
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
15,577 | Flathub 计划发展为通用的 Linux 应用商店 | https://news.itsfoss.com/flathub-app-store-plans/ | 2023-02-26T10:19:19 | [
"Flathub"
] | https://linux.cn/article-15577-1.html |
>
> Flathub 正在为全面的改变和改进做准备。以下是你需要了解的情况。
>
>
>

作为一个 Flatpak 仓库,[Flathub](https://flathub.org) 一直非常受欢迎,并且它也是 Canonical 的 [Snap Store](https://snapcraft.io/store) 的良好替代品。
而现在,背后支持它的 GNOME 和 KDE 等准备更进一步,启动了一个 **完全的品牌重塑和发展该平台的计划**。
让我们看看 Flathub 的未来。
### Flathub 的品牌重塑

随着 GNOME 的 Jakub Steiner **带头进行的品牌重塑**,Flathub 的外观和感觉都将发生改变。
他专注于使 Flathub 的新形象不至于太 “喧宾夺主”,而将重点始终放在应用程序本身。
他还提到:
>
> 在中性灰色的基础上建立一个品牌并不容易,但这恰恰是针对 Flathub 品牌的要点。
>
>
> 它为应用程序创造了闪耀的舞台,Flathub 本身并不炫目,它让应用程序成为你注意力的中心。
>
>
>
如果你对 UI/UX 感兴趣,我建议你阅读他的 [博文](https://blog.jimmac.eu/2023/flathub-brand-refresh/),以更详细地了解 Flathub 的新视觉识别。
### Flathub 应用商店的发展

[GNOME 基金会](https://foundation.gnome.org) 和 [KDE e.V](https://ev.kde.org) 在建立和改进 Flathub 方面一直进展良好。自 2017 年推出以来,Flathub 一直在以非常惊人的速度发展着。
**发生了什么?** 在上个月的一项最新 [提案](https://github.com/PlaintextGroup/oss-virtual-incubator/blob/main/proposals/flathub-linux-app-store.md) 中,计划了一些值得关注的事情,重点是使 Flathub 成为一个激励其发布者的 Linux 应用生态系统。
简单来说,他们想把 Flathub 变成一个**成熟的应用商店**,让发布者可以从他们的应用中获得收益,这应该会改善资金状况。
**为什么?** 这样做的理由是;如今的这种资金障碍阻碍了潜在的开发者开发开源应用程序,这反过来又阻碍了整个开源生态系统的发展。
提案中强调的另一件事是:
>
> 健康的应用程序生态系统对于开源软件桌面的成功至关重要,以便最终用户可以信任并控制他们面前的设备上的数据和开发平台。
>
>
>
**Flathub 将如何实现这一目标?** 定期捐赠或订阅系统是该计划的主要补充之一。
?️ 诸如防止滥用应用程序收录的审查工具、自动安全扫描,以及一些更细微的变化都已进入计划。
此外,Flathub 需要工具来防止误导性的应用名称、描述、屏幕截图等出现在平台上,并阻止它们,直到它们被审查,以保证被检查过。
总的来说,总结一下,以下是你可以期待的事情:
* 定期捐款系统或订阅系统
* 付费的应用程序
* 改进 Flathub 的应用审查流程和监测更新变化的内部工具
你可能会发现一些实施方案已经出现在 [Flathub 的测试门户](https://beta.flathub.org/en-GB),比如 [新的应用程序验证系统](https://news.itsfoss.com/verified-flatpak-apps/)。
此外,他们打算建立一个新的法律实体 **Flathub LLC**,来拥有和运营这项服务。
他们旨在通过它建立以下内容:
>
> 透明的治理流程以维护社区信任和问责制,并建立一个咨询委员会/赞助流程以在我们的拨款申请的同时吸引商业赞助。
>
>
>
? **现在你可能在想,他们预算如何?**
该提案提到,**未来一年的总预算为 20 万美元**。
其中包括 12 万美元的员工工资,以及 3 万美元的法律、专业和管理费用,最后 5 万美元用于平台的开发。
他们已经有 5 万美元用于前一阶段的开发,另外还有 10 万美元已经确认,所需预算的 50% 已经有了。
剩余的 10 万美元已经从 [Plaintext Group](https://www.plaintextgroup.com) 寻求,该集团是由 **谷歌前 CEO 埃里克·施密特** 创立的 Schmidt Futures 的一部分。
### 总结
好吧,我必须说这是一个非常值得关注的举措。
Flathub 已经受到了各类 Linux 用户的欢迎。因此,推动有助于资助该项目的功能,将 Flathub 变成一个丰富的应用生态系统,**有望成为桌面用户的通用 Linux 应用平台**。
? 可能这就是 Linux 桌面用户所需要的。你怎么看?请在下面的评论中分享你的想法。
---
via: <https://news.itsfoss.com/flathub-app-store-plans/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Flathub](https://flathub.org/?ref=news.itsfoss.com) has been a popular portal as a Flatpak repository and has also acted as a good alternative to Canonical's [Snap Store](https://snapcraft.io/store?ref=news.itsfoss.com).
And now, the folks behind it (including GNOME and KDE) are taking it a step further by initiating a **complete re-brand and plans to evolve** the platform.
Let's look at what Flathub's future holds.
## Flathub Rebrand
Flathub's look and feel are all set to change with the **rebranding spearheaded by Jakub Steiner** from GNOME.
He has focused on making the new identity of Flathub not too 'loud and shouty', with the spotlight always being on the apps themselves.
He also mentions:
Building a brand on neutral greys isn’t quite an easy sell, but precisely targets the main point of the Flathub brand.
It creates the stage for apps to shine. Flathub isn’t flashy by itself. It allows the apps to be at the center of your attention.
If you are into UI/UX, I recommend you go through his [blog post](https://blog.jimmac.eu/2023/flathub-brand-refresh/?ref=news.itsfoss.com) for a more detailed outlook on the new visual identity for Flathub.
## Flathub App Store to Evolve
The [GNOME Foundation](https://foundation.gnome.org/?ref=news.itsfoss.com) and [KDE e.V](https://ev.kde.org/?ref=news.itsfoss.com) have been making good progress to build and improve Flathub. It has been evolving at a very impressive rate since its launch in 2017.
**What is happening?: **In a recent [proposal](https://github.com/PlaintextGroup/oss-virtual-incubator/blob/main/proposals/flathub-linux-app-store.md?ref=news.itsfoss.com) last month, some interesting things have been planned that focus on making Flathub a Linux application ecosystem that incentivizes its publishers.
In simpler terms, they want to make Flathub into a **fully-fledged app store** that will let publishers earn off their apps, which should improve the funding situation.
**Why?: **The reasoning for a move like this is that; such financial barriers prevent potential developers from getting into developing open-source apps, which in turn hampers the growth of the open-source ecosystem as a whole.
Another thing highlighted in the proposal is:
A healthy application ecosystem is essential for the success of the OSS desktop, so end-users can trust and control their data and development platforms on the device in front of them.
**How will Flathub achieve this?: **A recurring donation or subscription system is one of the major additions planned.
🛠️ Things like review tools to prevent abusive application admissions, automated security scans, and a couple more subtle changes have been planned.
In addition, Flathub needs tooling to prevent misleading application names, descriptions, screenshots, etc., from being on the platform and to block them until they have been reviewed to keep things checked.
Overall, to sum up, here are the things that you can expect:
**Recurring donation system or subscription system****Paid applications****Internal tools to improve flathub's app review process and monitor changes for updates**
You may find some implementations showing up at [Flathub's beta portal](https://beta.flathub.org/en-GB?ref=news.itsfoss.com) like the [new app verification system](https://news.itsfoss.com/verified-flatpak-apps/).
Furthermore, they intend to establish a new legal entity, **Flathub LLC**, to own and operate the service.
They aim to establish the following with it:
A transparent governance process to help maintain community trust and accountability, and build an advisory board / sponsorship process to attract commercial sponsorship to the service in parallel to our grant applications.
💸 **Now you might be thinking, how will they fund all this?**
The proposal mentions that the **total budget for the coming year is $200,000 USD**.
It includes $120,000 towards staff salaries, and $30,000 towards legal, professional, and administration costs, with the final $50,000 going towards the platform's development.
They already have $50,000, being used for the previous phase of development, with another $100,000 already confirmed, bringing it to 50% of their required budget.
The remaining $100,000 has been sought from the [Plaintext Group](https://www.plaintextgroup.com/?ref=news.itsfoss.com), a part of Schmidt Futures, founded by the **former CEO of Google, Eric Schmidt**.
**Suggested Read **📖
[Flatpak vs. Snap: 10 Differences You Should KnowFlatpak vs Snap, know the differences and gain insights as a Linux user to pick the best.](https://itsfoss.com/flatpak-vs-snap/?ref=news.itsfoss.com)

## Concluding Thoughts
Well, I must say this is a very interesting move.
Flathub is already well-received by Linux users of all kinds. So, facilitating features that help fund projects and turn Flathub into a rich app ecosystem that can **potentially act as a universal Linux app platform for desktop users.**
*💬 Probably this is what Linux desktop users need. What do you think? Share your thoughts in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,579 | 当开源遇到学术出版:白金开放获取期刊 | https://opensource.com/article/22/5/platinum-open-access-academic-journals | 2023-02-27T11:28:01 | [
"期刊",
"开放获取"
] | https://linux.cn/article-15579-1.html | 
>
> 学者现在可以免费发表(文章),免费阅读(文章),与此同时仍然能够在专业成就的道路上持续进步。
>
>
>
学者们经常将他们的作品免费提供给公司,然后却要花钱购买它!你能想象农民在免费送出他们的食物之后再重新花钱买回来做晚餐吗?可能不能吧。像我这样的学者陷入这样的阴谋中几十年了,我们以工作保障为交换免费提供我们的作品,然后却要每年花几百万美元来阅读我们自己的文章。
幸运的是,情况正在发生改变。我刚刚完成的一项 [研究](https://doi.org/10.3390/knowledge2020013) 的结果显示:对于学者来说,获得工作保障的同时而不对此付出代价是可能的。我的研究发现数百种期刊是 <ruby> 白金开放获取 <rt> platinum open access </rt></ruby>(LCTT 译注:译名源自中文网络)的 —— 也就是说,它们不需要作者或者读者为同行评议的工作付费,却仍然拥有帮助学者在他们的职业生涯中取得成功的声望和读者群。
这一趋势正在扩张:[开放获取期刊目录](https://doaj.org/) 罗列了超过 17300 种期刊,这些期刊均提供了某种程度上的 <ruby> 开放获取 <rt> open access </rt></ruby>(OA)方式。该目录还提供了超过 12250 种无须 <ruby> 文章处理费 <rt> article-processing charges </rt></ruby>(APC)的期刊。我使用一段简易的开源 [Python 脚本](https://osf.io/mh4bx/) 来将该列表与另一按照期刊发表的文章被其他文章引用的频次排名的期刊列表(期刊影响因子列表)进行比较。很明显,最近几年来,总体的开放获取期刊与白金开放获取期刊均呈上升趋势。这一趋势可能有助于在避免学术奴役的同时加速科学发展。
### 学者的窘境
学者们通常是相当聪慧的,那么他们为什么如此长时间地投身于这种不利体系中呢?简而言之,学者陷于这样一个陷阱中:为了维系他们的工作和获得终身教职,他们需要在高 <ruby> 影响因子 <rt> impact factor </rt></ruby> 的期刊上发表文章。影响因子是一种基于最近两年间在给定期刊上发表的文章的平均引用数量的衡量指标。影响因子由 Web of Science 索引。对学者而言,影响因子是一个有影响力的衡量指标。
历史上,学术出版一直由一小部分主要出版商统治。他们采用基于订阅制的商业模式。在这样的商业模式中,学术作者撰写文章,评审同行的文章,也经常对这些文章进行编辑。这些工作都是没有任何报酬的。这些文章出版了,它们的版权则由那些主要的出版公司所有。即使是参与上述工作的学者也需要个人付费阅读这些文章(每篇文章大约 35 美元),或者由他们所在学校的图书馆付费订阅期刊上的所有文章。(订阅)所花的费用是相当可观的:单是一个出版商的所有文章的订阅费用通常超过一百万每年。
有很多显然的理由都说明这一体制是毫无意义的。由于限制对隐匿在付费专区后的受版权保护的科学文献的访问,使得科学进程陷于停滞。如果你因为无法查看而不知道前沿科技是什么的话,你就无法进行相应的前沿技术研究。科学家被划分为能够负担访问这些文章的费用的人,以及不能负担(这些费用的人)。发展中国家的学者往往难以支付,不过即使是财力雄厚的 [哈佛大学](https://www.theguardian.com/science/2012/apr/24/harvard-university-journal-publishers-prices) 也已经采取行动控制它的年度期刊费用。
文章作者的花费也同样高昂。每篇文章的文章处理费从几百美元到骇人听闻的几千美元不等。文章处理费对一些资金不足的学科尤其有害,比如人文学科与社会学科(与物理学、医学和工程学相比而言)。大量的文章处理费也强化了学术界的贫富差距,使得(学者的)专业成就依赖于是否有收入投入文章发表。还有哪种职业要求从业者付费为他人制造产品?
### 开放获取,解决之道!
开放获取行动可以解决上述问题,开放获取行动倡导使所有的学术文献对任何人都能自由自由获取。开放获取的出版量有明显上升:它占了当前同行评议文章的将近三分之一。
开放获取的优势分两个方面。首先,开放获取有利于科学整体,因为它提供了一个不受阻碍地阅读前沿技术的方式。这些技术有助于进一步做出重要的认知进步。其次,就学者个人层面而言,通过让他们的作品在网络上轻而易举地免费获得,提供了最大化他们作品的潜在受众的实际优势。
基于上述原因,资助者已经开始要求开放获取,尤其是科学领域的公共资助者。如果一项研究的公共资助者还需要在阅读研究内容时二次付费,这种做法很难站得住脚。
### 学术出版目前身处何方,以后又去向何处?
传统出版商仍然掌控着目前的局面,主要是因为认为他们垄断了具有影响因子的期刊这一认知。很多学者无视传统出版方式的缺点,仍然持续在基于订阅制的期刊上发表文章或者支付高昂的文章处理费,因为他们知道在高影响因子的期刊上发表文章是至关重要的,它能够提供赖以获取补助、终身教职与职位晋升的专业性的证明。
多年以前,学术界完全没有选择的余地:要么在具有影响因子的期刊上发表,要么在通过开放获取方式发表。现在他们可以通过开放获取方式发表并仍然能够通过以下三种方式之一享受影响因子的益处:
* <ruby> 绿色开放获取模式 <rt> Green OA </rt></ruby>:以传统方式出版后,再通过上传预印版或者接受版论文至开放仓库或者服务器完成自行归档。一些高校拥有用于上述目的的公共仓库。举例而言,<ruby> 韦仕敦大学 <rt> Western University </rt></ruby> 拥用 [Scholarship@Western](https://ir.lib.uwo.ca/) 公共仓库,该校的任何教师都可以在上面分享他们的作品。而没有自己机构的公共仓库的学者可以使用诸如 [preprints.org](https://www.preprints.org/)、[arXiv](https://arxiv.org/) 或 [OSF preprints](https://osf.io/preprints/) 等网络服务器。我也会将社交媒体用于学术,比如将 [Academia](https://westernu.academia.edu/JoshuaPearce/Papers) 或 [ResearchGate](https://www.researchgate.net/profile/Joshua-Pearce) 用于自行存档。由于不同的出版商设计了不同的规则,这是不方便查阅的,而且某种程度上是耗时耗时耗力的。
* <ruby> 金色开放获取模式 <rt> Gold OA </rt></ruby>:在日益壮大的具有影响因子的期刊列表上选一份期刊发表,它将使你的文章发表后可以自由获取但是需要文章处理费。这种方式易于查阅:开放获取设置内建于出版过程中,只需要像往常一样进行学术出版。这种方式的缺点是可能会从研究活动中拿出一部分资金用于文章处理的费用。
* <ruby> 白金开放获取模式 <rt> Platinum OA </rt></ruby>:在具有影响因子的白金开放获取期刊上发表。不需要为出版和阅读付费。挑战在于在你的学科中找到符合上述标准的期刊,不过情况正在持续变化。
有数以万计的期刊,但是只有几百种具有影响因子的白金开放获取期刊。对于学者,困难可能在于在他们的研究与符合他们预期的期刊之间找到一个合适的平衡。你可以在我的研究报告附录中找到本文提到的列表,或者使用上文提到的 Python 脚本自行更新列表数量。白金开放获取期刊的数量正在快速增长,因此如果你目前尚未找到合适的期刊,仍然可能在不久以后拥有一些可靠的期刊以供选择。祝你享受出版的乐趣!
---
via: <https://opensource.com/article/22/5/platinum-open-access-academic-journals>
作者:[Joshua Pearce](https://opensource.com/users/jmpearce) 选题:[lkxed](https://github.com/lkxed) 译者:[CanYellow](https://github.com/CanYellow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Academics routinely give away their work to companies for free—and then they buy it back! Can you imagine a farmer giving away free food and then paying to get it back for dinner? Probably not. Yet academics like me have been trapped for decades in a scheme where we give free work in exchange for job security and then pay millions of dollars a year to read our own writing.
Fortunately, this is changing. The results from a [study](https://doi.org/10.3390/knowledge2020013) I just finished show that it is possible for academics to get job security without paying for it. My study found hundreds of journals that are *platinum open access* (OA)—that is, they require neither the author nor the readers to pay for peer-reviewed work—yet still carry the prestige and readership to help academics succeed in their careers.
This trend is exploding: The [Directory of Open Access Journals](https://doaj.org/) lists over 17,300 journals that offer a means of OA at some level, and over 12,250 have no article-processing charges (APCs). I used a handy open source [Python script](https://osf.io/mh4bx/) to compare this list to a list of journals ranked by the frequency with which their published papers are cited in other articles (The Journal Impact Factor List). It is clear that the last few years have seen a growing trend towards both OA in general and platinum OA specifically. These trends have the potential to accelerate science while helping prevent academic servitude.
## The academic's dilemma
Academics are generally pretty intelligent, so why have they engaged in this disadvantageous system for so long? Simply put, academics have been caught in a trap: In order to keep their jobs and get tenure, they need to publish in journals with a high *impact factor*. An impact factor is a metric based on the mean number of citations to articles published in the last two years in a given journal, as indexed by the proprietary Web of Science. Impact factors are a prestige metric for academics.
Historically, academic publishing has been dominated by a handful of major publishers that used subscription-based business models. In this model, academic authors write articles, peer-review articles, and often do the editing of these articles—all for free. The articles are published under copyright owned by the major publishing companies. Then either the same academics pay to read these articles on an individual basis (~US $35/article), or their university libraries pay to subscribe to all of the articles in a journal. These costs can be astronomical: often over US $1 million per year for all titles from a single publisher.
This system is senseless for many obvious reasons. Scientific progress is bogged down by restricting access to copyrighted scientific literature squirreled away behind paywalls. It is hard to do state-of-the-art research if you do not know what it is because you cannot read it. Scientists are divided into those who can afford access to the literature and those who cannot. Academics in the developing world often struggle to pay, but even well-endowed [Harvard University](https://www.theguardian.com/science/2012/apr/24/harvard-university-journal-publishers-prices) has taken action to rein in its yearly journal expenses.
Costs to authors are similarly high. APC values range from a few hundred dollars to jaw-dropping thousands of dollars per article. APCs can be particularly damaging for some disciplines that are less well funded, such as the humanities and social sciences (as compared to physical and medical sciences or engineering). Substantial APCs also reinforce the wealth gap in academia, making professional success dependent on having income to invest in publishing. Is there another profession that asks workers to pay money to make products for others?
## Open access to the rescue!
This problem can be solved by the OA movement, which advocates for making all academic literature freely accessible to everyone. There is an unmistakable rise in OA publishing: It now makes up nearly a third of the peer-reviewed literature.
The benefits of OA are twofold. First, OA is a benefit to science overall, because it provides a frictionless means of reading the state of the art for making significant advancements in knowledge. Second, from an individual academic's point of view, OA provides the pragmatic advantage of enabling the broadest possible audience of their writing by making it freely and easily available on the internet.
Funders have begun to demand OA for these reasons, particularly public funders of science. It is hard to argue that if the public funds research, they should have to pay a second time to read it.
## Where is academic publishing now, and where it is going?
Conventional publishers still have control of this situation, largely because of the perception that they have a monopoly on journals with an impact factor. Despite the disadvantages of publishing the traditional way, many academics continue to publish in subscription-based journals or pay high APCs, knowing that publication in high impact factor journals is vital for demonstrating expertise for grants, tenure, and promotion.
A few years ago, academics simply had no choice: They could either publish in a journal with an impact factor or publish OA. Now they can publish OA and still get the benefits of an impact factor in one of three ways:
**Green OA:**Publish in a traditional way and then self-archive by uploading preprints or accepted versions of papers into an open repository or server. Some schools have an institutional repository for this purpose. For example, Western University has[Scholarship@Western](https://ir.lib.uwo.ca/), where any of their professors can share their work. Academics without their own institutional repos can use servers like[preprints.org](https://www.preprints.org/),[arXiv](https://arxiv.org/), or[OSF preprints](https://osf.io/preprints/). I also use social media for academics, like[Academia](https://westernu.academia.edu/JoshuaPearce/Papers)or[ResearchGate](https://www.researchgate.net/profile/Joshua-Pearce), for self-archiving. This can be complex to navigate because publishers have different rules, and it is somewhat time consuming.**Gold OA:**Publish in a growing list of journals with impact factors that make your paper freely available after publication but require an APC. This method is easy to navigate: Academics publish as usual and OA is built into the publishing process. The drawback is that funds going to APCs may be diverted from research activities.**Platinum OA:**Publish in platinum OA journals with an impact factor. No one pays either to read or to publish. The challenge here is finding a journal in your discipline that fits this criterion, but that continues to change.
There are tens of thousands of journals, but only a few hundred platinum OA journals with impact factors. This may make it hard for academics to find a good fit between what they study and a journal that matches their interests. See the Appendix in my [study](https://www.mdpi.com/2673-9585/2/2/13) for the list, or use the Python script mentioned above to run updated numbers for yourself. The number of platinum OA journals is growing quickly, so if you do not find something now you may have some solid journals to choose from soon. Happy publishing!
## Comments are closed. |
15,580 | 通过 apt-get 降级一个软件包 | https://itsfoss.com/downgrade-apt-package/ | 2023-02-27T11:58:22 | [
"apt"
] | https://linux.cn/article-15580-1.html | 
最近升级的软件引起问题了?虽然你总是可以调查问题以解决它,但有时,回到以前的工作版本可以节省时间和精力。如果新的版本引入了一个 bug,你可以在你这一边什么都不做,对吗?
好消息是,你可以在 Ubuntu 和 Debian 中轻松地降级 apt 软件包。
你所要做的就是像这样使用 `apt` 命令:
```
sudo apt install package_name=package-version-number
```
这似乎很容易,但你如何获得确切的版本号?还有哪些旧版本被支持?你可以通过以下方式获得这个细节:
```
sudo apt-cache policy package_name
```
让我用一个现实生活中的例子来解释这些。
### 降级 apt 包
最近,我正在更新承载 It's FOSS 社区论坛的 Ubuntu 服务器。
我做了通常的 `apt update && apt upgrade`,在更新安装时,事情变得糟糕。
很明显,最新版本的 Docker 不支持 aufs 存储驱动。为了减少停机时间,我选择了降级到以前的 Docker 版本。
检查当前安装的软件包版本:

然后检查可以安装的可用版本:
```
sudo apt-cache policy package_name
```
它可能会抛出一个巨大的列表,或者只是一个小列表:

如果它显示至少有一个比当前版本更早的版本,你就很幸运了。
现在,你可能认为一个软件包的版本号将只由数字组成。但情况可能并不总是这样。
基本上,你复制 500(优先级数字)之前的全部内容。
```
brave-browser:
Installed: 1.48.158
Candidate: 1.48.164
Version table:
1.48.164 500
500 https://brave-browser-apt-release.s3.brave.com stable/main amd64 Packages
*** 1.48.158 500
500 https://brave-browser-apt-release.s3.brave.com stable/main amd64 Packages
100 /var/lib/dpkg/status
1.47.186 500
500 https://brave-browser-apt-release.s3.brave.com stable/main amd64 Packages
1.47.171 500
500 https://brave-browser-apt-release.s3.brave.com stable/main amd64 Packages
1.46.153 500
```
当你得到了软件包的编号,用它来降级已安装的软件包,像这样:
```
sudo apt install package_name=package-version-number
```

当然,你会看到一个关于降级软件包的警告。

但是当这个过程完成,你的软件包就会被降级到给定的旧版本。
### 所以,也许要保留它?
所以,你刚刚学会了降级 apt 软件包。但如果你不注意的话,该软件包会在下一次系统更新时再次升级。
不希望这样吗?你可以 [阻止一个软件包被更新](https://itsfoss.com/prevent-package-update-ubuntu/)。像这样使用 `apt-mark` 命令:
```
sudo apt-mark hold package_name
```
我希望这个快速技巧能帮助你在需要时降级 apt 软件包。如果你有问题或建议,请告诉我。
---
via: <https://itsfoss.com/downgrade-apt-package/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

In a situation where a recently upgraded software is causing issues?
While you can always investigate the issue to fix it, at times, going back to the previous working version saves time and effort.
If the new version introduced a bug, you could do nothing on your end, right?
The good thing is that you can easily downgrade an apt package in Ubuntu and Debian.
All you have to do is to use the apt command like this:
`sudo apt install package_name=package-version-number`
That seems easy enough but how would you get the exact version number? Which old versions are supported? You can get that detail with:
`sudo apt-cache policy package_name`
Let me explain all this with a real-life example.
## Downgrading apt package
Recently, I was updating the Ubuntu server that hosts It's FOSS Community forum.
I did the usual apt update && apt upgrade and things went bonkers by the time updates were installed.
Apparently, the latest version of Docker didn't support the aufs storage driver. To reduce the downtime, I opted to downgrade to the previous Docker version.
Check the currently installed package version
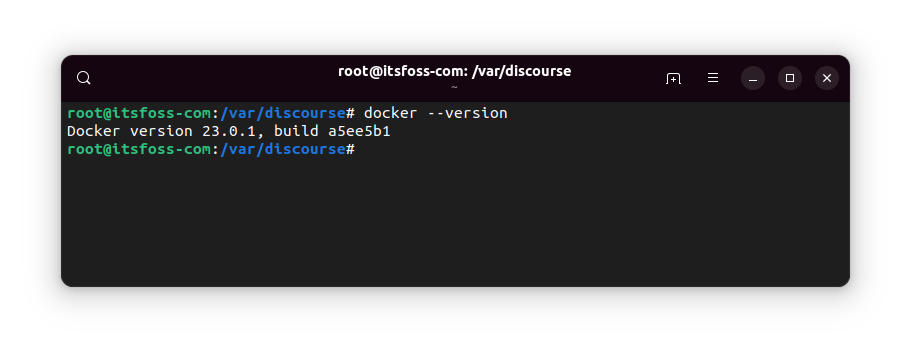
Then check for the available versions that could be installed:
`sudo apt-cache policy package_name`
It may throw a huge list or just a small one:
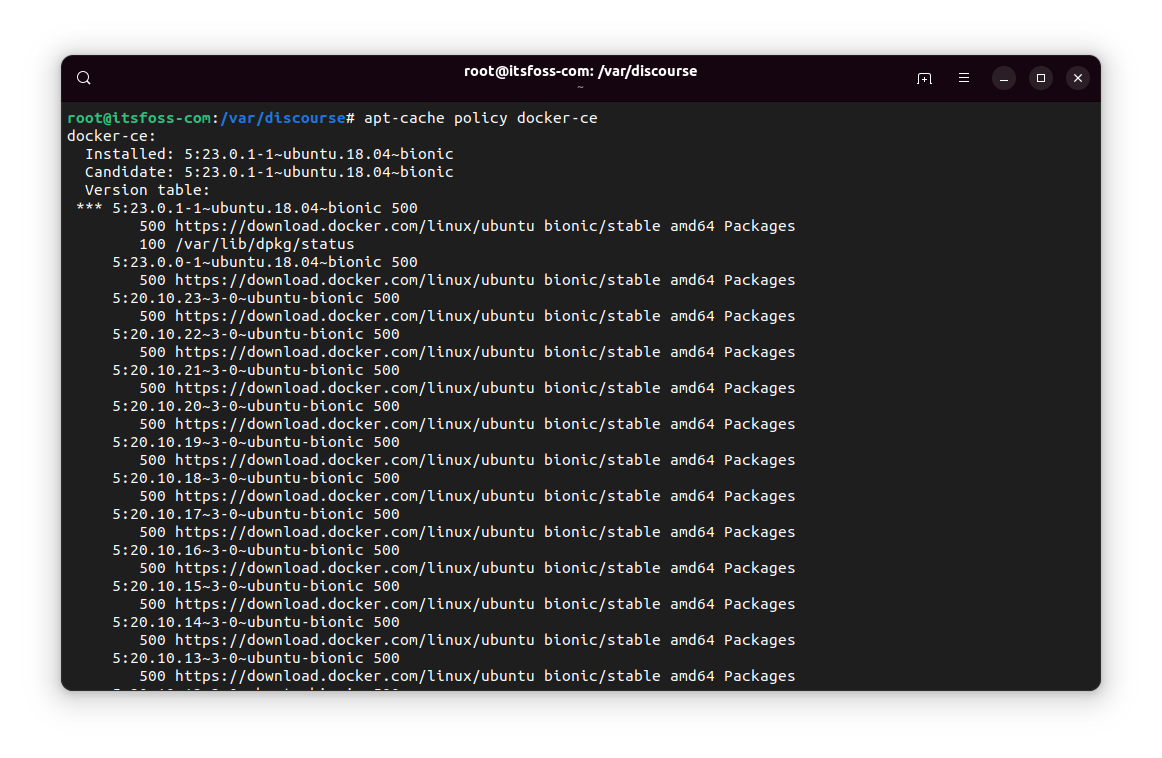
If it shows at least one older version than the current one, you are in luck.
Now, you may think that the version number of a package would be composed of just the numbers. But that may not always be the case.
Basically, you copy the entire stuff before 500 (the priority number).
```
brave-browser:
Installed: 1.48.158
Candidate: 1.48.164
Version table:
1.48.164 500
500 https://brave-browser-apt-release.s3.brave.com stable/main amd64 Packages
*** 1.48.158 500
500 https://brave-browser-apt-release.s3.brave.com stable/main amd64 Packages
100 /var/lib/dpkg/status
1.47.186 500
500 https://brave-browser-apt-release.s3.brave.com stable/main amd64 Packages
1.47.171 500
500 https://brave-browser-apt-release.s3.brave.com stable/main amd64 Packages
1.46.153 500
```
Once you have got the package number, use it to downgrade the installed package like this:
`sudo apt install package_name=package-version-number`
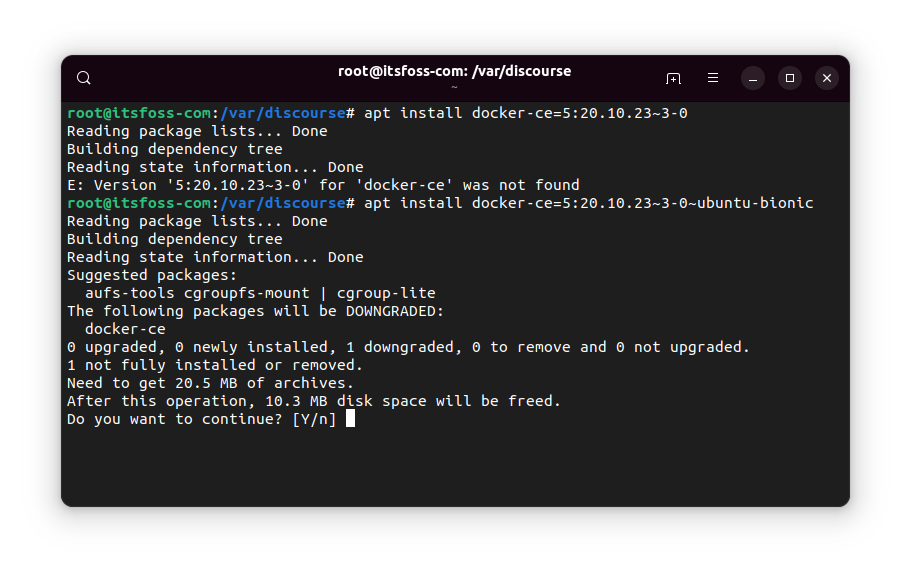
You'll see a warning about downgrading the package, of course.
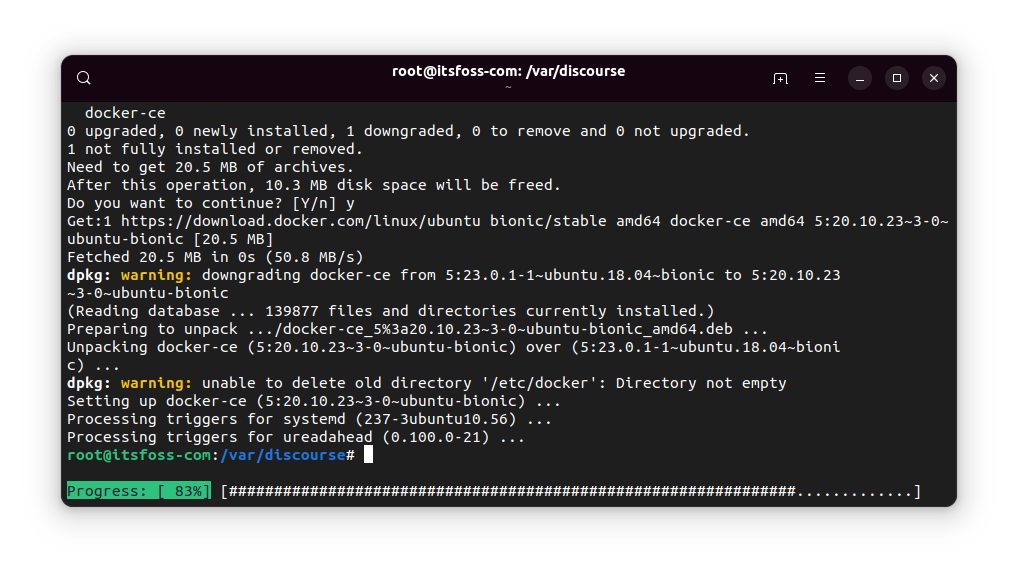
But once the process completes, your package would have been downgraded to the given older version.
## So, hold it, maybe?
So, you just learned to downgrade apt packages. But if you don't pay attention, the package will be upgraded again with the next system update.
Don't want that? You can [prevent a package from being updated](https://itsfoss.com/prevent-package-update-ubuntu/). Use the apt-mark command like this:
`sudo apt-mark hold package_name`
Want more details? Check out this article.
[How to Prevent a Package From Being Updated in Ubuntu and Debian-based Linux DistributionsBrief: Quick tutorial to show you how to prevent certain packages from being updated in Ubuntu and Debian based Linux distributions. When you update your Ubuntu system, all the applications, packages are updated at once. This is of course very convenient as you don’t have to worry about up…](https://itsfoss.com/prevent-package-update-ubuntu/)

I hope this quick tip helps you with downgrading the apt packages when the need arises. Let me know if you have questions or suggestions. |
15,582 | Endless OS 5.0:带有 Wayland 和丰富应用程序的最佳 GNOME 桌面 | https://www.debugpoint.com/endless-os-5-0-review/ | 2023-02-28T00:15:00 | [
"Endless OS"
] | /article-15582-1.html | 
>
> 新版本的 Endless OS 5.0 已经发布,带来了更多的功能和稳定性。下面是对这个版本的简要点评。
>
>
>
在不变性成为炒作对象之前,Endless OS 已经提供了一种基于 [OSTree](https://ostree.readthedocs.io/en/stable/) 的高效桌面体验。它基于 Debian 和 Ubuntu,但正在独立开发。由于其底层基于 OSTree,Endless OS 运行在其用户空间中,同时给你最好的桌面体验。
它是一个适合学校、小规模部署、实验室和离线使用情况的完美发行版。
新版本的 Endless OS 5.0 现在已经推出。下面是对其功能的快速回顾和深入点评。
>
> 我们相信,个人计算对生产力、学习和工作技能至关重要。
>
>
> 我们在过去 10 年中致力于设计和提供操作系统和工具,使人们能够获得和控制他们的技术。
>
>
> 借助我们的工具,我们可以通过使用和发现来提高生产力、创造力和学习,我们帮助各种背景的人以更有意义的方式参与数字经济。
>
>
> —— Endless OS 使命宣言
>
>
>
### Endless OS 5 点评
由于这个操作系统的目的是为不太富裕的人提供数字计算的机会,所以它提供了 Windows 安装程序。你可以直接下载它并在 Windows 环境中试用。
此外,它还提供了一个专门的独立 ISO 镜像,可以通过 U 盘进行安装。
上次我在 2021 年点评 Endless OS 时,它并没有提供 ARM 版本。我很惊讶地发现,它现在有一个 ARM 镜像,你可以在树莓派和其他 ARM 板上试用。
在我的测试安装中,一切都很顺利。它使用一个自定义的安装程序,类似于 Fedora 的 Anaconda 安装程序。然而,安装它需要一个完整的磁盘。如果你喜欢双启动,[在此](https://support.endlessos.org/en/installation/windows-installer/dual-boot) 有一个详细的指南。但是,我觉得它的设置有点复杂。

#### 登录和第一印象
这个版本基于 [Debian 11 “bullseye”](https://www.debugpoint.com/debian-11-features/),带有 Linux 主线 [内核 5.15](https://www.debugpoint.com/linux-kernel-5-15/)。此外,它还为该团队的原生应用程序提供了单独的软件仓库。其桌面基于 [GNOME 41](https://www.debugpoint.com/gnome-41-release/)。
这个版本在外观感受方面有一些改变。首先,底部面板被改变为显示基本的 GNOME 风格的停靠区。它总是可见的,当你把一个窗口移到它上面时,它就会消失。早些时候,它是一个固定的标准面板,有一个应用程序图标、系统托盘和正在运行的应用程序部件。
其次,它引入了一个新的顶部面板,遵循 GNOME 的设计。它包含活动、应用程序启动器和系统托盘。

和 Endless OS 4.0 的外观相比,它有很多改变:

#### 对 GNOME 桌面和工作区的独特定制
默认外观保持不变,包括带有搜索框的桌面应用程序视图。顶部面板上的应用程序是对运行中的应用程序和桌面视图的切换。
超级键(`Super`)也可以切换到正在运行的应用程序和工作区视图,这一点非常方便。窗口在右上方有最小化、最大化和关闭按钮;它们不需要调整。
然而,在这个版本中,有一个喜欢的功能被放弃了。在 [Endless OS 4.0](https://www.debugpoint.com/endless-os-review-2021) 中,当你点击桌面的空白部分时,它会立即将所有打开的窗口最小化,并向你显示桌面。然而,这个功能已经不再可用了。这是一个多么方便的功能,可以使工作流程更加顺畅。
#### 在 Endless OS 5.0 中引入 Wayland
现代显示服务器 Wayland 在这个版本中首次出现在 Endless OS 中。默认登录是 Wayland。然而,你可以从登录界面切换到 [X.Org](http://X.Org)。得益于 Wayland,你可以感受到 Endless OS 操作系统中流畅的动画、手势和性能。
#### 手势支持
Endless OS 5.0 还引入了多手势支持。你现在可以通过触控板/触摸板使用三指左右轻扫来浏览工作区。此外,三指向上滑动可以切换应用程序网格和工作空间。
支持的应用程序也可以使用捏合缩放,包括双指滚动。
这是一个非常需要的更新,以进一步提高你在 Endless OS 中的生产力。
#### 应用程序中心、Flatpak 和应用程序
Endless OS 作为一个不可变的发行版,你所有的应用程序都运行在一个独立的用户空间。默认情况下,它只支持 Flatpak 软件包。默认配置了世界上最大的 Flatpak 仓库 Flathub。你可以直接从 AppCenter 搜索并安装任何 Flatpak 应用程序。

然而,在默认情况下,几乎所有需要的应用程序都已经预装。如果你想处理文件,一个完整的 LibreOffice 包就在那里。它还包括预装了 Ad-Block 的 Chromium 网络浏览器!此外,你还得到了 Gedit 文本编辑器、Shotwell 图像查看器、Brasero 磁盘刻录应用程序、<ruby> 文件 <rt> Files </rt></ruby>应用作为文件管理器、管理你的学校/家庭工作流程的 Kolibri。
所有原生的 GNOME 应用程序现在都默认是 Flatpak 版本,而不是 APT 软件包。这是 Endless OS 5.0 的关键变化之一。

#### 帮助中心
Endless OS 的伟大功能之一是可以从帮助应用程序中获得离线帮助。你也可以通过桌面搜索功能访问它。
任何学生或首次使用的用户都可以快速了解桌面的基本功能,如 “如何更改密码” 或 “如何创建账户” 之类的问题。所有这些都可以作为离线帮助文件使用。

### 总结
Endless OS 5.0 带来了非常需要的变化,如 Wayland 和手势支持,同时坚持其原则,成为一个易于使用的大众发行版。它是一个设计良好、考虑周到的发行版,非常适合离线/远程使用、实验室、学校和社区。如果配置正确,Linux 可以影响数百万人 —— 对那些买不起昂贵软件的人来说。
另外,对于普通用户来说,如果你打算运行多年,这可能是一个完美的发行版。你可以把自己从升级、系统故障、命令、依赖性问题等的麻烦中解救出来。
这是该团队为社区发布的一个优秀版本。你可以从下面的链接下载它。
>
> **[下载 Endless OS](https://www.endlessos.org/os-windows-installer)**
>
>
>
你对这个版本的整体印象如何?请在评论栏里告诉我。
参见 [Endless OS 5.0 发布说明](https://support.endlessos.org/en/endless-os/release-notes/5) 。
---
via: <https://www.debugpoint.com/endless-os-5-0-review/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,583 | 在 Ubuntu GUI 中以 root 身份登录 | https://itsfoss.com/ubuntu-login-root/ | 2023-02-28T10:45:59 | [
"root"
] | https://linux.cn/article-15583-1.html | 
默认情况下,Ubuntu 禁用了 root 账户。你必须使用 `sudo` 命令来执行任何需要 root 权限的任务。
当然,这是为了你自己的安全。一直以 root 身份使用系统,就像手里拿着一把剑到处跑。它增加了把事情搞乱的机会。
以 root 身份登录在服务器中仍然很常见。在桌面方面,以 root 身份登录的情况相当少见。甚至 Kali Linux 也做了改变。
然而,有一些桌面用户想以 root 身份登录。这不是什么明智之举,但肯定是可以做到的。
在本指南中,我将向你展示如何在 Ubuntu 中 **以 root 身份登录 GNOME 桌面**。
### 如何在 GNOME 桌面上以 root 身份登录
>
> ? 我不建议在桌面上以 root 身份登录。你有 sudo 机制来满足你所有的 root 需求。只有在你有足够理由的情况下才这样做。本教程仅用于演示目的。你已经被警告过了。
>
>
>
#### 步骤 1:启用 root 账户
你想以 root 身份登录。但默认情况下,root 账户是禁用的。第一步是启用它。
改变 root 账户的密码,这将为你启用 root 账户:
```
sudo passwd root
```

不言而喻,你不应该忘记 root 密码。
#### 步骤 2:改变 GDM 配置
>
> ? 本教程的这一部分只对 GNOME 有效。请 [检查你的桌面环境](https://itsfoss.com/find-desktop-environment/) 并确保它是 GNOME。
>
>
>
Ubuntu 默认使用 GNOME,GNOME 使用 GDM 显示管理器。
为了允许以 root 身份登录到 GNOME,你需要对位于 `/etc/gdm3/custom.conf` 的 GDM 配置文件做一些修改。
对该配置文件做一个备份:
```
cp /etc/gdm3/custom.conf /etc/gdm3/custom.conf~
```
在最坏的情况下,如果你以某种方式把事情搞砸了,备份的文件可以用来从 TTY 上替换现有文件。
现在,用以下命令打开 GDM 文件:
```
sudo nano /etc/gdm3/custom.conf
```
并添加以下一行,允许 root 用户登录:
```
AllowRoot=true
```

按 `Ctrl+X` 退出 Nano,同时保存它。
#### 步骤 3:配置 PAM 认证
现在,你必须配置 PAM 认证守护进程文件,它可以通过以下命令打开:
```
sudo nano /etc/pam.d/gdm-password
```
在这个文件中,你必须注释掉以下带有 `#` 号的一行,该符号拒绝 GUI 中的 root 访问:
```
auth required pam_succeed_if.so user != root quiet_success
```

[保存修改并退出 nano](https://linuxhandbook.com/nano-save-exit/) 文本编辑器。
#### 步骤 4:以 root 身份登录
现在,重启你的系统:
```
reboot
```
在登录界面,选择 `Not listed` 选项,在用户名中输入 `root`,并输入你在本指南开头配置的密码:

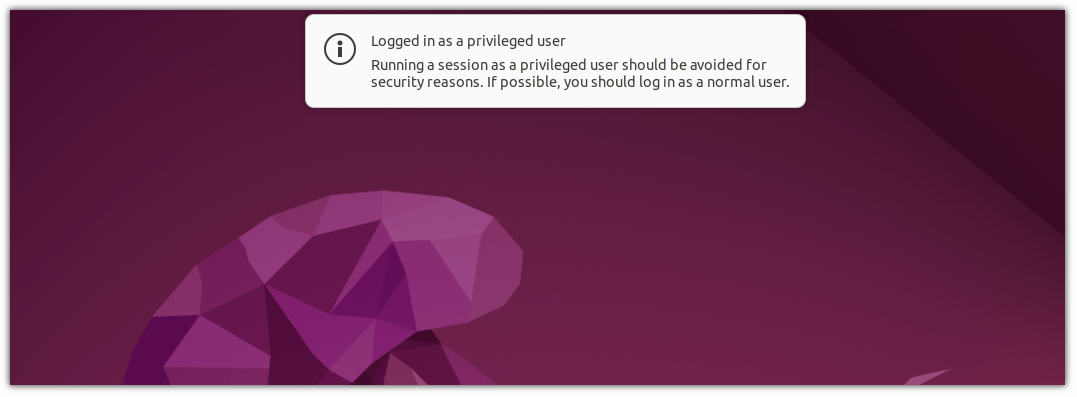
当你登录后,它就会通知你,**“logged in as a privileged user”**:

这就完成了! 现在,你正在以 root 身份运行你的 Ubuntu 系统。
### 以 root 用户身份运行系统时,你应该知道的事情
Ubuntu 默认禁用 root 账户是有原因的。想知道为什么吗?在这里你可以找到:
>
> **[Ubuntu 中的 root 用户-你应该知道的重要事项](https://itsfoss.com/root-user-ubuntu/#what-is-root)**
>
>
>
再说一遍,在你的桌面 Linux 系统中以 root 登录是不可取的。请遵守规范,远离这种(错误的)冒险。
---
via: <https://itsfoss.com/ubuntu-login-root/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

By default, Ubuntu disables the root account. You must use the sudo command for any tasks requiring root privileges.
This is for your own security, of course. Using the system as root all the time is like running around with a sword in your hand. It increases the chances of messing up things.
Logging in as root is still common in the servers. On the desktop side, it's quite rare to log in as root. Even Kali Linux has changed it.
And yet, a few desktop users want to log in as root. This is not something advisable but surely doable.
in this guide, I will show you how to **log in as a root in your GNOME desktop** using Ubuntu.
## How to login as a root in the GNOME desktop
### Step 1: Enable root account
You want to log in as root. But the root account is disabled by default. The first step is to enable it.
Change the root account password that will eventually enable the root account for you:
`sudo passwd root`
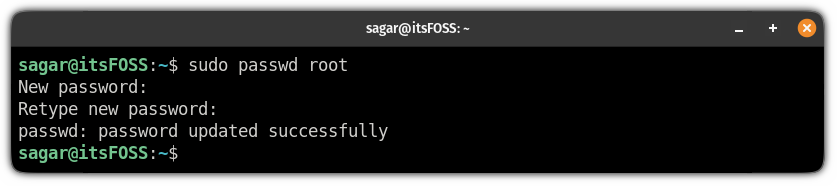
It goes without saying that you should not forget the root password.
### Step 2: Change GDM configuration
[check your desktop environment](https://itsfoss.com/find-desktop-environment/)and ensure that it is GNOME.
Ubuntu uses GNOME by default and GNOME uses the GDM display manager.
To allow log in as root into GNOME, you need to make some changes in the GDM configuration file located at `/etc/gdm3/custom.conf`
.
Make a backup of the config file:
```
cp /etc/gdm3/custom.conf /etc/gdm3/custom.conf~
```
In the worst case, if you somehow mess things up, the back up file can be used to replace the existing one from the TTY.
Now, open the GDM file with the following command:
```
sudo nano /etc/gdm3/custom.conf
```
And add the following line to allow the root login:
`AllowRoot=true`
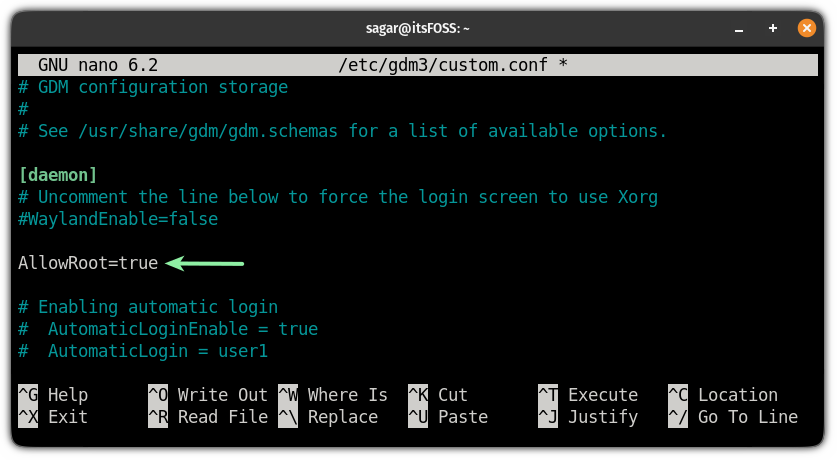
Press Ctrl+X to exit Nano while saving it.
### Step 3: Configure PAM authentication
Now, you will have to configure the PAM authentication daemon file, which can be opened by the following command:
`sudo nano /etc/pam.d/gdm-password`
In this file, you will have to comment out the following line with the `#`
symbol that denies the root access in GUI:
`auth required pam_succeed_if.so user != root quiet_success`
[Save changes and exit from the nano](https://linuxhandbook.com/nano-save-exit/) text editor.
### Step 4: Log in as root
Now, reboot your system:
`reboot`
At the login screen, select the `Not listed`
option, enter `root`
in username and enter the password that you configured at the beginning of this guide:
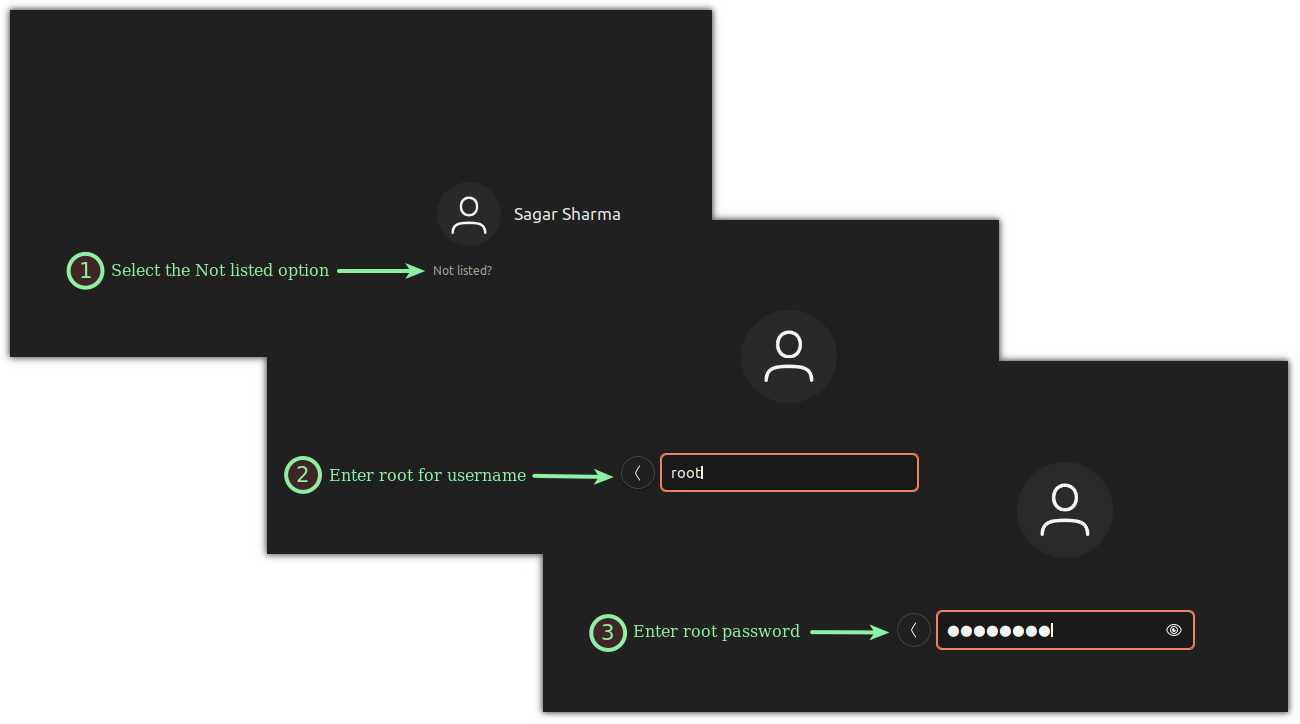
Once you log in, it will notify you by saying, **"logged in as a privileged user":**
That's it! Now, you are running your Ubuntu system as a root.
## Things you should know when running the system as a root user
There is a reason why Ubuntu disables a root account by default. Want to know why? Here you have it:
[Root User in Ubuntu- Important Things You Should KnowHow do you become root user in Ubuntu? Either you run commands with root privilege like this: sudo any_command Or you switch user in Ubuntu to root user like this: sudo su In both cases, you’ll have to enter your own user account’s password. But there’s](https://itsfoss.com/root-user-ubuntu/#what-is-root)

And again, it is not advisable to log in a s root in your desktop Linux system. Please follow the norms and stay away from such (mis) adventures. |
15,585 | 打开酒桶:“自酿啤酒” 4.0.0 版来了 | https://www.theregister.com/2023/02/27/homebrew_version_4_is_here | 2023-02-28T23:39:00 | [
"Homebrew"
] | https://linux.cn/article-15585-1.html |
>
> 用于 macOS(如果你需要的话,也包括 Linux)的附加软件包管理器。
>
>
>

如果你在 Mac 上的终端窗口工作,Homebrew 是一个方便的工具,它可以让你快速、轻松地安装广泛的 FOSS 世界中各种熟悉的工具。
这个附加的软件包管理器不需要超级用户权限,可以将程序安装到你的主目录中:它 “[对 macOS 的作用就像 apt-get 对 Debian 的作用](https://www.theregister.com/2018/08/08/researcher_found_homebrew_github_token_hidden_in_plain_sight/)”。新版本 [4.0.0](https://brew.sh/2023/02/16/homebrew-4.0.0/) 比以前更快,特别是在更新过程中。自动更新现在每天运行一次,而不是像 3.6 版那样每 5 分钟一次。虽然支持各种 Linux 发行版 —— 其基本要求非常宽松,内核 3.2 或更新版本,以及 Glibc 2.13 或更新版本 —— 但新版本不再正式支持 WSL1。

*Homebrew 团队合影,包括 “冒泡啤酒” —— 项目负责人 Mike McQuaid*
尽管 macOS 有 FOSS 的 [基础](https://opensource.apple.com/releases/),但苹果公司的产品是针对 Mac 用户设计的,他们倾向于生活在一个图形化的、点击式的世界里。这可能会让来自 Linux 的移民感到困惑:尽管 Mac 的终端环境继承了很多表面上看起来熟悉的来自 FreeBSD 的工具,但它们往往是过时的版本,或者有细微的不同。Linux 用户期望能够仅仅通过 `apt` 安装 python-3.11 或类似的工具。
这正是 Homebrew 被设计来解决的问题:安装 Homebrew 包,然后你输入 `brew install [email protected]` 就可以了。而且,至关重要的是,如果你在 macOS 上安装一个新版本的 Python,你可能会破坏操作系统的其他部分,而使用 Homebrew,你安装的任何东西都是你自己的 —— 它不会影响整个操作系统,也不会影响任何其他用户。
Homebrew 最初是为 macOS 建立的,但事实证明这个概念对 Linux 用户也很有用。你可能没有机器的 root 权限 —— 或者即使你有,那也可能只让你安装古老的版本,这些版本没有什么帮助,但你不能轻易更新。
该项目负责人 Mike McQuaid —— 当 Reg FOSS 部门的人在 FOSDEM 上见到他时,他正 [穿着](https://brew.sh/assets/img/blog/fosdem_2023.jpg) 华丽的衣服,像一杯冒泡的啤酒 —— 告诉我们:
>
> Linux 上的 Homebrew 曾经是一个被称为 “Linuxbrew” 的独立复刻。但随着时间的推移,到了如今这些努力和我们已经完全是一个项目了,共享我们的团队和基础设施等等。
>
>
> 它最初的用途是在高端生物信息学机器上,用户没有 root 权限来使用系统的软件包管理器,但想在该机器上从软件包管理器安装新的软件。
>
>
>
以前独立的 Linuxbrew 复刻早在 2019 年就被 [并入](https://brew.sh/2019/01/09/homebrew-1.9.0/) 了主项目的 1.9 版本。McQuaid 解释说,Homebrew 项目一些特异的 [术语](https://docs.brew.sh/Formula-Cookbook#homebrew-terminology),例如,“<ruby> 酒桶 <rp> ( </rp> <rt> cask </rt> <rp> ) </rp></ruby>” 和 “<ruby> 水龙头 <rp> ( </rp> <rt> tap </rt> <rp> ) </rp></ruby>”,都源自于合并的各种项目:
>
> Homebrew Cask 是一个独立的项目(现在基本上已经统一),允许 Homebrew 用于安装闭源软件的上游二进制包(相比之下,我们的主仓库 homebrew-core 只允许我们从源头构建自己的二进制的开源软件),例如 Chrome、Firefox 等。
>
>
> Homebrew 的 “我们从源代码构建” 的描述文件被称为 “<ruby> 配方 <rp> ( </rp> <rt> formulae </rt> <rp> ) </rp></ruby>”,我们用它构建我们的二进制包,“<ruby> 瓶子 <rp> ( </rp> <rt> bottle </rt> <rp> ) </rp></ruby>”。
>
>
> Homebrew 的 “分发上游二进制文件” 的描述文件被称为 “<ruby> 酒桶 <rp> ( </rp> <rt> cask </rt> <rp> ) </rp></ruby>”。
>
>
>
Homebrew 也可以在 Windows 10 或 11 上的 WSL 内工作,尽管在版本 4 中只支持 WSL2。它支持 Debian 和 Red Hat 家族的发行版,包括 Ubuntu、CentOS 和 RHEL,可以运行在 x86-64 和 Arm 32/64 机器上。
---
via: <https://www.theregister.com/2023/02/27/homebrew_version_4_is_here/>
作者:[Liam Proven](https://www.theregister.com/Author/Liam-Proven) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-15580-1.html) 荣誉推出
| 200 | OK | This article is more than **1 year old**
# Pop open a cask: Homebrew version 4.0.0 is here
## Add-on package manager for macOS (and Linux if you need it)
FOSS Fest Homebrew is a handy tool if you work in a terminal window on a Mac, which lets you quickly and easily install a wide variety of familiar tools from the wider FOSS world.
The add-on package manager doesn't need superuser permissions and installs programs into your home directory: it ["does for macOS what apt-get does for Debian"](https://www.theregister.com/2018/08/08/researcher_found_homebrew_github_token_hidden_in_plain_sight/). The new
[version 4.0.0](https://brew.sh/2023/02/16/homebrew-4.0.0/)is faster than before, especially when it comes to the update process. Automatic updates now run daily, rather than every five minutes as in version 3.6. While various Linux distros are supported – the basic [requirements] are a very modest kernel 3.2 or newer, and Glibc 2.13 or newer – the new version no longer officially supports WSL1.
Although macOS has FOSS [foundations](https://opensource.apple.com/releases/), Apple's offering is aimed at, well, Mac users, who tend to live in a graphical, point-and-click world. This can be disorienting to migrants from Linux: although the Mac's terminal environment inherits a lot of ostensibly-familiar tools from its roots in FreeBSD, they are often elderly versions, or are subtly different. Linux folks expect to just be able to `apt install python-3.11`
or the like.
This is what Homebrew was designed to fix: install the Homebrew package, and then you can type `brew install [email protected]`
and you're off. And, crucially, while if you install a new version of Python on macOS you might break other bits of the OS, with Homebrew, anything you install is yours alone – it won't affect the OS as a whole, or any other users.
Homebrew was originally built for macOS, but the concept proved useful for Linux users, too. Either you may not have root access to the machine – or even if you do, that may only let you install ancient versions which aren't much help, but you can't readily update.
[Apple splats zero-day bug, other gremlins in macOS, iOS](https://www.theregister.com/2023/02/15/apple_patches_zeroday_vulnerability/)[Microsoft hijacks Google's Chrome download page to beg you not to ditch Edge](https://www.theregister.com/2023/02/23/microsoft_edge_banner_chrome/)[Open source software has its perks, but supply chain risks can't be ignored](https://www.theregister.com/2023/02/22/open_software_supply_chain_risks/)[Researcher found Homebrew GitHub token hidden in plain sight](https://www.theregister.com/2018/08/08/researcher_found_homebrew_github_token_hidden_in_plain_sight/)
Project lead Mike McQuaid, who when the *Reg* FOSS desk met him at FOSDEM was resplendently [dressed](https://brew.sh/assets/img/blog/fosdem_2023.jpg) as a foaming pint, told us:
Homebrew on Linux used to be a separate fork known as "Linuxbrew". Over time, these efforts have got to where we are today, where we're entirely one project and share our team, infrastructure etc.
The original usage was on high-end bioinformatics machines where the users did not have root access to use the system package manager, but wanted to install new software from a package manager on that machine.
The formerly separate Linuxbrew fork was [merged](https://brew.sh/2019/01/09/homebrew-1.9.0/) into version 1.9 of the main project back in 2019. McQuaid explained that some of the project's idiosyncratic [terminology](https://docs.brew.sh/Formula-Cookbook#homebrew-terminology) (for example, "casks" and "taps") dates to various project merges:
Homebrew Cask was a separate project (now mostly unified) to allow Homebrew to be used to install upstream binary packages for closed-source software (in comparison,
`homebrew-core`
, our main repository, only allows open source software that we build our own binaries for from source) e.g. Google Chrome, Firefox, etc.Homebrew's "we build from source" description files are called "formulae" (from which we build our binary packages, "bottles").
Homebrew's "distribute upstream binaries" description files are called "casks".
Homebrew also works inside WSL on Windows 10 or 11, although in version 4, only WSL2 is supported. It supports Debian- and Red Hat-family distros if you need it, including Ubuntu, CentOS and RHEL, on x86-64 and both 32-bit and 64-bit Arm boxes. ®
12 |
15,586 | 使用 Terraform 来管理 OpenStack 集群 | https://opensource.com/article/23/1/terraform-manage-openstack-cluster | 2023-03-01T11:49:10 | [
"OpenStack",
"Terraform"
] | https://linux.cn/article-15586-1.html | 
>
> Terraform 是一种声明性语言,可以作为你正在建设的基础设施的蓝图。
>
>
>
在拥有一个 OpenStack 生产环境和家庭实验室一段时间后,我可以肯定地说,从管理员和租户的角度置备工作负载和管理它是很重要的。
Terraform 是一个开源的基础设施即代码(IaC)软件工具,用于 <ruby> 置备 <rt> provisioning </rt></ruby>网络、服务器、云平台等。Terraform 是一种声明性语言,可以作为你正在建设的基础设施的蓝图。你可以用 Git 来管理它,它有一个强大的 [GitOps](https://opensource.com/article/21/3/gitops) 使用场景。
本文介绍了使用 Terraform 管理 OpenStack 集群的基础知识。我使用 Terraform 重新创建了 OpenStack 演示项目。
### 安装 Terraform
我使用 CentOS 作为跳板机运行 Terraform。根据官方文档,第一步是添加 Hashicorp 仓库:
```
$ sudo dnf config-manager --add-repo https://rpm.releases.hashicorp.com/RHEL/hashicorp.repo
```
接下来,安装 Terraform:
```
$ sudo dnf install terraform -y
```
验证安装:
```
$ terraform –version
```
如果你看到返回的版本号,那么你已经安装了 Terraform。
### 为 OpenStack 提供者创建一个 Terraform 脚本
在 Terraform 中,你需要一个 <ruby> 提供者 <rt> provider </rt></ruby>,它是一个转换器,Terraform 调用它将你的 `.tf` 转换为对你正在协调的平台的 API 调用。
有三种类型的提供者:官方、合作伙伴和社区:
* 官方提供者由 Hashicorp 维护。
* 合作伙伴提供者由与 Hashicorp 合作的技术公司维护。
* 社区提供者是由开源社区成员维护的。
在这个 [链接](https://registry.terraform.io/providers/terraform-provider-openstack/openstack/1.49.0) 中有一个很好的 OpenStack 的社区提供者。要使用这个提供者,请创建一个 `.tf` 文件,并命名为 `main.tf`。
```
$ vi main.tf
```
在 `main.tf` 中添加以下内容:
```
terraform {
required_version = ">= 0.14.0"
required_providers {
openstack = {
source = "terraform-provider-openstack/openstack"
version = "1.49.0"
}
}
}
provider "openstack" {
user_name = “OS_USERNAME”
tenant_name = “OS_TENANT”
password = “OS_PASSWORD”
auth_url = “OS_AUTH_URL”
region = “OS_REGION”
}
```
你需要修改 `OS_USERNAME`、`OS_TENANT`、`OS_PASSWORD`、`OS_AUTH_URL` 和 `OS_REGION` 变量才能工作。
### 创建一个 Terraform 管理文件
OpenStack 管理文件的重点是置备外部网络、路由、用户、镜像、租户配置文件和配额。
此示例提供风格,连接到外部网络的路由、测试镜像、租户配置文件和用户。
首先,为置备资源创建一个 `AdminTF` 目录:
```
$ mkdir AdminTF
$ cd AdminTF
```
在 `main.tf` 中,添加以下内容:
```
terraform {
required_version = ">= 0.14.0"
required_providers {
openstack = {
source = "terraform-provider-openstack/openstack"
version = "1.49.0"
}
}
}
provider "openstack" {
user_name = “OS_USERNAME”
tenant_name = “admin”
password = “OS_PASSWORD”
auth_url = “OS_AUTH_URL”
region = “OS_REGION”
}
resource "openstack_compute_flavor_v2" "small-flavor" {
name = "small"
ram = "4096"
vcpus = "1"
disk = "0"
flavor_id = "1"
is_public = "true"
}
resource "openstack_compute_flavor_v2" "medium-flavor" {
name = "medium"
ram = "8192"
vcpus = "2"
disk = "0"
flavor_id = "2"
is_public = "true"
}
resource "openstack_compute_flavor_v2" "large-flavor" {
name = "large"
ram = "16384"
vcpus = "4"
disk = "0"
flavor_id = "3"
is_public = "true"
}
resource "openstack_compute_flavor_v2" "xlarge-flavor" {
name = "xlarge"
ram = "32768"
vcpus = "8"
disk = "0"
flavor_id = "4"
is_public = "true"
}
resource "openstack_networking_network_v2" "external-network" {
name = "external-network"
admin_state_up = "true"
external = "true"
segments {
network_type = "flat"
physical_network = "physnet1"
}
}
resource "openstack_networking_subnet_v2" "external-subnet" {
name = "external-subnet"
network_id = openstack_networking_network_v2.external-network.id
cidr = "10.0.0.0/8"
gateway_ip = "10.0.0.1"
dns_nameservers = ["10.0.0.254", "10.0.0.253"]
allocation_pool {
start = "10.0.0.1"
end = "10.0.254.254"
}
}
resource "openstack_networking_router_v2" "external-router" {
name = "external-router"
admin_state_up = true
external_network_id = openstack_networking_network_v2.external-network.id
}
resource "openstack_images_image_v2" "cirros" {
name = "cirros"
image_source_url = "https://download.cirros-cloud.net/0.6.1/cirros-0.6.1-x86_64-disk.img"
container_format = "bare"
disk_format = "qcow2"
properties = {
key = "value"
}
}
resource "openstack_identity_project_v3" "demo-project" {
name = "Demo"
}
resource "openstack_identity_user_v3" "demo-user" {
name = "demo-user"
default_project_id = openstack_identity_project_v3.demo-project.id
password = "demo"
}
```
### 创建一个租户 Terraform 文件
作为一个 <ruby> 租户 <rt> Tenant </rt></ruby>,你通常会创建虚拟机。你还为这些虚拟机创建网络和安全组。
这个例子使用上面由 Admin 文件创建的用户。
首先,创建一个 `TenantTF` 目录,用于与租户相关的置备:
```
$ mkdir TenantTF
$ cd TenantTF
```
在 `main.tf` 中,添加以下内容:
```
terraform {
required_version = ">= 0.14.0"
required_providers {
openstack = {
source = "terraform-provider-openstack/openstack"
version = "1.49.0"
}
}
}
provider "openstack" {
user_name = “demo-user”
tenant_name = “demo”
password = “demo”
auth_url = “OS_AUTH_URL”
region = “OS_REGION”
}
resource "openstack_compute_keypair_v2" "demo-keypair" {
name = "demo-key"
public_key = "ssh-rsa ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ"
}
resource "openstack_networking_network_v2" "demo-network" {
name = "demo-network"
admin_state_up = "true"
}
resource "openstack_networking_subnet_v2" "demo-subnet" {
network_id = openstack_networking_network_v2.demo-network.id
name = "demo-subnet"
cidr = "192.168.26.0/24"
}
resource "openstack_networking_router_interface_v2" "demo-router-interface" {
router_id = “XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX”
subnet_id = openstack_networking_subnet_v2.demo-subnet.id
}
resource "openstack_compute_instance_v2" "demo-instance" {
name = "demo"
image_id = "YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY"
flavor_id = "3"
key_pair = "demo-key"
security_groups = ["default"]
metadata = {
this = "that"
}
network {
name = "demo-network"
}
}
```
### 初始化你的 Terraform
创建 Terraform 文件后,你需要初始化 Terraform。
对于管理员:
```
$ cd AdminTF
$ terraform init
$ terraform fmt
```
对于租户:
```
$ cd TenantTF
$ terraform init
$ terraform fmt
```
命令解释:
* `terraform init` 从镜像源下载提供者用于置备此项目。
* `terraform fmt` 格式化文件,以便在仓库中使用。
### 创建一个 Terraform 计划
接下来,为你创建一个 <ruby> 计划 <rt> plan </rt></ruby>,看看将创建哪些资源。
对于管理员:
```
$ cd AdminTF
$ terraform validate
$ terraform plan
```
对于租户:
```
$ cd TenantTF
$ terraform validate
$ terraform plan
```
命令解释:
* `terraform validate` 验证 `.tf` 语法是否正确。
* `terraform plan` 在缓存中创建一个计划文件,所有管理的资源在创建和销毁时都可以被跟踪。
### 应用你的第一个 TF
要部署资源,使用 `terraform apply` 命令。该命令应用计划文件中的所有资源状态。
对于管理员:
```
$ cd AdminTF
$ terraform apply
```
对于租户:
```
$ cd TenantTF
$ terraform apply
```
### 接下来的步骤
之前,我写了一篇关于在树莓派上部署最小 OpenStack 集群的 [文章](https://opensource.com/article/20/12/openstack-raspberry-pi)。你可以找到更详细的 [Terraform 和 Ansible](https://www.ansible.com/blog/ansible-vs.-terraform-demystified?intcmp=7013a000002qLH8AAM) 配置,并通过 GitLab 实现一些 CI/CD。
---
via: <https://opensource.com/article/23/1/terraform-manage-openstack-cluster>
作者:[AJ Canlas](https://opensource.com/users/ajscanlas) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | After having an OpenStack production and home lab for a while, I can definitively say that provisioning a workload and managing it from an Admin and Tenant perspective is important.
Terraform is an open source Infrastructure-as-Code (IaC) software tool used for provisioning networks, servers, cloud platforms, and more. Terraform is a declarative language that can act as a blueprint of the infrastructure you're working on. You can manage it with Git, and it has a strong [GitOps](https://opensource.com/article/21/3/gitops) use case.
This article covers the basics of managing an OpenStack cluster using Terraform. I recreate the OpenStack Demo project using Terraform.
## Install Terraform
I use CentOS as a jump host, where I run Terraform. Based on the official documentation, the first step is to add the Hashicorp repository:
```
``````
$ sudo dnf config-manager \
--add-repo https://rpm.releases.hashicorp.com/RHEL/hashicorp.repo
```
Next, install Terraform:
```
````$ sudo dnf install terraform -y`
Verify the installation:
```
````$ terraform –version`
If you see a version number in return, you have installed Terraform.
## Create a Terraform script for the OpenStack provider
In Terraform, you need a provider. A provider is a converter that Terraform calls to convert your `.tf`
into API calls to the platform you are orchestrating.
There are three types of providers: Official, Partner, and Community:
- Official providers are Hashicorp maintained.
- Partner providers are maintained by technology companies that partner with Hashicorp.
- Community providers are maintained by open source community members.
There is a good Community provider for OpenStack in this [link](https://registry.terraform.io/providers/terraform-provider-openstack/openstack/1.49.0). To use this provider, create a `.tf`
file and call it `main.tf`
.
```
````$ vi main.tf`
Add the following content to `main.tf`
:
```
``````
terraform {
required_version = ">= 0.14.0"
required_providers {
openstack = {
source = "terraform-provider-openstack/openstack"
version = "1.49.0"
}
}
}
provider "openstack" {
user_name = “OS_USERNAME”
tenant_name = “OS_TENANT”
password = “OS_PASSWORD”
auth_url = “OS_AUTH_URL”
region = “OS_REGION”
}
```
You need to change the **OS_USERNAME**, **OS_TENANT**, **OS_PASSWORD**, **OS_AUTH_URL**, and **OS_REGION** variables for it to work.
## Create an Admin Terraform file
OpenStack Admin files focus on provisioning external networks, routers, users, images, tenant profiles, and quotas.
This example provisions flavors, a router connected to an external network, a test image, a tenant profile, and a user.
First, create an `AdminTF`
directory for the provisioning resources:
```
``````
$ mkdir AdminTF
$ cd AdminTF
```
In the `main.tf`
, add the following:
```
``````
terraform {
required_version = ">= 0.14.0"
required_providers {
openstack = {
source = "terraform-provider-openstack/openstack"
version = "1.49.0"
}
}
}
provider "openstack" {
user_name = “OS_USERNAME”
tenant_name = “admin”
password = “OS_PASSWORD”
auth_url = “OS_AUTH_URL”
region = “OS_REGION”
}
resource "openstack_compute_flavor_v2" "small-flavor" {
name = "small"
ram = "4096"
vcpus = "1"
disk = "0"
flavor_id = "1"
is_public = "true"
}
resource "openstack_compute_flavor_v2" "medium-flavor" {
name = "medium"
ram = "8192"
vcpus = "2"
disk = "0"
flavor_id = "2"
is_public = "true"
}
resource "openstack_compute_flavor_v2" "large-flavor" {
name = "large"
ram = "16384"
vcpus = "4"
disk = "0"
flavor_id = "3"
is_public = "true"
}
resource "openstack_compute_flavor_v2" "xlarge-flavor" {
name = "xlarge"
ram = "32768"
vcpus = "8"
disk = "0"
flavor_id = "4"
is_public = "true"
}
resource "openstack_networking_network_v2" "external-network" {
name = "external-network"
admin_state_up = "true"
external = "true"
segments {
network_type = "flat"
physical_network = "physnet1"
}
}
resource "openstack_networking_subnet_v2" "external-subnet" {
name = "external-subnet"
network_id = openstack_networking_network_v2.external-network.id
cidr = "10.0.0.0/8"
gateway_ip = "10.0.0.1"
dns_nameservers = ["10.0.0.254", "10.0.0.253"]
allocation_pool {
start = "10.0.0.1"
end = "10.0.254.254"
}
}
resource "openstack_networking_router_v2" "external-router" {
name = "external-router"
admin_state_up = true
external_network_id = openstack_networking_network_v2.external-network.id
}
resource "openstack_images_image_v2" "cirros" {
name = "cirros"
image_source_url = "https://download.cirros-cloud.net/0.6.1/cirros-0.6.1-x86_64-disk.img"
container_format = "bare"
disk_format = "qcow2"
properties = {
key = "value"
}
}
resource "openstack_identity_project_v3" "demo-project" {
name = "Demo"
}
resource "openstack_identity_user_v3" "demo-user" {
name = "demo-user"
default_project_id = openstack_identity_project_v3.demo-project.id
password = "demo"
}
```
## Create a Tenant Terraform file
As a Tenant, you usually create VMs. You also create network and security groups for the VMs.
This example uses the user created above by the Admin file.
First, create a `TenantTF`
directory for Tenant-related provisioning:
```
``````
$ mkdir TenantTF
$ cd TenantTF
```
In the `main.tf`
, add the following:
```
``````
terraform {
required_version = ">= 0.14.0"
required_providers {
openstack = {
source = "terraform-provider-openstack/openstack"
version = "1.49.0"
}
}
}
provider "openstack" {
user_name = “demo-user”
tenant_name = “demo”
password = “demo”
auth_url = “OS_AUTH_URL”
region = “OS_REGION”
}
resource "openstack_compute_keypair_v2" "demo-keypair" {
name = "demo-key"
public_key = "ssh-rsa ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ"
}
resource "openstack_networking_network_v2" "demo-network" {
name = "demo-network"
admin_state_up = "true"
}
resource "openstack_networking_subnet_v2" "demo-subnet" {
network_id = openstack_networking_network_v2.demo-network.id
name = "demo-subnet"
cidr = "192.168.26.0/24"
}
resource "openstack_networking_router_interface_v2" "demo-router-interface" {
router_id = “XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX”
subnet_id = openstack_networking_subnet_v2.demo-subnet.id
}
resource "openstack_compute_instance_v2" "demo-instance" {
name = "demo"
image_id = "YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY"
flavor_id = "3"
key_pair = "demo-key"
security_groups = ["default"]
metadata = {
this = "that"
}
network {
name = "demo-network"
}
}
```
## Initialize your Terraform
After creating the Terraform files, you need to initialize Terraform.
For Admin:
```
``````
$ cd AdminTF
$ terraform init
$ terraform fmt
```
For Tenants:
```
``````
$ cd TenantTF
$ terraform init
$ terraform fmt
```
Command explanation:
`terraform init`
downloads the provider from the registry to use in provisioning this project.`terraform fmt`
formats the files for use in repositories.
## Create a Terraform plan
Next, create a plan for you to see what resources will be created.
For Admin:
```
``````
$ cd AdminTF
$ terraform validate
$ terraform plan
```
For Tenants:
```
``````
$ cd TenantTF
$ terraform validate
$ terraform plan
```
Command explanation:
`terraform validate`
validates whether the`.tf`
syntax is correct.`terraform plan`
creates a plan file in the cache where all managed resources can be tracked in creation and destroy.
## Apply your first TF
To deploy the resources, use the `terraform apply`
command. This command applies all resource states in the plan file.
For Admin:
```
``````
$ cd AdminTF
$ terraform apply
```
For Tenants:
```
``````
$ cd TenantTF
$ terraform apply
```
## Next steps
Previously, I wrote an [article](https://opensource.com/article/20/12/openstack-raspberry-pi) on deploying a minimal OpenStack cluster on a Raspberry Pi. You can discover how to have more detailed [Terraform and Ansible](https://www.ansible.com/blog/ansible-vs.-terraform-demystified?intcmp=7013a000002qLH8AAM) configurations and implement some CI/CD with GitLab.
## Comments are closed. |
15,588 | Ubuntu 计划为精简桌面环境提供 ISO 镜像 | https://debugpointnews.com/ubuntu-mini-iso-announcement/ | 2023-03-02T09:13:00 | [
"Ubuntu",
"精简"
] | /article-15588-1.html | 
>
> Canonical 正在为 Ubuntu 23.04 “Lunar Lobster” 开发一个新的精简 Ubuntu ISO 镜像。
>
>
>
在回答一位 Ubuntu 用户提出的关于精简 Ubuntu ISO 镜像的可能性的问题时,开发者确认正在开发一个官方的精简 ISO 镜像(小于 200MB)。上述工作已经在进行中,并取得了很大的进展。计划为即将发布的 Ubuntu 23.04 “Lunar Lobster” 引入一个替代性的精简安装程序。
### Ubuntu 桌面的精简 ISO 镜像
Canonical/Ubuntu 从未正式支持过任何精简 ISO 镜像。在 Ubuntu 18.04 时代,遗留有一些非官方的 Ubuntu 精简 ISO 镜像,但它们都已经停产了。考虑到 Ubuntu Linux 的受欢迎程度,没有提供精简安装程序对一些人来说是个问题。
虽然有 Ubuntu 服务器镜像和 [云镜像](https://cloud-images.ubuntu.com/minimal/releases/kinetic/release-20221022/),但它们对于你的桌面使用情况来说,设置起来有点复杂。
例如,如果你想创建一个只有 GNOME 会话和基本功能的精简 Ubuntu 桌面,而不使用官方桌面安装程序,你只有一个选择:你需要安装 Ubuntu 服务器版作为基础,然后开始建立一个没有服务器组件的桌面。
虽然,Debian 已经提供了精简 ISO(即 netinst),它很容易使用,并且可以在任何程度上进行定制。但是,有一个类似于官方 Ubuntu 桌面定制版是一个好主意,可以根据需要建立你的系统(没有 Snap 或其他项目)。
根据邮件列表中的对话,ubuntu-mini-iso 的大小为 140MB,它需要通过网络下载几个软件包。它将提示你要下载的菜单项目。我猜它将类似于 Ubuntu 服务器版的菜单。

同样,Ubuntu 的所有官方版本都可能有一个精简版本。然而,我不确定当你包括一个桌面环境时,它将如何精简。Xubuntu 的开发者 Sean Davis [宣布](https://floss.social/@bluesabre/109939104067417830),一个精简版的 Xubuntu 镜像已经在开发中,并且可以作为 [日常构建版](https://cdimage.ubuntu.com/xubuntu/daily-live/current/) 下载。
所以,总的来说,这是 Canonical 的一个令人兴奋的举动。如果一切顺利的话,你实际上可以使用这个 ISO 构建你自己的 Ubuntu。你可以只添加 GNOME 桌面、删除 Snap、从 Debian 软件库中安装 Firefox,并添加任何你想要的软件包。这将是一个不错的精简版 Ubuntu 桌面。
Ubuntu 23.04 BETA 计划于 2023 年 3 月 30 日发布;最终版本预计于 2023 年 4 月 20 日发布。那时候你就可以试试 minimal-ubuntu-iso 了。
参考自 [邮件列表](https://lists.ubuntu.com/archives/ubuntu-devel/2023-February/042490.html)。
---
via: <https://debugpointnews.com/ubuntu-mini-iso-announcement/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,589 | 在 C 语言中使用 getopt 解析命令行短选项 | https://opensource.com/article/21/8/short-option-parsing-c | 2023-03-02T14:10:46 | [
"参数"
] | https://linux.cn/article-15589-1.html |
>
> 通过使用命令行让用户告诉程序要什么,可以让程序更加灵活。
>
>
>

在已经知道要处理什么文件和对文件进行哪些操作的情况下,编写处理文件的 C 语言程序就很容易了。如果将文件名“硬编码”在程序中,或者你的程序只以一种方式来处理文件,那么你的程序总是知道要做什么。
但是如果程序每次运行时能够对用户的输入做出反应,可以使程序更灵活。让用户告诉程序要处理什么文件,或者以不同的方式完成任务,要实现这样的功能就需要读取命令行参数。
### 读取命令行
一个 C 语言程序可以用如下声明开头:
```
int main()
```
这是启动 C 程序最简单的形式。但如果在圆括号中加入标准参数,你的程序就可以从命令行中读取选项了:
```
int main(int argc, char **argv)
```
`argc` 表示命令行中的参数个数。它总是一个至少为 1 的数。
`argv` 是一个二级指针,它指向一个字符串数组。这个数组中保存的是从命令行接收的各个参数。数组的第一个元素 `*argv[0]` 是程序的名称。`**argv` 数组的其它元素包含剩下的命令行参数。
下面我将写一个简单的示例程序,它能够回显通过命令行参数传递给它的选项。它跟 Linux 的 `echo` 命令类似,只不过我们的程序会打印出程序名。同时它还会调用 `puts` 函数将命令行选项按行打印输出。
```
#include <stdio.h>
int
main(int argc, char **argv)
{
int i;
printf("argc=%d\n", argc); /* debugging */
for (i = 0; i < argc; i++) {
puts(argv[i]);
}
return 0;
}
```
编译此程序,并在运行时提供一些命令行参数,你会看到传入的命令行参数被逐行打印出来:
```
$ ./echo this program can read the command line
argc=8
./echo
this
program
can
read
the
command
line
```
这个命令行将程序的 `argc` 置为 8,`**argv` 数组包含 8 个元素:程序名以及用户输入的 7 个单词。由于 C 语言中数组下标从 0 开始,所以这些元素的标号分别是 0 到 7。这也是在 `for` 循环中处理命令行参数时能够用 `i < argc` 作为比较条件的原因。
你也可以用这个方式实现自己的 `cat` 或 `cp` 命令。`cat` 命令的基本功能是显示一个或几个文件的内容。下面是一个简化版的`cat` 命令,它从命令行获取文件名:
```
#include <stdio.h>
void
copyfile(FILE *in, FILE *out)
{
int ch;
while ((ch = fgetc(in)) != EOF) {
fputc(ch, out);
}
}
int
main(int argc, char **argv)
{
int i;
FILE *fileptr;
for (i = 1; i < argc; i++) {
fileptr = fopen(argv[i], "r");
if (fileptr != NULL) {
copyfile(fileptr, stdout);
fclose(fileptr);
}
}
return 0;
}
```
这个简化版的 `cat` 命令从命令行读取文件名列表,然后将各个文件的内容逐字符地显示到标准输出上。假定我有一个叫做 `hello.txt` 的文件,其中包含数行文本内容。我能用自己实现的 `cat` 命令将它的内容显示出来:
```
$ ./cat hello.txt
Hi there!
This is a sample text file.
```
以这个简单程序为出发点,你也可以实现自己版本的其它 Linux 命令。比如 `cp` 命令,它从命令行读取两个文件名:要读取的文件和要写入的文件。
### 读取命令行选项
通过命令行读取文件名和其它文本固然很棒,但是如果想要程序根据用户给出的选项改变行为呢?比如 Linux 的 `cat` 命令就支持以下命令行选项:
* `-b` 显示非空行的行号
* `-E` 在行尾显示 `$`
* `-n` 显示行号
* `-s` 合并显示空行
* `-T` 将制表符显示为 `^I`
* `-v` 用 `^x` 和 `M-x` 方式显示非打印字符,换行符和制表符除外
这些以一个连字符开头的单字母的选项叫做短选项。通常短选项是分开使用的,就像这样 `cat -E -n`。但是也可以将多个短选项合并,比如 `cat -En`。
值得庆幸的是,所有 Linux 和 Unix 系统都包含 `getopt` 库。它提供了一种简单的方式来读取命令行参数。`getopt` 定义在头文件 `unistd.h` 中。你可以在程序中使用 `getopt` 来读取命令行短选项。
与其它 Unix 系统不同的是,Linux 上的 `getopt` 总是保证短选项出现在命令行参数的最前面。比如,用户输入的是 `cat -E file -n`。`-E` 在最前面,`-n` 在文件名之后。如果使用 Linux 的 `getopt` 来处理,程序会认为用户输入的是 `cat -E -n file`。这样做可以使处理过程更顺畅,因为 `getopt` 可以解析完所有短选项,剩下的文件名列表可以通过 `**argv` 来统一处理。
你可以这样使用 `getopt`:
```
#include <unistd.h>
int getopt(int argc, char **argv, char *optstring);
```
`optstring` 是由所有合法的选项字符组成的字符串。比如你的程序允许的选项是 `-E` 和 `-n`, 那么 `optstring` 的值就是 `"En"`。
通常通过在循环中调用 `getopt` 来解析命令行选项。每次调用时 `getopt` 会返回找到的下一个短选项,如果遇到无法识别的选项则返回 `'?'`。当没有更多短选项时它返回 `-1`,并且设置全局变量 `optind` 的值指向 `**argv` 中所有段选项之后的第一个元素。
下面看一个简单的例子。这个演示程序没有实现 `cat` 命令的所有选项,但它只是能够解析命令行。每当发现一个合法的命令行选项,它就打印出相应的提示消息。在你自己的程序中,你可能会根据这些命令行选项执行变量赋值等者其它操作。
```
#include <stdio.h>
#include <unistd.h>
int
main(int argc, char **argv)
{
int i;
int option;
/* parse short options */
while ((option = getopt(argc, argv, "bEnsTv")) != -1) {
switch (option) {
case 'b':
puts("Put line numbers next to non-blank lines");
break;
case 'E':
puts("Show the ends of lines as $");
break;
case 'n':
puts("Put line numbers next to all lines");
break;
case 's':
puts("Suppress printing repeated blank lines");
break;
case 'T':
puts("Show tabs as ^I");
break;
case 'v':
puts("Verbose");
break;
default: /* '?' */
puts("What's that??");
}
}
/* print the rest of the command line */
puts("------------------------------");
for (i = optind; i < argc; i++) {
puts(argv[i]);
}
return 0;
}
```
假如你把程序编译为 `args`,你可以通过尝试不同的命令行参数组合,来了解程序是怎么解析短选项,以及是怎么将其它的命令行参数留下来的。最简单的例子是将所有的选项都放在最前面,就像这样:
```
$ ./args -b -T file1 file2
Put line numbers next to non-blank lines
Show tabs as ^I
------------------------------
file1
file2
```
现在试试将两个短选项合并使用的效果:
```
$ ./args -bT file1 file2
Put line numbers next to non-blank lines
Show tabs as ^I
------------------------------
file1
file2
```
如果有必要的话,`getopt`可以对命令行参数进行重排:
```
$ ./args -E file1 file2 -T
Show the ends of lines as $
Show tabs as ^I
------------------------------
file1
file2
```
如果用户输入了错误的短选项,`getopt` 会打印一条消息:
```
$ ./args -s -an file1 file2
Suppress printing repeated blank lines
./args: invalid option -- 'a'
What's that??
Put line numbers next to all lines
------------------------------
file1
file2
```
### 下载速查表
`getopt` 还有更多的功能。例如,通过设计 `-s string` 或 `-f file` 这样的命令行语法规则,可以让短选项拥有自己的二级选项。你也可以告诉 `getopt` 在遇到无法识别的选项时不显示错误信息。使用 `man 3 getopt` 命令查看 `getopt(3)` 手册可以了解 `getopt` 的更多功能。
如果你需要 `getopt()` 和 `getopt_long()`的使用语法和结构上的提示,可以 [下载我制作的速查表](https://opensource.com/downloads/c-getopt-cheat-sheet)。它提供了最小可行代码,并列出了你需要了解的一些全局变量的含义。速查表的一面是 `getopt()` 的用法,另一面是 `getopt_long()`的用法。
---
via: <https://opensource.com/article/21/8/short-option-parsing-c>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Writing a C program to process files is easy when you already know what files you'll operate on and what actions to take. If you "hard code" the filename into your program, or if your program is coded to do things only one way, then your program will always know what to do.
But you can make your program much more flexible if it can respond to the user every time the program runs. Let your user tell your program what files to use or how to do things differently. And for that, you need to read the command line.
## Reading the command line
When you write a program in C, you might start with the declaration:
`int main()`
That's the simplest way to start a C program. But if you add these standard parameters in the parentheses, your program can read the options given to it on the command line:
`int main(int argc, char **argv)`
The `argc`
variable is the argument count or the number of arguments on the command line. This will always be a number that's at least one.
The `argv`
variable is a double pointer, an array of strings, that contains the arguments from the command line. The first entry in the array, `*argv[0]`
, is always the name of the program. The other elements of the `**argv`
array contain the rest of the command-line arguments.
I'll write a simple program to echo back the options given to it on the command line. This is similar to the Linux `echo`
command, except it also prints the name of the program. It also prints each command-line option on its own line using the `puts`
function:
```
#include <stdio.h>
int
main(int argc, char **argv)
{
int i;
printf("argc=%d\n", argc); /* debugging */
for (i = 0; i < argc; i++) {
puts(argv[i]);
}
return 0;
}
```
Compile this program and run it with some command-line options, and you'll see your command line printed back to you, each item on its own line:
```
$ ./echo this program can read the command line
argc=8
./echo
this
program
can
read
the
command
line
```
This command line sets the program's `argc`
to `8`
, and the `**argv`
array contains eight entries: the name of the program, plus the seven words the user entered. And as always in C programs, the array starts at zero, so the elements are numbered 0, 1, 2, 3, 4, 5, 6, 7. That's why you can process the command line with the `for`
loop using the comparison `i < argc`
.
You can use this to write your own versions of the Linux `cat`
or `cp`
commands. The `cat`
command's basic functionality displays the contents of one or more files. Here's a simple version of `cat`
that reads the filenames from the command line:
```
#include <stdio.h>
void
copyfile(FILE *in, FILE *out)
{
int ch;
while ((ch = fgetc(in)) != EOF) {
fputc(ch, out);
}
}
int
main(int argc, char **argv)
{
int i;
FILE *fileptr;
for (i = 1; i < argc; i++) {
fileptr = fopen(argv[i], "r");
if (fileptr != NULL) {
copyfile(fileptr, stdout);
fclose(fileptr);
}
}
return 0;
}
```
This simple version of `cat`
reads a list of filenames from the command line and displays the contents of each file to the standard output, one character at a time. For example, if I have one file called `hello.txt`
that contains a few lines of text, I can display its contents with my own `cat`
command:
```
$ ./cat hello.txt
Hi there!
This is a sample text file.
```
Using this sample program as a starting point, you can write your own versions of other Linux commands, such as the `cp`
program, by reading only two filenames: one file to read from and another file to write the copy.
## Reading command-line options
Reading filenames and other text from the command line is great, but what if you want your program to change its behavior based on the *options* the user gives it? For example, the Linux `cat`
command supports several command-line options, including:
`-b`
Put line numbers next to non-blank lines`-E`
Show the ends of lines as`$`
`-n`
`-s`
Suppress printing repeated blank lines`-T`
Show tabs as`^I`
`-v`
`^x`
and`M-x`
notation, except for new lines and tabs
These *single-letter* options are called *short options*, and they always start with a single hyphen character. You usually see these short options written separately, such as `cat -E -n`
, but you can also combine the short options into a single *option string* such as `cat -En`
.
Fortunately, there's an easy way to read these from the command line. All Linux and Unix systems include a special C library called `getopt`
, defined in the `unistd.h`
header file. You can use `getopt`
in your program to read these short options.
Unlike other Unix systems, `getopt`
on Linux will always ensure your short options appear at the front of your command line. For example, say a user types `cat -E file -n`
. The `-E`
option is upfront, but the `-n`
option is after the filename. But if you use Linux `getopt`
, your program will always behave as though the user types `cat -E -n file`
. That makes processing a breeze because `getopt`
can parse the short options, leaving you a list of filenames on the command line that your program can read using the `**argv`
array.
You use `getopt`
like this:
```
#include <unistd.h>
int getopt(int argc, char **argv, char *optstring);
```
The option string `optstring`
contains a list of the valid option characters. If your program only allows the `-E`
and `-n`
options, you use "`En"`
as your option string.
You usually use `getopt`
in a loop to parse the command line for options. At each `getopt`
call, the function returns the next short option it finds on the command line or the value `'?'`
for any unrecognized short options. When `getopt`
can't find any more short options, it returns `-1`
and sets the global variable `optind`
to the next element in `**argv`
after all the short options.
Let's look at a simple example. This demo program isn't a full replacement of `cat`
with all the options, but it can parse its command line. Every time it finds a valid command-line option, it prints a short message to indicate it was found. In your own programs, you might instead set a variable or take some other action that responds to that command-line option:
```
#include <stdio.h>
#include <unistd.h>
int
main(int argc, char **argv)
{
int i;
int option;
/* parse short options */
while ((option = getopt(argc, argv, "bEnsTv")) != -1) {
switch (option) {
case 'b':
puts("Put line numbers next to non-blank lines");
break;
case 'E':
puts("Show the ends of lines as $");
break;
case 'n':
puts("Put line numbers next to all lines");
break;
case 's':
puts("Suppress printing repeated blank lines");
break;
case 'T':
puts("Show tabs as ^I");
break;
case 'v':
puts("Verbose");
break;
default: /* '?' */
puts("What's that??");
}
}
/* print the rest of the command line */
puts("------------------------------");
for (i = optind; i < argc; i++) {
puts(argv[i]);
}
return 0;
}
```
If you compile this program as `args`
, you can try out different command lines to see how they parse the short options and always leave you with the rest of the command line. In the simplest case, with all the options up front, you get this:
```
$ ./args -b -T file1 file2
Put line numbers next to non-blank lines
Show tabs as ^I
------------------------------
file1
file2
```
Now try the same command line but combine the two short options into a single option string:
```
$ ./args -bT file1 file2
Put line numbers next to non-blank lines
Show tabs as ^I
------------------------------
file1
file2
```
If necessary, `getopt`
can "reorder" the command line to deal with short options that are out of order:
```
$ ./args -E file1 file2 -T
Show the ends of lines as $
Show tabs as ^I
------------------------------
file1
file2
```
If your user gives an incorrect short option, `getopt`
prints a message:
```
$ ./args -s -an file1 file2
Suppress printing repeated blank lines
./args: invalid option -- 'a'
What's that??
Put line numbers next to all lines
------------------------------
file1
file2
```
## Download the cheat sheet
`getopt`
can do lots more than what I've shown. For example, short options can take their own options, such as `-s string`
or `-f file`
. You can also tell `getopt`
to not display error messages when it finds unrecognized options. Read the `getopt(3)`
manual page using `man 3 getopt`
to learn more about what `getopt`
can do for you.
If you're looking for gentle reminders on the syntax and structure of `getopt()`
and `getopt_long()`
, [download my getopt cheat sheet](https://opensource.com/downloads/c-getopt-cheat-sheet). One page demonstrates short options, and the other side demonstrates long options with minimum viable code and a listing of the global variables you need to know.
## Comments are closed. |
15,592 | Artipie:可用于 Python 的开源仓库管理器 | https://opensource.com/article/22/12/python-package-index-repository-artipie | 2023-03-02T23:22:00 | [
"仓库",
"Artipie"
] | https://linux.cn/article-15592-1.html | 
>
> Artipie 是一个开源的自托管的仓库管理器,它不仅可以用于 Python。
>
>
>
在学生时代使用 Python 开发时,我发现我需要一些私人的集中存储。这样我就可以存储二进制和文本数据文件,以及 Python 软件包。我在 [Artipie](https://github.com/artipie) 中找到了答案,这是一个开源的自托管的软件仓库管理器。
在大学里,我和我的同事们对来自实验测量的大量数据进行研究。我使用 Python 来处理和可视化它们。当时我的大学同事是数学家,没有软件开发技术的经验。他们通常只是在闪存盘上或通过电子邮件传递数据和代码。我努力向他们介绍像 [Git](https://opensource.com/tags/git) 这样的版本管理系统,但没有成功。
### Python 仓库
Artipie 支持 [PyPI](https://pypi.org/) 仓库,与 [twine](https://github.com/pypa/twine) 和 [pip](https://pip.pypa.io/en/stable/) 兼容。这意味着你可以完全像在 [PyPI](https://pypi.org/) 和 [TestPyPI](https://test.pypi.org/) 仓库上安装或发布软件包那样使用 Artipie Python 仓库。
要创建你自己的 Python 仓库,你可以使用名为 [Artipie Central](https://central.artipie.com/signin) 的 Artipie 托管实例。当你登录后,你会看到一个列出你的仓库的页面(开始时是空的),以及一个添加新仓库的表单。为你的新仓库选择一个名字(例如,`mypython`),选择 `Python` 作为仓库类型,然后点击 “<ruby> 添加 <rt> Add </rt></ruby>” 按钮。
接下来,你会看到一个以 [YAML](https://www.redhat.com/sysadmin/yaml-beginners) 格式显示仓库设置的页面:
```
---
repo:
type: pypi
storage: default
permissions:
olenagerasimova:
- upload
"*":
- download
```
配置中的 `type` 映射设置了仓库的类型。在这个例子中,Python 仓库被配置为默认的 Artipie Central 存储。
`storage` 映射定义了所有仓库包的存储位置。这可以是任何文件系统或 S3 存储兼容的位置。Artipie Central 有一个预先配置的 `default` 存储,可以使用它进行测试。
`permissions` 映射允许为用户 `olenagerasimova` 上传,并允许任何人下载任何软件包。
为了确保这个仓库的存在和工作,在你的浏览器中打开 [索引页](https://central.artipie.com/olenagerasimova/pypi)。显示的是软件包列表。如果你刚刚创建了一个新的版本库,但还没有上传软件包,那么仓库的索引页是空白的。
### 二进制仓库
你可以在 Artipie 中存储任何种类的文件。存储类型是 `file` 或 `binary`,我用这个作为实验数据的存储。我把它作为 Python 可视化的输入。在 Artipie Central 可以创建一个文件仓库,与 Python 仓库的方式相同。你给它一个名字,选择 `binary` 类型,然后点击 “<ruby> 添加 <rt> Add </rt></ruby>” 按钮。
```
---
repo:
type: file
storage: default
permissions:
olenagerasimova:
- upload
- download
"*":
- download
```
这些设置基本上与 Python 相同。只有仓库的类型不同。在这个例子中,二进制仓库被称为 `data`。它包含三个带有一些数字的文本文件:
```
6
3.5
5
4
4.5
3
2.7
5
6
3
1.2
3.2
6
```
另外两个文件的形式相同(只是数字不同)。要想自己看这些文件,请在浏览器中打开链接 [一](https://central.artipie.com/olenagerasimova/data/y1.dat)、[二](https://central.artipie.com/olenagerasimova/data/y2.dat) 和 [三](https://central.artipie.com/olenagerasimova/data/y3.dat) 并下载文件,或者你可以用 `httpie` 执行 GET 请求:
```
httpie -a https://central.artipie.com/olenagerasimova/data/y1.dat > ./data/y1.da
```
这些文件是用 PUT 请求上传到 Artipie Central 的 `data` 存储库的:
```
httpie -a olenagerasimova:*** PUT
https://central.artipie.com/olenagerasimova/data/y1.dat @data/y1.dat
httpie -a olenagerasimova:*** PUT
https://central.artipie.com/olenagerasimova/data/y2.dat @data/y2.dat
httpie -a olenagerasimova:*** PUT
https://central.artipie.com/olenagerasimova/data/y3.dat @data/y3.dat
```
由于这个二进制仓库的 API 非常简单(HTTP `PUT` 和 `GET` 请求),用任何语言编写一段代码来上传和下载所需的文件都很容易。
### Python 项目
可以从我的 [GitHub 仓库](https://github.com/artipie/pypi-example)中获得一个 Python 项目的示例源代码。这个示例的主要想法是,从 Artipie Central 下载三个数据文件,将数字读入数组,并使用这些数组来绘制一个图。使用 `pip` 来安装这个例子包并运行它:
```
$ python3 -m pip install --index-url \
https://central.artipie.com/olenagerasimova/pypi/ \
pypiexample
$ python3 -m pypiexample
```
通过设置 `--index-url` 到 Artipie Central 的 Python 仓库,`pip` 从它那里下载软件包,而不是通常默认的 PyPi 仓库。运行这些命令后,会显示一个带有三条曲线的极坐标图,这是数据文件的可视化。
要将软件包发布到 Artipie Central 仓库,请用 `twine` 构建并上传:
```
commandline
$ python setup.py sdist bdist_wheel
$ twine upload --repository-url \
https://central.artipie.com/olenagerasimova/pypi
-u olenagerasimova -p *** dist/*
```
在 Artipie Central 中设置 `files` 仓库,并创建一个 Python 示例项目是多么容易。不过,你不必使用 Artipie Central。Artipie 可以自托管,所以你可以在你自己的本地网络上运行一个仓库。
### 将 Artipie 作为一个容器运行
将 Artipie 作为一个容器运行,设置起来就像安装 Podman 或 Docker 一样容易。假设你已经安装了其中之一,打开终端:
```
$ podman run -it -p 8080:8080 -p 8086:8086 artipie/artipie:latest
```
这将启动一个运行最新 Artipie 版本的新容器。它还映射了两个端口。你的仓库在 8080 端口提供服务。Artipie 的 Rest API 和 Swagger 文档在 8086 端口提供。新的镜像会生成一个默认的配置,打印一个正在运行的仓库列表,测试证书,以及一个指向 [Swagger](https://swagger.io/) 文档的链接到你的控制台。
你也可以使用 Artipie Rest API 来查看现有的仓库:
* 进入 Swagger 文档页面 `http://localhost:8086/api/index-org.html`。
* 在 “<ruby> 选择一个定义 <rt> Select a definition </rt></ruby>” 列表中,选择 “<ruby> 认证令牌 <rt> Auth token </rt></ruby>”。
* 生成并复制用户 `artipie` 的认证令牌,密码是 `artipie`。
* 切换到 “<ruby> 仓库 <rt> Repositories </rt></ruby>” 定义,点击 “<ruby> 认证 <rt> Authorize </rt></ruby>” 按钮,然后粘贴令牌。

对 `/api/v1/repository/list` 执行一个 GET 请求。在响应中,你会收到一个包含三个默认仓库的 JSON 列表:
```
[
"artipie/my-bin",
"artipie/my-docker",
"artipie/my-maven"
]
```
默认配置中不包括 Python 仓库。你可以通过从 Swagger 接口向 `/api/v1/repository/{user}/{repo}` 执行 PUT 请求来纠正。在这种情况下,`user` 是默认用户的名字(`artipie`),`repo` 是新仓库的名字。你可以把你的新 Python 代码库称为 `my-pypi`。下面是一个请求体的例子,包含带仓库设置的 JSON 对象:
```
{
"repo": {
"type": "pypi",
"storage": "default",
"permissions": {
"*": [
"download"
],
"artipie": [
"upload"
]
}
}
}
```
所有的 JSON 字段都和你在仪表板上创建 YAML 格式的仓库时一样。我们版本库的类型是 `pypi`,使用默认存储,任何人都可以下载,但只有用户 `artipie` 可以上传。
再次向 `/api/v1/repository/list` 发出 GET 请求,确保你的仓库被创建。现在,你有四个仓库:
```
[
"artipie/my-bin",
"artipie/my-docker",
"artipie/my-maven",
"artipie/my-pypi"
]
```
你已经创建了你自己的 Artipie 安装,包含了几个仓库! Artipie 镜像既可以在个人电脑上运行,也可以在私人网络内的远程服务器上运行。你可以用它来在一个公司、团体或大学内交换软件包。这是一个建立你自己的软件服务的简单方法,而且它不仅仅适用于 Python。花些时间来探索 Artipie,看看它能为你带来什么。
---
via: <https://opensource.com/article/22/12/python-package-index-repository-artipie>
作者:[Alena Gerasimova](https://opensource.com/users/olena) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | While developing with Python as a student, I found that I needed some private centralized storage. This was so I could store binary and text data files, as well as Python packages. I found the answer in [Artipie](https://github.com/artipie), an open source self-hosted software repository manager.
At university, my colleagues and I conducted research and worked with a lot of data from experimental measurements. I used Python to process and visualize them. My university colleagues at the time were mathematicians and didn't have experience with software development techniques. They usually just passed data and code on a flash drive or over email. My efforts to introduce them to a versioning system like [Git](https://opensource.com/tags/git) were unsuccessful.
## Python repository
Artipie supports the [PyPI](https://pypi.org/) repository, making it compatible with both [twine](https://github.com/pypa/twine) and [pip](https://pip.pypa.io/en/stable/). This means you can work with the Artipie Python repository exactly as you would when installing or publishing packages on the [PyPI](https://pypi.org/) and [TestPyPI](https://test.pypi.org/) repositories.
To create your own Python repository, you can use the hosted instance of Artipie called [Artipie Central](https://central.artipie.com/signin). Once you sign in, you see a page with your repositories listed (which is empty to begin with) and a form to add a new repository. Choose a name for your new repository (for example, `mypython`
), select "Python" as the repository type, and then click the **Add** button.
Next, you see a page with repository settings in the [YAML](https://www.redhat.com/sysadmin/yaml-beginners) format:
```
``````
---
repo:
type: pypi
storage: default
permissions:
olenagerasimova:
- upload
"*":
- download
```
The `type`
mapping in the configuration sets the repository type. In this example, the Python repository is configured with the default Artipie Central storage.
The `storage`
mapping defines where all of the repository packages are stored. This can be any file system or S3 storage compatible location. Artipie Central has a preconfigured `default`
storage that can be used for tests by anyone.
The `permissions`
mapping allows uploads for the user `olenagerasimova`
, and allows anyone to download any package.
To make sure this repository exists and works, open the [index page](https://central.artipie.com/olenagerasimova/pypi) in your browser. The packages list is displayed. If you've just created a new repository but have yet to upload a package, then the repository index page is blank.
## Binary repository
You can store any kind of file in Artipie. The storage type is called file or binary, and I use this as storage for experimental data. I use this as input for Python visualizations. A file repository can be created in Artipie Central the same way as a Python repository. You give it a name, choose the type **binary**, and then click the **Add** button.
```
``````
---
repo:
type: file
storage: default
permissions:
olenagerasimova:
- upload
- download
"*":
- download
```
The settings are basically the same as for Python. Only the repository type differs. The binary repository, in this example, is called `data`
. It contains three text files with some numbers:
```
``````
6
3.5
5
4
4.5
3
2.7
5
6
3
1.2
3.2
6
```
The other two files take the same form (only the numbers are different.) To see the files yourself, open the links [one](https://central.artipie.com/olenagerasimova/data/y1.dat), [two](https://central.artipie.com/olenagerasimova/data/y2.dat), and [three](https://central.artipie.com/olenagerasimova/data/y3.dat) in your browser and download the files, or you can perform a GET request using `httpie`
:
```
````httpie -a https://central.artipie.com/olenagerasimova/data/y1.dat > ./data/y1.da`
These files were uploaded to the Artipie Central `data`
repository with PUT requests:
```
``````
httpie -a olenagerasimova:*** PUT https://central.artipie.com/olenagerasimova/data/y1.dat @data/y1.dat
httpie -a olenagerasimova:*** PUT https://central.artipie.com/olenagerasimova/data/y2.dat @data/y2.dat
httpie -a olenagerasimova:*** PUT https://central.artipie.com/olenagerasimova/data/y3.dat @data/y3.dat
```
As this binary repository API is very simple (HTTP `PUT`
and `GET `
requests), it's easy to write a piece of code in any language to upload and download the required files.
## Python project
The source code of an example Python project is available from my [GitHub repository](https://github.com/artipie/pypi-example). The main idea of the example is to download three data files from Artipie Central, read the numbers into arrays, and use these arrays to draw a plot. Use pip to install the example package and run it:
```
``````
$ python3 -m pip install --index-url \
https://central.artipie.com/olenagerasimova/pypi/ \
pypiexample
$ python3 -m pypiexample
```
By setting the `--index-url`
to the Artipie Central Python repository, pip downloads the packages from it rather than the PyPi repository that serves as the usual default. After running the commands, a polar plot with three curves, a visualization of the data files is displayed.
To publish the package to the Artipie Central repository, build it with and use twine to upload it:
```
``````
commandline
$ python setup.py sdist bdist_wheel
$ twine upload --repository-url \
https://central.artipie.com/olenagerasimova/pypi
-u olenagerasimova -p *** dist/*
```
That's how easy it is to set up a `files`
repositories in Artipie Central, create a sample Python project, publish, and install it. You don't have to use Artipie Central, though. Artipie can be self-hosted, so you can run a repository on your own local network.
## Run Artipie as a container
Running Artipie as a container makes setup as easy as installing either Podman or Docker. Assuming you have one of these installed, open a terminal:
```
``````
$ podman run -it -p 8080:8080 -p 8086:8086 artipie/artipie:latest
```
This starts a new container running the latest Artipie version. It also maps two ports. Your repositories are served on port 8080. The Artipie Rest API and Swagger documentation are provided on port 8086. A new image generates a default configuration, printing a list of running repositories, test credentials, and a link to the [Swagger](https://swagger.io/) documentation to your console.
You can also use the Artipie Rest API to see existing repositories:
-
Go to the Swagger documentation page at
`http://localhost:8086/api/index-org.html`
**.** -
In the
**Select a definition**list, choose**Auth token** -
Generate and copy the authentication token for the user artipie with the password artipie
-
Switch to the
**Repositories**definition and click the**Authorize**button, and then paste in the token
(Seth Kenlon, CC BY-SA 4.0)
Perform a GET request for `/api/v1/repository/list`
. In response, you receive a JSON list with three default repositories:
```
``````
[ "artipie/my-bin",
"artipie/my-docker",
"artipie/my-maven" ]
```
The Python repository isn't included in the default configuration. You can correct that by performing a PUT request to `/api/v1/repository/{user}/{repo}`
from the Swagger interface. In this case, `user`
is the name of the default user (`artipie`
) and `repo`
is the name of the new repository. You can call your new Python repository `my-pypi`
. Here's an example request body, containing a JSON object with the repository settings:
```
``````
{ "repo": {
"type": "pypi",
"storage": "default",
"permissions": {
"*": [
"download"
],
"artipie": [
"upload"
] }
} }
```
All the JSON fields are the same as when you create a repository in the dashboard in YAML format. The type of our repository is `pypi`
, the default storage is used, and anyone can download but only the user `artipie`
can upload.
Make a GET request to `/api/v1/repository/list`
again to make sure your repository was created. Now, you have four repositories:
```
``````
[ "artipie/my-bin",
"artipie/my-docker",
"artipie/my-maven",
"artipie/my-pypi" ]
```
You've created your own Artipie installation, containing several repositories! The Artipie image can run both on a personal computer or on a remote server inside a private network. You can use it to exchange packages within a company, group, or university. It's an easy way to set up your own software services, and it's not just for Python. Take some time to explore Artipie and see what it can make possible for you.
## Comments are closed. |
15,594 | Linux 只是一个内核:这是什么意思? | https://itsfoss.com/linux-kernel-os/ | 2023-03-04T08:52:00 | [
"Linux",
"内核"
] | https://linux.cn/article-15594-1.html | 
>
> 这是一个困扰 Linux 用户的常见问题。这也是考试和面试中经常问到的一个问题。下面是你需要了解的所有内容。
>
>
>
*开源朗读者 | 徐斯佳*
你可能在网络上的各种论坛以及讨论区听过这句话:
>
> Linux 只是一个内核。
>
>
>
这让你感到好奇。它是个内核?还是个操作系统?两者之间有什么区别?
我将在本文中回答这些问题。
### Linux 是操作系统还是内核?
好吧,**从技术上讲,Linux 只是一个内核**,而不是一个操作系统。但是,术语 “Linux” 通常是指一个完整的操作系统,它包括一个 <ruby> 交互界面 <rt> Shell </rt></ruby>(例如:bash)和命令行和/或 GUI 工具来控制系统。这个完整的操作系统的正确叫法是 “Linux 发行版”。流行的 Linux 发行版有 Ubuntu、Red Hat 和 Debian。
早在 1991 年,Linus Torvalds 创建的只是一个内核。直到今天,他也在为 Linux 内核工作。他不再编写代码,而是监督哪些代码进入内核。
### 内核?什么东西?
内核是每个操作系统的中心。不仅仅是 Linux,Windows 和 macOS 也有内核。
将内核想象成操作系统的心脏。没有心脏,你就无法生存。没有内核,操作系统就无法存在。
但是,就像心脏需要一个身体来生存一样,内核需要其他人们可以在计算机上使用的程序和工具来构成一个完整的操作系统。
这是一个操作系统的典型架构:

在中心的内核与硬件交互。在它之上是与内核交互的 <ruby> 交互界面 <rt> Shell </rt></ruby>。然后你有应用程序、命令行和图形界面,为你提供使用系统的各种方式。
### 内核是引擎,操作系统是汽车
一个更好的类比是将内核想象成汽车的引擎,而操作系统则是汽车。
你不可能驾驶一个引擎,但是如果没有引擎,你也不能驾驶一辆汽车。你需要轮胎、转向机和其他组件才能将其变成一辆可以驾驶的汽车。
相似地,你不能直接使用内核。你需要 <ruby> 交互界面 <rt> Shell </rt></ruby>,其他工具和组件才能使用操作系统。

### Linux 对比 GNU/Linux
在类似的地方,你也会看到例如 “Linux 只是一个内核,[你所说的 Linux 实际上是 GNU/Linux](https://itsfoss.com/gnu-linux-copypasta/)” 的陈述。
在 Linus Torvalds 在 1991 年创建 Linux 之前,Richard Stallman 就创建了<ruby> 自由软件运动 <rt> Free Software movement </rt></ruby>和 GNU 项目。GNU 项目包括对流行的 UNIX 工具和命令的重新实现,例如 `ls`、`grep`、`sed` 等。
通常,你的 Linux 发行版会在 Linux 内核之上包含所有这些 GNU 工具。
这就是为什么纯粹主义者坚持称之为 GNU/Linux,以便人们不要忘记 GNU 对 Linux 成功的贡献和重要性。
### 最后……
**所以,如果你在面试或者考试中被问到这个问题,回答 “Linux 是一个内核,而不是一个操作系统”。这是你的老师或面试官在大多数情况下想要的答案。**
但是更深入一点,理解内核和操作系统之间的区别。
如果有人说:“我使用 Linux”,你就会明白这个人是指 Linux 发行版,而不仅仅是内核。诚然,没有必要用 “Linux 只是一个内核,而不是一个操作系统” 来纠正别人。
---
via: <https://itsfoss.com/linux-kernel-os/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You may have heard this in a number of forums and discussions on the internet.
Linux is just a kernel
And that made you curious. Is it a kernel? Is it an operating system? What's the difference between the two?
I'll answer those questions in this quick explainer.
## Is Linux an OS or kernel?
Well, **technically, Linux is just a kernel**, not an operating system. However, the term *Linux* is often referred to a complete operating system that includes a shell (like bash) and command line and/or GUI tools to control the system. The technically correct term for this complete operating system is Linux distribution or simply Linux distro. Examples of popular Linux distributions include Ubuntu, Red Hat, and Debian.
Back in 1991, what Linus Torvalds created was the kernel only. Even today, he works on the Linux kernel. He doesn't code anymore but supervises which code goes into the kernel.
## Kernel, what?
The kernel is at the center of every operating system. It's not just a Linux thing. Windows and macOS have kernels too.
Think of the kernel as the heart of an operating system. You cannot live without your heart. Your operating system cannot exist without a kernel.
However, just like a heart needs a body to live in, the kernel needs other programs and tools to make a complete operating system that people can use on their computers.
Here's the typical structure of an operating system:
The kernel is at the core interacting with the hardware. On top of that lies the shell that interacts with the kernel. And then you have applications, command line and graphical, to give you various ways of using the system.
## Kernel is the engine, OS is the car
A better analogy is to think of the kernel as the engine of a car and the operating system as the car.
You cannot drive an engine but you can also not drive a car without the engine. You need to have tires, steering, and other components to turn it into a car you can drive.
Similarly, you cannot use the kernel directly. You need shell and then other tools and components to use the operating system.

I have written an in-depth article with this analogy. I am not going to repeat it all. If you liked the analogy, do read the article 👇
[What is Linux? Why There are 100’s of Linux OS?Cannot figure out what is Linux and why there are so many of Linux? This analogy explains things in a simpler manner.](https://itsfoss.com/what-is-linux/)

## Linux vs GNU/Linux
On a similar line, you'll also come across statements like 'Linux is just a kernel, [what you are referring to as Linux is actually GNU Linux](https://itsfoss.com/gnu-linux-copypasta/)".
Even before Linus Torvalds created Linux in 1991, Richard Stallman created the Free Software movement and the GNU project. The GNU project encompasses the reimplementation of popular UNIX tools and commands like ls, grep, sed, etc.
Typically, your Linux distribution comes with all these GNU tools on top of the Linux kernel.
This is why purists insist on calling it GNU Linux so that people don't forget the contribution and importance of GNU in the success of Linux.
## In the end...
*So, if you are asked this question in viva or interview, reply with 'Linux is a kernel, not an operating system'. Mostly your teacher or interviewer is looking for that answer.*
But deep down, understand the difference between the kernel and the operating system.
If someone says, "I use Linux", you understand that the person is referring to a Linux distribution, not just the kernel. And sincerely, there is no need to correct someone with 'Linux is just a kernel, not an operating system'. |
15,595 | 终端基础:在 Linux 终端中创建目录 | https://itsfoss.com/make-directories/ | 2023-03-04T09:13:54 | [
"mkdir"
] | https://linux.cn/article-15595-1.html | 
在终端基础系列的 [上一章](https://itsfoss.com/change-directories/) 中,你学到了在 Linux 命令行中改变文件夹的知识。
我在最后给出了一个练习,简单地提到了创建目录。
在本系列的这一部分,我将讨论如何使用 `mkdir` 命令在 Linux 命令行中建立新的文件夹。
```
mkdir dir_name
```
`mkdir` 是 “<ruby> 创建目录 <rt> make directories </rt></ruby>” 的简称。让我们来看看这个命令的使用情况。
>
> ? 如果你不知道,文件夹在 Linux 中被称为目录。
>
>
>
### 在 Linux 中创建一个新目录
你现在应该已经熟悉了 [Linux 中绝对路径和相对路径的概念](https://linuxhandbook.com/absolute-vs-relative-path/)。如果没有,请参考 [本教程](https://linuxhandbook.com/absolute-vs-relative-path/)。
如果你的系统还没有打开终端,请打开它。通常情况下,你从主目录(`/home/username`)开始。但为了本教程和回忆一些事情,我假定你不在你的主目录中。
所以,先换到你的主目录:
```
cd
```
是的,如果你简单地输入 `cd`,没有任何选项和参数,它就会把你带到你的主目录。你也可以使用 `cd ~` 等方法。
在这里,建立一个新的目录,叫做 `practice`。
```
mkdir practice
```
你能切换到这个新建立的 `practice` 目录吗?
```
cd practice
```
很好!现在你有了一个专门的文件夹,你将在这里练习本系列中的 Linux 命令行教程。

### 创建多个新目录
你刚刚创建了一个新的目录。如果你要创建不止一个呢?比方说,有三个。
你可以对每个目录连续使用三次 `mkdir` 命令。这将会起作用。然而,这并不是真的需要。你可以像这样同时创建多个目录来节省时间和精力:
```
mkdir dir1 dir2 dir3
```
请继续这样做吧。你可以列出 `practice` 目录的内容,查看所有新创建的目录。以后会有更多关于 `ls` 命令的内容。

>
> ? 你不能在同一地方有两个同名的文件夹或文件。
>
>
>
### 创建多个嵌套的子目录
你现在知道了一次创建多个目录的方法。
但是,如果你要创建一个嵌套的目录结构呢?比方说,你需要在 `dir1` 里面的 `subdir1` 里面创建一个目录 `subdir2`。
```
dir1/subdir1/subdir2
```
这里的问题是 `subdir1` 并不存在。所以如果你尝试 `mkdir dir1/subdir1/subdir32`,你会得到一个错误:
```
abhishek@itsfoss:~/practice$ mkdir dir1/subdir1/subdir2
mkdir: cannot create directory ‘dir1/subdir1/subdir2’: No such file or directory
```
如果你不知道的话,你会选择 `mkdir dir1/subdir1`,然后运行 `mkdir dir1/subdir2`。这将会起作用。然而,有一个更好的方法。
你使用 `-p` 选项,它会在需要时创建父目录。如果你运行下面的命令:
```
mkdir -p dir1/subdir1/subdir2
```
它将创建 `subdir1`,然后在 `subdir1` 里面创建 `subdir2`。
>
> ? 不是命名惯例,但最好在文件和目录名中避免空格。使用下划线或破折号代替,因为处理文件/目录名中的空格需要额外精力。
>
>
>
### 测试你的知识
这是一个相当简短的教程,因为 `mkdir` 命令只有几个选项。
现在,让我给你一些实践练习,以利用你先前创建的 `practice` 目录。
* 不进入 `dir2` 目录,在其中创建两个新的子目录。
* 不进入 `dir3` 目录,创建两级嵌套子目录(`subdir1/subdir2`)
* 进入 dir2 目录。在这里,在你的主目录下创建一个名为 `temp_stuff` 的目录。不要担心,我们将在本系列教程的后面删除它。
* 回到父目录 `practice`,尝试创建一个名为 `dir3` 的目录。你看到一个错误。你能用 `-p` 选项使它消失吗?
你可以 [在社区论坛讨论这个练习](https://itsfoss.community/t/exercise-in-making-directories-in-linux-terminal/10227)。
在终端基础系列的下一章中,你将学习如何用 `ls` 命令列出一个目录的内容。
如果你有问题或建议,请告诉我。
---
via: <https://itsfoss.com/make-directories/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter 2: Making Directories in Linux Terminal
Learn to make new folders in the Linux command line in this part of the Terminal Basics tutorial series.
In the previous chapter of the Terminal Basics series, you learned about [changing folders in the Linux command line](https://itsfoss.com/change-directories/).
I gave an exercise at the end that briefly mentioned making directories.
In this part of the series, I'll discuss how to create new folders on the Linux command line using the mkdir command.
`mkdir dir_name`
mkdir is short of make directories. Let's see about using this command.
## Making a new directory in Linux
You should be familiar with the [concept of absolute and relative paths in Linux](https://linuxhandbook.com/absolute-vs-relative-path/) by now. If not, please refer to this tutorial.
[Absolute vs Relative Path in Linux: What’s the Difference?In this essential Linux learning chapter, know about the relative and absolute paths in Linux. What’s the difference between them and which one should you use.](https://linuxhandbook.com/absolute-vs-relative-path/)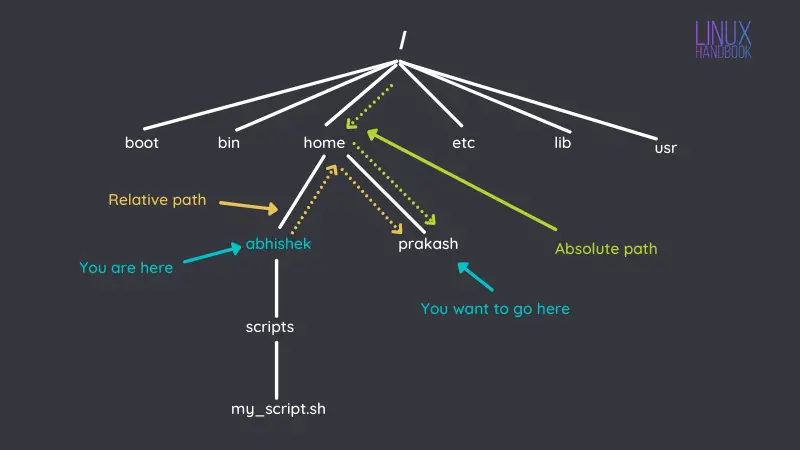

Open the terminal on your system if it is not already opened. Normally, you start with your home directory (/home/username). But for the sake of this tutorial and to recall a couple of things, I presume you are not in your home directory.
So, change to your home directory first.
`cd`
Yes. If you simply enter cd without any options and arguments, it takes you to your home directory. You could also use `cd ~`
among other methods.
Here, make a new directory called practice.
`mkdir practice`
Can you switch to this newly created practice directory?
`cd practice`
Great! Now you have a dedicated folder where you'll practice the Linux command line tutorials in this series.
## Creating multiple new directories
You just created a new directory. What if you have to create more than one? Let's say three of them.
You may use the mkdir command three times in a row for each of them. It will work. However, it is not really needed. You can save time and effort by creating multiple directories at the same time like this:
`mkdir dir1 dir2 dir3`
Go on and do that please. You can list the contents of the `practice`
directory to see all the newly created directories. More on the ls command later.
## Making multiple nested subdirectories
So, you now know about creating multiple directories at once.
But what if you have to create a nested directory structure? Let's say that you have to create a directory subdir2 inside subdir1 inside dir1.
`dir1/subdir1/subdir2`
The problem here is that subdir1 does not exist. So if you try `mkdir dir1/subdir1/subdir32, you'll get an error:
```
abhishek@itsfoss:~/practice$ mkdir dir1/subdir1/subdir2
mkdir: cannot create directory ‘dir1/subdir1/subdir2’: No such file or directory
```
If you didn't know better, you would go for `mkdir dir1/subdir1`
and then run `mkdir dir1/subdir2`
. That will work. However, there is a much better way.
You use the `-p`
option, which makes parent directories if needed. If you run the command below:
`mkdir -p dir1/subdir1/subdir2`
It will create subdir1 and then subdir2 inside subdir1.
## 📝 Test your knowledge
This is rather a short tutorial because the mkdir command has only a few options.
Now, let me give you some practice exercises to utilize the `practice`
directory you had created earlier.
- Without entering the
`dir2`
directory, create two new subdirectories in it. - Without entering the
`dir3`
directory, create two-level nested subdirectories (subdir1/subdir2) - Change to the dir2 directory. From here, create a directory named temp_stuff in your home directory. Don't worry; we will delete it later in this tutorial series.
- Go back to the parent
`practice`
directory and try to create a directory named`dir3`
. You see an error. Can you make it go away with the`-p`
option?
In the next chapter of the Terminal Basics series, you'll learn about [listing the contents of a directory](https://itsfoss.com/list-directory-content/) with the ls command.
Do let me know if you have questions or suggestions. |
15,597 | FFmpeg 6.0 发布:支持 WBMP 和 Radiance HDR 图像 | https://debugpointnews.com/ffmpeg-6-0/ | 2023-03-05T10:11:00 | [
"FFmpeg"
] | /article-15597-1.html | 
>
> 开源多媒体框架 FFmpeg 6.0 现已发布,带来了更新和改进。
>
>
>
流行的开源多媒体框架 FFmpeg 6.0 现已发布。这个主要的版本现在已可下载,并在多媒体项目中使用。其亮点变化包括两个新的图像格式支持,许多编解码器和其他增强功能。
下面是一个快速回顾。
### FFmpeg 6.0 新增内容
#### 主要变化
这个版本的主要亮点是对两种新图像格式的支持。[Radiance HDR 图像](https://en.wikipedia.org/wiki/RGBE_image_format)(RGBE)为用户在图像处理中提供了更好的色彩深度和动态范围。FFmpeg 6.0 现在包括对 [WBMP(无线应用协议位图)](https://en.wikipedia.org/wiki/Wireless_Application_Protocol_Bitmap_Format) 图像格式的支持,这在移动设备和网络应用中是常用的图像格式。
在 FFmpeg 6.0 中,新的 `-shortest_buf_duration` 选项允许用户为音频和视频缓冲区设置一个最小的持续时间,这可以确保在输出文件中使用最短的缓冲区时间。
从 FFmpeg 6.0 开始,线程必须被内置到软件中才能运行。在这个版本中,每个复用器都在一个单独的线程中运行。这提高了性能,使同时处理多个流的效率更高。
FFmpeg 6.0 中的 `cropdetect`(裁剪检测)过滤器现在包括一个新的模式,可以根据运动向量和边缘检测裁剪区域,为用户提供更精确的视频裁剪控制。
#### 过滤器
在这个版本中,大量的过滤器得到了更新,这将通过新的功能简化你的多媒体项目和工作流程。下面是一个快速的变化列表:
* `ddagrab` 过滤器现在支持桌面复制视频捕获,允许用户直接从他们的桌面上捕获视频。
* `a3dscope` 过滤器为用户提供了音频信号的 3D 范围显示,允许更精确的音频编辑和处理。
* `backgroundkey` 过滤器允许用户删除或替换视频片段中的背景,为视频编辑提供更大的灵活性。
* `showcwt` 多媒体过滤器允许用户将连续小波变换系数可视化,提供对信号和图像处理的洞察力。
* `corr` 视频过滤器对视频帧进行二维交叉关联,提供更精确的运动估计和稳定。
* `ssim360` 视频过滤器计算两个视频帧之间的 [结构相似度指数(SSIM)](https://en.wikipedia.org/wiki/Structural_similarity),为衡量 360 度视频的视频质量提供了一个指标。
#### 编解码器
在这个版本中,编解码器的更新是非常多的。
首先,FFmpeg 6.0 现在支持 NVENC AV1 编码,允许用户使用英伟达最新的压缩技术对视频进行编码。MediaCodec 解码器现在支持 NDKMediaCodec,为安卓设备提供更好的兼容性。其次,增加了一个新的 MediaCodec 编码器,允许在安卓设备上进行视频编码时进行硬件加速。
在此基础上,该版本包括了对 QSV(快速同步视频)的 oneVPL 支持,在英特尔 CPU 上进行视频编码时提供了更好的性能和质量。QSV AV1 编码器允许用户在英特尔 CPU 上使用硬件加速对 AV1 视频进行编码。
这个版本引入了对 10/12 位 422、10/12 位 444 HEVC 和 VP9 的 QSV 编解码支持,为用户提供更好的视频质量和性能。WADY DPCM 解码器和解复用器允许用户使用 WADY DPCM(差分脉冲编码调制)格式对音频进行解码和解复用,这种格式通常用于视频游戏配乐。
此外,现在还有一个 CBD2 DPCM 解码器,它允许用户使用 CBD2(共轭结构代数编码簿差分脉冲编码调制)格式解码音频。这种格式通常用于电信和语音编码应用。
#### 其他变化
这个变化清单很庞大,其中还包括 FFmpeg 程序的新 CLI 选项和其他错误修复。你可以在 GitHub 上阅读详细的 [变更日志](https://github.com/FFmpeg/FFmpeg/blob/master/Changelog)。
### 下载和安装
对于 Debian、Ubuntu 和相关的发行版,这个版本应该在几天内到达。请在 [Debian 跟踪页](https://ffmpeg.org/download.html) 中留意。
对于 Fedora、RHEL、CentOS,你可以通过 RPM Fusion 仓库获得这个版本。如果你已经设置了 RPM Fusion,请更新你的系统以获得它。
源代码和其他下载都可以在 [这里](https://ffmpeg.org/download.html) 下载。
另外,你可以在这里查看我们的独家文章中如何安装FFmpeg和基本使用方法。
>
> **[如何在 Ubuntu 和其他 Linux 中安装 FFmpeg](https://www.debugpoint.com/install-ffmpeg-ubuntu/)**
>
>
>
### 总结
有了 Radiance HDR 图像支持等新功能,以及对各种编解码的改进支持,FFmpeg 6.0 为用户提供了强大的音频和视频处理工具。
新的过滤器变化提供了先进的音频和视频处理能力,从去除或替换视频中的背景到执行运动估计和稳定。
总的来说,这是一个重要的里程碑式的更新,为音频和视频处理工作负载提供了更好的性能和更大的灵活性。
---
via: <https://debugpointnews.com/ffmpeg-6-0/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,598 | 5 个有用的 Linux Shell 转义序列 | https://opensource.com/article/23/2/escape-sequences-linux-shell | 2023-03-05T13:47:19 | [
"转义序列"
] | https://linux.cn/article-15598-1.html | 
>
> 如何在你的 Bash 终端使用这些秘密代码,请下载我们新的 Linux 元字符速查表。
>
>
>
我最近在读一篇 Don watkins [关于 Shell 元字符的文章](https://opensource.com/article/22/2/metacharacters-linux)。他的文章让我想到了你可以用 shell 输入做的所有的奇怪事情。虽然我可能还没有发现极端的情况,但是我经常发现 shell 转义序列,比如 `\b`、`\t` 和 `\f` 非常有用。
转义序列是一种特殊类型的终端输入。它们旨在让你能够输入物理键盘上没有的字符或触发事件。下面是我最喜欢的 Bash shell 的转义序列。
### 1、退格符
你可以在命令中输入若干退格符,以便在命令执行时触发。例如这个命令,你可能会认为它的输出是`ab`,但是看一下真正的输出:
```
$ echo a$'\b'b
b
```
从技术上来说,Shell 确实输出了 `ab`(你可以通过在命令后面附加 `| wc -m` 来确认这一点),但是全部输出的一部分是 `\b` 退格事件。退格键在输出 `b` 字符之前删除了 `a` 字符,因此输出只有 `b` 字符。
### 2、换行符
换行符是一个让你的 Shell 转到下一行的第 0 列的信号。这一点很重要,当使用像 [printf](https://opensource.com/article/20/8/printf) 这样的命令时,它不会像 `echo` 那样在输出的末尾自动添加换行符。看看不带 `\n` 换行符的 `printf` 语句和带换行符的 `printf` 语句之间的区别:
```
$ printf "%03d.txt" 1
001.txt$
$ printf "%03d.txt\n" 1
001.txt
$
```
### 3、换页符
`\f` 换页信号就像换行符,但是却并不是返回到第 0 列。下面是一个使用换页符而不是换行符的 `printf` 命令:
```
$ printf "%s\f" hello
hello
$
```
你的 Shell 提示符出现在下一行,但不是在下一行的行首。
### 4、制表符
有两种制表符转义序列:水平制表符 `\t` 和垂直制表符 `\v`。水平制表符如下所示:
```
$ echo a$'\t'b
a b
```
理论上,垂直制表符是相同的原理,但是在垂直空间中。然而,在大多数控制台上,一行的垂直间距是不可变的,所以它通常看起来很像一个换页符:
```
$ echo a$'\v'b
a
b
```
### 5、Unicode
Unicode 标准中有很多可用的字符,而你的键盘只有大约 100 个键。在 Linux 上有几种方法可以输入 [特殊字符](https://opensource.com/article/22/7/linux-compose-key-cheat-sheet),但是将它们输入到终端的一种方法是使用 Unicode 转义序列。这个转义序列以 `\u` 开头,后跟一个十六进制值。你可以在文件 `/usr/share/X11/locale/en_US.UTF-8/Compose` 中找到许多 Unicode 值。你也可以在 [https://www.Unicode.org/charts/](https://www.unicode.org/charts/) 查看 Unicode 规范。
这对于输入像圆周率 π(圆的周长与直径之比)等常见符号非常有用:
```
$ echo $'\u03C0'
π
```
还有许多其他的符号和字符:
```
$ echo $'\u270B'
✋
$ echo $'\u2658'
♘
$ echo $'\u2B67'
⭧
```
有盲文符号、音乐符号、字母、电气符号、数学符号、表情符号、游戏符号等等。事实上,有如此多的可用符号,有时你需要 `\U`(注意大写字母)Unicode 转义序列来访问高区的 Unicode。例如,这张红心 5 的扑克牌只出现在 `\U` 转义序列中:
```
$ echo $'\U1F0B5'
?
```
浏览一下 Unicode 规范,找到适合你的位置,并使用 `\u` 和 `\U` 来访问你需要的所有特殊符号。
### 除此之外
Bash Shell 的手册页中列出了 18 个转义序列,我发现其中一些更有用。我已经在本文中介绍了我最爱的几个,Don Watkins 也谈到了他在文章中最常用的元字符,但是还有更多待发现。有很多方法可以对字母和数字、子 Shell、数学方程等进行编码。为了更好地了解 Shell 可用的元字符,可以下载我们的 [元字符速查表](https://opensource.com/downloads/linux-metacharacters-cheat-sheet),你可以在使用计算机上最强大的应用程序 —— Linux 终端时将它放在手边。
---
via: <https://opensource.com/article/23/2/escape-sequences-linux-shell>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed/) 译者:[zepoch](https://github.com/zepoch) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recently read an [article about shell metacharacters](https://opensource.com/article/22/2/metacharacters-linux) by Opensource.com correspondent Don Watkins. His article made me think about all the weird things you could do with shell input. While I probably have yet to discover the extremes, I do often find shell escape sequences, like `\b`
and `\t`
and `\f`
strangely useful.
Escape sequences are a special type of terminal input. They're designed to make it possible for you to enter characters or events that you may not have on your physical keyboard. Here are my favorite escape sequences for the Bash shell.
## 1. Backspace
You can enter a backspace character as part of a command, more or less loading it to trigger once the command executes. For instance, looking casually at this command, you might expect its output to be `ab`
, but take a look at the actual output:
```
``````
$ echo a$'\b'b
b
```
Technically, the shell did output `ab`
(you can confirm that by appending `| wc -m`
to the command) but part of the total output was the `\b`
backspace event. The backspace removed `a`
before outputting `b`
, and so the viewable output is just `b`
.
## 2. Newline
A newline character is a signal for your shell to go to column 0 of the next line. This is essential when using a command like [printf](https://opensource.com/article/20/8/printf), which doesn't assume that you want a newline added to the end of your output, the way `echo`
does. Look at the difference between a `printf`
statement without the `\n`
newline character and one with it:
```
``````
$ printf "%03d.txt" 1
001.txt$
$ printf "%03d.txt\n" 1
001.txt
$
```
## 3. Form feed
A `\f`
form feed signal is like a newline character, but without the imperative to return to column 0. Here's a `printf`
command using a form feed instead of a newline:
```
``````
$ printf "%s\f" hello
hello
$
```
Your shell prompt is on the next line, but not at the start of the line.
## 4. Tab
There are two tab escape sequences: the `\t`
horizontal tab and the `\v`
vertical tab. The horizontal tab is exactly what you'd expect.
```
``````
$ echo a$'\t'b
a b
```
The vertical tab is, in theory, the same principle but in vertical space. On most consoles, though, the vertical spacing of a line isn't variable, so it usually ends up looking a lot like a form feed:
```
``````
$ echo a$'\v'b
a
b
```
## 5. Unicode
There are a lot of characters available in the Unicode standard, and your keyboard only has about 100 keys. There are a few ways to enter [special characters](https://opensource.com/article/22/7/linux-compose-key-cheat-sheet) on Linux, but one way to enter them into the terminal is to use the Unicode escape sequence. You start this escape sequence with `\u`
followed by a hexadecimal value. You can find many Unicode values in the file `/usr/share/X11/locale/en_US.UTF-8/Compose`
, or you can look at the Unicode specification at [https://www.unicode.org/charts/](https://www.unicode.org/charts/).
This can be a useful trick for entering common symbols like Pi (the ratio of a circle's circumference to its diameter):
```
``````
$ echo $'\u03C0'
π
```
There are lots of other symbols and characters, too.
```
``````
$ echo $'\u270B'
✋
$ echo $'\u2658'
♘
$ echo $'\u2B67'
⭧
```
There's Braille notation, musical notation, alphabets, electrical symbols, mathematical symbols, emoji, game symbols, and much more. In fact, there are so many available symbols that sometimes you need the `\U`
(note the capital letter) Unicode escape sequence to access Unicode in the high ranges. For instance, this 5-of-Hearts playing card only appears with the `\U`
escape sequence:
```
``````
$ echo $'\U1F0B5'
🂵
```
Have a look around on the Unicode specification to find your niche, and use `\u`
and `\U`
to access all the special symbols you need.
## Escape the shell
There are 18 escape sequences listed in the man page for the Bash shell, and some I find more useful than others. I've covered my favorites in this article, and Don Watkins talked about the metacharacters he uses most often in his article, yet there's still more to be discovered. There are ways to encode ranges of letters and numbers, subshells, mathematical equations, and more. For a good overview of metacharacters available for the shell, download our [metacharacter cheat sheet](https://opensource.com/downloads/linux-metacharacters-cheat-sheet) and keep it handy as you get better at using the most powerful application on your computer: the Linux terminal.
## 2 Comments |
15,600 | 5 个最好的 Arch Linux 衍生发行版,适合所有人 | https://www.debugpoint.com/best-arch-linux-distros/ | 2023-03-06T07:50:00 | [
"Arch Linux"
] | /article-15600-1.html |
>
> 我们点评了 2023 年最好的 Arch Linux 发行版,并探讨了它们的关键亮点,以便在你为工作流程选择它们之前加以考虑。
>
>
>

如果你是一个寻找强大而灵活的操作系统的 Linux 爱好者,那么 Arch Linux 是值得考虑的。Arch Linux 以其灵活性、定制化选项和极简设计而闻名。
它是那些喜欢 DIY,想从头开始构建自己的系统的 Linux 爱好者的热门选择。开发人员、程序员和游戏玩家经常选择 Arch Linux,因为它采用滚动发布模式,确保可以获得最新的应用程序和模块。
然而,设置 Arch Linux 可能令人生畏,特别是对初学者来说。这就是为什么有几个基于 Arch Linux 的发行版,它们旨在使安装和设置过程更容易,更方便用户使用。
与基于 Debian 的发行版相比,基于 Arch Linux 的发行版并不多。
**但是,你如何决定哪一个最适合你呢?**
好吧,你可以考虑几个在一般的使用情况下的常见因素。有几个标准可以列举如下:
* 安装的简易性(独立系统或双引导)
* 用户友好性
* 自定义选项
* 预先配置的软件包
* 常规维护
* 专业的硬件支持
* 社区帮助
在这份最佳 Arch Linux 衍生发行版清单中,我们探讨了现有的最佳发行版,看看它们如何满足普通用户的上述要点。
### 5 个最好的 Arch Linux 衍生发行版,适合所有人
#### EndeavourOS
EndeavourOS 是一个基于 Arch Linux 的轻量级和用户友好的发行版,旨在提供一个无忧的 Arch Linux 体验。它带有预装的桌面环境和预配置的软件包,让人很容易开始上手 Arch Linux。
它是三年前新推出的 Arch Linux 衍生发行版之一。由于它对 Arch Linux 用户体验的独特处理方式,在很短的时间内它就变得很受欢迎。

目前它被推荐为这个列表中第一的原因是:
* 它使用了一个 **友好的 Calamares 安装程序**,对于双启动或独立系统来说,效果非常好。
* 提供了 **专门的硬件支持**,如英伟达驱动程序和 ARM 镜像。
* EndeavourOS 的 **社区帮助** 非常棒,在 Telegram 频道和论坛的响应更快。
* 初次使用的用户可以通过友好的点击式操作来管理和更新 Arch Linux 系统。
* 它配备了 **现代的桌面环境**,如 Xfce、KDE Plasma、GNOME 和一些窗口管理器。
* 经验丰富的技术团队,以 **坚实的目标** 提供最好的 Arch Linux 发行版体验。
使用下面的下载链接试试吧。如果你想进一步探索,我们还有 [安装指南](https://www.debugpoint.com/endeavouros-install-guide/) 和 [Endeavour OS 评测](https://www.debugpoint.com/web-stories/endeavouros-review/)。
>
> **[下载 EndeavourOS](https://endeavouros.com/download/)**
>
>
>
#### Manjaro Linux
本列表中的第二个发行版是 Manjaro Linux,它是另一个优秀的 Arch Linux 衍生发行版,并且经过了时间的考验。这个发行版的主要目标是通过提供开箱即用的功能,使无论是初学者还是高级用户都能享受到 Arch Linux。

以下是 Manjaro Linux 的一些主要特点和优势,这些特点和优势使它成为每个人的完美 Arch Linux 衍生发行版。
* **用户友好的界面和桌面环境**:Manjaro Linux 带有 Xfce、KDE Plasma、GNOME、Budgie、Cinnamon 和 MATE 等桌面产品提供的简单易用的界面。此外,你也可以使用 i3 和 Sway 窗口管理器的定制版。
* **稳定性和 AUR 支持**:Majaro 会在 Arch Linux 进行重大更新的几天内得到更新。此外,它还设置了一个 Arch 用户库(AUR),提供大量的软件集合。
* **桌面管理**:配备了 Pamac 软件管理器,可以轻松通过 GUI 进行软件和软件包的安装。
* **安装**:Calamares 安装程序使在双启动或独立系统中的安装变得简单。此外,你可以购买带有 Manjaro 的 OEM 笔记本电脑,这些笔记本电脑也带有 Docker 镜像!
* **社区支持**:在本列表中的所有 Arch Linux 衍生发行版中,Manjaro 的使用率很高,所以你可以在网上获得大量的问题解决方案。此外,Manjaro 论坛的支持也很好。
你可以使用下面的链接下载 Manjaro Linux。要进一步探索,请阅读我们最近发表的 [Manjaro Linux 测评](https://www.debugpoint.com/manjaro-linux-review-2022/)。
>
> **[下载 Manjaro](https://manjaro.org/download/)**
>
>
>
#### Garuda Linux
本列表中的第三个 Arch 发行版是 Garuda Linux,它主要针对那些希望使用 Arch 发行版进行游戏的用户。不过,你也可以把它用于其他用途。
它配备了几乎所有流行的桌面和窗口管理器,如 KDE、Xfce、GNOME、LXQt-win、Cinnamon、Mate、Wayfire、Qtile、i3wm 和 Sway。因此,你的选择很广泛。
Garuda Linux 提供最好的特性之一是默认的 BTRFS 文件系统和 Zstd 压缩,可以让你的现代高端硬件有更好的性能。

下面是一些使其脱颖而出的主要特点和优势:
* 为在 Arch Linux 进行游戏做好了准备。
* 通过 GameMode 和 Gamemode-Tools 对 Steam 和 Lutris 提供了内置支持。
* 可以选用所有主要桌面和窗口管理器。
* 自定义主题和图标,看起来非常漂亮。
* 大量的预编译软件包,包括流行的 Chaotic-Aur。
>
> **[下载 Garuda Linux](https://garudalinux.org/downloads.html)**
>
>
>
#### ArcoLinux
ArcoLinux 是一个基于 Arch Linux 的用户友好型的高级发行版,它带有预装的桌面环境和一套预配置的软件包。它还包括一些工具和脚本,可以使 Arch Linux 的使用体验更加友好。

ArcoLinux 与本列表中的所有发行版有些不同。它有四个不同的产品,它们是:
* ArcoLinux XL:旗舰版本,具有完整的软件包,带有 Xfce。
* ArcoLinux XS:带有主线、LTS、Xanmod 和 Zen 等四种可选内核的极简变体,带有 Xfce。
* ArcoLinuxD:极简变体,没有桌面或软件包;需要你自己安装。
* ArcoLinuxB:极简变体,可以选择你的桌面和精简的软件。
正如你所看到的,它的设计相当独特。此外,如果你是 Arch Linux 的爱好者,你可以试试 ArcoLinux,这对你来说将是一个很好的学习经验。
该团队还提供了 1000 多个关于 ArcoLinux 的各种指南视频。请到下面的链接进行下载。另外,如果你想了解更多关于各种产品的信息,请访问 [此页面](https://www.arcolinux.info/arcolinux-editions/)。
>
> **[下载 ArcoLinux](https://www.arcolinux.info/downloads/)**
>
>
>
#### ArchLabs Linux
还记得 BunsenLabs Linux 吗?ArchLabs Linux 旨在成为具有 BunsenLabs Linux 外观的极简 Arch Linux 发行版。
它具有 dk 窗口管理器、tint2 面板和各种预装的应用程序,旨在提供一个简单而高效的桌面环境。ArchLabs Linux 是高度可定制的,并提供了各种工具和脚本,使用户能够轻松地配置和个性化他们的系统。

它是那些希望获得 Arch Linux 的灵活性和滚动发布更新的好处,但又喜欢更多用户友好和预先配置的桌面环境的用户的热门选择。
对于每个喜欢极简主义和窗口管理器的人来说,Arch Linux 是一个完美的发行版。
>
> **[下载ArchLabs Linux](https://archlabslinux.com/get/)**
>
>
>
### 还有几个 Arch Linux 发行版
所以,上面这些是我们认为最好的五个。然而,还有一些 Arch Linux 衍生发行版也同样优秀,但与上述名单相比,使用量可能较少。
以下是其中的一些,以及为什么它们同样是最好的。
**[Mabox Linux](https://www.debugpoint.com/mabox-linux-2022/)**:它是一个用户友好的、基于 Manjaro Linux 的轻量级 Linux 发行版。它的特点是 Openbox 窗口管理器,这是一个简单而高效的桌面环境,可以根据用户的喜好进行定制。
**[Archcraft Linux](https://www.debugpoint.com/archcraft-os-review/)**:它是一个基于 Arch Linux 的极简 Linux 发行版。它使用窗口管理器和轻量级应用程序,这使得它的速度超快。它预先配置了各种设置,为你提供了最好的开箱即用的窗口管理器体验。Archcraft Linux 使用 Calamares 系统安装程序进行安装,并包括 yay 软件包管理器,以方便从 Arch 用户资源库(AUR)中获取软件。
**[Bluestar Linux](https://sourceforge.net/projects/bluestarlinux/)**:它是一个使用 Arch Linux 作为基础的 Linux 发行版。它的目标是提供一个坚实的操作系统,在不影响美观的情况下,具有广泛的功能和易用性。
### 其他新发行版
此外,最近还推出了一些 Arch Linux 发行版,为 Arch Linux 提供了不同的使用方式。这些都试图在各种因素上做到独一无二。下面是其中的一些,以及它们的主要区别特征。你可能想看看它们,进一步探索基于 Arch Linux 的发行版。
* [XeroLinux](https://www.debugpoint.com/install-xerolinux-arch/)(拥有惊人的外观)
* [Exodia OS](https://www.debugpoint.com/exodia-os-first-look/)(基于 BSPWM 的 Arch Linux)
* [Crystal Linux](https://www.debugpoint.com/crystal-linux-first-look/)(完美结合了 GNOME 和 Arch Linux)
* [Hefftor Linux](https://www.debugpoint.com/hefftor-linux-review/)(基于 Xfce 和 Plasma 的时尚发行版)
### 总结
总之,Arch Linux 是一个高度可定制和灵活的发行版,许多资深的 Linux 用户都很喜欢。
无论你的需求或工作流程是什么,你都可以尝试这个列表中的东西。在有疑问时,可以尝试本列表中前三个发行版中的任何一个。
虽然对初学者来说可能会有畏难情绪,但这些 Arch Linux 发行版旨在提供更友好的用户体验,而不牺牲使 Arch Linux 如此受欢迎的灵活性和定制选项。
我希望你能找到令你感到舒适的 Arch Linux 发行版,能够满足你的需求。
---
via: <https://www.debugpoint.com/best-arch-linux-distros/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,601 | 管理大型 Postgres 数据库的 3 个技巧 | https://opensource.com/article/23/2/manage-large-postgres-databases | 2023-03-06T11:30:50 | [
"Postgres"
] | https://linux.cn/article-15601-1.html | 
>
> 在处理庞大的数据库时,请尝试这些方便的解决方案,以解决常见的问题。
>
>
>
关系型数据库 PostgreSQL(也被称为 Postgres)已经越来越流行,全球各地的企业和公共部门都在使用它。随着这种广泛的采用,数据库已经变得比以前更大了。在 Crunchy Data,我们经常与 20TB 以上的数据库打交道,而且我们现有的数据库还在继续增长。我的同事 David Christensen 和我收集了一些关于管理拥有巨大表的数据库的技巧。
### 大表
生产数据库通常由许多具有不同数据、大小和模式的表组成。常见的情况是,最终有一个巨大的、无序的数据库表,远远大于你数据库中的任何其他表。这个表经常存储活动日志或有时间戳的事件,而且对你的应用或用户来说是必要的。
真正的大表会因为很多原因造成挑战,但一个常见的原因是锁。对表的定期维护往往需要锁,但对大表的锁可能会使你的应用瘫痪,或导致堵塞和许多令人头痛的问题。我有一些做基本维护的技巧,比如添加列或索引,同时避免长期运行的锁。
**添加索引的问题**:在创建索引的过程中锁住表。如果你有一个庞大的表,这可能需要几个小时。
```
CREATE INDEX ON customers (last_name)
```
**方案**:使用 `CREATE INDEX CONCURRENTLY` 功能。这种方法将索引创建分成两部分,一部分是短暂的锁定,以创建索引,立即开始跟踪变化,但尽量减少应用阻塞,然后是完全建立该索引,之后查询可以开始使用它。
```
CREATE INDEX CONCURRENTLY ON customers (last_name)
```
### 添加列
在数据库的使用过程中,添加列是一个常见的请求,但是对于一个巨大的表来说,这可能是很棘手的,同样是由于锁的问题。
**问题**:当你添加一个新的默认值为一个函数的列时,Postgres 需要重写表。对于大表,这可能需要几个小时。
**方案**:将操作拆分为多条基本语句,总效果一致,但控制锁的时间。
添加列:
```
ALTER TABLE all_my_exes ADD COLUMN location text
```
添加默认值:
```
ALTER TABLE all_my_exes ALTER COLUMN location SET DEFAULT texas()
```
使用 `UPDATE` 来添加默认值:
```
UPDATE all_my_exes SET location = DEFAULT
```
### 添加约束条件
**问题**: 你想添加一个用于数据验证的检查约束。但是如果你使用直接的方法来添加约束,它将锁定表,同时验证表中的所有现有数据。另外,如果在验证的任何时候出现错误,它将回滚。
```
ALTER TABLE favorite_bands ADD CONSTRAINT name_check CHECK (name = 'Led Zeppelin')
```
**方案**:告诉 Postgres 这个约束,但不要验证它。在第二步中进行验证。这将在第一步中进行短暂的锁定,确保所有新的/修改过的行都符合约束条件,然后在另一步骤中进行验证,以确认所有现有的数据都通过约束条件。
告诉 Postgres 这个约束,但不要强制执行它:
```
ALTER TABLE favorite_bands ADD CONSTRAINT name_check CHECK (name = 'Led Zeppelin') NOT VALID
```
然后在创建后**验证**它:
```
ALTER TABLE favorite_bands VALIDATE CONSTRAINT name_check
```
### 想了解更多?
David Christensen 和我将在 3 月 9 号到 10 到在加州帕萨迪纳参加 SCaLE 的 Postgres Days。很多来自 Postgres 社区的优秀人士也会在那里。加入我们吧!
---
via: <https://opensource.com/article/23/2/manage-large-postgres-databases>
作者:[Elizabeth Garrett Christensen](https://opensource.com/users/elizabethchristensencrunchydatacom) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The relational database PostgreSQL (also known as Postgres) has grown increasingly popular, and enterprises and public sectors use it across the globe. With this widespread adoption, databases have become larger than ever. At Crunchy Data, we regularly work with databases north of 20TB, and our existing databases continue to grow. My colleague David Christensen and I have gathered some tips about managing a database with huge tables.
## Big tables
Production databases commonly consist of many tables with varying data, sizes, and schemas. It's common to end up with a single huge and unruly database table, far larger than any other table in your database. This table often stores activity logs or time-stamped events and is necessary for your application or users.
Really large tables can cause challenges for many reasons, but a common one is locks. Regular maintenance on a table often requires locks, but locks on your large table can take down your application or cause a traffic jam and many headaches. I have a few tips for doing basic maintenance, like adding columns or indexes, while avoiding long-running locks.
**Adding indexes problem**: Index creation locks the table for the duration of the creation process. If you have a massive table, this can take hours.
```
````CREATE INDEX ON customers (last_name)`
**Solution**: Use the **CREATE INDEX CONCURRENTLY** feature. This approach splits up index creation into two parts, one with a brief lock to create the index that starts tracking changes immediately but minimizes application blockage, followed by a full build-out of the index, after which queries can start using it.
```
````CREATE INDEX CONCURRENTLY ON customers (last_name)`
## Adding columns
Adding a column is a common request during the life of a database, but with a huge table, it can be tricky, again, due to locking.
**Problem**: When you add a new column with a default that calls a function, Postgres needs to rewrite the table. For big tables, this can take several hours.
**Solution**: Split up the operation into multiple steps with the total effect of the basic statement, but retain control of the timing of locks.
Add the column:
```
````ALTER TABLE all_my_exes ADD COLUMN location text`
Add the default:
```
``````
ALTER TABLE all_my_exes ALTER COLUMN location
SET DEFAULT texas()
```
Use **UPDATE** to add the default:
```
``````
UPDATE all_my_exes SET location = DEFAULT
```
## Adding constraints
**Problem**: You want to add a check constraint for data validation. But if you use the straightforward approach to adding a constraint, it will lock the table while it validates all of the existing data in the table. Also, if there's an error at any point in the validation, it will roll back.
```
``````
ALTER TABLE favorite_bands
ADD CONSTRAINT name_check
CHECK (name = 'Led Zeppelin')
```
**Solution**: Tell Postgres about the constraint but don't validate it. Validate in a second step. This will take a short lock in the first step, ensuring that all new/modified rows will fit the constraint, then validate in a separate pass to confirm all existing data passes the constraint.
Tell Postgres about the constraint but do not to enforce it:
```
``````
ALTER TABLE favorite_bands
ADD CONSTRAINT name_check
CHECK (name = 'Led Zeppelin') NOT VALID
```
Then **VALIDATE** it after it's created:
```
````ALTER TABLE favorite_bands VALIDATE CONSTRAINT name_check`
## Hungry for more?
David Christensen and I will be in Pasadena, CA, at SCaLE's Postgres Days, March 9-10. Lots of great folks from the Postgres community will be there too. Join us!
## Comments are closed. |
15,603 | 开源安全基金会(OpenSSF):回顾和展望 | https://www.linux.com/news/open-source-security-foundation-openssf-reflection-and-future/ | 2023-03-07T08:39:01 | [
"OpenSSF",
"安全"
] | https://linux.cn/article-15603-1.html | 
[开源安全基金会](https://openssf.org/)(OpenSSF)正式 [成立于 2020 年 8 月 3 日](https://www.linuxfoundation.org/en/press-release/technology-and-enterprise-leaders-combine-efforts-to-improve-open-source-security/)。本文将讨论 OpenSSF 创立的初衷,它成立之初六个月内的成就,以及它未来的愿景。
(LCTT 校注:原文发表于 2 年前, 但时至今日仍然有一些值得了解的信息。)
全世界都在推行开源软件(OSS)理念,所以开源软件的安全也至关重要。为了提升开源软件的安全性,业界已经做了大量工作,并取得了一些成果。这些成果包括:Linux 基金会的 <ruby> 核心基础设施计划 <rt> Core Infrastructure Initiative </rt></ruby>(CII)、GitHub 安全实验室的 <ruby> 开源安全联盟 <rt> Open Source Security Coalition </rt></ruby>(OSSC)和由谷歌以及其他公司创立的 <ruby> 联合开源软件计划 <rt> Joint Open Source Software Initiative </rt></ruby>(JOSSI)。
显然,如果这些成果合为一体,软件行业将发展得更加顺利。这三项成果在 2020 年合并为“旨在促进开源软件安全性的、由各行业巨头主导的跨行业联盟”。
OpenSSF 的确受益于这种“跨行业联盟”;它有几十个成员,(按字母顺序)包括 Canonical、 GitHub、谷歌、IBM、英特尔、微软和红帽。联盟的理事会成员还包括安全社区个人代表,这些个人代表是那些不能以企业名义作为联盟成员的个人。该联盟也创造了一些便于人们合作的组织结构:建立一些活跃的工作组,这种工作组确定(并公布)它存在的价值,其中的成员应当就该组织的技术愿景形成一致意见。
但是这并不重要,除非它们有实际成果。当时虽然处于早期,它们也确实取得了一些成果。它们发布了:
* [安全软件开发基础课程](https://openssf.org/blog/2020/10/29/announcing-secure-software-development-edx-course-sign-up-today/):在 edX 平台上有 3 门免费课程,旨在教授软件开发人员软件安全方面的知识。这些课程注重实际操作,任何开发人员都可以较轻松地学习,而不是那些需要耗费大量资源的理论或案例。开发人员也可以付费参加测试,从而获得认证,表明自己掌握了这些课程地内容。
* [安全评分卡](https://openssf.org/blog/2020/11/06/security-scorecards-for-open-source-projects/):为开源项目自动生成“安全分数”,帮助用户进行信任、风险和安全方面的决策。
* [关键性分数](https://github.com/ossf/criticality_score):基于一些参数,为开源项目自动生成关键性分数。临界分数可以让人们对世界上最重要的开源项目有更好的理解。
* [安全度量仪表盘](https://github.com/ossf/Project-Security-Metrics):这是较早时候发布的成果,它结合安全评分卡、CII 最佳实践和其他数据来源,提供与 OSS 项目有关的安全和支持信息的仪表盘。
* [OpenSSF CVE 基准测试](https://openssf.org/blog/2020/12/09/introducing-the-openssf-cve-benchmark/):基准测试由超过 200 个历史上的 JavaScript/TypeScript 漏洞(CVE)的脆弱代码和元数据组成。这将帮助安全团队评估市场上的各种安全工具,使他们能够用真实的代码库(而不是合成的测试代码)确定误报和漏报率。
* [OWASP 安全知识框架](https://owasp.org/www-project-security-knowledge-framework/):与 OWASP 的合作成果,它是一个知识库,包含了带检查清单的项目和使用多种编程语言的最佳代码样例。它还提供针对开发者如何使用特定的语言编写安全代码的培训材料,以及用于实际操作的安全实验室。
* 2020 年自由/开源软件贡献者调查报告:OpenSSF 和 LISH 发布了一份报告,其中详细说明了对开源软件贡献者的调查结果,并以此为依据,研究和确定提高 OSS 安全性和可持续性的方法。一共调查了 1200 名受访者。
现有的 [CII 最佳实践徽章](https://bestpractices.coreinfrastructure.org/) 项目已经与 OpenSSF 合并,将继续升级。现在项目有很多中文译者,翻译为斯瓦希里语的工作也在进行中,项目也进行了很多小改进,详细阐明获得徽章的要求。
2020 年 11 月举行的 OpenSSF 大会讨论了 OpenSSF 正在进行中的工作。最近,OpenSSF 有这些工作组:
* 漏洞披露
* 安全工具
* 安全最佳实践
* 对开源项目安全漏洞的识别(重点关注指标仪表盘)
* 对关键项目的保障
* 数字身份认证
除了持续更新已发布的项目,未来可能的工作还包括:
* 为减少重复工作,在多种技术指标中确定哪些是重复和关联的安全需求。这就是作为领导者与 OWASP 协作开发,也称为 <ruby> <a href="https://owasp.org/www-project-integration-standards/"> 通用需求枚举 </a> <rt> Common Requirements Enumeration </rt></ruby>(CRE)。CRE 旨在使用一种公共主题标识符,将标准和指南的各个部分联系起来,这种公共主题标识符的作用是令标准和方案制定者高效工作,令标准使用者能搜索到需要的信息,从而使双方对网络安全有相同的理解。
* 建一个网站,提供对安全度量仪表盘的免安装访问。再次强调,这将会提供各种来源(包括安全计分卡和 CII 最佳实践)的数据的简单展示。
* 开发对关键 OSS 项目的识别功能。哈佛大学和 LF 已经做过一些识别关键 OSS 项目的工作。未来一年内,他们会改进方法,添加新的数据来源,从而更好地进行鉴别工作。
* 资助一些关键的 OSS 项目,提高它们的安全性。预期将关注那些财力不足的项目,帮助这些项目提升整体性能。
* 识别和实现已改进和简化的技术,用于数字签名的提交和对身份的校验。
跟所有的 Linux 基金会项目一样,OpenSSF 的工作是由其成员决定的。如果你对大家所依赖的 OSS 安全有兴趣,你可以访问 OpenSSF 网站并以某种方式加入它们。参与的最好方式是出席工作组会议——会议每隔一周就举行,而且非常随意。通过合作,我们可以有所作为。欲了解更多信息,可以访问:
>
> **[https://openssf.org](https://openssf.org/)**
>
>
>
作者:[David A. Wheeler](mailto:[email protected]) Linux 基金会开源供应链安全总监
[本文](https://www.linuxfoundation.org/en/blog/openssf-reflection-and-future/) 首次发表于 [Linux 基金会网站](https://www.linuxfoundation.org/)。
---
via: <https://www.linux.com/news/open-source-security-foundation-openssf-reflection-and-future/>
作者:[The Linux Foundation](https://www.linuxfoundation.org/en/blog/openssf-reflection-and-future/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cool-summer-021](https://github.com/cool-summer-021) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [Open Source Security Foundation (OpenSSF)](https://openssf.org/) officially [launched on August 3, 2020](https://www.linuxfoundation.org/en/press-release/technology-and-enterprise-leaders-combine-efforts-to-improve-open-source-security/). In this article, we’ll look at why the OpenSSF was formed, what it’s accomplished in its first six months, and its plans for the future.
The world depends on open source software (OSS), so OSS security is vital. Various efforts have been created to help improve OSS security. These efforts include the Core Infrastructure Initiative (CII) in the Linux Foundation, the Open Source Security Coalition (OSSC) founded by the GitHub Security Lab, and the Joint Open Source Software Initiative (JOSSI) founded by Google and others.
It became apparent that progress would be easier if these efforts merged into a single effort. The OpenSSF was created in 2020 as a merging of these three groups into “a cross-industry collaboration that brings together leaders to improve the security of open source software (OSS).”
The OpenSSF has certainly gained that “cross-industry collaboration”; its dozens of members include (alphabetically) Canonical, GitHub, Google, IBM, Intel, Microsoft, and Red Hat. Its governing board also includes a Security Community Individual Representative to represent those not represented in other ways specifically. It’s also created some structures to help people work together: it’s established active working groups, identified (and posted) its values, and [agreed on its technical vision.](https://github.com/ossf/tac/blob/main/technical-vision.md)
But none of that matters unless they actually *produce* results. It’s still early, but they already have several accomplishments. They have released:
[Secure Software Development Fundamentals courses](https://openssf.org/blog/2020/10/29/announcing-secure-software-development-edx-course-sign-up-today/). This set of 3 freely-available courses on the edX platform is for software developers to learn to develop secure software. It focuses on practical steps that any software developer can easily take, not theory or actions requiring unlimited resources. Developers can also pay a fee to take tests to attempt to earn certificates to prove they understand the material.[Security Scorecards](https://openssf.org/blog/2020/11/06/security-scorecards-for-open-source-projects/). This auto-generates a “security score” for open source projects to help users as they decide the trust, risk, and security posture for their use case.[Criticality Score](https://github.com/ossf/criticality_score). This project auto-generates a criticality score for open source projects based on a number of parameters. The goal is to better understand the most critical open source projects the world depends on.[Security metrics dashboard](https://github.com/ossf/Project-Security-Metrics). This early-release work provides a dashboard of security and sustainment information about OSS projects by combining the Security ScoreCards, CII Best Practices, and other data sources.[OpenSSF CVE Benchmark](https://openssf.org/blog/2020/12/09/introducing-the-openssf-cve-benchmark/). This benchmark consists of vulnerable code and metadata for over 200 historical JavaScript/TypeScript vulnerabilities (CVEs). This will help security teams evaluate different security tools on the market by enabling teams to determine false positive and false negative rates with real codebases instead of synthetic test code.[OWASP Security Knowledge Framework (SKF)](https://owasp.org/www-project-security-knowledge-framework/). In collaboration with OWASP, this work is a knowledge base that includes projects with checklists and best practice code examples in multiple programming languages. It includes training materials for developers on how to write secure code in specific languages and security labs for hands-on work.[Report on the 2020 FOSS Contributor Survey](https://www.linuxfoundation.org/en/press-release/new-open-source-contributor-report-from-linux-foundation-and-harvard-identifies-motivations-and-opportunities-for-improving-software-security/), The OpenSSF and the Laboratory for Innovation Science at Harvard (LISH) released a report that details the findings of a contributor survey to study and identify ways to improve OSS security and sustainability. There were nearly 1,200 respondents.
The existing [CII Best Practices badge](https://bestpractices.coreinfrastructure.org/) project has also been folded into the OpenSSF and continues to be improved. The project now has more Chinese translators, a new ongoing Swahili translation, and various small refinements that clarify the badging requirements.
The [November 2020 OpenSSF Town Hall](https://openssf.org/blog/2020/11/23/openssf-town-hall-recording-now-available/) discussed the OpenSSF’s ongoing work. The OpenSSF currently has the following working groups:
- Vulnerability Disclosures
- Security Tooling
- Security Best Practices
- Identifying Security Threats to Open Source Projects (focusing on a metrics dashboard)
- Securing Critical Projects
- Digital Identity Attestation
Future potential work, other than continuously improving work already released, includes:
- Identifying overlapping and related security requirements in various specifications to reduce duplicate effort. This is to be developed in collaboration with OWASP as lead and is termed the
[Common Requirements Enumeration (CRE)](https://owasp.org/www-project-integration-standards/). The CRE is to “link sections of standard[s] and guidelines to each other, using a mutual topic identifier, enabling standard and scheme makers to work efficiently, enabling standard users to find the information they need, and attaining a shared understanding in the industry of what cyber security is.” [Source: “Common Requirements Enumeration”] - Establishing a website for no-install access to a security metrics OSS dashboard. Again, this will provide a single view of data from multiple data sources, including the Security Scorecards and CII Best Practices.
- Developing improved identification of critical OSS projects. Harvard and the LF have previously worked to identify critical OSS projects. In the coming year, they will refine their approaches and add new data sources to identify critical OSS projects better.
- Funding specific critical OSS projects to improve their security. The expectation is that this will focus on critical OSS projects that are not otherwise being adequately funded and will work to improve their overall sustainability.
- Identifying and implementing improved, simplified techniques for digitally signing commits and verifying those identity attestations.
As with all Linux Foundation projects, the work by the OpenSSF is decided by its participants. If you are interested in the security of the OSS we all depend on, check out the OpenSSF and participate in some way. The best way to get involved is to attend the working group meetings — they are usually every other week and very casual. By working together we can make a difference. For more information, see [https://openssf.org](https://openssf.org/)
**David A. Wheeler,**** Director of Open Source Supply Chain Security at the Linux Foundation**
The post [Open Source Security Foundation (OpenSSF): Reflection and Future](https://www.linuxfoundation.org/en/blog/openssf-reflection-and-future/) appeared first on [Linux Foundation](https://www.linuxfoundation.org/). |
15,604 | 每天使用开源的 9 种方法 | https://opensource.com/article/21/10/open-source-tools | 2023-03-07T15:34:23 | [
"开源"
] | /article-15604-1.html |
>
> 你可能会惊奇地发现,那些你每天使用的工具竟是开源的。
>
>
>

最近,我受邀介绍网络上可用的免费和开放资源。这次演讲是当地为保持我们社区的正常运转而做出的部分尝试 —— 由我家附近的 <ruby> 圣文德大学 <rt> St. Bonaventure University </rt></ruby> [Foster Center](https://www.sbu.edu/academics/schools-at-sbu/school-of-business/foster-center-for-responsible-leadership/foster-center-events) 赞助。 我分享的一些资源不是开源的而是免费的,但许多工具是开源的。
看到有不少人知道我所提到的工具真的很有趣。很多人并不知道他们每天使用的工具都是开源的,并且他们还可以与他人分享。
### 开源浏览器
使用网络需要一个好的浏览器,而 [Firefox 是开源的](https://opensource.com/article/21/9/switch-to-firefox),这一点很多在场的人并不清楚。除了是开源,Firefox 还具有强烈的隐私意识,这是许多用户越来越关注的问题。不过,有趣的是,即使是微软的新浏览器也是基于开源 Chromium 项目的。
### 开源网络隐私
通常,保护你的隐私和改善你的网络体验的另一种方法是使用 uBlock Origin 来阻止广告。根据他们的网站:
>
> uBlock Origin 是一个免费、开源、跨平台的内容过滤浏览器扩展——主要旨在以一种高效、用户友好的方法消除隐私侵犯。
>
>
>
其代码采用 [GPL v. 3.0](https://github.com/gorhill/uBlock) 许可证。
<ruby> 电子前沿基金会 <rt> Electronic Frontier Foundation </rt></ruby>(EFF)还维护 [Privacy Badger](https://privacybadger.org/)———— 这是一个根据 GPL v.3.0 许可的网络浏览器扩展程序。根据他们的 GitHub 存储库,它是:
>
> 一个可以自动学习阻止隐形的跟踪器的浏览器扩展程序。Privacy Badger 没有一个要阻止的列表,而是根据它们的行为自动发现跟踪器。
>
>
>
除了隐私之外,我的演讲还分享了安全密码的重要性。我的听众了解到了 [Bitwarden](https://github.com/bitwarden)。许多人不知道如何生成安全密码、区分不同网站的密码以及如何安全地存储它们。我演示了该软件如何创建密码并使用 Bitwarden 将这些密码存储在云中。我解释了用户如何通过浏览器插件、台式机和笔记本电脑应用程序以及在安卓或 iOS 移动设备上访问这些凭证。
### 开源通讯工具
本次演讲中,我谈到了通讯工具在我们生活中的无处不在,但同时它本身固有的不安全性。观众不知道 [Signal](https://opensource.com/article/19/10/secure-private-messaging)。我已经使用 Signal 几年了,并经常鼓励其他人将其视为一个安全的消息传递平台。在 Linux、macOS、Windows、[安卓](https://play.google.com/store/apps/details?id=org.thoughtcrime.securesms&referrer=utm_source%3DOWS%26utm_medium%3DWeb%26utm_campaign%3DNav) 和 [iOS](https://apps.apple.com/us/app/signal-private-messenger/id874139669) 上 [安装 Signal](https://signal.org/download/) 很容易,它提供了出色的 [文档](https://support.signal.org/) 支持,对不同的操作系统都有着详细的安装说明。Signal 使用你现有的手机号码,只要它可以发送和接收短信和打电话。当你第一次在手机上设置 Signal 时,它会在你的通讯录上搜索同样使用 Signal 的联系人。
### 开源办公工具
如果不提及我最喜欢的内容创建工具 [LibreOffice](https://opensource.com/article/21/9/libreoffice-tips),那么关于开源工具的介绍是不完整的。尽管它很受欢迎,但还是有许多人并不知道它的存在以及使用它所带来的自由。我每天都用它来写文章。我使用它来做表格而不是 Excel,有时我用它来做演示文稿。你可以在 Linux、macOS 和 Windows 上下载并安装它。LibreOffice 的优点之一是你真正拥有自己的文档,不需要昂贵的程序来访问它们。
### 开源博客软件
[WordPress](https://opensource.com/article/18/10/setting-wordpress-raspberry-pi) 是我最喜欢的博客引擎,你可以通过多种方式使用它,无论是分享你对世界大事的看法、为你的 [学生](https://opensource.com/article/20/4/wordpress-virtual-machine) 提供低成本写作平台,还是在网上为你的 [业务](https://opensource.com/article/21/3/wordpress-plugins-retail) 做宣传。
### 开源媒体库
在创建内容时,你需要可以轻松合法共享的图片来说明你的作品。[OpenClipart](https://openclipart.org/) 是我的首选。这里有数以千计的各种流行格式的图片,可以放在你的 LibreOffice 文档和博客文章中。此外,你可以通过 <ruby> <a href="https://search.creativecommons.org/"> 知识共享 </a> <rt> Creative Commons </rt></ruby> 找到你可以分享的图片,并注明适当的出处。知识共享提供的许可,使共享变得更容易。它是版权的延伸,让分享图片变得更容易。但请务必熟悉许可证之间的细微差别。
### 开源视频会议
疫情改变了会议和聚会的模式。正如 Chris Hermansen [此处](https://opensource.com/article/20/5/open-source-video-conferencing) 所报告的那样,Jitsi、Big Blue Button 和其他一些软件已经彻底改变了我们互动和学习的方式。
### 开源教育资源
开放教育资源解放了学习。通过 [OER Commons](https://www.oercommons.org/),你可以找到满足你需求的内容,从学前班到研究生和专业学位,它是公开许可的,因此你可以使用它并与他人分享。麻省理工学院(MIT)开放课件提供了麻省理工学院几乎所有的本科生和研究生项目内容,均根据知识共享 [非商业性共享方式](https://ocw.mit.edu/help/faq-cite-ocw-content/) 许可提供。[OpenStax](https://openstax.org/) 是莱斯大学的一项开放教科书计划,提供经过同行评审的教科书,这些教科书已公开许可并免费提供。
### 开源播客工具
播客已成为了解最新 [开源新闻](https://opensource.com/article/19/10/linux-podcasts-Jupiter-Broadcasting) 的好方法。你有没有想过做自己的播客?我熟悉一些很棒的开源工具能够帮你实现这一目标。[Audacity](https://opensource.com/article/20/4/audacity) 是我最喜欢的录音应用程序。我用它来翻录我的课堂教学、记录访谈和试验音效。它是一个 16 轨音频编辑器,你可以通过多种方式使用它。如果你有话要说或有技能要传授,你应该使用 [Open Broadcaster Software](https://opensource.com/article/20/4/open-source-live-stream)(OBS)。
### Linux
最后,向你的朋友介绍 Linux,他们中的许多人仍然不了解 Linux,让他们体验所有现成的免费软件。
除了在 [YouTube](https://youtu.be/aUgaYtN_sUU) 上录制和分享的演讲外,我还编制了一份资源链接列表,并在 [GitHub](https://github.com/donwatkins/Presentations/blob/master/fostercenter.md) 上分享。
---
via: <https://opensource.com/article/21/10/open-source-tools>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,606 | NixOS 系列 #1:你为什么要考虑使用 NixOS? | https://itsfoss.com/why-use-nixos/ | 2023-03-08T15:01:07 | [
"NixOS"
] | https://linux.cn/article-15606-1.html | 
NixOS……又一个使用不同软件包管理器的发行版??
好吧,NixOS 是 [高级 Linux 发行版](https://itsfoss.com/advanced-linux-distros/) 之一。
所以如果我写这个,我一定有一个充分的理由,对吗?嗯,有很多!
我已经使用它 3 个月了,它是如此之好,以至于我正在考虑从我一直以来最喜欢的 **Pop!\_OS 切换到 NixOS**。
在本指南中,我将分享 NixOS 在众多 Linux 发行版中脱颖而出的主要特点。
别担心,在我们继续之前,让我告诉你什么是 NixOS:
>
> 它是一个以 Nix 包管理器为核心的 Linux 发行版,为你省去了在其它的 Linux 发行版上设置 Nix 的麻烦,可以让你充分利用它的优势。由开发 Nix 的同一个团队构建。
>
>
>
### 使用 NixOS 的 6 个理由
NixOS 是一个有趣的从零开始构建的 [独立 Linux 发行版](https://itsfoss.com/independent-linux-distros/)。
每个人都可以通过使用 NixOS 学到很多东西,但**在我看来**,如果你是一个开发人员或计算机科学的学生,NixOS 应该非常合适。

让我告诉你为什么。
#### 1、不易损坏/易于恢复
就其核心而言,NixOS 是为长期使用而构建的。
这并不意味着它像 Debian 那样用多年前的软件包来保证稳定性,而是遵循一种不同的方法。
为了理解 NixOS 为何如此稳定,让我们谈谈用户一般是如何破坏他们的系统的,即“*依赖性问题或软件包冲突*”
在更新系统或安装一个新的软件包时,你一般会面临系统崩溃的风险。主要是因为你的软件包管理器无法满足依赖性,或者安装的软件包与现有系统冲突导致的。
**而 NixOS 有一个非常聪明的方法来处理这个问题。**
你看,每当你升级你的系统或安装一个软件包时,**系统的状态就会被重建**,被称为超过当前的“<ruby> 新世代 <rt> new generation </rt></ruby>”。

因此,如果你在使用新的软件包或更新时遇到任何麻烦,你可以随时回滚到“<ruby> 旧世代 <rt> old generation </rt></ruby>”,在那里你会找到**系统以前的状态**。
即使系统无法访问,你也能在启动时找到以前几代。
#### 2、可重复性
通过一个配置文件,你可以为其他物理系统创建一个你当前环境的副本。
这个功能给你带来的好处是,你可以使用 Nix 配置文件进行安装和配置。
当你有了适合你的用途的配置文件,将该文件发送到新的系统中,用你的配置文件替换默认的配置文件。就是这么简单!
**重建配置,升级系统,并通过给定的命令进行切换:**
```
sudo nixos-rebuild switch --upgrade
```
你将在几分钟内拥有与你的主机上完全相同的开发环境,并进行复制。
#### 3、轻松回滚
虽然你可能已经从 NixOS 的 “<ruby> 世代 <rt> generation </rt></ruby>” 特性中得到了灵感。
但还有更多的内容。?️
NixOS 在很大程度上依赖于符号链接。如果这对你来说是一个新概念,请参考下面的指南:
>
> **[如何在 Linux 中创建符号链接(完整指南)](https://linuxhandbook.com/symbolic-link-linux/)**
>
>
>
一般来说,在其他 Linux 发行版中,当你升级一个软件包时,新的软件包会取代旧的。
但 NixOS 不是这样的。
在 NixOS 中,软件包被隔离并存储在一个单独的目录中,这就是使用符号链接的原因。
每当你升级一个软件包时,**NixOS 会调整符号链接来定位新的软件包,但不会删除旧的**。
因此,如果你面临与新包的冲突,只需切换到旧世代,符号链接有助于定位旧版本的包。?
#### 4、Nix 包管理器
Nix 包管理器允许你访问超过 80,000 个软件包!不仅仅局限于 Linux,它还可以在 **macOS、WSL2、Docker 等平台**上使用。
而且,软件包的可用性与 AUR 相似,甚至比 AUR 更好,因为你应该在 Nix 包管理器上找到几乎所有的东西(我是认真的)。
例如,我想安装 Librewolf 浏览器,这在大多数 Linux 发行版的默认仓库中是不可用的。
但是,Nix 有它!这意味着你可以依靠 Nix 包管理器来安装几乎所有的软件包。
如果你有先前的 Linux 经验,它也相对容易理解。总而言之,**Nix 包管理器令人印象深刻**!
#### 5、使用同一软件包的多个版本
这对开发者来说可能是至关重要的,有些应用需要特定依赖的旧版本,而有些则需要最新的版本。
而且,正如我前面提到的,Nix 将包安装到一个特定的子目录中,每个包都是隔离的,所以一个包不会干扰另一个包!
在使用 Nix 之前,我使用虚拟机和容器来满足同一软件包的不同依赖性,尤其是 PHP,但 NixOS 为我的工作流程带来了奇迹。
#### 6、无需安装就能测试软件包的能力
你可以使用 [nix-shell](https://nixos.org/manual/nix/stable/command-ref/nix-shell.html),它通过临时修改 `$PATH` 环境变量来测试一个包。
而且没有任何限制。你能够测试每一个可供安装的软件包!
### NixOS 系列:让我们探索更多!
这是我们 Nix 系列的第一部分,我介绍了使用 NixOS 的原因。我相信更多的 Linux 用户应该去了解它,如果他们还没有了解的话。
在下一部分,我将解释如何在你的虚拟机中安装 NixOS。
? 欢迎在下面的评论中分享关于 NixOS 的其他内容的建议。
---
via: <https://itsfoss.com/why-use-nixos/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Why Should You Use NixOS?
NixOS is an exciting distribution. Let's take a look why you might want to give it a try.
NixOS... Yet another distro that uses a different package manager? **🤯**
Well, NixOS is one of the [advanced Linux distros](https://itsfoss.com/advanced-linux-distros/).
So if I'm writing this, I must have a rock-solid reason, right? Well, there are plenty!
I've been using it for 3 months, and it is so good that I'm considering switching from my all-time favorite **Pop!_OS to NixOS**.
And in this guide, I will share the key features of NixOS, making it stand out from the stack of Linux distros.
Fret not; before we move on, let me tell you what NixOS is:
It is a Linux distribution that uses the Nix package manager at its core to save you the trouble from setting it up on a different Linux distribution and letting you make the most out of Nix. Built by the same team that developed Nix.
## 6 Reasons to Use NixOS
NixOS is an interesting [independent Linux distro](https://itsfoss.com/independent-linux-distros/) built from scratch.
Everyone can learn a lot by using NixOS, but **in my opinion**, if you are a developer or a computer science student, NixOS should fit perfectly.
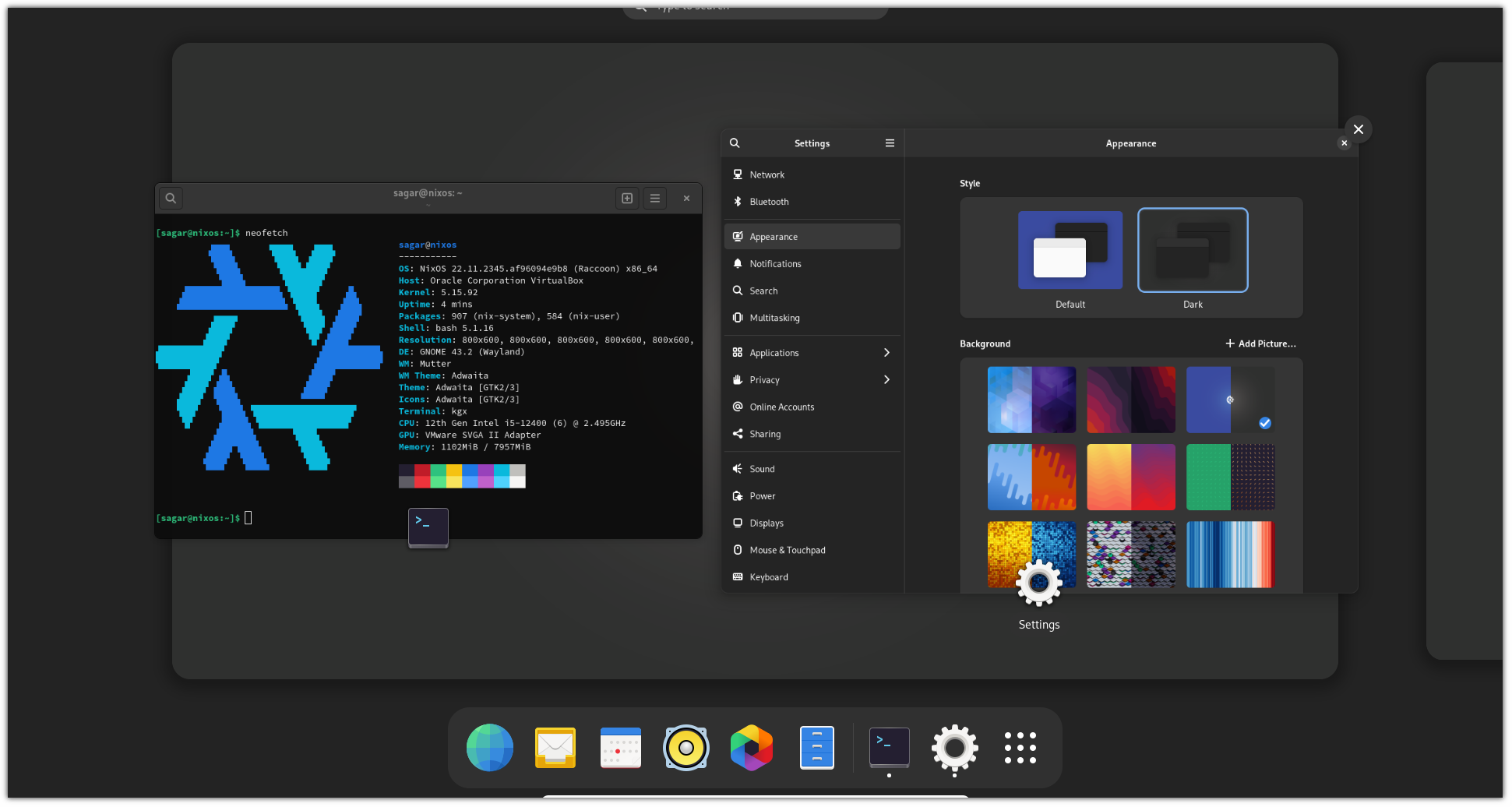
Let me tell you why.
### 1. Does Not Break Easily / Easy to Recover
By its core, NixOS is built to last long.
This does not mean that it ships with years-old packages like Debian does for stability but it follows a different approach.
To understand how NixOS is so stable, let's talk about how users generally break their system, i.e, "*dependency issues or package conflicts*"
You will generally face a significant system crash when updating your system or installing a new package. Mainly because your package manager could not satisfy the dependency or the installed package conflicts with the existing system.
**And NixOS has a very smart way of handling this issue.**
See, whenever you upgrade your system or install a package, the **system state is rebuilt**, termed as a "**new generation**" over the current.
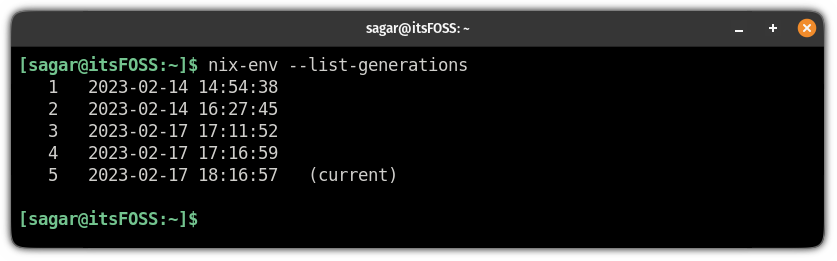
So if you face any trouble using the new package or update, you can always roll back to the old generation, where you will find the **previous state of the system.**
Even if the system is inaccessible, you will find the previous generations available at boot time.
### 2. Reproducibility
With one config file, you can create a replica of your current environment for other physical systems.
To benefit from this feature, you can use the Nix config file for installation and configuration purposes.
Once you have the config file that fits your purpose, send that file to the fresh install and replace the default config file with yours. It is that easy!
**Rebuild the config, upgrade the system, and make a switch by the given command:**
`sudo nixos-rebuild switch --upgrade`
And you will have the exact development environment that you had on your main machine replicated in a few minutes.
### 3. Easy Rollbacks
While you already may have got the idea from NixOS's feature of "**Generations**".
There's more to it. **🕵️**
NixOS heavily relies on symlinks (for good). If it is a new concept to you, refer to the guide below:
[How to Create Symbolic Links in Linux [Complete Guide]This detailed tutorial tells you what are symbolic links, how to create a symbolic links and other important things associated with symlinks.](https://linuxhandbook.com/symbolic-link-linux/)

Typically, with other Linux distros, when you upgrade a package, the new package replaces the old one.
But that's not the case with NixOS.
In NixOS, packages are isolated and stored inside a unique directory, and that is where the use of symbolic links comes in.
Whenever you upgrade a package, the **NixOS will tune the symbolic link to locate the new package but won't remove the old one**.
So if you face conflicts with the new package, just switch to the old generations, and symbolic links help locate the old version of a package. 😌
### 4. Nix package manager
The Nix package manager allows you to access more than 80,000 packages! Not just limited to Linux; it also works on **macOS, WSL2, Docker, and more platforms.**
And the availability of packages is similar to or even better than AUR as you should find almost everything (I mean it) on the Nix package manager.
For instance, I wanted to install the Librewolf browser, which is not available in the default repository of most Linux distros.
But Nix had it! This means you can rely on the Nix package manager for almost every package.
It is also relatively easy to understand if you have prior Linux experience. In a nutshell, **the Nix package manager is impressive!**
### 5. Use multiple versions of the same package
This can be crucial for developers, where some applications demand the old version of a specific dependency, whereas some require the latest one.
And as I mentioned earlier, nix installs packages to a specific sub-directory, and every package is isolated so one won't interfere with another!
Before using Nix, I used VMs and containers to meet different dependencies for the same package, especially with PHP, but NixOS did wonders for my workflow.
**Suggested Read 📖**
[Downgrading a Package via apt-get in Ubuntu and DebianYes! That’s totally possible. You can downgrade a recently updated package using the apt command in Ubuntu and Debian based distros. Here’s how to do that.](https://itsfoss.com/downgrade-apt-package/)

### 6. Ability to test packages without installation
You can use the [nix-shell](https://nixos.org/manual/nix/stable/command-ref/nix-shell.html), which will temporarily modify the $PATH environment variable and be used to test a package temporarily.
And there is no limitation. You are allowed to test every package that is available for installation!
## NixOS Series: Let's Explore More!
This was the first part of our Nix series, where I covered the reasons to use NixOS. I believe more Linux users should get to learn about it if they do not already.
In the next part, I will explain how to install NixOS in your VM. Stay tuned to our social media or RSS feed to read when we publish that.
💬 *Feel free to share suggestions on what else we should cover about NixOS in the comments below.* |
15,607 | 在 Linux 命令行上使用 dict 文字工具 | https://opensource.com/article/23/2/linux-dict-command | 2023-03-08T15:26:55 | [
"dict",
"字典"
] | /article-15607-1.html | 
>
> Linux 上的 dict 命令对作家来说非常有用,可以为他们的选词提供大量的字典和同义词。
>
>
>
作为一个作家,我经常需要确定单词的正确拼写或定义。我还需要使用词库来寻找替代词,这些词的内涵可能与我可能使用的词有些不同。因为我经常使用 Linux 命令行和文本模式工具来完成我的大部分工作,所以使用命令行词典是有意义的。
我非常喜欢使用命令行,原因有很多,其中最主要的原因是它对我来说更有效率。它也比任何一本或多本实体纸质字典,都要全面得多。我使用 Linux 的 `dict` 命令已经很多年了,我已经开始依赖它了。
### 在 Linux 上安装 dict
`dict` 程序在 Fedora 上没有默认安装,但它很容易安装。以下是如何在 Fedora 或类似发行版上安装:
```
$ sudo dnf install dictd
```
在 Debian 和类似发行版上,你还必须安装字典定义:
```
$ sudo apt install dictd dict-gcide
```
不需要额外的配置。这个非常简单的 `/usr/share/doc/dictd/dict1.conf` 文件指定了字典数据库的远程服务器。这个工具使用字典服务器协议(DICT),端口为 2628。
### 在 Linux 上使用 dict
在终端会话中,以非 root 用户的身份,输入 `dict <word>` 来获取一个或多个字典和词库的定义列表。例如,以这种方式查找 `memory` 这个词。
```
$ dict memory | less
6 definitions found
From The Collaborative International Dictionary of English v.0.48 [gcide]:
Memory \Mem"o*ry\, n.; pl. {Memories}. [OE. memorie, OF.
memoire, memorie, F. m['e]moire, L. memoria, fr. memor
mindful; cf. mora delay. Cf. {Demur}, {Martyr}, {Memoir},
{Remember}.]
[1913 Webster]
1. The faculty of the mind by which it retains the knowledge
of previous thoughts, impressions, or events.
[1913 Webster]
Memory is the purveyor of reason. --Rambler.
[1913 Webster]
2. The reach and positiveness with which a person can
remember; the strength and trustworthiness of one's power
to reach and represent or to recall the past; as, his
memory was never wrong.
[1913 Webster]
<SNIP>
From WordNet (r) 3.0 (2006) [wn]:
memory
n 1: something that is remembered; "search as he would, the
memory was lost"
2: the cognitive processes whereby past experience is
remembered; "he can do it from memory"; "he enjoyed
remembering his father" [syn: {memory}, {remembering}]
3: the power of retaining and recalling past experience; "he had
<SNIP>
From Moby Thesaurus II by Grady Ward, 1.0 [moby-thesaurus]:
78 Moby Thesaurus words for "memory":
RAM, anamnesis, anniversaries, archetypal pattern, archetype,
awareness, celebrating, celebration, ceremony, cognizance,
commemoration, consciousness, disk memory, dressing ship,
<SNIP>
From The Free On-line Dictionary of Computing (30 December 2018) [foldoc]:
memory
<storage> These days, usually used synonymously with {Random
Access Memory} or {Read-Only Memory}, but in the general sense
it can be any device that can hold {data} in
{machine-readable} format.
(1996-05-25)
From Bouvier's Law Dictionary, Revised 6th Ed (1856) [bouvier]:
MEMORY, TIME OF. According to the English common law, which has been altered
by 2 & 3 Wm. IV., c. 71, the time of memory commenced from the reign of
```
为了节省空间,我删去了这个结果的大部分内容,同时留下了足够的信息,以提供一个典型结果的概念。你也可以用双引号或单引号将多字短语括起来进行查询。
```
$ dict "air gapped"
```
### 字典
`dict` 命令使用一些在线字典,包括法律和技术字典。许多语言的字典也是可用的。你可以“列出”可用的字典数据库,如下面所示:
```
$ dict -D | less
Databases available:
gcide The Collaborative International Dictionary of English v.0.48
wn WordNet (r) 3.0 (2006)
moby-thesaurus Moby Thesaurus II by Grady Ward, 1.0
elements The Elements (07Nov00)
vera V.E.R.A. -- Virtual Entity of Relevant Acronyms (February 2016)
jargon The Jargon File (version 4.4.7, 29 Dec 2003)
foldoc The Free On-line Dictionary of Computing (30 December 2018)
easton Easton's 1897 Bible Dictionary
hitchcock Hitchcock's Bible Names Dictionary (late 1800's)
bouvier Bouvier's Law Dictionary, Revised 6th Ed (1856)
devil The Devil's Dictionary (1881-1906)
world02 CIA World Factbook 2002
gaz2k-counties U.S. Gazetteer Counties (2000)
gaz2k-places U.S. Gazetteer Places (2000)
gaz2k-zips U.S. Gazetteer Zip Code Tabulation Areas (2000)
fd-hrv-eng Croatian-English FreeDict Dictionary ver. 0.1.2
fd-fin-por suomi-português FreeDict+WikDict dictionary ver. 2018.09.13
fd-fin-bul suomi-български език FreeDict+WikDict dictionary ver. 2018.09.13
fd-fra-bul français-български език FreeDict+WikDict dictionary ver. 2018.09.13
fd-deu-swe Deutsch-Svenska FreeDict+WikDict dictionary ver. 2018.09.13
<SNIP>
```
你可以用 `-d` 选项指定单个字典:
```
$ dict -d gcide
```
### 总结
有时使用词库中的词汇并不是最好的写作方法,因为它可能会混淆你的意思。但我确实发现 `dict` 命令在为特定的意思选择最好的词方面有极大的帮助。它还能确保我使用的单词拼写正确。
关于 dict 的信息很匮乏。 这个 URL <http://www.dict.org/> 只提供了一个基于网络的字典界面。手册页涵盖了语法。但是这个命令是一个有用的、有趣的命令,可以随身携带。我承认在发现 `dict` 命令后,我花了很多时间尝试不同的东西,看看结果会是什么。我就是那个通读百科全书和字典的孩子。是的,我是\_那个\_孩子。除了在写作或阅读时是一个有用的工具外,`dict` 也可以是一个有趣的工具来满足一下好奇心。
---
via: <https://opensource.com/article/23/2/linux-dict-command>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,609 | 用树莓派集群进行并行和分布式计算 | https://opensource.com/article/23/3/parallel-distributed-computing-raspberry-pi-clusters | 2023-03-09T10:31:37 | [
"PDC",
"树莓派",
"集群"
] | /article-15609-1.html | 
>
> 这个使用树莓派集群的学术实验向远程教育学生介绍了并行和分布式计算(PDC)的概念。
>
>
>
自从树莓派推出以来,创造者们已经在这个简陋的袖珍芯片系统上开展了无数的计算机科学教育项目。其中包括许多探索低成本树莓派集群的项目,以介绍 <ruby> 并行和分布式计算 <rt> Parallel and Distributed Computing </rt></ruby>(PDC)概念。
英国 <ruby> 开放大学 <rt> Open University </rt></ruby>(OU)为不同年龄、经历和背景的学生提供远程教育,这就提出了一些在更传统的大学中没有面临的问题。开放大学使用树莓派集群向远程教育学生介绍 PDC 概念的实验始于 2019 年,并在一篇 [学术论文](https://doi.org/10.1080/02680513.2022.2118573) 中进行了介绍,但值得更广泛地了解。
该项目使用基于 [OctaPi 教程](https://projects.raspberrypi.org/en/projects/build-an-octapi) 的树莓派集群,该指令由 GCHQ 在知识共享许可协议下发布。八个树莓派使用一个路由器和一个交换机连接在一个私人网络中。其中一个树莓派充当主控,而其他的是服务器,将结果反馈给主控设备。用 Python 编写的程序运行在主控树莓派,而 `dispy` 包将活动分发在集群的各个处理核心上。
>
> **[OctaPi 教程](https://projects.raspberrypi.org/en/projects/build-an-octapi)**
>
>
>
他们为该集群开发了三个程序,你可以从 [Git 仓库](https://github.com/dg7692/TM129) 下载它们。
其中两个程序是基于文本的,并与搜索问题有关:旅行推销员和密码散列。作为完整的搜索问题,这些是教授 PDC 概念的理想选择。第三个程序是图形化的。图像组合器将三幅图像作为输入,其中有不重叠的障碍物。它通过对三幅图像的 RGBA 值进行逐个像素的比较并选择中位数来构建一个没有任何障碍物的图像。
### 使用集群
开放大学是一个远程学习机构,所以学生通过网页界面访问集群。对集群的远程访问使用大学的 OpenSTEM 实验室的基础设施。10 个集群(8 个用树莓派 4 构建,2 个用树莓派 3B+ 建造)被安装在机架上,用网络摄像头对准每个集群。
学生们选择要运行的程序,使用的核心数量,以及所选程序的参数。作为输出,他们可以看到该程序在单个树莓派上运行的时间与使用所选核数的集群的时间相比。学生还可以看到程序的输出,如密码散列结果、最小和最大的旅行推销员路线,或未遮挡的图像。

网络摄像头显示了集群的实时流。主控树莓派有一个 LED 显示屏,显示程序运行时的状态。网络摄像头让学生清楚地知道,他们是在用真正的专用硬件做实验,而不是得到模拟的或预先录制的结果。

每个程序都有两个与之相关的活动,描述了程序设计和 PDC 操作的不同方面。其中一个主要的学习点是,PDC 计算可以提供显著的性能优势,但代价是划分和分发问题以及反过来重新组合结果所花费的时间和资源。第二个学习点是,效率受程序设计的影响很大。
### 学生喜欢
目前,树莓派集群的使用是可选的。不过根据目前的研究结果,学生们很喜欢它,并因能远程接触到物理硬件而受到激励。
一位学生说:“能够使用真正的集群,而不是让它虚拟化,这真的很有趣”。
另一名学生补充说:“能够真正看到集群的工作,看到多核工作的真实效果,这真的很令人兴奋。能够亲自尝试,而不仅仅是阅读有关理论,这真是太好了!”
学生们正在使用集群开展旨在教授 PDC 原理的学习活动,而不是编写和运行他们自己的程序。开发低成本的树莓派集群供远程大学学生使用的经验表明,远程实践活动对教授 PDC 概念和吸引学生有好处。
当我向该项目背后的团队成员之一 Daniel Gooch 询问时,他说:“对我来说,我们的不同之处在于,我们采用了一套现有的树莓派教程,并致力于整合更多外围材料,以确保它能够应对我们操作的距离和规模。”
---
via: <https://opensource.com/article/23/3/parallel-distributed-computing-raspberry-pi-clusters>
作者:[Peter Cheer](https://opensource.com/users/visimpscot2) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,610 | 我如何用 Inkscape 实现图形创作自动化 | https://opensource.com/article/23/3/automate-graphics-production-inkscape | 2023-03-09T11:39:00 | [
"Inkscape"
] | https://linux.cn/article-15610-1.html | 
>
> 跟随这个 Inkscape 教程,大量创建会议讲座卡图形。
>
>
>
我录制了一个 [15 分钟长的教程](https://peertube.linuxrocks.online/w/sf8Vqgg3aRkPKpb7KMsHgH),演示如何在 [Inkscape](http://inkscape.org) 中从 CSV 文件或电子表格中自动生成图形(基本上是邮件合并类图形)。它使用了 Maren Hachmann 的 [Next Generator Inkscape 扩展](https://gitlab.com/Moini/nextgenerator)。
你可以在 [Fedora 设计团队在 Linux Rocks 上的 PeerTube 频道](https://peertube.linuxrocks.online/c/fedora_design/videos)(PeerTube 是开源的!)中观看。
在这篇文章中,我提供了一些关于这个教程相关的背景。我还包括了对视频中内容的一个非常简要的总结,以防你宁愿草草浏览文字而不看视频。
### 会议讲座卡图形
每个 Flock/Nest 都需要为你在举办虚拟会议的在线平台上的每个讲座提供一个图形。像这样的大型活动,通常有大约 50 个或更多的讲座。这需要大量手工制作的图形。
通过本教程,你将学习如何在 Inkscape 中制作这样的模板。

CSV 文件类似这样:
| CONFERENCENAME | TALKNAME | PRESENTERNAMES |
| --- | --- | --- |
| BestCon | The Pandas Are Marching | Beefy D. Miracle |
| Fedora Nest | Why Fedora is the Best Linux | Colúr and Badger |
| BambooFest 2022 | Bamboo Tastes Better with Fedora | Panda |
| AwesomeCon | The Best Talk You Ever Heard | Dr. Ver E. Awesome |
将它们结合起来,CSV 中的每一行生成一个图形,像这样:

会议图形是你如何应用这个教程的一个好例子。你也可以用它来生成名片(它输出的是 PDF)、个性化的生日邀请函、教室里学生的个性化图形(比如贴在学生课桌上的名卡),以及办公室的铭牌。你也可以用它来创建用于标记物品的图形。[作为 Fedora 设计团队的成员](https://matrix.to/#/#design:fedoraproject.org),你甚至可以用它来为 Fedora 制作很棒的横幅和图片!你可以用它来制作大量的不同用途。你可以应用这种技术的用途有很多,所以让你的想象力飞翔吧。
### Inkscape Next Generator 扩展
创建这些图片的第一步是安装 Maren Hachmann 为Inkscape 创建的 [Next Generator 扩展](https://gitlab.com/Moini/nextgenerator)。
* 到网站上下载 [next\_gen.inx](https://gitlab.com/Moini/nextgenerator/-/raw/master/next_gen.inx?inline=false) 和 [next\_gen.py](https://gitlab.com/Moini/nextgenerator/-/raw/master/next_gen.py?inline=false)。
* 然后进入 Inkscape的 “<ruby> 编辑 <rt> Edit </rt></ruby> > <ruby> 首选项 <rt> Preferences </rt></ruby> > <ruby> 系统 <rt> System </rt></ruby>”对话框。搜索 “<ruby> 用户扩展 <rt> User Extensions </rt></ruby>” 目录列表并点击 “<ruby> 打开 <rt> Open </rt></ruby>” 图标。将 .inx 和 .py 文件拖入该文件夹。
* 最后,你应该关闭所有打开的 Inkscape 窗口并重新启动 Inkscape。新的扩展在 “<ruby> 扩展 <rt> Extensions </rt></ruby>” 菜单下: “<ruby> 扩展 <rt> Extensions </rt></ruby> > <ruby> 输出 <rt> Export </rt></ruby> > Next Generator”。
### 创建一个模板
你的 CSV 文件的每个标题(在我的例子中:`ConferenceName`、`TalkName`、`PresenterNames`)都是一个变量,你可以把它放在 Inkscape 文件中,作为你的模板。[看一下 SVG 模板文件的例子](https://gitlab.com/fedora/design/team/tutorials/inkscape-automation/-/blob/main/template-simple.svg),以获得指导。如果你想让 `TalkName` 出现在你的模板中,在 Inkscape中创建一个文本对象,并将以下内容放入其中:
```
%VAR_TalkName%
```
当你运行扩展时,`%VAR_TalkName%` 文本将被替换为 CSV 中每一行列出的 `TalkName`。因此,对于第一行,`%VAR_TalkName%` 被替换为第一个图形的文本 `The Pandas Are Marching`。对于第二个图形,`TalkName` 是 `Why Fedora is the Best Linux`。继续,直到给每个图形的加上 `TalkName` 列。
### 运行生成器
一旦你的模板准备好了,通过加载你的 CSV,运行 `Next Generator` 扩展。然后,选择你想在每个文件名中使用的变量(标题名称),点击 “<ruby> 应用 <rt> Apply </rt></ruby>” 按钮。
在后面的文章中,我将提供一个关于这个扩展的更高级使用的教程,比如改变每个文件中包含的颜色和图形。
本文最初发表在作者的 [博客](https://blog.linuxgrrl.com/2022/07/19/how-to-automate-graphics-production-with-inkscape/)上,经许可后重新发表。
---
via: <https://opensource.com/article/23/3/automate-graphics-production-inkscape>
作者:[Máirín Duffy](https://opensource.com/users/mairin) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recorded a [15-minute long tutorial](https://peertube.linuxrocks.online/w/sf8Vqgg3aRkPKpb7KMsHgH) demonstrating how to automate the production of graphics from a CSV file or spreadsheet (basically a mailmerge type deal for graphics) in [Inkscape](http://inkscape.org). It uses the [Next Generator Inkscape extension](https://gitlab.com/Moini/nextgenerator) from Maren Hachmann.
You can watch it on the [Fedora Design Team Linux Rocks PeerTube channel](https://peertube.linuxrocks.online/c/fedora_design/videos) (PeerTube is open source!) or the embedded YouTube video below:
In this article, I provide some context for how this tutorial is useful. I also include a very high-level summary of the content in the video in case you'd rather skim text and not watch a video.
## Conference talk card graphics
Each Flock/Nest needs a graphic for each talk for the online platform you use to host a virtual conference. There are usually about 50 or more talks for large events like this. That's a lot of graphics to produce manually.
With this tutorial, you learn how to make a template like this in Inkscape:

(Máirín Duffy, CC BY-SA 4.0)
And a CSV file like this:
CONFERENCENAME | TALKNAME | PRESENTERNAMES |
BestCon | The Pandas Are Marching | Beefy D. Miracle |
Fedora Nest | Why Fedora is the Best Linux | Colúr and Badger |
BambooFest 2022 | Bamboo Tastes Better with Fedora | Panda |
AwesomeCon | The Best Talk You Ever Heard | Dr. Ver E. Awesome |
Combine them to generate one graphic per row in the CSV, like so:

(Máirín Duffy, CC BY-SA 4.0)
Conference graphics are a good example of how you can apply this tutorial. You could also use it to generate business cards (it outputs a PDF), personalized birthday invitations, personalized graphics for students in your classroom (like student name cards for their desks), and signage for your office. You can use it to create graphics for labeling items, too. You can even use it to create awesome banners and graphics for Fedora [as a member of the Fedora Design Team](https://matrix.to/#/#design:fedoraproject.org)! There are a ton of possibilities for how you can apply this technique, so let your imagination soar.
## The Inkscape Next Generator extension
The first step to create these images is to install [the Next Generator extension](https://gitlab.com/Moini/nextgenerator) for Inkscape created by Maren Hachmann:
- Go to the website and download the
[next_gen.inx](https://gitlab.com/Moini/nextgenerator/-/raw/master/next_gen.inx?inline=false)and[next_gen.py](https://gitlab.com/Moini/nextgenerator/-/raw/master/next_gen.py?inline=false)from the top level of the repo. - Then go into the
**Edit > Preferences > System**dialog in Inkscape. Search for the**User Extensions**directory listing and click the**Open**icon. Drag the .inx and .py files into that folder. - Finally, you should close all open Inkscape windows and restart Inkscape. The new extension is under the
**Extensions**menu:**Extensions > Export > Next Generator**.
## Create a template
Each header of your CSV file (in my example: ConferenceName, TalkName, PresenterNames) is a variable you can place in an Inkscape file that serves as your template. [Take a look at the example SVG template file](https://gitlab.com/fedora/design/team/tutorials/inkscape-automation/-/blob/main/template-simple.svg) for directions. If you want the TalkName to appear in your template, create a text object in Inkscape and put the following content into it:
```
````%VAR_TalkName%`
When you run the extension, the *%VAR_TalkName%* text is replaced with the *TalkName* listed for each row of the CSV. So for the first row, *%VAR_TalkName%* is replaced with the text *The Pandas Are Marching* for the first graphic. For the second graphic, the *TalkName* is *Why Fedora is the Best Linux*. You continue doing this until you get to the *TalkName* column for each graphic.
## Run the generator
Once your template is ready, run the Next Generator extension by loading your CSV. Then, select which variables (header names) you want to use in each file name and hit the **Apply** button.
In a future article, I will provide a tutorial on more advanced use of this extension, like changing colors and graphics included in each file.
*This article was originally published on the author's blog and has been republished with permission.*
## Comments are closed. |
15,612 | Vanilla OS 放弃 Ubuntu,转投 Debian Sid | https://debugpointnews.com/vanilla-os-debian/ | 2023-03-10T09:42:52 | [
"Vanilla OS"
] | /article-15612-1.html | 
>
> 即将推出的 Vanilla OS 2.0 “Orchid” 将基于 Debian Sid 而不是 Ubuntu Linux。
>
>
>
来自 Ubuntu 的 [Flatpak 决定](/article-15570-1.html) 的余震仍在继续!Vanilla OS 团队宣布,Vanilla OS 的下一个版本将不再基于 Ubuntu。它将基于 Debian Sid,这是 Debian Linux 的 “滚动” 版本,或者说 “不稳定” 版本。
>
> 如果你不知道,Vanilla OS 是一个新的不可变 Linux 发行版,它首次发布于去年。它的目标是提供 GNOME 桌面的 “原味” 体验。它有一套独特的工具,如 apx 软件包管理器、ABRoot 技术、原装 GNOME 体验等等。它基于标准的 Ubuntu 发布周期和版本进行发布。
>
>
>

### Vanilla OS 计划基于 Debian
由于这些重大变化,Vanilla OS 的下一个版本将被命名为 “2.0” “<ruby> 兰花 <rt> Orchid </rt></ruby>”。但为什么要远离 Ubuntu 呢?
正如该团队所说,花了更多的困难和精力 **“来恢复 Canonical 武断的工作流程”**,这需要更多的开发时间。另外,Ubuntu 提供的 GNOME 是根据 Canonical 的需求和愿景定制的。所以,没有太多的 “原味” 体验。
第二个原因是处理 Snap 的问题。经过几次测试和社区反馈,团队认为目前的 Snap 并不适合 Vanilla OS 的使用情况。例如,“启动慢、集中化” 的问题在 Snap 核心里没有得到解决,而且 Snap 不能在 Vanilla OS 的 apx 容器内运行。
### 发布模式
此外,脱离 Ubuntu 的基础会带来一个更灵活的发布周期,将不需要遵循每年两个版本的周期。这给了小型 FOSS 开发者和贡献者团队一些喘息的空间。
但是未来的发布模式是什么呢?团队将遵循一种临时性的发布方式,用著名的术语来说就是 —— “当需要或准备好时就会发布”。例如,如果某个 Debian Sid 软件包得到一个关键的 CVE 修复,那么你可能会立即得到一个 Vanilla OS 的小版本。所以,这要视情况而定,应该以需求为基础。
此外,该团队还计划减少 ISO 文件中的软件包数量,以减少软件包 “不稳定” 因素的风险。但根据我使用 Debian Sid 的经验,如果你遵循适当的更新并谨慎行事,它可以视作一个 “稳定” 的发行版。
另外,其他变化还有对 ABRoot 的 OCI 更新,以加强对更新的控制。在设置中的一个新的快速的高级选项是即将发布的版本中值得注意的内容。
在核心方面,基于 Debian Sid 软件包情况,新版本计划采用 GNOME 44 和主线内核 6+。
### 结论
总之,基于 Debian 的确是一个大的进步。虽然它确实在发布周期上提供了更多的灵活性,但在向用户提供稳定版之前,它也会对 Sid 软件包进行更仔细的测试。总的来说,在我们等待 Vanilla OS 2.0 “Orchid” 的测试版本时,未来的时间是令人期待的。
参考自 [公告](https://vanillaos.org/2023/03/07/vanilla-os-2.0-orchid-initial-work.html)。
---
via: <https://debugpointnews.com/vanilla-os-debian/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,613 | 精简版 Xubuntu:建立你自己的发行版的机会 | https://www.debugpoint.com/xubuntu-minimal/ | 2023-03-10T10:36:09 | [
"Xubuntu"
] | /article-15613-1.html |
>
> Xubuntu 团队从 23.04 版本开始推出了一个包含少量组件的精简 ISO。以下是它的情况。
>
>
>

几天前,Canonical [宣布](/article-15588-1.html),Ubuntu 23.04 “Lunar Lobster” 版本官方的精简 ISO 安装文件正在制作中。虽然截至发稿时,该镜像还没有出现,但 Xubuntu 团队设法推出了他们自己的精简 ISO 安装镜像。
Xubuntu 被数百万人使用,并且一直是许多其他发行版的基础。对于一些用户来说,默认安装可能带有太多的预装包和功能,导致系统臃肿,计算机性能降低。这就是 Xubuntu 精简安装发挥作用的地方。在这篇文章中,我们将采取实践的方式来安装和探索精简版 Ubuntu 的功能。
让我们看看你在 Xubuntu 精简安装中得到了什么,以及与普通桌面安装程序的比较。
### Xubuntu 精简安装
第一个明显的区别是精简安装与标准桌面安装程序的 ISO 镜像大小。它的大小大约减少了 39%。
| | 精简版 | 标准版 |
| --- | --- | --- |
| 桌面安装程序(ISO)大小 | 1.7 GB | 2.8 GB |
在使用精简版安装程序安装 Xubuntu 时,你不会在 Ubiquity 中看到“<ruby> 精简安装 <rt> minimal install </rt></ruby>”的选项。其余的安装步骤都是一样的,没有区别。
然而,主要的区别是在安装的系统上。最小安装只需要 7.2GB 的磁盘空间,而同一版本的标准安装则需要 11GB。
| | 精简版 | 标准版 |
| --- | --- | --- |
| 磁盘使用空间 | 7.2 GB | 11 GB |
因为许多应用程序被剥离了。

在 Xubuntu 的精简安装中,你会得到以下东西:
* 终端
* 文件管理器
* 所有的设置应用
* Synaptic 包管理器
* 屏幕截图应用
就这些了。
如果你把它与标准版相比,你就不会有以下的应用:
* Firefox 浏览器
* Thunderbird 邮件客户端
* 媒体播放器(音频和视频)
* LibreOffice 套件
* Transmission Torrent 客户端
* GNOME 软件
* 游戏
* Gigolo 远程连接客户端
* 磁盘使用工具
### 精简版 Xubuntu 上的 Snap 包
令我惊讶的是,精简版 Xubuntu 没有安装 Snap!甚至连 Snap 守护程序都没有。而且也没有 Flatpak。
所以,实际上你得到的是一个没有 Snap 的 Xubuntu 系统,但有一个核心的 Ubuntu 基础。

但我不确定主 Ubuntu 的精简 ISO 会有同样的情况。我想我们需要等待和观察。
### 接下来是什么?
所以,现在你有了一个初级的 Xubuntu 桌面。使用 Synaptic 包管理器,你可以开始构建和安装你喜欢的应用。
例如,你可以 [设置 Flatpak](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) 并从一个基本的浏览器、媒体播放器、LibreOffice 等开始。
如果你是一个开发者,你可以安装 Visual Studio Code 或一些 IDE。
以这个版本为基础,你可以为你的工作流程建立任何发行版。
### 总结
Xubuntu 精简安装对于那些想要完全控制他们系统上安装的东西,并且喜欢更快、更有效的基于 Ubuntu 的发行版的用户来说是一个很好的选择。
Xfce 的可定制性、轻量级特性和使用 synaptic 的包管理使它成为任何定制构建的理想选择。
你可以从这个 [页面](https://cdimage.ubuntu.com/xubuntu/daily-live/current/) 下载精简版 ISO。记住,它还没有正式发布,而且是一个日常构建的副本。所以使用它要**谨慎**。
---
via: <https://www.debugpoint.com/xubuntu-minimal/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,615 | Garuda Linux “Raptor” 230305 版本发布 | https://debugpointnews.com/garuda-linux-raptor-230305/ | 2023-03-11T09:48:00 | [
"Arch Linux",
"Garuda Linux"
] | /article-15615-1.html | 
>
> Garuda Linux 是流行的基于 Arch Linux 的发行版,它刚刚发布了一个新的版本 “Raptor” 230305,带来了新的功能和更新。
>
>
>

Garuda Linux 是一个基于 Arch Linux 的发行版,由于其开箱即用的体验、游戏支持和用户友好界面,在 Arch Linux 爱好者中越来越受欢迎。Garuda Linux 以其对性能、速度和稳定性的关注而闻名。
最近,Garuda Linux 发布了一个新的版本 “Raptor” 230305,带来了新的功能和更新。在这篇文章中,我们将介绍 Garuda Linux 的最新版本的新内容。
### Garuda “Raptor” 230305 的新内容
Garuda 的主要旗舰版是 dr460nized 版,采用 KDE Plasma 桌面环境,但它用 Latte Dock、图标主题等进行了大量定制。
由于 Latte Dock 现在已经没有支持了,Garuda 团队完全删除了 Latte Dock,用标准的 Plasma 面板取代了它。按照该团队的说法,“由于失去了顶栏颜色/透明度等功能,在一定程度上削弱了 dr460nized 版的吸睛因素”。
这的确是事实。但是,没有其他停靠区软件能像 Latte Dock 一样。我的意思是,虽然有,但它们都没有接近 Latte Dock 曾经提供的功能和灵活性。但好处是,KDE Plasma 在 Garuda 中可能会变得更稳定,因为它现在使用了原生的停靠区和面板。而且它看起来也很好!

那么,如果你已经在运行带有 Latte Dock 的早期版本的 Garuda 呢?
为了解决这个问题,团队调整了 “<ruby> Garuda 系统维护 <rt> Garuda System Maintenance </rt></ruby>” 应用程序,以检测你是否已经在运行 Latte Dock,并为你提供逐步迁移到新的面板的方法。一旦你确认从 Latte Dock 迁移,它还会备份你的配置,以防迁移过程中出现问题。这方面的更多信息可以在这个 [指南](https://wiki.garudalinux.org/en/dr460nized-migration) 中找到。
除了上述变化,Garuda Linux “Raptor” 230305 还重写了设置帮助,改进了标签式界面和检测英伟达硬件的能力。
这个版本的一个重要更新是,Garuda 现在使用 Dracut 来创建 initramfs,而不是像包括原本的 Arch Linux 在内的大多数 Arch 发行版常见的 mkiniticpio。
不止如此。从这个版本开始有了一个新的 “garuda” 软件库,它是为 Garuda Linux 专属的软件包创建的,并从当前的 Chaotic-AUR 软件库中移出。这是最大的变化之一,它通过 “garuda-update” 自动处理的。可以在 [这里](https://forum.garudalinux.org/t/separating-garuda-packages-from-chaotic-aur/20506) 了解更多。

在核心部分,这个版本带有最新的 [KDE Plasma 5.27.2](https://debugpointnews.com/kde-plasma-5-27-release/) 桌面和 Linux 内核 6.2.2。所以,由于滚动发布,你可以得到所有最新的软件包。
如果你想探索更多的更新,你可以 [在此](https://forum.garudalinux.org/t/garuda-linux-raptor-230305/26929#you-want-to-read-the-exhaustive-changelog-sure-it-can-be-found-below-as-usual-laughing-10) 阅读整个更新日志。
要下载它,请访问以下页面并选择你要下载的变体:
>
> **[下载 Garuda Linux](https://garudalinux.org/downloads.html)**
>
>
>
如果你已经在运行 Garuda Linux,那么从欢迎程序中启动 <ruby> Gaurda 帮助 <rt> Gaurda Assistance </rt></ruby>,并点击 “<ruby> 系统更新 <rt> system update </rt></ruby>”。
### 总结
这是一个重要的 Garuda 版本,涉及到其旗舰 KDE 版的所有主要组件。对 pacman 偏好和 Dracut 的核心更新更是影响了所有的版本。
然而,所有的变化都是为了使它成为一个比以前更稳定的系统。我希望它能继续带来这样的更新,成为最好的 Arch Linux 发行版之一。
参考自 [发布公告](https://forum.garudalinux.org/t/garuda-linux-raptor-230305/26929)。
---
via: <https://debugpointnews.com/garuda-linux-raptor-230305/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,616 | 将你的树莓派用作流媒体服务器 | https://opensource.com/article/23/3/raspberry-pi-streaming-server | 2023-03-11T10:19:00 | [
"流媒体",
"树莓派"
] | https://linux.cn/article-15616-1.html | 
>
> 用树莓派串流网络摄像头的实时视频,并将视频重新串流到社交网络。
>
>
>
出于各种原因,人们需要流式传输网络摄像头的实时视频。树莓派平台很适合此类应用。对于实时流媒体服务器等连续应用,它只需要很少的电力。可以与 Raspicam 相机模块、USB 摄像头或其他网络视频信号进行通信。该系统是一个 RTMP、HLS 和 SRT 服务器。这篇文章展示了如何将树莓派设置为流媒体服务器以使用 HLS 流媒体。你需要一个视频源才能把它作为流媒体服务器使用。
即使没有树莓派,你也可以完成这里描述的步骤。此外,还有针对 [Windows](https://docs.datarhei.com/restreamer/installing/windows)、[Linux](https://docs.datarhei.com/restreamer/installing/linux) 和 [macOS](https://docs.datarhei.com/restreamer/installing/mac) 的进一步安装说明。
### 设置
该应用程序是 datarhei [Restreamer](https://github.com/datarhei/restreamer),是 datarhei [Core](https://github.com/datarhei/core) 的图形用户界面。datarhei Core 在底层运行著名的媒体框架 FFmpeg。开始使用 datarhei Restreamer 的最简单方法是安装官方的 Docker 容器。通过 Docker Hub 的程序下载和安装是通过 `docker pull` 命令自动进行的。安装后,Restreamer 立即启动。如果你没有树莓派,可以使用 datarhei [Restreamer GitHub](https://github.com/datarhei/restreamer) 页面上的其他 Docker 容器之一(例如,支持 AMD64 或 GPU Cuda)。
datarhei Restreamer 和 datarhei Core 都是 [Apache 许可证 2.0](https://github.com/datarhei/restreamer/blob/2.x/LICENSE) 下的开源软件。
以下是在支持 GPU 的树莓派 3 及以上机型上的安装命令:
```
docker run -d --restart=always --name restreamer \
-v /opt/restreamer/config:/core/config -v /opt/restreamer/data:/core/data \
--privileged \
-p 8080:8080 -p 8181:8181 \
-p 1935:1935 -p 1936:1936 \
-p 6000:6000/udp \
datarhei/restreamer:rpi-latest
```
无论你使用哪条命令,你只需要 `--privileged` 选项来访问本地设备,如 USB 摄像头。
安装后,将 Raspberry Pi 连接到本地网络。然后在浏览器中进入 <http://device-ip:8181/ui> 打开基于 Web 的 GUI。
你应该看到以下屏幕:

分配好密码,系统就可以进行首次登录了。向导正在开始配置第一个视频源。
提示:上述 Docker 命令将带有登录名和密码的配置数据永久保存在 `/opt/restreamer/config` 文件夹中。
### 实施
该应用程序由三个逻辑部分组成:视频输入、系统仪表板和视频输出。视频输入和输出相互独立运行。
### 视频输入
该向导将帮助你从头开始创建一个视频源。这可以是一个 USB 视频源、树莓派摄像头,或者是一个网络源,如 IP 摄像头或来自网络的 m3u8 文件。HLS、RTMP 和实时 SRT 协议都可以使用。该向导可以帮助正确配置视频分辨率和声音。在最后一步,你可以分配不同 <ruby> 知识共享 <rt> Creative Commons </rt></ruby> 许可证。值得看一下视频信号的设置。你会发现几个选项,例如为垂直视频平台转码或旋转视频。
### 仪表板
成功创建视频信号后,你将进入仪表板。

它是所有其他设置的中心起点。要看到程序的全部功能,你可以在系统偏好中切换到专家模式。
仪表板包含以下内容:
* 视频信号设置。
* RTMP、SRT、HLS 服务器和快照的活动内容 URL。
* 用于重新流式传输的所有活动发布服务。
* 启动向导来创建额外的视频源。
* 系统菜单。
* 实时视频信号统计。
* 实时系统监控。
### 视频输出
有不同的方法来播放视频信号。
这个 [发布网站](https://demo.datarhei.com/) 是 Restreamer 最简单、即时可用且内部托管的登录页面。播放页面也可以传输到 Chromecast 和 AirPlay。调整背景图片和在播放器中添加标识等基本设置可以直接在 Restreamer 中进行。那些懂 HTML 的人可以为自己定制页面。高级用户可以注入代码,以使用网站的外部模块,如聊天。视频播放器下的统计模块显示活跃的观众和所有视图。“<ruby> 分享 <rt> Share </rt></ruby>” 按钮支持直播流的分发。网站的 HTTPS 证书通过 Let's Encrypt 激活,无需太多努力。通过简单的 HTTPS 端口转发到树莓派的 LAN IP,网站就可以公开访问。

发布服务是重新传输内容的一个好方法。对于流行的网站,如 YouTube、Twitch 或 PeerTube,有许多现成的模块。同样,对于其他流媒体软件、流行的 CDN 也是如此。对视频协议的完全控制允许流式传输到所有支持 RTMP、HLS 和 SRT 的目标地址。一个带有视频播放器的 HTML 片段代码在网页上工作。

### 使用树莓派播放流媒体节省电力
这篇文章展示了如何将树莓派变成一个流媒体服务器。树莓派平台允许你以省电的方式与各种视频信号互动。预先的设置使配置服务器变得很容易,高级用户可以对系统进行一些调整。你可以用它来做回放,在网站上托管实时流式传输,或使用 [OBS](https://opensource.com/article/20/6/obs-websockets-streaming) 集成到系统环境中。使用不同的视频源和传输协议作为项目的基础,提供了极大的灵活性,使这个系统具有高度的可定制性。此外,带有 FFmpeg 的 datarhei Core 使软件开发者很容易扩展所有的应用进程。
该程序将树莓派变成一个专门的流媒体服务器。你可以独立地直播到网站或多路直播到不同的视频网络,而无需额外的视频提供商。
可以使用登录名 “admin” 和密码 “demo” 在项目网站上安装之前测试功能齐全的 [演示](https://demo.datarhei.com/ui)。
---
via: <https://opensource.com/article/23/3/raspberry-pi-streaming-server>
作者:[Sven Erbeck](https://opensource.com/users/erbeck) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are various reasons to stream live video transmissions from webcams. The Raspberry Pi platform is perfect for such applications. It requires little power for continuous applications such as live-streaming servers. Communication with a Raspicam camera module, USB cam, or other network video signals is possible. The system is an RTMP, HLS, and SRT server. This article shows how to set up the Raspberry Pi as a streaming server to use HLS streaming. You need a video source to use it as a streaming server.
Even without a Raspberry Pi, you can do the steps described here. In addition, there are further installation instructions for [Windows](https://docs.datarhei.com/restreamer/installing/windows), [Linux](https://docs.datarhei.com/restreamer/installing/linux), and [macOS](https://docs.datarhei.com/restreamer/installing/mac) available.
## Setup
The application is datarhei [Restreamer](https://github.com/datarhei/restreamer), a graphical user interface for the datarhei [Core](https://github.com/datarhei/core). The datarhei Core runs the well-known media framework FFmpeg under the hood. The easiest way to start with datarhei Restreamer is to install the official Docker container. The download and installation of the program via Docker Hub are automatic with the `pull`
command. Restreamer starts immediately after the installation. If you don't have a Raspberry Pi, use one of the other Docker containers on the datarhei [Restreamer GitHub](https://github.com/datarhei/restreamer) page (e.g., AMD64 or GPU Cuda support).
datarhei Restreamer and datarhei Core are both open source software under the [Apache License 2.0](https://github.com/datarhei/restreamer/blob/2.x/LICENSE).
Here's the command for an installation on a Raspberry Pi 3 and above with GPU support:
```
``````
docker run -d --restart=always --name restreamer \
-v /opt/restreamer/config:/core/config -v /opt/restreamer/data:/core/data \
--privileged \
-p 8080:8080 -p 8181:8181 \
-p 1935:1935 -p 1936:1936 \
-p 6000:6000/udp \
datarhei/restreamer:rpi-latest
```
Regardless of which command you use, you only need the `--privileged`
option to access local devices, like a USB camera.
After installation, connect the Raspberry Pi to the local network. Then open the web-based GUI in a browser by navigating to [http://device-ip:8181/ui](http://device-ip:8181/ui).
You should see the following screen:
(Sven Erbeck, CC BY-SA 4.0)
Assign the password, and the system is ready for the first login. A wizard is starting to configure the first video source.
Hint: The above Docker command permanently stores the configuration data with the login name and password in the `/opt/restreamer/config`
folder.
## Implementation
The application consists of three logical parts: Video input, system dashboard, and video output. The video input and output run independently of each other.
## Video input
The wizard will help you to create a video source right from the start. This can be a USB video source, the Raspberry Pi camera, or a network source like an IP cam or an m3u8 file from a network. HLS, RTMP, and real-time SRT protocol are ready to use. The wizard helps to configure the video resolution and sound correctly. In the last step, you can assign different licenses from Creative Commons. It is worth taking a look at the video signal settings. You will find several options, like transcoding or rotating the video for vertical video platforms.
## Dashboard
After successfully creating the video signal, you will land in the dashboard.
(Sven Erbeck, CC BY-SA 4.0)
It is the central starting point for all other settings. To see the program's full functionality, you can switch to expert mode in system preferences.
The dashboard contains the following:
- Video signal settings.
- Active content URL for RTMP, SRT, HLS server, and snapshot.
- All active Publication Services for restreaming.
- Start the wizard to create additional video sources.
- The system menu.
- Live-Statistics for the video signal.
- Live-System monitoring.
## Video output
There are different ways to play the video signal.
The [publication website](https://demo.datarhei.com/) is the simplest, immediately-ready, and internally hosted landing page by Restreamer. The player page can also transmit to Chromecast and AirPlay. Basic settings like adjusting the background image and adding a logo in the player are possible directly in the Restreamer. Those who know HTML can customize the page for themselves. Advanced users can inject code to use the site with external modules like a chat. A statistics module under the video player shows the active viewers and all views. The **Share** button supports the distribution of the live stream. HTTPS certificates for the website are active with Let's Encrypt without much effort. With a simple port forwarding for HTTPS to the LAN IP of the Raspberry Pi, the website is publicly accessible.
(Sven Erbeck, CC BY-SA 4.0)
The publication services are a great way to restream content. There are numerous ready-made modules for popular websites like YouTube, Twitch, or PeerTube. Likewise, for other streaming software, to popular CDNs. Complete control over the video protocols allows streaming to all RTMP, HLS, and SRT-capable destination addresses. An HTML snippet code with the video player works on web pages.
(Sven Erbeck, CC BY-SA 4.0)
## Save power while streaming with Raspberry Pi
This article shows how to turn the Raspberry Pi into a streaming server. The Raspberry Pi platform allows you to interact with various video signals in a power-saving way. The pre-settings make it easy to configure the server, and advanced users can make some adjustments to the system. You can use it for restreaming, hosting for live-streaming on a website, or integration into system landscapes with [OBS](https://opensource.com/article/20/6/obs-websockets-streaming). Using different video sources and transport protocols offer great flexibility as a basis for a project and make this system highly customizable. Furthermore, the datarhei Core with FFmpeg makes it easy for software developers to extend all application processes.
The program turns the Raspberry Pi into a dedicated streaming server. Depending on your internet upload, you can live stream to websites or multi-stream to different video networks independently and without an additional video provider.
Test a fully functional [demo](https://demo.datarhei.com/ui) before installation on the project website with the login name **admin** and password **demo**.
## Comments are closed. |
15,618 | 如何在 RHEL 9 上分步安装 PgAdmin4 | https://www.linuxtechi.com/how-to-install-pgadmin-on-rhel/ | 2023-03-12T08:10:00 | [
"PgAdmin4",
"Postgresql"
] | https://linux.cn/article-15618-1.html | 
PgAdmin4 是一个自由开源的基于网络的 PostgreSQL 管理和开发平台。它可以与本地或远程的服务器上的 PostgreSQL 数据库服务器进行交互,并使用直观的交互式仪表板显示服务器的统计数据。
PgAdmin4 是对 PgAdmin3 的重写,提供了以下显著的功能:
* 具有直观的实时监控仪表盘的响应式 Web UI。
* 改进的 Web 界面,具有很酷的新面板和图标。
* 带有语法高亮的 SQL 查询编辑器。
* 全面的文档。
* 帮助你入门的有用提示。
在本指南中,我们将演示如何在 RHEL 9 上安装 PgAdmin4。
### 先决条件
在开始之前,确保你有一台 RHEL 9 服务器实例并安装了 PostgreSQL 数据库。请查看如何在 RHEL 9 上 [安装 PostgreSQL 15](https://www.linuxtechi.com/how-to-install-postgresql-on-rhel/) 的指南。
在安装了 PostgreSQL 服务器后,继续执行以下步骤。
### 步骤 1)在 RHEL 9 上添加 PgAdmin4 仓库
第一步是在 RHEL 9 上添加 PgAdmin4 仓库。但首先要安装 EPEL 仓库,它提供了基本的软件包。
```
$ sudo dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm
```
接下来,安装 PgAdmin4 仓库,如下所示:
```
$ sudo dnf install -y https://ftp.postgresql.org/pub/pgadmin/pgadmin4/yum/pgadmin4-redhat-repo-2-1.noarch.rpm
```
完成后,为 PgAdmin4 和 EPEL 仓库建立一个缓存,如下所示:
```
$ sudo dnf makecache
```
### 步骤 2)在 RHEL 9 上安装 PgAdmin4
安装好 PgAdmin4 和 EPEL 仓库后,继续使用 DNF 包管理器安装 PgAdmin4,如下所示:
```
$ sudo dnf install pgadmin4 -y
```
这将安装许多软件包,包括 PgAdmin4、Apache HTTP web 服务器和 Python 软件包,仅举几例:

要确认 PgAdmin4 是否已经安装,请运行以下命令:
```
$ rpm -qi pgadmin4
```
这将打印出相当多的信息,包括已安装软件包的名称、版本、发行和架构。

### 步骤 3)在 RHEL 9 上启动/启用 PgAdmin4
此时,PgAdmin4 已成功安装。然而,你需要更进一步,让它运行起来。要启动 PgAdmin4 服务,请运行以下命令:
```
$ sudo systemctl start httpd
```
还要确保每次系统启动时都能启动该服务。
```
$ sudo systemctl enable httpd
```
要确认 PgAdmin4 正在运行,请执行以下命令:
```
$ sudo systemctl status httpd
```

### 步骤 4)在 RHEL 9 上初始化 PgAdmin4
PgAdmin4 软件包提供了一个可配置的脚本来设置 PgAdmin 网络服务。这允许你创建一个用户账户,用来验证和配置 SELinux 策略和 Apache Web 服务器。
因此,如下运行该脚本:
```
$ sudo /usr/pgadmin4/bin/setup-web.sh
```
提供你将在登录页面上作为登录凭证使用的电子邮件和密码。
注意:有时,你可能会遇到如下 “semanage: command not found” 的错误。这表明缺少 `semanage` 包。

Semanage 是 SELinux(安全增强型 Linux)策略管理工具的简称,是一个用于配置 SELinux 策略某些方面的工具,不需要对策略源进行修改或重新编译。
为了解决这个错误,你需要检查提供 `semanage` 的软件包。你可以通过运行以下命令来完成:
```
$ sudo dnf provides /usr/sbin/semanage
```
从输出中,你可以看到 `semanage` 是由 `policycoreutils-python-utils-3.3-6.el9_0.noarch` 包提供的。

要安装这个软件包,请运行以下命令:
```
$ sudo dnf install policycoreutils-python-utils -y
```
再一次如下运行 Pgadmin4 安装脚本。 提供电子邮件地址和密码,在提示时输入 `y`。
```
$ sudo /usr/pgadmin4/bin/setup-web.sh
```

### 步骤 5)访问 PgAdmin4 的 Web 界面
此时,PgAdmin4 已经成功安装。要从网络浏览器访问它,请前往以下地址:
```
http://server-ip/pgadmin4
```
你会看到登录网页界面。请确保提供你在运行安装脚本时提供的 Email 和密码,并点击 “<ruby> 登录 <rt> Login </rt></ruby>”:

登录后,PgAdmin4 的仪表板将出现在视图中,如图所示:

要添加一个可以由 PgAdmin4 管理的服务器,请点击 “<ruby> 添加新服务器 <rt> Add New Server </rt></ruby>”:

在 “<ruby> 通用 <rt> General </rt></ruby>” 选项卡中,填写服务器的名称,并添加注释,以便更好地描述:

接下来,点击 “<ruby> 连接 <rt> Connection </rt></ruby>”,填写主机名/地址、端口、维护数据库、用户名和密码。然后最后点击 “<ruby> 保存 <rt> Save </rt></ruby>”:

此后,你会看到 PosrgreSQL 服务器的统计数据显示在互动和直观的仪表板上。在左边的侧边栏,你可以浏览各种 PostgreSQL 参数:

### 总结
我们希望你觉得本指南内容丰富,请在下面的评论部分发表你的疑问和反馈。
---
via: <https://www.linuxtechi.com/how-to-install-pgadmin-on-rhel/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Pgadmin4](https://www.pgadmin.org/) is a free and opensource web-based administration and development platform for PostgreSQL. It interacts with PostgreSQL database server on both local and remote servers and displays server statistics using intuitive and interactive dashboards.
Pgadmin4 is a rewrite of Pgadmin 3 and provides the following notable features:
- A responsive web UI with intutive and real-time monitoring dashboards
- An improved web interface with cool and new panels and icons.
- An SQL query editor with syntax highlighting.
- Extensive documentation.
- Useful tips to help you get started.
In this guide, we will demonstrate how to install Pgadmin4 on RHEL 9.
#### Prerequisites
Before you begin, ensure that you have a RHEL 9 server instance with PostgreSQL database server installed. Check out guide on [how to install PostgreSQL 15 on RHEL 9](https://www.linuxtechi.com/how-to-install-postgresql-on-rhel/).
With PostgreSQL server installed, carry on with the following steps.
## Step 1) Add Pgadmin4 Repository on RHEL 9
The first step is to add the Pgadmin4 repository on RHEL 9. But first, install the EPEL repository which provides essential software packages.
$ sudo dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm
Next, install Pgadmin4’s repository as follows.
$ sudo dnf install -y https://ftp.postgresql.org/pub/pgadmin/pgadmin4/yum/pgadmin4-redhat-repo-2-1.noarch.rpm
Once done, build a cache for Pgadmin4 and EPEL repositories as follows.
$ sudo dnf makecache
## Step 2) Install PgAdmin4 on RHEL 9
Once the Pgadmin4 and EPEL repositories are in place, proceed and install Pgadmin4 using the DNF package manager as shown.
$ sudo dnf install pgadmin4 -y
This installs a myriad of packages including Pgadmin4, Apache HTTP web servers, and Python packages to mention a few.
To confirm that Pgadmin4 has been installed, run the following command:
$ rpm -qi pgadmin4
This prints out quite some information including the name, version, release, and architecture of the installed package.
## Step 3) Start / Enable PgAdmin4 on RHEL 9
At this point, Pgadmin4 is successfully installed. However, you need to go a step further and get it running. To start the Pgadmin4 service, run the command:
$ sudo systemctl start httpd
Be sure also to enable the service to start every time the system boots.
$ sudo systemctl enable httpd
To confirm that Pgadmin4 is running run the command:
$ sudo systemctl status httpd
## Step 4) Initializing PgAdmin4 on RHEL 9
The Pgadmin4 package provides a configurable script for setting up the pgAdmin web service. This allows you to create a user account which is used to authenticate and configure SELinux policies and Apache web server.
Therefore, run the script as follows.
$ sudo /usr/pgadmin4/bin/setup-web.sh
Provide the email and password that you will use as login credentials on the login page.
NOTE: Sometimes, you may encounter a ‘semanage: command not found‘ error as shown in the output below. This indicates that the semanage package is missing.
Semanage, short for SELinux (Security-Enhanced Linux) policy management tool, is a utility used to configure some aspects of SELinux policy without requiring modification to or recompilation from policy sources.
To fix this error, you need to check for the package that provides semanage. You can do this by running the command:
$ sudo dnf provides /usr/sbin/semanage
From the output, you can see that semanage is provided by the policycoreutils-python-utils-3.3-6.el9_0.noarch package.
To install this package, run the following command.
$ sudo dnf install policycoreutils-python-utils -y
Once again, run the Pgadmn4 installation script as shown. Provide the email address and password and type ‘y’ when prompted.
$ sudo /usr/pgadmin4/bin/setup-web.sh
## Step 5) Access the Pgadmin4 Web Interface
At this point, Pgadmin4 is successfully installed. To access it from a web browser, head over to the following address:
http://server-ip/pgadmin4
You will get the following login web interface. Be sure to provide the Email and password you provided when running the installation script and click ‘Login’.
Once logged in, the Pgadmin4 dashboard will come to view as shown.
To add a server that can be administered by Pgadmin4, click ‘Add New Server’
On the ‘General’ tab fill out the name of the server and add comments for better description.
Next, click ‘Connection’ and fill out the Hostname/Address , Port , maintenance database , username and password. Then finally click ‘Save’.
Thereafter, you will see PosrgreSQL server statistics displayed on interactive and intuitive dashboards. On the left sidebar, you can browse various PostgreSQL parameters.
#### Conclusion
We hope you found this guide informative, kindly do post your queries and feedback in below comments section. |
15,619 | 在 Ubuntu 中安装 DOSBox 来玩复古游戏 | https://itsfoss.com/ubuntu-dosbox/ | 2023-03-12T09:11:39 | [
"DOSBox",
"游戏"
] | https://linux.cn/article-15619-1.html | 
DOSBox 是一款自由开源的软件,它可以让你模拟上个世纪的 MS-DOS 操作系统。
你为什么要这么做呢?因为怀旧:它可以让你游玩在 80 年代和 90 年代流行的 8 位游戏。
这其中包含了马里奥、魂斗罗、DOOM 等传奇游戏。
听起来不错吧?让我介绍一下如何在 Ubuntu 中安装 DOSBox。我还会向你展示如何在 DOSBox 中安装并游玩复古游戏。
DOSBox 也可以在其他 Linux 发行版中使用。除了安装部分,其余的指令应该对所有发行版都有效。
>
> ✋? DOS 是一个主要基于命令行的操作系统。使用 DOSbox 需要使用终端。
>
>
>
### 在 Ubuntu 中安装 DOSBox
DOSBox 包可以在 [Universe 软件仓库](https://itsfoss.com/ubuntu-repositories/) 中找到。这个仓库应该已经被启用了,所以可以使用下面的命令来安装 DOSBox:
```
sudo apt install dosbox
```
完成之后,从系统菜单中启动 DOSBox。
或者,你也可以使用终端来启动 DOSBox:
```
dosbox
```
**需要首先运行一次,因为它会为我们创建一个配置文件。实际上,第一次启动时不需要做任何事情,因为它会创建配置文件。**
然后在 DOSBox 终端中执行 `exit` 命令来关闭 DOSBox:
```
exit
```

如果你想要调整配置,配置文件位于 `~/.dosbox/dosbox-[版本].conf`。
在这个配置文件中,你可以调整几乎所有的东西,比如在启动 DOSBox 时进入全屏模式,更改核心等等。
但是(对我来说)启用全屏模式会使事情变得更糟,并且必须重新登录才能进入默认模式:

**所以,除非你知道你在做什么,否则不要修改配置。**
### 在 DOSBox 中安装游戏
你可以从互联网档案馆的软件库中访问数百款流行游戏。
>
> **[从互联网档案馆下载游戏](https://archive.org/details/softwarelibrary_msdos_games?tab=collection&ref=its-foss)**
>
>
>
每款游戏都有自己的 zip 文件,其中包含 .exe 文件。下载你喜欢的游戏。
然后,在你的主目录中[创建一个新目录](https://itsfoss.com/make-directories/),命名为 `dosbox`,并为你下载的游戏创建目录:
```
mkdir ~/dosbox && cd ~/dosbox
mkdir [游戏名称]
```
我下载了马里奥。你可以给目录起任何名字。这里没什么要求,只是为了管理游戏而已。

然后,将 `.zip` 文件解压到你刚刚创建的 `dosbox` 目录中:

如果你想的话,你也可以在终端中 [使用 unzip 命令](https://learnubuntu.com/unzip-file/?ref=its-foss) 来做同样的事情:
```
unzip ~/Downloads/MARIO.zip -d ~/dosbox/mario/
```
当你完成之后,启动 DOSBox:
```
dosbox
```
然后,将游戏挂载到虚拟 C 驱动器上:
```
mount c ~/dosbox/mario
```

然后,切换到虚拟 C 驱动器:
```
c:
```

最后,通过输入游戏的文件名来启动游戏:
```
mario
```
然后,享受游戏吧。

### 想要更多复古的东西?
如果你有不再使用的旧电脑或者树莓派,你可以把它们变成复古游戏机。有很多 Linux 项目就是为了这个目的而存在的。
>
> **[把你的电脑变成复古游戏机的 Linux 发行版](https://itsfoss.com/retro-gaming-console-linux-distros/)**
>
>
>
为什么只玩游戏呢?你也可以把复古的计算机终端带回来。
>
> **[用 Cool Retro Terminal 获得一个复古的 Linux 终端](https://itsfoss.com/cool-retro-term/)**
>
>
>
希望该指南对你有所帮助。你是如何在 Linux 上玩游戏的?在评论中告诉我吧。
---
via: <https://itsfoss.com/ubuntu-dosbox/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

DOSBox is free and open-source software that allows you to emulate the MS-DOS operating systems from the previous century.
Why would you want that? For nostalgia as it allows you to play the 8-bit games that were popular in the 80s and 90s.
That includes legendary games like Mario, Contra, DOOM, etc.
Sounds good? Let me walk you through how you can install DOSBox on Ubuntu. I will also show how you can install and play retro games.
**Dosbox is also available in other Linux distributions. Apart from the installation, the rest of the instructions should be valid for all distros.**
## Installing DOSBox on Ubuntu
The DOSBox package is available in [the universe repository](https://itsfoss.com/ubuntu-repositories/). Which should already be enabled so DOSBox can be installed using the following command:
`sudo apt install dosbox`
Once done, start the DOSBox from the system menu.
Alternatively, you can use the terminal for the same:
`dosbox`
**The first run is essential as it will create a configuration file for us. Actually, there is nothing to do on the first launch as it creates the configuration file. **
So close the DOSBox by executing `exit`
on the DOSBox terminal:
`exit`
If you want to tweak the configuration, the file is located at `~/.dosbox/dosbox-[version].conf`
.
Using this configuration, you can tweak almost everything, like entering full screen when you start DOSBox, changing cores, etc.
But enabling the full screen made things worse (for me) and had to log back in to get to the default:
**So know what you are doing or leave the config to default.**
## Install games on DOSBox
You can access hundreds of popular games from the software library of the internet archive.
Each game comes in its own zip file containing .exe file. Download the ones you like.
Next, [create a new directory](https://itsfoss.com/make-directories/) named `dosbox`
inside your home directory and also make directories for the games you have downloaded:
```
mkdir ~/dosbox && cd ~/dosbox
mkdir [game_name]
```
I have downloaded Mario. You can name the directories anything. There is no rules here., It's for organizing games. That's it.

Now, extract the `.zip`
file to the `dosbox`
directory that you've just created:
You can do the same [using the unzip command](https://learnubuntu.com/unzip-file/) in the terminal if you want:
`unzip ~/Downloads/MARIO.zip -d ~/dosbox/mario/`
Once you are done, start DOSBox:
`dosbox`
Next, mount the game to the virtual C drive:
`mount c ~/dosbox/mario`
Now, switch to the virtual C drive:
`c:`
And finally, start the game by typing the filename of the game:
`mario`
And enjoy the game.

## Want more retro stuff?
If you have an old system or a Raspberry Pi that you are not using anymore, you can turn that machine into a retro gaming console. There are various Linux projects just for this purpose.
[Linux Distros That Turn Your PC into Retro Gaming ConsoleSteam Deck is making news for all the right reasons. It is a fantastic piece of tech, powered by a variant of Arch Linux (SteamOS 3.0) developed by Valve. While you can install any other operating system in it, it is best to have it as it is for](https://itsfoss.com/retro-gaming-console-linux-distros/)

And why stop at games? You can get the vintage computer terminals back as well.
[Get a Vintage Linux Terminal with Cool Retro TerminalNostalgic about the past? Get a slice of the past by installing retro terminal app cool-retro-term which, as the name suggests, is both cool and retro at the same. Do you remember the time when there were CRT monitors everywhere and the terminal screen used to flicker? You don’t](https://itsfoss.com/cool-retro-term/)

I hope you will find this guide helpful. How do you game on Linux? Let me know in the comments. |
15,621 | 8 位有影响力的科技界女性 | https://opensource.com/article/23/3/international-womens-day-tech-influence | 2023-03-12T23:06:55 | [
"女性"
] | https://linux.cn/article-15621-1.html | 
>
> 社区成员分享了影响了其科技生涯的重要女性的故事。
>
>
>
一段开源之旅往往不是独自一人能完成的。你的爱好、职业和生活都受到了科技领域其他人的影响,而数据表明这其中一些影响力来自于女性。这是国际妇女节存在的众多原因之一,也是一起回顾你技术职业生涯中的女性的一个很好的理由。我们向 [Opensource.com](http://Opensource.com) 的贡献者询问了他们的想法。
### 励志的女性们
#### Kathleen Greenaway 博士
我的大学教授 [Kathleen Greenaway 博士](https://www.linkedin.com/in/kathleen-greenaway-4076247/) 是激励过我的女性之一。她正是我想成为的人。我记得她在一次关于打破玻璃天花板的女性活动中说,她无法相信这么多年后我们还在谈论这个问题。我现在发现自己也是这么想的。这只是其中一个例子,但她就是这样。
—— [Shanta Nathwani](https://opensource.com/users/shanta)
#### Hilary Mason
我对 PHP 的入门要归功于 [Hilary Mason](https://en.wikipedia.org/wiki/Hilary_Mason_(data_scientist)?wprov=sfti1)。当她在普罗维登斯 RI 的 Johnson & Wales 担任教授时,她开了一门服务器端编程的选修课。她向我们展示了 PHP,并在最后一个项目中让我们使用数据库构建了一些东西。我记得我建立了一个简单的登录系统和一个评论工具之类的。我喜欢告诉人们我是从一个女性那里学来的 PHP(她还是 [bit.ly](http://bit.ly) 的首席数据科学家!)
—— [John E. Picozzi](https://opensource.com/users/johnpicozzi)
#### Carie Fisher
对我来说,科技界最鼓舞人心的女性是 [Carie Fisher](https://www.linkedin.com/in/cariefisher)。我是在刚开始参与无障碍社区时遇到的她。她邀请我一起帮助项目,并在我申请工作、获得认证和在会议上发言时帮助我克服了冒名顶替综合症。在对技术包容性的激情和奉献精神上,只有少数人能与她相提并论。
—— [AmyJune Hineline](https://opensource.com/users/amyjune)
#### Kanopi Studios
我在技术领域工作了 25 年,并且经常是公司或部门中唯一的女性开发人员。然后我加入了 Kanopi Studios,这是一家由女性拥有和领导的机构,这里有许多聪明、精通技术的女性员工,我每天都从她们那里得到启发。我的性别不再是我事业成功的障碍。我感觉自己受到尊重和并被倾听,我的成就也得到认可。
—— [Cindy Williams](https://opensource.com/users/cindytwilliams)
#### Barbara Liskov 和 Sandi Metz
我认为 Barbara Liskov 是我们领域中最有影响力的人物之一,我也非常喜欢 Sandi Metz,她的演讲和教学技巧对我的职业生涯帮助很大。我推荐她的所有书籍和会议视频。
—— [benelori](https://opensource.com/users/benelori)
#### 家庭
在我的生活中,无论是个人还是职业上,我受到了许多女性的启发。我总是说我的母亲、姐姐和祖母在所有事情上都是我很好的参考对象。我现在有很棒的同事,他们也是我的榜样。我总是这样想:尽力和那些对你很重要的人保持紧密联系。在我刚学习编程开发那时候,我们没有任何参考榜样。没有人告诉我们 [第一个程序员是女性](https://opensource.com/article/18/10/first-computer-programmer-ada-lovelace),亦或我们能够拥有 WiFi 和 GPS 是多亏了一位女性。我现在正在读一本非常好的书 —— 《[The Invisible Woman](https://www.penguinrandomhouse.com/books/623964/the-invisible-woman-by-erika-robuck/)》,我强烈推荐。
—— [Marta Torre](https://opensource.com/users/martatorredev)
#### Sarah Drasner
《[我们其他人的工程管理](https://www.engmanagement.dev/)》由一位杰出的科技女性撰写,作者是 Sarah Drasner。这本书让我注意到了另一位杰出的科技女性。这本书(还有我们出色的开发经理 Jody,她将书的副本发给了业内的所有领头人物)促使我做出了一个决定——不断深化讨论,了解我们在面对反馈时的不同经历。我们意识到很多人可能甚至不知道如何谈论他们需要什么或者什么对他们有用。因此,我们希望可以用一场公开或随意的聊天对话作为一次非常有用的协作学习体验,在对话中,人们分享一些好的和坏的经历(当然这些分享都是非强制的)并看一些不同风格的案例。
—— [Fei Lauren](https://opensource.com/users/feilauren)
#### Sheryl Sandberg
在德国汉诺威举行的 WomenPower 会议上,有人推荐给我人生中的第一本关于科技界女性的书,它是<ruby> 雪莉·桑德伯格 <rt> Sheryl Sandberg </rt></ruby> 的 《[精益求精:女性、工作和领导意愿](https://leanin.org/book)》。我不仅对她自己的工作方式印象深刻,还对她如何成功地运用我们作为女性被赋予的权力以及她和公司的成功的是如何改变了我们的事例感到钦佩不已。
—— [Anne Faulhaber](https://opensource.com/users/afaulhab)
### 自己的影响力
在开源领域,或许比其他地方更甚,我们都是彼此影响着的。共享和协作的精神植根于开源的发展过程。告诉我们你在开源之旅中受到过谁的影响吧。
---
via: <https://opensource.com/article/23/3/international-womens-day-tech-influence>
作者:[AmyJune Hineline](https://opensource.com/users/amyjune) 选题:[lkxed](https://github.com/lkxed/) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A journey through open source is rarely something you do alone. Your hobby, career, and your life has been affected by others in the tech space, and statistically some of those people have been women. That's one of the many reasons International Women's Day exists, and it's a good excuse to reflect upon the women who have inspired your career in tech. We asked Opensource.com contributors for their thoughts.
## Inspirational women
### Dr. Kathleen Greenaway
One of the women that inspired me was my university professor, [Dr. Kathleen Greenaway](https://www.linkedin.com/in/kathleen-greenaway-4076247/). She was exactly who I wanted to be. I remember her saying at a women's event about breaking the glass ceiling that she couldn't believe that we were still talking about it so many years later. I now find myself thinking the very same thing. This is just one example, but she was it.
### Hilary Mason
I owe my knowledge and start in PHP to [Hilary Mason](https://en.wikipedia.org/wiki/Hilary_Mason_(data_scientist)?wprov=sfti1). While she was a professor at Johnson & Wales in Providence RI, she ran an elective study on server-side programming. She showed us PHP, and for a final project had us build something using a database. I think I built a simple login system and a commenting tool or something. I love telling folks I learned PHP from a woman (the lead data scientist at bit.ly, at that!)
### Carie Fisher
The most inspirational woman in tech for me is [Carie Fisher](https://www.linkedin.com/in/cariefisher). I met her when I first started getting involved in the accessibility community. She invited me to help with projects and helped me through my impostor syndrome when applying to jobs, getting certified, and speaking at conferences. Her compassion and devotion to digital inclusion is matched by only a few.
### Kanopi Studios
I've been working in tech for 25 years and have often been the only female developer in a company or department. Then I joined Kanopi Studios, a women-owned and led agency with many smart, tech-savvy women from whom I am inspired every day. My gender is no longer a barrier to my career success. I feel respected and heard, and my accomplishments are recognized.
### Barbara Liskov and Sandi Metz
I think Barbara Liskov is one of the most influential figures in our field I also really really like Sandi Metz, whose speaking and teaching skills helped me a lot in my career. I recommend any of her books or conference videos.
### Family
I have been inspired by a number of women in my life, both personally and professionally. I always say that my mother, my sister and my grandmother have been great references for me in everything. But I have great colleagues with whom I work today who, for me are my references. I always think something like: Those people who have been important to you, try to keep them close. When I was studying development, we had no references. No one taught us that the [first programmer was a woman](https://opensource.com/article/18/10/first-computer-programmer-ada-lovelace) or that we have WiFi or GPS, thanks to a woman. There is a very good book that I am reading right now [The Invisible Woman](https://www.penguinrandomhouse.com/books/623964/the-invisible-woman-by-erika-robuck/) that I highly recommend.
### Sarah Drasner
Written by an amazing woman in tech, it brought to my attention to another amazing woman in tech, [Engineering Management for the Rest of Us](https://www.engmanagement.dev/) by Sarah Drasner. This book (and the amazing dev manager, Jody, who sent copies to all the leads) is the reason I am going to be facilitating some discussions about how we experience feedback differently. We realized that a lot of folks may not even really know how to talk about what they need or what works for them, so an open/casual chat where we share some good and bad experiences (optionally, of course) and look at some examples of different styles will hopefully be a really helpful collaborative learning experience.
### Sheryl Sandberg
My first book about women in tech, which was recommended to me at the WomenPower conference in Hannover, Germany, was [Lean In: Women, Work and the Will to Lead](https://leanin.org/book) by Sheryl Sandberg. Not only was I impressed by her own way but very much by how she managed to use the powers we as women are given and what makes us different for her own success and the company's success.
## Your own influence
In open source, maybe more than anywhere, we all are influences on each other. Sharing and collaborating are built into the process of open source. Tell us about the influences you've had during your open source journey.
## 1 Comment |
15,622 | 如何在 Ubuntu 和其他 Linux 下安装 IDLE Python IDE | https://www.debugpoint.com/install-idle-ubuntu-linux/ | 2023-03-12T23:19:00 | [
"Python",
"IDLE"
] | /article-15622-1.html | 
>
> 在 Ubuntu 和其他发行版中,Python 的默认 IDE IDLE 没有被默认安装。在本指南中了解如何安装它。
>
>
>
IDLE(<ruby> 集成开发学习环境 <rt> <strong> I </strong> ntegrated <strong> D </strong> evelopment and <strong> L </strong> earning <strong> E </strong> nvironment </rt></ruby>)是一个 [Python IDE](https://www.debugpoint.com/5-best-python-ide-code-editor/),由 Python 语言本身编写,在 Windows 中通常作为 [Python 安装](https://www.debugpoint.com/install-python-windows/) 的一部分而安装。它是初学者的理想选择,使用起来很简单。对于那些正在学习 Python 的人,比如学生,它可以作为一个很好的 IDE 来开始使用。
语法高亮、智能识别和自动补全等基本功能是这个 IDE 的一些特点。你可以随时在官方 [文档](https://docs.python.org/3/library/idle.html) 中了解更多关于 IDLE 的功能。
### Ubuntu 和其他 Linux 中的 IDLE
所有的 Linux 发行版,包括 Ubuntu,都预装了 Python。即使你手动升级或安装了 Python 版本,IDLE IDE 也不会自带安装。你必须手动安装它。
对于 **Debian、Ubuntu、Linux Mint 和相关发行版**,打开终端,运行以下命令来安装 IDLE:
```
sudo apt update
```
```
sudo apt install idle3
```
当命令询问你是否要安装 IDLE 时,输入 `Yes`。命令完成后,IDLE 将被安装在你的 Ubuntu 系统中。
对于 **Fedora、RHEL、CentOS**,使用下面的命令来安装它:
```
sudo dnf update
```
```
sudo dnf install idle3
```
**Arch Linux** 用户可以使用以下命令进行安装:
```
sudo pacman -S python tk
```

### 启动 IDLE 并编写一个测试程序
在 Ubuntu、Debian、Linux Mint 和 Fedora 中安装后,你可以在应用菜单中找到 IDLE 的图标。见下图:

如果你使用的是 Arch Linux,你需要在命令行中运行以下内容来启动 IDLE:
```
idle
```
启动 IDLE 后,你应该看到主窗口,如下图所示:

默认情况下,它会显示一个 <ruby> 交互界面 <rt> Shell </rt></ruby>,你可以直接在每一行中执行 Python 代码。它的工作方式和任何 Shell 解释器一样。而当你点击回车键时,你会得到输出,还有三个 `>` 符号进入下一行,执行下一个命令。

IDLE 也允许你从它的文件菜单中打开任何 .py 文件。它将在一个单独的窗口中打开该文件,在那里你可以进行修改并直接运行它。你可以使用 `F5` 或者从选项 “<ruby> 运行 <rt> Run </rt></ruby> > <ruby> 运行模块 <rt> Run Module </rt></ruby>” 来运行。


输出会显示在一个单独的输出窗口中。在输出窗口中,你可以开始调试,进入一行或文件,查看堆栈跟踪和其他选项。

### 总结
现在你学会了如何在 Ubuntu 和其他发行版中安装 IDLE IDE,以及如何运行一条语句或一个 Python 程序。对于初学者来说,IDLE 是一个很好的起点,在进入更复杂的 IDE 之前,可以先掌握基础知识。
我希望这篇指南对你的 Python 之旅有所帮助。
---
via: <https://www.debugpoint.com/install-idle-ubuntu-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,624 | NixOS 系列 #2:如何在虚拟机上安装 NixOS? | https://itsfoss.com/install-nixos-vm/ | 2023-03-14T15:40:18 | [
"NixOS"
] | https://linux.cn/article-15624-1.html | 
如果你可以在任何 Linux 发行版上使用 Nix 包管理器,为什么还要安装 NixOS?
在使用 NixOS 几天之前,我经常想知道同样的事情。
当我意识到这些好处后,我就写了这篇文章来帮助你了解 [为什么你要考虑使用 NixOS](/article-15606-1.html)。如果你已经阅读了本系列的第一篇文章,那么你已经知道自己想要什么了。
那么,如何开始呢?考虑到它对许多人来说可能是一种新体验,你应该用它替换日常使用的系统还是将其安装为虚拟机?
我建议在你想要将其替换为你的主要操作系统之前在虚拟机上使用 NixOS。这适用于你想尝试的任何新事物,特别是 [先进的 Linux 发行版](https://itsfoss.com/advanced-linux-distros/),例如 NixOS。
### 使用 VirtualBox 在 VM 中安装 NixOS
在本教程中,我将使用 VirtualBox。
如果你使用的是 Ubuntu 并且不关心是否拥有最新版本,那么可以使用一个命令安装 VirtualBox:
```
sudo apt install virtualbox
```
想要安装最新版本?你可以参考下面的指南:
>
> **[如何在 Ubuntu 上安装 VirtualBox(初学者教程)](https://itsfoss.com/install-virtualbox-ubuntu/)**
>
>
>
如果你使用 Ubuntu 以外的任何发行版,你可以 [按照其官方下载页面的下载说明进行操作](https://www.virtualbox.org/wiki/Linux_Downloads)。
成功安装 VirtualBox 后,让我们从第一步开始。
#### 步骤 1:获 取NixOS 的 ISO 镜像
你需要前往 NixOS [官方下载页面](https://nixos.org/download.html)。
在 “NixOS: the Linux distribution” 部分,你会找到带有 GNOME 和 KDE 桌面的 ISO。
当然,也有最小化 ISO,但我建议使用两者之一(GNOME 和 KDE):

对于本教程,我将使用 GNOME。
请记住,你可以选择 GNOME 和 KDE 两种<ruby> 立付桌面环境 <rt> Live Desktop </rt></ruby>。
而在安装过程中,你可以选择自己喜欢的桌面环境,包括 **Xfce、Pantheon、Cinnamon、MATE** 等等!
#### 步骤 2:在 VirtualBox 中创建虚拟机
打开 VirtualBox 并单击 “<ruby> 新建 <rt> New </rt></ruby>” 按钮添加新的虚拟机:

它将打开一个提示,要求你添加有关要添加的虚拟机的信息。
你可以先命名虚拟机:
* 为你的虚拟机命名,以便你可以识别它是 NixOS 系统。所以我将其命名为 “NixOS”。
* 选择你刚刚下载的 ISO 镜像。
* 选择 “Linux” ISO 类型。
* 并在版本选择 “<ruby> 其它 Linux(64 位) <rt> Other Linux (64-bit) </rt></ruby>”。

选择所有内容后,单击 “<ruby> 下一步 <rt> Next </rt></ruby>” 按钮。
接下来,系统会要求你选择基本内存(RAM)、要分配给此虚拟机的处理器以及存储空间。
虽然 NixOS 没有提到官方要求,但我建议你为此安装至少拥有 **4GB RAM**、**2-4 个处理器内核**和 **30GB 空间**:

最后,它会显示你为此虚拟机所做选择的摘要:

如果一切正常,请单击 “<ruby> 完成 <rt> Finish </rt></ruby>” 按钮,它将为你创建一个 NixOS 虚拟机。
#### 步骤 3:安装 NixOS
创建完虚拟机后,你为 NixOS 虚拟机指定的名称应该显示在 VirtualBox 的虚拟机列表中。
选择 “NixOS” 虚拟机并单击“开始”按钮:

它将启动 NixOS <ruby> 立付桌面环境 <rt> Live Desktop </rt></ruby>,以便你可以试用 Linux 发行版。
##### 选择安装语言
启动进入 NixOS 后,安装程序将启动并要求你设置安装程序的首选语言:

##### 选择地区和时区
接下来,选择你所在的地区和区域。如果你不知道这一点,你可以从地图上选择你的国家,它会为你设置。
选择区域和区域后,它还会选择系统的首选语言、数字和日期区域设置。
当然,你可以根据需要进行更改,但对于大多数用户而言,选定的选项就可以正常工作:

##### 选择键盘布局
接下来,你将必须设置键盘布局。对于大多数用户来说,默认设置的 “English (US)” 应该可以正常工作。
如果你要进行其他操作,则可以在继续之前测试你的键盘配置。

之后,系统会要求你创建一个用户并为该用户设置密码。
你可以选择为虚拟机保留一个强密码或任何随机密码。

##### 选择你喜欢的桌面环境
使用 NixOS,你可以选择以下桌面环境:
* GNOME
* KDE(定制的最佳选择)
* Xfce
* Pantheon(ElementaryOS 附带的桌面环境)
* Cinnamon
* Enlightenment
* LXQt

##### 在 NixOS 上使用非自由软件
NixOS 遵循与 Fedora 类似的方法,你必须选择是否需要非自由软件。
我建议你启用非自由包:

##### 分区部分
由于这是一个虚拟机指南,我建议你使用自动对磁盘进行分区的 “<ruby> 擦除磁盘 <rt> Erase disk </rt></ruby>” 选项!

完成后,它将为你提供你所做选择的摘要:

如果一切正常,请单击 “<ruby> 安装 <rt> Install </rt></ruby>” 按钮,它将开始安装。
##### 不要重启而是关闭虚拟机
安装完成后,你可以选择重新启动虚拟机。
如果你这样做,**它将再次加载安装程序**!
要解决此问题,你必须更改引导顺序。
为此,请在安装完成后关闭虚拟机。
要关闭虚拟机,请从“<ruby> 文件 <rt> File </rt></ruby>”菜单中选择 “<ruby> 关闭 <rt> Close </rt></ruby>” 选项,然后选择 “<ruby> 关闭虚拟机电源 <rt> Power off the machine </rt></ruby>” 选项:

##### 更改 VirtualBox 中的启动顺序
要更改 NixOS 虚拟机 中的启动顺序,请打开该虚拟机的设置:

在设置中,选择 “<ruby> 系统 <rt> System </rt></ruby>”,你将找到启动顺序。
在这里,选择 “<ruby> 硬盘 <rt> Hard Disk </rt></ruby>” 并使用选项旁边的**向上箭头**图标并将其设为启动的第一个选项:

按下 “<ruby> 确定 <rt> OK </rt></ruby>”,它将保存你所做的更改。
**或者**,你可以移除我们添加的用于启动安装的光盘(ISO 镜像)。
#### 步骤 4:从 NixOS 安装启动
现在,启动你的 NixOS 虚拟机,你将看到一个 GRUB 屏幕:

选择默认选项,它将带你进入带有 GNOME 桌面的全新 NixOS 安装。

就是这些了!**请继续探索 NixOS!**
### 总结
这是关于如何在 VirtualBox 上安装 NixOS 的快速指南。
对于 NixOS 教程系列的下一部分,我将分享有关**安装和删除包**的建议。
? *敬请期待本系列的下一部分。在那之前,请随时分享你对 NixOS 的看法或在遵循指南时遇到任何问题!*
---
via: <https://itsfoss.com/install-nixos-vm/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Install NixOS on a Virtual Machine
Want to try NixOS? Get started by installing it on a virtual machine.
If you can use the Nix package manager on any Linux distro, why should you install the NixOS?
I often wondered about the same before using NixOS for a few days.
Once I realized the benefits, I wrote about it to help you know [why you might consider using NixOS](https://itsfoss.com/why-use-nixos/). If you have read the first article of the series, you already know what you want.
So, how to get started with it? Considering it can be a new experience for many, should you replace your daily driver with it or install it as a virtual machine?
I recommend using NixOS on a VM before you want to replace it as your primary operating system. This holds for anything new that you want to try, but specifically for [advanced Linux distributions](https://itsfoss.com/advanced-linux-distros/) like NixOS.
## Install NixOS in the VM Using VirtualBox
In this tutorial, I will be using VirtualBox.
And if you are using Ubuntu and don't care about having the latest version, VirtualBox can be installed using a single command:
`sudo apt install virtualbox`
Want to install the latest version? You can refer to the given guide:
[How to Install VirtualBox on Ubuntu [Beginner’s Tutorial]This beginner’s tutorial explains various ways to install VirtualBox on Ubuntu and other Debian-based Linux distributions. Oracle’s free and open-source offering VirtualBox is an excellent virtualization tool, especially for desktop operating systems. I prefer using it over VMWare Workstation i…](https://itsfoss.com/install-virtualbox-ubuntu/)

And if you are using anything besides Ubuntu, you can[ follow the download instructions from its official downloads page.](https://www.virtualbox.org/wiki/Linux_Downloads)
Once you have successfully installed VirtualBox, let us start with the first step.
### Step 1: Get the ISO image of NixOS
You need to head to NixOS [official download page](https://nixos.org/download.html).
And under the `NixOS: the Linux distribution`
section, you will find ISO with GNOME and KDE desktops.
Sure, there is a minimal ISO, too, but I would recommend going with either of the two (GNOME and KDE):
For the sake of this tutorial, I will be using GNOME.
Remember, you are given GNOME and KDE options for the live desktop!
And during installation, you get the option to choose your favorite desktop environment, including **Xfce, Pantheon, Cinnamon, MATE**, and more!
### Step 2: Create a virtual in VirtualBox
Open VirtualBox and click on the `New`
button to add a new virtual machine:
And it will open a prompt asking you to add information about the VM you want to add.
You can start by naming your VM:
**Name your VM so that you can identify it is a NixOS install. So I named it**`NixOS`
.**Choose the ISO image that you've downloaded recently.****Select**`Linux`
as a type of ISO.**And choose**`Other Linux (64-bit)`
for version.
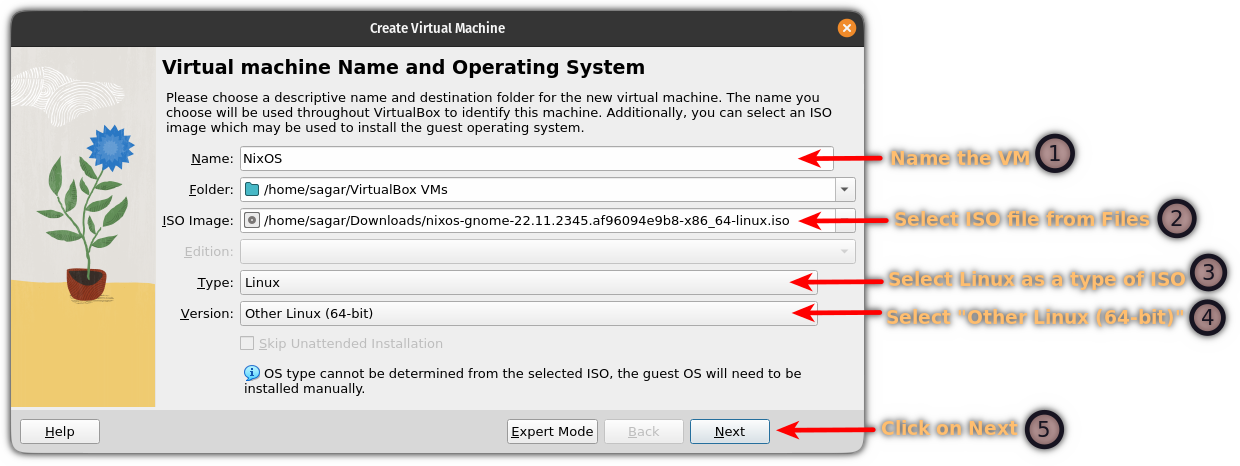
Once you select everything, click on the `Next`
button.
Next, you will be asked to choose the Base memory (RAM), processors you want to allocate to this VM, and storage space for this install.
While NixOS mentions no official requirements, I recommend you to have at least **4 gigs of RAM**, **2-4 processor cores**, and **30 GB of space** for this install:
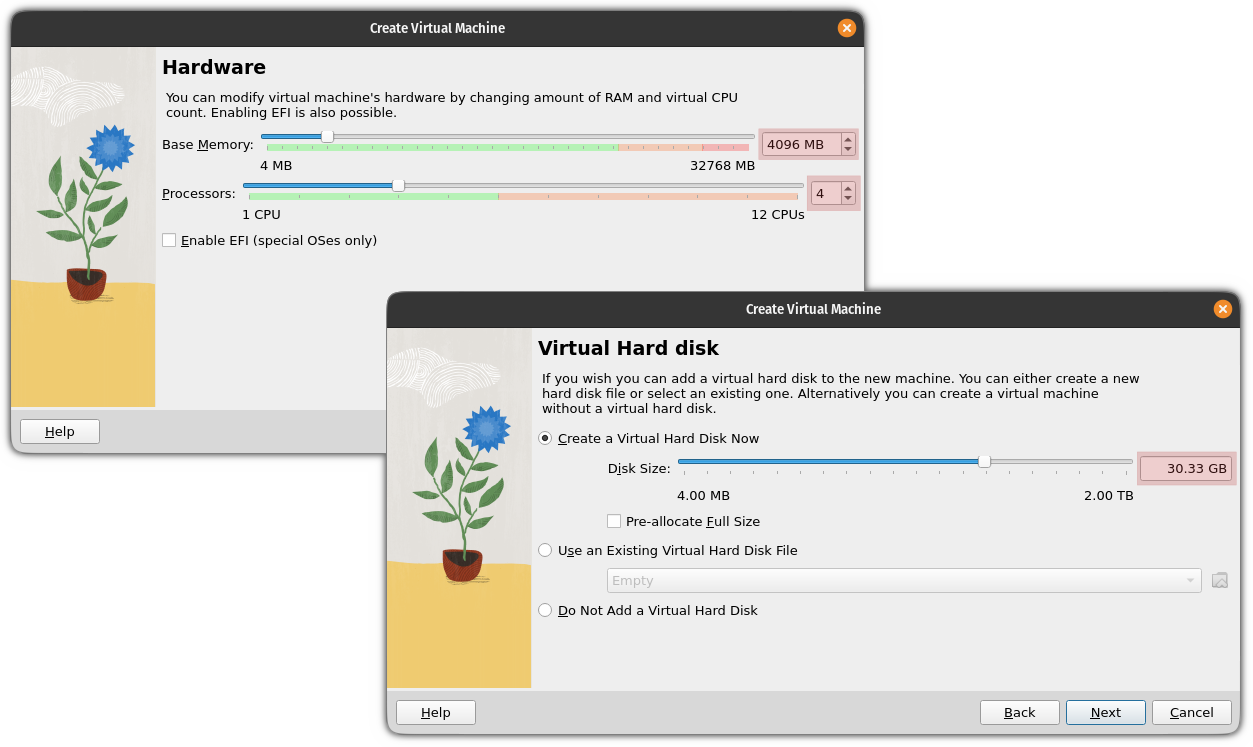
And in the end, it will show you the summary of the choices you made for this VM:
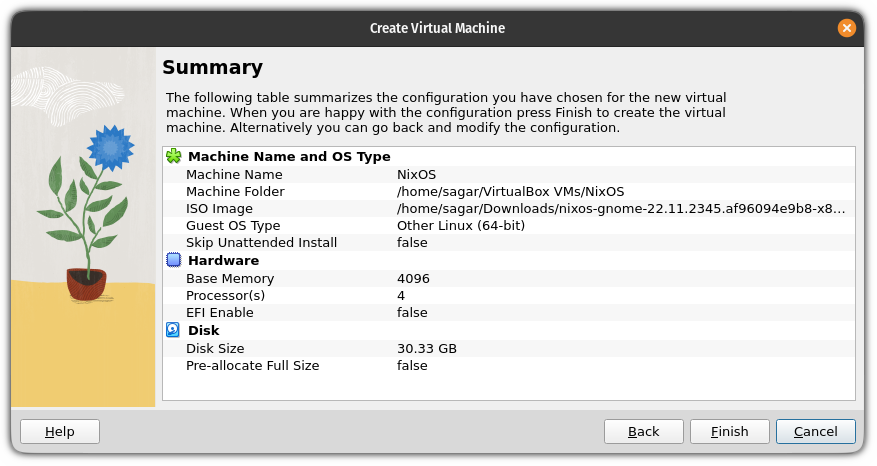
If everything seems fine, click on the `Finish`
button and it will create a NixOS virtual machine for you.
**Suggested Read 📖**
[How to Install Linux Inside Windows Using VirtualBoxUsing Linux in a virtual machine allows you to try Linux within Windows. This step-by-step guide shows you how to install Linux inside Windows using VirtualBox.](https://itsfoss.com/install-linux-in-virtualbox/)

### Step 3: Installing NixOS
Once you are done creating the VM, the name you gave to your NixOS VM should start reflecting in the VirtualBox list of VMs.
Select the NixOS VM and click on the start button:
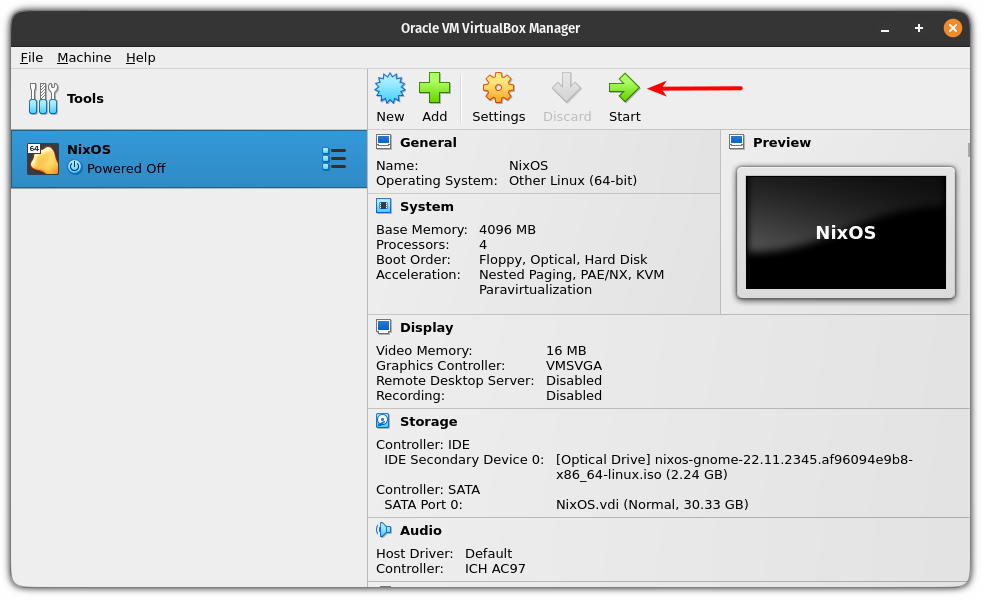
And it will start the NixOS live so you can try the Linux distro.
#### Select installer language
Once you boot into the NixOS, the installer will start and ask you to set the preferred language for the installer:

#### Choose region and timezone
Next, choose your region and zone. If you don't know this, you can select your country from the map, which will set things for you.
Once you select the region and zone, it will also select the preferred language, numbers, and date locale.
Sure, you can change if you want to, but for most users, the selected options will work just fine:
#### Select Keyboard layout
Next, you will have to set the keyboard layout. For most users, `English (US)`
with default setting should work fine.
If you are going with something else, you can test your keyboard configuration before proceeding.
After that, you are asked to create a user and set a password for that user.
You can choose to keep a strong password or just anything random for the VM.
#### Select your favorite Desktop Environment
With NixOS, you are given the following choices for the desktop environment:
- GNOME
- KDE (best choice for customization)
- Xfce
- Pantheon (a desktop environment that ships with ElementaryOS)
- Cinnamon
- Enlightenment
- LXQt
**Suggested Read 📖**
[KDE vs GNOME: What’s the Ultimate Linux Desktop Choice?Curious about the desktop environment to choose? We help you with KDE vs GNOME here.](https://itsfoss.com/kde-vs-gnome/)

#### Use non-free software on NixOS
NixOS follows a similar approach to Fedora, where you have to choose whether you want the non-free software.
I would recommend you enable non-free packages:
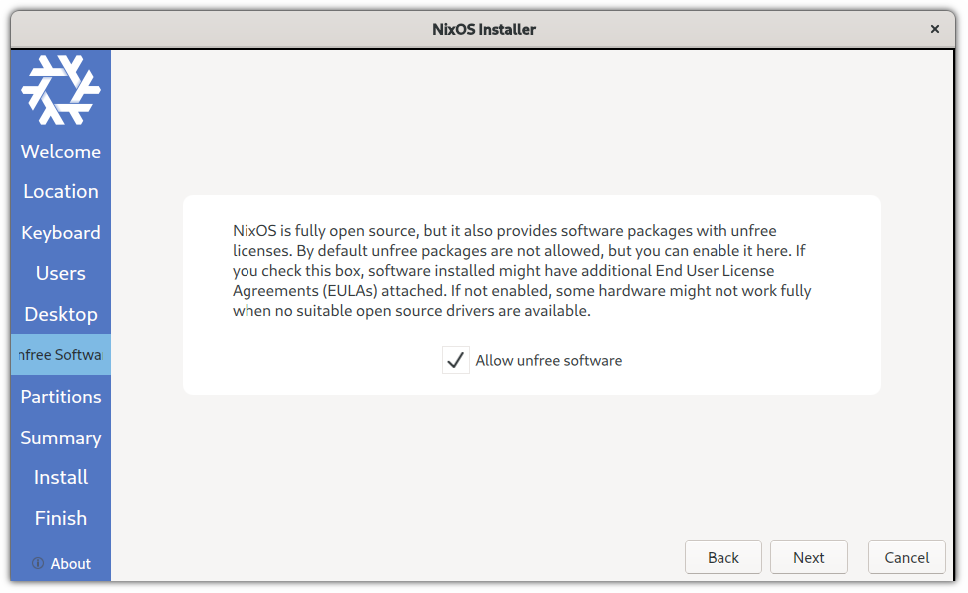
#### The partitions part
As this is a VM guide, I will recommend you go with the `Erase disk`
option that should partition the disk automatically!
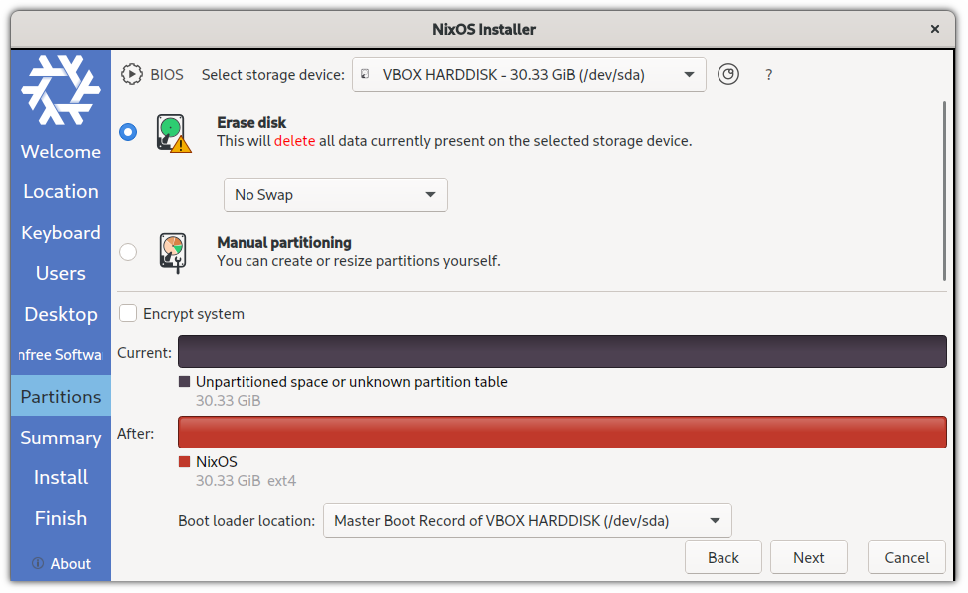
Once done, it will get you the summary of the choices you went with:
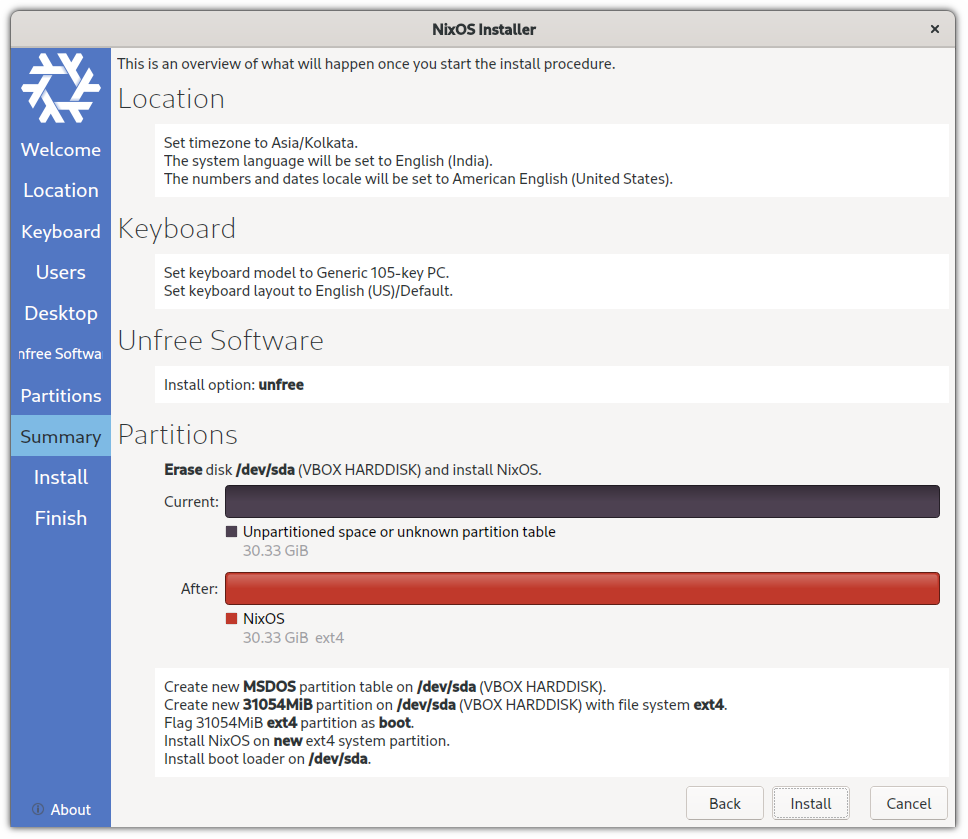
And if everything seems correct, click on the `Install`
button, and it will start the installation button.
#### Don't Reboot but turn off the VM
Once the installation is finished, you will be given the option to restart the VM.
And if you do so,** it will load the installer again**!
To solve this issue, you must make changes in the boot sequence.
And to do that, power off your VM once the installation is complete.
To power off the VM, select the `Close`
option from the **File menu** and select the `Power off the machine`
option:
#### Change the boot order in VirtualBox
To change the boot order in the NixOS VM, open the settings for that VM:
In settings, select `System`
and you will find the boot order.
Here, select the `Hard Disk`
and use the **up arrow** icon next to the options and make it the first option to boot:
Press `OK`
and it will save the changes you made.
**Alternatively**, you can remove the optical disk (ISO image) that we added to start the installation.
### Step 4: Boot from NixOS install
Now, start your NixOS VM, and you will see a GRUB screen:
Select the default option, and it will get you into the fresh install of NixOS with the GNOME desktop.
That's it! **Go on exploring NixOS!**
## Wrapping Up
This was a quick guide on how you can install NixOS on VirtualBox.
For the next part of this series, I shall share pointers on [installing and removing packages in NixOS](https://itsfoss.com/nixos-package-management/).
[NixOS Series #3: Install and Remove Packages in NixOSIt can be a bit different when installing and removing packages in NixOS. Here, we explain it to make things easy.](https://itsfoss.com/nixos-package-management/)

💬 *Stay tuned for the next part of the series. Until then, feel free to share your thoughts on NixOS and if you face any issues following the guide!* |
15,625 | 如何在 Linux 中安装和使用 htop | https://itsfoss.com/use-htop/ | 2023-03-14T16:29:39 | [
"top",
"htop"
] | https://linux.cn/article-15625-1.html | 
Windows 有其著名的任务管理器。Linux 有几个 GUI 和 [命令行的系统监视器](https://itsfoss.com/linux-system-monitoring-tools/)。每个 Linux 系统都都有几个这样的监视器。
在命令行中,`top` 命令可能是用于快速检查系统资源使用情况的最佳命令。
除了查看进程之外,[使用 top 命令](https://linuxhandbook.com/top-command/) 可能会很麻烦。而这就是 `htop` 的优势所在。抛开双关语不谈,`htop` 是一个类似于 `top` 的实用程序,但具有更好的、用户友好的界面。
在本指南中,我将向你展示如何在 Linux 中安装和使用 `htop`。
### 在 Linux 中安装 htop 实用程序
在大多数的 Linux 发行版中你不会找到预安装的 `htop`,但作为最流行的实用程序之一,你会在几乎每个 Linux 发行版的默认存储库中找到 `htop`。
因此,如果你的机器是基于 Debian/Ubuntu 驱动的,则以下命令应该可以完成你的工作:
```
sudo apt install htop
```
类似的,如果你使用的是 Fedora,则可以使用以下的命令:
```
sudo dnf install htop
```
如果你想避免从源代码构建包,还有一个 Snap 包可用:
```
sudo snap install htop
```
如果你使用的是其它的发行版或者想从源代码构建,你可以随时参考 [htop 的 GitHub 页面](https://github.com/htop-dev/htop)以获得详细说明。
完成安装后,你只需在终端中使用 `htop` 命令,它将反映系统中所有正在运行的进程:
```
htop
```

在 `htop` 中,每个部分都使用颜色标识,所以让我们看看使用 `htop` 时每种颜色表示什么。
##### htop 中不同的颜色和统计信息表示什么
让我们从 CPU 使用率栏开始,因为它使用的颜色最缤纷多彩。
#### CPU 使用率栏

* **绿色**:用户进程消耗的资源。
* **蓝色**:表示低优先级线程。
* **红色**:系统(内核)进程使用的 CPU 资源。
* **水蓝色**:表示虚拟化进程。
#### 内存使用率栏

* **绿色**:系统进程正在使用的内存。
* **蓝色**:缓冲页面使用的内存。
* **橙色**:分配给缓存页面的内存。
#### 统计数据

* **1.86** 是最后 1 分钟的平均负载。
* **1.75** 是最后 4 分钟的平均负载。
* **1.47** 是最后 15 分钟的平均负载。
* **Tasks: 166** 表示一共有 166 个正在运行的进程。
* **1249 thr** 表示这 166 个进程由 1249 个线程处理。
* **1 running** 表示在这 166 个进程中,只有一个进程处于运行中。
* **The load average** 表示一段时间内的平均系统负载。由于我的系统是 Hexa-Core,所以 6.0 以下的是没问题的。这个数字可能会超过,比如 6.1,所以即将要运行的进程必须等待正在进行的任务完成。
* **Uptime** 表示你登录后运行的时长。
现在,让我们跳到实际的实现部分。
### 如何在 Linux 中使用 htop
由于 `htop` 主要用于检查系统资源,让我们看看如何根据资源消耗对进程进行排序。
#### 根据资源消耗对进程进行排序
根据 CPU 和内存使用情况对进程进行排序最简单的方法是使用鼠标指针。将光标悬停在 CPU 或内存部分上,然后单击其中任何一个。
在那里你会看到一个三角形的图标 `△`,你可以根据它从最高到最低的资源消耗对进程进行排序:
但是,如果你正在处理远程服务器,你可能无法使用鼠标,在这种情况下,你可以使用键盘快捷键。
按 `F6`,它将显示每个可用的选项来对正在进行的进程进行排序:

你可以使用方向键选择一个首选的排序选项,然后按回车键,结果应该会如预期的那样反映出来。
#### 搜索特定进程
如果你想查找一个特定的进程及其资源消耗,你可以按 `F3`,它会给你一个搜索提示,如下所示:

例如,我搜索 `htop`,它用浅橙色高亮显示了进程。你可以按 `F3` 获得下一个结果。
#### 过滤正在运行的进程
虽然搜索可能会让你获得预期的结果,但我发现使用关键字的过滤过程更加有效,因为它提供了一个过程列表。
要过滤进程,你必须按 `F4` 并输入进程的名称。例如,我过滤了与 `gnome-boxes` 相关的进程:

#### 杀死进程
一旦找到最耗资源和不必要的进程,你只需按 `F9`,它就会向你显示终止信号:

我无法介绍所有的 15 个终止信号,我们有一个关于 [不同终止信息](https://linuxhandbook.com/termination-signals/) 的单独指南,因此如果你想了解更多信息,可以参考该指南。
但我会建议你首先使用 `SIGTERM`,因为它是终止进程的最有效和友好的方式。
#### 自定义 htop
在这里,我的目标是添加日期和时间并将配色方案更改为单色。
首先,按 `F2`,它会出现设置提示,允许用户更改 `htop` 的外观:

首先,将鼠标悬停在各个 `Colors` 部分并按回车键,这将允许我们更改配色方案。从那里,选择 `Monochromatic` 选项并按回车键保存更改:

现在,返回到设置选项,然后使用向左方向键探索可用的指标:

因为我打算添加日期和时间,所以我必须在找到它的选项后按回车键。
在这里,它允许你将日期和时间放置在左右两列中,你可以使用向上和向下的方向键更改列的顺序。
所以我将日期和时间指标放在最后一个样式选项中(你可以使用空格键更改样式):

完成日期和时间指标的对齐后,按回车键保存更改,然后按 `F10` 关闭设置提示。
### 总结
在本指南中,我解释了如何在不同的 Linux 发行版中安装 `htop` 实用程序,以及如何使用 `htop` 的一些基本功能来有效的管理系统资源。
但是 `htop` 可以做更多的事情,要了解更多信息,你可以随时参考它的手册页,我们有一个详细的指南,告诉你如何 [在 Linux 中充分利用手册页](https://linuxhandbook.com/man-pages/)。
---
via: <https://itsfoss.com/use-htop/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Windows has its famous task manager. Linux has several GUI and [command line system monitors](https://itsfoss.com/linux-system-monitoring-tools/). Every Linux system comes with a couple of them.
On the command line, the top command is perhaps the goto command for checking the system resource utilization quickly.
[Using top command](https://linuxhandbook.com/top-command/?ref=itsfoss.com) apart from viewing the processes could be tricky. And this is where htop tops top. Pun aside, htop is a top-like utility but with a better and user-friendly interface.
In this guide, I will be showing you how you can install and use htop in Linux.
## Install htop utility in Linux
You won’t find htop pre-installed on the majority of Linux distributions but being one of the most popular utilities, you will find htop in default repositories of almost every Linux distro.
So if your machine is powered by something that is based on Debian/Ubuntu, the following command should get your job done:
`sudo apt install htop`
Similarly, if you’re on Fedora, you can use the given command:
`sudo dnf install htop`
And there’s also a snap package available if you like to avoid building packages from the source:
`sudo snap install htop`
If you’re on something else or want to build from a source, you can always refer to [htop’s GitHub page](https://github.com/htop-dev/htop?ref=itsfoss.com) for detailed instructions.
Once you’re done with the installation, you just have to use the htop command in the terminal, and it will reflect all the ongoing processes in your system:
`htop`
In htop, there is a color coding for the individual section, so let’s have a look at what each color indicates while using htop.
#### What different colors and statistics indicate in htop
So let’s start with the CPU usage bar, as it utilizes the maximum number of colors.
### CPU usage bar

**Green:**Resources consumed by user processes.**Blue:**Indicates low-priority threads.**Red:**CPU resources used by system (kernel) processes.**Aqua blue:**Indicates virtualized processes.
### Memory bar

**Green:**Memory being utilized by system processes.**Blue:**Memory used by buffer pages.**Orange:**Memory allocated for cache pages.
### Statistics

**Tasks: 166**shows there is a total of 166 ongoing processes.**1249 thr**indicates that those 166 processes are handled by 1249 threads.**1 running**indicates that from those 166 processes, only one task is in a state of running.**The load**average indicates the average system load over a period of time. Since my system is Hexa-Core, anything under 6.0 is ok. This number may exceed, such as 6.1, so the upcoming processes have to wait for ongoing tasks to be completed.**1.86**is the average load for the last minute.**1.75**is the average load for the last 4 minutes.**1.47**is the average load for the last 15 minutes.**Uptime**tells how long the system has been running since last reboot.
Now, let’s jump to the actual implementation part.
## How to use htop in Linux
As the htop is mainly used to check for system resources, let’s have a look at how you can sort the processes based on resource consumption.
### Sort processes based on Resource Consumption
The easiest way to sort processes based on CPU and memory usage is to use your mouse pointer. Hover the cursor over the CPU or Memory section and click on any of those.
And there you will see an icon of a triangle `△`
and based on that you can sort the process based on highest to lowest resource consumption:
But if you are dealing with remote servers, you might not have the privilege to use a mouse and in those cases, you can use keyboard shortcuts.
Press **F6** and it will bring up every option available to sort the ongoing processes:
You can use arrow keys to select a preferred sorting option and then press the Enter key, results should reflect as intended.
### Search for a specific process
If you want to look for a specific process and its resource consumption, you can press **F3** and it will get you a search prompt as shown below:
For example, I searched for htop, and it highlighted the process with light orange color. And you can press **F3** for the next result.
### Filter ongoing processes
While searching may get you the intended results, I find the filtering process using keywords even more effective as it presents a list of processes.
To filter processes, you have to press **F4** and type the name of the process. For example, I filtered processes related to gnome-boxes:
### Kill process
Once you made it to find the most resource-hungry and unnecessary process, you just have to press **F9**, and it will present you with termination signals:
I can’t cover all 15 termination signals, we have a separate guide on [different termination signals](https://linuxhandbook.com/termination-signals/?ref=itsfoss.com), so you can refer to that guide if you intend to learn more about them.
But I will recommend you use SIGTERM first, as it is the most efficient and friendly way to kill the process.
### Customize htop
Here, my aim is to add a date and time and change the color scheme to monochrome.
First, press **F2**, and it will being setup prompt allowing users to change how htop looks:
First, hover to the `Colors`
sections and press Enter and it will allow us to change the color scheme. From there, select the Monochrome option and press Enter to save changes:
Now, go back to the setup option, and from there, use the left arrow key to explore available meters:
As I intend to add the Date and time, I have to press Enter once I find the option for it.
Here, it will allow you to place the date and time in any of the left and right columns and you can use the up and down arrow keys to change the order of columns.
So I placed the date and time meter with the last styling option (you can change styles using the spacebar):
Once you are done aligning the date and time meter, press the enter key to save changes and **F10** to close the setup prompt.
## More than htop?
htop is good. But there are other similar tools that might be better than it. Check them out if you want to.
[5 htop Alternatives to Monitor Your Linux SystemLooking for htop alternatives? Here are a few good options to monitor the system usage in real-time in Linux.](https://itsfoss.com/htop-alternatives/)

In this guide, I explained how you can install the htop utility in different Linux distributions and how you can use some basic functionalities of htop to manage system resources efficiently.
But htop can do a lot more and for that and to learn more, you can always refer to its man page, and we have a detailed guide on [how you can get the most out of the man page in Linux](https://linuxhandbook.com/man-pages/?ref=itsfoss.com). |
15,627 | R Markdown 语法新手指南 | https://itsfoss.com/r-markdown/ | 2023-03-15T09:09:00 | [
"Markdown"
] | https://linux.cn/article-15627-1.html | 
你可能已经了解过轻量级标记语言 Markdown。如果你是第一次接触这个概念,请参考我们的 [Markdown 指南](https://itsfoss.com/markdown-guide/)。概括来讲,它是一种用于创建纯文本文档的简单又高效的语言。
然而,Markdown 在制作详细的报告或技术文件方面可能还不够完善。
受益于 [knitr](https://www.r-project.org/nosvn/pandoc/knitr.html) 和 Pandoc 等软件包,**交互式文件格式 R Markdown** 早在 2014 年就出现了。它将纯文本与内嵌的 R 代码相结合,可以制作动态文件。
你可以使用 [各种 IDE](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) 和扩展来创建 R Markdown 文档,官方 IDE 为 **RStudio**。因此,在这篇文章中,我们将重点介绍**使用 RStudio 学习 R Markdown 语法**。
>
> ?(假如你没有了解过,)**R 编程语言** 是一种用于统计计算、图形表示和报告的语言。
>
>
>
### 配置 RStudio
通过合适的配置,你可以很轻松地用 RStudio 来编写 R Markdown。只需要安装一个软件包,就已经完成了大部分的工作!
安装 RStudio 后,在 “<ruby> 工具 <rt> Tools </rt></ruby>” 菜单中选择 “<ruby> 安装软件包 <rt> Install Packages </rt></ruby>” 选项。

在弹出的对话框中,搜索 “rmarkdown” 并安装。

>
> ? 如果你想使用类似 Python 的代码块,你需要安装额外的包。当你想在你的文档中包含这些包时,RStudio 会提示你安装所需的包。
>
>
>
安装完成后,你可以通过选择 “<ruby> 文件 <rt> File </rt></ruby> > <ruby> 新建文件 <rt> New File </rt></ruby> > R Markdown” 来新建一个 R Markdown 文档。

之后会提示你添加一些关于文件的信息(文件的元数据),把这些填上就可以了。

或者你可以创建一个空的文件从零开始。
### RMarkdown 语法
由于它是 “加强版的 Markdown”,因此大多数语法与 Markdown 是一样的。
它还有一些 Markdown 支持不完善的东西,比如**表格、数学方程式、代码块等等**。
下面是我们要介绍的内容的概括:
| RMarkdown 块名 | 语法 |
| --- | --- |
| 标题 | `# 一级标题``## 二级标题``### 三级标题``一级标题``=======``二级标题``-------` |
| 着重 | `*斜体*``_斜体_``**加粗**``__加粗__` |
| 列表 | 无序列表:`* 列表项``* 列表项``+ 子项``+ 子项`有序列表:`1. 列表项``2. 列表项``+ 子项``+ 子项` |
| 代码块 | 普通代码块:``````这里写代码``````R 代码块:````{r}``R 代码``````你也可以用其他的语言`行内 `代码`` |
| 链接 | 普通链接:粘贴 URL带标题的链接:`[显示的文本](URL_地址)`跳转到锚点: `[显示的文本](#锚点)` |
| 表格 | `| 列名 | 列名 | 列名 |``| ------ | ------ | ------ |``| 项内容 | 项内容 | 项内容 |``| 项内容 | 项内容 | 项内容 |` |
| 方程式 | 行内方程式 `$Equations$`展示方程式: `$$Equations$$` |
| 图片 | 无标题: ``有标题:`` |
| 引用块 | `> 输入你引用的内容` |
| 其他 | 上角标:`文本内容^上角标^`章或页水平分割线`=========` 或 `----------`行尾输入两个以上空格,即可添加人工行分割 |
#### YAML 头
在一个 R Markdown 文档的顶部,有一个 YAML 头,被两行 `---` 包围。这个块定义了文档的最终样式,通常包含一个标题、作者、日期和你想输出的文件类型。
支持的文件格式有三种:**HTML、PDF 和 Word**。
```
---
title: "Sample"
author: "It's FOSS"
date: "2023-02-08"
output: pdf_document
---
```
这可以在 RStudio 中设置新文件时添加,如上节所示。
#### 标题
在 R Markdown 中,有两种方法指定标题。我们可以使用 `#` 字符来表示不同级别的标题,比如:
```
# Heading Level 1
## Heading Level 2
### Heading Level 3
#### Heading Level 4
##### Heading Level 5
###### Heading Level 6
```
也可以用 `=` 和 `-` 分别表示一级和二级标题。
```
一级标题
===============
二级标题
---------------
```

#### 列表
有两种列表,一种是**无序列表**,用点句符来表示:
```
* Item 1
* Item 2
+ Sub 1
+ Sub 2
* Item 3
```
另一种是**有序列表**,用数字来排序:
```
1. Item 1
2. Item 2
+ Sub 1
+ Sub 2
3. Item 3
```

#### 段落中的文本格式
格式化文本有几种方式。

你可以使用斜体或加粗来着重表示文本:
* 斜体:在文本前后各输入一个星号或下划线
* 加粗:在文本前后各输入两个星号或下划线
```
*这里是斜体内容*
_这里是斜体内容_
**这里是加粗内容**
__这里是加粗内容__
```
>
> ? 你可以阅读我们的文章 [Markdown 中怎么让内容变成加粗和斜体](https://itsfoss.com/markdown-bold-italic/) 来了解更多内容。
>
>
>
如果你想使用上角标,在想变成上角标的内容前后加上 `^` 符号。
```
普通文本内容^上角标^
```
如果你想对文本内容加删除线,在文本前后加 `~~` 符号。
```
~~被删除的内容~~
```

#### 添加代码块
内嵌代码是 R Markdown 最主要的设计目的。我们有几种添加代码的方式。
##### 添加普通代码块
如果你想添加一个代码块来与其他的文本进行区分,可以使用下面的语法:
```
```
这里输入你的代码
```
```
你也可以尝试 [对添加的代码进行高亮显示](https://itsfoss.com/markdown-code-block/)。
如果你想添加代码并将其输出嵌入到文档中,你可以在后面加上语言,并用大括号包裹:
```
```{语言}
这里输入你的代码
```
```
你可以用 ``` 符号来添加行内代码。
```
这里是 `行内代码`
```
它看起来是这样的:

#### 链接
如果想添加普通文本链接,把它粘贴到行内就可以了。
```
https://itsfoss.com
```
添加超链接,使用下面的语法:
```
[文本内容](URL 地址)
```
当你想链接到本页内的某个锚点时,使用下面的语法:
```
[文本内容](#锚点名称)
```

#### 表格
表格的语法与 Markdown 相似:
```
| 列表 | 列表 | 列表 |
| --- | --- | --- |
|表格项|表格项|表格项|
|表格项|表格项|表格项|
```

>
> ? 还想了解更多?请阅读我们的 [用 Markdown 创建表格](https://itsfoss.com/markdown-table/) 指南。
>
>
>
#### 图片
添加图片使用下面的语法:
```

```
或
```

```

#### 块引用
RMarkdown 可以添加块引用。在被引用的行或段落前添加 `>`(大于号)。
```
这里是普通文本内容。
> 这里是块引用
```

>
> ? 如果你想了解更多块引用的内容,请阅读我们的 [Markdown 引用](https://itsfoss.com/markdown-quotes/) 指南。
>
>
>
#### 方程式
你可以用 RMarkdown 来添加方程式和展示复杂的 LaTex 方程式。
例如:
```
行内方程式:$Equation$
展示方程式:$$Equation$$
```

#### 章或页水平分割线
使用三个以上星号或减号来添加章或页水平分割线。
```
************
------------
```
你可以在行尾添加两个以上的空格来添加人工行分割。
### R Markdown 非常有用(备忘录)

>
> **[R Markdown 备忘录.pdf 下载文档](https://itsfoss.com/content/files/2023/02/R-Markdown-Cheat-Sheet.pdf)**
>
>
>
*? 你还知道其他关于 R Markdown 的内容吗?请在下面的评论区告诉我们。*
---
via: <https://itsfoss.com/r-markdown/>
作者:[Sreenath](https://itsfoss.com/author/sreenath/) 选题:[lkxed](https://github.com/lkxed/) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You probably already know about the lightweight Markdown markup language. Refer to our [Markdown guide](https://itsfoss.com/markdown-guide/), if you're new to the concept. Overall, it is a simple and effective language for creating plain-text documents.
However, Markdown may not be enough to make detailed reports or technical documents.
Hence, **R Markdown** as an **interactive file format** came into existence back in 2014 thanks to packages like [knitr](https://www.r-project.org/nosvn/pandoc/knitr.html) and [Pandoc]( knitr, and Pandoc). It combines plain text with in-line R code, helping you make a dynamic document.
To create R Markdown documents, you can use [various IDEs](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) and extensions to make it possible. However, the official IDE that helps you do it is **RStudio**. So, in this article, we will focus on **learning R Markdown syntax using RStudio**.
**R programming language**is used for statistical computing, graphics representation, and reporting.
**Suggested Read 📖**
[How to Install and Use R on UbuntuBrief: This tutorial teaches you to install R on Ubuntu. You’ll also learn how to run your first R program in Ubuntu using various methods. R, together with Python, is the most commonly used programming language for statistical computing and graphics, making it easy to work with data. With](https://itsfoss.com/install-r-ubuntu/)

## Setting RStudio
RStudio makes it easy to work with R Markdown by its setup process. You just need to install a package, and you are done for the most part!
Once you have RStudio installed, head to the Tools menu and select the *Install Packages* option.
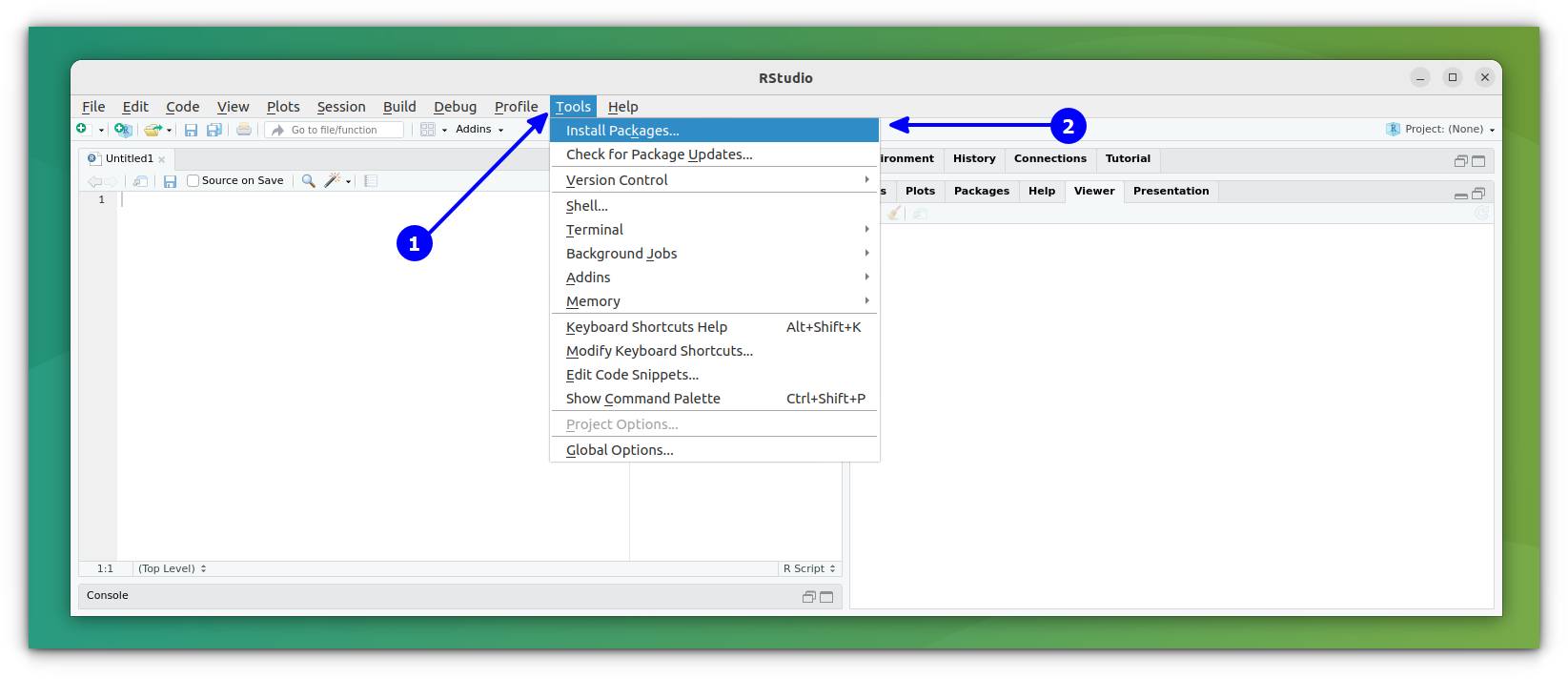
*Select Install Packages option under Tools menu (click to enlarge image)*
On the new dialog box, search for rmarkdown and install it.
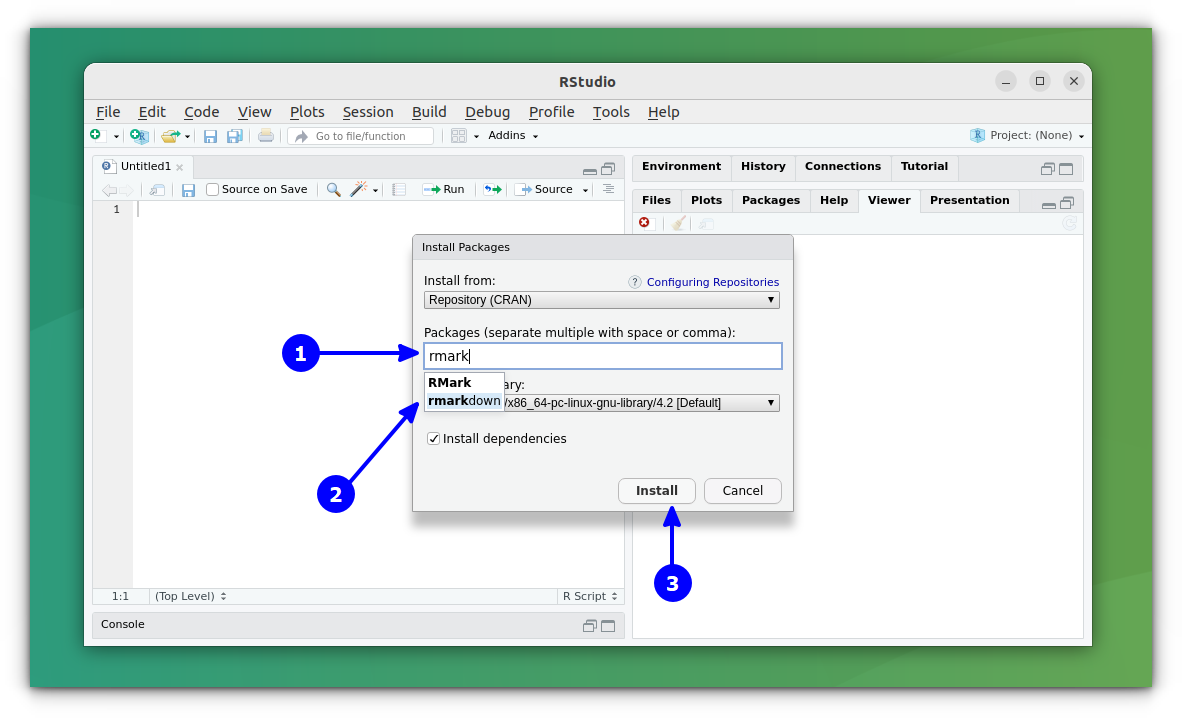
*Install RMarkdown Package (click to enlarge image)*
Once installed, you can start a new rmarkdown document by selecting **File > New > RMarkdown**.
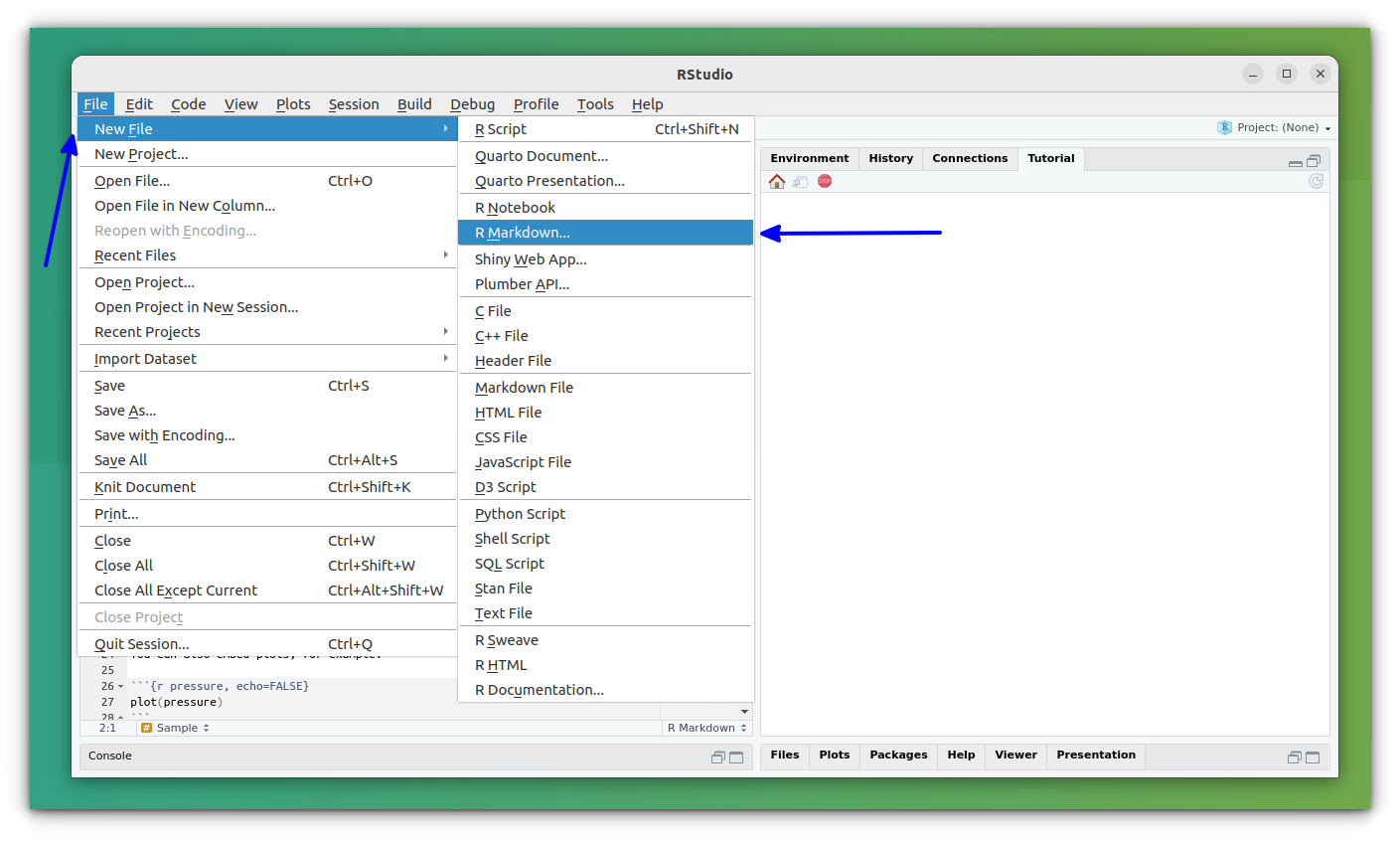
*Create a new RMarkdown Document (click to enlarge image)*
This will prompt you to add some information regarding the document (metadata for the file). Fill those up.
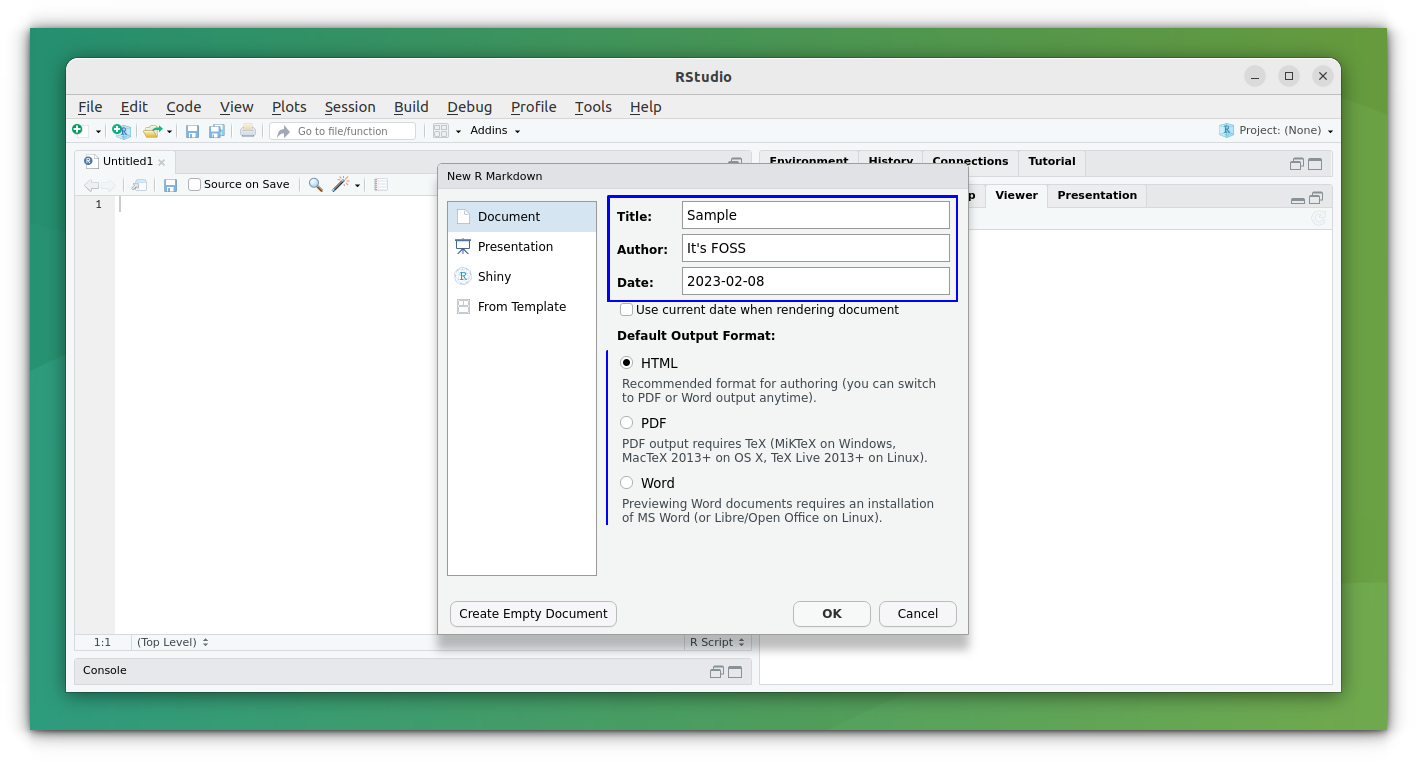
*New document in rmarkdown (click to enlarge image)*
Or you can create an empty document to start fresh.
## RMarkdown Syntax
Since it is just "**enhanced Markdown**," most syntax remains the same.
There would be some differences when you add things not usually supported with Markdown, like **tables, math equations, code chunks, etc.**
Here's a quick summary of what we will be covering:
Name of the RMarkdown Block | Proper Syntax |
---|---|
Heading | # Level 1 ## Level 2 ### Level 3 Level 1 ======= Level 2 ------- |
Emphasis | *Italics* _Italics_ **Bold** __Bold__ |
List | Unordered List * Item * Item + Sub + Sub Ordered List 1. Item 2. Item + Sub + Sub |
Code Chunk | Normal Code Block ``` Code Goes Here ``` R Code Block ```{r} R CODE ``` You can use other languages also. Inline `code` |
Links | Plain Link: Paste the URL Link with Caption: [Text](URL_Address) Link to a section: [Text](#Name-of-section) |
Table | | Column | Column | Column | | ------ | ------ | ------ | | Item | Item | Item | | Item | Item | Item | |
Equations | In line Equations: $Equations$ Display Equations: $$Equations$$ |
Images | Without Caption:  With Caption :  |
Block Quotes | > Type your Block Quotes |
Misc | Super Script : Text^Superscript^ Horizontal rule or Page Break: ========= or ---------- For Manual Line break, end line with 2+ spaces |
### The YAML Header
At the top of a Rmarkdown document, there is a YAML header enclosed within two `---`
. This block usually contains a title, author, date, and the file type you want to output, defining the **final look of the document.**
The file type is either **HTML, PDF, or Word.**
```
---
title: "Sample"
author: "It's FOSS"
date: "2023-02-08"
output: pdf_document
---
```
This can be added while setting the new document in RStudio, which is shown in the above section.
### Heading
In R Markdown, we can give heading in two different methods. Either we can use the # character for different levels of heading like:
```
# Heading Level 1
## Heading Level 2
### Heading Level 3
#### Heading Level 4
##### Heading Level 5
###### Heading Level 6
```
Or, `=`
and `-`
for level 1 and 2 headings, respectively.
```
Level 1 Heading
===============
Level 2 Heading
---------------
```
### Lists
There are two types of Lists, the first one is an **Unordered list**, or you could call them bullet points:
```
* Item 1
* Item 2
+ Sub 1
+ Sub 2
* Item 3
```
And the second one is the **Ordered list**, which is the numbered type:
```
1. Item 1
2. Item 2
+ Sub 1
+ Sub 2
3. Item 3
```
**Suggested Read 📖**
[Read and Organize Markdown Files in Linux Terminal With GlowGlow is a CLI tool that lets you render Markdown files in the Linux terminal. You can also organize Markdown files with it.](https://itsfoss.com/glow-cli-tool-markdown/)

### Format text within a paragraph
There are several ways to format text.
You can add emphasis to the text like italics or bold using:
- Italics: Place the text in between single asterisks or single underscore
- Bold: Place the text in between double asterisks or double underscores.
```
*This is Italicized text*
_This is Italicized text_
**This is Bold Text**
__This is Bold Text__
```
You can explore on this using our resource on [how to add bold and italic text in Markdown](https://itsfoss.com/markdown-bold-italic/).
If you want to add superscript to a text, place the text that should be superscript in between `^`
symbol.
`Normal Text^super_script^`
Or, if you want to add text strike-through, place the text in between two `~~`
symbol.
`~Strike Through this~~`
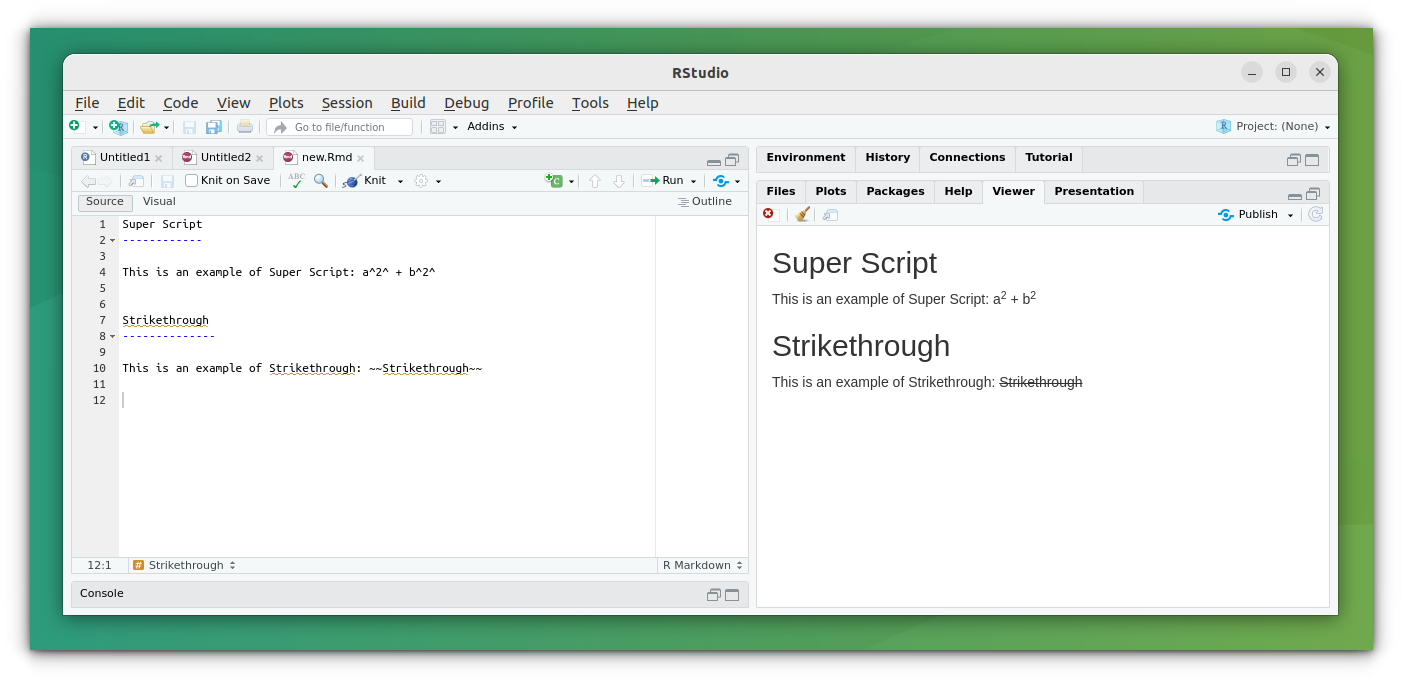
### Adding Code Chunks
Embedding code is the primary purpose of R Markdown. It allows us to add codes in several ways.
**Adding Normal code block.**
If you want to add a normal code block to separate it from other text, use the syntax below:
```
```
Your Code Goes Here
```
```
You can also try [adding code blocks with syntax highlighting](https://itsfoss.com/markdown-code-block/).
You should append the language in curly braces if you want to add code and embed its output to the document:
```
```{Language}
Your Code Goes Here
```
```
Or, you can add inline codes by placing the respective text between ` symbols.
` The `code` is a code`
Here's how it should look like:
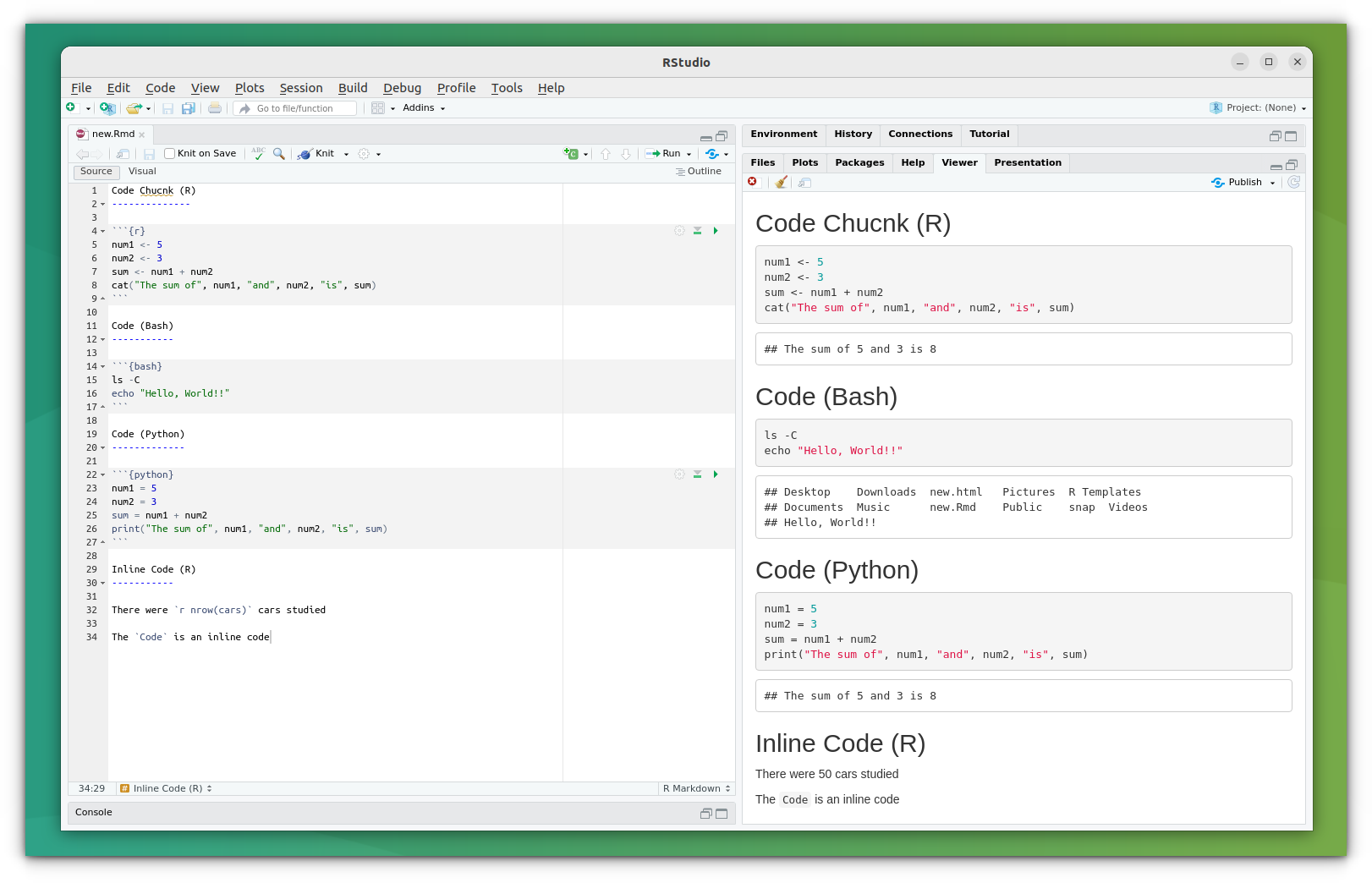
### Links
To add a link as plain text, just paste the link as it is in a line.
`https://itsfoss.com`
Or, to make a text hyperlink, use the syntax:
`[Text](URL Address)`
Another way to add a link is, when you want to link to a section of the page. In this case, use the syntax:
`[Text](#Name-of-section)`
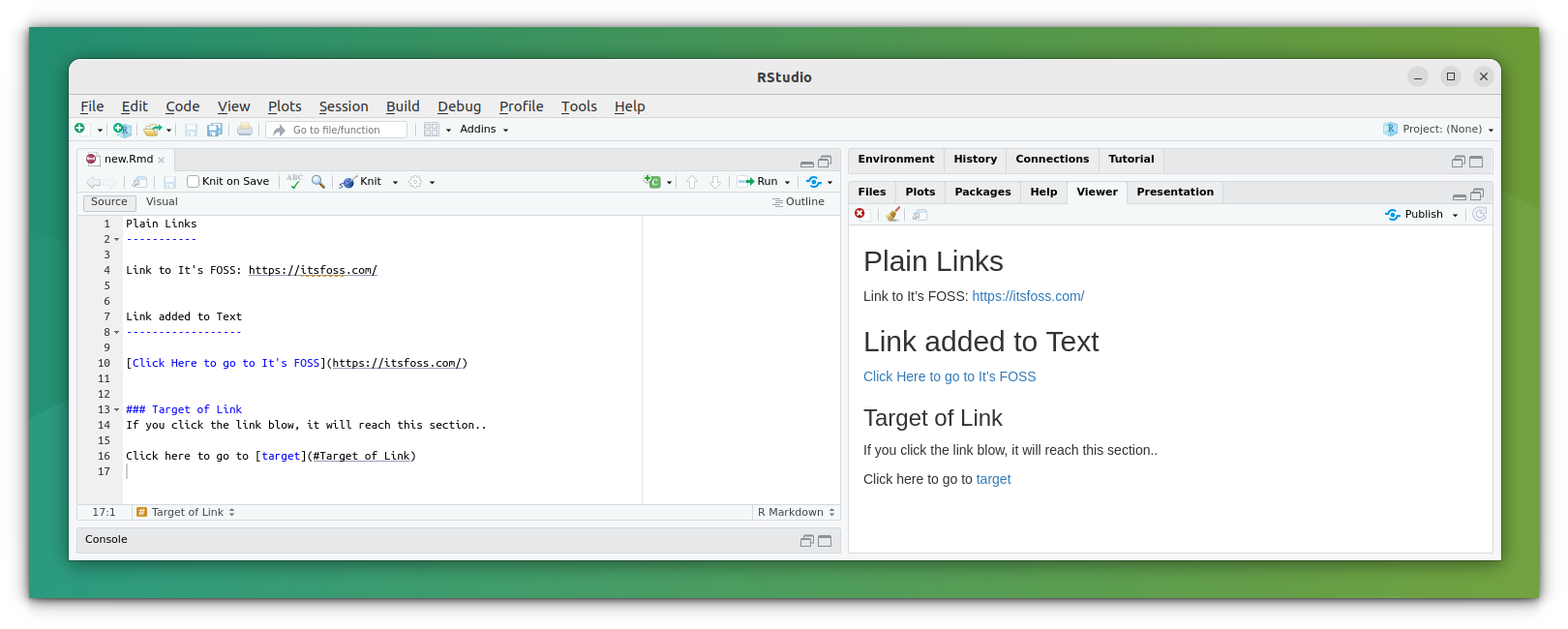
### Tables
The syntax for adding tables is similar to that of markdown.
```
|Column|Column|Column|
| --- | --- | --- |
|Item|Item|Item|
|Item|Item|Item|
```
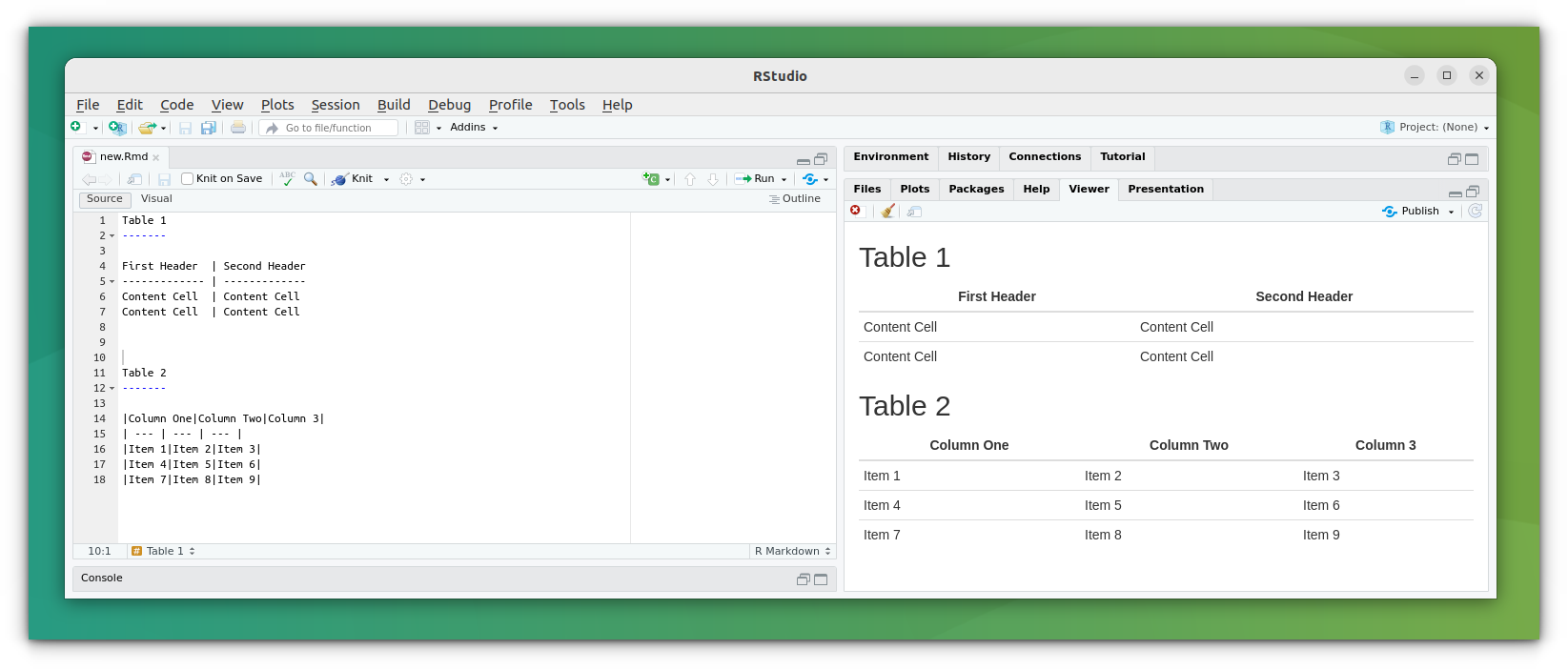
[creating tables in Markdown](https://itsfoss.com/markdown-table/).
### Images
To add an image, use the syntax:
```

OR

```
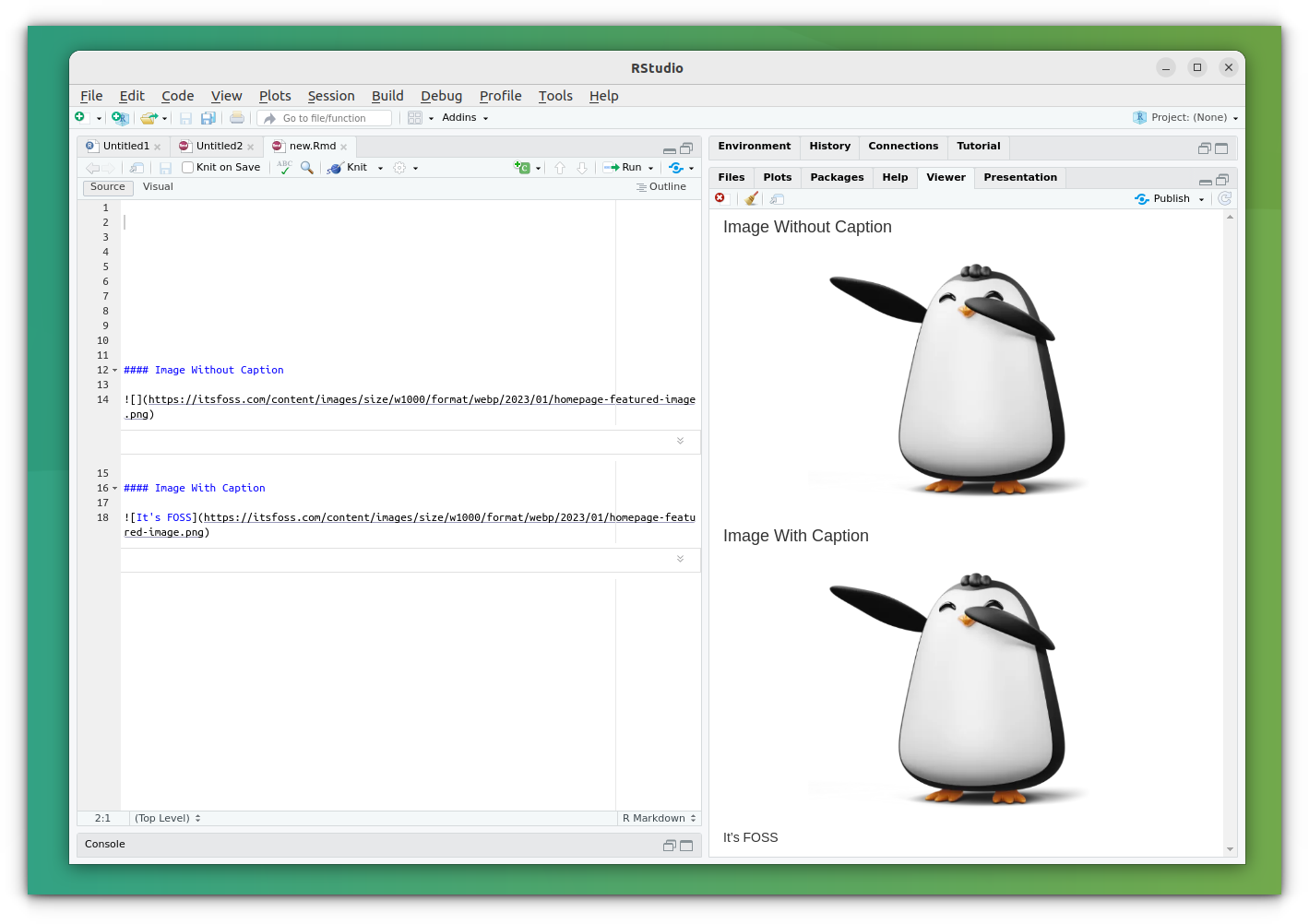
### Block Quotes
RMarkdown allows you to add block quotes. To use this, use the **> (greater than)** symbol in front of the line/paragraph you want to quote.
```
This is a normal text
> This is a Block Quote
```
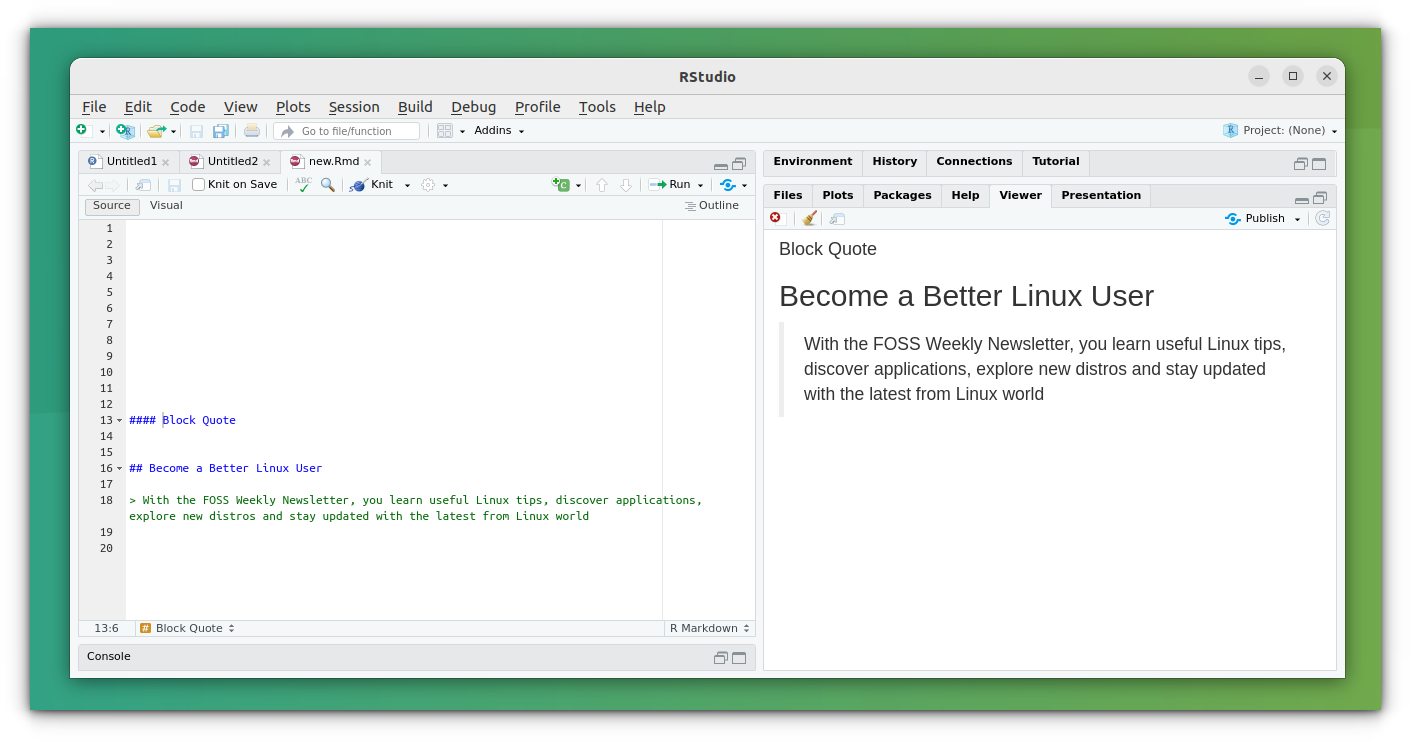
If you want to explore more use cases of blockquote, head to our [Markdown quotes](https://itsfoss.com/markdown-quotes/) guide.
### Equations
Using RMarkdown, you can add either equations or display complex LaTex equations.
For example:
```
In line Pythagorean Theorem: $Equation$
Display Equation: $$Equation$$
```
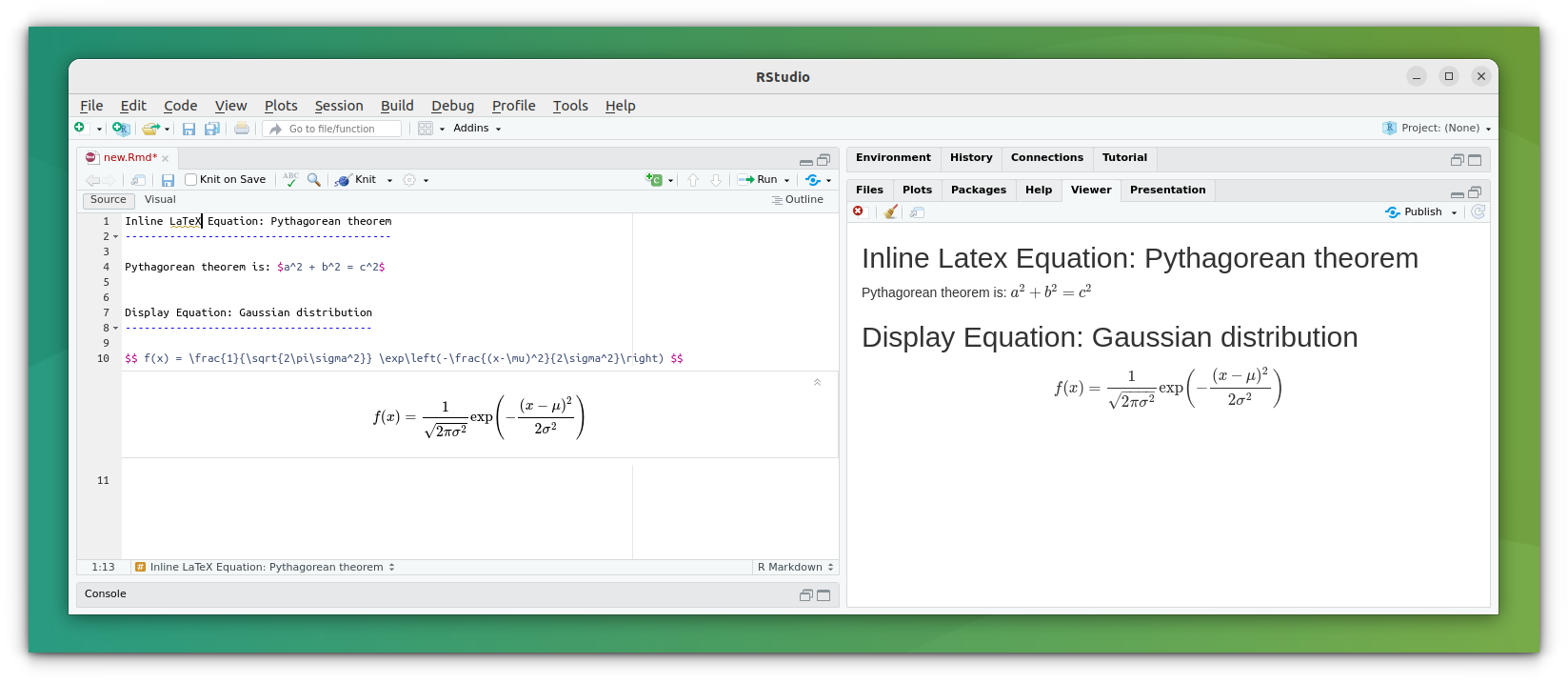
### Horizontal Rule / Page Break
Use three or more asterisks or dashes to add a horizontal rule /page break.
```
************
------------
```
If you want to add a manual line break, end that line with two or more spaces.
## Summary
## R Markdown is Useful (Cheat Sheet)
Whether you are working with scientific reports or want to create any other type of dynamic document, R Markdown is your best bet to make the most out of Markdown.
Here's a cheat sheet to help you summarize it all:

*💬 Did we miss something that you use with R Markdown? Share your thoughts in the comments down below.* |
15,628 | 把你的网盘从 iCloud 换成 Nextcloud | https://opensource.com/article/23/3/switch-icloud-nextcloud | 2023-03-15T15:30:00 | [
"Nextcloud",
"iCloud"
] | https://linux.cn/article-15628-1.html | 
>
> Nextcloud 是你自己的开源云。这里是如何进行转换的方法。
>
>
>
如果你对把数据提交给公司控制的云服务持谨慎态度,但同时又喜欢远程存储的便利性和基于 Web 的轻松访问,那么不止你是这样。云端因其广泛的功能而广受欢迎。但是 [云端服务不一定是封闭的](https://opensource.com/article/20/10/keep-cloud-open)。幸运的是,开源项目 Nextcloud 提供了个人和私有的云应用程序套件。
[安装](https://opensource.com/article/21/1/nextcloud-productivity) 和导入数据很容易 —— 包括通讯录、日历和照片。真正难办的是从 iCloud 等云提供商那里获取数据。在本文中,我将告诉你把自己的数据迁移到 Nextcloud 需要采取的步骤。
### 把你的数据迁移至 Nextcloud
和在 [安卓设备](https://opensource.com/article/23/3/switch-google-nextcloud) 上一样,首先你必须将现有数据从苹果的 iCloud 传输到 Nextcloud。然后,你可以为你的苹果设备设置两个新帐户,以完全自动同步通讯录和预约。苹果支持用于日历同步的 CalDAV 和用于通讯录同步的 CardDAV 开放协议,因此你甚至不需要安装额外的应用。
要导出你的通讯录,你可以在 iPhone 或者 iPad 上打开 “<ruby> 通讯录 <rt> Contacts </rt></ruby>” 应用或在网络浏览器中登录 iCloud:
* 选择要传输到 Nextcloud 的所有地址簿条目,然后选择 “<ruby> 文件 <rt> File </rt></ruby> > <ruby> 输出 <rt> Export </rt></ruby> > <ruby> 输出 vCard <rt> Export vCard </rt></ruby>” 以在本地磁盘上保存 .`vcf` 文件。
* 将 .`vcf` 文件导入 Nextcloud。为此,请选择 “<ruby> 通讯录 <rt> Contacts </rt></ruby>” 应用,点击左下角的 “<ruby> 设置 <rt> Settings </rt></ruby>” 并选择 “<ruby> 导入通讯录 <rt> Import contacts </rt></ruby>” 按钮。 在接下来的对话窗口中,点击 “<ruby> 选择本地文件 <rt> Select local file </rt></ruby>”,然后打开之前保存的 vCard。
要在你的 iPhone 或 iPad 上设置 CardDAV 帐户,请转至 “<ruby> 设置 <rt> Settings </rt></ruby> > <ruby> 通讯录 <rt> Contacts </rt></ruby> > <ruby> 帐户 <rt> Accounts </rt></ruby> > <ruby> 添加帐户 <rt> Add Account </rt></ruby>”:
* 选择 “<ruby> 其他 <rt> Other </rt></ruby>”,然后选择 “添加 CardDAV 帐户”。 在 “<ruby> 服务器 <rt> Server </rt></ruby>” 字段中,输入 Nextcloud 的 URL(例如,`https://nextcloudpi.local`)。 下面是 Nextcloud 帐户的用户名和密码。 打开新帐户的 “<ruby> 高级设置 <rt> Advanced Settings </rt></ruby>”。
* 确保启用了 “<ruby> 使用 SSL <rt> Use SSL </rt></ruby>” 选项。帐户 URL 通常设置正确。其中包含你的 Nextcloud 的主机名和你的用户名。
要在 macOS 上创建用于同步地址簿的新帐户,请打开 “<ruby> 通讯录 <rt> Contacts </rt></ruby>” 应用程序并从 “<ruby> 通讯录 <rt> Contacts </rt></ruby>” 菜单中选择 “<ruby> 添加帐户 <rt> Add Account </rt></ruby>”。 激活复选框 “<ruby> 其他通讯录账号 <rt> Other Contacts Account </rt></ruby>” 并单击 “<ruby> 继续 <rt> Continue </rt></ruby>”。你可以接受 “CardDAV” 条目。 在 “<ruby> 账户类型 <rt> Account Type </rt></ruby>” 下拉菜单中,选择 “<ruby> 手动 <rt> Manual </rt></ruby>” 输入。

输入你的 Nextcloud 用户名、密码和服务器地址。当前的 macOS 版本要求你在服务器地址中指定端口 443(用于 SSL)。例如,如果你的 Nextcloud 地址是 `https://nextcloudpi.local`,用户名是 `hej`,则在栏中输入以下内容:
```
https://nextcloudpi.local:443/remote.php/dav/principals/users/hej
```
### 同步你的日历
导出日历的方法类似,通过日历应用程序,你可以在浏览器、智能手机/平板电脑或 macOS 桌面上使用 iCloud 执行此操作。
首先,将日历设置为 “<ruby> 公共 <rt> public </rt></ruby>”。 这并不意味着每个人都可以访问你的日历。它仅用于生成日历订阅的链接。将 URL 复制到剪贴板。目前还无法将日历直接导入 Nextcloud,因为你不是用一个链接,而是用 .ics 文件(iCalendar)来导入。 以下是如何从链接生成这样的文件:
* 将链接复制到剪贴板
* 将链接粘贴到网络浏览器的地址栏中
* 更改 URL 的开头并将 `webcal` 替换为 `http`
* 按回车键并将 `.ics` 文件保存到你的磁盘上

现在可以导入 .ics 文件了。 先在 Nextcloud 中打开 “<ruby> 日历 <rt> Calendar </rt></ruby>” 应用程序,单击左下方的 “<ruby> 日历设置 <rt> Calendar settings </rt></ruby>”,然后单击 “<ruby> 导入日历 <rt> Import calendar </rt></ruby>”。 选择你保存在文件管理器中的 `.ics` 文件。
对所有 iCloud 日历重复此过程。之后,就该更换旧的 iCloud 同步服务了。
### 同步事件
要与 Nextcloud 同步新事件,请在你的客户端设备(智能手机、平板电脑、台式机)上设置一个新帐户:
* iPhone/iPad:<ruby> 设置 <rt> Settings </rt></ruby> / <ruby> 日历 <rt> Calendar </rt></ruby> / <ruby> 账户 <rt> Accounts </rt></ruby> / <ruby> 添加账户 <rt> Add Account </rt></ruby>,选择 “<ruby> 其他 <rt> Other </rt></ruby>”,然后选择 “<ruby> 添加 CalDAV 账户 <rt> Add CalDAV Account </rt></ruby>”。 在 “<ruby> 服务器 <rt> Server </rt></ruby>” 栏中,输入你的本地 Nextcloud URL,即 `https://nextcloudpi.local`。 你可以看到 Nextcloud 帐户的用户名和密码输入的位置。
* macOS:打开日历应用程序并从 “<ruby> 日历 <rt> Calendar </rt></ruby>” 菜单中选择 “<ruby> 添加账户 <rt> Add Account </rt></ruby>”。 激活复选框 “<ruby> 其他 CalDAV 账户 <rt> Other CalDAV Account </rt></ruby>” 并单击 “<ruby> 继续 <rt> Continue </rt></ruby>”。 从 “<ruby> 账户类型 <rt> Account Type </rt></ruby>” 下拉菜单中,选择 “<ruby> 手动 <rt> Manual </rt></ruby>” 输入。 输入你的 Nextcloud 用户名和密码以及 Nextcloud 服务器地址。不要忘记在服务器地址中指定端口 443(用于 SSL); 否则帐户设置将失败。
**提示:** 除了你的通讯录和日历,如果你想同步其他文件,如文档、照片、视频等,你可以安装苹果应用商店中提供 Nextcloud 应用程序。
本文改编自 Heike Jurzik 的《[树莓派上的 Nextcloud](https://www.amazon.de/-/en/gp/product/B0BTPZH8WT/ref=dbs_a_def_rwt_bibl_vppi_i4)》 一书。
---
via: <https://opensource.com/article/23/3/switch-icloud-nextcloud>
作者:[Heike Jurzik](https://opensource.com/users/hej) 选题:[lkxed](https://github.com/lkxed/) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you're wary of committing your data to cloud services controlled by a corporation but love the convenience of remote storage and easy web-based access, you're not alone. The cloud is popular because of what it can do. But the [cloud doesn't have to be closed](https://opensource.com/article/20/10/keep-cloud-open). Luckily, the open source Nextcloud project provides a personal and private cloud application suite.
It's easy to [install](https://opensource.com/article/21/1/nextcloud-productivity) and import data—including contacts, calendars, and photos. The real trick is getting your data from cloud providers like iCloud. In this article, I demonstrate the steps you need to take to migrate your digital life to Nextcloud.
## Migrate your data to Nextcloud
As with [Android devices](https://opensource.com/article/23/3/switch-google-nextcloud), first you must transfer existing data from Apple's iCloud to Nextcloud. Then you can set up two new accounts for your Apple devices to fully automatically synchronize address books and appointments. Apple supports CalDAV for calendars and CardDAV for contacts, so you don't even need to install an extra app.
To export your address book, you can either open the **Contacts** app on your iPhone/iPad or log into iCloud in your web browser:
-
Select all address book entries you want to transfer to Nextcloud and choose
**File > Export > Export vCard**to save a .`vcf`
file on your local disk. -
Import the .
`vcf`
file into Nextcloud. To do this, select the**Contacts**app, click**Settings**at the bottom left and select the**Import contacts**button. In the following dialogue window, click**Select local file**, and open the previously saved vCard.
To set up a CardDAV account on your iPhone or iPad, go to** Settings > Contacts > Accounts > Add Account**:
-
Select
**Other**and then**Add CardDAV account**. In the**Server**field, enter the URL of Nextcloud (for example,[https://nextcloudpi.local](https://nextcloudpi.local/)). Below this is space for the username and password of the Nextcloud account. Open the**Advanced Settings**for the new account. -
Ensure the
**Use SSL option**is enabled. The account URL is usually set correctly. It contains, amongst other things, the host name of your Nextcloud and your user name.
To create a new account on macOS for synchronizing address books, open the **Contacts** app and select **Add Account **from the **Contacts** menu. Activate the checkbox **Other Contacts Account** and click on **Continue**. You can accept the **CardDAV** entry. In the **Account Type** drop-down menu, select **Manual** entry.
(Heike Jurzik, CC BY-SA 4.0)
Enter your Nextcloud user name, password, and server address. The current macOS version requires you to specify port 443 (for SSL) in the server address. For example, if the address of your Nextcloud is [https://nextcloudpi.local](https://nextcloudpi.local) and the username is hej, then enter the following in the field:
[https://nextcloudpi.local:443/remote.php/dav/principals/users/hej](https://nextcloudpi.local:443/remote.php/dav/principals/users/hej)
## Syncing your calendars
Exporting your calendars works similarly. Through the Calendar app, you can do this with iCloud in the browser, on your smartphone/tablet, or the macOS desktop.
First, set the calendar to **public**. This doesn't mean that everyone can access your calendar. It's only used to generate a link for the calendar subscription. Copy the URL to the clipboard. It's not yet possible to import the calendar directly into Nextcloud because you don't need a link for this, but an `.ics`
file (iCalendar). Here is how to generate such a file from the link:
-
Copy the link to the clipboard
-
Paste the link into the address bar of a web browser
-
Change the beginning of the URL and replace
`webcal`
with`http`
-
Press
**Enter**and save the`.ics`
file on your disk
(Heike Jurzik, CC BY-SA 4.0)
You can now import the `.ics`
file. To do this, open the **Calendar** app in Nextcloud, click **Calendar settings** at the bottom left and then **Import calendar**. Select the `.ics`
file you saved in the file manager.
Repeat this process for all iCloud calendars. After that, it's time to replace the old iCloud synchronization service.
## Synchronizing events
To synchronize new events with Nextcloud, set up a new account on your client devices (smartphone, tablet, desktop):
-
**iPhone/iPad:**and then choose*Settings*/*Calendar*/*Accounts*/*Add Account*, select*Other***Add CalDAV Account**. In the**Server**field, enter your local Nextcloud URL, which is`https://nextcloudpi.local`
. You can see a space for the username and password of the Nextcloud account. -
macOS: Open the Calendar app and select
**Add Account**from the**Calendar**menu. Activate the checkbox**Other CalDAV Account**and click**Continue**. From the**Account Type**drop-down menu, select**Manual**entry. Enter your Nextcloud username and password as well as the Nextcloud server address. Don't forget to specify the port 443 (for SSL) in the server address; otherwise the account setup will fail.
**Tip:** If you want to synchronize other files like documents, photos, videos, and so on, in addition to your contacts and calendars, you can install the Nextcloud app offered in the App Store.
This article has been adapted from Heike Jurzik's book, [Nextcloud on the Raspberry Pi](https://www.amazon.de/-/en/gp/product/B0BTPZH8WT/ref=dbs_a_def_rwt_bibl_vppi_i4).
## Comments are closed. |
15,630 | 如何在 RHEL 8 上安装 MiniKube | https://www.linuxtechi.com/install-minikube-on-rhel-rockylinux-almalinux/ | 2023-03-15T23:17:00 | [
"Kubernetes",
"MiniKube"
] | https://linux.cn/article-15630-1.html | 
>
> 在这篇文章中,我们将逐步介绍如何在 RHEL 8、Rocky Linux 8 或 AlmaLinux 8 上安装 MiniKube。
>
>
>
MiniKube 是一个跨平台的开源工具,可以让你在本地机器上部署单节点 Kubernetes 集群。
Kubernetes,也被称为 k8s,或简称 Kube,是一个开源的容器编排平台,用于容器的自动化扩展和部署。MiniKube 集群帮助开发人员和管理员在集群中构建他们的测试环境。
##### MiniKube 的先决条件
* 最小化安装的 RHEL 8 或 Rocky Linux 8 或 AlmaLinux 8
* 本地配置的 RHEL 8 仓库或订阅
* 至少 2GB RAM 和 2 个 vCPU
* 20GB 硬盘空间
* 具有管理员身份的 sudo 用户
* 稳定的互联网连接
* Docker 或虚拟机管理器,如 VirtualBox、KVM 和 VMware 等
在这篇文章中,我们将使用 Docker 作为 MiniKube 的驱动程序。满足所有先决条件后,现在是时候卷起袖子动手了。
### 步骤 1)启用官方 Docker 仓库
要启用 Docker 官方仓库,运行:
```
$ sudo dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo
$ sudo dnf repolist
```

### 步骤 2)安装 Docker CE(社区版)
运行以下 `dnf` 命令来安装 Docker 及其依赖项:
```
$ sudo dnf install docker-ce docker-ce-cli containerd.io -y
```
输出:

安装 Docker 后启动并启用它的服务,运行以下 `systemctl` 命令:
```
$ sudo systemctl start docker
$ sudo systemctl start docker
```
允许你的本地用户在没有 `sudo` 的情况下运行 `docker` 命令,运行:
```
$ sudo usermod -aG docker $USER
$ newgrp docker
```
### 步骤 3)安装 kubectl 二进制文件
`kubectl` 是一个命令行工具,它通过 API 与 Kubernetes 集群进行交互。我们使用 `kubectl` 部署应用。默认情况下,`kubectl` 不包含在 RHEL 8 、Rocky Linux 8 或 AlmaLinux 8 软件包仓库中。因此,我们将使用下面的命令手动安装它:
```
$ curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
$ sudo cp kubectl /usr/local/bin/ && sudo chmod +x /usr/local/bin/kubectl
$ kubectl version --client
```
以上命令的输出如下所示:

### 步骤 4)下载 MiniKube 二进制文件并启动集群
安装 `kubectl` 后,让我们使用以下命令下载并安装 MiniKube 二进制文件:
```
$ curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
$ sudo install minikube-linux-amd64 /usr/local/bin/minikube
```
现在使用下面的命令启动 MiniKube 集群:
```
$ minikube start --driver docker
```

上面的输出确认 `minikube` 命令已经使用 `docker` 作为驱动程序启动了单节点 Kubernetes 集群。
运行下面的 `minikube` 命令来验证本地 Kubernetes 集群的状态:
```
$ minikube status
minikube
type: Control Plane
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
$
$ minikube ip
192.168.49.2
$
```
要停止 MiniKube 集群,请执行:
```
$ minikube stop
```
执行 `kubectl` 命令查看集群和节点信息:
```
$ kubectl cluster-info
$ kubectl get nodes
```

### 步骤 5)测试和验证 Kubernetes 集群
为了测试 Kubernetes 集群,让我们尝试使用 echo 服务器镜像创建 k8s 部署,它相当于 HTTP Web 服务器并将其作为服务暴露在端口 8080 上:
```
$ kubectl create deployment test-minikube --image=k8s.gcr.io/echoserver:1.10
deployment.apps/test-minikube created
$
```
要访问 `test-minikube` 部署,将其公开为服务,运行以下命令:
```
$ kubectl expose deployment test-minikube --type=NodePort --port=8080
service/test-minikube exposed
$
```
运行以下 `kubectl` 命令以获取上面创建的部署、<ruby> 容器荚 <rt> pod </rt></ruby> 和服务信息:
```
$ kubectl get deployment,pods,svc
```

要访问服务,请通过运行下面的命令获取其 URL:
```
$ minikube service test-minikube --url
http://192.168.49.2:32291
$
$ curl http://192.168.49.2:32291/
```

太好了,这意味着我们的 Kubernetes 集群工作正常,因为我们能够访问我们的示例应用。
##### 步骤 6)启用 MiniKube 插件
MiniKube 提供插件,可以为我们的集群添加额外的功能。要列出所有可用的插件,运行:
```
$ minikube addons list
```

Kubernetes 附带一个仪表板,可让你管理集群。在 MiniKube 中,仪表板已作为插件添加。所以要启用它,运行:
```
$ minikube addons enable dashboard
```
还要启用 nginx 入口控制器,运行:
```
$ minikube addons enable ingress
```

要访问仪表板,运行:
```
$ minikube dashbaord --url
```
这将在你系统的浏览器中启动仪表板。

就是这些了。我们已经成功地在 RHEL 8、Rocky Linux 8 或 AlmaLinux 8 上使用 MiniKube 安装了 Kubernetes。欢迎你在下面的评论部分分享你的反馈和意见。
---
via: <https://www.linuxtechi.com/install-minikube-on-rhel-rockylinux-almalinux/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this post, we will cover how to install minikube on RHEL 8, Rocky Linux 8 or AlmaLinux 8 step by step.
[Minikube](https://minikube.sigs.k8s.io/docs/start/) is a cross-platform and open-source tool that makes it possible for you to deploy a single-node Kubernetes cluster on your local machine.
Kubernetes, also known as k8s or simply as Kube, is an open-source container orchestration platform used for the automation scaling and deployment of containers.Minikube cluster helps developers and admins to build their test environment in minikube cluster.
#### Prerequisites of MiniKube
- Minimal Installed RHEL 8 or Rocky Linux 8 or AlmaLinux 8
- Locally Configured Repo or Subscription for RHEL 8.
- Minimum of 2 GB RAM and 2 vCPUs
- 20 GB hard disk space
[Sudo User](https://www.linuxtechi.com/create-sudo-user-on-rhel-rocky-linux-almalinux/)with admin- A stable internet connection
- Docker or virtual machine manager like VirtualBox, KVM,and VMware etc.
In this post, we will be using docker as driver for minikube. With all the prerequisites met, it’s time now to roll up our sleeves and get our hands dirty.
## Step 1) Enable Official Docker Repository
To enable docker official repository run,
$ sudo dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo $ sudo dnf repolist
## Step 2) Install Docker CE (Community Edition)
Run the following dnf command to install docker and its dependencies,
$ sudo dnf install docker-ce docker-ce-cli containerd.io -y
output,
Once docker is installed the start and enable it’s service, run following systemctl commands,
$ sudo systemctl start docker $ sudo systemctl start docker
Allow your local user to run docker commands without sudo, run
$ sudo usermod -aG docker $USER $ newgrp docker
## Step 3) Install Kubectl Binary
Kubectl is a command-line tool which interacts with Kubernetes cluster via APIs. Using kubectl we deploy our applications as deployment. By default, kubectl is not included in RHEL 8 , Rocky Linux 8 or AlmaLinux 8 package repositories. Therefore, we are going to manually install it using beneath commands,
$ curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" $ sudo cp kubectl /usr/local/bin/ && sudo chmod +x /usr/local/bin/kubectl $ kubectl version --client
Output of above commands would be something like below,
## Step 4) Download MiniKube Binary and Start Cluster
After installing the kubectl, let’s download and install minikube binary using the following commands,
$ curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 $ sudo install minikube-linux-amd64 /usr/local/bin/minikube
Now start minikube cluster using the beneath command,
$ minikube start --driver docker
Output above confirms that minikube command has started the single node Kubernetes cluster using docker as driver.
Run below minikube command to verify the status of your local Kubernetes cluster,
[sysops@localhost ~]$ minikube status minikube type: Control Plane host: Running kubelet: Running apiserver: Running kubeconfig: Configured [sysops@localhost ~]$ [sysops@localhost ~]$ minikube ip 192.168.49.2 [sysops@localhost ~]$
To stop stop the minikube cluster, execute,
$ minikube stop
Execute the “kubectl” commands to view cluster and node information
$ kubectl cluster-info $ kubectl get nodes
## Step 5) Test and Verify Kubernetes Cluster
To test Kubernetes cluster, let try to create k8s deployment using echo server image, it is equivalent to http web server and expose it as a service on port 8080,
[sysops@localhost ~]$ kubectl create deployment test-minikube --image=k8s.gcr.io/echoserver:1.10 deployment.apps/test-minikube created [sysops@localhost ~]$
To access test-minikube deployment, expose it as service, run the following command,
[sysops@localhost ~]$ kubectl expose deployment test-minikube --type=NodePort --port=8080 service/test-minikube exposed [sysops@localhost ~]$
Run below kubectl command to get deployment,pods and service information for above created deployment,
$ kubectl get deployment,pods,svc
To access service, get its url by running the beneath command.
[sysops@localhost ~]$ minikube service test-minikube --url http://192.168.49.2:32291 [sysops@localhost ~]$ [sysops@localhost ~]$ curl http://192.168.49.2:32291/
Great, it means our Kubernetes cluster is working fine as we are able to access our sample application.
#### Step 6) Enable MiniKube Addons
Minikube offers addons which can add additional functionality to our clusters. To list all available addons run,
$ minikube addons list
Kubernetes ships with a dashboard that allows you to manage your cluster. In Minikube, dashboard has been added as an addons. So to enable it, run
$ minikube addons enable dashboard
Also to enable nginx ingress controller, run
$ minikube addons enable ingress
To access the dashboard, run
$ minikube dashbaord --url
This will start the dashboard in your systems’s web vrowser.
And that’s just about it. We have managed to successfully install Kubernetes with Minikube on RHEL 8, Rocky Linux 8 or AlmaLinux 8. You are welcome to share your feedback and comments in below comments section.
**Also Read **: [How to Configure NFS based Persistent Volume in Kubernetes](https://www.linuxtechi.com/configure-nfs-persistent-volume-kubernetes/)
LokeshVery Good Article to set up minikube.
Lokesh[root@centosnews ~]# minikube dashboard –url
? Verifying dashboard health …
? Launching proxy …
? Verifying proxy health …
‘http://127.0.0.1:38423/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/’
Dashboard url is not working getting msg “This site can’t be reached”
Marco@Lokesh:
This worked for me: kubectl proxy –address=’0.0.0.0′ –disable-filter=true
For more info: https://stackoverflow.com/a/54960906
Phillip KnezevichThis is an excellent article, there’s been a few out there that I’ve tried with some error or lack of success. First article i’ve walked through that got it right e2e. Thanks!
RahulYou cant use ingress with the driver none, any workaround?
krishnaAfter Docker installation, one has to add user to ‘Docker’ group
sudo groupadd docker
sudo usermod -aG docker $USER
If not then one has to face the issue reported
‘https://github.com/kubernetes/minikube/issues/10589’
GaneshHey,
Thanks a lot for sharing such informative article and such crystal clear steps to setup the minikube.
Appreciated your efforts to share knowledge. |
15,631 | 世界上只有两个 Linux 发行版:Arch Linux 与其它 | https://www.debugpoint.com/arch-linux-vs-other-distros/ | 2023-03-16T09:16:00 | [
"Arch Linux"
] | /article-15631-1.html | 
>
> 如果你打算把 Arch Linux 作为日常用机,你应该考虑一下 Arch Linux 与其他发行版的不同优点。下面是一个快速比较。
>
>
>
(经提醒,标注原文标题:**Arch Linux 与其他 Linux 发行版,哪个更适合你?**)
如果你考虑改用 Linux,你会接触到数百个 Linux 发行版。每个 Linux 发行版都有其独特的功能、优势和劣势。
它们为用户提供了独特的功能、工具和界面的选择,以满足不同的需求。如果你想和 Arch Linux 进行比较,选择合适的 Linux 发行版,这可能会让人不知所措。
在这篇文章中,我将重点介绍 Arch Linux,它是最受欢迎的 Linux 发行版之一,并将它与其他流行的 Linux 发行版进行比较。
### 关于 Arch Linux 的一些说明
Arch Linux 是一个轻量级和高度可定制的 Linux 发行版,最初发布于 2002 年。与其他流行的发行版不同,Arch Linux 是一个简约的发行版,采用自己动手(DIY)的方式。它是为中高级 Linux 用户设计的,他们喜欢控制和灵活性而不是易用性。
Arch Linux 遵循滚动发布模式,这意味着你可以经常用最新的软件包更新你的系统。
#### Arch Linux 的优点
Arch Linux 有很多优点。然而,一个发行版到底好不好取决于你的使用情况或品味。这因人而异。但在我看来,Arch Linux 比其他 Linux 发行版有几个优势,比如:
* 轻量级和快速(原装版的 Arch,尤其是带有 Xfce 桌面的)
* 灵活性和定制化
* 最新的软件包
* 可靠和稳定(如果正确使用和维护的话)
* 通过 <ruby> Arch 用户仓库 <rt> Arch User Repository </rt></ruby>(AUR)收集最广泛的软件包
* 通过测试软件仓库和安装提供开发包
现在,让我们简单了解一下主要和流行的 Linux 发行版。
### 其他主要发行版的简要概述
#### Ubuntu
Ubuntu 由 Canonical 创建,它是最受欢迎的 Linux 发行版之一,为所有用户和各种使用情况而设计。你可以将 Ubuntu 用于日常工作、开发环境、休闲浏览等方面。它以 Debian 为基础,提供了一个用户友好的 GNOME 桌面环境界面和优秀的软件管理工具。Ubuntu 每年发布两个版本,每两年有一个长期版本。
#### Fedora
Fedora 由 Red Hat 开发和资助,它是另一个流行的 Linux 发行版。它是为中高级用户构建的。它提供最新的软件包,并具有最先进的桌面环境。许多用户喜欢 Fedora,因为它在采用现代技术时总是走在最前面。例如,Wayland 显示服务器,Piperwire 声音服务器,内存超出处理,以及许多其他技术都是由 Fedora 首先采用的。而 Ubuntu 紧随其后。
#### Debian
被称为 “通用操作系统” 的 Debian Linux 已经有二十多年的历史。它稳定、可靠,具有大量的软件包。Debian 以支持所有计算机架构而闻名。Debian 的 “稳定” 版本被认为是当今最稳定的 Linux 发行版。虽然,它的发布节奏比这个名单中的其他版本要慢一些。
#### CentOS
CentOS 以其稳定性、安全性和可靠性而闻名,被广泛用于企业环境中的服务器部署和管理。CentOS 基于红帽 Linux 企业版(RHEL),它为运行 Web 服务器、数据库和关键应用程序提供了一个强大和可扩展的平台。它提供的长期支持和频繁的更新使它在开发者、系统管理员和企业中很受欢迎。
### Arch Linux 与其他 Linux 发行版的比较
现在你对一些流行的 Linux 发行版有了一些了解,让我们把 Arch Linux 与其他 Linux 发行版进行比较。
#### 安装过程
多年来,与其他发行版相比,Arch Linux 的安装有一定的难度,因为它需要手动安装和配置。然而,Arch Linux 的安装过程为用户提供了更大的控制和定制选项。
但最近,Arch Linux 团队通过 [archinstall](https://www.debugpoint.com/archinstall-guide/) 脚本推出了一个菜单驱动的、易于操作的安装程序。利用它并掌握一些基本知识,现在可以直接安装 Arch Linux 了。此外,Arch Linux 还提供了 [虚拟机和 Docker 镜像](https://archlinux.org/download/),这对加快 Arch Linux 的部署非常有用。

另一方面,Ubuntu、Linux Mint 和 Fedora 等发行版有图形化的安装向导,更容易使用,适合初学者。
#### 软件包管理器
Arch Linux 的默认软件包管理器是 [Pacman](https://www.debugpoint.com/pacman-command-arch-examples/),它以其速度和可靠性著称。它还具有 [Arch 用户仓库(AUR)](https://www.debugpoint.com/aur-arch-linux/),这是一个由社区驱动的用户贡献的庞大的软件仓库。
相比之下,其他发行版,如 Ubuntu 和 Debian 使用 APT(<ruby> 高级软件包工具 <rt> Advanced Package Tool </rt></ruby>),而 Fedora 使用 DNF,它也是可靠和快速的。
但根据我的经验,如果你仔细选择镜像,Pacman 要比 APT 和 DNF 软件包管理器快。
#### 滚动发布与定期发布比较
Arch Linux 与其他发行版的一个重要区别是其滚动发布模式。Arch Linux 提供了持续的更新,因此用户可以随时获取最新的软件包。相比之下,像 Ubuntu 和 Fedora 这样的发行版通过他们的标准发布计划来提供,需要一些时间。
Fedora 每 6 个月左右就会有定期发布的版本。Ubuntu 每年也有两个版本。虽然定期发布的版本提供了稳定性,但它们可能没有最新的软件包可用。
所以,这要归结为你自己的需要和工作流程。
#### 自定义和控制
Arch Linux 是为希望完全控制和定制自己的系统的用户设计的。原装的 Arch Linux 安装只安装基本的软件包,用户可以根据自己的需要添加其他软件。
根据你的使用情况,你可以选择安装你喜欢的浏览器、文本编辑器、媒体播放器、图像编辑器等等。没有什么是强加给你的。
其他发行版,如 Ubuntu 和 Fedora 提供了更多的预装软件包,使它们对初学者来说更容易使用。然而,它们可能没有提供像 Arch Linux 那样多的控制和定制功能。
但是,提供预装软件使许多用户、学校、学生和想要一个有预建项目的系统的老年人更轻松。
#### 稳定性和安全性
Arch Linux 以其稳定性和安全性而闻名,这主要是由于它对软件包的安装采取了简约的方法。用户可以完全控制他们安装的软件包,这使得它不容易受到安全漏洞的影响。
此外,Linux 主线内核(主要和次要版本)每月都会在 Arch 软件仓库中率先发布。因此,总的来说,你可以放心,如果你保持你的 Arch Linux 定期更新,你几乎是安全的。
其他发行版,如 Debian 和 CentOS 也以其稳定性和安全性而闻名,但它们可能没有 Arch Linux 那样最新的软件包。
### 哪个 Linux 发行版适合你?
选择合适的 Linux 发行版取决于你的需求和专业水平。
如果你是一个有经验的 Linux 用户,想要完全控制和定制,Arch Linux 是一个很好的选择。如果你知道处理错误的基本方法,在错误升级的情况下可以绕过系统故障,那么它就是最好的选择。
然而,如果你是一个 [初学者](https://www.debugpoint.com/linux-distro-beginners/) 或者喜欢开箱即用的体验,Ubuntu、Linux Mint 或 Fedora 等发行版可能更好。
### 结论
选择合适的 Linux 发行版是一种挑战,但了解它们的差异可以帮助你做出明智的决定。
Arch Linux 是一个独特而强大的发行版,提供完全的控制和定制,但它可能并不适合所有人。
像 Ubuntu 和 Fedora 这样的流行发行版提供了易用性和更多的预装软件包,使它们成为初学者的绝佳选择。
最后,我希望这份指南能给你一个关于 Arch Linux 与其他发行版相比的基本指导。
加油。
---
via: <https://www.debugpoint.com/arch-linux-vs-other-distros/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,633 | 不编写代码也可以为开源项目做出贡献 | https://opensource.com/article/23/3/non-code-contribution-open-source | 2023-03-16T23:17:07 | [
"开源",
"贡献者"
] | https://linux.cn/article-15633-1.html | 
>
> 如果你想通过非代码贡献成为一个提交者,或者没有时间做代码贡献,那么第一步就是加入社区。
>
>
>
对于不同的人来说,开源“社区”意味着不同的东西。我认为开源有点像“爱情”,因为它是关于人和关系的。把开源当作一个社区,因为没有人,就没有源代码,无论是开源还是闭源。
我是 [Apache DolphinScheduler](https://dolphinscheduler.apache.org/en-us) 社区的成员。由于该项目有意保持低代码,因此它吸引了许多 [非软件开发人员](https://opensource.com/article/21/2/what-technical)。有时,那些不编写代码的人不确定是否有一种有意义的方式来为主要由源代码组成的开源项目做出贡献。我的经验告诉我,有,我将在本文中解释原因。
### 向社区做出贡献
在 Apache DolphinScheduler 项目中,我主要负责全球运营、影响力和社区关怀。
一些人会说项目是树而开源是土壤。这是一个恰当的比喻,它说明了积极培育你想要帮助成长的东西的重要性。
我有一个更简单的想法:尽一切可能使其变得更好。
一个社区需要不断的关注,不是因为它很贪心,而是因为它是生活的一部分。社区是你身边的人,无论是物理空间还是在线空间。
自从加入开源社区以来,我已经独立发起并组织了一些活动,包括:
* 平均每月在中国举办一次会议。
* 建议社区参与大数据领域内的技术分享。
* 协调了中国“大数据”领域几乎所有的开源项目,与这些社区进行了个别访问和交流。
在我看来,一个优秀的项目应该在一个良好的生态系统中成长。社区需要走出去,交换想法,分享资源,并与其他优秀的社区合作。每个人都应该感受到社区在工作中带来的好处。
我的海外扩张遵循相同的模式。当然,由于文化和语言的差异,这样做很困难。这需要耗费精力,但这是值得的。
到目前为止,我们已经在包括美国、印度、新加坡、德国、法国、芬兰等国家成功举办了会议。
所以我如何为 DolphinScheduler 做出贡献?我是否向项目提交代码?我是社区经理吗?我有正式的职称吗?
我认为自己是一个助手。我促进沟通和联系,这与任何代码贡献一样,都是 “Apache Way” 的一个例子。
### 从 DolphinScheduler 开始
我第一次接触开源是在开放原子基金会工作时,担任开源教育运营经理。作为中国第一个开源基金会,开放原子运营了以 [OpenHarmony](https://gitee.com/openharmony) 为代表的许多项目。
我加入了 DolphinScheduler 社区并发现了一群热衷于分享知识、提供指导和支持,并热衷于帮助其他人发现对他们自己的生活有用的工具的人。
DolphinScheduler 旨在成为一个拥有全球影响力的调度系统,帮助团队以 [敏捷](https://opensource.com/article/22/5/practical-tips-agile) 和高效的方式工作。
### 对社区的第一印象
听到社区对项目开发的抱怨是一件常见的事情。我们都会时不时地抱怨。也许你报告了一个错误,但开发人员没有解决你的问题。或者,也许你有一个很棒的功能想法,但团队忽略了它。如果你是一个开源社区的成员,你以前就听到过这些不满,如果你没有,你最终会听到。
我了解到,这些声音对于开源社区来说都很重要。这是一个好现象,因为当你听到这些反馈时,这意味着社区愿意发现错误,报告它们,提出问题和回答问题。听到这些抱怨可能会揭示项目结构中需要改进的地方。社区中是否有志愿者可以回应错误报告并对它们进行分类,以便它们能够被分配给正确的开发人员?是否有一个志愿者组等待成立,以便迅速回应项目论坛或论坛中新人的问题?
开源项目的门口有一个招待员可以帮助邀请犹豫不决的社区成员。招待员还可以确保没有“门槛”。每个人都受欢迎,每个人都有自己的贡献,即使他们能提供的只是互相帮助的氛围。
尽管你我都希望能为每个人解决技术问题,但这是不现实的。但任何人都愿意帮助找到解决方案,这是社区的一个伟大优势。这些用户自发地充当了社区的“客户服务”部门。
在 DolphinScheduler 项目中,我们有很多人(Yan Jiang、Xu Zhiwu、Zhang Qichen、Wang Yuxiang、Xiang Zihao、Yang Qiyu、Yang Jiahao、Gao Chufeng 和 Gao Feng,顺序不分先后!)。即使他们不开发解决方案,他们也不遗余力地寻找能够开发解决方案的人。
### 给社区的话
如果你希望通过非代码贡献成为提交者,或者没有时间进行代码贡献,那么第一步就是加入社区。没有注册表格或批准流程,但也没有快速通道。你通过参与加入社区。你通过可靠且持续的参与与其他人建立关系。
我随时都可以聊天,总是渴望谈论全球活动组织、文档、反馈等。
### 成为提交者
Apache DolphinScheduler 面临着许多挑战。大多数公司,即使是支持开源的公司,也会选择非开源的商业工具。我希望与社区合作伙伴一起,使 DolphinScheduler 成为世界级的调度系统。我希望每个人都可以收获他们想要的技术成果,而 DolphinScheduler 可以帮助他们实现这一目标。
加入我们的社区,帮助我们推广开放和敏捷的工作方式。或者找到一个需要你非编码技能的项目。发现让你的同龄人社区获得力量是多么酷和有趣!
---
via: <https://opensource.com/article/23/3/non-code-contribution-open-source>
作者:[Debra Chen](https://opensource.com/users/debra-chen) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | An open source "community" means different things to different people. I think of open source a little like "falling in love" because it is about people and relationships. Treat open source as a community because, without people, there is no source, open or otherwise.
I'm a member of the [Apache DolphinScheduler](https://dolphinscheduler.apache.org/en-us) community. Because that project is intentionally low-code, it appeals to many [people who aren't software developers](https://opensource.com/article/21/2/what-technical). Sometimes, people who don't write code aren't sure whether there's a meaningful way to contribute to an open source project that exists mainly because of source code. I know from experience that there is, and I will explain why in this article.
## Contributions to the community
In the Apache DolphinScheduler project, I'm mainly responsible for global operation, influence, and caring for the community.
Some people say that projects are big trees, with open source being the soil. That's an apt analogy, and it demonstrates the importance of actively nurturing the thing you're trying to help grow.
I have a simpler idea: Do everything possible to make it good.
A community requires constant attention, not because it's needy but because it is part of life. Community is the people living amongst you, whether in your physical or online space.
Since joining the open source community, I have independently initiated and organized events, including:
- Coordinated on average one meetup in China a month.
- Recommended the community participate in the technology shares within the big data field.
- Coordinated with almost all of the open source projects within China's "big data" field, visiting and communicating with those communities individually.
In my opinion, an excellent project should grow in a good ecology. And a community needs to go out to exchange ideas, share resources, and cooperate with other excellent communities. Everyone should feel the benefits brought to the community in their work.
My overseas expansion follows the same pattern. Of course, it's difficult to do that effectively due to differences in cultures and languages. It takes energy, but it's worth it.
So far, we have successfully held meetups overseas, including in the United States, India, Singapore, Germany, France, Finland, and more.
So how do I contribute to DolphinScheduler? Am I committing code to the project? Am I a community manager? Do I have an official title?
I think of myself as an assistant. I foster communication and connection, and that, as much as any code contribution, is an example of the "Apache Way."
## Get started with DolphinScheduler
I first learned about open source when I worked at OpenAtom Foundation as an open source education operation manager. As China's first open source foundation, OpenAtom operates many projects, exemplified by [OpenHarmony](https://gitee.com/openharmony).
I joined the DolphinScheduler community and found a group of people who were eager to share knowledge, provide guidance and support, and keen to help others discover a tool they would find useful in their own lives.
DolphinScheduler aims to be an influential scheduler worldwide, helping teams work in an [Agile](https://opensource.com/article/22/5/practical-tips-agile) and efficient way.
## First impressions of the community
It's common to hear complaints from the community about project development. We all have complaints from time to time. Maybe you reported a bug, but the developers didn't address your problem. Or maybe you had a great idea for a feature, but the team ignored it. If you're a member of an open source community, you've heard these grievances before, and if you haven't, you eventually will.
I've learned that these voices are all important to an open source community. It's a good sign when you hear this feedback because it means the community is willing to find bugs, report them, and ask and answer questions. Hearing those complaints may reveal places in the project's structure that need to be improved. Is there a volunteer from the community who can respond to bug reports and triage them so they get to the right developer? Is there a volunteer group waiting to be formed to respond promptly to questions from newcomers in your project's Discourse or forum?
A greeter at the door of your open source project can help invite tentative community members in. A greeter can also ensure that there's no "gatekeeping" happening. Everyone's welcome and everyone has something to contribute, even if all they can offer is an atmosphere of helping one another.
As much as you or I wish we could solve technical issues for everyone, it's not practical. But anyone can be willing to help find a solution—that's one of the great strengths of a community. These users spontaneously serve as their community's "customer service" department.
Within the DolphinScheduler project, we have many (Yan Jiang, Xu Zhiwu, Zhang Qichen, Wang Yuxiang, Xiang Zihao, Yang Qiyu, Yang Jiahao, Gao Chufeng, and Gao Feng, in no particular order!). Even though they don't develop the solution, they work tirelessly to find the person who can.
## Words to the community
If you want to become a committer through non-code contributions or don't have time to make a code contribution, then the first step is to join the community. There's no sign-up form or approval process, but there's also no fast track. You join a community by participating. Through reliable and consistent participation, you develop relationships with others.
I'm available for a chat and always eager to talk about global event organization, documentation, feedback, and more.
## Become a committer
Apache DolphinScheduler faces many challenges. Many companies, even ones that support open source, choose non-open business tooling. I want to work with community partners to make DolphinScheduler a world-class scheduling tool. I hope everyone can harvest the technical achievements they want and that DolphinScheduler helps get them there.
Join our community and help us promote an open and Agile way of working. Or find a project in need of your non-coding skills. Find out just how cool and fun it is to empower a community of your peers!
## 1 Comment |
15,634 | 云开发人员需要了解的硬件知识 | https://opensource.com/article/23/3/cloud-hardware | 2023-03-16T23:58:52 | [
"云计算",
"硬件"
] | /article-15634-1.html | 
>
> 云无处不在,所以硬件比以往任何时候都更加关键。
>
>
>
我们很容易忘记技术人员所取得的进步。在 2000 年代初期,大多数本地用户组(LUG)定期举行安装节。那时,要配置一台机器来很好地运行 Linux,我们必须了解有关硬件的详细信息以及如何配置它。现在,将近二十年后,有了一个项目,其核心理想是让一台计算机运行 Linux 就像 API 调用一样简单。在这个新世界中,运维人员和开发者等不再需要担心服务器中的硬件。这种变化对下一代的运维人员和开发者产生了深远的影响。
在计算机技术的早期,你不得不经常接触硬件。如果计算机需要更多内存,你只需添加它即可。随着时间的推移,技术也有了很大的发展。这最终使运维人员远离硬件。过去需要去数据中心一趟,现在变成了远程操作硬件的支持工单。最终,硬件被完全摆脱了。相反,你现在可以通过简单的命令召唤和摧毁“服务器”,而不必再担心硬件问题。
这里是真正的真相:硬件的存在是因为需要它来为云提供动力。但是,云到底是什么?
### 为什么硬件对云至关重要
云是建立在利用抽象集中的基础资源之上的。它的范围可以从简单的在你的 [家庭实验室](https://www.redhat.com/sysadmin/linux-homelab-rhel?intcmp=7013a000002qLH8AAM) 中运行几个虚拟机的管理程序,到复杂的包括定制服务器、网络设备、容器和从头开始设计的专注于规模效率的技术。
它们是模糊的。它们在进化。
今天那些进入技术领域的人没有那些更有经验的开发人员实践经验。许多人从最早与计算机交互时就接受过使用云的培训。他们不知道不用按钮来更改内存分配的世界。他们可以将注意力转移到技术栈的更高层次。然而,如果不了解他们所使用的基础架构所建立的基础,他们就会含蓄地放弃学习栈较低级别(包括硬件)的机会。这里没有说错,因为云基础设施的实施者和运维人员已经做出了特定的选择,有意让他们的产品更易于使用。
这意味着现在,你比以往任何时候都更需要有意识地考虑在选择使用云技术时你或其他人做出的权衡。大多数人在收到第一份超额的云账单或第一次因“吵闹的邻居”造成的中断之前,不会知道已经做出了哪些权衡。企业能否信任他们的供应商做出最适合他们运营的权衡?供应商会建议更有效或更有利可图的服务吗?让买家(或工程师!)当心。
有意识地考虑权衡取舍需要从多个角度审视你的要求和目标。基础设施决策和其中的权衡是该项目的整个过程、设计或使用模型所固有的。这就是为什么必须尽快计划它们的原因。必须考虑多种不同的路径,以便为你的项目找到一个合适的归宿。
首先是要实现的目标或提供的服务的轴心。这可能伴随着速度、质量或性能方面的要求。这本身可以驱动许多变量。你可能需要专用硬件(例如 GPU)才能以可接受的速度处理请求。此负载是否需要自动缩放?当然,这些路径是交织在一起的。问题已经跳转到“我的钱包会自动缩放吗?”
业务需求是要考虑的另一部分。你的项目可能有特定的安全或合规性要求,这些要求规定了数据的存储位置。邻近相关服务也是一个潜在的问题。这包括确保与附近证券交易所的 [低延迟连接](https://enterprisersproject.com/article/2022/5/edge-computing-latency-matters?intcmp=7013a000002qLH8AAM) 或能够提供高质量的本地视频缓存作为内容交付网络(CDN)的一部分。
然后是最后一部分,即所提供服务的价值和成本:一个人希望或可以花多少钱来满足要求。这与第一条路径紧密相关。你的业务是“什么”以及你的业务“如何”运作。这可以像你的企业更喜欢资本支出还是更喜欢运营支出一样普通。
当看到这些选项时,很容易看到改变任何一个变量都会开始改变其他变量。它们在本质上是相互交织的,一些技术可能允许这些变量动态变化。如果不了解较低层次的底层,你就有可能采取推动这种动态计费模式的路径。对一些人来说,这是首选。对其他人来说,这可能是令人恐惧的。
尽管在现代技术栈中,学习特定的硬件知识已变得更加可有可无,但我们希望这篇文章能鼓励你去研究你可能在不知不觉中错过的东西。硬件的改进是功能交付和效率提高的一个重要部分,将计算机从房间大小的怪物缩小到小到可以植入人体内。我们希望你花时间停下来,学习并考虑你的下一个项目将在什么硬件平台上运行,即使你不控制它。
如果你是一个还没有把头从云端拿出来的学生,去找一台 [旧电脑](https://opensource.com/article/22/4/how-linux-saves-earth),安装一根内存,挑战自己,学习新东西。
---
via: <https://opensource.com/article/23/3/cloud-hardware>
作者:[Jay Faulkner](https://opensource.com/users/jayf) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,636 | Kali Linux 推出用于防御性安全加固的 “Kali Purple” | https://debugpointnews.com/kali-linux-2023-1/ | 2023-03-18T07:23:00 | [
"Kali Linux"
] | /article-15636-1.html |
>
> Kali Linux 2023.1 发布了重大更新,并引入了一个新的变体 “Kali Purple”。
>
>
>

在 Kali Linux 的 10 周年纪念,该团队为你准备了一些好东西。Kali Linux 2023.1 是 Kali Linux 的常规软件包更新,它带来了最新的桌面环境和主线内核更新。
### Kali Linux 2023.1 推出 Kali Purple
这个版本的主要亮点是 [Kali Purple](https://gitlab.com/kalilinux/kali-purple/documentation/-/wikis/home),这是 Kali Linux 的一个新变体,带有 “防御性安全” 工具。Kali 团队目前正在将其作为技术预览版发布。
防御性安全软件可以实现各方面的安全加固,如漏洞扫描、事件跟踪和响应、数据包捕获、入侵检测等。现在你可以使用 Kali Purple 为你的应用程序或企业内置的所有工具。

Kali Purple 带来了 100 多个防御工具、文档、用于自动攻击脚本构建的 Kali CoPilot 以及更多工具。
* [Arkime](https://pkg.kali.org/pkg/arkime) - 完整的数据包捕获和分析
* [CyberChef](https://pkg.kali.org/pkg/cyberchef) - 网络瑞士军刀
* Elastic Security - 安全信息和事件管理
* [GVM](https://www.kali.org/tools/gvm/) - 漏洞扫描器
* [TheHive](https://pkg.kali.org/pkg/thehive) - 事件响应平台
* Malcolm - 网络流量分析工具套件
* [Suricata](https://pkg.kali.org/pkg/suricata) - 入侵检测系统
* [Zeek](https://pkg.kali.org/pkg/zeek) -(另一个)入侵检测系统
此外,为了与 美国《国家标准和技术研究所关键基础设施网络安全(NIST CSF)》的指导方针保持一致,为你配置了单独的菜单项目。它包括单独的应用类别 - 识别、保护、检测、响应和恢复。

此外,还为 Kali Purple 创建了一个单独的 Discord 频道,用于合作和为社区提供额外的帮助。
### Python 中的 Pip 变化
Python 的 `pip` 命令在(即将发布的)Debian 12 Bookworm 版本中正在发生变化。`pip` 命令用于安装 Python 模块。由于这些模块是用 `pip` 从外部安装的,它可能会破坏现有的 Debian 系统。
因此,从 Debian 12 开始,如果你试图用 `pip` 安装任何模块,你应该会得到一个 “<ruby> 外部管理的环境 <rt> externally-managed-environment </rt></ruby>”的错误。如下:

Kali Linux 团队从这个版本开始提供一个补丁,使你可以使用 `pip` 安装任何模块。但这只是暂时的解决方案,直到 Debian 12 稳定版。
所以,如果你是一个在 Kali Linux(或在 Debian)中使用 Python 环境的开发者,你肯定应该计划使用下面的 `apt` 命令来部署这些模块:
```
apt install python3-numpy
```
### 桌面环境和其他更新
默认桌面 Xfce 现在采用了 Xfce 4.18 版本,它带来了大量的功能,包括分割视图、图像预览和 Thunar 文件管理器中的其他功能。另外,KDE Plasma 版现在在 Kali Linux 2023.1 中的版本是 5.27。
Xfce 版的默认主题得到了改进,具有令人惊叹的外观;许多新的壁纸也包含在这个版本中。
最后,主线内核 6.1 现在可以在这个版本中使用,提供了最新的硬件、 CPU、GPU 和其他支持。
### 下载
如果你已经在运行 Kali Linux,只需运行系统升级就可以得到这个版本:
```
sudo apt update && sudo apt upgrade -y
```
对于新的下载,请访问下面的页面来获取 ISO。
>
> **[下载 Kali Linux](https://www.kali.org/get-kali/#kali-installer-images)**
>
>
>
如果你想试试 Kali Purple,请访问下面的页面:
>
> **[下载 Kali Purple ISO](https://cdimage.kali.org/kali-2023.1/kali-linux-2023.1-installer-purple-amd64.iso)**
>
>
>
参考自 [发布公告](https://www.kali.org/blog/kali-linux-2023-1-release/)。
---
via: <https://debugpointnews.com/kali-linux-2023-1/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,637 | 维基百科是如何帮助保持互联网的开放性的 | https://opensource.com/article/23/3/how-wikipedia-helps-keep-internet-open | 2023-03-18T08:39:00 | [
"维基百科"
] | https://linux.cn/article-15637-1.html | 
>
> 维基百科体现了互联网最初愿景的精神,而你也可以成为其中的一部分。
>
>
>
维基百科是最有意义的开源软件项目之一,原因之一是它远比你想象的庞大。而且,任何人都可以贡献内容,并且任何人都可以为项目背后的许多技术领域贡献代码,确保维基百科正常运行。
[超过 870 个维基百科及其附属网站](https://wikimediafoundation.org/our-work/wikimedia-projects/#a1-reference) 提供了多语言版本,它们服务于一个共同目标,“开发自由的教育内容,并有效地在全球范围内传播”。例如,<ruby> 维基共享资源 <rt> Wikimedia Commons </rt></ruby> 是一个自由的媒体文件库,截至今天,它已经拥有超过 6800 万张图片。<ruby> 维基文库 <rt> Wikisource </rt></ruby> 是一个自由的文本资源库,拥有超过 500 万篇文章和 72 种语言的活跃网站子域名。<ruby> 维基数据 <rt> Wikidata </rt></ruby> 是一个可访问的数据存储库,包含被 [多个与维基百科相关的网站](https://meta.wikimedia.org/wiki/Wikimedia_wikis) 所使用的超过 9900 万个数据项。
这些项目由 <ruby> 维基媒体基金会 <rt> Wikimedia Foundation </rt></ruby> 支持和维护,它是一个总部位于旧金山的非营利组织。基金会使全球数十万名志愿者为项目的自由知识作出贡献。在这个知识收集和生产的社区背后,有着大量的维护、技术支持和管理工作,以保持网站的正常运转。当然,从外部来看,你可能仍然好奇,开发维基百科的软件还需要做哪些工作。毕竟,它可是世界上最受欢迎的十大网站之一,致力于提供最好的信息。
事实上,每篇维基百科的文章都借助了成千上万的软件工具来创建、编辑和维护。这些步骤,确保了你在世界任何地方都能获得公平可靠快速的信息。当你浏览维基百科或任何其他维基网站时,你是在与一个称之为 [MediaWiki](https://www.mediawiki.org/wiki/MediaWiki) 的软件交互,这是一个强大的团队协作文档软件,用以支持维基百科的内容。它有一些默认特性,而为了进一步增强软件的功能,你可以安装各种扩展。数不胜数的扩展中,最著名的两个是:
* VisualEditor:一种适用于 MediaWiki 驱动的维基站点的 <ruby> 所见即所得 <rt> WYSIWYG </rt></ruby> 富文本编辑器。
* Wikibase:用于存储、管理和访问维基百科从 <ruby> 维基数据 <rt> Wikidata </rt></ruby> 上拉取的结构化数据。
所有这些优秀的辅助工具使现代维基百科愈发完善并正常运行,每一个都至关重要。
### 维基百科和 MediaWiki
总体来说维基百科的技术生态是非常庞大的!MediaWiki 是维基媒体世界中最受欢迎的软件之一,遵循开源代码许可,已经有超过四十万个项目和组织使用它来托管内容。例如,NASA 使用它来组织有关太空任务的内容和知识库!
此外,还有许多其他机器人、工具、桌面和移动应用可以帮助用户访问、创建、编辑和维护内容。例如,机器人可以自动化重复繁琐的任务,可以用来对抗恶意破坏、向新手推荐文章、进行文章事实核查等,这大大减轻了编辑的工作负担。InternetArchiveBot 也是个十分流行的机器人,常用于与 <ruby> 网站时光机 <rt> Wayback Machine </rt></ruby> 通信,修复维基百科上的死链。
上文中的 “工具”,指的是支持贡献者们工作的软件。比如,组织者可以使用这些 “工具” 开展 <ruby> 编辑松 <rt> editathons </rt></ruby>、举办各种活动、开设维基百科编辑教育课程等。截至 2022 年 5 月,机器人和工具的贡献占 870 个维基媒体编辑总量中的 36.6%,足以证明它们在整个生态中举足轻重。
Kiwix 是一款知名的离线阅读器桌面应用,它可以在网络连接有限的区域,特别是教育场所中提供对维基百科的访问。维基百科和维基共享资源的移动应用,也允许编辑者通过他们的移动设备贡献文章和媒体文件,这使我们的知识平台更加普及化,能够面向全球更广泛的受众。
下次当你浏览维基百科时,发现了文章在近期发生相关事件后有频繁的实时更改,你就能更好地想象屏幕后在发生什么啦。
### 维基百科的技术社区
维基百科启动于 2001 年,当时仅有约十名开发人员。自从 2003 年维基媒体基金会成立以来,开发人员的数量在近年里大幅增长。现在,约有一千名开发人员正在为知识运动中的各种项目做出贡献。这个数字每年都会波动,这取决于活跃贡献者和工作人员的数量、支持志愿开发人员的计划、以及全球性事件(如大流行)等因素。
技术社区的成员以各种方式和角色做出贡献。比如代码贡献者、文档编写、设计师、倡导者、导师、社区组织者、测试人员、翻译人员、网站管理员等。
根据一项关于新开发者的调查,维基媒体和其他开源项目一样,吸引了许多来自美国、欧洲和印度的贡献者,在世界各地不断壮大。
志愿开发者和维基百科编辑者有类似的动机。他们成为贡献者,是来支持自由知识事业、学习和获得新技能、改善其他编辑者的体验等等。来自印度的一位志愿开发者说:“我最初其实是作为编辑者加入的,但我还是着手摸索维基百科背后的技术,因为印地语维基百科社区中,能够通过技术手段解决我们当地语言需求的贡献者实在太少了。”
在 2021 年 7 月至 2022 年 6 月期间,仅考虑托管在维基媒体 Gerrit 实例中的代码仓库,514 名开发人员在 1225 个存储库中进行了 45,621 次合并改动。这些贡献中,48.52% 来自维基媒体基金会之外的其他组织和 [独立开发人员](https://wikimedia.biterg.io/)。其中一些开发人员还是不同地区的用户组、分会和附属机构的成员,致力于推广使用维基媒体项目和鼓励贡献。这些数字还不包括选择在外部托管代码的额外开发人员,或直接托管在维基页面上的代码,例如小工具或模块。
### 有所作为
维基百科是一个可供所有人使用的庞大知识库。在许多方面,它体现了互联网的最初愿景:作为信息、理解和协作的来源。
你可以作为贡献者成为维基百科的一份子,无论是通过在文章中分享你的知识,还是通过帮助构建使其所有工作成为可能的软件。如果你有兴趣加入维基媒体的技术社区,请浏览我们的开发者网站上的资源,并学习如何 [参与其中](https://developer.wikimedia.org/)。
---
via: <https://opensource.com/article/23/3/how-wikipedia-helps-keep-internet-open>
作者:[Srishti Sethi](https://opensource.com/users/srishakatux-0) 选题:[lkxed](https://github.com/lkxed/) 译者:[onionstalgia](https://github.com/onionstalgia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Wikipedia is one of the most significant open source software projects, in part because it's a lot bigger than you may realize. And yet anyone can contribute content, and anyone can contribute code to many technical areas of the projects that work behind the curtain to keep Wikipedia running.
[Over 870 Wikipedia and umbrella sites](https://wikimediafoundation.org/our-work/wikimedia-projects/#a1-reference) are available in different languages, and all of them operate with a common goal of “developing free educational content and disseminating it effectively and globally.” For example, Wikimedia Commons is a repository of free media files, and as of today, it has over 68 million images. Wikisource is a free library of textual sources with over 5 million articles and website subdomains active for 72 languages. Wikidata is an accessible repository of over 99 million data items used across [several Wikipedia-related sites](https://meta.wikimedia.org/wiki/Wikimedia_wikis).
These projects are supported and maintained by Wikimedia Foundation, a non-profit organization headquartered in San Francisco. The organization also empowers hundreds of thousands of volunteers worldwide to contribute free knowledge to these projects. Behind this community of knowledge gatherers and producers, a lot of work goes into maintenance, technical support, and administrative work to keep these sites up and running. From the outside looking in, you might still wonder what more work could remain in developing Wikipedia’s software. After all, it’s one of the top ten most visited internet websites in the world, and serves its purpose well and provides access to the best possible information.
The truth is that every article on Wikipedia leverages thousands of software tools for its creation, editing, and maintenance. These are crucial steps in ensuring equitable, reliable, and fast access to information no matter where you are in the world. When you browse Wikipedia or any other Wikimedia sites, the software you interact with is called [MediaWiki](https://www.mediawiki.org/wiki/MediaWiki), a powerful collaboration and documentation software that powers the content of Wikipedia. It comes with a default set of features. To further enhance the software’s capabilities, you can install various extensions. They’re too numerous to mention, but two notable extensions are:
- VisualEditor: A WYSIWYG rich-text editor for MediaWiki-powered wikis
- Wikibase: Allows storing, managing, and accessing structured data which Wikipedia pulls from Wikidata.
All of this apparent ancillary tooling makes the modern Wikipedia, and each one is important for its functioning.
## Wikimedia and Mediawiki
Overall, Wikipedia’s technology ecosystem is vast! As MediaWiki, one of the most popular software in the Wikimedia world, is available under an open source license, [over four hundred thousand projects](https://wikistats.wmcloud.org/) and organizations use it for hosting their content. For example, [NASA uses it](https://wikimediafoundation.org/news/2016/05/05/mediawiki-nasa/) to organize its content around space missions and their knowledge base!
In addition, there are many other bots, tools, desktop and mobile apps that help with content access, creation, editing, and maintenance. For example, bots in particular help drastically reduce the workload of editors by automating repetitive and tedious tasks, such as fighting vandalism, suggesting articles to newcomers, fact-checking articles, and more. InternetArchiveBot is a popular bot that frequently communicates with the Wayback Machine to fix dead links on Wikipedia.
Tools are software applications that support various contributors in their work. For example, organizers can access tools for conducting editathons, running campaigns, educational courses around Wikipedia editing, and so on. As of May 2022, bots and tools contribute 36.6% of edits made to 870 Wikimedia wikis, demonstrating their significant impact on the ecosystem.
[Kiwix](https://meta.wikimedia.org/wiki/Kiwix) is a well-known offline reader and a desktop application that provides access to Wikipedia in limited internet access regions, particularly in educational settings. Mobile apps for Wikipedia and Wikimedia Commons allow editors to contribute articles and media files through their devices too, making our knowledge platforms accessible to a larger audience around the world.
The next time you are browsing a Wikipedia article and notice frequent changes being made to it in real-time in the wake of a recent event, you might be able to visualize better what might be happening behind the scenes.
## Wikipedia’s technical community
Wikipedia was launched in 2001. It had about ten developers at that time. Since the inception of the Wikimedia Foundation in 2003, the developer pool has vastly grown over these years. About a thousand developers are now contributing to various projects within our knowledge movement. This number fluctuates yearly, depending on the number of active contributors and staff members, initiatives supporting volunteer developers, global events such as the pandemic, and so on.
Members in the technical community contribute in various ways and roles. There are code contributors, documentarians, designers, advocates, mentors, community organizers, testers, translators, site administrators, and more.
According to a survey conducted for new developers, Wikimedia draws a lot of contributors from the United States, Europe, and India like other open source projects and is growing in different regions of the world.
Volunteer developers have similar motivations as Wikipedia editors. They join as contributors to support the free knowledge mission, learn and gain new skills, improve the experience of other editors, and so on. One of the volunteer developers from India says, “While I joined as an editor, I started to familiarize myself with the tech behind Wikipedia because there were significantly fewer contributors in the Hindi Wikipedia community who could address our local language needs through technology.”
Between July 2021 and June 2022, looking only at code repositories hosted in Wikimedia’s Gerrit instance, 514 developers contributed 45,621 merged software changes to 1225 repositories. Of these contributions, 48.52% came from outside the Wikimedia Foundation by other organizations and [independent developers](https://wikimedia.biterg.io/). Some of these developers are also part of various user groups, chapters, and affiliate bodies working in different regions to promote the use and encourage contributions to Wikimedia projects. These numbers do not include the additional developers who chose to host their code externally instead, or code that is hosted directly on wiki pages, such as gadgets or modules.
## Making a difference
Wikipedia is a vast repository of knowledge, available to everyone. In many ways, it’s the embodiment of the original vision of what the internet can and should be: A source of information, understanding, and collaboration.
You can be a part of Wikipedia as a contributor, either by sharing your knowledge in articles, or by helping to build the software that makes it all possible. If you’re interested in joining Wikimedia’s technical community, then explore the resources on our developer site, and learn how to [get involved](https://developer.wikimedia.org/).
## Comments are closed. |
15,639 | Firefox 111 已发布,带来了原生系统通知 | https://debugpointnews.com/firefox-111/ | 2023-03-19T14:43:00 | [
"Firefox"
] | /article-15639-1.html |
>
> Firefox 111 已发布,带来了原生通知、新增的本地化语言以及增强的 Web 平台功能。
>
>
>

### Firefox 111 发布亮点

Firefox,一个流行的网络浏览器,已经发布了 111 版本,其中引入了几个新功能和增强功能。其中一个突出的新增功能是支持 Windows 原生的系统通知,为整个平台提供了更流畅和一致的用户体验。
除此之外,Firefox Relay 用户现在可以轻松地从 Firefox 凭据管理器中直接创建 Relay 邮箱。此功能仅适用于登录了 Firefox 帐户的用户,为其在线活动提供了额外的隐私和安全保护。
另外,Firefox 111 已经通过添加两个新的语言 – <ruby> 弗留利语 <rt> Silhe Friulian </rt></ruby>(fur)和 <ruby> 撒丁语 <rt> Sardinian </rt></ruby>(sc)– 来扩大其语言支持列表。这一举措旨在为世界各地的 Firefox 用户提供更好的可访问性和包容性。
在 Web 平台方面,Firefox 已经在表单元素上引入了 “rel” 属性,使开发人员可以更轻松地指定当前文档与表单目标之间的关系。这一功能与其他浏览器兼容,并简化了 Web 应用程序的开发过程。
最后,Firefox 已经启用了 <ruby> 原点私有文件系统访问 <rt> origin private file system access </rt></ruby>,这是一种新的存储 API,允许 Web 应用程序在沙箱中存储和检索文件系统中的数据。这一增强功能为开发人员提供了对数据存储和检索过程的更多控制,确保用户数据的安全性和隐私性。
### 下载和更新
对于 Linux 发行版,如果你通过发行版的官方仓库使用 Firefox,那么你应该在几天内获得此更新。
但是,你也可以从下面的页面下载此版本的压缩版本。有关其他下载选项,请访问我们的 [Firefox 下载指南](https://www.debugpoint.com/download-firefox/)。
>
> **[下载 Firefox 111](https://ftp.mozilla.org/pub/firefox/releases/111.0/)**
>
>
>
祝浏览愉快!
* [官方发布通知](https://www.mozilla.org/en-US/firefox/111.0/releasenotes/)
* [Beta110 发布通知](https://www.mozilla.org/en-US/firefox/111.0beta/releasenotes/)
* [开发者发布版本通知](https://developer.mozilla.org/en-US/docs/Mozilla/Firefox/Releases/111)
### 总结
总体来说,Firefox 111 版本提供了一系列新功能和增强功能,这些功能提高了用户体验,并为 Web 开发人员提供了更丰富的控制权和安全性。凭借其对可访问性、包容性和隐私方面的投入,Firefox 仍然是全球用户的首选浏览器。
---
via: <https://debugpointnews.com/firefox-111/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,640 | 数据科学家的开源社区分析指南 | https://opensource.com/article/22/12/data-scientists-guide-open-source-community-analysis | 2023-03-19T15:50:00 | [
"开源社区",
"数据科学"
] | https://linux.cn/article-15640-1.html | 
>
> 研究一下这个框架,来建立你自己的开源项目的数据分析。
>
>
>
在数据分析的黄金时代,开源社区也不能免俗。大家都热衷于将一些华丽的数字放到演示幻灯片上,但如果你掌握了正确的分析方法,这些信息可以为你带来更大的价值。
或许你认为作为一名 [数据科学家](https://enterprisersproject.com/article/2022/9/data-scientist-day-life?intcmp=7013a000002qLH8AAM),我会告诉你数据分析和自动化能为你的社区决策提供信息。但实际上,情况恰恰相反。利用数据分析来构建你现有的开源社区知识,吸收其他的知识,并发现潜在的偏见和没有思考过的观点。你或许是实施社区活动的专家,而你那些同事则是代码方面的专家。当你们每个人都在自己的知识背景下将信息可视化时,你们都可以从这些信息中受益。
让我们来面对现实吧。每个人都有一千零一件事情要做,而且总感觉一天的时间永远不够用。如果需要几个小时才能得到你的社区的答案,你就不可能有足够的精力去解决这些事情。但是,花时间创建一个全面发展的可视化项目,可以帮助你时刻掌握你所关心的社区的不同方面,这就将你从精疲力尽中解放了出来。
随着“数据驱动”思维的盛行,围绕开源社区的信息宝库可能是一种祝福,也可能是一种诅咒。下面我将分享一些方法,告诉你如何从数据干草堆中挑出有价值的信息。
### 你的预期是什么?
当考虑一个指标时,首先要明确你想提供的观点。以下是几个可能涉及的概念:
**告知性和影响性的行动:** 你的社区是否存在某个领域尚未被理解?你是否已迈出第一步?你是否试图确定特定方向?你是否正在衡量现有倡议的效果?
**暴露需要改进的领域和突出优势:** 有时你想宣传你的社区,突出它的优势,特别是在试图证明商业影响或为项目宣传时。然而,当涉及到向社区内部传递信息时,你通常需要从一堆指标中精准的找到你们的缺点,以此来帮助你们改进。虽然突出优点并非不可取,但需要在适当的时间和地点。不要把优势指标作为社区内部的拉拉队,告诉每个人都有多棒,而是要与外界分享,以获得认可或推广。
**社区和商业影响:** 数字和数据是许多企业的语言。但是这可能使得为你的社区进行宣传并真正展示其价值变得异常困难。数据可以成为用他们的语言说话的一种方式,并展示他们想看到的东西,以使你数据背后的潜在含义能够被有效转达。另一个角度是对开源的整体影响。你的社区是如何影响他人和生态系统的?
这些观点并非非此即彼,而是相互关联的。适当的框架将有助于创造一个更深思熟虑的衡量标准。

当人们谈论通用的数据科学或机器学习工作时,通常会描述这样的工作流程。我将重点关注第一步,即编写问题和度量标准,并简要提及第二步。从数据科学的角度来看,这个演示可以被视为这个步骤的一个案例研究。这一步有时会被忽视,但你的分析的实际价值始于此。你不能一天醒来就知道要看什么。从理解你想知道什么和你所拥有的数据开始,逐步实现更加深度的数据分析。
### 3个开源数据分析用例
以下是您在开源数据分析过程中可能遇到的三种不同场景。
#### 场景 1:现有数据分析
假设你开始进行分析,并且已经知道你将要研究的内容对你或你的社区是有用的。那么你该如何提高分析的价值呢?这里的想法是建立在“传统”的开源社区分析基础之上。假设你的数据表明,在项目的整个生命周期内,你共有 120 个贡献者。这是你可以放在幻灯片上的价值,但你不能从中做出决策。从仅有一个数字到获得洞见,逐步采取措施。例如,你可以从相同的数据中将贡献者分为活跃和流失的贡献者(那些已经有一段时间没有做出贡献的贡献者),以获得更深入的了解。
#### 场景 2:社区活动的影响测量

针对聚会、会议或其他任何社区外联活动,你如何看待你的影响力和目标?这两个步骤实际上互相影响。一旦你确定了活动的目标,就要确定可以用什么来检测效果。这些信息有助于设定活动的目标。在活动开始时,很容易陷入模糊的计划而非具体的计划的陷阱中。
#### 场景3:形成新的影响分析区

当你从头开始进行数据分析时,就会出现这种情况。前面的例子是这个工作流程的不同部分。这个工作流程是一个不断发展的循环;你可以随时进行改进或扩展。基于这个概念,以下是你应该经历的必要步骤。在本文的后面,将会有三个不同的例子,展示这种方法在现实世界中的应用。
#### 第一步:分解关注区和视角
首先,想象一下魔法 8 球——你可以问任何问题,摇一摇,就能得到答案的玩具。考虑你的分析领域。如果你能立即得到任何答案,那会是什么?
接下来,考虑数据。从你的魔法 8 球问题中,哪些数据源可能与问题或关注领域有关?
在数据背景下,哪些问题可以回答,让你更接近你提出的魔法 8 球问题?需要注意的是,如果你试图将所有的数据汇集在一起,你必须考虑到所做出的假设。
#### 第二步:将问题转化为指标
以下是第一步中每个子问题的处理过程:
* 选择所需的具体数据点。
* 确定可视化以实现目标分析。
* 假设这些信息的影响。
接下来,引入社区提供反馈并触发迭代开发过程。这个协作部分可能就是真正的魔力所在。最好的想法通常是在将一个概念带给某个人时产生的,会激发他们的灵感,这是你或他们无法想象的。
#### 第三步:分析实践
这一步是你开始处理你所创建的指标或可视化的影响。
首先要考虑的是,这个度量标准是否符合当前对社区的了解。
* 如果**是**:是否有假设得出的结果?
* 如果**不是**:你需要进一步调查,是否这是一个潜在的数据或计算问题,或者只是先前被误解的社区的一部分。
一旦你确定你的分析足够稳定,可以开始在信息上实施社区倡议。当你正在进行分析以确定下一步最佳步骤时,你应该确定衡量倡议成功的具体方法。
现在,观察这些由你的指标提供信息的社区倡议。确定是否可以用你之前建立的成功衡量指标观察到影响。如果没有,可以考虑以下几点:
* 你是否在衡量正确的事情?
* 倡议战略是否需要调整?
### 分析区的例子:新贡献者
#### 魔法 8 球问题是什么?
* 如何分析哪些人为持续的贡献者?
#### 我有什么数据可以纳入分析区和魔法 8 球问题?
* 仓库存在哪些贡献者的活动,包括时间戳?
现在你有了这些信息和一个魔法 8 球问题,把分析分成几个子部分执行。这个想法与上述步骤 2 和 3 相关。
**子问题 1:** “人们是怎么进入这个项目的”
这个问题的目的是先看看新的贡献者在做什么。
**数据:** GitHub 上的首次贡献随时间推移的数据(议题、PR、评论等)。

**可视化:** 按季度划分的首次贡献条形图。
**潜在的意义:** 在你与其他社区成员交谈后,进一步检查按季度细分的信息,以及贡献者是否为重复贡献者或仅仅是路过。你可以看到人们进来的时候在做什么,以及这是否能告诉你他们是否会留下来。

**从这些信息中了解到的可以采取的行动。**
* 目前的文档是否能够帮助到最常见的新手?你能不能更好地帮助和支持新人朋友,这将有助于他们中更多的人留下来?
* 是否有一个贡献领域在整体上并不常见,但重复贡献者却集中在这个区域?也许 PR 是重复贡献者的一个常见区域,但大多数人却不在这个区域工作。
**行动项目:**
* 给 “好的第一个问题” 贴上一致的标签,并将这些问题链接到贡献文档中。
* 在这些问题上添加一个 PR 伙伴。
**子问题 2:** “我们的代码库真的依赖于路过的贡献者吗?”
**数据:** GitHub 的贡献数据。

**可视化:** “贡献总额:按路过和重复贡献者的贡献进行细分。”
**根据这一信息可能采取的行动。**
* 这个比例是否达到了项目的目标?很多工作都是由路过贡献者完成的吗?这是否是一种未被充分利用的资源,项目是否没有尽到自己的责任来吸引他们?
### 分析:吸取教训
数字和数据分析并不是“事实”,它们可以支持任何观点。因此,在处理数据时,内部怀疑者应该非常积极,并进行反复迭代,以带来真正的价值。你不希望你的分析只是一个 “yes man”,因此花点时间退一步,评估你所做的假设。
如果一个指标只是指出了调查的方向,那也是一个巨大的胜利。你不可能看清或想到所有的事情,兔子洞可以是一个好事,对话的起点可以把你带到一个新的地方。
有时,你想测量的东西恰恰不在那里,但你也许能得到有价值的细节。不要假设你有所有的拼图碎片来获得你最初问题的准确答案。如果你开始强迫一个答案或解决方案,你会把自己带入一条由假设引领的危险道路。为分析的方向或目标的改变留出空间,可以让你获得比最初的想法更好的洞察力。
数据只是是一种工具,并不是标准答案,它可以汇集原本无法获得的见解和信息。将你想知道的东西分解成可管理的小块,并在此基础上进行分析,这是最重要的部分。
开源数据分析是一个很好的例子,说明你必须对所有的数据科学采取谨慎态度。
* 主题领域的细微差别是最重要的。
* 通过“问什么/答什么”的工作过程经常被忽视。
* 知道“问什么”可能是最难的部分,当你想出一些有洞察力和创新的东西时,这比你选择的任何工具都要重要。
如果你是一个没有数据科学经验的社区成员,正在寻找开始的地方,我希望这些信息能告诉你,你在这个过程中是多么重要和宝贵。你带来了社区的洞察力和观点。如果你是一个数据科学家或实施指标或可视化的人,你必须倾听你周围的声音,即使你也是一个活跃的社区成员。关于数据科学的更多信息列在本文的最后。
### 总结
把上面的例子作为建立你自己的开源项目的数据分析的框架。对你的结果有很多问题要问,知道这些问题和它们的答案可以把你的项目引向一个令人兴奋和富有成效的方向。
---
via: <https://opensource.com/article/22/12/data-scientists-guide-open-source-community-analysis>
作者:[Cali Dolfi](https://opensource.com/users/cdolfi) 选题:[lkxed](https://github.com/lkxed) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the golden age of data analysis, open source communities are not exempt from the frenzy around getting some big, fancy numbers onto presentation slides. Such information can bring even more value if you master the art of generating a well-analyzed question with proper execution.
You might expect me, a [data scientist](https://enterprisersproject.com/article/2022/9/data-scientist-day-life?intcmp=7013a000002qLH8AAM), to tell you that data analysis and automation will inform your community decisions. It's actually the opposite. Use data analysis to build on your existing open source community knowledge, incorporate others, and uncover potential biases and perspectives not considered. You might be an expert at implementing community events, while your colleague is a wiz at all things code. As each of you develops visualizations within the context of your own knowledge, you both can benefit from that information.
Let's have a moment of realness. Everyone has a thousand and one things to keep up with, and it feels like there is never enough time in a day to do so. If getting an answer about your community takes hours, you won't do it regularly (or ever). Spending the time to create a fully developed visualization makes it feasible to keep up with different aspects of the communities you care about.
With the ever-increasing pressure of being "data-driven," the treasure trove of information around open source communities can be a blessing and a curse. Using the methodology below, I will show you how to pick the needle out of the data haystack.
**What is your perspective?**
When thinking about a metric, one of the first things you must consider is the perspective you want to provide. The following are a few concepts you could establish.
**Informative vs. influencing action:** Is there an area of your community that is not understood? Are you taking that first step in getting there? Are you trying to decide on a particular direction? Are you measuring an existing initiative?
**Exposing areas of improvement vs. highlighting strengths:** There are times when you are trying to hype up your community and show how great it is, especially when trying to demonstrate business impact or advocate for your project. When it comes to informing yourself and the community, you can often get the most value from your metrics by identifying shortcomings. Highlighting strengths is not a bad practice, but there is a time and place. Don't use metrics as a cheerleader inside your community to tell you how great everyone is; instead, share that with outsiders for recognition or promotion.
**Community and business impact:** Numbers and data are the languages of many businesses. That can make it incredibly difficult to advocate for your community and truly show its value. Data can be a way to speak in their language and show what they want to see to get the rest of your messaging across. Another perspective is the impact on open source overall. How does your community impact others and the ecosystem?
These are not always either/or perspectives. Proper framing will help in creating a more deliberate metric.
(Cali Dolfi, CC BY-SA 4.0)
People often describe some version of this workflow when talking about general data science or machine learning work. I will focus on the first step, codifying problems and metrics, and briefly mention the second. From a data science perspective, this presentation can be considered a case study of this step. This step is sometimes overlooked, but your analysis's actual value starts here. You don't just wake up one day and know exactly what to look at. Begin with understanding what you want to know and what data you have to get you to the true goal of thoughtful execution of data analysis.
**3 data analysis use cases in open source**
Here are three different scenarios you might run into in your open source data analysis journey.
**Scenario 1: Current data analysis**
Suppose you are starting to go down the analysis path, and you already know what you're looking into is generally useful to you/your community. How can you improve? The idea here is to build off "traditional" open source community analysis. Suppose your data indicates you have had 120 total contributors over the project's lifetime. That's a value you can put on a slide, but you can't make decisions from it. Start taking incremental steps from just having a number to having insights. For example, you can break out the sample of total contributors into active versus drifting contributors (contributors who have not contributed in a set amount of time) from the same data.
**Scenario 2: Community campaign impact measurement**
(Cali Dolfi, CC BY-SA 4.0)
Consider meetups, conferences, or any community outreach initiative. How do you view your impacts and goals? These two steps actually feed into each other. Once you establish the campaign goals, determine what can be measured to detect the effect. That information helps set the campaign's goals. It's easy to fall into the trap of being vague rather than concrete with plans when a campaign begins.
**Scenario 3: Form new analysis areas to impact**
(Cali Dolfi, CC BY-SA 4.0)
This situation occurs when you work from scratch in data analysis. The previous examples are different parts of this workflow. The workflow is a living cycle; you can always make improvements or extensions. From this concept, the following are the necessary steps you should work through. Later in this article, there will be three different examples of how this approach works in the real world.
**Step 1: Break down focus areas and perspectives**
First, consider a magic eight ball—the toy you can ask anything, shake, and get an answer. Think about your analysis area. If you could get any answer immediately, what would it be?
Next, think about the data. From your magic eight-ball question, what data sources could have anything to do with the question or focus area?
What questions could be answered in the data context to move you closer to your proposed magic eight-ball question? It's important to note that you must consider the assumptions made if you try to bring all the data together.
**Step 2: Convert a question to a metric**
Here is the process for each sub-question from the first step:
- Select the specific data points needed.
- Determine visualization to get the goal analysis.
- Hypothesize the impacts of this information.
Next, bring in the community to provide feedback and trigger an iterative development process. The collaborative portion of this can be where the real magic happens. The best ideas often come when bringing a concept to someone that inspires them in a way you or they would not have imagined.
**Step 3: Analysis in action**
This step is where you start working through the implications of the metric or visualization you have created.
The first thing to consider is if this metric follows what is currently known about the community.
- If
**yes**: Are there assumptions made that catered to the results? - If
**no**: You want to investigate further whether this is potentially a data or calculation issue or if it is just a previously misunderstood part of the community.
Once you have determined if your analysis is stable enough to make inferences on, you can start to implement community initiatives on the information. As you are taking in the analysis to determine the next best step, you should identify specific ways to measure the initiative's success.
Now, observe these community initiatives informed by your metric. Determine if the impact is observable by your priorly established measurement of success. If not, consider the following:
- Are you measuring the right thing?
- Does the initiative strategy need to change?
**Example analysis area: New contributors**
**What is my magic eight-ball question?**
- Do people have an experience that establishes them as consistent contributors?
**What data do I have that goes into the analysis area and magic eight-ball question?**
- What contributor activity exists for repos, including timestamps?
Now that you have the information and a magic eight-ball question, break the analysis down into subparts and follow each of them to the end. This idea correlates with steps 2 and 3 above.
**Sub-question 1:** "How are people coming into this project?"
This question aims to see what new contributors are doing first.
**Data:** GitHub data on first contributions over time (issues, PR, comments, etc.).
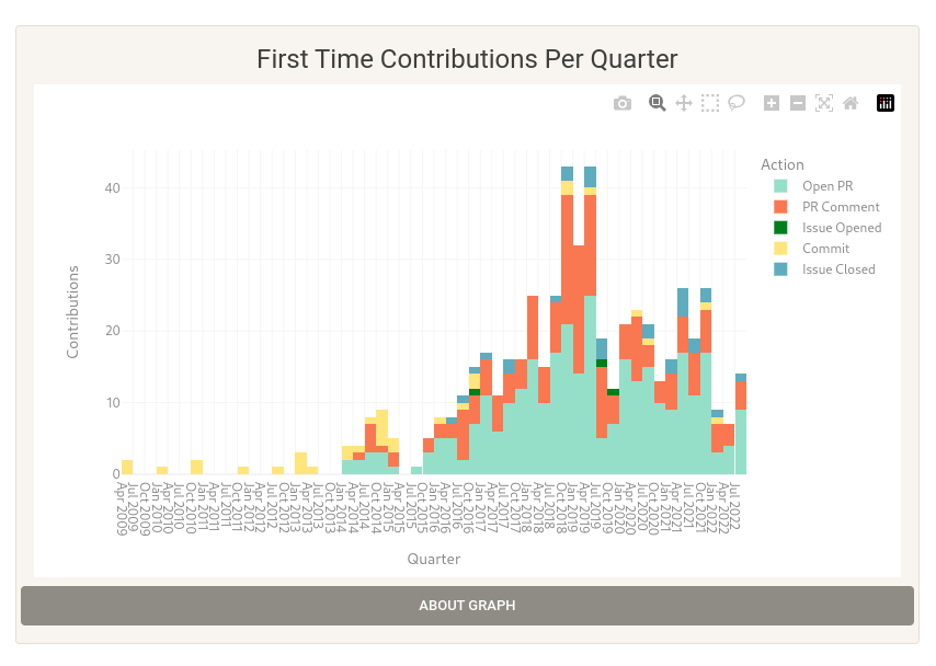
(Cali Dolfi, CC BY-SA 4.0)
**Visualization:** Bar chart with first-time contributions broken down by quarter.
**Potential extension:** After you talk with other community members, further examination breaks the information down by quarter and whether the contributor was a repeat or drive-by. You can see what people are doing when they come in and if that tells you anything about whether they will stick around.
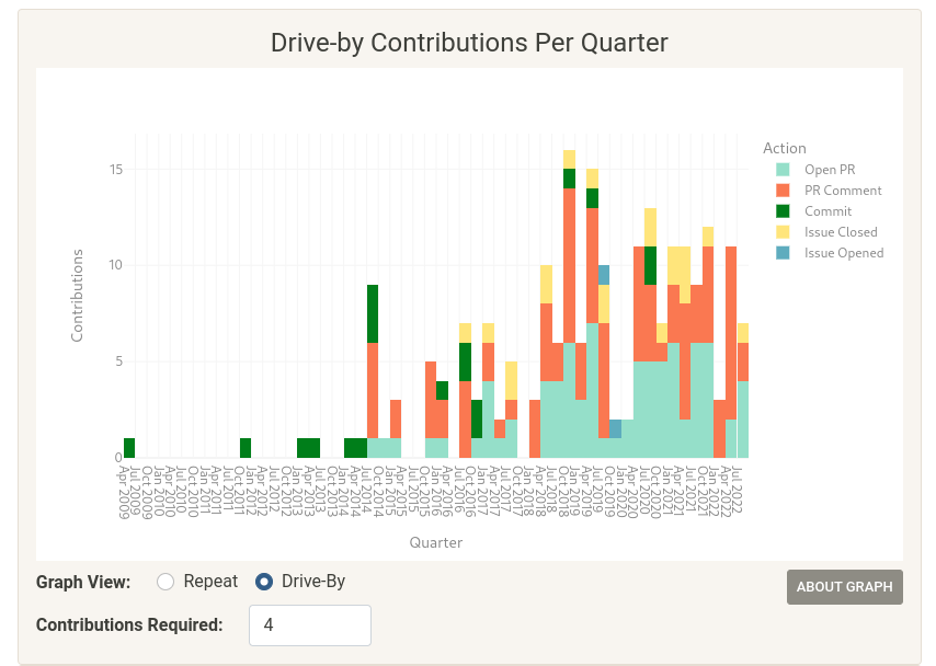
(Cali Dolfi, CC BY-SA 4.0)
**Potential actions informed by this information:**
- Does the current documentation support contributors for the most common initial contribution? Could you support those contributors better, and would that help more of them stay?
- Is there a contribution area that is not common overall but is a good sign for a repeat contributor? Perhaps PR is a common area for repeat contributors, but most people don't work in that area.
**Action items:**
- Label "good first issues" consistently and link these issues to the contribution docs.
- Add a PR buddy to these.
**Sub-question 2:** "Is our code base really dependent on drive-by contributors?"
**Data:** Contribution data from GitHub.
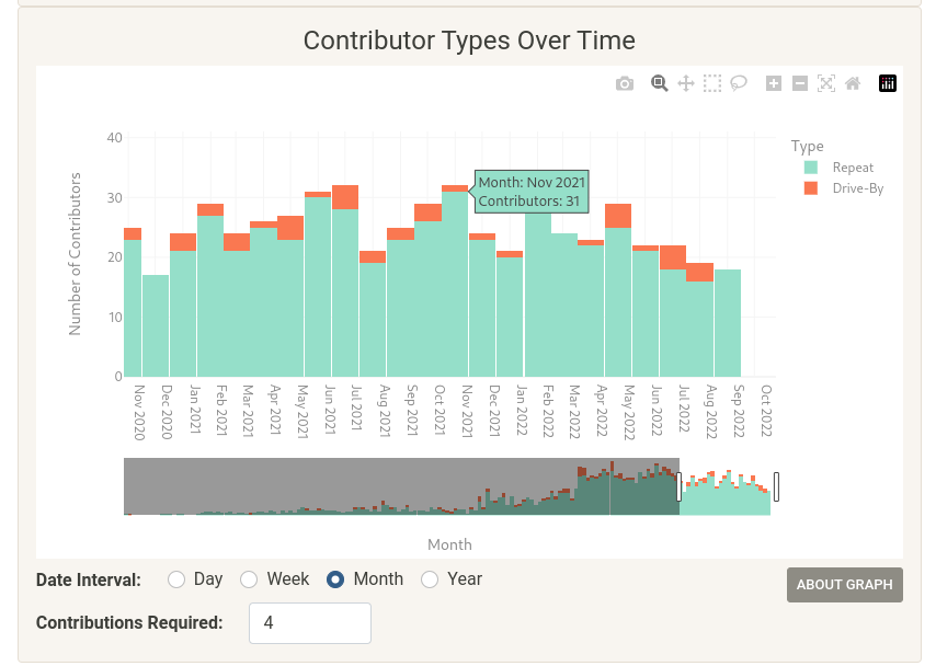
(Cali Dolfi, CC BY-SA 4.0)
**Visualization:** "Total contributions: Broken down by contributions by drive-by and repeat contributor."
**Potential actions informed by this information:**
- Does this ratio achieve the program's goals? Is a lot of the work done by drive-by contributors? Is this an underutilized resource, and is the project not doing its part to bring them in?
**Analysis: Lessons learned**
Number and data analysis are not "facts." They can say anything, and your internal skeptic should be very active when working with data. The iterative process is what will bring value. You don't want your analysis to be a "yes man." Take time to take a step back and evaluate the assumptions you've made.
If a metric just points you in a direction to investigate, that is a huge win. You can't look at or think of everything. Rabbit holes can be a good thing, and conversation starters can bring you to a new place.
Sometimes exactly what you want to measure is not there, but you might be able to get valuable details. You can't assume that you have all the puzzle pieces to get an exact answer to your original question. If you start to force an answer or solution, you can take yourself down a dangerous path led by assumptions. Leaving room for the direction or goal of analysis to change can lead you to a better place or insight than your original idea.
Data is a tool. It is not the answer, but it can bring together insights and information that would not have been accessible otherwise. The methodology of breaking down what you want to know into manageable chunks and building on that is the most important part.
Open source data analysis is a great example of the care you must take with all data science:
- The nuance of the topic area is the most important.
- The process of working through "what to ask/answer" is often overlooked.
- Knowing what to ask can be the hardest part, and when you come up with something insightful and innovative, it's much more than whatever tool you choose.
If you are a community member with no data science experience looking at where to start, I hope this information shows you how important and valuable you can be to this process. You bring the insights and perspectives of the community. If you are a data scientist or someone implementing the metrics or visualizations, you have to listen to the voices around you, even if you are also an active community member. More information on data science is listed at the end of this article.
**Wrap up**
Use the above example as a framework for establishing data analysis of your own open source project. There are many questions to ask of your results, and knowing both the questions and their answers can lead your project in an exciting and fruitful direction.
**More on data science**
Consider the following sources for more information on data science and the technologies that provide it with data:
## Comments are closed. |
15,642 | 被误用的罗伊·菲尔丁的有关描述性状态迁移(REST)的博士论文 | https://twobithistory.org/2020/06/28/rest.html | 2023-03-20T15:43:00 | [
"REST"
] | https://linux.cn/article-15642-1.html | 
符合 <ruby> 描述性状态迁移 <rt> REpresentational State Transfer </rt></ruby>(LCTT 译注:REST,译自审定公布名词数据库)的应用程序接口(API)无处不在。有趣的是又有多少人真正了解“符合描述性状态迁移”的应有之义呢?
大概我们中的大多数人都会跟 [黑客新闻网站上的这篇公开问答](https://news.ycombinator.com/item?id=7201871) 产生共鸣:
>
> 我阅读了几篇介绍描述性状态迁移(REST)的文章,甚至包括原始论文的部分章节。然而我仍然对REST 到底是什么只有一个相当模糊的想法。我开始认为没有人真的了解它,它仅仅是一个定义相当不充分的概念。
>
>
>
我曾经计划写一篇有关 REST 的博客,在里面探讨 REST 是如何成为这样一个在网络通信领域占主导地位的范式的。我通过阅读 [2000 年发表的 <ruby> 罗伊·菲尔丁 <rt> Roy Fielding </rt></ruby> 的博士论文](https://www.ics.uci.edu/~fielding/pubs/dissertation/fielding_dissertation_2up.pdf) 开始我的研究,这篇博士论文向世人介绍了 REST 的概念。在读过菲尔丁的博士论文以后,我意识到,相比之下,更引人注意的是菲尔丁的理论缘何受到如此普遍的误解。
(相对公平地说,)很多人知道 REST 源自菲尔丁的博士论文,但并没有读过该论文。因此对于这篇博士论文的原始内容的误解才得以流行。
最大的误解是:这篇博士论文直接解决了构建 API(API)的问题,我此前一直认为 REST 从一开始就打算成为构建在超文本传输协议(HTTP)之上的 <ruby> 网络 API <rt> Web API </rt></ruby>的架构模型,我相信很多人也这样认为。我猜测此前可能存在一个混乱的试验时期,开发人员采用完全错误的方式在 HTTP 基础上开发 API,然后菲尔丁出现了,并提出了将 REST 做为网络应用程序开发的正确方式。但是这种想法的时间线对不上:我们今天所熟知的网络服务的 API 并非是在菲尔丁出版他的博士论文之后才出现的新生事物。
菲尔丁的博士论文《架构风格与基于网络的软件架构设计》不是讨论如何在 HTTP 的基础上构建 API,而恰恰是讨论 HTTP 本身。菲尔丁是 HTTP/1.0 版规范的贡献者,同时也是 HTTP/1.1 版的共同作者。有感于从 HTTP 的设计中获得的架构经验,他的博士论文将 REST 视为指导 HTTP/1.1 的标准化过程的架构原则的精华。举例而言,他拒绝了使用新的 `MGET` 和 `MHEAD` 方法进行批量请求的提议,因为他认为这违反了 REST 所定义的约束条件,尤其是在一个符合 REST 的系统中传递的消息应该是易于代理和缓存的约束条件。<sup class="footnote-ref"> <a href="#fn1" id="fnref1"> [1] </a></sup> 因此,HTTP/1.1 转而围绕持久性连接设计,在此基础上可以发送多个 HTTP 请求。(菲尔丁同时认为网页保存在本地的浏览数据,即 cookie 是不符合 REST 的,因为它们在一个状态无关的系统中增加了状态描述,然而它们的应用已经根深蒂固了。<sup class="footnote-ref"> <a href="#fn2" id="fnref2"> [2] </a></sup>)菲尔丁认为,REST 并非构建基于 HTTP 的系统的操作指南,而是扩展 HTTP 的操作指南。
这并不意味着菲尔丁认为 REST 不能用于构建其他系统。只是他假定其他系统也是 “<ruby> 分布式超媒体系统 <rt> distributed hypermedia systems </rt></ruby>”。人们对 REST 还有另一个误解:认为它是一个可以用在任何网络应用中的通用架构。但是从这篇博士论文中菲尔丁介绍 REST 的部分你基本上能够得出如下的结论,“请注意,我们只设计了 HTTP,但是如果你发现你自己也在设计一个\_分布式超媒体系统\_,你也应该采用我们提出的称为 REST 的优秀架构,以让开发变得更容易”。有鉴于互联网已经存在了,我们尚不清楚为什么菲尔丁认为有人可能试图重新创建这样一个(和 HTTP 一样的)系统。或许在 2000 年的时候世界上仍然存在不只一个分布式超文本系统的空间吧。无论如何,菲尔丁已经说得很清楚了,REST 意在提供一套解决方案,来解决在试图经由网络连接超文本内容时出现的可扩展性与一致性问题,*而不是* 作为分布式应用的通用架构模型。
我们现在只记得菲尔丁的博士论文提出了 REST 的概念,但事实上,他的博士论文是在讨论一刀切的软件架构有多么糟糕,以及如何更好地选择符合你需求的软件架构。这篇博士论文中仅用了一个章节来讨论 REST 本身,大量的文本内容都都花在了对你能够在网络应用中运用的不同的架构风格 <sup class="footnote-ref"> <a href="#fn3" id="fnref3"> [3] </a></sup> 的分类上。这些架构风格包括:受 Unix 的管道设计启发的 <ruby> 管道-过滤器 <rt> Pipe-and-Filter </rt></ruby> (PF)风格,<ruby> 客户-服务器 <rt> Client-Server </rt></ruby> (CS)风格的多种改进,如 <ruby> 分层-客户-服务器 <rt> Layered-Client-Server </rt></ruby>(LCS)风格、<ruby> 客户-缓存-无状态-服务器 <rt> Client-Cache-Stateless-Server </rt></ruby>(C$SS)风格和<ruby> 分层-客户-缓存-无状态-服务器 <rt> Layered-Client-Cache-Stateless-Server </rt></ruby>(LC$SS)。这些缩略词未必实用,但是菲尔丁认为我们可以通过混合匹配现有风格提供的约束条件来派生出新的风格。REST 就是通过这种方式产生的,它本可以称之为 <ruby> 一致性-分层-按需代码-客户-缓存-无状态-服务器 <rt> Uniform-Layered-Code-on-Demand-Client-Cache-Stateless-Server </rt></ruby>(ULCODC$SS)风格,显然我们并没有这样做。菲尔丁建立上述分类是为了强调(每一种风格对应的)约束适用于不同的应用,而上述最后一种风格对应的约束是他所认为的最适用于 HTTP 的。
今天,REST 的无处不在是极具讽刺意味的。REST 在各种各样的网络应用中被盲目使用,但是菲尔丁最初只是将 REST 视作一种指引,通过它指导人们裁剪一种软件架构来适应独立应用的特殊需求。
我很难弄清楚这是如何发生的,毕竟菲尔丁已经明确地指出了不能让形式服从功能的陷阱。他在论文的一开始就作出了警告:由于没有正确地理解软件架构而“使用流行的架构设计是经常发生的”<sup class="footnote-ref"> <a href="#fn4" id="fnref4"> [4] </a></sup>。他在几页之后又重新强调了这一点:
>
> 一些架构风格经常被描述为适用于一切软件形式的“银弹”解决方案。然而,一名好的设计者应该选择能够满足解决特定问题的需要的架构风格<sup class="footnote-ref"> <a href="#fn5" id="fnref5"> [5] </a></sup>。
>
>
>
REST 本身就是一个特别糟糕的 “银弹” 解决方案。正如菲尔丁所指出的,它包含了可能不合适的利弊权衡,除非你试图构建一个分布式超媒体应用:
>
> REST 设计用来高效地进行大粒度的超媒体数据传输,并对网络应用场景中的常用见情形做了优化,但是可能会导致其在与其他形式的软件架构相互作用时不协调。<sup class="footnote-ref"> <a href="#fn6" id="fnref6"> [6] </a></sup>
>
>
>
菲尔丁提出 REST 是因为网络发展带来了“<ruby> 超越政府的可扩展性 <rt> anarchic scalability </rt></ruby>”这一棘手问题,菲尔丁的意思是需要以一种高性能的方式跨越组织和国家边界连接文件。REST 所施加的约束是经过精心选择的,以用来解决这一“超越政府的扩展性”问题。*面向公众* 的网络服务 API 同样需要解决类似的问题,因此可以理解为什么 REST 在这些应用中是适用的。然而,时至今日,如果发现一个工程团队使用 REST 构建了一个后端,即使这个后端只与工程团队完全控制的客户端通讯,也不会令人惊讶。我们都成为了 [<ruby> 蒙蒂巨蟒 <rt> Monty Python </rt></ruby> 的独幕滑稽剧](https://www.youtube.com/watch?v=vNoPJqm3DAY) 中的建筑师,那位建筑师按照屠宰场的风格设计了一座公寓大楼,因为屠宰场是他唯一具有的经验的建筑。(菲尔丁使用了这部滑稽剧中的一句台词作为他的博士论文的题词:打扰一下,你说的是“刀”吗?)(LCTT 校注:顺便说一句,Python 语言的名称来自于 “Monty Python” 这个英国超现实幽默表演团体的名字。)
有鉴于菲尔丁的博士论文一直在极力避免提供一种放之四海而皆准的软件架构,REST 又怎么会成为所有网络服务的事实上的标准呢?
我认为,在 21 世纪头十年的中期人们已经厌倦了简单对象访问协议(SOAP),因此想要创造另一种属于他们自己的四字首字母缩略词。
我只是半开玩笑。<ruby> 简单对象访问协议 <rt> Simple Object Access Protocol </rt></ruby>(SOAP)是一个冗长而复杂的协议,以致于你没法在不事先理解一堆互相关联的可扩展标记语言(XML)规范的基础上使用它。早期的网络服务提供基于 SOAP 的 API。在 21 世纪头十年中期,随着越来越多的 API 开始提供,被 SOAP 的复杂性激怒的软件开发者随之集体迁移。
SOAP 遭到了这群人的蔑视,Rails 之父 <ruby> 戴维·海涅迈尔·汉森 <rt> David Heinemeier Hansson </rt></ruby>(LCTT 译注:译自其所著的《重来》的中文版的作者译名)曾经评论:“我们感觉 SOAP 过于复杂了,它已经被企业人员接管。而当这一切发生的时候,通常没有什么好结果。”<sup class="footnote-ref"> <a href="#fn7" id="fnref7"> [7] </a></sup> 始于这一标志性的评论,Ruby-on-Rails 于 2007 年放弃了对 SOAP 的支持。“企业人员”总是希望所有内容都被正式指定,反对者认为这是浪费时间。
如果反对者不再继续使用 SOAP,他们仍然需要一些标准化的方式来进行工作。由于所有人都在使用 HTTP,而且代理与缓存的所有支持,每个人都至少会继续使用 HTTP 作为传输层,因此最简单的解决方案就是依赖 HTTP 的现有语义。这正是他们所做的工作。他们曾经称之为:<ruby> 去它的,重载 HTTP <rt> Fuck It, Overload HTTP </rt></ruby>(FIOH)。这会是一个准确的名称,任何曾经试图决定业务逻辑错误需要返回什么 HTTP 状态码的人都能证明这一点。但是在所有的 SOAP 正式规范工作的映衬下,这显得鲁莽而乏味。
幸运的是,出现了这篇由 HTTP/1.1 规范的共同作者创作的博士论文。这篇博士论文与扩展 HTTP 有某种模糊的联系,并给予了 FIOH 一个具有学术体面的外表。因此 REST 非常适合用来掩饰其实仅仅是 FIOH 的东西。
我并不是说事情就是这样发生的,也不是说在不敬业的创业者中确实存在着盗用 REST 的阴谋,但是这个故事有助于我理解,在菲尔丁的博士论文根本就不是讨论网络服务 API 的情况下,REST 是如何成为用于网络服务 API 的架构模型的。采用 REST 的约束存在一些效果,尤其是对于那些面向公众的需要跨越组织边界的 API 来说。这些 API 通常会从 REST 的“统一接口”中受益。这应该是 REST 起初在构建网络 API 时被提及的核心原因。但是,想象一下一种叫做 “FIOH” 的独立方法,它借用 “REST” 的名字只是为了营销,这有助于我解释我们今天所知道的 <ruby> REST 式 <rt> RESTful </rt></ruby> API 与菲尔丁最初描述的 REST 的架构风格之间的诸多差异。
举例而言,REST 纯粹主义者经常抱怨,那些所谓 RESTful API 实际并不是 REST API,因为它们根本就没有使用 <ruby> 超文本作为应用程序状态引擎 <rt> Hypermedia as The Engine of Application State </rt></ruby>(HATEOAS)。菲尔丁本人也做出过 [这样的批评](https://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-driven)。根据菲尔丁的观点,一个真正的 REST API 应当允许你通过跟随链接实现从一个基础端点访问所有的端点。如果你认为这些人的确在试图构建 RESTful API,那么存在一个明显的疏漏 —— 使用超文本作为应用程序状态引擎(HATEOAS)的确是菲尔丁最初提出的 REST 概念的基础,尤其是考虑到“描述性状态迁移(REST)”中的“状态迁移(ST)”意指使用资源之间的超链接进行状态机的导航(而不是像很多人所相信的那样通过线路传输资源状态)<sup class="footnote-ref"> <a href="#fn8" id="fnref8"> [8] </a></sup>。但是你试想一下,如果每个人都只是在构建 FIOH 的 API,并明里暗里的将之作为 REST API 宣传,或者更诚实一点说是作为 “RESTful” API 宣传,那么自然使用超文本作为应用程序状态引擎(HATEOAS)也就不重要了。
类似的,你可能会感到惊讶:尽管软件开发者喜欢不断地争论使用 `PUT` 方法还是使用 `PATCH` 方法来更新资源更加 RESTful,菲尔丁的博士论文却没有讨论哪个 HTTP 的操作方法应该映射到增删改查(CURD)操作。在 HTTP 操作与 CURD 操作之间建立一个标准的映射表是有用的,但是这一映射表是 FIOH 的一部分而不是 REST 的一部分。
这就是为什么,与其说没有人理解 REST,不如说我们应该认为 “REST” 这一术语是被误用了。REST API 这一现代概念与菲尔丁的 REST 架构之间存在历史联系,但事实上它们是两个不同的概念。历史联系适合作为确定何时构建 RESTful API 的指引而留在心底。你的 API 需要像 HTTP 那样跨越组织和政府边界吗?如果是的话,那么构建具有统一的可预测的接口的 RESTful API 可能是正确的方式。如果不是的话,你最好记住,菲尔丁更倾向于形式服从功能。或许类似 GraphQL 的方案或者仅仅 JSON-RPC 更适合你试图完成的工作。
---
1. Roy Fielding. “Architectural Styles and the Design of Network-based Software Architectures,” 128. 2000. University of California, Irvine, PhD Dissertation, accessed June 28, 2020, <https://www.ics.uci.edu/~fielding/pubs/dissertation/fielding_dissertation_2up.pdf>. [↩︎](#fnref1)
2. Fielding, 130. [↩︎](#fnref2)
3. Fielding distinguishes between software architectures and software architecture “styles.” REST is an architectural style that has an instantiation in the architecture of HTTP. [↩︎](#fnref3)
4. Fielding, 2. [↩︎](#fnref4)
5. Fielding, 15. [↩︎](#fnref5)
6. Fielding, 82 [↩︎](#fnref6)
7. Paul Krill. “Ruby on Rails 2.0 released for Web Apps,” InfoWorld. Dec 7, 2007, accessed June 28, 2020, <https://www.infoworld.com/article/2648925/ruby-on-rails-2-0-released-for-web-apps.html> [↩︎](#fnref7)
8. Fielding, 109. [↩︎](#fnref8)
---
via: <https://twobithistory.org/2020/06/28/rest.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[CanYellow](https://github.com/CanYellow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | RESTful APIs are everywhere. This is funny, because how many people really know what “RESTful” is supposed to mean?
I think most of us can empathize with [this Hacker News
poster](https://news.ycombinator.com/item?id=7201871):
I’ve read several articles about REST, even a bit of the original paper. But I still have quite a vague idea about what it is. I’m beginning to think that nobody knows, that it’s simply a very poorly defined concept.
I had planned to write a blog post exploring how REST came to be such a
dominant paradigm for communication across the internet. I started my research
by reading [Roy Fielding’s 2000
dissertation](https://www.ics.uci.edu/~fielding/pubs/dissertation/fielding_dissertation_2up.pdf),
which introduced REST to the world. After reading Fielding’s dissertation, I
realized that the much more interesting story here is how Fielding’s ideas came
to be so widely misunderstood.
Many more people know that Fielding’s dissertation is where REST came from than have read the dissertation (fair enough), so misconceptions about what the dissertation actually contains are pervasive.
The biggest of these misconceptions is that the dissertation directly addresses the problem of building APIs. I had always assumed, as I imagine many people do, that REST was intended from the get-go as an architectural model for web APIs built on top of HTTP. I thought perhaps that there had been some chaotic experimental period where people were building APIs on top of HTTP all wrong, and then Fielding came along and presented REST as the sane way to do things. But the timeline doesn’t make sense here: APIs for web services, in the sense that we know them today, weren’t a thing until a few years after Fielding published his dissertation.
Fielding’s dissertation (titled “Architectural Styles and the Design of
Network-based Software Architectures”) is not about how to build APIs on top of
HTTP but rather about HTTP itself. Fielding contributed to the HTTP/1.0
specification and co-authored the HTTP/1.1 specification, which was published
in 1999. He was interested in the architectural lessons that could be drawn
from the design of the HTTP protocol; his dissertation presents REST as a
distillation of the architectural principles that guided the standardization
process for HTTP/1.1. Fielding used these principles to make decisions about
which proposals to incorporate into HTTP/1.1. For example, he rejected a
proposal to batch requests using new `MGET`
and `MHEAD`
methods because he felt
the proposal violated the constraints prescribed by REST, especially the
constraint that messages in a REST system should be easy to proxy and
cache. 1 So HTTP/1.1 was instead designed around persistent connections over
which multiple HTTP requests can be sent. (Fielding also felt that cookies are
not RESTful because they add state to what should be a stateless system, but
their usage was already entrenched.
) REST, for Fielding, was not a guide to building HTTP-based systems but a guide to extending HTTP.
[2](#fn:2)This isn’t to say that Fielding doesn’t think REST could be used to build other
systems. It’s just that he assumes these other systems will also be
“distributed hypermedia systems.” This is another misconception people have
about REST: that it is a general architecture you can use for any kind of
networked application. But you could sum up the part of the dissertation where
Fielding introduces REST as, essentially, “Listen, we just designed HTTP, so if
you also find yourself designing a *distributed hypermedia system* you should
use this cool architecture we worked out called REST to make things easier.”
It’s not obvious why Fielding thinks anyone would ever attempt to build such a
thing given that the web already exists; perhaps in 2000 it seemed like there
was room for more than one distributed hypermedia system in the world. Anyway,
Fielding makes clear that REST is intended as a solution for the scalability
and consistency problems that arise when trying to connect hypermedia across
the internet, *not* as an architectural model for distributed applications in
general.
We remember Fielding’s dissertation now as the dissertation that introduced
REST, but really the dissertation is about how much one-size-fits-all software
architectures suck, and how you can better pick a software architecture
appropriate for your needs. Only a single chapter of the dissertation is
devoted to REST itself; much of the word count is spent on a taxonomy of
alternative architectural styles 3 that one could use for networked
applications. Among these is the Pipe-and-Filter (PF) style, inspired by Unix
pipes, along with various refinements of the Client-Server style (CS), such as
Layered-Client-Server (LCS), Client-Cache-Stateless-Server (C$SS), and
Layered-Client-Cache-Stateless-Server (LC$SS). The acronyms get unwieldy but
Fielding’s point is that you can mix and match constraints imposed by existing
styles to derive new styles. REST gets derived this way and could instead have
been called—but for obvious reasons was
not—Uniform-Layered-Code-on-Demand-Client-Cache-Stateless-Server (ULCODC$SS).
Fielding establishes this taxonomy to emphasize that different constraints are
appropriate for different applications and that this last group of constraints
were the ones he felt worked best for HTTP.
This is the deep, deep irony of REST’s ubiquity today. REST gets blindly used for all sorts of networked applications now, but Fielding originally offered REST as an illustration of how to derive a software architecture tailored to an individual application’s particular needs.
I struggle to understand how this happened, because Fielding is so explicit
about the pitfalls of not letting form follow function. He warns, almost at the
very beginning of the dissertation, that “design-by-buzzword is a common
occurrence” brought on by a failure to properly appreciate software
architecture. 4 He picks up this theme again several pages later:
Some architectural styles are often portrayed as “silver bullet” solutions for all forms of software. However, a good designer should select a style that matches the needs of a particular problem being solved.
[5]
REST itself is an especially poor “silver bullet” solution, because, as Fielding later points out, it incorporates trade-offs that may not be appropriate unless you are building a distributed hypermedia application:
REST is designed to be efficient for large-grain hypermedia data transfer, optimizing for the common case of the Web, but resulting in an interface that is not optimal for other forms of architectural interaction.
[6]
Fielding came up with REST because the web posed a thorny problem of “anarchic
scalability,” by which Fielding means the need to connect documents in a
performant way across organizational and national boundaries. The constraints
that REST imposes were carefully chosen to solve this anarchic scalability
problem. Web service APIs that are *public-facing* have to deal with a similar
problem, so one can see why REST is relevant there. Yet today it would not be
at all surprising to find that an engineering team has built a backend using
REST even though the backend only talks to clients that the engineering team
has full control over. We have all become the architect in [this Monty Python
sketch](https://www.youtube.com/watch?v=vNoPJqm3DAY), who designs an apartment
building in the style of a slaughterhouse because slaughterhouses are the only
thing he has experience building. (Fielding uses a line from this sketch as an
epigraph for his dissertation: “Excuse me… did you say ‘knives’?”)
So, given that Fielding’s dissertation was all about avoiding silver bullet software architectures, how did REST become a de facto standard for web services of every kind?
My theory is that, in the mid-2000s, the people who were sick of SOAP and wanted to do something else needed their own four-letter acronym.
I’m only half-joking here. SOAP, or the Simple Object Access Protocol, is a verbose and complicated protocol that you cannot use without first understanding a bunch of interrelated XML specifications. Early web services offered APIs based on SOAP, but, as more and more APIs started being offered in the mid-2000s, software developers burned by SOAP’s complexity migrated away en masse.
Among this crowd, SOAP inspired contempt. Ruby-on-Rails
dropped SOAP support in 2007, leading to this emblematic comment from Rails
creator David Heinemeier Hansson: “We feel that SOAP is overly complicated.
It’s been taken over by the enterprise people, and when that happens, usually
nothing good comes of it.” 7 The “enterprise people” wanted everything to be
formally specified, but the get-shit-done crowd saw that as a waste of time.
If the get-shit-done crowd wasn’t going to use SOAP, they still needed some standard way of doing things. Since everyone was using HTTP, and since everyone would keep using HTTP at least as a transport layer because of all the proxying and caching support, the simplest possible thing to do was just rely on HTTP’s existing semantics. So that’s what they did. They could have called their approach Fuck It, Overload HTTP (FIOH), and that would have been an accurate name, as anyone who has ever tried to decide what HTTP status code to return for a business logic error can attest. But that would have seemed recklessly blasé next to all the formal specification work that went into SOAP.
Luckily, there was this dissertation out there, written by a co-author of the HTTP/1.1 specification, that had something vaguely to do with extending HTTP and could offer FIOH a veneer of academic respectability. So REST was appropriated to give cover for what was really just FIOH.
I’m not saying that this is exactly how things happened, or that there was an actual conspiracy among irreverent startup types to misappropriate REST, but this story helps me understand how REST became a model for web service APIs when Fielding’s dissertation isn’t about web service APIs at all. Adopting REST’s constraints makes some sense, especially for public-facing APIs that do cross organizational boundaries and thus benefit from REST’s “uniform interface.” That link must have been the kernel of why REST first got mentioned in connection with building APIs on the web. But imagining a separate approach called “FIOH,” that borrowed the “REST” name partly just for marketing reasons, helps me account for the many disparities between what today we know as RESTful APIs and the REST architectural style that Fielding originally described.
REST purists often complain, for example, that so-called REST APIs aren’t
actually REST APIs because they do not use Hypermedia as The Engine of
Application State (HATEOAS). Fielding himself [has made this
criticism](https://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-driven).
According to him, a real REST API is supposed to allow you to navigate all its
endpoints from a base endpoint by following links. If you think that people are
actually out there trying to build REST APIs, then this is a glaring
omission—HATEOAS really is fundamental to Fielding’s original conception of
REST, especially considering that the “state transfer” in “Representational
State Transfer” refers to navigating a state machine using hyperlinks between
resources (and not, as many people seem to believe, to transferring resource
state over the wire). 8 But if you imagine that everyone is just building
FIOH APIs and advertising them, with a nudge and a wink, as REST APIs, or
slightly more honestly as “RESTful” APIs, then of course HATEOAS is
unimportant.
Similarly, you might be surprised to know that there is nothing in Fielding’s dissertation about which HTTP verb should map to which CRUD action, even though software developers like to argue endlessly about whether using PUT or PATCH to update a resource is more RESTful. Having a standard mapping of HTTP verbs to CRUD actions is a useful thing, but this standard mapping is part of FIOH and not part of REST.
This is why, rather than saying that nobody understands REST, we should just think of the term “REST” as having been misappropriated. The modern notion of a REST API has historical links to Fielding’s REST architecture, but really the two things are separate. The historical link is good to keep in mind as a guide for when to build a RESTful API. Does your API cross organizational and national boundaries the same way that HTTP needs to? Then building a RESTful API with a predictable, uniform interface might be the right approach. If not, it’s good to remember that Fielding favored having form follow function. Maybe something like GraphQL or even just JSON-RPC would be a better fit for what you are trying to accomplish.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
*Previously on TwoBitHistory…*
New post is up! I wrote about how to solve differential equations using an analog computer from the '30s mostly made out of gears. As a bonus there's even some stuff in here about how to aim very large artillery pieces.
— TwoBitHistory (@TwoBitHistory)[https://t.co/fwswXymgZa][April 6, 2020]
-
Roy Fielding. “Architectural Styles and the Design of Network-based Software Architectures,” 128. 2000. University of California, Irvine, PhD Dissertation, accessed June 28, 2020,
[https://www.ics.uci.edu/~fielding/pubs/dissertation/fielding_dissertation_2up.pdf](https://www.ics.uci.edu/~fielding/pubs/dissertation/fielding_dissertation_2up.pdf).[↩](#fnref:1) -
Fielding, 130.
[↩](#fnref:2) -
Fielding distinguishes between software architectures and software architecture “styles.” REST is an architectural style that has an instantiation in the architecture of HTTP.
[↩](#fnref:3) -
Fielding, 2.
[↩](#fnref:4) -
Fielding, 15.
[↩](#fnref:5) -
Fielding, 82.
[↩](#fnref:6) -
Paul Krill. “Ruby on Rails 2.0 released for Web Apps,” InfoWorld. Dec 7, 2007, accessed June 28, 2020,
[https://www.infoworld.com/article/2648925/ruby-on-rails-2-0-released-for-web-apps.html](https://www.infoworld.com/article/2648925/ruby-on-rails-2-0-released-for-web-apps.html)[↩](#fnref:7) -
Fielding, 109.
[↩](#fnref:8) |
15,643 | 终端基础:在 Linux 中创建文件 | https://itsfoss.com/create-files/ | 2023-03-20T16:11:07 | [
"终端"
] | https://linux.cn/article-15643-1.html | 
到目前为止,在这个终端基础系列中,你已经学会了:
* [更改目录](https://itsfoss.com/change-directories/)
* [创建新目录](https://itsfoss.com/make-directories/)
* [列出目录内容](https://itsfoss.com/list-directory-content/)
现在让我们学习如何在 Linux 命令行中创建文件。我将简要讨论向文件添加内容。但是,稍后将介绍有关编辑文本文件的详细信息。
### 使用 touch 命令创建一个新的空文件
使用 `touch` 命令非常简单。
```
touch filename
```
切换到你的主目录并创建一个名为 `practice_files` 的新目录,然后切换到该目录:
```
mkdir practice_files && cd practice_files
```
>
> ? `&&` 是一种组合两个命令的方法。只有当第一个命令执行成功时,第二个命令才会运行。
>
>
>
现在,创建一个名为 `new_file` 的新文件:
```
touch new_file
```
就是这样。你刚刚创建了一个新的空文件。
列出目录内容并使用 `ls -l` 命令检查文件的属性。

>
> ? `touch` 命令的最初目的是“触摸”文件并更改其时间戳。如果提供的文件不存在,它会创建一个具有该名称的新文件。
>
>
>
### 使用 echo 命令创建一个新文件
很久以前我就应该向你介绍 `echo` 命令。迟到总比不到好。`echo` 命令显示你提供给它的任何内容。因此得名“回声”。
```
echo Hello World
```
你可以使用重定向并将输出路由到文件。因此在此过程中创建一个新文件:
```
echo "Hello World" >> other_new_file
```
这样,你将创建一个名为 `other_new_file` 的新文件,其中包含文本 `Hello World`。

请记住,如果提供的文件已经存在,使用 `>>` 重定向,你将向文件添加一个新行。你也可以使用 `>` 重定向,但它会替换文件的现有内容。
更多关于重定向的信息可以在下面的教程中找到。
>
> **[解释:Linux 中的输入、输出和错误重定向](https://linuxhandbook.com/redirection-linux/?ref=its-foss)**
>
>
>
### 使用 cat 命令创建新文件
`cat` 命令的最初目的是连接文件。但是,它主要用于显示文件的内容。
它还可以使用选项创建新文件并添加内容。为此,你可以使用相同的 `>` 和 `>>` 重定向。
```
cat >> another_file
```
但是这个将创建一个新文件并允许你向其中添加一些文本。添加文本是可选的。**你可以使用 `Ctrl+d` 键退出 `cat` 输入模式。**

同样,附加模式 `>>` 在文件内容的末尾添加新文本,而覆盖模式 `>` 用新内容替换现有内容。
>
> ?️ 使用 `ls -l` 长列表显示并注意时间戳。现在 `touch` 文件:
>
>
>
```
touch other_new_file
```
你看到时间戳的区别了吗?
### 测试你的知识
你已经了解了如何创建新文件。这里有一些简单的练习来练习你刚刚学到的东西。它也包括前几章的一些内容。
* 使用 `touch` 命令创建三个新文件,分别命名为 `file1`、`file2` 和 `file3`。提示:你不需要运行 `touch` 三次。
* 创建一个名为 `files` 的目录,并在其中创建一个名为 `my_file` 的文件。
* 使用 `cat` 命令创建一个名为 `your_file` 的文件,并在其中添加以下文本 “This is your file”。
* 使用 `echo` 命令将新行 “This is our file” 添加到 `your_file`。
* 以相反的时间顺序显示所有文件(请参阅第 3 篇)。现在使用 `touch` 命令修改 `file2` 和 `file3` 的时间戳。现在再次按时间倒序显示内容。
这很有趣。你正在取得很好的进步。你已在本章中学会了创建新文件。接下来,你将学习如何查看文件的内容。
---
via: <https://itsfoss.com/create-files/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter 4: Creating Files in Linux
In this chapter of Linux Terminal Basics series for beginners, learn about creating new files using Linux commands.
So far, in this Terminal Basics series, you have learned to:
Let's now learn about creating files in the Linux command line. I'll briefly discuss adding content to the file. However, details on editing text files will be covered later.
## Create a new empty file with touch command
Using the touch command is pretty straightforward.
`touch filename`
Switch to your home directory and create a new directory called `practice_files`
and switch to this directory:
`mkdir practice_files && cd practice_files`
Now, create a new file named new_file:
`touch new_file`
That's it. You have just created a new empty file.
List the directory content and check the properties of the file with ls -l command.
## Create a new file using the echo command
I should have introduced you to the echo command long back. Better late than never. The echo command displays whatever you provide to it. Hence the name echo.
`echo Hello World`
You can use redirection and route the output to a file. And hence creating a new file in the process:
`echo "Hello World" >> other_new_file`
This way, you create a new file named `other_new_file`
with the text `Hello World`
in it.
Remember, if the provided file already exists, with >> redirection, you add a new line to the file. You can also use > redirection but then it will replace the existing content of the file.
More on redirection can be found in the below tutorial.
[Input Output & Error Redirection in Linux [Beginner’s Guide]Redirection is an essential concept in Linux. Learn how to use stdin, stdout, stderr and pipe redirection in Linux command line.](https://linuxhandbook.com/redirection-linux/)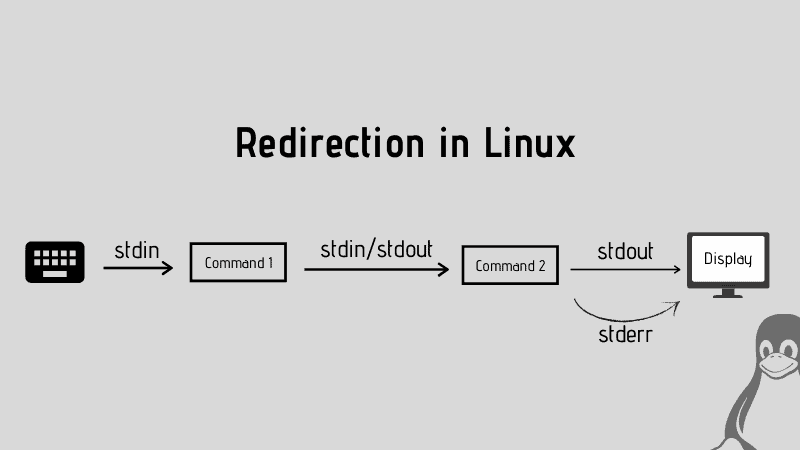

## Create new files using the cat command
The original purpose of the cat command was to concatenate files. However, it is primarily used for displaying the contents of a file.
It can also be used to create a new file with the option to add content. For that, you can use the same > and >> redirections.
`cat >> another_file`
But this one will create a new file and allow you to add some text to it. Adding text is optional. **You can exit the cat entering mode by using Ctrl+d or Ctrl+c keys.**
Again, the append mode >> adds new text at the end of file content while the clobber mode > replaces the existing content with new.
`touch other_new_file`
. Do you see the difference in the timestamps?## 📝 Test your knowledge
You have learned about creating new files. Here are a few simple exercises to practice what you just learned. It includes a little bit of the previous chapters as well.
- Use the touch command to create three new files named file1, file2 and file3. Hint: You don't need to run touch three times.
- Create a directory called files and create a file named my_file in it.
- Use the cat command to create a file called
`your_file`
and add the following text in it "This is your file". - Use the echo command to add a new line "This is our file" to your_file.
- Display all the files in reverse chronological order (refer to chapter 3). Now use the touch command to modify the timestamp of file2 and file3. Now display the content in reverse chronological order again.
That's pretty fun. You are making good progress. You have learned to create new files in this chapter. Next, you'll learn about viewing the contents of a file. |
15,645 | NixOS 系列 #3:在 NixOS 中安装和删除软件包 | https://itsfoss.com/nixos-package-management/ | 2023-03-21T09:09:24 | [
"NixOS"
] | https://linux.cn/article-15645-1.html | 
NixOS 中的打包系统是它最强大的地方。Nix 软件包管理器使用的语法与 `apt`、`dnf` 和其他软件包管理器大不相同。
这也是 [人们应该尝试使用 NixOS 的原因之一](/article-15606-1.html)。
在本指南中,我将分享两种在 NixOS 上安装和删除软件包的方法:
* 使用 Nix 软件包管理器
* 使用 `configuration.nix` 配置文件
>
> ⚠️ 使用 Nix 软件包管理器,你只能安装软件包,而不能安装 OpenSSH 或 Plex 服务器等服务。对于服务的安装,你必须使用 Nix 配置文件。
>
>
>
要安装任何软件包,必须知道它的确切名称,为此,我将从如何在 NixOS 中搜索软件包开始。
### 搜索软件包
要寻找软件包,你可以使用它的 [网页搜索](https://search.nixos.org/packages?ref=its-foss)。
你可以使用如下步骤:
* 在搜索栏中输入软件包的名称
* 选择适当的软件包(从给出的描述中决定)
* 点击 “nix-env” 标签页
* 复制 NixOS 命令(第一条)
例如,如果我想要 `librewolf` 包,我将执行以下操作:

你也可以通过终端做同样的事情。
要使用终端搜索软件包,你可以按照给定的命令语法进行:
```
nix-env -qaP --description [软件包名称]
```
例如,在这里,我搜索了 `librewolf`:

你必须复制输出的第一行,因为那是你需要安装的软件包的名称。
在这里它是 `nixos.librewolf`。
是的,它听起来可能没有像使用 [APT](https://itsfoss.com/apt-command-guide/) 或 DNF 时软件包名字那么方便。但是,我认为这并不是大问题。
一些妥协或许会换来一些好处?
### 在 NixOS 中安装一个软件包
要安装一个软件包,你所要做的就是使用以下命令语法:
```
nix-env -iA [软件包名称]
```
而且,如果你使用网络搜索来寻找软件包,你就已经有了安装所需的确切命令。
所以,假设我想安装 `librewolf',我将使用以下命令:
```
nix-env -iA nixos.librewolf
```
如果你想进行全系统的安装(让每个用户都能使用这个包),用 `sudo` 执行安装命令:
```
sudo nix-env -iA nixos.librewolf
```
就是这样!你将很快安装好你喜欢的软件包。
### 在 NixOS 中卸载一个软件包
要删除一个软件包,你可以参考下面的命令语法:
```
nix-env --uninstall [软件包名称]
```
因此,如果我必须删除 `librewolf` 包,我必须使用以下命令:
```
nix-env --uninstall librewolf
```
如果你仔细注意,我使用了 `librewolf` 而不是 `nixos.librewolf` 来安装。
这意味着你在删除软件包时要跳过 `nixos` 部分,这使事情变得简单而快速。
### 在 NixOS 中安装服务
正如我前面提到的,你不能使用 Nix 软件包管理器来安装像 OpenSSH、Plex 服务器、[Flatpak](https://itsfoss.com/what-is-flatpak/) 等服务。
从搜索服务到安装过程,都与你上面看到的不同。
所以让我先说说如何 **搜索服务**。
* 要搜索服务,请前往 Nix 软件包搜索 [网页](https://search.nixos.org/packages?ref=its-foss)
* 选择 “<ruby> NixOS 选项 <rt> NixOS options </rt></ruby>”(页面顶部菜单行的第三个选项)
* 输入你要找的服务的名称
* 复制服务的名称
例如,在这里,我正在搜索 OpenSSH 服务。

一旦你找到了这个名字,用下面的命令打开 `configuration.nix` 文件:
```
sudo nano /etc/nixos/configuration.nix
```
并在行末添加服务的名称(在 `}` 之前),如下:
```
[service_name] = true;
```
由于 **我想启用 OpenSSH**,我将添加以下内容:
```
services.openssh.enable = true;
```

一旦你在配置文件中添加了服务,[保存修改并退出 Nano](https://linuxhandbook.com/nano-save-exit/?ref=its-foss) 文本编辑器。
要启用该服务,请重建配置文件,并使用以下命令切换到所做的更改:
```
sudo nixos-rebuild switch
```
这就行了,你已经启用了该服务。
### 从 NixOS 卸载服务
要卸载一个服务,你所要做的就是在 `configuration.nix` 文件中删除或注释该服务的一行。
因此,首先,用以下命令打开配置文件:
```
sudo nano /etc/nixos/configuration.nix
```
寻找服务,并删除这一行或用 `#` 注释掉:

通过添加注释 `#`,我忽略了 OpenSSH 服务的加载,因为我不再需要它在我的系统上。
保存修改并退出文本编辑器。
最后,重建配置文件并进行切换:
```
sudo nixos-rebuild switch
```
### 使用 Nix 配置文件安装软件包
配置文件可以让你 **方便地一次性管理软件包**。
要使用 Nix 配置文件安装软件包,你必须在配置文件中输入软件包的名称、重建,然后切换到配置文件,就可以了。
首先,打开 `configuration.nix` 文件。
```
sudo nano /etc/nixos/configuration.nix
```
如果你想 **为一个特定的登录用户安装软件包**,将软件包的名称添加到用户的配置文件中。
用户配置文件看起来像这样:
```
users.users.sagar = {
isNormalUser = true;
description = "Sagar";
extraGroups = [ "networkmanager" "wheel" ];
packages = with pkgs; [
firefox
];
};
```
当然,它将显示你的用户名而不是 `sagar`。
你应该使用如下语法来添加软件包的名称:
```
packages = with pkgs; [
软件包名称
];
```
所以我们假设我也想安装 `Thunderbird`,那么我将添加它的名字,如下所示:

你必须在方括号内添加所有的软件包名称,不要用逗号。它必须像截图中描述的那样一个软件一个新的行。
但是如果你想在整个系统中安装这个包,那么你必须在 `environment.systemPackages` 下添加包的名字,比如:
```
environment.systemPackages = with pkgs; [
软件包名称
];
```

一旦你完成了在系统配置文件或用户配置文件,甚至两者中添加所需软件包的名称,你将需要按照同样的命令来完成安装:
```
sudo nixos-rebuild switch
```
这样就可以了!
### 使用 Nix 配置文件删除软件包
要删除软件包,你所要做的就是按照给定的简单步骤进行:
* 打开 Nix 配置文件
* 删除或注释掉软件包的名称
* 重新构建配置并进行切换
所以,让我们从第一步开始(打开配置文件):
```
sudo nano /etc/nixos/configuration.nix
```
接下来,注释掉用户配置文件或系统配置文件中的包的名称:

保存更改并退出配置文件。
最后,重建配置文件,并做一个切换来删除包:
```
sudo nixos-rebuild switch
```
这是这样!
>
> ? 目前,还没有官方的 GUI 工具来帮助你安装/删除软件包。你可能会发现一些由社区开发的项目,如 [nix-gui](https://github.com/nix-gui/nix-gui?ref=its-foss) 和 [nix42b](https://gitlab.com/juliendehos/nix42b?ref=its-foss),但它们不再被维护或仅仅处于早期开发阶段。
>
>
>
### 接下来...
我希望你喜欢阅读 NixOS 系列,就像我写它一样。
在下一篇中,我将强调一些在你安装 NixOS 后需要马上做的重要事情。
如果你认为我遗漏了什么或有其他建议,请在评论中告诉我。
---
via: <https://itsfoss.com/nixos-package-management/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Install and Remove Packages in NixOS
It can be a bit different when installing and removing packages in NixOS. Here, we explain it to make things easy.
The packaging system in NixOS is its strongest point. The Nix package manager uses a vastly different syntax than apt, dnf and other package managers.
It is also [one of the reasons why one should try using NixOS](https://itsfoss.com/why-use-nixos/).
In this guide, I will share two ways to install and remove packages on NixOS:
**Using the Nix package manager****Using**`configuration.nix`
config file
To install any package, it is necessary to know its exact name, and for that purpose, I will start with how you can search for packages in NixOS.
**Suggested Read 📖**
[NixOS Series #2: How to Install NixOS on a Virtual Machine?Want to try NixOS? Get started by installing it on a virtual machine.](https://itsfoss.com/install-nixos-vm/)

## Search packages
To look for packages, you can use its [web search](https://search.nixos.org/packages) using your preferred browser.
You can utilize its web search using the given steps:
**Enter the name of the package in the search bar****Select the appropriate package (decide from the given description)****Click on**`nix-env`
option**And copy the command for**`NixOS`
(first one)
For example, if I want `librewolf`
package, I will perform the following:
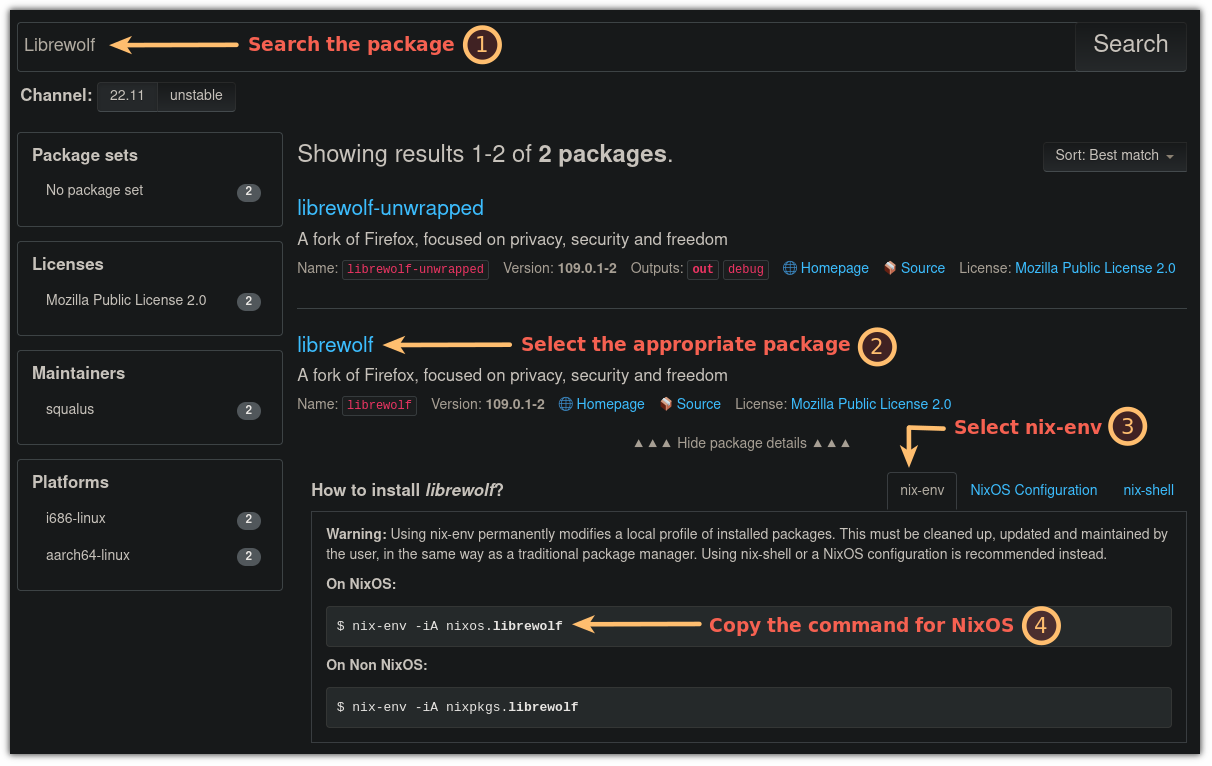
You can do the same through the** terminal**.
To search packages using the terminal, you can follow the given command syntax:
`nix-env -qaP --description [package_name]`
For example, here, I searched for the `librewolf`
:

You will have to copy the first line of the output as that is the name for the package you need to install.
For me, it was `nixos.librewolf`
.
Yes, **it may not sound as convenient as the package names** when using [APT](https://itsfoss.com/apt-command-guide/) or DNF. But, it is not too bad, I think.
Some compromises for some benefits, I guess?
**Suggested Read 📖**
[How to Install RPM Files on Fedora Linux [Beginner’s Tutorial]This beginner article explains how to install RPM packages on Fedora and Red Hat Linux. It also shows you how to remove those RPM packages afterwards. When you start using Fedora Linux in the Red Hat domain, sooner or later, you’ll come across .rpm files. Like .exe files in](https://itsfoss.com/install-rpm-files-fedora/)

## Install a package in NixOS
To install a package, all you have to do is use the following command syntax:
`nix-env -iA [package_name]`
And if you use the web search to look for the package, you will already have the exact command you need for the installation.
So let's say I want to install `librewolf`
, so I will be using the following command:
`nix-env -iA nixos.librewolf`
And if you want to perform a system-wide install (make this package available for every user), execute the installation command with `sudo`
:
`sudo nix-env -iA nixos.librewolf`
That's it! You will have your favorite package installed in no time.
## Uninstall a Package in NixOS
To remove a package, you can refer to the given command syntax:
`nix-env --uninstall [package_name]`
So if I have to remove the `librewolf`
package, I have to use the following command:
`nix-env --uninstall librewolf`
If you notice closely, I have used `librewolf`
instead of `nixos.librewolf`
what I used for the installation.
This means you will have to skip the `nixos`
part during removal of the package, which makes things easy and quick.
## Install services in NixOS
As I mentioned earlier, you can not use the nix package manager to install services like OpenSSH, Plex server, [Flatpak](https://itsfoss.com/what-is-flatpak/), etc.
From searching for the service to the installation process, it differs from what you saw above.
So let me start with how you can **search for a service**:
**To search for the service, head****over to the web page****for the Nix package search.****Select**`NixOS options`
(3rd option in the top-menu row of the page).**Enter the name of the service you are looking for.****Copy the name of the service.**
For example, here, I'm searching for OpenSSH service:
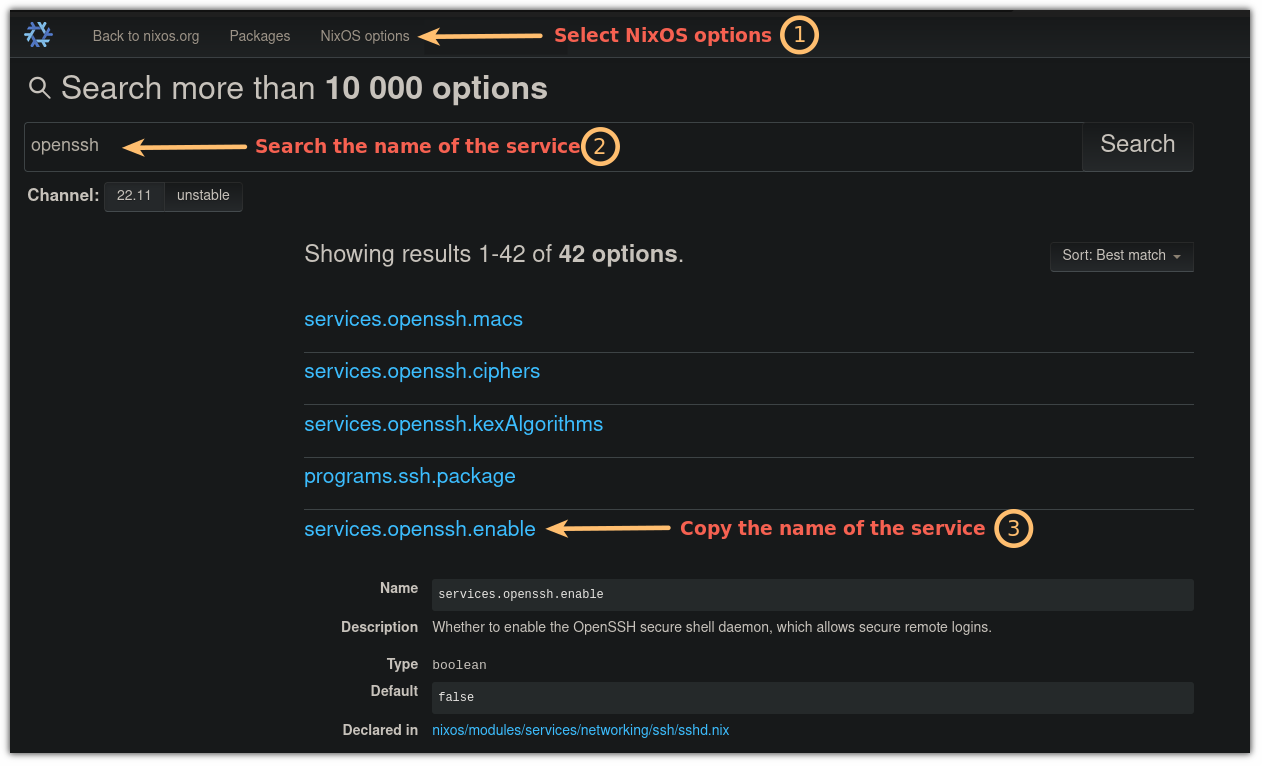
Once you have the name, open the `configuration.nix`
file using the following command:
`sudo nano /etc/nixos/configuration.nix`
And add the name of the service at the end of the line (before `}`
) in the following manner:
`[service_name] = true;`
As **I want to enable OpenSSH**, I will be adding the following:
`services.openssh.enable = true;`
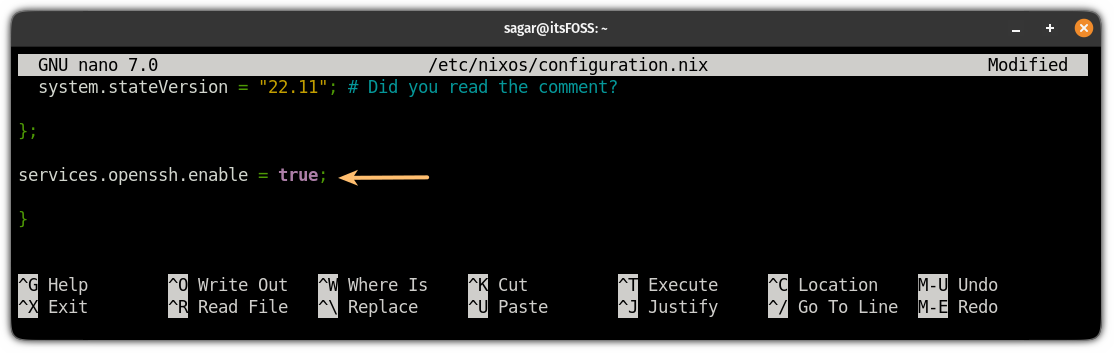
Once you are done adding the service to the config file, [save the changes and exit from the nano](https://linuxhandbook.com/nano-save-exit/) text editor.
To enable the service, rebuild the config file and switch to the changes using the following command:
`sudo nixos-rebuild switch`
That's it! You have the service enabled.
## Uninstall services from NixOS
To uninstall a service, all you have to do is remove or comment out the line for that service from `configuration.nix`
file.
So first, open the config file using the following command:
`sudo nano /etc/nixos/configuration.nix`
Look for the service and remove the line or comment it out with `#`
:
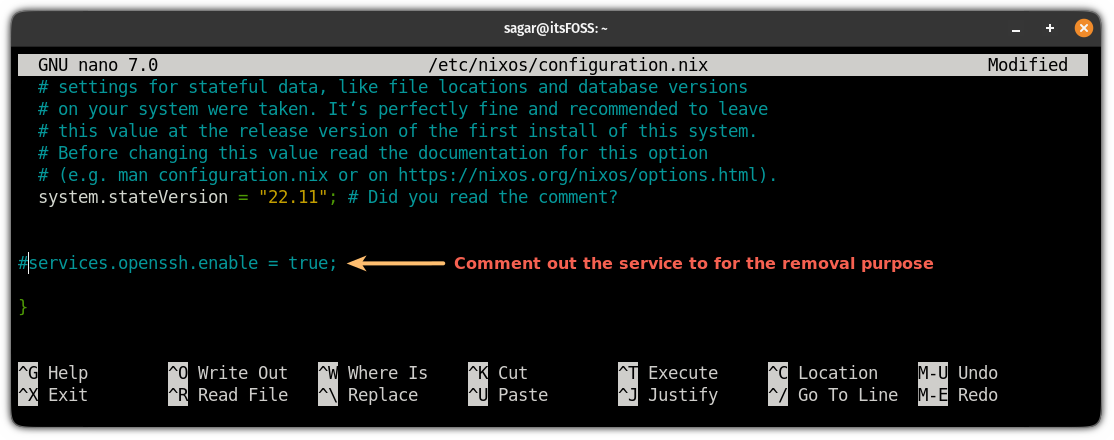
With the added comment #, I am ignoring the OpenSSH service to load up as I no longer want it on my system.
Once done, **save the change and exit from the text editor.**
And finally, rebuild the config file and make the switch:
`sudo nixos-rebuild switch`
## Install packages using Nix config file
The configuration file lets you** easily manage packages in one go**.
To install a package using the Nix config file, you have to enter the package's name in the config file, rebuild, and switch to the config file, and that's it.
First, open the `configuration.nix`
file:
`sudo nano /etc/nixos/configuration.nix`
If you want to **install a package for a specific logged-in user,** add the package's name to the user's profile.
The user profile looks like this:
```
users.users.sagar = {
isNormalUser = true;
description = "Sagar";
extraGroups = [ "networkmanager" "wheel" ];
packages = with pkgs; [
firefox
];
};
```
Sure, it will show your username instead of `sagar`
.
And you are supposed to add the name of the package using the syntax `packages = with pkgs; [package_name];`
So let's suppose I want to install `Thunderbird`
as well, then I will add its name as shown below:
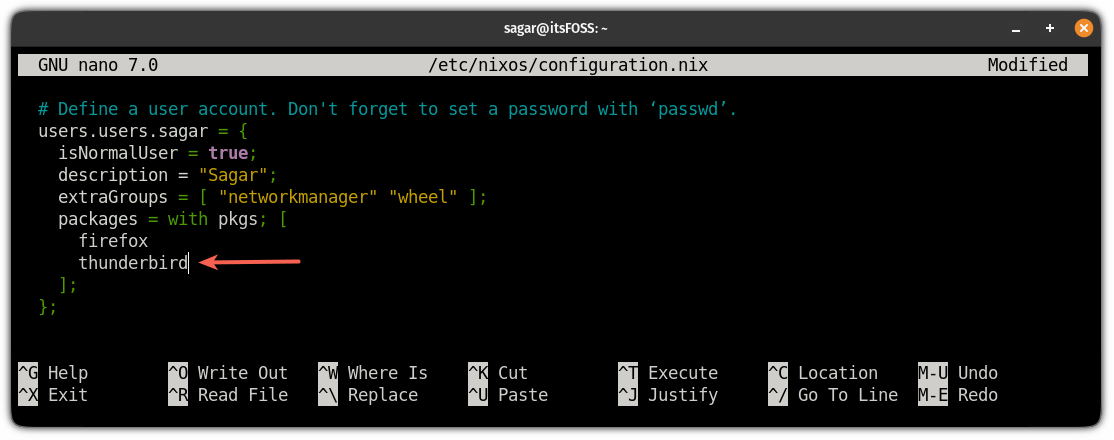
You must add **all the package names inside the square bracket** without commas. It has to be on a new line as the screenshot describes.
But **if you want to install this package system-wide**, then you will have to add the package name under **environment.systemPackages **like:
`environment.systemPackages = with pkgs; [package_name]`
;
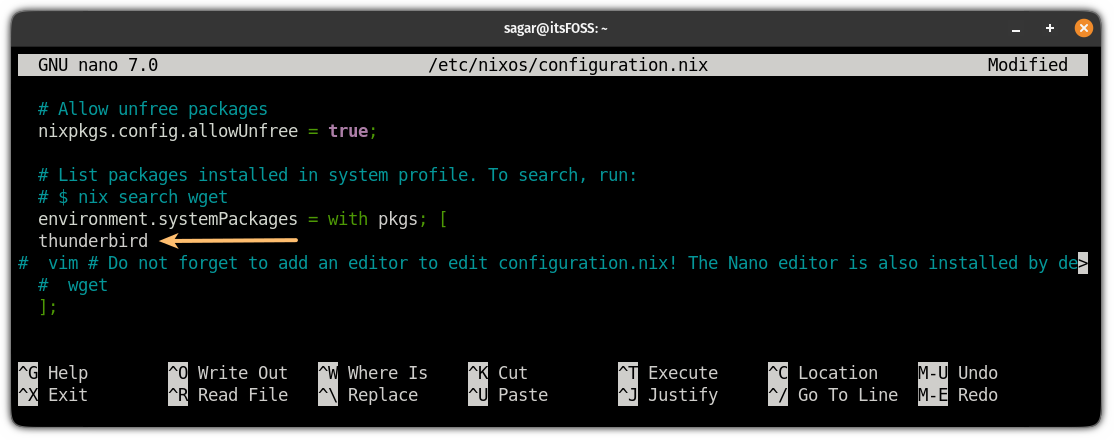
Once you are done adding the name of the required package in the system profile or user profile, or even both, you will have to follow the same command to complete the installation:
`sudo nixos-rebuild switch`
And you have it!
## Remove packages using the Nix config file
To remove the package, all you have to do is follow the given simple steps:
**Open the Nix config file****Remove or comment out the name of the package****Rebuild the config and make a switch**
So let's start with the first step (opening the config file):
`sudo nano /etc/nixos/configuration.nix`
Next, comment out the name of the packet from the user profile or system profile:
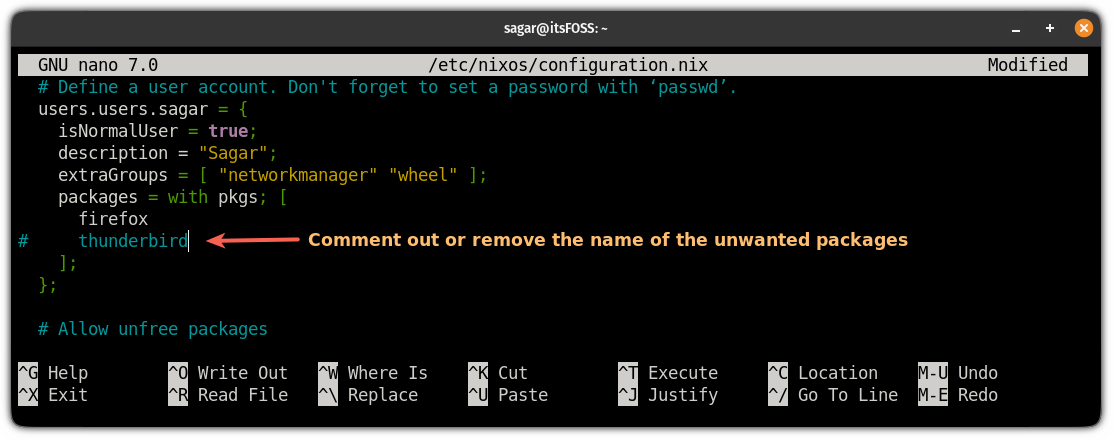
Save changes and exit from the config file.
And finally, rebuild the config and make a switch to remove the package:
`sudo nixos-rebuild switch`
That's it!
## Next Up...
I hope you enjoy reading the NixOS series as much as I do writing it.
In the next part, I highlight some **important things you need to do right after installing NixOS**.
[NixOS Series #4: Things To Do After Installing NixOSWhat do you do right after installing NixOS? Clueless? We got your back.](https://itsfoss.com/things-to-do-after-installing-nixos/)

*💬 If you think I'm missing out on something or have any other suggestions, please let me know in the comments. * |
15,646 | 我是如何毁掉我的树莓派的 | https://opensource.com/article/23/3/how-i-destroyed-my-raspberry-pi | 2023-03-21T15:47:17 | [
"树莓派",
"电源"
] | https://linux.cn/article-15646-1.html | 
>
> 多测量几次总比测量一次好。我掉到坑里,希望你可以不用。
>
>
>
我想写一篇文章来演示“如何使用树莓派实现莫某的自动化”,或围绕树莓派的其他一些有趣、好奇或有用的应用。正如你可能从标题中意识到的那样,我不能再提供这样的文章了,因为我毁了我心爱的树莓派。
树莓派是每个技术爱好者办公桌上的标准设备。因此,大量教程和文章告诉你可以用它做什么。这篇文章反而涵盖了阴暗面:我描述了你最好不要做的事情!
### 电缆颜色
在谈到实际的破坏点之前,我想提供一些背景。在房屋内外进行电气工作时,你必须处理不同颜色的电缆。在德国,每栋房子都连接到三相交流电网,你通常会发现以下电缆颜色:
* 零线:蓝色
* (PE)地线:黄绿色
* (L1)火线 1:棕色
* (L2)火线 2:黑色
* (L3)火线 3:灰色
例如,给灯接线时,你接零线(N,蓝色)和火线(L,有 1/3 的机会是棕色),它们之间的电压为 230V 交流电。
### 连接树莓派
今年早些时候,我写了一篇关于 [OpenWrt,家用路由器固件的开源替代品](https://opensource.com/article/22/7/openwrt-open-source-firmware) 的文章。在文章中,我使用了 TP-link 路由器设备。但是,最初的计划是使用我的树莓派 4。

我的想法是构建一个旅行路由器,我可以将其安装在我的大篷车中以改善露营地的互联网连接(我是那种离不开互联网的露营者)。为此,我在我的树莓派中添加了一个单独的 USB 无线网卡以连接第二个 Wifi 天线并安装了 [OpenWrt](https://openwrt.org/)。此外,我添加了一个 12V 至 5V DC/DC 转换器来连接大篷车中的 12V 接线。我用桌上的 12V 汽车电池测试了这个设置,它按预期工作。一切设置和配置完成后,我开始将其安装到我的大篷车中。
在我的大篷车里,我找到了一根蓝色和一根棕色的电线,将它与 12V 至 5V DC/DC 转换器相连,将保险丝放回,然后……

这个芯片,自己爆开了,它才是真正的降压变压器。我非常自信地认为蓝线是在 0V 电位上,棕色的是在 12V 上,我甚至没有测量。后来我了解到,蓝色的线是在 12V 上,而棕色的线是接地(这在汽车电子产品中很常见)。
### 总结
自从这次事故后,我的树莓派就再也启动不起来了。由于树莓派的价格飞涨,我不得不寻找替代品。幸运的是,我遇到了 TP-Link 旅行路由器,它也可以运行 Open-WRT 并且可以令人满意地完成它的工作。
最后:多测量几次总比测量一次好。
---
via: <https://opensource.com/article/23/3/how-i-destroyed-my-raspberry-pi>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I wanted to write an article demonstrating "How to automate XYZ with the Raspberry Pi" or some other interesting, curious, or useful application around the Raspberry Pi. As you might realize from the title, I cannot offer such an article anymore because I destroyed my beloved Raspberry Pi.
The Raspberry Pi is a standard device on every technology enthusiast's desk. As a result, tons of tutorials and articles tell you what you can do with it. This article instead covers the dark side: I describe what you had better not do!
## Cable colors
I want to provide some background before I get to the actual point of destruction. You have to deal with different cable colors when doing electrical work in and around the house. Here in Germany, each house connects to the three-phase AC supply grid, and you usually find the following cable colors:
- Neutral conductor: Blue
- (PE) Protective conductor: Yellow-green
- (L1) Phase 1: Brown
- (L2) Phase 2: Black
- (L3) Phase 3: Grey
For example, when wiring a lamp, you pick up neutral (N, blue) and phase (L, 1/3 chance that it is brown), and you get 230V AC between them.
## Wiring the Raspberry Pi
Earlier this year, I wrote an article about [OpenWrt, an open source alternative to firmware for home routers](https://opensource.com/article/22/7/openwrt-open-source-firmware). In the article, I used a TP-link router device. However, the original plan was to use my Raspberry Pi model 4.

(Stephan Avenwedde, CC BY-SA 4.0)
The idea was to build a travel router that I could install in my caravan to improve the internet connectivity at a campsite (I'm the kind of camper who can't do without the internet). To do so, I added a separate USB-Wifi-dongle to my Raspberry Pi to connect a second Wifi antenna and installed [OpenWrt](https://openwrt.org/). Additionally, I added a 12V-to-5V DC/DC converter to connect with the 12V wiring in the caravan. I tested this setup with a 12V vehicle battery on my desk, and it worked as expected. After everything was set up and configured, I started to install it in my caravan.
In my caravan, I found a blue and a brown wire, connected it with the 12V-to-5V DC/DC converter, put the fuses back in, and…

(Stephan Avenwedde, CC BY-SA 4.0)
The chip, which disassembled itself, is the actual step-down transformer. I was so confident that the blue wire was on 0V potential and the brown one was on 12V that I didn't even measure. I have since learned that the blue cable is on 12V, and the brown cable is on ground potential (which is pretty common in vehicle electronics).
## Wrap up
Since this accident, my Raspberry Pi has never booted up. Because the prices for the Raspberry Pi have skyrocketed, I had to find an alternative. Luckily, I came across the TP-Link travel router, which can also run Open-WRT and does its job satisfactorily. In closing: It's better to measure too often than one time too few.
## 2 Comments |
15,648 | 如何在 Linux 中使用旧相机作为网络摄像头 | https://opensource.com/article/22/12/old-camera-webcam-linux | 2023-03-21T23:36:00 | [
"相机",
"摄像头"
] | https://linux.cn/article-15648-1.html | 
>
> 我用 gphoto2 给我的旧单反相机带来了新的生命,把它变成了 Linux 电脑的网络摄像头。
>
>
>
今年,在我基本上放弃了 MacBook,转而使用 NixOS 机器之后,我开始在与人进行视频通话时被要求“打开摄像头”。这是一个问题,因为我没有网络摄像头。我考虑购买一个,但后来我意识到我有一台完好无损的 2008 年产的佳能 EOS Rebel XS 数码单反相机放在书架上。这台相机有一个 mini-USB 接口,所以我自然而然地思考:一台数码单反相机、一个 mini-USB 接口和一台台式电脑,是否意味着我能拥有一个网络摄像头?
只有一个问题。我的佳能 EOS Rebel XS 不能录制视频。它可以拍摄一些漂亮的照片,仅此而已。所以这结束了?
还是有别的办法?
恰好有一个叫做 [gphoto2](http://gphoto.org/) 的神奇的开源软件。一旦安装,它允许你从计算机控制各种支持的相机,并拍摄照片和视频。
### 支持的相机
首先,了解你的设备是否得到支持:
```
$ gphoto2 --list-cameras
```
### 拍摄图像
你可以用它拍照:
```
$ gphoto2 --capture-image-and-download
```
快门触发,图像会保存到你当前的工作目录中。
### 录制视频
我意识到了这里的潜力,所以尽管我的相机没有视频功能,我还是决定尝试 `gphoto2 --capture-movie` 命令。不知怎么,尽管我的相机不支持视频功能,`gphoto2` 仍然能够生成一个 MJPEG 文件!
在我的相机上,我需要将其置于“实时预览”模式下,然后 `gphoto2` 才能录制视频。这包括将相机设置为纵向模式,然后按下 “<ruby> 设置 <rt> Set </rt></ruby>” 按钮,使取景器关闭,相机屏幕显示图像。不幸的是,这还不足以将其用作网络摄像头。它仍然需要分配一个视频设备,例如 `/dev/video0`。
### 安装 ffmpeg 和 v4l2loopback
毫不奇怪,有一个开源的解决方案来解决这个问题。首先,使用你的包管理器安装 `gphoto2`、`ffmpeg` 和 `mpv`。例如,在 Fedora 、CentOS 、Mageia 和类似的 Linux 发行版上:
```
$ sudo dnf install gphoto2 ffmpeg mpv
```
在 Debian、Linux Mint 及其类似发行版:
```
$ sudo apt install gphoto2 ffmpeg mpv
```
我使用的是 NixOS,这是我的配置文件:
```
# configuration.nix
...
environment.systemPackages = with pkgs; [
ffmpeg
gphoto2
mpv
...
]
```
创建虚拟视频设备需要使用 `v4l2loopback` Linux 内核模块。在撰写本文时,该功能未包含在主线内核中,因此你需要自己下载和编译它:
```
$ git clone https://github.com/umlaeute/v4l2loopback
$ cd v4l2loopback
$ make
$ sudo make install
$ sudo depmod -a
```
如果你像我一样使用 NixOS ,你可以在 `configuration.nix` 中添加额外的模块包:
```
[...]
boot.extraModulePackages = with config.boot.kernelPackages;
[ v4l2loopback.out ];
boot.kernelModules = [
"v4l2loopback"
];
boot.extraModprobeConfig = ''
options v4l2loopback exclusive_caps=1 card_label="Virtual Camera"
'';
[...]
```
在 NixOS 上, 运行 `sudo nixos-rebuild switch`,然后重启。
### 创建一个视频设备
假设你的计算机当前没有 `/dev/video` 设备,你可以借助 `v4l2loopback` 在需要时创建一个。
运行以下命令,将 `gphoto2` 中的数据发送到 `ffmpeg`,使用设备如 `/dev/video0` 设备:
```
$ gphoto2 --stdout --capture-movie |
ffmpeg -i - -vcodec rawvideo -pix_fmt yuv420p -f v4l2 /dev/video0
```
你得到的输出是这样的:
```
ffmpeg version 4.4.1 Copyright (c) 2000-2021 the FFmpeg developers
built with gcc 11.3.0 (GCC)
configuration: --disable-static ...
libavutil 56. 70.100 / 56. 70.100
libavcodec 58.134.100 / 58.134.100
libavformat 58. 76.100 / 58. 76.100
libavdevice 58. 13.100 / 58. 13.100
libavfilter 7.110.100 / 7.110.100
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 9.100 / 5. 9.100
libswresample 3. 9.100 / 3. 9.100
libpostproc 55. 9.100 / 55. 9.100
Capturing preview frames as movie to 'stdout'. Press Ctrl-C to abort.[mjpeg @ 0x1dd0380] Format mjpeg detected only with low score of 25, misdetection possible!
Input #0, mjpeg, from 'pipe:':
Duration: N/A, bitrate: N/A
Stream #0:0: Video: mjpeg (Baseline), yuvj422p(pc, bt470bg/unknown/unknown), 768x512 ...
Stream mapping:
Stream #0:0 -> #0:0 (mjpeg (native) -> rawvideo (native))[swscaler @ 0x1e27340] deprecated pixel format used, make sure you did set range correctly
Output #0, video4linux2,v4l2, to '/dev/video0':
Metadata:
encoder : Lavf58.76.100
Stream #0:0: Video: rawvideo (I420 / 0x30323449) ...
Metadata:
encoder : Lavc58.134.100 rawvideoframe= 289 fps= 23 q=-0.0 size=N/A time=00:00:11.56 bitrate=N/A speed=0.907x
```
要查看来自网络摄像头的视频,请使用 `mpv` 命令:
```
$ mpv av://v4l2:/dev/video0 --profile=low-latency --untimed
```

### 自动启动你的网络摄像头
每次想使用网络摄像头时都需要执行一次命令有点麻烦。幸运的是,你可以在启动时自动运行此命令。我将其实现为一个 `systemd` 服务:
```
# configuration.nix
...
systemd.services.webcam = {
enable = true;
script = ''
${pkgs.gphoto2}/bin/gphoto2 --stdout --capture-movie |
${pkgs.ffmpeg}/bin/ffmpeg -i - \
-vcodec rawvideo -pix_fmt yuv420p -f v4l2 /dev/video0
'';
wantedBy = [ "multi-user.target" ];
};
...
```
在 NixOS 上,运行 `sudo nixos-rebuild switch`,然后重新启动你的计算机。你的网络摄像头已经开启并处于活动状态。
要检查是否存在任何问题,可以使用 `systemctl status webcam` 命令。它会告诉你服务最后一次运行的时间,并提供其以前输出的日志。这对于调试非常有用。
### 迭代以使其变得更好
止步于此也许很诱人。但是,考虑到当前的全球危机,我们可能需要思考是否有必要一直开着网络摄像头。这让我感到不太理想,原因如下:
* 这浪费电。
* 这类事情涉及隐私问题。
我的摄像头有一个镜头盖,所以说实话,第二个原因并不真的让我感到困扰。当我不使用网络摄像头时,我总是可以把镜头盖上。然而,让一个耗电量大的单反相机整天开着(更不用说需要解码视频所需的 CPU 开销),对我的电费并没有任何好处。
理想情况是:
* 我一直把相机插在电脑上,但是关闭的。
* 当我想使用网络摄像头时,我按下相机的电源按钮将其打开。
* 我的计算机会检测到相机并启动 systemd 服务。
* 使用网络摄像头完成后,我再次将其关闭。
为了实现这一点,你需要使用一个自定义的 udev 规则。
udev 规则可以告诉你的计算机,当它发现某个设备已经可用时执行某个任务。这可以是外部硬盘甚至是非 USB 设备。在这种情况下,你需要通过其 USB 连接识别相机。
首先,指定 udev 规则被触发时要运行的命令。你可以用一个 shell 脚本来完成(`systemctl restart webcam` 应该可以工作)。我运行的是 NixOS,所以我只需要创建一个派生包(一个 Nix 包),它会重新启动 systemd 服务:
```
# start-webcam.nix
with import <nixpkgs> { };
writeShellScriptBin "start-webcam" ''
systemctl restart webcam
# debugging example
# echo "hello" &> /home/tom/myfile.txt
# If myfile.txt gets created then we know the udev rule has triggered properly''
```
接下来,实际定义 udev 规则。查找摄像头的设备和厂商 ID。使用 `lsusb` 命令可以完成此操作。该命令可能已经安装在你的发行版上,但我不经常使用它,因此我只需要根据需要使用 `nix-shell` 安装它:
```
$ nix-shell -p usbutils
```
无论你的计算机上已经安装了它,还是刚刚安装,请运行 `lsusb` :
```
$ lsusb
Bus 002 Device 008: ID 04a9:317b Canon, Inc. Canon Digital Camera[...]
```
在此输出中,厂商 ID 为 `04a9`,设备 ID 为 `317b`。这已足以创建 udev 规则:
```
ACTION=="add", SUBSYSTEM=="usb",
ATTR{idVendor}=="04a9",
ATTR{idProduct}=="317b",
RUN+="/usr/local/bin/start-webcam.sh"
```
或者,如果你使用的是 NixOS:
```
# configuration.nix[...]let
startWebcam = import ./start-webcam.nix;[...]
services.udev.extraRules = ''
ACTION=="add", \
SUBSYSTEM=="usb", \
ATTR{idVendor}=="04a9", \
ATTR{idProduct}=="317b", \
RUN+="${startWebcam}/bin/start-webcam"'';[...]
```
最后,在你的 `start-webcam` systemd 服务中删除 `wantedBy = ["multi-user.target"];` 这一行。(如果保留它,则无论相机是否开启,该服务都会在下次重启时自动启动。)
### 重复使用旧技术
我希望这篇文章能让你在放弃一些旧技术之前三思而后行。Linux 可以为技术注入活力,无论是你的电脑还是数码相机或其他外围设备等简单的东西。
---
via: <https://opensource.com/article/22/12/old-camera-webcam-linux>
作者:[Tom Oliver](https://opensource.com/users/tomoliver) 选题:[lkxed](https://github.com/lkxed) 译者:[Pabloxllwe](https://github.com/Pabloxllwe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This year after largely abandoning my MacBook in favor of a NixOS machine, I started getting requests to "turn my camera on" when video calling people. This was a problem because I didn't have a webcam. I thought about buying one, but then I realized I had a perfectly good Canon EOS Rebel XS DSLR from 2008 lying around on my shelf. This camera has a mini-USB port, so naturally, I pondered: Did a DSLR, mini-USB port, and a desktop PC mean I could have a webcam?
There's just one problem. My Canon EOS Rebel XS isn't capable of recording video. It can take some nice pictures, but that's about it. So that's the end of that.
Or is it?
There happens to be some amazing open source software called [gphoto2](https://opensource.com/article/20/7/gphoto2-linux). Once installed, it allows you to control various supported cameras from your computer and it takes photos and videos.
## Supported cameras
First, find out whether yours is supported:
```
````$ gphoto2 --list-cameras`
## Capture an image
You can take a picture with it:
```
````$ gphoto2 --capture-image-and-download`
The shutter activates, and the image is saved to your current working directory.
## Capture video
I sensed the potential here, so despite the aforementioned lack of video functionality on my camera, I decided to try `gphoto2 --capture-movie`
. Somehow, although my camera does not support video natively, gphoto2 still manages to spit out an MJPEG file!
On my camera, I need to put it in "live-view" mode before gphoto2 records video. This consists of setting the camera to portrait mode and then pressing the **Set** button so that the viewfinder is off and the camera screen displays an image. Unfortunately, though, this isn't enough to be able to use it as a webcam. It still needs to get assigned a video device, such as `/dev/video0`
.
## Install ffmpeg and v4l2loopback
Not surprisingly, there's an open source solution to this problem. First, use your package manager to install `gphoto2`
, `ffmpeg`
, and `mpv`
. For example, on Fedora, CentOS, Mageia, and similar:
```
````$ sudo dnf install gphoto2 ffmpeg mpv`
On Debian, Linux Mint, and similar:
```
````$ sudo apt install gphoto2 ffmpeg mpv`
I use NixOS, so here's my configuration:
```
``````
# configuration.nix
...
environment.systemPackages = with pkgs; [
ffmpeg
gphoto2
mpv
...
```
Creating a virtual video device requires the `v4l2loopback`
Linux kernel module. At the time of this writing, that capability is not included in the mainline kernel, so you must download and compile it yourself:
```
``````
$ git clone https://github.com/umlaeute/v4l2loopback
$ cd v4l2loopback
$ make
$ sudo make install
$ sudo depmod -a
```
If you're using NixOS like me, you can just add the extra module package in `configuration.nix`
:
```
``````
[...]
boot.extraModulePackages = with config.boot.kernelPackages;
[ v4l2loopback.out ];
boot.kernelModules = [
"v4l2loopback"
];
boot.extraModprobeConfig = ''
options v4l2loopback exclusive_caps=1 card_label="Virtual Camera"
'';
[...]
```
On NixOS, run `sudo nixos-rebuild switch`
and then reboot.
## Create a video device
Assuming your computer currently has no `/dev/video`
device, you can create one on demand thanks to the `v4l2loopback`
.
Run this command to send data from `gphoto2`
to `ffmpeg`
, using a device such as `/dev/video0`
device:
```
``````
$ gphoto2 --stdout --capture-movie |
ffmpeg -i - -vcodec rawvideo -pix_fmt yuv420p -f v4l2 /dev/video0
```
You get output like this:
```
``````
ffmpeg version 4.4.1 Copyright (c) 2000-2021 the FFmpeg developers
built with gcc 11.3.0 (GCC)
configuration: --disable-static ...
libavutil 56. 70.100 / 56. 70.100
libavcodec 58.134.100 / 58.134.100
libavformat 58. 76.100 / 58. 76.100
libavdevice 58. 13.100 / 58. 13.100
libavfilter 7.110.100 / 7.110.100
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 9.100 / 5. 9.100
libswresample 3. 9.100 / 3. 9.100
libpostproc 55. 9.100 / 55. 9.100
Capturing preview frames as movie to 'stdout'. Press Ctrl-C to abort.
[mjpeg @ 0x1dd0380] Format mjpeg detected only with low score of 25, misdetection possible!
Input #0, mjpeg, from 'pipe:':
Duration: N/A, bitrate: N/A
Stream #0:0: Video: mjpeg (Baseline), yuvj422p(pc, bt470bg/unknown/unknown), 768x512 ...
Stream mapping:
Stream #0:0 -> #0:0 (mjpeg (native) -> rawvideo (native))
[swscaler @ 0x1e27340] deprecated pixel format used, make sure you did set range correctly
Output #0, video4linux2,v4l2, to '/dev/video0':
Metadata:
encoder : Lavf58.76.100
Stream #0:0: Video: rawvideo (I420 / 0x30323449) ...
Metadata:
encoder : Lavc58.134.100 rawvideo
frame= 289 fps= 23 q=-0.0 size=N/A time=00:00:11.56 bitrate=N/A speed=0.907x
```
To see the video feed from your webcam, use `mpv`
:
```
````$ mpv av://v4l2:/dev/video0 --profile=low-latency --untimed`
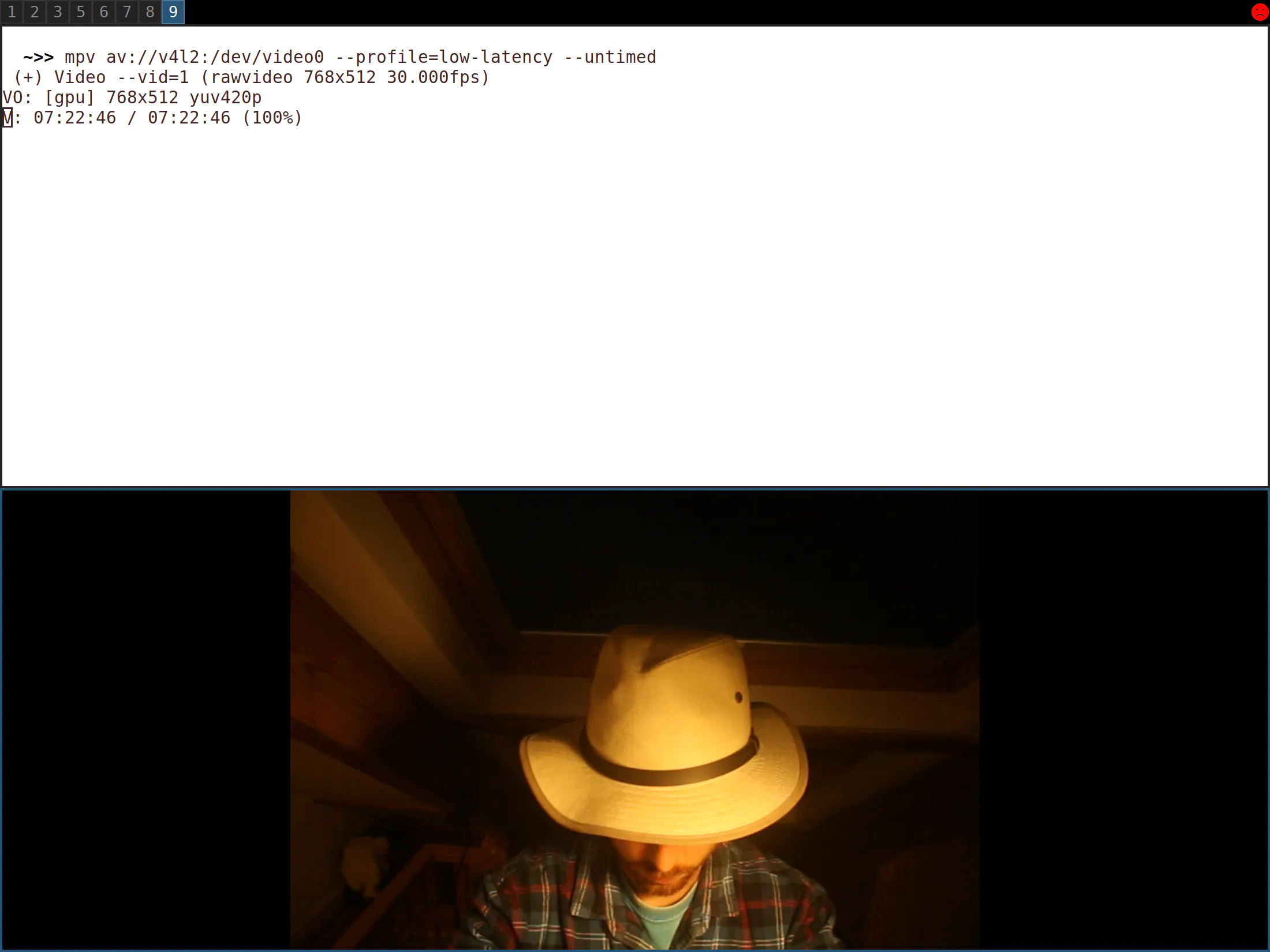
(Tom Oliver, CC BY-SA 4.0)
## Start your webcam automatically
It's a bit annoying to execute a command every time you want to use your webcam. Luckily, you can run this command automatically at startup. I implement it as a `systemd`
service:
```
``````
# configuration.nix
...
systemd.services.webcam = {
enable = true;
script = ''
${pkgs.gphoto2}/bin/gphoto2 --stdout --capture-movie |
${pkgs.ffmpeg}/bin/ffmpeg -i - \
-vcodec rawvideo -pix_fmt yuv420p -f v4l2 /dev/video0
'';
wantedBy = [ "multi-user.target" ];
};
...
```
On NixOS, run `sudo nixos-rebuild switch`
and then reboot your computer. Your webcam is on and active.
To check for any problems, you can use `systemctl status webcam`
. This tells you the last time the service was run and provides a log of its previous output. It's useful for debugging.
## Iterating to make it better
It's tempting to stop here. However, considering the current global crises, it may be pertinent to wonder whether it's necessary to have a webcam on all the time. It strikes me as sub-optimal for two reasons:
- It's a waste of electricity.
- There are privacy concerns associated with this kind of thing.
My camera has a lens cap, so to be honest, the second point doesn't really bother me. I can always put the lens cap on when I'm not using the webcam. However, leaving a big power-hungry DSLR camera on all day (not to mention the CPU overhead required for decoding the video) isn't doing anything for my electricity bill.
The ideal scenario:
- I leave my camera plugged in to my computer all the time but switched off.
- When I want to use the webcam, I switch on the camera with its power button.
- My computer detects the camera and starts the systemd service.
- After finishing with the webcam, I switch it off again.
To achieve this, you need to use a custom [udev rule](https://opensource.com/article/18/11/udev).
A udev rule tells your computer to perform a certain task when it discovers that a device has become available. This could be an external hard drive or even a non-USB device. In this case, you need it to [recognize the camera through its USB connection](https://opensource.com/article/22/1/cameras-usb-ports-obs).
First, specify what command to run when the udev rule is triggered. You can do that as a shell script (`systemctl restart webcam`
should work). I run NixOS, so I just create a derivation (a Nix package) that restarts the systemd service:
```
``````
# start-webcam.nix
with import <nixpkgs> { };
writeShellScriptBin "start-webcam" ''
systemctl restart webcam
# debugging example
# echo "hello" &> /home/tom/myfile.txt
# If myfile.txt gets created then we know the udev rule has triggered properly
''
```
Next, actually define the udev rule. Find the device and vendor ID of the camera. Do this by using the `lsusb`
command. That command is likely already installed on your distribution, but I don't use it often, so I just install it as needed using `nix-shell`
:
```
````$ nix-shell -p usbutils`
Whether you already have it on your computer or you've just installed it, run `lsusb`
:
```
``````
$ lsusb
Bus 002 Device 008: ID 04a9:317b Canon, Inc. Canon Digital Camera
[...]
```
In this output, the vendor ID is 04a9 and the device ID is 317b. That's enough to create the udev rule:
```
``````
ACTION=="add", SUBSYSTEM=="usb",
ATTR{idVendor}=="04a9",
ATTR{idProduct}=="317b",
RUN+="/usr/local/bin/start-webcam.sh"
```
Alternatively, if you're using NixOS:
```
``````
# configuration.nix
[...]
let
startWebcam = import ./start-webcam.nix;
[...]
services.udev.extraRules = ''
ACTION=="add", \
SUBSYSTEM=="usb", \
ATTR{idVendor}=="04a9", \
ATTR{idProduct}=="317b", \
RUN+="${startWebcam}/bin/start-webcam"
'';
[...]
```
Finally, remove the **wantedBy = ["multi-user.target"];** line in your `start-webcam`
systemd service. (If you leave it, then the service starts automatically when you next reboot, whether the camera is switched on or not.)
## Reuse old technology
I hope this article has made you think twice before chucking some of your old tech. Linux can breathe life back into technology, whether it's your [computer](https://opensource.com/article/22/4/how-linux-saves-earth) or something simple like a digital camera or some other peripheral.
## 1 Comment |
15,649 | Postgres DevOps 数据库管理员的日常 | https://opensource.com/article/23/3/postgres-devops-dba | 2023-03-22T07:52:37 | [
"DBA",
"Postgres"
] | https://linux.cn/article-15649-1.html | 
>
> 数据库管理员(DBA)的职责是什么?
>
>
>
在依赖 Postgres 作为主要数据库管理系统的现代 IT 组织中,Postgres DevOps DBA 发挥着关键作用。Postgres DevOps DBA 的角色涉及许多职责、技能和任务。其中一些包括:管理数据库设计和架构、基础设施管理、确保高可用性、安全性以及执行日常维护任务(调整、备份和恢复以及监控)。
本文总结了当今企业环境中 Postgres DevOps DBA 的常见职责和技能。
### 数据库设计和架构
Postgres DevOps DBA 的两个主要职责是数据库设计和架构。该角色必须对应用的数据存储要求和涉及的业务逻辑有更深入的了解。这些知识包括设计和创建数据库模式和表。它还意味着配置索引和其他数据库对象以优化查询性能,并选择使用正确的 Postgres 版本。该角色必须确保数据库的设计具有可扩展性和可维护性,同时考虑到未来的增长和数据保留需求。
### 性能调优
另一个关键的职责是性能调优。Postgres DevOps DBA 必须能够通过监控数据库性能指标和分析查询性能来识别和解决性能问题。该角色还必须对数据库有深入的了解,并能够对其进行配置以获得最佳性能,包括优化查询和索引、调整内存设置以及识别和解决性能瓶颈。
### 备份与恢复
备份和恢复也是职责的关键。DBA 必须对备份和恢复解决方案有深入的了解,并且必须设计和实施备份策略,以确保在数据丢失的情况下始终可以恢复数据。他们还必须验证恢复过程并实施高可用性和灾难恢复解决方案,以最大限度地减少停机时间和数据丢失。
### 安全
安全是另一个重要的职责。DBA 通过实施访问控制、加密和其他安全措施来保护数据,从而确保数据库安全。他们还必须了解最新的安全趋势和最佳实践,并加以实施以防范潜在威胁。
### 基础设施管理
基础设施管理也是一项重要职责。这些 DBA 必须管理硬件、网络和存储基础设施,并提供基础设施以支持 Postgres。他们还必须针对性能和可用性配置基础架构,并根据需要扩展基础架构以适应数据增长。
### 自动化和脚本
该角色必须能够使用 [Ansible](https://opensource.com/article/19/2/quickstart-guide-ansible)、Terraform 和 [Kubernetes](https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=7013a000002qLH8AAM) 等工具自动执行重复性任务,例如备份、监控和修补。他们还必须熟悉自动化最佳实践,以确保高效且有效地自动化任务。自动化减少了人为错误的可能性,提高了效率,并允许 DBA 专注于更复杂的任务。
### 监控和配置警报
监控数据库和基础设施并设置警报以通知他们问题非常重要。该角色还必须采取主动措施来防止停机和数据丢失,使用 Nagios、Zabbix 和 Prometheus 等监控工具来检测潜在问题。
### 合作
除了这些技术职责外,PostgreSQL DevOps DBA 还必须与其他 IT 团队(例如开发人员、运维人员和安全人员)协作,以将数据库集成到更大的 IT 生态系统中。DBA 还必须记录他们的工作,并及时了解 Postgres 和 [DevOps](https://opensource.com/article/20/12/remote-devops) 的最新趋势和最佳实践。这涉及与利益相关者合作以收集需求、确定优先级并使数据库与组织的更广泛目标保持一致。
### 总结
总之,Postgres DevOps DBA 在依赖 Postgres 作为主要数据库管理系统的现代 IT 组织中发挥着关键作用。你当前的技能和期望如何匹配此列表?作为现代数据库环境中的 DBA,你是否走在正确的道路上?
---
via: <https://opensource.com/article/23/3/postgres-devops-dba>
作者:[Doug Ortiz](https://opensource.com/users/dougortiz) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A Postgres DevOps DBA plays a critical role in modern IT organizations that rely on Postgres as their primary database management system. The role of a Postgres DevOps DBA involves many responsibilities, skills, and tasks. A few of these include: Managing the database design and architecture, infrastructure management, ensuring high availability, security, and performing routine maintenance tasks (tuning, backup and recovery, and monitoring).
This article summarizes the common responsibilities and skills expected of a Postgres DevOps DBA in today's enterprise environments.
## Database design and architecture
Two primary responsibilities of a Postgres DevOps DBA are database design and architecture. This role must have a greater understanding of the application's data storage requirements and the business logic involved. This knowledge includes designing and creating database schemas and tables. It also means configuring indexes and other database objects to optimize query performance, and choosing the right version of Postgres to use. The role must ensure the database is designed for scalability and maintainability, considering future growth and data retention needs.
## Performance tuning
Another critical area of responsibility is performance tuning. A Postgres DevOps DBA must be able to identify and resolve performance issues by monitoring database performance metrics and analyzing query performance. The role must also have a deep understanding of the database and be able to configure it for optimal performance, including optimizing queries and indexes, tuning memory settings, and identifying and addressing performance bottlenecks.
## Backup and recovery
Backup and recovery are also key areas of responsibility. The DBA must have a solid understanding of backup and recovery solutions and must design and implement a backup strategy that ensures that data is always recoverable in the event of data loss. They must also validate the recovery process and implement high-availability and disaster recovery solutions to minimize downtime and data loss.
## Security
Security is another critical area of responsibility. The DBA ensures the database is secure by implementing access controls, encryption, and other security measures to protect the data. They must also stay up-to-date with the latest security trends and best practices and implement them to protect against potential threats.
## Infrastructure management
Infrastructure management is also a key responsibility. These DBAs must manage the hardware, network, and storage infrastructure and provision the infrastructure to support Postgres. They must also configure the infrastructure for performance and availability and scale the infrastructure as necessary to accommodate data growth.
**[ Related read: 3 tips to manage large Postgres databases ]**
## Automation and scripting
This role must be able to automate repetitive tasks such as backups, monitoring, and patching using tools like [Ansible](https://opensource.com/article/19/2/quickstart-guide-ansible), Terraform, and [Kubernetes](https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=7013a000002qLH8AAM). They must also be familiar with automation best practices to ensure tasks are automated efficiently and effectively. Automation reduces the potential for human error, improves efficiency, and allows the DBA to focus on more complex tasks.
## Monitor and configure alerts
Monitoring the database and infrastructure and setting up alerts to notify them of issues is extremely important. The role must also take proactive measures to prevent downtime and data loss, using monitoring tools like Nagios, Zabbix, and Prometheus to detect potential issues.
## Collaboration
In addition to these technical responsibilities, a PostgreSQL DevOps DBA must also collaborate with other IT teams, such as developers, operations, and security, to integrate the database into the larger IT ecosystem. The DBAs must also document their work and stay up-to-date with the latest trends and best practices in Postgres and [DevOps](https://opensource.com/article/20/12/remote-devops). This involves engaging with stakeholders to gather requirements, establish priorities, and align the database with the organization's broader goals.
## Wrap up
In conclusion, a Postgres DevOps DBA plays a critical role in modern IT organizations that rely on Postgres as their primary database management system. How do your current skills and expectations match this list? Are you on the right track to excel as a DBA in modern database environment?
## Comments are closed. |
15,651 | Linux 上 5 款最好的 EPUB 阅读器 | https://www.debugpoint.com/epub-readers-linux/ | 2023-03-22T21:07:00 | [
"电子书"
] | /article-15651-1.html | 
>
> 你正在寻找 Linux 上最好的 EPUB 阅读器?这里是为你准备的最好的自由开源的 EPUB 阅读器。
>
>
>
你是一位热衷于阅读电子书的 Linux 用户吗?如果,是的,你必然知道在 Linux 发行版上的默认文档阅读器不能满足你作为一名书虫的所有要求。
EPUB 是一种广泛使用的开放电子书格式,大多数的电子书阅读器都支持。值得庆幸的是,在 Ubuntu 软件中心和其它存储库中有一些 EPUB 阅读器应用程序,你可以自由下载它们。.
但是,请记住,仅有几个好用的阅读器。并不是有很多!
在这篇文章中,我们将讨论在 Ubuntu Linux 上的最好的 EPUB 阅读器,这将增强你的阅读体验。我们也将探讨它们的特色功能和优点,以便你可以选择一个适合你的应用程序。
但是,在此之前,你认为在一个 “令人满意的” EPUB 阅读器中,应该有哪些功能呢?
### 在一款 EPUB 阅读器中所应该有的功能
* **用户界面**:一款好的 EPUB 阅读器应该有一个简单易懂的用户界面,它会使导航和自定义你的阅读体验变得简单。你并不是在阅读一本实体书,因此,对于 “实体书” 的阅读体验来说,用户界面是极其重要的!
* **自定义**:拥有自定义字体大小、字体类型、背景颜色和其它设置的能力,它们将增强你的阅读体验。
* **书架**:书架是一种很方便的特色功能,它允许你组织你的 EPUB 文件和保持追踪你的阅读进度。
* **注释**:在你的 EPUB 文件中,高亮显示、下划线和添加注释是一种很重要的特色功能,它会帮助你记住重点。
* **同步**:如果你在多台设备上阅读 EPUB 文件,同步你的阅读进度和书签是非常重要的,可以避免丢失你的追踪进度.
现在,让我们看看为 Ubuntu 和其它的 Linux 发行版提供的最好的 EPUB 阅读器,它们都涉及上述所有的特色功能。
### 在 Ubuntu 和其它 Linux 发行版上的最好的 EPUB 阅读器
#### Calibre
在这份列表上的第一款阅读器是 Calibre ,它是最好的和最完善的电子书管理解决方案。它是一款功能强大的 EPUB 阅读器,也提供电子书管理工具。它在用户中是一种流行的选择,因为它有丰富的特色功能集,包括:转换 EPUB 文件到不同的格式、编辑 EPUB 文件,甚至创建你自己的 EPUB 文件的功能。Calibre 也有一个用户友好的界面,允许你自定义你的阅读体验。

Calibre 正在持续更新,每个月都会有大量的特色功能和增强的功能。它的开发活动是非常活跃的,它是这份列表中最好的一个。
功能摘要:
* 支持多种电子书设备(基于安卓、iOS 的设备)
* EPUB 阅读器和管理器
* 为你的电子书库评级和标记
* 从互联网获取电子书的元数据
* 从流行的新闻源处阅读新闻,并制作电子书!
* 使用自动转换器来上传电子书到 Kindle 和其它的阅读器(当然,也可以下载)
* 内置可购买电子书的浏览器


你可以从其官方网站下载 Calibre 。或者,你可以为你的 Linux 发行版 [设置 Flatpak & Flathub](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) ,并单击下面的按钮(或使用命令)来安装:
>
> **[使用 Flatpak 来安装 Calibre](https://dl.flathub.org/repo/appstream/com.calibre_ebook.calibre.flatpakref)**
>
>
>
```
flatpak install com.calibre_ebook.calibre
```
针对其它的下载选项(Windows、macOS 和原生的 Linux 软件包),请访问 [这个网页](https://calibre-ebook.com/download)。
#### Foliate
我们在先前的 [最佳的 Ubuntu 应用程序(第 3 部分)](https://www.debugpoint.com/necessary-ubuntu-apps-2022/) 系列中介绍了 Foliate 。它是一款轻量现代的 EPUB 阅读器,它提供了一系列的自定义选项。它是基于 GTK4 的,并且与 GNOME 桌面环境无缝集成。它有一个平滑且易于导航的界面,并且有自定义字体大小、字体类型和行距的功能。

Foliate 也包含:一种针对夜间阅读的深色模式,一个调整内置颜色温度的选项,用以减少眼睛疲劳。
功能摘要:
* 沉浸式视图,主顶部工具条在阅读时自动隐藏
* 列入目录视图,支持从主要的电子书网站直接下载
* 多屏视图 – 双页面视图和滚动视图
* 自定义字体和行距
* 内置亮度控制,仅应用于应用程序本身!
* 阅读进度滑块
* 支持书签和注释
* 在书中搜索
* 快速字典查找


下载 Okular 的最好方式是使用 Flatpak 来下载。针对你的系统设置 [Flatpak & Flathub](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) ,并使用下面的链接(或使用下面提到的命令)来安装它:
>
> **[使用 Flatpak 来安装 Foliate](https://dl.flathub.org/repo/appstream/com.github.johnfactotum.Foliate.flatpakref)**
>
>
>
```
flatpak install com.github.johnfactotum.Foliate
```
要学习更多关于 Foliate 的信息,访问官方 [网站](https://johnfactotum.github.io/foliate/)。
#### Okular
KDE 自带的文档阅读器是 Okular ,它也支持 EPUB 文件。它是一款功能丰富的应用程序,它提供了一系列自定义选项,包括:字体大小、字体类型和背景颜色。Okular 也有内置注释功能,你可以使用它来注释你的 EPUB 文件。它也支持很多文件格式:
* EPUB
* PDF
* DjVU
* 图形文件: JPEG 、PNG 、GIF 、Tiff 、WebP
* 漫画文件: CBR 和 CBZ
不过,你不能使用 Okular 来管理收藏或下载电子书。

你可以在 Ubuntu 及其相关发行版中安装 Okular :
```
sudo apt install okular
```
针对 Fedora 及其相关发行版:
```
sudo dnf install okular
```
如果你更喜欢 Flatpak ,将你的系统设置为 Flatpak ,并使用下面的链接(或使用下面提到的命令)来安装 Flatpak:
>
> **[使用 Flatpak 格式安装 Okular](https://dl.flathub.org/repo/appstream/org.kde.okular.flatpakref)**
>
>
>
```
flatpak install org.kde.okular
```
#### Bookworm
在这份列表上的下一个 EPUB 阅读器是 Bookwork ,在我看来,它完全被低估了。它确实是一款 elementary OS 的应用程序,但是,对于所有的 Linux 发行版来说都是可以安装的。
它有简洁的界面,并提供一系列自定义选项,包括字体大小、字体类型和背景颜色。Bookworm 也允许你将你的 EPUB 文件组织到集合中,并保持追踪你的阅读进度。

另外,你可以使用一个内置的标签编辑器和评分系列来轻松地管理你的 EPUB 书籍。此外,它也支持注释、搜索、章节和键盘导航。
不可缺少的是,它支持 EPUB 、MOBI 、PDF 、EB2 、CBR 和 CBZ 文件。

安装是很容易的。如果你是一名 elementary OS 用户,你可以在 <ruby> 应用中心 <rt> AppCenter </rt></ruby> 中搜索 “bookworm” 。
针对 Ubuntu 及其相关发行版,你可以使用下面的 PPA 来安装它:
```
sudo add-apt-repository ppa:bookworm-team/bookwormsudo
apt-get update
sudo apt-get install com.github.babluboy.bookworm
```
如果你更喜欢 Flatpak ,将你的系统设置为 Flathub 和 Flatpak ,并使用下面的链接来安装它:
```
flatpak install com.github.babluboy.bookworm
```
要学习更多的信息,访问官方 [网站](https://babluboy.github.io/bookworm/)。
#### FBReader
在这份最好的 EPUB 阅读器列表中最后一款应用程序是 FBReader 。在你继续阅读之前,注意:它在 2015 年以前是开源软件。但是,它现在是闭源软件,不过,有一个开发者 SDK 是可用的。
它是一款流行的多功能的 EPUB 阅读器,所有的 Linux 发行版都可以获取使用。它有一个简单且用户友好的界面,允许你自定义你的阅读体验。FBReader 也支持各种电子书格式,包括:EPUB 、MOBI 、FB2 和 HTML 。它也提供一种书架特色功能,允许你组织你的电子书和保持追踪你的阅读进度。
FBRedaer 也支持在你的设备之间云同步你的库。

在 Linux 上安装 FBReader 是有一些难度的,因为它只提供 Snap 软件包。你可以在 [针对 Snap 设置你的系统](https://www.debugpoint.com/how-to-install-and-use-snap-packages-in-ubuntu/) 后,使用 `snap` 来安装它,如下所示。
```
sudo snap install fbreader
```
要学习更多关于 FBReader 的信息,访问官方 [网站](https://fbreader.org/en)。
### 在 Linux 上的更多的 EPUB 阅读器
#### Koodo reader
它是一个相当新的自由及开源的 EPUB 阅读器,带有大量的特色功能。并且它也看起来极好。唯一的问题是,它是使用 Javascript 、HTML 和 TypeScript 构建的。因此,它不是原生的应用程序,但是它是很快的。你可能会想尝试一下。在 Linux 上,Koodo reader 提供 AppImage 、本机的 deb 和 RPM 文件。
你可以 [在这里下载](https://koodo.960960.xyz/en) ,这里是一些截屏。



这里还有另外的两个 EPUB 阅读器,但是,不幸的是,它们已经不再继续开发了。
* [GNOME Books](https://gitlab.gnome.org/Archive/gnome-books)
* [epub CLI reader](https://github.com/rupa/epub)
### EPUB 阅读器的对比表
为使你更容易地选择适合你所需要的 EPUB 阅读器,我们创建了一个比较表,着重强调了上述 EPUB 阅读器的关键特色功能。
| EPUB 阅读器 | 用户界面 | 自定义 | 书架 | 注释 | 同步 |
| --- | --- | --- | --- | --- | --- |
| Calibre | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Foliate | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| Bookworm | ✔️ | ✔️ | ✔️ | ❌(受限) | ❌ |
| Okular | ✔️ | ✔️ | ❌ | ❌(受限) | ❌ |
| FBReader | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
### 去哪里获取免费的电子书?
很多网站为你提供来自著名作者的大量漫画和小说的收藏。最好的网站是 “Project Gutenberg” 。你可以下载来自所有分类中的 60,000 多本电子书。
使用下面的链接访问网站。在你下载电子书后,你可以使用上述任意的 EPUB 阅读器来制作和享受你的个人电子书收藏。
>
> **[Project Gutenberg](https://www.gutenberg.org/)**
>
>
>
你也可以尝试精选免费电子书的 standard ebooks。
>
> **[Standard eBooks](https://standardebooks.org/ebooks)**
>
>
>
### 总结
总而言之,在 Linux 上有几个可用的 EPUB 阅读器,它们提供大量的特色功能来增强你的阅读体验。如果你正在寻找一个功能丰富的 EPUB 阅读器,Calibre 是一个极好的选择,它也可以作为一个电子书管理器工具。Foliate 和 Bookworm 是一个轻量的现代的应用程序,非常适合那些看重自定义选项的人。
我希望通过上述的比较和详细的描述,你现在可以为你自己选择最好的 EPUB 阅读器了。
---
via: <https://www.debugpoint.com/epub-readers-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,652 | 用树莓派制作的问答售货机 | https://opensource.com/article/23/3/raspberry-pi-trivia-vending-machine | 2023-03-22T21:45:47 | [
"树莓派"
] | /article-15652-1.html | 
>
> 用树莓派取代食品售货机上的投币箱是一个天才之举。
>
>
>
作为在公共图书馆工作的教育工作者,我一直在关注 [树莓派](https://opensource.com/resources/raspberry-pi) 的有趣用途。在我看来,得克萨斯州达拉斯市的<ruby> 问答售货机 <rt> Trivia Vending Machine </rt></ruby>项目是这些神奇设备最具创意和最有趣的用途之一。使用树莓派取代食品售货机上的投币箱是 Greg Needel 和他的团队的一个天才之作。这个想法的潜在用途是深远的。请观看下面这个 [YouTube 短视频](https://www.youtube.com/watch?v=pDOhk-YAhys),了解问答自动售货机的运行情况。
最初的问答售货机专注于科学问题,但你可以制作一个问答售货机来回答任何问题:历史、公民、文学等等。如果你鼓励学生写自己的问题,并回答对方的问题,那将是最有吸引力的用途。请考虑这样:自动售货机可以不发放食物,而是发放当地企业的优惠券。我谋生的方式之一是教吉他课,我很乐意捐出一节吉他课作为问答售货机的优惠券。然而,学生必须积累适当数量的积分才能获得我的一堂吉他课。
把你的想象力再延伸一点。是否有可能让学生解决逻辑谜题,以便从自动售货机获得食物(或优惠券)?是的,这并不难创造。也许是数独谜题、[Wordle](https://opensource.com/article/22/1/word-game-linux-command-line)、KenKen、Sokoban 或任何其他谜题。学生可以用触摸屏玩这些谜题。国际象棋怎么样?当然,学生可以通过解决象棋谜题来获得食物(或优惠券)。
你是否注意到视频中原来的问答售货机又大又重? 设计一个更小的,可能是滚动手推车大小的三分之一,这可以在学校、图书馆、博物馆和创客嘉年华之间更容易运输。
问答售货机的内部由步进电机组成。你可以在网上购买二手的。在网络上搜索“二手自动售货机电机”会出现 [Vending World](https://vendingworld.com/small-vending-parts/vending-machine-motors-small-parts) 和 [VendMedic](https://www.vendmedic.com/product-category/vending-parts/vend-motors/) 网站。
如果你是创客空间的成员,请向其他成员介绍问答售货机。这是一个开放的发明,没有专利,所以任何人都可以制造它。(谢谢你,Greg Needel)我想为这样的设备编写代码并不太难。如果有人可以创建此类代码的 GitHub 仓库,以及可能附带的一些解释性截屏,那就太好了。
虽然问答售货机没有在红牛创意大赛中获奖,但这项发明还是值得获奖的。应该有人找到 Greg Needel 并给他一个合适的奖品。该奖项应该是什么样子的?可能是 2.5 万或 5 万美金的样子。我为 Greg Needel 和他的创意团队欢呼三声。他们把树莓派带到了这种计算机的发明者所希望的方向:修理工的快乐。大胆、美丽、开放。你还能要求更多吗?
最后一件事。问答售货机是几年前使用早期的树莓派型号制作的。当前的树莓派速度更快,响应更快。因此,你在上述视频中注意到的任何交互延迟在今天的树莓派上已不复存在。
哦,我非常想要一块糖果。我砸吧砸吧嘴。提醒我,我需要赚取多少积分才能获得士力架?不惜一切代价,我会不惜一切代价。
---
via: <https://opensource.com/article/23/3/raspberry-pi-trivia-vending-machine>
作者:[Phil Shapiro](https://opensource.com/users/pshapiro) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,656 | 用 CrowPi 树莓派套件了解关于计算机的一切 | https://opensource.com/article/21/9/raspberry-pi-crowpi2 | 2023-03-24T17:02:00 | [
"树莓派",
"CrowPi"
] | https://linux.cn/article-15656-1.html |
>
> CrowPi 是一个超棒的树莓派项目系统,安装在一个笔记本电脑般的外壳里。
>
>
>

我喜欢历史,也喜欢计算机,因此相比于计算机如何变成个人配件,我更喜欢听它在成为日常家用电器前的故事。[我经常听到的一个故事](https://opensource.com/article/21/8/my-first-programming-language) 是很久以前(反正在计算机时代算久远了)的计算机是多么的简单。事实上,它们简单到对于一个好奇的用户来说,弄清楚如何编程并不是十分困难。再看看现代计算机,它具有面向对象的编程语言、复杂的 GUI 框架、网络 API、容器等,但愈发令人担忧的是,计算工具正变得越来越难懂,对于那些没有接受过专门培训的人来说基本上无法使用。
从树莓派在 2012 年发布之日起,它就一直被定位为一个教育平台。一些第三方供应商通过附加组件和培训套件支持树莓派,以帮助所有年龄段的学习者探索编程、物理计算和开源。然而,直到最近,很大程度上还是要由用户来弄清楚市场上的所有部件如何组合在一起,直到我最近买了 CrowPi。

### CrowPi2 介绍
乌鸦是非常聪明的鸟。它们能识别并记住面孔,模仿听到的声音,解决复杂的谜题,甚至使用工具来完成任务。CrowPi 使用乌鸦作为其徽标和名字是恰当的,因为这个设备充满了探索、实验、教育的机会,最重要的是,充满了乐趣。
其设计很巧妙:它看起来像笔记本电脑,但远不止于此。当你从机壳中取出蓝牙键盘时,它会显示一个隐藏的电子设备工坊,配有 LCD 屏幕、16 个按钮、刻度盘、RFID 传感器、接近传感器、线路板、扬声器、GPIO 连接、LED 阵列等等。*而且这一切都是可编程的。*
顾名思义,该装置本身完全由树莓派提供支持,它牢固地固定在机壳底部。

默认情况下,你应该用电源适配器为设备充电,包装附带一个壁式插头,你可以将其插入机壳,而不是直接为树莓派供电。你还可以使用插入外部微型 USB 端口的电池电源。机壳内甚至还有一个抽屉,方便你存放电池。这样做的时候,有一根 USB 线从电池抽屉中弹出,并插入机壳电源端口,因此你不会产生这是一台“普通”笔记本电脑的错觉。然而,这样一台设备能够有如此美观的设计已经很理想了!
### 首次启动系统
CrowPi2 提供一张安装了 Raspbian 系统,贴有 “System” 标签的 microSD 卡,不过它同时还提供了装载 [RetroPie](https://opensource.com/article/19/1/retropie) 的第二张 microSD 卡。作为一个负责任的成年人(咳咳),我自然是先启动了 RetroPie。
RetroPie 总是很有趣,CrowPi2 附带两个超任风格的游戏控制器,确保你能获得最佳的复古游戏体验。
令人赞叹不已的是,启动实际的 Raspbian 系统的过程同样有趣,甚至可以说更有趣。它的登录管理器是一个自定义项目中心,有一些快速链接,如编程示例项目、Python 和 Arduino IDE、Scratch、Python 示例游戏、Minecraft 等。你也可以选择退出项目中心,只使用桌面。

对于习惯使用树莓派或 Linux 的人来说,CrowPi 桌面很熟悉,不过它也足够简单,所以很容易上手。左上角有应用程序菜单,桌面上有快捷图标,右上角有网络选择和音量控制的系统托盘等等。

CrowPi 上有很多东西可供选择,所以你可能很难决定从哪里开始。对我来说,主要分为四大类:编程、物理电子学、Linux 和游戏。
盒子里有一本使用说明,所以你会知道你需要怎样进行连接(例如,键盘是电池供电的,所以它有时确实需要充电,它和鼠标总是需要一个 USB 适配器)。虽然说明书很快就能读完,但这一例子也充分体现了 CrowPi 团队是如何认真对待说明书的。

### 编程
如果你想学习如何编码,在 CrowPi 上有很多成功的途径。你可以从中选择你觉得最满意的路径。
#### 1、Scratch
[Scratch](https://opensource.com/article/20/9/scratch) 是一个简单的可视化编码应用程序,可让你像拼 [乐高积木](https://opensource.com/article/20/6/open-source-virtual-lego) 一样将代码块组合在一起,制作出游戏和互动故事。这是开启编程之旅最简单的方法,我曾见过年仅 8 岁的孩子会花数小时来研究自己设计的游戏的最佳算法。当然,它不仅适合孩子们!成年人也可以从中获得很多乐趣。不知道从哪里开始?包装盒中有一本 99 页的小册子(打印在纸张上),其中包含 Scratch 课程和项目供你尝试。
#### 2、Java 和 Minecraft
Minecraft 不是开源的(虽然有 [几个开源项目](https://opensource.com/alternatives/minecraft) 复刻了它),但它有足够的可用资源,因此也经常被用来教授编程。Minecraft 是用 Java 编写的,CrowPi 同时装载有 [Minecraft Pi Edition](https://www.minecraft.net/en-us/edition/pi) 和 [BlueJ Java IDE](https://opensource.com/article/20/7/ide-java#bluej) ,如此可使学习 Java 变得比以往更容易、更有趣。
#### 3、Python 和 PyGame
CrowPi 上有几个非常有趣的游戏,它们是用 Python 和 [PyGame 游戏引擎](https://opensource.com/downloads/python-gaming-ebook) 编写的。你可以玩这些游戏,然后查看其源代码以了解游戏的运行方式。CrowPi 中包含 Geany、Thonny 和 [Mu](https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners) 编辑器,因此你可以使用 Python 立即开始编程。与 Scratch 一样,包装盒中有一本包含有课程的小册子,因此你可以学习 Python 基础知识。
### 电子器件
隐藏在键盘下的物理电子工坊本质上是一系列 Pi Hat(附着在上的硬件)。为了让你可以认识所有的组件,CrowPi 绘制了一张中英双语的折页图进行详细的说明。除此之外还有很多示例项目可以帮助你入门。 以下是一张小清单:
* **你好**:当你与 CrowPi 说话时,LCD 屏幕上打印输出“你好”。
* **入侵警报**:使用接近传感器发出警报。
* **远程控制器**:让你能够使用远程控制(是的,这个也包含在盒子里)来触发 CrowPi 上的事件。
* **RGB 俄罗斯方块**:让你可以在 LED 显示屏上玩俄罗斯方块游戏。
* **语音识别**:演示自然语言处理。
* **超声波音乐**:利用距离传感器和扬声器创建简易版的 <ruby> 特雷门琴 <rt> Theramin </rt></ruby>(LCTT 译注:世上唯一不需要身体接触的电子乐器)。
这些项目仅仅是入门级别而已,因为你还可以在现有的基础上搭建更多东西。当然,还有更多内容值得探索。包装盒里还有网络跳线、电阻、LED 和各种组件,这样你闲暇时也可以了解树莓派的 GPIO (通用输入输出端口)功能的所有信息。
不过我也发现了一个问题:示例项目的位置有点难找。找到演示项目很容易(它们就在 CrowPi 中心上),但源代码的位置并不是很容易被找到。我后来发现大多数示例项目都在 `/usr/share/code` 中,你可以通过文件管理器或终端进行访问。

### Linux
树莓派上运行的是 Linux 系统。如果你一直想更深入了解 Linux,那么 CrowPi 同样会是一个很好的平台。你可以探索 Linux 桌面、终端以及几乎所有 Linux 或开源应用程序。如果你多年来一直在阅读有关开源的文章,并准备深入研究开源操作系统,那么 CrowPi 会是你想要的平台(当然还有很多其他平台也可以)。
### 游戏
包装盒中包含的 **RetroPie** SD 卡意味着你可以重新启动切换为复古游戏机,并任意玩各种老式街机游戏。它跟 Steam Deck 并不完全相同,但也是一个有趣且令人振奋的小游戏平台。因为它配备的不是一个而是两个游戏控制器,所以它非常适合多人合作的沙发游戏。最重要的是,你不仅可以在 CrowPi 上玩游戏,还可以制作自己的游戏。
### 配备螺丝刀
自我坐下开始使用 CrowPi2 以来已经大约两周,但我还没有通关所有项目。有很多个晚上,我不得不强迫自己停下摆弄它,因为即使我厌倦了一个项目,我也会不可避免地发现还有其他东西可以探索。总而言之,我在盒子里找到了一个特别的组件,这个组件让我马上知道 CrowPi 和我就是天造地设:它是一把不起眼的小螺丝刀。盒子上没有撕开就不保修的标签。CrowPi 希望你去修补、拆解、探索和学习。它不是笔记本电脑,甚至也不仅仅是个树莓派;而是一个便携的、低功耗的、多样化的、开源的学习者工具包。
---
via: <https://opensource.com/article/21/9/raspberry-pi-crowpi2>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I like history, and I like computers, so I enjoy hearing stories about computing before computers were an everyday household appliance, much less a personal accessory. [One tale I hear often](https://opensource.com/article/21/8/my-first-programming-language) is about how the computers of long ago (in computer years, anyway) were pleasantly basic. They were so basic, in fact, that it was relatively trivial for a curious user to figure out how to program one. Looking at modern computers, with object-oriented programming languages, complex GUI frameworks, network APIs, containers, and more, there's genuine concern that the tools of the computing trade have become essentially inaccessible to anyone without specialized training.
From the day the Raspberry Pi was released in 2012, it has always been intended as an educational platform. Several third-party vendors support the Pi with add-ons and training kits to help learners of all ages explore programming, physical computing, and open source. However, until recently, it's largely been up to the user to figure out how all the pieces on the market fit together. And then I got a CrowPi.

Figure 1: The CrowPi is not a laptop.
## Introducing the CrowPi2
Crows are surprisingly intelligent birds. They recognize and remember faces, mimic sounds they've heard, solve complex puzzles, and even use tools to accomplish a task. It's fitting that the CrowPi uses the crow as its logo and namesake because this device is packed with opportunities for exploration, experimentation, education, and, best of all, fun.
The design itself is clever: It looks like a laptop, but it's much more than that. When you lift the Bluetooth keyboard from the case, it reveals a hidden electronics workshop, complete with an LCD screen, 16 buttons, dials, RFID sensor, proximity sensor, breadboard, speakers, GPIO connections, a LED array, and much more. *And it's all programmable.*
As its name implies, the unit itself is powered entirely by a Raspberry Pi, securely fastened within the underside of the case.

Figure 2: The CrowPi Pi board.
By default, you're meant to power the unit with a power adapter, and it ships with a wall adapter that you can plug into the case rather than powering the Pi directly. You can also use a battery supply plugged into an external micro-USB port. There's even a drawer built into the case so you can store your battery pack. When you do this, there's a USB cable popping out of the battery drawer and into the case power port, so there's no illusion that this is a "normal" laptop. However, with a device like this, that's pretty much the desired aesthetic!
## First boot
The CrowPi2 ships with Raspbian installed on a microSD card labeled **System**, although it includes a second microSD card loaded with [RetroPie](https://opensource.com/article/19/1/retropie), too. Being a responsible adult, I booted RetroPie first, naturally.
RetroPie is always fun, and the CrowPi2 ships with two SNES-style game controllers to ensure you have the optimal retro gaming experience.
Booting to the actual system is, amazingly, just as fun and arguably more so. The login manager is a custom project hub with quick links to sample coding projects, the Python and Arduino IDEs, Scratch, sample Python games, Minecraft, and more. You can also choose to exit the project hub and just use the desktop.

Figure 3: The CrowPi Hub.
The desktop is familiar to anyone used to the Raspberry Pi or Linux in general, but it's basic enough that it's easy to learn, too. There's an application menu in the top left, shortcut icons on the desktop, a system tray for network selection and volume control in the top right, and so on.
Figure 4: The CrowPi Desktop.
There's so much available on the CrowPi that it might be difficult to decide where to start. For me, there were four broad categories: Programming, physical electronics, Linux, and gaming.
There's an instruction manual in the box, so you know what you need to connect (for instance, the keyboard is battery-powered, so it does need charging sometimes, and it and the mouse always require a USB dongle). It's a quick read, though, and just one of the many examples of how seriously the CrowPi team takes documentation.

Figure 5: The CrowPi Docs.
## Programming
If you're keen to learn how to code, there are many paths to success on the CrowPi. You should take the path that you find the most satisfying.
### 1. Scratch
[Scratch](https://opensource.com/article/20/9/scratch) is a simple visual coding application that lets you make games and interactive stories using code blocks that fit together like [Lego pieces](https://opensource.com/article/20/6/open-source-virtual-lego). It's the easiest way to begin coding, and I've seen kids as young as eight spend hours puzzling over the optimal algorithm for a game of their own design. Of course, it's not only great for kids! Adults can have a lot of fun with it, too. Not sure where to start? There's a 99-page booklet (printed on actual paper) in the box with Scratch lessons and projects for you to try.
### 2. Java and Minecraft
Minecraft is not open source (although there are [several open source projects](https://opensource.com/alternatives/minecraft) that reimplement it), but there's enough source available that it's often used to teach programming. Minecraft was written in Java, and the CrowPi ships with both [Minecraft Pi Edition](https://www.minecraft.net/en-us/edition/pi) and the [BlueJ Java IDE](https://opensource.com/article/20/7/ide-java#bluej) to make learning Java easier and more fun than ever.
### 3. Python and PyGame
There are several really fun games on the CrowPi that were written in Python and the [PyGame game engine](https://opensource.com/downloads/python-gaming-ebook). You can play the games and then look at the source code to find out how the game works. The Geany, Thonny, and [Mu](https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners) editors are included on the CrowPi, so you can start programming in Python right away. As with Scratch, there's a booklet in the box with lessons so you can learn Python basics.
## Electronics
The physical electronics workshop concealed under the keyboard is essentially an array of Pi Hats. The whole thing is mapped out on a fold-out diagram in both English and Chinese so that you can identify all the components. There are plenty of sample projects to get you started. Here's a small list:
**Hello**prints "hello" on the LCD screen when you speak to the CrowPi.**Intrusion alarm**sounds an alarm using the proximity sensor.**Remote controller**enables you to use a remote control (yes, this too is included in the box) to trigger events on the CrowPi.**RGB Tetris**lets you play a game of Tetris on an LED display.**Voice recognition**demonstrates natural language processing.**Ultrasonic music**creates a rudimentary Theramin using distance sensors and a speaker.
Those projects are just the beginning because you can build upon what exists. There's more to explore, of course. Patch cables, resistors, LEDs, and all sorts of components are included in the box so that you can learn all about the Pi's GPIO capabilities at your leisure.
One problem: The location of the sample projects is a little difficult to find. It's easy to find the demos (they're on the CrowPi hub screen), but the location of the source code isn't immediately obvious. It turns out that most of the sample projects are in `/usr/share/code`
, which you can reach either through the file manager or a terminal.

Figure 6: The CrowPi Peripherals
## Linux
The Raspberry Pi runs Linux. If you've been meaning to learn more about Linux, the CrowPi is a great platform for that, too. You can explore the desktop, the terminal, and nearly any Linux or open source application you can find. If you've been reading about open source for years and are ready to dive into an open source OS, this could be a platform for that (and much more, obviously).
## Gaming
The **RetroPie** SD card included in the box means you can reboot into a retro game console and play any number of old-school arcade games. It's not exactly a Steam Deck, but it's a fun and inspiring little gaming platform. Because it comes with not one but two game controllers, it's ideal for couch co-op. And best of all, you not only can play games on the CrowPi, but you can make your own games, too.
## Screwdriver included
I got to sit down with the CrowPi2 for about two weeks, and I've barely been able to get through all of the projects. There have been many nights when I've had to force myself to step away from it because even after I've tired of one project, I inevitably find something else to explore. To sum it up, I found one component in particular in the box, and I immediately knew that the CrowPi and I were well suited to one another: It was a small, humble screwdriver. There's no voiding of warranty stickers here. The CrowPi wants you to tinker, to take things apart, explore, and learn. This isn't a laptop or even just a Pi; this is a portable, low-powered, diverse, and open source learner's toolkit.
## 1 Comment |
15,657 | 如何知道你是否使用了代理服务器? | https://itsfoss.com/check-proxy-server/ | 2023-03-24T17:40:23 | [
"代理"
] | https://linux.cn/article-15657-1.html | 
什么是代理?
代理是充当客户端和另一台服务器之间的中介的服务器或软件应用。它充当客户端和互联网之间的网关,允许用户访问在线资源,同时隐藏他们的身份、位置和其他个人信息。
代理通常用于增强安全性和隐私,并为你的网络添加过滤器/防火墙。
有几种类型的代理,如 HTTP 代理、SOCKS 代理、透明代理等。
除非你在透明代理后面,否则检查起来毫不费力。在这里,我将讨论检测透明代理和常用代理的方法。
### 如何检查你是否在透明代理后面
虽然每种类型的代理都有其特性和功能,但如果它是透明代理,你将无法在客户端的 PC 上检测到它。这是因为透明代理在后台静默运行,拦截所有流量而不修改它。
有时,可能是你的互联网服务提供商和内容交付网络使用它们来缓存资源的副本以节省带宽或只是为了监视/过滤网络。
有几种方法可以检查你是否在透明代理后面:
* **通过某些在线 IP 检测/检查网站获得的 IP 地址可能与你的计算机或设备的 IP 地址不匹配**。因为代理服务器正在拦截你的流量并将其与 IP 地址一起发送出去。
* **检查你的网络设置以查看是否配置了代理服务器。**
* **借助一些在线代理检测工具。**
* **连接到你知道不存在的服务器。** 如果网页上显示的错误看起来与平时不同,你可能使用了代理。
无论你喜欢与否,你始终可以使用 [VPN 服务](https://itsfoss.com/best-vpn-linux/) 绕过透明代理。
### 如何检查你是否在 Ubuntu 上使用代理
Ubuntu 或任何其他 Linux 发行版提供了多种检查方法。此处使用运行 GNOME 的 Ubuntu 22.10。
#### 使用 GNOME 设置
这是直接的 GUI 方式。打开 GNOME <ruby> 设置 <rt> Settings </rt></ruby> 并转到 “<ruby> 网络 <rt> Networks </rt></ruby>” 选项卡,然后按旁边的齿轮图标。

它应该默认 <ruby> 禁用 <rt> Disabled </rt></ruby>。
如果你在代理后面,你可以在这里看到不同的状态。在代理设置中,你可以看到,我在这里使用了代理(手动配置)。

可以使用 GNOME 桌面中的 `gsettings` 命令更改相同的代理状态。
```
gsettings set org.gnome.system.proxy mode 'none'
```
你可以将 `none` 替换为 `auto` 或 `manual`。请记住,此设置是临时的,仅适用于当前用户。
#### 使用命令行
你可以通过命令行以多种方式获取代理的状态。
##### 通过列出关联的环境变量获取代理的状态
打开终端并运行以下任一命令:
```
env | grep -i proxy
```
```
cat /etc/environment | grep -i proxy
```
```
set | grep -i proxy
```

空输出意味着没有配置代理。否则,它将打印相关的环境变量。
>
> ? 请注意,如果你将代理设置为环境变量,这将起作用。
>
>
>
或者,你可以回显每个代理变量以检查是否设置了特定的代理变量。
以下是你可以在终端中输入的内容:
```
echo $http_proxy
```
##### 使用 nmcli 命令检查
打开终端并输入:
```
nmcli connection show
```

这将列出你的连接和关联的 UUID 编号。记下要检查的连接的 UUID 编号。然后使用命令:
```
nmcli connection show <UUID or name> | grep -i "proxy"
```
这将列出变量,你可以在其中记下代理服务器和端口。

### 总结
我希望本指南可以帮助你了解你是否在使用代理。
我必须提一下,**并非所有代理配置都是恶意的。**
但是,了解你的系统是否配置了代理很重要。
---
via: <https://itsfoss.com/check-proxy-server/>
作者:[Sreenath](https://itsfoss.com/author/sreenath/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

**What is a proxy?**
A proxy is a server or software application that acts as an intermediary between a client and another server. It serves as a gateway between the client and the internet and allows users to access online resources while keeping their identity, location, and other personal information hidden.
Proxies are often used to enhance security, privacy, and add filters/firewall to your network.
There are several types of proxies like HTTP Proxy, SOCKS Proxy, Transparent Proxy, etc.
Unless you are behind a transparent proxy, it is effortless to check. Here, I shall discuss methods to detect both the transparent proxy and the usual proxies in use.
## How to check if you are behind a Transparent proxy
While each type of proxy has its features and functionalities, if it's a transparent proxy, you won't be able to detect it on the client's PC. This is because the transparent proxy operates silently in the background, intercepting all traffic without modifying it.
Occasionally, it could be your internet service provider and the Content Delivery Networks that use these to cache a copy of a resource to save bandwidth on their end or just to monitor/filter the network.
There are several ways to check if you are behind a transparent proxy:
**The IP address obtained through some online IP detect/check websites may not match the IP address of your computer or device.**Because the proxy server is intercepting your traffic and sending it out with its IP address.**Check your network settings to see if there is a proxy server configured.****Take the help of some online Proxy detection tools.****Connect to a server that you know does not exist.**If the error displayed on the webpage looks different from usual, you might be behind a proxy.
Whether you like it or not, you can always bypass the transparent proxy using a [VPN service](https://itsfoss.com/best-vpn-linux/).
**Suggested Read 📖**
[12 Simple Tools to Protect Your PrivacyQuick ways to enhance online privacy? Use these simple tools to take control of your data easily.](https://itsfoss.com/privacy-tools/)

## How to check if you are behind a proxy on Ubuntu
Ubuntu, or any other Linux distribution, offers several ways to check this. Here, Ubuntu 22.10 running GNOME is used for the purpose.
### Using GNOME Settings
This is the straightforward GUI way. Open the GNOME settings and go to the Networks tab and press the gear icon, adjacent to it.
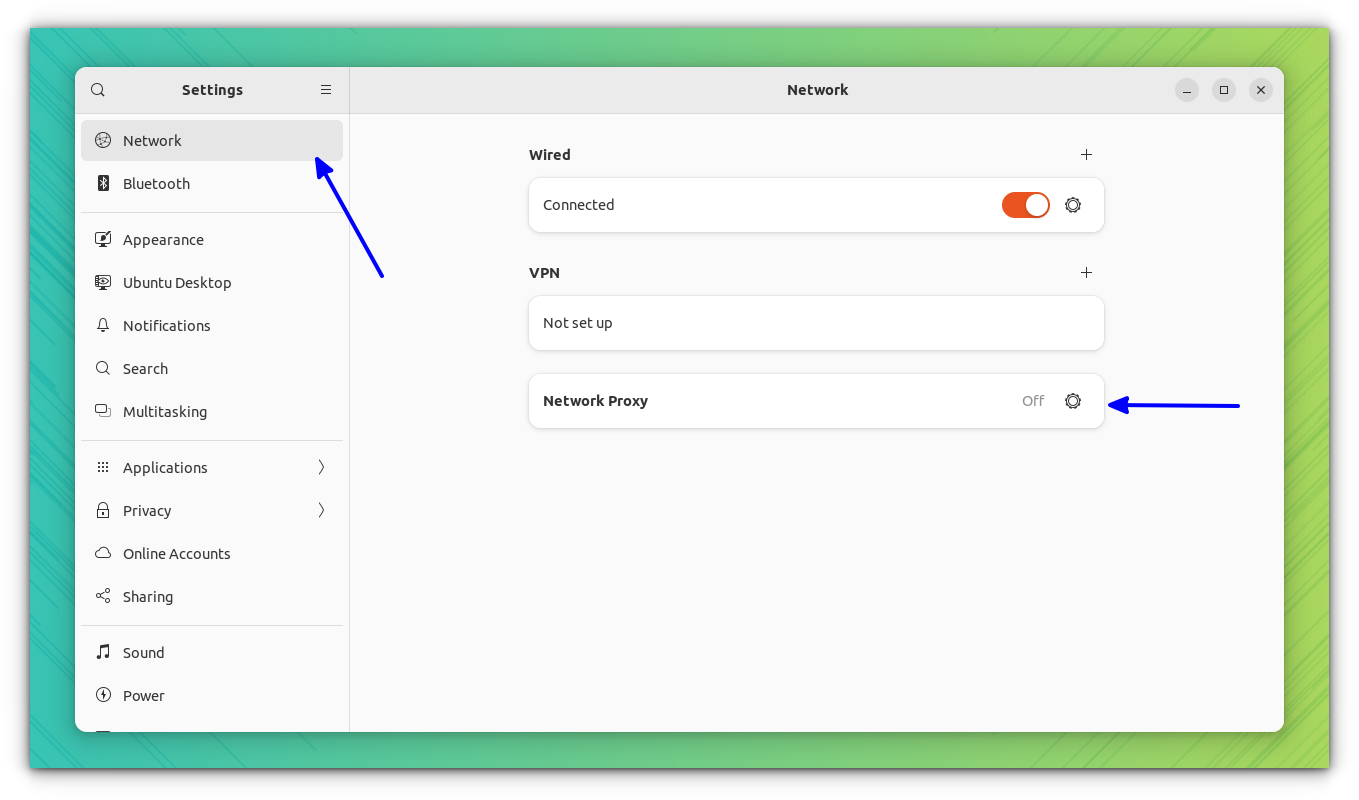
*Select the gear icon adjacent to the Network proxy section*
It should be **off by default**.
If you are behind a proxy, you can get a different status here. Inside the proxy settings, you can see that, I am using a proxy here (manually configured).
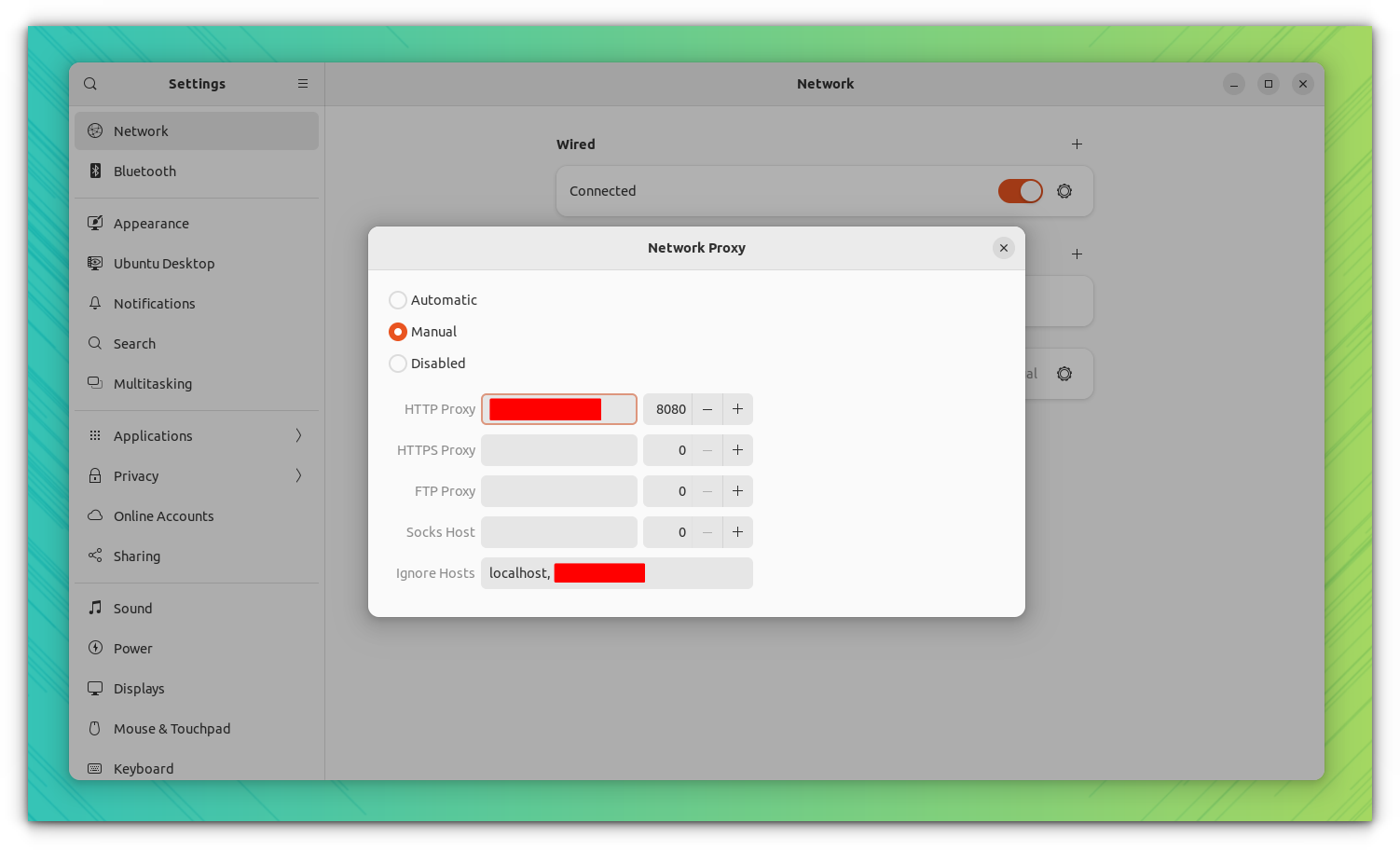
*Proxy details in GNOME Settings*
The same status of proxies can be changed using the gsettings command in GNOME DE.
`gsettings set org.gnome.system.proxy mode 'none'`
You can replace the `none`
with `auto`
or `manual`
. Remember that, this setting is temporary and only for the current user.
### Using the Command line
You can get the status of proxies through the command line in various ways.
**Getting the status of the proxy by listing the associated environment variables**
Open a terminal and run either of the following commands:
`env | grep -i proxy`
`cat /etc/environment | grep -i proxy`
`set | grep -i proxy`
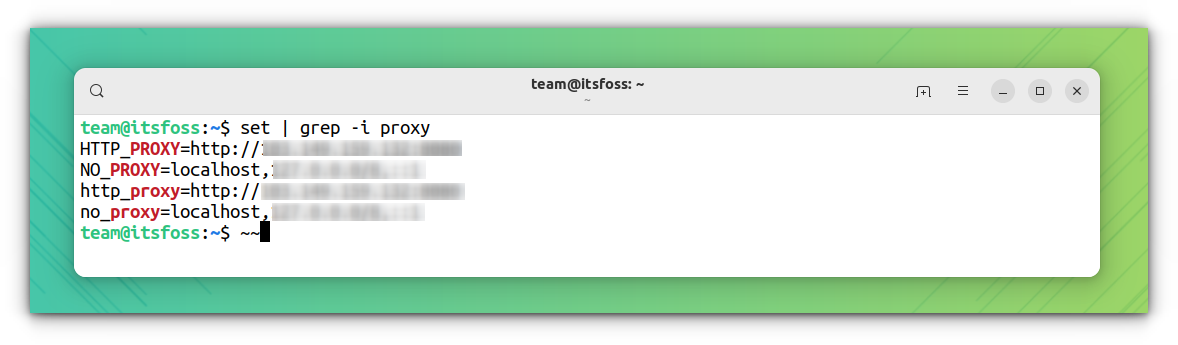
*Using*
`set`
command to check Proxy variablesAn empty output means that, there are no proxies configured. Else, it will print the relevant ENV variables.
Alternatively, you can echo each proxy variable to check whether that particular one is set.
Here's what you can type in the terminal:
`echo $http_proxy`
**Check using nmcli command**
Open a terminal and issue the command:
`nmcli connection show`
*List all the connections using nmcli command*
This will list your connections and the associated UUID numbers. Note the UUID number of the connection, you want to check. Then use the command:
`nmcli connection show <UUID or name> | grep -i "proxy"`
This will list the variables, where, you can note the proxy server and the port.
*Proxy details using nmcli command*
**Suggested Read 📖**
[5 Tools to Protect Your Email Address From Websites and NewslettersSimple tools that you can use to protect your email address!](https://itsfoss.com/protect-email-address/)

## Wrapping Up
I hope this guide helps you know if you are behind a proxy.
I must mention that **not all proxy configurations are malicious. **
However, it is important to know whether your system has a proxy configured or not. |
15,659 | GNOME 44 发布 | https://news.itsfoss.com/gnome-44-release/ | 2023-03-25T10:07:00 | [
"GNOME"
] | https://linux.cn/article-15659-1.html |
>
> GNOME 44 终于来了,它带来了重新打造的设置应用,更新了快速设置功能,改进了可访问性等等。
>
>
>

GNOME 可以说是\***最受欢迎的桌面环境**之一。
之前的 [GNOME 43 版本](https://news.itsfoss.com/gnome-43-release/) 就补充了许多有用的功能,而现在的 GNOME 44 版本也是一样。
让我们看看都有哪些内容。
### ? GNOME 44 有什么新功能?
我们最近已经分别介绍了 GNOME 44 的最佳功能;在这里,让我回顾一下这个发布的相关细节。
主要的亮点包括:
* 设置菜单的改造
* 快速设置的改进
* 文件选择器的网格视图
* 文件管理器的改进
#### 1、设置菜单的改造

设置菜单进行了小规模的改造,**可访问性面板被重新设计**,以提供一个更现代的导航体验。

然后,一项新的功能让你可以 **通过二维码分享 Wi-Fi 密码**,并且改进了鼠标/触摸板设置。
“设备安全”下的信息也得到了更新,以增加技术细节的清晰度。

#### 2、改进的快速设置菜单

快速设置面板已经得到了许多更新;它现在可以让你 **查看和管理当前连接的蓝牙设备**。
但你必须前往设置菜单来配对新设备。

另一个新增功能是**新的屏幕截图快捷方式**,可以毫不费力地从快速设置菜单中进行屏幕截图。
这还不是全部;GNOME 44 的快速设置菜单现在有一个检查**在后台运行的应用程序的巧妙方法**。

你可以在我们之前的报道中找到关于这个功能的更多细节:
>
> **[GNOME 正在(某种程度上)恢复在几年前删除的功能](/article-15551-1.html)**
>
>
>
#### 3、新的锁屏/登录窗口

GNOME 44 提供了**更新的锁屏和登录窗口**,有一个更大的用户头像和各种元素的细微变化,例如时钟的字体大小。
#### 4、GNOME 文件选取器中的缩略图

去年年底,我们看到了 GNOME 文件选取器的一个**长时间要求的功能** 的 [回归](https://news.itsfoss.com/gnome-file-picker/),而现在它终于到来了。
GNOME 的文件选取器从来没有一个合适的缩略图预览来查看文件。取而代之的是,它**依赖于一个普通的列表视图**。
直到现在。
它现在**带来了一个合适的缩略图视图**,可以通过点击文件选取器右上角的 “列表-网格视图” 切换进行切换。
#### ?️ 其他变化和改进

这些并不是 GNOME 44 带来的唯一改进;这里有一些值得一提的改进:
* 新壁纸。
* 对文件管理器的各种小更新带来了性能的提高。
* Epiphany 网页浏览器被移植到 GTK4,并进行了许多错误修正。
* 在 GNOME 软件应用中加入了一个新的过滤器,激活后只显示开源的应用程序。
* 对联系人应用进行了各种改进,能够以二维码的形式分享联系人。
* 对 GNOME Builder 的许多 UI 和风格进行了修复。
* 在 [GNOME Circle](https://circle.gnome.org/?ref=its-foss-news) 集合中添加了十个新的应用程序。
你可以通过 [官方发布说明](https://release.gnome.org/44/?ref=its-foss-news) 来了解更多。
### 开始使用 GNOME 44
你可以在下个月期待 GNOME 44 与 Ubuntu 23.04 和 Fedora 38 一起出现。
如果你迫不及待地想得到它,使用 [Boxes](https://wiki.gnome.org/Apps/Boxes?ref=its-foss-news) 安装 [GNOME OS](https://os.gnome.org/?ref=its-foss-news) 应该是一个测试它的好方法。
>
> **[GNOME](https://www.gnome.org/getting-gnome/?ref=its-foss-news)**
>
>
>
? 你对这个丰富的 GNOME 44 更新有何看法?你想在你的 Linux 系统上使用它吗?
---
via: <https://news.itsfoss.com/gnome-44-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

GNOME is arguably the **most popular desktop environment**.
The previous [GNOME 43 release](https://news.itsfoss.com/gnome-43-release/) was packed with many useful additions, and now the GNOME 44 release follows in the same steps.
Let's see what is on offer.
## 🆕 GNOME 44: What's New?
We recently covered the best features of GNOME 44 separately; here, let me give you a recap along with all the release details.
The key highlights include:
**Settings menu makeover****Quick settings improvements****File chooser grid view****File manager improvements**
[7 Cool GNOME 44 Features To Watch Out ForGNOME 44 is around the corner. Learn more about the features arriving with GNOME 44 release.](https://news.itsfoss.com/gnome-44/)

### 1. Settings Menu Makeover
The Settings menu has received a minor makeover, with the **Accessibility panel being redesigned** to provide a more modern navigation experience.
Then, a new feature lets you **share Wi-Fi passwords through a QR code,** and the improved mouse/touchpad settings.
The information under "**Device Security**" has also received updates to add clarity to the technical details.
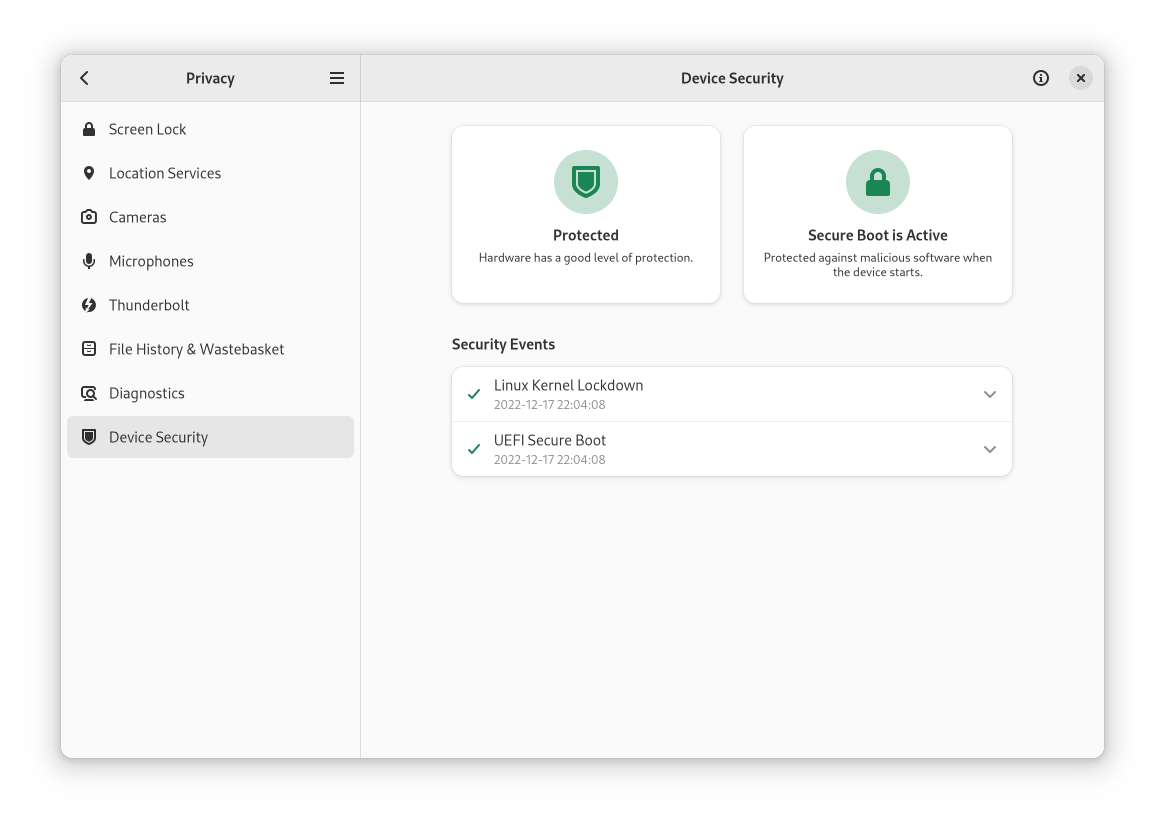
### 2. Improved Quick Settings Menu
The quick settings panel has received many updates; it now lets you** view and manage the currently connected Bluetooth devices. **
But you must head to the settings menu to pair a new device.
Another addition is the** new screenshot shortcut **that allows for the effortless capture of screenshots from the quick settings menu.
That is not all; GNOME 44's quick settings menu now features a nifty way of checking **apps running in the background.**
You can find more details on this feature in our previous coverage about it:
[GNOME is (kind of) Bringing Back a Feature It Had Removed a Few Years AgoGNOME design changes makes sense, as it brings back (sort of) a similar functionality that it removed earlier.](https://news.itsfoss.com/gnome-design-quick-access/)

### 3. New Lock Screen/Login Window

GNOME 44 features a **refreshed lock screen and login window** with a bigger user avatar and subtle changes to the various elements, such as the font size for the clock.
### 4. Thumbnails in GNOME File Picker
Late last year, we [saw the revival](https://news.itsfoss.com/gnome-file-picker/) of a **long-requested feature** for the GNOME file picker, and now it has finally arrived.
GNOME's file picker never had a proper thumbnail preview for viewing files. Instead, it **relied on a plain list view**.
Until now, that is.
It now **features a proper thumbnail view** that can be toggled by clicking on the 'list-grid view' toggle in the top-right of the file picker.
### 🛠️ Other Changes & Improvements
These were not the only improvements that have arrived with GNOME 44; here are some that are worth mentioning:
- New wallpapers
- Various minor updates to the File Manager resulted in improved performance.
- Epiphany web browser ported to GTK4 with many bug fixes.
- A new filter has been added to GNOME Software that only shows open-source apps when activated.
- Various improvements to the Contacts app, with the ability to share contacts as QR codes.
- Many UI and styling fixes for GNOME Builder.
- Ten new apps added to the
[GNOME Circle](https://circle.gnome.org/?ref=news.itsfoss.com)collection.
You can go through the [official release notes](https://release.gnome.org/44/?ref=news.itsfoss.com) to learn more.
## Get Started With GNOME 44
You can expect GNOME 44 with Ubuntu 23.04 and Fedora 38 next month.
If you cannot wait to get your hands on it, installing [GNOME OS](https://os.gnome.org/?ref=news.itsfoss.com) using [Boxes](https://wiki.gnome.org/Apps/Boxes?ref=news.itsfoss.com) should be a good way to test it.
*💬 What do you think of this expansive GNOME 44 update? Do you want to use it on your Linux system?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,660 | Python 中的输入函数:概念和示例 | https://www.debugpoint.com/input-function-python/ | 2023-03-25T13:18:00 | [
"Python"
] | /article-15660-1.html |
>
> 在这篇文章中,我将通过一些通俗易懂的例子来解释 Python 的 input() 函数的基础知识。
>
>
>

Python 是世界上最流行的编程语言之一,广泛应用于各种应用程序中。Python 中的一个基本概念是 `input()` 函数,它允许用户通过提供输入值与程序进行交互。
让我们看看 `input()` 函数是如何工作的,以及如何在 Python 程序中有效地使用它。
在开始之前,我希望你已经安装了 Python 并设置了一个基本的编辑器。如果没有,请参考我的以下指南:
* [如何在 Ubuntu 等 Linux 上安装 Python 3.11](/article-15230-1.html)
* [如何在 Windows 上安装 Python](/article-15480-1.html)
* [如何为 Python 设置 IDLE 编辑器](/article-15622-1.html)
### Python Input 函数
Python 中的 `input()` 函数用于接受用户输入的字符串。它提示用户输入一个值并等待用户提供输入。然后将用户的输入作为字符串存储在变量中,稍后可以在程序中使用。
#### 句法
```
input("your message to user")
```
当你运行 `input()` 函数时,它会向用户显示消息并 *等待* 输入。显示光标等待。当用户输入并按下回车键,`input()` 函数就会读取用户的输入。该值存储在你指定的变量中。
让我们看几个例子。
### 示例 1:简单的 input() 函数用法
以下代码片段接受输入并显示带有附加字符串的输出:
```
your_name = input("Enter your name:")
print("Hello " + your_name)
```
输出:
```
Enter your name:arindamHello arindam
```

### 示例 2:以整数和浮点数作为输入
在使用 `input()` 函数时,你还可以在运行时使用 `int()` 或 `float()` 将输入转换。这是一个例子:
```
no_of_books = int(input("Enter total books ordered:"))
print ("Total number of books:", no_of_books)
price_of_each_book = float(input("Enter unit price:"))
print ("Total price:", no_of_books * price_of_each_book)
```
输出:
```
Enter total books ordered:5
Total number of books: 5
Enter unit price:10.1
Total price: 50.5
```
### 示例 3:连接列表
你还可以使用其他函数(例如列表)来接受一组值并将它们转换为 Python 中的 [列表](https://docs.python.org/3/library/stdtypes.html?highlight=list#lists)。这是一个接受输入并将其转换为列表的示例。然后使用另一组值并附加到第一个列表:
```
# 获取第一个列表的输入
list_1 = list(input("Enter numbers for list 1:"))
# 获取第二个列表的输入
list_2 = list(input("Enter some letters for list 2:"))
# 循环遍历第二个列表并添加到第一个列表
for j in list_2:
list_1.append(j)
# 打印修改后的第一个列表
print(list_1)
```
输出:
```
Enter numbers for list 1:1234
Enter some letters for list 2:ABCD
['1', '2', '3', '4', 'A', 'B', 'C', 'D']
```
### 总结
我希望这个简单的指南通过几个示例阐明了 `input()` 函数。对于简单的场景,它是一个强大的功能,可以从标准输入中接受值。
---
via: <https://www.debugpoint.com/input-function-python/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,662 | 如何找到合适的 Debian ISO 来下载 | https://www.debugpoint.com/download-debian-iso/ | 2023-03-26T10:10:00 | [
"Debian"
] | /article-15662-1.html | 
>
> Linux 初学者可能会被官方的 Debian 下载 ISO 的页面弄得不知所措。这篇指南旨在简化下载体验。
>
>
>
对于 Debian 初学者来说,安装 Debian 可能会是一次艰难的经历。官方的下载页面包含了不少链接,以至于到底需要下载哪个令人困惑。
我准备这篇指南来帮助你从下载页面挑选合适的 Debian ISO 文件。
总的来说,你可以将 Debian ISO 文件分为两大类。它们是 “自由” 和 “非自由” 。
### 关于 “自由” 和 “非自由” Debian 镜像之间的一些注意事项
* Debian “非自由” 镜像是指包含不符合 Debian 自由软件准则的软件包的 Debian 操作系统的安装镜像。
* “非自由” 软件包包含专有的、有版权的或受许可证限制的软件,这些软件包禁止用户修改或分发代码。Debian 项目提供这些 “非自由” 镜像作为用户的一种可选下载项,以便他们使用需要专有驱动或固件的特定硬件设备或软件。
* “自由” 版本的 Debian,仅包含开源和可自由分发的软件包,这意味着用户有修改、分发和与他人分享的自由,而不受任何法律和道德上的限制。
从 Debian 12 “Bookworm”(即将发布)之后,非自由固件软件包将正式包含在主 ISO 文件中。因此,这篇指南将分为两个部分。
### 下载: Debian 12 “Bookworm”
这里是一份下载 ISO 版本的 Debian 12 “Bookworm” 的简单的表格(当前还不稳定,正在测试)。
| 描述 | 最大 ISO 体积 | **选择此 ISO 的情形** | ISO 下载链接(amd64) |
| --- | --- | --- | --- |
| 最小的体积;非常适合基本安装 | 700 MB | 你想下载基础的软件包,然后通过互联网来安装 | [iso-cd](https://cdimage.debian.org/cdimage/bookworm_di_alpha2/amd64/iso-cd/) |
| 完整的 DVD 体积 | 5 GB | 你想先下载所有的东西,然后开始安装,它非常适合离线安装 | [iso-dvd](https://cdimage.debian.org/cdimage/bookworm_di_alpha2/amd64/iso-dvd/) |
### 下载: Debian 11 “Bullseye”
#### 自由版本的 ISO 文件(没有专有软件包)
下面的 ISO 镜像是 “自由” 版本的镜像,这意味着它们不包含用于固件的大量专有软件包。
| 描述 | 最大 ISO 体积 | **选择此 ISO 的情形** | ISO 下载链接(amd64) |
| --- | --- | --- | --- |
| 最小的体积(网络安装 CD);需要联通互联网下载软件包 | 500 MB | 你有稳定高速的互联网,希望开始时下载较少 | [iso-cd](https://cdimage.debian.org/cdimage/release/current/amd64/iso-cd/) [torrent](https://cdimage.debian.org/cdimage/release/current/amd64/bt-cd/) |
| 完整的 CD 体积;带有 CD 1、2 和 3;对于最基础的安装,你只需要 CD 1 | 700 MB | 你希望下载基础的软件包,然后不使用互联网来安装它们 | [iso-cd](https://cdimage.debian.org/debian-cd/current/amd64/iso-cd/) [torrent](https://cdimage.debian.org/debian-cd/current/amd64/bt-cd/) |
| 完整的 DVD 体积;带有 DVD 1、2 和 3;对于最基础的安装,你只需要 DVD 1 | 5 GB | 你想先下载所有的东西,然后开始安装,这是离线安装的最理想方式 | [iso-dvd](https://cdimage.debian.org/cdimage/release/current/amd64/iso-dvd/) [torrent](https://cdimage.debian.org/cdimage/release/current/amd64/bt-dvd/) |
#### 非自由版本的 ISO 文件(带有专有软件包)
如果你有 Wi-Fi、蓝牙等特殊硬件 – 你可能会希望从下面的表中获取 “非自由” 版本的软件包。
| 类型 | 镜像种类 | **选择此 ISO 的情形** | ISO 下载链接(amd64) |
| --- | --- | --- | --- |
| 非自由 | 完整的 CD 、DVD | 你想要减少工作量,并希望 Debian 能够在所有受支持的硬件上工作 | [cd-dvd](https://cdimage.debian.org/cdimage/unofficial/non-free/cd-including-firmware/) (然后转到 `*-nonfree` 目录) |
| 非自由 | 完整的 CD 、DVD(<ruby> 立付 <rt> Live </rt></ruby>版) – 独立的桌面环境软件包 | 你想要减少工作量,Debian 能够工作,并且带有一个立付系统。立付系统也提供完整的安装 | [cd-dvd-live](https://cdimage.debian.org/cdimage/unofficial/non-free/cd-including-firmware/)(然后转到 `*-nonfree` 目录) |
### 其它的架构
#### 针对 Debian 11 “Bullseye”
* [arm64](http://ftp.debian.org/debian/dists/bullseye/main/installer-arm64/current/images/)
* [armel](http://ftp.debian.org/debian/dists/bullseye/main/installer-armel/current/images/)
* [armhf](http://ftp.debian.org/debian/dists/bullseye/main/installer-armhf/current/images/)
* [i386](http://ftp.debian.org/debian/dists/bullseye/main/installer-i386/current/images/)
* mips (不可用)
* [mips64el](http://ftp.debian.org/debian/dists/buster/main/installer-mips64el/current/images/)
* [mipsel](http://ftp.debian.org/debian/dists/bullseye/main/installer-mipsel/current/images/)
* [ppc64el](http://ftp.debian.org/debian/dists/bullseye/main/installer-ppc64el/current/images/)
* [s390x](http://ftp.debian.org/debian/dists/bullseye/main/installer-s390x/current/images/)
所有的镜像,下载链接: [单击这里](https://cdimage.debian.org/cdimage/)。
### 较旧的版本(Debian 10 “Buster”)
如果你需要一些针对 Debian 10 “Buster” 的镜像,请访问这个 [页面](https://www.debian.org/releases/buster/debian-installer/)。
### 总结
对新用户来说,如果想要从官方网站上下载 Debian ISO 镜像,网站的信息可能多到无所适从。因此,我以一种恰当的格式总结下载链接。我希望这篇文章有助于你找到适合于你系统的目标 Debian ISO 镜像。
---
via: <https://www.debugpoint.com/download-debian-iso/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,663 | NixOS 系列 #4:安装 NixOS 后要做的事 | https://itsfoss.com/things-to-do-after-installing-nixos/ | 2023-03-26T14:25:14 | [
"NixOS"
] | https://linux.cn/article-15663-1.html | 
安装之后,你会发现 NixOS 与通用的 Linux 发行版有很大的不同。
当然,作为 [高级 Linux 发行版](https://itsfoss.com/advanced-linux-distros/)之一,大多数新用户对它并不熟悉。
如果你不知道 [为什么你应该使用 NixOS](/article-15606-1.html),并且出于好奇而尝试它,那么在继续进行之前,知道它是为谁准备的至关重要。
虽然我假设你已经安装了这个发行版,但如果你是第一次使用,我建议先 [在虚拟机上安装 NixOS](/article-15624-1.html)。
### 1、更新软件包
即使你使用最新的 ISO 进行安装,也总是会有更新的。那么为什么不从更新软件包开始呢?
要升级软件包,首先,你必须在添加的频道中检查是否有更新:
```
nix-channel --update
```
然后,使用下面的命令来安装这些更新(如果有的话):
```
sudo nixos-rebuild switch --upgrade
```
这就行了!它将处理其余的事情。
### 2、在 NixOS 中改变主机名
如果你尝试用传统的方法 [改变主机名](https://itsfoss.com/change-hostname-ubuntu/)(使用 `hostnamectl` 命令),会出现以下错误:

在 NixOS 中,你可以用它的主配置文件轻松地改变主机名。使用如下命令:
```
sudo nano /etc/nixos/configuration.nix
```
在这个配置文件中,寻找以下一行:
```
networking.hostName = "nixos";
```
然后把它改成:
```
networking.hostName = "Your_Hostname";
```
例如,我把我的主机名改为 `itsFOSS`:
```
networking.hostName = "itsFOSS";
```

现在,[保存更改并退出 nano](https://linuxhandbook.com/nano-save-exit/?ref=its-foss) 文本编辑器。
为了使你对主机名的修改生效,执行以下命令:
```
sudo nixos-rebuild switch
```
最后,重新打开终端,主机名的变化应该反映出来。
### 3、设置 Flatpak
我知道你可能在想什么。Nix 软件包管理器已经提供了大量的软件包。那么,为什么你需要 Flatpak 呢?
安装你所需要的东西对于第一次使用的人来说可能有点费时。所以,Flatpak 应该能给你带来方便。
[设置 Flatpak](https://itsfoss.com/flatpak-guide/) 与你在 Ubuntu 上做的不一样。
要设置 Flatpak,你必须对 `configuration.nix` 文件进行修改,可以通过以下方式访问该文件:
```
sudo nano /etc/nixos/configuration.nix
```
[在 nano 中移动到最后一行](https://linuxhandbook.com/beginning-end-file-nano/?ref=its-foss),在 `}` 前添加以下一行:
```
services.flatpak.enable = true;
```

按 `Ctrl + O` 保存更改,按回车键,按 `Ctrl + X` 退出。
接下来,使用以下命令重建并切换到新的配置文件:
```
sudo nixos-rebuild switch
```
最后,使用下面的命令将 Flathub 软件库添加到系统中:
```
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
想知道到底什么是 Flatpak 包吗?你可以参考我们关于它的文章:
>
> **[什么是 Flatpak?你需要知道的关于这个通用包装系统的一切重要信息](https://itsfoss.com/what-is-flatpak/)**
>
>
>
### 4、启用垃圾收集
NixOS 以其不可改变性而闻名,这是有充分理由的。
每当你升级一个软件包时,旧的软件包不会被删除。只是指向旧包的符号链接将被指向最新的版本。
而这样做,你的系统中会积累下不必要的垃圾。
但是,删除每一个旧世代将违背 NixOS 的初衷。
所以,在这种情况下,你可以将你的系统配置为每周删除垃圾包。
要做到这一点,首先,打开 NixOS 配置文件:
```
sudo nano /etc/nixos/configuration.nix
```
并在配置文件末尾的 `}` 前添加以下一行:
```
# Automatic Garbage Collection
nix.gc = {
automatic = true;
dates = "weekly";
options = "--delete-older-than 7d";
};
```

保存修改并退出 nano 文本编辑器。
为了激活垃圾收集,重建并切换到新的配置文件:
```
sudo nixos-rebuild switch
```
如果你不确定垃圾收集器是否在后台正常运行,你可以用以下命令列出活动的计时器:
```
systemctl list-timers
```

正如你所看到的,Nix 垃圾收集器正在如期运行,并显示距离下次清理还有 5 天。
### 5、安装你喜欢的软件
我是说这是我们使用电脑的唯一原因 —— “为了使用我们最喜欢的软件”,如果还不是,我们就把它变成现实!
寻找软件包的最好地方是 [Nix 软件包搜索](https://search.nixos.org/packages?ref=its-foss),可以使用你喜欢的任何浏览器访问。
* 搜索软件包
* 选择软件包
* 点击 “nix-env” 并复制给定的 NixOS 的命令
* 执行该命令,就可以了
你可以查看我们的 [NixOS 软件包管理](/article-15645-1.html) 指南,了解所有的细节。
让我在这里给你一个简单的回顾。例如,在这里,我想安装 Librewolf,所以我采用了以下方法:

**但如果你想安装 SSH 或 Plex 等服务,上述方法就不能用了**。
为此,你得查看位于页面顶部的 “<ruby> NixOS 选项 <rt> NixOS options </rt></ruby>”。
因此,假设我想安装 OpenSSH,那么我必须按照给定的步骤进行:
* 进入 “NixOS 选项”。
* 搜索服务的名称
* 获取服务的名称并将其粘贴到 `configuration.nix` 中,将其值改为 `true`。

```
services.openssh.enable = true
```

在配置文件中加入这一行后,重建服务:
```
sudo nixos-rebuild switch
```
### 6、在 NixOS 中启用自动更新(可选)
一些用户喜欢启用自动更新功能,而另一些用户则可以在他们方便的时候更新软件包。
所以这完全取决于你。
**要启用自动更新**,首先打开 `configuration.nix` 文件:
```
sudo nano /etc/nixos/configuration.nix
```
接下来,在配置文件的末尾,在 `}` 之前添加以下一行:
```
# Auto system update
system.autoUpgrade = {
enable = true;
};
```

保存修改并退出 nano。
要启用自动更新,你必须用以下方法重建并切换到该文件:
```
sudo nixos-rebuild switch
```
你也可以用下面的命令检查 NixOS 的升级定时器:
```
systemctl list-timers
```

正如你所看到的,`nixos-upgrade.service` 正在后台如期运行!
### 7、减少交换度
如果你正在利用交换分区,你可能想减少交换度。
交换度只不过是你想要多积极地使用交换分区(或内存)的数值,其范围从 0 到 100。
交换度越小,你的系统就会越多地使用物理内存(RAM),而交换分区只不过是你的存储驱动器的一部分而已。
另外,存储驱动器的速度相对比内存慢,所以如果可能的话,你应该减少交换度。
要检查你的系统的默认交换度,请使用以下方法:
```
cat /proc/sys/vm/swappiness
```

而对于大多数 Linux 发行版,它被设置为 `60`。
我建议你把这个值降低到 `10`。
要做到这一点,首先,用以下命令打开配置文件:
```
sudo nano /etc/nixos/hardware-configuration.nix
```
并在 `}` 之前的行末添加以下一行:
```
boot.kernel.sysctl = { "vm.swappiness" = 10;};
```

保存修改并退出文本编辑器。
现在,重建配置并使用下面的方法切换到它:
```
sudo nixos-rebuild switch
```
现在,你可以再次检查交换度,它应该反映出变化:
```
cat /proc/sys/vm/swappiness
```

就这些了。
### 总结
如果你在第一次安装 NixOS 后马上遵循这些要点,你应该得到一个良好的用户体验。
当然,根据你的要求,还可以有一些其他的东西。但是,我认为上面提到的事情是最基本或最常见的事情。
在本系列的下一部分,我将讨论在 NixOS 上设置家庭管理器,这对有多个用户的系统应该是有帮助的。
? 安装NixOS后,你首先做什么?让我知道你的想法。
---
via: <https://itsfoss.com/things-to-do-after-installing-nixos/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Things to do After Installing NixOS
What do you do right after installing NixOS? Clueless? We got your back.
After installation, you will notice that NixOS is quite different from general-purpose Linux distributions.
Of course, as one of the [advanced Linux distributions](https://itsfoss.com/advanced-linux-distros/), it may not feel right at home to most new users.
If you do not know [why you should use NixOS](https://itsfoss.com/why-use-nixos/), and trying it out of curiosity, it is vital to know who it is for before proceeding.
While I assume you installed the distro already, if it is your first time, I suggest [installing NixOS on a virtual machine](https://itsfoss.com/install-nixos-vm/).
## 1. Update packages
Updates would always be there even if you used the latest ISO for the installation. So why not start by updating the packages?
To upgrade packages, first, you will have to check for updates in added channels:
`nix-channel --update`
And then, use the following command to install those updates (if any):
`sudo nixos-rebuild switch --upgrade`
That's it! It will take care of the rest.
## 2. Change hostname in NixOS
If you try the traditional way of [changing the hostname](https://itsfoss.com/change-hostname-ubuntu/) (using the `hostnamectl`
command), it will throw the following error:
With NixOS, you can change the hostname easily using its main config file, which you can access using the following command:
`sudo nano /etc/nixos/configuration.nix`
In this config file, look for the following line:
`networking.hostName = "nixos";`
And change it to:
`networking.hostName = "Your_Hostname";`
For example, I changed my hostname to `itsFOSS`
:
`networking.hostName = "itsFOSS";`
Now, [save changes and exit from the nano](https://linuxhandbook.com/nano-save-exit/) text editor.
To take effect from the change you made to hostname, execute the following command:
`sudo nixos-rebuild switch`
And finally, reopen the terminal, and the change in hostname should reflect. You may have to reboot in recent versions of NixOS.
**Suggested Read 📖**
[Vim vs Nano: What Should You Choose?Vim and Nano are two popular terminal text editors. How are they different? What’s best for you? Let us find out.](https://itsfoss.com/vim-vs-nano/)

## 3. Setup Flatpak
I know what you might be thinking. The Nix package manager already offers a plethora of packages. So, why do you need Flatpak?
Installing what you need could be a bit time-consuming for first-time users. So, Flatpak should make things convenient for you.
[Setting up Flatpak](https://itsfoss.com/flatpak-guide/) is not the same as you do on Ubuntu.
To setup Flatpak, you will have to make changes to the `configuration.nix`
file, which can be accessed using the following:
`sudo nano /etc/nixos/configuration.nix`
[Go to the end of the line in nano](https://linuxhandbook.com/beginning-end-file-nano/) and add the following line before the `}`
:
`services.flatpak.enable = true;`
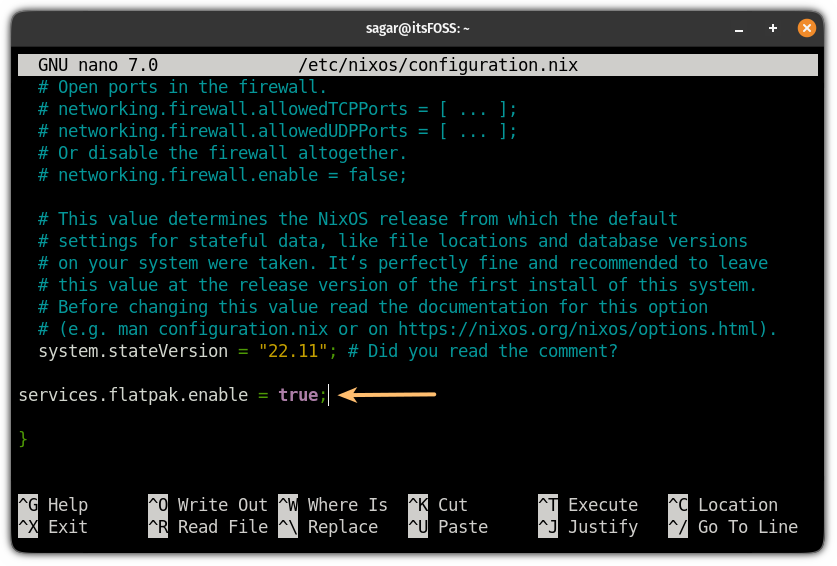
Save changes by pressing `Ctrl + O`
, hit enter and exit by `Ctrl + X`
.
Next, rebuild and switch to the new config file using the following command:
`sudo nixos-rebuild switch`
And finally, add the Flathub repository to the system using the following command:
`flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo`
Want to know what exactly is a Flatpak package? You can refer to our article on it:
[What is Flatpak? Everything Important You Need to Know About This Universal Packaging SystemWhat are Flatpak packages? Why is it called a universal packaging system, what problem does it solve and how does it work? Learn about Flatpak.](https://itsfoss.com/what-is-flatpak/)

## 4. Enable garbage collection
NixOS is known for being immutable, and there is a strong reason why.
Whenever you upgrade a package, the old package won't be removed. Just the symlinks of the old package will be given to the latest version.
And doing that, you will collect unnecessary trash from your system.
But removing every old generation will falsify the purpose of NixOS.
So, in that case, you can configure your system to remove garbage packages weekly.
To do that, first, open the nix configuration file:
`sudo nano /etc/nixos/configuration.nix`
And add the following line at the end of the config file before `}`
:
```
# Automatic Garbage Collection
nix.gc = {
automatic = true;
dates = "weekly";
options = "--delete-older-than 7d";
};
```
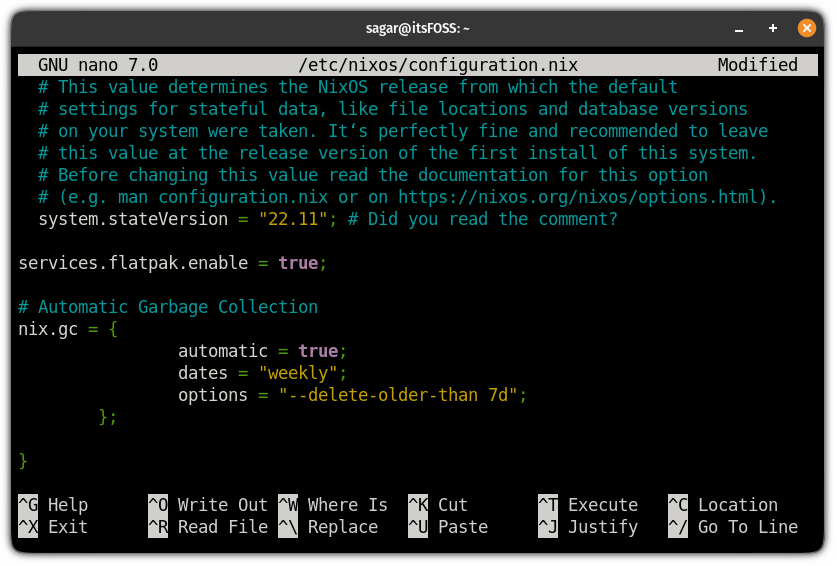
Save changes and exit from the nano text editor.
To activate the garbage collection, rebuild and switch to the new config file:
`sudo nixos-rebuild switch`
If you are not sure whether the garbage collector is running fine in the background, you can list active timers using the following command:
`systemctl list-timers`
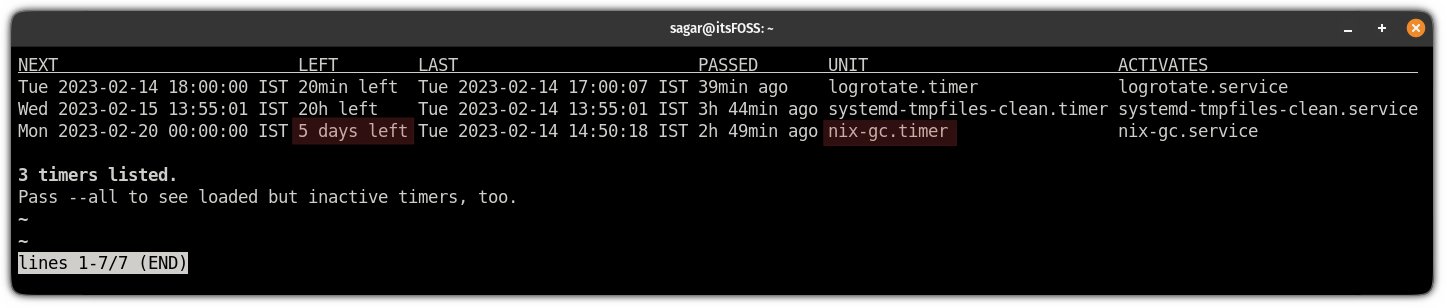
And as you can see, the Nix garbage collector is running as expected and shows 5 days left for the next cleanup.
## 5. Install your favorite software
I mean this is the only reason why we use computers. "To use our favorite software," and if there's none, we make it happen!
The best place to look for packages is the [Nix package search](https://search.nixos.org/packages) which can be accessed using any of your preferred browsers.
- Search package
- Select the package
- Click on
`nix-env`
and copy the given command for`NixOS`
- Execute that command, and that's it
You can check our [NixOS package management](https://itsfoss.com/nixos-package-management/) guide to get all the details.
Let me give you a quick recap here. For example, here, I want to install Librewolf, so I went with the following:
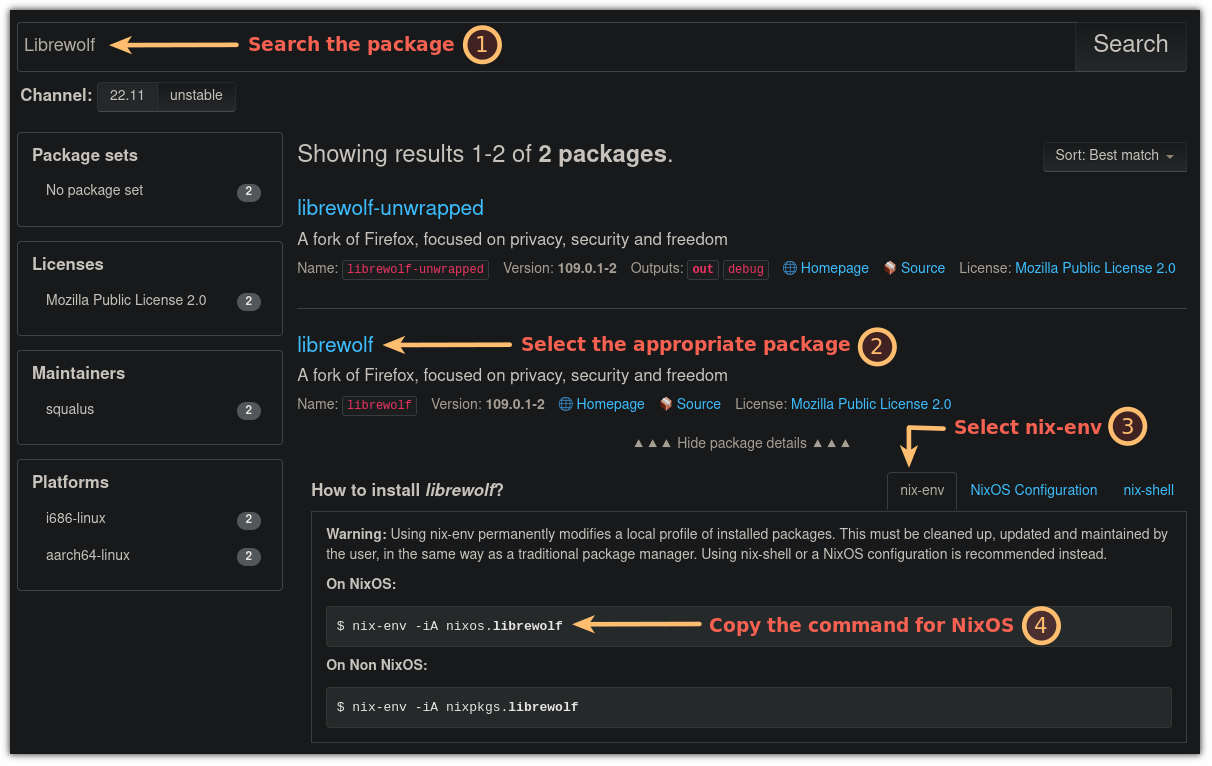
**But if you want to install services like SSH or plex, the above method won't work**.
For that, you will have to look into `NixOS options`
situated at the top of the page.
So let's say I want to install OpenSSH, so I have to follow the given steps:
- Go to
`NixOS options`
- Search the name of the service
- Get the name of the service and paste it to the
`configuration.nix`
by changing its value to`true`
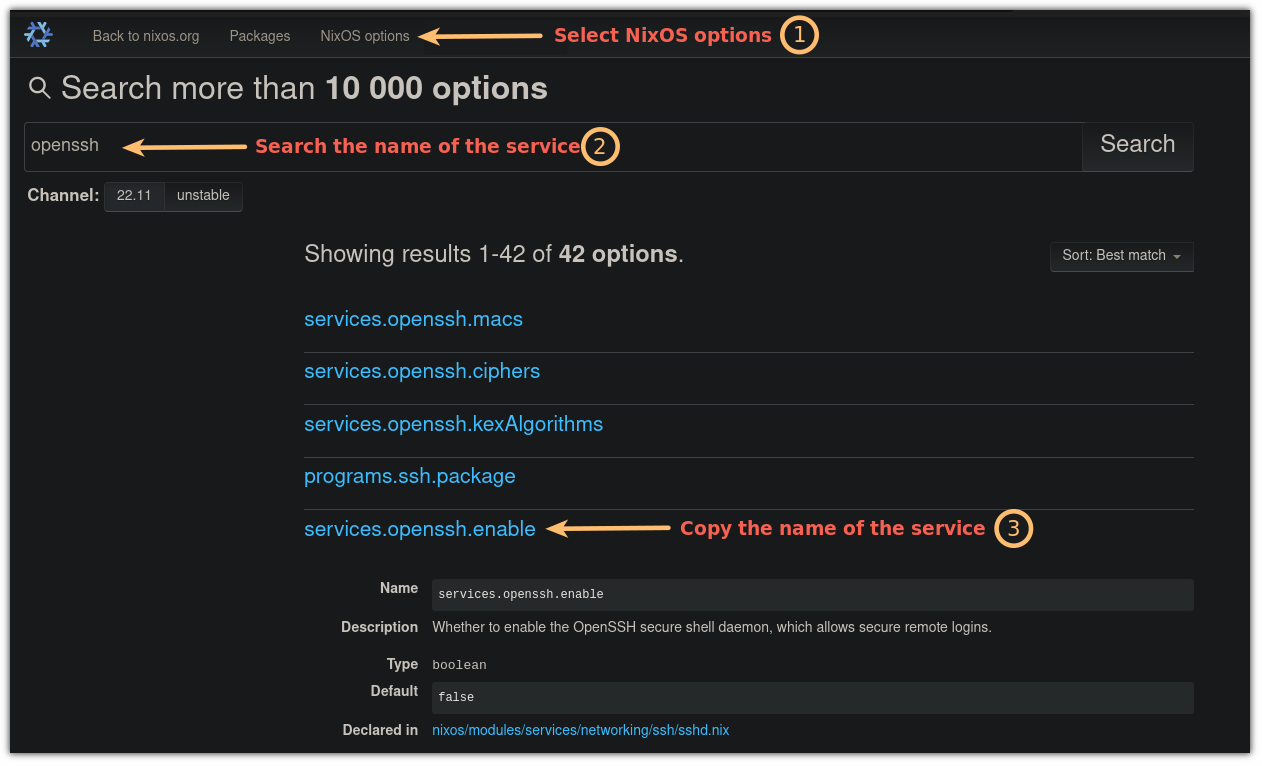
`services.openssh.enable = true`
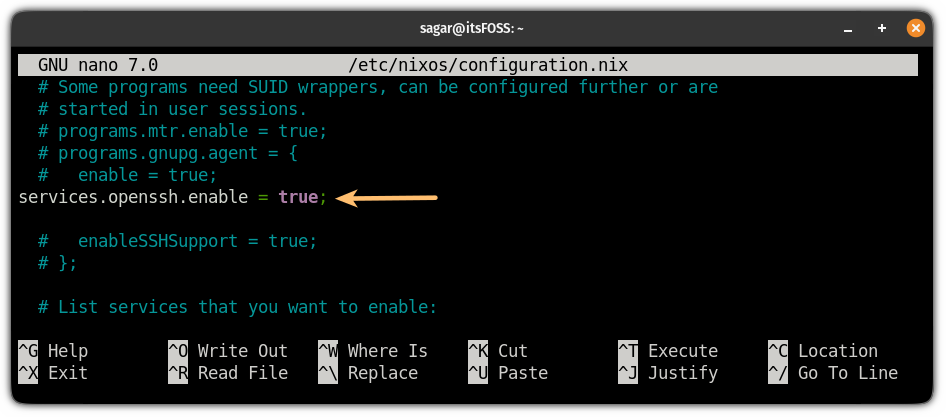
After adding the line to the config file, rebuild the service:
`sudo nixos-rebuild switch`
## 6. Enable auto-update in NixOS (optional)
Some users prefer to have auto-updates enabled, whereas others can update packages at their convenience.
So it is all up to you.
**To enable auto-update**, first open the `configuration.nix`
file:
`sudo nano /etc/nixos/configuration.nix`
Next, add the following line at the end of the config file before `}`
:
```
# Auto system update
system.autoUpgrade = {
enable = true;
};
```
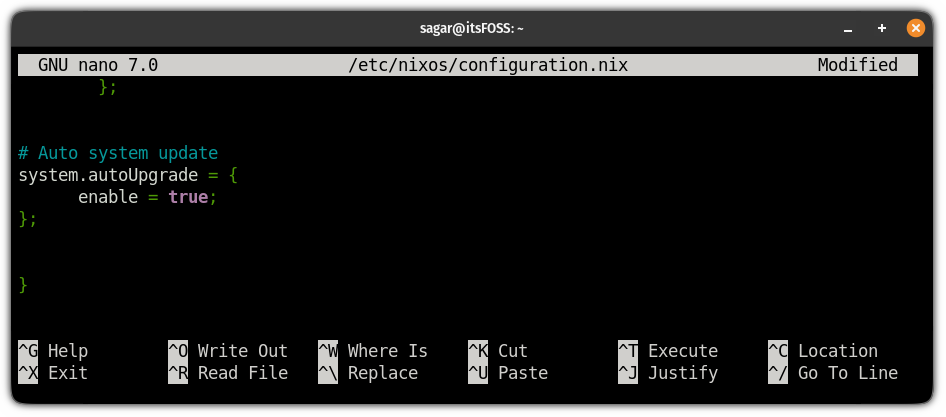
Save changes and exit from the nano.
To enable the auto-update, you will have to rebuild and switch to that file using the following:
`sudo nixos-rebuild switch`
You can also check the NixOS upgrade timer using the following command:
`systemctl list-timers`
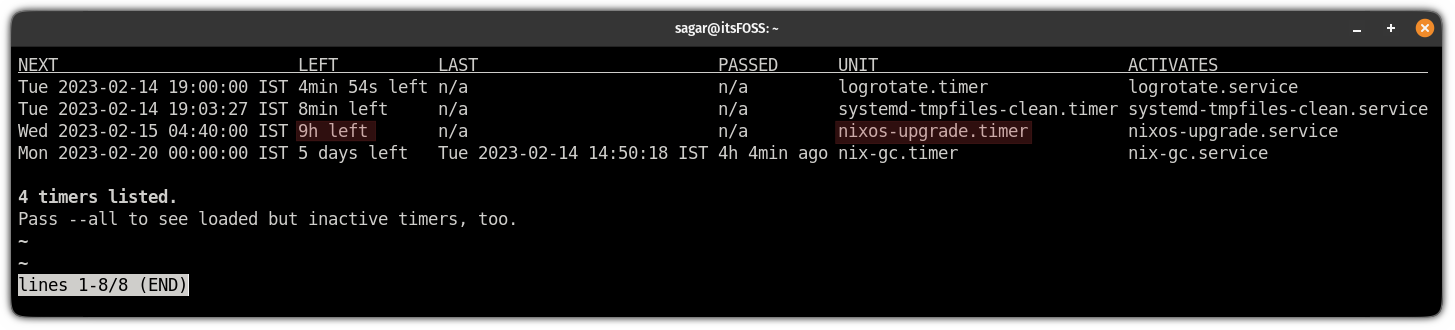
And as you can see, the `nixos-upgrade.service`
is running in the background as intended!
## 7. Reduce swapiness
If you are utilizing the swap partition, you may want to reduce the swapiness value.
Swapiness is nothing but the value of how aggressively you want to use the swap partition (or memory), which ranges from 0 to 100.
The lesser the swapiness, the more your system will use the physical memory (RAM), whereas a swap partition is nothing but a bit of part of your storage drive.
Also, storage drives are relatively slower than RAM, so you should reduce the swapiness if possible.
**Suggested Read 📖**
[How Much Swap Should You Use in Linux?How much should be the swap size? Should the swap be double of the RAM size or should it be half of the RAM size? Do I need swap at all if my system has got several GBs of RAM? Perhaps these are the most common asked questions about choosing](https://itsfoss.com/swap-size/)

To check the default swapiness of your system, use the following:
`cat /proc/sys/vm/swappiness`
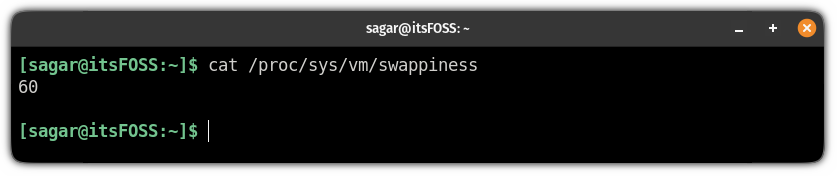
And for most Linux distributions, it is set to `60`
.
I would recommend you lower this value to `10`
.
To do that, first, open the configuration file using the following command:
`sudo nano /etc/nixos/hardware-configuration.nix`
And add the following line at the end of the line before `}`
:
`boot.kernel.sysctl = { "vm.swappiness" = 10;};`
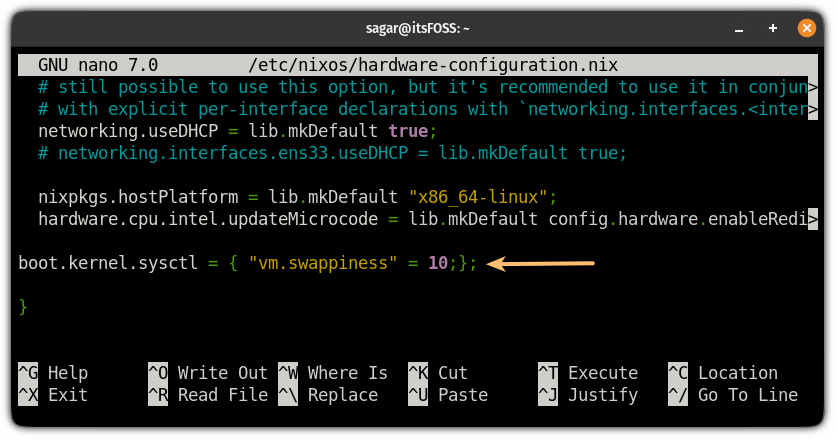
Save changes and exit from the text editor.
Now, rebuild the config and switch to it using the following:
`sudo nixos-rebuild switch`
And now, you can check the swapiness again and it should reflect the change:
`cat /proc/sys/vm/swappiness`
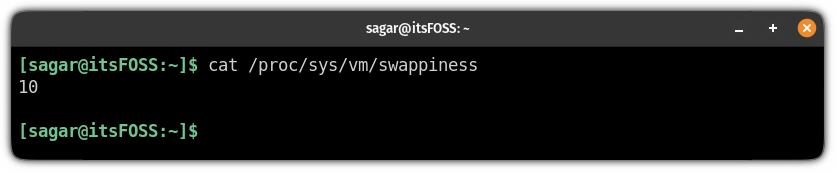
That's it!
## Wrapping Up
If you follow these points right after installing NixOS for the first time, you should get a good user experience.
Sure, there can be a few other things depending on your requirements. But, I think the above-mentioned things are the most essential or common things to do.
For the next part of this series, I shall discuss setting up the home manager on NixOS, which should be helpful for a system with multiple users.
💬 *What do you first do after installing NixOS? Let me know your thoughts.* |
15,665 | 为 GNOME 添加流行色彩: 强调色即将问世 | https://news.itsfoss.com/gnome-accent-colors/ | 2023-03-27T09:26:13 | [
"GNOME",
"强调色"
] | https://linux.cn/article-15665-1.html |
>
> GNOME 用户,你在等待这一刻吗?准备好选择你的颜色吧!
>
>
>

从 [Ubuntu 22.04 LTS](https://news.itsfoss.com/ubuntu-22-04-release/) 开始,Ubuntu 上就有了对强调色的支持,人们都很喜欢它。然而,遗憾的是,GNOME 从来没有这样的支持。
现在,得益于一项在 GNOME 中引入强调色支持的工作,这种情况正在改变。
**具体情况如何?** 最近,[Alexander Mikhaylenko](https://gitlab.gnome.org/exalm?ref=its-foss-news) 发出了一个附有 [合并请求](https://gitlab.gnome.org/GNOME/gnome-shell/-/merge_requests/2715?ref=its-foss-news) 的提议,以在 GNOME 中添加对强调色的支持。
在目前,它还处于一个 **早期开发中状态**,尚有很多工作要做,还有一些问题要在最终发布前解决。
通过查看其代码,很明显,**最初将提供对 10 种强调色的支持**,发布后可能会有更多的选择。
**想知道它可能看起来如何?**
在 Mastodon 上的一个 [讨论](https://crab.garden/@jamie/110063105101806314?ref=its-foss-news) 中,GNOME 基金会的成员 [Jamie](https://crab.garden/@jamie?ref=its-foss-news) 分享了一些由 Alexander 制作的模拟图,其中描绘了两种不同的配色。
一个是绿色的:

另一个是蓝色的:

我必须说,这些看起来不错 ?。想在非 Fedora 发行版上得到一些 Fedora 的爱吗?把它变成蓝色和其他东西?就它了!
>
> ? 请记住,你在上面看到的东西在最终发布前可能会有变化。
>
>
>
**预期时间?** 在上述讨论中被另一个用户问到时,Alexander 提到,我们可以 **预期强调色支持会在 GNOME 45 中出现**。
鉴于 GNOME 44 最近才发布,我们还需要等待一段时间才能真正看到它的实现。
但是,很高兴知道它有可能在不久之后出现。
我很喜欢 GNOME 终于得到了对强调色的支持,我希望这种等待是值得的。
如果你问我,我喜欢在我的 GNOME 系统上有绿色的强调色。你呢?
参考自: [OMG! Linux](https://www.omglinux.com/gnome-accent-colors-are-coming/?ref=its-foss-news)
---
via: <https://news.itsfoss.com/gnome-accent-colors/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Support for accent colors has been on Ubuntu since [22.04 LTS](https://news.itsfoss.com/ubuntu-22-04-release/), and people loved it. Sadly, GNOME never had that kind of support — yet.
Thanks to an **effort underway to introduce accent color support in GNOME, **that is changing.
**What is it?: **Recently, a proposal was sent out with a [merge request](https://gitlab.gnome.org/GNOME/gnome-shell/-/merge_requests/2715?ref=news.itsfoss.com) to add support for accent colors to GNOME, the development of which is being led by [Alexander Mikhaylenko](https://gitlab.gnome.org/exalm?ref=news.itsfoss.com).
In its current state, it's in a **very work-in-progress condition** with a lot of work pending as well as a few issues here and there which should be handled before the final release.
When looking at the code, it is clear that **initially support for 10 accent colors will be offered**, with the possibility of more options after release.
**Wondering how it might look?**
Well, in a [discussion](https://crab.garden/@jamie/110063105101806314?ref=news.itsfoss.com) on Mastodon, a few mockups made by Alexander were shared by a GNOME foundation member, [Jamie](https://crab.garden/@jamie?ref=news.itsfoss.com), that depicts two distinct colorways.
One is a green one.
The other is blue.
I must say these look nice! 😃 Want some Fedora love on your non-Fedora distro? Turn it to blue and something else? Choices, choices!
**When to expect?: **When asked by another user in the above-mentioned discussion, Alexander mentioned that we can **expect accent color support to arrive with GNOME 45**.
Seeing that GNOME 44 was recently released, we will have to wait a bit before we can actually see this being implemented.
**Suggested Read **📖
[GNOME 44 is Here With New Tricks Up its SleeveGNOME 44 is finally here with revamped settings, updated quick settings, accessibility improvements, and more.](https://news.itsfoss.com/gnome-44-release/)

But, it is good to know that there is a possibility of it happening soon after!
I do like that GNOME is finally getting support for accent colors, and I hope the wait is worth it.
**Via**: [omg!linux](https://www.omglinux.com/gnome-accent-colors-are-coming/?ref=news.itsfoss.com)
*💬 If you ask me, I would love having the Green accent color on my GNOME system. What about you?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,666 | 在没有构建系统的情况下编写 Javascript | https://jvns.ca/blog/2023/02/16/writing-javascript-without-a-build-system/ | 2023-03-27T12:04:20 | [
"Javascript",
"构建系统"
] | https://linux.cn/article-15666-1.html | 
嗨!这周我一直在写一些 Javascript,和往常一样,当我开始一个新的前端项目时,我面临的问题是:我是否应该使用构建系统?
我想谈谈构建系统对我有什么吸引力,为什么我(通常)仍然不使用它们,以及一些前端 Javascript 库要求你使用构建系统时,为什么我觉得这让我感到沮丧。
我写这篇文章是因为我看到的大多数关于 JS 的文章都假定你正在使用构建系统,而对于像我这样的人来说,编写非常简单的、不需要构建系统的小型 Javascript 项目时,构建系统可能反而添加了很多麻烦。
#### 什么是构建系统?
构建系统的思路是,你有一堆 Javascript 或 Typescript 代码,你想在把它放到你的网站上之前把它翻译成不同的 Javascript 代码。
构建系统可以做很多有用的事情,比如:
* (出于效率的考虑)将 100 多个 JS 文件合并成一个大的捆绑文件
* 将 Typescript 翻译成 Javascript
* 对 Typescript 进行类型检查
* 精简化
* 添加 Polyfills 以支持旧的浏览器
* 编译 JSX
* <ruby> 摇树优化 <rt> Tree Shaking </rt></ruby>(删除不使用的 JS 代码以减少文件大小)
* 构建 CSS(像 [tailwind](https://tailwindcss.com/) 那样)
* 可能还有很多其他重要的事情
正因为如此,如果你今天正在构建一个复杂的前端项目,你可能会使用 Webpack、Rollup、Esbuild、Parcel 或 Vite 等构建系统。
很多这些功能对我很有吸引力,我过去使用构建系统也是出于这样一些原因: 例如,[Mess With DNS](https://messwithdns.net/) 使用 Esbuild 来翻译 Typescript,并将许多文件合并成一个大文件。
#### 目标:轻松地对旧的小网站进行修改
我做了很多简单的小网站([之一](https://css-examples.wizardzines.com/)、[之二](https://questions.wizardzines.com)、[之三](https://sql-playground.wizardzines.com/)、[之四](https://nginx-playground.wizardzines.com/)),我对它们的维护精力大约为 0,而且我改变它们的频率很低。
我的目标是,如果我有一个 3、5 年前做的网站,我希望能在 20 分钟内,
* 在一台新的电脑上从 GitHub 获取源代码
* 做一些修改
* 把它放到互联网上
但我对构建系统(不仅仅是 Javascript 构建系统!)的经验是,如果你有一个 5 年历史的网站,要重新构建这个网站会非常痛苦。
因为我的大多数网站都很小,所以使用构建系统的 *优势* 很小 —— 我并不真的需要 Typescript 或 JSX。我只要有一个 400 行的 `script.js` 文件就可以了。
#### 示例:尝试构建 SQL 实验场
我的一个网站([SQL 试验场](https://sql-playground.wizardzines.com/))使用了一个构建系统(它使用 Vue)。我最后一次编辑该项目是在 2 年前,是在另一台机器上。
让我们看看我今天是否还能在我的机器上轻松地构建它。首先,我们要运行 `npm install`。下面是我得到的输出:
```
$ npm install
[lots of output redacted]
npm ERR! code 1
npm ERR! path /Users/bork/work/sql-playground.wizardzines.com/node_modules/grpc
npm ERR! command failed
npm ERR! command sh /var/folders/3z/g3qrs9s96mg6r4dmzryjn3mm0000gn/T/install-b52c96ad.sh
npm ERR! CXX(target) Release/obj.target/grpc/deps/grpc/src/core/lib/surface/init.o
npm ERR! CXX(target) Release/obj.target/grpc/deps/grpc/src/core/lib/avl/avl.o
npm ERR! CXX(target) Release/obj.target/grpc/deps/grpc/src/core/lib/backoff/backoff.o
npm ERR! CXX(target) Release/obj.target/grpc/deps/grpc/src/core/lib/channel/channel_args.o
npm ERR! CXX(target) Release/obj.target/grpc/deps/grpc/src/core/lib/channel/channel_stack.o
npm ERR! CXX(target) Release/obj.target/grpc/deps/grpc/src/core/lib/channel/channel_stack_builder.o
npm ERR! CXX(target) Release/obj.target/grpc/deps/grpc/src/core/lib/channel/channel_trace.o
npm ERR! CXX(target) Release/obj.target/grpc/deps/grpc/src/core/lib/channel/channelz.o
```
在构建 `grpc` 时出现了某种错误。没问题。反正我也不需要这个依赖关系,所以我可以花 5 分钟把它拆下来重建。现在我可以 `npm install` 了,一切正常。
现在让我们试着构建这个项目:
```
$ npm run build
? Building for production...Error: error:0308010C:digital envelope routines::unsupported
at new Hash (node:internal/crypto/hash:71:19)
at Object.createHash (node:crypto:130:10)
at module.exports (/Users/bork/work/sql-playground.wizardzines.com/node_modules/webpack/lib/util/createHash.js:135:53)
at NormalModule._initBuildHash (/Users/bork/work/sql-playground.wizardzines.com/node_modules/webpack/lib/NormalModule.js:414:16)
at handleParseError (/Users/bork/work/sql-playground.wizardzines.com/node_modules/webpack/lib/NormalModule.js:467:10)
at /Users/bork/work/sql-playground.wizardzines.com/node_modules/webpack/lib/NormalModule.js:499:5
at /Users/bork/work/sql-playground.wizardzines.com/node_modules/webpack/lib/NormalModule.js:356:12
at /Users/bork/work/sql-playground.wizardzines.com/node_modules/loader-runner/lib/LoaderRunner.js:373:3
at iterateNormalLoaders (/Users/bork/work/sql-playground.wizardzines.com/node_modules/loader-runner/lib/LoaderRunner.js:214:10)
at iterateNormalLoaders (/Users/bork/work/sql-playground.wizardzines.com/node_modules/loader-runner/lib/LoaderRunner.js:221:10)
at /Users/bork/work/sql-playground.wizardzines.com/node_modules/loader-runner/lib/LoaderRunner.js:236:3
at runSyncOrAsync (/Users/bork/work/sql-playground.wizardzines.com/node_modules/loader-runner/lib/LoaderRunner.js:130:11)
at iterateNormalLoaders (/Users/bork/work/sql-playground.wizardzines.com/node_modules/loader-runner/lib/LoaderRunner.js:232:2)
at Array.<anonymous> (/Users/bork/work/sql-playground.wizardzines.com/node_modules/loader-runner/lib/LoaderRunner.js:205:4)
at Storage.finished (/Users/bork/work/sql-playground.wizardzines.com/node_modules/enhanced-resolve/lib/CachedInputFileSystem.js:43:16)
at /Users/bork/work/sql-playground.wizardzines.com/node_modules/enhanced-resolve/lib/CachedInputFileSystem.js:79:9
```
[这个 Stack Overflow 的答案](https://stackoverflow.com/questions/69692842/error-message-error0308010cdigital-envelope-routinesunsupported) 建议运行 `export NODE_OPTIONS=--openssl-legacy-provider` 来解决这个错误。
这很有效,最后我得以 `npm run build` 来构建这个项目。
这其实并不坏(我只需要删除一个依赖关系和传递一个略显神秘的 Node 选项!),但我宁愿不被那些构建错误破坏。
#### 对我来说,对于小项目来说,构建系统并不值得
对我来说,一个复杂的 Javascript 构建系统对于 500 行的小项目来说似乎并不值得 —— 它意味着放弃了在未来能够轻松更新项目的能力,以换取一些相当微小的好处。
#### Esbuild 似乎更稳定一些
我想为 Esbuild 大声叫好: 我 [在 2021 年了解到 Esbuild](https://jvns.ca/blog/2021/11/15/esbuild-vue/),并用于一个项目,到目前为止,它确实是一种更可靠的构建 JS 项目的方式。
我刚刚尝试在一台新电脑上构建一个我最后一次改动在 8 个月前的 Esbuild 项目,结果成功了。但我不能肯定的说,两年后我是否还能轻松的建立那个项目。也许会的,我希望如此!
#### 不使用构建系统通常是很容易的
下面是 [Nginx 实验场](https://nginx-playground.wizardzines.com/) 代码中导入所有库的部分的样子:
```
<script src="js/vue.global.prod.js"></script>
<script src="codemirror-5.63.0/lib/codemirror.js"></script>
<script src="codemirror-5.63.0/mode/nginx/nginx.js"></script>
<script src="codemirror-5.63.0/mode/shell/shell.js"></script>
<script src="codemirror-5.63.0/mode/javascript/javascript.js"></script>
<link rel="stylesheet" href="codemirror-5.63.0/lib/codemirror.css">
<script src="script.js "></script>
```
这个项目也在使用 Vue,但它只是用 `<script src` 来加载 Vue —— 前端没有构建过程。
#### 一个使用 Vue 的无构建系统模板
有几个人问如何在没有构建系统的情况下开始编写 Javascript。当然,如果你想的话,你可以写原味的 JS,但我常用的框架是 Vue 3。
[这是我做的一个小模板](https://github.com/jvns/vue3-tiny-template),用于启动一个没有构建系统的 Vue 3 项目。它只有 2 个文件和大约 30 行的 HTML/JS。
#### 有些库需要你使用构建系统
构建系统这些事情最近盘旋在我的脑海里,因为这周我正在用 CodeMirror 5 做一个新项目,我看到有一个新版本,CodeMirror 6。
所以我想 —— 很酷,也许我应该使用 CodeMirror 6 而不是 CodeMirror 5。但是 —— 似乎没有构建系统你就不能使用 CodeMirror 6(根据 [迁移指南](https://codemirror.net/docs/migration/)),所以我打算坚持使用 CodeMirror 5。
同样地,你以前可以把 Tailwind 作为一个巨大的 CSS 文件下载,但是 [Tailwind 3](https://tailwindcss.com/docs/installation) 似乎根本不能作为一个大的 CSS 文件使用,你需要运行 Javascript 来构建它。所以我现在要继续使用 Tailwind 2。(我知道,我知道,你不应该使用大的 CSS 文件,但是它验收只有 300KB,而且我真的不希望有构建步骤)
(更正:看起来 Tailwind 在 2021 年发布了一个 [独立的命令行工具](https://tailwindcss.com/blog/standalone-cli),这似乎是一个不错的选择)
我不完全确定为什么有些库不提供无构建系统版本 —— 也许发布无构建系统版本会给库增加很多额外的复杂性,而维护者认为这不值得。或者,库的设计意味着由于某种原因,不可能发布无构建系统版本。
#### 我希望有更多的无构建系统的 Javascript 技巧
到目前为止,我的主要策略是:
* 在某个库的网站上搜索 “CDN”,找到一个单独的 Javascript 文件
* 使用 <https://unpkg.com> 来查看该库是否有一个我可以使用的内置版本
* 托管我自己的库的版本,而不是依赖可能崩溃的 CDN
* 编写我自己的简单集成方案,而不是拉入另一个依赖关系(例如,前几天我为 Vue 编写了自己的 CodeMirror 组件)。
* 如果我想要一个构建系统,就使用 Esbuild
还有一些看起来很有趣但我还没有研究过的东西:
* 这个 [关于 Javascript 注释中类型语法的 Typescript 建议](https://devblogs.microsoft.com/typescript/a-proposal-for-type-syntax-in-javascript/)
* 一般来说,ES 模块
---
via: <https://jvns.ca/blog/2023/02/16/writing-javascript-without-a-build-system/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
15,668 | Python 中的变量:概念与示例 | https://www.debugpoint.com/python-variables/ | 2023-03-28T09:00:00 | [
"Python"
] | /article-15668-1.html | 
>
> 本教程解释了 Python 中变量的概念、它们的类型,以及如何在实际项目中使用的示例。
>
>
>
在 Python 中,变量是存储值的保留内存位置。
它们是个名称,可以分配一个值给它并在整个代码中引用它。使用变量使值可访问并为值提供与你的代码相关的上下文/含义。
在开始之前,我希望你已经安装了 Python 并设置了一个基本的编辑器。如果没有,请参考我的以下指南:
* [如何在 Ubuntu/Linux 上安装 Python 3.11](/article-15230-1.html)
* [如何在 Windows 上安装 Python](/article-15480-1.html)
* [如何为 Python 设置 IDLE 编辑器](/article-15622-1.html)
### 变量规则
* 变量区分大小写。
* 变量名称只能包含大写和小写字母(A–Z、a–z)、数字(0–9)和下划线(\_)。
* 它们不能以数字开头。
* Python 变量是 [动态类型](https://en.wikipedia.org/wiki/Type_system)。
* Python 支持 Unicode 变量(例如 é 和 ü 等装饰字母,甚至中文、日文和阿拉伯符号)。
* 根据 [PEP 8 标准](https://peps.python.org/pep-0008/),变量名只能是小写,单词可以用下划线分隔(例如 total\_price)。
### Python 变量:示例
要在 Python 中创建一个变量,我们需要使用赋值运算符(`=`)为其赋值。例如,下面的代码行创建了一个名为 `x` 的变量并为其赋值 `10`:
```
x = 10
```
在 Python 中,变量是动态类型的,这意味着解释器可以根据分配给它的值来确定变量的数据类型。Python 支持各种类型的变量,包括整数、浮点数、字符串、布尔值和复数。
```
# 整型变量
age = 20
# 浮点变量
price = 4.99
# 字符串变量
name = "John Doe"
# 布尔变量
is_active = True
# 复数变量
z = 2 + 3j
```
变量在编程中很有用,因为它们允许我们存储和操作数据。例如,我们可以使用变量来执行数学运算、连接字符串以及根据布尔变量的值做出决策。
```
# 数学运算
x = 5
y = 10
z = x + y
print(z) # 输出:15
# 字符串连接
first_name = "John"
last_name = "Doe"
full_name = first_name + " " + last_name
print(full_name) # 输出:John Doe
```

变量也可以在现实世界的项目中用于存储和操作数据。例如,在 Web 应用中,我们可以使用变量来 [存储用户输入](/article-15660-1.html)、数据库查询以及向用户输出数据。
```
# 用户输入
name = input("What is your name? ")
print("Hello, " + name + "!") # 输出: Hello, John!
# 数据库查询
import sqlite3
conn = sqlite3.connect("example.db")
cursor = conn.cursor()
cursor.execute("SELECT * FROM users WHERE id = ?", (1,))
user = cursor.fetchone()
print(user) # 输出: (1, 'John Doe', '[email protected]')
# 输出数据给用户
balance = 100.00
print("Your current balance is ₹" + str(balance)) # 输出: Your current balance is ₹100.0
```
### 使用变量时的常见错误
在处理变量时,你可能会遇到一些常见错误。这里是其中的一些。
* `NameError`:当你尝试访问尚未定义的变量时会发生此错误。例如,如果你尝试打印一个尚未赋值的变量的值,你将得到一个 `NameError`。以下代码给出了 `NameError`,因为变量 `Full_name` 未定义。
```
# NameError 演示
first_name = "John"
last_name = "Doe"
full_name = first_name + " " + last_name
print(Full_name) # NameError
```

* `TypeError`:当你尝试对错误数据类型的变量进行操作时会发生此错误。例如,如果你尝试连接一个字符串和一个整数,你将得到 `TypeError`。下面的代码片段给出了 `TypeError`。
```
# TypeError 演示
first_name = "John"
age = 10
print(first_name + age)
```

* `ValueError`:当你尝试将变量转换为不同的数据类型但无法进行转换时会发生此错误。例如,如果你尝试将包含字母的字符串转换为整数,你将得到 `ValueError`。
```
# ValueError 演示
first_name = "John"
age = 10
print(int(first_name))
```

### 总结
了解变量对于任何 Python 开发人员来说都是必不可少的。变量允许我们存储和操作数据、执行数学运算、连接字符串等。如果你是 Python 编程的初学者,我希望本指南能够阐明这个概念。
---
via: <https://www.debugpoint.com/python-variables/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,669 | Ubuntu 23.04 “Lunar Lobster” 的最佳新功能 | https://www.debugpoint.com/ubuntu-23-04-features/ | 2023-03-28T17:09:00 | [
"Ubuntu"
] | /article-15669-1.html | 
>
> 介绍最新的 Ubuntu 23.04 “Lunar Lobster” 版本,它包含了大量的新功能和改进。
>
>
>
代号为 “<ruby> 月球龙虾 <rt> Lunar Lobster </rt></ruby>” 的 Ubuntu 23.04 是 2023 年的第一个短期版本,它将被支持 9 个月,直到 2024 年 1 月。这个版本采用了新的软件包和技术来改进 Ubuntu 的核心后台和进展工作。在某种程度上,许多变化是作为明年的 LTS 版本(Ubuntu 24.04)的准备工作而被确定的。
它的开发周期几乎接近结束。截至发稿时,测试版已经冻结。所以,现在是探索这个版本的新功能的好时机。
但在此之前,先来看看即将到来的里程碑:
* 测试版冻结: 2023 年 3 月 27 日
* 测试版发布: 2023 年 3 月 30 日
* 候选版本:2023 年 4 月 13 日
* 最终版本:2023 年 4 月 20 日

### Ubuntu 23.04 的新功能
#### 新的桌面安装程序
Ubuntu 新的基于 Rust 的桌面安装程序终于可以在这个版本中体验了。这项工作历经了两年多的时间。在经历了许多障碍和关键错误的修复后,现在已经稳定到可以在正式版本中发布。从这个版本开始,经典的 Ubiquity 被全新的安装程序所取代,如下面一组图片所示:




然而,正如我从一些消息来源听到的,旧的 Uqiuity 将继续保留(直到明年)。但我不完全确定旧的安装程序将如何启动。因为默认的 <ruby> 立付介质 <rt> Live Media </rt></ruby> 会启动新的安装程序。
与旧安装程序的相比,新的有一些变化。首先,相对于旧的 Uqiuity 对话框和小工具控制,外观和感觉更加现代。
关于分区的摘要细节现在作为一个单独的页面出现,而不是一个弹出框。
此外,Ubuntu 23.04 现在在安装前会询问深色/浅色模式选项。我不确定这样做的必要性,因为 Ubuntu 已经在一个单独的应用程序中定义了一些开箱步骤。
#### GNOME 44 桌面
Ubuntu 23.04 桌面版采用了 GNOME 44。这个版本的 GNOME 44 带来了一堆长期等待的更新。例如,在这个版本中,你可以在本地文件选取器对话框中体验到图像预览。此外,文件应用得到了期待已久的缺失功能,即原生的文件夹展开视图(树状视图)。你可以使用下面的设置来启用它。


在 GNOME 44 中的其他关键变化包括:文件应用现在支持在粘贴图像数据时创建文件,改进的无障碍设置页面可以提供更好的导航,以及大大改进的 GNOME 网页浏览器。
你可以在下面这篇功能亮点页面上了解更多关于 GNOME 44 的发布:
>
> **[GNOME 44 - 最佳功能](https://www.debugpoint.com/gnome-44/)**
>
>
>
#### 精简 ISO 镜像
这是一个令人惊讶的举动,Ubuntu 团队在这个版本中 [引入](https://debugpointnews.com/ubuntu-mini-iso-announcement/) 一个官方的精简 ISO 镜像(不到 200MB)。一旦发布,你可以使用这个精简 ISO 镜像来创建自定义的 Ubuntu Linux。截至发稿时,我们还没有得到这个精简镜像的日常构建 ISO。
然而,Xubuntu 团队 [已经发布了](https://www.debugpoint.com/xubuntu-minimal/) 一个精简 ISO 镜像,我尝试了一下。同样地,所有的官方风味版都有望得到他们自己的精简 ISO 文件。
更多的信息将在未来几天内到达。
#### 多用 Snap,少用 Flatpak
一些与 Snap 和 Flatpak 相关的重要变化即将到来,你应该为此做好准备。
首先,推行更多的 Snap 包是显而易见的,因为官方 Telegram 桌面应用程序现在在 Ubuntu 中使用 Snap 包。
此外,Ubuntu 计划将 Steam 桌面客户端作为 Snap 包发布,该客户端 [目前正在测试中](https://discourse.ubuntu.com/t/steam-call-for-testing/34575)。Steam 桌面客户端现在以原生 deb 和 Flatpak 包的形式提供。Steam Snap 预计将在今年年底到来,而不是在这个版本中。
与此同时,默认的 Flatpak 和 Flathub 集成现在已经正式从所有支持的 Ubuntu 官方风味版中 [移除](https://debugpointnews.com/ubuntu-flavours-flatpak/)。这个决定在网上引起了一些 “讨论”。
因此,从这个版本开始,Ubuntu MATE 和 Kubuntu 将不会默认搭载 Flatpak/Flathub。然而,你可以通过 [只需几个步骤](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) 安装它。
#### 新的应用程序
Ubuntu 23.04 的默认应用程序集合一如既往地进行了升级。然而,你可能会注意到一些关键的变化。
首先,LibreOffice 可能看起来有点不同。LibreOffice 团队最近改变了默认的图标主题,在 Ubuntu GNOME 的桌面环境中,它看起来非常棒。
在这个版本中包含的 LibreOffice 7.5 中, Writer 有一个改进的书签模块,Calc 电子表格有了新的数字格式,Impress 有了新的表格设计风格等等。
你可以在这里阅读更多关于 [LibreOffice 7.5 的功能](https://www.debugpoint.com/libreoffice-7-5/)。

Ubuntu 23.04 中其他应用程序的总结:
* [Firefox 111](https://debugpointnews.com/firefox-111/)(Snap)
* LibreOffice 7.5
* Transmission 3.0
* Shotwell 图像查看器 0.30
#### 官方风味版
对于所有的教育工作者和学生来说,有一个好消息。从 23.04 版本开始,Edubuntu 将 [正式出现](https://discourse.ubuntu.com/t/announcing-edubuntu-revival/32929)。它是 Ubuntu 官方风味版列表中的另一个补充。Edubuntu 可能会有一个更大的 ISO 文件(大约 5GB),并安装了所有与教育有关的 FOSS 软件。我将会有一篇单独的文章来点评这个风味版。
此外,如下的风味版都有其对应的桌面环境:
* 配备 [KDE Plasma 5.27](https://www.debugpoint.com/kde-plasma-5-27/) 的 Kubuntu
* 配备 [Xfce 4.18](https://www.debugpoint.com/xfce-4-18-review/) 的 Xubuntu
* 配备 MATE 1.26.1 的 Ubuntu MATE
* 配备 [LXQt 1.2](https://www.debugpoint.com/lxqt-1-2-0-features/) 的 Lubuntu
* 配备 Budgie 10.7 的 Ubuntu Budgie
Ubuntu Budgie 23.04 带来了一些令人兴奋的功能,如边缘平铺、热角等。
#### 内核和工具链更新
截至发稿时,每日构建副本都是 Linux 内核 6.1。然而,在内核冻结(2023 年 4 月 6 日)之前,目前的主线内核 6.2 可能会到达 Ubuntu 23.04。Linux 内核 6.2 改进了对 GPU、CPU、端口和 Rust 更新的支持。
在核心部分,Python 3.11 现在可以在 Ubuntu 23.04 中开箱即用。你不需要再单独 [安装 Python 3.11](https://www.debugpoint.com/install-python-3-11-ubuntu/)。值得一提的是,Python 3.12 版本将在今年发布,目前正在进行多次 RC 测试。
其他工具链的更新如下:
* GCC 13
* GlibC 2.37
* Ruby 3.1
* golang 1.2
* LLVM 16
#### Ubuntu 23.04 的新壁纸
桌面版本永远不会缺席一些新的很酷的壁纸。在成功的 [壁纸竞赛](https://debugpointnews.com/ubuntu-23-04-wallpaper-competition/) 之后,获胜者被选为以 “月亮和龙虾” 为特色的默认壁纸。
这里是默认的一张。而其余的你可以在 [这里](https://discourse.ubuntu.com/t/lunar-lobster-23-04-wallpaper-competition/33132) 找到。

### 下载
每日构建的 ISO 文件存在于以下 Ubuntu 桌面和风味版的链接中。
请注意,你不应该将这些作为主要用途。它们有一些错误(至少我发现了一些),而且还不完全稳定。
| Ubuntu 风味版 | .iso 镜像 - 日常构建 |
| --- | --- |
| Ubuntu 23.04 桌面(GNOME) | <https://cdimage.ubuntu.com/ubuntu/daily-live/pending/> |
| Xubuntu 23.04 | <https://cdimage.ubuntu.com/xubuntu/daily-live/current/> |
| Ubuntu MATE 23.04 | <https://cdimage.ubuntu.com/ubuntu-mate/daily-live/current/> |
| Ubuntu Kylin 23.04 | 尚无 |
| Lubuntu 23.04 | <https://cdimage.ubuntu.com/lubuntu/daily-live/current/> |
| Kubuntu 23.04 | <https://cdimage.ubuntu.com/kubuntu/daily-live/current/> |
| Ubuntu Budgie 23.04 | <https://cdimage.ubuntu.com/ubuntu-budgie/daily-live/current/> |
| Ubuntu Unity 23.04 | <https://cdimage.ubuntu.com/ubuntu-unity/daily-live/current/> |
| Edubuntu 23.04 | <https://cdimage.ubuntu.com/edubuntu/daily-live/current/> |
### 总结
总之,新的 Ubuntu 23.04 有望为桌面用户提供更流畅、更无缝的体验。
从改进的安全功能到增强的生产力工具和应用程序,这次更新肯定会让 Ubuntu 的爱好者和粉丝感到高兴。无论你是经验丰富的用户还是 Ubuntu 生态系统的新手,这个版本都值得一看。
最后,Ubuntu 23.04 将于 2023 年 4 月 20 日发布。
---
via: <https://www.debugpoint.com/ubuntu-23-04-features/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,671 | OpenWrt:一个开源的家用路由器固件替代品 | https://opensource.com/article/22/7/openwrt-open-source-firmware | 2023-03-29T10:54:00 | [
"OpenWrt"
] | https://linux.cn/article-15671-1.html | 
>
> OpenWrt 是一个基于 Linux 的开源操作系统,主要针对嵌入式网络设备。
>
>
>
如果你在家里阅读这篇文章,你可能是用一个 LTE/5G/DSL/WIFI 路由器联网的。这种设备通常负责在你的本地设备(智能手机、PC、电视等)之间路由数据包,并通过内置的调制解调器提供对 WWW 的访问。你家里的路由器很可能有一个基于网页的界面,用于配置该设备。这种界面往往过于简单,因为它们是为普通用户制作的。
如果你想要更多的配置选项,但又不想花钱买一个专业的设备,你应该看看其他的固件,如 [OpenWrt](https://openwrt.org)。
### OpenWrt 的特点
OpenWrt 是一个基于 Linux 的、针对嵌入式网络设备的开源操作系统。它主要用于替代各种家用路由器上的原始固件。OpenWrt 具备一个好的路由器应该具备的所有有用功能,如 DNS 服务器([dnsmasq](https://thekelleys.org.uk/dnsmasq/doc.html)),WiFi 接入点(AP)和客户端功能,用于调制解调器功能的 PPP 协议,而且,与标准固件不同,这一切都是可以完全配置的。
#### LuCI 网页界面
OpenWrt 可以通过命令行(SSH)或使用 GUI 配置界面([LuCI](https://openwrt.org/docs/guide-user/luci/start))进行远程配置。LuCI 是一个用 [Lua](https://opensource.com/article/20/2/lua-cheat-sheet) 编写的轻量级、可扩展的网页 GUI,它可以精确地配置你的设备。除了配置,LuCI 还提供了很多额外的信息,如实时图表、系统日志和网络诊断。

LuCI 有一些可选的扩展,以增加更多的配置选择。
#### 可写文件系统
它的另一个亮点是可写文件系统。原有的固件通常是只读的,而 OpenWrt 配备了一个可写的文件系统,这要归功于一个巧妙的解决方案,它将 OverlayFS 与 SquashFS/JFFS2 文件系统相结合,允许安装软件包以增强功能。在 [OpenWrt 文档](https://openwrt.org/docs/techref/flash.layout) 中可以找到更多关于文件系统架构的信息。
#### 扩展
OpenWrt 有一个相关的软件包管理器,[opkg](https://openwrt.org/docs/guide-user/additional-software/opkg),它允许安装额外的服务,比如 FTP 服务器、DLNA 媒体服务器、OpenVPN 服务器、用于实现文件共享的 Samba 服务器、控制电话的 Asterisk 等等。当然,有些扩展需要适当的底层硬件资源。
### 动机
你可能想知道为什么要冒着对你的设备造成不可修复的损害和失去保修的风险,而尝试更换路由器制造商的固件。如果你的设备以你想要的方式工作,那么你可能不应该。永远不要碰一个正在运行的系统!但是,如果你想增强功能,或者你的设备缺乏配置选项,那么你应该看看 OpenWrt 是否可以成为一种补救措施。
在我的例子中,我想要一个旅行用的路由器,当我在露营地的时候,我可以把它放在一个合适的位置,以便让其它设备与这个本地 WiFi 接入点(AP)保持良好连接。该路由器将作为一个普通的客户端连接到互联网,并广播它的 WiFi 接入点让我的其它设备连接到它。这样我就可以配置我的所有设备与这个路由器的接入点连接,当我在其他地方时我只需要改变路由器的客户端连接。此外,在一些露营地,你只能得到一个单一设备的访问代码,我可以通过这种设置来加强。
作为我的旅行路由器,我选择 TP-Link TL-WR902AC 的原因如下:
* 很小
* 两根 WiFi 天线
* 5V 电源(USB)
* 低功耗
* 成本效益高(你以 30 美元左右的价格得到它)
为了了解它的尺寸,这里是它在树莓派 4 旁边的样子:

尽管这个路由器带来了我所需要的所有硬件功能,但我很快发现,默认的固件并不能让我按照我想要的方式配置它。该路由器主要是作为一个 WiFi 接入点,它可以复制现有的 WiFi 网络或通过板载以太网接口将自己连接到网络。默认的固件对于这些使用情况是非常有限的。
(LCTT 译注:此型号国内没有销售,它的特点之一是可以通过插入 3G/4G USB 网卡连接到互联网,但由于它不在国内销售,所以没有支持哪种国内 3G/4G USB 网卡的说明,我 [查下来](https://www.tp-link.com/lk/support/3g-comp-list/tl-wr902ac/?location=1963) 似乎华为的 E3372h-320 是可用的。有相关实践的同学可以分享一下经验。
国内销售的其它类似型号只能通过以太网口或 WiFi 连接到互联网,这种情况下,如果只能通过 3G/4G 连接互联网,那需要另外买一个随身 WiFi /移动路由器。)
幸运的是,该路由器能够运行 OpenWrt,所以我决定用它来替换原来的固件。
### 安装
当你的 LTE/5G/DSL/WiFi 路由器符合 [最低要求](https://openwrt.org/supported_devices) 时,很有可能在它上面运行 OpenWrt。下一步,你要查看 [硬件表](https://openwrt.org/toh/start),检查你的设备是否被列为兼容,以及你要选择哪个固件包。OpenWrt 的 [TP-Link TL-WR902AC](https://openwrt.org/toh/tp-link/tl-wr902ac_v3) 的页面还包括安装说明,其中描述了如何刷入内部存储器。
刷入固件的过程在不同的设备之间可能会有所不同,所以我就不详细介绍了。简而言之,我必须通过将设备连接到一个具有特定 IP 地址的网络接口上的 TFTP 服务器,重命名 OpenWrt 固件文件,然后按复位按钮启动设备。
### 配置
一旦刷入成功,你的设备现在应该用新的固件启动了。现在启动可能需要更长的时间,因为与默认固件相比,OpenWrt 具有更多的功能。
为了开始配置,需要在你的 PC 和路由器之间建立一个直接的以太网连接,OpenWrt 在此充当了一个 DHCP 服务器,并将你的 PC 的以太网适配器配置为一个 DHCP 客户端。
在 Fedora Linux 上,要激活你的网络适配器的 DHCP 客户端模式,首先你必须通过运行找出连接的 UUID:
```
$ nmcli connection show
NAME UUID TYPE DEVICE
Wired Conn 1 7a96b...27a ethernet ens33
virbr0 360a0...673 bridge virbr0
testwifi 2e865...ee8 wifi --
virbr0 bd487...227 bridge --
Wired Conn 2 16b23...7ba ethernet --
```
选择你要修改的连接的 UUID,然后运行:
```
$ nmcli connection modify <UUID> ipv4.method auto
```
你可以在 [Fedora 联网维基](https://fedoraproject.org/wiki/Networking/CLI) 中找到更多关于这些命令的信息。
在你连接到路由器后,打开一个网页浏览器并导航到 <http://openwrt/>。现在你应该看到 LuCI 的登录管理器:

使用 `root` 作为用户名,并将密码留空。
### 配置 WiFi 和路由
要配置你的 WiFi 天线,请点击 “<ruby> 网络 <rt> Network </rt></ruby>” 菜单并选择 “<ruby> 无线 <rt> Wireless </rt></ruby>”。

在我的设备上,上面的天线 `radio0` 工作在 2.4GHz 模式,并连接到名为 `MOBILE-INTERNET` 的本地接入点。下面的天线 `radio1` 工作在 5GHz,有一个相关的接入点,SSID 为 `OpenWrt_AV`。通过点击 “<ruby> 编辑 <rt> Edit </rt></ruby>” 按钮,你可以打开设备配置,以决定该设备属于 LAN 还是 WWAN 网络。在我的例子中,接入点 `OpenWrt_AV` 属于 LAN 网络,客户端连接 `MOBILE-INTERNET` 属于 WWAN 网络。

配置的网络在 “<ruby> 接口 <rt> Interfaces </rt></ruby>” 面板的 “<ruby> 网络 <rt> Network </rt></ruby>” 下列出。

为了获得我想要的功能,网络流量必须在 LAN 和 WWAN 网络之间进行路由。路由可以在 “<ruby> 网络 <rt> Network </rt></ruby>” 面板的 “<ruby> 防火墙 <rt> Firewall </rt></ruby>” 部分进行配置。我没有在这里做任何改动,因为在默认情况下,网络之间的流量是被路由的,而传入的数据包(从 WWAN 到 LAN)必须通过防火墙。

因此,你需要知道的是一个接口是属于 LAN 还是 (W)WAN。这个概念使它相对容易配置,特别是对初学者来说。你可以在 [OpenWrt 联网基础](https://openwrt.org/docs/guide-user/base-system/basic-networking) 指南中找到更多信息。
### 专属门户
公共 WiFi 接入点通常受到 [专属门户](https://en.wikipedia.org/wiki/Captive_portal) 的保护,你必须输入一个访问代码或类似的代码。通常情况下,当你第一次连接到接入点并试图打开一个任意的网页时,这种门户就会出现。这种机制是由接入点的 DNS 服务器实现的。
默认情况下,OpenWrt 激活了一个安全功能,可以防止连接的客户端受到 [DNS 重新绑定攻击](https://en.wikipedia.org/wiki/DNS_rebinding)。OpenWrt 的重新绑定保护也阻止了专属门户网站被转发到客户端,所以你必须禁用重新绑定保护,以便你可以到达专属门户网站。这个选项在 “<ruby> 网络 <rt> Network </rt></ruby>” 菜单的 “<ruby> DHCP 和 DNS <rt> DHCP and DNS </rt></ruby>” 面板中。
### 尝试 OpenWrt
由于升级到 OpenWrt,我得到了一个基于商品硬件的灵活的旅行路由器。OpenWrt 使你的路由器具有完全的可配置性和可扩展性,而且由于其制作精良的网页 GUI,它也适合初学者使用。甚至有一些 [精选路由器](https://opensource.com/article/22/1/turris-omnia-open-source-router) 在出厂时已经安装了 OpenWrt。你还可以用很多 [可用的软件包](https://openwrt.org/packages/table/start) 来增强你的路由器的功能。例如,我正在使用 [vsftp](https://openwrt.org/docs/guide-user/services/nas/ftp.overview) FTP 服务器,在连接的 U 盘上托管一些电影和电视剧。看看该 [项目主页](https://openwrt.org/reasons_to_use_openwrt),在那里你可以找到许多切换到 OpenWrt 的理由。
图片来自: Stephan Avenwedde,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
---
via: <https://opensource.com/article/22/7/openwrt-open-source-firmware>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you're reading this article from home, you are probably connected with a LTE/5G/DSL/WIFI router. Such devices are usually responsible to route packets between your local devices (smartphone, PC, TV, and so on) and provide access to the world wide web through a built-in modem. Your router at home has most likely a web-based interface for configuration purposes. Such interfaces are often oversimplified as they are made for casual users.
If you want more configuration options, but don't want to spend for a professional device you should take a look at an alternative firmware such as [OpenWrt](https://openwrt.org).
## OpenWrt features
OpenWrt is a Linux-based, open source operating system targeting embedded network devices. It is mainly used as a replacement for the original firmware on home routers of all kinds. OpenWrt comes with all the useful features a good router should have like a DNS server ([dnsmasq](https://thekelleys.org.uk/dnsmasq/doc.html)), Wifi access point and client functionality, PPP protocol for modem functionality and, unlike with the standard firmware, everything is fully configurable.
## LuCI Web Interface
OpenWrt can be configured remotely by command line (SSH) or using [LuCI](https://openwrt.org/docs/guide-user/luci/start), a GUI configuration interface. LuCI is a lightweight, extensible web GUI written in [Lua](https://opensource.com/article/20/2/lua-cheat-sheet), which enables an exact configuration of your device. Besides configuration, LuCI provides a lot of additional information like real time graphs, system logs, and network diagnostics.
Stephan Avenwedde, [CC BY-SA](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
There are some optional extensions available for LuCI to add even further configuration choices.
## Writeable file system
Another highlight is the writeable filesystem. While the stock firmware is usually read-only, OpenWrt comes with a writeable filesystem thanks to a clever solution that combines OverlayFS with SquashFS and JFFS2 filesystems to allow installation of packages to enhance functionality. Find more information about the file system architecture in the [OpenWrt documentation](https://openwrt.org/docs/techref/flash.layout).
## Extensions
OpenWrt has an associated package manager, [opkg](https://openwrt.org/docs/guide-user/additional-software/opkg), which allows to install additional services. Some examples are an FTP server, a DLNA media server, an OpenVPN server, a Samba server to enable file sharing, or Asterisk (software to control telephone calls). Of course, some extensions require appropriate resources of the underlying hardware.
## Motivation
You might wonder why you should try to replace a router manufacture's firmware, risking irreparable damage to your device and loss of warranty. If your device works the way you want, then you probably shouldn’t. Never touch a running system! But if you want to enhance functionality, or if your device is lacking configuration options, then you should check whether OpenWrt could be a remedy.
In my case, I wanted a travel router which I can place on an appropriate position when I’m on a campsite in order to get a good connection to the local Wifi access point. The router should connect itself as an ordinary client and broadcasts it’s own access point for my devices. This allows me to configure all my devices to connect with the routers access points and I only have to change the routers client connection when I’m somewhere else. Moreover, on some campsites you only get an access code for one single device, which I can enhance with this setup.
As my travel router, I choose the TP-Link TL-WR902AC for the following reasons:
- Small
- Two Wifi antennas
- 5V power supply (USB)
- Low power consumption
- Cost effective (you get it for around $30)
To get an idea of the size, here it is next to a Raspberry Pi4:

Stephan Avenwedde, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
Even though the router brings all hardware capabilities I demand, I relatively quickly found out that the default firmware don’t let me configure it the way I wanted. The router is mainly intended as an Wifi access point, which repeats an existing Wifi network or connects itself to the web over the onboard Ethernet interface. The default firmware is very limited for these use cases.
Fortunately, the router is capable of running OpenWrt, so I decided to replace the original firmware with it.
## Installation
When your LTE/5G/DSL/WIFI router meets the [minimum requirements](https://openwrt.org/supported_devices), chances are high that it's possible to run OpenWrt on it. As the next step, you look in the [hardware table](https://openwrt.org/toh/start) and check whether your devices is listed as compatible, and which firmware package you have to choose. The page for the [TP-Link TL-WR902AC](https://openwrt.org/toh/tp-link/tl-wr902ac_v3) also includes the installation instructions which describe how to flash the internal memory.
The process of flashing the firmware can vary between different devices, so I won’t go into detail on this. In a nutshell, I had to connect the device over a TFTP server on a network interface with a certain IP address, rename the OpenWrt firmware file and then boot up the device considering pressing the reset button.
## Configuration
Once flashing was successfully, your device should now boot up with the new firmware. It may take a bit longer now to boot up as OpenWrt comes with much more features compared to the default firmware.
OpenWrt acts as a DHCP server, so in order to begin with configuration, make a direct Ethernet connection between your PC and the router, and configure your PC’s Ethernet adapter as a DHCP client.
On Fedora Linux, to activate the DHCP client mode for your network adapter, first you have to find out the connection UUID by running:
```
``````
$ nmcli connection show
NAME UUID TYPE DEVICE
Wired Conn 1 7a96b...27a ethernet ens33
virbr0 360a0...673 bridge virbr0
testwifi 2e865...ee8 wifi --
virbr0 bd487...227 bridge --
Wired Conn 2 16b23...7ba ethernet --
```
Pick the UUID for the connection you want to modify and then run:
```
````$ nmcli connection modify <UUID> ipv4.method auto`
You can find more information about these commands in the [Fedora Networking Wiki](https://fedoraproject.org/wiki/Networking/CLI).
After you have a connection to your router, open a web browser and navigate to [http://openwrt/](http://openwrt/). You should now see LuCI’s login manager:
Stephan Avenwedde, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
Use **root** as the username, and leave the password field blank.
## Configuring Wifi and routing
To configure your Wifi antennas, click on the **Network** menu and select **Wireless**.
Stephan Avenwedde, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
On my device, the antenna **radio0** on top operates in 2.4 GHz mode and is connected to the local access point called *MOBILE-INTERNET*. The antenna **radio1** below operates at 5 GHz and has an associated access point with the SSID *OpenWrt_AV*. With a click of the **Edit **button, you can open the device configuration to decide whether the device belongs to the *LAN* or WWAN network. In my case, the access point *OpenWrt_AV* belongs to the LAN network and the client connection *MOBILE-INTERNET* belongs to the WWAN network.
Stephan Avenwedde, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
Configured networks are listed under **Network**, in the **Interfaces** panel.
Stephan Avenwedde, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
In order to get the functionality I want, network traffic must be routed between the LAN and the WWAN network. The routing can be configured in the **Firewall** section of the **Network** panel. I didn’t change anything here because, by default, the traffic is routed between the networks, and incoming packets (from WWAN to LAN) have to pass the firewall.
So all you need to know is whether an interface belongs to LAN or (W)WAN. This concept makes it relatively easy to configure, especially for beginners. You can find more information in [OpenWrt’s basic networking](https://openwrt.org/docs/guide-user/base-system/basic-networking) guide.
## Captive portals
Public Wifi access points are often protected by a [captive portal](https://en.wikipedia.org/wiki/Captive_portal) where you have to enter an access code or similar. Usually, such portals show up when you are first connected to the access point and try to open an arbitrary web page. This mechanism is realized by the access point's DNS server.
By default, OpenWrt has a security feature activated that prevents connected clients from a [DNS rebinding attack](https://en.wikipedia.org/wiki/DNS_rebinding). OpenWrt’s rebind protection also prevents captive portals from being forwarded to clients, so you must disable rebind protection so you can reach captive portals. This option is in the **DHCP and DNS** panel of the **Network** menu.
Stephan Avenwedde, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
## Try OpenWrt
Thanks to an upgrade to OpenWrt, I got a flexible travel router based on commodity hardware. OpenWrt makes your router fully configurable and extensible and, thanks to the well-made web GUI, it's also appropriate for beginners. There are even a few [select routers](https://opensource.com/article/22/1/turris-omnia-open-source-router) that ship with OpenWrt already installed. You are also able to enhance your router's functionality with lots of [available packages](https://openwrt.org/packages/table/start). For example, I’m using the [vsftp](https://openwrt.org/docs/guide-user/services/nas/ftp.overview) FTP server to host some movies and TV series on a connected USB stick. Take a look at the [projects homepage](https://openwrt.org/reasons_to_use_openwrt), where you can find many reasons to switch to OpenWrt.
## Comments are closed. |
15,672 | 如何设置自己的保护隐私的 DNS 服务器 | https://opensource.com/article/23/3/open-source-dns-server | 2023-03-29T15:04:53 | [
"Adguard",
"DNS"
] | https://linux.cn/article-15672-1.html | 
>
> 通过开源项目 AdGuard Home 运行你自己的 DNS 服务器来控制你的互联网隐私。
>
>
>
域名服务器(DNS)将域名(如 example.com)与 IP 地址(如 93.184.216.34)相关联。这就是当你输入 URL 或搜索引擎返回 URL 供你访问时,你的网络浏览器如何知道在世界的哪个地方寻找数据。DNS 为互联网用户提供了极大的便利,但也并非没有缺点。例如,付费广告会出现在网页上,因为你的浏览器会自然的使用 DNS 来解析这些广告在互联网上“存在”的位置。同样,跟踪你在线活动的软件通常由通过 DNS 解析的服务启用。你不想完全关闭 DNS,因为它非常有用。但是你可以运行自己的 DNS 服务,以便更好地控制它的使用方式。
我相信运行自己的 DNS 服务器至关重要,这样你就可以阻止广告并保持你的浏览隐私,远离试图分析你的在线交互的提供商。我过去用过 [Pi-hole](https://opensource.com/article/18/2/block-ads-raspberry-pi),今天仍然推荐它。然而,最近,我一直在我的网络上运行开源项目 [AdGuard Home](https://github.com/AdguardTeam/AdGuardHome)。我发现它有一些值得探索的独特功能。
### AdGuard Home
在我使用过的开源 DNS 软件中,[AdGuard Home](https://github.com/AdguardTeam/AdGuardHome) 是最容易设置和维护的。你可以在一个项目中获得许多 DNS 解析解决方案,例如 DNS over TLS、DNS over HTTPS 和 DNS over QUIC。
你可以使用一个脚本将 AdGuard 设置为容器或本地服务:
```
$ curl -s -S -L \
https://raw.githubusercontent.com/AdguardTeam/AdGuardHome/master/scripts/install.sh
```
查看这个脚本以便了解它的作用。了解了它的工作过程后,再运行它:
```
$ sh ./install.sh
```
我最喜欢 AdGuard Home 的一些功能:
* 一个简单的管理界面
* 使用 AdGuard 阻止列表来阻止广告和恶意软件
* 单独配置网络上每个设备的选项
* 强制在特定设备上进行安全搜索
* 为管理界面设置 HTTPS,这样与它的远程交互是完全加密的
我发现 AdGuard Home 为我节省了时间。它的黑名单比 Pi-hole 上的黑名单更强大。你可以快速轻松地将其配置为 DNS over HTTPS。
### 没有更多的恶意软件
恶意软件是你计算机上不需要的内容。它并不总是对你有直接危险,但它可能会为第三方带来危险活动。这不是互联网最初的目的。我认为你应该托管自己的 DNS 服务,以保护你的互联网历史记录的私密性,并避免被微软、谷歌和亚马逊等已知跟踪器掌握。在你的网络上试用 AdGuard Home 吧。
---
via: <https://opensource.com/article/23/3/open-source-dns-server>
作者:[Amar Gandhi](https://opensource.com/users/amar1723) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A Domain Name Server (DNS) associates a domain name (like example.com) with an IP address (like 93.184.216.34). This is how your web browser knows where in the world to look for data when you enter a URL or when a search engine returns a URL for you to visit. DNS is a great convenience for internet users, but it's not without drawbacks. For instance, paid advertisements appear on web pages because your browser naturally uses DNS to resolve where those ads "live" on the internet. Similarly, software that tracks your movement online is often enabled by services resolved over DNS. You don't want to turn off DNS entirely because it's very useful. But you can run your own DNS service so you have more control over how it's used.
I believe it's vital that you run your own DNS server so you can block advertisements and keep your browsing private, away from providers attempting to analyze your online interactions. I've used [Pi-hole](https://opensource.com/article/18/2/block-ads-raspberry-pi) in the past and still recommend it today. However, lately, I've been running the open source project [Adguard Home](https://github.com/AdguardTeam/AdGuardHome) on my network. I found that it has some unique features worth exploring.
## Adguard Home
Of the open source DNS options I've used, [Adguard Home](https://github.com/AdguardTeam/AdGuardHome) is the easiest to set up and maintain. You get many DNS resolution solutions, such as DNS over TLS, DNS over HTTPS, and DNS over QUIC, within one single project.
You can set up Adguard as a container or as a native service using a single script:
```
``````
$ curl -s -S -L \
https://raw.githubusercontent.com/AdguardTeam/AdGuardHome/master/scripts/install.sh
```
Look at the script so you understand what it does. Once you're comfortable with the install process, run it:
```
````$ sh ./install.sh`
Some of my favorite features of AdGuard Home:
-
An easy admin interface
-
Block ads and malware with the Adguard block list
-
Options to configure each device on your network individually
-
Force safe search on specific devices
-
Set HTTPS for the admin interface, so your remote interacts with it are fully encrypted
I find that Adguard Home saves me time. Its block lists are more robust than those on Pi-hole. You can quickly and easily configure it to run DNS over HTTPS.
## No more malware
Malware is unwanted content on your computer. It's not always directly dangerous to you, but it may enable dangerous activity for third parties. That's not what the internet was ever meant to do. I believe you should host your own DNS service to keep your internet history private and out of the hands of known trackers such as Microsoft, Google, and Amazon. Try Adguard Home on your network.
## 1 Comment |
15,674 | 为什么程序员喜欢为 Linux 打包 | https://opensource.com/article/21/2/linux-packaging | 2023-03-29T23:13:39 | [
"Flatpak",
"打包"
] | https://linux.cn/article-15674-1.html |
>
> 程序员可以通过 Flatpak 轻松、稳定地发布他们的软件,让他们专注于他们的激情工作:编程。
>
>
>

如今,人们比以往任何时候都喜爱 Linux。在这个系列中,我将分享使用 Linux 的 21 个不同理由。今天,我将谈一谈是什么让 Linux 的打包成为程序员的理想选择。
程序员喜欢编程。这可能看起来是一个显而易见的说法,但重要的是要明白,开发软件所涉及的不仅仅是编写代码。它包括编译、文档、源代码管理、安装脚本、配置默认值、支持文件、交付格式等等。从一个空白的屏幕到一个可交付的软件安装程序,需要的不仅仅是编程,但大多数程序员宁愿编程也不愿打包。
### 什么是打包?
当食物被送到商店购买时,它是被包装好的。当直接从农民或从环保的散装或桶装商店购买时,包装是你所带的任何容器。当从杂货店购买时,包装可能是一个纸板箱、塑料袋、一个铁罐等等。
当软件被提供给广大计算机用户时,它也必须被打包起来。像食品一样,软件也有几种打包方式。开源软件可以不进行打包,因为用户在获得原始代码后,可以自己编译和打包它。然而,打包也有好处,所以应用程序通常以某种特定于用户平台的格式交付。而这正是问题的开始,因为软件包的格式并不只有一种。
对于用户来说,软件包使安装软件变得容易,因为所有的工作都由系统的安装程序完成。软件被从软件包中提取出来,并分发到操作系统中的适当位置。几乎没有任何出错的机会。
然而,对于软件开发者来说,打包意味着你必须学会如何创建一个包 —— 而且不仅仅是一个包,而是为你希望你的软件可以安装到的每一个操作系统创建一个独特的包。更加复杂的是,每个操作系统都有多种打包格式和选项,有时甚至是不同的编程语言。
### 为 Linux 打包
传统上,Linux 的打包方式似乎是非常多的。从 Fedora 衍生出来的 Linux 发行版,如 Red Hat 和 CentOS,默认使用 .rpm 包。Debian 和 Ubuntu(以及类似的)默认使用 .deb 包。其他发行版可能使用其中之一,或者两者都不使用,选择自定义的格式。当被问及时,许多 Linux 用户说,理想情况下,程序员根本不会为 Linux 打包他们的软件,而是依靠每个发行版的软件包维护者来创建软件包。所有安装在 Linux 系统上的软件都应该来自该发行版的官方软件库。然而,目前还不清楚如何让你的软件可靠地被一个发行版打包和包含,更不用说所有的发行版了。
### Linux 的 Flatpak
Flatpak 打包系统是为了统一和去中心化 Linux 作为开发者的交付目标而推出的。通过 Flatpak,无论是开发者还是其他人(Linux 社区的成员、不同的开发者、Flatpak 团队成员或其他任何人)都可以自由地打包软件。然后他们可以将软件包提交给 Flathub,或者选择自我托管软件包,并将其提供给几乎任何 Linux 发行版。Flatpak 系统适用于所有 Linux 发行版,所以针对一个发行版就等于针对所有发行版。
### Flatpak 技术如何工作
Flatpak 具有普遍吸引力的秘密是一个标准基础。Flatpak 系统允许开发者引用一套通用的软件开发者工具包(SDK)模块。这些模块由 Flatpak 系统的维护者进行打包和管理。当你安装 Flatpak 时,SDK 会根据需要被拉入,以确保与你的系统兼容。任何特定的 SDK 只需要一次,因为它所包含的库可以在任何 Flatpak 中共享。
如果开发者需要一个尚未包含在现有 SDK 中的库,开发者可以在 Flatpak 中添加该库。
结果不言自明。用户可以从一个叫做 [Flathub](https://flatpak.org/setup/) 的中央仓库在任何 Linux 发行版上安装数百个软件包。
### 开发者如何使用 Flatpak
Flatpak 被设计成可重复的,所以构建过程很容易被集成到 CI/CD 工作流程中。Flatpak 是在一个 [YAML](https://www.redhat.com/sysadmin/yaml-beginners) 或 JSON 清单文件中定义的。你可以按照我的 [介绍性文章](https://opensource.com/article/19/10/how-build-flatpak-packaging) 创建你的第一个 Flatpak,你也可以在 [docs.flatpak.org](https://docs.flatpak.org/en/latest/index.html) 阅读完整的文档。
### Linux 让它变得简单
在 Linux 上创建软件很容易,为 Linux 打包也很简单,而且可以自动化。如果你是一个程序员,Linux 使你很容易忘记打包这件事,因为它只需要针对一个系统,并可以整合到你的构建过程中。
---
via: <https://opensource.com/article/21/2/linux-packaging>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 2021, there are more reasons why people love Linux than ever before. In this series, I'll share 21 different reasons to use Linux. Today, I'll talk about what makes packaging for Linux ideal for programmers.
Programmers love to program. That probably seems like an obvious statement, but it's important to understand that developing software involves a lot more than just writing code. It includes compiling, documentation, source code management, install scripts, configuration defaults, support files, delivery format, and more. Getting from a blank screen to a deliverable software installer requires much more than just programming, but most programmers would rather program than package.
## What is packaging?
When food is sent to stores to be purchased, it is packaged. When buying directly from a farmer or from an eco-friendly bulk or bin store, the packaging is whatever container you've brought with you. When buying from a grocery store, packaging may be a cardboard box, plastic bag, a tin can, and so on.
When software is made available to computer users at large, it also must be packaged. Like food, there are several ways software can be packaged. Open source software can be left unpackaged because users, having access to the raw code, can compile and package it themselves. However, there are advantages to packages, so applications are commonly delivered in some format specific to the user's platform. And that's where the problems begin, because there's not just one format for software packages.
For the user, packages make it easy to install software because all the work is done by the system's installer. The software is extracted from its package and distributed to the appropriate places within the operating system. There's little opportunity for anything to go wrong.
For the software developer, however, packaging means that you have to learn how to create a package—and not just one package, but a unique package for every operating system you want your software to be installable on. To complicate matters, there are multiple packaging formats and options for each operating system, and sometimes even for the programming language being used.
## Packaging on Linux
Packaging options for Linux have traditionally seemed pretty overwhelming. Linux distributions derived from Fedora, such as Red Hat and CentOS, default to `.rpm`
packages. Debian and Ubuntu (and similar) default to `.deb`
packages. Other distributions may use one or the other, or neither, opting for a custom format. When asked, many Linux users say that ideally, a programmer won't package their software for Linux at all but instead rely on the package maintainers of each distribution to create the package. All software installed onto any Linux system ought to come from that distribution's official repository. However, it remains unclear how to get your software reliably packaged and included by one distribution, let alone all distributions.
## Flatpak for Linux
The Flatpak packaging system was introduced to unify and decentralize Linux as a delivery target for developers. With Flatpak, either a developer or anyone (a member of a Linux community, a different developer, a Flatpak team member, or anyone else) is free to package software. They can then submit the package to Flathub or choose to self-host the package and offer it to basically any Linux distribution. The Flatpak system is available to all Linux distributions, so targeting one is the same as targeting them all.
## How Flatpak technology works
The secret to Flatpak's universal appeal is a standard base. The Flatpak system allows developers to reference a common set of Software Developer Kit (SDK) modules. These are packaged and managed by the maintainers of the Flatpak system. The SDKs get pulled in as needed whenever you install a Flatpak, ensuring compatibility with your system. Any given SDK is only required once because the libraries it contains can be shared across any Flatpak calling for it.
If a developer requires a library not already included in an existing SDK, the developer can add that library in the Flatpak.
The results speak for themselves. Users may install hundreds of packages on any Linux distribution from one central repository, called [Flathub](https://flatpak.org/setup/).
## How developers use Flatpaks
Flatpaks are designed to be reproducible, so the build process is easily integrated into a CI/CD workflow. A Flatpak is defined in a [YAML](https://www.redhat.com/sysadmin/yaml-beginners) or JSON manifest file. You can create your first Flatpak by following my [introductory article](https://opensource.com/article/19/10/how-build-flatpak-packaging), and you can read the full documentation at [docs.flatpak.org](https://docs.flatpak.org/en/latest/index.html).
## Linux makes it easy
Creating software on Linux is easy, and packaging it up for Linux is simple and automatable. If you're a programmer, Linux makes it easy for you to forget about packaging by targeting one system and integrating that into your build process.
## Comments are closed. |
15,675 | 使用 Kubespray 安装 Kubernetes 集群 | https://www.linuxtechi.com/install-kubernetes-using-kubespray/ | 2023-03-30T07:45:00 | [
"Kubernetes"
] | https://linux.cn/article-15675-1.html | 
>
> 你是否正在寻找有关如何使用 Kubespray 安装 Kubernetes(k8s)的简单指南?
>
>
>
此页面上的分步指南将向你展示如何在 Linux 系统上使用 Kubespray 安装 Kubernetes 集群。
Kubespray 是一个自由开源的工具,它提供了 Ansible <ruby> 剧本 <rt> playbook </rt></ruby> 来部署和管理 Kubernetes 集群。它旨在简化跨多个节点的 Kubernetes 集群的安装过程,允许用户快速轻松地部署和管理生产就绪的 Kubernetes 集群。
它支持一系列操作系统,包括 Ubuntu、CentOS、Rocky Linux 和 Red Hat Enterprise Linux(RHEL),它可以在各种平台上部署 Kubernetes,包括裸机、公共云和私有云。
在本指南中,我们使用以下实验室:
* Ansible 节点(Kubespray 节点):最小安装的 Ubuntu 22.04 LTS(192.168.1.240)
* 3 个控制器节点:最小安装的 Rocky Linux 9(192.168.1.241/242/243)
* 2 个工作节点:最小安装的 Rocky Linux 9(192.168.1.244/245)
### Kubespray 的最低系统要求
* 主节点:1500 MB RAM、2 个 CPU 和 20 GB 可用磁盘空间
* 工作节点:1024 MB、2 个 CPU、20 GB 可用磁盘空间
* Ansible 节点:1024 MB、1 个 CPU 和 20 GB 磁盘空间
* 每个节点上的互联网连接
* 拥有 sudo 管理员权限
事不宜迟,让我们深入了解安装步骤。
### 步骤 1)配置 Kubespray 节点
登录到你的 Ubuntu 22.04 系统并安装 Ansible。运行以下一组命令:
```
$ sudo apt update
$ sudo apt install git python3 python3-pip -y
$ git clone https://github.com/kubernetes-incubator/kubespray.git
$ cd kubespray
$ pip install -r requirements.txt
```
验证 Ansible 版本,运行:
```
$ ansible --version
```

创建主机清单,运行以下命令,不要忘记替换适合你部署的 IP 地址:
```
$ cp -rfp inventory/sample inventory/mycluster
$ declare -a IPS=(192.168.1.241 192.168.1.241 192.168.1.242 192.168.1.243 192.168.1.244 192.168.1.245)
$ CONFIG_FILE=inventory/mycluster/hosts.yaml python3 contrib/inventory_builder/inventory.py ${IPS[@]}
```
修改清单文件,设置 3 个控制节点和 2 个工作节点:
```
$ vi inventory/mycluster/hosts.yaml
```

保存并关闭文件。
查看并修改文件 `inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml` 中的以下参数:
```
kube_version: v1.26.2
kube_network_plugin: calico
kube_pods_subnet: 10.233.64.0/18
kube_service_addresses: 10.233.0.0/18
cluster_name: linuxtechi.local
```

要启用 Kuberenetes 仪表板和入口控制器等插件,请在文件 `inventory/mycluster/group_vars/k8s_cluster/addons.yml` 中将参数设置为已启用:
```
$ vi inventory/mycluster/group_vars/k8s_cluster/addons.yml
```
```
dashboard_enabled: true
ingress_nginx_enabled: true
ingress_nginx_host_network: true
```
保存并退出文件。
### 步骤 2)将 SSH 密钥从 Ansible 节点复制到所有其他节点
首先在你的 Ansible 节点上为你的本地用户生成 SSH 密钥:
```
$ ssh-keygen
```
使用 `ssh-copy-id` 命令复制 SSH 密钥:
```
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
$ ssh-copy-id [email protected]
```
还要在每个节点上运行以下命令:
```
$ echo "sysops ALL=(ALL) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/sysops
```
### 步骤 3)禁用防火墙并启用 IPV4 转发
要在所有节点上禁用防火墙,请从 Ansible 节点运行以下 `ansible` 命令:
```
$ cd kubespray
$ ansible all -i inventory/mycluster/hosts.yaml -m shell -a "sudo systemctl stop firewalld && sudo systemctl disable firewalld"
```
运行以下 `ansible` 命令以在所有节点上启用 IPv4 转发和禁用交换:
```
$ ansible all -i inventory/mycluster/hosts.yaml -m shell -a "echo 'net.ipv4.ip_forward=1' | sudo tee -a /etc/sysctl.conf"
$ ansible all -i inventory/mycluster/hosts.yaml -m shell -a "sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab && sudo swapoff -a"
```
### 步骤 4)启动 Kubernetes 部署
现在,我们都准备好开始 Kubernetes 集群部署,从 Ansible 节点运行下面的 Ansible 剧本:
```
$ cd kubespray
$ ansible-playbook -i inventory/mycluster/hosts.yaml --become --become-user=root cluster.yml
```

现在监控部署,可能需要 20 到 30 分钟,具体取决于互联网速度和硬件资源。
部署完成后,我们将在屏幕上看到以下输出:

很好,上面的输出确认部署已成功完成。
### 步骤 5)访问 Kubernetes 集群
登录到第一个主节点,切换到 root 用户,在那里运行 `kubectl` 命令:
```
$ sudo su -
# kubectl get nodes
# kubectl get pods -A
```
输出:

完美,上面的输出确认集群中的所有节点都处于就绪状态,并且所有命名空间的 <ruby> 容器荚 <rt> Pod </rt></ruby> 都已启动并正在运行。这表明我们的 Kubernetes 集群部署成功。
让我们尝试部署基于 Nginx 的部署并将其公开为节点端口,运行以下 `kubectl` 命令:
```
$ kubectl create deployment demo-nginx-kubespray --image=nginx --replicas=2
$ kubectl expose deployment demo-nginx-kubespray --type NodePort --port=80
$ kubectl get deployments.apps
$ kubectl get pods
$ kubectl get svc demo-nginx-kubespray
```
以上命令的输出:

现在尝试使用工作节点的 IP 地址和节点端口(30050)访问此 Nginx 应用。
使用以下 `curl` 命令或 Web 浏览器访问此应用。
```
$ curl 192.168.1.245:30050
```
或者,

完美,这证实了应用可以在我们的集群之外访问。
### 步骤 6)Kubernetes 仪表板(GUI)
要访问 Kubernetes 仪表板,让我们首先创建服务帐户并分配管理员权限,以便它可以使用令牌访问仪表板。
在 kube-system 命名空间中创建名为 “admin-user” 的服务帐户:
```
$ vi dashboard-adminuser.yml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kube-system
```
保存并关闭文件。
```
$ kubectl apply -f dashboard-adminuser.yml
serviceaccount/admin-user created
```
创建集群角色绑定:
```
$ vi admin-role-binding.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kube-system
```
保存并退出文件。
```
$ kubectl apply -f admin-role-binding.yml
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
```
现在,为管理员用户创建令牌:
```
$ kubectl -n kube-system create token admin-user
```

复制此令牌并将其放在安全的地方,因为我们将使用令牌登录 Kubernetes 仪表板。
使用以下 `ssh` 命令从你的系统连接到第一个主节点:
```
$ ssh -L8001:localhost:8001 [email protected]
```
注意:替换适合你环境的 IP 地址。
登录后,切换到 root 用户并运行 `kubectl proxy` 命令:
```
$ sudo su -
# kubectl proxy
Starting to serve on 127.0.0.1:8001
```

打开系统的网络浏览器,如下设置代理:

完成代理设置后,将以下网址粘贴到浏览器中:
```
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/#/login
```

选择令牌登录并粘贴你在上面为管理员用户生成的令牌,然后单击“<ruby> 登录 <rt> Sign in </rt></ruby>”。

这就是本指南的全部内容,我希望你能从中找到有用的信息。请在下面的评论部分中发表你的疑问和反馈。
---
via: <https://www.linuxtechi.com/install-kubernetes-using-kubespray/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Are you looking for an easy guide on how to install Kubernetes (k8s) using kubespray?
The step-by-step guide on this page will show you how to install Kubernetes Cluster using kubespray on linux systems.
[Kubespray](https://github.com/kubernetes-sigs/kubespray) is a free and open-source tool that provide ansible playbooks to deploy and manage Kubernetes clusters. It is designed to simplify the installation process of Kubernetes clusters across multiple nodes, allowing users to deploy and manage a production-ready Kubernetes cluster quickly and easily.
It supports a range of operating systems, including Ubuntu, CentOS, Rocky Linux and Red Hat Enterprise Linux, and it can deploy Kubernetes on a variety of platforms, including bare metal, public cloud, and private cloud.
In this guide, we are using the following lab,
- Ansible Node (Kubespray Node): Minimal installed Ubuntu 22.04 LTS (192.168.1.240)
- 3 Controller Nodes: Minimal Installed Rocky Linux 9 (192.168.1.241/242/243)
- 2 Worker Nodes: Minimal Installed Rocky Linux 9 (192.168.1.244/245)
#### Minimum system requirements for kubespray
- Master Nodes: 1500 MB RAM, 2 CPU and 20 GB free disk space
- Worker Nodes: 1024 MB, 2 CPU, 20 GB free disk space
- Ansible Node: 1024 MB, 1CPU and 20 GB disk space
- Internet connectivity on each node
- Regular with sudo admin rights
Without any further delay, let’s deep dive into the installation steps,
## Step 1) Configure Kubespray Node
Login to your Ubuntu 22.04 system and install ansible. Run the following set of commands,
$ sudo apt update $ sudo apt install git python3 python3-pip -y $ git clone https://github.com/kubernetes-incubator/kubespray.git $ cd kubespray $ pip install -r requirements.txt
Verify the ansible version, run
$ ansible --version
Create the hosts inventory, run below commands and don’t forget to replace IP address that suits to your deployment.
$ cp -rfp inventory/sample inventory/mycluster $ declare -a IPS=(192.168.1.241 192.168.1.241 192.168.1.242 192.168.1.243 192.168.1.244 192.168.1.245) $ CONFIG_FILE=inventory/mycluster/hosts.yaml python3 contrib/inventory_builder/inventory.py ${IPS[@]}
Modify the inventory file, set 3 control nodes and 2 worker nodes
$ vi inventory/mycluster/hosts.yaml
Save and close the file
Review and modify the following parameters in file “inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml”.
kube_version: v1.26.2 kube_network_plugin: calico kube_pods_subnet: 10.233.64.0/18 kube_service_addresses: 10.233.0.0/18 cluster_name: linuxtechi.local
To enable addons like kuberenetes dashboard and ingress controller, set the parameters as enabled in the file “inventory/mycluster/group_vars/k8s_cluster/addons.yml”
$ vi inventory/mycluster/group_vars/k8s_cluster/addons.yml ----------- dashboard_enabled: true ingress_nginx_enabled: true ingress_nginx_host_network: true -----------
save and exit the file.
## Step 2) Copy SSH-keys from ansible node to all other nodes
First generate the ssh-keys for your local user on your ansible node,
$ ssh-keygen
Copy the ssh-keys using ssh-copy-id command,
$ ssh-copy-id[[email protected]]$ ssh-copy-id[[email protected]]$ ssh-copy-id[[email protected]]$ ssh-copy-id[[email protected]]$ ssh-copy-id[[email protected]]
Also Read: [How to Setup Passwordless SSH Login in Linux with Keys](https://www.linuxtechi.com/passwordless-ssh-login-keys-linux/)
Also run the following command on each node.
$ echo "sysops ALL=(ALL) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/sysops
## Step 3) Disable Firewall and Enable IPV4 forwarding
To disable firewall on all the nodes, run following ansible command from ansible node,
$ cd kubespray $ ansible all -i inventory/mycluster/hosts.yaml -m shell -a "sudo systemctl stop firewalld && sudo systemctl disable firewalld"
Run following ansible commands to enable IPv4 forwarding and disable swap on all the nodes,
$ ansible all -i inventory/mycluster/hosts.yaml -m shell -a "echo 'net.ipv4.ip_forward=1' | sudo tee -a /etc/sysctl.conf" $ ansible all -i inventory/mycluster/hosts.yaml -m shell -a "sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab && sudo swapoff -a"
## Step 4) Start Kubernetes deployment
Now, we are all set to start Kubernetes cluster deployment, run following ansible playbook from ansible node,
$ cd kubespray $ ansible-playbook -i inventory/mycluster/hosts.yaml --become --become-user=root cluster.yml
Now monitor the deployment, it may take 20 to 30 minutes depending on internet speed and hardware resources.
Once the deployment is completed, we will get following output on our screen,
Great, above output confirms that deployment is completed successfully.
## Step 5) Access Kubernetes cluster
Login to first master node, switch to root user, run kubectl commands from there,
$ sudo su - # kubectl get nodes # kubectl get pods -A
Output,
Perfect, output above confirms that all the nodes in the cluster are in ready state and Pods of all the namespace are up and running. This shows that our Kubernetes cluster is deployed successfully.
Let’s try to deploy nginx based deployment and expose it as nodeport, run the following kubectl commands
$ kubectl create deployment demo-nginx-kubespray --image=nginx --replicas=2 $ kubectl expose deployment demo-nginx-kubespray --type NodePort --port=80 $ kubectl get deployments.apps $ kubectl get pods $ kubectl get svc demo-nginx-kubespray
Output of above commands,
Now try accessing this nginx application using worker’s IP address and node port (30050)
Either use below curl command or web browser to access this application.
$ curl 192.168.1.245:30050
Or
Perfect, this confirms that application is accessible outside of our cluster.
## Step 6) Kubernetes Dashboard (GUI)
To access the Kubernetes dashboard, let’s first service account and assign admin privileges so that it can access dashboard using token.
Create service account with name ‘admin-user’ in kube-system namespace.
$ vi dashboard-adminuser.yml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system
save and close the file.
$ kubectl apply -f dashboard-adminuser.yml serviceaccount/admin-user created $
Create a cluster role binding,
$ vi admin-role-binding.yml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system
save and exit the file.
$ kubectl apply -f admin-role-binding.yml clusterrolebinding.rbac.authorization.k8s.io/admin-user created $
Now, create the token for admin-user,
$ kubectl -n kube-system create token admin-user
Copy this token and place it somewhere safe because we will use token to login Kubernetes dashboard.
Connect to first master node from your system using following ssh command
$ ssh -L8001:localhost:8001[[email protected]]
Note : Replace IP address that suits to your env.
After login, switch to root user and run ‘kubectl proxy‘ command,
$ sudo su - # kubectl proxy Starting to serve on 127.0.0.1:8001
Open the web browser of your system, set the proxy settings as shown below,
Once you are done with proxy settings, paste the following url in browser,
http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/#/login
Select the login mechanism as Token and paste the token that you have generated above for admin-user and then click on ‘Sign in’
That’s all from this guide, I hope you found it informative. Kindly do post your queries and feedback in below comments section.
BishIn this example Ricky Linux has been used, can Ubuntu 22.04 be used for Master and Worker Nodes?
Thanks,
~Bish
Pradeep KumarHi Bish,
Yes, You can also use Ubuntu 22.04 for master and worker nodes.
DurianIt’s great, I spent a day trying several deployment methods, and finally succeeded through your blog.
SalThis is great. Had good success with this. Unless I’m seeing things, I get to the dashboard with or without my browser set to use a proxy. That makes sense to me–I’m going to localhost (which is then tunneled and proxied) with or without my browser telling me to go to localhost.
Avinash KNice blog, can you please share the steps to upgrade a k8 cluster using Kubespray?
for example v1.21.6 to 1.26.0 |
15,677 | Ubuntu Cinnamon 正式成为 Ubuntu 官方风味版 | https://news.itsfoss.com/ubuntu-cinnamon-official/ | 2023-03-31T09:17:53 | [
"Ubuntu",
"Cinnamon"
] | https://linux.cn/article-15677-1.html |
>
> 在 Ubuntu 的混合风味中加入肉桂味,完美!
>
>
>

在等待下个月的 Ubuntu 23.04 吗?
好吧,我们已经提到,在 Ubuntu 23.04 版本的 [令人兴奋](https://news.itsfoss.com/ubuntu-23-04/) 的事情中,包括一个新的官方的 Cinnamon 风味(它最初是 Ubuntu Cinnamon Remix)。
而且,它\*\*现在是官方版本\*,因为 Ubuntu 的技术委员会以足够的票数 [批准了它](https://lists.ubuntu.com/archives/technical-board/2023-March/002725.html?ref=its-foss-news)。
### Ubuntu Cinnamon 23.04 值得期待的地方

如果你之前已经使用过 Ubuntu Cinnamon Remix(非官方),你可能对它有点概念了。
如果你想要一个带有 Cinnamon 桌面的 Ubuntu 风味版,而没有众多的特殊定制,Ubuntu Cinnamon 适合你。
而另一方面,Linux Mint 也是一个基于 Ubuntu 的 Cinnamon 桌面。然而,你会得到一个 Mint 特有的主题、图标、工具和调整,体验有所不同。
基本上,如果你使用 Linux Mint,它不会让你感觉到 “只是另一种 Ubuntu 风味”。
别忘了,Linux Mint 默认禁用 Snap,而且是 Flatpak 优先的,这与 Ubuntu Cinnamon 23.04 的情况完全相反。

所以,如果你喜欢使用 Snap 而不是 Flatpak,并且喜欢 Ubuntu 通常的风味版的工作方式,Ubuntu Cinnamon 是一个不错的补充。关于这个版本的其他一些值得注意的地方包括:
* 预装的应用程序,如 [Synaptic Package Manager](https://itsfoss.com/synaptic-package-manager/?ref=its-foss-news)、LibreOffice 等
* Ubuntu 的 Yaru 主题
* 没有像你期望的 Linux Mint 那样的 XApp
目前,根据其 [最新的日常构建](https://cdimage.ubuntu.com/ubuntucinnamon/daily-live/current/?ref=its-foss-news),Ubuntu Cinnamon 23.04 几乎已经准备好发布(将于下个月发布)。
它是否会赢得 Linux Mint 用户的青睐,那是另外一个故事。但是,**Ubuntu 上的新 Cinnamon 版应该会让更多的用户尝试 Cinnamon 桌面,这是件好事**。
Cinnamon 桌面融合了传统 Windows 风格的布局,并提供了更多的功能。
你可以在 [Ubuntu Cinnamon 博客](https://ubuntucinnamon.org/ubuntu-cinnamon-flavor-status-announcement/?ref=its-foss-news) 上阅读官方公告。
你考虑改用 Ubuntu Cinnamon 作为你的首选口味吗?请在评论中分享你的想法。
---
via: <https://news.itsfoss.com/ubuntu-cinnamon-official/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Waiting for Ubuntu 23.04 next month?
Well, we already mentioned that one of the [exciting things about the Ubuntu 23.04 release](https://news.itsfoss.com/ubuntu-23-04/) includes a new official Cinnamon flavor (originally, Ubuntu Cinnamon Remix).
And, that is **now official**, as the Technical Board of Ubuntu [approved it](https://lists.ubuntu.com/archives/technical-board/2023-March/002725.html?ref=news.itsfoss.com) with enough votes.
## Ubuntu Cinnamon 23.04: What to Expect?

If you already used Ubuntu Cinnamon Remix (unofficial) earlier, you may have an idea of how they approach it.
Nevertheless, if you wanted an Ubuntu flavor and Cinnamon desktop, without numerous special customizations, Ubuntu Cinnamon is your friend.
Linux Mint, on the other hand, is an option which is also based on Ubuntu featuring Cinnamon. However, you get a Mint-specific theme, iconography, tools, and tweaks that make it a different experience.
Basically, if you use Linux Mint, it is not going to feel like "*just another Ubuntu flavor*".
**Suggested Read **📖
[8 Reasons Why Linux Mint is Better Than Ubuntu for Linux BeginnersWhich one is better, Linux Mint or Ubuntu? This question has been there ever since Linux Mint came into the picture, and this article does not answer this question. Well, not entirely. So, what is this about, then? I have been an Ubuntu user for a long time. I stray](https://itsfoss.com/linux-mint-vs-ubuntu/?ref=news.itsfoss.com)

Not to forget, Linux Mint disables snap by default and is Flatpak-first, an entire opposite of what Ubuntu Cinnamon 23.04 will be.
So, if you prefer using snaps over Flatpak, and like how the usual Ubuntu flavors work on your system, Ubuntu Cinnamon is a nice addition. Some other points to note about this release include:
- Pre-installed apps like
[Synaptic Package Manager](https://itsfoss.com/synaptic-package-manager/?ref=news.itsfoss.com), LibreOffice, etc. - Ubuntu's Yaru theme
- No XApps like you expect with Linux Mint
Currently, Ubuntu Cinnamon 23.04 is almost ready for release (due for next month) as per its [latest daily build](https://cdimage.ubuntu.com/ubuntucinnamon/daily-live/current/?ref=news.itsfoss.com).
Whether it is going to win over Linux Mint users, that is a different story. But,** a new Cinnamon edition on Ubuntu should get more users to try the Cinnamon desktop, which is a good thing.**
The Cinnamon desktop is a blend of traditional Windows-style layout with more to offer.
You can read the official announcement on the [Ubuntu Cinnamon blog](https://ubuntucinnamon.org/ubuntu-cinnamon-flavor-status-announcement/?ref=news.itsfoss.com).
*💬 Do you think you will be switching to Ubuntu Cinnamon as your preferred flavor to others? Share your thoughts in the comments.*
**Suggested Read **📖
[Explained: Which Ubuntu Version Should I Use?Brief: Confused about Ubuntu vs Xubuntu vs Lubuntu vs Kubuntu?? Want to know which Ubuntu flavor you should use? This beginner’s guide helps you decide which Ubuntu should you choose. So, you’ve been reading about the reasons to switch to Linux and the benefits of using it, and](https://itsfoss.com/which-ubuntu-install/?ref=news.itsfoss.com)

## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,678 | 号称可以成为 ChatGPT 平替的开源模型 “Dolly” | https://news.itsfoss.com/open-source-model-dolly/ | 2023-03-31T09:54:18 | [
"ChatGPT",
"AI"
] | https://linux.cn/article-15678-1.html |
>
> 你需要一款 ChatGPT 的平替?还得是开源的?看起来我们已经被卷入了与 ChatGPT 的开源大战。
>
>
>

Databricks 这家软件公司,在各个领域都有所建树,尤其是在数据仓库和基于人工智能的解决方案方面。
最近,随着 ChatGPT 横空出世,Meta、谷歌甚至 Mozilla 都开始效仿 ChatGPT。
而现在,Databricks 开源了其 <ruby> <a href="https://en.wikipedia.org/wiki/Large_language_model?ref=its-foss-news"> 大型语言模型 </a> <rt> large language model </rt></ruby>(LLM)“Dolly”,也正在以自己的方式进行尝试。
我们一起来看看它。
**发生了什么?** 在最近的公告中,Databricks 介绍了他们号称 “**廉价构建**” 的 LLM,使用 [EleutherAI](https://www.eleuther.ai/?ref=its-foss-news) 的已经开源的参数 [模型](https://huggingface.co/EleutherAI/gpt-j-6B?ref=its-foss-news) 提供功能。
他们在该模型基础上稍作调整,赋予了 Dolly 指令诸如头脑风暴和文本生成的能力。
当你拿它与 GPT-3 中的 **1750 亿个参数** 比较时,Dolly 的 **60 亿个参数** 就可能显得微不足道。
但是,当 Databricks 的人看到即使数据量与 GPT-3 相差这么多,Dolly 也能 **展示很多与 ChatGPT 相同的能力** 时,他们感到非常震惊。
下面是他们展示的其中一个例子:

原始模型使用了 [Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html?ref=its-foss-news) 的数据,该模型由斯坦福大学以 Meta 的 [LLaMA](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/?ref=its-foss-news) LLM 为基础建立。
但是,正如你所看到的,原始模型产生了一个非常杂乱无章的结果,而 Dolly,通过不同的模型和调整,能够产生一个更为可用的答案。
>
> ? 有趣的事实:“<ruby> 多莉 <rt> Dolly </rt></ruby>” 名字取自世界上第一只克隆羊。
>
>
>
**为什么是现在?** 根据 Databricks 的说法,他们认为 \*\*许多公司更愿意建立自己的模型,\*\*而不是将数据发送给某个紧紧掌握模型只对外提供 API 的集中式供应商。
许多公司可能不愿意将他们最敏感的数据交给第三方,然后在模型质量、成本和所需行为方面进行各种权衡。
**你想看看吗?**
当然,但有一个问题。
你必须 **使用他们的平台来使用 Dolly**,他们已经开源了一个 [Databricks 笔记本](https://github.com/databrickslabs/dolly?ref=its-foss-news),可以帮助你在 Databricks 上构建它。
此外,如果你想获得训练好的权重,你必须联系他们。不过我不确定他们是否会免费提供使用权。
总而言之,这种开源其模型的举动应该对其他公司有好处,可以保护他们的数据、节省运营成本,其他公司也能使用它创建自己的模型。
你可以查看其 [公告博客](https://www.databricks.com/blog/2023/03/24/hello-dolly-democratizing-magic-chatgpt-open-models.html?ref=its-foss-news),以了解更多技术细节和其他计划。
---
via: <https://news.itsfoss.com/open-source-model-dolly/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Databricks is a software company that has established itself in a variety of sectors, with data warehousing, and AI-based solutions being their primary focus.
In recent times, we have seen the meteoric rise of ChatGPT, resulting in similar efforts from the likes of Meta, Google, and even Mozilla.
And now, Databricks is trying in their own way by open-sourcing its [large language model](https://en.wikipedia.org/wiki/Large_language_model?ref=news.itsfoss.com) (LLM) 'Dolly'.
Let's take a look at it.
**Suggested Read **📖
[Mozilla Plans to Work On Open-Source AI to Develop Solutions like ChatGPTMozilla’s getting into the A.I. game? I think we need more of this!](https://news.itsfoss.com/mozilla-open-source-ai/)

**What is happening?: **In a recent announcement, Databricks introduced what they term as **'a cheap-to-build'** LLM that functions by using an existing open-source parameter [model](https://huggingface.co/EleutherAI/gpt-j-6B?ref=news.itsfoss.com) by [EleutherAI](https://www.eleuther.ai/?ref=news.itsfoss.com).
The model has been slightly tweaked to give Dolly instruction following capabilities such as brainstorming and text generation.
When you compare the **175 billion parameters** in GPT-3, Dolly's** 6 billion parameters** might seem puny in comparison.
But, the folks over at Databricks were surprised when they saw that even with this much data, Dolly was **able to** **exhibit many of the same capabilities as ChatGPT**.
Below is one of the examples they showcased:

The original model used data from [Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html?ref=news.itsfoss.com), the model built by Stanford using the [LLaMA](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/?ref=news.itsfoss.com) LLM by Meta as a base.
But, as you can see, the original model produced a very haphazard result, whereas Dolly, with its different model and tweaks, was able to produce a far usable answer.
**Why now?: **According to Databricks, they think that **many companies would prefer to build their own model** rather than sending data to some centralized provider who has locked their model behind an API.
Many companies might not be comfortable handing over their most sensitive data to a third party, and then there are the various tradeoffs in terms of model quality, cost, and desired behavior.
**Do you want to check it out?**
Sure, but there's a catch.
You will have to **use their platform to use Dolly**, they have open-sourced a [Databricks notebook](https://github.com/databrickslabs/dolly?ref=news.itsfoss.com) that will help you build it on Databricks.
Moreover, if you want to get access to the trained weights, you will have to contact them. I am uncertain whether they will provide access to it for free, though.
In a nutshell, this move to open-source their model should be good for companies to help safeguard their data, save on operating costs, and more by enabling them to create their own model.
You can check out the[ announcement blog](https://www.databricks.com/blog/2023/03/24/hello-dolly-democratizing-magic-chatgpt-open-models.html?ref=news.itsfoss.com) to learn more about the technical details and other plans for it.
**Suggested Read **📖
[ChatGPT but Open Source: That’s What This Project is Aiming ForWill we finally have a working open-source alternative to ChatGPT? This looks promising!](https://news.itsfoss.com/open-source-chatgpt/)

## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,680 | 如何安装和使用 Neovim | https://itsfoss.com/install-neovim/ | 2023-04-01T17:37:35 | [
"Neovim",
"Vim"
] | https://linux.cn/article-15680-1.html | 
>
> 你一定已经听说过著名的 Vim 文本编辑器。然而,这篇文章是关于它的复刻 Neovim。
>
>
>
Vim 也是 Vi 的一个复刻,这使得 Neovim 成为复刻的复刻。所以,你最终可以使用任何东西,因为它有一些独特的特征。
如果你决定使用 Neovim,让我帮助你在 Ubuntu 和其他 Linux 发行版上开始使用它。
### Neovim 概述

[Neovim](https://neovim.io/?ref=itsfoss.com) 是一个以其简单的维护和社区贡献而闻名的项目。此外,开发工作很好地分配在多个开发人员之间。
对于最终用户而言,Neovim 的可扩展性远超人们的预期。Neovim 的目标是在不损害 Vim 传统功能的情况下提供更好的应用。
使用 [Neovim 的 GUI](https://itsfoss.com/neovim-gui-editors/),你可以获得增强的编辑体验。
### Neovim 的特点
虽然你可以在其官方网站及其 [GitHub 页面](https://github.com/neovim/neovim?ref=itsfoss.com) 上探索所有相关信息。让我强调一些特点:
* 现代图形界面
* 从多种语言访问 API,包括(C/C++、C#、Go、Haskell、Java/Kotlin、JavaScript/Node.js、Lua、Perl、Python、Ruby、Rust 等等)
* 嵌入式、可编写脚本的终端仿真器
* 异步任务控制
* 多个实例之间的共享数据
* XDG 基本目录支持
* 与大多数 Vim 插件兼容,包括 Ruby 和 Python 插件
>
> ? 我们建议你在开始使用 Vim 和 Neovim 之前,先了解其用法。
>
>
>
### 在 Ubuntu 和 Linux 上安装 Neovim
由于 Neovim 的流行,安装它很简单。因为 Neovim 在你选择的任何发行版的官方仓库中都可用。
>
> 如果你需要,我们还有一个 [在 Linux 上安装 Vim](https://itsfoss.com/install-latest-vim-ubuntu/) 的指南。
>
>
>
要在 Ubuntu 上安装 Neovim,只需单击停靠区中的 Ubuntu 软件图标。然后,搜索 Neovim。你可以根据自己的喜好选择 Snap 或 deb 版本。但是,deb 包版本是过时的 Neovim 版本。

如果你不想要 Snap 版本,你可以从 [Neovim 的 Github 发布页](https://github.com/neovim/neovim/releases/tag/stable?ref=itsfoss.com) 获取最新的 deb 文件。如果你仔细查看发布页面,还有一个 Appimage 文件。
如果你想使用终端而不是 GUI,你可以执行以下操作:
对于基于 **Ubuntu 和 Debian** 的发行版,输入以下命令进行安装:
```
sudo apt install neovim
```
对于 **Manjaro 和 Arch Linux**,使用以下命令更新你的系统并安装 Neovim:
```
sudo pacman -Syu neovim
```
对于 **Fedora**,使用以下命令:
```
sudo dnf install -y neovim
```
要安装 **Flatpak**,你可以使用此命令:
```
flatpak install flathub io.neovim.nvim
```
最后,要安装 **Snap 包**,请使用以下命令:
```
sudo snap install nvim --classic
```
如果你更喜欢从源代码构建软件,请遵循该项目的 Github 页面上给出的 [步骤](https://github.com/neovim/neovim/wiki/Installing-Neovim?ref=itsfoss.com#install-from-source)。
### 如何使用 Neovim
要在安装完成后使用 Neovim,只需从应用菜单启动它,方法是按超级键并输入 `neovim`。这将打开一个带有 Neovim 的终端窗口。

或者你可以打开你选择的任何终端仿真器并输入以下命令:
```
nvim
```
是的,不是 `neovim`,而是 `nvim`。例如,要编辑 `/etc/fstab`,请输入以下命令:
```
sudo nvim /etc/fstab
```
现在 fstab 文件将被打开,如下面的截图所示:

如果你无法退出编辑器,请不要担心,按下 `Shift+Z+Z`。例如,如果此快捷键令人困惑,请使用你需要的键在任何文本编辑器中输入大写的 `ZZ` 就明白了。
关于这一点,我应该重申,你需要学习 Vim 或 Neovim 并阅读文档才能有效地利用其所有功能。
### 总结
安装和启动 Neovim 非常简单,但学习它肯定需要一些键盘操作。
这只是编辑器的概述。我不是这方面的专家,但我希望这对所有初学者都有好处!
? 你使用 Neovim 吗? 在下面的评论中分享你的经验。
---
via: <https://itsfoss.com/install-neovim/>
作者:[Anuj Sharma](https://itsfoss.com/author/anuj/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You must have heard about the famous Vim text editor already. However, this article is about its fork, Neovim.
Vim is also a fork of vi which makes Neovim fork of a fork. So, you can end up using anything for some of its unique traits.
If you decide to use Neovim, let me help you get started with it on Ubuntu and other Linux distributions.
## Neovim: Overview
[Neovim](https://neovim.io) is a project known for its simple maintenance and community contributions. Moreover, the development effort is distributed well between multiple developers.
For end-users, Neovim is much more extensible than one would expect. The aim of Neovim is to provide better applications of it without compromising the traditional capabilities of Vim.
With a [GUI for Neovim,](https://itsfoss.com/neovim-gui-editors/) you can get an enhanced editing experience.
**Suggested Read 📖**
[Vim vs Nano: What Should You Choose?Vim and Nano are two popular terminal text editors. How are they different? What’s best for you? Let us find out.](https://itsfoss.com/vim-vs-nano/)

## Features of Neovim
While you can explore all about it on its official website and its [GitHub page](https://github.com/neovim/neovim). Let me highlight some features:
- Modern Graphical Interfaces
- API access from many language including (C/C++, C#, Go, Haskell, Java/Kotlin, JavaScript/Node.js, Lua, Perl, Python, Ruby, Rust to name a few)
- Embedded, scriptable terminal emulator
- Asynchronous job control
- Shared data among multiple instances
- XDG base directories support
- Compatible with most Vim plugins, including Ruby and Python plugins
**Suggested Read 📖**
[11 Pro Vim Tips to Get Better Editing ExperienceYou can learn plenty of Vim tips on your own, or you can learn it from others’ experiences.](https://linuxhandbook.com/pro-vim-tips/)

## Installing Neovim on Ubuntu and Linux
Installing Neovim is simple due to its popularity. As Neovim is available in official repos of any distribution you pick.
We also have a guide to [install Vim on Linux](https://itsfoss.com/install-latest-vim-ubuntu/), in case you want that.
To install Neovim on Ubuntu, just click on the Ubuntu Software icon in the dock. Then, search for Neovim. You can select the snap or the deb version as per your preference. However, the deb package version will be an outdated version of Neovim.
And, if you do not want the snap version, you can grab the latest deb file from the [Github releases page for Neovim](https://github.com/neovim/neovim/releases/tag/stable). If you look closer in the releases page, there is an Appimage file as well.
If you want to utilize the terminal instead of the GUI, here's what you can do:
For **Ubuntu and Debian** based distributions, enter the following command to install
```
sudo apt install neovim
```
For **Manjaro and Arch Linux**, use the below command to update your system and install Neovim
```
sudo pacman -Syu neovim
```
For **Fedora**, use the following command
`sudo dnf install -y neovim`
To install the **Flatpak**, you can use this command
```
flatpak install flathub io.neovim.nvim
```
Lastly, to install the **snap package** use the below command
`sudo snap install nvim --classic`
If you prefer building software from source, follow [the steps given on the project's Github page](https://github.com/neovim/neovim/wiki/Installing-Neovim#install-from-source).
## How to use Neovim
To use Neovim after installation is complete, just launch it from the application menu by pressing the super key and typing the name "neovim" without quotes. This will open a terminal window with Neovim open.
Or you can just open any Terminal Emulator of your choice and enter the following command
`nvim`
Yes, not "neovim" but just "**nvim**". For example, to edit */etc/fstab* enter the following command.
`sudo nvim /etc/fstab`
Now the fstab file will open as shown in the screenshot below.
Don't worry if you cannot exit the editor; press **Shift+Z+Z**. For example, if this shortcut key confuses, use the keys you need to type "ZZ" (uppercase) without quotes in any text editor.
On that note, I should re-iterate that you need to learn Vim or Neovim and go through the documentation to efficiently make use of all its features.
## Conclusion
Installing and launching Neovim is pretty straightforward but learning it will require some keyboard grinding for sure.
This was just an overview of the editor. I am not an expert on this, but I hope this serves well for all the beginners out there!
💬 *Do you use Neovim? Share your experience on it in the comments below.* |
15,681 | 用 Tekton 在 Kubernetes 中编写你的第一条 CI/CD 流水线 | https://opensource.com/article/21/11/cicd-pipeline-kubernetes-tekton | 2023-04-01T18:08:51 | [
"Kubernetes",
"CI/CD",
"Tekton"
] | https://linux.cn/article-15681-1.html |
>
> Tekton 是一个用于创建持续集成和持续交付(CI/CD)系统的 Kubernetes 原生开源框架。
>
>
>

Tekton 是一个用于创建持续集成和持续交付(CI/CD)系统的 Kubernetes 原生开源框架。通过对底层实施细节的抽象,它还可以帮助你在多个云供应商或企业内部系统中进行端到端(构建、测试、部署)应用开发。
### Tekton 介绍
[Tekton](https://github.com/tektoncd/pipeline) 最初被称为 [Knative Build](https://github.com/knative/build),后来被重组为独立的开源项目,有自己的 [治理组织](https://cd.foundation/),现在是属于 [Linux 基金会](https://www.linuxfoundation.org/projects/) 的项目。Tekton 提供了一个集群内的容器镜像构建和部署工作流程,换句话说,它是一个 <ruby> 持续集成 <rt> continuous integration </rt></ruby>(CI)和 <ruby> 持续交付 <rt> continuous delivery </rt></ruby>(CD)服务。它由 Tekton 流水线和几个支持组件如 Tekton CLI、Triggers 和 Catalog 等组成。
Tekton 是一个 Kubernetes 原生应用。它在 Kubernetes 集群中作为扩展被安装和运行,由一套Kubernetes 定制化资源组成,定义了你为流水线创建和复用的构建块。由于 Tekton 是一种 Kubernetes 原生技术,所以它非常容易扩展。当你需要增加你的工作负载时,你只需向你的集群添加节点就可以了。由于其可扩展的设计和社区贡献的组件库,它也很容易定制。
对于需要 CI/CD 系统来开展工作的开发人员,和为其组织内的开发人员建立 CI/CD 系统的平台工程师,Tekton 是理想选择。
### Tekton 组件
构建 CI/CD 流水线的过程非常复杂,因此 Tekton 为每一步都提供工具。以下是 Tekton 提供的主要组件:
* <ruby> 流水线 <rt> </rt> Pipeline</ruby>: 定义了一组 Kubernetes [自定义资源](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/),作为你用来组装 CI/CD 流水线的构建块。
* <ruby> 触发器 <rt> Triggers </rt></ruby>:一种 Kubernetes 自定义资源,允许你根据从事件有效载荷中提取的信息来创建流水线。例如,你可以在每次创建 Git 仓库的合并请求时,触发流水线的实例化和执行。
* <ruby> 命令行 <rt> CLI </rt></ruby>:提供一个名为 `tkn` 的命令行界面,你可以使用它从终端与 Tekton 进行交互。
* <ruby> 仪表盘 <rt> Dashboard </rt></ruby>:是 Tekton 流水线的一个基于网页的图形界面,显示流水线的执行信息。
* <ruby> 目录 <rt> Catalog </rt></ruby>:是一个高质量的、由社区贡献的 Tekton 构建块(任务、流水线等),可在你自己的流水线中使用。
* <ruby> 中心 <rt> Hub </rt></ruby>:是一个基于网页的图形界面,用于访问 Tekton 目录。
* <ruby> 操作员 <rt> Operator </rt></ruby>:是一种 Kubernetes [操作员模式](https://operatorhub.io/what-is-an-operator),你可以在 Kubernetes 集群中安装、更新、升级和删除 Tekton 项目。
* <ruby> 链 <rt> Chains </rt></ruby>:是一个 Kubernetes <ruby> 自定义资源定义 <rt> Custom Resource Definition </rt></ruby>(CRD)控制器,使你可以在 Tekton 中处理供应链安全的问题。正在开发中。
* <ruby> 结果 <rt> Results </rt></ruby>:旨在帮助用户对 CI/CD 工作负载历史进行逻辑分组,并将长期结果的存储从流水线控制器中分离出来。
### Tekton 术语

* <ruby> 步骤 <rt> Step </rt></ruby>:是 CI/CD 工作流程中最基本的实体,例如为 Python 网络应用程序运行一些单元测试或编译一个 Java 程序。Tekton 使用容器镜像执行每个步骤。
* <ruby> 任务 <rt> Task </rt></ruby>::kissing:\* 是按特定顺序排列的步骤的集合。Tekton 以 [Kubernetes 容器荚](https://kubebyexample.com/en/concept/pods) 的形式运行任务,其中每个步骤都成为 <ruby> 容器荚 <rt> pod </rt></ruby> 中的一个运行容器。
* <ruby> 流水线 <rt> Pipelines </rt></ruby>:是按特定顺序排列的任务的集合。Tekton 把所有任务连接成一个 <ruby> 有向无环图 <rt> directed acyclic graph </rt></ruby>(DAG),并按顺序执行图。换句话说,它创建了一些 Kubernetes 容器荚,并确保每个容器荚按预期成功运行。

* <ruby> 流水线运行 <rt> PipelineRun </rt></ruby>:顾名思义,是一条流水线的具体执行。
* <ruby> 任务运行 <rt> TaskRun </rt></ruby>:是一个任务的具体执行。你可以选择在流水线外运行一次任务运行,可以通过它查看任务中每个步骤执行的具体情况。
### 创建你的 CI/CD 流水线
开始使用 Tekton 的最简单方法是自己编写一个简单的流水线。如果你每天都在使用 Kubernetes,那你可能对 YAML 很熟悉,这正是 Tekton 流水线的定义方式。下面是一个克隆代码库的简单流水线的例子。
首先,创建一个 `task.yaml` 文件,用你喜欢的文本编辑器打开它。这个文件定义了你要执行的 <ruby> 步骤 <rt> Step </rt></ruby>。在这个例子中,就是克隆一个仓库,所以我把这个步骤命名为 “clone”。该文件设置了一些环境变量,然后使用一个简单的 shell 脚本来执行克隆。
接下来是 <ruby> 任务 <rt> Task </rt></ruby>。你可以把步骤看作是一个被任务调用的函数,而任务则设置步骤所需的参数和工作空间。
```
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: git-clone
spec:
workspaces:
- name: output
description: The git repo will be cloned onto the volume backing this Workspace.
params:
- name: url
description: Repository URL to clone from.
type: string
- name: revision
description: Revision to checkout. (branch, tag, sha, ref, etc...)
type: string
default: ""
steps:
- name: clone
image: "gcr.io/tekton-releases/github.com/tektoncd/pipeline/cmd/git-init:v0.21.0"
env:
- name: PARAM_URL
value: $(params.url)
- name: PARAM_REVISION
value: $(params.revision)
- name: WORKSPACE_OUTPUT_PATH
value: $(workspaces.output.path)
script: |
#!/usr/bin/env sh
set -eu
CHECKOUT_DIR="${WORKSPACE_OUTPUT_PATH}"
/ko-app/git-init \
-url="${PARAM_URL}" \
-revision="${PARAM_REVISION}" \
-path="${CHECKOUT_DIR}"
cd "${CHECKOUT_DIR}"
EXIT_CODE="$?"
if [ "${EXIT_CODE}" != 0 ] ; then
exit "${EXIT_CODE}"
fi
# Verify clone is success by reading readme file.
cat ${CHECKOUT_DIR}/README.md
```
创建第二个文件 `pipeline.yaml`,并用你喜欢的文本编辑器打开它。这个文件通过设置诸如可以运行和处理任务的工作区等重要参数来定义流水线。
```
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: cat-branch-readme
spec:
params:
- name: repo-url
type: string
description: The git repository URL to clone from.
- name: branch-name
type: string
description: The git branch to clone.
workspaces:
- name: shared-data
description: |
This workspace will receive the cloned git repo and be passed
to the next Task for the repo's README.md file to be read.
tasks:
- name: fetch-repo
taskRef:
name: git-clone
workspaces:
- name: output
workspace: shared-data
params:
- name: url
value: $(params.repo-url)
- name: revision
value: $(params.branch-name)
```
最后,创建一个 `pipelinerun.yaml` 文件,用喜欢的文本编辑器打开它。这个文件真正的运行流水线。它调用流水线中定义的参数(继而调用任务文件中定义的任务)。
```
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
name: git-clone-checking-out-a-branch
spec:
pipelineRef:
name: cat-branch-readme
workspaces:
- name: shared-data
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
params:
- name: repo-url
value: <https://github.com/tektoncd/pipeline.git>
- name: branch-name
value: release-v0.12.x
```
把不同工作分在不同的文件中的好处是,`git-clone` 任务可以在多条流水线中复用。
例如,假设你想为一个流水线项目做端到端的测试。你可以使用 `git-clone` 任务 **来让每一次测试都基于最新的代码**。
### 总结
只要你熟悉 Kubernetes,那 Tekton 对你来说就像其他 Kubernetes 原生应用一样简单。它有很多工具可以帮助你创建流水线并与之交互。如果你喜欢自动化,不妨试试 Tekton!
---
via: <https://opensource.com/article/21/11/cicd-pipeline-kubernetes-tekton>
作者:[Savita Ashture](https://opensource.com/users/savita-ashture) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Tekton is a Kubernetes-native open source framework for creating continuous integration and continuous delivery (CI/CD) systems. It also helps to do end-to-end (build, test, deploy) application development across multiple cloud providers or on-premises systems by abstracting away the underlying implementation details.
## Introduction to Tekton
[Tekton](https://github.com/tektoncd/pipeline), known initially as [Knative Build](https://github.com/knative/build), later got restructured as its own open source project with its own [governance organization](https://cd.foundation/) and is now a [Linux Foundation](https://www.linuxfoundation.org/projects/) project. Tekton provides an in-cluster container image build and deployment workflow—in other words, it is a continuous integration (CI) and continuous delivery (CD) service. It consists of Tekton Pipelines and several supporting components, such as Tekton CLI, Triggers, and Catalog.
Tekton is a Kubernetes native application. It installs and runs as an extension on a Kubernetes cluster and comprises a set of Kubernetes Custom Resources that define the building blocks you can create and reuse for your pipelines. Because it's a K-native technology, Tekton is remarkably easy to scale. When you need to increase your workload, you can just add nodes to your cluster. It's also easy to customize because of its extensible design and thanks to a community repository of contributed components.
Tekton is ideal for developers who need CI/CD systems to do their work and platform engineers who build CI/CD systems for developers in their organization.
## Tekton components
Building CI/CD pipelines is a far-reaching endeavor, so Tekton provides tools for every step of the way. Here are the major components you get with Tekton:
**Pipeline:**Pipeline defines a set of Kubernetes[Custom Resources](https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/)that act as building blocks you use to assemble your CI/CD pipelines.**Triggers:**Triggers is a Kubernetes Custom Resource that allows you to create pipelines based on information extracted from event payloads. For example, you can trigger the instantiation and execution of a pipeline every time a merge request gets opened against a Git repository.**CLI:**CLI provides a command-line interface called`tkn`
that allows you to interact with Tekton from your terminal.**Dashboard:**Dashboard is a web-based graphical interface for Tekton pipelines that displays information about the execution of your pipelines.**Catalog:**Catalog is a repository of high-quality, community-contributed Tekton building blocks (tasks, pipelines, and so on) ready for use in your own pipelines.**Hub:**Hub is a web-based graphical interface for accessing the Tekton catalog.**Operator:**Operator is a Kubernetes[Operator pattern](https://operatorhub.io/what-is-an-operator)that allows you to install, update, upgrade, and remove Tekton projects on a Kubernetes cluster.**Chains:**Chains is a Kubernetes Custom Resource Definition (CRD) controller that allows you to manage your supply chain security in Tekton. It is currently a work-in-progress.**Results:**Results aims to help users logically group CI/CD workload history and separate out long-term result storage away from the pipeline controller.
## Tekton terminology
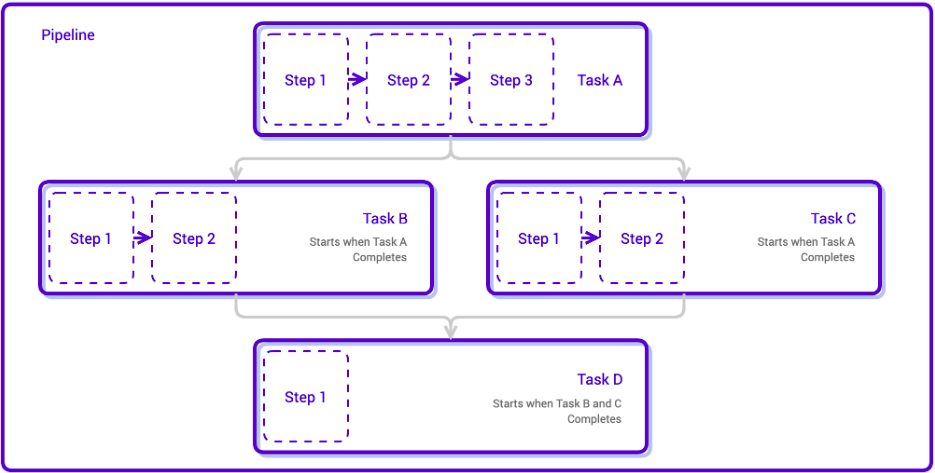
Source: Tekton documentation
**Step:**A step is the most basic entity in a CI/CD workflow, such as running some unit tests for a Python web app or compiling a Java program. Tekton performs each step with a provided container image.**Task:**A task is a collection of steps in a specific order. Tekton runs a task in the form of a[Kubernetes pod](https://kubebyexample.com/en/concept/pods), where each step becomes a running container in the pod.**Pipelines:**A pipeline is a collection of tasks in a specific order. Tekton collects all tasks, connects them in a directed acyclic graph (DAG), and executes the graph in sequence. In other words, it creates a number of Kubernetes pods and ensures that each pod completes running successfully as desired.
(Source:[Tekton documentation](https://tekton.dev/docs/concepts/concept-runs.png))**PipelineRun:**A PipelineRun, as its name implies, is a specific execution of a pipeline.**TaskRun:**A TaskRun is a specific execution of a task. TaskRuns are also available when you choose to run a task outside a pipeline, with which you may view the specifics of each step execution in a task.
## Create your own CI/CD pipeline
The easiest way to get started with Tekton is to write a simple pipeline of your own. If you use Kubernetes every day, you're probably comfortable with YAML, which is precisely how Tekton pipelines are defined. Here's an example of a simple pipeline that clones a code repository.
First, create a file called `task.yam`
**l** and open it in your favorite text editor. This file defines the steps you want to perform. In this example, that's cloning a repository, so I've named the step clone. The file sets some environment variables and then provides a simple shell script to perform the clone.
Next comes the task. You can think of a step as a function that gets called by the task, and the task sets parameters and workspaces required for steps.
```
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: git-clone
spec:
workspaces:
- name: output
description: The git repo will be cloned onto the volume backing this Workspace.
params:
- name: url
description: Repository URL to clone from.
type: string
- name: revision
description: Revision to checkout. (branch, tag, sha, ref, etc...)
type: string
default: ""
steps:
- name: clone
image: "gcr.io/tekton-releases/github.com/tektoncd/pipeline/cmd/git-init:v0.21.0"
env:
- name: PARAM_URL
value: $(params.url)
- name: PARAM_REVISION
value: $(params.revision)
- name: WORKSPACE_OUTPUT_PATH
value: $(workspaces.output.path)
script: |
#!/usr/bin/env sh
set -eu
CHECKOUT_DIR="${WORKSPACE_OUTPUT_PATH}"
/ko-app/git-init \
-url="${PARAM_URL}" \
-revision="${PARAM_REVISION}" \
-path="${CHECKOUT_DIR}"
cd "${CHECKOUT_DIR}"
EXIT_CODE="$?"
if [ "${EXIT_CODE}" != 0 ] ; then
exit "${EXIT_CODE}"
fi
# Verify clone is success by reading readme file.
cat ${CHECKOUT_DIR}/README.md
```
Create a second file called `pipeline.yaml`
, and open it in your favorite text editor. This file defines the pipeline by setting important parameters, such as a workspace where the task can be run and processed.
```
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: cat-branch-readme
spec:
params:
- name: repo-url
type: string
description: The git repository URL to clone from.
- name: branch-name
type: string
description: The git branch to clone.
workspaces:
- name: shared-data
description: |
This workspace will receive the cloned git repo and be passed
to the next Task for the repo's README.md file to be read.
tasks:
- name: fetch-repo
taskRef:
name: git-clone
workspaces:
- name: output
workspace: shared-data
params:
- name: url
value: $(params.repo-url)
- name: revision
value: $(params.branch-name)
```
Finally, create a file called `pipelinerun.yaml`
and open it in your favorite text editor. This file actually runs the pipeline. It invokes parameters defined in the pipeline (which, in turn, invokes the task defined by the task file.)
```
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
name: git-clone-checking-out-a-branch
spec:
pipelineRef:
name: cat-branch-readme
workspaces:
- name: shared-data
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
params:
- name: repo-url
value: https://github.com/tektoncd/pipeline.git
- name: branch-name
value: release-v0.12.x
```
The advantage of structuring your work in separate files is that the `git-clone`
task is reusable for multiple pipelines.
For example, suppose you want to do end-to-end testing for a pipeline project. You can use the `git-clone`
** **task to ensure that you have a fresh copy of the code you need to test.
## Wrap up
As long as you're familiar with Kubernetes, getting started with Tekton is as easy as adopting any other K-native application. It has plenty of tools to help you create pipelines and to interface with your pipelines. If you love automation, try Tekton!
## Comments are closed. |
15,684 | blendOS 的目标:取代所有的 Linux 发行版 | https://news.itsfoss.com/blendos/ | 2023-04-02T09:58:00 | [
"发行版",
"blendOS"
] | https://linux.cn/article-15684-1.html |
>
> Ubuntu Unity 的负责人提出了一个新的发行版,听起来像是每个人都可能想要关注的东西。
>
>
>

听起来太牵强了?
好吧,blendOS 把自己定位为发行版的终极杂拌。
blendOS 是 Rudra Saraswat 的一个新项目,他以基于 Ubuntu 的合成版而闻名,特别是 Ubuntu Unity(现在是官方的 [Ubuntu 风味版](https://itsfoss.com/which-ubuntu-install/?ref=its-foss-news))。
我想说的是,这个项目有一个非常准确的名字来表达它想要实现的目标。
但是,blendOS 的目标是如何成为所有人的替代品?它到底是什么?
### blendOS 不只是又一个 Linux 发行版

blendOS 是一个基于 Arch 的发行版,它支持每种类型的应用程序包。
如果你了解过 [carbonOS](https://news.itsfoss.com/carbonos/) 和 [Vanilla OS](https://news.itsfoss.com/vanilla-os-debian-ubuntu/),你应该对这类发行版中的一些共同点有了了解。
其中之一是,**不可变性**,意思是,操作系统的核心/基础保持不变,给你带来增强的安全性,以及更简单和可靠的更新。
同样,blendOS 也有以下的关键亮点:
* 不可变操作系统
* 支持多个软件包管理器,包括 Apt、DNF、Yum、Pacman 和 Yay
* 支持多种桌面环境
* Flathub 商店桌面应用
[blendOS](https://blendos.co/?ref=its-foss-news) 使用 Jade GUI(来自 [Crystal Linux](https://news.itsfoss.com/crystal-linux-dev/) 的安装程序)来提供一个无缝的安装体验。而且,Flathub 商店可以直接安装应用程序,而不是像人们想象的那样下载 Flatpakref文件。
为了使所有的发行版的软件包都能正常工作,blendOS 使用其软件包管理器 blend。
你仍然可以通过 Arch 容器在命令行使用 Pacman。
此外,它还支持,T2 Mac,即 2018 年后生产的英特尔 Mac。因此,如果你想在你已经拥有的设备上做实验,blendOS 应该可以使用。
>
> ? 截至目前,该项目还处于早期发展阶段。
>
>
>
预计一些直接的变化包括:

* 用 Podman 代替 Distrobox 的实现
* 一个新的 GUI 配置工具,支持管理覆盖层和容器
所以,是的,你现在看到的东西可能会有变化。然而,它仍然是听起来令人激动的东西。
你可以在其 [官方博客文章](https://blendos.co/future-of-blendos/?ref=its-foss-news) 中阅读其计划中的变化,并在其 [GitHub 页面](https://github.com/blend-os?ref=its-foss-news)中探索 blendOS。
>
> **[blendOS](https://blendos.co/?ref=its-foss-news)**
>
>
>
你对 blendOS 有什么看法?它值得关注吗?请在评论中告诉我!
---
via: <https://news.itsfoss.com/blendos/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Sounds too far-fetched?
Well, **blendOS** pitches itself to be the** ultimate distro-blend**.
blendOS is a new project by **Rudra Saraswat**, known for Ubuntu-based remixes, and Ubuntu Unity in particular (which is now an official [Ubuntu flavour](https://itsfoss.com/which-ubuntu-install/?ref=news.itsfoss.com)).
I would say the project has a pretty accurate name for what it wants to achieve.
*But, how does blendOS aim to be a replacement to all? What is it all about? *
## blendOS: Not Just Another Linux Distribution
blendOS is an Arch-based distro which supports every type of app package.
If you have read about ** carbonOS** and
[Vanilla O](https://news.itsfoss.com/vanilla-os-debian-ubuntu/)[S](https://news.itsfoss.com/vanilla-os-debian-ubuntu/), you should have a good idea about some common points among such distros.
One of them being, **immutability**, meaning, the core/base of the operating system remains unchanged, giving you an enhanced security, and simpler, and reliable updates.
Similarly, blendOS has the following key highlights:
- Immutable operating system
- Support for multiple package managers including
**apt, dnf, yum, pacman, and yay** - Multiple desktop environment support
- Flathub Store as a desktop app
[blendOS](https://blendos.co/?ref=news.itsfoss.com) uses Jade GUI (the installer from [Crystal Linux](https://news.itsfoss.com/crystal-linux-dev/)) to provide a seamless installation experience. And, the Flathub store can directly install apps, and not download flatpakref files, as one would expect.
To make all distribution packages work, blendOS uses its package manager **blend.**
You can still use pacman from a shell through an Arch container.
Additionally, it supports, T2 macs, i.e., Intel Macs made after 2018. So, if you want to experiment on a device that you already have, blendOS should work with it.
Some immediate changes expected include:
- Distrobox to be replaced with its implementation using Podman
- A new GUI configuration tool, with support for managing overlays and containers
So, yes, what you see right now is subject to change. However, it is still something that sounds exciting.
You can read about its planned changes in its [official blog post](https://blendos.co/future-of-blendos/?ref=news.itsfoss.com) and explore blendOS on its [GitHub page](https://github.com/blend-os?ref=news.itsfoss.com).
*💬 What do you think about blendOS? Is it worth keeping an eye out for? Let me know in the comments!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,685 | 三件可以用 systemd 做的令人惊讶的事情 | https://opensource.com/article/23/3/3-things-you-didnt-know-systemd-could-do | 2023-04-02T13:55:47 | [
"systemd"
] | https://linux.cn/article-15685-1.html | 
>
> 它不仅仅是为了让你的电脑启动得更快。
>
>
>
当 systemd 刚问世时,有很多关于它能加快启动时间的消息。这项功能对大多数人都有吸引力(对那些不重启的人来说就不那么重要了),所以在很多方面,这也是它今天仍然拥有的声誉。虽然 systemd 确实是在启动过程中并行启动服务起到了作用,但它的作用远不止于此。以下是你可能没有意识到 systemd 可以做的三件事,但你应该好好利用。
### 1、简化 Linux ps
如果你曾经使用过 `ps`,甚至只是 `top` 命令,那么你就会知道你的电脑一直都在运行数百个进程。有时,这正是你需要的信息,以便了解你的计算机或其用户在做什么。其他时候,你真正需要的是一个总体的概览。
`systemd-cgtop` 命令提供了一个基于<ruby> 控制组 <rt> cgroup </rt></ruby>任务安排的计算机负载的简单视图。[控制组](https://www.redhat.com/sysadmin/cgroups-part-four?intcmp=7013a000002qLH8AAM) 对现代 Linux 很重要,基本上是容器和 Kubernetes 的底层支持结构(这也是云计算可以扩展的原因),但它们也是家庭电脑上的有用结构。例如,从 `systemd-cgtop` 的输出中,你可以看到用户进程的负载,而不是系统进程:
```
Control Group Proc+ %CPU Memory Input/s Output/s
/ 183 5.0 1.6G 0B 3.0M
user.slice 4 2.8 1.1G 0B 174.7K
user.slice/user-1000.slice 4 2.8 968.2M 0B 174.7K
system.slice 65 2.2 1.5G 0B 2.8M
```
你也可以只查看你的用户空间进程,或者查看用户空间进程和内核线程。
这绝不是对 `top` 或 `ps` 的替代,而是从一个不同的、独特的角度来观察你的系统。在运行容器时,它可能是至关重要的,因为容器使用控制组。
### 2、Linux 定时任务
[Cron](https://opensource.com/article/17/11/how-use-cron-linux) 是 Linux 的一个经典组件。当你想安排一些事情定期发生时,你会使用 Cron。它很可靠,而且相当好地集成到你的系统中。
问题是,Cron 并不了解有些计算机会被关闭。如果你有一个安排在午夜的 Cron 任务,但你每天在 23:59 关闭你的电脑,那么你的 Cron 任务就永远不会运行。Cron 没有任何工具可以检测到一夜之间错过了工作。
作为对这个问题的回答,有一个很好的 [Anacron](https://opensource.com/article/21/2/linux-automation),但它不像 Cron 那样集成的好。要让 Anacron 运行,你需要做很多设置。
第二个选择是 systemd 计时器。和 Cron 一样,它也是内置的,可以随时使用。你需要写一个单元文件,这肯定比单行的 Crontab 条目多,但也很简单。例如,这里有一个单元文件,在开机 30 分钟后运行一个假想的备份脚本,但每天只运行一次。这可以确保我的电脑得到备份,并防止它每天尝试备份超过一次。
```
[Unit]
Description=Backup
Requires=myBackup.service
[Timer]
OnBootSec=30min
OnUnitActiveSec=1d
[Install]
WantedBy=timers.target
```
当然,你也可以干预并提示运行一个任务。多亏了 `OnUnitActiveSec` 指令,systemd 不会试图运行你手动激活的作业。
### 3、运行 Linux 容器
容器使启动一个复杂的服务变得非常容易。你可以在短短几分钟内运行一个 [Mattermost](https://opensource.com/education/16/3/mattermost-open-source-chat) 或 Discourse 服务器。在某些情况下,困难的部分是在你运行容器后管理和监控它们。Podman 使得管理它们变得容易,但是用什么来管理 Podman 呢?嗯,[你可以使用 systemd](https://www.redhat.com/sysadmin/podman-run-pods-systemd-services?intcmp=7013a000002qLH8AAM)。
Podman 有一个内置的命令来生成单元文件,这样你的容器就可以被 systemd 管理和监控:
```
$ podman generate systemd --new --files --name example_pod
```
然后你所要做的就是启动服务:
```
$ systemctl --user start pod-example_pod.service
```
和其他服务一样,systemd 确保你的容器荚在任何情况下都能运行。它记录问题,你可以用 `journalctl` 和其他重要的日志来查看,你也可以用 `systemd-cgtop` 在控制组中监控它的活动。
它不是 [Kubernetes 平台](https://www.redhat.com/en/technologies/cloud-computing/openshift/aws?intcmp=7013a000002qLH8AAM),但对于一两个容器来说,你只需要在可靠和可预测的基础上提供服务,Podman 和 systemd 是一对很棒的组合。
### 下载 systemd 电子书
systemd 的内容还有很多,你可以从作者 [David Both](https://opensource.com/users/dboth) 的新书《[systemd 实用指南](https://opensource.com/downloads/pragmatic-guide-systemd-linux)》中了解基础知识,以及很多实用的技巧。
---
via: <https://opensource.com/article/23/3/3-things-you-didnt-know-systemd-could-do>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When it first started out, there was a lot of press about systemd and its ability to speed up boot time. That feature had a mostly-universal appeal (it's less important to those who don't reboot), so in many ways, that's the reputation it still has today. And while it's true that systemd is the thing that launches services in parallel during startup, there's a lot more to it than that. Here are three things you may not have realized systemd could do but should be taking advantage. Get more tips from our new downloadable eBook, ** A pragmatic guide to systemd**.
## 1. Simplify Linux ps
If you've ever used the `ps`
or even just the `top`
command, then you know that your computer is running hundreds of processes at any given moment. Sometimes, that's exactly the kind of information you need in order to understand what your computer, or its users, are up to. Other times, all you really need is a general overview.
The `systemd-cgtop`
command provides a simple view of your computer's load based on the cgroups (control groups) tasks have been arranged into. [Control groups](https://www.redhat.com/sysadmin/cgroups-part-four?intcmp=7013a000002qLH8AAM) are important to modern Linux, and are essentially the support structures underneath containers and Kubernetes (which in turn are why the cloud scales the way it does), but also they're useful constructs on your home PC. For instance, from the output of `systemd-cgtop`
, you can see the load of your user processes as opposed to system processes:
```
``````
Control Group Proc+ %CPU Memory Input/s Output/s
/ 183 5.0 1.6G 0B 3.0M
user.slice 4 2.8 1.1G 0B 174.7K
user.slice/user-1000.slice 4 2.8 968.2M 0B 174.7K
system.slice 65 2.2 1.5G 0B 2.8M
```
You can also view just your userspace processes, or just your userspace processes and kernel threads.
This isn't a replacement for `top`
or `ps`
by any means, but it's an additional view into your system from a different and unique angle. And it can be vital when running containers, because containers use cgroups.
## 2. Linux cron
[Cron](https://opensource.com/article/17/11/how-use-cron-linux) is a classic component of Linux. When you want to schedule something to happen on a regular basis, you use cron. It's reliable and pretty well integrated into your system.
The problem is, cron doesn't understand that some computers get shut down. If you have a cronjob scheduled for midnight, but you turn your computer off at 23:59 every day, then your cronjob never runs. There's no facility for cron to detect that there was a missed job overnight.
As an answer to that problem, there's the excellent [anacron](https://opensource.com/article/21/2/linux-automation), but that's not quite as integrated as cron. There's a lot of setup you have to do to get anacron running.
A second alternative is systemd timers. Like cron, it's already built in and ready to go. You have to write a unit file, which is definitely more lines than a one-line crontab entry, but it's also pretty simple. For instance, here's a unit file to run an imaginary backup script 30 minutes after startup, but only once a day. This ensures that my computer gets backed up, and prevents it from trying to backup more than once daily.
```
``````
[Unit]
Description=Backup
Requires=myBackup.service
[Timer]
OnBootSec=30min
OnUnitActiveSec=1d
[Install]
WantedBy=timers.target
```
You can, of course, intervene and prompt a job to run with . Thanks to the `OnUnitActiveSec`
directive, systemd doesn't attempt to run a job you've manually activated.
## 3. Run Linux containers
Containers make starting up a complex service really easy. You can run a [Mattermost](https://opensource.com/education/16/3/mattermost-open-source-chat) or Discourse server in mere minutes. The hard part, in some cases, is managing and monitoring the containers once you have them running. Podman makes it easy to manage them, but what do use to manage Podman? Well, [you can use systemd](https://www.redhat.com/sysadmin/podman-run-pods-systemd-services?intcmp=7013a000002qLH8AAM).
Podman has a built-in command to generate unit files so your containers can be managed and monitored by systemd:
```
````$ podman generate systemd --new --files --name example_pod`
All you have to do then is start the service:
```
````$ systemctl --user start pod-example_pod.service`
As with any other service on your computer, systemd ensures that your pod runs no matter what. It logs problems, which you can view with `journalctl`
along with your other essential logs, and you can monitor its activity within cgroups using `systemd-cgtop`
.
It's no [Kubernetes platform](https://www.redhat.com/en/technologies/cloud-computing/openshift/aws?intcmp=7013a000002qLH8AAM), but for one or two containers that you just want to have available on a reliable and predictable basis, Podman and systemd are an amazing pair.
## Download the systemd eBook
There's a lot more to systemd, and you can learn the basics, along with lots of useful and pragmatic tips, from author [David Both](https://opensource.com/users/dboth) in his new complimentary ** pragmatic guide to systemd**.
## 2 Comments |
15,687 | 如何在 Ubuntu 22.04 上安装 CRI-O 容器运行时 | https://www.linuxtechi.com/install-crio-container-runtime-on-ubuntu/ | 2023-04-03T10:54:00 | [
"容器",
"CRI-O"
] | https://linux.cn/article-15687-1.html | 
CRI-O 是 Kubernetes 的开源轻量级容器运行时。它是使用 <ruby> 开放容器组织 <rt> Open Container Initiative </rt></ruby>(OCI)兼容运行时的 Kubernetes <ruby> 容器运行时接口 <rt> Container Runtime Interface </rt></ruby>(CRI)的实现。在运行 Kubernetes 时,它是 Docker 的完美替代品。
在本指南中,我们将逐步演示如何在 Ubuntu 22.04 LTS 上安装 CRI-O。
### 先决条件
在开始之前,这是你需要的:
* 具有 SSH 访问权限的 Ubuntu 22.04 实例
* 在实例上配置的 sudo 用户
* 快速稳定的互联网连接
有了这个,让我们开始吧。
### 步骤 1:更新系统并安装依赖
立即登录你的服务器实例,并按如下方式更新包列表:
```
$ sudo apt update
```
更新本地包索引后,按如下方式安装依赖项:
```
$ sudo apt install apt-transport-https ca-certificates curl gnupg2 software-properties-common -y
```
### 步骤 2:添加 CRI-O 存储库
要安装 CRI-O,我们需要在 Ubuntu 上添加或启用它的仓库。但首先,你需要根据操作系统和要安装的 CRI-O 版本定义变量。
因此,定义如下变量:
```
$ export OS=xUbuntu_22.04
$ export CRIO_VERSION=1.24
```
完成后,运行以下命令集以添加 CRI-O Kubic 仓库:
```
$ echo "deb https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/ /"| sudo tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable.list
$ echo "deb http://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable:/cri-o:/$CRIO_VERSION/$OS/ /"|sudo tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable:cri-o:$CRIO_VERSION.list
```

此后,为 CRI-O 仓库导入 GPG 密钥:
```
$ curl -L https://download.opensuse.org/repositories/devel:kubic:libcontainers:stable:cri-o:$CRIO_VERSION/$OS/Release.key | sudo apt-key add -
$ curl -L https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/Release.key | sudo apt-key add -
```
这会产生如下输出:

再次更新包索引,使系统与新添加的 CRI-O Kubic 仓库同步:
```
$ sudo apt update
```
### 步骤 3:在 Ubuntu 22.04 上安装 CRI-O
添加仓库后,使用 APT 包管理器安装 CRI-O 和运行时客户端:
```
$ sudo apt install cri-o cri-o-runc -y
```

安装后,启动并启用 CRI-O 守护程序:
```
$ sudo systemctl start crio
$ sudo systemctl enable crio
```
接下来,验证 CRI-O 服务是否正在运行:
```
$ sudo systemctl status crio
```
你应该看到以下输出,表明 CRI-O 服务正在按预期运行:

### 步骤 4:为 CRI-O 安装 CNI 插件
接下来,你需要安装 CNI(<ruby> 容器网络接口 <rt> Container Network Interface </rt></ruby>)以及 CNI 插件。请记住,环回和桥接配置已启用并且足以使用 CRI-O 运行 <ruby> 容器荚 <rt> Pod </rt></ruby>:
因此,要安装 CNI 插件,请运行以下命令:
```
$ sudo apt install containernetworking-plugins -y
```
安装后,编辑 CRI-O 配置文件:
```
$ sudo nano /etc/crio/crio.conf
```
取消注释 `network_dir` 和 `plugin_dirs` 部分,并在 `plugin_dirs` 下添加 `/usr/lib/cni/`。

保存更改并退出配置文件。
接下来,重启 CRIO 服务:
```
$ sudo systemctl restart crio
```
### 步骤 5:安装 CRI-O 工具
此外,你还需要安装 `cri-tools` 包,它提供了 `crictl` 命令行程序,用于交互和管理容器和 pod。
为此,请运行以下命令:
```
$ sudo apt install -y cri-tools
```
安装后,确认 `crictl` 的版本和 `RunTimeVersion` 如下:
```
$ sudo crictl --runtime-endpoint unix:///var/run/crio/crio.sock version
```

一定要检查 CRI-O 是否准备好使用以下命令部署容器荚:
```
$ sudo crictl info
```

`crictl` 命令提供自动补全功能,让你可以通过按 `TAB` 键自动补全命令。要启用命令补全,请运行以下命令:
```
$ sudo su -
# crictl completion > /etc/bash_completion.d/crictl
```
然后重新加载当前的 Bash 会话:
```
# source ~/.bashrc
```

要使用自动补全功能,你需要注销或启动新的终端会话。然后只需键入 `crictl` 命令并按 `TAB` 键即可查看所有选项。
```
$ crictl
```

### 步骤 6:使用 crictl 程序创建容器荚
至此,CRI-O 已完全安装和配置并准备好启动容器荚。在本节中,我们将在容器荚中创建一个 Apache Web 服务器并确认它是否正在处理请求。
首先,我们将使用容器荚配置文件设置一个沙箱或隔离环境,如下所示:
```
$ sudo nano apache_sandbox.json
```
然后我们将以下配置添加到文件中:
```
{
"metadata": {
"name": "apache-sandbox",
"namespace": "default",
"attempt": 1,
"uid": "hdishd83djaidwnduwk28bcsb"
},
"linux": {
},
"log_directory": "/tmp"
}
```
保存并退出。接下来使用以下命令创建容器荚。这会打印出很长的字母数字,它是容器荚 ID。
```
$ sudo crictl runp apache_sandbox.json
```
要确认容器荚已创建,请运行命令:
```
$ sudo crictl pods
```

要检索有关创建的容器荚的更多信息,请运行以下命令:
```
$ sudo crictl inspectp --output table 05ba2f0704f22
```
这将打印出 ID、名称、UID、命名空间、创建日期、内部 IP 等详细信息。

### 步骤 7:在容器荚中创建容器
这部分中,我们将在容器荚中创建一个 Apache Web 服务器容器。因此,使用 `crictl` 程序从 Docker Hub 拉取 Apache Web 服务器镜像:
```
$ sudo crictl pull httpd
```
你可以如图所示验证拉取的镜像:
```
$ sudo crictl images
```

接下来,我们将为 Apache Web 服务器定义一个容器配置文件:
```
$ sudo nano container_apache.json
```
复制并粘贴以下代码:
```
{
"metadata": {
"name": "apache"
},
"image":{
"image": "httpd"
},
"log_path":"apache.0.log",
"linux": {
}
}
```
保存并退出配置文件。
最后,要将容器连接到之前创建的沙盒容器荚,请运行以下命令:
```
$ sudo crictl create 05ba2f0704f22 container_apache.json apache_sandbox.json
```
这会向终端输出一长串字母数字 ID。请记下此 ID。
最后,使用 ID 启动 Apache Web 服务器容器,如下所示:
```
$ sudo crictl start 37f4d26510965452aa918f04d629f5332a1cd398d4912298c796942e22f964a7
```

要检查容器状态,请运行以下命令:
```
$ sudo crictl ps
```

要验证 Apache Web 服务器是否正在运行,请使用 `curl` 命令和容器荚的内部 ID 向 Web 服务器发送 HTTP 请求:
```
$ curl -I 10.85.0.2
```
以下输出确认 Web 服务器正在运行:

### 结论
这就是全部的指南。我们已经在 Ubuntu 22.04 上成功安装了 CRI-O,并继续创建容器荚和容器。欢迎你提出意见和反馈。
---
via: <https://www.linuxtechi.com/install-crio-container-runtime-on-ubuntu/>
作者:[James Kiarie](https://www.linuxtechi.com/author/james/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [CRI-O](https://cri-o.io/) is an opensource and lightweight container runtime for Kubernetes. It is an implementation of the Kubernetes Container Runtime Interface (CRI) using Open Container Initiative (OCI) compatible runtimes. It’s a perfect alternative to Docker when running Kubernetes.
In this guide, we will demonstrate how to install CRI-O on Ubuntu 22.04 LTS step by step.
#### Prerequisites
Before you start out, here is what you need:
- An instance of Ubuntu 22.04 with SSH access
- A
[sudo user](https://www.linuxtechi.com/how-to-create-sudo-user-on-ubuntu/)configured on the instance - Fast and stable internet connectivity
With that out of the way, let us get started out.
## Step 1: Update the system and Install dependencies
Right off the bat, log into your server instance and update the package lists as follows.
$ sudo apt update
Once the local package index has been updated, install the dependencies as follows.
$ sudo apt install apt-transport-https ca-certificates curl gnupg2 software-properties-common -y
## Step 2: Add CRI-O repository
To install CRI-O, we need to add or enable its repository on Ubuntu. But first, you need to define the variables based on the operating systems and the CRI-O version that you want to install.
As such, define the variables as shown below.
$ export OS=xUbuntu_22.04 $ export CRIO_VERSION=1.24
Once that is done, run the following set of commands to add the CRI-O Kubic repository.
$ echo "deb https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/ /"| sudo tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable.list $ echo "deb http://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable:/cri-o:/$CRIO_VERSION/$OS/ /"|sudo tee /etc/apt/sources.list.d/devel:kubic:libcontainers:stable:cri-o:$CRIO_VERSION.list
Thereafter, import the GPG key for the CRI-O repository
$ curl -L https://download.opensuse.org/repositories/devel:kubic:libcontainers:stable:cri-o:$CRIO_VERSION/$OS/Release.key | sudo apt-key add - $ curl -L https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/Release.key | sudo apt-key add -
This yields the following output as shown below.
Once again update the package index to synchronize the system with the newly added CRI-O Kubic repositories.
$ sudo apt update
## Step 3: Install CRI-O On Ubuntu 22.04
With the repositories added, install CRI-O and the runtime client using the APT package manager.
$ sudo apt install cri-o cri-o-runc -y
Once installed, start and enable the CRI-O daemon.
$ sudo systemctl start crio $ sudo systemctl enable crio
Next, verify if the CRI-O service is running:
$ sudo systemctl status crio
You should get the following output which shows that the CRI-O service is running as expected.
## Step 4: Install CNI Plugins For CRI-O
Next, you need to install the CNI (Container Network Interface) as well as the CNI plugins. Keep in mind that the loopback and bridge configurations are enabled and sufficient for running pods using CRI-O.
Therefore, to install the CNI plugins, run the following command.
$ sudo apt install containernetworking-plugins -y
Once installed, edit the CRI-O configuration file
$ sudo nano /etc/crio/crio.conf
Uncomment network_dir & plugin_dirs section and also add ‘/usr/lib/cni/’ under plugin_dirs section.
Save the changes and exit the configuration file.
Next, restart the CRIO service.
$ sudo systemctl restart crio
## Step 5: Install CRI-O tools
In addition, you also need to install the cri-tools package which provides the crictl command-line utility which is used for interacting and managing containers and pods.
To do so, run the command:
$ sudo apt install -y cri-tools
Once installed, confirm the version of crictl and RunTimeVersion as follows.
$ sudo crictl --runtime-endpoint unix:///var/run/crio/crio.sock version
Be sure to also check if CRI-O is ready to deploy pods using the following command:
$ sudo crictl info
The crictl command provides an autocompletion feature that lets you autocomplete commands by pressing the TAB key. To enable command completion run the following command.
$ sudo su - # crictl completion > /etc/bash_completion.d/crictl
Then reload the current bash session.
# source ~/.bashrc
To use the auto-completion feature, you will need to log out or start a new terminal session. Then simply type the crictl command and press the TAB key to view all the options.
$ crictl
## Step 6: Create a Pod using crictl utility
Up to this point, CRI-O is fully installed and configured and ready to spin up a pod. In this section, we will create an Apache web server inside a pod and confirm if it is serving requests.
First, we are going to set up a pod sandbox or an isolated environment using a pod configuration file as follows.
$ sudo nano apache_sandbox.json
We will then add the following configuration to the file.
{ "metadata": { "name": "apache-sandbox", "namespace": "default", "attempt": 1, "uid": "hdishd83djaidwnduwk28bcsb" }, "linux": { }, "log_directory": "/tmp" }
Save and exit. Next create the pod using the following command. This prints out long alphanumeric number which is the pod ID.
$ sudo crictl runp apache_sandbox.json
To confirm that the pod has been created, run the command.
$ sudo crictl pods
To retrieve more information about the created pod, run the command:
$ sudo crictl inspectp --output table 05ba2f0704f22
This prints out the ID, Name, UID, Namespace, date of creation, internal pod IP among other details.
## Step 7: Create a container inside a pod
In section we are going to create an Apache web server container inside the pod. So, use the crictl utility to pull an Apache web server image from Docker Hub.
$ sudo crictl pull httpd
You can verify the image pulled as shown.
$ sudo crictl images
Next, we are going to define a container configuration file for the Apache web server.
$ sudo nano container_apache.json
Copy and paste the following code.
{ "metadata": { "name": "apache" }, "image":{ "image": "httpd" }, "log_path":"apache.0.log", "linux": { } }
Save and exit the configuration file.
Finally, to attach the container to the sand box pod created earlier, run the command:
$ sudo crictl create 05ba2f0704f22 container_apache.json apache_sandbox.json
This outputs a large alphanumeric ID to the terminal.. Take note of this ID.
Finally, use the ID to start the Apache web server container as follows.
$ sudo crictl start 37f4d26510965452aa918f04d629f5332a1cd398d4912298c796942e22f964a7
To check the container status, run the command:
$ sudo crictl ps
To verify that the Apache web server is running, send a HTTP request to the web server using the curl command and the pod’s internal ID.
$ curl -I 10.85.0.2
The following output confirms that the web server is running.
#### Conclusion
That’s all from this, guide. We have successfully installed CRI-O on Ubuntu 22.04 and gone ahead to create a pod and container. Your comments and feedback are welcome.
Also Read: [How to Install Docker on Ubuntu 22.04 / 20.04 LTS](https://www.linuxtechi.com/install-use-docker-on-ubuntu/)
Juan SilvaFantastic install, thank you so very much, CRI seems like a great alternative to both docker and snap… |
15,688 | 将 Gedit 作为代码编辑器的 10 项增强调整 | https://itsfoss.com/gedit-tweaks/ | 2023-04-03T16:37:23 | [
"Gedit"
] | https://linux.cn/article-15688-1.html | 
>
> Gedit 是一个好的文本编辑器。用这些技巧、窍门和调整把它变成一个好的代码编辑器。
>
>
>
GNOME 可能已经抛弃了 Gedit 作为默认的文本编辑器,但它仍然是 Linux 老用户的最爱。
它主要是一个文本编辑器,但通过一些调整,它可以作为一个轻量级的代码编辑器使用。
是啊!为什么要用 VS Code 或其他专门的代码编辑器来编写 Bash 脚本或其他语言的简单程序?用 Gedit 也可以过一天。
我将在本文中分享一些我最喜欢的 Gedit 技巧和窍门。虽然大多数的调整对写代码是有益的,但有些对一般的文本写作也是有帮助的。
### 1、安装插件
可能个别人甚至不知道 Gedit 有强大的插件功能。你可以安装插件来获得额外的功能。
有两种类型的插件:
* 可以从编辑器菜单中访问的官方 Gedit 插件
* 第三方插件,可以从项目网站上下载,并放入插件目录中(下面讨论)。
Gedit 插件可以放在 `/usr/share/gedit/plugins` 或 `~/.local/share/gedit/plugins` 目录下。

你可以通过点击 “汉堡包” 菜单,然后打开 “<ruby> 首选项 <rt> Preferences </rt></ruby>” 窗口来访问可用和已安装的插件。

首选项窗口有 “<ruby> 插件 <rt> Plugins </rt></ruby>” 标签,你可以看到所有可用的插件。你可以使用复选框来启用和禁用这些插件。

### 2、在侧边栏中显示文件浏览器
如果你正在处理一个有多个文件和文件夹的项目,在侧边栏中用文件浏览器看到所有可用的文件是相当有用的。
进入 “首选项” -> “插件”,启用 “<ruby> 文件浏览器面板 <rt> File Browser Panel </rt></ruby>”。

之后,点击右上角的汉堡包菜单,从菜单 “<ruby> 查看 <rt> View </rt></ruby>” -> “<ruby> 侧面板 <rt> Side Panel </rt></ruby>” 启用侧面板视图。
现在把侧面板视图改为文件浏览器,如果还没有的话。

### 3、嵌入一个终端
是的!你可以在 Gedit 文本编辑器中直接嵌入一个终端。
这有什么意义呢?嗯,如果你正在写程序或脚本,嵌入终端可以帮助你运行脚本,并在编辑器中检查代码的变化。

要得到这个,首先要安装这个插件(针对 Ubuntu):
```
sudo apt install gedit-plugin-terminal
```
一旦插件安装完毕,从 “首选项” -> “插件” 中启用它。

嗯,从汉堡包菜单-> “查看”-> “<ruby> 底部面板 <rt> Bottom Panel </rt></ruby>” 中启用底部面板。

### 4、Markdown 预览
喜欢 Markdown 吗?我也是!
有几个适用于 Linux 的 Markdown 编辑器,但你不必为了使用 Markdown 而去安装另一个应用程序。
在一个名为 “[Gedit Markdown Preview](https://github.com/maoschanz/gedit-plugin-markdown_preview?ref=itsfoss.com)” 的插件的帮助下,Gedit 完全有能力呈现 Markdown 代码。
Arch 用户可以在 AUR 中找到它,软件包为 `gedit-plugin-markdown_preview`。
其他 Linux 用户可以找到 [项目网页上的安装说明](https://github.com/maoschanz/gedit-plugin-markdown_preview?ref=itsfoss.com#installation)。
一旦安装,在插件中启用它。你必须从汉堡包菜单 -> “查看”-> “侧面板” 中启用侧面板视图。

有了这个,它就开始在侧面板或底部窗格中显示 Markdown 文本的渲染文本。

### 5、创建代码片段
*好的码农编码,优秀码农复用。*
如果你发现自己重复使用同一段代码或文本,你可以将其保存为片段,并在需要时插入。这将为你节省一些时间(和挫折)。
先启用片段插件:

现在你可以从汉堡包菜单-> “<ruby> 管理片段 <rt> Manage Snippets </rt></ruby>” 来访问片段。

你会发现它已经有几个为各种编程语言添加的片段。

你也可以通过点击左下角的 “+” 号将你的片段添加到所需的文件夹中。你也可以为片段指定一个快捷键,以便更快速地插入它们。

例如,我为 [添加一个 Markdown 表格](https://itsfoss.com/markdown-table/) 添加了一个新的片段,并为其分配了一个键盘快捷键和 TAB 触发器(如上图所示)。现在,如果我在 Markdown 文档中按 `CTRL + Alt + S`,就会添加一个表格。或者,输入 `table` 并按下 `TAB` 键也会添加 Markdown 表格。
>
> ? 通常,片段被保存在 `/usr/share/gedit/plugins/snippet` 文件夹中作为 XML 文档,但我找不到新添加的片段被保存在哪里。
>
>
>
### 6、修复深色模式的问题
编码员喜欢深色模式。Gedit 遵守系统主题,如果你在操作系统层面切换到深色模式,它也会切换到深色模式。
一个主要的问题是,你无法阅读当前选定行的任何内容,因为文本和行的高亮部分都是白色的。

这个问题没有解决办法。然而,一个变通的办法是,要么禁用当前行的高亮显示,要么使用不同的颜色方案。
进入 “首选项” -> “<ruby> 字体和颜色 <rt> Font & Colors </rt></ruby>”,然后选择像 Oblivion 这样的深色方案。这将稍微改变颜色方案,但至少你能看到高亮行的文字。

### 7、快速高亮选中的文本
双击一个词,Gedit 就会高亮显示整个文档中出现的所有相同的词。

虽然有一个官方插件,但这个功能默认是不启用的。
进入 “首选项” -> “插件”,启用 “<ruby> 快速高亮 <rt> Quick Highlight </rt></ruby>” 选项。

### 8、显示行号
许多代码编辑器默认都会显示行号。当你看到 “第 X 行的语法错误 ” 时,它可以帮助你快速找到该行。
你可以通过进入 “首选项” -> “查看” -> “<ruby> 显示行号来启用行号 <rt> Display Line Numbers </rt></ruby>”:

你也可以从底部启用或停用它。

### 9、保存一个版本
如果你正在修改一个文件,也许建立一个备份副本会更好?Gedit 可以自动做到这一点。
在 “首选项” -> “<ruby> 编辑器 <rt> Editor </rt></ruby>” -> “<ruby> 创建一个备份副本 <rt> Create a Backup copy </rt></ruby>” 中启用这个功能。

一个在原文件名称后面加上 `~` 符号的文件将作为备份文件出现。

### 10、自动保存文件
既然我们在谈论版本和备份,那么 [在 Gedit 中启用自动保存](https://itsfoss.com/how-to-enable-auto-save-feature-in-gedit/) 怎么样?这样,如果你在处理一个文件时,忘记用 `Ctrl+S` 手动保存,修改的内容会自动保存。
>
> ? 这个功能对一个从未在磁盘上保存过的全新文档不起作用。
>
>
>
从 “偏好” -> “编辑器”,你可以启用 “<ruby> 自动保存 <rt> Autosave </rt></ruby>” 功能。默认情况下,它每 10 分钟自动保存一次,但你可以根据自己的喜好改变时间。

还有一个第三方的 [smart-auto-save 扩展](https://github.com/seanh/gedit-smart-autosave/?ref=itsfoss.com),可以在你停止输入时自动保存文档。

### 知道更多的 Gedit 技巧吗?
使用任何软件的乐趣之一是发现它不那么明显的功能。
在这里,你最喜欢哪个 Gedit 的调整?你知道一个没有多少人知道的 Gedit 的秘籍吗?在评论中与我们分享吧?
---
via: <https://itsfoss.com/gedit-tweaks/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

GNOME may have ditched Gedit as the default text editor but it is still a favorite of long-time Linux users.
It is primarily a text editor, but with some tweaks, it can work as a lightweight code editor.
Yeah! Why use VS Code or other dedicated code editors for writing Bash scripts or simple programs in other languages? Gedit saves the day.
I'll share some of my favorite Gedit tips and tricks in this article. While most of the tweaks are beneficial for writing codes, some could be helpful for general text writing as well.
## 1. Install plugins
Few people don't even know that Gedit has a robust plugin feature. You can install plugins to get additional features.
There are two kinds of plugins:
- Official Gedit plugins that are accessible from the editor menu
- Third-party plugins that can be downloaded from the project websites and placed into the plugins directory (discussed below)
The Gedit plugins can be located in `/usr/share/gedit/plugins`
or `~/.local/share/gedit/plugins`
directories.
You can access the available and installed plugins by clicking the Hamburger menu and then opening the Preference window,
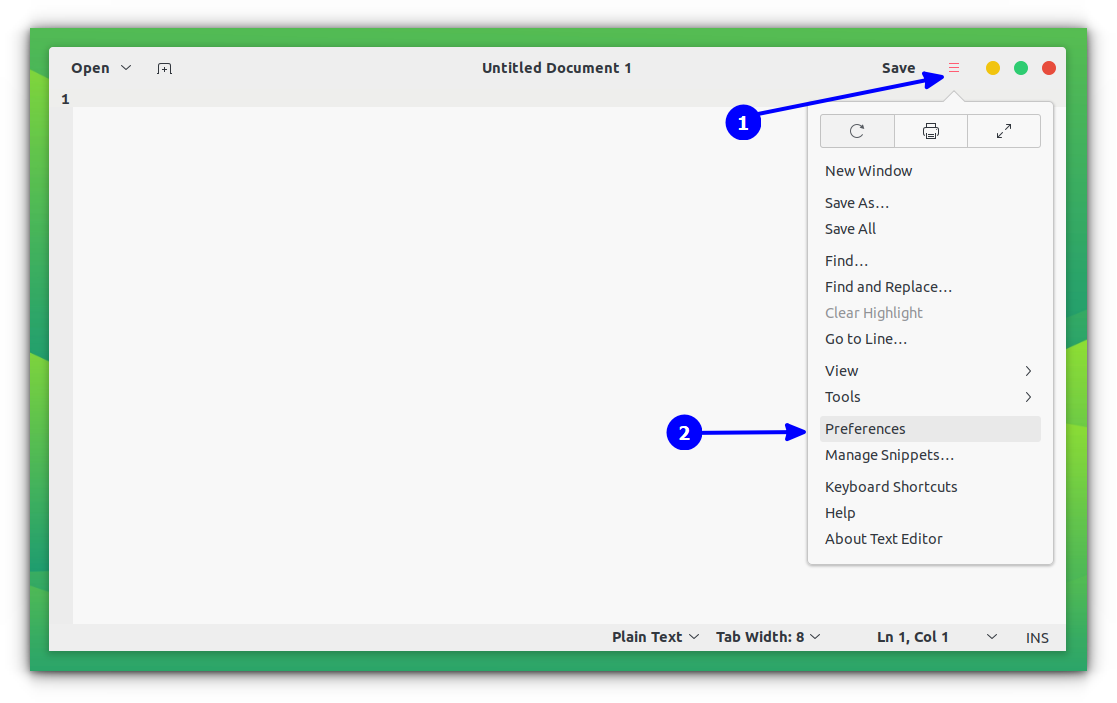
The Preferences window has the Plugins tab and you can see all the plugins available to you. You can use the checkbox to enable and disable the plugins.
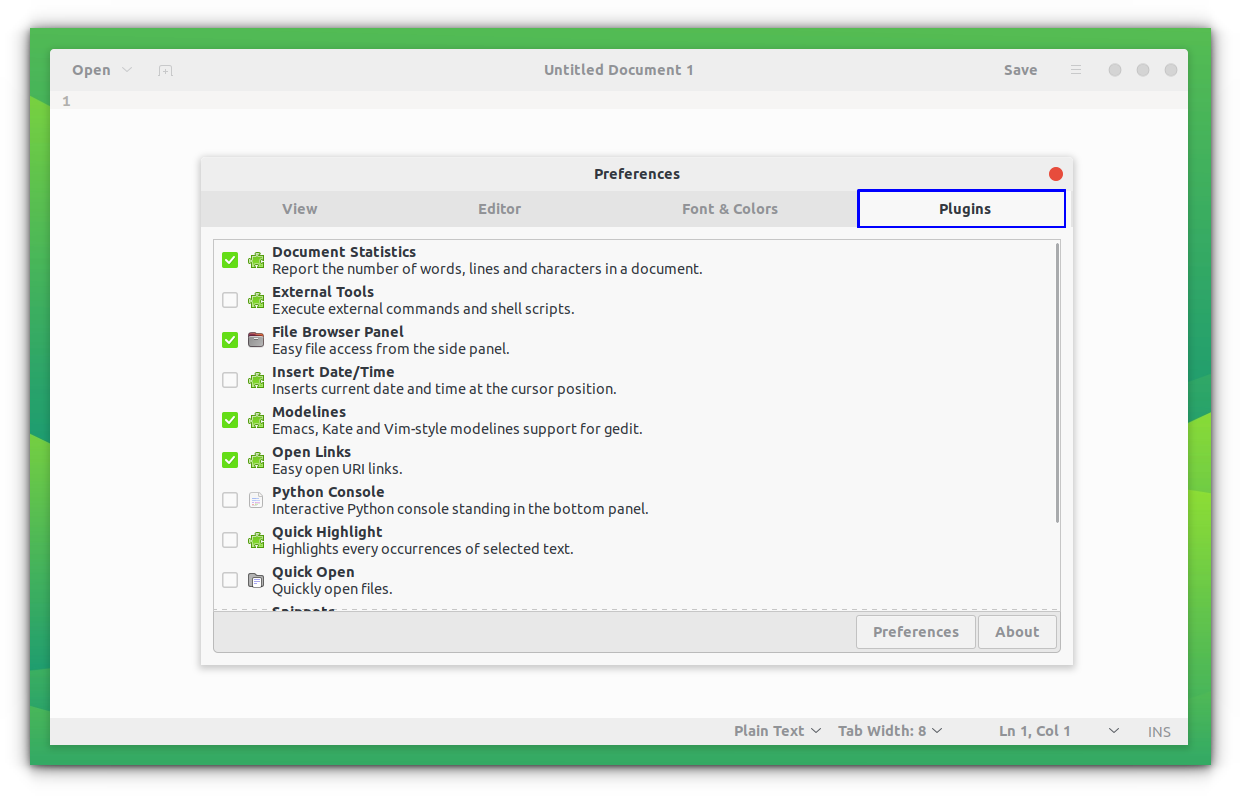
## 2. Show file browser in the side panel
If you are working on a project that has multiple files and folders, getting the file browser to see all the available files in the sidebar is quite helpful.
Go to **Preferences -> Plugins** and enable the **File Browser Panel**.
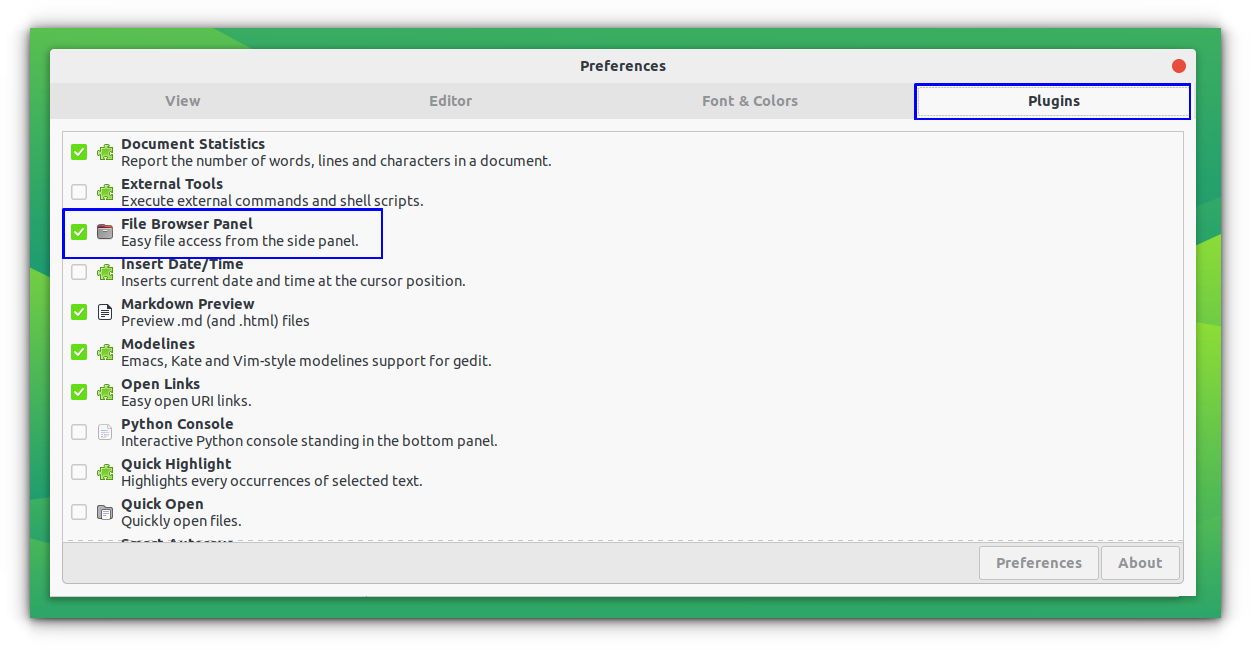
After that, click on the hamburger menu at top right and enable the Side Panel View from Menu **View -> Side Panel**
Now change the side panel view to file browser, if not already.
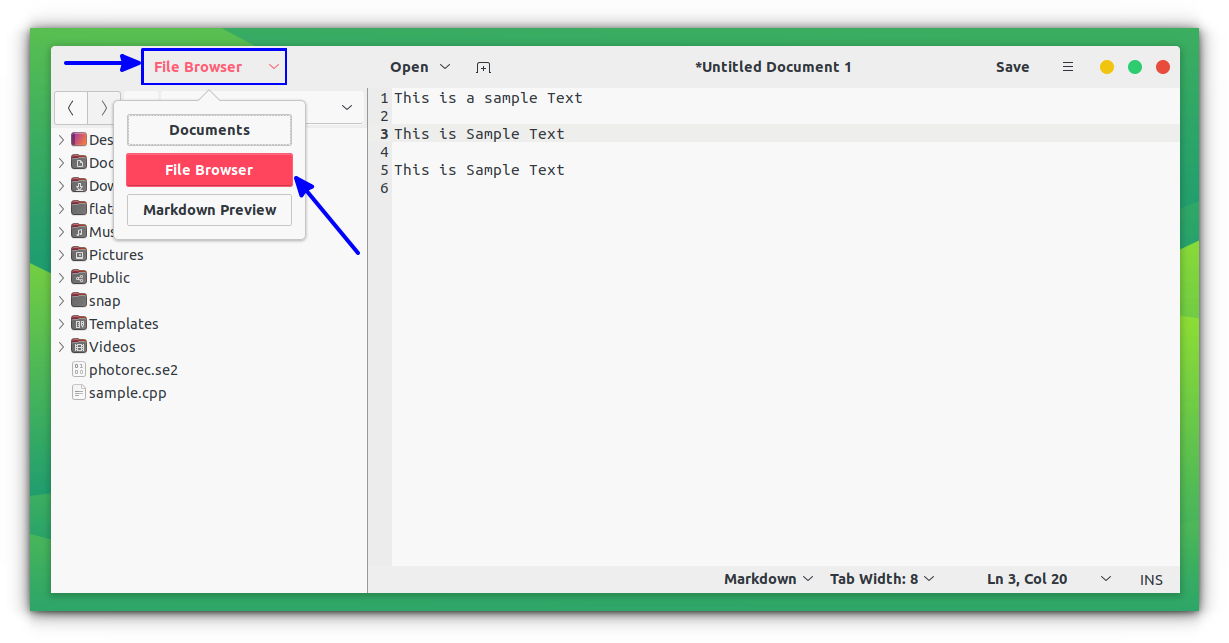
## 3. Embed a terminal
Yes! You can embed a terminal right into the Gedit text editor.
What's the point? Well, if you are writing programs or scripts, an embed terminal helps you run the script and check the code changes right there in the editor.
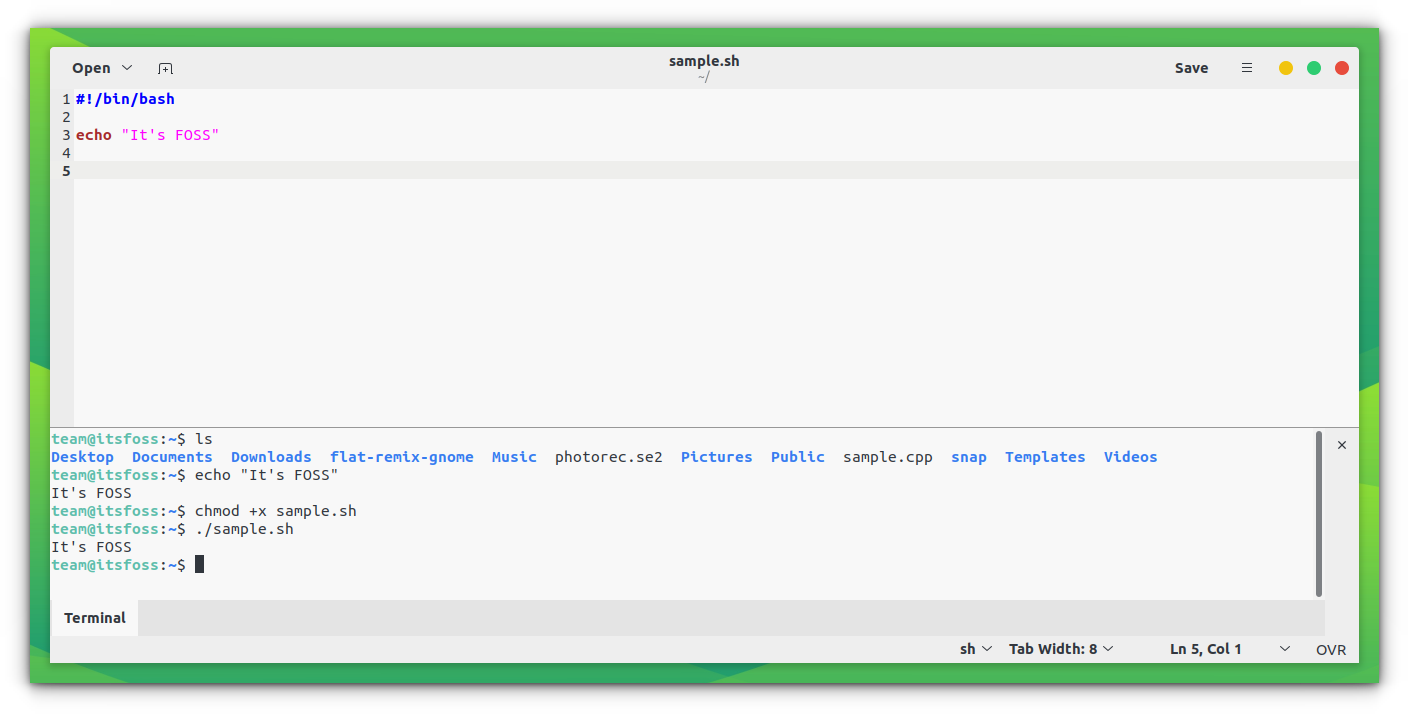
To get this, first install the plugin (for Ubuntu):
`sudo apt install gedit-plugin-terminal`
Once the plugin is installed, enable it from Preferences->Plugin.
Mow, enable bottom panel from hamburger menu -> **View -> Bottom Panel**
## 4. Markdown preview
Love Markdown? Me too!
There are several Markdown editors available for Linux but you don't have to install another application just to use Markdown.
With the help of a plugin, unsurprisingly called [Gedit Markdown Preview](https://github.com/maoschanz/gedit-plugin-markdown_preview), Gedit is perfectly capable of rendering Markdown code.
Arch users can find it in the AUR as gedit-plugin-markdown_preview package.
Other Linux users can find the [installation instructions on the project webpage](https://github.com/maoschanz/gedit-plugin-markdown_preview#installation).
Once it is installed, enable it in plugins. You must enable the side panel view from the hamburger menu --> View > Side panel
With that, it starts showing rendered text for Markdown text in the side or bottom pane.
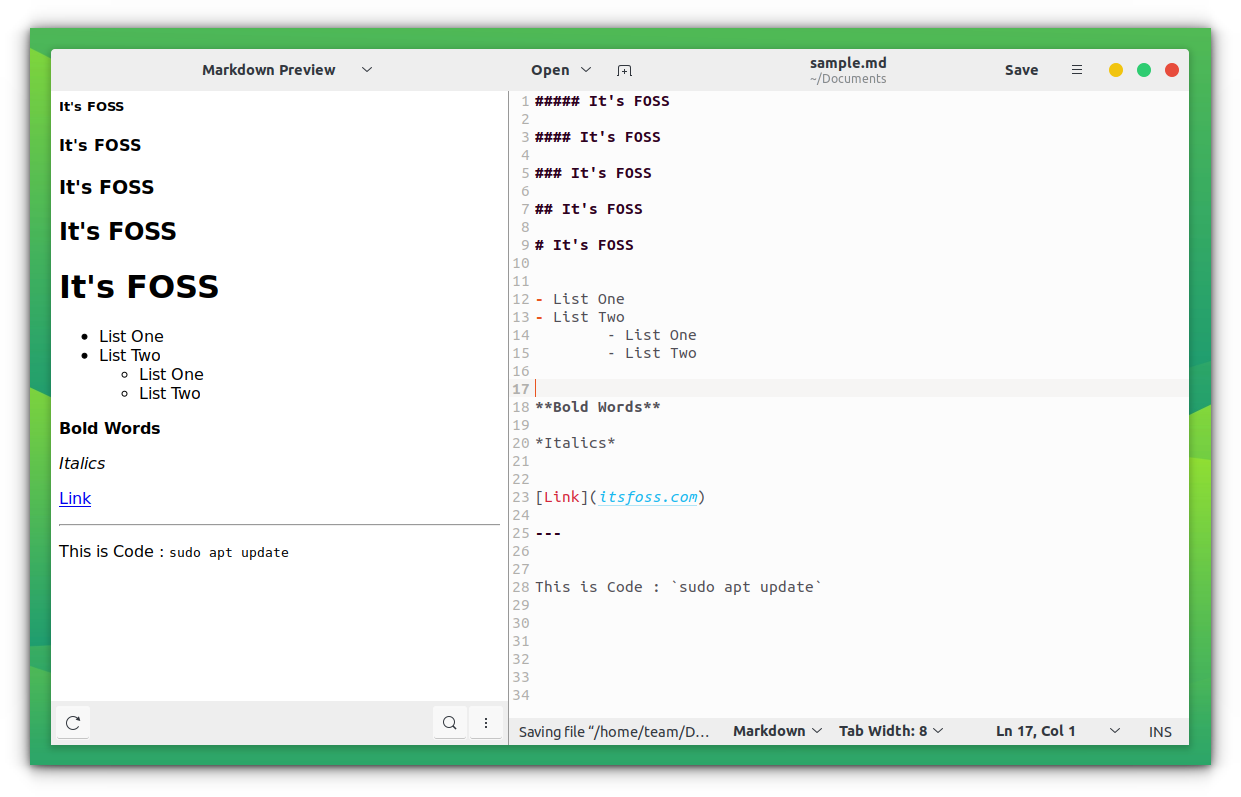
## 5. Create snippets
*Good coders code. Better coders reuse.*
If you find yourself reusing same piece of code or text, you can save it as snippet and insert it when needed. This will save you some time (and frustration).
Enable the Snippet plugin first.
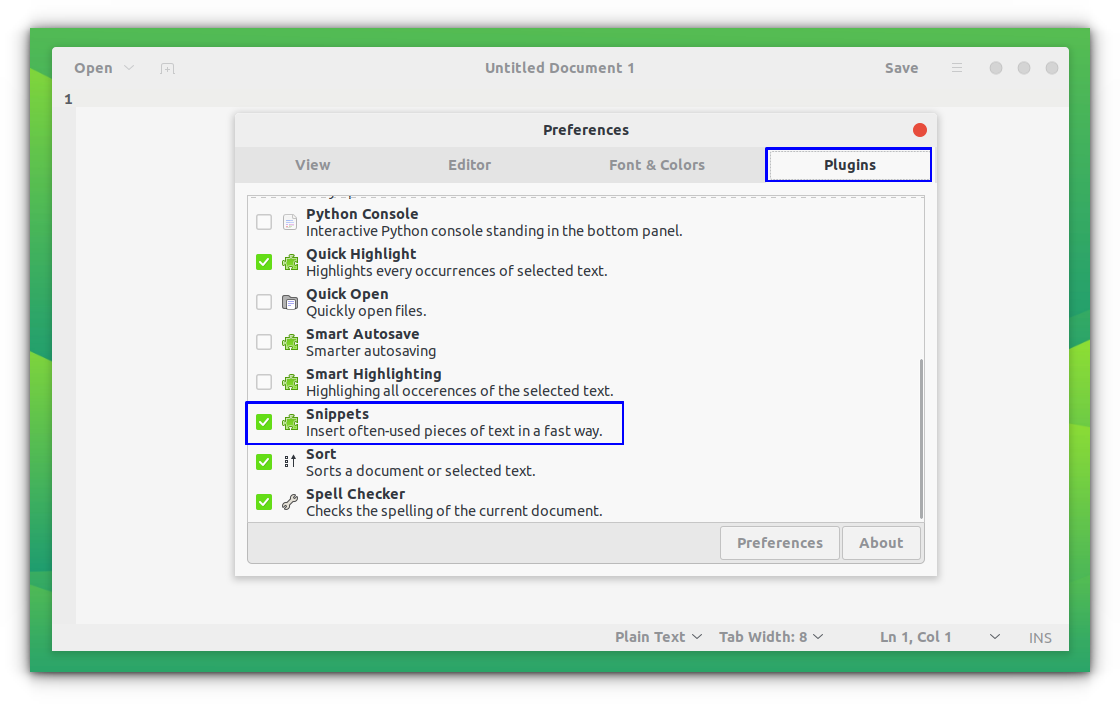
Now you can access the snippets from **Hamburger Menu -> Manage Snippets**
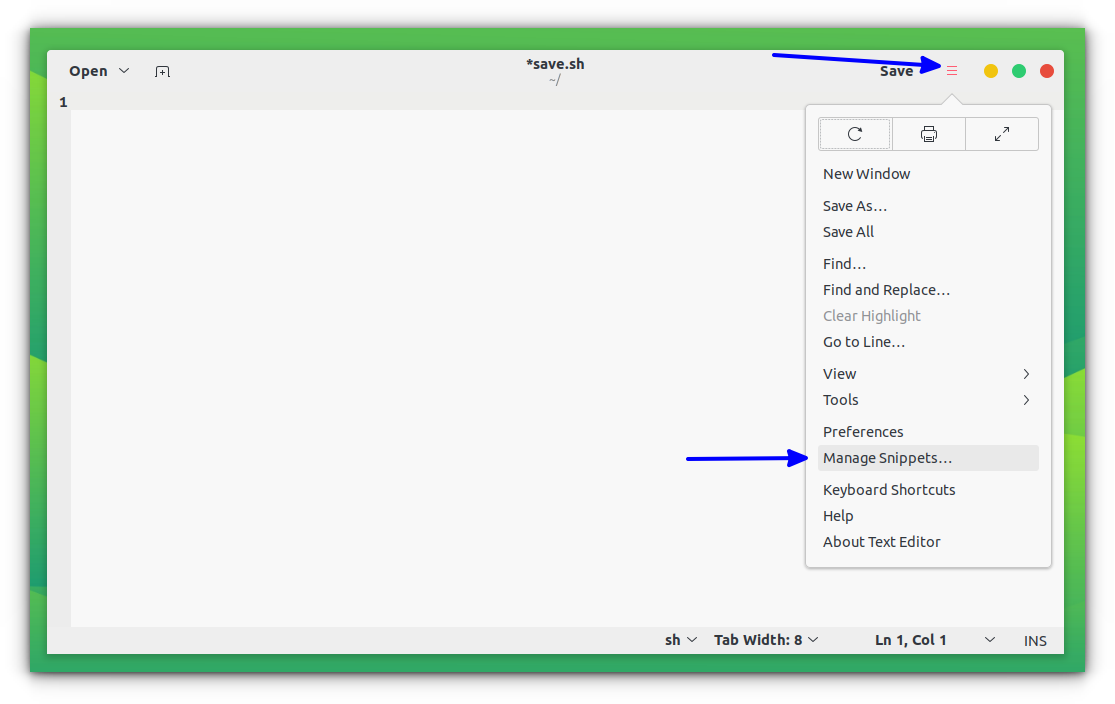
You'll find that it already has several snippets added for various programming languages.
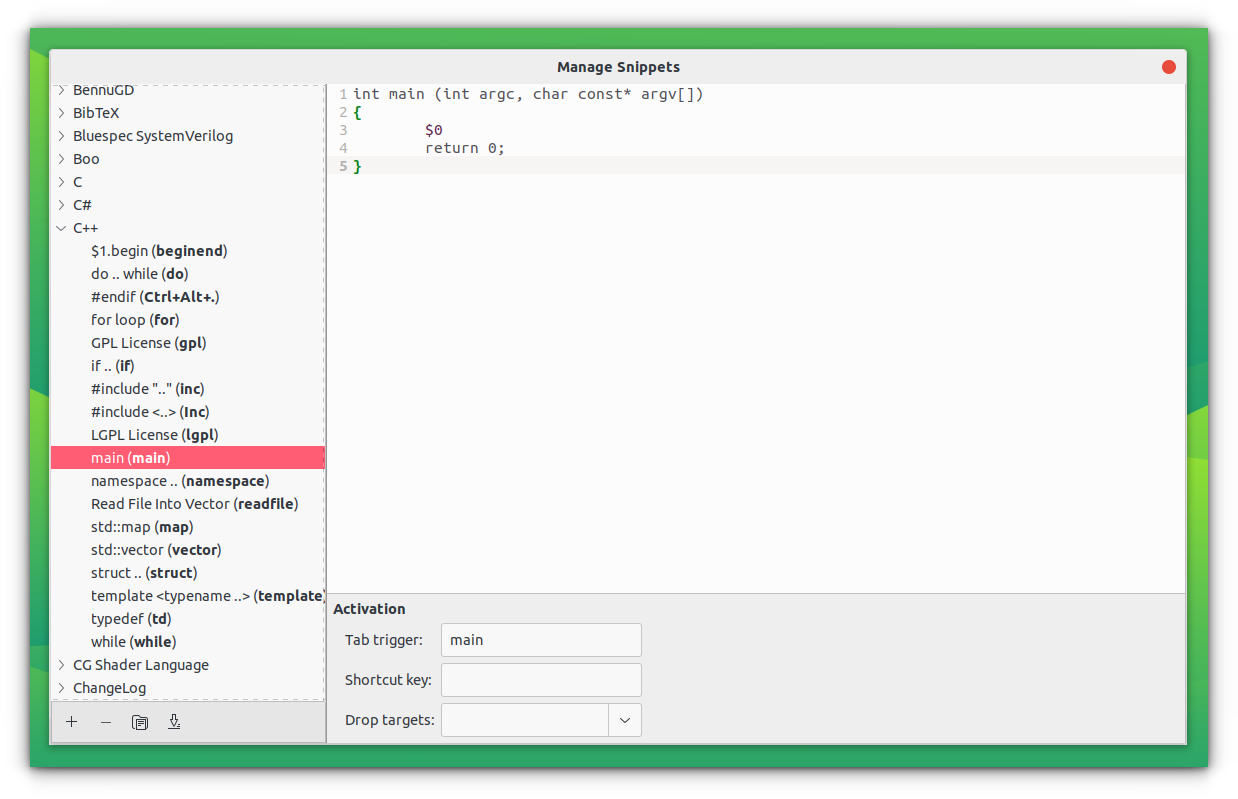
You can also add your snippets in the desired folder by clicking the + sign on the bottom left. You may also assign a shortcut key to snippets to insert them even more quickly.
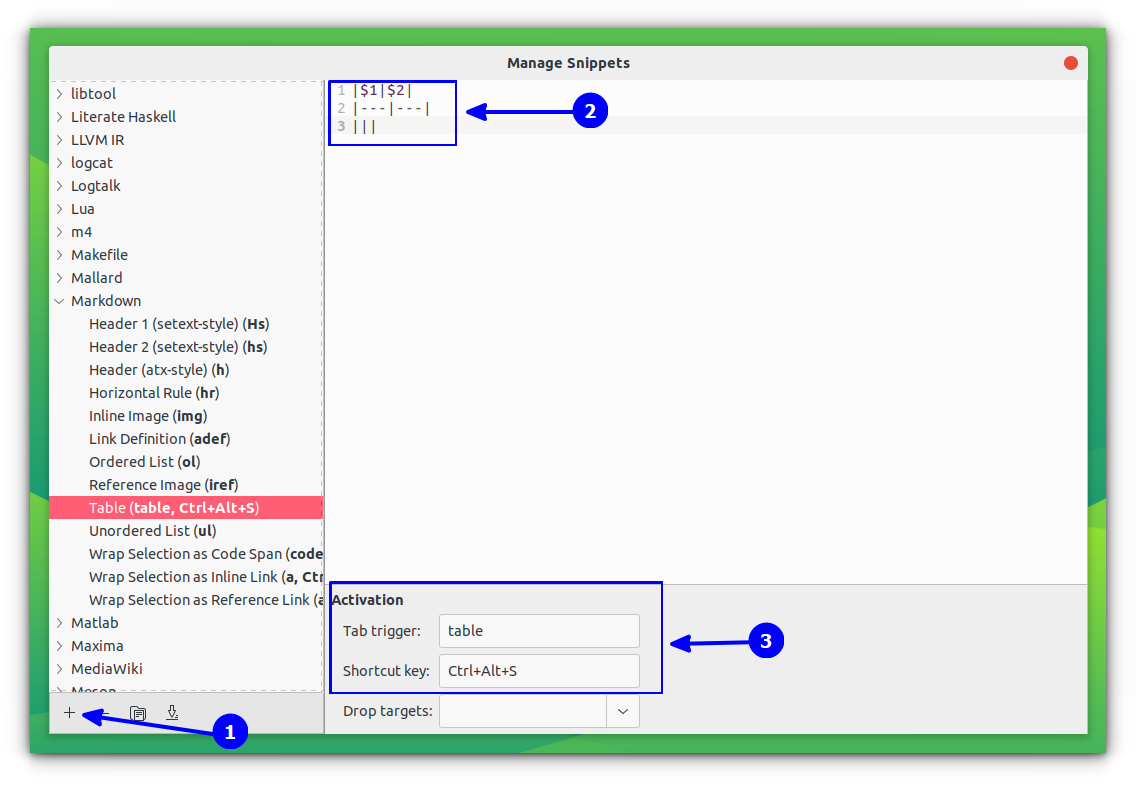
For example, I added a new snippet for [adding a Markdown table](https://itsfoss.com/markdown-table/) and assigned a keyboard shortcut and tab trigger to it (as seen in the above image). Now, if I press **CTRL + Alt + S **in a Markdown document, a table is added. Alternatively, typing **table **and pressing the TAB key also adds the Markdown table.
`/usr/share/gedit/plugins/snippet`
folder as XM docs, but I could not find where the newly added snippets are saved.## 6. Fix the dark mode problem
Coders love dark mode. Gedit adheres to the system theme, and if you switch to dark mode at the OS level, it also switches to dark mode.
The one major problem is that you cannot read anything on the currently selected line because both text and line highlights are white colored.
There is no fix for this. However, a workaround is to either disable highlighting the current line or use a different color scheme.I prefer choosing a different color scheme.
Go to Preferences -> Font & Colors and then select a dark color scheme like Oblivion. It will change the color scheme a little but at least you will be able to see the text on the highlighted lines.
## 7. Quick highlight selected text
Double-click a word and Gedit highlights all the occurrences of the same word in the entire document.
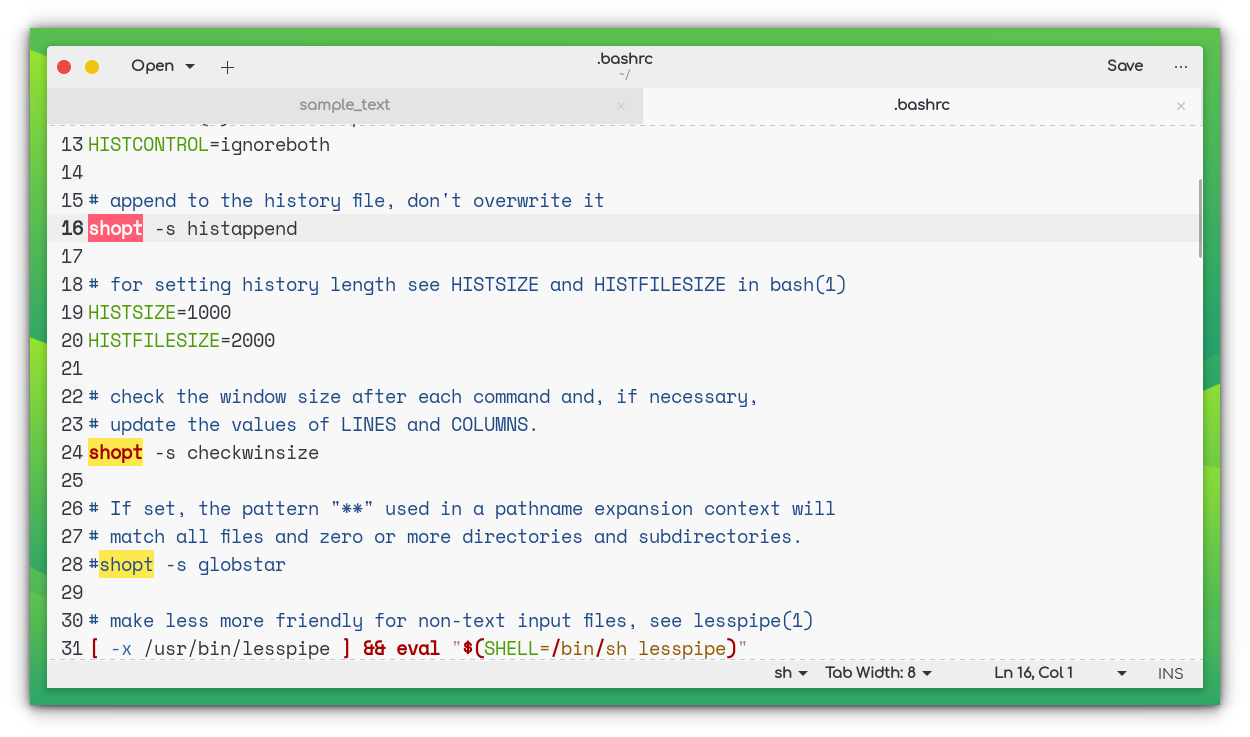
This feature is not enabled by default though an official plugin is available.
Go to Preferences -> Plugins and enable the Quick Highlight option.
**Quick highlight**default plugin in Preferences > Plugins
## 8. Show line numbers
Many code editors show the line numbers by default. It helps you quickly go to the line when you see a 'syntax error at line X'.
You can enable line numbers by going to **Preferences -> View -> Display Line Numbers:**
You may also enable or disable it from the bottom.
## 9. Save a version
If you are modifying a file, perhaps it would be better to create a backup copy? Gedit can do this automatically.
Enable this feature in **preferences -> Editor -> Create a Backup copy**.
A file with the name of the original file appended with a `~`
symbol will appear as the backup file.
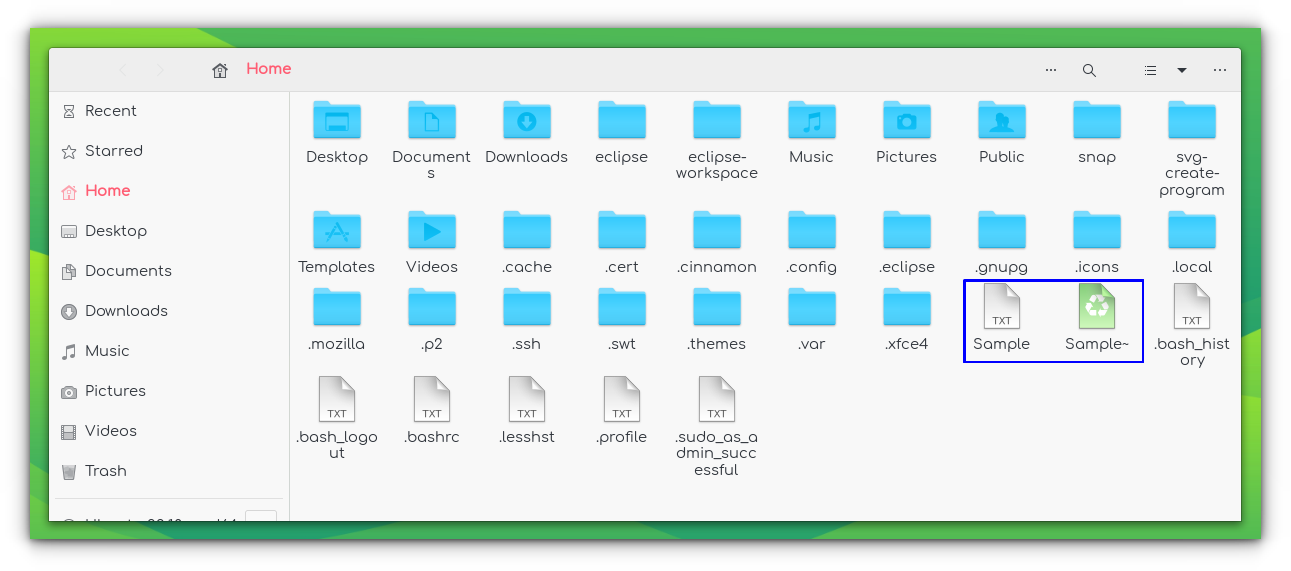
## 10. Autosave files
Since we are talking about versions and backups, how about [enabling autosave in Gedit](https://itsfoss.com/how-to-enable-auto-save-feature-in-gedit/)? This way, if you are working on a document and forgot to save it using Ctrl+S manually, the changes get saved automatically.
From **Preferences -> Editor**, you can enable the Autosave feature. By default, it autosaves every 10 minutes but you can change the duration to your liking.
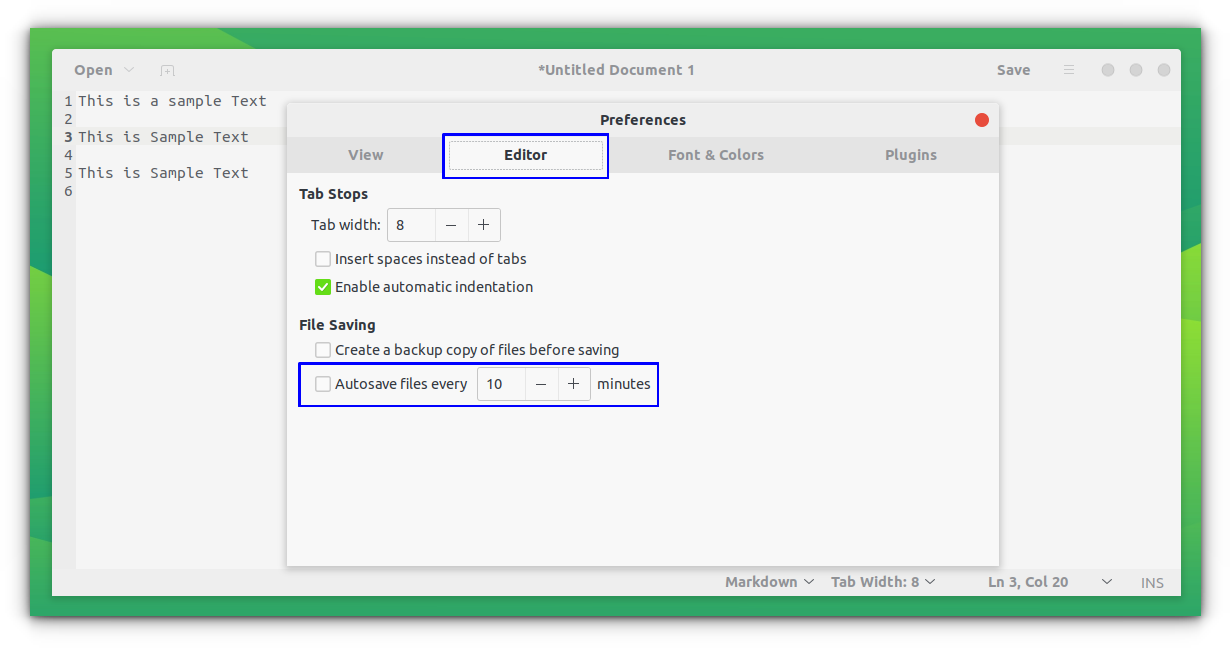
There is also a third-party [smart-auto-save extension](https://github.com/seanh/gedit-smart-autosave/) that autosaves the document as soon as you stop typing it.
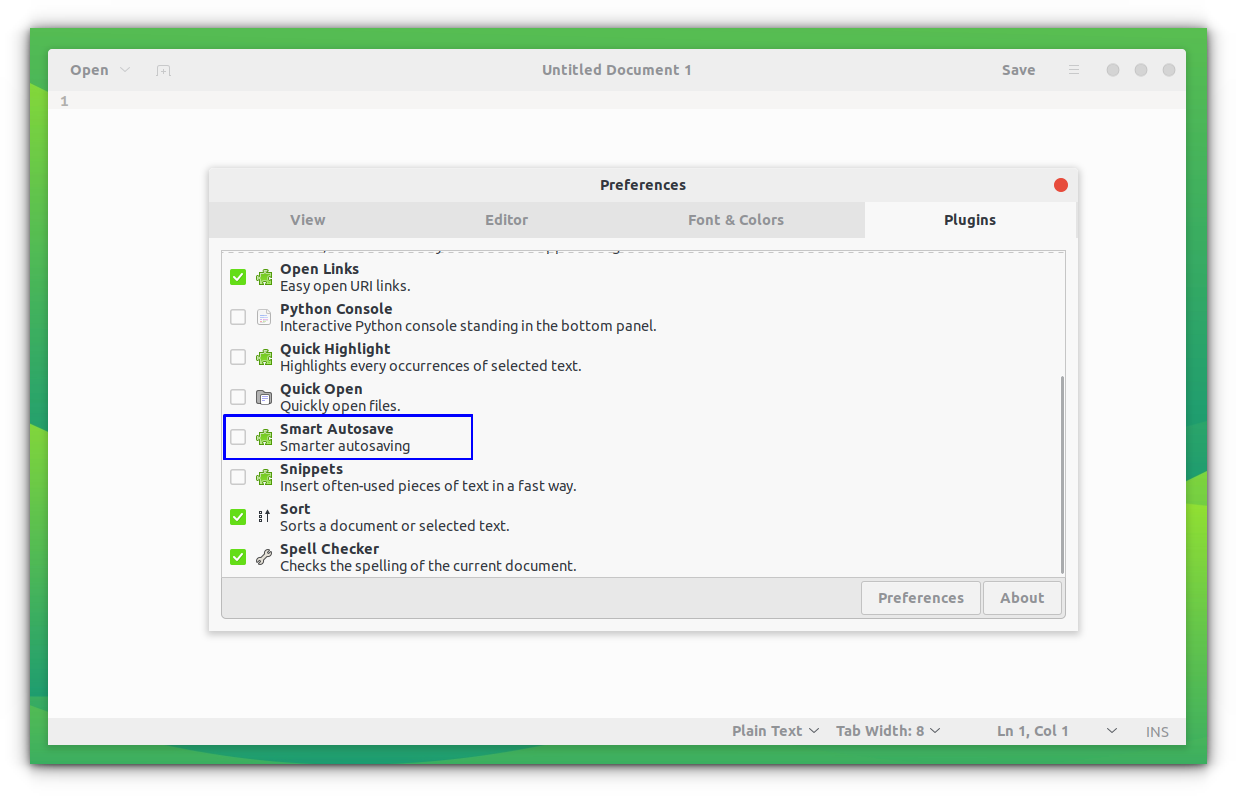
## Know more Gedit tricks?
If you want, you can also change the Gedit theme.
[Install and Use Additional Gedit Color ThemesDon’t like the default looks for the Gedit text editor? You can surely try to change the color themes. Here’s how to do that.](https://itsfoss.com/gedit-themes/)

One of the joys of using any piece of software is discovering it's not-so-obvious features. We have covered such application-specific tweaks in the past. Take a look at Nautilus tips:
[13 Ways to Tweak Nautilus File Manager in Linux to Get More Out of itNautilus is GNOME’s default file manager application, and you may have seen it in many Linux distributions. It’s a good file manager with plenty of features. However, you can enhance your experience by employing some tweaks and tips. I am going to share such tips and tweaks in](https://itsfoss.com/nautilus-tips-tweaks/)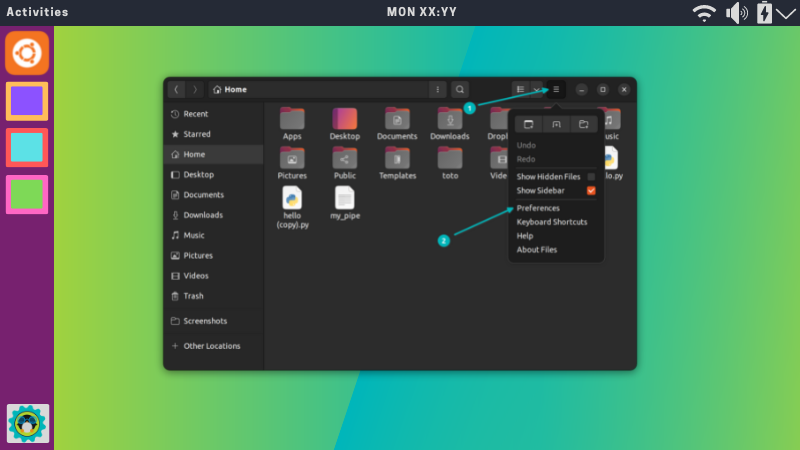

Or, the [Flatpak tips and tweaks](https://itsfoss.com/flatpak-tips-tweaks/):
[6 Tips and Tools to Enhance Your Flatpak Experience in LinuxIf you love using Flatpak applications, here are a few tips, tools, and tweaks to make your Flatpak experience better and smoother.](https://itsfoss.com/flatpak-tips-tweaks/)

Which Gedit tweaks you liked the most here? Do you know a killer Gedit feature that not many people are aware of? Share it with us in the comments? |
15,690 | 上古的 MIT Lisp 机器系统软件的最后一个版本恢复成功 | https://www.theregister.com/2023/03/31/mit_cadr_software_recovered/ | 2023-04-04T09:11:00 | [
"Lisp"
] | https://linux.cn/article-15690-1.html |
>
> 这是非常重要的、上古的计算机上运行的,古老软件的新版本。
>
>
>

LM-3 项目宣布了 MIT CADR <ruby> Lisp 机器 <rp> ( </rp> <rt> Lisp Machine </rt> <rp> ) </rp></ruby>系统软件的第 100 版,这是它的最后一个版本。它既是一个新的版本,也是一个非常 古老的版本。
前两天,IBM 的 Eric Moore 在 LinkedIn 上发布了关于这个版本的 [消息](https://www.linkedin.com/pulse/mit-lisp-machine-final-version-recovered-after-35-years-eric-moore/),他帮助了这项恢复工作。该项目的一个更详细的 [帖子](https://tumbleweed.nu/r/bug-lispm/forumpost/7475d8a3db) 描述了这个软件是什么,以及它是从哪里恢复的。
为什么这很重要?好吧,这款软件和它所运行的机器,是一场 “重要战斗” 的标志和纪念物。那场战斗是一场战争的一个阶段:一场以 “针锋相对的方式” 制造计算机的战争。“历史是由胜利者书写的”,温斯顿·丘吉尔 [不是](https://slate.com/culture/2019/11/history-is-written-by-the-victors-quote-origin.html) 第一个这样说的人。
这场战争和大多数战争一样,是两个 “对手阵营” 之间的战争。一方认为,制造计算机的正确方法是用最好的语言编写最好的软件,如果有必要的话,还要设计精工巧做的计算机来运行这些软件。另一方认为制造计算机的正确方法是制造小而快、容易而简单的软件和硬件,完成大多数人当时需要的工作。
同样,像大多数战争一样,这场战争是漫长而险恶的,双方都有一些肮脏的内斗。最终,有一方取得了决定性的胜利,但已经花了太长的时间,胜利者大多是开始战斗的那些人的后代和亲属。如今,他们甚至根本不记得有这么一场战争,而胜利的一方最终吸收了很多失败一方的想法和技术。最终的结果是,软件并不小而快,也不容易而简单。胜利的一方忘记了他们在战斗,也忘记了与之战斗的对手。
当胜利者忘记他们已经胜利了,也忘记了他们在战斗,这意味着失败者可以写一些最好的战争总结。一篇著名的报道是写自 1991 年的文章,名为《[Lisp:好消息,坏消息,如何大获全胜](https://www.dreamsongs.com/WIB.html)》,其中说:
>
> 这两种哲学被称为 “<ruby> 做正确的事 <rp> ( </rp> <rt> The Right Thing </rt> <rp> ) </rp></ruby>” 和 “<ruby> 差点则更好 <rp> ( </rp> <rt> Worse is Better </rt> <rp> ) </rp></ruby>”。
>
>
>
“做正确的事” 是麻省理工学院/斯坦福的设计风格。另一边呢?
>
> 早期的 Unix 和 C 就是使用这种设计流派的例子,我将把这种设计策略的使用称为“新泽西方式”。
>
>
>
这篇文章只有短短几页,但如果你现在没有时间,用一句话可以概况,即 “[差点则更好](https://www.dreamsongs.com/WorseIsBetter.html)”。
换句话说,一方从麻省理工学院和斯坦福大学开始,他们最终设计了一种叫做 <ruby> Lisp 机器 <rp> ( </rp> <rt> Lisp Machine </rt> <rp> ) </rp></ruby> 的计算机。另一方建立了 Unix 和后来专用的工作站,以快速运行 Unix,这需要可以快速运行编译的 C 代码的特殊处理器,它被称为 RISC 芯片。英特尔和 AMD 将 RISC 的一些技术和方法改编为 486 和奔腾芯片,AMD 则改编为皓龙和 x86-64,结果是 x86 电脑最终将 RISC 工作站赶出了市场。不过,今天,由于高端的 [苹果芯片 Mac](https://www.theregister.com/2023/01/17/apple_m2_max_pro/) 和低端的 [RISC-V](https://www.theregister.com/2023/02/09/balthazar_free_hardware_laptop/),RISC 正在复兴当中。
但是,x86、RISC 和 CISC,以及 [基于 Algol](https://www.theregister.com/2020/05/15/algol_60_at_60/) 的整个语言家族,包括从 BASIC 到 C++、到 Pascal、到 Go,基本上都是胜利一方的派别。而另一方现在几乎都被遗忘了,但有两个大的例子。一个是已故伟大的 <ruby> <a href="https://www.theregister.com/2011/10/24/father_lisp_ai_john_mccarthy_dies/"> 约翰·麦卡锡 </a> <rp> ( </rp> <rt> John McCarthy </rt> <rp> ) </rp></ruby> 创造的 Lisp,以及 [整个基于 Lisp 的操作系统](https://www.theregister.com/2022/03/29/non_c_operating_systems/) 所运行的 Lisp 机器。另一个是 [Smalltalk 和施乐公司的 Alto](https://www.theregister.com/2023/03/16/the_xerox_alto_50_years/)。

麻省理工学院第一次尝试建造运行 Lisp 的计算机是一台 1974 年的原型机,名为 [CONS](http://gunkies.org/wiki/CONS),它以 Lisp 的一个关键词命名。1979 年,它更成功的后代被称为 [CADR](http://gunkies.org/wiki/CADR)。CADR 计算机后来成为两家商业 Lisp 机器公司 LMI 和 Symbolics 的首批产品的基础,后者拥有互联网上的第一个 .com 域名。这些公司的成立,以及它们的软件的分拆,[开始了](https://www.gnu.org/gnu/rms-lisp.html) 一个叫 <ruby> 理查德·斯托曼 <rp> ( </rp> <rt> Richard Stallman </rt> <rp> ) </rp></ruby> 的年轻黑客的职业生涯。
这条蓝色的导火索启动了 Emacs、GNU 项目,以及 <ruby> 自由软件运动 <rp> ( </rp> <rt> Free Software movement </rt> <rp> ) </rp></ruby>。该项目建立了 GCC 等工具,这些工具被用来创建 Linux,而 Linux 本身也启动了 <ruby> 开源运动 <rp> ( </rp> <rt> Open Source movement </rt> <rp> ) </rp></ruby>。
这次恢复的软件是麻省理工学院 CADR Lisp 机器的系统软件的最终版本。该软件是从麻省理工学院 <ruby> <a href="https://archivesspace.mit.edu/repositories/2/resources/1265"> 技术广场磁带 </a> <rp> ( </rp> <rt> Tapes of Tech Square </rt> <rp> ) </rp></ruby>(ToTS)收藏中的备份磁带上提取的,但它花了十年的时间来提取数据,对其进行清理,并使其在 35 年后首次运行。这是一个庞大的 [工程](https://tumbleweed.nu/lm-3/)。
是的,如今可以运行这个软件,至少在软件模拟器上可以运行,比如最初由 [Brad Parker](http://www.unlambda.com/) 开发的 [usim](https://lisp-machine.org/hacking-usim-a-mit-cadr-lisp-machine-emulator/)。它的源代码和一些历史都在 [GitHub](https://github.com/unya/usim) 上。
---
via: <https://www.theregister.com/2023/03/31/mit_cadr_software_recovered/>
作者:[Liam Proven](https://www.theregister.com/Author/Liam-Proven) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-15684-1.html) 荣誉推出
| 200 | OK | This article is more than **1 year old**
# Version 100 of the MIT Lisp Machine software recovered
## A new version of very old software for a very old, but very important, computer
The LM-3 project has announced version 100, the last ever release of the system software for the MIT CADR Lisp Machine. So, both a new release and a very old one all at once.
[News](https://www.linkedin.com/pulse/mit-lisp-machine-final-version-recovered-after-35-years-eric-moore/) of this release came yesterday in a LinkedIn post by IBM's Eric Moore, who helped in the recovery effort. A more detailed [post](https://tumbleweed.nu/r/bug-lispm/forumpost/7475d8a3db) from the restoration project describes what the software is, and from where it was recovered.
Why does it matter? Well, this piece of software, and the machines it ran on, are markers, memorials of a significant battle. That battle was one stage in a war: a war of rival ways to make computers. "History is written by the victors," as Winston Churchill [wasn't](https://slate.com/culture/2019/11/history-is-written-by-the-victors-quote-origin.html) the first to say.
This war was, like most, between two rival camps. One side believed the right way to make computers was to write the best possible software in the best possible language, and if necessary, design special fancy computers to run that software. The other side believed the right way to make computers was to make software and hardware that was small, quick, easy, and simple, that did what most people needed at that point in time.
And again, like most wars, this one was long and vicious, with some dirty in-fighting on both sides. In the end, one side conclusively won, but it took long enough that the winners were mostly the descendants and relatives of the people who started fighting. Today, they don't even remember that there was a war at all, and the winning side ended up incorporating a lot of ideas and technologies from the losers. The end result was that the software wasn't small, or quick, or easy, or simple. The side that won forgot that they were fighting or that there was anyone to fight against.
When the winners forget they've won, or that they were fighting, that means that the losing side get to write some of the best summaries of the war. One famous account is a 1991 article called [Lisp: Good News, Bad News, How to Win Big](https://www.dreamsongs.com/WIB.html), which says:
The two philosophies are called *The Right Thing* and *Worse is Better*.
The Right Thing is the MIT/Stanford style of design. The other side?
Early Unix and C are examples of the use of this school of design, and I will call the use of this design strategy the New Jersey approach.
The article is only a few pages long, but if you don't have the time right now, there's a quite short, readable extract called [Worse is Better](https://www.dreamsongs.com/WorseIsBetter.html).
In other words, one side started up at MIT and Stanford University, and they ended up designing a type of computer called a Lisp Machine. The other side built Unix and later special workstations to run Unix fast, which needed special processors designed to run compiled C code fast, known as RISC chips. Intel and AMD adapted some of the techniques and methods from RISC into the 486 and Pentium Pro, and AMD with the Opteron and x86-64, and as a result x86 PCs ended up driving RISC workstations off the market. Today, though, thanks to [Apple Silicon Macs](https://www.theregister.com/2023/01/17/apple_m2_max_pro/) on the high end and [RISC-V](https://www.theregister.com/2023/02/09/balthazar_free_hardware_laptop/) on the low end, RISC is enjoying a renaissance.
But x86, and RISC and CISC, and the whole family of languages [based on Algol](https://www.theregister.com/2020/05/15/algol_60_at_60/), including everything from BASIC to C++ to Pascal to Go, are basically factions on the winning side. The other side is largely forgotten now, but there are two big examples. One is Lisp, as created by [the late great John McCarthy](https://www.theregister.com/2011/10/24/father_lisp_ai_john_mccarthy_dies/), and the Lisp Machines that [entire Lisp-based operating systems](https://www.theregister.com/2022/03/29/non_c_operating_systems/) ran on. The other is [Smalltalk and the Xerox Alto](https://www.theregister.com/2023/03/16/the_xerox_alto_50_years/).
MIT's first attempt to build a computer to run Lisp was a 1974 prototype called [CONS](http://gunkies.org/wiki/CONS), named after a Lisp keyword. In 1979, its more successful offspring was called [CADR](http://gunkies.org/wiki/CADR). The CADR computer went on to form the basis of the first products of two commercial Lisp Machine companies, LMI and Symbolics, the latter of whom had the first ever dot-com domain on the Internet. The founding of these companies, and the splitting of their software, [started](https://www.gnu.org/gnu/rms-lisp.html) the career of a young hacker called Richard Stallman.
[Croquet for Unity: Live, network-transparent 3D gaming... but it's so much more](https://www.theregister.com/2023/03/23/croquet_for_unity/)[ReMarkable emits Type Folio keyboard cover for e-paper tablet](https://www.theregister.com/2023/03/16/remarkable_launches_type_folio_keyboard/)[The quest to make Linux bulletproof](https://www.theregister.com/2023/02/16/bulletproof_linux/)[Linux luminaries discuss efforts to bring Rust to the kernel](https://www.theregister.com/2022/09/16/rust_in_the_linux_kernel/)
This is the blue touchpaper that started Emacs, the GNU Project, and so the Free Software movement. That project built tools such as GCC which were used to create Linux, which itself kicked off the Open Source movement.
What's been recovered is the final version of the system software of the MIT CADR Lisp Machine. The software was pulled off a backup tape in MIT's *Tapes of Tech Square* collection, or [ToTS](https://archivesspace.mit.edu/repositories/2/resources/1265) for short, but it's taken a decade of work to extract the data, clean it up, and get it running for the first time in 35 years. It's a big [project](https://tumbleweed.nu/lm-3/).
And yes, it is possible to run the software today, at least on software emulators, such as [usim](https://lisp-machine.org/hacking-usim-a-mit-cadr-lisp-machine-emulator/), originally by [Brad Parker](http://www.unlambda.com/). Its source and some history are on [Github](https://github.com/unya/usim). ®
### Bootnote
Thanks to reader Mike W for letting us know about this.
48 |
15,693 | 使用 Python 在 Mattermost 中创建 ChatOps 聊天机器人 | https://opensource.com/article/23/3/chatbot-mattermost-python | 2023-04-05T09:28:39 | [
"ChatOps"
] | https://linux.cn/article-15693-1.html | 
>
> 用一个简单的开源机器人在你的组织中实施 ChatOps。
>
>
>
ChatOps 是一种协作模型,它将人员、流程、工具和自动化连接到一个透明的工作流中。[Mattermost](https://mattermost.com/) 是一个开源、自托管的消息平台,使组织能够安全、有效和高效地进行通信。它是 Slack、Discord 和其他专有消息平台的绝佳 [开源替代品](https://opensource.com/alternatives/slack)。本文概述了在 Mattermost 上创建 ChatOps 机器人的步骤,包括必要的代码示例和解释。
### 先决条件
在开始之前,请确保你可以访问 Mattermost 服务器,[安装 Python](https://opensource.com/article/17/10/python-101),并 [使用 pip](https://opensource.com/article/20/3/pip-linux-mac-windows) 安装 Mattermost Python 驱动。
### 在 Mattermost 上创建一个机器人帐户
要创建机器人帐户,请访问 Mattermost 系统控制台,并添加具有适当访问权限的机器人帐户。获取机器人的用户名和密码以在 Python 脚本中使用。
### 设置 Mattermost Python 驱动
使用 `pip` 安装 Mattermost Python 驱动,并将其导入 Python 脚本。创建一个新的驱动实例并登录到 Mattermost 服务器。
### 在 Python 中创建 ChatOps 机器人
创建一个新的 Python 脚本,定义要导入的必要库,并使用 Mattermost 驱动的 API 实现机器人的功能。编写代码来处理消息、命令和其他事件,并使用 Mattermost 驱动的 API 方法向通道和用户发送消息和通知。最后,调试和测试 ChatOps 机器人。
### ChatOps 机器人代码示例
以下是响应用户消息的简单 ChatOps 机器人的示例 Python 代码:
```
from mattermostdriver import Driver
bot_username = 'bot_username'
bot_password = 'bot_password'
server_url = 'https://your.mattermost.server.url'
def main():
driver = Driver({'url': server_url, 'login_id': bot_username, 'password': bot_password, 'scheme': 'https'})
driver.login()
team = driver.teams.get_team_by_name('team_name')
channel = driver.channels.get_channel_by_name(team['id'], 'channel_name')
@driver.on('message')
def handle_message(post, **kwargs):
if post['message'] == 'hello':
driver.posts.create_post({
'channel_id': post['channel_id'],
'message': 'Hi there!'
})
driver.init_websocket()
if __name__ == '__main__':
main()
```
### 添加功能
在 Mattermost 上创建基本的 ChatOps 机器人后,你可以添加更多功能来扩展其功能。以下是步骤:
* **确定要添加的功能**:在编写代码之前,你必须确定要添加到 ChatOps 机器人的功能。可以是从发送通知到与第三方工具集成的任何事情。
* **编写代码**:确定要添加的功能后,就可以开始编写代码了。代码将取决于添加的功能,但你可以使用 Mattermost Python 驱动与 Mattermost API 交互并实现该功能。
* **测试代码**:编写代码后,重要的是对其进行测试以确保其按预期工作。在将其部署到生产服务器之前,你可以在开发服务器或测试通道中测试代码。
* **部署代码**:当你对其进行了测试并且它按预期工作,你就可以将其部署到你的生产服务器。遵循你组织的部署流程并确保新代码不会破坏任何现有功能。
* **记录新功能**:记录你添加到 ChatOps 机器人的新功能非常重要。这将使其他团队成员更容易使用该机器人并了解其功能。
一个 ChatOps Bot 功能示例是与第三方工具集成并提供某些任务的状态更新。
```
from mattermostdriver import Driver
import requests
bot_username = 'bot_username'
bot_password = 'bot_password'
server_url = 'https://your.mattermost.server.url'
def main():
driver = Driver({'url': server_url, 'login_id': bot_username, 'password': bot_password, 'scheme': 'https'})
driver.login()
team = driver.teams.get_team_by_name('team_name')
channel = driver.channels.get_channel_by_name(team['id'], 'channel_name')
@driver.on('message')
def handle_message(post, **kwargs):
if post['message'] == 'status':
# Make a request to the third-party tool API to get the status
response = requests.get('https://api.thirdpartytool.com/status')
if response.status_code == 200:
status = response.json()['status']
driver.posts.create_post({
'channel_id': post['channel_id'],
'message': f'The status is {status}'
})
else:
driver.posts.create_post({
'channel_id': post['channel_id'],
'message': 'Failed to get status'
})
driver.init_websocket()
if __name__ == '__main__':
main()
```
在此示例中,ChatOps 机器人监听命令 `status` 并向第三方工具 API 发出请求以获取当前状态。然后它会在发出命令的 Mattermost 频道中发布状态更新。这使团队成员无需离开聊天平台即可快速获取任务状态的更新。
### 开源 ChatOps
总之,在 Mattermost 上创建 ChatOps 机器人是一个简单的过程,可以为你组织的沟通和工作流程带来许多好处。本文提供了分步分解和代码示例,可帮助你开始创建你的机器人,甚至可以通过添加新功能对其进行自定义。现在你了解了基础知识,你可以进一步探索 ChatOps 和 Mattermost 以优化团队的协作和生产力。
---
via: <https://opensource.com/article/23/3/chatbot-mattermost-python>
作者:[Dr. Michael J. Garbade](https://opensource.com/users/drmjg) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ChatOps is a collaboration model that connects people, processes, tools, and automation into a transparent workflow. [Mattermost](https://mattermost.com/) is an open source, self-hosted messaging platform that enables organizations to communicate securely, effectively, and efficiently. It's a great [open source alternative](https://opensource.com/alternatives/slack) to Slack, Discord, and other proprietary messaging platforms. This article outlines the steps to create a ChatOps bot on Mattermost, including the necessary code examples and explanations.
## Prerequisites
Before starting, ensure that you have access to a Mattermost server, have [Python installed](https://opensource.com/article/17/10/python-101), and have installed the Mattermost Python driver [using pip](https://opensource.com/article/20/3/pip-linux-mac-windows).
## Create a bot account on Mattermost
To create a bot account, access the Mattermost System Console, and add a bot account with appropriate access permissions. Retrieve the bot's username and password for use in the Python script.
## Set up the Mattermost Python driver
Install the Mattermost Python driver using `pip`
, and import it in the Python script. Create a new driver instance and log in to the Mattermost server.
## Create the ChatOps bot in Python
Create a new Python script, define the necessary libraries to be imported, and implement the bot's functionality using the Mattermost driver's API. Write code to handle messages, commands, and other events, and use the Mattermost driver's API methods to send messages and notifications to channels and users. Finally, debug and test the ChatOps bot.
## Example of ChatOps bot code
Here is an example Python code for a simple ChatOps bot that responds to a user's message:
```
``````
from mattermostdriver import Driver
bot_username = 'bot_username'
bot_password = 'bot_password'
server_url = 'https://your.mattermost.server.url'
def main():
driver = Driver({'url': server_url, 'login_id': bot_username, 'password': bot_password, 'scheme': 'https'})
driver.login()
team = driver.teams.get_team_by_name('team_name')
channel = driver.channels.get_channel_by_name(team['id'], 'channel_name')
@driver.on('message')
def handle_message(post, **kwargs):
if post['message'] == 'hello':
driver.posts.create_post({
'channel_id': post['channel_id'],
'message': 'Hi there!'
})
driver.init_websocket()
if __name__ == '__main__':
main()
```
## Add features
Once you've created a basic ChatOps bot on Mattermost, you can add more features to extend its functionality. Here are the steps:
-
**Determine the feature you want to add**: Before writing the code, you must determine the feature to add to your ChatOps bot. This can be anything from sending notifications to integrating with third-party tools. -
**Write the code**: Once you have determined the feature you want to add, you can start writing the code. The code will depend on the feature you add, but you can use the Mattermost Python driver to interact with the Mattermost API and implement the feature. -
**Test the code**: After writing the code, it's important to test it to ensure that it works as expected. Before deploying it to your production server, you can test the code on a development server or in a test channel. -
**Deploy the code**: Once you have tested it and it works as expected, you can deploy it to your production server. Follow your organization's deployment process and ensure the new code doesn't break any existing functionality. -
**Document the new feature**: It's important to document the new feature you have added to your ChatOps bot. This will make it easier for other team members to use the bot and understand its capabilities.
One example of a ChatOps Bot feature could be integrating with a third-party tool and providing status updates on certain tasks.
```
``````
from mattermostdriver import Driver
import requests
bot_username = 'bot_username'
bot_password = 'bot_password'
server_url = 'https://your.mattermost.server.url'
def main():
driver = Driver({'url': server_url, 'login_id': bot_username, 'password': bot_password, 'scheme': 'https'})
driver.login()
team = driver.teams.get_team_by_name('team_name')
channel = driver.channels.get_channel_by_name(team['id'], 'channel_name')
@driver.on('message')
def handle_message(post, **kwargs):
if post['message'] == 'status':
# Make a request to the third-party tool API to get the status
response = requests.get('https://api.thirdpartytool.com/status')
if response.status_code == 200:
status = response.json()['status']
driver.posts.create_post({
'channel_id': post['channel_id'],
'message': f'The status is {status}'
})
else:
driver.posts.create_post({
'channel_id': post['channel_id'],
'message': 'Failed to get status'
})
driver.init_websocket()
if __name__ == '__main__':
main()
```
In this example, the ChatOps bot listens for the command "status" and makes a request to a third-party tool API to get the current status. It then posts the status update in the Mattermost channel where the command was issued. This allows team members to quickly get updates on the status of the task without having to leave the chat platform.
## Open source ChatOps
In summary, creating a ChatOps bot on Mattermost is a simple process that can bring numerous benefits to your organization's communication and workflow. This article has provided a step-by-step breakdown and code examples to help you get started on creating your bot and even customize it by adding new features. Now that you know the basics, you can further explore ChatOps and Mattermost to optimize your team's collaboration and productivity.
## Comments are closed. |
15,694 | Debian 12 “Bookworm” 的新功能和改进 | https://www.debugpoint.com/debian-12-features/ | 2023-04-05T11:20:00 | [
"Debian"
] | /article-15694-1.html | 
>
> 让我们给你总结一下即将发布的 Debian 12 “Bookworm” 的新功能和改进。
>
>
>
Debian 12 已经开发了几个月了,并且正在慢慢走向最终的发布版本。截止发稿时, 它当前正处于冻结状态下。这意味着预计不会有重大的软件包更改或改进。
这个发布版本带来一些新功能和改进,使其成为 Debian 爱好者期待的一个版本。在这篇文章中,我们将讨论 Debian 12 “Bookworm” 的最好的新功能,以及它们如何使用户受益。
让我们来看看。

### Debian 12 “Bookworm” 的新功能和改进
#### Linux 内核
这个发布版本采用了发布于 2022 年 12 月的 Linux 主线内核 6.1。从时间线上看,到目前为止,Debian 12 的内核版本号只比最新内核落后一个版本。因此,你将通过使用稳定的 Linux 内核 6.1 来获得最新的和最好的硬件支持。
这个内核的亮点功能包括:初步支持 Rust 框架、更新支持英特尔和 AMD 即将推出的 CPU/GPU 系列硬件、改善 Btrfs 和其它文件系统系统的性能等等。
如果你想要了解更多的话,我们已经有一篇关于 [内核 6.1 特性](https://www.debugpoint.com/linux-kernel-6-1/) 的专题文章。
#### 在安装程序中的非自由软件包
在 Debian 12 中出现了一个与 Debian 的 ISO 文件有关的重大更改。最初,Debian 就分别针对 “自由” 和 “非自由” 软件包提供了不同的 ISO 文件。专有的 “非自由” 软件包是单独的 ISO 文件的一部分。因此,如果你需要针对你的特殊硬件的驱动支持,那么你可以针对你的笔记本/台式机/服务器下载不同的 ISO 文件。
然而,这种体验使终端用户在选择恰当的 Debian 的 ISO 时感到迷惑。为此,Debian 团队去年发起一次社区投票,以选出如何处理 “非自由” 的最好的选项。
根据 [选出的结果](https://lists.debian.org/debian-vote/2022/10/msg00000.html) , 现在,基本的 ISO 文件现在包含 “自由” 和 “非自由” 的软件包。
那么,发生了什么变化?
在我们尝试现在官方的 Debian 的 ISO 文件时,你只需要选择一个包含所有东西的 ISO 文件 (DVD 大小的体积)。此外,也提供小型的网络安装的 ISO 文件,包含 “非自由” 固件。
你可以查看关于 Debian 的 ISO 文件的 [这篇指南](https://www.debugpoint.com/download-debian-iso/) 。
#### GNOME 在默认情况下使用 Pipewire
如果你在 Debian Linux 中使用 GNOME 桌面环境,那么,给你带来一个好消息。
Debian 12 和 GNOME 桌面环境 [在默认情况下,使用 Pipewire 和 Wireplumber 管理器](https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=1020249) 作为声音服务器,取代了 Pulseaudio 。现代化的 Pipewire 早就已经引入 Ubuntu 、Fedora 、Pop!\_OS 等其它领先的发行版。

#### 新版本的 Apt 软件包管理器(2.6)
Debian 12 引入 Apt 软件包管理器的最新的版本。[Apt 2.6](https://launchpad.net/ubuntu/+source/apt/+changelog) 版本专门处理了这个版本中引入的非自由 ISO 镜像支持。这些更改包含:默认启用非自由固件,Apt 将显示非自由软件包的更新。
#### 桌面环境
在 Debian 12 中,除 GNOME 桌面环境外,所有的主流桌面环境都是最新的。这是因为 [GNOME 44](https://www.debugpoint.com/gnome-44/) 才刚刚发布,由于工作日程计划不一样,因此它没有进入 “Bookworm” 。Debian 12 已经处于硬冻结状态。
因此,在 Debian 12 中,你将得到 [GNOME 43](https://www.debugpoint.com/gnome-43/) 版本,与最新的发布版本相比,它也没有落后多少。此外,如果你从 [Debian 11](https://www.debugpoint.com/debian-11-features/) 转换而来,那么,这将是一次重大的 GNOME 升级。
幸运的是,[KDE Plasma 5.27](https://www.debugpoint.com/kde-plasma-5-27/) 现在可以在这个发布版本中使用了。KDE Plasma 是 Plasma 5 的最终版本,并且在 Plasma 6 版本准备好之前,它可能会成为 LTS 。因此,它是一次重要的升级。KDE Plasma 维护人员成功地实现了这一目标。
另外,在 Debian 12 中的 [Xfce 4.18](https://www.debugpoint.com/xfce-4-18-review/) 通过令人惊艳的 Thunar 的特色功能带来了更好的桌面体验。此外,在 Debian 12 中,LXQt 1.2 、MATE 1.26 和 LXDE 11 都是最新的版本。
这里有一份摘要:
* GNOME 43
* KDE Plasma 5.27
* LXDE 11
* LXQt 1.2
* MATE 1.26
* Xfce 4.18
#### 核心模块和应用程序
大多数主要的应用程序都已经刷新版本。尤其是,Python 3.11 已经包含在 Debian 12 中,这将有助于帮助开发者和很多使用情况。此外,LibreOffice 7.4 和 Firefox 102.9 ESR 也是两个重要的更新。这里有一份关于主要应用程序和软件包升级的小列表:
* LibreOffice 7.4.4
* Firefox 102.9 ESR
* GIMP 2.10.32
* OpenJDK 11.6
* PHP 8.2
* Python 3.11+
* Samba 4.17
#### 杂项更新
* Debian 12 现在在双启动设置时可以检测到 Windows 11
* 在 Debian 和 Cinnamon 桌面环境中,默认启用支持屏幕阅读器
* 在 30 秒超时后,自动启动语音合成
* 更容易地检测多路径设备
* 支持多个 initrd 路径
* 支持新的 ARM 和 RISC-V 设备
* 放弃实验性的 DMRAID 支持
你可以 [在这里](https://lists.debian.org/debian-devel-announce/2022/09/msg00004.html) 了解更多的变化。
#### 默认的主题和墙纸
在每一次发布版本中,Debian 都会从引入一些来自社区的令人惊叹的艺术作品。Debian 12 以 “<ruby> 绿宝石 <rt> Emerald </rt></ruby>” 作为默认的艺术作品主题。
“*经过抛光和凿刻,或在它们原始和纯天然的状态下,宝石可以有无限的形状。”*
通过 Emerald 主题,创建者希望将光线与矿物质以一种简洁至近乎空灵的设计结合在一起。
默认主题和横幅可以在安装程序、动画 Plymouth 、壁纸等所有的位置都可以看到。
这里是一些选自 [官方画廊](https://wiki.debian.org/DebianArt/Themes/Emerald) 的图片。


### 如何下载 Debian 12
**注意**: Debian 12 尚未发布稳定版本。因此,不要在正式工作中使用它,也不要从 Bullseye 升级到 “Bookworm” 。
如果你正在运行 Debian 11 “Bullseye” ,你可以通过任意的文本编辑器来打开 `/etc/apt/sources.list` ,并添加下面的命令行。务必验证镜像 URL ,并更改下面的命令行。
```
deb http://http.us.debian.org/debian bookworm main non-free contrib
deb http://security.debian.org/ bookworm/updates main contrib non-free
deb http://http.us.debian.org/debian sid main non-free contrib
```
在添加这些命令行后,刷新 `apt` 缓存:
```
sudo apt update
```
接下来,运行下面的命令行来获取更新:
```
sudo apt dist-upgrade
```
下载全新的 ISO 文件,访问任意一个下面的链接。
>
> **[下载 Debian 12 (DVD) ISO – Alpha2](https://cdimage.debian.org/cdimage/bookworm_di_alpha2/amd64/iso-dvd/)**
>
>
>
### 总结
总而言之,Debian 12 “Bookworm” 是一个令人印象深刻的版本,带来了一些新的特色功能和改善。从最新的桌面环境到新内核和更新的软件包,这个发布版本为新用户和有经验的 Debian 用户都提供了很多东西。
因为它专注于稳定性、安全性和开源原则,所以,对于那些寻求替换 Ubuntu 和通用操作系统的人来说,Debian 12 “Bookworm” 可能是最好的选择。
这个版本的最终版本预期在 2023 年第二季度发布。
>
> **[Debian 12 更改日志(有点过时了)](https://www.debian.org/releases/bookworm/amd64/release-notes/ch-whats-new.en.html)**
>
>
>
---
via: <https://www.debugpoint.com/debian-12-features/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,696 | 技术领域小白必不可少的工作技巧和诀窍 | https://opensource.com/article/23/2/your-first-tech-job | 2023-04-06T00:07:00 | [
"技术工作"
] | /article-15696-1.html | 
>
> 开始一份新工作对任何人来说都让人害怕。下面是如何在你的第一份技术工作的早期阶段找到方向。
>
>
>
刚刚入职那几天确实令人害怕。 我现在依然可以清晰举出很多例子,例如在第一天上班前的晚上无法入睡,因为不知道第二天将要发生什么而内心崩溃。对于大多数人来说,开始一份新工作就像踏入未知领域。即使你已是行业的资深人士,不可否认的是,你内心可能还是会对即将发生的事情感到有点害怕。
可以理解的是,刚入职的时候你的事情很多。你要认识新的人,有新的项目和技术要了解,有文档要阅读,有教程要看完,还有没完没了的人事培训和要填的文件。这可能让你感觉压力山大,再加上你还面临着相当大程度的不确定性和未知数,以上种种能引起焦虑。
促使我写这篇文章有两个原因,首先是在我还是学生的时候,大部分讨论都围绕着如何找一份技术工作,却没有人谈论接下来发生的事情。如何在新角色中脱颖而出?现在回过头来看,我想我当时认为最困难的事情是得到一份工作,之后发生什么的一切我都可以自己弄清楚。
同样的,在我开始在这个行业工作之后,我发现大部分我看到的与职业相关的内容都是讨论如何从一个高级职位升到另一个高级职位。没有人真正谈论在此中间我们要做什么。实习生和初级工程师呢?他们在早期职业生涯中如何找到方向?
在拥有了三年全职软件工程师的经验(以及之前的几次实习)之后,我将这段时间的经历进行了复盘,并整理出一份我自己在适应新技术职位时使用过的技巧和诀窍清单。我想不只局限于前面的几个月,而是优先考虑如何让这段经历帮助你实现长期的成功。
### 反思现有的流程和文档
大多数新员工一开始要么拥有一大堆文档,要么根本没有。你可以将这视为一个机会,而不是被这两种可能性中的任何一种所淹没。
从现有文档中找到缺口,并想想你可以怎样为下一位入职的工程师做出这方面的改进。这不仅能显示你工作的主动性,还表明你致力于改进团队中的现有流程。
上述两种极端情况我都遇到过。我在没有任何文档的团队中工作过,也在一些更新文档方面很勤快的团队中工作过。对于前者,你的路径非常简单直接,你可以致力于创建那些缺失的文档。对于后者,你总是可以想办法改进已有的东西。有时,过多的书面文件也会让人感到害怕,尤其是对新员工而言。有些事情可能通过其他媒介进行更好地解释,比如视频教程或截屏。
### 勤问问题
我会建议你在开始一份新工作时研究一下公司是否会为你分配搭档。这在公司中是相当普遍的做法。工作搭档的主要作用是在你入职时为你提供帮助。我发现这非常有用,因为这个人能够针对你所有的问题给出指导,你就不必为了寻找合适的人或部门而四处奔波。
虽然我鼓励提问,但在提问之前也有必要做功课,包括:
* 做好调查。这包括进行网络搜索、查看论坛和阅读现有文档。使用所有可用的工具。然而,给自己设定时间规划是很重要的。你必须平衡好尽职调查与牢记手头项目截止日期和可交付成果。
* 说出来。作为母语不是英语的人,我建议你在提问之前大声把想法说出来。根据我的经验,我经常发现自己会用一种语言(通常是我的母语)思考但不得不用另一种语言来解释,而当我在一些困难的问题中挣扎时这一现象尤为突出。有时这颇有挑战性,因为经过翻译后的想法可能没那么容易理解。
* 组织思绪。当你在为某件事而苦苦挣扎时,可能同时有很多不同的想法在你的脑海中翻来覆去。这些想法可能对你来说都挺有道理的,但对于别人来说却不一定说得通。对此,我建议你坐下来,收集你的想法,写下来,然后大声说出来。这一做法可确保当你在解释自己的思维过程时,你能按照预期进行流畅地表达出来,听众也可以紧跟你的思路。
这种方法称为橡皮鸭调试法,是开发人员在调试时的常见做法。背后的概念是,有时向第三方解释你的问题非常有助于你找到解决方案,同时也证明了你出色的沟通技巧。
尊重别人的时间。即使你在向你的搭档求助时,也要意识到他们也有自己的日常任务要完成。 我尝试过的一些事情包括:
* 写下我的问题,然后留出一些时间与我的导师交流,以便与他们交谈。
* 整理问题而不是反复寻求帮助,这样导师可以在他们有空的时候着手解决。
* 安排 15-20 分钟的快速视频聊天,特别是如果你想共享屏幕,这一方法可以很好地展示你的发现。
我认为这些方法是更好的选择,因为这么做你能得到对方全部的关注,而不是在他们忙着其他事情的时候每隔几分钟打扰他们一下。
### 深入研究你的项目
即使在拥有出色文档的团队中,开始你的技术项目也可能非常艰巨,因为一个项目涉及多个部分。不过,随着时间的推移,你将了解团队是如何做事的。但是,通过记下一张实用清单,这包括基本项目设置、测试要求、审查和部署流程、任务跟踪和文档,你将迅速搞清楚一切,节省了你的时间和潜在的麻烦。
如果你开始的项目没有文档(我就遇到过这种情况),请看看你能不能找到当前或以前的项目所有者并了解基本的项目结构,这包括设置、部署等。
* 确定你的团队在 IDE(集成开发环境)中的偏好。你可以自由使用你喜欢的 IDE,但使用和团队相同的 IDE 会比较好,尤其是在调试的时候,因为 IDE 的选择会影响调试。不同的 IDE 提供不同程度的调试支持。
* 了解如何进行调试。我的意思不仅仅是使用打印语句(不是说这种方法有什么问题)。充分利用团队的经验!
* 了解测试要求。这可能取决于项目的范围和团队的一般惯例,越早弄清楚要求,你在后期推送自己的修改请求时就会越有信心。
* 可视化部署过程。这个过程可能因团队、公司等而异。无论这个过程是非正式或正式,请确保你了解自己提交的新代码是如何被部署至新环境中、部署流水线是什么样的、如何安全地部署代码更改、在构建失败后可以怎么做,如何回滚错误的更改,以及如何在生产环境中测试你的更改。
* 了解工单流程。了解如何记录工单以及要求的详细程度。你会由此发现每个公司各不相同。有的公司希望我们每天提交工单以显示我们的进度。有的公司可能不需要如此详细。
基于我刚才提到的所有内容,我建议你可以在入职头几周内做一个有益的、一体化的练习——跟随模仿另一位工程师并进行结对编码。这么做让你可以端到端地观察整个流程,从派单给工程师到部署到生产中都清清楚楚。
如果刚入职几周时你还没有机会亲身实践,可能你会感到沮丧。为了解决这个问题,你可以让你的经理也给你派一些初级的单子。这些通常是一些小任务,例如代码清理或添加单元测试。不过,它们允许你修补代码库,这有助于提高你的理解并给你带来成就感,这在新工作的初期是非常鼓舞人心的。
### 当你遇到困难时尤其要大声说出来
我想强调一下当你碰到困难时沟通的重要性。遇到困难总是难免的,尤其是在一份新工作的最初几个月,尽管这可能会令人沮丧,但这正是你的沟通技巧大放异彩的地方。
* 让工作中的阻碍和进步透明化。即使是像权限问题一样的小事(新员工常常遇到的障碍之一),也要确保你的经理知道。
* 如果有些工作耽搁了,不要等到最后一天才向团队报告。你的项目延迟会推动许多其他事情的发展。对于一些必要的项目延迟请提前告知,以便你的经理可以与相关人员分享这一信息。
* 不要因为匆忙而忘记全面测试代码的更改或为你的代码的写文档等事情。
### 获得技术大局观
获得技术大局观是我个人一直在努力改进的地方,并且我一直在积极改变自己对此的看法。
当年我开始实习时,我会非常专注于自己想学的东西。我会非常专注于我的项目,但对其他一切完全视而不见。多年后,我意识到对其他或相邻的项目视而不见可能不是最明智的。
首先,技术大局观会影响你对自身工作的理解。我曾经天真地以为,只要我专注于自己的项目就可以成为一名优秀的工程师。但事情并非如此。你应该花时间了解其他可能与你的项目有所交互的服务。你无需深入了解细节,但建立基本的理解也会大有帮助。
新员工的一个普遍经历是与公司其他人脱节,会有这种感觉很正常,尤其是在大公司。我是一个很快就会产生排斥感的人,所以当我刚到 Yelp 时 —— 这是一家比我以前的公司大得多的公司,项目规模也大得多,我优先考虑了解大局。我不仅努力建立对我的项目的理解,还认真了解了其他相邻项目。
在 Yelp 的头几周,我与团队中的其他各位工程师坐下来,请他们给我一个关于我将要做什么和项目的总体目标的概况。这种方法非常有用,因为我不仅根据工程师的资历和他们在项目上的工作时间得到了不同程度的解释,而且还加深了我对我将要从事的工作的理解。我参加这些会议的目的,是希望我对项目掌握的认识让我能够向街上的陌生人解释我所做的事。为此,我还请我的技术主管向我解释,当用户打开 Yelp 应用程序并搜索内容时,我的工作成果会在什么时候出现。
在这种情况下架构图也很有用,尤其是它能帮助你了解不同服务是如何交互的。
### 建立期望
在过去很长一段时间里,我以为自己只需要尽力而为,成为一名优秀的员工就行。只要我有在工作,达成目标,而且没有人投诉,那就足够好了,对吧?错!
你必须对你的职业有战略眼光。你不能只是将它外包给人们的一片好心,并希望自己只要达成了目标就能得到想要的结果。
* 在你开始新工作的那一刻就建立明确的标准。这因公司而异,因为有些组织有非常明确的措施,而其他组织可能几乎没有。如果是后者,我建议你在头几周内找你的经理坐下来谈谈,制定并统一一个标准。
* 确保你彻底了解公司将如何评估你以及采用什么方法进行评估。
我记得在我的第一份全职工作中,我对自己的第一次评估谈话一头雾水。整个谈话非常含糊不清,而且我对自己的长处、短处甚至可以如何改进都一无所知。
起初,我很容易地将一切都归咎于我的经理,因为作为新员工的我认为这是他们的工作,而不是我的职责。但随着时间的推移,我意识到,就我的绩效评估而言,我不能只是袖手旁观。你不能只做好工作并期望它就足够了。你必须积极参与到这些对话中。你必须确保你的努力和贡献被注意到。为了确保你的工作得到认可,你可以做很多事情,从定期参与技术设计对话到设置团建活动。
与建立期望相联系的还有积极寻求反馈的重要性。不要等到每三、四个月进行一次正式的绩效评估时才知道自己的表现如何。积极与你的经理建立反馈循环。虽然这听起来很可怕,但尝试定期进行寻求反馈的谈话。
### 在分布式团队中找到方向
在过去两年中我们的工作场所在不断变化,如今在远程和分布式团队中工作已成为常态,不再罕见。我列出了一些技巧,帮助你在分布式团队中快速找到工作方向:
* 建立核心时间并将其设置在你的日历上。核心时间是你的团队一致同意的几个小时,在这段时间里,大家都明白自己应该在线并能随时响应。这样做很方便,因为会议只会安排在这个时间段,让你在计划自己一天的工作时更轻松。
* 注意人们的时区和午餐时间。
* 在虚拟世界中,你需要付出更大的努力来维持社交互动,而小小的心意却可以大大有助于让工作环境更加友好。其中包括:
* 开始会议时,互相寒暄并询问人们周末/一天过得如何。这有助于打破僵局,让你能够与团队成员建立更私人的、超越工作的联系。
* 建议定期举行非正式的虚拟聚会,与团队进行一些随意的闲聊。
### 维持工作生活间的平衡
在你职业生涯刚开始的时候,你很容易认为只要投入很多时间就能成功,特别是考虑到我们全天候待命的“忙碌文化”,以及认为建立生活工作的平衡是在职业生涯下阶段才需要考虑的想法。但这些想法与事实相去甚远,因为工作与生活的平衡不会神奇地发生在你身上。你需要积极和非常勤奋地去找到个人的平衡点。
没有工作与生活平衡的可怕之处在于它是慢慢蔓延到你身上的。刚开始是你下班后还在查看电子邮件,然后慢慢地,你开始周末也在工作,一直感到疲惫不堪。
我列出了一些提示,可以帮助你避免这种情况:
* 关闭/暂停通知和电子邮件并将自己设置为离线。
* 不要在周末工作。刚开始是你需要在这一个周末工作,但不知不觉间,你会发现自己大部分周末都在工作。不管是什么工作,它可以等到星期一。
* 如果你是待命的工程师,请了解公司的相关政策。一些公司提供金钱补偿,而另一些公司可能会以休假代替。利用这个时间。不使用 PTO(带薪休假)和健康日等福利确实会缩短你的工作寿命。
### 总结
毫无疑问,开始一份新工作压力很大而且很困难。我希望这些方法和技巧会让你的头几个月变得更轻松,并为你在新职位上取得巨大成功做好准备。记住,勤沟通,确立职业目标,积极主动,有效地使用公司的工具。做到这些,我相信你会做得很好!
---
via: <https://opensource.com/article/23/2/your-first-tech-job>
作者:[Fatima](https://opensource.com/users/ftaj) 选题:[lkxed](https://github.com/lkxed/) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,697 | NixOS 系列 #5:如何在 NixOS 上设置主目录管理器 | https://itsfoss.com/home-manager-nixos/ | 2023-04-06T11:06:00 | [
"NixOS"
] | https://linux.cn/article-15697-1.html | 
在发表这篇文章之前,我解释了如何为一个单用户系统 [在 NixOS 中安装和删除软件包](/article-15645-1.html)。
但是,如果你正在供多个用户使用,有一个很好的方法来分别满足每个用户的需求。
在本指南中,我将指导你如何在 NixOS 上设置一个<ruby> 主目录管理器 <rp> ( </rp> <rt> Home Manager </rt> <rp> ) </rp></ruby>,以及如何使用它来安装软件包。
如果你是新读者,本系列中讨论的一些资源包括:
* [使用 NixOS 的原因](/article-15606-1.html)
* [在虚拟机上安装 NixOS](/article-15624-1.html)
* [安装 NixOS 后要做的事情](/article-15663-1.html)
### 在 NixOS 上设置主目录管理器
在本指南中,我将指导你通过 2 种方式来设置主目录管理器:
* 独立的主目录管理器(使用单独的配置文件)
* 作为一个 NixOS 模块(在 `configuration.nix` 文件中使用它)
那么,让我们从独立方式开始。
#### 独立安装的主目录管理器
如果你使用的是 NixOS 的稳定频道,你可以使用以下命令来配置主目录管理器:
```
nix-channel --add https://github.com/nix-community/home-manager/archive/release-22.11.tar.gz home-manager
```
在编写本指南时,稳定版是 `22.11`。
而 **如果你在一个不稳定的频道上**,请使用以下命令:
```
nix-channel --add https://github.com/nix-community/home-manager/archive/master.tar.gz home-manager
```
无论你使用稳定版还是不稳定版,下面的步骤都是一样的。
一旦完成,更新频道:
```
nix-channel --update
```
最后,使用下面的命令来安装主目录管理器:
```
nix-shell '<home-manager>' -A install
```
?️ 在安装时,可能会出现以下错误:

重新启动你的系统并再次使用安装命令,它将开始安装。
一旦完成,它将显示独立安装的主目录管理器的位置:

#### 将主目录管理器安装为 NixOS 模块
>
> ⚠️ 如果你选择将主目录管理器作为 NixOS 模块使用,你将需要 sudo 权限。
>
>
>
如果你在一个稳定的频道上(在写本文的时候,是 `22.11`),你可以使用下面的命令来添加主目录管理器的稳定频道:
```
sudo nix-channel --add https://github.com/nix-community/home-manager/archive/release-22.11.tar.gz home-manager
```
而 **如果你使用的是不稳定通道或主通道**,则使用以下命令:
```
sudo nix-channel --add https://github.com/nix-community/home-manager/archive/master.tar.gz home-manager
```
一旦你使用上面的任何一条命令完成了添加频道的工作,就用下面的方法更新频道:
```
sudo nix-channel --update
```
接下来,用以下方法打开 `configuration.nix` 文件:
```
sudo nano /etc/nixos/configuration.nix
```
并在 `imports []` 中添加以下一行:
```
<home-manager/nixos>
```

现在,跳到该行的末尾,在 `}` 前添加以下内容:
```
home-manager.users.{username} = { pkgs, ... }: {
home.packages = [ ] ;
};
```

上面这一行是为了方便安装和删除软件包而添加的,我接下来会告诉你。
现在,[保存修改并退出 Nano](https://linuxhandbook.com/nano-save-exit/?ref=itsfoss.com) 文本编辑器。
接下来,重建配置,并做一个切换:
```
sudo nixos-rebuild switch
```
但如果你使用的是稳定版,并使用上述命令,就会出现以下错误:
>
> ?️ 错误: 选项 `home-manager.users.user.home.stateVersion` 被使用但没有定义:
>
>
>

要解决这个问题,你必须在你的主目录管理器块中添加 `home.stateVersion`。
在写这篇文章时,我正在运行 22.11,所以整个主目录管理器块看起来像这样:
```
home-manager.users.{username} = { pkgs, ... }: {
home.stateVersion = "22.11";
home.packages = [ ] ;
};
```

保存修改,按 `Ctrl+O`,按回车键和 `Ctrl+X` 退出 Nano 文本编辑器。
现在,试着重建配置并再次进行切换,应该可以解决问题。
### 如何在 NixOS 上使用主目录管理器安装软件包
现在你已经安装了主目录管理器,如何用它来安装软件包:
#### 使用独立安装的主目录管理器
首先,用下面的方法打开配置文件:
```
nano /home/$USER/.config/nixpkgs/home.nix
```
跳到行末,在 `}` 前添加以下代码块:
```
home.packages = [];
```
现在,你所要做的就是在这两个大括号之间写上软件包的名称。
例如,如果我想安装 `htop`,我将得输入以下内容:
```
home.packages = [pkgs.htop];
```
是的,你通常要在软件包的名称后面加上 `pkgs.`。
但是,如果你想在每次安装新包时不使用 `pkgs.`,可以改变代码块的语法,如图所示:
```
home.packages = with pkgs; [];
```
而现在,你不再需要在每次安装时使用 `pkgs.`:
```
home.packages = with pkgs; [htop];
```
例如,在这里,我想安装 `htop`、`firefox`和 `libreoffice`,所以我的 `home` 块会看起来像这样:

一旦你完成了添加你喜欢的软件包,保存配置文件并使用以下命令来安装软件包:
```
home-manager switch
```
#### 使用 NixOS 模块方式
首先,用以下命令打开 `configuration.nix` 文件:
```
sudo nano /etc/nixos/configuration.nix
```
在配置部分,我已经添加了主目录管理器块,所以剩下的就是在 `home.packages = [ ];` 里面添加软件包的名称,格式如图所示:
```
home.packages = [ pkgs.package_name ] ;
```
>
> ?我已经在上节提到软件包名称前你可以使用 `pkgs.` 。
>
>
>
例如,如果我想 [安装 htop](https://itsfoss.com/use-htop/)、Firefox 和 LibreOffice,那么我将添加:
```
pkgs.htop pkgs.firefox pkgs.libreoffice
```
然后我的主目录管理器块会看起来像这样:

现在,保存修改并退出文本编辑器。
接下来,重建配置并使用以下命令进行切换:
```
sudo nixos-rebuild switch
```
这是这样!软件包将很快被安装。
### 这就结束了
我认为你应该选择独立安装,因为你不需要使用超级用户的权限。另外,如果你运行一个有多个用户的系统,为不同的用户拥有不同的配置文件是相当方便的。
因此,除非你想用一个文件来实现各种目的,否则我认为没有其他理由使用模块选项。
就这样,我结束了 NixOS 的初学者系列。我希望它能给你一个足够好的平台来熟悉这个独特的 Linux 发行版。
? 你喜欢 NixOS 系列文章吗?对于 NixOS 的初学者,我们还有什么要介绍的吗?请提供你的宝贵意见。
---
via: <https://itsfoss.com/home-manager-nixos/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Set up home-manager on NixOS
Here's how you can easily set up the home-manager to install/remove packages on NixOS.
Before publishing this, I explained how to [install and remove packages in NixOS](https://itsfoss.com/nixos-package-management/) for a single-user system.
But if you are running multiple users, there is an excellent way to cater needs of every user separately.
And in this guide, I will walk you through how you can set up a home manager on NixOS and how it can be used to install packages.
If you are new here, some resources discussed in this series include:
## Setup home-manager on NixOS
In this guide, I will walk you through 2 ways to set up a home manager:
- Standalone home manager (uses separate config file)
- As a nix module (using it inside
`configuration.nix`
file)
So let's start with the standalone option.
### Standalone installation of home-manager
If you are using a stable channel of NixOS, you can use the following command to configure the home manager:
`nix-channel --add https://github.com/nix-community/home-manager/archive/release-22.11.tar.gz home-manager`
While writing this guide, the stable release is `22.11`
.
And **if you are on an unstable channel**, use the following:
`nix-channel --add https://github.com/nix-community/home-manager/archive/master.tar.gz home-manager`
The following steps will remain the same whether you use stable or unstable.
Once done, update the channels:
`nix-channel --update`
And finally, use the following command to install the home manager:
`nix-shell '<home-manager>' -A install`
🛠️ While installing, it may throw the following error:
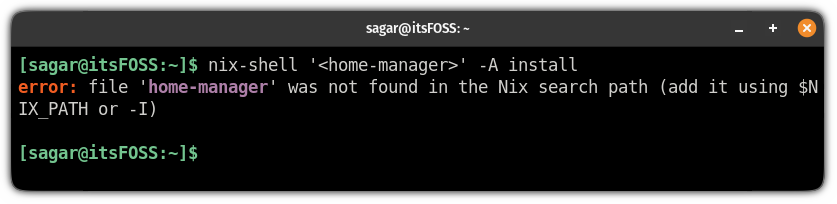
Reboot your system and use the installation command again, and it will start the installation.
Once done, it will show the location of the standalone installation of the home manager:
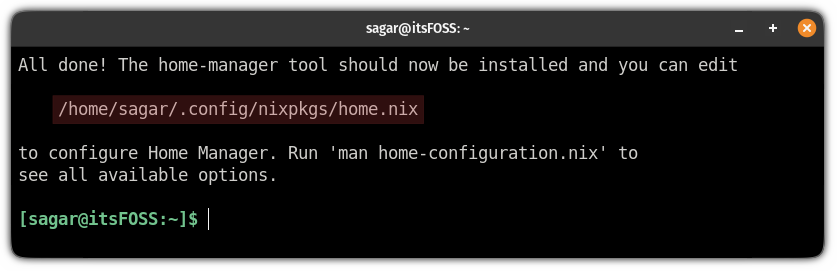
### Installing home-manager as a NixOS module
If you are on a stable channel (while writing, it is 22.11), you can use the following command to add the stable channel of the home manager:
`sudo nix-channel --add https://github.com/nix-community/home-manager/archive/release-22.11.tar.gz home-manager`
And **if you are using unstable or the master channel**, use the following:
`sudo nix-channel --add https://github.com/nix-community/home-manager/archive/master.tar.gz home-manager`
Once you are done adding a channel by using any of one command shown above, update the channel using the following:
`sudo nix-channel --update`
Next, open the `configuration.nix`
file using:
`sudo nano /etc/nixos/configuration.nix`
And add the following line inside the `imports []`
:
`<home-manager/nixos>`
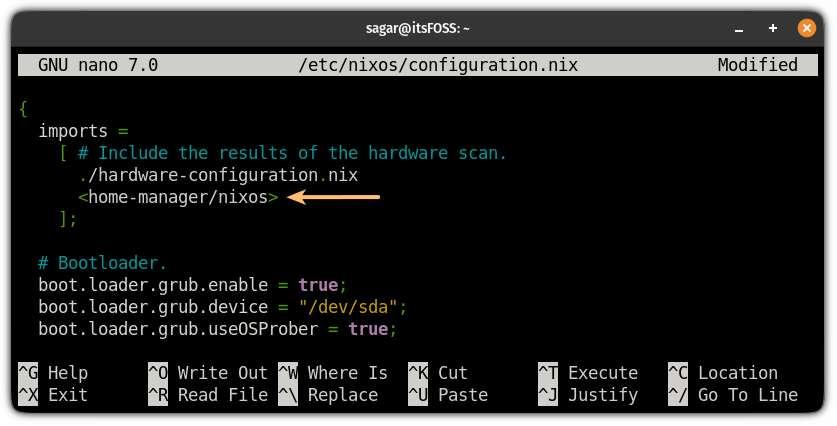
Now, jump to the end of the line and add the following before `}`
:
```
home-manager.users.{username} = { pkgs, ... }: {
home.packages = [ ];
};
```
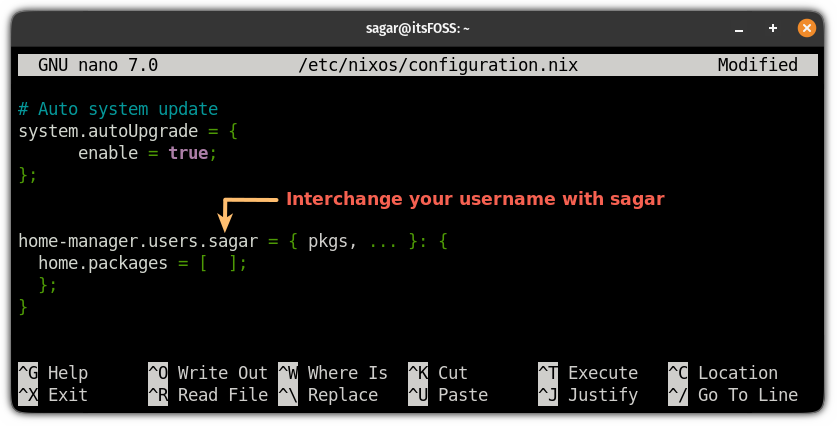
The above line was added to facilitate installing and removing packages I will show you next.
Now, [save changes and exit from the nano](https://linuxhandbook.com/nano-save-exit/) text editor.
Next, rebuild the config and make a switch:
`sudo nixos-rebuild switch`
But if you are using stable release and use the above command, it will throw the error saying :
🛠️ **error: The option `home-manager.users.user.home.stateVersion' is used but not defined:**
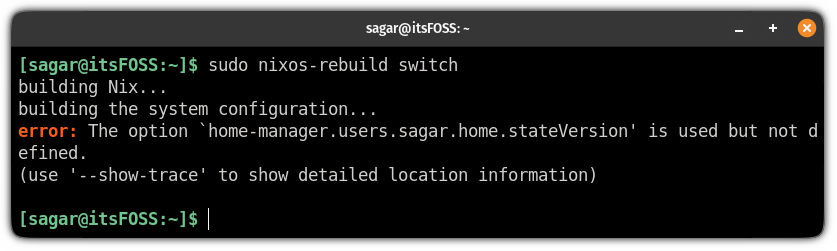
To solve this issue, you will have to add the `home.stateVersion`
in your home manager block.
While writing, I'm running 22.11, so the whole home manager block would look like this:
```
home-manager.users.{username} = { pkgs, ... }: {
home.stateVersion = "22.11";
home.packages = [ ];
};
```
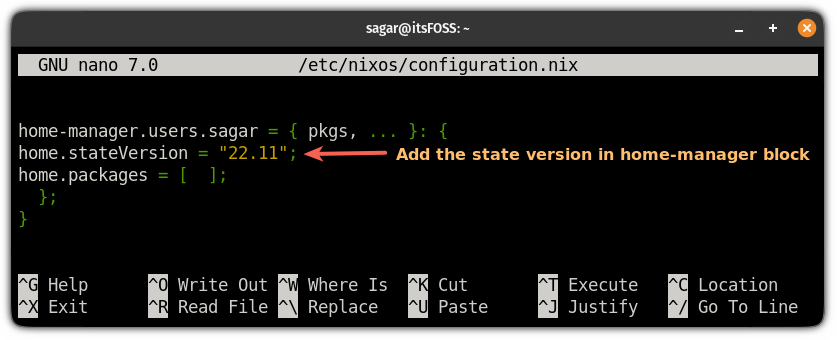
Save changes and exit from the nano text editor by pressing `Ctrl + O`
, hitting enter and `Ctrl + X`
.
Now, try to rebuild the config and make the switch again, and that should solve the issue.
## How to install packages using home-manager on NixOS
Now that you have home-manager installed, how to install packages with it:
### Using a standalone install of Home-manager
First, open the configuration file by using the following:
`nano /home/$USER/.config/nixpkgs/home.nix`
Jump to the end of the line and add the following code block before `}`
:
`home.packages = [];`
Now, all you have to do is write the package's name between those two braces.
For example, if I want to install** htop**, I will have to enter the following:
`home.packages = [pkgs.htop];`
Yes, you will have to usually append the name of the package with `pkgs.`
But if you want to get away with using `pkgs.`
using every time you install a new package, change the syntax of the code block as shown:
`home.packages = with pkgs; [];`
And now, you are no longer required to use `pkgs.`
for every installation:
`home.packages = with pkgs; [htop];`
For example, here, I wanted to install **htop, firefox, and LibreOffice** so my home block would look like this:
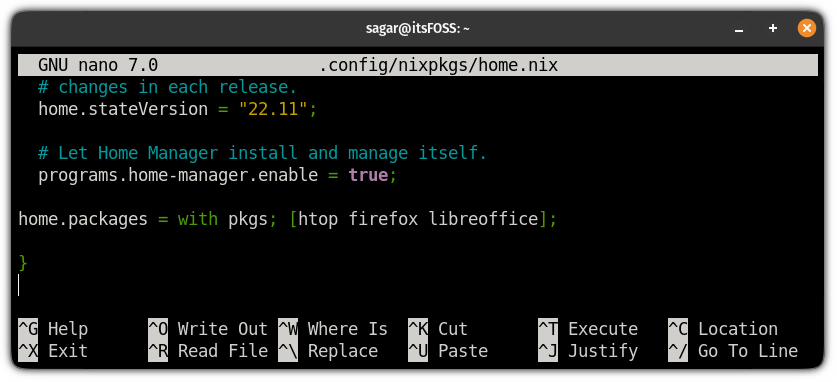
Once you are done adding your favorite packages, save the config file and use the following command to install packages:
`home-manager switch`
### Using the NixOS module
First, open the `configuration.nix`
file using the following command:
`sudo nano /etc/nixos/configuration.nix`
In the configuration part, I've already added the home manager block, so all it is left is to add the name of the package inside `home.packages = [ ];`
in the shown format:
`home.packages = [ pkgs.package_name ];`
`pkgs.`
before the package name in the above section (installing packages on the standalone home manager).For example, if I want to [install htop](https://itsfoss.com/use-htop/), Firefox, and LibreOffice, then I will add:
`pkgs.htop pkgs.firefox pkgs.libreoffice`
And my home manager block would look like this:
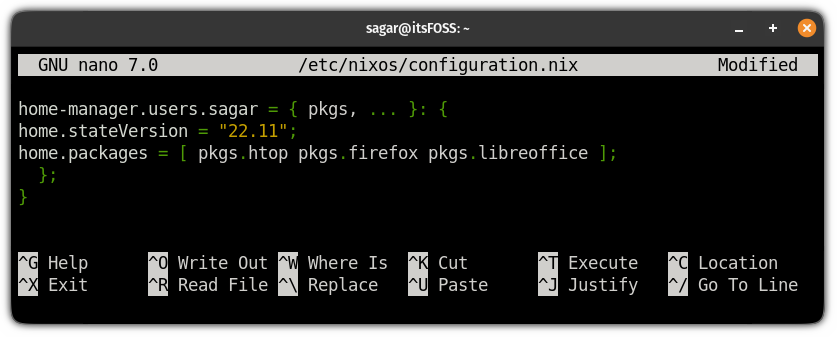
Now, save changes and exit from the text editor.
Next, rebuild the config and make a switch using the following command:
`sudo nixos-rebuild switch`
That's it! The packages will be installed in no time.
## 'Tis the end
I think you should go with the standalone installation, as you are not required to use the superuser privileges. Also, having separate config files for separate users is quite convenient if you run a system with multiple users.
So unless you want one file for every purpose, I see no other reason to use the module option.
With this, I conclude the NixOS beginner series. I hope it gets you a good enough platform to get familiar with this unique Linux distribution.
💬 *How did you like the NixOS series? Is there something else we should cover for NixOS beginners? Please provide your valuable feedback.* |
15,699 | 用 Emojicode 写一个可爱的程序 | https://opensource.com/article/23/4/emojicode | 2023-04-07T14:12:00 | [
"编程",
"表情符"
] | https://linux.cn/article-15699-1.html | 
>
> 这种有趣的开源语言是学习编码真正的完美选择。
>
>
>
在这篇文章中,我将介绍一个最好的编码语言,学习如何制作任何东西!它叫做 Emojicode,是由 Theo Belaire 在 2014 年创建的,它是一种开源的编程语言,使用 emoji 字符来表示其语法。当用 Emojicode 开发时,表情符被用来创建变量、函数和控制结构。因为它是一种静态类型的语言,变量类型必须在使用前声明,但它也支持类和继承等面向对象的概念。这种语言可以在每个操作系统上运行,它是一种超级有趣的编码方式,特别是当你是一个非英语母语的人时。这很有帮助,因为象形表示可以把我们大家聚集在一起,让我们以类似数学的方式说同样的语言。
### 先决条件
在本教程中,我使用的是基于 Debian 的操作系统。我的工具可能与你的操作系统的要求不同。以下是我所使用的工具:
* [Geany](https://github.com/geany/geany),一个 Linux 下的开源 IDE。
* IBus,它允许你挑选表情符并把它们放在你的编辑器中。我使用的界面被称为 **emoji picker**。
* 基于 Debian 的 Linux。
* 一个 C++ 编译器。我使用的是 `g++` 编译器。
* [Emojicode](https://github.com/emojicode/emojicode)
我使用的是 Linux 操作系统,但你可以 [阅读文档](https://www.emojicode.org/docs/) 了解在其他操作系统上使用它时可能需要采取的任何特殊步骤。
### 在 Linux 上安装 Emojicode
有几种方法可以在你的电脑上安装 Emojicode,但它们有一个很酷的 [神奇的安装页面](https://www.emojicode.org/docs/guides/),可以告诉你具体该怎么做。下面是我的做法:
```
$ wget https://github.com/emojicode/emojicode/releases/download/v1.0-beta.2/Emojicode-1.0-beta.2-Linux-x86_64.tar.gz -O emojicode.tar.gz \
&& tar -xzf emojicode.tar.gz && rm emojicode.tar.gz \
&& cd Emojicode-1.0-beta.2-Linux-x86_64 && ./install.sh \
&& cd .. && rm -r Emojicode-1.0-beta.2-Linux-x86_64
```
Emojicode 的安装过程提供了有用的反馈。

现在,你已经安装好了,是时候开始编写代码了!
### 它是怎么运作的?
首先,所有 Emojicode 文件的扩展名都以文件名 `.?` 结尾,但因为你不能在一般的文件名中这样做,所以它被翻译成 `filename.emojic`。这里是最重要的语法元素:
* 把 `?` 放在一行的开头,表示要执行哪些代码块
* 用 `?` 开始一个代码块
* 用 `?` 来结束一个代码块
* 想打印什么吗?就用 `? ? <string> ? ❗`
还有很多其他的,所以这里有一些实际的例子。
### 打印一首俳句
首先,试着打印一首漂亮的俳句来玩玩吧! 在这个例子中,我将添加一行注释。看看你是否能识别它。
```
??
? This is a single line comment for fun
? ?Emojicode is great,? ❗
? ?Fun and expressive code,? ❗
? ?no sadness, just joy.? ❗
?
```
现在我们需要保存我们的代码,并通过我们的编译器运行它,使之成为一个漂亮的可执行文件:
```
$ emojicodec haiku.emojic
$ ls
haiku haiku.emojic haiku.o
```
正如你所看到的,代码已经被编译并生成了两个文件,其中一个是可执行的。运行 `haiku` 文件:
```
$ ./haiku
Emojicode is great,
Fun and expressive code,
no sadness, just joy.
```
### 数学和变量操作
接下来,你要同时做几件事:一点点数学和变量的改变。首先,将一个变量赋值为 0:
```
0 ➡️ ??x
```
你刚刚使用蜡笔(`?`)表情符、新建(`?`)表情符和变量名称创建了一个新变量,同时还将该变量赋值为 0。
接下来,用磁铁(`?`)表情符打印一行包括该变量的内容:
```
? ?The value is ?x? ? ❗
```
接下来,使用加号(`➕`)和箭头(`⬅️`)表情符改变变量:
```
x ⬅️➕ 1
```
然后打印另一行的值。如此这般,然后打印出最终的数值。如下:
```
? ?
?Updating a variable using math
0 ➡️ ??x
? ?The value is ?x? ? ❗
x ⬅️➕ 1
? ?The value is ?x? ? ❗
x ⬅️➕ 15
? ?The value is ?x? ? ❗
x ⬅️➖ 9
? ?The value is ?x? ? ❗
x ⬅️➗ 2
? ?The final value is ?x? ? ❗
?
```
接下来,用 `emojicodec` 编译代码,然后用你的可执行代码来看看结果:
```
$ emojicodec math.emojic
$ ./math
The value is 0
The value is 1
The value is 16
The value is 7
The final value is 3
```
如你所见,作为变量打印出来的所有内容都已使用新数学进行了更新。你可以用许多数学表情符来进一步操作。下面是一些更多的运算符:
```
? is your modulo
◀ Less than
▶ Greater than
◀? less than or equal to
▶? greater than or equal to
```
### Emojicode 的怪癖
当我在文档中来回查看时,我发现了一些有趣的怪癖。其中之一是,当从用户那里抓取输入时,由于一些已知的编译器问题,耳朵的肤色很重要。
获取用户输入的动作是这样的:
```
??▶️??❗️
```
获取和分配用户输入的操作是这样的:
```
??▶️??❗️ ➡️ inputText
```
我试图让它工作,我的编译器出现了一些问题,我发现了这个问题。你也可能会在这里和那里遇到一些小问题。如果你遇到了,请创建一个 [议题](https://github.com/emojicode/emojicode/issues),这样它就有可能被修复。
### 没有技巧,只有很棒的代码
虽然我可以介绍更多内容,但我可以向你保证,这段令人惊叹的代码背后的文档非常丰富。尽管我写这篇文章只是为了赶上愚人节的乐趣,但我不得不承认这是有史以来最好的语言之一,因为它教会了你很多非常真实的编程概念。我恳切地建议把它作为一种有趣的方式来教你的一些朋友、孩子,或者是对编码感兴趣的同学。希望你度过了一个充满乐趣的愚人节!
---
via: <https://opensource.com/article/23/4/emojicode>
作者:[Jessica Cherry](https://opensource.com/users/cherrybomb) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this article, I'll cover the greatest coding language to learn how to make anything! It's called Emojicode. Created in 2014 by Theo Belaire, Emojicode is an open source programming language that uses emoji characters to represent its syntax. When working in Emojicode, emoji are used to create variables, functions, and control structures. Because it's a statically typed language, variable types must be declared before use, but it also supports object-oriented concepts like classes and inheritance. This language can be run on every OS, and it's a super fun way to code, especially if you're a non-native English speaker. This is helpful because pictographic representations can bring us all together and allow us to speak the same language in a way similar to math.
## Prerequisites
In this tutorial, I'm using a Debian-based OS. My tools may be different than what your OS may require. Here's what I'm using:
[Geany](https://github.com/geany/geany), an open source IDE for Linux.- IBus, which allows you to pick emoji and place them in your editor. The interface I'm using is called
**emoji picker**. - Debian-based Linux.
- A C++ compiler. I'm using the
`g++`
compiler. [Emojicode](https://github.com/emojicode/emojicode)
I'm using a Linux OS, but you can [read the docs](https://www.emojicode.org/docs/) to learn about any special steps you might need to take to use it on another OS.
## Install Emojicode on Linux
There are a couple ways to install Emojicode on your computer, but they have a cool [magic install page](https://www.emojicode.org/docs/guides/) that can tell you exactly what to do. Here's what I did:
```
``````
$ wget https://github.com/emojicode/emojicode/releases/download/v1.0-beta.2/Emojicode-1.0-beta.2-Linux-x86_64.tar.gz -O emojicode.tar.gz \
&& tar -xzf emojicode.tar.gz && rm emojicode.tar.gz \
&& cd Emojicode-1.0-beta.2-Linux-x86_64 && ./install.sh \
&& cd .. && rm -r Emojicode-1.0-beta.2-Linux-x86_64
```
This is the output of that command.
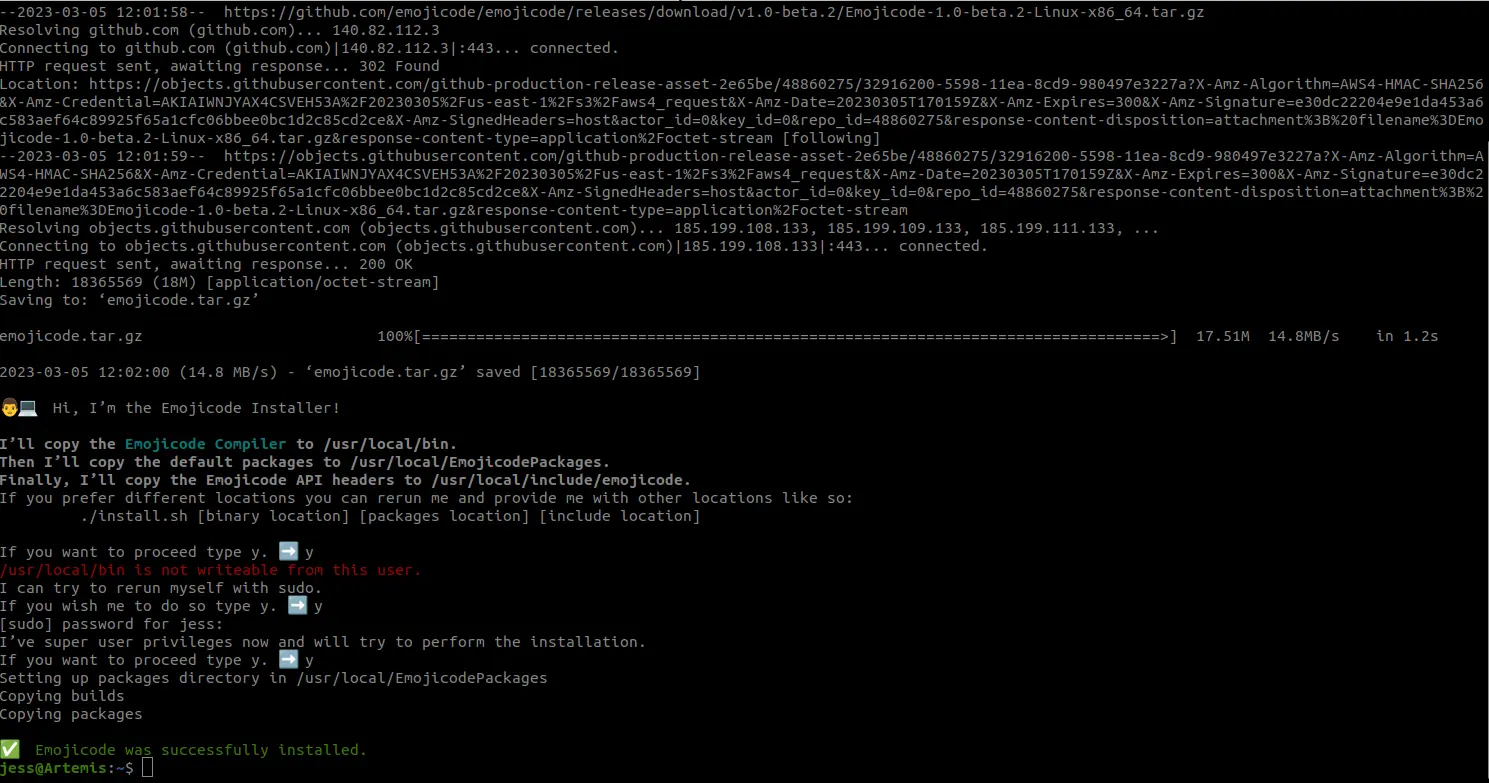
(Jess Cherry, CC BY-SA 4.0)
Now that you have everything installed, it's time to move on to some code!
## How does this whole thing work?
To start, all Emojicode file extensions end in filename.🍇 but because you can't do that in your average file name, it translates to `filename.emojic`
. Here are the most important syntax elements:
- Put 🏁 at the beginning of a line to indicate what blocks of code are meant to be executed
- Start a block of code with 🍇
- End a block of code using 🍉
- Want to print something? Just use 😀 🔤
`<string>`
🔤 ❗
There's way more to it, so here are some practical examples.
## Print a haiku
First up, try printing a nice haiku for fun! I'll add a single comment in this example. See if you can identify it.
```
``````
🏁🍇
💭 This is a single line comment for fun
😀 🔤Emojicode is great,🔤 ❗
😀 🔤Fun and expressive code,🔤 ❗
😀 🔤no sadness, just joy.🔤 ❗
🍉
```
Now we need to save our code and run it through our compiler to make a nice executable file:
```
``````
$ emojicodec haiku.emojic
$ ls
haiku haiku.emojic haiku.o
```
As you can see, the code has been compiled and generated two files, one of which is executable. Run the `haiku`
file:
```
``````
$ ./haiku
Emojicode is great,
Fun and expressive code,
no sadness, just joy.
```
## Math and variable manipulation
Next up, you're going to do a couple of things at once: a little bit of math and the changing of the variable. Start by assigning a variable to 0:
```
````0 ➡️ 🖍🆕x`
You just created a new variable by using the crayon emoji, and the new emoji next to the variable name, while also assigning that variable to 0.
Next, print a line that includes the variable using the magnets emoji:
```
````😀 🔤The value is 🧲x🧲 🔤 ❗`
Next, change the variable using the plus sign and arrow emojis:
```
````x ⬅️➕ 1`
Then print another line with the value. I continue this for a while and print the final value. Here's what I did:
```
``````
🏁 🍇
💭Updating a variable using math
0 ➡️ 🖍🆕x
😀 🔤The value is 🧲x🧲 🔤 ❗
x ⬅️➕ 1
😀 🔤The value is 🧲x🧲 🔤 ❗
x ⬅️➕ 15
😀 🔤The value is 🧲x🧲 🔤 ❗
x ⬅️➖ 9
😀 🔤The value is 🧲x🧲 🔤 ❗
x ⬅️➗ 2
😀 🔤The final value is 🧲x🧲 🔤 ❗
🍉
```
Next, compile the code using `emojicodec`
, and then use your executable code to see the outcome:
```
``````
$ emojicodec math.emojic
$ ./math
The value is 0
The value is 1
The value is 16
The value is 7
The final value is 3
```
As you can see, everything printed out as the variable was updated with the new math. You can take this even further with the many mathematic emojis available. Here are just a few more operators:
```
``````
🚮 is your modulo
◀ Less than
▶ Greater than
◀🙌 less than or equal to
▶🙌 greater than or equal to
```
## Emojicode quirks
While I was bouncing around the docs, I found some interesting quirks. One of those is that while grabbing input from a user, the skin tone of the ear matters due to some known compiler issue.
The action for getting user input is this:
```
````🆕🔡▶️👂🏼❗️`
The action for getting and assigning user input is this:
```
````🆕🔡▶️👂🏼❗️ ➡️ inputText`
I was attempting to get that to work but was having some issues with my compiler when I found that. You may also run into some small things here and there. If you do, be sure to create an [issue](https://github.com/emojicode/emojicode/issues), so it has a chance of being fixed.
## No tricks, just great code
While I could go through so much more, I can assure you the docs behind this amazing code are very extensive. Even though I was inspired to write this article just for fun in time April Fool's Day, I have to admit this is one of the best languages ever made because it teaches you a lot about very real programming concepts. I earnestly suggest this as a fun way to teach some of your friends, kids, or maybe a classmate, who is interested in coding. Hopefully, you have a fun-filled April Fool's Day!
## 2 Comments |
15,700 | 使用开源思维导图 Draw.io | https://opensource.com/article/21/12/open-source-mind-mapping-drawio | 2023-04-07T14:43:47 | [
"思维导图"
] | https://linux.cn/article-15700-1.html |
>
> 下次你需要头脑风暴、组织想法或计划项目时,不妨试试 [Draw.io](http://Draw.io)。
>
>
>

地图有一些特别之处。我记得小时候打开托尔金《霍比特人》的封面,盯着手绘的中土世界地图,感受简单的图画中蕴含着丰富的可能性。除了描述事物与其他事物之间的关系这一明显目的外,我认为地图在表达可能性方面做得很好。你可以到户外去,沿着这条路或那条路走,如果你这样做了,去想想你将能够看到的所有新的、令人兴奋的事物。
尽管如此,地图并不一定是有价值和充满可能性的文字。有些地图描述了一个思维过程、计划、算法,甚至是一些随机的想法,这些想法拼命地想要组合成一件潜在的艺术作品,它们被称之为“思维导图”、“流程图”或“创意板”。可以用开源的 Draw.io 应用程序去很容易地制作。
### 安装 Draw.io
Draw.io 是一个开源的在线应用程序,因此你可以将其作为在线应用程序使用,下载 [桌面版本](https://github.com/jgraph/drawio-desktop),或 [克隆 Git 存储库](https://github.com/jgraph/drawio) 并将其托管在你自己的服务器上。
### 使用 Draw.io 画图
当你第一次启动 Draw.io 时,你需要选择保存数据的位置。如果你自己托管 Draw.io,你的选择取决于你可以访问哪些 API 密钥。你可以从几个在线存储服务中为在线公共实例进行选择,这取决于你的帐户。如果你不想把你的数据存储在别人的服务器上,你也可以选择把你的工作保存在本地存储上。如果你还不确定,可以单击 “<ruby> 稍后决定 <rt> Decide later </rt></ruby>” 继续进入应用程序,而无需选择任何内容。
Draw.io 的交互界面中间有一个很大的工作空间,左边是主工具栏,顶部是工具栏,右边是属性面板。

工作流程很简单:
1. 从左侧工具栏中选择一个形状。
2. 在工作空间中编辑形状。
3. 添加另一个形状,并连接它们。
重复这个过程,你就得到了一张图。

### 项目规划
当你第一次接受一项大任务时,你通常对你想要的结果有一个非常清晰的想法。假设你想开始一个社区项目来画一幅壁画。你想要的结果是一幅壁画。它很容易定义,你可以或多或少地在脑海中描绘出结果。
然而,一旦你开始朝着目标前进,你就必须开始弄清楚细节。壁画应该画在哪里?即便知道画在哪,你如何获得在公共墙上作画的许可的?油漆呢?你应该用一种特殊的油漆吗?你会用刷子还是喷枪涂油漆?你需要什么样的专业设备来喷漆?画一幅壁画需要多少人和多长时间?画家工作时的支持服务怎么样?最后,这幅画是关于什么的?一个想法很快就会变得势不可挡,因为你离实现它越近。
这不仅仅适用于绘制壁画、制作戏剧或电影。它几乎适用于任何不平凡的努力。这正是像 Draw.io 这样的应用程序可以帮助绘制的。
以下是如何使用 Draw.io 创建项目流程图:
1. 从头脑风暴开始。没有什么想法是太小或太大的。为每个想法制作一个框,然后双击 Draw.io 工作空间中的框以输入文本。
2. 一旦在工作空间中你产生了可能想到的所有想法,就可以将它们拖放到相关的组中。我们的目标是创建一些小任务云或集群,因为它们是同一过程的一部分,所以或多或少会一起进行。
3. 一旦你确定了相关任务的集群,就为这些任务命名。例如,如果你正在绘制壁画,那么任务可能是 “许可”、“设计”、“购买”、“绘制”,这反映出你需要首先获得当地政府的许可,然后设计壁画,然后购买用品,最后绘制壁画。每个任务都有组成部分,但大体上,你现在已经确定了项目的工作流程。
4. 用箭头连接主要任务。并不是所有的过程都是完全线性的。例如,在你获得市议会的许可后,一旦你设计了你打算画的东西,你可能必须回到他们那里进行最终批准。这很正常。这是一个循环,有一些来回,但最终,你会突破这个循环,进入下一阶段。
5. 掌握好你的流程图,完成每一项任务,直到你达到最终目标。
### 思维导图
思维导图往往不是关于进步,而是关于保持某种状态或对许多想法进行展望。例如,假设你已经决定减少生活中的浪费。你对自己能做什么有一些想法,但你想组织和保存你的想法,这样你就不会忘记它们。
以下是如何使用 Draw.io 创建思维导图:
1. 从头脑风暴开始。没有什么想法是太琐碎或太大的。为每个想法制作一个框,然后双击 Draw.io 工作空间中的框以输入文本。也可以通过选择框并单击右侧属性面板中的色样,为框指定背景色。
2. 将你的想法分组或分类。
3. 可以选择将想法与彼此直接相关的箭头连接起来。

### 保存你的图表
你可以将图表保存为 PNG、JPG 图像、Draw.io XML 或纯 XML 文件。如果将其另存为 XML,则可以在 Draw.io 中再次打开它进行进一步编辑。导出的图像非常适合与他人共享。
### 使用 Draw.io
有很多很棒的绘图应用程序,但我不经常制作图表,所以可以随时使用 Draw.io。它的界面简单易用,结果干净专业。下次当你需要头脑风暴、组织想法或计划项目时,可以试试 Draw.io。
---
via: <https://opensource.com/article/21/12/open-source-mind-mapping-drawio>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FYJNEVERFOLLOWS](https://github.com/FYJNEVERFOLLOWS) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There's something special about maps. I remember opening the front book cover of JRR Tolkien's *The Hobbit* when I was younger, staring at the hand-drawn map of Middle Earth, and feeling the wealth of possibility contained in the simple drawing. Aside from their obvious purpose of actually describing where things are in relation to other things, I think maps do a great job of expressing potential. You could step outside and take the road this way or that way, and if you do, just think of all the new and exciting things you'll be able to see.
Maps don't have to be literal to be valuable and full of possibility, though. Some maps describe a thought process, plan, algorithm, or even random ideas desperately trying to fit together in a potential work of art. Call them "mind maps" or "flowcharts" or "idea boards." They're easy to make with the open source [Draw.io](http://draw.io) application.
## Install Draw.io
Draw.io is designed as an open source online app, so you can either use it as an online application, download the [desktop version](https://github.com/jgraph/drawio-desktop), or [clone the Git repository](https://github.com/jgraph/drawio) and host it on your own server.
## Mapping with Draw.io
When you first start Draw.io, you need to choose where you want to save your data. If you're hosting Draw.io yourself, your choices depend on which API keys you have access to. You can choose from several online storage services for the online public instance, depending on what you've got an account for. If you don't want to store your data on somebody else's server, you can also choose to save your work on a local drive. If you're unsure yet, you can click **Decide later** to continue into the app without choosing anything.
The Draw.io interface has a big workspace in the center, the main toolbar on the left, a toolbar along the top, and a properties panel on the right.
(Seth Kenlon, CC BY-SA 4.0)
The workflow is simple:
- Select a shape from the left toolbar.
- Edit the shape in the workspace.
- Add another shape, and connect them.
Repeat that process, and you've got a map.
(Seth Kenlon, CC BY-SA 4.0)
## Project planning
When you first take on a big task, you often have a pretty clear idea of your desired outcome. Say you want to start a community project to paint a mural. Your desired outcome is a mural. It's pretty easy to define, and you can more or less picture the results in your mind's eye.
Once you start moving toward your goal, however, you have to start figuring out the details. Where should the mural be painted? How do you get permission to paint on a public wall, anyway? What about paint? Is there a special kind of paint you ought to use? Will you apply the paint with brushes or airbrushes? What kind of specialized equipment do you need for painting? How many people and hours will it take to paint a mural? What about support services for the painters while they work? And what's the painting going to be about, anyway? A single idea can very quickly become overwhelming the closer you get to making it happen.
This doesn't just apply to painting murals, producing a play, or making a movie. It applies to nearly any non-trivial endeavor. And it's exactly what an application like Draw.io can help map out.
Here's how you can use Draw.io to create a project flowchart:
- Start with a brainstorming session. No thoughts are too trivial or big. Make a box for every idea, and double-click the box in the Draw.io workspace to enter text.
- Once you have all the ideas you can possibly think of on your workspace, drag and drop them into related groups. The goal is to create little clouds, or clusters, of tasks that more or less go together because they're part of the same process.
- Once you've identified the clusters of related tasks, give those tasks a name. For instance, if you're painting a mural, then the tasks might be
*approval*,*design*,*purchase*,*paint*, reflecting that you need to get permission from your local government first, then design the mural, then purchase the supplies, and finally paint the mural. Each task has component parts, but broadly you've now determined the workflow for your project. - Connect the major tasks with arrows. Not all processes are entirely linear. For instance, after you've obtained permission from your city council, you might have to come back to them for final approval once you've designed what you intend to paint. That's normal. It's a loop, there's some back and forth, but eventually, you break out of the loop to proceed to the next stage.
- Armed with your flowchart, work through each task until you've reached your ultimate goal.
## Mind mapping
Mind maps tend to be less about progress and more about maintaining a certain state or putting many ideas into perspective. For instance, suppose you've decided to reduce the amount of waste in your life. You have some ideas about what you can do, but you want to organize and preserve your ideas, so you don't forget them.
Here's how you can use Draw.io to create a mind map:
- Start with a brainstorming session. No thoughts are too trivial or big. Make a box for every idea, and double-click the box in the Draw.io workspace to enter text. You can also give boxes a background color by selecting the box and clicking a color swatch in the right properties panel.
- Arrange your ideas into groups or categories.
- Optionally, connect ideas with arrows that relate directly to one another.
(Seth Kenlon, CC BY-SA 4.0)
## Saving your diagram
You can save your diagram as a PNG, JPG image, Draw.io XML, or plain XML file. If you save it as XML, you can open it again in Draw.io for further editing. An exported image is great for sharing with others.
## Use Draw.io
There are many great diagramming applications, but I don't make diagrams often, so having Draw.io available is convenient at a moment's notice. Its interface is simple and easy to use, and the results are clean and professional. Next time you need to brainstorm, organize ideas, or plan a project, start with Draw.io.
## Comments are closed. |
15,702 | 开源软件:存在成功的捷径吗? | https://www.opensourceforu.com/2022/07/open-source-software-is-there-an-easy-path-to-success/ | 2023-04-08T12:22:51 | [
"开源"
] | https://linux.cn/article-15702-1.html |
>
> 开发开源软件背后的工作是相当庞大的。那么我们如何保证开源项目的成功呢?存在捷径吗?本文认为是没有的。
>
>
>

今天,开源已经风靡世界。很多大型企业在快速成功的诱惑下被推向开源。但真实情况是世界上并不存在成功的捷径。你无法做到通过一次努力就能让所有的开源项目正常运行。
事实上,上述公司早期遇到的许多挑战都不是技术上的,而是人员与文化上的。
开发一个能够在市场上获得成功的开源项目需要在开源的许多层面上下功夫。而维持这样的成功是一个持续的过程。所有这一切的关键在于找到以下这个非常基本的问题的正确答案:开源究竟是什么。
### 开源是代码
对于很多新用户而言,他们可能并不完全了解开源的不同层面,答案相当简单:开源就是软件!这当然没有错,毕竟我们多数人就是这样使用它的。不过,相比仅仅被视作软件而言,开源远不止这些。
任何开源项目的实质仍然是代码本身。代码是使一个开源项目有别于其他项目,并使其对用户有益的根本。当你从事开源工作的时候,代码和软件一样都是产品的一部分。
从零开始开发一个开源项目或者 <ruby> 复刻 <rt> fork </rt></ruby> 一个现有项目,即便是在面对一个庞大而复杂的代码库时,也需要编写成千上万行代码。尤其是在创建一个现有项目的复刻的情况下,在移除任何在先的许可证、宣传材料或者其他任何可能已经失去作用的文件时必须小心翼翼(LCTT 校注:部分开源项目不允许你改变其原有的许可证)。终究是一个项目的功能吸引了它的用户群并维持项目的持续发展。当最终用户在考虑是否使用开源软件的时候,他们会阅读项目的源代码,而他们在其中所看到的应当是那些能够建立他们的信心的内容。
### 开源是社区
如何参与到社区中也是产品构建的一部分。创建一个社区并维护一个健康的社区关系是开源的核心之一,但对于大部分的领导者而言也往往是最坚难的任务,很少有人能很好地维护它。你可以尝试建立基金会或者提供赞助,但是最终还是由人们自行决定是否想要加入社区。
重要的是与社区保持一定程度的透明度,并不断保持。社区成员可以在它想要的任何阶段参与进来。除了需要进行的工作之外,诸如安全设置、签发证书、注册商标等,尽可能多的将你所做的工作展示给社区是相当重要的,这有助于取得社区信任。归根到底,你需要对社区负责,你的项目成也社区,败也社区。这可能会导致你的项目开发更谨慎、更缓慢并且向社区公开,不过项目最终会进展顺利。
如此地公开你正在进行的工作似乎有些令人生怯,尤其是当你担心更新推迟或者是出现漏洞的影响的时候。不过,让社区成员知悉你的进展,不仅有助帮助你建立与社区之间的信任关系,而且能够让社区成员感到被认可。
另一方面,公开你的工作流也可以获得来自社区成员的监督,他们经常有自己的见解并向你反馈。记录这些反馈是很重要的,这使得你的开源项目如实地反映社区需求。他们是项目的最终用户,而他们的反馈则反映了他们如何看待你的项目的长期发展,以及你的项目最终将有多么成功或者主流。
举例而言,当我们在考虑一个新功能的时候,我们在 <ruby> 征求意见文档 <rt> Request for Comments </rt></ruby>(RFC)中发布一个征集意见的请求,我们会收到大量的反馈,我们必须认真思考应当如何吸收这些反馈。
因为开源是一个大型的合作项目,社区对支持开源项目的主动支持,使项目成为了最好的项目。并非所有的问题都要解决,但只要你有在倾听社区的呼声,社区就会有参与感。
参与到社区中也存在一些隐患。社区内部、项目维护与社区之间均可能存在不同意见,尤其是在涉及治理的问题上。治理对于一个开源项目来说是相当重要的。这也就是为什么拥有一份清晰的文档化的治理条例对于项目以及社区均是如此重要。
社区治理是一个关键的而又难啃的骨头。社区授权本身需要相当大的信任。对于一个拥有成千上万行代码的项目,在社区中寻找能够有效领导社区的人物是不容易的。不过开源项目经常是由更小的子项目组成的,这些子项目最好由社区中的某个人进行管理。这有助于社区更紧密地参与到项目中。
建立社区的过程不是一帆风顺的。让我列举一一些有助于维持社区与我的团队之间平衡的技巧。
**声明你的原则:** 尤其是在开源项目的早期,在项目代码仍在完善,很多事情还不完美的时候,项目之外的人员很难真正理解你所做的决定。向他们说明你做出决定所依据的原则,有助于你在思考过程上保持坦率,从而让社区不会错误地干扰你的事务。这一经验非常有效,在你做出决定时坚持遵循其中一项原则并展示出来是非常重要的。
**确定如何进行协作:** 你可以通过 Discord、Slack 或者邮件等途径完成这一工作。但是如果你试图同时使用它们,你将毫不意外的分散项目社区。社区人员将在所有这些途径上互相交流。选择一到两种沟通工具,投身于它们来保证社区的信息同步。
**珍惜反馈意见:** 倾听来自社区的反馈并付诸行动。即使需要你作出艰难的决定,你也应当向社区展示你是重视社区话语的。
**维护一套行为准则:** 如果你与社区打交道,你需要定义什么行为是可以接受的。一套落地的行为准则有助于在人们越过红线时警示他们。如果你可以提前制定这些你可以避免很多麻烦。
**考虑如何分发你的项目:** 存在这样的情况,因为你还没有准备好某一个组件,或者是因为存在一些你不希望所有人都能够访问的项目功能,所以你可能并不希望将你的项目完全向公众公开。关键是制定符合你的要求而不是向用户妥协的分发条款,如此,需要某种功能的用户可以获取所需项目的同时,不需要该功能的用户也不需要在开始使用该项目做出妥协。
**尽可能地避免投票:** 这是因为部分成员经常会赞成与大部分成员的意见相左的选项,这会使这些人产生一定程度的失望,并让他们觉得被项目所孤立。反之,尽量尝试询问他们想要解决什么问题,并尝试创造一个不需要付出代价的解决方案。
### 开源是许可
开源是给予你的用户如何使用你的软件的自由,而许可能够做到这一点。开源项目许可的好处在于,它保证了不论你作为维护者做了什么,你的所有最终用户以及利益相关方总是可以维护一系列的项目复刻版本,这些都是重要的项目复刻。
许可提供了人们可选择性,如果他们认为有必要,他们可以将项目带到不同的路径中。他们拥有创建副本的权利,这使得许多优秀的软件能够被开发出来。维护者有责任倾听他们的社区成员的声音,并以一个对项目的社区成员有利的方式运营项目。
我们推荐使用现有的许多可用的许可证,而不是独立制作你自己的许可条款,原因很简单,因为用户以及利益相关方通常都很熟悉常用的许可证,因此你不需要再花费时间在解释许可条款上。这将帮助你将你的精力集中在项目的其他部分上。
### 最后,开源是一项运动
开源包括了很多维度,也包含了很多人员。最重要的是,它是关于理解人们想要什么,并创建一个鼓励协作与透明的环境。开源也是关于创建社区,帮助建立走自己想走的开源项目的方式。维护者创造越多的机会让社区自由发挥,开源产品就越好,也越发成功。
开源是以上所有这些方面,而你的视野越宽阔,你就能越好的利用它。请考虑你如何能够在开源的每一个维度上出类拔萃,因为时至今日,开源的成功之路并无捷径。
---
via: <https://www.opensourceforu.com/2022/07/open-source-software-is-there-an-easy-path-to-success/>
作者:[Jules Graybill](https://www.opensourceforu.com/author/jules-graybill/) 选题:[lkxed](https://github.com/lkxed) 译者:[CanYellow](https://github.com/CanYellow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *There’s so much that goes on behind the scenes while developing open source software. So how does one make an open source project successful? Is there a shortcut? This article indicates there isn’t one.*
Open source has become all the rage now. Many entrepreneurs are drawn to it by the allure of quick success. But the truth is, there is no easy path to such success. There is no one thing that you can do to get all of open source right.
In fact, a lot of the challenges that companies face early on are not technology challenges, but are people and cultural challenges.
There are many layers of open source that need to be worked on to build a project that can become a hit in the market. And maintaining that success is an ongoing process. But at the crux of it all lies finding the right answer to a very basic question: what exactly is open source?
## Open source is the code
For many new users who may not be fully aware of the layers that make open source, the answer is fairly simple: open source is software! And that is not wrong, of course, since that is how most of us are using it. But there’s just so much more to open source than merely being touted as software.
The essence of any open source project still remains the code. It is what makes the project special and useful for the user. When you’re working in open source, the code is just as much a part of the product as the software.
Developing a project from the ground up, or even creating a fork of an existing project, requires thousands and thousands of lines of code to be written, even while handling such a large and complex codebase. Especially in the case of creating a fork, care must be taken to remove any prior licences, marketing material, or anything that might not be useful for the user anymore. After all, it is the features of a project that attract its user base and what retains it. When end users are deciding whether to use open source software, they will read the source code, and what they see there should be something that builds their confidence.
## Open source is the community
How you engage with the community is also a part of the task of building a product. Building a community and maintaining a healthy relationship with it is one of the most crucial aspects of open source, but is also often the hardest for most leaders as there is very little one can do to control it. One can try to lay the foundation and can be supportive but, ultimately, it’s the people who decide whether they want to join a community.
It is important to maintain a level of transparency with the community and keep it in the loop. The community can get involved at any step that it wants to. It’s really important that you show most of your work to the community while you are doing it, apart from things that need to be done confidentially, like setting up security, signing certificates, branding, and so on. This helps in winning its trust because, in the end, it is the community that you are liable to, and it can make or break your project. This may make the project work a lot more deliberate, slower and exposed, but it works well in the end.
Making your work-in-progress so open can seem daunting, especially when you are worried about the repercussions of a delay in updates or having a bug. Yet, making the community members privy to your moves will not only help you build a trustful relationship with them, but also make them feel appreciated.
However, making your workflow public will also invite scrutiny from the community members, who will often have their opinions and offer you their feedback. Taking note of this feedback is important, because that is how you can make your open source project truly for them. They are the end users and their feedback will reflect how they see your project panning out for them in the long run, and ultimately, how successful and mainstream your software becomes.
As an example, when we are thinking about a new feature, we publish a request for comments at RFC. We get a lot of feedback, and we have to think hard about how we can incorporate it.
Since open source is a largely collaborative work, there will be initiatives by the community to offer their support in making the project the best version possible. Not all of it will work out. But as long you are listening, the community will feel involved.
Engaging with the community has its pitfalls too. There may be differences of opinion within the community, and also between the maintainer and the community, especially when it comes to the matter of governance. Governance is something which is really important for an open source project to have. That is why it is important to have clear documented governance practices, which also include the community.
Community governance is a tough, but essential, nut to crack. Delegation in itself requires a lot of trust. For a project with millions of lines of code, it can be cumbersome to find someone in the community who can meaningfully lead it. But open source projects often consist of smaller sub-projects, which are better left handled by someone from the community. This helps the community to be more closely involved too.
Building a community always has its highs and lows. Let me list some of the tricks that helped maintain a healthy balance between the community’s and my team’s vision.
This practice is really helpful. It is also important to follow through and show that when you make a decision, it is guided by one of these principles.
|
## Open source is licensing
Open source is about giving your users autonomy over how they want to use your software, and licensing provides just that. What’s great about an open source licence is that regardless of what you as a maintainer do, all your end users and stakeholders can always maintain a certain set of forks, which are important forks.
Licensing gives people the option to take the project into a different direction if they deem it fit. They have the right to create a fork, which results in a lot of amazing software being developed. Maintainers have more responsibility to listen to their community members and to run the project in a way that works for them.
It’s advisable to make use of the many licences available instead of setting your own terms separately, simply because stakeholders and users are usually familiar with commonly used licences, so you do not have to waste time explaining them. This also helps you to focus your energy on the other parts of the project.
## Finally, open source is a movement
Open source involves many, many dimensions and people. Most importantly, it is about understanding what these people want and creating an environment that encourages collaboration and transparency. It is about building communities that help to build the open source project the way they want it to be. The more opportunity maintainers create to let them do that, the better the product is and the more successful it gets.
Open source is all of these things and the more expansive view you take, the better you can leverage it. Think about how you can excel in every dimension of open source because, at the end of the day, there is no easy path to open source success. |
15,703 | 使用这个开源的会计应用来管理你的小企业 | https://opensource.com/article/23/3/open-source-accounting-run-business | 2023-04-08T15:02:17 | [
"GnuCash",
"会计"
] | /article-15703-1.html | 
>
> 用 GnuCash 跟踪客户和发票的情况。
>
>
>
[GnuCash](https://www.gnucash.org/) 是一个强大而灵活的会计工具,可用于小企业的发票和会计。它的许多功能使它特别适合这一目的,包括跟踪支出和收入、生成报告和管理发票的能力。此外,GnuCash 是自由开源的,这使得资源有限的小企业也可以使用它。在这篇文章中,我会讨论 GnuCash 的特点,使你可以很容易地在自己的小企业中开始使用它。
几年前,我开始使用 GnuCash 进行个人财务管理,但发现它也可以作为我的小企业的一个有用工具。在我企业的大部分时间里,我一直在使用一个专有的解决方案。我逐渐厌倦了被迫定期升级以获取我的小企业的发票和报表。转而使用 GnuCash,使我能够在不牺牲任何功能的情况下,将我的小企业会计与我的个人财务相结合。
### 在 Linux 上安装 GnuCash
你可以从你的仓库中安装 GnuCash。在 Debian、Elementary 和类似的软件上:
```
$ sudo apt install gnucash
```
在 Fedora、CentOS、Mageia 和类似系统上:
```
$ sudo dnf install gnucash
```
### 企业版 GnuCash
GnuCash 带有一个账户设置向导,可以帮助你建立一个普通的商业账户配置。要访问它:
* 启动 GnuCash。
* 点击 “<ruby> 文件 <rt> File </rt></ruby>” 菜单,选择 “<ruby> 新文件 <rt> New File </rt></ruby>”。
按照屏幕上出现的 GnuCash 助手来创建你的新商业账户文件。
屏幕上的说明将指导你完成设置业务的过程。单击 “<ruby> 助手 <rt> Assistant </rt></ruby>” 窗口右上角的 “<ruby> 下一步 <rt> Next </rt></ruby>”。系统会提示你输入公司名称、地址、联系信息和你自己选择的公司 ID。你还必须选择默认税表和日期格式。
下一个页面提示你选择货币,有大量的货币支持。
然后提示你选择你要创建的账户。选择创建 “<ruby> 企业账户 <rt> Business Accounts </rt></ruby>” 的选项。你可以随时定制账户列表,GnuCash 提供了 [大量的文档](https://www.gnucash.org/docs/v4/C/gnucash-guide/bus_setup.html),帮助你更好地根据个人需求进行定制。
完成助手,然后单击 GnuCash “助手” 窗口右上角的 “<ruby> 应用 <rt> Apply </rt></ruby>”。
### 添加客户
GnuCash 的顶部菜单有一个标有 “<ruby> 业务 <rt> Business </rt></ruby>” 的菜单项。该菜单上的第一个项目是 “<ruby> 客户 <rt> Customers </rt></ruby>”,其次是 “<ruby> 客户概览 <rt> Customers Overview </rt></ruby>”。在这里你可以查看你所有客户的列表。
下一个项目是 “<ruby> 新客户 <rt> New Customer </rt></ruby>”。这是你输入新客户的地方。对话框为客户信息提供了一个位置,包括帐单信息、运输地址、电子邮件地址、电话号码等。
### 创建一个发票
添加客户后,你可以开始创建发票的过程。点击 “业务” 菜单,选择 “客户”,然后点击 “<ruby> 新发票 <rt> New Invoice </rt></ruby>”。
付款处理也很简单。这位于 “业务” 菜单中。选择 “客户”,然后 “<ruby> 处理付款 <rt> Process Payment </rt></ruby>”。
### 你在做生意了
如果你的业务需要,“业务” 菜单还包括输入供应商和雇员的选项。有一个菜单项用于销售税和许多其他选项,以确保你符合当地的要求。
使用 GnuCash,你的数据不是以专有格式存储的,所以如果你需要,你可以在将来迁移到任何其他平台。数据存储的开放标准,特别是当这些数据是法律要求的时候,是很重要的,可以让你完全拥有你的商业历史。使用 GnuCash 使你能控制你的小企业。
---
via: <https://opensource.com/article/23/3/open-source-accounting-run-business>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,705 | 可以替代微软 Exchange 的 5 个开源软件 | https://opensource.com/article/21/11/open-source-alternatives-微软-exchange | 2023-04-09T11:51:19 | [
"Exchange",
"群件"
] | https://linux.cn/article-15705-1.html |
>
> 不再将就于微软 Exchange 这一专有软件,试一试这些基于 Linux 系统的电子邮件和群件服务吧。
>
>
>

几十年来,微软 Exchange 一直统治着电子邮件和群件服务市场。作为领头羊,它主宰着企业界,无处不在的 Outlook 邮件客户端已成为群件的事实标准。由于 Exchange 与微软的 Office 产品紧密联系,无论是桌面客户端还是移动客户端,微软用户都可以轻松使用各种生产力软件和功能。
然而,许多公司对于将数据存储在微软的云中也心存疑虑。在本文中,我将介绍一些开源替代产品及其优势。这不仅与如何不再受供应商控制和降低成本有关,更关乎使用具有开放标准和不同安全级别的软件 —— 用于组件服务器本身及其背后的操作系统。
本文中介绍的这五个替代产品都是基于 Linux 的。 虽然 grommunio、Kopano、Nextcloud、ownCloud 和 OX App Suite 在功能上差异很大,吸引到的企业类型各不相同,但它们都提供免费版本,并可选择购买付费支持服务和附加组件。所有产品都可以在本地或云端运行。最重要的是,所有供应商都为其软件提供 SaaS(<ruby> 软件即服务 <rt> Software as a Service </rt></ruby>)解决方案。
### grommunio
[grommunio](https://grommunio.com/),以前被称为 grammm,在 AGPLv3 许可下发布的。它由奥地利同名公司开发和支持。与 Exchange 不同,grommunio 提供符合标准的邮件服务器,以及功能齐全的群件解决方案,具有电子邮件、联系人、日历、任务、文件共享等功能。grommunio 适用于各种开源和专有邮件客户端,如 Windows Mail、Outlook、Android、Apple Mail/iOS、Thunderbird 等,并支持旧的 RPC over HTTP 协议和 Outlook 标准协议 MAPI over HTTP。除此之外还包含:用于移动设备的 Exchange ActiveSync 和各种标准协议,如 CalDAV(日历)、CardDAV(地址簿)、IMAP、POP3、SMTP 和 LDAP,以及活动目录(用于同步用户帐户)。
外部对接的开源应用程序还提供了一些微软的 API 或协议不支持的功能。例如,开发人员合并了 [Jitsi](https://opensource.com/article/20/5/open-source-video-conferencing)(视频和音频电话软件)、[Mattermost](https://opensource.com/article/20/7/mattermost)(聊天软件)以及文件共享和同步([ownCloud](https://opensource.com/article/21/7/owncloud-windows-files))。除此之外,grommunio 还配备了基本的移动设备管理软件(MDM)。
grommunio 的设计面向各种不同的用户,并且与 Exchange 一样,它支持数据库分片(数据库在多个主机之间的水平分布)。灵活的存储后端允许管理员通过添加其他服务器或云帐户来扩展他们的设置。grommunio 仅将 MySQL 数据库用于元数据,而所有“内容”(例如邮件和群件对象)都存储在每个用户的 SQLite 数据库中。有关底层架构的更多信息,请查看 [该制造商的网站](https://grommunio.com/features/architecture/)。
其社区版是免费的,其中包括所有的 grommunio 功能并支持多达五个用户帐户。
### Kopano
来自德国和荷兰的软件制造商 Kopano 出品的 [Kopano](https://kopano.com/),也采用 AGPLv3 许可,基于 Zarafa 软件堆栈。与其前身不同,Kopano 的目标不只是成为 Exchange 的替代品。相反,它提供一个完整的群件解决方案,除了电子邮件、联系人、日历、任务、笔记和文档编辑这些标准功能外,它还包括实时通信。Kopano 可以与 [许多其他平台](https://kopano.com/products/interoperability/)、应用程序和服务交互,其中一些通过插件就能轻松实现。对于视频会议,Kopano 团队基于 WebRTC 开发了自己的开源解决方案:Kopano Meet 提供端到端加密,在 Windows、macOS、Linux、Android 和 iOS 客户端都适用。
Outlook 客户端通过 ActiveSync(Z-Push 库)或 [Kopano OL Extension](https://kb.kopano.io/display/WIKI/Setting+up+the+Kopano+OL+Extension)(KOE)来同步移动数据,KOE 是已经包含了 ActiveSync 的加强版。Kopano 提供本机 Web 客户端(WebApp)、移动设备客户端(Mobility)以及支持 Windows、Linux 和 macOS 的桌面版本(DeskApp)。它可以通过 IMAP、CalDAV 和 CardDAV 连接其他客户端。所有直接连接到 Kopano 服务器的应用程序都使用 SOAP(<ruby> 简单对象访问协议 <rt> Simple Object Access Protocol </rt></ruby>)中的 MAPI。
Kopano Groupware 和 Kopano ONE(Kopano Groupware 的特别版)都提供免费的社区版本。 Kopano Meet 还可以作为应用程序或容器下载。
### Nextcloud
[Nextcloud](https://nextcloud.com/) 在斯图加特和柏林(德国)都有办事处,采用 AGPLv3 许可。与 ownCloud 或 Dropbox 一样,用户可以通过桌面(Windows、Linux 和 macOS)、网络浏览器或本地应用程序(Android 和 iOS)访问该软件套件。从 18 版本开始,Nextcloud 除了拥有 Nextcloud Files(文件同步和共享)还包括了 Nextcloud Talk(通话、聊天和网络会议)和 Nextcloud Groupware(日历、联系人和邮件),并更名为 Nextcloud Hub。
用户和群组管理通过 OpenID 或 LDAP 进行。Nextcloud 支持各种存储后端,例如 FTP、S3 和 Dropbox。Nextcloud 可与多种数据库管理系统配合使用,包括 PostgreSQL、MariaDB、SQLite 和 Oracle 数据库。管理员可以通过 [Nextcloud 应用程序商店](https://apps.nextcloud.com/) 中的 200 多个应用程序扩展功能,其中包括实时通信、音频和视频聊天、任务管理、邮件等等。
Nextcloud 是完全免费的。最重要的是,该公司提供了 Nextcloud Enterprise 版本(针对企业部署进行了预配置、优化和强化)
### ownCloud
[ownCloud](https://owncloud.com/) 是由位于德国纽伦堡的 ownCloud GmbH 公司开发和维护的具有文件同步、共享和内容协作功能的软件。它的客户端-服务器软件的核心和许多社区应用程序都是在 AGPLv3 下发布的。一些扩展功能的企业应用程序以 ownCloud 商业许可证(OCL)的形式授权。
ownCloud 主要是一款内容协作软件,包括在线办公文档编辑、日历、联系人同步等功能。移动客户端支持 Android 和 iOS,桌面应用可以和 Windows、macOS 和 Linux 的原生文件管理器结合使用。它允许访问 Web 界面,无需安装专用客户端软件。ownCloud 支持 WebDAV、CalDAV 和 CardDAV 协议。LDAP 协议也包含其中,但 ownCloud 也可以连接到支持 OpenID Connect 身份验证标准的其他身份提供者。
ownCloud 可以整合微软 Office Online Server、Office 365 和微软 Teams,同时为微软 Outlook 和 eM 客户端提供可用插件。如有必要,外部存储功能可连接到不同的存储提供商,例如 Amazon S3、Dropbox、微软 SharePoint、Google Drive、Windows 网络驱动器(SMB)和 FTP。该供应商还为企业客户提供额外的功能,如端到端加密、勒索软件和防病毒保护等(请参阅 [完整功能列表](https://owncloud.com/features/))。
社区版免费且 100% 开源。
### OX App Suite
[Open-Xchange](https://www.open-xchange.com/) 成立于 2005 年,总部位于德国奥尔佩和纽伦堡。今天,OX 在多个欧洲国家、美国和日本设有办事处。[OX App Suite](https://www.open-xchange.com/products/ox-app-suite/) 是一个模块化的电子邮件、通信和协作平台,主要为电信公司、托管公司和其他提供基于云的服务的提供商而设计。
OX 后端在 GPLv2 协议下发布,前端(UI)在 AGPLv3 下发布。用户可以通过他们喜欢的浏览器(完全个性化的门户)或移动应用程序(Android 和 iOS)访问应用程序套件。或者,原生客户端(移动设备和台式机)也可用于 OX Mail 和 OX Drive。得益于 CardDAV 和 CalDAV 扩展、Exchange Active Sync 和适用于 Android 的 OX Sync App,联系人、日历和任务得以同步。
OX App Suite 包含用于电子邮件、联系人、日历和任务的应用程序。 还有其他工具和扩展可用,其中一些是开源的,一些功能则要付费,包括 OX Documents(文本文档、电子表格、演示文稿)、OX Drive(管理、共享和同步文件)、OX Guard(电子邮件和文件加密)等等。如需完整列表,请访问 OX 网站的 [一般条款和条件](https://www.open-xchange.com/terms-and-conditions/)。
该应用免费提供有限功能的社区版。
### 开源电子邮件和群件
电子邮件和群件服务并不是必须花(很多)钱才可获得,当然也没有必要满足于在别人的服务器上托管的专有解决方案。如果你不太热衷于管理职责,那么上述的这五个 Exchange 开源替代品都可以作为 SaaS 解决方案使用。另外,所有供应商都提供专业技术支持,你可以在本地运行软件,一切尽在你的掌握中,但你却不会感觉自己孤军无援。
(题图由 MJ 生成:Mail Cooperation Groupware Office Open Source hyper realistic, hyper detailed, intricate detail, beautiful lighting, very detailed,Illustration)
---
via: [https://opensource.com/article/21/11/open-source-alternatives-微软-exchange](https://opensource.com/article/21/11/open-source-alternatives-%E5%BE%AE%E8%BD%AF-exchange)
作者:[Heike Jurzik](https://opensource.com/users/hej) 选题:[lujun9972](https://github.com/lujun9972) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
15,706 | Xubuntu 23.04 的最佳新功能 | https://www.debugpoint.com/xubuntu-23-04/ | 2023-04-09T16:42:00 | [
"Xubuntu"
] | /article-15706-1.html | 
>
> 一些很酷的功能将在 Xubuntu 23.04 “Lunar Lobster” 版本中出现。
>
>
>
Xubuntu 23.04,基于即将发布的 [Ubuntu 23.04 “Lunar Lobster”](https://www.debugpoint.com/ubuntu-23-04-features/),将于 2023 年 4 月 20 日到达。这个最新版本建立在 Linux 内核 6.2 上,带来了最新的硬件、CPU、GPU 和文件系统支持。
从改进的小程序到更强大的 Thunar 文件管理器,Xubuntu 23.04 提供了大量的改进和错误修复,通过所有 Linux 桌面的 “OG” —— Xfce 4.18,提供了更精炼的用户体验。

如果你正在使用之前的 Xubuntu 22.10,那么你可能会注意到桌面环境的明显变化。Xubuntu 22.10 以开发版 Xfce 4.17 为特色,并带有来自 Xfce 4.18 少量功能。
考虑到这一点,让我们来看看 Xubuntu 23.04 “Lunar Lobster” 的最佳新功能。
### Xubuntu 23.04 的最佳新功能
#### Xfce 4.18 更新
这个版本中的一个重要变化是对 Xfce 桌面环境的更新。Xubuntu 23.04 基于 2022 年 12 月发布的 [最新的 Xfce 4.18](https://www.debugpoint.com/xfce-4-18-features/)。Xfce 4.18 是该桌面环境的一个重要里程碑,提供了对 GTK4 的更新、对 Wayland 的初始支持以及对核心原生应用的改造,更新量很大。
顶部主面板已经更新了新的设置和调整,而整体外观仍与早期版本相同。一些默认的面板小程序在这个版本中也被改变了,而桌面图标、右键上下文菜单和项目保持不变。

面板首选项得到了增强,有两个新的选项。首先,面板的长度现在是以像素为单位,而不是百分比。其次,增加了一个新的选项,“保持面板在窗口上方”,允许用户将窗口对话放到面板后面。在早期版本中,应用程序窗口只能达到面板边缘。
在 Xfce 4.18 中对时钟小程序的设置进行了大修。用户终于可以改变 Xfce 时钟小程序的字体风格,并且有四个时钟布局选项:只显示日期,只显示时间,日期和时间,以及时间和日期。
#### Thunar 文件管理器的更新
由于在 [Google Summer of Code 2022](https://debugpointnews.com/xfce-gsoc-2022/) 期间所做的工作,用户现在可以在 Thunar 的嵌入式侧边栏中看到图片预览,或者在独立模式下出现在右侧的新面板中,这可以通过偏好设置进行更改。
Thunar 的设置也得到了加强,增加了一个新的标签用于定制键盘快捷键。用户现在可以直接指定新的组合键,并从这个标签中改变现有的组合键。
一个新的搜索图标已经取代了工具栏中的重载按钮,当点击它时,它会在地址栏中调出搜索,用用户的搜索关键词进行递归搜索。重载按钮已被移至 “<ruby> 查看 <rt> View </rt></ruby>” 菜单。另一个新项目,“<ruby> 最近 <rt> Recent </rt></ruby>”,已被添加到左边的导航栏。同时,元数据被组织得更好了(从逗号分隔换成竖线分隔),一个新的上下文菜单项允许用户选择他们想要的选项。
Thunar 的主菜单也发生了重大变化。引入了一个新的 “<ruby> 书签 <rt> Bookmarks </rt></ruby>” 菜单,允许用户将当前文件夹作为快捷方式添加到侧边栏中。“<ruby> 编辑 <rt> Edit </rt></ruby>”菜单现在包括 “<ruby> 撤销 <rt> Undo </rt></ruby>” 和 “<ruby> 重做 <rt> Redo </rt></ruby>” 选项,而 “<ruby> 前往 <rt> Go </rt></ruby>” 菜单则有 “最近”和 “<ruby> 按文件搜索 <rt> Search for the file </rt></ruby>”选项。

Thunar 还首次通过 “<ruby> 视图 <rt> View </rt></ruby>” 菜单项增加了分割视图,使用户能够在视图面板中拖放项目。另外,为了组织你的文件夹以加快工作流程,Thunar 还为你的文件夹及其名称引入了背景颜色。

除了 Xfce 4.18 的功能外,Xubuntu 23.04 还为窗口管理器和桌面的提供了更多的错误修复和性能改进。这些改进是在底层进行的;用户可以期待一个更精巧的 Xfce 桌面体验。
虽然 Xfce 桌面核心和本地应用程序的 Wayland 迁移工作已经开始,但它仍然远远没有准备好。因此,这个 Xubuntu 23.04 可能是未来 Wayland 工作的基础,希望可以出现在下一个 Xubuntu LTS 之前。虽然,考虑到 Xfce 团队的规模和其他方面,这不太有信心。
#### 最小化 ISO
正如我之前所报道的,Xubuntu 23.04 也引入了一个最小化的 ISO 镜像,其中只有基本的 Xfce 桌面组件,没有任何额外的预装软件。你可以试试这个最小化的 ISO,为你的工作流程建立你自己的桌面设置。
最小化的 ISO 大小目前为 1.9GB,团队正在努力在未来的版本中进一步减少它。
你可以在 [这篇文章中](https://www.debugpoint.com/xubuntu-minimal/) 阅读更多关于 Xubuntu 最小化 ISO 的信息。

#### Flathub 和 Snap
几周前,Canonical 宣布已决定从所有 Ubuntu 官方风味版中默认删除 Flatpak 支持。因此,在 Xubuntu 23.04 中,你将不会默认安装 Flatpak。
Ubuntu 自己的 Snap 将默认安装所有相关组件,以运行几个 Snap 应用程序,如 Firefox。
但是,在 Xubuntu 中设置 Flatpak 和 Flathub 非常容易,[只需要两个命令](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/)。
#### 其他变化和总结
在核心方面,Xubuntu 23.04 基于 [Linux 内核 6.2](https://www.debugpoint.com/linux-kernel-6-2/) 主线版本,它带来了对领先制造商的最新 CPU/GPU 产品的支持。此外,这个内核版本还引入了内存优化、安全修复和许多附件支持。
应用程序栈和 GNOME 组件的更新如下:
* Firefox 111.0(Snap)
* Thunderbird 102.9
* Thunar 4.18.4
* Parole media player 4.18
* LibreOffice 7.5
* GNOME Software 44.0
* Catfish file search 4.16.4
* Transmission 3.0

在核心部分,Python 3.11 现在可以在 Xubuntu 23.04 中开箱即用。你不需要再单独 [安装 Python 3.11](https://www.debugpoint.com/install-python-3-11-ubuntu/) 了。值得一提的是,Python 3.12版本将在今年发布,目前正在进行多个 RC 测试。下面是这个版本中核心模块的总结:
* Python 3.11
* GCC 13
* GlibC 2.37
* Ruby 3.1
* golang 1.2
* LLVM 16
### 下载
你可以从下面的链接中下载 Xubuntu 23.04(测试版)。请记住,它仍然在进行测试。所以,请谨慎使用它。
>
> **[下载 Xubuntu 23.04 - Beta](https://cdimage.ubuntu.com/xubuntu/releases/lunar/beta/)**
>
>
>
如果你想要 Xubuntu 23.04 的最小化 ISO,你可以从下面的链接获得该文件。[了解更多关于 Xubuntu-mini](https://www.debugpoint.com/xubuntu-minimal/)。
>
> **[下载 Xubuntu 23.04 (mini-ISO) - Beta](https://cdimage.ubuntu.com/xubuntu/releases/lunar/beta/)**
>
>
>
### 总结
总之,Xubuntu 23.04 是一个重要的版本,具有 Xfce 4.18 桌面环境的若干改进和功能。由于专注于提高用户体验,Xubuntu 用户可以享受到最新的 Linux 内核、改进后的 Thunar 文件管理器以及其他一些调整和变化。
这将是 Xubuntu 对每个人来说最好的版本之一。
专题图片来源:[xfce-look](https://www.xfce-look.org/p/1953253)
---
via: <https://www.debugpoint.com/xubuntu-23-04/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,708 | 使用开源的思维导图工具 | https://opensource.com/article/23/3/open-source-mind-mapping | 2023-04-10T11:48:35 | [
"思维导图"
] | https://linux.cn/article-15708-1.html | 
>
> 使用思维导图与开源工具来做一个有影响力的演示。
>
>
>
在今天的世界和社交媒体中,许多人没有耐心阅读冗长的文字内容。视觉效果是吸引受众注意力的好方法。
你知道吗,3M 公司的研究得出结论,视觉的处理速度是文字的 60,000 倍?视觉比文字更有冲击力,能增强创造性思维和记忆。
### 一图胜千言
我收集了一些常见的 [Git 命令](https://opensource.com/downloads/cheat-sheet-git)。我把 Git 命令作为主话题,每个子话题都是一个带有定义的 Git 命令语法。为此,我使用了 Wisemapping。

不管你以前是否知道 [思维导图](https://opensource.com/article/21/12/open-source-mind-mapping-drawio) 是什么,现在你看到了思维导图,你就可以理解这个概念了。这就是视觉的力量。
### 如何创建一个思维导图?
* 从主话题开始,把它放在你的画板中间。
* 创建子话题并将它们与主话题联系起来。
* 你可以为每个子话题添加细节,如定义、例子等。
### 3 个你可以用来创建思维导图的开源工具
看看这三个开源工具,为你的想法创建一个视觉:
* [Wisemapping](https://www.wisemapping.com/)
* [Freeplane](https://opensource.com/article/19/1/productivity-tool-freeplane)
* [Semantik](https://waf.io/semantik.html)
维基百科对思维导图的定义是:将信息直观地组织成一个层次结构,显示整体中各部分之间的关系。思维导图从一个中心话题开始,然后建立起关系。它是一种结构化思想和创造有影响力的演示的视觉方式。
你可以在工作中使用思维导图。例如,我用思维导图来展示一个项目所计划的功能的高层概述。有了这些优秀的开源思维导图应用,你很容易就能开始将你的下一个项目可视化。试试用开源的思维导图吧。
*(题图:MJ:Thinking Brainstorming Creativity Ideas Discussion Illustrations Blue Gold Simplicity)*
---
via: <https://opensource.com/article/23/3/open-source-mind-mapping>
作者:[Amrita](https://opensource.com/users/amrita42) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In today's world and social media, many people don't have the patience to read lengthy textual content. Visuals are a great way to capture your audience's attention span.
Did you know that research at 3M Corporation concluded that visuals are processed 60,000 times faster than text? Visuals are more impactful than words and enhance creative thinking and memory.
## A picture is worth a thousand words
I looked at some of the common [Git commands](https://opensource.com/downloads/cheat-sheet-git). I used Git commands as the main topic; each sub-topic is a Git command syntax with a definition. For this, I used Wisemapping.
(Amrita Sakthivel, CC BY-SA 4.0)
Whether you knew what a [mind map](https://opensource.com/article/21/12/open-source-mind-mapping-drawio) was before or not, now that you've seen a mind map, you can now understand the concept.. That's the power of visuals.
## How do you create a mind map?
- Start with the main topic and place it in the middle of your drawing board.
- Create sub-topics and link them to the main topic.
- You can add details to each sub-topic, such as definitions, examples, etc.
## 3 open source tools you can use to create a mind map
Take a look at these three open source tools to create a visual of your idea:
Wikipedia defines a mind map as a diagram to visually organize information into a hierarchy, showing relationships among pieces of the whole. Mind mapping starts with a central theme and then builds relations. It is a visual way to structure thoughts and create impactful presentations.
You can use mind maps in your work. For example, I used a mind map to show a high-level overview of features planned for a project. With these excellent open source mind mapping applications, it's easy to get started visualizing your next project. Try mapping your mind with open source.
## 1 Comment |
15,709 | Rust 基础系列 #1: 创建并运行你的首个 Rust 程序 | https://itsfoss.com/rust-introduction/ | 2023-04-10T16:42:58 | [
"Rust"
] | https://linux.cn/article-15709-1.html | 
>
> 在 Rust 编程系列的第一篇中,你将学习如何用 Rust 编写和执行你的第一个程序。
>
>
>
Rust 是最快风靡开发者和科技公司的系统编程语言之一。日常使用它的开发者将其评为**最受欢迎的编程语言**之一,而它 [已经连续七年获此殊荣了](https://survey.stackoverflow.co/2022/?ref=itsfoss.com#section-most-loved-dreaded-and-wanted-programming-scripting-and-markup-languages)!
它是如此的受欢迎,以致于现在有两股巨大的推力将其带入 Linux 生态系统中:
* [将 Rust 作为 Linux 内核的二级支持语言](https://news.itsfoss.com/linux-kernel-6-1-release/?ref=itsfoss.com)
* System76 [正在使用 Rust 重写他们自己的桌面环境](https://news.itsfoss.com/pop-os-cosmic-rust/?ref=itsfoss.com)
而这还仅仅是在 Linux 生态系统中。安卓上的蓝牙软件 [Gabeldorsche](https://android.googlesource.com/platform//system/bt/+/83498aa554aea220fcff30b6310a0a7b4557969f/gd/rust/linux/stack/src/bluetooth.rs?ref=itsfoss.com) 现在也是由 Rust 编写的。
你是否也看到了 Rust 的流行趋势?那么你或许也想学习使用 Rust 进行编程。
### 为什么你要考虑 Rust 而不是其他编程语言?
首先,Rust 是一门 **类型安全的编程语言** 并且 **拥有极其严格的编译期检查**。因此,你首先会 “被迫” 写不出不安全的代码(好吧,通常是这样)。
Rust 编程语言有以下 “目标”:
* **性能**:Rust 的二进制文件和 C 语言的二进制文件一样快,有时甚至超过了 C++ 的二进制文件!
* **内存安全**:Rust 非常重视内存安全。
* **并发性**:对内存安全的关注消除了很多类似竞争的情况,并帮助你在程序中无畏并发。
以下是在 C/C++ 等语言中可能犯的一些错误(但 Rust 不会):
* 释放后使用
* 双重释放
* 越界访问
* 使用 `NULL`
* 不适当的指针运算或访问
* 使用未经初始化的变量
* 线程不安全的多线程
看看 [苹果](https://langui.sh/2019/07/23/apple-memory-safety/?ref=itsfoss.com)、[微软](https://msrc-blog.microsoft.com/2019/07/18/we-need-a-safer-systems-programming-language/?ref=itsfoss.com)、[谷歌](https://security.googleblog.com/2019/05/queue-hardening-enhancements.html?ref=itsfoss.com) 等大公司因这类 [0day](https://docs.google.com/spreadsheets/d/1lkNJ0uQwbeC1ZTRrxdtuPLCIl7mlUreoKfSIgajnSyY/view?ref=itsfoss.com#gid=1190662839) 错误而引起的问题吧。
现在你可能知道了为什么要选择 Rust 语言而不是其他编程语言,让我们开始学习 Rust 语言的系列教程吧!
### 目标受众
出于对 Rust 的热爱,我写了这个系列的 Rust 教程,帮助你熟悉 Rust 编程的概念。
这个教程系列是为已经熟悉 C 和 C++ 等编程语言的人准备的。我假设你已经知道了 *变量*、*函数*、*循环* 等基本术语。
我对你的唯一要求是你不懈的坚持与努力。
### 安装 Rust 工具链
我希望你能在本地安装 [Rust 工具链](https://itsfoss.com/install-rust-cargo-ubuntu-linux/)。你可以通过运行以下命令来做到这一点: (LCTT 译注:如果你使用 Linux 发行版,请不要直接安装软件源里的 Rust 工具链,尽管这样看起来很便捷。)
```
curl --proto '=https' --tlsv1.3 -sSf https://sh.rustup.rs | sh
```

除了 Rust 基本工具链,我还建议再安装一些工具,这些工具将在开发过程中帮助你:
```
rustup component add rust-src rust-analyzer rust-analysis
```
你还需要 [安装 gcc](https://learnubuntu.com/install-gcc/?ref=itsfoss.com)。否则,你可能会遇到“链接器 `cc` 未找到”的错误。该软件包在不同的发行版中都被称为 gcc。
在 Ubuntu 和 Debian 上使用:
```
sudo apt install gcc
```
>
> ? 如果你不希望在本地安装 Rust 工具链,不用担心。你还可以直接在你的浏览器中运行 Rust 代码!只要到 [Rust 试验场](https://play.rust-lang.org/?ref=itsfoss.com) 并把所讨论的代码粘贴在那里。
>
>
>
### Hello Rust!
自从 <ruby> 丹尼斯·里奇 <rt> Dennis Ritchie </rt></ruby> 和 <ruby> 布莱恩・柯林汉 <rt> Brian Kernighan </rt></ruby> 用 “Hello World” 程序介绍了 C 语言后,在 UNIX 世界里,你学习的任何新编程语言第一步都这样做,这已经成为一种习惯。
因此,让我们也用 Rust 编写我们的 Hello World 程序。
我将在我的家目录里 [新建一个项目目录](https://itsfoss.com/make-directories/) 叫做 `learn-rust-its-foss`。然后,在这里我将新建一个叫 `hello-world` 的目录。最后,在里面新建 `main.rs` 文件:
```
// 这串代码将打印字符
// "Hello world!" 将被打印到 `标准输出`
fn main() {
println!("Hello world!");
}
```
>
> ? 就像 C、C++ 和 Java 源代码文件相应的扩展名是 `.c`、`.cpp` 和 `.java`,Rust 的源文件扩展名是 `.rs`。
>
>
>
作为一个 C/C++ 程序员,你可能已经在 [Linux 上使用 GCC](https://learnubuntu.com/install-gcc/?ref=itsfoss.com),在 macOS 上使用 `Clang`,在 Windows 上使用 MSVC。但是为了编译 Rust 代码,该语言的创造者自己提供了一个官方的 `rustc` 编译器。
运行 Rust 程序和 [执行 C/C++ 程序](https://itsfoss.com/run-c-program-linux/) 是一样的。你首先编译代码,然后得到可执行文件,最后再运行这个可执行文件从而来运行代码。
```
$ ls
main.rs
$ rustc main.rs
$ ls
main main.rs
$ ./main
Hello world!
```
很好!
### 解读 Rust 代码
现在你已经编写、编译并运行了你的第一个 Rust 程序,让我们对 “Hello World” 的代码进行解读,并理解每一部分。
```
fn main() {
}
```
`fn` 关键字用来在 Rust 中声明一个函数。在它后面 `main` 是这个被声明函数的名字。像许多编译型编程语言一样,`main` 是一个特殊的函数,用来作为你的程序的入口。
任何写在 `main` 函数里的代码(在大括号 `{` `}` 之间)将在程序被启动时运行。
#### println 宏
在 `main` 函数中, 有一个语句(LCTT 译注:“语句” 区别于 “表达式”):
```
println!("Hello world!");
```
就像 C 语言的标准库有 `printf` 函数一样,Rust 语言的标准库有 `println` **宏**。宏类似于函数,但它以**感叹号**(`!`)来区分。你将在本系列的后面学习宏和函数的知识。
`println` 宏接收一个格式化的字符串,并把它放到程序的标准输出中(在我们的例子中,就是终端)。由于我希望输出一些文本而不是一个变量,我将把文本放在双引号(`"`)内。最后,我用一个分号来结束这个语句,表示语句的结束。
>
> ? 你只需知道,任何看起来像函数调用但在开头括号前有感叹号的东西,就是 Rust 编程语言中的一个宏。
>
>
>
#### 注释
Rust 遵循已知的 C 编程语言的注释风格。单行注释以两个正斜杠(`//`)开始,多行注释以 `/*` 开始,以 `*/` 结束。
```
// 这是一个多行注释
// 但是没有什么阻止你在
// 第二行或第三行也这样写
/*
* 这是一个“真•多行注释”
* 它看起来比较漂亮
*/
```
### 总结
你刚刚通过 Hello World 程序迈出了用 Rust 写代码的第一步。
作为一种练习,也许你可以编写并执行一个打印出 `Yes! I did Rust` 的 Rust 程序。
在本系列的下一部分中,你将学习在 Rust 程序中使用变量。敬请期待!
*(题图:MJ:computer sci-fi ,code secure ,"rust" ,gold blue slive ,background dark, high resolution super detailed)*
---
via: <https://itsfoss.com/rust-introduction/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lkxed](https://github.com/lkxed/) 译者:[mcfd](https://github.com/mcfd) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Rust Basics Series #1: Create and Run Your First Rust Program
In the first chapter of the Rust programming series, you learn to write and execute your first program in Rust.
So, you've decided to try coding in Rust.
And why not? After all, it is one of the fastest adopted systems programming languages by developers and tech companies. It is also the only language other than C that is used in Linux kernel code.
In the first part of the Rust Basics series, you'll learn to write your first ever Rust program.
Before you do that, you must install it first. Let's go on with that.
## Installing the Rust compiler
I would prefer that you have the [Rust compiler installed locally](https://itsfoss.com/install-rust-cargo-ubuntu-linux/). You can do so by running the following command:
`curl --proto '=https' --tlsv1.3 -sSf https://sh.rustup.rs | sh`
Apart from the Rust Compiler, I also recommend installing a few more tools that will help you in the development process:
```
rustup component add rust-src rust-analyzer rust-analysis
```
You also need to [install gcc](https://learnubuntu.com/install-gcc/). Otherwise, you may encounter `linker 'cc' not found`
error. The package is called gcc across distributions.
On Ubuntu and Debian use:
`sudo apt install gcc`
[Rust Playgrounds website](https://play.rust-lang.org/)and paste the code discussed here.
## Hello Rust!
Since Dennis Ritchie and Brian Kernighan introduced the C programming language with the "Hello world" program, it has become a custom in the UNIX world to do so with any new programming language you learn.
So let's write our Hello World program in Rust as well.
I will [create a project directory](https://itsfoss.com/make-directories/) called `learn-rust-its-foss`
in my home directory. In there, I create another directory called `hello-world`
. Inside that, I will create a `main.rs`
file:
```
// this code outputs the text
// "Hello world!" to `stdout`
fn main() {
println!("Hello world!");
}
```
As a C/C++ programmer, you might have used [gcc on Linux](https://learnubuntu.com/install-gcc/), `clang`
on macOS and MSVC on Windows. But to compile Rust code, the language creators themselves provide an official `rustc`
compiler.
Running a Rust program is the same as [executing C/C++ program](https://itsfoss.com/run-c-program-linux/). You compile the code to get the executable file and then run this executable to run the code.
```
$ ls
main.rs
$ rustc main.rs
$ ls
main main.rs
$ ./main
Hello world!
```
Nice!
## Deciphering Rust code
Now that you wrote, compiled and ran your first ever Rust program, let's de-structure the "Hello world" code and understand each part.
```
fn main() {
}
```
The `fn`
keyword is used to declare a function in Rust. Following it, `main`
is the name of this particular function that was declared. Like many compiled programming languages, the `main`
is a special function used as your program's entry point.
Any code written inside the `main`
function (between the curly brackets `{`
`}`
) gets executed upon program start-up.
### println macro
Inside the `main`
function, there is one statement:
```
println!("Hello world!");
```
Like the C language's standard library has the `printf`
function, Rust language's standard library has the `println`
**macro**. A macro is similar to a function but it is distinguished by the **exclamation mark**. You'll learn about macros and functions later in this series.
The `println`
macro takes in a format string and puts it to the program's output (in our case, that is terminal). Since I wish to output some text instead of a variable, I will enclose the text inside double quotes (`"`
). Finally, I end this statement using a semi-colon to denote the end of the statement.
### Commenting
Rust follows the known commenting style of the C programming language. A single line comment starts with two forward slashes (`//`
) and a multi-line comment is started by `/*`
and ends with `*/`
.
```
// this is a single-line comment
// but nothing stops me from doing the same
// on the second or third line too!
/*
* this is a "true" mutli-line comment
* because it is _fancy_
*/
```
## Conclusion
You just took the first step towards coding in Rust with the Hello World program.
As a practice, perhaps you can write and execute a Rust program that prints "Yes! I did Rust".
In the next part of the series, you'll learn to use variables in your Rust program. Stay tuned! |
15,711 | 一个更好的视频码头 | https://jao.io/blog/2021-01-11-an-even-better-video-wharf.html | 2023-04-11T15:02:00 | [
"embark",
"Emacs"
] | https://linux.cn/article-15711-1.html | 
之前,[我在写](https://jao.io/blog/2021-01-09-embarking-videos.html) 有关 [embark](https://github.com/oantolin/embark) 的内容,我的第一设备为启动远程视频流设计了一个新的 embark。embark 的作者 Omar Antolín Camarena 不仅阅读了这篇内容,还点评了一下我认为值得跟进的一些重大改进。
首先,你应该记得我们曾定义过一个检测视频 URL 的函数:
```
(defun jao-video-finder ()
"Check whether we're looking at a video URL.
Return (video-url . <URL>) if so."
(when-let ((url (thing-at-point-url-at-point)))
(when (string-match-p jao-video-url-rx url)
(cons 'video-url url))))
```
当我们得到了一个非空的 `url` 值,即便它不是一个视频链接,但它仍然是一个确切的 URL,并且 embark 已有了一个 `url` 类别,所以我们可以借助默认的 URL 寻检器存储一个新的句法分析,语句如下:
```
(when-let ((url (thing-at-point-url-at-point)))
(cons (if (string-match-p jao-video-url-rx url) 'video-url 'url) url))
```
这里有一个潜在的缺点就是:我们重写了 embark 的寻检器,`embark-target-url-at-point`,所以我们可能更愿意保留后者。
实际上多亏了 embark 的 *目标转换器* 我们才能做成。我们可以在 `embark-transformers-alist` 中添加任意一个函数,应用于任何一个给定类别的目标,而 embark 会将其转换后的值应用于它的操作中。Omar 很贴切地把这个过程称为“目标的精化”;我们具体做法如下:
```
(defun jao-refine-url-type (url)
"Refine type of URL in case it is a video."
(cons (if (string-match-p jao-video-url-rx url) 'video-url 'url) url))
(add-to-list 'embark-transformer-alist '(url . jao-refine-url-type))
```
通过这种策略,我们就不再需要 `jao-video-finder` 了,而且从概念上来说,我们的 `video-url` 应该被定义为一个精化操作而并非是一个目标 [脚注 1]。Omar 的第二个提议也与这个概念相契合:想必我们都希望所有关于 `url` 和我们的 `video-url` 的操作都是可用的,不是吗? 唔,这就是为什么我们用来定义行为的 `embark-define-keymap` 的宏可以通过使用关键字 [脚注 2] `:parent` 继承其他键映射中已经定义的所有操作的原因:
```
(embark-define-keymap jao-video-url-map
"Actions on URLs pointing to remote video streams."
:parent embark-url-map
("p" jao-play-video-url))
(add-to-list 'embark-keymap-alist '(video-url . jao-video-url-map))
```
这种继承键映射的功能并非是 embark 的附属功能:vanilla Emacs 键映射通过标准函数 `set-keymap-parent` 已经搞定它了。你可以完全不用 `embark-define-keymap` 来定义 `jao-video-url-map`,工作原理是一样的。
这样,我们的代码就能够更短,特征更多:谢谢你,Omar!
**脚注 1**:在某些情况下,保留 jao-video-finder 是有意义的,即,如果我们想要改变检测 URL 的功能的话。例如,我在使用 emacs-w3m 的时候,经常有一个 URL 作为文本属性储存了起来(实际文本是个链接文本)。要通过那里检索 URL,就需要调用 `w3m-anchor`,而用 `embark-target-url-at-point` 就会错过它。对于这种情况,我最终编写(并使用)`jao-video-finder` 将其通过下文定义:
```
(when-let ((url (or (w3m-anchor) (thing-at-point-url-at-point))))
(cons (if (string-match-p jao-video-url-rx url) 'video-url 'url) url))
```
另一种达成同件事情的方式(再次向 Omar 致敬)便是为 w3m 的锚点放置一个特定的巡检器(且继续使用 video-url 的转换器):
```
(defun jao-w3m-url-finder ()
(when-let ((url (w3m-anchor)))
(cons 'url url)))
(add-to-list 'embark-target-finders #'jao-w3m-url-finder)
```
这种方法更加模块化,并且取决于你们的喜好,且更加巧妙。这些功能都很小巧并且两种方法之间并没有太大的差别,但是如果其中某一种继续加入更多寻检器的话,前一种方法用起来来反而会让一切变得更糟。
**脚注 2**:在我最开始的例子中,我在视频地图中还添加了 `browse-url` 和 `browse-url-firefox`。前一个已不再重要,因为它已经在 `embark-url-map` 中出现过了,如果我们想让 `browse-url-firefox` 对 *所有* 的 URLs 可用,我们可以将其加入到 `embark-url-map` (谨记,embark 的键映射只是 Emacs 的键映射)。这是另一种扩展 embark 的简便方法。
*(题图:MJ:emacs video geek wallpaper dark plain background Illustration)*
---
via: <https://jao.io/blog/an-even-better-video-wharf.html>
作者:[jao](https://jao.io) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Drwhooooo](https://github.com/Drwhooooo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
15,712 | 用 Collabora Online 在不同类型的文件间转换 | https://opensource.com/article/23/4/open-source-collabora-online-interoperability | 2023-04-11T17:30:00 | [
"Office",
"文件格式"
] | /article-15712-1.html | 
>
> 探索 Collabora Online 的互操作性,使文档和电子表格在所有办公套件中兼容。
>
>
>
[Collabora Online](https://www.collaboraoffice.com/) 支持各种各样的文件和格式。不过,这个开源办公套件在互操作性方面的表现如何?本文仔细研究了 Collabora Online 与不同办公套件(如 Microsoft 365 和 Google Workspace)交换复杂文本文档和电子表格的能力。
[Collabora Online](https://opensource.com/article/22/7/open%20source-collabora-online) 是一款适用于云端或内部的开源办公套件,可以保护你的隐私,让你完全控制你的数据。该软件由位于剑桥的 Collabora Productivity Ltd 开发,其团队在世界各地工作。Collabora Online 以 LibreOffice 技术为基础,并主要使用 Mozilla Public License 2.0 许可。
Collabora Online 可以在任何现代网络浏览器中运行,不需要额外的插件或附加组件。它有一个完整的基于云的办公套件,包括一个文字处理器(Writer)、电子表格程序(Calc)、演示软件(Impress)和一个设计矢量图的应用(Draw)。
本文介绍了 Collabora Online 的一些新的互操作性功能,包括宏、动态字体加载和电子表格应用程序的 Sparklines 支持。这些功能扩展了现有的对微软文件格式的出色处理。
### 什么是互操作性,为什么它很重要?
一般来说,互操作性是指不同的设备或应用在一起工作和无缝交换数据的能力。在办公套件的背景下,互操作性主要是指文件格式。用户应该能够打开、编辑和保存 `.doc` 和 `.docx`、`.xls` 和 `.xlsx`、`.odt` 和 `.ods`文件,无论它们是用微软的 Word、苹果的 iWork 还是 LibreOffice 创建。
对于在线办公套件也是如此。通过确保文件可以在 Microsoft 365、Google Workspace 和 Collabora Online 之间交换,互操作性有助于提高生产力和促进协作。所有在线办公套件都可以保存各种格式的文件。它们还可以导入和导出最初在其他办公套件中创建的文档、电子表格和演示文稿。
### 管理宏,确保文件处理顺畅
经常引起问题的是带有宏的文件。它们通常是用特定的编程语言开发的,适用于某个特定的应用。虽然在 Google Sheets 中记录和编辑宏是可能的,但在微软 Office 中用 Visual Basic for Applications(VBA)实现的宏不能被转换,必须用 Google Apps Script 重新创建。打开带有 VBA 宏的 Word 文档会产生错误,并通知用户这些宏将被忽略或禁用。
Collabora Online 支持宏,并在容器内的服务器端运行它们。该功能默认是禁用的,管理员必须在 `coolwsd.xml` 配置文件中明确激活它。之后,用户可以选择在加载文档时允许使用宏。不过,有几个限制。例如,它不可能访问数据库源,访问其他(外部)文件,调用外部程序,使用控制形状,等等。多年来,由于活跃的社区以及客户和合作伙伴的贡献,Collabora Online 支持的代码和对象的数量已经大大增加。
### Collabora Online:动态字体加载
办公套件中互操作性的另一个关键方面是字体。使用含有在特定平台上无法使用的字体的文档,可能会导致错误、意外的格式变化,甚至是内容的完全丢失。
微软 Office 文档经常使用 Google Workspace 或 Collabora Online 中没有的默认字体。为了解决这个问题,办公套件经常建议替换掉缺失的字体。这通常是有用的,但有时会导致不好的结果。
从 22.05.7 版本(2022 年 11 月发布)开始,Collabora Online 可以列出缺失的字体并建议替换。它还可以下载必要的字体并将其添加到服务器上。一切都是动态进行的,而不会停机。新的字体在几分钟内就可以在编辑会话中使用,实现最佳的互操作性。

为了实现这一目标,在文档被渲染的同时,通过 API 追踪丢失字体的信息。一个 JSON 文件存储了需要添加的字体列表。`coolwsd.xml` 文件(服务器端的设置)指向该 JSON 文件。它每分钟检查一次修改情况,并下载缺少的字体。
### 探索 Sparkline:显示电子表格中的数据趋势
Sparkline 是在工作表中单个单元格内的微小图表,它可以将数据的趋势可视化。这些微型图表有不同的风格,包括线、条和柱。Sparkline 还支持不同的颜色和水平/垂直轴。与显示尽可能多的数据并与文本流分开的大型图表不同,Sparkline 被缩减为核心值,通常放在同一单元格中数据本身的旁边或后面。Sparkline 通常是为一个单元格定义的,但也可以将共享相同数据范围和属性的多个 Sparkline 进行分组,以便进行渲染。

Sparkline 是一个紧凑的参考,提供了一个快速的方法来说明趋势、模式、统计异常、增加和减少,同时避免了完整图表的复杂性。下面是一些不同的 Sparkline 类型:
* 线形图: 通过线段从左到右连接各点,对于显示在一定时间内变化的数据特别有用。
* 条形图: 使用水平排列的条形图表示数据,通常用于比较数字数据。
* 柱状图: 是比较一系列数值的理想选择。柱是垂直的,其长度表示数据的相对大小/价值。柱状图经常被用来表示不同类别或群体的数据。
要创建一个 Sparkline,你首先要为该函数定义一个输入数据范围(一列或一行中的两个或多个单元格)。你还可以决定你希望 Sparkline 出现的单元格。在大多数电子表格应用中,你右键点击迷你图表来调整其属性,选择图表类型,并选择颜色。Collabora Online 为此提供了一个单独的对话框,使得改变微型图表的风格变得简单而方便。
在三个线上办公软件之间交换带有 Sparkline 的文件是可能的,不会丢失图表及其格式。如果你想在 Microsoft 365、Google Workspace 和 Collabora Online 之间共享电子表格,请确保使用微软格式的 .xlsx 进行导入和导出,因为 Google Sheets 不能很好地处理 .ods 文件。
### 文件交换很容易
Collabora Online 提供了几个新的互操作性功能,使得与其他办公套件交换文件变得容易。宏程序支持、动态字体加载和 Sparkline 确保了文档的无缝处理,避免了意外的格式变化。使用 Collabora Online 来统一和简化你的办公工作。
***(题图:MJ:Office docs process dark plain background Illustration )***
---
via: <https://opensource.com/article/23/4/open-source-collabora-online-interoperability>
作者:[Heike Jurzik](https://opensource.com/users/hej) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,714 | 如何逐步安装 Kubernetes(k8s)指标服务器 | https://www.linuxtechi.com/how-to-install-kubernetes-metrics-server/ | 2023-04-12T10:09:00 | [
"Kubernetes"
] | https://linux.cn/article-15714-1.html | 
>
> 在这篇文章中,我们将逐步介绍如何安装 Kubernetes 指标服务器。
>
>
>
Kubernetes(k8s)指标服务器是一个组件,用于收集和聚合来自 Kubernetes 集群中各种来源(包括节点和 <ruby> 容器荚 <rt> Pod </rt></ruby>)的指标数据。此数据可用于监控和优化资源利用率、识别潜在问题并提高 Kubernetes 集群的整体性能。
指标服务器收集资源利用率数据,例如集群中节点和容器荚的 CPU 和内存使用情况。它提供了一个 API 端点,可用于查询此数据并检索集群中特定资源的指标。
##### 先决条件
* 启动并运行 Kubernetes 集群(v1.21 或更高版本)。
* `kubectl` 命令行工具已安装,并配置为与你的 Kubernetes 集群交互。
* 创建和修改 Kubernetes 对象的能力。
事不宜迟,让我们深入了解安装步骤。
### 步骤 1 下载指标服务器清单
第一步是从 Kubernetes GitHub 仓库下载最新的指标服务器清单文件。使用下面的 `curl` 命令下载 yaml 文件:
```
# curl -LO https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
```

如果你计划在高可用性模式下安装指标服务器,请下载以下清单文件:
```
# curl https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/high-availability-1.21+.yaml
```
### 步骤 2 修改指标服务器 Yaml 文件
接下来,你需要修改指标服务器的 yaml 文件以设置一些配置选项:
```
# vi components.yaml
```
找到 `container` 下的 `args` 部分,添加以下行:
```
- --kubelet-insecure-tls
```
在 `spec` 下,添加以下参数:
```
hostNetwork: true
```

保存并关闭文件。
### 步骤 3 部署指标服务器
现在,我们准备好部署指标服务器,运行以下 `kubectl` 命令:
```
# kubectl apply -f components.yaml
```

### 步骤 4 验证指标服务器部署
部署指标服务器后,通过检查在 `kube-system` 命名空间中运行的容器荚状态来验证它的状态:
```
# kubectl get pods -n kube-system
```

上面的输出确认指标服务器容器荚已启动并正在运行。
### 步骤 5 测试指标服务器安装
最后,你可以通过运行以下 `kubectl` 命令来测试指标服务器:
```
# kubectl top nodes
```
此命令应显示集群中每个节点的资源利用率,包括 CPU 和内存使用率。

要查看当前命名空间或特定命名空间的容器荚资源利用率,请运行:
```
# kubectl top pod
# kubectl top pod -n kube-system
```

这就是这篇文章的全部内容,我希望你能从中找到有用的信息。请在下面的评论部分发表你的反馈和疑问。
*(题图:MJ: Kubernetes container paper art light blue background ultra-detailed topview)*
---
via: <https://www.linuxtechi.com/how-to-install-kubernetes-metrics-server/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this post, we will cover to how to install Kubernetes metrics server step by step.
The [Kubernetes(k8s) Metrics Server](https://github.com/kubernetes-sigs/metrics-server) is a component that collects and aggregates metrics data from various sources in the Kubernetes cluster, including nodes and pods. This data can be used to monitor and optimize resource utilization, identify potential issues, and improve the overall performance of your Kubernetes cluster.
Metrics Server collects resource utilization data such as CPU and memory usage for nodes and pods in the cluster. It provides an API endpoint that can be used to query this data and retrieve metrics for specific resources in the cluster.
#### Prerequisites
- A Kubernetes cluster (v1.21 or high) up and running.
- kubectl command line tool installed and configured to interact to your Kubernetes cluster.
- The ability to create and modify Kubernetes objects.
Without any further delay, let’s deep dive into the installation steps.
## Step 1) Download Metrics Server Manifest
The first step is to download the latest Metrics Server manifest file from the Kubernetes GitHub repository. Use below curl command to download yaml file,
# curl -LO https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
If you are planning to install metrics server in high availability mode then download following manifest file.
# curl https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/high-availability-1.21+.yaml
## Step 2) Modify Metrics Server Yaml File
Next, you need to modify the Metrics Server yaml file to set some configuration options,
# vi components.yaml
Find the args section under the container section, add the following line:
- --kubelet-insecure-tls
Under the spec section, add following parameter,
hostNetwork: true
Save and close the file.
## Step 3) Deploy Metrics Server
Now, we are all set to deploy metrics server, run following kubectl command,
# kubectl apply -f components.yaml
## Step 4) Verify Metrics Server Deployment
After deploying the Metrics Server, verify it’s status by checking the pods status which is running in the kube-system namespace,
# kubectl get pods -n kube-system
Output above confirms that metrics-server pod is up and running.
## Step 5) Test Metrics Server Installation
Finally, you can test the metrics server by running following kubectl command,
# kubectl top nodes
This command should display the resource utilization for each node in your cluster, including CPU and memory usage.
To view pods resource utilization of your current namespace or specific namespace, run
# kubectl top pod # kubectl top pod -n kube-system
That’s all from this post, I have hope you found it informative. Please do post your feedback and queries in below comments section.
Also Read: [How to Install and Use Helm in Kubernetes](https://www.linuxtechi.com/install-use-helm-in-kubernetes/)
AlexReally helpful.
Precise and steightforward.
Thank you.
moran kamielPERFECT user guide.
thanks!
RameshPerfect. Works fine on my self hosted kubernetes running on Ubuntu 22.04.
Rovshan KalanovEven this command “kubectl get pods -n kube-system” shows metrics-server as Ready, but it is still showing “error: Metrics API not available” |
15,715 | 大家最喜欢的 Linux 终端字体 | https://opensource.com/article/23/4/linux-terminal-fonts | 2023-04-12T16:22:00 | [
"终端",
"字体"
] | https://linux.cn/article-15715-1.html | 
>
> 这是一个完全主观的列表,为你的 Linux 控制台提供一些有趣的字体建议。
>
>
>
最近,终端模拟器成为我的一个话题,它让我思考:大家最喜欢的终端字体是什么?
因此,我请贡献者分享了他们喜欢使用的字体。以下是他们的答案。
### VT323
我喜欢在我的 GNOME 终端中使用一个不一样的字体([VT323](https://fontsource.org/fonts/vt323)),而不是在我的编程时用的编辑器或其他使用等宽字体的应用程序中使用的字体(Source Code Pro)。我就是喜欢经典的 VT 风格字体的外观。
有时,我会切换到原始的 IBM EGA 字体,因为在我眼里它看起来真的很漂亮。但是我把 EGA 和 DOS 联系在一起,把 VT323 和经典的 Unix 终端联系在一起,所以我大部分时间都用 VT323。下面是我使用 VT323 作为等宽字体的 GNOME 终端的屏幕截图:

我设置终端使用 24pt 大小的 VT323 字体,使得终端界面呈现一个舒适的大窗口。如果我要打开一个终端窗口,我其实是想使用它来些实实在在的工作,而不是敲两下就退出。我可能会在那个终端窗口呆一段时间,所以它应该很大,很容易看到。我也更喜欢 80x25 布局(每行 80 个字符,共 25 行),因为我是一个老式 DOS 命令行玩家,25 行在我看来才是 “正确的” 行数:

—— [Jim Hall](https://opensource.com/users/jim-hall)
### 等宽的字体
我不觉得我会只使用一个特定的字体。我通常使用 [DejaVu](https://fontsource.org/fonts/dejavu-mono) 或 [Liberation](https://github.com/liberationfonts)。我喜欢等宽字体,因为它们更容易阅读。不过,我也不希望字母靠得太近。更重要的是,要能够区分数字 1 和小写的 L、数字 O 和大小的字母 Q 等等。另外,让所有特殊字符都能特别清楚地显示出来也很好。
我也喜欢让字体和背景之间呈现高对比度,所以我将背景设置为黑色,字符设置为白色。
—— [Greg Pittman](https://opensource.com/users/greg-p)
### Hack
我喜欢使用等宽字体,特别是在终端和代码编辑器中,因为它们更容易阅读。我使用 [Hack](https://sourcefoundry.org/hack/) 系列字体已经很多年了。它提供了一个很好的等宽字体,并提供了额外的字形和 Powerline 支持,我可以用它们在命令行上提供一些状态信息。

这是用 [Fontpreview tool](https://github.com/sdushantha/fontpreview) 工具生成的字体预览。

—— [Ricardo Gerardi](https://opensource.com/users/rgerardi)
### Victor Mono
我在终端和 IDE 中使用 [Victor Mono](https://rubjo.github.io/victor-mono/) 已经好几年了。斜体的等宽手写体可能不是一开始就会喜欢上的,我喜欢这样,因为这让代码注释的外观很独特,与代码的其余部分明显不同。下面是它在终端中的样子:

我在 IDE 和终端使用了 Solarized Dark 配色方案。如果可以的话,任何与工作或代码相关的东西都会使用相同的配色方案和相同的字体,所以一切看起来都很统一。这些年来,我使用了各种字体,但我总是试图在我的终端中使用与 IDE 中相同的字体。
—— [Chris Reynolds](https://opensource.com/users/jazzsequence)
### Monaco
目前,我用 16pt 大小的 Monaco 常规字形。(要比 12pt 或是 14pt 大小好多了。)
—— [Jenny Panighetti](https://twitter.com/elvenjen)
### 用粉红色来装点
这让我想起了有一次我恶作剧把团队里的其他开发者的终端都改成了粉红色(我是里面唯一的女性),一个婴儿粉的背景与深粉红色的文字的搭配。
我喜欢把我的个人终端弄得漂漂亮亮的,但在工作中,我会用黑底白字,并把字体弄成 16pt 左右,因为我喜欢较大的字体尺寸。
我总是把我的终端设置为 SF Mono 字体,但我把它加粗,并增大了一点,以便我可以更好地看到它。我最喜欢的颜色是粉红色或漂亮的水蓝色。我也喜欢终端的默认风格,它叫做 “Novel”。

—— [RachieVee](https://opensource.com/users/rachievee)
### 万事不决,问 ChatGPT
对于这个问题,我决定问问 [ChatGPT](https://opensource.com/article/23/2/chatgpt-vs-community)。以下是它的回答:
>
> 作为一个语言模型,我没有个人偏好,也没有能力拥有一种最喜欢的字体。但是,有一些流行的终端字体,包括 Monospace、Consolas 和 Inconsolata。这些字体很受欢迎,因为它们易于阅读,不同字符之间有明显的区别,即使在字体大小比较小的情况下也非常清晰。此外,它们被设计为适配在各种不同的操作系统和终端中得到更好的呈现,使它们成为开发人员和用户的通用选择。
>
>
>
我部分使用 GPT-3 生成了这段文字,GPT-3 是 OpenAI 的大规模语言生成模型。在生成草稿后,作者可以根据自己的喜好审查、编辑和修改,以符合个人的喜好,并对最终发布的内容承担最终责任。
—— [Stephanie Brinley](https://opensource.com/users/sbrinley)
### Fantasque Sans Mono
```
$ grep font ~/.Xdefaults
URxvt*font: xft:FantasqueSansMono-Regular:pixelsize=12:antialias=true
```
我不记得我是什么时候开始使用 [Fantasque Sans Mono](https://github.com/belluzj/fantasque-sans) 的,但我想这是我过去 8 年来的默认选择,无论是在 [Rxvt](https://opensource.com/article/19/10/why-use-rxvt-terminal) 还是 Konsole 中。我不知道我在 GNOME 终端中使用的是什么字体,很可能是 GNOME 上的默认字体。
—— [Seth Kenlon](https://opensource.com/users/seth)
### Jetbrains Mono
最近,我将 Tilix 设置为默认终端。我的 Tilix 配置与 Jim Hall 使用的设置类似。几个不同点是:
* 光标形状是下划线而不是块
* 字体是 [Jetbrains Mono](https://www.jetbrains.com/lp/mono/) Nerd Font Mono Medium 14

—— [Alan Formy-Duval](https://opensource.com/users/alanfdoss)
---
via: <https://opensource.com/article/23/4/linux-terminal-fonts>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lkxed](https://github.com/lkxed/) 译者:[Taivas Jumala](https://github.com//Taivasjumala) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Terminal emulators came up as a topic for me recently, and it got me thinking: What's everyone's favorite terminal font?
So I asked Opensource.com contributors to share what font they like to use. Here are their answers.
## VT323
I like to use a different font ([VT323](https://fontsource.org/fonts/vt323)) in my GNOME Terminal than the font I use (Source Code Pro) in my programming editors or other apps that use a monospace font. I just like the look of the classic VT-style font.
Sometimes, I switch to the original IBM EGA font, because to my eye it looks really nice. But I associate EGA with DOS, and I associate VT323 with classic Unix terminals, so I use VT323 most of the time. Here's my screenshot of GNOME Terminal using VT323 as the monospace font:
(Jim Hall CC BY-SA 4.0)
I set up the terminal using VT323 at 24 pt, which gives a nice big window. If I'm going to bring up a terminal window, I want to really use it to do real work, not just do one thing and exit. I'm probably going to stay in that terminal window for a while, so it should be big and easy to see. I also prefer 80x25, because I'm an old DOS command line guy and 25 lines looks "right" to my eyes:
(Jim Hall CC BY-SA 4.0)
## Monospaced fonts
I don't know that I have a specific font that I use. I usually use either [DejaVu](https://fontsource.org/fonts/dejavu-mono) or [Liberation](https://github.com/liberationfonts) Mono. I like monospaced fonts because they're easier to read. Even then, I don't want the letters to be too close together. The main thing is being able to tell a small "L" from the number 1, Q from O, and so on. It's also nice to have all special characters stand out clearly.
I also like a good contrast between the font and background, so I set the background to black and characters to white.
## Hack
I like to use monospaced fonts, particularly for the terminal and coding because they're easier to read. I've been using the [Hack](https://sourcefoundry.org/hack/) font family for years. It provides a nice monospace font combined with additional glyphs and Powerline characters that I can use to display status on the command line.

(Ricardo Gerardi CC BY-SA 4.0)
Here's the font preview generated with [Fontpreview tool](https://github.com/sdushantha/fontpreview).

(Ricardo Gerardi CC BY-SA 4.0)
## Victor Mono
I've been using [Victor Mono](https://rubjo.github.io/victor-mono/) for both my terminal and IDE for a few years. It's perhaps a bit of an acquired taste, because the italic characters are in a monospace cursive script. I like this because code comments have a distinct look that's noticeably different from the rest of the code. Here's what it looks like in a terminal:

(Chris Reynolds CC BY-SA 4.0)
I also use the Solarized Dark color scheme for both my IDE and the terminal. If I could, anything work or code related would all use the same color scheme, and the same fonts, so it all looks uniform. I've gone through various fonts over the years, but I always try to use the same thing in my terminal as in my IDE.
## Monaco
At the moment, Monaco regular at 16 pt (so much better than 12 or 14 pt fonts).
## Keeping it pretty in pink
This reminds me of the time I pranked the other devs on my team by making all of their terminals pink (I was the only woman). It was like a baby pink background with hot pink text.
I like to make my personal terminals pretty, but for work I leave it white on black and just make the font around 16 pt because I appreciate the larger font size.
I just leave my terminal set to SF Mono font, but I make it bolder and bump it up a few points so I can see it better. My favorite colors to use are pink or a nice aqua blue color. I also like the default style the terminal has, called "Novel".
(RachieVee CC BY-SA 4.0)
## Let's ask ChatGPT
For the heck of it, I decided to ask [ChatGPT](https://opensource.com/article/23/2/chatgpt-vs-community). Here was its response:
As a language model, I do not have personal preferences or the ability to have a favorite font. However, some popular terminal fonts include Monospace, Consolas, and Inconsolata. These fonts are popular because they are easy to read, have clear distinctions between different characters, and are highly legible even at small font sizes. Additionally, they are designed to work well with a variety of different operating systems and terminals, making them versatile choices for developers and users alike.
I generated this text in part with GPT-3, OpenAI's large-scale language-generation model. Upon generating draft language, the author reviewed, edited, and revised the language to my own liking and takes ultimate responsibility for the content of this publication.
## Fantasque Sans Mono
```
``````
$ grep font ~/.Xdefaults
URxvt*font: xft:FantasqueSansMono-Regular:pixelsize=12:antialias=true
```
I don't remember when I settled on [Fantasque Sans Mono](https://github.com/belluzj/fantasque-sans), but I guess it's been my default for the past 8 years now, both in [Rxvt](https://opensource.com/article/19/10/why-use-rxvt-terminal) and Konsole. I don't know what font I'm using in my GNOME terminal. Probably whatever the default is on GNOME.
## Jetbrains Mono
Lately, I have Tilix set as my default terminal. My Tilix config has similar settings to what Jim Hall uses. The few differences are:
- Cursor shape is underline instead of a block
- Font is
[Jetbrains Mono](https://www.jetbrains.com/lp/mono/)Nerd Font Mono Medium 14
(Alan Formy-Duval CC BY-SA 4.0)
## 8 Comments |
15,717 | 使用一块树莓派主板测量圆周率 | https://opensource.com/article/23/3/measure-pi-raspberry-pi | 2023-04-13T12:02:57 | [
"圆周率"
] | https://linux.cn/article-15717-1.html | 
>
> 用你的树莓派制作一个接近完美的圆。
>
>
>
世界各地将 3 月 14 日定为圆周率日。许多人通过在房子周围找到的物体测量圆周率来庆祝圆周率日。我想用我的树莓派 3B 为今年的圆周率日做一些类似的事情。继续阅读以了解我如何使用我的树莓派测量圆周率。
你需要什么:
* 树莓派单板机
* 方格纸
* 带毫米和厘米测量值的标尺
* 笔
### 1、画一个圆
圆周率是圆的周长与其直径的比值。要计算圆周率,我们需要测量一个完美绘制的圆的周长和直径。幸运的是,树莓派主板上的安装孔足够大,可以使用铅笔或钢笔。我通过一个树莓派板安装孔插入了一根图钉,小心地将针放在一张方格纸上两条线的交点上。
握住别针,我将一支笔插入对面的安装孔中,并通过将笔绕着别针移动来画一个圆圈。树莓派主板底面的焊点会卡在纸上,但小心点还是可以画好圆圈的。

### 2、把圆分成段
通过画一条穿过圆心的垂直线将圆分成两半,通过画一条穿过圆心的水平线将圆再次分成四分之一。当我画圆的时候,我把图钉正好放在图画纸上两条线的交点上,这样就很容易找到垂直和水平的中心线。你可以通过在对角线上画一条线来创造一个 “八分” 片。

进一步的划分是与尺子的练习。我用尺子找到“四分之一楔形”和“八分之一楔形”任意两个交点的中点,做成一个 1/16 的楔形。你可以使用相同的方法制作越来越小的 1/32 和 1/64 圆的切片。通过非常小心,我还能够在圆的 1/128 处测量出一个非常窄的楔形:

### 3、估算周长
我最小的楔形是一个圆的 1/128。如此小的切片,楔形的外弧非常小,我们可以用一条直线来近似它。这实际上不是圆周长的 1/128,但它足够接近,我们可以将其用作一个很好的估计。

使用我的尺子上的毫米测量值,我测量了我的 1/128 楔形的外弧为 3.8 毫米。这样,我可以估计圆的周长为 3.8 毫米乘以 128,即 486.4 毫米。要转换为厘米,除以十:**48.64cm**。
### 4、计算圆周率
圆周率的值是圆的周长与其直径的比值。我们在步骤 3 中估算了周长。测量直径是使用尺子测量圆周的简单练习。我的圆是 **15.4cm**。
现在我们知道了周长和直径,我们可以将圆周率计算为 48.64 除以 15.4,即 **3.158**。这与 pi 的实际值 3.141 相差不远。
测量圆周率是一项有趣的数学练习!各个年龄段的数学爱好者都可以使用方格纸、笔和尺子等简单工具自行测量圆周率。以一种有趣的新方式使用你的树莓派来绘制圆并独立测量圆周率。这是一个估计值,因为我们将圆上的 1/128 弧近似为一条直线,但这使我们无需太多努力就足够接近了。
(LCTT 校注:这真是对树莓派的“合理”应用,摔!)
*(题图:MJ: Circumference in high resolution, very detailed)*
---
via: <https://opensource.com/article/23/3/measure-pi-raspberry-pi>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | March 14th is celebrated around the world as Pi Day. Many people celebrate Pi Day by measuring pi with objects found around the house. I wanted to do something similar for this year's Pi Day using my Raspberry Pi 3B. Read on to learn how I measured pi using my Raspberry Pi.
What you'll need:
- Raspberry Pi single-board computer
- Graph paper
- Ruler with mm and cm measurements
- Pen
## 1. Draw a circle
Pi is the ratio of the circumference of a circle to its diameter. To calculate pi, we need to measure both the circumference and diameter of a perfectly drawn circle. Fortunately, the Raspberry Pi motherboard has mounting holes that are big enough to fit a pencil or pen. I stuck a pin through one Pi board mounting hole, careful to land the pin on the intersection of two lines on a piece of graph paper.
Holding the pin still, I inserted a pen in the opposite mounting hole and drew a circle by moving the pen around the pin. The solder points on the underside of the Raspberry Pi motherboard can catch on the paper, but you can draw a good circle if you are careful.

(Jim Hall, CC BY-SA 4.0)
## 2. Divide the circle into segments
Divide the circle in half by drawing a vertical line through the center of the circle and again into quarters by drawing a horizontal line through the circle. When I drew my circle, I placed the pin exactly on the intersection of two lines on the graph paper, which makes finding the vertical and horizontal center lines easy to find. You can create an "eighth" slice by drawing a line across the diagonal.
(Jim Hall, CC BY-SA 4.0)
Further divisions are an exercise with the ruler. I used the ruler to find the midpoint of any two intersections of the "quarter-wedge" and the "one-eighth wedge" to make a 1/16 wedge. You can use the same method to make smaller and smaller slices that are 1/32 and 1/64 of a circle. By being very careful, I was also able to measure a very narrow wedge at 1/128 of a circle:

(Jim Hall, CC BY-SA 4.0)
## 3. Estimate the circumference
My smallest wedge is 1/128 of a circle. With such a small slice, the outer arc of the wedge is so small that we can approximate it with a straight line. This will not actually be 1/128 of the circle's circumference, but it will be close enough that we can use it as a good estimate.

(Jim Hall, CC BY-SA 4.0)
Using the mm measurement on my ruler, I measured the outer arc of my 1/128 wedge at 3.8mm. With that, I can estimate the circumference of my circle as 3.8mm times 128, or 486.4mm. To convert to centimeters, divide by ten: **48.64cm**.
## 4. Calculate pi
The value of pi is the ratio of the circumference of a circle to its diameter. We estimated the circumference in step 3. Measuring the diameter is a simple exercise of using the ruler to measure across the circle. My circle is **15.4cm**.
Now that we know the circumference and diameter, we can calculate pi as 48.64 divided by 15.4, which is **3.158**. That's not too far off from the actual value of pi, at 3.141.
Measuring pi is a fun math exercise! Math fans of all ages can use simple tools such as graph paper, pen, and ruler to measure pi on their own. Use your Raspberry Pi in a fun, new way to draw a circle and measure pi independently. This is an estimate since we are approximating a 1/128 arc on a circle as a straight line, but this gets us close enough without too much effort.
## Comments are closed. |
15,718 | CachyOS:基于 Arch 的发行版,具有速度和易用性 | https://news.itsfoss.com/cachyos/ | 2023-04-13T15:59:34 | [
"Arch"
] | https://linux.cn/article-15718-1.html |
>
> 面向新手和专家的以性能为中心的基于 Arch 的发行版。
>
>
>

Arch Linux 适合于那些想在其系统上使用 Linux 的寻求挑战的高级用户。
然而,许多 [基于 Arch 的发行版](https://itsfoss.com/arch-based-linux-distros/?ref=news.itsfoss.com) 也可以使新用户通过简化操作来进入这个发行版家族。比如说,Garuda Linux、Manjaro Linux 等就适合新用户。
其中一个令人感兴趣的选项是 **CachyOS**。
好吧,你可能已经知道 [blendOS](https://news.itsfoss.com/blendos/)(它也是一个基于 Arch 的发行版,仍在开发中)。但这个和它一点也不一样,如果你正在探索基于 Arch 的发行版,你可以尝试一下。
### CachyOS 概述

CachyOS 为各种用户量身定制,无论你是专家还是新手。即使它相当新,也可以作为稳定版本使用。
它旨在提供极速体验,同时提供可定制性和稳定性。
所有这些都牢记安全性。
CachyOS 的一些重要亮点包括:
* 用 LTO 和 x86-64-v3 优化编译的桌面软件包。
* 可选择通过在线安装的桌面环境(包括 i3、bspwm 和 Openbox 窗口管理器)。
* 离线和在线安装方式
* 基于 GUI 和 CLI 的安装方式
* 优化的 Linux 内核,带有先进的 BORE 调度程序以增强性能和可靠性
### 初步印象
CachyOS 看起来像是一个精心打磨过的发行版。当我使用 ISO 启动虚拟机时,我注意到它确实支持英伟达显卡,这是一个很好的开端。

然后,使用离线或在线安装过程的方式很有帮助。通过在线安装过程,你可以根据自己的喜好安装桌面环境或窗口管理器。
完成后,欢迎屏幕从一开始就提供了所有基本功能。所以,这一点也很好。

你可以在欢迎屏幕上安装软件包、启用系统特定的设置以及调整应用程序/内核内容。当然,新手不应该做任何他们不知道的事情,但是这些都可以访问是很好的。

我尝试了 CachyOS 的 KDE 版本,它看起来很不错。
出于某种原因,主题是 KDE 的默认 Breeze Dark。我希望它可以开箱即用 CachyOS 的自定义主题。

所以,我不得不前往主题管理器设置并应用 CachyOS 主题,让它看起来独一无二。

它使用 Fish shell,打开终端,你就能看到非常出色的外观和感觉。

性能和安全性增强是其核心。因此,如果你不确定这代表了什么,你可以与其它发行版进行仔细比较。然而,根据一些 Reddit 上的主题,一些用户提到了它提升了 10-20% 的性能。
你可以阅读 CachyOS 的 [Phoronix 的性能分析](https://www.phoronix.com/review/cachyos-linux-perf?ref=news.itsfoss.com) 来了解更多。
与其他发行版不同,它具有自己的 Web 浏览器,即 Firefox 的一个复刻,并针对隐私和安全性进行了修改/增强。然而,它没有默认的视频播放器,这个应该是为了迎合新用户。
总体感觉像是一个经过深思熟虑的开箱即用的发行版。最重要的是,它的 [文档](https://wiki.cachyos.org/?ref=news.itsfoss.com) 非常到位,对初学者很有用。
### 下载 CachyOS
你可以在其 [官方网站](https://cachyos.org/?ref=news.itsfoss.com) 上找到 CachyOS 的 KDE 和 GNOME 版本。XFce 版本正在制作中。当然,你可以使用在线安装过程安装其他任何东西。
>
> **[CachyOS](https://cachyos.org/?ref=news.itsfoss.com)**
>
>
>
此外,如果你对他们在幕后所做的定制感到好奇,你可以浏览它的 [GitHub 页面](https://github.com/cachyos?ref=news.itsfoss.com)。
---
via: <https://news.itsfoss.com/cachyos/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Arch Linux is suitable for advanced users looking for a challenge to use Linux on their system.
However, many [Arch-based distributions](https://itsfoss.com/arch-based-linux-distros/?ref=news.itsfoss.com) have made it possible for new users to get into the distribution family by making things easier. Options like Garuda Linux, Manjaro Linux, and others make it convenient for new users.
And one of the exciting options among them is **CachyOS**.
Well, you might already know about [blendOS](https://news.itsfoss.com/blendos/) (which is also an Arch-based distro, still in the works). It is not remotely similar, but if you are exploring Arch-based distros, you can check it out.
**Suggested Read **📖
[Top 10 User-friendly Arch-Based Linux Distributions [2023]Want to experience Arch Linux without the hassle of the complicated installation and setup? Here are a few user-friendly Arch-based Linux distributions.](https://itsfoss.com/arch-based-linux-distros/?ref=news.itsfoss.com)

## CachyOS: Overview
CachyOS is tailored for all users, whether you are an expert or just starting out. It is available as a stable release even though it is fairly new.
It aims to provide a blazing-fast experience and offer customizability and stability simultaneously.
All of this keeping security in mind.
Some of the critical highlights of CachyOS include the following:
**Desktop****packages compiled with****LTO and x86-64-v3 optimization**.**Choice of desktop environments**with online installation process (including i3, bspwm, and Openbox window managers)**Offline and Online installation**options**GUI and CLI-based installation**options**Optimized Linux Kernel**with advanced BORE Scheduler for enhanced performance and reliability
## Initial Impression
CachyOS looks like a well-polished distribution. When I used the ISO to spin up a virtual machine, I noticed that it does support NVIDIA cards, which is a nice touch.

And then, the option to use an offline or online installation process was helpful. With the online installation process, you can install desktop environments or window managers as per your preference.
Once done, the welcome screen provided all the essential abilities from the get-go. So, good points for that as well.
You can install packages, enable system-specific settings, and tweak application/kernel stuff from the welcome screen. Of course, a newbie should not do anything they do not know, but it is good to have everything accessible.
I tried the KDE edition of CachyOS, which looks pretty good.
For some reason, the theme was KDE's default Breeze Dark. I expected it to have CachyOS's customized theme out of the box.
So, I had to head to the theme manager settings and apply the CachyOS theme for it to look unique.
It utilizes the fish shell, making the terminal look and feel excellent out of the box.
Performance and security enhancements are at their core. So, if you are unsure about the claims, you will have to compare things closely with another distro. However, per a couple of Reddit threads, some users mention a 10-20% performance uplift.
You can read [Phoronix's performance analysis](https://www.phoronix.com/review/cachyos-linux-perf?ref=news.itsfoss.com) of CachyOS for additional insights.
Unlike other distributions, it features its own web browser, a fork of Firefox, with modifications/enhancements for privacy and security. However, it missed out on a default video player, which should be given to cater to new users.
**Overall**: It feels like a well-thought-out distribution out of the box. To add a cherry on top, its [documentation](https://wiki.cachyos.org/?ref=news.itsfoss.com) is on point and incredibly useful for beginners.
**Suggested Read **📖
[carbonOS: This Upcoming Independent Distro is All About UX and Robust ExperiencecarbonOS is a new upcoming distro on the radar. Explore more about it here.](https://news.itsfoss.com/carbonos/)

## Download CachyOS
You can find KDE and GNOME editions of CachyOS on its [official website](https://cachyos.org/?ref=news.itsfoss.com). An XFCE edition is in the works. Of course, you can install anything else using its online installation process.
Additionally, you can explore its [GitHub page](https://github.com/cachyos?ref=news.itsfoss.com) if you are curious about the customizations they make under the hood.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,720 | 如何在 Linux 系统中使用 Ventoy 创建多重引导的 U 盘 | https://ostechnix.com/how-to-create-multiboot-usb-drives-with-ventoy-in-linux/ | 2023-04-14T09:12:00 | [
"USB",
"Ventoy"
] | https://linux.cn/article-15720-1.html | 
Ventoy 是一个自由开源和跨平台的程序,可以在 Linux、macOS 和微软的 Windows 中创建多重引导的 U 盘。
你不必周而复始地格式化你的 USB 设备,只需创建一次可引导的 U 盘即可,如有需要可在将来添加你想要的 ISO。
你甚至可以创建子文件夹,例如 Linux ISO、Windows ISO,并把各自的 ISO 文件放在相应的文件夹里。Ventoy 会自动为新添加的 ISO 生成菜单条目,并将它们添加到启动菜单中。
一旦你创建完多重引导的 U 盘,使用它启动你的系统,选择你想加载的 ISO,马上就可以使用它。就是如此简单!
### 功能
Ventoy 有很多有用的功能,如:
* 非常容易安装和使用。
* 快速(仅受限于复制 ISO 文件的速度)。
* 你不需要解压缩 ISO 文件。直接从 ISO 文件启动即可。
* 可被安装在 U 盘/本地硬盘/SSD 盘/NVMe 盘/SD 卡中。
* 它支持<ruby> 传统 <rt> Legacy </rt></ruby> BIOS、IA32 UEFI、x86\_64 UEFI、ARM64 UEFI、MIPS64EL UEFI 等(LCTT 译注:这些英文缩写都是代表了不同的 CPU 架构。如 IA32 是指英特尔 32 位体系架构,x86\_64 指基于 x86 架构的 64 位扩展架构,ARM64 则是 ARM 体系结构的 64 位扩展、MIPS64EL 是指 64 位小端序的 MIPS 架构)。
* 支持 IA32/x86\_64 UEFI 的安全启动。
* 支持主分区使用 FAT32/exFAT/NTFS/UDF/XFS/Ext2/Ext3/Ext4 格式。默认使用 exFAT。
* 支持在物理机中使用 Linux 发行版启动 vhd、vdi、raw 等格式的虚拟磁盘文件。
* 持久化的存储支持。
* 支持 MBR 和 GPT 两种分区格式都。默认使用 MBR。
* 你可以用大于 4 GB 的 ISO 文件创建引导盘。
* 几乎所有类型的操作系统都支持。开发者声称 Ventoy 已经测试过了超过 900 多个 ISO 文件。
* 支持 Linux 自动安装。意味着你可以添加你的模板或脚本来进行无人值守的部署。例如,Redhat/CentOS 的 kickstart 脚本,SUSE 的 autoYast xml,Debian 的 preseed 脚本。把脚本或模板放在 U 盘里,让 ventoy 使用它进行无人值守安装。你也可以在任何时候更新这些脚本。不需要创建新的 ISO 文件,只要使用原来的 ISO 即可。
* 支持 Windows 系统的自动安装。
* 在启动期间对 USB 盘写保护。
* 不影响 USB 启动盘的正常使用。这意味着你可以将 U 盘用于文件复制等其他用途。
* 当有新的 Ventoy 版本时可供升级时,无须重新创建 USB 启动盘。在版本升级过程中,数据不会被破坏。
* 当一个新的发行版发布时,不需要更新 Ventoy。
* 将 ISO 文件复制/粘贴到 U 盘中,即可添加一个新的操作系统,没有必要从头开始。
* 支持 <ruby> 内存盘 <rt> Memdisk </rt></ruby> 模式。在某些机器上,可能无法加载 ISO。在这种情况下,你可以使用 <ruby> 内存盘 <rt> Memdisk </rt></ruby> 模式。Ventoy 将把整个 ISO 文件加载到内存中,然后启动它。
* 插件框架。
* <ruby> 传统 <rt> Legacy </rt></ruby> 和 UEFI 的本地启动菜单风格。
* 有命令行界面、本地图形化界面和基于 Web 的图形化界面的版本可用。
* 支持主题和菜单风格的定制。
* 跨平台。它支持 Linux、manOS 和 Windows 等操作系统。
* 自由开源!
### 在 Linux 中用 Ventoy 创建多重启动的 U 盘
正如我之前提到的,Ventoy 有命令行界面、本地图形化界面和基于 Web 的图形化界面的版本可用。
#### 1. 使用 Ventoy 命令行创建多重启动的 U 盘
首先,你需要找到你的 U 盘名称。可以通过下面的指南,来了解在 Linux 中寻找磁盘驱动器细节的不同方法。
>
> **[如何在 Linux 中 寻找硬盘驱动器细节](https://ostechnix.com/how-to-find-hard-disk-drive-details-in-linux/)**
>
>
>
我将使用 `fdisk` 命令来查找我的 U 盘的详细信息:
```
$ sudo fdisk -l
```
样例输出:
```
[...]
Disk /dev/sdb: 14.54 GiB, 15597568000 bytes, 30464000 sectors
Disk model: Cruzer Blade
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x4d924612
```
如你所见,我的 U 盘的名称是 `/dev/sdb`。
接下来,从 [发布页](https://github.com/ventoy/Ventoy/releases) 下载最新的 Ventoy 脚本。截至编写本指南时,最新版本是 `1.0.77`(LCTT 译注:截至翻译完成时,最新版本是 `1.0.91`)。
到你下载脚本的位置,解压它。我把它解压在一个名为 `ventoy` 的文件夹中。使用 `cd` 命令切换到 `ventoy` 目录中:
```
$ cd ventoy
```
现在,运行以下命令来创建多重启动的 U 盘:
```
$ sudo sh Ventoy2Disk.sh -I /dev/sdb
```
将 `/dev/sdb` 替换为你的 U 盘名称。
这里,大写的 `-I` 参数意味着将无视之前是否安装过 ventoy,**强制安装 ventoy** 到 `sdb`。当你使用小写的 `-i`,若此时磁盘已经安装了 ventoy ,它会安装失败。
要启用安全启动支持,使用 `-s` 参数。默认情况下,这个选项是关掉的。
```
$ sudo sh Ventoy2Disk.sh -I -s /dev/sdb
```
你将被提示确认 USB 启动盘的创建过程。仔细检查 U 盘的名称,并输入 `Y`,按回车键继续:
样例输出:
```
**********************************************
Ventoy: 1.0.77 x86_64
longpanda [email protected]
https://www.ventoy.net
**********************************************
Disk : /dev/sdb
Model: SanDisk Cruzer Blade (scsi)
Size : 14 GB
Style: MBR
Attention:
You will install Ventoy to /dev/sdb.
All the data on the disk /dev/sdb will be lost!!!
Continue? (y/n) y
All the data on the disk /dev/sdb will be lost!!!
Double-check. Continue? (y/n) y
Create partitions on /dev/sdb by parted in MBR style ...
Done
Wait for partitions ...
partition exist OK
create efi fat fs /dev/sdb2 ...
mkfs.fat 4.2 (2021-01-31)
success
Wait for partitions ...
/dev/sdb1 exist OK
/dev/sdb2 exist OK
partition exist OK
Format partition 1 /dev/sdb1 ...
mkexfatfs 1.3.0
Creating... done.
Flushing... done.
File system created successfully.
mkexfatfs success
writing data to disk ...
sync data ...
esp partition processing ...
Install Ventoy to /dev/sdb successfully finished.
```

几秒钟后,多重启动的 U 盘将被创建。
上述命令将创建两个分区。你可以用 `fdisk` 命令来验证它:
```
$ sudo fdisk -l
```
样例输出:
```
[...]
Disk /dev/sdb: 14.53 GiB, 15597568000 bytes, 30464000 sectors
Disk model: Cruzer Blade
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x436cedd0
Device Boot Start End Sectors Size Id Type
/dev/sdb1 * 2048 30398463 30396416 14.5G 7 HPFS/NTFS/exFAT
/dev/sdb2 30398464 30463999 65536 32M ef EFI (FAT-12/16/32)
```
现在打开你的文件管理器,把 ISO 文件复制到第一个分区。不用担心你分不清楚哪个是第一个分区,你的文件管理器将只显示第一个分区。

你甚至可以为不同的 ISO 文件类型创建子文件夹。例如,你可以为存储 Linux ISO 文件创建一个子文件夹,为 BSD ISO 文件创建一个子文件夹,为 Windows ISO 文件创建一个子文件夹。
Ventoy 将扫描整个 U 盘,为所有可用的 ISO 文件创建菜单项,并自动将它们添加到 Ventoy 的主启动菜单中。
如果你喜欢用命令行方式复制 ISO 文件,请到你保存 ISO 文件的地方,用 `rsync` 程序从命令行复制所有 ISO 文件,如下所示:
```
$ rsync *.iso /media/$USER/ventoy/ --progress -ah
```
请注意,在某些 Linux 发行版中,U 盘可能被挂载在 `/run/media/` 位置。
大功告成!我们刚刚用 Ventoy 创建了多重引导的 U 盘。
用新制作的可引导 U 盘启动你的系统,你会对 Ventoy 的启动菜单感到满意:

选择你想启动的操作系统,并按下回车键加载它!
下面是用 Ventoy 创建的多重启动 U 盘的简短视频演示:
很酷,不是吗?确实如此!
如果你想在 Oracle Virtualbox 中用 U 盘启动,请参考以下指南:
>
> **[如何在 Linux 中从 U 盘 启动 Virtualbox 的虚拟系统?](https://ostechnix.com/how-to-boot-from-usb-drive-in-virtualbox-in-linux/)**
>
>
>
#### 2. 使用 Ventoy 图形化界面创建多重启动的 U 盘
最初,Ventoy 在 Linux 平台上没有任何图形化的用户界面。我们在 Linux 中只能使用Ventoy 的命令行模式创建 USB 启动盘。
幸运的是,Ventoy 从 1.0.36 版开始提供基于网页的图形用户界面,从 1.0.52 版开始提供本地化图形用户界面(使用 GTK/QT)。
相信我,Ventoy 的图形化用户界面使用起来非常简单!它的界面非常小巧,但它拥有我们所需要的一切,只需点击几下鼠标就能创建一个单一的或多重引导的启动盘。
打开你的终端,进入你下载最新 Ventoy 程序的位置。
```
$ cd Downloads/ventoy-1.0.77/
```
运行适配的 Ventoy 图形化用户界面可执行文件,这取决于发行版的架构。
* VentoyGUI.i386 - 32 位的 X86 架构的操作系统适用
* VentoyGUI.x86\_64 - 64 位的 X86 架构的操作系统适用
* VentoyGUI.aarch64 - ARM64 架构的操作系统适用
* VentoyGUI.mips64el - 龙芯 3A MIPS 架构的操作系统适用
我使用的是 Debian 11 X86 64 位系统,所以我运行以下命令:
```
$ ./VentoyGUI.x86_64
```
这就是 Ventoy 图形用户界面的样子。

Ventoy 会自动为你选择已插入的 U 盘。但是我建议你确认所选择的是否真的是你想格式化的 U 盘。

你将被提示确认该过程。点击 “OK” 继续。
##### Ventoy 选项和语言
从菜单栏中点击<ruby> 选项 <rt> Option </rt> <ruby> 按钮。 </ruby></ruby>

从 <ruby> 选项 <rt> Option </rt> <ruby> 下拉按钮,你可以做以下事情: </ruby></ruby>
* <ruby> 安全启动支持 <rt> Secure Boot Support </rt></ruby> - 勾选/取消勾选以启用或禁用安全启动。默认情况下,它处于选中状态以示启用。
* <ruby> 分区格式 <rt> Partition Style </rt></ruby> - 支持 MBR 和 GPT 分区格式。默认是 MBR。
* <ruby> 分区配置 <rt> Partition Configuration </rt></ruby> - 在这里,你可以选择在磁盘的末端保留一些空闲空间。
* <ruby> 清除 <rt> Clear </rt></ruby> Ventoy - 从你的磁盘中删除 Ventoy。
* <ruby> 显示所有设备 <rt> Show All Devices </rt></ruby> - 如果你想显示包括你的本地磁盘在内的所有连接的设备,请选中这个选项。在选择这个选项时要特别小心。你可能会不小心选择你的一个本地磁盘并将其格式化。
<ruby> 语言 <rt> Language </rt></ruby> 按钮允许你选择你喜欢的语言。
##### 更新 Ventoy
每当有新的 Ventoy 版本发布时,没有必要重新创建可引导的 USB 启动盘。你可以安全地将Ventoy 更新到新版本,而不会丢失 U 盘中的任何现有数据。
要将已安装的 Ventoy 版本更新到最新的可用版本,请插入 U 盘并启动 Ventoy 图形化用户界面,如上所示。
在 Ventoy 图形化用户界面中, 点击 <ruby> 更新 <rt> Update </rt></ruby> 按钮。

#### 3. 使用 Ventoy 基于 Web 的图形化用户界面创建多重启动的 USB 启动盘
Ventoy 基于 Web 的图形化用户界面与本地图形化用户界面完全相同。有一天,我在我的Fedora Linux 桌面系统上试用了 Ventoy 基于 Web 的用户界面。我很惊讶我是多么喜欢Ventoy 图形用户界面的简洁。
要了解如何使用 Ventoy 图形用户界面创建可引导的 U 盘,请参考以下链接:
>
> **[在 Linux 中用 Ventoy 基于 Web 的用户界面创建可引导的 U 盘](https://ostechnix.com/create-bootable-usb-drive-with-ventoy-webui-in-linux/)**
>
>
>
### 将 ISO 镜像加载到 RAM 中
就像我之前提到的,ISO 镜像在某些机器上可能无法启动,特别是在传统的 BIOS 模式下。这就是 <ruby> 内存盘 <rt> Memdisk </rt></ruby> 模式的用武之地。
当 <ruby> 内存盘 <rt> Memdisk </rt></ruby> 模式被启用时,Ventoy 将把整个 ISO 镜像文件加载到内存中启动。
在选择操作系统之前按 `F1` 键,启用 <ruby> 内存盘 <rt> Memdisk </rt></ruby>模式(译者注:从 1.0.83 版本开始,进入该模式的快捷键从 `F1` 改成了 `Ctrl+D`)。当 <ruby> 内存盘 <rt> Memdisk </rt></ruby> 模式启用时,你会在右上角看到通知。

现在,ISO 将被加载到内存中:

请再次按 `F1` 键以切换回正常模式。
### 创建持久化的可引导 U 盘
我们现在知道了如何在 Linux 中用 Ventoy 创建多重启动的 U 盘。我们可以使用这个可引导的 USB 启动盘来测试 Linux 发行版,而不必真的在硬盘上安装它们。
当你使用 <ruby> 立付 <rt> Live </rt></ruby> OS 时,你可以做各种事情,如安装应用程序、下载文件、播放媒体文件、创建文件和文件夹、按照你的喜好定制等等。
然而,一旦你重新启动系统,所有上述变化都将消失。如果你想让所有的改变在重启系统后仍然保留,你应该创建一个持久化的可引导的 U 盘。
Ventoy 能够制作持久化的 USB 启动盘。请参考下面的链接学习怎么做。
>
> **[在 Linux 中使用 Ventoy 创建持久化的可引导 U 盘](https://ostechnix.com/create-persistent-bootable-usb-using-ventoy-in-linux/)**
>
>
>
### 总结
信不信由你,Ventoy 是我用过的在 Linux 中创建多重引导(持久或非持久)的 USB 闪存盘工具中最简单、最快速、最巧妙的之一。
它真的做到了开箱即用!试一下吧,你不会失望的!
### 与 Ventoy 有关的安全问题
Ventoy 网站、论坛和该网站上的一些文件被一些杀毒软件标记为恶意软件或木马。请查看这些发布在该项目 GitHub 页面中的议题:
* <https://github.com/ventoy/Ventoy/issues/22>
* <https://github.com/ventoy/Ventoy/issues/83>
* <https://github.com/ventoy/Ventoy/issues/31>
然而,Manjaro 打包者 Linux Aarhus 在代码审查后认为:没有合理的理由怀疑这个应用程序的安全性。
他声称 “**没有混淆的代码**”。所以,我觉得 Ventoy 是可以**安全**使用的。
### 资源
* [Ventoy 官网](https://www.ventoy.net/en/index.html)
* [Ventoy GitHub 仓库](https://github.com/ventoy/Ventoy)
*(题图: MJ: USB disk bootload computer sci-fi future in sky stars)*
---
via: <https://ostechnix.com/how-to-create-multiboot-usb-drives-with-ventoy-in-linux/>
作者:[sk](https://ostechnix.com/author/sk/) 选题:[lkxed](https://github.com/lkxed) 译者:[hanszhao80](https://github.com/hanszhao80) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
15,721 | 使用 CSS 提升你的 HTML 文档 | https://opensource.com/article/22/8/css-html-project-documentation | 2023-04-14T15:52:15 | [
"CSS",
"HTML"
] | https://linux.cn/article-15721-1.html | 
>
> 使用 CSS 让你的 HTML 项目更具风格。
>
>
>
当你编写文档时,无论是为开源项目还是技术写作项目,你都应该有两个目标:文档应该写得好,同时要易于阅读。前者通过清晰的写作技巧和技术编辑来解决。第二个目标可以通过对 HTML 文档进行一些简单的更改来解决。
超文本标记语言(HTML)是互联网的支柱。自 1994 年“万维网”问世以来,所有网络浏览器都使用 HTML 来显示文档和网站。几乎与此同时,HTML 一直支持样式表,它是对 HTML 文档的一种特殊添加,用于定义文本在屏幕上的呈现方式。
单纯用 HTML 编写项目文档也是可以的。然而,纯 HTML 样式可能感觉有点简陋。因此,尝试向 HTML 文档添加一些简单的样式,为文档添加一点活力,并使文档更清晰、更易于阅读。
### 定义一个 HTML 文档
让我们从一个纯 HTML 文档开始,探索如何向其添加样式。一个空的 HTML 文档在顶部包含 `<!DOCTYPE html>` 定义,后面跟着一个 `<html>` 块来定义文档本身。 在 `<html>` 元素中,你还需要加上一个文档标头,其中包含有关文档的元数据,例如标题。文档正文的内容放在父 `<html>` 块内的 `<body>` 块中。
你可以使用以下 HTML 代码定义一个空白页面:
```
<!DOCTYPE html>
<html>
<head>
<title>这是一个新文档</title>
</head>
<body>
</body>
</html>
```
在另一篇关于 [用 HTML 编写项目文档](https://opensource.com/article/22/8/writing-project-documentation-html) 的文章中,我将一个开源棋盘游戏的自述文件从纯文本更新为 HTML 文档,并使用一些基本的 HTML 标记,如 `<h1>` 和 `<h2>` 作为标题和副标题,`<p>` 用于段落,`<b>` 和 `<i>` 用于粗体和斜体文本。让我们从那篇文章结束的地方继续讲:
```
<!DOCTYPE html>
<html>
<head>
<title>简易 Senet</title>
</head>
<body>
<h1>简易 Senet</h1>
<h2>游戏玩法</h2>
<p>游戏会自动为你“投掷”投掷棒,并在屏幕右下角显示结果。</p>
<p>如果“投掷”结果为零,你失去本轮机会。</p>
<p>轮到你的时候,游戏会自动选择
你在棋盘上的第一块棋子。 你不一定
能够用这个棋子走棋,所以选择你的棋子
移动,然后按 <i>Space</i>(或 <i>Enter</i>)移动
它。 你可以通过几种不同的方法进行选择:</p>
<ul>
<li><i>向上</i>/<i>向下</i>/<i>向左</i>/<i>向右</i> to
朝特定方块移动。</li>
<li>加号 (<b>+</b>) 或减号 (<b>-</b>) 使棋子在棋盘上向“左”或向“右”移动。
请注意,它们会自动遵循棋盘的“倒过来的 S”方向移动。</li>
<li><em>Tab</em>在棋盘上选择下一个你想要移动的棋子。</li>
</ul>
<p>要随时退出游戏,请按 <b>Q</b>(大写
Q)或按 <i>Esc</i>,这样游戏会提示你是否想要
放弃比赛。</p>
<p>如果你比对手更快将所有棋子移出棋盘,你就赢得了比赛。
这同时需要运气和游戏策略!</p>
</body>
</html>
```
此 HTML 文档演示了利用 HTML 的技术写作者经常使用的一些块和内联元素。块元素在围绕文本定义一个矩形。段落和标题就是块元素,因为它们从文档的左边缘延伸到右边缘。例如,`<p>` 在段落周围包含一个不可见的矩形。相比之下,内联元素的使用则紧跟在它们包围的文本。如果你在段落中的某些文本上使用 `<b>`,则只有被 `<b>` 和 `</b>` 包围的文本会变为粗体。
你可以将直接样式应用于此文档以更改字体、颜色和其他文本样式,但修改文档外观的更有效方法是将样式表应用于文档本身。你可以在 `<head>` 元素中使用其他元数据执行此操作。你可以为样式表引用文件,但在这个例子中,我使用 `<style>` 块在文档中定义样式表。以下是带有空样式表的 `<head>` :
```
<!DOCTYPE html>
<html>
<head>
<title>简易 Senet</title>
<style>
</style>
</head>
<body>
...
</body>
</html>
```
### 定义样式
由于你刚刚开始学习样式表,因此这里先演示一种基本样式:背景色。我喜欢从背景颜色开始,因为它有助于演示块和内联元素。让我们应用一个有点华丽的样式表,为所有 `<p>` 段落设置*浅蓝色*背景颜色,为 `<ul>` 无序列表设置*浅绿色*背景。对任何粗体文本使用*黄色*背景,对任何斜体文本使用*粉红色*背景。
你可以在 HTML 文档的 `<style>` 块中使用样式来定义这些样式。样式表使用与 HTML 文档不同的标记。样式语法看起来像 `element { style; style; style; ... }` 并使用花括号将多种文本样式组合到一个定义中。
```
<style>
p { background-color: lightblue; }
ul { background-color: lightgreen; }
b { background-color: yellow; }
i { background-color: pink; }
</style>
```
请注意,每个样式都以分号结尾。
如果在网页浏览器中查看此 HTML 文档,你可以看到 `<p>` 和 `<ul>` 块元素如何填充为矩形,而 `<b>` 和 `<i>` 内联元素仅突出显示粗体和斜体文本。 这种对比色的使用可能看起来不太好看,但我想你可以清楚看到块和内联元素:

### 应用样式
你可以使用样式使这个自述文件更易于阅读。 因为你刚刚开始学习样式,还是先只用一些简单的样式元素:
* `background-color` 设置背景颜色
* `color` 设置文字颜色
* `font-family` 使用不同的文本字体
* `margin-top` 在元素上方添加空间
* `margin-bottom` 在元素下方添加空间
* `text-align` 改变文本的对齐方式,例如靠左、靠右或居中
让我们重新开始你的样式表并将这些新样式应用到文档中。首先,在文档中使用更令人愉悦的字体。如果你的 HTML 文档没有指定字体,网络浏览器会为你选择一种。根据浏览器的设置方式,这可能是衬线字体(如我的屏幕截图中使用的字体)或无衬线字体。衬线字体在每个字母上添加了一个小笔画,这样在打印时更容易阅读。无衬线字体缺少这种额外的笔划,这使得文本在计算机显示器上显得更清晰。常见的衬线字体包括 Garamond 或 Times New Roman。 流行的无衬线字体包括 Roboto 和 Arial。
例如,要将文档正文字体设置为 Roboto,你可以使用以下样式:
```
body { font-family: Roboto; }
```
通过设置字体,你假设查看文档的人也安装了该字体。有些字体已经十分常见,以至于它们被认为是事实上的“网页安全”字体。 这些字体包括 Arial 等无衬线字体和 Times New Roman 等衬线字体。Roboto 是一种较新的字体,可能还无法随处可用。因此,网页设计师通常不会只列出一种字体,而是设置一种或多种“备用”字体。你可以通过用逗号分隔来添加这些替代字体。 例如,如果用户的系统上没有 Roboto 字体,你可以使用以下样式定义将 Arial 字体用作文本正文:
```
body { font-family: Roboto, Arial; }
```
所有网络浏览器都定义了默认的衬线和无衬线字体,你可以使用这些名称来引用它们。用户可以更改他们喜欢用于显示衬线和无衬线的字体,因此不太可能对每个人都一样,但在字体列表中使用 `serif` 或 `sans-serif` 通常是个好主意。通过添加该字体,至少用户可以大致了解你希望 HTML 文档的呈现方式:
```
body { font-family: Roboto, Arial, sans-serif; }
```
如果字体名称不止一个单词,则你必须在其两边加上引号。HTML 允许你在此处使用单引号或双引号。 为标题和副标题定义一些衬线字体,包括 Times New Roman:
```
h1 { font-family: "Times New Roman", Garamond, serif; }
h2 { font-family: "Times New Roman", Garamond, serif; }
```
请注意,H1 标题和 H2 副标题使用完全相同的字体定义。如果你想避免无谓的打字,可以使用样式表快捷方式为 H1 和 22 使用相同的样式定义:
```
h1, h2 { font-family: "Times New Roman", Garamond, serif; }
```
在编写文档时,许多技术作者更喜欢将主标题放在页面的中央。你可以在块元素(例如 H1 标题)上使用 `text-align` 来使标题居中:
```
h1 { text-align: center; }
```
为了让粗体和斜体文本更突出,请将它们置于稍微不同的颜色中。对于某些文档,我可能会使用深蓝表示粗体文本,使用深绿表示斜体文本。这些颜色非常接近黑色,但颜色的细微差别足以吸引读者的注意力。
```
b { color: darkblue; }
i { color: darkgreen; }
```
最后,我更喜欢在我的列表元素周围添加额外的间距,以使它们更易于阅读。如果每个列表项只有几个词,额外的空间可能无关紧要。但是我的示例文本中的中间项很长,可以换到第二行。 额外的空间有助于读者更清楚地看到此列表中的每个项目。 你可以使用边距样式在块元素上方和下方添加空间:
```
li { margin-top: 10px; margin-bottom: 10px; }
```
这种样式定义了一个距离,此处我将其指定为每个列表元素上方和下方的 10px(十个*像素*)。 你可以使用多种不同的距离度量。十像素实际上就是屏幕上十个像素的空间,无论是台式机显示器、笔记本电脑显示屏,还是手机或平板电脑屏幕。
假设你真的只是想在列表元素之间添加一个额外的空行,你也可以使用 `em` 来测量。`em` 是一个旧的排版术语,如果你指的是左右间距,它就是大写 `M` 的宽度,或者对于垂直间距,就是大写 `M` 的高度。所以你可以改用 1em 来写边距样式:
```
li { margin-top: 1em; margin-bottom: 1em; }
```
HTML 文档中的完整样式列表如下所示:
```
<!DOCTYPE html>
<html>
<head>
<title>简易 Senet</title>
<style>
body { font-family: Roboto, Arial, sans-serif; }
h1, h2 { font-family: "Times New Roman", Garamond, serif; }
h1 { text-align: center; }
b { color: darkblue; }
i { color: darkgreen; }
li { margin-top: 1em; margin-bottom: 1em; }
</style>
</head>
<body>
<h1>简易 Senet</h1>
<h2>游戏玩法</h2>
<p>游戏会自动为你“投掷”投掷棒,并在屏幕右下角显示结果。</p>
<p>如果“投掷”结果为零,你失去本轮机会。</p>
<p>轮到你的时候,游戏会自动选择
你在棋盘上的第一块棋子。 你不一定
能够用这个棋子走棋。所以选择你的棋子
移动,然后按 <i>Space</i>(或 <i>Enter</i>)移动
它。 你可以通过几种不同的方法进行选择:</p>
<ul>
<li><i>向上</i>/<i>向下</i>/<i>向左</i>/<i>向右</i> to
朝特定方块移动。</li>
<li>加号 (<b>+</b>) 或减号 (<b>-</b>) 使棋子在棋盘上向“左”或向“右”移动。
请注意,它们会自动遵循棋盘的“倒过来的 S”方向移动。</li>
<li><em>Tab</em>在棋盘上选择下一个你想要移动的棋子。</li>
</ul>
<p>要随时退出游戏,请按 <b>Q</b>(大写
Q)或按 <i>Esc</i>,这样游戏会提示你是否想要
放弃比赛。</p>
<p>如果你比对手更快将所有棋子移出棋盘,你就赢得了比赛。
这同时需要运气和游戏策略!</p>
</body>
</html>
```
在网页浏览器上查看时,你会看到采用无衬线字体的自述文件,标题和副标题使用衬线字体。 页面标题居中。粗体和斜体文本使用略有不同的颜色来吸引读者的注意力而不会分散注意力。 最后,列表项周围有额外的空间,使每个项目更易于阅读。

这是在技术写作中使用样式的简单介绍。掌握了基础知识后,你可能会对 [Mozilla 的 HTML 指南](https://developer.mozilla.org/en-US/docs/Web/HTML) 感兴趣。它包括一些很棒的初学者教程,因此你可以学习如何创建自己的网页。
有关 CSS 样式的更多信息,我推荐 [Mozilla 的 CSS 指南](https://developer.mozilla.org/en-US/docs/Web/CSS)。
*(题图: MJ:web internet traffic design)*
---
via: <https://opensource.com/article/22/8/css-html-project-documentation>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lkxed](https://github.com/lkxed) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you write documentation, whether that's for an open source project or a technical writing project, you should have two goals: The document should be written well, and the document should be easy to read. The first is addressed by clear writing skills and technical editing. The second can be addressed with a few simple changes to an HTML document.
HyperText Markup Language, or HTML, is the backbone of the internet. Since the dawn of the "World Wide Web" in 1994, every web browser uses HTML to display documents and websites. And for almost as long, HTML has supported the *stylesheet*, a special addition to an HTML document that defines how the text should appear on the screen.
You can write project documentation in plain HTML, and that gets the job done. However, plain HTML styling may feel a little spartan. Instead, try adding a few simple styles to an HTML document to add a little pizzazz to documentation, and make your documents clearer and easier to read.
## Defining an HTML document
Let's start with a plain HTML document and explore how to add styles to it. An empty HTML document contains the
You can define a blank page with this HTML code:
```
``````
<!DOCTYPE html>
<html>
<head>
<title>This is a new document</title>
</head>
<body>
</body>
</html>
```
In another article about [Writing project documentation in HTML](https://opensource.com/article/22/8/writing-project-documentation-html), I updated a Readme file from an open source board game from plain text to an HTML document, using a few basic HTML tags like
```
``````
<!DOCTYPE html>
<html>
<head>
<title>Simple Senet</title>
</head>
<body>
<h1>Simple Senet</h1>
<h2>How to Play</h2>
<p>The game will automatically "throw" the throwing sticks
for you, and display the results in the lower-right corner
of the screen.</p>
<p>If the "throw" is zero, then you lose your turn.</p>
<p>When it's your turn, the game will automatically select
your first piece on the board. You may or may not be
able to make a move with this piece, so select your piece
to move, and hit <i>Space</i> (or <i>Enter</i>) to move
it. You can select using several different methods:</p>
<ul>
<li><i>Up</i>/<i>down</i>/<i>left</i>/<i>right</i> to
navigate to a specific square.</li>
<li>Plus (<b>+</b>) or minus (<b>-</b>) to navigate "left"
and "right" on the board. Note that this will automatically
follow the "backwards S" shape of the board.</li>
<li><em>Tab</em> to select your next piece on the
board.</li>
</ul>
<p>To quit the game at any time, press <b>Q</b> (uppercase
Q) or hit <i>Esc</i>, and the game will prompt if you want
to forfeit the game.</p>
<p>You win if you move all of your pieces off the board
before your opponent. It takes a combination of luck and
strategy!</p>
</body>
</html>
```
This HTML document demonstrates a few common block and inline elements used by technical writers who write with HTML. Block elements define a rectangle around text. Paragraphs and headings are examples of block elements, because they extend from the left to the right edges of the document. For example,
You can apply direct styling to this document to change the font, colors, and other text styles, but a more efficient way to modify the document's appearance is to apply a *stylesheet* to the document itself. You can do that in the
```
``````
<!DOCTYPE html>
<html>
<head>
<title>Simple Senet</title>
<style>
</style>
</head>
<body>
...
</body>
</html>
```
## Defining styles
Since you're just starting to learn about stylesheets, let's demonstrate a basic style: background color. I like to start with the background color because it helps to demonstrate block and inline elements. Let's apply a somewhat gaudy stylesheet that sets a *light blue* background color for all *light green* background for the *yellow* background for any bold text, and a *pink* background for any italics text.
You define these using styles in the `element { style; style; style; ... }`
and uses curly braces to group together several text styles into a single definition.
```
``````
<style>
p { background-color: lightblue; }
ul { background-color: lightgreen; }
b { background-color: yellow; }
i { background-color: pink; }
</style>
```
Note that each style ends with a semicolon.
If you view this HTML document in a web browser, you can see how the

(Jim Hall, CC BY-SA 4.0)
## Applying styles
You can use styles to make this Readme document easier to read. You're just starting to learn about styles, you'll stick to a few simple style elements:
- background-color to set the background color
- color to set the text color
- font-family to use a different text font
- margin-top to add space above an element
- margin-bottom to add space below an element
- text-align to change how the text is displayed, such as to the left, to the right, or centered
Let's start over with your stylesheet and apply these new styles to your document. To begin, use a more pleasing font for your document. If your HTML document does not specify a font, the web browser picks one for you. Depending on how the browser is set up, this could be a *serif* font, like the font used in my screenshot, or a *sans-serif* font. Serif fonts have a small stroke added to each letter, which makes these fonts much easier to read in print. Sans-serif fonts lack this extra stroke, which makes text appear sharper on a computer display. Common serif fonts include Garamond or Times New Roman. Popular sans-serif fonts include Roboto and Arial.
For example, to set the document body font to Roboto, use this style:
```
````body { font-family: Roboto; }`
By setting a font, you assume the person viewing your document also has that font installed. Some fonts have become so common they are considered de facto "Web safe" fonts. These include sans-serif fonts like Arial and serif fonts such as Times New Roman. Roboto is a newer font and may not be available everywhere. So instead of listing just one font, web designers usually put one or more "backup" fonts. You can add these alternative fonts by separating them with a comma. For example, if the user doesn't have the Roboto font on their system, you can instead use Arial for the text body by using this style definition:
```
````body { font-family: Roboto, Arial; }`
All web browsers define a default serif and sans-serif font that you can reference with those names. Users can change which font they prefer to use for serif and sans-serif, so aren't likely to be the same for everyone, but using serif or sans-serif in a font list is usually a good idea. By adding that font, at least the user gets some approximation of how you want the HTML document to appear:
```
````body { font-family: Roboto, Arial, sans-serif; }`
If your font name is more than one word, you have to put quotes around it. HTML allows you to use either single quotes or double quotes here. Define a few serif fonts for the heading and subheading, including Times New Roman:
```
``````
h1 { font-family: "Times New Roman", Garamond, serif; }
h2 { font-family: "Times New Roman", Garamond, serif; }
```
Note that the
```
````h1, h2 { font-family: "Times New Roman", Garamond, serif; }`
When writing documentation, many technical writers prefer to center the main title on the page. You can use
```
````h1 { text-align: center; }`
To help bold and italics text to stand out, put them in a slightly different color. For certain documents, I might use *dark blue* for bold text, and *dark green* for italics text. These are pretty close to black, but with just enough subtle difference that the color grabs the reader's attention.
```
``````
b { color: darkblue; }
i { color: darkgreen; }
```
Finally, I prefer to add extra spacing around my list elements, to make these easier to read. If each list item was only a few words, the extra space might not matter. But the middle item in my example text is quite long and wraps to a second line. The extra space helps the reader see each item in this list more clearly. You can use the
```
````li { margin-top: 10px; margin-bottom: 10px; }`
This style defines a distance, which I've indicated here as *pixels*) above and below each list element. You can use several different measures for distance. Ten pixels is literally the space of ten pixels on your screen, whether that's a desktop monitor, a laptop display, or a phone or tablet screen.
Assuming you really just want to add an extra blank line between the list elements, you can also use *em* is an old typesetting term that is exactly the width of capital **M** if you refer to left and right spacing, or the height of a capital **M** for vertical spacing. So you can instead write the margin style using
```
````li { margin-top: 1em; margin-bottom: 1em; } `
The complete list of styles in your HTML document looks like this:
```
``````
<!DOCTYPE html>
<html>
<head>
<title>Simple Senet</title>
<style>
body { font-family: Roboto, Arial, sans-serif; }
h1, h2 { font-family: "Times New Roman", Garamond, serif; }
h1 { text-align: center; }
b { color: darkblue; }
i { color: darkgreen; }
li { margin-top: 1em; margin-bottom: 1em; }
</style>
</head>
<body>
<h1>Simple Senet</h1>
<h2>How to Play</h2>
<p>The game will automatically "throw" the throwing sticks
for you, and display the results in the lower-right corner
of the screen.</p>
<p>If the "throw" is zero, then you lose your turn.</p>
<p>When it's your turn, the game will automatically select
your first piece on the board. You may or may not be
able to make a move with this piece, so select your piece
to move, and hit <i>Space</i> (or <i>Enter</i>) to move
it. You can select using several different methods:</p>
<ul>
<li><i>Up</i>/<i>down</i>/<i>left</i>/<i>right</i> to
navigate to a specific square.</li>
<li>Plus (<b>+</b>) or minus (<b>-</b>) to navigate "left"
and "right" on the board. Note that this will automatically
follow the "backwards S" shape of the board.</li>
<li><em>Tab</em> to select your next piece on the
board.</li>
</ul>
<p>To quit the game at any time, press <b>Q</b> (uppercase
Q) or hit <i>Esc</i>, and the game will prompt if you want
to forfeit the game.</p>
<p>You win if you move all of your pieces off the board
before your opponent. It takes a combination of luck and
strategy!</p>
</body>
</html>
```
When viewed on a web browser, you see your Readme document in a sans-serif font, with serif fonts for the heading and subheading. The page title is centered. The bold and italics text use a slightly different color that calls the reader's attention without being distracting. Finally, your list items have extra space around them, making each item easier to read.

(Jim Hall, CC BY-SA 4.0)
This is a simple introduction to using styles in technical writing. Having mastered the basics, you might be interested in [Mozilla's HTML Guide](https://developer.mozilla.org/en-US/docs/Web/HTML). This includes some great beginner's tutorials so you can learn how to create your own web pages.
For more information on how CSS styling works, I recommend [Mozilla's CSS Guide](https://developer.mozilla.org/en-US/docs/Web/CSS).
## Comments are closed. |
15,723 | 14 岁那年,我提交了第一个拉取请求 | https://opensource.com/article/23/3/my-first-code-contribution-age-14 | 2023-04-15T09:03:27 | [
"开源贡献"
] | https://linux.cn/article-15723-1.html | 
>
> 年龄并不是为开源做贡献的障碍。
>
>
>
我叫 Neil Naveen,我是一个 14 岁的初中生,已经有七年的编码经验。我使用 [Golang](https://opensource.com/article/18/11/learning-golang) 编码也有两年了。
不过,编码并不是我唯一的爱好。我练习柔术已经有四年了,并参加过多次比赛。我对编码和柔术充满热情,因为它们教给了我重要的人生课程。
### Codecombat
我在 [Codecombat](https://codecombat.com) 上开始编码,它教会了我许多基本的编码技巧。
在我的编码历程中,最激动人心的时刻之一是我在 Codecombat 主办的多人竞技场中,在大约 50,000 名玩家中排名第 16。当时我只有 11 岁,这对我来说是一个不可思议的成就。它给了我继续探索和学习新事物的信心。
### Leetcode
在 Codecombat 之后,我转到了 [leetcode.com](https://leetcode.com/neilnaveen)。通过解决这个网站量身定制的问题,来磨练我的算法编码技能,以学习特定的算法。
### Coding Game
当我 13 岁时,我转到了 [Coding Game](https://www.codingame.com/profile/0fa733a2c7f92a829e4190625b5b9a485718854) 的机器人编程。这里的竞争更加激烈,因此我必须采用更好的算法。例如,在创建终极 <ruby> 井字游戏 <rt> tic-tac-toe </rt></ruby>人工智能时,我使用了 <ruby> 极小化极大算法 <rt> Minimax </rt></ruby> 和 <ruby> 蒙特卡洛树搜索 <rt> Monte Carlo Tree Search </rt></ruby> 等算法,使我的代码快速高效。
### GitHub CLI
有一天,我看到爸爸在使用一个叫 [GitHub CLI](https://github.com/cli/cli) 的开源工具,我被它迷住了。GitHub CLI 是一个允许用户直接从命令行与 GitHub 的 API 互动的工具,而不需要到 GitHub 网站上去。
又有一天,我父亲正在审查一个旨在检测依赖关系中的漏洞的机器人的 <ruby> 拉取请求 <rt> PR </rt></ruby>。
后来,我思考了 GitHub CLI 和这个机器人,并想知道 GitHub CLI 本身是否被一个安全机器人所监控。事实证明它没有。
所以我创建了一个修复程序,并包含了 GitHub CLI 的安全审计。
令我高兴的是,我的贡献被接受了。它被合并到了项目中,这对我来说是一个激动人心的时刻。能为一个像 GitHub CLI 这样受欢迎的工具的重要项目作出贡献,并帮助保护它,是一个极好的机遇。这是我的 PR 的链接:<https://github.com/cli/cli/pull/4473>
### 提交你的代码
我希望我的故事能激励其他年轻人去探索并为开源世界做出贡献。年龄并不是障碍。每个人都应该探索和贡献。如果你想看看我的网站,请到 [neilnaveen.dev](https://neilnaveen.dev)。你也可以看看我的 [Leetcode 个人资料](https://leetcode.com/neilnaveen/)。如果你有兴趣,可以看看我在 [CloudNativeSecurityCon](https://www.youtube.com/watch?v=K6NRUGol-rE) 的演讲记录。
我很感激迄今为止我所拥有的机会,我很兴奋地期盼我的未来。谢谢你阅读我的故事!
(LCTT 校注:我也接触过几位初中生,他们在技术和开源方面有这浓厚的兴趣,并取得了令人称道的进展。所以,看到这篇文章的同学们,你也可以的!)
*(题图:MJ:Kids programming learning carton)*
---
via: <https://opensource.com/article/23/3/my-first-code-contribution-age-14>
作者:[Neil Naveen](https://opensource.com/users/neilnaveen) 选题:[lkxed](https://github.com/lkxed/) 译者:[hanszhao80](https://github.com/hanszhao80) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | My name is Neil Naveen, and I'm a 14-year-old middle schooler who's been coding for seven years. I have also been coding in [Golang](https://opensource.com/article/18/11/learning-golang) for two years.
Coding isn't my only passion, though. I've been practicing Jiu-Jitsu for four years and have competed in multiple competitions. I'm passionate about coding and Jiu-Jitsu, as they teach me important life lessons.
## Codecombat
I started coding on [Codecombat](https://codecombat.com), which taught me many fundamental coding skills.
One of the most exciting moments in my coding journey was when I ranked 16th out of around 50,000 players in a multiplayer arena hosted by Code Combat. I was just 11 years old then, and it was an incredible achievement for me. It gave me the confidence to continue exploring and learning new things.
## Leetcode
After Codecombat, I moved on to [leetcode.com](https://leetcode.com/neilnaveen). This site helped me hone my algorithm coding skills with tailored problems to learn specific algorithms.
## Coding Game
When I turned 13, I moved on to bot programming on [Coding Game](https://www.codingame.com/profile/0fa733a2c7f92a829e4190625b5b9a485718854). The competition was much more intense, so I had to use better algorithms. For example, when creating ultimate tic-tac-toe AI, I used algorithms like Minimax and Monte Carlo Tree Search to make my code fast and efficient.
## GitHub CLI
One day, I saw my dad using an open source tool called [GitHub CLI](https://github.com/cli/cli), and I was fascinated by it. GitHub CLI is a tool that allows users to interact with the GitHub API directly from the command line without ever having to go to GitHub itself.
Another day, my dad was reviewing PRs from a bot designed to detect vulnerabilities in dependencies.
Later, I thought about GitHub CLI and this bot, and wondered whether GitHub CLI itself was being monitored by a security bot. It turned out that it was not.
So I created a fix and included a security audit for GitHub CLI.
To my delight, my contribution was accepted. It was merged into the project, which was a thrilling moment for me. It was an excellent opportunity to contribute to a significant project like a popular tool like GitHub CLI, and to help secure it. Here's the link to my PR: [https://github.com/cli/cli/pull/4473](https://github.com/cli/cli/pull/4473)
## Commit your code
I hope my story will inspire other young people to explore and contribute to the open source world. Age isn't a barrier to entry. Everyone should explore and contribute. If you want to check out my website, head over to [neilnaveen.dev](https://neilnaveen.dev). You can also check out my [Leetcode profile](https://leetcode.com/neilnaveen/). And if you're interested, check out my talk at [CloudNativeSecurityCon](https://www.youtube.com/watch?v=K6NRUGol-rE) recording.
I'm grateful for the opportunities I've had so far, and I'm excited to see what the future holds for me. Thank you for reading my story!
## Comments are closed. |
15,724 | Speek!:一个使用 Tor 的开源聊天应用程序 | https://itsfoss.com/speek/ | 2023-04-15T16:29:00 | [
"Tor",
"聊天软件"
] | https://linux.cn/article-15724-1.html | 
>
> 一个有趣的、开源的私人通讯软件,它利用 Tor 来保证你的通信安全和私密。
>
>
>
Speek 是一种网络通讯服务,它利用多种技术保证网络聊天的私密性。
它是端到端加密的、去中心化和开源的。
毫无疑问,它的目标是将自己定位为 [WhatsApp 的替代品](https://itsfoss.com/private-whatsapp-alternatives/) 之一和 [Linux 上的 Signal](https://itsfoss.com/install-signal-ubuntu/) 的竞争对手。
那么,它到底如何呢? 让我们一起来仔细看看细节。
### Speek! 适用于 Linux 和安卓的点对点即时消息应用程序
(LCTT 译注: <ruby> 点对点 <rt> Peer-to-Peer </rt></ruby>,又称对等式网络,是无中心服务器、依靠 <ruby> 对等点 <rt> peer </rt></ruby> 交换信息的互联网络体系,它的作用在于,减低以往网路传输中的节点,以降低资料遗失的风险。)

Speek!(名称中带有感叹号)是一种加密的聊天软件,旨在抗审查,同时保护数据隐私。
你也可以认为它是 [Session](https://itsfoss.com/session-messenger/) 的替代品,但有一些区别。
与其他可用的通讯软件相比,它是一个相当新的竞争对手。但是如果你想尝试开源的解决方案,它应该作为候选者。
虽然 Speek! 声称能保持匿名,但如果你需要的是完全匿名的话,你应该始终注意自己在设备上的活动。因为你需要考虑的不仅仅是即时通讯软件。

Speek! 利用去中心化的 Tor 网络来保证安全性和私密性。不仅如此,这样做可以让你无需电话号码就能使用服务。你只需要你的 Speek ID 就可以与人联系,而别人很难知道你的 ID。
(LCTT 译注:Tor 是一个可以实现匿名通信的自由软件。其名源于 <ruby> 洋葱路由器 <rt> The Onion Router </rt></ruby> 的英文缩写。)
### Speek! 的亮点

Speek! 的一些主要亮点包括:
* 端到端加密:除收件人外,没有人可以查看你的消息。
* 通过 TOR 路由流量:使用 TOR 路由消息,增强隐私。
* 没有中央服务器:增加了对审查的抵抗力,因为很难关闭服务。此外,没有针对黑客的单一攻击点。
* 无需注册:无需共享任何个人信息即可开始使用该服务。你只需要一个公钥来识别/添加用户。
* 自毁聊天:当你关闭应用程序时,消息会自动删除。增添了额外的隐私和安全性。
* 无元数据:它会在你交换消息时消除任何元数据。
* 私人文件共享:你还可以使用该服务安全地共享文件。
### 下载适用于 Linux 和其他平台的 Speek!
你可以从他们的 [官方网站](https://speek.network) 下载 Speek!。
在撰写本文时,Speek! 仅适用于 Linux、安卓、macOS 和 Windows。
对于 Linux,你会找到一个 [AppImage](https://itsfoss.com/appimage-interview/) 文件。如果你不知道 AppImage,可以参考我们的 [AppImage 指南](https://itsfoss.com/use-appimage-linux/) 来运行该应用程序。

另外,[Google Play 商店](https://play.google.com/store/apps/details?id=com.speek.chat) 上的安卓应用程序还比较早期。因此,你在尝试使用它时可以期待一下它的改进。
[Speek!](https://speek.network/)
### 关于 Speek! 的用户体验
这个应用的用户体验非常令人满意,包含了所有必备的功能。它可以更好,但已经很不错了。
嗯,关于 Speek! 的 GUI 没什么好说的。GUI 非常极简风。它的核心是一个聊天应用程序,而它做得恰如其分。没有动态,没有附近的人,没有不必要的附加组件。
在我使用这个应用程序的有限时间里,我很满意它的功能。它提供的功能使其成为一款出色的聊天应用程序,可通过其背后的所有技术提供安全和私密的消息传递体验。
如果将它与一些商业上更成功的聊天软件进行比较,它在功能上存在不足。但话又说回来,Speek! 的设计就不是一个只关注用户体验的时尚聊天应用。
因此,我只向注重隐私的用户推荐 Speek!。如果你想要平衡用户体验和功能,你可能希望继续使用像 Signal 这样的私人聊天软件。
你对于 Speek 又有什么看法?对于注重隐私的用户来说,它是一个很好的私人聊天软件吗? 请在下方评论区告诉我你的想法。
*(题图:MJ:A girl looks at her phone while two cats are peeking at her phone next to her.)*
---
via: <https://itsfoss.com/speek/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lkxed](https://github.com/lkxed) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief:** An interesting open-source private messenger that utilizes Tor to keep your communications secure and private.
Speek is an internet messaging service that leverages multiple technologies to help keep your internet chats private.
It is end-to-end encrypted, decentralized, and open-source.
Undoubtedly, it aims to pitch itself as one of the [WhatsApp alternatives](https://itsfoss.com/private-whatsapp-alternatives/) and a competitor to [Signal on Linux](https://itsfoss.com/install-signal-ubuntu/).
So, what is it all about? Let us take a closer look at the details.
## ‘Speek!’ A Peer-to-Peer Instant Messaging App for Linux and Android
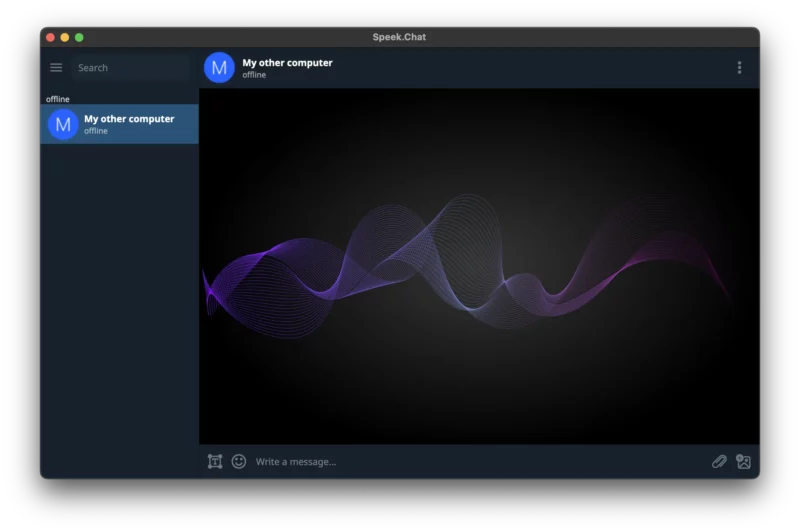
Speek! (with an exclamation mark as part of its name) is an encrypted chat messenger that aims to fight against censorship while keeping your data private.
To keep things simple, we ignore the exclamation mark for the rest of the article.
You can also find it as an alternative to [Session](https://itsfoss.com/session-messenger/), but with some differences.
It is a fairly new competitor compared to other messengers available. However, it should be a candidate to try as an open-source solution.
While it claims to keep you anonymous, you should always be cautious of your activities on your devices to ensure complete anonymity, if that’s what you require. It’s not just the messenger that you need to think of.
It utilizes a decentralized Tor network to keep things secure and private. And, this enables it to make the service useful without needing your phone number. You just require your Speek ID to connect with people, and it is tough for someone to know your ID.
## Features of Speek
Some key highlights include:
**End-to-end encryption**: No one except for the recipient can view your messages.**Routing traffic over TOR**: Using TOR for routing messages, enhances privacy.**No centralized server**: Increases resistance against censorship because it’s tough to shut down the service. Moreover, no single attack point for hackers.**No sign-ups**: You do not need to share any personal information to start using the service. You just need a public key to identify/add users.**Self-destructing chat**: When you close the app, the messages are automatically deleted. For an extra layer of privacy and security.**No metadata**: It eliminates any metadata when you exchange messages.**Private file sharing**: You can also use the service to share files securely.
## Download Speek For Linux and Other Platforms
You can download Speek from their [official website](https://speek.network).
At the time of writing this article, Speek is available only on Linux, Android macOS, and Windows.
For Linux, you will find an [AppImage](https://itsfoss.com/appimage-interview/) file. In case you are unaware of AppImages, you can refer to our [AppImage guide](https://itsfoss.com/use-appimage-linux/) to run the application.
And, the Android app on the [Google Play Store](https://play.google.com/store/apps/details?id=com.speek.chat) is fairly new. So, you should expect improvements when you try it out.
## Thoughts on Using Speek

The user experience for the app is pretty satisfying, and checks all the essentials required. It could be better, but it’s decent.
Well, there isn’t much to say about Speek’s GUI. The GUI is very minimal. It is a chat app at its core and does exactly that. No stories, no maps, no unnecessary add-ons.
In my limited time of using the app, I am satisfied with its functionalities. The features that it offers, make it a good chat app for providing a secure and private messaging experience with all the tech behind it.
If you’re going to compare it with some commercially successful chat apps, it falls short on features. But then again, Speek is not designed as a trendy chat app with a sole focus on user experience.
So, I would only recommend Speek for privacy-conscious users. If you want a balance of user experience and features, you might want to continue using private messengers like Signal.
*What do you think about Speek? Is it a good private messenger for privacy-focused users? Kindly let me know your thoughts in the comments section below.* |
15,726 | OpenBSD 7.3 发布,包含新功能和更新 | https://debugpointnews.com/openbsd-7-3/ | 2023-04-16T15:06:00 | [
"OpenBSD"
] | /article-15726-1.html | 
>
> OpenBSD 7.3 正式发布,有大量的软件包更新和改进。
>
>
>

OpenBSD 7.3 已经正式 [发布](https://www.openbsd.org/73.html),这是该系统的第 54 个版本。这个最新的版本建立在 OpenBSD 令人印象深刻的傲人记录之上 —— 它是一个安全可靠的操作系统,在二十多年的使用过程中,在默认安装中只发现了两个远程漏洞。
与以前的版本一样,OpenBSD 7.3 在广泛的系统领域提供了显著的改进。其中包括内核的改进,如增加了 `waitid(2)`、`pinsyscall(2)`、 `getthrname(2)` 和 `setthrname(2)` 函数,以及 `waitid(2)` 的 `WTRAPPED` 选项,等等。此外,新的内核 `autoconf_serial sysctl(8)` 允许用户区监控内核设备树状态的变化。
直接渲染管理器和图形驱动已经更新,引入了对 Ryzen 7000 “Raphael” 和 Ryzen 7020 和 7045 系列处理器以及 Radeon RX 7900 XT/XTX “Navi 31” 的支持,并改进了苹果芯片笔记本电脑和联想 x13s 的问题的解决方案。
此外,还改进了对网络硬件的支持,例如启用了 `em(4)` IPv4、 TCP 和 UDP 校验卸载,以及 82575、 82576、 i350 和 i210 芯片组设备上的硬件 VLAN 标记, 以及改进了 `mcx(4)` 性能。

除了上述的改进,OpenBSD 7.3 还包括一系列新的或改进的硬件和软件对 <ruby> 端口源码包 <rt> Port </rt></ruby> 和 <ruby> 二进制软件包 <rt> Package </rt></ruby> 的支持。一些来自外部供应商的主要组件包括 Xenocara、LLVM/Clang、GCC、Perl、NSD、Unbound、Ncurses、Binutils、Gdb、Awk 和 Expat。
OpenBSD 以最安全、最可靠的操作系统之一而闻名。在过去的二十年里,它的默认安装中只有两个远程漏洞,这一记录令人印象深刻。随着 OpenBSD 7.3 的发布,用户可以期待在几乎所有的系统领域都有显著的改进。
这个版本的内核改进,如增加了 `waitid(2)`、`pinsyscall(2)`、`getthrname(2)`、`setthrname(2)` 和 `clockintr(9)`,将为用户提供更简化的体验。Direct Rendering Manager 和图形驱动也得到了更新,包括对 Ryzen 7000 “Raphael”、Radeon RX 7900 XT/XTX “Navi 31” 和 Radeon RX 7600M(XT)等新设备的支持。
OpenBSD 7.3 还包括改进的网络硬件支持,在 82575、82576、i350 和 i210 芯片组的设备上启用 `em(4)` IPv4、TCP 和 UDP 校验和卸载以及硬件 VLAN 标记。此外,通过使用基于中断的命令完成,`mcx(4)` 的性能得到了提高。
至于端口源码包和二进制软件包,OpenBSD 7.3 包括了最新版本的应用程序、桌面和关键软件包。下面是关键端口源码包和二进制软件包的新项目列表:
**桌面和应用**
* Chromium 111.0.5563.110
* GNOME 43.3
* KDE 应用 22.12.3
* KDE 框架 5.103.0
* Xfce 4.18
* Krita 5.1.5
* LibreOffice 7.5.1.2
* Mozilla Firefox 111.0 和 ESR 102.9.0
* Mozilla Thunderbird 102.9.0
**核心开发软件包**
* Mutt 2.2.9 和 NeoMutt 20220429
* Node.js 18.15.0
* OCaml 4.12.1
* OpenLDAP 2.6.4
* PHP 7.4.33, 8.0.28, 8.1.16 和 8.2.3
* Postfix 3.5.17 和 3.7.3
* PostgreSQL 15.2
* Python 2.7.18, 3.9.16, 3.10.10 和 3.11.2
* Qt 5.15.8 和 6.4.2
* R 4.2.1
* Ruby 3.0.5, 3.1.3 和 3.2.1
* Rust 1.68.0
* Sudo 1.9.13.3
* MariaDB 10.9.4
* Mono 6.12.0.182
总的来说,最新发布的 OpenBSD 继续为用户提供安全可靠的操作系统,同时也在系统的各个领域进行了重大改进。我们鼓励用户升级到 OpenBSD 7.3,以利用这些新功能和改进。
OpenBSD 7.3 可以从官方网站下载,并有全面的发布说明,详细介绍了所有的新功能和改进。
>
> **[下载 OpenBSD 7.3(所有架构)](https://cdn.openbsd.org/pub/OpenBSD/7.3/)**
>
>
>
>
> **[详细的更新日志](https://www.openbsd.org/plus73.html)**
>
>
>
*(题图: MJ:Future computer with transparent screen, metal box, hd, ultra detailed, sci-fi)*
---
via: <https://debugpointnews.com/openbsd-7-3/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,727 | Arch Linux 的最佳 GUI 包管理器 | https://www.debugpoint.com/arch-linux-gui-package-managers/ | 2023-04-16T15:28:00 | [
"Arch Linux",
"包管理器"
] | /article-15727-1.html | 
>
> 让我们点评一些最好的 Arch Linux GUI 包管理器。选择最符合你需求的。
>
>
>
由于其可定制性、灵活性和尖端功能,Arch Linux 是高级用户和开发人员中最受欢迎和使用最广泛的 Linux 发行版之一。
由于其极简设计,在 Arch Linux 中安装软件的主要方式是使用终端通过命令行界面 (CLI)。
但并不是每个人都喜欢使用终端。基于图形用户界面(GUI)的包管理器是这些人的必备程序。有几个可选的包管理器。让我们了解一些比较流行的。
### 在 Arch Linux 上寻找基于 GUI 的包管理器要考虑什么?
在为 Arch Linux 选择基于 GUI 的包管理器时,必须考虑几个因素:
首先,它应该有一个干净易用的界面,对初学者来说很直观。
其次,它应该支持所有包管理操作,例如安装、删除、更新和搜索包。
第三,它应该具有高级功能,例如依赖项解析和对 AUR 包的支持。
最后,它应该是轻量级的,不会占用太多的系统资源。
### Arch Linux 的最佳 GUI 包管理器
#### 1、Pamac
此列表中的第一个 GUI 包管理器是 [Pamac](https://wiki.manjaro.org/index.php/Pamac),它由 Manjaro Linux 团队开发。具有漂亮且用户友好的界面,使其超级易于使用。
其直观的界面使用户可以轻松安装、删除和更新软件包。它建立在支持 AUR 的 [libalpm](https://man.archlinux.org/man/libalpm.3.en) 之上。Pamac 还支持 Snap 和 Flatpak 的 `appstream:///` 协议。因此,你可以直接从 appstream 链接启动该应用安装程序。此外,它还具有高级功能,例如依赖项解析和对 AUR 包的支持。此外,Pamac 是轻量级的,不会占用太多系统资源。

使用其 GUI,你可以浏览 Arch 仓库,还可以根据其功能查看应用。Pamac GUI 中有单独的部分,可以使你能够删除和卸载包,包括孤立的包。
它是最好的 GUI 包管理器之一。

Pamac 安装很容易。它在 Arch 用户仓库(AUR)中可用。你可以 [安装 Yay](https://www.debugpoint.com/install-yay-arch/) AUR 助手或任何其他助手来安装它。这是使用 Yay 安装的命令。该软件包位于 [此处](https://aur.archlinux.org/packages/pamac-aur-git)。如果你正在运行 [Manjaro Linux](https://www.debugpoint.com/manjaro-linux-review-2022/),它应该已经存在。
```
yay -S pamac-aur-git
```
#### 2、Octopi
接下来的 GUI 包管理器是 [Octopi](https://tintaescura.com/projects/octopi/),它是另一个漂亮的工具。它是使用 Qt 构建的,并带有一个高效的 GUI。在功能方面,它是一个非常先进的工具。
使用 Octopi,你可以搜索包、安装它们,当然也可以删除它们。此外,你可以查看直接从 Arch 仓库中获取的每个包的详细信息。例如,包版本、最后更新日期、新闻和其他信息。
此外,它允许你查看包的 PKGBUILD 信息。如果你想进一步调查包,这是一个很好的功能。
最后,它是超轻量级的,不会占用大量系统资源。我认为 Octopi 完全被低估了,它是 Arch Linux 功能丰富的软件管理器之一。

它在 AUR 中可用,你可以使用 [Yay](https://www.debugpoint.com/install-yay-arch/) 或任何 AUR 助手安装它。
```
yay -S --needed octopi
```
#### 3、GNOME “软件”应用
此列表中的第三个是你可能已经知道的 GNOME “<ruby> 软件 <rt> Software </rt></ruby>”应用。它是 Ubuntu、Fedora 和许多其他发行版的默认软件管理器。基于 GTK4,它支持所有类型的包,如 .deb、.rpm、Flatpak 和 Snap。在 Arch Linux 中,它支持主 Arch 仓库,包括用户仓库(AUR)。
但是,与此列表中的其他应用程序相比,它对系统资源的占用可能有点大。但它是一个现代的包管理器,可以很好地用于各种场景。

安装很简单,因为它在主 Arch 仓库中可用。你可以从终端使用以下命令安装它。
```
sudo pacman -S --needed gnome-software
```
#### 4. KDE “发现”应用
我个人最喜欢的是 KDE “<ruby> <a href="https://apps.kde.org/discover/"> 发现 </a> <rt> Discover </rt></ruby>”应用 ,它是 KDE Plasma 团队中最好的软件管理器之一。如果你使用过 Kubuntu 或任何其他 KDE Plasma 桌面,那么你已经熟悉它了。
“发现”应用支持所有主要的打包格式,包括 deb、rpm、Flatpak 和 Snap。它有一个定义明确的软件及其来源信息页面。你还可以按应用名称搜索或按应用类别浏览目录。
对于 Arch Linux,它可以从主 Arch 仓库和 AUR 中获取包和信息。

你可以在 Arch Linux 中使用以下命令安装它。
```
sudo pacman -S --needed discover
```
#### 5、Bauh
[Bauh](https://github.com/vinifmor/bauh) 是一个相对较新的基于 GUI 的 Arch Linux 包管理器。它具有简单且用户友好的界面,使用户可以轻松管理他们的包。
它的主窗口为你提供了在 Arch Linux 系统中管理应用程序的所有选项。主搜索框使你能够搜索应用程序。此外,你可以通过类型浏览,例如仅查看 Flatpak、AUR 等包。
此外,使用 Bauh 的主 GUI,你可以逐个降级和更新软件包,查看软件包信息,甚至直接启动应用。
良好设计的设置面板为你提供了所需的所有自定义选项。

在系统中 [设置](https://www.debugpoint.com/install-yay-arch/) AUR 之后,你可以使用以下命令安装它。
```
yay -S --needed bauh
```
### 还有几个
还有一些其他的包管理器可以在 Arch Linux 中使用。这是其中的一小部分。这些不是那么流行。但它们也可以作为替代方案。
* [Apper](https://apps.kde.org//system/apper/):使用 PackageKit 的应用和包管理器(来自 KDE 团队)
* [tkPacman](https://aur.archlinux.org/packages/tkpacman):使用 Tcl/Tk 构建的 pacman 轻量级 GUI
最后,你可以在官方 [Arch Wiki](https://wiki.archlinux.org/title/Pacman/Tips_and_tricks#Graphical) 中阅读更多相关信息。
### 总结
在本文中,我们讨论了一些适用于 Arch Linux 的最佳基于 GUI 的包管理器,包括 Pamac、Octopi、GNOME “软件”应用、KDE “发现”应用 和 Bauh。
这些包管理器中的每一个都有自己的优点和缺点,因此你可以选择最适合你需求的那个。
如果你要我推荐,我建议你试试这些:Pamac、Octopi 和 Bauh。它们都是很好的。
*(题图:MJ:software package manager hd, abstract)*
---
via: <https://www.debugpoint.com/arch-linux-gui-package-managers/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,729 | TUXEDO Stellaris 16(Gen5)是目前所能找到的终极 Linux 笔记本电脑 | https://news.itsfoss.com/tuxedo-stellaris-16-gen-5/ | 2023-04-17T15:12:41 | [
"笔记本电脑"
] | https://linux.cn/article-15729-1.html |
>
> 这款笔记本电脑拥有 RTX 4090 和 i9 处理器等规格,可谓惊人!你觉得呢?
>
>
>

TUXEDO 电脑是 Linux 领域的一个著名品牌,它提供了不同价格/性能的可定制的 Linux 笔记本和台式电脑。
顺便说一句,它是值得信赖的 [购买 Linux 电脑](https://itsfoss.com/get-linux-laptops/) 的地方之一。
在最近的公告中,他们推出了 **Stellaris 16 英寸笔记本电脑的下一个进化版**。
我必须说,这可以成为 Framework 最近宣布的高性能 16 英寸笔记本电脑的有力挑战者。
让我们来看看它。
### TUXEDO Stellaris 16 Gen 5 概览

这款笔记本电脑的主要亮点是,它采用了英伟达最新、最强大的 [RTX40 系列](https://www.nvidia.com/en-us/geforce/laptops/) 笔记本 GPU,提供了强大的图形性能和功能。
搭配了英特尔的顶级处理器 [i9 13900HX](https://ark.intel.com/content/www/us/en/ark/products/232171/intel-core-i913900hx-processor-36m-cache-up-to-5-40-ghz.html),其 24 个核心可以在高达 157W TDP(睿频)的情况下超频到 **极快的 5.40 GHz**,这是一个引人注目的组合。
但请记住,为了充分发挥笔记本电脑的运行潜力,TUXEDO 建议使用 **他们的外部水冷却解决方案**,[TUXEDO Aquaris](https://www.tuxedocomputers.com/en/Linux-Hardware/Accessories/Further-accessories/TUXEDO-Aquaris--External-Water-Cooling-Device_1.tuxedo),它可以通过磁力连接到笔记本电脑的背面。
>
> ? 在订购该笔记本电脑时,你必须为此支付额外费用。
>
>
>
该处理器在没有全速运行时,基本 TDP 为 55W,时钟速度为 3.90GHz。
对于这样一台轻薄的笔记本电脑来说,这仍然是一个不错的性能数字! ?
Stellaris 16 - Gen5 笔记本电脑的一些其它关键亮点如下:
* 外壳 1是由铝和塑料的组合组成。
* 一个 240 赫兹的 16 英寸 IPS 显示屏,支持英伟达 G-SYNC。
* GPU 最高可选英伟达 RTX 4090。
* 高达 64GB DDR5,5600MHz 的内存(2x32GB)。
* 99Wh 的电池,允许运行时间长达 10 小时(空闲),在典型负载下约 6-7 小时。
### TUXEDO Stellaris 16:是什么让它成为强者?
Stellaris 16 - Gen5 笔记本电脑上的高端硬件不仅吸引了游戏玩家,也吸引了其他各种用户,如内容创作者、AI/ML 工程师、UI/UX 艺术家等等。
那么,是什么让它囊括如此完整的用户群体呢?
嗯,是在各种可能的设置中自由选择。
首先,你可以从 RTX 4060 这种相对平静的 GPU 到疯狂的 RTX 4090 中挑选,其间还有 RTX 4070 和 RTX 4080 可选。

然后是键盘选项,你可以选择他们新增加的 [樱桃 MX Ultra-Low Profile](https://www.cherrymx.de/en/cherry-mx/mx-ultra-low-profile/mx-ulp-click.html) 机械键盘,以获得打字时的触觉和听觉感受,或者通常的静音薄膜键盘。
你还可以从广泛的键盘布局清单中挑选,包括英语、德语、西班牙语、匈牙利语,以及更多,还有带有背光的 TUX 超级键。
内存也不例外。你可以在两个性能层之间做出选择。一个是 “性能” 层,提供 DDR5 RAM,以迅速的 4800 MHz 运行,一个是 “高性能” 层,提供 DDR5 RAM,以令人瞠目的 5600 MHz 运行。
这些层级提供最大 64GB 的内存,采用来自 SK 海力士、三星和美光的内存条。
至于存储,两个 PCIe 4.0 x4 的 M.2 2280 SSD 插槽,配备各种三星 SSD。其阵容从三星 970 EVO Plus 开始,中间是三星 980,极速的三星 980 Pro 是该系列的顶配。
>
> ? 在两个 M.2 插槽都插满的情况下,最多可实现 4TB 的存储。
>
>
>
除此之外,Stellaris 16 - Gen5 具有 Wi-Fi 6E 和蓝牙 5.3,并预装了 [TUXEDO OS](https://www.tuxedocomputers.com/os),除非你在购买时选择不同的操作系统,如 Ubuntu 22.04 LTS、Kubuntu 22.04 LTS、Ubuntu Budgie 22.04 LTS 和 Windows 11 Home/Pro 等。
### 什么时候可以买到和价格
TUXEDO Stellaris 16 - Gen5 现在可预购,在 4 月底开始交付。
基本配置的价格为 1763.87 欧元,配备 i9 处理器、RTX 4060、运行频率为 5600 MHz 的 16GB 内存(2x 8GB),500GB 三星 980 固态硬盘和 TUXEDO 操作系统。
>
> **[预购](https://www.tuxedocomputers.com/en/TUXEDO-Stellaris-16-Gen5.tuxedo)**
>
>
>
前往 [官方商店列表](https://www.tuxedocomputers.com/en/TUXEDO-Stellaris-16-Gen5.tuxedo),并开始按照你的要求进行配置吧。
(LCTT 译注:原文带有受惠链接,但本文非收费软文。)
---
via: <https://news.itsfoss.com/tuxedo-stellaris-16-gen-5/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

TUXEDO Computers is a well-known brand in the Linux space that provide customizable Linux notebooks and Desktop PCs at various price/performance points.
Not to forget, it is one of the trusted places to [buy Linux computers](https://itsfoss.com/get-linux-laptops/?ref=news.itsfoss.com).
With a recent announcement, they have launched the** next evolution of their Stellaris 16-inch laptop.**
I must say that this can be a proper challenger to Framework's recently announced high-performance 16-inch Laptop.
Let's take a look at it.
**Suggested Read **📖
[Framework Unveils a New Laptop With Game-Changing Open Source Module SystemUpgradeable graphics, customizable keyboard modules, and what else? This sounds pretty spectacular!](https://news.itsfoss.com/framework-laptop-open-source-module/)

## TUXEDO Stellaris 16 Gen 5: Overview ⭐

The major highlight of this laptop is that it features Nvidia's latest and greatest [ RTX40 series](https://www.nvidia.com/en-us/geforce/laptops/?ref=news.itsfoss.com) of mobile GPUs that offer some great graphics performance and features.
Paired with Intel's top-of-the-line processor, the ** i9 13900HX**, with its 24-cores that can turbo up to a
**blazing fast 5.40 GHz**at a whopping
**157 W TDP**(Turbo), it is a compelling package.
Though keep in mind; that for running the laptop at its full potential, TUXEDO recommends using** their external water cooling solution**, [TUXEDO Aquaris](https://www.tuxedocomputers.com/en/Linux-Hardware/Accessories/Further-accessories/TUXEDO-Aquaris--External-Water-Cooling-Device_1.tuxedo?ref=news.itsfoss.com), which can be attached magnetically to the back of the laptop.
The processor can run at a base TDP of **55 W** with a 3.90 GHz clock speed when it is not running at full blast.
That's still a decent performance figure for such a thin laptop! 😮
Some other key highlights of the Stellaris 16 – Gen5 laptop are as follows:
**The chassis is made up of a combination of Aluminum and Plastics.****A 240 Hz 16-inch IPS display with Nvidia G-SYNC support.****GPU options up to an Nvidia RTX 4090.****Up to 64 GB DDR5, 5600 MHz RAM (2x 32 GB).****A 99 Wh Battery that allows for runtimes of up to 10 hours (idle), and around 6–7 hours under typical loads.**
## ⚡ TUXEDO Stellaris 16: What Makes it a Powerhouse?
The high-end hardware aboard the Stellaris 16 – Gen5 laptop won't only appeal to gamers but also to a wide variety of other users such as content creators, AI/ML engineers, UI/UX artists, and more.
**So, what makes it such a complete package?**
Well, it is the freedom of choosing from various possible setups.
For starters, you get to pick from a relatively calmer GPU in the form of an **RTX 4060**, all the way to the **insane RTX 4090,** with the **RTX 4070** and **RTX 4080** filling in the gaps.

Then there are the keyboard options that let you decide between their newly added [Cherry MX Ultra-Low Profile](https://www.cherrymx.de/en/cherry-mx/mx-ultra-low-profile/mx-ulp-click.html?ref=news.itsfoss.com) clicky switches for a tactile and audible feel during typing or the usual silent membrane switches.
You can also pick from an extensive** list of keyboard layouts** that include English, German, Spanish, Hungarian, and more with the backlit TUX super-key.
The RAM offerings are no less; you can decide between two performance tiers. One is a 'Performance' tier that offers **DDR5 RAM** running at a swift **4800 MHZ** and a 'High Performance' tier that offers DDR5 RAM running at an eye-watering **5600 MHz**.
These tiers offer a maximum of 64 GB RAM, mixing sticks from **SK Hynix**, **Samsung,** and **Micron**.
As for storage, two M.2 2280 SSD slots run on PCIe 4.0 x4 with various Samsung SSDs.
The lineup starts with a **Samsung 970 EVO Plus**, with the **Samsung 980** in the middle and the blazing-fast **Samsung 980 Pro **being the range-topper.
Besides that, the Stellaris 16 – Gen5 features **Wi-Fi 6E** with **Bluetooth 5.3** and comes with the ** TUXEDO OS pre-installed** unless you choose a different one at checkout.
**Suggested Read **📖
[15 Places Where You Can Buy Linux ComputersLooking for Linux laptops? Here I list some online shops that sell Linux computers or specialize only in Linux systems.](https://itsfoss.com/get-linux-laptops/?ref=news.itsfoss.com)

The OS offerings include the likes of **Ubuntu 22.04 LTS**, **Kubuntu 22.04 LTS**, **Ubuntu Budgie 22.04 LTS,** and **Windows 11 Home/Pro**.
## 💸 Availability and Pricing
The TUXEDO Stellaris 16 – Gen5 is **available for pre-order**, with **deliveries starting at the end of April**.
Prices start at **1763,87 EUR for the base config** with the i9 processor, an RTX 4060, 16 GB of RAM (2x 8 GB) running at 5600MHZ, a 500 GB Samsung 980 SSD, and TUXEDO OS.
Head over to the [official store listing](https://www.tuxedocomputers.com/en/TUXEDO-Stellaris-16-Gen5.tuxedo?ref=news.itsfoss.com), and start configuring as per your requirements.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,730 | 如何在 Linux 中合并 PDF 文件 | https://itsfoss.com/merge-pdf-linux/ | 2023-04-17T15:59:27 | [
"PDF"
] | https://linux.cn/article-15730-1.html | 
>
> 有多个关于同一主题的 PDF,现在你想将它们合并成一个 PDF?
>
>
>
或者你可能需要上传由不同文件组成的单个文件?许多政府和学术门户网站都要求这样做。
作为 Linux 用户,如果你遇到需要合并 PDF 的情况,本教程将帮助你。
在本教程中,我将分享三种合并多个 PDF 文件的方法:
* 使用 PDF Tricks GUI 工具
* 使用 LibreOffice(允许你选择页面)
* 使用 ImageMagick 命令行工具(Linux 教程会没有终端方法就结束么?)
你可以全部了解一下并选择最适合你的。
### 方法 1:使用 PDF Tricks GUI 工具在 Linux 中合并 PDF
在试用了多种 GUI 工具后,我发现 PDF Tricks 使用简单且易于导航。
此外,除了合并 PDF 文件之外,它还包括其他功能,包括:
* 压缩 PDF。
* 拆分 PDF。
* 将 PDF 转换为 JPG、PNG 和文本格式。
它以 [Flatpak](https://itsfoss.com/what-is-flatpak/) 的形式提供。请 [确保你的 Linux 系统启用了 Flatpak 支持](https://itsfoss.com/flatpak-guide/)。
我分享的是在 Ubuntu 上启用 Flatpak 的步骤:
```
sudo apt install flatpak
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
现在,使用以下命令在你的系统中安装 PDF Tricks:
```
flatpak install flathub com.github.muriloventuroso.pdftricks
```
完成安装后,从系统菜单中打开 PDF Tricks 应用。
第一次运行时,你会得到一个可以使用此工具执行的操作列表。显然,要合并 PDF 文件,请使用第三个选项。

在下一步中,单击 “<ruby> 添加文件 <rt> Add file </rt></ruby>” 并选择要合并的文件:

选择文件后,单击 “<ruby> 合并 <rt> Merge </rt></ruby>” 按钮:

它将打开系统的默认文件管理器。你可以在此处选择要保存合并文件的位置以及应命名的文件:

就是这样。合并后的 PDF 已保存。
如果你正在寻找,我们提供了一份 [可用于阅读和编辑 PDF 文件的最佳 PDF 阅读器](https://itsfoss.com/pdf-editors-linux/) 列表。
### 方法 2:使用 LibreOffice 合并 PDF 文件
很棒的 LibreOffice 能够处理许多与 PDF 相关的任务。你甚至可以 [使用 LibreOffice Draw 工具编辑 PDF 文件](https://itsfoss.com/edit-pdf-files-ubuntu-linux/) 来添加数字签名、添加文本等。
好处是你不需要安装其他应用。LibreOffice 已经安装在大多数发行版上,如果不是全部的话。
打开文件管理器并选择要合并的 PDF 文件。
右键单击选定的文件 > <ruby> 使用其他应用打开 <rt> Open With Other Application </rt></ruby> > LibreOffice Draw,它将打开选定的 PDF 文件。
它将在单独的 LibreOffice Draw 实例中打开你选择的每个 PDF 文件:

现在,你必须从左侧预览栏选择单个页面或整个 PDF 文件(使用 `Ctrl + A`)并将其拖放到要合并的文件的预览栏:
拖放后,单击左上角的第 5 个选项,提示是 <ruby> 直接导出为 PDF <rt> Export Directly as PDF </rt></ruby>:

将打开一个文件管理器,你可以从中定位并命名文件:

这就完成了!
### 更多技巧:在命令行中合并 PDF (对于高级用户)
如果我不包括命令行方法,那算什么 Linux 教程?要在命令行中合并 PDF 文件,你可以使用 ImageMagick。
ImageMagick 其实是一个图像相关的工具。PDF 文件本质上是图像,这就是 ImageMagick 可以处理它们的原因。
你可能甚至不需要单独 [安装 ImageMagick](https://itsfoss.com/install-imagemagick-ubuntu/),因为它已经默认安装在大多数发行版中。
例如,我将添加 3 个名为 pdf-1.pdf、pdf-2.pdf 和 pdf-3.pdf 的 PDF 文件,并将最终合并的 PDF 文件输出命名为 MergedFile.pdf(多么聪明):
```
convert pdf-1.pdf pdf-2.pdf pdf-3.pdf MergedFile.pdf
```
#### “no images defined” 故障排除
如果你看到这样的策略错误:

这个问题很容易解决。你只需在 ImageMagick 策略文件中进行少量更改。
打开策略文件进行编辑:
```
sudo nano /etc/ImageMagick-6/policy.xml
```
并查找以下行:
```
<policy domain="coder" rights="none" pattern="PDF" />
```
现在,你需要将 `rights="none"` 更改为 `rights=read|write`:
```
<policy domain="coder" rights="read|write" pattern="PDF" />
```

保存更改,现在你可以使用 ImageMagick 轻松合并文件:

### 总结
现在你知道了在 Linux 中合并 PDF 文件的几种方法。合并后的 PDF 文件可能很大。如果你需要在有大小限制的门户上传合并的 PDF 文件,你可以 [压缩 PDF 文件](https://itsfoss.com/compress-pdf-linux/)。
如果你在使用上述方法时遇到任何问题,请告诉我。
*(题图:MJ:process docs illustrations in high resolution)*
---
via: <https://itsfoss.com/merge-pdf-linux/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Got several PDFs on the same subject and now you want to combine them into a single PDF?
Or perhaps you need to upload a single file consisting of different files? Many government and academic portals require that.
As a Linux user, if you are in a situation where you need to merge PDFs, this tutorial will help you out.
In this tutorial, I’ll share three methods of combining multiple PDF files:
- Using PDF Tricks GUI tool
- Using LibreOffice (allows you to select pages as well)
- Using the ImageMagick command line tool (Can a Linux tutorial be completed without the terminal method?)
You can read them all and pick the one that works best for you.
## Method 1: Use PDF Tricks GUI tool to merge PDF in Linux
After experimenting with several GUI tools, I found that the PDF Tricks was straightforward to use and easy to navigate.
Furthermore, it includes additional functionality beyond only merging PDF files, including:
- Compress PDFs.
- Split PDFs.
- Compress PDFs (into JPG, PNG, and text formats).
It is available as a [Flatpak](https://itsfoss.com/what-is-flatpak/). Please [ensure that your Linux system has Flatpak support enabled](https://itsfoss.com/flatpak-guide/).
I am sharing the steps for enabling Flatpak on Ubuntu:
```
sudo apt install flatpak
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
Now, use the below command to install PDF Tricks in your system:
`flatpak install flathub com.github.muriloventuroso.pdftricks`
Once you are done with the installation, open the PDF Tricks application from the system menu.
On the first run, you will get you a list of actions you can perform with this tool. To merge PDF files, go with the third option, obviously.
In the next step, click on **Add file** and select the files you want to merge:
Once you select files, click on the **Merge** button:
And it will open the default file manager of your system. Here you can select where you want to save the merged file and what it should be named:
And that’s it. The combined pdf has been saved.
And if you are looking for a tool, we have a list of the [best PDF readers that you can use to read and edit PDF files.](https://itsfoss.com/pdf-editors-linux/)
[11 Best Linux PDF Editors You Can Use in 2023Looking for the best PDF editing options? You should find some awesome options here!](https://itsfoss.com/pdf-editors-linux/)

## Method 2: Merge PDF Files using LibreOffice
The awesome LibreOffice is capable of handling many PDF related tasks. You can even [edit PDF files with LibreOffice Draw tool](https://itsfoss.com/edit-pdf-files-ubuntu-linux/) for adding a digital signature, adding text, and much more.
The good thing is that you don’t need to install another application. LibreOffice is already installed on most distributions, if not all.
Open the file manager and select the PDF files that you want to merge.
**Right-click on selected files > Open With Other Application > LibreOffice Draw from there**, and it will open selected PDF files.
And it will open every PDF file you selected in a separate LibreOffice Draw instance:
Now, you have to **select individual pages or entire PDF file** (using Ctrl + A) from the left preview bar and drop it to the preview bar of the file that you want to combine with:
Once you are done with drag and drop, click on the 5th option from the top left, labeled as **Export Directly as PDF**:
And it will open a file manager from where you can locate and name the file:
And that’s it!
## Bonus Tip: Merge PDFs in the command line [For advanced users]
What kind of Linux tutorial would it be if I didn’t include the command line method? To merge PDF files in the command line, you can use ImageMagick.
ImageMagick is actually an image-related tool. PDF files are essentially images and this is why ImageMagick can work with them.
You probably don’t even need to [install ImageMagick](https://itsfoss.com/install-imagemagick-ubuntu/) as it is already installed in most distros by default.
For example, I will be adding 3 PDF files named pdf-1.pdf, pdf-2.pdf, and pdf-3.pdf and will name the final merged PDF file output as MergedFile.pdf (how clever):
`convert pdf-1.pdf pdf-2.pdf pdf-3.pdf MergedFile.pdf`
### Troubleshooting no images defined
If you see a policy error like this:
The problem is quite easy to solve. You just have to make minor changes in the ImageMagick policy file.
Open the policy file for editing:
`sudo nano /etc/ImageMagick-6/policy.xml`
And look for the following line:
`<policy domain="coder" rights="none" pattern="PDF" />`
Now, you have to change the `rights="none"`
to `rights=read|write`
:
`<policy domain="coder" rights="read|write" pattern="PDF" />`
Save the changes, and now you can easily merge files using ImageMagick:

## Wrapping Up
Now you know several ways of combining PDF files in Linux. Chances are that the merged PDF file is big in size. If you have to upload the merged PDF file on a portal that has size restrictions, you can [compress the PDF file](https://itsfoss.com/compress-pdf-linux/).
[How to Compress PDF in Linux [GUI & Terminal]Brief: Learn how to reduce the size of a PDF file in Linux. Both command line and GUI methods have been discussed. I was filling some application form and it asked to upload the necessary documents in PDF format. Not a big issue. I gathered all the scanned images and](https://itsfoss.com/compress-pdf-linux/)

Similarly, you can use this neat little trick for simple PDF editing tasks such as [adding comments and highlighting texts in PDF](https://itsfoss.com/annotate-pdf-linux/).
[How to Add Comments to PDF in LinuxYou don’t need a dedicated PDF editor to add comments and highlight text. Here’s how you can use GNOME’s Document Viewer to annotate PDFs in Linux.](https://itsfoss.com/annotate-pdf-linux/)

Let me know if you face any issues with above discussed methods. |
15,732 | Firefox 112 发布:右键单击显示密码、改进标签管理等! | https://debugpointnews.com/firefox-112/ | 2023-04-18T15:24:32 | [
"Firefox"
] | /article-15732-1.html | 
>
> Firefox 发布 112 版本,为我们带来了显示密码的新选择、同时改进了标签管理等。
>
>
>
Mozilla 于 2023 年 4 月 11 日发布了 Firefox 112,新版本包含一些令人兴奋的新功能和改进。该浏览器的最新版本带来了一些功能以增强用户体验和提高性能。

本次更新最明显的其中一个功能是,你只需右键单击密码字段即可显示密码。对于那些容易忘记登录凭据的人来说,这是一个方便的工具。

如今,Firefox 允许 Ubuntu Linux 用户从 Chromium Snap 包导入浏览器数据。但是,此功能仅在 Firefox 未以 Snap 包安装时才有效,这一问题 Mozilla 正在努力解决了。
在标签管理方面,Firefox 112 提供了一个新的选项,可以通过在标签列表面板中用鼠标中键点击来关闭标签。此外,快捷键 `(Cmd/Ctrl)-Shift-T` 用于取消关闭标签,当同一会话中没有更多已关闭的标签需要重新打开时,它现在会恢复之前的会话。
Firefox 还扩展了已知跟踪参数列表,对于 ETP Strict 用户,这些参数会从 URL 中删除。这进一步保护用户免受跨站点跟踪。
新的更新还可以在 Windows 中的英特尔 GPU 上叠加软件解码视频。这提高了缩小的视频质量,并减少了 GPU 的使用。
在其他功能方面,已弃用的 U2F Javascript API 现在默认处于禁用状态。但是,U2F 协议仍然可以通过 WebAuthn API 使用,并且可以使用 security.webauth.u2f 首选项重新启用 U2F API。
最后,日期选择器面板中添加了一个新的清除按钮,允许用户快速清除类型为“日期”或“本地日期-时间”的输入,从而为跨浏览器的用户体验提供一致性。
Firefox 112 可在 Windows、Mac 和 Linux 上下载,我们鼓励用户将浏览器更新到最新版本以获得更流畅、更安全的浏览体验。
你可以立即从以下链接下载最新版本。
>
> **[下载 Firefox 112](https://ftp.mozilla.org/pub/firefox/releases/112.0/)**
>
>
>
或者,你可以再等几天,Linux 发行版会对它进行测试并通过定期发行版更新让你也能用上 Firefox 112。
参考自:[changelog](https://www.mozilla.org/en-US/firefox/112.0/releasenotes/)
*(题图:MJ:Firefox illustation in high resolution, very detailed, 8k)*
---
via: <https://debugpointnews.com/firefox-112/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.