blog/2022/jun/30/give-up-github-launch/) 所述,Copilot 在使用他人的代码片段时,并没有保留来源信息:
“这反映了 GitHub 长期以来的问题,也是我们必须一齐放弃 GitHub 的关键原因。从 Copilot 中,从 GitHub 的代码托管服务中,从我们所见的基本每个领域,我们都发现 GitHub 的行为比其同行要差得多。我们也不相信 Amazon、Atlassian、GitLab 等其他盈利性的代码托管平台,能有杰出的表现。然而,将 GitHub 的行为与其同行相对比较一下,就能发现 GitHub 的行为要差得多了。”
GitHub 是全世界事实上的开源代码仓库。它是 YouTube、Twitter 和 Reddit 的混合体,但专为程序员及其代码服务。自然,替代品是有的。但是,从一个代码仓库生态切换到另一个,并不等同于用 Instagram 来替代 TikTok。微软在 2018 年花了 70 多亿美元来收购 GitHub。从那时起,微软就利用其 OpenAI 的主要受益者的地位,来共同开发 Copilot。并且,要访问 Copilot 服务,只能通过微软的特别邀请,或者支付订阅费。该举激怒了 SFC 及其他开源倡导者,因为微软和 OpenAI 实际上在将他人的代码货币化,同时让使用这些代码的人们不能正确地表明归属信息。
Copilot 必须毁灭。或者,微软和 OpenAI 可以造一台时光机,然后穿越到过去,将 Copilot 数据库中的每一点数据做标记,从而能够为所有输出提供正确的署名。但是,与其去关心你产品或者服务中的伦理问题,不如去鼓动人们,去开拓那荒野西部似的监管环境,后者总是更加简单的。
*(题图:MJ/1a101872-c0d6-475e-b3e2-3646c9a2d66b)*
---
via: <https://www.opensourceforu.com/2022/07/github-copilot-is-only-effective-because-it-steals-open-source-code/>
作者:[Laveesh Kocher](https://www.opensourceforu.com/author/laveesh-kocher/) 选题:[lkxed](https://github.com/lkxed) 译者:[Peaksol](https://github.com/TravinDreek) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Software Freedom Conservancy (SFC), a non-profit community of open source advocates, announced its withdrawal from GitHub today in a scathing blog post urging members and supporters to publicly condemn the platform. The SFC’s issue with GitHub stems from allegations that Microsoft and OpenAI trained an AI system called Copilot on data that had been made available under an open source licence. Open source code is not like a donation box where you can take whatever you want and use it however you want.
It’s closer to photography. Even if a photographer does not charge you to use one of their images, you are still required to give credit where credit is due. According to an SFC [blog post](https://sfconservancy.org/blog/2022/jun/30/give-up-github-launch/), Copilot does not do this when it comes to using other people’s code snippets:
“This harkens to long-standing problems with GitHub, and the central reason why we must together give up on GitHub. We’ve seen with Copilot, with GitHub’s core hosting service, and in nearly every area of endeavor, GitHub’s behavior is substantially worse than that of their peers. We don’t believe Amazon, Atlassian, GitLab, or any other for-profit hoster are perfect actors. However, a relative comparison of GitHub’s behavior to those of its peers shows that GitHub’s behavior is much worse.”
GitHub is the world’s de facto repository for open source code. It’s a cross between YouTube, Twitter, and Reddit, but for programmers and the code they create. Sure, there are alternatives. Switching from one code-repository ecosystem to another, however, is not the same as trading Instagram for TikTok. Microsoft paid more than $7 billion to acquire GitHub in 2018. Since then, Microsoft has used its position as OpenAI’s primary benefactor to collaborate on the development of Copilot. And access to Copilot is only available through a special invitation from Microsoft or through a paid subscription. The SFC and other open source advocates are outraged because Microsoft and OpenAI are effectively monetizing other people’s code while removing the ability for those who use that code to properly credit those who use it.
Copilot must be killed. Alternately, Microsoft and OpenAI could construct a time machine and travel back in time to label every single datapoint in Copilot’s database, allowing them to create a second model that gives proper credit to every output. But it’s always easier to take advantage of people and exploit the Wild West regulatory environment than it is to care about the ethics of the products and services you offer. |
15,918 | Tube Downloader:下载 YouTube 视频的开源工具 | https://news.itsfoss.com/tube-downloader/ | 2023-06-17T19:54:58 | [
"YouTube"
] | https://linux.cn/article-15918-1.html |
>
> 出于研究目的需要下载 YouTube 视频吗? Tube Downloader 可以提供帮助。
>
>
>

找到了你想要保存以供离线使用的 YouTube 视频,同时又想不选择他们的付费计划?
好吧,那么你可以使用 Tube Downloader。它是 “[yt-dlp](https://github.com:443/yt-dlp/yt-dlp)” 的前端,提供了一些简洁的功能。
>
> ? 未经许可下载 YouTube 视频是违反平台政策的。因此,这些工具在官方商店中不可用。我们不鼓励你将该工具用于非法目的,仅提及该工具用于研究和实验目的。
>
>
>
### Tube Downloader:概述 ⭐

**Tube Downloader 主要使用 C# 编写,是一个跨平台的开源工具**,可让你轻松直接从 YouTube 下载视频。
请允许我向你展示此应用的功能。
当你启动应用时,“<ruby> 添加下载 <rt> Add Download </rt></ruby>”按钮会显示一个友好的问候语。单击它以添加 YouTube 视频 URL,然后单击“<ruby> 验证 <rt> Validate </rt></ruby>”。

当你这样做时,你将看到用于选择文件格式、质量、字幕、保存位置等的选项。
>
> ? 你可以选择 MP3 作为仅下载音频的文件格式。
>
>
>
单击“<ruby> 下载 <rt> Download </rt></ruby>”开始下载视频。

你会在主页面上看到下载进度,你可以在其中看到视频的标题以及 URL 和下载速度。
此外,Tube Downloader 在下载完成时显示通知; 但是当我测试它时,它有点不稳定。

那不是全部。Tube Downloader 也有一些不错的自定义选项,例如:
* 适配系统主题。
* 在后台运行。
* 能够限制最大并发下载量。
* 设置下载速度限制。
* 选择使用 “Aria2” 作为替代下载器。
* 启用/禁用在下载的视频中包含元数据。
* 停止/重试所有下载并清除所有排队的下载。

这些可以从功能区菜单下的“<ruby> 首选项 <rt> Preferences </rt></ruby>”访问。
看到 Linux 客户端工作得相当好,Tube Downloader 对于下载那些令人上瘾的快乐的猫咪模因和其他东西是很有用的 ? (我们不做评价)。
### ? 获取 Tube Downloader
Tube Downloader 可在 **Linux** 和 **Windows** 中的 [Flathub](https://flathub.org:443/apps/org.nickvision.tubeconverter)、[Snap 商店](https://snapcraft.io:443/tube-converter) 和 [微软商店](https://apps.microsoft.com:443/store/detail/nickvision-tube-converter/9PD80NNX004P) 中获取 。
>
> **[Tube Downloader(Flathub)](https://flathub.org:443/apps/org.nickvision.tubeconverter)**
>
>
>
你还可以在 [GitHub](https://github.com:443/NickvisionApps/TubeConverter) 上查看其源代码。
你想知道我从 YouTube 下载了哪些视频吗? ?好吧,你可以在我们的 [YouTube 频道](https://www.youtube.com:443/@Itsfoss) 上查看这些内容。
---
via: <https://news.itsfoss.com/tube-downloader/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Found a YouTube video that you want to save for offline use while also not opting for their paid plan?
Well, then you can make use of Tube Converter. It is a front-end for '[yt-dlp](https://github.com/yt-dlp/yt-dlp?ref=news.itsfoss.com)' that offers some neat features.
## Tube Converter: Overview ⭐
Written primarily using C#, **Tube Converter is a cross-platform open-source tool** that allows you to download videos directly from YouTube without much hassle.
Allow me to show you the capability of this app.
When you launch the app, a nice greeting is shown with the '**Add Download**' button. Click on that to add a YouTube video URL, and then click on '**Validate**.'
When you do that, you will be shown options to select the file format, quality, subtitles, save location, and more.
Click on '**Download**' to start downloading the video.
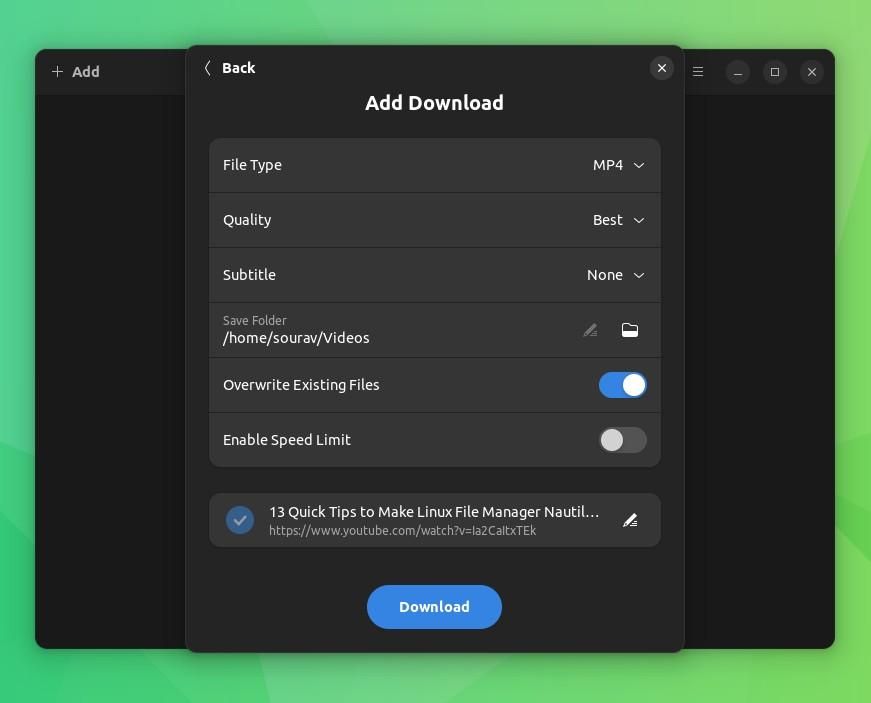
You are shown the progress of the download on the main screen, where you can see the title of the video and the URL and download speed.
Moreover, Tube Converter shows a notification when a download is finished; But when I tested that, it was a bit spotty.
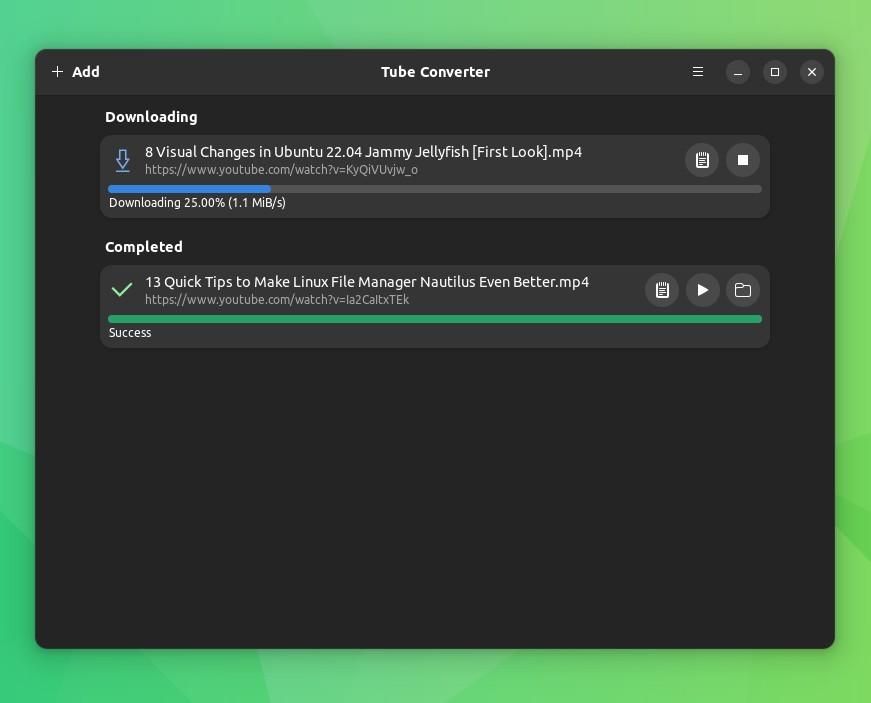
That's not all; Tube Converter also has some good customization options, such as:
**Adapting to the system theme.****Running in the background.****Ability to limit maximum concurrent downloads.****Set a download speed limit.****Option to use 'Aria2' as an alternative downloader.****Enable/Disable the inclusion of metadata in downloaded videos.****Stop/Retry all downloads and clear all queued downloads.**
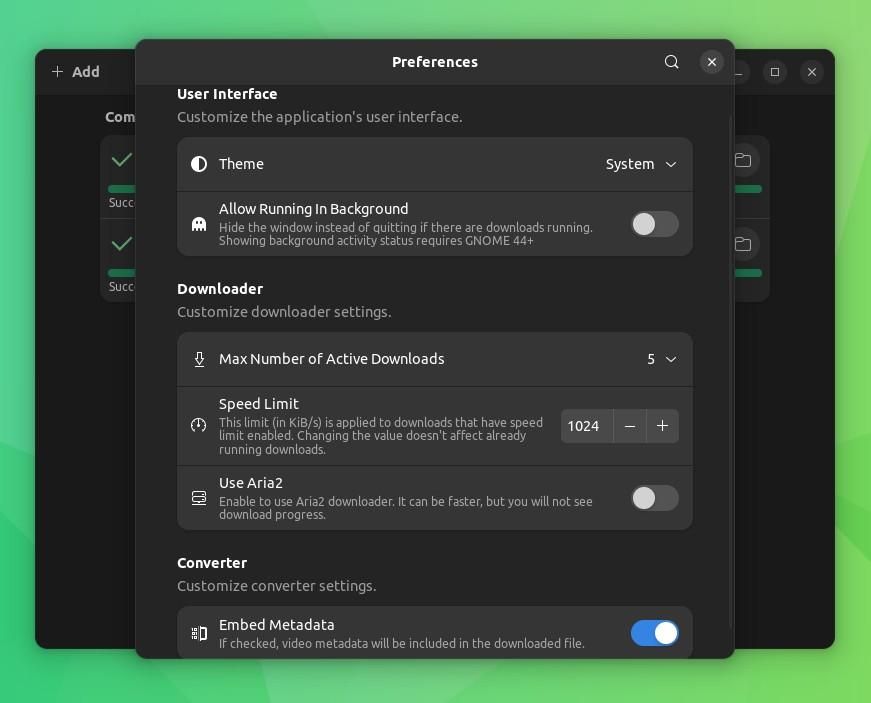
These can be accessed from 'Preferences' under the ribbon menu.
Seeing that the Linux client works quite well, Tube Converter is useful for downloading those addictive happy happy cat memes and other stuff 🐱 (we don't judge)
## 📥 Get Tube Converter
Tube Converter is available for **Linux** and **Windows** from [Flathub](https://flathub.org/apps/org.nickvision.tubeconverter?ref=news.itsfoss.com), [Snap Store](https://snapcraft.io/tube-converter?ref=news.itsfoss.com), and the [Microsoft Store](https://apps.microsoft.com/store/detail/nickvision-tube-converter/9PD80NNX004P?ref=news.itsfoss.com).
You can also look at its source code on [GitHub](https://github.com/NickvisionApps/TubeConverter?ref=news.itsfoss.com).
*Do you wonder what videos I download from YouTube? 🤔 Well, you can check those out on our YouTube channel.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,919 | 你的笔记本电脑上有哪些贴纸? | https://opensource.com/article/22/11/laptop-stickers | 2023-06-17T23:38:00 | [
"贴纸"
] | https://linux.cn/article-15919-1.html | 
>
> 你的笔记本电脑就像一块空白的画布,可以用来展示个性化的装饰。你最喜欢的贴纸是什么?参与我们的调查,然后看看其他开源爱好者都说了些什么。
>
>
>
去年 12 月刚刚换了工作用的笔记本电脑后,我意识到我有多么喜欢给我的工作设备贴贴纸。这些贴纸有些是过去活动的纪念品,有些是我热衷的项目的标志,还有一些则只是为了好玩!
因为好奇别人的笔记本上贴了什么,我对周围的同事朋友问了一圈。
### 无障碍倡导者

这是我的工作笔记本电脑(你能看出我对 Drupal 的热爱吗)。我最喜欢的贴纸是有轮椅的 Druplicon... 当 [Drupal 8 发布时,我们把这个标志](https://www.drupal.org/files/cta/graphic/drupal%208%20logo%20isolated%20CMYK%2072_1.png) 和轮椅结合在一起,因为我所在的机构专注于无障碍性。
— [AmyJune Hineline](https://opensource.com/users/amyjune)
### 充满活力的 Java

自从我还是个孩子的时候,我的电脑和其他东西上就一直有贴纸。我认为我最喜欢的要么是 “Tux”,要么是 “Linux Inside”。它们大多与领域相关,只有一些不相关的。在右下角,我有一个运行在“汤姆猫”上的 Java 贴纸(哈哈)- 这是我职业生涯中花费大部分时间的领域。
— [Alan Formy-Duval](https://opensource.com/users/alanfdoss)
### 实用目的

嗯,我没有贴任何贴纸。然而,我在我的两台笔记本电脑上粘了绒面条,用来固定我的移动硬盘,这样我在公交车上玩游戏时就不会掉落了。我还粘了一个锁槽。
— [Rikard Grossman-Nielsen](https://opensource.com/users/rikardgn)
### 保持外观

虽然这不是最装饰得最多的笔记本电脑,但我喜欢这套集合(你知道的,很难在没有旅行的情况下获得更多!)
我最喜欢的是“最后一个提交的人是维护者”。这是对维护状态的讽刺性评论,也承诺代码将因此而继续存在。
主要是关于我使用或贡献的事物,我认为有意义,或者只是觉得这个贴纸很棒。
— [John 'Warthog9' Hawley](https://opensource.com/users/warthog9)
### 盖掉 Windows
我从不在笔记本电脑上贴贴纸,因为对我来说,真正酷的贴纸似乎都是我没有的那些(一个脾气暴躁的老人说的)。
但是我孩子们在高中时用过的那台旧的组装计算机,一台拥有 3GHz Core Duo 处理器和 8GB 内存的机器上贴着一个我几年前在温哥华的 Linux 基金会开源峰会上拿到的 Open Mainframe 贴纸。我相当喜欢那个贴纸。
还有,因为在我的生活中,`Control` 键位于 `A` 键旁边,而不是在底部行,所以我周围有一些键盘上有一个 `CTRL` 贴纸在 `CapsLock` 键上,还有一个 `CAPS` 贴纸在 `Control` 键上,它们与 GNOME 调整工具中的 [交换 Ctrl 和 CapsLock 选项](https://opensource.com/article/18/11/how-swap-ctrl-and-caps-lock-your-keyboard) 一起使用。
最后,过去我会剥掉那些带有 Windows 标志的贴纸,因为当时我唯一的选择是购买带有 Windows 税的计算机,并用 Linux 贴纸覆盖上面的胶片。同样,对于带有 Windows 标志的 `Super` 键的键盘,我也会这样做。
### 纪念品

迄今为止,Kanopi 贴纸是我最喜欢的贴纸。它不仅闪闪发光,而且呈现出七彩光泽,它时刻提醒我这家公司是多么令人惊奇。他们真的把员工放在首位,并在选择与 Kanopi 的整体公司使命和愿景相符的客户项目时非常周到。
Curt V8 贴纸是对一位亲密朋友的纪念。他热爱福特,而我丈夫喜欢雪佛兰。这种有趣的竞争导致我们在车库里乱放着福特和雪佛兰的物品,这取决于我们在哪家住。每次我看到这个仿制的福特贴纸时,我都会微笑,因为我生活在一个雪佛兰家族。
各种贴纸代表了我们多年来的家庭冒险。约会之夜,朋友,家庭公路旅行,惊险的徒步探险(天使阁),以及我年幼孩子争取从每个城市和州获得一张警察贴纸的动力。
—[Kristine Strange](https://opensource.com/users/strangemama)
### 会议福利品

龙是 [我所就读大学的吉祥物](https://www.uab.edu)。我还贴了一些 Gilmore Girls 和咖啡贴纸。
这是我女儿房门的照片,上面贴满了我多年来从各种会议上带回来的贴纸。

— [Cindy Williams](https://opensource.com/users/cindytwilliams)
### 贴上鸡
这是我非工作用的笔记本电脑。我的工作笔记本电脑基本上被覆盖在一层蜂窝状的六边形贴纸中,上面印有我们的产品、我使用和支持的开源项目,以及至少一个 [Opensource.com](http://Opensource.com) 的六边形贴纸。 : )
我无法挑出最喜欢的,因为它们都是我喜欢的,否则我就不会把它们贴在我随身携带的笔记本电脑上。我特别喜欢鸡、渡鸦和手持刀具的 Sergi the Cat。


—[Kevin Sonney](https://opensource.com/users/ksonney)
### 美食趣味
我过去经常在笔记本电脑上贴满贴纸。去年买的这台电脑很快就贴满了:

我最喜欢的是杯子蛋糕和甜甜圈标志,因为是我自己画的。我刚刚购买了一台 [System76](https://opensource.com/article/19/5/system76-secret-sauce) 的 Darter Pro 笔记本电脑,我非常喜欢它。我得到了一堆很酷的贴纸,但我一直不确定是否要把它们贴在笔记本上。我不知道为什么。
— [DJ Billings](https://opensource.com/users/itsjustdj)
### 保持简洁

我在我的笔记本电脑上不贴很多贴纸,但目前正在使用的这台笔记本上贴着我最喜欢的两个贴纸,它是 System76 的 Darter Pro。
—[Don Watkins](https://opensource.com/users/don-watkins)
### 生活的必需品

我还包括了我的水瓶。我想我更喜欢那些贴纸。
啤酒,狗,音乐,牛角面包。我还需要什么?
— [Katie Sanders](https://enterprisersproject.com/user/katie-sanders)
### 我的座右铭

我最喜欢的贴纸是 “yeet or be yeeted”。
— [Faye Polson](https://twitter.com/faye_polson)
### 大蒜

大部分贴纸都是专业的,但 “Greetings from Hamunaptra”、“City of the Dead” 贴纸隐晦地参考了我最喜欢的电影之一《<ruby> 木乃伊 <rt> The Mummy </rt></ruby>》(1999),是由 Brendan Fraser 和 Rachel Weisz 主演的。
旗帜和 “Blackbeard's Bar & Grill” 贴纸指的是对我完全痴迷的 “Our Flag Means Death”。
而大蒜则是我朋友商店的 Cosmic Garlic 贴纸。大蒜在民间被用作各种疾病的草药疗法,所以在疫情期间把它放在笔记本电脑上似乎是一件好事。
— [Tiffany Bridge](https://tiff.is/)
### 开源项目

我通常会贴上我使用、贡献或钦佩的项目的贴纸。统计数据显示,我的笔记本电脑现在应该被覆盖了更多的贴纸。我已经三年没参加科技会议了,所以进展比以往慢一点。
— [Seth Kenlon](https://opensource.com/users/seth)
### Drupal 装点一新

我会添加一些代表我在技术领域的贴纸。所以我会包括我所参与的组织、我参加过的活动和我支持的项目。
见到人们笔记本电脑上的 Drupal 熊总是很有趣,因为我设计了它。
请注意,我所有的贴纸都贴在笔记本电脑外壳上以便保存。
— [April Sides](https://opensource.com/users/weekbeforenext)
### 对 WordPress 狂热

我很难选出最喜欢的,但可能是 “Michelle wapuu”!她就是我!
贴纸 “I press all the words” 和 “WordPress is my super power” 是来自 WordCamp Rochester,所以它们对我来说很重要。
基本上,如果我和某个贴纸有渊源(比如我在营地演讲过),或者我只是喜欢它,我就会贴上它!
— [Michelle Frechette](https://meetmichelle.online)
### 对艺术的热衷

我非常偏爱艺术贴纸。在电脑上看到艺术作品让我想起认识的人和使用这台电脑时的经历。
我最喜欢的是我的伴侣给我的悲伤表情 Midsommar 贴纸。第一次看完电影后,我们在剧院外花了几个小时讨论它,一直讨论到深夜。直到今天我们还在提到它。
— [Jonathan Daggerhart](https://opensource.com/users/daggerhart)
### 自定义外观

我在 2019 年买了一台新的旅行笔记本电脑,自那以后一直保持着原样,因为我没有参加任何活动。我的工作笔记本电脑上有一个女神 Ereshkigal 的定制外观贴纸,我以她的名字来命名这台电脑。
— Sallie Goetsch
### GNU Emacs

一个 GNU Emacs 的贴纸。
— [Sachin Patil](https://opensource.com/users/psachin)
### [Opensource.com](http://Opensource.com)
在看到大家的回复后,也许收到了非常聪明的社区经理寄来的一些很酷的贴纸...
好吧,好吧,我投降了!AmyJune、Don 和 Sachin 说服我在笔记本电脑上贴一个贴纸。
这是一张显示我笔记本电脑上独特贴纸的照片:

— Chris Hermansen
### 贴纸和开源
你不必为你的计算机贴满贴纸。这不是必须的,当然这也不能说明你比其他人更或更少热爱开源。但如果你喜欢一个开源项目,很有可能它有一款贴纸可以用来装饰你的计算机(或者你的门、水瓶或 USB 麦克风)。请放心,如果你热爱开源,同时你也喜欢贴纸,那两者之间有很强的交集!
*(题图:MJ/3f69639a-1aab-46d8-97ee-ab095de96e5f)*
---
via: <https://opensource.com/article/22/11/laptop-stickers>
作者:[AmyJune Hineline](https://opensource.com/users/amyjune) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Having just switched work laptops last December, I realized how much I love applying stickers to my work machines. Sometimes the stickers are souvenirs from past events, others are from projects that I am passionate about, and some are just for fun!
Curious to know what others had on their laptops, I asked!
## Accessibility advocate

(AmyJune Hineline, CC BY-SA 4.0)
Here is my work laptop (Can you tell my roots are in Drupal). My favorite decal is the Druplicon with the wheelchair... When [Drupal 8 came out, we took the logo](https://www.drupal.org/files/cta/graphic/drupal%208%20logo%20isolated%20CMYK%2072_1.png) and blended it with the wheelchair because the agency I worked with focused on accessibility.
## Fresh Java

(Alan Formy-Duval, CC BY-SA 4.0)
I have always had stickers on my computers and stuff since I was a kid. I think my favorite is either Tux or the Linux Inside. They are mostly field-relevant except for just a few. In the bottom-right corner, I have Java running on Tomcat (haha) - an area I spent much of my career doing.
## Utilitarian purpose

(Rikard Grossman-Nielsen, CC BY-SA 4.0)
Well, I don't have any stickers. However, I've glued Velcro bands on my two laptops to secure my external hard drive for when I'm gaming on the bus. I have also glued a lock notch on.
## Maintain the look

( John 'Warthog9' Hawley, CC BY-SA 4.0)
Not the most decorated laptop by far, but I like the collection (and you know, hard to get more without travel for a while!)
My favorite is the "last one to commit is the maintainer". It's a snarky comment on the state of maintainership, as well as a promise that the code will live on as a result.
Mostly it boils down to things I use or contribute to, think are meaningful, or just found the sticker awesome.
## Window covering
I never put stickers on my laptop because it seems to me the only really cool stickers are the ones I don't have (said the grumpy old man.)
But the old homebrew computer my kids used to use in high school, a 3GHz Core Duo with 8 GB of memory, has an Open Mainframe sticker on it that I grabbed at the Linux Foundation Open Source Summit here in Vancouver a few years ago. I quite like that one.
And because in my life, the **Control** key lives next to the **A**, not down on the bottom row, I have a few keyboards around with a **CTRL** sticker on the CapsLock key and a **CAPS** sticker on the **Control** key, which work together with the [swap Ctrl and CapsLock option in GNOME Tweak Tool](https://opensource.com/article/18/11/how-swap-ctrl-and-caps-lock-your-keyboard).
Finally, I used to peel off Windows stickers, back when my only option was buying computers and paying the Windows tax, and put Linux sticker over the gummy patch. Same with keyboards that had the Windows logo on the Super key.
## Mementos

(Kristine Strange, CC BY-SA 4.0)
The Kanopi sticker is by far my favorite sticker. Not only is it shiny and iridescent, but it's a constant reminder of how amazing this company is to work for. They seriously put their employees first, and they're super mindful in selecting client projects that align with Kanopi's overall company mission and vision.
The Curt V8 sticker is in remembrance of a dear friend. He loved Fords and my husband loves Chevys. The constant fun rivalry resulted in randomly placed Ford and Chevy objects snuck into garages depending on whose house we were at. I smile every time I see this Ford emulated sticker on my laptop, since I live in a Chevy family.
The variety of stickers represents the family adventures that we have been on throughout the years. Date nights, friends, family road trips, scary hiking adventures (Angels Landing), and my youngest's drive to get a police sticker from every city and state.
## Conference swag

(Cindy Williams, CC BY-SA 4.0)
The dragon is [my college mascot](https://www.uab.edu). I also have some Gilmore Girls and coffee stickers.
Here’s a photo of my daughter’s door, filled with stickers I’ve brought back from conferences over the years.

(Cindy Williams, CC BY-SA 4.0)
## Sticking with chicken
This is my not-work laptop. My work laptop is basically being covered in a honeycomb of hex-shaped stickers of our products, open source projects I use and support, and at least one Opensource.com hexagon. :)
I can’t pick a favorite, since they are all favorites, or I wouldn’t have them on the laptop that goes with me everywhere. I am overly fond of the chickens, the Raven, and Sergi the Cat with his knives.

(Kevin Sonney, CC BY-SA 4.0)

(Kevin Sonney, CC BY-SA 4.0)
## Foodie fun
I used to load up my laptops with stickers. The one I bought last year filled up fast:

(DJ Billings, CC BY-SA 4.0)
My favorite is the cupcake & donut one because I illustrated it.
I just bought a [System76](https://opensource.com/article/19/5/system76-secret-sauce) Darter Pro laptop and I love it. I got a bunch of really cool stickers with it, but I've been hesitant to put them on the laptop. I don't know why.
## Keeping it clean

(Don Watkins, CC BY-SA 4.0)
I don’t put a lot of stickers on my laptops but I’ve got my two favorites on my current laptop, which is System76 Darter Pro.
## Life's essentials

(Katie Sanders, CC BY-SA 4.0)
I included my water bottle, too. I think I like those stickers even more.
Beer, dogs, music, croissants. What else could I need in life?
## My mantra

(Faye Polson, CC BY-SA 4.0)
My favorite sticker is **yeet or be yeeted**.
## Garlic

(Tiffany Bridges, CC BY-SA 4.0)
Most of the stickers are professional, but the **Greetings from Hamunaptra, City of the Dead** sticker is a subtle reference to one of my favorite movies, **The Mummy** (1999) starring Brendan Fraser and Rachel Weisz.
The flags and the **Blackbeard’s Bar & Grill** stickers are references to **Our Flag Means Death**, which I am completely obsessed with.
And the garlic is the Cosmic Garlic sticker of my friend's shop. Garlic is a folk remedy for all kinds of diseases, so it seemed like a good thing to put on a laptop during a pandemic.
## Open source projects

(Seth Kenlon, CC BY-SA 4.0)
I usually cover my laptop with projects I use, contribute to, or admire. Statistically, my laptop should be layered with a lot more stickers by now. I haven't been to a tech conference in three years, so the pace has been slower than usual.
## Decked out in Drupal

(April Sides, CC BY-SA 4.0)
I add stickers that represent me in tech. So I include organizations I'm a part of, events I've attended, and projects I support.
It's always fun to see the Drupal bear on people’s laptops since I designed it.
Notice all of my stickers are on a laptop cover for preservability.
## Wild about WordPress

(Michelle Frechette', CC BY-SA 4.0)
My favorite is hard to pick, but probably the **Michelle wapuu**! She’s so me!
The stickers **I press all the words** and **WordPress is my super power** are from WordCamp Rochester, so those are near and dear to me.
Basically, I’ll add a sticker if I have a history with it (I spoke at the camp, for example), or I just like it!
## An eye for art

(Jonathan Daggerhart, CC BY-SA 4.0)
I heavily lean towards art stickers. Seeing art on my computer reminds me of the people I know and experiences I’ve had while using this computer.
My favorite is the sad-face Midsommar sticker that my partner gave me. After seeing the movie for the first time, we stood outside the theater discussing it for hours into the night. We still reference it to this day.
## Custom skin

(Sallie Goetsch, CC BY-SA 4.0)
I got a new travel laptop in 2019, and it remains pristine because I have not been to any events since then. My work laptop has a custom skin of the goddess Ereshkigal, after whom I named the computer.
—Sallie Goetsch
## GNU Emacs

(Sachin Patil, CC BY-SA 4.0)
## Opensource.com
*After seeing everyone's responses, and maybe getting some cool stickers in the mail from a very brilliant community manager...*
OK, OK, I give! AmyJune, Don, and Sachin convinced me to put ONE sticker on my laptop.
Here's a photo showing my laptop with its singular sticker:

(Chris Hermansen, CC BY-SA 4.0)
—Chris Hermansen
## Stickers and open source
You don't have to adorn your computer with stickers. It's not required, and it certainly doesn't mean you love open source more or less than anybody else. But if you love an open source project, there's a good chance that it's got a sticker you can use to decorate your computer (or your door, water bottle, or USB microphone). Rest assured that if you love open source and you love stickers, there's a strong intersection between the two!
## 1 Comment |
15,921 | Bash 基础知识系列 #1:创建并运行你的第一个 Bash Shell 脚本 | https://itsfoss.com/create-bash-script/ | 2023-06-19T11:01:02 | [
"Bash",
"脚本"
] | https://linux.cn/article-15921-1.html | 
>
> 这是一个新教程系列的开始。在这一篇中,你将熟悉 bash 脚本。
>
>
>
本系列假定你对 Linux 终端比较熟悉。你不必精通,但了解基础知识会很好。我建议阅读终端基础知识系列。
### 这个系列适合谁?
任何想开始学习 Bash Shell 脚本的人。
如果你是一名将 Shell 脚本作为课程的一部分的学生,那么本系列适合你。
如果你是普通的桌面 Linux 用户,本系列将帮助你了解在探索各种软件和修复程序时遇到的大多数 Shell 脚本。你还可以使用它来自动执行一些常见的重复性任务。
到本 Bash 基础系列结束时,你应该能够编写简单到中等水平的 Bash 脚本。
该系列的所有章节都有示例练习,你可以边做边学。
>
> ? 你将在这里学习 Bash Shell 脚本。虽然还有语法基本相同的其他 Shell,但它们的行为在某些方面仍然存在差异。Bash 是最常见和通用的 Shell,因此学习 Shell 脚本从 Bash 开始吧。
>
>
>
### 你的第一个 Shell 脚本:Hello World!
打开一个终端。现在 [创建一个新目录](https://itsfoss.com/make-directories/) 来保存你将在本系列中创建的所有脚本:
```
mkdir bash_scripts
```
现在 [切换到这个新创建的目录](https://itsfoss.com/change-directories/):
```
cd bash_scripts
```
让我们在这里 [创建一个新文件](https://itsfoss.com/create-files/):
```
touch hello_world.sh
```
现在,[编辑该文件](https://itsfoss.com/edit-files-linux/) 并向其中添加一行 `echo Hello World`。你可以使用 `cat` 命令的追加模式(使用 `>`)执行此操作:
```
[abhishek@itsfoss]:~/bash_scripts$ cat > hello_world.sh
echo Hello World
^C
```
我更喜欢在使用 `cat` 命令添加文本时添加新行。
按 `Ctrl+C` 或 `Ctrl+D` 键退出 `cat` 命令的追加模式。现在,如果你查看脚本 `hellow_world.sh` 的内容,你应该只看到一行。

关键时刻来了。你已经创建了第一个 Shell 脚本。是时候 [运行 Shell 脚本](https://itsfoss.com/run-shell-script-linux/) 了。
这样做:
```
bash hello_world.sh
```
`echo` 命令只是显示提供给它的任何内容。在这种情况下,Shell 脚本应该在屏幕上输出 “Hello World”。

恭喜! 你刚刚成功运行了第一个 Shell 脚本。多么酷啊!
以下是上述所有命令的重放,供你参考。

#### 另一种运行 Shell 脚本的方法
大多数时候,你将以这种方式运行 Shell 脚本:
```
./hello_world.sh
```
这将产生错误,因为作为脚本的文件还没有执行权限。
```
bash: ./hello_world.sh: Permission denied
```
给脚本添加执行权限:
```
chmod u+x hello-world.sh
```
现在,你可以像这样运行它:
```
./hello_world.sh
```

因此,你学习了两种运行 Shell 脚本的方法。是时候让我们将注意力转回 Bash 了。
### 把你的 Shell 脚本变成 Bash 脚本
感到困惑? 实际上,Linux 中有几种可用的 Shell。Bash、Ksh、Csh、Zsh 等等。其中,Bash 是最受欢迎的,几乎所有发行版都默认安装了它。
Shell 是一个解释器。它接受并运行 Linux 命令。虽然大多数 Shell 的语法保持不变,但它们的行为在某些点上可能有所不同。例如,条件逻辑中括号的处理。
这就是为什么告诉系统使用哪个 Shell 来解释脚本很重要。
当你使用 `bash hello_world.sh` 时,你明确地使用了 Bash 解释器。
但是当你以这种方式运行 Shell 脚本时:
```
./hello_world.sh
```
系统将使用你当前使用的任何 Shell 来运行脚本。
为避免由于不同的语法处理而导致不必要的意外,你应该明确告诉系统它是哪个 shell 脚本。
怎么做? 使用释伴(`#!`)。通常,`#` 用于 Shell 脚本中的注释。但是,如果 `#!` 用作程序的第一行,它的特殊用途是告诉系统使用哪个 Shell。
因此,更改 `hello_world.sh` 的内容,使其看起来像这样:
```
#!/bin/bash
echo Hello World
```
现在,你可以像往常一样运行 Shell 脚本,因为你知道系统将使用 Bash Shell 来运行脚本。

>
> ? 如果你觉得在终端中编辑脚本文件不方便,作为桌面 Linux 用户,你可以使用 Gedit 或其他 GUI 文本编辑器编写脚本并在终端中运行。
>
>
>
### ?️ 练习时间
是时候练习你学到的东西了。以下是该级别的一些基本练习:
* 编写一个打印 “Hello Everyone” 的 Bash 脚本
* 编写一个显示当前工作目录的 Bash 脚本(提示:使用 `pwd` 命令)
* 编写一个 Shell 脚本,使用以下列方式打印你的用户名:“My name is XYZ”(提示:使用 `$USER`)
答案可以在社区论坛的 [这个专门的帖子](https://itsfoss.community:443/t/practice-exercise-in-bash-basics-series-1-create-and-run-your-first-bash-shell-script/10682) 中讨论。
最后一个练习使用 `$USER`。这是一个打印用户名的特殊变量。
这就引出了 Bash 基础系列下一章的主题:变量。
请继续关注下面的内容。
*(题图:MJ/c8f6458a-84fe-4f77-9a9c-f82fef611935)*
---
via: <https://itsfoss.com/create-bash-script/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter #1: Create and Run Your First Bash Shell Script
Start learning bash scripting with this new series. Create and run your first bash shell script in the first chapter.
Ready to dive in the world of Bash shell scripting? It would be a lot better if you followed everything on your Linux system. Trust me, learning is better if you are doing it.
## Your first shell script: Hello World!
Open a terminal. Now [create a new directory](https://itsfoss.com/make-directories/) to save all the scripts you'll be creating in this series:
`mkdir bash_scripts`
Now [switch to this newly created directory](https://itsfoss.com/change-directories/):
`cd bash_scripts`
Let's [create a new file](https://itsfoss.com/create-files/) here:
`touch hello_world.sh`
Now, [edit the file](https://itsfoss.com/edit-files-linux/) and add `echo Hello World`
line to it. You can do this with the append mode of the cat command (using >):
```
abhishek@itsfoss:~/bash_scripts$ cat > hello_world.sh
echo Hello World
^C
```
I prefer adding new lines while using the cat command for adding text.
Press Ctrl+C or Ctrl+D keys to come out of the append mode of the cat command. Now if you check the contents of the script `hellow_world.sh`
, you should see just a single line.
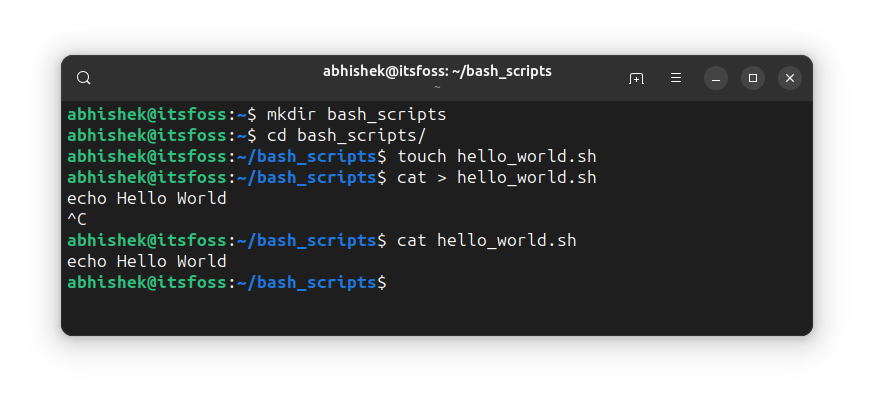
The moment of truth has arrived. You have created your first shell script. It's time to [run the shell script](https://itsfoss.com/run-shell-script-linux/).
Do like this:
`bash hello_world.sh`
The echo command simply displays whatever was provided to it. In this case, the shell script should output Hello World on the screen.
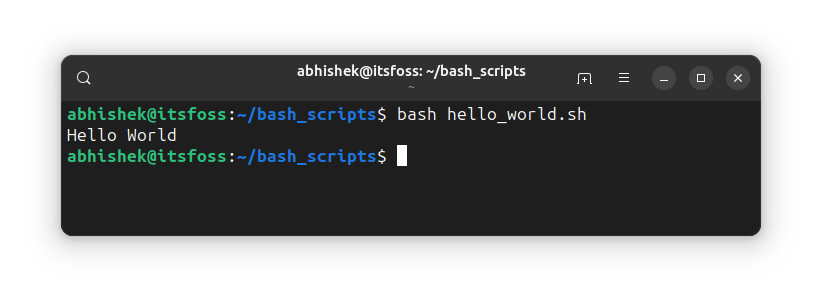
Congratulations! You just successfully ran your first shell script. How cool is that!
Here's a replay of all the above commands for your reference.
### Another way to run your shell scripts
Most of the time, you'll be running the shell scripts in this manner:
`./hello_world.sh`
Which will result in an error because the file for you as the script doesn't have execute permission yet.
`bash: ./hello_world.sh: Permission denied`
Add execute permission for yourself to the script:
`chmod u+x hello-world.sh`
And now, you can run it like this:
`./hello_world.sh`
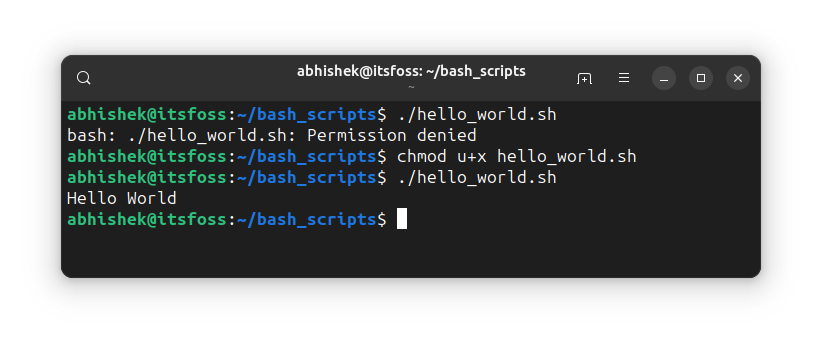
So, you learned two ways to run a shell script. It's time to focus on bash.
## Turn your shell script into a bash script
Confused? Actually, there are several shells available in Linux. Bash, ksh, csh, zsh and many more. Out of all these, bash is the most popular one and almost all distributions have it installed by default.
The shell is an interpreter. It accepts and runs Linux commands. While the syntax for most shell remains the same, their behavior may differ at certain points. For example, the handling of brackets in conditional logic.
This is why it is important to tell the system which shell to use to interpret the script.
When you used `bash hello_world.sh`
, you explicitly used the bash interpreter.
But when you run the shell scripts in this manner:
`./hello_world.sh`
The system will use whichever shell you are currently using to run the script.
To avoid unwanted surprises due to different syntax handling, you should explicitly tell the system which shell script it is.
How to do that? Use the shebang (#!). Normally, # is used for comments in shell scripts. However, if #! is used as the first line of the program, it has the special purpose of telling the system which shell to use.
So, change the content of the hello_world.sh so that it looks like this:
```
#!/bin/bash
echo Hello World
```
And now, you can run the shell script as usual knowing that the system will use bash shell to run the script.
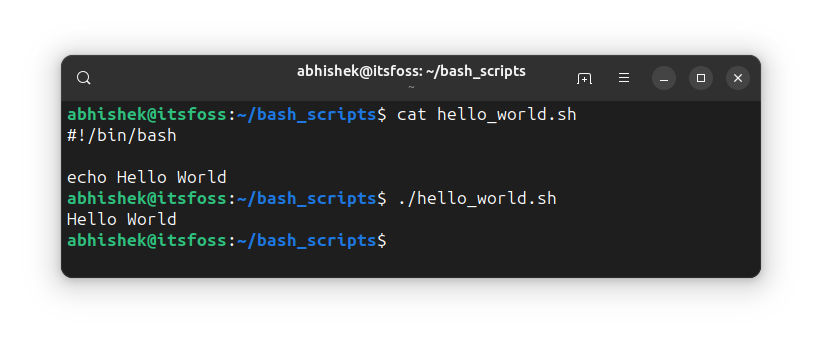
## 🏋️ Exercise time
It is time to practice what you learned. Here are some basic practice exercises for this level:
- Write a bash script that prints "Hello Everyone"
- Write a bash script that displays your current working directory (hint: use pwd command)
- Write a shell script that prints your user name in the following manner: My name is XYZ (hint: use $USER)
The answers can be discussed in [this dedicated thread](https://itsfoss.community/t/practice-exercise-in-bash-basics-series-1-create-and-run-your-first-bash-shell-script/10682) in the Community forum.
[Practice Exercise in Bash Basics Series #1: Create and Run Your First Bash Shell ScriptIf you are following the Bash Basics series on It’s FOSS, you can submit and discuss the answers to the exercise at the end of the chapter: Fellow experienced members are encouraged to provide their feedback to new members. Do note that there could be more than one answer to a given problem.](https://itsfoss.community/t/practice-exercise-in-bash-basics-series-1-create-and-run-your-first-bash-shell-script/10682)

The last practice exercise uses `$USER`
. That's a special variable that prints the user name.
And that brings me to the topic of the next chapter in the Bash Basics Series: Variables.
Keep on learning bash. |
15,922 | 比 Ubuntu 更好?Ubuntu 爱好者的 11 款最佳 Linux 发行版 | https://itsfoss.com/best-ubuntu-based-linux-distros/ | 2023-06-19T14:53:00 | [
"Ubuntu"
] | https://linux.cn/article-15922-1.html | 
如果你正在找寻适合你的系统的完美发行版,那么选择基于 Ubuntu 的发行版的可能性非常高。
你可能会问为什么。
嗯,毫不奇怪,Ubuntu 是 [最适合初学者的 Linux 发行版之一](https://itsfoss.com/best-linux-beginners/)。它也非常流行,这就是为什么你会发现它拥有庞大的用户社区。不仅如此,它还广泛用于 [云服务器](https://linuxhandbook.com/free-linux-cloud-servers/) 上。
因此,将 Ubuntu 作为 Linux 发行版的基础应该带来一些有用的优势,对吧?
这就是为什么我列出了基于 Ubuntu 的最佳发行版清单,希望你能找到一款足够出色,让你停止频繁更换发行版的选择。
### 1、Ubuntu 官方衍生版

如果你不喜欢 Ubuntu 官方提供的 GNOME 桌面环境,你可以尝试官方衍生版,它们在 Ubuntu 的基础上提供了不同的桌面环境。
简单来说,你将得到同样的 Ubuntu 使用体验,但拥有不同的用户界面。
为了让你的用户体验更加愉快,这些桌面环境已经进行了预调整和主题设置,这使它们成为了那些希望拿来即用的完美选择。
以下是可用的选项:
* Kubuntu(KDE Plasma)
* Lubuntu(最节约资源的选择,使用 LXDE/LXQT)
* Ubuntu Studio(面向创作者的发行版)
* Ubuntu Budgie(Budgie 桌面环境)
* Ubuntu Kylin(专为中国用户定制)
* Ubuntu MATE(使用 MATE 桌面和工具)
* Xubuntu(Xfce 桌面)
此外,你还可以在 Ubuntu 22.10 中发现一个带有经典 Unity 桌面环境的新的官方衍生版,因为 [Ubuntu Unity Remix 现已成为官方 Ubuntu 衍生版](https://news.itsfoss.com/unity-remix-official-flavor/)。
>
> **[解析:我应该使用哪个 Ubuntu 版本?](https://itsfoss.com/which-ubuntu-install/)**
>
>
>
>
> **[Ubuntu 衍生版](https://ubuntu.com/desktop/flavours)**
>
>
>
### 2、Linux Mint

Linux Mint 的主要特点:
* 默认不使用 Snap。
* 使用 Cinnamon 桌面环境,提供直观、易用的体验。
* 精美的用户界面。
* 对于 Windows 用户而言,具有熟悉的操作体验。
* 管理编解码器和硬件驱动程序非常方便。
如果我要用一句话来描述 Linux Mint,那就是 “简洁优雅的用户体验,足够满足高级用户的需求”。
通过 Linux Mint 的 Cinnamon 桌面环境,你可以期待到一个精心打磨和定制的体验。现在由 Linux Mint 团队开发的 Timeshift 之类的工具,可以让你享受无缝的使用体验。
Linux Mint 包括了基本必备的应用软件,包括办公套件和满足多媒体消费需求的应用程序,非常适合初学者使用。
>
> **[Linux Mint](https://linuxmint.com/)**
>
>
>
### 3、Pop!\_OS

Pop!\_OS 的主要特点:
* 开箱即用的英伟达显卡支持。
* COSMIC 桌面(定制的 GNOME 使用体验)。
* 提供窗口管理器的基本功能。
* 一个用于从灾难中恢复系统的恢复分区。
由受欢迎的开源硬件制造商 System76 开发,Pop!\_OS 22.04 LTS 是我目前的主力操作系统,而背后有着充分的理由。
Pop!\_OS 定期更新 Linux 内核包,在本文撰写时运行 Linux 内核 5.19。是的,我知道你可以 [轻松升级到最新的内核](https://itsfoss.com/upgrade-linux-kernel-ubuntu/),但官方支持更为便捷,这正是 Pop!\_OS 作为基于 Ubuntu 的发行版的优势所在。
除了最新的内核外,你还将得到一个美观的 COSMIC 桌面,以及一些预安装的应用程序,如用于方便地安装 deb 包的 Eddy,还默认应用磁盘加密以及许多其他功能,让你获得愉快的体验!
>
> **[Pop!\_OS](https://pop.system76.com/)**
>
>
>
### 4、KDE Neon

KDE Neon 的主要特点:
* 基于 Ubuntu 平台,提供最原生的 KDE 使用体验。
* 提供最新版本的 KDE Plasma。
除非你追求最新的 KDE 体验,否则 KDE Neon 可能不适合你。换句话说,它并非旨在作为日常使用的操作系统,而是旨在提供最前沿的 KDE 体验。
如果你想体验 KDE 的最新功能,KDE Neon 仍然是最佳的基于 Ubuntu 的发行版之一。
还有很多其他基于 KDE Plasma 的发行版;如果你不是非要追求最新的体验,那么 Kubuntu 是你最好的选择。
此外,KDE Neon 仅预装了最基本的工具,以让用户有足够的空间可以自行决定在特定任务中使用什么工具。
>
> **[KDE Neon](https://neon.kde.org/download)**
>
>
>
### 5、elementaryOS

elementaryOS 的主要特点:
* 使用 Pantheon,最优雅的桌面环境之一。
* 支持画中画模式。
* 专门定制的应用中心。
所以,如果你是 macOS 的粉丝,又想体验 Linux,elementaryOS 绝对不会让你失望。
开发者专门为 elementaryOS 开发了 Pantheon 桌面环境,你会注意到它在每个方面都非常注重细节,无论是暗色模式还是强调色彩。你将会在 elementary OS 中获得出色的用户体验。
与其他 Ubuntu 发行版相比,elementaryOS 的发布周期可能不太频繁。但他们在每个版本中都致力于提供稳定的使用体验。
>
> **[elementaryOS](https://elementary.io/)**
>
>
>
### 6、Zorin OS

Zorin OS 的主要特点:
* 提供类似于 Windows 和 macOS 的不同布局。
* 能够在不需要任何调整的情况下安装 Windows 软件。
* Zorin OS 的精简版可以让十多年前的计算机重焕生机。
Zorin OS 是另一个基于 Ubuntu 的发行版,为用户提供了精心打磨的体验。其壁纸、用户界面调整和其他改进使 Linux 看起来令人惊艳。
你可以使用其工具 Zorin Connect 无缝集成你的移动设备和计算机,这样你就可以传输文件、控制音频播放,甚至使用移动设备作为触控板!
>
> **[Zorin OS](https://zorin.com/os/download/)**
>
>
>
### 7、Linux Lite

Linux Lite 的主要特点:
* 极为轻量级。
* 使用 Xfce 和 LTS 版本的 Ubuntu,提供稳定的使用体验。
* 易于使用。
所以,如果你正在寻找一个开箱即用的轻量级发行版,那么 Linux Lite 就是为像你这样的用户而设计的。它是最好的(也是最简单的)[类似于 Windows 的 Linux 发行版](https://itsfoss.com/windows-like-linux-distributions/) 之一。
稳定性是 Linux Lite 的另一个核心特点,这也解释了为什么它使用 Xfce 作为其桌面环境。
>
> **[Linux Lite](https://www.linuxliteos.com/download.php)**
>
>
>
### 8、Voyager

Voyager 的主要特点:
* 用户可以在其二合一版本中在 GNOME 和 Xfce 会话之间切换。
* 预先配置了图形用户界面元素和插件,以提供愉快的使用体验。
Voyager 是一个基于 Xubuntu 的 Linux 发行版,在其最新的 22.04 LTS explorer 版本中提供了 GNOME 和 Xfce。
这个发行版从一开始就提供了用户选择。如果你喜欢人体工程学,可以启动 GNOME 会话;或者选择 Xfce 以获得更简单和更快的体验。
Voyager 提供了一个定制外观,带给用户古老而有格调的 Linux 使用体验。
我会向喜欢在不同环境之间切换、寻找定制化体验和稳定性的人推荐使用。
>
> **[Voyager](https://voyagerlive.org/)**
>
>
>
### 9、Feren OS

Feren OS 的主要特点:
* 提供一个开箱即用的最小化配置且经过精调的 KDE 使用体验。
* 定制化,但对系统资源占用较低。
* 带有预调优的网络浏览器管理器,以获取更好的体验。
我已经提到了 Zorin OS 如何提供预配置的布局以适应你自己,但它是基于 GNOME 的。那么如果你是 KDE 的粉丝呢?那么 Feren OS 就是为你而设计的!
除了提供预配置的 KDE 使用体验外,Feren OS 的内存占用也令人信服,我给任何想要开始使用基于 KDE Plasma 桌面的 Ubuntu 发行版的人强烈推荐 Feren OS。
>
> **[Feren OS](https://ferenos.weebly.com/)**
>
>
>
### 10、LXLE

LXLE 的主要特点:
* 极其轻量级。
* 几乎整个系统都保持了主题的一致性。
LXLE 是基于 Lubuntu 的,因此你可以想象到它的内存占用会很轻。它是最好的 [轻量级 Linux 发行版之一](https://itsfoss.com/lightweight-linux-beginners/)。
因此,如果要用一个词来概括整个发行版,那就是“高效”。但这还不止。你还可以获得大量的自定义选项和预安装的壁纸集以适配外观。
当我在虚拟机中使用它时,我对系统的轻盈程度感到惊讶(**空闲时使用 360Mb 的内存**)。对于新的 Linux 用户来说,可能不是一个舒适的体验,但如果你不介意经典的用户界面和各种新东西,那么值得一试。
>
> **[LXLE](https://lxle.net/)**
>
>
>
### 11、UbuntuDDE Remix

UbuntuDDE Remix 的主要特点:
* 深度桌面环境
* 美观的用户界面
你喜欢基于 Debian 的深度 Linux 发行版吗?但是,你对尝试它没有兴趣吗?
嗯,在这种情况下,你可以尝试一下 UbuntuDDE Remix。它虽然不是官方的版本,但是它与基于 Ubuntu 的系统配合得非常好。
与深度 Linux 不同,它并非主要为中国用户定制的。因此,你会发现语言设置和软件源设置比深度 Linux 更好。
>
> **[UbuntuDDE Remix](https://ubuntudde.com/)**
>
>
>
### 你理想的基于 Ubuntu 的发行版
Ubuntu 仍然是为新手和高级用户提供易于使用的体验的首选。
有时候我们只想完成任务,而不需要定制或控制发行版的任何方面。在这种情况下,基于 Ubuntu 的发行版可以节省你的时间,并根据你的偏好提供很多选项。
**如果你必须使用上述提到的发行版中的一个,你会选择哪个?请在评论中分享 ?**
*(题图:MJ/541cb931-34af-4926-b713-6193bdd63095)*
---
via: <https://itsfoss.com/best-ubuntu-based-linux-distros/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you’re on your journey of finding that perfect distro for your system, the chances of you ending up with Ubuntu-based distros are pretty high.
And, you're maybe wondering why?
Well, it is no surprise that Ubuntu is one of the most [beginner-friendly Linux distros](https://itsfoss.com/best-linux-beginners/). It is also incredibly popular, which is why you will also find a massive user community backing it. Not just that, it is also widely used on [cloud servers](https://linuxhandbook.com/free-linux-cloud-servers/?ref=itsfoss.com).
So, having Ubuntu as the base for any Linux distribution should come with useful perks, right?
And that is why I came up with a list of the best Ubuntu-based distros in hopes that you may find something worthy enough to stop you from committing any [deadly sins of distrohopping](https://itsfoss.com/distrohopping-issues/). 😆
## 1. Official Ubuntu Flavors
If you do not like Ubuntu’s official offering with GNOME, you can try one of the many [official flavors](https://ubuntu.com/desktop/flavours) that provide a different desktop environment on top of Ubuntu.
In simpler terms, you’re going to get the same Ubuntu experience, but, with a different user interface.
To make your user experience more pleasant, these desktop environments are pre-configured and themed accordingly, making them **the perfect choice if you’re looking for something that works out of the box**.
These are the currently available **official Ubuntu flavors**:
**Kubuntu**(KDE Plasma)**Lubuntu**(The least resource-hungry offering, using LXDE/LXQT)**Ubuntu Studio**(A distro for creators)**Ubuntu Budgie**(Budgie desktop)**Ubuntu Kylin**(Tailored for Chinese users)**Ubuntu Unity**(Unity desktop)**Ubuntu MATE**(MATE desktop and tools)**Xubuntu**(Xfce desktop)
If you were confused about [which Ubuntu version to opt for](https://itsfoss.com/which-ubuntu-install/), our handy guide can be a great resource:
**Suggested Read 📖**
[Explained: Which Ubuntu Version Should I Use?Confused about Ubuntu vs Xubuntu vs Lubuntu vs Kubuntu?? Want to know which Ubuntu flavor you should use? This beginner’s guide helps you decide which Ubuntu should you choose.](https://itsfoss.com/which-ubuntu-install/)

## 2. Linux Mint
If I had to describe Linux Mint in one line, it would be, “Simple and elegant user experience with enough room for advanced users”.
With Linux Mint’s Cinnamon desktop, you can expect a polished and tailored experience and tools like Timeshift just sweeten the deal further, giving you a seamless experience with everything.
Linux Mint includes the essentials, which include an office suite, a set of applications to satisfy your multimedia consumption needs, and more. These perks make it perfect for beginners.
**Key Features of Linux Mint:**
- Beautiful UI.
- No Snap by default.
- Familiar experience for Windows users.
- Managing codecs and hardware drivers is pretty convenient.
- A straightforward, easy-to-use experience with the Cinnamon desktop environment.
## 3. Pop!_OS
Developed by System76, a popular open-source hardware manufacturer, Pop!_OS 22.04 LTS is what I preferred to use as my daily driver for a long time, and there’s a strong reason behind it.
**Pop!_OS regularly updates its Linux kernel package**, running Linux kernel 6.6.6 at the time of writing. Yes, I’m aware that you can [easily upgrade to the latest kernel in Ubuntu](https://itsfoss.com/upgrade-linux-kernel-ubuntu/), but having official support is convenient, which is where Pop!_OS excels as an Ubuntu-based distro.
Apart from the latest kernel, you also get a beautiful cosmic desktop, and some preinstalled apps such as Eddy to install deb packages conveniently, apply disk encryption by default, and many other features to have a pleasant experience!
**Key Features of Pop!_OS:**
- Out-of-the-box support for Nvidia graphics.
- Cosmic Desktop (Customized GNOME experience).
- Provides basic functionality of Window manager.
- A recovery partition to revive the system from disasters.
## 4. KDE Neon
If you don't want the latest KDE experience, then KDE Neon is not for you. In other words, it is** not tailored as a daily driver but aims to provide the bleeding edge KDE experience**.
It is still one of the best Ubuntu-based distributions if you want to experience KDE’s latest offerings with an Ubuntu base.
There are plenty of other distros based on KDE Plasma; Kubuntu is your best bet if you do not necessarily want the latest experience.
And apart from that, KDE Neon ships with the bare minimum set of preinstalled tools, so users can have enough room to decide what they prefer for specific tasks.
**Key Features of KDE Neon:**
- Gets you the most recent version of KDE Plasma.
- The most vanilla KDE offering with an Ubuntu base.
- Features the latest officially released KDE software package.
## 5. elementary OS
So, you are **a fan of macOS and want to enjoy Linux? **Well, then elementary OS will not disappoint you in any way.
As the developers have developed Pantheon desktop just for elementary OS, you’d notice the attention to detail in every aspect, be it a dark mode or the accent colors. You get a great user experience with elementary OS.
Compared to other Ubuntu distributions, it may not have a fast release cycle. But, they tend to offer a solid experience with every release.
**Key Features of elementary OS:**
- A tailored App Center.
- Has a picture-in-picture mode.
- Uses Pantheon, one of the most elegant desktop environments.
## 6. Zorin OS
Zorin OS is yet another Ubuntu-based distro that **gives you a polished experience**. It makes Linux look stunning with its wallpapers, user interface tweaks, and other changes.
You can **use its Zorin Connect tool to integrate your mobile device and computer seamlessly** so that you can transfer files, control audio playback, and even use the mobile device as a touchpad!
**Key features of Zorin OS**:
- Ability to install Windows software without many tweaks.
- A lite version of Zorin OS can revive a PC over a decade old.
- Different layouts are available, resembling Windows and macOS.
## 7. Linux Lite
If you are **searching for a lightweight distro that just works out of the box**, then Linux Lite is made for users like you. It is one of the best (and simple) [Windows-like Linux distributions](https://itsfoss.com/windows-like-linux-distributions/) to install.
Stability is another core feature of Linux Lite that explains why it uses Xfce as its main desktop environment.
**Key Features of Linux Lite:**
- Easy to use.
- Extremely lightweight.
- You can expect a stable experience with Xfce and the LTS version of Ubuntu.
## 8. Voyager
Voyager is an Ubuntu-based Linux distro that features GNOME and Xfce in its recent [23.10 avatar](https://voyagerlive.org/voyager-23-10/).
The distribution **provides user choice from the get-go**. If you like ergonomics, start a GNOME session or go with Xfce for a simpler and faster experience.
Voyager comes with a customized interface made to feel like an old, classy Linux experience.
I’d recommend this to anyone who loves to switch between environments, is seeking a customized experience, and the stability of Ubuntu.
**Key Features of Voyager:**
- Get regular updates based on the latest Ubuntu releases.
- Users can switch between GNOME and Xfce sessions in its 2-in-1 edition.
- Pre-configured with GUI elements and plugins to have a pleasant user experience.
## 9. Feren OS
I already mentioned how Zorin OS offers you pre-configured layouts to better suit your preferences, but, it features GNOME. **What if you’re a KDE fan?**
Well, then Feren OS is just the one for you!
Apart from **a pre-configured KDE experience**, the memory footprint was also convincing to have Feren OS on this list. I’d suggest Feren OS to anyone who wants to get started with an Ubuntu-based distro powered by KDE Plasma desktop.
**Key Features of Feren OS:**
- Customized yet quite light on system resources.
- Web browser manager with pre-tweaked browsers for a better experience.
- Gets you a minimally configured and fine-tuned KDE experience out-of-the-box.
## 10. Rhino Linux
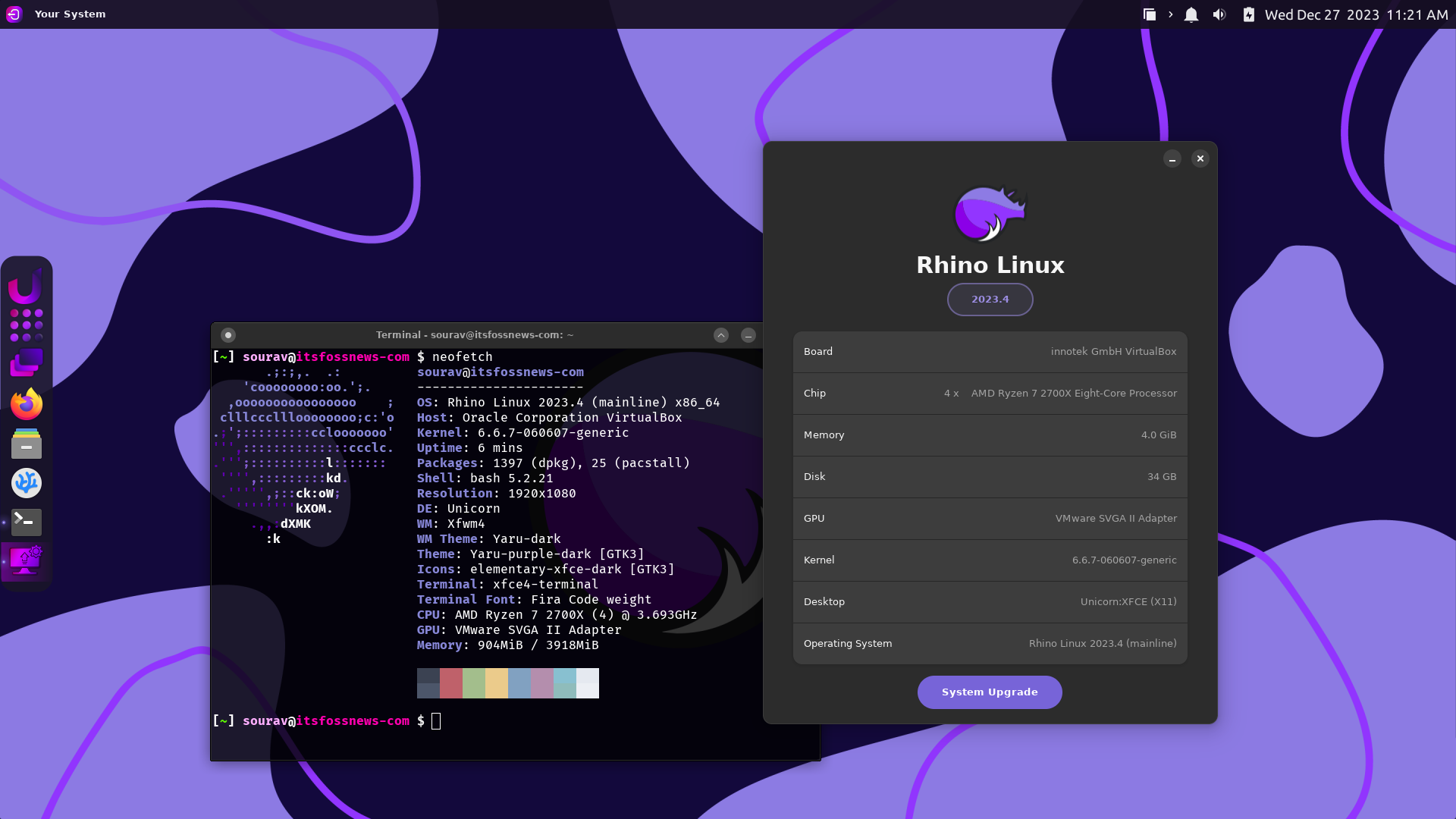
As the successor to the Rolling Rhino Remix project, Rhino Linux is **an unofficial variant of Ubuntu that tries to provide users with a stable rolling-release experience** that is not really common.
I have yet to try it, but going by the looks of it, it looks like a viable option for those looking for some Arch Linux niceties, but with Ubuntu.
**Key Features of Rhino Linux:**
- A rolling-release distro
- Features the Pacstall package manager.
- Uses a heavily customized version of XFCE.
**Suggested Read 📖**
[What is a Rolling Release Distribution?What is rolling release? What is a rolling release distribution? How is it different from the point release distributions? All your questions answered.](https://itsfoss.com/rolling-release/)

## 11. UbuntuDDE Remix
Do you like the [Deepin](https://www.deepin.org/index/en) Linux distribution, based on Debian? But, not interested in trying it?
Well, in that case, you can try UbuntuDDE Remix. It is **not an official flavor**, but it works pretty well with Ubuntu at its base.
Unlike Deepin Linux, it is** not primarily tailored for Chinese users**. So, you will find the language settings and the repositories set to the ones that work better than on Deepin Linux.
**Key Features of UbuntuDDE Remix:**
- Beautiful user interface
- A modern control center
- Deepin desktop environment
## What's Your Perfect Ubuntu-based Distro?
Ubuntu remains the dominant choice to provide an easy-to-use experience to newbies and advanced users.
Every so often, we just want to get things done without the need to customize or control the various aspects of our distribution. In such cases, Ubuntu-based distros like the ones listed above save your time and give you plenty of options according to your preference.
*💬 If you have to use one of the above-mentioned distros, which one would it be? Share it in the comments!* |
15,924 | Zathura: 使用键盘操作的极简文档查看器 | https://itsfoss.com/zathura-document-viewer/ | 2023-06-20T09:33:34 | [
"PDF",
"文档查看器"
] | https://linux.cn/article-15924-1.html | 
文档查看器是每个 Linux 发行版的必备软件,可以用来阅读 PDF 等格式的文件。
Ubuntu 等发行版上的文档查看器一般是 [GNOME 中的 Evince](https://wiki.gnome.org/Apps/Evince)(LCTT 译注:读作 [/ɪˈvɪns/](https://en.wiktionary.org/wiki/evince))。Evince 支持多种文件格式,非常方便。
但是除了 Evince,还有很多其他的文档阅读应用。比如 Linux 上优秀的电子书阅读应用 [Foliate](https://itsfoss.com/foliate-ebook-viewer/)(LCTT 译注:读作 [/ˈfəʊlɪɪt/](https://en.wiktionary.org/wiki/foliate))。
最近我又发现了另一个文档查看器:Zathura。
### 用 Zathura 获得摆脱鼠标的阅读体验
[Zathura](https://pwmt.org/projects/zathura/) 是一个高度可定制的文档查看器,基于 [girara 用户界面](https://git.pwmt.org/pwmt/girara) 和几个文档库。girara 实现了一个简单、最小的用户界面。
Zathura 的加载速度极快。它极其简约,没有侧边栏、菜单栏等元素。(LCTT 译注:其实 Zathura 的界面没有那么单一,按 `Tab` 键可以显示索引页;Zathura 有一个 `guioptions` 选项来设置是否显示命令行、状态栏、水平滚动条、垂直滚动条等 GUI 元素。)

按 `:` 键可以打开 Zathura 的命令行提示符,按 `Esc` 键可以退出命令行。
如果要新建书签,可以输入 `:bmark` 后面跟想要对这个书签设置的索引号。

按 `F` 键可以高亮所有链接,每条链接附带一个序号,并且界面底部会显示命令行提示符。在命令行中输入链接对应的序号,按下回车可以用系统默认的浏览器打开该链接。

Zathura 还支持自动重新载入。如果文件被其他应用修改(LCTT 译注:比如在修改 LaTeX 源文件并重新编译得到新的 PDF 之后), Zathura 会自动重载修改后的文件。
你还可以安装 [插件](https://pwmt.org/projects/zathura/plugins/) 来扩展 Zathura 的功能,比如阅读 <ruby> 漫画 <rt> comics </rt></ruby> 或 PostScript 文件。
但 Zathura 有一个问题,它的界面上没有任何文档或帮助选项,初次使用会有点困难。
你可以从其 Zathura 的 [手册页](https://itsfoss.com/linux-man-page-guide/) 获取默认键盘快捷键信息。以下是其中的一部分:
* `R`:旋转
* `D`:在单页和双页查看模式之间切换
* `F`:高亮当前屏幕内的链接
* `H` `J` `K` `L`:使用 Vim 类型键移动(LCTT 译注:HJKL 分别为左、下、上、右)
* `↑` `↓` `←` `→` 键或 `PgUp`/`PgDown` 或鼠标/触摸板:上下移动
* `/`:搜索文本,按 `n` 或 `N` 移动到下一个或上一个搜索(类似于 `less` 命令)
* `Q`:关闭
Zathura 的项目网站提供了 [如何配置该软件的文档](https://pwmt.org/projects/zathura/documentation/),不过我觉得写得不太清晰。(LCTT 译注:安装 Zathura 之后,可以使用 `man zathurarc` 查看本地的 Zathura 配置手册。)
### 在 Linux 上安装 Zathura
大多数 Linux 发行版的软件仓库都包含了 Zathura,比如 Ubuntu、Fedora、Arch 和 Debian(查找自 [pkgs.org 网站](https://pkgs.org/))。你可以使用你的发行版上的包管理器或软件中心来安装它。
在 Debian 和 Ubuntu 系发行版上可以使用下面的命令安装 Zathura:
```
sudo apt install zathura
```
在 Fedora 上可以使用:
```
sudo dnf install zathura
```
[在 Arch Linux 上使用 pacman 安装 Zathura](https://itsfoss.com/pacman-command/):
```
sudo pacman -Sy zathura
```
如果你想查看 Zathura 的源代码,可以访问它在 GitLab 上的软件仓库:
>
> **[Zathura 源代码](https://git.pwmt.org/pwmt/zathura)**
>
>
>
### 总结
坦诚地说,我并不喜欢不使用鼠标的工具,所以我更喜欢 Nano 而不是 Vim,因为我记不住 Vim 上数不清的快捷键。(LCTT 译注:其实 Zathura 对鼠标是有一定支持的,单击鼠标左键可以打开链接,按住鼠标左键可以选中并复制文本,按住鼠标中键可以拖动视图,`Ctrl` + 滚动滑轮可以缩放视图。)
我知道有很多人坚信键盘比鼠标更高效。但我并不愿意专门学习如何配置文档查看器,主要是因为我在桌面上很少阅读大量文档,当我偶尔需要查看 PDF 时,默认的应用已经够用了。
当然,我不是说 Zathura 没有用处。如果你需要处理大量 PDF 或 LaTeX 等的文档,而且偏爱于键盘操作,Zathura 可能会成为你下一个最喜爱的工具。
*(题图:MJ/80da04de-1312-43c1-86d7-3be340b12bd7)*
---
via: <https://itsfoss.com/zathura-document-viewer/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tanloong](https://github.com/tanloong) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Every Linux distribution comes with a document viewer app that lets you read PDF and other documents.
Most of the time, it is [Evince from GNOME](https://wiki.gnome.org/Apps/Evince) that is displayed as Document Viewer in Ubuntu and some other distributions. Evince is a handy tool and supports a wide variety of document formats.
However, there are other applications for reading documents. Take [Foliate](https://itsfoss.com/foliate-ebook-viewer/) for example. It’s an excellent [application for reading ebooks on Linux](https://itsfoss.com/best-ebook-readers-linux/).
I recently came across another document viewer called Zathura.
## Enjoy a mouse-free document reading experience with Zathura
[Zathura](https://pwmt.org/projects/zathura/) is a highly customizable document viewer based on the [girara user interface](https://git.pwmt.org/pwmt/girara) and several document libraries. girara implements a simple and minimalist user interface.
Zathura sure feels to load fast. It is minimalist, so you just get an application window with no sidebar, application menu or anything of that sort.

You may open its command line prompt by pressing the : key. You may close the CLI prompt with Esc key.
If you want to create a bookmark, type :bmark and then provide an index number to the bookmarked page.

You may highlight all the links by pressing the F key. It will also display a number beside the highlighted URL and the command line prompt will appear at the bottom. If you type the URL number and press enter, the URL will be opened in the default web browser.

Zathura also has automatic reloading feature. So if you make some changes to the document with some other application, the changes will be reflected as Zathura reloads the document.
You may also install additional plugins to improve the capabilities of Zathura and use it for reading comics or PostScript.
The problem with Zathura is that you won’t see any documentation or help option anywhere on the application interface. This makes things a bit more difficult if you are not already familiar with the tool.
You may get the default keyboard shortcuts information from its [man page](https://itsfoss.com/linux-man-page-guide/). Here are a few of them:
- R: Rotate
- D: Toggle between single and double page viewing mode
- F: Highlight all links on the current screen
- HJKL: Moving with the Vim type keys
- Arrows or PgUp/PgDown or the mouse/touchpad for moving up and down
- / and search for text, press n or N for moving to next or previous search (like less command)
- Q: Close
You may find the documentation on the project website to learn about configuration, but I still found it confusing.
## Installing Zathura on Linux
Zathura is available in the repositories of the most Linux distributions. I could see it available for Ubuntu, Fedora, Arch and Debian, thanks to the [pkgs.org website](https://pkgs.org/). This means that you can use the [package manager of your distribution](https://itsfoss.com/package-manager/) or the software center to install it.
On Debian and Ubuntu based distributions, use this command to install Zathura:
`sudo apt install zathura`
On Fedora, use:
`sudo dnf install zathura`
[Use pacman command on Arch Linux](https://itsfoss.com/pacman-command/):
`sudo pacman -Sy zathura`
And if you want to have a look at its source code, you may visit its GitLab repository:
## Conclusion
I’ll be honest with you. I am not a fan of mouse-free tools. This is why I prefer Nano over Vim as I cannot remember so many shortcuts.
I know there are people who swear by their keyboards. However, I would prefer not to spend time learning to configure a document viewer. This is more because I do not read too many documents on my desktop and for the limited PDF viewing, the default application is sufficient.
It’s not that Zathura does not have it usage. If you are someone who has to deal a lot with documents, be it PDF or LaTex, Zathura could be your next favorite tool if you are a keyboard love. |
15,926 | 十大采用 KDE Plasma 的 Linux 发行版 | https://www.debugpoint.com/top-linux-distributions-kde-plasma/ | 2023-06-20T14:49:00 | [
"KDE",
"Linux 发行版"
] | /article-15926-1.html | 
>
> 你是否计划在 Linux 上采用以 KDE Plasma 为基础的稳定桌面环境,并打算将其作为日常工作环境?在这里,我们为你介绍与 KDE Plasma 更好集成的前十个 Linux 发行版。
>
>
>
KDE Plasma 桌面环境如今已经成为数百万用户的选择。借助活跃的开发者和社区的支持,它不断改进并推出与技术潮流相符的新功能。经过多年的发展,KDE 技术现在已经能够运行在桌面、笔记本电脑、平板电脑、手机和手持游戏设备上。这对于一个桌面环境来说是非常令人惊叹的,不是吗?
我经常听到或读到 KDE 桌面的各种问题,或者与 GNOME 相比被认为它的“选项太多”。我同意这些观点。但是我们不能忽视一个事实,尽管有这些争议和不同看法,KDE Plasma 桌面环境仍然是任何个人或企业使用场景的首选解决方案之一。它有一个成熟的路线图,采用独特的 Qt 技术构建,甚至能够在汽车和其他平台上运行。此外,它还有一个专门的基金会,拥有大量开发者,每天在努力改进这个桌面环境。
这就是为什么我撰写这篇文章的目的。有数百种 Linux 发行版支持 KDE Plasma 桌面环境。但是应该选择哪一个呢?它们各自有什么优势和劣势?哪一个对我来说最好?我们将在本文中尝试回答所有这些问题,并帮助你自行做出决策。
### KDE Plasma 桌面的十大 Linux 发行版
我基于使用情况而非技术术语(如安装、终端使用等)编制了以下列表。
#### 1、Kubuntu

[Kubuntu](https://kubuntu.org/) 是 Ubuntu Linux 操作系统的官方 KDE Plasma 桌面版本。它使用与 Ubuntu 相同的基础软件包,并遵循 Ubuntu 的发布计划。这意味着它在 Ubuntu 发布新版本时也会发布新版本。由于基于 Ubuntu,你可以享受到伴随 Kubuntu 版本的庞大的帮助和支持社区。Kubuntu 是目前最广泛使用的 KDE Plasma 桌面。
优点:
* 在质量方面非常稳定 - 包括 LTS 和非 LTS 版本
* LTS 版本提供 5 年支持
* 庞大的社区帮助系统
* 易于使用
缺点:
* 需要大约 6 个月的延迟才能获得 KDE Plasma 桌面的最新版本。这是因为 Ubuntu 要求的稳定性。
>
> **[下载 Kubuntu](https://kubuntu.org/getkubuntu/)**
>
>
>
#### 2、KDE Neon
[KDE Neon](https://neon.kde.org/) 是 KDE 官方的 Linux 发行版,它提供了来自 KDE 社区的最新 KDE Plasma 桌面、KDE 框架和 KDE 应用程序。这个基于 Ubuntu 的 Linux 发行版直接来自 KDE 开发团队。KDE Neon 有两个版本:用户版和开发者版。用户版适用于所有希望体验经过测试且可用的最新 KDE Plasma 桌面的人。它可能会有一些小问题,但对我来说并不是致命问题。开发者版则专为开发人员提供,其中包含最新的软件包。这适合那些在 Linux 平台上有一些经验,并且有时间解决偶尔问题的人,但它也相当稳定。

优点:
* 最新的 KDE 应用程序、软件包和框架
* 基于 Ubuntu 基础
* 第一时间获得新的 KDE Plasma 版本
缺点:
* 可能会有偶尔的问题
>
> **[下载 KDE Neon](https://neon.kde.org/download)**
>
>
>
#### 3、Fedora KDE 定制版
[Fedora Linux](https://spins.fedoraproject.org/en/kde/) 是一个由红帽拥有并得到社区支持的基于 RPM 包管理器的 Linux 发行版。这个自由开源的 Linux 发行版提供领先的软件包和技术,并支持 KDE Plasma 版本。尽管其官方版本采用 GNOME 桌面,但也提供了一个 KDE Plasma 的“定制版”。每年会有两次 Fedora 发布,你可以在每个发布版本中获得最新的 KDE 软件包。理论上,它与 Kubuntu 类似,唯一的区别在于其底层的软件包管理和一个不同的赞助公司。

优点:
* 设计良好且稳定的 Linux 发行版
* 每年提供两次新的 KDE Plasma 发布
* 适合新手和高级用户
* 提供多功能的社区支持
缺点:
* Fedora Linux 使用 KDE 可能对完全新手用户来说稍微复杂
>
> **[下载 Fedora KDE 定制版](https://spins.fedoraproject.org/kde/download/index.html)**
>
>
>
#### 4、OpenSUSE KDE 版
[openSUSE](https://get.opensuse.org/leap/) 是一个为新手和有经验的用户定制的完备的 Linux 发行版。它由 SUSE Linux 和其他公司赞助。它支持 KDE Plasma 桌面作为其中一个桌面环境选择。使用 OpenSUSE KDE 版,你可以选择最新的 KDE 技术的滚动发布版本(称为 Tumbleweed),或者选择稳定且经过充分测试的 KDE Plasma 的长期支持版本(称为 Leap)。如果你想尝试非 Ubuntu、非 Fedora 的 KDE Plasma 发行版,那么这是一个不错的选择。

优点:
* 具有良好商业声誉的 Linux 发行版,因此提供了与 KDE 配套的高质量 Linux 系统
* 提供滚动发布和长期支持版本
* 支持多种硬件平台(单板设备、瘦客户端终端、台式机、笔记本电脑、PowerPC 等)
缺点:
* 可能不太出名的 Linux 发行版,因此通过论坛获得的免费支持可能较少
>
> **[下载 OpenSUSE KDE 版本(Leap)](https://get.opensuse.org/leap/)**
>
>
>
#### 5、Manjaro KDE 版
[Manjaro Linux](https://manjaro.org/) 是基于 Arch Linux 的 Linux 发行版,采用滚动发布模型。它是一个非常快速、用户友好的桌面操作系统,具有自动硬件检测、多个 Linux 内核支持和良好设计的配置设置等许多优点。Manjaro 带有的 KDE Plasma 桌面非常适合那些略懂 Linux 而又想体验带有 KDE 的 Arch Linux 的人。
优点:
* 滚动发布模型,在官方 Plasma 发布后一两周内提供最新的 KDE Plasma 桌面软件包
* 提供了用于 Arch 的图形化安装程序选项
* 通过论坛提供良好的社区支持
缺点:
* 由于持续的软件包更新,基于 Arch Linux 的发行版有时可能会出现错误和不稳定情况
* 可能不适合完全新手用户,或者那些希望在多年内无需重新安装的稳定系统
>
> **[下载 Manjaro KDE](https://manjaro.org/download/)**
>
>
>
#### 6、EndeavourOS KDE 版
[EndeavourOS](https://endeavouros.com/) 是一个相对较新的基于 Arch Linux 的 Linux 发行版,作为其支持的选择之一,它支持 KDE Plasma。它提供了易于使用的安装程序和预配置的桌面环境。这个 Linux 发行版的最大卖点之一是你可以选择安装哪些软件,并且预装了基于图形界面的桌面调整脚本。这是一个令人期待的发展中的 Linux 发行版。
优点:
* 基于 Arch Linux 的 KDE Plasma 桌面易于安装
* 一键操作的预制脚本,用于执行各种桌面操作(如更新)
* 支持多个 Arch Linux 内核版本
* 适合希望体验和学习带有 KDE Plasma 的 Arch Linux 的新用户
缺点:
* 相对较新的 Linux 发行版,由社区支持
* 如果你的组织计划为多个安装单位采用这个 KDE Plasma 版本,不大会选择这个发行版
>
> **[下载 EndeavourOS](https://endeavouros.com/latest-release/)**
>
>
>
#### 7、MX Linux KDE 版
[MX Linux](https://mxlinux.org/) 是一个基于 Debian 稳定分支的 Linux 发行版。Debian 是一个通用的 Linux 操作系统,是 Ubuntu 和所有衍生版的上游,它是所有这些 Linux 发行版的核心。它很少会出现问题,不会给你一个不稳定的系统。拥有了 Debian 的强大功能,MX Linux 又通过提供自家的实用工具和软件包来提供自己的特色。它的 KDE 版本非常适合所有用户,可以使用多年,特别是如果你想要一个稳定的 KDE 桌面系统。但是,由于 Debian 的发布周期较慢,你可能无法立即获得最新的技术。这意味着要获取最新的 KDE Plasma 技术,你可能需要等待 1.5 到 2 年。
优点:
* 稳定的 Linux 系统,带有经过充分测试的 KDE Plasma 软件包
* 适用于稳定性优于最新功能的系统
* 适合新用户和有经验的用户
* 为低配和老旧硬件提供良好的支持
* MX Linux 提供了一些最好的专有实用工具,可用于完成各种桌面任务
缺点:
* 它遵循 Debian 的稳定版本发布方式。因此,升级的 KDE Plasma 桌面版本需要花费数年的时间才能到达你这里。
>
> **[下载 MX Linux KDE 版本](https://mxlinux.org/download-links/)**
>
>
>
#### 8、Garuda Linux
[Garuda Linux](https://garudalinux.org/) 也是一个基于 Arch 的滚动发布发行版,其中一个版本提供了 KDE Plasma 桌面。它提供了一个易于使用的 Calamares 安装程序和其他图形工具来管理你的桌面系统。
Garuda 与其他基于 Arch 的发行版的显著区别在于它提供了一些开箱即用的工具来管理系统性能。其中一些工具包括 Zram、CPU 管理器以及用于内存管理的定制工具。
优点:
* 基于 Arch 的 Linux,具有用于内存管理的定制工具
* 官方支持的 KDE Plasma 版本
缺点:
* 相对较新的 Linux 发行版,于 2020 年 3 月首次发布
* 需要相对较高的硬件配置才能正常运行(最低 8GB 内存,40GB 存储空间)
>
> **[下载 Garuda Linux](https://garudalinux.org/downloads.html)**
>
>
>
#### 9、Nitrux
Nitrux 是一个针对 KDE Plasma 的独特 Linux 发行版。我想将它加入到这个列表中,是因为它提供了独特的开箱即用的外观。Nitrux 是一个基于 Debian SID 不稳定分支的 Linux 发行版。它提供了一个自定义的 KDE Plasma 桌面,使用了 “修改版 Plasma” Kvantum 主题进行增强。从技术上讲,这个桌面被称为 NX-Desktop,它是 KDE Plasma 的变种,提供了各种外观和感觉上的变化。这个 Linux 发行版基于 Debian 不稳定分支,使用 AppImage 进行应用程序部署,提供了最新的 KDE Plasma 技术。
优点:
* 提供了最佳的自定义 KDE Plasma 桌面版本
* 美观的 Nitrix 图标和主题,搭配 Kvuntum 强大的功能
* 支持 AppImage
缺点:
* 由于基于 Debian 的 SID 分支,有时会不稳定
* 完全依赖 AppImage,有时会产生问题
* 不适合 KDE Plasma 的初学者用户
>
> **[下载 Nitrux](https://nxos.org/)**
>
>
>
#### 10、KaOS
我想在这里提到的最后一个发行版是 [KaOS](https://kaosx.us/),这是因为它的独特性。KaOS 是一个专为提供全新 KDE Plasma 桌面而特殊设计的 Linux 发行版,重点关注 Qt 和 KDE。它是一个滚动发布的 Linux 发行版,并且不基于 Ubuntu/Fedora,它是一个独立的 Linux 发行版。此外,它通过自家仓库提供软件包,相比于直接从 Arch Linux 获取的软件包,具有额外的质量保证。它仅适用于64位系统。
优点:
* 精心设计的 KDE Plasma 适用于新用户
* 滚动发布的自家仓库为稳定性提供了最新的 KDE Plasma 软件包,并提供了额外的质量保证
缺点:
* 不太流行,因此在论坛和谷歌搜索方面可能会得到较少的支持
* 对于完全的新用户来说,可能还不够成熟,因为找到错误可能需要更多的 Linux 知识。
>
> **[下载 KaOS](https://kaosx.us/pages/download/)**
>
>
>
### 其它基于 KDE Plasma 的 Linux 发行版
除了以上列表,你可能还想考虑从头开始安装带有 KDE 桌面的纯净 Debian 稳定版。这样可以既获得 Debian 的稳定性,又可以自定义所需的 KDE 软件包。你可以按照我们的 [Debian 安装指南](https://www.debugpoint.com/2021/01/install-debian-buster/) 来安装。
另外,我认为还有一个需要在这里提及的 Linux 发行版是 [Q4OS](https://q4os.org/)。原因是它提供了 Trinity 桌面环境,那是一个 KDE 3 的分支,而不是最新的 KDE Plasma 5+ 系列。早期的 KDE 3 版本非常可爱,拥有自己独特的美学特征。喜欢早期 KDE 桌面和小部件的用户可能会喜欢 Q4OS。
### 如何找出最适合你的 KDE Plasma Linux 发行版呢?
当你选择 Linux 发行版和桌面环境时,会考虑多个因素。例如,你可能始终需要最新的 KDE 技术,即使它有点不稳定也可以接受。另一方面,你可能需要非常稳定的系统,不需要最新的 KDE 技术。因此,基于这个思路,我们为你准备了一个快速对比表格,以帮助你做出决策。

### 结论
我们列出了一些提供了 KDE Plasma 桌面的最佳 Linux 发行版。我们还列出了一些优缺点和比较。现在,哪个是你或你的团队/学校/组织的最佳选择,完全取决于你的决策。但是说实话,这取决于你的用例、你所处的情况或者你通过采用 KDE Plasma 桌面来解决的问题。
选择很主观,每个人口味不同。考虑到这一点,我希望这些信息能为你在选择完美的 Linux 发行版中采用 KDE Plasma 桌面提供一些指导。请在下方评论框中告诉我你对上述列表和比较的看法。
*(题图:MJ/6954a449-0ab8-42d0-9d3b-d6660732a382)*
---
via: <https://www.debugpoint.com/top-linux-distributions-kde-plasma/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,928 | 使用 Bash 制作 Web 安全颜色 | https://opensource.com/article/23/4/web-safe-color-guide-bash | 2023-06-21T13:37:00 | [
"Web 安全色"
] | /article-15928-1.html | 
>
> 使用 Bash 中的 for 循环,为网页创建一个方便的调色板。
>
>
>
当计算机显示器的调色板有限时,网页设计师通常使用一组 [Web 安全颜色](https://en.wikipedia.org/wiki/Web_colors#Web-safe_colors) 来创建网站。虽然在较新设备上显示的现代网站可以显示比最初的 Web 安全调色板更多的颜色,但我有时喜欢在创建网页时参考 Web 安全颜色。这样我就知道我的网页在任何地方都看起来不错。
你可以在网上找到 Web 安全调色板,但我想拥有自己的副本以方便参考。你也可以使用 Bash 中的 `for` 循环创建一个。
### Bash for 循环
[Bash 中的 for 循环](https://opensource.com/article/19/6/how-write-loop-bash) 的语法如下所示:
```
for 变量 in 集合 ; do 语句 ; done
```
例如,假设你想打印从 1 到 3 的所有数字。你可以快速在 Bash 命令行上编写一个 `for` 循环来为你完成这项工作:
```
$ for n in 1 2 3 ; do echo $n ; done
1
2
3
```
分号是标准的 Bash 语句分隔符。它们允许你在一行中编写多个命令。如果你要在 Bash 脚本文件中包含这个 `for` 循环,你可以用换行符替换分号并像这样写出 `for` 循环:
```
for n in 1 2 3
do
echo $n
done
```
我喜欢将 `do` 和 `for` 放在同一行,这样我更容易阅读:
```
for n in 1 2 3 ; do
echo $n
done
```
### 一次多个 for 循环
你可以将一个循环放在另一个循环中。这可以帮助你迭代多个变量,一次做不止一件事。假设你想打印出字母 A、B 和 C 与数字 1、2 和 3 的所有组合。你可以在 Bash 中使用两个 `for` 循环来实现,如下所示:
```
#!/bin/bash
for number in 1 2 3 ; do
for letter in A B C ; do
echo $letter$number
done
done
```
如果将这些行放在名为 `for.bash` 的 Bash 脚本文件中并运行它,你会看到九行显示了所有字母与每个数字配对的组合:
```
$ bash for.bash
A1
B1
C1
A2
B2
C2
A3
B3
C3
```
### 遍历 Web 安全颜色
Web 安全颜色是从十六进制颜色 `#000`(黑色,即红色、绿色和蓝色值均为零)到 `#fff`(白色,即红色、绿色和蓝色均为最高),每个十六进制值的步进为 0、3、6、9、c 和 f。
你可以在 Bash 中使用三个 `for` 循环生成 Web 安全颜色的所有组合的列表,其中循环遍历红色、绿色和蓝色值。
```
#!/bin/bash
for r in 0 3 6 9 c f ; do
for g in 0 3 6 9 c f ; do
for b in 0 3 6 9 c f ; do
echo "#$r$g$b"
done
done
done
```
如果将其保存在名为 `websafe.bash` 的新 Bash 脚本中并运行它,你就会看到所有 Web 安全颜色的十六进制值的迭代:
```
$ bash websafe.bash | head
#000
#003
#006
#009
#00c
#00f
#030
#033
#036
#039
```
要制作可用作 Web 安全颜色参考的 HTML 页面,你需要使每个条目成为一个单独的 HTML 元素。将每种颜色放在一个 `<div>` 元素中,并将背景设置为 Web 安全颜色。为了使十六进制值更易于阅读,将其放在单独的 `<code>` 元素中。将 Bash 脚本更新为如下:
```
#!/bin/bash
for r in 0 3 6 9 c f ; do
for g in 0 3 6 9 c f ; do
for b in 0 3 6 9 c f ; do
echo "<div style='background-color:#$r$g$b'><code>#$r$g$b</code></div>"
done
done
done
```
当你运行新的 Bash 脚本并将结果保存到 HTML 文件时,你可以在浏览器中查看所有 Web 安全颜色的输出:
```
$ bash websafe.bash > websafe.html
```

这个网页不是很好看。深色背景上的黑色文字无法阅读。我喜欢应用一些 HTML 样式来确保十六进制值在颜色矩形内以黑色背景上的白色文本显示。为了使页面看起来非常漂亮,我还使用 HTML 网格样式来排列每行六个框,每个框之间留出一些空间。
要添加这种额外的样式,你需要在 for 循环前后包含其他 HTML 元素。顶部的 HTML 代码定义样式,底部的 HTML 代码关闭所有打开的 HTML 标签:
```
#!/bin/bash
cat<<EOF
<!DOCTYPE html>
<html lang="en">
<head>
<title>Web-safe colors</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<style>
div {
padding-bottom: 1em;
}
code {
background-color: black;
color: white;
}
@media only screen and (min-width:600px) {
body {
display: grid;
grid-template-columns: repeat(6,1fr);
column-gap: 1em;
row-gap: 1em;
}
div {
padding-bottom: 3em;
}
}
</style>
</head>
</body>
EOF
for r in 0 3 6 9 c f ; do
for g in 0 3 6 9 c f ; do
for b in 0 3 6 9 c f ; do
echo "<div
style='background-color:#$r$g$b'><code>#$r$g$b</code></div>"
done
done
done
cat<<EOF
</body>
</html>
EOF
```
这个完成的 Bash 脚本以 HTML 格式生成 Web 安全颜色指南。每当你需要引用网络安全颜色时,运行脚本并将结果保存到 HTML 页面。现在你可以在浏览器中看到 Web 安全颜色的演示,作为你下一个 Web 项目的简单参考:
```
$ bash websafe.bash > websafe.html
```

*(题图:MJ/abf9daf2-b72f-4929-8dd8-b77fb5b9d39b)*
---
via: <https://opensource.com/article/23/4/web-safe-color-guide-bash>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,931 | 5 个令人惊讶的 Linux 用途 | https://opensource.com/article/22/5/surprising-things-i-do-linux | 2023-06-22T11:05:00 | [
"Linux"
] | https://linux.cn/article-15931-1.html |
>
> Linux 主导着大多数互联网、大部分云计算和几乎所有的超级计算机。我也喜欢在 Linux 上进行游戏、办公工作和发挥创造力。
>
>
>

*开源朗读者 | 徐斯佳*
当你习惯于一个操作系统时,很容易将其他操作系统看作是“应用程序”。如果你在桌面上使用一种操作系统,你可能会认为另一种操作系统是人们用来运行服务器的应用程序,而又一种操作系统是用来玩游戏的应用程序,依此类推。有时我们会忘记操作系统是计算机管理无数任务的部分(从技术上讲,每秒数百万个任务),它们通常设计成能够执行各种任务。当有人问我 Linux *能做什么* 时,我通常会问他们想让它做什么。这没有一个单一的答案,所以这里有五个让我惊讶的 Linux 用途。
### 1、用 Linux 进行激光切割

在离我最近的创客空间里,有一台巨大的工业机器,大约和一张沙发一样大小,可以根据一个简单的线条图设计文件来切割各种材料。这是一台强大的激光切割机,令我惊讶的是,我第一次使用它时发现它只需要通过 USB 线连接到我的 Linux 笔记本电脑上。事实上,在许多方面,与许多台式打印机相比,连接这台激光切割机更容易,因为许多台式打印机需要过于复杂和臃肿的驱动程序。
使用 Inkscape 和 [一个简单的插件](https://github.com/JTechPhotonics/J-Tech-Photonics-Laser-Tool/releases/tag/v1.0-beta_ink0.9),你可以为这台工业激光切割机设计切割线条。你可以为你的树莓派笔记本设计一个外壳,使用这些知识共享的设计方案来建造 [一个密码锁盒](https://msraynsford.blogspot.com/2016/10/laser-cut-cryptex.html)、切割一个店面标牌,或者你心目中的其他任何想法。而且,你可以完全使用开源软件来完成这些操作。
### 2、在 Linux 上进行游戏

开源游戏一直都有,最近一段时间也有一些备受瞩目的 Linux 游戏。我建造的第一台游戏电脑就是一台 Linux 电脑,我觉得我邀请过来一起玩沙发合作游戏的人们都没有意识到他们是在 Linux 上进行游戏。这是一种流畅顺滑的体验,而且取决于你愿意在硬件上花费多少,可能上无止境吧。
更重要的是,不仅游戏正在进入 Linux,整个平台也在进一步发展。Valve 推出的 Steam Deck 是一款非常受欢迎的掌上游戏机,它运行的是 Linux。更好的是,许多开源软件也在 Steam 上发布,包括 [Blender](http://blender.org) 和 [Krita](http://krita.org),这鼓励了更广泛的采用。
### 3、在 Linux 上进行办公工作

Linux,就像生活一样,并不总是刺激的。有时,你需要一台计算机来完成一些普通的事情,比如支付账单、制定预算,或者为学校写论文或工作写报告。无论任务是什么,Linux 都可以作为一台日常的桌面电脑。你可以在 Linux 上进行“平常”的工作。
不仅局限于知名的应用程序。我在优秀的 LibreOffice 套件中做了很多工作,但在我最旧的电脑上,我使用更简洁的 Abiword。有时,我喜欢试试 KDE 的官方套件 Calligra,当需要进行精确的 [设计工作](https://opensource.com/article/21/12/desktop-publishing-scribus)(包括 [专门的过程式设计工作](https://opensource.com/article/19/7/rgb-cube-python-scribus))时,我使用 Scribus。
使用 Linux 进行日常任务最好的地方在于,最终没有人知道你用了什么工具来完成最终产品。你的工具链和工作流程属于你自己,结果和封闭的、非开源软件产生的结果一样好,甚至更好。我发现,使用 Linux 进行日常任务让这些任务对我来说更有趣,因为开源软件本质上允许我开发达到自己预期结果的路径。我可以尝试创建解决方案,帮助我 [高效完成工作](https://opensource.com/article/21/1/raspberry-pi-productivity),或者帮助我 [自动化重要任务](https://opensource.com/article/22/5/remote-home-assistant),但我也享受系统的灵活性。我不想去适应我的工具链,而是调整我的工具,使它们为我工作。
### 4、在 Linux 上进行音乐制作

我是一个业余音乐家,在开始将所有制作工作转移到计算机之前,我拥有几台合成器、音序器和多轨录音机。我转向计算机音乐之所以用了比较长的时间,是因为我觉得它对我来说不够模块化。当你习惯于将物理设备互相连接,通过滤波器、效果器、混音器和辅助混音器来路由声音时,全功能应用程序看起来有点令人失望。
并不是说全功能应用程序没有受到欣赏。我喜欢能够打开一个应用程序,如 [LMMS](https://opensource.com/life/16/2/linux-multimedia-studio),它恰好拥有我想要的一切。然而,在实际使用中,似乎没有一个计算机音乐应用程序真正拥有我所需要的一切。
当我转向 Linux 时,我发现它以模块化为基本原则构建了一个庞大的音乐制作环境。我找到了 [音序器](https://opensource.com/article/21/12/midi-loops-seq24)、合成器、混音器、录音器、补丁台等的应用程序。我可以在计算机上建立自己的工作室,就像我在现实生活中建立自己的工作室一样。在 Linux 上,音频制作得到了飞速发展,今天,开源 [应用程序](https://opensource.com/article/17/6/qtractor-audio) 可以作为统一的控制中心,同时保留了从系统其他位置提取声音的可扩展性。对于像我这样的拼贴式制作人来说,这是一个梦幻般的工作室。
### 5、在 Linux 上进行复古计算

我不喜欢扔掉旧电脑,因为很少有旧电脑是真正报废的。通常,旧电脑只是被世界其他部分“超越”了。操作系统变得过于臃肿,旧电脑无法处理,因此你不再能获得操作系统和安全更新,应用程序开始要求你的旧电脑没有的资源,等等。
我倾向于 [收留旧电脑](https://opensource.com/article/19/7/how-make-old-computer-useful-again),将它们用作实验室机器或家庭服务器。最近,我发现在旧电脑上添加一块固态硬盘作为根分区,并使用 XFCE 或类似的轻量级桌面环境,使得即使是十年前的电脑,也可以愉快地用于期望的工作。平面设计、网页设计、编程、定格动画等任务在低配置机器上都是小菜一碟,更不用说简单的办公工作了。有了 Linux 驱动的机器,真不知道为什么企业还要升级。
每个人都有自己喜欢的“救援”发行版。我个人喜欢 Slackware 和 Mageia,它们都还发布了 32 位的安装镜像。Mageia 也是基于 RPM 的,所以你可以使用像 `dnf` 和 `rpmbuild` 这样的现代打包工具。
### 多说一句:Linux 服务器
好吧,我承认在服务器上使用 Linux 并不令人惊讶。实际上,对于那些了解 Linux 但自己不使用 Linux 的人来说,当提到 “Linux” 时,数据中心通常是他们首先想到的。然而,这种假设的问题在于它似乎明显地认为 Linux 在服务器上应该表现出色,好像 Linux 根本不需要努力一样。这是一种令人赞赏的情绪,但实际上,Linux 在服务器上表现出色是因为全球开发团队付出了巨大努力,让 Linux 在其所从事的工作上特别有效。
Linux 之所以成为强大的操作系统,主要是因为它驱动着大部分互联网、[主导着大部分云计算](https://opensource.com/article/20/10/keep-cloud-open)、几乎所有现有的超级计算机以及更多应用领域。Linux 并非止步不前,尽管它有着丰富的历史,但它并没有深陷传统而无法进步。新技术正在不断发展,Linux 也是这一进步的一部分。现代 Linux 适应了不断变化的世界对增长需求的要求,使得系统管理员能够为全世界的人们提供网络服务。
这并不是 Linux 的全部能力,但也绝非小小的成就。
### Linux 并不那么令人惊讶
我还记得第一次遇到一个从小就使用 Linux 的人的事情。在我使用 Linux 的大部分时间里,这种情况似乎很少发生,但最近这种情况相对较为普遍。我记得最令人惊讶的一次是遇到一个年轻的女士,带着幼儿,看到我当时穿着的那件极客风格的 T 恤衫,她随意地提到她也使用 Linux,因为她从小就接触它。这实际上让我有点嫉妒,但随后我想起,在我成长的过程中,桌面电脑上根本没有 Unix 的 *存在*。然而,想到 Linux 在过去几十年里的轻松发展,确实令人愉快。成为其中的一员更是乐趣无穷。
*(题图:MJ/e529833a-8ec1-4fff-997b-2ef3f107bc68)*
---
via: <https://opensource.com/article/22/5/surprising-things-i-do-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you're used to one operating system, it can be easy to look at other operating systems almost as if they were apps. If you use one OS on your desktop, you might think of another OS as the app that people use to run servers, and another OS as the app that plays games, and so on. We sometimes forget that an operating system is the part of a computer that manages a countless number of tasks (millions per second, technically), and they're usually designed to be capable of a diverse set of tasks. When people ask me what Linux *does*, I usually ask what they *want* it to do. There's no single answer, so here are five surprising things I do with Linux.
## 1. Laser cutting with Linux
(MSRaynsford, CC BY-NC 4.0)
At my nearest makerspace, there's a big industrial machine, about the size of a sofa, that slices through all kinds of materials according to a simple line-drawing design file. It's a powerful laser cutter, and I the first time I used it I was surprised to find that it just connected to my Linux laptop with a USB cable. In fact, in many ways, it was easier to connect to this laser cutter than it is to connect with many desktop printers, many of which require over-complicated and bloated drivers.
Using Inkscape and [a simple plugin](https://github.com/JTechPhotonics/J-Tech-Photonics-Laser-Tool/releases/tag/v1.0-beta_ink0.9), you can design cut lines for industrial laser cutters. Design a case for your Raspberry Pi laptop, use these Creative Commons design plans to build [a cryptex lockbox](https://msraynsford.blogspot.com/2016/10/laser-cut-cryptex.html), cut out a sign for your shopfront, or whatever it is you have in mind. And do it using an entirely open source stack.
## 2. Gaming on Linux

The Lutris desktop client
Open source has [always had games](https://opensource.com/article/20/5/open-source-fps-games), and there have been some high profile Linux games in the recent past. The first gaming PC I built was a Linux PC, and I don't think any of the people I had over for friendly couch co-op games realized they were using Linux by playing. And that's a good thing. It's a smooth and seamless experience, and the sky's the limit, depending on how much you want to spend on hardware.
What's more is that it's not just the games that have been coming to Linux, but the platform too. Valve's recent Steam Deck is a popular handheld gaming console that runs Linux. Better still, many open source software titles have been publishing releases on Steam, including [Blender](http://blender.org) and [Krita](http://krita.org), as ways to encourage wider adoption.
## 3. Office work on Linux
Linux, like life, isn't always necessarily exciting. Sometimes, you need a computer to do ordinary things, like when you pay bills, make a budget, or write a paper for school or a report for work. Regardless of the task, Linux is also normal, everyday desktop computer. You can use Linux for the mundane, the everyday, the "usual".
You're not limited to just the big name applications, either. I do my fair share of work in the excellent LibreOffice suite, but on my oldest computer I use the simpler Abiword instead. Sometimes, I like to explore Calligra, the KDE office suite, and when there's precision [design work](https://opensource.com/article/21/12/desktop-publishing-scribus) to be done (including [specialized procedural design work](https://opensource.com/article/19/7/rgb-cube-python-scribus)), I use Scribus.
The greatest thing about using Linux for everyday tasks is that ultimately nobody knows what you used to get to the end product. Your tool chain and your workflow is yours, and the results are as good or better than what locked-down, non-open software produces. I have found that using Linux for the everyday tasks makes those tasks more fun for me, because open source software inherently permits me to develop my own path to my desired outcome. I try to create solutions that help me [get work done efficiently](https://opensource.com/article/21/1/raspberry-pi-productivity), or that help me [automate important tasks](https://opensource.com/article/22/5/remote-home-assistant), but I also just enjoy the flexibility of the system. I don't want to adapt for my tool chain, I want to adapt my tools so that they work for me.
## 4. Music production on Linux
I'm a hobbyist musician, and before I started doing all of my production on computers I owned several synthesizers and sequencers and multi-track recorders. One reason it took me as long as it did to switch to computer music was that it didn't feel modular enough for me. When you're used to wiring physical boxes to one another to route sound through filters and effects and mixers and auxiliary mixers, an all-in-one application looks a little underwhelming.
It's not that an all-in-one app isn't appreciated, by any means. I like being able to open up one application, like [LMMS](https://opensource.com/life/16/2/linux-multimedia-studio), that happens to have everything I want. However, in practice it seems that no music application I tried on a computer actually had everything I needed.
When I switched to Linux, I discovered a landscape built with modularity as one of its founding principles. I found applications that were just [sequencers](https://opensource.com/article/21/12/midi-loops-seq24), applications that were just synthesizers, mixers, recorders, patch bays, and so on. I could build my own studio on my computer just as I'd built my own studio in real life. Audio production has developed in leaps and bounds on Linux, and today there are open source [applications](https://opensource.com/article/17/6/qtractor-audio) that can act as a unified control center while retaining the extensibility to pull in sounds from elsewhere on the system. For a patchwork producer like me, it's a dream studio.
## 5. Retro computing on Linux
I don't like throwing away old computers, because very rarely do old computers actually die. Usually, an old computer is "outgrown" by the rest of the world. Operating systems get too bloated for an old computer to handle, so you stop getting OS and security updates, applications start to demand resources your old computer just doesn't have, and so on.
I tend to [adopt old computers](https://opensource.com/article/19/7/how-make-old-computer-useful-again), putting them to work as either lab machines or home servers. Lately, I find that adding an SSD drive to serve as the root partition, and using XFCE or a similar lightweight desktop, makes even a computer from the previous decade a pleasantly usable machine for a lot more work than you might expect. Graphic design, web design, programming, stop-motion animation, and much more, are trivial tasks on low spec machines, to say nothing of simple office work. With Linux driving a machine, it's a wonder businesses ever upgrade.
Everybody has their favorite "rescue" distribution. Mine are Slackware and Mageia, both of which still release 32-bit installer images. Mageia is RPM-based, too, so you can use modern packaging tools like `dnf`
and `rpmbuild`
.
## Bonus: Linux servers
OK, I admit Linux on servers isn't at all surprising. In fact, to people who know of Linux but don't use Linux themselves, a data center is usually the first thing that pops into their heads when "Linux" is mentioned. The problem with that assumption is that it can make it seem obvious that Linux ought to be great on the server, as if Linux doesn't even have to try. It's a flattering sentiment, but the fact is that Linux is great on servers because there's a monumental effort across global development teams to make Linux especially effective at what it does.
It isn't by chance that Linux is the robust operating system that powers most of the internet, [most of the cloud](https://opensource.com/article/20/10/keep-cloud-open), nearly all the supercomputers in existence, and more. Linux isn't stagnate, and while it has a rich history behind it, it's not so steeped in tradition that it fails to progress. New technologies are being developed all the time, and Linux is a part of that progress. Modern Linux adapts to growing demands from a changing world to make it possible for systems administrators to provide networked services to people all over the world.
It's not everything Linux can do, but it's no small feat, either.
**[ Red Hat Enterprise Linux turns 20 this year: How enterprise Linux has evolved from server closet to cloud ]**
## Linux isn't that surprising
I remember the first time I met someone who'd grown up using Linux. It never seemed to happen for most of the time I've been a Linux user, but lately it's relatively common. I think the most surprising encounter was with a young woman, toddler in tow, who saw whatever geeky t-shirt I was wearing at the time and casually mentioned that she also used Linux, because she'd grown up with it. It actually made me a little jealous, but then I remembered that Unix on a desktop computer simply *didn't exist* when I was growing up. Still, it's fun to think about how casual Linux has become over the past few decades. It's even more fun to be a part of it.
## 2 Comments |
15,932 | R 语言 stats 包中的函数 | https://www.opensourceforu.com/2022/08/the-functions-in-the-r-stats-package/ | 2023-06-22T11:47:00 | [
"R 语言"
] | https://linux.cn/article-15932-1.html | 
我们已经学习了 R 语言的基础知识,包括其语法以及语法所对应的语义,现在准备使用 R 向统计学领域进发。本文是 R 系列的第十一篇文章,我们将学习如何使用 R 语言 stats 包中提供的统计函数。
与此系列之前的文章一样,我们将使用安装在 Parabola GNU/Linux-libre(x86-64)上的 R 4.1.2 版本来运行文中的代码。
```
$ R --version
R version 4.1.2 (2021-11-01) -- "Bird Hippie"
Copyright (C) 2021 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under the terms of the
GNU General Public License versions 2 or 3.
For more information about these matters see https://www.gnu.org/licenses/
```
### mean 函数
在 R 中 `mean` 函数用来计算算术平均值。该函数接受一个 R 对象 `x` 作为参数,以及一个 `trim` 选项来在计算均值之前剔除任意比例的数据(LCTT 译注:比如对于一个含有 7 个元素的向量 `x`,设置 `trim` 为 0.2 表示分别去掉 `x` 中最大和最小的前 20% —— 即 1.4 个 —— 的元素,所去掉的元素的个数会向下取整,所以最终会去掉 1 个最大值和 1 个最小值;`trim` 取值范围为 `[0, 0.5]`,默认为 0)。<ruby> 逻辑参数 <rt> logical argument </rt></ruby>(`TRUE` 或 `FALSE`)`na.rm` 可以设置是否忽略空值(`NA`)。该函数的语法如下:
```
mean(x, trim = 0, na.rm = FALSE, ...)
```
该函数支持数值、逻辑值、日期和 <ruby> 时间区间 <rt> time intervals </rt></ruby>。下面是使用 `mean` 函数的一些例子:
```
> mean(c(1, 2, 3))
2
> mean(c(1:5, 10, 20))
6.428571
> mean(c(FALSE, TRUE, FALSE))
0.3333333
> mean(c(TRUE, TRUE, TRUE))
1
```
我们使用 UCI 机器学习库提供的一个采集自葡萄牙银行机构的“银行营销数据集”作为样本数据。该数据可用于公共研究,包含 4 个 csv 文件,我们使用 `read.csv()` 函数导入其中的 `bank.csv` 文件。
```
> bank <- read.csv(file="bank.csv", sep=";")
> bank[1:3,]
age job marital education default balance housing loan contact day
1 30 unemployed married primary no 1787 no no cellular 19
2 33 services married secondary no 4789 yes yes cellular 11
3 35 management single tertiary no 1350 yes no cellular 16
month duration campaign pdays previous poutcome y
1 oct 79 1 -1 0 unknown no
2 may 220 1 339 4 failure no
3 apr 185 1 330 1 failure no
```
下面是计算 `age` 列均值的示例:
```
> mean(bank$age)
41.1701
```
### median 函数
R 语言 `stats` 包中的 `median` 函数用来计算样本的中位数。该函数接受一个数值向量 `x`,以及一个逻辑值 `na.rm` 用来设置在计算中位数之前是否去除 `NA` 值。该函数的语法如下:
```
median(x, na.rm = FALSE, ...)
```
下面是使用该函数的两个例子:
```
> median(3:5)
4
> median(c(3:5, 50, 150))
[1] 5
```
现在我们可以计算银行数据中 `age` 列的中位数:
```
> median(bank$age)
39
```
### pair 函数
`pair` 函数用来合并两个向量,接受向量 `x` 和向量 `y` 两个参数。`x` 和 `y` 的长度必须相等。
```
Pair(x, y)
```
该函数返回一个 `Pair` 类的列数为 2 的矩阵,示例如下:
```
> Pair(c(1,2,3), c(4,5,6))
x y
[1,] 1 4
[2,] 2 5
[3,] 3 6
attr(,"class")
[1] "Pair"
```
该函数常用于像 T 检验和 Wilcox 检验等的 <ruby> 配对检验 <rt> paired test </rt></ruby>。
### dist 函数
`dist` 函数用来计算数据矩阵中各行之间的距离矩阵,接受以下参数:
| 参数 | 描述 |
| --- | --- |
| `x` | 数值矩阵 |
| `method` | 距离测量方法 |
| `diag` | 若为 TRUE,则打印距离矩阵的对角线 |
| `upper` | 若为 TRUE,则打印距离矩阵的上三角 |
| `p` | 闵可夫斯基距离的幂次(见下文 LCTT 译注) |
该函数提供的距离测量方法包括:<ruby> 欧式距离 <rt> euclidean </rt></ruby>、<ruby> 最大距离 <rt> maximum </rt></ruby>、<ruby> 曼哈顿距离 <rt> manhattan </rt></ruby>、<ruby> 堪培拉距离 <rt> canberra </rt></ruby>、<ruby> 二进制距离 <rt> binary </rt></ruby> 和 <ruby> 闵可夫斯基距离 <rt> minkowski </rt></ruby>,默认为欧式距离。
>
> LCTT 译注:
>
>
> * **欧式距离**指两点之间线段的长度,比如二维空间中 A 点 和 B 点 的欧式距离是  ;
> * **最大距离**指 n 维向量空间中两点在各维度上的距离的最大值,比如 A 点 (3,6,8,9) 和 B 点 (1,8,9,10) 之间的最大距离是 ,等于 2;
> * **曼哈顿距离**指 n 维向量空间中两点在各维度上的距离之和,比如二维空间中 A 点 和 B 点 之间的曼哈顿距离是 ;
> * **堪培拉距离**的公式是  ;
> * **二进制距离**首先将两个向量中的各元素看作其二进制形式,然后剔除在两个向量中对应值均为 0 的维度,最后计算在剩下的维度上两个向量间的对应值不相同的比例,比如 V1=(1,3,0,5,0) 和 V2=(11,13,0,15,10) 的二进制形式分别是 (1,1,0,1,0) 和 (1,1,0,1,1),其中第 3 个维度的对应值均为 0,剔除该维度之后为 (1,1,1,0) 和 (1,1,1,1),在剩余的 4 个维度中只有最后一个维度在两个向量之间的值不同,最终结果为 0.25;
> * **闵可夫斯基距离**是欧式距离和曼哈顿距离的推广,公式是 ,当 p = 1 时相当于曼哈顿距离,当 p = 2 时相当于欧式距离。
>
>
>
下面是使用欧式距离计算 `age` 列距离矩阵的示例:
```
> dist(bank$age, method="euclidean", diag=FALSE, upper=FALSE, p=2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
2 3
3 5 2
4 0 3 5
5 29 26 24 29
6 5 2 0 5 24
7 6 3 1 6 23 1
8 9 6 4 9 20 4 3
9 11 8 6 11 18 6 5 2
10 13 10 8 13 16 8 7 4 2
11 9 6 4 9 20 4 3 0 2 4
12 13 10 8 13 16 8 7 4 2 0 4
13 6 3 1 6 23 1 0 3 5 7 3 7
14 10 13 15 10 39 15 16 19 21 23 19 23 16
15 1 2 4 1 28 4 5 8 10 12 8 12 5 11
16 10 7 5 10 19 5 4 1 1 3 1 3 4 20 9
17 26 23 21 26 3 21 20 17 15 13 17 13 20 36 25 16
18 7 4 2 7 22 2 1 2 4 6 2 6 1 17 6 3 19
19 5 8 10 5 34 10 11 14 16 18 14 18 11 5 6 15 31 12
20 1 2 4 1 28 4 5 8 10 12 8 12 5 11 0 9 25 6 6
21 8 5 3 8 21 3 2 1 3 5 1 5 2 18 7 2 18 1 13 7
22 12 9 7 12 17 7 6 3 1 1 3 1 6 22 11 2 14 5 17 11 4
23 14 11 9 14 15 9 8 5 3 1 5 1 8 24 13 4 12 7 19 13 6 2
26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
...
```
改用二进制距离的计算结果如下:
```
> dist(bank$age, method="binary", diag=FALSE, upper=FALSE, p=2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
2 0
3 0 0
4 0 0 0
5 0 0 0 0
6 0 0 0 0 0
7 0 0 0 0 0 0
8 0 0 0 0 0 0 0
9 0 0 0 0 0 0 0 0
10 0 0 0 0 0 0 0 0 0
11 0 0 0 0 0 0 0 0 0 0
12 0 0 0 0 0 0 0 0 0 0 0
13 0 0 0 0 0 0 0 0 0 0 0 0
14 0 0 0 0 0 0 0 0 0 0 0 0 0
15 0 0 0 0 0 0 0 0 0 0 0 0 0 0
16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
17 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
19 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
```
### quantile 函数
`quantile` 函数用于计算数值向量 `x` 的分位数及其对应的概率。当设置 `na.rm` 为 `TRUE` 时,该函数将忽略向量中的 `NA` 和 `NaN` 值。概率 0 对应最小观测值,概率 1 对应最大观测值。该函数的语法如下:
```
quantile(x, ...)
```
`quantile` 函数接受以下参数:
| 参数 | 描述 |
| --- | --- |
| `x` | 数值向量 |
| `probs` | 概率向量,取值为 `[0, 1]`(LCTT 译注:默认为 `(0, 0.25, 0.5, 0.75, 1)`) |
| `na.rm` | 若为 `TRUE`,忽略向量中的 `NA` 和 `NaN` 值 |
| `names` | 若为 `TRUE`,在结果中包含命名属性 |
| `type` | 整数类型,用于选择任意一个九种分位数算法(LCTT 译注:默认为 7) |
| `digits` | 小数精度 |
| … | 传递给其他方法的额外参数 |
`rnorm` 函数可用于生成正态分布的随机数。它可以接受要生成的观测值的数量 `n`,一个均值向量以及一个标准差向量。下面是一个计算 `rnorm` 函数生成的随机数的四分位数的示例:
```
> quantile(x <- rnorm(100))
0% 25% 50% 75% 100%
-1.978171612 -0.746829079 -0.009440368 0.698271134 1.897942805
```
下面是生成银行年龄数据对应概率下的分位数的示例:
```
> quantile(bank$age, probs = c(0.1, 0.5, 1, 2, 5, 10, 50)/100)
0.1% 0.5% 1% 2% 5% 10% 50%
20.0 22.6 24.0 25.0 27.0 29.0 39.0
```
### IQR 函数
`IQR` 函数用于计算向量中数值的 <ruby> 四分位距 <rt> interquartile range </rt></ruby>。其语法如下:
```
IQR(x, na.rm = FALSE, type = 7)
```
参数 `type` 指定了一个整数以选择分位数算法,该算法在 [Hyndman and Fan (1996)](https://www.amherst.edu/media/view/129116/.../Sample+Quantiles.pdf) 中进行了讨论。下面是计算银行年龄四分位距的示例:
```
> IQR(bank$age, na.rm = FALSE, type=7)
16
```
### sd 函数
`sd` 函数用来计算一组数值中的标准差。该函数接受一个 <ruby> 数值向量 <rt> numeric vector </rt></ruby> `x` 和一个逻辑值 `na.rm`。`na.rm` 用来设置在计算时是否忽略缺失值。该函数的语法如下:
```
sd(x, na.rm = FALSE)
```
对于长度为 0 或 1 的向量,该函数返回 `NA`。下面是两个例子:
```
> sd(1:10)
3.02765
> sd(1)
NA
```
下面是计算 `age` 列标准差的示例:
```
> sd(bank$age)
10.57621
```
R 语言 stats 包中还有很多其他函数,鼓励你自行探索。
*(题图:MJ/ee6b533d-69fc-4baa-a985-cc4e499b5029)*
---
via: <https://www.opensourceforu.com/2022/08/the-functions-in-the-r-stats-package/>
作者:[Shakthi Kannan](https://www.opensourceforu.com/author/shakthi-kannan/) 选题:[lkxed](https://github.com/lkxed) 译者:[tanloong](https://github.com/tanloong) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We have learnt the basics of the R programming language, its syntax and semantics, and are now ready to delve into the statistics domain using R. In this eleventh article in the R series, we will learn to use the statistics functions available in the R stats package.
As we have done in the earlier parts of this series, we are going to use the R version 4.1.2 installed on Parabola GNU/Linux-libre (x86-64) for the code snippets.
$ R --version R version 4.1.2 (2021-11-01) -- “Bird Hippie” Copyright (C) 2021 The R Foundation for Statistical Computing Platform: x86_64-pc-linux-gnu (64-bit) R is free software and comes with ABSOLUTELY NO WARRANTY. You are welcome to redistribute it under the terms of the GNU General Public License versions 2 or 3. For more information about these matters see https://www.gnu.org/licenses/
## Mean
The R function for calculating the arithmetic mean is mean. It accepts an R object ‘x’ as an argument, and a ‘trim’ option to trim any fractions before computing the mean value. The ‘na.rm’ logical argument can be used to ignore any NA values. Its syntax is as follows:
mean(x, trim = 0, na.rm = FALSE, ...)
The function supports numerical and logical values, as well as date and time intervals. A few examples for the mean function are given below:
> mean(c(1, 2, 3)) 2 > mean(c(1:5, 10, 20)) 6.428571 > mean(c(FALSE, TRUE, FALSE)) 0.3333333 > mean(c(TRUE, TRUE, TRUE)) 1
Consider the ‘Bank Marketing Data Set’ for a Portuguese banking institution that is available from the UCI Machine Learning Repository available at *https://archive.ics.uci.edu/ml/datasets/Bank+Marketing*. The data can be used for public research. There are four data sets available, and we will use the read.*csv()* function to import the data from a ‘bank*.csv*’ file.
> bank <- read.csv(file=”bank.csv”, sep=”;”) > bank[1:3,] age job marital education default balance housing loan contact day 1 30 unemployed married primary no 1787 no no cellular 19 2 33 services married secondary no 4789 yes yes cellular 11 3 35 management single tertiary no 1350 yes no cellular 16 month duration campaign pdays previous poutcome y 1 oct 79 1 -1 0 unknown no 2 may 220 1 339 4 failure no 3 apr 185 1 330 1 failure no
We can find the mean age from the bank data as follows:
> mean(bank$age) 41.1701
## Median
The *median* function in the R stats package computes the sample median. It accepts a numeric vector ‘x’, and a logical value ‘na.rm’ to indicate if it should discard ‘NA’ values before computing the median. Its syntax is as follows:
median(x, na.rm = FALSE, ...)
A couple of examples are given below:
> median(3:5) 4 > median(c(3:5, 50, 150)) [1] 5
We can now find the median age from the bank data set as follows:
> median(bank$age) 39
## Pair
The* pair* function can be used to combine two vectors. It accepts two arguments, and vectors ‘x’ and ‘y’. Both the vectors should have the same length. The syntax is as follows:
Pair(x, y)
The function returns a two column matrix of class ‘Pair’. An example is given below:
> Pair(c(1,2,3), c(4,5,6)) x y [1,] 1 4 [2,] 2 5 [3,] 3 6 attr(,”class”) [1] “Pair”
The function is used for paired tests such as *t.test* and *wilcox.test*.
## dist
The *dist* function is used to calculate the distance matrix for the rows in a data matrix, and accepts the following arguments:
Argument |
Description |
x |
A numeric matrix |
method |
The distance measure to be used |
diag |
Prints diagonal of distance matrix if TRUE |
upper |
Prints upper triangle of distance matrix if TRUE |
p |
Power of the Minkowski distance |
The distance measurement methods supported are: ‘euclidean’, ‘maximum’, ‘manhattan’, ‘canberra’, ‘binary’ and ‘minkowski’. The distance measurement for the age data set using the Euclidean distance is given below:
> dist(bank$age, method=”euclidean”, diag=FALSE, upper=FALSE, p=2) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 2 3 3 5 2 4 0 3 5 5 29 26 24 29 6 5 2 0 5 24 7 6 3 1 6 23 1 8 9 6 4 9 20 4 3 9 11 8 6 11 18 6 5 2 10 13 10 8 13 16 8 7 4 2 11 9 6 4 9 20 4 3 0 2 4 12 13 10 8 13 16 8 7 4 2 0 4 13 6 3 1 6 23 1 0 3 5 7 3 7 14 10 13 15 10 39 15 16 19 21 23 19 23 16 15 1 2 4 1 28 4 5 8 10 12 8 12 5 11 16 10 7 5 10 19 5 4 1 1 3 1 3 4 20 9 17 26 23 21 26 3 21 20 17 15 13 17 13 20 36 25 16 18 7 4 2 7 22 2 1 2 4 6 2 6 1 17 6 3 19 19 5 8 10 5 34 10 11 14 16 18 14 18 11 5 6 15 31 12 20 1 2 4 1 28 4 5 8 10 12 8 12 5 11 0 9 25 6 6 21 8 5 3 8 21 3 2 1 3 5 1 5 2 18 7 2 18 1 13 7 22 12 9 7 12 17 7 6 3 1 1 3 1 6 22 11 2 14 5 17 11 4 23 14 11 9 14 15 9 8 5 3 1 5 1 8 24 13 4 12 7 19 13 6 2 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 ...
The binary distance measurement output for the same bank age data is as follows:
> dist(bank$age, method=”binary”, diag=FALSE, upper=FALSE, p=2) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 2 0 3 0 0 4 0 0 0 5 0 0 0 0 6 0 0 0 0 0 7 0 0 0 0 0 0 8 0 0 0 0 0 0 0 9 0 0 0 0 0 0 0 0 10 0 0 0 0 0 0 0 0 0 11 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 0 0 0 0 0 0 0 13 0 0 0 0 0 0 0 0 0 0 0 0 14 0 0 0 0 0 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 17 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 19 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
## Quantile
The quantiles can be generated for a numeric vector ‘x’ along with their given probabilities using the quantile function. The ‘NA’ and ‘NaN’ values are not allowed in the vector, unless ‘na.rm’ is set to TRUE. The probability of 0 is for the lowest observation and 1 for the highest. Its syntax is as follows:
quantile(x, ...)
The quantile function accepts the following arguments:
Argument | Description |
x | A numeric vector |
probs | A vector of probabilities between 0 and 1 |
na.rm | NA and NaN values are ignored if TRUE |
names | If TRUE, the result has the names attribute |
type | An integer to select any of the nine quantile algorithms |
digits | The decimal precision to use |
… | Additional arguments passed to or from other methods |
The *rnorm* function can be used to generate random values for the normal distribution. It can take ‘n’ number of observations, a vector of ‘means’, and a vector ‘sd’ of standard deviations as its arguments. We can obtain the quantiles for the values produced by the ‘rnorm’ function. For example:
> quantile(x <- rnorm(100)) 0% 25% 50% 75% 100% -1.978171612 -0.746829079 -0.009440368 0.698271134 1.897942805
The quantiles for bank age data with the following probabilities can be generated as follows:
> quantile(bank$age, probs = c(0.1, 0.5, 1, 2, 5, 10, 50)/100) 0.1% 0.5% 1% 2% 5% 10% 50% 20.0 22.6 24.0 25.0 27.0 29.0 39.0
## Interquartile range
The *IQR* function computes the interquartile range for the numeric values of a vector. Its syntax is as follows:
IQR(x, na.rm = FALSE, type = 7)
The ‘type’ argument specifies an integer to select the quantile algorithm, which is discussed in Hyndman and Fan (1996). The interquartile range for the bank age can be computed as shown below:
> IQR(bank$age, na.rm = FALSE, type=7) 16
## Standard deviation
The *sd* function is used to calculate the standard deviation for a set of values. It accepts a numeric vector ‘x’ and a logical value for ‘na.rm’ to remove missing values. Its syntax is as follows:
sd(x, na.rm = FALSE)
The standard deviation for a vector with length zero or 1 is ‘NA’. A couple of examples are given below:
> sd(1:10) 3.02765 > sd(1) NA
We can calculate the standard deviation for the bank age column as follows:
> sd(bank$age) 10.57621
You are encouraged to explore more functions available in the stats packages available in R. |
15,934 | 包含 Openbox 的 7 个极简 Linux 发行版 | https://itsfoss.com/openbox-distros/ | 2023-06-23T09:33:00 | [
"Openbox"
] | https://linux.cn/article-15934-1.html | 
[Openbox](http://openbox.org/wiki/Main_Page) 是一款适用于 Linux 的轻量级、可配置的窗口堆叠式管理器。它支持许多标准,适用于任何桌面环境。
可能让你惊讶的是,**LXDE 和 LXQT 桌面环境都是基于 Openbox 构建的**。你甚至可以用它替换桌面环境的窗口管理器。
当然,你几乎可以在任何 Linux 发行版上安装 Openbox。不过,配置它需要时间和精力。
一个更简单的方法是使用提供 Openbox 变种的发行版。在本文中,我列出了一些能够让你轻松体验 Openbox 的发行版。
**注意:** 列表按字母顺序排列,不代表排名。
### 1、Archcraft

如果你想体验 Openbox 窗口管理器,Archcraft 是一个不错的选择。不像其他发行版,Openbox 是这个发行版的默认桌面环境,所以你可以期待它的表现优秀。
它提供了一个精简且轻量的环境,只需不到 500MB 的内存即可运行,而且外观上也没有降级。其界面元素风格统一。
你可以通过简单点击来切换主题,如果你喜欢,它还提供了类似 Windows 的用户界面。
对于资深用户来说,它内置了对 AUR 和 Chaotic-AUR 的支持。与其他发行版不同的是,它提供了最佳的开箱即用体验。
>
> **[Archcraft](https://archcraft.io/)**
>
>
>
### 2、ArcolinuxB Openbox

如果你想学习 Arch(Arcolinux 项目的主要目标),ArcolinuxB Openbox 是一个非常优秀的 Linux 桌面发行版。
它是 ArcolinuxB 项目的众多变种之一。你可能会遇到一些学习曲线和不完善的地方。
与 Archcraft 不同,你在这里不会看到完全统一的界面元素,可能需要进行一些调整来获得良好的体验。
>
> **[ArcolinuxB](https://arcolinuxb.com/)**
>
>
>
### 3、AV Linux MX Edition

AV Linux MX Edition 是基于 MX Linux 的一个版本,使用 Openbox 作为窗口管理器。
它使用高性能的 [Liquorix 内核](https://liquorix.net/#features),提供了音频方面爱好者所需要的低延迟。它还通过 Wine-staging 支持 Windows 音频。
如果你是一位音频专业人士并且使用 Linux,你可能想尝试一下这个发行版。对于一些用户来说,它可能显得臃肿,因为预装了许多应用程序。
>
> **[AV Linux](http://www.bandshed.net/avlinux/)**
>
>
>
### 4、Bunsenlabs Linux

BunsenLabs Linux 是一个基于 Debian 的发行版,提供了一个轻量且易于定制的 Openbox 桌面环境。该项目是 [CrunchBang Linux](https://en.wikipedia.org/wiki/CrunchBang_Linux) 的分支。
它仍然基于 Debian 10,所以在软件仓库中你将获取到较旧版本的应用程序。然而,由于包含了硬件和多媒体支持,它具有相当好的开箱即用体验,与 Debian 不同。
它的界面与 Archcraft 类似,还提供了丰富的 Conky 配置选项。
>
> **[BunsenLabs Linux](https://www.bunsenlabs.org/)**
>
>
>
### 5、Crunchbang++

正如其名字所示,Crunchbang++ 是 Crunchbang 的一个分支,并尽量保持与原版接近。
对于不了解的人来说,Crunchbang 是一个几乎在十年前停止开发的流行 Openbox 发行版。
Crunchbang++ 是一个极简且轻量级的发行版。它可能会让一些用户怀旧。它基于 Debian 11,相比 Bunsenlabs 可以提供更新的软件包。
>
> **[Crunchbang++](https://crunchbangplusplus.org/)**
>
>
>
### 6、Mabox Linux

Mabox Linux 是一个基于 Manjaro 的现代发行版,专注于定制化或 <ruby> 美化 <rt> ricing </rt></ruby>。
由于使用了轻量级组件,它是一个极简且快速的系统。由于采用滚动更新机制,你还可以获得更新的软件版本。
该发行版的一些独特功能包括 Colorizer(根据壁纸更改强调颜色)、Quicktiling(用于轻松进行窗口平铺)和可定制的菜单/面板。这么多的定制化功能可能让一些极简主义者感到有些害怕。
>
> **[Mabox Linux](https://maboxlinux.org/)**
>
>
>
### 7、Sparky Linux Openbox

Sparky Linux 是一个基于 Debian 的 Linux 发行版,也提供 Openbox 作为另一种桌面环境选择。
它有一个基于 Debian Testing 的版本,对于需要更新应用程序的用户来说非常有用。它致力于为 Debian 提供开箱即用的体验,并将定制化留给用户。因此,在这里你可能不会看到太多花哨的界面效果。
>
> **[Sparky Linux](https://sparkylinux.org/)**
>
>
>
### 总结
还有其他几个 Linux 发行版可以安装 Openbox。
但在这个列表中,我列出了那些在 <ruby> 立付 <rt> Live </rt></ruby> 介质中提供 Openbox ,其中一些还将 Openbox 作为默认桌面环境。
你最喜欢的 Openbox 发行版是哪个?你喜欢它预先定制好还是更喜欢自己进行定制?欢迎你提出建议。
*(题图:MJ/19d5a524-8229-4c14-89d1-f8287c34eeae)*
---
via: <https://itsfoss.com/openbox-distros/>
作者:[Anuj Sharma](https://itsfoss.com/author/anuj/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Openbox](http://openbox.org/wiki/Main_Page) is a lightweight, configurable, stacking window manager available for Linux. It supports many standards making it a good fit for any desktop.
You will be surprised to know that **LXDE and LXQT desktop environments are built around Openbox**. You can even replace the window manager of your desktop environment with it.
Of course, you can install Openbox on almost any Linux distribution. However, configuring it takes time and effort.
An easier way out would to be to use a distribution that provides an Openbox variant. In this article, I list some distros that give you an out-of-the-box Openbox experience.
**Note:** The list is in alphabetical order and is not a ranking.
## 1. Archcraft
This is one of the exciting choices if you want to get your hands on the Openbox window manager. Openbox is the default desktop for the distro so you can expect it to be great unlike other distros.
It provides a minimal and lightweight environment as it can run under 500 MB without compromising the looks. The UI elements are cohesive.
You can switch themes with just a click. It also provides Windows like UI if you like that.
For power users it has built in support for AUR and Chaotic-AUR. Unlike any other distros, it provides the best out of box experience.
## 2. ArcolinuxB Openbox
It should be an excellent distro for your Linux desktop if you want to learn Arch (The main motive of Arcolinux project).
It is one of the many flavors of ArcolinuxB project. One can expect slight learning curve and rough edges.
You will not see cohesive UI elements as Archcraft here and it may need some tinkering to get a good experience.
## 3. AV Linux MX Edition
AV Linux MX Edition is based on MX Linux but with Openbox as the window manager.
It uses the high-performance [Liquorix Kernel](https://liquorix.net/#features) and provides low latency audio which is desired by audiophiles. It also has support for Windows Audio via Wine-staging.
You may want to try this out if you are an audio professional and a Linux user. It may seem bloated to some users, as it comes with many pre-installed apps.
## 4. Bunsenlabs Linux
BunsenLabs Linux is a Debian-based distribution offering a lightweight and easily customizable Openbox desktop. The project is a fork of [CrunchBang Linux](https://en.wikipedia.org/wiki/CrunchBang_Linux).
It is still based on Debian 10, so you will get the older versions of apps in repos. However, it has quite a good out-of-box experience due to the inclusion of hardware and multimedia support, unlike Debian.
It has an interface as cohesive as Archcraft and also provides a great range of conky configurations.
## 5. Crunchbangplusplus
As the name suggests, it is a Crunchbang fork, and tries to stay as close as possible to the original.
For those unaware, Crunchbang was a popular Openbox distribution discontinued almost a decade ago.
Crunchbang++ is minimal and lightweight. It may make some users nostalgic. It is based on Debian 11, which can provide newer packages as compared to Bunsenlabs.
## 6. Mabox Linux
Mabox Linux is a modern Manjaro-based distribution that focuses on customization or ricing.
It is minimal and fast due to use of light components. You also get newer software due to rolling release.
Some of the exclusive features of this distro are Colorizer (changes accent colors according to wallpaper), Quicktiling(for easily tiling windows) and customizable menus/panels. This much customization may intimidate some minimalists.
## 7. Sparky Linux Openbox
Sparky Linux is a Debian-based Linux distribution which also provides Openbox as an alternative desktop.
It has an edition with Debian Testing, which can be useful for users who need newer apps. It is focused on providing out of box experience for Debian and keeps the customization to users. Thus, you might not see that much eye candy here.
## Wrapping Up
There are several other Linux distributions on which you can install Openbox.
But, for this list, I have listed the ones which provide Openbox in live media and some of them have Openbox as their default desktop also.
What is your favorite Openbox distribution? Do you like it pre-customized or prefer to customize the yourself? Your suggestions are always welcome. |
15,935 | Rust 基础系列 #8:编写里程碑 Rust 程序 | https://itsfoss.com/milestone-rust-program/ | 2023-06-23T11:44:00 | [
"Rust"
] | https://linux.cn/article-15935-1.html | 
到目前为止,我们已经讲解了包括 [变量、可变性、常量](/article-15771-1.html)、[数据类型](/article-15811-1.html)、[函数](/article-15855-1.html)、[if-else 语句](/article-15896-1.html) 和 [循环](/article-15908-1.html) 在内的一些关于 Rust 编程的基础知识。
在 Rust 基础系列的最后一章里,让我们现在用 Rust 编写一个程序,使用这些主题,以便更好地理解它们在现实世界中的用途。让我们来编写一个相对简单的程序,用来从水果市场订购水果。
### 我们程序的基本结构
来让我们首先向用户问好,并告诉他们如何与程序交互。
```
fn main() {
println!("欢迎来到水果市场!");
println!("请选择要购买的水果。\n");
println!("\n可以购买的水果:苹果、香蕉、橘子、芒果、葡萄");
println!("购买完成后,请输入“quit”或“q”。\n");
}
```
### 获取用户输入
上面的代码非常简单。目前,你不知道接下来该做什么,因为你不知道用户接下来想做什么。
所以让我们添加一些代码,接受用户输入并将其存储在某个地方以便稍后解析,然后根据用户输入采取适当的操作。
```
use std::io;
fn main() {
println!("欢迎来到水果市场!");
println!("请选择要购买的水果。\n");
println!("\n可以购买的水果:苹果、香蕉、橘子、芒果、葡萄");
println!("购买完成后,请输入“quit”或“q”。\n");
// 获取用户输入
let mut user_input = String::new();
io::stdin()
.read_line(&mut user_input)
.expect("无法读取用户输入。");
}
```
有三个新元素需要告诉你。所以让我们对这些新元素进行浅层次的探索。
#### 1. 理解 use 关键字
在这个程序的第一行,你可能已经注意到我们“使用”(哈哈!)了一个叫做 `use` 的新关键字。Rust 中的 `use` 关键字类似于 C/C++ 中的 `#include` 指令和 Python 中的 `import` 关键字。使用 `use` 关键字,我们从 Rust 标准库 `std` 中“导入”了 `io`(输入输出)模块。
>
> LCTT 译注:“使用”在原文中为“use”,与新介绍的关键字一样。
>
>
>
你可能会想知道为什么我们在可以使用 `println` 宏来将某些内容输出到标准输出时,导入 `io` 模块是必要的。Rust 的标准库有一个叫做 `prelude` 的模块,它会自动被包含。该模块包含了 Rust 程序员可能需要使用的所有常用函数,比如 `println` 宏。(你可以在 [这里](https://doc.rust-lang.org/std/prelude/index.html) 阅读更多关于 `std::prelude` 模块的内容。)
Rust 标准库 `std` 中的 `io` 模块是接受用户输入所必需的。因此,我们在程序的第一行添加了一个 `use` 语句。
#### 2. 理解 Rust 中的 String 类型
在第 11 行,我创建了一个新的可变变量 `user_input`,正如它的名字所表示的那样,它将被用来存储用户输入。但是在同一行,你可能已经注意到了一些“新的”东西(哈哈,又来了!)。
>
> LCTT 译注:“新的”在原文中为“new”,在第 11 行的代码中,原作者使用了 `String::new()` 函数,所以此处的梗与“使用”一样,原作者使用了一个在代码中用到的单词。
>
>
>
我没有使用双引号(`""`)声明一个空字符串,而是使用 `String::new()` 函数来创建一个新的空字符串。
`""` 与 `String::new()` 的区别是你将在 Rust 系列的后续文章中学习到的。现在,只需要知道,使用 `String::new()` 函数,你可以创建一个**可变**的,**位于堆上**的字符串。
如果我使用 `""` 创建了一个字符串,我将得到一个叫做“字符串切片”的东西。字符串切片的内容也位于堆上,但是字符串本身是**不可变**的。所以,即使变量本身是可变的,作为字符串存储的实际数据是不可变的,需要被**覆盖**而不是修改。
#### 3. 接受用户输入
在第 12 行,我调用了 `std::io` 的 `stdin()` 函数。如果我在程序的开头没有导入 `std::io` 模块,那么这一行将是 `std::io::stdin()` 而不是 `io::stdin()`。
`sdtin()` 函数返回一个终端的输入句柄。`read_line()` 函数抓住这个输入句柄,然后,正如它的名字所暗示的那样,读取一行输入。这个函数接受一个可变字符串的引用。所以,我传入了 `user_input` 变量,通过在它前面加上 `&mut`,使它成为一个可变引用。
>
> ⚠️ `read_line()` 函数有一个 *怪癖*。这个函数在用户按下回车键之后 **停止** 读取输入。因此,这个函数也会记录换行符(`\n`),并将一个换行符存储在你传入的可变字符串变量的结尾处。
>
>
>
所以,请在处理它时要么考虑到这个换行符,要么将它删除。
### Rust 中的错误处理入门
最后,在这个链的末尾有一个 `expect()` 函数。让我们稍微偏题一下,来理解为什么要调用这个函数。
`read_line()` 函数返回一个叫做 `Result` 的枚举。我会在后面的文章中讲解 Rust 中的枚举,但是现在只需要知道,枚举在 Rust 中是非常强大的。这个 `Result` 枚举返回一个值,告诉程序员在读取用户输入时是否发生了错误。
`expect()` 函数接受这个 `Result` 枚举,并检查结果是否正常。如果没有发生错误,什么都不会发生。但是如果发生了错误,我传入的消息(`无法读取用户输入。`)将会被打印到 STDERR,*程序将会退出*。
>
> ? **所有我简要提及的新概念将会在后续的新 Rust 系列文章中讲解。**
>
>
>
现在我希望你应该已经理解了这些新概念,让我们添加更多的代码来增加程序的功能。
### 验证用户输入
我接受了用户的输入,但是我没有对其进行验证。在当前的上下文中,验证意味着用户输入了一些“命令”,我们希望能够处理这些命令。目前,这些命令有两个“类别”。
第一类用户可以输入的命令是用户希望购买的水果的名称。第二个命令表示用户想要退出程序。
我们的任务现在是确保用户输入不会偏离 *可接受的命令*。
```
use std::io;
fn main() {
println!("欢迎来到水果市场!");
println!("请选择要购买的水果。\n");
println!("\n可以购买的水果:苹果、香蕉、橘子、芒果、葡萄");
println!("购买完成后,请输入“quit”或“q”。\n");
// 获取用户输入
let mut user_input = String::new();
io::stdin()
.read_line(&mut user_input)
.expect("无法读取用户输入。");
// 验证用户输入
let valid_inputs = ["苹果", "香蕉", "橘子", "芒果", "葡萄", "quit", "q"];
user_input = user_input.trim().to_lowercase();
let mut input_error = true;
for input in valid_inputs {
if input == user_input {
input_error = false;
break;
}
}
}
```
要使验证更容易,我创建了一个叫做 `valid_inputs` 的字符串切片数组(第 17 行)。这个数组包含了所有可以购买的水果的名称,以及字符串切片 `q` 和 `quit`,让用户可以传达他们是否希望退出。
用户可能不知道我们希望输入是什么样的。用户可能会输入“Apple”、“apple”或 “APPLE” 来表示他们想要购买苹果。我们的工作是正确处理这些输入。
在第 18 行,我通过调用 `trim()` 函数从 `user_input` 字符串中删除了尾部的换行符。为了处理上面提到的问题,我使用 `to_lowercase()` 函数将所有字符转换为小写,这样 “Apple”、“apple” 和 “APPLE” 都会变成 “apple”。
现在,来看第 19 行,我创建了一个名为 `input_error` 的可变布尔变量,初始值为 `true`。稍后在第 20 行,我创建了一个 `for` 循环,它遍历了 `valid_inputs` 数组的所有元素(字符串切片),并将迭代的模式存储在 `input` 变量中。
在循环内部,我检查用户输入是否等于其中一个有效字符串,如果是,我将 `input_error` 布尔值的值设置为 `false`,并跳出 `for` 循环。
### 处理无效输入
现在是时候处理无效输入了。这可以通过将一些代码移动到无限循环中来完成,如果用户给出无效输入,则 *继续* 该无限循环。
```
use std::io;
fn main() {
println!("欢迎来到水果市场!");
println!("请选择要购买的水果。\n");
let valid_inputs = ["苹果", "香蕉", "橘子", "芒果", "葡萄", "quit", "q"];
'mart: loop {
let mut user_input = String::new();
println!("\n可以购买的水果:苹果、香蕉、橘子、芒果、葡萄");
println!("购买完成后,请输入“quit”或“q”。\n");
// 读取用户输入
io::stdin()
.read_line(&mut user_input)
.expect("无法读取用户输入。");
user_input = user_input.trim().to_lowercase();
// 验证用户输入
let mut input_error = true;
for input in valid_inputs {
if input == user_input {
input_error = false;
break;
}
}
// 处理无效输入
if input_error {
println!("错误: 请输入有效的输入");
continue 'mart;
}
}
}
```
这里,我将一些代码移动到了循环内部,并重新组织了一下代码,以便更好地处理循环的引入。在循环内部,第 31 行,如果用户输入了一个无效的字符串,我将 `continue` `mart` 循环。
### 对用户输入做出反应
现在,所有其他的状况都已经处理好了,是时候写一些代码来让用户从水果市场购买水果了,当用户希望退出时,程序也会退出。
因为你也知道用户选择了哪种水果,所以让我们问一下他们打算购买多少,并告诉他们输入数量的格式。
```
use std::io;
fn main() {
println!("欢迎来到水果市场!");
println!("请选择要购买的水果。\n");
let valid_inputs = ["苹果", "香蕉", "橘子", "芒果", "葡萄", "quit", "q"];
'mart: loop {
let mut user_input = String::new();
let mut quantity = String::new();
println!("\n可以购买的水果:苹果、香蕉、橘子、芒果、葡萄");
println!("购买完成后,请输入“quit”或“q”。\n");
// 读取用户输入
io::stdin()
.read_line(&mut user_input)
.expect("无法读取用户输入。");
user_input = user_input.trim().to_lowercase();
// 验证用户输入
let mut input_error = true;
for input in valid_inputs {
if input == user_input {
input_error = false;
break;
}
}
// 处理无效输入
if input_error {
println!("错误: 请输入有效的输入");
continue 'mart;
}
// 如果用户想要退出,就退出
if user_input == "q" || user_input == "quit" {
break 'mart;
}
// 获取数量
println!(
"\n你选择购买的水果是 \"{}\"。请输入以千克为单位的数量。
(1 千克 500 克的数量应该输入为 '1.5'。)",
user_input
);
io::stdin()
.read_line(&mut quantity)
.expect("无法读取用户输入。");
}
}
```
在第 11 行,我声明了另一个可变变量,它的值是一个空字符串,在第 48 行,我接受了用户的输入,但是这次是用户打算购买的水果的数量。
#### 解析数量
我刚刚增加了一些代码,以已知的格式接受数量,但是这些数据被存储为字符串。我需要从中提取出浮点数。幸运的是,这可以通过 `parse()` 方法来完成。
就像 `read_line()` 方法一样,`parse()` 方法返回一个 `Result` 枚举。`parse()` 方法返回 `Result` 枚举的原因可以通过我们试图实现的内容来轻松理解。
我正在接受用户的字符串,并尝试将其转换为浮点数。浮点数有两个可能的值。一个是浮点数本身,另一个是小数。
字符串可以包含字母,但是浮点数不行。所以,如果用户输入的不是浮点数和小数,`parse()` 函数将会返回一个错误。
因此,这个错误也需要处理。我们将使用 `expect()` 函数来处理这个错误。
```
use std::io;
fn main() {
println!("欢迎来到水果市场!");
println!("请选择要购买的水果。\n");
let valid_inputs = ["苹果", "香蕉", "橘子", "芒果", "葡萄", "quit", "q"];
'mart: loop {
let mut user_input = String::new();
let mut quantity = String::new();
println!("\n可以购买的水果:苹果、香蕉、橘子、芒果、葡萄");
println!("购买完成后,请输入“quit”或“q”。\n");
// 读取用户输入
io::stdin()
.read_line(&mut user_input)
.expect("无法读取用户输入。");
user_input = user_input.trim().to_lowercase();
// 验证用户输入
let mut input_error = true;
for input in valid_inputs {
if input == user_input {
input_error = false;
break;
}
}
// 处理无效输入
if input_error {
println!("错误: 请输入有效的输入");
continue 'mart;
}
// 如果用户想要退出,就退出
if user_input == "q" || user_input == "quit" {
break 'mart;
}
// 获取数量
println!(
"\n你选择购买的水果是 \"{}\"。请输入以千克为单位的数量。
(1 千克 500 克的数量应该输入为 '1.5'。)",
user_input
);
io::stdin()
.read_line(&mut quantity)
.expect("无法读取用户输入。");
let quantity: f64 = quantity
.trim()
.parse()
.expect("请输入有效的数量。");
}
}
```
如你所见,我通过变量遮蔽将解析后的浮点数存储在变量 `quantity` 中。为了告诉 `parse()` 函数,我的意图是将字符串解析为 `f64`,我手动将变量 `quantity` 的类型注释为 `f64`。
现在,`parse()` 函数将会解析字符串并返回一个 `f64` 或者一个错误,`expect()` 函数将会处理这个错误。
### 计算价格 + 最后的修饰
现在我们知道了用户想要购买的水果及其数量,现在是时候进行计算了,并让用户知道结果/总价了。
为了真实起见,我将为每种水果设置两个价格。第一个价格是零售价,我们在购买少量水果时向水果供应商支付的价格。水果的第二个价格是当有人批量购买水果时支付的批发价。
批发价将会在订单数量大于被认为是批发购买的最低订单数量时确定。这个最低订单数量对于每种水果都是不同的。每种水果的价格都是每千克多少卢比。
想好了逻辑,下面是最终的程序。
```
use std::io;
const APPLE_RETAIL_PER_KG: f64 = 60.0;
const APPLE_WHOLESALE_PER_KG: f64 = 45.0;
const BANANA_RETAIL_PER_KG: f64 = 20.0;
const BANANA_WHOLESALE_PER_KG: f64 = 15.0;
const ORANGE_RETAIL_PER_KG: f64 = 100.0;
const ORANGE_WHOLESALE_PER_KG: f64 = 80.0;
const MANGO_RETAIL_PER_KG: f64 = 60.0;
const MANGO_WHOLESALE_PER_KG: f64 = 55.0;
const GRAPES_RETAIL_PER_KG: f64 = 120.0;
const GRAPES_WHOLESALE_PER_KG: f64 = 100.0;
fn main() {
println!("欢迎来到水果市场!");
println!("请选择要购买的水果。\n");
let valid_inputs = ["苹果", "香蕉", "橘子", "芒果", "葡萄", "quit", "q"];
'mart: loop {
let mut user_input = String::new();
let mut quantity = String::new();
println!("\n可以购买的水果:苹果、香蕉、橘子、芒果、葡萄");
println!("购买完成后,请输入“quit”或“q”。\n");
// 读取用户输入
io::stdin()
.read_line(&mut user_input)
.expect("无法读取用户输入。");
user_input = user_input.trim().to_lowercase();
// 验证用户输入
let mut input_error = true;
for input in valid_inputs {
if input == user_input {
input_error = false;
break;
}
}
// 处理无效输入
if input_error {
println!("错误: 请输入有效的输入");
continue 'mart;
}
// 如果用户想要退出,就退出
if user_input == "q" || user_input == "quit" {
break 'mart;
}
// 获取数量
println!(
"\n你选择购买的水果是 \"{}\"。请输入以千克为单位的数量。
(1 千克 500 克的数量应该输入为 '1.5'。)",
user_input
);
io::stdin()
.read_line(&mut quantity)
.expect("无法读取用户输入。");
let quantity: f64 = quantity
.trim()
.parse()
.expect("请输入有效的数量。");
total += calc_price(quantity, user_input);
}
println!("\n\n总价是 {} 卢比。", total);
}
fn calc_price(quantity: f64, fruit: String) -> f64 {
if fruit == "apple" {
price_apple(quantity)
} else if fruit == "banana" {
price_banana(quantity)
} else if fruit == "orange" {
price_orange(quantity)
} else if fruit == "mango" {
price_mango(quantity)
} else {
price_grapes(quantity)
}
}
fn price_apple(quantity: f64) -> f64 {
if quantity > 7.0 {
quantity * APPLE_WHOLESALE_PER_KG
} else {
quantity * APPLE_RETAIL_PER_KG
}
}
fn price_banana(quantity: f64) -> f64 {
if quantity > 4.0 {
quantity * BANANA_WHOLESALE_PER_KG
} else {
quantity * BANANA_RETAIL_PER_KG
}
}
fn price_orange(quantity: f64) -> f64 {
if quantity > 3.5 {
quantity * ORANGE_WHOLESALE_PER_KG
} else {
quantity * ORANGE_RETAIL_PER_KG
}
}
fn price_mango(quantity: f64) -> f64 {
if quantity > 5.0 {
quantity * MANGO_WHOLESALE_PER_KG
} else {
quantity * MANGO_RETAIL_PER_KG
}
}
fn price_grapes(quantity: f64) -> f64 {
if quantity > 2.0 {
quantity * GRAPES_WHOLESALE_PER_KG
} else {
quantity * GRAPES_RETAIL_PER_KG
}
}
```
对比之前的版本,我做了一些改动……
水果的价格可能会波动,但是在我们程序的生命周期内,这些价格不会波动。所以我将每种水果的零售价和批发价存储在常量中。我将这些常量定义在 `main()` 函数之外(即全局常量),因为我不会在 `main()` 函数内计算每种水果的价格。这些常量被声明为 `f64`,因为它们将与 `quantity` 相乘,而 `quantity` 是 `f64`。记住,Rust 没有隐式类型转换 ?
当水果名称和用户想要购买的数量被存下来之后,`calc_price()` 函数被调用来计算用户指定数量的水果的价格。这个函数接受水果名称和数量作为参数,并将价格作为 `f64` 返回。
当你看到 `calc_price()` 函数的内部时,你会发现它是许多人所说的包装函数。它被称为包装函数,因为它调用其他函数来完成它的脏活。
因为每种水果都有不同的最低订单数量,才能被认为是批发购买,为了确保代码在未来可以轻松维护,每种水果都有单独的函数负责计算价格。
所以,`calc_price()` 函数所做的就是确定用户选择了哪种水果,并调用相应的函数来计算所选水果的价格。这些水果特定的函数只接受一个参数:数量。这些水果特定的函数将价格作为 `f64` 返回。
现在,`price_*()` 函数只做一件事。它们检查订单数量是否大于被认为是批发购买的最低订单数量。如果是这样,`quantity` 将会乘以水果的每千克批发价格。否则,`quantity` 将会乘以水果的每千克零售价格。
由于乘法行末尾没有分号,所以函数返回乘积。
如果你仔细看看 `calc_price()` 函数中水果特定函数的函数调用,这些函数调用在末尾没有分号。这意味着,`price_*()` 函数返回的值将会被 `calc_price()` 函数返回给它的调用者。
而且 `calc_price()` 函数只有一个调用者。这个调用者在 `mart` 循环的末尾,这个调用者使用这个函数返回的值来增加 `total` 的值。
最终,当 `mart` 循环结束(当用户输入 `q` 或 `quit` 时),存储在变量 `total` 中的值将会被打印到屏幕上,并且用户将会被告知他/她需要支付的价格。
### 总结
这篇文章中,我使用了之前讲解的 Rust 编程语言的所有主题来创建一个简单的程序,这个程序仍然在某种程度上展示了一个现实世界的问题。
现在,我写的代码肯定可以用一种更符合编程习惯的方式来写,这种方式最好地使用了 Rust 的喜爱特性,但是我还没有讲到它们!
所以,敬请关注后续的 **将 Rust 带入下一个层次** 系列,并学习更多 Rust 编程语言的内容!
Rust 基础系列到此结束。欢迎你的反馈。
*(题图:MJ/6d486f23-e6fe-4bef-a28d-df067ef2ec06)*
---
via: <https://itsfoss.com/milestone-rust-program/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Rust Basics Series #8: Write the Milestone Rust Program
In the final chapter of the Rust Basics Series, recall the concepts you learned and write a somewhat complex Rust program.
So long, we have covered a handful of fundamental topics about programming in Rust. Some of these topics are [variables, mutability, constants](https://itsfoss.com/rust-variables), [data types](https://itsfoss.com/rust-data-types-01), [functions](https://itsfoss.com/rust-functions), [if-else statements](https://itsfoss.com/rust-conditional-statements) and [loops](https://itsfoss.com/rust-loops).
In the final chapter of the Rust Basics series, let us now write a program in Rust that uses these topics so their real-world use can be better understood. Let's work on a *relatively simple* program to order fruits from a fruit mart.
## The basic structure of our program
Let us first start by greeting the user and informing them about how to interact with the program.
```
fn main() {
println!("Welcome to the fruit mart!");
println!("Please select a fruit to buy.\n");
println!("\nAvailable fruits to buy: Apple, Banana, Orange, Mango, Grapes");
println!("Once you are done purchasing, type in 'quit' or 'q'.\n");
}
```
## Getting user input
The above code is very simple. At the moment, you do not know what to do next because you do not know what the user wants to do next.
So let's add code that accepts the user input and stores it somewhere to parse it later, and take the appropriate action based on the user input.
```
use std::io;
fn main() {
println!("Welcome to the fruit mart!");
println!("Plase select a fruit to buy.\n");
println!("Available fruits to buy: Apple, Banana, Orange, Mango, Grapes");
println!("Once you are done purchasing, type in 'quit' or 'q'.\n");
// get user input
let mut user_input = String::new();
io::stdin()
.read_line(&mut user_input)
.expect("Unable to read user input.");
}
```
There are three new elements that I need to tell you about. So let's take a shallow dive into each of these new elements.
### 1. Understanding the 'use' keyword
On the first line of this program, you might have noticed the use (haha!) of a new keyword called `use`
. The `use`
keyword in Rust is similar to the `#include`
directive in C/C++ and the `import`
keyword in Python. Using the `use`
keyword, we "import" the `io`
(input output) module from the Rust standard library `std`
.
You might be wondering why importing the *io* module was necessary when you could use the `println`
macro to *output* something to STDOUT. Rust's standard library has a module called `prelude`
that gets automatically included. The prelude module contains all the commonly used functions that a Rust programmer might need to use, like the `println`
macro. (You can read more about `std::prelude`
module [here](https://doc.rust-lang.org/std/prelude/index.html).)
The `io`
module from the Rust standard library `std`
is necessary to accept user input. Hence, a `use`
statement was added to the 1st line of this program.
### 2. Understanding the String type in Rust
On line 11, I create a new mutable variable called `user_input`
that, as its name suggests, will be used to store the user input down the road. But on the same line, you might have noticed something new (haha, again!).
Instead of declaring an empty string using double quotes with nothing between them (`""`
), I used the `String::new()`
function to create a new, empty string.
The difference between using `""`
and `String::new()`
is something that you will learn later in the Rust series. For now, know that, with the use of the `String::new()`
function, you can create a String that is ** mutable** and lives on the
**.**
*heap*If I had created a string with `""`
, I would get something called a "String slice". The String slice's contents are on the heap too, but the string itself is **immutable**. So, even if the variable itself is mutable, the actual data stored as a string is immutable and needs to be *overwritten* instead of modification.
### 3. Accepting the user input
On line 12, I call the `stdin()`
function that is part of `std::io`
. If I had not included the `std::io`
module in the beginning of this program, this line would be `std::io::stdin()`
instead of `io::stdin()`
.
The `stdin()`
function returns an input handle of the terminal. The `read_line()`
function grabs onto that input handle and, as its name suggests, reads a line of input. This function takes in a reference to a mutable string. So, I pass in the `user_input`
variable by preceding it with `&mut`
, making it a mutable reference.
*. This function stops reading the input*
*quirk**the user presses the Enter/Return key. Therefore, this function also records that newline character (\n) and a trailing newline is stored in the mutable string variable that you passed in.*
**after**So please, either account for this trailing newline when dealing with it or remove it.
## A primer on error handling in Rust
Finally, there is an `expect()`
function at the end of this chain. Let's divert a bit to understand why this function is called.
The `read_line()`
function returns an Enum called `Result`
. I will get into Enums in Rust later on but know that Enums are very powerful in Rust. This `Result`
Enum returns a value that informs the programmer if an error occurred when the user input was being read.
The `expect()`
function takes this `Result`
Enum and checks if the result was okay or not. If no error occurs, nothing happens. But if an error did occur, the message that I passed in (`"Unable to read user input."`
) will be printed to STDERR and *the program will exit*.
**All the new concepts that I have briefly touched on will be covered in a new Rust series later.**Now that you hopefully understand these newer concepts, let's add more code to increase the functionality.
## Validating user input
I surely accepted the user's input but I have not validated it. In the current context, validation means that the user inputs some "command" that *we expect to handle*. At the moment, the commands are of two "categories".
The first category of the command that the user can input is the name of fruit that the user wishes to buy. The second command conveys that the user wants to quit the program.
So our task now is to make sure that the input from the user does not diverge from the *acceptable commands*.
```
use std::io;
fn main() {
println!("Welcome to the fruit mart!");
println!("Plase select a fruit to buy.\n");
println!("Available fruits to buy: Apple, Banana, Orange, Mango, Grapes");
println!("Once you are done purchasing, type in 'quit' or 'q'.\n");
// get user input
let mut user_input = String::new();
io::stdin()
.read_line(&mut user_input)
.expect("Unable to read user input.");
// validate user input
let valid_inputs = ["apple", "banana", "orange", "mango", "grapes", "quit", "q"];
user_input = user_input.trim().to_lowercase();
let mut input_error = true;
for input in valid_inputs {
if input == user_input {
input_error = false;
break;
}
}
}
```
To make validation easier, I created an array of string slices called `valid_inputs`
(on line 17). This array contains the names of all the fruits that are available for purchase, along with the string slices `q`
and `quit`
to let the user convey if they wish to quit.
The user may not know how we expect the input to be. The user may type "Apple" or "apple" or "APPLE" to tell that they intend to purchase Apples. It is our job to handle this correctly.
On line 18, I trim the trailing newline from the `user_input`
string by calling the `trim()`
function on it. And to handle the previous problem, I convert all the characters to lowercase with the `to_lowercase()`
function so that "Apple", "apple" and "APPLE" all end up as "apple".
Now on line 19, I create a mutable boolean variable called `input_error`
with the initial value of `true`
. Later on line 20, I create a `for`
loop that iterates over all the elements (string slices) of the `valid_inputs`
array and stores the iterated pattern inside the `input`
variable.
Inside the loop, I check if the user input is equal to one of the valid strings, and if it is, I set the value of `input_error`
boolean to `false`
and break out of the for loop.
## Dealing with invalid input
Now is time to deal with an invalid input. This can be done by moving some of the code inside an infinite loop and *continuing* said infinite loop if the user gives an invalid input.
```
use std::io;
fn main() {
println!("Welcome to the fruit mart!");
println!("Plase select a fruit to buy.\n");
let valid_inputs = ["apple", "banana", "orange", "mango", "grapes", "quit", "q"];
'mart: loop {
let mut user_input = String::new();
println!("\nAvailable fruits to buy: Apple, Banana, Orange, Mango, Grapes");
println!("Once you are done purchasing, type in 'quit' or 'q'.\n");
// get user input
io::stdin()
.read_line(&mut user_input)
.expect("Unable to read user input.");
user_input = user_input.trim().to_lowercase();
// validate user input
let mut input_error = true;
for input in valid_inputs {
if input == user_input {
input_error = false;
break;
}
}
// handle invalid input
if input_error {
println!("ERROR: please enter a valid input");
continue 'mart;
}
}
}
```
Here, I moved some of the code inside the loop and re-structured the code a bit to better deal with this introduction of the loop. Inside the loop, on line 31, I `continue`
the `mart`
loop if the user entered an invalid string.
## Reacting to user's input
Now that everything else is handled, time to actually write code about purchasing fruits from the fruit market and quit when the user wishes.
Since you also know which fruit the user chose, let's ask how much they intend to purchase and inform them about the format of entering the quantity.
```
use std::io;
fn main() {
println!("Welcome to the fruit mart!");
println!("Plase select a fruit to buy.\n");
let valid_inputs = ["apple", "banana", "orange", "mango", "grapes", "quit", "q"];
'mart: loop {
let mut user_input = String::new();
let mut quantity = String::new();
println!("\nAvailable fruits to buy: Apple, Banana, Orange, Mango, Grapes");
println!("Once you are done purchasing, type in 'quit' or 'q'.\n");
// get user input
io::stdin()
.read_line(&mut user_input)
.expect("Unable to read user input.");
user_input = user_input.trim().to_lowercase();
// validate user input
let mut input_error = true;
for input in valid_inputs {
if input == user_input {
input_error = false;
break;
}
}
// handle invalid input
if input_error {
println!("ERROR: please enter a valid input");
continue 'mart;
}
// quit if user wants to
if user_input == "q" || user_input == "quit" {
break 'mart;
}
// get quantity
println!(
"\nYou choose to buy \"{}\". Please enter the quantity in Kilograms.
(Quantity of 1Kg 500g should be entered as '1.5'.)",
user_input
);
io::stdin()
.read_line(&mut quantity)
.expect("Unable to read user input.");
}
}
```
On line 11, I declare another mutable variable with an empty string and on line 48, I accept input from the user, but this time the quantity of said fruit that the user intends to buy.
### Parsing the quantity
I just added code that takes in quantity in a known format, but that data is stored as a string. I need to extract the float out of that. Lucky for us, it can be done with the `parse()`
method.
Just like the `read_line()`
method, the `parse()`
method returns the `Result`
Enum. The reason why the `parse()`
method returns the `Result`
Enum can be easily understood with what we are trying to achieve.
I am accepting a string from users and trying to convert it to a float. A float has two possible values in it. One is the floating point itself and the second is a decimal number.
While a String can have alphabets, a float does not. So, if the user entered something *other* than the [optional] floating point and the decimal number(s), the `parse()`
function will return an error.
Hence, this error needs to be handled too. We will use the `expect()`
function to deal with this.
```
use std::io;
fn main() {
println!("Welcome to the fruit mart!");
println!("Plase select a fruit to buy.\n");
let valid_inputs = ["apple", "banana", "orange", "mango", "grapes", "quit", "q"];
'mart: loop {
let mut user_input = String::new();
let mut quantity = String::new();
println!("\nAvailable fruits to buy: Apple, Banana, Orange, Mango, Grapes");
println!("Once you are done purchasing, type in 'quit' or 'q'.\n");
// get user input
io::stdin()
.read_line(&mut user_input)
.expect("Unable to read user input.");
user_input = user_input.trim().to_lowercase();
// validate user input
let mut input_error = true;
for input in valid_inputs {
if input == user_input {
input_error = false;
break;
}
}
// handle invalid input
if input_error {
println!("ERROR: please enter a valid input");
continue 'mart;
}
// quit if user wants to
if user_input == "q" || user_input == "quit" {
break 'mart;
}
// get quantity
println!(
"\nYou choose to buy \"{}\". Please enter the quantity in Kilograms.
(Quantity of 1Kg 500g should be entered as '1.5'.)",
user_input
);
io::stdin()
.read_line(&mut quantity)
.expect("Unable to read user input.");
let quantity: f64 = quantity
.trim()
.parse()
.expect("Please enter a valid quantity.");
}
}
```
As you can see, I store the parsed float in the variable `quantity`
by making use of variable shadowing. To inform the `parse()`
function that the intention is to parse the string into `f64`
, I manually annotate the type of the variable `quantity`
as `f64`
.
Now, the `parse()`
function will parse the String and return a `f64`
or an error, that the `expect()`
function will deal with.
## Calculating the price + final touch ups
Now that we know which fruit the user wants to buy and its quantity, it is time to perform those calculations now and let the user know about the results/total.
For the sake of realness, I will have two prices for each fruit. The first price is the retail price, which we pay to fruit vendors when we buy in small quantities. The second price for fruit will be the wholesale price, when someone buys fruits in bulk.
The wholesale price will be determined if the order is greater than the minimum order quantity to be considered as a wholesale purchase. This minimum order quantity varies for every fruit. The prices for each fruit will be in Rupees per Kilogram.
With that logic in mind, down below is the program in its final form.
```
use std::io;
const APPLE_RETAIL_PER_KG: f64 = 60.0;
const APPLE_WHOLESALE_PER_KG: f64 = 45.0;
const BANANA_RETAIL_PER_KG: f64 = 20.0;
const BANANA_WHOLESALE_PER_KG: f64 = 15.0;
const ORANGE_RETAIL_PER_KG: f64 = 100.0;
const ORANGE_WHOLESALE_PER_KG: f64 = 80.0;
const MANGO_RETAIL_PER_KG: f64 = 60.0;
const MANGO_WHOLESALE_PER_KG: f64 = 55.0;
const GRAPES_RETAIL_PER_KG: f64 = 120.0;
const GRAPES_WHOLESALE_PER_KG: f64 = 100.0;
fn main() {
println!("Welcome to the fruit mart!");
println!("Please select a fruit to buy.\n");
let mut total: f64 = 0.0;
let valid_inputs = ["apple", "banana", "orange", "mango", "grapes", "quit", "q"];
'mart: loop {
let mut user_input = String::new();
let mut quantity = String::new();
println!("\nAvailable fruits to buy: Apple, Banana, Orange, Mango, Grapes");
println!("Once you are done purchasing, type in 'quit' or 'q'.\n");
// get user input
io::stdin()
.read_line(&mut user_input)
.expect("Unable to read user input.");
user_input = user_input.trim().to_lowercase();
// validate user input
let mut input_error = true;
for input in valid_inputs {
if input == user_input {
input_error = false;
break;
}
}
// handle invalid input
if input_error {
println!("ERROR: please enter a valid input");
continue 'mart;
}
// quit if user wants to
if user_input == "q" || user_input == "quit" {
break 'mart;
}
// get quantity
println!(
"\nYou choose to buy \"{}\". Please enter the quantity in Kilograms.
(Quantity of 1Kg 500g should be entered as '1.5'.)",
user_input
);
io::stdin()
.read_line(&mut quantity)
.expect("Unable to read user input.");
let quantity: f64 = quantity
.trim()
.parse()
.expect("Please enter a valid quantity.");
total += calc_price(quantity, user_input);
}
println!("\n\nYour total is {} Rupees.", total);
}
fn calc_price(quantity: f64, fruit: String) -> f64 {
if fruit == "apple" {
price_apple(quantity)
} else if fruit == "banana" {
price_banana(quantity)
} else if fruit == "orange" {
price_orange(quantity)
} else if fruit == "mango" {
price_mango(quantity)
} else {
price_grapes(quantity)
}
}
fn price_apple(quantity: f64) -> f64 {
if quantity > 7.0 {
quantity * APPLE_WHOLESALE_PER_KG
} else {
quantity * APPLE_RETAIL_PER_KG
}
}
fn price_banana(quantity: f64) -> f64 {
if quantity > 4.0 {
quantity * BANANA_WHOLESALE_PER_KG
} else {
quantity * BANANA_RETAIL_PER_KG
}
}
fn price_orange(quantity: f64) -> f64 {
if quantity > 3.5 {
quantity * ORANGE_WHOLESALE_PER_KG
} else {
quantity * ORANGE_RETAIL_PER_KG
}
}
fn price_mango(quantity: f64) -> f64 {
if quantity > 5.0 {
quantity * MANGO_WHOLESALE_PER_KG
} else {
quantity * MANGO_RETAIL_PER_KG
}
}
fn price_grapes(quantity: f64) -> f64 {
if quantity > 2.0 {
quantity * GRAPES_WHOLESALE_PER_KG
} else {
quantity * GRAPES_RETAIL_PER_KG
}
}
```
Compared to the previous iteration, I made some changes...
The fruit prices may fluctuate, but for the lifecycle of our program, these prices will not fluctuate. So I store the retail and wholesale prices of each fruit in constants. I define these constants outside the `main()`
functions (i.e. globally) because I will not calculate the prices for each fruit inside the `main()`
function. These constants are declared as `f64`
because they will be multiplied with `quantity`
which is `f64`
. Recall, Rust doesn't have implicit type casting ;)
After storing the fruit name and the quantity that the user wants to purchase, the `calc_price()`
function is called to calculate the price of said fruit in the user provided quantity. This function takes in the fruit name and the quantity as its parameters and returns the price as `f64`
.
Looking inside the `calc_price()`
function, it is what many people call a wrapper function. It is called a wrapper function because it calls other functions to do its dirty laundry.
Since each fruit has a different minimum order quantity to be considered as a wholesale purchase, to ensure that the code can be maintained easily in the future, the actual price calculation for each fruit is split in separate functions for each individual fruit.
So, all that the `calc_price()`
function does is to determine which fruit was chosen and call the respective function for chosen fruit. These fruit-specific functions accept only one argument: quantity. And these fruit-specific functions return the price as `f64`
.
Now, `price_*()`
functions do only one thing. They check if the order quantity is greater than the minimum order quantity to be considered as a wholesale purchase for said fruit. If it is such, `quantity`
is multiplied by the fruit's wholesale price per Kilogram. Otherwise, `quantity`
is multiplied by the fruit's retail price per Kilogram.
Since the line with multiplication does not have a semi-colon at the end, the function returns the resulting product.
If you look closely at the function calls of the fruit-specific functions in the `calc_price()`
function, these function calls do not have a semi-colon at the end. Meaning, the value returned by the `price_*()`
functions will be returned by the `calc_price()`
function to its caller.
And there is only one caller for `calc_price()`
function. This is at the end of the `mart`
loop where the returned value from this function is what is used to increment the value of `total`
.
Finally, when the `mart`
loop ends (when the user inputs `q`
or `quit`
), the value stored inside the variable `total`
gets printed to the screen and the user is informed about the price he/she has to pay.
## Conclusion
With this post, I have used all the previously explained topics about the Rust programming language to create a simple program that still somewhat demonstrates a real-world problem.
Now, the code that I wrote can definitely be written in a more idiomatic way that best uses Rust's loved features but I haven't covered them yet!
So stay tuned for follow-up **Take Rust to The Next Level series** and learn more of the Rust programming language!
The Rust Basics series concludes here. I welcome your feedback. |
15,937 | Linux 中的模糊文件搜索 | https://itsfoss.com/fuzzy-file-search-linux/ | 2023-06-24T00:10:37 | [
"模糊搜索"
] | https://linux.cn/article-15937-1.html | 
>
> 像 fzf 和 fzy 这样的现代工具将 Linux 终端中的文件搜索提升到了一个新的水平。
>
>
>
在 Linux 命令行中,如何 [搜索文件](https://learnubuntu.com:443/find-files/)?你可以使用 [find 命令](https://linuxhandbook.com:443/find-command-examples/)。这是标准答案,没有问题。
通常,你键入带有搜索参数的命令,按回车键,然后它会显示搜索结果。
你可以通过模糊搜索来提升终端中的文件搜索体验。
模糊搜索是一种近似搜索算法或技术。在这种搜索中,通过名称搜索指定位置的文件,并实时显示结果给用户。
模糊搜索在网络搜索引擎中很受欢迎,用户开始输入术语后,它会开始显示与该术语相关的结果。
在本文中,我将讨论两个命令行工具,它们可以让你在 Linux 中执行模糊搜索:
* `fzf`:模糊查找工具
* `fzy`:模糊选择工具
### fzf:Linux 中的模糊查找工具
`fzf` 是一款可用于 Linux 的模糊搜索工具,你可以通过它进行交互式文件搜索。
在 Ubuntu 中安装 `fzf`,打开终端并运行以下命令:
```
sudo apt install fzf
```
虽然 `fzf` 本身可以正常工作,但最好与其他工具配合使用,以充分发挥其功能。
#### 使用 fzf
打开终端并运行:
```
fzf
```
这将打开一个 `fzf` 提示符,在当前工作目录中搜索文件。

##### 为 fzf 应用边框
你可以使用 `--border` 选项为 `fzf` 应用边框,有多种边框可用,如 `rounded`(圆角)、`sharp`(尖角)等。
```
fzf --border=rounded
```

##### 应用背景和前景颜色
使用颜色属性,你可以为 `fzf` 设置 ANSI 颜色,可以作为背景、前景或两者都设置。

```
fzf --color="bg:black,fg:yellow"
```
你可以串联这些选项,使 `fzf` 在视觉上更加美观。
现在,让我展示一些 `fzf` 模糊搜索的实际用法。
#### 使用 fzf 在 Bash 历史中进行搜索
当然,Bash 历史记录中有 `CTRL+R` 的反向搜索功能。但如果你想使用 `fzf` 来获得更好的外观,可以运行以下命令:
```
history | fzf
```

#### 使用 fzf 结合 tree 命令
[tree 命令](https://linuxhandbook.com:443/tree-command/) 会列出文件和目录,并显示它们的层级关系。
使用 `fzf` 结合 `tree` 命令可以帮助你找到特定文件的绝对路径。
```
tree -afR /home/$USER | fzf
```

>
> ? 上述命令会调用 `tree` 并以递归方式列出包括隐藏文件在内的所有文件(`-a`)。同时,`-f` 选项告诉 `tree` 列出完整路径。
>
>
>
#### 在 fzf 中预览文件
有时,如果你可以获得你搜索的文件的小型预览,那会很有帮助。
幸运的是,`fzf` 提供了一个预览选项。你可以使用 `--preview` 来访问它。我在这里使用 `find` 命令使其更加有用。
```
find /home/$USER -type f | fzf --preview 'less {}'
```
在这里,当你滚动浏览结果时,它将使用 `less` 显示文本文件。
>
> ? 如果你使用其他命令如 `ls` 等,请不要使用 `-l` 等选项,因为这将显示额外的详细信息(文件权限)。这些额外的详细信息会破坏 `fzf` 预览所需的格式。在使用预览功能时,输入到 `fzf` 的应该只是文件名。
>
>
>
如果你已安装了 `bat`,也可以使用它来预览文件。
```
find /home/$USER -type f | fzf --preview 'bat --color always {}'
```

对于 Ubuntu 用户,可以使用 `batcat` 来调用 `bat`。因此运行:
```
find /home/$USER -type f | fzf --preview 'batcat --color always {}'
```
>
> ? [为这些命令创建别名](https://linuxhandbook.com:443/linux-alias-command/),这样你就不需要反复输入它们。
>
>
>
#### 从任何地方使用 fzf 进入任何目录(高级技巧)
这比以前要复杂一些。在这里,你不能直接将 `fzf` 和 `cd` 连接在一起,因为它们是不同的进程。
你可以创建一个别名并使用以下命令:
```
cd $(find /home/$USER -type d | fzf)
```
或者,你可以按照下面解释的方法进行操作。
为此,你可能需要在 `bashrc` 中添加一个函数。让我将这个函数称为 `finder`。现在请添加以下行到你的 `bashrc` 中。
```
finder() {
local dir
dir=$(find required/location/to/search/and/enter -type d | fzf)
if [[ -n "$dir" ]]; then
cd "$dir" || return
fi
}
```
现在,你应该 [输入路径](https://itsfoss.com/change-directories/),其中包含你要搜索并进入的目录。
例如,我已经使用 `/home/$USER` 替换了该部分,表示我要从任何位置进入我的主目录中的任何目录。
保存你的 `bashrc` 文件后,要么重启终端,要么运行以下命令:
```
source ~/.bashrc
```
之后,你可以在终端上运行 `finder` 命令,一旦找到要进入的目录,按回车键即可。

#### 将选择内容复制到剪贴板
到目前为止,你已经了解了如何使用 `fzf`,它提供了搜索结果或预览。
现在,如果你想要复制某个项目的位置,你不必手动执行此操作。也有相应的解决方案。
首先,确保你已经安装了 `xclip`。
```
sudo apt install xclip
```
然后像这样将其传递给 `xclip`:
```
fzf | xclip -selection clipboard
```
这将复制你按下回车键的那些行到剪贴板上。
#### 其他用途
正如我之前所说,你可以使用任何涉及大量文本,并希望交互式搜索特定内容的命令。
* `cat ~/.bashrc | fzf` - 在 Bashrc 文件中搜索
* `lsblk | fzf` - 在锁定设备列表中搜索
* `ps -aux | fzf` - 在进程列表中搜索
### 另一个选择:Fzy,模糊选择器
与 `fzf` 不同,`fzy` 是一个模糊选择器,它会根据输入提供一个菜单供你选择。
例如,如果你将 `fzy` 与 `ls` 命令一起使用,它将给你提供一个类似菜单的界面。

默认情况下,它会显示十个条目。
#### 使用 fzy 进入目录
与 `fzf` 类似,你也可以使用 `fzy` 进入当前工作目录中的目录:
```
cd $(find -type d | fzy)
```

#### 使用任何编辑器打开文件
或者使用你喜欢的编辑器打开文件:
```
nano $(find -type f | fzy)
```

### 附加内容:自定义文件和图像预览
下面的命令将在 **Ubuntu** 中打开一个专门的自定义提示符,用于模糊搜索,你可以通过滚动来预览文本文件。
```
find /home/$USER -type f | fzf --color="bg:black,fg:yellow" --preview 'batcat --color always {}' --preview-window=bottom
```
为了方便访问,可以在你的 `bashrc` 文件中为此创建一个别名。
或者在使用 `timg` 命令行图像查看器时,在 `fzf` 中进行图像预览并滚动。使用以下命令进行安装:
```
sudo apt install timg
```
>
> ? 请注意,图像查看器无法正确显示图像,因为这不是 `fzf` 预览的主要目的。
>
>
>
```
fzf --preview 'timg -g 200x100 {}' --preview-window=right:90
```
对于那些喜欢折腾的人,可以尝试对此部分进行优化。
### 现代化的替代方案
大多数 Linux 命令都是从 UNIX 时代继承下来的。它们虽然老旧,但功能如预期。但这并不意味着它们不能改进。
我的意思是,你不需要重新发明轮子,但你总是可以努力改进轮子。
像 `fzf` 和 `fzy` 这样的现代化工具将 Linux 终端中的文件搜索提升到了一个新的水平。以下是一些其他有趣的命令行工具。
我尝试给出了这些模糊搜索工具的一些实际示例。希望你对它们感到足够有启发性。如果你打算使用它们,请在评论中告诉我。
*(题图:MJ/d25e71fa-f24e-49be-9579-e0520a8f6e18)*
---
via: <https://itsfoss.com/fuzzy-file-search-linux/>
作者:[Sreenath](https://itsfoss.com/author/sreenath/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

How do you [find files in the Linux command line](https://learnubuntu.com/find-files/)? You use the [find command](https://linuxhandbook.com/find-command-examples/). That's the standard answer and there is nothing wrong with it.
Usually, you type the command with your search parameters, press enter and it displays the findings.
You can improve your file-finding experience in the terminal with fuzzy search.
Fuzzy search is an approximate search algorithm or technique. Here, files from a specified location are searched by name and the user will get real-time results.
Fuzzy search is popular in web search engines, where a user starts entering the term, and it starts showing results related to the term.
In this article, I am going to discuss two CLI tools that give you the ability to perform fuzzy searches in Linux:
- Fzf: Fuzzy finder
- Fzy: Fuzzy selector
## Fzf, the Fuzzy Finder in Linux
Fzf is a fuzzy search tool available for Linux, where you can search for files interactively.
To install `fzf`
in Ubuntu, open a terminal and run:
`sudo apt install fzf`
While `fzf`
itself works properly, it is wise to use it in conjunction with other tools to make most out of it.
### Using fzf
Open a terminal and run:
`fzf`
This will open a prompt of `fzf`
where you can search for files in the current working directory.
`fzf`
#### Apply a border to fzf
You can use the `--border`
option of fzf. There are several options like rounded, sharp etc.
`fzf --border=rounded`
`fzf`
with border#### Apply background and foreground color
Using the color property, you can set ANSI colors to `fzf`
either as background, foreground or both.
`fzf --color="bg:black,fg:yellow" `
You can concatenate the options to make `fzf`
visually pleasing.
Now, let me show some practical usage of the fuzzy search with fzf.
### Use fzf to search within bash history
Of course, there is CTRL+R reverse search in the bash history. But if you want to use `fzf`
to get a better look, run:
`history | fzf`
`fzf`
to search within bash history### Use fzf with tree command
[Tree command](https://linuxhandbook.com/tree-command/) lists files and directories along with their hierarchical connection.
Using `fzf`
with `tree`
command can help you find the absolute path of a particular file.
`tree -afR /home/$USER | fzf`
The above command will invoke `tree`
and list all files (-a) including hidden ones in a recursive fashion (-R). Also, the `-f`
option tells tree to list the full path.
### Preview files in fzf
Sometimes, it will be helpful if you get a small preview of the file you are searching.
Luckily, `fzf`
provides a preview option. You can access it by using `--preview`
. I am here using `find`
command to make it even more useful.
`find /home/$USER -type f | fzf --preview 'less {}'`
Here, while you scroll through the result, it will display the text files using less.
If you are using other commands like `ls`
, etc. do not use options like `-l`
, that will display added details (file permissions). These additional details will break the required format needed for `fzf`
preview. the hile using preview feature, the input to `fzf`
should only be the filename.
If you have `bat`
installed, you can use it for previewing files as well.
`find /home/$USER -type f | fzf --preview 'bat --color always {}'`
For Ubuntu users, bat is available as `batcat`
. So run:
`find /home/$USER -type f | fzf --preview 'batcat --color always {}'`
[Create an alias](https://linuxhandbook.com/linux-alias-command/) for these commands, so that you don't want to type these again and again.
### Use fzf to cd into any directory from anywhere (advance)
This is a bit trickier than the previous. Here, you cannot just directly pipe `fzf`
and `cd`
together because both are different processes.
You can create an alias like:
`cd $(find /home/$USER -type d | fzf)`
Or, you can follow the method explained below.
To do this, you may need to add a function to your bashrc. Let me call this function as `finder`
. Now add the following lines to your bashrc.
```
finder() {
local dir
dir=$(find required/location/to/search/and/enter -type d | fzf)
if [[ -n "$dir" ]]; then
cd "$dir" || return
fi
}
```
Now, you should [enter the location](https://itsfoss.com/change-directories/) where the directories you want to search and enter are present.
For example, I have replaced that part with `/home/$USER`
to indicate that I have to [use cd](https://itsfoss.com/cd-command/) into any directories in my Home from anywhere.
Once you saved your bashrc, either restart the terminal or run:
`source ~/.bashrc`
After this, you can run finder from the terminal and once you located the directory you want to enter, press Enter key.
### Copy the selection to Clipboard
Till now, you have seen using `fzf`
and in all cases, it gives either a search result or preview.
Now, if you want to copy the location of an item, you don't necessarily need to do it manually. There is a solution for that too.
First, make sure you have Xclip installed.
`sudo apt install xclip`
Now pipe it to xclip like this:
`fzf | xclip -selection clipboard`
This will copy whatever lines you have pressed the enter key, on to your clipboard.
### Other Uses
Like I said earlier, you can use any command that involves a significant amount of text, and you want to search for a particular thing interactively.
`cat ~/.bashrc | fzf`
- Search Inside Bashrc`lsblk | fzf`
- Search inside the list of lock devices`ps -aux | fzf`
- Search inside process list
## Another choice: Fzy, the Fuzzy Selector
Unlike `fzf`
, `fzy`
is a fuzzy selector, where you will be provided a menu to select, depending on the input.
For example, if you are using `fzy`
in conjunction with `ls`
command, it will give you a menu like interface.
`fzy`
commandBy default, it will show you ten entries in view.
**Enter into a directory using fzy**
Similar to fzf, fzy can also be used to enter into a directory in the current working directory using:
`cd $(find -type d | fzy)`
### Open a file using any editor
Or open a file using your favorite editor by:
`nano $(find -type f | fzy)`
## Bonus: A Customized file and image preview
The below command will open a dedicated customized prompt in **Ubuntu **for fuzzy search, where you can preview text files by scrolling through them.
`find /home/$USER -type f | fzf --color="bg:black,fg:yellow" --preview 'batcat --color always {}' --preview-window=bottom`
Create an alias for this in your bashrc for easy access.
Or preview an image in fzf while scrolling using `timg`
command line image viewer. Install it using:
`sudo apt install timg`
Remember that the image viewer will not display a proper image, as that is not the primary purpose of fzf preview
`fzf --preview 'timg -g 200x100 {}' --preview-window=right:90`
For those who are tinkerers, try to make this part by refining.
## Modern alternatives to rescue
Most Linux commands have been inherited from UNIX-era. They are old but work as expected. But this doesn't mean they cannot be improved.
I mean, you don't need to reinvent the wheel but you can always work on improving the wheels.
Modern tools like fzf and fzy take the file search in Linux terminal to the next level. Here are some other such command line tools you may find interesting.
[Modern Alternatives to Some of the Classic Linux CommandsConsider yourself a modern Linux user? Have you tried these modern replacements of the classic Linux commands yet?](https://itsfoss.com/legacy-linux-commands-alternatives/)

I have tried giving some practical examples for these fuzzy search tools. I hope you find them inspiring enough for you. Let me know in the comments if you are going to use them. |
15,938 | 在 Ubuntu、Linux Mint 和 Windows 中升级到最新的 LibreOffice | https://www.debugpoint.com/libreoffice-upgrade-update-latest/ | 2023-06-24T09:32:00 | [
"LibreOffice"
] | /article-15938-1.html |
>
> 这篇初学者指南解释了在 Ubuntu、Linux Mint 和 Windows 中升级到最新 LibreOffice 所需的步骤。
>
>
>

[LibreOffice](https://www.libreoffice.org/) 被全球数百万用户使用,是当今最流行的免费办公套件。它由电子表格程序 (Calc)、文档处理器(Writer)、演示文稿(Impress)、绘图(Draw)和数学模块组成,可帮助你完成大部分办公、商务、学术和日常工作。
由于与 DOCX、PPTX 和 XLSX 等专有文件格式兼容,LibreOffice 可以作为付费的微软 Office 套件的出色替代品。它是 Apache OpenOffice 生产力套件的一个分支,由数以千计的全球贡献者积极开发。

### 升级到最新的 LibreOffice
LibreOffice 改变了它的版本命名方式,不再采用"Fresh"和"Still"的概念。现在,LibreOffice 有一个**社区**版和一个推荐的**企业**版。这是因为许多企业使用带有最新功能的最新 LibreOffice 版本,这对开发工作造成了阻碍。因此,团队建议企业用户从 LibreOffice 官方合作伙伴那里获得付费支持,以获得长期支持。你可以在 [此处](https://blog.documentfoundation.org/blog/2021/02/03/libreoffice-7-1-community/) 阅读博文。
以下是当前的版本:
#### 最新的 LibreOffice 版本
* 当前的 LibreOffice 社区版本系列是 **LibreOffice 7.4.x**。
* LibreOffice 稳定推荐的商业版本是 **LibreOffice 7.3.x**。
### 在 Ubuntu、Linux Mint 和其他基于 Ubuntu 的发行版中升级到最新的 LibreOffice
[Ubuntu 22.04 LTS Jammy Jellyfish](https://www.debugpoint.com/2022/01/ubuntu-22-04-lts/) 具有 LibreOffice 7.3.x。
**Ubuntu 20.04 LTS** 目前有 LibreOffice 6.4.7,很快就会得到下一次迭代的更新。
**Ubuntu 18.04 LTS** 支持到 [2023 年 4 月](https://www.debugpoint.com/ubuntu-release-dates-wiki/),具有 LibreOffice 6.2 版本。Linux Mint 19.x 也提供了相同的版本。你仍然可以在 Ubuntu 18.04 或 Linux Mint 19.x 中下载并安装 LibreOffice 6.3.x 版本。
坚持使用发行版提供的 LibreOffice 版本是比较明智的。此外,除非你需要最新的功能,否则不应升级。如果你喜欢尝试,你可以继续:
#### 通过 PPA
你可以使用官方 LibreOffice PPA 安装和升级到最新的版本。打开终端并在 Ubuntu 或 Linux Mint 中运行以下命令。
```
sudo add-apt-repository ppa:libreoffice/ppa
```
```
sudo apt update && sudo apt install libreoffice
```
要**降级** LibreOffice 并删除 PPA,请从终端按顺序运行以下命令。
```
sudo add-apt-repository --remove ppa:libreoffice/ppa
```
```
sudo apt install ppa-purge && sudo ppa-purge ppa:libreoffice/ppa
```
#### 通过 Snap
你也可以选择通过下面的选项用 Snap 安装最新的LibreOffice。[Snap 包](https://www.debugpoint.com/2016/07/how-to-install-and-use-snap-packages-in-ubuntu/) 可以作为独立包在受支持的 Linux 发行版中使用。因此,你可以保留现有的 LibreOffice 安装并仍然运行最新的 Snap 版本。
请记住,从技术上讲,你可以使用一个 Snap 版本并行运行两个版本的 LibreOffice。但是,请确保可能存在轻微的文件关联问题和其他问题。这也适用于 Flatpak。
>
> **[用 Snap 下载 LibreOffice](https://snapcraft.io/libreoffice)**
>
>
>
#### 通过 Flatpak
Flatpak 是另一种方式,你可以通过它获得最新的 LibreOffice 以及发行版提供的版本。你可以[安装 Flatpak](https://www.debugpoint.com/2018/07/how-to-install-flatpak-apps-ubuntu-linux/) 并通过以下链接下载 LibreOffice。
>
> **[用 Flatpak 下载 LibreOffice](https://flathub.org/apps/details/org.libreoffice.LibreOffice)**
>
>
>
#### Windows 升级
对于 Windows,你不能直接从现有安装升级。你可以从 [本页](https://www.libreoffice.org/download/download/) 下载最新的 LibreOffice 并进行安装。在安装过程中,你现有的版本将被卸载。
### 升级故障排除
如果升级后遇到任何问题或系统不稳定,最好进行全新安装。因此,你可以从 [此链接](https://www.libreoffice.org/download/download/) 下载最新版本并进行安装。如果你使用的是 Ubuntu 或 Linux Mint,请不要忘记在安装最新版本之前先删除现有版本。
最后,如果你在 Ubuntu Linux 和其他操作系统中升级到最新的 LibreOffice 时遇到问题,请在下方发表评论。
---
via: <https://www.debugpoint.com/libreoffice-upgrade-update-latest/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,940 | 10 个最好的 Xfce 桌面环境的 Linux 发行版 | https://www.debugpoint.com/best-xfce-distributions/ | 2023-06-25T16:45:00 | [
"Xfce"
] | /article-15940-1.html | 
>
> 一份新鲜的最佳 Linux 发行版清单,提供轻量级的 Xfce 桌面环境。
>
>
>
Xfce 是一个以速度、性能和资源效率为重点的轻量级桌面环境。它在不牺牲功能的情况下,提供了一个干净直观的用户界面。它采用了经过时间验证的、传统的图标和菜单驱动的用户界面,对提高生产力非常有效。此外,Xfce 还允许用户根据自己的偏好进行个性化设置。
许多 Linux 发行版都将 Xfce 作为其主打桌面环境,并进行了各种调整和定制。如果你喜欢 Xfce 并希望将其用于日常驱动程序,可以查看以下发行版的清单。
排名仅基于我们的推荐和各个发行版的新鲜度。
### 带有 Xfce 桌面环境的最佳 Linux 发行版
#### 默认带有 Xfce 的 Debian
Debian Linux 以其稳定性和可靠性而闻名,提供了 Xfce 作为默认的桌面环境。当你安装 Debian 桌面的 ISO 时,如果没有选择特定环境,它会安装 Xfce。
Debian 和 Xfce 的强大组合提供了稳定性、安全性和广泛的软件仓库,非常适合各类用户。无论你是寻找可靠的桌面操作系统还是稳定的服务器平台,Debian 和 Xfce 都提供了用户友好的体验,可以根据你的具体需求进行定制。

如果你不喜欢 Ubuntu,但想要在 APT 生态系统中使用 Xfce,你可以考虑使用带有 Xfce 的 Debian Linux。这将是一个理想的组合,适用于高效的日常使用发行版。最后,你将能够通过此变体体验原始的 Xfce 桌面环境。
你可以从下面的页面下载 Debian Xfce ISO 文件。
>
> **[下载带有 Xfce 桌面环境的 Debian](https://cdimage.debian.org/debian-cd/current-live/amd64/iso-hybrid/)**
>
>
>
#### Linux Mint Xfce 版本
如果你是 Linux Mint 的粉丝,希望使用 Xfce 桌面环境,那么你应该尝试它的 Xfce 版本。尽管 Mint 的主打的是 Cinnamon 桌面,但 Xfce 版也同样出色。
Linux Mint Xfce 版本引入了许多很酷的 Mint 应用程序(Xapps),使 Xfce 桌面对你来说更具生产力。内置的自定义和主题也让它在外观上优于默认的 Xfce 感觉。

此外,你还可以轻松享受顺滑的系统更新、版本升级以及许多系统级操作,只需点击几下。Linux Mint Xfce 版本提供了一个顺滑且愉悦的计算体验,可能是最稳定且易于使用的 Xfce 发行版。
你可以通过以下链接下载 Linux Mint Xfce ISO。
>
> **[下载 Linux Mint Xfce Edition](https://linuxmint.com/download.php)**
>
>
>
#### MX Linux
MX Linux 是一款受欢迎且可能是最受关注的新兴发行版,因其多样性和简单性而受到许多用户的关注。它基于 Debian 的稳定版本,并配备了定制的 Xfce 桌面环境。
在其核心部分,MX Linux 是没有 systemd 的。因此,你可以轻松使用这个超快的发行版在旧硬件上运行。MX Linux 还提供了 “MX 工具”,简化了在桌面上执行各种任务的过程。这些工具涵盖了系统管理、硬件设置和软件包管理等多个功能,使用户能够轻松定制自己的体验。

以下是 MX Linux 成为此列表中值得考虑的一个产品的一些关键原因:
* 基于 Debian 的稳定版本
* Xfce 桌面环境,并提供 Fluxbox 选项
* 无 systemd
* 出色的性能和稳定性
* 可访问广泛的软件仓库
* 方便定制的 MX 工具
>
> **[下载 MX Linux](https://mxlinux.org/download-links/)**
>
>
>
#### Fedora Xfce 版本
如果你想要基于 Fedora 的 Xfce 桌面环境,那么你的选择相对有限。其中一个选择是 Fedora Xfce 版本,它带来了最新的软件包和升级。Fedora Xfce 通常每年两次提供最新版本的 Xfce 桌面环境。此外,Fedora Linux 带来了最新的技术升级和软件包,使其成为基于 Xfce 的发行版的最佳选择。

Fedora Linux 中的 Xfce 桌面环境是其原装版本,没有任何定制。因此,你可以根据自己的喜好和需求 [自定义 Xfce 桌面环境](https://www.debugpoint.com/customize-xfce-modern-look-2020-edition/)。此外,Fedora Linux 提供了一个广泛的软件仓库,提供各种应用程序、库和开发工具。
你可以从以下页面下载 Fedora Xfce 版本。
>
> **[下载 Fedora Xfce 版本(种子文件)](https://torrent.fedoraproject.org/)**
>
>
>
#### Xubuntu
Xubuntu 是将受欢迎的 Xfce 桌面环境与 Ubuntu 操作系统集成在一起的 Linux 发行版。它为用户提供了轻量级、高效的计算体验,并融入了熟悉的 Ubuntu 生态系统。Xubuntu 专注于 Xfce 桌面环境,能够实现快速响应的用户界面,并节省系统资源。

然而,Xubuntu 遵循 Ubuntu 的基础软件包,其中包括 Snap 和其他 Ubuntu 桌面应用程序。如果你能接受这些,那么 Xubuntu 是一个稳定的基于 Xfce 的发行版的绝佳选择。
你可以从以下页面下载 Xubuntu。
>
> **[下载 Xubuntu](https://xubuntu.org/download/)**
>
>
>
#### EndeavourOS
EndeavourOS 是这个列表中第一个基于 Arch Linux 的 Xfce 发行版。三年前,一个小团队的贡献者们开始了 EndeavourOS,以继承已停止的 Antergos 项目。从那时起,EndeavourOS 因其简便的安装、用户体验和功能而变得受欢迎。
尽管还有其他几个桌面环境可用,但 EndeavourOS 默认配备 Xfce 桌面环境。它的 Xfce 桌面环境经过了轻微的定制,这个基于 Arch Linux 的发行版提供了几乎原汁原味的 Xfce 桌面环境。

如果你曾经尝试过 EndeavourOS,你一定会“感受”到作为 Arch Linux 发行版,对于终端用户来说,执行任务有多么地“轻松”。这个发行版的座右铭是成为一款“面向大众”的 Arch Linux 通用目的发行版,摒弃了新用户对 Arch Linux 安装的恐惧和使用 Arch 的优越感。
EndeavourOS 是其他提供 Xfce 和 Arch Linux 的发行版中最好的选择。你可以从以下页面下载 EndeavourOS。
>
> **[下载 EndeavourOS](https://endeavouros.com/latest-release/)**
>
>
>
#### Linux Lite
Linux Lite 6.0,又名 Linux Lite 操作系统,基于 Ubuntu 并遵循其 LTS(长期支持)生命周期。这意味着在 Ubuntu Linux 发布后的五年内,你将获得类似的发布时间表和安全更新。轻量级桌面环境 Xfce 是其主要且唯一的桌面环境。Linux Lite 操作系统主要针对希望开始他们的 Linux 之旅的 Windows 用户。因此,你可以将其视为一个“桥梁” Linux 发行版。

它提供的 Xfce 桌面环境经过轻微的主题、壁纸和字体定制。不过,它是另一个基于 Ubuntu 的带有 Xfce 的发行版。你可以试试看。
你也可以阅读有关 [Linux Lite 评论](https://www.debugpoint.com:443/?s=linux+lite+review) 中有关其性能和其他方面的内容。
>
> **[下载 Linux Lite](https://www.linuxliteos.com/download.php)**
>
>
>
#### Manjaro Xfce
Manjaro Linux 是一款著名且经受时间考验的发行版,将 Arch Linux 带给了广大用户。它经过精心设计,旨在打破“Arch Linux 很难”的迷思。此外,一旦开始使用,你不会感觉到它是一个 Arch Linux 发行版。它可能感觉更像是基于 Debian 或 Fedora 的发行版。
尽管 Manjaro Linux 也提供了其他桌面环境,如 KDE Plasma,但它的 Xfce 变体也是以基于 Arch Linux 核心为基础设计的。如果你需要另一款基于 Arch Linux 的带有 Xfce 的发行版,可以尝试它。
你可以在我发布的 [多篇点评](https://www.debugpoint.com:443/?s=endeavouros) 中了解更多关于这个发行版的信息。

>
> **[下载 Manjaro Linux](https://manjaro.org/download/)**
>
>
>
#### Peppermint OS
接下来是 Peppermint OS,这是一个基于 Debian 稳定版的发行版,非常适合日常使用。它包括预安装的应用程序,帮助你快速上手,并带有定制的 Xfce 桌面环境。之前,Peppermint OS 使用的是 LXDE,但最近切换到了 Xfce。

除了基于 Debian 之外,Peppermint OS 还具有两个关键应用程序:Peppermint Welcome 应用程序为新用户提供有关发行版的基本概述;另一个应用程序,Peppermint Hub,提供了一些快捷方式,用于管理你的系统,比如更改主题和从软件仓库下载软件。如果你是 Peppermint OS 的新用户,Peppermint Hub 可以从一个便捷位置处理大多数系统管理任务。
你可以尝试一下,但是 Xfce 桌面体验与本列表中的第一个发行版相同。
>
> **[下载 Peppermint OS](https://peppermintos.com/)**
>
>
>
#### Kali Linux
Kali Linux 是网络安全行业中广为人知的发行版,它基于 Debian 的测试分支,在这个列表中它是一个必不可少的选项。尽管它是针对某个特定领域的,但默认的 Xfce 桌面环境使它成为这个列表中的另一个候选项。
Kali Linux 配备了各种专门用于渗透测试、漏洞评估和数字取证的工具。这些工具包括密码破解、网络扫描和无线攻击,使其成为评估和保护系统的理想解决方案。

它的 Xfce 桌面环境经过大量定制,使其成为外观出色的发行版之一。但是,它面向的是专门的用例。因此,你应该只将 Kali 用于那些特定功能。
>
> **[下载 Kali Linux](https://www.kali.org/get-kali/)**
>
>
>
### 对于你来说哪个是最好的?
嗯,这要取决于你的个人喜好和使用场景。如果你不确定,我建议你尝试 Linux Mint Xfce 或 MX Linux。它们应适用于各种用途。
如果你需要 Fedora 或 Arch Linux 基础,可以尝试 Fedora Xfce 或 EndeavourOS。
其余的发行版可能适用于需要 Ubuntu 或 Debian 基础的特定用例。
### 结论
总之,我们介绍了几个针对 Xfce 桌面环境进行优化的优秀 Linux 发行版。无论你是初学者还是高级用户,这些发行版都为你的计算需求提供了轻量、高效和可定制的平台。每个发行版都具有独特的功能和优势。
希望你能找到适合你的喜爱的基于 Xfce 的发行版!
*(题图:MJ/a1b83f34-f5c2-43cd-aeb8-9f614c5dd1aa)*
---
via: <https://www.debugpoint.com/best-xfce-distributions/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,941 | 如何在 Kubernetes 集群上安装 Ansible AWX | https://www.linuxtechi.com/install-ansible-awx-on-kubernetes-cluster/ | 2023-06-25T17:26:00 | [
"Ansible",
"Kubernetes"
] | https://linux.cn/article-15941-1.html | 
>
> 在本文中,我们将逐步向你展示如何在 Kubernetes(k8s)集群上安装 Ansible AWX。
>
>
>
Ansible AWX 是一个强大的开源工具,用于管理和自动化 IT 基础设施。AWX 为 Ansible 提供图形用户界面,使你可以轻松创建、安排和运行 Ansible <ruby> 剧本 <rt> Playbook </rt></ruby>。
另一方面,Kubernetes 是一种流行的容器编排平台,广泛用于部署和管理容器化应用。
先决条件:
* Kubernetes 集群
* Kubectl
* 具有 sudo 权限和集群管理员权限的普通用户
* 互联网连接
### 步骤 1:安装 Helm
如果你的系统上安装了 Helm,则在命令下运行以进行安装,
```
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
$ chmod +x get_helm.sh
$ ./get_helm.sh
$ helm version
```

### 步骤 2:安装 AWX chart
在 Kubernetes 上安装 AWX 的最简单方法是使用 AWX Helm “<ruby> 海图 <rt> chart </rt></ruby>”。因此,要通过 “海图” 安装 AWX,首先使用以下 `helm` 命令添加仓库。(LCTT 译注:Kubernetes 生态中大量使用了和航海有关的比喻,因此本文在翻译时也采用了这些比喻)
```
$ helm repo add awx-operator https://ansible.github.io/awx-operator/
"awx-operator" has been added to your repositories
$
```
注意:如果你之前已经添加过此仓库,请在命令下运行以获取最新版本的软件包。
```
$ helm repo update
```
要通过 Helm 安装 awx-operator,请运行:
```
$ helm install ansible-awx-operator awx-operator/awx-operator -n awx --create-namespace
```

这将下载 AWX 海图并将其安装在 `awx` 命名空间中的 Kubernetes 集群上。安装过程可能需要几分钟,请耐心等待。
### 步骤 3:验证 AWX 操作员安装
安装成功后,你可以通过运行以下命令来验证 AWX <ruby> 操作员 <rt> operator </rt></ruby> 状态:
```
$ sudo kubectl get pods -n awx
```
你应该看到这样的东西:

### 步骤 4: 创建 PV、PVC 并部署 AWX yaml 文件
AWX 需要 postgres <ruby> 容器荚 <rt> pod </rt></ruby> 的持久卷。那么,让我们首先为本地卷创建一个存储类。
注意:在本文中,我使用本地文件系统作为持久卷。
```
$ vi local-storage-class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
namespace: awxprovisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
```
保存并关闭文件,然后运行:
```
$ kubectl create -f local-storage-class.yaml
$ kubectl get sc -n awx
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION
local-storage kubernetes.io/no-provisioner Delete WaitForFirstConsumer false
$
```
接下来使用以下 `pv.yaml` 文件创建持久卷(PV):
```
$ vi pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: postgres-pv
namespace: awx
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/storage
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-worker
```
保存并退出文件。

重要说明:确保文件夹 `/mnt/storage` 存在于工作节点上,如果不存在,则在工作节点上使用 `mkdir` 命令创建它。在我们的例子中,工作节点是 `k8s-worker`。
执行下面的命令在 `awx` 命名空间中创建 `postgres-pv`。
```
$ kubectl create -f pv.yaml
```
成功创建 PV 后,使用 `pvc.yaml` 文件创建 PersistentVolumeClaim:
```
$ vi pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-13-ansible-awx-postgres-13-0
namespace: awx
spec:
storageClassName: local-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
```

要创建 PVC,请运行以下 `kubectl` 命令:
```
$ kubectl create -f pvc.yaml
```
使用下面的命令验证 PV 和 PVC 的状态:
```
$ kubectl get pv,pvc -n awx
```
现在,我们都准备好部署 AWX 实例了。创建一个包含以下内容的 `ansible-awx.yaml` 文件:
```
$ vi ansible-awx.yaml
---
apiVersion: awx.ansible.com/v1beta1
kind: AWX
metadata:
name: ansible-awx
namespace: awx
spec:
service_type: nodeport
postgres_storage_class: local-storage
```

保存并关闭文件。
执行以下 `kubectl` 命令来部署 awx 实例:
```
$ kubectl create -f ansible-awx.yaml
```
等待几分钟,然后检查 `awx` 命名空间中的容器荚状态。
```
$ kubectl get pods -n awx
```

### 步骤 5:访问 AWX Web 界面
要访问 AWX Web 界面,你需要创建一个公开 awx-web 部署的服务:
```
$ kubectl expose deployment ansible-awx-web --name ansible-awx-web-svc --type NodePort -n awx
```
此命令将创建一个 `NodePort` 服务,该服务将 AWX Web 容器的端口映射到 Kubernetes 节点上的端口。你可以通过运行以下命令找到端口号:
```
$ kubectl get svc ansible-awx-web-svc -n awx
```
这将输出如下内容:
```
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ansible-awx-web-svc NodePort 10.99.83.248 <none> 8052:32254/TCP 82s
```
在此示例中,Web 服务在端口 32254 上可用。

默认情况下,admin 用户是 Web 界面的 `admin`,密码在 `<resourcename>-admin-password` 机密信息中。要检索管理员密码,请运行:
```
$ kubectl get secrets -n awx | grep -i admin-password
ansible-awx-admin-password Opaque 1 109m
$
$ kubectl get secret ansible-awx-admin-password -o jsonpath="{.data.password}" -n awx | base64 --decode ; echo
l9mWcIOXQhSKnzZQyQQ9LZf3awDV0YMJ
$
```
你现在可以打开 Web 浏览器并进入 `http://<node-ip>:<node-port>/` 来访问 AWX Web 界面。在上面的示例中,URL 是:
```
http://192.168.1.223:3225
```

输入凭据后单击登录。

恭喜! 你已在 Kubernetes 上成功安装 Ansible AWX。你现在可以使用 AWX 来自动化你的 IT 基础架构,并让你作为系统管理员的生活更轻松。
*(题图:MJ/bfd354aa-2ee5-4555-98b8-ac5207cbeabe)*
---
via: <https://www.linuxtechi.com/install-ansible-awx-on-kubernetes-cluster/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this post, we will show you how to install Ansible AWX on Kubernetes (k8s) cluster step by step.
[Ansible AWX](https://github.com/ansible/awx) is a powerful open-source tool for managing and automating IT infrastructure. AWX provides a graphical user interface for Ansible, allowing you to easily create, schedule, and run Ansible playbooks.
Kubernetes, on the other hand, is a popular container orchestration platform that is widely used for deploying and managing containerized applications.
#### Prerequisites
- Kubernetes cluster
- Kubectl
- A regular user with sudo rights and cluster admin rights
- Internet connectivity
## Step :1 Install helm
In case you, [helm](https://www.linuxtechi.com/install-use-helm-in-kubernetes/) is installed on your system then run beneath commands to install,
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 $ chmod +x get_helm.sh $ ./get_helm.sh $ helm version
## Step 2: Install the AWX chart
The easiest way to install AWX on Kubernetes is by using the AWX Helm chart. So, to install AWX via chart, first add its repository using following helm command.
$ helm repo add awx-operator https://ansible.github.io/awx-operator/ "awx-operator" has been added to your repositories $
Note: If you had already added this repository before, then run beneath command to get latest version of packages.
$ helm repo update
To install awx-operator via chart, run
$ helm install ansible-awx-operator awx-operator/awx-operator -n awx --create-namespace
This will download the AWX chart and install it on your Kubernetes cluster in awx namespace.The installation process may take a few minutes, so be patient.
## Step 3: Verify AWX operator installation
After the successful installation, you can verify AWX operator status by running below command
$ sudo kubectl get pods -n awx
You should see something like this:
## Step:4 Create PV, PVC and deploy AWX yaml file
AWX requires persistent volume for postgres pod. So, let’s first create a storage class for local volume
Note: In this post, I am using local file system as persistent volume.
$ vi local-storage-class.yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: local-storage namespace: awx provisioner: kubernetes.io/no-provisioner volumeBindingMode: WaitForFirstConsumer
Save and close the file and then run ,
$ kubectl create -f local-storage-class.yaml $ kubectl get sc -n awx NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION local-storage kubernetes.io/no-provisioner Delete WaitForFirstConsumer false $
Next create persistent volume(pv) using following pv.yaml file,
$ vi pv.yaml apiVersion: v1 kind: PersistentVolume metadata: name: postgres-pv namespace: awx spec: capacity: storage: 10Gi volumeMode: Filesystem accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Delete storageClassName: local-storage local: path: /mnt/storage nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - k8s-worker
Save & exit the file.
Important note : Make sure folder “/mnt/storage” exists on worker node, if it does not exist then create it using mkdir command on worker node. In our case worker node is “k8s-worker”
Execute the beneath command to create postgres-pv in awx namespace.
$ kubectl create -f pv.yaml
Once pv is created successfully then create persistentvolumecliam using pvc.yaml file,
$ vi pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: postgres-13-ansible-awx-postgres-13-0 namespace: awx spec: storageClassName: local-storage accessModes: - ReadWriteOnce resources: requests: storage: 10Gi
To create pvc, run following kubectl command
$ kubectl create -f pvc.yaml
Verify the status of pv and pvc using beneath command
$ kubectl get pv,pvc -n awx
Now, we are all set to deploy AWX instance. Create an ansible-awx.yaml file with following content
$ vi ansible-awx.yaml --- apiVersion: awx.ansible.com/v1beta1 kind: AWX metadata: name: ansible-awx namespace: awx spec: service_type: nodeport postgres_storage_class: local-storage
save and close the file.
Execute following kubectl command to deploy awx instance,
$ kubectl create -f ansible-awx.yaml
Wait for couple of minutes and then check pods status in awx namespace.
$ kubectl get pods -n awx
## Step 5: Access AWX Web Interface
To access the AWX web interface, you need to create a service that exposes the awx-web deployment:
$ kubectl expose deployment ansible-awx-web --name ansible-awx-web-svc --type NodePort -n awx
This command will create a NodePort service that maps the AWX web container’s port to a port on the Kubernetes node. You can find the port number by running:
$ kubectl get svc ansible-awx-web-svc -n awx
This will output something like this:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ansible-awx-web-svc NodePort 10.99.83.248 <none> 8052:32254/TCP 82s
In this example, the web service is available on port 32254.
By default, the admin user is admin for web interface and the password is available in the <resourcename>-admin-password secret. To retrieve the admin password, run
$ kubectl get secrets -n awx | grep -i admin-password ansible-awx-admin-password Opaque 1 109m $ $ kubectl get secret ansible-awx-admin-password -o jsonpath="{.data.password}" -n awx | base64 --decode ; echo l9mWcIOXQhSKnzZQyQQ9LZf3awDV0YMJ $
You can now access the AWX web interface by opening a web browser and navigating to `http://<node-ip>:<node-port>/`. In the example above, the URL would be
http://192.168.1.223:3225
Click on Log In after entering the credentials.
Congratulations! You have successfully installed Ansible AWX on Kubernetes. You can now use AWX to automate your IT infrastructure and make your life as a sysadmin easier.
NekasasHi,
When I am trying to access AWX console it requires SSL certificate. How to bypass this?
paul sI have been exploring ansible solutions to create all AWX-related config via ansible, like inventory, jobs, etc. Is there a way to do this via the helm chart, so I can configure this at startup? I have left-over ansible tasks that create all of this, but I was hoping there’s a more “kubernetes”-way to do this (i.e. config via helm chart specs)…
Ambika NagarajHi,
Thank you for the excellent guide!
When I deploy AWX instance ansible-aws-task and ansible-aws-web getting failed and status is “CrashLoopBackoff”
ambi@kube-master:~/awx$ kubectl get pods -n awx
NAME READY STATUS RESTARTS AGE
ansible-awx-postgres-13-0 1/1 Running 0 2m39s
ansible-awx-task-8567b4d6d5-htrz8 0/4 Init:CrashLoopBackOff 4 (39s ago) 2m18s
ansible-awx-web-6766ddb5c8-8xk25 1/3 CrashLoopBackOff 2 (13s ago) 16s
awx-operator-controller-manager-6569d67f4c-nqtmh 2/2 Running 0 114m
ambi@kube-master:~/awx$
—————–
describe pod shows following logs
Events:
Type Reason Age From Message
—- —— —- —- ——-
Normal Scheduled 99s default-scheduler Successfully assigned awx/ansible-awx-task-8567b4d6d5-htrz8 to kube-worker
Normal Pulled 2s (x5 over 99s) kubelet Container image “quay.io/ansible/awx-ee:latest” already present on machine
Normal Created 2s (x5 over 99s) kubelet Created container init
Normal Started 1s (x5 over 99s) kubelet Started container init
Warning BackOff 1s (x9 over 97s) kubelet Back-off restarting failed container init in pod ansible-awx-task-8567b4d6d5-htrz8_awx(a0c528db-ec4a-4ced-9dca-9bd3004fa782)
==================
Cannot really find what’s going on in the logs
le-awx”,”namespace”:”awx”,”error”:”exit status 2″,”stacktrace”:”github.com/operator-framework/ansible-operator-plugins/internal/ansible/runner.(*runner).Run.func1\n\tansible-operator-plugins/internal/ansible/runner/runner.go:269″}
{“level”:”error”,”ts”:”2024-01-03T14:07:45Z”,”msg”:”Reconciler error”,”controller”:”awx-controller”,”object”:{“name”:”ansible-awx”,”namespace”:”awx”},”namespace”:”awx”,”name”:”ansible-awx”,”reconcileID”:”e9b8d090-4f0d-444c-91d0-4f3528f5e6e3″,”error”:”event runner on failed”,”stacktrace”:”sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).reconcileHandler\n\t/home/runner/go/pkg/mod/sigs.k8s.io/[email protected]/pkg/internal/controller/controller.go:329\nsigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).processNextWorkItem\n\t/home/runner/go/pkg/mod/sigs.k8s.io/[email protected]/pkg/internal/controller/controller.go:274\nsigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).Start.func2.2\n\t/home/runner/go/pkg/mod/sigs.k8s.io/[email protected]/pkg/internal/controller/controller.go:235″}
=================
Could anyone please help me, Thank You!
JonathanI was able to go through all the steps but i mm getting an error on my ansible-awx-web pod. It gives a status of CrashLoopBackOff and when i look at the logs the error says psycopg.OperationalError: connection failed: password authentication failed for user “awx”
How can I fix my yaml to solve this error?
Kool TatchanAfter running this step
$ kubectl create -f ansible-awx.yaml
i get errror when create container” Warning FailedMount 6s (x7 over 37s) kubelet MountVolume.NewMounter initialization failed for volume “postgres-pv” : path “/mnt/storage” does not exist”
How can I fix my yaml to solve this error?
SKAlready mentioned in article ensure the /mnt/storage path is exist. |
15,943 | 使用开源 API 网关实现可伸缩 API | https://opensource.com/article/23/1/api-gateway-apache-apisix | 2023-06-26T17:00:35 | [
"API"
] | https://linux.cn/article-15943-1.html | 
>
> 采用 Apache APISIX 的 API 主导架构。
>
>
>
API 网关是一个单一节点,提供对 [API](https://www.redhat.com/en/topics/api/what-are-application-programming-interfaces) 调用入口。网关聚合了所请求的服务,并相应传回合适的响应信息。为了令你的 API 网关有效地工作,设计一个可靠、高效且简洁地 API 至关重要。本文介绍一种设计风格,但只要你理解其中的重点内容,它就能解决你的相关问题。
### 由 API 主导的方法
API 主导的方法是将 API 置于应用程序和它们需要访问的业务能力之间的通信核心,从而在所有数字通道上一致地交付无缝功能。API 主导的连接是指使用一种可重用、且设计得当的 API 来连接数据和应用程序的方法。
### API 主导的架构
API 主导的架构是一种架构方法,它着眼于实现重用 API 的最佳方式。它能解决以下问题:
* 保护 API,使外界无法在未授权情况下访问 API
* 确保应用程序能找到正确的 API 端点
* 限制对 API 的请求次数,从而确保持续的可用性
* 支持持续集成、测试、生命周期管理、监控、运维等等
* 防止错误在栈间传播
* 对 API 的实时监测和分析
* 实现可伸缩和灵活的业务能力(例如支持 [微服务](https://www.redhat.com/en/topics/microservices/what-are-microservices?intcmp=7013a000002qLH8AAM) 架构)
### API 资源路由
实现一个 API 网关,把它作为与所有服务通信的单一入口点,意味着使用者只需要知道 URL 就能使用 API。将请求路由到相应的服务端点,并执行相应的功能是 API 网关的职责。

由于客户端应用程序不需要从多个 HTTP 端点调用功能,这个办法就减少了 API 使用者的操作复杂度。对每个服务来说,也不需实现一个单独的层级去实现认证、授权、节流和速度限制。大多数API 网关,如开源的 [Apache APISIX](https://apisix.apache.org/docs/apisix/terminology/api-gateway/),已经包含了这些核心功能。
### API 基于内容的路由
基于内容的路由机制也使用 API 网关根据请求的内容进行路由调用。例如,一个请求可能是基于 HTTP 请求的头部内容或消息体被路由,而不只基于它的目标 URI。
考虑这样一个场景:为了将负载在多个数据库实例间均分,需要对数据库进行分区。当记录总数较大,单个数据库实例难以管理负载时,常常会用这个办法。
还有一个更好的办法,就是把记录在多个数据库实例间分散开来。然后你实现多个服务,每个不同的数据库都有一个服务,把一个 API 网关作为访问所有服务的唯一入口。然后,你可以配置你的 API 网关,根据从 HTTP 头或有效载荷中获得的密钥,将调用路由到相应的服务。

在上面的图表中,一个 API 网关向多个客户服务暴露一个单一的 `/customers` 资源,每个服务都有对应的不同数据库。
### API 地理路由
API 地理路由解决方案根据 API 调用的来源将其路由到最近的 API 网关。为了防止地理距离导致的延迟问题(例如一个位于亚洲的客户端调用了位于北美地区的 API),你可以在多个地区部署 API 网关。对于一个 API 网关,你可以在每个区域使用不同的子域名,让应用程序基于业务逻辑选择最近的网关。因此 API 网关就提供了内部负载均衡,确保进入的请求分布于可用的实例之间。

通常使用 DNS 流量管理服务和 API 网关,针对该区域的负载均衡器解析子域名,定位到距离最近的网关。
### API 聚合器
这项技术对多个服务执行操作(例如查询),并向客户端服务以单个 HTTP 响应的形式返回结果。API 聚合器使用 API 网关在服务器端代表使用者来执行这项工作,而非让客户端程序多次调用 API。
假定你有一款移动端 APP,对不同的 API 发起多次调用。这增加了客户端代码的复杂性,导致网络资源的过度使用,而且由于延迟性,用户体验也不好。网关可以接收所有需要的信息,可以要求认证和验证,并理解来自每个 API 的数据结构。它也可以传递响应的有效载荷,因此它们也会作为一个用户需要的统一负载传回移动端。

### API 集中认证
在这种设计中,API 网关就是一个集中式认证网关。作为一个认证者,API 网关在 HTTP 请求头中查找访问凭据(例如不记名的令牌)。然后它借助于身份验证提供方执行验证凭据的业务逻辑。

使用 API 网关的集中式身份验证能解决很多问题。它完全取代了应用程序中的用户管理模块,通过对来自客户端应用程序的身份验证请求的快速响应来提高性能。Apache APISIX 提供了一系列插件,支持不同的 API 网关认证方法。

### API 格式转换
API 格式转换是通过同一传输方式将有效载荷从一种格式转换为另一种格式的能力。例如,你可以通过 HTTPS 从 XML/SOAP 格式转换为 JSON 格式,反之亦然。API 网关提供了支持 [REST API](https://www.redhat.com/en/topics/api/what-is-a-rest-api?intcmp=7013a000002qLH8AAM) 的功能,可以有效地进行负载和传输的转换。例如,它可以把消息队列遥测传输(MQTT)转换为 JSON 格式。

Apache APISIX 能够接收 HTTP 请求,对其进行代码转换,然后将其转发给 gRPC 服务。它通过 [gRPC Transcode](https://apisix.apache.org/docs/apisix/plugins/grpc-transcode/) 插件获取响应并将其以 HTTP 格式返回给客户端。
### API 的可观察性
现在,你知道 API 网关为进入各种目的地的流量提供了一个中心控制点。但它也可以是一个中心观察点,因为就监控客户端和服务器端的流量来说,它有独特的资格。为了收集监测工具所需要的数据(结构化日志、度量和跟踪),你可以对 API 网关作出调整。
Apache APISIX 提供了 [预先构建的连接器](https://apisix.apache.org/docs/apisix/plugins/prometheus/),因此你可以跟外部监测工具结合使用。你可以利用这些连接器从你的 API 网关收集日志数据,进一步获得有用的指标,并获取完整可见的服务使用情况。
### API 缓存
API 缓存通常在网关内部实现。它可以减少对端点的调用次数,同时通过缓存上游的响应,改进了请求延迟的情况。如果网关缓存对请求资源有一个新副本,它会直接使用这个副本来响应这个请求,而不必对端点发出请求。如果缓存数据不存在,就将请求传到目标上游服务。

### API 错误处理
由于各种原因,API 服务可能会出错。在这种情况下,API 服务需要有一定的弹性,来应对可预见的错误。你也希望确保弹性机制能正常工作。弹性机制包括错误处理代码、断路器、健康检查、回退、冗余等等。新式的 API 网关支持各种常见错误处理功能,包括自动重试和超时设置。

API 网关作为一个协调器,它会根据各方面情况来决定如何管理流量、将负载均衡发送到一个健康的节点,还能快速失败。当有异常状况,它也会向你发出警示。API 网关也保证路由和其他网络级组件能协同将请求传给 API 进程。它能帮助你在早期检测出问题,并修复问题。网关的错误注入机制(类似于 Apache APISIX 使用的那种)可用于测试应用程序或微服务 API 在各种错误发生时的弹性。
### API 版本管理
版本管理是指定义和运行多个并发的 API 版本的功能。这点也很重要,因为 API 是随着时间推移不断改进的。如果能对 API 的并发版本进行管理,那么 API 使用者就可以较快地切换到新的版本。这也意味着较老的版本可以被废弃并最终退役。API 也跟其他应用程序类似,无论是开发新功能还是进行错误修复,都存在演变的过程。

你可以使用 API 网关来实现 API 版本管理。版本管理可以是请求头,查询参数或路径。
### APISIX 的网关
如果你需要令 API 服务可伸缩,就需要使用 API 网关。Apache APISIX 提供了必要的功能,可以实现健壮的入口,它的好处是显而易见的。它遵循 API 主导的架构,并且有可能改变客户端与托管服务交互的方式。
本文经作者许可,从 [Apache APISIX](https://apisix.apache.org/blog/2022/10/27/ten-use-cases-api-gateway/) 博客改编并转载。
*(题图:MJ/f1d05345-48f5-4e3e-9c65-a2ba9105614a)*
---
via: <https://opensource.com/article/23/1/api-gateway-apache-apisix>
作者:[Bobur Umurzokov](https://opensource.com/users/iambobur) 选题:[lkxed](https://github.com/lkxed) 译者:[cool-summer-021](https://github.com/cool-summer-021) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | An API gateway is a single point of entry for incoming calls to an [application programming interface (API)](https://www.redhat.com/en/topics/api/what-are-application-programming-interfaces). The gateway aggregates the services being requested and then returns the appropriate response. To make your API gateway effective, it's vital for you to design a reliable, efficient, and simple API. This is an architectural puzzle, but it's one you can solve as long as you understand the most important components.
## API-Led approach
An API-Led approach puts an API at the heart of communication between applications and the business capabilities they need to access in order to consistently deliver seamless functionality across all digital channels. **API-Led connectivity** refers to the technique of using a reusable and well-designed API to link data and applications.
## API-Led architecture
API-Led architecture is an architectural approach that looks at the best ways of reusing an API. API-Led architecture addresses things like:
- Protecting an API from unauthorized access.
- Ensuring that consuming applications can always find the right API endpoint.
- Throttling or limiting the number of calls made to an API to ensure continuous availability.
- Supporting continuous integration, testing, lifecycle management, monitoring, operations, and so on.
- Preventing error propagation across the stack.
- Real-time monitoring of an API with rich analytics and insight.
- Implementing scalable and flexible business capabilities (for example, supporting a
[microservice](https://www.redhat.com/en/topics/microservices/what-are-microservices?intcmp=7013a000002qLH8AAM)architecture.)
## API resource routing
Implementing an API gateway as the single entry point to all services means that API consumers only have to be aware of one URL. It becomes the API gateway's responsibility to route traffic to the corresponding service endpoints, and to enforce policies.
(Bobur Umurzokov, CC BY-SA 4.0)
This reduces complexity on the API consumer side because the client applications don't need to consume functionality from multiple HTTP endpoints. There's also** **no need to implement a separate layer for authentication, authorization, throttling, and rate limiting for each service. Most API gateways, like the open source [Apache APISIX](https://apisix.apache.org/docs/apisix/terminology/api-gateway/) project, already have these core features built in.
## API content-based routing
A content-based routing mechanism also uses an API gateway to route calls based on the content of a request. For example, a request might be routed based on the HTTP header or message body instead of just its target URI.
Consider a scenario when database sharding is applied in order to distribute the load across multiple database instances. This technique is typically applied when the overall number of records stored is huge and a single instance struggles to manage the load.
A better solution is to spread records across multiple database instances. Then you implement multiple services, one for each unique datastore, and adopt an API gateway as the only entry point to all services. You can then configure your API gateway to route calls to the corresponding service based on a key obtained either from the HTTP header or the payload.
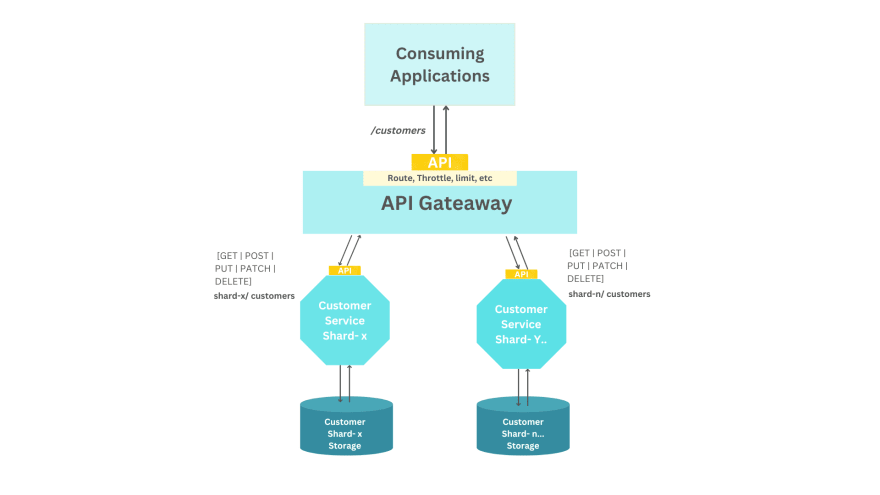
(Bobur Umurzokov, CC BY-SA 4.0)
In the above diagram, an API gateway is exposing a single `/customers`
resource for multiple customer services, each with a different data store.
## API geo-routing
An API geo-routing solution routes an API call to the nearest API gateway based on its origin. In order to prevent latency issues due to distance (for example, a consuming application from Asia calling an API located in North America), you can deploy an API gateway in multiple regions across the world. You can use a different subdomain for each API gateway in each region, letting the consuming application determine the nearest gateway based on application logic. Then, an API gateway provides internal load balancing to make sure that incoming requests are distributed across available instances.
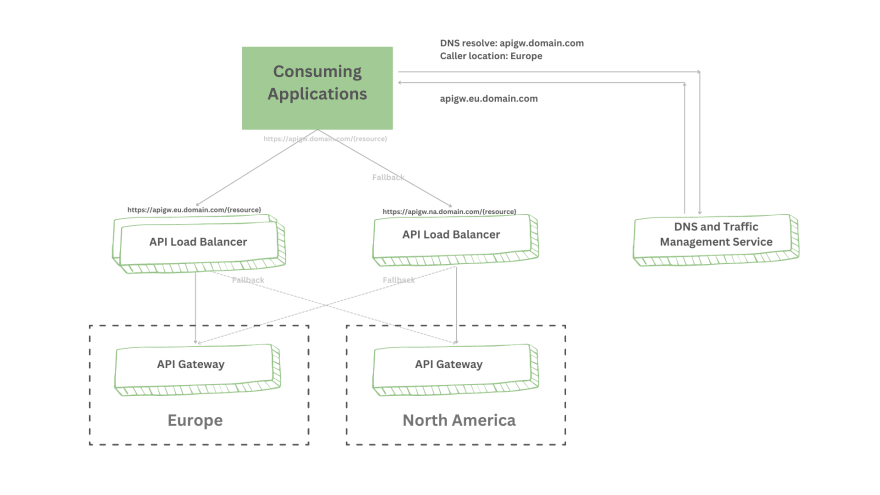
(Bobur Umurzokov, CC BY-SA 4.0)
It's common to use a DNS traffic management service and an API gateway to resolve each subdomain against the region's load balancer to target the nearest gateway.
## API aggregator
This technique performs operations (for example, queries) against multiple services, and returns the result to the client service with a single HTTP response. Instead of having a client application make several calls to multiple APIs, an API aggregator uses an API gateway to do this on behalf of the consumer on the server side.
Suppose you have a mobile app that makes multiple calls to different APIs. This increases complexity in the client-side code, it causes over-utilization of network resources, and produces a poor user experience due to increased latency. An API gateway can accept all information required as input, and can request authentication and validation, and understand the data structures from each API it interacts with. It's also capable of transforming the response payloads so they can be sent back to the mobile app as a uniform payload needed for the consumer.
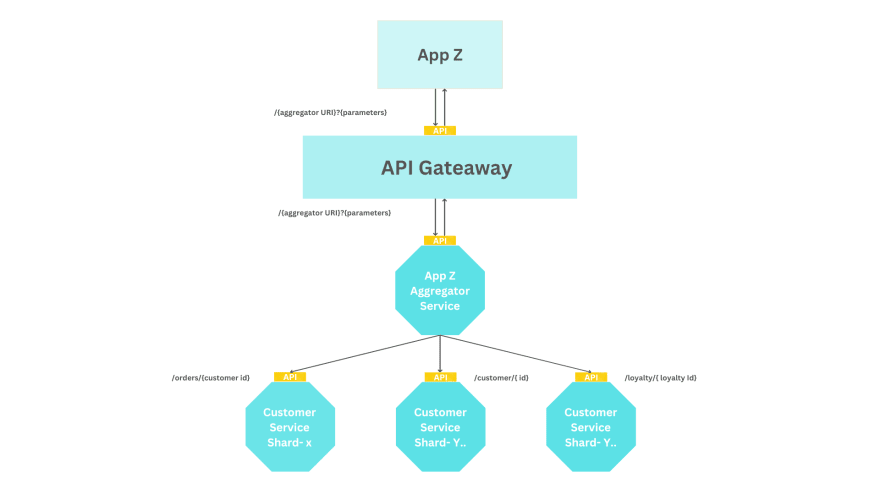
(Bobur Umurzokov, CC BY-SA 4.0)
## API centralized authentication
In this design, an API gateway acts as a centralized authentication gateway. As an authenticator, an API gateway looks for access credentials in the HTTP header (such as a bearer token.) It then implements business logic that validates those credentials with an identity provider.
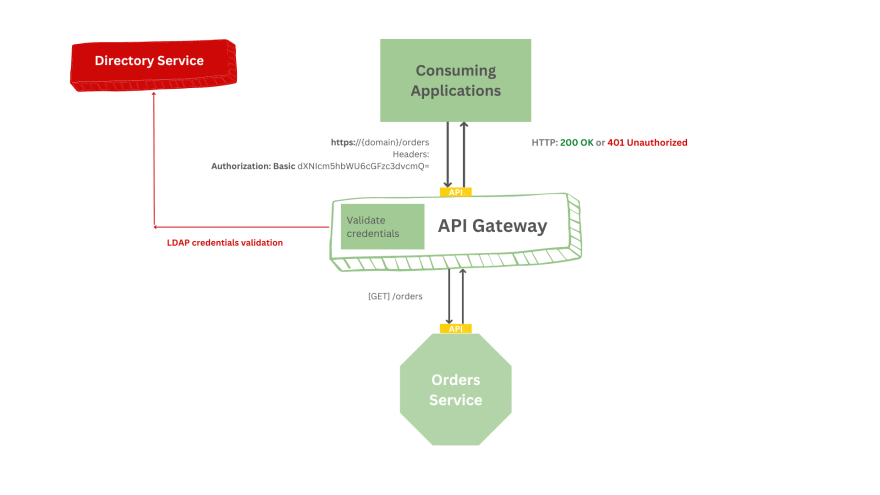
(Bobur Umurzokov, CC BY-SA 4.0)
Centralized authentication with an API gateway can solve many problems. It completely offloads user management from an application, improving performance by responding quickly to authentication requests received from client applications. Apache APISIX offers a [variety of plugins](https://apisix.apache.org/docs/apisix/plugins/openid-connect/) to enable different methods of API gateway authentication.
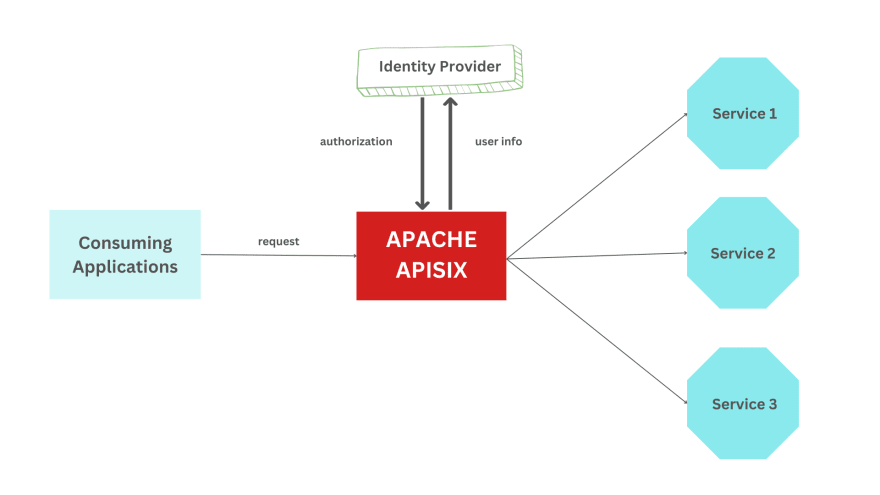
(Bobur Umurzokov, CC BY-SA 4.0)
## API format conversion
API format conversion is the ability to convert payloads from one format to another over the same transport. For example, you can transfer from XML/SOAP over HTTPS to JSON over HTTPS, and back again. An API gateway offers capabilities in support of a [REST API](https://www.redhat.com/en/topics/api/what-is-a-rest-api?intcmp=7013a000002qLH8AAM) and can do payload conversions and transport conversions. For instance, a gateway can convert from a message queue telemetry transport (MQTT) over TCP (a very popular transport in IoT) to JSON over HTTPS.
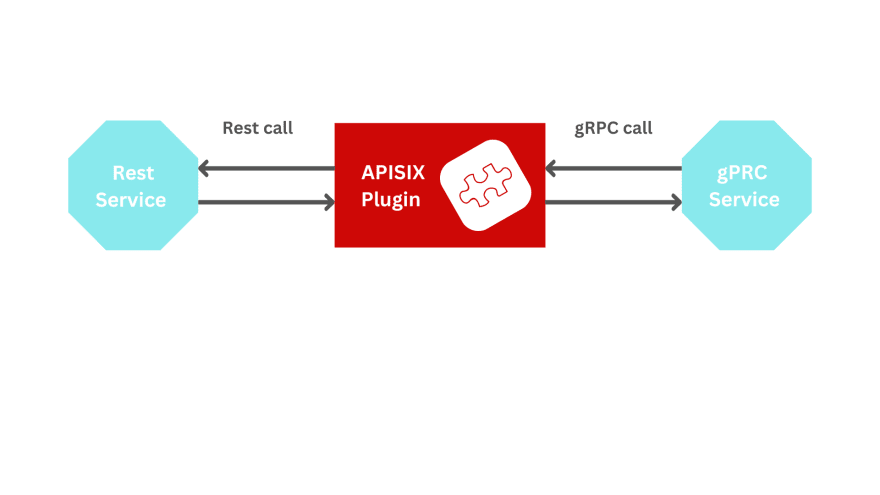
(Bobur Umurzokov, CC BY-SA 4.0)
Apache APISIX is able to receive an HTTP request, transcode it, and then forward it to a gRPC service. It gets the response and returns it back to the client in HTTP format by means of its [gRPC Transcode](https://apisix.apache.org/docs/apisix/plugins/grpc-transcode/) plug-in.
## API observability
By now, you know that an API gateway offers a central control point for incoming traffic to a variety of destinations. But it can also be a central point for observation, because it's uniquely qualified to monitor all traffic moving between the client and service networks. You can adjust an API gateway so that the data (structured logs, metrics, and traces) can be collected for use with specialized monitoring tools**.**
Apache APISIX provides [pre-built connectors](https://apisix.apache.org/docs/apisix/plugins/prometheus/) so you can integrate with external monitoring tools. You can leverage these connectors to collect log data from your API gateway to further derive useful metrics and gain complete visibility into how your services are being used. You can also manage the performance and security of your API in your environment.
## API caching
API caching is usually implemented inside the API gateway. It can reduce the number of calls made to your endpoint, and also improve the latency of requests to your API by caching a response from upstream. If the API gateway cache has a fresh copy of the requested resource, it uses that copy to satisfy the request directly instead of making a request to the endpoint. If the cached data is not found, the request travels to the intended upstream services.
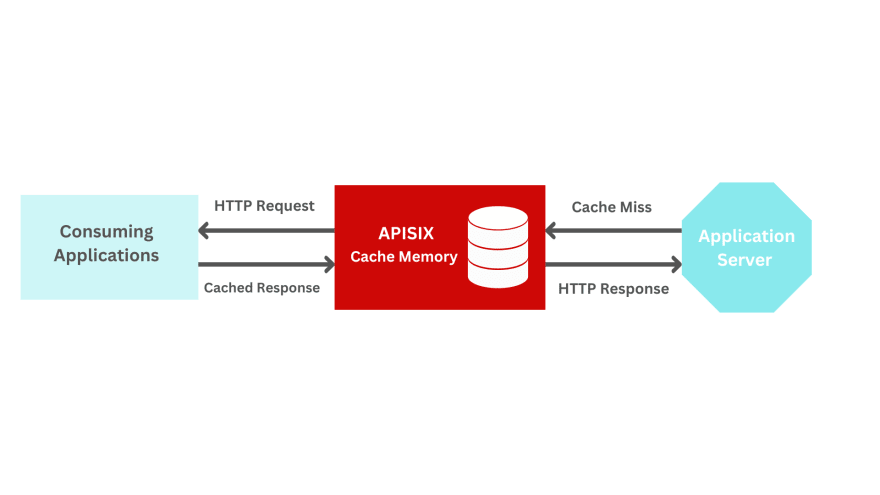
(Bobur Umurzokov, CC BY-SA 4.0)
## API fault handling
API services may fail due to any number of reasons. In such scenarios, your API service must be resilient enough to deal with predictable failures. You also want to ensure that any resilience mechanisms you have in place work properly. This includes error handling code, circuit breakers, health checks, fallbacks, redundancy, and so on. Modern API gateways support all the most common error-handling features, including automatic retries and timeouts.
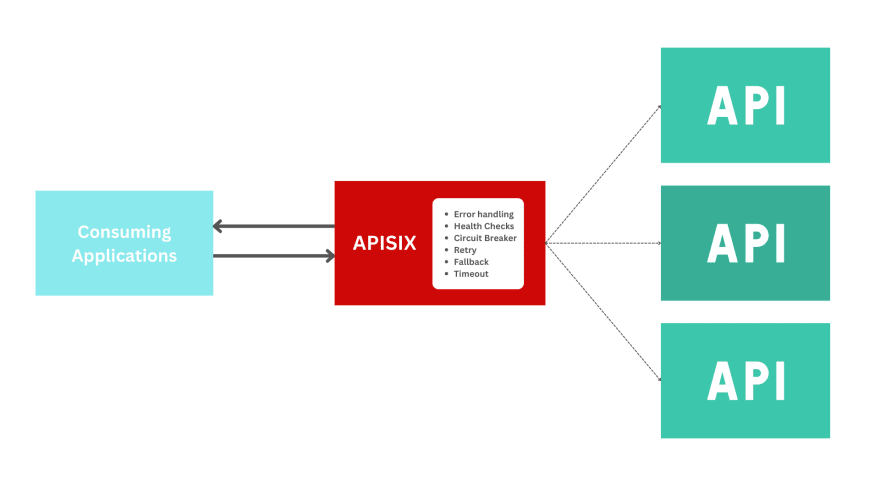
(Bobur Umurzokov, CC BY-SA 4.0)
An API gateway acts as an orchestrator that can use a status report to decide how to manage traffic, send load balances to a healthy node, and can fail fast. It can also alert you when something goes wrong. An API gateway also ensures that routing and other network-level components work together successfully to deliver a request to the API process. It helps you detect a problem in the early stage, and to fix issues. A fault injection mechanism (like the one Apache APISIX uses) at the API gateway level can be used to test the resiliency of an application or microservices API against various forms of failures.
## API versioning
This refers to having the ability to define and run multiple concurrent versions of an API. This is particularly important, because an API evolves over time. Having the ability to manage concurrent versions of an API enables API consumers to incrementally switch to newer versions of an API. This means older versions can be deprecated and ultimately retired. This is important because an API, just like any other software application, should be able to evolve either in support of new features or in response to bug fixes.
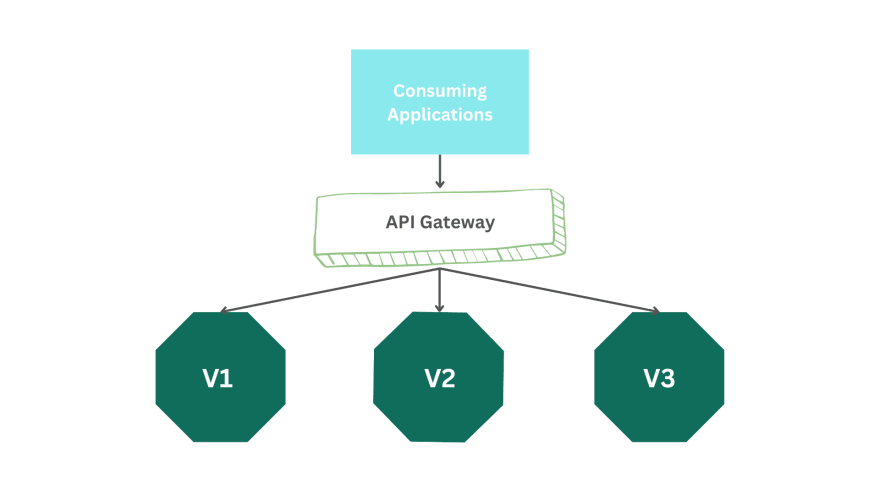
(Bobur Umurzokov, CC BY-SA 4.0)
You can use an API gateway to implement API versioning. The versioning can be a header, query parameter, or path.
## Gateway to APISIX
If you want to scale your API services, you need an API gateway. The Apache APISIX project provides essential features for a robust entrypoint, and its benefits are clear. It aligns with an API-Led architecture, and is likely to transform the way your clients interact with your hosted services.
*This article has been adapted and republished from the Apache APISIX blog with the author's permission.*
## Comments are closed. |
15,944 | 5 种预防开源许可违规的方法 | https://www.opensourceforu.com/2022/08/5-ways-to-prevent-open-source-licensing-violations/ | 2023-06-26T18:24:59 | [
"许可证"
] | https://linux.cn/article-15944-1.html | 
开发人员可以通过将开源软件集成到其代码库中,节省时间并避免重复发明轮子。然而,这也带来了严重的许可侵权风险。你必须遵守适用于重新使用的开源代码的众多开源许可证之一。如果你不这样做,你(或你所在公司)有可能因违反开源许可证条款而被起诉。即使这种诉讼并不普遍发生,它们确实存在。实际上,考虑到现在许多开源项目由希望保护其在开源社区中的投资的企业运营,这种情况在未来可能更加频繁发生。
### 1、熟悉开源许可证
了解开源许可证是防止开源许可侵权问题中最重要的一步。很容易认为所有开源许可证都施加相同的条件,或者它们都基本要求源代码的持续可用性。实际上,有数十种不同的开源许可证,它们都有着非常不同的条款。简单地认为只要你从一个开源项目获取代码,你可以随意使用它并保持源代码可访问,这是一个严重的错误。几个开源许可证的一个典型但经常被忽视的条件可能是需要向原始作者提供致谢。
### 2、记录你使用的开源内容
建立一个标准化的方法来记录你使用开源代码的情况是一个优秀的做法。导入模块或从 GitHub 粘贴代码并不难。但如果你不追踪代码来自何处以及使用了何种许可证,你可能会忘记在代码库中如何以及在哪里集成开源内容。此外,如果你在借用代码时无法证明自己遵守了有效的许可条件,那么在开源许可证发生变化时可能会产生问题。考虑在文档维基(如果有的话)中添加一个页面,列出你使用的开源代码,以避免出现这个问题。每当你包含开源组件或依赖时,至少在你自己的源代码中添加注释。
### 3、避免使用未经授权的开源组件
有时,你可能会偶然发现一个隐藏的 GitHub 存储库或其他源代码托管位置,其中包含你希望使用的代码,但没有提到任何许可指南。你可能会认为代码的创建者希望让其成为开源代码,并且你可以根据自己的意愿使用它。但这是一个危险的假设。开发人员可能会后续对代码设置特定的许可条件,并要求你遵守这些条件,这可能导致未来产生许可侵权的指控。除非你有非常充分的理由,否则避免使用缺乏明确许可限制的模糊代码。
### 4、创建自己的开源代码
将你自己的软件完全开源是减少与开源许可相关风险的一种方法。这意味着你将自动遵守任何要求保留派生源代码的开源许可条件。然而,请记住,仅仅开放你自己的代码并不能确保完全遵守许可证。你仍然需要努力确保你遵守每个许可证的规定,因为适用于你借用的代码的许可证可能与你选择的开源许可证不同。然而,你无需担心与源代码共享相关的任何条款。
### 5、自动检测开源组件
虽然在代码库内手动跟踪你如何使用开源是很好的做法,但通过使用能够自动识别开源组件和依赖项的软件,你可以降低出错的可能性。在这里,我们应该考虑两种不同类型的工具。一种是源代码组成分析(SCA)软件,它会自动扫描源代码并识别从值得信任的外部来源获取的元素。另一种是软件供应链管理解决方案,除其他功能外,还支持查找和监控应用程序堆栈中的任何开源依赖项。
*(题图:MJ/2168d466-cfc3-47de-a8a5-fc7ebaaa445f)*
---
via: <https://www.opensourceforu.com/2022/08/5-ways-to-prevent-open-source-licensing-violations/>
作者:[Laveesh Kocher](https://www.opensourceforu.com/author/laveesh-kocher/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Developers can save time and avoid having to reinvent the wheel by integrating open source software into their codebases. However, it also carries a significant danger of infringement on licences. You must adhere to whatever of the many open source licences that apply to reused open source code. If you don’t, you (or the company you work for) run the danger of being sued for breaking the terms of the open source licences. Even if these lawsuits are not widespread, they do occur. In fact, given that many open source projects are now run by businesses keen to protect their investment in open source communities, they may occur more frequently in the future.
- Become familiar with open source licencing
Understanding open source licences is the single most crucial step in preventing concerns with open source licencing infringement. It’s simple to think that all open source licences impose the same conditions or that they all essentially call for the continued availability of the source code. In fact, there are dozens upon dozens of different open source licences, and they all have quite different terms. It’s a grave error to believe that simply because you get code from an open source project, you can use it whatever you like as long as you maintain the source code accessible. One typical — yet frequently missed — condition of several open source licences can be the necessity to provide credit to the original authors.
- Record Your Use of Open Source
Creating a standardised method for documenting when you use open source code is a second excellent practise. Importing a module or pasting code from GitHub is simple enough. But if you don’t keep track of where that code comes from or under what licence, you can forget how and where you’re integrating open source into your codebase. Additionally, it becomes more difficult to demonstrate that you complied with the licencing conditions in effect when you borrowed the code, which could be problematic if the open source licence in force changes. Consider adding a page to your documentation wiki (if you have one) that lists the open source code you used to avoid this problem. Whenever you include open source components or dependencies, you should at the very least add comments inside your own source code.
- Steer clear of unauthorised open source components
There are occasions when you may stumble across a hidden GitHub repository or other source code hosting location that has code you wish to use but doesn’t mention any licence guidelines. You could be tempted to believe that the creators of the code want it to be open source and that you can use it whatever you like. But that’s a perilous supposition. It’s possible that the developers will subsequently set specific licence conditions on the code and require you to abide by them, which could result in claims of licencing infringement in the future. Avoid using obscure code that lacks clear licencing restrictions unless you have a very solid reason to do so.
- Create Open Source Code of Your Own
Making your own software totally open source is one method to reduce some of the risks associated with open source licencing. This implies that you’ll automatically adhere to any open source licencing conditions that call for the preservation of derivative source code. However, keep in mind that merely opening up your own code doesn’t ensure complete licencing compliance. You’ll still need to put in some effort to make sure you abide by the rules of each licence because the licences that apply to the code you borrowed may not be the same as the open source licence you select. However, you won’t have to worry about any clauses pertaining to source code sharing.
- Detect Open Source Components Automatically
Although it’s great practise to manually track where and how you utilise open source inside your codebase, you can lower the likelihood of mistakes by employing software that identifies open source components and dependencies automatically. Here, we should think about two different kinds of tools. One of these is Source Composition Analysis, or SCA, software that automatically scans source code and identifies elements that were taken from trusted outside sources. The other is software supply chain management solutions, which support finding and monitoring any open source dependencies present in your application stack in addition to other things. |
15,946 | 弃 Ubuntu 转 Manjaro 一周后的使用体验 | https://news.itsfoss.com/manjaro-linux-experience/ | 2023-06-27T11:06:39 | [
"Manjaro"
] | https://linux.cn/article-15946-1.html | 
通常,我用的是基于 Ubuntu 的发行版进行工作,如 Pop!\_OS、Zorin OS、Linux Mint 或 Ubuntu 本身。
它们不会干扰我的工作,同时又提供了顺滑的软件更新。更不用说,它们与我使用的英特尔-英伟达系统相容性良好。
所有的一切(可能是主观的)都能开箱即用。
然而,最近我决定在实体机上切换到 Arch Linux(我大部分时间都是在虚拟机上使用它)。
结果,我最终选择使用了 **Manjaro Linux**(一款基于 Arch 的发行版)。
### 我选择 Manjaro Linux 的原因
令我惊讶的是,即使是使用 **Arch Linux 的立付 USB**,我甚至无法解决 “nouveau DRM: core notifier timeout” 错误,更别提继续安装了。是的,我知道有向导式的 Arch Linux 安装程序,但是不论怎么样,连接的显示器都会闪烁并突出显示这个错误。
解决这个问题的最好办法是不使用我的最近刚刚升级的英伟达显卡。
*很遗憾,我更喜欢英伟达的显卡……*
AMD 的 RX 6600 XT 的价格与 RTX 3060 Ti 相当;对于 1440p 来说,购买那款显卡是没有意义的。
因此,在我这个情况下,RTX 3060 Ti 可能是问题所在。
虽然我找到了一些解决问题的方法,但是我太懒了。我只是想看看能否在不用付出太多努力的情况下体验一下 Arch Linux。
**所以,我做了以下的事情:**
下一个最佳选择就是尝试任何一个专门简化了麻烦的 [最佳的基于 Arch 的发行版](https://itsfoss.com/arch-based-linux-distros/),对吧?
这就是 **Manjaro Linux** 登场的地方。
Manjaro Linux 是一款流行的基于 Arch 的发行版,并且我注意到每次更新时都有各种改进(在虚拟机上使用时)。
此外,我喜欢 Manjaro 默认主题的强调色,很适合我的桌面体验。
所以,我决定试试看……
### Manjaro Linux: 起步有点困难

使用专有的英伟达驱动程序安装 Manjaro 时我没有遇到任何问题。然而,最近的一个小版本更新,**Manjaro Linux 21.2.6,** 把我的系统弄乱了。
我无法访问登录界面和 [TTY](https://itsfoss.com/what-is-tty-in-linux/)(我只能看到主板制造商的标志)
因此,我只能使用最新的 ISO 重新安装 Manjaro Linux,到目前为止一切都还好(千万别出问题)。
在我使用 Manjaro Linux 的过程中,我注意到了一些事情,有好有坏。
在这里,我分享一些我的经历。如果你还没有尝试过,这些经验应该对你帮助很大,可以让你更多地了解它。
#### 1、简单的安装
基于 Arch 的发行版的主要亮点是使安装过程变得简单。对我来说,完全没有遇到任何问题。
在我的第二块硬盘上安装 Manjaro Linux 是一件轻而易举的事情。引导加载程序正确配置,显示了 Manjaro 主题的启动菜单,让我可以选择 Windows/Manjaro Linux 进行双启动。
#### 2、Manjaro 欢迎页

当尝试新东西时,欢迎体验在用户体验中占据了一大部分重要性。在这方面,Manjaro Linux 没有让人失望。
如果你仔细关注欢迎屏幕上提供的信息,你可以获得所有必要的信息。
GNOME 布局管理器能让你选择一个合适的布局,使你更加舒适。

然而,当我尝试在这里启用“**窗口平铺**”功能时,它却无法正常工作:

#### 3、包管理器快速且功能丰富

考虑到 GNOME 是我最喜欢的桌面环境,我在软件中心(甚至是像 Pop!\_Shop 这样特定于发行版的商店)上有过糟糕的经历。
虽然它们可以完成工作,但有时它们对我的期望反应不及预期。
在 Manjaro Linux 中,我发现安装了 [Pamac](https://wiki.manjaro.org/index.php/Pamac) 作为包管理器。这似乎是 [在 Manjaro Linux 上安装和卸载软件的最佳方式之一](https://itsfoss.com/install-remove-software-manjaro/)。
根据我的经验,它在安装和卸载软件时非常快速。在安装某些软件时,你还会收到关于软件包冲突或是否需要替换/删除某些软件包的提示。当你安装某些东西时,包管理器提供了关于可选/必需依赖项的大量信息。
总体来说,体验非常流畅,没有出现任何麻烦。为了提升体验,包管理器还可以通过调整 pamac 的偏好设置,快速启用对 **Flatpaks/Snaps/AUR** 的支持。

所以,你不必使用终端或不同的软件商店。一切都可在一个统一的平台下获得,这大大节省了时间。
#### 4、尝试 ZSH Shell

我习惯于在基于 Ubuntu 的发行版上使用 Bash shell。然而,Manjaro Linux 默认使用 Zsh shell。我相信 Zsh 比 Bash 更好,不过我很快会在另一篇文章中介绍并深入比较。
换句话说,我可以直接尝试不同的东西。令我兴奋的是,终端提示符和遵循 Manjaro 品牌的Shell(或终端)的主题也采用了 Manjaro 的强调色,非常令人印象深刻!

因此,我没有必要在此处 [自定义终端的外观](https://itsfoss.com/customize-linux-terminal/)。
要了解更多信息,你可以查看一些关于 [Zsh 是什么](https://linuxhandbook.com/why-zsh/) 以及 [如何安装它](https://linuxhandbook.com/install-zsh/) 的信息。
#### 5、缺乏官方软件支持

我希望这个情况能够很快改善。但目前来说,许多软件/工具只提供对 Ubuntu 和 Fedora 的官方支持。
你可以在各种工具中找到官方的 DEB/RPM 包,但它们都不能直接在 Manjaro Linux 上使用。
你得依赖 Arch Linux 仓库或 [AUR](https://itsfoss.com/aur-arch-linux/) 中提供的软件包。
幸运的是,很有可能在 AUR 或社区或发行版开发者维护的仓库中找到所需的软件。就像我能够在 Manjaro Linux 上运行 [Insync](https://itsfoss.com/recommends/get-insync/),并使用文件管理器的集成扩展。
然而,由于缺乏对该平台的官方支持,你可能会错过一些功能或快速更新。
当然,如果你依赖于 [Flatpak](https://itsfoss.com/what-is-flatpak/) 或 Snap 软件包,这对你来说应该不是个问题。此外,如果你是 Linux 的新手,你可以参考我们的 [Flatpak 指南](https://itsfoss.com/flatpak-guide/) 获取更多信息。
#### 6、缺少分数缩放
我有一个由 1080p 和 1440p 分辨率组成的双显示器。因此,分数缩放很有帮助,但我可以不用它来操作。
要在 Manjaro 上启用分数缩放,你需要安装支持 X11 缩放的 Mutter 和 GNOME 控制中心软件包。这些软件包包括:
* `mutter-x11-scaling`
* `gnome-control-center-x11-scaling`
这将替换你现有的 Mutter 和 GNOME 控制中心软件包。因此,你将失去桌面的默认主题/强调色设置。
你可能需要使用 GNOME “<ruby> 调整 <rt> Tweaks </rt></ruby>”应用来将一切调整正确。但是,这可能会令人感觉麻烦。
### 总结
总体而言,我喜欢在 Manjaro Linux 上的桌面体验。如果那个更新没有搞坏我的系统,我认为我会继续使用 Manjaro Linux 作为我的新日常操作系统。
你认为 Manjaro Linux 的优点和缺点是什么?我在我的新体验中有遗漏了什么吗?作为一个有经验的 Arch Linux 用户,你有任何建议吗?
请在下方评论中告诉我你的想法。
*(题图:MJ/2726c4dd-5611-4ace-8c77-0db894ad6a23)*
---
via: <https://news.itsfoss.com/manjaro-linux-experience/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Primarily, I rely on Ubuntu-based distributions like Pop!_OS, Zorin OS, Linux Mint, or Ubuntu itself for work.
They get out of the way when I work on something, along with seamless software updates. Not to forget, they get along well with my Intel-Nvidia-powered system.
Everything (can be subjective) works out of the box.
However, I recently decided to switch to Arch Linux on bare metal (because I mostly used it on virtual machines).
And then, I ended up using **Manjaro Linux** (an Arch-based distro).
## Here’s Why I Picked Manjaro Linux
To my surprise, I couldn’t even get past the “*nouveau DRM: core notifier timeout*” error, let alone proceed with the installation when using a **live USB for Arch Linux**. Yes, I’m aware of the[ guided installer with Arch Linux](https://news.itsfoss.com/arch-new-guided-installer/), but the connected displays just kept on flickering, highlighting this error, no matter what.
The best solution to this problem was not to get an NVIDIA card with my recent upgrade.
*Too bad, I prefer Nvidia GPUs…*
AMD’s RX 6600 XT is similarly priced to RTX 3060 Ti; it did not make sense to get that card for 1440p.
So, yes, RTX 3060 Ti can be the problem in my case.
While I found some methods to troubleshoot the issue, I was too lazy. I just wanted to see if I could experience Arch Linux without putting in a great effort.
**So, here’s what I did:**
The next-best option would be to try any of the [best Arch-based distros](https://itsfoss.com/arch-based-linux-distros/?ref=news.itsfoss.com) tailored to make things easy, right?
And that’s where **Manjaro Linux** comes in.
Manjaro Linux is a popular Arch-based distro, and I’ve noticed regular improvements to it with every update (while using it on a VM).
Furthermore, I like Manjaro’s default theme accent color for my desktop experience.
So, I decided to give it a try…
## Manjaro Linux: Rough Start
I did not have any issues installing Manjaro with proprietary Nvidia drivers. However, a recent point update, i.e., **Manjaro Linux 21.2.6,** messed up the system.
I couldn’t access the login screen and the [TTY](https://itsfoss.com/what-is-tty-in-linux/?ref=news.itsfoss.com) (all I could see was the motherboard’s manufacturer logo)
So, I had to re-install Manjaro Linux using the latest ISO, and so far, so good (touch wood).
And during my usage of Manjaro Linux, I noticed a few things that make up for its good and bad points.
Here, I highlight some of my experiences. These insights should help you explore more about it if you haven’t tried it yet.
### 1. Easy Installation
The primary highlight of an Arch-based distro is to make things easy to set up. And I had no issues whatsoever.
It was a breeze installing Manjaro Linux on my secondary drive. The bootloader was correctly configured to display the Manjaro-themed boot menu that lets me select Windows/Manjaro Linux for dual-boot.
### 2. Manjaro Hello
The welcome experience makes up for a significant part of a user experience when trying something new. And Manjaro Linux does not disappoint in this regard.
You get all the essential information if you pay close attention to the information available via the welcome screen.
The GNOME Layouts Manager lets you pick a suitable layout to get yourself comfortable.
However, I couldn’t get the “**Window Tiling**” functionality working when I tried to enable it here:
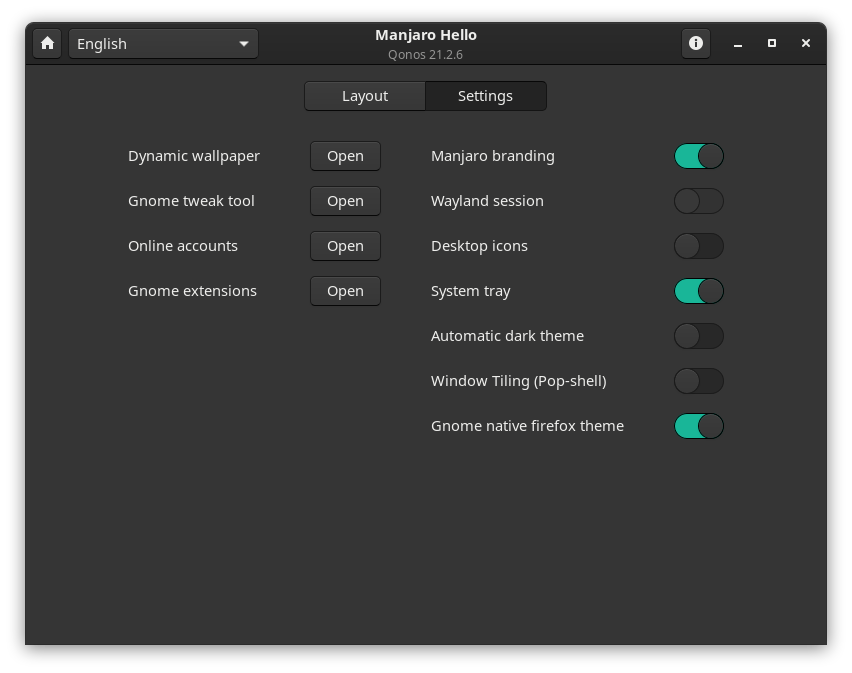
### 3. Package Manager is Fast and Versatile
Considering that GNOME is my favorite desktop environment, I have had terrible experiences with the software center (or even with distro-specific stores like Pop!_Shop).
While they get the work done, sometimes they do not respond or aren’t responsive enough as I expect them to be.
With Manjaro Linux, I found [Pamac](https://wiki.manjaro.org/index.php/Pamac?ref=news.itsfoss.com) installed as the package manager. It seems to be one of the [best ways to install and remove software on Manjaro Linux](https://itsfoss.com/install-remove-software-manjaro/?ref=news.itsfoss.com).
In my experience, it was blazing fast with installations and removing packages. You also get prompts for conflicts in packages or if something needs to be replaced/removed. The package manager gives plenty of information about the optional/required dependencies when you install something.
Overall, it was a pretty good experience without any slowdowns. To sweeten the experience, the package manager lets you quickly enable the support for **Flatpaks/Snaps/AUR** by tweaking the preferences of pamac.
So, you do not have to use the terminal or different software stores. Everything will be available under a single roof, which is a big time saver.
### 4. Trying out the ZSH Shell
I am used to the bash shell on Ubuntu-based distros. However, Manjaro Linux features the ZSH shell by default. I believe ZSH is better than bash, but I’ll take a deep dive into the comparison with a separate article soon.
In other words, I get to try something different out of the box. To my excitement, the terminal prompt and the theme for the shell (or the terminal) that follows the Manjaro branding accent colors look pretty impressive!
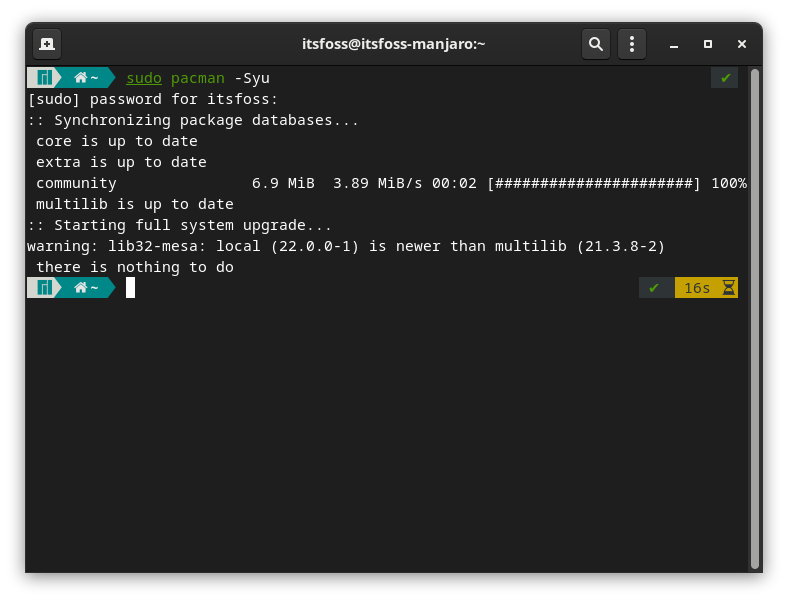
Hence, I do not need to [customize the look of the terminal here](https://itsfoss.com/customize-linux-terminal/?ref=news.itsfoss.com).
To explore more, you might want to check some of our resources on [what ZSH is](https://linuxhandbook.com/why-zsh/?ref=news.itsfoss.com) and [how to install it](https://linuxhandbook.com/install-zsh/?ref=news.itsfoss.com).
### 5. Lack of Official Software Support
I hope this improves soon. But, as of now, many software/utilities offer direct support for Ubuntu and Fedora only.
You can find official DEB/RPM packages for various tools, but neither will work directly with Manjaro Linux.
You will have to rely on the packages available in Arch Linux repositories or [AUR](https://itsfoss.com/aur-arch-linux/?ref=news.itsfoss.com).
Fortunately, there are good chances to find the software in AUR or their repositories maintained by the community or distro developers. Just like I was able to get [Insync](https://itsfoss.com/recommends/get-insync/?ref=news.itsfoss.com) (*affiliate link*) to work on Manjaro Linux with file manage integration extensions available.
However, without official support for the platform, you may/may not miss out on some features or quick updates.
Of course, if you rely on [Flatpak](https://itsfoss.com/what-is-flatpak/?ref=news.itsfoss.com) or Snap packages, it should not be an issue for you. Furthermore, if you are new to Linux, you can refer to our [Flatpak guide](https://itsfoss.com/flatpak-guide/?ref=news.itsfoss.com) for more information.
### 6. No Fractional Scaling
I have a dual-monitor setup with 1080p + 1440p resolutions. So, fractional scaling helps, but I can manage without it.
To enable fractional scaling on Manjaro, you will have to install x11-scaling enabled packages for Mutter and GNOME control center. The packages include:
**mutter-x11-scaling****gnome-control-center-x11-scaling**
This will replace your existing mutter and gnome control center packages. So, you will lose the default theme/accent settings for your desktop.
You may have to utilize GNOME Tweaks to get things right. But, it can turn out to be an annoying experience.
## Final Thoughts
Overall, I enjoy the desktop experience with Manjaro Linux. If another system update doesn’t break the experience, I think I will continue with Manjaro Linux as my new daily driver.
*What do you think are the strong/weak points for Manjaro Linux? Did I miss something as part of my new experience? Do you have any suggestions as an experienced Arch Linux user?*
*Please let me know your thoughts in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,947 | 使用 GNOME 在 Fedora 中启用分数缩放 | https://www.debugpoint.com/fractional-scaling-fedora/ | 2023-06-27T15:59:00 | [
"分数缩放"
] | /article-15947-1.html | 
>
> 以下是在 GNOME 版本的 Fedora 工作站中启用分数缩放的步骤。
>
>
>
<ruby> <a href="https://wiki.gnome.org/Initiatives/FracionalScaling"> 分数缩放 </a> <rt> Fractional Scaling </rt></ruby> 是一项方便的功能,可让你最大程度地优化 HiDPI 显示器和高分辨率笔记本电脑。通过微调缩放比例,你可以创建平衡良好、既不太大也不太小且美观的桌面显示。虽然通过分辨率设置也可以,但由于操作系统的限制,它们通常符合你的实际情况。
此外,它还允许你增加显示屏上文本和其他 UI 元素的大小,而不会使所有内容显得模糊。如果你有高分辨率显示器并希望使文本更易于阅读,这将很有用。
Ubuntu 20.04 LTS 在 2020 年引入了 100%、125%、150%、175% 和 200% 的分数缩放。它可以在“<ruby> 显示 <rt> Display </rt></ruby>”页面下的“<ruby> 设置 <rt> Settings </rt></ruby>”中找到。
但在默认 GNOME 桌面的 Fedora 工作站中,只有 100% 和 200% 缩放可用。

### 如何使用 GNOME 在 Fedora 中启用分数缩放
打开终端窗口(`CTRL+ALT+T`)。
运行以下命令。此命令在带有 GNOME 的 Fedora 中启用 125%、150% 和 175% 缩放因子。
```
gsettings set org.gnome.mutter experimental-features "['scale-monitor-framebuffer']"
```
重启 Fedora。
打开 “设置” 应用,你应该会看到新的缩放因子。

但是,重要的是要注意分数缩放并不总是完美的。某些应用程序可能无法正确缩放。例如,如果应用程序设计不当,非 GTK 应用可能看起来很模糊。
此外,请务必注意,由于 GPU 的渲染工作量更大,分数缩放可能会增加笔记本电脑的功耗。
### 一些使用说明
根据我的测试,上述命令在 Wayland 中应该是有效的。
如果你不想使用上述命令,但仍想获得类似的体验,那么你可以按照以下步骤操作:
使用 `sudo dnf install gnome-tweaks` 安装 GNOME “<ruby> 调整 <rt> Tweaks </rt></ruby>” 应用。
转到 “<ruby> 字体 <rt> Fonts </rt></ruby>” 设置并更改比例因子。
示例:如果你想保持 100% 缩放比例但想要更大的字体,请尝试缩放比例设为 1.1 或 1.2。根据你的需要进行调整。

* 125%:这是分数缩放的典型值。它将文本大小和 UI 元素增加 25% 而不会使所有内容显得模糊。
* 150%:对于想要放大文本和其他 UI 元素但又不想增加显示分辨率的人来说,这是一个很好的值。
* 175%:对于想要使文本和其他 UI 元素变得非常大的人来说,这是一个很好的值。
尝试不同的缩放因子对于找到最适合你的缩放因子至关重要。最佳缩放因子将取决于你的显示器尺寸、视力和偏好。
我希望本指南有所帮助。
*(题图:MJ/4346b556-57ed-4c76-b2c9-e651e0d229f5)*
---
via: <https://www.debugpoint.com/fractional-scaling-fedora/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,949 | “发行版快闪”的七个错误 | https://itsfoss.com/distrohopping-issues/ | 2023-06-28T00:07:49 | [
"发行版"
] | https://linux.cn/article-15949-1.html | 
>
> 你在“发行版快闪”中做错了什么?你能做得更好吗?当然可以。在这里,我们告诉你如何做。
>
>
>
“<ruby> 发行版快闪 <rt> Distro hopping </rt></ruby>” 是指经常尝试新的 Linux 发行版,以寻找乐趣或找到适合你的完美发行版的习惯。
毕竟,有着 [数百种 Linux 发行版](https://itsfoss.com/what-is-linux/),而且时不时就有新的版本出现。你可能会担心错过它们,而去尝试 Linux 社区的最新潮流。
无论你为何这样做,不管你喜欢与否,人们会犯下一些错误,这让“发行版快闪”的体验变得糟糕。
这些错误是什么?让我带你一一了解:
### 1、不进行备份

嗯,你想要更换发行版,由于过于兴奋,你毫不犹豫就切换了。
但是,如果你没有备份重要的、经常访问的数据,你可能需要重新配置系统和组织你需要的数据。
所以,如果你有备份,无论你做什么,你需要的数据始终可访问,并帮助你在发行版之间快速的跳来跳去。
### 2、不检查显卡的驱动支持

用户常常忽略发行版与其系统中的显卡的兼容性,而抱怨发行版有问题。
你必须确保你的发行版对你的显卡有开箱即用的支持。
如果你像我一样有一块英伟达显卡,你应该只选择提供带有英伟达支持的 ISO,或在启动菜单中内置了该支持的发行版。
例如,在 Linux Mint 上你需要 [安装英伟达驱动](https://itsfoss.com/nvidia-linux-mint/)。虽然大部分情况下这是一个简单且没什么麻烦的过程,但并不是每个人都愿意为之付出努力。你也可以选择 [Pop!\_OS](https://pop.system76.com/) 或 [Ubuntu](https://itsfoss.com/getting-started-with-ubuntu/),它们默认情况下与英伟达显卡兼容良好。
### 3、抱有过高期望

没有谁能完美地挑选出你需要和你可能喜欢的东西。
所以,不要听从他人的建议。自己进行研究,选择你想尝试的下一个发行版。
即使你知道你想要什么,也不要期望新的发行版一定会比你当前的发行版更好。各个发行版在许多方面都有所不同。
**你的下一个发行版可能解决了你遇到的问题,但也可能会带来你没有预料到的新问题。** 最好假设你可能会遇到你没有预料到的困扰。
所以,如果你要进行“发行版快闪”,请先系好安全带。
### 4、在物理机上安装发行版
**不要安装新的发行版来替换你当前的发行版**。
如果你直接在你的计算机上更换发行版,可能会导致一些问题,你可能需要先花时间修复这些问题,甚至在了解或体验 Linux 发行版的最佳部分之前就要这样做。
相反,你应该使用 **<ruby> 立付 <rt> Live </rt></ruby>环境** 或 **虚拟机** 来尝试发行版。
通常,你可以从启动菜单或“<ruby> 试用 <rt> Try </rt></ruby>”选项中进入立付环境,以在安装 Linux 发行版之前测试一下。
另外,你可以尝试使用 [虚拟机来运行 Linux 发行版](https://itsfoss.com/why-linux-virtual-machine/)。通过使用虚拟机,你可以学习该发行版并进行各种测试,而无需麻烦地更改主机系统。
通过这个选项,你无需改变你的主机系统。你可以测试所有基本要素,如 **网络连接、应用程序可用性、预装工具** 等等,而无需放弃当前的发行版。
### 5、忽视你的使用场景
发行版太多反而让事情变得混乱。
一个发行版的某个部分或特性可能引起了你的注意,这让你认为其他部分也适合你。
你接下来想要尝试的任何发行版应该完全符合你的需求才行。如果它提供了更多或不同的功能,对你来说不一定是好处。
例如,一个发行版可能提供更多的可定制性,这一般是很好的。但如果你不需要那么多控制权,那些提供的选项可能会让你感到不知所措,或者很快对你来说就会像是无用软件。
你可以了解一下有哪些 [最佳 Linux 发行版](https://itsfoss.com/best-linux-distributions/),并根据文章中提到的特点对它们进行分析。
一个例子是特定的使用场景,比如寻找一个在旧计算机上运行良好的 [轻量级发行版](https://itsfoss.com/lightweight-linux-beginners/):
或者你正在寻找一些安全、可靠和未来可靠的系统?[不可变的 Linux 发行版](https://itsfoss.com/immutable-linux-distros/) 应该适合你。
或者...
你想要 [玩游戏](https://itsfoss.com/linux-gaming-distributions/) 吗?也有相应的选择!
简而言之,不要选择一个不适合你使用场景的发行版。
### 6、更换日常工具

除了发行版,一些用户还更换了他们每天使用的工具。
考虑到工具对你的用户体验有重大影响,它最终会改变你的工作流程。你可能这样做是为了尝试新东西,但你应该坚持那些始终适合你的工具。
也许你已经用上了 [最佳基本应用程序](https://itsfoss.com/essential-linux-applications/),为什么要改变呢?
只有当工具在新的发行版上无法按预期工作时,你才应该寻找替代方案。
### 7、不选择桌面环境
有几件事可以帮助你缩小在系统上安装 Linux 发行版的选择。
其中之一就是 [桌面环境](https://itsfoss.com/what-is-desktop-environment/)。
当然,在选择一个桌面环境之前,你应该了解一下有哪些 [最佳桌面环境](https://itsfoss.com/best-linux-desktop-environments/)。一旦选择了一个,与你想要尝试带有任何桌面环境的发行版相比,你就不必频繁切换发行版。
### 你应该停止“发行版快闪”吗?
你想要探索不同的发行版,并找到最适合自己的一个,这并没有错。
然而,如何从一个发行版“快闪”到另一个发行版可能会让这个过程变得麻烦,并且你可能会抱怨。
你应该 **遵循本文中提到的上述要点**,在想要切换之前使用 **虚拟机** 尝试新的发行版。
现在,你应该能在“发行版快闪”的过程中获得顺滑的体验了。
? 请在下方评论中分享你的“发行版快闪”经历。你会这样做吗?
*(题图:MJ/5bdb860a-0505-476e-bb38-014ee8fe733e)*
---
via: <https://itsfoss.com/distrohopping-issues/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Distro hopping is the habit of regularly trying new Linux distributions to explore for fun or to find the perfect distro for you.
After all, there are [hundreds of Linux distributions](https://itsfoss.com/what-is-linux/) and new ones are released regularly. Your FOMO (fear of missing out) kicks in and you go on to try the latest buzz of the Linux town.
No matter why you do it, whether you hate it or like it, people make a few mistakes, which makes the experience of distro hopping hellish.
What can those be? Let me take you through it:
## 1. Not Taking Backups

Well, you thought of changing the distro, and because of the excitement, you did it.
But, if you do not have a backup of your important/frequently accessible stuff, you might have to configure things and organize the data you need on your system.
So, if you have a backup, no matter what you do, the data you need always stays accessible and helps you quickly hop from one distro to another.
## 2. Not Checking Graphics Driver Support

Users often forget about the compatibility of a distro with the GPU on their system and end up complaining about the distro.
You must ensure that your distro has out-of-the-box support for your graphics card.
If you have an Nvidia graphics card like me, you should only prefer distributions that offer an ISO with Nvidia support or have the support built-in and available in the boot menu.
For instance, you need to [install Nvidia drivers on Linux Mint](https://itsfoss.com/nvidia-linux-mint/). While it is an easy and hassle-free process for the most part, not everyone would want to make an effort. You could go with [Pop!_OS](https://pop.system76.com) or [Ubuntu](https://itsfoss.com/getting-started-with-ubuntu/), which works well with Nvidia graphics cards by default.
## 3. Hoping Things to be Better

Nobody else can perfectly pick what you need and what you might like.
So, do not go with anyone's suggestion. Do your research, and pick the distro you want to try next.
Even though you know what you want, do not expect the experience to be better than your current distro. The distributions differ in many aspects.
**Your next distribution can solve a problem you had and add issues you did not. **It is better to assume that you might have troubles you did not anticipate.
So, fasten your seatbelt if you distro hop.
## 4. Installing Distros on Bare Metal
**Do not install the distro** and **replace your current distro.**
If you directly change the distro on your workstation, things might break, and you might spend time fixing them first, even before learning or experiencing the best parts of the Linux distribution.
Instead, you should try the distro using the **live environment **or **a virtual machine**.
Usually, you get a live environment from the boot menu or a "Try" option to test things before installing a Linux distribution.
Also, you can try [Linux distros using a virtual machine](https://itsfoss.com/why-linux-virtual-machine/). With a VM, you can learn about the distro and test things without hassle.
With that option, you do not need to change your host. You can test all the essentials like **network connectivity, app availability, pre-installed utilities**, and more without needing to ditch the current distro.
**Suggested Read 📖**
[10 Reasons to Run Linux in Virtual MachinesYou can run any operating system as a virtual machine to test things out or for a particular use case. When it comes to Linux, it is usually a better performer as a virtual machine when compared to other operating systems. Even if you hesitate to install Linux on bare](https://itsfoss.com/why-linux-virtual-machine/)

## 5. Ignoring Your Use-Case
The choices of distros available can make things confusing.
One part or feature of a distro could have had your attention, leading you to think that the rest suits you.
Any distribution you want to try next should perfectly suit your requirements. If it offers something more or different, it may not necessarily be a bonus for you.
For instance, a distro could offer more customizability, which is always good. But if you do not need that control, the options included could be overwhelming or seem like bloatware to you soon enough.
You can explore the [best Linux distros](https://itsfoss.com/best-linux-distributions/) and analyze them based on their specialties mentioned in the article.
One example is a specific use case of looking for a [lightweight distro](https://itsfoss.com/lightweight-linux-beginners/) that runs well on old computers:
[16 Best Lightweight Linux Distributions for Older ComputersDon’t throw your old computer just yet. Use a lightweight Linux distro and revive that decades-old system.](https://itsfoss.com/lightweight-linux-beginners/)

Or are you looking for something secure, reliable, and future-proof?
[Immutable Linux distributions](https://itsfoss.com/immutable-linux-distros/) should serve you well.
[11 Future-Proof Immutable Linux DistributionsImmutability is a concept in trend. Take a look at what are the options you have for an immutable Linux distribution.](https://itsfoss.com/immutable-linux-distros/)

Or...
Do you want to play games? There are options for that too!
[Best Distributions for Gaming on LinuxIf you are a hardcore PC gamer, Linux might not be your first choice. That’s fair because Linux isn’t treated as a first-class citizen when it comes to gaming. You won’t find the most awaited games of the year available on Linux natively. Not to forget that](https://itsfoss.com/linux-gaming-distributions/)

In a nutshell, do not pick a distro that does not suit to your use cases.
## 6. Changing Your Daily Driving Tools

Along with the distro, some users change the tools they use to get work daily.
Considering the tools affect your user experience significantly, it will eventually change your workflow. You may have done it to experiment with new things. But you should stick to the tools that always work for you.
Maybe you are already using the [best essential apps](https://itsfoss.com/essential-linux-applications/) available, why change?
If the tool does not work as intended with the new distro, only then you should look for alternatives.
## 7. Not Picking a Desktop Environment
There are a couple of things that can help you narrow down the choices you have for installing Linux distros on your system.
And the [desktop environment](https://itsfoss.com/what-is-desktop-environment/) is a big one.
Of course, you should explore the [best desktop environments](https://itsfoss.com/best-linux-desktop-environments/) available before making a favorite. Once you select one, you do not have to distro hop much compared to when you wanted to try distro with any desktop environment.
[8 Best Desktop Environments For LinuxA list of the best Linux Desktop Environments with their pros and cons. Have a look and see which desktop environment you should use.](https://itsfoss.com/best-linux-desktop-environments/)

## Should You Stop Distrohopping?
It is not bad that you want to explore options and see what fits you best.
However, how you hop from one distro to another could make the process troublesome, and you may end up complaining.
You should **follow the above pointers** mentioned in this article and try distros using a **virtual machine** before you want to switch.
Now, you should have a seamless experience with the distro hopping journey.
*💬 Share your distro-hopping adventures in the comments below. Do you do it or not?* |
15,950 | 如何安装和使用 GNOME Boxes 来创建虚拟机 | https://www.debugpoint.com/install-use-gnome-boxes/ | 2023-06-28T15:18:00 | [
"虚拟机",
"Boxes"
] | /article-15950-1.html | 
>
> 本快速教程解释了安装和使用 GNOME Boxes 以及创建虚拟机的步骤,以及一些提示和故障排除。
>
>
>
虚拟化是使用抽象硬件层运行虚拟实例(而不是实际实例)的过程。通俗地说,它允许你同时安装和运行多个操作系统(Linux、Windows)。
[虚拟机](https://www.redhat.com/en/topics/virtualization/what-is-a-virtual-machine) 是一个模拟操作系统,它运行在另一个操作系统之上,并使用与主机相同的硬件和存储空间。虽然,你可以控制可以分配给虚拟机的共享内存或空间量。
有多种软件可用于创建虚拟机,例如 [Virtual Box](https://www.debugpoint.com/tag/virtualbox/)、KVM、Hyper-V、VMWare player 和 GNOME Boxes。
但老实说,它们中的大多数使用起来都很复杂,有时还不够稳定。[GNOME Boxes](https://wiki.gnome.org/Apps/Boxes) 是另一个自由开源的软件,它非常易于使用,通过抽象出大量选项让你可以轻松创建和管理虚拟机。
### 安装 GNOME Boxes
如果你正在运行 Fedora 的 GNOME 定制版,你应该已经安装了它。但是,对于 Ubuntu、Linux Mint、Kubuntu 和其他发行版,你只需运行以下命令即可将其安装到你的系统中。
```
sudo apt install gnome-boxes
```
#### 通过 Flatpak
它也可以通过 Flatpak 包获得。我会推荐你使用这个版本。首先,使用 [本指南](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) 在系统中安装 Flatpak,然后从终端运行以下命令进行安装。
```
flatpak install flathub org.gnome.Boxes
```
### 使用 GNOME Boxes 创建虚拟机
从应用菜单启动 GNOME Boxes。
要创建虚拟机,你需要要虚拟化的操作系统的镜像(\*.ISO)。
你可以从发行版的官方下载页面下载任何操作系统 ISO 镜像。对于本指南,我使用的是 Pop!\_OS,这是一个优秀的 Linux 发行版。
启动后,单击顶部的 “+” 图标启动并选择“<ruby> 创建虚拟机 <rt> Create a virtual machine </rt></ruby>”。

在下一个窗口中,你可以选择已经可用的下载,或者你可以选择你的 ISO 文件作为操作系统源。单击“<ruby> 操作系统镜像文件 <rt> Operating system image file </rt></ruby>”并选择你的 ISO 文件。
分配虚拟机的内存和存储空间。请记住,你的虚拟机将从主机系统获取内存和存储空间。所以尽量不要分配为最大值。
例如,在下图中,我从主机系统的 8GB 总内存中为虚拟机(客户机)分配了 2GB 内存。
同样,如果你只是想测试操作系统,也请选择最小存储空间。但是,如果你正在为服务器或严肃的工作创建虚拟机,请合理分配你要分配的空间或内存量。
另一件需要记住的重要事情是,除非你删除虚拟机,否则你允许的存储磁盘空间将被永久占用。因此,即使你的虚拟机没有使用整个分配的空间,你也不会获得那么多的可用磁盘空间。

继续安装。
在分区窗口中,你应该看到一个硬盘和一个分区,这就是虚拟机的磁盘空间。通常,它们被命名为 `/dev/vda` 或者 `/dev/sda`。
不用担心;你可以随意使用此分区,这不会影响你的物理磁盘分区或实际主机系统上的任何数据。安装 Linux 时遵循相同的 `/root` 分区,然后继续。

完成安装后,你应该会在虚拟机中看到新的操作系统。在 GNOME Boxes 中,你应该会看到一个系统条目。你可以单击它启动虚拟机。
你可以使用虚拟机操作系统的内部关闭选项关闭虚拟机。
如果需要,你还可以通过选择上下文菜单选项来删除虚拟机。

你还可以从属性窗口检查你的虚拟机使用了多少内存和 CPU。
请注意,你可以使用属性调整现有虚拟机的内存和其他项目。

### 故障排除
以下是你在使用 GNOME Boxes 时可能遇到的一些常见错误或问题。
#### 1、虚拟机中的分辨率问题
如果你的虚拟机分辨率很低,这与你的主机系统不兼容,那么你必须安装以下项目。在客户系统(而不是主机系统)中打开终端并运行以下命令。
对于基于 Ubuntu 的发行版:
```
sudo apt install spice-vdagent spice-webdavd
```
对于 Fedora 系统:
```
sudo dnf install spice-vdagent spice-webdavd
```
这两个包有助于确定合适的分辨率、在主机和客户之间复制/粘贴、通过公共文件夹共享文件等。
安装后,重新启动客户系统;或者你可以在重启后注销并重新登录一次,你应该会看到正确的分辨率。
#### 2、在 Ubuntu 18.04 中 GNOME Boxes 不能启动虚拟机
如果你在 Boxes 3.34 中创建虚拟机,那么你应该知道有一个错误导致你的虚拟机无法启动。要解决这个问题,你必须执行一些额外的步骤。请记住,最新的 Boxes 3.36 不需要这些。
打开终端窗口并运行以下命令来更改 qemu 配置文件:
```
sudo gedit /etc/modprobe.d/qemu-system-x86.conf
```
在上面的文件中添加以下行并保存:
```
group=kvm
```
现在,运行以下命令将你的用户名添加到 KVM 组。
```
sudo usermod -a -G kvm <你的帐户名称>
```
### 总结
在本文中,你了解了如何安装和使用 GNOME Boxes 来利用虚拟化。我希望它能帮助你。
?️ 如果你遇到任何错误或对 GNOME Boxes 的虚拟机有任何疑问,请使用下面的评论栏告诉我。
*(题图:MJ/b4d091cf-9585-468b-9ce6-ba0b0c69cce4)*
---
via: <https://www.debugpoint.com/install-use-gnome-boxes/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,952 | 哞~ 我的 Linux 终端里有头牛 | https://itsfoss.com/cowsay/ | 2023-06-28T22:53:40 | [
"cowsay"
] | https://linux.cn/article-15952-1.html | 
>
> cowsay 是一个有趣的小型 Linux 命令行实用程序,它有各种使用方式。以下是几个示例。
>
>
>
如果你想的话,Linux 终端可以是一个有趣的地方。
当然,终端一般用在严肃的场合,但你可以使用 [有趣的 Linux 命令](https://itsfoss.com/funny-linux-commands/) 来娱乐自己。
`cowsay` 就是其中之一。它可以在终端上显示一头牛。

`cowsay` 的一个特点是,如果与其他命令组合使用,它可以用于一些 “严肃的场合”。比如,在共享的 Linux 服务器上使用它来显示 “每日消息”,以供多个用户查看。
听起来有趣吗?是时候~~喂养~~安装一个了。
### 安装 Cowsay
`cowsay` 是一个受欢迎的工具,它可以在大多数 Linux 发行版的软件仓库中找到。
要在 Debian 和 Ubuntu 系统上安装 `cowsay`,请打开终端并运行:
```
sudo apt install cowsay
```
对于 Fedora,请使用:
```
sudo dnf install cowsay
```
在基于 Arch Linux 的发行版中,请使用:
```
sudo pacman -S cowsay
```
### 使用 Cowsay
顾名思义,这是一头以 ASCII 艺术展示的牛,能输出输入的文本。默认情况下,`cowsay` 提供了几个选项来调整这头 ASCII 牛的外观和样式。
#### 普通的 cowsay
```
cowsay <文本>
```
这将在牛讲话的气泡中打印你提供的任何文本。

或者,你可以使用管道重定向,将另一个命令(比如 `echo`)的输出作为 `cowsay` 的输入。
```
echo "Hello" | cowsay
```
#### 贪婪的牛
这里,牛的眼睛看起来有点贪婪,它是美元符号。
```
cowsay -g <消息>
```

#### 使用特殊字符作为眼睛
你可以使用 `-e` 选项,然后提供你希望作为眼睛的两个字符。默认是 `OO`。
```
cowsay -e hh Hello
```

在上面的截图中,两个 `h` 将出现在眼睛的位置。
>
> ? 如果你输入的字符已被任何默认选项使用,比如 `$$`,那么它将被覆盖。
>
>
>
#### 使用其他字符代替牛
`cowsay` 还提供了许多其他 ASCII 图像,你可以通过 `-f` 选项使用它们。
使用 `-l` 选项列出它们:
```
cowsay -l
```

现在,要打印上述图像之一,请使用:
```
cowsay -f <牛文件名称> <消息>
```

类似地,在更新的版本中,你可以使用 `-r` 选项随机打印上述图像之一。
```
cowsay -r Hello
```
#### 其他选项
| 选项 | 用途 |
| --- | --- |
| `-b` | 启用博格模式 |
| `-d` | 看起来死了的牛 |
| `-p` | 陷入偏执状态的牛 |
| `-s` | 看起来迷迷糊糊的牛 |
| `-t` | 一只疲倦的牛 |
| `-y` | 让牛年轻一些 |
### 使用 Cowthink
`cowthink` 是与 `cowsay` 一起提供的辅助程序。它显示的是思维泡泡而不是说话泡泡。如果你熟悉漫画书的标注,这将更有意义。
```
cowthink Hello
```

所有在 `cowsay` 中提到的选项在这里同样适用。
### 使用 Cowsay 和 Fortune
通过管道重定向,你可以将 `cowsay` 与另一个流行的有趣的 Linux 命令 `fortune` 结合使用。
>
> ? 在 Ubuntu 中可以使用 `sudo apt install fortune lolcat` 命令安装 `fortune` 和 `lolcat`。
>
>
>
对于那些不知道 `fortune` 是什么的人来说,它是一个小程序,在终端上打印名人名言。你可以像这样作为独立命令来运行它:
```
fortune
```
要使用 `cowsay` 打印 `fortune` 的内容,运行:
```
fortune | cowsay
```

你还可以添加 `cowsay` 的选项来使输出更好:
```
fortune | cowsay -f dragon
```
### 用 lolcat 把牛变成彩色的
许多人都熟悉 `lolcat` 给文本添加的彩虹效果。那么为什么不将其与上述程序一起使用呢?你只需要将 `cowsay` 命令连接到 `lolcat` 命令上即可。
```
cowsay Hello | lolcat
```

现在,如果你想同时添加 `fortune` 和各种 `cowsay` 选项,请使用所有这些选项,并将整个命令的输出都连接到 `lolcat`,就像这样:
```
fortune | cowsay -f tux | lolcat
fortune | cowthink -f tux | lolcat
```

### 第三方牛文件(适用于高级用户)
对默认的 `cowsay` 牛文件不感兴趣吗?别担心,有许多不同的牛文件可供选择,由热心的开发者创建。我在这里介绍两个:<https://github.com/bkendzior/cowfiles> 和 <https://github.com/paulkaefer/cowsay-files>。
你可以按照它们的 `README` 所述从这些存储库安装牛文件,或者只需从存储库中下载所需的牛文件(.cow)并将它们粘贴到 `/usr/share/cowsay/site-cows/` 下。现在,你可以通过文件名访问该牛文件:
```
cowsay -f <新文件名> Hello
```
在屏幕截图中,你可以看到我使用了一个下载下来的牛文件,名为 `C3PO.cow`。
对于那些想要创建自己的图像的人,可以访问 [Charc0al 的 cowsay 文件](https://charc0al.github.io/cowsay-files/converter/)。

在这里,你可以下载现有的文件,或者转换一些图像(建议不大于 50×50)以满足需求。
### 其他有趣的用法
#### 使用 cowsay 提示输入 sudo 命令的密码
```
sudo -p "$(cowsay '如果你知道密码,请在此输入。否则请离开:')" <command>
```

#### 将 cowsay 作为 bash 配置的一部分,以便在每次打开终端时看到欢迎
对于像 Fedora 中的较新版本的 `cowsay`,可以将 `fortune | cowsay -r | lolcat` 添加到你的 `~/.bashrc` 中。现在,每次打开终端时,都会打印一个带有不同名言的新牛文件。
对于没有随机选项(`-r`)的较旧版本的 `cowsay`,你可以手动获取不同的文件,并使用 `fortune | cowsay -f <要使用的特定牛文件的名称> | lolcat`。
#### 使用 cowsay 显示其他命令的输出
你可以让 `lsblk` 等命令使用 `cowsay` 打印输出。只需将这些命令连接起来。
```
lsblk | cowsay
```
#### 在 Fedora 中使用 cowsay-beefymiracle
`beefymiracle` 是 Fedora 中提供的一个 cowsay 包。这里的牛变成了牛肉(我这颗素食主义者的心在哭泣 ?)。
使用下面的命令来安装它:
```
sudo dnf install cowsay-beefymiracle
```
现在,运行:
```
cowsay -f beefymiracle <消息>
```

### 更多:XCowsay
`xcowsay` 是普通的 cowsay 的图形替代品。这里,牛不再是 ASCII 图形,而是一个真实的图像。你可以通过以下方式进行安装:
```
sudo apt install xcowsay
```
现在运行:
```
xcowsay <消息>
```
这将根据文本的长度,在一段特定的时间内显示图形化的牛,然后消失,**但你可以点击它立即隐藏。**

更有趣的是,牛可以“梦见”图像而不是文本。甚至牛的图像可以更改为随机图像。
使用以下命令之一:
```
xcowsay --dream=file
```
或者
```
xcowsay --image=file --dream=file
```


你可以查看 `xcowsay` 的手册页面以了解更多选项。
### 更多终端中的 ASCII 乐趣
喜欢 ASCII 艺术吗?可以尝试用 [Neofetch](https://itsfoss.com/using-neofetch/) 以 ASCII 格式显示你所使用的发行版的徽标。
为什么只限于徽标呢?Linux 终端上还有很多 ASCII 工具。
不要停止在终端中寻找乐趣。
希望你喜欢这篇关于以各种格式使用 `cowsay` 的教程。惊人的是,这个小工具提供了如此多的选项,有这么多的使用方式。
你最喜欢哪个 cowsay 的例子?不要说牛肉的那个 ?
*(题图:MJ/bd304f28-2476-4496-93d2-50fdae0a8831)*
---
via: <https://itsfoss.com/cowsay/>
作者:[Sreenath](https://itsfoss.com/author/sreenath/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The Linux terminal can be a fun place if you want it to be.
Of course, it is used for serious work but you have [funny Linux commands](https://itsfoss.com/funny-linux-commands/) to amuse yourself.
The cowsay is one such tool. It gives you a cow in the terminal.

The thing about cowsay is that it could be used for 'serious work' if combined with other commands. One such example is using it to display the 'message of the day' on a shared Linux server with multiple users.
Sounds interesting? Time to ̶m̶i̶l̶k̶ install it.
## Install Cowsay
Cowsay is a popular tool and it is available in the repositories of most Linux distributions.
To install cowsay in Debian and Ubuntu system, open a terminal and run:
`sudo apt install cowsay`
For Fedora, use:
`sudo dnf install cowsay`
And in Arch Linux based distros, use:
`sudo pacman -S cowsay`
## Using Cowsay
As the name suggests, this is an ASCII talking cow, that outputs text provided as its input. By default, cowsay provides several options to tweak the look and appearance of the ASCII cow.
### Normal Cowsay
`cowsay <Text>`
This will print whatever text you provided in a speechbubble with the cow .
Or you can provide output of another command, say `echo`
as input to cowsay using pipes redirection.
`echo "Hello" | cowsay`
### Greedy Cow
Here, cow appears to be greedy, with Dollar eyes.
`cowsay -g <message>`
### Use Special Characters as eyes
You can use the `-e`
option, and then provide two characters that you want to appear as eyes. The default is “OO”.
`cowsay -e hh <hello>`
Here, in the above screenshots, two “h” will appear in place of eyes.
### Use another character instead of the cow
Cowsay provides many other ASCII images also, which you can use through the option `-f`
.
List them with option `-l`
:
`cowsay -l`
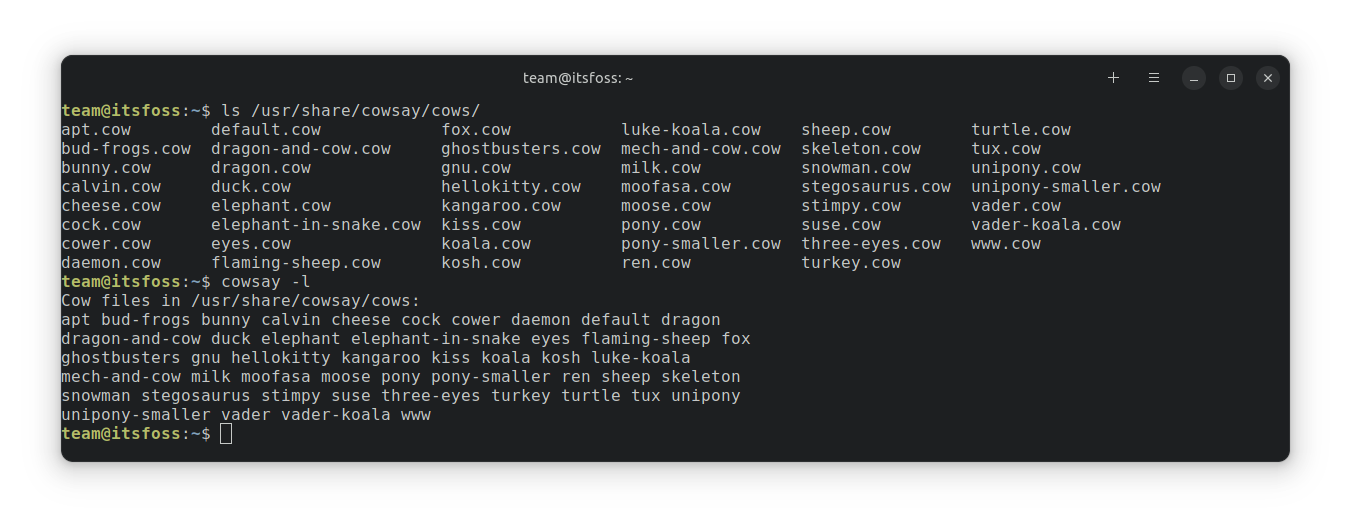
Now, to print one of the above images, use:
`cowsay -f <cowfile name> <message>`
Similarly, in newer versions, you can use `-r`
option to randomly print one of the above images.
`cowsay -r Hello`
### Other options
Option | Use |
---|---|
-b | Invokes Borg mode |
-d | Causes the cow to appear dead |
-p | Causes a state of paranoia to come over the cow |
-s | Makes the cow appear thoroughly stoned |
-t | A tired cow |
-y | Brings on the cow’s youthful appearance |
## Using Cowthink
Cowthink is an adjoint program that come with cowsay. Instead of the speach bubble, it displays the thought bubble. It will make more sense to you if you are familiar with comic book notations.
`cowthink Hello`
All the options that were mentioned with cowsay will work here as well.
## Using Cowsay with Fortune
With the help of pipe redirection, you can use cowsay along with another popular fun Linux command, the `fortune`
command.
`sudo apt install fortune lolcat`
For those of you, who don’t know what `fortune`
, it is a small program, that prints quotes from famous persons on a terminal. You can run it as a standalone command like:
`fortune`
To simply print what fortune says using cowsay, run:
`fortune | cowsay`
You can also add the cowsay options to make it better:
`fortune | cowsay -f dragon `
## Using a colorful cow with lolcat
Many of you know lolcat and its rainbow effects on texts. So why not use it along with the above programs? All you have to do is to pipe the cowsay command to lolcat.
`cowsay Hello | lolcat`
Now, if you want to add `fortune`
and various `cowsay`
options along with this, use all such options and pipe the entire thing to lolcat, like this:
```
fortune | cowsay -f tux | lolcat
fortune | cowthink -f tux | lolcat
```
## Third-party cow files (for advanced users)
Not interested in the default cowsay cow files? Do not worry, there are a huge number of different cowfiles out there, created by enthusiast developers. Two of them, I will mention here. [https://github.com/bkendzior/cowfiles](https://github.com/bkendzior/cowfiles) and [https://github.com/paulkaefer/cowsay-files](https://github.com/paulkaefer/cowsay-files)
You can either install the cowfiles from these repositories as mentioned on their README, or just download the required cowfile (.cow) from the repository and paste them on `/usr/share/cowsay/site-cows/`
. Now, you can access that cowfile using its name:
`cowsay -f <new file name> Hello`
You can see in the screenshot I have used a downloaded cow file, called C3PO.cow.
For those of you, who want to create your own images, you can visit [Charc0al’s cowsay file](https://charc0al.github.io/cowsay-files/converter/).
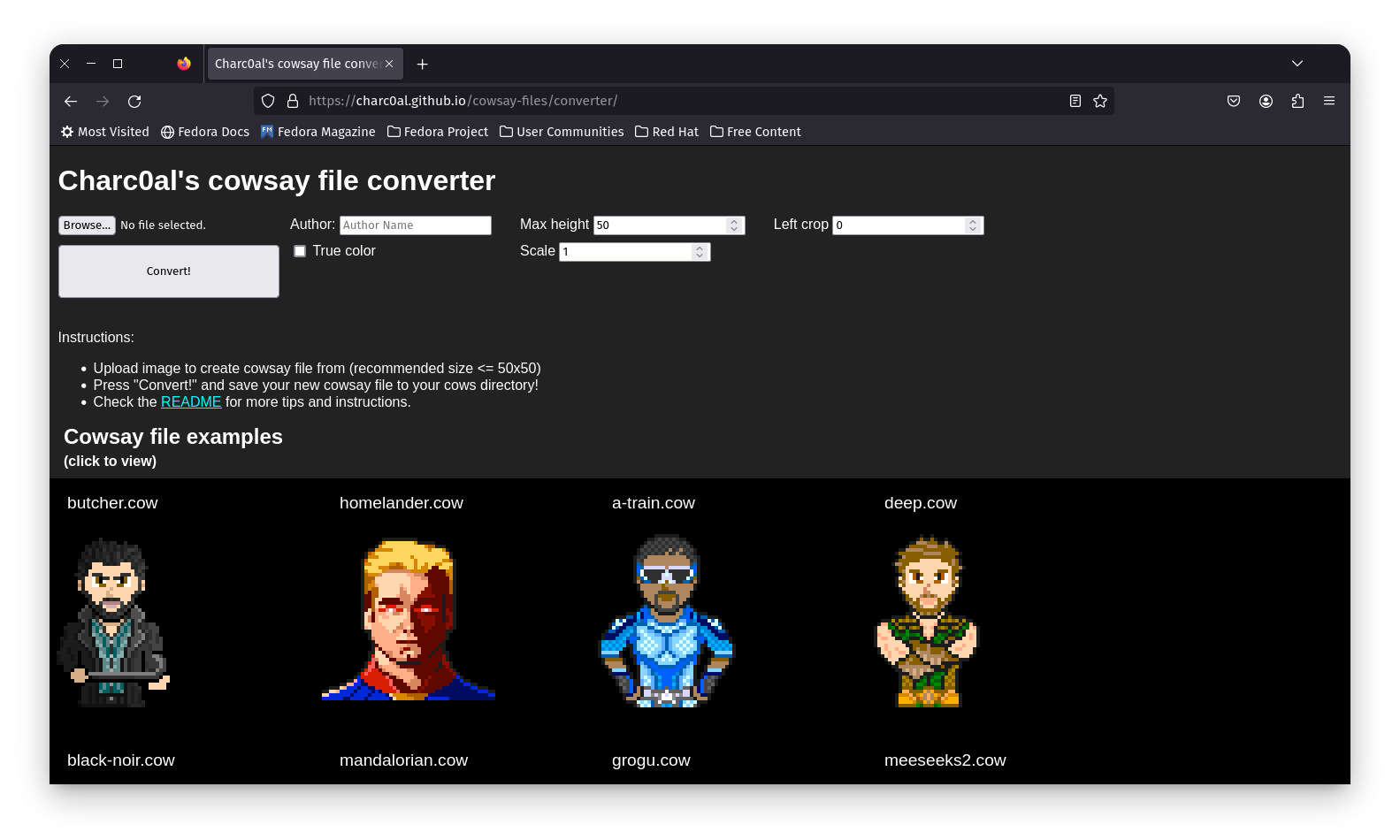
Here, you can either download the existing files, or convert some of your images (recommend no larger than 50 × 50) for the purpose.
## Other funny uses
**Use cowsay prompt to enter password in sudo commands:**
`sudo -p "$(cowsay 'If you know the password, enter it here. Or just go away:')" <command>`
**Make cowsay as an entry to your bash config, so you are greeted every time you open the terminal.**
- For newer cowsay versions, like those in Fedora, add
`fortune | cowsay -r | lolcat`
to your`~/.bashrc`
. Now, each time, you open the terminal, a new cowfile with a different quote will be printed. - For older versions of cowsay, where you cannot get the random (-r) option, you can get different files manually, and use
`fortune | cowsay -f <name of particular cowfile to use> | lolcat`
.
**Make other commands show output using cowsay**
You can make commands like `lsblk`
to print the output using cowsay. Just pipe those commands.
`lsblk | cowsay`
**Use cowsay-beefymiracle in Fedora**
`beefymiracle`
is a cowsay package available in Fedora. The cow is turned into beef here (my vegetarian heart cries 😢).
Use the below command to install it:
`sudo dnf install cowsay-beefymiracle`
Now, run:
`cowsay -f beefymiracle <message>`
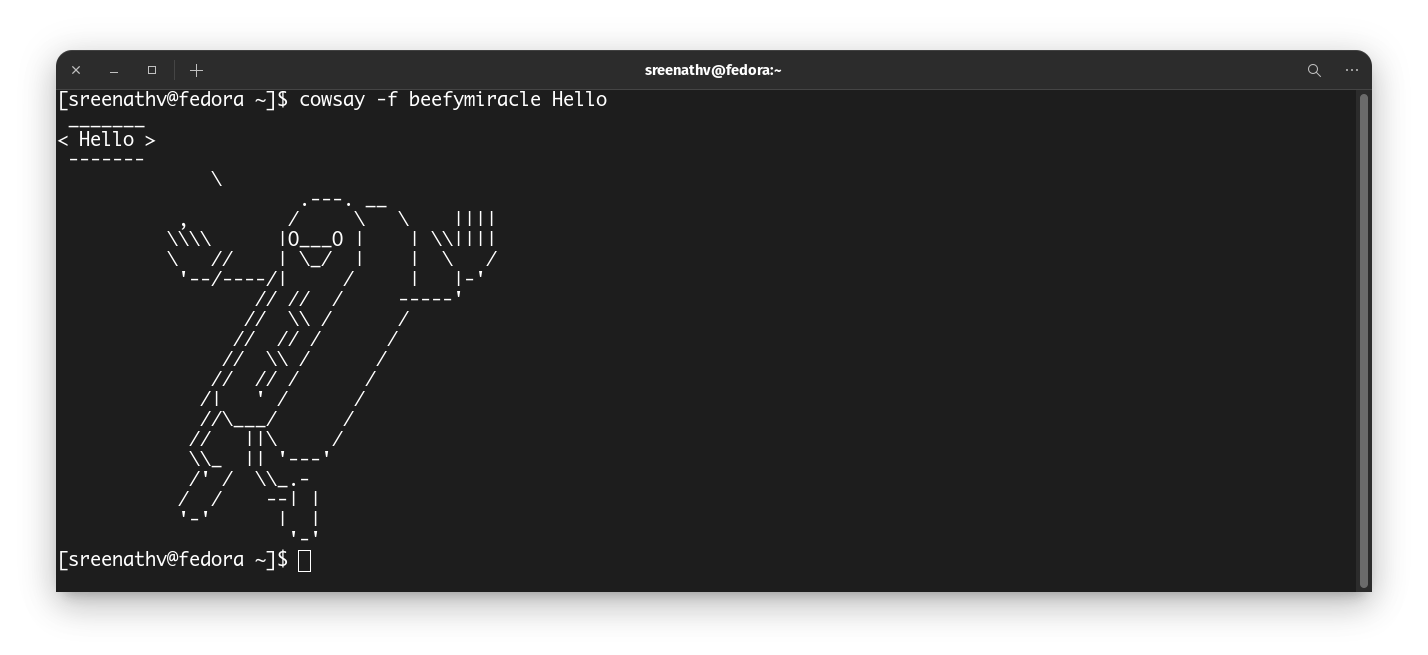
## Bonus: XCowsay
`xcowsay`
is a graphical alternative to the normal cowsay. Here, the cow is no more ASCII, but a proper image. You can install it by:
`sudo apt install xcowsay`
Now run:
`xcowsay <message>`
This will display the graphical cow for a specific amount of time according to the length of the text, and then disappears. **You can click on it to hide it immediately, though.**

`xcowsay`
commandWhat is more interesting is the cow can 'dream' images instead of texts. Or even the cow image can be changed to random images.
Use either:
```
xcowsay --dream=file
OR
xcowsay --image=file --dream=file
```


You can explore the man page of `xcowsay`
for more options.
## More ASCII fun in the terminal
Love ASCII? How about displaying your distribution's logo in ASCII format with [Neoftech](https://itsfoss.com/using-neofetch/)?
[Display Linux Distribution Logo in ASCII Art in TerminalWondering how they display Linux logo in terminal? With these tools, you can display logo of your Linux distribution in ASCII art in the Linux terminal.](https://itsfoss.com/display-linux-logo-in-ascii/)

Why restrict with logo? Here are more ASCII tools for Linux terminal.
[10 Tools to Generate and Have Fun With ASCII Art in Linux TerminalLinux terminal is not as scary as you think. Of course, it could be intimidating in the beginning but once you know the terminal better, you start loving it. You are likely to use the terminal for serious work. But there are many fun stuff you can do in the](https://itsfoss.com/ascii-art-linux-terminal/)

Don't stop the fun in the terminal.
[12 Linux Commands to Have Some Fun in the TerminalSo, you think Linux terminal is all work and no fun? These funny Linux commands will prove you wrong. The Linux terminal is the place to get serious work done. We have plenty of useful linux command tips and tricks to help you with that. But, did you know that](https://itsfoss.com/funny-linux-commands/)

I hope you liked this tutorial on using cowsay in various formats. It's amazing that this little tool comes with so many options and there are so many ways to use it.
Which cowsay example did you like the most here? Don't say beef one 💔 |
15,953 | Linux 版 WhatsApp | https://www.debugpoint.com/whatsapp-for-linux/ | 2023-06-29T15:23:00 | [
"WhatsApp"
] | /article-15953-1.html | 
>
> 一款出色的 Flatpak 应用,可从 Linux 桌面访问 WhatsApp。
>
>
>
WhatsApp 是流行的手机通讯平台,在许多国家都很受欢迎。用户通常通过 Play 商店或 App Store 中的移动应用访问它。然而,WhatsApp 从未推出任何适用于 Linux 的官方桌面客户端。
尽管你可以使用浏览器访问 WhatsApp,这是从任何桌面(包括 Linux)访问消息的官方方式。
一个新的非官方 WhatsApp Flatpak 桌面应用出现了,你可以无缝地使用它进行通信。
那么,这个 GTK 应用有哪些功能?
### “Linux 版 WhatsApp” 的功能

借助这款新的桌面应用,Linux 桌面用户可以在他们最喜欢的桌面环境中享受 WhatsApp 的所有熟悉功能。现在,你可以在 Linux 发行版上轻松访问所有功能,例如发送消息、共享媒体文件以及进行语音和视频通话。
“Linux 版 WhatsApp” 应用还提供键盘快捷键,确保应用内的无缝导航和交互。使用此应用,你可以放大和缩小以仔细查看图像和文本,或切换到全屏模式以获得无干扰的聊天体验。该应用还包括一个系统托盘图标,即使在应用最小化时也可以快速访问和通知。
此外,你可以自定义应用以满足你的喜好。通过按 `Alt+H`,你可以轻松显示或隐藏标题栏,从而更好地控制工作区。该应用还支持系统语言的本地化,确保你可以轻松地与世界各地的朋友和家人进行交流。

Linux 版 WhatsApp 应用的一项值得注意的功能是支持系统语言的拼写检查。要启用此功能,你必须安装相应的词典,例如美国英语的 hunspell-en\_us 包。
### 技术细节
如果你想知道,它不是一个 Electron 应用。它是使用原生 C++ 编写的,确保了最佳的性能和安全性。它依赖于各种免费和开源库,例如 intltool、gtkmm-3.0、webkit2gtk-4.0、ayatana-appindicator3-0.1、libcanberra 以及用于拼写检查的 libhunspell(可选)。
你可以从 [GitHub 上的源码](https://github.com/eneshecan/whatsapp-for-linux)了解有关此应用的更多信息。
### 安装
首先,你必须为你的 Linux 发行版设置 Flatpak 和 Flathub。使用 [本指南](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) 来设置。
安装后,运行以下命令进行安装。
```
flatpak install com.github.eneshecan.WhatsAppForLinux
```
你可以在应用列表中找到该应用。
### 运行应用
打开应用后,设置与 WhatsApp 网页类似。打开手机的 WhatsApp 应用并扫描应用中的二维码。这样就完成了。

请注意,这是一个非官方的应用。因此,请谨慎使用。你还可以查看 GitHub 以获取有关此应用的更多详细信息。
*(题图:MJ/de9d18fe-fb3f-4d88-8723-761ebbee5f38)*
---
via: <https://www.debugpoint.com/whatsapp-for-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,955 | i3 窗口管理器终极定制指南 | https://itsfoss.com/i3-customization/ | 2023-06-30T10:26:00 | [
"定制",
"i3"
] | https://linux.cn/article-15955-1.html | 
>
> 在这份超详细的指南中了解如何通过 i3 窗口管理器来自定义系统的外观和体验。
>
>
>
你可能在网上(尤其是通过 `r/unixporn` 子区)看到过很多炫酷的截图,用户可以根据个人喜好自定义他们的桌面并与大家分享。
这是因为 Linux 允许你自定义桌面体验的方方面面。
而结果?就是比任何 Mac 或 Windows 系统**更具视觉和感知效果**。
来看一下这个 ?

**看起来像一个 Linux Mint 系统吗?** ?
但是你怎样才能做到这样呢?**自定义你的 Linux 桌面外观是很困难的**。
答案就在于 **窗口管理器**。如果你能配置好窗口管理器,你就能自定义外观。
在本指南中,我将引导你完成使用 **i3 窗口管理器** 进行基本配置。它是 [Linux 上最好的窗口管理器之一](https://itsfoss.com/best-window-managers/)。
>
> ? “<ruby> 加料 <rt> Rice </rt></ruby>” 是一个常用的词汇,用来指代在桌面上进行视觉改进和自定义。**引用自** [/r/unixporn](https://www.reddit.com/r/unixporn) (LCTT 译注:“加料”一词来自于购买便宜的亚洲汽车,并给它们安装售后零件,以让它更好地类似于赛车。)
>
>
>
在遵循本指南之前,你需要了解以下内容:
* 在本指南中,**我将使用 Arch Linux** 来演示步骤,但你可以使用你喜欢的任何发行版,结果也是一样的。
* 请记住,本指南是 **对 i3 进行“加料”定制的基础**。
在按照本指南进行操作后,你应该得到以下预期结果:

>
> ? 为了节省你的时间,我已经在 [GitHub](https://github.com/itsfoss/text-files/tree/master/i3_config_files) 上上传了与本文相关的所有 i3 配置文件,你可以通过这些文件实现我们在本文中所期望的最终外观。
>
>
>
>
> **[下载 i3 配置文件](https://github.com/itsfoss/text-files/tree/master/i3_config_files)**
>
>
>
**首先**,让我们开始安装 **i3 窗口管理器**。
### 在 Linux 上安装 i3 窗口管理器
基于 Ubuntu/Debian:
```
sudo apt install xorg lightdm lightdm-gtk-greeter i3-wm i3lock i3status i3blocks dmenu terminator
```
Arch Linux:
```
sudo pacman -S xorg lightdm lightdm-gtk-greeter i3-wm i3lock i3status i3blocks dmenu terminator
```
当你完成安装后,使用以下命令启用 lightdm 服务:
```
sudo systemctl enable lightdm.service
```
然后启动 lightdm 服务:
```
sudo systemctl start lightdm.service
```
这将启动 lightdm 登录界面,并要求你输入用户名密码。
如果你安装了多个桌面环境,你可以从选择菜单中选择 i3:

当首次登录 i3 时,它会询问你是否要创建一个 i3 配置文件。
按下回车键创建一个新的 i3 配置文件:

接下来,它会询问你选择 `Win` 或 `Alt` 键哪个作为修饰键(`mod`)。
我建议你选择 `Win`(或者 `Super` 键),因为大多数用户已经习惯将其用作快捷键:

现在你可以开始使用 i3 窗口管理器了。
但在我们开始定制之前,让我先介绍一下你如何使用 i3。
### i3 窗口管理器的按键绑定
让我们从基础知识开始。
窗口管理器的基本功能是将多个窗口水平和垂直地组合在一起,这样你就可以同时监视多个进程。
结果是这样的:

你可以使用以下按键绑定执行更多操作:
| 按键绑定 | 描述 |
| --- | --- |
| `Mod + Enter` | 打开终端。 |
| `Mod + ←` | 切换到左侧窗口。 |
| `Mod + →` | 切换到右侧窗口。 |
| `Mod + ↑` | 切换到上方窗口。 |
| `Mod + ↓` | 切换到下方窗口。 |
| `Mod + Shift + ←` | 将窗口移动到左侧。 |
| `Mod + Shift + →` | 将窗口移动到右侧。 |
| `Mod + Shift + ↑` | 将窗口移动到上方。 |
| `Mod + Shift + ↓` | 将窗口移动到下方。 |
| `Mod + f` | 将焦点窗口切换到全屏模式。 |
| `Mod + v` | 下一个窗口将垂直放置。 |
| `Mod + h` | 下一个窗口将水平放置。 |
| `Mod + s` | 启用堆叠式窗口布局。 |
| `Mod + w` | 启用选项卡式窗口布局。 |
| `Mod + Shift + Space` | 启用浮动窗口(针对焦点窗口)。 |
| `Mod + 鼠标左键单击` | 使用鼠标拖动整个窗口。 |
| `Mod + 0-9` | 切换到另一个工作区。 |
| `Mod + Shift + 0-9` | 将窗口移动到另一个工作区。 |
| `Mod + d` | 打开应用程序启动器(D 菜单)。 |
| `Mod + Shift + q` | 关闭焦点窗口。 |
| `Mod + Shift + c` | 重新加载 i3 配置文件。 |
| `Mod + Shift + r` | 重启 i3 窗口管理器。 |
| `Mod + Shift + e` | 退出 i3 窗口管理器。 |
我知道按键绑定很多,但如果你每天练习它们,你很快就会习惯。
如果你想知道,你可以根据需要更改按键绑定,后面的指南中我会分享如何做到这一点。
现在,让我们来看看配置部分。
### 在 Arch Linux 中启用 AUR
如果你刚刚安装了 Arch Linux,可能还没有启用 AUR。
这意味着你错过了 Arch Linux 最重要的特性。
要 [启用 AUR](https://itsfoss.com/aur-arch-linux/),你需要使用 AUR 包管理器。在这里,我将使用 `yay`。
首先,安装 `git`:
```
sudo pacman -S git
```
现在,克隆 `yay` 存储库并切换到 `yay` 目录:
```
git clone https://aur.archlinux.org/yay-git.git && cd yay
```
最后,构建包:
```
makepkg -si
```
还有其他一些 [AUR 包管理器](https://itsfoss.com/best-aur-helpers/),比如 Paru,如果你想使用除 `yay` 之外的其他工具,你可以继续或者探索其他选项。
### 更改 i3 窗口管理器的分辨率
如果你使用虚拟机运行窗口管理器,可能会遇到问题,尤其是显示分辨率可能被锁定在 `1024x768` 上,就像我一样。
因此,你需要执行以下命令,指定所需的显示分辨率:
```
xrandr --output [显示名称] --mode [分辨率]
```
要找到已连接显示器的名称,你需要使用以下形式的 `xrandr` 命令:
```
xrandr | grep -w 'connected'
```

在我的情况下,显示名称是 `Virtual-1`。
因此,如果我想将分辨率更改为 `1920*1080`,我需要执行以下命令:
```
xrandr --output Virtual-1 --mode 1920x1080
```
**但这只是暂时生效**。要使其永久生效,你需要在 i3 配置文件中进行更改。
首先,打开配置文件:
```
nano ~/.config/i3/config
```
通过按下 `Alt + /` 来在 `nano` 中 [跳到文件末尾](https://linuxhandbook.com/beginning-end-file-nano/),并使用以下语法来永久更改显示分辨率:
```
# 显示分辨率
exec_always xrandr --output [显示名称] --mode [分辨率]
```
结果应该是这样的:

完成后,[保存更改并退出 nano](https://linuxhandbook.com/nano-save-exit/) 文本编辑器。
现在,使用 `Mod + Shift + r` 重新启动 i3 窗口管理器,以使你对配置文件所做的更改生效!
### 在 i3 窗口管理器中更改壁纸
默认情况下,i3 的外观比较陈旧,你可能想切换回之前的桌面环境。
但是通过更改壁纸,你可以改变整个系统的氛围。
在 i3 中有多种方式可以更改壁纸,但在这里,我将向你展示如何使用 `feh` 实用工具。
首先,让我们从安装开始:
对于基于 **Arch 的发行版**:
```
sudo pacman -S feh
```
对于 **Ubuntu/Debian** 系的发行版:
```
sudo apt install feh
```
安装完成后,你可以从互联网上下载你喜欢的壁纸。接下来,**打开 i3 配置文件**:
```
nano ~/.config/i3/config
```
跳到文件的末尾,使用如下所示的 `feh` 命令:
```
# 显示壁纸
exec_always feh --bg-fill /path/to/wallpaper
```
在我的情况下,壁纸位于 `Downloads` 目录中,所以我的命令如下:

保存更改并退出 `nano` 文本编辑器。
为了使配置文件的更改生效,使用 `Mod + Shift + r` 重新启动 i3 窗口管理器。
我的效果如下:

### 自定义 i3 锁屏界面
默认情况下,如果你想锁定系统,你需要执行以下命令:
```
i3lock
```
锁屏界面如下所示:

下面,我将向你展示:
* 如何创建自定义快捷方式以锁定 i3 会话
* 如何更改锁屏界面的壁纸
为了使锁屏界面更加美观,你需要使用 `i3lock-color` 包。
但首先,你需要移除现有的 `i3lock`,因为它会与 `i3lock-color` 冲突:
在 Arch Linux 上移除它:
```
sudo pacman -R i3lock
```
对于 Ubuntu/Debian 用户:
```
sudo apt remove i3lock
```
完成后,你可以使用 AUR 包管理器安装 `i3lock-color`:
```
yay i3lock-color
```
如果你使用的是基于 Ubuntu 的系统,你需要从头编译它。你可以在他们的 GitHub 页面上找到 [详细的说明](https://github.com/Raymo111/i3lock-color)。
安装完成后,让我们创建一个新目录并创建一个新文件来存储锁屏界面的配置:
安装好 `i3lock-color` 后,你可以创建一个新目录并创建一个新文件来存储锁屏界面的配置:
```
mkdir ~/.config/scripts && nano ~/.config/scripts/lock
```
将以下文件内容粘贴到文件中,定义锁屏界面的样式:
```
#!/bin/sh
BLANK='#00000000'
CLEAR='#ffffff22'
DEFAULT='#00897bE6'
TEXT='#00897bE6'
WRONG='#880000bb'
VERIFYING='#00564dE6'
i3lock \
--insidever-color=$CLEAR \
--ringver-color=$VERIFYING \
\
--insidewrong-color=$CLEAR \
--ringwrong-color=$WRONG \
\
--inside-color=$BLANK \
--ring-color=$DEFAULT \
--line-color=$BLANK \
--separator-color=$DEFAULT \
\
--verif-color=$TEXT \
--wrong-color=$TEXT \
--time-color=$TEXT \
--date-color=$TEXT \
--layout-color=$TEXT \
--keyhl-color=$WRONG \
--bshl-color=$WRONG \
\
--screen 1 \
--blur 9 \
--clock \
--indicator \
--time-str="%H:%M:%S" \
--date-str="%A, %Y-%m-%d" \
--keylayout 1 \
```
保存更改并退出文本编辑器。
>
> ? 在网上可以找到各种不同的 i3 锁屏样式的 bash 脚本。这只是一个示例,对于大多数情况来说是一个较为简单的选项。
>
>
>
现在,使用 [chmod 命令](https://linuxhandbook.com/chmod-command/) 将该文件设置为可执行文件:
```
sudo chmod +x .config/scripts/lock
```
接下来,你需要对配置文件进行一些更改,以添加该配置文件的路径以使其生效。
此外,我将向你展示如何使用自定义键盘快捷键锁定屏幕。
首先,打开配置文件:
```
nano ~/.config/i3/config
```
使用 `Alt + /` 跳至行尾并粘贴以下内容:
```
# 锁屏快捷键
bindsym $mod+x exec /home/$USER/.config/scripts/lock
```
在上面的示例中,我将 `mod + x` 作为锁定屏幕的快捷键,你可以选择任何你喜欢的快捷键。
最后的配置文件将如下所示:

相当不错,不是吗?
### 在 i3 窗口管理器中更改主题和图标
我知道你可能会想到这个问题。
你为什么需要图标呢?你并不仅仅使用窗口管理器来使用命令行工具。
有时候,使用图形界面更加方便,比如使用文件管理器。所以,在处理这些工具时,你希望界面看起来更好看?
因此,在本部分中,我将向你展示:
* 如何在 i3 中更改主题
* 如何在 i3 中更改图标
让我们从安装主题开始。
在这里,我将使用 `materia-gtk-theme` 和 `papirus` 图标,但你可以使用任何你喜欢的主题和图标。
在 Arch 中安装主题,使用以下命令:
```
sudo pacman -S materia-gtk-theme papirus-icon-theme
```
在 Ubuntu/Debian 系统中:
```
sudo apt install materia-gtk-theme papirus-icon-theme
```
但仅仅安装还不能完成任务。**你需要像使用 GNOME “<ruby> 调整 <rt> Tweaks </rt></ruby>” 应用更改主题一样来应用主题。**
**在 i3 中,你可以使用 `lxappearance` 工具** 来更改主题和图标。
在 Arch 中安装 `lxappearance`,使用以下命令:
```
sudo pacman -S lxappearance
```
在 Ubuntu/Debian 系统中:
```
sudo apt install lxappearance
```
安装完成后,使用 `Mod + d` 启动 D 菜单,然后输入 `lxappearance`,并在第一个结果上按回车键。
在这里,选择你喜欢的主题。我这里选择 `Materia-dark`。
选择主题后,点击应用按钮以应用更改:

同样地,要更改图标,选择 “<ruby> 图标主题 <rt> Icon Theme </rt></ruby>”,选择图标主题,然后点击应用按钮:

应用主题和图标后,我的文件管理器如下所示:

### 在 i3 窗口管理器中为工作区设置图标
默认情况下,工作区仅由数字表示,这并不是你想要使用工作区的最理想方式。
因此,在本部分中,我将引导你如何使用合适的图标更改工作区的名称。
为了在配置文件中使用图标,首先你需要安装名为 `Awesome` 的新字体:
对于基于 Arch 的发行版:
```
sudo pacman -S ttf-font-awesome
```
对于 Ubuntu/Debian 系统:
```
sudo apt install fonts-font-awesome
```
安装完成后,打开 i3 配置文件:
```
nano ~/.config/i3/config
```
在这个配置文件中,找到工作区的部分,你将会看到为每个工作区给出的变量:

在这个部分,你需要用你想要的名称替换给出的工作区数字。
我将把第一个工作区命名为 “programs”,因为**在本教程的后面部分,我将展示如何将特定的应用程序分配到特定的工作区。**
我主要使用前 5 个工作区,所以我会相应地命名它们:
```
# 定义默认工作区的名称,稍后我们将在其中配置键绑定。
# 我们使用变量来避免在多个地方重复使用名称。
set $ws1 "1: Terminal"
set $ws2 "2: Firefox"
set $ws3 "3: VMWare"
set $ws4 "4: Spotify"
set $ws5 "5: Shutter"
set $ws6 "6"
set $ws7 "7"
set $ws8 "8"
set $ws9 "9"
set $ws10 "10"
```
现在让我们为配置文件中提到的每个应用程序添加图标。
你可以 [参考 awesome 字体的备忘单](https://fontawesome.com/v5/cheatsheet) 来找到合适的图标。
将图标复制粘贴到名称前面:
```
# 定义默认工作区的名称,稍后我们将在其中配置键绑定。
# 我们使用变量来避免在多个地方重复使用名称。
set $ws1 "1: Terminal"
set $ws2 "2: Firefox"
set $ws3 "3: VMWare"
set $ws4 "4: Spotify"
set $ws5 "5: Shutter"
set $ws6 "6"
set $ws7 "7"
set $ws8 "8"
set $ws9 "9"
set $ws10 "10"
```
不要担心它看起来可怕!
完成后,使用 `Mod + e` 退出 i3,然后再次登录以应用你刚刚所做的更改。
我的效果如下图所示:

字体看起来太小?是时候解决这个问题了!
### 在 i3 中更改标题窗口和状态栏的字体
首先,让我们安装新的字体(我将在这里使用 Ubuntu 字体)。
要在 Arch 上安装 Ubuntu 字体,请执行以下操作:
```
sudo pacman -S ttf-ubuntu-font-family
```
如果你使用的是 Ubuntu,你已经安装了这些字体!
安装完成后,打开配置文件:
```
nano ~/.config/i3/config
```
在配置文件中,找到 `font pango:monospace 8` 这一行,这是默认字体。
找到那行后,添加字体名称和大小,如下所示:
```
font pango:Ubuntu Regular 14
```
然后,使用 `Mod + Shift + r` 重新启动窗口管理器,这样就完成了工作:

### 在 i3 窗口管理器中分配应用程序到工作区
在给工作区命名之后,你会想要将特定的软件分配到相应的工作区中。
例如,如果我将第二个工作区命名为 “Firefox”,那么我只想在该工作区中使用 Firefox。
那么要如何实现呢?
为了做到这一点,你需要找到每个要分配的应用程序的类名。
**听起来复杂?** 让我告诉你如何做。
首先,将应用程序和终端并排打开。例如,在这个例子中,我将 Firefox 和终端并排打开:

现在,在终端中执行 `xprop` 命令,它会改变鼠标指针的形状:
```
xprop
```
接下来,将鼠标悬停在应用程序上,并在应用程序窗口内的任何位置单击,如图所示:

类名将在以下行的最后一个字符串中找到:
```
WM_CLASS(STRING) = "Navigator", "firefox"
```
在我的情况下,Firefox 浏览器的类名将是 `firefox`。
对所有你想要分配到工作区的应用程序重复这个过程。
**一旦你知道每个你想要分配到工作区的应用程序的类名,打开配置文件:**
```
nano ~/.config/i3/config
```
使用 `Alt + /` 将 `nano` 定位到文件末尾,并使用以下语法将应用程序分配到工作区:
```
# 分配应用到工作区
for_window [class="类名"] move to workspace $[工作区变量]
```
作为参考,下面是我为不同应用程序分配了 4 个工作区后的配置文件示例:

现在,无论在哪个工作区打开任何应用程序,它都会自动放置在配置的工作区中。非常方便! ?
### 在 i3 窗口管理器中让终端变透明
要启用透明效果,你需要安装 `picom` 合成器并对配置文件进行一些更改。
让我们从安装开始。
对于基于 Arch 的发行版:
```
sudo pacman -S picom
```
对于基于 Ubuntu/Debian 的发行版:
```
sudo apt install picom
```
安装完成后,你需要告诉系统使用 `picom`。
首先打开配置文件:
```
nano ~/.config/i3/config
```
在配置文件的末尾插入以下行:
```
# 使用 picom 合成器实现透明效果
exec_always picom -f
```
这里,我使用 `-f` 标志来在切换工作区、打开新应用程序等时启用淡入淡出效果。
保存并退出文本编辑器。
现在,使用 `Mod + Shift + r` 重新启动 i3。
接下来,打开终端,打开 “<ruby> 首选项 <rt> Preference </rt></ruby>”,然后选择“<ruby> 配置文件 <rt> Profiles </rt></ruby>”,选择“<ruby> 背景 <rt> Background </rt></ruby>”,然后选择“<ruby> 透明背景 <rt> Transparent background </rt></ruby>”选项。
从这里,你可以调整透明度:

### 在 i3 窗口管理器中自定义状态栏
默认情况下,状态栏显示各种信息,但没有图标。
因此,在这个部分,我将展示如何从状态栏中删除一些元素以及如何为它们添加图标。
但是,在这里,我将在 `/etc/i3status.conf` 中创建一个原始状态栏的副本,以便如果出现任何错误,你可以随时恢复到默认配置。
首先,在 `.config` 目录下创建一个新的目录:
```
mkdir .config/i3status
```
在以下命令中,我使用了 [cp 命令来复制文件](https://linuxhandbook.com/cp-command/):
```
sudo cp /etc/i3status.conf ~/.config/i3status/i3status.conf
```
接下来,使用 [chown 命令更改所有者](https://linuxhandbook.com/chown-command/),以便你可以进行所需的更改:
```
sudo chown $USER:$USER ~/.config/i3status/i3status.conf
```
现在,你需要通过修改 i3 配置文件来指示窗口管理器使用新的 i3status 配置文件。首先打开配置文件:
```
nano ~/.config/i3/config
```
在该配置文件中查找 `status_command i3status` 这一行。这是你将提供新状态配置文件路径的行。
找到该行后,进行以下更改:
```
bar {
status_command i3status -c /home/$USER/.config/i3status/i3status.conf
}
```
最终的结果应该如下所示:

保存更改并退出文本编辑器。
现在,让我们从状态栏中删除不必要的指示器。
首先,打开 i3status 配置文件:
```
nano .config/i3status/i3status.conf
```
在这里,你可以将以 `order` 开头的行注释掉,这些行实际上是指示器的变量。
**例如,在这里**,我禁用了 `ipv6`、`wireless _first_`、`battery all` 和 `load` 这些对我来说不必要的指示器:
```
#order += "ipv6"
#order += "wireless _first_"
order += "ethernet _first_"
#order += "battery all"
order += "disk /"
#order += "load"
order += "memory"
order += "tztime local"
```
然后,[在浏览器中打开 awesome font 列表](https://fontawesome.com/v5/cheatsheet),找到与状态栏中列出的项目相关的适当图标。
在我的设置中,我删除了以下内容:
* 删除了显示可用内存的行
* 删除了显示以太网连接速度的行
最终,我的状态栏如下所示:

### 在 i3 窗口管理器中改变颜色方案
更改 i3 窗口管理器中的颜色方案是这个指南中最重要的部分,因为窗口管理器最吸引人的地方就是你选择的窗口装饰颜色。
>
> ? 我将为每个颜色声明变量,这样你只需更改变量本身的值,就可以轻松地获得新的颜色方案。
>
>
>
首先,打开 i3 配置文件:
```
nano ~/.config/i3/config
```
使用 `Alt + /` 快捷键到达文件末尾,并使用以下语法添加变量来存储颜色:
```
# 窗口的色彩方案
set $bgcolor #523d64
set $in-bgcolor #363636
set $text #ffffff
set $u-bgcolor #ff0000
set $indicator #a8a3c1
set $in-text #969696
# 边框 背景 文本 指示器(显示下一个窗口位置的线条)
client.focused $bgcolor $bgcolor $text $indicator
client.unfocused $in-bgcolor $in-bgcolor $in-text $in-bgcolor
client.focused_inactive $in-bgcolor $in-bgcolor $in-text $in-bgcolor
client.urgent $u-bgcolor $u-bgcolor $text $u-bgcolor
```
在这里:
* `bgcolor` 表示背景色。
* `in-bgcolor` 表示非活动窗口的背景色。
* `text` 是文本颜色。
* `u-bgcolor` 表示紧急操作的背景色。
* `indicator` 是标示下一个窗口位置的线条的颜色。
* `in-text` 是非活动窗口的文本颜色。
对于本指南,我仅使用了四个基本类别:
* `client.focused` 定义了焦点窗口的颜色。
* `client.unfocused` 定义了失去焦点时窗口的装饰。
* `client.focused_inactive` 当其中一个容器处于焦点但当前没有焦点时,显示的颜色。
* `client.urgent` 定义了紧急操作时的颜色。
>
> ? 除了这四个类别,还有更多类别,请参考 [官方 i3 配置手册](https://i3wm.org/docs/userguide.html#client_colors) 以了解更多信息。
>
>
>
一旦你对配置文件进行了更改,请使用 `Mod + Shift + r` 重新启动 i3。
如果你按照我的颜色方案,设置应该如下所示:

那么,状态栏的颜色怎么办?当然可以改!
#### 更改 i3 窗口管理器中状态栏的颜色方案
在本节中,你将意识到为什么我使用变量来存储颜色,因为我将使用相同的变量来为我的状态栏上色!
要在状态栏中使用颜色,你需要在 i3 配置文件的 `bar {...}` 部分进行更改。
首先,打开配置文件:
```
nano ~/.config/i3/config
```
在配置文件中查找 `bar {...}` 部分。
找到该部分后,创建一个颜色部分,并为状态栏定义颜色和类别,与你为窗口所做的相同:
```
bar {
status_command i3status -c /home/$USER/.config/i3status/i3status.conf
colors {
background $bgcolor
separator #191919
# border background text
focused_workspace $bgcolor $bgcolor $text
inactive_workspace $in-bgcolor $in-bgcolor $text
urgent_workspace $u-bgcolor $u-bgcolor $text
}
}
```
在这里,我使用了 `focused_workspace`、`inactive_workspace` 和 `urgent_workspace` 这三个类别,根据需要定义了相应的颜色。
保存更改后,重新启动 i3,状态栏也会显示颜色。
### 设置 i3 状态栏的透明度
本节将向你展示如何使 i3 状态栏透明。
在此之前,让我们先更改 i3 状态栏的字体。
这里,我将使用 Droid 字体,使其看起来干净而带有一种极客风格。
要在 Arch Linux 上安装 Droid 字体,请使用以下命令:
```
sudo pacman -S ttf-droid
```
对于 Ubuntu/Debian 系统,请使用以下命令:
```
sudo apt install fonts-droid-fallback
```
安装完成后,打开配置文件:
```
nano ~/.config/i3/config
```
进入 `bar {...}` 部分,并按下面的示例输入字体名称和大小:
```
font pango: Droid Sans Mono 11
```

完成后,请重新启动 i3,字体将会被更改!
要使状态栏透明,你可以使用现有十六进制代码中的额外两个数字来定义透明度。
如果你想要控制透明度,我建议你查看 [此指南,其中提供了从 0 到 100% 透明度的代码范围](https://gist.github.com/lopspower/03fb1cc0ac9f32ef38f4)。
为此,我将在配置文件中使用两个新变量。首先,打开配置文件:
```
nano ~/.config/i3/config
```
在这里,我为背景颜色添加了 60% 的透明度,并为非活跃背景颜色添加了 30% 的透明度:
```
set $bgcolor #523d6499
set $in-bgcolor #3636364D
```
如果你仔细观察,我在现有的十六进制颜色代码中添加了两位数字来定义透明度。例如,使用 `99` 来表示 `60%` 的透明度,而使用 `4D` 来表示 `30%` 的透明度。
此外,我添加了两个新变量,透明度不同但颜色相同,作为背景使用,使其看起来更好:
```
set $focused-ws #523d6480
set $bar-color #523d640D
```
完成后,让我们修改 `bar {...}` 部分来应用透明度。
在 `bar {...}` 中添加两行代码:
```
i3bar_command i3bar --transparency
tray_output none
```
请注意,使用 `tray_output none`,它将不会在托盘中显示任何图标。如果你不希望出现这种行为,则可以跳过此行,只添加第一行以实现透明度。
一旦完成,修改状态栏的颜色方案,例如更改背景颜色、边框和活动工作区的背景。
修改后,配置文件应如下所示:

为了使你所做的更改生效,请重新启动 i3,你将得到透明的窗口和状态栏:

### 在窗口管理器中使用 i3blocks
默认的 i3 状态栏在我看来毫无用处;怎么样让它变得有用起来呢?
在本部分,我将解释如何添加以下功能:
* 软件包更新
* 内存使用情况
* 磁盘使用情况
* 音量指示器
* Spotify 指示器
>
> ? 要实现这些功能,你需要使用一些脚本,这些脚本将允许你向状态栏添加所需的操作。不用担心,我不会让你手动输入脚本;GitHub 上有各种脚本可供选择,几乎涵盖了你所需的所有方面。
>
>
>
但在此之前,你需要进行一些配置,以存储脚本并指示 i3 使用 i3block 的配置,而不是使用 i3bar。
如果你在本指南的开头按照给定的说明进行操作,那么 i3blocks 已经安装好了,并且配置文件位于 `/etc/i3blocks.conf`。
*如果你希望快速下载块配置文件以进行设置而不阅读其他内容,请点击以下链接:*
>
> **[i3 配置文件](https://github.com/itsfoss/text-files/tree/master/i3_config_files)**
>
>
>
在本教程中,我将创建一个副本,使用它代替原始的配置文件,因此首先我们要创建一个目录来存储配置文件的副本:
```
mkdir ~/.config/i3blocks
```
现在,创建一个原始配置文件的副本:
```
sudo cp /etc/i3blocks.conf ~/.config/i3blocks/
```
最后,使用 `chown` 命令更改文件的所有者,以便你进行所需的更改:
```
sudo chown $USER:$USER ~/.config/i3blocks/i3blocks.conf
```
要启用 i3blocks,在 i3 配置文件中进行一些更改:
```
nano ~/.config/i3/config
```
进入 `bar {...}` 部分,在这里,你需要将 `status_command` 更改为 `i3blocks` 并添加 i3blocks 配置文件的路径,如下所示:

完成后,使用 `Mod + Shift + r` 重新启动 i3 窗口管理器,整个状态栏都会被更改,并显示如下:

不要担心,你将很快使状态栏比以前的 i3bar 更有价值和好看。
#### 添加磁盘块
如果你想要显示磁盘剩余空间,可以添加此块。
在这里,我将使用 `nano` 创建并打开用于磁盘块的配置文件。
```
nano ~/.config/scripts/disk
```
然后粘贴以下行:
```
#!/usr/bin/env sh
DIR="${DIR:-$BLOCK_INSTANCE}"
DIR="${DIR:-$HOME}"
ALERT_LOW="${ALERT_LOW:-$1}"
ALERT_LOW="${ALERT_LOW:-10}" # color will turn red under this value (default: 10%)
LOCAL_FLAG="-l"
if [ "$1" = "-n" ] || [ "$2" = "-n" ]; then
LOCAL_FLAG=""
fi
df -h -P $LOCAL_FLAG "$DIR" | awk -v label="$LABEL" -v alert_low=$ALERT_LOW '
/\/.*/ {
# full text
print label $4
# short text
print label $4
use=$5
# no need to continue parsing
exit 0
}
END {
gsub(/%$/,"",use)
if (100 - use < alert_low) {
# color
print "#FF0000"
}
}
'
```
保存更改并从文本编辑器中退出。
现在,将此文件设置为可执行:
```
sudo chmod +x ~/.config/scripts/disk
```
接下来,打开 I3blocks 配置文件:
```
nano ~/.config/i3blocks/i3blocks.conf
```
根据你想要放置磁盘块的位置,粘贴以下行:
```
[disk]
command=/home/$USER/.config/scripts/disk
LABEL=
#DIR=$HOME
#ALERT_LOW=10
interval=30
```
完成后,保存更改并使用 `Mod + Shift + r` 重新启动 i3,状态栏中将显示带有磁盘图标的可用磁盘空间。
#### 添加内存块
这将是状态栏中指示系统中已使用内存的块。
首先,创建并打开一个新文件用于新的块:
```
nano ~/.config/scripts/memory
```
然后在新文件中粘贴以下行:
```
#!/usr/bin/env sh
TYPE="${BLOCK_INSTANCE:-mem}"
PERCENT="${PERCENT:-true}"
awk -v type=$TYPE -v percent=$PERCENT '
/^MemTotal:/ {
mem_total=$2
}
/^MemFree:/ {
mem_free=$2
}
/^Buffers:/ {
mem_free+=$2
}
/^Cached:/ {
mem_free+=$2
}
/^SwapTotal:/ {
swap_total=$2
}
/^SwapFree:/ {
swap_free=$2
}
END {
if (type == "swap") {
free=swap_free/1024/1024
used=(swap_total-swap_free)/1024/1024
total=swap_total/1024/1024
} else {
free=mem_free/1024/1024
used=(mem_total-mem_free)/1024/1024
total=mem_total/1024/1024
}
pct=0
if (total > 0) {
pct=used/total*100
}
# full text
if (percent == "true" ) {
printf("%.1fG/%.1fG (%.f%%)\n", used, total, pct)
} else {
printf("%.1fG/%.1fG\n", used, total)
}
# short text
printf("%.f%%\n", pct)
# color
if (pct > 90) {
print("#FF0000")
} else if (pct > 80) {
print("#FFAE00")
} else if (pct > 70) {
print("#FFF600")
}
}
' /proc/meminfo
```
保存更改并从文本编辑器中退出。
现在,要使其生效,你需要使用以下命令将此文件设置为可执行:
```
sudo chmod +x ~/.config/scripts/memory
```
接下来,打开 i3blocks 配置文件:
```
nano ~/.config/i3blocks/i3blocks.conf
```
并将以下内容粘贴到你希望在状态栏中显示内存使用情况的位置:
```
[memory]
command=/home/$USER/.config/scripts/memory
label=
interval=30
```
保存更改并从文本编辑器中退出。重新启动 i3 以使更改生效!
#### 添加更新指示块
这是最有帮助的指示器,它显示需要更新的旧软件包数量。
首先,使用以下命令安装依赖项以使其正常工作:
```
sudo pacman -S pacman-contrib
```
现在,创建一个新文件来存储脚本:
```
nano ~/.config/scripts/arch-update
```
然后粘贴以下内容:
```
#!/usr/bin/env python3
import subprocess
from subprocess import check_output
import argparse
import os
import re
def create_argparse():
def _default(name, default='', arg_type=str):
val = default
if name in os.environ:
val = os.environ[name]
return arg_type(val)
strbool = lambda s: s.lower() in ['t', 'true', '1']
strlist = lambda s: s.split()
parser = argparse.ArgumentParser(description='Check for pacman updates')
parser.add_argument(
'-b',
'--base_color',
default = _default('BASE_COLOR', 'green'),
help='base color of the output(default=green)'
)
parser.add_argument(
'-u',
'--updates_available_color',
default = _default('UPDATE_COLOR', 'yellow'),
help='color of the output, when updates are available(default=yellow)'
)
parser.add_argument(
'-a',
'--aur',
action = 'store_const',
const = True,
default = _default('AUR', 'False', strbool),
help='Include AUR packages. Attn: Yaourt must be installed'
)
parser.add_argument(
'-y',
'--aur_yay',
action = 'store_const',
const = True,
default = _default('AUR_YAY', 'False', strbool),
help='Include AUR packages. Attn: Yay must be installed'
)
parser.add_argument(
'-q',
'--quiet',
action = 'store_const',
const = True,
default = _default('QUIET', 'False', strbool),
help = 'Do not produce output when system is up to date'
)
parser.add_argument(
'-w',
'--watch',
nargs='*',
default = _default('WATCH', arg_type=strlist),
help='Explicitly watch for specified packages. '
'Listed elements are treated as regular expressions for matching.'
)
return parser.parse_args()
def get_updates():
output = ''
try:
output = check_output(['checkupdates']).decode('utf-8')
except subprocess.CalledProcessError as exc:
# checkupdates exits with 2 and no output if no updates are available.
# we ignore this case and go on
if not (exc.returncode == 2 and not exc.output):
raise exc
if not output:
return []
updates = [line.split(' ')[0]
for line in output.split('\n')
if line]
return updates
def get_aur_yaourt_updates():
output = ''
try:
output = check_output(['yaourt', '-Qua']).decode('utf-8')
except subprocess.CalledProcessError as exc:
# yaourt exits with 1 and no output if no updates are available.
# we ignore this case and go on
if not (exc.returncode == 1 and not exc.output):
raise exc
if not output:
return []
aur_updates = [line.split(' ')[0]
for line in output.split('\n')
if line.startswith('aur/')]
return aur_updates
def get_aur_yay_updates():
output = check_output(['yay', '-Qua']).decode('utf-8')
if not output:
return []
aur_updates = [line.split(' ')[0] for line in output.split('\n') if line]
return aur_updates
def matching_updates(updates, watch_list):
matches = set()
for u in updates:
for w in watch_list:
if re.match(w, u):
matches.add(u)
return matches
label = os.environ.get("LABEL","")
message = "{0}<span color='{1}'>{2}</span>"
args = create_argparse()
updates = get_updates()
if args.aur:
updates += get_aur_yaourt_updates()
elif args.aur_yay:
updates += get_aur_yay_updates()
update_count = len(updates)
if update_count > 0:
if update_count == 1:
info = str(update_count) + ' update available'
short_info = str(update_count) + ' update'
else:
info = str(update_count) + ' updates available'
short_info = str(update_count) + ' updates'
matches = matching_updates(updates, args.watch)
if matches:
info += ' [{0}]'.format(', '.join(matches))
short_info += '*'
print(message.format(label, args.updates_available_color, info))
print(message.format(label, args.updates_available_color, short_info))
elif not args.quiet:
print(message.format(label, args.base_color, 'system up to date'))
```
保存更改并从文本编辑器中退出。
现在,使用以下命令将此文件设置为可执行:
```
sudo chmod +x ~/.config/scripts/arch-update
```
接下来,打开 i3blocks 配置文件:
```
nano ~/.config/i3blocks/i3blocks.conf
```
并将以下内容粘贴到所需的位置:
```
[arch-update]
command=/home/$USER/.config/scripts/arch-update
interval=3600
markup=pango
LABEL=
```
保存更改并重新加载 i3 窗口管理器,它将显示需要更新的软件包数量。
如果你正在使用 Ubuntu,你可以 [按照 GitHub 页面上的说明](https://github.com/vivien/i3blocks-contrib/tree/master/apt-upgrades) 进行操作。
#### 添加音量指示块
添加音量指示块需要一些努力,因为你希望它的行为符合预期。你需要实现以下功能:
* 使用媒体控制键管理音量的键绑定
* 添加一个指示音量的音量块
但要做到这一点,首先你需要安装一些依赖项。
如果你使用的是 Arch Linux,请使用以下命令:
```
sudo pacman -S pulseaudio-alsa pulseaudio-bluetooth pulseaudio-equalizer pulseaudio-jack alsa-utils playerctl
```
如果你使用的是 Ubuntu/Debian 系统,请使用以下命令:
```
sudo apt install pulseaudio-module-bluetooth pulseaudio-equalizer pulseaudio-module-jack alsa-utils playerctl
```
接下来,让我们看看如何在 i3 窗口管理器中启用媒体控制键。
首先,打开 i3 配置文件:
```
nano ~/.config/i3/config
```
转到文件的末尾,并粘贴以下内容:
```
# Key bindings for Media control keys
bindsym XF86AudioPlay exec playerctl play
bindsym XF86AudioPause exec playerctl pause
bindsym XF86AudioNext exec playerctl next
bindsym XF86AudioPrev exec playerctl previous
```
现在,让我们为此块创建一个新文件:
```
nano ~/.config/scripts/volume
```
然后粘贴以下内容:
```
#!/usr/bin/env bash
if [[ -z "$MIXER" ]] ; then
MIXER="default"
if command -v pulseaudio >/dev/null 2>&1 && pulseaudio --check ; then
# pulseaudio is running, but not all installations use "pulse"
if amixer -D pulse info >/dev/null 2>&1 ; then
MIXER="pulse"
fi
fi
[ -n "$(lsmod | grep jack)" ] && MIXER="jackplug"
MIXER="${2:-$MIXER}"
fi
if [[ -z "$SCONTROL" ]] ; then
SCONTROL="${BLOCK_INSTANCE:-$(amixer -D $MIXER scontrols |
sed -n "s/Simple mixer control '\([^']*\)',0/\1/p" |
head -n1
)}"
fi
# The first parameter sets the step to change the volume by (and units to display)
# This may be in in % or dB (eg. 5% or 3dB)
if [[ -z "$STEP" ]] ; then
STEP="${1:-5%}"
fi
NATURAL_MAPPING=${NATURAL_MAPPING:-0}
if [[ "$NATURAL_MAPPING" != "0" ]] ; then
AMIXER_PARAMS="-M"
fi
#------------------------------------------------------------------------
capability() { # Return "Capture" if the device is a capture device
amixer $AMIXER_PARAMS -D $MIXER get $SCONTROL |
sed -n "s/ Capabilities:.*cvolume.*/Capture/p"
}
volume() {
amixer $AMIXER_PARAMS -D $MIXER get $SCONTROL $(capability)
}
```
保存更改并退出配置文件。
接下来,打开 I3blocks 配置文件:
```
nano ~/.config/i3blocks/i3blocks.conf
```
然后粘贴以下内容:
```
[volume]
command=/home/$USER/.config/scripts/volume
LABEL=♪
#LABEL=VOL
interval=1
signal=10
#STEP=5%
MIXER=default
#SCONTROL=[determined automatically]
#NATURAL_MAPPING=0
```
保存更改并重新加载 i3,从现在开始,音量快捷键将起作用,并且指示器将按预期工作!
>
> ? 如果遇到音频/视频不工作等问题,请使用此命令,它应该解决该问题:
>
>
>
```
systemctl --user disable --now pipewire.{socket,service} && systemctl --user mask pipewire.socket
```
#### 添加 Spotify 块
我将使用 [firatakandere](https://github.com/firatakandere) 的脚本来添加此功能。在继续之前,你可以先查看一下该脚本。
首先,创建并打开一个用于 Spotify 块的新文件:
```
nano ~/.config/scripts/spotify.py
```
然后粘贴以下内容:
```
#!/usr/bin/python
import dbus
import os
import sys
try:
bus = dbus.SessionBus()
spotify = bus.get_object("org.mpris.MediaPlayer2.spotify", "/org/mpris/MediaPlayer2")
if os.environ.get('BLOCK_BUTTON'):
control_iface = dbus.Interface(spotify, 'org.mpris.MediaPlayer2.Player')
if (os.environ['BLOCK_BUTTON'] == '1'):
control_iface.Previous()
elif (os.environ['BLOCK_BUTTON'] == '2'):
control_iface.PlayPause()
elif (os.environ['BLOCK_BUTTON'] == '3'):
control_iface.Next()
spotify_iface = dbus.Interface(spotify, 'org.freedesktop.DBus.Properties')
props = spotify_iface.Get('org.mpris.MediaPlayer2.Player', 'Metadata')
if (sys.version_info > (3, 0)):
print(str(props['xesam:artist'][0]) + " - " + str(props['xesam:title']))
else:
print(props['xesam:artist'][0] + " - " + props['xesam:title']).encode('utf-8')
exit
except dbus.exceptions.DBusException:
exit
```
完成后,使用以下命令使其可执行:
```
sudo chmod +x ~/.config/scripts/spotify.py
```
现在,打开 I3blocks 配置文件:
```
nano ~/.config/i3blocks/i3blocks.conf
```
然后粘贴以下内容(建议将其粘贴到块的开头):
```
[spotify]
label=
command=/home/$USER/.config/scripts/spotify.py
color=#81b71a
interval=5
```
保存更改,退出配置文件,并重新启动 i3。
添加了我提到的块后,状态栏将如下所示:

你可以查看我的主屏幕,其中包含这些块(点击下方的图片查看)。

>
> ? 如果你对那些默认块(文档和问候语)的位置感到困惑,我用了几个注释将它们禁用以实现所示的外观!
>
>
>
### 在 Linux 中使用 i3gaps
如果你想在窗口之间添加间隙,可以使用 `i3gaps`。在颜色方案之后,`i3gaps` 是这个指南中最关键的元素。
要使用间隙,你必须对 i3 配置文件进行一些更改。
打开 i3 配置文件:
```
nano ~/.config/i3/config
```
转到文件的末尾,并粘贴以下内容:
```
# default gaps
gaps inner 15
gaps outer 5
# gaps
set $mode_gaps Gaps: (o)uter, (i)nner, (h)orizontal, (v)ertical, (t)op, (r)ight, (b)ottom, (l)eft
set $mode_gaps_outer Outer Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_inner Inner Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_horiz Horizontal Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_verti Vertical Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_top Top Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_right Right Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_bottom Bottom Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_left Left Gaps: +|-|0 (local), Shift + +|-|0 (global)
bindsym $mod+Shift+g mode "$mode_gaps"
mode "$mode_gaps" {
bindsym o mode "$mode_gaps_outer"
bindsym i mode "$mode_gaps_inner"
bindsym h mode "$mode_gaps_horiz"
bindsym v mode "$mode_gaps_verti"
bindsym t mode "$mode_gaps_top"
bindsym r mode "$mode_gaps_right"
bindsym b mode "$mode_gaps_bottom"
bindsym l mode "$mode_gaps_left"
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_outer" {
bindsym plus gaps outer current plus 5
bindsym minus gaps outer current minus 5
bindsym 0 gaps outer current set 0
bindsym Shift+plus gaps outer all plus 5
bindsym Shift+minus gaps outer all minus 5
bindsym Shift+0 gaps outer all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_inner" {
bindsym plus gaps inner current plus 5
bindsym minus gaps inner current minus 5
bindsym 0 gaps inner current set 0
bindsym Shift+plus gaps inner all plus 5
bindsym Shift+minus gaps inner all minus 5
bindsym Shift+0 gaps inner all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_horiz" {
bindsym plus gaps horizontal current plus 5
bindsym minus gaps horizontal current minus 5
bindsym 0 gaps horizontal current set 0
bindsym Shift+plus gaps horizontal all plus 5
bindsym Shift+minus gaps horizontal all minus 5
bindsym Shift+0 gaps horizontal all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_verti" {
bindsym plus gaps vertical current plus 5
bindsym minus gaps vertical current minus 5
bindsym 0 gaps vertical current set 0
bindsym Shift+plus gaps vertical all plus 5
bindsym Shift+minus gaps vertical all minus 5
bindsym Shift+0 gaps vertical all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_top" {
bindsym plus gaps top current plus 5
bindsym minus gaps top current minus 5
bindsym 0 gaps top current set 0
bindsym Shift+plus gaps top all plus 5
bindsym Shift+minus gaps top all minus 5
bindsym Shift+0 gaps top all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_right" {
bindsym plus gaps right current plus 5
bindsym minus gaps right current minus 5
bindsym 0 gaps right current set 0
bindsym Shift+plus gaps right all plus 5
bindsym Shift+minus gaps right all minus 5
bindsym Shift+0 gaps right all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_bottom" {
bindsym plus gaps bottom current plus 5
bindsym minus gaps bottom current minus 5
bindsym 0 gaps bottom current set 0
bindsym Shift+plus gaps bottom all plus 5
bindsym Shift+minus gaps bottom all minus 5
bindsym Shift+0 gaps bottom all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_left" {
bindsym plus gaps left current plus 5
bindsym minus gaps left current minus 5
bindsym 0 gaps left current set 0
bindsym Shift+plus gaps left all plus 5
bindsym Shift+minus gaps left all minus 5
bindsym Shift+0 gaps left all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
```
保存更改并退出配置文件。
使用 `Mod + Shift + r` 重新加载 i3,并会看到窗口之间的间隙:

但是,如果你想调整间隙的大小怎么办?这非常简单,只需要简单的步骤即可完成:
* 按下 `Mod + Shift + g` 进入间隙模式
* 使用给定的选项选择要更改的内容
* 使用 `+` 或 `-` 增加/减小间隙
* 完成后,按 `Esc` 键退出间隙模式
就是这样!
### 我们忘记自定义终端了吗?
不用担心;你可以 [切换到 Zsh](https://itsfoss.com/zsh-ubuntu/),这是一个不同的 shell,使终端看起来与众不同,或者探索一些鲜为人知的 [Linux Shell](https://itsfoss.com/shells-linux/)。
无论如何,你都可以 [自定义现有终端](https://itsfoss.com/customize-linux-terminal/),或选择不同的 [终端模拟器](https://itsfoss.com/linux-terminal-emulators/)。
**我希望你不再畏难如何美化系统!** ?
*如果你有任何建议或想展示你的配置,请在评论部分留言。*
*(题图:MJ/2874542d-6a8f-4b27-8e65-477389a0dcca)*
---
via: <https://itsfoss.com/i3-customization/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You might have come across dope screenshots (especially via `r/unixporn`
Subreddit), where users customize their desktops to their heart's desire and share it with the world. Linux lets you customize every aspect of your desktop experience, which is why it is possible.
And, the result? Something that** feels and looks way better than any Mac or Windows system.**
Just look at this 😌

**Does it look like a Linux Mint system? **😲
But how can you achieve something like that? **It is tough to customize** the look of your Linux desktop.
The answer to your questions lies in the** window manager. **If you can configure a window manager, you can customize the look.
For this guide, I will walk you through a basic configuration you can do with the **i3 window manager. **It is one of the [best window managers for Linux](https://itsfoss.com/best-window-managers/).
**Via**
[/r/unixporn](https://www.reddit.com/r/unixporn)
Things you should know before following this guide:
- In this guide,
**I will use Arch Linux**to demonstrate the steps, but you can use any of your preferred distros and have the same result. - Remember, this guide will be a basic foundation for the
**i3 ricing**.
And here's the result of what you should expect after following this guide:
[GitHub](https://github.com/itsfoss/text-files/tree/master/i3_config_files), with which you can achieve the final look of what we intend from this article.
**First,** let's start with installing the **i3 window manager**.
## Install i3 Window Manager on Linux
For **Ubuntu/Debian** base:
`sudo apt install xorg lightdm lightdm-gtk-greeter i3-wm i3lock i3status i3blocks dmenu terminator`
For **Arch Linux**:
`sudo pacman -S xorg lightdm lightdm-gtk-greeter i3-wm i3lock i3status i3blocks dmenu terminator`
Once you are done with the installation, enable the lightdm service using the following command:
`sudo systemctl enable lightdm.service`
And start the lightdm service:
`sudo systemctl start lightdm.service`
That will start the lightdm greeter that will ask you to enter the password for your username.
And if you have multiple desktop environments installed, you can choose i3 from the selection menu:
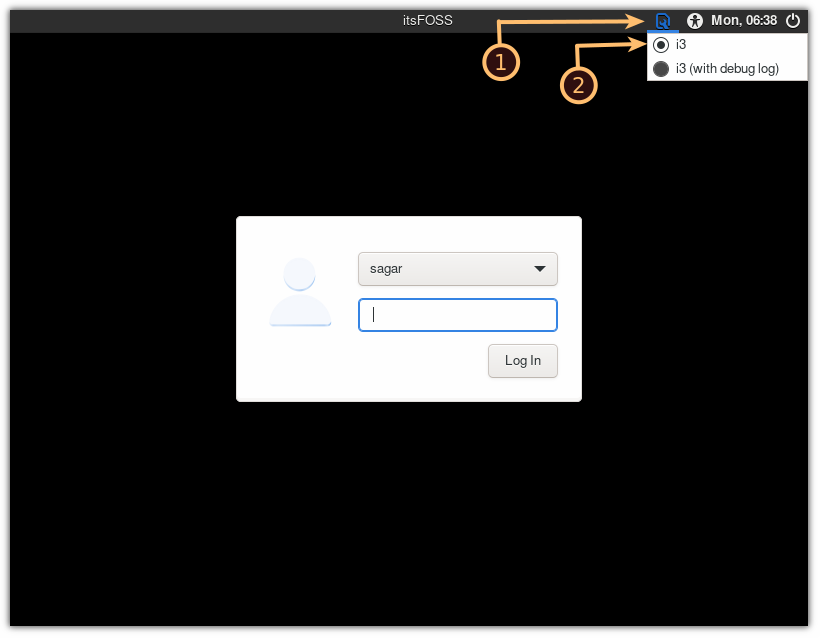
Once you log in to your first i3 instance, it will ask you whether you want to create an i3 config file.
Press `Enter`
to create a new i3 config file:
Next, it will ask you to choose between `Win`
and `Alt`
key, which should behave as `mod`
key.
I would recommend you go with the `Win`
(or the Super) key as most of the users are already used to it for shortcuts:
And your i3 window manager is ready to use.
But before we jump to the customization part, let me walk you through how you can use the i3 in the first place.
## Keybindings of i3 Window Manager
So let's start with the basics.
The basic functionality of the window manager is to frame multiple windows horizontally and vertically, so you can monitor multiple processes simultaneously.
And the result looks like this:
You can do a lot more than this using the following keybindings:
Keybiding | Description |
---|---|
`Mod + Enter` |
Open terminal. |
`Mod + ←` |
Focus left. |
`Mod + →` |
Focus right. |
`Mod + ↑` |
Focus up. |
`Mod + ↓` |
Focus down. |
`Mod + Shift + ←` |
Move the window to the left side. |
`Mod + Shift + →` |
Move the window to the right side. |
`Mod + Shift + ↑` |
Move the window up. |
`Mod + Shift + ↓` |
Move the window down. |
`Mod + f` |
Toggle the focused window to full-screen. |
`Mod + v` |
The next window will be placed vertically. |
`Mod + h` |
The next window will be placed horizontally. |
`Mod + s` |
Enables the stacked window layout. |
`Mod + w` |
Enables the tabbed window layout. |
`Mod + Shift + Space` |
Enables the floating window (for focused window). |
`Mod + Left-mouse-click` |
Drag the entire window using the mouse. |
`Mod + 0-9` |
Switch to another workspace. |
`Mod + Shift + 0-9` |
Move the window to another workspace. |
`Mod + d` |
Open the application launcher (D menu). |
`Mod + Shift + q` |
Kills the focused window. |
`Mod + Shift + c` |
Reloads the I3 config file. |
`Mod + Shift + r` |
Restart the I3 WM. |
`Mod + Shift + e` |
Exit I3 WM. |
I know an overwhelming number of keybindings are available, but if you practice them daily, you'll get used to them in no time.
And if you are wondering, you can change the keybindings at your convenience, which I will share in the later part of this guide.
Now, let's have a look at the configuration part.
## Enable AUR in Arch Linux
So if you have a fresh installation of Arch Linux, you may not have enabled the AUR.
This means you are missing out on the most crucial feature of the Arch.
To [enable the AUR](https://itsfoss.com/aur-arch-linux/), you'd need AUR to utilize the AUR package helper. Here, I will be using the yay.
[What is Arch User Repository (AUR)? How to Use AUR on Arch and Manjaro Linux?What is AUR in Arch Linux? How do I use AUR? Is it safe to use? This article explains it all.](https://itsfoss.com/aur-arch-linux/)

First, install the git:
`sudo pacman -S git`
Now, clone the yay repository and change your directory to yay:
`git clone https://aur.archlinux.org/yay-git.git && cd yay`
And finally, build the package:
`makepkg -si`
There are some other [AUR package helpers](https://itsfoss.com/best-aur-helpers/) like Paru, so if you want to use something else apart from yay, you can proceed, or explore other options.
## Change resolution of i3 WM
You will face issues, especially if you are using a virtual machine for window manager where the display resolution may be locked at `1024x768`
, as is in my case.
So you will have to execute the following command by specifying the desired display resolution:
`xrandr --output [Display_name] --mode [resolution]`
To find the name of the connected display, you will have to use the xrandr command in the following manner:
`xrandr | grep -w 'connected'`

In my case, it is `Virtual-1`
.
So if I want to change the resolution to `1920*1080`
, I will have to execute the following:
`xrandr --output Virtual-1 --mode 1920x1080`
**But this will only work temporarily**. To make it permanent, you will have to make changes in the i3 config file.
First, open the config file:
`nano ~/.config/i3/config`
[Go to the end of the file in nano](https://linuxhandbook.com/beginning-end-file-nano/) by pressing `Alt + /`
and use the following syntax to change the display resolution permanently:
```
# Display Resolution
exec_always xrandr --output [Display_name] --mode [Resolution]
```
The result should look like this:

Once done, [save changes and exit from the nano](https://linuxhandbook.com/nano-save-exit/) text editor.
Now, restart the i3 WM using the `Mod + Shift + r`
to take effect from the changes you've made to the config file and that's it!
## Change wallpaper in the i3 Window manager
By default, i3 will look dated, and you may want to switch back to your previous desktop environment.
But by changing the wallpaper itself, you can start changing the whole vibe of the system.
And there are various ways to change the wallpaper in i3, but here, I will be showing you how you can use the `feh`
utility.
First, let's start with the installation itself:
For **Arch-based distros:**
`sudo pacman -S feh`
For **Ubuntu/Debian based-distros:**
`sudo apt install feh`
Once done, you can download your favorite wallpaper from the internet. Next, **open the i3 config file:**
`nano ~/.config/i3/config`
Go to the end of the file and use the feh command as mentioned:
```
# Display Wallpaper
exec_always feh --bg-fill /path/to/wallpaper
```
In my case, the wallpaper was in the `Downloads`
directory, so my command would look like this:
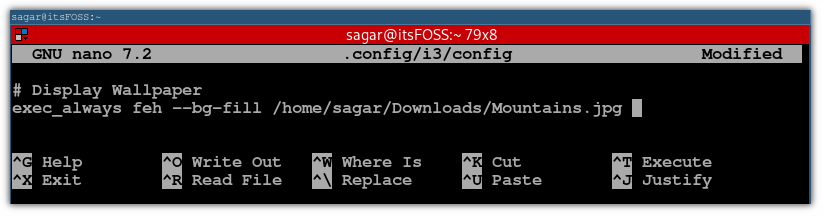
Save changes and exit from the nano text editor.
To take effect from the changes you made to the config file, restart the i3 window manager using `Mod + Shift + r`
.
Mine looks like this:

## Customize i3 lock screen
By default, if you want to lock the system, you will have to execute the following command:
`i3lock `
And the lock screen looks like this:
So here, I will show you:
**How to create a custom shortcut to lock the i3 session****How to change the lock screen wallpaper**
To make the lock screen beautiful, you'd have to use the `i3lock-color`
package.
But first, you'd have to remove the existing `i3lock`
as it will conflict with the `i3lock-color`
:
To remove it from Arch:
`sudo pacman -R i3lock`
For Ubuntu/Debian users:
`sudo apt remove i3lock`
Once done, you can install the `i3lock-color`
using the AUR helper:
`yay i3lock-color`
And if you're on an Ubuntu base, you'd have to build it from scratch. You can find [detailed instructions on their GitHub page](https://github.com/Raymo111/i3lock-color).
Once you are done with the installation, let's create a new directory and make a new file to store the configuration for the lock screen:
`mkdir ~/.config/scripts && nano ~/.config/scripts/lock`
And paste the following file contents to define the lock screen styling:
```
#!/bin/sh
BLANK='#00000000'
CLEAR='#ffffff22'
DEFAULT='#00897bE6'
TEXT='#00897bE6'
WRONG='#880000bb'
VERIFYING='#00564dE6'
i3lock \
--insidever-color=$CLEAR \
--ringver-color=$VERIFYING \
\
--insidewrong-color=$CLEAR \
--ringwrong-color=$WRONG \
\
--inside-color=$BLANK \
--ring-color=$DEFAULT \
--line-color=$BLANK \
--separator-color=$DEFAULT \
\
--verif-color=$TEXT \
--wrong-color=$TEXT \
--time-color=$TEXT \
--date-color=$TEXT \
--layout-color=$TEXT \
--keyhl-color=$WRONG \
--bshl-color=$WRONG \
\
--screen 1 \
--blur 9 \
--clock \
--indicator \
--time-str="%H:%M:%S" \
--date-str="%A, %Y-%m-%d" \
--keylayout 1 \
```
Save changes and exit from the text editor.
Now, make this file executable [using the chmod command](https://linuxhandbook.com/chmod-command/):
`sudo chmod +x .config/scripts/lock`
Next, you'd have to introduce some changes to the config file to add the path to this config file to make it work.
Furthermore, here's where I will show you how you can use the custom keyboard shortcut for the lock screen.
First, open the config file:
`nano ~/.config/i3/config`
Jump to the end of the line using `Alt + /`
and paste the following lines:
```
# Shortcut for Lockscreen
bindsym $mod+x exec /home/$USER/.config/scripts/lock
```
In the above, I have used `mod + x`
as a shortcut to lock the screen, you can use any of your preferred ones.
And the end would look like this:
Pretty neat. Isn't it?
## Change theme and icons in the i3 Window manager
I know what you might be thinking.
Why would you need icons in the first place? But you don't need only to be using CLI tools with the window manager.
There are times when opting for GUI is more convenient, such as using a file manager. So, when dealing with such utilities, you want to make it look better (and prettier?)
So in this section, I will show you:
**How to change the theme in i3****How to change the icons in i3**
Let's start with the installation of the theme.
Here, I will be using the `materia-gtk-theme`
and `papirus`
icons. But you can use any of your preferred ones.
To install the theme in Arch, use the following:
`sudo pacman -S materia-gtk-theme papirus-icon-theme`
For Ubuntu/Debian base:
`sudo apt install materia-gtk-theme papirus-icon-theme`
But installing won't get the job done. **You'd have to apply the theme as you use the GNOME tweaks to change the theme.**
**In i3, you can use the lxappearance utility** to change the theme and icons.
To install lxappearance in Arch, use the following:
`sudo pacman -S lxappearance`
For Ubuntu/Debian base:
`sudo apt install lxappearance`
Once you are done with the installation, start the dmenu using `Mod + d`
and type **lxappearance, **and hit enter on the first result.
Here, choose the theme of your liking. I'm going with the `Materia-dark`
here.
Select the theme and click on the apply button to apply the changes:
Similarly, to change the icon, select the `Icon Theme`
, choose the icon theme and hit the apply button:
After applying the theme and icons, my file manager looks like this:
## Set icons for workspaces in the i3 window manager
By default, the workspaces are indicated by numbers only, which is not the most ideal way you want to use the workspace.
So in this section, I will walk you through how you can change the name of the workspaces with appropriate icons.
To use the icons in the config file, first, you will have to install new fonts named `Awesome`
:
For Arch-based distros:
`sudo pacman -S ttf-font-awesome`
For Ubuntu/Debian base:
`sudo apt install fonts-font-awesome`
Once done, open the i3 config file:
`nano ~/.config/i3/config`
In this config file, look for the workspace section where you will be given variables for each workspace:
In this section, you must interchange the number given to the workspace with what you want to name it.
I will be naming it as programs as **in the later part of this tutorial, I will show how you can allocate the specific workspace to the specific application. **
I mostly use the first 5 workspaces, so I will name them accordingly:
```
# Define names for default workspaces for which we configure key bindings later on.
# We use variables to avoid repeating the names in multiple places.
set $ws1 "1: Terminal"
set $ws2 "2: Firefox"
set $ws3 "3: VMWare"
set $ws4 "4: Spotify"
set $ws5 "5: Shutter"
set $ws6 "6"
set $ws7 "7"
set $ws8 "8"
set $ws9 "9"
set $ws10 "10"
```
Now let's add the icons for each application mentioned in the config file.
You can [refer to the cheatsheet of the awesome font](https://fontawesome.com/v5/cheatsheet) to find the appropriate icon.
Copy and paste the icons in front of the name:
```
# Define names for default workspaces for which we configure key bindings later>
# We use variables to avoid repeating the names in multiple places.
set $ws1 "1: Terminal"
set $ws2 "2: Firefox"
set $ws3 "3: VMWare"
set $ws4 "4: Spotify"
set $ws5 "5: Shutter"
set $ws6 "6"
set $ws7 "7"
set $ws8 "8"
set $ws9 "9"
set $ws10 "10"
```
Don't worry if it looks horrific!
Once done, exit i3 using the `Mod + e`
and log back in again to take effect from the changes you've just made.
Mine looks like this:
Do fonts look too small? It's time to address this!
## Change the font of the title window and bar in the i3
First, let's install new fonts. (I will be using Ubuntu fonts here).
To install the Ubuntu fonts in Arch, use the following:
`sudo pacman -S ttf-ubuntu-font-family`
And if you are on Ubuntu, you already have them installed!
Once done, open the config file:
`nano ~/.config/i3/config`
In the config file, look for the `font pango:monospace 8`
line as this is the default font.
Once you find that line, add the name of the font and size as shown:
`font pango:Ubuntu Regular 14`
Now, restart the window manager using the `Mod + Shift + r`
and that should do the job:
## Allocate applications to workspaces in the i3 window manager
After naming the workspaces, you will want to allocate specific software to that workspace.
Such as, if I named my second workspace Firefox then I would want to use Firefox only inside that workspace.
So how do you do that?
To do so, you must find the name of the class of each application you want to allocate.
**Sounds complex?** Let me tell you how to do so.
First, run start the application and terminal side by side. For example, here, I opened the Firefox and terminal side by side:
Now, execute the xprop command in the terminal, and it will change the cursor shape:
`xprop`
Next, hover the cursor on the application and click anywhere inside the application window as shown:
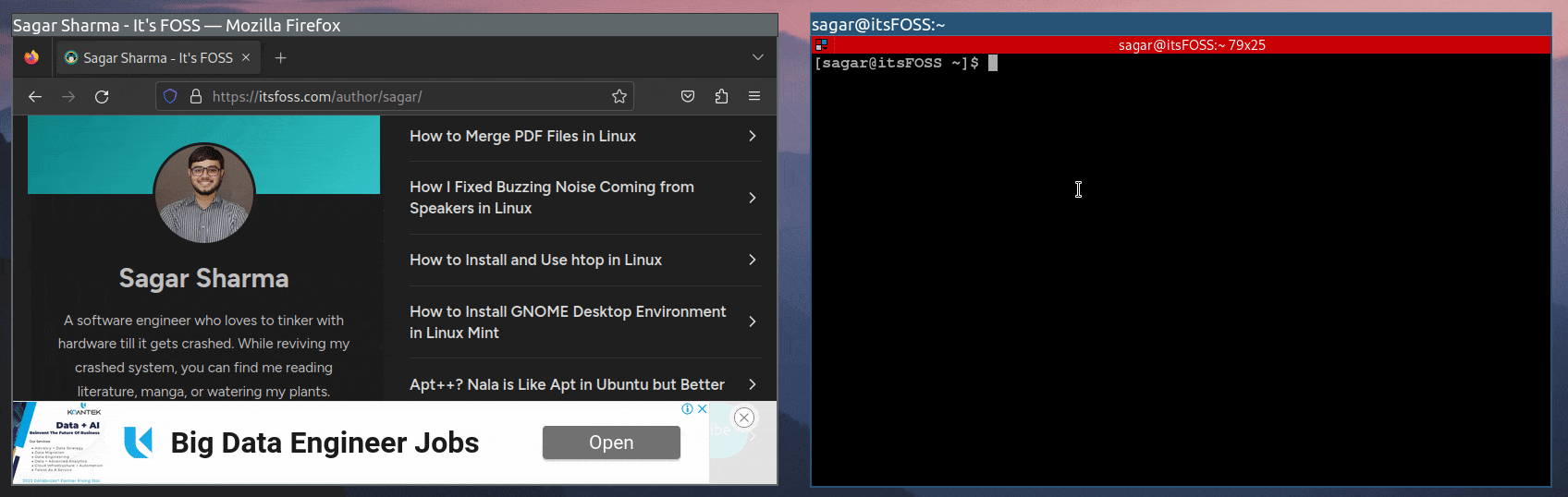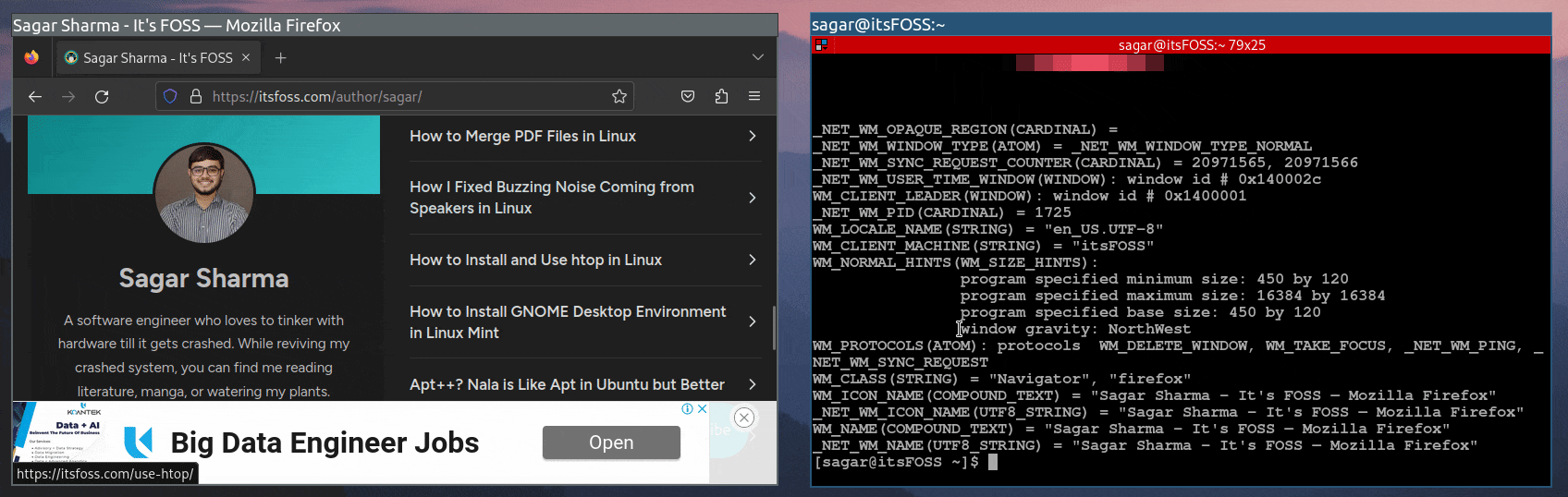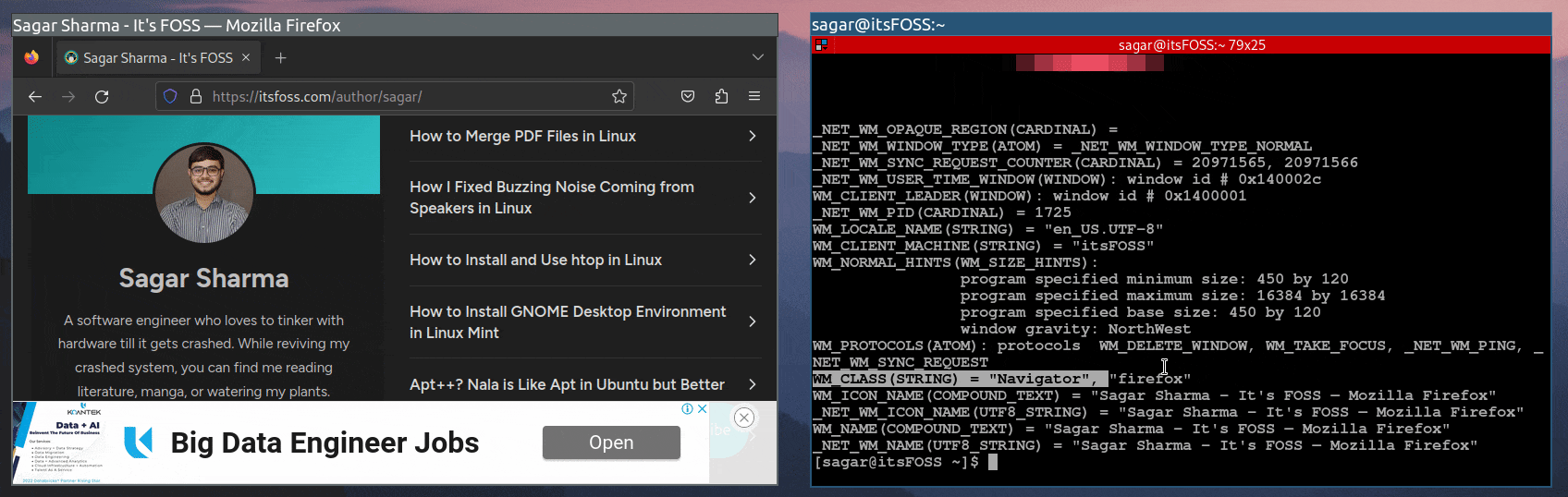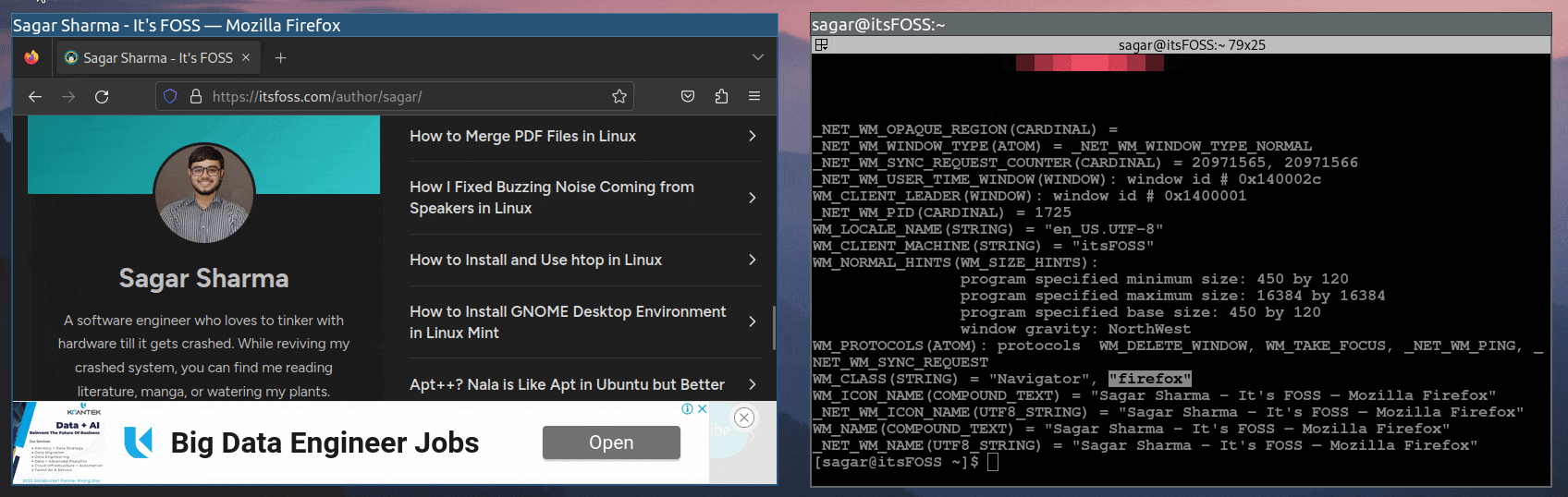
The class name will be found in the last sting of characters in the following line:
`WM_CLASS(STRING) = "Navigator", "firefox"`
In my case, the class name for the Firefox browser will be `firefox`
.
Repeat the process for all the applications you want to allocate to workspaces.
**Once you know the class names for every application you want to allocate a workspace, open the configuration file:**
`nano ~/.config/i3/config`
Go to the end of the file in the nano using `Alt + /`
and use the following syntax to allocate the applications to the workspace:
```
# Allocate applications to workspaces
for_window [class="class_name"] move to workspace $[workspace_variable]
```
For reference, here's how my config looks like after allocating 4 workspaces to different applications:
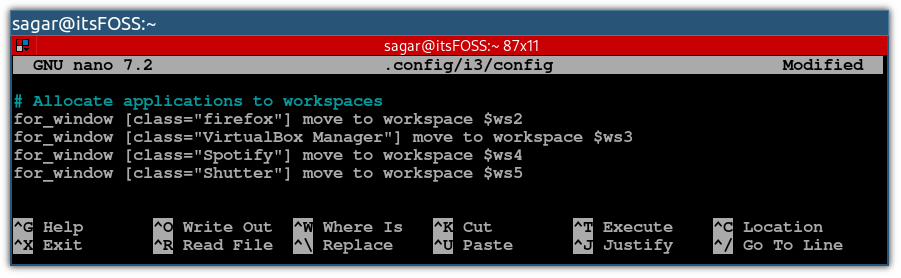
And now, if you open any application from any workspace, it will be placed in to configured workspace automatically. Pretty handy! 😊
## Make the terminal transparent in the i3 window manager
To enable transparency, you must install a picom compositor and make a few changes to the config file.
So let's start with the installation.
For Arch-based distro:
`sudo pacman -S picom`
For Ubuntu/Debian base:
`sudo apt install picom`
After the installation, you'd need to instruct the system to use the picom.
So open the config file first:
`nano ~/.config/i3/config`
Go to the end of the line in the config file and paste the following line:
```
# Transparency with picom compositor
exec_always picom -f
```
Here, I have used the `-f`
flag is used to enable the fading effect while switching between workspaces, opening new applications, etc.
Save and exit from the text editor.
Now, restart i3 using `Mod + Shift + r`
.
Next, open the terminal, open Preference, and now, click on the Profiles, select Background, and select the `Transparent background`
option.
From here, you can choose the transparency:
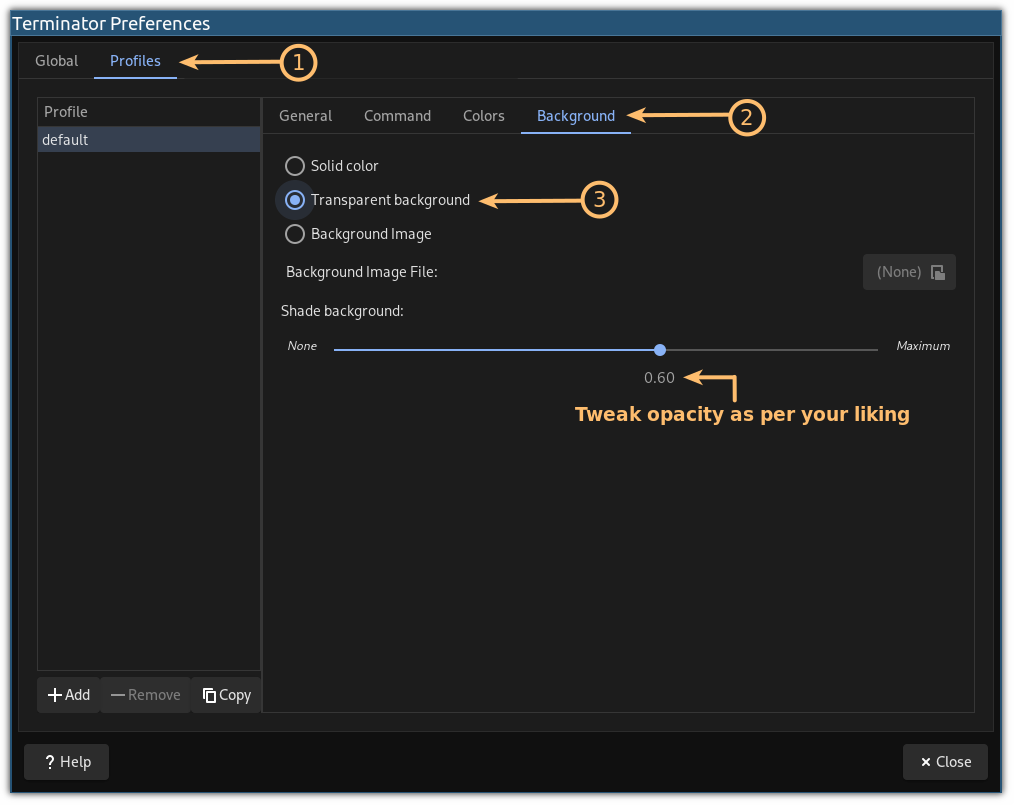
## Customize the status bar in the i3 WM
By default, the status bar shows all sorts of information with no icons.
So in this section, I will be showing how you can remove some elements from the status bar and how you can add icons to them.
But here, I will be creating a copy of the original status bar available in `/etc/i3status.conf`
as if you make any mistake, you can always roll back to the default one.
First, create a new directory inside the `.config`
using the following:
`mkdir .config/i3status`
In the following command, I've used [the cp command to copy files](https://linuxhandbook.com/cp-command/):
`sudo cp /etc/i3status.conf ~/.config/i3status/i3status.conf`
Next, [change the ownership using the chown command](https://linuxhandbook.com/chown-command/) which will allow you to make desired changes:
`sudo chown $USER:$USER ~/.config/i3status/i3status.conf`
Now, you must instruct the window manager to use the new i3status config file by modifying the i3 config. So first, open the config file:
`nano ~/.config/i3/config`
In this config file look for the `status_command i3status`
line. This is the line where you will be providing the path to the new status config file.
Once you find that line, make the following changes:
```
bar {
status_command i3status -c /home/$USER/.config/i3status/i3status.conf
}
```
So, the end result should look like this:
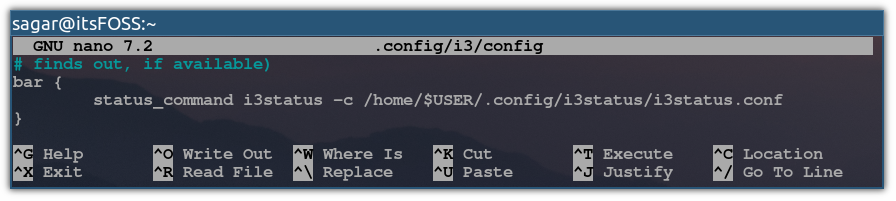
Save changes and exit from the text editor.
Now, let's remove the unnecessary indicators from the status bar.
To do so, first, open the i3status config file:
`nano .config/i3status/i3status.conf`
Here, you can comment out the names starting with "order" which are nothing but variables for the indicator.
**For example, here**, I disabled `ipv6`
, `wireless _first_`
, `battery all`
and `load`
as they were unnecessary for me:
```
#order += "ipv6"
#order += "wireless _first_"
order += "ethernet _first_"
#order += "battery all"
order += "disk /"
#order += "load"
order += "memory"
order += "tztime local"
```
Now, [open the awesome font cheat sheet](https://fontawesome.com/v5/cheatsheet) in the browser and find relevant icons for the items that are listed in the status bar.
In my setup, I have removed the following:
- Removed line indicating available RAM
- Removed line showing speed for my ethernet connection
And in the end, my bar looks like this:
## Change the color scheme in the i3 window manager
This is the most crucial section of this guide, as the most attractive thing in the window manager is the colors you choose to decorate windows.
So first, open the I3 config file:
`nano ~/.config/i3/config`
And go to the end of the file by using `Alt + /`
and use the following syntax to add variables to store colors:
```
# Color shemes for windows
set $bgcolor #523d64
set $in-bgcolor #363636
set $text #ffffff
set $u-bgcolor #ff0000
set $indicator #a8a3c1
set $in-text #969696
# border background text indicator (a line which shows where the next window will be placed)
client.focused $bgcolor $bgcolor $text $indicator
client.unfocused $in-bgcolor $in-bgcolor $in-text $in-bgcolor
client.focused_inactive $in-bgcolor $in-bgcolor $in-text $in-bgcolor
client.urgent $u-bgcolor $u-bgcolor $text $u-bgcolor
```
Here,
`bgcolor`
indicates the background color.`in-bgcolor`
indicates background color for inactive windows.`text`
is for the text color.`u-bgcolor`
indicates the background for urgent action.`indicator`
is color for the line, which indicates where the next window will be placed.`in-text`
text color when inactive.
And for this guide, I have only used 4 basic classes which are:
`client.focused`
defines colors for the focused windows.`client.unfocused`
decides how to decorate windows when not focused.`client.focused_inactive`
shows colors when one of the containers is focused but does not have the focus at the moment.`client.urgent`
defines colors when urgent action is needed.
[official i3 configuration manual](https://i3wm.org/docs/userguide.html#client_colors)to learn more.
Once you make changes to the config file, restart the I3 using `Mod + Shift + r`
.
And if you followed my color scheme, the setup should look like this:
But what about the changing colors for the status bar? Why not!
### Changing the color scheme for the status bar in i3
In this section, you'd realize why I used variables to store colors, as I will use the same variables to color my status bar!
To use colors in the status bar, you will have to make changes in the `bar {...}`
section of the I3 config file.
First, open the configuration file:
`nano ~/.config/i3/config`
In the configuration file, look for the `bar {...}`
section.
Once you find the section, create a color section and define colors and classes for the status bar as the same you did for Windows:
```
bar {
status_command i3status -c /home/$USER/.config/i3status/i3status.conf
colors {
background $bgcolor
separator #191919
# border background text
focused_workspace $bgcolor $bgcolor $text
inactive_workspace $in-bgcolor $in-bgcolor $text
urgent_workspace $u-bgcolor $u-bgcolor $text
}
}
```
Here, I have used 3 classes: `focused_workspace`
, `inactive_workspace`
, and `urgent_workspace`
which will define the colors accordingly.
Once you make changes, save them and restart the I3 and the status bar will have colors too.
## Make i3 bar transparent
This section will show you how to make the i3 bar transparent.
But before that, let's change the fonts for the i3 bar.
Here, I will use the droid fonts to make it look clean and with a nerdy theme.
To install droid fonts in Arch, use the following:
`sudo pacman -S ttf-droid`
And for Ubuntu/Debian base:
`sudo apt install fonts-droid-fallback`
Once done, open the config file:
`nano ~/.config/i3/config`
And go to the `bar {...}`
section and enter the font name with the size as shown:
`font pango: Droid Sans Mono 11`
Once done, restart the i3, and the fonts will be changed!
To make the bar transparent, you can use the extra two digits in the existing hexadecimal code to define the transparency.
And if you want to control transparency, I would recommend you check out this [guide which gives codes ranging from 0 to 100% transparency](https://gist.github.com/lopspower/03fb1cc0ac9f32ef38f4).
For this purpose, I will use two new variables in the config file. So first, open the config file:
`nano ~/.config/i3/config`
Here, I changed and added a transparency of 60% to the background color and added 30% transparency to the inactive background color:
```
set $bgcolor #523d6499
set $in-bgcolor #3636364D
```
If you notice closely, I've added two-digit numbers in the existing hex color code defining transparency. Such as `99`
is used for `60%`
transparency whereas `4D`
is used for the `30%`
transparency.
Also, I added two new variables with different transparency and the same color as a background to make it look better:
```
set $focused-ws #523d6480
set $bar-color #523d640D
```
Once you do so, let's change the bar section to apply transparency.
Here, you'd have to add two new lines in the `bar {...}`
:
```
i3bar_command i3bar --transparency
tray_output none
```
Remember, using the `tray_output none`
line, it won't show any icons in the tray so if you don't want this behavior, skip this and only add the 1st line for transparency.
Once done, change the color scheme for the bar such as changing the background color, border, and background for the focused workspace.
After making changes, the config should look like this:
To take effect from the changes you've made, restart the i3 and you'd have transparent windows and bar:
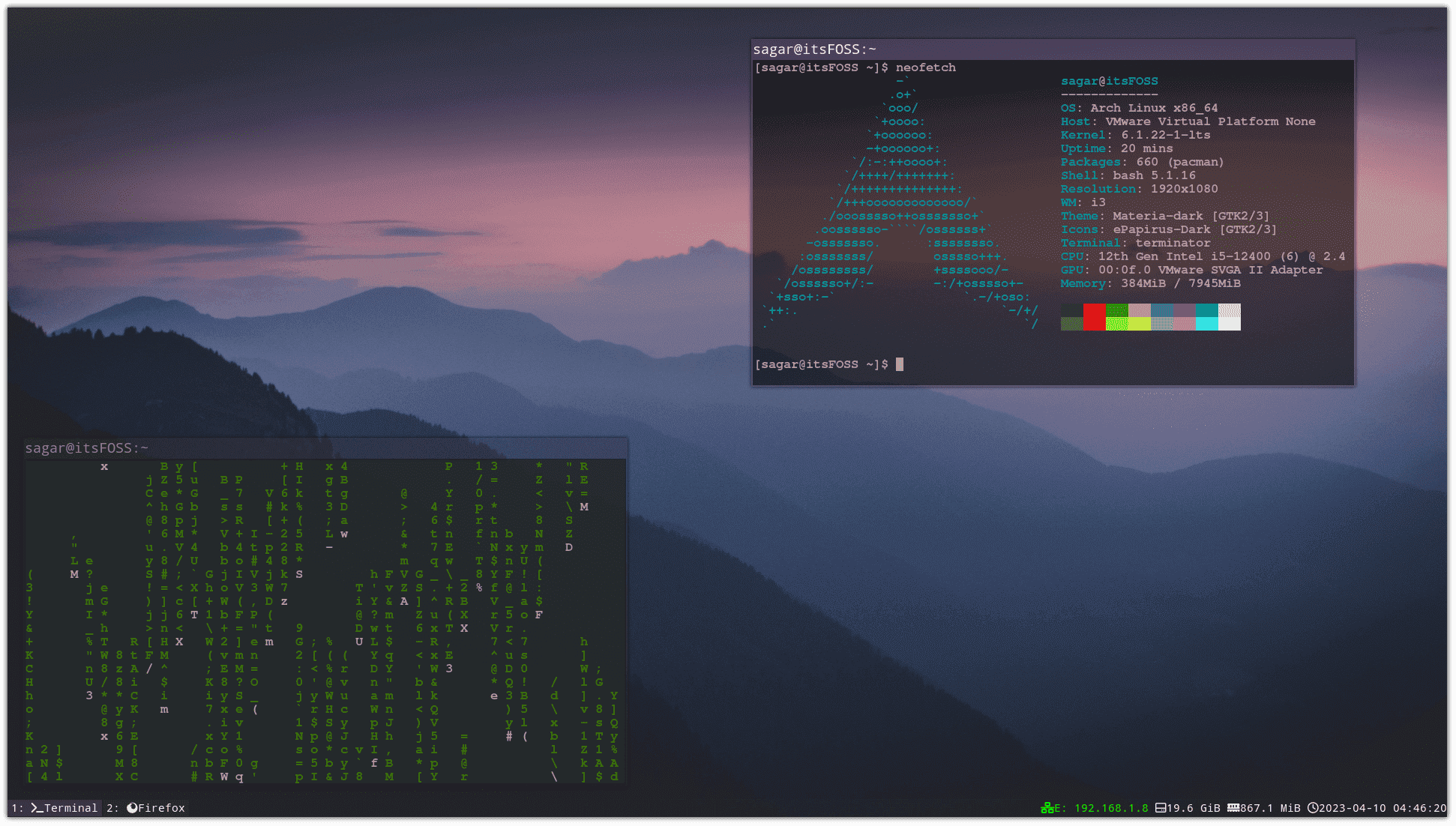
## Use i3 Blocks in the window manager
The default bar you get with i3 is useless (in my opinion); how about making it functional?
In this part, I will explain how you can add:
**Package updates****Memory usage****Disk usage****Volume indicator****Spotify indicator**
But before that, you'd have to make some arrangements to store scripts and instruct i3 to use the configuration of i3block instead of i3bar.
If you followed the given instructions at the beginning of this guide, the i3blocks is already installed, and the config file is located at `/etc/i3blocks.conf`
.
*Want to download the block config files to quickly set them up without reading the rest? Considering you know what you are doing by now, you can download them here:*
For this tutorial, I will create a copy and use that instead of the original config file so let's create a directory first to store the copy of the config file:
`mkdir ~/.config/i3blocks`
Now, create a copy for the original config file:
`sudo cp /etc/i3blocks.conf ~/.config/i3blocks/`
And finally, use the chown command to change the owner of the file which will let you make the desired changes:
`sudo chown $USER:$USER ~/.config/i3blocks/i3blocks.conf`
To enable the i3blocks, you have to make some changes to the i3 config file:
`nano ~/.config/i3/config`
Go to the `bar {...}`
section and here, you'd have to change the status_command with `i3blocks`
and add the path to the i3blocks config file as shown:
Once done, restart the I3 window manager using `Mod + Shift + r`
and the entire status bar will be changed and look like this:

Don't worry; you will make it more valuable and good-looking than your previous i3bar in no time.
### Adding disk block
Add this block if you want to display the space left on the disk.
Here, I will use the nano to create and open the config file for the disk block.
`nano ~/.config/scripts/disk`
And paste the following lines:
```
#!/usr/bin/env sh
DIR="${DIR:-$BLOCK_INSTANCE}"
DIR="${DIR:-$HOME}"
ALERT_LOW="${ALERT_LOW:-$1}"
ALERT_LOW="${ALERT_LOW:-10}" # color will turn red under this value (default: 10%)
LOCAL_FLAG="-l"
if [ "$1" = "-n" ] || [ "$2" = "-n" ]; then
LOCAL_FLAG=""
fi
df -h -P $LOCAL_FLAG "$DIR" | awk -v label="$LABEL" -v alert_low=$ALERT_LOW '
/\/.*/ {
# full text
print label $4
# short text
print label $4
use=$5
# no need to continue parsing
exit 0
}
END {
gsub(/%$/,"",use)
if (100 - use < alert_low) {
# color
print "#FF0000"
}
}
'
```
Save changes and exit from the text editor.
Now, make this file executable:
`sudo chmod +x ~/.config/scripts/disk`
Next, open the I3blocks config file :
`nano ~/.config/i3blocks/i3blocks.conf`
And paste the following lines according to whether you want to place the disk block:
```
[disk]
command=/home/$USER/.config/scripts/disk
LABEL=
#DIR=$HOME
#ALERT_LOW=10
interval=30
```
Once done, save the changes and restart the I3 using `Mod + Shift + r`
and the available disk space will reflect with the disk icon in the status bar.
**Suggested Read 📖**
[How to Properly Theme KDE Plasma [An in-depth Guide]If you have been using Linux for some time, you know about KDE Plasma, the desktop environment. Many distributions ship KDE Plasma as the default (or flagship) desktop environment. Hence, it is not surprising to find it among the best desktop environments. KDE Plasma desktop is famous…](https://itsfoss.com/properly-theme-kde-plasma/)

### Adding memory block
This will be a block in the status bar indicating the memory used in the system.
First, create and open a new file for a new block:
`nano ~/.config/scripts/memory`
And paste the following line in the new file:
```
#!/usr/bin/env sh
TYPE="${BLOCK_INSTANCE:-mem}"
PERCENT="${PERCENT:-true}"
awk -v type=$TYPE -v percent=$PERCENT '
/^MemTotal:/ {
mem_total=$2
}
/^MemFree:/ {
mem_free=$2
}
/^Buffers:/ {
mem_free+=$2
}
/^Cached:/ {
mem_free+=$2
}
/^SwapTotal:/ {
swap_total=$2
}
/^SwapFree:/ {
swap_free=$2
}
END {
if (type == "swap") {
free=swap_free/1024/1024
used=(swap_total-swap_free)/1024/1024
total=swap_total/1024/1024
} else {
free=mem_free/1024/1024
used=(mem_total-mem_free)/1024/1024
total=mem_total/1024/1024
}
pct=0
if (total > 0) {
pct=used/total*100
}
# full text
if (percent == "true" ) {
printf("%.1fG/%.1fG (%.f%%)\n", used, total, pct)
} else {
printf("%.1fG/%.1fG\n", used, total)
}
# short text
printf("%.f%%\n", pct)
# color
if (pct > 90) {
print("#FF0000")
} else if (pct > 80) {
print("#FFAE00")
} else if (pct > 70) {
print("#FFF600")
}
}
' /proc/meminfo
```
Save changes and exit from the text editor.
Now, to make this work, you'd have to make this file executable using the following command:
`sudo chmod +x ~/.config/scripts/memory`
Next, open the I3blocks config file:
`nano ~/.config/i3blocks/i3blocks.conf`
And paste the following at the place where you want to show the RAM consumption in the status bar:
```
[memory]
command=/home/$USER/.config/scripts/memory
label=
interval=30
```
Save changes and exit from the text editor. Restart i3 to take effect from the changes!
### Adding the update indicator block
This is the most helpful indicator, as it shows the number of old packages that need to be updated.
First, install use the following command to install dependencies to make this work:
`sudo pacman -S pacman-contrib`
Now, create a new file that will be used to store the script:
`nano ~/.config/scripts/arch-update`
And paste the following:
```
#!/usr/bin/env python3
import subprocess
from subprocess import check_output
import argparse
import os
import re
def create_argparse():
def _default(name, default='', arg_type=str):
val = default
if name in os.environ:
val = os.environ[name]
return arg_type(val)
strbool = lambda s: s.lower() in ['t', 'true', '1']
strlist = lambda s: s.split()
parser = argparse.ArgumentParser(description='Check for pacman updates')
parser.add_argument(
'-b',
'--base_color',
default = _default('BASE_COLOR', 'green'),
help='base color of the output(default=green)'
)
parser.add_argument(
'-u',
'--updates_available_color',
default = _default('UPDATE_COLOR', 'yellow'),
help='color of the output, when updates are available(default=yellow)'
)
parser.add_argument(
'-a',
'--aur',
action = 'store_const',
const = True,
default = _default('AUR', 'False', strbool),
help='Include AUR packages. Attn: Yaourt must be installed'
)
parser.add_argument(
'-y',
'--aur_yay',
action = 'store_const',
const = True,
default = _default('AUR_YAY', 'False', strbool),
help='Include AUR packages. Attn: Yay must be installed'
)
parser.add_argument(
'-q',
'--quiet',
action = 'store_const',
const = True,
default = _default('QUIET', 'False', strbool),
help = 'Do not produce output when system is up to date'
)
parser.add_argument(
'-w',
'--watch',
nargs='*',
default = _default('WATCH', arg_type=strlist),
help='Explicitly watch for specified packages. '
'Listed elements are treated as regular expressions for matching.'
)
return parser.parse_args()
def get_updates():
output = ''
try:
output = check_output(['checkupdates']).decode('utf-8')
except subprocess.CalledProcessError as exc:
# checkupdates exits with 2 and no output if no updates are available.
# we ignore this case and go on
if not (exc.returncode == 2 and not exc.output):
raise exc
if not output:
return []
updates = [line.split(' ')[0]
for line in output.split('\n')
if line]
return updates
def get_aur_yaourt_updates():
output = ''
try:
output = check_output(['yaourt', '-Qua']).decode('utf-8')
except subprocess.CalledProcessError as exc:
# yaourt exits with 1 and no output if no updates are available.
# we ignore this case and go on
if not (exc.returncode == 1 and not exc.output):
raise exc
if not output:
return []
aur_updates = [line.split(' ')[0]
for line in output.split('\n')
if line.startswith('aur/')]
return aur_updates
def get_aur_yay_updates():
output = check_output(['yay', '-Qua']).decode('utf-8')
if not output:
return []
aur_updates = [line.split(' ')[0] for line in output.split('\n') if line]
return aur_updates
def matching_updates(updates, watch_list):
matches = set()
for u in updates:
for w in watch_list:
if re.match(w, u):
matches.add(u)
return matches
label = os.environ.get("LABEL","")
message = "{0}<span color='{1}'>{2}</span>"
args = create_argparse()
updates = get_updates()
if args.aur:
updates += get_aur_yaourt_updates()
elif args.aur_yay:
updates += get_aur_yay_updates()
update_count = len(updates)
if update_count > 0:
if update_count == 1:
info = str(update_count) + ' update available'
short_info = str(update_count) + ' update'
else:
info = str(update_count) + ' updates available'
short_info = str(update_count) + ' updates'
matches = matching_updates(updates, args.watch)
if matches:
info += ' [{0}]'.format(', '.join(matches))
short_info += '*'
print(message.format(label, args.updates_available_color, info))
print(message.format(label, args.updates_available_color, short_info))
elif not args.quiet:
print(message.format(label, args.base_color, 'system up to date'))
```
Save changes and exit from the text editor.
Now, make this file executable using the following:
`sudo chmod +x ~/.config/scripts/arch-update`
Next, open the i3blocks config file:
`nano ~/.config/i3blocks/i3blocks.conf`
And paste the following lines at desired space:
```
[arch-update]
command=/home/$USER/.config/scripts/arch-update
interval=3600
markup=pango
LABEL=
```
Save the changes and reload the i3 window manager, and it will show the number of packages that need to be updated.
And if you are using Ubuntu, you can [follow these instructions on the GitHub page](https://github.com/vivien/i3blocks-contrib/tree/master/apt-upgrades).
### Adding volume indicator block
Adding a volume indicator block takes a little bit more effort as you want to behave as you would expect. So, the things that you need to achieve with the block are:
**Adding key bindings to manage volume with media control keys****Adding a volume block indicating the volume**
But to do so, first, you'd have to install some dependencies.
So if you are using Arch, use the following:
`sudo pacman -S pulseaudio-alsa pulseaudio-bluetooth pulseaudio-equalizer pulseaudio-jack alsa-utils playerctl`
And if you're using Ubuntu/Debian base, use the following:
`sudo apt install pulseaudio-module-bluetooth pulseaudio-equalizer pulseaudio-module-jack alsa-utils playerctl`
Now, let's look at how you can enable the media control keys in the i3 window manager.
First, open the i3 config file:
`nano ~/.config/i3/config`
Go to the end of the file and paste the following:
```
# Key bindings for Media control keys
bindsym XF86AudioPlay exec playerctl play
bindsym XF86AudioPause exec playerctl pause
bindsym XF86AudioNext exec playerctl next
bindsym XF86AudioPrev exec playerctl previous
```
Now, let's create a new file for this block:
`nano ~/.config/scripts/volume`
And paste the following:
```
#!/usr/bin/env bash
if [[ -z "$MIXER" ]] ; then
MIXER="default"
if command -v pulseaudio >/dev/null 2>&1 && pulseaudio --check ; then
# pulseaudio is running, but not all installations use "pulse"
if amixer -D pulse info >/dev/null 2>&1 ; then
MIXER="pulse"
fi
fi
[ -n "$(lsmod | grep jack)" ] && MIXER="jackplug"
MIXER="${2:-$MIXER}"
fi
if [[ -z "$SCONTROL" ]] ; then
SCONTROL="${BLOCK_INSTANCE:-$(amixer -D $MIXER scontrols |
sed -n "s/Simple mixer control '\([^']*\)',0/\1/p" |
head -n1
)}"
fi
# The first parameter sets the step to change the volume by (and units to display)
# This may be in in % or dB (eg. 5% or 3dB)
if [[ -z "$STEP" ]] ; then
STEP="${1:-5%}"
fi
NATURAL_MAPPING=${NATURAL_MAPPING:-0}
if [[ "$NATURAL_MAPPING" != "0" ]] ; then
AMIXER_PARAMS="-M"
fi
#------------------------------------------------------------------------
capability() { # Return "Capture" if the device is a capture device
amixer $AMIXER_PARAMS -D $MIXER get $SCONTROL |
sed -n "s/ Capabilities:.*cvolume.*/Capture/p"
}
volume() {
amixer $AMIXER_PARAMS -D $MIXER get $SCONTROL $(capability)
}
```
Save changes and exit from the config file.
Next, open the I3blocks config file:
`nano ~/.config/i3blocks/i3blocks.conf`
And paste the following:
```
[volume]
command=/home/$USER/.config/scripts/volume
LABEL=♪
#LABEL=VOL
interval=1
signal=10
#STEP=5%
MIXER=default
#SCONTROL=[determined automatically]
#NATURAL_MAPPING=0
```
Save changes and reload the I3 and from now on, the volume shortcuts will work and the indicator will work as expected!
`systemctl --user disable --now pipewire.{socket,service} && systemctl --user mask pipewire.socket`
### Adding Spotify block
I will be using a script from [firatakandere](https://github.com/firatakandere) to add this. You can check it out before going through it.
First, create and open a new file for the Spotify block:
`nano ~/.config/scripts/spotify.py`
And paste the following:
```
#!/usr/bin/python
import dbus
import os
import sys
try:
bus = dbus.SessionBus()
spotify = bus.get_object("org.mpris.MediaPlayer2.spotify", "/org/mpris/MediaPlayer2")
if os.environ.get('BLOCK_BUTTON'):
control_iface = dbus.Interface(spotify, 'org.mpris.MediaPlayer2.Player')
if (os.environ['BLOCK_BUTTON'] == '1'):
control_iface.Previous()
elif (os.environ['BLOCK_BUTTON'] == '2'):
control_iface.PlayPause()
elif (os.environ['BLOCK_BUTTON'] == '3'):
control_iface.Next()
spotify_iface = dbus.Interface(spotify, 'org.freedesktop.DBus.Properties')
props = spotify_iface.Get('org.mpris.MediaPlayer2.Player', 'Metadata')
if (sys.version_info > (3, 0)):
print(str(props['xesam:artist'][0]) + " - " + str(props['xesam:title']))
else:
print(props['xesam:artist'][0] + " - " + props['xesam:title']).encode('utf-8')
exit
except dbus.exceptions.DBusException:
exit
```
Once done, use the following command to make it executable:
`sudo chmod +x ~/.config/scripts/spotify.py`
Now, open the I3blocks config file:
`nano ~/.config/i3blocks/i3blocks.conf`
And paste the following lines (I would recommend you paste them at the beginning of the block):
```
[spotify]
label=
command=/home/$USER/.config/scripts/spotify.py
color=#81b71a
interval=5
```
Save changes, exit from the config file, and restart the I3.
Once you added the blocks I mentioned, the bar will look like this:

You can take a look at my home screen with the blocks (by clicking on the image below).
## Use I3 gaps in Linux
If you want to have gaps between the windows, you can use `i3gaps`
and after color schemes, `I3gaps`
is the most crucial element in this guide.
To use the gaps, you must make some changes in the i3 config file.
So open the I3 config file:
`nano ~/.config/i3/config`
Go to the end of the file and paste the following:
```
# default gaps
gaps inner 15
gaps outer 5
# gaps
set $mode_gaps Gaps: (o)uter, (i)nner, (h)orizontal, (v)ertical, (t)op, (r)ight, (b)ottom, (l)eft
set $mode_gaps_outer Outer Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_inner Inner Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_horiz Horizontal Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_verti Vertical Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_top Top Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_right Right Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_bottom Bottom Gaps: +|-|0 (local), Shift + +|-|0 (global)
set $mode_gaps_left Left Gaps: +|-|0 (local), Shift + +|-|0 (global)
bindsym $mod+Shift+g mode "$mode_gaps"
mode "$mode_gaps" {
bindsym o mode "$mode_gaps_outer"
bindsym i mode "$mode_gaps_inner"
bindsym h mode "$mode_gaps_horiz"
bindsym v mode "$mode_gaps_verti"
bindsym t mode "$mode_gaps_top"
bindsym r mode "$mode_gaps_right"
bindsym b mode "$mode_gaps_bottom"
bindsym l mode "$mode_gaps_left"
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_outer" {
bindsym plus gaps outer current plus 5
bindsym minus gaps outer current minus 5
bindsym 0 gaps outer current set 0
bindsym Shift+plus gaps outer all plus 5
bindsym Shift+minus gaps outer all minus 5
bindsym Shift+0 gaps outer all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_inner" {
bindsym plus gaps inner current plus 5
bindsym minus gaps inner current minus 5
bindsym 0 gaps inner current set 0
bindsym Shift+plus gaps inner all plus 5
bindsym Shift+minus gaps inner all minus 5
bindsym Shift+0 gaps inner all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_horiz" {
bindsym plus gaps horizontal current plus 5
bindsym minus gaps horizontal current minus 5
bindsym 0 gaps horizontal current set 0
bindsym Shift+plus gaps horizontal all plus 5
bindsym Shift+minus gaps horizontal all minus 5
bindsym Shift+0 gaps horizontal all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_verti" {
bindsym plus gaps vertical current plus 5
bindsym minus gaps vertical current minus 5
bindsym 0 gaps vertical current set 0
bindsym Shift+plus gaps vertical all plus 5
bindsym Shift+minus gaps vertical all minus 5
bindsym Shift+0 gaps vertical all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_top" {
bindsym plus gaps top current plus 5
bindsym minus gaps top current minus 5
bindsym 0 gaps top current set 0
bindsym Shift+plus gaps top all plus 5
bindsym Shift+minus gaps top all minus 5
bindsym Shift+0 gaps top all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_right" {
bindsym plus gaps right current plus 5
bindsym minus gaps right current minus 5
bindsym 0 gaps right current set 0
bindsym Shift+plus gaps right all plus 5
bindsym Shift+minus gaps right all minus 5
bindsym Shift+0 gaps right all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_bottom" {
bindsym plus gaps bottom current plus 5
bindsym minus gaps bottom current minus 5
bindsym 0 gaps bottom current set 0
bindsym Shift+plus gaps bottom all plus 5
bindsym Shift+minus gaps bottom all minus 5
bindsym Shift+0 gaps bottom all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
mode "$mode_gaps_left" {
bindsym plus gaps left current plus 5
bindsym minus gaps left current minus 5
bindsym 0 gaps left current set 0
bindsym Shift+plus gaps left all plus 5
bindsym Shift+minus gaps left all minus 5
bindsym Shift+0 gaps left all set 0
bindsym Return mode "$mode_gaps"
bindsym Escape mode "default"
}
```
Save changes and exit from the config file.
Reload i3 using `Mod + Shift + r`
and you'd see the gaps between windows:
But what if you want to resize the gaps? It is quite simple and can be done in simple steps:
- Press
`Mod + Shift + g`
to enter the gaps mode - Choose what you want to change by using the given options
- Use
`+`
or`-`
to increase/decrease gaps - Once done, press the
`Esc`
key to exit the gaps mode
And that's it!
## Did we forget to customize the Terminal?
Fret not; you can [switch to ZSH](https://itsfoss.com/zsh-ubuntu/), a different shell, to make the terminal look different or explore some lesser-known [Linux shells](https://itsfoss.com/shells-linux/).
Either way, you can [customize the existing terminal](https://itsfoss.com/customize-linux-terminal/) or pick different [terminal emulators](https://itsfoss.com/linux-terminal-emulators/).
**I hope you will no longer fear ricing! **😎
*If you have any suggestions or want to show off your setup, please do so in the comments section.* |
15,957 | 真正轻量级的 Linux 记事本 | https://www.debugpoint.com/lightweight-notepad-linux/ | 2023-07-01T11:17:00 | [
"记事本"
] | /article-15957-1.html |
>
> 轻量级、资源友好的基于 GUI 的基本记事本列表,适用于 Ubuntu 和其他 Linux。
>
>
>

Linux 是一个因其速度、稳定性和灵活性而广受欢迎的操作系统。Linux 的一个关键特点是能够根据你的需求自定义和配置系统。这包括选择适合你系统的正确应用程序和工具。本教程将介绍一些适用于 Linux 的最佳轻量级记事本。我们将查看它们的特点、优缺点,并提供选择适合你需求的正确记事本的建议。无论你是学生、程序员,还是喜欢做笔记的普通用户,一款优秀的记事本对于任何 Linux 用户来说都是必不可少的工具。
### Ubuntu 和其他发行版的最佳轻量级记事本
#### 1、Mousepad
该列表中的第一个是流行的文本编辑器 - Mousepad。它是 Xfce 桌面环境的默认文本编辑器,使用 GTK 开发。它简单轻便,但与本列表中的 Leafpad 相比,它具有更多的设置和功能。
你可以将其视为具有一些额外功能的 Leafpad。
其关键特点包括深浅色主题、标签式编辑、字体和插件功能。你可以在安装后和使用过程中发现更多类似的设置。
下面是其外观示例:

由于 Mousepad 在所有主要的 Linux 发行版仓库中都可用,所以安装非常简单。
对于 Ubuntu、Linux Mint 和相关发行版,使用以下命令进行安装。
```
sudo apt install mousepad
```
对于 Fedora Linux,请使用以下命令:
```
sudo dnf install mousepad
```
而 Arch Linux 用户可以使用以下命令进行安装:
```
sudo pacman -S mousepad
```
#### 2、Featherpad
[FeatherPad](https://github.com/tsujan/FeatherPad) 是一个独立于桌面环境的基于 Qt 的轻量级文本编辑器,适用于 Ubuntu 和其他 Linux 发行版。它的一些关键特性包括拖放支持、分离和附加标签、虚拟桌面感知,以及一个可选的固定搜索栏,并有每个标签的入口。
此外,它可以在搜索时立即突出显示找到的匹配项,提供了一个停靠窗口用于文本替换,并支持显示行号和跳转到特定行。
此外,Featherpad 可以检测文本编码,为常见的编程语言提供语法高亮,并支持会话管理。它还具有拼写检查(使用 Hunspell)、文本缩放、打印和自动保存等功能。

安装 Featherpad 很简单。
对于 Ubuntu 和相关的发行版,你可以使用终端中的以下命令进行安装:
```
sudo apt install featherpad
```
对于 Fedora Linux,请使用以下命令进行安装:
```
sudo dnf install featherpad
```
Arch Linux 用户可以使用以下命令进行安装:
```
sudo pacman -S featherpad
```
#### 3、Leafpad
[Leafpad](http://tarot.freeshell.org/leafpad/v) 是一个基于 GTK 的简单的轻量级 Linux 文本编辑器。它旨在快速、易于使用,并且需要最少的资源。Leafpad 具有干净直观的用户界面,提供了你所需的所有基本文本编辑工具,如剪切、复制和粘贴,并支持撤消和重做。此外,它还支持多种编程语言的语法高亮,使其成为程序员的有用工具。
由于其简单和高效性,Leafpad 是 Linux 用户的热门选择。它可能是 Windows 记事本应用程序的完美替代品。它具有所有基本功能,包括自动换行、行号、字体选择和自动缩进。
下面是它的外观示例。这是列表中最简单和轻量级的记事本。

但是,在 Ubuntu 上安装 Leafpad 有些棘手。不幸的是,它在 Universe 仓库中不可用,只能作为 Snap 软件包而不是 Flatpak 软件包使用。
但是,你可以从 Debian 仓库中获取并在 Ubuntu 中安装它。
从 Debian 仓库下载 deb 文件,并使用以下命令进行安装。
```
wget http://ftp.us.debian.org/debian/pool/main/l/leafpad/leafpad_0.8.18.1-5_amd64.deb
```
```
sudo dpkg -i leafpad_0.8.18.1-5_amd64.deb
```
Fedora 用户可以使用以下命令进行安装:
```
sudo dnf install leafpad
```
Arch Linux 用户可以使用以下命令进行安装:
```
sudo pacman -S leafpad
```
#### 4、Beaver 编辑器
[Beaver](https://sourceforge.net/projects/beaver-editor/) 编辑器是一个轻量级、启动快速的文本编辑器,具有极少的依赖性。它是基于 GTK+2 库构建的,不需要额外安装的库,非常适合在较旧的计算机和小型 Linux 发行版上使用。Beaver 的核心功能包括基本功能和语法高亮,还可以通过插件添加额外功能。其界面简洁高效,并包含高质量的 Tango 美术作品。

这是一个有些老旧的应用程序,但它仍然正常工作。目前,它仅适用于 Ubuntu 和相关的发行版。你可以下载预编译的 deb 文件,并使用以下命令进行安装:
```
wget https://www.bristolwatch.com/debian/packages/beaver_amd64.deb
```
```
sudo dpkg -i beaver_amd64.deb
```
#### 5、Gedit
[Gedit 文本编辑器](https://wiki.gnome.org/Apps/Gedit) 是 GNOME 桌面环境的默认文本编辑器,被数百万用户在诸如 Ubuntu 和 Fedora 等各种 Linux 发行版上使用。它是核心 GNOME 应用程序的一部分,旨在成为一个轻量级的通用文本编辑器。然而,通过其设置和已安装的插件,Gedit 也包含许多增强生产力的功能,使得它能够与其他流行的文本编辑器竞争。
尽管如此,它最近已经从 GNOME 桌面的默认编辑器标签中“降级”。基于现代 GTK4 的 [GNOME 文本编辑器](https://www.debugpoint.com/gnome-text-editor/) 已取而代之。
但它仍然是最好的编辑器之一,你可以通过插件和 [各种技巧](https://www.debugpoint.com/gedit-features/) 将其从简单的编辑器扩展为更高级的编辑器。

要安装它,请使用以下命令(针对 Ubuntu 和相关发行版):
```
sudo apt install gedit
```
对于 Fedora Linux 用户,请使用以下命令进行安装。
```
sudo dnf install gedit
```
最后,Arch Linux 用户可以使用以下命令进行安装:
```
sudo pacman -S gedit
```
#### 6. Xed
如果你使用 Linux Mint,那么你可能听说过 Xed。Xed 是 Linux Mint 的默认文本编辑器,它非常轻量级。作为一个 “Xapp” 应用程序,它遵循 Linux Mint 的设计和功能指南,提供简单的用户界面、强大的菜单、工具栏和功能。
Xed 的一些主要特点包括:
* 传统的用户界面,保持简洁易用
* 强大的工具栏和上下文菜单选项,增强功能的能力
* 语法高亮显示
* 配置选项,如标签、编码等
* 支持 UTF-8 文本
* 编辑远程服务器文件
* 广泛的插件支持,可根据需要添加更多高级功能
* 支持概览地图
* 可缩放的编辑窗口
Xed 是最好的编辑器之一,可作为 Linux 系统上轻量级记事本的替代品。

如果你使用的是 Linux Mint,它应该是默认安装的。然而,在 Ubuntu 中安装它需要运行一系列命令。打开终端并运行以下命令来在 Ubuntu 中安装 Xed。
```
wget http://packages.linuxmint.com/pool/import/i/inxi/inxi_3.0.32-1-1_all.deb
wget http://packages.linuxmint.com/pool/backport/x/xapp/xapps-common_2.4.2+vera_all.deb
wget http://packages.linuxmint.com/pool/backport/x/xapp/libxapp1_2.4.2+vera_amd64.deb
wget http://packages.linuxmint.com/pool/backport/x/xed/xed-common_3.2.8+vera_all.deb
wget http://packages.linuxmint.com/pool/backport/x/xed/xed_3.2.8+vera_amd64.deb
```
```
sudo dpkg -i inxi_3.0.32-1-1_all.deb
sudo dpkg -i xapps-common_2.4.2+vera_all.deb
sudo dpkg -i libxapp1_2.4.2+vera_amd64.deb
sudo dpkg -i xed-common_3.2.8+vera_all.deb
sudo dpkg -i xed_3.2.8+vera_amd64.deb
```
有关更多详情,请访问 [Xed 的 GitHub 存储库](https://github.com/linuxmint/xed)。
### 内存和资源比较
由于我们在讨论性能,这是比较的关键,我们列出了上述所有应用程序在最新的 Ubuntu 安装中消耗的内存。
正如你所看到的,Xfce 的 Mousepad 最轻量级,而 Gedit 最占资源。
| 应用程序名称 | Ubuntu 闲置时消耗的内存 |
| --- | --- |
| Mousepad | 303 KB |
| Featherpad | 1.7 MB |
| Leafpad | 7.7 MB |
| Beaver pad | 11.1 MB |
| Gedit | 30.2 MB |
| Xed | 32.1 MB |
### 总结
总之,在 Linux 上选择一个轻量级的记事本对于各种用途至关重要。无论你是需要记笔记、编写代码还是编辑文本,轻量级记事本可以让你的工作更快、更轻松、更高效。Linux 操作系统提供了各种记事本应用程序,每个应用程序都具有其独特的功能和能力。
这份轻量级 Linux 记事本的前几名(应用程序)列表探讨了一些应用程序,包括 Leafpad、Gedit、Mousepad 和其他应用程序。
无论你选择哪个记事本,你可以确信它将提供你在 Linux 系统上完成工作所需的功能。
你最喜欢哪个?在评论框里告诉我吧。
---
via: <https://www.debugpoint.com/lightweight-notepad-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,958 | 在 Debian 中将用户添加到 SUDOERS 组的 2 种方法 | https://www.debugpoint.com/add-users-sudoers/ | 2023-07-01T17:40:00 | [
"sudo"
] | /article-15958-1.html | 
>
> 以下是如何将用户添加到 Debian Linux 中的 SUDOERS 组的方法。
>
>
>
在 Debian Linux 中,SUDOERS 组在向用户授予管理权限方面发挥着至关重要的作用。将用户添加到 SUDOERS 组使他们能够以 root 权限执行命令,从而为他们提供必要的管理访问权限以在 Debian 系统上执行各种任务。
在安装 Debian Linux 的过程中,如果你将 `root` 帐户的密码保留为空,那么系统中的 [创建的第一个用户](https://www.debian.org/releases/stable/amd64/ch06s03.en.html#user-setup-root) 将拥有管理权限。但是,如果你设置了 `root` 密码,那么用户名将不具有 sudo 权限。因此,在使用用户帐户执行管理任务时,你可能会遇到以下类似的错误。
```
<username> is not in the sudoers file. This incident will be reported.
```

本文旨在提供有关在 Debian 中向 SUDOERS 组添加用户的分步指南,确保你可以有效地管理用户权限和系统安全。
### 如何将用户添加到 Debian 中的 SUDOERS 组
要将用户添加到 Debian 中的 SUDOERS 组,请按照以下简单步骤操作:
* 单击“终端”图标或使用快捷键 `Ctrl+Alt+T`,打开 Debian 系统上的终端。
* 使用以下命令切换到 root 用户:
```
su -
```
系统将提示你提供 root 密码。输入 root 密码并按回车键。
以 root 用户身份登录后,输入以下命令。确保根据你的用户名进行更改。在此示例中,将 `arindam` 替换为你的用户名。
```
/sbin/addgroup arindam sudo
```
如果上面的命令无效,还可以使用下面的命令:
```
usermod -aG sudo arindam
```
按退出离开 root 提示符。注销并重新登录。现在你可以使用你的用户名执行任何管理操作。
### 另一种方法
你可以使用与下面相同的命令进入 root 帐户。使用 root 账号登录:
```
su -
```
然后使用 `nano` 或 `visudo` 或任何编辑器打开 `/etc/sudoers` 文件。
```
nano /etc/sudoers
```
添加以下行和用户名。根据你的用户名替换 `arindam`。
```
arindam ALL=(ALL) ALL
```
保存并关闭文件。然后,注销并重新登录。这应该会给用户名 root 权限。
### 验证 SUDOERS 组成员
要验证用户是否已成功添加到 SUDOERS 组,你可以打开一个新的终端窗口并输入以下命令。将 `arindam` 替换为你添加到 SUDOERS 组的用户的实际用户名。
```
sudo -l -U arindam
```
如果用户是 SUDOERS 组的成员,你将看到他们拥有的权限列表。这是一个示例,你可以看到我的用户名具有所有访问权限。

### 结束语
将用户添加到 SUDOERS 组将授予他们重要的管理权限。在授予用户此类访问权限之前,仔细考虑用户的可信度和责任非常重要。sudo 使用不当可能会导致系统意外损坏或受损。
请记住在委派管理权限时要小心谨慎,并定期检查用户权限以维护安全的 Debian 系统。
*(题图:MJ/c71c2f28-51c7-44c7-87be-af88088bf459)*
---
via: <https://www.debugpoint.com/add-users-sudoers/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,961 | 观点:红帽公司的自杀企图 | https://news.itsfoss.com/red-hat-fiasco/ | 2023-07-02T17:20:00 | [
"红帽",
"RHEL",
"CentOS"
] | https://linux.cn/article-15961-1.html |
>
> 红帽公司将其源代码放在付费墙后面的最新决定,今天可能会对其直接竞争对手造成一定伤害,但对红帽公司自身而言,这将对之后产生负面影响。
>
>
>

基于我对 RHEL 和其他红帽产品的热爱,我不得不现在表达一些严厉的看法。**我**之所以这样做,是因为我希望 RHEL [及/或其克隆版] 对每个人都是 *可获得的*。
请原谅这次我用词有些激烈,因为我从内心不希望 RHEL 成为 **对业余爱好者不可及** 的产品。免费的 RHEL 开发者许可证只是转移话题而已,相比于 **真正的 RHEL 克隆版存在的时候**,它削弱了 **广大动手爱好者社区** 的热情。
>
> ?️ 对于我的使用场景来说,使用免费订阅的 RHEL 使我感到满意。实际上,我正在使用的就是免费订阅。本文是关于如果保持这种状态会对 RHEL 产生怎样的影响。
>
>
>
### 快速回顾:事情是如何走到这一步的
我相信你现在都已经知道为什么红帽公司最近频频出现在新闻中:
但是,如果你对正在发生的事情一无所知,让我给你一个快速时间线的指引,帮助你理解:
1. 红帽公司拥有一个**出色**的 Linux 发行版,名为 <ruby> 红帽企业 Linux <rt> Red Hat Enterprise Linux </rt></ruby>(RHEL),支持周期长达 **10** 年。
2. 与其他任何 Linux 发行版一样,用于构建 RHEL(或 RHEL 的 **克隆版**)的源代码是公开可用的。
3. CentOS 利用上述源代码,去除商标,并创建了一个几乎 1 比 1 的 RHEL 拷贝。(我说“几乎”是因为 RHEL 的商标 **必须** 被删除。)
4. 那些不愿意支付费用只是为了第一次尝试 RHEL 的爱好者社区,现在可以使用 CentOS 来看看是否喜欢它。
5. 这个人中的一部分人随后向他们的高层管理人员介绍了 RHEL 及其 **通过 CentOS 初步体验** 到的卓越表现,他们很可能转向在 RHEL 上支持他们的产品或在部署中使用 RHEL。
6. 由于 CentOS 是免费的,爱好者社区得以扩大。像 [Jeff Geerling](https://www.jeffgeerling.com:443/) 这样的人使用 CentOS 来教授对 **扮演系统管理员感兴趣** 的新一代爱好者,让他们了解他的 [开源存储库](https://github.com:443/geerlingguy?tab=repositories&q=ansible&type=&language=&sort=) 中诸如 Ansible 之类的很棒的内容。
7. CentOS 的二进制文件在 RHEL 更新后几周才发布。因此,[红帽收购了 CentOS](https://www.redhat.com:443/en/about/press-releases/red-hat-and-centos-join-forces),以确保 CentOS 不会落后于 RHEL 的更新。
8. 几年后,[CentOS Stream](https://itsfoss.com:443/centos-stream-faq/) 的惨淡出场,导致了 CentOS 的消亡。
9. [Rocky Linux](https://rockylinux.org:443/about) 和 [Alma Linux](https://almalinux.org:443/blog/introducing-almalinux-beta-a-community-driven-replacement-for-centos/) 出现填补了 CentOS 留下的空白。它们使用的是公开可用的 RHEL 源代码。
10. 红帽公司开始限制源代码的访问,只允许其付费客户以及任何拥有免费的开发者订阅的人访问。
>
> ? 我特意没有提到 IBM 收购红帽的事情,因为如果红帽的某个人有勇气在 [官方场合](https://www.redhat.com:443/en/blog/red-hats-commitment-open-source-response-gitcentosorg-changes) 公开说,“**只是简单地重建代码,没有增加价值或以任何方式改变代码,对开源公司来说都是真正的威胁。**”,他们肯定也可以直承 IBM 参与了这些决定。但几乎每个红帽员工都公开否认了这种指责。所以我也不相信 IBM 自己搬起石头砸自己的脚。但你可以根据自己的心来决定是否相信。
>
>
>
>
> 不,当我说 IBM 可能没有参与这个决定时,我并不是在讽刺。他们 **有可能参与**,但我不这么认为。
>
>
>
### 亲爱的红帽公司,你刚刚做了什么?
你向社区提供一款免费的产品(CentOS)。然后你在提供这个免费产品的过程中(CentOS)改变它的的支持周期,并将其“替代品”(CentOS Stream)用作你闪亮的企业产品(RHEL)的“测试场”。
然后那些水蛭们拿起你闪亮产品的源代码,创建了一个 CentOS 的接替者(Rocky Linux 和 Alma Linux)。你不喜欢这样,所以对它们进行了 “软付费墙” 的限制。
现在,虽然 **你有权利这样做**(因为你从为 RHEL 提供支持而不是 RHEL 本身赚钱),但我会解释为什么这对 **你自己来说** 是一个糟糕的举动。
* **问题:** RHEL 在企业环境中为什么如此受欢迎?
* **答案:** CentOS ~~Stream~~。
* **问题:** 在线教程用什么来教授 RHEL?
* **答案:** CentOS ~~Stream~~。
* **问题:** 那些跟随上述在线教程的学习者用什么来学习 RHEL?
* **答案:** CentOS ~~Stream~~。
* **问题:** 当这些学生成为老师时,他们会向询问如何入门 Linux 系统管理员的人推荐什么?
* **答案:** CentOS ~~Stream~~。
* **问题:** 如果有人愿意购买 RHEL 的许可证,但因为没有公开的软件仓库而犹豫不决,他们会用什么?
* **答案:** CentOS ~~Stream~~。
简而言之,如果红帽公司继续对 RHEL 的克隆产品制造麻烦,以下是可能出现的情况:
* 许多参与企业部署的客户和专业人士将考虑放弃 RHEL,并且不再对其提供支持。
* 新用户将开始考虑使用 **Ubuntu、Debian、openSUSE** 或其他长期存在的替代产品。
* 大学和 IT 培训也将转向替代方案,例如 Ubuntu 或 openSUSE,而不再纠结于 RHEL 克隆、CentOS Stream 和 Fedora 之间。
此外,根据他们的 [FAQ](https://developers.redhat.com:443/articles/faqs-no-cost-red-hat-enterprise-linux),小型企业和大学无法使用免费的红帽开发者订阅:
>
> 无费用的、无支持的红帽开发者订阅是为个人和个人帐户设计的。
>
>
>
**除非红帽公司友好对待 RHEL 克隆产品,否则我无法再看到这个生态系统中会有任何新的参与者了。** 这实在令人沮丧,因为 RHEL 是一款出色的产品。是的,它可能不像 Fedora 那样前沿,但是使用起来仍然很有乐趣!
我会引用 Brian Stevens 的 [一句话](https://www.redhat.com:443/en/about/press-releases/red-hat-and-centos-join-forces) 来阐述观点:
>
> 我们的信仰核心是,当有共同目标或问题的人们可以自由地联结和合作时,他们汇集起来的创新可以改变世界。我们相信开源的开发过程能够产生更好的代码,而用户社区会创造出一个让代码具有影响力的受众。
>
>
>
RHEL 是一款企业级发行版,因此红帽公司几乎不会致力于为在树莓派上运行 RHEL 提供支持。猜猜是哪些发行版为树莓派提供了企业级 Linux 镜像。提示一下,它们是 [Rocky Linux](https://rockylinux.org:443/alternative-images/) 和 [Alma Linux](https://almalinux.org:443/blog/almalinux-for-raspberry-pi-updates-october-2021/)。我敢打赌,红帽公司并没有统计出有多少人使用 RHEL 是因为他们先在树莓派上尝试使用 Rocky/Alma Linux,然后转而使用 RHEL。**我就是其中之一**(使用免费的 RHEL 许可证,也就那点价值)。
那么对于 RHEL 来说,这意味着什么?我不是 **先知**(此处双关 “Oracle”,哈哈!),所以无法预测 RHEL 的未来。
我远不是一个“引领潮流者”,也不知道有多少人受到我 [关于 Podman 的报道](https://linuxhandbook.com:443/tag/podman/) 的积极影响。尝试使用 Podman 并非没有原因。我先在 Fedora 上试用,然后通过使用 Rocky Linux 在一个“生产级”环境中进行 **大量实验**,最后在 RHEL 上部署了一些我自己的服务。这并不是说“如果我没有这么做,其他人就不会这样做”,但你不能否认,从我和 **许多其他人** 这样的多方共同努力中产生的内容所带来的 **影响**。顺便说一下,是我促使 [Abhishek](https://itsfoss.com:443/team/) 去报道 Podman,而不是相反。
当然,上述提到的“贡献”有些可能对红帽公司没有帮助,但它们对于 **红帽公司的客户群体** 来说是有帮助的。
### 所以,我们应该感到担忧吗?也是,也不是。
红帽公司做出的决定,从商业角度来看是有道理的。但也不完全是。从短期目标来看是有道理的,但从长期来看则不然。
红帽公司作为一家自豪地向上游贡献的公司,他们不会停止继续贡献。即使通过“软付费墙”来限制 RHEL 的代码,**红帽公司仍将继续向上游贡献**。红帽公司将继续在 [新的](https://fedoramagazine.org:443/announcing-the-display-hdr-hackfest/) [发展](https://news.itsfoss.com/red-hat-accessibility-gnome/) 上 [进行](https://developer.nvidia.com:443/blog/nvidia-releases-open-source-gpu-kernel-modules/) [创新](https://lists.fedoraproject.org:443/archives/list/[email protected]/thread/IXNTPGKHWTW7H7XVMZICSJRUDOHO2KJC/)。
他们只是不再像以前那样将 RHEL 的“秘密配方”(在你期望的意义上)开放了。这个秘密的配方本身并不是“专有的”。红帽在 RHEL 中提供的几乎所有东西都是开源的。
他们的秘密在于 **将补丁向后移植到 RHEL 稳定包** 中。将这些补丁仅提供给 RHEL 的客户,这是一个非常公平的 **商业决策**。这些补丁也可以公开用于同一软件包的 **不同版本**。将补丁应用于使“旧版本”软件包保持最新状态的任务非常困难。
**所以,我理解他们为什么做出这个决定。**
**红帽并没有将 RHEL 变为闭源**(至少从技术上来说)。
红帽依然是一家出色的公司,其拥有经过验证的开源产品组合。我每天都在使用其中一些产品,比如:**在树莓派 4 上运行 RHEL([是的,这是可能的!](https://nitter.net:443/thefossguy/status/1527935333899583488))、(无需 root 的)Podman、Cockpit、Ansible、systemd 等等!**
### 以下你应该感到担忧的原因
如果 RHEL 不是自由提供的 —— 不是指免费,而是像 Debian、Ubuntu 甚至 Fedora 那样无需账户即可下载 —— 那么对于想要进入企业 Linux 生态系统的新人来说,他们的数量将继续减少。我认为是这样……
如果这个数量减少了,实际上推荐企业使用和支付 RHEL 的人数也会减少。你知道这会引发什么样的循环。
* 对 RHEL 感兴趣的新人变少 → 购买的 RHEL 订阅变少
* 红帽的收入减少 → 对上游项目的贡献减少(如 systemd、Podman、Linux 内核、GNOME、Wayland、英伟达合作等)
* 最终 → Linux 生态系统的总体改进变少
当然,红帽并不是唯一向 Linux 生态系统做出贡献的公司,但你不能否认它对推动生态系统全面向前 **流动** 所产生的巨大影响!
### 我对红帽声明的回应
>
> ✋ 我并不是在攻击 Mike McGrath。这只是对他的陈述的直接回应。我相信作为一个 RHEL 用户,我有权利表达自己的观点,因为我非常喜欢它,以至于通过树莓派 4B 上的 RHEL 部署了个人博客。
>
>
>
除非另有说明,以下所有引文均摘自 [这篇博文](https://www.redhat.com:443/en/blog/red-hats-commitment-open-source-response-gitcentosorg-changes)。
#### 引文 1
>
> 我感觉大部分对我们近期对下游源代码的决策所引发的愤怒,大部分来自 **那些不愿意为 RHEL 所付出时间、精力和资源买单的人**,或者那些想要将其重新打包以谋取自己利益的人。
>
>
>
是的,这完全公平,但我要一直强调这一点,直到你意识到,如果没有广大社区在 CentOS 及其后续产品上的培训,RHEL 就什么都不是。
**现在的 IT 专业人员中包括曾经在这个群体中的人,而你现在给他们打上了 “那些不愿意为所付出时间...”的标签。** ?
通过展示这样的立场,你会让更少的人接触企业级 Linux,并且之后使用 RHEL 的人数显著减少。
#### 引文 2
>
> 我们必须为从事这项工作的人支付报酬 —— 那些在漫长的工作时间和夜晚中辛勤工作、相信开源价值观的热情贡献者。简单地将这些个人产生的代码重新打包并原样转售,而没有增加任何价值,会导致这个开源软件的生产不可持续。这包括关键的向后移植工作和 [上游正在开发的未来功能和技术](https://www.redhat.com:443/en/about/our-community-contributions)。如果这项工作变得不可持续,它将停止,这对任何人来说都不好。
>
>
>
这不仅是一个完全合理的观点,而且也是残酷的现实。开源软件的资金不足。当任何人都可以无需付出实际回报就使用你的产品时,为开源软件筹集资金也变得非常困难。
但是,如果社区没有免费获得 RHEL(在限制源代码之前),那么它可能不会像今天这样取得巨大的成功。社区通过自由探索 RHEL,并使其成为更为壮大。
我不是让红帽公司做慈善事业,只是白白地免费提供。我希望红帽公司有足够的资金来改进上游。但是应该在 **某个地方** 找到一种折中方案。
再次强调,免费订阅并不等同于 RHEL 的克隆。当然,我写过关于如何 [免费获取红帽企业版 Linux](https://linuxhandbook.com:443/get-red-hat-linux-free/) 的文章。然而,这并不是相同的精神。我在这里 [引用 Jeff Geerling 的话](https://www.jeffgeerling.com:443/blog/2023/dear-red-hat-are-you-dumb):
>
> “不,请不要说‘但你可以使用你的红帽开发者订阅!’我在 Debian、Ubuntu、Arch 等系统上可以不使用它。你明白我的意思。”
>
>
>
#### 引文 3
>
> 最近,我们已经确定,拥有一个下游的重构者没有价值。
>
>
>
绝对是有价值的!我不会在这里重复我是如何通过 RHEL 的重构版本进入 RHEL 的这一点。
Windows 之所以受欢迎,只是因为微软允许盗版存在(和更便宜的许可证密钥)。
如果他们加强了控制,没有一个家庭会在 Vista 的继任者上花一分钱。我并不是要将 Vista(一款灾难性的操作系统)与 RHEL 进行比较,但这个类比大多数人应该有共鸣,你可以想想没有得到 Windows 许可证退款时的那种不甘。
#### 引文 4
>
> 通常公认的观点是,这些免费重构就是产生 RHEL 专家并转化为销售的渠道,这并不是现实情况。我希望我们生活在那样的世界,但实际情况并非如此。相反,我们发现了一群用户,其中许多用户属于大型或非常大型的 IT 组织,他们希望获得 RHEL 的稳定性、周期和硬件生态系统,而无需实际支持维护者、工程师、编写人员和许多其他角色。
>
>
>
**...你确定吗?** ?
当然,从免费用户转化为 RHEL 客户的转化率可能不是很高,但我敢打赌,这个比例不会低于 30%。如果你坚持这样做,新客户的数量将不到当前新“注册”用户的 10%。
**对于利用免费的 RHEL 开发者许可证也可以提出同样的论点。**对于那些不愿意支付 RHEL 费用的人来说,使用临时电子邮件 ID 创建新的红帽账户以便利用免费的开发者订阅是一项不容忽视的任务。
当我们谈论转化率时,有多少专业人士正是使用 RHEL 的克隆版本进行内部产品开发(以便与 RHEL 进行适配),但实际上为使用 RHEL 的客户提供支持呢?
**你如何衡量由第三方支持提供给客户的价值?** **你不能**,它不是一种可以衡量的有形物质。
我想扯远了,但这确实是真实发生的事件。我目前所使用的 [小镇当地的] ISP 使用 RHEL 对用户进行身份验证,因为他从一个向他出租互联网线路的公司获得了一个可以在 ~~CentOS 和~~ RHEL 上部署的身份验证产品。
猜猜他们在内部是用什么开发来与 RHEL 对接? ?
#### 引文 5
>
> 仅仅是重建代码,不添加价值,也不以任何方式进行更改,对开源公司来说是一个真正的威胁。这是对开源的真正威胁,这可能将开源重新变成只有业余爱好者和黑客参与的活动。
>
>
>
那么像 Rocky Linux 和 Alma Linux 这样的 RHEL 克隆做的工作还不够重要,不足以与“仅仅重建代码,**不添加价值,也不以任何方式进行更改**”相区分吗?
>
> ? 我不知道如何更礼貌地重新表述这句话,所以请不要往心里去。这来自于对 RHEL 的热爱,而不是对红帽(管理层)的误导性愤怒。
>
>
>
* [Rocky Linux](https://rockylinux.org:443/alternative-images/) 和 [Alma Linux](https://almalinux.org:443/blog/almalinux-for-raspberry-pi-updates-october-2021/) 都为树莓派提供镜像,这使得在沉浸于企业级 Linux 这个隐喻的幸福海洋之前,可以更容易、更便宜地试水。
* Alma Linux 有一个名为 [Elevate](https://almalinux.org:443/elevate/) 的工具,允许 **所有用户**(这显然包括 RHEL,甚至是 Alma 的“竞争对手” Rocky Linux)升级到主要版本(例如从 7.x 到 8.x,等等)。我相信红帽公司的客户会喜欢这样的工具。
* Rocky Linux 有一个名为 [Peridot](https://github.com:443/rocky-linux/peridot) 的构建工具。它使任何人都可以拥有一个**自定义构建的 RHEL**。这个构建可以基于 Rocky Linux,或者甚至可以是公司的内部 RHEL 克隆,以防止供应链攻击。
这个回答也涉及到前面引用中的以下子引用:
>
> 仅仅将这些个人创造的代码重新打包,并原样转售,而不添加任何价值,会导致这个开源软件的生产无法持续下去。
>
>
>
它们正在为企业 Linux 生态系统增加价值,*而不是直接为 RHEL* 增加价值。
### 关于 CentOS Stream……
CentOS Stream 是一个奇怪的产品。在任何意义都不算糟糕(至少我个人是这么认为的),但是很奇怪。它与 RHEL 在以下关键方面存在差异,其中之一肯定会成为某些人的绝对禁忌:
* 它是 RHEL 的测试组,这使得对于 RHEL 和特别兴趣小组(SIG)来说更加便利,但是对于你的使用情况而言,可能会有帮助,也可能没有。
* CentOS Stream 不使用数字版本号的命名方案。这样一个微小的变化,在 CentOS Stream 上的测试时,可能会破坏为 RHEL 设计的脚本。同样的情况也可能出现在安全更新方面,正如 [一位 Twitter 用户所描述的](https://nitter.net:443/opdroid1234/status/1672067314789888000)。
* 正如我之前提到的,安全修复在 CentOS Stream 上发布较晚。虽然这可能有一些原因,但对于依靠 RHEL 克隆版本的小企业来说,并没有帮助,因为它们仍然容易受到威胁。
### 结论
现在 CentOS Stream 已经存在,RHEL 的 **开发** 比以往更加开放。但巧合的是,**RHEL 的源代码** 却被置于一个软性付费墙之后,受制于 [Red Hat 的最终用户许可协议(EULA)](https://www.jeffgeerling.com:443/blog/2023/gplv2-red-hat-and-you)。
目前这可能对红帽有所帮助。但如果保持这种立场,甚至不需要采取其他措施打击 RHEL 克隆产品,我相信围绕企业级 Linux 的用户、开发者和支持社区将会逐渐衰落...
我认为从长远来看,这将会伤害到红帽,因为随着周围的社区消亡,只有疲惫不堪的 IT 专业人员(意思是:**被迫使用它的人,就像使用 Oracle 产品一样**)才会继续使用 RHEL,甚至更糟糕的是,使用 Oracle Linux。
我在这里并不是在抨击红帽的员工。而是希望让你知道,如果继续这样发展下去,热爱 RHEL 的社区将会消亡。
我不愿意看到那种局面 ?
我真心地祝愿红帽在推动 Linux 生态系统前进方面一切顺利!真心的 ❤️
>
> ✍️ 此观点来自 Pratham Patel,一位热爱红帽的开源爱好者和探索者。
>
>
>
---
via: <https://news.itsfoss.com/red-hat-fiasco/>
作者:[Pratham Patel](https://news.itsfoss.com/author/team/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I have been forced to be a bit harsh right now based on how much I love RHEL and other Red Hat products. **I t is because I want RHEL** [and/or its clones]
**.**
**to be***accessible*to everyoneExcuse my tone this time because my heart doesn't want RHEL to be ** inaccessible to hobbyists**. The free RHEL developer license is just whataboutism and dilutes the enthusiasm felt by the
**compared to when**
**broader hobbyists' and tinkerers' community****.**
**true RHEL clones existed**I, with my use case, am happy using RHEL with the free subscription. In fact, that's what I'm using right now. This article is about what happens *to* RHEL if this is maintained.
## A Quick Recap of the Events That Led to This
I'm sure you all know by now why Red Hat has been in the news recently:
[Red Hat’s Source Code Lockout Spells Disaster for CentOS Alternatives: Rocky Linux and AlmaLinux in Trouble?Red Hat’s new move means that RHEL-source code is only accessible to users with subscriptions. What do you think about this?](https://news.itsfoss.com/red-hat-restricts-source-code/)

But, if you have no idea what's going on, lemme give you pointers to a quick timeline that should help you understand:
- Red Hat has an
Linux distribution called Red Hat Enterprise Linux with a support cycle of**excellent****10**.**years** - Like any other Linux distribution, the source code used to build RHEL (or a
of RHEL) was available publicly.*clone* - CentOS came into existence by taking the aforementioned source, removing trademarks, and creating an almost 1-to-1 copy of RHEL. (I say
because RHEL trademarks*almost*to be removed.)**need** - The enthusiast community--that didn't bother paying fees
--can now use CentOS to see if they like it.*just to try out RHEL for the first time* - A subset of people from that group then inform their higher management about RHEL and how good it is
**based on their****initial**and most likely switch to cater to either supporting their products on RHEL or using RHEL for their deployments.**experience with CentOS** - The enthusiast community grows because CentOS is free. People like
[Jeff Geerling](https://www.jeffgeerling.com/?ref=news.itsfoss.com)use CentOS to teach up-and-coming enthusiasts interested inabout awesome stuff like Ansible with*cosplaying as a sysadmin*[his](https://github.com/geerlingguy?tab=repositories&q=ansible&type=&language=&sort=&ref=news.itsfoss.com).**open source repositories** - CentOS's binaries were released a few weeks
RHEL's updates. So**after**[Red Hat acquired CentOS](https://www.redhat.com/en/about/press-releases/red-hat-and-centos-join-forces?ref=news.itsfoss.com)to ensure that CentOS didn't lag behind RHEL's updates. - A few years later the
[CentOS Stream](https://itsfoss.com/centos-stream-faq/?ref=news.itsfoss.com)fiasco happened, killing CentOS. [Rocky Linux](https://rockylinux.org/about?ref=news.itsfoss.com)and[Alma Linux](https://almalinux.org/blog/introducing-almalinux-beta-a-community-driven-replacement-for-centos/?ref=news.itsfoss.com)come up to fill the void left by CentOS. They use the RHEL's source which is publicly available.- Red Hat
[starts restricting the source code](https://news.itsfoss.com/red-hat-restricts-source-code/)to its customers and anyone else with a free developer subscription.
I specifically didn't mention IBM buying Red Hat because, if someone from Red Hat has the guts to publicly say, ** "Simply rebuilding code, without adding value or changing it in any way, represents a real threat to open source companies everywhere."** in an
[official capacity](https://www.redhat.com/en/blog/red-hats-commitment-open-source-response-gitcentosorg-changes?ref=news.itsfoss.com), they can also be trusted to be blunt about IBM's involvement in these decisions. But almost every Red Hat employee has publicly denied this accusation. Therefore, I don't believe IBM shot themselves in their foot either. But you are free to believe what your heart says.
And no, I'm not being sarcastic when I say IBM is probably not involved in this decision. They
*, but I don't think so.*
*may be*## Dear Red Hat, What Did You Just Do?
You offer a product to the community * for free* (CentOS). Then you switch the support window of that free product mid-cycle (CentOS) and use its "alternative" (CentOS Stream) as a
**for your shiny, enterprise product (RHEL).**
**testing ground**The leeches then take the source code of your shiny product and create a successor to CentOS (Rocky Linux and Alma Linux). You don't like that so you "soft-paywall" them.
Now while ** you are well within your rights to do so** (because you earn money from providing support for RHEL and not from RHEL itself), I'll explain why this is a bad move
**.**
**for yourself**** Question:** Why is RHEL so popular in enterprise environments?
**CentOS**
**Answer:**** Question:** What did online tutorials use to teach about RHEL?
**CentOS**
**Answer:**** Question:** What do the followers of said online tutorials use to learn about RHEL?
**CentOS**
**Answer:**** Question:** When said student becomes a teacher, what will they recommend to someone who asks how to get started as a Linux sysadmin?
**CentOS**
**Answer:**** Question:** If someone is willing to pay for RHEL's license but is hesitant to use it because of non-public public software repository, what will they use?
**CentOS**
**Answer:**In a nutshell, if Red Hat continues to cause trouble for RHEL clones, here's what you can expect:
- Many customers and professionals helping with enterprise deployments will consider abandoning RHEL and not supporting it.
- New users will start considering
or something else which is there to stay.**Ubuntu, Debian, openSUSE** - Universities/IT Courses will also switch to replacements like Ubuntu or openSUSE instead of dabbling between RHEL clones, CentOS Stream, and Fedora.
Moreover, small businesses and universities cannot use the free Red Hat Developer Subscription as per their [FAQ](https://developers.redhat.com/articles/faqs-no-cost-red-hat-enterprise-linux?ref=news.itsfoss.com):
The no-cost self-supported Red Hat Developer Subscription for Individuals is designed for individuals and personal accounts.
*Unless Red Hat is friendly towards RHEL clones, I don't see any newcomers in this ecosystem anymore.* And, this is just depressing, as RHEL is a fantastic product. Yes, it's not as bleeding edge as even Fedora, but man it is still fun to use!
I will let this [quote from Brian Stevens](https://www.redhat.com/en/about/press-releases/red-hat-and-centos-join-forces?ref=news.itsfoss.com) be here...
It is core to our beliefs that when people who share goals or problems are free to connect and work together, their pooled innovations can change the world. We believe the open source development process produces better code, and a community of users creates an audience that makes code impactful.
RHEL is an enterprise distribution so Red Hat will almost never work at providing support for running RHEL on Raspberry Pi. Guess which distributions provide EL images for Raspberry Pis. Hint, it is [Rocky Linux](https://rockylinux.org/alternative-images/?ref=news.itsfoss.com) and [Alma Linux](https://almalinux.org/blog/almalinux-for-raspberry-pi-updates-october-2021/?ref=news.itsfoss.com). I bet Red Hat doesn't have a number on how many people are using RHEL because they tried it out on their Raspberry Pi first with Rocky/Alma Linux and then switched to RHEL. * I'm one of them.* (With the free RHEL license, for what its worth.)
So what does this mean for RHEL? I'm not an * Oracle* (haha!) so I can't predict the future for RHEL.
I am far from a "trend setter" and I don't know how many people have been positively influenced by my [Podman coverage](https://linuxhandbook.com/tag/podman/?ref=news.itsfoss.com). Trying out Podman didn't come out of the blue. I did that by dipping my toes on Fedora first, then ** experimented a lot** with a "production-grade" environment by using Rocky Linux and then finally deployed some of my own services on RHEL. Not to say "If I didn't do it, no one would have", but you can't deny the
*by making accessible content like this, from me and*
*impact***. FYI, I prompted**
**many others**[Abhishek](https://itsfoss.com/team/?ref=news.itsfoss.com)to cover Podman, not the other way around.
Sure, some of the above mentioned "contributions" may not help Red Hat, but it helps * whom Red Hat serves as their customers*.
## So, Should We Be Worried? Yes, and No.
** The decision that Red Hat has taken, does make sense as a business.** But it also doesn't. It makes sense for short term goals. Not in the long term.
Red Hat, as a company that proudly contributes back to its upstream – that will never stop. Even by "soft-paywalling" RHEL code, ** Red Hat will continue contributing to the upstream.** Red Hat will continue
[innovating](https://fedoramagazine.org/announcing-the-display-hdr-hackfest/?ref=news.itsfoss.com)
[on](https://news.itsfoss.com/red-hat-accessibility-gnome/)
[new](https://developer.nvidia.com/blog/nvidia-releases-open-source-gpu-kernel-modules/?ref=news.itsfoss.com)
[developments](https://lists.fedoraproject.org/archives/list/[email protected]/thread/IXNTPGKHWTW7H7XVMZICSJRUDOHO2KJC/?ref=news.itsfoss.com).
They just won't keep their RHEL * secret sauce* “open” (in the sense that you expect it to be) anymore. And this secret sauce is nothing “proprietary” in itself. Almost everything that Red Hat offers in RHEL is open source.
Their secret sauce is with * backporting patches to RHEL's stable packages*. And it is a completely fair
*to provide these patches--which are publicly available for a*
*business decision**of the same package – to only RHEL customers. The task of applying patches to keep an “older version” of a package up-to-date is very difficult.*
*different version***So, I do understand why they made this decision.**
** Red Hat is NOT close sourcing RHEL** (at least technically).
Red Hat is still an excellent company that has a proven open-source portfolio. I use some of these products on a day-to-day basis like: *RHEL on the Raspberry Pi 4 (**yes, it's possible!**), [Rootless] Podman, Cockpit, Ansible, systemd, and many more!*
## Here's Why You Should Worry
If RHEL isn't freely available--not * free of cost*, but accessible to download like Debian, Ubuntu and even Fedora; without an account – the newcomers looking at being introduced to the enterprise Linux ecosystem will keep on decreasing in numbers. I think so...
If that number goes down, the people who do actually recommend RHEL in business to use and pay for it will go down too. And you know what loop this triggers.
- Fewer newcomers interested in RHEL → Less RHEL subscriptions purchased
- Less revenue for Red Hat → Fewer Red Hat contributions to Upstreams (
*systemd, Podman, Linux Kernel, Guh-NOME, Wayland, Nvidia collaboration, etc.)* - Finally, → Fewer improvements to the Linux ecosystem in general
Sure, Red Hat isn't the only company contributing back to the Linux ecosystem, but you can't deny its monstrous impact on pushing the ecosystem full * stream* ahead!
## My Response to Red Hat Statements
I'm not attacking Mike McGarth. This is just a direct response to his statements. I believe that I have the right to communicate my point of view as an RHEL user who ended up loving it so much as to deploy his personal blog via RHEL from his Raspberry Pi 4B.
Unless specified otherwise, all the following quotes are taken from [this blog post](https://www.redhat.com/en/blog/red-hats-commitment-open-source-response-gitcentosorg-changes?ref=news.itsfoss.com).
### Quote 1
I feel that much of the anger from our recent decision around the downstream sources comes from either those who do not want to pay for the time, effort and resources going into RHEL or those who want to repackage it for their own profit.
Yes, that's completely fair, but again, I'll harp on this point until you realize that RHEL is nothing without the community at large that has been ** trained on CentOS and its successors alike**.
** The current IT professionals include people who once were in the group which you now tag under the umbrella **of “
*".😒*
*either those who do not want to pay for the time....*By displaying such a stance, you are making sure that there are significantly less number of people who are introduced to the enterprise Linux, and later work with RHEL.
### Quote 2
We have to pay the people to do that work — those passionate contributors grinding through those long hours and nights who believe in open source values. Simply repackaging the code that these individuals produce and reselling it as is, with no value added, makes the production of this open source software unsustainable. That includes critical backporting work and[future features and technologies under development upstream.]If that work becomes unsustainable, it will stop, and that's not good for anyone.
This is not only a perfectly reasonable take, but it is also the harsh reality. Open source is underfunded. It is also severely hard to raise funding for open source when anybody can just use your product without giving practically anything in return.
But, if the community did not get RHEL for free (before restricting the source code), it may not have been a huge success as it is today. The community explored RHEL and made it a bigger player because it is free.
I'm not asking Red Hat to be a charity and just give it away. I want Red Hat to have more than enough funding to spend it on improving upstream. But there should be a middle ground * somewhere*.
Again, the free subscription is not an equivalent for a RHEL clone. Sure, I have written about [how to get Red Hat Enterprise Linux for free](https://linuxhandbook.com/get-red-hat-linux-free/?ref=news.itsfoss.com). However, it's not the same spirit. I'll
[quote Jeff Geerling](https://www.jeffgeerling.com/blog/2023/dear-red-hat-are-you-dumb?ref=news.itsfoss.com)here:
And no, please don't post "but you can use your Red Hat Developer Subscription!" I don't have to with Debian. Or Ubuntu. Or Arch. Or... you get the point.
### Quote 3
More recently, we have determined that there isn’t value in having a downstream rebuilder.
There most definitely is! I won't repeat myself here about how the RHEL rebuilds are the entry point for nerds like me into RHEL itself.
Windows is popular only because MSFT allowed pirated versions to exist (and cheaper license keys).
Had they clamped down, no household would have spent a dime on Vista's successors. I don't mean to compare Vista--the disaster of an OS--to RHEL, but this is an analogy that most of you will relate to, grudgingly, as you recall not getting that Windows license refund.
### Quote 4
The generally accepted position that these free rebuilds are just funnels churning out RHEL experts and turning into sales just isn’t reality. I wish we lived in that world, but it’s not how it actually plays out. Instead, we’ve found a group of users, many of whom belong to large or very large IT organizations, that want the stability, lifecycle and hardware ecosystem of RHEL without having to actually support the maintainers, engineers, writers, and many more roles that create it.
** ... are you sure? **😮
Sure, the conversion rate from free users to RHEL customers may not be that high, but I bet you it's not less than 30%. If you keep up with this, the amount of new customers will be less than 10% of current new “sign-ups”.
** The same argument can be made for taking advantage of the free developer license for RHEL.** Creating new Red Hat accounts with temporary email IDs to take advantage of the free developer subscription is a non-trivial task for those who are uninterested in paying for RHEL.
While we are talking about conversion rate, how many of these professionals just use a RHEL clone for their internal product development (to match against RHEL) but do actually provide their customers with support when they use RHEL?
**How do you measure the value provided to your customers by a third party's support?*** You can't*, it isn't something tangible that you can measure.
I'll go on a side tangent where this actual thing happened. My current [small town, local] ISP uses RHEL to authenticate [me and other] users because the company from whom he leased his Internet line, it has an authentication product ready to be deployed on ~~CentOS and~~ RHEL.
Guess what they used internally to develop against RHEL? 😊
### Quote 5
Simply rebuilding code, without adding value or changing it in any way, represents a real threat to open source companies everywhere. This is a real threat to open source, and one that has the potential to revert open source back into a hobbyist- and hackers-only activity.
So the work that RHEL clones like Rocky Linux and Alma Linux did as the following projects is not significant enough to be accounted as separate from "simply rebuilding code, ** without adding value or changing it in a way**"?
I don't know how to rephrase this more politely so please don't take it personally. This comes from the love for RHEL, not misdirected anger at Red Hat [management].
[Rocky Linux](https://rockylinux.org/alternative-images/?ref=news.itsfoss.com)and[Alma Linux](https://almalinux.org/blog/almalinux-for-raspberry-pi-updates-october-2021/?ref=news.itsfoss.com), both have images for Raspberry Pis, making it even more accessible and cheaper to test the waters before bathing in the metaphorical blissful ocean of Enterprise Linux.- Alma Linux has a tool called
[Elevate](https://almalinux.org/elevate/?ref=news.itsfoss.com)built with the help of Red Hat's Leapp framework, which allows(this obviously includes RHEL and even Alma's "competitor", Rocky Linux) to upgrade from major versions (i.e. from 7.x to 8.x and likewise). I'm sure Red Hat's customers would love such a tool.**all users** - Rocky Linux has a build tool called
[Peridot](https://github.com/rocky-linux/peridot?ref=news.itsfoss.com). It allows anyone to have a. This build may be based off Rocky Linux, or it can even be a company's internal RHEL clone deployed to prevent supply chain attacks.**custom build of RHEL**
This reply is also relevant to the following sub-quote from a prior quote:
Simply repackaging the code that these individuals produce and reselling it as is, with no value added, makes the production of this open source software unsustainable.
They are adding value, *to the EL ecosystem*, just not
*.*
*directly to RHEL*## About CentOS Stream...
CentOS Stream is a weird product. Not bad in any sense (at least in my opinion) but weird. It differs from RHEL in the following key ways, one of which is definitely a deal breaker for * someone*:
- It is the testing group for RHEL, which makes things easier for RHEL and SIGs (Special Interest Group) but for your use-case, it may or may not help.
- CentOS Stream doesn't use NVER naming scheme. A minor change like this can break scripts meant to work on RHEL by testing on CentOS Stream. The same can be the case for security updates as
[described by a user on Twitter](https://nitter.net/opdroid1234/status/1672067314789888000?ref=news.itsfoss.com). - As I mentioned, security fixes come late to CentOS Stream; while there are some reasons to do that, it does not help small businesses that remain vulnerable by using RHEL clones.
## Conclusion
Now that CentOS Stream exists, the *development* of RHEL is more open than ever. But, coincidentally,
**is locked behind a soft paywall that is**
**RHEL's own source**[.](https://www.jeffgeerling.com/blog/2023/gplv2-red-hat-and-you?ref=news.itsfoss.com)
**subject to Red Hat's EULA**This may help Red Hat for now. But if this stance is maintained, without even taking another action against RHEL clones, the user, developer, and support community around Enterprise Linux will wither out, I believe...
I think this will end up hurting Red Hat in the long term as the community around dies out and only exhausted IT professionals (meaning: * people who are forced to work with it, like with Oracle products*) are left using RHEL or worse, Oracle Linux.
I'm not ranting here to call out Red Hat employees. But instead, to let you know that if this is the way you proceed, the community, which loves RHEL, will die out.
I don't want that 😔
I wish Red Hat all the luck in pushing the Linux ecosystem forward! Genuinely ❤️
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,963 | Fedora 工作站 39 可能会默认使用 Anaconda Web UI 安装程序 | https://news.itsfoss.com/fedora-workstation-39-webui/ | 2023-07-03T13:55:10 | [
"Fedora",
"Anaconda"
] | https://linux.cn/article-15963-1.html |
>
> 新的 Anaconda Web UI 安装程序可能会随 Fedora 工作站 39 一同推出。
>
>
>

长期以来,Fedora 的安装体验一直未曾改变。
然而,这个新的 Web UI 安装程序已经开发了一年多的时间,现在离正式实现的目标更近了。
**为什么现在是时候了?**
在我们上次 [了解](https://news.itsfoss.com/fedora-new-web-ui-install-dev/) 即将到来的 **Anaconda WebUI 安装程序**时,它的进展相当不错。
而现在,它已经提交了一份 **变更提案**,旨在将这个安装程序添加到 Fedora 工作站中,以提供现代化的用户体验。该提案正等待 Fedora 工程和指导委员会(FESCo)的审查。
让我们再次来看看即将到来的安装程序和提案,以及可以期待在 Fedora 发布中看到它的时间。
### Anaconda WebUI:概述 ⭐

**目前 Fedora 使用的旧的安装程序是基于 GTK3 的**,在许多情况下已被证明效率低下和不安全。新的 Anaconda WebUI 安装程序旨在解决这个问题。
它使用了一个由 Anaconda 团队开发的 **基于 PatternFly 的现代后端和用户界面**。
后端由 [Python](https://www.python.org:443/)、[DBus](https://www.freedesktop.org:443/wiki/Software/dbus/)、[Cockpit](https://cockpit-project.org:443/)、[React](https://reactjs.org:443/) 和 [PatternFly](https://www.patternfly.org:443/) 组成,旨在从一开始解决许多已知的用户体验问题,并为一致的安装体验铺平了道路。
变更提案还提到了新 UI 的一些关键亮点,包括:
* 向导式解决方案而非中心轮毂式。
* 新的欢迎屏幕用于选择语言(将从系统中配置的语言预先选择)。
* 时区和日期配置。
* 磁盘选择。
* 引导式分区。
* 配置审核。
* 安装进度。
* 内置帮助。
主要关注的重点是向用户提供类似向导的体验,提供更多信息,并帮助他们更好地完成安装过程。
这个新安装程序添加了很多功能,听起来是一个很好的用户体验改变! ?
**那么,我们可以期待什么时候呢?**
由于这个变更需要经过 FESCo 的批准,一切取决于投票过程的进行。
但是,我相当有信心这个变更会得到批准,因为 [变更提案](https://fedoraproject.org:443/wiki/Changes/AnacondaWebUIforFedoraWorkstation) 已经设定了 **在 Fedora 39 中发布新的 Anaconda WebUI 安装程序** 的目标。
? 这个变更批准只是时间问题;您对此有什么看法?
---
via: <https://news.itsfoss.com/fedora-workstation-39-webui/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Fedora's installation experience has remained unchanged for quite a while now.
However, the new Web UI installer, which has been in the works for over a year, is now closer to implementation than ever before.
**Why now?**
When we last [looked](https://news.itsfoss.com/fedora-new-web-ui-install-dev/) at the upcoming **Anaconda WebUI installer**, the progress was quite good.
But now, a **change proposal has finally been filed** to **add the installer to Fedora Workstation** to provide a modern user experience. The proposal is pending review from the Fedora Engineering and Steering Committee (FESCo).
Let's look at the upcoming installer and the proposal, taking a second peek, and when to expect it to arrive with a Fedora release.
## Anaconda WebUI: Overview ⭐
The **existing installer for Fedora uses an old GTK3 base**, known for being **inefficient** and **insecure** in numerous instances. The new Anaconda WebUI installer aims to mitigate that.
It uses a **modern backend with a PatternFly-based user interface** developed by the Anaconda team.
The backend consists of [Python](https://www.python.org/?ref=news.itsfoss.com), [DBus](https://www.freedesktop.org/wiki/Software/dbus/?ref=news.itsfoss.com), [Cockpit](https://cockpit-project.org/?ref=news.itsfoss.com), and [React](https://reactjs.org/?ref=news.itsfoss.com)/[PatternFly](https://www.patternfly.org/?ref=news.itsfoss.com). These are set to address many known UX issues from the get-go and have made way for a consistent install experience.
The change proposal also mentions a few key highlights of the new UI that include the following:
**Wizard solution instead of hub and spoke.****New welcome screen to select language (will be preselected from a language configured in the system).****Timezone and date configuration.****Disk selection****Guided partitioning****Review Configuration****Installation progress****Build-in help**
The primary focus is on presenting a wizard-like experience with more information to the users and helping them better along the installation process.
That's a lot of additions to the new installer; it sounds like a good user experience change! 😃
**Suggested Read **📖
[risiOS: An Easy-to-Use Fedora-based Linux DistributionAre you a fan of Fedora? You might like risiOS for its tweaks and out-of-the-box utilities.](https://news.itsfoss.com/risi-os/)

**So, when can we expect this?**
As this change is subject to approval by FESCo, it all depends on how the voting process goes.
But, I am pretty confident that this change will be approved, as the [change proposal](https://fedoraproject.org/wiki/Changes/AnacondaWebUIforFedoraWorkstation?ref=news.itsfoss.com) has set a **targeted release of the new Anaconda WebUI installer with Fedora 39**.
*💬 It's only a matter of time before this change is approved; what do you think of it?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,964 | Clipboard:一款旨在提高你的工作效率的开源应用 | https://news.itsfoss.com/clipboard/ | 2023-07-03T15:31:00 | [
"剪贴板"
] | https://linux.cn/article-15964-1.html |
>
> Clipboard 是一个有用的开源工具,具有许多可提高你的工作效率的功能。
>
>
>

想要一个新的智能剪贴板管理器吗? ?
这就是 **Clipboard 项目** 背后的人们对其剪贴板管理器的看法。他们称之为“第二大脑”,可以随时随地记住任何事情。
你认为呢? 让我们看一下:
### Clipboard:概述 ⭐

[Clipboard](https://getclipboard.app/) 主要用古老的 **C++ 编程语言**编写,提供了许多功能,例如复制/粘贴文本、文件、目录、二进制数据、无限剪贴板等等!
此外,它 **与主要的 GUI 剪贴板系统无缝集成** 并支持西班牙语、葡萄牙语和土耳其语等语言。
让我向你展示它是如何工作的。
>
> ? 由于这是一个基于终端的应用,因此你必须使用各种命令来操作 Clipboard。
>
>
>
因此,你要做的第一件事是使用以下命令复制文件的内容:
```
cb copy 'filename'
```

然后进行粘贴,你可以使用以下命令:
```
cb paste
```

要加载所有剪贴板,你可以使用以下命令:
```
cb show
```

最后,最吸引我们注意的功能是最近添加的 **无限剪贴板历史记录** 功能。
你可以使用此命令访问完整的剪贴板历史记录:
```
cb hs
```

这个剪贴板应该会 **吸引那些更喜欢使用基于终端的应用** 而不是基于 GUI 的应用的用户。它提供了非常简单的用户体验以及所有合适的工具。
不要忘了,它包含的功能比我讨论的更多,其中包括:
* 制作脚本来自动化你的工作流程
* 能够粘贴你拥有的每种类型的数据,包括二进制数据
那些喜欢图形界面的应用的人可以选择 [Pano 剪贴板管理器](https://news.itsfoss.com/pano-clipboard-manager/)。它是一个轻量级的剪贴板管理器,与 GNOME 集成得很好。
### ? 获取 Clipboard
你可以通过从 [GitHub](https://github.com/Slackadays/Clipboard) 获取或浏览其 [官方网站](https://getclipboard.app/) 开始你的剪贴板之旅。它还包含所有必要的安装指南和文档。
>
> **[Clipboard (GitHub)](https://github.com/Slackadays/Clipboard)**
>
>
>
? 你对 Clipboard 有何看法? 你会尝试一下吗? 你还有其他值得推荐的吗? 在下面的评论中分享你的想法。
*(题图:MJ/fc3f6192-b073-49e4-8ba5-d72d820ff8a7)*
---
via: <https://news.itsfoss.com/clipboard/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Want a new, 𝘳𝘪𝘥𝘰𝘯𝘬𝘶𝘭𝘪𝘤𝘪𝘰𝘶𝘴𝘭𝘺 smart clipboard manager? 🤔
That is what the folks behind **The Clipboard Project** think of their clipboard manager. They call it a 'second brain' that remembers anything, anytime, anywhere.
So, what do you say? Let us take a look at it:
## Clipboard: Overview ⭐
Written primarily in the venerable **C++ programming language**, [Clipboard](https://getclipboard.app/?ref=news.itsfoss.com) offers a number of features such as copying/pasting text, files, directories, binary data, infinite clipboards, and more!
Furthermore, it **seamlessly integrates with major GUI clipboard systems** and supports languages like Español, Portuguese, and Türkçe.
Let me show you how it works.
So, the first thing you will be doing is to copy the contents of a file by using the following command:
`cb copy 'filename'`
Then to paste, you can use the following:
`cb paste`
For loading all your clipboards, you can use this command:
`cb show`
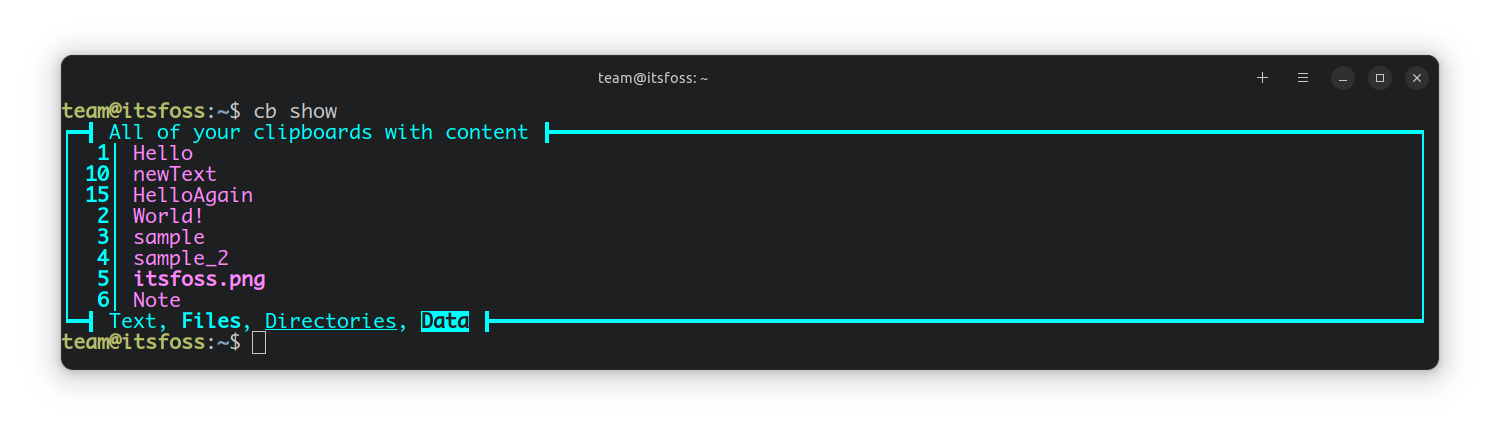
And finally, the feature that grabbed our attention the most was the recently added **unlimited clipboard history** feature.
You can use this command to access the complete clipboard history:
`cb hs`
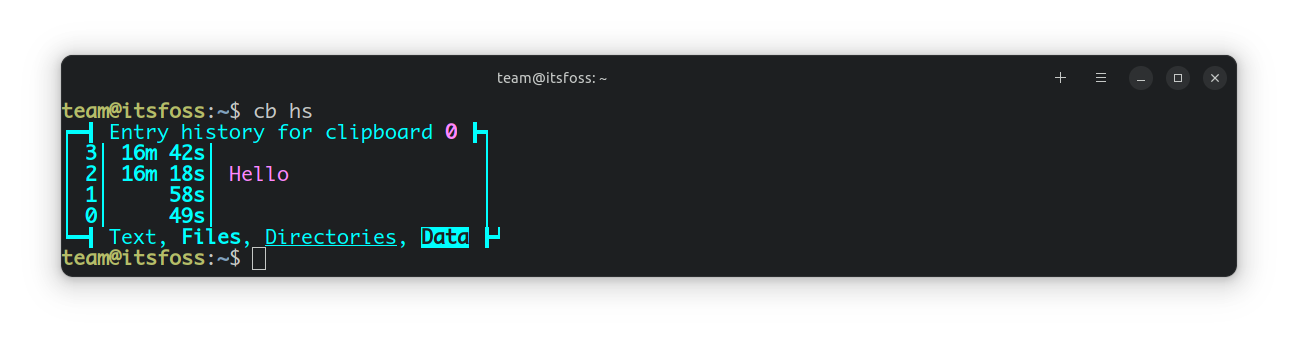
Clipboard should **appeal to users who prefer using terminal-based apps **over GUI-based apps; it offers a very minimal user experience with all the right tools to go with it.
Not to forget, it is packed with more features than I discussed, some of which include:
- Make scripts to automate your workflows
- Ability to paste every type of data you have got, including binary data
Those who prefer apps with a graphical interface can opt for [Pano clipboard manager](https://news.itsfoss.com/pano-clipboard-manager/). It is a lightweight clipboard manager that integrates quite well with GNOME.
[Pano Clipboard Manager is An Awesome GNOME Extension You NeedA nifty clipboard manager that offers a visually-rich interface and valuable options.](https://news.itsfoss.com/pano-clipboard-manager/)

## 📥 Get Clipboard
You can begin your Clipboard journey by getting it from [GitHub](https://github.com/Slackadays/Clipboard?ref=news.itsfoss.com) or exploring its [official website](https://getclipboard.app/?ref=news.itsfoss.com). It also contains all the necessary installation guides and documentation.
*💬 What do you think of Clipboard? Will you be giving this a try? Do you have any other favorites to recommend? Share your thoughts in the comments down below. *
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,966 | 为什么黑客更喜欢使用 Kali Linux? | https://www.debugpoint.com/why-kali-linux/ | 2023-07-04T15:20:00 | [
"黑客",
"Kali Linux"
] | /article-15966-1.html | 
>
> 以下是为什么大多数黑客和渗透测试人员喜欢使用 Kali Linux 的几个原因。
>
>
>
Kali Linux 是一个基于 Debian “测试版” 的 Linux 操作系统,创建于近十年前。在过去几年里,它在黑客和网络安全专业人员中非常流行。随着对数字基础设施的越来越多的依赖和网络威胁的不断增长,网络安全对于普通用户和企业来说变得更加重要。
道德黑客和渗透测试人员在识别漏洞和加强系统安全方面发挥着重要作用。由于 Kali Linux 具备为安全测试和分析而量身定制的全面工具和功能,因此成为他们的首选操作系统。

### 概述
[Kali Linux](https://www.kali.org/) 由 Offensive Security(一家美国信息安全公司)维护,并得到社区中数千名贡献者的支持。它跟随 Debian 的 “测试版” 分支的发展,保持与最新软件包的同步,为黑客们提供了最新模块来进行工作。
此外,Kali Linux 支持多种架构,例如 x86、x86-64、armel 和 armhf,这有助于黑客在广泛的硬件范围内使用。
使用此发行版的最大优势之一是它适用于多个技术平台,你可以下载和使用。以下是其中一些平台:
* 32 位和 64 位的安装镜像(ISO)
* 预构建的虚拟机镜像
* ARM 架构镜像
* 用于移动设备的安卓镜像
* Docker 和 LXD 镜像
* 可在各个厂商提供的云中使用
* 只读的 LIVE ISO 镜像
* 可在 Windows 的 Linux 子系统(WSL)上使用
### 为何它备受青睐
#### 强大的渗透测试工具
Kali Linux 提供了丰富的渗透测试工具,使黑客能够识别并利用漏洞。这些工具包括网络扫描器、密码破解器、无线攻击框架和 Web 应用程序评估工具。这个操作系统内置了如此之多的工具,极大地简化了黑客的工作流程,使他们能够有效专注于目标。
#### 全面的安全评估
使用这个发行版,黑客可以对各种目标进行全面的安全评估。他们可以模拟真实攻击,分析系统弱点,制定有效的安全策略。该操作系统提供了漏洞扫描、网络映射和系统指纹识别等工具,使黑客能够从不同角度评估目标系统的安全状况。
#### 反取证分析和事件响应
Kali Linux 还包括用于数字取证和事件响应的工具。黑客可以利用这些工具来调查安全漏洞,收集证据和分析受损系统。该操作系统支持数据恢复、内存分析和网络取证,有助于进行彻底的调查,并帮助恢复遭受损害的系统。
#### 无线网络审计
由于其固有的弱点,无线网络往往是黑客的主要目标。Kali Linux 提供了全面的用于审计和保护无线网络的工具。黑客可以使用这些工具来识别弱加密协议,发现隐藏网络,并进行数据包分析以检测恶意活动。这使得他们能够评估无线网络的安全性并提出缓解策略。
### 大量的工具
以下是默认情况下(截至最新版本)Kali Linux 提供的一些工具类别的简要列表:
* **信息收集**
+ DNS 分析
+ IDS/IPS 识别
+ 活动主机识别
+ 网络和端口扫描器
+ OSINT 分析
+ 路由分析
+ SMB 分析
+ SMTP 分析
+ SNMP 分析
+ SSL 分析
* **漏洞分析**
+ 模糊测试工具
+ VoIP 工具
* **Web 应用程序分析**
+ CMS 和框架识别
+ Web 应用程序代理
+ Web 爬虫和目录暴力破解
+ Web 漏洞扫描器
* **数据库评估**
+ SQLite 数据库浏览器
* **密码攻击**
+ 离线攻击工具
+ 在线攻击工具
+ 哈希传递工具
+ 密码分析和密码列表
* **无线网络攻击**
+ 802.11 无线工具
+ 蓝牙攻击工具
* **逆向工程工具**
+ Clang
+ NASM shell
* **利用工具**
+ Metasploit
+ Searchsploit
+ MSF 载荷生成器
+ 社会工程学工具包
* **嗅探和欺骗**
+ 网络嗅探器
+ 欺骗和中间人攻击
+ 后渗透
* **取证**
+ 反取证工具
+ 取证镜像工具
+ PDF 取证工具
+ Sleuth Kit 套件
* **报告工具**
+ Cutycapt
+ Faraday start
+ Pipal
* **社会工程学工具**
你可以在详尽的工具门户网站了解更多信息:
>
> **[访问 Kali Linux 工具门户网站](https://www.kali.org/tools/)**
>
>
>

### 开源特性
黑客偏爱 Kali Linux 的主要原因之一是它的开源特性。作为一款开源操作系统,Kali Linux 允许黑客访问和修改源代码以满足其需求。这使得他们可以自由定制系统并添加自己的工具或功能。开源社区还积极参与开发和改进 Kali Linux,以确保其与最新的安全技术保持同步。
### 社区支持与合作
Kali Linux 拥有一个庞大的安全专业人员、黑客和爱好者社区。这个社区通过分享知识、开发新工具和为其他用户提供支持来积极合作,以增强操作系统的功能。
可通过论坛、在线教程和社区驱动的文档获取宝贵资源并在需要时寻求帮助,确保使用 Kali Linux 的黑客能够获得支持。
团队还提供了多种培训和学习方式。其中也包括了一个学习路径,供希望在网络安全领域追求职业发展的学生参考,并提供相关认证。
### 定制和灵活性
另一个优点是 Kali Linux 高度的定制和灵活性。黑客可以根据自己的特定需求和喜好来定制操作系统。他们可以按照自己的要求安装和配置工具,创建自定义脚本并构建个性化的工作流程。这种定制水平使得黑客可以优化自己的生产力并简化渗透测试过程。
### 持续更新和改进
Kali Linux 是一个不断更新和改进的操作系统。开发人员和社区成员积极致力于增强现有工具、添加新功能并解决任何安全漏洞。这些更新确保使用 Kali Linux 的黑客可以获得最新的工具和技术,使他们始终处于网络安全进展的前沿。

### 道德使用
重要的是要注意,Kali Linux 旨在用于道德黑客和安全测试目的。道德黑客利用他们的技能来发现漏洞并保护系统,而不是从事恶意活动。
Kali Linux 倡导对黑客工具的负责和合法使用,强调获得适当授权和遵守道德准则的重要性。该操作系统是网络安全专业人员增强组织安全性、促进更安全的数字环境的强大工具。
简而言之,**请勿将** Kali Linux 用于非法或未经授权的用途。
### 结论
我希望这份概述介绍了 Kali Linux 及其为全球安全专业人员所偏爱的免费开源操作系统的原因。它以 Debian 为基础,配备了数千种工具和便捷的访问方式,使它成为每个人都值得考虑的选择。
你可以在 [官方网站](https://www.kali.org/get-kali/) 上下载 Kali Linux。
*(题图:MJ/95d89a95-50fe-4fdf-a06a-e4287092cee9)*
---
via: <https://www.debugpoint.com/why-kali-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,967 | 在 Linux 中使用 cd 命令 | https://itsfoss.com/cd-command/ | 2023-07-04T15:42:02 | [
"cd"
] | https://linux.cn/article-15967-1.html | 
>
> 了解如何使用用于切换目录的一个基本但必不可少的 Linux 命令。
>
>
>
Linux 中的 `cd` 命令用于更改目录。`cd` 实际上是“<ruby> 更改目录 <rt> change directories </rt></ruby>”的缩写。
这是你必须了解的 [基本 Linux 命令](https://itsfoss.com/essential-ubuntu-commands/)之一。
使用 `cd` 命令非常简单:
```
cd path_to_directory
```
不可能比这更简单了,对吧。
然而,你应该理解它的路径部分,以便轻松地浏览 [文件系统](https://linuxhandbook.com:443/linux-directory-structure/) 而不会感到困惑。
这是绝对路径和相对路径的快速回顾:

如果你需要更多细节,我建议你阅读这篇文章:
>
> **[Linux 上的绝对路径和相对路径有什么不同](https://linuxhandbook.com/absolute-vs-relative-path/?ref=itsfoss.com)**
>
>
>
让我们看一些使用 `cd` 命令的示例。
### 使用绝对路径更改目录
从视觉上看会更容易理解。看下图。

我当前的位置是我的主目录(`/home/abhishek`),我必须进入 `scripts` 目录中的 `python` 目录。
假设我想使用绝对路径。`python` 目录的绝对路径是 `/home/abhishek/scripts/python`。
```
cd /home/abhishek/scripts/python
```

### 使用相对路径更改目录
让我们举同样的例子,但这次我将采用相对路径。

我的主目录到 `python` 目录的相对路径是 `scripts/python`。让我们用这个:
```
cd scripts/python
```

### 进入上级目录
到目前为止,你一直在进入下级。如果你必须进入上级目录怎么办?
假设你位于 `/home/abhishek/scripts/python` 中,并且必须将目录添加到 `scripts`?

使用绝对路径始终是一种选择,但它相当冗长。相反,你可以使用特殊的目录符号 `..`。双点 (`..`)表示父目录或上一级目录。单点(`.`)表示当前目录。
```
cd ..
```
这是一个例子:

你可以使用 `..` 在 Linux 文件系统层次结构中向上移动路径。
假设我在上图中的 `python` 目录中,想要进入 `code` 目录。这是我能做的:
```
cd ../../code
```

### 进入主目录
如果你在所有这些目录切换中感到迷失并想回到主目录,有很多简单的快捷方式。
事实上,最简单的就是使用不带任何选项的 `cd` 命令。
```
cd
```
这将使你从文件系统上的任何位置返回主目录。
或者,你可以使用 `~` 符号,表示主目录。
```
cd ~
```

### 进入根目录
尽管你不会像前一个那样经常使用它,但了解一下仍然有好处。
如果你想返回文件系统开始的根目录,请使用以下命令:
```
cd /
```
这里不涉及“魔法”。当放在路径开头使用时,`/` 表示根。不要将它与路径分隔符混淆。

### 切换回上一级目录
这是一个救命稻草,或者我应该说是“省时稻草”。当你深入目录结构,然后转到另一个目录,然后你觉得需要返回到以前的位置时,此快捷方式会有所帮助。
```
cd -
```
还不清楚吗? 让我举个例子。
我位于 `/etc/apt/sources.list.d`。从这里,进入 `/home/abhishek/scripts/python` 来处理我的代码。然后我意识到我必须再次检查 `/etc/apt/sources.list.d` 目录中的某些内容。
通常的方法是这样做,这让我再次输入所有路径:

但聪明的方法是使用这个:

看吧,无需再次输入冗长的路径。如期工作!
### ?️ 练习时间
如果你想练习 `cd` 命令,这里有一些练习供你使用。
* 打开终端并进入 `/var/log` 目录。[检查目录内容](https://itsfoss.com/list-directory-content/)。你看到了什么?
* 现在,进入 `/var` 目录。这是一个上级目录。
* 从这里返回你的主目录。
这些内容足以让你熟悉 `cd` 命令。以下是你应该了解的其他一些重要命令。
>
> **[每个 Ubuntu 用户都应该知道的 31 条 Linux 命令](https://itsfoss.com/essential-ubuntu-commands/)**
>
>
>
如果你有疑问或建议,请告诉我。
*(题图:MJ/6fbaa345-651a-4cb9-a752-130eda922790)*
---
via: <https://itsfoss.com/cd-command/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The cd command in Linux is used for changing directories. cd is actually short for change directories.
It's one of the [essential Linux commands](https://itsfoss.com/essential-ubuntu-commands/) that you must know.
Using the cd command is quite simple:
`cd path_to_directory`
It cannot go any simple than this, can it?
However, it's the path part that you should understand to easily travel through the [filesystem](https://linuxhandbook.com/linux-directory-structure/) without getting confused.
Here's a quick recall of absolute and relative paths.
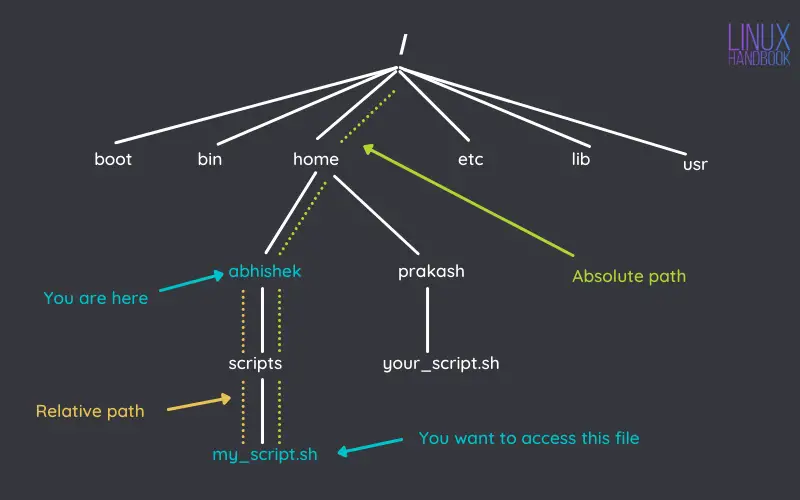
And if you need more details, I recommend reading this article.
[Absolute vs Relative Path in Linux: What’s the Difference?In this essential Linux learning chapter, know about the relative and absolute paths in Linux. What’s the difference between them and which one should you use.](https://linuxhandbook.com/absolute-vs-relative-path/)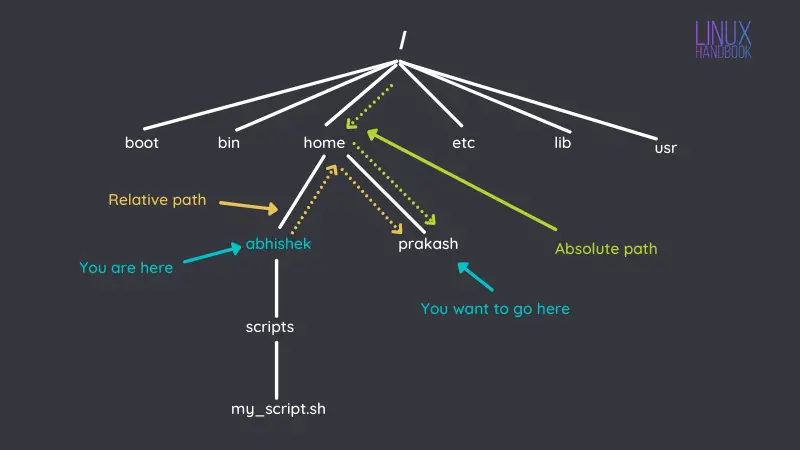

Let's see some examples of using the cd command.
## Use absolute path to change the directory
It will be easier to understand visually. Look at the image below.
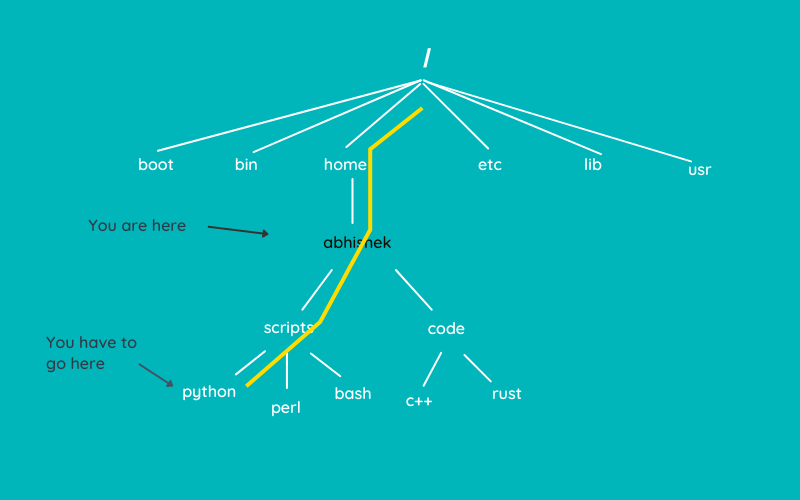
My current location is my home directory (`/home/abhishek`
) and I have to go to the `python`
directory inside the `scripts`
directory.
Let's say I want to use the absolute path. The absolute path to the pyth`/home/abhishek/scripts/python`
.
`cd /home/abhishek/scripts/python`
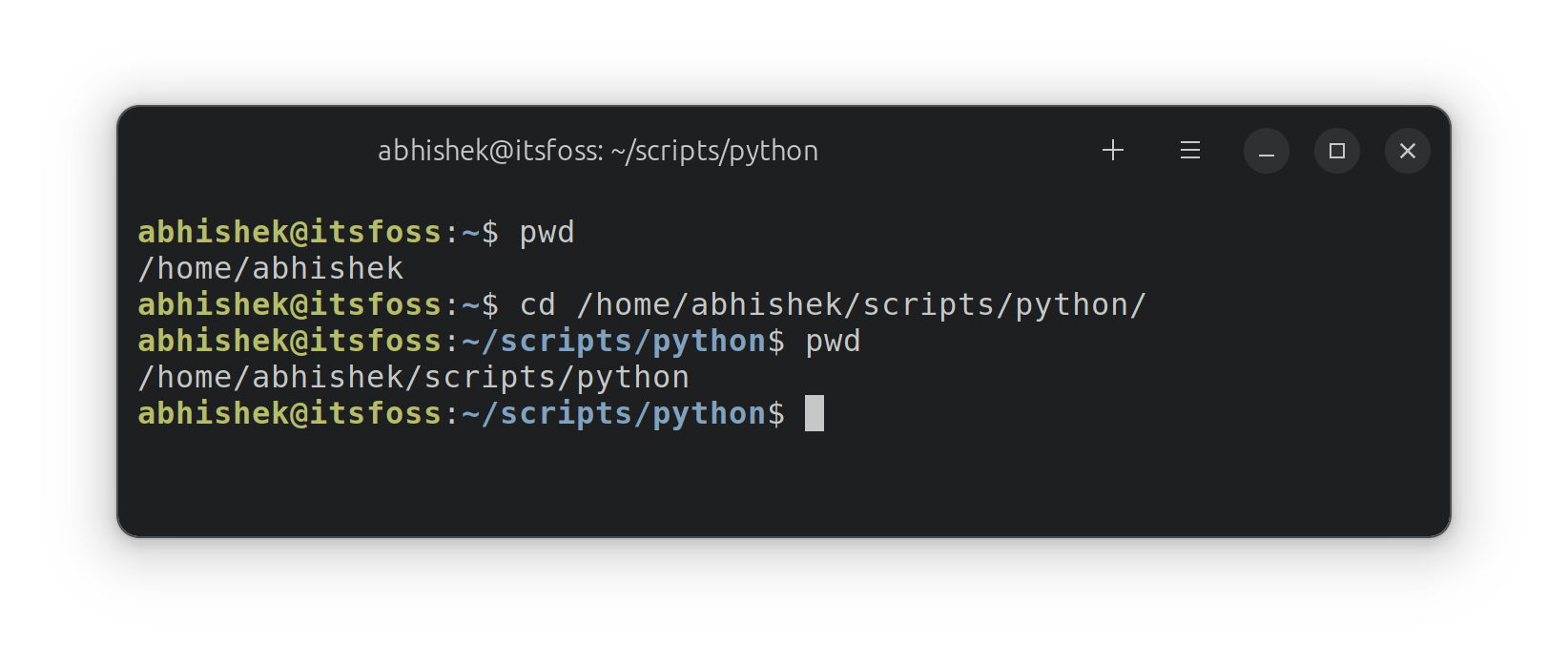
## Use relative path to change directories
Let's take the same example but this time, I'll take the relative path.
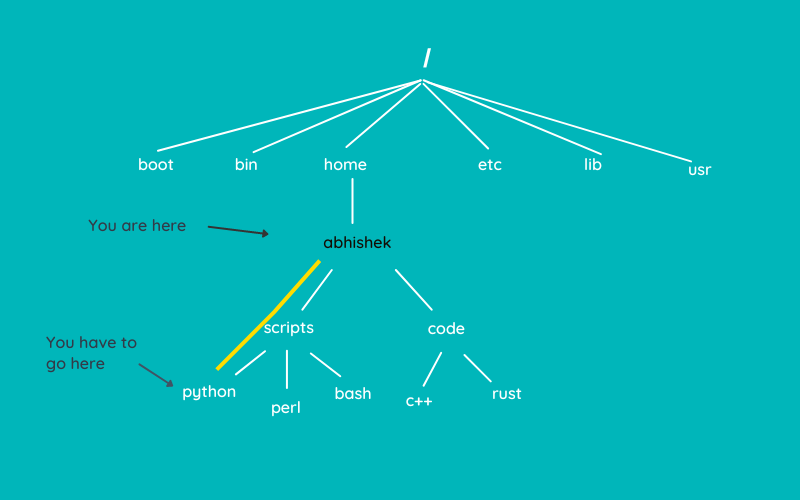
The relative path to the `python`
directory from my home directory is `scripts/python`
. Let's use this:
`cd scripts/python`
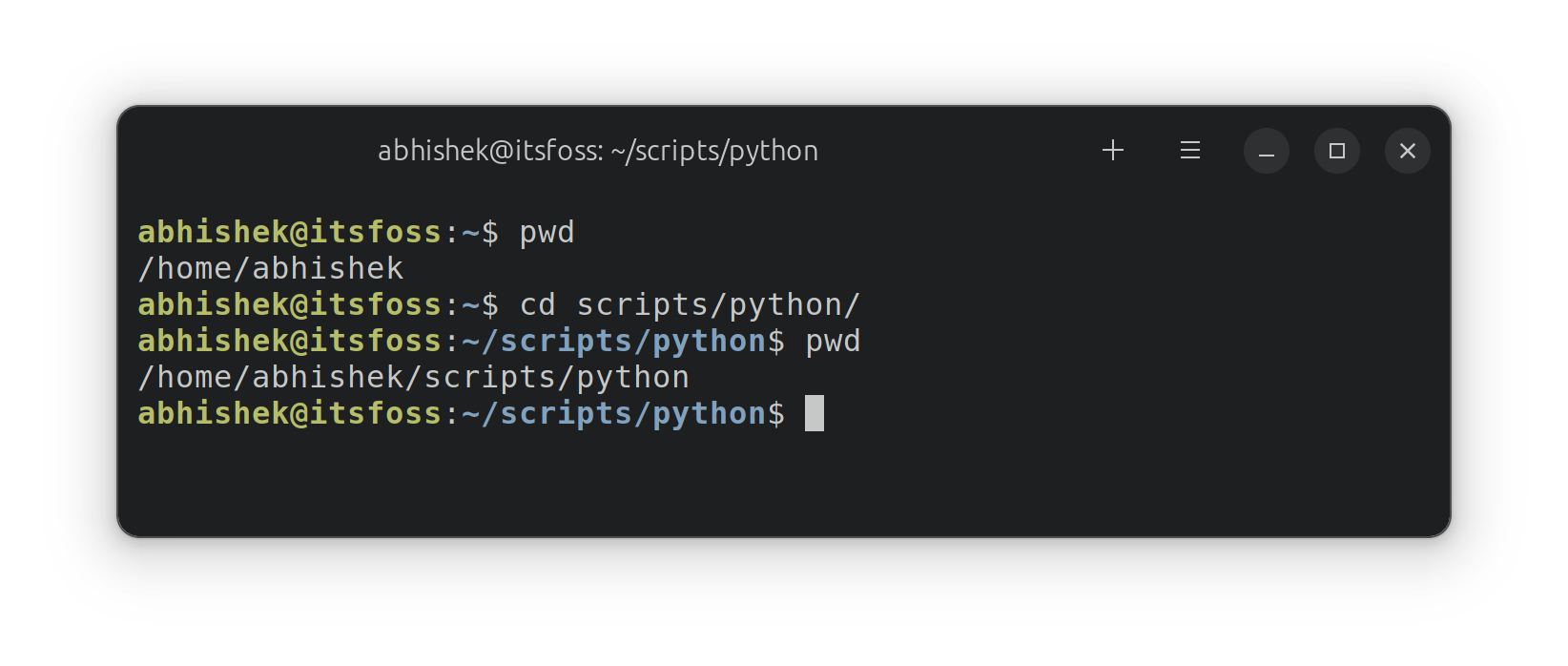
## Go up the directory
So far, you are going down the 'flow'. What if you have to go up a directory?
Let's say, you are in `/home/abhishek/scripts/python`
and you have to up a directory to `scripts`
?.
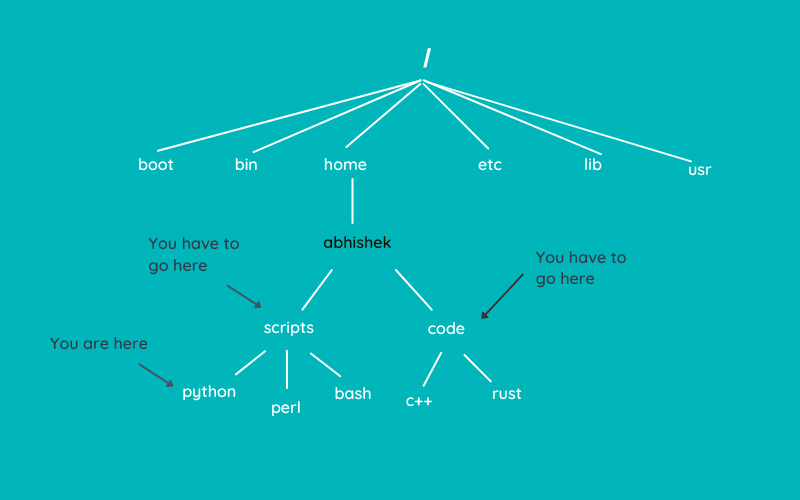
Using the absolute path is always an option but it is quite lengthy. Instead, you can use the special directory notation `..`
. The double dots (..) mean parent directory or up a directory. Single dot (.) means the current directory.
`cd ..`
Here's an example:
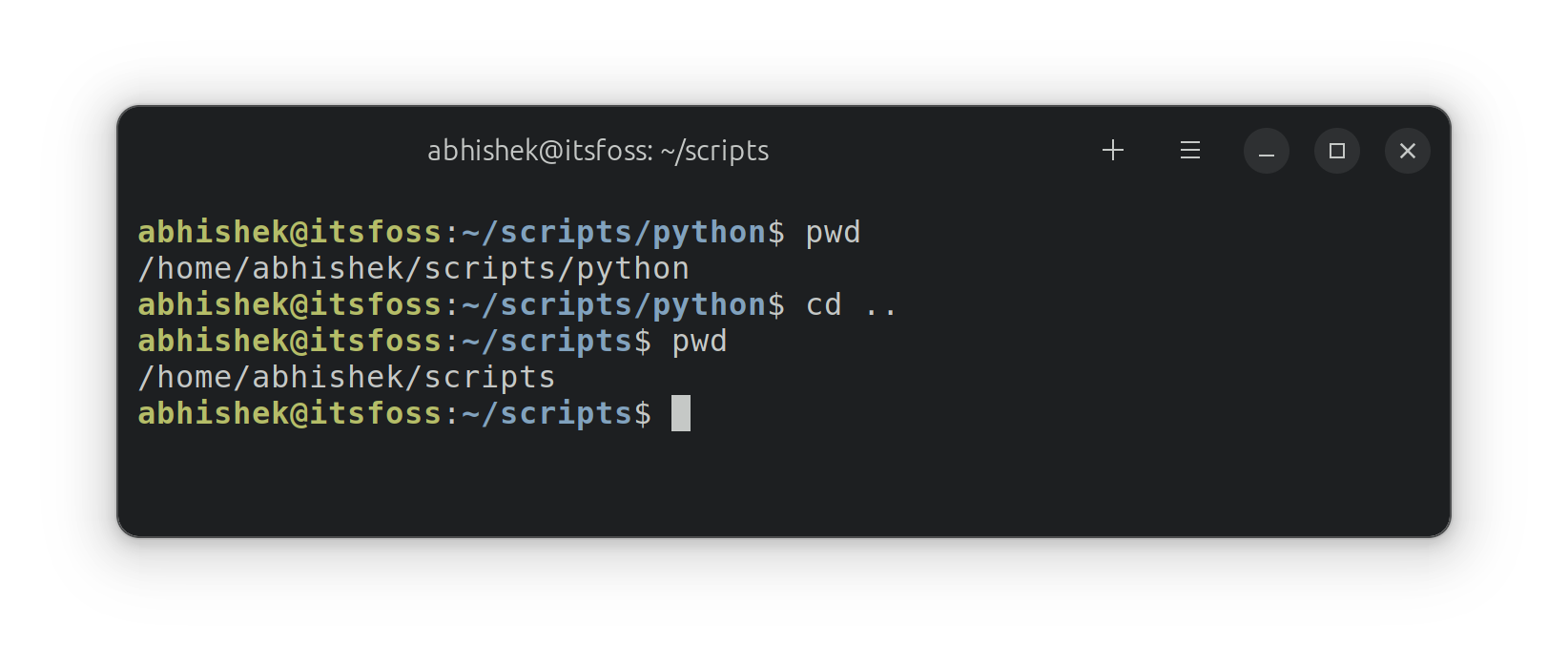
You can use the `..`
to travel up the path in the Linux filesystem hierarchy.
Suppose I am in the `python`
directory in the above image and want to go to the `code`
directory. Here's what I could do:
`cd ../../code`
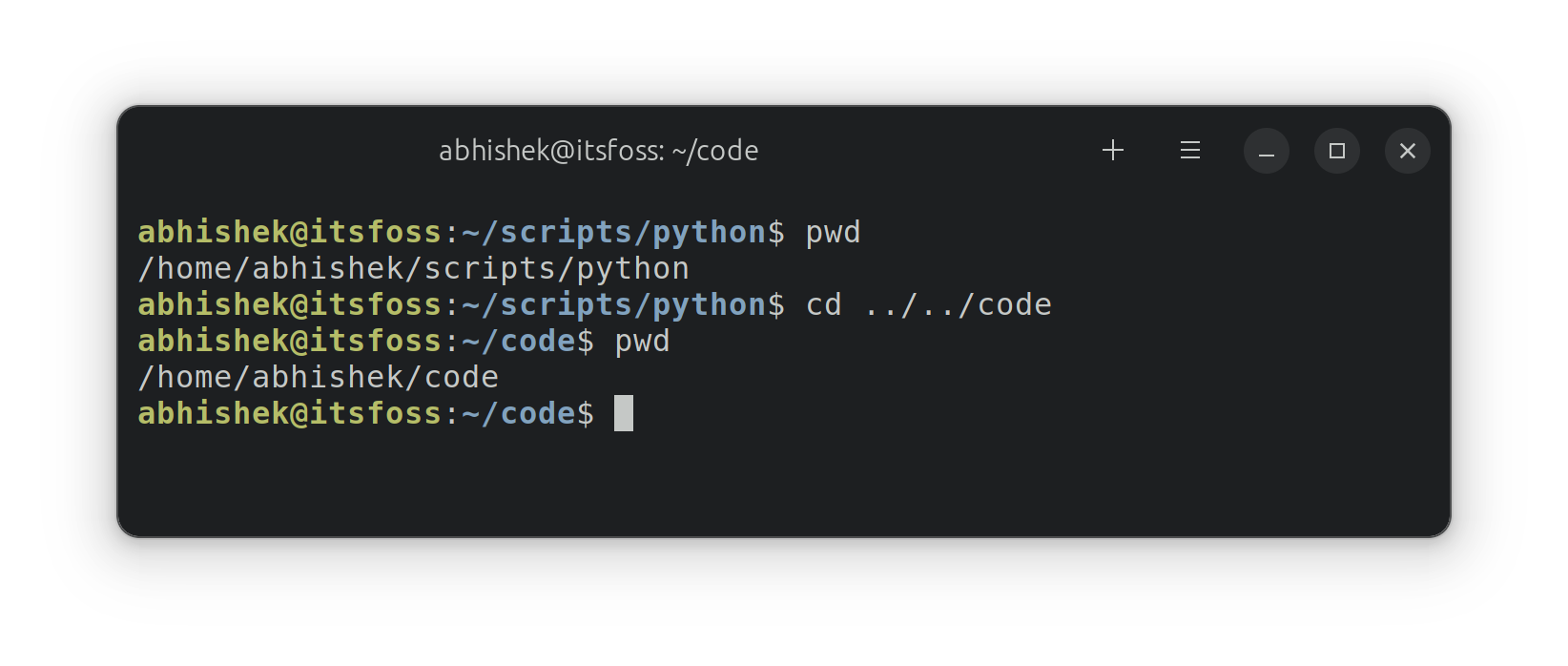
## Go to the home directory
If you feel lost in all these directory travels and want to go back home, there are so many simple shortcuts.
In fact, the simplest of them is to use the cd command without any option.
`cd`
That will take you back to your home directory from anywhere on the filesystem.
Alternatively, you can use the `~`
notation which means home directory.
`cd ~`
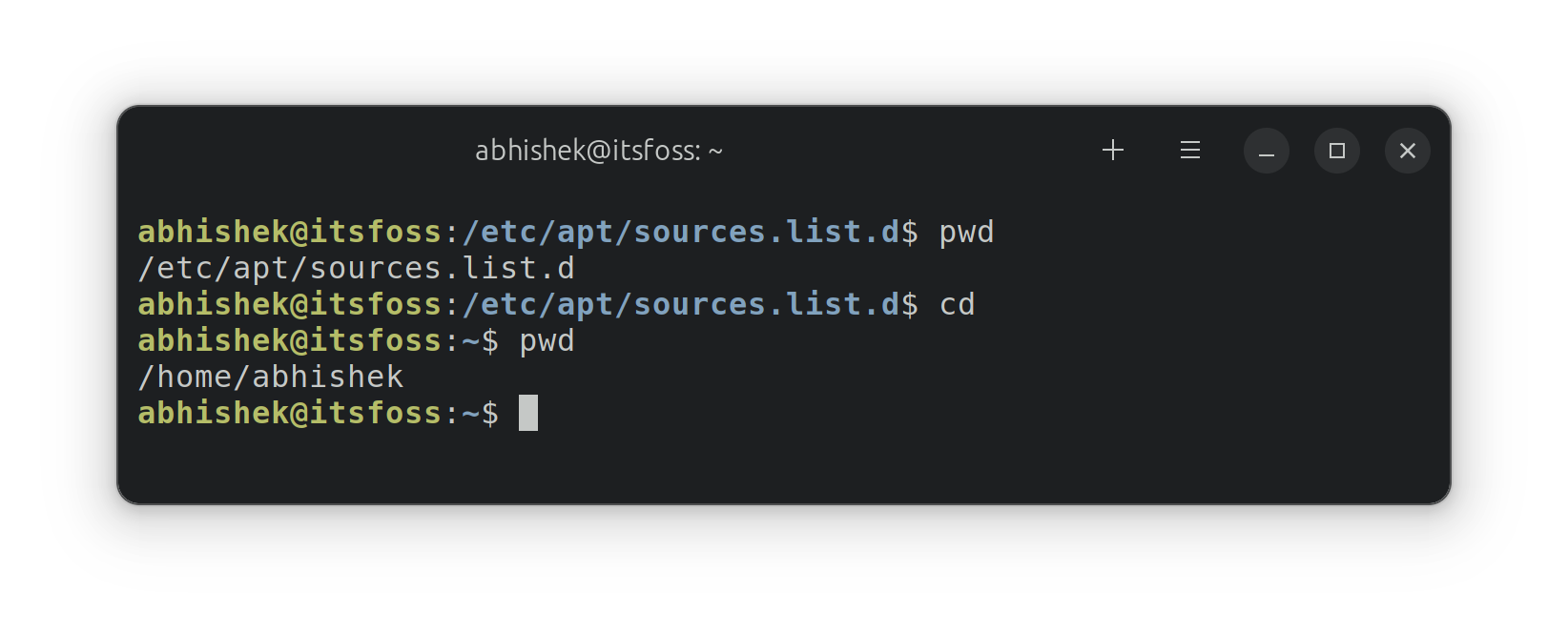
## Go to the root directory
Though you won't use it as often as the previous one, it is still good to know.
If you want to go back to the root directory from where the filesystem begins, use this:
`cd /`
There is no 'magic' involved here. `/`
denotes root when used at the beginning of a path. Don't confuse it with path separators.

## Switch back to the previous directory
This is a lifesaver or should I say timesaver. When you are deep inside a directory structure and then go to another directory and then you feel the need to go back to the previous location, this shortcut helps.
`cd -`
Not clear yet? Let me show an example.
I am in the location `/etc/apt/sources.list.d`
. From here, I go to `/home/abhishek/scripts/python`
to work on my code. And then I realized that I have to check something again in `/etc/apt/sources.list.d`
directory.
The usual approach would be to do this which makes me type all the path again:
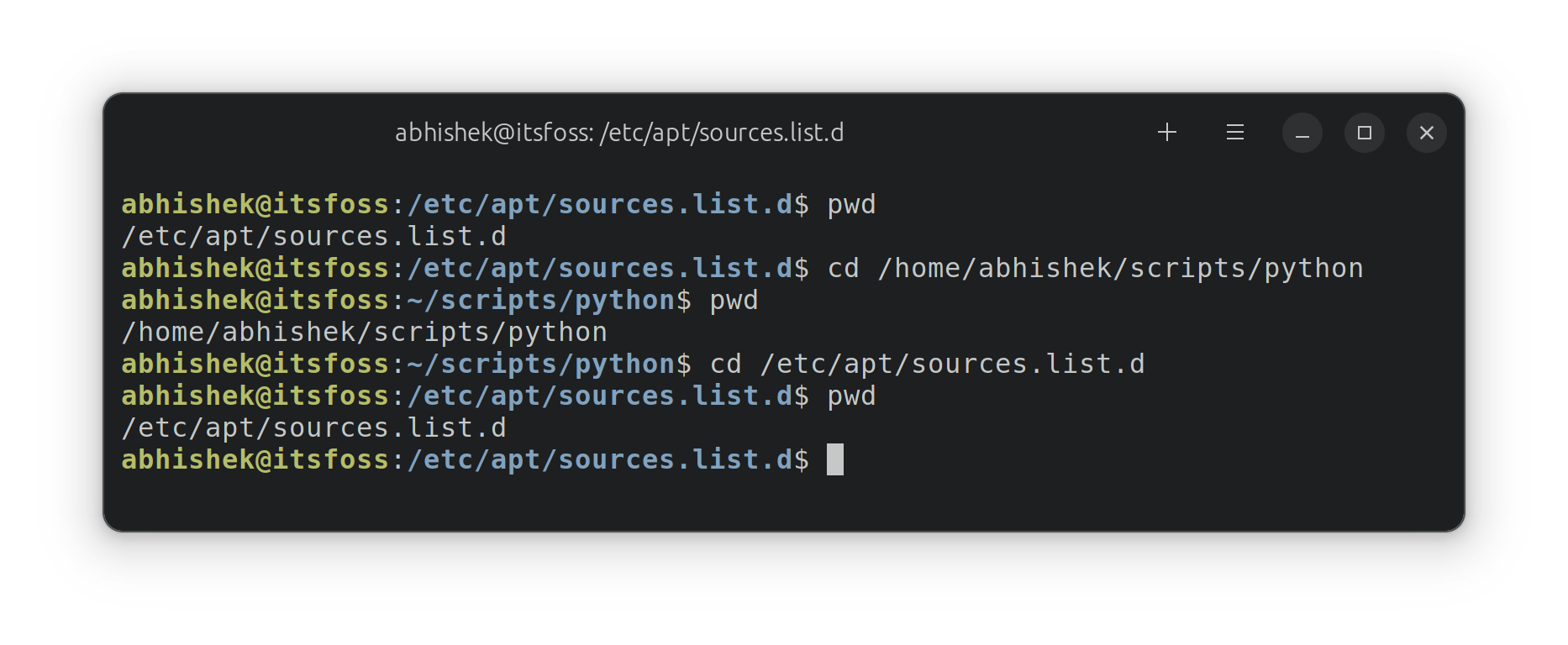
But the smart approach is to use this:
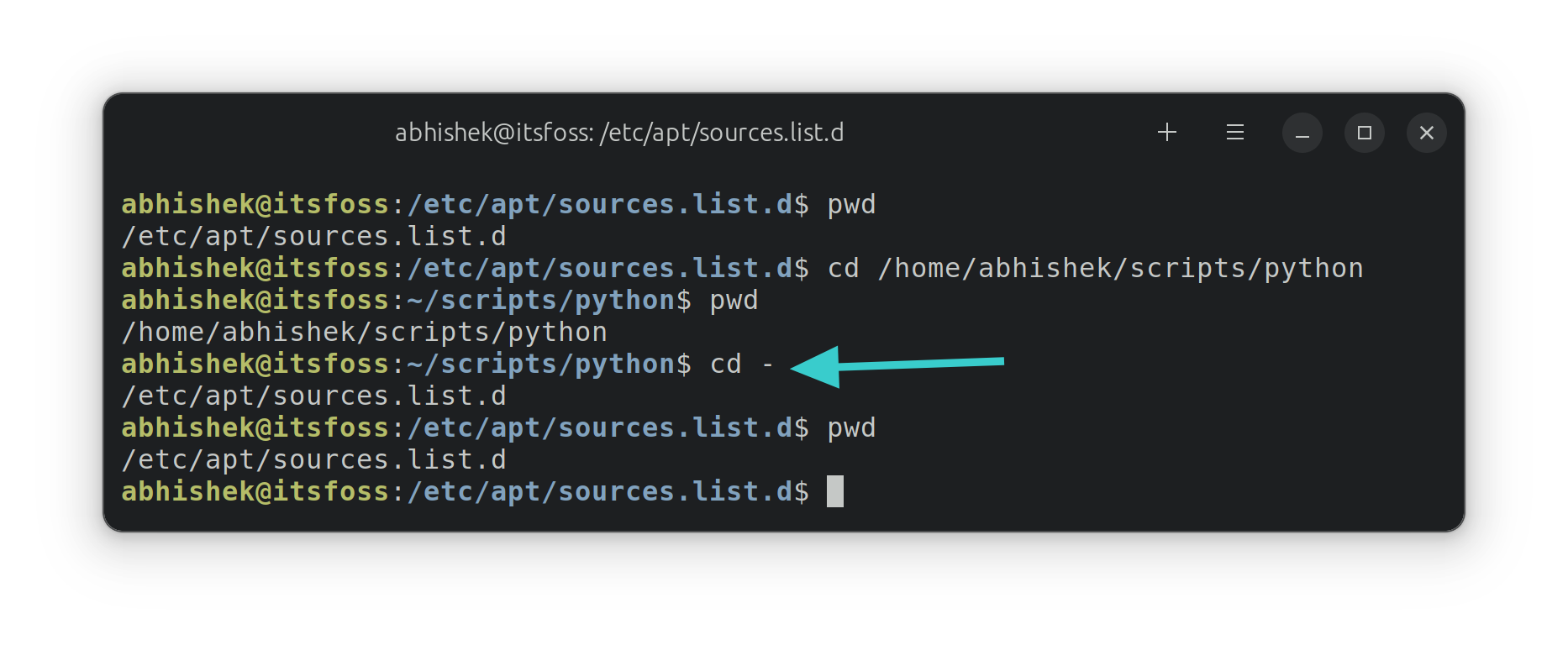
See, no need to type the lengthy path again. Works wonder!
## 🏋️ Exercise time
If you want to practice the cd command, here's a little practice exercise for you.
- Open a terminal and go to the
`/var/log`
directory.[Check the directory contents](https://itsfoss.com/list-directory-content/). What do you see? - Now, go to
`/var`
directory. This is up a directory. - From here, go back to your home directory.
And that's good enough content for you to get familiar with the cd command. Here are some other important commands you should know about.
[31 Basic Yet Essential Ubuntu CommandsAn extensive list of essential Linux commands that every Ubuntu user will find helpful in their Linux journey.](https://itsfoss.com/essential-ubuntu-commands/)

Let me know if you have questions or suggestions. |
15,969 | 如何在 Ubuntu 22.04 中安装和使用 Wireshark | https://www.linuxtechi.com/install-use-wireshark-ubuntu/ | 2023-07-05T15:48:00 | [
"tcpdump",
"Wireshark"
] | https://linux.cn/article-15969-1.html | 
>
> 技术兄弟们,大家好,在这篇文章中我们将介绍如何在 Ubuntu 22.04 中安装和使用 Wireshark。
>
>
>
Wireshark 是自由开源的、跨平台的、基于 GUI 的网络数据包分析器,可用于 Linux、Windows、MacOS、Solaris 等。它实时捕获网络数据包并以人类可读的格式呈现它们。它使我们能够监控微观层面的网络数据包。它还有一个名为 `tshark` 的命令行程序,它执行与 Wireshark 相同的功能,但通过终端而不是通过 GUI。
Wireshark 可用于网络故障排除、分析、软件和通信协议开发,也可用于教育目的。Wireshark 使用名为 `pcap` 的库来捕获网络数据包。
### Wireshark 的功能
* 支持检查数百种协议
* 能够实时捕获数据包并保存它们以供以后离线分析
* 一些用于分析数据的过滤器
* 捕获的数据可以动态压缩和解压缩
* 支持多种数据分析文件格式,输出也可以保存为 XML、CSV、纯文本格式
* 可以从以太网、WiFi、蓝牙、USB、帧中继、令牌环等多种接口捕获数据
### 先决条件
* 预装 Ubuntu 22.04
* 具有 sudo 权限的本地用户
* 互联网连接
### Wireshark 安装步骤
#### 从 Ubuntu 仓库安装
Wireshark 包可在默认的 Ubuntu 仓库中找到,并且可以使用以下命令简单地安装。但你可能无法获得最新版本的 wireshark。
```
$ sudo apt update
$ sudo apt install wireshark
```

选择 “Yes” 允许非超级用户使用 Wireshark 捕获数据包:

安装成功后,访问 Wireshare UI。从“<ruby> 活动 <rt> Activities </rt></ruby>”中搜索 “wireshark”,然后单击其图标。

以上确认你的 Wireshark 安装已成功完成。
#### 安装最新的版本
如果要安装最新版本的 Wireshark,我们必须使用以下 `apt` 命令启用官方 Wireshark 仓库:
```
$ sudo add-apt-repository ppa:wireshark-dev/stable
$ sudo apt update
```
现在,安装最新版本的 Wireshark,运行:
```
$ sudo apt install wireshark -y
```
安装 Wireshark 后,验证其版本:
```
$ wireshark --version
```

要允许普通用户使用 Wireshark 使用和捕获数据包,请运行以下命令:
```
$ sudo dpkg-reconfigure wireshark-common
```
选择 “Yes” 并按回车键。

使用 `usermod` 命令将本地用户添加到 `wireshark` 组:
```
$ sudo usermod -aG wireshark $USER
$ newgrp wireshark
```
要使上述更改生效,请重新启动系统。
```
$ sudo reboot
```
### 使用 Wireshark 捕获数据包
启动 Wireshark,从“活动”->搜索 “wireshark”。

单击 Wireshark 图标,

所有这些都是我们可以捕获网络数据包的接口。根据你系统上的界面,此页面可能会有所不同。
我们选择 “enp0s3” 来捕获该接口的网络流量。选择接口后,我们网络上所有设备的网络数据包开始填充(请参阅下面的截图):

第一次看到此页面时,我们可能会被此屏幕中显示的数据淹没,并且可能会想到如何整理这些数据,但不用担心,Wireshark 的最佳功能之一就是它的过滤器。
我们可以根据 IP 地址、端口号对数据进行排序/过滤,还可以使用源和目标过滤器、数据包大小等,还可以将 2 个或更多过滤器组合在一起以创建更全面的搜索。我们可以在“<ruby> 应用显示过滤器 <rt> Apply a Display Filter </rt></ruby>”选项卡中编写过滤器,也可以选择已创建的规则之一。要选择预建过滤器,请单击“旗帜”图标,然后点击“应用显示过滤器”选项卡。

我们还可以根据颜色代码来过滤数据,默认情况下,浅紫色是 TCP 流量,浅蓝色是 UDP 流量,黑色标识有错误的数据包,要查看这些代码的含义,请单击“<ruby> 查看 <rt> View </rt></ruby>”->“<ruby> 颜色规则 <rt> Coloring Rules </rt></ruby>”,我们也可以更改这些代码。

获得所需的结果后,我们可以单击任何捕获的数据包以获取有关该数据包的更多详细信息,这将显示有关该网络数据包的所有数据。
要停止捕获数据包,请单击红色停止按钮,然后将捕获的数据包保存到文件中。

### 总结
Wireshark 是一款非常强大的工具,需要一些时间来适应和掌握它,这篇文章将帮助你开始使用。请随时在下面的评论栏中提出你的疑问或建议。
*(题图:MJ/63c09e75-a3e7-4dbf-ac6f-0233bdd34ad8)*
---
via: <https://www.linuxtechi.com/install-use-wireshark-ubuntu/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello techies, in this post we will cover how to install and use wireshark in Ubuntu 22.04.
Wireshark is free and open source, cross platform, GUI based Network packet analyzer that is available for Linux, Windows, MacOS, Solaris etc. It captures network packets in real time & presents them in human readable format. It allows us to monitor the network packets up to microscopic level. It also has a command line utility called ‘tshark‘ that performs the same functions as Wireshark but through terminal & not through GUI.
Wireshark can be used for network troubleshooting, analyzing, software & communication protocol development & also for education purposed. Wireshark uses a library called ‘pcap‘ for capturing the network packets.
#### Wireshark Features
- Support for a hundreds of protocols for inspection,
- Ability to capture packets in real time & save them for later offline analysis,
- A number of filters to analyzing data,
- Data captured can be compressed & uncompressed on the fly,
- Various file formats for data analysis supported, output can also be saved to XML, CSV, plain text formats,
- data can be captured from a number of interfaces like ethernet, wifi, bluetooth, USB, Frame relay , token rings etc.
#### Prerequisites
- Pre Installed Ubuntu 22.04
- Local User with sudo rights
- Internet Connectivitiy
## Wireshark Installation Steps
Wireshark package is available with default Ubuntu repositories & can be simply installed using the following commands. But there might be chances that you will not get the latest version of wireshark.
$ sudo apt update $ sudo apt install wireshark
Choose Yes to allow non-superusers to capture packets using wireshare
Post successfull installation, access Wireshare UI. Search wireshark from Activities and then click on its icon.
Above confirms that your wireshark installation is completed successfully.
In order to install latest version of wireshark, we must enable official wireshark repository using following apt commands.
$ sudo add-apt-repository ppa:wireshark-dev/stable $ sudo apt update
Now, Install latest version of wireshark, run
$ sudo apt install wireshark -y
Once the Wireshark is installed, verify its version,
$ wireshark --version
To allow your regular user to use and capture packets using wireshark, run following command
$ sudo dpkg-reconfigure wireshark-common
Choose ‘Yes’ and hit enter
Add your local user to wireshark group using usermod command
$ sudo usermod -aG wireshark $USER $ newgrp wireshark
To make above changes into the affect, reboot your system once.
$ sudo reboot
## Capture Packets Using Wireshark
Start the wireshark, from Activities –> Search Wireshark
Click on Wireshark icon,
All these are the interfaces from where we can capture the network packets. Based on the interfaces you have on your system, this screen might be different for you.
We are selecting ‘enp0s3’ for capturing the network traffic for that inteface. After selecting the inteface, network packets for all the devices on our network start to populate (refer to screenshot below)
First time we see this screen we might get overwhelmed by the data that is presented in this screen & might have thought how to sort out this data but worry not, one the best features of Wireshark is its filters.
We can sort/filter out the data based on IP address, Port number, can also used source & destination filters, packet size etc & can also combine 2 or more filters together to create more comprehensive searches. We can either write our filters in ‘Apply a Display Filter’ tab , or we can also select one of already created rules. To select pre-built filter, click on ‘flag’ icon , next to ‘Apply a Display Filter’ tab,
We can also filter data based on the color coding, By default, light purple is TCP traffic, light blue is UDP traffic, and black identifies packets with errors , to see what these codes mean, click View -> Coloring Rules, also we can change these codes.
After we have the results that we need, we can then click on any of the captured packets to get more details about that packet, this will show all the data about that network packet.
To stop capruring the packet, click on Red button and then save the captured packets to a file.
#### Concusion
Wireshark is an extremely powerful tool takes some time to getting used to & make a command over it, this post will help you get started. Please feel free to drop in your queries or suggestions in the comment box below.
HZI beg your pardon, but… are you sure, it is a good idea, to allow any user to capture the network traffic?? O.K., it is good to demonstrate, using capabilities but… As far as I know, there is a group for users, who need the right using wireshark.
Pradeep KumarIt is for the demonstration only. For real time environment , we can add specific users to a Wireshark group. |
15,970 | 树莓派的五种最奇特的用途 | https://opensource.com/article/23/3/most-curious-uses-raspberry-pi | 2023-07-05T16:54:18 | [
"树莓派"
] | https://linux.cn/article-15970-1.html | 
>
> 人们使用树莓派做各种各样的事情。有哪些用途让你特别好奇的吗?
>
>
>
最近,我在一个电话会议上听到有人说开源社区是好奇心和解决问题的文化的结合。好奇心是我们解决问题的基础。在解决各种规模的问题时,我们使用了大量的开源工具,其中包括在功能极为方便的树莓派上运行的 [Linux](https://opensource.com/article/19/3/learn-linux-raspberry-pi)。
我们每个人都有各种不同的生活经历,所以我向我们的作者社区询问了他们所遇到的最奇特的树莓派用途。我有一种预感,这些令人惊奇的构建将会为其他人激发灵感。
### 使用树莓派进行实验
对我来说,树莓派是在家庭网络中增加额外开发资源的绝佳工具。如果我想要创建一个新的网站或者尝试一个新的软件工具,我不必让我的桌面 Linux 机器因为一堆我可能只在实验时使用一次的软件包而变得笨重。相反,我会将它设置在我的树莓派上。
如果我认为我将要做一些冒险的事情,我会使用备份的启动环境。我有两张 microSD 卡,这样我就可以在树莓派上插一张卡,同时设置第二张卡进行任何我想要的实验。额外的 microSD 卡成本并不高,但在我想要在第二个镜像上进行实验的时候,它能节省大量时间。只需关机,换下 microSD 卡,重新启动,立即就可以在专用的测试系统上工作。
当我不进行实验时,我的树莓派充当打印服务器,将我的非 WiFi 打印机连接到家庭网络上。它还是一个方便的 SSH 文件服务器,让我可以快速备份重要文件。
— [Jim Hall](https://opensource.com/users/jim-hall)
### 树莓派的流行
我见过的树莓派最令人惊讶的事情是它使小型单板计算机的概念变得流行和通俗化,并使其真正实用于大众。
在树莓派出现之前,我们有类似的小型单板计算机,但它们往往是小众的、昂贵的,并且从软件角度来看让人拒之千里。树莓派价格便宜,便宜到任何人都可以轻松为一个项目获得一台(不考虑目前难以获得的情况)。一旦它变得便宜,人们就会克服软件挑战,使其足够好以解决许多基本的计算任务,甚至可以将完整的真正的计算机用于特定任务,而不仅仅是微控制器。
我们拥有大量好的、相对廉价的小型单板计算机,这促进了各种调试、玩耍和 [实验](https://opensource.com/article/20/8/kubernetes-raspberry-pi)。人们愿意尝试新的想法,甚至推动了更多业余爱好者的硬件开发来支持这些想法。
老实说,这是我从树莓派看到的最令人惊奇和激进的事情:它根本性地改变了人们对计算的认知,尤其是树莓派擅长的领域,并不仅仅催生了自己的生态系统,现在还催生了无数其他多样化的生态系统。
— [John ‘Warthog9' Hawley](https://opensource.com/users/warthog9)
### 蜜蜂的树莓派
在 2018 年,我和我的弟弟曾经养过几个蜂箱,并使用树莓派和各种传感器来监测蜂箱的温度和湿度。我们还计划在夏天实施蜂箱秤,以观察蜜蜂的产蜜情况,并在冬天测量重量,以查看蜜蜂是否有足够的食物。不过我们最终没有实施这个计划。
我们的小型监测解决方案基于树莓派 2B,运行 Raspbian Stretch(基于 Debian 9),并连接了一个温湿度传感器(DHT11)。在蜂箱内我们有三到四个这样的传感器,用于测量蜂箱入口孔、盖子下方和最低框架的温度。我们直接将传感器连接到树莓派,并使用 Python\_DHT 传感器库读取数据。我们还建立了 [InfluxDB](https://opensource.com/article/17/8/influxdb-time-series-database-stack)、Telegraf,并最终设置了 [Grafana](https://opensource.com/article/21/3/raspberry-pi-grafana-cloud) 来可视化数据。
如果你想了解更多关于我们的设置的信息,我们在 [Linux Magazine](https://www.linux-magazine.com/index.php/layout/set/print/Issues/2018/214/Monitoring-Beehives) 上发表了一篇关于我们小型监测解决方案的文章。
— [Heike Jurzik](https://opensource.com/users/hej)
### 树莓派的复古计算
我希望用树莓派创建一个模拟如何使用“开关和指示灯”将机器语言编程到旧式计算机的项目。使用树莓派的 GPIO 引脚,这看起来相当简单。例如,他们的在线手册上展示了如何使用 GPIO 开关控制 LED 的开关,或者使用按钮进行输入。我认为只需一些 LED 和开关,再加上在树莓派上运行的小程序,就可以模拟旧式计算机。不过,我缺乏空闲时间来从事这样的项目,这就是为什么我编写了 [Toy CPU](https://opensource.com/article/23/1/learn-machine-language-retro-computer) 来模拟它。
— [Jim Hall](https://opensource.com/users/jim-hall)
### 使用树莓派打造玩具
当我女儿四岁的时候,她要求圣诞节时给她买一个“巨齿鲨音乐盒”。她能在脑海中完美地想像出来。它会是粉红色的、闪闪发光的,上面有她的名字。当她打开盒子时,会播放这部热门电影的主题曲。她可以将巨齿鲨和其他宝贝都放在盒子里。在网上和商店里到处搜索后,我发现没有一个能与她的想象相媲美。于是我和丈夫决定,在我们自己的玩具店(也就是他的家庭办公室)自己动手制作一个。而这一切的核心当然是树莓派。他使用光传感器和 Python 脚本,让音乐在恰当的时刻播放。我们将科技设备谨慎地放置在音乐盒的底部,并根据她的审美进行装饰。那一年,开源技术让圣诞魔法成为了可能!
— [Lauren Pritchett](https://opensource.com/users/lauren-pritchett)
*(题图:MJ/aa8f1412-0f1d-4780-99db-22d6522010b7)*
---
via: <https://opensource.com/article/23/3/most-curious-uses-raspberry-pi>
作者:[AmyJune Hineline](https://opensource.com/users/amyjune) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently, I was on a call where it was said that the open source community is a combination of curiosity and a culture of solutions. And curiosity is the basis of our problem-solving. We use a lot of open source when solving problems of all sizes, and that includes [Linux](https://opensource.com/article/19/3/learn-linux-raspberry-pi) running on the supremely convenient Raspberry Pi.
We all have such different lived experiences, so I asked our community of writers about the most curious use of a Raspberry Pi they've ever encountered. I have a hunch that some of these fantastic builds will spark an idea for others.
## Experimentation with the Raspberry Pi
For me, the Raspberry Pi has been a great tool to add extra development resources on my home network. If I want to [create a new website](https://opensource.com/article/22/3/run-drupal-raspberry-pi) or experiment with a new software tool, I don't have to bog down my desktop Linux machine with a bunch of packages that I might only use once while experimenting. Instead, I set it up on my Raspberry Pi.
If I think I'm going to do something risky, I use a backup boot environment. I have two microSD cards, which allows me to have one plugged into the Raspberry Pi while I set up the second microSD to do whatever experimenting I want to do. The extra microSD doesn't cost that much, but it saves a ton of time for the times when I want to experiment on a second image. Just shutdown, swap microSD cards, reboot, and immediately I'm working on a dedicated test system.
When I'm not experimenting, my Raspberry Pi acts as a print server to put my non-WiFi printer on our home network. It is also a handy file server over SSH so that I can make quick backups of my important files.
**— Jim Hall**
## The popularity of the Raspberry Pi
The most amazing thing I've seen about the Raspberry Pi is that it normalized and commoditized the idea of the small-board computers and made them genuinely and practically available to folks.
Before the Raspberry Pi, we had small-board computers in a similar fashion, but they tended to be niche, expensive, and nigh unapproachable from a software perspective. The Raspberry Pi was cheap, and cheap to the point of making it trivial for anyone to get one for a project (ignoring the current round of unobtainium it's been going through). Once it was cheap, people worked around the software challenges and made it good enough to solve many basic computing tasks, down to being able to dedicate a full and real computer to a task, not just a microcontroller.
We've got a plethora of good, cheap-ish, small-board computers, and this gives way to tinkering, toying, and [experimenting](https://opensource.com/article/20/8/kubernetes-raspberry-pi). People are willing to try new ideas, even spurring more hobbyist hardware development to support these ideas.
Honestly, that is by far the most amazing and radical thing I've seen from the Raspberry Pi: how it's fundamentally changed everyone's perception of what computing, at the level of what the Raspberry Pi excels at anyway, is and given rise not only to its own ecosystem but now countless others in diversity.
## Raspberry Pi for the bees
In 2018, my younger brother and I used to have several beehives and used a Raspberry Pi and various sensors to monitor the temperature and humidity of our hives. We also planned to implement a hive scale to observe honey production in summer and measure the weight in winter to see if the bees had enough food left. We never got around to doing that.
Our little monitoring solution was based on a Raspberry Pi 2 Model B, ran Raspbian Stretch (based on Debian 9), and had a temperature and humidity sensor connected (DHT11). We had three or four of those sensors in the hives to measure the temperature at the entrance hole, under the lid, and in the lowest frame. We connected the sensor directly to the Pi and used the Python_DHT sensor library to read the data. We also set up [InfluxDB](https://opensource.com/article/17/8/influxdb-time-series-database-stack), Telegraf, and finally, [Grafana](https://opensource.com/article/21/3/raspberry-pi-grafana-cloud) to visualize the data.
If you want to know more about our setup, we published an article on our little monitoring solution in [Linux Magazine](https://www.linux-magazine.com/index.php/layout/set/print/Issues/2018/214/Monitoring-Beehives).
## Go retro with the Raspberry Pi
One thing I would love to create with the Raspberry Pi is a simulation of how to program machine language into an old-style computer using "switches and lights." This looks to be fairly straightforward using the GPIO pins on the Raspberry Pi. For example, their online manual shows examples of how to use GPIO to switch an LED on and off or to use buttons to get input. I think it should be possible with some LEDs and switches, plus a small program running on the Raspberry Pi to emulate the old-style computer. But I lack the free time to work on a project like this, which is why I wrote the [Toy CPU](https://opensource.com/article/23/1/learn-machine-language-retro-computer) to emulate it.
**— Jim Hall**
## Build a toy with the Raspberry Pi
When my daughter was four, she asked for a "Trolls music box" for Christmas. She could picture it perfectly in her head. It would be pink and sparkly with her name on it. When she opened the box, the theme song from the popular movie would play. She could store her trolls and other treasures in the box. After searching everywhere online and in stores, I could not find one that measured up to her imagination. My husband and I decided we could build one ourselves in our own toyshop (i.e., his home office). The center of it all was, of course, the Raspberry Pi. He used light sensors and a Python script to make the song play at just the right moment. We placed the tech discreetly in the bottom of the music box and decorated it with her aesthetic in mind. That year, holiday magic was made possible with open source!
## 4 Comments |
15,972 | 适用于 Linux 的 5 个最佳 PDF 编辑器 | https://www.debugpoint.com/pdf-editors-ubuntu/ | 2023-07-06T18:33:00 | [
"PDF"
] | /article-15972-1.html | 
>
> 我们列出了适用于 Ubuntu 和其他 Linux 发行版的最佳自由及开源的 PDF 编辑器。并根据它们的 PDF 编辑功能进行比较。
>
>
>
正在寻找适用于 Ubuntu 的自由及开源 PDF 编辑器?继续阅读本文以了解 Ubuntu 的最佳 PDF 编辑器以及如何使用它们编辑 PDF 文件的分步指南。
Ubuntu 是深受开发人员、学生和专业人士欢迎的操作系统。编辑 PDF 文件是许多用户的常见任务,但找到适合该工作的工具可能很困难。在本文中,我们将介绍一些最好的免费和开源的 PDF 编辑器及其功能。
### 适用于 Ubuntu 和其他发行版的最佳免费 PDF 编辑器
#### LibreOffice Draw
LibreOffice 是一款流行的开源办公生产力套件。它的绘图组件名为 “LibreOffice Draw”,能够编辑 PDF。在此列表中的所有应用中,LibreOffice Draw 是在 Linux 中编辑 PDF 文件的最佳选择。
让我们看看如何编辑示例 PDF 和选项。
* 打开 LibreOffice Draw 并单击“<ruby> 文件 <rt> File </rt></ruby>”>“<ruby> 打开 <rt> Open </rt></ruby>”
* 选择你要编辑的 PDF 文件
* 根据需要编辑 PDF 文件
* 保存编辑后的 PDF 文件
这是正在编辑文本的示例图片。

关于 LibreOffice Draw 的一些使用说明:
* LibreOffice Draw 本身将 PDF 组件检测为小的文本或图像块。例如,如果 PDF 文件中有一个段落,它会将其检测为单独的文本块。请参见下图。
* 这可能有点棘手,但你仍然可以仔细编辑它。
* 此外,你还可以在 PDF 文件中添加文本框和其他组件。

#### Inkscape
流行的 [Inkscape](https://inkscape.org/) 图形编辑器可以编辑和修改 PDF 文件。它提供的读取单个 PDF 组件的功能是无与伦比的,而且完全被低估了。
Inkscape 允许你通过外部库的 “Popller/Cairo 导入”或内置的内部 PDF 导入工具来导入 PDF 文件。你也可以告诉 Inkscape 将 PDF 字体与你系统中任何最接近的字体相匹配。

打开 PDF 时,你可以单独编辑 PDF 中的章节、单词、线条、段落或绘图。每个组件都会被识别并表示为单独的层,以进行更高级的编辑。
编辑完成后,你可以再次将其导出成 PDF。

如果你想要高级 PDF 编辑,Inkscape 是最好的选择。步骤概述如下。
* 打开 Inkscape 并单击“<ruby> 文件 <rt> File </rt></ruby>”>“<ruby> 打开 <rt> Open </rt></ruby>”
* 选择你要编辑的 PDF 文件
* 根据需要编辑 PDF 文件
* 导出编辑后的 PDF 文件
你可以[在 Linux 系统安装 Flatpak](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) 和 Flathub,并使用以下命令安装 Inkscape。
```
flatpak install org.inkscape.Inkscape
```
#### GIMP
许多人不知道流行的光栅图形编辑器 [GIMP](https://www.gimp.org/) 也可以打开并允许你编辑 PDF。在 GIMP 中打开 PDF 文件会提示你将每个 PDF 页面分别作为图像文件的图层打开。你现在可以编辑图像并最终从 GIMP 将它们导出为 PDF。

但有一个问题。每个 PDF 页面都成为 GIMP 中的静态图像。其中包括文本、图表、图标等。因此,如果你想修改它,你可能需要匹配字体大小、通过 GIMP 选择删除部分等等。
因此,总的来说,你可以进行高级编辑,但无法修改其上的现有文本。
使用方法很简单。
* 打开 GIMP 并单击“<ruby> 文件 <rt> File </rt></ruby>”>“<ruby> 打开 <rt> Open </rt></ruby>”
* 选择你要编辑的 PDF 文件
* 根据需要编辑 PDF 文件。
* 另存为编辑后的 PDF 文件
你可以 [在 Linux 系统安装 Flatpak](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) 和 Flathub,并使用以下命令安装 GIMP。
```
flatpak install org.gimp.GIMP
```

#### Okular
KDE 社区流行的文档查看器应用 [Okular](https://okular.kde.org/) 的 PDF 编辑功能有限。它没有加载一整套 PDF 编辑功能。不过,你可以在 Okular 中执行一些高级注释。
因此,我认为它在这个列表中占有一席之地是当之无愧的。
在 PDF 中使用 Okular 可以执行以下操作:
* 添加文本作为注释
* 使用各种颜色高亮显示 PDF 中的文本
* 添加注释、箭头和手绘图。
**但是,你无法使用 Okular 修改现有 PDF 内容。**
注释完成后,你可以将文件另存为 PDF。
你可以 [在 Linux 系统安装 Flatpak](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) 和 Flathub,并使用以下命令安装 Okular。
```
flatpak install org.kde.okular
```

#### Scribus
[Scribus](http://www.scribus.net/) 是最古老的开源桌面出版程序之一,它以 PDF 和 Postscript 格式生成商业级输出,主要(但不限于)用于 Linux。
虽然主要用于设计,但它可以打开 PDF 文件并提供有限的编辑选项。
导入选项允许你选择将 PDF 文本导入为矢量图像还是文本。此外,你还可以调整 PDF 组件的大小、将其分组/取消分组、更改文本等。
完成后,你可以将其保存回 PDF 文件。它是被低估的程序之一,你可以尝试使用它在 Ubuntu 和其他发行版中编辑 PDF。
你可以 [在 Linux 系统安装 Flatpak](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) 和 Flathub,并使用以下命令安装 Scribus。
```
flatpak install net.scribus.Scribus
```


### 其他商业和非自由及开源替代品
你可能想尝试一些商业的、非自由及开源软件的选项。这里是其中的一些。
* [Sejda PDF Desktop](https://www.sejda.com/desktop)(最多免费 3 个任务,200 页,每天 50 MB)
* [PDFedit(当前未维护,使用旧库)](https://sourceforge.net/projects/pdfedit/)
* [Master PDF editor(商业)](https://code-industry.net/masterpdfeditor/)
### 总结
我们推荐的免费 PDF 编辑器是 Inkscape 和 LibreOffice Draw。它们都能够满足从基本到高级的使用水平,并且效果良好。
你可以尝试其他选项,但结果可能会根据 PDF 文件的复杂程度而有所不同。
此外,你始终可以选择商业选项以获得更多功能。
我希望本指南可以帮助你为 Ubuntu 和其他 Linux 发行版选择最好的免费 PDF 编辑器。
*(题图:MJ/3ea2b1da-87e4-4839-97e9-5937f93c64eb)*
---
via: <https://www.debugpoint.com/pdf-editors-ubuntu/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,973 | 使用 pdftk 为 PDF 文档创建书签 | https://opensource.com/article/22/1/pdf-metadata-pdftk | 2023-07-06T18:51:00 | [
"PDF"
] | https://linux.cn/article-15973-1.html | 
>
> 充分利用现有的技术,提供书签以帮助用户。
>
>
>
在 [介绍 pdftk-java](https://opensource.com/article/21/12/edit-pdf-linux-pdftk) 中, 我展示了如何在脚本中使用 `pdftk-java` 来快速修改 PDF 文件。
但是,`pdftk-java` 最有用的场景是处理那种动辄几百页的没有目录的大 PDF 文件。这里所谓的目录不是指文档前面供打印的目录,而是指显示在 PDF 阅读器侧边栏里的目录,它在 PDF 格式中的正式叫法是“<ruby> 书签 <rt> bookmarks </rt></ruby>”。

如果没有书签,就只能通过上下滚动或全局搜索文本来定位想要的章节,这非常麻烦。
PDF 文件的另一个恼人的小问题是缺乏元数据,比如标题和作者。如果你打开过一个标题栏上显示类似 “Microsoft Word - 04\_Classics\_Revisited.docx” 的 PDF 文件,你就能体会那种感觉了。
`pdftk-java` 让我能够创建自己的书签,我再也不面对这些问题了。
### 在 Linux 上安装 pdftk-java
正如 `pdftk-java` 的名称所示的,它是用 Java 编写的。它能够在所有主流操作系统上运行,只要你安装了 Java。
Linux 和 macOS 用户可以从 [AdoptOpenJDK.net](https://adoptopenjdk.net/releases.html) 安装 Java(LCTT 译注:原文为 Linux,应为笔误)。
Windows 用户可以安装 [Red Hat's Windows build of OpenJDK](https://developers.redhat.com/products/openjdk/download)。
在 Linux 上安装 pdftk-java:
1. 从 Gitlab 仓库下载 [pdftk-all.jar release](https://gitlab.com/pdftk-java/pdftk/-/jobs/1527259628/artifacts/raw/build/libs/pdftk-all.jar),保存至 `~/.local/bin/` 或 [其它路径](https://opensource.com/article/17/6/set-path-linux) 下.
2. 用文本编辑器打开 `~/.bashrc`,添加 `alias pdftk='java -jar $HOME/.local/bin/pdftk-all.jar'`
3. 运行 `source ~/.bashrc` 使新的 Bash 设置生效。
### 数据转储
修改元数据的第一步是抽取 PDF 当前的数据文件。
现在的数据文件可能并没包含多少内容,但这也是一个不错的开端。
```
$ pdftk mybigfile.pdf \
data_dump \
output bookmarks.txt
```
生成的 `bookmarks.txt` 文件中包含了输入 PDF 文件 `mybigfile.pdf` 的所有元数据和一大堆无用数据。
### 编辑元数据
用文本编辑器(比如 [Atom](https://opensource.com/article/20/12/atom) 或 [Gedit](https://opensource.com/article/20/12/gedit))打开 `bookmarks.txt` 以编辑 PDF 元数据。
元数据的格式和数据项直观易懂:
```
InfoBegin
InfoKey: Creator
InfoValue: Word
InfoBegin
InfoKey: ModDate
InfoValue: D:20151221203353Z00&apos;00&apos;
InfoBegin
InfoKey: CreationDate
InfoValue: D:20151221203353Z00&apos;00&apos;
InfoBegin
InfoKey: Producer
InfoValue: Mac OS X 10.10.4 Quartz PDFContext
InfoBegin
InfoKey: Title
InfoValue: Microsoft Word - 04_UA_Classics_Revisited.docx
PdfID0: f049e63eaf3b4061ddad16b455ca780f
PdfID1: f049e63eaf3b4061ddad16b455ca780f
NumberOfPages: 42
PageMediaBegin
PageMediaNumber: 1
PageMediaRotation: 0
PageMediaRect: 0 0 612 792
PageMediaDimensions: 612 792
[...]
```
你可以将 `InfoValue` 的值修改为对当前 PDF 有意义的内容。比如可以将 `Creator` 字段从 `Word` 修改为实际的作者或出版社名称。比起使用导出程序自动生成的标题,使用书籍的实际标题会更好。
你也可以做一些清理工作。在 `NumberOfPages` 之后的行都不是必需的,可以删除这些行的内容。
### 添加书签
PDF 书签的格式如下:
```
BookmarkBegin
BookmarkTitle: My first bookmark
BookmarkLevel: 1
BookmarkPageNumber: 2
```
* `BookmarkBegin` 表示这是一个书签。
* `BookmarkTitle` 书签在 PDF 阅读器中显示的文本。
* `BookmarkLevel` 书签层级。如果书签层级为 2,它将出现在上一个书签的小三角下。如果设置为 3,它会显示在上一个 2 级书签的小三角下。这让你能为章以及其中的节设置书签。
* `BookmarkPageNumber` 点击书签时转到的页码。
为你需要的章节创建书签,然后保存文件。
### 更新书签信息
现在已经准备好了元数据和书签,你可以将它们导入到 PDF 文件中。实际上是将这些信息导入到一个新的 PDF 文件中,它的内容与原 PDF 文件相同:
```
$ pdftk mybigfile.pdf \
update_info bookmarks.txt \
output mynewfile.pdf
```
生成的 `mynewfile.pdf` 包含了你设置的全部元数据和书签。
### 体现专业性
PDF 文件中是否包含定制化的元数据和书签可能并不会影响销售。
但是,关注元数据可以向用户表明你重视质量保证。增加书签可以为用户提供便利,同时亦是充分利用现有技术。
使用 `pdftk-java` 来简化这个过程,用户会感激不尽。
*(题图:MJ/f8869a66-562d-4ee4-9f2d-1949944d6a9c)*
---
via: <https://opensource.com/article/22/1/pdf-metadata-pdftk>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In [introducing pdftk-java](https://opensource.com/article/21/12/edit-pdf-linux-pdftk), I explained how I use the `pdftk-java`
command to make quick, often scripted, modifications to PDF files.
However, one of the things `pdftk-java`
is most useful for is when I've downloaded a big PDF file, sometimes with hundreds of pages of reference text, and discovered that the PDF creator didn't include a table of contents. I don't mean a printed table of contents in the front matter of the book; I mean the table of contents you get down the side of your PDF reader, which the PDF format officially calls "bookmarks."
(Seth Kenlon, CC BY-SA 4.0)
Without bookmarks, finding the chapter you need to reference is cumbersome and involves either lots of scrolling or frustrating searches for words you think you remember seeing in the general area.
Another minor annoyance of many PDF files is the lack of metadata, such as a proper title and author in the PDF properties. If you've ever opened up a PDF and seen something generic like "Microsoft Word - 04_Classics_Revisited.docx" in the window title bar, you know this issue.
I don't have to deal with this problem anymore because I have `pdftk-java`
, which lets me create my own bookmarks.
## Install pdftk-java on Linux
As its name suggests, pdftk-java is written in Java, so it works on all major operating systems as long as you have Java installed.
Linux and macOS users can install Linux from [AdoptOpenJDK.net](https://adoptopenjdk.net/releases.html).
Windows users can install [Red Hat's Windows build of OpenJDK](https://developers.redhat.com/products/openjdk/download).
To install pdftk-java on Linux:
- Download the
[pdftk-all.jar release](https://gitlab.com/pdftk-java/pdftk/-/jobs/1527259628/artifacts/raw/build/libs/pdftk-all.jar)from its Gitlab repository and save it to`~/.local/bin/`
or[some other location in your path](https://opensource.com/article/17/6/set-path-linux). - Open
`~/.bashrc`
in your favorite text editor and add this line to it:`alias pdftk='java -jar $HOME/.local/bin/pdftk-all.jar'`
- Load your new Bash settings:
`source ~/.bashrc`
## Data dump
The first step in correcting the metadata of a PDF is to extract the data file that the PDF currently contains.
There's probably not much to the data file (that's the problem!), but it gives you a good starting place.
```
$ pdftk mybigfile.pdf \
data_dump \
output bookmarks.txt
```
This produces a file called `bookmarks.txt`
, and it contains all the metadata assigned to the input file (in this example, `mybigfile.pdf`
), plus a lot of bloat.
## Editing metadata
To edit the metadata of the PDF, open your `bookmarks.txt`
file in your favorite text editor, such as [Atom](https://opensource.com/article/20/12/atom) or [Gedit](https://opensource.com/article/20/12/gedit).
The format is mostly intuitive, and the data contained within it is predictably neglected:
```
InfoBegin
InfoKey: Creator
InfoValue: Word
InfoBegin
InfoKey: ModDate
InfoValue: D:20151221203353Z00'00'
InfoBegin
InfoKey: CreationDate
InfoValue: D:20151221203353Z00'00'
InfoBegin
InfoKey: Producer
InfoValue: Mac OS X 10.10.4 Quartz PDFContext
InfoBegin
InfoKey: Title
InfoValue: Microsoft Word - 04_UA_Classics_Revisited.docx
PdfID0: f049e63eaf3b4061ddad16b455ca780f
PdfID1: f049e63eaf3b4061ddad16b455ca780f
NumberOfPages: 42
PageMediaBegin
PageMediaNumber: 1
PageMediaRotation: 0
PageMediaRect: 0 0 612 792
PageMediaDimensions: 612 792
[...]
```
You can edit InfoValue fields to contain data that makes sense for the PDF you're repairing. For instance, instead of setting the Creator key to the value Word, you could set it to the actual author's name or the publishing house releasing the PDF file. Rather than giving the document the default export string of the application that produced it, give it the book's actual title.
There's also some cleanup work you can do. Everything below the `NumberOfPages`
line is also unnecessary, so remove those lines.
## Adding bookmarks
PDF bookmarks follow this format:
```
BookmarkBegin
BookmarkTitle: My first bookmark
BookmarkLevel: 1
BookmarkPageNumber: 2
```
`BookmarkBegin`
indicates that you're creating a new bookmark.`BookmarkTitle`
contains the text that's visible in the PDF viewer.`BookmarkLevel`
sets the inheritance level of this bookmark. If you set a BookmarkLevel to 2, it appears within a disclosure triangle of the previous bookmark. If you set a BookmarkLevel to 3, it appears within a disclosure triangle of the previous bookmark, as long as the previous bookmark is set to 2. This setting gives you the ability to bookmark, for example, a chapter title as well as section headings within that chapter.`BookmarkPageNumber`
determines what PDF page the user is taken to when they click the bookmark.
Create bookmarks for each section of the book that you think is important, then save the file.
## Updating bookmark info
Now that you have your metadata and bookmarks set, you can apply them to your PDF—actually, you’ll apply them to a new PDF that contains the same content as the old PDF:
```
$ pdftk mybigfile.pdf \
update_info bookmarks.txt \
output mynewfile.pdf
```
This produces a file called `mynewfile.pdf`
, containing all of your metadata and bookmarks.
## Professional publishing
The difference between a PDF with generic metadata and no bookmarks and a PDF with personalized metadata values and useful bookmarks probably isn't going to make or break a sale.
However, paying attention to the small details like metadata shows that you value quality assurance, and providing bookmarks to your users is helpful and takes advantage of the technology available.
Use `pdftk-java`
to make this process easy, and your users will thank you.
## Comments are closed. |
15,976 | SparkyLinux 7 “Orion Belt” 评测:稳定性与新鲜感的结合 | https://www.debugpoint.com/sparkylinux-7-review/ | 2023-07-07T07:18:00 | [
"SparkyLinux"
] | /article-15976-1.html | 
>
> 我们评测了最新的 SparkyLinux 7 “Orion Belt”,它带来了最新、最好的 Debian 12 软件包。
>
>
>
SparkyLinux 是著名的基于 Debian 的桌面 Linux 发行版,又推出了它的最新版本 SparkyLinux 7 “Orion Belt”。自 [SparkyLinux 6.0](https://www.debugpoint.com/sparky-linux-6-review/) 以来,经过近两年的开发,这个主要版本已经发布。这个备受期待的版本结合了 Debian 12 的稳定性优势和 SparkyLinux 的尖端功能,承诺提供卓越的用户体验。
让我们深入研究这个主要版本的细节,并了解它的性能和其他发行版方面。
### SparkyLinux 7 “Orion Belt”
#### 核心更新
SparkyLinux 以其多样化的桌面风格而脱颖而出,确保适合每个用户。无论你喜欢视觉上令人惊叹的 KDE Plasma、轻量级 LXQt、经典 MATE、可定制的 Xfce 还是简约的 Openbox,SparkyLinux 7 都提供了令人印象深刻的选择,以满足各种喜好和要求。
SparkyLinux 7 的核心是 Debian 12 “Bookworm”,为稳定性和可靠性提供了坚实的基础。Debian 12 几天前发布,作为该项目的一个重要里程碑,它是历史上最好的 Debian 版本之一。也就是说,在 SparkyLinux 7 中,用户可以期望从 Debian “Bookworm” 和 Sparky “Orion Belt” 仓库更新所有软件包,确保最新的软件版本随时可用。
此版本默认由 Linux 内核 6.1 LTS 提供支持。但是,如果你更喜欢前沿的主线内核,那么你可以在不稳定的仓库中获取 6.3 和 5.15 LTS。

#### 增强的应用和软件
内置应用堆栈已更新,包括基本应用。你可以使用稳定的 Firefox 102.12 ESR、Thunderbird 102.12、VLC 3.0 和 LibreOffice 7.4 作为关键应用。如果你更喜欢最新的 Firefox,那么可以使用 Firefox 114,它可以在单独的 Sparky 仓库中找到。
Sparky APTus AppCenter 是一款用于管理软件安装和更新的集成工具,已更新至版本 20230530,增强了用户的便利性。在一项重大更改中,systemd-timesyncd 取代了 ntp 以简化时间同步。
SparkyLinux 的旗舰产品 Xfce 桌面版本为 4.18,这是这款轻量级桌面的最新更新版本。此外,你还可以找到其他版本,例如 KDE Plasma 5.27、LXQt 1.2 和 MATE 1.26。
该团队还投入了大量精力来改进 amd64 ISO 映像,使其能够在具有 UEFI 主板和启用安全启动的机器上启动,从而扩展了对现代系统的兼容性。
那么,关于这个版本的更新就到这里了。我们来看看性能吧。

#### 安装和性能
我使用 SparkyLinux Xfce 版本进行了本次评测的测试。Calamares 3.2.61 的安装很顺利,没有任何错误。如果你正在安装,你应该注意<ruby> 立付 <rt> live </rt></ruby>介质的密码是 “live”,这是启动安装程序所必需的。
所有更新脚本(包括欢迎应用)在安装后运行良好。欢迎程序可让你快速访问所有系统信息和桌面功能。
我通过 Firefox(运行 YouTube 的 4 个以上选项卡)、文件管理器、绘图应用、终端、VLC、Synaptic 包管理器和 AppCenter 来运行这个版本。资源占用稍高一些。
此负载的内存消耗约为 2 GB,CPU 使用率平均约为 2%。SparkyLinux 7(Xfce)默认安装占用 5.2 GB 磁盘空间。
所以,总的来说,我相信它运行得相当好,但考虑到 Xfce 桌面,内存消耗似乎有点高。

### 总结
SparkyLinux 7 “Orion Belt” 带来了 Debian 的精华,为用户提供稳定性和多功能性的平衡组合。SparkyLinux 凭借其广泛的桌面风格、精选应用和专业版本,可以满足广泛的用户需求。
该版本将持续近两年的维护和安全更新。因此,你可以放心地采用它作为你的日常使用。
你可以从其 [官方网站](https://sparkylinux.org/download/) 下载 SparkyLinux。
参考自 [发布公告](https://sparkylinux.org/sparky-7-0-orion-belt/)
*(题图:MJ/2be08f20-13c3-4c3c-bb84-0bf5be77f86c/)*
---
via: <https://www.debugpoint.com/sparkylinux-7-review/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,977 | 15 个最佳 GTK 主题 | https://www.debugpoint.com/best-gtk-themes/ | 2023-07-07T18:31:00 | [
"主题",
"GTK"
] | /article-15977-1.html | 
>
> 我们为各种 Linux 发行版提供了一个全新的最佳 GTK 主题列表。
>
>
>
桌面外观在你的 Linux 整体体验中起着重要作用。GTK 主题提供了一种简单而强大的方式来定制你的桌面环境的外观。应用 GTK 主题使你可以更改颜色、窗口装饰和整体样式,以适应你的喜好。
除了 KDE Plasma 和 LXQt 之外,大多数受欢迎的桌面环境都基于 GTK。因此,了解当今最好的 GTK 主题是很重要的。
在 Linux 上安装 GTK 主题相对简单。安装说明通常在主题的官方网站上。通常,它包括下载主题文件并将它们(提取后)放置在主目录下的 `~/.themes` 文件夹中。
让我们深入了解在 2023 年最流行的前 15 个 GTK 主题。
### 2023 年最佳 GTK 主题
#### Orchis
Orchis 是一款备受推崇的 GTK 主题,因其清新独特的设计而广受欢迎。受到 macOS Big Sur 外观的启发,Orchis 为 Linux 桌面带来了流畅而现代的外观。
Orchis 因其将 macOS Big Sur 的优雅引入 Linux 生态系统而受到认可。通过结合现代设计和 Fluent Design 语言的元素,Orchis 提供了一个视觉吸引力和一致性的用户界面,增强了整体桌面体验。无论你喜欢浅色还是深色变体,Orchis 都为你的 Linux 桌面提供了一种清新而精致的外观。

>
> **注意**:该主题支持 libadwaita/GTK4 主题。因此,适用于 GNOME 40+ 桌面。
>
>
>
你可以从下面的页面下载并获取安装说明。
>
> **[下载 Orchis 主题](https://github.com/vinceliuice/Orchis-theme)**
>
>
>
#### WhiteSur
WhiteSur 是一个受到 macOS Big Sur 流畅设计启发的 GTK 主题。以下是其主要特点:
* 采用了 macOS Big Sur 的美学设计,带有圆角和半透明窗口。
* 提供了浅色和深色模式以满足不同偏好。
* 在基于 GTK 的应用程序中保持一致的设计。
* 注重细节,具有平滑动画和清晰的阴影。
* 可自定义选项,包括强调色、窗口装饰和按钮样式。

WhiteSur 兼容多种 Linux 桌面环境,如 GNOME、Xfce 和 Cinnamon,使其能够受到广大用户的喜爱。通过 WhiteSur 干净统一的界面,在你的 Linux 桌面上体验 macOS Big Sur 的优雅。
>
> **注意**:该主题还支持 GTK4/libadwaita 主题。
>
>
>
你可以从下面的页面下载主题并获取安装说明。
>
> **[下载 WhiteSur 主题](https://github.com/vinceliuice/WhiteSur-gtk-theme)**
>
>
>
#### Vimix
Vimix 是一款受欢迎的 GTK 主题,为 Linux 桌面环境提供时尚现代的外观。以下是它的主要特点:
* Vimix 采用了时尚现代的设计风格,具有扁平界面、简洁线条和细微渐变。
* 该主题提供了多种颜色变体,包括浅色的 Vimix Light 和深色的 Vimix Dark。
* Vimix 兼容多种 Linux 桌面环境,包括 GNOME、Xfce、Cinnamon 等,适用于各种 Linux 用户。

Vimix 通过现代设计元素的结合、颜色的多样性以及与各种桌面环境的兼容性而受到欢迎。其时尚的外观和自定义选项使其成为寻求视觉上愉悦和一致用户界面的 Linux 用户的绝佳选择。
>
> **注意**:它支持现代的 GTK4/libadwaita 主题。
>
>
>
你可以从下面的页面下载 Vimix 主题。
>
> **[下载 Vimix 主题](https://github.com/vinceliuice/vimix-gtk-themes)**
>
>
>
#### Prof-GNOME-theme
Prof-GNOME-theme 是一个著名的 GTK 主题,为 Linux 桌面环境(特别是 GNOME)带来了专业而精致的外观。以下是其主要特点:
* Prof-GNOME-theme 采用了简洁而专业的设计,呈现出极简主义的风格、优雅的线条和精致的美学。
* 该主题采用了细腻而优雅的调色板,专注于中性色调和柔和的变化,营造出宁静而专业的氛围。
* 该主题确保在基于 GTK 的应用程序中保持一致,为整个桌面环境提供了协调和和谐的体验。

Prof-GNOME-theme 受到专业人士和欣赏干净精致桌面环境的用户的青睐。它注重细节,专注于专业主义,使它成为那些寻求精致而优雅外观的 Linux 桌面用户的绝佳选择。
你可以从下面的页面下载该主题并获取安装说明:
>
> **[下载 Prof-GNOME 主题](https://www.gnome-look.org/p/1334194)**
>
>
>
#### Ant
Ant 是一款受欢迎的 GTK 主题,以其简洁和极简主义的设计而闻名。其主要特点包括:
* 清爽而扁平的美学,带有微妙的阴影。
* 一致且清晰的图标。
* 色彩平衡而悦目。
* 支持浅色和深色变体。
* 与 GNOME 桌面环境无缝集成。

用户可以在其 Linux 系统上享受到 Ant 主题带来的现代且视觉上愉悦的体验。其简约和优雅外观,使其成为寻求 GTK 应用程序和桌面的精致外观的人士的首选。
你可以从下面的页面下载 Ant 主题。
>
> **注意**:该主题**不支持** GTK4/libadwaita。
>
>
>
>
> **[下载 Ant 主题](https://www.gnome-look.org/p/1099856/)**
>
>
>
#### Flat Remix
Flat Remix 是一款备受赞誉的 GTK 主题,为 Linux 桌面提供了清新现代的外观。它的主要特点包括:
* 扁平和极简主义的设计,色彩鲜明。
* 在基于 GTK 的应用程序中保持一致和统一的外观。
* 全面的图标集,提供精细的视觉体验。
* 支持浅色和深色变体。

Flat Remix 为 Linux 桌面环境带来了愉悦的触感,提升了整体美学和用户体验。其鲜明的色彩和协调的设计使其受到喜欢清洁和现代界面的用户的欢迎。
>
> **注意**:该主题**不支持** GTK4/libadwaita。
>
>
>
你可以从下面的页面下载 Flat Remix 主题。
>
> **[下载 Flat Remix 主题](https://drasite.com/flat-remix-gnome)**
>
>
>
#### Fluent
Fluent GTK 主题是一款现代时尚的主题,受到了微软的 Fluent Design System 的启发。以下是其主要特点:
* 光滑和精致的外观,融入了 Fluent Design 的深度、动态和透明度原则。
* 基于 Fluent 的图标提供了一致和统一的外观。
* 与基于 GTK 的应用程序无缝集成,提供一致的用户体验。
* 支持浅色和深色模式,允许用户个性化他们的桌面。
* 持续开发和定期更新,确保与最新的 GTK 版本兼容。

Fluent GTK 主题为 Linux 桌面带来了微软设计的优雅风采,吸引了欣赏现代和精致视觉体验的用户。其遵循 Fluent Design 指南并持续发展,使其成为寻求现代和精致 GTK 主题的人士的理想选择。
>
> **注意**:该主题支持 GTK4/libadwaita 主题。
>
>
>
你可以从下面的页面下载 Fluent GTK 主题并获取安装说明。
>
> **[下载 Fluent GTK 主题](https://github.com/vinceliuice/Fluent-gtk-theme)**
>
>
>
#### Grvbox
Grvbox 是一款受 Vim 著名配色方案 [gruvbox](https://github.com/morhetz/gruvbox) 启发的热门 GTK 主题。以下是其主要特点:
* 温暖复古的调色板让人想起老式终端界面。
* 经过精心设计,提供舒适和愉悦的视觉体验。
* 提供浅色和深色变体,让用户选择其喜好的风格。
* 与基于 GTK 的应用程序无缝集成,确保一致和统一的外观。
* 定期更新和社区支持,确保与最新的 GTK 版本兼容。

Grvbox 主题为 Linux 桌面带来了怀旧的魅力,唤起了熟悉和简约的感觉。其精心选择的颜色和注重细节,使其受到那些欣赏基于 GTK 的应用程序和桌面环境的复古魅力的爱好者的喜爱。
>
> **注意**:该主题支持 GTK4/libadwaita 主题。
>
>
>
你可以从下面的页面获取 Grvbox 主题的下载和安装说明:
>
> **[下载 Grvbox 主题](https://github.com/Fausto-Korpsvart/Gruvbox-GTK-Theme)**
>
>
>
#### Graphite
Graphite 是适用于基于 GTK 的桌面环境的深色主题。它旨在简约而优雅,非常适合希望拥有干净、无干扰界面的用户。
Graphite 主题基于 Adwaita 主题,并拥有许多相同的功能。但是,Graphite 具有更暗的色彩调色板和更加简约的设计。

如果你正在寻找一款既简约又优雅的深色主题,那么 Graphite 主题是一个很好的选择。它易于安装和使用,并与许多桌面环境兼容。
几个月前,我对该主题进行了评估,你可能会对此感兴趣:[Graphite 主题概述](https://www.debugpoint.com/graphite-theme-gnome/)。
**注意**:该主题支持 GTK4/libadwaita。
你可以使用下面页面上的说明安装此主题。
>
> **[Graphite GTK 主题](https://github.com/vinceliuice/Graphite-gtk-theme)**
>
>
>
#### Material
Material 是一款受到 Material for Neovim 和 Graphite 主题(上面有提到)启发的广为人知的 GTK 主题。以下是其主要特点:
* 清爽现代的美学,采用扁平设计元素和鲜明色彩。
* 一致且协调的图标设计,符合 Material Design 的指南。
* 提供浅色和深色变体,让用户自定义视觉体验。
* 与基于 GTK 的应用程序无缝集成,确保统一的外观和感觉。
* 定期更新和社区支持,确保与最新的 GTK 版本兼容。

Material 主题将流行的 Material Design 风格带到了 Linux 桌面,提供了视觉上令人愉悦且直观的用户体验。凭借其时尚的设计和与各种 GTK 环境的兼容性,Material 主题受到喜欢现代和和谐界面的用户的欢迎。
>
> **注意**:该主题支持现代的 GTK4/libadwaita 主题。
>
>
>
你可以从下面的页面下载并安装 Material 主题:
>
> **[下载 Material 主题](https://github.com/Fausto-Korpsvart/Material-GTK-Themes)**
>
>
>
#### Arc
Arc 主题是 Linux 社区中受欢迎的 GTK 主题,以其流线型和现代的设计而闻名。它提供了干净、简约的外观,与各种桌面环境(特别是 GNOME)相得益彰。以下是 Arc 主题的一些主要特点:
* 美观的设计,拥有平滑曲线和扁平界面
* 多种颜色变体,包括 Arc、Arc-Darker 和 Arc-Dark
* 可更改按钮样式、标题栏布局和窗口边框的选项
Arc 主题将美学和功能性融为一体,成为许多寻求视觉上愉快和一致用户界面的 Linux 用户的首选。

>
> 然而,当前版本的主题**不支持**现代的 GTK4/libadwaita。
>
>
>
你可以从下面的官方仓库中下载 Arc 主题(这是原始 Arc 主题的另一个分支):
>
> **[下载 Arc 主题](https://github.com/jnsh/arc-theme)**
>
>
>
此外,在 Ubuntu 及相关发行版上,你可以使用以下命令进行安装:
```
sudo apt install arc-theme
```
#### Nordic
Nordic 是一款备受赞誉的 GTK 主题,受到北欧地区宁静景色的启发。以下是其主要特点:
* 细腻而舒缓的调色板让人想起极光和雪景。
* 浅色和深色元素的和谐组合,提供最佳的对比度和可读性。
* 高度精心设计的图标完美地补充了整体美学。
* 跨平台兼容,使用户可以在各种基于 GTK 的环境中享受 Nord 主题。
* 定期更新和社区支持,确保持续的改进和兼容性。

Nordic 主题为 Linux 桌面带来了宁静和优雅的氛围,让用户沉浸在一个视觉上迷人的环境中。其精心选择的颜色和对细节的关注,使其在寻求视觉上愉快和放松的 GTK 主题的 Linux 系统用户中广受欢迎。
它还附带了一个适用于 Firefox 的主题,以获得更好的外观和集成。
>
> **注意**:该主题支持现代的 GTK4/libadwaita 主题。
>
>
>
你可以从下面的页面下载 Nordic 主题:
>
> **[下载 Nordic 主题](https://github.com/EliverLara/Nordic)**
>
>
>
#### Adapta
Adapta 是一款备受赞誉的 GTK 主题,以其多功能性和现代设计而闻名。
Adapta 主题增强了 Linux 桌面的时尚和适应性风格,允许用户在保持精致和统一外观的同时个性化他们的界面。它的灵活性和持续发展使其成为那些寻求现代且可定制的 GTK 主题的人们的首选。
然而,这个优秀主题的开发已经**停止**了多年。你仍然可以从下面的官方页面下载并使用该主题:
>
> **[下载 Adapta 主题](https://github.com/adapta-project/adapta-gtk-theme)**
>
>
>
#### Equilux
Equilux 是一款适用于基于 GTK+ 的桌面环境的暗色主题。它的设计旨在中性且不分散注意力,非常适合在低光环境下使用或对亮色敏感的人士。
Equilux 主题基于 Materia 主题,并拥有许多相同的功能。然而,Equilux 使用了更柔和的调色板,使其更适合于暗环境。

如果你正在寻找一款既中性又不分散注意力的暗色主题,那么 Equilux 主题是一个很好的选择。它易于安装和使用,并且与各种桌面环境兼容。
>
> **注意**:该主题的开发已经 [停止](https://github.com/ddnexus/equilux-theme)。不会有进一步的更新。
>
>
>
你可以在下面的页面上找到该主题的当前版本:
>
> **[下载 Equilux 主题](https://www.gnome-look.org/p/1182169/)**
>
>
>
#### Paper
Paper 是一款广为人知的 GTK 主题,以其简约而优雅的设计而闻名。以下是其主要特点:
* 干净而扁平的视觉风格,具有微妙的阴影效果。
* 精心设计的图标提供了一致且精致的外观。
* 提供多种颜色变体,包括浅色和深色主题。
* 维护良好且积极开发,确保与最新的 GTK 版本兼容。
* 支持 GNOME、Xfce 和 Unity 等流行的桌面环境。

Paper 以其极简的风格和注重细节的特点,为用户提供了视觉上愉悦和和谐的桌面体验。其多样的颜色选项和与多种桌面环境的兼容性,使其成为寻求时尚和现代外观的 Linux 爱好者的热门选择。
>
> **注意**:该主题的开发在 2016 年已**结束**。不支持现代的 GTK4+。
>
>
>
>
> **[下载 Paper 主题](https://github.com/snwh/paper-gtk-theme)**
>
>
>
### 关于 Adwaita 的说明
流行的 Adwaita 主题是最好和最稳定的 GTK 主题之一。我之前没有将其列入上述列表的原因是它已经作为默认主题包含在许多发行版中,用户已经在其系统中安装了该主题。
### 总结
上述 GTK 主题代表了各种风格的不同口味,从现代设计到充满活力和丰富多彩的美学。无论你偏好极简的外观还是视觉上惊艳的界面,都可以找到适合你口味的 GTK 主题。我鼓励你尝试上述主题并搭配各种图标和鼠标主题,以获得更好的体验。
部分图片来源归属于各自的作者。
*(题图:MJ/cf5c27f6-ea23-4d9b-a311-168c45d9ea92)*
---
via: <https://www.debugpoint.com/best-gtk-themes/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,979 | 云服务架构完全指南 | https://www.opensourceforu.com/2022/09/a-complete-guide-to-cloud-service-architectures/ | 2023-07-08T20:36:00 | [
"云计算"
] | https://linux.cn/article-15979-1.html | 
>
> 经过大约 16 年的演变,云计算已经成为一种几乎所有网民都在使用的技术。它可以作为一种服务,用于满足各类企业和消费者的需求。因此,在云计算中正在使用多种服务架构,旨在根据最新的需求来定制所需技术。本文就如今使用的所有服务架构,提供一份完全指南。
>
>
>
尽管在全球范围内建立互相协同的计算机网络的构想在 20 世纪 60 年代初就提出了,但直到 2006 年,谷歌的首席执行官 <ruby> 埃里克·施密特 <rt> Eric Schmidt </rt></ruby> 在当时的背景下引入了“<ruby> 云计算 <rt> cloud computing </rt></ruby>”一词,这种构想才成为一种正式的概念。
云计算可以简单理解为遍布于世界各地的远程服务器网络,通过互联网共享数据和协同工作,从而为企业和消费者提供服务。虽然这样的定义比较武断,但它包含了云计算背后的核心思想。促成这项技术发展的主要因素是对“数据粘性”的需求,就是令数据更容易被各种设备访问,同时也要减少数据丢失的风险。如果用户甲只在一台服务器上保存了数据,对于用户甲来说,只要有一台服务器中断,数据就很有可能永久性丢失。这种做法无异于“把所有鸡蛋放在同一个篮子里”,从来都不是一个好办法,特别是当你在处理对公司和消费者具有重要意义的数据时。但如果你在多台服务器上备份了用户甲的数据,将有两个主要好处:其一,即使一台服务器中断,用户甲仍然可以正常获取数据;其二,云服务可以从负荷最小的、离他最近的那台正常运作的服务器获取数据。这使用户甲可以在不同设备上更快、更容易地获取数据。
历经大约 16 年的发展,云计算从起初只是一种用于备份图片的工具,变为了互联网的骨干。如今几乎所有的应用,从 Office 到 Asana 以及 Todolist,都利用云计算来实现实时访问和数据共享。几乎任意一款你能想像到的应用都在使用云计算。从 Gmail 和 YouTube,到Instagram,一切都使用云计算,以提供快速、便捷、可靠的数据访问功能。
提供云计算服务的公司称为云服务提供商。亚马逊、谷歌、微软、Salesforce、Cloud9 等都是 B2B 和 B2C 领域的云服务提供商。
在早期,云服务供应商通常指提供三类服务:
* <ruby> 软件即服务 <rt> Software as a Service </rt></ruby>(SaaS)
* <ruby> 平台即服务 <rt> Platform as a Service </rt></ruby>(PaaS)
* <ruby> 基础设施即服务 <rt> Infrastructure as a Service </rt></ruby>(IaaS)
然而,随着行业需求不断发展,区块链和 AI 等新技术的出现,云服务提供商也开发了新的模式,用于更好地满足客户的各种需求。本文将详细论述如今大众普遍使用的那些云计算模式。
### 云端的架构
我们已经了解了什么是云计算,以及它是如何发展成一个高达 4450 亿美元产值的行业,现在我们从技术视角来理解云计算。通常一个云端架构都由两个主要部件组成 —— <ruby> 前台 <rt> front-end </rt></ruby>和 <ruby> 后台 <rt> back-end </rt></ruby>。

前台包含客户端基础设施,有终端设备和用于与云端通信的应用程序界面。在现实世界里,你的智能手机和谷歌云端硬盘就是前台,它们用于访问谷歌云。
后台包含云端基础设施,包括运行云计算服务所需的一切设备。服务器、虚拟机、服务和存储都是由云端基础设施提供的。为了对它们有个全局的概念,现在我们来了解一下后台的每个组件。
* <ruby> 应用 <rt> Application </rt></ruby>:用户或企业使用的、通过互联网与云端互动的任何应用程序的后台。
* <ruby> 服务 <rt> Service </rt></ruby>:云端提供的服务型基础设施。本文将详细论述各种不同的服务。
* <ruby> 运行时 <rt> Runtime </rt></ruby>:提供给虚拟机的运行时和执行系统。
* <ruby> 存储 <rt> Storage </rt></ruby>:具有灵活的伸缩性的用户/企业数据获取和管理系统。
* <ruby> 基础设施 <rt> Infrastructure </rt></ruby>:运行云端所需的硬件和软件。
* <ruby> 安全 <rt> Security </rt></ruby>和<ruby> 管理 <rt> Management </rt></ruby>:建立安全机制,保护用户/企业数据,管理各个云服务单元,避免过载和服务停机。
### 软件即服务(SaaS)
“软件即服务”是一种云计算模式,通过互联网将软件和应用程序作为一种服务提供。谷歌云端硬盘或谷歌工作空间都是比较典型的例子。谷歌云端硬盘内的所有应用,例如文档、工作表、幻灯片、表格等,它们都可以通过使用浏览器访问,并自动保存于云端。你可以在任意设备上获取文件的最新版本。你唯一需要做的就是登录你的账户。这就是“软件即服务”模式的优点。你不需要在你的设备上安装任何东西,也不需要使用你的本地存储空间,你可以直接访问云端的应用程序,并省略了使用本地软件时的很多繁杂操作。SaaS 一般遵循“按需付费”法则,你只要为你需要的服务支付费用。你总是可以通过支付更多的费用来购买更多的存储和/或功能,或者根据你的要求来降低你的套餐。
#### SaaS 的好处
1. SaaS 具有高度的可伸缩性,这归功于它的“按需付费”思想。你可以根据自身需求增加/减少存储空间或程序功能。
2. 考虑到它提供的特性,如通过任何操作系统的任何设备进行实时访问,它是非常合算的。
3. 它在客户端涉及的工作很少。不需要安装或进行复杂的步骤,就可以完成软件的初始化。你可以从你的浏览器和/或应用程序中舒适地使用它。
4. 不必手动安装,软件会自动更新,而且更新过程中你也不必等待。
### 平台即服务(PaaS)
并不是每家科技初创公司都有必要的资源来维护自己的基础设施,以便在云端运行他们的应用程序。公司(尤其是创业型公司)通常更倾向于把应用部署于云端,这样就不必处理后台基础设施了。这就是“平台即服务”这种模式的用武之地了。Heroku 等公司提供了基于“平台即服务”的云端解决方案,令公司和个人可以在不需要直接与硬件交互的情况下就能部署并运行他们的应用程序。跟“软件即服务”类似,这种模式也提供了灵活性,你只需选择所需的服务,同时也从基础设施的角度提供了可伸缩性和安全性。
#### PaaS 的好处
1. 省去了操作云端基础设施的麻烦。你将其外包给在其云中托管你的应用程序的公司。这令你能专注于应用程序开发工作的各个生命周期。
2. PaaS 是可扩展的。你可以根据需要增加或减少存储需求、附加服务等。
3. 你设置的唯一安全参数是针对你自己的应用程序。云安全是由你的云服务提供商处理的。
4. 对公司和个人来说,把应用程序托管在云端,在时间和成本上都是合算的,特别是那些无法承担基础设施建设成本的创业型公司。
### 基础设施即服务(IaaS)
IaaS 相对于 PaaS 更进一步,给予用户更多的自主权。在 IaaS 模式中,云服务提供商让你对云端的底层基础设施进行操控。简而言之就是你可以根据公司需要自行设计云端环境,从专用服务器和虚拟机,到运行于服务器的操作系统,你还可以设置带宽,创建自己的安全协议,以及创建云基础设施所需的其他项目。亚马逊 AWS 和谷歌计算引擎(GCE)都是使用 IaaS 模式的很好的例子。鉴于此模式还可以实现用户对硬件的自主操控,它也被称为硬件即服务(HaaS)。
#### IaaS 的好处
1. “按需付费”模式中的细粒度灵活性。你可以自行决定运行多少台虚拟机以及使用多少时间。你还可以按小时付费。
2. 以“按需付费”为核心思想,它具有高度的可伸缩性。
3. 完全的自主权,对基础设施中的一切事项的控制,省去了在公司所在地点驻场维护服务器的麻烦。
4. 大多数公司保证正常运行时间、安全性和 24/7 的现场技术支持,这对企业来说非常重要。
### 存储即服务(StaaS)
谷歌云端硬盘、OneDrive、Dropbox 和 iCloud 是 <ruby> 存储即服务 <rt> Storage as a Service </rt></ruby> 行业内大名鼎鼎的产品。StaaS 就像它听起来那么简单。如果你需要的只是通过任意设备可以实时访问的云端存储空间,StaaS 就是可用的选项之一。很多公司和个人都使用这样的服务来备份自己的数据。
#### StaaS 的好处
1. 借助内置的版本控制系统,实时访问最新数据。
2. 可以使用安装任意操作系统的任何设备访问数据。
3. 随着你创建、编辑和删除文件,实时备份你的数据。
4. 遵循“按需付费”模式,你可以根据需要自行确定存储空间大小。
### 一切即服务(XaaS)
IaaS、PaaS、SaaS 和 StaaS 的混合版,就是所谓的“<ruby> 一切即服务 <rt> Anything/Everything as a Service </rt></ruby>”模式,它在云计算相关社区内快速引发关注。客户可能有多种多样的需求,这些需求可能是各种不同模式的混合。在这种场景下,应当为用户提供自由选择所需服务的功能,让他们从各种不同的层级选择服务,从而创建自定义的“按需付费”模式。这种方式的好处在于,让用户根据自身需求自由选择相应的云服务。
#### XaaS 的好处
1. 可以选择你喜欢的东西和你喜欢的方式。
2. 只需要为你需要的服务支付费用,而且不需要支付任何基于层级系统的基本费用。
3. 选择你的基础设施、平台和功能的粒度水平。
4. 只要使用得当,无论在时间、成本、效用上,XaaS 都是非常有效的。
### 功能即服务(FaaS)
在某些情况下,公司或个人需要 PaaS,但不是所有的功能都需要。例如,基于触发器的系统,如定时任务,只需要在无服务器系统上运行一段代码或一个函数,就可以实现一个特定的目标。例如某客户需要创建一个网站的流量监测系统,在页面下载量达到一定数量时发送通知。这样的需求简而言之就是在云端运行一段持续检查要执行的触发器的代码。使用 PaaS 的成本较高。此时就是“<ruby> 功能即服务 <rt> Function as a Service </rt></ruby>”发挥作用的时候了。许多公司,例如 Heroku,向客户提供 FaaS,它只存储一段代码或一个方法,只会在被触发的情况下运行。
#### FaaS 的好处
1. 你只需要支付代码运行的费用。托管代码通常是不收费的,除非计算成本很高。
2. 它不会有使用 PaaS 的那些麻烦,却让你享受所有好处。
3. 无论如何,你都不必关心底层基础设施。因此,你只需要上传代码,而不必关心任何虚拟机维护相关事宜。
4. FaaS 让你的开发更加敏捷,即编写函数式代码。
### 区块链平台即服务(BPaaS)
近年来,区块链席卷了科技行业。它是目前最受欢迎的技术之一,比它更受欢迎的只有人工智能和数据科学相关技术。区块链如此吸引人的原因是它提供了安全、可伸缩和透明的开放式账本架构。这些功能对于许多应用程序都是必要的,例如银行、选举系统,甚至社交媒体也需要这些功能。随着如此广泛的应用,有必要能够在云上托管这样的产品,其模式专门满足这种技术的需求。这就是<ruby> 区块链平台即服务 <rp> ( </rp> <rt> Blockchain Platform as a Service </rt> <rp> ) </rp></ruby>(BPaaS)发挥作用的地方。如今,包括亚马逊 AWS 和微软 Azure 在内的许多公司,都在为专门寻求在云中托管基于区块链的应用程序的客户提供BPaaS解决方案。
#### BPaaS 的好处
1. 它满足了区块链行业的特定需求,例如支持用于编写智能合约的专用语言。
2. 通过提供 API 桥接,支持与区块链(如以太坊)集成。
3. 支持在区块链技术的应用中使用自定义数据库。
4. 云的所有优点它也同样具备,即“按需付费”功能、可扩展性、安全性和访问便捷性。
*(题图:MJ/db8225c1-e970-4bc4-80db-514368955af2)*
---
via: <https://www.opensourceforu.com/2022/09/a-complete-guide-to-cloud-service-architectures/>
作者:[Mir H.S. Quadri](https://www.opensourceforu.com/author/shah-quadri/) 选题:[lkxed](https://github.com/lkxed) 译者:[cool-summer-021](https://github.com/cool-summer-021) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *In its roughly 16 years of evolution, cloud computing has evolved to become a technology that is used by almost everyone who uses the Internet. It can be used as a service to support various types of business and consumer requirements. Therefore, multiple service architectures are being used in cloud computing to customise the technology as per modern day needs. This article provides a complete guide to all the service architectures being used today.*
While the idea of having a network of computers collaborating across the world has existed since the early 1960s, the formal conceptualisation of it occurred in 2006 when Eric Schmidt, the then CEO of Google, introduced the term ‘cloud computing’ in its modern day context.
Cloud computing can be simply understood as a network of remote servers across the world, sharing data and collaborating over the Internet to provide services to businesses and customers. Albeit an arbitrary definition, it does cover the core idea behind cloud computing. The primary motivating factor for such a technology was to create more ‘stickability in data’, i.e., to make data more easily accessible across the devices whilst reducing the risks of data loss. If a user x has data in only one server, the chances of permanent data loss for x are higher given that all it takes is one server outage. That is equivalent to the proverbial ‘putting all your eggs in one basket’ method, which is never a good idea especially when you are dealing with data that can be critical for businesses and consumers. But if you replicate the data of x in multiple servers across the globe, it will have two major benefits. For one, x will still be able to access his/her data even if a server is facing an outage. Second, the cloud can provide x with access to its data from a server that is available closest to it with the least amount of load. This makes data faster and more easily accessible across different devices for x.
In its roughly 16 years of evolution, cloud computing has gone from being something used simply for backing up photos to becoming the backbone of the Internet. Almost every app today, from Microsoft Office to Asana and Todoist, makes use of cloud computing for real-time access and sharing of data. Almost any app that you can think of uses cloud computing. Everything from Gmail and YouTube, to Instagram and even WhatsApp, uses cloud computing in the background to provide fast, easy, and reliable access to data.
The companies that provide cloud computing services are called cloud service providers. Amazon, Google, Microsoft, Salesforce, Cloud9, etc, all provide cloud as a service in both B2B and B2C contexts.
In the early days, cloud service providers generally offered only three types of services to their customers:
- Software as a Service (SaaS)
- Platform as a Service (PaaS)
- Infrastructure as a Service (IaaS)
However, as the industry requirements have evolved with new technologies such as blockchain and AI coming into the picture, cloud service providers have come up with new models to better serve the varying requirements of their customers. In this article, we are going to go through all the cloud computing service models currently being used in the market.
## The architecture of a cloud
Now that we have an idea of what cloud computing is and how it evolved into becoming a 445 billion dollar industry, let us try to understand the cloud from a technical perspective. A generalised architecture of a cloud can be conceptualised as consisting of two major components — the front-end and the back-end.

The front-end contains the client infrastructure, i.e., the device and the user interface of the application used for communicating with the cloud. In a real-world context, your smartphone and the Google Drive app are the front-end client infrastructure that can be used for accessing the Google cloud.
The back-end contains the cloud infrastructure, i.e., all the mechanisms and machinery required to run a cloud computing service. The servers, virtual machines, services and storage are all provided by the cloud infrastructure, as shown in ure 1. Let’s quickly go through each component of the back-end in order to get a complete picture.
*Application:*The back-end of whatever app the user or business uses to interact with the cloud via the Internet.*Service:*The infrastructure for the type of service that the cloud provides. We are going to go into detail about all the different types of services in this article.*Runtime:*The provision of runtime and execution made available to the virtual machines.*Storage:*The acquisition and management of user/business data with the flexibility of scaling.*Infrastructure:*The hardware and software required to run the cloud.*Security and management:*Putting security mechanisms in place to protect user/business data as well as managing individual units of the cloud architecture to avoid overload and service outages.
## Software as a Service (SaaS)
Software as a Service is a cloud computing model that provides software and applications as a service over the Internet. A good example of this is Google Drive or Google Workspace. All the apps available in Google Drive such as docs, sheets, slides, forms, etc, can be accessed online using a Web browser and saved automatically to the cloud. You can access the latest version of your documents through any device. All you need to do is login to your account. This is the benefit of having the Software as a Service model. Instead of having to install anything to your device locally or using your local storage space, you can directly access the software application in the cloud thus removing a lot of the liabilities that come with localised software. SaaS often follows the ‘pay as you go’ model, i.e., you pay for the services you need. You can always purchase more storage and/or features by paying more or downgrade your package as per your requirements.
*Benefits of SaaS*
- SaaS is highly scalable, thanks to the ‘pay as you go’ model. You can increase/decrease storage and/or the features of the apps as and how you need to.
- It is considerably cost-effective given the features it provides such as real-time access through any device with any operating system.
- It involves low effort at the customer-end. No installations or confusing steps are required to initialise the software. You can use it from the comfort of your browser and/or app.
- Software updates automatically without you having to install it or wait for installation at your end.
## Platform as a Service (PaaS)
Not every tech startup has the required resources to maintain their own infrastructure to run their apps on the cloud. In many cases, companies (especially startups) prefer to have their app hosted on the cloud without having to handle all the backend infrastructure. It is in situations such as these where a Platform as a Service model comes into play. Companies such as Heroku cloud offer PaaS architecture-based cloud solutions for companies and individuals to host and run their apps in the cloud without having any direct contact with the hardware infrastructure. Like SaaS, this model also provides flexibility in choosing only the services you require along with scalability and security from an infrastructural perspective.
*Benefits of PaaS*
- No hassle of handling the cloud infrastructure. You outsource that to the company that hosts your app in their cloud. This helps you focus solely on your app development life cycle.
- PaaS is scalable. You can increase or decrease your storage requirements, add-on services, etc, as per your requirements.
- The only security parameters you set are for your own app. The cloud security is dealt with by your cloud service provider.
- It is time- and cost-effective for companies and individuals looking to host their apps in the cloud, especially startups that cannot afford to build their own infrastructure.
## Infrastructure as a Service (IaaS)
Infrastructure as a Service goes one step deeper than PaaS, providing customers with even more autonomy. In an IaaS model, the cloud service provider gives you control over the underlying infrastructure of the cloud. Simply put, you get to design your own cloud environment customised to your company’s requirements all the way from dedicated servers and virtual machines, to operating systems running on the servers, setting bandwidths, creating your own security protocols, and pretty much everything else that goes into creating a cloud infrastructure. Amazon AWS and Google Compute Engine are great examples of IaaS models. Given the autonomy over the hardware that this model provides, it is also referred to as Hardware as a Service (HaaS).
*Benefits of IaaS*
- Granular flexibility in the ‘pay as you go’ model. You get to decide how many VMs you want to run and for how long. You can even pay by the hour.
- Highly scalable, given that it follows the ‘pay as you go’ model to its core.
- Complete autonomy and control over everything in the infrastructure without the hassle of maintaining the servers physically at your company location.
- Most companies guarantee uptime, security and 24/7 on-site customer support, which can be essential for enterprises.
## Storage as a Service (StaaS)
Google Drive, OneDrive, Dropbox, and iCloud are some of the big names in the industry providing Storage as a Service to their customers. StaaS is as simple as it sounds. If all you require is storage in the cloud that is accessible to you in real-time through any of your devices, then the StaaS model is the one to choose. Many companies and individuals make use of this service model to back up their data.
*Benefits of StaaS*
- Access your data in its most updated form in real-time with the help of built-in version control systems.
- Access your data through any type of device with any operating system.
- Back-up your data in real-time as and how you create, edit, and delete your files.
- Scale your storage as and how you require. StaaS follows the ‘pay as you go’ model.
## Anything/Everything as a Service (XaaS)
A hybrid version of the IaaS, PaaS, SaaS, and StaaS, is what is being called the Anything/Everything as a Service model, and is quickly gaining traction in the cloud community. It is possible for a customer to have requirements that are so varied that they might be a mishmash of all the different models. In such a scenario, complete autonomy is provided to customers to select the services from different tiers to create their own custom ‘pay as you go’ model. This has the benefit of giving complete freedom to the customer to use the cloud on their own terms.
*Benefits of XaaS*
- Choose what you like, how you like and as you like.
- Pay only for exactly what you need without having to pay for any base fee predicated on a tier system.
- Select your infrastructure, platform, and functionality on a granular level.
- If used appropriately, XaaS can be the most time-, cost- and work-effective method of hosting your application on the cloud.
## Function as a Service (FaaS)
In certain cases, companies or individuals require the benefits of PaaS without having to use all its functionality. For example, trigger-based systems such as cron jobs only require a piece of code or a function to run on a serverless system to achieve a particular objective. For instance, a customer may want to create a website traffic monitoring system that sends a notification the moment a certain number of page downloads occur. In such a case, the customer requirements are simply to run a piece of code in the cloud that keeps checking for a trigger to execute. Using a PaaS model can be a costly solution. This is where Function as a Service comes in. Many companies such as Heroku offer FaaS to their customers to host only a specific piece of code or function that is reactionary and only activates upon a trigger.
*Benefits of FaaS*
- You only pay for the number of executions of the code. You are generally not charged for hosting your code unless it is computationally expensive.
- It removes all the liability of PaaS while giving you all its benefits.
- You are not responsible for the underlying infrastructure in any way. Therefore, you can simply upload your code without having to worry about any maintenance of the virtual machines.
- FaaS provides you with the ability to be agile, i.e., to write functional code.
## Blockchain Platform as a Service (BPaaS)
Blockchain has taken the tech industry by storm in recent years. It is one of the most in-demand technologies right now, surpassed marginally by AI and data science related technologies. What makes blockchain so attractive is its open-ledger architecture providing security, scalability, and transparency. These features are necessary for many applications such as banking, electoral systems, and even social media. With such wide-ranging applications, it becomes necessary to be able to host such products on the cloud with a model that specifically caters to the needs of this technology. This is where BPaaS comes into the picture. Many companies today, including big names such as Amazon AWS and Microsoft Azure, are providing BPaaS solutions for customers specifically looking to host blockchain based apps in the cloud.
*Benefits of BPaaS*
- It caters to the specific needs of the blockchain industry such as support for custom languages used for writing smart contracts.
- Supports integrations with pre-eminent blockchains such as Ethereum by providing API bridges.
- Supports custom databases used in the application life cycle of blockchain technologies.
- It has all the goodness of the cloud with the ‘pay as you go’ feature, scalability, security, and ease of access. |
15,981 | Nobara 38 发布,提供增强的游戏和内容创作体验 | https://debugpointnews.com/nobara-38/ | 2023-07-09T16:09:00 | [
"Nobara"
] | /article-15981-1.html |
>
> 探索 Nobara 38 版本的新功能,该版本随 Fedora 38 一起发布。
>
>
>
基于 [Fedora 38](https://debugpointnews.com/fedora-38-release/) 的预期版本 Nobara 38 终于发布了,它带来了一系列用户友好的修复和功能增强。Nobara 是 Fedora Linux 的修改版本,旨在解决用户面临的常见问题,并提供开箱即用的顺滑的游戏、流媒体和内容创建体验。凭借一系列附加软件包和自定义功能,Nobara 38 将 Fedora 提升到了新的高度。
Nobara 38 中值得注意的改进之一是为视频调色软件 Davinci Resolve 实施了一个临时方案。当 Davinci Resolve 的安装程序从终端运行时,会提示用户执行一个向导,执行必要的操作以确保顺利运行。这包括将它的 glib2 库移动到一个备份文件夹中,详见官方 Davinci Resolve 论坛。

在游戏领域,Nobara 38 引入了 Payday 2 原生 Linux 版本的临时方案。鉴于 OpenGL 实现目前已损坏且对原生版本的官方支持已被放弃,该版本利用 zink 驱动程序来确保无缝游戏。据 GamingOnLinux 报道,这确保了 Linux 用户可以继续使用 Payday 2,不会出现任何问题。
此外,Nobara 38 合并了 Udev 规则来增强控制器支持。具体来说,添加了一条规则,强制对 045e:028e “Xbox 360” 控制器设备使用内核 xpad 驱动程序。这使得 GPD Win Max 2 和 GPD Win 4 等在报告为该设备的控制时,能够保持控制器兼容性,同时仍然允许安装可选的 xone/xpadneo 驱动程序以实现无线适配器,并改进对 Xbox One 控制器的蓝牙支持。
为了优化不同设备类型的性能,Nobara 38 引入了特定的 I/O 调度程序。NVMe 设备将使用 “none”,SSD 将使用 “mq-deadline”,HDD/机械驱动器将使用 “bfq”。这些规则可确保每种设备类型以其最佳效率运行。
在桌面环境方面,Nobara 38 默认提供自定义主题的 GNOME 桌面,但用户也可以选择标准 GNOME 和 KDE 版本。这种灵活性允许用户根据自己的喜好个性化他们的计算体验。
Nobara 38 还对几个关键组件进行了更新。值得注意的是,GNOME 44 融入了基于 Mutter 44 更新和重新构建的可变刷新率(VRR)补丁,提供了更流畅的视觉体验。GStreamer 1.22 已修补了 AV1 支持,可实现更好的多媒体播放,并且 OBS-VAAPI 和 AMF AV1 支持也已启用,尽管后者需要 AMD 的专业编码器。
Mesa 图形库基于 LLVM 15 构建,而不是 Fedora 当前的 LLVM 16,以避免与 Team Fortress 2 的兼容性问题。此外,Mesa 还进行了修补以启用 VAAPI AV1 编码支持,从而增强了视频编码功能。
Nobara Package Manager(现在称为 yumex)在 Nobara 38 中得到了重大改进。它现在拥有管理 Flatpak 的能力,为用户提供了更全面的软件管理解决方案。此外,软件包更新也得到了简化,引入了“更新系统”按钮,方便系统更新。
Blender 是流行的开源 3D 创建套件,已在 Nobara 38 中进行了修补,以使用 `WAYLAND_DISPLAY=""` 环境变量启动。这解决了菜单在 Wayland 下渲染不正确并妨碍可用性的问题,确保用户获得流畅的 Blender 体验。
Nautilus 是 GNOME 中的默认文件管理器,现在允许用户直接从右键菜单中以管理员身份执行文件和打开文件夹。此功能提供了一种执行管理任务的便捷方法,无需执行其他步骤。
在 Flatpak 方面,Nobara 38 删除了 Fedora Flatpak 仓库,因为它们基本上未使用。建议升级到 Nobara 38 的用户删除从 Fedora 仓库安装的所有 Flatpak,然后从 Flathub 仓库重新安装它们。Flathub flatpak 仓库现在是 Nobara 38 中的默认仓库,为系统和用户安装提供了更广泛的应用选择。此外,还实施了一种临时方案来解决最近与用户更新相关的崩溃问题。
为了增强整体用户体验,Nobara 欢迎应用现在将 Davinci Resolve 向导作为可选步骤提供。这简化了 Davinci Resolve 的设置过程,并确保用户可以轻松地将软件集成到他们的工作流程中。
除了这些显著的变化之外,Nobara 38 还包括 Fedora 38 中存在的所有其他软件包更新和改进。
要下载 Nobara 38 并探索其新功能,请访问 Nobara Project 官方网站。
>
> **[下载 Nobara 38 – KDE](https://nobara-images.nobaraproject.org/Nobara-38-KDE-2023-06-25.iso)**
>
>
>
>
> **[下载 Nobara 38 – GNOME](https://nobara-images.nobaraproject.org/Nobara-38-GNOME-2023-06-25.iso)**
>
>
>
参考自官方 [通告](https://nobaraproject.org/2023/06/25/june-25-2023/)。
---
via: <https://debugpointnews.com/nobara-38/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,982 | 最佳开源电子邮件服务器 | https://itsfoss.com/open-source-email-servers/ | 2023-07-09T19:18:30 | [
"电子邮件"
] | https://linux.cn/article-15982-1.html | 
>
> 这是一份可以用于发送/接收电子邮件并存储邮件的开源邮件服务器列表。
>
>
>
无论你使用何种 [电子邮件客户端](https://itsfoss.com/best-email-clients-linux/),使用像 Gmail、Proton Mail 和 Outlook 这样的电子邮件服务非常方便。
为了实现这一切,你利用的是它们的邮件服务器进行电子邮件传输。因此,你的电子邮件的安全性、可靠性和隐私性取决于他人。
但是,如果你希望拥有自己的电子邮件基础设施并控制数据,那么你需要一个开源电子邮件服务器来解决这个问题。
让我解释得更清楚一些,电子邮件服务器可以让你:
* 构建自己的邮件后端以存储电子邮件帐户
* 通过自托管来掌控安全性和可靠性
* 在你首选的服务器架构上进行托管
* 让你能够创建无限数量的帐户
当然,这些并不适用于终端用户。中小型企业的系统管理员和自托管者才能用得上这些软件。
考虑到你现在对开源电子邮件服务器的好处有了一定了解,下面是一些你可以找到的最佳选项:
>
> ? 这个列表包括邮件服务器和一些能够构建/创建邮件服务器的解决方案。其中一些可能提供托管服务,而另一些可以进行自托管。
>
>
>
### 1、Postal
[Postal](https://github.com/postalserver/postal) 是一个功能丰富的邮件服务器,可供网站和服务器使用。它专为**出站邮件**而设计,没有邮箱管理功能。(LCTT 译注:出站邮件指外发邮件,入站邮件指接收邮件供邮件客户端收取。)
它的 [文档](https://docs.postalserver.io/) 对于入门非常有帮助。你可以使用 Docker 在服务器上配置 Postal。
使用 Postal,你可以为多个组织创建邮件服务器/用户,访问出站/入站消息队列,实时的递交信息,并使用内置功能确保电子邮件能够传递。
主要亮点:
* 实时的递交信息
* 点击和打开追踪
* 专为出站邮件设计
>
> ? 维护和配置你的电子邮件服务器并非易事。只有在全面了解可靠地发送/接收电子邮件所需的一切情况下,才应继续设置邮件服务器。
>
>
>
### 2、mailcow

[mailcow](https://mailcow.email/) 是一个邮件服务器套件,其中包含帮助你构建 Web 服务器、管理邮箱等工具。
如果你不打算发送交易性电子邮件,mailcow 可以助你一臂之力。你可以将其视为一个团队协作工具。
(LCTT 译注:交易性电子邮件是指促进商业交易或关系的电子邮件,或提供关于正在进行的商业交易的最新信息。常见的例子包括: 订单确认、通知电子邮件等,例如,运输确认和更新,或订单退款。)
与其他邮件服务器一样,它与 Docker 搭配使用,每个容器是一个应用程序,它们之间相互连接。
mailcow 的 Web 用户界面可让你在一个地方完成所有操作。你可以在其 [GitHub 页面](https://github.com/mailcow/mailcow-dockerized) 或 [文档](https://docs.mailcow.email/) 中了解更多关于该项目的信息。
主要亮点:
* 易于管理和更新
* 可提供经济实惠的付费支持
* 如果需要,可以与其他邮件服务器配合使用
### 3、Cuttlefish

想要一个简单的交易性邮件服务器吗?[Cuttlefish](https://cuttlefish.io/) 是一个简单易用的开源邮件服务器。
你可以通过简单的 Web 用户界面查看统计数据,监控出站邮件。
与一些完整的电子邮件服务(如 SendGrid 或 Mailgun)相比,Cuttlefish 在功能方面可能没有那么全面,**它目前仍处于测试阶段(beta)**。如果你需要超级简单且可靠的解决方案,可以选择它。
在其 [GitHub 页面](https://github.com/mlandauer/cuttlefish) 上了解更多信息。
主要亮点:
* 简单的交易性邮件服务器
* 简单易用
### 4、Apache James

[James](https://james.apache.org/) 是 “Java Apache Mail Enterprise Server” 的缩写。
顾名思义,James 是一个使用 Java 构建的面向企业的开源邮件服务器。根据需求,你可以将该邮件服务器用作 SMTP 中继或 IMAP 服务器。
与其他邮件服务器相比,James 可能不是最容易配置或安装的。但是,你可以查看其 [文档](https://james.apache.org/server/install.html) 或 [GitHub 页面](https://github.com/apache/james-project) 来自行评判。
主要亮点:
* 配置完成后易于管理
* 可靠,并被开源企业使用
* 分布式服务器
### 5、Haraka
[Haraka](https://haraka.github.io/) 是一个使用 Node.js 构建的现代开源 SMTP 服务器。如果你可以为你的业务/网站构建它,你就不需要寻找其他 [SMTP 服务](https://linuxhandbook.com/smtp-services/)。
这个邮件服务器专为提供最佳性能而设计。Haraka 的一个亮点是,它具有模块化插件系统,允许程序员根据需要更改服务器的行为。
你可以将其视为一款出色的可扩展的出站邮件递交服务器。一些知名的网站如 Craigslist 和 DuckDuckGo Email Protection 就使用了 Haraka。
在其 [GitHub 页面](https://github.com/haraka/Haraka) 上可以了解更多信息。
主要亮点:
* 使用 Node.js 构建
* 插件系统以扩展功能
### 6、Modoboa

[Modoboa](https://modoboa.org/en/) 是一个多合一的开源解决方案。
它可以帮助你构建邮件服务器,并为你管理电子邮件帐户。你可以创建日历,无限制添加域名,创建过滤规则和访问 Webmail。如果你希望获得专业帮助来设置和管理系统,Modoboa 还提供付费维护选项。
除了是一个多功能解决方案外,它还提供了一种快速入门的方式来构建你的电子邮件基础架构。
主要亮点:
* 全能选项
* 提供付费帮助
* 内置监控功能
### 7、Postfix
Postfix 是一种 <ruby> 邮件传输代理 <rt> Mail Transfer Agent </rt></ruby>(MTA)。它本身可能不是一个独立的服务器,但它可以与其他一些解决方案配合使用来构建电子邮件服务器。
虽然 mailcow 包含了 [Postfix](https://www.postfix.org/)(你可以将其配置与类似的解决方案一起使用),但你也可以根据你的使用情况选择单独使用它。在 Ubuntu 服务器中,Postfix 也是默认的邮件传输代理。
Postfix 可以用作外部 SMTP。不要忘记,你还可以设置 Postfix 与 Gmail [配合使用](https://www.linode.com/docs/guides/configure-postfix-to-send-mail-using-gmail-and-google-workspace-on-debian-or-ubuntu/)。Postfix 容易配置,并且其文档对于使用它非常有用。
主要亮点:
* 易于配置
* 灵活
### 8、Maddy
[Maddy](https://maddy.email/) 是一个轻量级邮件服务器实现的不错选择。官方描述称它是一款“*可组合的一体化邮件服务器*”。
与 mailcow 相比较,你会发现 Maddy 提供了一些与 mailcow 相同的功能,也就是说它不仅仅局限于出站邮件等功能。
Maddy 在使用场景上非常受欢迎,它可以用单一实现替代多个选项,如 Postfix。你可以通过 SMTP 和 IMAP 使用 Maddy 进行发送、接收和存储消息。文章撰写时,存储功能仍处于测试阶段(beta)。
主要亮点:
* 轻量级
* 替代多种用例,比如 Postfix 等选项
* 不依赖 Docker
### 9、Dovecot
[Dovecot](https://www.dovecot.org/) 是一个开源的 IMAP 服务器,作为 <ruby> 邮件传递代理 <rt> Mail Delivery Agent </rt></ruby>(MDA)发挥作用。它可以与 Postfix 一起工作,因为它们执行不同的任务。
与其他解决方案相比,Dovecot 提供了易于管理、可靠的电子邮件发送功能和自我修复能力。
对于大型基础设施,Dovecot 提供了专业支持的高级方案。
主要亮点:
* 易于管理
* 自我修复能力
* 专注于性能
### 10、[Poste.io](http://Poste.io)

[Poste.io](https://poste.io/) 使用了邮件服务器解决方案,如 Haraku、Dovecot 和其他开源组件。从垃圾邮件过滤工具到防病毒引擎,应有尽有。
如果你想使用其中一些组件设置一个开源邮件服务器,并能够轻松管理和保护系统,[Poste.io](http://Poste.io) 是一个很好的选择。
主要亮点:
* 使用多个开源邮件服务器组件进行易管理和构建
* 管理面板界面
### 11、iRedMail
[iRedMail](https://www.iredmail.org/) 类似于 mailcow,它帮助你使用各种开源组件构建邮件服务器。你还可以使用创建的邮件服务器管理你的日历。
尽管你可以自行设置,但如果需要,它也提供付费的专业支持。
你将获得一个 Web 面板,在支持的 Linux 发行版上进行托管,并能够创建无限数量的账户。
主要亮点:
* 简单易用
* Web 面板进行易管理
### 12、Mailu

[Mailu](https://mailu.io/2.0/) 是一个基于 Docker 的邮件服务器,可以为你提供最好的服务,同时限制了一些功能。
这并不意味着它不好;Mailu 的目标是专注于必要功能,而不添加对大多数人无用的许多功能。即便如此,它仍然通过添加 ARM 支持、Kubernetes 支持和其他一些功能而脱颖而出。
你将获得一个标准的邮件服务器、高级电子邮件功能、Web 管理界面和注重隐私的功能。
主要亮点:
* 简单的界面
* 关注于功能而不是花俏的解决方案
* ARM 支持
### 准备构建和管理你的邮件服务器了吗?
使用开源工具和邮件服务器,你可以掌握你的数据,并为你的业务或网站管理/优化电子邮件通信。
正如我所提到的,这需要很多工作。因此,如果你希望拥有定制化的体验并且有一个可以负责的团队,那么开源自托管的邮件服务器是可行的选择。
? 当然,还有很多其他选项可供选择,比如 [mail in a box](https://mailinabox.email/),可以帮助你快速部署邮件服务器。
在这里,我们尝试为你挑选最佳选择以供参考。你最喜欢的开源邮件服务器是什么?
*(题图:MJ/f85c5c41-a598-4382-8821-73c701fc842b)*
---
via: <https://itsfoss.com/open-source-email-servers/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It is convenient to use email services like Gmail, Proton Mail, and Outlook to send and receive emails, no matter what [email client](https://itsfoss.com/best-email-clients-linux/) you use.
And, for all of that, you utilize their mail servers for email transactions. So, your emails' security, reliability, and privacy depend on someone else.
But what if you want to own your email infrastructure and have the data in your control? You need an open-source email server, which should solve your problem.
If you are still curious, an email server lets you:
**Build your mail backend to store email accounts****Take control of the security and reliability by self-hosting****Host on your preferred server architecture****It gives you the ability to make unlimited accounts**
Of course, this is not for the end users. Sysadmins in small to midscale businesses, self hosters will find these software interesting.
Considering now you have an idea of the benefits of an open-source email server, here are some of the best options that you can find:
## 1. Postal
[Postal](https://github.com/postalserver/postal) is a feature-rich mail server that can be utilized by websites and servers. It is **tailored for outgoing emails** with no mailbox management features.
The [documentation](https://docs.postalserver.io) is helpful to get started with all the essentials. You can utilize a docker and configure Postal on your server.
With Postal, you can create mail servers/users for multiple organizations, access outgoing/incoming message queue, real-time delivery information, and built-in features to ensure emails get delivered.
**Key Highlights:**
- Real-time delivery information
- Click and open the tracking
- Tailored for outgoing emails
## 2. mailcow
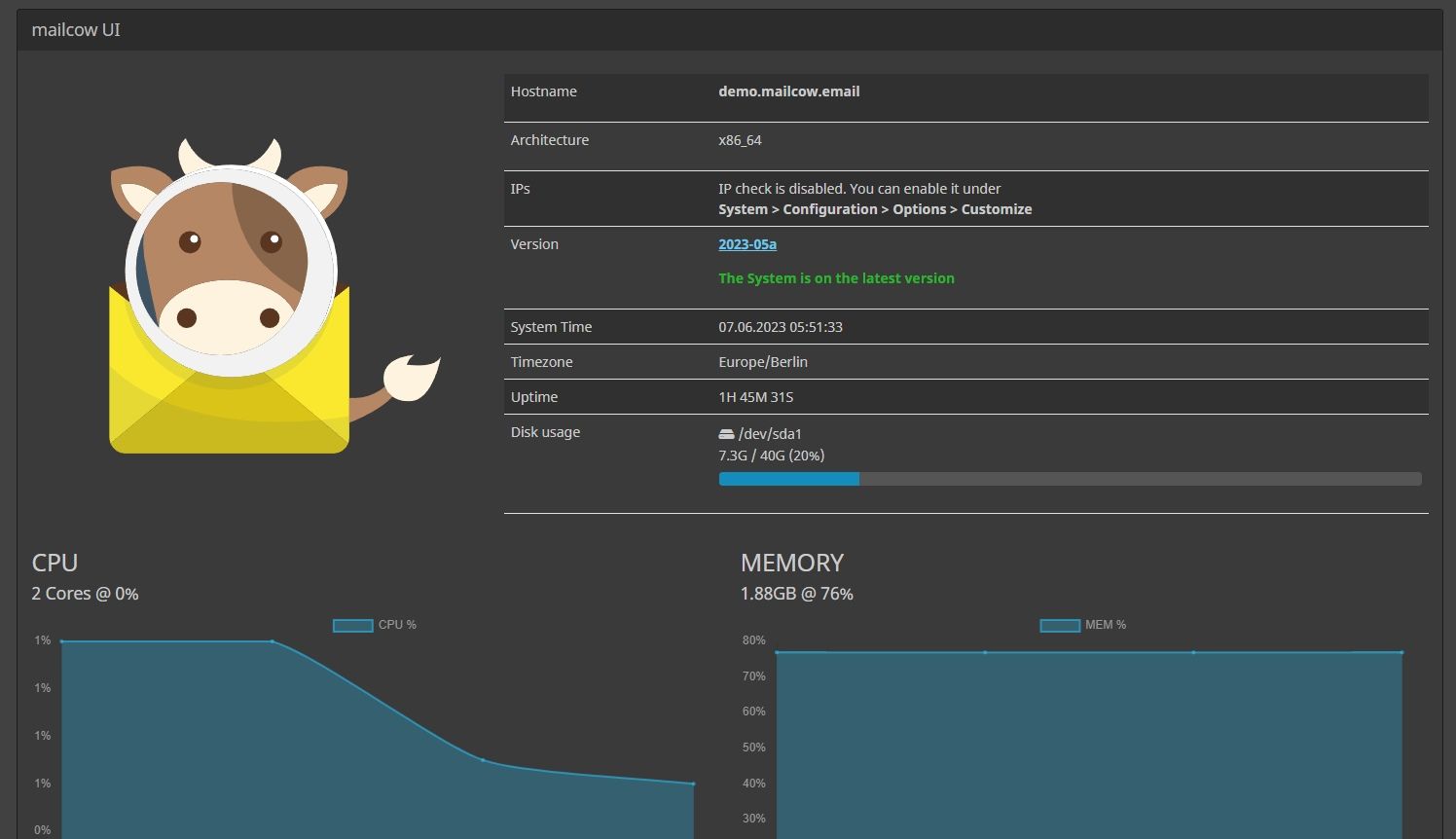
[mailcow](https://mailcow.email) is a mail server suite with tools that help you build a web server, manage your mailbox, and more.
If you are not looking to send transactional emails, mailcow has your back. You can consider it as a groupware.
Like other mail servers, it works with Docker, where each container represents an application, all connected.
mailcow's web interface lets you do everything from a single place. You can explore more about the project on its [GitHub page](https://github.com/mailcow/mailcow-dockerized) or [documentation](https://docs.mailcow.email).
**Key Highlights:**
- Easy to manage and update
- Affordable paid support
- Can be coupled with other mail servers if needed
**Suggested Read 📖**
[10 Free & Paid SMTP Services For Transactional and Bulk EmailsHere are some of the most popular SMTP relay services with their plans for your web app notifications.](https://linuxhandbook.com/smtp-services/)

## 3. Cuttlefish
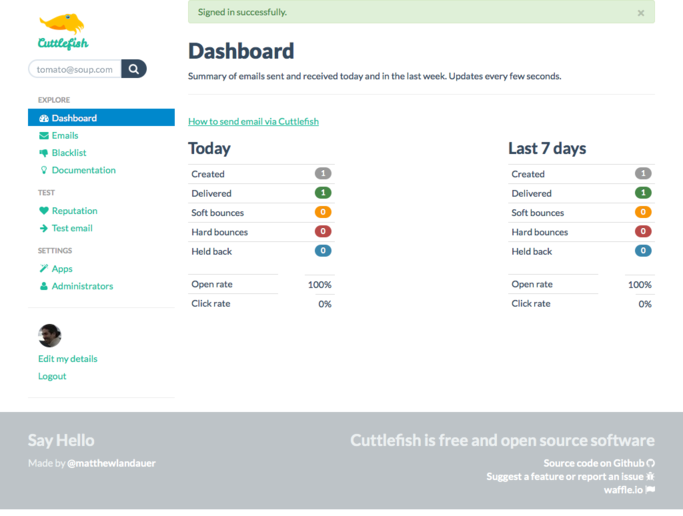
Want a simple transactional email server? [Cuttlefish](https://cuttlefish.io) is a no-nonsense open-source mail server that is incredibly easy to use.
You get a simple web UI to check the stats and keep an eye on your outgoing emails.
Compared to some full-fledged email services like Sendgird or Mailgun, Cuttlefish does not offer all kinds of features, **considering it is in beta** at the time. You can only opt for it if you need something super simple and you want to work reliably.
Explore more about it on its [GitHub page](https://github.com/mlandauer/cuttlefish).
**Key Highlights **
- Simple transactional email server
- Easy to use
## 4. Apache James

[James](https://james.apache.org) is short for **Java Apache Mail Enterprise Server**.
As the name suggests, it is an enterprise-focused open source mail server built with Java. You can use the email server as SMTP relay or an IMAP server, as per requirements.
Compared to others, James may not be the easiest to configure or install. However, you can look at its [documentation](https://james.apache.org/server/install.html) or [GitHub page](https://github.com/apache/james-project) to judge for yourself.
**Key Highlights:**
- Easy administration after setup
- Reliable and used by open-source enterprises
- Distributed server
## 5. Haraka
[Haraka](https://haraka.github.io) is a modern open source SMTP server built with Node.js. If you can build it for your business/website, you do not need to look for other [SMTP services](https://linuxhandbook.com/smtp-services/).
The mail server is tailored to provide the best performance. One of the highlights of Haraka is that it features a modular plugin system that will allow programmers to change the server's behavior to their heart's extent.
You can consider it an excellent scalable outbound mail delivery server. Some popular names like Craigslist and DuckDuckGo Email Protection make use of Haraka.
Explore more about it on its [GitHub page](https://github.com/haraka/Haraka).
**Key Highlights:**
- Built using Node.js
- Plugin system to extend functionalities
## 6. Modoboa
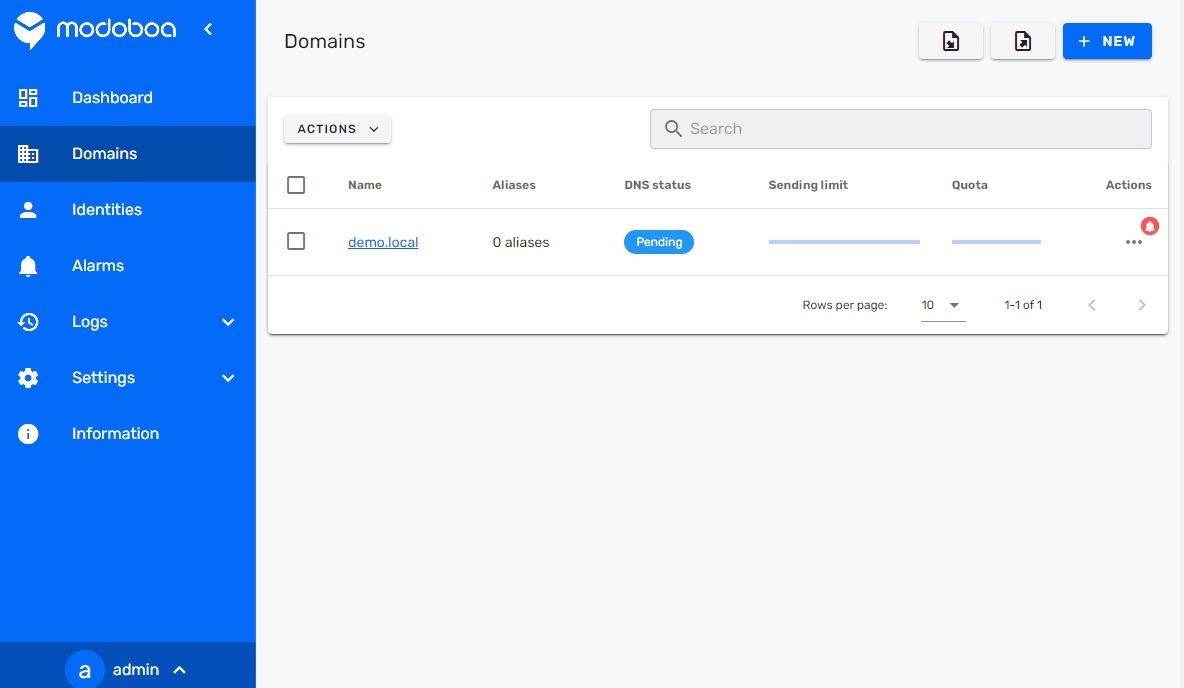
[Modoboa](https://modoboa.org/en/) is an all-in-one open-source solution.
It can help you build a mail server and give you the ability to manage your emails. You can create calendars, add unlimited domains, create filtering rules, and access webmail. Modoboa also provides paid maintenance options if you want their professional help setting it up and managing it.
Not just an all-rounder solution, but it offers a quick way to get started with your email infrastructure.
**Key Highlights:**
- All-in-one option
- Paid assistance available
- Built-in monitoring
## 7. Postfix
Postfix is a Mail Transfer Agent. It may not be a server on its own, but it couples with some other solutions that help you build an email server.
While mailcow includes [Postfix](https://www.postfix.org) (and you can configure it along with similar solutions), you can choose to use it separately per your use case. Postfix is also the default Mail Transfer Agent in the Ubuntu server.
Postfix can be used as an external SMTP. Not to forget, you can also set up Postfix to [work with Gmail](https://www.linode.com/docs/guides/configure-postfix-to-send-mail-using-gmail-and-google-workspace-on-debian-or-ubuntu/). It is easy to configure, and the documentation available for it is plenty useful.
**Key Highlights:**
- Easy to configure
- Flexible
**Suggested Read 📖**
[Best Secure Email Services For Privacy Concerned PeopleCan you call Gmail, Outlook, YahooMail etc secure email services? Well, they’re definitely secure in the way that your data is (usually) safe from outside attackers. But when we talk of secure email service, the focus is on data security and privacy. Most of these free email services snoop](https://itsfoss.com/secure-private-email-services/)

## 8. Maddy
[Maddy](https://maddy.email) is a great choice if you need a lightweight mail server implementation. The official description says it is a "*Composable all-in-one mail server*".
When you compare Maddy with mailcow, you will find that it offers some of the features you get with mailcow, meaning it is not just limited to outgoing emails like others.
Maddy is popular for its use case, where it can replace multiple options like Postfix with a single implementation. You can send/receive, and store messages with Maddy via SMTP and IMAP. The storage feature is in beta at the time of writing the article.
**Key Highlights:**
- Lightweight
- Replaces multiple use-cases that you get with options like Postfix
- No dependency on Docker
## 9. Dovecot
[Dovecot](https://www.dovecot.org) is an open-source IMAP server that works as a Mail Delivery Agent. It can work together with Postfix as both do different things.
Compared to other solutions, it offers easy administration, reliable email-sending capabilities, and self-healing powers.
Dovecot offers a premium offering for large infrastructure with professional support.
**Key Highlights:**
- Easy Administration
- Self-healing capabilities
- Performance-focused
## 10. Poste.io
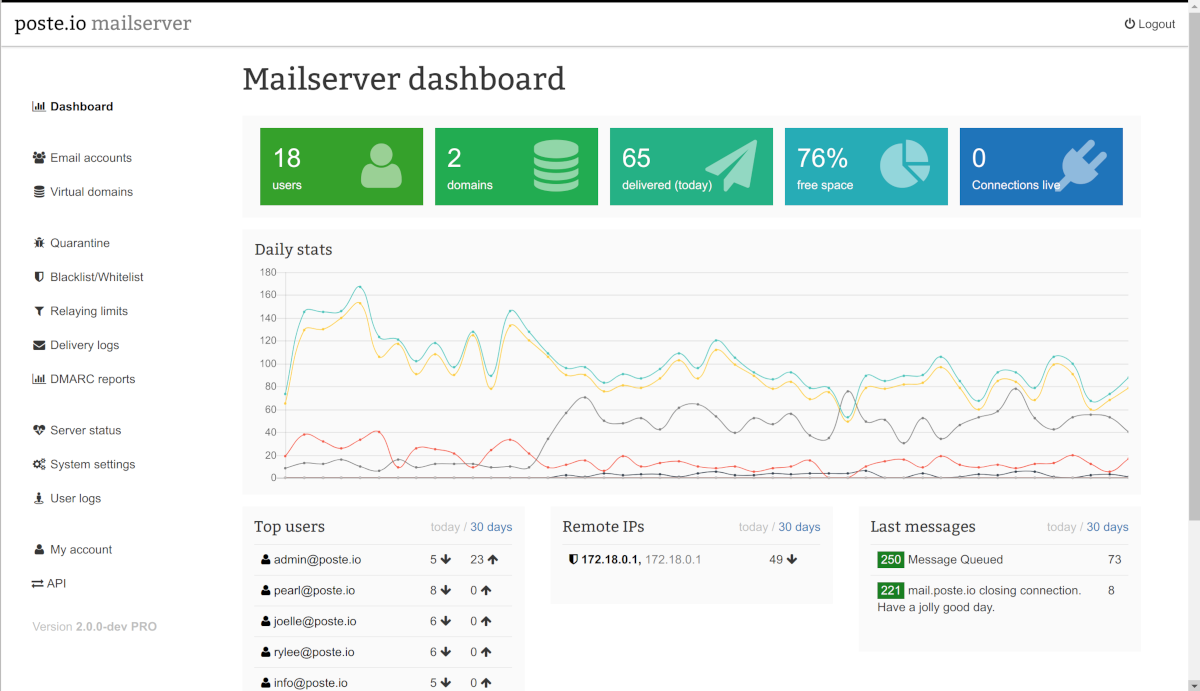
[Poste.io](https://poste.io) utilizes mail server solutions like Haraku, Dovecot, and other open-source components. Ranging from tools for spam filtering to an antivirus engine.
If you want to set up an open-source mail server using some of these components and be able to manage and secure things easily, Poste.io is an excellent choice.
**Key Highlights:**
- Easy to manage and build using multiple open-source mail server components
- Admin panel interface
## 11. iRedMail
[iRedMail](https://www.iredmail.org) is similar to mailcow which helps you build a mail server utilizing various open-source components. You can also manage your calendars with the mail server created.
While you can set it up for yourself, it provides paid professional support if you need it.
You get a web panel, Linux distro support to host it on, and the ability to create unlimited accounts.
**Key Highlights:**
- Easy to use
- Web panel for easy management
## 12. Mailu
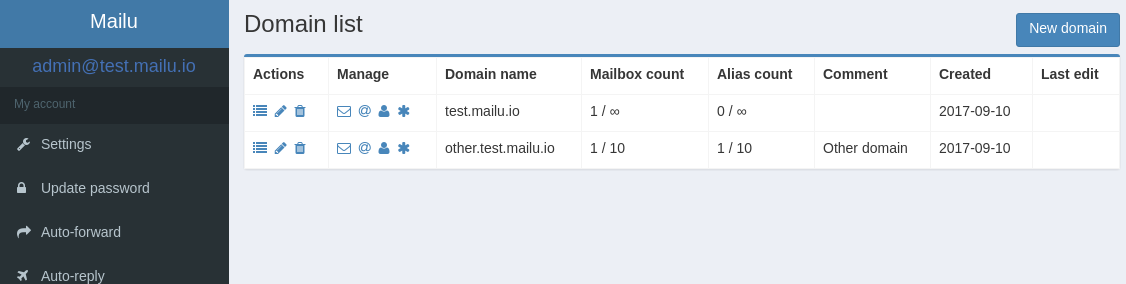
[Mailu](https://mailu.io/2.0/) is a Docker-based mail server that gives you the best of everything while limiting some features.
That does not mean it is bad; Mailu aims to focus on the necessary features without adding many capabilities that are not useful for most. Even with this objective, it stands out by adding ARM support, Kubernetes support, and a couple more things.
You get a standard mail server, advanced email features, a web admin interface, and privacy-focused features.
**Key Highlights:**
- Simple interface
- Focused solution without bells and whistles
- ARM support
## Ready to Build and Manage Your Email Server?
With open-source tools and email servers, you can take control of your data and manage/optimize email transactions for your business or website.
As I mentioned, it takes a lot of work to do it. So, open-source self-hostable email servers can work if you want to have a customized experience and have a team that can be responsible for it.
💬 *I am sure there are many more options, like **mail in a box**, to help you deploy a mail server quickly.*
*Here, we tried to pick the best ones for your convenience. What is your favorite open-source email server?* |
15,984 | 在不到 30 分钟内构建一个树莓派监控仪表盘 | https://opensource.com/article/23/3/build-raspberry-pi-dashboard-appsmith | 2023-07-10T10:29:00 | [
"监控",
"仪表盘"
] | https://linux.cn/article-15984-1.html | 
>
> 使用 Python 制作一个 API 来监控你的树莓派硬件,并使用 Appsmith 建立一个仪表盘。
>
>
>
如果你想知道你的树莓派的性能如何,那么你可能需要一个树莓派的仪表盘。在本文中,我将演示如何快速构建一个按需监控仪表盘,以实时查看你的树莓派的 CPU 性能、内存和磁盘使用情况,并根据需要随时添加更多视图和操作。
如果你已经使用 Appsmith,你还可以直接导入 [示例应用程序](https://github.com/appsmithorg/foundry/tree/main/resources/blogs/Raspberry%20Pi%20Dashboard) 并开始使用。
### Appsmith
Appsmith 是一个开源的 [低代码](https://www.redhat.com/architect/low-code-platform?intcmp=7013a000002qLH8AAM) 应用构建工具,帮助开发人员轻松快速地构建内部应用,如仪表盘和管理面板。它是一个用于仪表盘的很好选择,并减少了传统编码方法所需的时间和复杂性。
在此示例的仪表盘中,我显示以下统计信息:
* CPU
+ 占用百分比
+ 频率或时钟速度
+ 计数
+ 温度
* 内存
+ 占用百分比
+ 可用内存百分比
+ 总内存
+ 空闲内存
* 磁盘
+ 磁盘使用百分比
+ 绝对磁盘空间使用量
+ 可用磁盘空间
+ 总磁盘空间
### 创建一个端点
你需要一种从树莓派获取这些数据并传递给 Appsmith 的方法。[psutil](https://psutil.readthedocs.io/en/latest/) 是一个用于监控和分析的 Python 库,而 [Flask-RESTful](https://flask-restful.readthedocs.io/en/latest/) 是一个创建 [REST API](https://www.redhat.com/en/topics/api/what-is-a-rest-api?intcmp=7013a000002qLH8AAM) 的 Flask 扩展。
Appsmith 每隔几秒钟调用 REST API 以自动刷新数据,并以 JSON 对象作为响应,其中包含所有所需的统计信息,如下所示:
```
{ "cpu_count": 4,
"cpu_freq": [
600.0,
600.0,
1200.0 ],
"cpu_mem_avail": 463953920,
"cpu_mem_free": 115789824,
"cpu_mem_total": 971063296,
"cpu_mem_used": 436252672,
"cpu_percent": 1.8,
"disk_usage_free": 24678121472,
"disk_usage_percent": 17.7,
"disk_usage_total": 31307206656,
"disk_usage_used": 5292728320,
"sensor_temperatures": 52.616 }
```
#### 1、设置 REST API
如果你的树莓派尚未安装 Python,请在树莓派上打开终端并运行此安装命令:
```
$ sudo apt install python3
```
现在为你的开发设置一个 [Python 虚拟环境](https://opensource.com/article/20/10/venv-python):
```
$ python -m venv PiData
```
接下来,激活该环境。你必须在重新启动树莓派后执行此操作。
```
$ source PiData/bin/activate
$ cd PiData
```
为了安装 Flask、Flask-RESTful 和以后需要的依赖项,请在你的 Python 虚拟环境中创建一个名为 `requirements.txt` 的文件,并将以下内容添加到其中:
```
flask
flask-restful
gunicorn
```
保存文件,然后使用 `pip` 一次性安装它们。你必须在重新启动树莓派后执行此操作。
```
(PyData)$ python -m pip install -r requirements.txt
```
接下来,创建一个名为 `pi_stats.py` 的文件来存放使用 `psutil` 检索树莓派系统统计信息的逻辑。将以下代码粘贴到 `pi_stats.py` 文件中:
```
from flask import Flask
from flask_restful import Resource, Api
import psutil
app = Flask(__name__)
api = Api(app)
class PiData(Resource):
def get(self):
return "RPI Stat dashboard"
api.add_resource(PiData, '/get-stats')
if __name__ == '__main__':
app.run(debug=True)
```
这段代码的作用如下:
* 使用 `app = Flask(name)` 来定义嵌套 API 对象的应用程序。
* 使用 Flask-RESTful 的 [API 方法](https://flask-restful.readthedocs.io/en/latest/api.html#id1) 来定义 API 对象。
* 在 Flask-RESTful 中将 `PiData` 定义为具体的 [Resource 类](https://flask-restful.readthedocs.io/en/latest/api.html#flask_restful.Resource) ,以公开每个支持的 HTTP 方法。
* 使用 `api.add_resource(PiData, '/get-stats')` 将资源 `PiData` 附加到 API 对象 `api`。
* 每当你访问 URL `/get-stats` 时,将返回 `PiData` 作为响应。
#### 2、使用 psutil 读取统计信息
要从你的树莓派获取统计信息,你可以使用 `psutil` 提供的这些内置函数:
* `cpu_percentage`、`cpu_count`、`cpu_freq` 和 `sensors_temperatures` 函数分别用于获取 CPU 的占用百分比、计数、时钟速度和温度。`sensors_temperatures` 报告了与树莓派连接的所有设备的温度。要仅获取 CPU 的温度,请使用键 `cpu-thermal`。
* `virtual_memory` 函数可返回总内存、可用内存、已使用内存和空闲内存的统计信息(以字节为单位)。
* `disk_usage` 函数可返回总磁盘空间、已使用空间和可用空间的统计信息(以字节为单位)。
将所有函数组合到一个 Python 字典中的示例如下:
```
system_info_data = {
'cpu_percent': psutil.cpu_percent(1),
'cpu_count': psutil.cpu_count(),
'cpu_freq': psutil.cpu_freq(),
'cpu_mem_total': memory.total,
'cpu_mem_avail': memory.available,
'cpu_mem_used': memory.used,
'cpu_mem_free': memory.free,
'disk_usage_total': disk.total,
'disk_usage_used': disk.used,
'disk_usage_free': disk.free,
'disk_usage_percent': disk.percent,
'sensor_temperatures': psutil.sensors_temperatures()['cpu-thermal'][0].current,
}
```
下一节将使用该字典。
#### 3、从 Flask-RESTful API 获取数据
为了在 API 响应中看到来自树莓派的数据,请更新 `pi_stats.py` 文件,将字典 `system_info_data` 包含在 `PiData` 类中:
```
from flask import Flask
from flask_restful import Resource, Api
import psutil
app = Flask(__name__)
api = Api(app)
class PiData(Resource):
def get(self):
memory = psutil.virtual_memory()
disk = psutil.disk_usage('/')
system_info_data = {
'cpu_percent': psutil.cpu_percent(1),
'cpu_count': psutil.cpu_count(),
'cpu_freq': psutil.cpu_freq(),
'cpu_mem_total': memory.total,
'cpu_mem_avail': memory.available,
'cpu_mem_used': memory.used,
'cpu_mem_free': memory.free,
'disk_usage_total': disk.total,
'disk_usage_used': disk.used,
'disk_usage_free': disk.free,
'disk_usage_percent': disk.percent,
'sensor_temperatures': psutil.sensors_temperatures()['cpu-thermal'][0].current, }
return system_info_data
api.add_resource(PiData, '/get-stats')
if __name__ == '__main__':
app.run(debug=True)
```
你的脚本已经就绪,下面运行 `PiData.py`:
```
$ python PyData.py
* Serving Flask app "PiData" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not run this in a production environment.
* Debug mode: on
* Running on http://127.0.0.1:5000 (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
```
你有了一个可以工作的 API。
#### 4、将 API 提供给互联网
你可以在本地网络中与 API 进行交互。然而,要在互联网上访问它,你必须在防火墙中打开一个端口,并将传入的流量转发到由 Flask 提供的端口。然而,正如你的测试输出建议的那样,在 Flask 中运行 Flask 应用程序仅适用于开发,而不适用于生产。为了安全地将 API 提供给互联网,你可以使用安装过程中安装的 `gunicorn` 生产服务器。
现在,你可以启动 Flask API。每次重新启动树莓派时都需要执行此操作。
```
$ gunicorn -w 4 'PyData:app'
Serving on http://0.0.0.0:8000
```
要从外部世界访问你的树莓派,请在网络防火墙中打开一个端口,并将流量定向到你树莓派的 IP 地址,端口为 8000。
首先,获取树莓派的内部 IP 地址:
```
$ ip addr show | grep inet
```
内部 IP 地址通常以 10 或 192 或 172 开头。
接下来,你必须配置防火墙。通常,你从互联网服务提供商(ISP)获取的路由器中嵌入了防火墙。通常,你可以通过网络浏览器访问家用路由器。路由器的地址有时会打印在路由器的底部,它以 192.168 或 10 开头。不过,每个设备都不同,因此我无法告诉你需要点击哪些选项来调整设置。关于如何配置防火墙的完整描述,请阅读 Seth Kenlon 的文章 《[打开端口并通过你的防火墙路由流量](https://opensource.com/article/20/9/firewall)》。
或者,你可以使用 [localtunnel](https://theboroer.github.io/localtunnel-www/) 来使用动态端口转发服务。
一旦你的流量到达树莓派,你就可以查询你的 API:
```
$ curl https://example.com/get-stats
{
"cpu_count": 4,
"cpu_freq": [
600.0,
600.0,
1200.0 ],
"cpu_mem_avail": 386273280,
...
```
如果你已经执行到这一步,那么最困难的部分已经过去了。
#### 5、重复步骤
如果你重新启动了树莓派,你必须按照以下步骤进行操作:
* 使用 `source` 重新激活 Python 环境
* 使用 `pip` 刷新应用程序的依赖项
* 使用 `gunicorn` 启动 Flask 应用程序
你的防火墙设置是持久的,但如果你使用了 localtunnel,则必须在重新启动后启动新的隧道。
如果你愿意,可以自动化这些任务,但那是另一个教程的内容。本教程的最后一部分是在 Appsmith 上构建一个用户界面,使用拖放式小部件和一些 JavaScript,将你的树莓派数据绑定到用户界面。相信我,从现在开始很容易!
### 在 Appsmith 上构建仪表盘

要制作一个像这样的仪表盘,你需要将公开的 API 端点连接到 Appsmith,使用 Appsmith 的小部件库构建用户界面,并将 API 的响应绑定到小部件上。如果你已经使用 Appsmith,你可以直接导入 [示例应用程序](https://github.com/appsmithorg/foundry/tree/main/resources/blogs/Raspberry%20Pi%20Dashboard) 并开始使用。
如果你还没有,请 [注册](https://appsmith.com/sign-up) 一个免费的 Appsmith 帐户。或者,你可以选择 [自托管 Appsmith](https://docs.appsmith.com/getting-started/setup)。
### 将 API 作为 Appsmith 数据源连接
登录到你的 Appsmith 帐户。
* 在左侧导航栏中找到并点击 “<ruby> 查询或 JS <rt> QUERIES/JS </rt></ruby>” 旁边的 “+” 按钮。
* 点击 “<ruby> 创建一个空白 API <rt> Create a blank API </rt></ruby>”。
* 在页面顶部,将你的项目命名为 “PiData”。
* 获取你的 API 的 URL。如果你使用的是 localtunnel,则是一个 `localtunnel.me` 地址,总是在末尾添加 `/get-stats` 以获取统计数据。将其粘贴到页面的第一个空白字段中,然后点击 “RUN” 按钮。
确保在 “<ruby> 响应 <rt> Response </rt></ruby>” 面板中看到成功的响应。

### 构建用户界面
Appsmith 的界面非常直观,但如果你感到迷失,我建议你查看 [在 Appsmith 上构建你的第一个应用程序](https://docs.appsmith.com/getting-started/start-building) 教程。
对于标题,将 “<ruby> 文本 <rt> Text </rt></ruby>”、“<ruby> 图像 <rt> Image </rt></ruby>” 和 “<ruby> 分隔线 <rt> Divider </rt></ruby>” 小部件拖放到画布上。将它们排列如下:

“<ruby> 文本 <rt> Text </rt></ruby>” 小部件包含你页面的实际标题。键入比“Raspberry Pi Stats”更酷的内容。
“<ruby> 图像 <rt> Image </rt></ruby>” 小部件用于展示仪表盘的独特标志。你可以使用你喜欢的任何标志。
使用 “<ruby> 开关 <rt> Switch </rt></ruby>” 小部件来切换实时数据模式。在 “<ruby> 属性 <rt> Property </rt></ruby>” 面板中进行配置,以从你构建的 API 获取数据。
对于主体部分,使用来自左侧的小部件库的以下小部件创建一个 CPU 统计信息区域,使用以下小部件:
* <ruby> 进度条 <rt> Progress Bar </rt></ruby>
* <ruby> 统计框 <rt> Stat Box </rt></ruby>
* <ruby> 图表 <rt> Chart </rt></ruby>
对于内存和磁盘统计信息部分,重复相同的步骤。磁盘统计信息部分不需要图表,但如果你能找到用途,那也可以使用它。
你的最终小部件布局应该类似于以下:

最后一步是将 API 的数据绑定到你的小部件上。
### 将数据绑定到小部件上
返回到画布,并在三个类别的部分中找到你的小部件。首先设置 CPU 统计信息。
要将数据绑定到 “<ruby> 进度条 <rt> Progress Bar </rt></ruby>” 小部件:
* 单击 “<ruby> 进度条 <rt> Progress Bar </rt></ruby>” 小部件,以打开右侧的 “<ruby> 属性 <rt> Property </rt></ruby>” 面板。
* 查找 “<ruby> 进度 <rt> Progress </rt></ruby>” 属性。
* 单击 “JS” 按钮以激活 JavaScript。
* 在 “<ruby> 进度 <rt> Progress </rt></ruby>” 字段中粘贴 `{{PiData.data.cpu_percent ?? 0}}`。此代码引用了你的 API 的数据流,名为 `PiData`。Appsmith 将响应数据缓存在 `PiData` 的 `.data` 运算符内。键 `cpu_percent` 包含了 Appsmith 用来显示 CPU 利用率百分比的数据。
* 在 “<ruby> 进度条 <rt> Progress Bar </rt></ruby>” 小部件下方添加一个 “<ruby> 文本 <rt> Text </rt></ruby>” 小部件作为标签。

在 CPU 部分有三个 “<ruby> 统计框 <rt> Stat Box </rt></ruby>” 小部件。将数据绑定到每个小部件的步骤与绑定 “<ruby> 进度条 <rt> Progress Bar </rt></ruby>” 小部件的步骤完全相同,只是你需要从 `.data` 运算符中绑定不同的数据属性。按照相同的步骤进行操作,但有以下例外:
* 使用 `{{${PiData.data.cpu_freq[0]} ?? 0 }}` 来显示时钟速度。
* 使用 `{{${PiData.data.cpu_count} ?? 0 }}` 来显示 CPU 计数。
* 使用 `{{${(PiData.data.sensor_temperatures).toPrecision(3)} ?? 0 }}` 来显示 CPU 温度数据。
如果一切顺利,你将得到一个漂亮的仪表盘,如下所示:

### CPU 利用率趋势图
你可以使用 “<ruby> 图表 <rt> Chart </rt></ruby>” 小部件将 CPU 利用率显示为趋势线,并使其随时间自动更新。
首先,单击小部件,在右侧找到 “<ruby> 图表类型 <rt> Chart Type </rt></ruby>” 属性,并将其更改为 “<ruby> 折线图 <rt> LINE CHART </rt></ruby>”。为了显示趋势线,需要将 `cpu_percent` 存储在数据点数组中。你的 API 目前将其作为单个时间数据点返回,因此可以使用 Appsmith 的 `storeValue` 函数(Appsmith 内置的 `setItem` 方法的一个原生实现)来获取一个数组。
在 “<ruby> 查询或 JS <rt> QUERIES/JS </rt></ruby>” 旁边单击 “+” 按钮,并将其命名为 “utils”。
将以下 JavaScript 代码粘贴到 “<ruby> 代码 <rt> Code </rt></ruby>” 字段中:
```
export default {
getLiveData: () => {
//When switch is on:
if (Switch1.isSwitchedOn) {
setInterval(() => {
let utilData = appsmith.store.cpu_util_data;
PiData.run()
storeValue("cpu_util_data", [...utilData, {
x: PiData.data.cpu_percent,
y: PiData.data.cpu_percent
}]);
}, 1500, 'timerId')
} else {
clearInterval('timerId');
}
},
initialOnPageLoad: () => {
storeValue("cpu_util_data", []);
}
}
```
为了初始化 `Store`,你在 `initialOnPageLoad` 对象中创建了一个 JavaScript 函数,并将 `storeValue` 函数放在其中。
你使用 `storeValue("cpu_util_data", []);` 将 `cpu_util_data` 中的值存储到 `storeValue` 函数中。此函数在页面加载时运行。
到目前为止,每次刷新页面时,代码都会将 `cpu_util_data` 中的一个数据点存储到 `Store` 中。为了存储一个数组,你使用了 `x` 和 `y` 的下标变量,两者都存储了来自 `cpu_percent` 数据属性的值。
你还希望通过设定存储值之间的固定时间间隔来自动存储这些数据。当执行 [setInterval](https://docs.appsmith.com/reference/appsmith-framework/widget-actions/intervals-time-events#setinterval) 函数时:
* 获取存储在 `cpu_util_data` 中的值。
* 调用 API `PiData`。
* 使用返回的最新 `cpu_percent` 数据将 `cpu_util_data` 更新为 `x` 和 `y` 变量。
* 将 `cpu_util_data` 的值存储在键 `utilData` 中。
* 仅当设置为自动执行函数时,才重复执行步骤 1 到 4。你使用 Switch 小部件将其设置为自动执行,这就解释了为什么有一个 `getLiveData` 父函数。
在 “<ruby> 设置 <rt> Settings </rt></ruby>” 选项卡中,找到对象中的所有父函数,并在 “<ruby> 页面加载时运行 <rt> RUN ON PAGE LOAD </rt></ruby>” 选项中将 `initialOnPageLoad` 设置为 “Yes(是)”。

现在刷新页面进行确认。
返回到画布。单击 “<ruby> 图表 <rt> Chart </rt></ruby>” 小部件,并找到 “<ruby> 图表数据 <rt> Chart Data </rt></ruby>” 属性。将绑定 `{{ appsmith.store.disk_util_data }}` 粘贴到其中。这样,如果你自己多次运行对象 `utils`,就可以获得图表数据。要自动运行此操作:
* 查找并单击仪表盘标题中的 “<ruby> 实时数据开关 <rt> Live Data Switch </rt></ruby>” 小部件。
* 查找 `onChange` 事件。
* 将其绑定到 `{{ utils.getLiveData() }}`。JavaScript 对象是 `utils`,而 `getLiveData` 是在你切换开关时激活的函数,它会从你的树莓派获取实时数据。但是还有其他实时数据,因此同一开关也适用于它们。继续阅读以了解详情。
将数据绑定到内存和磁盘部分的小部件与你在 CPU 统计信息部分所做的方式类似。
对于内存部分,绑定如下所示:
* 进度条中的绑定为:`{{( PiData.data.cpu_mem_avail/1000000000).toPrecision(2) \* 100 ?? 0 }}`。
* 三个统计框小部件的绑定分别为:`{{ \${(PiData.data.cpu_mem_used/1000000000).toPrecision(2)} ?? 0 }} GB`、`{{ \${(PiData.data.cpu_mem_free/1000000000).toPrecision(2)} ?? 0}} GB` 和 `{{ \${(PiData.data.cpu_mem_total/1000000000).toPrecision(2)} ?? 0 }} GB`。
对于磁盘部分,进度条和统计框小部件的绑定分别变为:
* 进度条的绑定为:`{{ PiData.data.disk_usage_percent ?? 0 }}`。
* 三个统计框小部件的绑定分别为:`{{ \${(PiData.data.disk_usage_used/1000000000).toPrecision(2)} ?? 0 }} GB`、`{{ \${(PiData.data.disk_usage_free/1000000000).toPrecision(2)} ?? 0 }} GB` 和 `{{ \${(PiData.data.disk_usage_total/1000000000).toPrecision(2)} ?? 0 }} GB`。
这里的图表需要更新你为 CPU 统计信息创建的 `utils` 对象,使用 `storeValue` 键名为 `disk_util_data`,嵌套在 `getLiveData` 下面,其逻辑与 `cpu_util_data` 类似。对于磁盘利用率图表,我们存储的 `disk_util_data` 的逻辑与 CPU 利用率趋势图的逻辑相同。
```
export default {
getLiveData: () => {
//When switch is on:
if (Switch1.isSwitchedOn) {
setInterval(() => {
const cpuUtilData = appsmith.store.cpu_util_data;
const diskUtilData = appsmith.store.disk_util_data;
PiData.run();
storeValue("cpu_util_data", [...cpuUtilData, { x: PiData.data.cpu_percent,y: PiData.data.cpu_percent }]);
storeValue("disk_util_data", [...diskUtilData, { x: PiData.data.disk_usage_percent,y: PiData.data.disk_usage_percent }]);
}, 1500, 'timerId')
} else {
clearInterval('timerId');
}
},
initialOnPageLoad: () => {
storeValue("cpu_util_data", []);
storeValue("disk_util_data", []);
}
}
```
通过使用 `utils` JavaScript 对象在打开和关闭真实数据开关时触发的数据流可视化如下所示:

在打开实时数据开关时,图表会变成这样:

整体上,它既漂亮,又简约,而且非常有用。
### 祝你使用愉快!
当你对 `psutils`、JavaScript 和 Appsmith 更加熟悉时,我相信你会发现可以轻松无限地调整你的仪表板,实现非常酷的功能,例如:
* 查看先前一周、一个月、一个季度、一年或根据你的树莓派数据允许的任何自定义范围的趋势
* 为任何统计数据的阈值违规构建报警机制
* 监控连接到你的树莓派的其他设备
* 将 `psutils` 扩展到另一台安装有 Python 的计算机上
* 使用其他库监控你家庭或办公室的网络
* 监控你的花园
* 跟踪你自己的生活习惯
在下一个令人兴奋的项目中,祝你玩得愉快!
*(题图:MJ/9754eb1f-1722-4897-9c35-3f20c285c332)*
---
via: <https://opensource.com/article/23/3/build-raspberry-pi-dashboard-appsmith>
作者:[Keyur Paralkar](https://opensource.com/users/keyur-paralkar) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you’ve ever wondered about the performance of your Raspberry Pi, then you might need a dashboard for your Pi. In this article, I demonstrate how to quickly building an on-demand monitoring dashboard for your Raspberry Pi so you can see your CPU performance, memory and disk usage in real time, and add more views and actions later as you need them.
If you’re already using Appsmith, you can also import the [sample app](https://github.com/appsmithorg/foundry/tree/main/resources/blogs/Raspberry%20Pi%20Dashboard) directly and get started.
## Appsmith
Appsmith is an open source, [low-code](https://www.redhat.com/architect/low-code-platform?intcmp=7013a000002qLH8AAM) app builder that helps developers build internal apps like dashboards and admin panels easily and quickly. It’s a great choice for your dashboard, and reduces the time and complexity of traditional coding approaches.
For the dashboard in this example, I display usage stats for:
- CPU
- Percentage utilization
- Frequency or clock speed
- Count
- Temperature
- Memory
- Percentage utilization
- Percentage available memory
- Total memory
- Free memory
- Disk
- Percentage disk utilization
- Absolute disk space used
- Available disk space
- Total disk space
## Creating an endpoint
You need a way to get this data from your Raspberry Pi (RPi) and into Appsmith. The [psutils](https://psutil.readthedocs.io/en/latest/) Python library is useful for monitoring and profiling, and the [Flask-RESTful](https://flask-restful.readthedocs.io/en/latest/) Flask extension creates a [REST API](https://www.redhat.com/en/topics/api/what-is-a-rest-api?intcmp=7013a000002qLH8AAM).
Appsmith calls the REST API every few seconds to refresh data automatically, and gets a JSON object in response with all desired stats as shown:
```
``````
{ "cpu_count": 4,
"cpu_freq": [
600.0,
600.0,
1200.0 ],
"cpu_mem_avail": 463953920,
"cpu_mem_free": 115789824,
"cpu_mem_total": 971063296,
"cpu_mem_used": 436252672,
"cpu_percent": 1.8,
"disk_usage_free": 24678121472,
"disk_usage_percent": 17.7,
"disk_usage_total": 31307206656,
"disk_usage_used": 5292728320,
"sensor_temperatures": 52.616 }
```
## 1. Set up the REST API
If your Raspberry Pi doesn’t have Python on it yet, open a terminal on your Pi and run this install command:
```
````$ sudo apt install python3`
Now set up a [Python virtual environment](https://opensource.com/article/20/10/venv-python) for your development:
```
````$ python -m venv PiData`
Next, activate the environment. You must do this after rebooting your Pi.
```
``````
$ source PiData/bin/activate
$ cd PiData
```
To install Flask and Flask-RESTful and dependencies you’ll need later, create a file in your Python virtual environment called `requirements.txt`
and add these lines to it:
```
``````
flask
flask-restful
gunicorn
```
Save the file, and then use `pip`
to install them all at once. You must do this after rebooting your Pi.
```
````(PyData)$ python -m pip install -r requirements.txt`
Next, create a file named `pi_stats.py`
to house the logic for retrieving the RPi’s system stats with `psutils`
. Paste this code into your `pi_stat.py`
file:
```
``````
from flask import Flask
from flask_restful import Resource, Api
import psutil
app = Flask(__name__)
api = Api(app)
class PiData(Resource):
def get(self):
return "RPI Stat dashboard"
api.add_resource(PiData, '/get-stats')
if __name__ == '__main__':
app.run(debug=True)
```
Here’s what the code is doing:
- Use app = Flask(
**name**) to define the app that nests the API object. - Use Flask-RESTful’s
[API method](https://flask-restful.readthedocs.io/en/latest/api.html#id1)to define the API object. - Define PiData as a concrete
[Resource class](https://flask-restful.readthedocs.io/en/latest/api.html#flask_restful.Resource)in Flask-RESTful to expose methods for each supported HTTP method. - Attach the resource,
`PiData`
, to the API object,`api`
, with`api.add_resource(PiData, '/get-stats')`
. - Whenever you hit the URL
`/get-stats`
,`PiData`
is returned as the response.
## 2. Read stats with psutils
To get the stats from your Pi, you can use these built-in functions from `psutils`
:
`cpu_percentage`
,`cpu_count`
,`cpu_freq`
, and`sensors_temperatures`
functions for the percentage utilization, count, clock speed, and temperature respectively, of the CPU`sensors_temperatures`
reports the temperature of all the devices connected to the RPi. To get just the CPU’s temperature, use the key`cpu-thermal`
.`virtual_memory`
for total, available, used, and free memory stats in bytes.`disk_usage`
to return the total, used, and free stats in bytes.
Combining all of the functions in a Python dictionary looks like this:
```
``````
system_info_data = {
'cpu_percent': psutil.cpu_percent(1),
'cpu_count': psutil.cpu_count(),
'cpu_freq': psutil.cpu_freq(),
'cpu_mem_total': memory.total,
'cpu_mem_avail': memory.available,
'cpu_mem_used': memory.used,
'cpu_mem_free': memory.free,
'disk_usage_total': disk.total,
'disk_usage_used': disk.used,
'disk_usage_free': disk.free,
'disk_usage_percent': disk.percent,
'sensor_temperatures': psutil.sensors_temperatures()\['cpu-thermal'
][0].current, }
```
The next section uses this dictionary.
## 3. Fetch data from the Flask-RESTful API
To see data from your Pi in the API response, update `pi_stats.py`
to include the dictionary `system_info_data`
in the class `PiData`
:
```
``````
from flask import Flask
from flask_restful import Resource, Api
import psutil
app = Flask(__name__)
api = Api(app)
class PiData(Resource):
def get(self):
memory = psutil.virtual_memory()
disk = psutil.disk_usage('/')
system_info_data = {
'cpu_percent': psutil.cpu_percent(1),
'cpu_count': psutil.cpu_count(),
'cpu_freq': psutil.cpu_freq(),
'cpu_mem_total': memory.total,
'cpu_mem_avail': memory.available,
'cpu_mem_used': memory.used,
'cpu_mem_free': memory.free,
'disk_usage_total': disk.total,
'disk_usage_used': disk.used,
'disk_usage_free': disk.free,
'disk_usage_percent': disk.percent,
'sensor_temperatures': psutil.sensors_temperatures()['cpu-thermal'][0].current, }
return system_info_data
api.add_resource(PiData, '/get-stats')
if __name__ == '__main__':
app.run(debug=True)
```
Your script’s ready. Run the `PiData.py`
script:
```
``````
$ python PyData.py
* Serving Flask app "PiData" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not run this in a production environment.
* Debug mode: on
* Running on http://127.0.0.1:5000 (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
```
You have a working API!
## 4. Make the API available to the internet
You can interact with your API on your local network. To reach it over the internet, however, you must open a port in your firewall and forward incoming traffic to the port made available by Flask. However, as the output of your test advised, running a Flask app from Flask is meant for development, not for production. To make your API available to the internet safely, you can use the `gunicorn`
production server, which you installed during the project setup stage.
Now you can start your Flask API. You must do this any time you’ve rebooted your Pi.
```
``````
$ gunicorn -w 4 'PyData:app'
Serving on http://0.0.0.0:8000
```
To reach your Pi from the outside world, open a port in your network firewall and direct incoming traffic to the IP address of your PI, at port 8000.
First, get the internal IP address of your Pi:
```
````$ ip addr show | grep inet`
Internal IP addresses start with 10 or 192 or 172.
Next, you must configure your firewall. There’s usually a firewall embedded in the router you get from your internet service provider (ISP). Generally, you access your home router through a web browser. Your router’s address is sometimes printed on the bottom of the router, and it begins with either 192.168 or 10. Every device is different, though, so there’s no way for me to tell you exactly what you need to click on to adjust your settings. For a full description of how to configure your firewall, read Seth Kenlon’s article [Open ports and route traffic through your firewall](https://opensource.com/article/20/9/firewall).
Alternately, you can use [localtunnel](https://theboroer.github.io/localtunnel-www/) to use a dynamic port-forwarding service.
Once you’ve got traffic going to your Pi, you can query your API:
```
``````
$ curl https://example.com/get-stats
{
"cpu_count": 4,
"cpu_freq": [
600.0,
600.0,
1200.0 ],
"cpu_mem_avail": 386273280,
...
```
If you have gotten this far, the toughest part is over.
## 5. Repetition
If you reboot your Pi, you must follow these steps:
- Reactivate your Python environment with
`source`
- Refresh the application dependencies with
`pip`
- Start the Flask application with
`gunicorn`
Your firewall settings are persistent, but if you’re using localtunnel, then you must also start a new tunnel after a reboot.
You can automate these tasks if you like, but that’s a whole other tutorial. The final section of this tutorial is to build a UI on Appsmith using the drag-and-drop widgets, and a bit of Javascript, to bind your RPi data to the UI. Believe me, it’s easy going from here on out!
## Build the dashboard on Appsmith.
(Keyur Paralkar, CC BY-SA 4.0)
To get to a dashboard like this, you need to connect the exposed API endpoint to Appsmith, build the UI using Appsmith’s widgets library, and bind the API’s response to your widgets. If you’re already using Appsmith, you can just import the [sample app](https://github.com/appsmithorg/foundry/tree/main/resources/blogs/Raspberry%20Pi%20Dashboard) directly and get started.
If you haven’t done so already, [sign up](https://appsmith.com/sign-up) for a free Appsmith account. Alternately, you can [self-host Appsmith](https://docs.appsmith.com/getting-started/setup).
## Connect the API as an Appsmith datasource
Sign in to your Appsmith account.
- Find and click the
**+**button next to**QUERIES/JS**in the left nav. - Click
**Create a blank API.** - At the top of the page, name your project
**PiData**. - Get your API’s URL. If you’re using localtunnel, then that’s a
`localtunnel.me`
address, and as always append`/get-stats`
to the end for the stat data. Paste it into the first blank field on the page, and click the**RUN**button.
Confirm that you see a successful response in the **Response** pane.
(Keyur Paralkar, CC BY-SA 4.0)
## Build the UI
The interface for AppSmith is pretty intuitive, but I recommend going through [building your first application on Appsmith](https://docs.appsmith.com/getting-started/start-building) tutorial if you feel lost.
For the title, drag and drop a Text, Image, and Divider widget onto the canvas. Arrange them like this:

(Keyur Paralkar, CC BY-SA 4.0)
The Text widget contains the actual title of your page. Type in something cooler than “Raspberry Pi Stats”.
The Image widget houses a distinct logo for the dashboard. You can use whatever you want.
Use a Switch widget for a toggled live data mode. Configure it in the **Property** pane to get data from the API you’ve built.
For the body, create a place for CPU Stats with a Container widget using the following widgets from the Widgets library on the left side:
- Progress Bar
- Stat Box
- Chart
Do the same for the Memory and Disk stats sections. You don’t need a Chart for disk stats, but don’t let that stop you from using one if you can find uses for it.
Your final arrangement of widgets should look something like this:
(Keyur Paralkar, CC BY-SA 4.0)
The final step is to bind the data from the API to the UI widgets you have.
## Bind data to the widgets
Head back to the canvas and find your widgets in sections for the three categories. Set the CPU Stats first.
To bind data to the Progress Bar widget:
- Click the Progress Bar widget to see the Property pane on the right.
- Look for the Progress property.
- Click the
**JS**button to activate Javascript. - Paste
`{{PiData.data.cpu_percent ?? 0}}`
in the field for**Progress**. That code references the stream of data from of your API named`PiData`
. Appsmith caches the response data within the`.data`
operator of`PiData`
. The key`cpu_percent`
contains the data Appsmith uses to display the percentage of, in this case, CPU utilization. - Add a Text widget below the Progress Bar widget as a label.
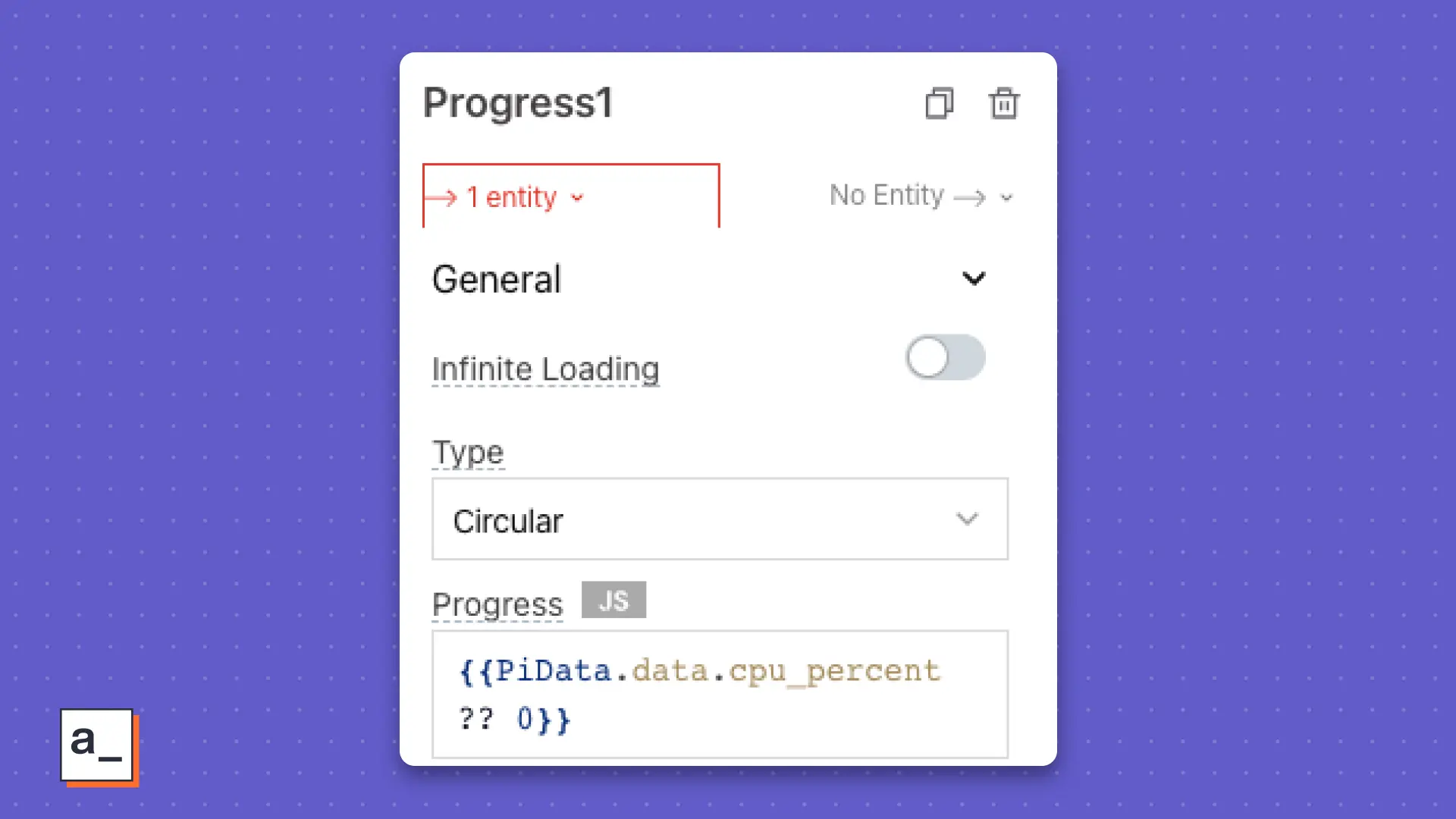
(Keyur Paralkar, CC BY-SA 4.0)
There are three Stat Box widgets in the CPU section. Binding data to each one is the exact same as for the Progress Bar widget, except that you bind a different data attribute from the `.data`
operator. Follow the same procedure, with these exceptions:
`{{${PiData.data.cpu_freq[0]} ?? 0 }}`
to show clock speed.`{{${PiData.data.cpu_count} ?? 0 }}`
for CPU count.`{{${(PiData.data.sensor_temperatures).toPrecision(3)} ?? 0 }}`
for CPU temperature data.
Assuming all goes to plan, you end up with a pretty dashboard like this one:
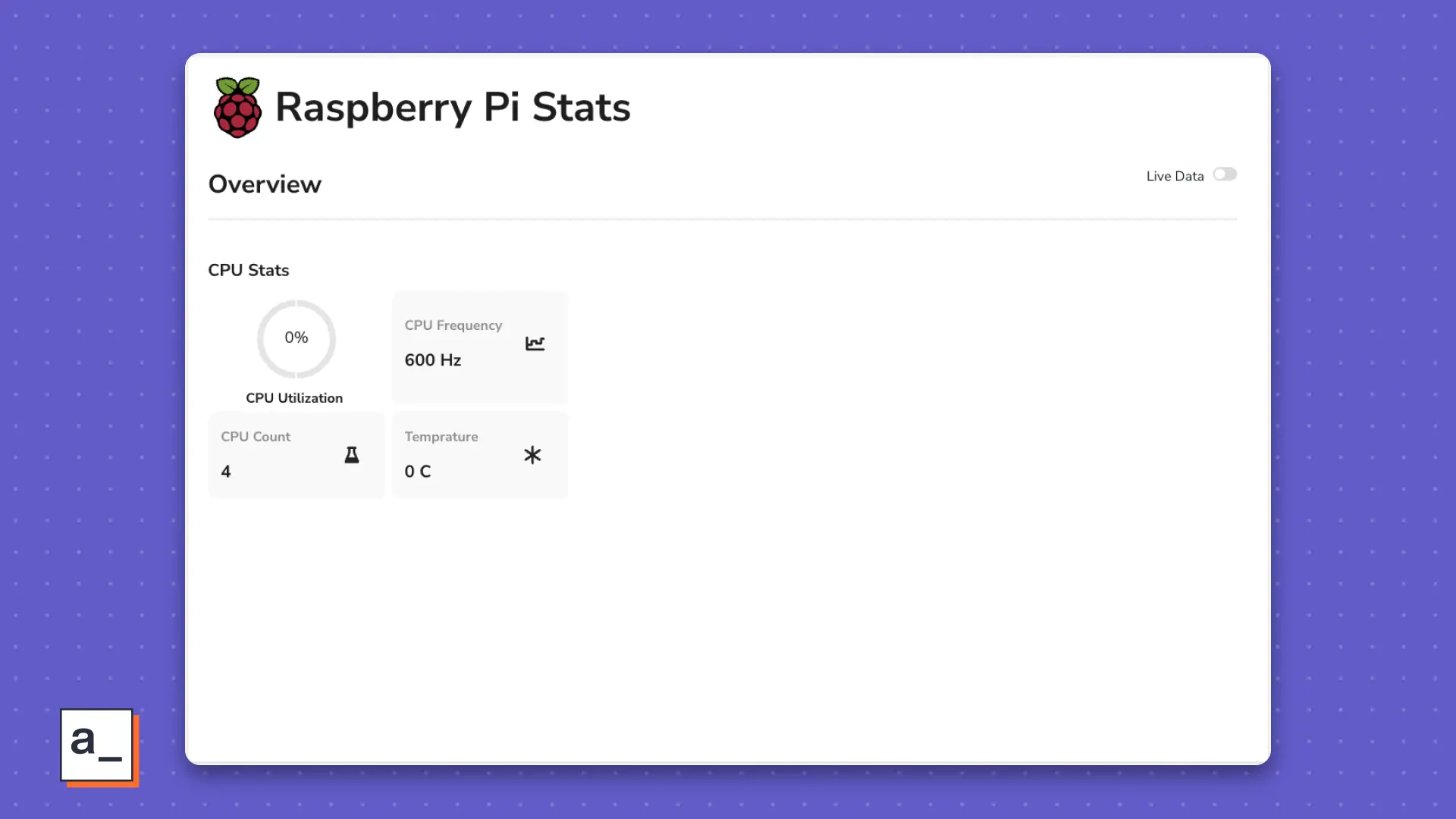
(Keyur Paralkar, CC BY-SA 4.0)
## CPU utilization trend
You can use a Chart widget to display the CPU utilization as a trend line, and have it automatically update over time.
First, click the widget, find the Chart Type property on the right, and change it to LINE CHART. To see a trend line, store `cpu_percent`
in an array of data points. Your API currently returns this as a single data point in time, so use Appsmith’s `storeValue`
function (an Appsmith-native implementation of a browser’s `setItem`
method) to get an array.
Click the **+** button next to **QUERIES/JS** and name it **utils**.
Paste this Javascript code into the **Code** field:
```
``````
export default {
getLiveData: () => {
//When switch is on:
if (Switch1.isSwitchedOn) {
setInterval(() => {
let utilData = appsmith.store.cpu_util_data;
PiData.run()
storeValue("cpu_util_data", [...utilData, {
x: PiData.data.cpu_percent,
y: PiData.data.cpu_percent
}]);
}, 1500, 'timerId')
} else {
clearInterval('timerId');
}
},
initialOnPageLoad: () => {
storeValue("cpu_util_data", []);
}
}
```
To initialize the `Store`
, you’ve created a JavaScript function in the object called `initialOnPageLoad`
, and you’ve housed the `storeValue`
function in it.
You store the values from `cpu_util_data`
into the `storeValue`
function using `storeValue("cpu_util_data", []);`
. This function runs on page load.
So far, the code stores one data point from `cpu_util_data`
in the `Store`
each time the page is refreshed. To store an array, you use the `x`
and `y`
subscripted variables, both storing values from the `cpu_percent`
data attribute.
You also want this data stored automatically by a set interval between stored values. When the function [setInterval](https://docs.appsmith.com/reference/appsmith-framework/widget-actions/intervals-time-events#setinterval) is executed:
- The value stored in
`cpu_util_data`
is fetched. - The API
`PiData`
is called. `cpu_util_data`
is updated as`x`
and`y`
variables with the latest`cpu_percent`
data returned.- The value of
`cpu_util_data`
is stored in the key`utilData`
. - Steps 1 through 4 are repeated if and only if the function is set to auto-execute. You set it to auto-execute with the Switch widget, which explains why there is a
`getLiveData`
parent function.
Navigate to the **Settings** tab to find all the parent functions in the object and set `initialOnPageLoad`
to **Yes** in the **RUN ON PAGE LOAD** option.
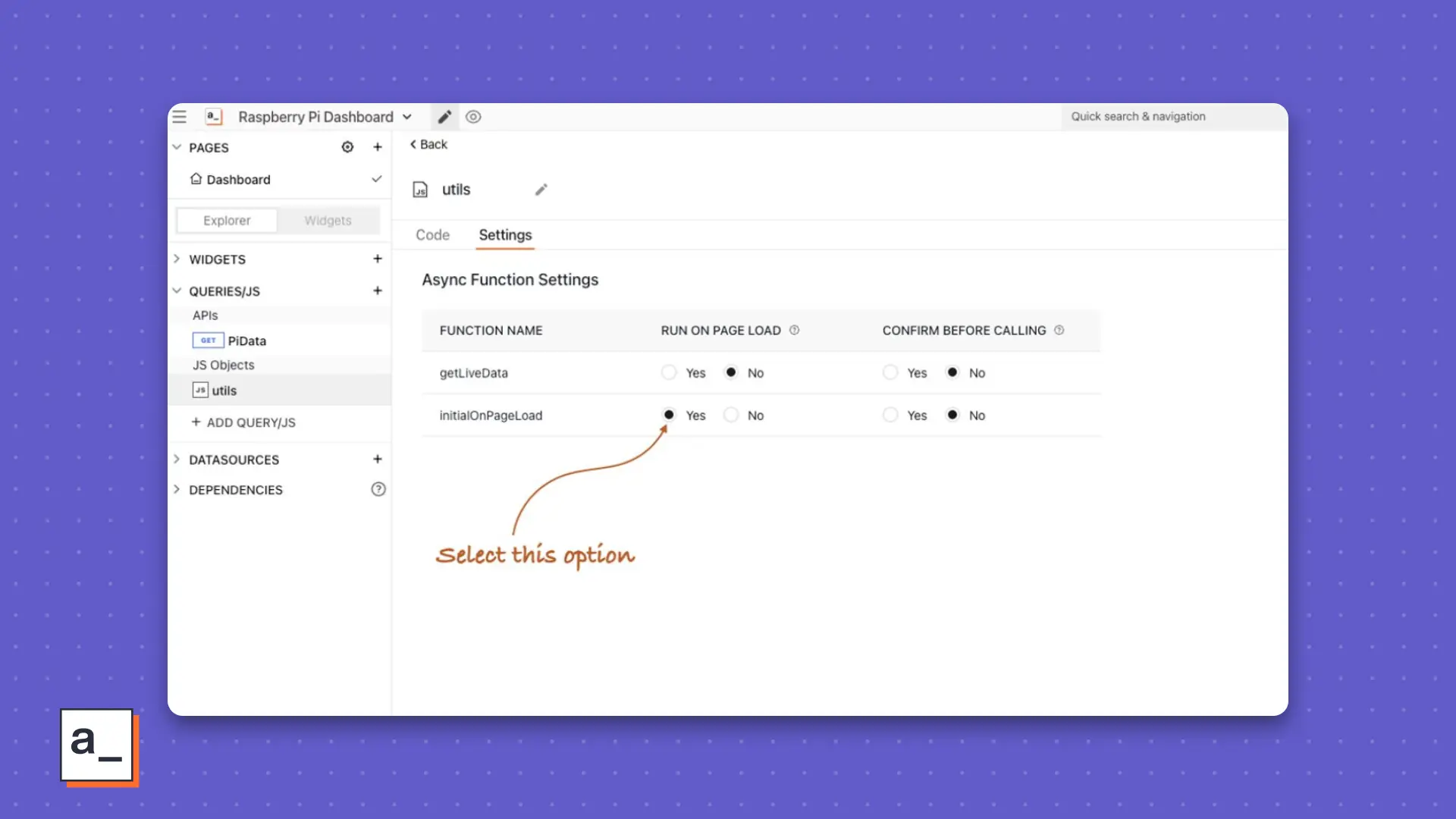
(Keyur Paralkar, CC BY-SA 4.0)
Now refresh the page for confirmation
Return to the canvas. Click the Chart widget and locate the Chart Data property. Paste the binding `{{ appsmith.store.disk_util_data }}`
into it. This gets your chart if you run the object `utils`
yourself a few times. To run this automatically:
- Find and click the
**Live Data Switch**widget in your dashboard’s title. - Look for the
`onChange`
event. - Bind it to
`{{ utils.getLiveData() }}`
. The Javascript object is`utils`
, and`getLiveData`
is the function that activates when you toggle the Switch on, which fetches live data from your Raspberry Pi. But there’s other live data, too, so the same switch works for them. Read on to see how.
## Bind all the data
Binding data to the widgets in the Memory and Disk sections is similar to how you did it for the CPU Stats section.
For Memory, bindings change to:
`{{( PiData.data.cpu_mem_avail/1000000000).toPrecision(2) \* 100 ?? 0 }}`
for the Progress Bar.`{{ \${(PiData.data.cpu_mem_used/1000000000).toPrecision(2)} ?? 0 }} GB`
,`{{ \${(PiData.data.cpu_mem_free/1000000000).toPrecision(2)} ?? 0}} GB`
, and`{{ \${(PiData.data.cpu_mem_total/1000000000).toPrecision(2)} ?? 0 }} GB`
for the three Stat Box widgets.
For Disk, bindings on the Progress Bar, and Stat Box widgets change respectively to:
`{{ PiData.data.disk_usage_percent ?? 0 }}`
`{{ \${(PiData.data.disk_usage_used/1000000000).toPrecision(2)} ?? 0 }} GB`
`{{ \${(PiData.data.disk_usage_free/1000000000).toPrecision(2)} ?? 0 }} GB`
and`{{ \${(PiData.data.disk_usage_total/1000000000).toPrecision(2)} ?? 0 }} GB`
for the three Stat Box widgets.
The Chart here needs updating the `utils`
object you created for CPU Stats with a `storeValue`
key called `disk_util_data`
nested under `getLiveData`
that follows the same logic as `cpu_util_data`
. For the disk utilization chart, we store disk_util_data that follows the same logic as that of the CPU utilization trend chart.
```
``````
export default {
getLiveData: () => {
//When switch is on:
if (Switch1.isSwitchedOn) {
setInterval(() => {
const cpuUtilData = appsmith.store.cpu_util_data;
const diskUtilData = appsmith.store.disk_util_data;
PiData.run();
storeValue("cpu_util_data", [...cpuUtilData, { x: PiData.data.cpu_percent,y: PiData.data.cpu_percent }]);
storeValue("disk_util_data", [...diskUtilData, { x: PiData.data.disk_usage_percent,y: PiData.data.disk_usage_percent }]);
}, 1500, 'timerId')
} else {
clearInterval('timerId');
}
},
initialOnPageLoad: () => {
storeValue("cpu_util_data", []);
storeValue("disk_util_data", []);
}
}
```
Visualizing the flow of data triggered by the Switch toggling live data on and off with the `utils`
Javascript object looks like this:
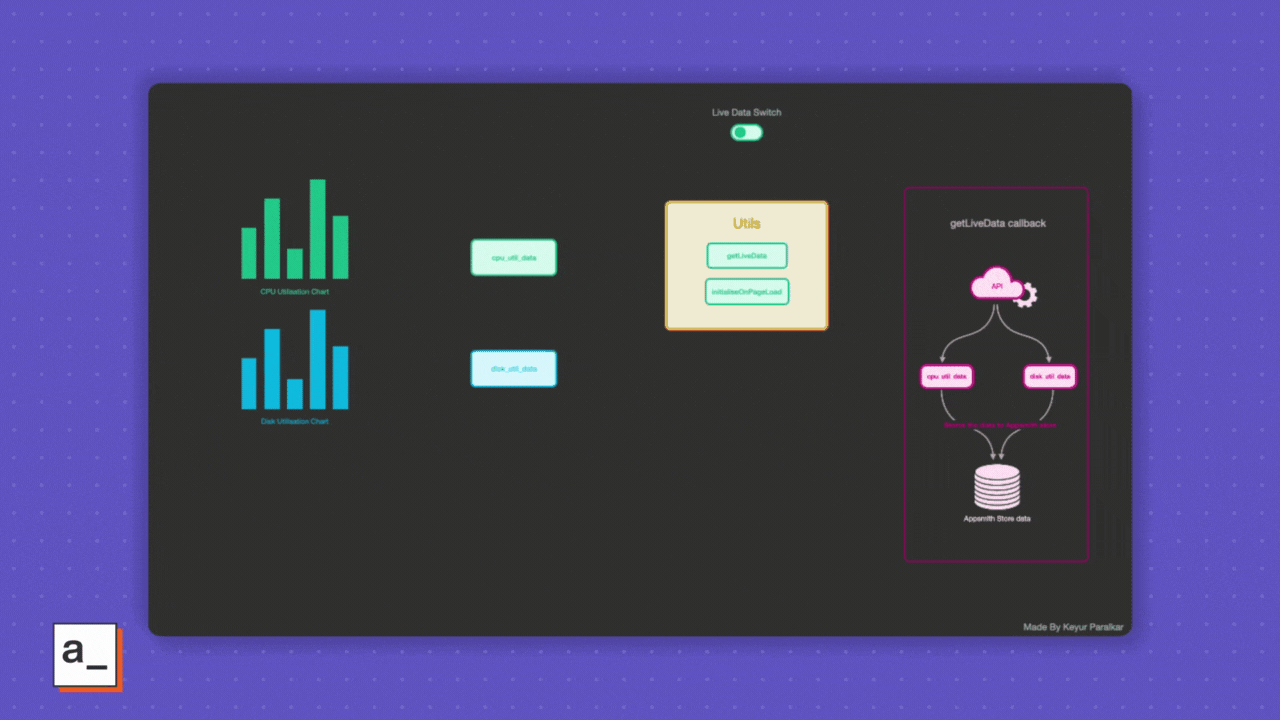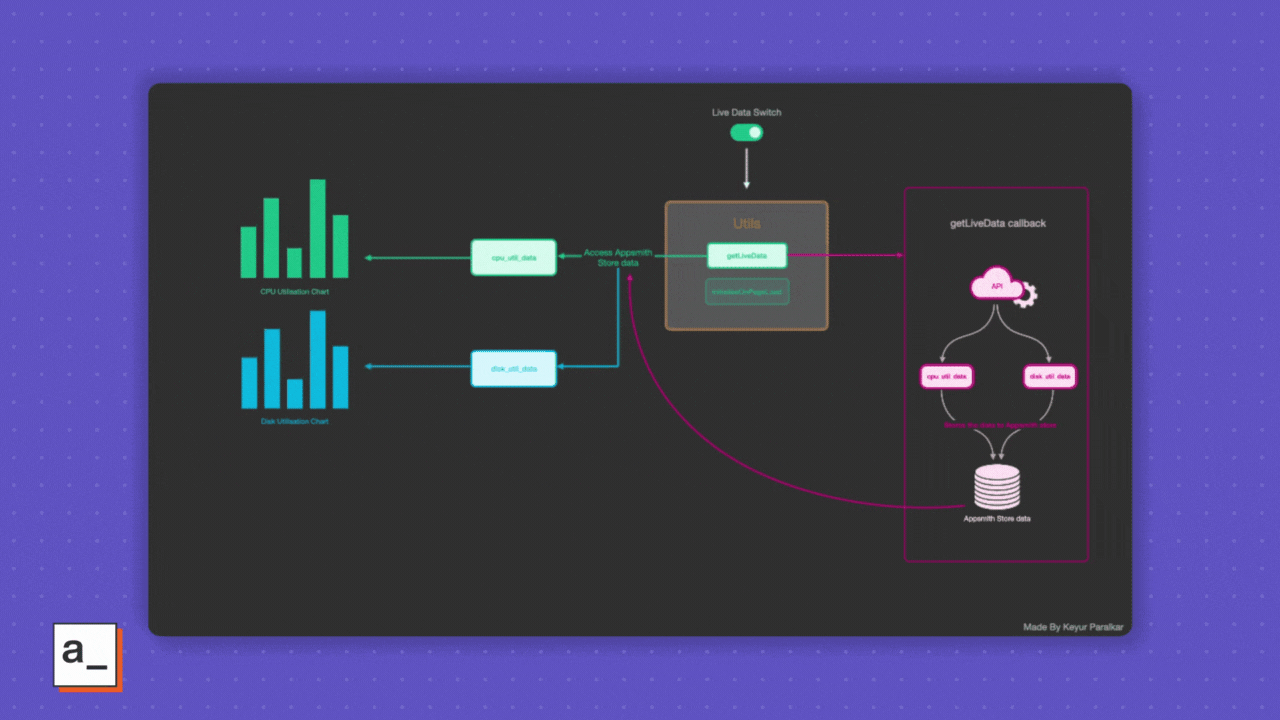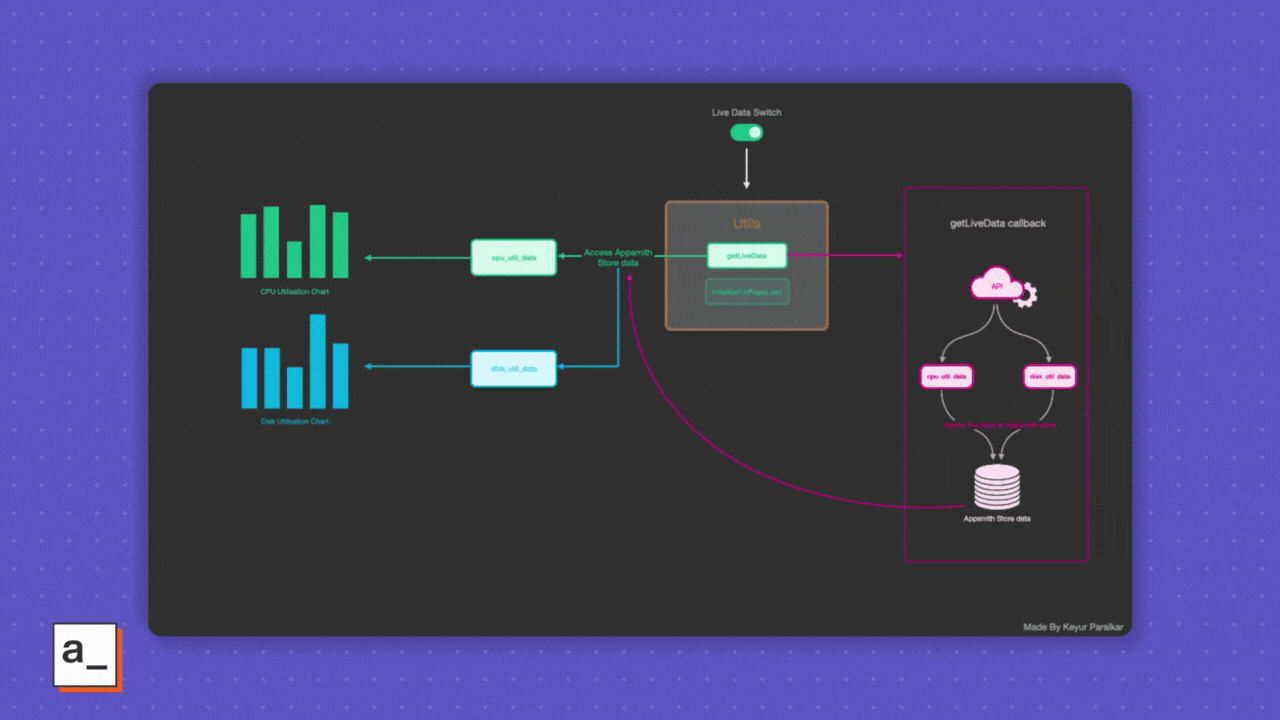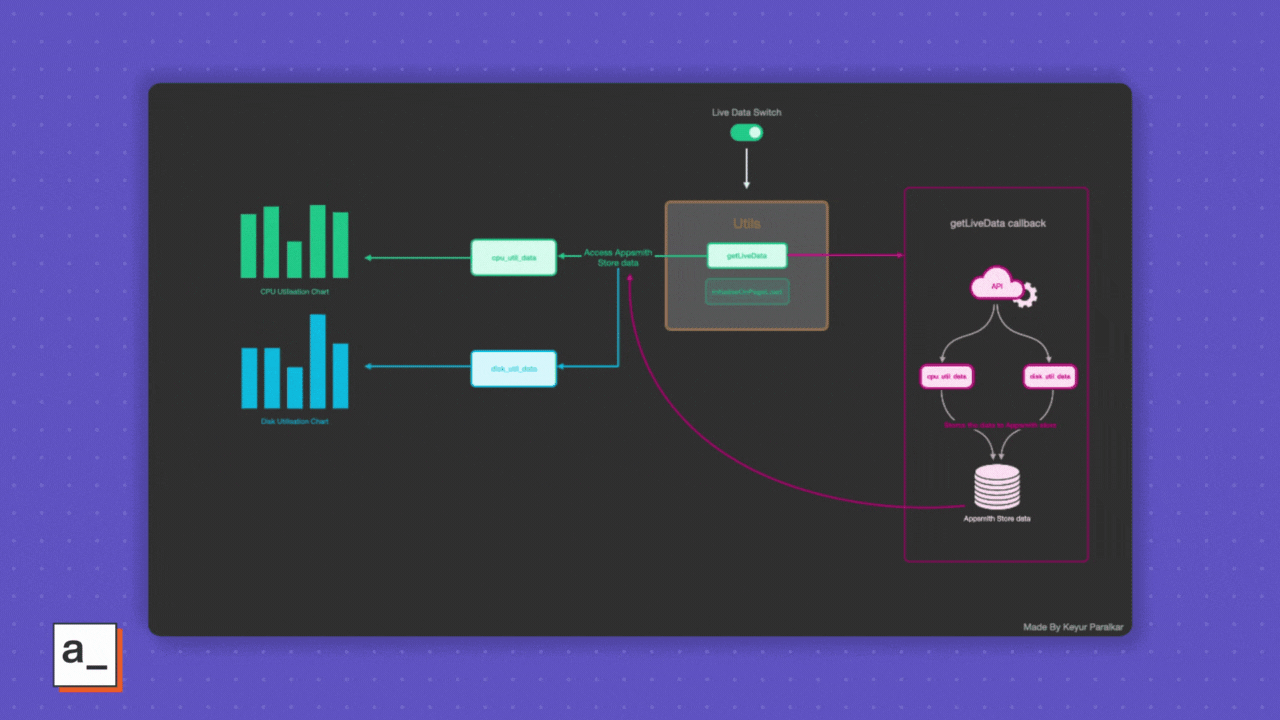
(Keyur Paralkar, CC BY-SA 4.0)
Toggled on, the charts change like this:
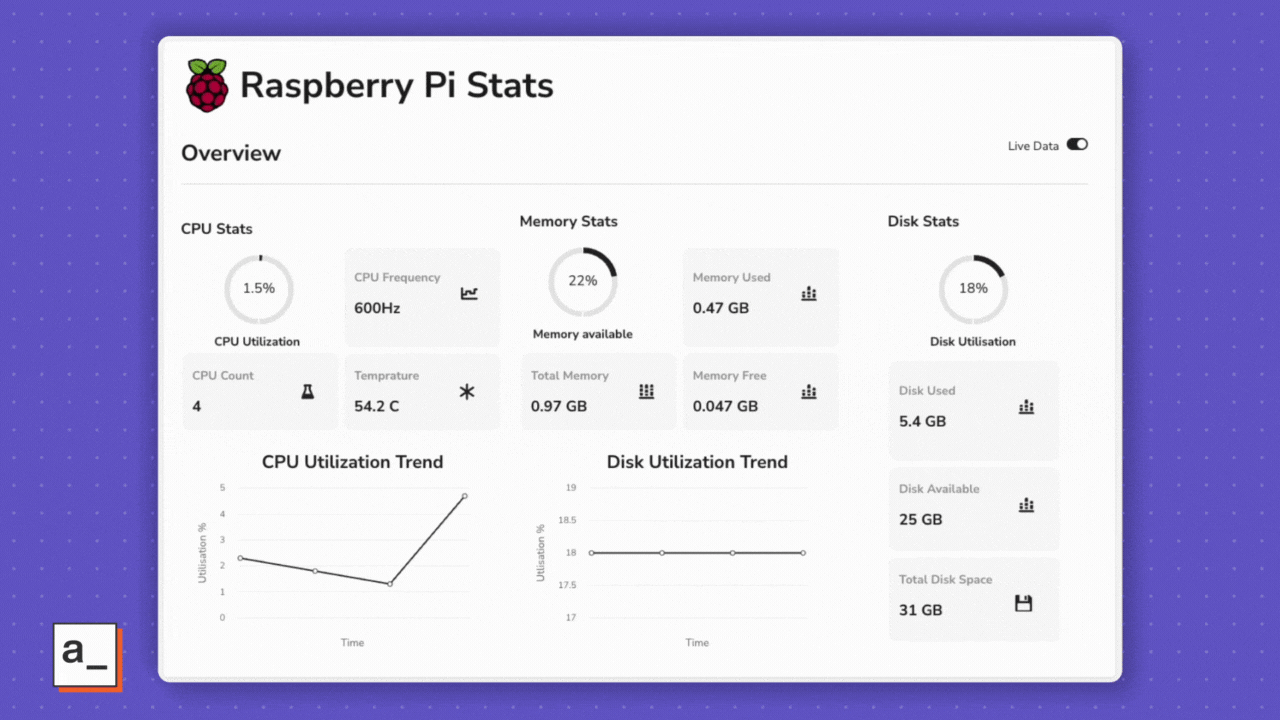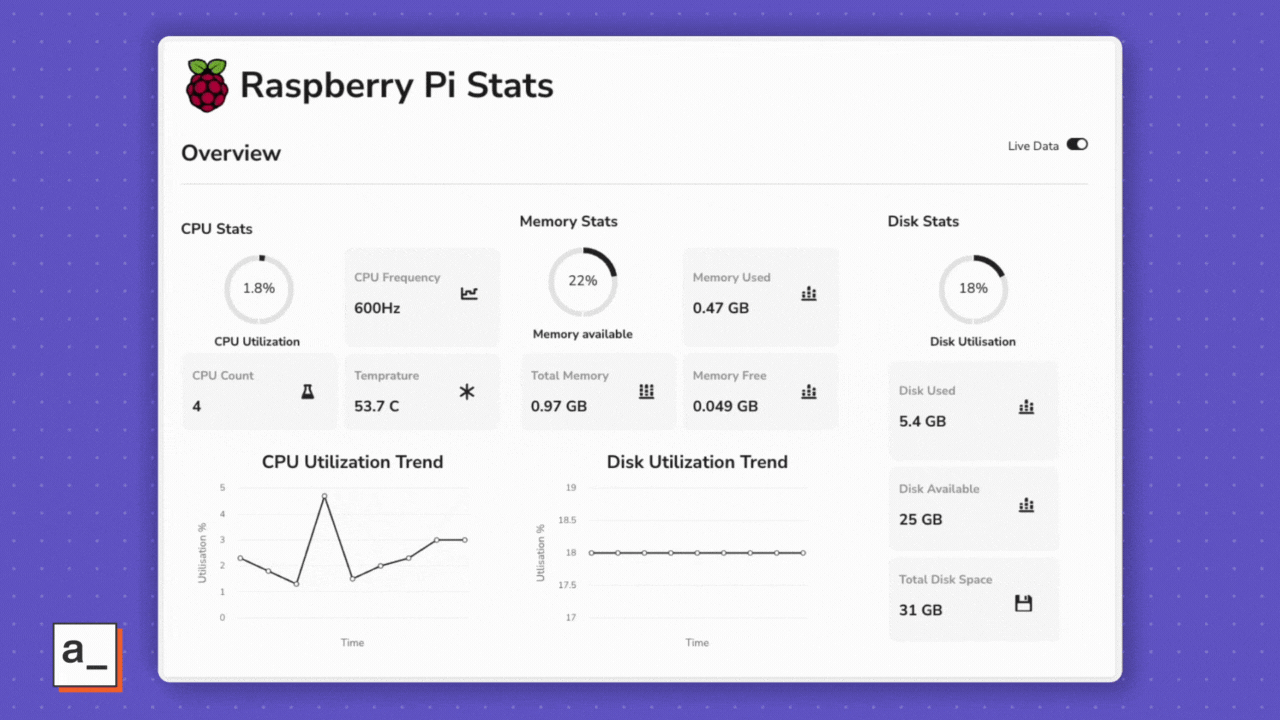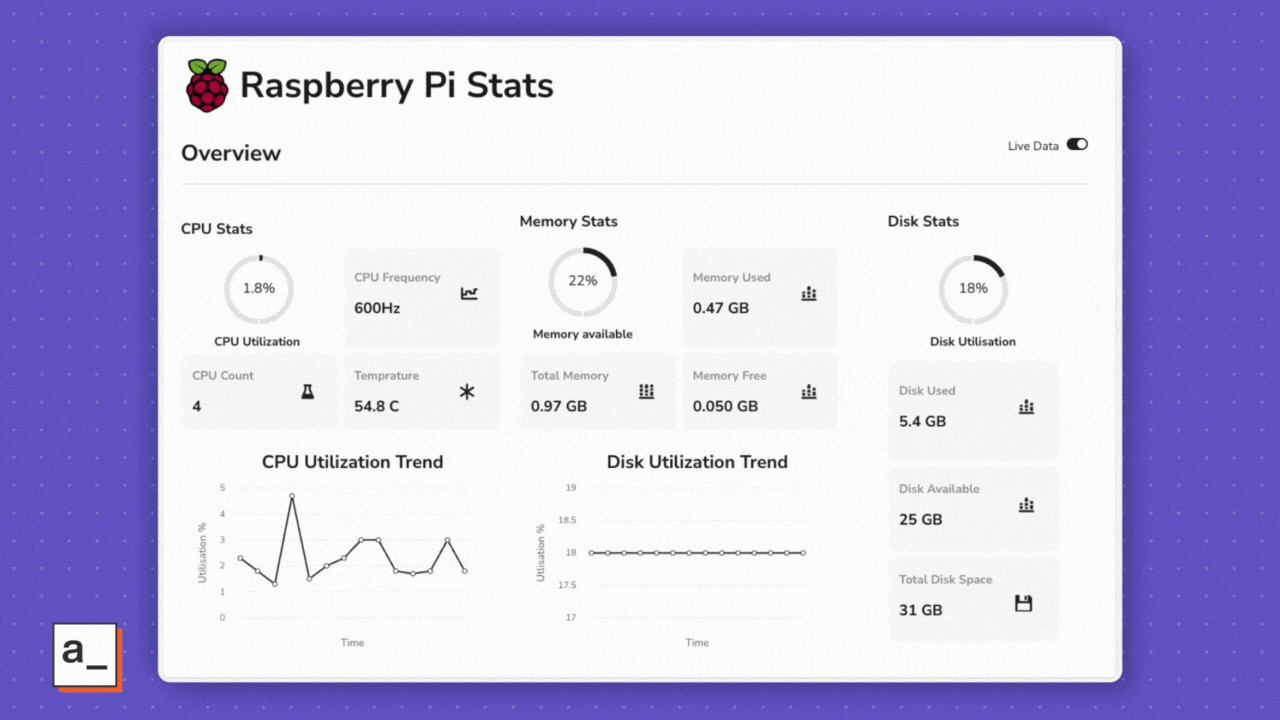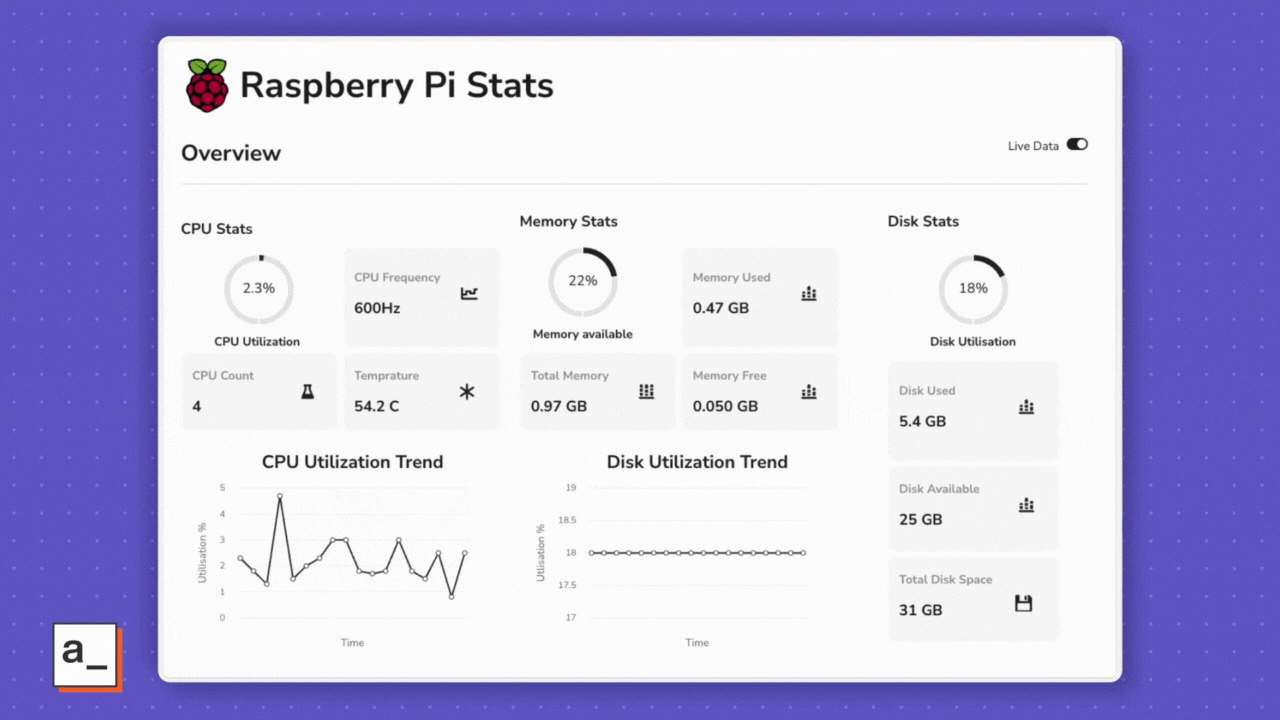
(Keyur Paralkar, CC BY-SA 4.0)
Pretty, minimalistic, and totally useful.
## Enjoy
As you get more comfortable with `psutils`
, Javascript, and Appsmith, I think you’ll find you can tweak your dashboard easily and endlessly to do really cool things like:
- See trends from the previous week, month, quarter, year, or any custom range that your RPi data allows
- Build an alert bot for threshold breaches on any stat
- Monitor other devices connected to your Raspberry Pi
- Extend
`psutils`
to another computer with Python installed - Monitor your home or office network using another library
- Monitor your garden
- Track your own life habits
Until the next awesome build, happy hacking!
## Comments are closed. |
15,985 | 如何从 Ubuntu 中删除软件仓库 | https://itsfoss.com/remove-software-repositories-ubuntu/ | 2023-07-10T16:49:26 | [
"软件仓库"
] | https://linux.cn/article-15985-1.html | 
>
> 从 `apt-add-repository` 到“软件及更新”工具,这里有几种从 Ubuntu 移除软件仓库的方法。
>
>
>
你可以 [在 Ubuntu 中添加外部仓库](https://itsfoss.com/adding-external-repositories-ubuntu/) 来访问官方仓库中不可用的软件包。
例如,如果你 [在 Ubuntu 中安装 Brave 浏览器](https://itsfoss.com/brave-web-browser/),则将其仓库添加到你的系统中。如果你添加了一个 PPA,它也会添加为外部仓库。
当你不需要特定软件时,请将其删除。但是,外部仓库仍然存在。你还可以也应该将其删除以保持系统原始状态。
Ubuntu 可以让你轻松删除软件仓库。有不同的方法可以做到这一点:
* 使用 `apt-add-repository` 命令删除仓库
* 使用 GUI 删除仓库(对于桌面用户)
* 通过修改 `/etc/apt/sources.list` 文件的文件内容(针对专家)
但在此之前,如果你对这个概念不熟悉,我强烈建议你 [熟悉包管理器的概念](https://itsfoss.com/package-manager/) 和仓库。
### 方法 1、使用 apt 删除仓库?
你知道你还可以使用 [apt 命令](https://itsfoss.com/apt-command-guide/) 来删除仓库吗? 嗯,从技术上讲,它不是核心 `apt` 命令的一部分,但它的工作方式类似。
在处理外部仓库时,你可以使用 `add-apt-repository` 或者 `apt-add-repository` 命令(两者是同一命令)。
首先,使用以下命令列出添加的仓库:
```
apt-add-repository --list
```

完成后,你可以按所示方式使用带有 `-r` 标志的 `apt-add-repository` 命令来从列表中删除:
```
sudo apt-add-repository -r repo_name
```
例如,如果我想删除 `yarn` 仓库,我必须使用以下命令:
```
sudo add-apt-repository -r deb https://dl.yarnpkg.com/debian/ stable main
```

按回车键进行确认。
接下来,使用以下命令更新仓库:
```
sudo apt update
```
现在,如果你列出已启用的仓库,你将不会在此处找到已删除的仓库:
```
apt-add-repository --list
```

这就完成了!
### 方法 2、使用 GUI 删除 Ubuntu 中的软件仓库?️
>
> ? 不建议删除你一无所知的仓库,因为它可能会限制你将来安装你最喜欢的软件包,因此请确保你知道自己在做什么。
>
>
>
作为 [最适合初学者的发行版之一](https://itsfoss.com/best-linux-beginners/),你可以使用 GUI 来删除仓库,而无需使用终端。
为此,首先从系统菜单打开“<ruby> 软件及更新 <rt> software & updates </rt></ruby>”应用:

现在,单击“<ruby> 其他软件 <rt> Other Software </rt></ruby>”部分,它将列出系统中的 PPA 和外部仓库。
列出中勾选的 ✅ 是已启用的。
要删除仓库,你必须遵循**三个简单的步骤**:
* 选择需要删除的仓库
* 点击“<ruby> 删除 <rt> Remove </rt></ruby>”按钮
* 最后,点击“<ruby> 关闭 <rt> Close </rt></ruby>”按钮

单击关闭按钮后,它将打开一个提示,要求你在进行更改时更新信息。
只需单击 “<ruby> 重新载入 <rt> Reload </rt></ruby>” 按钮即可:

或者,你可以从命令行更新仓库以使更改生效:
```
sudo apt update
```
### 方法 3、通过目录来删除仓库(对于专家??)
之前,我解释了如何使用工具(GUI 和 CLI)来删除仓库。在这里,你将修改负责管理仓库的系统目录(`/etc/apt/sources.list.d`)。
首先,将工作目录更改为 `sources.list.d` 并列出其内容:
```
cd /etc/apt/sources.list.d/ && ls
```

在这里,你将找到所有仓库的列表。
如果你仔细观察,一个仓库将有两个文件。一个带有 `.list` 扩展名,另一个带有 `.save` 扩展名。
你必须删除具有 `.list` 扩展名的文件:
```
sudo rm Repo_name.list
```
例如,在这里,我使用以下命令删除了 **node 仓库**:
```
sudo rm nodesource.list
```

要使更改生效,请使用以下命令更新仓库索引:
```
sudo apt update
```
想了解更多有关 [sources.list](https://itsfoss.com/sources-list-ubuntu/) 的信息吗?阅读 [这篇文章](https://itsfoss.com/sources-list-ubuntu/)。
### 附加步骤:删除仓库后删除 GPG 密钥(对于高级用户)
如果你希望在删除仓库后删除 GPG 密钥,请按以下步骤操作。
首先,使用以下命令列出现有的 GPG 密钥:
```
apt-key list
```
现在,输出可能会让某些用户感到困惑。
以下是要记住的事情:
* GPG 密钥名称将放置在虚线(`----`)上方
* 公钥在第二行
例如,以下是 Chrome GPG 密钥的相关数据:

要删除 GPG 密钥,你可以使用公钥的最后两个字符串(不带任何空格)。
例如,以下是我将如何使用 Chrome 浏览器公钥的最后两个字符串(D38B 4796)删除其 GPG 密钥:
```
sudo apt-key del D38B4796
```

同样,你也可以使用整个公钥。但这一次,你必须在两个字符串之间包含空格,如下所示:
```
sudo apt-key del "72EC F46A 56B4 AD39 C907 BBB7 1646 B01B 86E5 0310"
```
### 小心添加和删除的内容
特别是当你是 Linux 新用户时,你会遇到许多感兴趣的软件,对仓库添加了又删除。
虽然尝试是件好事,但你应该始终小心添加/删除到系统中的任何内容。你应该记住一些事情,例如:*它包含更新的软件包吗? 它是受信任或维护的仓库吗?*
保持谨慎将使你的系统免受不必要的仓库和软件包的影响。
**我希望本指南可以帮助你删除不需要的仓库!**
如果你遇到任何问题请在下面评论。
*(题图:MJ/3d436ed6-76fc-47ef-88c3-b5f3e2862c7d)*
---
via: <https://itsfoss.com/remove-software-repositories-ubuntu/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You can [add external repositories in Ubuntu](https://itsfoss.com/adding-external-repositories-ubuntu/) to access packages unavailable in the official repositories.
For example, if you [install Brave browser in Ubuntu](https://itsfoss.com/brave-web-browser/), you add its repository to your system. If you add a PPA, that is added as an external repository too.
When you don't need the specific software, you remove it. However, the external repository is still added. You can, and you should also remove it to keep your system pristine.
Ubuntu lets you remove a software repository easily. There are different ways to do that:
**Using apt-add-repository command to remove the repository****Using GUI to remove the repository (for desktop users)****By modifying the file contents of the /etc/apt/sources.list file (for experts)**
But before that, I highly advise [getting familiar with the concept of package managers](https://itsfoss.com/package-manager/) and repositories if you are new to this concept.
[What is a Package Manager in Linux?Learn about packaging system and package managers in Linux. You’ll learn how do they work and what kind of package managers available.](https://itsfoss.com/package-manager/)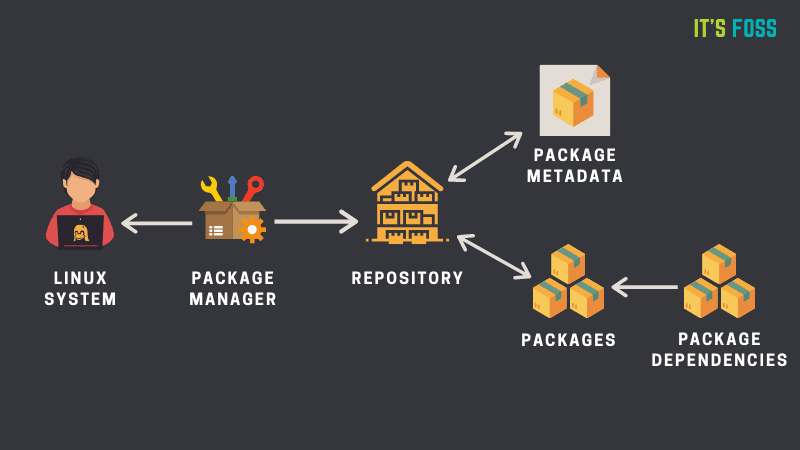

## Method 1. Remove the repository using apt 🤖
Did you know you can also use the [apt command](https://itsfoss.com/apt-command-guide/) to remove repositories? Well, technically, it's not part of the core apt command but it works in similar fashion.
You can use the `add-apt-repository`
or `apt-add-repository`
commands (both represent the same command) while dealing with external repositories.
First, list the added repositories using the following command:
`apt-add-repository --list`
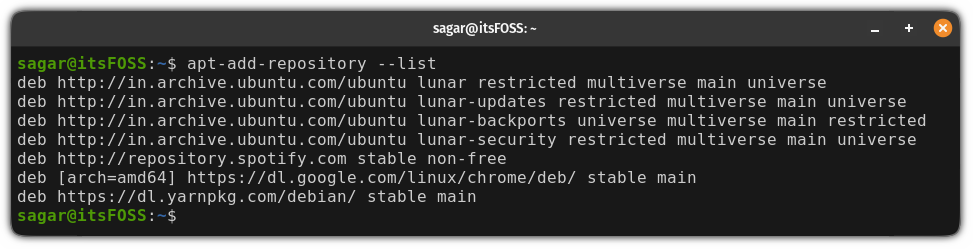
Once done, you can use the apt-add-repository command with the `-r`
flag in shown manner to remove the directory:
`sudo apt-add-repository -r repo_name`
For example, if I want to remove the **yarn** repository, I would have to use the following command:
`sudo add-apt-repository -r deb https://dl.yarnpkg.com/debian/ stable main`
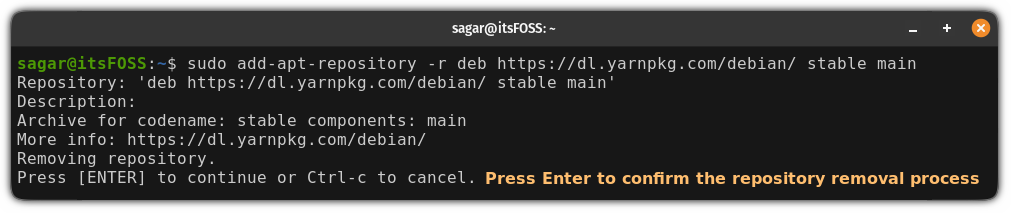
Press the **Enter** key for confirmation.
Next, update the repositories using the following:
`sudo apt update`
And now, if you list enabled repositories, you won't find the removed repository here:
`apt-add-repository --list`
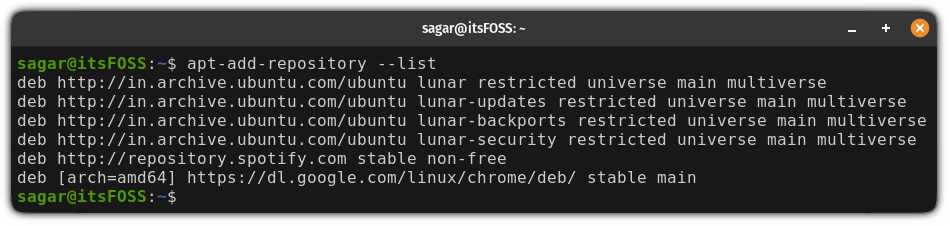
There you have it!
[Using apt Commands in Linux [Ultimate Guide]This guide shows you how to use apt commands in Linux with examples so that you can manage packages effectively.](https://itsfoss.com/apt-command-guide/)

## Method 2. Remove the software repository in Ubuntu using GUI 🖥️
Being [one of the best distros for beginners,](https://itsfoss.com/best-linux-beginners/) You can use GUI to remove the repository without needing the terminal.
To do so, first, open the software and updates the app from the system menu:
Now, click on `Other Software`
section, and it will list PPAs and external repositories in your system.
The ones listed as checked ✅ are enabled ones.
To remove a repository, you'd have to follow **three simple steps**:
**Select a repository that needs to be removed****Click on the remove button****And finally, hit the close button**
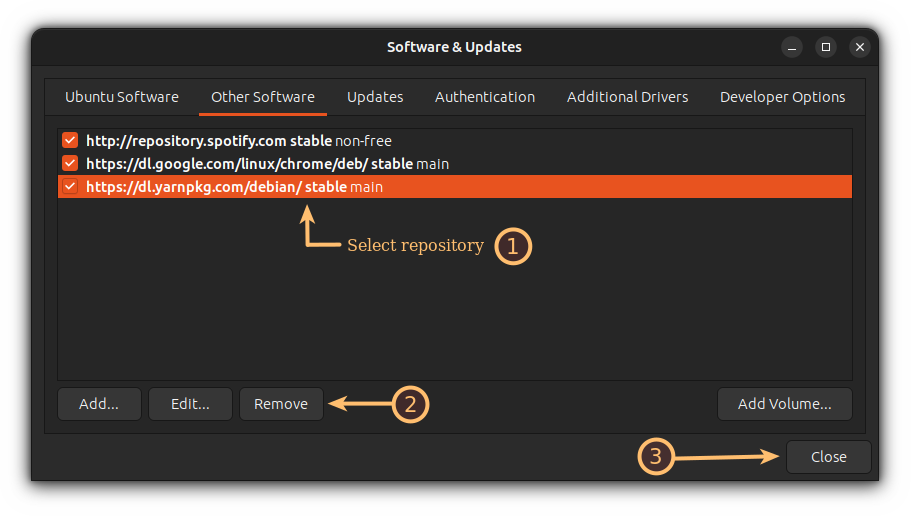
Once you click on the close button, it will open a prompt asking you to update the information as you make changes.
Simply click on the `Reload`
button:
Alternatively, you can update the repository from the command line to take effect from the changes:
`sudo apt update`
## Method 3. Remove the repository by removing its directory (for experts 🧑💻)
Previously, I explained how you could use tools (GUI and CLI) to remove a repository; here, you will modify the system directory (**/etc/apt/sources.list.d**) responsible for managing repositories.
So first, change your working directory to `sources.list.d`
and list its contents:
`cd /etc/apt/sources.list.d/ && ls`
Here, you will find the list of all the repositories.
If you notice carefully, there will be two files for one repo. Once with the `.list`
extension and one with the `.save`
extension.
You will have to remove the one having the `.list`
extension:
`sudo rm Repo_name.list`
For example, here, I removed the **node repo** using the command below:
`sudo rm nodesource.list`

To take effect from the changes, update the repository index with:
`sudo apt update`
Want to know more about the [sources.list](https://itsfoss.com/sources-list-ubuntu/)? Read this article.
[What is the Use of sources.list File in Ubuntu Linux?Understanding the concept of sources.list in Ubuntu will help you understand and fix common update errors in Ubuntu.](https://itsfoss.com/sources-list-ubuntu/)

## Additional Step: Remove GPG keys after removing the repository (for advanced users)
If you wish to remove the GPG keys after removing the repository, here's how you do it.
First, list the existing GPG keys using the following command:
`apt-key list`
Now, the output may seem confusing to some users.
Here's what to remember:
- The GPG key name will be placed above the dashed line (----)
- The public key is in the second line
For example, here's the relevant data of the Chrome GPG key:
To remove the GPG key, you can use the last two strings of the public key (without any space).
For example, here's how I will remove the GPG key of the Chrome browser using the last two strings of its public key (D38B 4796):
`sudo apt-key del D38B4796`
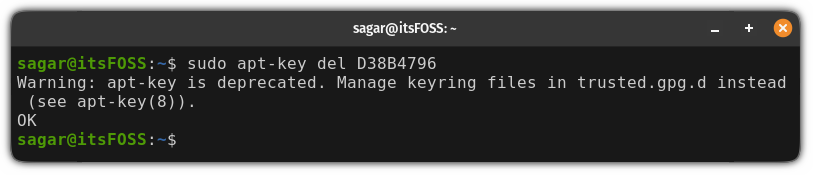
Similarly, you can also use the entire public key. But this time, you have to include spaces between two strings, as shown:
`sudo apt-key del "72EC F46A 56B4 AD39 C907 BBB7 1646 B01B 86E5 0310"`
## Careful with what you add and what you remove
Especially when you are a new Linux user, you will encounter many exciting things and repositories you will add and remove.
While it is good to experiment, you should always be careful about anything you add/remove to your system. You should keep some things in mind, like: *Does it include updated packages? Is it a trusted or maintained repository?*
Being cautious will keep your system free from unnecessary repositories and packages.
**I hope this guide helps you remove the repository you do not want! **
*Feel free to let me know if you face any issues in the comments below, and consider joining our It's FOSS Community forum to get faster help! * |
15,987 | 什么是 CloudReady?它是 Chrome OS 的开源替代品吗? | https://itsfoss.com/cloudready/ | 2023-07-11T14:32:00 | [
"Chrome OS",
"CloudReady"
] | https://linux.cn/article-15987-1.html | 
>
> CloudReady 日趋流行,尤其是在使用低端硬件的用户中。我决定了解一下它并分享我的发现。
>
>
>
### 什么是 CloudReady?
[CloudReady](https://www.neverware.com/) 是一个基于谷歌的 Chromium OS 开源代码仓库的操作系统。Neverware 公司是 CloudReady 背后的组织,它开发的 CloudReady 可以部署到现有的 PC 和 Mac 上,由于其对硬件的要求极低,因此可以保证在上述硬件上的性能提升。大体上来说,CloudReady 把你的旧计算机变成了 Chromebook。2020 年底 [Google 收购了 Neverware](https://9to5google.com/2020/12/15/google-acquires-cloudready-os/)。
在分享我的经验和想法之前,让我先进一步介绍以下它。
### 谁应该尝试 CloudReady?

CloudReady 主要是面向那些能够从使用类 Chromebook 设备中获益,但是已经在硬件设备上进行了投入的机构。下面是我想到的一些例子:
* 经过 CloudReady 扩展的 Chromium OS 用户界面足够简单,用户从 macOS 或 Windows 转向使用 CloudReady 几乎不需要培训。
* 更好的安全性,用户不会被安装充斥于 macOS 和 Windows 上的恶意软件。
* Chromium OS 的硬件要求低,能够在老旧的硬件上良好运行。
* 通过“<ruby> 谷歌管理控制台 <rt> Google Admin Console </rt></ruby>”来管理计算机。
* 简单初始安装过程。
下面是运行 CloudReady 的最低硬件要求:
* **CPU**:任何 2008 年之后的 CPU (没有提及对 ARM 架构 CPU 的支持情况,暂且认为仅支持 x86 架构 CPU,即英特尔和 AMD 的 CPU)
* **内存**:2 GB 及以上
* **存储**:16GB 及以上
* 具备访问 BIOS 或 UEFI 的权限——为了能够从 USB 安装程序启动
如果你不确定自己的上网本是否能够运行 CloudReady,Neverware 公司发布了能够运行 CloudReady 的认证机型清单。目前该清单已包含超过 450 种机型。你可以通过 [这个官方链接来核查自己的机型](https://guide.neverware.com/supported-devices/)。
### CloudReady 与 Chrome OS 有什么不同?
如果你的主要使用目的是以下场景,那么 CloudReady 能够满足你的需要:
* 通过 “<ruby> Neverware 管理门户 <rt> Neverware Admin Portal </rt></ruby>”([到 Google 完成收购为止](https://cloudreadykb.neverware.com/s/article/Neverware-is-now-part-of-Google-FAQ))或 “<ruby> 谷歌管理控制台 <rt> Google Admin Console </rt></ruby>” 来管理 CloudReady 设备。
* 你的工作可以通过网页浏览器来完成(基于网络服务)。
当你了解到“CloudReady 是一个基于 Chrome OS 的操作系统”时,你一定认为它至少应该能够运行安卓应用。
遗憾的是,事实并非如此。开源的 Chromium OS 不支持安卓运行时框架/服务,因此在 CloudReady 中不可用。由于一些法律和技术上的原因,Neverware 并没有将安卓运行时添加到 CloudReady 中。
另一方面它也阻止你<ruby> 侧载 <rt> side-loading </rt></ruby> APK,因为根本没有运行安卓应用的东西。
当我试图从<ruby> 应用抽屉 <rt> app drawer </rt></ruby> 启动 Play Store 时,它在浏览器中打开了谷歌 Play Store 的网页。这真是个坏消息。然而得益于 CloudReady 是基于“<ruby> 面向网络 <rt> </rt> web focused</ruby>”的操作系统的,我的 Chromium 浏览器扩展运行良好。

所以如果你想通过 CloudReady 把自己的旧笔记本变成一个非触屏的平板,那你就不太走运了。
### 为什么会有 CloudReady?
你也许会疑惑,既然已经有了 Chrome OS,为什么 Neverware 还要投入资源开发 CloudReady 这个 “克隆体” 呢?
仔细观察运行 Chrome OS 的设备,你就会发现它们都是预装设备。也就是说 Chrome OS 只适用于生产 Chromebook 的 OEM 厂商。
对于微软的 Windows,OEM 厂商可以预装 Windows,用户也可以下载单独的 ISO。然而,谷歌并不提供可用于在电脑上安装 Chrome OS 的 ISO。
所以需要开发一个基于 Chromium OS 的操作系统,让你能够将其安装到已有的 PC 或 Mac 上。
CloudReady 为你提供一种安装基于 Chromium OS,企业用户也可以通过 Neverware 获得官方支持服务。
### 获取 CloudReady

**CloudReady 提供三个版本:家庭版(免费)、教育版(付费)和企业版(付费)**。如果你想先体验一下 CloudReady,那就选家庭版。
Neverware 不提供 ISO 镜像,但它提供一个启动 U 盘制作工具。这个工具仅限 Windows 操作系统。
Neverware 同时提供一个 RAW 文件,你可以用 [任何基于 Chromium 的浏览器](https://news.itsfoss.com/chrome-like-browsers-2021/) 的 [Chromebook 恢复扩展](https://chrome.google.com/webstore/detail/chromebook-recovery-utili/pocpnlppkickgojjlmhdmidojbmbodfm?hl=en) 来制作启动 U 盘。
>
> **[下载 CloudReady 家庭版](https://www.neverware.com/freedownload)**
>
>
>
如果你想要在虚拟机里体验 CloudReady 的话,Neverware 提供了 “.ova” 文件。该 “.ova” 文件无法在 VirtualBox 上使用,它旨在与 VMware 一起使用。
>
> **[下载 CloudReady “.ova” 文件](https://cloudreadykb.neverware.com/s/article/Download-CloudReady-Image-For-VMware)**
>
>
>
### Ubuntu Web:ChromeOS 和 CloudReady 的替代品?
如果你想要在旧电脑上使用 CloudReady,但是它缺少安卓运行时这点让你失望了,也许你可以试试 [Ubuntu Web](https://ubuntu-web.org/)。

正如其名称所示,Ubuntu Web 是面向寻找 Chrome OS 替代品的人群的 Linux 发行版。
Ubuntu Web 有与 Ubuntu 一样的同步能力,让你能够用 [/e/ Cloud](https://e.foundation/ecloud/)(一个专注于隐私的 Google 云同步服务替代品)实现同步。
最重要的是 Ubuntu Web 默认附带了 [Waydroid](https://waydro.id/)。
Waydroid 是一种“基于容器的方式,可以在 GNU/Linux 系统上运行一个完整的 Android 系统”。也就是说你可以在 Ubuntu Web 上运行安卓应用(不像 CloudReady)。
### 总结
尽管你可能会觉得 CloudReady 与 Chrome OS 相比并没有太多的优势,但对于那些想要部署集中管理的、基于 Chromium OS 的操作系统,但又不想在 Chromebook 上投资的组织来说,它似乎是一个不错的选择。
对于使用低端硬件的家庭用户来说,它也是一个不错的选择,但是我们 [已经有很多轻量级的 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/)。
你是否已经使用过 CloudReady?或者你是第一次在这里听说它?你对这个项目的总体看法是什么呢?
*(题图:MJ/5c18795b-6978-48a0-a6f7-baffde69ab48)*
---
via: <https://itsfoss.com/cloudready/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | CloudReady is getting popular, especially among people with low-end hardware. So, I decided to take a look at it and share my findings with you in this article.
## What is CloudReady?
[CloudReady](https://www.neverware.com/) is an operating system based on Google’s open-source Chromium OS code-base. Neverware, the organization behind CloudReady, developed the CloudReady OS to be deployed on already existing PC and Mac hardware and guarantees performance uplift on said hardware due to its minimal hardware requirements. Basically, CloudReady turns your older computer into Chromebooks. [Neverware was acquired by Google](https://9to5google.com/2020/12/15/google-acquires-cloudready-os/) itself in late 2020.
Before I share my experience and opinion on it, let me tell you a bit more about it.
## Is CloudReady for you?
CloudReady is primarily aimed at institutions that would benefit from Chromebook-like devices but already have invested in hardware. Below are a few examples that come to my mind:
- User Interface of Chromium OS, and by extension CloudReady is simple enough that there is seldom any need to re-train the staff to switch from macOS or Windows to CloudReady’s UI.
- Better security – because users can’t install traditional malware ridden apps that are available for macOS and Windows.
- Chromium OS has low requirements for hardware, so it is pretty much guaranteed to run on your older hardware.
- Managing computers through the Google Admin Console.
- Relatively easy initial setup.
Here are the minimum hardware requirements for running CloudReady:
**CPU**: Any CPU made available after the year 2008 should work (no mention of ARM CPUs so assume only X86 – Intel and AMD – CPUs are supported)**RAM**: 2 GB or more**Storage**: 16GB or more- Full access to BIOS or UEFI – in order boot from the USB installer
If you wonder whether your current netbook works well with CloudReady, Neverware has published a list of netbooks that are certified to run CloudReady. Currently, there are over 450 models that are certified. You can [check your model against the official list at this link](https://guide.neverware.com/supported-devices/).
## How does CloudReady compare with Chrome OS?
If your primary goals are either of the following, you will be satisfied with CloudReady:
- Managing CloudReady devices with Neverware Admin Portal (
[until the Google acquisition is complete](https://cloudreadykb.neverware.com/s/article/Neverware-is-now-part-of-Google-FAQ)) or through Google Admin Console. - Work at your organization can be done within a web browser (using web based services).
When you hear the words “It is an Operating System based on Chrome OS”, you would assume that at the very least, it can run Android apps.
Sadly, that is not the case. There is **no support for the Android** Runtime (ART) framework/service for open source Chromium OS, and hence is not available in CloudReady. Neverware has not pursued adding Android Runtime to CloudReady due to several legal and technical reasons.
This, in turn, prevents you from even side-loading an APK, since there is nothing that can run those Android apps.
When I tried launching Play Store from the app drawer, it opened the Google Play Store webpage for me in the browser. So bad news on that front… But, since CloudReady is based on an Operating System that is “web-focused”, my Chromium browser extensions appear to be working flawlessly.
So, if you are looking to use your old laptop as a non-touch tablet with CloudReady, you are a bit out of luck.
## Why does CloudReady even exist?
You might have wondered that if Chrome OS already exists, why did Neverware devote their resources to create a ‘clone’ called CloudReady?
If you look carefully at devices that run Chrome OS, they are pre-builts. This indicates that Chrome OS is only available to OEMs that make Chromebooks.
With Microsoft’s Windows, OEMs get Windows to preinstall, and a separate ISO is also available for users to download. However, Google doesn’t provide you with an ISO which you can use to install Chrome OS on your computer.
Hence, the need to create an operating system based on Chromium OS code-base. Something that you can install on your already existing PC and Mac hardware.
On top of providing you with a way to install a Chromium OS-based operating system, Neverware has options for Enterprise users who would want official support for their operating system. You get that with CloudReady.
## Getting CloudReady
**CloudReady offers three editions: Home edition (free), Education, and Enterprise (both paid)**. If you want to give it a try first, the obvious choice will be to go with the home edition first.
Neverware does not provide you with an ISO. But, Neverware does give you a tool to create bootable USBs with their USB Maker tool, it is Windows only.
Neverware also provides you with a RAW file that you can use to manually create a bootable USB from any operating system using the [Chromebook Recovery Utility extension](https://chrome.google.com/webstore/detail/chromebook-recovery-utili/pocpnlppkickgojjlmhdmidojbmbodfm?hl=en) from [any Chromium based browser.](https://news.itsfoss.com/chrome-like-browsers-2021/)
Since Neverware does not provide an ISO, if you want to try it out as a Virtual Machine, Neverware provides with a “.ova” file. But, this “.ova” file won’t work with VirtualBox. It is intended to be used with VMware.
## Ubuntu Web: An alternative to both ChromeOS and CloudReady?
If you are someone who hoped to use CloudReady on your old computer or laptop but got disappointed by the fact that ART is absent in CloudReady, maybe give [Ubuntu Web](https://ubuntu-web.org/) a try.
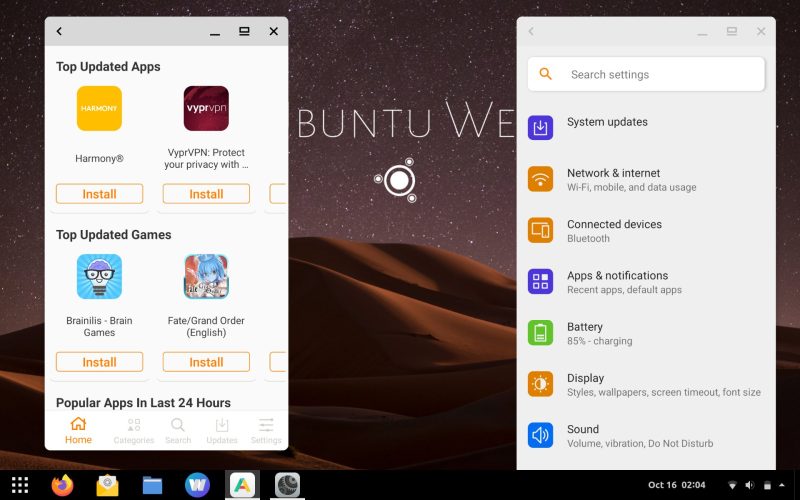
As its name might suggest, it is a Linux distribution that is aimed at people looking at Chrome OS alternatives.
Ubuntu Web has the same, familiar Ubuntu base, which provides you with the ability to sync with [/e/ Cloud](https://e.foundation/ecloud/), a privacy-focused alternative to Google’s Cloud syncing services.
The cherry on top is that Ubuntu Web ships with [Waydroid](https://waydro.id/) by default.
If you didn’t know about Waydroid, it is a “container-based approach to boot a full Android system on a regular GNU/Linux system”. This means, it will run your Android apps (unlike CloudReady).
## Conclusion
CloudReady appears to be a good option for organizations that want to deploy a centrally managed Chromium OS-based operating system but don’t want to invest in Chromebooks.
It could also be a good option for home users with low-end hardware, but we [already have plenty of lightweight Linux distributions](https://itsfoss.com/lightweight-linux-beginners/) for that.
Have you used CloudRead already or are you hearing about it for the first time here? What’s your overall opinion of this project? |
15,988 | Ubuntu Linux 的 7 个最佳应用坞 | https://www.debugpoint.com/best-docks-linux/ | 2023-07-11T16:27:00 | [
"停靠区",
"应用坞"
] | /article-15988-1.html | 
>
> 看看以下哪个 Linux 应用坞最适合你。
>
>
>
<ruby> 应用坞 <rt> Dock </rt></ruby> 在提升 Ubuntu 或其他 Linux 发行版上的用户体验和生产力方面起着至关重要的作用。凭借其流线型和直观的设计,应用坞可快速访问经常使用的应用程序、系统设置和工作区管理。
应用坞是个复杂的应用程序,在 Linux 生态系统中仅有少数活跃项目可用。这可能是因为桌面环境提供了将相应的默认面板转换为应用坞的内置功能。
然而,以下是适用于 Ubuntu 和其他 Linux 发行版的 7 个最佳应用坞。
### Linux 的最佳应用坞
#### Plank
最受欢迎和知名的应用坞是 [Plank](https://launchpad.net/plank),许多发行版将其作为默认应用坞。例如,elementary OS 使用 Plank 做为其 Pantheon 桌面环境的应用坞。
Plank 的最佳特性是其完备性,无需进行任何自定义。它在默认设置下外观出色,并能适应任何发行版。

你可以使用以下命令在 Ubuntu、Linux Mint 及相关发行版上安装 Plank:
```
sudo apt install plank
```
安装完成后,你可以通过命令提示符中输入 `plank`,或通过应用程序菜单启动它。如果你在 Ubuntu 上使用它,请确保使用任何 [GNOME 扩展](https://www.debugpoint.com/gnome-extensions-2022/)(例如 Just Perfection)隐藏默认的左侧 <ruby> 启动器 <rt> Dash </rt></ruby>。
**注意:** Plank 在 Wayland 上无法工作。你需要使用 [X.Org](http://X.Org) 会话。
#### Dash to Dock 扩展
如果你正在使用最新的 Ubuntu GNOME 桌面环境,则可以尝试 “Dash to Dock” 扩展。它不是独立的应用程序,但可以将你的启动器转换为简单的应用坞。

该扩展还提供了几个功能,如在多个监视器上显示应用坞、设置大小/图标大小和位置。你还可以自定义其不透明度,使用内置主题并更改应用坞的颜色。
要安装此扩展,先安装 [扩展管理器](https://www.debugpoint.com/how-to-install-and-use-gnome-shell-extensions-in-ubuntu/),然后搜索 “[Dash to Dock](https://extensions.gnome.org/extension/307/dash-to-dock/)” 并安装。
#### Dock from Dash 扩展
还有另一个 GNOME 扩展,称为 “Dock from Dash”。乍一看,它与 “Dash to Dock” 看起来可能完全相同,但存在一些区别。
与 “Dash to Dock” 相比,此扩展轻量,使用的资源较少。它也仅提供了一些选项,只提供简单的应用坞功能。
此外,它还可以自动隐藏应用坞,并可自定义延迟和行为。
因此,如果你想要一个轻量级的 GNOME 扩展,仅具有应用坞功能,请选择它。
要安装此扩展,先安装 [扩展管理器](https://www.debugpoint.com/how-to-install-and-use-gnome-shell-extensions-in-ubuntu/),然后搜索 “[Dock from Dash](https://extensions.gnome.org/extension/4703/dock-from-dash/)” 并安装。

#### Latte Dock
[Latte Dock](https://invent.kde.org/plasma/latte-dock) 以其庞大的自定义选项而闻名。它是 KDE 系统的一部分,并带有许多依赖项。我将其添加到此列表的主要原因是它是目前最好的应用坞。
然而,问题在于该项目目前没有在维护。Latte Dock 的开发者已经 [离开了该项目](https://psifidotos.blogspot.com/2022/07/latte-dock-farewell.html)。KDE 的自动化机制使该项目保持维护模式。因此,如果需要,只需进行少量调整,它就能正常工作。
许多发行版,如 Garuda Linux,曾将其作为默认选项的一部分。但现在已经不再使用 Latte Dock。

你可以使用以下命令安装 Latte Dock。如果你在 Ubuntu 上安装它,请记住它将下载大量的 KDE 生态系统的软件包。因此,建议你在任何 [基于 KDE Plasma 的 Linux 发行版](https://www.debugpoint.com/top-linux-distributions-kde-plasma/) 上使用 Latte 应用坞以获得最佳体验。
```
sudo apt install latte-dock
```
#### Docky
如果你想要一个类似 macOS 风格的应用坞,可以尝试使用 Docky。[Docky](https://launchpad.net/~docky-core/+archive/ubuntu/stable) 是一个简单易用的应用坞,与 GNOME 桌面环境紧密集成。它是一个轻量、快速和可自定义的应用坞,可用于启动应用程序、访问文件和管理窗口。
总体而言,Docky 提供了一个视觉吸引力强、可自定义且高效的解决方案,可用于管理应用程序并提升桌面体验。

但是有一个问题。
Docky 的开发已经停滞。其最后一次发布是在 2015 年,目前它处于最低限度的维护模式。但是,你仍然可以在 Ubuntu 上安装它,需要进行一些额外的步骤,因为你需要手动下载依赖项并安装它们。
在 Ubuntu 中打开终端,并按顺序运行以下命令以安装 Docky。
```
wget -c http://archive.ubuntu.com/ubuntu/pool/universe/g/gnome-sharp2/libgconf2.0-cil_2.24.2-4_all.deb
wget -c http://archive.ubuntu.com/ubuntu/pool/main/g/glibc/multiarch-support_2.27-3ubuntu1_amd64.deb
wget -c http://archive.ubuntu.com/ubuntu/pool/universe/libg/libgnome-keyring/libgnome-keyring-common_3.12.0-1build1_all.deb
wget -c http://archive.ubuntu.com/ubuntu/pool/universe/libg/libgnome-keyring/libgnome-keyring0_3.12.0-1build1_amd64.deb
wget -c http://archive.ubuntu.com/ubuntu/pool/universe/g/gnome-keyring-sharp/libgnome-keyring1.0-cil_1.0.0-5_amd64.deb
sudo apt install *.deb
wget -c http://archive.ubuntu.com/ubuntu/pool/universe/d/docky/docky_2.2.1.1-1_all.deb
sudo apt install ./docky_2.2.1.1-1_all.deb
```
安装之后,你可以在应用菜单中找到它。
#### DockbarX
如果你是 Xfce 桌面的忠实用户,可能听说过 [DockbarX](https://github.com/M7S/dockbarx)。它在 Xfce 上运行得很好,但你也可以在 Ubuntu、Linux Mint 或 Arch Linux 上安装它。
DockbarX 带有大量的自定义选项和调整,可以让你的桌面看起来令人惊艳。此外,它还支持内置主题,省去了你调整应用坞的功夫。
DockbarX 的一个独特功能是从应用坞直接显示正在运行应用程序的窗口预览。

以下是在 Ubuntu 中安装的步骤:
```
sudo add-apt-repository ppa:xuzhen666/dockbarx
sudo apt update
sudo apt install dockbarx
sudo apt install dockbarx-themes-extra
```
如果你使用的是 Arch Linux,你可以设置任何 [AUR 辅助工具,如 Yay](https://www.debugpoint.com/install-yay-arch/),并使用以下命令安装它。
```
yay -S dockbarx
```
#### KSmoothDock
如果你喜欢在应用坞中显示更多的界面动画效果,那么你可以考虑使用 [KSmoothDock](https://dangvd.github.io/ksmoothdock/)。它具备所有常见的应用坞功能,并附加了一些额外的特性。
KSmoothDock 的主要吸引力在于“抛物线缩放效果”,如果你喜欢动画效果,这是一种非常不错的体验。

此外,它还提供了图标和面板大小、透明度等自定义选项。它是一个构建良好的应用坞,在 KDE Plasma 系列的发行版中应该非常完美。
它提供了一个预编译的 deb 文件进行安装,你可以从 KDE 商店下载:
>
> **[下载 KSmoothDock](https://store.kde.org/p/1081169)**
>
>
>
### 一些不活跃的 Linux 应用坞
除了上述的选项外,还有一些非常受欢迎的应用坞已经停止了开发。这些应用坞当前已经无法正常工作,并且安装它们需要很多努力。你可以查看它们的源代码进行实验。
[Cairo Dock](https://glx-dock.org/): 对于最新的 Ubuntu 发行版,目前已不可用。[最后一个稳定版本](https://launchpad.net/~cairo-dock-team/+archive/ubuntu/ppa)发布于 2015 年。
[Avant Window Navigator](https://github.com/p12tic/awn): 目前无法正常工作。[最后一个发布版](https://launchpad.net/~awn-testing/+archive/ubuntu/ppa) 发布于 2013 年。
### 总结
无论你是喜欢简约的应用坞还是喜欢带有动画效果的重型应用坞,希望上述列表可以帮助你选择最适合你需求的应用坞。不幸的是,几乎大多数应用坞都没有积极的开发,而且也没有新的应用坞在开发。
探索这些选项,尝试不同的应用坞,并找到一个能够增强你的 Ubuntu 或其他 Linux 桌面体验的应用坞。请在评论中告诉我你使用和喜欢的 Linux 应用坞!
*(题图:MJ/5a640365-8b47-43cc-8d72-2f0af8fc9099)*
---
via: <https://www.debugpoint.com/best-docks-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,991 | Bash 基础知识系列 #2:在 Bash 中使用变量 | https://itsfoss.com/bash-use-variables/ | 2023-07-12T11:17:00 | [
"脚本",
"Bash"
] | https://linux.cn/article-15991-1.html | 
>
> 在本章的 Bash 基础知识系列中,学习在 Bash 脚本中使用变量。
>
>
>
在 Bash 基础知识系列的第一部分中,我简要提到了变量。现在是时候在本章中详细了解它们了。
如果你曾经进行过任何类型的编码,你一定熟悉术语“变量”。
如果没有,请将变量视为保存信息的盒子,并且该信息可以随着时间的推移而改变。
让我们看看如何使用它们。
### 在 Bash shell 中使用变量
打开终端并使用一个随机的数字 4 初始化变量:
```
var=4
```
现在你有一个名为 `var` 的变量,它的值为 `4`。想验证一下吗? **通过在变量名前添加 `$` 来访问变量的值**。这称为参数扩展。
```
[abhishek@itsfoss]:~$ echo The value of var is $var
The value of var is 4
```
>
> ? 变量初始化时 `=` 前后不能有空格。
>
>
>
如果需要,你可以将该值更改为其他值:

在 Bash shell 中,变量可以是数字、字符或字符串(包括空格在内的字符)。

>
> ? 与 Linux 中的其他事物一样,变量名称也区分大小写。它们可以由字母、数字和下划线 “`_`” 组成。
>
>
>
### 在 Bash 脚本中使用变量
你是否注意到我没有运行 shell 脚本来显示变量示例? 你可以直接在 shell 中做很多事情.当你关闭终端时,你创建的那些变量将不再存在。
但是,你的发行版通常会添加全局变量,以便可以在所有脚本和 shell 中访问它们。
让我们再写一些脚本.你应该之前创建了脚本目录,但无论哪种情况,此命令都会处理该目录:
```
mkdir -p bash_scripts && cd bash_scripts
```
基本上,如果 `bash_scripts` 目录尚不存在,它将创建它,然后切换到该目录。
这里让我们使用以下文本创建一个名为 `knock.sh` 的新脚本。
```
#!/bin/bash
echo knock, knock
echo "Who's there?"
echo "It's me, $USER"
```
更改文件权限并运行脚本。你在上一章中已经学到了。
这是它为我生成的内容:

**你是否注意到它如何自动将我的名字添加到其中?** 这就是包含用户名的全局变量 `$USER` 的魔力。
你可能还注意到,我有时将 `"` 与 `echo` 一起使用,但其他时候则不使用。这是故意的。[bash 中的引号](https://linuxhandbook.com:443/quotes-in-bash/) 有特殊含义。它们可用于处理空格和其他特殊字符。让我展示一个例子。
### 处理变量中的空格
假设你必须使用一个名为 `greetings` 的变量,其值为 `hello and welcome`。
如果你尝试像这样初始化变量:
```
greetings=Hello and Welcome
```
你会得到这样的错误:
```
Command 'and' not found, but can be installed with:
sudo apt install and
```
这就是为什么你需要使用单引号或双引号:
```
greetings="Hello and Welcome"
```
现在你可以根据需要使用该变量。

### 将命令输出分配给变量
是的!你可以将命令的输出存储在变量中并在脚本中使用它们。这称为命令替换。
```
var=$(command)
```
这是一个例子:
```
[abhishek@itsfoss]:~$ today=$(date +%D)
[abhishek@itsfoss]:~$ echo "Today's date is $today"
Today's date is 06/19/23
[abhishek@itsfoss]:~$
```

旧语法使用反引号而不是 `$()` 进行命令替换。虽然它可能仍然有效,但你应该使用新的推荐符号。
>
> ? 变量会更改值,除非你声明一个“常量”变量,如下所示:`readonly pi=3.14`。在这种情况下,变量 `pi` 的值无法更改,因为它被声明为 `readlonly`。
>
>
>
### ?️ 练习时间
是时候练习你所学到的东西了。这里有一些练习来测试你的学习情况。
**练习 1**:编写一个 bash 脚本,以以下格式打印你的用户名、当前工作目录、主目录和默认 shell。
```
Hello, there
My name is XYZ
My current location is XYZ
My home directory is XYZ
My default shell is XYZ
```
**提示**:使用全局变量 `$USER`、`$PWD`、`$HOME` 和 `$SHELL`。
**练习 2:** 编写一个 bash 脚本,声明一个名为 `price` 的变量.使用它来获取以下格式的输出:
```
Today's price is $X
Tomorrow's price is $Y
```
其中 X 是变量 `price` 的初始值,并且明天价格翻倍。
**提示**:使用 `\` 转义特殊字符 `$`。
练习的答案可以在社区的这个专用帖子中讨论。
在 Bash 基础知识系列的下一章中,你将了解如何通过传递参数和接受用户输入来使 bash 脚本具有交互性。
*(题图:MJ/37c5c26e-3289-4ebd-b8ae-88eb8a3b2eb1)*
---
via: <https://itsfoss.com/bash-use-variables/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter #2: Using Variables in Bash
In this chapter of the Bash Basics series, learn about using variables in Bash scripts.
In the first part of the Bash Basics Series, I briefly mentioned variables. It is time to take a detailed look at them in this chapter.
If you have ever done any kind of coding, you must be familiar with the term 'variable'.
If not, think of a variable as a box that holds up information, and this information can be changed over time.
Let's see about using them.
## Using variables in Bash shell
Open a terminal and use initialize a variable with a random number 4:
`var=4`
So now you have a variable named `var`
and its value is `4`
. Want to verify it? **Access the value of a variable by adding $ before the variable name**. It's called parameter expansion.
```
abhishek@itsfoss:~$ echo The value of var is $var
The value of var is 4
```
`=`
during variable initialization.If you want, you can change the value to something else:
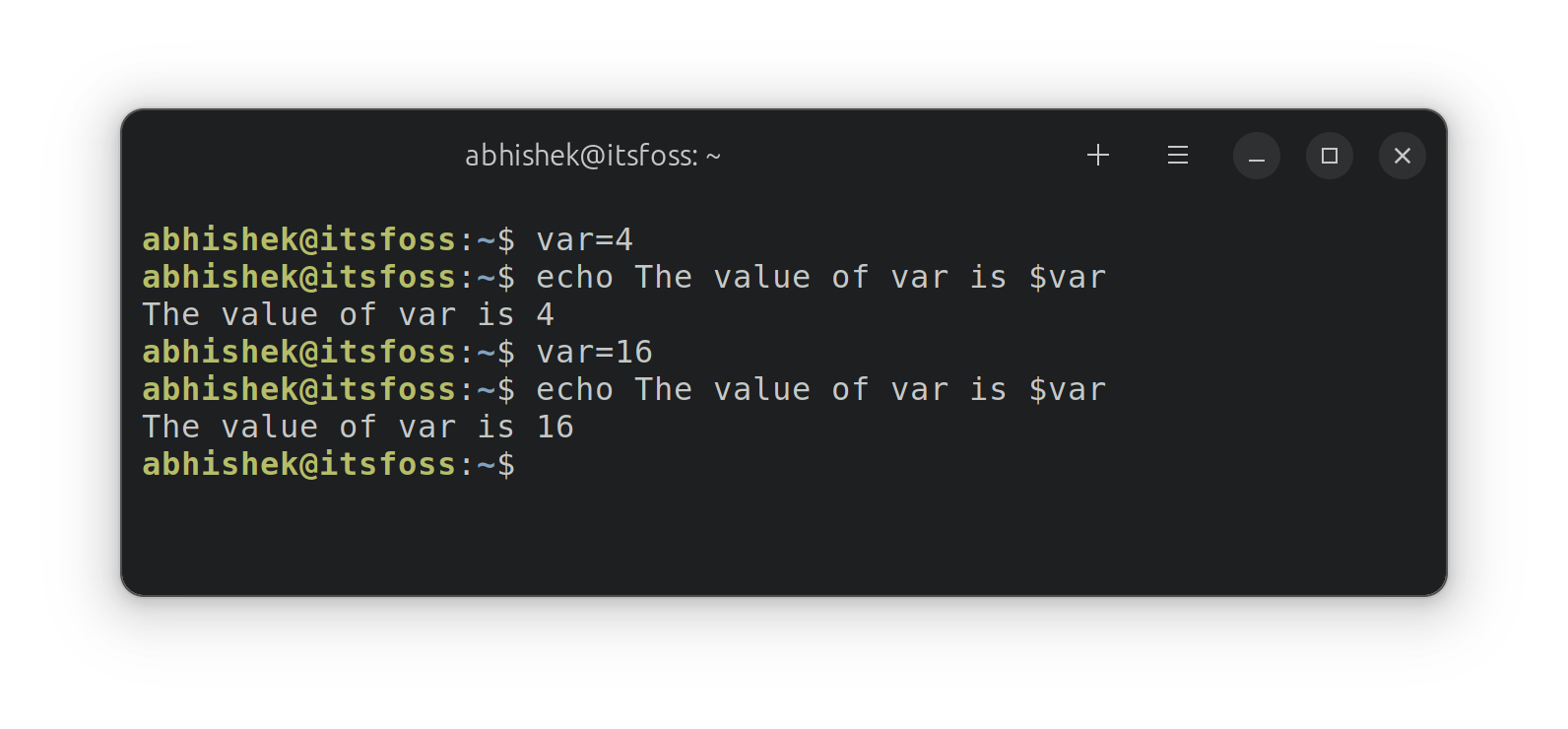
In Bash shell, a variable can be a number, character, or string (of characters including spaces).
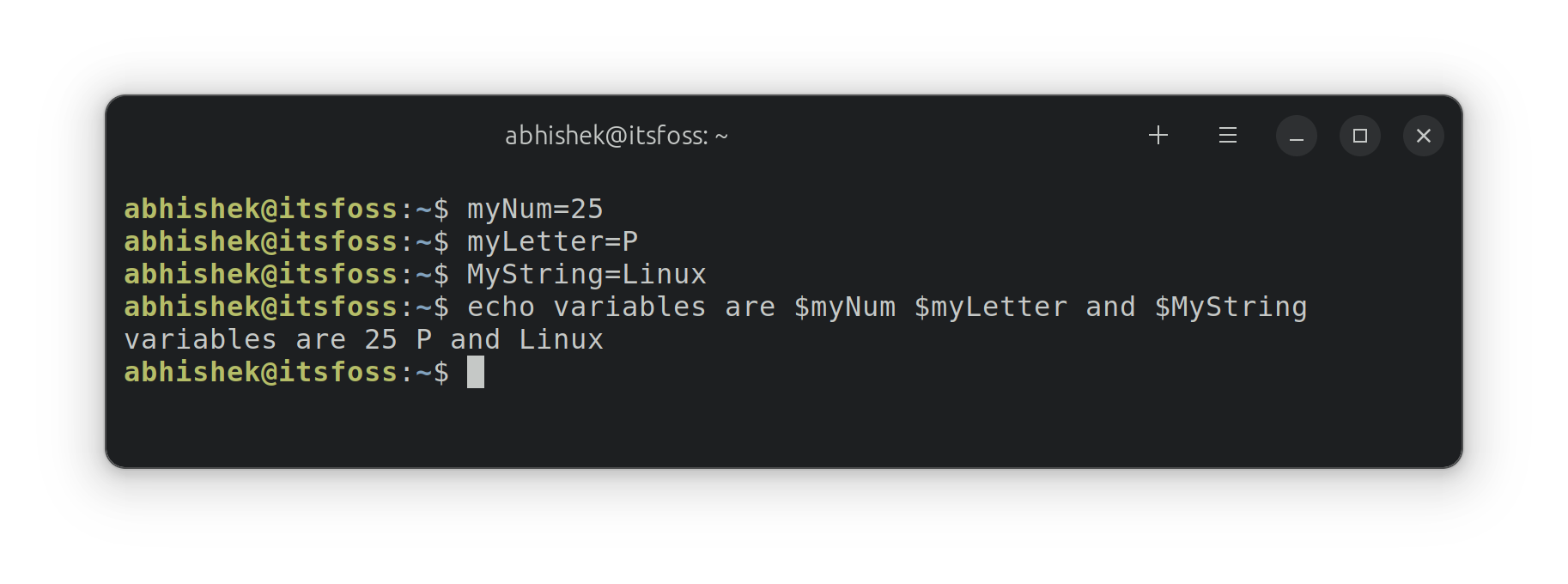
## Using variables in Bash scripts
Did you notice that I didn't run a shell script to show the variable examples? You can do a lot of things in the shell directly. When you close the terminal, those variables you created will no longer exist.
However, your distro usually adds global variables so that they can be accessed across all of your scripts and shells.
Let's write some scripts again. You should have the script directory created earlier but this command will take care of that in either case:
`mkdir -p bash_scripts && cd bash_scripts`
Basically, it will create `bash_scripts`
directory if it doesn't exist already and then switch to that directory.
Here. let's create a new script named `knock.sh`
with the following text.
```
#!/bin/bash
echo knock, knock
echo "Who's there?"
echo "It's me, $USER"
```
Change the file permission and run the script. You learned it in the previous chapter.
Here's what it produced for me:
**Did you notice how it added my name to it automatically?** That's the magic of the global variable $USER that contains the username.
You may also notice that I used the " sometimes with echo but not other times. That was deliberate. [Quotes in bash](https://linuxhandbook.com/quotes-in-bash/) have special meanings. They can be used to handle white spaces and other special characters. Let me show an example.
## Handling spaces in variables
Let's say you have to use a variable called `greetings`
that has the value `hello and welcome`
.
If you try initializing the variable like this:
`greetings=Hello and Welcome`
You'll get an error like this:
```
Command 'and' not found, but can be installed with:
sudo apt install and
```
This is why you need to use either single quotes or double quotes:
`greetings="Hello and Welcome"`
And now you can use this variable as you want.
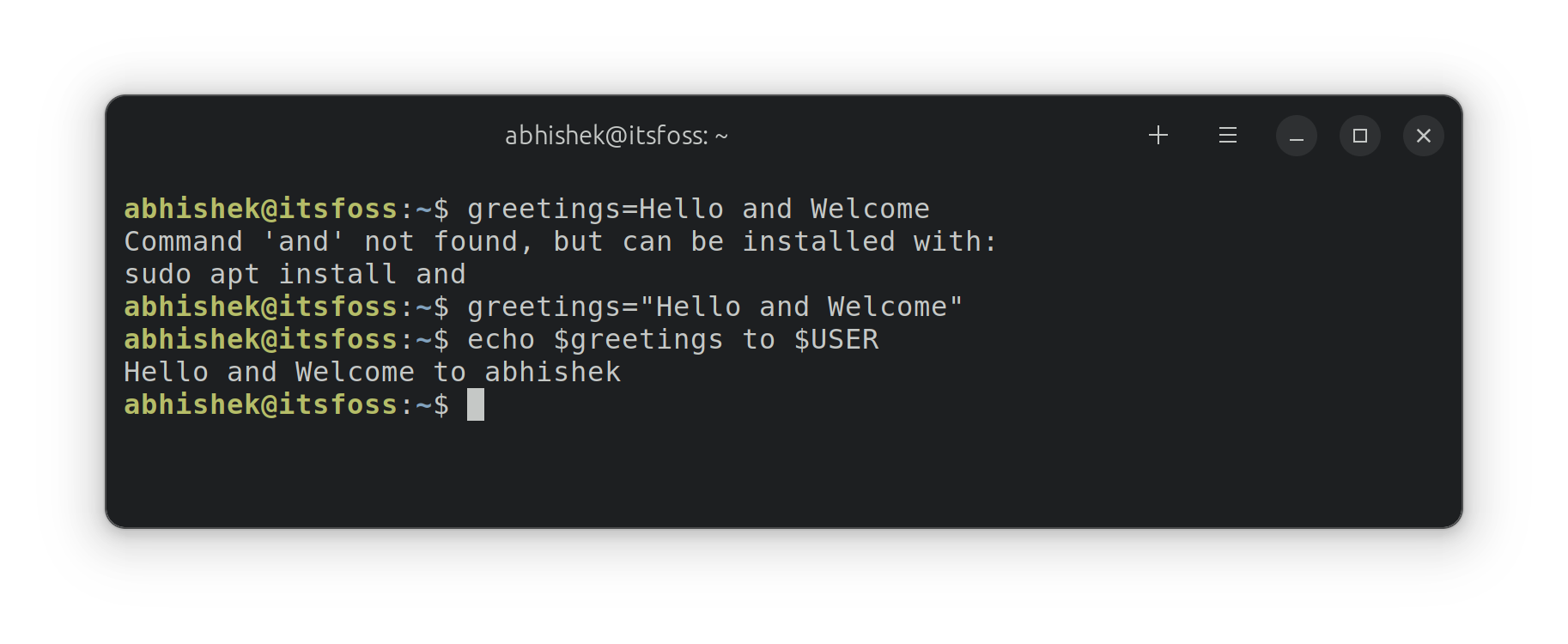
## Assign the command output to a variable
Yes! You can store the output of a command in a variable and use them in your script. It's called command substitution.
`var=$(command)`
Here's an example:
```
abhishek@itsfoss:~$ today=$(date +%D)
abhishek@itsfoss:~$ echo "Today's date is $today"
Today's date is 06/19/23
abhishek@itsfoss:~$
```
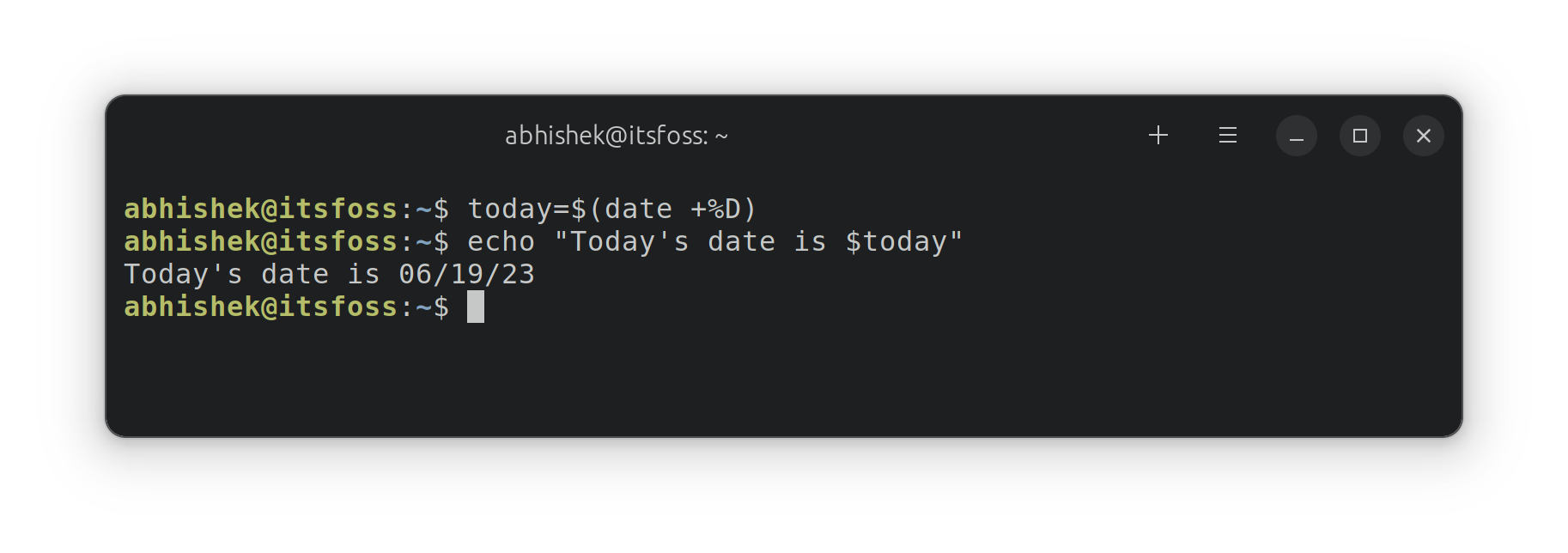
The older syntax used backticks instead of $() for the command substitution. While it may still work, you should use the new, recommended notation.
`readonly pi=3.14`
. In this case, the value of variable `pi`
cannot be changed because it was declared `readonly`
.## 🏋️ Exercise time
Time to practice what you learned. Here are some exercise to test your learning.
**Exercise 1**: Write a bash script that prints your username, present working directory, home directory and default shell in the following format.
```
Hello, there
My name is XYZ
My current location is XYZ
My home directory is XYZ
My default shell is XYZ
```
**Hint**: Use global variables $USER, $PWD, $HOME and $SHELL.
**Exercise 2: **Write a bash script that declares a variable named `price`
. Use it to get the output in the following format:
```
Today's price is $X
Tomorrow's price is $Y
```
Where X is the initial value of the variable `price`
and it is doubled for tomorrow's prices.
**Hint**: Use \ to escape the special character $.
The answers to the exercises can be discussed in this dedicated thread in the community.
[Practice Exercise in Bash Basics Series #2: Using Variables in BashIf you are following the Bash Basics series on It’s FOSS, you can submit and discuss the answers to the exercise at the end of the chapter: Fellow experienced members are encouraged to provide their feedback to new members. Do note that there could be more than one answer to a given problem.](https://itsfoss.community/t/practice-exercise-in-bash-basics-series-2-using-variables-in-bash/10742)

In the next chapter of the Bash Basics Series, you'll see how to make the bash scripts interactive by passing arguments and accepting user inputs.
[Bash Basics #3: Pass Arguments and Accept User InputsLearn how to pass arguments to bash scripts and make them interactive in this chapter of the Bash Basics series.](https://itsfoss.com/bash-pass-arguments/)

Enjoy learning bash. |
15,993 | Solus 4.4 发布,带来实用的升级并计划放弃 MATE 版本 | https://news.itsfoss.com/solus-4-4-released/ | 2023-07-12T18:51:19 | [
"Solus"
] | https://linux.cn/article-15993-1.html |
>
> Solus 4.4 有了一些令人印象深刻的升级,不久以后将推出一款新版本。
>
>
>

Solus 是一个许久没有出现在新闻中的名字,我们上一次听说它是今年 4 月份它经历了 [又一次动荡](https://news.itsfoss.com/solus-revival/)。
幸运的是,新的组织重组似乎奏效了,因为现在我们在近两年后迎来了新发布!
Solus 是最棒的 [独立 Linux 发行版](https://itsfoss.com/independent-linux-distros/) 之一,提供了非常适合初学者的用户体验。
和它的上一个版本 Solus 4.3 相比,它带来了许多改进,这个新版本的目标是超越之前的版本。
让我们看看 Solus 最新版本有什么新特性。
### ? Solus 4.4: 有什么新内容?

Solus 4.4 带来了许多改进,其中一些最显著的包括以下内容:
* 更好的硬件支持
* 桌面环境升级
* 更新的应用程序套件
#### 更好的硬件支持
前所未有的,Solus 4.4 使用 **Linux 内核 6.3.8** 作为强大的基础来支持各种硬件。硬件支持包括:
* 安全启动
* 英特尔 Arc 显卡
* 英伟达 40 系列显卡
* AMD Radeon RX 7600、7900 XT 和 7900 XTX 显卡
* 增强对各种光传感器和加速度计的支持
* 以及更多
#### 桌面环境升级
这是你将找到 Solus 中最关键的错误修复和提升用户体验的改进之处。由于提供了四个不同的版本,我们将介绍每个版本中的新功能。
##### GNOME 43.5

Solus 4.4 **采用了最新的 [GNOME 43.5](https://gitlab.gnome.org/GNOME/gnome-software/-/releases/43.5) 版本**,带来了许多调整。默认的窗口主题切换到了 Adwaita,且默认启用了深色模式。
此外,更新了系统用户界面的样式,重新设计了系统状态菜单,方便快速更改常用设置。
##### MATE 将被 XFCE 取代

而对于 MATE 版本,Solus 4.4 **采用了最新的 [MATE 1.27.1](https://github.com/mate-desktop/mate-desktop/releases/tag/v1.27.1) 版本**。它包括**各种可靠性和可访问性的修复**,**更改了键盘驱动程序**,以及将 **qxl 视频驱动程序设为处理虚拟化视频驱动程序支持的默认驱动程序**。
遗憾的是,Solus 开发团队决定在未来的版本中 **淘汰 MATE 版本**,并采用 XFCE 版本。这其中的关键原因是 MATE 项目处于非常 **衰败的状态**,并且 **没有计划支持 Wayland**。
#### Budgie 10.7.2

对于 Budgie 版本,Solus 4.4 **采用了 [Budgie 10.7.2](https://blog.buddiesofbudgie.org/budgie-10-7-2/) 版本**,使 Solus 能够利用**新的应用索引器**、**重新设计的设置菜单**、**可访问性改进**等功能。
此外,Solus 现在**默认使用 Nemo 文件管理器**,不再使用 Nautilus。原因是 Nautilus 被更改为 GTK4 和 libadwaita,不再符合系统其他部分的外观和感觉。
#### KDE Plasma

同样,在 Plasma 版本中,Solus 4.4 **采用了最新的 [Plasma 5.27.5](https://kde.org/announcements/plasma/5/5.27.5/) 版本**,以及 **KDE Frameworks 5.106.0**、**KDE Gear 23.04.2** 和 **KDE 分支的 QT 5.15.9**。
这带来了许多新功能;其中一些亮点包括:
* 默认应用启动器被 [Kickoff](https://userbase.kde.org/Plasma/Kickoff) 替换
* Wayland 会话默认提供
* [KSysGuard](https://apps.kde.org/ksysguard/) 被 [System Monitor](https://apps.kde.org/plasma-systemmonitor/) 替换
* 新的“总览视图”,可用于管理所有活动的桌面/应用程序
* 支持大屏幕模式
#### 更新的应用套件
除了上述更改之外,Solus 4.4 还包括更新的应用套件,其中包括:
* Firefox 114.0.1
* LibreOffice 7.5.3.2
* Thunderbird 102.12.0
* Budgie、GNOME 和 MATE 版本的默认音乐播放器为 Rhythmbox
* Budgie 和 GNOME 上的视频播放使用 Celluloid
* MATE 上的视频播放使用 VLC Player
* Plasma 上的音频播放使用 Elisa,视频播放使用 Haruna
你可以查看 [发布公告](https://getsol.us/2023/07/08/solus-4-4-released/) 以深入了解这个重大版本更新。
### ? 下载 Solus 4.4
Solus 的此版本有 **四个不同的版本**,你可以从 [官方网站](https://getsol.us/download/) 获取它们。
>
> **[Solus 4.4](https://getsol.us/download/)**
>
>
>
---
via: <https://news.itsfoss.com/solus-4-4-released/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Solus is a name that has not made the news for some time now, the last time we heard about it was back in April this year when it went through [yet another shake up](https://news.itsfoss.com/solus-revival/).
Luckily, the new organizational restructure seems to have worked, as we now have a **new release after almost two years!**
You see, Solus is one of the best [independent Linux distros](https://itsfoss.com/independent-linux-distros/?ref=news.itsfoss.com) that offers a very beginner-friendly user experience.
The last release was Solus 4.3, which offered many improvements, and the new one aims to one-up that.
**Suggested Read **📖
[Solus 4.3 Released with Budgie 10.3.5 and GNOME 40.2Solus, the independent Linux distribution, has just announced their third installment of their 4.x “Fortitude” series. This release brings improved hardware support, a new kernel, and updated desktop environments. Read on for an exciting look into what this new release brings. Solus 4.3:…](https://news.itsfoss.com/solus-4-3-release/)

Let's see what the latest release of Solus has to offer.
## 🆕 Solus 4.4: What's New?
Solus 4.4 is packed with many improvements; some of the most notable ones include the following:
**Better Hardware Support****Desktop Environment Upgrades****Updated Application Suite**
### Better Hardware Support
Solus 4.4 uses the **Linux Kernel 6.3.8 **as a strong foundation for supporting a wide range of hardware, which was not seen before. The hardware support consists of:
**Secure Boot****Intel Arc GPUs****NVIDIA 40 Series GPUs****AMD Radeon RX 7600, 7900 XT, and 7900 XTX cards.****Enhanced support for various light sensors and accelerometers.****And More.**
### Desktop Environment Upgrades
This is where you will find the most critical bug fixes, and quality-of-life improvements with Solus. As it is offered in four different editions, we will cover what's new in each.
**GNOME 43.5**
Solus 4.4 **features the latest ****GNOME 43.5**** release** with many tweaks. The default shell theme was switched to Adwaita, and dark mode was enabled by default.
Then there's the updated system UI styling, which features the redesigned system status menu, allowing for quick changes to the commonly used settings.
**MATE Retires in Favour of XFCE**

And, in the case of the MATE edition, Solus 4.4 **features the latest ****MATE 1.27.1**** release**. It includes **various reliability/accessibility fixes**, **a keyboard driver change**, and the **qxl video driver being the default driver** to handle virtualization video driver support.
Sadly, the Solus dev team has **decided to deprecate the MATE edition in favor of an XFCE edition** with future releases of Solus. The key reason behind it was the MATE project being in a **very dilapidated state**, with **no plans for a Wayland implementation**.
**Budgie 10.7.2**

In the case of the Budgie edition, Solus 4.4 **features the ****Budgie 10.7.2**** release, **which allows Solus to take advantage of the **new application indexer**, **redesigned settings menu**, **accessibility improvements,** and more.
Furthermore, Solus now **uses the Nemo file manager by default**, doing away with Nautilus. The reason is that Nautilus was changed to GTK4 and libadwaita, which no longer matches the look and feel of the rest of the system.
**Plasma**

Similarly, in the case of the Plasma edition. Solus 4.4 **features the latest Plasma Desktop 5.27.5 release** alongside
**KDE Frameworks 5.106.0**,
**KDE Gear 23.04.2**, and the
**KDE branch for QT 5.15.9.**
This has resulted in many new features; some highlights include:
**The default application launcher was replaced with**[Kickoff](https://userbase.kde.org/Plasma/Kickoff?ref=news.itsfoss.com).**Wayland Session is made available out of the box.**[KSysGuard](https://apps.kde.org/ksysguard/?ref=news.itsfoss.com)was replaced in favor of[System Monitor](https://apps.kde.org/plasma-systemmonitor/?ref=news.itsfoss.com).**A new 'Overview View', that can be used to manage all the active desktops/applications.****Support for Big Screen Mode.**
**Suggested Read **📖
[💕Valentine’s Gift for KDE Users Arrive in the Form of Plasma 5.27 ReleaseKDE Plasma 5.27 has landed with plenty of improvements.](https://news.itsfoss.com/kde-plasma-5-27-release/)

### Updated Application Suite
Other than the above-mentioned changes, Solus 4.4 features an updated application suite that includes:
**Firefox 114.0.1****LibreOffice 7.5.3.2****Thunderbird 102.12.0****Rhyhmbox as the default music player for Budgie, GNOME, and MATE editions.****Celluloid for video playback on Budgie and GNOME.****VLC Player for video playback on MATE.****Elisa for audio playback, and Haruna for video playback on Plasma.**
You may review the [release announcement](https://getsol.us/2023/07/08/solus-4-4-released/?ref=news.itsfoss.com) to dive deeper into this major release.
## 📥 Download Solus 4.4
This release of Solus is available in **four different editions; you** can get them from the [official website](https://getsol.us/download/?ref=news.itsfoss.com).
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,994 | Zorin OS 升级程序现已推出,为你提供无忧的更新体验 | https://news.itsfoss.com/zorin-os-upgrader/ | 2023-07-13T15:42:51 | [
"Zorin OS"
] | https://linux.cn/article-15994-1.html |
>
> 你终于可以升级 Zorin OS 版本而无需重新安装。虽迟但到。
>
>
>

Zorin OS 无疑是 [最美丽的 Linux 发行版](https://itsfoss.com:443/beautiful-linux-distributions/) 之一。它基于 Ubuntu LTS,以全面的软件包为用户提供类似(但不限于) Windows 的体验。
然而,它缺乏无缝升级方式。
在最近的一份公告中,Zorin OS 背后的人们终于推出了一个新的更新程序来处理该操作系统的所有升级工作! ?
考虑为什么它是初学者的不错选择之一的另一个原因是什么? 我想是这样...
>
> **[Zorin OS 是初学者理想选择的 5 个原因](https://news.itsfoss.com/why-zorin-os-beginners/)**
>
>
>
因此,事不宜迟,让我们简单地看一下。
### Zorin OS 更新程序:初步印象 ⭐

Zorin OS 更新程序的到来是理所当然的,因为多年来开发人员**收到了来自用户的许多请求**,希望能有这样一个的**一站式**解决方案。
以前,想要切换到较新版本或更改变体的用户必须完全重新安装 Zorin OS,并且必须从头开始设置系统。
现在,不用了!
Zorin OS 更新程序是一个简洁的解决方案,允许用户**轻松执行主要版本或变体升级**,而无需全新安装 Zorin OS。
**例如:** 假设你使用的是 Zorin OS 15 Core。你可以使用此应用升级到 Zorin OS 16 Core 甚至 Zorin OS 16 Pro。
好了,继续。
让我们看看更新程序及其工作原理。我们还在本文的底部向你展示了如何使用它。
当你启动该应用时,你将看到一个页面,其中包含 Zorin OS 安装的当前版本/变体以及可用升级的列表。

当你继续操作时,你可以选择包含所有附加功能的正常安装,也可以选择包含核心程序的最小安装。

**如果你要升级到 Zorin OS Pro**,你必须输入你的电子邮件地址和支持代码才能继续升级。

之后,你将看到开始升级的最终提示页面。
他们建议你提前备份数据。如果在升级过程中出现问题,你可以回退。

升级过程开始时,会显示一个进度页面,其中所有重要的升级阶段都会高亮显示。

一切设置完毕后,你可以重启系统以完成操作系统升级过程。

### ? 如何访问 Zorin OS 更新程序
你所需要做的就是**更新你的系统**以安装新的 Zorin OS 升级工具。
但是,它**目前处于 Beta 测试**,尚未作为稳定的工具提供。你可以在接下来的几周内期待它。
>
> ℹ️ 通过 Zorin 菜单 → <ruby> 系统工具 <rt> System Tools </rt></ruby> → <ruby> 软件更新程序 <rt> Software Updater </rt></ruby> 更新你的系统
>
>
>
你可以尝试手动安装测试版,但需要自行承担风险。
打开终端并输入以下命令:
```
sudo apt update
sudo apt install zorin-os-upgrader
```
然后,要开始升级过程,请启动“<ruby> 升级 Zorin OS <rt> Upgrade Zorin OS </rt></ruby>”应用,然后按照屏幕上的说明进行操作。
**对于 Zorin OS 15 的用户:** 如果你在首次启动升级应用时没有看到任何升级选项,那么需要在终端中运行以下命令:
```
gsettings set com.zorin.desktop.upgrader show-test-upgrades true
```
你可以阅读 [官方帮助指南](https://help.zorin.com:443/docs/getting-started/upgrade-zorin-os/#upgrading-from-zorin-os-15-or-newer) 以获取更多信息。
---
via: <https://news.itsfoss.com/zorin-os-upgrader/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Zorin OS is undoubtedly one of the [most beautiful Linux distributions](https://itsfoss.com/beautiful-linux-distributions/?ref=news.itsfoss.com) out there. Based on Ubuntu LTS, it gives users a Windows-like experience (not limited to) in a well-rounded package.
However, it lacked a seamless way to upgrade.
In a recent announcement, the folks behind Zorin OS unveiled a new updater app to handle all OS upgrades, finally! 🤩
Another reason to consider why it is one of the good choices for beginners? I think so...
[5 Reasons Why Zorin OS is an Ideal Choice for BeginnersZorin OS is undoubtedly one of the most beautiful Linux distributions available. However, it is not just limited to how it looks. Compared to some other options available, it offers a nice user experience overall. And, which is why, we also recommend it as one of the top choices for](https://news.itsfoss.com/why-zorin-os-beginners/)

So, without any further ado, let's briefly look at it.
## Zorin OS Updater: Initial Impressions ⭐

Zorin OS Updater's arrival was a given, seeing that the devs had **received many requests from users** over the years for a **one-stop solution like this**.
Previously, users who wanted to switch to a newer release or change the variant would have to do a complete reinstall of Zorin OS and had to set up their system from scratch.
Well, no more!
The Zorin OS Updater app is a neat solution that allows users to **perform major release or variant upgrades effortlessly** without needing a clean install of Zorin OS.
**For example:** Let's say you are on Zorin OS 15 Core; you can use this app to upgrade to Zorin OS 16 Core or even Zorin OS 16 Pro.
**Suggested Read **📖
[Zorin OS 16.2 Released, It’s All About Useful RefinementsZorin OS 16.2 is a sweet upgrade with essential refinements across the board.](https://news.itsfoss.com/zorin-os-16-2-release/)

So, moving on.
Let's look at the updater app and how it works. We also show you how to use it briefly at the bottom section of this article.
When you launch the app, you are shown a page with the current version/variant of your Zorin OS installation and a list of available upgrades.
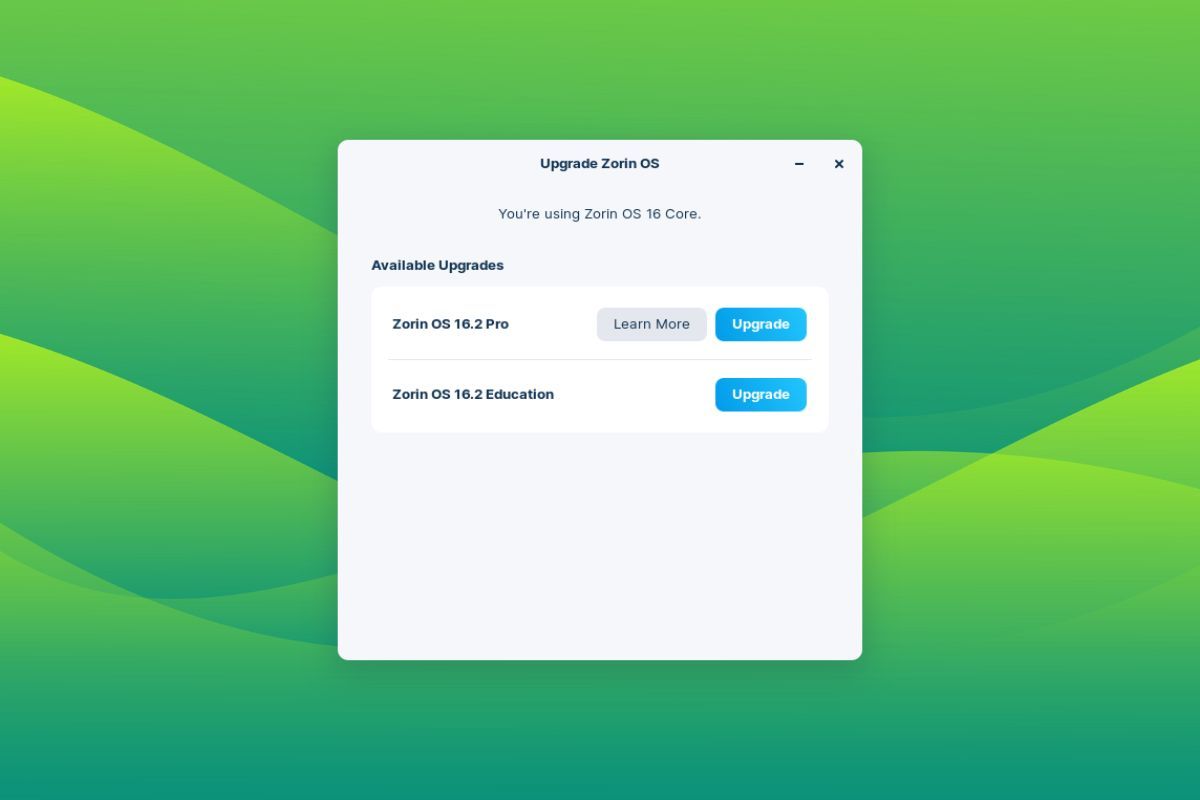
When you proceed, you can either choose from a normal installation with all the bells and whistles, or you can go for the minimal installation with the core utilities.
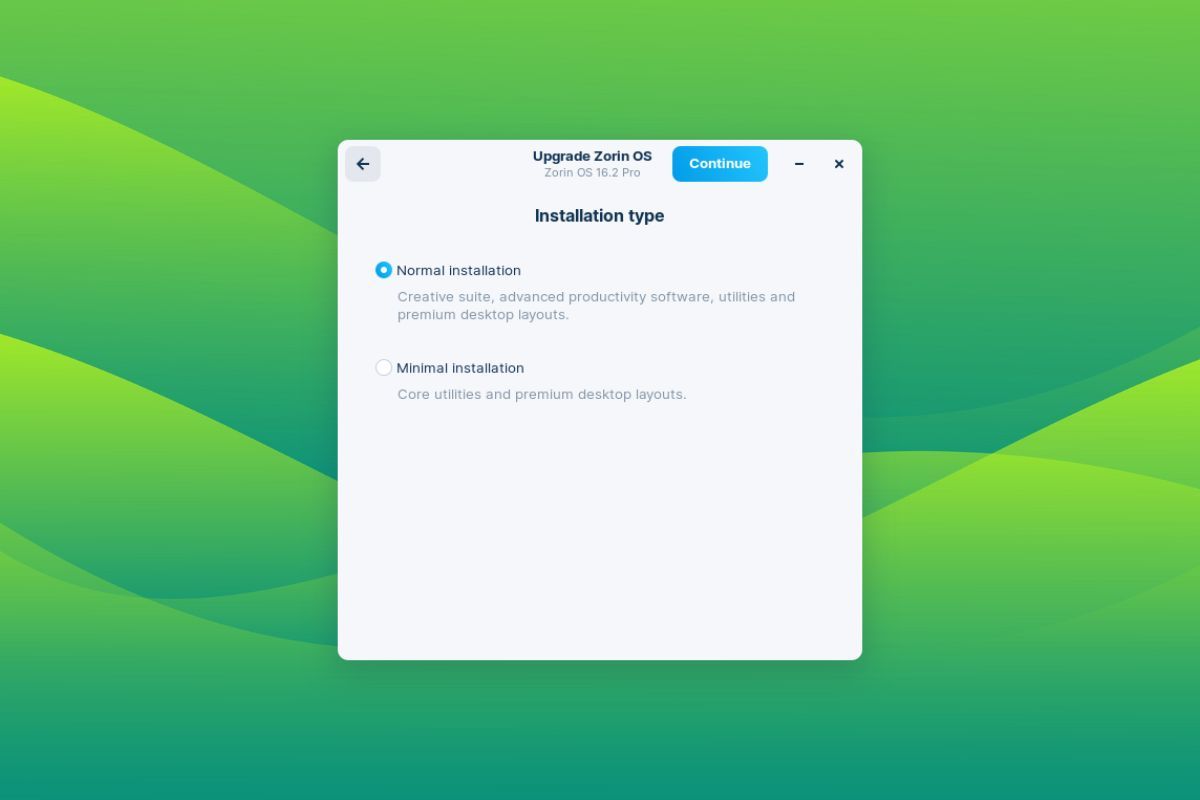
**If you are upgrading to Zorin OS Pro**, you must enter your email address and support code to proceed with the upgrade.
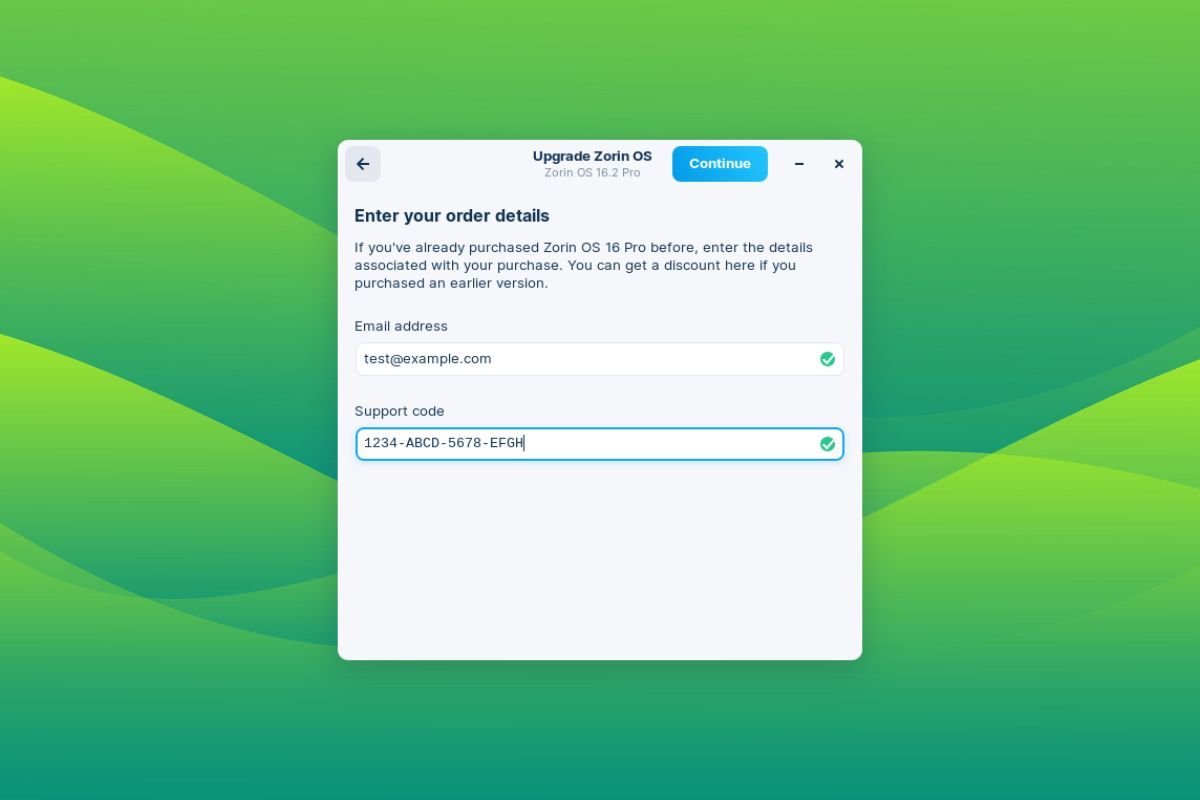
After that, you will be shown a final prompt screen for beginning the upgrade.
They recommend you back up your data beforehand. If something were to go wrong during the upgrade process, you would have something to fall back to.
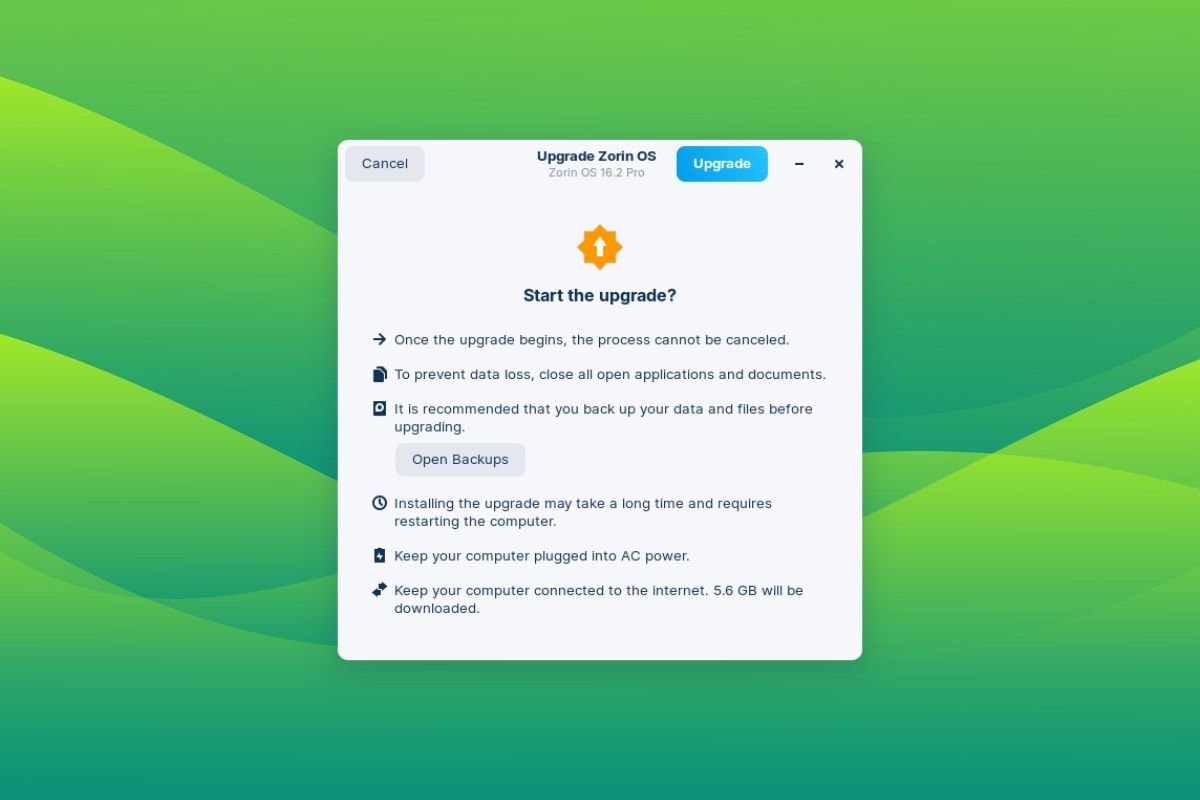
When the upgrade process starts, a progress screen is shown with all the essential upgrade stages being highlighted.

After everything is set, you can reboot your system to finish the OS upgrade process.

## 📖 How to Access Zorin OS Updater
All you need to do is **update your system** to get the new Zorin OS Upgrade tool installed.
However, it is **currently in beta testing** and not yet available as a stable tool. You can expect it in the next few weeks.
You can try manually installing the beta version at your risk.
Open the terminal and enter these commands:
```
sudo apt update
sudo apt install zorin-os-upgrader
```
Then, to start the upgrade procedure, launch the '**Upgrade Zorin OS**' app, and follow the on-screen instructions.
**For users of Zorin OS 15: **If you don't see any upgrade options when you first launch the upgrade app, then you will need to run the following command in the terminal:
`gsettings set com.zorin.desktop.upgrader show-test-upgrades true`
You can read the [official help guide](https://help.zorin.com/docs/getting-started/upgrade-zorin-os/?ref=news.itsfoss.com#upgrading-from-zorin-os-15-or-newer) for more information.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,995 | 在 Linux 终端显示动画式 ASCII 生日祝福 | https://itsfoss.com/birthday-wish-linux-terminal/ | 2023-07-13T16:25:00 | [
"生日",
"ASCII 艺术"
] | https://linux.cn/article-15995-1.html | 
>
> 通过在 Linux 终端创建 ASCII 生日动画,让你所爱的人的特殊日子更加特别。
>
>
>
生日是特殊的日子,从亲朋好友那里收到生日祝福是非常令人满足和愉悦的。
作为 Linux 用户,你可以通过终端给朋友和家人带来一些酷炫的生日祝福。
这是我为 Abhishek 先生的生日制作的生日卡片(或者说动画)。
我们团队的每个人都非常喜欢它,所以我受到请求要按照它做一个教程。我很乐意满足请求,因为这可能对我们的读者有所帮助 ?
>
> ✋ 这个教程需要在终端中编辑配置文件。熟练使用 Linux 终端和命令会更容易理解和跟随本教程。
>
>
>
### 安装 PyBirthdayWish
PyBirthdayWish 是一个小型的 Python 程序,通过它你可以创建漂亮的终端生日祝福,还可以播放音乐!
这个程序本身在 Ubuntu 的默认软件仓库中不可用,你需要使用 Pip 进行安装。
>
> **[PyBirthdayWish GitHub](https://github.com:443/hemantapkh/PyBirthdayWish)**
>
>
>
首先,使用以下命令在 Ubuntu 中 [安装 Pip](https://itsfoss.com/install-pip-ubuntu/):
```
sudo apt install python3-pip
```
安装完 Pip 后,你可以克隆该存储库并安装该程序:
```
git clone https://github.com/hemantapkh/PyBirthdayWish.git && cd PyBirthdayWish && pip install -r requirements.txt
```
在他们的存储库中,你可以查看 `.requirements.txt` 文件,了解上述命令中所需的依赖项。
安装完成后,在你克隆的 `PyBirthdayWish` 目录中运行以下命令:
```
python3 PyBirthdayWish.py
```
这将要求你按下 `F11` 键,然后按回车键进入全屏模式,然后播放动画。


这里还有音乐,但这里没有展示。
它非常可定制化。**让我展示一下你可以通过这个工具进行的各种级别的可选定制。**
### 创建默认的生日祝福动画
在上述程序中,有三个用于动画的 Python 文件。它们是 `example`(默认)、`art` 和 `artwithstars`。你可以打开这三个文件来了解其内容。

现在,如果你想使用 `artwithstars` 文件代替默认的 `example` 文件,在 [任何可用的文本编辑器](https://itsfoss.com/command-line-text-editors-linux/) 中打开 `config.py`,将 `arts` 的条目替换为所需的名称,然后保存,如下面的截图所示:

之后,在 `PyBirthdayWish` 目录中运行:
```
python3 PyBirthdayWish.py
```
你将得到新的动画效果。
### 创建自定义的生日祝福
如果你想打印你所爱的人的名字,而不是默认的文字,这需要一点耐心,因为你需要在不破坏原文件的情况下编辑 art 文件。
首先,备份你想要的设计 art 文件。即在同一个 `arts` 目录中将文件复制一份,并给它一个不同的名称,比如 `friend.py`。
现在,用你选择的文本编辑器打开设计 art 文件。将文件中的文字替换为你需要的内容。最好使用符号 `| _ \ /` 等来创建文本和设计。你可以使用一个 [在线工具将文字转换为 ASCII 艺术](https://patorjk.com:443/software/taag/#p=display&f=Big&t=Friend)。

>
> ? 输入一个字符将使动画的其余部分向前移动一个字符。同样,删除一个字符会使设计的其余部分向后移动一个字符。因此,如果删除一个字符,请添加一个空格。同样地,如果在某一行上添加了一个新字符,请删除一个空格。这应该实时进行,这样你就可以查看更改。这样,你就可以使剩余的设计匹配,并在完成时保持外观不变。
>
>
>
编辑完成后保存文件。现在,打开 `config.py` 并将 art 文件更改为你的文件,以显示你所做的更改。

现在你可以运行程序,以获得你所需的文字出现在动画中:
```
python3 PyBirthdayWish.py
```
### 使用自己的音乐文件
你可以使用自己的音乐文件作为这个动画的一部分。
>
> ? 如果你计划在 YouTube 或其他网站上上传视频,请使用无版权的音乐以避免问题。
>
>
>
将你的音乐文件复制到克隆的目录中。

编辑 `config.py` 文件以添加新的音乐,如下面的截图所示:

完成!现在,如果执行运行命令 `python3 PyBirthdayWish.py`,自定义音乐将与动画一起播放。
### 创建一个可执行文件
**如果你想将上述祝福消息作为可执行文件发送给朋友,这也是可行的。**
关联的 `pyinstaller` 将安装到 `.local/bin` 目录中,它不在你的路径中。
所以使用以下命令将该目录添加到你的路径中,[添加到你的路径中](https://itsfoss.com/add-directory-to-path-linux/):
```
export PATH=$PATH:/home/team/.local/bin
```
要使其永久生效,将其添加到你的 `~/.bashrc` 文件中。
当你完成 art 文件的编辑并更改配置文件以反映更改后,使用以下命令创建一个可执行文件:
```
pyinstaller --noconfirm --onefile --console --icon "icon.ico" --no-embed-manifest --add-data "arts:arts/" --add-data "config.py:." --add-data "HappyBirthday.mp3:." --add-data "PyBirthdayWish.py:." "PyBirthdayWish.py"
```
它将在 `PyBirthdayWish/dist` 目录下创建一个名为 `PyBirthdayWish` 的可执行文件。

将此可执行文件复制并发送给任何想查看它的人。他们可以使用以下命令执行它:
```
./PyBirthdayWish
```
>
> ? 请始终谨慎运行来自未知外部来源的可执行文件。
>
>
>
### 更多终端乐趣
像生日一样,圣诞节也是一个特殊的时刻。如果你愿意,你可以给你的 Linux 桌面增添一些节日气氛。
>
> **[用 Linux 的方式庆祝圣诞节:为你的 Linux 系统增添圣诞气氛](https://itsfoss.com/christmas-linux-wallpaper/)**
>
>
>
如果你喜欢 ASCII 动画,你可能也会喜欢 ASCII 艺术。
>
> **[在 Linux 终端将图像转换为 ASCII 艺术图像](https://itsfoss.com/ascii-image-converter/)**
>
>
>
为什么就止步于此呢?探索更多 ASCII 工具吧。
>
> **[在 Linux 终端生成 ASCII 艺术并从中获得乐趣的 10 个工具](https://itsfoss.com/ascii-art-linux-terminal/)**
>
>
>
享受以这种有趣的方式使用 Linux ?
? 如果你在使用这个工具时遇到任何问题,请告诉我,我会尽力在我所能的范围内提供帮助。
*(题图:MJ/dfa0185d-e9f9-4c1a-886e-e42c9bb8d687)*
---
via: <https://itsfoss.com/birthday-wish-linux-terminal/>
作者:[Sreenath](https://itsfoss.com/author/sreenath/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Birthdays are special occasions, and it’s very satisfying and a pleasure to get birthday wishes from loved ones.
As a Linux user, you can surprise our friends and family with some cool birthday wishes from the terminal.
Here's a birthday card (or should I say animation) I created for the birthday of Abhishek Sir.
Everyone in the team liked it so much that I was requested to do a tutorial on it. I am only glad to comply as it may help our readers :)
This tutorial requires editing config files in the terminal. Proficiency with Linux terminals and commands make it easier to follow this tutorial.
## Install PyBirthdayWish
PyBirthdayWish is a small Python program through which you can create beautiful terminal birthday wishes. With music too!
The program itself is not available in the default repositories of Ubuntu. You need to install it using Pip.
First, [install pip in Ubuntu](https://itsfoss.com/install-pip-ubuntu/), using the command below:
`sudo apt install python3-pip`
Once Pip is installed, you can clone the repo and install the program:
`git clone https://github.com/hemantapkh/PyBirthdayWish.git && cd PyBirthdayWish && pip install -r requirements.txt`
On their repo, you can check the `.requirements.txt`
file to know what are the requirements as mentioned in the above command.
After the installation is complete, inside the `PyBirthdayWish`
directory, that you have cloned, run the command below:
`python3 PyBirthdayWish.py`
This will ask you to press F11 and then enter to go full screen mode and then play the animation.
Birthday Wish Animation in Terminal
There is music too, but not shown here.
It's highly customizable. **Let me show various levels of optional customization you can do with this tool.**
## Create the default birthday wish
In the above program, there are three wish Python files that can be used for the animation. They are, * example *(default),
*and*
`art`
*. You can open these three files in text editor to get an overview.*
`artwithstars`

Now, if you want to use the * artwithstars* file instead of the default example, open the
*in*
`config.py`
[any available text editor](https://itsfoss.com/command-line-text-editors-linux/), replace the
*entry with the required name and save it, as shown in the screenshot below:*
`arts`
After that, in the `PyBirthdayWish`
directory, run:
`python3 PyBirthdayWish.py`
And you will get the new animation.
## Create a custom birthday wish
What if you want to print the name of your loved one, instead of the default text? This needs a little bit of patience because you need to edit the art file without destroying it.
First, make a backup copy of the design art files you want. Which is basically copying the file in the same `arts`
directory but with a different name; say `friend.py`
.
Now, open the design art file with the text editor of your choice. Replace the text in the art file with the one you need. It will be wise to use the symbols `| _ \ /`
for creating the text, design etc. You can use an [online tool to convert text to ASCII](https://patorjk.com/software/taag/#p=display&f=Big&t=Friend).
Typing one character moves the rest of the animation one character forward. Similarly, removing a character moves the rest of the design, one character backward. So, you should add a space if you remove a character. Similarly, remove one space if you added a new character on a particular line. This should be done in real-time so that you can view the changes. This way, you can match the rest of the design and not destroy the looks, when completed.
After completing the edit, save it. Now, open *config.py* and change the art file to show your file.
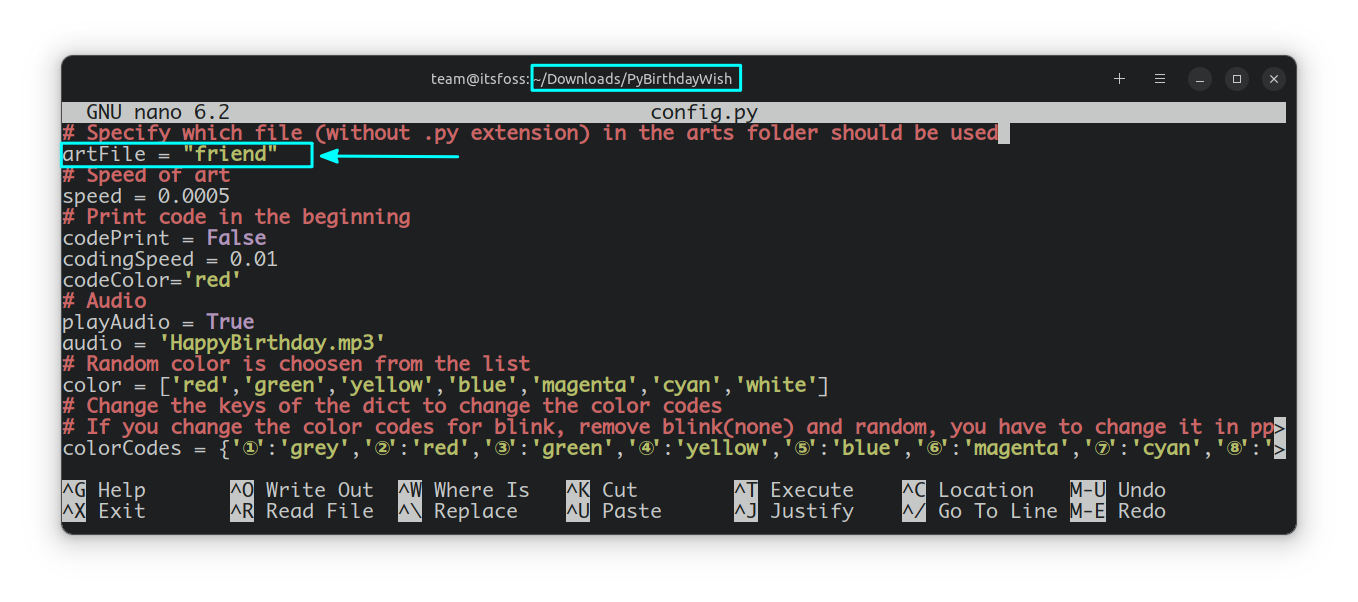
You can now run to get your required text inside the animation:
`python3 PyBirthdayWish.py`
## Use your own music file
You can use your own music file as part of this animation.
If you are planning to upload the video on YouTube of other such sites, please use copyright-free music to avoid issues.
Copy your music file inside the cloned directory.
Edit the *config.py* file to add the new music, as shown in the screenshot below:
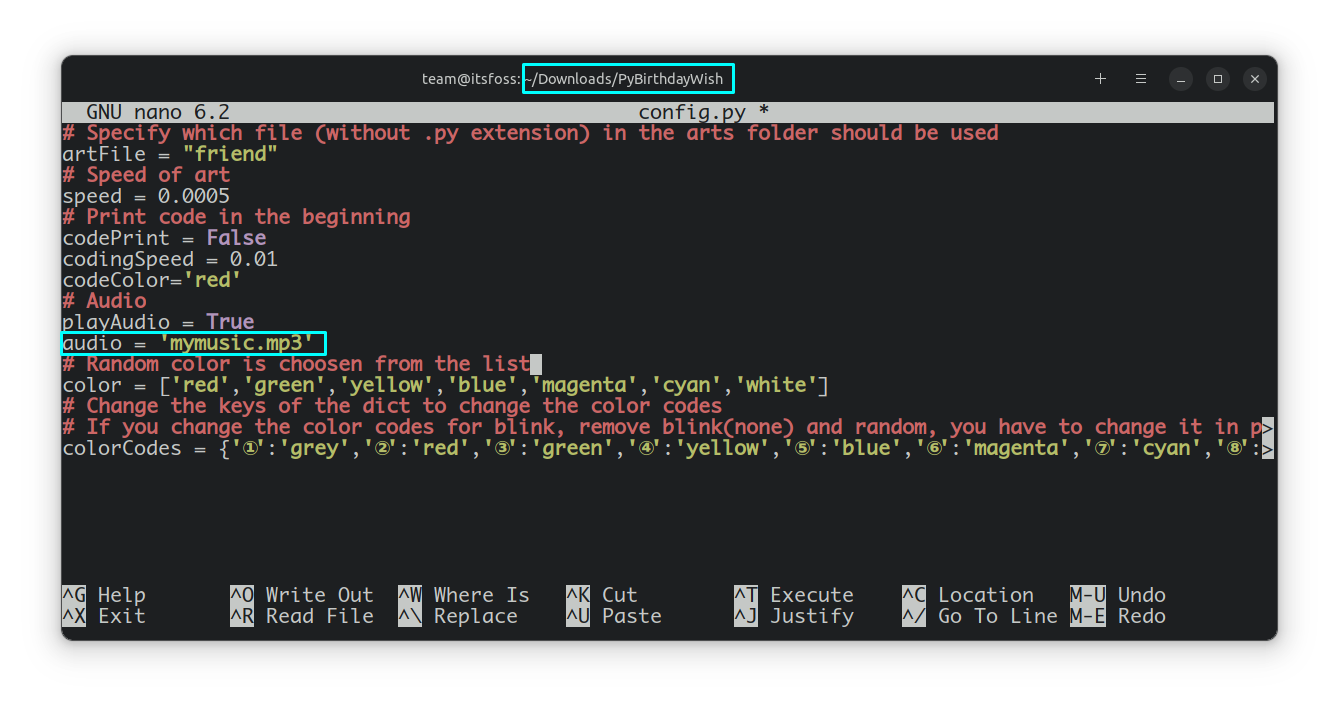
Done! Now, if you execute the run command, `python3 PyBirthdayWish.py`
, the custom music will be played along with the animation.

#### New Book: Efficient Linux at the Command Line
Pretty amazing Linux book with lots of practical tips. It fills in the gap, even for experienced Linux users. Must have in your collection.
[Get it from Amazon](https://amzn.to/3MPjiHw)
## Create an executable
**If you want to send the above wish message as an executable to a friend, there is a way for this too. **
An associated pyinstaller will be installed to the `.local/bin`
directory, which will not be on your path.
So [add that directory to your path](https://itsfoss.com/add-directory-to-path-linux/) using:
`export PATH=$PATH:/home/team/.local/bin`
To make it permanent, add it to your `~/.bashrc`
file.
After you are done with the art file editing and changing the config file to reflect the change, use the command below to create an executable:
`pyinstaller --noconfirm --onefile --console --icon "icon.ico" --no-embed-manifest --add-data "arts:arts/" --add-data "config.py:." --add-data "HappyBirthday.mp3:." --add-data "PyBirthdayWish.py:." "PyBirthdayWish.py"`
It will create an executable file named “PyBirthdayWish” to the `PyBirthdayWish/dist`
directory.
Copy this executable and send to anybody who want to view this. They can execute it with:
`./PyBirthdayWish`
Always be cautious while running executables from unknown external sources.
## More terminal fun
Like Birthdays, Christmas too is a special occasion. You can give some festive touch to your Linux desktop if you want.
[Celebrate Christmas in Linux Way: Give Your Linux System a Christmas TouchIt’s the holiday season and many of you might be celebrating Christmas already. From the team of It’s FOSS, I would like to wish you a Merry Christmas and a happy new year. To continue the festive mood, I’ll show you some really awesome Linux wallpapers on](https://itsfoss.com/christmas-linux-wallpaper/)

If you liked ASCII animation, you may like ASCII art, too.
[Convert Images to ASCII Art in Linux TerminalWant some fun in the Linux terminal? How about converting a regular image into ASCII art? This tool lets you convert any image into ASCII art.](https://itsfoss.com/ascii-image-converter/)

And why just stop here? Explore more ASCII tools.
[10 Tools to Generate and Have Fun With ASCII Art in Linux TerminalLinux terminal is not as scary as you think. Of course, it could be intimidating in the beginning but once you know the terminal better, you start loving it. You are likely to use the terminal for serious work. But there are many fun stuff you can do in the](https://itsfoss.com/ascii-art-linux-terminal/)

Enjoy using Linux in this fun way :)
*🗨 Let me know if you face any issues with this tool and I'll try to help in my capacity.* |
15,996 | Linux 爱好者线下沙龙:LLUG 2023 上海来咯 | https://jinshuju.net/f/R1YHy0 | 2023-07-13T17:59:00 | [
"LLUG"
] | https://linux.cn/article-15996-1.html | 
6 月份,LLUG 在北京亦庄举办了 2023 年的 [第一次活动](/article-15883-1.html)。活动取得了圆满的 [成功](/article-15929-1.html),不少小伙伴来线下和我们一起交流技术、分享自己工作中的所思所想。其后,全国各地的小伙伴纷纷响应,想知道下一场 LLUG 活动在哪里举办。
终于, 7 月场的活动定了,离开帝都,我们来到了魔都 - **上海。**
**2023 年 7 月 23 日下午,我们将在上海举行 LLUG 2023 · 上海场,**欢迎大家来到现场,和我们一起交流技术,分享自己工作过程中的所思所想。
本次活动依然由 Linux 中国和 OpenAnolis 社区联合主办,奇虎 360、图灵社区、SlashData 等提供了支持。
> OpenAnolis 社区是国内的顶尖 Linux 发行版社区,我们希望在普及 Linux 知识的同时,也能让中国的 Linux 发行版,为更多人知晓,推动国产发行版的发展和进步。
本次活动我们除了特邀嘉宾分享之外,还增加了“闪电演讲”环节,自愿邀请参与线下活动的同学们,用 5 分钟时间,介绍自己想要分享的内容。
活动地点:**上海市尚嘉中心附近**

如果你在上海,又对 Linux、开源、极客、技术等主题感兴趣,欢迎你来到 LLUG 的线下会场,和我们一起,畅聊技术!来到现场参与现场互动,我们将送上技术图书等奖品,鼓励你的勇敢!


如果你因为有事,没办法来到线下,那也没问题,我们的活动也会在 Linux 中国视频号、Linux 中国 B 站账号等开启同步直播。
当然,我们更希望你能亲自来到线下,和我们一起畅聊技术!感受久违的当面聊技术的快乐!
**点击下面的链接,填写问卷即可报名活动,并在活动前收到我们的提醒**~此外,也可以在问卷中反馈你想听的内容,我们将竭尽所能,邀请行业专家,针对大家感兴趣的话题进行分享。
>
> **[点此报名](https://jinshuju.net/f/R1YHy0)**
>
>
>
*(题图:MJ/20bf5b71-9de8-4bbf-ab63-a5cc5cc215bc)*
| 302 | Found | null |
15,998 | Linux 桌面的十个最佳光标主题 | https://www.debugpoint.com/best-cursor-themes/ | 2023-07-14T13:43:00 | [
"主题",
"光标"
] | /article-15998-1.html | 
>
> 一个用于各种 Linux 桌面的最佳光标主题的混合列表。
>
>
>
在 [定制 Linux 桌面](https://www.debugpoint.com/category/themes) 时,我们经常忽视光标主题。一个经过深思熟虑选择的光标主题可以提升你的 Linux 桌面,增添个性化的风格并提升整体美感。从简约而精致的设计到奇妙而有趣的动画,这里是十个适合每个人的最佳光标主题。
### 如何在 Linux 桌面下载和安装光标主题
对于下面列出的所有主题,在相应页面上找到下载链接。下载压缩文件并解压缩。然后,将顶层的主题文件夹复制到 Linux 发行版中的 `~/.icons` 或 `/usr/share/icons` 目录中。然后按照下面的步骤进行相应桌面的设置。
#### Xfce
从应用菜单中选择 “<ruby> 设置 <rt> Settings </rt></ruby> > <ruby> 设置管理 <rt> Settings manager </rt></ruby> > <ruby> 鼠标和触摸板 <rt> Mouse and Touchpad </rt></ruby>”。然后转到 “<ruby> 主题 <rt> Themes </rt></ruby>” 选项卡并选择相应的光标主题。你还可以选择光标大小。

#### KDE Plasma
从 KDE 应用菜单打开 “<ruby> 系统设置 <rt> System Settings </rt></ruby>”。然后选择 “<ruby> 工作空间主题 <rt> Workspace theme </rt></ruby> > <ruby> 光标 <rt> Cursors </rt></ruby>”。选择主题并点击 “<ruby> 应用 <rt> Apply </rt></ruby>”。

#### GNOME
对于 GNOME 桌面,请安装 GNOME “<ruby> 调整 <rt> Tweaks </rt></ruby>” 工具。你可以在基于 Debian 的系统上使用以下命令进行安装。
```
sudo apt install gnome-tweak-tool
```
安装后,你可以打开 GNOME 调整工具并选择 “<ruby> 外观 <rt> Appearance </rt></ruby>”。然后从下拉菜单中选择光标。

### Linux 的最佳光标主题
#### Bibata
Bibata 是一套备受赞誉的光标主题,已成为寻求个性化体验的用户的最爱。这个主题因其独特的圆角外观和各种颜色选项而最近变得流行起来。
这个多功能主题有各种变体,包括 Bibata Original Amber 和 Bibata Modern Amber,分别具有带有黄色调的尖锐或圆角边缘。同样,Bibata Original Classic 和 Bibata Modern Classic 提供带有尖锐或圆角边缘的黑色光标。而 Bibata Original Ice 和 Bibata Modern Ice 提供带有尖锐或圆角边缘的白色光标。



你可以从下面的页面下载这个主题。
>
> **[下载 Bibata 光标(Ice)](https://www.gnome-look.org/p/1197198/)**
>
>
>
#### Phinger
Phinger 光标以其复杂的设计和精心的工程而闻名,是最复杂和“过度设计”的光标主题之一。它与 GNOME、MATE 和 Xfce 桌面环境兼容,并为不同 Linux 发行版的用户提供了多功能选项。该主题拥有黑白两种变体,确保简约而精致的光标体验。

你可以从下面的页面下载它,并按照上面给出的说明进行安装。
>
> **[下载 Phinger 光标](https://github.com/phisch/phinger-cursors)**
>
>
>
#### Comix
Comix 光标是个早期的光标主题,为你的 Linux 桌面注入了令人愉悦的漫画风格。这个 X11 鼠标主题包含 12 个独特的光标主题,每个主题都设计成在提升桌面工作流程的同时唤起一种活泼有趣的氛围。

Comix 光标提供了六种颜色选择(黑色、蓝色、绿色、橙色、红色和白色),为用户提供了一系列选择,以适应他们的个人风格和桌面美学。Comix 主题中的每个光标都具有微妙的阴影效果,为其注入活力和深度。这种动态元素增强了光标的视觉吸引力,并为桌面工作流程增添了一种动感。
你可以从下面的页面下载这个光标主题。
>
> **[下载 Comix 光标](https://www.gnome-look.org/p/999996)**
>
>
>
#### McMojave
McMojave 光标从 macOS 获得灵感,是一个 x-cursor 主题,它基于流行的 capitaine-cursors 主题。这个主题旨在重新创建在 macOS 中找到的熟悉的光标样式,让 Linux 用户在他们的桌面上享受一丝 Mac 的体验。
(LCTT 译注:x-cursor 是一种标准,用于描述和命名光标主题的文件格式和规范。x-cursor 主题通常用于 Linux 操作系统中的桌面环境,如 GNOME、KDE 和 Xfce。)

尽管 McMojave 光标旨在重现 macOS 的光标体验,但它也为喜欢添加个人特色的用户提供了自定义选项。用户可以根据自己的喜好进行调整和修改,从而在 Linux 上实现个性化的光标体验。
你可以从下面的页面下载 McMojave 光标。
>
> **[下载 McMojave 光标](https://github.com/vinceliuice/McMojave-cursors)**
>
>
>
#### Layan
Layan 光标是一个 x-cursor 主题,灵感来自受欢迎的 Layan GTK 主题,并融入了成熟的 capitaine-cursors 的元素。这个独特的光标主题给 Linux 桌面体验增添了一丝时髦感。
与传统的箭头形状光标不同,Layan 光标采用了独特的椭圆形状设计。这种非传统的形状为整体光标体验增添了一种活泼和时髦的元素,使它与更传统的主题有所区别。

你可以使用下面的链接进行下载。
>
> **[下载 Layan 光标](https://www.gnome-look.org/p/1365214/)**
>
>
>
#### Material
Material 光标是 Linux 用户长期以来的最爱,提供了一个视觉上吸引人的光标主题,得到了无数忠实用户的认可。该光标主题有三种颜色变体,即 Material(蓝灰)、Dark 和 Light,以及从 24 像素到 64 像素的多种尺寸选项,适应了各种偏好和桌面环境。

成千上万的人每天都依赖于这个光标主题,展示了它持久的吸引力和可靠性。
凭借其三种颜色变体、多样的尺寸选项和广泛的采用,这个光标主题旨在提升你 Linux 桌面的美学,提供令人愉悦和沉浸式的光标体验。
你可以使用下面的链接下载这个光标主题。
>
> **[下载 Material 光标](https://www.gnome-look.org/p/1346778/)**
>
>
>
#### Oreo
Oreo 光标以其丰富多彩的材质设计和迷人的动画为你的 Linux 桌面增添了令人愉悦的元素。这些光标旨在为你的光标体验增添一丝奇趣和个性。

Oreo 光标的独特之处在于其迷人的动画效果。这些动画光标注入了一种活泼和生动的元素,使你与桌面的交互感觉更具吸引力和愉悦感。
此外,这个主题通过提供自定义颜色生成器更进一步。用户可以使用配置文件创建自己的光标颜色方案,为光标设计带来无限的可能性和个性化。
你可以使用下面的链接下载这个主题。
>
> **[下载 Oreo 光标](https://www.gnome-look.org/p/1360254/)**
>
>
>
#### Bibata Rainbow
Bibata Rainbow 光标扩展自受欢迎的 Bibata 光标主题,引入了半动画的彩虹颜色,增强了你的 Linux 桌面体验。这些光标是使用 clickgen 精心制作,并用 puppeteer 渲染的,确保高质量的视觉效果和平滑的动画。

Bibata Rainbow 中的每个光标包含大约 23 个帧,即使在 HiDPI(高像素密度)环境下,也能实现平滑的动画效果。这确保了具有高分辨率显示屏的用户可以享受无缝和视觉上令人愉悦的光标体验。
你可以使用下面的链接下载 Bibata Rainbow 光标主题。
>
> **[下载 Bibata Rainbow 光标](https://www.gnome-look.org/p/1445634/)**
>
>
>
#### Miniature
Miniature 光标是从一个同名 Windows 光标主题移植的,它提供了一种以小尺寸为特点的独特光标体验。顾名思义,这些光标被设计成紧凑型,可能非常适合各种用途。该主题整体采用清晰的白色,并提供了一个扁平设计和一个带有微妙阴影效果的变体。

你可以从下面的链接下载这个光标主题。
>
> **[下载 Miniature 光标](https://github.com/nxll/miniature)**
>
>
>
#### Capitaine
Capitaine 光标是一个 x-cursor 主题,灵感来自 macOS,基于 KDE Breeze 图标包,提供了一种视觉上协调的光标体验。这个光标主题旨在与 La Capitaine 图标包完美配合,为你的 Linux 桌面创建一个统一的视觉风格。

Capitaine 光标提供了白色和黑色两种变体,让用户可以根据自己的桌面环境或个人偏好选择最合适的颜色。无论你喜欢浅色还是深色光标,Capitaine 光标都能满足你的需求。
你可以使用下面的链接下载这个主题。
>
> **[下载 Capitaine 光标](https://github.com/keeferrourke/capitaine-cursors)**
>
>
>
### 结论
在本文中,我们介绍了一些令人着迷的 Linux 光标主题,展示了一系列受欢迎的选择,可以改变你与桌面的交互方式。我希望你能找适合你 Linux 桌面上喜爱的主题或图标包的完美光标。
以上所有的光标主题都在最新的发行版和桌面版本中进行了测试。你可以尝试它们!
图片来源:各个主题作者。
*(题图:MJ/35aaca9e-9ff3-49f2-b311-20e7fcfb5c9d)*
---
via: <https://www.debugpoint.com/best-cursor-themes/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,999 | 构建成功的开源项目的重要建议 | https://opensource.com/article/22/9/build-open-source-project | 2023-07-14T14:56:53 | [
"开源项目"
] | https://linux.cn/article-15999-1.html | 
>
> 使用这些步骤来为你的第一个或接下来的项目打下坚实的基础。
>
>
>
[开源](https://opensource.com/resources/what-open-source) 是一个蓬勃发展且有益的生态系统,它通过分散模式和社区贡献开发的软件,公开解决社区和行业问题。
随着这个生态系统的爆炸式发展,许多开发者想要参与并且构建新的开源项目。问题是:如何成功实现这一目标呢?
这篇文章将会揭秘开源项目的生命周期与结构。给你一个对开源项目内部运作的概述,并根据我个人的经验,向你展示如何构建一个成功和可持续发展的项目。
### 对开源的简单概述
<ruby> <a href="https://opensource.org"> 开源促进会 </a> <rt> Open Source Initiative </rt></ruby>(OSI)提供了对“<ruby> 开源 <rt> Open Source </rt></ruby>”的正式、详细的定义,但是维基百科提供了一个很好的总结:
>
> 开源软件是指根据许可证发布的计算机软件,版权持有人授予用户使用、研究、更改和向任何人、为了任何目的分发软件和它的源代码的权利。
>
>
>
开源软件通常在网络上有公开的代码,它由多人合作或一人开发。这就需要与来自不同地区、不同文化和不同技术背景的人合作,而且往往是远程合作。
### 开源项目的构成
就像人类的身体,一个开源项目由多个结构组成,这些结构构成了整个系统。我认为它们是两个分支:人员(微观)和文档(宏观)。
#### 分支一:人员
通常,一个开源项目包括以下人群:
* 创建者:创建项目的人
* 维护者:积极管理整个项目的人
* 贡献者:为项目做贡献的人(像你一样的人!)
* 用户:使用这个项目的人,包括开发者和非技术客户
* 工作组:将贡献者分成特定领域的小组,专注于围绕特定主题领域(如文档、指引、测试、DevOps、代码审查、性能、研究等)的集合。
* 赞助人:为项目提供资金支持的人
当你准备构建一个新项目时,你需要考虑以上列表中的每一个群组。你对他们每个人有什么计划?
* 对于维护者,请确定任用维护者的标准。通常,积极的贡献者就是最适合的维护者。
* 对于用户和贡献者,你需要准备可靠的文档、引导流程和他们使用你的项目取得成功所需的一切。
* 对于工作组,请确定你是否需要它们,以及你的项目将来如何有逻辑地拆分。
* 最后,对于赞助人,你必须提供足够的数据和有关你项目的信息,以便他们选择赞助你。
你不必在你项目的起始阶段解决上面所有问题。然而,在早期阶段思考它们是很明智的,这样你就能打下正确的基础,确保未来的扩建项目能够站稳脚跟并取得成功。
#### 分支二:文档
开源项目通常包括下列文档,通常为纯文本或 markdown 格式:
* 许可证(`License`): 这份法律文件解释了如何以及在何种程度上可以自由使用、修改和共享本项目。OSI 网站上有 OSI 认可的许可证列表。如果没有明确的许可证,你的项目在法律上就不是开源的!
* 行为准则:该文件概述了任何决定以任何方式参与项目的人的规则、规范、可接受做法和责任(包括当有人违反任何规则时会发生什么)。[贡献者公约](https://www.contributor-covenant.org/version/2/1/code_of_conduct) 是一个很好的示例,它是开源的(采用知识共享许可协议)。
* 自述文件(`README`):这个文件向新用户介绍你的项目。在很多 Git 托管网站上,比如 GitLab、GitHub 和 Codeberg,自述文件会显示在仓库的初始文件列表下。这里通常会提供文档,以及其他必要文档的链接。
* 文档(`Documentation`):这是一个包含所有本项目文件资源的文件或目录,包括指南、API 参考、教程等。
* 贡献指南(`Contributing`):包含一份说明如何为项目做出贡献的文件,包括安装指南、配置等。
* 安全(`Security`):包括一个解释如何提交漏洞报告或安全问题的文件。
此外,一个项目通常有用于议题、支持和协作的网页。
大致包括:
* 议题或错误报告:用户可以报告错误的地方。该页面还为开发人员提供了一个地方,让他们可以分配自己的任务来修复一个或多个错误。
* 拉取或合并请求:提供功能增强建议和错误解决方案的地方。这些补丁可以由任何人创建,由维护者审核,然后合并到项目代码中。
* 讨论:维护者、贡献者和用户讨论开源项目的地方。它可以是一个专门的网站,也可以是协作编码网站中的一个论坛。
大多数项目还通过在线聊天的形式为社区成员之间的对话和互动提供交流渠道。
### 许可证
[许可证](https://opensource.com/tags/licensing) 也许是创建开源项前需要考虑的最简单但也是最重要的标准。许可证定义了允许使用、修改和共享项目源代码和其他组件的条款和条件。
许可证包含大量的法律术语,很多人并不完全理解。我使用 [choosealicense.com](https://choosealicense.com),它可以帮助你根据你的目标社区、你从使用你的代码的人那里获得补丁的愿望,或者你允许别人使用你的代码而不分享他们对你的代码所做的改进来选择许可证。

这为何时使用 MIT 许可或 GNU GPLv3 许可提供了指导。它还建议为社区做出贡献的人们使用该社区所偏好的许可证。该图表还指出,还有更多许可证可供选择。网站 [choosealicense.com](http://choosealicense.com) 有一个基于文本的版本,可以链接到更详细的信息。
### 创建一个开源项目的 13 个阶段
现在是关键问题:如何开始开源软件项目?
以下是我所认为的开源项目的各个阶段。
1. 集思广益,撰写提纲,妥善记录。
2. 开始根据你的想法进行开发。这通常包括确定要使用的正确工具和技术栈、编写一些代码、对代码进行版本控制、调试、喝点咖啡、在 StackOverflow 上闲逛、使用其他开源项目、睡觉、构建一些东西来解决确定的问题 —— 或者只是为了好玩!
3. 在本地测试项目,根据需要编写一些单元测试和集成测试,根据需要设置 [CI/CD 管道](https://opensource.com/article/19/9/intro-building-cicd-pipelines-jenkins),创建一个暂存分支(在合并到主分支之前测试代码的测试分支),并完成部署项目所需的其他工作。
4. 编写 [良好有效的文档](https://slides.com/bolajiayodeji/effective-oss-docs)。这应该包括你的项目是做什么的,为什么它是有用的,如何开始使用它(使用、安装、配置、贡献),以及人们在哪里可以得到支持。
5. 确保记录所有你希望使用的代码约定。使用诸如 <ruby> 代码检查工具 <rt> Linter </rt></ruby>、代码格式化工具、Git 钩子和 <ruby> 注释规范化工具 <rt> Commitizen </rt></ruby> 命令行工具等工具来执行这些约定。
6. 选择合适的许可证并创建自述文件。
7. 在互联网上发布项目(可能最初是一个私有的资源库,在这一步将其公开)。
8. 建立发布和记录更新日志的流程(你可以使用 Changesets 等工具)。
9. 向全世界推广项目!你可以在社交媒体上发帖、创办新闻简讯、私下与朋友分享、进行产品发布、现场直播或其他任何你知道的传统营销策略。
10. 使用任何可用的融资平台寻求资金支持,如 Open Collective、GitHub Sponsors、Patreon、Buy me a Coffee、LiberaPay 等。当你在这些平台上创建账户时,请在项目文档和网站中添加相关链接。
11. 围绕你的项目建立一个社区。
12. 在必要时,考虑引入工作组,将项目管理分成合理的部分。
13. 不断实施新理念,维持项目背后的资源和人员。
随着项目的进展,对项目的不同部分进行评估非常重要。这将为你提供可用于评估和未来发展战略的数据。
### 现在开始一个项目吧!
我希望这篇文章能帮助你推进你一直在考虑的项目。
你可以将其用作指南,并在构建你的一流开源软件项目时填补我遗漏的任何空白。
*(题图:MJ/a22b4011-9b1e-41e6-a73f-bdeac4858007)*
---
via: <https://opensource.com/article/22/9/build-open-source-project>
作者:[Bolaji Ayodeji](https://opensource.com/users/bolajiayodeji) 选题:[lkxed](https://github.com/lkxed) 译者:[wcjjdlhws](https://github.com/wcjjdlhws) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Open source](https://opensource.com/resources/what-open-source) is a flourishing and beneficial ecosystem that publicly solves problems in communities and industries using software developed through a decentralized model and community contributions. Over the years, this ecosystem has grown in number and strength among hobbyists and professionals alike. It's mainstream now—even proprietary companies use open source to build software.
With the ecosystem booming, many developers want to get in and build new open source projects. The question is: How do you achieve that successfully?
This article will demystify the lifecycle and structure of open source projects. I want to give you an overview of what goes on inside an open source project and show you how to build a successful and sustainable project based on my personal experience.
## A quick introduction to open source
The [Open Source Initiative](https://opensource.org) (OSI) provides a formal, detailed definition of open source, but Wikipedia provides a nice summary:
Open source software is computer software that is released under a license in which the copyright holder grants users the rights to use, study, change, and distribute the software and its source code to anyone and for any purpose.
Open source software is public code, usually on the internet, developed either collaboratively by multiple people or by one person. It's about collaborating with people from different regions, cultures, and technical backgrounds, often working remotely. This is why creating a project that welcomes everyone and enables different people to work together is essential.
## The anatomy of an open source project
Like the human body, an open source project is made up of several structures that form the entire system. I think of them as two branches: the people (microscopic) and the documents (macroscopic).
### Branch one: people
Generally, an open source project includes the following sets of people:
**Creators:**Those who created the project**Maintainers:**Those who actively manage the entire project**Contributors:**Those who contribute to the project (someone like you!)**User:**Those who use the project, including developers and nontechnical customers**Working group:**A collection of contributors split into domain-specific groups to focus on a discussion or activity around a specific subject area (such as documentation, onboarding, testing, DevOps, code reviews, performance, research, and so on)**Sponsor:**Those who contribute financial support to the project
You need to consider each group in the list above as you prepare to build a new project. What plan do you have for each of them?
- For maintainers, decide on the criteria you want to use to appoint them. Usually, an active contributor makes the best maintainer.
- For users and contributors, you want to prepare solid documentation, an onboarding process, and everything else they need to succeed when working with your project.
- For working groups, decide whether you need them and how your project may be logically split in the future.
- Finally, for sponsors, you must provide enough data and information about your project to enable them to choose to sponsor you.
You don't need to have all of these figured out at the start of your project. However, it's wise to think about them at the early stages so you can build the right foundations to ensure that future additions stand firm and lead to a successful project.
### Branch two: documents
Open source projects usually include the following documents, usually in plain text or markdown format:
**License:**This legal document explains how and to what extent the project can be freely used, modified, and shared. A list of OSI-approved licenses is available on the OSI website. Without an explicit license, your project is not legally open source!
**Code of conduct:**This document outlines the rules, norms, acceptable practices, and responsibilities of anyone who decides to participate in the project in any way (including what happens when someone violates any of the rules). The[Contributor Covenant](https://www.contributor-covenant.org/version/2/1/code_of_conduct)is a good example and is open source (licensed under a Creative Commons license).
**README:**This file introduces your project to newcomers. On many Git hosting websites, such as GitLab, GitHub, and Codeberg, the README file is displayed under the initial file listing of a repository. It's common to feature documentation here, with links to other necessary documents.
**Documentation:**This is a file or directory containing all documentation resources for the project, including guides, API references, tutorials, and so on.
**Contributing:**Include a document explaining how to contribute to the project, including installation guides, configuration, and so on.
**Security:**Include a file explaining how to submit vulnerability reports or security issues.
Additionally, a project usually has web pages for issues, support, and collaboration.
Broadly, these include:
**Issues or bug reports:**A place where users can report bugs. This page also provides a place developers can go to assign themselves the task of fixing one or more of them.
**Pull or merge requests:**A place with proposed feature enhancements and solutions to bugs. These patches may be created by anyone, reviewed by the maintainers, then merged into the project's code.
**Discussions:**A place where maintainers, contributors, and users discuss an open source project. This may be a dedicated website or a forum within a collaborative coding site.
Most projects also have a communication channel in the form of an online chat for conversations and interactions between community members.
## Licensing
[Licensing](https://opensource.com/tags/licensing) is perhaps the easiest but most important criterion to consider before creating an open source project. A license defines the terms and conditions that allow the source code and other components of your project to be used, modified, and shared.
Licenses contain tons of legal jargon that many people don't fully understand. I use [choosealicense.com](https://choosealicense.com), which helps you choose a license based on your intended community, your desire to get patches back from those using your code, or your willingness to allow people to use your code without sharing improvements they make to it.

(Bolaji Ayodeji, CC BY-SA 4.0)
## 13 phases of creating an open source project
Now for the essential question: How do you start an open source software project?
Here is a list of what I consider the phases of an open source project.
- Brainstorm your idea, write a synopsis, and document it properly.
- Begin developing your idea. This usually involves figuring out the right tools and stacks to use, writing some code, version controlling the code, debugging, drinking some coffee, hanging around StackOverflow, using other open source projects, sleeping, and building something to solve a defined problem—or just for fun!
- Test the project locally, write some unit and integration tests as required, set up
[CI/CD pipelines](https://opensource.com/article/19/9/intro-building-cicd-pipelines-jenkins)as needed, create a staging branch (a test branch where you test the code live before merging into the main branch), and do anything else you need to deploy the project.
- Write
[good and effective documentation](https://slides.com/bolajiayodeji/effective-oss-docs). This should cover what your project does, why it is useful, how to get started with it (usage, installation, configuration, contributing), and where people can get support.
- Ensure to document all code conventions you want to use. Enforce them with tools like linters, code formatters, Git hooks, and the commitizen command line utility.
- Choose the right license and create a README.
- Publish the project on the internet (you might have a private repository initially, and make it public at this step).
- Set up the processes for making releases and documenting changelogs (you can use tools like Changesets).
- Market the project to the world! You can make a post on social media, start a newsletter, share it with your friends privately, do a product hunt launch, live stream, or any other traditional marketing strategy you know.
- Seek funding support by using any of the available funding platforms, like Open Collective, GitHub Sponsors, Patreon, Buy me a Coffee, LiberaPay, and so on. When you create accounts with these platforms, add a link to it in your project's documentation and website.
- Build a community around your project.
- Consider introducing working groups to break your project's management into logical parts when required.
- Continuously implement new ideas that sustain the resources and people behind your project.
It's important to measure different parts of your project as you progress. This provides you with data you can use for evaluation and future growth strategies.
## Now start a project!
I hope this article helps you move forward with that project you've been thinking about.
Feel free to use it as a guide and fill any gaps I missed as you build your awesome open source software project.
## 2 Comments |
16,001 | Bash 基础知识系列 #3:传递参数和接受用户输入 | https://itsfoss.com/bash-pass-arguments/ | 2023-07-15T09:43:57 | [
"Bash",
"脚本"
] | https://linux.cn/article-16001-1.html | 
>
> 在 Bash 基础系列的这一章中,学习如何向 Bash 脚本传递参数并使它们具有交互性。
>
>
>
来让 Bash 脚本有参数吧 ?
你可以通过向 Bash 脚本传递变量来使其更加有用和更具交互性。
让我通过示例详细向你展示这一点。
### 将参数传递给 Shell 脚本
当你运行 Shell 脚本时,你可以按以下方式向其中添加其他变量:
```
./my_script.sh var1 var2
```
在脚本内部,你可以使用 `$1` 作为第一个参数,`$2` 作为第二个参数,依此类推。
>
> ? `$0` 是一个特殊变量,保存正在执行的脚本的名称。
>
>
>
让我们通过一个实际的例子来看看。切换到保存练习 Bash 脚本的目录。
```
mkdir -p bash_scripts && cd bash_scripts
```
现在,创建一个名为 `arguments.sh` (我想不出更好的名称)的新 Shell 脚本,并向其中添加以下行:
```
#!/bin/bash
echo "Script name is: $0"
echo "First argument is: $1"
echo "Second argument is: $2"
```
保存文件并使其可执行。现在像往常一样运行脚本,但这次向其中添加任意两个字符串。你将看到屏幕上打印的详细信息。
>
> ? 参数由空格(空格、制表符)分隔。如果参数中有空格,请使用(英文)双引号将其引起来,否则它将被视为单独的参数。
>
>
>

>
> ? Bash 脚本最多支持 255 个参数。但对于参数 10 及以上,你必须使用花括号 `${10}`、`${11}`...`${n}`。
>
>
>
正如你所看到的,`$0` 代表脚本名称,而其余参数存储在编号变量中。你还可以在脚本中使用一些其他特殊变量。
| 特殊变量 | 变量描述 |
| --- | --- |
| `$0` | 脚本名称 |
| `$1`、`$2`、……`$9` | 脚本参数 |
| `${n}` | 脚本参数从 10 到 255 |
| `$#` | 参数数量 |
| `$@` | 所有参数 |
| `$$` | 当前 Shell 的进程 ID |
| `$!` | 最后执行的命令的进程 ID |
| `$?` | 最后执行命令的退出状态 |
>
> ?️♀️ 修改上面的脚本以显示参数数量。
>
>
>
#### 如果参数数量不匹配怎么办?
在上面的示例中,你为 Bash 脚本提供了两个参数并在脚本中使用了它们。
但是,如果你只提供一个参数或三个参数怎么办?
让我们实际做一下吧。

正如你在上面所看到的,当你提供的参数超出预期时,结果仍然是一样的。不使用其他参数,因此不会产生问题。
但是,当你提供的参数少于预期时,脚本将显示空白。如果脚本的一部分依赖于缺少的参数,这可能会出现问题。
### 接受用户输入并制作交互式 Bash 脚本
你还可以创建提示用户通过键盘提供输入的 Bash 脚本。这使你的脚本具有交互性。
`read` 命令提供了此功能。你可以这样使用它:
```
echo "Enter something"
read var
```
上面的 `echo` 命令不是必需的,但最终用户不会知道他们必须提供输入。然后用户在按回车键之前输入的所有内容都存储在 `var` 变量中。
你还可以显示提示消息并在单行中获取值,如下所示:
```
read -p "Enter something? " var
```
让我们看看它的实际效果。创建一个新的 `interactive.sh` Shell 脚本,内容如下:
```
#!/bin/bash
echo "What is your name, stranger?"
read name
read -p "What's your full name, $name? " full_name
echo "Welcome, $full_name"
```
在上面的示例中,我使用 `name` 变量来获取名称。然后我在提示中使用 `name` 变量,并在 `full_name` 变量中获取用户输入。我使用了两种使用 `read` 命令的方法。
现在,如果你授予执行权限,然后运行此脚本,你会注意到该脚本显示 `What is your name, stranger?`,然后等待你从键盘输入内容。你提供输入,然后它会显示 `What's your full name` 消息,并再次等待输入。
以下是供你参考的示例输出:

### ?️ 练习时间
是时候练习你所学到的东西了。尝试为以下场景编写简单的 Bash 脚本。
**练习 1**:编写一个带有三个参数的脚本。你必须使脚本以相反的顺序显示参数。
预期输出:
```
abhishek@itsfoss:~/bash_scripts$ ./reverse.sh ubuntu fedora arch
Arguments in reverse order:
arch fedora ubuntu
```
**练习 2**:编写一个脚本,显示传递给它的参数数量。
提示:使用特殊变量 `$#`。
预期输出:
```
abhishek@itsfoss:~/bash_scripts$ ./arguments.sh one and two and three
Total number of arguments: 5
```
**练习 3**:编写一个脚本,将文件名作为参数并显示其行号。
提示:使用 `wc` 命令来计算行号。
你可以在社区中讨论你的解决方案。
很好! 现在你可以(传递)参数了 ? 在下一章中,你将学习在 Bash 中执行基本数学运算。
*(题图:MJ/5a75aa2f-1cb1-4009-a4e6-683cf61bc892)*
---
via: <https://itsfoss.com/bash-pass-arguments/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter #3: Passing Arguments and Accepting User Inputs
Learn how to pass arguments to bash scripts and make them interactive in this chapter of the Bash Basics series.
Let's have arguments... with your bash scripts 😉
You can make your bash script more useful and interactive by passing variables to it.
Let me show you this in detail with examples.
## Pass arguments to a shell script
When you run a shell script, you can add additional variables to it in the following fashion:
`./my_script.sh var1 var2`
Inside the script, you can use $1 for the 1st argument, $2 for the 2nd argument and so on.
Let's see it with an actual example. Switch to the directory where you keep your practice bash scripts.
```
mkdir -p bash_scripts && cd bash_scripts
```
Now, create a new shell script named `arguments.sh`
(I could not think of any better names) and add the following lines to it:
```
#!/bin/bash
echo "Script name is: $0"
echo "First argument is: $1"
echo "Second argument is: $2"
```
Save the file and make it executable. Now run the script like you always do but this time add any two strings to it. You'll see the details printed on the screen.
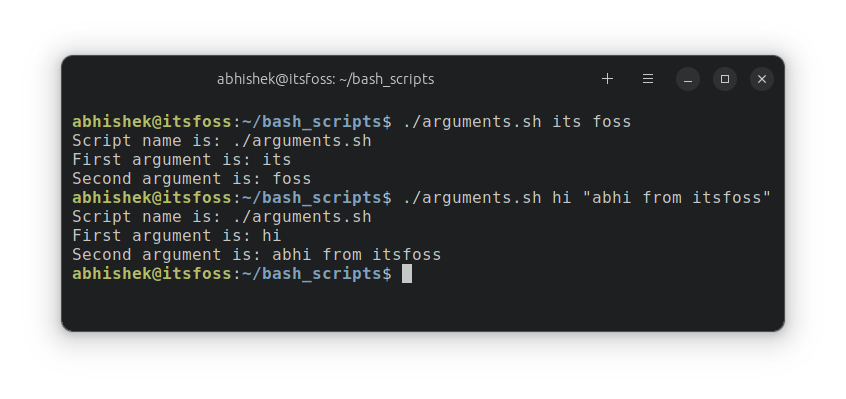
As you can see, the $0 represents the script name while the rest of the arguments are stored in the numbered variables. There are some other special variables that you may use in your scripts.
Special Variable | Description |
---|---|
$0 | Script name |
$1, $2...$9 | Script arguments |
${n} | Script arguments from 10 to 255 |
$# | Number of arguments |
$@ | All arguments together |
$$ | Process id of the current shell |
$! | Process id of the last executed command |
$? | Exit status of last executed command |
### What if the number of arguments doesn't match?
In the above example, you provided the bash script with two arguments and used them in the script.
But what if you provided only one argument or three arguments?
Let's do it actually.
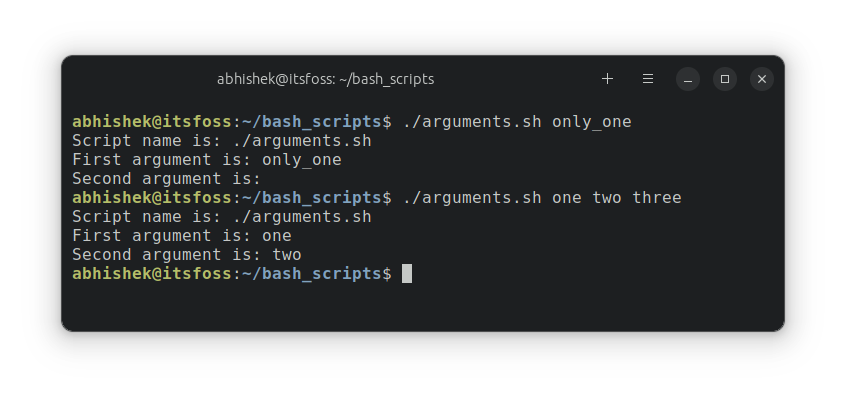
As you can see above, when you provided more than expected arguments, things were still the same. Additional arguments are not used so they don't create issues.
However, when you provided fewer than expected arguments, the script displayed empty space. This could be problematic if part of your script is dependent on the missing argument.
## Accepting user input and making an interactive bash script
You can also create bash scripts that prompt the user to provide input through the keyboard. This makes your scripts interactive.
The read command provides this feature. You can use it like this:
```
echo "Enter something"
read var
```
The echo command above is not required but then the end user won't know that they have to provide input. And then everything that the user enters before pressing the return (enter) key is stored in `var`
variable.
You can also display a prompt message and get the value in a single line like this:
`read -p "Enter something? " var`
Let's see it in action. Create a new `interactive.sh`
shell script with the following content:
```
#!/bin/bash
echo "What is your name, stranger?"
read name
read -p "What's your full name, $name? " full_name
echo "Welcome, $full_name"
```
In the above example, I used the `name`
variable to get the name. And then I use the `name`
variable in the prompt and get user input in `full_name`
variable. I used both ways of using the read command.
Now if you give the execute permission and then run this script, you'll notice that the script displays `What is your name, stranger?`
and then waits for you to enter something from the keyboard. You provide input and then it displays `What's your full name`
type of message and waits for the input again.
Here's a sample output for your reference:
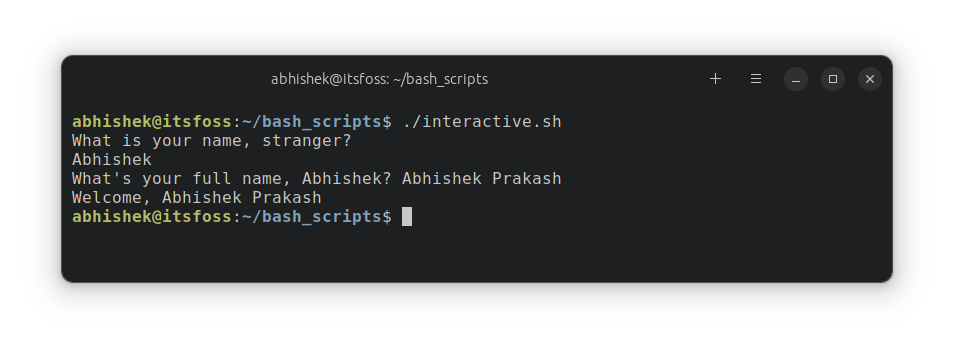
## 🏋️ Exercise time
Time to practice what you learned. Try writing simple bash scripts for the following scenarios.
**Exercise 1**: Write a script that takes three arguments. You have to make the script display the arguments in reverse order.
**Expected output**:
```
abhishek@itsfoss:~/bash_scripts$ ./reverse.sh ubuntu fedora arch
Arguments in reverse order:
arch fedora ubuntu
```
**Exercise 2**: Write a script that displays the number of arguments passed to it.
**Hint**: Use special variable $#
**Expected output**:
```
abhishek@itsfoss:~/bash_scripts$ ./arguments.sh one and two and three
Total number of arguments: 5
```
**Exercise 3**: Write a script that takes a filename as arguments and displays its line number.
**Hint**: Use wc command for counting the line numbers.
You may discuss your solution in the community.
[Practice Exercise in Bash Basics Series #3: Pass Arguments and Accept User InputsIf you are following the Bash Basics series on It’s FOSS, you can submit and discuss the answers to the exercise at the end of the chapter: Fellow experienced members are encouraged to provide their feedback to new members. Do note that there could be more than one answer to a given problem.](https://itsfoss.community/t/practice-exercise-in-bash-basics-series-3-pass-arguments-and-accept-user-inputs/10799)

Great! So now you can (pass) argument :) In the next chapter, you'll learn to perform basic mathematics in bash. |
16,002 | 10 分钟让你了解 Linux ABI | https://opensource.com/article/22/12/linux-abi | 2023-07-15T11:42:49 | [
"ABI"
] | https://linux.cn/article-16002-1.html | 
>
> 熟悉 ABI 的概念、ABI 稳定性的重要性以及 Linux 稳定 ABI 中包含的内容。
>
>
>
>
> LCTT 译注:昨天,AlmaLinux 称将 [放弃](/article-16000-1.html) 对 RHEL 的 1:1 兼容性,但将保持对 RHEL 的 ABI 兼容,以便在 RHEL 上运行的软件可以无缝地运行在 AlmaLinux 上。可能有的同学对 ABI 的概念还不是很清楚,因此翻译此文供大家了解。
>
>
>
许多 Linux 爱好者都熟悉 Linus Torvalds 的 [著名告诫](https://lkml.org/lkml/2018/12/22/232):“我们不破坏用户空间”,但可能并非每个听到这句话的人都清楚其含义。
这个“第一规则”提醒开发人员关于应用程序的二进制接口(ABI)的稳定性,该接口用于应用程序与内核之间的通信和配置。接下来的内容旨在使读者熟悉 ABI 的概念,阐述为什么 ABI 的稳定性很重要,并讨论 Linux 稳定 ABI 中包含了哪些内容。Linux 的持续增长和演进需要对 ABI 进行变更,其中一些变更引起了争议。
### 什么是 ABI?
ABI 表示 <ruby> 应用程序二进制接口 <rt> Applications Binary Interface </rt></ruby>。理解 ABI 概念的一种方式是考虑它与其他概念的区别。对于许多开发人员来说,<ruby> 应用程序编程接口 <rt> Applications Programming Interface </rt></ruby>(API)更为熟悉。通常,库的头文件和文档被认为是其 API,以及还有像 [HTML5](https://www.w3.org/TR/2014/REC-html5-20141028/) 这样的标准文档。调用库或交换字符串格式数据的程序必须遵守 API 中所描述的约定,否则可能得到意外的结果。
ABI 类似于 API,因为它们规定了命令的解释和二进制数据的交换方式。对于 C 程序,ABI 通常包括函数的返回类型和参数列表、结构体的布局,以及枚举类型的含义、顺序和范围。截至 2022 年,Linux 内核仍然几乎完全是 C 程序,因此必须遵守这些规范。
“[内核系统调用接口](https://www.kernel.org/doc/html/v6.0/admin-guide/abi-stable.html#the-kernel-syscall-interface)” 的描述可以在《[Linux 手册第 2 节](https://www.man7.org/linux/man-pages/dir_section_2.html)》中找到,并包括了可从中间件应用程序调用的类似 `mount` 和 `sync` 的 C 版本函数。这些函数的二进制布局是 Linux ABI 的第一个重要组成部分。对于问题 “Linux 的稳定 ABI 包括哪些内容?”,许多用户和开发人员的回答是 “sysfs(`/sys`)和 procfs(`/proc`)的内容”。而实际上,[官方 Linux ABI 文档](https://www.kernel.org/doc/html/v6.0/admin-guide/abi.html) 确实主要集中在这些 [虚拟文件系统](https://opensource.com/article/19/3/virtual-filesystems-linux) 上。
前面着重介绍了 Linux ABI 在程序中的应用方式,但未涵盖同等重要的人为因素。正如下图所示,ABI 的功能需要内核社区、C 编译器(如 [GCC](https://gcc.gnu.org/) 或 [clang](https://clang.llvm.org/get_started.html))、创建用户空间 C 库(通常是 [glibc](https://www.gnu.org/software/libc/))的开发人员,以及按照 [可执行与链接格式(ELF)](https://www.man7.org/linux/man-pages/man5/elf.5.html) 布局的二进制应用程序之间的合作努力。

### 为什么我们关注 ABI?
来自 Torvalds 本人的 Linux ABI 的稳定性保证,使得 Linux 发行版和个人用户能够独立更新内核,而不受操作系统的影响。
如果 Linux 没有稳定的 ABI,那么每次内核需要修补以解决安全问题时,操作系统的大部分甚至全部内容都需要重新安装。显然,二进制接口的稳定性是 Linux 的可用性和广泛采用的重要因素之一。

如上图所示,内核(在 `linux-libc-dev` 中)和 Glibc(在 `libc6-dev` 中)都提供了定义文件权限的位掩码。显然,这两个定义集必须一致!`apt` 软件包管理器会识别软件包提供每个文件。Glibc ABI 的潜在不稳定部分位于 `bits/` 目录中。
在大部分情况下,Linux ABI 的稳定性保证运作良好。按照 <ruby> <a href="https://en.wikipedia.org/wiki/Conway's_law"> 康韦定律 </a> <rt> Conway's Law </rt></ruby>,在开发过程中出现的烦人技术问题往往是由于不同软件开发社区之间的误解或分歧所致,而这些社区都为 Linux 做出了贡献。不同社区之间的接口可以通过 Linux 包管理器的元数据轻松地进行想象,如上图所示。
### Y2038:一个 ABI 破坏的例子
通过考虑当前正在进行的、[缓慢发生](https://www.phoronix.com/news/MTc2Mjg) 的 “Y2038” ABI 破坏的例子,可以更好地理解 Linux ABI。在 2038 年 1 月,32 位时间计数器将回滚到全零,就像较旧车辆的里程表一样。2038 年 1 月听起来还很遥远,但可以肯定的是,如今销售的许多物联网设备仍将处于运行状态。像今年安装的 [智能电表](https://www.lfenergy.org/projects/super-advanced-meter-sam/) 和 [智能停车系统](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7506899/) 这样的普通产品可能采用的是 32 位处理器架构,而且也可能不支持软件更新。
Linux 内核已经在内部转向使用 64 位的 `time_t` 不透明数据类型来表示更晚的时间点。这意味着像 `time()` 这样的系统调用在 64 位系统上已经变更了它们的函数签名。这些努力的艰难程度可以在内核头文件中(例如 [time\_types.h](https://github.com/torvalds/linux/blob/master/include/uapi/linux/time_types.h))清楚地看到,在那里放着新的和 `_old` 版本的数据结构。

Glibc 项目也 [支持 64 位时间](https://www.phoronix.com/scan.php?page=news_item&px=Glibc-More-Y2038-Work),那么就大功告成了,对吗?不幸的是,根据 [Debian 邮件列表中的讨论](https://groups.google.com/g/linux.debian.ports.arm/c/_KBFSz4YRZs) 来看,情况并非如此。发行版面临难以选择的问题,要么为 32 位系统提供所有二进制软件包的两个版本,要么为安装介质提供两个版本。在后一种情况下,32 位时间的用户将不得不重新编译其应用程序并重新安装。正如往常一样,专有应用程序才是一个真正的头疼问题。
### Linux 稳定 ABI 里到底包括什么内容?
理解稳定 ABI 有些微妙。需要考虑的是,尽管大部分 sysfs 是稳定 ABI,但调试接口肯定是不稳定的,因为它们将内核内部暴露给用户空间。Linus Torvalds 曾表示,“不要破坏用户空间”,通常情况下,他是指保护那些 “只想它能工作” 的普通用户,而不是系统程序员和内核工程师,后者应该能够阅读内核文档和源代码,以了解不同版本之间发生了什么变化。下图展示了这个区别。

普通用户不太可能与 Linux ABI 的不稳定部分进行交互,但系统程序员可能无意中这样做。除了 `/sys/kernel/debug` 以外,sysfs(`/sys`)和 procfs(`/proc`)的所有部分都是稳定的。
那么其他对用户空间可见的二进制接口如何呢,包括 `/dev` 中的设备文件、内核日志文件(可通过 `dmesg` 命令读取)、文件系统元数据或在内核的 “命令行” 中提供的 “引导参数”(在引导加载程序如 GRUB 或 u-boot 中可见)呢?当然,“这要视情况而定”。
### 挂载旧文件系统
除了 Linux 系统在引导过程中出现挂起之外,文件系统无法挂载是最令人失望的事情。如果文件系统位于付费客户的固态硬盘上,那么问题确实十分严重。当内核升级时,一个能够在旧内核版本下挂载的 Linux 文件系统应该仍然能够挂载,对吗?实际上,“这要视情况而定”。
在 2020 年,一位受到伤害的 Linux 开发人员在内核的邮件列表上 [抱怨道](https://lwn.net/ml/linux-kernel/20201006050306.GA8098@localhost/):
>
> 内核已经接受这个作为一个有效的可挂载文件系统格式,没有任何错误或任何类型的警告,而且已经这样稳定地工作了多年……我一直普遍地以为,挂载现有的根文件系统属于内核<->用户空间或内核<->现有系统边界的范围,由内核接受并被现有用户空间成功使用的内容所定义,升级内核应该与现有用户空间和系统兼容。
>
>
>
但是有一个问题:这些无法挂载的文件系统是使用一种依赖于内核定义,但并未被内核使用的标志的专有工具创建的。该标志未出现在 Linux 的 API 头文件或 procfs/sysfs 中,而是一种 [实现细节](https://en.wikipedia.org/wiki/Encapsulation_(computer_programming))。因此,在用户空间代码中解释该标志意味着依赖于“[未定义行为](https://en.wikipedia.org/wiki/Undefined_behavior)”,这是个几乎会让每个软件开发人员都感到战栗的短语。当内核社区改进其内部测试并开始进行新的一致性检查时,“[man 2 mount](https://www.man7.org/linux/man-pages/man2/mount.2.html)” 系统调用突然开始拒绝具有专有格式的文件系统。由于该格式的创建者明确是一位软件开发人员,因此他未能得到内核文件系统维护者的同情。

### 线程化内核的 dmesg 日志
`/dev` 目录中的文件格式是否保证稳定或不稳定?[dmesg 命令](https://www.man7.org/linux/man-pages/man1/dmesg.1.html) 会从文件 `/dev/kmsg` 中读取内容。2018 年,一位开发人员 [为 dmesg 输出实现了线程化](https://lkml.org/lkml/2018/11/24/180),使内核能够“在打印一系列 `printk()` 消息到控制台时,不会被中断和/或被其他线程的并发 `printk()` 干扰”。听起来很棒!通过在 `/dev/kmsg` 输出的每一行添加线程 ID,实现了线程化。密切关注的读者将意识到这个改动改变了 `/dev/kmsg` 的 ABI,这意味着解析该文件的应用程序也需要进行相应的修改。由于许多发行版没有编译启用新功能的内核,大多数使用 `/bin/dmesg` 的用户可能没有注意到这件事,但这个改动破坏了 [GDB 调试器](https://sourceware.org/gdb/current/onlinedocs/gdb/) 读取内核日志的能力。
确实,敏锐的读者会认为 GDB 的用户运气不佳,因为调试器是开发人员工具。实际上并非如此,因为需要更新以支持新的 `/dev/kmsg` 格式的代码位于内核自己的 Git 源代码库的 “树内” 部分。对于一个正常的项目来说,单个代码库内的程序无法协同工作就是一个明显的错误,因此已经合并了一份 [使 GDB 能够与线程化的 /dev/kmsg 一起工作的补丁](https://lore.kernel.org/all/[email protected]/)。
### 那么 BPF 程序呢?
[BPF](https://opensource.com/article/19/8/introduction-bpftrace) 是一种强大的工具,可以在运行的内核中监控甚至实时进行配置。BPF 最初的目的是通过允许系统管理员即时从命令行修改数据包过滤器,从而支持实时网络配置。[Alexei Starovoitov 和其他人极大地扩展了 BPF](https://lwn.net/Articles/740157/),使其能够跟踪任意内核函数。跟踪明显是开发人员的领域,而不是普通用户,因此它显然不受任何 ABI 保证的约束(尽管 [bpf() 系统调用](https://www.man7.org/linux/man-pages/man2/bpf.2.html) 具有与其他系统调用相同的稳定性承诺)。另一方面,创建新功能的 BPF 程序为“[取代内核模块成为扩展内核的事实标准手段](https://lwn.net/Articles/909095/)”提供了可能性。内核模块使设备、文件系统、加密、网络等工作正常,因此明显是“只希望它工作”的普通用户所依赖的设施。问题是,与大多数开源内核模块不同,BPF 程序传统上不在内核源代码中。
2022 年春季,[一个提案](https://lwn.net/ml/ksummit-discuss/CAO-hwJJxCteD_BHZTeqQ1f7gWOHoj+05qP8bmFsRYVfMc_3FxQ@mail.gmail.com/) 成为了焦点,该提案提议使用微型 BPF 程序而不是设备驱动程序补丁,对广泛的人机接口设备(如鼠标和键盘)提供支持。
随后进行了一场激烈的讨论,但这个问题显然在 [Torvalds 在开源峰会上的评论](https://lwn.net/ml/ksummit-discuss/[email protected]/) 中得到解决:
>
> 他指出,如果你破坏了“普通(非内核开发人员)用户使用的真实用户空间工具”,那么你需要修复它,无论是否使用了 eBPF。
>
>
>
一致意见似乎正在形成,即希望其 BPF 程序在内核更新后仍能正常工作的开发人员 [将需要将其提交到内核源代码库中一个尚未指定的位置](https://lwn.net/ml/ksummit-discuss/[email protected]/)。敬请关注后继发展,以了解内核社区对于 BPF 和 ABI 稳定性将采取什么样的政策。
### 结论
内核的 ABI 稳定性保证适用于 procfs、sysfs 和系统调用接口,但也存在重要的例外情况。当内核变更破坏了“树内”代码或用户空间应用程序时,通常会迅速回滚有问题的补丁。对于依赖内核实现细节的专有代码,尽管这些细节可以从用户空间访问,但它并没有受到保护,并且在出现问题时得到的同情有限。当像 Y2038 这样的问题无法避免 ABI 破坏时,会以尽可能慎重和系统化的方式进行过渡。而像 BPF 程序这样的新功能提出了关于 ABI 稳定性边界的尚未解答的问题。
### 致谢
感谢 [Akkana Peck](https://shallowsky.com/blog/)、[Sarah R. Newman](https://www.socallinuxexpo.org/scale/19x/presentations/live-patching-down-trenches-view) 和 [Luke S. Crawford](https://www.amazon.com/Book-Xen-Practical-System-Administrator/dp/1593271867) 对早期版本材料的有益评论。
*(题图:MJ/da788385-ca24-4be5-bc27-ad7e7ef75973)*
---
via: <https://opensource.com/article/22/12/linux-abi>
作者:[Alison Chaiken](https://opensource.com/users/chaiken) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many Linux enthusiasts are familiar with Linus Torvalds' [famous admonition](https://lkml.org/lkml/2018/12/22/232), "we don't break user space," but perhaps not everyone who recognizes the phrase is certain about what it means.
The "#1 rule" reminds developers about the stability of the applications' binary interface via which applications communicate with and configure the kernel. What follows is intended to familiarize readers with the concept of an ABI, describe why ABI stability matters, and discuss precisely what is included in Linux's stable ABI. The ongoing growth and evolution of Linux necessitate changes to the ABI, some of which have been controversial.
## What is an ABI?
ABI stands for Applications Binary Interface. One way to understand the concept of an ABI is to consider what it is not. Applications Programming Interfaces (APIs) are more familiar to many developers. Generally, the headers and documentation of libraries are considered to be their API, as are standards documents like those for [HTML5](https://www.w3.org/TR/2014/REC-html5-20141028/), for example. Programs that call into libraries or exchange string-formatted data must comply with the conventions described in the API or expect unwanted results.
ABIs are similar to APIs in that they govern the interpretation of commands and exchange of binary data. For C programs, the ABI generally comprises the return types and parameter lists of functions, the layout of structs, and the meaning, ordering, and range of enumerated types. The Linux kernel remains, as of 2022, almost entirely a C program, so it must adhere to these specifications.
"[The kernel syscall interface](https://www.kernel.org/doc/html/v6.0/admin-guide/abi-stable.html#the-kernel-syscall-interface)" is described by [Section 2 of the Linux man pages](https://www.man7.org/linux/man-pages/dir_section_2.html) and includes the C versions of familiar functions like "mount" and "sync" that are callable from middleware applications. The binary layout of these functions is the first major part of Linux's ABI. In answer to the question, "What is in Linux's stable ABI?" many users and developers will respond with "the contents of sysfs (/sys) and procfs (/proc)." In fact, the [official Linux ABI documentation](https://www.kernel.org/doc/html/v6.0/admin-guide/abi.html) concentrates mostly on these [virtual filesystems](https://opensource.com/article/19/3/virtual-filesystems-linux).
The preceding text focuses on how the Linux ABI is exercised by programs but fails to capture the equally important human aspect. As the figure below illustrates, the functionality of the ABI requires a joint, ongoing effort by the kernel community, C compilers (such as [GCC](https://gcc.gnu.org/) or [clang](https://clang.llvm.org/get_started.html)), the developers who create the userspace C library (most commonly [glibc](https://www.gnu.org/software/libc/)) that implements system calls, and binary applications, which much be laid out in accordance with the Executable and Linking Format ([ELF](https://www.man7.org/linux/man-pages/man5/elf.5.html)).
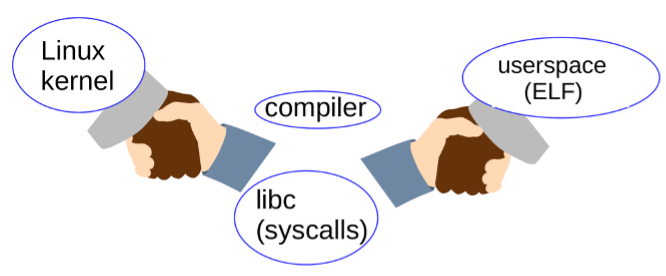
(Alison Chaiken, CC BY-SA 4.0)
## Why do we care about the ABI?
The Linux ABI stability guarantee that comes from Torvalds himself enables Linux distros and individual users to update the kernel independently of the operating system.
If Linux did not have a stable ABI, then every time the kernel needed patching to address a security problem, a large part of the operating system, if not the entirety, would need to be reinstalled. Obviously, the stability of the binary interface is a major contributing factor to Linux's usability and wide adoption.
(Alison Chaiken, CC BY-SA 4.0)
As the second figure illustrates, both the kernel (in linux-libc-dev) and Glibc (in `libc6-dev`
) provide bitmasks that define file permissions. Obviously the two sets of definitions must agree! The `apt`
package manager identifies which software project provided each file. The potentially unstable part of Glibc's ABI is found in the `bits/`
directory.
For the most part, the Linux ABI stability guarantee works just fine. In keeping with [Conway's Law](https://en.wikipedia.org/wiki/Conway's_law), vexing technical issues that arise in the course of development most frequently occur due to misunderstandings or disagreements between different software development communities that contribute to Linux. The interface between communities is easy to envision via Linux package-manager metadata, as shown in the image above.
## Y2038: An example of an ABI break
The Linux ABI is best understood by considering the example of the ongoing, [slow-motion](https://www.phoronix.com/news/MTc2Mjg) "Y2038" ABI break. In January 2038, 32-bit time counters will roll over to all zeroes, just like the odometer of an older vehicle. January 2038 sounds far away, but assuredly many IoT devices sold in 2022 will still be operational. Mundane products like [smart electrical meters](https://www.lfenergy.org/projects/super-advanced-meter-sam/) and [smart parking systems](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7506899/) installed this year may or may not have 32-bit processor architectures and may or may not support software updates.
The Linux kernel has already moved to a 64-bit `time_t`
opaque data type internally to represent later timepoints. The implication is that system calls like `time()`
have already changed their function signature on 64-bit systems. The arduousness of these efforts is on ready display in kernel headers like [time_types.h](https://github.com/torvalds/linux/blob/master/include/uapi/linux/time_types.h), which includes new and "_old" versions of data structures.

([marneejill](https://flic.kr/p/Lk5a6L), CC BY-SA 2.0)
The Glibc project also [supports 64-bit time](https://www.phoronix.com/scan.php?page=news_item&px=Glibc-More-Y2038-Work), so yay, we're done, right? Unfortunately, no, as a [discussion on the Debian mailing list](https://groups.google.com/g/linux.debian.ports.arm/c/_KBFSz4YRZs) makes clear. Distros are faced with the unenviable choice of either providing two versions of all binary packages for 32-bit systems or two versions of installation media. In the latter case, users of 32-bit time will have to recompile their applications and reinstall. As always, proprietary applications will be a real headache.
## What precisely is in the Linux stable ABI anyway?
Understanding the stable ABI is a bit subtle. Consider that, while most of sysfs is stable ABI, the debug interfaces are guaranteed to be *un*stable since they expose kernel internals to userspace. In general, Linus Torvalds has pronounced that by "don't break userspace," he means to protect ordinary users who "just want it to work" rather than system programmers and kernel engineers, who should be able to read the kernel documentation and source code to figure out what has changed between releases. The distinction is illustrated in the figure below.
(Alison Chaiken, CC BY-SA 4.0)
Ordinary users are unlikely to interact with unstable parts of the Linux ABI, but system programmers may do so inadvertently. All of sysfs (`/sys`
) and procfs (`/proc`
) are guaranteed stable except for `/sys/kernel/debug`
.
But what about other binary interfaces that are userspace-visible, including miscellaneous ABI bits like device files in `/dev`
, the kernel log file (readable with the `dmesg`
command), filesystem metadata, or "bootargs" provided on the kernel "command line" that are visible in a bootloader like GRUB or u-boot? Naturally, "it depends."
## Mounting old filesystems
Next to observing a Linux system hang during the boot sequence, having a filesystem fail to mount is the greatest disappointment. If the filesystem resides on an SSD belonging to a paying customer, the matter is grave indeed. Surely a Linux filesystem that mounts with an old kernel version will still mount when the kernel is upgraded, right? Actually, "[it depends](https://lwn.net/Articles/833696/)."
In 2020 an aggrieved Linux developer [complained on the kernel's mailing list](https://lwn.net/ml/linux-kernel/20201006050306.GA8098@localhost/):
The kernel already accepted this as a valid mountable filesystem format, without a single error or warning of any kind, and has done so stably for years. . . . I was generally under the impression that mounting existing root filesystems fell under the scope of the kernel<->userspace or kernel<->existing-system boundary, as defined by what the kernel accepts and existing userspace has used successfully, and that upgrading the kernel should work with existing userspace and systems.
But there was a catch: The filesystems that failed to mount were created with a proprietary tool that relied on a flag that was defined but not used by the kernel. The flag did not appear in Linux's API header files or procfs/sysfs but was instead an [implementation detail](https://en.wikipedia.org/wiki/Encapsulation_(computer_programming)). Therefore, interpreting the flag in userspace code meant relying on "[undefined behavior](https://en.wikipedia.org/wiki/Undefined_behavior)," a phrase that will make software developers almost universally shudder. When the kernel community improved its internal testing and started making new consistency checks, the "[man 2 mount](https://www.man7.org/linux/man-pages/man2/mount.2.html)" system call suddenly began rejecting filesystems with the proprietary format. Since the format creator was decidedly a software developer, he got little sympathy from kernel filesystem maintainers.

(Kernel developers working in-tree are protected from ABI changes. Alison Chaiken, CC BY-SA 4.0)
## Threading the kernel dmesg log
Is the format of files in `/dev`
guaranteed stable or not? The [command dmesg](https://www.man7.org/linux/man-pages/man1/dmesg.1.html) reads from the file `/dev/kmsg`
. In 2018, a developer [made output to dmesg threaded](https://lkml.org/lkml/2018/11/24/180), enabling the kernel "to print a series of printk() messages to consoles without being disturbed by concurrent printk() from interrupts and/or other threads." Sounds excellent! Threading was made possible by adding a thread ID to each line of the `/dev/kmsg`
output. Readers following closely will realize that the addition changed the ABI of `/dev/kmsg`
, meaning that applications that parse that file needed to change too. Since many distros didn't compile their kernels with the new feature enabled, most users of `/bin/dmesg`
won't have noticed, but the change broke the [GDB debugger](https://sourceware.org/gdb/current/onlinedocs/gdb/)'s ability to read the kernel log.
Assuredly, astute readers will think users of GDB are out of luck because debuggers are developer tools. Actually, no, since the code that needed to be updated to support the new `/dev/kmsg`
format was "[in-tree](https://unix.stackexchange.com/questions/208638/linux-kernel-meaning-of-source-tree-in-tree-and-out-of-tree)," meaning part of the kernel's own Git source repository. The failure of programs within a single repo to work together is just an out-and-out bug for any sane project, and a [patch that made GDB work with threaded /dev/kmsg](https://lore.kernel.org/all/[email protected]/) was merged.
## What about BPF programs?
[BPF](https://opensource.com/article/19/8/introduction-bpftrace) is a powerful tool to monitor and even configure the running kernel dynamically. BPF's original purpose was to support on-the-fly network configuration by allowing sysadmins to modify packet filters from the command line instantly. [Alexei Starovoitov and others greatly extended BPF](https://lwn.net/Articles/740157/), giving it the power to trace arbitrary kernel functions. Tracing is clearly the domain of developers rather than ordinary users, so it is certainly not subject to any ABI guarantee (although the [bpf() system call](https://www.man7.org/linux/man-pages/man2/bpf.2.html) has the same stability promise as any other). On the other hand, BPF programs that create new functionality present the possibility of "[replacing kernel modules as the de-facto means of extending the kernel](https://lwn.net/Articles/909095/)." Kernel modules make devices, filesystems, crypto, networks, and the like work, and therefore clearly are a facility on which the "just want it to work" user relies. The problem arises that BFP programs have not traditionally been "in-tree" as most open-source kernel modules are. A proposal in spring 2022 to [provide support to the vast array of human interface devices (HIDs) like mice and keyboards via tiny BPF programs](https://lwn.net/ml/ksummit-discuss/CAO-hwJJxCteD_BHZTeqQ1f7gWOHoj+05qP8bmFsRYVfMc_3FxQ@mail.gmail.com/) rather than patches to device drivers brought the issue into sharp focus.
A rather heated discussion followed, but the issue was apparently settled by [Torvalds' comments at Open Source Summit](https://lwn.net/ml/ksummit-discuss/[email protected]/):
He specified if you break 'real user space tools, that normal (non-kernel developers) users use,' then you need to fix it, regardless of whether it is using eBPF or not.
A consensus appears to be forming that developers who expect their BPF programs to withstand kernel updates [will need to submit them to an as-yet unspecified place in the kernel source repository](https://lwn.net/ml/ksummit-discuss/[email protected]/). Stay tuned to find out what policy the kernel community adopts regarding BPF and ABI stability.
## Conclusion
The kernel ABI stability guarantee applies to procfs, sysfs, and the system call interface, with important exceptions. When "in-tree" code or userspace applications are "broken" by kernel changes, the offending patches are typically quickly reverted. When proprietary code relies on kernel implementation details that are incidentally accessible from userspace, it is not protected and garners little sympathy when it breaks. When, as with Y2038, there is no way to avoid an ABI break, the transition is made as thoughtfully and methodically as possible. Newer features like BPF programs present as-yet-unanswered questions about where exactly the ABI-stability border lies.
#### Acknowledgments
Thanks to [Akkana Peck](https://shallowsky.com/blog/), [Sarah R. Newman](https://www.socallinuxexpo.org/scale/19x/presentations/live-patching-down-trenches-view), and [Luke S. Crawford](https://www.amazon.com/Book-Xen-Practical-System-Administrator/dp/1593271867) for their helpful comments on early versions of this material.
## Comments are closed. |
16,004 | Terminator:适用于 Linux 专业人员的平铺终端仿真器 | https://itsfoss.com/terminator/ | 2023-07-16T17:02:28 | [
"终端",
"Terminator"
] | https://linux.cn/article-16004-1.html |
>
> 你可能已经看到一些同事或 UP 主们在一个终端窗口中运行多个终端会话。
>
>
>

一些专业的 Linux 用户会使用 `screen` 或 [tmux 命令](https://linuxhandbook.com/tmux/) 来分割多个窗格。这些命令可以在任何终端应用程序中使用,但需要较大的学习曲线。
如果你想要在同一应用窗口中拥有多个终端会话而不涉及 `tmux` 或 [screen 命令](https://linuxhandbook.com/screen-command/) 的复杂性,“终结者” 是你的好帮手。

不,我指的不是那个“终结者”。是这个 ?

你的系统上安装的 [终端仿真器](https://itsfoss.com/linux-terminal-emulators/) 可能具有多标签支持。而 Terminator 支持多个可调整大小的终端面板。
它模拟了类似平铺窗口管理器的功能,并将终端面板平铺在单个窗口中。
在本文中,我将向你展示如何在 Ubuntu 和其他 Linux 发行版中安装和使用 Terminator。
但在此之前,让我们快速了解一下 Terminator 提供的功能。
### Terminator 可在同一窗口中提供多个终端会话
[Terminator](https://github.com/gnome-terminator/terminator) 是一个基于 GNOME 终端的 GTK 应用程序,使用了 VTE3(GTK3 虚拟终端仿真器小部件)。
作为一个基于 GNOME 终端的应用程序,它与 GNOME 桌面环境相关联,因此有一些依赖性。
然而,即使有 GNOME 的依赖性,我发现该应用程序相对轻巧。可能在其他桌面环境中使用它不会成为问题。
从外表上看,Terminator 可能与其他终端仿真器相似。但是,Terminator 具有无限可能性,我将在后面的章节中向你展示它们。

#### 功能特点
让我总结一下 Terminator 的一些主要功能:
* 平铺布局的终端
* 支持多个标签页
* 拖拽终端面板(出色的鼠标支持)
* 类似于平铺窗口管理器的键盘快捷键
* 可以保存布局和配置文件,以便快速启动
* 通过插件可扩展功能
### 安装 Terminator
安装 Terminator 就像安装其它软件包一样简单,因为它在你能想到的所有主流发行版的官方软件源中都可用。
为了方便起见,我在下面列出了一些主要发行版的命令。
对于基于 Ubuntu 和 Debian 的发行版,请执行以下命令安装 Terminator:
```
sudo apt install terminator
```
对于基于 Fedora 和红帽的发行版,请使用以下命令:
```
sudo dnf install terminator
```
对于基于 Arch 和 Manjaro 的发行版,请执行以下命令更新并安装 Terminator:
```
sudo pacman -Syu terminator
```
注意:某些长期支持版本的发行版软件源中可能没有最新版本的 Terminator。
你还可以使用发行版提供的图形包管理器来安装 Terminator。但是,通过图形界面安装终端仿真器是无趣的。
### 使用 Terminator
当你启动 Terminator 时,默认窗口看起来就像一个简单的终端窗口。但是,经过一些耐心,它可以在一个窗口内像平铺窗口管理器一样工作。

Terminator 允许你使用鼠标通过水平和垂直分割来创建新的面板。

然而,使用键盘快捷键会更快。你需要一些时间来适应这些键,但最终你会掌握它们的。
在这里,我在第一个面板中打开了 [htop](https://itsfoss.com/use-htop/),如下图所示。

要在右侧创建一个新的终端面板,只需按下 `Ctrl + Shift + e` 快捷键。其次,我在右侧面板中使用了 [neofetch](https://itsfoss.com/using-neofetch/),如下图所示。

最后,我使用 `Ctrl + Shift + o` 快捷键在带有 `neofetch` 的面板下方创建了另一个面板,并在此处启动了 `cmatrix`。这是其中一个无用但 [有趣的 Linux 命令](https://itsfoss.com/funny-linux-commands/)。

上面是在本指导中完成的操作的最终屏幕截图。现在你明白我为什么说 Terminator 在一个窗口中创建了类似平铺窗口管理器的环境了吧。
如果你需要在不安装平铺窗口管理器的情况下打开多个终端,这种平铺功能将非常方便。Terminator 也支持标签页,但我认为平铺功能是该应用程序的特点。
Terminator 是少数几个配有出色文档的应用程序之一。如果你需要更多信息,请参阅其 [文档](https://gnome-terminator.readthedocs.io/en/latest/)。
### 结论
我相信所有终端仿真器都支持标签页界面。但是,当你需要同时关注多个会话时,必须在标签之间切换并不方便。
Terminator 可能不像 [Blackbox](https://itsfoss.com/blackbox-terminal/) 或 [GNOME Console](https://itsfoss.com/gnome-console/) 那样好看。但它拥有老练的 Linux 用户喜爱的功能。
它提供的功能可能并不是每个 Linux 用户都需要或想要的。我将把决定权交给你,你来决定它是否值得你投入时间。
*(题图:MJ/0b403aa1-810a-4f9f-9e52-1d42d8fe2b6a)*
---
via: <https://itsfoss.com/terminator/>
作者:[Anuj Sharma](https://itsfoss.com/author/anuj/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You might have seen some colleagues or YouTubers using a terminal window with multiple terminal sessions running in it.
Some pro Linux users do the multiple split pane with screen or [tmux commands](https://linuxhandbook.com/tmux/?ref=itsfoss.com). These commands work in any terminal application but involve a steep learning curve.
If you want multiple terminal sessions in the same application window without the complexity of the tmux or [screen commands](https://linuxhandbook.com/screen-command/?ref=itsfoss.com), Terminator is your friend.
No, not that terminator. This terminator 👇
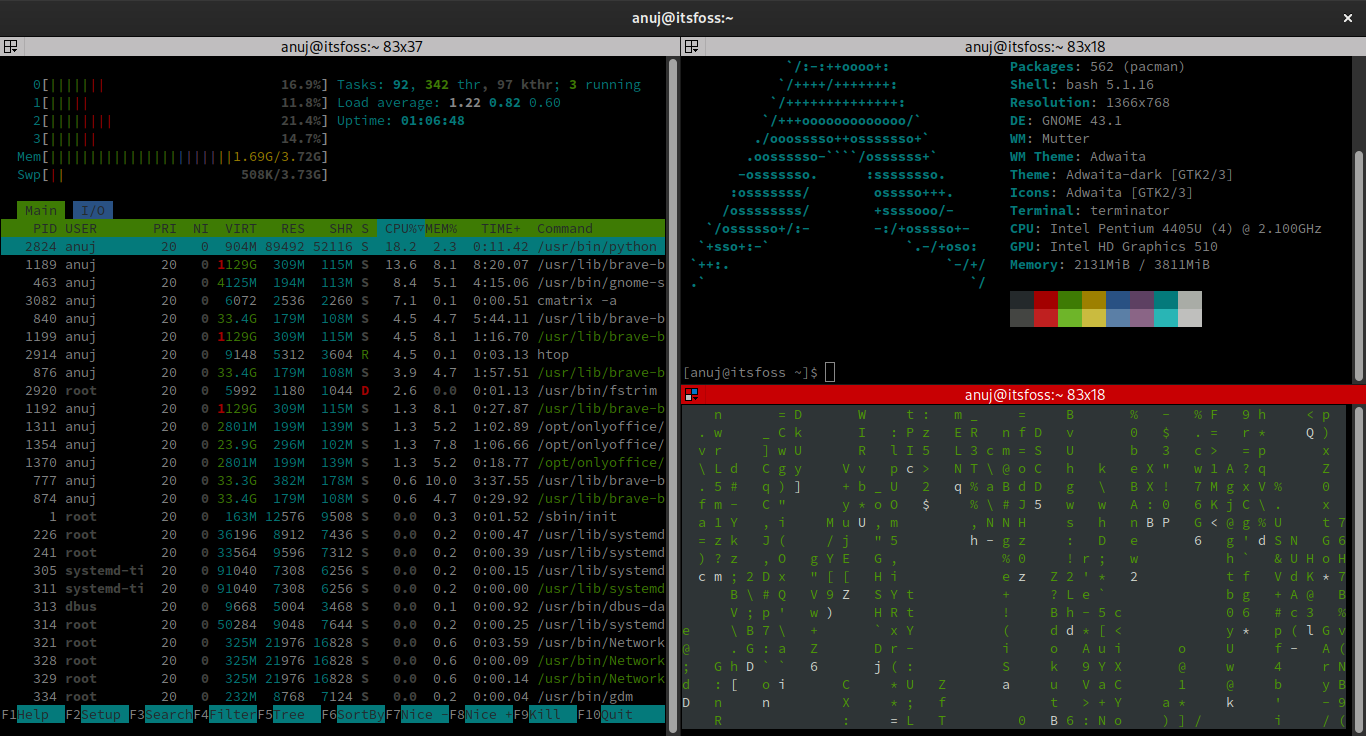
The [terminal emulators](https://itsfoss.com/linux-terminal-emulators/) installed on your system may have multiple-tab support. On the other hand, Terminator supports multiple resizable terminal panels.
It emulates something like a tiling window manager and tiles the terminal panel in a single window.
In this article, I’ll show you how to install and use Terminator in Ubuntu and other Linux distributions.
But before that, let’s have a quick look at the features Terminator offers.
## Terminator gives you multiple terminal sessions in the same window
[Terminator](https://github.com/gnome-terminator/terminator?ref=itsfoss.com) is a GTK application based on GNOME Terminal that uses VTE3 (Virtual Terminal Emulator widget GTK3).
Being an application based on GNOME Terminal it has some dependencies linked with the GNOME Desktop Environment.
However, I found the application relatively lightweight, even with the GNOME dependencies. Perhaps it should not be a problem to use it on other desktop environments.
From the outside, Terminator might look like any other terminal emulator. But the possibilities are endless with Terminator and I will show them to you in later sections.
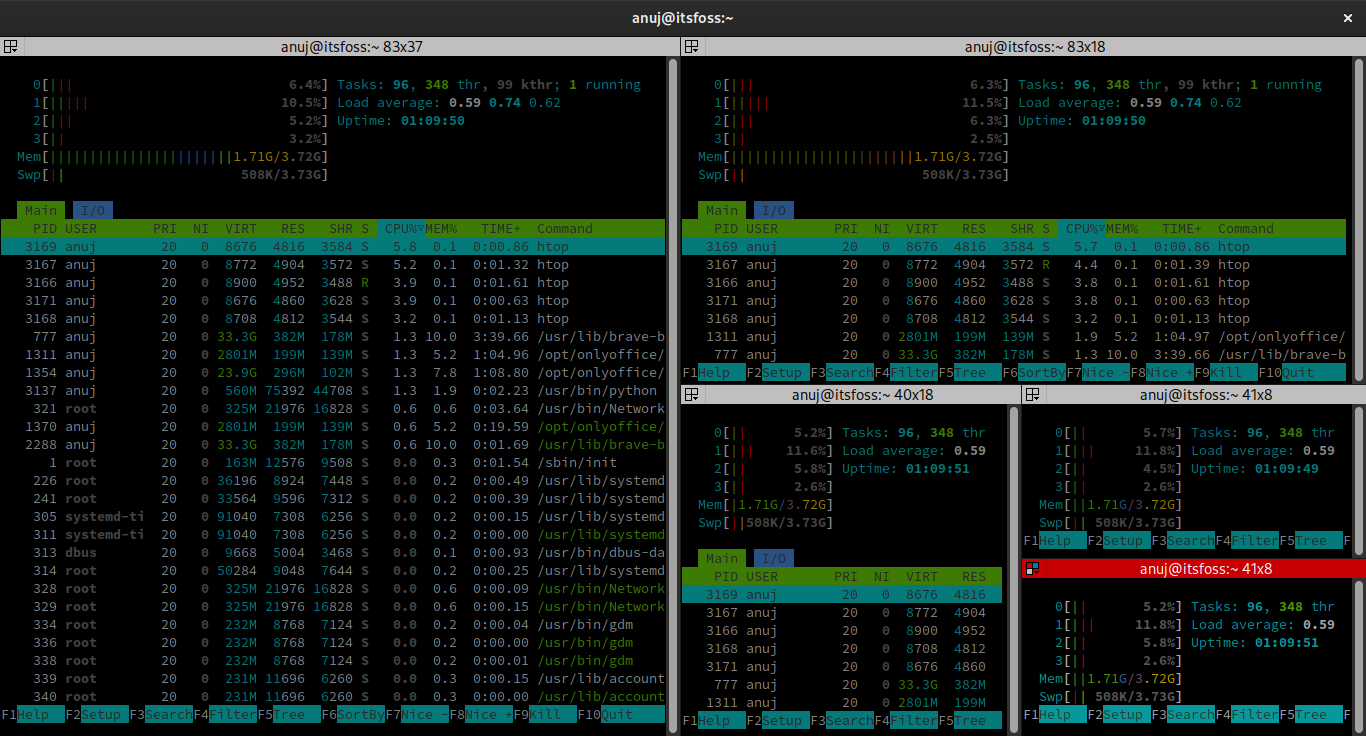
### Features
Let me summarize some of the main features of Terminator:
- Terminals in tiling layout
- Supports multiple tabs
- Drag and drop terminal panel (great mouse support)
- Keyboard shortcuts akin to tiling window managers
- Saving layouts and profiles so one can get a quick head start
- Extensible through plugins
## Installing Terminator
Installing Terminator is as simple as installing any other package because it is available in the official repositories of all mainstream distributions you can name.
For your convenience, I have listed the commands for some major distributions below.
For Ubuntu and Debian based distributions, enter the below command to install Terminator:
`sudo apt install terminator`
For Fedora and Red Hat based distributions, use:
`sudo dnf install terminator`
For Arch and Manjaro based distributions, enter the below command to update and install Terminator:
`sudo pacman -Syu terminator`
Note: You might not get the latest version of Terminator in some of the Long term release distributions’ repos.
One can also install Terminator using the Graphical Package Manager provided by your distribution. But, there is no fun in installing a Terminal Emulator from the GUI.
## Using Terminator
When you launch Terminator default window will look like a simple Terminal window. But, with some patience, it can work like a tiling window manager inside a single window.
Terminator allows you to use the mouse for creating new panes by splitting the present one horizontally and vertically.
However, you’ll be a lot faster with keyboard shortcuts. It takes some time to get used to the keys but you’ll get there eventually.
Here, I opened [htop](https://itsfoss.com/use-htop/) in the first panel as shown below.
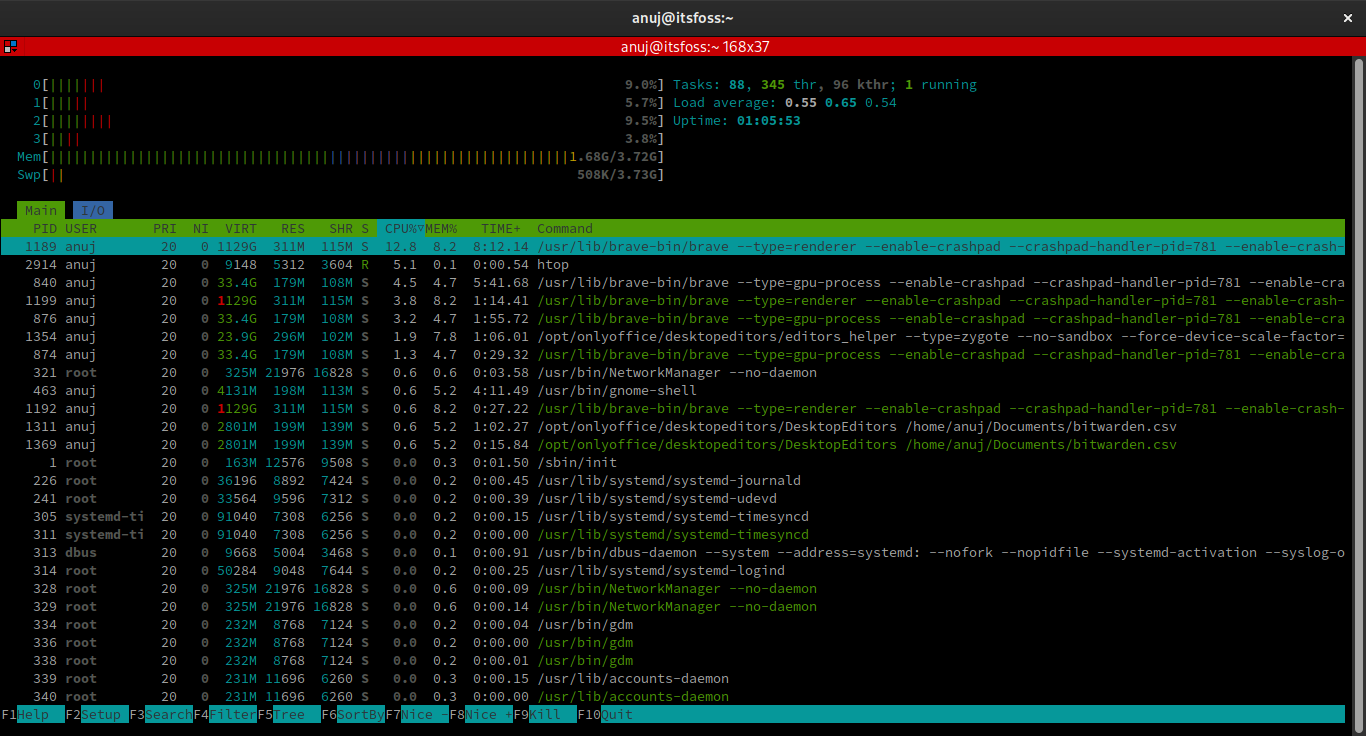
To create a new terminal panel to the right, just enter `Ctrl + Shift + e`
shortcut keys. Secondly, I have used [neofetch](https://itsfoss.com/using-neofetch/) in the right panel, as shown below.
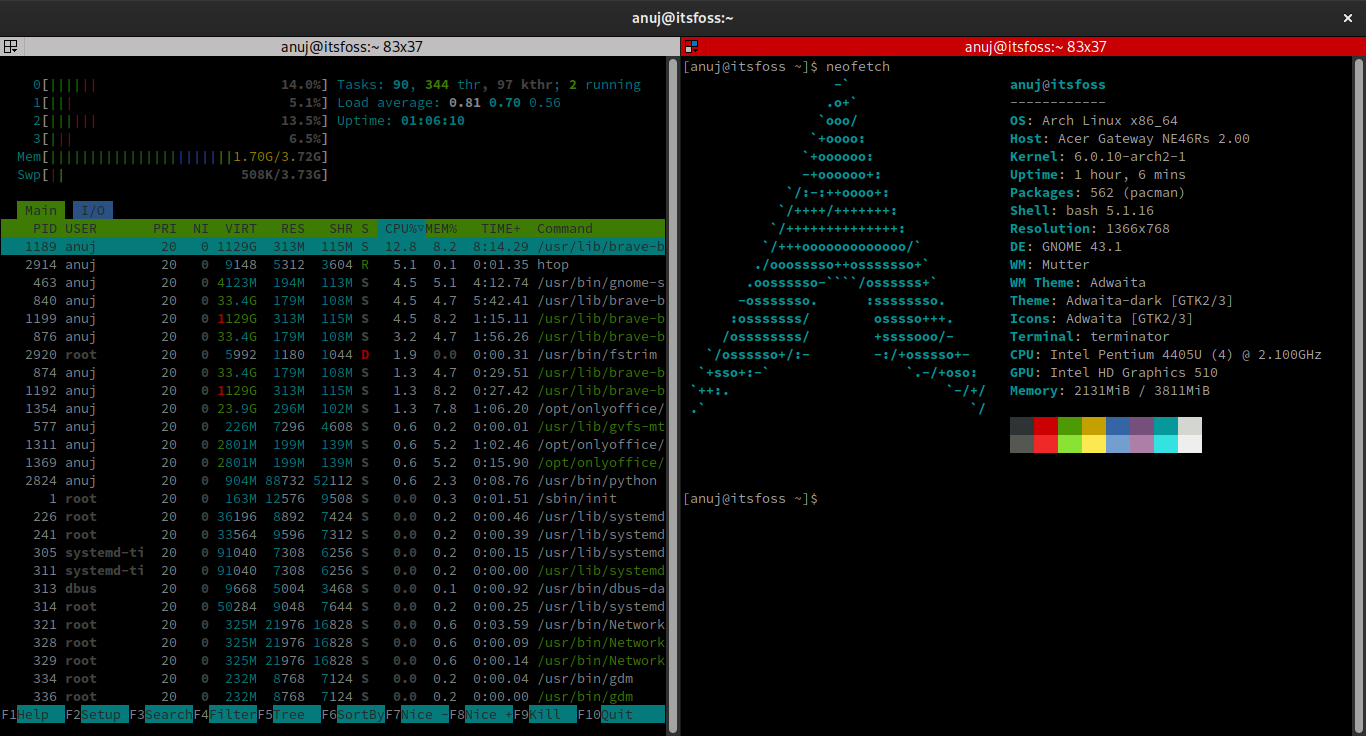
Lastly, I created another panel below the one with neofetch using `Ctrl + Shift + o`
shortcut keys and launched [cmatrix](https://itsfoss.com/using-cmatrix/) here. It’s one of those useless but [amusing Linux commands](https://itsfoss.com/funny-linux-commands/).

Above is the final screenshot of what I did in this walkthrough. Now you understand why I said that Terminator creates a tiling window manager like environment in a single window.
This tiling feature will come in handy if you need to open many terminals without installing a Tiling Window Manager. Terminator also supports tabs but the tiling feature is the USP of this application, in my opinion.
Terminator is one of the few applications that come with great documentation. If you need more information, please take a look at its [documentation](https://gnome-terminator.readthedocs.io/en/latest/?ref=itsfoss.com).
## Conclusion
I believe all terminal emulators support tabbed interface. But you’ll have to switch between the tabs and it’s not convenient when you have to keep an eye on multiple sessions simultaneously.
Terminator may not look as good as [Blackbox](https://itsfoss.com/blackbox-terminal/) or [GNOME Console](https://itsfoss.com/gnome-console/). But it has features that seasoned Linux users love.
It serves a purpose that may not be what every Linux user needs or wants. I leave it up to you to decide if it is worth your time. |
16,006 | Bash 基础知识系列 #4:算术运算 | https://itsfoss.com/bash-arithmetic-operation/ | 2023-07-17T11:04:00 | [
"脚本",
"Bash"
] | https://linux.cn/article-16006-1.html | 
>
> 在本系列的第四章,学习在 Bash 中使用基本数学运算。
>
>
>
你可以使用 Bash 脚本做很多事情。对变量执行简单的算术运算就是其中之一。
Bash shell 中算术运算的语法如下:
```
$((arithmetic_operation))
```
假设你必须计算两个变量的总和。你这样做:
```
sum=$(($num1 + $num2))
```
`(())` 内空格的使用没有限制。你可以使用 `$(( $num1+ $num2))`、`$(( $num1+ $num2 ))` 或者 `$(( $num1+ $num2 ))`。它们都一样。
在通过示例详细讨论之前,我先分享一下它支持的算术运算符。
### Bash 中的基本算术运算符
以下是 Bash shell 中算术运算符的列表。
| 运算符 | 描述 |
| --- | --- |
| `+` | 加法 |
| `-` | 减法 |
| `*` | 乘法 |
| `/` | 整数除法(不带小数) |
| `%` | 模除法(仅余数) |
| `**` | 求幂(a 的 b 次方) |
>
> ? Bash 不支持浮点数(小数)。你必须使用其他命令(例如 `bc`)来处理它们。
>
>
>
### Bash 中的加法和减法
让我们通过编写一个脚本来看看它,该脚本从用户那里获取两个数字,然后打印它们的总和和减法。
```
#!/bin/bash
read -p "Enter first number: " num1
read -p "Enter second number: " num2
sum=$(($num1+$num2))
sub=$(($num1-$num2))
echo "The summation of $num1 and $num2 is $sum"
echo "The substraction of $num2 from $num1 is $sub"
```
我相信你熟悉上一章中使用 `read` 命令来 [在 Bash 中接受用户输入](https://itsfoss.com/bash-pass-arguments/)。
你应该关注这两行:
```
sum=$(($num1+$num2))
sub=$(($num1-$num2))
```
将此脚本保存为 `sum.sh` 并运行它。给它一些输入并检查结果。

### Bash 中的乘法
现在让我们转向乘法。
这是一个将公里转换为米的示例脚本(这给美国读者带来了麻烦 ?)。作为参考,1 公里等于 1000 米。
```
#!/bin/bash
read -p "Enter distance in kilometers: " km
meters=$(($km*1000))
echo "$km KM equals to $meters meters"
```
将脚本保存为 `multi.sh`,赋予其执行权限并运行它。这是一个示例输出:

看起来不错,不是吗? 让我们继续进行除法。
### Bash 脚本中的除法
让我们用一个非常简单的脚本来看看除法:
```
#!/bin/bash
num1=50
num2=5
result=$(($num1/$num2))
echo "The result is $result"
```
你很容易猜到结果:
```
The result is 10
```
没关系。但是让我们更改数字并尝试将 50 除以 6。结果如下:
```
The result is 8
```
**但这不正确。** 正确答案应该是 8.33333。
这是因为 Bash 默认情况下只处理整数。你需要额外的命令行工具来处理浮点(小数)。
最流行的工具是 [bc](https://www.gnu.org/software/bc/manual/html_mono/bc.html),它是一种处理数学运算的非常强大的计算器语言。不过,你现在不需要关注细节。
你必须通过管道将算术运算“回显”给 `bc`:
```
echo "$num1/$num2" | bc -l
```
于是,将之前的脚本修改为:
```
#!/bin/bash
num1=50
num2=6
result=$(echo "$num1/$num2" | bc -l)
echo "The result is $result"
```
现在你得到结果:
```
The result is 8.33333333333333333333
```
请注意 `result=$(echo "$num1/$num2" | bc -l)`,它现在使用你在 [本系列第 2 章](https://itsfoss.com/bash-use-variables/) 中看到的命令替换。
`-l` 选项加载标准数学库。默认情况下,`bc` 最多保留 20 位小数。你可以通过以下方式将比例更改为较小的位数:
```
result=$(echo "scale=3; $num1/$num2" | bc -l)
```
让我们看看 Bash 中浮点的更多示例。
### 在 Bash 脚本中处理浮点
让我们修改 `sum.sh` 脚本来处理浮点。
```
#!/bin/bash
read -p "Enter first number: " num1
read -p "Enter second number: " num2
sum=$( echo "$num1+$num2" | bc -l)
sub=$( echo "scale=2; $num1-$num2" | bc -l)
echo "The summation of $num1 and $num2 is $sum"
echo "The substraction of $num2 from $num1 is $sub"
```
现在尝试运行它,看看是否可以正确处理浮点:

### ?️? 练习时间
是时候一起做一些数学和 Bash 练习了。
**练习 1**:创建一个脚本,接受以 GB 为单位的输入并以 MB 和 KB 为单位输出其等效值。
**练习 2**:编写一个带有两个参数并以指数格式输出结果的脚本。因此,如果输入 2 和 3,输出将为 8,即 2 的 3 次方。
**提示**:使用幂运算符 `**`。
**练习 3**:编写一个将摄氏度转换为华氏度的脚本。
**提示**:使用公式 F = C x (9/5) + 32。你必须在此处使用 `bc` 命令。
你可以在社区中讨论练习及其方案。
在下一章中,你将 [了解 Bash 中的数组](https://itsfoss.com/bash-arrays/)。敬请关注。
*(题图:MJ/8a9dfb90-99a4-4203-bc44-d805d09bc16f)*
---
via: <https://itsfoss.com/bash-arithmetic-operation/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter #4: Arithmetic Operations
In the fourth chapter of the series, learn to use basic mathematics in Bash.
You can do a lot of things with bash scripts. Performing simple arithmetic operations with the variables is one of them.
The syntax for arithmetic operations in the bash shell is this:
`$((arithmetic_operation))`
Let's say you have to calculate the sum of two variables. You do it like this:
`sum=$(($num1 + $num2))`
There is no restriction on the use of white space inside the (()). You can use `$(( $num1+ $num2))`
, `$(( $num1+ $num2 ))`
or `$(( $num1+ $num2 ))`
. It all will work the same.
Before I discuss it in detail with examples, let me share the arithmetic operators it supports.
## Basic arithmetic operators in Bash
Here's a list of the arithmetic operators in the Bash shell.
Operator | Description |
---|---|
+ | Addition |
- | Subtraction |
* | Multiplication |
/ | Integer division (without decimal) |
% | Modulus division (only remainder) |
** | Exponentiation (a to the power b) |
`bc`
to deal with them.## Addition and subtraction in bash
Let's see it by writing a script that takes two numbers from the user and then prints their sum and subtraction.
```
#!/bin/bash
read -p "Enter first number: " num1
read -p "Enter second number: " num2
sum=$(($num1+$num2))
sub=$(($num1-$num2))
echo "The summation of $num1 and $num2 is $sum"
echo "The substraction of $num2 from $num1 is $sub"
```
I believe you are familiar with using the read command to [accept user input in bash](https://itsfoss.com/bash-pass-arguments/) from the previous chapter.
You should focus on these two lines:
```
sum=$(($num1+$num2))
sub=$(($num1-$num2))
```
Save this script as `sum.sh`
and run it. Give it some inputs and check the result.
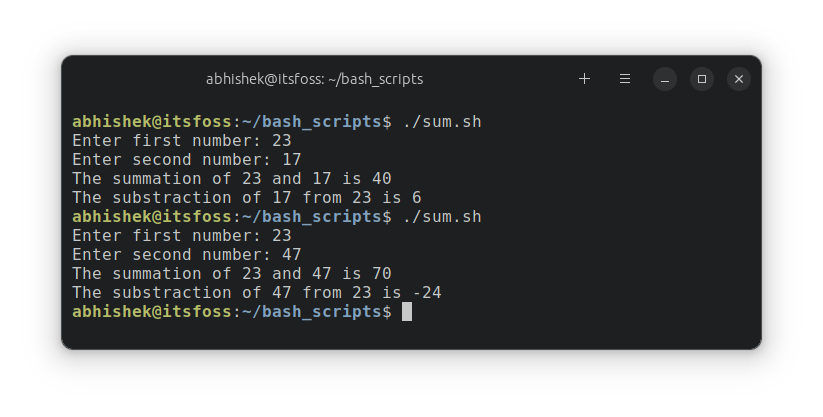
## Multiplication in bash
Let's move to multiplication now.
Here's a sample script that converts kilometers into meters (and troubles US readers :D). For reference, 1 kilometer is equal to 1000 meters.
```
#!/bin/bash
read -p "Enter distance in kilometers: " km
meters=$(($km*1000))
echo "$km KM equals to $meters meters"
```
Save the script as `multi.sh`
, give it execute permission and run it. Here's a sample output:
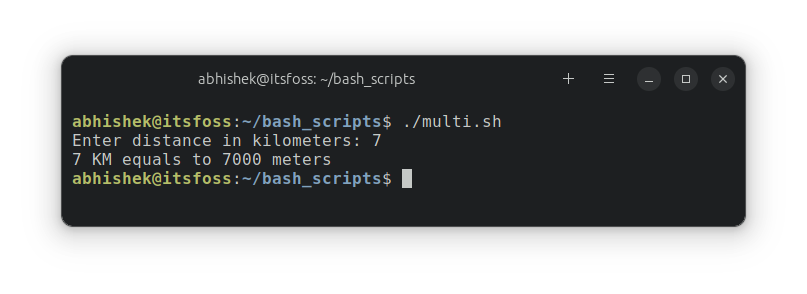
Looks good, no? Let's move on to division.
## Division in bash scripts
Let's see division with a very simple script:
```
#!/bin/bash
num1=50
num2=5
result=$(($num1/$num2))
echo "The result is $result"
```
You can easily guess the result:
`The result is 10`
That's fine. But let's change the numbers and try to divide 50 by 6. Here's what it shows as result:
`The result is 8`
**But that's not correct. **The correct answer should be 8.33333.
That's because bash only deals with integers by default. You need additional CLI tools to handle floating points (decimals).
The most popular tool is [bc](https://www.gnu.org/software/bc/manual/html_mono/bc.html) which is quite a powerful calculator language to deal with mathematical operations. However, you don't need to go into detail for now.
You have to 'echo' the arithmetic operation to bc via pipe:
`echo "$num1/$num2" | bc -l`
So, the previous script is modified into:
```
#!/bin/bash
num1=50
num2=6
result=$(echo "$num1/$num2" | bc -l)
echo "The result is $result"
```
And now you get the result:
`The result is 8.33333333333333333333`
Notice the `result=$(echo "$num1/$num2" | bc -l)`
, it now uses the command substitution that you saw in [chapter 2 of this series](https://itsfoss.com/bash-use-variables/).
The `-l`
option loads standard math library. By default, bc will go up to 20 decimal points. You can change the scale to something smaller in this way:
`result=$(echo "scale=3; $num1/$num2" | bc -l)`
Let's see some more examples of floating points in bash.
## Handling floating points in bash scripts
Let's modify the `sum.sh`
script to handle floating points.
```
#!/bin/bash
read -p "Enter first number: " num1
read -p "Enter second number: " num2
sum=$( echo "$num1+$num2" | bc -l)
sub=$( echo "$num1-$num2" | bc -l)
echo "The summation of $num1 and $num2 is $sum"
echo "The substraction of $num2 from $num1 is $sub"
```
Try running it now and see if handles floating points properly or not:
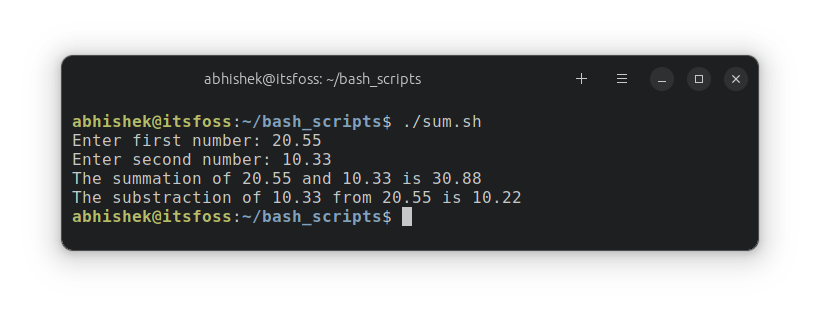
## 🏋️🤸 Exercise time
Time to do some maths and bash exercises together.
**Exercise 1**: Create a script that accepts input in GB and outputs its equivalent value in MB and KB.
**Exercise 2**: Write a script that takes two arguments and outputs the result in exponential format.
So, if you enter 2 and 3, the output will be 8, which is 2 to the power 3.
**Hint**: Use the exponentiation operator **
**Exercise 3**: Write a script that converts Centigrade to Fahrenheit.
**Hint**: Use the formula F = C x (9/5) + 32. You'll have to use `bc`
command here.
You can discuss the exercises and their solution in the community.
[Practice exercise in Bash Basics Series #4: Arithmetic OperationsIf you are following the Bash Basics series on It’s FOSS, you can submit and discuss the answers to the exercise at the end of the chapter: Fellow experienced members are encouraged to provide their feedback to new members. Do note that there could be more than one answer to a given problem.](https://itsfoss.community/t/practice-exercise-in-bash-basics-series-4-arithmetic-operations/10831)

In the next chapter, you'll [learn about arrays in Bash](https://itsfoss.com/bash-arrays/). Stay tuned.
[Bash Basics Series #5: Using Arrays in BashTime to use arrays in bash shell scripts in this chapter. Learn to add elements, delete them and get array length.](https://itsfoss.com/bash-arrays/)
 |
16,007 | 7 个最佳的开源基于 Web 的电子邮件客户端 | https://itsfoss.com/open-source-web-based-email-clients/ | 2023-07-17T13:50:26 | [
"电子邮件",
"Webmail"
] | https://linux.cn/article-16007-1.html | 
电子邮件服务将会一直存在,即便去中心化技术会接管互联网。
然而,随着大型科技公司试图控制新兴技术的方方面面,你如何掌控自己的电子邮件服务呢?
无论是企业还是个人,自托管的开源 Web 邮件服务始终是值得考虑的选项。你自己的服务器、你自己的数字基础架构,上面搭上你自己的电子邮件服务平台。这样,你就无需依赖供应商或第三方来管理你的电子邮件服务。你可以按照自己的方式办事。
### 为什么应该自托管电子邮件服务?

自托管一个可用作基于 Web 的电子邮件客户端或与电子邮件应用程序同步的服务,这不是点击一下就完成的过程。
那么,为什么要这么费事呢?难道你不能使用一些诸如 [Proton Mail](https://itsfoss.com/recommends/protonmail) 和 Tutanota 之类的 [注重隐私的最佳电子邮件服务](https://itsfoss.com/secure-private-email-services/) 吗?
当然可以。
但是对于企业来说,自托管 Web 邮件的一些优势包括:
* 用户可以完全掌控电子邮件数据。
* 你可以自己构建符合电子邮件服务要求的基础设施。
* 它为个人、小型企业和企业提供了可扩展性。
* 你可以创建无限数量的电子邮件帐户和邮件别名。
* 用户可以轻松应用高级过滤器和其他保护机制,无需付费订阅。
在这里,我列出了一些你可以选择的最佳选项。
### 1、Roundcube

主要亮点:
* 适合桌面使用
* 持续维护
* 大多数服务器托管提供商都提供
* 可自定义的用户界面
* PGP 加密
Roundcube 是一款流行的基于 PHP 的 Webmail 软件,提供简单的用户界面和所有基本功能。
大多数服务器托管提供商都已预安装它。你只需为你的域名配置它或创建电子邮件帐户即可开始使用。
你还可以在自己的服务器上安装并自定义它。
>
> **[Roundcube](https://roundcube.net)**
>
>
>
### 2、Cypht

主要亮点:
* 轻量级
* 模块化
Cypht 是一种不错的 Webmail 解决方案,提供多个电子邮件帐户的综合视图。
它采用了模块化的方法,可以轻松通过插件为你的体验添加功能。
与其他解决方案不同,你还可以使用它添加 RSS 订阅,将其用作新闻阅读器。
>
> **[Cypht](https://cypht.org/index.html)**
>
>
>
### 3、Squirrelmail

主要亮点:
* 轻量级
* 稳定
* 支持 PGP 加密插件
Squirrelmail 是一款经典的基于 PHP 的、支持 IMAP 和 SMTP 协议的 Webmail 软件。它功能不算多,但如果你需要一个轻量级和稳定的 Webmail 软件来托管,它能满足基本需求。
尽管外观简单,但它已经存在很长时间,并具备一些功能,如通讯录、文件夹操作和 MIME 支持。
大多数 Web 托管提供商都已经预装了 Squirrelmail。
>
> **[Squirrelmail](https://www.squirrelmail.org/)**
>
>
>
### 4、Rainloop

主要亮点:
* 无需数据库
* 简单用户界面
* 轻量级
Rainloop 是一款简单的电子邮件解决方案,支持 IMAP 和 SMTP 协议。
它还支持 OpenPGP 加密。与其他一些解决方案不同,它不需要数据库。直接访问邮件服务器,无需在 Web 服务器上存储任何内容。
由于支持插件,你可以扩展某些功能。
>
> **[Rainloop](https://www.rainloop.net)**
>
>
>
### 5、Horde

主要亮点:
* 预装于 Web 托管提供商
* 简单而功能丰富
Horde 是一款开源的群件 Webmail 软件,预装于各种 Web 服务器托管提供商。它支持 IMAP。
我通常使用 Horde 来访问我的域名下的 Webmail,从未让我失望过。它提供了简单而高效的用户界面和许多基本功能。
与其他软件类似,它基于 PHP 框架,开发人员可以轻松使用。
>
> **[Horde](https://www.horde.org)**
>
>
>
### 6、SOGo

主要亮点:
* Material Design 用户界面
* 支持 Outlook
* 提供在线演示
SOGo 是一款现代化的开源解决方案,采用了谷歌的 Material Design 用户界面和其电子邮件服务器。
它包括支持日历和通讯录,并提供友好的基于 AJAX 的 Web 界面。
你还可以获得对微软 Outlook 和 ActiveSync 的支持,这使你可以无缝同步电子邮件、联系人、事件和任务。你可以通过在线演示进行尝试。如果令人满意,你可以下载它到你的服务器上使用。
在其 [GitHub 页面](https://github.com/Alinto/sogo/) 可以了解更多信息。
>
> **[SOGo](https://www.sogo.nu)**
>
>
>
### 7、Afterlogic WebMail Lite

主要亮点:
* 可提供企业支持选项
* 支持社交登录
* OpenPGP 加密
Afterlogic WebMail Lite 是一个有趣的开源 Webmail,支持插件。
它还支持使用外部服务进行身份验证。例如,你可以使用谷歌帐户登录到你的电子邮件帐户。
虽然开源版本提供了所有功能和 OpenPGP 加密支持,但你也可以用于商业使用。
此外,你还可以选择专业版本以获得技术支持、优先修复、个人日历、移动版本和添加多个 IMAP 帐户的功能。
>
> **[Afterlogic WebMail Lite](https://afterlogic.org/webmail-lite)**
>
>
>
### 值得提及
有几个正在积极开发的开源项目可以供你尝试。
当然,我们不建议将它们用于商业或个人用途。你可以尝试它们,看看是否想以某种方式为它们的发展做出贡献。
我想提及几个此类邮件服务项目。
#### Mailpile
虽然它应该在上面的列表中占据一席之地,但是在用 Python 3 重写完成之前,[Mailpile](https://www.mailpile.is) 的开发已经停止。

Mailpile 是一款快速且现代化的开源 Webmail,具备加密和隐私功能。
#### Cuttlefish

[Cuttlefish](https://cuttlefish.io) 是一个自由开源的交易性电子邮件服务。它旨在成为 [SendGrid](https://sendgrid.com) 等专有服务的替代品。
它目前还处于早期开发阶段。
#### Pinbox
Pinbox 是一个自托管的 Webmail 解决方案,灵感来自于谷歌收件箱。
[Pinbox](https://github.com/msp301/pinbox) 是一个正在进行中的工作,需要一些先决条件才能正常工作。
### 总结
Squirrelmail、Horde 和 Roundcube 仍然是最流行的选项之一,你可以在大多数托管提供商处轻松访问它们。
当然,这些选项并不总是外观时尚或具备像谷歌工作空间甚至 Zoho 那样的功能,但你足够进行基本的电子邮件工作。
*(题图:MJ/603715d8-4562-4d7b-96f5-99ba76ad5a1b)*
---
via: <https://itsfoss.com/open-source-web-based-email-clients/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Email services are here to stay, even if decentralized tech takes over the internet.
However, with big tech trying to control everything new aspect of emerging technologies, how can you take charge of your email service?
Whether a business/enterprise or an individual, a self-hosted open-source webmail service is always an option worth considering. Your server, your digital infrastructure, and your email service platform. This way, you do not have to rely on a vendor or a third party to manage your email services. You do it your way.
## Why Should You Self-Host an Email Service?
It is **not a one-click process** to self-host a service, which you can use as a web-based email client or sync with an email app.
So, why bother? Can’t you use some of the [best privacy-focused email services](https://itsfoss.com/secure-private-email-services/) like [Proton Mail](https://itsfoss.com/recommends/protonmail) and Tutanota?
Well, yes, you can.
But, for businesses and enterprises, some advantages of self-hosting webmail include:
**The user gets total control over email data.****You get the ability to build your infrastructure that meets the requirements of your email services.****It provides scalability for individuals, small businesses, and enterprises.****You can create unlimited email accounts and email aliases.****Users can easily apply advanced filters and other protection mechanisms without paying for a subscription.**
Here, I list some of the best options that you can pick.
## 1. Roundcube
**Key Highlights:**
- Good fit for desktop use
- Actively maintained
- Available with most server hosting providers
- Customizable UI
- PGP Encryption
Roundcube is a popular PHP-based webmail software that provides all the essential features in a simple user interface.
With most of the server hosting providers, you already get it pre-installed. You have to configure it for your domain or create email accounts to get started.
You can also install it and customize it on your server.
## 2. Cypht
**Key Highlights:**
- Lightweight
- Modular
Cypht is an interesting webmail solution that provides a combined view of multiple email accounts.
While it is built with a modular approach, it is easy to add functionalities to your experience with plugins.
Unlike others, you can also use it to add RSS feeds and utilize it as a newsreader.
## 3. Squirrelmail
**Key Highlights:**
- Lightweight
- Stable
- PGP Encryption plugin support
A classic PHP-based with IMAP and SMTP protocol support. It does not include many features, but it gets the basics right if you want lightweight and stable webmail software to host.
While it looks like a barebone implementation, it has been around for a long time with features like address book, folder manipulation, and MIME support.
It also comes bundled in with most web hosting providers.
## 4. Rainloop
**Key Highlights:**
- No database required
- Simple user interface
- Lightweight
Rainloop is a straightforward email solution that supports IMAP and SMTP protocols.
It also supports OpenPGP encryption. Unlike some others, it does not require a database. Direct access to the mail server is maintained without requiring storing anything locally on the web server.
You can extend certain functionalities thanks to plugin support.
## 5. Horde
**Key Highlights**
- Bundled with web hosting providers
- Simple and feature-rich
Horde is an open-source groupware webmail software that comes bundled with various web server hosting providers. It supports IMAP.
I usually prefer Horde when accessing the webmail for my domains, which has never disappointed me. It offers a simple and effective user interface and many essential features.
Like others, it is a PHP-based framework that makes it easy for developers to work with.
## 6. SOGo
**Key Highlights:**
- Material design UI
- Outlook support
- Online demo available
SOGo is a modern open-source solution that features Google’s material design UI with its email server.
It includes support for calendar and address books while providing a friendly AJAX-based web interface.
You also get support for Microsoft Outlook and ActiveSync, which lets you synchronize emails, contacts, events, and tasks seamlessly. An online demo is available for you to try. If it sounds good, you can download it for your server.
Explore more about it on its [GitHub page](https://github.com/Alinto/sogo/).
## 7. Afterlogic WebMail Lite

Key Highlights:
- Enterprise support options are available
- Social sign-in support
- OpenPGP Encryption
An interesting open-source webmail with plugin support.
It supports authentication using external services as well. For instance, you can use your Google account to sign in to your email account.
While you get all the features and OpenPGP encryption support with the open-source edition, you can choose to use it commercially as well.
Additionally, you can opt for the pro version to get technical support, a priority fix, a personal calendar, a mobile version, and the ability to add multiple IMAP accounts.
## Interesting Mentions
Several open-source projects are under active development that you can experiment with.
Of course, we do not recommend using them for business or personal use. You can try them out to see if you want to contribute to their development in some way.
I would like to mention a couple of such mail service projects.
### Mailpile
While it deserves a spot in the list above, the development for [Mailpile](https://www.mailpile.is) has halted until Python3 rewrite is complete.
It is a fast and modern open-source webmail with encryption and privacy-centric features.
### Cuttlefish
[Cuttlefish](https://cuttlefish.io) is a free and open-source transactional email service. It aims to be an alternative to proprietary services like [SendGrid](https://sendgrid.com).
It is in its early stages of development.
### Pinbox
A self-hosted webmail solution that gets its inspiration from Google Inbox.
[Pinbox](https://github.com/msp301/pinbox) a work in progress and needs a few prerequisites to make it work.
## Wrapping Up
Squirrelmail, Horde, and Roundcube remain of the most popular options that can be easily accessed with most hosting providers.
Of course, these options are not always modern looking or have features like Google Workspace or even Zoho but you get enough to do the necessary emailing. |
16,009 | 如何在 C 语言中安全地读取用户输入 | https://opensource.com/article/22/5/safely-read-user-input-getline | 2023-07-18T10:44:30 | [
"输入",
"安全"
] | https://linux.cn/article-16009-1.html | 
>
> `getline()` 提供了一种更灵活的方法,可以在不破坏系统的情况下将用户数据读入程序。
>
>
>
在 C 语言中读取字符串是一件非常危险的事情。当读取用户输入时,程序员可能会尝试使用 C 标准库中的 `gets` 函数。它的用法非常简单:
```
char *gets(char *string);
```
`gets()` 从标准输入读取数据,然后将结果存储在一个字符串变量中。它会返回一个指向字符串的指针,如果没有读取到内容,返回 `NULL` 值。
举一个简单的例子,我们可能会问用户一个问题,然后将结果读入字符串中:
```
#include <stdio.h>
#include <string.h>
int main()
{
char city[10]; // 例如 "Chicago"
// 这种方法很糟糕 .. 不要使用 gets
puts("Where do you live?");
gets(city);
printf("<%s> is length %ld\n", city, strlen(city));
return 0;
}
```
输入一个相对较短的值就可以:
```
Where do you live?
Chicago
<Chicago> is length 7
```
然而,`gets()` 函数非常简单,它会天真地读取数据,直到它认为用户完成为止。但是它不会检查字符串是否足够容纳用户的输入。输入一个非常长的值会导致 `gets()` 存储的数据超出字符串变量长度,从而导致覆盖其他部分内存。
```
Where do you live?
Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch
<Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch> is length 58
Segmentation fault (core dumped)
```
最好的情况是,覆盖部分只会破坏程序。最坏的情况是,这会引入一个严重的安全漏洞,恶意用户可以通过你的程序将任意数据插入计算机的内存中。
这就是为什么在程序中使用 `gets()` 函数是危险的。使用 `gets()`,你无法控制程序尝试从用户读取多少数据,这通常会导致缓冲区溢出。
### 安全的方法
`fgets()` 函数历来是安全读取字符串的推荐方法。此版本的 `gets()` 提供了一个安全检查,通过仅读取作为函数参数传递的特定数量的字符:
```
char *fgets(char *string, int size, FILE *stream);
```
`fgets()` 函数会从文件指针读取数据,然后将数据存储到字符串变量中,但最多只能达到 `size` 指定的长度。我们可以更新示例程序来测试这一点,使用 `fgets()` 而不是 `gets()`:
```
#include <stdio.h>
#include <string.h>
int main()
{
char city[10]; // 例如 "Chicago"
puts("Where do you live?");
// fgets 虽好但是并不完美
fgets(city, 10, stdin);
printf("<%s> is length %ld\n", city, strlen(city));
return 0;
}
```
如果编译运行,你可以在提示符后输入任意长的城市名称。但是,程序只会读取 `size` = 10 数据存储到字符串变量中。因为 C 语言在字符串末尾会添加一个空(`\0`)字符,这意味着 `fgets()` 只会读取 9 个字符到字符串中。
```
Where do you live?
Minneapolis
<Minneapol> is length 9
```
虽然这肯定比 `fgets()` 读取用户输入更安全,但代价是如果用户输入过长,它会“切断”用户输入。
### 新的安全方法
更灵活的解决方案是,如果用户输入的数据比变量可能容纳的数据多,则允许字符串读取函数为字符串分配更多内存。根据需要调整字符串变量大小,确保程序始终有足够的空间来存储用户输入。
`getline()` 函数正是这样。它从输入流读取输入,例如键盘或文件,然后将数据存储在字符串变量中。但与 `fgets()` 和 `gets()` 不同,`getline()` 使用 `realloc()` 调整字符串大小,确保有足够的内存来存储完整输入。
```
ssize_t getline(char **pstring, size_t *size, FILE *stream);
```
`getline()` 实际上是一个名为 `getdelim()` 的类似函数的装饰器,它会读取数据一直到特殊分隔符停止。本例中,`getline()` 使用换行符(`\n`)作为分隔符,因为当从键盘或文件读取用户输入时,数据行由换行符分隔。
结果证明这是一种更安全的方法读取任意数据,一次一行。要使用 `getline()`,首先定义一个字符串指针并将其设置为 `NULL` ,表示还没有预留内存,再定义一个 `size_t` 类型的“字符串大小” 的变量,并给它一个零值。当你调用 `getline()` 时,你需要传入字符串和字符串大小变量的指针,以及从何处读取数据。对于示例程序,我们可以从标准输入中读取:
```
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char *string = NULL;
size_t size = 0;
ssize_t chars_read;
// 使用 getline 读取长字符串
puts("Enter a really long string:");
chars_read = getline(&string, &size, stdin);
printf("getline returned %ld\n", chars_read);
// 检查错误
if (chars_read < 0) {
puts("couldn't read the input");
free(string);
return 1;
}
// 打印字符串
printf("<%s> is length %ld\n", string, strlen(string));
// 释放字符串使用的内存
free(string);
return 0;
}
```
使用 `getline()` 读取数据时,它将根据需要自动为字符串变量重新分配内存。当函数读取一行的所有数据时,它通过指针更新字符串的大小,并返回读取的字符数,包括分隔符。
```
Enter a really long string:
Supercalifragilisticexpialidocious
getline returned 35
<Supercalifragilisticexpialidocious
> is length 35
```
注意,字符串包含分隔符。对于 `getline()`,分隔符是换行符,这就是为什么输出中有换行符的原因。 如果你不想在字符串值中使用分隔符,可以使用另一个函数将字符串中的分隔符更改为空字符。
通过 `getline()`,程序员可以安全地避免 C 编程的一个常见陷阱:你永远无法知道用户可能会输入哪些数据。这就是为什么使用 `gets()` 不安全,而 `fgets()` 又太笨拙的原因。相反,`getline()` 提供了一种更灵活的方法,可以在不破坏系统的情况下将用户数据读入程序。
*(题图:MJ/4b23132f-8916-42ae-b2da-06fd2812bea8)*
---
via: <https://opensource.com/article/22/5/safely-read-user-input-getline>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lkxed](https://github.com/lkxed) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Reading strings in C used to be a very dangerous thing to do. When reading input from the user, programmers might be tempted to use the `gets`
function from the C Standard Library. The usage for `gets`
is simple enough:
`char *gets(char *string);`
That is, `gets`
reads data from standard input, and stores the result in a string variable. Using `gets`
returns a pointer to the string, or the value NULL if nothing was read.
As a simple example, we might ask the user a question and read the result into a string:
```
``````
#include <stdio.h>
#include <string.h>
int
main()
{
char city[10]; // Such as "Chicago"
// this is bad .. please don't use gets
puts("Where do you live?");
gets(city);
printf("<%s> is length %ld\n", city, strlen(city));
return 0;
}
```
Entering a relatively short value with the above program works well enough:
```
``````
Where do you live?
Chicago
<Chicago> is length 7
```
However, the `gets`
function is very simple, and will naively read data until it thinks the user is finished. But `gets`
doesn't check that the string is long enough to hold the user's input. Entering a very long value will cause `gets`
to store more data than the string variable can hold, resulting in overwriting other parts of memory.
```
``````
Where do you live?
Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch
<Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch> is length 58
Segmentation fault (core dumped)
```
At best, overwriting parts of memory simply breaks the program. At worst, this introduces a critical security bug where a bad user can insert arbitrary data into the computer's memory via your program.
That's why the `gets`
function is dangerous to use in a program. Using `gets`
, you have no control over how much data your program attempts to read from the user. This often leads to buffer overflow.
# The safer way
The `fgets`
function has historically been the recommended way to read strings safely. This version of `gets`
provides a safety check by only reading up to a certain number of characters, passed as a function argument:
`char *fgets(char *string, int size, FILE *stream);`
The `fgets`
function reads from the file pointer, and stores data into a string variable, but only up to the length indicated by `size`
. We can test this by updating our sample program to use `fgets`
instead of `gets`
:
```
``````
#include <stdio.h>
#include <string.h>
int
main()
{
char city[10]; // Such as “Chicago”
// fgets is better but not perfect
puts(“Where do you live?”);
fgets(city, 10, stdin);
printf("<%s> is length %ld\n", city, strlen(city));
return 0;
}
```
If you compile and run this program, you can enter an arbitrarily long city name at the prompt. However, the program will only read enough data to fit into a string variable of `size`
=10. And because C adds a null (‘\0') character to the ends of strings, that means`fgets`
will only read 9 characters into the string:
```
``````
Where do you live?
Minneapolis
<Minneapol> is length 9
```
While this is certainly safer than using `fgets`
to read user input, it does so at the cost of "cutting off" your user's input if it is too long.
# The new safe way
A more flexible solution to reading long data is to allow the string-reading function to allocate more memory to the string, if the user entered more data than the variable might hold. By resizing the string variable as necessary, the program always has enough room to store the user's input.
The `getline`
function does exactly that. This function reads input from an input stream, such as the keyboard or a file, and stores the data in a string variable. But unlike `fgets`
and `gets`
, `getline`
resizes the string with `realloc`
to ensure there is enough memory to store the complete input.
`ssize_t getline(char **pstring, size_t *size, FILE *stream);`
The` getline`
is actually a wrapper to a similar function called `getdelim`
that reads data up to a special delimiter character. In this case, `getline`
uses a newline ('\n') as the delimiter, because when reading user input either from the keyboard or from a file, lines of data are separated by a newline character.
The result is a much safer method to read arbitrary data, one line at a time. To use `getline`
, define a string pointer and set it to NULL to indicate no memory has been set aside yet. Also define a "string size" variable of type `size_t`
and give it a zero value. When you call `getline`
, you'll use pointers to both the string and the string size variables, and indicate where to read data. For a sample program, we can read from the standard input:
```
``````
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int
main()
{
char *string = NULL;
size_t size = 0;
ssize_t chars_read;
// read a long string with getline
puts("Enter a really long string:");
chars_read = getline(&string, &size, stdin);
printf("getline returned %ld\n", chars_read);
// check for errors
if (chars_read < 0) {
puts("couldn't read the input");
free(string);
return 1;
}
// print the string
printf("<%s> is length %ld\n", string, strlen(string));
// free the memory used by string
free(string);
return 0;
}
```
As the `getline`
reads data, it will automatically reallocate more memory for the string variable as needed. When the function has read all the data from one line, it updates the size of the string via the pointer, and returns the number of characters read, including the delimiter.
```
``````
Enter a really long string:
Supercalifragilisticexpialidocious
getline returned 35
<Supercalifragilisticexpialidocious
> is length 35
```
Note that the string includes the delimiter character. For `getline`
, the delimiter is the newline, which is why the output has a line feed in there. If you don't want the delimiter in your string value, you can use another function to change the delimiter to a null character in the string.
With` getline`
, programmers can safely avoid one of the common pitfalls of C programming. You can never tell what data your user might try to enter, which is why using `gets`
is unsafe, and `fgets`
is awkward. Instead, `getline`
offers a more flexible way to read user data into your program without breaking the system.
## Comments are closed. |
16,010 | 20 个恐怖传说:在技术上犯过的最糟糕错误 | https://opensource.com/article/22/10/technology-horror-stories | 2023-07-18T14:56:00 | [] | https://linux.cn/article-16010-1.html | 
>
> 一些系统管理员、网页设计师、工程师和程序员分享了他们在命令行上经历的最可怕的经历。
>
>
>
每个开发人员内心最害怕的事情是什么?在你的代码开始运行前的宁静时刻,什么最让你感到恐怖?你见过或写过最可怕的代码是什么?
### 错误的权限
我负责一台服务器,然后我通过 FTP 上传了一些东西。显示了一些奇怪的东西,所以我想权限可能需要改变一下。
不用说,我愚蠢地关闭了读取权限并使网站瘫痪了。(当没有人能访问时,网站就没啥用了。)
我花了几个小时才修复好。这是很多年前我在一个机构担任唯一的网页开发人员时的事情。
— [Miriam Goldman](https://opensource.com/users/miriamgoldman)
### 混乱的 HTML
我曾经因 WordPress 的默认主题有可用的更新而使一个客户的网站瘫痪,这个客户当时是《华尔街日报》畅销书榜上的一位作者。
他的开发人员在主题中硬编码了 HTML,而不是创建一个子主题。而我运行了更新操作。
那个年代,人们不容易实现每晚备份,所以我花了几个小时打电话给托管提供商。像分阶段发布、子主题、每晚备份或手动备份这样的东西现在都很常见,还有自动更新和手动回滚的能力。但在那个时代并不常见。
— [Courtney Robertson](https://opensource.com/users/courtneyrdev)
### 密钥不再秘密
我想我们中的许多人在公共代码中看到过密钥。或者另一个经典案例:我的一个朋友从开发服务器向 10 万个用户发送电子邮件。
— [John E. Picozzi](https://opensource.com/users/johnpicozzi)
### Unix 混乱
这是一个 Unix 的故事。今天在 [Linux](https://opensource.com/tags/linux) 中已经修复了这个问题。
在我要向管理层进行一个重要的新组件演示的前一天,我需要更新我的代码(这是在 [Git](https://opensource.com/downloads/cheat-sheet-git) 存在之前的年代)。我进入我的主目录,找到项目目录,然后删掉了一切。不幸的是,在那个版本的 Unix 中,该命令会跟随符号链接进行删除,并且我有一个链接指向代码的最新版本(并不是所有代码都在源代码系统中,因为它还处于测试阶段)。
好在一天后,大楼里出现了网络问题,因此演示推迟了一天,我们设法恢复了代码。那是三十多年前的事情。即使现在我也不知道网络问题是巧合,还是我们的系统管理员试图帮助我们(如果是这样,那确实奏效了!)
— [Josh Salomon](https://opensource.com/users/joshs)
### 命令式编程
看到 CSS 文件中到处都是 `!important;` 而不是正确使用特异性。
我曾经不得不覆盖和定制一个 WordPress 主题几乎所有的 CSS,因为该网站的所有者坚持不换一个更接近他想要的设计的新主题。
那个主题开发者最后一次更新是在 2018 年,但网站至今仍在使用。
— [Christi Nickerson](http://cnickerson.com)
### 错误引用
在我以前的职位上,我的前任在代码注释中引用了 Journey 的《Any Way You Want It》歌词错误。
— [Ben Cotton](https://opensource.com/users/bcotton)
### Algol68 的幽灵
在上世纪 60 年代末到 70 年代初,Algol68 的复杂性使许多有影响力的人望而却步,包括 Niklaus Wirth 在内。我记得当时最常见的抱怨之一是:“谁能为这样一个复杂的怪物写一个编译器呢?” 但是事实上,许多人都开发过。此外,许多在 [Algol68](https://opensource.com/article/20/12/learn-algol-68) 中发展出来的或至少以形式化的概念出现在后来的其他语言中,尤其是在 C 语言和 Bourne shell 中(感谢 Steve Bourne)。
Algol68 的一些概念并没有经过很好的演化。例如,处理“书”和“章节”等的 I/O 概念在今天有些奇怪。像将字符集等问题留给实现本身处理似乎相当过时。
但是其中一些概念在今天仍然极为重要,例如产生值的表达式、强类型化(Algol68 中称为“模式”的类型)、[堆内存和垃圾回收](https://opensource.com/article/22/6/garbage-collection-java-virtual-machine)、运算符的定义和重载等等。
有好的地方,也有不好的地方。
Algol68 是一门值得学习的语言,即使只是为了了解现代计算中的许多想法的来源以及在路上丢失了多少。
— [Chris Hermansen](https://opensource.com/users/clhermansen)
### 密码暴露
我为一个新的支持客户进行技术审计时,发现之前的开发人员将密码以明文形式存储在整个主题中,并使用了糟糕的方式连接到远程数据库。他们的 composer 文件也异常庞大。每次我尝试在本地运行网站时,需要花费五分钟的时间。过时的依赖项、我无法访问的仓库,问题还有很多。
— [Miriam Goldman](https://opensource.com/users/miriamgoldman)
### 迷宫般的代码
我见过的最可怕的代码是一段 PDP-11 汇编语言,位于一个名为 RSTS 的操作系统的内核中,今天已经没有人记得它了。当时源代码记录在胶片上,我跟随这段代码路径经过几个转折,试图弄清楚正在发生的事情。然后,我遇到了这条指令:
```
MOV R5,PC
```
我举起双手尖叫了起来。真的,我尖叫了。办公室里的人以为我撞到头了,或者心脏病发作了。
那个年代,内存是宝贵的,`MOV` 指令使用的内存比 `BR`(即“分支”)指令稍微少一点。将寄存器 5 的内容复制到程序计数器实际上是一个廉价的无条件跳转,跳转到寄存器 5 中存储的地址。但是,我不知道寄存器 5 中存储了什么,也不知道如何找到它。
时至今日,将近 40 年过去了,我仍然想知道是谁写出这样的代码,以及如何调试它。
— [Greg Scott](https://opensource.com/users/greg-scott)
### 差一个
我在自动化行业工作,其中的可编程逻辑控制器(PLC)使用一些相当奇怪的语言进行编程。
让我印象深刻的一个例子是,在 [ST](https://en.wikipedia.org/wiki/Structured_text) 语言中,你可以定义数组从索引 1 开始。这意味着第一个元素在位置 1 而不是 0。每当我看到这个时,我都会抓狂。
— [Stephan Avenwedde](https://opensource.com/users/hansic99)
### 分歧
有一次在一个从测试环境到生产环境的发布期间,我让 MongoDB 实例停机了 40 分钟。我们的测试环境与生产环境有所分歧。只是一个数据库配置的差异,没什么太激动人心的东西。但这是一个很好的教训,要确保你的测试和生产环境保持同步!
— [Em Nouveau](https://opensource.com/users/nouveau)
### 神秘的低语
这是一个仍在运行且正常的项目,但我已经修改了代码以隐藏源代码。
```
for(int c =0; y < yyy && c < ccc; y++, c++){// some code here}
```
乍看起来,它似乎是一个无害的循环。但也许你会问为什么有两个变量、两个停止条件以及两个增量。然后你会意识到只有一个初始化器,第二个变量(`y`)在这个循环之前在不同的代码块中被初始化。
当我意识到这一点时,我花了大约一个小时的时间来理解为什么代码是这样编写的,以及它应该如何工作。显然,代码中没有 `c` 的注释,并且变量名是无意义的(代码中被称为 `c`,`y` 有一个稍微具有意义的名称,但不足以解释它的意义,即使是今天我也不知道它的作用)。
— [Josh Salomon](https://opensource.com/users/joshs)
### 关键数据
大约在 1980 年,我在大学毕业后得到了我的第一份工作。我是印第安那州一所工程学院的计算中心副主管。这是一个两人 IT 部门的辅助职位。我在 PDP-11/40 上处理行政计算,使用 RK05 可移动的“披萨碟”磁盘驱动器(每个驱动器容量为 2.5 MB)。每个行政办公室都有一个驱动器,而我工作的一部分就是每周进行磁盘对磁盘的备份。但是那个夏天我很忙,连续四周没有备份过注册办公室的数据。然后我意识到了风险,所以我确保开始进行每月的磁盘到磁带备份。
我从 11/40 上卸载了注册办公室的磁盘驱动器,然后装在了带有一台 9 磁道磁带驱动器的 11/70 上,并开始进行备份。几分钟后,我听到磁盘驱动器里传来一阵刮擦的声音。是的,磁头撞上了磁盘。在短短几分钟内,我摧毁了所有注册办公室的数据,以及最新的备份 —— 一个四周前的 9 磁道磁带。
当我不得不面对注册办公室主任,并告诉他我已经摧毁了他所有的数据时,那一刻真的很尴尬。
如今,我告诉新的 IT 人员,只有在你摧毁了某人的关键数据,而且无法恢复时,你才算是专业人士。永远记住你胃里的那种感觉。
— [Greg Scott](https://opensource.com/users/greg-scott)
### 愤怒的暴民
一个客户篡改了 WordPress 核心代码以添加后续在常规更新中发布的功能,但他们却不明白为什么在每次尝试更新 LearnDash 时网站都会崩溃。(他们也不喜欢我们的报告指出了他们糟糕的开发实践。)于是他们赶我们走,称我们是骗子和无能之辈。但直到今天,我仍然具有他们域名的委派访问权限,以及两个域名的生产和开发环境的 wp-admin 访问权限。
此外,尽管我们给了一个加密位置的链接用于共享访问凭据,他们却通过电子邮件发送了我们的登录信息。
— [Laura Byrne](http://twitter.com/@NewYorkerLaura)
### 不要忘记备份
我在企业网络上的工作经验不多,所以我没有使任何服务器崩溃过。然而,作为一个年轻人,我曾经试图帮助一个人解决 IT 问题,不知何故导致 Windows 95 崩溃,并不得不免费重新安装。
作为一个非常年轻的 Amiga 用户,我最悲伤的时刻之一是我的保存磁盘坏掉了,里面装满了所有我的文件,原因是某种机械故障。如今,我已经学会更好地备份我的重要个人文件。
— [Rikard Grossman-Nielsen](https://opensource.com/users/rikardgn)
### 万恶之源
当时我刚开始接触 Linux,之前我用的是 DOS,借助 Norton Commander 进行操作。后来,Midnight Commander 发布了,我非常喜欢它。当时我使用的 Linux 发行版(Jurix)没有打包 Midnight Commander,所以我自己从源代码编译了它,就像我那个时候使用的其他软件一样。它完美地运行了,突然间我在 Linux 上感到更亲切了。
这不是一个恐怖的故事。
我的同事告诉我不要以 root 身份运行 Midnight Commander,无论它有多么让人舒适。但是 root 权限很方便,感觉更像 DOS,所以我无视了他们的建议。结果就是:我意外地删除了整个 `/etc` 目录的内容。在那之前,我从来没有用过备份功能,但是那一天我意识到备份实际上是有用的。
27 年过去了,我仍然记得这个故事,并定期进行备份。
— [Peter Czanik](https://opensource.com/users/czanik)
### 幻觉
最糟糕的项目是一家代理机构让我做的一个一屏的页面,一开始看起来很简单。我说我可以用一些 HTML、CSS,也许加点 JavaScript,将其组合起来。但他们特别要求我不要这样做。他们希望我将设计图剪切下来,然后使用 CSS 在页面中定位这些元素。他们还要求我将所有的 CSS 内嵌到 HTML 文件中,因为他们真的只想要**一个页面**。
其中的文本都不是真实的文本。
除了定位这些图片所需的元素之外,其他都不是真正的 HTML 元素。
我告诉他们,设计足够简单,我可以用实际的代码将其组合起来,但他们不想要那样。他们只想让我花时间将这些碎片拼凑在一起,然后转而做其他项目。他们让我做了两个类似的一屏网站。
这实在伤害了我的前端灵魂。为我来说,这个项目在身体上是痛苦的。这是一个试用合同职位,当他们给我提供全职工作时,我礼貌地拒绝了。
— [Rachel Vasquez](https://opensource.com/users/rachievee)
### 内存破坏
对我来说,最可怕的事情就是 ANSI C99 中可能发生的内存破坏。在一个屏幕录像中,我捕捉到了这个(不完全是)超自然现象,可以在这个 [YouTube 视频片段](https://youtu.be/Go6r-CT06zc?t=103) 中观看到。

标有 `file` 的 GtkEntry 显示了一些随机的符号。我检查了一下 [代码](https://git.savannah.nongnu.org/cgit/gsequencer.git/tree/ags/app/ags_export_soundcard_callbacks.c?h=4.4.x#n397),但没有发现任何问题。
`ags_export_soundcard_open_response_callback()` 函数是一个回调函数,用于处理 `GtkFileChooserDialog` 的 `response` 事件。(顺便说一句,用于解决这个问题的工具是 [valgrind](https://opensource.com/article/21/8/memory-programming-c)。)

— [Joël Krähemann](https://opensource.com/users/joel2001k)
### Python 的恐怖之处
我见过的最可怕的编程特性是 Python 中对 `dict` 的访问权限。在运行时改变对象的类型违背了我的编程行为准则。
* [Josh Salomon](https://opensource.com/users/joshs)
### 缝合怪网络
在 2006 年,我用 Fedora 和一些脚本构建了一台防火墙,并说服了一家托管在合作数据中心的大型网站的客户,将其专有的防火墙替换为我的防火墙。我建立了系统并在一个清晨的 4 点到达现场进行安装。那时我才发现(饱受痛苦地)他在防火墙后面有一个带有公共 IP 地址的负载均衡器。客户经历了一个 5 分钟的停机时间,但我重新连接了一切恢复到原来的状态。
我发现了一种通过使用代理 ARP 来处理他复杂的网络配置的方法。这个想法是,当外部世界的任何人发出负载均衡器的 ARP 请求时,我会进行回应。几天后,我再次在凌晨 4 点出现并安装了我的系统。这次,我把整个数据中心的所有设备都给搞宕了。我设置了我的代理 ARP 来回应所有请求,因此局域网上的所有流量最终都找到了我并消失在黑洞中。
当我意识到我做了什么时,我把一切都恢复到原来的状态。但是损害已经造成。如果有人在 2006 年的一个清晨美国中部时间大约 4 点钟尝试浏览你最喜欢的网站,它没有响应,那可能是我的错。我通过在机架上安装并启动一个系统,让整个数据中心的网站都宕机了。
网站运营商愤怒地抗议,而我则黯然离开。他们再也没有邀请我回去再试。真是遗憾,我觉得再试试桥接可能会起作用。
— [Greg Scott](https://opensource.com/users/greg-scott)
### 你的恐怖故事
你最喜欢的与技术相关的恐怖故事是什么?在评论中告诉我们(但要友善,并更改项目名称以保护无辜者!)
---
via: <https://opensource.com/article/22/10/technology-horror-stories>
作者:[AmyJune Hineline](https://opensource.com/users/amyjune) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Halloween will be here before you know it! This fun, over-the-top holiday is a great time to ponder the mortal fears of the developer in each of us. What haunts you the most, in the quiet moments just before your code starts to run?
Getting into the spirit of Halloween, I asked some Opensource.com writers: *What's the scariest code you've seen or written?*
## Bad permissions
I was responsible for a server, and I FTP'd something up. There were some funky things displaying, so I thought some permissions needed to be changed.
Needless to say, I foolishly turned off read mode and took down the site. (A website is not much good when nobody can access it.)
It took me hours to fix. This was at an agency years ago when I was the sole web developer.
## Shambling HTML
I took down a client's website, who was an author on the Wall Street Journal bestseller list at the time, because the original WordPress default theme had an update available.
His developer had hardcoded HTML into the theme instead of creating a child theme. I ran the update.
This was in the days when folks didn't have nightly backups easily, so I spent hours on the phone with the hosting provider. Things like staging, child themes, nightly backups, or manual backups, are all now normal things, as well as the ability to auto-update and manually roll back. Not so in that era.
## Not-so-secret key
I think many of us have seen a secret key in public code before. Or another favorite: A friend of mine sending emails to 100,000 users from the dev server.
## Unix mix-up
This is a Unix story. It's fixed in [Linux](https://opensource.com/tags/linux) today.
A day before I was going to give an important demo of a new component to management, I had to refresh my code (this was way before [Git](https://opensource.com/downloads/cheat-sheet-git) existed.) I went to my home directory, found the project directory, and deleted everything. Unfortunately, in that flavor of Unix, this command *followed* symbolic links, and I had a link to the latest version of the code (not all was on the source code system as it was still in the testing phase).
A day later, there was a network problem in the building, so the demo was delayed for a day, and we managed to recover. It was more than three decades ago. Even now I have no clue whether the network problem was a coincidence or an attempt of our sysadmin to save us (if so, it worked!)
## Imperative
Seeing `!important;`
all over a CSS file instead of proper use of specificity.
I once had to override and customize almost all of a WordPress theme's CSS because the owner of the site wouldn't budge on getting a new theme that was closer to the design he wanted.
That same theme was last updated by the developer in 2018, and the website is still using it.
## Misquoted
In a previous role, my predecessor misquoted the lyrics to Journey's "Any Way You Want It" in a code comment.
## The ghost of Algol68
Algol68's complexity, back in the late 1960s and early 1970s, frightened away many influential people, including Niklaus Wirth. The most common complaint I can recall back then was along the lines of "who could write a compiler for such a complicated beast?" And yet many people did. Moreover, many of the concepts developed or at least formalized as [Algol68](https://opensource.com/article/20/12/learn-algol-68) appeared in later languages, notably in C and the Bourne shell (thanks to Steve Bourne).
Some of Algol68's concepts have not aged well. The concept of I/O dealing with "books" and "chapters," and so on, is a bit weird today. Leaving things like character sets to the implementation seems pretty old-fashioned.
But some are, or should be, tremendously relevant today, such as expressions that yield a value, strong typing (types in Algol68 are called "modes"), [heap memory and garbage collection](https://opensource.com/article/22/6/garbage-collection-java-virtual-machine), definition and overloading of operators, and more.
Sticking with the Hallowe'en theme, both tricks and treats.
Algol68 is a language that merits study, if for no other reason than to see where so many of modern computing's ideas came from, and to see how many have been lost along the way.
## Passwords exposed
I was doing a tech audit for an incoming support client, and the previous developer put passwords in plain text throughout the full theme, and used horrible ways to connect to a remote database. Their composer file was also ghoulishly bloated. It took five minutes every time I tried to get the site up and running locally. Outdated dependencies, repos I could not access, the list goes on.
## The maze
The scariest code I ever saw was a piece of PDP-11 assembly language in the kernel of an operating system named RSTS, which nobody remembers today. Source code was on microfiche in those days, and I had followed this code path through a few twists and turns, trying to figure out what was going on. And then, I ran into this instruction:
```
````MOV R5,PC`
I threw up my hands and wailed. I really did wail. People in the office thought I'd hit my head, or had a heart attack.
In those days, memory was precious and a `MOV`
instruction used a teeny tiny bit less memory than a `BR`
(for "branch") instruction. Copying the contents of register 5 into the program counter was really a cheap unconditional branch to the address stored in register 5. Except, I had no clue what was stored in register 5, or how to find it.
To this day, almost 40 years later, I wonder who would write code like that and how anyone could debug it.
## Off by one
I work in the automation industry, where the PLCs are programmed in some pretty weird languages.
An example that haunts me is the fact that in the language [ST](https://en.wikipedia.org/wiki/Structured_text), you can define arrays to begin at index 1. It means that the first element is at position 1, not 0. It drives me nuts when I see it.
## Divergence
I took a MongoDB instance down for 40 minutes once during a stage-to-prod launch. Our staging environment had diverged from production. It was just a database configuration difference—not very exciting. But it's a good lesson to make sure your staging and prod environments are in sync!
## Unearthly whispers
This is from a project that's still alive and kicking, but I've changed the code to hide the source.
```
``````
for (int c = 0; y < yyy && c < ccc; y++, c++) {
// some code here
}
```
It seems like an innocent loop at first. But maybe you're asking why there are two variables with two stop conditions and two increments. And then you realize there's only one initializer and the second variable (`y`
) is initialized before this loop in a different code block.
When I realized this, it took me about an hour to understand why the code was written in this way, and how it's supposed to work. Obviously, there were no `c`
comments and the variable names are meaningless (`c`
is called `c`
in the code and `y`
has a bit more meaningful name, but not meaningful enough to explain to me its meaning, not even today when I understand what it does).
## Critical data
Around 1980, I got my first job after college. I was the Assistant Computing Center Director at an engineering college in Indiana. That's a fancy title for the second-in-command of a two-person IT shop. I handled administrative computing on a PDP-11/40, with RK05 removable "pizza platter" disk drives (2.5 MB each.) Each admin office had one drive, and part of my job was to back them up, disk to disk, every week. But I got busy over that summer and skipped the Registrar's Office four weeks in a row. And then I realized the risk, so I made sure to start my monthly disk-to-tape backup.
I dismounted the Registrar's pizza platter from the 11/40 and mounted it on the 11/70, which had a 9-track tape drive, and started my backup. A few minutes later, I heard a scraping noise inside that disk drive. Yep, the heads crashed. In a few short minutes, I'd destroyed all the Registrar's data, and the then-most-recent backup, which was a four-week-old 9 track tape.
It was a, well, *uncomfortable* moment when I had to look the Registrar department head in the eye and tell him I had destroyed all his data.
Today, I tell new IT people you're not a pro until you've destroyed somebody's critical data, and there's no way to recover it. Remember that feeling in the pit of your stomach forever.
## Angry mob
A client hacked WordPress core to add features that later came out in a routine update and couldn't understand why the site kept crashing every time they attempted to update LearnDash. (They also didn't like our report that called out their poor development practices.) They basically showed us the door calling us liars and incompetents. To this day, I still have delegate access to their domains and wp-admin access to production and development of two domains.
They also, despite us sharing a link to an encrypted location for sharing access credentials, sent our logins over emails.
## Don't forget to backup
I've not worked much on corporate networks, so I haven't downed any servers. However, as I young person, I tried to help a person with an IT problem and somehow caused Windows 95 to crash, and had to reinstall it for free.
Another of my saddest moments as a very young Amiga user was when my save disk, containing all my files, broke due to some mechanical failure. Nowadays, I've gotten better at backing up more of my important personal files.
## Root of all evil
I was new to Linux, and I'd just come from DOS where I used Norton Commander. Then Midnight Commander got released and I was very happy about it. It wasn't packaged for the Linux distro I used at the time (Jurix), so I compiled it myself from source, just like other software I used at that time. It worked perfectly well, and suddenly I felt more at home on Linux.
That's not the horror story.
My colleagues told me not to run Midnight Commander as root, regardless of how comforting it was. But root was easy, and it felt more like DOS, so I ignored their advice. Long story short: I accidentally removed the content of the entire `/etc`
directory. Until that time, I'd never had to use backups, but that day I learned that backups are actually useful.
27 years later, I still remember this story, and I do regular backups.
## Illusion
The worst project one agency had me "make" was a one-pager that seemed straightforward at first. I said I'd be able to hash it together with some HTML and CSS, maybe a little Javascript. But they specifically asked me *not* to do that. They wanted me to cut out the design and literally use CSS to position those pieces around the page. They also had me add all CSS inline, directly into the HTML file, because they literally wanted **one page**.
None of the text was real text.
There were no real HTML elements aside from the ones needed to position those images.
I told them that the design was simple enough that I could throw it together with actual code, but they didn't want that. They only wanted me to spend the time to cobble the pieces together and then move on to a different project. They had me make two little one-page sites like that.
It hurt my front-end soul. It was physically *painful* for me to do that project. It was a temp-to-perm gig, and when they offered me full-time, I politely declined.
## Corruption
The scariest things to me are memory corruptions that can occur in ANSI C99. During a screencast, I captured this (not quite) paranormal occurrence in this [YouTube clip](https://youtu.be/Go6r-CT06zc?t=103).
The GtkEntry labeled `file`
shows some random glyphs. I've double checked the [code](https://git.savannah.nongnu.org/cgit/gsequencer.git/tree/ags/app/ags_export_soundcard_callbacks.c?h=4.4.x#n397), but didn't find any issues.
The `ags_export_soundcard_open_response_callback()`
function is a callback to the "response" event of GtkFileChooserDialog. (For the record, the tool to target this problem is [valgrind](https://opensource.com/article/21/8/memory-programming-c).)
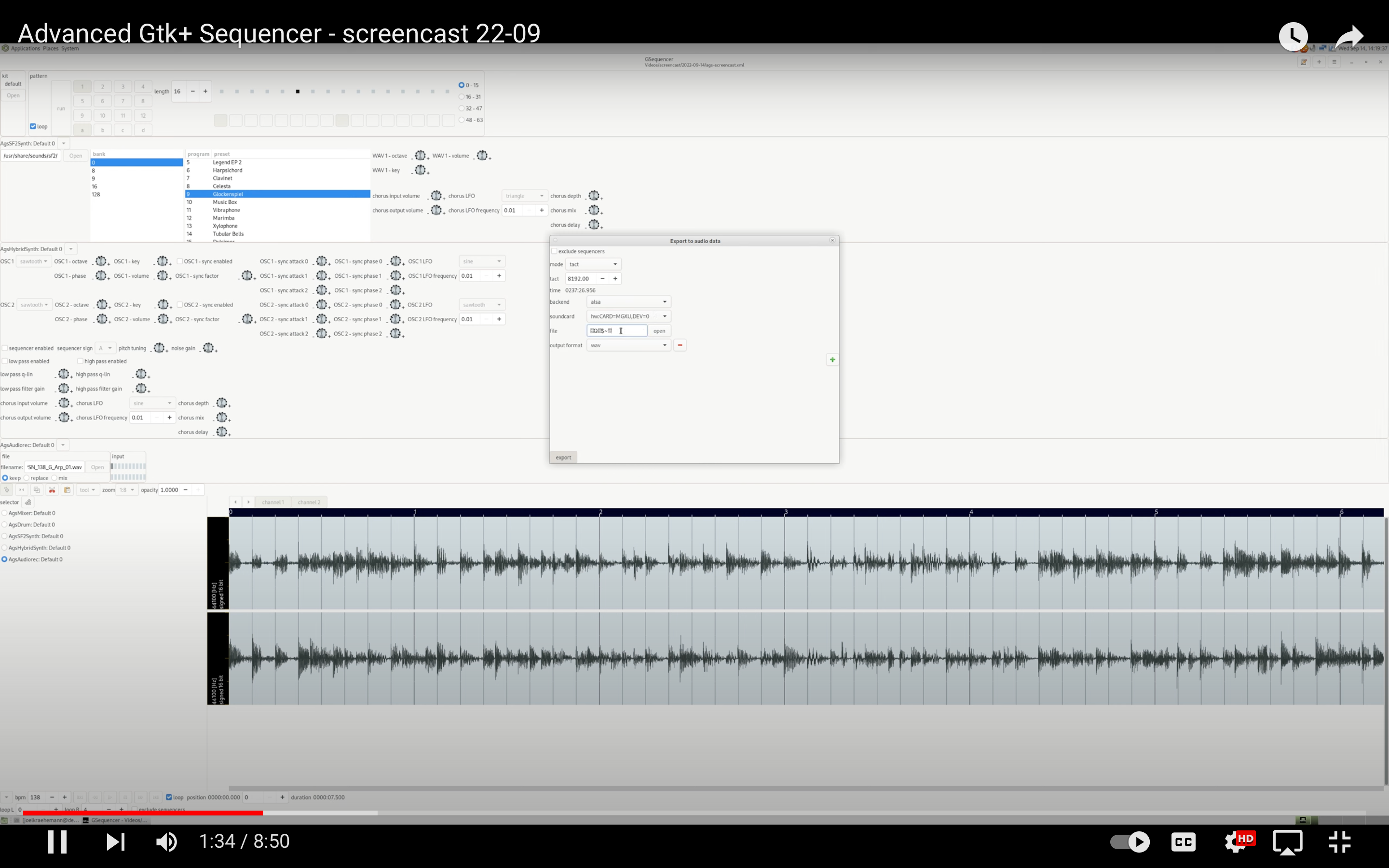
(Joël Krähemann, CC BY-SA 4.0)
## Python fears
The most horrific programming feature I ever saw is the access Python gives to its `dict`
. Changing the type of an object at runtime is against my programming code of conduct.
## Franken-net
In 2006, I built firewalls based on Fedora and a bunch of scripting, and persuaded a customer with a large website inside a colo center to replace a proprietary firewall with one of mine. I built it and showed up to install it at 4AM one morning. That was when I learned (the hard way) that he had a load balancer behind his firewall, but with a public IP address. The customer endured a 5-minute outage, but I reconnected everything to the original, and it all came back online.
I found a way to handle his franken-net configuration by using proxy ARP. The idea was whenever anyone from the outside world did an ARP request for the load balancer, I would answer. A few days later, I showed up at 4AM again and installed my system. This time, I knocked everything in the entire colo center offline. I had set up my proxy ARP to respond to *everything*, and so all traffic on the LAN eventually found me and disappeared into a black hole.
Once I realized what I'd done, I put it all back the way it was. But the damage was done. If you tried to browse your favorite website around 4AM US Central time one morning in 2006 and it didn't respond, it might have been my fault. I knocked an entire colo site offline by installing one system in a rack and turning it on.
The website operator screamed and I slunk out the door. They never invited me back to try again. That was a shame, because bridging probably would have worked.
## Your horror story
What's your favorite technology-related horror story? Tell us in the comments (but be nice, and change project names to protect the innocent!)
## 4 Comments |
16,012 | 不可变发行版 blendOS 发布最新版本 | https://news.itsfoss.com/blendOS-v3-released/ | 2023-07-19T14:16:31 | [
"blendOS"
] | https://linux.cn/article-16012-1.html |
>
> blendOS v3 已经来到,并带来了重大升级!
>
>
>

blendOS 是一个 [不可变发行版](https://itsfoss.com/immutable-linux-distros/),它的目标(野心)是取代所有 Linux 发行版。我们最近 [介绍了它](/article-15684-1.html) 之前的版本。该项目由 [Ubuntu Unity](https://news.itsfoss.com/unity-remix-official-flavor/) 的首席开发者 Rudra Saraswat 领导,其进展一直良好。
在最近的公告中,他们推出了一个带来了许多改进的新版本,使 **blendOS** 更加接近其目标。
让我们看看这个版本有什么内容。
### ? blendOS v3 “Bhatura”:有什么新内容?

作为一个支持大多数软件包的 **基于 Arch 的发行版**,最新版本的 blendOS 的名字来源于印度美食中的一道美味佳肴 “[印度炸麦饼](https://en.wikipedia.org/wiki/Bhatura)”。
这个版本提供了很多东西,值得注意的亮点包括:
* 更好的桌面环境支持
* 直观的应用安装
* 支持附加发行版
* 改进的系统更新
* 新的命令行程序
#### 更好的桌面环境支持

blendOS 现在 **支持 7 种桌面环境**,其中包括:
* [GNOME](https://www.gnome.org/)
* [KDE Plasma](https://kde.org/plasma-desktop/)
* [Cinnamon](https://github.com/linuxmint/Cinnamon)
* [XFCE](https://www.xfce.org/)
* [Deepin](https://www.deepin.org/en/dde/)
* [MATE](https://mate-desktop.org/)
* [LXQt](https://lxqt-project.org/)
**现在支持的太多啦!** ?
你可以通过在终端中运行 `system track` 命令轻松地在这些之间切换。
#### 直观的应用安装

此版本的 blendOS 现在提供了双击 **DEB**、**RPM**、**pkg.tar.zst** 甚至 **APK** 包将它们安装到容器中的功能。
>
> ? 对于 APK:你需要从设置启用安卓应用支持。
>
>
>
#### 支持附加发行版

blendOS 现在**支持在容器中运行十个发行版**,并且能够通过单用户/多用户安装 [运行 NixOS](https://itsfoss.com/why-use-nixos/)。以下是支持的发行版:
* Arch Linux
* AlmaLinux 9
* Crystal Linux
* Debian
* Fedora 38
* Kali Linux (滚动版)
* Neurodebian Bookworm
* Rocky Linux
* Ubuntu 22.04
* Ubuntu 23.04
#### 改进的系统更新

**blendOS v3 使用 ISO 进行系统更新。** 与传统发行版不同,它允许重建系统,更新大小在 **10-100 MB** 范围内。
多亏了 [zsync](https://github.com/AppImageCommunity/zsync2),更新下载的大小才如此之小。更新在后台下载,下次启动时,当前的根文件系统将被替换,同时保持任何自定义系统包完好无损。
**根据开发者的说法**,此更新系统解决了 Arch Linux 等滚动发行版的重大缺陷,防止任何数据丢失或系统故障,提供了出色的稳定性。
#### 新的命令行程序

最后,它引入了**两个新的命令行程序**; 一个是 `system`,另一个是 `user`。
`system` 将允许你安装软件包,甚至切换桌面。而 `user` 将使你能够创建/管理容器及其关联。
就是这样。对于此版本的亮点,你可以通过 [发布公告](https://blendOS.co/blend-os-v3/) 博客来了解有关此精彩版本的更多信息。
### ? 下载 blendOS v3 “Bhatura”
blendOS v3 **有七个不同的版本**,从 GNOME 版本一直到 Deepin 版本。
你可以从 [官方网站](https://docs.blendOS.co/guides/installation-guide/#mirror-list) 获取它们,你也可以在其中查看安装指南。
>
> **[blendOS v3 “Bhatura”](https://docs.blendOS.co/guides/installation-guide/#mirror-list)**
>
>
>
---
via: <https://news.itsfoss.com/blendOS-v3-released/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
16,013 | 你应该使用新的、较为冷门的 Linux 发行版,还是坚持使用主流的发行版? | https://news.itsfoss.com/obscure-or-maintsream-distro/ | 2023-07-19T15:31:03 | [
"发行版",
"Linux"
] | https://linux.cn/article-16013-1.html | 
当你开始在桌面上使用 Linux 时,你可能会选择像 Ubuntu 或者 Linux Mint 这样的 [对初学者友好的发行版](https://itsfoss.com/best-linux-beginners/)。
随着你逐渐熟悉 Linux 并且开始喜欢上它,你会加入各种社交渠道上的 Linux 相关社区,关注分享 Linux 内容的网站。而当你这样做的时候,你也会发现一些新的、相对不知名的发行版。
因为你对这个领域还比较陌生,你可能会被诱惑尝试一个接一个的发行版,从而陷入“[发行版快闪](/article-15949-1.html)”的陷阱。

于是你开始问自己这个问题:“我应该使用一个未知的发行版,还是像大多数人那样使用流行的发行版呢”?
简单的答案是坚持使用主流的发行版,但真正的答案需要你自己思考。
### 使用新的、较为冷门的发行版存在的问题
使用“全新的、个人开发者的发行版”存在一个主要问题,那就是不确定性。你无法确定这个项目将会存在多久。可能是一年,也可能是一个月。
我曾经见过几个发行版出现这种情况。比如,[SemiCode OS](https://itsfoss.com/semicode-os-linux/) 由于为程序员而创建而变得流行。类似的发行版 Emperor OS 最近消失了。这只是被停止开发的发行版长列表中的几个例子。
你可能会说,一个有一定用户基础的旧发行版也可能出现同样的情况。这是对的,但通常情况下,有一个社区和多个开发者参与项目。这样你就有一定的保证。
由于开发者的经验不足,新的发行版可能会缺失关键功能。例如,在撰写本文时,看起来令人惊艳的 Garuda Linux 官方并不推荐双启动。

尽管 Garuda Linux 拥有相当数量的支持者和几名开发者参与项目,但仍存在这个问题。
### 大多数新的发行版没有提供实质性的内容
你经常会遇到一些全新的发行版,它们基于一些其他流行的发行版,比如 Ubuntu 或 Arch Linux。唯一的不同可能只在于默认的应用程序、主题和壁纸。
如果它是一个“面向程序员的发行版”,它可能会默认安装一些编程应用程序。如果它是一个“游戏发行版”,它可能会默认安装一些工具,如 Steam、Wine 和 [Lutris](https://lutris.net/)。你不太可能在图形或硬件方面看到真正的优化。
这就是为什么很多人说,已经有了数百个发行版的拥挤空间中,我们不需要更多的发行版。毕竟,在主流发行版中安装所需的应用程序并不难。
### 我反对这些新的发行版吗?
绝对不是。
你可能会觉得几乎没有提供任何价值的新发行版是多余的。你可能是对的,因为这些项目可能对你来说无关紧要,但对于开发它的人来说,它们是重要的。
你有没有试过学习一门编程语言?第一个教程通常是一个“Hello World”的程序。即便是高级程序员也是从“Hello World”开始的。
婴儿不会直接开始跑步。到达那个阶段需要时间。
我对这些项目的看法也是一样的。如果有人热爱 Linux 并且对创建自己的“操作系统”感到兴奋,就让他们去做吧。如果你不想鼓励他们,也不要泼冷水。
大多数项目都是从相同的方式开始的。Linux Mint 是一款非常受欢迎的 Linux 发行版。它于 2006 年开始,并以 Kubuntu 为基础。
真的需要“一个基于 Ubuntu 的类似发行版”吗?实际上并不需要。但看看 Linux Mint 如今的地位。
### 那么,你应该使用新的发行版还是不应该使用呢?
总体而言,这取决于你自己。
如果你不喜欢频繁格式化你的系统,并且希望继续正常生活,那就坚持使用主流的发行版。
如果你喜欢实验,不介意频繁更换操作系统并且愿意冒着搞乱系统的风险,那么你可以尝试新的发行版。就个人而言,我建议你在虚拟机中尝试它们。如果你能有一台空闲的系统专门用于实验,那就更好了。
你也可以使用那些在社区中存在多年,但不如 Ubuntu、Mint、Fedora 和 Debian 等发行版流行的发行版。像 [PCLinuxOS](http://www.pclinuxos.com/)、[Puppy Linux](https://puppylinux.com/)、Peppermint OS 等项目拥有一个较小但活跃的社区。它们绝对是一个可靠的选择,即使用于你的主系统也没有问题。
在选择发行版时,除了基础发行版外,你还应该看看该发行版是否经常更新,并拥有一个活跃的社区。你只需要查看该项目的论坛,看看社区中是否有足够的活动即可。
### 你更喜欢哪种类型的发行版?
这是我在选择新的较为冷门发行版和流行的主流发行版之间提出的想法和建议。
那你呢?你更喜欢哪种类型的发行版?
*(题图:MJ/930988c0-443d-4d61-a603-1466a5e33d85)*
---
via: <https://news.itsfoss.com/obscure-or-maintsream-distro/>
作者:[Abhishek](https://news.itsfoss.com/author/root/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you start using Linux on your desktop, you probably stick with the [beginner-friendly distros](https://itsfoss.com/best-linux-beginners/?ref=news.itsfoss.com) like Ubuntu or Linux Mint.
As you get familiar with Linux and start loving it, you join Linux related communities on various social channels, follow websites that share Linux content (like It’s FOSS). And when you do that, you also start discovering new, rather unknown distributions.
Since you are new to the scene, you may get tempted to try one distro after another and fell down the ‘distrohopping’ slope.

This is when you start asking this question, “should I use an unknown distro or should I stay with the popular distributions like most people”?
The simpler answer is to stay with the mainstream distributions but the real answer needs some thinking from your end.
## The problem with using the new, obscure distributions
The major problem with the ‘brand new, lone developer distro’ is the uncertainty. You don’t know how long the project will live. It could be a year, it could be a month.
I have seen this with several distributions. There was [SemiCode OS](https://itsfoss.com/semicode-os-linux/?ref=news.itsfoss.com) that got popular because it was created for programmers. A similar distribution called Emperor OS disappeared recently. These are just a few examples from the long list of distros that were discontinued within a couple of years of their inception.
You may say the same could happen with an older distribution with decent user base as well. That’s true, but usually, there is a community and more than one developer working on the project. You have some assurance there.
Due to the lack of experience from the developer(s), the new distros may miss out on crucial features. For example, the astonishing looking Garuda Linux doesn’t officially recommend dual booting at the time of writing this article.
This is when Garuda Linux has a decent following and a few developers involved with the project.
## Most new distros don’t offer anything of substance
You’ll often come across brand new distributions that are based on some other popular distributions like Ubuntu or Arch Linux. The only thing that differs is probably the default applications, theme and wallpapers.
If it’s a ‘distro for programmers’, it will have a few programming applications installed by default. If it’s a ‘gaming distribution’, it probably will be coming with a few tools like Steam, Wine, [Lutris](https://lutris.net/?ref=news.itsfoss.com) installed. You are not likely to see some real optimization on the graphics or hardware part.
This is the reason many people say that we don’t need more distributions in an already crowded space with hundreds of distributions. After all, it’s not that difficult to install the required applications in the mainstream distributions.
## Am I against these new distros?
Absolutely not.
You may feel like there is no need for new distros that hardly add anything of value. You maybe right because those projects might not matter to you, but they do matter to the person who is developing it.
Have you ever tried to learn a programming language? The first tutorial is often a ‘hello world’ program. Even the advanced programmers start from the ‘hello world’.
Babies don’t start running straight away. It takes time to go to that stage.
I see the projects in the same way. If someone loves Linux and is excited to create their own ‘operating system’, let them do that. If you prefer not to encourage them, don’t discourage them as well.
Most project starts the same way. Linux Mint is a hugely popular Linux distribution. It was started back in 2006 and based itself on Kubuntu.
Was there really a need of ‘a similar distro based on Ubuntu’? Not really. But look where Linux Mint stands today.
## So, should you use new distros or not?
Overall, it all depends on you.
If you don’t like formatting your systems all the time and would like to continue with your life, stay with the mainstream distros.
If you like to experiment and don’t mind messing up with your system and change operating systems frequently, you may very well try the new distros. Personally, I would advise trying them in virtual machines. If you can have a spare system just for the experimentation, even better.
You may also use distributions that have been on the scene for years but they are not as popular as the likes of Ubuntu, Mint, Fedora and Debian. Projects like [PCLinuxOS](http://www.pclinuxos.com/?ref=news.itsfoss.com), [Puppy Linux](https://puppylinux.com/?ref=news.itsfoss.com), Peppermint OS etc. have a smaller but active community. They are definitely a dependable choice, even for your main system.
While choosing a distribution, apart from the base distro, you should also see if the distro gets regular updates and has an active community. You just have to check the project forum and see if there are enough activities in the community.
## What do you prefer?
That’s what I think and suggest when it comes to choosing between new, obscure distros and the popular, mainstream ones.
How about you? What kind of distributions do you prefer?
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,015 | Linux 桌面拥有近一半的 Linux 桌面市场! | https://www.theregister.com/2023/07/18/linux_desktop_debate/ | 2023-07-20T11:52:55 | [
"Linux",
"桌面"
] | https://linux.cn/article-16015-1.html |
>
> 如果人们能停止争论谁算谁不算,那就会加倍了。
>
>
>

Linux 现在占据全球桌面操作系统市场略超过 3%,不包括 4% 多的 ChromeOS(虽然 ChromeOS 实际上 *也是* Linux,但是它是“错误类型”的 Linux)。
Web 服务器统计聚合网站 Statcounter 上周宣布,截至 2023 年 6 月,Linux [占据](https://gs.statcounter.com/os-market-share/desktop/worldwide) 全球桌面操作系统使用量的 3%。然而,ChromeOS 的使用量仍然超过 Linux,这意味着 Linux 桌面占不到一半的 Linux 桌面市场的份额。如果你感到这话有点奇怪,那你是对的。
显然,Linux 桌面的使用量为 3.08%,落后于 ChromeOS 的 4.15%。问题在于,ChromeOS 实际上 *也是* 一种 Linux 发行版。它是一种奇怪的发行版,在几个方面不符合标准,它目前的版本基于 Gentoo Linux [构建](https://www.theregister.com/2023/02/14/chromeos_opinion_column/),是几年前从基于 Ubuntu 转换而来的。
我们认为更准确的计算结果应该是,Linux 现在占据了 Statcounter 统计的使用数据的 7.23%,而 ChromeOS 占据了一半以上:总计 57.4%。这似乎是一个更积极的解释,Linux 粉丝应该会乐于接受,但显然事实并非如此。例如,Linux 布道网站 Linuxiac 在其报道中甚至没有 [提到](https://linuxiac.com/linux-hits-3-percent-market-share/) ChromeOS。
(顺便说一下,我们怀疑 “未知” 类别下的 3.23% 操作系统很可能也是 Linux 用户,只是他们的极度谨慎遮掩了他们的用户代理或其他信息。)
为什么 ChromeOS *不* 算进去呢?它是一个在标准 glibc C 库之上构建的 Linux 内核和 Linux 用户空间。你可以打开 Shell。如果你愿意,你还可以运行一个 [Debian 容器](https://www.theregister.com/2018/04/27/linux_vms_on_chrome_os/),并在其中安装和运行任何 Debian 应用;我们的实验性 ChromeOS Flex 机器运行着 Firefox 和 DOSemu。
如果有人说 “安卓不是 Linux”,这还是有一定的道理的。你不能轻松免费地下载它,也不能在自己的通用个人电脑上运行它。尽管有一些实验性的基于安卓的桌面操作系统,但迄今为止它们都失败了。在其原生平台的智能手机和平板电脑上,你无法在安卓上运行普通的 Linux 应用程序。它是一种不同类型的系统,尽管*从技术上*讲,它是一个带有 Linux 内核的系统。但仅此而已。它甚至使用了奇怪的、非标准的、非 GPL 许可的 libc,名为 "Bionic"。默认情况下,除了内核之外,它没有任何其他类似 Linux 的东西。没有 Shell,没有桌面,没有 X11 或 Wayland,什么都没有。
但 ChromeOS 不是如此。在其独特的 GUI 层下(与 macOS 不同,它是 [开源](https://chromium.googlesource.com/chromium/src.git/+/lkgr/ash/) 的),它是一个相对标准的 Linux,可以直接在 x86 和 ARM 平台上运行标准的 Linux 应用程序。因此,它是目前最成功的桌面 Linux。
它不是*典型的* Linux,因为典型的 Linux 是给怀有技术痴迷的黑客人群使用的工具,这种操作系统永远不会成为主流,除非有人强迫人们使用它。
ChromeOS 是一个去除了 Linux 特性的 Linux 桌面。没有关于分区的选择。没有奇怪的双启动机制。不用选择桌面环境或软件包管理器。甚至没有软件包管理器!
从重要的方面来看,ChromeOS 是一个主流、商业成功、精心设计的面向最终用户的桌面操作系统,而且它确实是一个 Linux 系统。
因此,自由开源软件(FOSS)阵营的力量自然对它充满敌意。当然他们愿意这么做。他们是如何表达这种蔑视呢?他们声称它不是一个“真正的 Linux”。
Unix 就像一种宗教:不知何故,它鼓励分裂和分散的派别,每个派别都否认其他派别的合法性。这几乎成了 Unix 的定义特征之一。
如果我们忽略所有商业版的 Unix,因为它们实际上都已经 [不复存在](https://www.theregister.com/2023/01/17/unix_is_dead/),只关注 FOSS 阵营,有大约十几个竞争派别:NetBSD、FreeBSD、OpenBSD、DragonflyBSD、Minix、HURD 和 L4 及其 [各种分派](https://www.theregister.com/2022/02/24/neptune_os_sel4_windows/)、Plan 9([9front](https://www.theregister.com/2022/11/02/plan_9_fork_9front/)、HarveyOS、Jeanne 等)、Inferno、[xv6](https://github.com/mit-pdos/xv6-public)、[v7/86](https://www.nordier.com/),当然还有 Linux 和数千个不同的发行版。
确切地说,只有 **两个** 基于 Linux 的操作系统在面向非技术用户的 GUI 系统中取得了大规模的商业成功。一个拥有 [数十亿用户](https://www.theregister.com/2012/06/11/android_activation_nears_one_million_daily/),另一个则有 [数亿用户](https://www.theregister.com/2021/05/05/chromebook_shipments_canalys_figures/)。它们都来自谷歌,并且都具有一个定义性的特征:自由开源软件(FOSS)世界拒绝接受它们。
ChromeOS 有两个版本:普通的 ChromeOS 只能通过购买专门为其设计的硬件来获得(就像苹果的 macOS 一样),而另一个是 ChromeOS Flex。Flex 过去被称为 Neverware Cloudready。Neverware 起源于 Hexxeh 对普通个人电脑 [重新混编和重构](https://www.theregister.com/2010/11/08/google_chrome_os_is_not_android/) 的 ChromiumOS。Hexxeh 开发了 ChromeOS Flow,它是 ChromeOS Flex 的直接前身:两者都是可以用在通用个人电脑硬件上的 ChromeOS。这是其中一个重要的方面,它表明 ChromeOS 就是又一个 Linux 发行版。
ChromeOS Flex 不像安卓。从重要的方面来看,它就是一个 Linux。它既是自由 [开源](https://www.chromium.org/chromium-os/) 的,也有多个混编和重构版本。它可以在通用的具有普通 BIOS 或 UEFI(包括安全启动)的设备上运行。它有自己独特的桌面环境。你可以打开一个 Shell,并安装和运行任何任意的 Linux 应用程序。
外观上它看起来像一个 Linux,行为也像一个 Linux,并且像任何其他桌面 Linux 一样运行。它基于通用的 Linux 内核,使用与其他桌面 Linux 相同的 Linux 二进制文件执行 Linux 相关的操作。
它没有 systemd,但感谢伟大的 Torvalds 大神以及他的使徒圣·Cox,它还不是 Linux 发行版的要求。它使用的是 upstart,这是一种最广泛使用的初始化系统之一。
当某种特定形式的基于 Linux 的操作系统开始变得主流,并被 [大约一半](https://www.bankmycell.com/blog/how-many-android-users-are-there) 的人使用时,Linux 世界的真正信徒们会放弃它,这完全符合 Linux 世界的特点。安卓不是 Linux。好吧,他们某种程度上是对的。
但是对于 ChromeOS,尤其是 ChromeOS Flex 来说呢?当然,所有的倡导者都会声称它不是真正的 Linux,但随之而来的很快就变成了一个“[没有真正的苏格兰人](https://www.scribbr.com/fallacies/no-true-scotsman-fallacy/)”的争论。红帽族认为 Ubuntu 是垃圾,Debian 迷们认为其他一切都是垃圾,Arch 族认为自己是真正的前沿,Slackware 爱好者认为其他人都是新手,而 NixOS 的那些人则认为其他所有人仍然停留在某个石器时代……
*(题图:MJ/3dcb3470-0b08-41bf-b826-be5afac57775)*
---
via: <https://www.theregister.com/2023/07/18/linux_desktop_debate/>
作者:[Liam Proven](https://www.theregister.com/Author/Liam-Proven) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-16013-1.html) 荣誉推出
| 200 | OK | This article is more than **1 year old**
# Linux has nearly half of the desktop OS Linux market
## It would be twice as much if people could stop arguing about who counts and who doesn't
Opinion Linux is now a little more than three percent of global desktop OS market, excluding the just-over *four* percent that is ChromeOS. Which is *also* Linux, but the *wrong kind* of Linux.
Web server statistics aggregator Statcounter announced last week that as of June 2023, Linux [accounts](https://gs.statcounter.com/os-market-share/desktop/worldwide) for three percent of worldwide desktop operating system use. However, this is still surpassed by ChromeOS, which means that desktop Linux has less than half of the desktop Linux market. If you feel that this is a bit weird, we agree with you.
Apparently, desktop Linux use measures 3.08 percent, lagging about a quarter behind the usage of ChromeOS at 4.15 percent. The problem with this is that ChromeOS is *also* a Linux distribution. It's a strange distro, non-standard in several ways, but current versions are [built on](https://www.theregister.com/2023/02/14/chromeos_opinion_column/) the basis of Gentoo Linux, switching from an Ubuntu basis some years earlier.
We feel that a more accurate reckoning would be that Linux has now reached 7.23 percent of Statcounter's usage figures, with ChromeOS at just over half: 57.4 percent of the total. That seems like a more positive interpretation, one that Linux fans would be keen to make, but apparently not. By example, Linux advocacy site Linuxiac doesn't even [mention](https://linuxiac.com/linux-hits-3-percent-market-share/) ChromeOS in its write-up.
(As an aside, we suspect that quite a lot of the 3.23 percent of OSes grouped under "Unknown" are probably *also* Linux users, just extra-paranoid ones who are obscuring their user-agent or something.)
Why *shouldn't* ChromeOS count? It's a Linux kernel and a Linux userland on top of the standard `glibc`
C library. You can open a shell. If you want, you can [run a Debian container](https://www.theregister.com/2018/04/27/linux_vms_on_chrome_os/) and once you're in there install and run any Debian app; *The Reg* FOSS desk's experimental ChromeOS Flex machine runs Firefox and DOSemu.
If someone said "Android is not a Linux," that is defensible. You can't easily download it for free, and you can't run it on your own generic off-the-shelf computer. There have been a few experimental Android-based desktop OSes, but so far they've all flopped. On its native platform of smartphones and tablets, you can't run ordinary Linux apps on Android. It's a different sort of beast, even though *technically* it is a Linux inasmuch as it has a Linux kernel. But that's about it. It even has a weird, non-standard, non-GPL `libc`
, "Bionic". By default and unless cracked, aside from the kernel, it has nothing else Linux-like about it. No shell, no desktop, no X11 or Wayland, nothing.
But that's not the case for ChromeOS. Underneath its unique GUI layer – which, unlike the one in macOS, is [open source](https://chromium.googlesource.com/chromium/src.git/+/lkgr/ash/) – it's a relatively standard Linux which can run standard Linux apps, out of the box, on both x86 and Arm. As such, it's the most successful desktop Linux there is.
It's not a *typical* Linux, because typical Linuxes are tools for nerdy hacker types, and that kind of OS will never, ever go mainstream unless someone forces people to use it. (As the [government of the People's Republic of China is currently doing](https://www.theregister.com/2022/07/03/china_openkylin/), but that is irrelevant to this. No Google inside the Great Firewall means no ChromeOS.)
ChromeOS is a desktop Linux with the Linuxiness stripped out. No choice about partitioning. No weird dual-boot mechanisms. No choice of desktops or package managers. No package manager!
But in every way that matters, it is mainstream, it is commercially successful, it's a polished end-user desktop OS, and it's a Linux.
So naturally the Forces of FOSS hate it. Of *course* they do. And how do they express that contempt? By saying it's not a True Linux.
Unix is like a religion: somehow, it encourages schisms and splinter sects, all of whom deny that the others are legitimate. It's almost a defining characteristic.
Ignoring all the commercial Unixes as [they are effectively all dead now](https://www.theregister.com/2023/01/17/unix_is_dead/), and just looking at the FOSS ones, there are about a dozen rival sects: NetBSD, FreeBSD, OpenBSD, DragonflyBSD, Minix, HURD and L4 and its [various splinter groups](https://www.theregister.com/2022/02/24/neptune_os_sel4_windows/), Plan 9 ([9front](https://www.theregister.com/2022/11/02/plan_9_fork_9front/), HarveyOS, Jeanne etc.), Inferno, [xv6](https://github.com/mit-pdos/xv6-public), [v7/86](https://www.nordier.com/), and of course, Linux and its thousand distributions.
[AlmaLinux project climbs down from being a one-to-one RHEL clone](https://www.theregister.com/2023/07/17/almalinux_project_switches_focus/)[Three signs that Wayland is becoming the favored way to get a GUI on Linux](https://www.theregister.com/2023/07/13/wayland_is_coming/)[SUSE announces its own RHEL-compatible distro... again](https://www.theregister.com/2023/07/12/suse_announces_rhel_fork/)[Oracle pours fuel all over Red Hat source code drama](https://www.theregister.com/2023/07/10/oracle_ibm_rhel_code/)
Precisely two (2) Linux-based OSes have enjoyed large-scale commercial success as user-facing GUI systems for non-technical users. One has [billions of users](https://www.theregister.com/2012/06/11/android_activation_nears_one_million_daily/), the other a [significant fraction of a billion](https://www.theregister.com/2021/05/05/chromebook_shipments_canalys_figures/). Both are from Google, and both share a defining attribute: the FOSS world rejects them.
ChromeOS comes in two flavors: there's ordinary ChromeOS, which you can only get by buying hardware built to run it (just like Apple's macOS), and there's [ChromeOS Flex](https://www.theregister.com/2022/02/16/google_chrome_os/). Flex [used to be called Neverware Cloudready](https://www.theregister.com/2022/02/16/google_chrome_os/). Neverware grew from [Hexxeh's remixed and rebuilt ChromiumOS](https://www.theregister.com/2010/11/08/google_chrome_os_is_not_android/) for ordinary PCs. Hexxeh made ChromeOS Flow, and that is the direct grandparent of ChromeOS Flex: both are ChromeOS for generic PC hardware. That is the significant angle. It shows that ChromeOS is just another Linux distro.
ChromeOS Flex is not like Android. It is a Linux in every way that matters. It's both small-f free and it's [open source](https://www.chromium.org/chromium-os/); there have been multiple remixes and rebuilds. It runs on generic kit with ordinary BIOS or UEFI, including with Secure Boot. It has a desktop, albeit its own unique one. You can pop a shell and install and run any arbitrary Linux app.
It looks like a Linux, it acts like a Linux, and it runs like a Linux. It is based on a generic Linux kernel, and it does Linuxy stuff with Linuxy binaries like any other desktop Linux.
It doesn't have systemd, but thank the great god Torvalds and his apostle St Cox that is not yet a requirement for a Linux distro. It has `upstart`
, which was one of the most widespread init systems.
It is 100 percent on-brand for the Linux world that when one specific form of Linux-based OS goes mainstream, and is used by [approximately half](https://www.bankmycell.com/blog/how-many-android-users-are-there) the human race, the True Believers of the Linux world disown it. Android is not a Linux. OK, they kind of have a point.
But ChromeOS, and especially ChromeOS Flex? Of course, all the advocates decry it as not being a True Linux, but then again, this just quickly descends into a ["no true Scotsman"](https://www.scribbr.com/fallacies/no-true-scotsman-fallacy/) argument. As it is, the Fedora lot think Ubuntu is junk, and the Debianisti think everything else is junk, and the Arch folk think they are the true cutting edge, [Slackware](http://www.slackware.com/changelog/current.php?cpu=x86_64) enthusiasts consider everyone else newbies, while the NixOS folk think all the rest are still in the stone age somewhere… ®
239 |
16,016 | Bash 基础知识系列 #5:在 Bash 中使用数组 | https://itsfoss.com/bash-arrays/ | 2023-07-20T15:03:00 | [
"脚本",
"Bash"
] | https://linux.cn/article-16016-1.html | 
>
> 本章将介绍如何在 Bash Shell 脚本中使用数组。学习添加元素、删除元素和获取数组长度。
>
>
>
在本系列的前面部分中,你了解了变量。变量中可以有单个值。
数组内部可以有多个值。当你必须一次处理多个变量时,这会使事情变得更容易。你不必将各个值存储在新变量中。
因此,不要像这样声明五个变量:
```
distro1=Ubuntu
distro2=Fedora
distro3=SUSE
distro4=Arch Linux
distro5=Nix
```
你可以在单个数组中初始化它们所有:
```
distros=(Ubuntu Fedora SUSE "Arch Linux" Nix)
```
与其他一些编程语言不同,你不使用逗号作为数组元素分隔符。
那挺好的。让我们看看如何访问数组元素。
### 在 Bash 中访问数组元素
使用索引(数组中的位置)访问数组元素。要访问索引 N 处的数组元素,请使用:
```
${array_name[N]}
```
>
> ? 与大多数其他编程语言一样,Bash Shell 中的数组从索引 0 开始。这意味着第一个元素的索引为 0,第二个元素的索引为 1,第 n 个元素的索引为 `n-1`。
>
>
>
因此,如果你想打印 SUSE,你将使用:
```
echo ${distros[2]}
```

>
> ? `${` 之后或 `}` 之前不能有任何空格。你不能像 `${ array[n] }` 那样使用它。
>
>
>
### 一次访问所有数组元素
假设你要打印数组的所有元素。
你可以一一使用 `echo ${array[n]}` 但这确实没有必要。有一个更好更简单的方法:
```
${array[*]}
```
这将为你提供所有数组元素。

### 在 Bash 中获取数组长度
如何知道数组中有多少个元素? 有一个专门的方法 [在 Bash 中获取数组长度](https://linuxhandbook.com:443/array-length-bash/):
```
${#array_name[@]}
```
就这么简单,对吧?

### 在 Bash 中添加数组元素
如果必须向数组添加其他元素,请使用 `+=` 运算符 [将元素追加到 Bash 中的现有数组](https://linuxhandbook.com:443/bash-append-array/):
```
array_name+=("new_value")
```
这是一个例子:

>
> ? 追加元素时使用 `()` 很重要。
>
>
>
你还可以使用索引将元素设置在任何位置。
```
array_name[N]=new_value
```
**但请记住使用正确的索引编号。** 如果在现有索引上使用它,新值将替换该元素。
如果你使用“越界”索引,它仍会添加到最后一个元素之后。例如,如果数组长度为 6,并且你尝试在索引 9 处设置新值,则该值仍将作为最后一个元素添加到第 7 个位置(索引 6)。

### 删除数组元素
你可以使用 Shell 内置的 `unset` 通过提供索引号来删除数组元素:
```
unset array_name[N]
```
这是一个示例,我删除了数组的第四个元素。

你还可以通过 unset 来删除整个数组:
```
unset array_name
```
>
> ? Bash 中没有严格的数据类型规则。你可以创建一个同时包含整数和字符串的数组。
>
>
>
### ?️ 练习时间
让我们练习一下你所学到的有关 Bash 数组的知识。
**练习 1**:创建一个 Bash 脚本,其中包含五个最佳 Linux 发行版的数组。全部打印出来。
现在,用 “Hannah Montanna Linux” 替换中间的选择。
**练习 2**:创建一个 Bash 脚本,该脚本接受用户提供的三个数字,然后以相反的顺序打印它们。
预期输出:
```
Enter three numbers and press enter
12 23 44
Numbers in reverse order are: 44 23 12
```
我希望你喜欢通过本系列学习 Bash Shell 脚本。在下一章中,你将学习如何使用 `if-else`。敬请关注。
*(题图:MJ/09477e2f-2bf9-4fdf-bc1e-c894a068adf2)*
---
via: <https://itsfoss.com/bash-arrays/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter #5: Using Arrays in Bash
Time to use arrays in bash shell scripts in this chapter. Learn to add elements, delete them and get array length.
In the earlier part of the series, you learned about variables. The variables can have a single value in it.
Arrays can have several values inside it. This makes things easier when you have to deal with several variables at a time. You don't have to store individual values in a new variable.
So, instead of declaring five variables like this:
```
distro1=Ubuntu
distro2=Fedora
distro3=SUSE
distro4=Arch Linux
distro5=Nix
```
You can initialize all of them in a single array:
`distros=(Ubuntu Fedora SUSE "Arch Linux" Nix)`
Unlike some other programming languages, you don't use commas as array element separators.
That's good. Let's see how to access the array elements.
## Accessing array elements in bash
The array elements are accessed using the index (position in the array). To access array element at index N, use:
`${array_name[N]}`
`nth`
element has index `n-1`
.So, if you want to print the SUSE, you'll use:
`echo ${distros[2]}`
`${`
or before `}`
. You CANNOT use it like ${ array[n] }.## Access all array elements at once
Let's say you want to print all the elements of an array.
You may use echo ${array[n]} one by one but that's really not necessary. There is a better and easier way:
`${array[*]}`
That will give you all the array elements.
## Get array length in bash
How do you know how many elements are there in an array? There is a dedicated way to [get array length in Bash](https://linuxhandbook.com/array-length-bash/):
`${#array_name[@]}`
That's so simple, right?
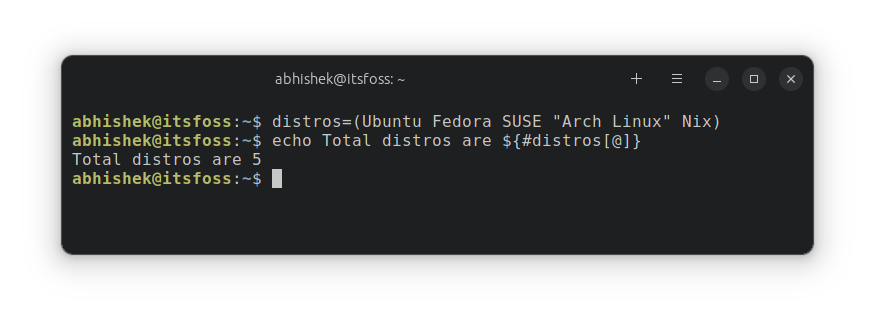
## Add array elements in bash
If you have to add additional elements to an array, use the `+=`
operator to [append element to existing array in bash](https://linuxhandbook.com/bash-append-array/):
`array_name+=("new_value")`
Here's an example:
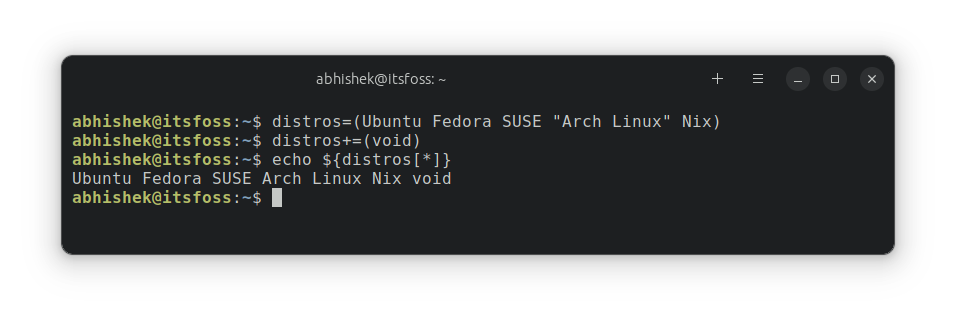
`()`
while appending an element.You can also use the index to set the element at any position.
`array_name[N]=new_value`
**But remember to use the correct index number.** If you use it on an existing index, the new value will replace the element.
If you use an 'out of bound' index, it will still be added after the last element. For example, if the array length is six and you try to set a new value at index 9, it will still be added as the last element at the 7th position (index 6).
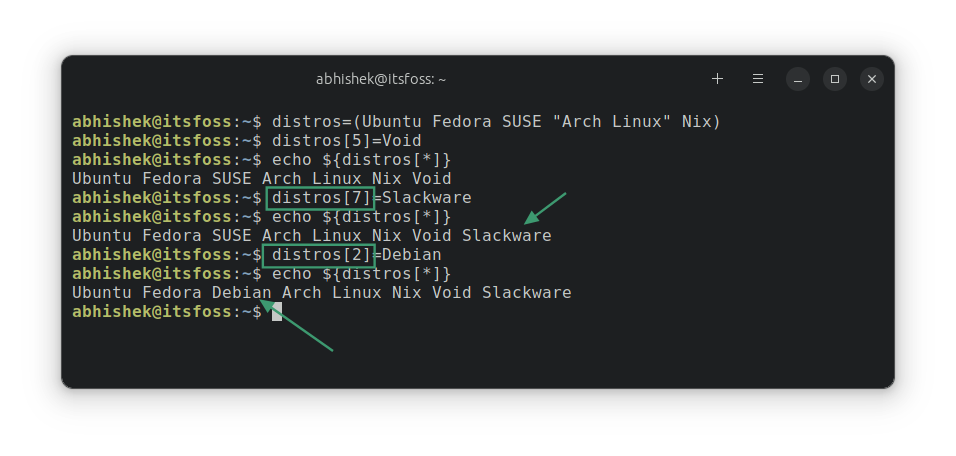
## Delete an array element
You can use `unset`
shell built-in to remove an array element by providing the index number:
`unset array_name[N]`
Here's an example, where I delete the 4th element of the array.
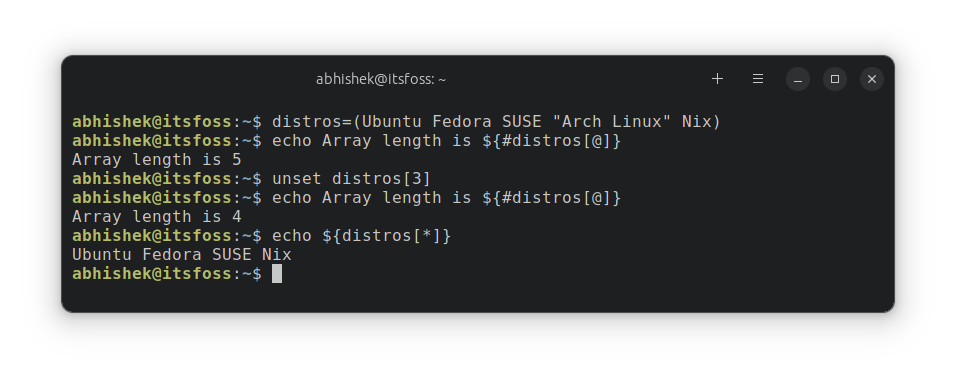
You can also delete the entire array with unset:
`unset array_name`
## 🏋️ Exercise time
Let's practice what you learned about bash arrays.
**Exercise 1**: Create a bash script that has an array of five best Linux distros. Print them all.
Now, replace the middle choice with Hannah Montanna Linux.
**Exercise 2**: Create a bash script that accepts three numbers from the user and then prints them in reverse order.
Expected output:
```
Enter three numbers and press enter
12 23 44
Numbers in reverse order are: 44 23 12
```
You can discuss your answers in the dedicated thread in the Community.
[Practice Exercise in Bash Basics Series #5: Using Arrays in BashIf you are following the Bash Basics series on It’s FOSS, you can submit and discuss the answers to the exercise at the end of the chapter: Fellow experienced members are encouraged to provide their feedback to new members. Do note that there could be more than one answer to a given problem.](https://itsfoss.community/t/practice-exercise-in-bash-basics-series-5-using-arrays-in-bash/10924)

I hope you are enjoying learning bash shell scripting with this series. In the next chapter, you'll learn about [handling strings in bash](https://itsfoss.com/bash-strings/). Stay tuned.
[Bash Basics Series #6: Handling String OperationsIn this chapter of the Bash Basics series, learn to perform various common string operations like extracting, replacing and deleting substrings.](https://itsfoss.com/bash-strings/)
 |
16,017 | Linux 爱好者线下沙龙:LLUG 2023 ,上海 · 集合 | https://jinshuju.net/f/R1YHy0 | 2023-07-20T19:17:00 | [
"LLUG"
] | https://linux.cn/article-16017-1.html | 
自打 LLUG 北京活动举办,大家就开始纷纷希望 LLUG 能够在自己所在的城市中举办,其中,呼声最高的,莫过于上海。
终于,大家千呼万唤的 LLUG 上海,来了。
7 月 23 日下午,我们将在上海举办 LLUG 线下活动,和大家一起聊聊 Linux 和开源技术方面的新动态,给 Linux 爱好者们送些小福利,以及邀请业界大咖,来给大家做个线下分享。本次我们分享的主题是:**社区与云**。
具体议程如下:
| 时间 | 议程 | 演讲者 |
| --- | --- | --- |
| 14:00 - 14:30 | 签到 | |
| 14:30 - 15:00 | 《浅谈云计算架构设计》 | 肖力某创业公司技术合伙人,腾讯云 TVP,中国商业联合会互联网应用工作委员会智库专家 |
| 15:00 - 15:10 | 《龙蜥技术认证课程介绍》 | 蔡佳丽龙蜥社区运营委员 |
| 15:10 - 15:30 | 茶歇 | |
| 15:30 - 16:00 | LCTT Tools 发布 | 白宦成(Bestony)Linux 中国技术负责人 |
| 16:00 - 16:30 | 神秘话题 | 老王(wxy)Linux 中国创始人 |
| 16:30 - 17:30 | 闪电演讲 & 自由交流 | |
### 活动信息
活动主办方:Linux 中国
联合主办方:龙蜥社区(OpenAnolis)
活动支持:奇虎 360、图灵社区、SlashData
活动地点:**上海市普陀区云岭东路570号**
活动时间:**2023 年 7 月 23 日,下午 14:00 ~ 17:00**
报名方式:点击[链接](https://jinshuju.net/f/R1YHy0)报名,或扫描下方二维码提交报名信息

如果你要来现场,不妨扫码加群,和我们更早的交流起来。到时候,咱们现场见!

### One More Thing
我们将会在活动现场举办线下抽奖,如果来到现场,别忘了参与互动,进行线下的抽奖哦~我们为大家准备了技术图书、小米背包、充电头等精选好物,期待在现场见到你哦~

| 302 | Found | null |
16,019 | Geary 44 电子邮件应用添加了两项实用增强功能 | https://news.itsfoss.com/geary-44-release/ | 2023-07-21T11:42:34 | [
"电子邮件"
] | https://linux.cn/article-16019-1.html |
>
> Geary 44 听起来是一个有趣的版本,有一些有用的变化。
>
>
>

Geary 是 [Linux 上最好的电子邮件客户端](https://itsfoss.com:443/best-email-clients-linux/) 之一,多年来增加了一些相当不错的更新。
它是 GNOME 项目下的一个电子邮件应用,**为 GNOME 桌面**(不限于)量身定制,支持 IMAP 和 SMTP 协议,使其能够与大多数网络邮件服务完美集成。
几天前,它发布了具有重要改进的新版本。让我们快速浏览一下这些内容。
### ? Geary 44:有什么新内容?

Geary 44 是一个相对较小的版本,有两个重要的补充。第一个是**重新设计的标题栏**,第二个是**重新设计的对话列表。**
新的“选择”按钮已添加到搜索按钮附近的标题栏中,并且消息视图工具栏图标的位置已更改。

当我们上次查看 Geary 时,它有不同的对话列表布局。但现在,**重新设计的对话列表让邮件阅读体验变得更好**。
你知道,这让我想知道 Geary 的这个版本与即将重新设计的 Thunderbird 相比会如何。你可能需要做出一些选择,是吗??
#### ?️ 其他更改和改进
除了上面提到的之外,还有一些值得注意的变化:
* 修复网络检测问题。
* 各种用户界面翻译改进。
* 系统挂起时使用挂起引擎。
* 多个错误修复和用户界面调整。
你可以浏览 [发行说明](https://gitlab.gnome.org:443/GNOME/geary/-/tags/44.0) 以了解有关此版本的更多信息。
### ? 获取 Geary 44
你可以从 [GitLab](https://gitlab.gnome.org:443/GNOME/geary) 上提供的源代码构建 Geary,也可以从 [Flathub 商店](https://flathub.org:443/apps/org.gnome.Geary) 获取它。
>
> **[Geary 44 (Flathub)](https://flathub.org:443/apps/org.gnome.Geary)**
>
>
>
? 如果你要尝试此版本的 Geary,请告诉我们!
---
via: <https://news.itsfoss.com/geary-44-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Geary is one of the [best email clients for Linux](https://itsfoss.com/best-email-clients-linux/?ref=news.itsfoss.com) that has been receiving some pretty decent updates over the years.
It's an email application under the GNOME project that has been **tailored for the GNOME desktop** (not limited to), with support for the IMAP and SMTP protocols that allow it to integrate neatly with most webmail services.
A few days back, a new version released with key improvements. Let's take a quick look at those.
## 🆕 Geary 44: What's New?
Geary 44 is a relatively minor release with two significant additions. First is the **reworked headerbar,** and second is the **redesigned conversation list.**
A new 'select' button has been added to the header bar near the search button, and the position of the message view toolbar icons has been changed.
When we last looked at Geary, it had a different conversation list layout. But now,** the** **redesigned conversation list just makes the mail reading experience so much better**.
You know, this makes me wonder how this release of Geary will fare against the upcoming redesign of Thunderbird. You may have to make some choices, eh? 🤩
**Suggested Read **📖
[Mozilla Gives a Sneak Peek on Thunderbird 115 Supernova Folder Design ChangesThunderbird shares details on design changes coming with its supernova upgrade.](https://news.itsfoss.com/thunderbird-supernova/)

### 🛠️ Other Changes and Improvements
Other than those mentioned above, here are some changes worth noting:
**A fix for network detection issues.****Various user interface translation improvements.****A suspend engine is used when the system is suspended.****Multiple bug fixes and user interface tweaks.**
You can go through the [release notes](https://gitlab.gnome.org/GNOME/geary/-/tags/44.0?ref=news.itsfoss.com) to learn more about this release.
## 📥 Get Geary 44
You can either build Geary from its source code available on [GitLab](https://gitlab.gnome.org/GNOME/geary?ref=news.itsfoss.com) or get it from the [Flathub store](https://flathub.org/apps/org.gnome.Geary?ref=news.itsfoss.com).
*💬 Let us know if you will be trying out this release of Geary!*
**Via: omg! linux!**
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,020 | DNS 故障集锦 | https://jvns.ca/blog/2022/01/15/some-ways-dns-can-break/ | 2023-07-21T12:23:00 | [
"DNS"
] | https://linux.cn/article-16020-1.html | 
当我第一次知道 DNS 时,我想它应该不会很复杂。不就是一些存储在服务器上的 DNS 记录罢了。有什么大不了的?
但是教科书上只是介绍了 DNS 的原理,并没有告诉你实际使用中 DNS 可能会以多少种方式破坏你的系统。这可不仅仅是缓存问题!
所以我 [在 Twitter 上发起了一个提问](https://twitter.com/b0rk/status/1481265429897261058),征集人们遇到的 DNS 问题,尤其是那些一开始看起来与 DNS 没什么关系的问题。(“总是 DNS 问题”这个梗)
我不打算在这篇文章中讨论如何解决或避免这些问题,但我会放一些讨论这些问题的链接,在那里可以找到解决问题的方法。
### 问题:网络请求缓慢
如果你的网络比预期的要慢,这是因为某些原因导致 DNS 解析器变慢了。这可能是解析器负载过大或者存在内存泄漏等原因导致的。
我的路由器的 DNS 转发器曾遇到过这个问题,导致我的所有 DNS 请求很慢。我通过重启路由器解决了这个问题。
### 问题:DNS 超时
一些网友提到由于 DNS 查询超时,他们的网络请求需要耗时 2 秒多甚至 30 秒。这跟“网络请求缓慢”问题类似,但情况要更糟糕,因为 DNS 请求就会消耗掉几秒钟时间。
Sophie Haskins 有一篇关于 Kubernete DNS 超时的博客文章 [一次 Kube DNS 踩坑经历](https://blog.sophaskins.net/blog/misadventures-with-kube-dns/)。
### 问题:ndots 设置
一些网友提到在 `/etc/resolv.conf` 中设置 `ndots:5` 时会出现问题。
下面是从 [这篇](https://pracucci.com/kubernetes-dns-resolution-ndots-options-and-why-it-may-affect-application-performances.html)《Kubernetes 容器荚中 `/etc/resolv.conf` 里设置 `ndots:5` 为什么会拖慢你的程序性能》中引用的 `/etc/resolv.conf`文件。
```
nameserver 100.64.0.10
search namespace.svc.cluster.local svc.cluster.local cluster.local eu-west-1.compute.internal
options ndots:5
```
如果你用上面的配置文件,想要查询得域名是 `google.com`,那么你的程序会调用 `getaddrinfo` 函数,而它会依次查询以下域名:
1. `google.com.namespace.svc.cluster.local.`
2. `google.com.svc.cluster.local.`
3. `google.com.cluster.local.`
4. `google.com.eu-west-1.compute.internal.`
5. `google.com.`
简单来说,它会检查 `google.com` 是不是 `search` 这一行中的某个子域名。
所以每发起一次 DNS 查询,你都得先等待前 4 次查询失败后才能获取到最终查询结果。
### 问题:难以判断系统使用的 DNS 解析器
这本身并不是一个问题,但当你遇到 DNS 问题时,一般都会跟 DNS 解析器有关。我没有一种判断 DNS 解析器的万能方法。
下面是我知道的方法:
* 在 Linux 系统上,最常见的是通过 `/etc/resolv.conf` 来选择 DNS 解析器。但是也有例外,比如浏览器可能会忽略 `/etc/resolv.conf`,而是使用 <ruby> 基于 HTTPS 的 DNS <rt> DNS-over-HTTPS </rt></ruby> 服务。
* 如果你使用的是 UDP DNS,你可以通过 `sudo tcpdump port 53` 来查看 DNS 请求被发送到了哪里。但如果你使用的是基于 HTTPS 的 DNS 或 <ruby> 基于 TLS 的 DNS <rt> DNS over TLS </rt></ruby>,这个方法就不行了。
我依稀记得这在 MacOS 系统上会更加令人迷惑,我也不清楚原因。
### 问题:DNS 服务器返回 NXDOMAIN 而不是 NOERROR
这是我曾经遇到过的一个 Nginx 不能解析域名的问题。
* 我设置 Nginx 使用一个特定的 DNS 服务器来解析 DNS 查询
* 当访问这个域名时,Nginx 做了两次查询,第一次是对 `A` 的,第二次是对 `AAAA` 的
* 对于 `A` 的查询,DNS 服务器返回 `NXDOMAIN`
* Nginx 认为这个域名不存在,然后放弃查询
* 对于 `AAAA` 的查询 DNS 服务器返回了成功
* 但 Nginx 忽略了对 `AAAA` 返回的查询结果,因为它前面已经放弃查询了
问题出在 DNS 服务器本应该返回 `NOERROR` 的——那个域名确实存在,只是没有关于 `A` 的记录罢了。我报告了这个问题,然后他们修复了这个问题。
我自己也写出过这个问题,所以我理解为什么会发生这种情况——很容易想当然地认为“没有要查询的记录,就应该返回 `NXDOMAIN` 错误码”。
### 问题:自动生效的 DNS 缓存
如果你在生成一个域名的 DNS 记录之前就访问这个域名,那么这个记录的缺失会被缓存起来。当你第一次遇到这个问题时一定会非常吃惊——我也是去年才知道有这个问题。
缓存的 TTL 就是域名的 <ruby> 起始权限记录 <rt> Start of Authority </rt></ruby>(SOA) 记录的 TTL ——比如对于 `jvns.ca` ,这个值是一个小时。
### 问题:Nginx 永久缓存 DNS 记录
如果你在 Nginx 中使用下面的配置:
```
location / {
proxy_pass https://some.domain.com;
}
```
Nginx 只会在启动的时候解析一次 `some.domain.com`,以后不会再对其进行解析。这是非常危险的操作,尤其是对于那些 IP 地址经常变动的域名。它可能平安无事地运行几个月,然后突然在某个凌晨两点把你从床上纠起来。
针对这个问题已经有很多众所周知的方法了,但由于本文不是关于 Nginx 的,所以我不打算深入探讨它。但你第一次遇到它时一定会很惊讶。
这是一篇关于这个问题发生在 AWS 负载均衡器上的 [博客文章](https://medium.com/driven-by-code/dynamic-dns-resolution-in-nginx-22133c22e3ab)。
### 问题:Java 永久缓存 DNS 记录
跟上面类似的问题,只是出现在 Java 上:[据说](https://docs.aws.amazon.com/sdk-for-java/v1/developer-guide/java-dg-jvm-ttl.html) 这与你 Java 的配置有关。“JVM 的默认 TTL 设置可能会导致只有 JVM 重启时才会刷新 DNS 记录。”
我还没有遇到过这个问题,不过我那些经常写 Java 的朋友遇到过这个问题。
当然,任何软件都可能存在永久缓存 DNS 的问题,但据我所知它经常出现在 Nginx 和 Java 上。
### 问题:被遗忘的 /etc/hosts 记录
这是另一种缓存问题:`/etc/hosts` 中的记录会覆盖你的常规 DNS 设置!
让人迷惑的是 `dig` 命令会忽略 `/etc/hosts` 文件。所以当你使用 `dig whatever.com` 来查询 DNS 信息时,它会告诉你一切正常。
### 问题:电子邮件未发送 / 将成为垃圾邮件
电子邮件是通过 DNS(MX 记录, SPF 记录, DKIM 记录)来发送和验证的,所以有些电子邮件问题其实是 DNS 问题。
### 问题:对国际化域名无效
你可以使用非 ASCII 字符甚至是表情符来注册域名,比如 [拉屎网 https://?.la](https://xn--ls8h.la/)。
DNS 能够处理国际化域名是因为 `?.la` 会被用 punycode 编码将转换为 `xn--ls8h.la`。
尽管已经有了 DNS 处理国际化域名的标准,很多软件并不能很好地处理国际化域名。Julian Squires 的 [干掉 Chrome 浏览器的表情符!!](https://www.youtube.com/watch?v=UE-fJjMasec) 就是一个非常有趣的例子。
### 问题:TCP DNS 被防火墙拦截
有人提到一些防火墙会允许在 53 端口上使用 UDP 协议,但是禁止 TCP 协议。然而很多 DNS 查询需要在 53 端口上使用 TCP,这可能会导致很难排查的间歇性的问题。
### 问题:musl 不支持 TCP DNS
很多应用程序使用 `libc` 的 `getaddrinfo` 来做 DNS 查询。`musl` 是用在 Alpine Docker 容器上的 `glibc` 替代品。而它不支持 TCP DNS。如果你的 DNS 查询的响应数据超过 DNS UDP 数据包的大小(512 字节)就会出现问题。
我对此仍然不太清楚,我下面我的理解也可能是错的:
1. `musl` 的 `getaddrinfo` 发起一个 DNS 请求
2. DNS 服务器发现请求的响应数据太大了,没法放入一个 DNS 数据包中
3. DNS 服务器返回一个<ruby> 空截断响应 <rt> empty truncated response </rt></ruby>,并期望客户端通过 TCP DNS 重新用发起查询
4. 但 `musl` 不支持 TCP DNS,所以根本不会重试
关于这个问题的文章:[在 Alpine Linux 上的 DNS 解析问题](https://christoph.luppri.ch/fixing-dns-resolution-for-ruby-on-alpine-linux)。
### 问题:getaddrinfo 不支持轮询 DNS
<ruby> 轮询 <rt> round robin </rt></ruby> DNS 是一种 <ruby> 负载均衡 <rt> load balancing </rt></ruby> 技术,每次 DNS 查询都会获得一个不同的 IP 地址。显然如果你使用 `gethostbyname` 做 DNS 查询不会有任何问题,但是用 `getaddrinfo` 就不行了。因为 `getaddrinfo` 会对获得的 IP 地址进行排序。
在你从 `gethostbyname` 切换到 `getaddrinfo` 时可能完全不会意识到这可能会引起负载均衡问题。
这个问题可能会非常隐蔽,如果你不是用 C 语言编程的话,这些函数调用被隐藏在各种调用库背后,你可能完全意识不到发生了这种改变。所以某次看似人畜无害的升级就可能导致你的 DNS 负载均衡失效。
下面是讨论这个的一些文章:
* [getaddrinfo 导致轮询 DNS 失效](https://groups.google.com/g/consul-tool/c/AGgPjrrkw3g)
* [getaddrinfo,轮询 DNS 和 happy eyeballs 算法](https://daniel.haxx.se/blog/2012/01/03/getaddrinfo-with-round-robin-dns-and-happy-eyeballs/)
### 问题:启动服务时的竞争条件
有人 [提到](https://mobile.twitter.com/omatskiv/status/1481305175440646148) 使用 Kubernete DNS 时遇到的问题:他们有两个同时启动的容器,一旦启动就会立即尝试解析对方的地址。由于 Kubernete DNS 还没有改变,所以 DNS 查询会失败。这个失败会被缓存起来,所以后续的查询会一直失败。
### 写在最后
我所列举的不过是 DNS 问题的冰山一角,期待大家告诉我那些我没有提到的问题和相关链接。我希望了解这些问题在实际中是如何发生的以及如何被解决的。
*(题图:MJ/f512f18e-2e1d-4614-bed1-b0a0c373e14d)*
---
via: <https://jvns.ca/blog/2022/01/15/some-ways-dns-can-break/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
16,022 | 什么是 KDE Connect?怎么用? | https://www.debugpoint.com/2022/01/kde-connect-guide/ | 2023-07-22T14:20:00 | [
"手机",
"安卓",
"KDE Connect"
] | /article-16022-1.html | 
>
> 什么是 KDE Connect?它的主要特性是什么?它应该如何安装?本文提供了基本的使用指南。
>
>
>
科技日新月异。有各种软件、硬件和不同外形的设备。未来,不同设备之间将无缝集成,工作流程会跨越多个设备。每一天,我们都在向跨所有联网设备发送和接收数据的状态迈进。而 KDE Connect 就是引领 Linux 桌面系统向这一天进展的一面旗帜。
### 什么是 KDE Connect?
[KDE Connect](https://kdeconnect.kde.org/) 是由 KDE 桌面团队开发的,提供了 Linux 系统与其他系统,如 Windows、MacOS、Android 及 Linux,的无缝连接。
KDE Connect 安装后会使你拥有接收电话的通知、发送或接受短信、浏览文件、发送或接受文件等许多功能。
此外,KDE Connect 在无线网络上遵循安全协议,以防止任何隐私泄露。它是自由开源的软件,出现任何隐患的可能性微乎其微。组合了这些优良特性,KDE Connect 是一款出色的工具。
下文介绍你如何安装和使用它。
### 安装 KDE Connect
本文将为你展示如何在 Linux 发行版和安卓智能手机之间连接。Windows 与安卓的连接也应是如此。
KDE Connect 的设置是一个双向过程。你必须在你的 Linux 发行版和你的安卓智能手机都安装 KDE Connect。
#### 在 Linux 发行版上安装
在你的 Linux 发行版上安装 KDE Connect 很简单。其在所有的主流 Linux 发行版的官方仓库中都可用。如果你在用 Ubuntu,并且想在终端安装,运行如下指令:
```
sudo apt install kdeconnect
```
Fedora:
```
sudo dnf install kdeconnect
```
Arch Linux:
```
pacman -S kdeconnect
```
或在 “<ruby> 软件 <rt> Software </rt></ruby>” 应用中搜索并安装。
对于 Windows 和其他 Linux 发行版,请参考 [这个页面](https://kdeconnect.kde.org/download.html) 的其他几种下载安装方式。
#### 在安卓智能手机上安装
在安卓设备中,在谷歌 Play 商店中搜索 “KDE Connect” 并安装。
>
> **[谷歌 Play 商店中的 KDE Connect](https://play.google.com/store/apps/details?id=org.kde.kdeconnect_tp&hl=en_IN&gl=US)**
>
>
>
如果你在使用某个自由版本的安卓,你可以用下面的链接来通过 F-droid 安装。(感谢我们的读者提出这一条)。
>
> **[F-droid 商店中的 KDE Connect](https://f-droid.org/en/packages/org.kde.kdeconnect_tp/)**
>
>
>
### 设置 KDE Connect
KDE Connect 可以连接相同网络中的设备。因此,确保你的 Linux 系统和安卓设备都连接到了同一个无线网络中。
打开你手机里的 KDE Connect。你应该可以见到你的 Linux 系统的名称。如果没有看到任何内容,确保你的设备和 Linux 都连接到了同一个网络后点击“<ruby> 刷新 <rt> Refresh </rt></ruby>”。

打开 Linux 中的 KDE Connect,你应当见到你的手机进入了下图展示的样子。

现在,点开你手机的名称然后点击 “<ruby> 配对 <rt> Pair </rt></ruby>”。
紧接着你的手机就会收到一个提醒:是否接受配对。选择 “<ruby> 接受 <rt> Accept </rt></ruby>”。

代表你的手机的图标应当转为绿色 ,这表示你的手机和 Linux 系统都已经连接且配对。

默认情况下,程序会开启以下特性:
* 多媒体控制
* 远程输入
* 远程演示
* 搜寻设备
* 分享文件
以下的特性需要你的安卓设备的额外权限。因为它们与隐私相关,这意味着你需要手动启用它们。
* 短信发送及接收
* 控制媒体播放器
* 手机上接受电脑的键盘输入
* 提醒同步
* 来电提醒
* 联系人同步
* 接受鼠标操作
对于这些特性,你需要去手动打开选项,并在安卓手机中授予权限。然后你就可以在 Linux 设备中享受这些服务了。
### 示例:提醒同步
我将为你演示提醒同步选项应在何处打开。打开你安卓手机中的 KDE Connect 程序,进入 “<ruby> 已连接设备 <rt> Connected Device </rt></ruby>” 部分。打开 “<ruby> 提醒同步 <rt> Notification Sync </rt></ruby>” 并选择 “<ruby> 打开设置应用 <rt> OPEN SETTINGS </rt></ruby>”。
对 KDE Connect 启用通知访问,然后点击 “<ruby> 允许 <rt> Allow </rt></ruby>”。

之后将展示你手机上的提醒到你的 Linux 设备。例如,下面的提醒是我在我的测试安卓设备中收到的。

同样的信息也展现在了 Linux 系统中的 KDE Connect。

同样地,在给 KDE Connect 权限后,你可以启动对你可用的其他服务。
### 总结
我希望这个指南可以帮助你在你的 Linux 系统和手机中设置 KDE Connect。
你可以在给与一些主要权限后,轻松地设置几个特性,以使 KDE Connect 应用程序发挥最大优势。配置完成后,你不再需要一直看你的手机。因为你可以在工作时轻易地在你的台式电脑或笔记本上阅读提示、回消息。
你觉得 KDE Connect 怎么样?发在下面的评论框来让我知道吧。
*(题图:MJ/5b09a037-14c3-4f62-a15a-dfd9fb2c7b3a)*
---
via: <https://www.debugpoint.com/2022/01/kde-connect-guide/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[yjacks](https://github.com/yjacks) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
16,023 | 如何在 Linux 主机和 KVM 中的 Windows 客户机之间共享文件夹 | https://www.debugpoint.com/kvm-share-folder-windows-guest/ | 2023-07-22T15:59:00 | [
"共享",
"KVM"
] | /article-16023-1.html | 
>
> 在本指南中,你将了解如何在 Linux 主机(例如使用 KVM 的 Fedora、Ubuntu 或 Linux Mint)下运行的 Windows 客户机之间共享文件夹。
>
>
>
[virt-manager](https://virt-manager.org/) 应用(带有 [libvirt](https://libvirt.org/manpages/libvirtd.html))和软件包提供了一组灵活的工具来管理 Linux 中的虚拟机。它是自由开源的,用于 KVM 虚拟机和其他虚拟机管理程序。
在上一篇文章中,我解释了 [如何在 Linux 客户机和 Linux 主机之间共享文件夹](https://www.debugpoint.com/share-folder-virt-manager/)。然而,当你尝试使用 Windows 客户机和 Linux 主机创建共享文件夹时,这是一个有点困难和复杂的过程。因为两种操作系统的工作方式不同,需要进行大量配置。
按照下面提到的说明在 Windows 客户机和 Linux 主机之间共享文件夹。
### 关于 virtiofs 的说明
共享文件和文件夹由名为 virtiofs 的 libvirt 共享文件系统提供支持。它提供了访问主机上目录树的所有功能和参数。由于大多数 virt-manager 虚拟机配置都会转换为 XML,因此共享文件/文件夹也可以由 XML 文件指定。
注意:如果你正在寻求在**两台 Linux 计算机**(客户机和主机)之间使用 KVM 进行文件共享,请 [阅读此文](https://www.debugpoint.com/share-folder-virt-manager/)。
### 使用 KVM 在 Windows 客户机和 Linux 主机之间共享文件夹
以下说明假设你已在任何 Linux 主机的 virt-manager 中安装了 Windows。如果没有,你可以阅读有关如何在 Linux 中安装 Windows 的完整指南。
#### 在 virt-manager 中设置挂载标签
首先,确保你的客户虚拟机已关闭。从 virt-manager GUI 中,选择虚拟机并单击“<ruby> 打开 <rt> Open </rt></ruby>”以调出控制台设置。

单击工具栏中显示虚拟硬件详细信息的图标。然后单击左侧面板上的“<ruby> 内存 <rt> Memory </rt></ruby>”。
选择选项“<ruby> 启用共享内存 <rt> Enable shared memory </rt></ruby>”。单击“<ruby> 应用 <rt> Apply </rt></ruby>”。
确保 XML 在 XML 选项卡中显示 `<access mode="shared"/>`,如下所示。
```
<memoryBacking>
<source type="memfd"/>
<access mode="shared"/>
</memoryBacking>
```

单击底部的“<ruby> 添加硬件 <rt> Add hardware </rt></ruby>”。
从添加新硬件窗口的左侧面板中选择“<ruby> 文件系统 <rt> Filesystem </rt></ruby>”。
然后在详细信息选项卡中选择 “<ruby> 驱动 <rt> Driver </rt></ruby>” 为 “virtiofs”。单击“<ruby> 浏览 <rt> browse </rt></ruby> > <ruby> 浏览本地 <rt> browse local </rt></ruby>”并从 Linux 系统中**选择主机路径**。
在“<ruby> 目标路径 <rt> Target path </rt></ruby>”中,输入你想要的任何名称。它只是一个文件标签,将在挂载过程中使用。目标路径中的此名称将作为 Windows 中的驱动器挂载,即资源管理器中的我的电脑。
我已添加 “linux\_pictures” 作为目标挂载标签。
因此,如果我想访问图片文件夹(`/home/debugpoint/Pictures`),示例设置可能如下:

单击“<ruby> 完成 <rt> Finish </rt></ruby>”。
上述配置的 XML 设置如下。你可以在 XML 选项卡中找到它。
```
<filesystem type="mount" accessmode="passthrough">
<driver type="virtiofs"/>
<source dir="/home/debugpoint/Pictures"/>
<target dir="linux_pictures"/>
<address type="pci" domain="0x0000" bus="0x05" slot="0x00" function="0x0"/>
</filesystem>
```
在 virt-manager 主窗口中,右键单击 Windows 虚拟机,然后单击“<ruby> 运行 <rt> Run </rt></ruby>”启动虚拟机。如果未显示虚拟机,请单击“显示图形控制台”(工具栏中的监视器图标)。
#### 设置 WinFSP – 适用于 Windows 的 FUSE
确保 Windows 虚拟机(客户机)正在运行。
首先,我们需要安装 WinFSP(Windows File System Proxy)– FUSE for Windows。这使你能够毫无困难地挂载任何类 UNIX 文件系统。
从客户 Windows 计算机打开 WinFSP 的 GitHub 页面。
>
> **[下载 WinFSP 安装程序](https://github.com/winfsp/winfsp/releases/)**
>
>
>
下载 WinFSP .msi 安装程序。
在 Windows 虚拟机上安装软件包。安装软件包时请确保选择 “Core”。完成安装。

#### 创建 VirtIO-FS 服务
进入 `stable-virtio` 文件夹,从以下地址下载 `virtio-win-guest-tools.exe`。
>
> **[下载 virtio-win-guest-tools](https://fedorapeople.org/groups/virt/virtio-win/direct-downloads/)**
>
>
>

在 Windows 虚拟机上安装软件包。

安装完成后,**重启** Windows 虚拟机。
重启后,在开始菜单中搜索打开“设备管理器”。
进入系统设备并查找 “VirtIO FS 设备”。它应该被识别并且驱动程序应该由 Red Hat 签名。
**注意**:(可选)如果你看到感叹号,即未检测到驱动程序,请按照 [此处](https://virtio-fs.gitlab.io/howto-windows.html) 说明下载 ISO 文件、安装它并手动检测驱动程序。

打开开始菜单并搜索“服务”。
向下滚动找到 “VirtIO-FS Service”。右键单击并单击“开始”启动该服务。
或者,你可以以管理员身份从 PowerShell/命令提示符运行以下命令来启动服务。
```
sc create VirtioFsSvc binpath="C:\Program Files\Virtio-Win\VioFS\virtiofs.exe" start=auto depend="WinFsp.Launcher/VirtioFsDrv" DisplayName="Virtio FS Service"
```
```
sc start VirtioFsSvc
```

服务启动后,打开资源管理器,你应该看到你在上面第一步中创建的挂载标签,该标签应映射为 Z 驱动器。见下图。

你现在可以根据需要使用修改后的权限访问整个 Linux 文件夹。
以下是在 Linux Mint 和 Windows 客户虚拟机中访问的同一文件夹的并排比较。

### 总结
我希望你现在能够在 Windows 客户机和 Linux 主机系统之间共享文件夹。本文在 Linux Mint 中测试了上述方法。它应该也适用于 Ubuntu、Fedora。
如果上述方法有效,请在下面发表评论以造福他人。
### 参考
* <https://virtio-fs.gitlab.io/howto-windows.html>
* <https://docs.fedoraproject.org/en-US/quick-docs/creating-windows-virtual-machines-using-virtio-drivers/>
* <https://github.com/virtio-win/virtio-win-pkg-scripts/blob/master/README.md>
* <https://github.com/virtio-win/kvm-guest-drivers-windows/issues/473>
*(题图:MJ/91c30453-5939-4368-b885-c4cb84e732bf)*
---
via: <https://www.debugpoint.com/kvm-share-folder-windows-guest/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
16,025 | 在 Linux 中使用 cat 命令 | https://itsfoss.com/cat-command/ | 2023-07-23T14:43:19 | [
"cat"
] | https://linux.cn/article-16025-1.html | 
>
> `cat` 命令的用途不仅仅是显示文件内容。
>
>
>
`cat` 命令用于打印文本文件的文件内容。至少,大多数 Linux 用户都是这么做的,而且没有什么问题。
`cat` 实际上代表 “<ruby> 连接 <rt> concatenate </rt></ruby>”,创建它是为了 [合并文本文件](https://linuxhandbook.com:443/merge-files/)。但只要有一个参数,它就会打印文件内容。因此,它是用户在终端中读取文件而无需任何其他选项的首选。
### 在 Linux 中使用 cat 命令
要使用 `cat` 命令,你必须遵循给定的命令语法:
```
cat [options] Filename(s)
```
这里:
* `[options]` 用于修改 `cat` 命令的默认行为,例如使用 `-n` 选项获取每行的数字。
* `Filename` 是你输入要使用的文件的文件名的位置。
为了简单起见,我将在本指南中使用名为 `Haruki.txt` 的文本文件,其中包含以下文本行:
```
Hear the Wind Sing (1979)
Pinball, 1973 (1980)
A Wild Sheep Chase (1982)
Hard-Boiled Wonderland and the End of the World (1985)
Norwegian Wood (1987)
Dance Dance Dance (1990)
South of the Border, West of the Sun (1992)
The Wind-Up Bird Chronicle (1994)
Sputnik Sweetheart (1999)
Kafka on the Shore (2002)
After Dark (2004)
1Q84 (2009-2010)
Colorless Tsukuru Tazaki and His Years of Pilgrimage (2013)
Men Without Women (2014)
Killing Commendatore (2017)
```
那么,在没有任何选项的情况下使用时,输出会是什么? 好吧,让我们看一下:
```
cat Haruki.txt
```

正如你所看到的,它打印了整个文本文件!
但你可以做的远不止这些。让我向你展示一些实际例子。
#### 1、创建新文件
大多数 Linux 用户使用 `touch` 命令来 [创建新文件](https://itsfoss.com/create-files/),但使用 `cat` 命令也可以完成相同的操作!
在这种场景下,`cat` 命令比 `touch` 命令有一个优势,因为你可以在创建文件时向文件添加文本。听起来很酷。不是吗?
为此,你需要使用 `cat` 命令,将文件名附加到 `>` 后面,如下所示:
```
cat > Filename
```
例如,在这里,我创建了一个名为 `NewFile.txt` 的文件:
```
cat > NewFile.txt
```
当你这样做了,就会有一个闪烁的光标要求你写一些东西,最后,你可以使用 `Ctrl + d` 来保存更改。
**如果你想创建一个空文件,则只需按 `Ctrl + d` 而不进行任何更改。**

这就好了!现在,你可以使用 `ls` 命令来显示 [当前工作目录的内容](https://itsfoss.com/list-directory-content/):

#### 2、将文件内容复制到另一个文件
考虑一个场景,你要将 `FileA` 的文件内容重定向到 `FileB`。
当然,你可以复制和粘贴。但是如果有几百或几千行怎么办?
简单。你可以使用 `cat` 命令来重定向数据流。为此,你必须遵循给定的命令语法:
```
cat FileA > FileB
```
>
> ? 如果使用上述语法重定向文件内容,它将删除 `FileB` 的文件内容,然后重定向 `FileA` 的文件内容。
>
>
>
例如,我将使用两个文本文件 `FileA` 和 `FileB`,其中包含以下内容:

现在,如果我使用从 `FileA` 到 `FileB` 的重定向,它将删除 `FileB` 的数据,然后重定向 `FileA` 的数据:
```
cat FileA > FileB
```

同样,你可以对多个文件执行相同的操作:
```
cat FileA FileB > FileC
```

可以看到,上面的命令删除了 `FileC` 的数据,然后重定向了 `FileA` 和 `FileB` 的数据。
#### 3、将一个文件的内容附加到另一个文件
有时你想要将数据附加到现有数据,在这种情况下,你必须使用 `>>` 而不是单个 `>`:
```
cat FileA >> FileB
```
例如,在这里,我将把两个文件 `FileA` 和 `FileB` 重定向到 `FileC`:
```
cat FileA.txt FileB.txt >> FileC.txt
```

如你所见,它保留了 `FileC.txt` 的数据,并将数据附加在末尾。
>
> ? 你可以使用 `>>` 向现有文件添加新行。使用 `cat >> filename` 并开始添加所需的文本,最后使用 `Ctrl+D` 保存更改。
>
>
>
#### 4、显示行数
你可能会遇到这样的情况,你想查看行数,这可以使用 `-n` 选项来实现:
```
cat -n File
```
例如,在这里,我将 `-n` 选项与 `Haruki.txt` 一起使用:

#### 5、删除空行
在文本文档中留下多个空白行? `cat` 命令将为你修复它!
为此,你所要做的就是使用 `-s` 标志。
但使用 `-s` 标志有一个缺点。你仍然留有一行空白:

正如你所看到的,它有效,但结果接近预期。
那么如何删除所有空行呢? 通过管道将其传递给 `grep` 命令:
```
cat File | grep -v '^$'
```
这里,`-v` 标志将根据指定的模式过滤掉结果,`'^$'` 是匹配空行的正则表达式。
以下是我在 `Haruki.txt` 上使用它时的结果:
```
cat Haruki.txt | grep -v '^$'
```

当获得完美的输出,你可以将其重定向到文件以保存输出:
```
cat Haruki.txt | grep -v '^$' > File
```

### 这就是你到目前为止所学到的
以下是我在本教程中解释的内容的快速摘要:
| 命令 | 描述 |
| --- | --- |
| `cat <Filename>` | 将文件内容打印到终端。 |
| `cat >File` | 创建一个新文件。 |
| `cat FileA > FileB` | `FileB` 的文件内容将被 `FileA` 覆盖。 |
| `cat FileA >> FileB` | `FileA` 的文件内容将附加到 `FileB` 的末尾。 |
| `cat -n File` | 显示行数,同时省略文件的文件内容。 |
| `cat File | more` | 将 `cat` 命令通过管道连接到 `more` 命令以处理大文件。请记住,它不能让你向上滚动! |
| `cat File | less` | 将 `cat` 命令通过管道传输到 `less` 命令,这与上面类似,但它允许你双向滚动。 |
| `cat File | grep -v '^$'` | 从文件中删除所有空行。 |
### ?️ 练习时间
如果你学到了新东西,用不同的可能性来执行它是最好的记忆方式。
为此,你可以使用 `cat` 命令进行一些简单的练习。它们将是超级基本的,就像 `cat` 一样是[最基本的命令之一](https://learnubuntu.com:443/top-ubuntu-commands/)。
出于练习目的,你可以 [使用 GitHub 上的文本文件](https://github.com:443/itsfoss/text-files)。
* 如何使用 `cat` 命令创建空文件?
* 将 `cat` 命令生成的输出重定向到新文件 `IF.txt`
* 能否将三个或更多文件输入重定向到一个文件? 如果是,该如何做?
*(题图:MJ/f06c9b9c-689e-4a67-abe9-0487e26bd34b)*
---
via: <https://itsfoss.com/cat-command/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The cat command is used to print the file contents of text files.
At least, that's what most Linux users use it for and there is nothing wrong with it.
Cat actually stands for 'concatenate' and was created to [merge text files](https://linuxhandbook.com/merge-files/). But withsingle argument, it prints the file contents. And for that reason, it is a go-to choice for users to read files in the terminal without any additional options.
## Using the cat command in Linux
To use the cat command, you'd have to follow the given command syntax:
`cat [options] Filename(s)`
Here,
`[options]`
are used to modify the default behavior of the cat command such as using the`-n`
option to get numbers for each line.`Filename`
is where you'll enter the filename of the file that you want to work with.
To make things easy, I will be using a text file named `Haruki.txt`
throughout this guide which contains the following text lines:
```
Hear the Wind Sing (1979)
Pinball, 1973 (1980)
A Wild Sheep Chase (1982)
Hard-Boiled Wonderland and the End of the World (1985)
Norwegian Wood (1987)
Dance Dance Dance (1990)
South of the Border, West of the Sun (1992)
The Wind-Up Bird Chronicle (1994)
Sputnik Sweetheart (1999)
Kafka on the Shore (2002)
After Dark (2004)
1Q84 (2009-2010)
Colorless Tsukuru Tazaki and His Years of Pilgrimage (2013)
Men Without Women (2014)
Killing Commendatore (2017)
```
So, what will be the output when used without any options? Well, let's have a look:
`cat Haruki.txt`
As you can see, it printed the whole text file!
But you can do a lot more than just this. Let me show you some practical examples.
### 1. Create new files
Most Linux users use the touch command to [create new files](https://itsfoss.com/create-files/) but the same can be done using the cat command too!
The cat command has one advantage over the touch command in this case, as you can add text to the file while creating. Sounds cool. Isn't it?
To do so, you'd have to use the cat command by appending the filename to the `>`
as shown:
`cat > Filename`
For example, here, I created a file named `NewFile.txt`
:
`cat > NewFile.txt`
Once you do that, there'll be a blinking cursor asking you to write something and finally, you can use `Ctrl + d`
to save the changes.
**If you wish to create an empty file, then just press the Ctrl + d without making any changes.**
That's it! Now, you can use the ls command to show the [contents of the current working directory](https://itsfoss.com/list-directory-content/):
### 2. Copy the file contents to a different file
Think of a scenario where you want to redirect the file content of **FileA** to the **FileB**
Sure, you can copy and paste. But what if there are hundreds or thousands of lines?
Simple. You use the cat command with the redirection of data flow. To do so, you'd have to follow the given command syntax:
`cat FileA > FileB`
If you use the above syntax to redirect file contents, it will erase the file contents of the FileB and then will redirect the file contents of the FileA.
For example, I will be using two text files FileA and FileB which contains the following:
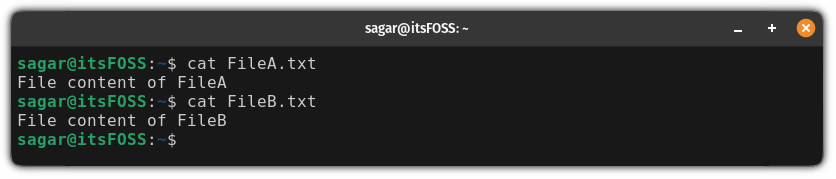
And now, if I use the redirection from FileA to FileB, it will remove the data of FileB and then redirect the data of FileA:
`cat FileA > FileB`

Similarly, you can do the same with multiple files:
`cat FileA FileB > FileC`
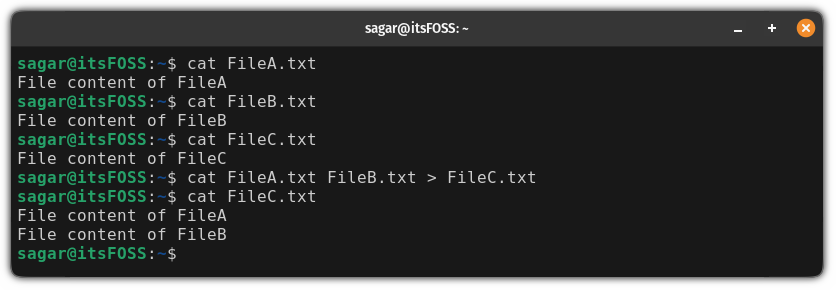
As you can see, the above command removed the data of FileC and then redirected the data of FileA and FileB.
### Append the content of one file to another
There are times when you want to append data to the existing data and in that case, you'll have to use the `>>`
instead of single `>`
:
`cat FileA >> FileB`
For example, here, I will be redirecting two files `FileA`
and `FileB`
to the `FileC`
:
`cat FileA.txt FileB.txt >> FileC.txt`
As you can see, it preserved the data of the `FileC.txt`
and the data was appended at the end of it.
You can use the `>>`
to add new lines to an existing file. Use `cat >> filename`
and start adding the text you want and finally save the changes with `Ctrl+D`
.
### 4. Show the numbers of line
You may encounter such scenarios where you want to see the number of lines, and that can be achieved using the `-n`
option:
`cat -n File`
For example, here, I used the `-n`
option with the `Haruki.txt`
:
### 5. Remove the blank lines
Left multiple blank lines in your text document? The cat command will fix it for you!
To do so, all you have to do is use the `-s`
flag.
But there's one downside of using the `-s`
flag. You're still left with one blank space:
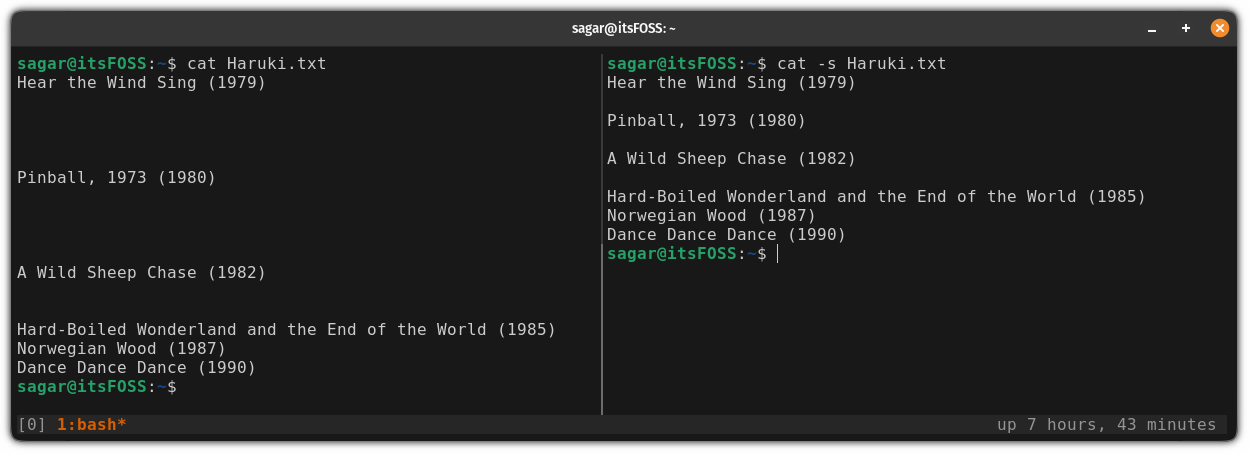
As you can see, it works but the results are close to the expectations.
So how would you remove all the empty lines? By piping it to the grep command:
`cat File | grep -v '^$'`
Here, the `-v`
flag will filter out the results as per `the `
specified pattern and `'^$'`
is a regular expression that matches the empty lines.
And here are the results when I used it over the `Haruki.txt`
:
`cat Haruki.txt | grep -v '^$'`
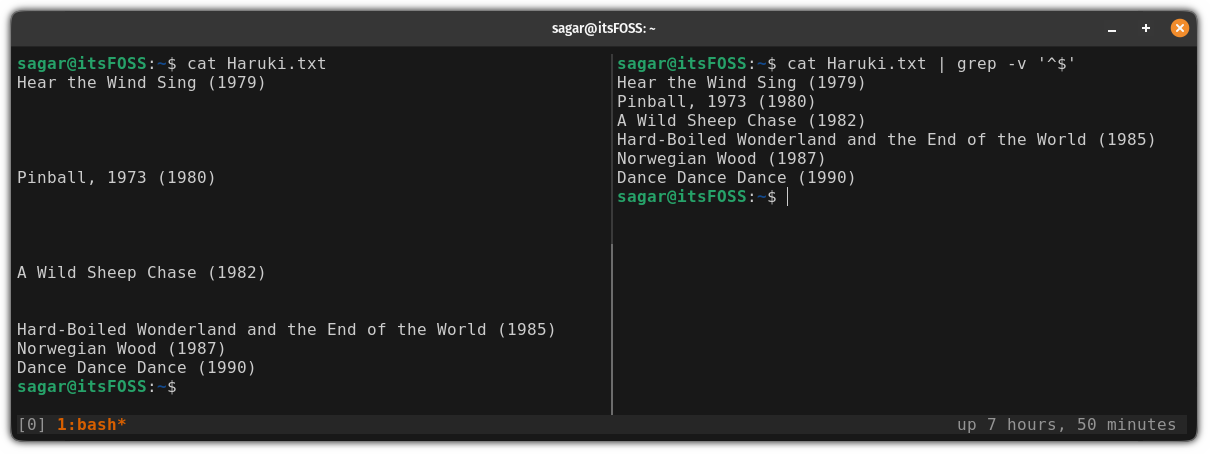
Once you have the perfect output, you can redirect it to a file to save the output:
`cat Haruki.txt | grep -v '^$' > File`
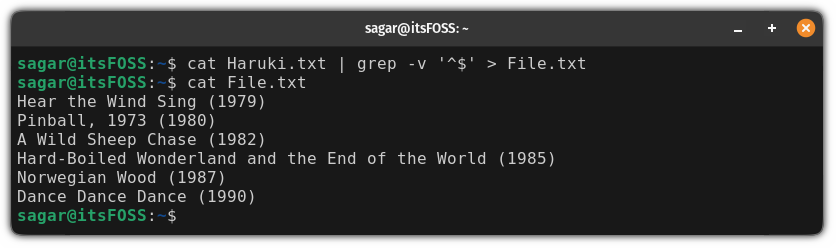
## That's what you've learned so far
Here's a quick summary of what I explained in this tutorial:
Command | Description |
---|---|
`cat <Filename>` |
Prints the file content to the terminal. |
`cat >File` |
Create a new file. |
`cat FileA > FileB` |
File contents of the `FileB` will be overridden by the `FileA` . |
`cat FileA >> FileB` |
File contents of the `FileA` will be appended at the end of the `FileB` . |
`cat -n File` |
Shows the number of lines while omitting the file contents of the File. |
`cat File | more` |
Piping the cat command to the more command to deal with large files. Remember, it won't let you scroll up! |
`cat File | less` |
Piping the cat command to the less command, which is similar to above, but it allows you to scroll both ways. |
`cat File | grep -v '^$'` |
Removes all the empty lines from the file. |
## 🏋️It's time to exercise
If you learned something new, executing it with different possibilities is the best way to remember.
And for that purpose, here are some simple exercises you can do with the cat command. They will be super basic as cat too is[ one of the most basic commands](https://learnubuntu.com/top-ubuntu-commands/).
For practice purposes, you can [use our text files from GitHub.](https://github.com/itsfoss/text-files)
- How would you create an empty file using the cat command?
- Redirect output produced by the cat command to a new file
`IF.txt`
- Can you redirect three or more file inputs to one file? If yes, then how? |
16,028 | 如何在 Ubuntu 中安装 Wine | https://itsfoss.com/install-wine-ubuntu/ | 2023-07-24T09:20:00 | [
"Wine"
] | https://linux.cn/article-16028-1.html | 
>
> 想在 Ubuntu 上运行仅限 Windows 的软件?Wine 就是你的朋友。学习在 Ubuntu Linux 中安装 Wine。
>
>
>
只要稍加努力,你可以使用 Wine 来 [在 Linux 上运行 Windows 应用程序](https://itsfoss.com/use-windows-applications-linux/) 。当你必须在 Linux 上运行一个仅有 Windows 版本的应用程序时,Wine 是一个你可以尝试的工具。
请注意:**你不能使用 Wine 来运行每一个 Windows 游戏或软件**。请浏览 [已支持的应用程序的数据库](https://appdb.winehq.org/)。评估为白金级或黄金级的软件更有可能与 Wine 一起平稳的运行。
如果你已经找到一个仅有 Windows 版本的软件,并且 [Wine](https://www.winehq.org/) 也很好地支持它,现在希望使用它,这篇教程将帮助你在 Ubuntu 上安装 Wine 。
>
> ? 如果你在此之前已经安装了 Wine ,你应该完全地移除它,以避免一些冲突。此外,你应该参考它的 [下载页面](https://wiki.winehq.org/Download) 来获取特定 Linux 发行版的附加说明。
>
>
>
### 在 Ubuntu 上安装 Wine
这里有很多方法来在你的系统上安装 Wine 。几乎所有的 Linux 发行版都在它们的软件包存储库中提供 Wine 。
大多数的时候,Wine 的最新稳定版本都可以通过软件包存储库获得。
* 从 Ubuntu 的存储库中安装 Wine(简单,但是可能不是最新的版本)
* 从 Wine 的存储库中安装 Wine(稍微复杂一些,但是提供最新的版本)
请耐心等待,按照步骤逐步安装和 Wine 。这里有一些相关的步骤。
>
> ? 请记住,Wine 会安装很多很多的软件包。你将看到一份庞大的软件包列表,安装大小差不多 1.3 GB 。
>
>
>

#### 方法 1. 从 Ubuntu 安装 Wine(简单)
Wine 可以在 Ubuntu 的官方存储库中获得,你可以在那里简单地安装它。不过,这种方法获取的版本可能不能最新的。
即使你正在使用一个 64 位的 Ubuntu 安装,你也想要在你的发行版上添加 32 位架构的支持,这将有利于你安装特殊的软件。
输入下面的命令:
```
sudo dpkg --add-architecture i386
```
接下来,安装 Wine 使用:
```
sudo apt update
sudo apt install wine
```
#### 方法 2: 从 Wine 的存储库安装最新的版本
Wine 是一个日新月异的程序。因此,始终建议安装 Wine 的最新稳定版本,以获取更多软件的支持。
首先,移除已存在的 Wine 安装。
步骤 1: 确保添加 32 位架构支持:
```
sudo dpkg --add-architecture i386
```
步骤 2: 下载和添加存储库密钥:
```
sudo mkdir -pm755 /etc/apt/keyrings
sudo wget -O /etc/apt/keyrings/winehq-archive.key https://dl.winehq.org/wine-builds/winehq.key
```
步骤 3: 现在,下载 WineHQ 源文件文件。
>
> ? 这个步骤取决于你正在使用的 Ubuntu 或 Mint 的版本。请 [检查你的 Ubuntu 版本](https://itsfoss.com/how-to-know-ubuntu-unity-version/) 或 [Mint 版本](https://itsfoss.com/check-linux-mint-version/) 。在你掌握这些信息后,分别使用针对你的相对应的版本的命令。
>
>
>
针对 **Ubuntu 23.04 Lunar Lobster** ,使用下面的命令:
```
sudo wget -NP /etc/apt/sources.list.d/ https://dl.winehq.org/wine-builds/ubuntu/dists/lunar/winehq-lunar.sources
```
如果你持有 **Ubuntu 22.04 或 Linux Mint 21.X 系列**,使用下面的命令:
```
sudo wget -NP /etc/apt/sources.list.d/ https://dl.winehq.org/wine-builds/ubuntu/dists/jammy/winehq-jammy.sources
```
如果你正在运行 **Ubuntu 20.04 或 Linux Mint 20.X 系列**,使用:
```
sudo wget -NP /etc/apt/sources.list.d/ https://dl.winehq.org/wine-builds/ubuntu/dists/focal/winehq-focal.sources
```
**Ubuntu 18.04 或 Linux Mint 19.X 系列**用户,可以使用下面的命令来添加源文件文件:
```
sudo wget -NP /etc/apt/sources.list.d/ https://dl.winehq.org/wine-builds/ubuntu/dists/bionic/winehq-bionic.sources
```
在完成后,更新软件包信息和安装 Wine 的稳定版本软件包。
```
sudo apt install --install-recommends winehq-stable
```
如果你现有开发版本或暂存版本,相应地使用 `winehq-devel` 或 `winehq-staging` 。
### 初始化 Wine 配置
在 Wine 安装后,运行下面的命令:
```
winecfg
```
这将创建用于安装 Windows 应用程序的 **虚拟的 C: 驱动器** 。

在按照这些步骤时,有时,你可能在文件管理器的邮件菜单中找不到 “<ruby> 使用 Wine Windows 程序加载器打开 <rt> Open With Wine Windows Program Loader </rt></ruby>” 的选项。
在这种情况下,通过 [创建软链接](https://learnubuntu.com/ln-command/) 到适当的目录来修复它:
```
sudo ln -s /usr/share/doc/wine/examples/wine.desktop /usr/share/applications/
```
然后,重新启动你的系统来获取更改。
### 使用 Wine 来运行 Windows 应用程序
在你安装 Wine 并通过运行 `winecfg` 将其配置后, 现在是安装 Windows 应用程序的时间了。
在这里,7Zip.exe 文件是用于演示目的的。我知道我应该使用一个更好的示例,因为 7Zip 在 Linux 上是可获得的。不过,对于其它的应用程序来说,接下来的流程是相同的。
首先,从它的 [官方下载页面](https://www.7-zip.org/download.html) 下载 7Zip 文件。
现在,在该文件上右键单击,并选择“使用 Wine Windows 程序加载器打开”选项:

这将提示我们安装该文件。单击 “<ruby> 安装 <rt> <strong> Install </strong> </rt></ruby>” 并让其完成。在完成后,你可以像其它的一些原生应用程序一样打开 7zip 。

你可以使用 `wine uninstaller` 命令来卸载任意已安装的应用程序。
这里是一篇关于在 Linux 上 [使用 Wine 来运行 Windows 软件](https://itsfoss.com/use-windows-applications-linux/) 的专业教程。
### 从 Ubuntu 中移除 Wine
如果你没有发现 Wine 有趣,或者,如果 Wine 不能正确地运行你想要的应用程序,你可能需要卸载 Wine 。为此,按照下面的步骤。
#### 通过 Ubuntu 存储库移除已安装的 Wine
为通过存储库移除已安装的 Wine ,首先运行:
```
sudo apt remove --purge wine
```
更新你的软件包信息:
```
sudo apt update
```
现在,使用 `autoclean` 命令来清理本地存储库中已检索取回的几乎不再有用的软件包文件。
```
sudo apt-get autoclean
sudo apt-get clean
```
移除那些已安装但不再需要的软件包:
```
sudo apt autoremove
```
现在,重新启动系统。
#### 如果 Wine 存储库移除 Wine 安装
移除已安装的 `wine-stable` 软件包。
```
sudo apt remove --purge wine-stable
```
更新你的软件包信息:
```
sudo apt update
```
现在,使用 `autoclean` 和 `clean` 命令来清理本地存储库中已检索取回的几乎不再有用的软件包文件。
```
sudo apt-get autoclean
sudo apt-get clean
```
移除先前添加的源文件文件。使用你的相对应的发行版文件夹。在这里,使用的是 Ubuntu 22.04 。
```
sudo rm /etc/apt/sources.list.d/winehq-jammy.sources
```
在这移除后,更新你的系统信息:
```
sudo apt update
```
可选,如果你希望的话,移除你先前添加的密钥文件。
```
sudo rm /etc/apt/keyrings/winehq-archive.key
```
现在,手动移除剩余的一些的文件。
### 还有一些关于使用 Wine 的问题?
你也可以翻阅我们关于使用 Wine 的教程。它应该能回答你可能想要解决的问题。
没有比 Wine 工程的网站更好的地方了。它们有一个专业的常见问题解答页面:
>
> **[Wine 的 FAQ](https://wiki.winehq.org/FAQ)**
>
>
>
如果你还有问题,你可以浏览 [它们的维基](https://wiki.winehq.org/Main_Page) 来查看详细的 [文档](https://www.winehq.org:443/documentation) 或者在 [它们的论坛](https://forum.winehq.org/) 中询问你的疑问。
或者,如果你不介意花一些钱,你可以选择 CrossOver 。它基本上就是 Wine ,但是有高级的支持。你也可以联系他们的团队来解决你的问题。
我的意见是,在你不能找到一款你必需使用的替换软件时,你应该求助于 Wine 。事实上,在这种情况下,不能保证与 Wine 一起工作。
但是,Wine 为从 Windows 迁移到 Linux 提供了一些希望。
---
via: <https://itsfoss.com/install-wine-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

With some effort, you can [run Windows applications on Linux](https://itsfoss.com/use-windows-applications-linux/) using Wine. Wine is a tool you can try when must use an Windows-only application on Linux.
Please note that **you CANNOT run any Windows games or software with Wine**. Please go through the [database of supported applications](https://appdb.winehq.org/). The software rated platinum or gold have a higher chance of running smoothly with Wine.
If you have found a Windows-only software that [Wine](https://www.winehq.org/) supports well and now looking to use it, this tutorial will help you with the Wine installation on Ubuntu.
[download page](https://wiki.winehq.org/Download)for additional instructions for specific Linux distributions.
## Installing Wine on Ubuntu
There are various ways to install Wine on your system. Almost all the Linux distros come with Wine in their package repository.
Most of the time, the latest stable version of Wine is available via the package repository.
**Install WINE from Ubuntu’s repository (easy but may not be the latest version)****Install WINE from Wine’s repository (slightly more complicated but gives the latest version)**
Please be patient and follow the steps one by one to install and use Wine. There are several steps involved here.
*Wine download and installed size*
### Method 1. Install WINE from Ubuntu (easy)
Wine is available in Ubuntu's Official repositories, where you can easily install it. However, the version available this way may not be the latest.
Even if you are using a 64-bit installation of Ubuntu, you will need to add 32-bit architecture support on your distro, which will benefit you in installing specific software.
Type in the commands below:
`sudo dpkg --add-architecture i386`
Then install Wine using:
```
sudo apt update
sudo apt install wine
```
### Method 2: Install the latest version from Wine’s repository
Wine is one such program that receives heavy developments in a short period. So, it is always recommended to install the latest stable version of Wine to get more software support.
**First, remove any existing Wine installation**.
**Step 1**: Make sure to add 32-bit architecture support:
`sudo dpkg --add-architecture i386`
**Step 2**: Download and add the repository key:
```
sudo mkdir -pm755 /etc/apt/keyrings
sudo wget -O /etc/apt/keyrings/winehq-archive.key https://dl.winehq.org/wine-builds/winehq.key
```
**Step 3**: Now download the WineHQ sources file.
[check your Ubuntu version](https://itsfoss.com/how-to-know-ubuntu-unity-version/)or
[Mint version](https://itsfoss.com/check-linux-mint-version/). Once you have that information, use the commands for your respective versions.
For **Ubuntu 23.04 Lunar Lobster**, use the command below:
`sudo wget -NP /etc/apt/sources.list.d/ https://dl.winehq.org/wine-builds/ubuntu/dists/lunar/winehq-lunar.sources`
If you have **Ubuntu 22.04 or Linux Mint 21.X series**, use the command below:
`sudo wget -NP /etc/apt/sources.list.d/ https://dl.winehq.org/wine-builds/ubuntu/dists/jammy/winehq-jammy.sources`
If you are running **Ubuntu 20.04 or Linux Mint 20.X series**, use:
`sudo wget -NP /etc/apt/sources.list.d/ https://dl.winehq.org/wine-builds/ubuntu/dists/focal/winehq-focal.sources`
**Ubuntu 18.04 or Linux Mint 19.X series** users can use the command below to add the sources file:
`sudo wget -NP /etc/apt/sources.list.d/ https://dl.winehq.org/wine-builds/ubuntu/dists/bionic/winehq-bionic.sources`
Once done, update the package information and install the wine-stable package.
`sudo apt install --install-recommends winehq-stable`
If you want the development or staging version, use `winehq-devel`
or `winehq-staging`
respectively.
## Initial Wine configuration
Once Wine is installed, run the following:
`winecfg`
This will create the **virtual C: Drive** for installing Windows applications.
*C: Drive in Nautilus File Manager*
While following these steps, sometimes, you may not find the “**Open With Wine Windows Program Loader**” option in Nautilus right-click menu.
In that case, fix it by [creating a soft link](https://learnubuntu.com/ln-command/) to appropriate directory:
`sudo ln -s /usr/share/doc/wine/examples/wine.desktop /usr/share/applications/`
And restart your system to get the change.
## Using Wine to run Windows applications
Once you have installed Wine and configured it by running `winecfg`
, now is the time to install Windows apps.
Here, the 7Zip.exe file is used for demonstration purposes. I know I should have used a better example, as 7Zip is available on Linux. Still, the process remains the same for other applications.
Firstly, download the 7Zip .exe file from their [official downloads page](https://www.7-zip.org/download.html).
Now, right-click on the file and select "Open With Wine Windows Program Loader" option:
*Open EXE file with Wine Program loader*
This will prompt us to install the file. Click **Install** and let it complete. Once done, you can open the 7zip like any other native app.
*7Zip in Ubuntu Activities Overview*
You can use `wine uninstaller`
command to uninstall any installed application.
Here's a dedicated tutorial on [using Wine to run Windows software](https://itsfoss.com/use-windows-applications-linux/) on Linux:
[Run Windows Applications on Linux [Beginners Guide]Here’s a detailed step-by-step guide with screenshots to show how you can run Windows software on Linux using Wine.](https://itsfoss.com/use-windows-applications-linux/)

## Remove Wine from Ubuntu
If you don't find Wine interesting or if Wine doesn't run the application you want properly, you may need to uninstall Wine. To do this, follow the below steps.
**Remove Wine installed through the Ubuntu repository**
To remove wine installed through repositories, first run:
`sudo apt remove --purge wine`
Update your package information:
`sudo apt update`
Now, use the `autoclean`
command to clear the local repository of retrieved package files that are virtually useless.
```
sudo apt-get autoclean
sudo apt-get clean
```
Remove those packages that are installed but no longer required using:
`sudo apt autoremove`
Now reboot the system.
**Remove Wine installed through the Wine repository**
Remove the installed `wine-stable`
package.
`sudo apt remove --purge wine-stable`
Update your package information:
`sudo apt update`
Now, use the `autoclean`
and `clean`
command to clear the local repository of retrieved package files that are virtually useless.
```
sudo apt-get autoclean
sudo apt-get clean
```
Now remove the sources file added earlier. Use your respective distribution folder. Here, Ubuntu 22.04 is used.
`sudo rm /etc/apt/sources.list.d/winehq-jammy.sources`
Once this is removed, update your system package information:
`sudo apt update`
Optionally, remove the key file you had added earlier if you want.
`sudo rm /etc/apt/keyrings/winehq-archive.key`
Now remove any residual files manually.
## Still have questions about using Wine?
You may also go through our tutorial on using Wine. It should answer some more questions you might have.
[Run Windows Applications on Linux [Beginners Guide]Here’s a detailed step-by-step guide with screenshots to show how you can run Windows software on Linux using Wine.](https://itsfoss.com/use-windows-applications-linux/)

There is no place better than the Wine Project website. They have a dedicated FAQ (frequently asked questions) page:
If you still have questions, you can browse through [their wiki](https://wiki.winehq.org/Main_Page) for detailed [documentation](https://www.winehq.org/documentation) or ask your doubts in [their forum](https://forum.winehq.org/).
Alternatively, if you don't mind spending some money, you can opt for CrossOver. It's basically Wine but with premium support. You can also contact their team for your questions.
[Purchase CrossOver Through the CodeWeavers Store Today!Buy CrossOver Mac and CrossOver Linux through the CodeWeavers store. Choose from 12 month and lifetime license plans. Renewals are also available for purchase.](https://www.codeweavers.com/store?ad=838)

In my opinion, you should resort to Wine only when you cannot find an alternative to the software you must use. Even in that case, it's not guaranteed to work with Wine.
And yet, Wine provides some hope for Windows migrants to Linux. |
16,030 | Llama 2 vs GPT-4:有何区别? | https://www.debugpoint.com/llama-2-vs-gpt-4/ | 2023-07-24T22:33:00 | [
"AI",
"GPT-4",
"Llama 2"
] | /article-16030-1.html | 
>
> 了解 Llama 2 和 GPT-4 之间的主要区别,它们是自然语言处理的领先巨头。揭示它们的优势、劣势以及它们如何塑造语言技术的未来。
>
>
>
在撰写内容时,有两个关键因素至关重要,“<ruby> 困惑度 <rt> perplexity </rt></ruby>”和“<ruby> 爆发性 <rt> burstiness </rt></ruby>”。困惑度衡量文本的复杂程度。而爆发性则比较句子的变化程度。人类倾向于以较大的爆发性写作,例如长句或复杂句与短句并存。人工智能生成的句子往往更加均一。
在自然语言处理领域,Llama 2 和 GPT-4 是两个杰出的参与者,吸引了研究人员和爱好者的关注。这些大型语言模型展示出独特的功能和特点。
虽然 GPT-4 由 OpenAI 已经发布一段时间,但 Meta 与微软合作推出了 Llama 2,这是 LLaMa 扩展语言模型的改进版本。
让我们深入探讨这两个模型之间的关键区别,以了解它们的特点之所在。
### Llama 2:简单易用
Llama 2 是其前身 LLaMa 的升级版本,以其简洁高效的特点震撼了科技界。尽管它支持的语言范围较窄,仅包括 20 种语言,但其性能令人印象深刻,可以与 GPT-4、Claude 或 Bard 等重量级模型相媲美。令人惊讶的是,尽管参数比 GPT-3 模型少,但 Llama 2 可以在单个 GPU 上高效运行,使其成为各种应用的更便捷选择。
Llama 2 真正的特点是它专门训练于公开可获得的数据集,使其对研究人员和开发人员更加可用。更为引人注目的是,尽管仅在 1,000 个精确提示的相对较小数据集上进行训练,它依然实现了有竞争力的结果。
### GPT-4
在 2023 年 3 月,OpenAI 自豪地推出了其最新的创作——GPT-4,这一力作轰动了语言模型领域。GPT-4 在许多任务中表现卓越,包括专业医学和法律考试,展示了其多功能和高水平的能力。
GPT-4 的一个显著特点是相对于之前的版本,它能够扩展最大输入长度。这个增强功能使其能够处理更加广泛和复杂的语言数据,为自然语言理解和生成开辟了新的可能性。
此外,GPT-4 拥有广泛的语言支持,支持 26 种语言。这种多样的语言能力扩大了其在全球范围内的覆盖和适用性,使其成为多语言项目和应用的首选。
### 区别:Llama 2 与 GPT-4
在比较 Llama 2 和 GPT-4 时,我们可以看到两个模型都有各自独特的优缺点。Llama 2 以其简洁高效的特点脱颖而出,尽管其数据集较小且语言支持有限,但其表现卓越。其易用性和有竞争力的结果使其成为某些应用的有力选择。
另一方面,GPT-4 在各种任务上的出色表现和广泛的语言支持使其成为更复杂和多样化项目的强大选择。然而,关于其模型架构和训练数据集的详细信息缺乏,还有一些问题尚待回答。
下表显示了两个模型的一些基准分数(以及其他热门模型):
| 基准测试 | <ruby> 样本数 <rt> Shot </rt></ruby> | GPT-3.5 | GPT-4 | PaLM | PaLM-2-L | Llama 2 |
| --- | --- | --- | --- | --- | --- | --- |
| MMLU (5 样本) | 70 | 78.3 | 86.1 | – | – | 86.4 |
| TriviaQA (1 样本) | 69.3 | 33 | 37.5 | – | – | 81.4 |
| Natural Questions (1 样本) | 68.9 | 37.5 | 52.3 | – | – | 85 |
| GSM8K (8 样本) | 85 | 56.5 | 56.8 | – | – | 87 |
| HumanEval (0 样本) | 48.1 | 92 | 56.7 | – | – | 51.2 |
| BIG-Bench Hard (3 样本) | 29.3 | 56.8 | 26.2 | – | – | 29.9 |
### 常见问题解答
1、Llama 2 和 GPT-4 的主要区别是什么?
主要区别在于设计和性能。Llama 2 注重简洁高效,而 GPT-4 具有扩展的输入长度和广泛的语言支持。
2、哪个模型更适合多语言模型?
GPT-4 适用于多语言项目,因为它支持 26 种语言,为全球应用提供了更广泛的范围。
3、Llama 2 可以运行在单个 GPU 上吗?
是的,Llama 2 可以在单个 GPU 上有效运行,使其成为各种应用的实用选择。
4、Llama 2 支持多少种语言?
Llama 2 支持 20 种语言,虽然比 GPT-4 稍少,但仍覆盖了相当广泛的语言范围。
5、GPT-4 是否有可用的基准测试?
不幸的是,没有提及 GPT-4 的具体基准测试,因此对其性能还有一些问题没有答案。
### 结论
Llama 2 和 GPT-4 代表了自然语言处理领域的前沿进展。尽管数据集较小,Llama 2 以其简洁性、易用性和有竞争力的性能令人印象深刻。另一方面,GPT-4 的多功能性、高水平和广泛的语言支持使其成为处理复杂项目的杰出选择。这两个模型对自然语言处理的发展做出了重要贡献,为语言技术在我们生活中发挥更加重要的作用铺平了道路。
基准测试参考:
* MMLU Benchmark (Multi-task Language Understanding): <https://arxiv.org/abs/2009.03300>
* Papers With Code: <https://paperswithcode.com/paper/measuring-massive-multitask-language>
* GPT-4 Technical Report: <https://arxiv.org/abs/2303.08774>
* PaLM: Scaling Language Modeling with Pathways: <https://www.marktechpost.com/2022/04/04/google-ais-latest-540-billion-parameter-model-pathways-language-model-called-palm-unlocks-new-tasks-proportional-to-scale/>
* Llama 2: Open Foundation and Fine-Tuned Chat Models: [https://www.youtube.com/watch?v=Xdl\_zC1ChRs](https://www.youtube.com:443/watch?v=Xdl_zC1ChRs)
*(题图:MJ/60e112f7-3399-49fd-9157-c6b03de5efea)*
---
via: <https://www.debugpoint.com/llama-2-vs-gpt-4/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
16,031 | 在 Ubuntu 上安装和使用 Flatpak | https://itsfoss.com/flatpak-ubuntu/ | 2023-07-24T23:00:00 | [
"Flatpak"
] | https://linux.cn/article-16031-1.html | 
>
> Ubuntu 可能默认安装了 Snap,但你仍然可以使用 Flatpak 通用软件包。
>
>
>
Linux 世界有三种“通用”打包格式,允许在“任何” Linux 发行版上运行:Snap、Flatpak 和 AppImage。
Ubuntu 内置了 Snap,但大多数发行版和开发人员都避免使用它,因为它的闭源性质。他们更喜欢 [Fedora 的 Flatpak 打包系统](https://itsfoss.com/what-is-flatpak/)。
作为 Ubuntu 用户,你并不局限于 Snap。你还可以在 Ubuntu 系统上使用 Flatpak。
在本教程中,我将讨论以下内容:
* 在 Ubuntu 上启用 Flatpak 支持
* 使用 Flatpak 命令来管理包
* 从 Flathub 获取包
* 将 Flatpak 软件包添加到软件中心
听起来很令人兴奋? 让我们一一看看。
### 在 Ubuntu 上安装 Flatpak
你可以使用以下命令轻松安装 Flatpak:
```
sudo apt install flatpak
```
对于 **Ubuntu 18.04 或更早版本**,请使用 PPA:
```
sudo add-apt-repository ppa:flatpak/stable
sudo apt update
sudo apt install flatpak
```
#### 添加 Flathub 仓库
你已在 Ubuntu 系统中安装了 Flatpak 支持。但是,如果你尝试安装 Flatpak 软件包,你将收到 [“No remote refs found”](https://itsfoss.com/no-remote-ref-found-flatpak/) 错误。这是因为没有添加 Flatpak 仓库,因此 Flatpak 甚至不知道应该从哪里获取应用。
Flatpak 有一个名为 “Flathub” 的集中仓库,可以从此处找到并下载许多 Flatpak 应用。
你应该添加 Flathub 仓库来访问这些应用。
```
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```

安装并配置 Flatpak 后,**重启你的系统**。否则,已安装的 Flatpak 应用将不会在你的系统菜单上可见。
不过,你始终可以通过运行以下命令来运行 Flatpak 应用:
```
flatpak run <package-name>
```
### 常用 Flatpak 命令
现在你已经安装了 Flatpak 打包支持,是时候学习包管理所需的一些最常见的 Flatpak 命令了。
#### 搜索包
如果你知道应用名称,请使用 Flathub 网站或使用以下命令:
```
flatpak search <package-name>
```

>
> ? 除了搜索 Flatpak 包之外,在其他情况下, 指的是正确的 Flatpak 包名称,例如 `com.raggesilver.BlackBox`(上面截图中的应用 ID)。你还可以使用应用 ID 的最后一个词 `Blackbox`。
>
>
>
#### 安装 Flatpak 包
以下是安装 Flatpak 包的语法:
```
flatpak install <remote-repo> <package-name>
```
由于几乎所有时候你都会从 Flathub 获取应用,因此远程仓库将是 `flathub`:
```
flatpak install flathub <package-name>
```

在极少数情况下,你可以直接从开发人员的仓库安装 Flatpak 包,而不是 Flathub。在这种情况下,你可以使用如下语法:
```
flatpak install --from https://flathub.org/repo/appstream/com.spotify.Client.flatpakref
```
#### 从 flatpakref 安装包
这是可选的,也很少见。但有时,你会获得应用的 `.flatpakref` 文件。这**不是离线安装**。.flatpakref 包含有关从何处获取包的必要详细信息。
要从此类文件安装,请打开终端并运行:
```
flatpak install <path-to-flatpakref file>
```

#### 从终端运行 Flatpak 应用
再说一遍,这是你不会经常做的事情。大多数情况下,你将在系统菜单中搜索安装应用并从那里运行该应用。
但是,你也可以使用以下命令从终端运行它们:
```
flatpak run <package-name>
```
#### 列出已安装的 Flatpak 软件包
想要查看你的系统上安装了哪些 Flatpak 应用? 像这样列出它们:
```
flatpak list
```

#### 卸载 Flatpak 包
你可以通过以下方式删除已安装的 Flatpak 包:
```
flatpak uninstall <package-name>
```
如果你想**清除不再需要的剩余包和运行时**,请使用:
```
flatpak uninstall --unused
```

它可能会帮助你 [在 Ubuntu 上节省一些磁盘空间](https://itsfoss.com/free-up-space-ubuntu-linux/)。
### Flatpak 命令总结
以下是你在上面学到的命令的快速摘要:
| 用途 | 命令 |
| --- | --- |
| 搜索包 | `flatpak search` |
| 安装包 | `flatpak install` |
| 列出已安装的包 | `flatpak list` |
| 从 flatpakref 安装 | `flatpak install <package-name.flatpakref>` |
| 卸载软件包 | `flatpak uninstall` |
| 卸载未使用的运行时和包 | `flatpak uninstall --unused` |
### 使用 Flathub 探索 Flatpak 包
我知道通过命令行搜索 Flatpak 包并不是最好的体验,这就是 [Flathub 网站](https://flathub.org:443/en-GB) 的用武之地。
你可以在 Flathub 上浏览 Flatpak 应用,它提供了更多详细信息,例如经过验证的发布商、下载总数等。
你还将在应用页面底部获得安装应用所需的命令。


### 额外信息:使用支持 Flatpak 软件包的软件中心
你可以将 Flatpak 包添加到 GNOME 软件中心,并使用它以图形方式安装软件包。
有一个专用插件可以将 Flatpak 添加到 GNOME 软件中心。
>
> ? 从 Ubuntu 20.04 开始,Ubuntu 默认的软件中心是 Snap Store,并且不支持 Flatpak 集成。因此,安装以下软件包将产生两个软件中心:一个 Snap 和另一个 DEB。
>
>
>

```
sudo apt install gnome-software-plugin-flatpak
```

### 总结
你在这里学到了很多东西。你学习了在 Ubuntu 中启用 Flatpak 支持并通过命令行管理 Flatpak 软件包。你还了解了与软件中心的集成。
我希望你现在对 Flatpaks 感觉更舒服一些。既然你发现了三个通用软件包之一,那么再 [了解一下 Appimages](https://itsfoss.com/use-appimage-linux/) 怎么样?
如果你有疑问或遇到任何问题,请告诉我。
*(题图:MJ/d03886af-9b7f-401e-a964-da0e5d6531a2)*
---
via: <https://itsfoss.com/flatpak-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The Linux world has three 'universal' packaging formats that allow running on 'any' Linux distribution; Snap, Flatpak and AppImage.
Ubuntu comes baked-in with Snap but most distributions and developers avoid it because of its close source nature. They prefer [Fedora's Flatpak packaging system](https://itsfoss.com/what-is-flatpak/).
As an Ubuntu user, you are not restricted to Snap. You also can use Flatpak on your Ubuntu system.
In this tutorial, I'll discuss the following:
- Enabling Flatpak support on Ubuntu
- Using Flatpak commands to manage packages
- Getting packages from Flathub
- Add Flatpak packages to Software Center
Sounds exciting? Let's see them one by one.
## Installing Flatpak on Ubuntu
You can easily install Flatpak using the following command:
`sudo apt install flatpak`
For ** Ubuntu 18.04 or older versions**, use PPA:
```
sudo add-apt-repository ppa:flatpak/stable
sudo apt update
sudo apt install flatpak
```
### Add Flathub repo
You have installed Flatpak support in your Ubuntu system. However, if you try to install a Flatpak package, you'll get '[No remote refs found' error](https://itsfoss.com/no-remote-ref-found-flatpak/). That's because there are no Flatpak repositories added and hence Flatpak doesn't even know from where it should get the applications.
Flatpak has a centralized repository called Flathub. A number of Flatpak applications can be found and downloaded from here.
You should add the Flathub repo to access those applications.
```
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
Once Flatpak is installed and configured, **restart your system**. Otherwise, installed Flatpak apps won't be visible on your system menu.
Still, you can always run a flatpak app by running:
`flatpak run <package-name>`
## Common Flatpak Commands
Now that you have Flatpak packaging support installed, it's time to learn some of the most common Flatpak commands needed for package management.
### Search for a Package
Either use Flathub website or use the following command, if you know the application name:
`flatpak search <package-name>`
Except for searching a flatpak package, on other instances, the <package-name> refers to the proper Flatpak package name, like `com.raggesilver.BlackBox`
(Application ID in the above screenshot). You may also use the last word `Blackbox`
of the Application ID.
### Install a Flatpak package
Here's the syntax for installing a Flatpak package:
`flatpak install <remote-repo> <package-name>`
Since almost all the times you'll be getting applications from Flathub, the remote repository will be `flathub`
:
`flatpak install flathub <package-name>`
In some rare cases, you may install Flatpak packages from the developer's repository directly instead of Flathub. In that case, you use a syntax like this:
`flatpak install --from https://flathub.org/repo/appstream/com.spotify.Client.flatpakref`
### Install a package from flatpakref
This is optional and rare too. But sometime, you will get a `.flatpakref`
file for an application. This is **NOT an offline installation**. The .flatpakref has the necessary details about where to get the packages.
To install from such a file, open a terminal and run:
`flatpak install <path-to-flatpakref file>`
### Run a Flatpak application from the terminal
Again, something you won't be doing it often. Mostly, you'll search for the installing application in the system menu and run the application from there.
However, you can also run them from the terminal using:
`flatpak run <package-name>`
### List installed Flatpak packages
Want to see which Flatpak applications are installed on your system? List them like this:
`flatpak list`
### Uninstall a Flatpak package
You can remove an installed Flatpak package in the following manner:
`flatpak uninstall <package-name>`
If you want to **clear the leftover packages and runtimes, that are no longer needed**, use:
`flatpak uninstall --unused`
It may help you [save some disk space on Ubuntu](https://itsfoss.com/free-up-space-ubuntu-linux/).
## Flatpak commands summary
Here's a quick summary of the commands you learned above:
Usage | Command |
---|---|
Search for Packages | flatpak search |
Install a Package | flatpak install |
List Installed Package | flatpak list |
Install from flatpakref | flatpak install <package-name.flatpakref> |
Uninstall a Package | flatpak uninstall |
Uninstall Unused runtimes and packages | flatpak uninstall --unused |
## Using Flathub to explore Flatpak packages
I understand that searching for Flatpak packages through the command line is not the best experience and that's where the [Flathub website](https://flathub.org/en-GB) comes into picture.
You can browse the Flatpak application on Flathub, which provides additional details like verified publishers, total number of downloads etc.
You'll also get the commands you need to use for installing the applications at the bottom of the application page.
Application Details in Flathub Official Website
## Bonus: Use Software Center with Flatpak package support
You can add the Flatpak packages to the GNOME Software Center application and use it for installing packages graphically.
There is a dedicated plugin to add Flatpak to GNOME Software Center.
Since Ubuntu 20.04, the default software center in Ubuntu is Snap Store and it does not support flatpak integration. So, installing the below package will result in two software centers simultaneously: one Snap and another DEB.

`sudo apt install gnome-software-plugin-flatpak`
## Conclusion
You learned plenty of things here. You learned to enable Flatpak support in Ubuntu and manage Flatpak packages through the command line. You also learned about the integration with the Software Center.
I hope you feel a bit more comfortable with Flatpaks now. Since you discovered one of the three universal packages, how about [learning about Appimages](https://itsfoss.com/use-appimage-linux/)?
[How to Use AppImage in Linux [Complete Guide]What is AppImage? How to run it? How does it work? Here’s the complete guide about using AppImage in Linux.](https://itsfoss.com/use-appimage-linux/)

*Let me know if you have questions or if you face any issues.* |
16,033 | GDB 调试器如何通过调用帧信息来确定函数调用关系 | https://opensource.com/article/23/3/gdb-debugger-call-frame-active-function-calls | 2023-07-26T06:26:18 | [
"调试",
"函数"
] | /article-16033-1.html | 
>
> 从调试器中获取函数调用关系。
>
>
>
在我的 [上一篇文章](https://opensource.com/article/23/2/compiler-optimization-debugger-line-information) 中,我展示了如何使用 `debuginfo` 在当前指令指针(IP)和包含它的函数或行之间进行映射。该信息对于显示 CPU 当前正在执行的代码很有帮助。不过,如果能显示更多的有关当前函数调用栈及其正在执行语句的上下文对我们定位问题来说也是十分有助的。
例如,将空指针作为参数传递到函数中而导致非法内存访问的问题,只需查看当前执行函数行,即可发现该错误是由尝试通过空指针进行访问而触发的。但是,你真正想知道的是导致空指针访问的函数调用的完整上下文,以便确定该空指针最初是如何传递到该函数中的。此上下文信息由回溯提供,可以让你确定哪些函数可能对空指针参数负责。
有一点是肯定的:确定当前活动的函数调用栈不是一项简单的操作。
### 函数激活记录
现代编程语言具有局部变量,并允许函数可以调用自身的递归。此外,并发程序具有多个线程,这些线程可能同时运行相同的函数。在这些情况下,局部变量不能存储在全局位置。对于函数的每次调用,局部变量的位置必须是唯一的。它的工作原理如下:
* 每次调用函数时,编译器都会生成函数激活记录,以将局部变量存储在唯一位置。
* 为了提高效率,处理器堆栈用于存储函数激活记录。
* 当函数被调用时,会在处理器堆栈的顶部为该函数创建一条新的函数激活记录。
* 如果该函数调用另一个函数,则新的函数激活记录将放置在现有函数激活记录之上。
* 每次函数返回时,其函数激活记录都会从堆栈中删除。
函数激活记录的创建是由函数中称为“<ruby> 序言 <rt> prologue </rt></ruby>”的代码创建的。函数激活记录的删除由函数“<ruby> 尾声 <rt> epilogue </rt></ruby>”处理。函数体可以利用堆栈上为其预留的内存来存储临时值和局部变量。
函数激活记录的大小可以是可变的。对于某些函数,不需要空间来存储局部变量。理想情况下,函数激活记录只需要存储调用 *该* 函数的函数的返回地址。对于其他函数,除了返回地址之外,可能还需要大量空间来存储函数的本地数据结构。帧大小的可变导致编译器使用帧指针来跟踪函数激活帧的开始。函数序言代码具有在为当前函数创建新帧指针之前存储旧帧指针的额外任务,并且函数尾声必须恢复旧帧指针值。
函数激活记录的布局方式、调用函数的返回地址和旧帧指针是相对于当前帧指针的恒定偏移量。通过旧的帧指针,可以定位堆栈上下一个函数的激活帧。重复此过程,直到检查完所有函数激活记录为止。
### 优化复杂性
在代码中使用显式帧指针有几个缺点。在某些处理器上,可用的寄存器相对较少。具有显式帧指针会导致使用更多内存操作。生成的代码速度较慢,因为帧指针必须位于寄存器中。具有显式帧指针可能会限制编译器可以生成的代码,因为编译器可能不会将函数序言和尾声代码与函数体混合。
编译器的目标是尽可能生成快速代码,因此编译器通常会从生成的代码中省略帧指针。正如 [Phoronix 的基准测试](https://www.phoronix.com/review/fedora-frame-pointer) 所示,保留帧指针会显着降低性能。不过省略帧指针也有缺点,查找前一个调用函数的激活帧和返回地址不再是相对于帧指针的简单偏移。
### 调用帧信息
为了帮助生成函数回溯,编译器包含 DWARF 调用帧信息(CFI)来重建帧指针并查找返回地址。此补充信息存储在执行的 `.eh_frame` 部分中。与传统的函数和行位置信息的 `debuginfo` 不同,即使生成的可执行文件没有调试信息,或者调试信息已从文件中删除,`.eh_frame` 部分也位于可执行文件中。 调用帧信息对于 C++ 中的 `throw-catch` 等语言结构的操作至关重要。
CFI 的每个功能都有一个帧描述条目(FDE)。作为其步骤之一,回溯生成过程为当前正在检查的激活帧找到适当的 FDE。将 FDE 视为一张表,每一行代表一个或多个指令,并具有以下列:
* 规范帧地址(CFA),帧指针指向的位置
* 返回地址
* 有关其他寄存器的信息
FDE 的编码旨在最大限度地减少所需的空间量。FDE 描述了行之间的变化,而不是完全指定每一行。为了进一步压缩数据,多个 FDE 共有的起始信息被分解出来并放置在通用信息条目(CIE)中。 这使得 FDE 更加紧凑,但也需要更多的工作来计算实际的 CFA 并找到返回地址位置。该工具必须从未初始化状态启动。它逐步遍历 CIE 中的条目以获取函数条目的初始状态,然后从 FDE 的第一个条目开始继续处理 FDE,并处理操作,直到到达覆盖当前正在分析的指令指针的行。
### 调用帧信息使用实例
从一个简单的示例开始,其中包含将华氏温度转换为摄氏度的函数。 内联函数在 CFI 中没有条目,因此 `f2c` 函数的 `__attribute__((noinline))` 确保编译器将 `f2c` 保留为真实函数。
```
#include <stdio.h>
int __attribute__ ((noinline)) f2c(int f)
{
int c;
printf("converting\n");
c = (f-32.0) * 5.0 /9.0;
return c;
}
int main (int argc, char *argv[])
{
int f;
scanf("%d", &f);
printf ("%d Fahrenheit = %d Celsius\n",
f, f2c(f));
return 0;
}
```
编译代码:
```
$ gcc -O2 -g -o f2c f2c.c
```
`.eh_frame` 部分展示如下:
```
$ eu-readelf -S f2c |grep eh_frame
[17] .eh_frame_hdr PROGBITS 0000000000402058 00002058 00000034 0 A 0 0 4
[18] .eh_frame PROGBITS 0000000000402090 00002090 000000a0 0 A 0 0 8
```
我们可以通过以下方式获取 CFI 信息:
```
$ readelf --debug-dump=frames f2c > f2c.cfi
```
生成 `f2c` 可执行文件的反汇编代码,这样你可以查找 `f2c` 和 `main` 函数:
```
$ objdump -d f2c > f2c.dis
```
在 `f2c.dis` 中找到以下信息来看看 `f2c` 和 `main` 函数的执行位置:
```
0000000000401060 <main>:
0000000000401190 <f2c>:
```
在许多情况下,二进制文件中的所有函数在执行函数的第一条指令之前都使用相同的 CIE 来定义初始条件。 在此示例中, `f2c` 和 `main` 都使用以下 CIE:
```
00000000 0000000000000014 00000000 CIE
Version: 1
Augmentation: "zR"
Code alignment factor: 1
Data alignment factor: -8
Return address column: 16
Augmentation data: 1b
DW_CFA_def_cfa: r7 (rsp) ofs 8
DW_CFA_offset: r16 (rip) at cfa-8
DW_CFA_nop
DW_CFA_nop
```
本示例中,不必担心增强或增强数据条目。由于 x86\_64 处理器具有 1 到 15 字节大小的可变长度指令,因此 “代码对齐因子” 设置为 1。在只有 32 位(4 字节指令)的处理器上,“代码对齐因子” 设置为 4,并且允许对一行状态信息适用的字节数进行更紧凑的编码。类似地,还有 “数据对齐因子” 来使 CFA 所在位置的调整更加紧凑。在 x86\_64 上,堆栈槽的大小为 8 个字节。
虚拟表中保存返回地址的列是 16。这在 CIE 尾部的指令中使用。 有四个 `DW_CFA` 指令。第一条指令 `DW_CFA_def_cfa` 描述了如果代码具有帧指针,如何计算帧指针将指向的规范帧地址(CFA)。 在这种情况下,CFA 是根据 `r7 (rsp)` 和 `CFA=rsp+8` 计算的。
第二条指令 `DW_CFA_offset` 定义从哪里获取返回地址 `CFA-8` 。在这种情况下,返回地址当前由堆栈指针 `(rsp+8)-8` 指向。CFA 从堆栈返回地址的正上方开始。
CIE 末尾的 `DW_CFA_nop` 进行填充以保持 DWARF 信息的对齐。 FDE 还可以在末尾添加填充以进行对齐。
在 `f2c.cfi` 中找到 `main` 的 FDE,它涵盖了从 `0x40160` 到(但不包括)`0x401097` 的 `main` 函数:
```
00000084 0000000000000014 00000088 FDE cie=00000000 pc=0000000000401060..0000000000401097
DW_CFA_advance_loc: 4 to 0000000000401064
DW_CFA_def_cfa_offset: 32
DW_CFA_advance_loc: 50 to 0000000000401096
DW_CFA_def_cfa_offset: 8
DW_CFA_nop
```
在执行函数中的第一条指令之前,CIE 描述调用帧状态。然而,当处理器执行函数中的指令时,细节将会改变。 首先,指令 `DW_CFA_advance_loc` 和 `DW_CFA_def_cfa_offset` 与 `main` 中 `401060` 处的第一条指令匹配。 这会将堆栈指针向下调整 `0x18`(24 个字节)。 CFA 没有改变位置,但堆栈指针改变了,因此 CFA 在 `401064` 处的正确计算是 `rsp+32`。 这就是这段代码中序言指令的范围。 以下是 `main` 中的前几条指令:
```
0000000000401060 <main>:
401060: 48 83 ec 18 sub $0x18,%rsp
401064: bf 1b 20 40 00 mov $0x40201b,%edi
```
`DW_CFA_advance_loc` 使当前行应用于函数中接下来的 50 个字节的代码,直到 `401096`。CFA 位于 `rsp+32`,直到 `401092` 处的堆栈调整指令完成执行。`DW_CFA_def_cfa_offset` 将 CFA 的计算更新为与函数入口相同。这是预期之中的,因为 `401096` 处的下一条指令是返回指令 `ret`,并将返回值从堆栈中弹出。
```
401090: 31 c0 xor %eax,%eax
401092: 48 83 c4 18 add $0x18,%rsp
401096: c3 ret
```
`f2c` 函数的 FDE 使用与 `main` 函数相同的 CIE,并覆盖 `0x41190` 到 `0x4011c3` 的范围:
```
00000068 0000000000000018 0000006c FDE cie=00000000 pc=0000000000401190..00000000004011c3
DW_CFA_advance_loc: 1 to 0000000000401191
DW_CFA_def_cfa_offset: 16
DW_CFA_offset: r3 (rbx) at cfa-16
DW_CFA_advance_loc: 29 to 00000000004011ae
DW_CFA_def_cfa_offset: 8
DW_CFA_nop
DW_CFA_nop
DW_CFA_nop
```
可执行文件中 `f2c` 函数的 `objdump` 输出:
```
0000000000401190 <f2c>:
401190: 53 push %rbx
401191: 89 fb mov %edi,%ebx
401193: bf 10 20 40 00 mov $0x402010,%edi
401198: e8 93 fe ff ff call 401030 <puts@plt>
40119d: 66 0f ef c0 pxor %xmm0,%xmm0
4011a1: f2 0f 2a c3 cvtsi2sd %ebx,%xmm0
4011a5: f2 0f 5c 05 93 0e 00 subsd 0xe93(%rip),%xmm0 # 402040 <__dso_handle+0x38>
4011ac: 00
4011ad: 5b pop %rbx
4011ae: f2 0f 59 05 92 0e 00 mulsd 0xe92(%rip),%xmm0 # 402048 <__dso_handle+0x40>
4011b5: 00
4011b6: f2 0f 5e 05 92 0e 00 divsd 0xe92(%rip),%xmm0 # 402050 <__dso_handle+0x48>
4011bd: 00
4011be: f2 0f 2c c0 cvttsd2si %xmm0,%eax
4011c2: c3 ret
```
在 `f2c` 的 FDE 中,函数开头有一个带有 `DW_CFA_advance_loc` 的单字节指令。在高级操作之后,还有两个附加操作。`DW_CFA_def_cfa_offset` 将 CFA 更改为 `%rsp+16`,`DW_CFA_offset` 表示 `%rbx` 中的初始值现在位于 `CFA-16`(堆栈顶部)。
查看这个 `fc2` 反汇编代码,可以看到 `push` 用于将 `%rbx` 保存到堆栈中。 在代码生成中省略帧指针的优点之一是可以使用 `push` 和 `pop` 等紧凑指令在堆栈中存储和检索值。 在这种情况下,保存 `%rbx` 是因为 `%rbx` 用于向 `printf` 函数传递参数(实际上转换为 `puts` 调用),但需要保存传递到函数中的 `f` 初始值以供后面的计算使用。`4011ae` 的 `DW_CFA_advance_loc` 29字节显示了 `pop %rbx` 之后的下一个状态变化,它恢复了 `%rbx` 的原始值。 `DW_CFA_def_cfa_offset` 指出 pop 将 CFA 更改为 `%rsp+8`。
### GDB 使用调用帧信息
有了 CFI 信息,[GNU 调试器(GDB)](https://opensource.com/article/21/3/debug-code-gdb) 和其他工具就可以生成准确的回溯。如果没有 CFI 信息,GDB 将很难找到返回地址。如果在 `f2c.c` 的第 7 行设置断点,可以看到 GDB 使用此信息。GDB在 `f2c` 函数中的 `pop %rbx` 完成且返回值不在栈顶之前放置了断点。
GDB 能够展开堆栈,并且作为额外收获还能够获取当前保存在堆栈上的参数 `f`:
```
$ gdb f2c
[...]
(gdb) break f2c.c:7
Breakpoint 1 at 0x40119d: file f2c.c, line 7.
(gdb) run
Starting program: /home/wcohen/present/202207youarehere/f2c
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
98
converting
Breakpoint 1, f2c (f=98) at f2c.c:8
8 return c;
(gdb) where
#0 f2c (f=98) at f2c.c:8
#1 0x000000000040107e in main (argc=<optimized out>, argv=<optimized out>)
at f2c.c:15
```
### 调用帧信息
DWARF 调用帧信息为编译器提供了一种灵活的方式来包含用于准确展开堆栈的信息。这使得可以确定当前活动的函数调用。我在本文中提供了简要介绍,但有关 DWARF 如何实现此机制的更多详细信息,请参阅 [DWARF 规范](https://dwarfstd.org/Download.php)。
*(题图:MJ/4004d7c7-8407-40bd-8aa8-92404601dba0)*
---
via: <https://opensource.com/article/23/3/gdb-debugger-call-frame-active-function-calls>
作者:[Will Cohen](https://opensource.com/users/wcohen) 选题:[lkxed](https://github.com/lkxed/) 译者:[jrglinux](https://github.com/jrglinux) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
16,034 | 5 个专注于隐私保护的 Linux 发行版 | https://www.debugpoint.com/privacy-linux-distributions-2022/ | 2023-07-26T06:58:00 | [
"隐私",
"Linux 发行版"
] | /article-16034-1.html | 
>
> 我们在这篇文章中列出了 2023 年排名前 5 的专注于隐私保护的 Linux 发行版,旨在提供给你在选择之前的参考。
>
>
>
随着疫情和远程办公的普及,网络隐私成为一个主要关注点。随着我们越深入数字世界,网络安全和隐私变得对每个人的日常生活都至关重要。几乎每天都会看到 [公共漏洞(CVE)](https://en.wikipedia.org/wiki/Common_Vulnerabilities_and_Exposures),一个月中也会爆出几个 [零日漏洞](https://en.wikipedia.org/wiki/Zero-day_(computing)) 和勒索软件攻击。
幸运的是,与 Windows 相比,Linux 通常在设计上就相对安全。此外,如果你在日常工作中使用 Linux 发行版时遵循一些最佳实践,大多数 Linux 发行版也是安全的。
此外,一些特定的 [Linux 发行版](https://www.debugpoint.com/category/distributions) 为你的工作和个人使用提供了额外的安全层和工具。例如,如果你想在互联网上实现完全匿名,或者你是网络安全专家,你可能会考虑一些区别于普及的主流 Linux 发行版,如 Ubuntu 或 Fedora 的其他发行版。
以下是提供更好隐私保护和安全性的 5 个 Linux 发行版的列表。
### 2023年度最佳隐私专用 Linux 发行版
#### 1、Tails
<ruby> 匿名隐私系统 <rt> The Amnesic Incognito Live System </rt></ruby>(简称 Tails)是一种基于 Debian 的 Linux 发行版,让你在浏览网页时完全匿名。它主要使用 Tor 网络,通过其网络重定向流量以隐藏你的位置和其他私密信息。此外,它还配备了处理电子邮件、浏览器和其他工具所需的所有必要安全应用程序。
如果你需要一种内置完全隐私功能的 Linux 发行版,请选择 Tails。

优点:
* 与 Tor 网络完美集成
* 预配置了 NoScript、HTTPS anywhere 和其他相关插件的浏览器(Firefox)
* 内置比特币钱包、无线网络审计工具,并配备 Onion Circuits
* <ruby> 立付介质 <rt> Live medium </rt></ruby>
更多详情:
* 主页:<https://tails.boum.org/>
* 发行频率:每年 5 到 6 次发布
* 发行类型:Debian(稳定版)、GNOME、LIVE 图像、仅支持 64 位、x86\_64
* 下载:<https://tails.boum.org/install/index.en.html>
#### 2、Parrot OS
Parrot OS(以前称为 Parrot Security OS)也是一种基于 Debian 的 Linux 发行版,主要面向网络安全专业人员和渗透测试人员,为他们提供了一种完整的 Linux 发行版,提供了他们所需的所有工具。
此外,你还可以将其用作日常使用,具有用于数字取证工作的内置沙盒选项。此外,它可以使用其容器化技术连接到其他设备。

优点:
* 基于 Debian 的立付系统
* 提供多种桌面风格选择
* 运行的应用程序都被隔离在沙盒中
* 非常适合数字取证工作
更多详情:
* 主页:<https://parrotsec.org/>
* 发行频率:每年 2 到 3 次发布
* 发行类型:Debian(测试版)、MATE 和 KDE Plasma、LIVE 图像、仅支持 64 位、x86\_64
* 下载:<https://parrotsec.org/download/>
#### 3、Qubes OS
Qubes OS 是一种基于 Fedora Linux 的独特 Linux 发行版。Qubes 提供多个“虚拟机”(被称为“Qubes”),用于托管应用程序。该方法有效地将“个人”、“工作”或其他用户定义的工作流程隔离开来。
此外,为了区分不同的“虚拟机”,该发行版为配置文件提供了色彩代码,以便你知道哪个正在运行哪个应用程序。
使用这种方法,如果你在一个“虚拟机”中遭受身份泄露或下载了恶意软件,系统的其他部分都是安全的。这种方法被称为“安全隔离”,非常适合需要在互联网上保护隐私的科技爱好者和普通用户。

优点:
* 通过独立的“虚拟机”实现“安全隔离”
* 内置沙盒支持
* 提供完全磁盘加密
* 通过色彩代码标记的“Qubes”,方便进行工作流程导航
更多详情:
* 主页:<http://qubes-os.org/>
* 发行频率:每年 2 到 3 次发布
* 发行类型:Fedora、Xfce、桌面版、仅支持 64 位、x86\_64
* 下载:<https://www.qubes-os.org/downloads/>
#### 4、Kali Linux
Kali Linux 是基于 Debian 测试分支的最受欢迎的渗透测试 Linux 发行版。以印度教女神“卡利”命名,这个 Linux 发行版提供了适用于树莓派和其他设备的 32 位、64 位和 ARM 版本。此外,它搭载了大量的工具,使安全研究人员和网络安全专家能够在其他发行版上拥有优势。

优点:
* Kali Linux 几乎成为安全研究人员的“行业标准”发行版
* 提供完全磁盘加密
* 支持 i686、x86 和 ARM
* LIVE 系统
* 提供完善的文档,以及用于自定义 Kali Linux 进行特定研究的培训套件
* Kali Linux 提供付费的渗透测试认证课程
更多详情:
* 主页:<http://www.kali.org/>
* 发行频率:每年 3 到 4 次发布
* 发行类型:Debian(测试版)、GNOME、KDE Plasma 等等、桌面版和 LIVE 等等、32 位和 64 位、x86\_64、i686、ARM
* 下载:<http://www.kali.org/downloads/>
#### 5、Whonix Linux
Whonix 是另一种基于 Debian 的独特设计的 Linux 发行版。它作为虚拟机在 VirtualBox 中运行,从而提供了一个不能驻留在磁盘上、在多次重启后不会丢失的操作系统。
此外,其独特的设计提供了一个连接到 Tor 网络的网关组件,以及一个名为“工作站”的第二个组件,负责运行所有用户应用程序。这些用户应用程序连接到网关,为应用程序和用户提供完全匿名性。最后,这种独特的两阶段隔离方法在确保完全隐私的同时,减轻了多种风险。

优点:
* 两阶段隔离,分离网络和用户应用程序
* 支持 Tor 网络,提供 Tor 浏览器和即时通讯等应用程序
* 预装了主要应用程序
* 支持 Linux 内核运行时保护
更多详情:
* 主页:<https://www.whonix.org/>
* 发行频率:每年发布 1 次
* 发行类型:Debian、桌面版、Xfce、64 位、x86\_64
* 下载:<https://www.whonix.org/>
### 其它
除了上述列表,我们还要提到 Linux Kodachi 和 BlackArch Linux,它们与上述发行版本类似。
首先,[Linux Kodachi](https://www.digi77.com/linux-kodachi/) 也是一个基于 Debian 的发行版,使用 Tor 网络为用户提供隐私保护。它配备了 Xfce 桌面环境,并提供仅支持64位的安装程序。
除了 Kodachi,还有 [BlackArch Linux](http://blackarch.org/),它是本列表中唯一基于 Arch Linux 的发行版。它采用了窗口管理器(如 Fluxbox、Openbox),而不是桌面环境,并提供了 1000 多个适用于渗透测试和安全分析的应用程序。
### 总结
最后,我希望这个 2023 年顶级隐私专注的 Linux 发行版列表能给你保护自己和你在互联网上的隐私提供一个起点。
最后但并非最不重要的是,我要提醒你,如果你将上述发行版与 Tor 网络一起使用,请不要使用这些发行版进行任何银行或金融交易(尤其是那些使用手机验证的多因素身份验证的交易)。因为 Tor 会通过不同的国家路由你的流量,因此最好不要在这些发行版上进行金融工作。
图像来自各个发行版及维基百科。
*(题图:MJ/0603df83-3221-4a15-9312-011325786414)*
---
via: <https://www.debugpoint.com/privacy-linux-distributions-2022/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
16,037 | 发展中国家面临的三个关键开源挑战 | https://opensource.com/article/23/4/challenges-open-source-developing-countries | 2023-07-27T07:37:21 | [
"开源"
] | https://linux.cn/article-16037-1.html | 
>
> 开源在发展中国家面临着许多困难,这些困难使人们对开源的看法以及与开源的联系变得不准确、不贴切。
>
>
>
>
> 编者按:本文作者 Ahmed Sobeh 是 Aiven 开源项目办公室的开源工程经理。他来自埃及,在开源领域有各种经验。本文是他对埃及的开源文化的见解。
>
>
>
当我回国,和科技行业或其他行业的人谈起我的工作和我每天参与的话题时,我通常会对 <ruby> <a href="https://opensource.com/article/20/5/open-source-program-office"> 开源计划办公室 </a> <rt> Open Source Programs Office </rt></ruby>(OSPO)这个想法感到困惑。一家公司在没有明显的直接经济利益的情况下为开源项目做出贡献,这种概念在文化上很难理解或解释。
作为一个在发展中国家出生并成长的人,我理解并赞同这个观点。曾几何时,我对开源软件的唯一理解是,它是一种无需付费、无需等待特定问题或附加功能发布即可使用的软件。我可以自己在本地做任何我需要的事情。
在发展中国家,开源面临着许多困难,这些困难使人们对它的看法和相关印象变得不准确和脱节。我将在本文中讨论这些问题。
### 发展中国家的开源挑战
开源在这些地区面临的挑战主要分为三个部分:
* 社会与文化
* 资源与基础设施
* 政府管理
### 社会与文化
众所周知,科技中的文化,特别是其中的开源部分,源自它所存在的社会文化。这就是为什么在当今世界,开源更有可能在世界较发达地区得到维持和维护。
但是,试想一个完美的社会,一个最适合开源发展、维持和维护的社会。这个社会的文化是什么样的?其主要特征是什么?
#### 开放和透明
开源想要发展,社会文化必须尽可能开放和透明。信息必须可以自由公开地获取,这在许多欠发达地区是一个巨大的问题。信息往往受到繁文缛节的制约,普通公民难以获取,更不用说那些试图为开源做出贡献的人了。
#### 自由
“自由”这个词有许多不同的含义与解释。有言论自由、表达自由、选择自由、信仰自由、宗教自由等等。在本文中,我最关心的自由方面是在没有更高层机构干预的情况下建立新社区和组织的能力。这是开源的本质。分布式协作模式是一种高效的协作模式,在这种模式下,大型团体在没有强大的中央权威指挥的情况下开展合作。这是大多数这些地区面临的另一个重大挑战。新的社区和组织往往会受到质疑、密切监视,不幸的是,在某些情况下,甚至会因为害怕可能出现的新思想或其他原因而遭到起诉并最终被关闭。
#### 充满活力
充满活力的文化对开源的发展至关重要。准备接受和实行新想法的文化是发展开源最理想的地方。抵制改变和倾向于固守传统方法会阻止社会接受新的技术和方法,这是大部分发展中国家中的主要问题。
这些地区抵制改变背后最重要也是最常见的原因是对未知的恐惧。把对未知的恐惧作为“发展中国家”的问题来讨论是不公平的。这是在哪里都常见问题,甚至在发达国家。但是恐惧背后的一些原因是发展中国家特有的。主要原因有两个,一是对科技行业的能力缺乏信心,二是缺乏责任感。企业和个人都不信任现有软件解决方案的功能,更不用说开源解决方案了。有一种观点认为,开源软件不安全、不可靠。当人们不相信软件开发者的能力时这种担忧会被放大。其次,人们不相信该系统会对使用软件或法律冲突中可能出现的错误或问题追究责任。
### 资源、基础设施和经济
经济挑战是发展中国家开源面临的最明显的困难,影响着这些地区的开源开发者和社区。
#### 供应和资金
开源开发人员在发展中国家努力解决供应问题。无论是上网还是使用设备,当你每天都在努力获取资源时,就很难成为一名固定的开源贡献者。这些国家的数字鸿沟十分巨大。依然有许多地区没有正常、稳定和高速的互联网连接。在设备方面,这些地区也与世界其他地区存在市场差距。没有足够的资金购买最新、最强大的机器始终是个难题,但同时也存在供应问题。在这些地区,建立和运行最大的开源项目所需的现代化、功能强大的技术设备并不总能提供。
这些问题使得自我教育和学习具有挑战性。由于这些供应问题,开源开发人员很难选择一个开源项目,自行学习所有相关知识,并开始为其做出贡献。
在这种情况下,如何建立开源社区呢?项目最终只能由少数拥有稳定高速互联网连接和最新设备的特权人士来维护。剩下的将是零星的、偶尔来自他人的贡献,很难被视为一个社区。一旦出现有偿工作的机会,即使是这些人也会消失。我亲眼见过多次这种情况。有人会开始了解一个开源项目,研究特定的堆栈或提高自己的技能,并开始为其做出贡献。但一旦出现了有偿工作的机会,即使是作为第二份工作,他们也会完全放弃开源项目。这是有道理的。任何个人都必须优先考虑自己和家人的生存手段。
这种资源匮乏和对少数特权人群的依赖,也使其几乎不可能为营销活动、社区建设活动以及最后但并非最不重要的文献本地化尝试提供资金。
#### 本地化
英语是互联网语言,但对许多国家来说并非如此。虽然几乎所有的开发人员都会说基本的英语,但并不是每个人都有能力理解文档、架构资源和技术规范,使他们能够有意义地 [为开源项目做出贡献](https://opensource.com/article/22/3/contribute-open-source-2022)。由于没有相应的文档,发展中国家的开发人员很难找到进入开源项目的切入点。为此所需的时间和资源通常会使这些地区的潜在贡献者望而却步。
#### 员工合同
几乎所有的软件员工合同都旨在将开发人员的每一行代码、贡献或想法货币化。任何参与外部项目的行为都会受到雇佣公司的质疑,而雇佣公司往往会阻止开发人员为开源做贡献,以避免法律问题。法律偏向于公司和组织,阻止软件开发人员做出外部贡献。
#### 知识产权法
发展中国家的法律框架往往不具备处理知识产权和开源许可细微差别的能力。与发达国家相比,发展中国家的知识产权法律可能较弱或不够全面,执法效力也可能较低。这可能使创作者和贡献者难以保护自己的作品,并防止他人在未经许可的情况下使用。
此外,开源许可证可能很复杂。许多发展中国家可能不具备有效驾驭这些许可的法律专业知识或资源。这可能使开发人员很难在不无意中违反许可证条款的情况下为开源项目做出贡献。
另一个问题是,知识产权法和开源许可证有时被视为发展中国家创新和发展的障碍。批评者认为,这些法律和许可会扼杀创造力,阻碍知识和技术的传播,尤其是在资源和技术有限的地区。
总体而言,发展中国家围绕知识产权法和开源贡献所面临的挑战是复杂的、多方面的,需要采取细致入微的方法来应对这些国家所面临的独特情况和挑战。
### 专有软件交易
美国和欧洲的科技巨头与发展中地区的政府签订了价值数十亿美元、长达数十年的软件供应协议。一旦有人当选,并决定开始采用开源软件,他们就会发现摆脱这些交易需要付出巨大的代价。
### 开源并非一帆风顺
这些只是开放源代码在发展中国家面临的一些困难。要改善这种状况,使开源技术的采用和发展变得可行,还有许多工作要做。在今后的文章中,我将深入探讨具体的解决方案,但现在,我想说的是,任何事情都要从个人做起。当我们每个人都 “众包” 开放文化时,我们生活和工作所在地区的文化也会随之改变。尽你所能,将开放源代码带入你的社区,看看它会带来什么。
*(题图:MJ/e9f5a8be-b0bd-425a-8199-248f5c0abe16)*
---
via: <https://opensource.com/article/23/4/challenges-open-source-developing-countries>
作者:[Ahmed Sobeh](https://opensource.com/users/ahmed-sobeh) 选题:[lkxed](https://github.com/lkxed/) 译者:[wcjjdlhws](https://github.com/wcjjdlhws) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When I go back home and talk to people in the tech industry, or any other industry for that matter, about what I do and the topics I'm involved in daily, I'm usually met with bemusement at the idea of an [Open Source Programs Office (OSPO)](https://opensource.com/article/20/5/open-source-program-office). The concept of a company contributing to an open source project without obvious immediate financial benefit can be culturally strange to understand or explain.
As someone born and raised in a country that has been trying to develop for quite some time, I understand and relate to that. There was a point in time when my only understanding of open source was that it was software that I could use without paying and without needing to wait for a specific issue or additional feature to be released. I could just do whatever I needed myself, locally.
Open source faces many struggles in developing countries that make how it's perceived and its associations inaccurate and out of touch. I will discuss these struggles in this article.
## Open source challenges in developing countries
The challenges that open source faces in these regions can be divided into three main areas:
- Society and culture
- Resources and infrastructure
- Governance
## Society and culture
It's no secret that the culture of tech in general, and specifically the open source part of it, feeds off the culture of the society where it exists. That's why, in today's world, open source has a better chance of being sustained and maintained in the more developed parts of the world.
But imagine a perfect society, optimal for open source to grow, be sustained, and maintained. What does the culture of that society look like? What are its main characteristics?
### Open and transparent
For open source to thrive, the society's culture must be as open and transparent as possible. Information must be freely and publicly accessible, which is a huge issue in many underdeveloped regions. Information is often red-taped and is unavailable to the average citizen, let alone someone who's trying to contribute to open source.
**[ Related read Global communication in open source projects ]**
### Free
The word "free" has many different meanings and implications. There's freedom of speech, expression, choice, belief, religion, and many others. The aspect of freedom I'm most concerned with in this context is the ability to start new communities and organizations without a higher authority intervening. That's the essence of open source. Distributed modes of collaboration, in which large groups work together without a strong centralized authority directing them, are highly effective. This is another major challenge in most of these regions. New communities and organizations are often questioned, closely monitored, and unfortunately, in some cases, even prosecuted and eventually shut down for fear of the new ideas that may emerge or other reasons.
### Dynamic
A dynamic culture is essential for the growth of open source. A culture that's ready to accept and implement new ideas is the perfect place for open source to grow. Being resistant to change and preferring to stick with traditional approaches can limit society's willingness to adopt new technologies and solutions, which is a major issue in most underdeveloped countries.
The greatest and most common reason behind resistance to change in these regions is the fear of the unknown. It would be unfair to discuss fear of the unknown as a "developing countries" problem. It's a common issue everywhere, even in the developed world. But some reasons behind this fear are specific to underdeveloped regions. The two main reasons are a lack of trust in the competence of the tech industry and a lack of accountability. Businesses and individuals do not trust the capabilities of the software solutions on offer, let alone open source solutions. There's an idea that open source software is unsafe and insecure. This concern is magnified when people do not trust the competence of the software developers. Second, people do not trust the system to hold anyone accountable for any possible mistakes or issues arising from using the software or in legal conflicts.
## Resources, infrastructure, and economy
Economic challenges are the most obvious struggle for open source in developing countries, impacting open source developers and communities in these regions.
### Access and funds
Open source developers struggle with issues of accessibility in developing countries. Whether it's access to the internet or equipment, it can be difficult to become a regular open source contributor when you struggle to reach resources daily. The digital divide in these regions is huge. There are still many areas without regular, stable, and high-speed internet connections. There's also a market gap between these regions and the rest of the world when it comes to equipment. There's always the challenge of not having enough funds to buy the latest, most powerful machines, but there's also an availability problem. The modern, powerful tech equipment needed to build and run the biggest open source projects isn't always available in these regions.
These concerns make self-education and learning challenging. It's difficult for an open source developer to pick an open source project, learn all about it on their own, and start contributing to it due to these access issues.
And how do you build an open source community under these circumstances? Projects would end up being maintained by the privileged few with access to stable high-speed internet connections and the latest equipment. The rest would be spotty, occasional contributions from others that can hardly be considered a community. And even those would disappear once the chance of paid work appears. I've personally seen it multiple times. Someone would start learning about an open source project to research a specific stack or improve their skills and begin contributing to it. But once the opportunity of paid work appeared, even as a second job, they dropped the open source project completely. It makes sense. Any individual must prioritize a means of survival for themselves and their family.
This lack of resources and dependence on a privileged few would also make it almost impossible to fund marketing campaigns, community-building events, and, last but not least, documentation localization attempts.
### Localization
English is the language of the internet, but not for many these countries. While almost all developers speak English at a basic level, not everyone has the ability to comprehend and understand documentation, architecture resources, and technical specifications to the level that enables them to meaningfully [contribute to an open source project](https://opensource.com/article/22/3/contribute-open-source-2022). The non-existence of adapted documentation makes it difficult for developers in developing countries to find an entry point into open source projects. The time and resources required to do that usually discourage potential contributors from these regions.
**[ Also read How open source weaves connections between countries ]**
### Employee contracts
Almost all software employee contracts are designed to monetize every single line of code, contribution, or thought the developer might have. Any participation in external projects can be a cause for questioning by the employing company, which all too often discourages developers from contributing to open source to avoid legal issues. Laws favor corporations and organizations and prevent software developers from making external contributions.
### Intellectual property laws
Legal frameworks in developing countries are often ill-equipped to handle the nuances of intellectual property rights and open source licensing. Intellectual property laws in developing countries may be weaker or less comprehensive than those in developed countries, and enforcement may be less effective. This can make it difficult for creators and contributors to protect their work and prevent others from using it without permission.
In addition, open source licensing can be complex. Many developing countries may not have the legal expertise or resources to navigate these licenses effectively. This can make it tough for developers to contribute to open source projects without inadvertently violating the terms of the license.
Another issue is that intellectual property laws and open source licensing are sometimes seen as hindrances to innovation and development in developing countries. Critics argue that these laws and licenses can stifle creativity and prevent the spread of knowledge and technology, particularly in areas where access to resources and technology is limited.
Overall, the challenges surrounding intellectual property laws and open source contributions in developing countries are complex and multifaceted, requiring a nuanced approach that accounts for the unique circumstances and challenges these countries face.
## Proprietary software deals
Tech giants based in the US and Europe enter into billion-dollar, decades-long deals with governments in developing regions to supply them with software. On the off chance that someone gets elected into a position and decides to start an initiative to adopt open source software, they find that getting out of these deals would cost a fortune.
## Open isn't always easy
These are just some of the struggles open source faces in developing countries. There's much to be done to improve the situation and make adopting and growing open source feasible. In future articles, I will delve into specific solutions, but for now, I'll note that, as with everything, it starts with the individual. As we each "crowdsource" an open culture, the culture of the regions where we live and work changes. Bring open source to your community in whatever small way you can, and see where it leads.
## Comments are closed. |
16,038 | Linux Shell 介绍:Bash、Zsh 和 Fish | https://www.debugpoint.com/linux-shells/ | 2023-07-27T15:27:00 | [
"Shell"
] | /article-16038-1.html | 
>
> 关于著名的 Linux Shell - Bash、Zsh 和 Fish 的一些注释和特性。
>
>
>
Linux 之所以强大,是因为它提供了用于与系统进行交互的多功能的命令行界面。在这中情况下,Shell 扮演了用户和 Linux 内核之间的桥梁。本文将探讨三种流行的 Linux Shell - Bash、Zsh 和 Fish,并深入了解它们的独特特性和功能。
### 理解 Linux Shell
#### 什么是 Shell?
Shell 是一个命令行解释器,允许你通过文本命令与操作系统进行交互。它接收你的输入,处理它,并与 Linux 内核通信以执行所请求的操作。最后,它会给你一个输出。
(LCTT 译注:“Shell” 一词大约取自其“界面”、“外壳”的含义。)
Shell 在 Linux 中起着至关重要的作用,因为它们使用户能够执行各种任务,从简单的文件导航到复杂的系统管理任务。不同的 Shell 提供各种功能,因此选择适合你工作流程的 Shell 至关重要。
### Bash
[Bash](https://www.gnu.org/software/bash/),全称 “Bourne Again SHell”,是 Linux 发行版中最广泛使用的默认 Shell 之一。它以其简洁和兼容性而闻名,是初学者的优秀选择。
#### Bash 的特点
Bash 具有众多特性,包括:
* 命令历史:使用箭头键轻松访问先前执行的命令。
* `Tab` 键补全:节省时间,让 Bash 为你自动完成文件名和命令。
* 脚本编写:编写和运行 Shell 脚本以自动化重复任务。从这个角度来看,它也是一个程序。
* Bash 在大多数 GNU/Linux 系统中默认安装。
* 配置设置存储在家目录下的 `.bashrc` 文件中。
和其他 Shell 一样,Bash 有其优点和缺点。使用 Bash 的一些优势包括广泛的使用性、详尽的文档以及庞大的社区支持。然而,Bash 可能缺乏其他 Shell 中存在的一些现代化特性。

#### 安装
* 在 Linux 发行版中打开终端。
* 输入 `bash --version` 检查是否已安装 Bash。
* 若尚未安装,使用软件包管理器安装 Bash。例如,在 Ubuntu 上,输入 `sudo apt-get install bash`。
* 对于 Fedora 和基于 RPM 的 Linux,请使用 `sudo dnf install bash`。
### Zsh
[Zsh](https://www.zsh.org/),全称 “Z Shell”,是一种强大且功能丰富的 Shell,深受经验丰富的用户欢迎。它吸取了 Bash 和其他 Shell 的优点,提升了用户体验。
#### Zsh 的优势
Zsh 提供了几个优势,包括:
* 高级自动补全:Zsh 在 Bash 的基础上提供了更多上下文感知的建议,超越了简单的 `Tab` 键补全。
* 当你按下 `Tab` 键时,Zsh 会显示可能的值以供选择,同时进行自动补全。
* 插件支持:通过社区中提供的各种插件,扩展 Zsh 的功能。
* 这里有一个 [庞大的 Zsh 主题集合](https://github.com/unixorn/awesome-zsh-plugins)。
* 你还可以使用 [Oh My Zsh 脚本](https://www.debugpoint.com/oh-my-zsh-powerlevel10k/) 进行广泛的自定义。

Zsh 的复杂性可能使新手感到不知所措,其丰富的配置选项可能会使初学者感到困惑。
以下是安装 Zsh 的方法:
* 在 Linux 发行版中打开终端。
* 输入 `zsh --version` 检查是否已安装 Zsh。
* 如果尚未安装,请使用软件包管理器安装 Zsh。
* 例如,在 Ubuntu 上,输入 `sudo apt-get install zsh`。
* 对于 Fedora 和基于 RPM 的发行版,输入 `sudo dnf install zsh`。
### Fish Shell
[Fish](https://fishshell.com/),全称 “Friendly Interactive SHell”,着重于用户友好性和易用性。它拥有现代、直观的界面,特别适合新的 Linux 用户。
#### Fish 的独特特性
Fish 的独特之处在于:
* 语法高亮:使用彩色标记文本来区分命令、选项和参数。
* 自动建议:Fish 根据你的历史记录和当前输入智能地建议命令。
* Fish 被设计为开箱即用的高效工具。但是,你可以通过创建 `~/.config/fish/config.fish` 文件并添加自定义配置来进一步个性化它。
虽然 Fish 在用户友好性方面表现出色,但其独特的设计可能并不适合所有人。一些高级用户可能会发现某些功能在高级使用方面有所限制。

#### Fish Shell 的安装
* 在 Linux 发行版中打开终端。
* 输入 `fish --version` 检查是否已安装 Fish。
* 如果尚未安装,请使用软件包管理器安装 Fish。例如,在 Ubuntu 上,输入 `sudo apt-get install fish`。
* 对于 Fedora 和其他基于 RPM 的发行版,输入 `sudo dnf install fish`。
### Bash、Zsh 和 Fish 的比较
为了帮助你决定哪种 Shell 适合你的需求,让我们从各个方面比较这三个流行选择:
#### 性能与速度
Bash 以其速度和高效性而闻名,适用于资源受限的系统。Zsh 虽然稍慢一些,但其广泛的功能和能力弥补了这一点。作为更具交互性的 Shell,Fish Shell 可能会略微降低性能,但提供了愉快的用户体验。
#### 用户界面和体验
Bash 的界面简单明了,非常适合初学者,而 Zsh 和 Fish 提供了更引人注目和交互式的界面。Zsh 的高级自动补全和 Fish 的语法高亮为用户创造了视觉上的吸引力。
#### 可定制性和插件
Zsh 在可定制性方面表现出色,允许用户对其 Shell 环境进行微调。通过庞大的插件集合,Zsh 提供了无与伦比的可扩展性。Fish 则采取了更有主见的方式,专注于开箱即用的可用性,这可能对某些用户有所限制。
### 选择合适的 Shell
选择合适的 Shell 与你的具体需求和经验水平密切相关。
如果你是 Linux 的新手并且更喜欢简单、无花俏的体验,Bash 是一个极好的起点。它的易用性和详尽的文档使其非常适合初学者。
对于希望更多掌握控制权并愿意花时间进行定制的经验丰富的用户来说,Zsh 强大的功能和插件提供了一个令人兴奋和动态的环境。
如果你对自动化任务和编写复杂的 Shell 脚本感兴趣,Bash 在 Linux 生态系统中的广泛应用和全面支持使其成为一个可靠的选择。
### 结论
Bash、Zsh 和 Fish 各有其优势,满足不同用户偏好。如果你刚接触 Linux,Bash 的简单性使其成为一个极好的起点。精通用户和那些寻求定制化的用户可能会觉得 Zsh 更吸引人,而 Fish 的用户友好设计则适合寻求直观界面的初学者。最终,选择权在你手中,探索这些 Shell 将带来更高效和愉悦的 Linux 使用体验。
你最喜欢的 Shell 是什么?在下方的评论框中告诉我。
*(题图:MJ/b6490b57-63bd-4fdd-bd3f-bf6d4aef1c4a)*
---
via: <https://www.debugpoint.com/linux-shells/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
16,040 | 如何在 Linux 中安装 Jupyter Notebook | https://www.debugpoint.com/install-jupyter-ubuntu/ | 2023-07-28T06:35:00 | [
"Jupyter Notebook"
] | /article-16040-1.html | 
>
> 如何在 Ubuntu 或 Debian Linux 中安装 Jupyter Notebook 的简单教程。
>
>
>
[Jupyter](https://jupyter.org/) Notebook 是一款功能强大的基于 Web 的交互式开发工具,可让你创建和共享实时代码、可视化和交互式数据。其笔记本格式结合了代码和文本,使其成为数据探索、分析和协作项目的绝佳选择。
在本教程中,我们将逐步指导你在基于 Ubuntu 或 Debian 的系统上安装 Jupyter Notebook,使你能够利用其多功能性并扩展编程能力。
### 安装 pip
在开始之前,请确保你的系统上已安装 `pip`(Python 包安装程序)。如果你已经安装了 `pip`,则可以跳过此步骤。否则,请按照以下说明进行安装。你还可以访问 [此页面](https://www.debugpoint.com/pip-command-not-found/) 获取详细说明。
打开终端窗口(`Ctrl+Alt+T`)并输入以下命令,按回车键:
```
sudo apt updatesudo apt install python3-pip
```
系统可能会提示你输入密码。提供它并等待安装完成。
### 安装 virtualenv
尽管不是强制性的,但建议在 Jupyter Notebook 安装中通过此工具隔离你的工作环境。这可以确保你安装的任何更改或软件包都不会干扰系统的 Python 环境。要设置虚拟环境,请按照以下步骤操作:
在终端中,输入以下命令:
```
sudo apt install python3-virtualenv
```
等待安装完成。完成后,继续下一步。
### 创建虚拟环境
创建虚拟环境是一个简单的过程。以下是专门为 Jupyter Notebook 设置新虚拟环境的方法:
进入到要在其中创建虚拟环境的目录。在终端中运行以下命令:
```
virtualenv my-jupyter-env
```
此命令创建一个名为 `my-jupyter-env` 的新目录,其中将包含虚拟环境文件。

你还可以通过任何文件管理器验证该目录是否在你的主文件夹下创建成功。

输入以下命令激活虚拟环境:
```
source my-jupyter-env/bin/activate
```
你会注意到终端提示符发生变化,表明你现在位于虚拟环境中。

### 安装 Jupyter Notebook
激活虚拟环境后,你现在可以继续安装 Jupyter Notebook:
在终端中,输入以下命令:
```
pip install jupyter
```
此命令会获取必要的包并在虚拟环境中安装 Jupyter Notebook。

### 启动 Jupyter Notebook
安装完成后,你就可以启动 Jupyter Notebook:
在终端中,输入以下命令:
```
jupyter notebook
```
执行命令后,Jupyter Notebook 将启动,你应该看到类似于以下内容的输出:

你的默认 Web 浏览器将打开,显示 Jupyter Notebook 界面。

### 关闭并重新启动
如果要关闭 Notebook 服务器,请确保关闭并保存所有笔记。关闭浏览器。然后在终端窗口中按 `CTRL+C`。它会提示你是否要关闭服务器。输入 `Yes` 并按回车键。最后,关闭终端窗口。
要再次重新启动服务器,你需要按上面的描述运行 `virtualenv my-jupyter-env` 等所有命令
### 总结
恭喜! 你已在 Ubuntu 或 Debian 系统上成功安装 Jupyter Notebook。通过执行上述步骤,你现在可以利用 Jupyter 的交互式开发环境轻松编写代码、创建可视化并探索数据。
请记住,Jupyter Notebook 支持各种编程语言,包括 Python,并提供大量插件来进一步扩展其功能。
*(题图:MJ/e3436c7f-435d-491e-9032-b945730cb000)*
---
via: <https://www.debugpoint.com/install-jupyter-ubuntu/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
16,041 | 每年都是某个人的 “Linux 桌面之年” | https://news.itsfoss.com/filiming-with-foss-tech/ | 2023-07-28T07:40:05 | [
"Linux",
"桌面"
] | https://linux.cn/article-16041-1.html | 当我的第一部特别电影获得批准时,我正处于为期两年的 Linux 实验中。我是如何使用(大多数)开源软件技术制作我的电影的呢?

我在 2020 年爱上了 Linux。时机不可能更尴尬了。
世界卫生组织宣布我们这一生中的第一次大流行病降临。我刚刚从工作中休假,打算利用这段时间完成硕士学位,并完成我处女作《第一次言辞》的续集。
但作家是一群善变的人。有时我们的注意力可以持续数周,锐利无比。有时,我们的注意力却像金鱼一样短暂。
那时我处在金鱼模式中。
我需要一些东西来逃离我日复一日的生活:醒来,写几个小时,开始学习,完成课程作业,重复。
互联网上的某个地方有人提到,大流行病为人们提供了在日常计算中尝试 Linux 的最佳机会。
立刻,金鱼般的大脑被吸引住了。
这是有充分理由的:
20 年前,我放弃了电影学院,选择攻读计算机科学学士学位。
令我惊讶的是,我发现自己喜欢上了大部分课程(直到我们学习《Java 编程入门》时,我因此退学了,但这是另外一个故事);《计算机体系结构》、《网络》和《系统管理》模块真的引起了我的兴趣,我发现自己在学校实验室里花更多时间在安装了 Linux 的机器上。
关键是我和 Linux 之间有历史。
而在 2020 年,时机刚刚好。
### 疫情期间的技术爱好者生活
在我退学后的几年里,我远离了计算机引发我内心的那些好奇心。
作为对电影学院的替代,我成为了一名小说家。
我从信息技术转向了市场营销,并花费了 20 多年的时间为平面、电视、广播和数字平台撰写广告文案。
我创办了自己的广告代理公司。
在这 20 年里,我们目睹了社交媒体与互联网变得同义。
到了 2020 年,我决定永远离开广告界,其中很大一部分原因是我对技术的幻想破灭,尤其是对社交媒体的失望,特别是社交媒体以冷漠的方式伤害我们,无论是个人还是整个社会。
虽然我知道社交媒体并不等同于互联网,但在我的脑海中很难将它们分开。作为一个广告人,我也觉得自己在使社交媒体无处不在方面起到了一定的作用。
**拥有自己的 Linux 桌面之年,在整个大流行期间让我保持理智。**
### 2022 年:我首部特别电影
到了 2022 年,我已经在我的笔记本电脑上日常使用 Linux。我还买了一台旧的 ThinkPad T420,安装了 Ubuntu Server,并开始运行 Plex 和 NextCloud 的实例。
我在 Linux 上感到很自在,几乎将所有的写作工作都从 MS Word 和云存储转移到了 Vim 和 GitHub 上。
就在这时,我接到了一位制片人的电话,批准了我的首部特别电影。
此时,我需要做一个决定。在片场剪辑镜头时,我需要使用行业标准的非线性编辑器(NLE)。我对 Adobe Premiere 很熟悉,但我知道没有 Linux 版本。我已经尝试过 Kden Live 和其他几个自由开源软件的替代品,包括内置 NLE 的 Blender,但都不太满意。
更重要的是,我担心我的写作流程 —— 完全基于(Neo)Vim 和 Git ——对我的合作作者来说太陌生。
### 你好,Windows?
此时,我不得不问自己 Linux 是否准备好应对我未来的电影工作。为了回答这个问题,我提醒自己以下几点:
#### Linux 对非技术人员/非程序员来说是开放的(且易于接触)
我已经足够老了,记得当年 Ubuntu Linux 免费向世界上的任何人寄送安装光盘。那时,我遇到了一系列我无法解决的硬件问题,而且在我主要工具(MS Word)的高质量替代品方面非常匮乏。
到了 2020 年代,Linux 已经变得截然不同。安装过程非常简单,帮助文档非常详尽,还有 Linux 的 YouTube 资源,使过渡变得更加顺利,我所有的硬件都完美地工作,我准备彻底放弃 MS Word。
#### Git 是作家的(秘密)好朋友
自从我第一次理解了 Git 的含义和它的用途以来,我就一直这样认为:不向作家教授 Git 是一种罪过。Linus Torvalds 无意间创造了作家的好朋友。
是的,我知道当 Git 无法正常工作时会有多么令人沮丧,但是将软件工程师处理大型代码库、多人贡献的复杂 Git 工作流程剥离后,你会发现它核心的功能似乎刚好为数字时代的作家量身定制。
与此同时,我和我的合作作者面临两个问题。由于我们位于不同的大陆,我们需要一个满足以下条件的系统:
以一种不会将文件弄得一团糟而无法阅读的方式追踪更改(这样在 MS Word、谷歌文档上进行协作会非常痛苦);
以行业标准格式格式化剧本,而无需购买 Final Draft 等剧本撰写软件。
Git 和 GitHub 满足了第一个要求。而专门为剧本撰写创建的标记语法 [Fountain](https://fountain.io/) 解决了第二个问题。
#### Linux 和好莱坞
这可能会让很多人感到惊讶,但自上世纪 90 年代以来,Linux 已经牢固地融入了好莱坞的后期制作工作流程中。
早在 1998 年,《泰坦尼克号》这样具有标志性的电影的后期制作中,Linux 就扮演了至关重要的角色。BlackMagic 的 <ruby> <a href="https://www.blackmagicdesign.com/products/davinciresolve"> 达芬奇调色软件 </a> <rt> aVinci Resolve </rt></ruby> 最初是一款在基于 CentOS 或 RHEL 的系统上运行的首选色彩分级工具。
如今,达芬奇调色软件已成为一款功能完备的编辑器,是电影制片人和 YouTuber 们的首选工具。对我们 Linux 用户而言,该公司继续提供其软件的免费版本以供 Fedora 和基于 Debian 的系统使用。对于 Arch 用户,AUR 中也提供了一个达芬奇调色软件版本,尽管我没有亲自测试过。具体效果可能因人而异。
### 如何在大部分 FOSS 技术的支持下完成我的电影
让我分享一下我的电影制作工作流程。
#### 前期制作
##### 影片概念说明
我使用 NeoVim 和 Org 模式语法编写了 [影片概念说明](https://www.studiobinder.com/blog/what-is-a-film-treatment-definition/#:~:text=A%20film%20treatment%20is%20a,or%20even%20purchasing%20your%20idea.)。Org 模式对于编写类似报告的文档结构非常有用。[Vim-org](https://www.vim.org/scripts/script.php?script_id=3642) 能够轻松将文档导出为 PDF、LaTeX、HTML 和 doc 格式。我喜欢将我的文档保存为开放文件标准,以确保在各种设备间的可移植性,所以我选择了 PDF 格式。下面的截图是电影拍摄前的最终影片概念说明:

##### 剧本
我与合作作者商定了一种简单的工作流程。我在一天的时间里向她介绍了 VSCode、Fountain、Git 和 GitHub 的基本知识,之后她就得心应手了。此后的合作过程基本上是无缝的,基于 Git 的工作流程对我们两个人来说几乎成为自然而然的事情。请记住,我们两个人都不具备软件背景。下面的图片显示了 NeoVim 上正在编辑的 Fountain 剧本文件,而右侧的屏幕上是 [Zathura PDF 阅读器](https://pwmt.org/projects/zathura/) 即时渲染的剧本。

#### 制作
##### 每日镜头回顾
我们在锡哈拉加雨林进行了主要拍摄,这是该国最古老的森林之一。我们在那里待了一个星期。我带上了我的日常使用机(一台运行 Ubuntu Studio 20.04 的 Dell XPS 9750),在一天的拍摄结束后使用达芬奇调色软件来回顾当天的镜头。
##### 使用 Rsync 进行备份
负责备份每日镜头素材的工作人员会在主硬盘上进行备份,然后在其他外部存储设备上进行二次备份。由于我也带了我的 ThinkPad 服务器,我使用 [Rsync](https://www.wikiwand.com/en/Rsync) 自动化进行备份。
#### 后期制作
##### 编辑
尽管我的 XPS 笔记本内部配置足以处理这个项目,但我并不打算在上面进行影片编辑。最初,我是在工作室的一台运行达芬奇调色软件的 Windows 机器上进行编辑的。不幸的是,2022 年第二季度,斯里兰卡经济陷入了自由落体,该国已经无法偿还债务。燃料短缺和停电使得我无法前往工作室进行编辑工作,增加了我的困扰。
就在这时,我的调色师建议我们将项目转移到我的笔记本电脑上,这样我就可以在家工作。他多年来一直在 CentOS 上运行达芬奇调色软件,他认为在 Ubuntu 机器上做同样的工作没有问题。为了确保我可以进行快速编辑,他将代理素材转码为 [ProRes 422](https://support.apple.com/en-us/HT202410) 720p。
一旦我们克服了这些小问题,编辑本身就是非常稳定和无压力的操作。完成后,我的电影制作人朋友们都在问我一台运行 Linux 的笔记本电脑是如何处理这个项目的。
### 结论:我们到达目的地了吗?
在某个时刻,每个最近转向 Linux 的人都会参与到“Linux 桌面之年”的辩论中。
三年过去了,我的观念发生了变化:从理想主义(大约在 2030 年左右),到现实主义(永远不会发生),再到我目前的立场:《Linux 桌面之年》掌握在“技术探索者”的手中。
“技术探索者”被技术所吸引,有时超出主流的范畴。
而作为对社交媒体技术和大型科技公司感到幻灭的人,我正好处于尝试 Linux 桌面的理想状态。
如果以我的经验为例,大多数精通技术的人都可以实现 “Linux 桌面之年”。通过使用其他自由开源软件工具(如 Git、Fountain、Markdown、LaTeX、Org 模式和(Neo)Vim),我相信像我这样的小说家和电影制片人类型的人有足够的理由转向 Linux。
当然,如果 Black Magic 没有推出达芬奇调色软件的 Linux 版本,我就不能说这番话,但幸运的是,他们不是 Adobe 或微软。
要让人们接受 Linux 桌面,关键是专有软件的开发者们也要加入进来,承认 Linux 领域有一些用户需要与 Windows 和 Mac 领域同样的工具。如果这种情况发生,我们可能会看到 “Linux 桌面” 从梗成为现实。
>
> ? 由斯里兰卡的小说家/电影制片人 [Theena Kumaragurunathan](https://theena.net/) 撰写。他的首部小说已在 [亚马逊 Kindle](https://www.amazon.com/First-Utterance-Miragian-Cycles-Book-ebook/dp/B08MBX8GRZ) 上发售,并且他的第一部长片正在筹备发行中。
>
>
>
*(题图:MJ/1bace6a9-5d11-4cae-921c-18a850b7bff1)*
---
via: <https://news.itsfoss.com/filiming-with-foss-tech/>
作者:[Theena Kumaragurunathan](https://news.itsfoss.com/author/team/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I fell in love in 2020. The timing couldn't have been more awkward.
The WHO had declared that the first pandemic of our lifetimes was upon us. I had just taken a sabbatical from work, intending to spend the time finishing a Master's, and the follow-up to my debut novel * First Utterance*.
But writers are a moody bunch. Sometimes our focus is razor sharp and sustained over weeks. Sometimes, we have the attention span of goldfish.
I was in goldfish mode.
I needed something to escape my daily grind: wake up, write for a few hours, get to study, finish assignments for classes, repeat.
Someone, somewhere on the internet mentioned that the pandemic offered the best opportunity for people to experiment with Linux for their daily computing.
Immediately, the goldfish brain's attention was grabbed.
There was a good reason for this:
20 years earlier, I had forgone film school for a Bachelor's in Computer Science.
To my surprise, I found myself enjoying most of the course (until we arrived at *Introduction to Programming with Java*, causing me to drop out of my undergrad, but that's a whole other story); *computer architecture*, *networking* and *system administration* modules had really piqued my interest, and I found myself at the school lab spending more time on the machines that had Linux installed on them.
The point is there was history between Linux and I.
And in 2020, the timing was just right.
## Nerdery in the Time of Corona
In the years after I dropped out of my Computer Science undergrad, I had ventured well away from the many curiosities that computing kindled within me.
In lieu of film school, I became a novelist.
I moved from IT to Marketing, and spent the better part of 20 years writing ad copy for print, TV, radio, and digital platforms.
I started my own advertising agency.
In those 20 years, we saw [social media become synonymous with the internet](https://www.cambridge.org/core/journals/law-and-social-inquiry/article/abs/is-facebook-the-internet-ethnographic-perspectives-on-open-internet-governance-in-brazil/CF7526E09C0E05DCD587DC8E0E01D9C1?ref=news.itsfoss.com).
By 2020, I had decided to leave advertising for good, and a large portion of that was how disillusioned I had become with technology, particularly social media, and particularly the callous ways in which social media was harming us, as individuals and societies.
And though I know social media isn't the internet, it was still very hard to uncouple it in my mind. Being in advertising, I also felt like I had played a small role in making social media damningly ubiquitous.
*My Year of Linux Desktop kept me sane through the pandemic.*
## 2022: My First Feature Film
By the time 2022 rolled over, I was daily driving Linux on my laptop. I also had bought myself an old ThinkPad T420, installed Ubuntu Server on it, and began running instances of Plex and NextCloud.
I was comfortable on Linux, having moved almost all [my writing work from MS Word and Cloud-based storage to Vim and GitHub](https://news.itsfoss.com/configuring-vim-writing/).
And that's when I got the call from a producer, greenlighting my first film.
At this point, I had a decision to make. I would be cutting dailies while on set which meant I would need an industry standard Non-Linear Editor (NLE). I was comfortable on Adobe Premiere but knew there was no Linux port. I had already tried Kden Live and a couple of other FOSS alternatives, including Blender (which has a built-in NLE) but was left unsatisfied.
More immediately, I was worried that my writing workflow - which had become completely (Neo)Vim and Git-centric - would be too alien for my co-writer.
## Hello, Windows?!
At this point, I had to ask myself if Linux was ready for my film work ahead. To answer that, I reminded myself of the following:
### Linux is Open (and Accessible) for Non-Tech/Non-Programmers
I am old enough to have tried Ubuntu Linux way back when they were shipping installation CDs to anyone in the world, for free. Back then, I had a host of hardware problems that I couldn't resolve, and a serious dearth in quality alternatives for my main tool: MS Word.
The Linux of 2020s was vastly different. Installation was a breeze, the help documentation was incredibly exhaustive, Linux YouTube existed making the transition all the more seamless, all my hardware worked flawlessly, and I was ready to abandon MS Word for good.
### Git is A Writer's (Secret) Best Friend
I have thought this countless times since I first understood what Git was and what it was trying to do: the fact that Git isn't taught to writers is *criminal*. Linus Torvald inadvertently created a writer's best friend.
Yes, I am aware of how frustrating Git can be when it isn't working, but strip away all that complexity in Git workflows that software engineers deal with when grappling with large code bases that have contributions from multiple individuals, and you are left with a core functionality that is seemingly custom-built for writers in the digital age.
Meanwhile, my co-writer and I were faced with two issues. Being in two different continents, we needed a system that checked the following boxes:
Tracked changes in a way that didn't make the file an unreadable mess (which makes collaboration on MS Word, Google Docs an absolute pain)
Format the script in industry standard format without the need to purchase screenwriting software such as Final Draft.
Git and GitHub fit the first requirement. [Fountain](https://fountain.io/?ref=news.itsfoss.com), a markup syntax created specifically for screenwriting, answered the second question.
### Linux and Hollywood
It might surprise a lot of people, but Linux has firmly embedded itself into Hollywood post-production workflows since the 90s.
As far back as 1998, Linux was a critical part of the post-production work in as iconic a film as [Titanic](https://www.linuxjournal.com/article/2494?ref=news.itsfoss.com). [BlackMagic's DaVinci Resolve](https://www.blackmagicdesign.com/products/davinciresolve?ref=news.itsfoss.com) began its life as a colour-grading tool of choice, running on CentOS or RHEL-based systems.
Today, DaVinci Resolve is a fully-fledged editor and is the tool of choice for film-makers and YouTubers. Luckily for us Linux users, the company has continued to make its free version of the software available for Fedora and Debian-based systems. Arch users: the AUR has a version of DaVinci Resolve available as well, though I haven't tested it. Your mileage may vary.
## How I Made My Feature Film Using Mostly FOSS Tech
Let me share my filmmaking workflow
### Pre-Production
#### Film Treatment
I wrote the [film treatment](https://www.studiobinder.com/blog/what-is-a-film-treatment-definition/?ref=news.itsfoss.com#:~:text=A%20film%20treatment%20is%20a,or%20even%20purchasing%20your%20idea.) using NeoVim using [Org mode](https://orgmode.org/?ref=news.itsfoss.com) syntax. Orgmode is great for writing report-like document structures. [Vim-org](https://www.vim.org/scripts/script.php?script_id=3642&ref=news.itsfoss.com) allows for easy export to PDF, LaTeX, HTML and doc formats. I like to keep my documentation in open file standards, ensuring portability across devices so I chose PDF. The screenshot below is the final film treat for the film before principal photography began:
#### Script
My co-writer and I worked settled on a simple workflow. I gave her a very basic introduction to VSCode, Fountain, Git and GitHub over the course of a day, after which she was up and running. The collaborative process there after was mostly seamless, with the Git based workflow becoming almost natural for both of us. Bear in mind, neither of us are from a software background. The image below is the script in fountain file being edited on NeoVim, while the right screen is [Zathura PDF reader](https://pwmt.org/projects/zathura/?ref=news.itsfoss.com) live rendering the script.
### Production
#### Reviewing Dailies
Principal photograph was in Sinharaja Rain Forest, one of the most ancient forsests in the country. We were to be there for a week. I took my daily driver (a Dell XPS 9750 running Ubuntu Studio 20.04) to the set and used DaVinci Resolve to review dailies after the end of a day's shoot.
#### Backup using Rsync
The crew responsible for backing up daily footage would back up the material on a master hard disk, before making secondary backups on other external storage. Since I had taken my ThinkPad server along as well, I used that to automate the backing up using [Rsync](https://www.wikiwand.com/en/Rsync?ref=news.itsfoss.com).
### Post-Production
#### Editing
I wasn't intending to edit the film on my XPS laptop though it certainly had the internals to handle the project. Originally, I was editing in a studio on a Windows machine running DaVinci Resolve. Unfortunately, the second quarter of 2022 saw Sri Lanka's economy free-falling after the country had defaulted on its debt payments. Adding to the misery, both fuel shortages and power cuts meant there was no way I could visit the studio to do the work.
It was at this point that my color-gradist suggested that we move the project to my laptop so I could work from home. He had worked on DaVinci Resolve running on CentOS for years and saw no issue doing the same on an Ubuntu machine. To make extra sure, he transcoded proxy footage to [ProRes 422](https://support.apple.com/en-us/HT202410?ref=news.itsfoss.com) 720p to ensure that I could edit at speed.
Once we overcame these little hurdles, the editing itself was a very stable and stress-free operation. Once I finished, I had questions from my filmmaker friends on how a laptop running Linux handled the project. The below image is a screenshot running neofetch on that machine.
## Conclusion: Are We There Yet?
At some point, every recent Linux convert will join the * Year of Linux Desktop* debate.
Three years into my journey, my thoughts on that have changed: from the idealistic (*sometime around the 2030s*), to the realist (*It's never happening*), to my current position: *The Year of Linux Desktop* is in the hands of the *Tech-curious*.
The *Tech-curious* are drawn to technology, sometimes outside the umbrella of the mainstream.
And I, disillusioned from social media technology and giant tech corporations in general, was in the perfect mindspace for experimenting with Linux desktop.
If my experience is anything to go by, the Year of Linux Desktop is within grasp for most tech-savvy people. With the addition of other FOSS tools like Git, Fountain, Markdown, LaTeX, Org Mode, and (Neo)Vim, I believe there is a good case for novelist-filmmakers types like myself to make the jump.
Of course, I wouldn't have been able to say this if Black Magic hadn't made a Linux port of DaVinci Resolve, but fortunately, they aren't Adobe or Microsoft.
For people to embrace Linux Desktop, it is critical that makers of proprietary software also buy-in, acknowledging that there are users in the Linux space who require the same tools as their counterparts in the Windows and Mac lands. If and when that happens, we might just see Linux Desktop graduate from meme to reality.
[Theena Kumaragurunathan](https://theena.net/?ref=news.itsfoss.com), a novelist / filmmaker based in Sri Lanka. His debut novel is out on
[Amazon kindle](https://www.amazon.com/First-Utterance-Miragian-Cycles-Book-ebook/dp/B08MBX8GRZ?ref=news.itsfoss.com)and his first feature film is currently is finalizing distribution.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,043 | 如何在 Kubernetes 集群中设置动态 NFS 配置 | https://www.linuxtechi.com/dynamic-nfs-provisioning-kubernetes/ | 2023-07-28T22:29:00 | [
"NFS",
"k8s"
] | https://linux.cn/article-16043-1.html | 
>
> 在这篇文章中,我们将向你展示如何在 Kubernetes(k8s)集群中设置动态 NFS 配置。
>
>
>
Kubernetes 中的动态 NFS 存储配置允许你按需自动为 Kubernetes 应用配置和管理 NFS(网络文件系统)卷。它允许创建持久卷(PV)和持久卷声明(PVC),而无需手动干预或预配置存储。
NFS 配置程序负责动态创建 PV 并将其绑定到 PVC。它与 NFS 服务器交互,为每个 PVC 创建目录或卷。
### 先决条件
* 预装 Kubernetes 集群
* 具有 Kubernetes 集群管理员权限的普通用户
* 互联网连接
事不宜迟,让我们深入探讨步骤:
### 步骤 1、准备 NFS 服务器
就我而言,我将在 Kubernetes 主节点(Ubuntu 22.04)上安装 NFS 服务器。登录主节点并运行以下命令:
```
$ sudo apt update
$ sudo apt install nfs-kernel-server -y
```
创建以下文件夹并使用 NFS 共享它:
```
$ sudo mkdir /opt/dynamic-storage
$ sudo chown -R nobody:nogroup /opt/dynamic-storage
$ sudo chmod 777 /opt/dynamic-storage
```
在 `/etc/exports` 文件中添加以下条目:
```
$ sudo vi /etc/exports
/opt/dynamic-storage 192.168.1.0/24(rw,sync,no_subtree_check)
```
保存并关闭文件。
注意:不要忘记更改导出文件中适合你的部署的网络。
要使上述更改生效,请运行:
```
$ sudo exportfs -a
$ sudo systemctl restart nfs-kernel-server
$ sudo systemctl status nfs-kernel-server
```

在工作节点上,使用以下 `apt` 命令安装 `nfs-common` 包。
```
$ sudo apt install nfs-common -y
```
### 步骤 2、安装和配置 NFS 客户端配置程序
NFS 子目录外部配置程序在 Kubernetes 集群中部署 NFS 客户端配置程序。配置程序负责动态创建和管理由 NFS 存储支持的持久卷(PV)和持久卷声明(PVC)。
因此,要安装 NFS 子目录外部配置程序,首先使用以下命令集安装 `helm`:
```
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
$ chmod 700 get_helm.sh
$ ./get_helm.sh
```
运行以下命令来启用 `helm` 仓库:
```
$ helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner
```
使用以下 `helm` 命令部署配置程序:
```
$ helm install -n nfs-provisioning --create-namespace nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner --set nfs.server=192.168.1.139 --set nfs.path=/opt/dynamic-storage
```

上面的 `helm` 命令将自动创建 `nfs-provisioning` 命名空间,并安装 NFS 配置程序的容器荚/部署、名称为 `nfs-client` 的存储类,并将创建所需的 rbac。
```
$ kubectl get all -n nfs-provisioning
$ kubectl get sc -n nfs-provisioning
```

完美,上面的输出确认了配置程序容器荚和存储类已成功创建。
### 步骤 3、创建持久卷声明(PVC)
让我们创建 PVC 来为你的容器荚或部署请求存储。PVC 将从存储类 `nfs-client` 请求特定数量的存储:
```
$ vi demo-pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: demo-claim
namespace: nfs-provisioning
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Mi
```
保存并关闭文件。

运行以下 `kubectl` 命令以使用上面创建的 YML 文件创建 PVC:
```
$ kubectl create -f demo-pvc.yml
```
验证 PVC 和 PV 是否创建:
```
$ kubectl get pv,pvc -n nfs-provisioning
```

太好了,上面的输出表明 PV 和 PVC 创建成功。
### 步骤 4、测试并验证动态 NFS 配置
为了测试和验证动态 NFS 配置,请使用以下 YML 文件启动测试容器荚:
```
$ vi test-pod.yml
kind: Pod
apiVersion: v1
metadata:
name: test-pod
namespace: nfs-provisioning
spec:
containers:
- name: test-pod
image: busybox:latest
command:
- "/bin/sh"
args:
- "-c"
- "touch /mnt/SUCCESS && sleep 600"
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: demo-claim
```

使用以下 `kubectl` 命令部署容器荚:
```
$ kubectl create -f test-pod.yml
```
验证 `test-pod` 的状态:
```
$ kubectl get pods -n nfs-provisioning
```

登录到容器荚并验证 NFS 卷是否已安装。
```
$ kubectl exec -it test-pod -n nfs-provisioning /bin/sh
```

太棒了,上面容器荚的输出确认了动态 NFS 卷已安装且可访问。
最后删除容器荚和 PVC,查看 PV 是否自动删除。
```
$ kubectl delete -f test-pod.yml
$ kubectl delete -f demo-pvc.yml
$ kubectl get pv,pvc -n nfs-provisioning
```

这就是这篇文章的全部内容,希望对你有所帮助。请随时在下面的评论部分发表你的疑问和反馈。
*(题图:MJ/75dae36f-ff68-4c63-81e8-281e2c239356)*
---
via: <https://www.linuxtechi.com/dynamic-nfs-provisioning-kubernetes/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this post, we will show you how to setup dynamic nfs provisioning in Kubernetes (k8s) cluster.
Dynamic NFS storage provisioning in Kubernetes allows you to automatically provision and manage NFS (Network File System) volumes for your Kubernetes applications on-demand. It enables the creation of persistent volumes (PVs) and persistent volume claims (PVCs) without requiring manual intervention or pre-provisioned storage.
The NFS provisioner is responsible for dynamically creating PVs and binding them to PVCs. It interacts with the NFS server to create directories or volumes for each PVC.
#### Prerequisites
- Pre-installed Kubernetes Cluster
- A Regular user which has admin rights on Kubernetes cluster
- Internet Connectivity
Without any further delay, let’s deep dive into steps
## Step1) Prepare the NFS Server
In my case, I am going to install NFS server on my Kubernetes master node (Ubuntu 22.04). Login to master node and run following commands,
$ sudo apt update $ sudo apt install nfs-kernel-server -y
Create the following folder and share it using nfs,
$ sudo mkdir /opt/dynamic-storage $ sudo chown -R nobody:nogroup /opt/dynamic-storage $ sudo chmod 2770 /opt/dynamic-storage
Add the following entries in /etc/exports file
$ sudo vi /etc/exports /opt/dynamic-storage 192.168.1.0/24(rw,sync,no_subtree_check)
Save and close the file.
Note: Don’t forget to change network in exports file that suits to your deployment.
To make above changes into the effect, run
$ sudo exportfs -a $ sudo systemctl restart nfs-kernel-server $ sudo systemctl status nfs-kernel-server
On the worker nodes, install nfs-common package using following [apt command](https://www.linuxtechi.com/apt-command-ubuntu-debian-linux/).
$ sudo apt install nfs-common -y
## Step 2) Install and Configure NFS Client Provisioner
[NFS subdir external provisioner](https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner) deploy the NFS client provisioner in your Kubernetes cluster. The provisioner is responsible for dynamically creating and managing Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) backed by NFS storage.
So, to install NFS subdir external provisioner, first install helm using following set of commands,
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 $ chmod 700 get_helm.sh $ ./get_helm.sh
Enable the helm repo by running following beneath command,
$ helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner
Deploy provisioner using following helm command
$ helm install -n nfs-provisioning --create-namespace nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner --set nfs.server=192.168.1.139 --set nfs.path=/opt/dynamic-storage
Above helm command will automatically create nfs-provisioning namespace and will install nfs provisioner pod/deployment, storage class with name (nfs-client) and will created the required rbac.
$ kubectl get all -n nfs-provisioning $ kubectl get sc -n nfs-provisioning
Perfect, output above confirms that provisioner pod and storage class is created successfully.
## Step 3) Create Persistent Volume Claims (PVCs)
Let’s a create PVC to request storage for your pod or deployment. PVC will request for a specific amount of storage from a StorageClass (nfs-client).
$ vi demo-pvc.yml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: demo-claim namespace: nfs-provisioning spec: storageClassName: nfs-client accessModes: - ReadWriteMany resources: requests: storage: 10Mi
save & close the file.
Run following kubectl command to create pvc using above created yml file,
$ kubectl create -f demo-pvc.yml
Verify whether PVC and PV are created or not,
$ kubectl get pv,pvc -n nfs-provisioning
Great, above output shows that pv and pvc are created successfully.
## Step 4) Test and Verify Dynamic NFS Provisioning
In order to test and verify dynamic nfs provisioning, spin up a test pod using following yml file,
$ vi test-pod.yml kind: Pod apiVersion: v1 metadata: name: test-pod namespace: nfs-provisioning spec: containers: - name: test-pod image: busybox:latest command: - "/bin/sh" args: - "-c" - "touch /mnt/SUCCESS && sleep 600" volumeMounts: - name: nfs-pvc mountPath: "/mnt" restartPolicy: "Never" volumes: - name: nfs-pvc persistentVolumeClaim: claimName: demo-claim
Deploy the pod using following kubectl command,
$ kubectl create -f test-pod.yml
Verify the status of test-pod,
$ kubectl get pods -n nfs-provisioning
Login to the pod and verify that nfs volume is mounted or not.
$ kubectl exec -it test-pod -n nfs-provisioning /bin/sh
Great, above output from the pod confirms that dynamic NFS volume is mounted and accessible.
In the last, delete the pod and PVC and check whether pv is deleted automatically or not.
$ kubectl delete -f test-pod.yml $ kubectl delete -f demo-pvc.yml $ kubectl get pv,pvc -n nfs-provisioning
That’s all from this post, I hope you have found it informative. Feel free to post your queries and feedback in below comments section.
RaScaThat’s a great how-to, many thanks!
Just would like to add a consideration about permissions. The NFS directory that we’re using here to share the content, so /opt/dynamic-storage, gets the number of the beast (at least in Linux): 777.
This can’t possibly be right. Those kind of permissions are too wide and a security risk, it can simply be avoided by using something like:
> sudo chown -R nobody:nogroup /storage
> sudo chmod 2770 /storage
The setgid does the trick here, and you don’t have a directory opened for rwx to the world.
With that said, the resources that get created by the provisioner are in any case 777:
> sudo ls -la /storage/
total 12
drwxrws— 3 nobody nogroup 4096 giu 9 12:24 .
drwxr-xr-x 22 root root 4096 giu 9 12:20 ..
drwxrwxrwx 2 nobody nogroup 4096 giu 9 12:25 nfs-provisioning-demo-claim-pvc-3483691c-492f-4a84-875d-897efe855978
But that’s how the provisioner work, and so should be explored there (the project doesn’t seem to be maintained anymore ‘https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner/issues/286’ ).
Great work, btw! |
16,044 | 专为技术写作人员提供的 7 条 Git 技巧 | https://opensource.com/article/22/11/git-tips-technical-writers | 2023-07-29T08:21:20 | [
"Git"
] | /article-16044-1.html | 
>
> 跟随这个演示来了解我如何使用 Git 为 Foreman 编写文档。
>
>
>
作为 [ATIX](https://atix.de/en/) 的技术作家,我的任务包括为 [Foreman](https://opensource.com/article/17/8/system-management-foreman) 创建和维护存放在 [github.com/theforeman/foreman-documentation](https://github.com/theforeman/foreman-documentation) 的文档。Git 帮助我跟踪内容的版本,并与开源社区进行协作。它是我存储工作成果、共享和讨论改进的重要工具。我主要使用的工具包括浏览器、用 OpenSSH 连接 Foreman 实例、用 [Vim](https://opensource.com/resources/what-vim) 编辑源文件,以及使用 Git 进行版本控制。
本文重点介绍在开始使用 Git 和为 Foreman 文档做贡献时经常遇到的挑战。适用于中级 Git 用户。
### 先决条件
* 你已在系统上安装和配置了 Git。你至少需要设置用户名和电子邮件地址。
* 你在 [github.com](https://github.com/) 上拥有一个帐户。GitHub 本身并不是一个开源项目,但它是许多开源 Git 存储库的托管站点(包括 Foreman 的文档)。
* 你已将 [foreman-documentation](https://github.com/theforeman/foreman-documentation) 存储库复刻到你自己的账户或组织(例如,`github.com/<My_User_Account>/foreman-documentation`,这里 `<My_User_Account>` 是你的 GitHub 用户名)。有关更多信息,请参阅 Kedar Vijay Kulkarni 的 [Kedar Vijay Kulkarni 的 Git 逐步指南](https://opensource.com/article/18/1/step-step-guide-git)。
* 你已将你的 SSH 公钥添加到 GitHub。这是将你的更改推送到 GitHub 所必需的。有关更多信息,请参阅 Nicole C. Baratta 的《[GitHub 简单指引](https://opensource.com/life/15/11/short-introduction-github)》。
### 对 Foreman 文档做出贡献
Foreman 是一个开源项目,依靠社区的贡献而发展壮大。该项目欢迎所有人的参与,并且只有一些要求才能做出有意义的贡献。这些要求和惯例在 [README.md](https://github.com/theforeman/foreman-documentation/blob/master/guides/README.md#contribution-guidelines) 和 [CONTRIBUTING.md](https://github.com/theforeman/foreman-documentation/blob/master/CONTRIBUTING.md#contributing-to-foreman-documentation) 文件中有详细记录。
以下是在处理 Foreman 文档时最常见的一些任务。
#### 我想开始贡献 Foreman 文档
1、从 [github.com](http://github.com) 克隆存储库:
```
$ git clone [email protected]:theforeman/foreman-documentation.git
$ cd foreman-documentation/
```
2、重命名远程存储库:
```
$ git remote rename origin upstream
```
3、可选:确保你的本地主分支跟踪 theforeman 组织的 `foreman-documentation` 存储库的 `master` 分支:
```
$ git status
```
这将自动将你置于默认分支(本例中为 `master`)的最新提交上。
4、如果你的账户或组织中尚未有该存储库的 <ruby> 复刻 <rt> Fork </rt></ruby>,请创建一个。前往 [github.com/theforeman/foreman-documentation](https://github.com/theforeman/foreman-documentation) 并点击 “<ruby> 复刻 <rt> Fork </rt></ruby>” 按钮。
5、将你的复刻添加到你的存储库中:
```
$ git remote add github [email protected]:<My_User_Account>/foreman-documentation.git
```
你的本地存储库现在有两个远程存储库:`upstream` 和 `github`。
#### 我想扩展 Foreman 文档
对于简单的更改,比如修正拼写错误,你可以直接创建一个拉取请求(PR)。
1、创建一个分支,例如 `fix_spelling`。`git switch` 命令用于切换当前所在的分支,`-c` 参数用于创建分支:
```
$ git switch -c fix_spelling
```
2、进行你的更改。
3、添加你的更改并进行提交:
```
$ git add guides/common/modules/abc.adoc
$ git commit -m "Fix spelling of existing"
```
良好的 Git 提交消息的重要性无需再强调。提交消息告诉贡献者你做了哪些工作,因为它与代码库的其余部分一起保存,所以它在查看代码时起到历史注释的作用,帮助了解代码的演化过程。有关优秀的 Git 提交消息的更多信息,请参阅由 cbeams 撰写的 《[创建完美的 Git 提交信息的 7 条规则](https://cbea.ms/git-commit/#seven-rules)》。
4、可选但建议的操作:查看并验证与默认分支的差异。`foreman-documentation` 的默认分支称为 `master`,但其他项目可能有不同的命名(例如 `main`、`dev` 或 `devel`)。
```
$ git diff master
```
5、将分支推送到 GitHub。这将发布你的更改到你的代码库副本:
```
$ git push --set-upstream github fix_spelling
```
6、点击终端中 Git 提供的链接来创建一个拉取请求(PR):
```
remote: Create a pull request for 'fix_spelling' on Github by visiting:
remote: https://github.com/_My_User_Account_/foreman-documentation/pull/new/fix_spelling
```
7、在解释中说明社区*为什么*应该接受你的更改。对于修正拼写错误等简单 PR,这并不是必需的,但对于重大更改则很重要。
#### 我想将我的分支变基到 master
1、确保你的本地 `master` 分支跟踪的是 [github.com/theforeman/foreman-documentation](https://github.com/theforeman/foreman-documentation) 的 `master` 分支,而不是你自己命名空间下的 `foreman-documentation`:
```
$ git switch master
```
此时应该显示 `Your branch is up to date with 'upstream/master'`,其中 `upstream` 是指向 `github.com/theforeman/foreman-documentation` 的远程存储库的名称。你可以通过运行 `git remote -v` 来查看远程存储库设置情况。
2、从远程获取可能的更改。`git fetch` 命令会从远程下载被跟踪的分支,并且使用 `--all` 选项可以同时更新所有分支。在使用其他分支时这是必要的。`--prune` 选项会删除对已不存在的分支的引用。
```
$ git fetch --all --prune
```
3、将可能的更改从 `upstream/master` 拉取到你的本地 `master` 分支。`git pull` 命令将跟踪的分支上的提交复制到当前分支。这用于将你的本地 `master` 分支“更新”为远程(在本例中为 GitHub)`master` 分支的最新状态。
```
$ git pull
```
4、将你的分支 <ruby> 变基 <rt> rebase </rt></ruby> 到 `master`。
```
$ git switch my_branch
$ git rebase -i master
```
#### 我在 master 分支上意外地提交了代码
1、创建一个分支来保存你的工作:
```
$ git switch -c my_feature
```
2、切换回 `master` 分支:
```
$ git switch master
```
3、回退 `master` 分支上的最后一次提交:
```
$ git reset --soft HEAD~1
```
4、切换回 `my_feature` 分支并继续工作:
```
$ git switch my_feature
```
#### 我想修改我的提交消息
1、如果你的分支只有一次提交,可以使用 `git amend` 来修改你的最后一次提交:
```
$ git commit --amend
```
这假设你没有将其他文件添加到暂存区(即,没有运行过 `git add My_File`,并且没有进行提交)。
2、使用 `--force` 选项将你的 “更改” 推送到 GitHub,因为 Git 提交消息是你现有提交的一部分,所以你正在更改分支上的历史记录:
```
$ git push --force
```
#### 我想重新整理单个分支上的多个更改
1、可选但强烈推荐:从 GitHub 获取更改。
```
$ git switch master
$ git fetch
$ git pull
```
这确保你将其他更改按照它们被合并到 `master` 中的顺序直接合并到你的分支中。
2、若要重新整理你的工作,请对你的分支进行变基并根据需要进行更改。对于将分支变基到 `master`,这意味着你需要更改你的分支上第一个提交的父提交:
```
$ git rebase --interactive master
```
使用你喜欢的编辑器打开变基交互界面,将第一个单词 `pick` 替换为你要修改的提交。
* 使用 `e` 来对你的提交进行实际更改。这会中断你的变基操作!
* 使用 `f` 将一个提交与其父提交合并。
* 使用 `d` 完全删除一个提交。
* 移动行以改变你更改的顺序。
成功进行变基后,你自己的提交将位于 `master` 上最后一个提交的顶部。
#### 我想从其他分支复制一个提交
1、从稳定分支(例如名为 `3.3` 的分支)获取提交的 ID,请使用 `-n` 选项限制提交数量:
```
$ git log -n 5 3.3
```
2、通过挑选提交来复制更改到你的分支。`-x` 选项将提交的 ID 添加到你的提交消息中。这仅建议在从稳定分支挑选提交时使用:
```
$ git switch My_Branch
$ git cherry-pick -x Commit_ID
```
### 更多技巧
在 ATIX,我们运行一个 [GitLab](https://about.gitlab.com/) 实例,用于内部共享代码、协作以及自动化测试和构建。对于围绕 Foreman 生态系统的开源社区,我们依赖于 GitHub。
我建议你始终将名为 `origin` 的远程指向你的*内部的*版本控制系统。这样做可以防止在纯粹凭记忆进行 `git push` 时向外部服务泄露信息。
此外,我建议使用固定的命名方案来命名远程。我总是将指向自己的 GitLab 实例的远程命名为 `origin`,将指向开源项目的远程命名为 `upstream`,将指向我在 Github 上的复刻的远程命名为 `github`。
对于 `foreman-documentation`,该存储库具有相对较平的历史记录。当处理更复杂结构时,我倾向于以非常可视化的方式思考 Git 存储库,其中节点(提交)指向线上的节点(分支),这些分支可以交织在一起。图形化工具如 `gitk` 或 [Git Cola](https://opensource.com/article/20/3/git-cola) 可以帮助可视化你的 Git 历史记录。一旦你完全掌握了 Git 的工作原理,如果你更喜欢命令行,可以使用别名。
在进行具有大量预期合并冲突的大型变基之前,我建议创建一个“备份”分支,以便你可以快速查看差异。请注意,要永久删除提交是相当困难的,因此在进行重大更改之前,请在本地 Git 存储库中进行测试。
### Git 对技术文档编写者的帮助
Git 对技术文档编写者来说是一个巨大的帮助。不仅可以使用 Git 对文档进行版本控制,还可以与他人积极地进行协作。
*(题图:MJ/1fb1dd43-e460-4e76-9ff6-b6ef76570f7e)*
---
via: <https://opensource.com/article/22/11/git-tips-technical-writers>
作者:[Maximilian Kolb](https://opensource.com/users/kolb) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
16,046 | 使用开源工具来举办线上大会 | https://opensource.com/article/23/4/open-source-tools-virtual-conference | 2023-07-30T07:38:00 | [
"线上大会"
] | https://linux.cn/article-16046-1.html | 
>
> 下面是使用开源工具来举办一场线上活动的方法。
>
>
>
在 2023 年 1 月举办了首届 <ruby> <a href="http://creativefreedomsummit.com/"> 创意自由峰会 </a> <rt> Creative Freedom Summit </rt></ruby> 后,[Fedora 设计团队](https://fedoraproject.org/wiki/Design) 发现使用开源工具来举办线上大会非常有效。
在本文中,我将分享一些关于这场大会的背景信息,为什么对我们来说使用开源工具来举办大会很重要,以及为实现这一目标我们的团队所使用的具体工具和配置。我还会谈谈哪些工作做的很好,在以及我们 2024 年下一届峰会中需要改进的地方。
### 创意自由峰会
创意自由峰会是 Marie Nordin 在审查了 [Fedora 用户与贡献者年度大会(Flock)](http://flocktofedora.org/) 的演讲提交后提出的一个想法。在 2022 年 8 月的 Flock 大会上,她收到了大量与开源设计和创意相关的演讲提交,远远超出我们能够接受的数量。由于存在许多关于开源设计的优秀想法,她想知道是否有机会举办一个独立的开源创意大会,专门面向在创作中使用开源工具的创意人士。
Marie 在 2022 年秋季向 Fedora 设计团队提出了这个想法,我们开始筹划这个会议,会议于 2023 年 1 月 17 日至 19 日举行。由于这是我们第一次举办这样一场新的会议,我们决定首先基于 Flock 提交的演讲和我们自己的开源创意人士网络,邀请其中一些人士担任演讲嘉宾。几乎每位我们邀请的演讲者都答应演讲,所以我们没有接受其他人的提交。明年我们需要找到更好的解决办法,所以目前我们还没有开源的投稿管理工具可供介绍。
### 在开源大会中使用开源工具
自从最初的大流行封锁以来,Fedora 的 Flock 大会一直使用 Hopin 虚拟平台在线举办,尽管 Hopin 不是开源的,但对开源工具很友好。Fedora 几年前开始使用 Hopin,它确实提供了专业的会议体验,包括内置的赞助商展位/博览厅、分会场、大厅聊天对话和管理工具。通过 Hopin 来举办创意自由峰会对我们来说可行,因为作为 Fedora 赞助的活动,我们可以使用 Fedora 的 Hopin 环境。再次强调,Hopin 不是开源的。
作为一个长期(约 20 年)的开源贡献者,我可以告诉你,做出这样的决定总是很困难的。如果你的大会专注于开源,使用专有平台来举办你的活动可能会有些奇怪。然而,随着我们社区和活动的规模和复杂性不断增长,开发一个集成的开源会议系统变得更具挑战性。
并不存在正确或错误的答案。在做出这个决定时,你必须权衡很多因素:
* 预算
* 人力资源
* 基础设施
* 技术能力
* 活动的复杂性/正式性/文化
我们没有为这次活动安排任何预算。我们有一支志愿者团队可以投入一些工作时间。我们有 Fedora Matrix 服务器作为可以加入的支持基础设施,并且有一个托管的 WordPress 系统用于网站。我和队友 Madeline Peck 在举办每周的 Fedora 设计团队的 [视频会议](https://opensource.com/article/23/3/video-templates-inkscape) 方面具有一定的技术能力和经验。我们希望这次活动是低调、单一会场和非正式的,所以对于一些小故障或瑕疵我们有一定的容忍度。我们对尝试使用开源工具组合也有很大的热情。
现在你了解了我们在做出这个决定时的一些考虑因素,这可能有助于你在为自己的活动做决策时参考。
### 一个开源会议技术栈
以下是会议技术栈的工作方式。
#### 概述
直播组件:
* **直播流**: 我们通过 PeerTube 频道将主舞台和社交活动进行实时直播。会议参与者可以从我们的 PeerTube 频道观看直播。PeerTube 提供了一些注重隐私的分析功能,可以跟踪直播观众和活动后观看次数。
* **直播舞台 + 社交活动房间**: 我们设有一个用于演讲者和主持人的直播舞台,使用 Jitsi 确保只有有权限的人可以上镜。我们额外设有一个 Jitsi 会议室,用于社交活动,允许任何希望参与社交活动的人上镜。
* **后台**: 我们有一个名为“后台”的 Matrix 频道,用于在活动期间与演讲者、主持人和志愿者协调工作。
* **公告和问答**: 我们通过共享的 Etherpad(后来转移到 [Hackmd.io](http://Hackmd.io))来管理问答和每日议程。
* **集成和集中化的会议体验**: 使用 Matrix 的 Element 客户端,我们将直播视频和 Etherpad 嵌入到一个公共的 Matrix 频道中,供会议使用。我们根据频道中的参与人数来监控整体会议出席情况。我们在整个会议期间设有实时聊天,并从聊天和嵌入的用于问答的 Etherpad 中接受观众提问。
* **会议网站**: 我们有一个由 Ryan Gorley 设计精美的网站,托管在 WordPress 上,网站提供了基本信息和链接,包括如何参加会议、日期/时间和议程。
活动后组件:
* **活动后调查**: 我们使用开源的 LimeSurvey 系统向参会者发送了一份活动后的调查,以了解他们的参会体验。我在这篇文章中使用了该调查的一些数据。
* **活动后的视频编辑和字幕**: 我们的会议没有实时字幕系统,但在我能做到的情况下,我在频道中即时记录了演讲的笔记,与会者对此表示非常感激。活动后,我们使用了 Kdenlive(活动中演讲中展示的工具之一)来编辑视频并生成字幕。
* **活动录像**: PeerTube 会自动将直播录像发布到频道,从而使参会者可以看到他们可能错过的演讲的几乎即时录像。
接下来,我将介绍一些细节。
### 使用 PeerTube 进行直播

我们在创意自由峰会的直播中使用了由 [LinuxRocks.online](https://linuxrocks.online/) 慷慨提供的 [LinuxRocks PeerTube 平台](https://peertube.linuxrocks.online/c/creativefreedom/videos)。PeerTube 是一个自由开源的去中心化视频平台,也是 <ruby> 联邦宇宙 <rt> Fediverse </rt></ruby> 的一部分。
PeerTube 最好的特点之一(我所了解的其他平台所没有的)是,在直播结束后,你会在 PeerTube 上的频道上获得一个几乎即时的重播录像。我们的聊天室用户将这视为该平台的主要优点。如果某位参与者错过了他们非常感兴趣的一个会议,他们可以在该演讲结束后的几分钟内观看到它。这不需要志愿者组织团队进行手动干预、上传或协调,PeerTube 会自动完成。
以下是使用 PeerTube 进行直播的工作方式:你在频道上创建一个新的直播流,它会给你一个直播流 URL 和一个用于授权流媒体的密钥。这个 URL 和密钥可以反复使用。我们进行配置,使得录像会在直播结束后立即发布到我们创建直播流 URL 的频道上。接下来,在开始直播时将 URL 和密钥复制/粘贴到 Jitsi 中。这意味着你不必为会议期间的每个演讲生成新的 URL 和密钥,组织者管理这些将会带来相当大的工作量。相反,我们可以重复使用相同的 URL 和密钥,将其共享在会议组织者之间的共同文档中(我们每个人都有不同的演讲托管时间段)。团队中任何具有该文档访问权限的人都可以启动直播。
#### 如何生成 PeerTube 中的直播流 URL 和密钥
以下部分逐步介绍了如何在 PeerTube 中生成直播流的 URL 和密钥。
##### 1、创建 PeerTube 上的直播视频
登录到 PeerTube,并点击右上角的 “<ruby> 发布 <rt> Publish </rt></ruby>” 按钮:

##### 2、设置选项
点击 “<ruby> 进行直播 <rt> Go live </rt></ruby>” 选项卡(从左数第四个),并设置以下选项:
* <ruby> 频道 <rt> Channel </rt></ruby>:(你希望直播发布在的频道名称)
* <ruby> 隐私 <rt> Privacy </rt></ruby>:公开
* 单选按钮:<ruby> 普通直播 <rt> Normal live </rt></ruby>
然后选择 “<ruby> 进行直播 <rt> Go live </rt></ruby>” 。 (不用担心,你还不会真正开始直播,还有更多数据需要填写。)

##### 3. 基本信息(暂时不要点击更新按钮)
首先,在 <ruby> 基本信息 <rt> Basic info </rt></ruby> 选项卡中填写信息,然后在下一步选择 <ruby> 高级设置 <rt> Advanced settings </rt></ruby> 选项卡。填写直播流的名称、描述、标签、类别、许可证等。在转码复选框启用后记得发布。
这样一来,一旦直播结束,录制视频将自动发布到你的频道上。
##### 4. 高级设置
你可以上传一个“待机”图像,当观看直播流 URL 并等待开始时,该图像会显示在所有人面前。

这是我们在创意自由峰会上使用的待机图像:

##### 5. 在 PeerTube 上开始直播
选择右下角的 “<ruby> 更新 <rt> Update” 按钮。直播流将显示如下,直到你从 Jitsi 开始直播: </rt></ruby>

##### 6. 将直播流的 URL 复制粘贴到 Jitsi
这是 PeerTube 的最后一步。一旦直播流启动,点击视频下方右侧的 “...” 图标:

选择 “<ruby> 显示直播信息 <rt> Display live information </rt></ruby>”。你将看到如下对话框:

你需要复制直播的 RTMP URL 和直播流密钥。将它们合并成一个 URL,然后将其复制粘贴到 Jitsi。
以下是我测试运行时的这两个文本块示例,可供复制:
* 直播的 RTMP URL:`rtmp://peertube.linuxrocks.online:1935/live`
* 直播流密钥:`8b940f96-c46d-46aa-81a0-701de3c43c8f`
你需要将这两个文本块合并,并在它们之间加上 `/`,如下所示:
```
rtmp://peertube.linuxrocks.online:1935/live/8b940f96-c46d-46aa-81a0-701de3c43c8f
```
### Jitsi 的直播舞台 + 社交活动室
我们在我们的 “直播舞台” 上使用了自由开源的托管平台 [Jitsi Meet](https://meet.jit.si/) 视频会议平台。我们在 <https://meet.jit.si> 上创建了一个自定义 URL 的 Jitsi 会议室,并只与演讲者和会议组织者共享了该 URL。
我们配置了会议室的等候室(该功能在你加入新创建的会议室后在会议设置中可用),这样演讲者可以在他们的演讲前几分钟加入而不用担心打断前一个演讲。我们的主持人志愿者在前一个会话结束后让他们进入。另一个选项是给会议室添加密码。我们只是配置了一个等候室就行了。在测试时似乎发现,会议室中的管理状态并不是持久的。如果一个管理员离开了会议室,他们似乎会失去管理员状态和设置,比如等候室的设置。我通过让我的电脑保持打开的状态,使 Jitsi 会议室在整个会议期间可用和活动。(在这方面,你的情况可能会有所不同。)
Jitsi 提供了内置的直播选项,你可以将视频服务的 URL 发布到 Jitsi 中,它会将你的视频流式传输到该服务。我们对这种方法有信心,因为这是我们主办和直播每周举行的 [Fedora 设计团队会议](https://peertube.linuxrocks.online/c/fedora_design_live/videos) 的方式。对于创意自由峰会,我们将我们的 Jitsi 直播舞台(用于演讲者和主持人)连接到 [Linux Rocks PeerTube 上的一个频道](https://peertube.linuxrocks.online/c/creativefreedom/videos)。
Jitsi 允许演讲者共享屏幕来展示幻灯片或进行实时演示。
#### 将 Jitsi 直播到 PeerTube
1、加入会议并点击屏幕底部红色挂断按钮旁边的 “...” 图标。

2、从弹出菜单中选择 “<ruby> 开始直播 <rt> Start live stream </rt></ruby>”。

3、复制并粘贴 PeerTube 的 URL + 密钥文本

4、倾听 Jitsi 机器人朋友的声音
几秒钟后,会出现一个女性声音告诉你,“Live streaming is on.”(直播已开启)。一旦听到这个声音,微笑吧!你正在进行直播。
5、停止直播
这将停止你设置的 PeerTube URL 的工作,所以重复这些步骤可以重新启动直播。
#### Jitsi 技巧
##### 通过开关 Jitsi 的流来管理录制
我们在会议中认识到,在演讲之间关闭 Jitsi 的直播流会更好,这样你将在 PeerTube 上针对每个演讲发布一个原始录制文件。第一天我们让它一直运行,因此一些录制中包含了多个演讲的视频,这使得那些试图赶上进度的人使用即时回放功能更困难。他们需要在视频中寻找他们想观看的演讲,或者等待我们在几天或几周后发布编辑过的版本。
#### 避免音频回音
我们在活动期间实时发现的另一个问题是音频回音。这在我们的测试中并没有出现,这完全是我的错(对所有参加的人道歉)。我负责设置 Jitsi/PeerTube 的链接、监控流和协助主持活动。尽管我知道一旦直播开始,我需要关闭所有已打开的 PeerTube 浏览器标签,但我可能打开了比我想象中更多的 PeerTube 标签,或者直播会在我可用于监控聊天的 Element 客户端中自动开始播放。我没有很方便地静音 Element 的方法。在我进行的一些演讲者介绍中,你会注意到我知道在音频回音开始之前大约有 30 秒的时间,因此我做的介绍非常匆忙/急促。
我认为有更简单的方法来避免这种情况:
* 尽量确保主持人/活动主持人不是负责设置/监控流和聊天的同一个人。(根据你每次拥有多少义工人员的情况,这并不总是可能的。)
* 如果可能,使用一台电脑监控流,另一台电脑担任主持人角色。这样,你在用于监控的电脑上只需按一下静音按钮,简化了你在另一个电脑上的主持体验。
这是一件值得提前练习和完善的事情。
### 后台:Element

我们在会议开始前大约一周设置了一个 “后台” 邀请制聊天室,并邀请了所有的演讲者加入。这有助于确保以下几点:
* 我们的演讲者在活动开始之前就加入了 Element/Matrix,并有机会在注册遇到任何问题时都可以获得帮助(实际上没有人遇到问题)。
* 在活动开始之前,我们与所有演讲者建立了一个实时的交流渠道,以便我们能够轻松地发送公告和更新。
在活动期间,这个聊天室成为一个有用的地方,用于协调演讲者之间的过渡,提醒日程是否延迟,以及在一个情况下,当我们的演讲者出现紧急情况无法按原定时间发言时,迅速重新安排演讲时间。
我们还为主持人设置了一个房间,但在我们的情况下,它是多余的。我们只是使用后台频道进行协调。我们发现两个频道很容易监控,但三个频道对于方便起见有点太多了。
### 公告和问答:Etherpad/Hackmd.io

我们在 Element 主频道中设置了一个固定的小部件,提供有关活动的一般信息,包括每日日程安排、行为准则等。我们还为每个演讲设置了一个问答部分,让与会者可以在其中提出问题,主持人会为演讲者朗读这些问题。
在开始的一两天中,我们发现一些与会者在加载 Etherpad 小部件时遇到问题,因此我们改为在频道中固定一个内嵌的 [hackmd.io](http://hackmd.io) 文档作为小部件,那似乎效果更好一些。我们并不 100% 确定小部件加载问题的具体原因,但我们可以在频道主题中发布一个原始(非内嵌)链接,这样参与者就可以绕过通过小部件访问时可能遇到的任何问题。
### 综合和集中的会议体验

通过 Fedora 的 Element 服务器使用 Matrix 是参加会议的关键地方。Element 中的 Matrix 聊天室具有小部件系统,可以将网站嵌入到聊天室中,成为体验的一部分。这个功能对于将我们的 Matrix 聊天室作为集中参会的地方非常重要。
我们将 PeerTube 的直播嵌入到了聊天频道中,在上面的截图中左上角可以看到。会议结束后,我们可以分享未编辑的视频回放的播放列表。现在,我们志愿者项目编辑视频的工作已经完成,该频道中有按顺序排列的编辑演讲的播放列表。
如前一节所讨论的,我们在右上角嵌入了一个 [hackmd.io](http://hackmd.io) 笔记,用于发布当天的日程安排、公告以及一个用于问答的区域。我本来想设置一个 Matrix 机器人来处理问答,但我在运行时遇到了一些困难。不过,这可能是明年一个很酷的项目。
在会议期间,与会者直接在主要聊天窗口下方进行交流,同时与小部件进行互动。
在将 Matrix/Element 聊天室作为在线会议的中心地点时,有几个要考虑的因素,例如:
* 在 Element 桌面客户端或桌面系统的 Web 浏览器上会有最佳体验。但是,你也可以在 Element 移动客户端中查看小部件(尽管一些参与者在发现此功能时遇到了困难,其用户界面不太明显)。其他 Matrix 客户端可能无法查看小部件。
* 如果需要,与会者可以根据自己的喜好自行组合体验。那些不使用 Element 客户端参加会议的用户报告称加入聊天并直接查看 PeerTube 直播 URL 没有问题。我们在频道主题中分享了直播 URL 和 hackmd URL,以便那些不想使用 Element 的用户也可以访问。
### 网站
[Ryan Gorley](https://mastodon.social/@ryangorley) 使用 [WordPress](https://wordpress.com/) 开发了 [创意自由峰会网站](https://creativefreedomsummit.com/)。该网站由 WPengine 托管,是一个单页网站,其中嵌入了来自 [sched.org](http://sched.org) 的会议日程安排。在网站顶部,有一个标题为 “Create. Learn. Connect.” 的屏幕截图,背景是蓝色和紫色的渐变效果。
### 后续活动
#### 后续调查
我们使用开源调查工具 LimeSurvey。在会议结束后的一两周内,我们通过 Element 聊天频道和 PeerTube 视频频道向与会者发送了调查,以了解他们对我们活动的看法。活动组织者们继续定期开会。在这些会议的其中一个议题是共同撰写 [hackmd.io](http://hackmd.io) 文档,以制定调查问题。以下是我们从活动中学到的一些对你计划自己的开源线上会议可能有兴趣的事项:
* 绝大多数与会者(共 70% 的受访者)是通过 Mastodon 和 Twitter 得知本次活动的。
* 33% 的与会者使用 Element 桌面应用程序参加会议,30% 使用 Element 聊天 Web 应用程序。因此,大约有 63% 的与会者使用了集成的 Matrix/Element 体验。其他与会者直接在 PeerTube 上观看或在会后观看了回放。
* 35% 的与会者表示他们通过聊天与其他创意人建立了联系,因此如果你的目标是促进人际交流和连接,聊天体验对于活动来说非常重要。
#### 字幕
在活动期间,我们收到了与会者的积极反馈,他们对其他与会者在聊天中实时添加的演讲字幕表示赞赏,并希望能够提供实时字幕以提升可访问性。虽然本文未提及实时字幕的相关软件,但有一些开源解决方案可供选择。其中一个工具是 Live Captions,在 Seth Kenlon 撰写的一篇文章《[在 Linux 上的开源视频字幕](https://opensource.com/article/23/2/live-captions-linux)》中进行了介绍。虽然这个工具主要用于本地观看视频内容的与会者,但我们有可能让会议主持人在 Jitsi 中运行它并与直播共享。其中一种方法是使用开源广播工具 [OBS](https://obsproject.com/),这样每个观看直播的人都能受益于字幕功能。
在会后编辑视频时,我们发现了内置于我们首选的开源视频编辑软件 [Kdenlive](https://kdenlive.org/) 中的一项功能,它能够自动生成字幕并自动放置到视频中。在 [Kdenlive 手册](https://docs.kdenlive.org/en/effects_and_compositions/speech_to_text.html) 中有关于如何使用这个功能的基本说明。Fedora 设计团队成员 Kyle Conway 在协助会后视频编辑时,制作了一份 [详细教程(包括视频指导):如何在 Kdenlive 中自动生成并添加字幕](https://gitlab.com/groups/fedora/design/-/epics/23#video-captioning-and-handoff)。如果你对这个功能感兴趣,阅读和观看这个教程会非常有帮助。
#### 视频编辑志愿者工作
活动结束后,我们在会议的 Element 频道中召集了一组志愿者,共同进行视频编辑工作,包括添加标题卡、片头/片尾音乐以及进行整体清理。我们自动生成的一些重播录像可能会分为两个文件,或者与其他多个演讲合并在一个文件中,因此需要重新组装或裁剪。
我们使用 [GitLab Epic](https://gitlab.com/groups/fedora/design/-/epics/23) 来组织这项工作,其中包含常见问题和寻找按技能组织的志愿者的帮助,每个视频工作都附加有相应的议题。我们为每个视频设置了一系列自定义标签,以明确该视频的状态以及需要何种帮助。所有视频的编辑工作都已完成,其中一些视频需要为其在 [创意自由峰会频道](https://peertube.linuxrocks.online/c/creativefreedom/videos) 上的描述区域撰写内容。许多视频都有自动生成的字幕,但字幕中可能存在拼写错误和其他常见的自动生成文本错误,还需要进行编辑修正。

我们通过让志愿者从创意自由峰会的 PeerTube 主频道的未编辑录像中下载原始视频来传递这些视频文件(由于文件大小可能相当大)。当志愿者准备好分享编辑好的视频时,我们有一个私人的 PeerTube 账户,他们可以将视频上传到该账户。具有主频道账户访问权限的管理员会定期从私人账户中获取视频,并将其上传到主账户中。请注意,PeerTube 并没有一个多个账户访问同一频道的系统,因此我们不得不进行密码共享,这可能有些令人紧张。我们认为这是一个合理的妥协,可以限制掌握主要密码的人数,同时仍然可以让志愿者提交编辑好的视频而不会太过麻烦。
### 准备尝试一下吗?
我希望这个对于我们如何使用开源工具集来举办创意自由峰会的全面描述能够激发你尝试在你的开源活动中使用这些方法。让我们知道进展如何,并随时联系我们如果你有问题或改进建议!我们的频道链接为:<https://matrix.to/#/#creativefreedom:fedora.im>
*(题图:MJ/cb6a4ea4-95ed-40cb-9e78-85f8676219f2)*
---
via: <https://opensource.com/article/23/4/open-source-tools-virtual-conference>
作者:[Máirín Duffy](https://opensource.com/users/mairin) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [The Fedora Design Team](https://fedoraproject.org/wiki/Design) discovered that using open source tools to run a virtual conference can be quite effective by hosting the first [Creative Freedom Summit](http://creativefreedomsummit.com/) in January 2023.
In this article, I'll share some background on the conference, why using open source tools to run it was important to us, and the specific tools and configurations our team used to make it all work. I'll also talk about what worked well and what will need improvement at our next summit in 2024.
## What is Creative Freedom Summit?
The Creative Freedom Summit was an idea Marie Nordin came up with after reviewing talk submissions for [Flock, the annual Fedora users and contributors conference](http://flocktofedora.org/). She received many talk submissions for the August 2022 Flock relating to design and creativity in open source—far more than we could possibly accept. With so many great ideas for open source design-related talks out there, she wondered if there would be space for a separate open source creativity conference focused on creatives who use open source tools to produce their work.
Marie brought this idea to the Fedora Design Team in the fall of 2022, and we started planning the conference, which took place January 17-19, 2023. Since it was our first time running a new conference like this, we decided to start with invited speakers based on some of the Flock submissions and our own personal network of open source creatives. Almost every speaker we asked gave a talk, so we didn't have room to accept submissions. We will need to figure out this next year, so we don't have an open source CFP (Call for Papers) management tool for that to tell you about yet.
## Using open source for open source conferences
Since the initial COVID pandemic lockdowns, Fedora's Flock conference has been run virtually using Hopin, an online conference platform that isn't open source but is friendly to open source tools. Fedora started using it some years ago, and it definitely provides a professional conference feel, with a built-in sponsor booth/expo hall, tracks, hallway chat conversations, and moderation tools. Running the Creative Freedom Summit using Hopin was an option for us because, as a Fedora-sponsored event, we could access Fedora's Hopin setup. Again, Hopin is not open source.
Now, as a long-term (~20 years) open source contributor, I can tell you that this kind of decision is always tough. If your conference focuses on open source, using a proprietary platform to host your event feels a little strange. However, as the scale and complexity of our communities and events have grown, the ability to produce an integrated open source conference system has become more challenging.
There is no right or wrong answer. You have to weigh a lot of things when making this decision:
- Budget
- People power
- Infrastructure
- Technical capability
- Complexity/formality/culture of the event
We didn't have any budget for this event. We did have a team of volunteers who could put some work hours into it. We had the Fedora Matrix Server as a piece of supported infrastructure we could bring into the mix and access to a hosted WordPress system for the website. Teammate Madeline Peck and I had the technical capability/experience of running the live, weekly Fedora Design Team [video calls](https://opensource.com/article/23/3/video-templates-inkscape) using PeerTube. We wanted the event to be low-key, single-track, and informal, so we had some tolerance for glitches or rough edges. We also all had a lot of passion for trying an open source stack.
Now you know a little about our considerations when making this decision, which might help when making decisions for your event.
## An open source conference stack
Here is how the conference tech stack worked.
### Overview
**Live components**
**Livestream**: We streamed the stage and the social events to a PeerTube channel. Conference attendees could watch the stream live from our PeerTube channel. PeerTube includes some privacy-minded analytics to track the number of livestream viewers and post-event views.**Live stage + social event room**: We had one live stage for speakers and hosts using Jitsi, ensuring only those with permission could be on camera. We had an additional Jitsi meeting room for social events that allowed anyone who wanted to participate in the social event to go on camera.**Backstage**: We had a "Backstage" Matrix channel to coordinate with speakers, hosts, and volunteers in one place while the event was going on.**Announcements and Q&A**: We managed Q&A and the daily schedule for the conference via a shared Etherpad (which we later moved to Hackmd.io).**Integrated and centralized conference experience**: Using Matrix's Element client, we embedded the livestream video and an Etherpad into a public Matrix room for the conference. We used attendance in the channel to monitor overall conference attendance. We had a live chat throughout the conference and took questions from audience members from the chat and the embedded Q&A Etherpad.**Conference website**: We had a beautifully-designed website created by Ryan Gorley hosted on WordPress, which had the basic information and links for how to join the conference, the dates/times, and the schedule.
### Post-event components
**Post-event survey**: We used the open source LimeSurvey system to send out a post-event survey to see how things went for attendees. I use some of the data from that survey in this article.**Post-event video editing and captioning**: We didn't have a live captioning system for the conference, but as I was able, I typed live notes from talks into the channel, which attendees greatly appreciated. Post-event, we used Kdenlive (one of the tools featured in talks at the event) to edit the videos and generate captions.**Event recordings**: PeerTube automagically posts livestream recordings to channels, making nearly instant recordings available for attendees for talks they may have missed.
I'll cover some details next.
## Livestream with PeerTube
(Máirín Duffy, CC BY-SA 4.0)
We used the [LinuxRocks PeerTube platform](https://peertube.linuxrocks.online/c/creativefreedom/videos) generously hosted by [LinuxRocks.online](https://linuxrocks.online/) for the Creative Freedom Summit's livestream. PeerTube is a free and open source decentralized video platform that is also part of the Fediverse.
One of the best features of PeerTube (that other platforms I am aware of don't have) is that after your livestream ends, you get a near-instant replay recording posted to your channel on PeerTube. Users in our chatroom cited this as a major advantage of the platform. If an attendee missed a session they were really interested in, they could watch it within minutes of that talk's end. It took no manual intervention, uploading, or coordination on the part of the volunteer organizing team to make this happen; PeerTube automated it for us.
Here is how livestreaming with PeerTube works: You create a new livestream on your channel, and it gives you a livestreaming URL + a key to authorize streaming to the URL. This URL + key can be reused over and over. We configured it so that the recording would be posted to the channel where we created the livestreaming URL as soon as a livestream ended. Next, copy/paste this into Jitsi when you start the livestream. This means that you don't have to generate a new URL + key for each talk during the conference—the overhead of managing that for organizers would have been pretty significant. Instead, we could reuse the same URL + key shared in a common document among conference organizers (we each had different shifts hosting talks). Anyone on the team with access to that document could start the livestream.
### How to generate the livestream URL + key in PeerTube
The following section covers generating the livestream URL + key in PeerTube, step-by-step.
**1. Create stream video on PeerTube**
Log into PeerTube, and click the **Publish** button in the upper right corner:

(Máirín Duffy, CC BY-SA 4.0)
**2. Set options**
Click on the **Go live** tab (fourth from the left) and set the following options:
- Channel: (The channel name you want the livestream to publish on)
- Privacy: Public
- Radio buttons: Normal live
Then, select **Go Live**. (Don't worry, you won't really be going live quite yet, there is more data to fill in.)
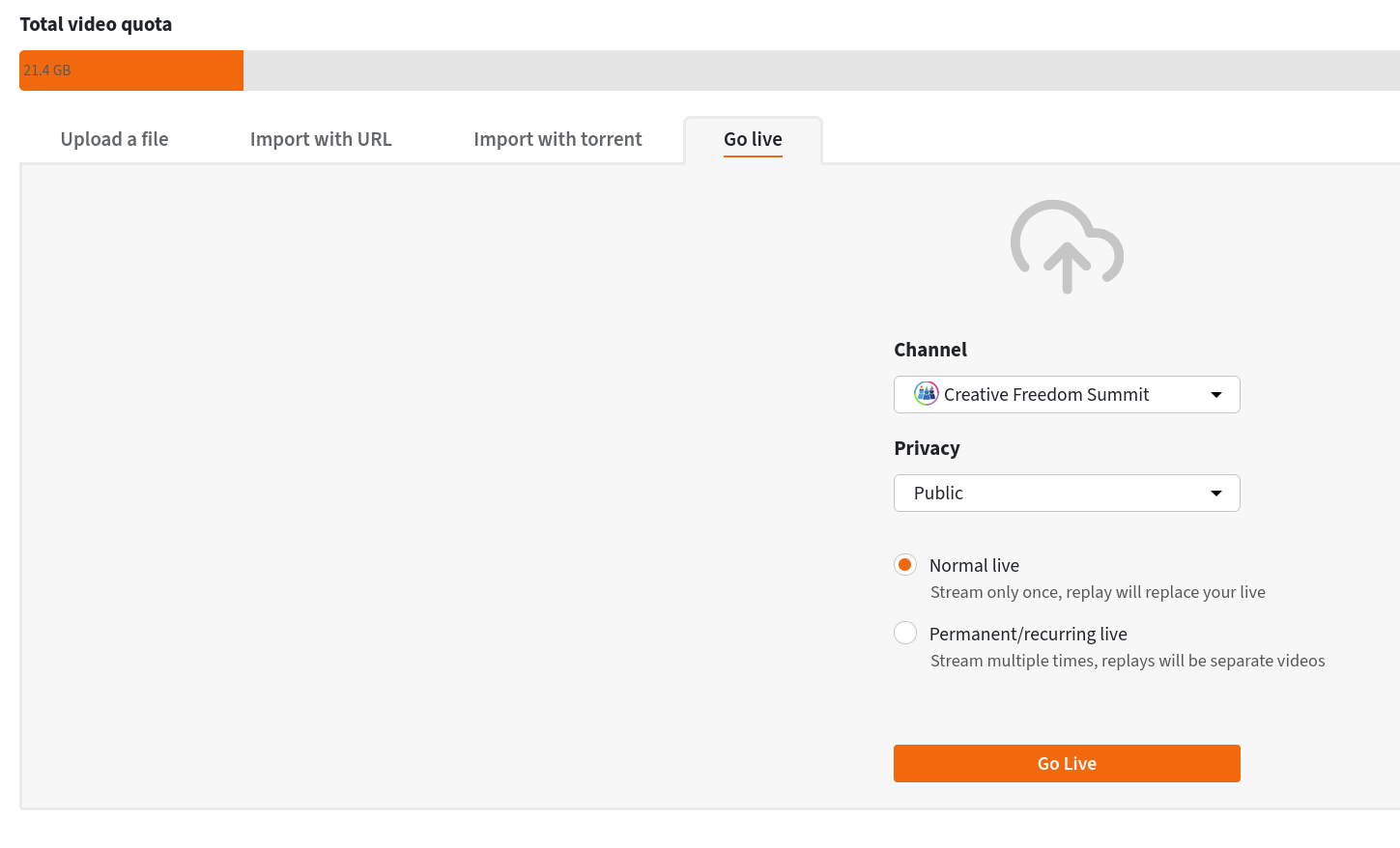
(Máirín Duffy, CC BY-SA 4.0)
**3. Basic info (don't click update yet)**
First, fill out the **Basic Info** tab, then choose the **Advanced Settings** tab in the next step. Fill out the name of the livestream, description, add tags, categories, license, etc. Remember to publish after the transcoding checkbox is turned on.
This ensures once your livestream ends, the recording will automatically post to your channel.
**4. Advanced settings**
You can upload a "standby" image that appears while everyone is watching the stream URL and waiting for things to start.
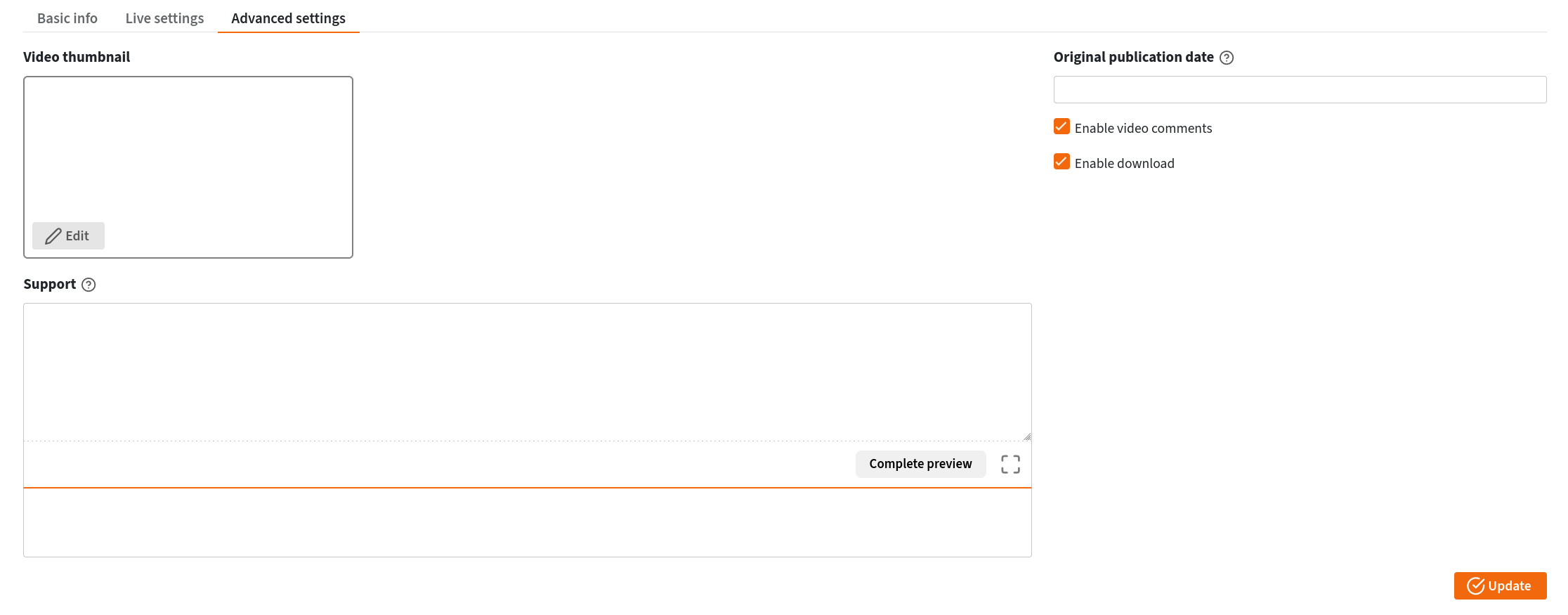
(Máirín Duffy, CC BY-SA 4.0)
This is the standby image we used for the Creative Freedom Summit:

(Máirín Duffy, CC BY-SA 4.0)
**5. Start livestream on PeerTube**
Select the **Update** button in the lower right corner. The stream will appear like this—it's in a holding pattern until you start streaming from Jitsi:

(Máirín Duffy, CC BY-SA 4.0)
**6. Copy/paste the livestream URL for Jitsi**
This is the final step in PeerTube. Once the livestream is up, click on the **…** icon under the video and towards the right:
(Máirín Duffy, CC BY-SA 4.0)
Select **Display live information**. You'll get a dialog like this:
(Máirín Duffy, CC BY-SA 4.0)
You must copy both the live RTMP URL and the livestream key. Combine them into one URL and then copy/paste that into Jitsi.
The following are examples from my test run of these two text blocks to copy:
- Live RTMP Url:
**rtmp://peertube.linuxrocks.online:1935/live** - Livestream key:
**8b940f96-c46d-46aa-81a0-701de3c43c8f**
What you'll need to paste into Jitsi is these two text blocks combined with a** /** between them, like so:
**rtmp://peertube.linuxrocks.online:1935/live/8b940f96-c46d-46aa-81a0-701de3c43c8f**
## Live stage + social event room: Jitsi
We used the free and open source hosted [Jitsi Meet](https://meet.jit.si/) video conferencing platform for our "live stage." We created a Jitsi meeting room with a custom URL at ** https://meet.jit.si** and only shared this URL with speakers and meeting organizers.
We configured the meeting with a lobby (this feature is available in meeting settings once you join your newly-created meeting room) so speakers could join a few minutes before their talk without fear of interrupting the presentation before theirs. (Our host volunteers let them in when the previous session finished.) Another option is to add a password to the room. We got by just by having a lobby configured. It did seem, upon testing, that the moderation status in the room wasn't persistent. If a moderator left the room, they appeared to lose moderator status and settings, such as the lobby setup. I kept the Jitsi room available and active for the entire conference by leaving it open on my computer. (Your mileage may vary on this aspect.)
Jitsi has a built-in livestreaming option, where you can post a URL to a video service, and it will stream your video to that service. We had confidence in this approach because it is how we host and livestream weekly [Fedora Design Team meetings](https://peertube.linuxrocks.online/c/fedora_design_live/videos). For the Creative Freedom Summit, we connected our Jitsi Live Stage (for speakers and hosts) to [a channel on the Linux Rocks PeerTube](https://peertube.linuxrocks.online/c/creativefreedom/videos).
Jitsi lets speakers share their screens to drive their own slides or live demos.
## Livestreaming Jitsi to PeerTube
1. Join the meeting and click the **…** icon next to the red hangup button at the bottom of the screen.
(Máirín Duffy, CC BY-SA 4.0)
2. Select **Start live stream** from the pop-up menu.

(Máirín Duffy, CC BY-SA 4.0)
3. Copy/paste the PeerTube URL + key text
(Máirín Duffy, CC BY-SA 4.0)
4. Listen for your Jitsi Robot friend
A feminine voice will come on in a few seconds to tell you, "Live streaming is on." Once she sounds, smile! You're livestreaming.
5. Stop the livestream
This stops the PeerTube URL you set up from working, so repeat these steps to start things back up.
### Jitsi tips
**Managing Recordings by turning the Jitsi stream on and off**
We learned during the conference that it is better to turn the Jitsi stream off between talks so that you will have one raw recording file per talk posted to PeerTube. We let it run as long as it would the first day, so some recordings have multiple presentations in the same video, which made using the instant replay function harder for folks trying to catch up. They needed to seek inside the video to find the talk they wanted to watch or wait for us to post the edited version days or weeks later.
**Preventing audio feedback**
Another issue we figured out live during the event that didn't crop up during our tests was audio feedback loops. These were entirely my fault (sorry to everyone who attended). I was setting up the Jitsi/PeerTube links, monitoring the streams, and helping host and emcee the event. Even though I knew that once we went live, I needed to mute any PeerTube browser tabs I had open, I either had more PeerTube tabs open than I thought and missed one, or the livestream would autostart in my Element client (which I had available to monitor the chat). I didn't have an easy way to mute Element. In some of the speaker introductions I made, you'll see that I knew I had about 30 seconds before the audio feedback would start, so I gave very rushed/hurried intros.
I think there are simpler ways to avoid this situation:
- Try to ensure your host/emcee is not also the person setting up/monitoring the streams and chat. (Not always possible, depending on how many volunteers you have at any given time.)
- If possible, monitor the streams on one computer and emcee from another. This way, you have one mute button to hit on the computer you're using for monitoring, and it simplifies your hosting experience on the other.
This is something worth practicing and refining ahead of time.
## Backstage: Element
(Máirín Duffy, CC BY-SA 4.0)
We set up a "Backstage" invite-only chat room a week or so before the conference started and invited all our speakers to it. This helped us ensure a couple of things:
- Our speakers were onboarded to Element/Matrix well before the event's start and had the opportunity to get help signing up if they had any issues (nobody did).
- We started a live communication channel with all speakers before the event so that we could send announcements/updates pretty easily.
The channel served as a useful place during the event to coordinate transitions between speakers, give heads up about whether the schedule was running late, and in one instance, quickly reschedule a talk when one of our speakers had an emergency and couldn't make their original scheduled time.
We also set up a room for hosts, but in our case, it was extraneous. We just used the backstage channel to coordinate. We found two channels were easy to monitor, but three were too many to be convenient.
## Announcements and Q&A: Etherpad/Hackmd.io
(Máirín Duffy, CC BY-SA 4.0)
We set up a pinned widget in our main Element channel with general information about the event, including the daily schedule, code of conduct, etc. We also had a section per talk of the day for attendees to drop questions for Q&A, which the host read out loud for the speaker.
We found over the first day or two that some attendees were having issues with the Etherpad widget not loading, so we switched to an embedded hackmd.io document pinned to the channel as a widget, and that seemed to work a little better. We're not 100% sure what was going on with the widget loading issues, but we were able to post a link to the raw (non-embedded) link in the channel topic, so folks could get around any problems accessing it via the widget.
## Integrated and centralized conference experience
(Máirín Duffy, CC BY-SA 4.0)
Matrix via Fedora's Element server was the single key place to go to attend the conference. Matrix chat rooms in Element have a widget system that allows you to embed websites into the chat room as part of the experience. That functionality was important for having our Matrix chat room serve as the central place to attend.
We embedded the PeerTube livestream into the channel—you can see it in the screenshot above in the upper left. Once the conference was over, we could share a playlist of the unedited video replays playlist. Now that our volunteer project for editing the videos is complete, the channel has the playlist of edited talks in order.
As discussed in the previous section, we embedded a hackmd.io note in the upper right corner to post the day's schedule, post announcements, and an area for Q&A right in the pad. I had wanted to set up a Matrix bot to handle Q&A, but I struggled to get one running. It might make for a cool project for next year, though.
Conversations during the conference occurred right in the main chat under these widgets.
There are a couple of considerations to make when using a Matrix/Element chat room as the central place for an online conference, such as:
- The optimal experience will be in the Element desktop client or a web browser on a desktop system. However, you can view the widgets in the Element mobile client (although some attendees struggled to discover this, the UI is less-than-obvious). Other Matrix clients may not be able to view the widgets.
- Attendees can easily DIY their own experience piecemeal if desired. Users not using the Element client to attend the conference reported no issues joining in on the chat and viewing the PeerTube livestream URL directly. We shared the livestream URL and the hackmd URL in the channel topic, making it accessible to folks who preferred not to run Element.
## Website
(Máirín Duffy, CC BY-SA 4.0)
[Ryan Gorley](https://mastodon.social/@ryangorley) developed the [Creative Freedom Summit website](https://creativefreedomsummit.com/) using [WordPress](https://wordpress.com/). It is hosted by WPengine and is a one-pager with the conference schedule embedded from sched.org.
## Post-event
### Post-event survey
We used the open source survey tool LimeSurvey. We sent it out within a week or two to attendees via the Element Chat channel and our PeerTube video channel to learn more about how we handled the event. The event organizers continue to meet regularly. One topic we focus on during these post-event meetings is developing the questions for the survey in a shared hackmd.io document. The following are some things we learned from the event that might be of interest to you in planning your own open source powered online conference:
- By far, most event attendees learned about the event from Mastodon and Twitter (together, covering 70% of respondents).
- 33% of attendees used the Element desktop app to attend, and 30% used the Element Chat web app. So roughly 63% of attendees used the integrated Matrix/Element experience. The rest watched directly on PeerTube or viewed replays after.
- 35% of attendees indicated they made connections with other creatives at the event via the chat, so the chat experience is pretty important to events if part of your goal is enabling networking and connections.
### Captioning
During the event, we received positive feedback from participants who appreciated when another attendee live-captioned the talk in the chat and wished out loud for live captioning for better accessibility. While the stack outlined here did not include live captioning, there are open source solutions for it. One such tool is Live Captions, and Seth Kenlon covered it in an opensource.com article, [Open source video captioning on Linux](https://opensource.com/article/23/2/live-captions-linux). While this tool is meant for the attendee consuming the video content locally, we could potentially have a conference host running it and sharing it to the livestream in Jitsi. One way to do this is using the open source broadcasting tool [OBS](https://obsproject.com/) so everyone watching the livestream could benefit from the captions.
While editing the videos post-event, we discovered a tool built into [Kdenlive](https://kdenlive.org/), our open source video editor of choice, that generates and automatically places subtitles in the videos. There are basic instructions on how to do this in the [Kdenlive manual](https://docs.kdenlive.org/en/effects_and_compositions/speech_to_text.html). Fedora Design Team member Kyle Conway, who helped with the post-event video editing, put together a [comprehensive tutorial (including video instruction) on automatically generating and adding subtitles to videos in Kdenlive](https://gitlab.com/groups/fedora/design/-/epics/23#video-captioning-and-handoff). It is well worth the read and watch if you are interested in this feature.
### Video editing volunteer effort
When the event was over, we rallied a group of volunteers from the conference Element channel to work together on editing the videos, including title cards and intro/outro music, and general cleanup. Some of our automatic replay recordings were split across two files or combined in one file with multiple other talks and needed to be reassembled or cropped down.
We used a [GitLab epic to organize the work](https://gitlab.com/groups/fedora/design/-/epics/23), with an FAQ and call for volunteer help organized by skillset, with issues attached for each video needed. We had a series of custom labels we would set on each video so it was clear what state the video was in and what kind of help was needed. All the videos have been edited, and some need content written for their description area on the [Creative Freedom Summit channel](https://peertube.linuxrocks.online/c/creativefreedom/videos). Many have auto-generated subtitles that have not been edited for spelling mistakes and other corrections common with auto-generated text.
(Máirín Duffy, CC BY-SA 4.0)
We passed the videos around—the files could be quite large—by having volunteers download the raw video from the unedited recording on the main PeerTube channel for the Creative Freedom Summit. When they had an edited video ready to share, we had a private PeerTube account where they could upload it. Admins with access to the main channel's account periodically grabbed videos from the private account and uploaded them to the main account. Note that PeerTube doesn't have a system where multiple accounts have access to the same channel, so we had to engage in a bit of password sharing, which can be nerve-wracking. We felt this was a reasonable compromise to limit how many people had the main password but still enable volunteers to submit edited videos without too much hassle.
## Ready to give it a try?
I hope this comprehensive description of how we ran the Creative Freedom Summit conference using an open source stack of tools inspires you to try it for your open source event. Let us know how it goes, and feel free to reach out if you have questions or suggestions for improvement! Our channel is at: [https://matrix.to/#/#creativefreedom:fedora.im](https://matrix.to/#/#creativefreedom:fedora.im)
*This article is adapted from Run an open source-powered virtual conference and is republished with permission.*
## Comments are closed. |
16,047 | Bash 基础知识系列 #6:处理字符串操作 | https://itsfoss.com/bash-strings/ | 2023-07-30T09:00:53 | [
"Bash",
"脚本"
] | https://linux.cn/article-16047-1.html | 
在大多数编程语言中,你都会找到字符串数据类型。字符串基本上是一组字符。
但 Bash Shell 有所不同。字符串没有单独的数据类型。这里一切都是变量。
但这并不意味着你不能像在 C 和其他编程语言中那样处理字符串。
在 Bash Shell 中可以查找子字符串、替换子字符串、连接字符串以及更多字符串操作。
在 Bash 基础知识系列的这一部分中,你将学习基本的字符串操作。
### 在 Bash 中获取字符串长度
让我们从最简单的选项开始。也就是获取字符串的长度。这很简单:
```
${#string}
```
让我们在示例中使用它。

正如你所看到的,第二个示例中有两个单词,但由于它用引号引起来,因此它被视为单个单词。连空格都算作一个字符。
### 在 Bash 中连接字符串
用技术术语来说是字符串 <ruby> 连接 <rt> concatenation </rt></ruby>,这是 Bash 中最简单的字符串操作之一。
你只需像这样一个接一个地使用字符串变量:
```
str3=$str1$str2
```
还能比这更简单吗?我觉得不能。
让我们看一个例子。这是我的示例脚本,名为 `join.sh`:
```
#!/bin/bash
read -p "Enter first string: " str1
read -p "Enter second string: " str2
joined=$str1$str2
echo "The joined string is: $joined"
```
以下是该脚本的运行示例:

### 在 Bash 中提取子字符串
假设你有一个包含多个字符的大字符串,并且你想要提取其中的一部分。
要提取子字符串,需要指定主字符串、子字符串的起始位置和子字符串的长度,如下所示:
```
${string:$pos:$len}
```
>
> ? 和数组一样,字符串中的定位也是从 0 开始。
>
>
>
这是一个例子:

即使你指定的子字符串长度大于字符串长度,它也只会到达字符串末尾。
### 替换 Bash 中的子字符串
假设你有一个大字符串,并且你想用另一个字符串替换其中的一部分。
在这种情况下,你可以使用这种语法:
```
${string/substr1/substr2}
```
>
> ✋ 只有第一次出现的子字符串才会以这种方式替换。如果要替换所有出现的地方,请使用 `${string//substr1/substr2}`
>
>
>
这是一个例子:

正如你在上面看到的,“good” 一词被替换为 “best”。我将替换的字符串保存到同一字符串中以更改原始字符串。
>
> ? 如果未找到子字符串,则不会替换任何内容。它不会导致错误。
>
>
>
### 在 Bash 中删除子字符串
我们来谈谈删除子字符串。假设你要删除字符串的一部分。在这种情况下,只需将子字符串提供给主字符串,如下所示:
```
${string/substring}
```
>
> ✋ 通过这种方式,仅删除第一次出现的子字符串。如果要删除所有出现的内容,请使用 `${string//substr}`
>
>
>
如果找到子字符串,则将从字符串中删除它。
让我们通过一个例子来看看。

不用说,如果没有找到子字符串,则不会删除它。它不会导致错误。
### ?️ 练习时间
现在是你通过简单练习来实践字符串操作的时候了。
**练习 1**:声明一个字符串 “I am all wet”。现在通过用 “set” 替换单词 “wet” 来更改此字符串。
**练习 2**:创建一个字符串,以 `112-123-1234` 格式保存电话号码。现在,你必须删除所有 `-`。
这应该会给你一些在 Bash 中使用字符串的不错的练习。在下一章中,你将学习如何在 Bash 中使用 `if-else` 语句。敬请关注。
*(题图:MJ/aa73b2c9-6d2f-42e2-972d-94fab56d30cc)*
---
via: <https://itsfoss.com/bash-strings/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter #6: Handling String Operations
In this chapter of the Bash Basics series, learn to perform various common string operations like extracting, replacing and deleting substrings.
In most programming languages, you'll find a string data type. A string is basically a group of characters.
Bash shell is different though. There is no separate data type for strings. Everything is a variable here.
But that doesn't mean that you cannot deal with strings in the same way you do in C and other programming languages.
Finding substrings, replacing substrings, joining strings and many more string operations are possible in Bash shell.
In this part of the Bash Basics Series, you'll learn the basic string manipulations.
## Get string length in bash
Let's start with the simplest option. Which is to get the length of a string. It's quite simple:
`${#string}`
Let's use it in an example.
As you can see, the second example had two words in it but since it was in quotes, it was treated as a single word. Even the space is counted as a character.
## Join strings in bash
The technical term is concatenation of strings, one of the simplest possible string operations in bash.
You just have to use the string variables one after another like this:
`str3=$str1$str2`
Can it go any simpler than this? I don't think so.
Let's see it with an example. Here is my example script named `join.sh`
:
```
#!/bin/bash
read -p "Enter first string: " str1
read -p "Enter second string: " str2
joined=$str1$str2
echo "The joined string is: $joined"
```
Here's a sample run of this script:
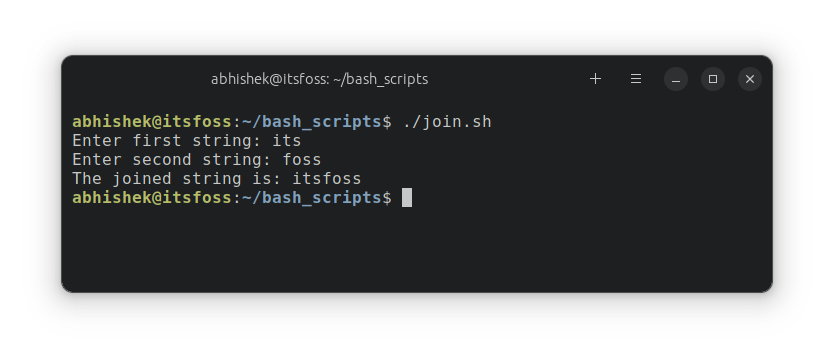
## Extract substring in bash
Let's say you have a big string with several characters and you want to extract part of it.
To extract a substring, you need to specify the main string, the starting position of the substring and the length of the substring in the following manner:
`${string:$pos:$len}`
Here's an example:
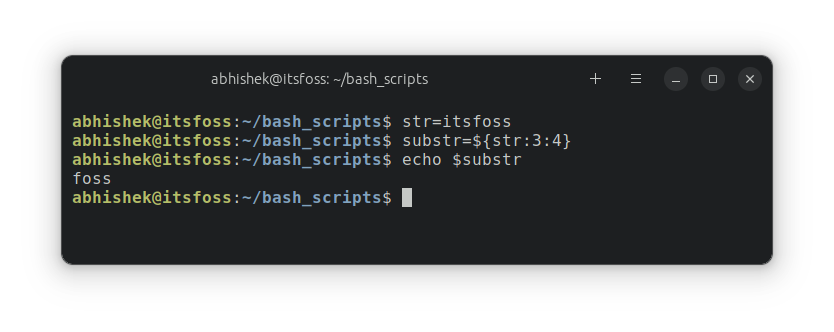
Even if you specify the substring length greater than the string length, it will only go till the end of the string.
## Replace substring in bash
Let's say you have a big string and you want to replace part of it with another string.
In that case, you use this kind of syntax:
`${string/substr1/substr2}`
`${string//substr1/substr2}`
Here's an example:
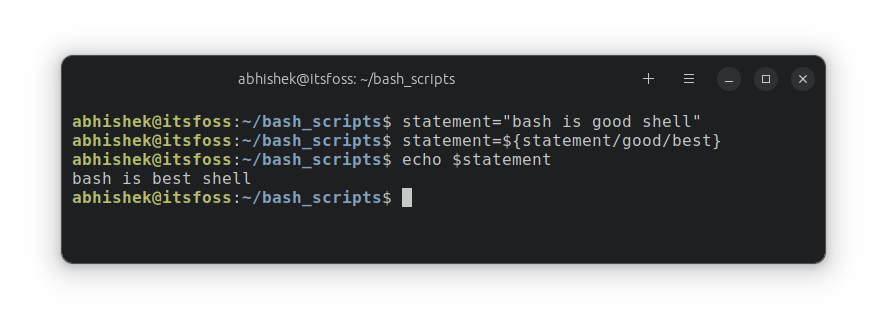
As you can see above, the word good was replaced with best. I saved the replaced string to the same string to change the original.
## Delete substring in bash
Let's talk about removing substrings. Let's say you want to remove part of a string. In that case, just provide the substring to the main string like this:
`${string/substring}`
`${string//substr}`
If the substring is found, it will be deleted from the string.
Let's see this with an example.
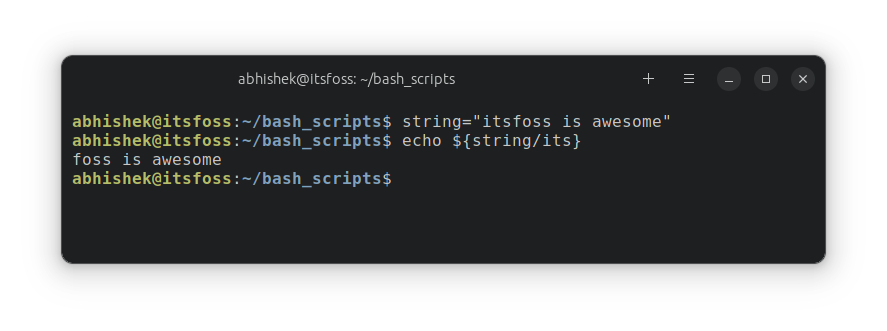
This goes without saying that if the substring is not found, it is not deleted. It won't result in an error.
## 🏋️ Exercise time
It's time for you to practice string manipulation with simple exercises.
**Exercise 1**: Declare a string 'I am all wet'. Now change this string by replacing the word wet with set.
**Exercise 2**: Create a string that saves phone numbers in the following format `112-123-1234`
. Now, you have to delete all `-`
.
The answers can be discussed in this dedicated thread in the Community.
[Practice Exercise in Bash Basics Series #6: Handling String OperationsIf you are following the Bash Basics series on It’s FOSS, you can submit and discuss the answers to the exercise at the end of the chapter: Fellow experienced members are encouraged to provide their feedback to new members. Do note that there could be more than one answer to a given problem.](https://itsfoss.community/t/practice-exercise-in-bash-basics-series-6-handling-string-operations/10925)

That should give you some decent practice with strings in bash. In the next chapter, you'll learn about [using if-else statements in bash](https://itsfoss.com/bash-if-else/).
[Bash Basics Series #7: If Else StatementIf this, then that else something else. Doesn’t make sense? It will after you learn about the if-else statements in bash shell scripting.](https://itsfoss.com/bash-if-else/)

Stay tuned. |
16,049 | 探索 Shell 脚本的威力 | https://www.opensourceforu.com/2022/05/shell-scripting-is-still-going-strong/ | 2023-07-31T07:10:32 | [
"Shell",
"脚本"
] | https://linux.cn/article-16049-1.html | 
>
> 本文章向你介绍了 Shell 脚本的基础知识以及其在日常生活中的重要性。
>
>
>
当我们登录到一个 UNIX/Linux 系统时,我们首先注意到的是闪烁的光标和 `$` 符号之间的空格。这就是 Shell(交互界面)。多年来,它一直是一种无处不在(有时甚至是唯一的)与计算机交互的界面。在图形用户界面(GUI)出现和流行之前,终端和 Shell 是唯一的机制,可以让计算机按照我们的意图进行操作。乍一看,我们可能会想知道 Shell 的作用,除了将命令传递给底层操作系统以进行执行之外。我们中的大多数人熟悉像 `ls`(用于列出目录内容),`cd`(用于更改当前目录)等命令。通过 Shell,我们可以执行这些命令。Shell 理解我们输入的文本 - 将其转换为标记 - 然后在操作系统上执行这些标记。
### 不同的 Shell 变种
最初,终端使用了朴素的 Bourne Shell(即 Sh)。多年来,许多不同的 Shell 变种被开发出来和使用。其中一些流行的包括 C Shell(Csh) 和 Korn Shell(Ksh)。Sh 在一段时间内不再受欢迎,但通过其最新的化身 —— Bourne Again Shell(Bash),它再次流行起来。
### Shell 实际上是做什么的?
Shell 是操作系统(OS)和用户之间的直接接口。通过使用命令和应用程序来使用计算机上安装的工具,我们可以使计算机按照我们的意愿工作。一些命令是安装在操作系统上的应用程序,而某些命令则是直接内置在 Shell 中的。在 Bash 中内置的一些命令包括 `clear`、`cd`、`eval` 和 `exec`,还有 `ls` 和 `mkdir` 这样的应用程序。内置在 Shell 中的命令因 Shell 而异。
在本文中,我们将涵盖与 Bash 相关的几个方面。
### 更多关于 Shell 的内容
我们中的大多数人都用过像 `ls`、`cd` 和 `mkdir` 这样的命令。当我们在一个目录上运行 `ls -l` 命令时,该目录中的所有子目录和文件都会在屏幕上列出。如果数量很大,屏幕会滚动。如果终端不支持滚动条(在很多年里都是如此),则无法查看已滚动过的条目。为了克服这个问题,我们使用像 `more` 和 `less` 这样的命令。它们允许我们逐页查看输出。通常使用的命令是:
```
ls -l | less
```
在这里 Shell 是在做什么?看起来像是单个命令,实际上是 `ls` 和 `less` 两个命令依次执行。管道符(`|`)将这两个程序连接起来,但连接由 Shell 管理。由于有了管道符,Shell 连接了这两个程序——它将 `ls` 命令的标准输出连接到 `less` 的标准输入(stdin)。管道功能使我们能够将任何程序的输出作为另一个程序的输入提供,而无需对程序进行任何更改。这是许多 UNIX/Linux 应用程序的理念——保持应用程序简单,然后将许多应用程序组合在一起以实现最终结果,而不是让一个程序做很多事情。
如果需要,我们可以将 `ls` 的输出重定向到文件中,然后使用 `vi` 查看它。为此,我们使用以下命令:
```
ls -l > /tmp/my_file.txt
vi /tmp/my_file.txt
```
在这种情况下,`ls` 的输出被重定向到一个文件中。这由 Shell 进行管理,它理解 `>` 符号表示重定向。它将其后面的标记视为文件。
### 使用 Shell 自动化
结合命令的能力是使用 Shell 命令创建自动化脚本的关键要素之一。在我最近的项目中,我们使用集群模式执行 Python/Spark(PySpark)应用程序。每个应用程序执行了许多结构化查询语言(SQL)语句 - SparkSQL。为了跟踪应用程序的进展,我们会打印有关正在执行的 SQL 的详细信息。这样可以让我们保留应用程序中正在发生的情况的日志。由于应用程序在集群模式下执行,要查看日志,我们必须使用以下 `yarn` 命令:
```
yarn log –applicationId [application_id]
```
在大多数情况下,应用程序生成的日志非常大。因此,我们通常将日志导入到 `less` 中,或将其重定向到一个文件中。我们使用的命令是:
```
yarn log –aplicationId [application_id] | less
```
我们的开发团队有 40 人。每个人都必须记住这个命令。为了简化操作,我将这个命令转换成了一个 Bash 脚本。为此,我创建了一个以 `.sh` 为扩展名的文件。在 UNIX 和 Linux 系统上,文件扩展名并不重要。只要文件是可执行的,它就能工作。扩展名在 MS Windows 上有意义。
### 需要记住的重要事项
Shell 是一个解释器。这意味着它会逐行读取程序并执行它。这种方法的限制在于错误(如果有)在事先无法被识别。直到解释器读取和执行它们时,错误才会被识别出来。简而言之,假如我们有一个在前 20 行完美执行,但在第 21 行由于语法错误而失败的 Shell 程序。当脚本在第 21 行失败时,Shell 不会回滚/撤销之前的步骤。当发生这样的情况时,我们必须纠正脚本并从第一行开始执行。因此,例如,如果在遇到错误之前删除了几个文件,脚本的执行将停止,而文件将永远消失。
我创建的脚本是:
```
#!/bin/bash
yarn log –applicationId 123 | less
```
…其中 123 是应用程序的 ID。
第一行的前两个字符是特殊字符(“释伴”)。它们告诉脚本这是一个可执行文件,并且该行包含要用于执行的程序的名称。脚本的其余行传递给所提到的程序。在这个例子中,我们将执行 Bash。即使包含了第一行,我们仍然必须使用以下命令对文件应用执行权限:
```
chmod +x my_file.sh
```
在给文件设置了执行权限之后,我们可以如下执行它:
```
./my_file.sh
```
如果我们没有给文件设置执行权限,我们可以使用以下命令执行该脚本:
```
sh ./my_file.sh
```
### 传递参数
你很快就会意识到,这样的脚本很方便,但立即变得无用。每次执行 Python/Spark 应用程序时,都会生成一个新的 ID。因此,对于每次运行,我们都必须编辑文件并添加新的应用程序 ID。这无疑降低了脚本的可用性。为了提高其可用性,我们应该将应用程序 ID 作为参数传递:
```
#!/bin/bash
yarn –log -applicationId ${1} | less
```
我们需要这样执行脚本:
```
./show_log.sh 123
```
脚本将执行 `yarn` 命令,获取应用程序的日志并允许我们查看它。
如果我们想将输出重定向到一个文件中怎么办?没问题。我们可以将输出重定向到一个文件而不是发送给 `less`:
```
#!/bin/bash
ls –l ${1} > ${2}
view ${2}
```
要运行脚本,我们需要提供两个参数,命令变为:
```
./my_file.sh /tmp /tmp/listing.txt
```
当执行时,`$1` 将绑定到 `/tmp`,`$2` 将绑定到 `/tmp/listing.txt`。对于 Shell,参数从一到九命名。这并不意味着我们不能将超过九个参数传递给脚本。我们可以,但这是另一篇文章的主题。你会注意到,我将参数命名为 `${1}` 和 `${2}`,而不是 `$1` 和 `$2`。将参数名称封闭在花括号中是一个好习惯,因为它使我们能够无歧义地将参数作为较长变量的一部分组合起来。例如,我们可以要求用户将文件名作为参数,并使用它来形成一个更大的文件名。例如,我们可以将 `$1` 作为参数,创建一个新的文件名为 `${1}_student_names.txt`。
### 使脚本更健壮
如果用户忘记提供参数怎么办?Shell 允许我们检查这种情况。我们将脚本修改如下:
```
#!/bin/bash
if [ -z "${2}" ]; then
echo "file name not provided"
exit 1
fi
if [ -z "${1}" ]; then
echo "directory name not provided"
exit 1
fi
DIR_NAME=${1}
FILE_NAME=${2}
ls -l ${DIR_NAME} > /tmp/${FILE_NAME}
view /tmp/${FILE_NAME}
```
在这个程序中,我们检查是否传递了正确的参数。如果未传递参数,我们将退出脚本。你会注意到,我以相反的顺序检查参数。如果我们在检查第一个参数存在之前检查第二个参数的存在,如果只传递了一个参数,脚本将进行到下一步。虽然可以按递增顺序检查参数的存在,但我最近意识到,从九到一检查会更好,因为我们可以提供适当的错误消息。你还会注意到,参数已分配给变量。参数一到九是位置参数。将位置参数分配给具名参数可以在出现问题时更容易调试脚本。
### 自动化备份
我自动化的另一个任务是备份。在开发的初期阶段,我们没有使用版本控制系统。但我们需要有一个机制来定期备份。因此,最好的方法是编写一个 Shell 脚本,在执行时将所有代码文件复制到一个单独的目录中,将它们压缩,并使用日期和时间作为后缀来上传到 HDFS。我知道,这种方法不如使用版本控制系统那样清晰,因为我们存储了完整的文件,查找差异仍然需要使用像 `diff` 这样的程序;但它总比没有好。尽管我们最终没有删除代码文件,但团队确实删除了存储助手脚本的 `bin` 目录!!!而且对于这个目录,我没有备份。我别无选择,只能重新创建所有的脚本。
一旦建立了源代码控制系统,我很容易将备份脚本扩展到除了之前上传到 HDFS 的方法之外,还可以将文件上传到版本控制系统。
### 总结
如今,像 Python、Spark、Scala 和 Java 这样的编程语言很受欢迎,因为它们用于开发与人工智能和机器学习相关的应用程序。尽管与 Shell 相比,这些语言更强大,但“不起眼”的 Shell 提供了一个即用即得的平台,让我们能够创建辅助脚本来简化我们的日常任务。Shell 是相当强大的,尤其是因为我们可以结合操作系统上安装的所有应用程序的功能。正如我在我的项目中发现的那样,即使经过了几十年,Shell 脚本仍然非常强大。我希望我已经说服你尝试一下了。
### 最后一个例子
Shell 脚本确实非常方便。考虑以下命令:
```
spark3-submit --queue pyspark --conf "[email protected]" --conf "spark.yarn.keytab=/keytabs/abcd.keytab" --jars /opt/custom_jars/abcd_1.jar --deploy-mode cluster --master yarn $*
```
我们要求在执行 Python/Spark 应用程序时使用此命令。现在想象一下,这个命令必须每天被一个由 40 个人组成的团队多次使用。大多数人会在记事本中复制这个命令,每次需要使用时,会将其从记事本中复制并粘贴到终端中。如果复制粘贴过程中出现错误怎么办?如果有人错误使用了参数怎么办?我们如何调试使用的是哪个命令?查看历史记录并没有太多帮助。
为了让团队能够简单地执行 Python/Spark 应用程序,我们可以创建一个 Bash Shell 脚本,如下所示:
```
#!/bin/bash
[email protected]
KEYTAB_PATH=/keytabs/abcd.keytab
MY_JARS=/opt/custom_jars/abcd_1.jar
MAX_RETRIES=128
QUEUE=pyspark
MASTER=yarn
MODE=cluster
spark3-submit --queue ${QUEUE} --conf "spark.yarn.principal=${SERVICE_PRINCIPAL}" --conf "spark.yarn.keytab=${KEYTAB_PATH}" --jars ${MY_JARS} --deploy-mode ${MODE} --master ${MASTER} $*
```
这展示了一个 Shell 脚本的强大之处,让我们的生活变得简单。根据你的需求,你可以尝试更多的命令和脚本,并进一步探索。
*(题图:MJ/f32880e8-0cdc-4897-8a1c-242c131111bf)*
---
via: <https://www.opensourceforu.com/2022/05/shell-scripting-is-still-going-strong/>
作者:[Bipin Patwardhan](https://www.opensourceforu.com/author/bipin-patwardhan/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *This article introduces you to the basics of shell scripting and its importance in day-to-day life. A shell script is a command-line interpreter that runs on a UNIX/Linux shell.*
The first thing we notice when we log into a UNIX/Linux system is the blinking cursor next to the $ sign. This is the shell. It has been – for many decades – the ubiquitous (and many times the only) interface to interact with a computer. Before the advent and popularity of graphical user interfaces (GUIs), the terminal and the shell were the only mechanism to make the computer do what we wanted it to do. At first glance, one may wonder what the shell does – other than passing commands to the underlying operating system for execution. Most of us are familiar with commands like ‘ls’ (for listing contents of a directory), ‘cd’ (for changing the current directory), and so on. It is through the shell that we can execute these commands. The shell understands the text we type — converts it into tokens — and then executes them on the operating system.
**Flavours**
Initially, the terminal started with the humble Bourne shell or ‘sh’. Over the years, many shell variants were developed and used. Some of the popular ones are ‘C Shell’ / ‘csh’ and ‘Korn Shell’ / ‘ksh’. ‘sh’ fell out of favour for a few years, but has gained popularity once again through its recent avatar, namely ‘bash’ / ‘Bourne Again Shell’.
**What does the shell actually do?**
The shell is the immediate interface between the operating system (OS) and the user. We make the computer do what we want, by using commands and applications supported by the tools installed on the computer we are using. Some commands are applications installed on the operating system, while some are built into the shell itself. Some of the commands built into bash are ‘clear’, ‘cd’, ‘eval’, and ‘exec’, to name a few, while commands like ‘ls’, and ‘mkdir’ are applications. The commands built into the shell vary as per the shell.
In this article, we cover a few aspects related to ‘bash’.
**More about the shell**
Most of us have used commands like ‘ls’, ‘cd’, and ‘mkdir’. When we run the ‘ls -l’ command on a directory, all the directories and files in that directory are listed on the screen. If the number is large, the screen scrolls. If the terminal does not support scroll bars (as was the case for many years), there is no way to look at the entries that have scrolled past. To help overcome this, we use commands like ‘more’ and ‘less’. These allow us to view the output on a page-by-page basis. The command typically used is:
ls -l | less
What is the shell doing here? What looks like a single command is actually two commands executing one after the other, ls and less. The pipe (‘|’) connects the two programs, but the connection is managed by the shell. Because of the pipe character, the shell connects the two programs – it connects the standard output of the ls command and connects it to the standard input or standard in or stdin of less. The pipe feature allows us to take the output of any program and provide it as the input to another program – without us having to do any changes to the programs. This is the philosophy of many UNIX/Linux applications — keep the applications simple and then combine many applications together to achieve the end result, rather than having one program do many things.
If needed, we can redirect the output of ls to a file and then view it using ‘vi’. For this, we use the command:
ls -l > /tmp/my_file.txt vi /tmp/my_file.txt
In this case, the output of ls is being redirected to a file. This is managed by the shell, which understands the ‘>’ symbol to mean redirection. It treats the token that follows as a file.
**Automation using shell**
This ability to combine commands is one of the key elements for the creation of automation scripts using shell commands. In my most recent project, we were executing Python/Spark (PySpark) applications using cluster mode. Each application executed many structured query language (SQL) statements – SparkSQL. To keep track of application progress, we were printing details about the SQL being executed. This allowed us to maintain a log of what was happening in the application. As the applications were executed in cluster mode, to view the log, we had to use the yarn command as follows:
yarn log –applicationId [application_id]
In most cases, the log produced by an application was very large. So we typically piped the log to ‘less’ or redirected it to a file. The command we used was:
yarn log –aplicationId [application_id] | less
Our development team had a strength of 40 people. Each one had to remember this command. To make it simpler, I converted this command into a bash script. For this, I created a file with a ‘.sh’ extension. On UNIX and Linux systems, file extension does not matter. As long as the file is an executable, it will work. Extensions have significance on MS Windows.
**Important thing to remember**
The shell is an interpreter. This means that it will read the program line by line and execute it. The limitation of this approach is that errors (if any) are not identified upfront. Errors are not identified till they are read and executed by the interpreter. In short, we can have a shell program that will execute perfectly for the first 20 lines and then fail due to a syntax error on line 21. When the script fails at line 21, the shell does not unroll/undo the previous steps. When such a thing occurs, we have to correct the script and start execution from the first line. Thus, as an example, if we have deleted a few files before encountering an error, execution of the shell script will stop, but the files are gone forever.
The script I created was:
#!/bin/bash yarn log –applicationId 123 | less
…where 123 was the application ID.
The first two characters of the first line are magic characters. They tell the script that this is an executable file and the line contains the name of the program to be used for execution. The remaining lines of the script are passed to the program mentioned. In this case, we are going to execute bash. Even after including the first line, we have to apply execute permissions to the file using:
chmod +x my_file.sh
After giving execute permissions to the file, we can execute it as:
./my_file.sh
If we do not give execute permissions to the file, we can execute the script as:
sh ./my_file.sh
**Passing parameters**
You will realise quickly that such a script is handy, but becomes useless immediately. Each time we execute the Python/Spark application, a new ID is generated. Hence, for each run, we have to edit the file and add the new application ID. This definitely reduces the usability of the script. To be useful, we should be passing the application ID as a parameter:
#!/bin/bash yarn –log -applicationId ${1} | less
We need to execute the script as:
./show_log.sh 123
The script will execute the yarn command, fetch the log for the application and allow us to view it.
What if we want to redirect the output to a file? Not a problem. Instead of sending the output to less, we can redirect it to a file:
#!/bin/bash ls –l ${1} > ${2} view ${2}
To run the script, we have to provide two parameters, and the command becomes:
./my_file.sh /tmp /tmp/listing.txt
When executed, $1 will bind to /tmp and $2 will bind to /tmp/listing.txt. For the shell, the parameters are named from one to nine. This does not mean we cannot pass more than nine parameters to a script. We can, but that is the topic of another article. You will note that I have mentioned the parameters as ${1} and ${2} instead of $1 and $2. It is a good practice to enclose the name of the parameter in curly brackets as it allows us to unambiguously combine the parameters as part of a longer variable. For example, we can ask the user to provide file name as a parameter and then use that to form a larger file name. As an example, we can take $1 as the parameter and create a new file name as ${1}_student_names.txt.
**Making the script robust**
What if the user forgets to provide parameters? The shell allows us to check for such conditions. We modify the script as below:
#!/bin/bash if [ -z “${2}” ]; then echo “file name not provided” exit 1 fi if [ -z “${1}” ]; then echo “directory name not provided” exit 1 fi DIR_NAME=${1} FILE_NAME=${2} ls -l ${DIR_NAME} > /tmp/${FILE_NAME} view /tmp/${FILE_NAME}
In this program, we check if the proper parameters are passed. We exit the script if parameters are not passed. You will note that I am checking the parameters in reverse order. If we check for the presence of the first parameter before checking the presence of the second parameter, the script will pass to the next step if only one parameter is passed. While the presence of parameters can be checked in ascending order, I recently realised that it might be better to check from nine to one, as we can provide proper error messages. You will also note that the parameters have been assigned to variables. The parameters one to nine are positional parameters. Assigning positional parameters to named parameters makes it easy to debug the script in case of issues.
**Automating backup**
Another task that I automated was that of taking a backup. During development, in the initial days, we did not have a version control system in place. But we needed to have a mechanism to take regular backups. So the best method was to write a shell script that, when executed, copied all the code files into a separate directory, zipped them and then uploaded them to HDFS, using the date and time as the suffix. I know that this method is not as clean as having a version control system, as we store complete files and finding differences still needs the use of a program like diff; however, it is better than nothing. While we did not end up deleting the code files, the team did end up deleting the bin directory where the helper scripts were stored!!! And for this directory I did not have a backup. I had no choice but to re-create all the scripts.
Once the source code control system was in place, I easily extended the backup script to upload the files to the version control system in addition to the previous method uploading to HDFS.
**Summing up**
These days, programming languages like Python, Spark, Scala, and Java are in vogue as they are used to develop applications related to artificial intelligence and machine learning. While these languages are far more powerful when compared to shells, the ‘humble’ shell provides a ready platform that allows us to create helper scripts that ease our day-to-day tasks. The shell is quite powerful, more so because we can combine the powers of all the applications installed on the OS. As I found out in my project, even after many decades, shell scripting is still going strong. I hope I have convinced you to give it a try.
**One for the road**
Shell scripts can be very handy. Consider the following command:
spark3-submit --queue pyspark --conf “spark.yarn.principal= [email protected] --conf “spark.yarn.keytab=/keytabs/abcd.keytab --jars /opt/custom_jars/abcd_1.jar --deploy-mode cluster --master yarn $*
We were expected to use this command while executing a Python/Spark application. Now imagine this command has to be used multiple times a day, by a team of 40 people. Most of us will copy this command in Notepad++, and each time we need to use it, we will copy it from Notepad++ and paste it on the terminal. What if there is an error during copy paste? What if someone uses the parameters incorrectly? How do we debug which command was used? Looking at history does not help much.
To make it simple for the team to get on with the task of Python/Spark application execution, we can create a bash shell script as follows:
#!/bin/bash [email protected] KEYTAB_PATH=/keytabs/abcd.keytab MY_JARS=/opt/custom_jars/abcd_1.jar MAX_RETRIES=128 QUEUE=pyspark MASTER=yarn MODE=cluster spark3-submit --queue ${QUEUE} --conf “spark.yarn.principal=${SERVICE_PRINCIPAL} --conf “spark.yarn.keytab=${KEYTAB_PATH} --jars ${MY_JARS} --deploy-mode ${MODE} --master ${MASTER} $*
This demonstrates how powerful a shell script can be and make our life easy. You can try more commands and scripts as per your requirement and explore further. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.