
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
15,424 | Budgie 10.7 即将带来 3 项关键改进 | https://news.itsfoss.com/budgie-10-7-features/ | 2023-01-08T12:52:35 | [
"Budgie"
] | https://linux.cn/article-15424-1.html |
>
> Budgie 10.7 有很多有价值的改进。请看本文。
>
>
>

Budgie 是一个旨在将杂乱无章降到最低,为用户提供一个干净/简约的体验的桌面环境。
早在 2022 年 1 月,Solus 的前联合负责人 Joshua Strobl [离开了 Solus](https://news.itsfoss.com/solus-co-lead-resign-budgie-serpent/),从事 [SerpentOS](https://serpentos.com) 的开发,但他还继续参与 Budgie 的开发。
因此,他将该项目复刻到一个新的代码仓库,并成立了 [Buddies Of Budgie](https://blog.buddiesofbudgie.org) 组织。三个月后,他们发布了 **Budgie 10.6**。
这是一个很不错的版本,即使不是很特别。
展望未来,他们发布了 2023 年的计划,其中包括发布 **Budgie 10.7**。
[Joshua Strobl](https://joshuastrobl.com) 在博文中也提到了更多计划内容:
>
> 至少,它应该是一个很好的基础,并为 Budgie 桌面今年的发展方向提供一个清晰的蓝图:Budgie 10.x 将会增加新的功能、QoL 改进和修复。Budgie 11 的开发工作也将起步。
>
>
>
### Budgie 10.7 可以期待什么?
Budgie 10.7 的开发工作自去年以来一直在进行。它本应在 2022 年发布,但需要更多的时间来提供一个完美的体验。
已经完成了很多工作,但其中一些值得注意的三个变化是:
* 对 Budgie 菜单的更新
* 新的 Budgie 屏幕截图工具
* 对 Budgie 运行对话框的改进
#### 对 Budgie 菜单的更新

在这个版本中,Budgie 菜单将得到一些改进,例如。
* 一个新的电源菜单,包含所有常用的选项,如**暂停、休眠、注销和关闭电源**。
* 更新的个人用户菜单可以快速访问 XDG 目录。这将让你直接打开文件管理器窗口进入主页、文档、音乐等文件夹。
* 快速访问 Budgie 控制中心和桌面设置。
* 能够从菜单本身显示各种桌面设置。
#### Budgie 屏幕截图工具

终于,你不再需要下载另一个工具来在 Budgie 上进行截图;从 10.7 开始,它将具有一个原生的屏幕截图应用程序。
它将支持对屏幕、窗口的捕捉,甚至是进行选区捕捉。
#### 对 Budgie 运行对话框的改进

Budgie 运行对话框将获得许多改进,例如:
* 一个新的应用程序索引器将被用于 Budgie 菜单,以寻找和分类应用程序。它应该能提供一个 “可预测的模糊搜索体验”。
* 根据显示器的工作区域改进对话框的大小计算。
* 更好的应用程序名称和描述的标签样式。
### 发布和未来计划
根据他们的 [公告](https://blog.buddiesofbudgie.org/state-of-the-budgie-2022/),他们打算在 2023 年第一季度的某个时候发布 Budgie 10.7。他们还没有确定一个具体的日期。
并计划在不久之后发布带有错误修复的 10.7.1 版本,然后在 2023 年第二季度发布 Budgie 10.8。
---
via: <https://news.itsfoss.com/budgie-10-7-features/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Budgie is a desktop environment designed to keep clutter to a minimum and provide users with a clean/minimal experience.
Back in January 2022, the former-co-lead of Solus, **Joshua Strobl** [left Solus](https://news.itsfoss.com/solus-co-lead-resign-budgie-serpent/) to work on [SerpentOS](https://serpentos.com/?ref=news.itsfoss.com), but he continued to work on Budgie.
So, he forked the project into a new repository and formed the [Buddies Of Budgie](https://blog.buddiesofbudgie.org/?ref=news.itsfoss.com) organization. Three months after that, they released **Budgie 10.6**.
It was a good release, if not extraordinary.
**Related Read 📖**
[Budgie 10.6 is Here as its First Release Under the New OrganizationBack in January, ex-co-lead of Solus Joshua Strobl made headlines after leaving Solus to work on SerpentOS. You can read more about it in our original coverage. However, he still wanted to work on the Budgie desktop environment, so he forked the project (in a new repository) and formed the](https://news.itsfoss.com/budgie-10-6-release/)

Moving forward, they have shared the plans for 2023 which include the release of **Budgie 10.7**.
[Joshua Strobl](https://joshuastrobl.com/?ref=news.itsfoss.com) also mentioned more about the plans in the blog post:
At the very least, it should serve as a good foundation to build on and provide a clear picture on where Budgie Desktop is going this year: Budgie 10.x will receive new features, QoL improvements, and fixes. Budgie 11 development will be underway.
## Budgie 10.7: What Can You Expect?
The development of Budgie 10.7 has been going on since last year. It was supposed to release in 2022, but more time was required to serve a polished experience.
A lot of work has been done, but some of the notable ones include the following three changes:
**Updates to Budgie Menu****New Budgie Screenshot Tool****Improvements to Budgie Run Dialog**
### Updates to Budgie Menu
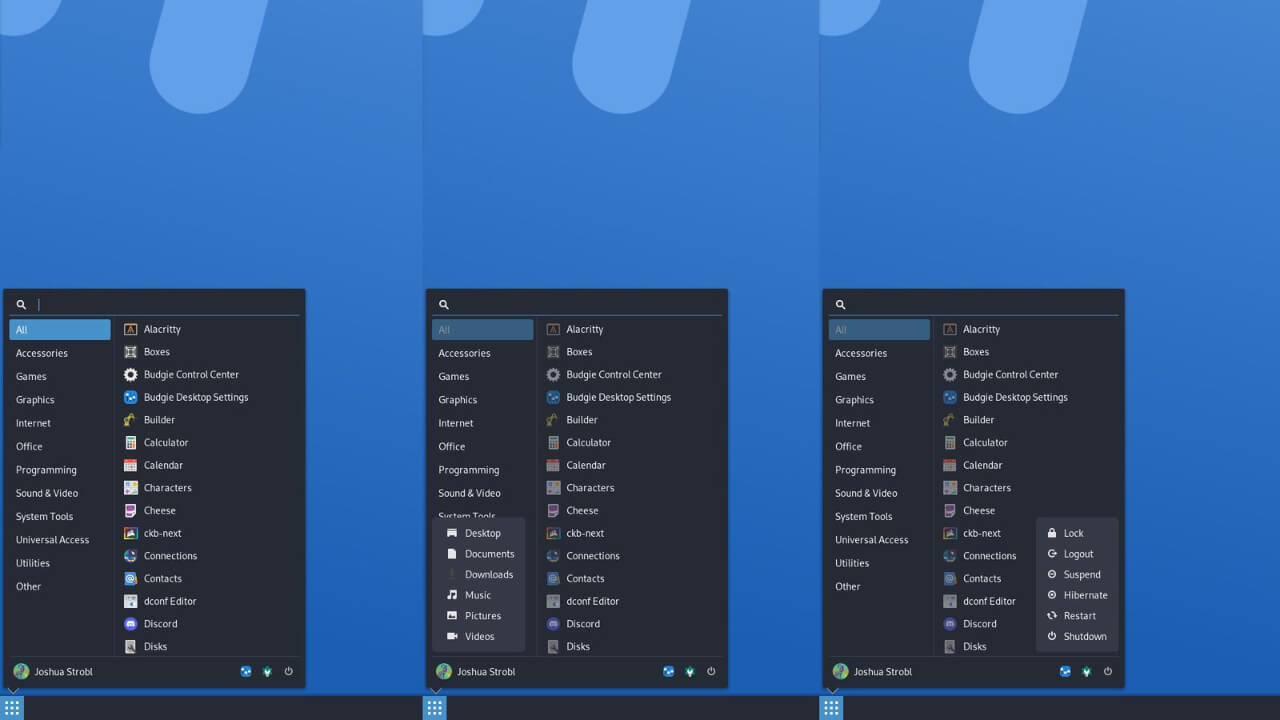
For this release, Budgie Menu is set to receive several improvements, such as:
- A new power menu with all the usual options, such as
**Suspend, Hibernate, Logout, and Power Off**. - Updated personal user menu with quick XDG directory access. This will let you open a file manager window directly into folders like Home, Documents, Music, etc.
- Quick access to Budgie Control Center and Desktop Settings.
- Ability to show various desktop settings from the menu itself.
### Budgie Screenshot Tool
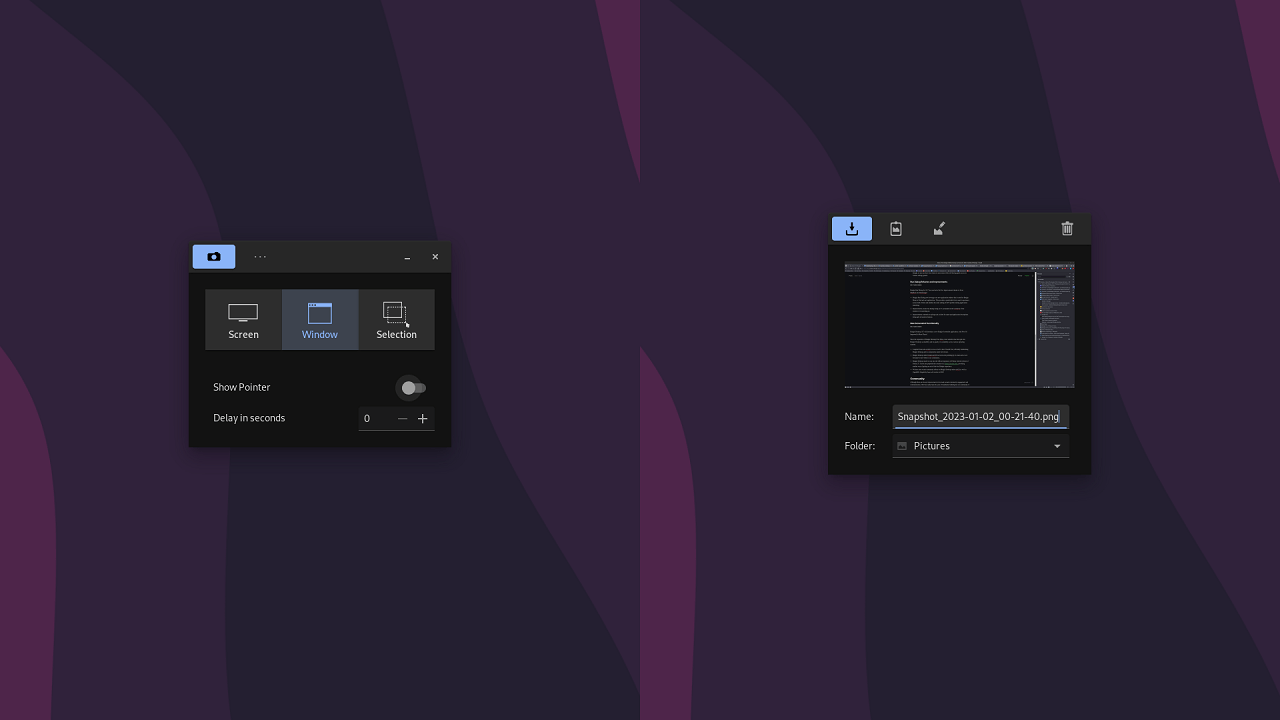
Finally, you won't need to download another tool to take a screenshot on Budgie; from 10.7 onwards, it will feature a native screenshot application.
It will have capture support for the screen, window, and even selection capture!
### Improvements to Budgie Run Dialog
The Budgie Run dialog will receive many improvements, such as:
- A new application indexer will be used for Budgie Menu to find and sort applications. It is supposed to provide a 'predictable fuzzy search experience'.
- Improved calculation of dialog sizing according to the work area of the monitor.
- Better styling of labels for application names and descriptions.
## Release & Future Plans
According to their [announcement](https://blog.buddiesofbudgie.org/state-of-the-budgie-2022/?ref=news.itsfoss.com), they intend to release Budgie 10.7 sometime in **Q1, 2023. **They haven't settled for a specific date yet.
A 10.7.1 release with bug fixes has been planned soon after, and the release of **Budgie 10.8** in Q2, 2023.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,426 | Home Assistant:谷歌助理、Alexa 和 Siri 的开源替代品 | https://news.itsfoss.com/open-source-assistant/ | 2023-01-09T14:06:25 | [
"语音助理"
] | https://linux.cn/article-15426-1.html |
>
> 一个开源助手可以取代谷歌助理、Alexa 和 Siri?
>
>
>

**Home Assistant** 是一个开源的智能家居平台,专注于为用户提供本地控制和隐私。它可以从树莓派或甚至本地服务器上运行。
他们还有一个订阅服务,可以获得额外的功能,如支持 Alexa 和谷歌助理,它由一家名为 “[Nabu Casa](https://www.nabucasa.com)” 的公司管理。
>
> ? 该公司由 Home Assistant 的创始人 [Paulus Schoutsen](https://twitter.com/balloob) 领导。
>
>
>
在上周的 [博客](https://www.home-assistant.io/blog/2022/12/20/year-of-voice/) 中,Paulus 宣布了**一个新的开源项目,旨在提供一个没有主动互联网连接的语音助手**,也无需任何其他大型科技公司的语音助手。
这是 *一个对谷歌助理、Alexa 和 Siri 的开源挑战者?* ?
让我们看看这到底是怎么回事。
**它是什么?** 这将是 Home Assistant 应用的一部分,将提供在本地运行语音命令的能力,以控制连接的智能设备。
Paulus 还断言,他们最重要的优先事项是支持不同的语言,他说:
>
> 人们需要能够用自己的语言说话,因为对于智能家居的语音助手来说,这是最容易接受和唯一可以接受的语言。
>
>
>
为了推动这一努力,Rhasspy 的创造者 [Mike Hansen](https://synesthesiam.com) 已经被拉来实现这一目标。
对于那些不知道的人来说,[Rhasspy](https://rhasspy.readthedocs.io) 是另一个开源软件,专门提供一个由其用户社区支持的完全离线的语音助手。
如果你问我,我觉得 Home Assistant 的这个功能将由 Rhasspy 提供,这是一件好事。
*为什么要重新发明已经存在的东西?最好是在它的基础上进行改进。*
**可以期待什么?** 最初,这个语音助手做不到做你可能期待的事情。因此,像进行网络搜索、打电话、玩语音游戏等,都是不可能的。
它所关注的反而是**语音助手应该有的基本功能**。这样做是为了确保他们面前的工作是可控的。
他们的目标是从几个动作开始,然后围绕它们建立语言模型。
在目前的状态下,Home Assistant 在其用户界面上支持 62 种不同的语言。他们计划用他们的语音助手增加对所有这些语言的支持。
**何时期待?** 他们已经开始了这方面的工作,为每种语言建立一个 [意图匹配句子集合](https://github.com/home-assistant/intents)。
这意味着社区可以通过将智能设备的命令改编成各自的母语,来为语音助手的发展做出贡献。
他们的目标是在 **2023** 年的某个时候发布,并提到这将是“*语音年*”。
我认为一个可以离线工作的开源语音助手可以是一个非常有用的东西。它可以让你不受大科技公司的任何追踪。
? *还有一个额外的好处是,它的开发背后有一个庞大的社区,有什么理由不喜欢呢?*
---
via: <https://news.itsfoss.com/open-source-assistant/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

**Home Assistant **is an open-source smart home platform that focuses on providing local control and privacy to its users. It can run off a Raspberry Pi or even a local server.
They also have a subscription service for access to additional features such as support for Alexa and Google Assistant, which is managed by a company called '[Nabu Casa](https://www.nabucasa.com/?ref=news.itsfoss.com)'.
[Paulus Schoutsen](https://twitter.com/balloob?ref=news.itsfoss.com), the founder of Home Assistant.
In a [blog](https://www.home-assistant.io/blog/2022/12/20/year-of-voice/?ref=news.itsfoss.com) last week, Paulus announced **a new open-source project that aims to offer a voice assistant without an active internet connection** or any other big tech voice assistants.
So, an *open-source challenger to Google, Alexa, and Siri? *😲
Let's see what this is all about, then.
**What is it?: **This will be a part of the Home Assistant application and will offer the ability to run voice commands locally to control the connected smart devices.
Paulus also asserts that their most important priority is to support different languages, he says:
People need to be able to speak in their own language, as that is the most accessible and only acceptable language for a voice assistant for the smart home.
To fuel this endeavor, the creator of Rhasspy, [Mike Hansen](https://synesthesiam.com/?ref=news.itsfoss.com), has been roped in to make this possible.
For those of you who don't know, [Rhasspy](https://rhasspy.readthedocs.io/?ref=news.itsfoss.com) is another open-source software that specializes in providing a fully offline voice assistant that is backed by its community of users.
If you ask me, I feel that this feature of Home Assistant will be powered by Rhasspy, which is a good thing.
*Why reinvent something that already exists? It's better to improve upon it.*
**What to expect?: **Initially, the voice assistant won't be able to do things you might expect. So, things like making a web search, making calls, playing voice games, etc., are a no-go.
What it will focus on instead are the **basics of what a voice assistant should be**; this was done to make sure that the work ahead of them was manageable.
They aim to start with a few actions and then build up language models around them.
In its current state, Home Assistant supports 62 different languages in its user interface. They plan to add support for all these languages with their voice assistant.
**When to expect?: **They have already started work on this by building a [collection of intent matching sentences](https://github.com/home-assistant/intents?ref=news.itsfoss.com) for every language.
What this means is that the community can contribute to the development of the voice assistant by adapting the commands for smart devices to their respective native languages.
They aim for a release sometime in **2023 **and have mentioned that it will be the '*year of voice*'.
I think an open-source voice assistant that works offline can be a very useful thing to have; it lets you be free of any tracking from big tech.
💬 *With the added benefit of having a large community behind its development of it, what's not to like?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,427 | 在 Linux 中创建定时器 | https://opensource.com/article/21/10/linux-timers | 2023-01-09T15:02:00 | [
"定时器"
] | https://linux.cn/article-15427-1.html |
>
> 这是一个演示如何创建 POSIX 兼容的间隔定时器的教程。
>
>
>

对开发人员来说,定时某些事件是一项常见任务。定时器的常见场景是看门狗、任务的循环执行,或在特定时间安排事件。在这篇文章中,我将演示如何使用 [timer\_create(...)](https://linux.die.net/man/2/timer_create) 创建一个 POSIX 兼容的间隔定时器。
你可以从 [GitHub](https://github.com/hANSIc99/posix_timers) 下载下面样例的源代码。
### 准备 Qt Creator
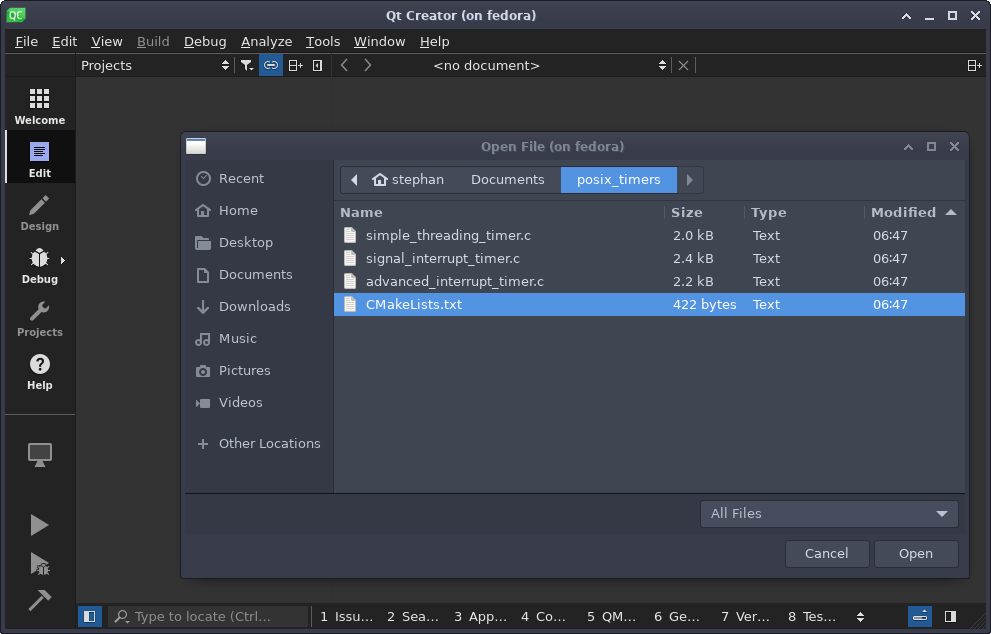
我使用 [Qt Creator](https://www.qt.io/product/development-tools) 作为该样例的 IDE。为了在 Qt Creator 运行和调试样例代码,请克隆 [GitHub](https://github.com/hANSIc99/posix_timers) 上的仓库,打开 Qt Creator,在 “<ruby> 文件 <rt> File </rt></ruby> -> <ruby> 打开文件或项目…… <rt> Open File or Project... </rt></ruby>” 并选择 “CMakeLists.txt”:

*在 Qt Creator 中打开项目*
选择工具链之后,点击 “<ruby> 配置项目 <rt> Configure Project </rt></ruby>”。这个项目包括三个独立的样例(我们在这篇文章中将只会用到其中的两个)。使用绿色标记出来的菜单,可以在每个样例的配置之间切换,并为每个样例激活在终端运行 “<ruby> 在终端中运行 <rt> Run in terminal </rt></ruby>”(用黄色标记)。当前用于构建和调试的活动示例可以通过左下角的“<ruby> 调试 <rt> Debug </rt></ruby>” 按钮进行选择(参见下面的橙色标记)。

*项目配置*
### 线程定时器
让我们看看 `simple_threading_timer.c` 样例。这是最简单的一个。它展示了一个调用了超时函数 `expired` 的间隔定时器是如何被创建的。在每次过期时,都会创建一个新的线程,在其中调用函数 `expired`:
```
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <signal.h>
#include <unistd.h>
#include <string.h>
#include <errno.h>
void expired(union sigval timer_data);
pid_t gettid(void);
struct t_eventData{
int myData;
};
int main()
{
int res = 0;
timer_t timerId = 0;
struct t_eventData eventData = { .myData = 0 };
/* sigevent 指定了过期时要执行的操作 */
struct sigevent sev = { 0 };
/* 指定启动延时时间和间隔时间
* it_value和it_interval 不能为零 */
struct itimerspec its = { .it_value.tv_sec = 1,
.it_value.tv_nsec = 0,
.it_interval.tv_sec = 1,
.it_interval.tv_nsec = 0
};
printf("Simple Threading Timer - thread-id: %d\n", gettid());
sev.sigev_notify = SIGEV_THREAD;
sev.sigev_notify_function = &expired;
sev.sigev_value.sival_ptr = &eventData;
/* 创建定时器 */
res = timer_create(CLOCK_REALTIME, &sev, &timerId);
if (res != 0){
fprintf(stderr, "Error timer_create: %s\n", strerror(errno));
exit(-1);
}
/* 启动定时器 */
res = timer_settime(timerId, 0, &its, NULL);
if (res != 0){
fprintf(stderr, "Error timer_settime: %s\n", strerror(errno));
exit(-1);
}
printf("Press ETNER Key to Exit\n");
while(getchar()!='\n'){}
return 0;
}
void expired(union sigval timer_data){
struct t_eventData *data = timer_data.sival_ptr;
printf("Timer fired %d - thread-id: %d\n", ++data->myData, gettid());
}
```
这种方法的优点是在代码和简单调试方面用量小。缺点是由于到期时创建新线程而增加额外的开销,因此行为不太确定。
### 中断信号定时器
超时定时器通知的另一种可能性是基于 [内核信号](https://man7.org/linux/man-pages/man3/signal.3p.html)。内核不是在每次定时器过期时创建一个新线程,而是向进程发送一个信号,进程被中断,并调用相应的信号处理程序。
由于接收信号时的默认操作是终止进程(参考 [signal](https://linux.die.net/man/7/signal) 手册页),我们必须要提前设置好 Qt Creator,以便进行正确的调试。
当被调试对象接收到一个信号时,Qt Creator 的默认行为是:
* 中断执行并切换到调试器上下文。
* 显示一个弹出窗口,通知用户接收到信号。
这两种操作都不需要,因为信号的接收是我们应用程序的一部分。
Qt Creator 在后台使用 GDB。为了防止 GDB 在进程接收到信号时停止执行,进入 “<ruby> 工具 <rp> ( </rp> <rt> Tools </rt> <rp> ) </rp></ruby> -> <ruby> 选项 <rt> Options </rt></ruby>” 菜单,选择 “<ruby> 调试器 <rt> Debugger </rt></ruby>”,并导航到 “<ruby> 本地变量和表达式 <rt> Locals & Expressions </rt></ruby>”。添加下面的表达式到 “<ruby> 定制调试助手 <rt> Debugging Helper Customization </rt></ruby>”:
```
handle SIG34 nostop pass
```

*Sig 34 时不停止*
你可以在 [GDB 文档](https://sourceware.org/gdb/onlinedocs/gdb/Signals.html) 中找到更多关于 GDB 信号处理的信息。
接下来,当我们在信号处理程序中停止时,我们要抑制每次接收到信号时通知我们的弹出窗口:

*Signal 34 弹出窗口*
为此,导航到 “GDB” 标签并取消勾选标记的复选框:

*定时器信号窗口*
现在你可以正确的调试 `signal_interrupt_timer`。真正的信号定时器的实施会更复杂一些:
```
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <signal.h>
#include <time.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#define UNUSED(x) (void)(x)
static void handler(int sig, siginfo_t *si, void *uc);
pid_t gettid(void);
struct t_eventData{
int myData;
};
int main()
{
int res = 0;
timer_t timerId = 0;
struct sigevent sev = { 0 };
struct t_eventData eventData = { .myData = 0 };
/* 指定收到信号时的操作 */
struct sigaction sa = { 0 };
/* 指定启动延时的时间和间隔时间 */
struct itimerspec its = { .it_value.tv_sec = 1,
.it_value.tv_nsec = 0,
.it_interval.tv_sec = 1,
.it_interval.tv_nsec = 0
};
printf("Signal Interrupt Timer - thread-id: %d\n", gettid());
sev.sigev_notify = SIGEV_SIGNAL; // Linux-specific
sev.sigev_signo = SIGRTMIN;
sev.sigev_value.sival_ptr = &eventData;
/* 创建定时器 */
res = timer_create(CLOCK_REALTIME, &sev, &timerId);
if ( res != 0){
fprintf(stderr, "Error timer_create: %s\n", strerror(errno));
exit(-1);
}
/* 指定信号和处理程序 */
sa.sa_flags = SA_SIGINFO;
sa.sa_sigaction = handler;
/* 初始化信号 */
sigemptyset(&sa.sa_mask);
printf("Establishing handler for signal %d\n", SIGRTMIN);
/* 注册信号处理程序 */
if (sigaction(SIGRTMIN, &sa, NULL) == -1){
fprintf(stderr, "Error sigaction: %s\n", strerror(errno));
exit(-1);
}
/* 启动定时器 */
res = timer_settime(timerId, 0, &its, NULL);
if ( res != 0){
fprintf(stderr, "Error timer_settime: %s\n", strerror(errno));
exit(-1);
}
printf("Press ENTER to Exit\n");
while(getchar()!='\n'){}
return 0;
}
static void
handler(int sig, siginfo_t *si, void *uc)
{
UNUSED(sig);
UNUSED(uc);
struct t_eventData *data = (struct t_eventData *) si->_sifields._rt.si_sigval.sival_ptr;
printf("Timer fired %d - thread-id: %d\n", ++data->myData, gettid());
}
```
与线程定时器相比,我们必须初始化信号并注册一个信号处理程序。这种方法性能更好,因为它不会导致创建额外的线程。因此,信号处理程序的执行也更加确定。缺点显然是正确调试需要额外的配置工作。
### 总结
本文中描述的两种方法都是接近内核的定时器的实现。不过,即使 [timer\_create(...)](https://linux.die.net/man/2/timer_create) 函数是 POSIX 规范的一部分,由于数据结构的细微差别,也不可能在 FreeBSD 系统上编译样例代码。除了这个缺点之外,这种实现还为通用计时应用程序提供了细粒度控制。
---
via: <https://opensource.com/article/21/10/linux-timers>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lujun9972](https://github.com/lujun9972) 译者:[FigaroCao](https://github.com/FigaroCao) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The timing of certain events is a common task for a developer. Common scenarios for timers are watchdogs, cyclic execution of tasks, or scheduling events for a specific time. In this article, I show how to create a POSIX-compliant interval timer using [timer_create(...)](https://linux.die.net/man/2/timer_create).
You can download the source code for the following examples from [GitHub](https://github.com/hANSIc99/posix_timers).
## Prepare Qt Creator
I used [Qt Creator](https://www.qt.io/product/development-tools) as the IDE for this example. To run and debug the example code in Qt Creator, clone the [GitHub](https://github.com/hANSIc99/posix_timers) repository, open Qt Creator, and go to **File -> Open File or Project...** and choose the **CMakeLists.txt**:
Open a project in Qt Creator (CC-BY-SA 4.0)
After selecting the toolchain, click on **Configure Project**. The project contains three independent examples (we will only cover two of them in this article). With the green-marked menu, switch between the configurations for each example and activate **Run in terminal **for each of them (see the yellow mark below). The currently active example for building and debugging can be selected over the **Debug** button on the bottom left corner (see the orange mark below):
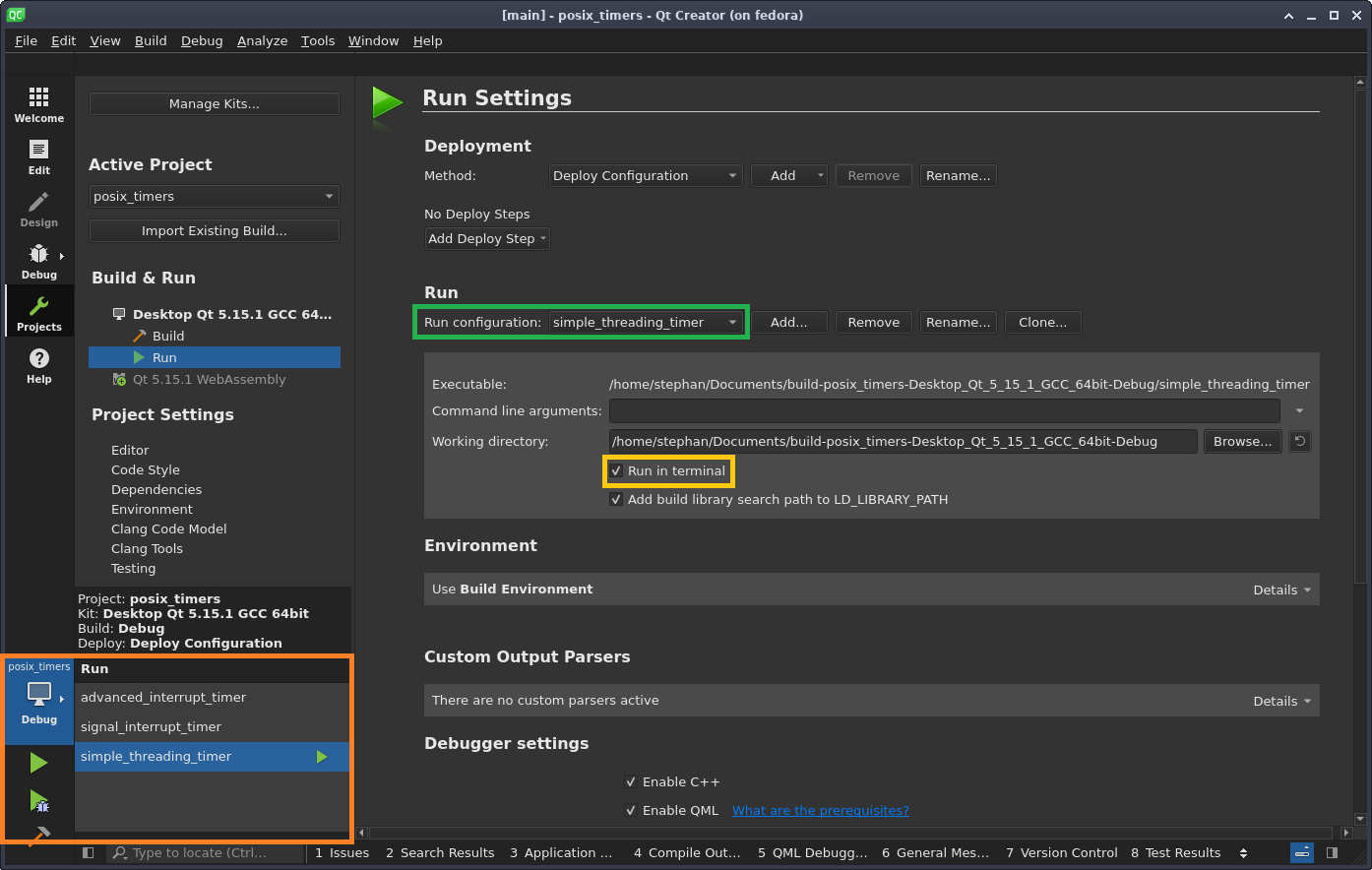
Project configuration (CC-BY-SA 4.0)
## Threading timer
Let's take a look at the *simple_threading_timer.c* example. This is the simplest one: It shows how an interval timer is created, which calls the function **expired** on expiration. On each expiration, a new thread is created in which the function **expiration** is called.
```
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <signal.h>
#include <unistd.h>
#include <string.h>
#include <errno.h>
void expired(union sigval timer_data);
pid_t gettid(void);
struct t_eventData{
int myData;
};
int main()
{
int res = 0;
timer_t timerId = 0;
struct t_eventData eventData = { .myData = 0 };
/* sigevent specifies behaviour on expiration */
struct sigevent sev = { 0 };
/* specify start delay and interval
* it_value and it_interval must not be zero */
struct itimerspec its = { .it_value.tv_sec = 1,
.it_value.tv_nsec = 0,
.it_interval.tv_sec = 1,
.it_interval.tv_nsec = 0
};
printf("Simple Threading Timer - thread-id: %d\n", gettid());
sev.sigev_notify = SIGEV_THREAD;
sev.sigev_notify_function = &expired;
sev.sigev_value.sival_ptr = &eventData;
/* create timer */
res = timer_create(CLOCK_REALTIME, &sev, &timerId);
if (res != 0){
fprintf(stderr, "Error timer_create: %s\n", strerror(errno));
exit(-1);
}
/* start timer */
res = timer_settime(timerId, 0, &its, NULL);
if (res != 0){
fprintf(stderr, "Error timer_settime: %s\n", strerror(errno));
exit(-1);
}
printf("Press ETNER Key to Exit\n");
while(getchar()!='\n'){}
return 0;
}
void expired(union sigval timer_data){
struct t_eventData *data = timer_data.sival_ptr;
printf("Timer fired %d - thread-id: %d\n", ++data->myData, gettid());
}
```
The advantage of this approach is its small footprint, in terms of code and simple debugging. The disadvantage is the additional overhead due to the creation of a new thread on expiration and, consequently, the less deterministic behavior.
## Interrupt Signal Timer
Another possibility to be notified by an expired timer is based on a [kernel signal](https://man7.org/linux/man-pages/man3/signal.3p.html). Instead of creating a new thread each time the timer expires, the kernel sends a signal to the process, the process is interrupted, and the corresponding signal handler is called.
As the default action when receiving a signal is to terminate the process (see [signal](https://linux.die.net/man/7/signal) man page), we have to prepare Qt Creator in advance so that properly debugging is possible.
The default behavior of Qt Creator when the debuggee receives a signal is:
- Interrupt execution and switch to the debugger context.
- Display a pop-up window that notifies the user about the reception of a signal.
Both actions are not wanted as the reception of a signal is part of our application.
Qt Creator uses GDB in the background. In order to prevent GDB from stopping the execution when the process receives a signal, go to **Tools** -> **Options**, select **Debugger**, and navigate to **Locals & Expressions**. Add the following expression to *Debugging Helper Customization*:
`handle SIG34 nostop pass`
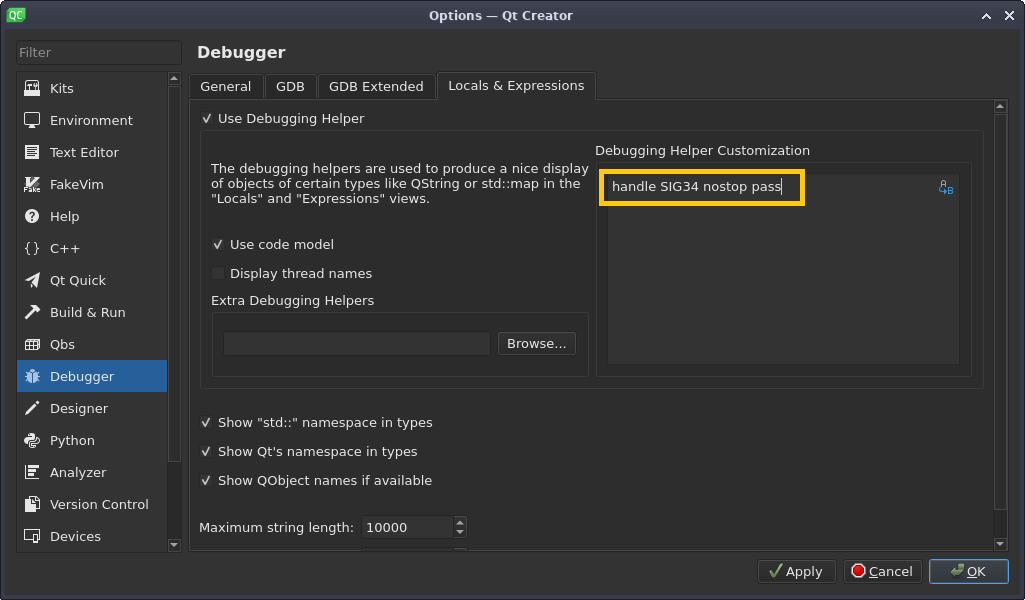
Sig 34 no stop with error (CC-BY-SA 4.0)
You can find more information about GDB signal handling in the [GDB documentation](https://sourceware.org/gdb/onlinedocs/gdb/Signals.html).
Next, we want to suppress the pop-up window that notifies us every time a signal is received when we stop in the signal handler:
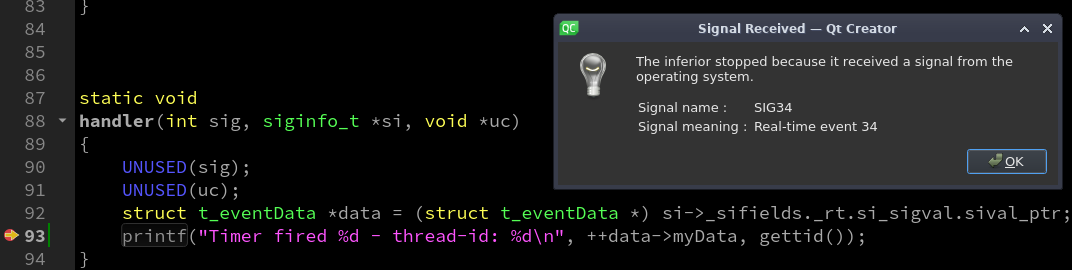
Signal 34 pop-up box (CC-BY-SA 4.0)
To do so, navigate to the tab **GDB** and uncheck the marked checkbox:
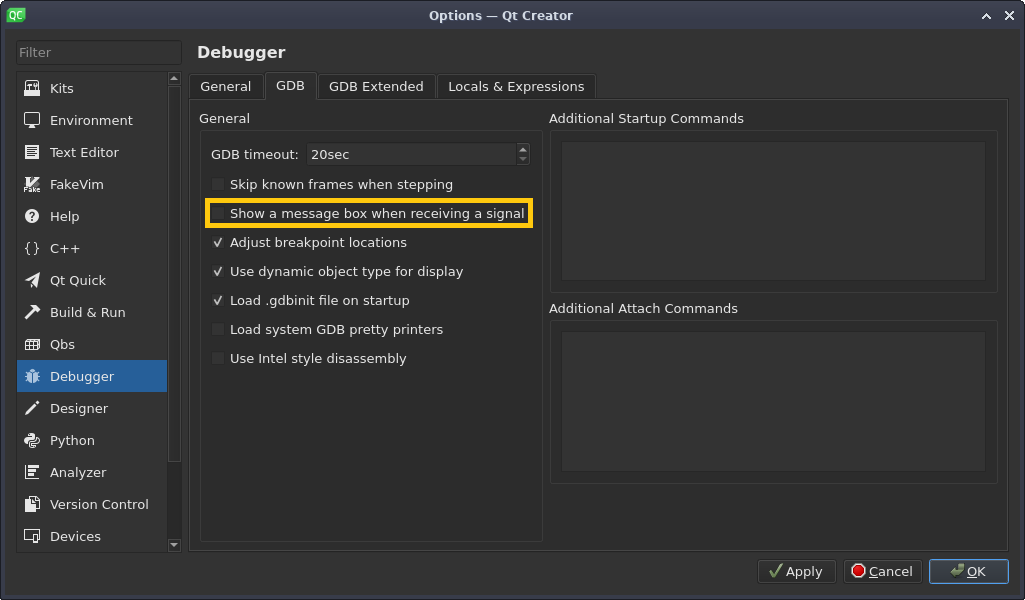
Timer signal windows (CC-BY-SA 4.0)
Now you can properly debug the *signal_interrupt_timer*. The actual implementation of the signal timer is a bit more complex:
```
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <signal.h>
#include <time.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#define UNUSED(x) (void)(x)
static void handler(int sig, siginfo_t *si, void *uc);
pid_t gettid(void);
struct t_eventData{
int myData;
};
int main()
{
int res = 0;
timer_t timerId = 0;
struct sigevent sev = { 0 };
struct t_eventData eventData = { .myData = 0 };
/* specifies the action when receiving a signal */
struct sigaction sa = { 0 };
/* specify start delay and interval */
struct itimerspec its = { .it_value.tv_sec = 1,
.it_value.tv_nsec = 0,
.it_interval.tv_sec = 1,
.it_interval.tv_nsec = 0
};
printf("Signal Interrupt Timer - thread-id: %d\n", gettid());
sev.sigev_notify = SIGEV_SIGNAL; // Linux-specific
sev.sigev_signo = SIGRTMIN;
sev.sigev_value.sival_ptr = &eventData;
/* create timer */
res = timer_create(CLOCK_REALTIME, &sev, &timerId);
if ( res != 0){
fprintf(stderr, "Error timer_create: %s\n", strerror(errno));
exit(-1);
}
/* specifz signal and handler */
sa.sa_flags = SA_SIGINFO;
sa.sa_sigaction = handler;
/* Initialize signal */
sigemptyset(&sa.sa_mask);
printf("Establishing handler for signal %d\n", SIGRTMIN);
/* Register signal handler */
if (sigaction(SIGRTMIN, &sa, NULL) == -1){
fprintf(stderr, "Error sigaction: %s\n", strerror(errno));
exit(-1);
}
/* start timer */
res = timer_settime(timerId, 0, &its, NULL);
if ( res != 0){
fprintf(stderr, "Error timer_settime: %s\n", strerror(errno));
exit(-1);
}
printf("Press ENTER to Exit\n");
while(getchar()!='\n'){}
return 0;
}
static void
handler(int sig, siginfo_t *si, void *uc)
{
UNUSED(sig);
UNUSED(uc);
struct t_eventData *data = (struct t_eventData *) si->_sifields._rt.si_sigval.sival_ptr;
printf("Timer fired %d - thread-id: %d\n", ++data->myData, gettid());
}
```
In contrast to the threading timer, we have to initialize the signal and register a signal handler. This approach is more performant as it won't cause the creation of additional threads. For this reason, the execution of the signal handler is also more deterministic. The drawback is clearly the extra configuration effort to debug this properly.
## Summary
Both methods described in this article are close-to-the-kernel implementations of timers. Even if the [timer_create(...)](https://linux.die.net/man/2/timer_create) function is part of the POSIX specification, it is not possible to compile the sample code on a FreeBSD system due to small differences in data structures. Besides this drawback, such an implementation gives you fine-grained control for general-purpose timing applications.
## Comments are closed. |
15,430 | who 命令的解释与示例 | https://www.debugpoint.com/who-command-linux/ | 2023-01-10T13:02:00 | [
"who"
] | /article-15430-1.html | 
>
> 这里是一个关于理解 Linux 中 who 命令的初学者指南,并带有几个例子。
>
>
>
这篇文章是 [Linux 命令](https://www.debugpoint.com/category/linux-commands)学习系列的一部分。
### who 命令
Linux 中的 `who` 命令用于显示当前登录到系统中的用户的信息。它显示用户的登录名,用户登录的终端,用户登录的时间,以及远程主机名(如果有)。
#### 语法
下面是 `who` 命令的基本语法:
```
who [OPTION]... [ FILE | ARG1 ARG2 ]
```
### 各种 who 命令和开关的例子
默认情况下,`who` 读取文件 `/var/run/utmp`,其中包含当前登录的用户的信息。如果没有指定选项,它会显示每个用户的登录名、终端和登录时间。
```
who
```
它给出了以下输出。你可以看到它显示了登录名是 `debugpoint`,终端 ID `tty2` 和登录的日期和时间。
```
debugpoint tty2 2023-01-01 11:22 (tty2)
```

然而,如果你在虚拟机中运行上述命令,你应该看到同样的情况,但终端 ID 将是 x11 服务器的显示名称,即 `:0`。
```
❯ who
debugpoint :0 2023-01-01 23:36 (:0)
```
要显示当前用户的用户名和信息,使用下面的方法:
```
whoami
```
使用 `-b` 选项查看最后一次系统启动时间:
```
❯ who -b
system boot 2023-01-01 23:36
```
显示当前系统中登录的用户数:
```
❯ who -q
debugpoint
users=1
```
所有上述命令与 `-H` 选项配对时,你会有一个更好的含标题行的信息,如下所示:
```
who -H
NAME LINE TIME COMMENT
debugpoint tty2 2023-01-01 11:22 (tty2)
```
如果你想在 Linux 中显示与 `who` 命令有关的所有信息,请使用选项 `-a`:
```
who -aH
NAME LINE TIME IDLE PID COMMENT EXIT
system boot 2023-01-01 11:19
run-level 5 2023-01-01 11:19
debugpoint + tty2 2023-01-01 11:22 13:26 2042 (tty2)
```
像往常一样,你可以使用下面的重定向将 `who` 命令的输出保存到任何文件:
```
who > user_details.txt
```
#### who 命令选项的例子总结
下面是一些 `who` 命令的例子和它们的解释:
下面是一些可以与 `who` 命令一起使用的选项:
* `-a`: 显示每个用户的主机名、登录时间和进程
* `-b`: 显示上次系统启动的时间
* `-d`: 显示死进程(已终止但未从 utmp 文件中删除的进程)
* `-H`: 显示标题行
* `-l`: 显示长格式的登录进程
* `-m`: 只显示在 `ARG1 ARG2` 指定的终端上登录的用户的名字和行。
* `-q`: 显示已登录用户的数量
* `-u`: 显示拥有未脱离进程的用户的信息
* `-w`: 显示已经登录的用户信息,格式与 utmp 文件相同
### 总结
我希望这篇文章能够帮助你了解 `who` 命令及其基本原理。你也可以阅读 [who 手册页](https://man7.org/linux/man-pages/man1/who.1.html)来了解更多。如果你有任何问题,请告诉我。
---
via: <https://www.debugpoint.com/who-command-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,432 | Oh My Zsh 和 Powerlevel10k:天作之合 | https://www.debugpoint.com/oh-my-zsh-powerlevel10k/ | 2023-01-10T17:28:00 | [
"Oh My Zsh",
"Zsh"
] | /article-15432-1.html |
>
> 这是一篇快速而简单的指南,用 Oh My Zsh 和 Powerlevel10k 主题改造你的 Zsh 终端 Shell,使其在 Ubuntu 和其他 Linux 发行版中看起来很酷。
>
>
>

大多数 Linux 发行版中的默认 Shell 是 Bash。Bash 是一个可靠的和传统的工具。然而,它缺乏一些自定义功能,比如漂亮的颜色、光标支持等等。
你可以使用另一个 Shell,即 Zsh 来得到更多的设置调整,并帮助你扩展你的 Bash Shell 体验。
这个简单的指南解释了如何安装 Zsh、Oh My Zsh 并应用 Powerlevel10k 主题。
### Oh My Zsh 和 Powerlevel10k 安装和配置指南
#### 1、安装 Zsh 和改变 Shell
打开一个终端,使用以下适用于你的发行版的命令安装 Zsh。
Ubuntu、Debian、Linux Mint 和所有相关的发行版:
```
sudo apt install zsh
```
Fedora:
```
sudo dnf install zsh
```
Arch:
```
pacman -S zsh
```
安装完成后,找出 Zsh 的安装路径:
```
whereis zsh
```
然后使用当前用户的 Zsh 可执行路径改变 Shell。
```
chsh -s /usr/bin/zsh <用户名 >
```

关闭并再次打开终端。然后你应该看到 Zsh 的首次设置。选择选项 2。它将用一个默认的主题改变你的 Shell 提示符的外观,如下图所示:

#### 2、安装 Oh My Zsh
Oh My Zsh 是一套可以进一步定制 Zsh 的脚本。
首先,我们将从 GitHub 上下载 Oh My Zsh 脚本来安装它。如果你有 `wget` 和 `git` 软件包,那就最好了。如果还没有安装,请使用以下命令 [安装 wget](https://www.debugpoint.com/wget-not-found-error/) & git:
```
sudo apt install wget
sudo apt install git
```
然后用下面的命令安装 Oh My Zsh:
```
sh -c "$(wget -O- https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
```
然后你应该看到 Oh My Zsh 及默认主题 Robbyrussell 应用到了你的终端。

Oh My Zsh 还附带了其他的主题,你可以 [使用这篇指南](https://www.debugpoint.com/install-use-zsh/) 安装它们。然而,在本教程中,我将谈论一个特定的主题,即 Powerlevel10k。
#### 3、为 Oh My Zsh 安装 Powerlevel10k 主题
打开终端,运行以下命令,从 GitHub 上克隆 Powerlevel10k 代码库,并将文件放到 Oh My Zsh 的配置文件夹中。
```
git clone https://github.com/romkatv/powerlevel10k.git $ZSH_CUSTOM/themes/powerlevel10k
```
用文本编辑器打开 `~/.zshrc` 文件,将 `ZSH_THEME` 变量设为 `"powerlevel10k/powerlevel10k"`。
```
cd ~
```
```
nano .zshrc
```
默认情况下,它应该是 Robbyrussell。删除 `”robbyrussell"`,添加下面的 `"powerlevel10k/powerlevel10k"`。
更改后,你的 `~/.zshrc` 文件应该是这样的:
```
ZSH_THEME="powerlevel10k/powerlevel10k”
```
保存并关闭该文件(`CTRL+O`、回车和 `CTRL+X`)。

重新启动你的终端,启动首次向导来设置 Powerlevel10k 主题。
#### 4、Powerleve10k 的首次设置
安装后启动终端时,Powerlevel10k 会提示你各种问题以了解你的 Linux 发行版设置。所以,根据你的需要按下键,按照你的口味来定制你的终端。下面是一些问题的例子截图,可以给你一些启发。


最后,你可以保存文件,享受你的终端的新面貌。

如果你想再次重启配置向导,运行以下程序。你可以随心所欲地做,次数不限。
```
p10k configure
```
基本设置就这样结束了。如果你想了解更多,请继续阅读。
### 更多配置(高级用法)
#### 5、安装 Dracula GNOME 终端主题
如果你使用的是带有原生终端应用的 GNOME 桌面,你可以试试令人惊叹的 Drakula 主题。要做到这一点,打开一个终端,运行下面的命令来下载该主题:
```
git clone https://github.com/dracula/gnome-terminalcd gnome-terminal
```
打开 GNOME “终端”应用,进入偏好设置。通过点击 “+” 添加一个新的配置文件,并命名为 “drakula”。然后进入颜色标签,取消勾选 “<ruby> 使用系统主题的颜色 <rt> use colors from system theme </rt></ruby>” 选项。

回到终端,运行以下程序。当出现提示时,选择你刚才创建的配置文件名称,如上所述。
```
./install.sh
```

一旦安装完成,回到偏好设置中,将 Drakula 配置文件标记为默认。
#### 6、Zsh 的自动补完和语法高亮
你可能想试试由社区开发的两个可用于 Zsh 的插件。它们是 zsh-autosuggestions 和 zsh-syntax-highlighting。
打开终端,运行以下程序,下载 zsh-autosuggestions,并将其放在插件文件夹中:
```
git clone https://github.com/zsh-users/zsh-autosuggestions.git $ZSH_CUSTOM/plugins/zsh-autosuggestions
```
同样地,为语法高亮插件运行以下程序:
```
git clone https://github.com/zsh-users/zsh-syntax-highlighting.git $ZSH_CUSTOM/plugins/zsh-syntax-highlighting
```
通过文本编辑器打开 `~/.zshrc`文件(使用以下命令),并找到 `plugins=(git)` 一行。并将其替换为以下内容:
```
nano ~/.zshrc
```
```
plugins=(git zsh-autosuggestions zsh-syntax-highlighting)
```
使用 `CTRL+O`、回车和 `CTRL+X` 保存并关闭该文件。
关闭并打开你的终端。现在,你应该可以使用自动建议和语法高亮了。
### 总结
这样就好了!你现在应该已经在你的系统上安装了 Oh My Zsh 和 Powerlevel10k 主题。你可以根据自己的需要,进一步定制 Powerlevel10k 主题的外观和行为。
干杯。
---
via: <https://www.debugpoint.com/oh-my-zsh-powerlevel10k/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,433 | 酷冷至尊(CoolerMaster)的 MasterPlus 软件即将开源 | https://news.itsfoss.com/coolermaster-open-source-software/ | 2023-01-11T10:54:14 | [
"MasterPlus",
"散热器"
] | https://linux.cn/article-15433-1.html |
>
> MasterPlus 将被彻底改造并推出开源版本?听起来不错!
>
>
>

大多数游戏/外设软件套装要么是专有的,要么是没有对 Linux 的官方支持。
因此,我们必须不断寻找开源工具来配置我们的硬件以获得原生功能。
像 [Piper](https://github.com/libratbag/piper)、[OpenRGB](https://openrgb.org)、[Solaar](https://github.com/pwr-Solaar/Solaar) 等在这些情况下都很有用。
但是,有时候,即使是这些也是不够的。
幸运的是,[酷冷至尊(CoolerMaster)](https://www.coolermaster.com) 已经决定发布其 [MasterPlus](https://masterplus.coolermaster.com) 软件的开源版本,旨在为其散热器和第三方的散热器提供服务。
**虽然这并不能保证它可以用在 Linux 系统上,但我们绝对可以期待它。**
此举也应该鼓励雷蛇和罗技这样公司考虑制作精简过的开源工具。
让我们看看酷冷至尊打算怎么做。
### MasterPlus 开源版本:我们目前所知的情况

**酷冷至尊在最近的 [CES 2023](https://www.ces.tech) 活动中透露了他们计划发布新的 MasterPlus 开源版本**。感谢来自 [Boring Text Reviews](https://boringtextreviews.com/exclusive-say-goodbye-to-bloated-closed-source-software-coolermaster-to-release-new-open-source-version-of-its-software-with-api-integration-and-it-can-work-with-other-coolers-too) 的 Albert 让我们注意到了这一点。
**预期会有什么?** 对 MasterPlus 软件进行了全面的重新设计,有一个 API 插件系统,允许非酷冷至尊散热器与之整合。
他们已经澄清,酷冷至尊的独有功能不能配合其他散热器一起工作。因此,诸如检测 AIO 散热器的泄漏或计算 PSU 的效率等,都不能对第三方产品进行跟踪。
相反,该应用程序将只支持读取基本的性能信息,如温度和风扇速度,并能够配置 ARGB 设备。
如果你问我,**这总比没有好。** 而且,如果你的系统碰巧使用了酷冷至尊的组件,这对你来说是一个令人兴奋的消息!
酷冷至尊还展示了 API 系统的潜在应用,让它与一个照片应用程序挂钩,用它来控制集成在电脑机箱侧面的辅助显示器。
此外,他们还介绍了其软件的全面云整合。但遗憾的是,这部分不会开源。
**什么时候?** 我们还没有 MasterPlus 开源的具体发布日期。
但是,如果让我猜,2023 年的某个时候是最好的选择。
? *即使该工具没有被确认可以在 Linux 上工作,对开源工具来说也是一个好的开始,不是吗?你怎么看?*
---
via: <https://news.itsfoss.com/coolermaster-open-source-software/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Most gaming/peripheral software suits are either proprietary or not officially available for Linux.
As a result, we must constantly look for open-source tools to configure our hardware to get native functionality.
The likes of [Piper](https://github.com/libratbag/piper?ref=news.itsfoss.com), [OpenRGB](https://openrgb.org/?ref=news.itsfoss.com), [Solaar](https://github.com/pwr-Solaar/Solaar?ref=news.itsfoss.com), etc. come in handy in these situations.
But, sometimes, even these are not enough.
Luckily, [CoolerMaster](https://www.coolermaster.com/?ref=news.itsfoss.com) has decided to release an open-source version of its [MasterPlus](https://masterplus.coolermaster.com/?ref=news.itsfoss.com) software that aims to work with its coolers and non-CoolerMaster coolers.
**While this does not guarantee its availability for Linux systems, we can definitely hope for it.**
This move should also encourage other companies like Razer and Logitech to consider making open-source tools that do away with bloat found in them.
Let's see what CoolerMaster plans to do.
## MasterPlus Open-Source Version: What We Know So Far
**CoolerMaster revealed their plans to release a new MasterPlus open-source version **in the recent [CES 2023](https://www.ces.tech/?ref=news.itsfoss.com) event. Kudos to **Albert** from [Boring Text Reviews](https://boringtextreviews.com/exclusive-say-goodbye-to-bloated-closed-source-software-coolermaster-to-release-new-open-source-version-of-its-software-with-api-integration-and-it-can-work-with-other-coolers-too?ref=news.itsfoss.com) for bringing this to our attention.
**What to expect?: **A complete redesign of the MasterPlus software, with an API plug-in system that allows non-CoolerMaster coolers to integrate with it.
They have clarified that exclusive CoolerMaster features won't work with other coolers. So, things such as detecting a leak in an AIO cooler or calculating the PSU's efficiency can't be tracked for third-party products.
Instead, the application will only support reading basic performance info such as temperature and fan speed with the ability to configure ARGB devices.
If you ask me, **this is better than nothing. **And, if you happen to use CoolerMaster components for your system, it is an exciting news for you!
CoolerMaster also showcased a potential application of the API system by letting it hook into a photo application and using it to control a secondary display integrated into a computer case's side.
Furthermore, they also introduced full cloud integration for their software. But sadly, this will not be made open-source.
**When to expect?: **
We do not have a concrete release date for the open sourcing of MasterPlus.
But, if I were to guess, sometime in 2023 would be the best bet.
💬 *Even if the tool is not confirmed to work for Linux users, on open-source tool is a good start, isn't it? What do you think?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,434 | MySQL 字符串指南 | https://opensource.com/article/23/1/strings-mysql | 2023-01-11T16:14:12 | [
"MySQL",
"字符串"
] | https://linux.cn/article-15434-1.html | 
>
> 了解 MySQL 如何存储和显示你的字符串变量,以便你能更好地控制你的数据。
>
>
>
字符串是你在 MySQL 中使用的最常见的数据类型之一。许多用户在他们的数据库中插入和读取字符串,而没有认真地了解过它们。本文旨在让你深入了解 MySQL 如何存储和显示你的字符串变量,以便你能更好地控制你的数据。
你可以把字符串分成两类:二进制和非二进制。你可能在大多数时候想到的是非二进制字符串。非二进制字符串有字符集和排序的不同。另一方面,二进制字符串存储诸如 MP3 文件或图像等东西。即使你在二进制字符串中存储了一个词,比如“歌曲”,它的存储方式也与非二进制字符串不同。
我将重点讨论非二进制字符串。MySQL 中的所有非二进制字符串都与字符集和排序相关。字符串的字符集控制哪些字符可以存储在字符串中,而它的排序方式控制当你显示字符串时如何排序。
### 字符集
要查看你系统中的字符集,请运行以下命令:
```
SHOW CHARACTER SET;
```
这个命令将输出四列数据,包括字符集:
* 名称
* 简要描述
* 默认的排序方式
* 字符集中每个字符的最大尺寸
MySQL 过去默认为 `latin1` 字符集,但自 8.0 版以来,默认为 `utf8mb4`。现在的默认排序方式是 `utf8mb4_0900_ai_ci`。`ai` 表示该排序对音调不敏感( `á` = `a`),而 `ci` 则指定它对大小写不敏感(`a` = `A`)。
不同的字符集将其字符存储在内存中不同大小的块中。例如,从上面的命令可以看出,存储在 `utf8mb4` 的字符被存储在 1 到 4 个字节大小的内存中。如果你想看看一个字符串是否包含多字节的字符,你可以使用 `CHAR_LENGTH()` 和 `LENGTH()` 函数。`CHAR_LENGTH()` 显示一个字符串包含多少个字符,而 `LENGTH()` 显示一个字符串有多少个字节,根据字符集的不同,它可能与一个字符串的字符长度相同,也可能不相同。下面是一个例子:
```
SET @a = CONVERT('data' USING latin1);
SELECT LENGTH(@a), CHAR_LENGTH(@a);
+------------+-----------------+
| LENGTH(@a) | CHAR_LENGTH(@a) |
+------------+-----------------+
| 4 | 4 |
+------------+-----------------+
```
这个例子表明,`latin1` 字符集以单字节为单位存储字符。其他字符集,如 `utf16`,允许多字节的字符:
```
SET @b = CONVERT('data' USING utf16);
SELECT LENGTH(@b), CHAR_LENGTH(@b);
+------------+------------------+
| LENGTH(@b) | CHAR_LENGTH(@b) |
+------------+------------------+
| 8 | 4 |
+------------+------------------+
```
### 排序
当你运行带有 `ORDER BY` 子句的 SQL 语句时,字符串排序方式将决定值的显示方式。你对排序方式的选择是由你选择的字符集决定的。当你运行上面的 `SHOW CHARACTER SET` 命令时,你看到了每个字符集的默认排序方式。你可以很容易地看到某个特定字符集的所有排序方式。例如,如果你想查看 `utf8mb4` 字符集允许哪些排序,请运行:
```
SHOW COLLATION LIKE 'utf8mb4%';
```
排序方式可以是不区分大小写的,也可以是区分大小写的,或者是二进制的。让我们建立一个简单的表,向其中插入一些值,然后用不同的排序方式查看数据,看看输出结果有什么不同:
```
CREATE TABLE sample (s CHAR(5));
INSERT INTO sample (s) VALUES
('AAAAA'), ('ccccc'), ('bbbbb'), ('BBBBB'), ('aaaaa'), ('CCCCC');
SELECT * FROM sample;
+-----------+
| s |
+-----------+
| AAAAA |
| ccccc |
| bbbbb |
| BBBBB |
| aaaaa |
| CCCCC |
+-----------+
```
在不区分大小写的情况下,你的数据会按字母顺序返回,但不能保证大写的单词会排在小写的单词之前,如下图所示:
```
SELECT * FROM sample ORDER BY s COLLATE utf8mb4_turkish_ci;
+-----------+
| s |
+-----------+
| AAAAA |
| aaaaa |
| bbbbb |
| BBBBB |
| ccccc |
| CCCCC |
+-----------+
```
另一方面,当 MySQL 运行大小写敏感的搜索时,每个字母的小写将排在大写之前:
```
SELECT * FROM sample ORDER BY s COLLATE utf8mb4_0900_as_cs;
+-----------+
| s |
+-----------+
| aaaaa |
| AAAAA |
| bbbbb |
| BBBBB |
| ccccc |
| CCCCC |
+-----------+
```
而按二进制排序方式将返回所有大写的值,然后再返回小写的值:
```
SELECT * FROM sample ORDER BY s COLLATE utf8mb4_0900_bin;
+-----------+
| s |
+-----------+
| AAAAA |
| ccccc |
| bbbbb |
| BBBBB |
| aaaaa |
| CCCCC |
+-----------+
```
如果你想知道一个字符串使用哪种字符集和排序,你可以使用被恰当命名的 `charset` 和 `collation` 函数。运行 MySQL 8.0 或更高版本的服务器将默认使用 `utf8mb4` 字符集和 `utf8mb4_0900_ai_ci` 排序:
```
SELECT charset('data');
+-------------------+
| charset('data') |
+-------------------+
| utf8mb4 |
+-------------------+
SELECT collation('data');
+--------------------+
| collation('data') |
+--------------------+
| utf8mb4_0900_ai_ci |
+--------------------+
```
你可以使用 `SET NAMES` 命令来改变所使用的字符集或排序方式。
要从 `utf8mb4` 字符集改为 `utf16`,运行这个命令:
```
SET NAMES 'utf16';
```
如果你想选择默认以外的排序方式,你可以在 `SET NAMES` 命令中添加一个 `COLLATE` 子句。
例如,假设你的数据库存储西班牙语的单词。MySQL 的默认排序(`utf8mb4_0900_ai_ci`)将 `ch` 和 `ll` 视为两个不同的字符,并将它们排序。但在西班牙语中,`ch` 和 `ll` 是单独的字母,所以如果你想让它们按正确的顺序排序(分别排在 `c` 和 `l` 之后),你需要使用不同的排序。一个选择是使用 `utf8mb4_spanish2_ci` 排序方式:
```
SET NAMES 'utf8mb4' COLLATE 'utf8mb4_spanish2_ci';
```
### 储存字符串
MySQL 允许你为你的字符串值选择不同的数据类型。(甚至比其他流行的数据库,如 PostgreSQL 和 MongoDB 更多。)
下面是 MySQL 的二进制字符串数据类型的列表、它们的非二进制对应物,以及它们的最大长度:
* `binary`:`char`(255)
* `varbinary`:`varchar`(65,535)
* `tinyblob`:`tinytext`(255)
* `blob`:`text`(65,535)
* `mediumblob`:`mediumtext`(16,777,215)
* `longblob`:`longtext`(4,294,967,295)
要记住的一件重要事情是,与被存储在可变长度的字段中的 `varbinary`、`varchar`、`text` 和 `blob` 类型不同(也就是说,只使用需要的空间),MySQL 将二进制(`binary`)和字符(`char`)类型存储在固定长度的字段。因此,像 `char(20)` 或 `binary(20)` 这样的值将总是占用 20 个字节,即使你在其中存储了少于 20 个字符。对于二进制类型,MySQL用 ASCII NUL 值(`0x00`)填充这些值,对于 字符类型,用空格填充。
在选择数据类型时要考虑的另一件事是,你是否希望在字符串后面的空格被保留或剥离。在显示数据时,MySQL 会从以字符数据类型存储的数据中剥离空格,但不会剥离 `varchar` 的空格。
```
CREATE TABLE sample2 (s1 CHAR(10), s2 VARCHAR(10));
INSERT INTO sample2 (s1, s2) VALUES ('cat ', 'cat ');
SELECT s1, s2, CHAR_LENGTH(s1), CHAR_LENGTH(s2) FROM sample2;
+---------+---------+-----------------------------------+
| s1 | s2 | CHAR_LENGTH(s1) | CHAR_LENGTH(s2) |
+---------+---------+-----------------------------------+
| cat | cat | 3 | 10 |
+---------+---------+-----------------------------------+
```
### 总结
字符串是数据库中最常用的数据类型之一,而 MySQL 仍然是当今最流行的数据库系统之一。我希望你能从这篇文章中学到一些新的东西,并能用你的新知识来提高你的数据库技能。
---
via: <https://opensource.com/article/23/1/strings-mysql>
作者:[Hunter Coleman](https://opensource.com/users/hunterc) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Strings are one of the most common data types you will use in MySQL. Many users insert and read strings in their databases without thinking too much about them. This article aims to give you a bit of a deep dive into how MySQL stores and displays your string variables so that you can have better control over your data.
You can break strings into two categories: binary and nonbinary. You probably think about nonbinary strings most of the time. Nonbinary strings have character sets and collations. Binary strings, on the other hand, store things such as MP3 files or images. Even if you store a word in a binary string, such as **song**, it is not stored in the same way as in a nonbinary string.
I will focus on nonbinary strings. All nonbinary strings in MySQL are associated with a character set and a collation. A string's character set controls what characters can be stored in the string, and its collation controls how the strings are ordered when you display them.
## Character sets
To view the character sets on your system, run the following command:
```
````SHOW CHARACTER SET;`
This command will output four columns of data, including the character set:
- Name
- Brief description
- Default collation
- Maximum size of each character in the character set
MySQL used to default to the **latin1** character set, but since version 8.0, the default has been **utf8mb4**. The default collation is now **utf8mb4_0900_ai_ci**. The **ai** indicates that this collation is accent insensitive (**á = a**), and the **ci** specifies that it is case insensitive (**a = A**).
Different character sets store their characters in various-sized chunks of memory. For example, as you can see from the above command, characters stored in **utf8mb4** are stored in memory from one to four bytes in size. If you want to see if a string has multibyte characters, you can use the **CHAR_LENGTH()** and **LENGTH()** functions. **CHAR_LENGTH()** displays how many characters a string contains, whereas **LENGTH()** shows how many bytes a string has, which may or may not be the same as a string's length in characters, depending on the character set. Here is an example:
```
``````
SET @a = CONVERT('data' USING latin1);
SELECT LENGTH(@a), CHAR_LENGTH(@a);
+------------+-----------------+
| LENGTH(@a) | CHAR_LENGTH(@a) |
+------------+-----------------+
| 4 | 4 |
+------------+-----------------+
```
This example shows that the **latin1** character set stores characters in single-byte units. Other character sets, such as **utf16**, allow multibyte characters:
```
``````
SET @b = CONVERT('data' USING utf16);
SELECT LENGTH(@b), CHAR_LENGTH(@b);
+------------+------------------+
| LENGTH(@b) | CHAR_LENGTH(@b) |
+------------+------------------+
| 8 | 4 |
+------------+------------------+
```
## Collation
A string's collation will determine how the values are displayed when you run a SQL statement with an **ORDER BY** clause. Your choice of collations is determined by what character set you select. When you ran the command `SHOW CHARACTER SET`
above, you saw the default collations for each character set. You can easily see all the collations available for a particular character set. For example, if you want to see which collations are allowed by the **utf8mb4** character set, run:
```
````SHOW COLLATION LIKE 'utf8mb4%';`
A collation can be case-insensitive, case-sensitive, or binary. Let's build a simple table, insert a few values into it, and then view the data using different collations to see how the output differs:
```
``````
CREATE TABLE sample (s char(5));
INSERT INTO sample (s) VALUES
('AAAAA'), ('ccccc'), ('bbbbb'), ('BBBBB'), ('aaaaa'), ('CCCCC');
SELECT * from sample;
+-----------+
| s |
+-----------+
| AAAAA |
| ccccc |
| bbbbb |
| BBBBB |
| aaaaa |
| CCCCC |
+-----------+
```
With case-insensitive collations, your data is returned in alphabetical order, but there is no guarantee that capitalized words will come before lowercase words, as seen below:
```
``````
SELECT * from sample ORDER BY s COLLATE utf8mb4_turkish_ci;
+-----------+
| s |
+-----------+
| AAAAA |
| aaaaa |
| bbbbb |
| BBBBB |
| ccccc |
| CCCCC |
+-----------+
```
On the other hand, when MySQL runs a case-sensitive search, lowercase will come before uppercase for each letter:
```
``````
SELECT * from sample ORDER BY s COLLATE utf8mb4_0900_as_cs;
+-----------+
| s |
+-----------+
| aaaaa |
| AAAAA |
| bbbbb |
| BBBBB |
| ccccc |
| CCCCC |
+-----------+
```
And binary collations will return all capitalized words before lowercase words:
```
``````
SELECT * from sample ORDER BY s COLLATE utf8mb4_0900_bin;
+-----------+
| s |
+-----------+
| AAAAA |
| BBBBB |
| CCCCC |
| aaaaa |
| bbbbb |
| ccccc |
+-----------+
```
If you want to know which character set and collation a string uses, you can use the aptly named **charset** and **collation** functions. A server running MySQL version 8.0 or higher will default to using the **utf8mb4** character set and **utf8mb4_0900_ai-ci** collation:
```
``````
SELECT charset('data');
+-------------------+
| charset('data') |
+-------------------+
| utf8mb4 |
+-------------------+
SELECT collation('data');
+--------------------+
| collation('data') |
+--------------------+
| utf8mb4_0900_ai_ci |
+--------------------+
```
You can use the `SET NAMES`
command to change the character set or collation used.
To change from the **utf8mb4** character set to **utf16**, run this command:
```
````SET NAMES 'utf16';`
If you would also like to choose a collation other than the default, you can add a **COLLATE** clause to the `SET NAMES`
command.
For example, say your database stores words in the Spanish language. The default collation for MySQL (**utf8mb4_0900_ai_ci**) sees ch and ll as two different characters and will sort them as such. But in Spanish, ch and ll are individual letters, so if you want them sorted in the proper order (following c and l, respectively), you need to use a different collation. One option is to use the **utf8mb4_spanish2_ci** collation.
```
````SET NAMES 'utf8mb4' COLLATE 'utf8mb4_spanish2-ci';`
## Storing strings
MySQL allows you to choose between several data types for your string values. (Even more so than other popular databases such as PostgreSQL and MongoDB.)
Here is a list of MySQL's binary string data types, their nonbinary equivalents, and their maximum length:
**binary:**char (255)**varbinary:**varchar (65,535)**tinyblob:**tinytext (255)**blob:**text (65,535)**mediumblob:**mediumtext (16,777,215)**longblob:**longtext (4,294,967,295)
One important thing to remember is that unlike the varbinary, varchar, text, and blob types, which are stored in variable length fields (that is, using only as much space as needed), MySQL stores binary and char types in fixed length fields. So a value such as **char(20)** or **binary(20)** will always take up 20 bytes, even if you store less than 20 characters in them. MySQL pads the values with the **ASCII NUL** value (**0x00**) for binary types and spaces for char types.
Another thing to consider when choosing data types is whether you want spaces after the string to be preserved or stripped. When displaying data, MySQL strips whitespace from data stored with the char data type, but not varchar.
```
``````
CREATE TABLE sample2 (s1 char(10), s2 varchar(10));
INSERT INTO sample2 (s1, s2) VALUES ('cat ', 'cat ');
SELECT s1, s2, CHAR_LENGTH(s1), CHAR_LENGTH(s2) from sample2;
+---------+---------+-----------------------------------+
| s1 | s2 | CHAR_LENGTH(s1) | CHAR_LENGTH(s2) |
+---------+---------+-----------------------------------+
| cat | cat | 3 | 10 |
+---------+---------+-----------------------------------+
```
## Wrap up
Strings are one of the most common data types used in databases, and MySQL remains one of the most popular database systems in use today. I hope that you have learned something new from this article and will be able to use your new knowledge to improve your database skills.
## Comments are closed. |
15,437 | w 命令的解释与示例 | https://www.debugpoint.com/w-command-linux-examples/ | 2023-01-12T10:09:00 | [
"w 命令"
] | /article-15437-1.html |
>
> 下面是一份关于理解 Linux 和 BSD 中的 w 命令的初学者指南,并附有几个例子。
>
>
>

这篇文章是 [Linux 命令](https://www.debugpoint.com/category/linux-commands)学习系列的一部分。
### w 命令
`w` 命令是 Linux 中的一个工具,它显示当前登录到系统中的用户及其进程的信息。它显示谁已登录,以及他们正在做什么活动。这意味着它可以显示他们在系统中运行什么进程。
### 语法
下面是 `w` 命令的基本语法:
```
w [options] [username]
```
`w` 命令接受一个可选的选项列表,然后是一个可选的用户名。如果指定了用户名,`w` 将只显示该用户拥有的进程信息。
### w 命令的例子及其用法
下面是一些使用 `w` 命令的例子。
当你只用 `w` 运行它时,它显示以下输出:
```
$ w
21:45:07 up 1 day, 12:48, 1 user, load average: 1.05, 0.85, 0.56
USER TTY LOGIN@ IDLE JCPU PCPU WHAT
debugpoi tty2 Thu08 36:48m 0.03s 0.03s /usr/libexec/gnome-session-binary
```

解释:`USER` 列给出了用户名,然后是终端号、登录日期时间、空闲时间、CPU 使用率,以及用户正在执行的进程。
* `USER` - 在你的 Linux 或 BSD 系统中登录的用户名称。
* `TTY` - 当前会话的终端标识符号。
* `FROM` - 用户的主机名或 IP 地址。
* `LOGIN@` - 用户登录的时间。它有时会根据你的系统设置显示日期。
* `IDLE` - 用户与终端交互后的空闲时间。
* `JCPU` - 该会话的所有用户进程使用的 CPU 时间。
* `PCPU` - 该用户的进程(在 `WHAT` 字段中提到)使用的时间。
* `WHAT` - 当前带参数的进程。
下面是 `w` 命令的另一个例子,有两个用户在虚拟机环境中登录。正如你所看到的,显示了两个用户名与当前运行的带有进程参数的独立进程。

让我们看一下这个命令的一些选项。
要停止显示标题,使用 `-h` 选项。它与 `--no-header` 开关相同。
```
$ w -h
```
`-f` 选项可以在输出中切换 `FROM` 字段的可见性。
```
$ w -f
```
使用 `-s` 选项打印一个简短的输出,不包括 `JCPU`、`PCPU` 和 `LOGIN@` 信息。
```
$ w -s
```
要显示一个特定用户(例如,`debugpoint`)拥有的所有进程的列表:
```
$ w debugpoint
```
### 结束语
我希望这篇文章能帮助你了解 `w` 命令及其基本原理。你也可以阅读 [w 手册页](https://linux.die.net/man/1/w) 来了解更多。如果你有任何问题,请告诉我。
---
via: <https://www.debugpoint.com/w-command-linux-examples/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,439 | OBS Studio 29 发布,但对 Linux 用户来说变化不大 | https://news.itsfoss.com/obs-studio-29-release/ | 2023-01-13T09:38:53 | [
"OBS"
] | https://linux.cn/article-15439-1.html |
>
> OBS Studio 29 是一个令人兴奋的版本,在所有平台上都有关键的改进。
>
>
>

[OBS Studio](https://obsproject.com) 是最受欢迎的开源屏幕录制和流媒体软件之一。
许多 Linux 用户和内容创作者都在使用它,它有一套相当不错的工具和功能,可以让你录制和串流内容。
它的上一个主要版本发布于 2022 年 9 月,它带来了对苹果芯片的原生支持、更新了用户界面、改进了颜色支持等等。
它的下一个版本,即 v29,似乎有点意思,但对 Linux 用户来说变化不大 ?
### OBS Studio 29 的新变化

这个版本有大量的改进和修复;其中一些亮点包括:
* 对 Linux 的媒体键支持
* 新的音频过滤器
* 改进的英伟达视频和音频过滤器
* 更好的编码器支持
* 各种修复和改进
**媒体键支持:** 你终于可以用键盘上的媒体键来控制 Linux 上的 OBS 的播放或音量了。
**新的音频过滤器:** OBS Studio 29 具有两个新的音频滤波器,一个向上压缩滤波器和一个 3 波段均衡器滤波器。
**改进的英伟达视频和音频过滤器:** 对这些过滤器进行了各种改进。
增加了一个新的屏蔽刷新滑块,同时支持时间处理,这应该是为了提供更好的屏蔽质量。
**更好的编码器支持:**,OBS Studio 29 对几个编码器的支持得到了改善,例如:
* Windows 上的用于 AMD [RX7000 系列](https://en.wikipedia.org/wiki/Radeon_RX_7000_series) 的 AV1 编码器。
* Windows 上的用于英特尔 [Arc GPU](https://www.intel.in/content/www/in/en/products/details/discrete-gpus/arc.html) 的 AV1 编码器。
* Windows 上的英特尔 HEVC 编码器。
* macOS 上的原生 HEVC 和 ProRes 编码器。
>
> ? 注意,这些编码器只支持 Windows 或 macOS。可悲的是,他们少了对 Linux 的支持。我们希望在 OBS Studio 的未来版本中加入这些功能。
>
>
>
**各种修复和改进:** 除了上面列出的那些,OBS Studio 29 还有很多其他的变化,例如:
* Websockets 5.1.0
* 回放缓冲区的内存限制现在被限制在已安装的系统内存的 75%,而不是固定在 8GB。
* 支持对 SRT 和 RIST 输出的加密和认证。
* 能够检查和/或静音个别的浏览器底座。
* 在视频捕获的情况下,支持更高的刷新率。
关于更多的技术细节,你可以查看 [官方发布说明](https://github.com/obsproject/obs-studio/releases/tag/29.0.0)。
### 下载 OBS Studio 29
要获得最新的 OBS Studio 29,你可以使用 [Flatpak](https://flathub.org/apps/details/com.obsproject.Studio),这是推荐的方法。
你也可以看看其官方下载页面中提到的其他安装方法。
>
> **[OBS Studio 29](https://obsproject.com/download)**
>
>
>
---
via: <https://news.itsfoss.com/obs-studio-29-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[OBS Studio](https://obsproject.com/?ref=news.itsfoss.com) is one of the most popular open-source screen recording and streaming software.
Used by many Linux users and content creators, it has a pretty neat set of tools and features that lets you record and stream content.
Its last major release was back in September 2022, which brought in native support for Apple Silicon, updated UI, improved color support, and more.
**Related Read 📖**
[OBS Studio 28.0 is a Massive Upgrade With Qt6, HDR Support; Also Works on Apple SiliconOBS Studio 28.0 gets a visual refresh, and gears up for modern use-cases with new tech support.](https://news.itsfoss.com/obs-studio-28-release/)

Its next release, v29, seems to be a bit interesting, but not so much for Linux users 😞
## OBS Studio 29: What's New?
This release has plenty of improvements and fixes; some of the highlights include the following:
**Media key support for Linux****New Audio Filters****Improved NVIDIA Video and Audio Filters****Better Encoder Support****Various Fixes and Improvements**
**Media key support: **You can finally use the media keys on your keyboard to control the playback or the volume with OBS on Linux.
**New Audio Filters: **OBS Studio 29 features two new audio filters, an upward compressor filter, and a 3-band equalizer filter.
**Improved NVIDIA Video and Audio Filters: **Various improvements have been made to these filters.
A new Mask Refresh slider has been added, alongside support for temporal processing, that is supposed to provide better quality masking.
**Better Encoder Support: **Well, OBS Studio 29 received improved support for several encoders, such as:
- AMD AV1 Encoder for
[RX7000 series](https://en.wikipedia.org/wiki/Radeon_RX_7000_series?ref=news.itsfoss.com)of GPUs on Windows. - Intel AV1 Encoder for
[Arc GPUs](https://www.intel.in/content/www/in/en/products/details/discrete-gpus/arc.html?ref=news.itsfoss.com)on Windows. - Intel HEVC Encoder on Windows.
- Native HEVC and ProRes encoders for macOS.
Sadly, they miss out on support for Linux. We hope these are added in a future release of OBS Studio.
**Various Fixes and Improvements: **Apart from the ones listed above, OBS Studio 29 features plenty of other changes, such as:
- Websockets 5.1.0
- The replay buffer's memory limit is now limited to 75% of installed system RAM, instead of being fixed to 8 GB.
- Support for encryption and authentication for SRT and RIST outputs.
- Ability to inspect and/or mute individual browser docks.
- Support for higher refresh rates in case of video captures.
For more technical details, you can go through the [official release notes](https://github.com/obsproject/obs-studio/releases/tag/29.0.0?ref=news.itsfoss.com).
## Download OBS Studio 29
To get the latest OBS Studio 29, you can get the [Flatpak](https://flathub.org/apps/details/com.obsproject.Studio?ref=news.itsfoss.com), the recommended method.
You can also explore other installation methods mentioned in its official download page.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,440 | 通过编写“猜数字”游戏来学习 Ada 编程语言 | https://opensource.com/article/23/1/learn-ada-simple-game | 2023-01-13T17:39:30 | [
"猜数字",
"Ada"
] | https://linux.cn/article-15440-1.html |
>
> 这个 "猜数字 "游戏是学习新编程语言的一个很好的入门程序,因为它以一种相当直接的方式锻炼了几个常见的编程概念。
>
>
>

当你想 [学习一种新的编程语言](https://opensource.com/article/20/10/learn-any-programming-language) 时,把注意力放在编程语言的共同点上是很好的:
* 变量
* 表达式
* 语句
这些概念是大多数编程语言的基础。一旦你理解了它们,你就可以开始琢磨其他的东西了。因为编程语言通常有相似之处,一旦你知道一种语言,你就可以通过了解其差异来学习另一种语言的基础知识。
学习新语言的一个好方法是用一个标准程序进行练习。这使你能够专注于语言,而不是程序的逻辑。在这个系列文章中,我使用了一个“猜数字”的程序,在这个程序中,计算机在 1 到 100 之间挑选一个数字,并要求你猜出来。程序循环进行,直到你猜对数字为止。
这个程序锻炼了编程语言中的几个概念:
* 变量
* 输入
* 输出
* 条件判断
* 循环
这是一个学习新的编程语言的很好的实践实验。
### 安装 Ada
[Ada 编程语言](https://opensource.com/article/21/10/learn-ada-2021) 是一种独特的、高度结构化的语言,有专门一群开发者使用它。Ada 的工具链是 GNU Ada 开发环境,多被称为 GNAT。
你可以使用你的发行版的包管理器在 Linux 上安装 GNAT。在 Fedora、CentOS 或类似系统上:
```
$ sudo dnf install gcc-gnat
```
在 Debian、Linux Mint 及衍生版上:
```
$ sudo apt install gnat
```
在 macOS 和 Windows 上,你可以从 [Adacore 网站](https://www.adacore.com/download/more) 下载一个安装程序(从下拉菜单中选择你的平台)。
### 在 Ada 中猜数字
创建一个名为 `game.adb` 的文件。
这个程序使用的两个内置 Ada 库:`Text_IO` 和 `Numerics.Discrete_Random`:
```
with Ada.Text_IO;
use Ada.Text_IO;
with Ada.Numerics.Discrete_Random;
```
#### 过程头
<ruby> 过程 <rt> procedure </rt></ruby> 的名称必须与文件的名称一致。第一部分是定义变量。
注意,`discrete_random` 是专门针对特定范围的。在这里,允许数字范围:
```
procedure Game is
type randRange is range 1..100;
package Rand_Int is new ada.numerics.discrete_random(randRange);
use Rand_Int;
gen : Generator;
num : randRange;
incorrect: Boolean := True;
guess: randRange;
```
#### 过程逻辑
该逻辑从 `reset(gen)` 开始。这将初始化随机数发生器,确保每次运行程序时,用 `random(gen)` 初始化的数字将是不同的。
下一步是运行循环:
* 输出猜测的指令
* 读取该行
* 将其转换为 `randRange`。
* 将其与数字进行核对
如果数字匹配,`incorrect` 被设置为 `False`,导致循环的下一次迭代退出。
最后,程序在退出前会打印出对猜测正确性的确认:
```
begin
reset(gen);
num := random(gen);
while incorrect loop
Put_Line ("Guess a number between 1 and 100");
declare
guess_str : String := Get_Line (Current_Input);
begin
guess := randRange'Value (guess_str);
end;
if guess < num then
Put_line("Too low");
elsif guess > num then
Put_line("Too high");
else
incorrect := False;
end if;
end loop;
Put_line("That's right");
end Game;
```
### 编译程序
编译 Ada 程序的最简单方法是使用 `gnatmake`:
```
$ gnatmake game.adb
aarch64-linux-gnu-gcc-10 -c game.adb
aarch64-linux-gnu-gnatbind-10 -x game.ali
aarch64-linux-gnu-gnatlink-10 game.ali
```
这将生成一个名为 `game` 的二进制文件。
### 运行程序
程序的每次运行都会有一些不同。这是一个例子:
```
$ ./game
Guess a number between 1 and 100
50
Too low
Guess a number between 1 and 100
75
Too low
Guess a number between 1 and 100
82
Too low
Guess a number between 1 and 100
90
Too high
Guess a number between 1 and 100
87
Too low
Guess a number between 1 and 100
88
That's right
```
### 学习 Ada
这个“猜数字”游戏是学习新的编程语言的一个很好的入门程序,因为它以一种相当直接的方式锻炼了几个常见的编程概念。通过在不同的编程语言中实现这个简单的游戏,你可以展示这些语言的一些核心概念,并比较它们的细节。
你有喜欢的编程语言吗?你会如何用它来写“猜数字”的游戏?请关注本系列文章,看看你可能感兴趣的其他编程语言的例子吧!
---
via: <https://opensource.com/article/23/1/learn-ada-simple-game>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you want to [learn a new programming language](https://opensource.com/article/20/10/learn-any-programming-language), it's good to focus on the things programming languages have in common:
- Variables
- Expressions
- Statements
These concepts are the basis of most programming languages. Once you understand them, you can start figuring out the rest. Because programming languages usually share similarities, once you know one language, you can learn the basics of another by understanding its differences.
A good way to learn new languages is practicing with a standard program. This allows you to focus on the language, not the program's logic. I'm doing that in this article series using a "guess the number" program, in which the computer picks a number between one and 100 and asks you to guess it. The program loops until you guess the number correctly.
This program exercises several concepts in programming languages:
- Variables
- Input
- Output
- Conditional evaluation
- Loops
It's a great practical experiment to learn a new programming language.
## Install Ada
The [Ada programming language](https://opensource.com/article/21/10/learn-ada-2021) is a unique and highly structured language with a dedicated developer base. The toolchain for Ada is the GNU Ada Development Environment, better known as GNAT.
You can install GNAT on Linux using your distribution's package manager. On Fedora, CentOS, or similar:
```
````$ sudo dnf install gcc-gnat`
On Debian, Linux Mint, and derivatives:
```
````$ sudo apt install gnat`
On macOS and Windows, you can download an installer from the [Adacore website](https://www.adacore.com/download/more) (choose your platform from the drop-down menu).
## Guess the number in Ada
Create a file called `game.adb`
.
The two built-in Ada libraries this program uses are `Text_IO`
and `Numerics.Discrete_Random`
:
```
``````
with Ada.Text_IO;
use Ada.Text_IO;
with Ada.Numerics.Discrete_Random;
```
### Procedure head
The name of the procedure must match the name of the file. The first part is defining the variables.
Note that the `discrete_random`
is specialized to a specific range. In this case, the range of numbers allowed:
```
``````
procedure Game is
type randRange is range 1..100;
package Rand_Int is new ada.numerics.discrete_random(randRange);
use Rand_Int;
gen : Generator;
num : randRange;
incorrect: Boolean := True;
guess: randRange;
```
### Procedure logic
The logic starts by `reset(gen)`
. This initializes the random number generator, ensuring the number, initialized with `random(gen)`
, will be different each time you run the program.
The next step is to run the loop:
- Output the instructions for a guess
- Read the line
- Convert it to
`randRange`
- Check it against the number
If the number matches, incorrect is set to **False**, causing the next iteration of the loop to exit.
Finally, the program prints a confirmation of the guess correctness before exiting:
```
``````
begin
reset(gen);
num := random(gen);
while incorrect loop
Put_Line ("Guess a number between 1 and 100");
declare
guess_str : String := Get_Line (Current_Input);
begin
guess := randRange'Value (guess_str);
end;
if guess < num then
Put_line("Too low");
elsif guess > num then
Put_line("Too high");
else
incorrect := False;
end if;
end loop;
Put_line("That's right");
end Game;
```
## Build the program
The easiest way to compile an Ada program is to use `gnatmake`
:
```
``````
$ gnatmake game.adb
aarch64-linux-gnu-gcc-10 -c game.adb
aarch64-linux-gnu-gnatbind-10 -x game.ali
aarch64-linux-gnu-gnatlink-10 game.ali
```
This generates a binary called `game`
.
## Run the program
Each run of the program will be a little different. This is one example:
```
``````
$ ./game
Guess a number between 1 and 100
50
Too low
Guess a number between 1 and 100
75
Too low
Guess a number between 1 and 100
82
Too low
Guess a number between 1 and 100
90
Too high
Guess a number between 1 and 100
87
Too low
Guess a number between 1 and 100
88
That's right
```
## Learn Ada
This "guess the number" game is a great introductory program for learning a new programming language because it exercises several common programming concepts in a pretty straightforward way. By implementing this simple game in different programming languages, you can demonstrate some core concepts of the languages and compare their details.
Do you have a favorite programming language? How would you write the "guess the number" game in it? Follow this article series to see examples of other programming languages that might interest you!
## Comments are closed. |
15,442 | 如何在 Rust 中读取和写入文件 | https://opensource.com/article/23/1/read-write-files-rust | 2023-01-14T16:41:00 | [
"Rust"
] | /article-15442-1.html |
>
> 跟随这个演示,学习如何在 Rust 中使用文件系统模块。
>
>
>

知道如何读写文件对各种用途都很有用。在 Rust 中,这项任务是通过标准库中的文件系统模块([std::fs](https://doc.rust-lang.org/std/fs/))完成的。在这篇文章中,我将向你介绍如何使用这个模块。
为了演示这项任务,我准备了一些示例代码,也可以在 [GitHub](https://github.com/hANSIc99/rust_file_io) 上找到。
### 准备工作
在使用 Rust 时,失败的函数会返回 [Result](https://doc.rust-lang.org/std/result/enum.Result.html) 类型。尤其是文件系统模块会返回专门的类型 [std::io::Result<T, Error>](https://doc.rust-lang.org/std/io/type.Result.html)。有了这些知识,你可以从 `main()` 函数中返回相同的类型:
```
fn main() -> std::io::Result<()> {
/* ...code comes here... */
```
### Rust 文件写入
在 Rust 中执行文件的 I/O 操作是相对容易的。写入文件可以简化为一行:
```
use std::fs;
fs::write("favorite_websites.txt", b"opensource.com")?;
Ok(())
```
使用错误传播操作符 `(?)`,错误信息被传递到调用函数中,随后可以处理错误。由于 `main()` 是调用栈中唯一的其他函数,如果写操作失败,错误信息将被传递到控制台输出。
[fs::write](https://doc.rust-lang.org/std/fs/fn.write.html) 函数的语法是非常先进的。第一个参数是文件路径,它必须是 [std::path::Path](https://doc.rust-lang.org/std/path/struct.Path.html) 类型。第二个参数是内容,它实际上是一个字节切片(`[u8]`)。Rust 将传递的参数转换为正确的类型。幸运的是,这些类型基本上是下面的例子中所处理的唯一类型。
使用文件描述符类型 [std::fs::File](https://doc.rust-lang.org/std/fs/struct.File.html) 可以实现对写操作更简洁的访问:
```
let mut file = fs::File::create("favorite_websites.txt")?;
file.write_all(b"opensource.com\n")?;
Ok(())
```
由于文件类型实现了 [Write](https://doc.rust-lang.org/std/io/trait.Write.html) 特性,所以可以使用相关的方法来写入文件。然而,`create` 方法可以覆盖一个已经存在的文件。
为了获得对文件描述符的更多控制,必须使用 [std::fs::OpenOptions](https://doc.rust-lang.org/std/fs/struct.OpenOptions.html#) 类型。这提供了类似于其他语言中的打开模式:
```
let mut file = fs::OpenOptions::new()
.append(true)
.open("favorite_websites.txt")?;
file.write_all(b"sourceforge.net\n")?;
```
### Rust 文件读取
适用于写的东西也适用于读。读取也可以通过简单的一行代码来完成:
```
let websites = fs::read_to_string("favorite_websites.txt")?;
```
以上一行读取文件的内容并返回一个字符串。除了读取字符串,还有 [std::fs::read](https://doc.rust-lang.org/std/fs/fn.read.html) 函数,如果文件包含二进制数据,该函数会将数据读成一个字节向量。
下一个例子显示了如何将文件的内容读入内存,随后逐行打印到控制台:
```
let file = fs::File::open("favorite_websites.txt")?;
let lines = io::BufReader::new(file).lines();
for line in lines {
if let Ok(_line) = line {
println!(">>> {}", _line);
}
}
```
### 总结
如果你已经熟悉了其他编程语言,你可能已经注意到没有 `close-` 函数(或类似的)来释放文件句柄。在 Rust 中,当相关变量超出作用域,文件句柄就会被释放。为了定义关闭行为,可以在文件表示的周围应用作用域 `({ })`。我建议你熟悉 [Read](https://doc.rust-lang.org/std/io/trait.Read.html) 和 [Write](https://doc.rust-lang.org/std/io/trait.Write.html) 特性,因为你可以在许多其他类型中找到这个特性的实现。
---
via: <https://opensource.com/article/23/1/read-write-files-rust>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,443 | 适用于 Linux 的五大流媒体直播应用 | https://www.debugpoint.com/live-streaming-applications-linux-2022/ | 2023-01-14T17:24:00 | [
"直播",
"流媒体",
"OBS"
] | /article-15443-1.html | 
>
> 本文列出了 Linux 上的五大流媒体直播应用,包括了它们的功能、亮点、下载详情和对比。
>
>
>
现在是为你的业务纳入在线视频内容的最佳时机。为什么?因为研究表明,全球在线视频市场正以每年约 20% 的速度增长。
而且,由于开发者们提供的一些优秀软件,任何人都可以轻松地创建视频内容,并在 YouTube 和 Twitch 等几个流行的平台上传播。如果你仔细想想,你会发现如今你在网上观看的视频内容比基于文本的内容更多。
因此,在这篇文章中,我们将列出一些适用于 Ubuntu 和其他 Linux 的免费软件,这些软件很容易用于为你和你的企业创建超级有趣的流媒体内容。
### Linux 的五大流媒体直播应用
#### OBS Studio
本列表中的第一个免费应用程序是 OBS Studio(即 Open Broadcaster Software)。它是一个具有屏幕广播功能的流媒体直播应用程序,可用于 Linux、Windows 和 macOS。
出于几个原因,OBS Studio 是这个名单上最好的一个。它内置了编码,支持 RTMP 广播、多源、网络摄像头、绿屏、捕捉卡和你的应用程序窗口。
其用户界面相当简单明了,功能丰富。你可以从第三方开发的插件中获得帮助,以扩展其功能,例如,在直播时将 Twitter 上的实时推文混入你的流媒体。不过,OBS 不支持多比特率流媒体。

如何安装:
OBS Studio 可以在所有 Linux 发行版的官方软件库中找到。详细的安装说明见下面的链接。
>
> **[下载 OBS Studio](https://obsproject.com/wiki/install-instructions#linux)**
>
>
>
更多信息:
* [主页](https://obsproject.com/)
* [文档](https://obsproject.com/wiki/Home)
#### VokoscreenNG
我们将在这个列表中介绍的第二个应用程序是 VokoscreenNG。它复刻了已停止的 Vokoscreen 项目。这个新的应用程序完全用 Qt 和 GStreamer 库编写。它可以记录你的屏幕,并接受多个音频源和视频源。VokoscreenNG 的工具箱也相当引人注目。它包括一个放大镜、计时器、系统托盘插件,可以简化你的工作流程。
它可以免费用于 Linux 和 Windows。

如何安装:
你可以从下面的链接下载用于 Linux 系统的压缩可执行文件。下载后,将其解压,然后执行二进制文件来启动该应用程序。
记住,这个应用程序需要在你的 Linux 系统中安装 X11、PulseAudio 和 GStreamer 插件才能工作。如果你使用的是带有 Wayland 和 Pipewire 声音服务器的现代 Linux 系统(例如 Fedora),这个应用程序可能无法工作。
>
> **[下载 VokoscreenNG](https://linuxecke.volkoh.de/vokoscreen/vokoscreen-download.html)**
>
>
>
更多信息:
* [主页](https://linuxecke.volkoh.de/vokoscreen/vokoscreen.html)
#### Restreamer
Restreamer 应用程序可以让你直接在你的网站上直播视频和截屏,而无需任何流媒体服务商。也可以用这个应用程序使用流行的流媒体解决方案,如 YouTube、Twitch等。
这个应用程序功能丰富,有一个不错的功能列表。下面是对其功能的快速介绍:
* 支持 H.264 流媒体
* 内置 HTML5 视频播放
* 可用于 Linux、macOS、Windows 和 Docker 镜像
* 支持你自己的网站和 YouTube、Twitchm、Facebook、Vimeo、Wowza 等。
* 支持多个视频源:[网络摄像机](https://www.debugpoint.com/2018/08/onvifviewer-internet-camera-viewer-for-linux/)、USB 摄像机或任何 H.2645 流媒体
* 编码和音频源支持
* 支持 JPEG 形式的定期快照
* 通过 JSON HTTP API 访问流状态,以便进行额外的编程

如何安装:
安装 Restreamer 有点麻烦,因为它是通过 Docker 镜像发布的。你可以在下面的链接中找到在 Linux、Windows 和 MacOS 安装的说明。
>
> **[下载 Restreamer](https://datarhei.github.io/restreamer/docs/installation-index.html)**
>
>
>
更多信息:
* [主页](https://datarhei.github.io/restreamer/)
* [文档](https://datarhei.github.io/restreamer/docs/index.html)
* [源代码](https://github.com/datarhei/restreamer)
#### ffscreencast
ffscreencast 是一个使用 ffmpeg 库的命令行流媒体应用程序。它利用了 ffmpeg 的强大功能,并作为它的一个封装器。尽管它是以命令行的形式出现的,但你可以直接通过终端使用其强大的功能,如多源和录音设备。它也支持多种显示设置。你还可以在你的桌面截屏上叠加你的摄像机画面。
如何安装:
要安装这个应用程序,你需要克隆它的 Git 代码库,然后将其内容复制到 `/bin`目录,以便全局执行 `ffscreencast` 命令。
```
git clone https://github.com/cytopia/ffscreencast
cd ffscreencastsudo
cp bin/ffscreencast /usr/local/bin
```
你可以在终端用 `ffscreencast` 命令来运行这个应用程序。
>
> **[源代码和主页](https://github.com/cytopia/ffscreencast)**
>
>
>
#### Open Streaming Platforms
本列表中的最后一个应用是 Open Streaming Platforms(OSP),这是一个开源的 RTMP 流媒体软件,可以作为 YouTube LIVE、[Twitch.tv](http://Twitch.tv) 等的自托管替代品。

如果使用得当,这个应用程序功能丰富且强大。因为它有以下的基本功能:
* 从 Open Broadcast Software(OBS)等输入源进行 RTMP 直播。
* 每个用户有多个频道,允许一个用户同时广播多个流,而不需要多个账户。
* 视频流记录和按需播放。
* 手动上传来源于 OSP 之外的 MP4 视频。
* 视频剪辑,为值得注意的时刻创建更短的视频。
* 频道所有者的实时聊天管理(禁止/解禁)。
* 管理员控制的自适应流媒体。
* 受保护的频道,只允许你想要的观众访问。
* 实时频道,当流媒体没有直播时,继续聊天和闲逛。
* Webhooks:通过完全可定制的 HTTP 请求将 OSP 连接到其他服务,这可以传递信息。
* 将你的流媒体或视频直接嵌入到另一个网页中,很容易。
* 通过 Facebook 或 Twitter 快速分享频道或视频。
* 能够将用户界面定制为你自己的个人外观的主题
如何安装:
要安装 Open Streaming Platform,请按照以下页面的详细说明进行。
>
> **[下载 Open Streaming Platform](https://wiki.openstreamingplatform.com/Install/Standard)**
>
>
>
更多信息:
* [主页](https://openstreamingplatform.com/)
* [源代码](https://gitlab.com/Deamos/flask-nginx-rtmp-manager)
* [文档](https://wiki.openstreamingplatform.com/)
### 总结
可用于 Linux 的自由开源的流媒体应用程序不多。然而,有几个商业性的流媒体应用程序,它们可能会给你更多的选择、质量和支持。但正如我所说,它们可能要花费你一些钱。所以,如果你是流媒体世界的新手,你可能想从上面列出的用于 Linux 系统的免费流媒体应用程序开始。我希望这篇文章能给你一些想法,让你根据自己的需要使用,并让你开始使用。
请在下面的评论栏里告诉我你最喜欢的流媒体软件。
加油。
---
via: <https://www.debugpoint.com/live-streaming-applications-linux-2022/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,445 | Mastodon 继续增长,Medium 的新社区平台也加入了 | https://news.itsfoss.com/medium-mastodon/ | 2023-01-15T10:54:17 | [
"Mastodon",
"Medium"
] | https://linux.cn/article-15445-1.html |
>
> Mastodon 的又一次胜利!Medium 为其用户推出了一个 Mastodon 实例。
>
>
>

Mastodon 在最近一段时间的增长是巨大的;越来越多的人正在转向这个 Twitter 的替代品。
如果你不熟悉 Mastodon,它是目前 [最好的主流社交媒体替代品](https://itsfoss.com/mainstream-social-media-alternaives/) 之一,有可能成为 Twitter 的替代品,它是 **完全开源和去中心化的**。
随着 Twitter 的不断发生变化和去年埃隆·马斯克对它的收购,更多的用户开始对 Mastodon 这个平台产生了浓厚的兴趣。
Vivaldi [最近推出了](https://news.itsfoss.com/vivaldi-mastodon-integration/) 其由 Mastodon 驱动的社区,[Mozilla 基金会](https://blog.mozilla.org/en/mozilla/mozilla-launch-fediverse-instance-social-media-alternative/) 也在考虑类似的东西。
现在,[Medium](https://medium.com) 已经向前迈出了一步,推出了它们的 Mastodon 实例。
### Medium 启动了一个由 Mastodon 驱动的社区
在 [最近的公告](https://blog.medium.com/medium-embraces-mastodon-19dcb873eb11) 中,Medium 在 [me.dm](https://me.dm/) 推出了其 Mastodon 实例,专注于 “帮助他们的作者、出版物和读者在 <ruby> 联盟宇宙 <rt> Fediverse </rt></ruby> 中找到一个家”。
该网站(即 Mastodon 实例)旨在成为 Medium 的用户的专属空间。

换句话说,它将成为 Medium 用户的专属社交网络平台。
有了这个网络平台,他们也可以开始进行 500 字以内的短文写作了。
Medium 的 CEO 提到:
>
> 相比之下,Mastodon 主要是为 500 字以内的短文写作服务的。用一个不太双关的说法:今天,我们正在借助 Mastodon 上的实例([me.dm](http://me.dm))将我们用于发表长文的 Medium 扩展到短文 medium(小写 m)。除了更简短的形式外,Mastodon 还带来了围绕联盟概念的重要创新。
>
>
>
因此,看起来 Medium 正在试水和尝试新的东西。
对于那些喜欢一目了然的内容而不是冗长信息的用户来说,可能是一件好事。
如果操作得当,这对他们来说会有很好的效果。
\*\*那么,你怎样才能加入 Medium 的 Mastodon 平台?
>
> ? 你看,最初,**只有选定的作者和出版物** 才能进入这个 Mastodon 实例。现有的 Medium 用户可以尝试发送一个 [注册请求](https://me.dm/auth/sign_up),但要经过他们的批准。
>
>
>
因此,如果你发送一个注册请求,你得等待批准。
他们还计划作为付费会员的额外服务来邀请作家和读者。
他们已经在为他们的 Mastodon 实例开发一个 “用 Medium 注册” 的选项,这应该是为了让你更容易开始使用。
关于这一点,他们提到:
>
> 有这么多的 Mastodon 实例可供选择,我们计划让 [me.dm](http://me.dm) 一开始就有几个重要的好处:可靠的基础设施和审核,一个短域名让你更容易分享你的用户名,为新用户提供更好的入门培训,以及一个有趣的本地信息源。
>
>
>
### 去中心化和开源平台的步伐加快了
去中心化的平台正在变得比人们十年前预期的更加流行。
最大的促成因素是大型科技公司越来越多的不稳定的变化和决定,迫使用户不断调整他们在社交媒体平台上的互动方式和理由。
有了开源和去中心化的平台,用户得到了透明度,更多的数据控制,以及更多的自由。
我们可能没有想到,Mastodon 作为一个平台,逐渐成为各种组织的社区建设的一个重要组成部分。因此,我们非常期待在不久的将来看到更多变化。
? 欢迎在下面的评论中分享你的想法。
---
via: <https://news.itsfoss.com/medium-mastodon/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Mastodon's growth in recent times has been massive; more and more people are switching to this Twitter alternative than ever before.
If you are not familiar with Mastodon, it is one of the [best mainstream social media alternatives](https://itsfoss.com/mainstream-social-media-alternaives/?ref=news.itsfoss.com) out there, potentially as a replacement for Twitter, which is **completely open-source and decentralized**.
With constant changes to Twitter and last year's takeover by Elon Musk, more users have taken a keen interest in Mastodon as a platform.
Vivaldi [recently launched](https://news.itsfoss.com/vivaldi-mastodon-integration/) its Mastodon-powered community, and [Mozilla Foundation](https://blog.mozilla.org/en/mozilla/mozilla-launch-fediverse-instance-social-media-alternative/?ref=news.itsfoss.com) is also considering something similar.
Now, [ Medium](https://medium.com/?ref=news.itsfoss.com) has taken a step forward by launching a Mastodon instance.
**Suggested Read 📖**
[Twitter Quitter? 7 Best Mastodon Instances You Can JoinUnlike Twitter, there is no single Mastodon website. You have to join one of the ‘instances’ and here are the best ones you can rely on.](https://itsfoss.com/best-mastodon-instances/?ref=news.itsfoss.com)

## Medium Starts a Mastodon-Powered Community
In a [recent announcement](https://blog.medium.com/medium-embraces-mastodon-19dcb873eb11?ref=news.itsfoss.com), Medium launched its Mastodon instance at [me.dm](https://me.dm/?ref=news.itsfoss.com), focusing on “*helping their authors, publications, and readers find a home in the Fediverse*”.
The website (or Mastodon instance) aims to be a **dedicated space** for the **users of Medium. **
In other words, it** **will be an exclusive social network platform for Medium users.
With the web platform, they are also venturing into short-form writing of 500 characters or less.
The **CEO of Medium** mentions:
By contrast, Mastodon is primarily for short-form writing of 500 characters or less. Not to be overly punny: Today we are extending what we do into the short-form medium (lowercase m) with an instance on Mastodon, me.dm.
Aside from being short-form, Mastodon also brings an important innovation around the concept of federation.
So, it looks like Medium is testing the waters and trying something new.
Probably a good thing for users who prefer bite-sized content instead of lengthy information.
It can work out well for them if done correctly.
**So, how can you join Medium's Mastodon platform?**
**only select authors and publications**will be given access to this Mastodon instance.
Existing Medium users can try sending a
[sign-up request](https://me.dm/auth/sign_up?ref=news.itsfoss.com), subject to their approval.
So, if you send a signup request, you will have to wait for approval.
They also** plan to invite writers and readers as an additional service** **within their paid membership**.
They are already working on a '**sign-up with Medium**' option for their Mastodon instance, which is supposed to make it easy to get started.
On this, they mention that:
With so many Mastodon instances to choose from, we plan for me.dm to have a few important benefits out of the gate: reliable infrastructure and moderation, a short domain name to make sharing your username easier, better onboarding for new users, and an interesting local feed.
[Unlocator Smart DNSRemove geographic blocks from streaming services using Unlocator Smart DNS. Simple to use and with a full free trial included.](https://unlocator.com/account/aff/go/KeijkZZVhNSBsJmLTeQr?cr=aHR0cHM6Ly91bmxvY2F0b3IuY29tL3NtYXJ0LWRucy8%3D&ref=news.itsfoss.com)

## Decentralized and Open-Source Platforms Picking Up Pace
Decentralized platforms are becoming more popular than one would have expected a decade ago.
The big contributing factor is the number of volatile changes/decisions taken by big tech companies forcing users to constantly adjust how/why they interact on a social media platform.
With an open-source and decentralized platform, users get transparency, more data control, and more freedom.
We may not have expected Mastodon as a platform to gradually become an essential part of community building for various organizations. So, it will be exciting to see what else we have in store for the near future.
💭 *Feel free to share your thoughts in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,446 | whereis 命令的解释与示例 | https://www.debugpoint.com/whereis-command-linux/ | 2023-01-15T14:51:00 | [
"whereis"
] | /article-15446-1.html |
>
> 这是一份关于如何理解 Linux 和 BSD 中 `whereis` 命令的初学者指南,还包括几个例子。
>
>
>

这篇文章是 [Linux 命令](https://www.debugpoint.com/category/linux-commands) 学习系列的一部分。
### whereis 命令
`whereis` 命令是一个命令行程序,可以帮助你找出任何二进制可执行文件、源文件或手册页的路径或位置。
在告诉你如何使用 `whereis` 命令之前,让我们先看看其语法。
### 语法
以下是 whereis 命令的语法:
```
whereis [OPTIONS] FILE_NAME
```
`whereis` 命令的参数是你要搜索的程序名或文件名。该参数是必须的。
默认情况下,它在环境变量(如 `HOME`、`USER`、`SHELL` 等)中定义的路径中搜索程序。
让我们看下一些例子。
### Linux 和 BSD 中 whereis 命令的例子
下面是 `whereis` 命令的一个简单例子,我试图搜索 `firefox`。在下面的输出中,你可以看到包含 `firefox` 文件或可执行文件的路径列表。
```
$ whereis firefox
firefox: /usr/bin/firefox /usr/lib64/firefox /etc/firefox /usr/share/man/man1/firefox.1.gz
```

带有选项 `-l` 的命令会显示其搜索的路径列表。比如:
```
$ whereis -l
bin: /usr/bin
bin: /usr/sbin
bin: /usr/lib
bin: /usr/lib64
bin: /etc
bin: /usr/games
bin: /usr/local/bin
bin: /usr/local/sbin
bin: /usr/local/etc
bin: /usr/local/lib
bin: /usr/local/games
```
如果 `whereis` 命令没有找到任何东西,它只显示参数的名称。例如,如果我在 Linux 中搜索 `nano`,它没有安装,它的输出如下:
```
$ whereis nano
```
```
nano:
```
如果你想搜索更多的参数,你可以随时添加多个参数。例如,下面的命令同时搜索 `bash` 和 `nano`,输出结果是这样的:
```
$ whereis bash nano
bash: /usr/bin/bash /usr/share/man/man1/bash.1.gz /usr/share/info/bash.info.gz
nano: /usr/bin/nano /usr/share/nano /usr/share/man/man1/nano.1.gz /usr/share/info/nano.info.gz
```
你也可以使用 `-b` 选项搜索特定的文件类型,比如二进制文件。下面的命令只告诉你 `nano` 的二进制路径。
```
$ whereis -b nano
nano: /usr/bin/nano /usr/share/nano
```
同样,`-s` 选项可以搜索源文件,而 `-m` 选项可以搜索手册页。
```
$ whereis -m nano
nano: /usr/share/man/man1/nano.1.gz /usr/share/info/nano.info.gz
```
你也可以结合上面的选项来进行更广泛的搜索。例如,下面的命令可以搜索 `nano` 和 `firefox` 的二进制、手册页;而对于 `bash`,只搜索手册页。
```
$ whereis -bm nano firefox -m bash
nano: /usr/bin/nano /usr/share/nano /usr/share/man/man1/nano.1.gz /usr/share/info/nano.info.gz
firefox-m:
bash: /usr/bin/bash /usr/share/man/man1/bash.1.gz /usr/share/info/bash.info.gz
```
下面是选项的摘要:
| 选项 | 描述 |
| --- | --- |
| `-b` | 只搜索二进制文件。 |
| `-m` | 只搜索手册页部分。 |
| `-s` | 只搜索源码。 |
| `-u` | 搜索不寻常的条目。如果一个文件没有所要求的每种类型的条目,就被称为不寻常。因此,`whereis -m -u *` 会查询当前目录中没有文档的那些文件。 |
| `-B` | 改变或限制 `whereis` 搜索二进制文件的地方。 |
| `-M` | 更改或限制 `whereis` 搜索手册的位置。 |
| `-S` | 更改或以其他方式限制 `whereis` 搜索源码的位置。 |
| `-f` | 终止上一个目录列表并指示文件名的开始,并且必须在使用任何 `-B`、`-M` 或 `-S` 选项时使用。 |
### 总结
我希望这篇文章能够帮助你理解 `whereis` 命令及其基本原理。你也可以阅读 [whereis 手册页](https://linux.die.net/man/1/whereis) 来了解更多。如果你有任何问题,请告诉我。
---
via: <https://www.debugpoint.com/whereis-command-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,448 | Ubuntu 23.04 “月球龙虾” 壁纸比赛开始了 | https://debugpointnews.com/ubuntu-23-04-wallpaper-competition/ | 2023-01-16T10:27:00 | [
"壁纸",
"Ubuntu"
] | /article-15448-1.html | 
>
> 喜欢数字绘画或摄影?这个壁纸比赛可以让你的照片出现在 Ubuntu 23.04 的官方版本中。
>
>
>
### Ubuntu 23.04 的壁纸比赛
Ubuntu 23.04 “<ruby> 月球龙虾 <rt> Lunar Lobster </rt></ruby>” 版本将于 2023 年 4 月发布。按照时间表,在即将到来的 BETA 版本之前,官方壁纸比赛现在已经开始。
按照官方的指导方针,你必须拥有你所发布的图片的权利,而且必须是原创。可以说,不应该考虑人工智能生成的图像。
此外,你提交的图片应该至少有 3840x2160px 的尺寸,文件大小不应超过 10MB。文件格式以 SVG 和 WebP 为佳。然而,标准格式如 PNG 和 JPG 也可以接受。
此外,你的图片不应该有任何水印、标志或文字,如 “Lunar Lobster” 或 “Ubuntu”。你可以在 [这里](https://gitlab.gnome.org/GNOME/gnome-backgrounds/-/blob/main/README.md) 阅读详细的指导原则。
最后,你的壁纸可以以官方吉祥物 —— “月球” 和 “龙虾” 为特色。
提交截止日期为 2023 年 2 月 6 日,最终获胜者将在 2023 年 2 月 18 日社区投票后公布。

### 如何提交?
前往官方 Discourse 论坛的帖子下提交你的作品。请务必提到你的名字和 Twitter,如果被选中的话,可以得到 Ubuntu 团队的致谢。
>
> **[提交壁纸](https://discourse.ubuntu.com/t/lunar-lobster-23-04-wallpaper-competition/33132)**
>
>
>
戴上你的创意帽子,提交所有那些很酷的壁纸吧!
*图片来源:各自的作者*
---
via: <https://debugpointnews.com/ubuntu-23-04-wallpaper-competition/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,449 | Discourse 3.0 发布,增加了很多需要的功能 | https://news.itsfoss.com/discourse-3-0-release/ | 2023-01-16T14:57:47 | [
"Discourse"
] | https://linux.cn/article-15449-1.html |
>
> 开源论坛软件 Discourse 有了一个新的重大版本升级!让我们看看有什么新东西。
>
>
>

Discourse 是一个开源的论坛平台,以其丰富的功能和第三方集成而闻名。
它也是 [最好的开源论坛软件](https://itsfoss.com/open-source-forum-software/) 之一,你可以部署在你的 Linux 服务器上来建立一个社区。
现在,我们来看看 Discourse 的最新版本。
在 [Discourse 2.0](https://blog.discourse.org/2018/05/discourse-2-0-released/) 发布已近五年之后,**Discourse 3.0 终于来了**。
这个版本包含了大量的新功能和改进,让我带你看看:
### ? Discourse 3.0 的新变化

Discourse 3.0 提供了很多东西,其中一些值得注意的亮点包括:
* 新的设置向导
* 用户状态
* 通知菜单
* 新的侧边栏
* 实时聊天
* 用户提示
#### 新的设置向导

Discourse 现在有一个新的设置向导,可以让你快速配置一些最重要的选项。
因此,像将社区设置为私人、仅邀请、需要批准等选项在论坛设置的初始阶段就会显示出来。
#### 用户状态

与现在大多数社区平台的做法类似,Discourse 现在也支持设置用户状态。
用户可以设置一个自定义的表情符号和文字,在整个平台上显示在他们的头像附近,无论是帖子、聊天还是用户卡中。
#### 通知菜单

这终于实现了。
Discourse 现在有一个专门的通知菜单,让你更容易跟踪你在论坛上的活动。
#### 新的侧边栏

这是的另一项你可能会喜欢的用户体验改进。
你现在可以在新的侧边栏上添加聊天频道、标签和类别,以方便访问你想追踪的东西。
论坛的管理员也可以为游客和新成员设置一个默认的侧边栏配置;这样,每个人都可以对论坛提供的内容有一个很好的展望。
#### 实时聊天

Discourse 现在支持实时聊天;频道管理员可以选择创建一个非正式的讨论、展示,甚至是备忘录的空间,如果这对他们有用的话。
Discourse 的产品经理 Rishabh Nambiar 提到:
>
> 我们的目标是,当对话在快节奏的聊天和慢节奏的讨论之间转换时,赋予社区以综合的体验。
>
>
> 当想法被激发出来,在一个更容易被发现的地方,聊天信息可以被引用到话题中,讨论可以随着时间的推移而继续,并允许不同时间和地点的人以后加入进来。
>
>
>
#### 用户提示

这个功能对不熟悉 Discourse 的新用户很有帮助。
当用户第一次使用某个特定的功能时,他们会得到与 Discourse 的功能相关的提示。
#### ?️ 其他变化和改进
上面提到的并不是这次发布的 Discourse 的全部变化,下面是其他一些亮点:
* 改造了标签系统。
* 改进了搜索界面。
* 更新了开源工具。
* 改进了错误页面。
* 新的闪屏。
* 改进了页面加载动画。
* 更快的图像预加载。
如果你想深入了解这个版本的技术细节,请查阅 [发行说明](https://meta.discourse.org/t/discourse-version-3-0/)。
### ? 获取 Discourse 3.0
如果你使用的是 [Discourse 的托管计划](https://www.discourse.org/pricing),你一定已经收到了 3.0 的更新,你所要做的就是通过你的管理设置启用新功能。
如果你是自我托管,你必须通过点击管理仪表板上的“更新”按钮手动更新你的实例。
对于新用户,请在他们的官方网站上探索更多关于 Discourse 的信息。
>
> **[Discourse](https://www.discourse.org)**
>
>
>
---
via: <https://news.itsfoss.com/discourse-3-0-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Discourse is an open-source forum platform known for its vast features and third-party integrations.
It is also one of the [best open-source forum software](https://itsfoss.com/open-source-forum-software/?ref=news.itsfoss.com) you can deploy on your Linux servers to build a community.
The ** It's FOSS Community** forum is
**also**
**powered by Discourse**. If you have any questions or want to join in discussing Linux/Open-Source stuff with like-minded people, feel free to sign up on our community forum.
Now, moving on to Discourse's latest release.
**Discourse 3.0 is finally here**.
This comes almost **five years** after the release of [Discourse 2.0.](https://blog.discourse.org/2018/05/discourse-2-0-released/?ref=news.itsfoss.com)
This release is packed with plenty of new features and improvements; let me take you through them.
## 🆕 Discourse 3.0: What's New?
Discourse 3.0 has a lot to offer; some of the notable highlights include:
**New Setup Wizard****User Status****Notifications Menu****New Sidebar****Real-Time Chat****User Tips**
### New Setup Wizard
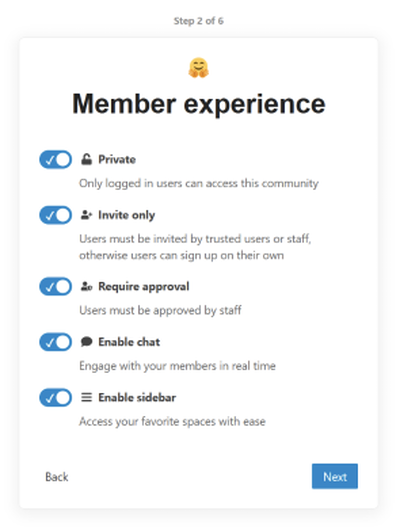
Discourse now features a new setup wizard that lets you quickly configure some of the most important options.
So, options like setting a community to **Private, Invite Only, Require Approval,** and more are shown during the initial stages of the set-up of your forum.
### User Status

Similar to what most community platforms are doing nowadays, Discourse now has support for setting user status.
Users can set a custom emoji and text to be displayed near their avatar across the platform, be it posts, chat, or in the user card.
### Notifications Menu
Finally, this has become a reality.
Discourse now has a dedicated notifications menu, making it easier to track your activity on the forums.
### New Sidebar
This is yet **another user experience improvement** that you might like.
You can now add chat channels, tags, and categories to the new sidebar for easy access to the things you want to keep track of.
Admins of forums can also set a default sidebar config for visitors and new members; this way, everyone can get a great outlook of what a forum offers.
### Real-Time Chat
Discourse now has support for real-time chats; channel admins can choose to create a space for informal discussion, showcase, or even memes if it works for them.
Discourse's **Product Manager**, *Rishabh Nambiar, *mentions:
Our goal is to empower communities with an integrated experience as conversations shift between faster-paced chat and slower-paced discussions.
When ideas are sparked that belong in a more discoverable place, chat messages can be quoted in topics where the discussion can continue over time and allow people in different times and places to join in later.
### User Tips
This feature can be helpful to new users who are unfamiliar with Discourse.
Users will be provided with tips related to the features of Discourse when they use a particular feature for the first time.
### 🛠️ Other Changes & Improvements
The above-mentioned are not the only changes coming to Discourse with this release; here are some other highlights:
**The hashtag system has been revamped.****The search UI has been improved.****Open-source tooling has been updated.****Improved error pages.****New splash screen.****Improved page loading spinner.****Faster image preloads.**
If you want a deep dive into the technical details of this release, go through the [release notes](https://meta.discourse.org/t/discourse-version-3-0/?ref=news.itsfoss.com).
## 📥 Get Discourse 3.0
If you are on [Discourse's hosting plan](https://www.discourse.org/pricing?ref=news.itsfoss.com), you must have already received the 3.0 update, and all you have to do is enable the new features via your admin settings.
**Suggested Read 📖**
[Setup Discourse Forum on Digital Ocean [With Free SSL]This step-by-step tutorial teaches you to install a Discourse forum on Digital Ocean cloud server properly. You’ll have a functioning SMTP server with a free SSL installed on your forum.](https://linuxhandbook.com/set-up-discourse-digital-ocean/?ref=news.itsfoss.com)

And, if you are self-hosted, you must manually update your instance by clicking on the '**Update**' button on your admin dashboard.
For new users, explore more about Discourse on their official site.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,450 | Cinnamon 是一个被低估的神奇 Linux 桌面环境 | https://itsfoss.com/why-cinnamon/ | 2023-01-16T16:46:44 | [
"Cinnamon"
] | https://linux.cn/article-15450-1.html | 
>
> Linux Mint 是我最喜欢的发行版之一,其旗舰版的默认 Cinnamon 桌面是我如此喜欢它的原因。
>
>
>
Cinnamon 桌面提供的用户体验可能并不炫目花哨。但是,用户有充分的理由喜欢这个桌面环境,并可以轻松地用它来完成工作。
在日复一日工作中,我们想要的是,一个能按预期工作且不造成妨碍的用户界面。
我认为 Cinnamon 桌面做对了几件事,可以给你带来了令人兴奋的体验。让我在这里介绍其中一些。
>
> 如果你还不知道,Cinnamon 桌面是由 Linux Mint 的创建者 Clement Lefebvre 于 2011 年创建的 GNOME 3 复刻版,并经过多年的改进。
>
>
>
### 1、熟悉的用户界面

构建 Cinnamon 的主要目的是为了保持 GNOME 2 的桌面风格。
而这就是为什么与最流行的消费级桌面操作系统 Windows 相比,你会看到一个熟悉的桌面布局。
当然,随着时间的推移,Windows 11 已经进化了它的通常布局。但是,访问开始菜单、任务栏、托盘中的系统图标和几个窗口装饰使其易于掌握。
无论你是 Windows 用户还是 macOS 用户,Cinnamon 的桌面布局都不应该让你感到有什么挑战。

为了进一步帮助你,Linux Mint 的 “欢迎屏幕” 为你迅速提供了各种信息。
### 2、轻量级
为了获得舒适的 Cinnamon 桌面体验(通常使用 Linux Mint),有以下最低系统要求:
* 4GB 内存
* 100 GB 的磁盘空间
* 1024×768 分辨率的屏幕
在现代计算时代,这些规格应该适合几乎所有人。所以,你不必担心需要一个疯狂的内存或磁盘空间来运行由 Cinnamon 驱动的 Linux 发行版。
当然,你可以尝试 [在 Ubuntu 上安装 Cinnamon 桌面](https://itsfoss.com/install-cinnamon-on-ubuntu/)。
但是,在本文中,我们认为 Linux Mint 是理想的使用案例。
### 3、快速的性能而不牺牲用户体验
当我们想到一个轻量级的桌面环境时,我们通常会想象一个注重性能的、平淡无奇的用户界面。

在 Cinnamon 桌面上,情况并非如此。它确实包括了各种细微的动画和特色的图标/主题,即使不是最好的,其外观也相当现代。
它以极简的方式让你看起来很赏心悦目。
通常情况下,我很喜欢漂亮的用户界面,但我仍然可以接受 Linux Mint 的简单直接的用户体验,并在双显示器设置(1440p + 1080p)上运行它。
它可能不是 Linux Mint Cinnamon 版最好的双显示器体验(对我来说,第二个屏幕上没有停靠区和面板),但需要改进地方不多。
### 4、默认的自定义选项
你可能已经知道,在提供开箱即用的定制能力方面,KDE 可能是最棒的。
如果你对这种方式感到好奇,我们有超级有用的指南:
* [KDE 定制指南](https://itsfoss.com/kde-customization/)
* [如何正确地给 KDE Plasma 定制主题(深度指南)](https://itsfoss.com/properly-theme-kde-plasma/)
* [最佳的 KDE Plasma 华丽主题](https://itsfoss.com/best-kde-plasma-themes/)
但是,对于许多用户来说,这有些过于复杂了。
我认为 Linux Mint 给出了适量的额外控制/定制,你也可以在它的欢迎屏幕上了解到这些。

一些你可以轻松定制的元素包括:
* 桌面颜色(强调色)
* 浅色/深色主题切换
* 面板布局
* 图标、按钮和鼠标指针
你可以前往系统设置,并导航到 “主题”,找到必要的调整项。
推荐阅读:
>
> **[在 Linux 上定制 Cinnamon 桌面的 7 种方法](https://itsfoss.com/customize-cinnamon-desktop/)**
>
>
>
### 5、为你的体验增色的官方附加组件

Linux Mint 支持各种插件来增强你的体验。这些都是 [Cinnamon 调味品](https://cinnamon-spices.linuxmint.com) 产品的一部分。它们包括:
* 主题
* 扩展程序
* <ruby> 小程序 <rt> Applet </rt></ruby>
* <ruby> 桌面组件 <rt> Desklet </rt></ruby>
小程序和桌面组件是小型程序,你可以分别在面板(靠近系统托盘)和桌面上添加。

你可以管理系统默认的小程序,也可以从官方软件库下载更多的小程序。

同样,你可以从可用的默认程序中添加桌面组件,或者从软件库中获得新的。

大量有价值的实用程序可以用来监控系统资源、检查天气,以及更多。
此外,你还可以访问社区构建的各种主题,可以很容易地给你一个你一直想要的外观。

通过补充上述所有的 “调味品”,你可以使用扩展来使面板透明,在桌面上添加水印,启用窗口平铺,并添加一些令人兴奋的窗口动画。

### 6、兼容和无缝的用户体验
为什么我再次强调用户体验?
Cinnamon 桌面最棒的地方在于它以尊重和支持所有功能的方式发展。
例如,如果你想安装一个你在 KDE Plasma 上喜欢使用的应用程序,它在这里也应该以同样的方式工作。Cinnamon 桌面没有什么特别之处,会破坏这种体验。

同样地,该桌面增加了一些试图与其他桌面环境的服务共存的功能。例如,支持使用 GNOME 在线账户的日历事件。
### 7、面板定制

停靠区、任务栏或面板是用户界面的一个组成部分。
是的,其他的桌面环境也允许你在某种程度上同样定制这些。但在 Cinnamon 中,你可以得到大量的控制权来调整它。
我认为你可以得到一个用户想要的所有基本选项。
### 总结
GNOME 和 KDE Plasma 是流行的桌面环境。然而,Cinnamon 在提供最佳用户体验的基本部分上并不逊色。
你对 Cinnamon 桌面环境有什么看法?你更喜欢用 Linux Mint 来尝试它吗?在下面的评论部分分享你的想法。
---
via: <https://itsfoss.com/why-cinnamon/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux Mint is one of my favorite distributions. The flagship (or default) Cinnamon desktop is why I like it so much.
The user experience offered by Cinnamon desktop may not be mind-blowing or fancy. But, the desktop environment provides enough reasons for users to like it and easily work with it to get things done.
At the end of the day, that’s what we want. A user interface that works as expected and does not get in the way.
I think Cinnamon desktop does a few things right to give you an exciting experience. Let me mention some of those here.
**If you did not know**, the Cinnamon desktop is a fork of GNOME created in
**2011**by
**Clement Lefebvre**(Linux Mint creator) with enhancements over the years.
## 1. Familiar User Interface

The primary objective of building Cinnamon was to keep the GNOME 2 desktop style alive.
And that is why you get a familiar desktop layout compared to the most popular consumer desktop operating system, i.e., Windows.
Of course, Windows 11 has evolved its usual layout with time. But, accessing a start menu, a taskbar, system icons in the tray, and a couple of window decorations make it easy to grasp.
Whether you are a Windows user or a macOS user, the Cinnamon desktop layout should not feel challenging at all.
To help you further, the “**Welcome Screen**” in Linux Mint provides you with all the information quickly.
## 2. Lightweight
To get a comfortable experience with Cinnamon desktop (usually with Linux Mint), you have the following system requirements:
- 4 GB RAM
- 100 GB of disk space
- 1024×768 resolution screen
In the modern computing age, these specifications should suit almost everyone. So, you do not have to worry about needing an insane amount of memory or disk space to run a Linux distro powered by Cinnamon.
Of course, you can try [installing Cinnamon desktop on Ubuntu](https://itsfoss.com/install-cinnamon-on-ubuntu/).
But, for this article, we consider Linux Mint as the ideal use case.
## 3. Fast Performance Without Sacrificing User Experience
When we think about a lightweight desktop environment—we usually imagine a bland user interface that focuses on performance.
With Cinnamon desktop, that is not the case. It does include subtle animations and features icons/themes that make up for a modern look, if not the best.
It looks pleasing to the eyes with a minimal approach.
Typically, I am a sucker for pretty user interfaces, but I can still live with Linux Mint’s straightforward user experience running it on a dual-monitor setup (**1440p + 1080p**).
It may not be the best dual-monitor experience with Linux Mint Cinnamon edition (no dock/panel on the second screen for me). So, there is little room for improvement.
## 4. Default Customization Options
You might already know that KDE is probably the king when it comes to giving the ability to customize out-of-the-box.
We have super useful guides if you are curious about going that way:
[KDE Customization Guide](https://itsfoss.com/kde-customization/)[How to Properly Theme KDE Plasma [In-depth Guide]](https://itsfoss.com/properly-theme-kde-plasma/)[Best Gorgeous KDE Plasma Themes](https://itsfoss.com/best-kde-plasma-themes/)
But, for many users, it is **overwhelming**.
I think Linux Mint gives the right amount of extra controls/customizations, which you also learn on its **Welcome Screen**.
Some of the elements that you can easily customize include:
- Desktop color (accent)
- Light/Dark theme toggle
- Panel layout
- Icons, buttons, and mouse pointer.
You can head to the system settings and navigate to “Themes” to find the essential tweaks.
[7 Ways to Customize Cinnamon Desktop in Linux [Beginner’s Guide]Linux Mint is one the best Linux distributions for beginners. Especially Windows users that want to switch to Linux, will find its flagship Cinnamon desktop environment very familiar. Cinnamon gives a traditional desktop experience and many users like it as it is. It doesn’t mean you have to co…](https://itsfoss.com/customize-cinnamon-desktop/)

## 5. Official Add-ons to Spice Up Your Experience
Linux Mint supports various add-ons to enhance your experience. These are all part of its [Cinnamon Spices](https://cinnamon-spices.linuxmint.com/?ref=itsfoss.com) offering. They include:
- Themes
- Extensions
- Applets
- Desklets
Applets and Desklets are tiny programs that you can add on top of the panel (near the system tray) and the desktop, respectively.
You can manage system default applets or download more from the official repositories:
Similarly, you can add a Desklet from the available defaults or get a new one from the repositories.
Plenty of valuable utilities to monitor system resources, check the weather, and more.
In addition, you get access to various themes built by the community that could easily give you the look you always wanted.
To complement all the above spices, you can use extensions to make the panel transparent, add a watermark to your desktop, enable windows tiling, and add some exciting window animations.
## 6. Compatible and Seamless User Experience
Why do I highlight the user experience again?
The best part about Cinnamon desktop is that it evolves in a way that respects and supports all functionalities.
For instance, if you want to install an app you enjoyed using on KDE Plasma, it should work the same way here. There’s nothing special with Cinnamon desktop that would break the experience.
Similarly, the desktop adds features that try to co-exist with services from other desktop environments. For instance, calendar events support using GNOME Online Accounts.
## 7. Panel Customization
The dock, taskbar, or panel comprises an integral part of the user interface.
Yes, other desktop environments allow you to customize the same to some extent. With Cinnamon, you get a good amount of control to tweak it.
I think you get all the essential options a user would want.
## Wrapping Up
I believe the system updates mechanism in Cinnamon is better than others.
[Beginner’s Guide to System Updates in Linux MintNew to Linux Mint? It has an excellent system updater tool. Learn about this tool and the best practices you should follow.](https://itsfoss.com/linux-mint-update/)

It's just one of many things Mint does better than Ubuntu.
[8 Reasons Why Linux Mint is Better Than Ubuntu for Linux BeginnersWhich one is better, Linux Mint or Ubuntu? This question has been there ever since Linux Mint came into the picture, and this article does not answer this question. Well, not entirely. So, what is this about, then? I have been an Ubuntu user for a long time. I stray](https://itsfoss.com/linux-mint-vs-ubuntu/)

GNOME and KDE Plasma are [popular desktop environments](https://itsfoss.com/best-linux-desktop-environments/). However, Cinnamon is not far off on essential parts to provide an optimal user experience.
*What do you think of the Cinnamon desktop environment? Do you prefer to try it with Linux Mint? Share your thoughts in the comments section below.* |
15,452 | Linux 已准备好禁用微软的 RNDIS 驱动程序,但是…… | https://news.itsfoss.com/linux-disable-microsoft-rndis/ | 2023-01-17T12:41:19 | [
"RNDIS",
"USB"
] | https://linux.cn/article-15452-1.html |
>
> Linux 内核将不再支持 RNDIS 驱动程序。这是一个好的举措吗?这对你意味着什么?在这里了解一下。
>
>
>

微软的 RNDIS 协议(即 <ruby> 远程网络驱动接口规范 <rt> Remote Network Driver Interface Specification </rt></ruby> 的简称),是一个专有的 USB 协议,用于计算机上的虚拟以太网功能。
这方面最常见的使用情况是通过连接到电脑上的 USB,使用手机的移动网络连接互联网,也称为 <ruby> <a href="https://en.wikipedia.org/wiki/Tethering"> 系连 </a> <rt> Tethering </rt></ruby>。
尽管它主要在 Windows 上工作,但它成为 Linux 内核的一部分已经有一段时间了。
但这种情况很快就会改变。
### 向 RNDIS 协议说再见?

**发生了什么?** 周一,[Greg Kroah-Hartman](https://twitter.com/gregkh) 创建了 [usb.git rndis-removal](https://git.kernel.org/pub/scm/linux/kernel/git/gregkh/usb.git/commit/?h=rndis-removal&id=5eb127bb9741c1480aff95ffa4e1bd4cd9b5b16d) 分支,其中他提到禁用 Linux 上所有 RNDIS 协议驱动程序的实现。
在该提交中他提到:
>
> 微软的 RNDIS 协议按照设计是不安全的,在任何连接不信任的主机或设备的系统上使用它都是脆弱的。因为该协议不可能变得安全,所以只要禁用所有的 RNDIS 驱动,就可以防止任何人再使用它们。Windows 只在 XP 和更新一些的系统中需要用它,比这更早的 Windows 系统可以使用正常的 USB 类协议来代替,没有这些问题。
>
>
>
正如最初由 [Phoronix](https://www.phoronix.com/news/Linux-Disabling-RNDIS-Drivers) 报道的那样,一旦这个协议在 Kconfig 选项中被标记为 “损坏”,它将再保留一段时间,最终从内核中删除。
但是**为什么呢?**
众所周知,RNDIS 在 Windows 之外的平台上的实现是一团糟,并带来了相当多的安全风险。此外,RNDIS 并不像以前那样广泛使用了,它带来的安全风险可能是作出这一决定的主要原因之一。
**这对目前的用户有影响吗?你应该担心吗?**
如果我们看一下对这一即将到来的变化的 [Reddit 讨论](https://www.reddit.com/r/linux/comments/108avzx/linux_preparing_to_disable_drivers_for_microsofts/),我们会发现许多用户仍然很担心**这是否会破坏大家的 USB 连接**。
考虑到许多安卓手机仍然使用 RNDIS 而不是 CDC NCM(一种较新的协议),用户似乎对这一举措感到困惑 ?;不只是用户,一位 [谷歌的内核网络开发人员](https://lkml.org/lkml/2022/11/23/1502) 也提出了这个议题,但我们还没有看到对此的回应。
**但不是每个人都使用主线 Linux 内核?如果你不想受到这种变化的影响,你是否应该坚持使用 LTS 版本的内核?**
此外,用户希望更清楚地了解这是否会影响到所有人。
但是,从目前来看,Greg 可能并没有给出更多的细节来说服一些相关用户。
? 当然,我们不是 Linux 内核维护者。所以,最好等这个提交通过时,我希望 Linux 内核维护者能比我们知道更多的信息。
? 你对这个计划中的 Linux 内核的变化有什么看法?请在下面的评论中分享你的想法。
---
via: <https://news.itsfoss.com/linux-disable-microsoft-rndis/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Microsoft's RNDIS protocol, short for Remote Network Driver Interface Specification, is a proprietary USB protocol for virtual Ethernet functionality on computers.
The most common use case of this would be using your phone's mobile network to connect to the internet on your computer via USB, also known as [Tethering](https://en.wikipedia.org/wiki/Tethering?ref=news.itsfoss.com).
Even though it mainly works on Windows, it has been part of the Linux kernel for a while now.
But that is set to change soon.
## Say Goodbye to RNDIS Protocol?
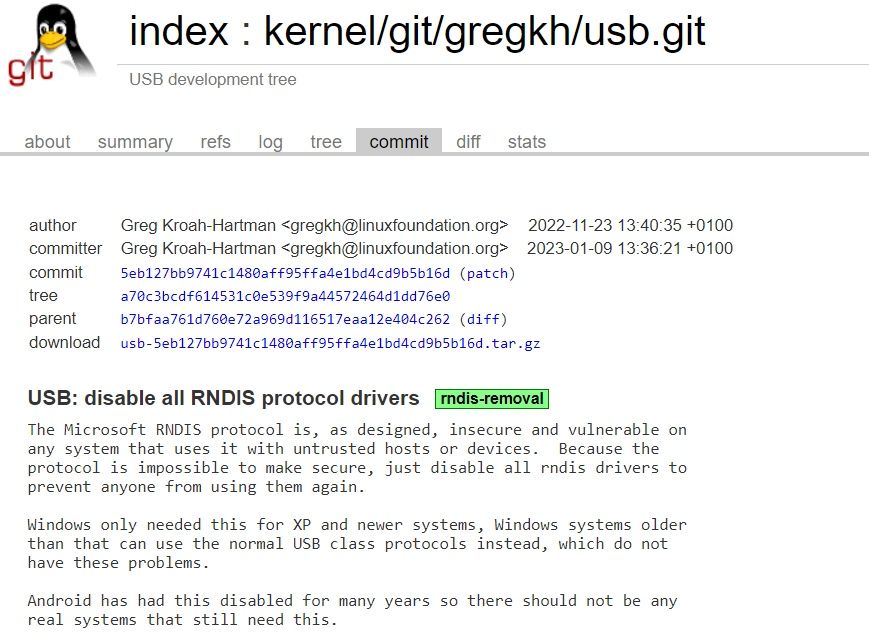
**What is happening?: **On Monday, [Greg Kroah-Hartman](https://twitter.com/gregkh?ref=news.itsfoss.com) created the [usb.git rndis-removal](https://git.kernel.org/pub/scm/linux/kernel/git/gregkh/usb.git/commit/?h=rndis-removal&id=5eb127bb9741c1480aff95ffa4e1bd4cd9b5b16d&ref=news.itsfoss.com) branch, where he mentions disabling the implementation of all RNDIS protocol drivers on Linux.
With the commit, he mentions:
The Microsoft RNDIS protocol is, as designed, insecure and vulnerable on
any system that uses it with untrusted hosts or devices. Because the
protocol is impossible to make secure, just disable all rndis drivers to
prevent anyone from using them again.
Windows only needed this for XP and newer systems, Windows systems older than that can use the normal USB class protocols instead, which do not have these problems.
Android has had this disabled for many years so there should not be any
real systems that still need this.
As initially reported by [Phoronix](https://www.phoronix.com/news/Linux-Disabling-RNDIS-Drivers?ref=news.itsfoss.com), once this protocol is marked 'BROKEN' in the Kconfig option, it will stay there for a while and ultimately be removed from the kernel.
But **why?**
The implementation of RNDIS is known to be a mess on platforms apart from Windows and poses quite a few security risks. In addition, RNDIS is not being used as widely as before, and the security risks it presents might be one of the main reasons for this decision.
**Does this have an impact on current users? Should you be worried?**
If we look at a [Reddit thread](https://www.reddit.com/r/linux/comments/108avzx/linux_preparing_to_disable_drivers_for_microsofts/?ref=news.itsfoss.com) discussing this upcoming change, we would see that many users remain curious **if this would break USB tethering for everyone.**
Users seem confused about this move, considering many Android phones still use RNDIS instead of CDC NCM (a newer protocol) 😕 Not just users; a [Kernel Networking Developer at Google](https://lkml.org/lkml/2022/11/23/1502?ref=news.itsfoss.com) also flagged this issue, but we do not see a response to that yet.
**But not everyone uses mainline Linux Kernel? Should you stick to an LTS version of the kernel if you do not want to be impacted by this change?**
Furthermore, users wanted more clarity on how this does not impact everyone.
But, as of now, **Greg** may not have mentioned a lot of details to convince some of the concerned users.
🤔 Of course, we aren't Linux Kernel maintainers. So, it is best to wait until this commit gets through, and I hope that the Linux Kernel maintainers shed more light on it than we already know.
💭 *What are your thoughts on this planned change for the Linux Kernel? Share your thoughts in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,454 | lnav: 用于 Linux 的高级日志文件浏览器 | https://www.debugpoint.com/advanced-log-file-viewer-lnav-ubuntu-linux/ | 2023-01-18T10:16:00 | [
"lnav"
] | /article-15454-1.html | 
>
> 如果你想调试或排除任何问题,你需要一个像 lnav 这样的高级日志文件查看器。它在任何 Linux 系统的终端都能创造奇迹。
>
>
>
### lnav: 日志文件查看器
`lnav` 可以即时解压缩所有的压缩日志文件,并将它们合并在一起进行漂亮的显示。显示是根据错误/警告的类型进行解析和格式化的,这有助于快速浏览成千上万的日志,特别是在服务器中。
在分析日志的时候,时间戳是非常重要的。所以 `lnav` 会根据时间戳合并多个日志,这对追踪系统问题很有帮助。
大多数重要的日志文件格式检测都是内置的,包括如下:
* <ruby> 通用网络访问日志 <rt> Common Web Access Log </rt></ruby>格式
* CUPS page\_log
* Syslog
* Glog
* VMware ESXi/vCenter 日志
* dpkg.log
* uwsgi
* “通用”:任何以时间戳开头的信息
* Strace
* sudo
* GZIP、BZIP
这还不是全部,`lnav` 还能实现以下功能,使其成为 Linux 系统的重要应用:
* 根据正则表达式过滤消息
* 错误日志的时间轴视图
* 漂亮的打印视图,这有助于重新格式化
* 使用 SQL 查询日志
* 在搜索时,日志会实时更新
* 通过正则表达式高亮显示语法(比如你想在整个日志中找出一个 IP 地址)
* 显示的日志中任何单词的 Tab 补全!!

要查看上述功能的截图和了解更多信息,请访问 [本页面](http://lnav.org/features/) 。
### 如何安装
这个程序在 Ubuntu、Debian 的官方仓库中可以找到。使用以下命令安装它。
```
sudo apt install lnav
```
而对于 Fedora、RHEL 用户,使用下面的命令:
```
sudo dnf install lnav
```
另外,开发者还提供了一个离线的独立可执行文件,你不需要安装。你可以从 [GitHub 发布页](https://github.com/tstack/lnav/releases/) 下载压缩包,然后按以下方式执行:
```
./lnav
```
**注意**:它也可用于 macOS,你可以在上述 GitHub 页面找到。
### lnav: 如何使用(基础)
简单的命令语法是:
```
lnav [options] [logfile1 logfile2 …]
```
如果你直接运行 `lnav` 命令,它会显示你系统中的所有日志(`/var/log/messages` 和 `/var/log/syslog`)
```
lnav
```
要查看任何特定的日志文件,在命令行中输入:
```
lnav /var/log/syslog
```
使用 `-t` 参数在你的日志输出中添加时间戳:
```
lnav -t /var/log/syslog
```
以下是 `lnav` 的一些关键开关:
* `-d file`:将调试信息写入给定的文件。
* `-a`:加载所有最新的日志文件类型。
* `-r`:也加载较早的轮转的日志文件。
* `-t`:在标准输入中读入的数据行上预加时间戳。
* `-w file`:将标准输入的内容写入该文件。
* `-c cmd`:在文件加载后执行命令。
* `-f path`:执行给定文件中的命令。
* `-n`:不使用 curses UI 运行(无头模式)。

要进一步阅读和探索,请访问 [官方文档](https://docs.lnav.org/en/latest/intro.html)。
---
via: <https://www.debugpoint.com/advanced-log-file-viewer-lnav-ubuntu-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,455 | 你可以尝试的 5 个 NeoVim GUI 编辑器 | https://itsfoss.com/neovim-gui-editors/ | 2023-01-18T16:04:10 | [
"NeoVim",
"Vim"
] | https://linux.cn/article-15455-1.html | 
Vim 很不错,但 NeoVim 更新一些,甚至更棒。Vim 和 NeoVim 都是基于终端的文本编辑器,具有类似的功能。
如果你是一个习惯于使用 [像 VS Code 这样的 GUI 文本编辑器](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) 的人,并且希望拥有 NeoVim 提供的类似功能,你应该了解一下这些 GUI 编辑器。
虽然我知道你可以把 NeoVim 作为你目前的文本编辑器的插件,但直接使用 NeoVim 工作要比管理插件更有效和方便。
在选择 NeoVim 的 GUI 时,有一些不同的选择,我把一些最好的 GUI 列在下面:
### 1、Neovide

主要特点:
* 动画光标
* 平滑滚动
* 动画窗口
* 模糊的浮动窗口
* 支持表情符号
[Neovide](https://neovide.dev/index.html) 旨在成为一个简单的 NeoVim GUI。
虽然你不会看到很多图形元素,它只是增加了一些诸如动画之类的 GUI 功能。它使用了一个叫 Skulpin 的库来渲染动画。
而我在使用 Neovide 时最喜欢的地方是它拥有一个动画光标和平滑滚动。你看一看这个就明白了:

看起来很酷。对吗?
### 2、Neovim Qt

主要特点:
* 悬停功能
* 多个 GUI 标签
* 自动制表符补完
* 跨平台支持
顾名思义,[Neovim Qt](https://github.com/equalsraf/neovim-qt) 是用 Qt5 库构建的,你会经常看到它在 KDE 中使用。它没有太多花哨的东西,只是增加了一些额外的 GUI 功能,如多个标签,自动制表符补完等。
因此,如果你已经在使用 Qt5 库,并希望为 NeoVim 提供一个精简的 GUI,它将工作的很好,并为你省去一些依赖安装。
推荐:
>
> **[Vim vs Nano:你应该选择哪个?](https://itsfoss.com/vim-vs-nano/)**
>
>
>
### 3、Uivonim

主要特点:
* WebGL GPU 渲染和多线程
* 支持 VSCode 扩展
* Nyancat(经典猫咪动画的 ANSI 文本程序)
* 悬停和代码动作
[Uivonim](https://github.com/smolck/uivonim) 是 Veonim(一个建立在 VSCode 插件和 NeoVim 上的简单 IDE)的复刻版,采用 Electron 框架编写,如果你从 VSCode 转换过来,它是一个完美的选择。
而 Uivonim 的唯一目标是提供丰富的 NeoVim 体验,支持 NeoVim 的最新功能,包括浮动窗口、内置 LSP 等等。你不需要依赖 VSCode 扩展来获得这些功能。
### 4、FVim

主要特点:
* 脱离窗口(使用 `Ctrl+w`,`GE`)
* 自定义弹出式菜单条目图标
* 支持 HiDPI
* GPU 加速
[FVim](https://github.com/yatli/fvim) 是一个用 F# + Avalonia 构建的 NeoVim 的跨平台 GUI,带有一些突破性的功能,如高性能渲染(在 4K 显示器上支持 60FPS)。
而我经常使用脱离窗口的功能,因为我更喜欢为不同的文本文件设置独立的窗口。另外,如果你是一个资深的远程用户,FVim 也不会让你失望。
### 5、Goneovim

主要特点:
* 支持一个带有 Bash 和 Zsh 的终端
* 迷你地图
* 动画光标
* HiDPI 缩放
* 外部浮动窗口
顾名思义,[Goneovim](https://github.com/akiyosi/goneovim) 是用 Go 语言编写的,是 Gonvim 的一个复刻品。它提供了足够的 GUI 功能来完成你的工作,如动画光标、像素级滚动等。
而且它在让你获得基本的文本编辑功能方面也并不差,比如对文本文件的拖放支持。
### 总结
这是我对 NeoVim 的图形用户界面的一些好的选择,我希望你能找到你想要的东西。
如果我错过了任何你喜欢的东西,请在评论中告诉我。
---
via: <https://itsfoss.com/neovim-gui-editors/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Vim is awesome. NeoVim is newer and even more awesome. Both Vim and NeoVim are terminal-based text editors with similar features.
If you are someone who is accustomed to using [GUI text editors like VS Code](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) and wish to have the similar functionality that NeoVim provides, you should explore GUI options.
Although I know you can use NeoVim as an add-on for your current text editor, working directly with NeoVim is much more effective and convenient for managing plugins.
There are a few different options available when choosing a NeoVim GUI, and I have put together a list of some of the best ones below.
## 1. Neovide
**Key Features:**
- Animated cursor
- Smooth scrolling
- Animated windows
- Blurred floating windows
- Emoji support
[Neovide](https://neovide.dev/index.html) aims to be a no-nonsense graphical user interface for NeoVim.
While you won’t see many graphical elements, it only adds some GUI features, such as animations, using a library called Skulpin to render animations.
And my favorite part of using Neovide is having an animated cursor and smooth scrolling. I mean, have a look at this:
Looks cool. Right?
## 2. Neovim Qt
**Key Features:**
- Hover features
- Multiple GUI tabs
- Auto tab completion
- Cross-platform support
As the name suggests, [Neovim Qt](https://github.com/equalsraf/neovim-qt) is built with the Qt5 library, which you’ll often see being used by KDE. Nothing too fancy, adds some additional GUI features like multiple tabs, auto-tab completion, and more.
So if you are already using Qt5 libraries and want a minimal GUI for NeoVim, this would work like a charm and save you some dependencies.
**Recommended:** [Vim vs Nano: What Should You Choose?](https://itsfoss.com/vim-vs-nano/)
## 3.** Uivonim**
**Key Features:**
- WebGL GPU rendering and multithreading
- Support for VSCode extensions
- Nyancat (ANSI-text program for classic cat animation)
- Hover and code actions
[Uivonim](https://github.com/smolck/uivonim) is a fork of Veonim (A simple IDE built on VSCode plugins and NeoVim) written in electron, making it the perfect choice if you switch from VSCode.
And the only goal of uivonim is to provide a rich NeoVim experience that supports the latest features of NeoVim, including floating windows, built-in LSP, and more. You do not need to rely on VSCode extensions to get these features.
## 4. FVim
**Key Features:**
- Detach windows (using
`Ctrl+w and GE`
). - Custom popup menu entry icons.
- HiDPI support.
- GPU acceleration.
[FVim](https://github.com/yatli/fvim) is a cross-platform GUI for NeoVim built with F# + Avalonia that comes with some groundbreaking features such as high-performance rendering (60FPS on 4K display).
And I often use the detach window feature as I prefer to have separate windows for different text files. Also, if you are an advanced remote user, FVim won’t let you down either.
## 5. Goneovim
**Key Features:**
- Support for a terminal with bash and zsh
- Minimap
- Animated cursor
- High DPI scaling
- External float window
As its name suggests, [Goneovim](https://github.com/akiyosi/goneovim) is written in GO and is a fork of Gonvim. And offers enough GUI features to get your job done such as an animated cursor, pixel scrolling, and more.
And it does not compromise on getting you basic text editing features, such as drag-and-drop support for text files.
**Useful Read**: [How to Install Latest Vim on Ubuntu Linux](https://itsfoss.com/install-latest-vim-ubuntu/)
## Wrapping Up
This was my take on what are some good options when it comes to GUI for NeoVim and I hope you found what you were looking for.
If I missed any of your favorites, let me know your thoughts in the comments. |
15,457 | Unix 已落幕,Unix 仍长存 | https://www.theregister.com/2023/01/17/unix_is_dead | 2023-01-18T23:42:00 | [
"Unix"
] | https://linux.cn/article-15457-1.html |
>
> 不要指望再看到任何更多的 AIX 大新闻了。这意味着最后剩下的 Unix 是 …… Linux。
>
>
>

这是一个时代的结束。正如上周报道的那样,IBM 已经将 AIX 的开发转移到印度。在它支付了 340 亿美金买下了红帽,有了自己的 FOSS 版本的 Unix 后,为什么还要为一个昂贵的美国团队支付费用来维护它自己的官方 Unix 的专有版本呢?!
自从我们报道“大蓝”推出 [不支持 AIX](https://www.theregister.com/2015/11/02/ibm_linux_mainframes/) 的新 POWER 服务器后,我们就察觉到了这一点 —— 而这已经是近八年前的事了。即使这已经是明摆的事,它也是一个重大事件。AIX 是最后一个正在积极开发的专有 Unix,在官方的 Open Group [名单](https://www.opengroup.org/openbrand/register) 的 10 个条目中就占了 4 个。
在甲骨文公司内部,Solaris 正处于 [维护模式](https://www.theregister.com/2022/08/19/oracle_solaris_updated/)。几乎整整六年前,我们报道了下一个主要版本 Solaris 12 已经从甲骨文的路线图上 [消失](https://www.theregister.com/2017/01/18/solaris_12_disappears_from_oracles_roadmap/) 了。HPE 的 HP-UX 也处于维护模式,因为没有新的硬件可以运行它。安腾现在真的 [已经死了](https://www.theregister.com/2019/02/01/intel_kills_itanium_again/),而最后 HP-UX 只能在这上面运行。自从我们报道惠普调查但 [取消](https://www.theregister.com/2012/05/23/hp_project_blackbird_redwood_hp_ux/) 了将其移植到 x86-64 的努力以来,已经过去了十年。
SCO Group 的最后一个化身 Xinuos [仍然存在](https://www.theregister.com/2021/03/31/ibm_redhat_xinuos/),它提供的不是一个而是两个专有的 Unix 变体:SCO [OpenServer](https://www.xinuos.com/products/openserver-6/) 是 SCO Xenix 的后代,而 [UnixWare](https://www.xinuos.com/products/unixware-7/) 是 Novell 的 Unix 的后代。我们注意到,OpenServer 10,一个基于 FreeBSD 10 的更现代的操作系统,已经从 Xinuos 的主页上消失了。值得指出的是,SCO Group 是以前被称为 [Caldera](https://www.theregister.com/2002/08/27/sco_lives_caldera_reinvents_itself/) 的公司,与 1980 年代与微软 [共同创建](https://www.theregister.com/2000/01/31/ms_sells_stake_in_sco/) Xenix 的 Santa Cruz Operation 不是同一个 SCO。
曾经有 [两个](https://www.theregister.com/2022/08/30/kylin_the_multiple_semiofficial_chinese/) 中国的 Linux 发行版通过了 Open Group 的测试,可以使用 Unix 商标:[浪潮 K/UX](https://www.opengroup.org/openbrand/register/brand3617.htm) 和 [华为 EulerOS](https://www.opengroup.org/openbrand/register/brand3622.htm)。虽然这两家公司都丢掉了这个相当 [昂贵](https://www.opengroup.org/openbrand/Brandfees.htm) 的商标。但这里的重要细节是,Linux 通过并被认证为 UNIX™。而且这不仅仅是一个发行版,尽管这两个都是 CentOS Linux 的衍生产品。我们怀疑任何 Linux 都会轻而易举地通过,因为许多非类 Unix 操作系统以前都通过了。
其他操作系统已经通过了,或者可能很容易就会通过。IBM 的 z/OS 活得很好:2021 年推出了 [2.5 版本](https://www.theregister.com/2021/07/28/z_os_2_5_launch/),2022 年大蓝开始提供 [云实例](https://www.theregister.com/2022/06/29/ibm_cloud_mainframe_launch/)。z/OS 有一个与 Unix 兼容的环境,已经通过了兼容性测试,所以正式来说,它是一个 UNIX™,即使这不是它最初的原生 API。
“OpenVMS” 这个名字中的 “Open” 最初 [是指](https://www.pcmag.com/encyclopedia/term/openvms) 它在 1991 年的第五版中获得的 POSIX 兼容性,并首次应用于 DEC 的 Alpha CPU 的新版本。去年,VMS 软件公司发布了适用于 x86-64 管理程序的 [9.2 版本](https://www.theregister.com/2022/05/10/openvms_92/)(以及一个支持的机器,HPE [DL380](https://www.hpe.com/psnow/doc/a00008180enw.html))。
自从 1993 年的 Windows NT 以来,Windows 就有了一个 POSIX 环境。现在,有了 WSL,它可以说有了两个,而且我们怀疑,如果微软有这样的想法,它可以把 Windows 认证为一个官方的 Unix 兼容的操作系统。
在我们最近关于 Haiku Beta 4 的 [报道](https://www.theregister.com/2023/01/11/haiku_beta_4/) 中,我们说它并不是真正的 Unix。正如你所看到的,在文章的结尾处有一个编辑说明,解释了为什么。
我们听取了 Haiku 的主要全职开发人员的意见,他坚决不同意我们的观点。在他看来,Haiku 现在有很强的 Unix 兼容性,文件系统中有一些主要的 Unix 目录,有一套相当完整的 Unix API 调用,有一个 Unix shell,等等,这意味着 Haiku 绝对是一个 Unix。我们认为,由于它是 BeOS 的重新实现,有自己原生的文件系统、API、GUI 等等,它是一种不同的东西,只是提供了 Unix 兼容性。
但这说明了在 21 世纪准确定义 “Unix” 一词的含义的困难。自从 1993 年 Novell 从 AT&T [收购](https://www.theregister.com/2013/07/25/novell_peaked_with_netware_four/) 了 Unix 系统实验室,保留了代码,并将商标捐赠给 Open Group 后,Unix 就不再意味着 “基于 AT&T 的代码”。从那时起,如果通过了 Open Group 的测试(并且你支付了使用商标的费用),它就是 UNIX™。Haiku 还没有,所以它不是。Linux 有,所以它是。但 z/OS 也是如此,它是 OS/390 的直接后裔,或者说它是 IBM MVS 在 1974 年推出时的名字。换句话说,它是一个实际上并不基于、类似于、甚至与 Unix 有关的操作系统。
这意味着最后一个官方商标的商业 UNIX™ 是苹果的 macOS 13,在专有的 GUI 层之下,无论如何,它主要是一个名为 Darwin 的开源操作系统。内核 [XNU](https://github.com/apple/darwin-xnu) 是基于 Mach 的,内核中的 “Unix 服务器” 来自 FreeBSD。
所以,从 2023 年起,开源真的赢了。现在有比以往更多的类 Unix 操作系统,还有一些非常不类似于 Unix 的操作系统与之高度兼容,但是官方路线,就所有的意图和目的而言,已经死亡和消失。所有专有的、商业的 Unix 们现在都是在维持而已:它们会得到基本的错误修复和安全更新,但我们不会看到任何重大的新版本。
让我们为之献花。
---
via: <https://www.theregister.com/2023/01/17/unix_is_dead>
作者:[Liam Proven](https://www.theregister.com/Author/Liam-Proven "Read more by this author") 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-15455-1.html) 荣誉推出
| 200 | OK | This article is more than **1 year old**
# Unix is dead. Long live Unix!
## Don't expect to see any more big AIX news. What does that leave us with?
Comment It's the end of an era. As *The Reg* covered last week, IBM has transferred development of AIX to India. Why should IBM pay for an expensive US-based team to maintain its own proprietary flavor of official Unix when it paid 34 billion bucks for its own FOSS flavor in Red Hat?
Here at *The Reg* FOSS desk, we've felt this was coming ever since we reported that Big Blue [was launching](https://www.theregister.com/2015/11/02/ibm_linux_mainframes/) new POWER servers which *didn't* support AIX – already nearly eight years ago. Even if it was visibly coming over the horizon, this is a significant event: AIX is the last proprietary Unix which was in active development, and constitutes four of the 10 entries in the official Open Group [list](https://www.opengroup.org/openbrand/register).
Within Oracle, [Solaris is in maintenance mode](https://www.theregister.com/2022/08/19/oracle_solaris_updated/). Almost exactly six years ago, we reported that the next major release, Solaris 12, [had disappeared from Oracle's roadmap](https://www.theregister.com/2017/01/18/solaris_12_disappears_from_oracles_roadmap/). HPE's HP-UX is also in maintenance mode because there's no new hardware to run it on. [Itanium really is dead now](https://www.theregister.com/2019/02/01/intel_kills_itanium_again/) and at the end that's all HP-UX could run on. It's over a decade since we reported that HP investigated but [canceled an effort to port it to x86-64](https://www.theregister.com/2012/05/23/hp_project_blackbird_redwood_hp_ux/).
The last incarnation of the SCO Group, Xinuos, [is still around](https://www.theregister.com/2021/03/31/ibm_redhat_xinuos/) and offers not one but two proprietary UNIX variants: SCO [OpenServer](https://www.xinuos.com/products/openserver-6/), descended from SCO Xenix, and [UnixWare](https://www.xinuos.com/products/unixware-7/), descended from Novell's Unix. We note that OpenServer 10, a more modern OS based on FreeBSD 10, has disappeared from Xinuos's homepage. It's worth pointing out that the SCO Group was [the company formerly known as Caldera](https://www.theregister.com/2002/08/27/sco_lives_caldera_reinvents_itself/), and *isn't* the same SCO as the Santa Cruz Operation which [co-created Xenix with Microsoft](https://www.theregister.com/2000/01/31/ms_sells_stake_in_sco/) in the 1980s.
There used to be [two Chinese Linux distros](https://www.theregister.com/2022/08/30/kylin_the_multiple_semiofficial_chinese/) which had passed the Open Group's testing and could use the Unix trademark: [Inspur K/UX](https://www.opengroup.org/openbrand/register/brand3617.htm) and [Huawei EulerOS](https://www.opengroup.org/openbrand/register/brand3622.htm). Both companies have let the rather [expensive](https://www.opengroup.org/openbrand/Brandfees.htm) trademark lapse, though. But the important detail here is that Linux passed and was certified as a UNIX™. And it wasn't just one distro, although both were CentOS Linux derivatives. We suspect that any Linux would breeze through because many un-Unix-like OSes have passed before.
Other OSes have passed or probably easily would, though. IBM's z/OS is alive and well: [version 2.5 came out in 2021](https://www.theregister.com/2021/07/28/z_os_2_5_launch/) and in 2022 Big Blue [started offering cloud instances](https://www.theregister.com/2022/06/29/ibm_cloud_mainframe_launch/). z/OS has a Unix-compatible environment which has passed the compatibility tests so officially, it's a UNIX™, even if that wasn't its original native API.
The "open" in the name "OpenVMS" originally [referred](https://www.pcmag.com/encyclopedia/term/openvms) to the POSIX compatibility it gained with version 5, way back in 1991, and was first applied to the new version for DEC's Alpha CPUs. Last year [VMS Software released version 9.2](https://www.theregister.com/2022/05/10/openvms_92/) for x86-64 hypervisors (and a single supported box, HPE's [DL380](https://www.hpe.com/psnow/doc/a00008180enw.html)).
Ever since Windows NT in 1993, Windows has had a POSIX environment. Now, with WSL, it arguably has two of them, and we suspect that if Microsoft were so inclined, it could have Windows certified as an official Unix-compatible OS.
[IBM shifts remaining US-based AIX dev jobs to India – source](https://www.theregister.com/2023/01/12/ibm_aix_developer_jobs/)[Haiku beta 4: BeOS rebuild / almost ready for release / A thing of beauty](https://www.theregister.com/2023/01/11/haiku_beta_4/)[What did Unix fans learn from the end of Unix workstations?](https://www.theregister.com/2022/12/13/unix_workstations_lessons/)[NixOS 22.11 'Raccoon': Like a proof of concept you can do things with](https://www.theregister.com/2022/12/13/nixos_2211_raccoon/)
In our recent story on [Beta 4 of Haiku](https://www.theregister.com/2023/01/11/haiku_beta_4/), we said it wasn't really a Unix. As you can see, there's an editor's note attached to the end of the story explaining why.
We had heard from Haiku's primary full-time developer, who vigorously disagreed with our point of view. To his mind, the fact that Haiku now has strong Unix compatibility, with some of the main Unix directories present in its filesystem, a quite complete set of Unix API calls, a Unix shell, and so on, means that Haiku is quite definitely a Unix. We feel that inasmuch as it's a reimplementation of BeOS, with its own native filesystem, API, GUI and so on, it's something different, which offers Unix compatibility *as well*.
But this illustrates the difficulty of defining precisely what the word "Unix" means in the 21st century. It hasn't meant "based on AT&T code" since [Novell bought Unix System Labs from AT&T](https://www.theregister.com/2013/07/25/novell_peaked_with_netware_four/) in 1993, kept the code, and donated the trademark to the Open Group. Since that time, if it passes the Open Group's testing (and you pay a fee to use the trademark), it's UNIX™. Haiku hasn't so it isn't. Linux has so it is. But then so is z/OS, which is a direct descendant of OS/390, or IBM MVS as it was called when it was launched in 1974. In other words, an OS which isn't actually based on, similar to, or even related to Unix.
Which means that the last officially trademarked commercial UNIX™ is Apple's macOS 13, which underneath the proprietary GUI layer is mostly an open source OS called Darwin anyway. The kernel, [XNU](https://github.com/apple/darwin-xnu), is based on Mach with an in-kernel "Unix server" derived from FreeBSD.
So, as of 2023, open source really has won. There are more Unix-like OSes than ever, and some very un-Unix-like OSes which are highly compatible with it, but the official line is, to all intents and purposes, dead and gone. All the proprietary, commercial Unixes are now on life support: they will get essential bug fixes and security updates, but we won't be seeing any major new releases.
Send flowers. ®
178 |
15,458 | apt remove 和 apt purge: 有什么区别? | https://itsfoss.com/apt-remove/ | 2023-01-19T11:37:00 | [
"删除",
"apt"
] | https://linux.cn/article-15458-1.html | 
如果你想 [在 Ubuntu 上使用终端卸载软件](https://itsfoss.com/apt-remove/),可以使用:
```
sudo apt remove package_name
```
但是在很多论坛,你可能会看到别人说,如果你想彻底删除软件就用 `apt purge`。
你可能会觉得很困惑,因为 `apt purge` 和 `apt remove` 看起来是一样的。
```
sudo apt purge package_name
```
为什么会有两个如此像的命令来删除软件包呢?两者之间有什么不同呢?下面将为你揭晓。
### apt-remove 和 apt-purge 有什么不同?
`apt-remove` 和 `apt-purge` 的相同之处就是都可以卸载软件包,但是运行 `apt-purge` 除了可以删除安装包之外,还可以清除相关的配置文件。这是两者之间唯一的不同点。要注意的是这两条命令都不能删除用户主目录中相关的应用程序文件。
你是否遇到过这样的情况,卸载一个软件然后重新安装,却发现之前的设置都还在。这是因为用 `apt remove` 不能删除该软件的相关配置文件。
#### 哪些东西被删除了?哪些还在?
我分享一个使用 `apt remove` 和 `apt purge` 两个命令分别卸载 mplayer 这个软件的实际例子。重点是看每次操作后还残余哪些文件。
这是删除前的文件:

现在运行 `apt remove` 这个命令:

下面的是还残留在系统中的文件:

我们可以看到,有两个地方残留着 mplayer 的文件: `/etc` 和 `/home/abhishek`。
这次我们重新安装 mplayer,然后用 `apt purge` 来卸载软件。

现在让我们看看与 mplayer 相关的文件:

我们可以看到 `/etc` 目录下的文件已经没有了。
但是在主目录中的文件呢?`apt purge` 会删除它们吗?
答案是否定的。`apt` 命令不会删除主目录中的配置文件。所以它们仍然在系统中,除非你手动删除。但是这些文件所占的空间真的很小,几乎不占磁盘空间。
值得注意的是,不是所有的软件在主目录或者 `/etc` 目录下都有配置文件。
#### 使用 apt remove 或者 apt purge 的效果
我能想到的一个实际例子就是 Discord,你用 deb 文件 [在 Ubuntu 上安装了 Discord](https://itsfoss.com/install-discord-linux/)。然后登录自己的账号,之后又卸载并重新用 deb 文件安装。
现在如果你打开 Discord,你会发现你的账号自动登录了。是不是觉得很奇怪?
这是个功能,像一些软件,比如 Discord、VirtualBox,它们会提供更新,就是卸载现在的版本然后下载新的(尽管你不知道它内部怎么进行的),但是它在卸载的时候,这些软件的配置文件没有被删除,所以等你打开这些软件的时候就会自动登录。
当你想卸载一个软件,但是想保留你过去使用该软件留下的配置文件的时候,你就可以用 `apt remove`。
但是,有时候用它不能满足你的需求,比如当你没有配置好一个软件的时候,你想要重新开始,这个时候用 `apt purge` 就比较合适。
#### 运行 apt purge 是否可以用通配符删除?
当你删除一个包的时候,它会提示 `removing package-name*`。这意味着它会删除以这个包名开头的所有文件。

我在手册页之类的文档中没有找到关于这个问题的答案。所以我自己做了一个小测试,我安装了 espeak 和 espeak-ng 这两个软件,espeak\* 应该可以通配扩展到 espeak-ng。
但是当我用 `apt purge` 删除 espeak 包时,espeak-ng 包还在,没有被一并删除。因此,这似乎是有一种防止通配符的扩展的机制。
### 那么,你应该使用 apt remove 还是 apt purge 呢?
很少有人会一直使用 `apt purge`。
在我看来,一般清况下,用 `apt remove` 就可以了,但是当你想删除那些自定义配置文件时,你就得用 `apt purge`。
不管是用 `apt remove` 还是 `apt purge`,你都需要从用户的主目录中删除残余的配置文件,并运行 `apt autoremove` 来清除任何依赖的包。
现在到你啦。你现在对 `apt remove` 和 `apt purge` 的区别更加了解吗?你更喜欢使用哪一个呢?
---
via: <https://itsfoss.com/apt-remove/>
作者:[Abhishek Prakash](https://itsfoss.com/) 选题:[lkxed](https://github.com/lkxed) 译者:[Tingze-G](https://github.com/Tingze-G) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

How do you uninstall apt packages in Ubuntu using the terminal? It’s quite simple, actually.
If you know the package name, just use it with the apt remove command like this:
`sudo apt remove package_name`
Even if you do not know the exact package name, tab completion is there to help you. You may also use the older apt-get remove command here.
`sudo apt-get remove package_name`
Both [apt and apt-get commands](https://itsfoss.com/apt-vs-apt-get-difference/) are pretty much alike. The new and recommended command is apt, which I would also suggest using.
If you want to remove multiple packages, you can do that in a single command:
`sudo apt remove package_1 package_2 package_3`
Let’s see all this in more detail.
## Uninstall apt packages
The [apt command](https://itsfoss.com/apt-command-guide/) gives you all the essential tools to manage the APT packages. For uninstalling a package, it provides the remove option.
`sudo apt remove package_name`
You need to use the exact package name. How do you get that? You can use the tab completion feature. Try entering the first few starting letters and press tab. It will show the possible package names you can use.
For example, I typed sudo apt remove mp and press the tab. My system shows that there are two installed packages with names starting with mp.
Alternatively, you can [list all the installed packages with apt](https://itsfoss.com/list-installed-packages-ubuntu/) and look for the package name:
`apt list --installed`
This will be a huge output and you may have to use the grep command to filter on the result.
I decide to remove the MPlayer from my system. The package name is mplayer (with all small letters). This is important because Linux is case-sensitive.
`sudo apt remove mplayer`
Installing and removing packages in Ubuntu requires that you have admin privileges. This is why you need to use sudo before the apt remove command.
It asks to enter a password. It’s your user account’s password. When you type the command, nothing is displayed on the screen. That’s expected behavior. Type the password and press enter.
As you can see in the screenshot below, it will show what packages are going to be removed. It also informs what dependency packages should be removed afterward.
You have to press y or the enter key to continue with package removal.
## Cleaning up after package removal (optional)
As you can see in the previous screenshot, it says, “The following packages were automatically installed and are no longer required” and then lists three packages.
These are dependency packages that were installed automatically when mplayer was installed.
So, what can you do? You can use the suggested command to remove these packages.
`sudo apt autoremove`
Do you really need to do that? No. You can just go ahead with your work after apt remove.
The dependency packages will stay in the system. Usually, you should try running the apt autoremove commands every few weeks. It will remove all the dependency packages that are not required anymore, [delete the older Linux kernel versions](https://itsfoss.com/remove-old-kernels-ubuntu/) and thus [free up disk space](https://itsfoss.com/free-up-space-ubuntu-linux/) for you.
## Dealing with configuration files after package removal
You should know that uninstalling apt package with apt remove does not remove user settings and configuration files (located under /etc directory).
This way, if you install the same application again, you may reuse your custom configuration.
Let’s take our example. Here are all the mplayer related directories before uninstalling it:
After removal, you can still see some files:
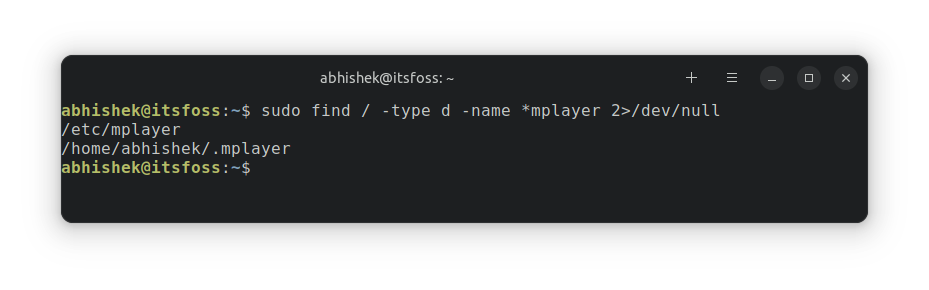
in certain cases, you might want the application to start afresh. You can use the apt purge command to uninstall apt applications and remove their configuration files located under /etc.
`sudo apt purge package_name`
Remember that even apt purge will not remove application-related files located under the user’s home directory. Those are really small files and do not take up a lot of space. If you are particular about these things, you can look for such files and manually remove them. There is no magic command for this.
## Summary
To summarize:
- The apt remove command removes the specified packages.
- The remaining dependencies need to be removed separately with apt autoremove command.
- It doesn’t remove configuration and other user settings. If you install the same application again, it will likely have your user-defined settings.
I hope you find this beginner’s article about removing apt package helpful.
Please let me know if certain things are unclear in the comments and I’ll be happy to answer your questions. |
15,460 | 构建高效的 DevOps 文化的 6 个技巧 | https://opensource.com/article/23/1/tips-effective-devops-culture | 2023-01-19T23:58:37 | [
"DevOps"
] | https://linux.cn/article-15460-1.html |
>
> 无论你是刚刚开始在你的组织中使用 DevOps,还是仅仅想改善你现有的文化,请考虑这些技巧以及它们与你组织的未来的关系。
>
>
>

你为什么要构建 [DevOps](https://opensource.com/resources/devops) 文化?开发团队和运维团队的精简协作有很多好处。效率是首要目标:提高新软件部署的速度,减少等待的时间。培养同事之间的信任可以提升员工的满意度,激发新的创新,并对盈利能力产生积极的影响。
[DevOps](https://opensource.com/article/22/2/devops-documentation-maturity) 是一个很广泛的思想,大家的理解也见仁见智。每个公司对于如何实行 DevOps 也各不相同。这种意见的多样性实际上是一件好事 —— 这么多的观点对于建立更强大的团队是很有用的。本指南将探讨在 DevOps 文化中鼓励同事之间更好地合作的最高技巧。
下面每个部分从不同的视角介绍 DevOps 文化,并探讨了将它引入员工队伍的方法。

### 流程的持续发展
DevOps 文化的这一核心原则使它与许多其他类型的工作场所的风气区别开来。DevOps 哲学说,犯错是有积极意义的,因为这表明你在尝试新的想法。
DevOps 文化的核心是不停地创造。实际上,这意味着当测试结果显示事情由于你的改动而变坏时,不要懊恼。我们要认识到,进化的过程不是线性的,通往成功的道路也从来不是一条直线。
DevOps 专家 [Gene Kim](https://enterprisersproject.com/user/gene-kim) 主张勇于承担风险和进行实验。鼓励你的团队尝试不寻常的任务,以得到新的领悟。
你的组织应该以利润为导向吗?你能允许你的团队尝试一些新东西(非指个人兴趣项目)吗?持续的流程发展意味着对升级目前的方法持开放态度。优秀的销售领导懂得,结果比出勤率更重要,因此,关注团队的工作方式而不是工作量的多少始终是关键。
### 随时提供反馈并积极寻求反馈
成员之间增加信任是蓬勃发展的 DevOps 文化的另一个关键特征。无论你的员工是在学习如何建立联盟网络联系,还是试图设计他们的下一个 [用户体验](https://opensource.com/article/22/7/awesome-ux-cli-application) 调查,每个人都应该对他们工作的反馈持开放态度。但是,除非你的团队成员尊重彼此的意见,并相信反馈是本着善意的精神提出的,否则这永远不会发生。
这种文化听起来可能是很难培养的;事实上,一些公司会比其他公司更努力地实现这一点。诚然,给予和接受反馈的成功很大程度上取决于员工的个性。在招聘过程中,也可以对此进行筛选。
在你期望员工随时向同事提供反馈并主动寻求反馈之前,你应该以身作则。高管应该以身作则,公开要求公司成员对其战略决策提出探究性问题,并提供相应的反馈。

### 不断改进
在同事之间增加对智力信任的基础上,你的团队应该寻找方法来改善其工作。DevOps 的性质意味着软件开发团队将比传统方法更迅速地进行部署。
这种开放的改进文化可以对开发和运维以外的部门产生积极的影响。你也可以自己去探索企业还有哪些领域会受到积极的影响。
留意培训和提高技能的机会。即使一个培训课程没有广告上说的那么突出,但有机会与行业专家建立联系,并与未来建立联系,这可以提高你的组织内的思想多样性。
### 为以后的开发保存当前的想法
频繁使用的 [Git](https://opensource.com/article/22/11/git-concepts) 账户应该是你的 DevOps 工具链的一部分。你可以用 Git 作为软件开发和其他相关项目中产生的脚本的共同仓库。Git 作为 “版本控制” 工具而被熟知,Git 允许程序员保存他们工作的迭代、复用或改进其他人的工作。
你的目标是能够保留好的想法以供将来使用。某个方法由于某种原因没有成功。然而,那套想法在当时是错误的,并不意味着它在未来永远无法成为有用的东西。
由于 DevOps 的整个重点在于生产环境中的软件的端到端所有权,因此节省开发的迭代真正支持这一原则。你希望看到对手头的软件测试项目的持续关注和投入。
一个简单的方法是要求开发者在开发者合同和最终项目报告中包含对未来工作的想法。确保技术服务经理知道他们应该要求提供在建设过程中出现的旁门左道的想法的例子。意识到这些小创新的人越多,在需要的时候就越有可能有人记住一个。
### 坐在一起(物理上或逻辑上)
目标是对彼此的工作角色以及它们之间的相互关系有一个共同的理解。你可以通过几个简单的方法实现这一目标,用一句话概括:坐在一起。邀请其他团队参加你们的会议,完整地分享用户反馈报告。一起吃午饭,一起计划虚拟的快乐时光,一般来说,要确保你的同事都在一起。大约 90% 的拥有成熟的 DevOps 协议的团队报告说,他们清楚地了解自己对其他团队的责任,而在不成熟的 DevOps 团队中,只有大约 46% 的工作者清楚地了解自己的责任。
虽然与志同道合的人结成小团体,只与被雇来执行与你相同任务的员工在一起是很诱人的,但这对整个企业来说是很糟糕的。无论你喜欢与否,所有的人都是多面手,能够在一系列的情况下贡献自己的独特才能。
密切协作的理念是尊重任何人对其周围正在进行的产品或工作流程提出改进建议的能力。如果你与公司内的其他部门保持一定的距离,你将会错过无数次分享智慧想法的机会。毕竟,你往往在交流中学习得最好。
### 致力于自动化
你应该以提高效率和加速流程的名义,寻求将单调的和重复的任务变为自动化。每个行业都有无聊的 —— 说得直白一点,就是愚蠢的 —— 每天或每周都要进行的工作。
无论是手工将数据从一页复制到另一页,还是手工打出音频记录,每个级别的工作人员都应该坚持让机器在可能的情况下承担这些负担。现实是自动化技术每年都在进步,操作流程也应该如此。[自动化测试](https://opensource.com/article/20/7/open-source-test-automation-frameworks) 对 DevOps 非常关键,它是 CALMS 框架的第二个原则(其中的 “C” 代表 “文化”)。
你怎样才能实现这一点?邀请员工公开表达他们认为工作的哪些方面可以自动化,然后 —— 这里是关键的部分 —— 支持实现自动化所需的设施。这可能意味着每年花 600 美元订阅一个软件程序、一套完整的企业应用现代化解决方案,或开发人员用两天时间来建立一个在内部使用新工具。
无论哪种方式,你都应该评估自动化的好处,考虑你可以为每个人节省多少时间。DevOps 的统计数据不断表明,现代公司通过整合这些有益的原则,年复一年地得到了很大的改善。
### 探索成功的新工作方式
文化转变不会在一夜之间发生。不过,你越早开始,就越早看到结果。根据我的经验,当变化真正对以前进行了改进时,人们会接受它。DevOps 为这种改进提供了一个框架。无论你是刚刚在你的组织中开始使用 DevOps,还是仅仅想改善你现有的文化,请考虑以上几点以及它们与你组织的未来的关系。
---
via: <https://opensource.com/article/23/1/tips-effective-devops-culture>
作者:[Yauhen Zaremba](https://opensource.com/users/yauhen-zaremba) 选题:[lkxed](https://github.com/lkxed) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Why would you want to build a [DevOps](https://opensource.com/resources/devops) culture? There are many benefits to the streamlined collaboration of the development and operations teams. A major goal is efficiency: Increasing the speed of new software deployments and reducing idle time for workers. Fostering trust between colleagues can improve employee satisfaction, produce new innovations, and positively impact profitability.
[DevOps](https://opensource.com/article/22/2/devops-documentation-maturity) is a broad philosophy with a range of interpretations. In other words, you can visit 40 companies and find 40,000 different ideas about using DevOps effectively in the workplace. This diversity of opinion is actually a good thing–so many perspectives are useful for building stronger teams. This guide will look at the top tips for encouraging better collaboration between colleagues within a DevOps culture.
Each section offers a different aspect of DevOps culture and looks at ways to introduce it into your workforce.
(Seth Kenlon, CC BY-SA 4.0)
## Continuous development of processes
This core tenet of DevOps culture sets it apart from many other types of workplace ethos. The DevOps philosophy says that it is essential to make mistakes because it shows you are trying out new ideas.
The heart of DevOps culture is a commitment to evolving creativity. Practically, that means not yelling at your direct reports when test results show that things were better before they changed it. It means recognizing that progress is not linear and success is never a straight line.
DevOps expert [Gene Kim](https://enterprisersproject.com/user/gene-kim) advocates for risk-taking and experimentation. This implies letting your team work on unusual tasks to find new insights.
Should your organization be profit-driven? Can you allow your teams to try something new? I'm talking about something other than unrelated passion projects. Continuous process development means being open to upgrading present methods. Great sales leaders appreciate that results matter more than presenteeism, so it is always crucial to focus on how teams are working rather than how much.
## Readily give feedback and actively seek it
Increased trust between individuals is another key feature of a thriving DevOps culture. Whether your staff is learning how to build affiliate network contacts or trying to design their next [UX](https://opensource.com/article/22/7/awesome-ux-cli-application) survey, everyone should be open to feedback on their work. But this will never happen until your teammates respect each other's opinions and trust that feedback is given in a spirit of good intention.
This culture may sound impossible to cultivate; indeed, some companies will struggle to achieve this more than others. Granted, a large part of the success of giving and receiving feedback depends on the personalities of your employees. It is possible to screen for this during the recruitment process.
Before you expect staff to readily offer feedback to colleagues and seek it in the first place, you should lead by example. Members of the C-suite should be modeling this behavior, openly asking members of the company to pose probing questions about their strategic decisions, and providing balanced feedback.
(Seth Kenlon, CC BY-SA 4.0)
## Always look for improvements
Building on increased intellectual trust between colleagues, your team should look for ways to improve its work. The nature of DevOps means the software development team will be producing deployments more rapidly than with traditional approaches.
However, this culture of openness to improvement can positively impact departments beyond development and operations. Ask yourself what other areas of your business could do with a burst of optimism.
Be on the lookout for training and upskilling opportunities. Even if a training course is less salient than advertised, the chance to network with industry professionals and build contacts for the future can only enhance the diversity of ideas within your organization.
## Save ideas for later development
Part of your DevOps toolchain should be a heavily used account on [Git](https://opensource.com/article/22/11/git-concepts). You can use Git as a common repository for scripts produced during software development and other related projects. Known as "version control," Git allows programmers to save iterations of their work and reuse or improve the work of others.
You're aiming for the ability to keep hold of good ideas for future use. A certain pathway did not work out for specific reasons. However, just because that set of ideas was wrong for the time it was conceived does not mean it can never become helpful in the future.
As the entire focus of DevOps rests on end-to-end ownership of software in production, saving iterations of developments truly supports this principle. You want to see an improved focus on and commitment to the software testing project at hand.
A simple way to incorporate this is to request that developers include ideas for future work in the developer contract and final project report. Make sure tech services managers know they should ask for examples of side-branching ideas that cropped up during the build. The more minds aware of these little innovations, the more likely someone will remember one when needed.
## Sit close together (physically or virtually)
The goal is to share a common understanding of one another's job roles and how they interrelate. You can achieve this in a few simple ways, summarized by three words: Sit close together. Invite other teams to your meetings and share user feedback reports in their entirety. Have lunch together, plan virtual happy hours together, and generally make sure your colleagues are in close proximity. About 90% of teams with a mature DevOps protocol report a clear understanding of their responsibilities to other teams compared to only about 46% of workers in immature DevOps teams.
Although it can be tempting to form cliques with like-minded folk and only hang out with staff hired to carry out the same tasks as you, this is terrible for the business as a whole. Whether you like it or not, all humans are multi-faceted and capable of contributing their unique talents to a whole host of scenarios.
The idea of closer collaboration is to honor the ability of anyone to suggest improvements to the products or work processes going on around them. If you only ever sit at a distance from the other departments within the company, you will miss countless opportunities to share intelligent ideas. After all, you often learn best in the free flow of ideas during a conversation.
## Commit to automation
You should be looking to automate mundane and repetitive tasks in the name of efficiency and process acceleration. Every industry has boring–and quite frankly, silly–exercises carried out daily or weekly.
Whether this is manually copying data from one page to another or typing out audio transcripts by hand, staff at every level should insist that machines take on such burdens where possible. The reality is automation technology advances every single year, and operational processes should, too. [Automation testing](https://opensource.com/article/20/7/open-source-test-automation-frameworks) is so crucial to DevOps that it is the second principle of the CALMS framework (the "C" of which stands for "culture").
How can you make this happen? Invite staff to openly express which aspects of their job they feel could be automated and then–here is the crucial part–support the facilities needed to automate them. That might mean a $600 annual subscription to a software program, a complete enterprise application modernization, or two days of developers' time to build a new tool to use in-house.
Either way, you should assess the benefits of automation and consider how much time you could save for everyone. DevOps statistics continually indicate just how much better off modern companies are by integrating these beneficial principles year after year.
## Explore new ways of working successfully
A culture shift doesn't happen overnight. The sooner you start, though, the sooner you see results. In my experience, people embrace change when it's a genuine improvement on what has gone before. DevOps provides a framework for such improvements. Whether you're just getting started with DevOps in your organization or simply want to improve your existing culture, consider the above points and how they relate to your organization's future.
## Comments are closed. |
15,461 | 用复古电脑程序 Toy CPU 学习低级编程 | https://opensource.com/article/23/1/learn-machine-language-retro-computer | 2023-01-20T19:00:00 | [
"编程",
"Altair",
"低级语言"
] | /article-15461-1.html | 
>
> 我写了一个名为 “Toy CPU” 的教育性复古计算机程序,以便我的学生能够学习机器语言。
>
>
>
我兼职教授大学课程,包括一个对所有专业开放的一般计算机主题的课程。这是一门入门课程,向学生讲授技术是如何运作的,以消除围绕计算的神秘感。
虽然不是计算机科学课程,但这门课的一个部分涉及计算机编程。我通常用非常抽象的术语谈论编程,所以不会让听众听不懂。但是今年,我想让我的学生以 “老派” 的方式做一些需要 “动手” 的编程。同时,我又想保持简单,以便让每个人都能跟上。
我喜欢将我的课程结构化,以显示你是如何从 “那里” 到 “这里” 的。理想情况下,我会让我的学生学习如何编写一个简单的程序。然后,我将从这里开始,展示现代编程是如何让开发人员创建更复杂的程序的。我决定尝试一种非常规的方法 —— 教学生学习终极的低级别编程语言:机器语言。
### 机器语言编程
早期的个人电脑如 Apple II(1977 年)、TRS-80(1977 年)和 IBM PC(1981 年)让用户用键盘输入程序,并在屏幕上显示结果。但计算机并不总是带有屏幕和键盘。
Altair 8800 和 IMSAI 8080(均为 1975 年制造)要求用户使用面板上的 “开关和灯” 输入程序。你可以用机器语言输入指令,使用一组开关,机器会点亮 LED 灯以代表每个二进制指令的 1 和 0。

对这些早期机器进行编程,需要了解被称为 “<ruby> 操作码 <rt> opcode </rt></ruby>” (操作代码的简称)的机器语言指令,以执行基本操作,如将两个数字相加或将一个值存储到计算机的存储器中。我想向我的学生展示程序员是如何通过开关和灯,手工输入一系列指令和内存地址的。
然而,在这门课上,使用实际的 Altair 8800 就有点太复杂了。我需要一些简单的、任何初级水平的学生都能掌握的东西。理想情况下,我希望能找到一个简单的 “业余” 复古计算机,其工作原理与 Altair 8800 相似,但我无法找到一个价格低于 100 美元的合适的 “类似 Altair” 的设备。我找到了几个 “Altair” 软件模拟器,但它们忠实地再现了 Altair 8800 的操作码,这对我的需求来说太过沉重。
我决定编写我自己的 “教育” 复古计算机。我称它为 “Toy CPU”。你可以在我的 [GitHub 代码库](https://github.com/freedosproject/toycpu) 上找到它,包括几个可以运行的版本。第一版是一个实验性的原型,运行在 [FreeDOS](https://opensource.com/downloads/guide-using-freedos) 上。第二版是一个更新的原型,在 Linux 上用 [ncurses](https://opensource.com/article/21/8/ncurses-linux) 运行。版本 3 是一个 FreeDOS 程序,在图形模式下运行。
### Toy CPU 的编程
Toy CPU 是一个非常简单的复古计算机。它只有 256 字节的内存和一个最小化的指令集,其目的是在复制 “开关和灯” 编程模式的同时保持简单化。它的界面模仿 Altair 8800,有一系列 8 个 LED 灯,分别代表计数器(程序的 “行号”)、指令、累积器(用于临时数据的内部存储器)和状态。
当你启动 Toy CPU 时,它通过清除内存来模拟 “启动”。当它启动时,它也会在屏幕右下方的状态灯中显示 “INI”(初始化)。“PWR”(电源)灯亮表示 Toy CPU 已被打开。

当 Toy CPU 准备好让你进入一个程序时,它通过状态灯指示 “INP”(“输入”模式),并让你从程序的计数器 0 开始。Toy CPU 的程序总是从计数器 0 开始。
在 “输入” 模式下,用上下方向键显示不同的程序计数器,按回车键编辑当前计数器上的指令。当你进入 “编辑” 模式时,Toy CPU 的状态灯上会显示 “EDT”(“编辑” 模式)。

Toy CPU 有一张速查表,被 “贴” 在显示屏的前面。它列出了 Toy CPU 可以处理的不同操作码。
* `00000000`(`STOP`):停止程序执行。
* `00000001`(`RIGHT`):将累加器中的位向右移动一个位置。值 `00000010` 变成 `00000001`,`00000001` 变成 `00000000`。
* `00000010`(`LEFT`):将累加器中的位向左移动一个位置。值 `01000000` 变成 `10000000`,`10000000` 变成 `00000000`。
* `00001111`(`NOT`):对累加器进行二进制非操作。例如,值 `10001000` 变成 `01110111`。
* `00010001`(`AND`):对累加器用存储在某一地址的值进行二进制与操作。该地址被存储在下一个计数器中。
* `00010010`(`OR`):对累积器用存储在某一地址的值进行二进制或运算。
* `00010011`(`XOR`):对累加器用存储在某一地址的值进行二进制异或运算。
* `00010100`(`LOAD`):将一个地址的值加载(复制)到累加器中。
* `00010101`(`STORE`): 存储(复制)累加器中的值到一个地址。
* `00010110`(`ADD`):将存储在某一地址的数值加入到累加器中。
* `00010111`(`SUB`):从累积器中减去储存在某一地址的数值。
* `00011000`(`GOTO`):转到(跳到)一个计数器地址。
* `00011001`(`IFZERO`):如果累加器为零,转到(跳到)一个计数器地址。
* `10000000`(`NOP`):空操作,可以安全地忽略。
当处于 “编辑” 模式时,使用左右方向键选择操作码中的一个位,然后按空格键在关闭(0)和开启(1)之间翻转数值。当你完成编辑后,按回车键回到 “输入” 模式。

### 一个示例程序
我想通过输入一个简短的程序来探索 Toy CPU,将两个数值相加,并将结果存储在 Toy CPU 的内存中。实际上,这执行的是算术运算 `A+B=C`。要创建这个程序,你只需要几个操作码:
* `00010100`(`LOAD`)
* `00010110`(`ADD`)
* `00010101`(`STORE`)
* `00000000`(`STOP`)
`LOAD`、`ADD` 和 `STORE` 指令需要一个内存地址,这个地址总是在下一个计数器的位置。例如,程序的前两条指令是:
```
计数器 0:00010100
计数器 1:某个内存地址,第一个值 A 存放在那里
```
计数器 0 中的指令是 `LOAD` 操作,计数器 1 中的值是你存储某个值的内存地址。这两条指令一起将内存中的数值复制到 Toy CPU 的累加器中,在那里你可以对该数值进行操作。
将一个数字 `A` 装入累加器后,你需要将数值 `B` 加到它上面。你可以用这两条指令来做:
```
计数器 2:00010110
计数器 3:存储第二个值 B 的内存地址
```
假设你把值 `1`(`A`)装入累加器,然后把值 `3`(`B`)加到它上面。现在累加器的值是 `4`。现在你需要用这两条指令把数值 `4` 复制到另一个内存地址(`C`):
```
计数器 4:00010101
计数器 5:一个内存地址(C),我们可以在那里保存新的值
```
把这两个值加在一起后,现在可以用这条指令结束程序:
```
计数器 6: 00000000
```
计数器 6 之后的任何指令都可以供程序作为存储内存使用。这意味着你可以用计数器 7 的内存来储存值 `A`,计数器 8 的内存来储存值 `B` ,计数器 9 的内存来储存值 `C`。你需要将这些分别输入到 Toy CPU 中:
```
计数器 7:00000001(1)
计数器 8:00000011(3)
计数器 9:00000000(0,以后会被覆盖)
```
在弄清了所有指令和 `A`、`B` 和 `C` 的内存位置后,现在可以将完整的程序输入到 Toy CPU 中。这个程序将数值 1 和 3 相加,得到 4:
```
计数器 0:00010100
计数器 1:00000111(7)
计数器 2:00010110
计数器 3:00001000(8)
计数器 4:00010101
计数器 5:00001001(9)
计数器 6:00000000
计数器 7:00000001(1)
计数器 8:00000011(3)
计数器 9:00000000(0,以后会被覆盖)
```
要运行程序,在 “输入” 模式下按下 `R` 键。Toy CPU 将在状态灯中显示 “RUN”(“运行” 模式),并从计数器 0 开始执行你的程序。
Toy CPU 有一个明显的延迟,所以你可以看到它执行程序中的每一步。随着程序的进行,你应该看到计数器从 `00000000`(0)移动到 `00000110`(6)。在计数器 1 之后,程序从内存位置 7 加载数值 `1`,累积器更新为 `00000001`(1)。在计数器 3 之后,程序将加数值 `3`,并更新累加器显示 `00000100`(4)。累加器将保持这种状态,直到程序在计数器 5 之后将数值存入内存位置 9,然后在计数器 6 结束。

### 探索机器语言编程
你可以使用 Toy CPU 来创建其他程序,并进一步探索机器语言编程。通过用机器语言编写这些程序来测试你的创造力。
### 一个在累积器上闪灯的程序
你能点亮累加器上的右四位,然后是左四位,然后是所有的位吗?你可以用两种方法之一来写这个程序。
一种直接的方法是,从不同的内存地址加载三个数值,像这样:
```
计数器 0:LOAD
计数器 1:“右边”
计数器 2:LOAD
计数器 3:“左边”
计数器 4:LOAD
计数器 5:“所有”
计数器 6:STOP
计数器 7:00001111(“右边”)
计数器 8:11110000(“左边”)
计数器 9:11111111(“全部”)
```
写这个程序的另一种方法是尝试使用 `NOT` 和 `OR` 二进制操作。这样可以得到一个更小的程序:
```
计数器 0:LOAD
计数器 1:“右边”
计数器 2:NOT
计数器 3:OR
计数器 4:“右边”
计数器 5:STOP
计数器 6:00001111(“右边”)
```
### 从一个数字开始倒数
你可以把 Toy CPU 作为一个倒数计时器。这个程序行使 `IFZERO` 测试,只有当累加器为零时,程序才会跳转到一个新的计数器:
```
计数器 0:LOAD
计数器 1:“初始值”
计数器 2:IFZERO(这也是倒计时的“开始”)
计数器 3:“结束”
计数器 4:SUB
计数器 5:“1”
计数器 6:GOTO
计数器 7:“开始”
计数器 8:STOP
计数器 9:00000111(“初始值”)
计数器 10:00000001(“1”)
```
Toy CPU 是学习机器语言的一个好方法。我在入门课程中使用了 Toy CPU,学生们说他们发现写第一个程序很困难,但写下一个程序就容易多了。学生们还表示,用这种方式编写程序其实很有趣,他们学到了很多关于计算机实际工作的知识。Toy CPU 既具有教育性,也很有趣味性!
---
via: <https://opensource.com/article/23/1/learn-machine-language-retro-computer>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,463 | 2023 年值得期待的 11 个新发行版 | https://news.itsfoss.com/new-distros-2023/ | 2023-01-21T11:56:00 | [
"Linux",
"发行版"
] | https://linux.cn/article-15463-1.html |
>
> 你对 2023 年有什么期待?试试这些发行版吧!
>
>
>

是时候向 2022 年说再见了!?
2022 年有很多发行版发布,其中有一些非常出色。
随着人们越来越关注用户体验和性能,Linux 发行版在过去的一年中有了显著的发展。
对于你我这样的最终用户,可以有几个选择。你可以尝试一些 [对初学者友好的选项](https://itsfoss.com/best-linux-beginners/) 或者尝试一些 [面向资深用户的发行版](https://itsfoss.com/advanced-linux-distros/)。
在本文中,我将重点介绍一些你可以尝试一下看看的新发行版。这些发行版可能不一定能取代现有的流行发行版。但是,如果你想尝试一些新的东西,可以试试列表中的这些。
所以,你在 2023 年可以期待什么??
好吧,为了回答这个问题,让我们踏上发行版之旅吧!
>
> ? 新的发行版可能不适合生产环境。如果你不介意尝试新的东西,可以尝试这些选项。
>
>
>
### 1、Vanilla OS

Vanilla OS 是一个基于 Ubuntu 的发行版,它是 [Bottles](https://usebottles.com) 的创建者 Mirko Brombin 的心血结晶。
它旨在提供一个具有\*\*干净、原生的 GNOME 体验,以及<ruby> 按需不变性 <rt> on-demand immutability </rt></ruby>\*\*和优秀的首次安装体验。
>
> LCTT 译注:<ruby> 按需不变性 <rt> on-demand immutability </rt></ruby>,指一个可以按需让文件不可更改的功能,用于确保系统文件不会被随意更新。 可参考 [此链接](https://documentation.vanillaos.org/docs/almost/)。
>
>
>
如果你想尝试一些新的东西并且想尝试一下按需不变性这个令 Vanilla OS 如此独特的功能,可以尝试一下这个发行版。
它还没有稳定版本,在一段时间内也不会有,预计将在 2023 年进行许多改进。
>
> **[Vanilla OS](https://vanillaos.org)**
>
>
>
### 2、XeroLinux

这个兴趣项目 [XeroLinux](https://itsfoss.com/xerolinux/) 是 Steve(即 TechXero)启动的,这个项目并不打算成为一个主流发行版,也没有各种花里胡哨的东西。
这个 “养眼” 版的 Arch Linux 衍生版提供了令人愉快的开箱即用体验和一些令人兴奋的功能。
如果你希望获得更加易用的 Arch Linux 体验,可以尝试这个。
**从 2023 年 1 月起**,XeroLinux 将切换到每月发布的计划。所以,你可以期待 2023 年有很多更新!
>
> **[XeroLinux](https://xerolinux.xyz)**
>
>
>
### 3、Crystal Linux

Crystal Linux 是一个即将发布的基于 Arch 的发行版,它希望**提供一个易于使用的桌面体验,以及现代 Linux 技术**。
在目前的状态下,它可能不适合新手,而具有 Linux 使用经验的人更有可能喜欢它。
所以,就目前而言,我建议已经熟悉 Linux 的用户可以尝试一下 Crystal Linux。
我预计 Crystal Linux 将在 2023 年有一个稳定版本,该版本将具有许多功能和改进,而这些功能和改进都是基于目前可用的 [beta 版本](https://getcryst.al)。
>
> **[Crystal Linux](https://getcryst.al)**
>
>
>
### 4、TUXEDO OS

[TUXEDO OS](https://news.itsfoss.com/tuxedo-os/) 是一个由 TUXEDO 计算机公司(一个专注 Linux 的硬件制造商)提供的基于 Ubuntu 的发行版。
它提供了 KDE Plasma 桌面环境,还有一些额外的功能,例如用于微调硬件的 **TUXEDO 控制中心**,以及一个用于解决驱动程序与缺少软件包的问题的配置服务 **TUXEDO Tomte**。
如果你想要一个**不同的 KDE 驱动的体验**,我建议你尝试一下。
最开始,它只作为预装系统在 TUXEDO 的笔记本和台式电脑上提供。
但是后来,它在 2022 年 9 月获得了一个通用版本,称为 “TUXEDO OS 1”。它将在 2023 年获得大量更新。
>
> **[TUXEDO OS](https://www.tuxedocomputers.com/en/TUXEDO-OS_1.tuxedo)**
>
>
>
### 5、EuroLinux

[EuroLinux](https://news.itsfoss.com/eurolinux-desktop/) 是一个具有**企业级特性**的、基于 RHEL 的发行版。它以可靠的软件包提供了稳定性和安全性。
它基于 **RHEL 9**,可以提供与其他 [基于 RHEL 的服务器发行版](https://itsfoss.com/rhel-based-server-distributions/)(如 Rocky Linux,CentOS,AlmaLinux 等)的无缝兼容性。
它旨在以熟悉的用户界面布局吸引 Windows 和 macOS 用户,在屏幕底部提供了一个半透明的菜单栏。
你应该尝试一下,因为整个软件包相当充分,可以同时满足 Linux 和 Windows/macOS 用户的需要。
它现在已经发布了稳定版本,也在 2023 年有更新计划。
>
> **[EuroLinux](https://en.euro-linux.com/eurolinux/desktop/)**
>
>
>
### 6、Zinc

[Zinc](https://teejeetech.com/tag/zinc/) 是一个 **基于 Ubuntu 的发行版**,经过了调整后提供了一个独特的体验。现有的 Ubuntu 用户可能会惊讶于它所提供的内容。
它基于 **Xubuntu** 的最新 LTS 版本,使用了 XFCE 桌面环境,并对其进行了许多改进,例如集成的 Linux AppImage 支持、deb-get 包安装程序、BTRFS 作为默认文件系统等。
如果你正确的配置了它,它可以成为你的日用操作系统的替代品。
它遵循稳定的发布模式,因此你可以期待 2023 年的重大更新!
>
> **[Zinc](https://teejeetech.com/tag/zinc/)**
>
>
>
### 7、CachyOS

[CachyOS](https://cachyos.org) 尝试使 **Arch Linux 变得对初学者更加友好**,让任何人都可以使用。它很受欢迎,因为它具有高度的可定制性,而且还拥有最新的软件。
它旨在为你提供一个快速、安全且易于使用的操作系统。
该操作系统适用于想要试验和尝试新事物的用户。
CachyOS 是一个滚动发布的发行版,因此你可以期待它在 2023 年获得大量更新。
>
> **[CachyOS](https://cachyos.org)**
>
>
>
### 8、risiOS

在基于 Arch 和 Ubuntu 的 Linux 发行版的海洋中,[risiOS](https://risi.io) 是一道难得的风景。
该项目基于 Fedora Linux,其起源于美国西雅图。
它使用 **GNOME 桌面环境** 为用户提供了一个高度可定制的体验,同时还提供了 **自定义的 ZSH 版本**。
如果你希望尝试一个基于 Fedora 的发行版,这可能是你的新选择!
risiOS 会在稳定版本间隔中推送一些小更新。在 2023 年,它还有更多的东西可以提供给你。
>
> **[risiOS](https://risi.io)**
>
>
>
### 9、Exodia OS

#$\*\*!又是一个基于 Arch 的 Linux 发行版?
是的。? 好吧,看起来今年我们已经受够了基于 Arch 的发行版了,这并不一定是坏事!
认识一下 [Exodia OS](https://exodia-os.github.io/exodia-website/),一个基于 Arch 的 Linux 发行版,旨在为安全领域的用户提供高度可定制的体验。
其功能包括**为各种网络安全领域预装的工具、命令行界面应用、ElKowars wacky widgets (EWW)、Zsh 等**。
如果你是一个网络安全专家或爱好者,你可以试试!
他们为三个不同的使用场景提供了三个版本。你可以期待他们在 2023 年继续推送必要的更新和功能添加。
>
> **[Exodia OS](https://exodia-os.github.io/exodia-website/)**
>
>
>
### 10、Kumandar Linux

乍一看,你可能会认为这是 Windows 7,但如果仔细观察,你会发现这是 [Kumandar Linux](https://www.kumander.org)。
它基于**Debian 11,并使用自定义的 XFce 版本**。
该名称在中文中的含义为 “指挥官”,以向开发者的第一台电脑 [Commodore VIC20](https://en.wikipedia.org/wiki/VIC-20) 致敬。
如果你喜欢 Windows 7,但想在 Linux 上体验同样的体验,那么你可以试试!
目前,该系统只发布了早期的候选版本。但是,你可以期待在 2023 年发布稳定版本,希望如此!
>
> **[Kumander](https://www.kumander.org)**
>
>
>
### 11、Ubuntu Unity

[今年早些时候](https://news.itsfoss.com/unity-remix-official-flavor/),Ubuntu Unity 被宣布为 Ubuntu 的官方版本,是 Ubuntu 的一个翻版。
它使用了 2010 - 2017 年间 Ubuntu 中使用的 Unity 桌面界面,该界面后来被 Canonical 使用 GNOME 取代。
开发工作如火如荼,年轻的首席开发人员正在推动更新和增加新功能。
想要尝试不同风格的 Ubuntu 的用户可以试试这个系统。它提供了 LTS 和非 LTS 版本。
>
> **[Ubuntu Unity](https://ubuntuunity.org/)**
>
>
>
### 总结
即使有了这份全面的清单,我也可能遗漏了一些。 ?
但是。
或许 2023 年会有惊喜的发布占据头版,或者一些现有的发行版会尝试一些不同的东西。
但在那之前,
*? 请告诉我你在 2023 年期待着哪些发行版?*
---
via: <https://news.itsfoss.com/new-distros-2023/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It's time to say goodbye to 2022! 📆
There were many distro releases in 2022, some more extraordinary than others.
With the trend shifting towards focusing more on the user experience and performance side of things, Linux distributions have significantly evolved over the past year.
As for you, the end-user, you now have several options. You can try some [beginner-friendly options](https://itsfoss.com/best-linux-beginners/?ref=news.itsfoss.com) or [distros for advanced users](https://itsfoss.com/advanced-linux-distros/?ref=news.itsfoss.com).
Here, I focus on new options that you can give a try. These distros may not necessarily replace the popular distributions available. But if you want to try something new and different, feel free to go through the list.
So, what can you expect in 2023? 🤔
Well, to answer that. Allow me to take you on a distro journey!
## 1. Vanilla OS
Vanilla OS is an Ubuntu-based distro that is the brainchild of Mirko Brombin, the creator of [Bottles](https://usebottles.com/?ref=news.itsfoss.com).
It aims to provide a **clean, vanilla GNOME experience with on-demand immutability** and an exceptional first-time setup experience.
You can check it out if you want something new and want to try out the on-demand immutability features that make Vanilla OS so unique.
It is yet to receive a stable release (soon) and is set to receive many improvements in 2023.
### Related Read 📖
[‘Don’t be Afraid to Contribute’: Mirko Brombin Talks about Vanilla OS and Other Future ProjectsA conversation with Mirko Brombin, founder of Vanilla OS and Bottles creator.](https://news.itsfoss.com/interview-mirko-brombin/)

## 2. XeroLinux
Steve a.k.a. TechXero, started [XeroLinux](https://itsfoss.com/xerolinux/?ref=news.itsfoss.com) as a passion project that was not meant to be a mainstream distro with all the bells and whistles.
An **'eye-candy' version of Arch Linux** offers a pleasant out-of-the-box experience with a few exciting features.
You can try this if you want a more accessible Arch Linux experience.
## 3. Crystal Linux
Crystal Linux is an upcoming Arch-based distro that wants to **provide an easy-to-use desktop experience coupled with modern Linux technologies**.
In its current form, it may not be welcoming to newcomers, and people with experience using Linux are likelier to like it.
So, for now, I would suggest users who are already familiar with Linux give Crystal Linux a try.
I expect Crystal Linux to have a stable release sometime in 2023 with many features and improvements over the [beta version](https://git.getcryst.al/crystal?ref=news.itsfoss.com) that is available right now.
### Recommended Read 📖
[Crystal Linux: An Avant-garde Mix of Arch Linux and GNOMECrystal Linux is an upcoming Arch-based distro with a focus to make the setup easy while using latest technologies. Sounds interesting?](https://news.itsfoss.com/crystal-linux-dev/)

## 4. TUXEDO OS

[TUXEDO OS](https://news.itsfoss.com/tuxedo-os/) is an Ubuntu-based offering from TUXEDO Computers, a Linux-focused hardware manufacturer.
It features the KDE Plasma desktop environment with extras like **TUXEDO Control Center** to fine-tune your hardware and **TUXEDO Tomte**, a configuration service for resolving driver/missing package issues.
I suggest you try this if you want a **different KDE-powered experience**.
Initially, it was only made available as a pre-installed operating system on TUXEDO laptops and computers.
But later, it received a general use release back in September 2022 dubbed as 'TUXEDO OS 1'. It is set to receive plenty of updates in 2023.
### Related Read 📖
[Best Linux Distributions For Everyone in 2022 - It’s FOSSWhich is the best Linux distribution? There is no definite answer to that question. This is why we have compiled this list of best Linux in various categories.](https://itsfoss.com/best-linux-distributions/?ref=news.itsfoss.com)

## 5. EuroLinux

An RHEL-based distro with **enterprise perks** is what [EuroLinux](https://news.itsfoss.com/eurolinux-desktop/) is. It provides stability and security in a solid package.
Based on **RHEL 9**, it can provide seamless compatibility with other [RHEL-based server distros](https://itsfoss.com/rhel-based-server-distributions/?ref=news.itsfoss.com) such as Rocky Linux, CentOS, AlmaLinux, and more.
It aims to lure in Windows and macOS users with a familiar user interface layout with its implementation of a translucent dock at the bottom of the screen.
You should try this because the overall package is quite adequate and can cater to both Linux and Windows/macOS users.
It is now available as stable release, with updates planned for 2023.
## 6. Zinc
[Zinc](https://teejeetech.com/tag/zinc/?ref=news.itsfoss.com) is an **Ubuntu-based distro** that has been tweaked to provide a unique experience. Existing Ubuntu users may be surprised to see what it has to offer.
Based on the latest LTS release of **Xubuntu**, it uses the XFCE desktop environment with numerous improvements, such as integrated Linux AppImage support, deb-get package installer, BTRFS as the default file system, and more.
This distro can be a viable alternative to replace your daily driver, provided it is set up correctly.
It follows a stable release model, so you can expect significant updates in 2023!
## 7. CachyOS
[CachyOS](https://cachyos.org/?ref=news.itsfoss.com) tries to make **Arch Linux a beginner-friendly affair** that anyone can use. It is popular because of its high level of customizability and also because it has the newest software.
It aims to provide you with a fast and secure operating system that is easy to use.
This OS is for users who want to experiment and try something new.
CachyOS is a rolling-release distro, so you can expect it to receive a ton of updates in 2023.
## 8. risiOS
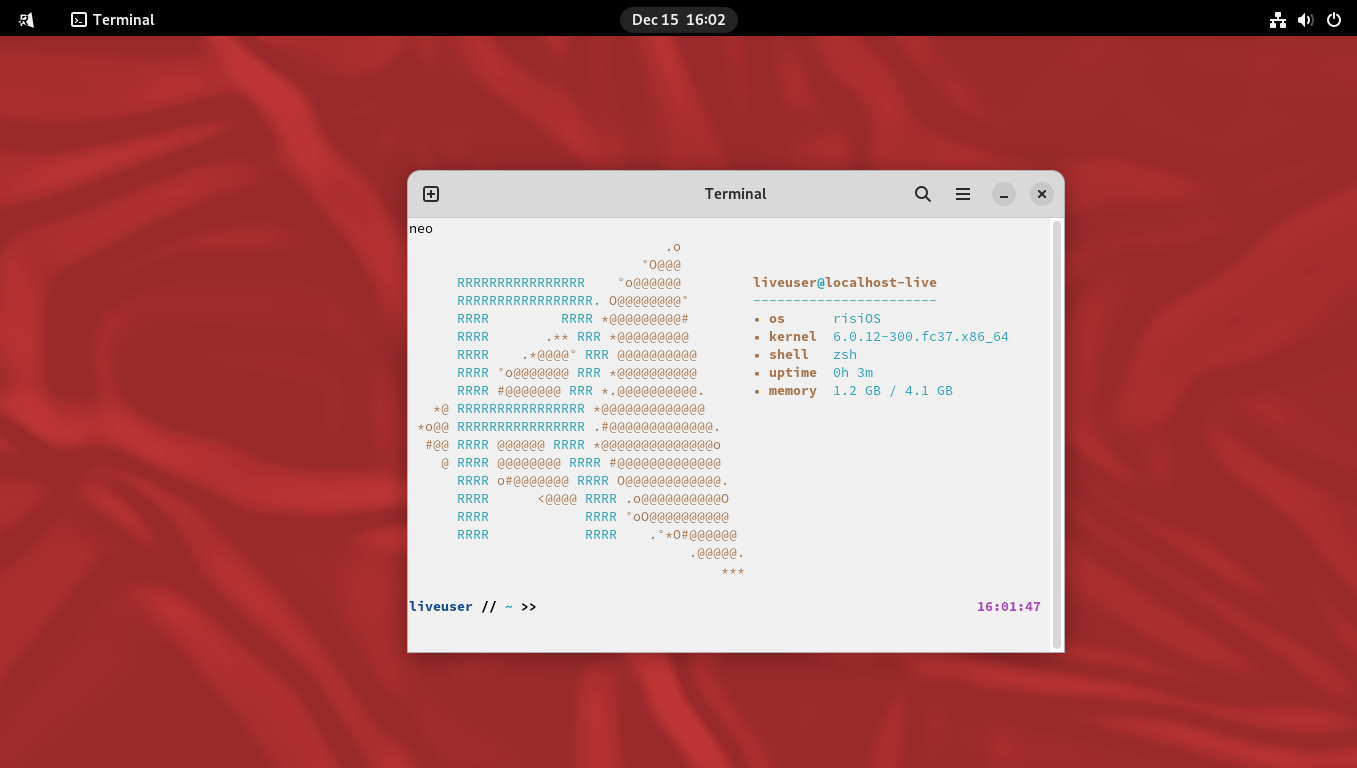
In a sea of Arch and Ubuntu-based Linux distros, [risiOS](https://risi.io/?ref=news.itsfoss.com) is a rare sight to see.
Based on Fedora Linux, the project saw its beginnings in Seattle, USA.
It uses the **GNOME desktop environment** to provide users with a highly customizable experience with a **customized ZSH version**.
If you want to try a Fedora-based distro, this can be something new for you!
risiOS gets a stable release with minor updates pushed in between. It has much more to give in 2023.
## 9. Exodia OS
Another Arch-based Linux distro!#$**?
Yes. 🤭 Well, it looks like this year, we have had enough of Arch-based distros, which is not necessarily bad!
Meet [Exodia OS](https://exodia-os.github.io/exodia-website/?ref=news.itsfoss.com), an Arch-based Linux distro that aims to be highly customizable for users in cybersecurity fields.
Its feature set includes pre-installed** tools for all cybersecurity fields, TUI Apps, ElKowars wacky widgets (EWW), zsh, and more**.
If you are a cybersecurity expert or an enthusiast, you can give this a try!
They offer three releases for different use cases. You can expect them to keep pushing essential updates and feature additions in 2023.
## 10. Kumandar Linux
At first glance, you would think that it is Windows 7, but if you look closer, you will find that it is [Kumandar Linux](https://www.kumander.org/?ref=news.itsfoss.com).
It is based on **Debian 11 and uses a customized version of XFCE**.
The name stands for 'Commander' in English and pays homage to the developer's first computer, the [Commodore VIC20](https://en.wikipedia.org/wiki/VIC-20?ref=news.itsfoss.com).
If you liked the Windows 7 experience but wanted the same thing on Linux. Then you can give this a try!
Currently, only the early-release candidate has been released. But you can expect a stable release in 2023, hopefully!
## 11. Ubuntu Unity
Declared as an official flavor of Ubuntu [earlier this year](https://news.itsfoss.com/unity-remix-official-flavor/), Ubuntu Unity is a remix of Ubuntu.
It features the **Unity desktop interface** used in Ubuntu from 2010-2017, which was dropped in favor of GNOME.
The development has been in full swing, with the young lead developer pushing updates and feature additions.
Users who want to try a different flavor of Ubuntu can give this a shot. It offers both LTS and non-LTS releases.
**So, wrapping up.**
Even with this comprehensive list, I may have missed out on some. 🤔
But.
Maybe a surprise release will take the headlines in 2023, or some existing distro will try something different.
Until then.
*💬 Do tell me what distribution you are excited about in 2023?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,464 | Colorblind Filters:帮助色盲用户的 GNOME 扩展 | https://www.debugpoint.com/colorblind-filters-gnome-extension/ | 2023-01-21T12:29:00 | [
"色盲",
"GNOME"
] | /article-15464-1.html | 
>
> 一个不错的 GNOME 扩展:Colorblind Filters,它为色盲用户带来了许多调整选项。
>
>
>
无障碍是计算和操作系统的一个重要方面。它包括对视力障碍、色盲和许多其他健康症状的管理设置。流行的 Linux 桌面环境,如 GNOME 和 KDE Plasma,具有无障碍设置,以帮助所有这些情况。
感谢 GNOME 扩展生态系统,有大量的专门扩展可以帮助这些用户。我遇到的其中一个扩展是[“Colorblind Filters”](https://extensions.gnome.org/extension/5589/colorblind-filters/)。
### Colorblind Filters – GNOME 扩展
根据维基百科,*"色盲通常涉及无法区分红色和绿色的深浅。遗传性色盲症没有治疗方法。如果色盲是由其他疾病引起的,治疗潜在的原因会有帮助。"*。
因此,你有可以调整你的 Linux 桌面设置的选项是很重要的。
#### 设置扩展程序和 Flatpak
首先,确保你已经启用了 Flatpak 和 GNOME 扩展。并且安装了扩展管理器。你可以参考这个关于如何 [设置 flatpak](https://www.debugpoint.com/how-to-install-flatpak-apps-ubuntu-linux/) 和启用 [GNOME 扩展](https://www.debugpoint.com/how-to-install-and-use-gnome-shell-extensions-in-ubuntu/) 的详细指南,或者从终端运行以下命令(对于 Ubuntu、Linux Mint 等)。
```
sudo apt install flatpak
sudo apt install gnome-software-plugin-flatpak
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
reboot
```
对于 Fedora 用户,使用以下命令。
```
sudo dnf install flatpak
sudo dnf install gnome-software-plugin-flatpak
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
reboot
```
完成后,安装扩展管理器:
```
flatpak install com.mattjakeman.ExtensionManager
```
#### 安装扩展
从应用菜单中打开扩展管理器。搜索 “colorblind”。并安装该扩展(见下图)。

安装后,你可以在系统托盘上看到一个小眼睛图标。你可以点击它来启用预定义的颜色过滤器。

右键点击眼睛图标以获得更多设置。这个扩展带来了色盲集合、模拟和额外选项的所有必要定制。目前有以下选项:
* 纠正和模拟(具有高对比度)
+ 红色盲
+ 绿色盲
+ 蓝黄色盲
* 额外的调整
+ GBR 和 BRG 的通道混合器
+ 亮度反转
+ 颜色反转

使用最适合你的眼睛的那个。
### 总结
我认为苹果的 macOS 和 iOS 已经实现了比 Windows 或 Linux 更好的无障碍。然而,Linux 桌面在这些应用和扩展方面也不落后。另外,还有一些专门的 Linux 发行版,如 “[Accessible Coconut](https://www.debugpoint.com/accessible-coconut-linux-visually-impaired/)”,它是为专门的需求而建立的。
我希望 Colorblind GNOME 扩展对你日常使用 Linux 和 GNOME 桌面有帮助。
干杯。
---
via: <https://www.debugpoint.com/colorblind-filters-gnome-extension/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,466 | Wordbook:适用于 GNOME 的离线英语词典应用 | https://www.debugpoint.com/wordbook-offline-dictionary/ | 2023-01-22T12:00:00 | [
"词典"
] | /article-15466-1.html | 
>
> 遇见 Wordbook:一个 GNOME 桌面的离线词典应用。
>
>
>
我们大多在谷歌、DDG 或其他搜索引擎上搜索单词信息,如含义、同义词、反义词等。
由于今天几乎每个人都有一个连接互联网的手机,在谷歌上搜索可能更容易。
但对于离线使用,在没有互联网连接的情况下,你可以尝试 [Wordbook](https://github.com/fushinari/Wordbook)。
### Wordbook:离线词典应用
这个应用在本质上是非常基础的,但它的能力足以完成工作。Wordbook 目前支持一个**英英字典**。在其核心部分,它使用 [Open English WordNet 数据库](https://github.com/globalwordnet/english-wordnet) 进行定义。Open English Wordnet 是 [Princeton Wordnet项目](https://wordnet.princeton.edu/) 的一个开源复刻。
Wordbook 应用还可以使用 [eSpeak](https://espeak.sourceforge.net/) – 一个自由开源的语音合成器来发音。

然而,在第一次运行时,它需要一次性上网,以下载离线数据。仅此而已。其他值得注意的功能包括实时搜索、双击搜索和带有 HTML 标记的自定义定义。
Wordbook 是一个 [GNOME 应用](https://www.debugpoint.com/tag/gnome-app),使用现代的 GTK4 和 libadwaita 构建。因此,它与 GNOME 桌面的浅色和深色主题整合得很好。你也可以使用 Wordbook 的随机单词功能来学习新单词以增加你的词汇量。
### 安装
你可以很容易地从 Flathub 将其作为 Flatpak 应用安装。为 Flatpak 和 Flathub 设置你的系统,然后从终端使用以下命令安装它:
```
flatpak install com.github.fushinari.Wordbook
```
安装后,你可以在应用菜单中找到它。
### 结束语
我希望你在学校或商业工作中使用这个小小的应用。如果你在写论文和较长的段落,离线特性是很方便的。
你知道其他 Linux 的离线字典吗?请在评论栏里告诉我们。
---
via: <https://www.debugpoint.com/wordbook-offline-dictionary/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,467 | 编写好 Git 提交信息的 11 个技巧 | https://opensource.com/article/22/12/git-commit-message | 2023-01-22T18:43:01 | [
"Git",
"提交信息"
] | https://linux.cn/article-15467-1.html | 
>
> 我请社区的开源从业者分享了他们关于编写有用的 Git 提交信息的建议。
>
>
>
最近,当需要更新时,我一直在密切关注从产品和服务获得的变更日志。以下是一些示例:
* 修复了一些错误。
* 进行了一些可访问性改进。
* 我们已经进行了改进,并修复了错误,以实现更顺畅地运行。
当我想到我还是一名初级开发人员写的一些首次提交信息时,我不得不沮丧地垂下头:
* 用鼠标点了一下,现在一切似乎都正常了。
* 执行了程序员 X 告诉我的操作,现在横幅是蓝色的。
这可真令人沮丧!我向我们的贡献者们提出了以下问题:
* 什么是好的 Git 提交信息?
* 什么是坏的 Git 提交信息?
* 你认为一个项目应该有哪些关于提交信息所写内容的规则?
以下是他们的答案:
### 易阅读的文笔是关键
与你写任何东西一样,你应该考虑谁会阅读它。然后相应地调整信息的数量和深度。
提高你的自然语言和写作技能对于软件开发的职业生涯顺利发展至关重要。重要的不仅仅是代码。
—— [Camilla Conte](https://opensource.com/users/spotlesstofu)
### 具有描述性,不要假设
我在 [OpenStack](https://opensource.com/resources/what-is-openstack) 社区中花了很多时间合作,与我在像“野外”的其他随意的项目中看到的相比,它的代码审查者有一些相当严格的标准。
我花在撰写一条可靠的提交信息的时间,往往要比编写实际的代码实现或修复程序的时间长得多。有时,提交信息可能会比它们解释的代码变化长很多倍。
总结一些贡献者指导:
* 描述为什么要做出改变,而不仅仅是改变了什么
* 第一个提交行是最重要的(就像电子邮件的主题行)
* 不要假设审查者了解你正在修复的原始问题
* 不要假设审查者可以访问外部 Web 服务或网站(总结缺陷报告和其他相关讨论)
* 不要假设代码是不言自明的和自我说明的(尽管没有必要重复你在代码注释中也提出的观点)
* 不要只包含与更改的早期修订相关的信息(我们希望贡献者将修订压扁在一起,并相应地编辑其提交信息)。
《OpenStack 贡献者指南》中有一个关于该主题的 [简短章节](https://docs.openstack.org/contributors/common/git.html#commit-messages)。
—— [Jeremy Stanley](https://opensource.com/users/fungi)
### 未来的你会感谢自己
我非常同意 Jeremy 的观点。+1000。
Jeremy 说:“描述为什么要做出改变,而不仅仅是改变了什么。”
想象一下,你是旁观者,在遥远的未来试图理解这个提交。
正如老话所说,设身处地为他人着想。
—— [Leigh Morresi](https://opensource.com/users/dgtlmoon)
### 使用 bug ID
我建议在提交信息的开头添加 bug ID,这样在以后使用 [grep 命令](https://opensource.com/downloads/grep-cheat-sheet) 跟踪提交信息时就会更方便。
例如:
```
$ git commit -m "BZ#19xxxxx
```
要写出深思熟虑的提交,请考虑以下事项:
* 我为什么要做这些更改?
* 我的更改产生了什么影响?
* 为什么有更改的必要?
* 更改的依据是什么?
—— [Agil Antony](https://opensource.com/users/agantony)
### 讲述整个故事
我喜欢想象每个提交信息都有一个隐藏的前缀,上面写着 “By applying this(通过应用这个)”。
一个好的提交信息包括将要发生的事情以及原因。仅仅有工单作参考是不够的,因为这分散了信息;Git 是去中心化的。作为一名软件开发人员,我想知道为什么当前要考虑做出更改。正在解决的具体问题是什么?考虑(并放弃)了哪些替代解决方案?在创建变更集的过程中发现了哪些影响当前内容的意外情况?
缩短提交信息没有什么好处。你未来的自己和未来的同事会感激你深入地解释了问题,以及为什么这个变更集是解决方案。认真学习和利用那些内容丰富的“烹饪”博客。然而,在此,仅仅是把生活经验替换成了项目的问题罢了(LCTT 译注:意思是要认真学习和模仿优秀、详细的提交信息)。
—— [Lisa Seelye](https://opensource.com/users/lisa)
### 但不要过于冗长
一个好的 Git 提交信息包含有关所做操作的信息,而不要包含其他信息。例如,如果你需要更新 `.gitignore`,只需写 “更新了 .gitignore” 即可。人们可以自行深入到提交本身中了解更多细节。它不需要冗长。
糟糕的提交信息类似于“哦,糟糕”或“试试这个”。当然,我也曾经犯过这样的错误,但这对于任何需要一目了然地查看提交信息的人来说都没有任何帮助。
提交信息的规则非常主观。他们可能因领导和团队而异。但至少要提供一些有关提交的上下文信息。特别是如果它是一个大的更改。没有人有时间浏览 1000 多个具有大量更改历史的文件。
—— [Miriam Goldman](https://opensource.com/users/miriamgoldman)
### 使用现在时
我喜欢项目经理风格的提交信息,用现在时而不是将来时的术语编写(例如,“添加” 而不是“已添加”)。然而,这通常只有在频繁提交时才有可能。当你面临最后期限时,你能记住的只有“我是如何做的”而已。然而,写得好的提交不仅有助于合作者,而且有助于提交者回忆历史。
—— [Chris Okpada](https://opensource.com/users/ojchris)
### 不要依赖链接
我想提醒同事们的一件事是,你不仅仅是向给你的提交作批准的人解释。你还要向未来的开发人员和用户解释,他们在使用 bisect 或 blame 定位问题时发现了这个提交,并试图了解其相关性。
如果提供的唯一的上下文是指向某个外部系统的链接,并且在未来很长一段时间内,它所链接的系统不再使用,或者该用户无法访问,那么你的提交信息将变得无用,可能还不如空白。
我经常去挖掘一些开源项目的 Git 历史,发现有些提交信息无非就是一个 Bug ID,或者是某个公司内部的和专用的缺陷跟踪器的链接。
不要依赖链接!
—— [Jeremy Stanley](https://opensource.com/users/fungi)
### 清晰简洁的变更日志
作为一名发布沟通经理,我会经常阅读整个发布版块。我还会与开发人员会面,讨论任何尚未明确的领域。然后我提前测试了版本。之后,我将通过寻找变更日志和相应的修订或新内容来撰写发布文章。
变更日志是开发人员的个人提醒,但也有相应的提议和工单。你应该适当地将产品名称大写,使用拼写检查器,与标点符号和句子结构保持一致。首席开发人员也应该校对这些。你的客户,即开发人员,正在阅读这些内容。在运行更新之前,他们应该了解哪些信息能更好地为客户服务?
—— [Courtney Robertson](https://opensource.com/users/courtneyrdev)
### 具体一点
作为一个经常性的发布经理,我喜欢带有组件名称的提交的信息,以及对更改内容的简要描述。在我们忘记了你聪明的分支名称之后,还可以参考一下这项工作的请求来自何处,这有助于将修复程序联系在一起。
* “修复致命错误”并不是理想的提交。
* “ISS-304: 修复具有合作伙伴角色的用户在登录访问控制功能中的致命错误”更好。
* “ISS-304: 登录访问控制:修复 `getPartnerId()` 的致命错误”也更好。
我可以查看 Git 提交、分支、合并提交之间的整个关系,并检查更改的各个行和文件。但我在发布过程中没有这样的时间。我希望能够在项目管理工具回溯这项工作的源头,了解哪些组件正在被更改,以及以何种方式进行更改。
—— [Ryan Price](https://opensource.com/users/liberatr)
### 让它成为一种习惯
我最喜欢犯的错误是“在我切换分支之前提交”,因为我必须处理其他更紧急的事情。有时候,我需要把我目前的工作提交给一个完全不同的项目。我的经理的策略是让我们像平时一样工作。但当我们变基时,他希望我们在有意义的地方压扁提交,并编写更好的信息。我不能说我们总是这样做,但他的方法确实有道理。
我也有很多“这个坏了,不知道为什么”类型的信息(哈哈),我尝试了一些东西,但想在尝试其他东西之前提交该尝试,以防方法 A 比方法 B 更接近解决问题。我已经写了 10 多年了。
—— [RachieVee](https://opensource.com/users/rachievee)
你的提交信息建议或提示是什么?让我们在评论中知道。
---
via: <https://opensource.com/article/22/12/git-commit-message>
作者:[AmyJune Hineline](https://opensource.com/users/amyjune) 选题:[lkxed](https://github.com/lkxed) 译者:[ZhangZhanhaoxiang](https://github.com/ZhangZhanhaoxiang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Lately, I have been paying closer attention to the changelogs I get from products and services when updates are needed. Here are some examples:
- Fixed some bugs.
- Made some accessibility improvements.
- We've made improvements and fixed bugs for a smoother ride.
When I think about some of the first commit messages I made as a junior developer I have to hang my head in dismay:
- Pointed and clicked around a bit and now things seem to work.
- Did what programmer X told me to do and now the banner is blue.
This can be frustrating! I asked our community of contributors the following questions:
- What makes a good Git commit message?
- What makes a bad one?
- What rules do you think a project should have around what a commit message contains?
Here are their answers:
## Great writing is key
As with anything you write, you should think about who is going to read it. Then adapt the amount and depth of information accordingly.
Improving your natural language and writing skills is essential for a healthy career in software development. It's not just code that counts.
## Be descriptive and don't assume
I spend a lot of my time collaborating in the [OpenStack](https://opensource.com/resources/what-is-openstack) community, and its code reviewers have some fairly exacting standards compared to what I see from other projects "in the wild."
I'll often spend far longer composing a solid commit message than I do writing the actual code implementation or fix. Sometimes commit messages can end up many times longer than the diffs they're explaining.
To summarize some of the contributor guidance:
- Describe why a change is being made, not just what is changing
- The first commit line is the most important (like the subject line of an email)
- Don't assume reviewers understand the original problem you're fixing
- Don't assume the reviewer has access to external web services or the site (summarize defect reports and other relevant discussions)
- Don't assume the code is self-evident and self-documenting (though there is no need to repeat points you also make in your code comments)
- Don't include information only relevant to earlier revisions of the change (we expect contributors to squash revisions together and edit their commit messages accordingly).
There's a brief section on the topic in the OpenStack Contributors Guide: [https://docs.openstack.org/contributors/common/git.html#commit-messages](https://docs.openstack.org/contributors/common/git.html#commit-messages)
## Your future self will thank you
I cannot agree more with Jeremy. +1000
Jeremy said, "describe why a change is being made, not just what's changing."
Imagine you're someone else, in a faraway future, trying to work out this commit.
Put yourself in other people's shoes, as the old saying goes.
## Use the bug ID
I recommend adding the bug ID at the start of the commit message so that it's easier to track the commits at a later stage using the [ grep command](https://opensource.com/downloads/grep-cheat-sheet).
For example:
```
````$ git commit -m "BZ#19xxxxx `
To come up with thoughtful commits, consider the following:
- Why have I made these changes?
- What effect have my changes made?
- Why was the change needed?
- What are the changes in reference to?
## Tell the whole story
I like to imagine there is a hidden prefix to every commit message that reads "By applying this."
A good commit message includes exactly what will happen and why. It is insufficient to merely have the work ticket reference because that decentralizes the information; Git is decentralized. As a software developer, I want to know why the proposed changes are being considered. What specific problem is being addressed? What alternate solutions were considered (and discarded)? What unexpected things were discovered during the creation of the changeset that influenced the current content?
There's no prize for shortest commit message. Your future self and future colleagues will appreciate you going into depth to explain the problem and why this changeset is the answer. Harness those cooking blogs where there's a five-paragraph life story. Here, however, make the problem the subject of the life story.
## But don't be overly verbose
A good git commit message contains information about what was done, and nothing else. For instance, if you needed to update the .gitignore, just say "updated .gitignore." Folks can dive into the commit itself for more details. It doesn't need to be verbose.
A bad commit message is something like, "oh crap" or "try this". Granted, I've been guilty of this, but it doesn't help anyone if they need to look at commits at a glance.
Rules are very subjective. They can differ from lead to lead and team to team. But at the very least, give some contextual information about the commit. Especially if it's a large one. No one has time to skim through 1000+ files with a heavy change history.
## Use present tense
I like project manager-styled commit messages written in present and not future terms (for example, "add" instead of "added"). However, it's usually only possible if commits are frequent. There's only so much "how did I do it" you can remember when you're faced with a deadline. Yet, well-written commits not only help collaborators, but are also helpful to the committer in recollecting history.
## Don't rely on links
One thing I like to remind colleagues of is that you're not just explaining to the people who are going to decide whether to approve your commit. You're also explaining to future developers and users who have found this commit in a bisect or blame operation and are trying to understand its relevance.
If the only context supplied is a link to some external system, and that far in the future the system it links to is no longer in use or has otherwise become inaccessible to that individual, your commit message has been rendered useless and may just as well be blank.
All too often, I go digging in the Git history of some open source project, and find commit messages which are nothing more than a bug ID or a link to some company's internal and private defect tracker.
Don't be that project!
## Clear and concise changelogs
As a release communications manager, I often read the entire release board. I also met with developers to discuss any areas that weren't clear yet. Then I tested the release early. After that, I would write a release post by sourcing the changelogs and corresponding revised or new content.
The changelogs are personal reminders for developers, but also have corresponding issues and tickets for them. You should capitalize product names appropriately, use a spell checker, be consistent with punctuation, and sentence structure. The lead developer should proofread these as well. Your customers, that are developers, are reading these. What information should they know before running the update to better serve their customers?
## Be specific
As a frequent release manager, I like messages that name the component a commit touches, and a brief description of what was changed. Also having a reference back to where the request for this work came from helps to tie fixes together long after we forgot about your clever branch name.
- "fix fatal error" is not ideal.
- "ISS-304: Fix fatal error in Login Access Control function for users
with the Partner role" is better. - "ISS-304: Login Access Control: fix fatal error in getPartnerId()" is
better still.
I can look at the entire relationship between a Git commit, branch, merge commit, and inspect the individual lines and files that were changed. But I don't have that kind of time in the middle of a release. I want to be able to relate back to the source of this work in the project management tool, have some idea of which components are being changed, and in what way.
## Make it a habit
My favorite commit that I'm guilty of is, "commit before I switch branches" because I have to work on something else more urgent. Sometimes, I need to commit my current work to a totally different project. My manager's strategy is to have us work as we normally do. But then when we rebase, he wants us to squash commits where it makes sense and write better messages. I can't say we always do this, but his method does make sense.
I have a lot of "this is broken don't know why" type messages too (haha) where I try things but want to commit that attempt before I try something else in case method A was closer to fixing the issue than method B. Writing code is a hot mess. And I've been writing it for over 10 years.
What commit message advice or tips do you live by? Let us know in the comments.
## 1 Comment |
15,469 | 上世纪的 BBC Micro 和如今的 Codecademy | https://twobithistory.org/2019/03/31/bbc-micro.html | 2023-01-23T13:21:00 | [
"BBC Micro",
"Codecademy"
] | https://linux.cn/article-15469-1.html | 
20 世纪 70 年代末期,计算机突然成为了某种普罗大众能够买回家的商品;而此前的几十年间,它一直只是听命于企业级霸主的神秘而笨重的机器。少数狂热的爱好者注意到了它是多么的吸引人,并争相购买了属于自己的计算机。对更多的人而言,微型计算机的到来引发了对未来的无助焦虑。同时期的杂志上的一则广告承诺,家用计算机将“让您的孩子在学校享有不公平的优势”。广告中展示了一位打着领带,身着时髦的西装外套的男孩子急切地举手回答问题,而在他的身后,他的那些显得不那么聪明的同学们闷闷不乐地望着他。这则广告以及其它类似的广告在暗示:世界正在疾速改变,而如果你不立即学习如何使用这些令人生畏的新设备之一,你和你的家人就会被时代所抛弃。
在英国,这些焦虑转化为政府高层对国家竞争力的担忧。从各种意义上,20 世纪 70 年代对英国来说都是平平无奇的十年,通胀与失业率高企。与此同时,一系列的罢工让伦敦陷于一次又一次的停电中。一篇 1979 年的政府报告担心:没有跟上计算机技术浪潮将“为我们糟糕的工业表现平添又一个影响因素”<sup class="footnote-ref"> <a href="#fn1" id="fnref1"> [1] </a></sup>。英国似乎已经在计算机技术的角逐中落后了 —— 所有的大型的计算机公司都是美国的,而集成电路则在日本和中国台湾制造。
由英国政府建立的公共服务广播公司英国广播公司(BBC)作出了一个大胆的举动,决定通过帮助英国人战胜他们对计算机的反感,来解决英国的国家竞争力问题。BBC 发起了 “<ruby> <a href="https://clp.bbcrewind.co.uk/history"> 计算机认知计划 </a> <rt> Computer Literacy Project </rt></ruby>”,该计划包括多个教育方向的努力:几部电视连续剧、一些相关书籍、一个支持团队网络以及一款名为 [BBC Micro](https://bbcmicro.computer/) 的特别定制的微型计算机。该项目是如此成功,以致于 1983 年 《[BYTE](https://archive.org/details/byte-magazine?tab=about)》杂志的一位编辑写道:“与美国相比,英国人对微型计算机感兴趣的比例更高。”<sup class="footnote-ref"> <a href="#fn2" id="fnref2"> [2] </a></sup> 这位编辑惊讶于在英国举办的 <ruby> 第五届个人计算机世界展 <rt> Fifth Personal Computer World Show </rt></ruby> 的人数比参加当年的西海岸计算机展的人数更多。超过六分之一的英国人观看了由该计划制作的第一部电视连续剧,并最终售出了 150 万台 BBC Micro 微型计算机。<sup class="footnote-ref"> <a href="#fn3" id="fnref3"> [3] </a></sup>
去年,一份包含了由计算机认知计划制作的每一部电视连续剧和所有出版资料的 [档案](https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/) 被发布在了互联网上。我抱着极大的兴趣观看了这些电视连续剧,并试图想象在 20 世纪 80 年代早期学习计算机使用是什么样子。但事实证明,更有趣的是计算机是如何被教授的。今天,我们仍然担心技术发展使人们落伍。富有的科技企业家与政府花费大量的资金试图教孩子们“编码”。我们拥有诸如 [Codecademy](https://www.codecademy.com/) 这样的网站,通过新技术的运用进行交互式编程教学。我们可能假定这种方式比 80 年代的呆板的电视连续剧更高效,不过真的是这样吗?
### 计算机认知计划
1975 年发布的 [Altair 8800](https://twobithistory.org/2018/07/22/dawn-of-the-microcomputer.html) 拉开了微型计算机革命的大幕。不到两年,Apple II、TRS-80 以及 Commodore PET 也都相继发布。全新的计算机的销量爆发式增长。1978 年,BBC 在一部名为 《<ruby> <a href="https://www.bbc.co.uk/iplayer/episode/p01z4rrj/horizon-19771978-now-the-chips-are-down"> 芯片来了 </a> <rt> Now the Chips Are Down </rt></ruby>》(LCTT 译注:对于非英国区域的读者,可以在 [这里](https://archive.org/details/BBCHorizon19771978NowTheChipsAreDown) 观看该纪录片)的纪录片中探讨了这些新机器必将会带来的剧烈的社会变革。
该纪录片充满担忧。在前 5 分钟内,解说员提到这种微电子器件将“彻底改变我们的生活方式”。随着诡异的合成音乐的播放,屏幕上绿色的电脉冲围绕着放大后的芯片起舞,解说员进一步说,这种芯片“正是日本放弃造船业的原因,也将成为我们的孩子们长大后失业的原因”。该纪录片继续探讨了机器人如何用于汽车自动化组装,以及欧洲的手表业如何在与美国的电子表行业竞争中败下阵来。它指责英国政府在应对未来的大规模失业的准备上做得不够。
该纪录片据信可能在英国议会上展示过。<sup class="footnote-ref"> <a href="#fn4" id="fnref4"> [4] </a></sup> 包括工业署和人力服务委员会在内的一些政府代表,开始对尝试提高英国公众对计算机的认识感兴趣。人力服务委员会为来自 BBC 的教育部门提供了资助,让他们的一个团队到日本、美国以及其他国家进行了实地考察。该研究团队完成了一份报告,历数了微电子技术在工业制造、劳动关系与办公室工作等领域的哪些方面将发生重大改变。70 年代末,BBC 决定制作一部十集电视连续剧,帮助普通英国人“学习如何使用和控制计算机,避免产生被计算机支配的感受”<sup class="footnote-ref"> <a href="#fn5" id="fnref5"> [5] </a></sup>。这一努力最终成为了一个与 “<ruby> 成人认知计划 <rt> Adult Literacy Project </rt></ruby>” 相似的多媒体项目。成人认知计划是 BBC 此前进行的一项工作,包括一部电视连续剧以及补充课程,帮助两百万人提高他们的阅读能力。
计算机认知计划背后的制作方热衷于以“实操”示例为特色的电视连续剧。这样如果观众拥有一台微型计算机在家里,他们就可以亲自动手尝试。这些例子必须使用 BASIC 语言,因为这是在几乎所有的微型计算机上都使用的编程语言(实际是整个 <ruby> 交互界面 <rt> shell </rt></ruby>)。但是制作者面临一个棘手的问题:微型计算机制造商均拥有他们自己的 BASIC 方言,因此不论他们选择哪一种方言,他们都不可避免地疏远大部分的观众。唯一切实可行的方案是创造一种全新的 BASIC 方言 —— BBC BASIC,以及与之配合使用的微型计算机。英国公众可以购买这种全新的微型计算机,并依照示例操作,而不需要担心软硬件上的差异带来的问题。
BBC 的电视制作人与节目主持人并不具备自行制造微型计算机的能力,因此他们汇总了一份他们预期的计算机的规范,并邀请英国的微型计算机公司推出满足该规范要求的新机器。这份规范要求提供一种相对更强劲的计算机,因为 BBC 的制作方认为相应的设备应当能够运行真实有用的应用程序。计算机认知计划的技术顾问还建议:如果必须要教授全体国人一种 BASIC 方言的话,那么最好选择表现良好的方言(他们可能没有确切地这样说,不过我认为这就是他们的真实想法)。BBS BASIC 通过允许递归调用与局部变量弥补了一些 BASIC 语言的常见缺点。<sup class="footnote-ref"> <a href="#fn6" id="fnref6"> [6] </a></sup>
BBC 最终决定由一家位于剑桥的名为 Acorn Computers 的公司制造 BBC Micro 计算机。在选择 Acorn 公司的时候,BBC 没有接受来自 [Clive Sinclair](https://en.wikipedia.org/wiki/Sinclair_Research) 的申请,他经营着一家 Sinclair Research 公司。1980 年,Sinclair 公司通过 Sinclair ZX80 为英国开拓了微型计算机的大众市场。虽然 Sinclair 公司的新产品 ZX81 更便宜,但是性能不足以满足 BBC 的要求。而 Acorn 的新型计算机(内部被称为 Proton)的原型机更加昂贵,但是性能更好,更具备扩展性。BBC 对此印象深刻。该型号的计算机从未以 “Proton” 的名字上市或销售过,因为它在 1981 年 12 月以 “BBC Micro” 的名字发布了。BBC Micro 又被亲切地称为 “The Beeb”,你可以以 235 英磅的价格购得其 16k 内存的版本,或者以 335 英磅的价格获得其 32k 内存的版本。
到了 1980 年,Acorn 在英国计算机行业逐渐衰微,但是 BBC Micro 帮助 Acorn 公司创立了其遗留至今的宝贵遗产。时至今日,世界范围内最流行的微处理器指令集是 ARM 架构,“ARM” 如今代表的是 “<ruby> 先进 RISC 架构设备 <rt> Advanced RISC Machine </rt></ruby>”,然而最初它代表的是 “<ruby> Acorn RISC 架构设备 <rt> Acorn RISC Machine </rt></ruby>”。ARM 架构背后的 ARM 控股公司就是 Acorn 公司在 1990 年之后的延续。

*BBC Micro 的一幅差劲的图片,我摄于美国加州山景城的<ruby> 计算机历史博物馆 <rt> Computer History Museum </rt></ruby>*
### 《计算机程序》电视连续剧
作为计算机认知计划的一部分,他们最终制作了十几部不同的电视连续剧。第一部作品是一部名为 《计算机程序The Computer Programme》 的十集电视连续剧。该连续剧在 1982 年初播出了十周。每周晚上有一百万人收看该节目,还有 25 万人在每周日与周一的下午收看该节目的重播。
该电视节目由两名主持人主持:Chris Serle 和 Ian McNaught-Davis。Serle 扮演初学者,而 McNaught-Davis 扮演专家,他具有专业的大型计算机编程经验。这是一个启发性的方式,有些 [略显笨拙的过渡](https://twitter.com/TwoBitHistory/status/1112372000742404098) —— Serle 经常直接从与 McNaught-Davis 的对话中,过渡到面向镜头的边走边说的讲述,此时你不禁会疑惑 McNaught-Davis 是否还站在画面之外。不过这意味着 Serle 可以表达观众肯定会有的关注 —— 他可能会惊恐地看着满屏的 BASIC 语言,并提出类似“这些美元符号是什么意思”的问题。在节目中的某些时刻,Serle 与 McNaught-Davis 会坐在计算机前进行事实上的结对编程。McNaught-Davis 会在各个地方留下一些线索,而 Serle 则试图将它们弄清楚。如果这一节目仅仅由一个无所不知的讲述者主持,那么它的亲和力就会差很多。
该节目也在努力展示计算在普通人生活中的实际应用。到 80 年代早期,家用电脑已经开始与年轻男孩和电子游戏联系在一起。计算机认知计划的制作方试图避免采访“令人印象深刻的、有能力的年轻人”,因为这可能会“加剧老年观众的焦虑”,而该节目正打算吸引这一人群对计算感兴趣 <sup class="footnote-ref"> <a href="#fn7" id="fnref7"> [7] </a></sup>。在该系列的第一集中,该节目的 “现场” 记者 Gill Nevill 采访了一位女性,她购买了一台 Commodore PET 计算机用于辅助管理她的糖果店。这位名叫 Phyllis 的女性受访者看上去大约 60 多岁,但她在使用 PET 完成她的会计工作上没有任何问题,甚至已经开始使用 PET 为其他企业做计算机工作,这听上去像是一个有前途的自由职业的开端。Phyllis 说她并不介意计算机工作逐步取代她的糖果店生意,因为她更喜欢计算机工作。这次采访要是换成对一名青少年的采访,介绍了他是如何修改 《[Breakout](https://en.wikipedia.org/wiki/Breakout_(video_game))》 电子游戏,以使之运行更快并更具挑战性,不过这就几乎鼓舞不了任何人。另一方面,如果普罗大众中的 Phyllis 都会使用计算机,那么你当然也可以。
虽然该节目以大量的 BASIC 编程为特色,不过它实际想要教给观众的是,计算机通常是如何工作的。该节目通过类比的方法解释了其中的一般原则。在第二集中,有一个关于 [Jacquard](https://www.scienceandindustrymuseum.org.uk/objects-and-stories/jacquard-loom) 织机(LCTT 译注:中文网络译为雅卡尔提布机)的延伸讨论,主要是两个方面:其一,它揭示了计算机并不仅仅基于昨天发明的神秘技术 —— 计算的一些基本原则可以上溯到两百年前,就跟你可以在卡片上打孔来控制纺织机的想法一样简单;其二,经线与纬线的交织用来证明二元选择(即纬线是从上方还是下方穿过经线)在不断重复时足以产生巨大变化。当然,节目接下来继续讨论信息是如何使用二进制存储的。
在该节目中接下来是一个蒸汽管风琴的章节,该管风琴能够演奏编码在一卷长长的、分段的打孔卡片的音乐。这个类比用以解释 BASIC 中的 <ruby> 子程序 <rt> subroutine </rt></ruby>。Serle 与 McNaught-Davis 将整卷的打孔卡片摊开在演播室的地板上,然后指出看上去像是重复的副歌的分段。McNaught-Davis 解释说,如果你将这些重复的卡片分段剪下,并以某种方式添加一条指令,回到第一次播放该副歌的最初的分段,这就是子程序。这是一个绝妙的解释,它在人们的脑海中的印象非常深刻。
我仅仅摘录了一些例子,不过我认为,总的来看该节目尤为擅长通过解释计算机实现功能所依赖的原理,使计算机不再神秘。这一节目本可以专注于 BASIC 教学,不过它并没有这样做。这被证明是一个相当明智的选择。在 1983 年写就的一篇回忆文章中,计算机认知计划的总制作人 John Radcliffe 如是写道:
>
> 如果计算机将如我们所相信的那样重要,对这一新主题的真正理解对每个人都很重要,也许与文字读写能力同等重要。不管是在我们这里还是在美国,在计算机认知的主要路线上的早期思路均集中于编程上。然而随着我们思想的发展,尽管我们意识到“动手”体验在个人计算机上的价值,但我们开始降低对编程的重视,而更多的强调广泛的理解,将微型计算机与大型计算机联系起来,鼓励人们获取一系列应用程序与高级语言的经验,并将这些经验同现实世界中的工业与商业活动中的经验联系起来……。我们相信,一旦人们掌握了这些最简单的原则,它们将可以进一步深入该主题。
>
>
>
后来,Radcliffe 又以类似的口吻写道:
>
> 围绕着这一系列节目的主要阐释目标有很多争论。一些人认为,在使用微型计算机上的实际细节上给予建议,对本项目而言尤为重要。但我们的结论是,如果该系列节目要拥有可持续性的教育价值,它就必须通过对计算原理的解释,成为进入真实计算世界的一种方式。这需要通过对微型计算机上的室内演示,通过类比方式解释其中的原则,以及通过电影说明实际应用的真实例子来实现。不仅仅是微型计算机,小型机以及大型机也将被展示。
>
>
>
我喜爱这一连续剧,尤其是其中关于小型机与大型机的部分。计算机认知计划背后的制作方旨在帮助英国人找准定位:计算身处何处又去向何方?计算机现在能做什么,未来又能做什么?学习一些 BASIC 语言是回答这些问题的一个部分,但是仅仅理解 BASIC 语言似乎不足以使人们认知计算机。
### 如今的计算机认知
如果你现在搜索“学习编码”,你看到的排在第一的是指向 Codecademy 网站的链接。如果要说存在一个“计算机认知计划”的现代替代品 —— 具有相同的影响与目标,那就是 Codecademy。
“<ruby> 学习编码 <rt> learn to code </rt></ruby>” 是 Codecademy 的口号。我认为我不是第一个指出这一点的人 —— 事实上我可能在某个地方读过这句话,只是现在拿来用而已。但是这里使用的是 “<ruby> 编码 <rt> code </rt></ruby>” 而非 “<ruby> 编程 <rt> program </rt></ruby>”,这说明了一些问题。这表明你学习的重要内容是如何读懂代码,如何阅读满屏的 Python 代码的意思,而不是目光呆滞、不知所云。我能够理解为什么对于普通人而言,这似乎是成为专业程序员的主要障碍。专业程序员整日盯着布满编程术语的计算机屏幕,如果我想要成为一个专业程序员,我最好确保我能够理解这些天书一样的字符。但是理解语法并不是成为程序员的最大的挑战。在更大的障碍面前,它很快将变成微不足道。仅仅以掌握一门编程语言的语法为目标,你可能能够 *阅读* 代码,但是无法做到 *编写* 代码以解决全新的问题。
我最近学习了 Codecademy 的 《编程基础》 课程。如果你对编程感兴趣(而不是对网页开发或者数据科学),并且没有任何编程经验,这是 Codecademy 推荐你学习的课程。里面有几节关于计算机科学史的课时,不过都是流于表面而没有深入研究。(感谢上帝,[一位高尚的互联网秩序义务维护者](https://twitter.com/TwoBitHistory/status/1111305774939234304) 指出了其中存在的一个特别恶劣的错误)。该课程的主要目的是教授你编程语言的通用结构要素:变量、函数、控制流、循环等。换句话说,该课程聚焦于为了让你理解天书般的代码中的模式,而所需要知道的内容。
公平地看,Codecademy 也提供了其他内容深入的课程。但是即使是如 《计算机科学之路》 这样的课程也几乎只仅仅专注于编程以及程序中表达的概念。有人可能会反驳说这才是重点 —— Codecademy 的主要特点就是提供给你一些交互式的、带有自动反馈的编程课程。在有限的自动化课程中能够灌输给学员的内容只有这么多,因此学员的脑海里也没有更多的空间容纳更多其他的内容。但是负责启动计算机认知计划的 BBC 的制作人也面临同样的问题。他们意识到受限于他们的传播媒介,“通过电视节目所能获得的学习内容的容量也是受限的”<sup class="footnote-ref"> <a href="#fn8" id="fnref8"> [8] </a></sup>。虽然在他们所能传达的信息总量上存在相似的限制,但是 BBC 的制作人选择强调在学习 BASIC 语言上的一般原则。难道 Codecademy 就不能将其中一两节交互式可视化的课时替换为编织经线与纬线的 Jacquard 织机的案例吗?
我一直在大声鼓吹 “一般原则”,因此让我再解释下我认为的一般原则是什么,以及为什么它们如此重要。J. Clark Scott 出了一本有关计算机的书,书名为 《<ruby> 但是它怎么知道? <rt> But How Do It Know? </rt></ruby>》。这个书名来自书的序言里的一则笑话:一个店员向人群推销保温瓶,说保温瓶可以让热食始终是热的,冷食始终是冷的。一名听众对这个新发明感到惊讶,问道,但是它怎么知道(根据你给它的食物类型的不同选择做相应的事情呢)?笑点在于保温瓶当然不能感知食物的温度然后据此做出决定 —— 保温瓶仅仅制作成保证冷食必然保持冷的,热食必然保持热的就可以了。人们也以(笑话中的那个听众)一样的方式看待计算机,相信计算机就是数字大脑,能够基于提供给它们的代码 “选择” 做一件事或者另一件事。但是了解一些有关计算机如何工作的知识,哪怕是很初级水平的理解,也能让(人们理解中的)计算机摆脱(做判断的)侏儒。这就是为什么 Jacquard 织机是一个很好的有助理解的例子。一开始它似乎是一种难以置信的设备,它读取打孔卡片,然后以某种方式“知道”编织正确的样式。现实是显而易见的:每一行孔都对应一根线,而一行中有孔的地方对应着提起的线。理解了这些虽然不会有助于你用计算机完成新的事情,但是将使你自信于你不是在跟某些神秘事物打交道。我们应当尽快将这种自信的感受传授给初学者。
唉,可能真正的问题是没有人想要了解 Jacquard 织机。根据 Codecademy 如何强调他们教授的专业应用来判断,很多人开始使用 Codecademy 可能是因为他们相信这有助于 “提升” 他们的职业水平。他们没有来由地相信,首要的问题是理解编程的专业术语,因此他们才想要 “学习编码”。他们想要在他们所拥用的。每天晚上晚餐与就寝之间的一两个小时里尽快完成这件事。Codecademy 毕竟只是一门投其所好的生意,而非一些有关 18 世纪就发明了的机器的间接说明。
另一方面,计算机认知计划是供职于 BBC 的一群制作人与公务员所认为的,将计算机的使用教给国民的最好的方式。我承认,因为这一群人教会大众他们无法以己之力所能求得的事物,而赞美这一群人的建议多少有点精英主义。但我情不自禁认为他们做对了。许多人使用 BBC Micro 第一次学会了使用计算机,他们中的很多人进而成为了成功的软件开发者或游戏设计师。[正如我曾经所说的](https://twobithistory.org/2018/09/02/learning-basic.html),我怀疑在计算机已经变得相对简单的时代里,学习使用计算机是一个巨大的优势。不过或许这群人所拥有的另一个优势在于有像 《计算机程序》 这样的尽己所能不仅仅教授编程,而且教授计算机是为什么又是如何运行程序的节目。在看完 《计算机程序》 之后,你可能并不能理解计算机屏幕上的所有天书般的编程术语,但是实际上你也并不需要,因为你知道无论 “代码” 是什么样子,计算机总是在重复做基础的事情。在完成了 Codecademy 上的一到两个课程之后,你可能能够感受一些天书般的编程术语,但是对你来说,一台计算机仍然只是一台能够以某种方式将天书般的字符转化为运行的软件的魔法机器。但这并不是计算机认知。
---
1. Robert Albury and David Allen, Microelectronics, report (1979). [↩︎](#fnref1)
2. Gregg Williams, “Microcomputing, British Style”, Byte Magazine, 40, January 1983, accessed on March 31, 2019, <https://archive.org/stream/byte-magazine-1983-01/1983_01_BYTE_08-01_Looking_Ahead#page/n41/mode/2up>. [↩︎](#fnref2)
3. John Radcliffe, “Toward Computer Literacy,” Computer Literacy Project Achive, 42, accessed March 31, 2019, [https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/media/Towards Computer Literacy.pdf](https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/media/Towards%20Computer%20Literacy.pdf). [↩︎](#fnref3)
4. David Allen, “About the Computer Literacy Project,” Computer Literacy Project Archive, accessed March 31, 2019, <https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/history>. [↩︎](#fnref4)
5. ibid. [↩︎](#fnref5)
6. Williams, 51. [↩︎](#fnref6)
7. Radcliffe, 11. [↩︎](#fnref7)
8. Radcliffe, 5. [↩︎](#fnref8)
---
via: <https://twobithistory.org/2019/03/31/bbc-micro.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[CanYellow](https://github.com/CanYellow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the late 1970s, the computer, which for decades had been a mysterious, hulking machine that only did the bidding of corporate overlords, suddenly became something the average person could buy and take home. An enthusiastic minority saw how great this was and rushed to get a computer of their own. For many more people, the arrival of the microcomputer triggered helpless anxiety about the future. An ad from a magazine at the time promised that a home computer would “give your child an unfair advantage in school.” It showed a boy in a smart blazer and tie eagerly raising his hand to answer a question, while behind him his dim-witted classmates look on sullenly. The ad and others like it implied that the world was changing quickly and, if you did not immediately learn how to use one of these intimidating new devices, you and your family would be left behind.
In the UK, this anxiety metastasized into concern at the highest levels
of government about the competitiveness of the nation. The 1970s had been, on
the whole, an underwhelming decade for Great Britain. Both inflation and
unemployment had been high. Meanwhile, a series of strikes put London through
blackout after blackout. A government report from 1979 fretted that a failure
to keep up with trends in computing technology would “add another factor to our
poor industrial performance.” 1 The country already seemed to be behind in
the computing arena—all the great computer companies were American, while
integrated circuits were being assembled in Japan and Taiwan.
In an audacious move, the BBC, a public service broadcaster funded by the
government, decided that it would solve Britain’s national competitiveness
problems by helping Britons everywhere overcome their aversion to computers. It
launched the *Computer Literacy Project*, a multi-pronged educational effort
that involved several TV series, a few books, a network of support groups, and
a specially built microcomputer known as the BBC Micro. The project was so
successful that, by 1983, an editor for BYTE Magazine wrote, “compared to the
US, proportionally more of Britain’s population is interested in
microcomputers.” 2 The editor marveled that there were more people at the
Fifth Personal Computer World Show in the UK than had been to that year’s West
Coast Computer Faire. Over a sixth of Great Britain watched an episode in the
first series produced for the
*Computer Literacy Project*and 1.5 million BBC Micros were ultimately sold.
[3](#fn:3)[An
archive](https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/)
containing every TV series produced and all the materials published for the
*Computer Literacy Project* was put on the web last year. I’ve had a huge
amount of fun watching the TV series and trying to imagine what it would have
been like to learn about computing in the early 1980s. But what’s turned out to
be more interesting is how computing was *taught*. Today, we still worry
about technology leaving people behind. Wealthy tech entrepreneurs and
governments spend lots of money trying to teach kids “to code.” We have
websites like Codecademy that make use of new technologies to teach coding
interactively. One would assume that this approach is more effective than a
goofy ’80s TV series. But is it?
## The Computer Literacy Project
The microcomputer revolution began in 1975 with the release of [the Altair
8800](/2018/07/22/dawn-of-the-microcomputer.html). Only two
years later, the Apple II, TRS-80, and Commodore PET had all been released.
Sales of the new computers exploded. In 1978, the BBC explored the dramatic
societal changes these new machines were sure to bring in a documentary called
“Now the Chips Are Down.”
The documentary was alarming. Within the first five minutes, the narrator explains that microelectronics will “totally revolutionize our way of life.” As eerie synthesizer music plays, and green pulses of electricity dance around a magnified microprocessor on screen, the narrator argues that the new chips are why “Japan is abandoning its ship building, and why our children will grow up without jobs to go to.” The documentary goes on to explore how robots are being used to automate car assembly and how the European watch industry has lost out to digital watch manufacturers in the United States. It castigates the British government for not doing more to prepare the country for a future of mass unemployment.
The documentary was supposedly shown to the British Cabinet. 4 Several
government agencies, including the Department of Industry and the Manpower
Services Commission, became interested in trying to raise awareness about
computers among the British public. The Manpower Services Commission provided
funds for a team from the BBC’s education division to travel to Japan, the
United States, and other countries on a fact-finding trip. This research team
produced a report that cataloged the ways in which microelectronics would
indeed mean major changes for industrial manufacturing, labor relations, and
office work. In late 1979, it was decided that the BBC should make a ten-part
TV series that would help regular Britons “learn how to use and control
computers and not feel dominated by them.”
The project eventually became a multimedia endeavor similar to the
[5](#fn:5)*Adult Literacy Project*, an earlier BBC undertaking involving both a TV series and supplemental courses that helped two million people improve their reading.
The producers behind the *Computer Literacy Project* were keen for
the TV series to feature “hands-on” examples that viewers could try on their
own if they had a microcomputer at home. These examples would have to be in
BASIC, since that was the language (really the entire shell) used on almost all
microcomputers. But the producers faced a thorny problem: Microcomputer
manufacturers all had their own dialects of BASIC, so no matter which dialect
they picked, they would inevitably alienate some large fraction of their
audience. The only real solution was to create a new BASIC—BBC BASIC—and a
microcomputer to go along with it. Members of the British public would be able
to buy the new microcomputer and follow along without worrying about
differences in software or hardware.
The TV producers and presenters at the BBC were not capable of building a
microcomputer on their own. So they put together a specification for the
computer they had in mind and invited British microcomputer companies to
propose a new machine that met the requirements. The specification called for a
relatively powerful computer because the BBC producers felt that the machine
should be able to run real, useful applications. Technical consultants for the
*Computer Literacy Project* also suggested that, if it had to be a BASIC
dialect that was going to be taught to the entire nation, then it had better be
a good one. (They may not have phrased it exactly that way, but I bet that’s
what they were thinking.) BBC BASIC would make up for some of BASIC’s usual
shortcomings by allowing for recursion and local variables.[6](#fn:6)
The BBC eventually decided that a Cambridge-based company called Acorn Computers would make the BBC Micro. In choosing Acorn, the BBC passed over a proposal from Clive Sinclair, who ran a company called Sinclair Research. Sinclair Research had brought mass-market microcomputing to the UK in 1980 with the Sinclair ZX80. Sinclair’s new computer, the ZX81, was cheap but not powerful enough for the BBC’s purposes. Acorn’s new prototype computer, known internally as the Proton, would be more expensive but more powerful and expandable. The BBC was impressed. The Proton was never marketed or sold as the Proton because it was instead released in December 1981 as the BBC Micro, also affectionately called “The Beeb.” You could get a 16k version for £235 and a 32k version for £335.
In 1980, Acorn was an underdog in the British computing industry. But the BBC Micro helped establish the company’s legacy. Today, the world’s most popular microprocessor instruction set is the ARM architecture. “ARM” now stands for “Advanced RISC Machine,” but originally it stood for “Acorn RISC Machine.” ARM Holdings, the company behind the architecture, was spun out from Acorn in 1990.
*A bad picture of a BBC Micro, taken by me at the Computer History Museum
in Mountain View, California.*
## The Computer Programme
A dozen different TV series were eventually produced as part of the *Computer
Literacy Project*, but the first of them was a ten-part series known as *The
Computer Programme*. The series was broadcast over ten weeks at the beginning
of 1982. A million people watched each week-night broadcast of the show; a
quarter million watched the reruns on Sunday and Monday afternoon.
The show was hosted by two presenters, Chris Serle and Ian McNaught-Davis.
Serle plays the neophyte while McNaught-Davis, who had professional experience
programming mainframe computers, plays the expert. This was an inspired setup.
It made for [awkward
transitions](https://twitter.com/TwoBitHistory/status/1112372000742404098)—Serle
often goes directly from a conversation with McNaught-Davis to a bit of
walk-and-talk narration delivered to the camera, and you can’t help but wonder
whether McNaught-Davis is still standing there out of frame or what. But it
meant that Serle could voice the concerns that the audience would surely have.
He can look intimidated by a screenful of BASIC and can ask questions like,
“What do all these dollar signs mean?” At several points during the show, Serle
and McNaught-Davis sit down in front of a computer and essentially pair
program, with McNaught-Davis providing hints here and there while Serle tries
to figure it out. It would have been much less relatable if the show had been
presented by a single, all-knowing narrator.
The show also made an effort to demonstrate the many practical applications of
computing in the lives of regular people. By the early 1980s, the home computer
had already begun to be associated with young boys and video games. The
producers behind *The Computer Programme* sought to avoid interviewing
“impressively competent youngsters,” as that was likely “to increase the
anxieties of older viewers,” a demographic that the show was trying to attract
to computing. 7 In the first episode of the series, Gill Nevill, the show’s
“on location” reporter, interviews a woman that has bought a Commodore PET to
help manage her sweet shop. The woman (her name is Phyllis) looks to be
60-something years old, yet she has no trouble using the computer to do her
accounting and has even started using her PET to do computer work for other
businesses, which sounds like the beginning of a promising freelance career.
Phyllis says that she wouldn’t mind if the computer work grew to replace her
sweet shop business since she enjoys the computer work more. This interview
could instead have been an interview with a teenager about how he had modified
*Breakout*to be faster and more challenging. But that would have been encouraging to almost nobody. On the other hand, if Phyllis, of all people, can use a computer, then surely you can too.
While the show features lots of BASIC programming, what it really wants to teach its audience is how computing works in general. The show explains these general principles with analogies. In the second episode, there is an extended discussion of the Jacquard loom, which accomplishes two things. First, it illustrates that computers are not based only on magical technology invented yesterday—some of the foundational principles of computing go back two hundred years and are about as simple as the idea that you can punch holes in card to control a weaving machine. Second, the interlacing of warp and weft threads is used to demonstrate how a binary choice (does the weft thread go above or below the warp thread?) is enough, when repeated over and over, to produce enormous variation. This segues, of course, into a discussion of how information can be stored using binary digits.
Later in the show there is a section about a steam organ that plays music encoded in a long, segmented roll of punched card. This time the analogy is used to explain subroutines in BASIC. Serle and McNaught-Davis lay out the whole roll of punched card on the floor in the studio, then point out the segments where it looks like a refrain is being repeated. McNaught-Davis explains that a subroutine is what you would get if you cut out those repeated segments of card and somehow added an instruction to go back to the original segment that played the refrain for the first time. This is a brilliant explanation and probably one that stuck around in people’s minds for a long time afterward.
I’ve picked out only a few examples, but I think in general the show excels at
demystifying computers by explaining the principles that computers rely on to
function. The show could instead have focused on teaching BASIC, but it did
not. This, it turns out, was very much a conscious choice. In a retrospective
written in 1983, John Radcliffe, the executive producer of the *Computer
Literacy Project*, wrote the following:
If computers were going to be as important as we believed, some genuine understanding of this new subject would be important for everyone, almost as important perhaps as the capacity to read and write. Early ideas, both here and in America, had concentrated on programming as the main route to computer literacy. However, as our thinking progressed, although we recognized the value of “hands-on” experience on personal micros, we began to place less emphasis on programming and more on wider understanding, on relating micros to larger machines, encouraging people to gain experience with a range of applications programs and high-level languages, and relating these to experience in the real world of industry and commerce…. Our belief was that once people had grasped these principles, at their simplest, they would be able to move further forward into the subject.
Later, Radcliffe writes, in a similar vein:
There had been much debate about the main explanatory thrust of the series. One school of thought had argued that it was particularly important for the programmes to give advice on the practical details of learning to use a micro. But we had concluded that if the series was to have any sustained educational value, it had to be a way into the real world of computing, through an explanation of computing principles. This would need to be achieved by a combination of studio demonstration on micros, explanation of principles by analogy, and illustration on film of real-life examples of practical applications. Not only micros, but mini computers and mainframes would be shown.
I love this, particularly the part about mini-computers and mainframes. The
producers behind *The Computer Programme* aimed to help Britons get
situated: Where had computing been, and where was it going? What can computers
do now, and what might they do in the future? Learning some BASIC was part of
answering those questions, but knowing BASIC alone was not seen as enough to
make someone computer literate.
## Computer Literacy Today
If you google “learn to code,” the first result you see is a link to
Codecademy’s website. If there is a modern equivalent to the *Computer Literacy
Project*, something with the same reach and similar aims, then it is
Codecademy.
“Learn to code” is Codecademy’s tagline. I don’t think I’m the first person to
point this out—in fact, I probably read this somewhere and I’m now ripping it
off—but there’s something revealing about using the word “code” instead of
“program.” It suggests that the important thing you are learning is how to
decode the code, how to look at a screen’s worth of Python and not
have your eyes glaze over. I can understand why to the average person this
seems like the main hurdle to becoming a professional programmer. Professional
programmers spend all day looking at computer monitors covered in gobbledygook,
so, if I want to become a professional programmer, I better make sure I can
decipher the gobbledygook. But dealing with syntax is not the most challenging
part of being a programmer, and it quickly becomes almost irrelevant in the face
of much bigger obstacles. Also, armed only with knowledge of a programming
language’s syntax, you may be able to *read* code but you won’t be able to
*write* code to solve a novel problem.
I recently went through Codecademy’s “Code Foundations” course, which is the
course that the site recommends you take if you are interested in programming
(as opposed to web development or data science) and have never done any
programming before. There are a few lessons in there about the history of
computer science, but they are perfunctory and poorly researched. (Thank
heavens for [this noble internet
vigilante](https://twitter.com/TwoBitHistory/status/1111305774939234304), who
pointed out a particularly egregious error.) The main focus of the course is
teaching you about the common structural elements of programming languages:
variables, functions, control flow, loops. In other words, the course focuses
on what you would need to know to start seeing patterns in the gobbledygook.
To be fair to Codecademy, they offer other courses that look meatier. But even
courses such as their “Computer Science Path” course focus almost exclusively
on programming and concepts that can be represented in programs. One might
argue that this is the whole point—Codecademy’s main feature is that it
gives you little interactive programming lessons with automated feedback. There
also just isn’t enough room to cover more because there is only so much you can
stuff into somebody’s brain in a little automated lesson. But the producers at
the BBC tasked with kicking off the *Computer Literacy Project* also had this
problem; they recognized that they were limited by their medium and that “the
amount of learning that would take place as a result of the television
programmes themselves would be limited.” 8 With similar constraints on the
volume of information they could convey, they chose to emphasize general
principles over learning BASIC. Couldn’t Codecademy replace a lesson or two
with an interactive visualization of a Jacquard loom weaving together warp and
weft threads?
I’m banging the drum for “general principles” loudly now, so let me just
explain what I think they are and why they are important. There’s a book by J.
Clark Scott about computers called *But How Do It Know?* The title comes from
the anecdote that opens the book. A salesman is explaining to a group of people
that a thermos can keep hot food hot and cold food cold. A member of the
audience, astounded by this new invention, asks, “But how do it know?” The joke
of course is that the thermos is not perceiving the temperature of the food and
then making a decision—the thermos is just constructed so that cold food
inevitably stays cold and hot food inevitably stays hot. People
anthropomorphize computers in the same way, believing that computers are
digital brains that somehow “choose” to do one thing or another based on the
code they are fed. But learning a few things about how computers work, even at
a rudimentary level, takes the homunculus out of the machine. That’s why the
Jacquard loom is such a good go-to illustration. It may at first seem like an
incredible device. It reads punch cards and somehow “knows” to weave the right
pattern! The reality is mundane: Each row of holes corresponds to a thread, and
where there is a hole in that row the corresponding thread gets lifted.
Understanding this may not help you do anything new with computers, but it will
give you the confidence that you are not dealing with something
magical. We should impart this sense of confidence to beginners as soon as we
can.
Alas, it’s possible that the real problem is that nobody wants to learn about the Jacquard loom. Judging by how Codecademy emphasizes the professional applications of what it teaches, many people probably start using Codecademy because they believe it will help them “level up” their careers. They believe, not unreasonably, that the primary challenge will be understanding the gobbledygook, so they want to “learn to code.” And they want to do it as quickly as possible, in the hour or two they have each night between dinner and collapsing into bed. Codecademy, which after all is a business, gives these people what they are looking for—not some roundabout explanation involving a machine invented in the 18th century.
The *Computer Literacy Project*, on the other hand, is what a bunch of
producers and civil servants at the BBC thought would be the best way to
educate the nation about computing. I admit that it is a bit elitist to suggest
we should laud this group of people for teaching the
masses what they were incapable of seeking out on their own. But I can’t help
but think they got it right. Lots of people first learned about computing using
a BBC Micro, and many of these people went on to become successful software
developers or game designers.
[As I’ve written before](/2018/09/02/learning-basic.html),
I suspect learning about computing at a time when computers were relatively
simple was a huge advantage. But perhaps another advantage these people had is
shows like *The Computer Programme*, which strove to teach not just programming
but also how and why computers can run programs at all. After watching *The
Computer Programme*, you may not understand all the gobbledygook on a computer
screen, but you don’t really need to because you know that, whatever the “code”
looks like, the computer is always doing the same basic thing. After a course
or two on Codecademy, you understand some flavors of gobbledygook, but to you a
computer is just a magical machine that somehow turns gobbledygook into running
software. That isn’t computer literacy.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
*Previously on TwoBitHistory…*
FINALLY some new damn content, amirite?
— TwoBitHistory (@TwoBitHistory)
Wanted to write an article about how Simula bought us object-oriented programming. It did that, but early Simula also flirted with a different vision for how OOP would work. Wrote about that instead![https://t.co/AYIWRRceI6][February 1, 2019]
-
Robert Albury and David Allen, Microelectronics, report (1979).
[↩](#fnref:1) -
Gregg Williams, “Microcomputing, British Style”, Byte Magazine, 40, January 1983, accessed on March 31, 2019,
[https://archive.org/stream/byte-magazine-1983-01/1983_01_BYTE_08-01_Looking_Ahead#page/n41/mode/2up](https://archive.org/stream/byte-magazine-1983-01/1983_01_BYTE_08-01_Looking_Ahead#page/n41/mode/2up).[↩](#fnref:2) -
John Radcliffe, “Toward Computer Literacy,” Computer Literacy Project Achive, 42, accessed March 31, 2019,
[https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/media/Towards Computer Literacy.pdf](https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/media/Towards Computer Literacy.pdf).[↩](#fnref:3) -
David Allen, “About the Computer Literacy Project,” Computer Literacy Project Archive, accessed March 31, 2019,
[https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/history](https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/history).[↩](#fnref:4) -
ibid.
[↩](#fnref:5) -
Williams, 51.
[↩](#fnref:6) -
Radcliffe, 11.
[↩](#fnref:7) -
Radcliffe, 5.
[↩](#fnref:8) |
15,470 | 在 virt-manager 的主机和客户机之间共享文件夹 | https://www.debugpoint.com/share-folder-virt-manager/ | 2023-01-23T16:36:00 | [
"virt-manager",
"文件夹共享"
] | /article-15470-1.html | 
>
> 在本指南中,你将学习如何在 virt-manager 的 KVM、QEMU 和 libvirt 的主机和客户机之间共享文件夹。
>
>
>
[virt-manager](https://virt-manager.org/) 应用或软件包使用 [libvirt](https://libvirt.org/manpages/libvirtd.html) 库来提供虚拟机管理服务。它有一个桌面界面,有助于创建、删除和管理多个虚拟机。
virt-manager 桌面界面及其组件为各种个人和商业场景提供了灵活的虚拟机管理服务。它是一个自由开源的应用,主要用于 KVM 虚拟机。然而,它也可以支持其他管理程序,如 Xen 和 LXC。
在之前的文章中,我解释了 [如何使用 virt-manager 创建虚拟机](https://www.debugpoint.com/virt-manager/)。这篇文章介绍了如何在客户机和主机之间无缝访问文件和文件夹。
### 关于 virtiofs 的说明
共享文件和文件夹是由名为 virtiofs 的 libvirt 共享文件系统提供的。它提供了访问主机上的目录树的所有功能和参数。由于大多数 virt-manager 虚拟机的配置都被翻译成 XML,所以共享文件/文件夹也可以通过 XML 文件来指定。
### 在 virt-manager中共享文件夹
首先,确保你的客户机关闭了电源。在 virt-manager GUI 中,选择虚拟机,点击“<ruby> 打开 <rt> Open </rt></ruby>”,弹出控制台设置。

点击工具条上显示虚拟硬件细节的图标。然后点击左边面板上的“<ruby> 内存 <rt> Memory </rt></ruby>”。
选择选项 “<ruby> 启用共享内存 <rt> Enable shared memory </rt></ruby>”。点击应用。

然后点击底部的 “<ruby> 添加硬件 <rt> Add hardware </rt></ruby>”。

在添加新硬件的窗口中,从左边的面板上选择 “<ruby> 文件系统 <rt> File system </rt></ruby>”。
然后在 “<ruby> 细节 <rt> Details </rt></ruby>” 标签中选择 “<ruby> 驱动程序 <rt> Driver </rt></ruby>” 为 “virtiofs”。点击 “<ruby> 浏览 <rt> Browse </rt></ruby> > <ruby> 浏览本地 <rt> browse local </rt></ruby>”,**选择你想在客户机内访问的主机路径**。
在目标路径中,输入你想要的任何名字。这只是一个文件标签,将在挂载时使用。
所以,如果我想访问 `Pictures/Screenshots` 文件夹(`/home/debugpoint/Pictures/Screenshots`),示例设置可以是这样:

下面是上述配置的 XML 设置。你可以在 XML 标签中找到它。
```
<filesystem type="mount" accessmode="passthrough">
<driver type="virtiofs"/>
<binary path="/usr/libexec/virtiofsd"/>
<source dir="/home/debugpoint/Pictures/Screenshots"/>
<target dir="mount_tag_pictures"/>
<alias name="fs1"/>
<address type="pci" domain="0x0000" bus="0x08" slot="0x00" function="0x0"/>
</filesystem>
```
点击 “<ruby> 完成 <rt> Finish </rt></ruby>”。在 virt-manager 主窗口中,右键点击虚拟机,点击运行,启动虚拟机。确保点击“<ruby> 显示图形控制台 <rt> show the graphical console </rt></ruby>”(如果虚拟机没有显示,点击工具条上的监视器图标)。
在客户机中,创建一个你想挂载主机文件夹的文件夹。在这个例子中,我使用了 `/mnt/pictures`。
```
sudo mkdir /mnt/pictures
```
最后,使用你在上述步骤中创建的标签将主机文件夹挂载到这个新文件夹。使用下面的命令在终端做这件事。确保根据你的系统改变下面命令中的标签和文件夹名称。
```
sudo mount -t virtiofs mount_tag_pictures /mnt/pictures
```
现在你可以在 virt-manager 中的主机和客户机之间的无缝地浏览文件夹和添加/删除项目。

### 总结
我希望这个方案能帮助你从客户机上访问主机文件和文件夹。记住,你的用户 ID,也就是用来启动 virt-manager 应用的用户,应该有同样的权限来访问主机文件夹。
如果你遇到任何错误,上述指南帮助了你,请在下面留言。
* [参考](https://libvirt.org/kbase/virtiofs.html)
---
via: <https://www.debugpoint.com/share-folder-virt-manager/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,472 | 完整指南:使用 VirtualBox 在 Windows 上安装 Ubuntu | https://www.debugpoint.com/install-ubuntu-windows-virtualbox/ | 2023-01-23T23:02:00 | [
"Ubuntu",
"虚拟机",
"VirtualBox"
] | /article-15472-1.html | 
>
> 本教程将指导你用最简单的步骤在 Windows 上的 Oracle VirtualBox 上安装 Ubuntu 桌面版。
>
>
>
[VirtualBox](https://www.debugpoint.com/tag/virtualbox) 是 Oracle 的一款流行的虚拟化软件,可用于 Linux、mac 和 Windows 系统。它是灵活的,并提供了许多功能来实现虚拟化。这是在 Windows 中体验 Ubuntu 而不安装它的最佳且简单的方法。然而,我强烈建议将 Ubuntu 以双引导的方式安装在物理机上,从而更好地体验 Ubuntu。
下面列出的步骤假设你是第一次在 Windows 中安装 Ubuntu。因此,这些步骤有点描述性,也有点冗长。此外,以下步骤适用于 Windows 10 和 Windows 11 作为宿主机。
### 你需要什么
* 可上网的 PC
* 用于安装的 Ubuntu Linux ISO 镜像文件
* 安装了 VirtualBox 的 Windows 系统
### 使用 VirtualBox 在 Windows 上安装 Ubuntu
#### 下载并安装必要的东西
从以下链接下载 Ubuntu Linux 桌面版 ISO 镜像文件。
>
> **[下载 Ubuntu 桌面版](https://ubuntu.com/download/desktop)**
>
>
>
此外,请从下面的官方网站下载 Oracle VirtualBox 安装程序。
>
> **[下载 VirtualBox](https://www.virtualbox.org/wiki/Downloads)**
>
>
>

#### 如何安装和配置 VirtualBox
Windows 中的 VirtualBox 需要 “Microsoft Visual C++ 2019 Redistrobutiable package”。你必须先安装它。从以下链接下载软件包(X64 架构):
>
> **[下载 MSVC](https://learn.microsoft.com/en-us/cpp/windows/latest-supported-vc-redist?view=msvc-170)**
>
>
>


完成以上安装后,从以下链接下载最新的 Python 包。Python 绑定也是 Windows 端 VirtualBox 安装所需的依赖项。
>
> **[下载 Python for Windows](https://www.python.org/downloads/windows/)**
>
>
>
然后,启动 VirtualBox 安装程序并按照屏幕上的说明进行安装。
安装后,重新启动 Windows 系统。
#### 为 Ubuntu 设置虚拟机
从开始菜单启动 VirtualBox。

在 VirtualBox 窗口工具栏上,单击 “<ruby> 新建 <rt> New </rt></ruby>”。

* 在创建虚拟机窗口中,输入虚拟机的名称。它可以是标识此版本 Ubuntu 的任何名称。
* 保持 “<ruby> 文件夹 <rt> Folder </rt></ruby>” 不变。这是创建虚拟机文件的路径。
* 在 “<ruby> ISO 镜像文件 <rt> ISO Image </rt></ruby>” 一栏,浏览你下载的 Ubuntu ISO 文件。
* 然后选择 “<ruby> 跳过无人值守安装 <rt> Skip Unattended installation </rt></ruby>”。如果不选择此选项,将在虚拟机中创建一个 [默认用户 id(vboxuser)和密码](https://www.debugpoint.com/virtualbox-id-password/)。让我们暂时不要管它。

* 单击 “<ruby> 硬件 <rt> Hardware </rt></ruby>” 部分,并调整虚拟机所需的内存。一般的经验是,虚拟机的内存大小应该小于主机系统中的物理内存。我建议对于 8 GB 内存系统的虚拟机使用 2 GB 到 4 GB。要选择 4 GB 内存,拖动滑块(或键入)使其为 4096 MB(即 4×1024)。
* 选择 2 或 4 核处理器。

* 单击 “<ruby> 硬盘 <rt> Hard Disk </rt></ruby>” 部分,并保持文件位置不变。
* 为 Ubuntu 安装提供至少 20 GB 到 25 GB 的容量。
* 硬盘文件类型值保持为 VDI(VirtualBox 磁盘镜像)
* 不要选择 “<ruby> 预分配完整大小 <rt> Pre-allocate Full Size </rt></ruby>”。
* 最后,单击 “<ruby> 完成 <rt> Finish </rt></ruby>”。

你应该在 VirtualBox 的左侧面板上看到一个新条目,其中包含一个 Ubuntu 22.04 条目(你之前设置的名称)。
选择条目并单击 “<ruby> 开始 <rt> Start </rt></ruby>” 以引导到虚拟机:

#### 使用 VirtualBox 安装 Ubuntu
成功引导后,你应该看到以下屏幕,其中显示了安装 Ubuntu 的各种选项。选择 “<ruby> 尝试 Ubuntu <rt> Try Ubuntu </rt></ruby>” 或 “<ruby> 安装 Ubuntu <rt> Install Ubuntu </rt></ruby>”。
在欢迎屏幕中,单击 “<ruby> 尝试 Ubuntu <rt> Try Ubuntu </rt></ruby>”。过了一会儿,你会看到下面的 Ubuntu <ruby> 临场 <rt> Live </rt></ruby>桌面。如果要更改分辨率,请右键单击桌面并选择显示设置。并将分辨率更改为 1400×900。

在桌面上,双击 “<ruby> 安装 Ubuntu <rt> Install Ubuntu </rt></ruby>”。

在下一组屏幕中,根据需要选择 “<ruby> 语言 <rt> Language </rt></ruby>” 和 “<ruby> 键盘布局 <rt> Keyboard Layout </rt></ruby>”。


安装屏幕为你提供所需的安装类型。选择 “<ruby> 正常安装 <rt> Normal Installation </rt></ruby>”,然后在 “<ruby> 其他选项 <rt> Other options </rt></ruby>” 下选择两个选项。

由于你是在虚拟磁盘空间中安装的,即它只是一个文件,因此你可以安全地选择 “<ruby> 擦除磁盘并安装 Ubuntu <rt> Erase disk and install Ubuntu </rt></ruby>” 选项。

点击 “<ruby> 立即安装 <rt> Install Now </rt></ruby>” 并 “<ruby> 继续 <rt> Continue </rt></ruby>”。

然后选择 “<ruby> 地区 <rt> region </rt></ruby>”,添加“<ruby> 你的名字 <rt> Your name </rt></ruby>”、“<ruby> 计算机名称 <rt> Your computer's name </rt></ruby>”、“<ruby> 用户名 <rt> Username </rt></ruby>” 和 “<ruby> 密码 <rt> Password </rt></ruby>”。这将是安装后登录 Ubuntu 的用户 id 和密码。
单击 “<ruby> 继续 <rt> Continue </rt></ruby>” 开始安装。等到它完成。

安装完成后,单击 “<ruby> 立即重新启动 <rt> Restart Now </rt></ruby>”。等待几秒钟,你将看到一个登录屏幕。使用用户 id 和密码登录。你应该看到 Ubuntu 桌面在 Windows 端 VirtualBox 中作为 VM 运行。



### 安装后配置和提示(可选)
#### 安装客体机增强项
成功安装后,应为 Windows 宿主机和 Ubuntu 客体机安装 “<ruby> VirtualBox 客体机增强项 <rt> VirtualBox guest additions </rt></ruby>”。客体机增强项是一组需要安装在客体虚拟机(即 Ubuntu)内的软件包,以启用 **共享文件夹、双向复制 / 粘贴、自动更改分辨率** 和许多类似功能。
要安装它,请引导到 Ubuntu。从 VirtualBox 菜单中,选择“<ruby> 设备 <rt> Devices </rt></ruby> > <ruby> 插入客体机增强 CD 镜像 <rt> Insert Guest Additions CD Image </rt></ruby>”。必要的软件包将安装在 Ubuntu 中。

打开文件管理器并打开装入的文件夹,如下所示。然后右键单击 > 选择 “<ruby> 在终端中打开 <rt> open in terminal </rt></ruby>”。

然后运行以下命令:
```
sudo ./VBoxLinuxAdditions.run
```

完成上述命令后,重新启动 Ubuntu VM。
#### 启用 Windows 和 Ubuntu 之间的复制和粘贴
要在 Windows 和 Ubuntu 系统之间启用复制和粘贴,请从菜单中选择 “<ruby> 设备 <rt> Devices </rt></ruby> > <ruby> 共享剪贴板 <rt> Shared Clipboard </rt></ruby> > <ruby> 双向 <rt> Bi-directional </rt></ruby>”。

#### 关闭 Ubuntu VM
理想情况下,你应该从自己的关机菜单中关闭 VM。但是,你也可以从 VirtualBox 主窗口关闭。右键单击虚拟机名称并选择 “<ruby> 关闭 <rt> Close </rt></ruby> > <ruby> 关机 <rt> Poweroff </rt></ruby>”。

#### 如何删除 Ubuntu 并删除所有数据
如果要完全删除虚拟机(例如 Ubuntu)及其数据,请选择 “<ruby> 删除 <rt> Remove </rt></ruby>” 和 “<ruby> 删除所有文件 <rt> Delete All Files </rt></ruby>”。


### 结语
在本教程中,你学习了使用 VirtualBox 在 Windows(10 或 11)上安装 Ubuntu 的最简单方法。此外,你还学习了几步安装后配置 Ubuntu VM 的基本步骤。你可以对 VirtualBox 中的其他任何 Linux 发行版使用上述步骤。
如果你有任何疑问,欢迎在下面发表评论。
---
via: <https://www.debugpoint.com/install-ubuntu-windows-virtualbox/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[ZhangZhanhaoxiang](https://github.com/ZhangZhanhaoxiang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,473 | 如何在 Java 中使用方法 | https://opensource.com/article/23/1/java-methods | 2023-01-24T18:29:00 | [
"Java",
"方法"
] | https://linux.cn/article-15473-1.html |
>
> 在这个简便的教程中,我们可以了解到 Java 中方法的定义,如何使用方法,以及何时使用方法。
>
>
>

Java 中的方法(在许多其他编程语言中称为“函数”)是被组合在一起并标记为可重用的一块代码。方法很有用,因为它们允许你在不重写相同代码的情况下,执行相同的操作或一系列操作,这不仅意味着你的工作量减少,还意味着出现问题时需要维护和调试的代码减少。
方法存在于类中,因此标准 Java 样板代码适用:
```
package com.opensource.example;
public class Example {
// 在此写代码
}
```
在这样一个简单的单文件应用程序中,包定义并不是绝对必要的,但它是一个很好的习惯,而且大多数 IDE 都强制执行它。
默认情况下,Java 会寻找在类中运行的 `main` 方法。方法可以是公有的或私有的,也可以是静态的或非静态的,但 `main` 方法必须是公有的、静态的,Java 编译器才能识别和使用它。当方法是公有的时,它可以从类外部执行。要在程序启动时调用 `Example` 类,其 `main` 方法必须是可访问的,因此将其设置为 `public`。
下面是两个方法的简单演示:一个 `main` 方法在调用 `Example` 类时默认执行,另一个 `report` 方法接受 `main` 的输入并执行简单操作。
为了模拟任意数据输入,我使用了 `if`-`then` 语句,该语句根据你启动应用程序的时间在两个字符串之间进行选择。换句话说,`main` 方法首先设置一些数据(在现实生活中,这些数据可以来自用户输入,也可以来自应用程序其他地方的其他方法),然后 “调用” `report`方法,将处理后的数据作为输入提供:
```
package com.opensource.example;
public class Example {
public static void main(String[] args) {
// 生成一些数据
long myTime = System.currentTimeMillis();
String weather;
if ( myTime%2 == 0 ) {
weather = "party";
} else {
weather = "apocalypse";
}
// 调用其他方法
report(weather);
}
private static void report(String day) {
System.out.printf("Welcome to the zombie %s\n", day);
}
}
```
运行代码:
```
$ java ./Example.java
Welcome to the zombie apocalypse
$ java ./Example.java
Welcome to the zombie party
```
请注意,同一 `report` 方法有两个不同的结果。当然,在这个简单的演示中,不需要第二种方法。模拟数据生成的 `if`-`then` 语句可能生成了相同的结果。但是,当一个方法执行一项复杂的任务时,比如将图像调整为缩略图,然后使用调整后的图像在屏幕上生成小部件,那么附加组件的“费用”就很有意义了。
### 何时使用 Java 方法
很难知道何时使用方法,何时只将数据发送到 [Java 流](https://opensource.com/article/20/1/javastream) 或循环中。如果你面临这个决定,答案通常是使用一种方法。原因如下:
* 方法开销少。它们不会给代码增加处理开销。
* 方法减少代码的行数。
* 方法是特定的。查找名为 `resizeImage` 的方法通常比查找隐藏在从驱动器加载图像的函数中某个循环中的代码更容易。
* 方法是可重用的。当你第一次编写方法时,你可能会 *认为* 它只对应用程序中的一个任务有用。然而,随着应用程序的编写,你可能会发现自己正在使用一种你认为“已完成”的方法。
### 函数式编程与面向对象编程
函数式编程利用方法作为执行任务的主要构造。创建一个方法,该方法接受一种数据,处理该数据,并输出新数据。将许多方法串在一起,你就拥有了一个动态且功能强大的应用程序。像 C 和 [Lua](https://opensource.com/article/22/11/lua-worth-learning) 这样的编程语言就是这种编码风格的例子。
用代码完成任务的另一种方式是 Java 使用的面向对象模型。在面向对象编程中,方法是模板的组成部分。你可以创建对象,而不是将数据从一个方法发送到另一个方法,并可以通过使用它们的方法来更改它们。
从面向对象的角度来看,这是一个简单的 “僵尸末日” 演示程序。在函数方法中,我使用一种方法生成数据,另一种方法使用该数据执行操作。面向对象的等价物是具有表示工作单元的类。这个示例应用程序向用户显示一条当天的消息,宣布这一天会有僵尸派对或是僵尸末日。编写一个“天”对象,然后查询该对象以了解其特性是有意义的。作为演示面向对象构造的不同方面的借口,新的示例应用程序还将统计有多少僵尸出现在派对上(或末日)。
Java 为每个类使用一个文件,因此要创建的第一个文件是 `Day.Java`,它用作 `Day` 对象:
```
package com.opensource.example;
import java.util.Random;
// 类
public class Day {
public static String weather;
public int count;
// 构造方法
public Day() {
long myTime = System.currentTimeMillis();
if ( myTime%2 == 0 ) {
weather = "paradise";
} else {
weather = "apocalypse";
}
}
// 方法
public String report() {
return weather;
}
public int counter() {
Random rand = new Random();
count = count + rand.nextInt(100);
return(count);
}
}
```
在“类”部分中,创建了两个域:天象 `weather` 和计数 `count`。`weather` 是静态的。在一天的过程中(在这种假想的情况下),`weather` 不会改变。要么是派对 `paradise`,要么是末日 `apocalypse`,持续了一整天。然而,僵尸的数量在一天中会增加。
在“构造方法”部分,确定当天的天象。它是作为一个 [构造方法](https://opensource.com/article/19/6/what-java-constructor) 完成的,因为它只在类最初被调用时发生一次。
在“方法”部分,`report` 方法只返回由构造方法确定和设置的天象报告。然而,`counter` 方法生成一个随机数,并将其添加到当前僵尸计数中。
换句话说,这个类做了三件不同的事情:
* 表示应用程序定义的“天”。
* 设置当天不变的天气报告。
* 设置一天中不断增加的僵尸数量。
要使用这所有,请创建第二个文件:
```
package com.opensource.example;
public class Example {
public static void main(String[] args) {
Day myDay = new Day();
String foo = myDay.report();
String bar = myDay.report();
System.out.printf("Welcome to a zombie %s\n", foo);
System.out.printf("Welcome to a zombie %s\n", bar);
System.out.printf("There are %d zombies out today.\n", myDay.counter());
System.out.printf("UPDATE: %d zombies. ", myDay.counter());
System.out.printf("UPDATE: %d zombies. ", myDay.counter());
}
}
```
因为现在有两个文件,所以使用 Java IDE 运行代码是最简单的,但是如果不想使用 IDE,可以创建自己的 [JAR 文件](https://opensource.com/article/21/8/fastjar)。运行代码以查看结果:
```
Welcome to a zombie apocalypse
Welcome to a zombie apocalypse
There are 35 zombies out today.
UPDATE: 67 zombies. UPDATE: 149 zombies.
```
无论调用 `report` 方法多少次,`weather` 都保持不变,但调用 `counter` 方法的次数越多,僵尸的数量就会增加。
### Java 方法
方法(或函数)是编程中的重要组成。在 Java 中,你可以将它们作为函数式编程的单个类的一部分使用,也可以在面向对象编程的类之间使用它们。两种类型的编程对于解决同一个问题有不同的视角,因此没有对与错之分。通过反复尝试,积累一点经验,你会知道哪一个最适合某个特定的问题。
---
via: <https://opensource.com/article/23/1/java-methods>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed) 译者:[ZhangZhanhaoxiang](https://github.com/ZhangZhanhaoxiang) 校对:[wxy](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A method in Java (called a "function" in many other programming languages) is a portion of code that's been grouped together and labeled for reuse. Methods are useful because they allow you to perform the same action or series of actions without rewriting the same code, which not only means less work for you, it means less code to maintain and debug when something goes wrong.
A method exists within a class, so the standard Java boilerplate code applies:
```
``````
package com.opensource.example;
public class Example {
// code here
}
```
A package definition isn't strictly necessary in a simple one-file application like this, but it's a good habit to get into, and most IDEs enforce it.
By default, Java looks for a `main`
method to run in a class. Methods can be made public or private, and static or non-static, but the main method must be public and static for the Java compiler to recognize and utilize it. When a method is public, it's able to be executed from outside the class. To call the `Example`
class upon start of the program, its `main`
method must be accessible, so set it to `public`
.
Here's a simple demonstration of two methods: one `main`
method that gets executed by default when the `Example`
class is invoked, and one `report`
method that accepts input from `main`
and performs a simple action.
To mimic arbitrary data input, I use an if-then statement that chooses between two strings, based on when you happen to start the application. In other words, the `main`
method first sets up some data (in real life, this data could be from user input, or from some other method elsewhere in the application), and then "calls" the `report`
method, providing the processed data as input:
```
``````
package com.opensource.example;
public class Example {
public static void main(String[] args) {
// generate some data
long myTime = System.currentTimeMillis();
String weather;
if ( myTime%2 == 0 ) {
weather = "party";
} else {
weather = "apocalypse";
}
// call the other method
report(weather);
}
private static void report(String day) {
System.out.printf("Welcome to the zombie %s\n", day);
}
}
```
Run the code:
```
``````
$ java ./Example.java
Welcome to the zombie apocalypse
$ java ./Example.java
Welcome to the zombie party
```
Notice that there are two different results from the same `report`
method. In this simple demonstration, of course, there's no need for a second method. The same result could have been generated from the if-then statement that mimics the data generation. But when a method performs a complex task, like resizing an image into a thumbnail and then generating a widget on screen using that resized image, then the "expense" of an additional component makes a lot of sense.
## When to use a Java method
It can be difficult to know when to use a method and when to just send data into a [Java Stream](https://opensource.com/article/20/1/javastream) or loop. If you're faced with that decision, the answer is usually to use a method. Here's why:
- Methods are cheap. They don't add processing overhead to your code.
- Methods reduce the line count of your code.
- Methods are specific. It's usually easier to find a method called
`resizeImage`
than it is to find code that's hidden in a loop somewhere in the function that loads images from the drive. - Methods are reusable. When you first write a method, you may
*think*it's only useful for one task within your application. As your application grows, however, you may find yourself using a method you thought you were "done" with.
## Functional vs. object-oriented programming
Functional programming utilizes methods as the primary construct for performing tasks. You create a method that accepts one kind of data, processes that data, and outputs new data. String lots of methods together, and you have a dynamic and capable application. Programming languages like C and [Lua](https://opensource.com/article/22/11/lua-worth-learning) are examples of this style of coding.
The other way to think of accomplishing tasks with code is the object-oriented model, which Java uses. In object-oriented programming, methods are components of a template. Instead of sending data from method to method, you create objects with the option to alter them through the use of their methods.
Here's the same simple zombie apocalypse demo program from an object-oriented perspective. In the functional approach, I used one method to generate data and another to perform an action with that data. The object-oriented equivalent is to have a class that represents a work unit. This example application presents a message-of-the-day to the user, announcing that the day brings either a zombie party or a zombie apocalypse. It makes sense to program a "day" object, and then to query that day to learn about its characteristics. As an excuse to demonstrate different aspects of object-oriented construction, the new sample application will also count how many zombies have shown up to the party (or apocalypse).
Java uses one file for each class, so the first file to create is `Day.java`
, which serves as the Day object:
```
``````
package com.opensource.example;
import java.util.Random;
// Class
public class Day {
public static String weather;
public int count;
// Constructor
public Day() {
long myTime = System.currentTimeMillis();
if ( myTime%2 == 0 ) {
weather = "paradise";
} else {
weather = "apocalypse";
}
}
// Methods
public String report() {
return weather;
}
public int counter() {
Random rand = new Random();
count = count + rand.nextInt(100);
return(count);
}
}
```
In the `Class`
section, two fields are created: `weather`
and `count`
. Weather is static. Over the course of a day (in this imaginary situation), weather doesn't change. It's either a party or an apocalypse, and it lasts all day. The number of zombies, however, increases over the course of a day.
In the `Constructor`
section, the day's weather is determined. It's done as a [constructor](https://opensource.com/article/19/6/what-java-constructor) because it's meant to only happen once, when the class is initially invoked.
In the `Methods`
section, the `report`
method only returns the weather report as determined and set by the constructor. The `counter`
method, however, generates a random number and adds it to the current zombie count.
This class, in other words, does three very different things:
- Represents a "day" as defined by the application.
- Sets an unchanging weather report for the day.
- Sets an ever-increasing zombie count for the day.
To put all of this to use, create a second file:
```
``````
package com.opensource.example;
public class Example {
public static void main(String[] args) {
Day myDay = new Day();
String foo = myDay.report();
String bar = myDay.report();
System.out.printf("Welcome to a zombie %s\n", foo);
System.out.printf("Welcome to a zombie %s\n", bar);
System.out.printf("There are %d zombies out today.\n", myDay.counter());
System.out.printf("UPDATE: %d zombies. ", myDay.counter());
System.out.printf("UPDATE: %d zombies. ", myDay.counter());
}
}
```
Because there are now two files, it's easiest to use a Java IDE to run the code, but if you don't want to use an IDE, you can create your own [JAR file](https://opensource.com/article/21/8/fastjar). Run the code to see the results:
```
``````
Welcome to a zombie apocalypse
Welcome to a zombie apocalypse
There are 35 zombies out today.
UPDATE: 67 zombies. UPDATE: 149 zombies.
```
The "weather" stays the same regardless of how many times the `report`
method is called, but the number of zombies on the loose increases the more you call the `counter`
method.
## Java methods
Methods (or functions) are important constructs in programming. In Java, you can use them either as part of a single class for functional-style coding, or you can use them across classes for object-oriented code. Both styles of coding are different perspectives on solving the same problem, so there's no right or wrong decision. Through trial and error, and after a little experience, you learn which one suits a particular problem best.
## Comments are closed. |
15,475 | 如何在 Ubuntu 和 Fedora 中设置 Python 开发环境 | https://www.debugpoint.com/setup-python-environment-ubuntu-fedora/ | 2023-01-24T11:15:00 | [
"Python"
] | /article-15475-1.html | 
>
> 本文将帮助你了解在 Ubuntu 和 Fedora 中设置 Python 开发环境的基础知识和步骤。
>
>
>
[Python](https://www.python.org/) 由于其强大的库、简单的语法和可移植性,在过去几年中变得很流行。目前几乎所有的企业系统都在使用它。
因此,如果你正试图建立你的 Python 环境,并想知道如何开始等等,那么你就找到正确的地方了。在这里,我试图给你一些开始的步骤。
### 在 Ubuntu 和 Fedora 中设置 Python 开发环境
#### Python 版本
如果你刚刚开始 Python 开发,那么建议你使用最新的 Python 3.x 进行开发,因为 Python 2.x 已经不再支持了。几乎所有领先的 Linux 发行版都取消了对 Python 2 的依赖。
如果你正在运行 Fedora 或 Ubuntu 的最新发行版,那么你应该已经安装了 Python 3.x,并设置为默认解释器。例如,Fedora 37 和 Ubuntu 22.04 LTS 将 [Python 3.11](https://www.debugpoint.com/install-python-3-11-ubuntu/) 作为默认的 Python 交互界面。
找到你的 Python 版本的一个快速方法是在 Ubuntu 和 Fedora 的终端运行以下命令:
```
python2
```
```
python3
```

如果你运行的是早期版本的 Ubuntu 或 Fedora,那么你可以使用以下命令安装最新的 Python 3.x:
Ubuntu:
```
sudo apt install python3
```
Fedora:
```
sudo dnf install python3
```
另外,运行下面的命令,找出当前系统中 Python 可执行文件的路径:
```
Which python
```
#### 切换默认解释器的版本
如果你的系统安装了多个 Python 版本 —— 2.x 和 3.x,并且你想在它们之间切换,也是可以的。
如果你只安装了一个版本,你可以跳过这一节。
要进行切换,首先,从终端运行 `python`,找出默认的可执行路径。理想情况下,它应该是 `/usr/bin/python`。现在,运行下面的程序,找出通往可执行文件的符号链接:
```
ln -l /usr/bin/python
```
```
lrwxrwxrwx 1 root root .... /usr/bin/pyhton -> python2
```
现在检查一下 `$PATH` 变量,确定系统查找可执行文件的路径连接顺序:
```
echo $PATH
```

你可以看到 `/usr/local/bin` 在 `/usr/bin/` 之前,那么你可以创建一个软符号链接到 `python3`。然后你的解释器在运行 `python` 命令时就会找到最新的 Python 3 而不是 Python 2。
```
ls -s /usr/bin/python3 /usr/local/bin/python
```
现在你应该注销并再次登录以清除任何哈希条目,或者你可以运行 `hash -r` 来清除它们。
现在你可以从终端运行 `python`,你应该有最新的 Python 3 了。
#### Python IDE
集成开发环境(IDE)可以帮助你编写、编译和执行你的代码。有 [几个免费的 Python 集成开发环境](https://www.debugpoint.com/5-best-python-ide-code-editor/) —— 如 PyCharm、Eclipse、Eric 等,你可以使用。但那将是另一篇关于其优点和缺点的文章。
如果你从官方 [python.org](https://www.python.org/) 网站下载 Python,Python 还带着一个叫做 IDLE 的默认开发环境。IDLE 适合于起步,之后你可以决定选择任何一个最好的免费 Python IDE。
在 Ubuntu 和 Fedora 中,IDLE 并没有和 Python 一起被默认包含,你必须手动安装它。从终端运行下面的命令来手动安装 IDLE:
Ubuntu:
```
sudo apt install idle
```
Fedora:
```
sudo dnf install python-tools
```
安装后,你可以从命令行空闲启动 IDLE 或从应用程序中搜索。

现在,你可以使用 IDLE 开始你的开发。大部分的基本选项你可以在 IDLE 的文件菜单中找到。
我希望这篇指南解释了你在开始 Python 开发之前应该知道的东西。 尽管本指南主要是针对 Ubuntu 和 Fedora 的,但你仍然可以在所有基于 Ubuntu 和 Fedora 的发行版上参考它。如果你在 Python 环境设置方面遇到问题,请在下面的评论区告诉我。
---
via: <https://www.debugpoint.com/setup-python-environment-ubuntu-fedora/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,476 | EndeavourOS:你对完美的 Arch 发行版的搜寻到此为止 | https://www.debugpoint.com/endeavouros-review/ | 2023-01-24T20:58:00 | [
"Arch Linux",
"EndeavourOS"
] | /article-15476-1.html | 
>
> 我们整体点评了最近发布的 EndeavourOS “Cassini”。
>
>
>
每年,个人和小型团队们推出了数以百计的 Linux 发行版。它们大多是 Debian、Ubuntu、Fedora 或 Arch Linux 的直接衍生品,再加上一些定制的东西。这也难怪每年都有因为缺乏贡献、愿景和坚持而死亡的发行版。
三年前,作为已停止的 Antergos 项目的延续,一个由贡献者们组成的小团队发起了 EndeavourOS 项目。从那时起,由于其安装简单,用户体验和功能,它已经变得很受欢迎。

### 点评 EndeavourOS
如果你曾经试过它,你就会很明显地发现,他们花了很多心血来开发这个发行版。这个发行版的口号是成为一个面向大众的 “通用” Arch Linux 发行版,摒弃了新用户对 Arch Linux 安装的恐惧,以及使用 Arch 时的优越感。
如果你曾经尝试过 EndeavourOS,你一定会 “感觉” 到作为一个 Arch 发行版,对最终用户来说,在桌面上执行的事情是多么的 “容易”。
#### 安装和可供选择的桌面
通过 “独有的” Calamares 安装程序,它的安装变得超级简单。除此之外,EndeavourOS 团队还特别注意在安装步骤中为你提供了大部分的选项。例如,无需用户干预的临场介质直接启动。它会启动欢迎屏幕。欢迎屏幕要做的事就是提供让你在系统中安装它所有必要选项。

默认情况下,ISO 提供了一个轻量级的 Xfce 桌面。然而,EndeavourOS 也为你提供了各种桌面环境和窗口管理器(见下文)。而且它们都经过测试,可以正常工作。如果你在安装过程中连接到了互联网,你可以通过 Calamares 安装程序来安装这些。这意味着你不需要在基本的 Xfce 设置后重新安装它们。
此外,如果你是一个资深用户,只想安装一个基本的 Arch Linux,不需要任何桌面,那也是可以的。只要在安装时使用 “<ruby> 无桌面 <rt> No desktop </rt></ruby>” 选项就可以了!
尽管 Arch Linux 最近创建了一个自动脚本 `archinstall` 来使安装更容易,但通过 EndeavourOS 的 ISO 来获得 Arch 的基本安装仍然更快、更容易。

此外,你可以在三个选项中选择:GRUB、systemd-boot 或 “<ruby> 无启动器 <rt> no bootloader </rt></ruby>”,这是 EndeavourOS “Cassini” 版本的亮点功能之一。此外,你还可以选择你要安装的软件包(仅在线模式支持)。例如,你可能需要一个基本的系统来开始使用。或者,你可能想安装一些与视频/音频或开发工作有关的应用程序。所有这些你都可以在这个版本中选择。
安装通过检测我的测试机中安装的其他操作系统而完成,很顺利。在“Cassini” 版本中,该团队还将 mkinitcpio 换成了 [dracut](https://wiki.archlinux.org/title/Dracut),以获得更好的性能,减少启动相关问题的失败。
#### “Xfce” 旗舰版的桌面体验
第一次登录后,你会再次看到欢迎程序,其中有一个 “安装后” 可以做的项目列表。开发人员提供了一个非常周到的列表。这包括改变墙纸、更新 Arch 镜像、安装英伟达驱动等初始任务。许多 Linux 发行版都有一个欢迎程序,但我认为这个程序是一个完善的软件包。

默认的外观是你能得到的定制的最好的 Xfce 桌面。通过定制,它成为一个外观良好的发行版,远非默认的 Xfce 可比。定制包括 GRUB 菜单、登录屏幕和桌面等等。
Xfce 主菜单配置了更多的项目,终端略带透明,使用 Qogir 图标主题。所有这些变化都辅以令人惊叹的壁纸和 Arc-Darker 默认 Xfce 主题。

#### 性能
尽管有桌面环境,Arch Linux 的性能总是更好。它总是令人感觉更快,因为它的内部并不臃肿。除此之外,[Xfce 桌面 4.18](https://www.debugpoint.com/xfce-4-18-features/) 在 “Cassini” 版本中还做了额外的性能优化,你可以在浏览桌面的时候感受到。
在空闲状态下,它使用了大约 700MB 的内存和平均 4% 的 CPU 占用。这是性能基线。资源使用量可能会根据你打开的应用程序的数量而增加。在我之前对 EndeavourOS 的点评中,其性能表现也类似。
不仅如此,它在默认的 Xfce 安装中只使用了 4GB 的磁盘空间。然而,你可能需要安装额外的重型软件,如 LibreOffice、GIMP 或 KDenlive,这将占用更多磁盘空间。

#### 在 EndeavourOS 中执行日常任务有多容易?
EndeavourOS 的一大特点是一些基于 Python 的 GUI 工具,可以使你在 Arch Linux 中的生活变得简单。例如,你可以从 Arch 和 EndeavourOS 的软件仓库中获得更新通知、一键从 AUR 安装软件、一键更新镜像和你的系统。你不需要从终端运行任何命令。这对 Arch Linux 的新用户来说是一个很大的帮助。


#### 处理滚动发布的独特方式,以实现稳定性
Arch Linux 作为一个滚动发布的发行版,往往会出现故障。例如,在 Arch 主仓库的每个月的内核更新期间,一些系统可能会出现故障。由于它的受欢迎程度和开发者的主动性,如果出现问题,你会得到通知和相关的解决方法。
最近 Arch Linux 中的 GRUB 问题,给用户带来了大量的启动问题,EndeavourOS 团队通过适当的沟通,给用户提供了解决方法,真的 [处理得很好](https://endeavouros.com/news/full-transparency-on-the-grub-issue/)。
因此,如果你最终遇到一个不稳定的系统,你也不会真的迷失。
此外,Pacman 的配置已被定制过,使用 EndeavourOS 选择的镜像,以确保你的体验是完美的。
#### 对开源硬件和 ARM 的正式支持
在这个 EndeavourOS “Cassini” 版本中,官方支持了 Pinebook Pro 笔记本电脑。该团队在 Manjaro 软件包的基础上与 Pine64 团队合作,为你提供了独家的 Arch 软件包,使该笔记本开箱即用。此外, EndeavourOS ARM 镜像也可用于树莓派 4。
#### 社区帮助
EndeavourOS 最大的好处之一是社区帮助 —— 这是即时的!这主要是指其专门的 [Telegram 频道](https://endeavouros.com/community/),在那里你可以在几分钟内得到对你的 EndeavourOS 的任何问题的回应。我曾经去过这个频道,管理员/贡献者们都很友好,很有帮助。
此外,你也可以从官方论坛和其他社交渠道获得帮助。
### 总结
在结束对 EndeavourOS 的 [“Cassini” 版本](https://endeavouros.com/news/cassini-packed-with-new-features-is-here/) 的点评时,我想说这是一个构建得最好的发行版,而且组织良好。开发者和团队有一个建立通用的 Arch Linux 发行版的清晰路线图。另外,通过对 ARM 和 Pinebook Pro 的支持以及其他举措,其愿景也很明确。
总而言之,对于每一个希望在 Arch Linux 中拥有一个运行时间更长、更稳定的系统的人来说,这是一个完美的发行版。
你可以从 [官方网站](https://endeavouros.com/download/) 下载 EndeavourOS。
让我们举杯!
---
via: <https://www.debugpoint.com/endeavouros-review/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,480 | 如何在 Windows 上安装 Python | https://www.debugpoint.com/install-python-windows/ | 2023-01-25T21:18:00 | [
"Python"
] | /article-15480-1.html | 
>
> 这个简单的指南演示了如何在 Windows 上下载和安装 Python。
>
>
>
这篇文章是用最新的 Python 3.11 稳定版测试的。
在学习如何在 Windows 上安装 Python 之前,你可能想看看如何在 Linux 发行版(如 Ubuntu)上[轻松安装](/article-15475-1.html) Python。如果你打算成为一名开发者,最好在 Linux 中尝试 Python。那么,你可能想看看 [如何在 Windows 之外安装 Linux(如 Ubuntu)](https://www.debugpoint.com/complete-guide-how-dual-boot-ubuntu-windows/)。
Python 是一种流行的通用编程语言,在过去十年中成为开发者的选择。而且它的受欢迎程度与日俱增。它被广泛用于网络开发、复杂系统、数据科学、机器学习和所有科学领域。
你可能遇到的 Python 有两个版本。Python2 目前已经不支持了。而 Python3 系列是持续支持的版本。
### 检查 Python 是否已经安装
在 Windows 上安装它之前,你应该检查它是否已经安装。一般来说,它应该没有安装,不像在 Ubuntu (和其他 Linux 发行版)中,Python 是预先安装的。
从开始菜单中,打开“命令提示符”。
并输入以下内容:
```
python --version
```
如果 Python 是可用的,它将显示一个包含版本细节的信息。
### 下载并安装 Python
打开下面的 Python 官方下载页面。
>
> **[下载 Python](https://www.python.org/downloads/)**
>
>
>

在顶部,你应该看到当前的稳定版本。点击下载链接。如果你正在寻找任何特定的版本,在这个页面上向下滚动,在 “Python releases by version number:” 的标签下下载特定的版本。
下载后,进入下载文件夹,运行安装程序。
按照屏幕上的指示进行安装。


安装完成后,验证 Python 的版本。
### 验证 Python 版本
从开始菜单,打开“命令提示符”,运行以下命令。
```
python --version
```

你应该看到你的系统当前安装的 Python 包的版本。另外,你也可以运行下面的程序来获得一个 Python 交互式 shell。
```
python
```
你可以用 `CTRL+Z` 和回车键退出这个交互界面。
### 检查 PATH 变量
你应该检查系统变量 `PATH`,看看 Python 的可执行位置是否存在。这应该是使用安装程序自动更新的。
从开始菜单中,搜索“<ruby> 系统变量 <rt> system variables </rt></ruby>”并打开它。

在“系统属性”对话框中,点击“<ruby> 高级 <rt> Advanced </rt></ruby> > <ruby> 环境变量 <rt> Environment Variables </rt></ruby>”。在用户变量部分,对照路径变量,检查 Python 的安装位置是否存在。请参考下面的图片作为指导。
如果你看到所有的路径都存在,你就可以运行你的 Python 项目了。

### 创建并运行你的第一个 Python 程序
一个额外的步骤,这里是你如何编码和运行你的第一个 Python 程序。你可以使用任意 [推荐的 Python 编辑器](https://www.debugpoint.com/5-best-python-ide-code-editor/) 来编写你的程序。
下面是一个简单的程序,它在控制台中输出文本 `debugpoint.com`。
```
# Sample Python program
print("debugpoint.com")
```
用任意名字保存文件。这里我把它保存为 `hello.py`,放在 E 盘。`.py` 是 Python 源码的扩展名。
要运行这个程序,请打开命令提示符,在 E 盘中执行以下内容。
```
python hello.py
```
输出:

### 结束语
我希望这个简单的初学者指南能够帮助你在 Windows 中安装 Python,验证安装并运行你的第一个程序。
如果你遇到问题,请在下面的评论栏中告诉我。
---
via: <https://www.debugpoint.com/install-python-windows/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,481 | 使用时间序列数据,用开源工具助力你的边缘项目 | https://opensource.com/article/23/1/time-series-data-edge-open-source-tools | 2023-01-25T22:06:23 | [
"时间序列"
] | https://linux.cn/article-15481-1.html | 
>
> InfluxData 是一个开源的时间序列数据库平台。下面介绍了它是如何被用于边缘应用案例的。
>
>
>
收集到的随时间变化的数据称为时间序列数据。今天,它已经成为每个行业和生态系统的一部分。它是不断增长的物联网行业的一大组成部分,将成为人们日常生活的重要部分。但时间序列数据及其需求很难处理。这是因为没有专门为处理时间序列数据而构建的工具。在这篇文章中,我将详细介绍这些问题,以及过去 10 年来 InfluxData 如何解决这些问题。
### InfluxData
InfluxData 是一个开源的时间序列数据库平台。你可能通过 [InfluxDB](https://opensource.com/article/17/8/influxdb-time-series-database-stack) 了解该公司,但你可能不知道它专门从事时间序列数据库开发。这很重要,因为在管理时间序列数据时,你要处理两个问题:存储生命周期和查询。
在存储生命周期中,开发人员通常首先收集和分析非常详细的数据。但开发人员希望存储较小的、降低采样率的数据集,以描述其趋势,而不占用太多的存储空间。
查询数据库时,你不希望基于 ID 查询数据,而是希望基于时间范围进行查询。使用时间序列数据最常见的一件事是在一段时间内对其进行汇总。在典型的关系型数据库中存储数据时,这种查询是很慢的,这种数据库使用行和列来描述不同数据点的关系。专门为处理时间序列数据而设计的数据库可以更快地处理这类查询。InfluxDB 有自己的内置查询语言:Flux,这是专门为查询时间序列数据集而构建的。

### 数据采集
数据采集和数据处理都有一些很棒的工具。InfluxData 有 12 个以上的客户端库,允许你使用自己选择的编程语言编写和查询数据。这是自定义用法的一个很好的工具。开源摄取代理 Telegraf 包括 300 多个输入和输出插件。如果你是一个开发者,你也可以贡献自己的插件。
InfluxDB 还可以接受上传小体积历史数据集的 CSV 文件,以及大数据集的批量导入。
```
import math
bicycles3 = from(bucket: "smartcity")
|> range(start:2021-03-01T00:00:00z, stop: 2021-04-01T00:00:00z)
|> filter(fn: (r) => r._measurement == "city_IoT")
|> filter(fn: (r) => r._field == "counter")
|> filter(fn: (r) => r.source == "bicycle")
|> filter(fn: (r) => r.neighborhood_id == "3")
|> aggregateWindow(every: 1h, fn: mean, createEmpty:false)
bicycles4 = from(bucket: "smartcity")
|> range(start:2021-03-01T00:00:00z, stop: 2021-04-01T00:00:00z)
|> filter(fn: (r) => r._measurement == "city_IoT")
|> filter(fn: (r) => r._field == "counter")
|> filter(fn: (r) => r.source == "bicycle")
|> filter(fn: (r) => r.neighborhood_id == "4")
|> aggregateWindow(every: 1h, fn: mean, createEmpty:false)join(tables: {neighborhood_3: bicycles3, neighborhood_4: bicycles4}, on ["_time"], method: "inner")
|> keep(columns: ["_time", "_value_neighborhood_3","_value_neighborhood_4"])
|> map(fn: (r) => ({
r with
difference_value : math.abs(x: (r._value_neighborhood_3 - r._value_neighborhood_4))
}))
```
### Flux
Flux 是我们的内部查询语言,从零开始建立,用于处理时间序列数据。它也是我们一些工具的基础动力,包括 <ruby> 任务 <rt> task </rt></ruby>、<ruby> 警报 <rt> alert </rt></ruby> 和 <ruby> 通知 <rt> notification </rt></ruby>。要剖析上面的 Flux 查询,需要定义一些东西。首先,“<ruby> 桶 <rt> bucket </rt></ruby>”就是我们所说的数据库。你可以配置存储桶,然后将数据流添加到其中。查询会调用 `smartcity` 存储桶,其范围为特定的一天(准确地说是 24 小时)。你可以从存储桶中获取所有数据,但大多数用户都包含一个数据范围。这是你能做的最基本的 Flux 查询。
接下来,我添加过滤器,将数据过滤到更精确、更易于管理的地方。例如,我过滤分配给 id 为 3 的社区中的自行车数量。从那里,我使用 `aggregateWindow` 获取每小时的平均值。这意味着我希望收到一个包含 24 列的表,每小时一列。我也对 id 为 4 的社区进行同样的查询。最后,我将这两张表相叠加,得出这两个社区自行车使用量的差异。
如果你想知道什么时候是交通高峰,这是不错的选择。显然,这只是 Flux 查询功能的一个小例子。但它提供了一个很好的例子,使用了 Flux 附带的一些工具。我还有很多的数据分析和统计功能。但对于这一点,我建议查看 Flux 文档。
```
import "influxdata/influxdb/tasks"
option task = {name: PB_downsample, every: 1h, offset: 10s}
from(bucket: "plantbuddy")
|>range(start: tasks.lastSuccess(orTime: -task.every))
|>filter(fn: (r) => r["_measurement"] == "sensor_data")
|>aggregateWindow(every: 10m, fn:last, createEmpty:false)
|>yield(name: "last")
|>to(bucket: "downsampled")
```
### 任务
InfluxDB <ruby> 任务 <rt> task </rt></ruby> 是一个定时 Flux 脚本,它接收输入数据流并以某种方式修改或分析它。然后,它将修改后的数据存储在新的存储桶中或执行其他操作。将较小的数据集存储到新的存储桶中,称为“<ruby> 降采样 <rt> downsampling </rt></ruby>”,这是数据库的核心功能,也是时间序列数据生命周期的核心部分。
你可以在当前任务示例中看到,我已经对数据进行了降采样。我得到每 10 分钟增量的最后一个值,并将该值存储在降采样桶中。原始数据集在这 10 分钟内可能有数千个数据点,但现在降采样桶只有 60 个新值。需要注意的一点是,我还使用了范围内的 `lastSuccess` 函数。这会告诉 InfluxDB 从上次成功运行的时间开始运行此任务,以防它在过去 2 小时内失败,在这种情况下,它可以追溯 3 个小时内的最后一次成功运行。这对于内置错误处理非常有用。

### 检查和警报
InfluxDB 包含一个 <ruby> 警报 <rt> Alert </rt></ruby> 或 <ruby> 检查 <rt> Check </rt></ruby> 和 <ruby> 通知 <rt> notification </rt></ruby> 系统。这个系统非常简单直白。首先进行检查,定期查看数据以查找你定义的异常。通常,这是用阈值定义的。例如,任何低于 32°F 的温度值都被指定为“WARN”值,高于 32°F 都被分配为“OK”值,低于 0°F 都被赋予“CRITICAL”值。从那开始,你的检查可以按你认为必要的频率运行。你的检查以及每个检查的当前状态都有历史记录。在不需要的时候,你不需要设置通知。你可以根据需要参考你的警报历史记录。
许多人选择设置通知。为此,你需要定义一个 <ruby> 通知端点 <rt> notification endpoint </rt></ruby>。例如,聊天应用程序可以进行 HTTP 调用以接收通知。然后你定义何时接收通知,例如,你可以每小时运行一次检查。你可以每 24 小时运行一次通知。你可以让通知响应值更改,例如,“WARN”更改为“CRITICAL”,或者当值为“CRITICAL”时,无论如何都从“OK”更改为“WARN”。这是一个高度可定制的系统。从这个系统创建的 Flux 代码也可以编辑。

### 边缘
最后,我想把所有的核心功能放在一起,包括最近发布的一个非常特别的新功能。“Edge to cloud” 是一个非常强大的工具,允许你运行开源 InfluxDB,并在出现连接问题时在本地存储数据。连接修复后,它会将数据流传输到 InfluxData 云平台。
这对于边缘设备和重要数据非常重要,因为任何数据丢失都是有害的。你定义一个要复制到云的存储桶,然后该存储桶有一个磁盘支持的队列来本地存储数据。然后定义云存储桶应该复制到的内容。在连接到云端之前,数据都存储在本地。
### InfluxDB 和物联网边缘
假设你有一个项目,你想使用连接到植物上的物联网传感器 [监测家里植物的健康状况](https://opensource.com/article/22/5/plant-care)。该项目是使用你的笔记本电脑作为边缘设备设置的。当你的笔记本电脑合上或关闭时,它会在本地存储数据,然后在重新连接时将数据流传到我的云存储桶。

需要注意的一点是,在将数据存储到复制桶之前,这会对本地设备上的数据进行降采样。你的植物传感器每秒提供一个数据点。但它将数据压缩为一分钟的平均数,因此存储的数据更少了。在云账户中,你可以添加一些警报和通知,让你知道植物的水分何时低于某个水平,需要浇水。也可以在网站上使用视觉效果来告诉用户植物的健康状况。
数据库是许多应用程序的主干。在像 InfluxDB 的时间序列数据库平台中使用带有时间戳的数据可以节省开发人员的时间,并使他们能够访问各种工具和服务。InfluxDB 的维护者喜欢看到人们在我们的开源社区中构建什么,所以请与我们联系,并与其他人共享你的项目和代码!
---
via: <https://opensource.com/article/23/1/time-series-data-edge-open-source-tools>
作者:[Zoe Steinkamp](https://opensource.com/users/zoesteinkamp) 选题:[lkxed](https://github.com/lkxed) 译者:[ZhangZhanhaoxiang](https://github.com/ZhangZhanhaoxiang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Gathering data as it changes over the passage of time is known as time-series data. Today, it has become a part of every industry and ecosystem. It is a large part of the growing IoT sector and will become a larger part of everyday people's lives. But time-series data and its requirements are hard to work with. This is because there are no tools that are purpose-built to work with time-series data. In this article, I go into detail about those problems and how InfluxData has been working to solve them for the past 10 years.
## InfluxData
InfluxData is an open source time-series database platform. You may know about the company through [InfluxDB](https://opensource.com/article/17/8/influxdb-time-series-database-stack), but you may not have known that it specialized in time-series databases. This is significant, because when managing time-series data, you deal with two issues — storage lifecycle and queries.
When it comes to storage lifecycle, it's common for developers to initially collect and analyze highly detailed data. But developers want to store smaller, downsampled datasets that describe trends without taking up as much storage space.
When querying a database, you don't want to query your data based on IDs. You want to query based on time ranges. One of the most common things to do with time-series data is to summarize it over a large period of time. This kind of query is slow when storing data in a typical relational database that uses rows and columns to describe the relationships of different data points. A database designed to process time-series data can handle queries exponentially faster. InfluxDB has its own built-in querying language: Flux. This is specifically built to query on time-series data sets.
(Zoe Steinkamp, CC BY-SA 4.0)
## Data acquisition
Data acquisition and data manipulation come out of the box with some awesome tools. InfluxData has over 12 client libraries that allow you to write and query data in the coding language of your choice. This is a great tool for custom use cases. The open source ingest agent, Telegraf, includes over 300 input and output plugins. If you're a developer, you can contribute your own plugin, as well.
InfluxDB can also accept a CSV upload for small historical data sets, as well as batch imports for large data sets.
```
``````
import math
bicycles3 = from(bucket: "smartcity")
|> range(start:2021-03-01T00:00:00z, stop: 2021-04-01T00:00:00z)
|> filter(fn: (r) => r._measurement == "city_IoT")
|> filter(fn: (r) => r._field == "counter")
|> filter(fn: (r) => r.source == "bicycle")
|> filter(fn: (r) => r.neighborhood_id == "3")
|> aggregateWindow(every: 1h, fn: mean, createEmpty:false)
bicycles4 = from(bucket: "smartcity")
|> range(start:2021-03-01T00:00:00z, stop: 2021-04-01T00:00:00z)
|> filter(fn: (r) => r._measurement == "city_IoT")
|> filter(fn: (r) => r._field == "counter")
|> filter(fn: (r) => r.source == "bicycle")
|> filter(fn: (r) => r.neighborhood_id == "4")
|> aggregateWindow(every: 1h, fn: mean, createEmpty:false)
join(tables: {neighborhood_3: bicycles3, neighborhood_4: bicycles4}, on ["_time"], method: "inner")
|> keep(columns: ["_time", "_value_neighborhood_3","_value_neighborhood_4"])
|> map(fn: (r) => ({
r with
difference_value : math.abs(x: (r._value_neighborhood_3 - r._value_neighborhood_4))
}))
```
## Flux
Flux is our internal querying language built from the ground up to handle time-series data. It's also the underlying powerhouse for a few of our tools, including tasks, alerts, and notifications. To dissect the flux query from above, you need to define a few things. For starters, a "bucket" is what we call a database. You configure your buckets and then add your data stream into them. The query calls the smartcity bucket, with the range of a specific day (a 24-hour period to be exact.) You can get all the data from the bucket, but most users include a data range. That's the most basic flux query you can do.
Next, I add filters, which filter the data down to something more exact and manageable. For example, I filter for the count of bicycles in the neighborhood assigned to the id of 3. From there, I use aggregateWindow to get the mean for every hour. That means I expect to receive a table with 24 columns, one for every hour in the range. I do this exact same query for neighborhood 4 as well. Finally, I join the two tables and get the differences between bike usage in these two neighborhoods.
This is great if you want to know what hours are high-traffic hours. Obviously, this is just a small example of the power of flux queries. But it gives a great example of some of the tools flux comes with. I also have a large amount of data analysis and statistics functions. But for that, I suggest checking out the Flux documentation.
```
``````
import "influxdata/influxdb/tasks"
option task = {name: PB_downsample, every: 1h, offset: 10s}
from(bucket: "plantbuddy")
|>range(start: tasks.lastSuccess(orTime: -task.every))
|>filter(fn: (r) => r["_measurement"] == "sensor_data")
|>aggregateWindow(every: 10m, fn:last, createEmpty:false)
|>yield(name: "last")
|>to(bucket: "downsampled")
```
## Tasks
An InfluxDB task is a scheduled Flux script that takes a stream of input data and modifies or analyzes it in some way. It then stores the modified data in a new bucket or performs other actions. Storing a smaller data set into a new bucket is called "downsampling," and it's a core feature of the database, and a core part of the time-series data lifecycle.
You can see in the current task example that I've downsampled the data. I'm getting the last value for every 10-minute increment and storing that value in the downsampled bucket. The original data set might have had thousands of data points in those 10 minutes, but now the downsampled bucket only has 60 new values. One thing to note is that I'm also using the last success function in range. This tells InfluxDB to run this task from the last time it ran successfully, just in case it has failed for the past 2 hours, in which case it can go back three hours in time to the last successful run. This is great for built-in error handling.
(Zoe Steinkamp, CC BY-SA 4.0)
## Checks and alerts
InfluxDB includes an alerting or checks and notification system. This system is very straightforward. You start with a check that looks at the data periodically for anomalies that you've defined. Normally, this is defined with thresholds. For example, any temperature value under 32° F gets assigned a value of `WARN`
, and anything above 32° F gets assigned a value of `OK`
, and anything below 0° F gets a value of `CRITICAL`
. From there, your check can run as often as you deem necessary. There is a recorded history of your checks and the current status of each. You are not required to set up a notification when it's not needed. You can just reference your alert history as needed.
Many people choose to set up their notifications. For that, you need to define a notification endpoint. For example, a chat application could make an HTTP call to receive your notifications. Then you define when you would like to receive notifications, for example you can have checks run every hour. You can run notifications every 24 hours. You can have your notification respond to a change in the value, for example `WARN`
to `CRITICAL`
, or when a value is `CRITICAL`
, regardless of it changing from `OK`
to `WARN`
. This is a highly customizable system. The Flux code that's created from this system can also be edited.
(Zoe Steinkamp, CC BY-SA 4.0)
## Edge
To wrap up, I'd like to bring all the core features together, including a very special new feature that's recently been released. Edge to cloud is a very powerful tool that allows you to run the open source InfluxDB and locally store your data in case of connectivity issues. When connectivity is repaired, it streams the data to the InfluxData cloud platform.
This is significant for edge devices and important data where any loss of data is detrimental. You define that you want a bucket to be replicated to the cloud, and then that bucket has a disk-backed queue to store the data locally. Then you define what your cloud bucket should replicate into. The data is stored locally until connected to the cloud.
## InfluxDB and the IoT Edge
Suppose you have a project where you want to [monitor the health of household plants](https://opensource.com/article/22/5/plant-care) using IoT sensors attached to the plant. The project is set up using your laptop as the edge device. When your laptop is closed or otherwise off, it stores the data locally, and then streams it to my cloud bucket when reconnected.
(Zoe Steinkamp, CC BY-SA 4.0)
One thing to notice is that this downsamples data on the local device before storing it in the replication bucket. Your plant's sensors provide a data point for every second. But it condenses the data to be an average of one minute so you have less data to store. In the cloud account, you might add some alerts and notifications that let you know when the plant's moisture is below a certain level and needs to be watered. There could also be visuals you could use on a website to tell users about their plants' health.
Databases are the backbone of many applications. Working with time-stamped data in a time series database platform like InfluxDB saves developers time, and gives them access to a wide range of tools and services. The maintainers of InfluxDB love seeing what people are building within our open source community, so connect with us and share your projects and code with others!
## 1 Comment |
15,483 | 文字间的战斗与其救世主 Unicode | https://itsfoss.com/unicode-linux/ | 2023-01-27T12:35:27 | [
"Unicode"
] | https://linux.cn/article-15483-1.html | 
我们都知道如何从键盘输入文字,不是吗?
那么,请允许我挑战你在你最爱的文本编辑器中输入这段文字:

这段文字难以被输入因为它包含着:
* 键盘上没有的印刷符号,
* 平假名日文字符,
* 为符合平文式罗马字标准,日本首都的名字中的两个字母 “o” 头顶带有长音符号,
* 以及最后,用西里尔字母拼写的名字德米特里。
毫无疑问,想要在早期的电脑中输入这样的句子是不可能的。这是因为早期电脑所使用的字符集有限,无法兼容多种书写系统。而如今类似的限制已不复存在,马上我们就能在文中看到。
### 电脑是如何储存文字的?
计算机将字符作为数字储存。它们再通过表格将这些数字与含有意义的字形一一对应。
在很长一段时间里,计算机将每个字符作为 0 到 255 之间的数字储存(这正好是一个字节的长度)。但这用来代表人类书写所用到的全部字符是远远不够的。而解决这个问题的诀窍在于,取决于你住在地球上的哪一块区域,系统会分别使用不同的对照表。
这里有一张在法国常被广泛使用的对照表 [ISO 8859-15](https://en.wikipedia.org/wiki/ISO/IEC_8859-15):

如果你住在俄罗斯,你的电脑大概会使用 [KOI8-R](https://en.wikipedia.org/wiki/KOI8-R) 或是 [Windows-1251](https://en.wikipedia.org/wiki/Windows-1251) 来进行编码。现在让我们假设我们在使用后者:

对于 128 之前的数字,两张表格是一样的。这个范围与 [US-ASCII](https://en.wikipedia.org/wiki/ASCII) 相对应,这是不同字符表格之间的最低兼容性。而对于 128 之后的数字,这两张表格则完全不同了。
比如,依据 Windows-1251,字符串 “said Дмитрий” 会被储存为:
```
115 97 105 100 32 196 236 232 242 240 232 233
```
按照计算机科学的常规方法,这十二个数字可被写成更加紧凑的十六进制:
```
73 61 69 64 20 c4 ec e8 f2 f0 e8 e9
```
如果德米特里发给我这份文件,我在打开后可能会看到:
```
said Äìèòðèé
```
这份文件 *看起来* 被损坏了,实则不然。这些储存在文件里的数据,即数字,并没有发生改变。被显示出的字符与 *另一张表格* 中的数据相对应,而非文字最初被写出来时所用的编码表。
让我们来举一个例子,就以字符 “Д” 为例。按照 Windows-1251,“Д” 的数字编码为 196(c4)。储存在文件里的只有数字 196。而正是这同样的数字在 ISO8859-15 中与 “Ä” 相对应。这就是为什么我的电脑错误地认为字形 “Ä” 就是应该被显示的字形。

多提一句,你依然可以时不时地看到一些错误配置的网站展示,或由 [用户邮箱代理](https://en.wikipedia.org/wiki/Email_client) 发出的对收件人电脑所使用的字符编码做出错误假设的邮件。这样的故障有时被称为乱码(LCTT 译注:原文用词为 [mojibake](https://en.wikipedia.org/wiki/Mojibake), 源自日语 *文字化け*)。好在这种情况在今天已经越来越少见了。

### Unicode 拯救了世界
我解释了不同国家间交换文件时会遇到的编码问题。但事情还能更糟,同一个国家的不同生产商未必会使用相同的编码。如果你在 80 年代用 Mac 和 PC 互传过文件你就懂我是什么意思了。
也不知道是不是巧合,[Unicode](https://en.wikipedia.org/wiki/Unicode) 项目始于 1987 年,主导者来自<ruby> 施乐 <rt> Xerox </rt></ruby>和……<ruby> 苹果 <rt> Apple </rt></ruby> 。
这个项目的目标是定义一套通用字符集来允许同一段文字中 *同时* 出现人类书写会用到的任何文字。最初的 Unicode 项目被限制在 65536 个不同字符(每个字符用 16 位表示,即每个字符两字节)。这个数字已被证实是远远不够的。
于是,在 1996 年 Unicode 被扩展以支持高达 100 万不同的 <ruby> <a href="https://en.wikipedia.org/wiki/Code_point"> 代码点 </a> <rt> code point </rt></ruby>。粗略来说,一个“代码点”可被用来识别字符表中的一个条目。Unicode 项目的一个核心工作就是将世界上正在被使用(或曾被使用)的字母、符号、标点符号以及其他文字仓管起来,并给每一项条目分配一个代码点用以准确分辨对应的字符。
这是一个庞大的项目:为了让你有个大致了解,发布于 2017 年的 Unicode 版本 10 定义了超过 136,000 个字符,覆盖了 139 种现代和历史上的语言文字。
随着如此庞大数量的可能性,一个基本的编码会需要每个字符 32 位(即 4 字节)。但对于主要使用 US-ASCII 范围内字符的文字,每个字符 4 字节意味着 4 倍多的储存需求以及 4 倍多的带宽用以传输这些文字。

所以除了 [UTF-32](https://en.wikipedia.org/wiki/UTF-32),Unicode 联盟还定义了更加节约空间的 [UTF-16](https://en.wikipedia.org/wiki/UTF-16) 和 [UTF-8](https://en.wikipedia.org/wiki/UTF-8) 编码,分别使用了 16 位和 8 位。但只有 8 位该如何储存超过 100,000 个不同的值呢?事实是,你不能。但这其中窍门在于用一个代码值(UTF-8 中的 8 位以及 UTF-16 中的 16 位)来储存最常用的一些字符。再用几个代码值储存最不常用的一些字符。所以说 UTF-8 和 UTF-16 是 *可变长度* 编码。尽管这样也有缺陷,但 UTF-8 是空间与时间效率之间一个不错的折中。更不用提 UTF-8 可以向后兼容大部分 Unicode 之前的 1 字节编码,因为 UTF-8 经过了特别设计,任何有效的 US-ASCII 文件都是有效的 UTF-8 文件。你也可以说,UTF-8 是 US-ASCII 的超集。而在今天已经找不到不用 UTF-8 编码的理由了。当然除非你书写主要用的语言需要多字节编码,或是你不得不与一些残留的老旧系统打交道。
在下面两张图中,你可以亲自比较一下同一字符串的 UTF-16 和 UTF-8 编码。特别注意 UTF-8 使用了一字节来储存拉丁字母表中的字符,但它使用了两字节来存储西里尔字母表中的字符。这是 Windows-1251 西里尔编码储存同样字符所需空间的两倍。


### 而这些对于打字有什么用呢?
啊……知道一些你的电脑的能力与局限以及其底层机制也不是什么坏事嘛。特别是我们马上就要说到 Unicode 和十六进制。现在……让我们再聊点历史。真的就一点,我保证……
……就说从 80 年代起,电脑键盘曾经有过 [`Compose` 键](https://en.wikipedia.org/wiki/Compose_key)(有时候也被标为 `Multi` 键)就在 `Shift` 键的下边。当按下这个键时,你会进入 “<ruby> 组合 <rt> Compose </rt></ruby>” 模式。一旦在这个模式下,你便可以通过输入助记符来输入你键盘上没有的字符。比如说,在组合模式下,输入 RO 便可生成字符 ®(当作是 O 里面有一个 R 就能很容易记住)。

现在很难在现代键盘上看到 `Compose` 键了。这大概是因为占据主导地位的 PC 不再用它了。但是在 Linux 上(可能还有其他系统)你可以模拟 `Compose` 键。这项设置可以通过 GUI 开启,在大多数桌面环境下调用“键盘”控制面板:但具体的步骤取决于你的桌面环境以及版本。如果你成功启用了那项设置,不要犹豫,在评论区分享你在你电脑上所采取的具体步骤。
(LCTT 译注:如果有读者想要尝试,建议将 `Compose` 键设为大写锁定键,或是别的不常用的键,`Ctrl` 和 `Alt` 会被大部分 GUI 程序优先识别为功能键。还有一些我自己试验时遇到过的问题,在开启 `Compose` 键前要确认大写锁定是关闭的,输入法要切换成英文,组合模式下输入大小写敏感。我试验的系统是 Ubuntu 22.04 LTS。)
至于我自己嘛,我现在先假设你用的就是默认的 `Shift+AltGr` 组合来模拟 `Compose` 键。(LCTT 校注:`AltGr` 在欧洲键盘上是指右侧的 `Alt` 键,在国际键盘上等价于 `Ctrl+Alt` 组合键。)
那么,作为一个实际例子,尝试输入 “LEFT-POINTING DOUBLE ANGLE QUOTATION MARK(左双角引号)”(LCTT 译注:Guillemet,是法语和一些欧洲语言中的引号,与中文的书名号不同),你可以输入 `Shift+AltGr` `<<`(你在敲助记符时不需要一直按着 `Shift+AltGr`)。如果你成功输入了这个符号,你自己应该也能猜到要怎么输入 “RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK(右双角引号)” 了。
来看看另一个例子,试试 `Shift+AltGr` `---` 来生成一个 “EM DASH(长破折号)”(LCTT 译注:中文输入法的长破折号由两个 “EM DASH” 组成)。要做到这个,你需要按下主键盘上的的 [连字符减号](https://en.wikipedia.org/wiki/Hyphen-minus) 键而非数字键盘上的那个。
值得注意的是 `Compose` 键在非 GUI 环境下也能工作。但是取决于你使用的是 X11 控制台还是只显示文字的控制台,它们所支持的组合按键顺序并不相同。
在控制台上,你可以通过命令 `dumpkeys` 来查看支持的组合按键列表(LCTT 译注:可能需要 root 权限):
```
dumpkeys --compose-only
```
在 GUI 下,组合键是在 Gtk/X11 层被实现的。想要知道 Gtk 所支持的助记符,可以查看页面:<https://help.ubuntu.com/community/GtkComposeTable>
### 我们可以避免对 Gtk 字符组合的依赖吗?
或许我是个纯粹主义者,但是我为 Gtk 这种对 Compose 键进行硬编码的方式感到悲哀。毕竟,不是所有 GUI 应用都会使用 Gtk 库。而且我如果想要添加我自己的助记符的话就只能重新编译 Gtk 了。
幸好在 X11 层也有对字符组合的支持。在以前则是通过令人尊敬的 [X 输入法(XIM)](https://en.wikipedia.org/wiki/X_Input_Method)。
这个方法在比起基于 Gtk 的字符组合能够在更加底层的地方工作,同时具备优秀的灵活性并兼容很多 X11 应用。
比如说,假设我只是想要添加 `-->` 组合来输入字符 `→` (U+2192,RIGHTWARDS ARROW(朝右箭头)),我只需要新建 `~/.XCompose` 文件并写入以下代码:
```
cat > ~/.XCompose << EOT
# Load default compose table for the current local
include "%L"
# Custom definitions
<Multi_key> <minus> <minus> <greater> : U2192 # RIGHTWARDS ARROW
EOT
```
然后你就可以启动一个新的 X11 应用,强制函数库使用 XIM 作为输入法,并开始测试:
```
GTK_IM_MODULE="xim" QT_IM_MODULE="xim" xterm
```
新的组合排序应该可以在你刚启动的应用里被输入了。我鼓励你通过 `man 5 compose` 来进一步学习组合文件格式。
在你的 `~/.profile` 中加入以下两行来将 XIM 设为你所有应用的默认输入法。这些改动会在下一次你登录电脑时生效:
```
export GTK_IM_MODULE="xim"
export QT_IM_MODULE="xim"
```
这挺酷的,不是吗?这样你就可以随意的加入你想要的组合排序。而且在默认的 XIM 设置中已经有几个有意思的组合了。试一下输入组合键 `LLAP`。
但我不得不提到两个缺陷。XIM 已经比较老了,而且只适合我们这些不太需要多字节输入法的人。其次,当你用 XIM 作为输入法的时候,你就不能利用 `Ctrl+Shift+u` 加上代码点来输入 Unicode 字符了。什么?等一下?我还没聊过那个?让我们现在来聊一下吧:
### 如果我需要的字符没有对应的组合键排序该怎么办?
组合键是一个不错的工具,它可以用来输入一些键盘上没有的字符。但默认的组合集有限,而切换 XIM 并为一个你一生仅用一次的字符来定义一个新的组合排序十分麻烦。
但这能阻止你在同一段文字里混用日语、拉丁语,还有西里尔字符吗?显然不能,这多亏了 Unicode。比如说,名字 “あゆみ” 由三个字母组成:
* [“HIRAGANA LETTER A(平假名字母 あ)” (U+3042)](http://www.fileformat.info/info/unicode/char/3042/index.htm)
* [“HIRAGANA LETTER YU(平假名字母 ゆ)” (U+3086)](http://www.fileformat.info/info/unicode/char/3086/index.htm)
* 以及 [“HIRAGANA LETTER MI(平假名字母 み)” (U+307F)](http://www.fileformat.info/info/unicode/char/307F/index.htm)
我在上文提及了 Unicode 字符的正式名称,并遵循了全部用大写拼写的规范。在它们的名字后面,你可以找到它们的 Unicode 代码点,位于括号之间并写作 16 位的十六进制数字。这让你想到什么了吗?
不管怎样,一旦你知道了的一个字符的代码点,你就可以按照以下组合输入:
* `Ctrl+Shift+u`,然后是 `XXXX`(你想要的字符的 *十六进制* 代码点)然后回车。
作为一种简写方式,如果你在输入代码点时不松开 `Ctrl+Shift`,你就不用敲回车。
不幸的是,这项功能的实现是在软件库层而非 X11 层,所以对其支持在不同应用间并不统一。以 LibreOffice 为例,你必须使用主键盘来输入代码点。而在基于 Gtk 的应用则接受来自数字键盘的输入。
最后,当我和我的 Debian 系统上的控制台打交道时,我发现了一个类似的功能,但它需要你按下 `Alt+XXXXX` 而 `XXXXX` 是你想要的字符的 *十进制* 的代码点。我很好奇这究竟是 Debian 独有的功能,还是因为我使用的语言环境(Locale) 是 `en_US.UTF-8`。如果你对此有更多信息,我会很愿意在评论区读到它们的!
| GUI | 控制台 | 字符 |
| --- | --- | --- |
| `Ctrl+Shift+u` `3042` `Enter` | `Alt+12354` | あ |
| `Ctrl+Shift+u` `3086` `Enter` | `Alt+12422` | ゆ |
| `Ctrl+Shift+u` `307F` `Enter` | `Alt+12415` | み |
### 死键
最后值得一提的是,想要不(必须)依赖 Compose 键来输入键组合还有一个更简单的方法。
你的键盘上的某些键是专门用来创造字符组合的。这些键叫做 <ruby> <a href="https://en.wikipedia.org/wiki/Dead_key"> 死键 </a> <rt> Dead Key </rt></ruby>。这是因为当你按下它们一次,看起来什么都没有发生,但它们会悄悄地改变你下一次按键所产生的字符。这个行为的灵感来自于机械打字机:在使用机械打字机时,按下一个死键会印下一个字符,但不会移动字盘。于是下一次按键则会在同一个地方印下另一个字符。视觉效果就是两次按键的组合。
我们在法语里经常用到这个。举例来说,想要输入字母 `ë` 我必须按下死键 `¨` 然后再按下 `e` 键。同样地,西班牙人的键盘上有着死键 `~`。而在北欧语系下的键盘布局,你可以找到 `°` 键。我可以念很久这份清单。

显然,不是所有键盘都有所有死键。实际上,你的键盘上是找不到大部分死键的。比如说,我猜在你们当中只有小部分人——如果真的有的话——有死键 `¯` 来输入 `Tōkyō` 所需要的长音符号(“平变音符”)。
对于那些你键盘上没有的死键,你需要寻找别的解决方案。好消息是,我们已经用过那些技术了。但这一次我们要用它们来模拟死键,而非“普通”键。
那么,我们的第一个选择是利用 `Compose` `-` 来生成长音符号(你键盘上有的连字符减号)。按下时屏幕上什么都不会出现,但当你接着按下 `o` 键你就能看到 `ō`。
Gtk 在组合模式下可以生成的一系列死键都能在 [这里](https://help.ubuntu.com/community/GtkDeadKeyTable) 找到。
另一个解决方法则是利用 Unicode 字符 “COMBINING MACRON(组合长音符号)”(U+0304),然后字母 `o`。我把细节都留给你。但如果你好奇的话,你会发现你打出的结果有着微妙的不同,你并没有真地打出 “LATIN SMALL LETTER O WITH MACRON(小写拉丁字母 O 带长音符号)”。我在上一句话的结尾用了大写拼写,这就是一个提示,引导你寻找通过 Unicode 组合字符按更少的键输入 `ō` 的方法……现在我将这些留给你的聪明才智去解决了。
### 轮到你来练习了!
所以,你都学会了吗?这些在你的电脑上工作吗?现在轮到你来尝试了:根据上面提出的线索,加上一点练习,现在你可以完成文章开头给出的挑战了。挑战一下吧,然后把成果复制到评论区作为你成功的证明。
赢了也没有奖励,或许来自同伴的惊叹能够满足你!
---
via: <https://itsfoss.com/unicode-linux/>
作者:[Sylvain Leroux](https://www.yesik.it/) 选题:[lkxed](https://github.com/lkxed) 译者:[yzuowei](https://github.com/yzuowei) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We all know how to type text on the keyboard. Don’t we?
So, may I challenge you to type that text in your favorite text editor:

This text is challenging to type since it contains:
- typographical signs not directly available on the keyboard,
- hiragana Japanese characters,
- the name of the Japanese capital written with a macron on top of the two letters “o” to comply with the Hepburn romanization standard,
- and finally, the first name Dmitrii written using the Cyrillic alphabet.
No doubt, writing such a sentence on early computers would have been simply impossible. Because computers used limited character sets, unable to let coexist several writing systems. But today such limitations are lifted as we will see in this article.
## How do computers store text?
Computers stores characters as numbers. And they use tables to map those numbers to the glyph used to represent them.
For a long time, computers stored each character as a number between 0 and 255 (which fits exactly one byte). But that was far from being sufficient to represent the whole set of characters used in human writing. So, the trick was to use a different correspondence table depending on where in the world you lived.
Here is the [ISO 8859-15](https://en.wikipedia.org/wiki/ISO/IEC_8859-15) correspondence table commonly used in France:
But if you lived in Russia, your computer would have probably used the [KOI8-R](https://en.wikipedia.org/wiki/KOI8-R) or [Windows-1251](https://en.wikipedia.org/wiki/Windows-1251) encoding instead. Let’s assume that later was used:
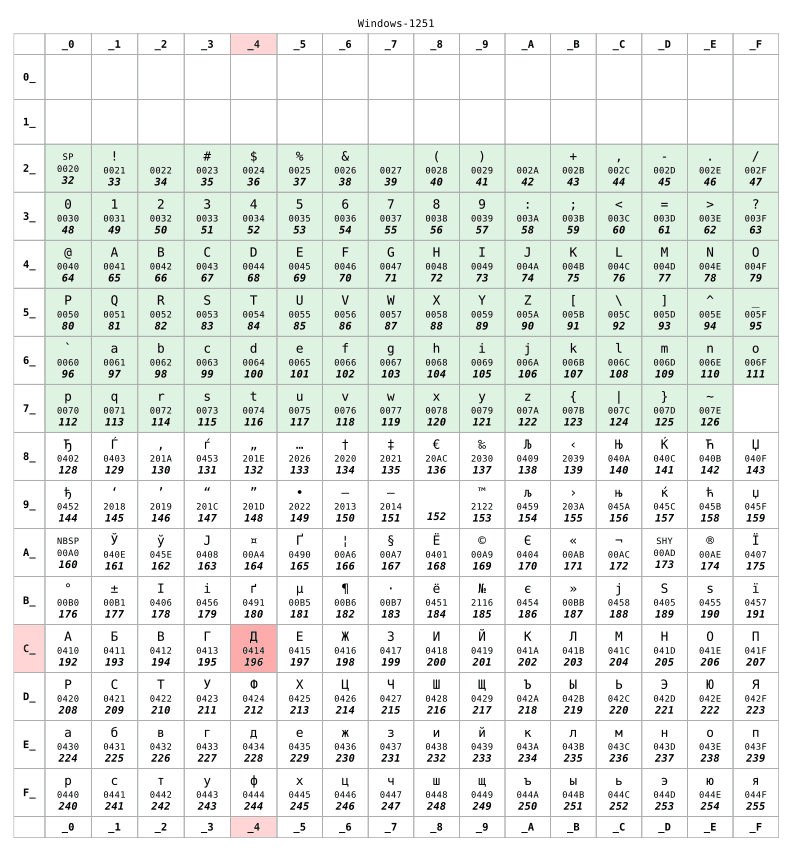
For numbers lower than 128, the two tables are identical. This range is corresponding to the [US-ASCII](https://en.wikipedia.org/wiki/ASCII) standard, some kind of minimum-compatible set between characters tables. But beyond 128, the two tables are completely different.
For example, according to Windows-1251, the string *“said Дмитрий”* is stored as:
115 97 105 100 32 196 236 232 242 240 232 233
To follow a common practice in computer sciences, those twelve numbers can be rewritten using the more compact hexadecimal notation:
73 61 69 64 20 c4 ec e8 f2 f0 e8 e9
If Dmitrii sends me that file, and I open it I might end up seeing that:
said Äìèòðèé
The file *appears* to be corrupted. But it isn’t. The data— that is the *numbers*–stored in that file don’t have changed. As I live in France, my computer has *assumed* the file to be encoded as ISO8859-15. And it displayed the characters *of that table* corresponding to the data. And not the character of the encoding table used when the text was originally written.
To give you an example, take the character Д. It has the numeric code 196 (c4) according to Windows-1251. The only thing stored in the file is the number 196. But that same number corresponds to Ä according to ISO8859-15. So my computer wrongly believed it was the glyph intended to be displayed.
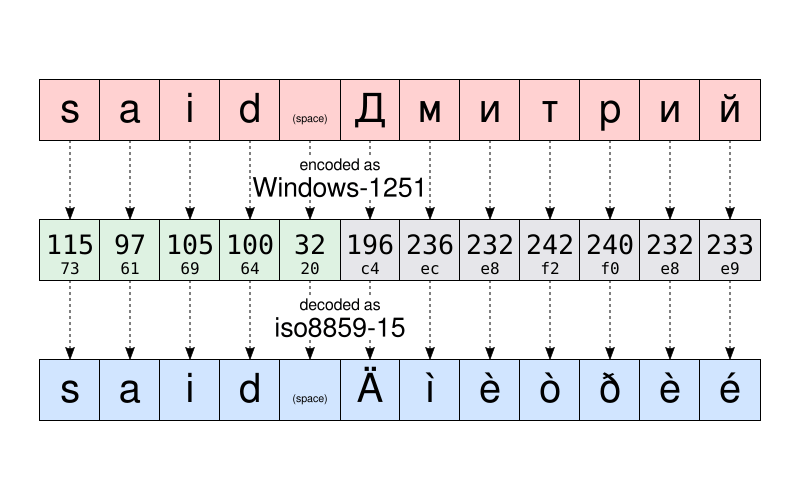
As a side note, you can still occasionally see an illustration of those issues on ill-configured websites or in email send by [mail user agents](https://en.wikipedia.org/wiki/Email_client) making false assumptions about the character encoding used on the recipient’s computer. Such glitches are sometimes nicknamed [mojibake](https://en.wikipedia.org/wiki/Mojibake). Hopefully, this is less and less frequent today.
## Unicode comes to save to the day
I explained encoding issues when exchanging files between different countries. But things were even worst since the encodings used by different manufacturers for the same country were not always the same. You can understand what I mean if you had to exchange files between Mac and PC in the 80s.
Is it a coincidence or not, the [Unicode](https://en.wikipedia.org/wiki/Unicode) project started in 1987, led by people of Xerox and … Apple.
The goal of the project was to define a universal character set allowing to *simultaneously* use any character used in human writing within the same text. The original Unicode project was limited to 65536 different characters (each character being represented using 16 bits— that is two bytes per character). A number that has proven to be insufficient.
So, in 1996 Unicode has been extended to support up to 1 million different [code points](https://en.wikipedia.org/wiki/Code_point). Roughly speaking, a “code point” a number that identifies an entry in the Unicode character table. And one core job of the Unicode project is to make an inventory of all letters, symbols, punctuation marks and other characters that are (or were) used worldwide, and to assign to each of them a code point that will uniquely identify that character.
This is a huge project: to give you some idea, the version 10 of Unicode, published in 2017, defines over 136,000 characters covering 139 modern and historic scripts.
With such a large number of possibilities, a basic encoding would require 32 bits (that is 4 bytes) per character. But for text using mainly the characters in the US-ASCII range, 4 bytes per character means 4 times more storage required to save the data and 4 times more bandwidth to transmit them.
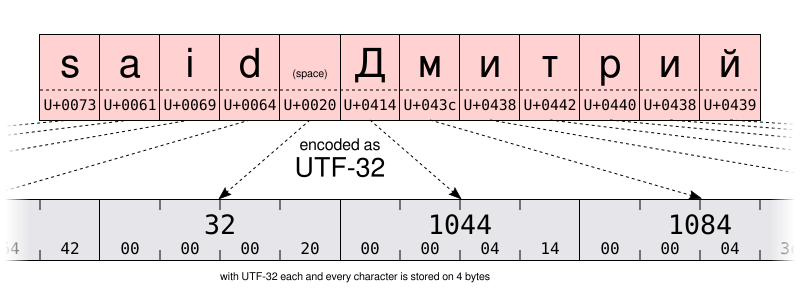
So besides the [UTF-32](https://en.wikipedia.org/wiki/UTF-32) encoding, the Unicode consortium defined the more space-efficient [UTF-16](https://en.wikipedia.org/wiki/UTF-16) and [UTF-8](https://en.wikipedia.org/wiki/UTF-8) encodings, using respectively 16 and 8 bits. But how to store over 100,000 different values in only 8 bits? Well, you can’t. But the trick is to use one code value (8 bits in UTF-8, 16 in UTF-16) to store the most frequently used characters. And to use several code values for the least commonly used characters. So UTF-8 and UTF-16 are *variable length* encoding. Even if this has drawbacks, UTF-8 is a good compromise between space and time efficiency. Not mentioning being backward compatible with most 1-byte pre-Unicode encoding, since UTF-8 was specifically designed so any valid US-ASCII file is also a valid UTF-8 file. In a sense, UTF-8 is a superset of US-ASCII. And today, there is no reason for not using the UTF-8 encoding. Unless of course if you write mostly with languages requiring multi-byte encodings or if you have to deal with legacy systems.
I let you compare the UTF-16 and UTF-8 encoding of the same string on the illustrations below. Pay special attention to the UTF-8 encoding using one byte to store the characters of the Latin alphabet. But using two bytes to store characters of the Cyrillic alphabet. That is twice more space than when storing the same characters using the Windows-1251 Cyrillic encoding.
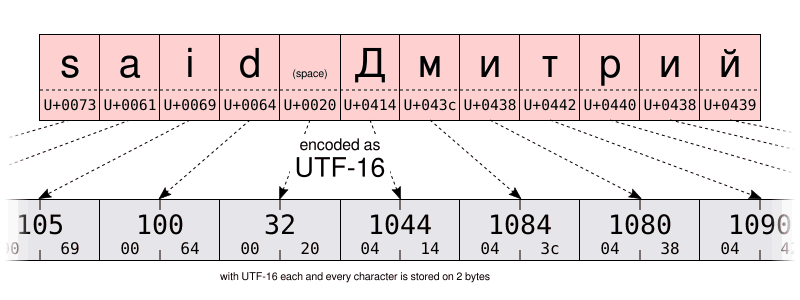
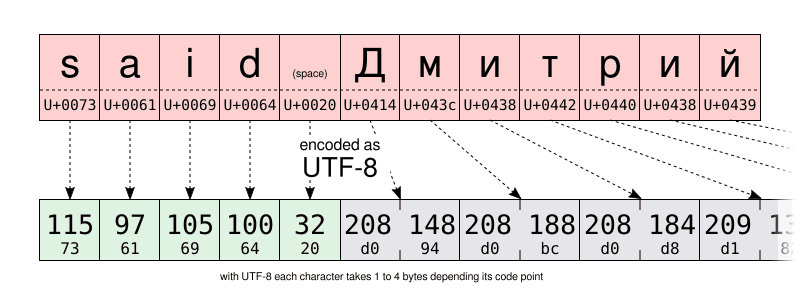
## And how does that help for typing text?
Well… It doesn’t hurt to have some knowledge of the underlying mechanism to understand the capabilities and limitations of your computer. Especially we will talk about Unicode and hexadecimal a little later. But for now… a little bit more history. Just a little bit, I promise…
… just enough to say starting in the 80s, computer keyboard used to have a [compose key](https://en.wikipedia.org/wiki/Compose_key) (sometimes labeled the “multi” key) next to the shift key. By pressing that key, you entered in “compose” mode. And once in that mode, you were able to enter characters not directly available on your keyboard by entering mnemonics instead. For example, in compose mode, typing `RO` produced the ® character (which is easy to remember as an R inside an O).

It is now a rarity to see the compose key on modern keyboards. Probably because of the domination of PCs that don’t make use of it. But on Linux (and possibly on other systems?) you can emulate the compose key. This is something that can be configured in the GUI on many desktop environments using the “keyboard” control panel: But the exact procedure varies depending on your desktop environment or even depending its version. If you changed that setting, don’t hesitate to use the comment section to share the specific steps you’ve followed on your computer.
As for myself, for now, I will assume you use the default `Shift`+`AltGr` combination to emulate the compose key.
So, as a practical example, to enter the LEFT-POINTING DOUBLE ANGLE QUOTATION MARK, you can type `Shift`+`AltGr` `<``<` (you don’t have to maintain `Shift`+`AltGr` pressed when entering the mnemonic). If you managed to do that, I think you should be able to guess by yourself how to enter the *RIGHT-POINTING* DOUBLE ANGLE QUOTATION MARK.
As another example, try `Shift`+`AltGr` `-``-``-` to produce an EM DASH. For that to work, you have to press the [hyphen-minus](https://en.wikipedia.org/wiki/Hyphen-minus) key on the main keyboard, not the one you will find on your numeric keypad.
Worth mentioning the “compose” key works in a non-GUI environment too. But depending if you use you use X11 or a text-only console, the supported compose key sequence are not the same.
On the console, you can check the list of supported compose key by using the `dumpkeys`
command:
dumpkeys --compose-only
On the GUI, compose key is implemented at Gtk/X11 level. For a list of all mnemonics supported by the Gtk, take a look at that page: [https://help.ubuntu.com/community/GtkComposeTable](https://help.ubuntu.com/community/GtkComposeTable)
## Is there a way to avoid relying on Gtk for character composition?
Maybe I’m a purist, but I found somewhat unfortunate the compose key support being hard-coded in Gtk. After all, not all GUI applications are using that library. And I cannot add my own mnemonics without re-compiling the Gtk.
Hopefully, there is support for character composition at X11-level too. Formerly, through the venerable [X Input Method (XIM)](https://en.wikipedia.org/wiki/X_Input_Method).
This will work at lower-level than Gtk-based character composition. But will allow a great amount of flexibility. And will work with many X11 applications.
For example, let’s imagine I just want to add the `-``-``>` composition to enter the → character (U+2192 RIGHTWARDS ARROW), I would create a `~/.XCompose`
file containing those lines:
cat > ~/.XCompose << EOT # Load default compose table for the current local include "%L" # Custom definitions <Multi_key> <minus> <minus> <greater> : U2192 # RIGHTWARDS ARROW EOT
Then you can test by starting a new X11 application, forcing libraries to use XIM as input method:
GTK_IM_MODULE="xim" QT_IM_MODULE="xim" xterm
The new compose sequence should be available in the application you launched. I encourage you to learn more about the compose file format by typing `man 5 compose`
.
To make XIM the default input method for all your applications, just add to your `~/.profile`
file the following two lines. that change will be effective the next time you’ll open a session on your computer:
export GTK_IM_MODULE="xim" export QT_IM_MODULE="xim"
It’s pretty cool, isn’t it? That way you can add all the compose sequences you might want. And there are already a couple of funny ones in the default XIM settings. Try for example to press `compose` `L``L``A``P`.
Well, I must mention two drawbacks though. XIM is relatively old and is probably only suitable for those of us who don’t regularly need multi-bytes input methods. Second, when using XIM as your input method, you no longer can enter Unicode characters by their code point using the `Ctrl`+`Shift`+`u` sequence. What? Wait a minute? I didn’t talk about that yet? So let’s do it now:
## What if there is no compose key sequence for the character I need?
The compose key is a nice tool to type some characters not available on the keyboard. But the default set of combinations is limited, and switching to XIM and defining a new compose sequence for a character you will need only once in a lifetime can be cumbersome.
Does that prevent you to mix Japanese, Latin and Cyrillic characters in the same text? Certainly not, thanks to Unicode. For example, the name あゆみ is made of:
I mentioned above the official Unicode character names, following the convention to write them in all upper cases. After their name, you will find their Unicode code point, written between parenthesis, as a 16-bit hexadecimal number. Does that remind you something?
Anyway, once you know the code point of a character, you can enter it using the following combination:
`Ctrl`+`Shift`+`u`, then`XXXX`(the*hexadecimal*code point of the character you want) and finally`Enter`.
As a shorthand, if you don’t release `Ctrl`+`Shift` while entering the code point, you won’t have to press `Enter`.
Unfortunately, that feature is implemented at software library level rather than at X11 level. So the support may be variable among different applications. In LibreOffice, for example, you have to type the code point using the main keyboard. Whereas Gtk-based application will accept entry from the numeric keypad as well.
Finally, when working at the console on my Debian system, there is a similar feature, but requiring instead to press `Alt`+`XXXXX` where XXXXX is the code point of the character you want, but written in *decimal* this time. I wonder if this is Debian-specific or related to the fact I’m using the en_US.UTF-8 locale. If you have more information about that, I would be curious to read you in the comment section!
GUI | Console | Character |
---|---|---|
|
|
あ |
|
|
ゆ |
|
|
み |
## Dead keys
Last but not least, there is a simpler method to enter key combinations that do not rely (necessarily) on the compose key.
Some keys on your keyboard were specifically designed to create a combination of characters. Those are called [dead keys](https://en.wikipedia.org/wiki/Dead_key). Because when you press them once, nothing seems to happen. But they will silently modify the character produced by the next key you will press. This is a behavior inspired from mechanical typewriter: with them, pressing a dead key imprinted a character, but will not move the carriage. So the next keystroke will imprint another character at the same position. Visually resulting in a combination of the two pressed keys.
We use that a lot in French. For example, to enter the letter “ë” I have to press the `¨` dead key followed by the `e` key. Similarly, Spanish people have the `~` dead key on their keyboard. And on the keyboard layout for Nordic languages, you can find the `°` key. And I could continue that list for a very long time.
Obviously, not all dead keys are available on all keyboard. I fact, most dead keys are NOT available on your keyboard. For example, I assume very few of you— if any— have a dead key `¯` to enter the macron (“flat accent”) used to write Tōkyō.
For those dead keys that are not directly available on your keyboard, you need to resort to other solutions. The good news is we’ve already used those techniques. But this time we will use them to emulate dead keys. Not “ordinary” keys.
So, a first option could be to generate the macron dead key by using `Compose` `-` (the hyphen-minus key available on your keyboard). Nothing appears. But if after that you press the `o` key it will finally produce “ō”.
The list of dead keys that Gtk can produce using the compose mode can be found [here](https://help.ubuntu.com/community/GtkDeadKeyTable).
A different solution would use the Unicode COMBINING MACRON (U+0304) character. Followed by the letter o. I will leave the details up to you. But if you’re curious, you may discover this leads to a very subtlely different result, rather than really producing a LATIN SMALL LETTER O WITH MACRON. And if I wrote the end of the previous sentence in all uppercase, this is a hint guiding you toward a method to enter ō with fewer keystrokes than by using a Unicode combining character… But I let that to your sagacity.
## Your turn to practice!
So, did you get it all? Does that work on your computer? It’s your turn to try that: using the clues given above, and a little bit of practice, now you can enter the text of the challenge given in the beginning of this article. Do it, then copy-paste your text in the comment section below as proof of your success.
There is nothing to win, except maybe the satisfaction of impressing your peers! |
15,484 | Pandas:用于数据分析和数据科学的最热门 Python 库 | https://www.opensourceforu.com/2022/08/pandas-the-popular-python-library-for-data-analysis-and-data-science/ | 2023-01-27T16:34:31 | [
"Pandas",
"Python"
] | https://linux.cn/article-15484-1.html | 
>
> Pandas 是一个十分流行的 Python 第三方库。本文介绍了 Pandas 库中的一些特性和函数,并且我们鼓励读者亲手使用 Pandas 库,来解决实际的业务问题。
>
>
>
Pandas 为 Python 中数据分析提供了基础和高级的构建组件。Pandas 库是用于数据分析与数据操作的最强大和最灵活的开源**分析工具**之一,并且它还提供了用于建模和操作表格数据(以行和列组织的数据)的**数据结构**。
Pandas 库有两个主要的数据结构:第一个是 “<ruby> 系列 <rt> Series </rt></ruby>”,该数据结构能够很方便地从 Python 数组或字典中**按位置或指定的索引名称**来检索数据;第二个是“<ruby> 数据帧 <rt> DataFrames </rt></ruby>”,该数据结构将数据存储在行和列中。列可以通过列名访问,行通过索引访问。列可以有不同类型的数据,包括列表、字典、序列、数据帧、NumPy 数组等。
### Pandas 库可以处理各种文件格式
有各种各样的文件格式。用于数据分析的工具必须能够提供处理各种文件格式的方法。
Pandas 可以读取各种文件格式,例如 CSV 文件、JSON 文件、XML 文件、Parquet 文件、SQL 文件,详见下表。
| | 写入 | 读取 |
| --- | --- | --- |
| CSV 文件 | `to_csv` 函数 | `read_csv` 函数 |
| JSON 文件 | `to_json` 函数 | `read_json` 函数 |
| Parquet 文件 | `to_parquet` 函数 | `read_parquet` 函数 |
| SQL 文件 | `to_sql` 函数 | `read_sql` 函数,`read_sql_query` 函数,`read_sql_table` 函数 |
| XML 文件 | `to_xml` 函数 | `read_xml` 函数 |
### 使用 Pandas 进行数据清理
在现实场景中,很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理。此外,数据还会有需要 <ruby> 屏蔽 <rt> mask </rt></ruby> 的敏感和机密信息。接下来,Pandas 提供了清理、丢弃、替换、屏蔽等方法,来处理这些坏数据。
#### Pandas 清洗空值:
a. 空行可以使用 `df.dropna(inplace=True)` 方法来删除。
b. 空值可以使用 `df.fillna(<value>, inplace=True)` 方法来替换。还可以指定某一个列来替换该列的空数据。
#### Pandas 屏蔽数据:
c. 要屏蔽所有不满足条件 `my_list.where(my_list < 5)` 的敏感数据的值,可以使用 `my_list.mask(my_list < 5)`。
#### Pandas 清洗重复数据:
d. 要删除重复数据,可以使用 `drop_duplicates()` 方法:
```
df.drop_duplicates(‘<column>’, keep = False)
df.drop_duplicates(‘<column>’, keep = ‘first’)
df.drop_duplicates(‘<column>’, keep = ‘last’)
```
### 使用 Pandas 进行数据分析
下面的表格列出了 Pandas 中进行数据分析的各种函数,以及其语法。(请注意:`df` 代表一个 <ruby> 数据帧 <rt> DataFrame </rt></ruby> 数据结构的实例。)
| 语法 | 描述 |
| --- | --- |
| `df.head(x)` | `head()` 函数用于读取前面的 x 行,如果不填参数 x,默认返回 5 行 |
| `df.tail(x)` | `tail()` 函数用于读取尾部的 x 行,如果不填参数 x ,默认返回最后 5 行,空行各个字段的值返回 NaN |
| `loc(x:y)` | Loc 函数返回指定行的数据,也可以对数据进行切片 |
| `groupby('<column>')` | 对指定列的数据进行分组 |
| `df['column'].sum()` | 计算指定列数据的总和 |
| `df['column']. mean()` | 计算指定列数据的算术平均值 |
| `df['column'].min()` | 计算指定列数据的最小值 |
| `df['column'].max()` | 计算指定列数据的最大值 |
| `df.sort_values(['column'])` | 在指定列上根据数值进行排序,默认升序 |
| `df.size` | 返回元素的个数,即为行数 \* 列数 |
| `df.describe` | 返回对各列的统计汇总 |
| `pd.crosstab(df['column1'], df['column2'], margins = True)` | 创建 `column1` 和 `column2` 的交叉表 |
| `df.duplicated([column1, 'column2'])` | 根据 `column1` 和 `column2` 中的重复值,返回 `True` 或 `False` |
### Pandas 的优点
* 支持多索引(层次索引),方便分析多维数据。
* 支持数据透视表的创建,堆栈和取消堆栈操作。
* 可以使用 Pandas 处理有限值的分类数据。
* 支持分组和聚合运算。
* 可以禁用排序。
* 支持行级过滤(获取满足过滤条件的行)和列级过滤(只选择需要的列)。
* 有助于重塑数据集(数组的维度变换)。还可以转置数组的值,并转换为列表。当你使用 Python 处理数据时,可以将 Pandas 数据帧转换为多维 NumPy 数组。
* 支持面向标签的数据切片。
### Pandas 的不足
Pandas 的代码和语法与 Python 不同,所以人们需要额外再学习 Pandas。此外,相较于 Pandas,像三维数据这样的高维数据会在 NumPy 等其他库有更好的处理。
### 总结
Pandas 能够大幅提升数据分析的效率。它与其他库的兼容性使它在其他 Python 库中都能有效地使用。
---
via: <https://www.opensourceforu.com/2022/08/pandas-the-popular-python-library-for-data-analysis-and-data-science/>
作者:[Phani Kiran](https://www.opensourceforu.com/author/phani-kiran/) 选题:[lkxed](https://github.com/lkxed) 译者:[chai001125](https://github.com/chai001125) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Pandas is a popular Python library. This article describes a few features and functions available in this library, and encourages readers to use it for practical business problems.*
Pandas provides fundamental and high-level building blocks for practical, real world data analysis in Python. It is one of the most powerful and flexible open source tools for data analysis and manipulation, and provides data structures for modelling and manipulating tabular data (data in rows and columns).
Pandas has two primary data structures. The first is a ‘series’ data structure that helps to retrieve data from the array or dictionary of Python objects. Data can be retrieved either by position or by specifying the index name. The second is the ‘dataframes’ data structure to store data in rows and columns. Columns have column names and rows are accessed using indexes. Columns can have different types of data including lists, dictionaries, pandas series, another dataframe, NumPy arrays, etc.
## Processing various file types
Data is often available in various formats. It is imperative that the tool used for data analysis is able to provide a wide range of methods for handling it.
With Pandas, one can read various file types like CSV, JSON, XML, Parquet, SQL (see Table 1).
Write |
Read |
|
CSV | to_csv |
read_csv |
JSON | to_json |
Read_json |
Parquet | to_parquet |
read_parquet |
SQL | to_sql |
read_sql, read_sql_query, read_sql_table |
XML | to_xml |
read_xml |
## Data cleansing using Pandas
In real-world scenarios, data is often incomplete and includes bad data. It is sometimes duplicated. Also, data includes sensitive and confidential information, which needs to be masked. Pandas offers ways to handle bad data by using methods like cleaning, dropping, replacing, masking, etc.
a. Empty rows can be removed with the *df.dropna(inplace=True)* operation.
b. Empty values can be replaced with *df.fillna(<value>, inplace=True)*. We can specify the column name to be placed in a particular column.
c. You can mask the values for sensitive and non-public data for all items NOT satisfying the condition *my_list.where(my_list < 5)*. Masking of values satisfying the condition can be done with* my_list.mask(my_list < 5)*.
d. Duplicates can be dropped from a dataframe using:
df.drop_duplicates(‘<column>’, keep = False) df.drop_duplicates(‘<column>’, keep = ‘first’) df.drop_duplicates(‘<column>’, keep = ‘last’)
## Data analysis using Pandas
Table 2 lists the various functions in Pandas that perform data analysis as well as the syntax for usage. (Note: df stands for dataframe.)
Function |
Description |
Syntax |
Head | Head() function returns the first five rows |
df.head(x) |
tail | tail() function returns the last five rows by default |
df.tail(x) |
Loc | Loc function returns a particular row. Slicing of the data is also possible |
loc(x:y) |
Groupby | Groups data on a particular column | groupby(‘<column>’) |
Sum | Sum of values in a particular column | df[‘column’].sum() |
Mean | Average of values in a particular column | df[‘column’]. mean() |
Min | Minimum value in a particular column | df[‘column’].min() |
Max | Maximum value in a particular column | df[‘column’].max() |
Sort | Sorts dataframe in a column | df.sort_values([‘column’]) |
Size | Rows * columns | df.size |
Describe | Describes details of the dataframe | df.describe |
Crosstab | Creates a frequency tabulation of rows and columns | pd.crosstab(df[‘column1’], df[‘column2’], margins = True) |
Duplicated | Returns True or False based on duplicate values in Column1 and Column2 |
df.duplicated([column1, ‘column2’]) |
## Advantages of Pandas
- It supports multi-index (hierarchical index) used for easy analysis of data having a large number of dimensions.
- It supports the creation of pivot tables, stack and unstack operations.
- Categorical data containing finite values can be processed with Pandas.
- It supports grouping and aggregations.
- Sorting can be explicitly disabled.
- It supports filtering at both row-level (gets the rows satisfying the filter condition) and column-level (selects only the required columns).
- Helps in reshaping of data sets. You can also transpose the values of the array and convert to a List. When you are processing data using Python, you can convert the Pandas dataframe to a multi-dimensional NumPy array; the values member variable is used for this.
- Supports label-oriented slicing of data.
## The disadvantages
The code and syntax of Pandas is different from Python, which leads to a steep learning curve for some users. Also, a few concepts like three dimensional data are better handled in other libraries like NumPy.
Pandas really elevates the data analysis process in an efficient manner. Its compatibility with other libraries makes it very conducive for use in various scenarios. |
15,486 | Twitter 和 Mastodon 的四个关键区别 | https://opensource.com/article/22/11/twitter-vs-mastodon | 2023-01-28T09:32:00 | [
"Mastodon"
] | https://linux.cn/article-15486-1.html | 
>
> Mastodon 并不是一家公司。所有 Mastodon 实例都由各自所属服务器的贡献者负责支持维护的。以下是它的一些其他优势。
>
>
>
社交媒体并不总是社交性的,有时我们还需要足够的推动力来改变我们工作和阅读的内容。我在 2008 年开始使用 Twitter 作为 RSS 阅读器的替代品,这彻底颠覆了我那时的阅读和学习方式。世界各地的教育家和自由与开放源码(FOSS)倡导者的推文让我了解并参与到一个无与伦比的学习网络中。但这在过去的六年间,事情发生了变化,以及最近它的所有权发生了变化,造成我阅读的内容更多是由算法驱动的,而不是出于我个人的兴趣和选择。在几年前的 [Opensource.com](http://Opensource.com) 记者编辑碰头会中,[Seth Kenlon](https://opensource.com/users/seth) 建议我试试 [Mastodon](https://joinmastodon.org/)。于是我在 2019 年加入了 [Fosstodon](https://fosstodon.org/about/)。Fosstodon 是一个专为喜欢自由和开源软件的同好们搭建的实例。
### Mastodon 与 Twitter 对比
作为一个墨守成规的人,改变对我来说并不容易,尽管 Twitter 变得越来越让人厌倦,我还一直在使用。可是到了 2022 年的春天,Twitter 的出售危机让我重新考虑使用 Fosstodon 了。
### 1、收藏而不是点赞
Mastodon 的界面与 Twitter 很相似。但在 Mastodon上,你不是“点赞”一个帖子,而是通过点击帖子下方的星标来“收藏”一个帖子。

### 2、分享帖子
在 Twitter 上,重新分享是“<ruby> 转推 <rt> retweet </rt></ruby>”,但在 Mastodon,它是“<ruby> 转嘟 <rt> boost </rt></ruby>”。你可以点击帖子下方的双箭头图标来转嘟。

### 3、Mastodon 实例
任何人都可以运行一个 Mastodon 实例,这让不同的实例上发展出了独特的社区(类似在 Twitter 上围绕特定标签形成的社区,不过 Mastodon 也有标签),有些实例有一套独特的规则。举个例子,和我以前的社交网络不同,Fosstodon 上采取了内容审核制度。最初这让我觉得有些严格,我发了一个与自由与开放源码软件无关的帖子,然后帖子就被删除了。我被告知的删除原因是,我没有给帖子打上 “内容警告”。这惹怒了我,于是我尝试寻找别的实例,发现了几个更符合我胃口的。其中一个是 [Mastodon.social](https://mastodon.social/about),另一个是 [Scholar.social](https://scholar.social/about/more),前者是一个泛用的实例,没有预设的发帖主题,后者则是一个学术专用的实例。当然,他们也都制定有严格的行为规范。
每个实例都有规则,虽然在表述上略有不同,但都清楚地说明了可以接受和不可接受的行为。Fosstodon 公布了它的 [行为规范](https://hub.fosstodon.org/coc/),确立了站点的规则和预期。
### 4、开源社交网络
如果你也想运行自己的 Mastodon 实例或协助开发一个,好消息是,Mastodon 是开源的。它使用 AGPLv3 许可证,它的源代码可以在 [Git 仓库](https://github.com/mastodon/mastodon) 获得。Mastodon 使用 [ActivityPub](https://en.wikipedia.org/wiki/ActivityPub) 协议与世界各地的服务器通信。
Mastodon 不是互联网上的单一的网站,而是一系列横跨全球并相互通信的网站们。这个联邦网络被称为 “<ruby> 联邦宇宙 <rt> Fediverse </rt></ruby>”。不像其他社交网站有单一的所有者,任何人都可以在服务器上运行 Mastodon 或者其他 ActivityPub 协议网站。
从用户的角度来看,这一开始时其实并不重要。你可以在任何 Mastodon 实例上注册,然后连接到其余所有的实例。
不过,这种分布式设计是有其好处的。如果你碰见一个实例上的社区内容你不想看,你可以从屏蔽该实例中的某个用户,或者屏蔽整个实例。
过去的一个月里,我又回到了 Fosstodon,主要还是因为我热衷开源。我很享受在 Fosstodon 上分享开源内容,而 Fosstodon 上的其他用户也都能乐于看到关于自由和开源软件的帖子。当我有一些内容不适合在 Fosstodon 上分享时,我会分享到 Scholar.social 或者 Mastodon.social 上。
不是所有的实例都有关注的主题,即便是那些有主题的实例,主题常常也是仅作参考,而不是严格作为删帖的依据。如果你有特定的兴趣,也许就能找到一个围绕这个话题建立的社区,然后马上就能收获及时的关注。当然,你也依然能够与其他实例的用户交流。
### 试试 Mastodon
Mastodon 不是一家公司,所有 Mastodon 实例都是由各自所属的服务器的贡献者负责支持维护的。有些能很容易地通过 Patreon 或 PayPal 提供支持。
我发现,联邦宇宙是个很温馨的地方,把快乐带回给了社交网络。你加入了 Mastodon 了吗?有没有什么收获?请在评论中告诉我们。
---
via: <https://opensource.com/article/22/11/twitter-vs-mastodon>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lkxed](https://github.com/lkxed) 译者:[onionstalgia](https://github.com/onionstalgia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Social media is not always sociable, and sometimes we need a sufficient impetus to change what we do and what we read. I began using Twitter as a replacement for my RSS reader in 2008, which revolutionized how I read and learned up to that point. Tweets from educators and free and open source (FOSS) advocates worldwide kept me informed and engaged in a learning network that was without equal. That's changed over the past half dozen years, and recently a change in ownership and the shaping of what I read was driven more by an algorithm than by my personal interests and choices. During a yearly meetup of correspondents and editors of Opensource.com a few years ago, [Seth Kenlon](https://opensource.com/users/seth) suggested giving [Mastodon](https://joinmastodon.org/) a try. I joined [Fosstodon](https://fosstodon.org/about/) in 2019. Fosstodon is a Mastodon instance for a community of like-minded people who enjoy free and open source software.
## Mastodon vs Twitter
Change is not easy. Being a creature of habit, I stayed with my old standby even though it was becoming increasingly tiresome. The threat of its sale in the spring of 2022 invited me to reconsider Fosstodon.
## 1. Favorite instead of like
The Mastodon interface is similar to Twitter. Rather than "liking" a post, you "favorite" a post on Mastodon by clicking the star icon under the post content.
(Don Watkins, CC BY-SA 4.0)
## 2. Share a post
Re-sharing on my old network is a "retweet," but on Mastodon, it's a "boost." You click the double-arrow icon under the post content to boost a post.
(Don Watkins, CC BY-SA 4.0)
## 3. Mastodon instances
Because anyone can run a Mastodon instance, different instances not only have unique communities (like the ones that form around specific hashtags on Twitter, but Mastodon also has hashtags). Some have a unique set of rules. For instance, unlike my former social network, there were content moderation rules on Fosstodon that seemed strict initially. I made a post unrelated to FOSS software, and my post was removed. I was told it had been removed because I'd not issued a "content warning." That irked me, so I looked for another instance and found a couple more to my liking. One was [Mastodon.social](https://mastodon.social/about), and the other [Scholar.social](https://scholar.social/about/more). The former is a general server with no expectation about what you will post. The latter was an instance dedicated to academics. In all cases, there are well-enforced codes of conduct.
Each instance has rules, and while they differ slightly in the description, they clearly spell out what is and is not acceptable behavior. Fosstodon published its [code of conduct](https://hub.fosstodon.org/coc/), which established the rules and expectations of behavior on the site.
## 4. Open source social networking
If you want to run your own Mastodon instance or help develop one, you'll be happy to know that Mastodon is open source. It uses an AGPLv3 license, and its source code is available as a [Git repository](https://github.com/mastodon/mastodon). The software provides a social network server that uses the [ActivityPub](https://en.wikipedia.org/wiki/ActivityPub) protocol to communicate with other servers worldwide.
Mastodon is not a single site on the internet but a series of sites spanning the globe and communicating with each other. This federated network is referred to as the "fediverse." Unlike other social networks, where there's a single owner of the network, Mastodon and other ActivityPub sites are owned by anyone who runs a server.
From a user's perspective, this doesn't matter at first. You can sign up on any Mastodon instance and then connect to all other instances.
**[ Related read Switching from Twitter to Mastodon: What sysadmins need to know ]**
There is power to this distributed design, though. If you encounter an instance with a community producing content you'd rather not see, you can block either a single user from that instance or the whole instance.
In the past month, I've returned to Fosstodon primarily because open source is my passion. I enjoy sharing open source content on Fosstodon because the other users of Fosstodon are generally receptive to posts about free and open source software. When I have something to share that's not considered appropriate on Fosstodon, I share it on Scholar.social or Mastodon.social.
Not all instances have topics they focus on, and even those that do often use their topical interests as a guideline rather than grounds for strict removal of posts. If you have a particular interest, you might be able to find a community built around that topic, and you're likely to see that you have an instant audience. Of course, you'll still always be able to communicate with users of other instances, too.
## Try Mastodon
Mastodon is not a corporation. All of its instances are staffed and supported by each server's contributors. Some instances make it easy to support them with Patreon or PayPal.
I have found the fediverse a welcoming place that brings joy back into social networking. Have you joined Mastodon? What are your takeaways? Let us know in the comments.
## 3 Comments |
15,487 | 在 Linux 上用 zram 替代传统交换空间 | https://opensource.com/article/22/11/zram-swap-linux | 2023-01-28T11:39:43 | [
"zram",
"交换空间"
] | https://linux.cn/article-15487-1.html | 
>
> zram 是一个用于创建内存压缩缓存的工具,特别是可以用作交换空间。
>
>
>
我在我的电脑上花了很多时间(我是说工作),我发现了很多有趣的东西。其中最近引起我注意的是 `zram0` 设备。我是在几个月前写一篇文章时第一次注意到它,它显示在 `lsblk` 命令的输出中:
```
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 931.5G 0 disk
├─sda1 8:1 0 600M 0 part
[...]
zram0 252:0 0 8G 0 disk [SWAP]
```
它被识别为交换空间,这就是首先引起我的好奇心的原因,所以我做了一些研究。zram 最初被称为 “<ruby> 压缩缓存 <rt> compcache </rt></ruby>”,即 “压缩的高速缓存”。事实证明,zram 是一个用于创建内存内压缩缓存的工具,特别是作为交换空间使用。
但为什么呢?
当我开始研究 zram 时,我只发现了几篇关于将 zram 用于交换空间的基础文章。起初,这对我来说似乎有点违反直觉。毕竟,如果你的内存快用完了,你把页面交换到内存中的虚拟驱动器中,有什么好处呢?
然后我找到了 Fedora 项目的维基页面,它提议使用 <ruby> <a href="https://fedoraproject.org/wiki/Changes/SwapOnZRAM"> zram 交换空间 </a> <rt> swap-on-zram </rt></ruby>。该建议说:“交换是有用的,除了它的速度很慢。zram 是一个使用了压缩的内存驱动器。在启动时创建一个 zram 交换空间,并且不再使用默认的交换分区。”
该页面的其余部分是关于它的细节、好处、副作用和反馈。
### Linux 上用于交换空间的 zram
使用 zram 作为交换空间,与常规的基于分区或基于文件的交换空间做的事情相同。当内存压力过大时,一些最近使用最少的数据会被移到交换空间。平均来说,它会被压缩到其原始大小的 50% 左右,并被放置在内存的 zram 空间中。这比将这些内存页存储在硬盘上要快得多,并可以释放出它所使用的内存用于其他用途。
### 节省交换空间
我试图找到关于配置多少交换空间或 zram 交换空间的总结建议。这使我重新回顾了交换空间的设置,以及我之前的文章《[现代 Linux 系统的正确交换空间是多少?](https://opensource.com/article/19/2/swap-space-poll)》。就我所知,从 RHEL 和 Fedora 的最新文档来看,推荐的交换空间数量并没有改变。不过,该文档忽略了 zram 的使用。
然而,在不使用 zram 的旧版 Linux 或 zram 被禁用的情况下,之前文章中的表格仍然为交换空间的分配提供了一个好的起点。
我找到的关于 zram 功能的文档在 zram 如何根据内存大小分配空间,以及分配给 zram 交换空间的数量方面是不一致的。
由于缺乏权威性的文档,我进行了一些实验来凭经验确定用于分配 zram 交换空间的算法。我为此使用了我自己的物理和虚拟系统。结果很有趣,与我迄今为止发现的任何文档都不一致。
在所有足够大的系统上,zram 的默认大小是 8GB,但在内存较小的主机上通常会大大减少。在我用于测试的一台虚拟机(VM)上,可以访问 4GB 的内存,zram 的虚拟交换空间被分配为 3.8GB。我的一台旧戴尔电脑拥有 8GB 的内存,zram 被设置为 7.6GB。当内存减少到 2GB 时,zram 就减少到 1.9GB。
我拥有的所有内存超过 8GB 的物理和虚拟主机都显示正好是 8GB 的 zram。这包括我拥有 64GB 内存的主工作站和其他拥有 16GB 或 32GB 内存的主机。
基于这几个数据点,我可以得出这样的结论:目前的默认设置是最多 8GB 的 zram,而在 8GB 或以下的主机上,zram 占内存的 95%。
我读过一些文章,其中提到了 zram 交换空间的其他大小,甚至高达 100% 的内存,但这些似乎都是理论上的,而不是现实。
你的发行版可能不同,但这里是 Fedora 和类似发行版的实际 zram 交换空间的分配情况:
* 内存 ⇐ 8 GB:0.95 × 内存
* 内存 > 8 GB:8 GB
请注意,zram 交换空间大小的算法并没有基于对任何给定的现实世界的系统或应用程序的 “最佳” 交换大小的建议。这种 zram 交换空间的分配是一种相当概率性的方法,它应该在广泛的 Linux 主机上运行良好。然而,最大的 zram 交换空间大小被配置为 8GB,而且我一直推荐 8GB 作为传统交换空间的最大容量,我想我可以说它反映了 zram 交换空间的最佳大小。
### 管理 zram 交换空间
zram 的默认值保存在 `/usr/lib/systemd/zram-generator.conf` 配置文件中。以下是我的一个测试虚拟机,分配了 5097GB 的内存。
```
# cat /usr/lib/systemd/zram-generator.conf
# This config file enables a /dev/zram0 device with the default settings:
# - size - same as available RAM or 8GB, whichever is less
# - compression - most likely lzo-rle
#
# To disable, uninstall zram-generator-defaults or create empty
# /etc/systemd/zram-generator.conf file.
[zram0]zram-size= min(ram, 8192)
```
你可以在 `zram-generator.conf` 配置文件的最后一行改变默认的 zram 交换空间大小。但我建议不要这样做,除非你能明确说明这样做的原因,并在你做任何改变后测试你的结果。像 Linux 中的许多其他配置默认值一样,zram 的默认值已经被很好地测试过了,适合大多数使用情况。
### 监控 zram
可以使用 `zramctl` 工具来查看 zram 的当前状态。
```
# zramctl
NAME ALGORITHM DISKSIZE DATA COMPR TOTAL STREAMS MOUNTPOINT
/dev/zram0 lzo-rle 4.8G 4K 80B 12K 4[SWAP]
```
传统的 `swapon` 命令也可以用来查看交换,包括作为交换使用的 zram:
```
# swapon --show
NAME TYPE SIZE USED PRIO
/dev/zram0 partition 4.8G 0B 100
```
需要注意的是,`zramctl` 在不包含数据时不报告 zram,所以结果会包含空输出。而像 `lsblk`、`swapon`、 `top`、`free`、`htop` 等工具,即使不包含数据,也会显示 zram。
### 停用 zram
`swapoff -a` 命令会关闭 zram 交换空间以及用作交换的传统 HDD 或 SSD 存储。`swapon -a` 命令在 zram 为空时不显示它,可以使用 `zramctl /dev/zram0` 代替。
```
# swapon --show# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:00 120G 0 disk
├─sda1 8:10 1G 0 part /boot/efi
├─sda2 8:20 1G 0 part /boot
└─sda3 8:30 118G 0 part
├─vg01-root 253:00 10G 0 lvm /
├─vg01-swap 253:10 3G 0 lvm [SWAP]
├─vg01-usr 253:10 30G 0 lvm /usr
├─vg01-home 253:20 10G 0 lvm /home
├─vg01-var 253:30 30G 0 lvm /var
└─vg01-tmp 253:40 10G 0 lvm /tmp
sr0 11:01 1024M 0 rom
zram0 252:00 0B 0 disk
# zramctl## zramctl /dev/zram0
NAME ALGORITHM DISKSIZE DATA COMPR TOTAL STREAMS MOUNTPOINT
/dev/zram0 lzo-rle 0B 0B 0B 0B 4
```
注意,`/dev/zram0` 在这些命令中并没有显示为交换空间,直到它被用于该目的。这给我造成了一些困惑,直到我的实验表明这是事实。
### 创建 zram 交换空间
zram 本身已经存在了大约 20 年,但只是在过去的一两年里才在一些发行版上作为交换空间使用。你的一些或所有主机上当前的 Linux 环境可能没有用 zram 创建交换空间。如果是这种情况,它可以很容易地被补救。
对于 Fedora 32,它是默认使用 zram 交换空间之前的最后一个版本,它只需要三个简单的命令。
首先,验证是否存在 `zram-swap.service` 文件,它作为 `zram` RPM 包的一部分安装:
```
# systemctl status zram-swap
● zram-swap.service - Enable compressed swap in memory using zram
Loaded: loaded (/usr/lib/systemd/system/zram-swap.service; disabled; vendor preset: disabled)
Active: inactive (dead)
```
接下来,安装 `zram-generator-defaults` 和 `zram-generator` 软件包:
```
# dnf install zram-generator-defaults zram-generator
```
启用并启动 `zram-swap` 服务:
```
# systemctl enable zram-swap.service# systemctl start zram-swap.service
```
然后验证 `zram0` 是否存在并被用作交换空间:
```
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:00 120G 0 disk
├─sda1 8:10 2G 0 part /boot
└─sda2 8:20 118G 0 part
├─vg01-root 253:00 10G 0 lvm /
├─vg01-swap 253:10 3G 0 lvm [SWAP]
├─vg01-usr 253:20 35G 0 lvm /usr
├─vg01-tmp 253:30 15G 0 lvm /tmp
├─vg01-var 253:40 35G 0 lvm /var
└─vg01-home 253:50 20G 0 lvm /home
sr0 11:01 1024M 0 rom
zram0 252:00 7.5G 0 disk [SWAP]
```
### 用 zram 改进交换空间
这就是全部内容了。在 Fedora 上这很容易。不同的发行版可能也一样简单,只是软件包名称和命令的细节可能不同。在你的电脑上试试 zram 交换空间吧。在我的下一篇文章中,我将进一步演示一些 zram 选项。
---
via: <https://opensource.com/article/22/11/zram-swap-linux>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I spend a lot of time playing (I mean *working*) on my computers, and I've found a lot of interesting things. One that has most recently come to my attention is the `zram0`
device. I first noticed it when working on one of my Opensource.com articles several months ago. It showed up in the output from the `lsblk`
command:
```
``````
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 931.5G 0 disk
├─sda1 8:1 0 600M 0 part
[...]
zram0 252:0 0 8G 0 disk [SWAP]
```
It's identified as swap space, which is what first piqued my curiosity, so I did some exploration. Zram was originally called "compcache," which stands for "compressed cache." It turns out that zram is a tool for creating an in-RAM compressed cache, specifically for use as swap space.
But Why?
When I began researching zram, all I found were a couple of basic articles about using zram for swap space. At first, this seemed a bit counterintuitive to me. After all, if you're running out of RAM and you swap pages into a virtual drive in RAM, what's gained?
I then found the Fedora Project wiki page that proposed the use of [Swap on zram](https://fedoraproject.org/wiki/Changes/SwapOnZRAM). The proposal says: "Swap is useful, except when it's slow. zram is a RAM drive that uses compression. Create a swap-on-zram during start-up. And no longer use swap partitions by default."
The rest of the page is about details, benefits, side effects, and feedback.
## Zram for swap space on Linux
Using zram for swap space is intended to do the same thing as regular partition-based or file-based swap space. When memory pressure becomes too great, some of the least recently used data is moved to swap space. On average, it's compressed to about 50% of its original size, and placed in zram space in RAM. This is much faster than storing those memory pages on a hard drive and frees up the RAM it was using for other use.
## Saving on swap
I tried to find revised recommendations for how much swap or zram swap to configure. This led me back to a reassessment of swap, and my previous article, [What's the right amount of swap space for a modern Linux system?](https://opensource.com/article/19/2/swap-space-poll) As far as I can tell from the most current documentation for RHEL and Fedora, the recommended amount of swap space has not changed. That documentation, however, ignores the use of zram.
However, the tables in that previous article still provide a good starting point for swap space allocation when using older releases of Linux that don't use zram or in cases where zram has been disabled.
The documents I found for the Zram feature are inconsistent in terms of how zram is allocated with respect to RAM size, and the amount of space allocated to zram swap.
Due to the lack of authoritative documentation, I performed some experiments to empirically determine the algorithm used to allocate zram swap. I used my own physical and virtual systems for this. The results are interesting and do not match any documentation I've so far found.
The default size of zram is 8 GB on all systems large enough to support that, but it's typically reduced significantly on hosts with small amounts of RAM. On one virtual machine (VM) I use for testing, with access to 4 GB of RAM, the zram virtual swap space is allocated to 3.8 GB. One old Dell I have contains 8 GB of RAM, and the zram is set to 7.6 GB. When RAM is reduced to 2 GB, Zram is reduced to 1.9 GB.
All physical and virtual hosts I have with more than 8 GB of RAM show exactly 8 GB of zram. This includes my primary workstation with 64 GB of RAM and other hosts with 16 GB or 32 GB of RAM.
Based on these few data points, I can draw the conclusion that the current default settings are for 8 GB of zram at most, and for zram to be 95% of RAM on hosts with 8 GB or less.
I have read a number of articles that mention other sizes for zram swap, even up to 100% of RAM, but those all seem to be theoretical rather than reality.
Your distribution may be different, but here are the actual zram swap allocations for Fedora and similar distributions:
-
**RAM ⇐ 8 GB:**0.95 × RAM -
**RAM > 8 GB:**8 GB
Be aware that the zram swap size algorithm is not based on any recommendations for the "best" swap size for any given real-world system or application. This zram swap allocation is a rather probabilistic approach to what should work well on a wide range of Linux hosts. However, the fact that the maximum zram swap size is configured for 8 GB and the fact that I have always recommended 8 GB as the maximum amount of traditional swap, I think I can say it's reflective of the optimum sizes for zram swap.
## Managing zram swap
Zram defaults are stored in the `/usr/lib/systemd/zram-generator.conf`
configuration file. The following is from one of my test VMs with 5097 GB of RAM allocated.
```
``````
# cat /usr/lib/systemd/zram-generator.conf
# This config file enables a /dev/zram0 device with the default settings:
# - size - same as available RAM or 8GB, whichever is less
# - compression - most likely lzo-rle
#
# To disable, uninstall zram-generator-defaults or create empty
# /etc/systemd/zram-generator.conf file.
[zram0]
zram-size = min(ram, 8192)
```
You can change the default Zram swap size in the last line of the `zram-generator.conf`
configuration file. I recommend against doing that, unless you can definitively show a reason for doing so, and test your results once you make any changes. Like many other configuration defaults in Linux, the zram ones have been well-tested and are appropriate for most use cases.
## Monitor zram
The zramctl utility can be used to view the current state of zram.
```
``````
# zramctl
NAME ALGORITHM DISKSIZE DATA COMPR TOTAL STREAMS MOUNTPOINT
/dev/zram0 lzo-rle 4.8G 4K 80B 12K 4 [SWAP]
```
The traditional `swapon`
command can also be used to view swap including zram used as swap:
```
``````
# swapon --show
NAME TYPE SIZE USED PRIO
/dev/zram0 partition 4.8G 0B 100
```
One thing to be aware of is that `zramctl`
does not report on zram when it contains no data, so the results contain null output. Tools like `lsblk`
, `swapon`
, `top`
, `free`
, `htop`
, and so on, do show zram even when it contains no data.
## Deactivate zram
The `swapoff -a`
command turns off `zram`
swap as well as traditional HDD or SSD storage used as swap. The `swapon -a`
command does not show zram when it is empty. Use `zramctl /dev/zram0`
instead.
```
``````
# swapon --show
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 120G 0 disk
├─sda1 8:1 0 1G 0 part /boot/efi
├─sda2 8:2 0 1G 0 part /boot
└─sda3 8:3 0 118G 0 part
├─vg01-root 253:0 0 10G 0 lvm /
├─vg01-swap 253:1 0 3G 0 lvm [SWAP]
├─vg01-usr 253:1 0 30G 0 lvm /usr
├─vg01-home 253:2 0 10G 0 lvm /home
├─vg01-var 253:3 0 30G 0 lvm /var
└─vg01-tmp 253:4 0 10G 0 lvm /tmp
sr0 11:0 1 1024M 0 rom
zram0 252:0 0 0B 0 disk
# zramctl
#
# zramctl /dev/zram0
NAME ALGORITHM DISKSIZE DATA COMPR TOTAL STREAMS MOUNTPOINT
/dev/zram0 lzo-rle 0B 0B 0B 0B 4
```
Note that `/dev/zram0`
doesn't show up in these commands as swap space until it's being used for that purpose. This caused me some confusion until my experiments showed it to be the case.
## Creating Zram Swap
Zram itself has been around for about 20 years, but has only been in use as swap space on some distributions for the last year or two. The current Linux installation on some or all of your hosts may not have been created with zram for swap. If that's the case, it can be easily remedied.
For Fedora 32, the last release prior to the default use of zram for swap, it only takes three easy commands.
First, verify the presence of the `zram-swap.service`
file, installed as part of the `zram`
RPM package.
```
``````
# systemctl status zram-swap
● zram-swap.service - Enable compressed swap in memory using zram
Loaded: loaded (/usr/lib/systemd/system/zram-swap.service; disabled; vendor preset: disabled)
Active: inactive (dead)
```
Next, install the `zram-generator-defaults`
and `zram-generator`
packages.
```
````# dnf install zram-generator-defaults zram-generator`
Enable and start the zram-swap service:
```
``````
# systemctl enable zram-swap.service
# systemctl start zram-swap.service
```
And then verify that `zram0`
exists, and is being used as swap space:
```
``````
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 120G 0 disk
├─sda1 8:1 0 2G 0 part /boot
└─sda2 8:2 0 118G 0 part
├─vg01-root 253:0 0 10G 0 lvm /
├─vg01-swap 253:1 0 3G 0 lvm [SWAP]
├─vg01-usr 253:2 0 35G 0 lvm /usr
├─vg01-tmp 253:3 0 15G 0 lvm /tmp
├─vg01-var 253:4 0 35G 0 lvm /var
└─vg01-home 253:5 0 20G 0 lvm /home
sr0 11:0 1 1024M 0 rom
zram0 252:0 0 7.5G 0 disk [SWAP]
```
## Improve swap with zram
That's all there is to it. It was easy with Fedora. Different distributions will likely be just as easy, with some possible different details in the package names and commands. Give zram swap a try on your computer. In my next article, I'll demonstrate some further zram options.
## Comments are closed. |
15,489 | 开源代码评审的十个通用步骤 | https://opensource.com/article/22/10/code-review | 2023-01-29T14:08:49 | [
"代码评审"
] | https://linux.cn/article-15489-1.html | 
>
> 只要你遵循这些通用流程,代码评审并不可怕。
>
>
>
你是否需要在你还没有完全理解整个项目时就对代码进行评审?抑或你避开了评审,以免让你看起来不知道如何进行。
本篇文章想要告诉你一个更好的方法。<ruby> 代码评审 <rt> code review </rt></ruby> 并不需要你知道所有事情。实际上,就我个人经验而言,这种情况非常普遍。
我还记得作为实习生加入 <ruby> 红帽 <rt> Red Hat </rt></ruby> 的时候,被要求参与代码评审。我们当时采取的是 +1 或 -1 的投票系统,而我在一开始的时候常常踌躇于该如何评审。我发现我会问自己,如果我对于一处改动给予了 +1,而别人却投了 -1,我是不是看起来很蠢?
如果你对一处改动投了 +1,而别人投了 -1,这又意味着什么呢?答案是不意味任何事!你可能只是漏掉了一处别人注意到的细节。这不意味着世界末日。这也是为什么我们会用投票系统。正如同所有开源项目一样,代码合并是一项协同工作。
最近,我接到了太多的代码评审工作,以至于我几乎做不过来。我同时也注意到,参与评审的贡献者数量正在稳步减少。
出于这个原因,我想要写一篇文章阐述我对代码评审的个人观点。在这篇文章里,我会分享一些诀窍与技巧。我将会向你展示几个用来问自己的问题,以及在评审代码时需要注意的一些地方。
### 代码评审的目的是什么?
你是否曾写过一个非常简单的补丁?你认为它是如此微不足道,不需要审查。或许你直接就合并了它。直到晚些时候,你意识到你犯了个错误,一个明显的或是愚蠢的错误,比如错误的缩进,比如几行重复的代码而不是调用函数(是的,这些都是经验之谈!)。
如果有其他人来审查代码,就会发现这些东西。
代码评审的一个目的便是为你带来一双新的眼睛,从新的视角看待你要尝试解决的问题。这种新的背景也正是为什么代码评审至关重要。
你可能认为你必须是一个语言专家,才能审查别人的代码、项目,或两者。让我来告诉你一个所有代码评审者都想跟你说的秘密吧:大错特错!你并不需要完全理解该项目或者编程语言,就可以为一个改动提供全新的视角。下面,我将向你展示代码评审的通用流程。
### 代码评审的通用流程
这是我的代码评审流程,拆分成了几个要点。这个流程包含了我会问自己的一些问题,以帮助我专注于代码的变化以及其后果。你不需要严格依照这个顺序来进行评审。如果有任何原因导致你无法执行其中的某一步,跳过那一步就好。
#### 1、理解改动,它想要解决的问题,以及为什么要这么做
为什么需要改动的解释以及任何相关背景都应该被放在 <ruby> 提交 <rt> commit </rt></ruby> 信息里。如果没有,请要求提供,并请投 -1 直到相关信息被提供。
改动想解决的问题需要被解决吗?它是项目应当关注的问题,还是与项目完全无关?
#### 2、你会如何实现解决方案?它会不一样吗?
在这个时候,你应该已经知道代码改动是为了什么。换做是你会怎么做?在进一步对改动进行细节评审前,先思考这个问题。如果你想出了一个不一样的解决方案,并且你认为你的方案更好,在评审中提出来。你不需要投 -1;去问问作者为什么没有往那个方向走,看看这次讨论会把你们带向何方。
#### 3、运行有改动和没有改动的代码
我通常会在代码中设置几个断点,运行代码并检查新代码是如何与其余部分互动的。
如果你无法运行整个代码,试着将带有新代码的函数复制到一个新的本地文件,模拟输入数据,然后运行。这在你不知道怎么运行整个项目,或者无法接触到运行所需的特殊环境时很有帮助。
#### 4、新代码会破坏任何东西吗?
我是说,任何东西。想一想可能的后果。
以一个新的命令行选项为例,它会总是被目标所接受吗?
是否存在这样一种情况,使得新选项无法被接受或是会与其他东西起冲突?
或许新代码是导入了新的东西。那么这个新的库,以及可能的新的依赖关系,能够在老版本或者项目的运行系统中被找到吗?
安全方面呢?新的依赖足够安全吗?你至少可以在网上快速地搜索一下。还有,注意一下控制台日志里的警告。有的时候在同一个库里也可以找到更安全的函数。
#### 5、新代码是否有效?
你刚刚确认了被提出的解决方案大概是正确的。现在该检查代码本身了。你需要关注代码的有效性和必要性。
检查新代码的风格。它与项目的代码风格相匹配吗?任何开源项目都(应该)有一份文档告知(新)贡献者项目所遵循的风格和优秀实践。
比如说,OpenStack 社区的所有项目都有一份 HACKING.rst 文件。你经常也能找到一份[新贡献者指南](https://docs.openstack.org/tempest/latest/contributor/contributing.html)包含所有必须知道的信息。
#### 6、确认所有新增的变量和导入都被使用
你正在评审的代码常常已经过多次迭代,有的时候代码的最终版本与初始版已迥然不同。所以我们很容易忘记一些在历史版本中加入的变量与引用。自动化检测通常会用到 lint 工具,类似 Python 中的 [flake8][12]。
(LCTT 译注:[lint](https://codedocs.org/what-is/lint-software) 指编程中用来发现代码潜在错误和约束代码风格的工具,起源于 C 语言编程中的静态分析工具 `lint`。“lint” 本意为衣服上积累的绒毛与灰尘,“lint” 的取名寓意则在于捕捉编程时产生的“绒毛与灰尘”)
(LCTT 校注:我建议,“Lint” 工具可以翻译为 “代码清理” 或 “代码清洁” 工具。)
你可以在不声明新变量的情况下重写代码吗?通常情况下你可以,但问题是这样是否更好。这会带来什么益处吗?我们的目标不是要创造尽可能多的单行代码,而是写出高效且易读的代码。
#### 7、新的函数和方法是否必要?
项目里的别的地方是否存在可以被复用的功能类似的函数?确保避免重新发明轮子以及重新实现已经被定义的逻辑永远都是值得的。
#### 8、有单元测试吗?
如果补丁增加了新的函数或者在函数内添加了新的逻辑,它也应该附带对应的单元测试。新函数的作者总是比别人更适合写该函数的单元测试。
#### 9. 验证重构
如果这次提交对现有代码进行了重构(它可能重命名了某个变量,或者是改变了的变量的作用域,或者是通过加减参数来改变函数的足迹,又或者是删去了某个东西),问一问你自己:
* 这个可以被删除吗?它会影响到稳定分支吗?
* 所有出现的地方都删掉了吗?
你可以利用 [grep 命令](https://opensource.com/downloads/grep-cheat-sheet) 来查找。你不会相信有多少次我投 -1 就是因为这个。这是一个任何人都会犯的简单错误,也正因如此任何人都可以发现它。
提交的所有者很容易忽略这些事情,这完全可以理解。我也犯过很多次这种错误。我最终发现问题的根源在于我太急于提出评审,以至于我忘记了对仓库进行整体检查。
除了对项目仓库的检查外,检查其他代码用户也十分必要。如果有别的项目导入了这个项目,它们可能也需要进行重构。在 OpenStack 社区中,我们有对应的工具来查询别的社区项目。
#### 10、项目文档是否需要做出更改?
你可以再一次使用 [grep 命令](https://www.redhat.com/sysadmin/how-to-use-grep) 来检查在项目文档中是否提到了相关的代码改动。用常识来判断这次改动是否需要被收入文档以告知最终用户,还是只是一个不会影响用户体验的内部变化。
#### 额外提示:考虑周到
当你在评审完新代码后提出建议或评论时,要考虑周到,反馈准确,描述详尽。如果有你不理解的地方就发出提问。如果你认为代码存在错误,解释你的理由。记住,如果作者不知道什么地方出了问题,他们就无法修复它。
### 最后几句
唯一的坏评审是没有评审。通过评审和投票,你提供了你的观点并为此投票。没有人指望你来做出最终决定(除非你是核心维护者),但是投票系统允许你提供你的观点和意见。相信我,补丁所有者会很高兴你这么做了的。
你能想到别的要点来给出好的评审吗?你是否有我不知道的特殊技巧?在评论中分享它们吧!
---
via: <https://opensource.com/article/22/10/code-review>
作者:[Martin Kopec](https://opensource.com/users/martin-kopec) 选题:[lkxed](https://github.com/lkxed) 译者:[yzuowei](https://github.com/yzuowei) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Have you ever found yourself in a situation where you needed to do a code review but didn't fully understand the project? Maybe you did not review it to avoid looking like you didn't know what you were doing.
This article assures you that there's a better way. You don't need to know everything to provide a code review. In fact, based on my experience, that's quite common.
I remember when I joined Red Hat as an intern and was asked to help with code reviews. We used a system of +1 or -1 votes, and I was initially very hesitant to weigh in. I found myself asking whether when I gave a +1 on a change but then someone else voted -1, would I look foolish?
What does happen if someone votes -1 on a change you've vote +1? The answer is nothing! You might have missed a detail that the other person noticed. It's not the end of the world. That's why we have this voting system. Like the rest of open source, merging code is a collaborative effort.
Lately, I've been so inundated with code reviews that I can hardly keep up with them. I also noticed that the number of contributors doing these reviews steadily decreased.
For this reason, I'm writing about my point of view on writing a code review. In this article, I'll share some helpful tips and tricks. I'll show you a few questions you should ask yourself and a few ideas of what to look for when doing a code review.
## What is the purpose of a code review?
Have you ever written a really simple patch? Something you think is so trivial that it doesn't require a review? Maybe you merged it straight away. Later, it turns out there was a mistake, something obvious or silly, like the wrong indentation or a few duplicated lines of code instead of a function call (yes, I'm speaking from experience!).
*A code review by someone else would have caught these things.*
The point of a code review is to bring a fresh pair of eyes with a new perspective on the problem you're trying to solve. That new context is exactly the reason a code review is crucial.
You may think that you must be an expert in the language to review someone else's code, the project, or both. Here's a secret all code reviewers want you to know: That's wrong! You don't need to fully understand the project or the language to provide a fresh perspective on a change. There's a universal process of code review.
## The universal process of a code review
Here's my process for code review, grouped into a couple of points. The process provides questions I ask myself to help me focus on a code change and its consequences. You don't need to go in this specific order. If there's a step, you can't execute for any reason, just move to another step.
## 1. Understand the change, what it's trying to solve, and why
The explanation of why the change is needed and any relevant context should be in the commit message. If it isn't, request it and feel free to -1 until it's provided.
Is it something that needs to be solved? Is it something the project should focus on, or is it completely out of scope?
## 2. How would you implement the solution? Would it be different?
At this point, you know what the code change is about. How would you have done it? Think about this before reviewing the change in detail. If the solution you have in mind is different from the one you're reviewing, and you think it's better, bring that up in the review. You don't need to -1 it; just ask why the author didn't go in this direction and see how the discussion evolves.
## 3. Run the code with and without the change
I usually put a few breakpoints into the code, run it, and inspect how the new code interacts with the rest.
If you can't run the whole code, try to copy the function containing the new code to a new local file, simulate the input data, and run that. This is helpful when you either don't know how to run the whole project or when it requires a specific environment to which you don't have access.
## 4. Can the new code break anything?
I mean, really anything. Think about the consequences.
In the case of a new command-line option, will it always be accepted by the target?
Can a situation occur when the option wouldn't be accepted or when it could conflict with something?
Maybe it's a new import. Is the new library, and possibly a new dependency, available in the older releases or systems you ship the project for?
What about security? Is the new dependency safe to use? The least you can do is run a quick Internet search to find out. Also, look for warnings in the console log. Sometimes there are more secure methods within the same library.
## 5. Is the code effective?
You've determined that the proposed solution is probably correct. Now it's time to check the code itself, its effectiveness, and its necessity.
Check the style of the new code. Does it match the style of the project? Any open source project has (or should have) a document informing (new) contributors about the styles and good practices the project follows.
For instance, every project in the OpenStack community has a HACKING.rst file. There's often also [a guide for new contributors](https://docs.openstack.org/tempest/latest/contributor/contributing.html) with all the must-know information.
## 6. Check that all new variables and imports are used
Often, there have been many iterations of the code you're reviewing, and sometimes the final version is very different from when it started. It's easy to forget an import or a new variable that was needed in a former version of the new code. Automation usually checks these things using linting tools like [flake8](https://opensource.com/article/19/5/python-flake8) in the case of Python code.
Can you rewrite the code without declaring new variables? Well, usually, yes, but the question is whether it's better that way. Does it bring any benefit? The goal isn't to create as many one-liners as possible. The goal is to write code that is both efficient and easy to read.
## 7. Are the new functions or methods necessary?
Is there a similar function that can be reused somewhere in the project? It's always worth helping to avoid reinventing the wheel and re-implementing logic that's already been defined.
## 8. Are there unit tests?
If the patch adds a new function or new logic in a function, it should also include new unit tests for that. It's always better when the author of a new function also writes unit tests for it.
## 9. Verify refactoring
If the commit refactors existing code (it renames a variable, changes variable scope, changes the footprint of a function by adding or removing arguments, or removes something), ask yourself:
- Can this be removed? Will it affect the stable branch?
- Are all the occurrences deleted?
You can use the [grep command](https://opensource.com/downloads/grep-cheat-sheet) to find out. You wouldn't believe how many times I've voted -1 just because of this. This is a simple mistake that anyone can make, but that also means anyone can uncover it.
The owner of the commit can easily overlook these things, which is totally understandable. It's happened to me many times too. I'd finally figured out the root of the problem I'd been fixing, so I was in a rush to propose the review, and then I forgot to check the whole repo.
Apart from the project's repository, sometimes it's also necessary to check other code consumers. If some other project imports this one, they may need refactoring, too. In the OpenStack community, we have a tool that searches across every community project.
## 10. Does project documentation need to be modified?
Again, you can use the [grep command](https://www.redhat.com/sysadmin/how-to-use-grep) to check whether the project documentation mentions anything related to the code change. Apply common sense to determine whether a change needs to be documented for end users or it's just an internal change that doesn't affect user experience.
## Bonus tip: Be considerate
Be considerate, precise, and descriptive if you make a suggestion or comment on something after you've reviewed the new code. Ask questions if you don't understand something. If you think the code is wrong, explain why you think so. Remember, the author can't fix it if they don't know what's broken.
## Final words
The only bad review is no review. By reviewing and voting, you provide your point of view and vote only for that. Nobody expects you to give the final yes or no (unless you're a core maintainer!), but the voting system allows you to provide your perspective and opinion. A patch owner will be glad you did it, trust me.
Can you think of any other steps for a good review? Do you have any special technique different from mine? Let us all know in the comments!
## Comments are closed. |
15,490 | GNOME 的研究报告称 90% 以上的系统都安装了 Flatpak | https://news.itsfoss.com/gnome-research-report/ | 2023-01-29T15:15:51 | [
"GNOME",
"Flatpak"
] | https://linux.cn/article-15490-1.html |
>
> GNOME 的调查数据揭示了一些令人感兴趣的用户偏好。这是否会影响 GNOME 在不久的将来的开发决策?让我们拭目以待。
>
>
>

在 2022 年 8 月,GNOME 开发了 [一个工具](https://news.itsfoss.com/gnome-improve-tool/),让用户可以匿名提供关于他们的系统配置、扩展和 GNOME 调整的设置。
这是为了**帮助 GNOME 深入了解**用户的偏好,并在分析数据的基础上做出更好的决定。
GNOME 设计团队的成员 [Allan Day](https://twitter.com/allanday) 在最近的一篇博文中分享了收集的数据。它包含了一些有趣的洞察和发现。
让我带你了解一下:
### 研究报告的发现
本研究报告包括来自 2,517 个用户的数据,这些用户的硬件和软件配置各不相同。
>
> ? 这些数据是使用 [gnome-info-collect 工具](https://gitlab.gnome.org/vstanek/gnome-info-collect/) 从向 GNOME 提供数据的人那里获得的,并不代表 GNOME 的全部用户。
>
>
>
最初,他们收到了 2,560 个回复,但由于一些数据没有来自使用 GNOME 的系统或来自虚拟机,他们不得不从数据集中删除一些。
它包含什么?它含有匿名的非敏感数据指标,显示了用户是如何设置他们的系统的。
>
> ? 这对 GNOME 团队来说可以有很大的用处,他们现在可以使用这些数据来做出设计和开发的决定。
>
>
>
其中一个引起我们注意的数据指标是在他们的 GNOME 系统上使用 Flatpak 的人的百分比。
**超过 90% 的系统都安装了 Flatpak。**
在 2517 个用户中,有高达 2344 个用户在他们的 GNOME 系统上安装了 Flatpak。其中 2,102 人完全启用了它。
在这样一个小的数据集中,这是一个巨大的数字! ?
关于这一点,Allan 有这样的补充说明:
>
> Flatpak 和 Flathub 对 GNOME 的战略方向至关重要,所以了解它们的采用程度是很有用的。这种采用程度也与 GNOME 的软件应用设计有关。
>
>
>
除此之外,一些关键的收获包括:
* 最常用的默认网页浏览器是 Mozilla Firefox。
* 在使用 GNOME 的人中,最常用的发行版是 Fedora。
* 谷歌是配置了在线账户的用户的首选账户。
* GIMP 是安装在 GNOME 上最受欢迎的应用程序之一,紧随其后的是 VLC。
* 83% 的用户至少启用了一个 GNOME 扩展。
我建议你通过该 [研究报告](https://blogs.gnome.org/aday/2023/01/18/gnome-info-collect-what-we-learned/) 来获得更深入的了解。
### 这是否有助于改善 GNOME 的体验?
收集这些数据是为了通过分析和提供给设计和开发团队来改善桌面体验。
然而,收集到的数据仍然相当有限,可能无法代表大多数的 GNOME 用户。
为了解决这个问题,博文中提到:
>
> 总的来说,这些数据对于 GNOME 项目应该专注于哪些功能给出了一些有力的提示。它也提供了关于哪些功能不应该被优先考虑的证据。需要记住的是,虽然我们在这里有关于一些 GNOME 用户做出的决定的证据,但这些数据并没有让我们深入了解为什么他们会做出这样的决定。
>
>
>
GNOME 团队希望在根据这些数据做出决定时保持谨慎。而且,像这样的调查应该能让他们更好地了解用户的偏好,并把重点放在基本层面上更重要的东西上。
当然,不可能照顾到每一种类型的用户。但是,只要基本面得到了照顾,桌面体验最终应该得到改善。
你对这些发现有什么看法?欢迎在下面的评论中分享你的想法。
---
via: <https://news.itsfoss.com/gnome-research-report/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

In **August 2022**, GNOME developed [a tool](https://news.itsfoss.com/gnome-improve-tool/) that let users provide anonymous insights about their system configuration, extension, and GNOME-tuned settings.
This was meant to **help GNOME learn** more about its users' preferences and to make better decisions based on analyzing the data.
[Allan Day](https://twitter.com/allanday?ref=news.itsfoss.com), a member of the GNOME design team, shared the collected data in a recent blog post. It contains some interesting insights and findings.
Let me take you through it.
## Research Report Findings
The research report consists of **data from 2,517 users** across varying hardware and software configurations.
[gnome-info-collect tool](https://gitlab.gnome.org/vstanek/gnome-info-collect/?ref=news.itsfoss.com), and does not represent the whole user base of GNOME.
Initially, they had received **2,560 responses**, but they had to remove some from the dataset due to them not using a GNOME installation or being on a virtual machine.
**What does it contain?: **It has anonymized non-sensitive data metrics that show how users were setting up their systems.
**great use to the GNOME team**, who can now use this data to make design and developmental decisions.
One such data metric that caught our eye was the **percentage of people using Flatpak** on their GNOME system.
**Over 90% of systems had Flatpak installed.**
Of the 2,517 users, a whopping 2,344 users had Flatpak installed on their GNOME system. With 2,102 of them having it fully enabled.
That is a huge number in such a small data set! 🤯
On this, Allan had this to add:
Flatpak and Flathub are both important to GNOME’s strategic direction, so it is useful to know the extent of their adoption. This adoption level is also relevant to the design of GNOME’s Software app.
**Other than that, some key takeaways included:**
- The most used default web browser was
**Mozilla Firefox**. - The most used distro among the participants with GNOME was
**Fedora**. **Google**was the account of choice for users using the online account configuration feature.**GIMP**was one of the most popular apps installed on GNOME, followed closely by**VLC**.**83%**of users had at least one**GNOME extension**enabled.
I suggest you go through the [research report](https://blogs.gnome.org/aday/2023/01/18/gnome-info-collect-what-we-learned/?ref=news.itsfoss.com) to get an even more in-depth look.
## Will This Help Improve the GNOME Experience?
Collecting this data was to improve the desktop experience by analyzing it and providing it to the design and development teams.
However, the data collected is still quite limited and may not represent the majority of GNOME users.
To address that, the blog post mentions:
Overall, the data gives some strong hints about which features should be concentrated on by the GNOME project. It also provides evidence about which features shouldn’t be prioritized.
It needs to be remembered that, while we have evidence here about some of the decisions that some GNOME users are making, the data doesn’t give us much insight into why they are making the decisions that they are.
The GNOME team wants to be cautious about making decisions based on this data. And, surveys like these should give them a better understanding of user preferences and focus on what's more important on a fundamental level.
Of course, it is impossible to cater to every type of user. But, as long as the fundamentals have been taken care of, the desktop experience should eventually improve.
*💬 What are your thoughts on these findings? Feel free to share your thoughts in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,492 | 关于开源,你需要知道些什么 | https://opensource.com/article/22/11/get-started-open-source | 2023-01-30T11:09:38 | [
"开源"
] | https://linux.cn/article-15492-1.html | 
>
> 一份用简单直白的语句来解释开源的新手指南。
>
>
>
要是你想要(或需要)知道 [开源](https://opensource.com/resources/what-open-source) 的意思究竟是什么。我会介绍开源的一些基础,无论你是对项目贡献感兴趣,还是在想要融入的新工作圈子里总是听到这个名词,因为这个词总是被人不断的提起。
我坦白,我这个人没什么技术经验,在极具技术性的开源社区中从事着内容设计的边缘工作。考虑到我原来的背景是营销与传播,我决定换工作时感觉就像离了水的鱼儿。[Git](https://opensource.com/resources/what-is-git)、数据科学、软件的来龙去脉……直到一年后的今天,我依然感到难以消化。
但这正是为什么我要写这篇文章。我想要让开源变得不那么令人生畏。毕竟,开源的中心是一个支持型的学习社区 —— 这个社区对所有人开放,无论你是否有技术经验。
我会从基础中的基础开始。
### 什么是开源?
在此声明,业界对开源的定义可以在 <ruby> <a href="https://opensource.org/osd"> 开放源代码促进会 </a> <rt> Open Source Initiative </rt></ruby> 的网站找到。
然而,大众对“开源”软件的认知通常为它不用花钱,它的源代码是公开的,任何人都可以对其贡献,你可以重新发布它或者用它做任何你想做的事。
这里面有些是真的,而有些则属于常见的误解,其中之一就是关于花费。
#### 开源只要 0 元
这是真的吗?大部分情况下是,但不是所有情况。开源软件的本质在于代码的公开性,所以获取软件本身确实不需要花费。但是,依赖开源项目营利的公司也确实存在。但如果软件不需要花钱,开源公司又是如何生存的?他们该如何盈利?
拥有“免费产品”这个概念本身是反直觉的。但你要知道:一个公司不一定要靠出售软件来赚钱,它也可以从产品的管理,数据的储存,以及对客户的支持中获利。
很多公司都采用了订阅模式,他们提供客户支持服务以帮助客户解决软件问题并为客户解答疑惑。数据储存也并非免费,这也是能为公司带来收入的另一领域。从这个角度来说,在销售的“产品”不是软件,而是订阅服务。
* **开源代码是公开访问的**:这是真的吗?是的,永远都是。“开源”一词的先决条件正是这份公开性。源代码必须允许被查看、使用、修改和重新发布。
* **你可以用这份代码做任何你想做的事**:这是真的吗?依情况而定。许可证条款会对你对代码的使用方式作出限制,但你通常都可以用代码做你想做的事。无论是调整该项目以满足特殊需求,还是以此为基础做些别的,开源软件允许你和其他所有人对其修改。
* **任何人都可以贡献开源项目**:这是真的吗?是的,但有限制。所有有 [合适技能](https://opensource.com/life/16/1/8-ways-contribute-open-source-without-writing-code) 的人都可以贡献开源。但是,这不意味着所有的贡献都会被接受和采纳。
比如说,你对一个目标是对地球上所有的鸟类进行分类的项目感兴趣。你恰好很喜欢恐龙,特别是那些最终进化成如今的鸟类的恐龙。于是,你为所有最像鸟类的恐龙提交了条目。项目所有者在看到这些后可能会想:“不错,这都是些很棒的史前鸟类。”但他们也可能会认为:“嗯……这些恐龙看起来像鸟,但他们还不是鸟,因此他们不属于鸟类百科。”
幸运的是,项目里的工作通常有法可依。开源项目通常有着贡献指南和行为准则,所以你不用担心你会加入什么使得项目脱轨的东西。
### 为什么选择开源呢?
那么,在众多贡献之后(如果这些贡献完成的话),为什么人们愿意免费赠送他们的软件?如果有那么多人为此付出了时间与精力,他们为什么不能联合起来为软件明码标价?
这个问题有很多回答。我在这里给出了一些:
* 创业是艰难的,如果你开发的项目展现不出赚钱的潜力则尤其如此。召集一群志同道合的人,没有承诺也没有对薪水的期望,相对而言要简单得多。
* 大部分开源社区的成员对软件的改进或者实现感兴趣,但他们没有时间或者不愿意将项目作为他们的全职工作。有时候开源代表的是热情驱动的项目、极客组成的团体,还有凝聚众人智慧对恼人问题的解决方案。
* 围绕各种规模的开源项目形成的团体促进了支持型社区的成形,在这里贡献者与旁观者都可以练习他们的技能,改进他们常用的软件,互教互学,并为发声被听到而感到振奋。很多开源社区本质上就是高度集中的线上爱好者俱乐部。
### 我该如何参与呢?
现在你可能会问你自己:“我知道了这些信息又可以做些什么呢?我能贡献开源项目吗?如果我不够优秀的话该怎么办?”
不要害怕 —— 即便是 [新手](https://opensource.com/article/18/4/get-started-open-source-project) 也欢迎为开源项目做贡献。在与社区一起朝着更大的目标共同努力的同时,你也得到了一个磨练技能的绝佳机会。况且,正如我之前所说,最坏的情况也不过是你的提交不被“鸟类百科”所接受(而这也是因为项目的所有者看不到你对鸟类百科的愿景,那是一片关于鸟类知识的网络天地,鸟与他们的祖先在那里愉快地共存)。
你需要会写代码来贡献开源吗?与大众认知相违的是,[你不需要](https://opensource.com/article/22/8/non-code-contribution-powers-open-source)。项目“需要举全村之力”以兴旺,这意味着他们需要来自不同背景的人的贡献。视觉设计师、撰稿人、营销、评审、翻译、主题爱好者,甚至只是最终产品的用户,都是可贵的贡献者。他们不仅是帮忙搭建并改进了产品,他们也识别出了漏洞,提出了修改建议,为项目做出宣传,最终使得社区强大。
简单来说,不论你的背景是什么,经验有多少,只要你对开源或是某个特别的项目感兴趣,你几乎可以保证会被张开双臂欢迎。
### 现在就加入开源吧
还是不确定应该从哪开始?这里有些能帮助你的想法和资源:
* [Up For Grabs](https://up-for-grabs.net/?ref=hackernoon.com#/) 是一份“专门为新贡献者策划任务的开源项目清单。”这里很适合新贡献者们来寻找简单的初次 PR 机会,这次机会也能让你探寻你更喜欢哪种贡献。
* 来看看 GitHub 上的这份 [新手友好项目](https://github.com/MunGell/awesome-for-beginners) 列表吧。
* 如果你还是缺乏灵感,考虑一下[贡献](https://github.com/patternfly)(或一起“飞”) <ruby> 红帽 <rt> Red Hat </rt></ruby>的开放设计系统 [PatternFly](https://www.patternfly.org/v4/get-started/design)。
* LCTT 夹带私货:你还可以通过参与 LCTT 的翻译工作来首次体验如何参与开源,这几乎简单到你只需要懂一点点英文和一些热情,本文就是由开源贡献者翻译贡献而成的。入口在此: <https://linux.cn/lctt/>
---
via: <https://opensource.com/article/22/11/get-started-open-source>
作者:[Katie Edwards](https://opensource.com/users/kaedward) 选题:[lkxed](https://github.com/lkxed) 译者:[yzuowei](https://github.com/yzuowei) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | So you want (or need) to figure out what ["open source"](https://opensource.com/resources/what-open-source) really means. I'll cover the basics of open source, whether you're interested in contributing to a project or want to be in the loop at a new job where the term keeps getting thrown around.
Full disclosure: I am a person with little technical experience, working in the content-design fringes of a very technical open source environment. Given my background in marketing and communication, I felt like a fish out of water when I made this career switch. [Git](https://opensource.com/resources/what-is-git), data science, the ins and outs of software… It was, and still is a year later, a lot to comprehend.
But that's why I'm writing this piece. I want to help make open source a little less intimidating. After all, at the center of open source is a supportive learning community—built for everyone, technically experienced or not.
I'll start with the absolute basics.
## What is open source?
For the record, the industry definition of open source is available at the [Open Source Initiative](https://opensource.org/osd) site.
However, the popular perception of "open source" software is usually that it doesn't cost anything, the source code is accessible, anyone can contribute to it, and you can redistribute it or do whatever else you want with it.
Some of that is true, and some of it plays into a few common misconceptions, one of which is cost.
### Open source costs $0
Is it true? Usually, but not always. By nature of its code being publicly available, open source software can be obtained at no cost. However, for-profit companies do exist around open source projects. But if the software is available at no cost, how do open source companies even exist? How do they make money?
The concept of having a "free product" is counter-intuitive. But that's just the thing: A company doesn't have to sell software to profit from the management of products, storage of data, and customer support.
Many companies follow a subscription model, offering customer support in case of bugs or general confusion. Data storage isn't free, so that is another area where these companies can bring in income. In this regard, the "product" isn't the software; it's the benefit of a subscription.
**The source code is accessible**: Is it true? Yes, always. This accessibility is a prerequisite for adopting the term "open source." The source code must be available to view, use, modify, and redistribute.**You can do whatever you want with the code**: Is it true? It depends. Subject to licensing terms, there are some limitations on how you can use code, but you can generally use it however you'd like. Whether that means tweaking a project to fit a specific need or using it as the basis for something else, open source software is yours, and everyone else's, to modify.**Anyone can contribute to open source projects**: Is it true? Yes - within limits. Anyone with the[right skill set](https://opensource.com/life/16/1/8-ways-contribute-open-source-without-writing-code)can contribute to open source. However, that doesn't mean all contributions are always accepted and implemented.
For example, say you're interested in a project where the end goal is a catalog of all the types of birds in the world. You're really into dinosaurs, specifically dinosaurs that may have eventually evolved into modern-day birds. So, you contribute entries for all of the most bird-like dinosaurs. The project owners could see this and think, "Sweet, those are some great prehistoric birds." However, they're also allowed to say, "Hmm, those dinosaurs are like birds, but they're technically not birds yet. They probably don't belong on Birdpedia."
Luckily, projects don't usually work under lawless conditions. Open source projects typically come with contribution guidelines and codes of conduct, so you don't have to worry about your additions flying off the rails.
## Why open source?
So, after all the contributions are made (if it's ever actually done), why would people give away their software for no cost? If so many people put their time and effort into creating something, why wouldn't they band together and slap a price tag on it?
This question comes with a lot of answers. Here are a few:
- Starting a business is hard, especially if the project you're working on doesn't form the strong foundation for a money machine. It can be easier to rally a bunch of like-minded people without commitments or the expectation of paychecks.
- Most open source communities consist of people interested in improving software or bringing it into existence but don't have the time or interest to commit to working full-time on a project. Sometimes open source represents passion projects, geek groups, and crowd-sourced solutions to annoying problems.
- The groups that form around open source projects of all sizes foster supportive communities where contributors and onlookers alike can practice their skills, improve software they regularly use, teach and learn from each other, and feel empowered to make their voices heard. Many open source communities are essentially hyper-focused online hobby clubs.
## Where do I get involved?
Now you may ask yourself, "But what do I do with this information? Can I contribute to open source projects? What if I'm not good enough yet?"
Never fear—even [beginners](https://opensource.com/article/18/4/get-started-open-source-project) are welcome to contribute to open source projects. It's a great way to hone your skills while working with a community towards a larger goal. And, as I talked about earlier, the worst that can happen is your changes aren't merged into Birdpedia (and that's because those product owners just can't see your vision of a Birdpedia where birds and their ancestors gleefully coexist in an online world of bird-related knowledge).
**[ Related read Why do we contribute to open source software? ]**
Do you have to know how to code to contribute to projects? Contrary to popular belief, [no, you don't](https://opensource.com/article/22/8/non-code-contribution-powers-open-source). Projects "take a village" to thrive, which means they need input from people of all different backgrounds. Visual designers, writers, marketers, reviewers, translators, subject matter enthusiasts, and even just users of the resulting product are all valuable contributors. Not only do they help build out and improve products, but they identify bugs, suggest improvements, spread the word about the project, and generally strengthen the community.
In short, no matter what your background or experience, if you're interested in open source or a specific project, you're nearly guaranteed to be welcomed with open arms.
## Get started with open source now
Still not sure where to begin? Here are some ideas and resources to get you started:
[Up For Grabs](https://up-for-grabs.net/?ref=hackernoon.com#/)is a "list of open source projects which have curated tasks specifically for new contributors." This is a great place to find an easy first PR opportunity, which is a great way to find out what kind of contributions you'll enjoy.- Check out this list of
[beginner-friendly projects](https://github.com/MunGell/awesome-for-beginners)on GitHub. - If you're still not feeling inspired, consider
[contributing](https://github.com/patternfly)to (or flying with)[PatternFly](https://www.patternfly.org/v4/get-started/design), Red Hat's open design system.
## 2 Comments |
15,493 | 给你的终端一个复古的外观 | https://www.debugpoint.com/cool-retro-terminal/ | 2023-01-30T15:42:54 | [
"终端",
"复古"
] | /article-15493-1.html |
>
> 想让你的终端有一个复古的外观?本指南将帮助你在 Linux 发行版中安装 Cool Retro Terminal 应用程序。
>
>
>

你有没有想过如何在你的 Linux 终端中模仿那些老式 CRT 显示器的外观?
那些 CRT 屏幕有自己的粉丝。如果你把苹果 2 或 IBM 3278 终端之类与今天的 4K 显示器显示相比较,它们的外观真的很酷。我并不是说 4K 显示器不好,但有时传统的显示器会让我们想起那些过去的日子。闲话少说。让我们开始安装这个应用程序。
### Cool Retro Terminal
该应用程序是自由开源的。它被称为 [cool-retro-term](https://github.com/Swordfish90/cool-retro-term)。它是轻量级的,有许多自定义选项,有预先设置的配置文件,如 Apple 2 等。它还能在你的终端中提供那些静态噪音和扫描线效果。很酷,不是吗?
它是用 Qt 构建的,需要 Qt 5.2 或更高版本。如果你使用的是最新的 Linux 发行版,在依赖性方面你应该没问题。

### 如何下载和安装 Cool Retro Terminal
Ubuntu、Linux Mint 和其他基于 Debian 的发行版:
使用下面的简单命令在你的 Ubuntu 和其他相关发行版中安装这个应用程序:
```
sudo apt install cool-retro-term
```
Arch Linux:
这个软件包在 Arch 用户仓库(AUR)中可用。如果你没有启用 AUR,请使用 [本指南](https://www.debugpoint.com/2021/01/install-yay-arch/) 启用它,然后使用以下命令来安装它:
```
pacman -S cool-retro-term
```
Fedora、RHEL 和其他相关发行版:
对于 Fedora 和其他相关的 Linux,使用下面的命令来安装这个应用程序:
```
sudo dnf install cool-retro-term
```
Appimage:
也有一个 AppImage 格式的独立的可执行程序,你可以直接下载并运行。不需要安装。按照下面的命令来做:
```
wget https://github.com/Swordfish90/cool-retro-term/releases/download/1.1.1/Cool-Retro-Term-1.1.1-x86_64.AppImage
chmod a+x Cool-Retro-Term-1.1.1-x86_64.AppImage
./Cool-Retro-Term-1.1.1-x86_64.AppImage
```
注意:在 GitHub 中,没有 1.2.0 以后的版本的 AppImage 构建版。
### 配置
安装完成后,你可以在应用程序菜单中找到终端应用程序 “Cool Retro Term”。那么,启动该应用程序并享受其中吧。
请记住,这覆盖你的 Linux 发行版中的默认控制台/终端应用程序。它是一个独立的控制台应用程序。
配置选项可以通过右键菜单访问。
上下文菜单给你提供了以下预设。然后你可以通过设置窗口对它们中的每一个进行颜色和外观设置的配置。例如,如果你想要更多的透明度、对比度或更多的噪音、环境光或闪烁。所有这些都可以从下面的设置窗口通过几个选项进行配置。
而且,你可以轻松地制作你自己的主题。


### 总结
Cool Retro Terminal 是一个用于 Linux 桌面的老式显示管终端,它可以让你体验到如同坐在复古终端前的感觉。你可能喜欢,也可能不喜欢,而且人们几乎不把它作为日常使用。但它仍然是一个漂亮的终端,可以时不时地体验一下,以摆脱平凡的终端。
你喜欢复古的外观吗?你最喜欢的主题是什么?请在下面的评论区告诉我。
---
via: <https://www.debugpoint.com/cool-retro-terminal/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,495 | Java 循环语句的简要指南 | https://opensource.com/article/23/1/java-loops | 2023-01-31T09:30:59 | [
"while",
"循环"
] | https://linux.cn/article-15495-1.html | 
>
> 无论你使用的是 `while` 循环、`do`/`while` 循环,还是无限循环,了解循环的工作原理对 Java 编程至关重要。
>
>
>
只要某些预定的条件为真,一个 `while` 循环就会执行一组任务。这被认为是一个控制结构,可以指导程序的流程。它是一种你可以通过定义一个条件来告诉你的代码要做什么的方法,它可以测试它,并根据它发现的情况采取行动。Java 中的两种 `while` 循环是 `while` 和 `do`/`while`。
### Java while 循环
`while` 循环的目的是对数据进行迭代,直到某个条件得到满足。要创建一个 `while` 循环,你需要提供一个可以测试的条件,然后是你想要运行的代码。Java 有几个内置的测试函数,其中最简单的是数学运算符(`<`, `>`, `==`, 等等):
```
package com.opensource.example;
public class Example {
public static void main(String[] args) {
int count = 0;
while (count < 5) {
System.out.printf("%d ", count);
count++;
}
}
}
```
在这个简单的例子中,条件是变量 `count` 小于 5。因为 `count` 被实例化为 0,然后在 `while` 循环的代码中增加 1,所以程序总共迭代了 5 次:
```
$ java ./while.java
0 1 2 3 4
```
在它进行第六次迭代之前,条件不再是真的,所以循环结束。
`while` 循环的条件语句是至关重要的。弄错了可能意味着你的循环永远不会执行。例如,假设你把 `count == 5` 作为条件:
```
while (count == 5) {
System.out.printf("%d ", count);
count++;
```
当你运行这段代码时,它的构建和运行都很成功,但什么也没有发生:
```
$ java ./while.java
$
```
循环被跳过了,因为 `count` 被设置为 0,而且在第一次遇到 while 循环的时候,它还是 0。循环从未开始,`count` 也从未被递增。
与此相反的是,当一个条件开始为真,并且永远不会为假时,这将导致一个无限循环。
### Java do while 循环
与 `while` 循环相似,`do`/`while` 循环在每次迭代结束时测试条件,而不是在开始时测试条件。有了这个循环,循环中的代码至少运行一次,因为没有进入的入口,只有退出的出口:
```
package com.opensource.example;
public class Example {
public static void main(String[] args) {
int count = 9;
do {
System.out.printf("%d ", count);
count++;
} while(count == 5);
}
}
```
在这个示例代码中,`count` 被设置为 9。循环重复的条件是 `count` 等于 5,但是 9 不等于 5。不过,这个检查要到第一次迭代结束时才进行:
```
$ java ./do.java
9
```
### Java 无限循环
无限循环,正如它的名字所示,永远不会结束。有时它们是被错误地创建的,但无限循环确实有一个有效的场景。有时你想让一个进程无限地继续下去(在功能上是无限的,因为你不能保证你需要它什么时候停止),因此你可能会把你的条件设置为不可能满足的东西。
假设你写了一个应用程序,在僵尸天启期间计算留在你附近的僵尸的数量。为了模拟需要多少个循环才能达到 0 个僵尸的不确定性,我的演示代码从操作系统中检索了一个时间戳,并将计数器(`c`)的值设置为从该时间戳得出的某个数字。因为这是一个简单的例子,你不会真的想陷入一个无限循环,这段代码倒数到 0,并使用 `break` 函数来强制结束循环:
```
package com.opensource.example;
public class Example {
public static void main(String[] args) {
long myTime = System.currentTimeMillis();
int c;
if ( myTime%2 == 0 ) {
c = 128;
} else {
c = 1024;
}
while(true) {
System.out.printf("%d Zombies\n", c);
// break for convenience
if ( c <= 0 ) { break; }
c--;
}
}
}
```
你可能要运行几次才能触发不同的僵尸总数,但有时你的程序会迭代 128 次,有时会迭代 1024 次:
```
$ java ./zcount.java
1024 Zombies
1023 Zombies
[...]
0 Zombies
```
你能说出为什么循环的终点是 0 而不是 -1 吗?
### Java 循环
循环使你能够控制程序的执行流程。迭代在编程中很常见,无论你使用 `while` 循环、`do`/`while` 循环还是无限循环,了解循环的工作原理都是至关重要的。
---
via: <https://opensource.com/article/23/1/java-loops>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A while loop performs a set of tasks for as long as some predefined condition is true. This is considered a control structure that directs the flow of a program. It's a way for you to tell your code what to do by defining a condition that it can test, and take action based on what it finds. The two kinds of while loops in Java are while and do while.
## Java while loop
A while loop is meant to iterate over data until some condition is satisfied. To create a while loop, you provide a condition that can be tested, followed by the code you want to run. Java has several built-in test functions, the simplest of which are mathematical operators (`<`
, `>`
, `==`
, and so on):
```
``````
package com.opensource.example;
public class Example {
public static void main(String[] args) {
int count = 0;
while (count < 5) {
System.out.printf("%d ", count);
count++;
}
}
}
```
In this simple example, the condition is that the variable `count`
is less than 5. Because `count`
is instantiated at 0, and then incremented by 1 in the code within the while loop, the program iterates a total of 5 times:
```
``````
$ java ./while.java
0 1 2 3 4
```
Before it can iterate a sixth time, the condition is no longer true, so the loop ends.
The conditional statement for a while loop is vital. Getting it wrong could mean that your loop never executes. For instance, suppose you had set `count == 5`
as the condition:
```
``````
while (count == 5) {
System.out.printf("%d ", count);
count++;
```
When you run the code, it builds and runs successfully, but nothing happens:
```
``````
$ java ./while.java
$
```
The loop has been skipped because `count`
was set to 0, and it's still 0 at the moment the while loop is first encountered. The loop never has a reason to start and `count`
is never incremented.
The reverse of this is when a condition starts as true and can never be false, this results in an infinite loop.
## Java do while loop
Similar to the while loop, a do while loop tests for the conditional at the end, not the beginning, of each iteration. With this, the code in your loop runs at least once because there's no gateway to entry, only a gateway to exit:
```
``````
package com.opensource.example;
public class Example {
public static void main(String[] args) {
int count = 9;
do {
System.out.printf("%d ", count);
count++;
} while(count == 5);
}
}
```
In this sample code, `count`
is set to 9. The condition for the loop to repeat is that `count`
is equal to 5. But 9 isn't equal to 5. That check isn't performed until the end of the first iteration, though:
```
``````
$ java ./do.java
9
```
## Java infinite loops
An infinite loop, as its name suggests, never ends. Sometimes they're created by mistake, but an infinite loop does have a valid use case. Sometimes you want a process to continue indefinitely (that's functionally infinite because you can't guarantee when you need it to stop), and so you might set your condition to something impossible to meet.
Suppose you've written an application that counts the number of zombies remaining in your neighborhood during a zombie apocalypse. To simulate uncertainty over how many loops are required to get to 0 zombies, my demo code retrieves a timestamp from the operating system and sets the value of the counter (`c`
) to some number derived from that timestamp. Because this is a simple example and you don't really want to get trapped in an infinite loop, this code counts down to zero and uses the `break`
function to force the loop to end:
```
``````
package com.opensource.example;
public class Example {
public static void main(String[] args) {
long myTime = System.currentTimeMillis();
int c;
if ( myTime%2 == 0 ) {
c = 128;
} else {
c = 1024;
}
while(true) {
System.out.printf("%d Zombies\n", c);
// break for convenience
if ( c <= 0 ) { break; }
c--;
}
}
}
```
You may have to run it a few times to trigger a different total number of zombies, but sometimes your program iterates 128 times and other times 1,024 times:
```
``````
$ java ./zcount.java
1024 Zombies
1023 Zombies
[...]
0 Zombies
```
Can you tell why the loops end at 0 and not at -1?
## Java loops
Loops give you control over the flow of your program's execution. Iteration is common in programming, and whether you use a while loop, a do while loop, or an infinite loop, understanding how loops work is vital.
## Comments are closed. |
15,496 | 《LCTT 术语词典》 | https://github.com/LCTT/TranslateProject/blob/master/Dict.md | 2023-01-31T13:13:00 | [
"LCTT",
"翻译"
] | https://linux.cn/article-15496-1.html | 
本文收录了 LCTT 自创和选用的翻译词汇。
为什么要自创翻译词汇?在翻译过程中,我们发现一些非缩写的英语术语沿袭使用了英语单词/短语,而没有得体的、公认的、正式的对应中文翻译。我们认为,中英文混杂是对原生语言的一种污染(英文缩写除外,这是为了减少冗长的语句),按照本地化的宗旨,应该对这些词汇进行翻译,并在必要时创造新的词汇。故此,我们在几年的翻译中,逐渐推敲和形成了一些新的译法,并在我们翻译的文章中使用和推广。
对这些译法,我们尽量遵循“信达雅”的原则。但鉴于水平所及,肯定会有所不足,虽然也有不断的调整和改进,但仍希望得到大家的反馈和指正。
我们采用的方法是:
* 音似:中文读音近似于英文原词
* 意近:中文字的意思接近英文原意
* 组词:根据上述两条组成新的词汇,以避免和原有词汇混淆
此外,需要说明的是,有些译法可能已经被其他人在别的地方更早提出,但限于我们的学识和搜索能力,并未发现和了解到,并非我们故意剽窃。
顺便说一句,2014 年对 “Shebang”(`#!`)一词翻译时,来自于 LCTT 早期重要贡献者 GOLinux 提出的 “[释伴](/article-3664-1.html)” 译法,是我们第一次创造新的翻译词汇,也是我们形成这样的想法的起点。
除了自创的翻译词汇外,这里还收录了一些选用的翻译词汇。有一些词汇存在多种译法,我们在翻译和使用过程中,采用了某个译法,在此列出以保持一致。
### F
#### Fork:复刻
Fork 行为/操作广泛用于进程管理、版本管理和软件衍生方面。此词汇也长期缺乏确定的译法。
此前,提议者对 Fork 给出了 “复刻” 的译法。基本意思是,根据上游/父本复制一份,然后在此基础上进行修改,从而形成“衍生品”。
有趣的是,我们发现 GitHub 的 [部分中文文档](https://docs.github.com/zh/actions/managing-workflow-runs/approving-workflow-runs-from-public-forks) 中也采用了此译法,不知道是不是受到了我们的影响。
* 提议者:wxy
* 首次链接:</article-7877-1.html>
### H
#### Here Document:现场文档
在编程领域,“here document” 是一个常见的术语,特指在脚本语言(如 Perl、Bash)中,能够直接在代码内部嵌入并处理一个数据块或文本串的技术。尽管传统上我们将它翻译为“嵌入式文档” 或不翻译,但这个译法似乎并不能完全地体现出原文的感觉和含义。
为了让这个概念变得更为直观和易理解,我们建议将 “here document” 翻译为 “现场文档”。“现场”相比于“嵌入式”,更好的传达了文档就在代码的当前位置,或代码“现场”的含义。这样的译法也与原文 “here document” 中 “here”(这里)的含义更为契合。我们希望这个译法能够在未来得到更广泛的使用和认可,让编程的世界因语言的精准而变得更美好。
PS., 该译法和解释得到了 ChatGPT 的建议和生成。
* 提议者:wxy
* 首次链接:</article-16298-1.html>
### L
#### Live:立付
Live 原意多指“现场”、“实时”,在计算机环境中使用时也多引用此意。但对它的翻译就颇费神,因为无论是在 Live Patch,还是更多见的 Live USB/CD、Live Session,其实都不好翻译为“现场”、“实时”。
提议者之前曾经尝试创造了新的“[临场](/article-12854-1.html)”词汇,但是感觉有些不够达意。经过推敲,提议者再次推荐使用“立付”,在照顾发音的同时,取其“立时交付”之意。这样,Live USB/CD 可以译做 “立付 USB/CD”,Live Session 可以译做 “立付会话”。
而对于 Live Stream,提议者建议依旧翻译为“直播”、“实时流”。对于 Live Patch,还是采用 “热补丁” 这样的意译。
* 提议者:wxy
* 首次链接(临场):</article-12854-1.html>
* 首次链接(立付):</article-15499-1.html>
#### Repo(Repository):代码仓库/软件仓库
Repository 主要用于两个场景,一个是用于版本管理的代码仓库,一个是用于分发软件/组件/制品的软件仓库。
鉴于两种场景的差异,建议在使用时,分别注明“代码仓库”或“软件仓库”,也可简称为 “代码仓”或“软件仓”。
### S
#### Shebang [ʃɪ'bæŋ]:释伴
Shebang(也称为 Hashbang)是一个由井号和叹号构成的字符序列(`#!`),出现在脚本文件的第一行的前两个字符,后跟解释器路径,如:`#!/bin/sh`,这通常是 Linux 中 shell 脚本的标准起始行。
长期以来,Shebang 都没有正式的中文名称。提议者将其翻译为:“释伴”,即解释伴随行的简称,同时又是 Shebang 的音译。(关于这个词汇的翻译,在下面的首次链接中有其它的建议和讨论。)
* 提议者:GoLinux
* 首次链接:</article-3664-1.html>
#### Shell :交互界面
Shell 是 Unix/Linux 等系统的 `sh`、`bash` 等命令行的接口程序,包括 DOS/Windows 的 `command.com`/`cmd.exe` 等其实也属于此类,只是通常不这样称呼。
这个词汇也是一个一直没有翻译而径直使用的计算机词汇。我们也没有见到(找到)合适的翻译。但是我们在 LCTT 译者 CanYellow 翻译的一篇文章中见到他将其翻译为 “交互界面”,我们认为这是一种好的翻译。
* 提议者:CanYellow
* 首次链接:</article-15469-1.html>
### 说明
此文档会根据建议不断更新,其固定地址为: <https://github.com/LCTT/TranslateProject/blob/master/Dict.md> ,欢迎大家提交议题或拉取请求来完善它。
| 200 | OK | You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
{{ message }}
This repository has been archived by the owner on Apr 9, 2024. It is now read-only. |
15,498 | 一个正在开发中的 ChatGPT GNOME 扩展 | https://news.itsfoss.com/chatgpt-gnome-extension-development/ | 2023-02-01T15:55:36 | [
"GNOME",
"ChatGPT"
] | https://linux.cn/article-15498-1.html |
>
> 你想要一个人工智能的 GNOME 桌面吗?下面这个扩展可以实现这个功能!
>
>
>

[ChatGPT](https://chat.openai.com) 是一个在当下十分流行的聊天机器人,它可以与用户进行互动,用户就像在对话一样。
最近,关于 ChatGPT 的新闻时常出现在人们的视野之中,有时是关于 ChatGPT 的坏消息。
不难看出,ChatGPT 有其两面性。事实上,对于任何人工智能的实现都同样如此。
一方面,ChatGPT 这一工具的巨大潜力给许多人留下了深刻的印象。但另一方面,因人们对它的滥用/误用,导致 ChatGPT 在科技界引起了轩然大波。
人们对 ChatGPT 滥用/误用太多了,以至于其创建者 [OpenAI](https://openai.com) 开发了一种工具来检测 ChatGPT 的使用情况,这个内容可以进一步访问 [此网页](https://news.itsfoss.com/openai-chatgpt-detection/)。
现在,我注意到在一个 Reddit 讨论中,一位开发人员提到了一些有趣的事情。
一个用户名为 [HorrorPills](https://github.com/HorrorPills) 的开发人员已经开始**为 ChatGPT 开发 GNOME 扩展**。
这听起来非常有趣,让我们继续来看看吧。
### 这个扩展仍在开发中:让我们持续保持关注吧!

这是一个 GNOME 桌面扩展,将 ChatGPT 添加到了桌面的 <ruby> 系统托盘 <rt> system tray </rt></ruby> 中。
现在,这个 GNOME 桌面扩展还处于未完成的状态,它已经具有了基本的功能,但仍存在一些错误。
正如它的开发者 [所说](https://www.reddit.com/r/linux/comments/10ay23v/comment/j46yp15/) 的那样:
你需要有一个 **ChatGPT 帐户**,才能使用这个扩展程序,并且需要用到你的键盘,才能进行定位,因为现在这个扩展的光标功能还有很多问题。
此外,这个扩展**对 GNOME 43 的支持也很不完整**,他们提供了一个临时的修复程序,并将这个进一步完善的任务添加到此扩展的后续开发中。
如果你喜欢的话,你可以**试试这个扩展**。你可以通过它的 [GitHub 仓库](https://github.com/HorrorPills/ChatGPT-Gnome-Desktop-Extension),来获取运行它所需的所有说明和文件。
它的开发人员还 [表示](https://www.reddit.com/r/linux/comments/10avlgs/comment/j4al4cg/):当这个扩展变得更加稳定时,他们会将这个扩展发布到 **GNOME 扩展** [网站](https://extensions.gnome.org) 上去。
此外,开发人员还 [透露](https://www.reddit.com/r/linux/comments/10avlgs/comment/j48uofo/):他们在未来可能会实现 **KDE Plasma 的 ChatGPT 扩展**。
---
via: <https://news.itsfoss.com/chatgpt-gnome-extension-development/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[chai001125](https://github.com/chai001125) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[ChatGPT](https://chat.openai.com/?ref=news.itsfoss.com) is a popular chatbot that can interact with its users as if they are having a conversation.
Recently, ChatGPT has been in the news, sometimes for the wrong reasons.
You see, there are two sides to the ChatGPT saga. In fact, for any artificial intelligence implementation.
On one side, the potential of this tool has impressed many. But on the other side, it has led to quite a ruckus in the tech world for its abuse/misuse.
So much so it has led its creator, [OpenAI](https://openai.com/?ref=news.itsfoss.com), to develop a tool to detect its use.
[Combatting Academic Dishonesty: OpenAI to Help Detect ChatGPT TextWe’re living in the age of AI already. To not make that worse, the makers of ChatGPT have decided to help detect text generated by the tool.](https://news.itsfoss.com/openai-chatgpt-detection/)

Now, I spotted a Reddit thread where a developer mentioned something interesting.
A developer who goes by the user handle '[HorrorPills](https://github.com/HorrorPills?ref=news.itsfoss.com)' has started working on a **GNOME extension for ChatGPT**.
This sounds interesting; let's take a look.
## Work in Progress: Let's Keep an Eye!
This is a GNOME desktop extension that adds ChatGPT to the system tray of your desktop.
In its current form, it is in a **very work-in-progress state**, with basic functionality and a few bugs here and there.
As [noted](https://www.reddit.com/r/linux/comments/10ay23v/comment/j46yp15/?ref=news.itsfoss.com) by the developer:
You will need an **existing ChatGPT account** to use this extension and your keyboard to navigate around it because the mouse cursor implementation is quite buggy.
Moreover, **support for GNOME 43 is also quite patchy**, with a temporary fix being provided and added to the to-do list in the development of this extension.
If you like, you can **give this extension a try**. It's available via its [GitHub repo](https://github.com/HorrorPills/ChatGPT-Gnome-Desktop-Extension?ref=news.itsfoss.com), with all the instructions and files required to run it.
The developer has also [said](https://www.reddit.com/r/linux/comments/10avlgs/comment/j4al4cg/?ref=news.itsfoss.com) that they will be making this available on the **GNOME extensions** [website](https://extensions.gnome.org/?ref=news.itsfoss.com) when the extension is more stable.
Furthermore, they have also [hinted](https://www.reddit.com/r/linux/comments/10avlgs/comment/j48uofo/?ref=news.itsfoss.com) at a possible **KDE Plasma implementation** in the future.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,499 | Fedora Media Writer:顶级的立付 USB 创建器 | https://www.debugpoint.com/fedora-media-writer/ | 2023-02-01T16:30:00 | [
"ISO",
"USB"
] | /article-15499-1.html |
>
> 关于安装和使用 Fedora Media Writer 从 Linux 和 Windows 创建立付 USB 的教程。
>
>
>

### Fedora Media Writer
社区和 Fedora Linux 团队开发并维护了 [Fedora Media Writer 应用](https://github.com/FedoraQt/MediaWriter)。这个应用可以将任何 ISO 镜像写入你的闪存盘(U 盘)中。此外,Fedora Media Writer 还有直接从 Fedora 镜像中下载 ISO 文件的功能,前提是你有一个稳定的互联网连接。
此外,它还为你提供了一个下载选项列表:比如官方版本、新兴版本、定制版和实验室版本的镜像。
不仅如此,你还可以使用这个灵巧的工具将任何其他 ISO 镜像写入你的闪存。它不总是需要 Fedora ISO。
虽然有其他流行的工具可以用来创建 <ruby> 立付 <rt> Live </rt></ruby> USB ,比如 [Etcher](https://www.debugpoint.com/2021/01/etcher-bootable-usb-linux/)、Ventoy 和 Rufus,但考虑到该团队是从主流 Fedora Linux 与贡献者一起开发的,你仍然可以尝试使用此程序。
>
> **LCTT 译注**:特此说明一下使用 “立付” 一词作为 “Live” 的中文翻译。
>
>
> Live 原意多指“现场”、“实时”,在计算机环境中使用时也多引用此意。但对它的翻译就颇费神,因为无论是在 Live Patch,还是更多见的 Live USB/CD、Live Session,其实都不好翻译为“现场”、“实时”。
>
>
> 提议者之前曾经尝试创造了新的“[临场](/article-12854-1.html)”词汇,但是感觉有些不够达意。经过推敲,提议者再次推荐使用“立付”,在照顾发音的同时,取其“立时交付”之意。这样,Live USB/CD 可以译做 “立付 USB/CD”,Live Session 可以译做 “立付会话”。
>
>
> 详见我们发布的[《LCTT 术语词典》](/article-15496-1.html)。
>
>
>
因此,综上所述,这里是 Fedora Media Writer 的快速功能亮点。
#### Fedora Media Writer 的功能摘要
* 适用于 Linux、Windows 和 macOS
* 直接下载 + 写入镜像到 USB 闪存
* 官方版本(Workstation、IoT、Server)下载
* 新兴版本(Silverblue、Kinoite)下载
* 定制版(KDE Plasma、Xfce 等)
* 实验室(Fedora Astronomy、Robotic 等)
* 可作为 Linux 发行版的 Flatpak 包
* 同时,可以将任何其他 ISO 镜像(非 Fedora)写入 U 盘。
* 能够格式化 U 盘,恢复 U 盘
* 基于 Qt
### 如何安装
#### Linux
Fedora Media Writer 以 Flatpak 的形式提供给 Linux 发行版。要在任何 Linux(如 Fedora、Ubuntu 或 Linux Mint)中安装它,请 [按照这个指南设置 Flatpak](https://flatpak.org/setup/)。
然后,点击下面的链接进行安装。这将启动你的 Linux 发行版的官方软件程序(如 <ruby> 发现 <rt> Discover </rt></ruby>应用、GNOME <ruby> 软件 <rt> Software </rt></ruby> 应用)。安装后,你可以通过应用程序菜单启动它。
>
> **[以 Flatpak 形式安装 Fedora Media Writer](https://dl.flathub.org/repo/appstream/org.fedoraproject.MediaWriter.flatpakref)**
>
>
>
#### Windows
如果你是一个计划迁移到 Linux(如 Fedora)的 Windows 用户,它是一个完美的工具。你需要从 GitHub 上下载 exe 安装程序(链接如下),并按照屏幕上的指示进行安装。
>
> **[用于 Windows 的最新安装程序(exe)](https://github.com/FedoraQt/MediaWriter/releases/latest)**
>
>
>
安装完成后,你可以从开始菜单启动它。
#### macOS
对于 macOS,你可以在上述链接中获取 dmg 文件。
>
> **[用于 macOS 的最新安装程序(dmg)](https://github.com/FedoraQt/MediaWriter/releases/latest)**
>
>
>
### 如何使用 Fedora Media Writer 在 Linux 中创建立付 USB
第一个页面给你两个主要选项。<ruby> 自动下载 <rt> Download automatically </rt></ruby> 选项用于即时下载 ISO 镜像。第二个选项是直接从你的磁盘上写入已经下载的 ISO 文件。
如果你已经插上了 USB,你应该看到它是第三个选项。第三个选项是格式化并删除你 U 盘中的所有数据,并将其恢复到出厂设置。
此外,你也可以用这个工具来格式化你的 USB 闪存。你不需要任何命令或任何花哨的东西。需要注意的一点是,这个选项只有在你的 U 盘有数据时才可见。如果它已经被格式化了,该工具可以检测到它,但不会显示恢复它的选项!! ?
#### 自动下载和写入

<ruby> 自动下载 <rt> Download automatically </rt></ruby>选项为你提供了以下页面,可以从镜像中下载任何你想要的 Fedora ISO。这对很多人来说很有用,因为它消除了单独下载 ISO 文件、验证校验和等的麻烦。

在选择了发行版之后,最后的页面会给你版本(Fedora 36、35 等)和架构(x86、ARM 等)的选项。另外,你应该看到目标 USB。点击 “<ruby> 下载并写入 <rt> Download & Write </rt></ruby>”,开始这个过程。

#### 从磁盘上写入一个现有的 ISO 文件
当你选择 “<ruby> 选择 ISO 文件 <rt> select .iso file </rt></ruby>” 时,你可以从系统中选择该文件。之后,选择目标 USB 驱动器,然后点击 “<ruby> 写入 <rt> Write </rt></ruby>”,开始这个过程。



写入操作完成后,你可以看到如上所示的确认信息。在我的测试中,写一个大约 3GB 的 ISO 需要大约 3 到 4 分钟。
### 使用 Fedora Media Writer 在 Windows、macOS 中创建 LIVE USB
在 Windows 和 macOS 中使用这个工具的步骤是一样的,就像上面显示的 Linux 一样。你可以在安装后轻松找到快捷方式,并以同样的方式启动。

### 结束语
我希望本指南能帮助你在日常的 USB 写入工作中使用 Fedora Media Writer。另外,这个工具的好处是你可以用它来格式化/恢复你的 U 盘。你不再需要 GParted 或 GNOME <ruby> 磁盘 <rt> Disks </rt></ruby> 应用了。
对于 Linux、Windows 和 macOS 用户来说,这是一个非常棒的程序。
加油。
---
via: <https://www.debugpoint.com/fedora-media-writer/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,501 | Kodi 20.0 发布,支持 AV1 视频和 Steam Deck 控制器 | https://news.itsfoss.com/kodi-20-nexus-release/ | 2023-02-02T10:17:48 | [
"Kodi"
] | https://linux.cn/article-15501-1.html |
>
> Kodi 20 版本增加了多项重要功能。
>
>
>

[Kodi](https://kodi.tv) 是 Kodi 基金会开发的跨平台开源媒体播放器,提供了大量功能。
它的上一个主要版本是**两年前**发布的 [Kodi 19 “Matrix”](https://news.itsfoss.com/kodi-19-release/)。
**Kodi “Nexus”** 是改进后的主要版本,它提供了几个新功能和改进。
让我们来看看这些。
### ? Kodi 20 “Nexus” 更新了什么?
这次发布带来了很多新的特性,较为突出的有:
* AV1 编解码支持
* 增强的 PVR 支持
* 更新后的数据抓取器
* 多个修复和改进

#### AV1 编解码支持
Kodi 现在在 Linux 平台上支持开源的免版税的 [AV1 编解码](https://en.wikipedia.org/wiki/AV1)。
通过 [视频加速 API](https://en.wikipedia.org/wiki/Video_Acceleration_API)(VA-API)实现了解码 AV1 的硬件加速,并且还为视频输入流增加了 AV1 支持。
#### 增强的 PVR 支持
通过 [PVR](https://kodi.wiki/view/PVR) 观看电视和收听广播也得到了许多改进,其中一些值得注意的改进包括:
* 重新设计过的频道管理器。
* 能够显示特定频道或录音的提供方。
* 能够按提供方对频道和录音进行排序。
* 支持只读录音。
* 改进后的 EPG 搜索。
* 自动清理缓存的 PVR 图像。
* PVR 客户端插件的多实例支持。
* Estuary 主题下的 PVR 体验调整。
#### 更新后的数据抓取器
TVDB 电视节目抓取器已更新,以防止其在加载损坏的“视频流”和“信息标记视频”后出现问题。
>
> ?️ 建议旧版 Kodi 20 的用户更新到最新版本,避免使用此抓取器时出现问题。
>
>
>
此外,更新后的 Python 电视节目抓取器,解决了一个潜在的问题,即新的抓取器使用的 XML 格式与现有的程序不同的问题。
因此,当你向库中现有的电视节目添加新集时,即便你正在使用 NFO 文件,你也必须刷新节目以下载新集指南。
#### ?️ 多个修复和改进
除此之外,Kodi 20 还提供了一些修复和改进,例如:
* Steam Deck 控制器的内置支持。
* 开始支持 NFSv4 的文件系统。
* 默认支持光盘。
* 使用通用缓冲区管理 API 时,能够设置使用 HDR 输出。
* 解决了 DRMPrime 的一个问题。
* 多个对于图文电视的支持。
* 修复了单机游戏的黑屏问题。
要了解更多信息,请阅读 [官方公告](https://kodi.tv/article/kodi-20-0-nexus-release)。
### ? 下载 Kodi 20
Kodi 20 “Nexus” 可从 [官方网站](https://kodi.tv/download/) 及其 [GitHub 仓库](https://github.com/xbmc/xbmc/releases/tag/20.0-Nexus) 获取。
在应用商店和官方软件库也可以获取到。
Kodi v21(代号:Omega)正在开发中。如果你想从这次发布中获得更多内容,请关注下一个版本。
---
via: <https://news.itsfoss.com/kodi-20-nexus-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[natsumm](https://github.com/natsumm) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Kodi](https://kodi.tv/?ref=news.itsfoss.com) is a cross-platform open-source media player developed by the Kodi Foundation that offers a plethora of features.
Its previous major release was [Kodi 19 'Matrix'](https://news.itsfoss.com/kodi-19-release/) which came **almost two years ago**.
Now, an improved release is here, called** Kodi 'Nexus'**. It promises several new features and improvements.
Let's take a look at those.
## 🆕 Kodi 20 'Nexus': What's New?
The release is bringing in plenty of new things. Some of the highlights include:
**AV1 Codec Support****Enhanced PVR support****Updated Scrapers****Various Fixes and Improvements**
### AV1 Codec Support
Kodi now features support for the open, royalty-free [AV1 codec](https://en.wikipedia.org/wiki/AV1?ref=news.itsfoss.com) on Linux.
Hardware acceleration for decoding AV1 was made possible through [Video Acceleration API](https://en.wikipedia.org/wiki/Video_Acceleration_API?ref=news.itsfoss.com) (VA-API), and AV1 support was also added for InputStream.
### Enhanced PVR support
TV watching and radio listening via [PVR](https://kodi.wiki/view/PVR?ref=news.itsfoss.com) has also received many improvements, some of the notable ones include:
- A redesigned channel manager.
- Ability to show the provider of a specific channel or recording.
- Ability to sort channels and recordings by provider.
- Support for read-only recordings.
- Improvements to EPG search.
- Automatic cleanup of cached PVR images.
- Various performance improvements.
- Multi-instance support for PVR client-addons.
- Various tweaks to the PVR experience under the Estuary theme.
### Updated Scrapers
The TVDB TV Show scraper was updated to prevent breakage after introducing a change that broke the 'VideoStreamDetail' and 'InfoTagVideo; Python APIs.
Furthermore, the Python TV Show scrapers were updated to fix a potentially confusing issue where the new scrapers were using a different XML format than the existing providers used.
Due to that, now, when you add new episodes to existing TV shows in your library, you will have to refresh the show to download the new episode guide. Even if you are using the NFO files.
### 🛠️ Various Fixes and Improvements
Other than that, Kodi 20 features several fixes and improvements, such as:
- Built-in support for Steam Deck controller.
- Initial support for the NFSv4 file system.
- 'Continue Watching' feature for certain video folders.
- Support for mounting optical media by default.
- Ability to set HDR output when using the Generic Buffer Management API.
- Addressed an issue with DRMPrime.
- Various Teletext improvements.
- Fixed black screen issue with standalone games.
To explore more, you can read the [official announcement post](https://kodi.tv/article/kodi-20-0-nexus-release?ref=news.itsfoss.com).
## 📥 Download Kodi 20
Kodi 20 'Nexus' is available from the [official website](https://kodi.tv/download/?ref=news.itsfoss.com) and its [GitHub repository](https://github.com/xbmc/xbmc/releases/tag/20.0-Nexus?ref=news.itsfoss.com).
It should be available on app stores and official repositories as well.
Kodi v21 (codename: Omega) development is already underway. So, if you wanted more from this release, keep an eye on the next one.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,502 | 我的第一个拉取请求被合并了! | https://opensource.com/article/22/9/first-pull-request-merged | 2023-02-02T17:08:02 | [
"PR",
"贡献"
] | https://linux.cn/article-15502-1.html | 
>
> 体验为开源做出贡献的快乐。
>
>
>
难以用言语形容我在收到合并通知(如下图)时的喜悦,当然这要归功于现在我上的工程学校 [AltSchool Africa](https://www.altschoolafrica.com/)。

在此之前,我曾多次接触过开源的概念,了解了它在技术领域的重要性,甚至参加过开源会议(比如 OSCAFest)。我曾多次跃跃欲试,但当打开 GitHub 来想创建些东西时,冒名顶替综合症就会冒出来。
时间来到 2022 年 8 月 8 日星期一,当观看了 Bolaji 为开源做贡献的视频之后,我重新振奋起来。不过,想要把我学到的东西付诸实践,我注意到需要下面几个步骤:
步骤:
1. 我要下定决心,做好为一个开源项目做出贡献的心理建设。
2. 我要根据我的技能水平进行筛选,我从一个站点([Good First Issues](https://goodfirstissues.com/))寻找我开始的第一个项目。我不停地往下翻看,直到找到了一个符合心意的项目。
3. 我要确定自己掌握完成项目所需的 [Git 和 GitHub](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/getting-started/about-collaborative-development-models) 知识。
>
> **LCTT 译注:**
>
>
> “[Good First Issues](https://goodfirstissues.com/)” 这个网站主要是针对那些想为开源软件做贡献,但不知道从哪里开始或如何开始的开发者。通过为开发者提供过滤器,该网站使他们能够根据自己熟悉的编程语言来浏览和选择问题和存储库。此外,他们还可以选择他们想要解决的问题的类型。
>
>
>
### 项目
经过长时间查找,我终于找到了一个名为 [确保没有缺失的 alt 属性](https://github.com/mdn/content/issues/19334) 的项目。我所要做的,就是为网站上的图片提供描述性的 `alt` 值。图片的 `alt` 值有助于提高网站的辅助功能,这样屏幕阅读器就可以向视障人士提供图像的详细描述了。这很简单,对吧?是的,但假如我没有下定决心想要作出贡献,我就不会找到这项目,在我心中开源仍将是个神话。
我心潮澎湃,直到发现这个项目是来自 [MDN](https://developer.mozilla.org/en-US/) 的。等等,<ruby> MDN <rt> Mozzila 开发者网络 </rt></ruby>?干和 Mozilla 的开发者一样的事儿?他们会合并我这么小儿科的贡献吗?[冒名顶替综合症](https://opensource.com/article/20/9/imposter-syndrome) 又开始了。
在检查这个议题时,我看到有人已经在提交贡献了,于是我鼓起勇气开始翻阅项目的内容。阅读和理解这个项目颇花费了我一些时间,而另一个要克服的,就是清楚处理这个议题我要怎么做。
这个项目就像你想的那么简单。
于是,我挑选了两幅图片着手尝试。我给它们的 `alt` 属性赋值,提交我的更改,然后发出拉取请求。从提交请求到收到批准邮件的这段时间,我充满了自我怀疑。我要不要关闭拉取请求?这可是 MDN 啊。好吧,这甚至都不算编程…… 如果请求没有被合并怎么办?我恐怕再也不会想为开源做出贡献了。不过,所有的疑虑都在我看到审阅者发来的这些邮件时烟消云散:



我喜出望外,这激发了我去检查更多图片的热情,也给了我发请求解决其他议题所需的勇气。

### 总结
我希望你能从这篇文章中感受到以下几点:
* 开源是面向所有人的。你在刚刚访问的那个网站上看到拼写错误了吗?你帮助订正了拼写错误,这就是为开源做出了贡献。
* 没有任何技能是微不足道的。如你所见,我所做出的贡献,只需要对 HTML 最基本的了解。
* 能阻止你做出贡献的只有你自己。
* 要想让雪球滚起来,需要做的就只是提交第一个贡献。
我衷心希望你能从我的经历中获得什么,并且今天就付诸实践。这也就是我想贡献的另一个领域,那么,我们下一篇文章见,也祝你开源愉快!
这篇文章最初发布于 [我的第一个拉取请求被合并](https://dev.to/jhhornn/i-got-my-first-pull-request-merged-3ei9),并经许可转载。
---
via: <https://opensource.com/article/22/9/first-pull-request-merged>
作者:[Oluwaseun](https://opensource.com/users/jhhornn) 选题:[lkxed](https://github.com/lkxed) 译者:[onionstalgia](https://github.com/onionstalgia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Words cannot express my joy when I got the notification about the merge below, and I owe it to my current engineering school, [AltSchool Africa](https://www.altschoolafrica.com/).
(Awosise Oluwaseun, CC BY-SA 4.0)
Before this, I had been introduced to open source many times, told about its importance in the tech space, and even attended open source conferences (e.g., OSCAFest). I had all the instant excitement to start, but imposter syndrome set in on opening GitHub to create something.
Fast forward to Monday, the 8th of August, 2022, when I watched Bolaji's video on contributing to open source. I felt pumped again, but I wanted to apply what I learned, so I noted some steps.
The steps:
- I made up my mind I was going to contribute to a project.
- I was focused on a site (
[good first issue](https://goodfirstissues.com/)) to pick my first project from, which I filtered to suit my skill level. I kept opening the next page till I found one. - I made sure I was equipped with the required
[Git and GitHub](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/getting-started/about-collaborative-development-models)knowledge to complete the project.
## The project
After long hours searching for projects, I finally found one titled, [Ensure no missing alt attributes](https://github.com/mdn/content/issues/19334). I was to give descriptive alt values to images from the site. Alt values in images help to improve the accessibility of the site such that screen readers can provide a detailed description of the image to, say, a visually impaired person. Easy right? Yes, but if I didn't make up my mind to get the first contribution, I wouldn't find it, and open source would continue to be a myth to me.
I was still pumped until I discovered it was from [MDN](https://developer.mozilla.org/en-US/). Wait, MDN? As in Mozilla developer? Will they merge my contribution even with how seemingly easy it looks? [Imposter syndrome](https://opensource.com/article/20/9/imposter-syndrome) set in.
Upon checking the issue, I saw that people were already contributing. I summoned my courage and started reading about it. Taking my time to read and understand the project and how I needed to approach the issue was another challenge I had to overcome.
The project is as easy as you try to understand it.
So, I picked two images to begin with. I gave alt values to them, committed my changes, then made a pull request. The time between when I made the pull request and when I got the approval mail was full of self-doubts. Should I close the pull request? This is MDN. Well, it's not coding... What if I don't get merged? I might never contribute again. All it took to clear all of the doubts were the emails I got from my reviewer below:
(Awosise Oluwaseun, CC BY-SA 4.0)
(Awosise Oluwaseun, CC BY-SA 4.0)
(Awosise Oluwaseun, CC BY-SA 4.0)
I was indeed delighted, and this inspired me to check for more. It gave me the courage I needed to request additional issues to solve.
(Awosise Oluwaseun, CC BY-SA 4.0)
## Summary
A few lessons I'd love you to take home from this article are:
- Open source is for all. Do you see that typo on that site you just visited? You helping to correct it is a way of contributing.
- No skillset is too small. A basic understanding of HTML was what I needed to contribute.
- Only you can stop yourself from contributing.
- The first contribution is all you need to get the ball rolling.
I hope you have been able to pick something from my story and apply it today. This is another space I'd like to keep contributing to, so see you in my next article, and happy open sourcing!
*This article originally appeared on I got my first Pull Request merged! and is republished with permission.*
## 1 Comment |
15,504 | 如何使用机器学习来分析情感 | https://www.opensourceforu.com/2022/09/how-to-analyse-sentiments-using-machine-learning/ | 2023-02-03T11:22:59 | [
"情感分析",
"机器学习"
] | https://linux.cn/article-15504-1.html | 
本文将帮助你理解 <ruby> 情感分析 <rt> sentiment analysis </rt></ruby> 的概念,并且学习如何使用机器学习进行情感分析。我们使用了不同的机器学习算法进行情感分析,然后将各个算法的准确率结果进行比较,以确定哪一种算法最适合这个问题。
情感分析是自然语言处理(NLP)中的一个重要的内容。情感指的是我们对某一事件、物品、情况或事物产生的感觉。情感分析是一个从文本中自动提取人类情感的研究领域。它在上世纪 90 年代初才慢慢地开始发展起来。
本文将让你明白如何将机器学习(ML)用于情感分析,并比较不同机器学习算法的结果。本文的目标不在于研究如何提高算法性能。
如今,我们生活在一个快节奏的社会中,所有的商品都能在网上购买到,每个人都可以在网上发表自己的评论。而一些商品的负面网络评论可能会损害公司的声誉,从而影响公司的销售额。因此对公司来说,通过商品评论来了解客户真正想要什么变得非常重要。但是这些评论数据太多了,无法一个个地手动查看所有的评论。这就是情绪分析诞生的缘由。
现在,就让我们看看如何用机器学习开发一个模型,来进行基本的情绪分析吧。
### 现在就开始吧!
#### 获取数据
第一步是选择一个数据集。你可以从任何公开的评论中进行选择,例如推文或电影评论。数据集中至少要包含两列:标签和实际的文本段。
下图显示了我们选取的部分数据集。

接下来,我们导入所需的库:
```
import pandas as pd
import numpy as np
from nltk.stem.porter import PorterStemmer
import re
import string
```
正如你在上面代码看到,我们导入了 `NumPy` 和 `Pandas` 库来处理数据。至于其他库,我们会在使用到它们时再说明。
数据集已准备就绪,并且已导入所需的库。接着,我们需要用 `Pandas` 库将数据集读入到我们的项目中去。我们使用以下的代码将数据集读入 Pandas <ruby> 数据帧 <rt> DataFrame </rt></ruby> 类型:
```
sentiment_dataframe = pd.read_csv(“/content/drive/MyDrive/Data/sentiments - sentiments.tsv”,sep = ‘\t’)
```
#### 数据处理
现在我们的项目中已经导入好数据集了。然后,我们要对数据进行处理,以便算法可以更好地理解数据集的特征。我们首先为数据集中的列命名,通过下面的代码来完成:
```
sentiment_dataframe.columns = [“label”,”body_text”]
```
然后,我们对 `label` 列进行数值化:`negative` 的评论替换为 1,`positive` 的评论替换为 0。下图显示了经过基本修改后的 `sentiment_dataframe` 的值。

#### 准备好特征值、目标值
下一步是数据的预处理。这是非常重要的一步,因为机器学习算法只能理解/处理数值形数据,而不能理解文本,所以此时要进行特征抽取,将字符串/文本转换成数值化的数据。此外,还需要删除冗余和无用的数据,因为这些数据可能会污染我们的训练模型。我们在这一步中去除了噪声数据、缺失值数据和不一致的数据。
对于情感分析,我们在数据帧中添加特征文本的长度和标点符号计数。我们还要进行词干提取,即将所有相似词(如 “give”、“giving” 等)转换为单一形式。完成后,我们将数据集分为两部分:特征值 X 和 目标值 Y。
上述内容是使用以下代码完成的。下图显示了执行这些步骤后的数据帧。

```
def count_punct(text):
count = sum([1 for char in text if char in string.punctuation])
return round(count/(len(text) - text.count(“ “)),3)*100
tokenized_tweet = sentiment_dataframe[‘body_text’].apply(lambda x: x.split())
stemmer = PorterStemmer()
tokenized_tweet = tokenized_tweet.apply(lambda x: [stemmer.stem(i) for i in x])
for i in range(len(tokenized_tweet)):
tokenized_tweet[i] = ‘ ‘.join(tokenized_tweet[i])
sentiment_dataframe[‘body_text’] = tokenized_tweet
sentiment_dataframe[‘body_len’] = sentiment_dataframe[‘body_text’].apply(lambda x:len(x) - x.count(“ “))
sentiment_dataframe[‘punct%’] = sentiment_dataframe[‘body_text’].apply(lambda x:count_punct(x))
X = sentiment_dataframe[‘body_text’]
y = sentiment_dataframe[‘label’]
```
#### 特征工程:文本特征处理
我们接下来进行文本特征抽取,对文本特征进行数值化。为此,我们使用<ruby> 计数向量器 <rt> CountVectorizer </rt></ruby>,它返回词频矩阵。
在此之后,计算数据帧 X 中的文本长度和标点符号计数等特征。X 的示例如下图所示。

#### 使用的机器学习算法
现在数据已经可以训练了。下一步是确定使用哪些算法来训练模型。如前所述,我们将尝试多种机器学习算法,并确定最适合情感分析的算法。由于我们打算对文本进行二元分类,因此我们使用以下算法:
* K-近邻算法(KNN)
* 逻辑回归算法
* 支持向量机(SVMs)
* 随机梯度下降(SGD)
* 朴素贝叶斯算法
* 决策树算法
* 随机森林算法
#### 划分数据集
首先,将数据集划分为训练集和测试集。使用 `sklearn` 库,详见以下代码:
```
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.20, random_state = 99)
```
我们使用 20% 的数据进行测试,80% 的数据用于训练。划分数据的意义在于对一组新数据(即测试集)评估我们训练的模型是否有效。
##### K-近邻算法
现在,让我们开始训练第一个模型。首先,我们使用 KNN 算法。先训练模型,然后再评估模型的准确率(具体的代码都可以使用 Python 的 `sklearn` 库来完成)。详见以下代码,KNN 训练模型的准确率大约为 50%。
```
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
model.score (X_test,y_test)
0.5056689342403629
```
##### 逻辑回归算法
逻辑回归模型的代码十分类似——首先从库中导入函数,拟合模型,然后对模型进行评估。下面的代码使用逻辑回归算法,准确率大约为 66%。
```
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit (X_train,y_train)
model.score (X_test,y_test)
0.6621315192743764
```
##### 支持向量机算法
以下代码使用 SVM,准确率大约为 67%。
```
from sklearn import svm
model = svm.SVC(kernel=’linear’)
model.fit(X_train, y_train)
model.score(X_test,y_test)
0.6780045351473923
```
##### 随机森林算法
以下的代码使用了随机森林算法,随机森林训练模型的准确率大约为 69%。
```
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
model.score(X_test,y_test)
0.6938775510204082
```
##### 决策树算法
接下来,我们使用决策树算法,其准确率约为 61%。
```
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model = model.fit(X_train,y_train)
model.score(X_test,y_test)
0.6190476190476191
```
##### 随机梯度下降算法
以下的代码使用随机梯度下降算法,其准确率大约为 49%。
```
from sklearn.linear_model import SGDClassifier
model = SGDClassifier()
model = model.fit(X_train,y_train)
model.score(X_test,y_test)
0.49206349206349204
```
##### 朴素贝叶斯算法
以下的代码使用朴素贝叶斯算法,朴素贝叶斯训练模型的准确率大约为 60%。
```
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X_train, y_train)
model.score(X_test,y_test)
0.6009070294784581
```
#### 情感分析的最佳算法
接下来,我们绘制所有算法的准确率图。如下图所示。

可以看到,对于情感分析这一问题,随机森林算法有最佳的准确率。由此,我们可以得出结论,随机森林算法是所有机器算法中最适合情感分析的算法。我们可以通过处理得到更好的特征、尝试其他矢量化技术、或者使用更好的数据集或更好的分类算法,来进一步提高准确率。
既然,随机森林算法是解决情感分析问题的最佳算法,我将向你展示一个预处理数据的样本。在下图中,你可以看到模型会做出正确的预测!试试这个来改进你的项目吧!

---
via: <https://www.opensourceforu.com/2022/09/how-to-analyse-sentiments-using-machine-learning/>
作者:[Jishnu Saurav Mittapalli](https://www.opensourceforu.com/author/jishnu-saurav-mittapalli/) 选题:[lkxed](https://github.com/lkxed) 译者:[chai001125](https://github.com/chai001125) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article will help you understand the concept of sentiment analysis and learn how it is done. It uses different machine learning algorithms for sentiment analysis, and then compares them to decide which one is the best for the particular problem described here.
Sentiment analysis is a major area in the field of natural language processing. A sentiment is any opinion or feeling that we have about an event, a product, a situation or anything else. Sentiment analysis is the field of research in which human sentiments are automatically extracted from the text. This field started evolving in the early 90s.
This article will help you understand how machine learning (ML) can be used for sentiment analysis, and compare the different ML algorithms that can be used. It does not try to improve the performance of any of the algorithms or methods.
In today’s fast paced world, everything is online and everyone can post their views. A few negative online comments may hurt a company’s reputation and, thereby, its sales. Now that everything’s online, everyone can post their views and opinions. It becomes very important for companies to go through these to understand what their customers really want. But since there is so much data, it cannot be gone through manually. This is where sentiment analysis comes in.
Let us now start developing a model to do a basic sentiment analysis.
## Let’s start!
The first step is to select a data set. You can choose from any publicly available reviews or comments such as tweets or movie reviews. The two columns that should definitely be there in the data set are the label and the actual piece of text.
Figure 1 shows a small sample of how the data looks.


Now we need to import the required libraries:
import pandas as pd import numpy as np from nltk.stem.porter import PorterStemmer import re import string
As you can see in the above code, we have imported NumPy and Pandas for processing the data. We will look at the other imported libraries when we use them.
Now that the data set is ready and the libraries are imported, we need to bring the former into our project. The Pandas library is used for this purpose. We bring the data set into the Pandas data frame using the following line of code:
sentiment_dataframe = pd.read_csv(“/content/drive/MyDrive/Data/sentiments - sentiments.tsv”,sep = ‘\t’)
Now that we have the data set in our project, let us manipulate it so that our algorithm can understand the features better. We begin by giving names to our columns in the data set. This is done by using the line of code given below:
sentiment_dataframe.columns = [“label”,”body_text”]
We then assign numerical labels to the classes — negative is replaced with 1 and positive is replaced with 0. Figure 2 shows how the data frame looks at this stage.

The next step is the preprocessing of the data. This is a very important step as it helps us to convert string/text data into numerical data (machine learning algorithms can understand/process numerical data and not text). Also, the redundant and useless data needs to be removed as it may taint our training model. We remove the noisy data, missing values and other non-consistent data in this step.
We will add the features text length and punctuation count in the data frame specifically for this application. We will also do the stemming, i.e., we will convert all similar words (like ‘give’, ‘giving’, etc) into a single form. Once this is done, we divide the data set into two — X and Y — where X is the features and Y is the prediction class.
This is done using the following piece of code. Figure 3 shows the data frame after these steps are taken.
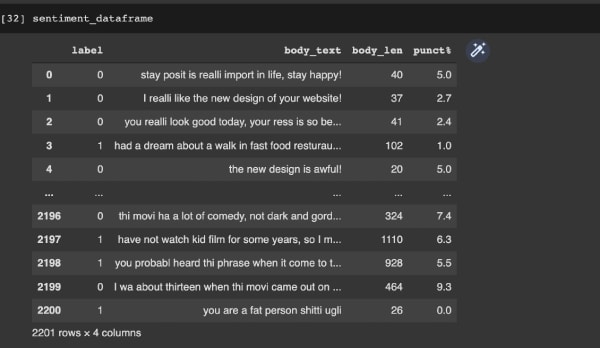

def count_punct(text): count = sum([1 for char in text if char in string.punctuation]) return round(count/(len(text) - text.count(“ “)),3)*100 tokenized_tweet = sentiment_dataframe[‘body_text’].apply(lambda x: x.split()) stemmer = PorterStemmer() tokenized_tweet = tokenized_tweet.apply(lambda x: [stemmer.stem(i) for i in x]) for i in range(len(tokenized_tweet)): tokenized_tweet[i] = ‘ ‘.join(tokenized_tweet[i]) sentiment_dataframe[‘body_text’] = tokenized_tweet sentiment_dataframe[‘body_len’] = sentiment_dataframe[‘body_text’].apply(lambda x:len(x) - x.count(“ “)) sentiment_dataframe[‘punct%’] = sentiment_dataframe[‘body_text’].apply(lambda x:count_punct(x)) X = sentiment_dataframe[‘body_text’] y = sentiment_dataframe[‘label’]
We now need to convert the string into numerical data. We use a count vectorizer for this purpose; that is, we get the counts of each word and convert it into a vector.
After this, features such as length of text and punctuation count in the dataframe, i.e., X, are calculated. A sample of X is shown in Figure 4.
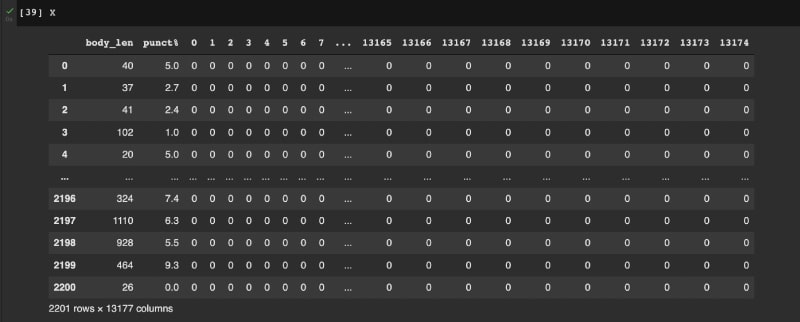

Now the data is ready for training. The next step is to determine which algorithms we are going to use for training our model. As has been mentioned before, we are going to try several algorithms and determine the best one for sentiment analysis. Since we are basically trying to do binary classification, the following algorithms can be used:
- K-nearest neighbors (KNN)
- Logistic regression
- Support vector machines (SVMs)
- Stochastic gradient descent
- Naive Bayes
- Decision tree
- Random Forest
We first need to split our data set into testing and training data. This is done by using the sklearn library using the following code:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.20, random_state = 99)
We will use 20 per cent of the data for testing and 80 per cent for the training part. We will separate the data because we want to test on a new set of data whether our model is working properly or not.
Now let us start with the first model. We will try the KNN algorithm first, and use the sklearn library for this. We will first train the model and then assess its performance (all of this can be done using the sklearn library in Python itself). The following piece of code does this, and we get an accuracy of around 50 per cent.
from sklearn.neighbors import KNeighborsClassifier model = KNeighborsClassifier (n_neighbors=3) model.fit(X_train, y_train) model.score (X_test,y_test) 0.5056689342403629
The code is similar in the logistic regression model — we first import the function from the library, fit the model, and then test it. The following piece of code uses the logistic regression algorithm. The output shows we got an accuracy of around 66 per cent.
from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit (X_train,y_train) model.score (X_test,y_test) 0.6621315192743764
The following piece of code uses SVM. The output shows we got an accuracy of around 67 per cent.
from sklearn import svm model = svm.SVC(kernel=’linear’) model.fit(X_train, y_train) model.score(X_test,y_test) 0.6780045351473923
The following piece of code uses the Random Forest algorithm, and we get an accuracy of around 69 per cent.
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() model.fit(X_train, y_train) model.score(X_test,y_test) 0.6938775510204082
Next we use the Decision tree algorithm, which gives an accuracy of around 61 per cent.
from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model = model.fit(X_train,y_train) model.score(X_test,y_test) 0.6190476190476191
The following piece of code uses the stochastic gradient descent algorithm. The output shows that we got an accuracy of around 49 per cent.
from sklearn.linear_model import SGDClassifier model = SGDClassifier() model = model.fit(X_train,y_train) model.score(X_test,y_test) 0.49206349206349204
The following piece of code uses Naive Bayes. We get an accuracy of around 60 per cent.
from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X_train, y_train) model.score(X_test,y_test) 0.6009070294784581
Now that we have checked out all the algorithms, let us graph their accuracy performance. The graph is shown in Figure 5.

As you can see, the random forest algorithm gave the best accuracy for this problem and we can conclude that it is the best fit for sentiment analysis amongst ML algorithms. We can improve the accuracy much more by getting better features, trying out other vectorising techniques, and using a better data set or newer classification algorithms.
Now that random forest is seen as the best algorithm for this problem, I am going to show you a sample prediction. In Figure 6, you can see that the right predictions are being made! Do try this out to improve upon this project!
 |
15,505 | 迎接 ecode:一个即将推出的具有全新图形用户界面框架的现代、轻量级代码编辑器 | https://news.itsfoss.com/ecode-editor/ | 2023-02-03T13:34:40 | [
"代码编辑器"
] | https://linux.cn/article-15505-1.html |
>
> 一个正在开发中令人兴奋的新代码编辑器,基于其自己的 GUI 框架。
>
>
>

如果你看看周围的开源代码编辑器,有几个有前途的新项目可能会挑战 Visual Studio Code 的地位。
当然,这可能不会很快发生。**但对支持新项目持乐观态度也无妨。**
我们最近在这里介绍了其中的一些选择:
现在,我偶然发现了另一个编辑器,“**ecode**”。这个项目的作者提到,它从 [Lite XL](https://itsfoss.com/lite-xl/) 等编辑器中获得了灵感。
有什么不同?
* 它建立在其新的 GUI 框架 [eepp](https://github.com/SpartanJ/eepp/) 之上,该框架专注于提供一个丰富的用户界面。
* 虽然它的目标是使用最少的资源,但 ecode 的理念针对的是有 SSD、高核心数和良好的 GPU 加速的**现代硬件**系统。
* 该代码编辑器可以被编译为在任何现代浏览器中运行。然而,目前的重点并不在网页版的开发上。

这听起来不错。那么,让我们看一看。
>
> ? 该项目正在大力开发中。你不应该在日常工作中依赖这个工具。
>
>
>
### ecode 的特点

[ecode](https://github.com/SpartanJ/ecode) 是一个功能强大的编辑器,从一开始就有所有的基本功能。
当然,它有计划随着开发的进展增加更多的东西。就目前而言,这里有一些关键的亮点:
* 可移植
* 语法高亮
* 终端支持
* 自动补全
* 可定制的颜色方案
* 可定制的键盘绑定
* LSP 支持
* <ruby> 缩略视图 <rt> Minimap </rt></ruby>
* 插件管理器
* 深色和浅色模式
* 各种类型的分割视图以适应不同的工作流程
我在 Linux Mint 上简单地试了一下这个编辑器,它看起来确实是正在开发中。
但是,即使在其早期阶段,它也支持广泛的语言和相应的语法高亮。

你可以从一组预定义的主题中快速定制编辑器的主题。
对于编写大量代码(冗长的片段)并需要快速浏览的用户来说,缩略视图将非常方便。
最初,当我在一个空白区域右键点击时,该应用崩溃了。但是,随着下一个版本 **0.4.1**(在发表这篇文章的时候)的更新,它很快就被修复了。所以,我想说**开发进展似乎很有希望**。

### 下载 ecode
你可以尝试一下 [在线演示](https://cdn.ensoft.dev/eepp-demos/demo-fs.html?run=ecode.js) 来快速测试一些选项。
有一个可用于所有 Linux 发行版的 AppImage 软件包。也有用于 macOS 和 Windows 的软件包。
你可以从它的 [GitHub 发布页](https://github.com/SpartanJ/ecode/releases/tag/ecode-0.4.1) 获得这些包,或者探索它的 [源码](https://github.com/SpartanJ/eepp/)。
>
> **[下载 ecode](https://github.com/SpartanJ/ecode/releases/tag/ecode-0.4.1)**
>
>
>
? 有这么多有前途的新代码编辑器在开发中,你认为我们会对微软的 VS Code 有一个好的竞争吗?
---
via: <https://news.itsfoss.com/ecode-editor/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you look around for open-source code editors, a couple of promising new projects may challenge the likes of Visual Studio Code.
Sure, that may not happen anytime soon. **But it does not hurt to be optimistic about supporting new projects.**
We recently covered some of those options here:
[5 Upcoming Code Editors that May Challenge the Supremacy of Visual Studio CodeInteresting code editors that might replace Visual Studio Code for you in 2023!](https://news.itsfoss.com/upcoming-code-editors/)

Now, I have stumbled upon another editor, "**ecode**". The project's author mentions that it takes inspiration from editors like [Lite XL](https://itsfoss.com/lite-xl/?ref=news.itsfoss.com).
**What's different?**
- It is built on top of its
**new GUI framework**which focuses on providing a rich user interface.[eepp](https://github.com/SpartanJ/eepp/?ref=news.itsfoss.com) - While it aims to use minimal resources, ecode's philosophy targets
**modern hardware**with systems that have SSDs, high cores count, and decent GPU acceleration. - The code editor can be compiled to run in any modern browser. However, the current focus is not on the development of the web version.
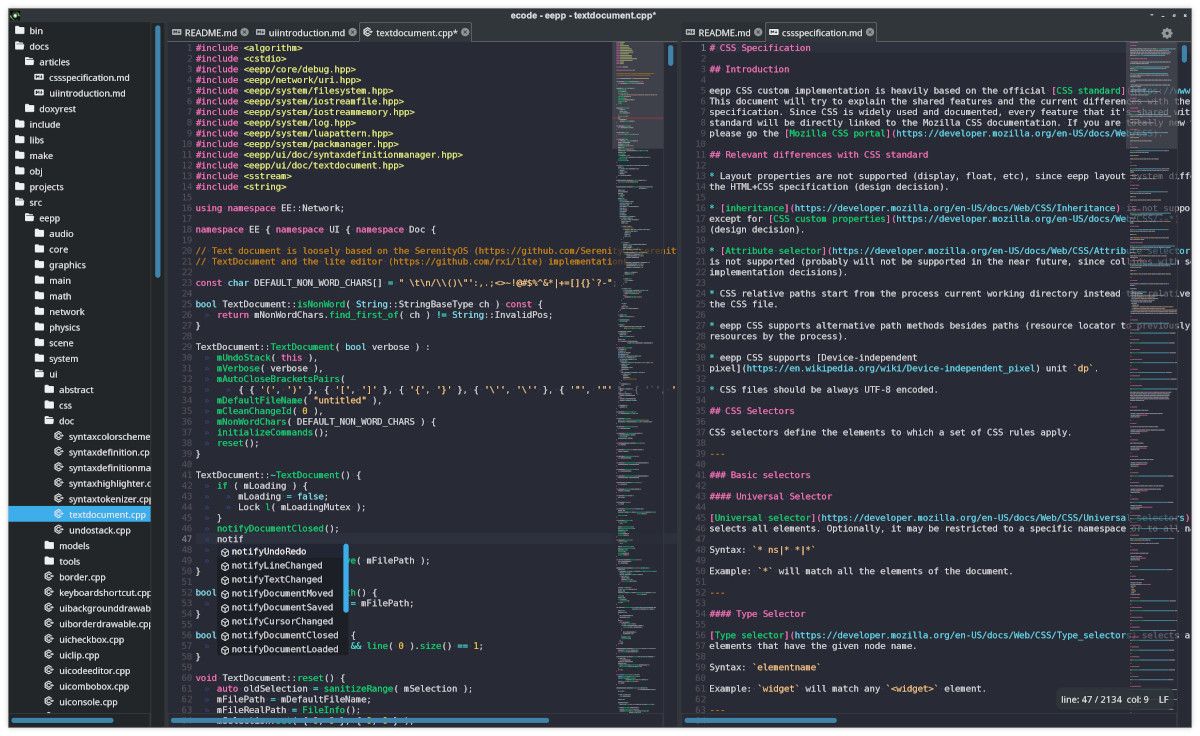
That sounds good. So, let us take a look.
[Learn to Code - for Free | CodecademyLearn the technical skills to get the job you want. Join over 50 million people choosing Codecademy to start a new career (or advance in their current one).](https://www.pjtra.com/t/SENKSU5HTE1DSEdPTkdGQ0hHSUtOTg?ref=news.itsfoss.com)

## Features of ecode
[ecode](https://github.com/SpartanJ/ecode?ref=news.itsfoss.com) is a capable editor with all the essentials loaded from the start.
Sure, it has plans to add more stuff as the development progresses. As it stands, here are some of the key highlights:
**Portable****Syntax highlighting****Terminal support****Auto-completion****Customizable color schemes****Customizable keyboard bindings****LSP Support****Minimap****Plugin manager****Dark and light mode****Various types of split views to adapt to different workflows**
I tried the editor briefly on Linux Mint, and it sure looks like a work in progress.
But, even in its early stages, it supports the essentials to support a wide range of languages and syntax highlights accordingly.
You can customize the editor's theme quickly from a set of pre-defined themes.
The minimap will be handy for users who write a lot of code (lengthy snippets) and need to navigate it quickly.
The app crashed for me initially as I performed a right-click in a blank area. But, it was quickly fixed with the next version update, **0.4.1** (at the time of publishing this). So, I would say the **development progress seems promising**.
[Cloud IDE · Online Code Editor · CodeanywhereSave time by deploying a development environment in seconds. Collaborate, code, learn, build, and run your projects directly from your browser.](https://codeanywhere.com/?ref=itsfoss)

## Download ecode
You can try the [live demo](https://cdn.ensoft.dev/eepp-demos/demo-fs.html?run=ecode.js&ref=news.itsfoss.com) available to test-drive some options quickly.
An AppImage file is available for all Linux distributions. Packages for macOS and Windows are also available.
You can get these packages from its [GitHub releases section](https://github.com/SpartanJ/ecode/releases/tag/ecode-0.4.1?ref=news.itsfoss.com) or explore its [source code](https://github.com/SpartanJ/eepp/?ref=news.itsfoss.com).
💬 With so many promising new code editors in development, do you think we'll have a good competition to Microsoft's VS Code?
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,506 | elementary OS 7 发布 | https://news.itsfoss.com/elementary-os-7-release/ | 2023-02-03T17:16:59 | [
"elementary OS"
] | https://linux.cn/article-15506-1.html |
>
> 在一年后,elementary OS 7 出现了,带来一些激动人心的微妙变化!
>
>
>

elementary OS 6.1 是一个令人印象深刻的版本。终于,过去了一年,下一个主要的升级,elementary OS 7 “Horus” 来了。
这些变化可能不算大规模的翻新,正如以前 [报道](https://news.itsfoss.com/elementary-os-7-dev-updates/),开发的重点更多的是在细化上。
### elementary OS 7:有什么新内容?
主要的改进领域包括:
* <ruby> 应用中心 <rt> AppCenter </rt></ruby>
* 应用程序和系统更新
* 侧载/替代商店
* 改进的初次安装体验
* 应用程序的改进
#### 应用中心升级

在每一次重大的升级中,<ruby> 应用中心 <rt> AppCenter </rt></ruby>都得到了很大的重视。虽然它已经提供了完美的体验,但它变得越来越好了,更快的性能、更好的调整以适应不同屏幕分辨率或窗口大小。
应用的描述是这次的亮点。你可以一次看到应用程序的更多屏幕截图,让你对应用程序有更好的了解。

这些图片还包括了图片说明,应该有助于视力有关的残疾用户访问应用程序页面。
从大的方面来说,屏幕截图融入到以应用程序的默认重点颜色为特色的背景中,看起来很不错。
此外,应用程序的描述也会给你提供更多关于该应用程序如何积极维护的信息,以及最近的发布说明。
#### 应用程序更新

你现在可以选择切换是否要自动更新应用程序。
Flatpak 的首选项保持不变;你可以选择让它们自动更新,而不是手动检查。
此外,系统更新一旦下载并准备好,就会离线安装,可以给你一个顺滑的体验。
#### 第三方应用商店
elementaryOS 7 应用中心上的应用程序放在其独立的 Flatpak 软件仓库上。
然而,你仍然可以添加 Flathub 作为软件仓库,以获得更多的 Flatpak 应用程序。
为了告知你这一区别,应用中心会提到一些警告,如 “<ruby> 非策划的 <rt> Non-Curated </rt></ruby>”,这样你就知道它是来自另一个应用商店。

当你第一次尝试从第三方商店安装一个应用程序时,这样的弹出警告只会出现一次。
#### 支持网页应用程序

该版本包括 GNOME Web 43,它支持创建网页应用程序,可在应用程序菜单中找到。
你可以在 GNOME Web 中管理所安装的网页应用程序。
#### 重新设计的图标

elementaryOS 已经被视作最漂亮的 Linux 发行版之一。
为了提升体验,几乎每一个应用程序的图标都被重新设计,以提供一个更现代和更有表现力的用户体验。
#### 安装和初次体验

安装体验随着升级而变得更加直接了当。
换句话说,你在安装程序中的看到屏幕数量将减少,但仍然可以得到所有的基本信息,包括警告和系统要求。
安装程序现在可以提示你选择左键或右键设置为鼠标的主按钮。

从系统主题偏好到自动更新,你可以在安装后直接配置所有必要的东西。
#### 新的音乐多媒体应用程序

为了提供更好的多媒体体验,该音乐应用程序已经从头开始完全重写,在各种使用情况下都能很好地工作。
你可以设置本地音乐位置、预览音频文件、获得正确的元数据信息,以及更多。
#### 其他变化
你会发现其他几个细微的改进。其中一些包括:
* 邮件应用现在采用了更现代、更扁平的设计,以提高响应速度。
* 邮件应用程序现在支持微软 365 账户。
* 在任务应用中对新创建的任务列表的离线支持。
* 在线账户设置包括对 CalDAV 账户的离线支持。
* 切换选择文件夹,只需点击一下。
* 重新设计的打印机设置。
* 电源配置文件管理设置。
你可以参考 [官方公告](https://blog.elementary.io/os-7-available-now/) 了解更多细节。
### 下载 elementary OS 7
>
> ? 当我尝试最新的 RC 构建版时,我的英伟达显卡驱动的系统启动时出现了一个反色的(看起来很奇怪)的彩色屏幕。这对最终版本来说可能不是一个问题。
>
>
>
你可以从 [官方网站](https://elementary.io) 上获取最新的 ISO。我希望他们能够为英伟达系统增加一个单独的 ISO,但对于其他系统,它应该可以正常工作。
>
> **[elementary OS 7](https://elementary.io)**
>
>
>
另外,你必须得重新安装,而不是从 elementary OS 6 升级。在你继续安装之前,请查看其 [官方 FAQ](https://github.com/elementary/os/wiki/OS-7-Horus-FAQ)。
---
via: <https://news.itsfoss.com/elementary-os-7-release/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

elementary OS 6.1 was an impressive release. It has been more than a year, and finally, the next major upgrade, **elementary OS 7 'Horus'**, landed.
The changes may not be considered a massive overhaul, but the development focus was more on** refinements**, as previously [reported](https://news.itsfoss.com/elementary-os-7-dev-updates/).
## elementary OS 7: What's New?
The main areas of improvement include:
**AppCenter****App & System Updates****Sideloading or Alternate Stores****Improved onboarding and installation experience****App improvements**
### AppCenter Upgrades
With every major upgrade, much emphasis is put on AppCenter. While it already offers a polished experience, it gets better with faster performance and better adjustment to different screen resolutions or window sizes.
The app descriptions are the highlight this time. You get to see more screenshots of an app at once, giving you a better view of applications.
The images also include captions that should help make app pages accessible to users with vision-related disabilities.
Overall, the screenshots blend in with a background featuring the default accent color of the app, making it look good.
Furthermore, the app descriptions will also give you more information on how actively the app is maintained, along with the recent release notes.
### App Updates
You now get an option to toggle if you want automatic app updates.
The preferences for Flatpak remain the same; instead of manually checking for it, you can opt to have them update automatically.
In addition, system updates will be installed offline once downloaded and prepared to give you a seamless experience.
### Third-Party App Store
elementaryOS 7 relies on its separate Flatpak repository for the applications on AppCenter.
However, you can still add Flathub as a repository and get more Flatpak apps.
To inform you of the difference, the AppCenter will mention some warning like "**Non-Curated**", so you know it is from an alternate store.
The pop-up warning will only appear once when you try to install an app from a third-party store for the first time.
### Web App Support
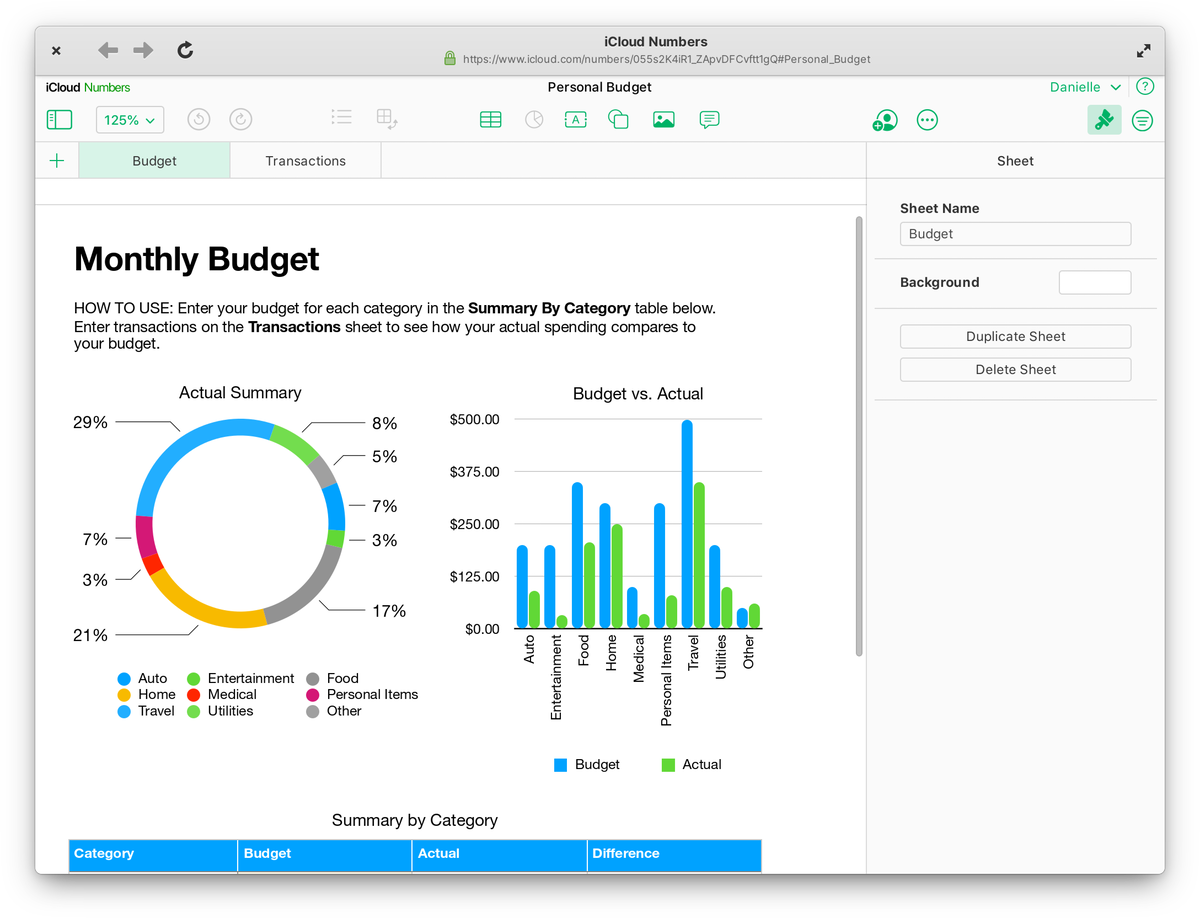
The release includes GNOME Web 43, which supports creating web apps that can be found in the applications menu.
You can manage the web apps installed from within GNOME Web.
### Redesigned Icons
elementaryOS is already known as one of the best beautiful Linux distributions.
To elevate the experience, almost every app icon has been redesigned to provide a more modern and expressive user experience.
### Installation & Onboarding Experience
The installation experience is getting more straightforward with upgrades.
In other words, you will have less number of screens in the installer but still, get all the essential information that includes warnings and system requirements.
The installer now prompts you to choose between left-click or right-click as the primary mouse button.
From system theme preferences to automatic updates, you can configure all the essential things right after installation.
### New Music 7 Multimedia App
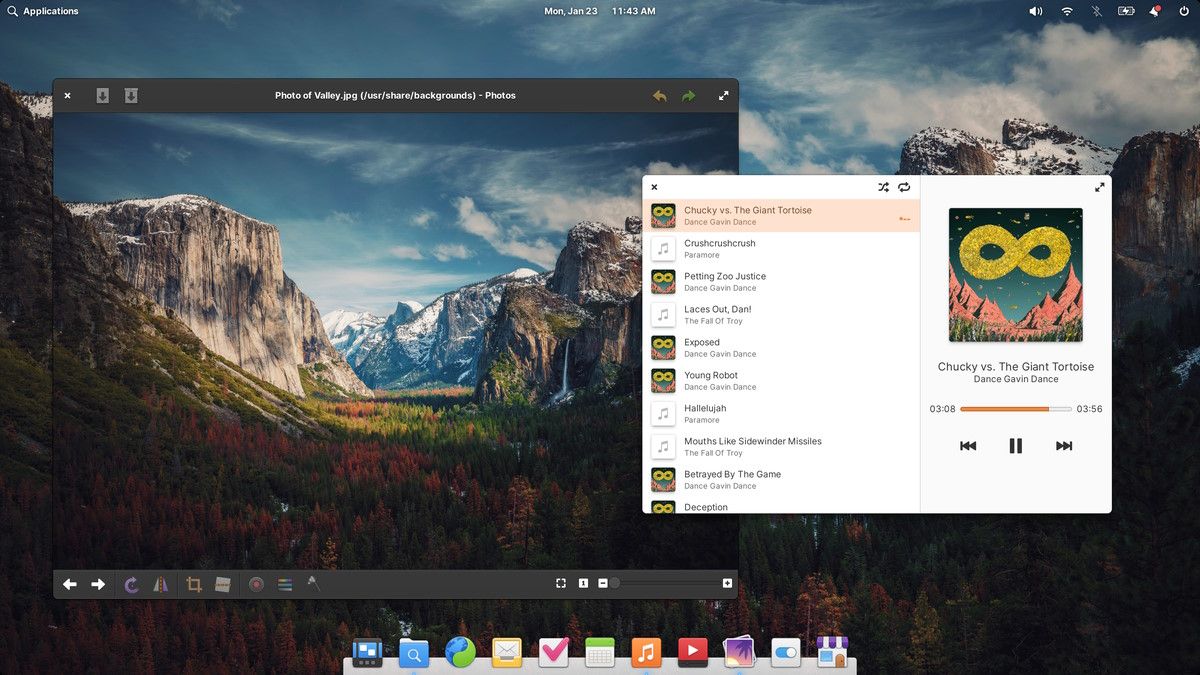
To provide a better multimedia experience, the Music app has been completely rewritten from scratch, which works well for various use cases.
You can curate local music locations, preview audio files, get correct metadata info, and more.
### Other Changes
You will find several other subtle refinements. Some of those include:
**The mail app now features a more modern and flatter design for improved responsiveness****The mail app now supports Microsoft 365 accounts****Offline support for newly created task lists on the Tasks app****Online Accounts settings include offline support for CalDAV accounts****Toggle to choose folders with a single click****Redesigned printer settings****Power profile management settings**
You can refer to the [official announcement](https://blog.elementary.io/os-7-available-now/?ref=news.itsfoss.com) for more details.
## Download elementary OS 7
You can grab the latest ISO from the [official website](https://elementary.io/?ref=news.itsfoss.com). I wish they would add a separate ISO for NVIDIA systems, but for the rest, it should work fine.
Also, you will have to go for a re-install instead of upgrading from elementary OS 6. Check out its [official FAQ](https://github.com/elementary/os/wiki/OS-7-Horus-FAQ?ref=news.itsfoss.com) before you proceed to install.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,508 | System76 即将推出的 COSMIC 桌面正在酝酿大变化 | https://news.itsfoss.com/system76-pop-os-cosmic-de-changes/ | 2023-02-04T11:37:00 | [
"System76",
"COSMIC"
] | https://linux.cn/article-15508-1.html |
>
> System76 介绍了其即将推出的由 Rust 开发的 COSMIC 桌面环境的开发细节。让我们来看看。
>
>
>

Pop!\_OS 的开发者们 [早在 2021 年](https://news.itsfoss.com/pop-os-cosmic-rust/) 就开始着手开发他们**基于 Rust 的桌面环境** COSMIC。
其目标是制作一些你已经熟悉的 Pop!\_OS 的东西,但为你提供一个更快和更可扩展的桌面环境。
System76 也决定 [不发布 Pop!\_OS 22.10](https://news.itsfoss.com/no-pop-os-21-10/),以专注于它的开发。
另外,我们的一个社区贡献者尝试了它的一个早期版本,它看起来很有希望:
>
> **建议阅读** ?
>
>
> 我试用了 System76 新的基于 Rust 的 COSMIC 桌面!如果你还不知道,System76 的开发者一直在开发一个新的桌面环境(被称为 COSMIC),它是用 Rust 编写的:一种内存安全和超快的编程语言。从头开始创建一个桌面环境并不是一件简单的事。这涉及到创建从合成器、...
>
>
> 
>
>
>
时间过去了一年,我们现在对这个桌面环境有了更多的期待。
让我们来探索一下 System76 为我们准备了什么。
### COSMIC 桌面的 3 项关键性的改进
>
> ? 我们讨论的这些变化和草图在最终发布时可能会有变化。
>
>
>
在 [最近的一篇博文](https://blog.system76.com/post/more-on-cosmic-de-to-kick-off-2023) 中,来自 System76 的 Alex 让我们看到了 COSMIC 桌面环境的发展状况。
让我带你看看其中值得注意的亮点:
* 新的用户界面功能
* 重新打造的设置应用
* 新的壁纸功能
### 1、新的用户界面功能

一个新的 [SegmentedButton](https://github.com/pop-os/libcosmic/pull/56) 部件被用来处理 COSMIC 桌面环境中各处的标签和分段式按钮。
它的目的是给人一种简洁、有条理、更集中的菜单体验,而分段式按钮则允许在选择时进行操作。
他们还举了一个例子来解释这对用户界面有什么帮助:
>
> 当你定制你的桌面以使用水平工作区而不是垂直工作区时,例如,你的选择将导致桌面反映这种行为。
>
>
>
### 2、重新打造的设置应用

首先,“设置” 应用得到了彻底的整改,现在搜索结果显示为一个连续的、可滚动的、来自不同设置面板的结果列表。
>
> ?️ 在最新几轮的内部用户(UX)测试后,具体设置进行了调整。
>
>
>
然后是各种设置面板本身的改造。让我带你了解一下。
#### 显示调整

开发人员将图形模式和深浅色选项移至显示设置面板。在测试过程中,他们发现大多数用户到显示设置中去是希望找到这些设置。

此外,当使用多个显示器时,显示设置将根据显示器被组织到专门的选项卡中,并有改变或添加颜色配置文件的选项。
#### 电源选项

这个设置面板现在可以显示连接的无线设备的电池电量和所有连接设备的概览。
你还可以根据你的要求选择电源配置文件,并限制笔记本电脑的电池充电,以保护电池寿命。
#### 地区和语言选择

该设置已被划分为不同的类别,以便于访问。它们被分为几个的类别,以选择日历、日期、温度和测量的区域格式。
#### 声音
声音设置中增加了一个新的选项,可以让你调整个别警报和应用程序的音量。

此外,拥有两个或更多扬声器的用户现在可以使用新的扬声器测试工具来优化其设置。
### 3、新的壁纸功能

COSMIC 桌面环境可以让你设置一张壁纸,每个显示器一张,或者让你以幻灯片的形式循环播放多张壁纸。这是给**多显示器用户的一个好消息!**
你还可以对每张壁纸在切换到下一张之前在屏幕上停留的时间进行精细控制。
### ?️ 其他改进措施
除了上面提到的面向用户的变化之外,还有一些内在的改进,包括:
* 一个新的动态渲染器,[iced-dyrend](https://github.com/pop-os/iced/commit/f1310e47617c3046a3cd98e20e373247f19327af) 已经由 System76 首席工程师实现,旨在动态调整你的 GPU 应该使用什么渲染程序。如果你有 GPU,它可以在 OpenGL 或 Vulkan 之间切换;如果你没有,则可以在 [Softbuffer](https://github.com/rust-windowing/softbuffer/) 之间切换。
* 通过 [cosmic-text](https://github.com/pop-os/cosmic-text) 进行的文本渲染已经与 Softbuffer 0.2.0 配对,允许 [libcosmic](https://github.com/pop-os/libcosmic) 部件库的软件渲染后端在任何操作系统上使用。
* 开发者还测试了 XWayland 的实现,使 COSMIC 桌面环境能够运行使用 X11 窗口系统的应用程序。
* COSMIC 桌面环境已经通过 [cosmic-time](https://github.com/pop-os/cosmic-time) 动画库加入了对动画的支持。它包含了默认应用程序所使用的动画,并使用 [Iced](https://github.com/iced-rs/iced) 工具箱构建。
开发者还提到:
>
> 虽然 COSMIC 桌面环境是为 Pop!\_OS 开发的,但我们的目标是让它的元素也能在其他操作系统上使用。
>
>
>
这是很好的消息!如果你想知道 COSMIC 桌面环境是否是 Pop!\_OS 独有的东西,也许你也可以在发行版上试试它,希望如此! ?
---
via: <https://news.itsfoss.com/system76-pop-os-cosmic-de-changes/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The developers of Pop!_OS started working on their **Rust-based desktop environment** 'COSMIC' [back in 2021](https://news.itsfoss.com/pop-os-cosmic-rust/).
The goal was to make something familiar to what you already get with Pop!_OS but provide you with a faster and more extensible desktop environment.
System76 also chose [not to release Pop!_OS 22.10](https://news.itsfoss.com/no-pop-os-21-10/) to focus on its development.
Not to forget, one of our community contributors gave an early build a try, which looked pretty promising.
**Suggested Read **📖
[I Tried System76’s New Rust-based COSMIC Desktop!If you didn’t know already, System76 developers have been working on a new Desktop Environment (dubbed COSMIC) written in Rust: a memory-safe and superfast programming language. Creating a desktop environment from scratch is no small feat. That involves creating everything from the compositor,…](https://news.itsfoss.com/system76-rust-cosmic-desktop/)

Fast-forward a year, we now have a better look at what to expect with this desktop environment.
Let's explore what System76 has in store for us.
## COSMIC Desktop: 3 Key Enhancements
In a [recent blog post](https://blog.system76.com/post/more-on-cosmic-de-to-kick-off-2023?ref=news.itsfoss.com), Alex from System76 gave us a good look at the state of development of the COSMIC desktop environment.
Let me take you through the notable highlights of it:
**New UI Features****Settings Revamped****New Wallpaper Feature**
## 1. New UI Features
A new '[SegmentedButton](https://github.com/pop-os/libcosmic/pull/56?ref=news.itsfoss.com)' widget is being used for handling tabs and segmented buttons around COSMIC DE.
It is meant to give a clean, organized, and more focused menu experience, whereas the segmented buttons allow actions to be done when selected.
They also give an example to explain how this helps with the UI:
So while you’re customizing your desktop to use horizontal workspaces instead of vertical, for example, your selection will cause the desktop to reflect this behavior.
## 2. Revamped Settings
Firstly, the Settings app has received a complete overhaul, with the search results now showing up as a continuous, scrollable list of results from various settings panels.
Then there are the remakes of the various settings panels themselves. Let me take you through them:
### Display Tweaks
The developers have moved the graphics modes and night light options to the display settings panel. During testing, they found that most users go to the display settings expecting to find those settings.
Additionally, when using multiple displays, the display settings will be organized into dedicated tabs according to the display, with options to change or add a color profile.
### Power Options
This settings panel now shows the battery level of connected wireless devices and an overview of all the connected devices.
You can also select power profiles based on your requirements and limit battery charging for your Laptop to preserve battery life.
### Region and Language Selection
This setting has been divided into different categories for ease of access. They have been divided into categories to select regional formats for calendar, date, temperature, and measurement.
### Sound
A new option has been added to the Sound setting that lets you adjust the volume of individual alerts and applications.
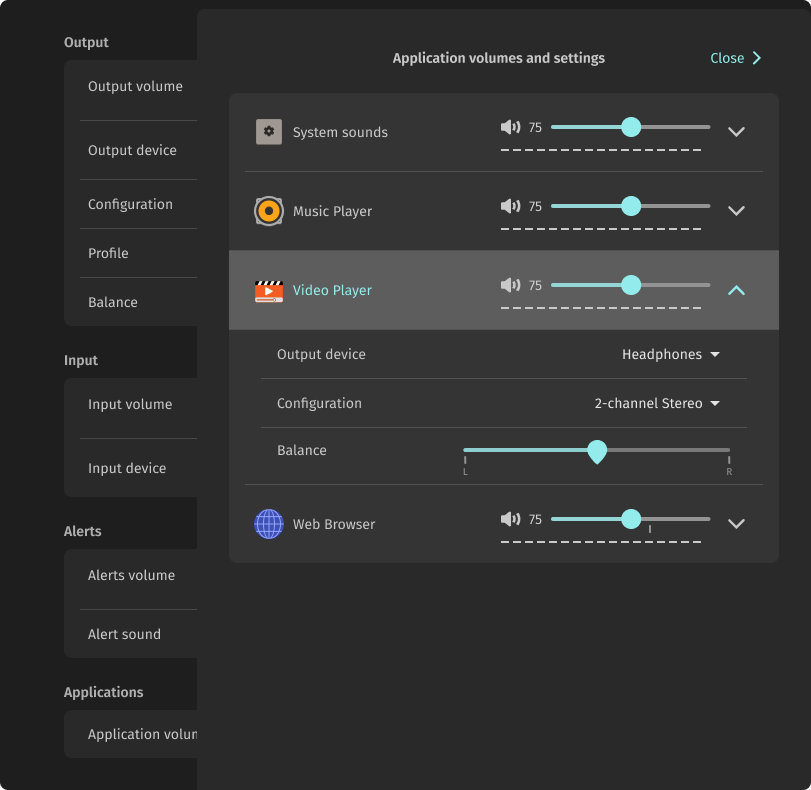
Furthermore, users with two or more speakers can now use the new speaker testing tool to optimize their setup.
## 3. New Wallpaper Feature
COSMIC DE will let you set a single wallpaper, one per display, or let you cycle through multiple wallpapers as a slideshow. Finally, **a good news for multi-monitor users!**
You will also have fine control over how long each wallpaper gets to stay on the screen before switching to the next one.
## 🛠️ Other Improvements
In addition to the user-facing changes mentioned above, several under-the-hood refinements include:
- A new Dynamic renderer, '
[iced-dyrend](https://github.com/pop-os/iced/commit/f1310e47617c3046a3cd98e20e373247f19327af?ref=news.itsfoss.com)' has been implemented by System76 Principal Engineer, meant to adjust what rendering program your GPU should use dynamically. It can switch between OpenGL or Vulkan if you have a GPU, or[Softbuffer](https://github.com/rust-windowing/softbuffer/?ref=news.itsfoss.com)if you don't. - Text rendering via '
[cosmic-text](https://github.com/pop-os/cosmic-text?ref=news.itsfoss.com)' has been paired with Softbuffer 0.2.0 to allow the software-rendering back-end for the '[libcosmic](https://github.com/pop-os/libcosmic?ref=news.itsfoss.com)' widget library to be used on any OS. - The developers have also tested an XWayland implementation that would let COSMIC DE run applications that use the X11 windowing system.
- Animations support has been added to COSMIC DE via the '
[cosmic-time](https://github.com/pop-os/cosmic-time?ref=news.itsfoss.com)' animation crate. It contains animations used by the default applications and was built using the '[Iced](https://github.com/iced-rs/iced?ref=news.itsfoss.com)' toolkit.
The developers also mentioned:
While COSMIC DE is being developed for Pop!_OS, our goal is to make its elements available for use on other operating systems, too.
This is good to hear! If you were wondering if COSMIC DE was something Pop!_OS exclusive, maybe you will be able to use it on distros, too, hopefully! 😊
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,509 | 使用 BookStack 写文档,一个开源的 Confluence 替代品 | https://opensource.com/article/23/1/bookstack-open-source-documentation | 2023-02-04T18:09:00 | [
"知识库"
] | https://linux.cn/article-15509-1.html | 
>
> BookStack 是一个开源的、基于网页的文档系统,它允许你创建一个结构化的知识库,供个人、团队或公司使用。
>
>
>
BookStack 是一个开源的、基于网页的文档系统,它允许你创建一个结构化的知识库供个人、团队或公司使用。BookStack 专注于易用性和设计,以适合具有潜在的混合技术技能的受众。它建立在 PHP 框架 Laravel 之上,使用 MySQL 或 MariaDB 作为数据存储。
在尝试为我的工作场所寻找文档或维基系统后,我构建了 BookStack。[Confluence](https://opensource.com/article/20/9/open-source-alternatives-confluence) 是最符合我要求的选项,但基于用户的定价带了的阻碍。Confluence 的封闭性也对我要构建的文档的寿命提出了质疑。最后,我决定建立自己的平台来满足我的需求。我用 MIT 许可发布它,以回馈我多年来喜爱并从中受益的开源社区。
### 内容层次和组织选项
为了保持熟悉和直观,BookStack 使用了现实世界的书籍术语来描述其组织结构。文档内容被创建为 “<ruby> 页 <rt> Page </rt></ruby>”:
* “页” 属于一个特定的 “<ruby> 书 <rt> Book </rt></ruby>”。
* 在一本书中,“页” 可以选择性地被分组为 “<ruby> 章节 <rt> Chapter </rt></ruby>”。
* 随着文档的增长,你可以使用 “<ruby> 书架 <rt> Shelve </rt></ruby>” 来对 “书” 进行分类,如果需要,“书” 可以成为多个书架的一部分。
这种结构是 BookStack 的核心,而且往往是决定 BookStack 是否适合你的使用情况的选择因素。
在这个核心层次上,BookStack 还提供了标签、用户收藏夹和高级搜索功能,以确保内容可被发现。
### 编写文档
在 BookStack 中编写文档的主要方法是通过使用其所见即所得(WYSIWYG)编辑器,它利用了开源的 [Tiny](https://github.com/tinymce/) 项目。这个编辑器提供了一系列的内容格式,包括:
* 各种标题级别
* 代码块
* 可折叠的块
* 表格
* 图片
* 链接
* iFrame 嵌入
* 提醒呼出
* 项目符、编号和任务列表
* 绘图(通过与开源 [diagrams.net](https://www.diagrams.net/) 的整合)
如果你喜欢 [Markdown](https://opensource.com/article/19/9/introduction-markdown),你可以使用内置的 Markdown 编辑器,它提供实时预览并支持与所见即所得编辑器相同的功能集。如果权限允许,你甚至可以根据你所编辑的页面,在这些编辑器选项之间跳转。
### 你的数据是如何存储的
如果使用了 Markdown,除了原始的 Markdown 内容外,文档以相对简单的 HTML 格式存储在 [MySQL 或 MariaDB](https://opensource.com/downloads/mariadb-mysql-cheat-sheet) 数据库中。很多设计和开发决定都是为了保持这种 HTML 格式的简单性。它尽可能地使用普通的标准 HTML 元素,以确保原始文档内容保持开放和可移植。
上传的图片、附件和创建的图纸被保存在本地文件系统中,但也可以选择存储在一个与 s3 兼容的数据存储中,比如开源的 [MinIO](https://github.com/minio/)。
为了保持你的内容可访问性,有内置的选项可以将内容导出为 PDF、HTML、纯文本或 Markdown。对于外部使用,有一个 HTTP REST API 和一个 Webhook 系统。在扩展方面,一个 “逻辑主题系统” 允许在广泛的系统事件中运行自定义的 PHP 代码。
### 为商业做好准备
BookStack 具有一系列的功能来支持商业环境。内置了对一系列认证选项的支持,包括 SAML2、OpenID Connect 和 LDAP,允许使用 [KeyCloak](https://www.keycloak.org/) 等平台轻松实现单点登录。也支持多因子认证(MFA),并且可以根据角色进行授权。审计日志提供整个实例的修改活动的完整可见性。
一个完全基于角色的权限系统为管理员提供了对系统内容的创建、查看、更新和删除操作的完全控制。这允许每个角色的系统默认值,以及在每个层次项目基础上设置自定义权限的选项。
### 支持的社区
经过 7 年多的积极开发,BookStack 的社区已经发展到了各种讨论和支持的渠道。我们现在有:
* [我们的文档站点](https://www.bookstackapp.com/docs/)
* [YouTube 上的视频指南](https://www.youtube.com/c/BookStackApp)
* [一个 subreddit](https://www.reddit.com/r/bookstack)
* [一个活跃的 GitHub 问题列表](https://github.com/BookStackApp/BookStack/issues)
* [付费业务支持](https://www.bookstackapp.com/support)
如果你想体验一下 BookStack,你可以 [在我们的演示网站](https://demo.bookstackapp.com/books/bookstack-demo-site/page/logging-in-to-the-demo-site) 试试。要了解如何设置你自己的实例,请访问 [我们文档中的安装页面](https://www.bookstackapp.com/docs/admin/installation/)。
---
via: <https://opensource.com/article/23/1/bookstack-open-source-documentation>
作者:[Dan Brown](https://opensource.com/users/ssddanbrown) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | BookStack is an open source, web-based documentation system, that allows you to create a structured knowledge store for personal, team, or company use. BookStack focuses on ease-of-use and design to provide an experience suitable for an audience with, potentially, mixed skills in technology. It's built upon the PHP framework Laravel, with MySQL or MariaDB used as a datastore.
I built BookStack after attempting to find a documentation or wiki system for my workplace. [Confluence](https://opensource.com/article/20/9/open-source-alternatives-confluence) was the closest option to suit my requirements but the user-based pricing introduced a barrier. The closed nature of Confluence also raised questions to the longevity of the documentation I'd be building. In the end, I decided to build my own platform to suit my needs. I released it under the MIT license to give back to the open source community that I'd come to love and benefit from over the years.
## Content hierarchy and organization options
To keep things familiar and intuitive, BookStack makes use of real-world book terms to describe its organization structure. Documentation content is created as a "Page":
- Pages belong to a specific "Book".
- Within a Book, Pages can optionally be grouped up into "Chapters".
- As your documentation grows, you can then use "Shelves" to categorize Books, with Books being able to be part of multiple shelves if needed.
This structure sits at the heart of BookStack, and can often be the love-it-or-hate-it deciding aspect of whether BookStack is suitable for your use case.
Upon this core hierarchy, BookStack also provides tagging, user favorites, and advanced search capabilities to ensure content remains discoverable.
## Writing documentation
The primary method of writing documentation in BookStack is through the use of its what-you-see-is-what-you-get (WYSIWYG) editor, which makes use of the open source [Tiny](https://github.com/tinymce/) project. This editor provides a range of content formats including:
- Various header levels
- Code blocks
- Collapsible blocks
- Tables
- Images
- Links
- iFrame embeds
- Alert callouts
- Bullet, numbered and tasks lists
- Drawings (through intregration with the open source
[diagrams.net](https://www.diagrams.net/))
If you prefer [Markdown](https://opensource.com/article/19/9/introduction-markdown), you can use the built-in Markdown editor, which provides a live preview and supports the same feature set as the WYSIWYG editor. If permission allows, you can even jump between these editor options depending on the page you're editing.
## How your data is stored
Documentation is stored within a [MySQL or MariaDB](https://opensource.com/downloads/mariadb-mysql-cheat-sheet) database in a relatively simple HTML format, in addition to the original Markdown content if Markdown was used. A lot of design and development decisions have been made to keep this HTML format simplistic. It uses plain standard HTML elements where possible, to ensure raw documentation content remains open and portable.
Uploaded images, attachments, and created drawings are saved on the local filesystem but can optionally be stored in an s3-compatible datastore like the open source [MinIO](https://github.com/minio/).
To keep your content accessible, there are built-in options to export content as PDF, HTML, plain text, or Markdown. For external consumption, there's a HTTP REST API and a webhook system. In terms of extension, a "logical theme system" allows running of custom PHP code upon a wide range of system events.
## Ready for business
BookStack comes with a range of features to support business environments. Support for a range of authentication options are built-in, including SAML2, OpenID Connect, and LDAP allowing easy single-sign-on usage with platforms such as [KeyCloak](https://www.keycloak.org/). MFA options are available and can be mandated based upon role. An audit log provides full visibility of modification activities across an instance.
A full role-based permission system provides administrators full control over create, view, update, and delete actions of system content. This allows per-role system defaults, with options to set custom permissions on a per-hierarchy item basis.
## A community of support
After being active for over 7 years, the community for BookStack has grown with various avenues for discussion and support. We now have:
[Our documentation site](https://www.bookstackapp.com/docs/)[Video guides on YouTube](https://www.youtube.com/c/BookStackApp)[A subreddit](https://www.reddit.com/r/bookstack)[An active GitHub issues list](https://github.com/BookStackApp/BookStack/issues)[Paid-for business support](https://www.bookstackapp.com/support)
If you want to play with BookStack, you can try it out [on our demo site](https://demo.bookstackapp.com/books/bookstack-demo-site/page/logging-in-to-the-demo-site). To learn how to set up your own instance, visit the [installation page of our documentation](https://www.bookstackapp.com/docs/admin/installation/).
## Comments are closed. |
15,511 | LibreOffice 7.5 发布:漂亮的新应用图标和酷炫功能 | https://news.itsfoss.com/libreoffice-7-5-release/ | 2023-02-05T11:24:00 | [
"LibreOffice"
] | https://linux.cn/article-15511-1.html |
>
> 通过全新的应用程序图标和其他改进,LibreOffice 7.5 似乎有了新的形象。
>
>
>

LibreOffice 7.5 社区版来了,带来**许多功能升级和新的应用图标**。
之前的主要版本 [7.4 版](https://news.itsfoss.com/libreoffice-7-4-release/) 为微软的专有文件格式提供了更好的 “互操作性”,并**进一步巩固了 LibreOffice** 作为 Linux 上 [微软 Office 的最佳开源替代品](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/) 之一的地位。
而现在,一个新的版本来了,里面有很多东西。
让我们来看看带来了什么好东西。
### ? LibreOffice 7.5 的新变化
在这个版本中,对 LibreOffice 的所有程序都做了大量的改进;一些关键的亮点包括:
* 新的应用程序图标
* Writer 的改进
* Calc 的改进
* Impress & Draw 的改进
* 深色模式的改进
#### 新的应用程序图标

LibreOffice 现在具有一套新的应用程序图标,看起来相当现代。这些图标在 GNOME 和 KDE Plasma 等新一代的桌面环境中看起来都很漂亮。
下面是它与旧图标的对比情况。令人耳目一新,对吗?

同样,开发者也更新了 LibreOffice 整个界面上用于各种媒体类型/文件的图标集。
#### Writer 的改进

Writer 应用程序得到了大量的改进,值得注意的包括:
* 增加了一个新的纯文本类型。
* 标题和标签的内容控件。
* 新的组合框类型和将内容控件导出为 PDF 的能力。
* 对丹麦语、荷兰语、爱沙尼亚语、德语、匈牙利语、挪威语和瑞典语等语言的拼写检查有所改进。
* 在表格中,当列与合并单元格相交时,对它的检测得到了改进。
* 书签的编辑和可访问性得到了改进。
* 一个可以应用于图像、嵌入对象和文本框的装饰性标签,以允许辅助软件在导出的 PDF 中忽略它们。
#### Calc 的改进

在非文本格式的单元格中,带有前导撇号(')的单元格输入现在将永久删除第一个撇号以防止混淆。
增加了对 Kamenický 和 Mazovia 编码的支持,同时对条件格式化进行了改进。
此外,在函数向导中搜索一个术语时,现在会通过函数描述以及它们的名称进行匹配。
#### Impress & Draw 的改进
Impress 现在支持在媒体形状中添加裁剪过的视频,还修复了 EMF 图形的模糊问题。

在 Draw 里,增加了对修改表格样式和创建新表格的基本支持。修改后的样式被保存到文档中,并可以做成模板和共享。
>
> ?️ 你可以通过右键单击 “表格设计” 侧边栏面板中的设计来访问修改表格样式的功能。
>
>
>
#### ?️ 其他变化和改进
这些并不是 7.5 版本中对 LibreOffice 的唯一改进。
像\*\*更好地支持深色和高对比度的主题,支持图表中的数据表格,对核心的各种改进,以及更多的东西使它成为一个完善的版本。一些改进是针对 macOS 和 Windows 等平台的,以及针对 Linux 的。
你可以从 [官方发布说明](https://wiki.documentfoundation.org/ReleaseNotes/7.5) 或 [公告](https://blog.documentfoundation.org/blog/2023/02/02/tdf-announces-libreoffice-75-community/) 中查看所有的技术变化。
### 下载 LibreOffice 7.5
LibreOffice 7.5 可以从 [官方下载页面](https://www.libreoffice.org/download/download-libreoffice/) 获得。
你可以找到 deb 和 rpm 文件以及用于 Windows 和 macOS(Intel/ARM)的 软件包。
>
> **[LibreOffice 7.5](https://www.libreoffice.org/download/download-libreoffice/)**
>
>
>
你也可以选择 Torrent 文件以获得更顺畅的下载体验。
对于现有的用户,根据你的 Linux 发行版,预计在未来几天/几周会有更新。你可以选择 Flatpak 包以更快地获得最新版本。
---
via: <https://news.itsfoss.com/libreoffice-7-5-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

LibreOffice 7.5 community edition is here with **many feature upgrades and new app icons**.
The previous major release [version 7.4](https://news.itsfoss.com/libreoffice-7-4-release/) bought in better 'interoperability' with Microsoft's proprietary file formats and **further solidified LibreOffice** as one of the [best open-source alternatives to Microsoft Office](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/?ref=news.itsfoss.com) on Linux.
And now, a new release is here with a lot in store.
Let's take a look at what this has to offer.
## 🆕 LibreOffice 7.5: What's New?
With this release, plenty of improvements have been made to all the programs of LibreOffice; some key highlights include:
**New App Icons****Writer Improvements****Calc Improvements****Impress & Draw Improvements****Dark mode improvement**
### New App Icons

LibreOffice now features a new set of app icons that look pretty modern. These will look neat with current-gen desktop environments such as GNOME and Plasma.
Here's how it looks compared to the old icon; refreshing, right?
Similarly, the developers have also updated the icon set used throughout LibreOffice's interface for various media types/files.
### Writer Improvements
The Writer app has received a host of improvements, notable ones include:
- A new plain text type was added.
- Content controls for titles and tags.
- New combo box type and ability to export content controls to PDF.
- Spellcheck has improved for various languages such as Danish, Dutch, Estonian, German, Hungarian, Norwegian, and Swedish.
- In case of tables, column detection has improved when it intersects with merged cells.
- Bookmark editing and accessibility has been improved.
- A decorative tag can be applied to images, embedded objects, and text frames to allow assistive software to ignore them in exported PDFs.
### Calc Improvements
Cell inputs with the leading ' apostrophe in cells that are not formatted as Text will now permanently remove the first apostrophe to prevent confusion.
Support for Kamenický and Mazovia encodings was added, alongside improvements to conditional formatting.
In addition, when searching for a term in the Function Wizard, it will now match the function descriptions as well as their names.
### Impress & Draw Improvements
Impress now has support for adding cropped videos in media shapes and also includes a fix for an EMF graphics issue where it would appear blurry.
In the case of Draw, essential support was added for modifying table styles and creating new ones. Modified styles are saved into the document and can be made into templates and shared.
### 🛠️ Other Changes and Improvements
These were not the only improvements to LibreOffice with the 7.5 release.
Things like **better support for dark and high contrast themes**, support for data tables in charts, various improvements to the core, and more make this a packed release. Some refinements are targeted for platforms like macOS and Windows, along with Linux.
You can check all the technical changes from the [official release notes](https://wiki.documentfoundation.org/ReleaseNotes/7.5?ref=news.itsfoss.com) or the [announcement](https://blog.documentfoundation.org/blog/2023/02/02/tdf-announces-libreoffice-75-community/?ref=news.itsfoss.com).
## Download LibreOffice 7.5
LibreOffice 7.5 is available from the [official download page](https://www.libreoffice.org/download/download-libreoffice/?ref=news.itsfoss.com).
You can find deb and rpm files along with packages for Windows and macOS (Intel/ARM).
You can also opt for a Torrent file for an even smoother download experience.
For existing users, depending on your Linux distribution, expect an update in the coming days/weeks. You may opt for the Flatpak package for faster access to the latest version.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,512 | GNOME 截图工具的新旧截图方式 | https://www.debugpoint.com/gnome-screenshot-tool-usage/ | 2023-02-05T14:20:00 | [
"截图",
"GNOME"
] | /article-15512-1.html |
>
> 以下是关于 GNOME 截图工具的细节,它的用法、安装方法以及如何用新旧两种方式启动它们。
>
>
>

2022 年,GNOME 改变了其默认的截图工具,并将截图功能构建为 GNOME Shell 的一部分。它不再是一个独立的应用了。
早些时候,GNOME 为主要的 Linux 发行版,如 Ubuntu 和 Fedora,提供了一个原生的 GTK 应用 gnome-screenshot。然而,从 [GNOME 42](https://www.debugpoint.com/gnome-42/) 开始,这个功能已经被移除。因此从 [Ubuntu 22.04](https://www.debugpoint.com/ubuntu-22-04-review/) 和 Fedora 36 开始,你只能得到以下新的截图 UI 作为默认的截图工具。
这一变化从根本上破坏了许多工作流程。因为它不是一个你可以单独启动的可执行文件,你只能依赖键盘上的 `Print-Screen` 键。而且只能通过应用搜索找到它的快捷方式。
因此,在新的 GNOME 截图 UI 中捕捉延迟的屏幕截图变得更有挑战性。
下面是一些你仍然可以使用旧的 GNOME 截图工具的方法,以及如何手动触发新的截图 UI。
### GNOME 截图工具:如何安装旧版 GUI
如果你使用的是 Ubuntu 22.04 及以上版本,或者任何基于 Ubuntu 的带有 GNOME 桌面的发行版,运行以下命令来安装它。
```
sudo apt install gnome-screenshot
```
而对于 Fedora 用户,使用下面的命令。
```
sudo dnf install gnome-screenshot
```
如果你在 Arch Linux 或者 Manjaro Linux 中使用 GNOME 桌面,那么使用下面的命令来安装它。
```
pacman -S gnome-desktop
```
安装后,通过应用程序菜单启动它。


为了进一步定制,你可以打开设置,从 GNOME Shell 的新 UI 中移除 `Print-Screen` 的按键绑定,并通过以下命令创建一个自定义的键盘快捷方式:
```
gnome-screenshot --window <窗口>
gnome-screenshot --area <区域>
gnome-screenshot <全屏>
```
### GNOME 截图 UI:如何通过命令行手动触发它
当你从键盘上按下 `Print-Screen` 键时执行的功能是 [GNOME Shell 代码](https://gitlab.gnome.org/GNOME/gnome-shell/-/blob/main/js/ui/screenshot.js#L2210) 的一部分。不幸的是,它被保护在 dbus API 内,你不能直接调用它。
这样做是为了让你在 Wayland 下安全,这样就不会有任意的代码通过任何脚本获得对 dbus 调用函数的访问。
然而,这破坏了许多使用场景和人们多年来编写的脚本。例如,许多用户报告说 [Zoom](https://www.debugpoint.com/zoom-install-linux-ubuntu-download/) 在 GNOME-Wayland 下的视频会议通话 [中断](https://community.zoom.com/t5/Meetings/Wayland-screen-sharing-broken-with-GNOME-41-on-Fedora-35/m-p/22539) 就是因为这个原因,最终通过下面这个关闭安全模式的方法解决了这个问题。
让我们看看如何关闭它并触发 gnome-shell 的截图。
在使用下面的步骤之前,请谨慎行事。因为它可能会开放你的 GNOME Shell,让你任意访问脚本。请确保你知道你在做什么。
首先,你需要打开 [GNOME looking glass](https://wiki.gnome.org/Projects/GnomeShell/LookingGlass) 来关闭安全模式。
按 `ALT+F2` 并输入以下内容:
```
lg
```

在顶部选择 “Evaluator”,在命令窗口中,输入以下内容。然后点击回车。
```
global.context.unsafe_mode = true
```

你应该看到一个响应,即它已被关闭。

现在按 `Esc` 键关闭 “looking glass”。并打开一个终端。
输入以下内容以启动截图工具:
```
gdbus call --session --dest org.gnome.Shell --object-path /org/gnome/Shell --method org.gnome.Shell.Eval 'Main.screenshotUI.open();'
```
你应该看到新的 GNOME Shell 截图被触发了。

如果你想关闭它,再次打开 `lg` 并将其设置为 `false`。
```
global.context.unsafe_mode = false
```
### 结束语
从使用上来说,通过关闭安全模式,你仍然可以通过任何 shell 脚本使用新的截图功能。但不建议这样做。最好是使用旧的 GNOME 截图工具来避免所有的麻烦。
干杯。
---
via: <https://www.debugpoint.com/gnome-screenshot-tool-usage/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,514 | 发现 Linux SpaceFM 文件管理器的威力 | https://opensource.com/article/22/12/linux-file-manager-spacefm | 2023-02-06T15:55:00 | [
"文件管理器"
] | https://linux.cn/article-15514-1.html | 
>
> 如果你对 Linux 上的文件管理器感到满意,但你想尝试一个设计上有点不同的文件管理器,SpaceFM 值得一看。
>
>
>
SpaceFM 是一个使用 GTK 工具包的 Linux 的标签式文件管理器,所以它很适合在 [GNOME](https://opensource.com/article/19/12/gnome-linux-desktop)、[Mate](https://opensource.com/article/19/12/mate-linux-desktop)、[Cinnamon](https://opensource.com/article/19/12/cinnamon-linux-desktop) 等的桌面上使用。SpaceFM 还具有一个内置的设备管理器系统,所以它特别适合于 [Fluxbox](https://opensource.com/article/19/12/fluxbox-linux-desktop) 或 [fvwm](https://opensource.com/article/19/12/fvwm-linux-desktop) 之类的窗口管理器,它们通常不包括图形设备管理器。如果你对 Linux 上的文件管理器满意,但你想尝试一个设计上有点不同的文件管理器,SpaceFM 值得一看。
### 安装 SpaceFM
在 Linux 上,你可能会在你的发行版的仓库中找到 **SpaceFM**。在 Fedora、Mageia、OpenMandriva 和类似的软件中:
```
$ sudo dnf install spacefm
```
在 Debian 和基于 Debian 的系统上:
```
$ sudo apt install spacefm
```
### 面板
我不知道为什么 SpaceFM 被称为 SpaceFM,但可能是因为它致力于让你把窗口中的每一点空间都用来做有用的事情。默认情况下,SpaceFM 实际上是相当简单的、标准的文件管理器。它有一个列出你的文件的面板,一个工具栏,和一个菜单栏。

所有的“常规”规则都适用。
* **双击**打开一个目录或在其默认的应用中打开一个文件。
* **右键点击**可获得一个上下文菜单,提供许多标准选项(复制、粘贴、重命名、查看属性、创建新文件夹,等等)。
不过,SpaceFM 使自己与众不同的方式是它的面板系统。SpaceFM 默认显示一个面板。这就是占据大部分空间的文件列表窗口。但它最多可以有四个面板视图,再加上一些用于某些特定任务的额外面板。
### 打开一个新的面板
在你的文件管理器中,你可以看到两个目录,而不是看到一个目录。要在自己的窗格中调出另一个目录,按 `Ctrl+2` 或进入 “<ruby> 视图 <rt> View </rt></ruby>” 菜单,选择 “<ruby> 面板二 <rt> Panel 2 </rt></ruby>”。或者,点击菜单面板中从左开始的第二个绿点图标。
有了两个面板,你可以把文件从一个目录移到另一个目录,而不需要打开一个新的文件管理器窗口,或者你可以浏览两个目录来比较其内容。
但为什么要满足于两个面板呢?也许你更想一次看到三个目录。要在一个专门的窗格中调出第三个目录,请按 `Ctrl+3` 或进入 “<ruby> 视图 <rt> View </rt></ruby>” 菜单,选择 “<ruby> 面板三 <rt> Panel 3 </rt></ruby>”。或者,点击菜单面板中从左开始的第三个绿点图标。这个面板出现在 SpaceFM 窗口的底部。
打开三个面板后,你可以在几个目录之间移动文件,或将文件从一个公共的“垃圾场”(如你的桌面或下载文件夹)分类到特定的目录。
当然,当你尝试了三个面板,你可能会发现自己很想拥有第四个面板。要在自己的窗格中打开第四个目录,以此类推。或者,点击菜单面板中从左开始的第四个绿点图标。这个会在面板三旁边打开,并将你的 SpaceFM 窗口分成四份。

那么 *第五个* 面板呢?好吧,实际上 SpaceFM 仅有四个面板。如果你真的想有第五个面板,你必须打开一个新的 SpaceFM 窗口。然而,仍有更多的面板,用于文件列表以外的信息,可供探索。
### 特殊面板
在 “<ruby> 视图 <rt> View </rt></ruby>” 菜单中可以看到,除了文件面板外,还有一些特定的任务面板可以选择显示。这包括:
* “<ruby> 任务管理器 <rt> Task manager </rt></ruby>”:列出正在进行的文件管理器进程。这不是一个通用的任务管理器,所以要设置 nice 值或检测僵尸 PID,[htop 或 top](https://opensource.com/life/16/2/open-source-tools-system-monitoring) 仍然是你应该选择的工具。
* “<ruby> 书签 <rt> Bookmarks </rt></ruby>”:常用文件夹的链接,如桌面、文档、下载和任何你想保持方便的位置。
* “<ruby> 设备 <rt> Devices </rt></ruby>”:USB 驱动器和远程文件系统。
* “<ruby> 文件树 <rt> File tree </rt></ruby>”:按照目录继承顺序查看文件系统。
这些面板在 SpaceFM 的左侧打开,但它们是堆叠的。你可以同时打开书签、设备、任务和文件树,尽管它会有一个非常高的 SpaceFM 窗口。
### 为 SpaceFM 腾出空间
SpaceFM 是一个可配置的多任务文件管理器。它最大限度地增加了你可以在一个窗口中展示的信息,并让你决定什么是重要的,以及什么时候重要。本文重点介绍了 SpaceFM 的面板,因为至少在我看来,这些是该应用最独特的方面。然而,SpaceFM 还有很多东西,包括插件、首选项、设计模式、键盘快捷键和自定义。这不是一个小型应用,尽管它是轻量级的。花些时间在 SpaceFM 上,因为你永远不知道你会发现什么。
---
via: <https://opensource.com/article/22/12/linux-file-manager-spacefm>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | SpaceFM is a tabbed file manager for Linux using the GTK toolkit, so it fits right in on desktops like [GNOME](https://opensource.com/article/19/12/gnome-linux-desktop), [Mate](https://opensource.com/article/19/12/mate-linux-desktop), [Cinnamon](https://opensource.com/article/19/12/cinnamon-linux-desktop), and others. SpaceFM also features a built-in device manager system, so it's particularly good for window managers, like [Fluxbox](https://opensource.com/article/19/12/fluxbox-linux-desktop) or [fvwm](https://opensource.com/article/19/12/fvwm-linux-desktop), which typically don't include a graphical device manager. If you're happy with the file managers on Linux, but you want to try one that's a little bit different in design, SpaceFM is worth a look.
## Install SpaceFM
On Linux, you're likely to find **SpaceFM** in your distribution's software repository. On Fedora, Mageia, OpenMandriva, and similar:
```
````$ sudo dnf install spacefm`
On Debian and Debian-based systems:
```
````$ sudo apt install spacefm`
## Panels
I don't know why SpaceFM is called SpaceFM, but it could be because it makes a concerted effort to let you use every bit of space in its window for something useful. By default, SpaceFM is actually pretty simple, standard-issue file manager. It has a single panel listing your files, a toolbar, and a menu bar.
(Seth Kenlon, CC BY-SA 4.0)
All the "usual" rules apply.
-
**Double-click**to open a directory or to open a file in its default application. -
**Right-click**for a contextual menu providing lots of standard options (copy, paste, rename, view properties, create a new folder, and so on).
The way SpaceFM sets itself apart, though, is its panel system. SpaceFM displays one panel by default. That's the big file window listing your files. But it can have up to four panel views, plus a few bonus panels for some specific tasks.
## Opening a new panel
Instead of seeing one directory in your file manager, you can see two. To bring up another directory in its own pane, press **Ctrl+2** or go to the **View** menu and select **Panel 2**. Alternatively, click the second green dot icon from the left in the menu panel.
With two panels, you can move files from one directory to another without opening a new file manager window, or you can browse two directories to compare their contents.
But why settle for two panels? Maybe you'd rather see *three* directories at once. To bring up a third directory in a dedicated pane, press **Ctrl+3** or go to the **View** menu and select **Panel 3**. Alternatively, click the third green dot icon from the left in the menu panel. This panel appears at the bottom of the SpaceFM window.
With three panels open, you can move files between several directories, or sort files from a common "dumping ground" (like your Desktop or Downloads folder) into specific directories.
Of course, once you've tried three panels you'll probably find yourself itching for a fourth. To open a fourth directory in its own pane, press **Ctrl+4** or go to the **View** menu and select **Panel 4**. Alternatively, click the fourth green dot icon from the left in the menu panel. This one opens next to Panel 3, splitting your SpaceFM window into even quarters.
(Seth Kenlon, CC BY-SA 4.0)
What about a *fifth* panel? Well, actually SpaceFM stops at four panels. If you really do want a fifth panel, you have to open a new SpaceFM window. However, there are still more panels, used for information other than file listings, to explore.
## Special panels
The **View** menu reveals that in addition to file panels, there are additionally task-specific panels you can choose to display. This includes:
-
**Task manager**: Lists ongoing file manager processes. This isn't a general-purpose task manager, so to set nice values or detect a zombie apocalypse of undead PIDs,[htop or top](https://opensource.com/life/16/2/open-source-tools-system-monitoring)is still your utility of choice. -
**Bookmarks**: Links to common folders, such as Desktop, Documents, Downloads, and any location you want to keep handy. -
**Devices**: USB thumb drives and remote file systems. -
**File tree**: A view of your file system in order of directory inheritance.
These panels open on the left side of SpaceFM, but they do stack. You can have bookmarks, devices, tasks, and a file tree open at once, although it helps to have a very tall SpaceFM window.
## Make space for SpaceFM
SpaceFM is a configurable multi-tasking file manager. It maximizes the information you can build into a single window, and it lets you decide what's important, and when. This article has focused on the panels of SpaceFM because those are, at least in my view, the most unique aspect of the application. However, there's a lot more to SpaceFM, including plugins, preferences, a design mode, keyboard shortcuts, and customization. This isn't a small application, even though it is a lightweight one. Spend some time with SpaceFM, because you never know what you'll discover.
## 1 Comment |
15,515 | 9 款最佳的去中心化通讯软件 Matrix 的客户端 | https://itsfoss.com/best-matrix-clients/ | 2023-02-06T16:39:00 | [
"Matrix",
"去中心化"
] | https://linux.cn/article-15515-1.html | 
Matrix 是一套开放的网络标准,专用于去中心化实时加密通讯。
这套标准由 [Matrix.org](http://Matrix.org) 基金会发布和维护。[Matrix.org](http://Matrix.org) 基金会是一个非营利性组织,致力于创建一个开放、独立且不断演进的通讯平台。
如果一款应用支持 Matrix 协议,那就可以视它为 Matrix 客户端。
### 为何要选用 Matrix 客户端?
[Matrix](https://matrix.org/) 客户端致力于安全性和隐私性,并且提供了一个去中心化的网络,令许多特性得以实现。
自 2019 年(正式版本发布)以来,部分组织以及政府机构便开始逐渐采用 Matrix 协议,从而搭建安全、隐私、可靠的通讯平台。
就实际而言,去中心化的协议实现了不同组织间的相互通讯,同时也使得这个通讯协议得以抵抗审查。
如果你想要逃脱科技巨头的魔爪,那 Matrix 就是正确的选择。
不仅如此,你还可以运行自己的服务器,并加入 Matrix 网络。换言之,通讯的基础设施是去中心化的,但你仍然能够根据需要,对其进行部署和配置。
如果你好奇的话,Matrix 协议具备了你需要的所有基本功能:
* 去中心化交流
* 端到端加密
* WebRTC 语音通话 / 视频通话
* 实时同步
* 消息已读用户显示
* “正在输入中” 提示
* 群组聊天
而且,我还要再强调一次:这个项目是**开源**的!
所以,Matrix 客户端已经是不二之选了。对那些注重隐私和安全的用户来说,则更是如此。
>
> LCTT 译注:实际上,Matrix 只是在隐私和便利之间达成了一种相对的平衡。它是将类似 Mastodon 的 <ruby> 联邦 <rt> federated </rt></ruby> 网络结构用在了聊天中,也就是说,虽然整个网络去中心化成了许多节点,但节点服务器的运营者仍然能对其用户进行少量掌控。但总的来说,相对那些中心化的聊天应用而言,Matrix 是个值得考虑的替代品。
>
>
>
### 9 款最佳的开源 Matrix 客户端
本文中,我将介绍一些最好用的 Matrix 客户端,其中主要是桌面客户端(Linux、Windows、macOS),同时也推荐一些移动客户端和终端客户端。
#### 1、Element

[Element](https://itsfoss.com/element/) 是最佳的 Slack 开源替代品之一。它可以用于个人通讯,也能用于群组聊天。
你可以免费使用,不过你也可以选择自己搭建服务器,或者付费使用托管的家庭服务器。Element 提供了许多有用的功能,让你能够高效协作,并与你的团队或好友加密通讯。
>
> LCTT 译注:如同 Mastodon 一样,自费搭建服务器或者付费使用服务器,对大部分用户而言都是不必要的。初学者建议前往 <https://joinmatrix.org/servers/>,并选择一个现有的服务器进行注册,其中许多服务器都是免费开放注册,并且国内可以连接的。下述的订阅功能也并不是必要的。
>
>
>
如果你选择付费订阅,你还能将 Signal、WhatsApp 和 Telegram 聊天并入其中。
它支持 Linux、Windows 和 macOS,同时还提供 Android 和 iOS 的手机客户端。并且,你还能在网页浏览器中使用它。因此,这是个方便的选择。
>
> LCTT 译注:国内用户可能会在桌面客户端遇到错误,导致无法使用 Element。这是因为它在首次启动会连接 [matrix.org](http://matrix.org),但是国内用户无法访问这个地址。要解决此问题,须手动修改配置文件(篇幅有限,详见相关教程)。实在无法解决,可使用基于 Element 的 [SchildiChat](https://schildi.chat/),或下文列出的其他客户端。
>
>
>
>
> **[Element](https://element.io/)**
>
>
>
#### 2、Rocket.Chat

[Rocket.Chat](https://itsfoss.com/rocket-chat/) 是另一个 Slack 替代品,我们更喜欢把它当成团队内部的通讯工具。
你可以在 Linux、Windows 和 macOS 上使用它,也可以获取 Android 和 iOS 的手机应用。
尽管你可以选择自建服务器或付费订阅,但它也宣布正在添加 [Matrix 协议的支持](https://news.itsfoss.com/rocket-chat-matrix/)。
本文创作之时,已经可以在 alpha 版中使用 Matrix 网络。不过,稳定版应该很快就会发布了。所以,如果你已经在使用 Rocket.Chat,或者想把它当作 Matrix 客户端来使用,那么敬请关注后续版本的发布。
>
> **[Rocket.Chat](https://rocket.chat/)**
>
>
>
#### 3、NeoChat

NeoChat 是一个简单的 Matrix 客户端,目前在 KDE 社区的管理下积极开发。
与 Element 不同,它只支持 Linux 和 Windows,特别是为 KDE Plasma 量身定做。你也可以在其他桌面环境使用它。
你可以在 KDE 的 “<ruby> 发现 <rt> Discover </rt></ruby>” 软件中心、Flathub 以及 Snap 商店安装它。它不支持手机平台。所以,如果有桌面用户想要一个简单的 Matrix 客户端,那 NeoChat 也是一个不错的选择。
>
> LCTT 译注:纠正一下,NeoChat 也支持安卓,可直接下载二进制,也可在 F-Droid 中添加 KDE 仓库后下载。除此之外,它还支持 macOS。详见其源代码仓库。
>
>
>
了解更多,可以查看它的 [源代码](https://invent.kde.org/network/neochat)。
>
> **[NeoChat](https://apps.kde.org/neochat/)**
>
>
>
#### 4、FluffyChat

FluffyChat 在用户体验方面,是一个美观(可爱)的 Matrix 客户端。
如果你想要一个简单又直观的 Matrix 客户端,并且支持桌面和手机(安卓和 iOS),那么 FluffyChat 是一个不错的选择。
Linux 用户可以从 Snap 商店或 Flathub 安装它。它并不提供 Windows 和 macOS 的原生应用支持,但你可以在网页浏览器中使用它。
如果你好奇的话,可以从它的 [GitLab 页面](https://gitlab.com/famedly/fluffychat) 了解更多。
>
> **[FluffyChat](https://fluffychat.im/)**
>
>
>
#### 5、Fractal

Fractal 是一款用于 GNOME 桌面的 Matrix 聊天客户端,使用 Rust 编写。正如其描述所说,它的界面经过优化,适合大型团队的协作。
由于它以 Flatpak 的形式发布,你可以在任何 Linux 发行版上安装它,无论桌面环境如何。
如果你喜欢能够在系统上快速运行的应用,那 Fractal 可能是不错的选择。可以前往它的 [GitLab 页面](https://gitlab.gnome.org/GNOME/fractal) 了解更多。
>
> **[Fractal](https://wiki.gnome.org/Apps/Fractal)**
>
>
>
#### 6、Hydrogen Web(实验性)

在找其它的精简的(专注性能)Matrix 客户端吗?
Hydrogen 聊天客户端提供轻量级体验、离线功能,并有着广泛的浏览器支持。
虽然仍未完工,但 Element 背后的同一支团队正在开发着它。所以,如果你期待看到一个轻量的 Matrix 客户端替代品,你可以在它的 [GitHub 页面](https://github.com/vector-im/hydrogen-web/) 跟进该项目。
>
> **[Hydrogen](https://github.com/vector-im/hydrogen-web/)**
>
>
>
#### 7、Matrix Commander(基于命令行)
如果你想要用终端在 Matrix 网络上来收发文字消息,这个命令行工具就十分不错。
当然,并非一切都能在终端完成。所以,最好创建 cron 任务来实现消息提醒、机器人等用例。
你可以在 [PyPi](https://pypi.org/project/matrix-commander/) 或者 Docker Hub 上找到它。
>
> **[Matrix Commander](https://github.com/8go/matrix-commander)**
>
>
>
#### 8、Gomuks(基于命令行)

想试试用 Go 写的终端 Matrix 客户端?
并非每个人都可以尝试。不过,如果你喜欢用 Go 写的命令行工具,可以用 Gomuks 这个简单的 Matrix 客户端来进行基本聊天。
你可以在它的 [GitHub Releases 部分](https://github.com/tulir/gomuks/releases) 找到其 Linux、Windows 和 macOS 的二进制文件。
>
> **[Gomuks](https://maunium.net/go/gomuks/)**
>
>
>
#### 9、Syphon(Alpha 版)

我们通常会避免列出仍处于早期开发的程序。但是,Syphon 作为一个手机专用的 Matrix 客户端,是一个有趣的选择。
如果你想要为你的安卓 / iOS 设备安装一个类似 Signal 的开源 Matrix 客户端,那选择 Syphon 也不错。用户界面看起来很熟悉(但并不是完全照抄的)。如果你想实验一下,那可以试试。
>
> **[Syphon](https://syphon.org/)**
>
>
>
### 总结
Matrix 协议也许没能流行于所有组织和人群之中。但是,可以证明的是,作为一个开源项目,它能称得上是一个隐私可靠的去中心化网络。
最好的一点在于,你可以选择你想要的客户端,而不必被迫使用特定的应用才能在多个设备之间进行通信。
所以,你会选择什么作为你最喜欢的 Matrix客户端?
---
via: <https://itsfoss.com/best-matrix-clients/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:[Peaksol](https://github.com/TravinDreek) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Matrix is an open network standard tailored for secure decentralized real-time communication.
It is published and maintained by a non-profit, Matrix.org Foundation. They aim to create an open, independent, and evolving communication platform.
If an application supports the Matrix protocol, you can consider it a Matrix client.
## Why Should You Choose a Matrix Client?
[Matrix](https://matrix.org/?ref=itsfoss.com) clients focus on security and privacy and offer a decentralized network that provides opportunities for numerous things.
Since 2019 (when it got out of beta), several organizations and government authorities have gradually adopted the Matrix protocol to empower their communication platforms for security, privacy, and reliability.
For instance, a decentralized protocol makes way for cross-communication between organizations and gives you a communication protocol that is resistant to censorship.
Matrix protocol is the right choice if you want something that gets you away from the big tech.
Not just limited to that, you also get the ability to run your server to join the Matrix network. In other words, you get a decentralized infrastructure for communication while still having some control over it to set it up and configure it as per your requirements.
In case you are curious, Matrix protocol has all the essential features one would need, including:
- Decentralized conversations
- End-to-End encryption
- WebRTC VoIP/Video calling
- Real-time sync
- Read receipts
- Typing Notifications
- Group conversations
And I should highlight this again: It is an **open-source** project!
So, it is a no-brainer to opt for Matrix clients, especially now that more users care about their privacy and security.
Here, I shall highlight some of the most helpful open-source Matrix clients, primarily for desktop (Linux, Windows, macOS), while mentioning mobile and terminal clients.
## 1. Element
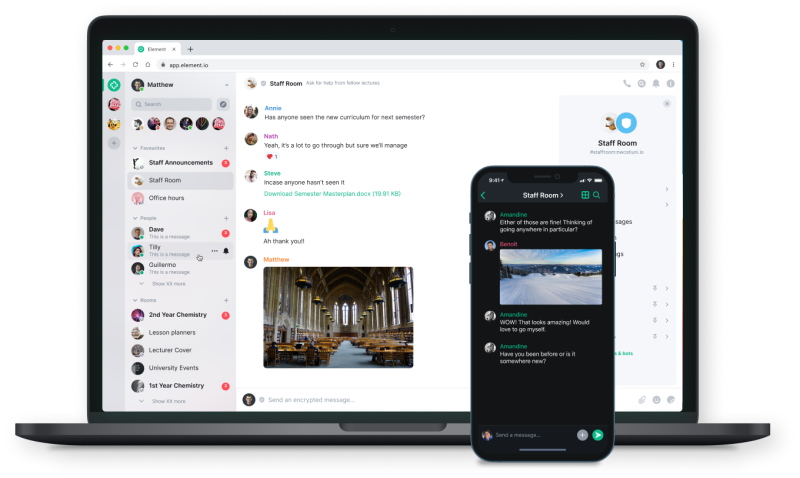
[Element](https://itsfoss.com/element/) is one of the best open-source Slack alternatives. You can use it for personal communication and team chat as well.
It is free to get started, but you can self-host your server or pay a premium for a managed home server. You get various useful features to collaborate effectively and securely communicate with your team/friends.
If you opt to pay for a subscription, you can even bring your Signal, WhatsApp, and Telegram chats into one place.
It supports Linux, Windows, and macOS while offering a proper mobile client for Android and iOS. Additionally, you can use it through the web browser. So, it should be a convenient option.
## 2. Rocket.Chat
[Rocket.Chat](https://itsfoss.com/rocket-chat/) is yet another Slack alternative that we used for our internal team communication and liked it for the time we interacted with it.
It is available for Linux, Windows, and macOS. You also get mobile applications for Android and iOS.
While it allows you to self-host or opt for a premium subscription, it also announced adding [support for Matrix protocol integration](https://news.itsfoss.com/rocket-chat-matrix/?ref=itsfoss.com) in 2022.
So, Rocket.Chat can be a flexible option for your use-case, with or without Matrix protocol integration.
[Start free with $5 welcome credit](https://www.pikapods.com/)😎
## 3. NeoChat
NeoChat is a simple Matrix client actively developed under KDE’s umbrella.
Unlike Element, it is only available for Linux and Windows, and particularly tailored for KDE Plasma. You can use it on other desktop environments as well.
You can install it through KDE’s Discover software center, Flathub, and Snap Store. It is not available for mobile platforms. So, it can be a good candidate for desktop users who prefer a straightforward Matrix client.
Check out its [source code](https://invent.kde.org/network/neochat?ref=itsfoss.com) to explore more about it.
## 4. FluffyChat
FluffyChat makes up for a good-looking (cute) Matrix client in terms of user experience.
If you want a simple and intuitive Matrix client on your desktop with mobile apps (Android and iOS) available, FluffyChat is an impressive option.
For Linux, you can install it from the Snap Store or Flathub. It does not offer native apps for Windows and macOS, but you can use it through the web browser.
If you are curious, you can check out its [GitHub page](https://github.com/krille-chan/fluffychat).
## 5. Fractal
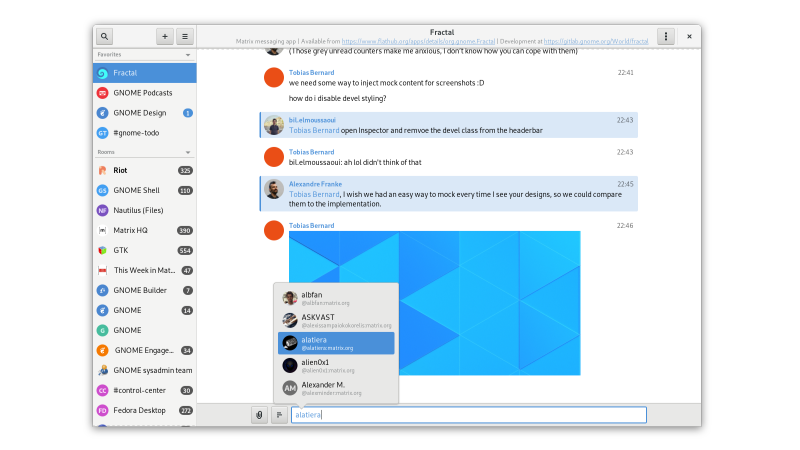
Fractal is a Matrix messaging client for GNOME desktop, written in Rust. As described, it provides an optimized interface fit for collaboration in large groups.
Considering it is available as a Flatpak, you can install it on any Linux distribution, irrespective of the desktop environment.
Fractal seems an excellent option for users focusing on applications that perform the fastest on their system. You can head to its [GitLab page](https://gitlab.gnome.org/GNOME/fractal?ref=itsfoss.com) to research more about it.
## 6. Hydrogen Web (Experimental)
Looking for another minimal (performance-focused) Matrix client?
Hydrogen is a chat client that aims to provide a lightweight experience, offline functionality, and wide browser support.
While it is still a work in progress, it is being developed by the same team behind the Element messenger. So, if you longingly expect a lightweight Matrix client as an alternative to others, you might want to follow the project on its [GitHub page](https://github.com/vector-im/hydrogen-web/?ref=itsfoss.com).
## 7. Matrix Commander (CLI-based)
This command-line tool can be the perfect fit if you want to use the terminal to send/receive text messages via the Matrix network.
Of course, you cannot do everything from the terminal. So, it is best suited for creating cron jobs for message reminders, or bots, and similar use-cases.
You can find it on [PyPi](https://pypi.org/project/matrix-commander/?ref=itsfoss.com) and Docker Hub as well.
## 8. Gomuks (CLI-based)
Need a terminal-based Matrix client written in Go?
Not for everyone to try. But, if you are someone who likes to use command-line tools written in Go, Gomuks can be a straightforward Matrix client for basic messaging.
You can find the binaries for Linux, Windows, and macOS on its [GitHub releases section](https://github.com/tulir/gomuks/releases?ref=itsfoss.com).
## 9. Syphon (Alpha)
We usually avoid listing programs in their early stages of development. However, Syphon is an interesting option as a mobile-exclusive Matrix client.
If you want a Signal-like open-source Matrix client for your Android/iOS device, Syphon can be an exciting choice. The user interface looks familiar (but not an exact copy of it). You can try it out if you are looking to experiment.
## Wrapping Up
Matrix protocol may not be entirely popular across every organization and demographic. However, it is proving to be one of the most robust decentralized networks for privacy and reliability as an open-source project.
The best thing is that you get to choose the client you want, without being forced to use a particular app for communication across multiple devices.
So, what would you pick as your favorite Matrix client? |
15,517 | 在 GNOME Boxes 里的客体机和宿主机之间共享文件夹 | https://www.debugpoint.com/share-folder-gnome-boxes/ | 2023-02-07T12:13:00 | [
"虚拟机",
"共享",
"Boxes"
] | /article-15517-1.html | 
>
> 使用下面的步骤在 GNOME Boxes 应用中的宿主机和客体机之间共享一个文件夹。
>
>
>
GNOME Boxes 是一个创建和管理虚拟机的前端应用。它主要是为 GNOME 桌面开发的。然而,你可以在其他桌面环境中使用它,如 KDE Plasma 和其他环境。
在后端,它使用 QEMU、KVM 和 libvirt 技术,并提供一个易于使用的用户界面来管理多个虚拟机。
如果你想了解更多,你也可以参考关于 GNOME Boxes 创建虚拟机的 [这些指南](https://www.debugpoint.com/tag/boxes)。
在之前的文章中,我们已经解释了如何在 [virt-manager](https://www.debugpoint.com/share-folder-virt-manager/) 和 [VirtualBox](https://www.debugpoint.com/share-folder-between-host-guest-virtualbox/) 中共享文件夹。而下面的步骤也解释了 GNOME Boxes 的情况。
### 如何在 GNOME Boxes 中共享文件夹和文件
GNOME Boxes 主要支持 [SPICE 协议](https://www.spice-space.org/index.html) 来实现远程访问、共享和许多虚拟化功能。SPICE 是虚拟化领域中最古老的开源包之一。
#### 1、初始设置
首先,确保在**客体机系统中安装以下 spice 软件包**。
```
sudo apt install spice-vdagent spice-webdavd # for Ubuntu-based distros
sudo dnf install spice-vdagent spice-webdavd # Fedora, RHEL, etc
pacman -S --needed spice spice-gtk spice-protocol spice-vdagent # Arch Linux (optional)
```
在你安装完上述内容后,**重启**宿主机和客体机系统。
在宿主机系统中(对于 GNOME 桌面),打开 “<ruby> 设置 <rt> Settings </rt></ruby>”,进入 “<ruby> 共享 <rt> Sharing </rt></ruby>” 面板。
使用顶部的切换按钮**启用共享**。
然后,点击 “<ruby> 文件共享 <rt> File Sharing </rt></ruby>” **启用文件共享**。请确保启用网络。密码是可选的。如果你想为你的共享文件夹启用基于密码的认证,请启用它。


关闭设置窗口。
打开 GNOME Boxes。右键单击虚拟机并选择 “<ruby> 偏好 <rt> Preferences </rt></ruby>”。
在偏好设置窗口中点击 “<ruby> 设备和共享 <rt> Devices and Shares </rt></ruby>”,并点击共享文件夹下的 “[+]” 按钮。
在 “<ruby> 本地文件夹 <rt> Local Folder </rt></ruby>” 下:从你的宿主机中选择你想在客体机中访问的文件夹。
在 “<ruby> 名称 <rt> Name </rt></ruby>” 中,给予你想要的任何名称。这个名称将在客人的文件管理器中可见。
点击 “<ruby> 保存 <rt> Save </rt></ruby>”。

#### 2、为客体机设置
启动你的客体机虚拟机。
在客体机虚拟机内,打开文件管理器。如果你使用的是 GNOME 桌面,打开 Nautilus(即 “<ruby> 文件 <rt> Files </rt></ruby>” 应用)。
点击 “<ruby> 其他位置 <rt> Other Locations </rt></ruby>”。你应该在 “<ruby> 网络 <rt> Networks </rt></ruby>” 下看到 “<ruby> Spice 客户端文件夹 <rt> Spice client folder </rt></ruby>”。
双击它,你应该看到你的宿主机系统的文件夹内容。
有时,上述文件夹需要一些时间才能出现。如果它不可见,请等待 1 或 2 分钟。通过 `F5` 刷新文件管理器窗口。

#### 3、一些故障排除
此外,如果你看到以下错误,那么你需要手动访问该路径。
```
Unable to access location - HTTP Error: Could not connect: Connection refused
```

在文件管理器中按下 `CTRL+L`,调出地址栏。在地址栏中,输入以下内容:
```
dav://localhost:9843
```
然后点击回车。然后你应该看到文件夹的内容。SPICE 服务器使用 `dav` 协议,它在 9843 端口连接客体机和宿主机。

就这样了。现在你可以在 GNOME Boxes 中使用客体机和宿主机之间的文件共享。
下面是一个客体机和宿主机访问同一个文件夹的截图。

如果你遇到任何错误,请在下方发表评论。
[这篇文章中使用了一些来自 GitLab 的参考资料。](https://gitlab.gnome.org/GNOME/gnome-boxes/-/issues/430)
---
via: <https://www.debugpoint.com/share-folder-gnome-boxes/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,518 | Mozilla 放弃的 Servo 浏览器引擎将在 2023 年重新回归 | https://news.itsfoss.com/mozilla-servo-web-engine/ | 2023-02-07T18:05:00 | [
"浏览器",
"Servo",
"ChatGPT"
] | https://linux.cn/article-15518-1.html |
>
> 根据其开发规划,开源的 Rust 驱动的 Servo 浏览器引擎计划返回该领域。
>
>
>

>
> 编辑按:此文的翻译是一次 AI 实验。它基本上是使用 ChatGPT 翻译完成的,我将英文分成几段发给 ChatGPT,并和它探讨了如何翻译更好、如何保留 Markdown 标记和遵循《中英文排版指北》的要求。在往复了几次之后,ChatGPT 基本上可以给出还算满意的答复,有些地方超乎我的预期,有些地方则不如我用来对照的 DeepL。在最终发表前,我还稍做了润色。
>
>
> 另外,由于在一个小时内提交了太多的请求而被限流,所以还等待了一段时间。
>
>
> 最后,我请 ChatGPT 给这次实验和阅读这篇文章的读者说几句。
>
>
>
> >
> > **编辑**:好了,翻译完了,感谢您的工作。这次翻译是一次实验,用来看看像你这样的 AI 可以在翻译方面做到什么程度。最后,我想请你给看到这篇译文的读者说几句。
> >
> >
> > **ChatGPT**:感谢您对我们进行翻译能力的评估。作为 OpenAI 训练的大型语言模型,我们致力于提供高质量的翻译服务。我们希望未来能够继续为您的语言需求提供支持,让沟通变得更加容易。
> >
> >
> >
>
>
>
Servo 是一个基于 Rust 的实验性浏览器引擎,最初由 Mozilla 的研究部门开发,但后来 [转移](https://servo.org/blog/2020/11/17/servo-home/) 到 [Linux 基金会](https://www.linuxfoundation.org) 作为一个社区维护的项目。
从那时起,尽管参与的成员一直在努力,但没有重大的发展。
直到现在。
随着团队发布了一份充满希望的规划,2023 年 Servo 的前景正在改善。
让我带你了解一下。
### ? 2023 年路线图:概览

由于在 1 月份获得了 [新的资金](https://servo.org/blog/2023/01/16/servo-2023/),Servo 项目 **复活** 了。
为了确保目标的明确,开发团队发布了今年的路线图,以展示其计划的良好前景。
关于这一点,他们还补充说:
>
> 我们正在重启所有通常的活动,包括 PR 整理和审查、项目的公共沟通、安排 [TSC](https://servo.org/governance/tsc/) 会议。我们还将进行一些外部宣传,以吸引更多的协作者、合作伙伴,和有兴趣合作、参与与资助项目的潜在赞助商。
>
>
>
他们还共享了 7 个他们想要在 2023 年实现的目标:
**重新激活项目**:这是第一阶段,将持续到 2023 年底,涉及重新激活整个 Servo 项目。
**项目推广**:在项目重新活跃起来的 [GitHub](https://github.com/servo) 页面的推动下,他们计划宣传该项目,进行一些推广努力。这将吸引更多的协作者、公司和伙伴,他们可能对贡献或资助项目感兴趣。
**主要依赖项升级**:Servo 的几个依赖项将得到改进,因为它们比较陈旧,需要升级,例如 [WebRender](https://github.com/servo/webrender) 和 [Stylo](https://wiki.mozilla.org/Quantum/Stylo)。
**布局引擎选择**:Servo 目前有两个布局引擎:2013(原引擎)和2020(新引擎)。他们将与贡献者和社区一起决定选择哪个作为长期发展的引擎。
**对基本 CSS2 支持的进展**:在完成上述两件事后,他们计划朝着基本的 [CSS2 符合性](https://www.w3.org/TR/1998/REC-CSS2-19980512/conform.html) 努力。
**探索安卓支持**:他们希望探索支持安卓平台以及其他平台的可能性,因为他们已经在过去对该平台进行了试验。
**可嵌入的浏览器引擎实验**:对于路线图的最后阶段,他们的目标是将 Servo 变成一个“可嵌入的浏览器渲染引擎”。团队也在探索这方面的可能性,让某种 Servo 演示在嵌入式设备上运行,或者研究现有的项目,如 [Tauri](https://tauri.app)。
你可以通过 [官方公告](https://servo.org/blog/2023/02/03/servo-2023-roadmap/) 了解更多关于该路线图的信息。
### 总结
一个用 Rust 开发的网页引擎可以产生奇迹,比基于 [Blink](https://www.chromium.org/blink/) 或 [Gecko](https://developer.mozilla.org/en-US/docs/Glossary/Gecko) 的替代品更优秀。
此外,我们几乎每天使用的浏览器再多一个开源替代品不应该是一件坏事,它将让我们有更多选择。
? 你对 Servo 计划重新开始,并专注于回到最初设计的轨道上有什么看法?
---
via: <https://news.itsfoss.com/mozilla-servo-web-engine/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed) 译者:[ChatGPT](https://chat.openai.com/) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Servo is a rust-based experimental browser engine initially developed by the **research wing of Mozilla** but was later [delegated](https://servo.org/blog/2020/11/17/servo-home/?ref=news.itsfoss.com) to [The Linux Foundation](https://www.linuxfoundation.org/?ref=news.itsfoss.com) as a community-maintained project.
Since then, no significant development has taken place, even though the members involved have been trying to do their best.
Until now.
Things are looking up for Servo in 2023, as the team behind it has shared a promising roadmap.
Let me take you through it.
## 📢 Roadmap for 2023: Overview
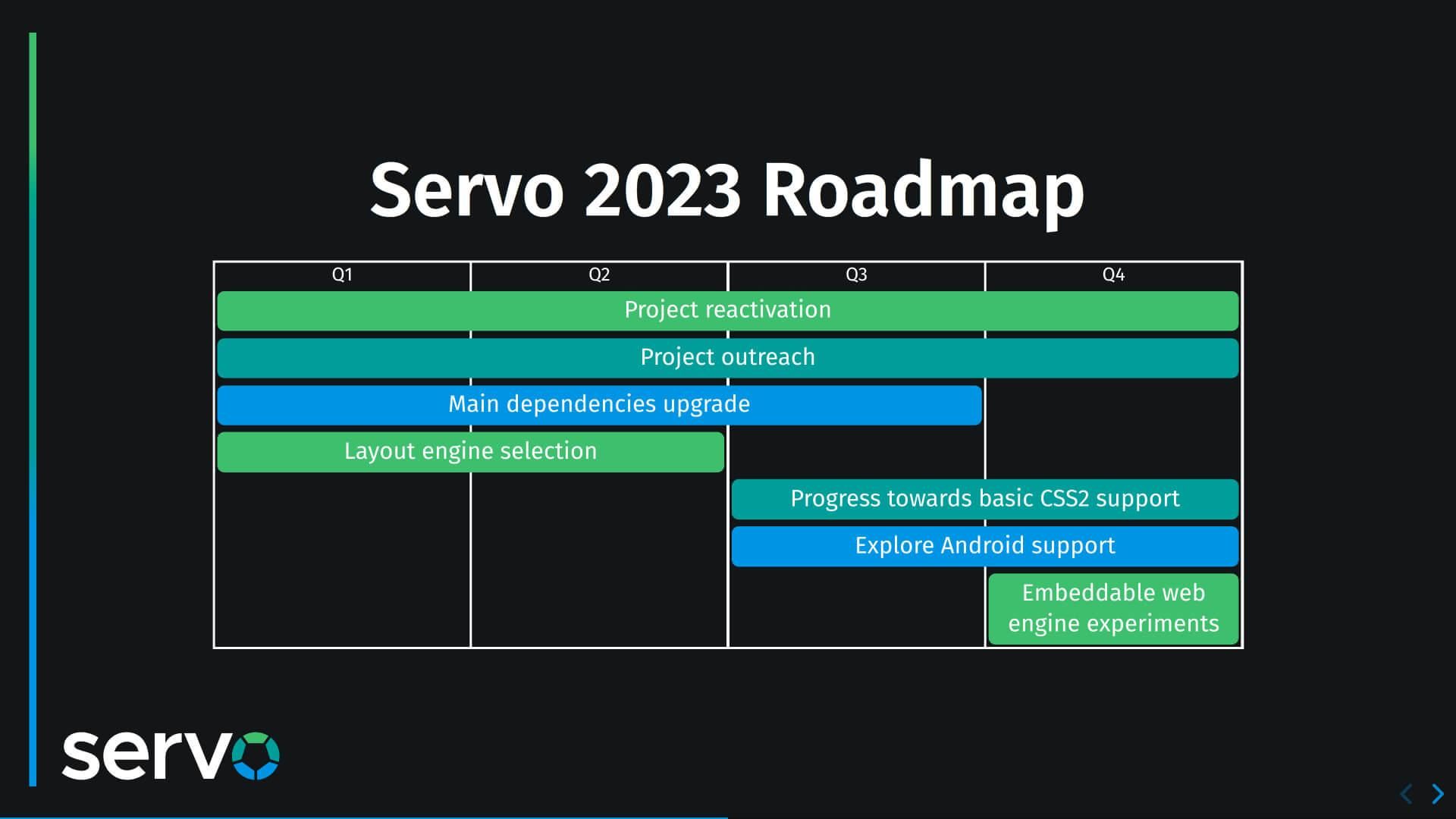
The Servo project **came back from the dead** thanks to the [new funding](https://servo.org/blog/2023/01/16/servo-2023/?ref=news.itsfoss.com) they received in January.
To further solidify their intent, the development team has **shared a roadmap for this year** that shows a good outlook on the things they have planned.
On this, they also add:
We’re restarting all the usual activities, including PR triage and review, public communications about the project, and arranging[TSC]meetings.
We will also make some outreach efforts in order to attract more collaborators, partners, and potential sponsors interested in working, participating, and funding the project.
They have also shared 7 goals that they want to achieve in 2023.
**Project Reactivation: **This is the first stage that will continue until the end of 2023 and will involve reactivating the Servo project as a whole.
**Project Outreach: **Fueled by the renewed activity on the project's [GitHub](https://github.com/servo?ref=news.itsfoss.com) page, they plan to make some outreach efforts by spreading the word about the project.
This will be done to attract more collaborators, companies, and partners who may be interested in contributing to or funding the project.
**Main Dependencies Upgrade: **Several dependencies of Servo will be worked upon as they have been in a dilapidated condition and require upgrading, such as [WebRender](https://github.com/servo/webrender?ref=news.itsfoss.com) and [Stylo](https://wiki.mozilla.org/Quantum/Stylo?ref=news.itsfoss.com).
**Layout Engine Selection: **Servo currently has two layout engines, 2013 (the original one) and 2020 (the new one).
They will be deciding, along with the contributors and the community, which option to go with for the long term.
**Progress Towards Basic CSS2 Support: **After the above two things are done, they plan to work towards basic [CSS2 conformance](https://www.w3.org/TR/1998/REC-CSS2-19980512/conform.html?ref=news.itsfoss.com).
**Explore Android Support: **They want to explore the possibility of supporting Android along with other platforms, as they have already experimented with the platform in the past.
**Embeddable Web Engine Experiments: **For the final stage of the roadmap, they aim to make Servo into an 'embeddable web rendering engine.'
The team is also exploring possibilities in this regard by having some sort of Servo demo running on embedded devices or looking into existing projects such as [Tauri](https://tauri.app/?ref=news.itsfoss.com).
You can go through the [official announcement](https://servo.org/blog/2023/02/03/servo-2023-roadmap/?ref=news.itsfoss.com) to learn more about the roadmap.
## Final Thoughts
A rust-powered web engine could do wonders and be superior to [Blink](https://www.chromium.org/blink/?ref=news.itsfoss.com) or [Gecko](https://developer.mozilla.org/en-US/docs/Glossary/Gecko?ref=news.itsfoss.com)-based alternatives.
Furthermore, another open-source alternative to something we use almost daily shouldn't be a bad thing and will let us have many options.
*💬 What do you think about Servo's aim to restart things and focus on getting back on the track it was initially designed for?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,520 | 如何从 Debian 稳定版切换到测试版 | https://itsfoss.com/switch-debian-stable-testing/ | 2023-02-08T12:27:00 | [
"Debian"
] | https://linux.cn/article-15520-1.html | 
如果你正在寻找最稳定的 Linux 发行版,当然,Debian 是正确的选择。
特别是如果你打算在服务器上使用它。
但是,在桌面方面,情况就有点不同了。我的意思是,你得到的软件包至少是一年前的,对新时代硬件的支持甚至更糟。
那么,在这种情况下,你会怎么做呢?好吧,你可以使用 Debian <ruby> 测试版 <rt> Testing </rt></ruby>。
但在跳到解释部分之前,让我们简单了解一下 Debian 测试版。
### 什么是 Debian 测试版?
Debian 社区为你提供 3 种不同的 Debian:
* Debian <ruby> 稳定版 <rt> Stable </rt></ruby>(你从他们的主页上默认得到的东西)。
* Debian <ruby> 测试版 <rt> Testing </rt></ruby>(有**新的软件包**,比 Debian 不稳定版更少出现故障)。
* Debian <ruby> 不稳定版 <rt> Unstable </rt></ruby>(拥有最新的软件包,是**所有版本中最脆弱的**)。
因此,Debian 测试版可以被认为是稳定性和新软件包之间的一个折中点。
我已经玩了一段时间的 Debian 测试版,没有遇到任何问题。
事实上,许多 Debian 用户喜欢测试版而不是稳定版。尽管名字叫“测试”,但它是相当可用的。
但是,**我还是建议你在虚拟机上进行实验**,尝试用你的主要工具来使用它,如果事情进展顺利,你可以在主系统中应用这些变化。
### 从 Debian 稳定版切换到 Debian 测试版
**警告:你不能从 Debian 测试版降级到 Debian 稳定版,因为安装脚本和安装工具只是为了用新版本替换旧版本而设计的。**
另外,我建议在你的主机上应用上述步骤之前,[使用 timeshift 创建一个备份](https://itsfoss.com/backup-restore-linux-timeshift/) 。
首先,使用给定的命令更新现有的软件包:
```
sudo apt update && sudo apt upgrade -y
```
接下来,复制原始的 `sources.list` 文件:
```
sudo cp /etc/apt/sources.list sources.list.backup
```
现在,让我们开始第一步的工作。
#### 步骤 1:编辑 sources.list 文件
有两种方法可以编辑 `sources.list` 文件。要么你可以用 `testing` 手动改变当前版本的名称,要么你可以 [使用 sed 命令](https://linuxhandbook.com/sed-command-basics/) 来完成。
而我要用第二种方法来使整个过程更简单。你只需要使用给定的命令,它就会为你把 `bullseye` 替换成 `testing`:
```
sudo sed -i 's/bullseye/testing/g' /etc/apt/sources.list
```
现在,打开你的终端,使用给定的命令来打开 `sources.list` 文件:
```
sudo nano /etc/apt/sources.list
```
并注释掉有 `security.debian.org` 和任何以 `updates` 结尾的行,如下所示:

如果你像我一样使用 `nano`,你可以按 `Alt + /` 跳到该行的最后。然后你要添加以下一行:
```
deb http://security.debian.org testing-security main
```

然后 [保存修改并退出 nano](https://linuxhandbook.com/nano-save-exit/) 文本编辑器。
#### 步骤 2:更新仓库并安装新的软件包
现在,更新仓库索引,它会显示大量的更新等待:
```
sudo apt update
```

现在,你可以使用给定的命令,它将为你提供最新的软件包:
```
sudo apt upgrade
```
坐下来,放松一下,因为这将需要一些时间。
完成后,它将向你展示从 Debian 稳定版切换到测试版时的变化列表:

如果你愿意,你可以阅读,或者你可以**直接按** `q` 继续。
现在,它会告诉你,你系统上安装的一些库需要重新启动。按 `TAB` 键,它将选择 “OK”,然后按**回车**:。

接下来,它会问你是否要在软件包升级期间重启服务。这里你有一个选择。由于我只做桌面使用,我将选择 “YES”。

完成后,你可以重启你的系统,然后使用下面的命令,让你刚才的改变完全生效:
```
sudo apt full-upgrade
```
现在,重启你的系统,你就会拥有最新的软件包。比如**我进入系统时我在运行 GNOME 43**:

### 总结
在本教程中,我解释了如何从 Debian 稳定版切换到 Debian 测试版。我希望这对你会有帮助。
如果你遇到任何问题或有任何疑问,请在评论中告诉我。
---
via: <https://itsfoss.com/switch-debian-stable-testing/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you are looking for the most stable Linux distribution, sure, Debian is the right choice.
Especially if you are planning to use it on servers.
But, on the desktop side, things are a bit different. I mean, you are given packages that are at least a year old and support for new-age hardware is even worse.
So what do you do in those cases, Well, you can use Debian testing!
But before jumping to the explanation part, let’s briefly understand Debian testing.
## What is Debian Testing?
Debian offers you 3 variants of Debian:
- Debian stable (what you get by default from their homepage).
- Debian testing (has
**newer packages**and breaks less often than Debian unstable). - Debian unstable (has the most recent packages and is
**considered the most fragile of all**).
So Debian testing can be considered a sweet spot between stability and fresh packages.
I’ve been playing around with Debian testing for some time and haven’t faced any issues.
In fact, many Debian users prefer the testing variant over the stable version. Despite the name testing, it is pretty usable.
But still, **I would recommend you to experiment with this on VM,** try using it with your primary tools and if things go well, you can apply those changes in the main system.
## Switch from Debian stable to Debian testing
*Warning: You can not downgrade from Debian testing to Debian stable, as installer scripts and installation tools are only designed to replace the older version with the new one.*
Also, I would recommend [using timeshift to create a backup](https://itsfoss.com/backup-restore-linux-timeshift/) before applying the shown steps on your main machine.
First, update the existing packages using the given command:
`sudo apt update && sudo apt upgrade -y`
Next, make a copy of original `sources.list`
file:
`sudo cp /etc/apt/sources.list sources.list.backup`
Now, let’s start with the first step.
### Step 1: Edit sources.list file
There are two ways of editing `sources.list`
file. Either you can manually alter the current release name with `testing`
or you can [use the sed command](https://linuxhandbook.com/sed-command-basics/) to get your job done.
And I’m going with a 2nd one to make the whole process easier. You just have to use the given command, and it will replace `bullseye`
with `testing`
for you:
`sudo sed -i 's/bullseye/testing/g' /etc/apt/sources.list`
Now, open your terminal and use the given command to open `sources.list`
files:
`sudo nano /etc/apt/sources.list`
And comment out the lines having `security.debian.org`
and anything that ends with `-updates`
as shown below:
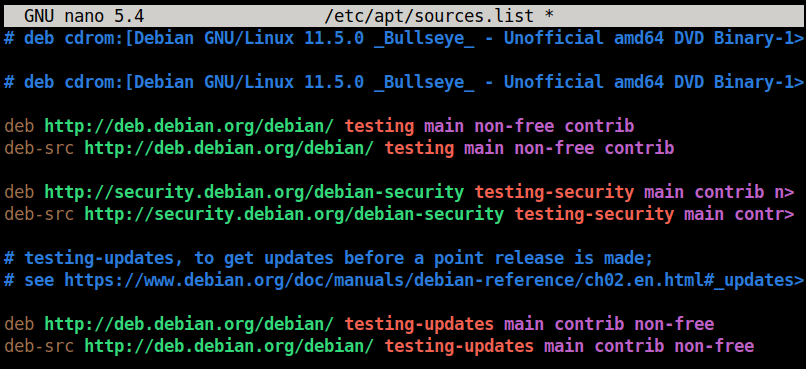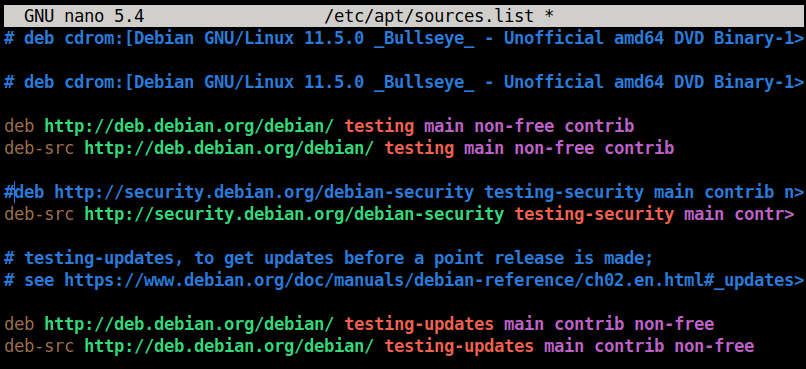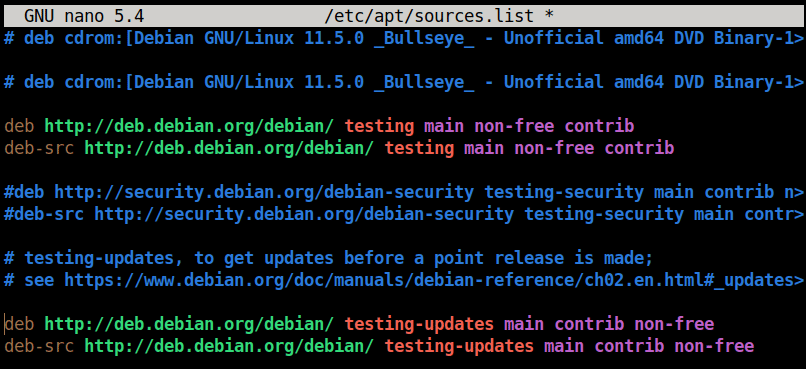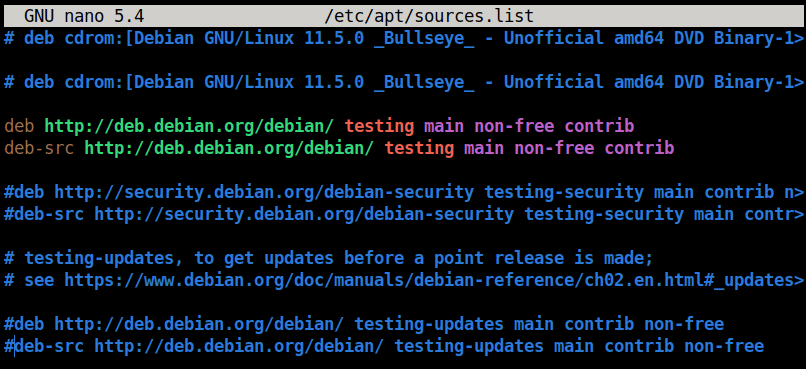
If you are using nano as I do, you can press `Alt + /`
to jump to the end of the line. And then you have to add the following line:
`deb http://security.debian.org testing-security main`
And [save the changes and exit from the nano](https://linuxhandbook.com/nano-save-exit/) text editor.
### Step 2: Update the Repository and install new packages
Now, update the repository index, and it will show you a massive update pending:
`sudo apt update`
Now, you can use the given command, and it will get you the most recent packages:
`sudo apt upgrade`
Sit back and relax as it is going to take a while.
Once done, it will present you with the list of changes made as you switched from Debian stable to testing:
You can read if you want or you can **just press q** to proceed further.
Now, it will show you the message that some of the libraries installed on your system needs to restart. Press the **TAB** key, and it will select the **OK** option, and then press **Enter:**
Next, it will ask you whether you want to restart services during the package upgrade. Here you have a choice. As I’m doing this for desktop usage only, I will go with `YES`
:
Once done, you can reboot your system and then use the following command to have full effect from the changes you’ve just made:
`sudo apt full-upgrade`
Now, reboot your system, and you’ll have the most recent packages. Such as** I was running GNOME 43** when I got into the system:
## Wrapping Up
In this tutorial, I explained how you could switch from Debian stable to Debian testing. I hope this will be helpful to you.
And if you face any issues or have any queries, let me know in the comments. |
15,521 | 7 个最佳的基于 Gentoo Linux 的发行版 | https://itsfoss.com/gentoo-based-distros/ | 2023-02-08T17:08:24 | [
"Gentoo"
] | https://linux.cn/article-15521-1.html | 
>
> Gentoo Linux 是 [适合高级用户的最佳 Linux 发行版](https://itsfoss.com/advanced-linux-distros/) 之一。如果你想要类似的东西,但又想轻松些,那么基于 Gentoo 的发行版是你的解决方案。
>
>
>
Gentoo Linux 以其软件包管理器 [Portage](https://wiki.gentoo.org/wiki/Portage) 而闻名,它允许你根据你的要求定制每个软件包,并从头开始构建/配置。这样,你就能以最好的方式来优化你的系统体验。
然而,可以理解的是,由于它的学习曲线或设置它所需付出的努力,不是每个人都喜欢使用 Gentoo Linux ?。
所以,在这种情况下,你可以尝试基于 Gentoo Linux 的发行版,可更简单轻松些。
让我重点介绍其中一些,它们比裸机版的 Gentoo Linux 要好一些。
>
> ? 该列表没有特定的排名顺序。
>
>
> **另外**,像 Gentoo Linux 一样,基于它的发行版并不是为新用户定制的。所以,你可能应该在尝试它们之前仔细阅读每个项目的文档。
>
>
>
### 1、Calculate Linux

[Calculate Linux](https://www.calculate-linux.org) 专注于提供**即开即用、用户友好的体验**。
它是基于 Gentoo 的,并且仍然向后兼容它。你可以通过 Calculate Linux 得到一个滚动发布的版本,但你也可以根据你的要求选择测试版或稳定版的更新版本。
它有桌面、服务器、云和测试等不同版本。选择你需要的那个。
### 2、CLIP OS

[CLIP OS](https://clip-os.org/en/) 是一个值得关注的基于 Gentoo 的发行版,旨在提供由法国国家网络安全局(ANSSI)建立的安全体验。
该项目有两个版本,其中 v4.0 是一个不再开发的参考版本,你可以研究其源代码,并以你喜欢的方式使用它来构建你的 Gentoo 特有体验。
而 v5.0 是一个积极开发的项目,在写这篇文章时正处于测试阶段。它听起来可能与 Qubes OS 相似,但它在各方面都有不同。
在你想尝试它之前,你得构建一个 CLIP OS 镜像。
### 3、Funtoo

[Funtoo](https://www.funtoo.org/) 是一个基于 Gentoo 的发行版,由 Gentoo Linux 的创造者(前负责人)开发。
支撑 Funtoo 的哲学与 Gentoo 有点不同。因此,社区的方法也不同。
你可以下载它的 “next” 版本以获得最新的体验,或者选择它的 1.4 版本以获得长期的稳定性。
这两个版本都是滚动发布的发行版,只是一个提供较新的软件包。
### 4、LiGurOS

[LiGurOS](https://liguros.gitlab.io) 是 Gentoo 系列操作系统中的又一个选择。它的目的是提供一个**快速而安全的体验**,同时确保 AMD 和英特尔处理器的最新功能能够很好地工作。
你会发现两个不同的版本,一个是稳定版,一个是滚动版。它还可以让你选择你喜欢的服务管理器,其中包括对 openRC 的支持。然而,你得构建安装镜像来使用它。
在它的 [GitLab 页面](https://gitlab.com/liguros) 上了解更多关于这个项目的信息。
### 5、Pentoo

[Pentoo Linux](https://www.pentoo.ch) 是 [用于渗透测试的最佳 Linux 发行版](https://itsfoss.com/linux-hacking-penetration-testing/) 之一。
你可以找到 32 位和 64 位系统的可安装镜像。开箱即用,你可以得到定制的工具、定制的内核、XFCE 4 窗口管理器,以及更多。
### 6、Redcore Linux

[Redcore Linux](https://redcorelinux.org/#hero) 是一个**基于 Gentoo Linux 测试分支**的发行版,有一个加固后的配置文件以获得更好的安全性。
它是 Kogaion Linux(最初是基于 Sabayon Linux)的继承者,而这两个发行版都不再维护。负责它的原始开发小组的成员之一决定用 Redcore 延续其思想。
这个发行版的目的是使 Gentoo Linux 能够很容易地安装在兼容的系统上。
### 7、Gentoo Studio

[Gentoo Studio](https://gentoostudio.org) 是一个为**实时 Linux 音频制作系统**量身定做的基于 Gentoo Linux 的产品。
它打包了各种音频应用程序,并默认允许你有不同的自定义选项。
与一些专注于工作室的发行版不同,你也许需要检查它所支持的软件包/实用程序是否符合你的制作要求。
? 名单上你最喜欢的是什么?我们是否错过了你的最爱?请在下面的评论区告诉我们。
---
via: <https://itsfoss.com/gentoo-based-distros/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Gentoo Linux is one of the [best Linux distributions for advanced users](https://itsfoss.com/advanced-linux-distros/). Want something similar but maybe easier? Gentoo-based distros are your solution.
Gentoo Linux is famous for its package manager, [Portage](https://wiki.gentoo.org/wiki/Portage), which allows you to customize every package per your requirements and build/configure things from the ground up. This way, you get to optimize your system experience in the best possible way.
However, it is understandable that not everyone prefers using Gentoo Linux because of its learning curve or the effort required to set it up😫
So, in that case, you can try Gentoo-based Linux distributions that make things easier.
Let me highlight some options that do a few things better than having Gentoo Linux barebones.
**Also**, like Gentoo Linux, the distros based on it are not tailored for new users. So, you might want to read the documentation of each project thoroughly before trying them out.
## 1. Calculate Linux
[Calculate Linux](https://www.calculate-linux.org) focuses on providing **a user-friendly experience out-of-the-box**.
It is based on Gentoo and still backward compatible with it. You get a rolling-release distribution with Calculate Linux, but you can also choose between testing or stable updates per your requirements.
There are different editions of desktop, server, cloud, and testing. Pick the one you need.
## 2. CLIP OS
[CLIP OS](https://clip-os.org/en/) is an interesting Gentoo-based distribution that aims to provide a secure experience built by the **National Cybersecurity Agency of France (ANSSI)**.
There are two versions of the project where v4.0 is a non-working reference where you can explore the source code and use it however you like for building your Gentoo-powered experience.
And v5.0 is an actively developed project in the beta phase when writing this. It may sound similar to Qubes OS, but it differs in various ways.
You will have to build an image CLIP OS before you want to try it.
**Suggested Read 📖**
[13 Independent Linux Distros That are Built From ScratchThere are hundreds of Linux distributions available. But most of them fall into these three categories: Debian, Red Hat (Fedora) and Arch Linux. Using a distribution based on Debian/Ubuntu, Red Hat/SUSE or Arch Linux has its advantages. They are popular and hence their package manager offe…](https://itsfoss.com/independent-linux-distros/)

## 3. Funtoo
[Funtoo](https://www.funtoo.org/) is a Gentoo-based distro by the **creator (former lead) of Gentoo Linux**.
The philosophy that powers Funtoo is a bit different than Gentoo. Hence, the community approach differs.
You can download its "next" edition release to get the latest experience or opt for its **1.4-release **for long-term stability.
Both the editions are rolling-release distros, one offering newer packages.
## 4. LiGurOS
[LiGurOS](https://liguros.gitlab.io) is yet another option in the Gentoo family of operating systems. It aims to provide a **fast and secure experience** while ensuring the latest features of AMD and Intel processors work well.
You will find two different releases, one stable and a rolling. It also gives you the choice of your favorite services manager, supporting openRC as one of them. However, you will have to build the install image to use it.
Explore more about the project on its [GitLab page](https://gitlab.com/liguros).
## 5. Pentoo
[Distrowatch](https://distrowatch.com/table.php?distribution=pentoo)
[Pentoo Linux](https://www.pentoo.ch) is one of the [best Linux distributions for penetration testing](https://itsfoss.com/linux-hacking-penetration-testing/).
You can find installable images for both 32-bit and 64-bit systems. Out of the box, you get customized tools, a customized kernel, XFCE 4 window manager, and more.
## 6. Redcore Linux

[Distrowatch](https://distrowatch.com/table.php?distribution=redcore)
[Redcore Linux](https://redcorelinux.org/#hero) is a distribution **based on the Gentoo Linux testing branch**, with a hardened profile for better security.
It is a successor of Kogaion Linux (which was initially based on Sabayon Linux), none of which is maintained anymore. One of the members of the original development group responsible for it decided to continue the idea with Redcore.
This distribution aims to make it easy to install Gentoo Linux on a compatible system easily.
## 7. Gentoo Studio
[Gentoo Studio](https://gentoostudio.org) is a tailored offering for **real-time Linux audio production systems** based on Gentoo Linux.
It packs in various audio applications and allows you different customization options by default.
Unlike some studio-focused distributions, you may want to check the packages/utilities it supports out of the box for your production requirements.
💬*What is your favorite on the list? Did we miss any of your favorites? Let us know in the comments section below.*
**Suggested Read 📖**
[Secure Your Online Privacy With These Linux DistributionsBrief: This article shows you the list of best privacy-focused Linux distributions. This article is intended for readers who are extremely concerned about their only privacy. Privacy is a serious and much-debated issue. In this age of cyber espionage and electronic surveillance, privacy becomes…](https://itsfoss.com/privacy-focused-linux-distributions/)
 |
15,523 | 5 个适合视力障碍者的 Linux 发行版 | https://itsfoss.com/visual-impaired-linux/ | 2023-02-08T23:37:43 | [
"视障",
"无障碍性",
"发行版"
] | https://linux.cn/article-15523-1.html | 
>
> 有哪些最适合视障用户的 Linux 发行版?让我们一起来看看。
>
>
>
如果有人视力障碍或失明,他们可能会依赖声音提示或其他交互方式(如盲文)来阅读和交流。
他们怎样才能使用 Linux 发行版?
嗯,一般来说,无障碍软件有助于使之成为可能。
**但是,有哪些 Linux 发行版是注重无障碍性的?哪些是为视障用户量身定做的最佳发行版呢?**
我在这里重点列出一些最好的选择。在此之前,在为视障用户尝试/推荐 Linux 之前,有一些必要的要点需要注意。
### Linux 是视障用户的理想选择吗?
**不幸的是,并不太是**。
与 Windows 和 macOS 相比,Linux 上可用的无障碍软件/选择比较有限。
即使 [红帽公司去年聘请了一位盲人软件工程师](https://news.itsfoss.com/red-hat-accessibility-gnome/) 来帮助改进,但这是一项正在进行的工作,可能体验还不够顺滑。
我看到一个一年前的 [Reddit 讨论](https://www.reddit.com/r/linux/comments/s3vvot/state_of_accessibility_on_linux_perspective_of_a/),一个盲人用户分享了他在 Linux 上的无障碍状态的体验,听起来可能并不太顺利。
它**仍然是可用的,这取决于你想做什么**和你选择的发行版。
一些值得注意的地方包括:
* 不是每个桌面环境都提供良好的无障碍功能。你可以探索和实验,但 GNOME 和 KDE 是可以接受的选择。
* Linux 发行版中关于无障碍的文档可能并不全面。所以,你可能想在开始之前进行探索和研究。这里有 [GNOME](https://wiki.gnome.org/Accessibility) 和 [KDE](https://community.kde.org/Accessibility) 文档的链接。
* 你可以随时安装 [流行的 Linux 发行版](https://itsfoss.com/best-linux-distributions/),如 Ubuntu,并通过屏幕阅读器工具进行设置,以开始使用。
然而,有些发行版会给你带来开箱即用的良好体验,可能值得尝试。
下面是你的最佳选择:
>
> ? 该列表没有特定的排名顺序。
>
>
>
### 1、Accessible-Coconut(AC)

[Accessible-Coconut](https://zendalona.com/accessible-coconut/) 是一个基于 Ubuntu MATE 的、由社区开发的 Linux 操作系统。
安装后,你会发现使视力障碍者能够获得 Linux 体验的所有必要的工具或软件。
其中包括一个支持语音合成和盲文的屏幕阅读器、屏幕放大镜、控制台屏幕阅读器、电子书扬声器、一个支持 Daisy 格式的播放器等等。
其内置的软件以更好的无障碍性而闻名。所以,你可能不需要在安装操作系统后寻找替代品。
>
> **[Accessible Coconut](https://zendalona.com/accessible-coconut/)**
>
>
>
### 2、Vojtux
Vojtux 是一个基于 Fedora 的非官方发行版,由一位盲人软件工程师创建。
对于大多数用户来说,这是一个令人兴奋的选择,因为创建者知道视障用户需要什么。默认情况下,你在登录时就开始使用 Orca 屏幕阅读器,并启用 Qt 无障碍功能,这是一个为额外的语音合成和其他软件定制的库。
另外,有趣的是,你会发现一个可以快速打开和关闭显示器的脚本。
然而,你必须在安装前构建 <ruby> 立付 <rt> Live </rt></ruby> 介质 ISO。因此,如果你没有这方面的技术知识,你可以问问周围的朋友,他们会愿意为你构建它。
你可以在它的 [GitHub 页面](https://github.com/vojtapolasek/vojtux) 或其创造者的 [相关博文](https://opensource.com/article/22/9/linux-visually-impaired-users) 上了解更多信息。
>
> **[Vojtux GitHub](https://github.com/vojtapolasek/vojtux)**
>
>
>
### 3、Trisquel

Trisquel 是一个基于 Ubuntu 的 Linux 发行版,采用 Linux-libre 内核。它是为家庭、办公室和教育机构定制的。
与其他一些选择不同,Trisquel 在默认情况下注重无障碍功能,比如启用了 Orca 屏幕阅读器。你可以在他们的网站上找到音频指南和支持屏幕阅读器的手册。
前往其 [官方网站](https://trisquel.info/en),探索更多关于它的信息,并下载 ISO。
>
> **[Trisquel](https://trisquel.info/en)**
>
>
>
### 4、Ubuntu MATE

如果你想使用主流发行版,[Ubuntu MATE](https://ubuntu-mate.org) 将很适合喜欢传统桌面用户体验的用户。
你可以找到预装的 Orca 屏幕阅读器和其他工具,给你一个良好的无障碍体验。
>
> **[Ubuntu MATE](https://ubuntu-mate.org)**
>
>
>
### 5、Fedora Workstation

[Fedora Workstation](https://getfedora.org/en/workstation/) 是想要体验 GNOME 桌面环境的用户的最佳选择。
你会发现它安装了最新的 GNOME 桌面。因此,你很可能最终在 Fedora 上获得无障碍体验。
不要忘记,众所周知,Fedora 用户社区热衷于将无障碍性放在首位,并尽快修复任何报告的问题。
>
> **[Fedora Workstation](https://getfedora.org/en/workstation/)**
>
>
>
? 你的选择是什么?我们是否错过了任何其他选择?请在下面的评论中分享你的想法。
---
via: <https://itsfoss.com/visual-impaired-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If a user is visually impaired or blind, they may rely on sound prompts or other interactions (like Braille) to read and communicate.
How can they use a Linux distribution?
Well, in general, accessibility software help make it possible.
**But** **what are the Linux distributions that focus on accessibility? What are the best distros tailored for visually impaired users?**
I focus on listing some of the best options here. Before that, there are some essential pointers to note before you try/recommend Linux for visually challenged users.
## Is Linux Ideal for Visually Challenged Users?
**Unfortunately, not entirely.**
Compared to Windows and macOS, the accessibility software/options available are limited on Linux.
Even though [Red Hat hired a blind software engineer](https://news.itsfoss.com/red-hat-accessibility-gnome/) last year to help improve things, it is a work in progress and may not be a seamless experience.
I came across a year-old [Reddit thread](https://www.reddit.com/r/linux/comments/s3vvot/state_of_accessibility_on_linux_perspective_of_a/) where a blind user shares his experience on the state of accessibility on Linux, and it may not sound good.
It is **still usable depending on what you want to do** and which distro you choose.
Some of the points worth noting include:
- Not every desktop environment offers good accessibility options. You can explore and experiment, but GNOME and KDE are acceptable options.
- The documentation for accessibility in Linux distributions may not be comprehensive. So, you might want to explore and research before getting started. Here are the links to
[GNOME](https://wiki.gnome.org/Accessibility)and[KDE](https://community.kde.org/Accessibility)documentation. - You can always install
[popular Linux distributions](https://itsfoss.com/best-linux-distributions/)like Ubuntu and set it up with screen reader tools to get started.
However, some distributions might give you a good experience out of the box and may be worth trying.
Here are your best picks:
## 1. Accessible-Coconut (AC)

[Accessible-Coconut](https://zendalona.com/accessible-coconut/) is a community-driven Linux operating system based on Ubuntu MATE.
Out of the box, you will find all the essential tools or software needed to make the Linux experience accessible for people with visual impairment.
Some of those include a **screen reader** that supports speech synthesis and Braille, **screen magnification**, a screen reader for the console, an **ebook speaker**, a daisy player, and more.
The software that comes baked in is known for better accessibility. So, you may not need to search for alternatives after installing the operating system.
## 2. Vojtux
Vojtux is an unofficial Fedora-based distribution created by a blind software engineer.
It is an exciting option for most users because the creator knows what visually impaired users need. By default, you will have the Orca screen reader starting at login, with Qt accessibility enabled, a custom repository for extra voice synthesis and other software.
Also, interestingly, you will find a script that can turn your monitor on and off quickly.
However, you must build the live media ISO before installing it. So, if you do not have technical knowledge for that, you may ask around your friends who would be willing to set it up for you.
You can learn more about it on its [GitHub page](https://github.com/vojtapolasek/vojtux) or a [blog post about it](https://opensource.com/article/22/9/linux-visually-impaired-users) by its creator.
## 3. Emmabuntus
A Debian-based distribution with 64-bit and 32-bit support, aiming to make it easy for new users to learn Linux and utilize older computers to reduce e-waste.
[Emmabuntus](https://emmabuntus.org/) can be used in a school setting or home usage, given the pre-installed utilities available for file transfer, photo/video, and more. The entire distribution is aimed at helping the youth and contribute to the society. For instance, it features a LILO search engine that finances social and environmental projects.
Along with a range of pre-installed software, it features a custom accessibility setting menu to help visually impaired users which includes things like a calculator in accessibility mode, screen reader, scanner, and more.
## 4. Trisquel

Trisquel is a Ubuntu-based Linux distribution with a Linux-libre kernel. It is tailored for home, office, and education institutions.
Unlike some other options, Trisquel focuses on accessibility features by default, like having the Orca screen reader enabled. You can find audio guides on their website and screen-reader-friendly manuals.
Head to its [official website](https://trisquel.info/en) to explore more about it and download the ISO.
## 5. Ubuntu MATE

If you want to go with mainstream distributions, [Ubuntu MATE](https://ubuntu-mate.org) will be a good fit for users who like a traditional desktop approach to user experience.
You can find the Orca screen reader pre-installed and other tools that give you a good accessibility experience.
## 6. Fedora Workstation
[Fedora Workstation](https://getfedora.org/en/workstation/) is the best bet for users who want to experience the best of the GNOME desktop environment.
You will find the latest GNOME desktop installed. So, it is likely that you will end up having an accessible experience on Fedora.
Not to forget, the community of Fedora users is known to be passionate about keeping accessibility at the forefront and fixing any issues reported as soon as possible.
💬 *What would be your pick? Did we miss any other options? Do share your thoughts in the comments below.* |
15,525 | 通过编写嵌入式系统入门边缘计算 | https://opensource.com/article/21/3/rtos-embedded-development | 2023-02-10T06:57:55 | [
"RTOS"
] | https://linux.cn/article-15525-1.html | 
>
> 用于操控无线调制解调器的 AT 设备包是 RTOS 最流行的扩展功能之一。
>
>
>
RTOS 是一个开源的 [嵌入式设备操作系统](https://opensource.com/article/20/6/open-source-rtos),由 RT-Thread 开发。它为开发者提供了标准化的、友好的基础架构,开发者可以基于各种设备编写代码,它包含大量有用的类库和工具包,使开发过程更加便捷。
RTOS 使用的是模块方式,以便于扩展,这一点跟 Linux 类似。各种软件包可以让开发者将 RTOS 用于任何想要的目标设备。RTOS 最常用的一种扩展是 AT 设备包,它包含各种不同 AT 设备(例如调制解调器)的移植文件和示例代码。
在超过 62,000 次下载中(截止至撰写本文时),最流行的 RTOS 扩展之一是 AT 设备包,其中包括用于不同 AT 设备的移植文件和示例代码。
### 关于 AT 命令
起初,AT 命令是一个协议,用于控制拨号调制解调器。随着调制解调器技术发展到较高的带宽,它仍然可以用作轻量级而高效的设备控制协议,主流的移动电话厂商也联手开发了一系列 AT 命令,用于控制移动电话上的 GSM 模块。
如今,AT 命令仍然在网络通信领域具有通用性,很多设备,例如 WiFi、蓝牙、4G,都支持 AT 命令。
如果你正在创建用于边缘计算输入、监控或物联网(IoT)的专用设备,则你可能接触到一些 RTOS 支持的 AT 设备,包括 ESP8266、ESP32、M26、MC20、RW007、MW31、SIM800C、W60X、SIM76XX、A9/A9G、BC26、AIR720、ME3616、M 6315、BC28 和 EC200X。
RT-Thread 包含套接字抽象层(SAL)组件,SAL 实现了多种网络协议和接口的抽象,为上层提供了一系列标准的 [BSD 套接字](https://en.wikipedia.org/wiki/Berkeley_sockets) API。SAL 进而接管了 AT 的套接字接口,所以开发者只需要考虑网络应用层提供的网络接口。
这个软件包实现了设备(包括上述设备)上的 AT 套接字功能,支持通过标准套接字接口以 AT 命令的形式通信。[RT-Thread 编程指南](https://github.com/RT-Thread/rtthread-manual-doc/blob/master/at/at.md) 中就有关于这些功能的详细介绍。
at\_device 软件包是在 LGPLv2.1 许可证下分发的,借助 [RT-Thread Env 工具](https://www.rt-thread.io/download.html?download=Env) 可以方便地获取到。该工具包含一个配置器和一个包管理器,它们分别用于配置内核和组件功能,可以用于定制组件并管理在线包。有了这些工具,开发者可以像搭积木一样构建系统。
### 获取 AT 设备包
为了使用配置了 RTOS 的 AT 设备,你必须启用 AT 组件库和 AT 套接字功能,需要:
* RT\_Thread 4.0.2+
* RT\_Thread AT 组件 1.3.0+
* RT\_Thread SAL 组件
* RT-Thread netdev 组件
AT 设备包已经针对多种版本进行了相应的更新。版本不同,配置选项也相应地不同,因此必须针对相应的系统版本进行适配。目前最常用的 AT 设备包版本有:
* V1.2.0: 针对低于 V3.1.3 的 RT-Thread,V1.0.0 的 AT 组件
* V1.3.0: 针对低于 V3.1.3 的 RT-Thread,V1.1.0 的 AT 组件
* V1.4.0: 针对低于 V3.1.3 或等于 V4.0.0 的 RT-Thread,V1.2.0 的 AT 组件
* V1.5.0: 针对低于 V3.1.3 或等于 V4.0.0 的 RT-Thread,V1.2.0 的 AT 组件
* V1.6.0: 针对低于 V3.1.3 或等于 V4.0.1 的 RT-Thread,V1.2.0 的 AT 组件
* V2.0.0/V2.0.1: 针对高于 V3.1.3 的 RT-Thread,V1.3.0 的 AT 组件
* 最新版: 针对高于 V3.1.3 的 RT-Thread,V1.3.0 的 AT 组件
获取正确的版本的过程主要是在生成菜单时自动完成的。它基于现有的系统环境提供最合适的 AT 设备包。
正如前文提到的,不同的版本需要不同的配置选项。例如,
```
RT-Thread online packages --->
IoT - internet of things --->
-*- AT DEVICE: RT-Thread AT component porting or samples for different device
[ ] Enable at device init by thread
AT socket device modules (Not selected, please select) --->
Version (V1.6.0) --->
```
按线程启用 AT 设备初始化的选项决定了配置是否创建一个单独的线程来初始化设备网络。
2.x 版本支持同时启用多个 AT 设备:
```
RT-Thread online packages --->
IoT - internet of things --->
-*- AT DEVICE: RT-Thread AT component porting or samples for different device
[*] Quectel M26/MC20 --->
[*] Enable initialize by thread
[*] Enable sample
(-1) Power pin
(-1) Power status pin
(uart3) AT client device name
(512) The maximum length of receive line buffer
[ ] Quectel EC20 --->
[ ] Espressif ESP32 --->
[*] Espressif ESP8266 --->
[*] Enable initialize by thread
[*] Enable sample
(realthread) WIFI ssid
(12345678) WIFI password
(uart2) AT client device name
(512) The maximum length of receive line buffer
[ ] Realthread RW007 --->
[ ] SIMCom SIM800C --->
[ ] SIMCom SIM76XX --->
[ ] Notion MW31 --->
[ ] WinnerMicro W60X --->
[ ] AiThink A9/A9G --->
[ ] Quectel BC26 --->
[ ] Luat air720 --->
[ ] GOSUNCN ME3616 --->
[ ] ChinaMobile M6315 --->
[ ] Quectel BC28 --->
[ ] Quectel ec200x --->
Version (latest) --->
```
这个版本包含了很多其他选项,其中也有启用示例代码的选项,这对初学者或使用不熟悉的设备的开发者很有帮助。
你也可以设置相应选项,选择你想用来给你的组件供电的针脚、指示电源状态的针脚、样本设备使用的串行设备的名称,以及样本设备接收数据的最大长度。在合适的设备上,你也可以设置 SSID 和密码。
简而言之,控制选项是够用的。
* V2.x.x 版本支持同时启用多个 AT 设备,欲查看启用的设备信息,在 [finsh shell](https://www.rt-thread.org/download/rttdoc_1_0_0/group__finsh.html) 中执行 `ifocnfig` 命令即可。
* V2.X.X 版本需要设备在使用前先注册;注册可以在样例目录中进行,或在应用层以自定义方式进行。
* 针脚选项,例如电源针脚和电源状态针脚是按照设备的硬件连接来配置的。如果硬件的开启功能不可用,它们就会被设置为 `-1`。
* 一台AT 设备应当对应一个序列名称,每台设备的 AT 客户端名称应当是不同的。
### AT 组件配置选项
当选择了 AT 组件包,启用了设备支持,AT 组件的客户端功能也就默认选择完成了。对 AT 组件来说,这就意味着有更多的选项要设置:
```
RT-Thread Components --->
Network --->
AT commands --->
[ ] Enable debug log output
[ ] Enable AT commands server
-*- Enable AT commands client
(1) The maximum number of supported clients
-*- Enable BSD Socket API support by AT commnads
[*] Enable CLI(Command-Line Interface) for AT commands
[ ] Enable print RAW format AT command communication data
(128) The maximum length of AT Commonds buffer
```
与 AT 设备包有关的配置选项有:
* 支持的客户端最大个数:选择 AT 设备包中的多台设备时,需要将该选项配置为对应的设备台数;
* 通过 AT 命令启用 BSD 套接字 API 功能:当选择 AT 设备包时默认选择该选项。
* AT 命令的最大长度:AT 命令可发送的数据的最大长度
### 一切皆有可能
当你开始进行嵌入式系统编程,你会很快意识到,你可以创造自己想象得到得任何东西。RTOS 旨在帮助你实现它,它的那些功能包为你提供了良好的开端。现在,设备的互联也是可期待的。边缘的物联网技术必须能够通过各种协议进行通信,而 AT 协议是关键。
---
via: <https://opensource.com/article/21/3/rtos-embedded-development>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lkxed](https://github.com/lkxed) 译者:[cool-summer-021](https://github.com/cool-summer-021) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | RTOS is an open source [operating system for embedded devices](https://opensource.com/article/20/6/open-source-rtos) developed by RT-Thread. It provides a standardized, friendly foundation for developers to program a variety of devices and includes a large number of useful libraries and toolkits to make the process easier.
Like Linux, RTOS uses a modular approach, which makes it easy to extend. Packages enable developers to use RTOS for any device they want to target. One of RTOS's most popular extensions is the AT device package, which includes porting files and sample code for different AT devices (i.e., modems).
At over 62,000 downloads (at the time of this writing, at least), one of the most popular extensions to RTOS is the AT device package, which includes porting files and sample code for different AT devices.
## About AT commands
AT commands were originally a protocol to control old dial-up modems. As modem technology moved on to higher bandwidths, it remained useful to have a light and efficient protocol for device control, and major mobile phone manufacturers jointly developed a set of AT commands to control the GSM module on mobile phones.
Today, the AT protocol is still common in networked communication, and there are many devices, including WiFi, Bluetooth, and 4G, that accept AT commands.
If you're creating purpose-built appliances for edge computing input, monitoring, or the Internet of Things (IoT), some of the AT devices supported by RTOS that you may encounter include ESP8266, ESP32, M26, MC20, RW007, MW31, SIM800C, W60X, SIM76XX, A9/A9G, BC26, AIR720, ME3616, M 6315, BC28, and EC200X.
RT-Thread contains the Socket Abstraction Layer (SAL) component, which implements the abstraction of various network protocols and interfaces and provides a standard set of [BSD socket](https://en.wikipedia.org/wiki/Berkeley_sockets) APIs to the upper level. The SAL then takes over the AT socket interface so that developers just need to consider the network interface provided by the network application layer.
This package implements the AT socket on devices (including the ones above), allowing communications through standard socket interfaces in the form of AT commands. The [RT-thread programming guide](https://github.com/RT-Thread/rtthread-manual-doc/blob/master/at/at.md) includes descriptions of specific functions.
The at_device package is distributed under an LGPLv2.1 license, and it's easy to obtain by using the [RT-Thread Env tool](https://www.rt-thread.io/download.html?download=Env). This tool includes a configurator and a package manager, which configure the kernel and component functions and can be used to tailor the components and manage online packages. This enables developers to build systems as if they were building blocks.
## Get the at_device package
To use AT devices with RTOS, you must enable the AT component library and AT socket functionality. This requires:
- RT_Thread 4.0.2+
- RT_Thread AT component 1.3.0+
- RT_Thread SAL component
- RT-Thread netdev component
The AT device package has been updated for multiple versions. Different versions require different configuration options, so they must fit into the corresponding system versions. Most of the currently available AT device package versions are:
- V1.2.0: For RT-Thread versions less than V3.1.3, AT component version equals V1.0.0
- V1.3.0: For RT-Thread versions less than V3.1.3, AT component version equals V1.1.0
- V1.4.0: For RT-Thread versions less than V3.1.3 or equal to V4.0.0, AT component version equals V1.2.0
- V1.5.0: For RT-Thread versions less than V3.1.3 or equal to V4.0.0, AT component version equals V1.2.0
- V1.6.0: For RT-Thread versions equal to V3.1.3 or V4.0.1, AT component version equals V1.2.0
- V2.0.0/V2.0.1: For RT-Thread versions higher than V4.0.1 or higher than 3.1.3, AT component version equals V1.3.0
- Latest version: For RT-Thread versions higher than V4.0.1 or higher than 3.1.3, AT component version equals V1.3.0
Getting the right version is mostly an automatic process done in menuconfig. It provides the best version of the at_device package based on your current system environment.
As mentioned, different versions require different configuration options. For instance, version 1.x supports enabling one AT device at a time:
```
``````
RT-Thread online packages --->
IoT - internet of things --->
-*- AT DEVICE: RT-Thread AT component porting or samples for different device
[ ] Enable at device init by thread
AT socket device modules (Not selected, please select) --->
Version (V1.6.0) --->
```
The option to enable the AT device init by thread dictates whether the configuration creates a separate thread to initialize the device network.
Version 2.x supports enabling multiple AT devices at the same time:
```
``````
RT-Thread online packages --->
IoT - internet of things --->
-*- AT DEVICE: RT-Thread AT component porting or samples for different device
[*] Quectel M26/MC20 --->
[*] Enable initialize by thread
[*] Enable sample
(-1) Power pin
(-1) Power status pin
(uart3) AT client device name
(512) The maximum length of receive line buffer
[ ] Quectel EC20 --->
[ ] Espressif ESP32 --->
[*] Espressif ESP8266 --->
[*] Enable initialize by thread
[*] Enable sample
(realthread) WIFI ssid
(12345678) WIFI password
(uart2) AT client device name
(512) The maximum length of receive line buffer
[ ] Realthread RW007 --->
[ ] SIMCom SIM800C --->
[ ] SIMCom SIM76XX --->
[ ] Notion MW31 --->
[ ] WinnerMicro W60X --->
[ ] AiThink A9/A9G --->
[ ] Quectel BC26 --->
[ ] Luat air720 --->
[ ] GOSUNCN ME3616 --->
[ ] ChinaMobile M6315 --->
[ ] Quectel BC28 --->
[ ] Quectel ec200x --->
Version (latest) --->
```
This version includes many other options, including one to enable sample code, which might be particularly useful to new developers or any developer using an unfamiliar device.
You can also control options to choose which pin you want to use to supply power to your component, a pin to indicate the power state, the name of the serial device the sample device uses, and the maximum length of the data the sample device receives. On applicable devices, you can also set the SSID name and password.
In short, there is no shortage of control options.
- V2.X.X version supports enabling multiple AT devices simultaneously, and the enabled device information can be viewed with the
`ifocnfig`
command in[finsh shell](https://www.rt-thread.org/download/rttdoc_1_0_0/group__finsh.html). - V2.X.X version requires the device to register before it's used; the registration can be done in the samples directory file or customized in the application layer.
- Pin options such as
**Power pin**and**Power status pin**are configured according to the device's hardware connection. They can be configured as`-1`
if the hardware power-on function is not used. - One AT device should correspond to one serial name, and the
**AT client device name**for each device should be different.
## AT components configuration options
When the AT device package is selected and device support is enabled, client functionality for the AT component is selected by default. That means more options—this time for the AT component:
```
``````
RT-Thread Components --->
Network --->
AT commands --->
[ ] Enable debug log output
[ ] Enable AT commands server
-*- Enable AT commands client
(1) The maximum number of supported clients
-*- Enable BSD Socket API support by AT commnads
[*] Enable CLI(Command-Line Interface) for AT commands
[ ] Enable print RAW format AT command communication data
(128) The maximum length of AT Commonds buffer
```
The configuration options related to the AT device package are:
**The maximum number of supported clients**: Selecting multiple devices in the AT device package requires this option to be configured as the corresponding value.**Enable BSD Socket API support by AT commands**: This option will be selected by default when selecting the AT device package.**The maximum length of AT Commands buffe:**The maximum length of the data the AT commands can send.
## Anything is possible
When you start programming embedded systems, you quickly realize that you can create anything you can imagine. RTOS aims to help you get there, and its packages offer a head start. Interconnected devices are the expectation now. IoT technology on the [edge](https://www.redhat.com/en/topics/edge-computing) must be able to communicate across various protocols, and the AT protocol is the key.
## Comments are closed. |
15,526 | systemd 日志维护指南(附实例) | https://www.debugpoint.com/systemd-journald-clean/ | 2023-02-10T07:29:00 | [
"日志",
"journalctl",
"systemd"
] | /article-15526-1.html | 
>
> systemd 内置了很多管理系统日志的功能。在本指南中,我们将介绍如何管理系统日志,并对其采取轮换、归档和清除日志等操作。我们还解释了手动系统日志清理方法和使用配置文件的变化。
>
>
>
如果你的 Linux 发行版支持 [systemd](https://www.freedesktop.org/wiki/Software/systemd/),那么从启动时开始,它每秒钟都会从系统的所有进程和应用程序中收集日志。所有这些日志事件都由 systemd 的 `journald` 守护程序管理。journald 收集所有的日志(信息、警告、错误等),并将其作为二进制数据存储在磁盘文件中。
由于日志保留在磁盘中,而且每秒钟都在收集,所以它占用了巨大的磁盘空间;特别是对于旧的系统、服务器来说。例如,在我的一个运行了一年左右的测试系统中,日志文件的大小是 GB 级的。
如果你管理多个系统、服务器,建议一定要正确管理 journald 日志,以便高效运行。让我们来看看如何管理日志文件。
### systemd 日志维护
使用 systemd 的 `journalctl` 工具,你可以查询这些日志,对其进行各种操作。例如,查看不同启动时的日志文件,检查特定进程或应用程序的最后警告和错误。如果你对这些不了解,我建议你在学习本指南之前先快速浏览一下此教程:[使用 journalctl 查看和分析 systemd 日志(附实例)](https://www.debugpoint.com/2020/12/systemd-journalctl/) 》。
#### 物理日记的日志文件在哪里?
systemd 的 journald 守护进程在每次启动时都会收集日志。这意味着,它根据启动情况对日志文件进行分类。
日志以二进制形式存储在路径 `/var/log/journal`,文件夹为机器 ID。
比如说:


另外,请记住,根据系统配置,运行时日志文件被存储在 `/run/log/journal/`。而这些在每次启动时都会被删除。
#### 我可以手动删除日志文件吗?
你可以,但不要这样做。相反,请按照下面的说明,使用 `journalctl` 工具清除日志文件以释放磁盘空间。
#### systemd 的日志文件占用了多少磁盘空间?
打开一个终端,运行以下命令。
```
journalctl --disk-usage
```
这应该为你提供系统中的日志文件实际使用的数量。

如果你有一个图形化的桌面环境,你可以打开文件管理器,浏览路径 `/var/log/journal`,并检查属性。
#### systemd 日志清理过程
清理日志文件的有效方法应该是通过 `journald.conf` 配置文件来完成。正常情况下,即使 `journalctl` 提供了删除日志文件的工具,你也不应该手动删除这些文件。
让我们来看看如何 [手动](https://www.debugpoint.com#delete-using-journal-conf) 删除它,然后我将解释 `journald.conf` 中的配置变化,这样你就不需要时不时地手动删除文件;相反,systemd 会根据你的配置自动处理它。
##### 手动删除
首先,你必须 `flush` 和 `rotate` 日志文件。<ruby> 轮换 <rt> rotate </rt></ruby>是将当前活动的日志文件归档,并立即开始创建一个新的日志文件继续记录日志。<ruby> 冲洗 <rt> flush </rt></ruby> 开关要求日志守护进程将存储在 `/run/log/journal/` 中的所有日志数据冲入 `/var/log/journal/`,如果持久性存储被启用的话。
然后,在 `flush` 和 `rotate` 之后,你需要用 `vacuum-size`、`vacuum-time` 和 `vacuum-files` 选项运行 `journalctl` 来强制 systemd 清除日志。
例 1:
```
sudo journalctl --flush --rotate
```
```
sudo journalctl --vacuum-time=1s
```
上面这组命令会删除所有存档的日志文件,直到最后一秒。这有效地清除了一切。因此,在运行该命令时要小心。

清理完毕后:

你也可以根据你的需要在 `--vacuum-time` 的数字后面提供以下后缀:
* `s`:秒
* `m`:分钟
* `h`:小时
* `days`:天
* `months`:月
* `weeks`:周
* `years`:年
例 2:
```
sudo journalctl --flush --rotate
```
```
sudo journalctl --vacuum-size=400M
```
这将清除所有存档的日志文件,并保留最后 400MB 的文件。记住这个开关只适用于存档的日志文件,不适用于活动的日志文件。你也可以使用后缀,如下所示。
* `K`:KB
* `M`:MB
* `G`:GB
例 3:
```
sudo journalctl --flush --rotate
```
```
sudo journalctl --vacuum-files=2
```
`vacuum-files` 选项会清除所有低于指定数量的日志文件。因此,在上面的例子中,只有最后两个日志文件被保留,其他的都被删除。同样,这只对存档的文件有效。
如果你愿意,你可以把两种选项结合起来,但我建议不要这样做。然而,如果同时使用两个选项,请确保先用 `--rotate` 选项运行。
### 使用配置文件自动删除
虽然上述方法很好,也很容易使用,但建议你使用 journald 配置文件来控制日志文件的清理过程,该文件存在于 `/etc/systemd/journald.conf`。
systemd 为你提供了许多参数来有效管理日志文件。通过组合这些参数,你可以有效地限制日志文件所占用的磁盘空间。让我们来看看。
| journald.conf 参数 | 描述 | 实例 |
| --- | --- | --- |
| `SystemMaxUse` | 指定日志在持久性存储中可使用的最大磁盘空间 | `SystemMaxUse=500M` |
| `SystemKeepFree` | 指定在将日志条目添加到持久性存储时,日志应留出的空间量。 | `SystemKeepFree=100M` |
| `SystemMaxFileSize` | 控制单个日志文件在被轮换之前在持久性存储中可以增长到多大。 | `SystemMaxFileSize=100M` |
| `RuntimeMaxUse` | 指定在易失性存储中可以使用的最大磁盘空间(在 `/run` 文件系统内)。 | `RuntimeMaxUse=100M` |
| `RuntimeKeepFree` | 指定将数据写入易失性存储(在 `/run` 文件系统内)时为其他用途预留的空间数量。 | `RuntimeMaxUse=100M` |
| `RuntimeMaxFileSize` | 指定单个日志文件在被轮换之前在易失性存储(在 `/run` 文件系统内)所能占用的空间量。 | `RuntimeMaxFileSize=200M` |
如果你在运行中的系统的 `/etc/systemd/journald.conf` 文件中添加这些值,那么在更新文件后,你必须重新启动 journald。要重新启动,请使用以下命令。
```
sudo systemctl restart systemd-journald
```
### 核实日志文件
在你清理完文件后,检查日志文件的完整性是比较明智的。要做到这一点,请运行下面的命令。该命令显示了日志文件是否通过(`PASS`)、失败(`FAIL`)。
```
journalctl --verify
```

### 总结
希望本指南能帮助你了解 systemd 日志管理流程的基本情况。通过这些,你可以通过限制空间、清除旧的日志文件来管理系统或服务器中的日志文件所使用的磁盘空间。这些只是指导性的命令,你可以通过多种方式组合这些命令来实现你的系统需求。
* [journalctl 手册](https://www.freedesktop.org/software/systemd/man/journalctl.html)
* [journald.conf 手册](https://www.freedesktop.org/software/systemd/man/journald.conf.html)
---
via: <https://www.debugpoint.com/systemd-journald-clean/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,529 | 通过“猜数字”游戏学习 Basic | https://opensource.com/article/23/2/learn-basic-coding-game | 2023-02-11T10:38:00 | [
"猜数字",
"Basic"
] | https://linux.cn/article-15529-1.html | 
>
> 本教程让你通过编写一个 “猜数字” 游戏来探索 Basic。
>
>
>
用多种语言编写同一个应用是学习新的编程语言的好方法。大多数编程语言都有某些共同点,如:
* 变量
* 表达式
* 语句
这些概念是大多数编程语言的基础。当你理解了它们,你就可以开始研究其他的东西了。
编程语言通常有一些相似之处。当你了解了一种编程语言,你就可以通过认识其差异来学习另一种语言的基础知识。
用标准程序进行练习是学习新语言的一个好方法。它使你能够专注于语言,而不是程序的逻辑。在这个系列文章中,我使用了一个“猜数字”的程序,在这个程序中,计算机在 1 到 100 之间挑选一个数字,并要求你猜出来。程序循环进行,直到你猜对数字为止。
这个程序锻炼了编程语言中的几个概念:
* 变量
* 输入
* 输出
* 条件判断
* 循环
这是学习一种新的编程语言的很好的实践。本文主要介绍 Basic。
### 在(Bywater)Basic 中猜数字
对于 Basic 编程语言,没有真正的标准。维基百科说:“BASIC(<ruby> 初学者通用符号指令代码 <rt> Beginners' All-purpose Symbolic Instruction Code </rt></ruby>)是一个通用的高级编程语言系列,旨在方便使用”。[BWBasic](https://yeolpishack.net/repos/ChipMaster/bwBASIC) 的实现是在 GPL 下提供的。
你可以通过编写一个“猜数字”游戏来探索 Basic。
### 在 Linux 上安装 Basic
在 Debian 或 Ubuntu 中,你可以用以下方法安装 Basic:
```
$ apt install -y bwbasic
```
下载 Fedora、CentOS、Mageia 和其他任何 Linux 发行版的最新版本 tarball。解压并设置可执行,然后从终端运行它:
```
$ tar --extract --file bwbasic*z
$ chmod +x bywater
$ ./bywater
```
在 Windows 上,[下载 .exe 版本](https://github.com/nerun/bwbasic/releases)。
### Basic 代码
下面是我的实现:
```
10 value$ = cint(rnd * 100) + 1
20 input "enter guess"; guess$
30 guess$ = val(guess$)
40 if guess$ < value$ then print "Too low"
50 if guess$ > value$ then print "Too high"
60 if guess$ = value$ then 80
70 goto 20
80 print "That's right"
```
Basic 程序可以是编号的,也可以是不编号的。通常情况下,写程序时最好不编号,但用编号的行来写,可以更容易地引用各个行。
按照惯例,编码者将行写成 10 的倍数。这种方法允许在现有的行之间插入新的行,以便进行调试。下面是我对上述方法的解释:
* 10 行:使用内置的 `rnd` 函数计算一个 1 到 100 之间的随机值,该函数生成一个 0 到 1 之间的数字,不包括 1。
* 20 行:询问一个猜测,并将该值放入 `guess$` 标量变量。30 行将该值转换为一个数字。
* 40 行和 50 行:根据比较结果,给猜测者以反馈。
* 70 行:回到循环的起点。
* 60 行:通过将控制权转移到 80 行来打破循环。80 行是最后一行,所以程序在这之后退出。
### 输出示例
下面是将该程序放入 `program.bas` 后的一个例子:
```
$ bwbasic program.bas
Bywater BASIC Interpreter/Shell, version 2.20 patch level 2
Copyright (c) 1993, Ted A. Campbell
Copyright (c) 1995-1997, Jon B. Volkoff
enter guess? 50
Too low
enter guess? 75
Too low
enter guess? 88
Too high
enter guess? 80
Too low
enter guess? 84
Too low
enter guess? 86
Too high
enter guess? 85
That's right
```
### 开始学习
这个“猜数字”游戏是学习新的编程语言的一个很好的入门程序,因为它以一种相当直接的方式锻炼了几个常见的编程概念。通过在不同的编程语言中实现这个简单的游戏,你可以展示这些语言的一些核心概念,并比较它们的细节。
你有喜欢的编程语言吗?你会如何用它来写“猜数字”的游戏?请关注本系列文章,看看你可能感兴趣的其他编程语言的例子吧!
---
via: <https://opensource.com/article/23/2/learn-basic-coding-game>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Writing the same application in multiple languages is a great way to learn new ways to program. Most programming languages have certain things in common, such as:
- Variables
- Expressions
- Statements
These concepts are the basis of most programming languages. Once you understand them, you can start figuring the rest out.
Programming languages usually share some similarities. Once you know one programming language, you can learn the basics of another by recognizing its differences.
Practicing with a standard program is a good way of learning a new language. It allows you to focus on the language, not the program's logic. I'm doing that in this article series using a "guess the number" program, in which the computer picks a number between one and 100 and asks you to guess it. The program loops until you guess the number correctly.
This program exercises several concepts in programming languages:
- Variables
- Input
- Output
- Conditional evaluation
- Loops
It's a great practical experiment to learn a new programming language. This article focuses on Basic.
## Guess the number in (Bywater) Basic
There is no real standard for the Basic programming language. Wikipedia says, "BASIC (Beginners' All-purpose Symbolic Instruction Code) is a family of general-purpose, high-level programming languages designed for ease of use." The [BWBasic](https://yeolpishack.net/repos/ChipMaster/bwBASIC) implementation is available under the GPL.
You can explore Basic by writing a version of the "guess the number" game.
## Install Basic on Linux
In Debian or Ubuntu, you can install Basic with the following:
```
````$ apt install -y bwbasic`
Download the latest release tarball for Fedora, CentOS, Mageia, and any other Linux distribution. Extract it, make it executable, and then run it from a terminal:
```
``````
$ tar --extract --file bwbasic*z
$ chmod +x bywater
$ ./bywater
```
On Windows, [download the .exe release](https://github.com/nerun/bwbasic/releases).
## Basic code
Here is my implementation:
```
``````
10 value$ = cint(rnd * 100) + 1
20 input "enter guess"; guess$
30 guess$ = val(guess$)
40 if guess$ < value$ then print "Too low"
50 if guess$ > value$ then print "Too high"
60 if guess$ = value$ then 80
70 goto 20
80 print "That's right"
```
Basic programs can be numbered or unnumbered. Usually, it is better to write programs unnumbered, but writing them with numbered lines makes it easier to refer to individual lines.
By convention, coders write lines as multiples of 10. This approach allows interpolating new lines between existing ones for debugging. Here's an explanation of my method above:
- Line 10: Computes a random value between 1 and 100 using the built-in
**rnd**function, which generates a number between 0 and 1, not including 1. - Line 20: Asks for a guess and puts the value in the
**guess$ scalar**variable. Line 30 converts the value to a numeric one. - Lines 40 and 50: Give the guesser feedback, depending on the comparison.
- Line 70: Goes to the beginning of the loop.
- Line 60:
*Breaks*& the loop by transferring control to line 80. Line 80 is the last line, so the program exits after that.
## Sample output
The following is an example of the program after putting it in `program.bas`
:
```
``````
$ bwbasic program.bas
Bywater BASIC Interpreter/Shell, version 2.20 patch level 2
Copyright (c) 1993, Ted A. Campbell
Copyright (c) 1995-1997, Jon B. Volkoff
enter guess? 50
Too low
enter guess? 75
Too low
enter guess? 88
Too high
enter guess? 80
Too low
enter guess? 84
Too low
enter guess? 86
Too high
enter guess? 85
That's right
```
## Get started
This "guess the number" game is a great introductory program for learning a new programming language because it exercises several common programming concepts in a pretty straightforward way. By implementing this simple game in different programming languages, you can demonstrate some core concepts of the languages and compare their details.
Do you have a favorite programming language? How would you write the "guess the number" game in it? Follow this article series to see examples of other programming languages that might interest you!
## 3 Comments |
15,530 | 提高 LibreOffice 生产力的技巧 | https://opensource.com/article/21/9/libreoffice-tips | 2023-02-11T16:19:00 | [
"LibreOffice"
] | https://linux.cn/article-15530-1.html | 
>
> 今天我将和大家分享一些 LibreOffice 的键盘快捷键和排版技巧,希望能够帮你省下宝贵的时间。
>
>
>
LibreOffice 是我首选的生产力应用程序。它是向教育工作者和学生推荐 Linux 发行版的最有力理由之一,无论是 PK-12 还是高等教育。新的学年快到了,我想也是时候推荐一些 LibreOffice 快捷方式和技巧,它们可以为你节省宝贵的时间。
### 使用键盘快捷键让你工作更快捷
我平时经常使用键盘快捷键,以下是适用于所有 LibreOffice 应用程序的最常见的快捷键
* `Ctrl+N` — 创建新文档
* `Ctrl+O` — 打开一个文档
* `Ctrl+S` — 保存文档
* `Ctrl+Shift+S` — 另存为
* `Ctrl+P` — 打印文档
这些是仅适用于 LibreOffice Writer 的快捷键:
* `Home` — 移动到当前行的初始位置
* `End` — 移动至当前行的结尾位置
* `Ctrl+Home` — 将光标移动到文档的初始位置
* `Ctrl+End` — 将光标移动到文档的结尾位置
* `Ctrl+A` — 全选
* `Ctrl+D` — 双下划线
* `Ctrl+E` — 居中
* `Ctrl+H` — 查找并替换
* `Ctrl+L` — 左对齐
* `Ctrl+R` — 右对齐
功能键也大有用处:
* `F2` — 打开公式栏
* `F3` — 自动补完
* `F5` — 打开导航器
* `F7` — 打开拼写和语法
* `F11` — 打开格式和排版
* `Shift+F11` — 创建新样式
### 文档格式
文档格式有很多种,LibreOffice 支持其中很多文档格式。默认情况下,LibreOffice 将文档保存为 <ruby> 开放文档格式 <rt> Open Document Format </rt></ruby>(ODF),这是一种开源标准,将样式表和数据存储在 ZIP 容器中,文本文档标记为 ODT,电子表格标记为 ODS,演示文稿标记为 ODP。它是一种灵活的格式,由 LibreOffice 社区和文档基金会维护。
ODF 是默认启用的,因此你无需执行任何操作即可让 LibreOffice 使用这种格式。
另一种文档开放规范是微软的 [Office Open XML(OOXML)格式](https://www.iso.org/standard/71691.html)。它是一个 ISO 标准,并得到所有主要办公解决方案的良好支持。
如果你与使用微软 Office 的人一起工作(它本身不是开源的,但它确实使用开放的 OOXML 格式),那么他们肯定习惯于 DOCX、XLSX 和 PPTX 格式,并且可能无法打开 ODT、ODS 或 ODP 文件。你可以通过在 LibreOffice 中将 OOXML 设置为默认格式来避免很多混乱。
将 OOXML 设置为你的首选格式:
1. 单击 “<ruby> 工具 <rt> Tools </rt></ruby>” 菜单并选择菜单底部的 “<ruby> 选项 <rt> Options </rt></ruby>”。
2. 在 “<ruby> 选项 <rt> Options </rt></ruby>” 窗口中,单击左侧面板中的 “<ruby> 加载/保存 <rt> Load/Save </rt></ruby>” 类别,然后选择 “<ruby> 常规 <rt> General </rt></ruby>”。

3. 导航到 “<ruby> 默认文件格式和 ODF 设置 <rt> Default File Format and ODF Settings </rt></ruby>” 部分。
4. 在 “<ruby> 文档类型 <rt> Document type </rt></ruby>” 选择 “<ruby> 文本文档 <rt> Text document </rt></ruby>”,并在 “<ruby> 始终另存为 <rt> Always save as </rt></ruby>” 下拉列表选择 “Open XML (Transitional) (\*.docx) ”。
5. 点击 “<ruby> 应用 <rt> Apply </rt></ruby>” 然后点击 “<ruby> 确定 <rt> OK </rt></ruby>”。
6. 取消选择 “<ruby> 未以 ODF 或默认格式保存时发出警告 <rt> Warn when not saving in ODF or default format </rt></ruby>” 以避免在保存时出现确认对话框。 
按照相同的逻辑重复,重复相同的过程用于 XLSX 和 PPTX 文档。
### 让办公更自由
LibreOffice 项目由蓬勃发展的用户和开发人员社区与文档基金会共同管理。这包括工程指导委员会、董事会、独立开发人员、设计师和翻译人员等。这些团队始终欢迎各位的贡献,因此如果你渴望参与一个超赞的开源项目,请不要犹豫 [参与进来](https://www.libreoffice.org/community/get-involved/)。
---
via: <https://opensource.com/article/21/9/libreoffice-tips>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | LibreOffice is my productivity application of choice. It's one of the most potent reasons for recommending Linux distributions to educators and students, whether PK-12 or higher education. Now that the school year is upon us, I thought I would recommend some LibreOffice shortcuts and tips that might save you valuable time.
## Work faster with keyboard shortcuts
I use a lot of keyboard shortcuts. Here are the most common shortcuts that apply to all LibreOffice applications.
**Ctrl**+**N**—Create a new document**Ctrl**+**O**—Open a document**Ctrl**+**S**—Save a document**Ctrl**+**Shift**+**S**—Save as**Ctrl**+**P**—Print a document
Here are some shortcut keys just for LibreOffice Writer:
**Home**—Takes you to the beginning of the current line.**End**—Takes you to the end of a line.**Ctrl**+**Home**—Takes the cursor to the start of the document**Ctrl**+**End**—Takes the cursor to the end of the document**Ctrl**+**A**—Select All**Ctrl**+**D**—Double Underline**Ctrl**+**E**—Centered**Ctrl**+**H**—Find and Replace**Ctrl**+**L**—Align Left**Ctrl**+**R**—Align Right
Function keys have value too:
**F2**—Opens the formula bar**F3**—Completes auto-text**F5**—Opens the navigator**F7**—Opens spelling and grammar**F11**—Opens styles and formatting**Shift**+**F11**—Creates a new style
## Document formats
There are lots of document formats out there, and LibreOffice supports a good number of them. By default, LibreOffice saves documents to the Open Document Format, an open source standard that stores stylesheets and data in a ZIP container labeled as ODT for text documents, ODS for spreadsheets, and ODP for presentations. It's a flexible format and is maintained by the LibreOffice community as well as the Document Foundation.
The Open Document Format is on by default, so you don't need to do anything to get LibreOffice to use it.
Another open specification for documents is Microsoft's [Office Open XML format](https://www.iso.org/standard/71691.html). It's an ISO standard and is well supported by all the major office solutions.
If you work with folks using Microsoft Office (which itself is not open source, but it does use the open OOXML format), then they're definitely used to DOCX, XLSX, and, PPTX formats and probably can't open ODT, ODS, or ODP files. You can avoid a lot of confusion by setting LibreOffice to save to OOXML by default.
To set OOXML as your preferred format:
- Click on the
**Tools**menu and select**Options**at the bottom of the menu. - In the
**Options**window, click on the**Load/Save**category in the left panel and select**General**.
(Don Watkins,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)) - Navigate to the
**Default File Format and ODF Settings**section. - Choose
*Text document*for the**Document type**and choose*Open XML (Transitional) (*.docx)*for the**Always save as**drop-down list. - Click
**Apply**and then**OK**. - Deselect the
**Warn when not saving in ODF or default format**to avoid confirmation dialogue boxes when saving.
(Don Watkins,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
Repeat the same process XLSX and PPTX documents by following the same logic.
## Free your office
The LibreOffice project is managed by a thriving community of users and developers, in tandem with the Document Foundation. This includes an Engineering Steering Committee, a Board of Directors, independent developers and designers and translators, and more. These teams are always open to your contribution, so if you're eager to participate in a great open source project, don't hesitate to [get involved](https://www.libreoffice.org/community/get-involved/).
## 2 Comments |
15,531 | GNOME 2 的 Linux 文件管理器 Caja | https://opensource.com/article/22/12/linux-file-manager-caja | 2023-02-12T09:35:00 | [
"文件管理器",
"GNOME"
] | /article-15531-1.html | 
>
> 如果你是 GNOME 2 的粉丝,那么你肯定会发现 Caja 很熟悉,如果你从来没有使用过 GNOME 2,那么你可能会在 Mate 中找到你的新宠桌面。
>
>
>
在 GNOME 3 之前是 GNOME 2(废话),在其作为常见的默认 Linux 桌面之一的统治期间,它拥有了一个热心的粉丝群。[Mate 项目](https://opensource.com/article/19/12/mate-linux-desktop)(以植物 *yerba mate* 命名)最初是为了延续 GNOME 2 桌面的生命力,它起初是使用 GTK 2(基于 GNOME 2 的工具包)开发的,后来升级为 GTK 3。该桌面包含了一个 Caja 文件管理器,这是一个简单而强大的应用,可以帮助你分类和组织你的数据。
### 安装 Caja
Caja 并不完全是一个独立的应用。它与 Mate 桌面紧密相连,所以要试用它,你必须安装 Mate。
你可能会发现 Mate 包含在你的 Linux 发行版的仓库中,或者你可以下载并安装一个将 Mate 作为默认桌面的发行版。不过,在你安装之前,要注意它是为了提供完整的桌面体验,所以会和桌面一起安装许多 Mate 应用。如果你运行一个不同的桌面,你可能会发现自己有多余的应用(两个 PDF 阅读器,两个媒体播放器,两个文件管理器,等等)。要评估 Caja 不会对你的电脑做重大改动,可以使用 [GNOME Boxes](https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization) 在虚拟机中安装一个基于 Mate 的发行版。

### 清晰的布局
你可能首先注意到的是 Caja 的清晰而直接的布局。在 Caja 窗口的顶部有一个工具栏,上面有一些常用任务的按钮。我喜欢这样的设计。功能不是隐藏在右键菜单中,也不是只有在操作后才能发现,更不是埋在菜单中。窗口的“显而易见”的操作被直接列在上面。
主工具栏下面是位置栏。它显示你当前的路径,可以是一系列的按钮,也可以是可编辑的文本。使用路径左边的 “<ruby> 编辑 <rt> Edit </rt></ruby>” 按钮来切换它是否可编辑。
### 可配置
对于 GNOME 2 或 Caja 的长期用户来说,主工具栏可能是多余的,尤其是当你知道了调用常用操作的键盘快捷键后。这就是为什么 Caja 的界面是可配置的。你可以从 “<ruby> 查看 <rt> View </rt></ruby>” 菜单中禁用 Caja 窗口的主要组件,包括:
* 主工具条
* 位置栏
* 侧面板
* 附加面板
* 状态栏
简而言之,你可以按你的想法精简 Caja。

### 标记你的文件夹
有些人是 “可视化” 人。他们喜欢根据自己对数据的看法来组织文件和文件夹,而不是根据计算机对数据的解释。例如,如果对你来说最重要的两个文件夹是**音乐**和**工作**,就很难让计算机相信这两者之间有任何关系。按字母顺序两者也排不到一起,而且每个文件夹的内容可能完全不同(一个是媒体文件,另一个是电子表格)。
### Caja 提供了一些帮助
使用 Caja,你可以在一个窗口内手动放置目录,Caja 会记住这个位置。更重要的是,Caja 有多种标志可供你用作视觉标签。你可以在 “<ruby> 编辑 <rt> Edit </rt></ruby>” 菜单的 “<ruby> 背景和标志 <rt> Backgrounds and Emblems </rt></ruby>” 中找到它们。将它们拖放到文件和文件夹中以帮助它们区分。

### Caja
Caja 是最诱人的文件管理器之一。它的可配置性足以吸引许多不同的使用场景,而且在这些配置选项中,你很可能找到适合你的工作流程。如果你是 GNOME 2 的粉丝,那么你肯定会发现 Caja 很熟悉,如果你从来没有使用过 GNOME 2,那么你可能会在 Mate 中找到你的新宠桌面。
---
via: <https://opensource.com/article/22/12/linux-file-manager-caja>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,532 | Linux 6.1 内核被批准为长期支持版本 | https://news.itsfoss.com/linux-kernel-6-1-is-now-an-lts-version/ | 2023-02-12T10:57:00 | [
"Linux",
"内核"
] | https://linux.cn/article-15532-1.html |
>
> 作为 2022 年的最后一个内核,经过一个多月的等待,现在 Linux 6.1 被批准为长期支持版本。
>
>
>

Linux 6.1 内核是 2022 年的最后一个内核版本,通常这些版本会被批准为长期支持版本。
但是这次,将其作为 LTS 版本的决定被推迟了。
在决定是否将其用于长期使用之前,还在等待一些来自内核相关人员的关键反馈的测试结果。
幸好,这些问题已经得到解决,现在 **Linux 6.1 是一个长期支持版本**。
让我带你了解这一举措的要点。
### Linux 6.1 现在正在成为长期支持版本
自从 12 月份发布以来,Linux 稳定分支维护者 **Greg Kroah-Hartman** 就计划将 Linux 6.1 作为一个长期支持版本,但是一些待定的反馈导致该决定被推迟了。
现在,他和共同维护者 Sasha Levin 终于收到了足够的反馈,表明将 Linux 内核 6.1 作为一个长期支持版本维护是合理的。
按照目前的情况,Linux 6.1 内核预期将于 **2026 年 12 月** 结束支持,如果有足够多的用户或公司对其感兴趣,那么它的生命周期可能会延长。

最初,它的生命周期被计划为 2 年,但是后来被更新为了 **当前的 4 年**。
你还会注意到,同时许多 Linux 内核都被作为长期支持版本维护。
### Linux 6.1 内核:概述
如果你错过了这个版本,下面是 Linux 内核 6.1 的一些亮点:
* 对 Rust 的实验性支持
* 对 AMD PC 的优化
* 对英特尔 Meteor Lake 的初始支持
* 优化 ARM 架构 SoC 的支持
这些并不是新版本的全部内容;你可以阅读我们的文章以了解更多信息。
>
> **[Linux 内核 6.1 发布,初步支持 Rust](https://news.itsfoss.com/linux-kernel-6-1-release/)**
>
>
>
参考自:[Phoronix](https://www.phoronix.com/news/Linux-6.1-LTS-Official)
? 考虑到这是一个长期支持版本,你可以预见到很多未来的发行版升级将会包含 Linux 6.1 内核。你认为你会更喜欢使用哪个版本?
---
via: <https://news.itsfoss.com/linux-kernel-6-1-is-now-an-lts-version/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux Kernel 6.1 was the last kernel release of 2022; usually, these end up as an LTS release.
But this time around, the decision to make it LTS was delayed.
Some key feedback was pending from the kernel stakeholders around test results before they planned on using this kernel for the long term.
Fortunately, those things have since been resolved, and now **Linux Kernel 6.1 is an LTS release.**
Let me take you through the gist of this move.
## Linux 6.1 is Now Officially an LTS Release
Since its debut in December, **Greg Kroah-Hartman**, the Linux stable maintainer, was planning on Linux 6.1 as an LTS release, but the pending feedback delayed the move.
Now, he and co-maintainer Sasha Levin have finally received enough responses that maintaining Linux Kernel 6.1 as an LTS makes sense.
As things stand right now, the projected end-of-life for 6.1 is **December 2026,** with the potential for an extension if enough users or companies are interested in using it.
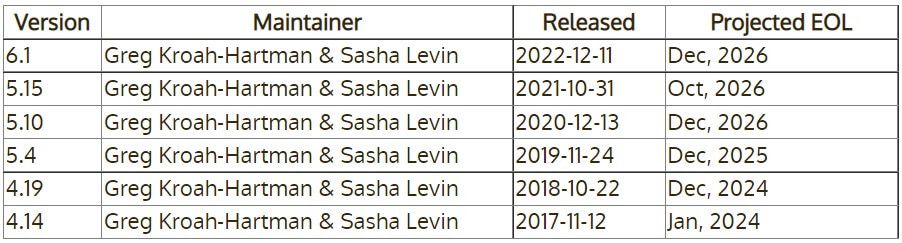
Initially, this was planned for a 2-year LTS cycle but was later updated to the **current 4-year maintenance period**.
You will also notice that many Linux Kernels are being maintained concurrently as LTS versions.
## Linux Kernel 6.1: Overview
If you missed out on the release, Here are some of the highlights that arrived with Linux Kernel 6.1:
**Experimental Support for Rust****Optimizations for AMD PCs****Initial Support for Intel Meteor Lake****Improved ARM SoC Support**
These are not the only things on offer; you may go through our article for a better outlook.
[Linux Kernel 6.1 Released With Initial Rust CodeLinux Kernel 6.1 is now available! Potentially an LTS version considering it is the last stable release of the year.](https://news.itsfoss.com/linux-kernel-6-1-release/)

**Via:** [Phoronix](https://www.phoronix.com/news/Linux-6.1-LTS-Official?ref=news.itsfoss.com)
💬 *Considering this is an LTS version, you can expect future distro upgrades to include Linux Kernel 6.1. What do you think will you prefer to use?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,534 | 管理对新手友好的开源社区的三个步骤 | https://opensource.com/article/21/8/beginner-open-source-community | 2023-02-12T22:28:34 | [
"开源项目",
"开源社区",
"新手"
] | /article-15534-1.html |
>
> 作为一个开源项目的成员,你可以做很多事情来帮助新手找到为项目作出贡献的方式。
>
>
>

当有人刚开始为开源做贡献时,最好从对新手友好的故障和议题开始。但在他们修复故障之前,他们必须要能够找到这类问题。作为一个开源项目的成员,你可以做很多事情来帮助新手找到为项目贡献的方式。
鉴于此,[AnitaB.org 开源社区](https://github.com/anitab-org) 优先考虑让我们的社区做到对新手友好。我们提倡包容性,确保不同经验和水平的贡献者都可以参与进来,并且他们的贡献不止限于跟编程有关。
我最近在 [Upstream 2021](https://youtu.be/l8r50jCr-Yo),即 Tidelift 活动中介绍了我们在 [AnitaB.org](https://anitab.org/) 上所做的一些社区工作,该活动启动了“维护者周”,这是一个为期一周的开源维护者庆祝活动。在活动中我讨论了我们策略的三个主要部分:
* 我们如何沟通
* 项目和议题
* 开源项目
### 我们如何沟通
透明度是开源的重要组成部分,我们将透明度原则应用于我们的沟通方式。实际上,这意味着我们所有的社区会议都是公开进行的,并且影响我们设置 Zulip 聊天的方式以及我们提供文档的方式。
#### 开放会议
任何人都可以加入我们的会议,并讨论与我们社区相关的话题。他们可以参与讨论或者旁听。会议相关信息在我们的社区日历中都可以找到。在这些通话中我们通常只使用语音聊天,我们发现这可以让人们在参与时感觉更自在。
我们举办以项目为中心的会议和一些分类的会议。会议上,来自不同领域的人们可以讨论同一个项目并帮助改进我们的流程。偶尔,我们会有“<ruby> 自由提问 <rt> Ask Me Anything </rt></ruby>(AMA)”会议,任何人都可以来问任何与开源相关的问题。
所有会议我们都会在共享文档中进行记录,并在 [我们的 Zulip](https://anitab-org.zulipchat.com/) 中共享摘要和文档链接。
#### 我们的 Zulip 聊天
开源 Zulip 聊天平台是我们的主要社区交流渠道,虽然我们也在 Github 的评论区讨论议题和<ruby> 拉取请求 <rt> Pull Request </rt></ruby>(PR)。一般来说,我们禁用了私人消息以确保我们尽可能透明。对于这条规则,我们只有少数例外,那些私人聊天是管理员在处理我们运行程序的后勤工作所用的。我们发现这种方法更受欢迎,它还使我们能够更清楚公共聊天中的违规行为。
我们在 Zulip 聊天室分享所有会议摘要,包括讨论的要点、行动项目和文档。这些听起来好像是些显而易见的要求,但我一直惊讶于很多开源项目并不提供会议笔记,所以 Zulip 可以让那些没有参加会议的人也随时了解情况。
在 Zulip上,我们讨论项目路线图,回答社区的问题和疑问,并积极**促进人们通过不同的方式方法和在不同的场景下做出自己的贡献**。有时我们为贡献者的成就而庆祝 —— 无论是为了突出他们测试或者审查的第一个拉取请求,还是强调我们志愿者所做的出色工作。
#### 文档
我们尽量保持**关于我们流程的开放文档**,例如常见问题解答,以便这些社区成员可以按照自己的节奏和时间了解社区。这是为了让他们在联系我们之前了解我们的工作方式以及我们从事的工作类型。
### 项目和议题
关于我们的项目和议题管理,我们鼓励通过多种方式做出贡献,我们为新手专门创建特定的议题,并尝试让项目的设置变得简单。
#### 多种贡献的方式
我们努力创建**需要不同贡献的问题**,例如文档、测试、设计和外展。这是为了让任何人 —— 无关他们的经验水平和兴趣领域 —— 都能做出贡献。这样能够帮助社区参与进来,而且我们发现它使成员能够从一些省力但有价值的任务开始一步步做出贡献。
我们提倡的贡献类型有:
* 不同复杂性的编程任务。
* 质量保证任务 —— 贡献者可以测试我们的应用程序或拉取请求并报告错误。
* 社区成员可以参与讨论的设计会议。此外,创建模型和重新设计我们应用程序某些部分的机会,并探索改进用户体验。
* 外展任务,我们主要在 Zulip 上推广,我们建议在我们的 Medium 出版物上发表博客,介绍他们的开源经验和他们的贡献。
* 文档任务,可以包括一般社区文档或我们在 Docusaurus 上的项目文档。
#### 仅限新手的问题
我们将一些**议题标记为“仅限新手”**。这些问题适用于尚未为议题存储库做出贡献的人。为议题做标签还使我们能够让人们在贡献者大量涌入时开始他们的开源之旅,例如,在 [谷歌编程之夏(GSoC)](https://summerofcode.withgoogle.com/) 申请期间。
有时,这些可能是“唾手可得的果实”,可以让他们熟悉作出贡献和提交拉取请求的过程。
#### 简单的项目设置
我们也很在意为我们的项目提供**新手友好的安装设置**。我们注意到最活跃的项目通常是最容易设置的。我们知道,为你不熟悉的项目做出贡献可能需要付出很多努力并且关乎贡献体验的成败。
我们尝试提供有关如何在多个操作系统上运行我们项目的说明。在过去,我们有一些项目有单独的说明,可以在 Unix 环境下运行,我们注意到贡献者在 Windows 上运行这些项目有些困难。自那以后我们不断进行改进,以避免贡献者在 Zulip 上寻求帮助时出现混乱。
我们根据贡献者的经验,一直在改进我们最活跃的项目之一 [mentorship-backend](https://github.com/anitab-org/mentorship-backend#readme) 的自述文件。新手在这个项目中遇到的困难之一是设置与配置电子邮件帐户相关的部分环境变量,以使后台功能能够发送电子邮件。但是,由于此功能对于本地开发并不重要,因此默认情况下,我们将电子邮件设置设为可选,以便将电子邮件打印到终端,而不是发送给用户。这种方法仍然使贡献者可以看到这些电子邮件。与此更改类似,我们将 [SQLite 数据库](https://opensource.com/article/21/2/sqlite3-cheat-sheet) 作为本地开发的默认设置,以避免对 Postgres 数据库进行额外设置,虽然我们在部署版本中会使用到 Postgres。
我们注意到,一些贡献者在为我们的 [bridge-in-tech-backend](https://github.com/anitab-org/bridge-in-tech-backend) 项目做出贡献时觉得很困难,该项目的设置很复杂,并且包含的步骤比 [mentorship-backend](https://github.com/anitab-org/mentorship-backend#readme) 多得多。自从我们在一个开源项目中注意到这一点以来,我们一直在探索如何改进其结构。
对于我们的大多数项目,我们还提供应用程序的实时体验版本或打包版本,以便贡献者无需设置即可测试项目。这有助于我们为那些对开发设置不感兴趣或不熟悉的贡献者提供一种方式,来尝试我们应用程序的最新版本,并通过报告发现的任何错误来做出贡献。我们在 [质量保证指南](https://github.com/anitab-org/documentation/blob/master/quality-assurance.md) 中放了这些应用程序的链接。
### 开源计划
我们在社区中组织了两个主要计划:开源黑客(OSH)(一个为期一个月的项目)和 Open Source Ambassadors(一个为期六个月的项目)。
#### 开源黑客(OSH)
在此计划中,我们在多个类别的贡献中创建议题 —— 文档、编码、外展、测试和设计(类似于 [谷歌的 Code-in](https://codein.withgoogle.com/) 竞赛)。 参与者可以为每个类别至少贡献一次并获得电子证书。一个议题可能包含多个类别,并且无需合并拉取请求也能使贡献有效。
我们为这个计划选取几个项目,请导师们集思广益为参与者创造议题。项目开始后参与者可以认领议题并开始作出贡献。导师们会支持帮助并审查他们的贡献。
这种方法鼓励贡献的多样性,并欢迎任何人,无论他们的编码能力如何,都可以在友好和不怕出错的环境中做出贡献。
#### 开源大使
在此计划中,我们从社区中选择大使,理想情况下他们将涵盖我们旨在促进的每一类贡献。至今该计划已启动了两次。
该计划旨在让成员通过回答社区的议题、协助贡献者参与并为他们指定的类别宣传来帮助管理项目和计划。
第一个计划举行时我们接受了所有的申请者。我们评估了社区成员的兴趣所在,并为那些想要做出贡献但最初不敢踏出第一步的人提供了一个体系。
第一个计划的举办给了我们很多启发。因为我们的活动中既有经验丰富的开源贡献者和社区成员,也有初来乍到缺乏经验的新手,因此项目的执行要求管理员进行大量的管理工作。一些社区大使信心十足准备好进一步采取新措施,而其他大使则需要更多支持。到了第二个,我们决定缩减该计划,只接受那些已经熟悉社区、可以领导倡议和项目并帮助我们培训新人的贡献者。
第二个计划中形成了正反馈循环。那些在第一个计划中还是新手的大使们,通过为上一个项目做出贡献并且从项目经验中学习之后能够做到轻松带领项目。
这种方法的改变使管理员能够更加专注于支持大使团队,帮助他们传播我们的使命,并继续让我们的社区对新手友好,并指导更多人做出贡献。
### 总结
这些计划帮助我们提高了对开源贡献和回馈的不同方式的认识。通过它们,我们发现志愿者通过管理项目和举办公开会议来提供帮助,这有助于管理社区并为我们的贡献者提供指导。
尽管我们得到了贡献者的良好反响,并帮助人们做出了他们的第一个贡献,但我们仍有很大的改进空间。我们将继续改进我们项目的设置和贡献指南,以改善贡献者的体验。我们还将继续专注于确保我们的组织始终拥有并推动不同类别的问题,促进包容性,以便任何有意愿做出贡献的人都能出自己的一份力。
---
via: <https://opensource.com/article/21/8/beginner-open-source-community>
作者:[Isabel Costa](https://opensource.com/users/isabelcmdcosta) 选题:[lujun9972](https://github.com/lujun9972) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,535 | 2023 年十佳 Linux 服务器发行版 | https://www.linuxtechi.com/top-10-linux-distributions-for-servers/ | 2023-02-13T09:24:00 | [
"Linux",
"服务器"
] | https://linux.cn/article-15535-1.html | 
由于具备多种优势,Linux 操作系统是各类服务器中的热门选择。首先,它是免费(少数商业发行版除外,如 RHEL 和 SUSE Linux Enterprise Server)和开源的。它的开源性意味着开发者可以查看其源代码并进行修改,而且可以根据规定的许可条款重新发布。其次,通常 Linux 被认为是稳定、通用的,且比 Windows 更为安全。最后,Linux 可以轻松地部署在各类平台,如裸机、虚拟机和云环境。
在这篇文章中,我们重点介绍了十佳 Linux 服务器发行版。
### 1、红帽企业 Linux(RHEL)
<ruby> <a href="https://www.redhat.com/en"> 红帽企业 Linux </a> <rt> Red Hat Enterprise Linux </rt></ruby>(RHEL),是专门为企业环境开发的商业 Linux 发行版。它是一个性能驱动、可靠安全的操作系统,提供了增强的可用性和无缝部署,使其成为服务器环境的理想选择。
RHEL 支持裸机、虚拟机和云环境中的各种工作负载。实际上,红帽是世界领先的开源解决方案供应商,提供了众多产品,包括 Red Hat OpenShift、Ansible 自动化平台、Open 混合云、JBoss 企业应用平台和 SAP 等等。

### 2、Ubuntu 服务器
由 Canonical 开发和维护的 Ubuntu 是最流行和广泛使用的 Linux 发行版之一。Ubuntu 是一个基于 Debian 的 Linux 发行版,完全自由开源,以其桌面版而闻名,它直观、用户友好,被认为是学者和初学者的理想选择。Ubuntu 有 3 个版本,即:<ruby> 桌面版 <rt> Desktop </rt></ruby>、<ruby> 服务器版 <rt> Server </rt></ruby>和 <ruby> 核心版 <rt> Core </rt></ruby>。
虽然桌面版在全球范围内得到了大量使用,但服务器版也为服务器环境提供了一个坚实的平台。首先,它可以部署在任何环境中,无论是在物理机、虚拟机还是云环境中,都具备广泛的扩展功能。这意味着可以随时增加资源用来满足不断变化的需求。
由于服务器版本非常精简,没有任何图形用户界面,因此相对轻量,资源开销低。这意味着 CPU 和内存的使用也会较低。因此,提高了性能,并具备企业级的稳定性。
除了在物理数据中心和虚拟服务器上安装外,Ubuntu 服务器还可以在 AWS 和 Azure 等公共云中使用。据 Canonical 称,55%的 OpenStack 云运行在 Ubuntu 上。 此外,你可以付费获得自己管理的 Openstack 云。

### 3、Debian
Debian 是最早的 Linux 发行版之一,以其稳定性而闻名。它有三个版本:<ruby> 稳定版 <rt> Stable </rt></ruby>、<ruby> 不稳定版 <rt> Unstable </rt></ruby> 和 <ruby> 测试版 <rt> Testing </rt></ruby>。
Debian 稳定版是官方发布的最新 Debian 发行版,是服务器和台式机最受欢迎的版本。这个分支的所有软件包都经过了严格的测试和调试,因此被认为是可以运行生产工作负载的。
Debian 服务器是一个快速可靠的操作系统,强调安全性和稳定性。正是由于这个原因,它成为服务器环境的一个完美选择。此外,它提供了广泛的硬件支持,有超过 59,000 个软件包,是迄今为止所有操作系统中软件包数量最多的。
就像 Ubuntu 服务器一样,Debian 轻量,功能多,非常适合企业工作负载。实际上,它比 Ubuntu 更稳定,更易于管理。

### 4、SUSE Linux 企业服务器
在提供优秀服务器平台方面,另一位具有竞争力的对手是 <ruby> SUSE Linux 企业服务器 <rt> SUSE Linux Enterprise Server </rt></ruby>(SLES)。该服务器操作系统是由位于德国的 SUSE 公司创建和维护的。
SLES 是一个为处理企业级工作负载而建立的商业发行版。它可以适应任何环境,并针对稳定性、可靠性和安全性进行了优化。它的高可扩展性,使 IT 团队能够有效地部署他们的应用程序和服务,以应对不断增长的业务需求。
最新的 SLES 版本提供了易于管理的互操作。它还针对 Docker 容器、Kubernetes 和地理集群提供了更多的支持和兼容。后者提供了高可用的灵活性,使 IT 团队能够配置跨越多个数据中心区域的复制集群。
SUSE Linux Enterprise Server 不仅支持内部工作负载,而且支持云服务,包括微软 Azure、谷歌计算引擎和亚马逊 Web 服务。
### 5、OpenSUSE Leap
由 OpenSUSE 项目开发,OpenSUSE 是一个基于 RPM 的非商业 Linux 发行版,由 SUSE 公司开发和维护。同样是自由开源的,OpenSUSE 提供了两个版本:
* OpenSUSE Leap
* OpenSUSE Tumbleweed
OpenSUSE TumbleWeed 是 OpenSUSE 的滚动发行版本。它包含最新的稳定应用程序,包括内核、Git、Samba、桌面应用程序等等。因此,它是开发人员或高级用户的完美选择,他们需要利用最新的软件堆栈进行工作负载。然而,由于频繁的内核更新,导致与其他第三方驱动模块的不一致,它并不是服务器的理想选择。
OpenSUSE Leap 是将 OpenSUSE 用于服务器的首选。它是一个开源和社区驱动的发行版,发布周期较慢,因此,比 TumbleWeed 更适合。社区驱动,这意味着它在发布之前要经过严格的测试。
Leap 相对来说更容易使用,并提供高性能和稳定性,是处理企业级工作负载的理想选择。它是商业服务器发行版(如 SLES 和 RHEL)的优秀替代方案,并允许企业在裸机和云部署上部署他们的工作负载。

### 6、Rocky Linux
Rocky Linux 是一个作为 CentOS Linux 的替代品而开发的 Linux 发行版,后者在 2021 年 12 月 31 日达到了 EOL(寿命终止)。它是一个自由而开源的 Linux 发行版,具备稳定性、可靠性且定期更新,并在 10 年的支持生命周期内完全免费。
Rocky Linux 是一个企业级操作系统,旨在与 RHEL 100% 兼容,目前正在由社区大力开发。
自从 CentOS Linux 不合时宜地突然停产后,导致该发行版获得较高人气。它可以服务器和台式电脑上安装,也提供了公有云供应商(如亚马逊 AWS 和谷歌计算引擎)上的定制镜像。
Rocky Linux 开发者提供了一个迁移脚本,允许用户从其他企业版(如 CentOS Linux 和 Oracle Linux)迁移到 Rocky Linux。

### 7、AlmaLinux
另一个为填补 CentOS Linux 留下的空白的选择是 AlmaLinux。同样一个完全自由开源的企业操作系统。
AlmaLinux 最初是由 CloudLinux 创建的,但目前是由社区驱动的。它提供了一个生产级的企业操作系统,与 RHEL 1:1 二进制兼容。简而言之,它是 RHEL 的克隆,简而言之,它是 RHEL 的克隆,并免费提供坚实的稳定性和 RHEL 所带来的优势。
作为一个企业级的服务器操作系统,AlmaLinux 可以轻松运行关键工作负载。此外,它提供长期支持的定期发布。

### 8、Oracle Linux
由甲骨文公司开发的 Oracle Linux 是一个安全和高性能的操作系统,由 RHEL 源代码编译而成。它针对混合部署和多云部署进行了优化,与 Rocky 和 AlmaLinux 一样,Oracle Linux 与 RHEL 是 100% 二进制兼容。
对于数据中心,Oracle Linux 是一个可行的选项,当然也可以作为 EOL 的 CentOS 的完美替代品。由于它的稳定性和性能,是企业应用的理想选择。
与 RHEL 和 SUSE 等商业 Linux 发行版不同,Oracle Linux 可以完全免费下载、使用和重新发布。它在 GNU 通用公共许可证(GPLv2)下是可用的。
### 9、Fedora 服务器
Fedora 是 Fedora 项目开发和维护的自由开源的 Linux 发行版,该项目由红帽赞助。
Fedora 作为 RHEL 的上游社区发行版。所有的应用程序在推送到 RHEL 之前都要经过严格的测试。因此,它被称为“最前沿”的操作系统,这意味着它定期获得最新的软件应用程序和更新。
长久以来,Fedora 以其工作站版本而受欢迎,该版本是为笔记本电脑和台式电脑打造的。随着时间的推移,它已经扩展到包括其他版本,如 Fedora 服务器、Fedora IoT 和 Fedora CoreOS。
Fedora 服务器是一个强大、可靠、灵活的操作系统,拥有最好和最新的数据中心技术。作为一个领先的版本,它提供了开源社区的最新技术,并且易于安装、设置和使用各种工具进行管理,如 Cockpit 网络控制台。
Fedora 也十分快速稳定,而且相当安全,非常适合生产和企业工作负载,其新版本每 6 个月推送一次。

### 10、Fedora CoreOS
最后一个是 Fedora CoreOS。这是一个专门为运行容器化应用程序和工作负载优化的最小操作系统。根据其主页,它自称是 “一个自动更新的最小操作系统,用于安全且大规模地运行容器化工作负载”。
通常情况下,它与 Podman 和 Docker 一起发行,并有三个版本,即 <ruby> 稳定版 <rt> Stable </rt></ruby>、<ruby> 测试版 <rt> Testing </rt></ruby> 和 <ruby> 下一版 <rt> Next </rt></ruby>。你可以获得用于裸机服务器和虚拟化环境的镜像,以及由亚马逊网络服务(AWS)和谷歌云平台(GCP)等主要云提供商托管的云镜像。
### 结论
这是关于 Linux 服务器发行版最好的总结。希望你看完这个指南后能有所收获。对我们的指南有什么想法吗?非常欢迎你的反馈。
>
> LCTT 校注:此文并未提及主要由中国开发者/企业主导的企业级 Linux 发行版,在我看来,龙蜥操作系统(Anolis OS)、欧拉操作系统(openEuler)和统信 UOS 都具备相当优良的特性和可靠的支持,在选型时可以考虑。
>
>
>
---
via: <https://www.linuxtechi.com/top-10-linux-distributions-for-servers/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed) 译者:[Veryzzj](https://github.com/Veryzzj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux operating system is a popular choice for servers – and for multiple reasons. First, it’s free (with exception of a few commercial distributions such as RHEL and SUSE Linux Enterprise Server ) and open-source. Its open-source nature implies that developers can view its source code, modify it and redistribute it according to the laid-out license terms. In addition, Linux is generally considered stable, versatile, and more secure than Windows. Furthermore, it can easily be deployed across various platforms such as bare-metal, virtual, and cloud environments.
In this article, we highlight the top 10 Linux distributions for servers.
## 1) Red Hat Enterprise Linux (RHEL)
[Red Hat Enterprise Linux](https://www.redhat.com/en), abbreviated as RHEL, is a commercial Linux distribution that was developed specifically for enterprise environments. It is a performance-driven, reliable, and secure operating system that provides enhanced usability and seamless deployment which makes it ideal for server environments.
RHEL supports a wide range of workloads in bare-metal, virtual, and cloud environments. In fact, it’s the world’s leading open-source solutions provider offering a myriad of products including Red Hat OpenShift, Ansible automation platform, Open hybrid cloud, JBoss Enterprise Application Platform, and SAP to mention a few.
## 2) Ubuntu Server
Developed and maintained by Canonical, Ubuntu is one of the most popular and widely used Linux distributions. It is a Debian-based Linux distribution that is absolutely free and open-source and is renowned for Its Desktop edition which is intuitive, user-friendly, and considered ideal for learners and beginners. Ubuntu comes in 3 editions namely; Desktop, Ubuntu Server, and Core.
While the Desktop Edition enjoys massive global usage, the Server edition also offers a solid platform for server environments. First, it can be deployed in any environment, be it on a physical, virtual, or cloud environment with extensive scale-out functionality. This implies you can add resources on the go to meet evolving demands.
And since the server version is completely stripped down without any GUI, it’s relatively lightweight leading to low resource overhead. This means low CPU and memory usage. This consequently leads to improved performance and enterprise-grade stability.
Apart from installing it on physical data centers and virtual servers, Ubuntu server is available in public clouds such as AWS and Azure. According to Canonical, 55% of OpenStack clouds run on Ubuntu. In addition, you can have your own managed Openstack cloud for a fee.
## 3) Debian
Debian is one of the earliest Linux distributions that is renowned for its rock-solid stability. It comes in three variants: Stable, Unstable, and Testing.
The Debian stable branch is the latest officially released distribution of Debian and is the most popular version for servers and desktop PCs. All packages shipped with this branch have undergone rigorous testing and debugging, and are hence considered ready for production workloads.
Debian server is tailored to be a fast and reliable operating system with an emphasis on security and stability. It’s for this reason that it makes for a perfect choice for server environments. In addition, It provides extensive hardware support with over 59,000 software packages, by far the greatest number of packages provided by any OS.
Just like Ubuntu Server, Debian is lightweight, versatile, and highly stable for enterprise workloads. In fact, it is considered more stable and easier to manage than Ubuntu.
#### 4) SUSE Linux Enterprise Server
Another formidable and worthy contender in providing an excellent platform for servers is [SUSE Linux Enterprise Server ( SLES )](https://www.suse.com/products/server/). The server operating system is created and maintained by SUSE, a German-based organization.
SLES is a commercial distribution that was built to handle enterprise-grade workloads. It is adaptable to any environment and is optimized for stability, reliability, and security. It is highly scalable and allows IT teams to efficiently deploy their applications and services in response to growing business demands.
The latest SLES release provides interoperability with ease of administration. It also provides increased support and compatibility with Docker containers, Kubernetes, and geo-clusters. The latter provides flexibility with high availability allowing IT teams to configure replication clusters that span multiple data center regions.
SUSE Linux Enterprise Server not only supports in-house workloads but is also offered on popular cloud providers including Microsoft Azure, Google Compute Engine, and Amazon Web Services.
#### 5) OpenSUSE Leap
Developed by the OpenSUSE project, [OpenSUSE](https://www.opensuse.org/) is a non-commercial RPM-based Linux distribution that is developed and maintained by SUSE. OpenSUSE is free and open-source and provides two editions:
- OpenSUSE Leap
- OpenSUSE Tumbleweed
OpenSUSE TumbleWeed is the rolling release version of OpenSUSE. It contains the latest stable applications including an updated kernel, git, SAMBA, desktop applications, and many more. It, therefore, makes a perfect distribution of choice for developers or power users who need to leverage the latest software stacks in their workloads. However, due to frequent kernel updates, it’s not the ideal choice for servers since frequent updates can cause inconsistencies with other third-party driver modules.
OpenSUSE Leap is the preferred OpenSUSE option for servers. It’s an open-source and community-driven distribution that has a slower release cycle and, hence, a better fit than TumbleWeed. It is community-driven and this means that it undergoes rigorous testing before being released.
Leap is comparatively easy to use and offers high performance and stability ideal for handling enterprise-grade workloads. It is a great alternative to commercial server distributions such as SLES and RHEL and allows companies to deploy their workloads both on bare metal and cloud deployments.
## 6) Rocky Linux
[Rocky Linux](https://www.linuxtechi.com/how-to-install-rocky-linux-9-step-by-step/) is a Linux distribution that was developed as a replacement for CentOS Linux which reached EOL ( End Of Life ) on 31st, December 2021. It is a free and opensource Linux distribution that is enterprise-ready, providing rock-solid stability, reliability, and regular updates with a 10-year support lifecycle at absolutely no cost
Rocky Linux is an enterprise operating system designed to be 100% bug-for-bug compatible with Red Hat Enterprise Linux and is currently under intensive development by the community.
The distribution has gained massive popularity since the untimely discontinuation of CentOS Linux. It can be installed on both servers, and desktop computers. It’s also available in custom-built images on Public cloud providers such as Amazon AWS, and Google Compute Engine.
Rocky Linux developers have availed a migration script that allows users to migrate from other enterprise editions such as CentOS Linux and Oracle Linux to Rocky Linux.
## 7) AlmaLinux
Another alternative that was developed to plug in the gap left by CentOS Linux is [AlmaLinux](https://www.linuxtechi.com/how-to-install-almalinux-8-step-by-step/). This is yet another enterprise operating system that is completely free and opensource.
AlmaLinux was originally created by CloudLinux but is currently community driven. It offers a production-grade enterprise operating system that is 1:1 binary compatible with Red Hat Enterprise Linux (RHEL). In a nutshell, it’s a clone of RHEL and provides rock-solid stability and benefits that come with RHEL at no cost.
Being an Enterprise-grade server OS, AlmaLinux can comfortably run heavy and critical workloads. In addition, it provides regular releases that come with long-term support.
## 8) Oracle Linux
Developed by Oracle Corporation, [Oracle Linux](https://www.oracle.com/linux/) is a secure and high-performance operating system that is compiled from RHEL source code. It is optimized for hybrid and multi-cloud deployments, and just like Rocky and AlmaLinux, Oracle Linux is 100% binary compatible with Red Hat Linux.
Oracle Linux is a viable option for data centers and certainly a perfect replacement for CentOS which reached EOL. It is rock-solid stable and posts incredible performance ideal for enterprise applications.
Unlike Commercial Linux distributions such as RHEL and SUSE, Oracle Linux is completely free to download, use and redistribute. It is available under the GNU General Public License (GPLv2)
## 9) Fedora Server
Fedora is a free and open-source Linux distribution that is developed and maintained by Fedora Project which is sponsored by Red Hat.
Fedora serves as the upstream, community distribution of Red Hat Enterprise Linux. All the applications go through rigorous testing before they are pushed to RHEL. As such, it is referred to as a ‘Bleeding Edge’ operating system. This implies is regularly gets the latest software applications and updates.
For a long time, Fedora has been popular for its Workstation Edition which was built for laptop and desktop computers. Over time, it has expanded to include other editions such as Fedora Server, Fedora IoT, and Fedora CoreOS.
Fedora Server is a robust, reliable, and flexible operating system that ships with the best and latest data center technologies. As a leading-edge edition, it offers the very latest technologies in the open-source community. It is easy to install, set up, and administer using various tools such as Cockpit web console.
Fedora is also fast, remarkably stable, and secure. It works just fine for production and enterprise workloads. New releases of Fedora are pushed out once every 6 months.
## 10) Fedora CoreOS
Last on our list is Fedora CoreOS. This is a minimal operating system that is optimized specifically for running containerized applications and workloads. According to its home page, it touts itself as “an automatically-updating, minimal operating system for running containerized workloads securely and at scale.”
By default, it ships with both podman and docker and comes in three release streams namely: Stable, Testing, and Next. You can get images for bare-metal servers and virtualized environments as well as cloud images that are hosted by major cloud providers such as Amazon Web Service (AWS) and Google Cloud Platform (GCP).
#### Conclusion
That was a round-up of the best Linux distributions for servers. We hope you found this guide insightful. Any thoughts on our guide? Your feedback is very much welcome. |
15,537 | 如何在 Arch Linux 中安装 GNOME 桌面 | https://www.debugpoint.com/gnome-arch-linux-install/ | 2023-02-13T22:02:00 | [
"Arch Linux",
"GNOME"
] | /article-15537-1.html | 
>
> 本指南解释了在 Arch Linux 中安装 GNOME 桌面所需的步骤。
>
>
>
本指南有两部分:第一部分是关于安装基本的 Arch 系统;第二部分是在 Arch Linux 基础上安装完整的 GNOME 桌面环境。
### 什么是 GNOME 桌面?
GNOME 是一个流行的桌面环境,是如 Ubuntu 和 Fedora 等许多基于桌面的顶级 Linux 发行版的默认桌面。几乎所有的定制版都提供了一个 GNOME 桌面版本。
GNOME 桌面是稳定和用户友好的桌面之一,因此它被许多普通和高级用户所青睐。如果你想要一个在你进行工作时保持隐形的桌面,GNOME 就是这样的一个。它不会在你工作时妨碍你。因此,尽管有许多关于 GNOME 3(目前的版本)速度慢、资源重等争议,它仍然是许多人的流行和默认选择。
说了这么多,让我们来看看如何在裸机 Arch 中安装 GNOME 桌面。
### 在 Arch Linux 中安装 GNOME 桌面
#### 第一部分:安装 Arch Linux
如果你已经安装了 Arch Linux,你可以跳过这一步,直接进入下面安装 GNOME 桌面部分。
要快速安装 Arch Linux 基础版,请遵循以下步骤。你也可以访问 [该指南](https://www.debugpoint.com/2020/11/install-arch-linux/),了解如何将 Arch Linux 安装为双启动或在虚拟机中的完整教程。
本文下面介绍的步骤是安装 Arch 的传统方式。新手请按照下面的指南链接,以更现代的方式使用 `archinstall` 脚本。完成后,回来通过第二部分的步骤继续 GNOME 安装。
>
> **[现代方式:使用 archinstall 脚本安装(推荐)](https://www.debugpoint.com/archinstall-guide/)**
>
>
>
##### 传统方式:下载 Arch Linux
从下面的链接下载 Arch Linux 的 .iso 文件。它也提供了磁力链接和种子链接。下载后,将 ISO 写入 USB 驱动器。然后从该驱动器启动。
>
> **[下载 Arch Linux](https://www.archlinux.org/download/)**
>
>
>
如果你打算通过 GNOME Boxes、virt-manager 把它安装成一个虚拟机镜像,那么你就不需要把它写入 U 盘。
##### 启动和配置分区
从 Arch Linux ISO 启动后,你必须运行一系列的命令来安装基本系统。
首先,运行下面的命令,找出设备标识符。
```
fdisk -l
```

然后用设备标识符,运行下面的命令,开始对你的磁盘进行分区。请确保根据你的系统改变 `/dev/sda`。
```
cfdisk /dev/sda
```
在下一个提示中选择 `label type = dos`。
选择自由空间,并从底部选择 “<ruby> 新建 <rt> New </rt></ruby>” 选项。在这个例子中,我将创建三个分区,如下图所示:
```
/dev/sda1 - 1G - for /boot
/dev/sda2 - 5G - for root
/dev/sda3 - 1G - for swap
```

在下一个屏幕中,提供引导分区的分区大小(在这个例子中,我给出了 1GB)。选择它作为主分区。
对大小为 5GB 的主根分区重复同样的步骤。

用同样的步骤创建一个大小为 1G 的交换分区(你可以根据你的需要改变它)。创建交换分区后,确保在底部选择 “<ruby> 类型 <rt> Type </rt></ruby>”,并用 “Linux Swap/Solaris” 选项将其标记为交换分区。

一旦完成,使用底部的 “<ruby> 写入 <rt> Write </rt></ruby>” 选项将变化写入磁盘。**确保你在写入前做了备份,因为这是你系统中的一个永久性变化。**
在你继续之前,运行下面的命令来检查。你可以看到在这个例子中,有三个分区被列出。
```
fdisk -l
```

依次运行下面的命令,在上面新创建的分区中格式化并创建一个 ext4 文件系统。请确保你根据你的需要改变 `/dev/sda1` 和 `/dev/sda2`:
```
mkfs.ext4 /dev/sda1
mkfs.ext4 /dev/sda2
mkswap /dev/sda3
swapon /dev/sda3
```
完成后,装载系统并创建必要的目录:
```
mount /dev/sda2 /mnt
mkdir /mnt/boot /mnt/var /mnt/home
mount /dev/sda1 /mnt/boot
```
同样,确保你根据你的系统改变 `/dev/sda1`、`/dev/sda2` 和 `/dev/sda3`。

##### 安装基础系统
我希望你已经连接到互联网了。如果没有,请尝试使用 USB 网卡或 Arch 安装程序自动配置和检测的有线网络连接。如果你没有可用的有线连接,请按照 [该指南](https://www.debugpoint.com/2020/11/connect-wifi-terminal-linux/) 使用 Arch Linux 安装程序配置一个无线或 Wi-Fi 网络。
依次运行下面的命令,将基本系统安装到已安装的分区中。下载的大小约为 400MB。
```
pacman -Syy
pacstrap /mnt base base-devel linux linux-firmware nano dhcpcd net-tools grub
```

一旦完成,就会生成文件系统表,没有它你就无法启动系统。
```
genfstab -U /mnt >> /mnt/etc/fstab
```
##### 配置基础系统
依次按照下面的命令来配置基本系统。这涉及到设置你的地域、语言、添加一个登录用户,以及设置互联网:
```
arch-chroot /mnt
nano /etc/locale.gen
```
通过去掉开头的 `#` 来取消对你所选择的 <ruby> 语言环境 <rt> locale </rt></ruby> 的注释。在本指南中,我选择了 `en_US.UTF-8 UTF-8`,按 `CTRL+O`、回车和 `CTRL+X` 退出 nano。

使用以下方法生成语言环境:
```
locale-gen
```
如果你不想手动去 `/etc/locale.gen` 设置语言,也可以使用以下命令设置语言:
```
echo LANG=en_US.UTF-8 > /etc/locale.conf
export LANG=en_US.UTF-8
```
设置当地的时区:
```
ln -s /usr/share/zoneinfo/America/New_York /etc/localtime
```
同样,你可以根据你的需要来选择它们。你可以通过以下命令列出当地的时区:
```
ls /usr/share/zoneinfo
ls /usr/share/zoneinfo/America
```
设置硬件时钟,创建一个主机名,并使用以下命令依次启用互联网的 DHCP。你可以根据你的想法,将 `arindam-pc` 改为任何主机名:
```
hwclock --systohc --utc
echo arindam-pc > /etc/hostname
systemctl enable dhcpcd
```
下一步是设置根用户的密码,创建一个管理员用户,并在 `sudoers` 文件中添加该用户。
依次按照下面的命令进行操作。请确保根据你的需要将用户名从 `debugpoint` 改为其他名称:
```
passwd rootuseradd -m -g users -G wheel -s /bin/bash debugpointpasswd debugpoint
```

打开 `sudoers` 文件,添加以下几行:
```
nano /etc/sudoers
```
添加以下几行。由于你已经创建了 `root` 用户,该条目应该已经有了:
```
root ALL=(ALL) ALL
debugpoint ALL=(ALL) ALL
```

依次使用如下命令安装 Grub,设置初始化 Ramdisk 环境,卸载系统:
```
grub-install /dev/sda
grub-mkconfig -o /boot/grub/grub.cfg
mkinitcpio -p linux
exit
```

然后重新启动你的系统。如果你是在一个物理系统中安装的,在这一步要拔掉 USB 介质。
```
umount /mnt/boot
umount /mnt
reboot
```
你现在已经成功地安装了 Arch Linux 基本系统。现在是安装完整的 GNOME 桌面的时候了。

#### 第二部分:在 Arch Linux 中安装 GNOME
重启后,从 Grub 中选择 Arch Linux。在 Arch Linux 的提示符下,开始依次运行以下命令。这些命令安装 Xorg 服务器、显示管理器、GNOME 桌面组件、控制器包和其他应用程序。
所有的命令都使用默认值,即在要求时按回车。
安装 Xorg 服务器。安装大小约为 80MB:
```
sudo pacman -S --needed xorg
```
安装显示管理器、GNOME 桌面。安装大小约为 300MB:
```
sudo pacman -S --needed gnome gnome-tweaks nautilus-sendto gnome-nettool gnome-usage gnome gnome-multi-writer adwaita-icon-theme xdg-user-dirs-gtk fwupd arc-gtk-theme seahosrse gdm
```
上面的安装会要求提供几个软件包的选项。选择你想要的任何一个。如果你不确定,在询问时选择 “jack”、“noto-sans” 和 “xdg-portal-desktop-gnome”。
安装应用程序。这只是一个参考。你也可以安装你所需要的:
```
sudo pacman -S --needed firefox vlc filezilla leafpad xscreensaver archlinux-wallpaper
```
现在是时候把显示管理器和网络管理器作为服务启用了。这样,下次登录时,它们就可以由 systemd 自动运行。
```
systemctl enable gdm
systemctl enable NetworkManager
```
使用 `reboot` 命令重新启动系统:
```
reboot
```

如果一切顺利,你应该在 GNOME 桌面上看到一个漂亮的登录提示。使用你刚刚创建的凭证登录。迎接你的应该是 Arch Linux 漂亮而干净的 GNOME 43 桌面。
我希望这个指南能帮助你在裸机 Arch 安装 GNOME 桌面。
---
via: <https://www.debugpoint.com/gnome-arch-linux-install/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,538 | 如何在 Ubuntu 中安装 DOSBox 玩老游戏 | https://www.debugpoint.com/install-dosbox-ubuntu/ | 2023-02-14T14:26:00 | [
"模拟器",
"DOS"
] | /article-15538-1.html | 
>
> 了解如何在 Ubuntu 中安装 DOSBox,并配置它来玩旧式 DOS 游戏。
>
>
>
DOSBox 是一个自由开源的操作系统模拟器,可以在现代 Linux 系统中运行。它有几个组件可以模仿旧的硬件,以运行旧的程序和游戏。
这一切使得在现代 Linux 发行版中享受旧游戏和应用程序成为可能。
在本指南中,我将向你展示如何安装 DOSBox,配置它,并玩一个示例游戏。
### 在 Ubuntu 中安装 DOSBox
DOSBox 的主软件包在所有主要的 Linux 发行版中都可用。
在 Ubuntu、Debian、LinuxMint 和相关发行版中,使用以下命令安装它:
```
sudo apt install dosbox
```
在 Fedora、CentOS、RHEL 和相关发行版中,使用以下命令安装它:
```
sudo dnf install dosbox
```
在 Arch Linux 中,使用以下命令安装它:
```
pacman -S --needed dosbox
```
安装就结束了。现在是配置和运行的时候了。
### 运行 DOSBox
安装后,从终端键入以下内容:
```
dosbox
```
它将显示以下界面,这是 DOSBox 提示符。第一次运行非常重要,因为它会创建 DOSBox 配置文件。
键入 `exit` 暂时关闭 DOSBox。

配置文件为你提供了几个调整设置的选项。在 Ubuntu 中,该文件创建在 `~/.dosbox/dosbox-[version].conf`。
在 Fedora 中,它从以下路径加载临时配置文件 `~/.config/dosbox/dosbox-staging.conf`.
默认情况下,你可以使用默认配置。但是如果你愿意,你可以修改它。
例如,如果你想全屏启动 DOSBox,你可以启用或禁用相关设置。像这样:
```
fullscreen=false
fulldouble=false
fullresolution=original
windowresolution=original
output=surface
autolock=true
sensitivity=100
waitonerror=true
```
你可以在 [官方文档](https://www.dosbox.com/wiki/Dosbox.conf#Sections) 中找到所有的设置选项。
### 下载以及游玩老游戏
有许多网站提供旧的 DOS 游戏。我使用过下面的网站,它提供了一套可以在现代系统中玩的老游戏。
所以,访问下面的网站,下载你想要的任何游戏。
>
> **[下载 DOS 游戏](https://archive.org/details/softwarelibrary_msdos_games?tab=collection)**
>
>
>
在你的 `/home` 目录下创建一个文件夹,并将其命名为 `dosbox`:
```
cd ~
mkdir dosbox
```
现在,解压你下载的游戏(应该是一个 .exe 文件),在 `~/dosbox` 目录下创建一个单独的文件夹。
例如,我下载了游戏 “马里奥和路易吉(1994)”。我在 `dosbox` 文件夹中创建了一个名为 `mario` 的文件夹,并将游戏文件放进去。

现在从终端启动 dosbox:
```
dosbox
```
并键入以下内容,将游戏挂载到虚拟的 C: 盘中:
```
mount c ~/dosbox/mario
```
以上命令完成后,将驱动器更改为 C::
```
c:
```
现在,你可以输入游戏的文件名来运行游戏:
```
mario
```


### 键盘或控制器映射
默认情况下,DOSBox 会自动检测键盘或你插入的控制器。但是,如果你想更改游戏按键绑定,可以从终端运行以下命令:
```
dosbox -startmapper
```
它将显示以下界面,每个键上都标记有事件。你可以点开任何一个键,根据自己的习惯进行更改。

### 结论
我希望你在 Ubuntu 和其他发行版中安装了 DOSBox 之后,能够运行你最喜欢的 DOS 游戏。DOSBox 是最酷的软件之一,你可以使用它来运行任何程序,例如 [Turbo C](https://www.debugpoint.com/setting-up-dosbox-in-ubuntu-to-run-turbo-c/) 等。
如果你有任何麻烦或问题,请在评论区告诉我。
享受游戏吧!
---
via: <https://www.debugpoint.com/install-dosbox-ubuntu/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[gpchn](https://github.com/gpchn) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,539 | zip 命令的解释与示例 | https://www.debugpoint.com/zip-command-linux-examples/ | 2023-02-14T14:48:00 | [
"zip"
] | /article-15539-1.html |
>
> 这是一份关于理解 Linux 中的 zip 命令的初学者指南,并附有一些例子。
>
>
>

这篇文章是 [Linux 命令](https://www.debugpoint.com/category/linux-commands)学习系列的一部分。
zip 文件是一个包含一个或多个文件的压缩档案。它作为一种无损数据压缩技术被广泛使用。由于压缩,它占用的磁盘空间更少,在计算机网络上传输时需要的数据也更少。
这些压缩文件可以在 Linux、Windows 和 macOS 中轻松提取。有各种支持压缩 zip 文件的软件,也提供提取它们的功能。
由于它很流行,几乎所有的操作系统都内置了这个功能。
在本教程中,我们将谈论几种基于终端的方法来压缩 Linux 中的文件。
### Linux 中的 Zip 命令示例
#### 语法
在 Linux 中,你需要使用的压缩文件的程序名称是 `zip`。下面是基本的语法:
```
zip [压缩文件名] file1 file2 file3
```
以下是正式的语法:
```
zip [-options] [-b path] [-t mmddyyyy] [-n suffixes] [zipfile list] [-xi list]
```
理想情况下,`zip` 命令应该被安装在所有主流的 Linux 发行版中。如果没有,使用下面的命令来安装它。
#### 在 Debian、Ubuntu 和相关发行版上安装
```
sudo apt install zip
```
#### 在 Fedora、基于 RHEL 的系统上安装
```
sudo dnf install zip
```
#### 在 Arch Linux 上安装
```
pacman -S zip
```
让我们继续看一些例子。
#### 如何压缩文件和文件夹
我的测试目录中有以下三个文件。它们是 `file1.txt`、`file2.txt` 和 `file3.txt`。如果我想用 zip 压缩三个文件,并创建一个 `myfiles.zip` 的压缩包,用下面的命令就可以了。
```
zip myfiles.zip file1.txt file2.txt file3.mp3
```
输出:
```
adding: file1.txt (stored 0%)
adding: file2.txt (stored 0%)
adding: file3.mp3 (deflated 13%)
```

这里你应该记住几个要点。
* 当创建一个 zip 文件时,你应该有对当前目录的修改权限。
* zip 文件格式不包含权限,即读(4)、写(2),和执行(1)。所以,创建该文件的用户成为该文件的所有者。
* 如果你想使用带有权限的 zip,可以尝试使用 `tar` 命令(将在后面的教程中解释)。
* 在上面的输出中,`zip` 命令显示了被添加到存档中的文件名和压缩方法。
* 在目标文件名中指定 .zip 文件名的扩展名并不是必须的。如果你省略了 .zip,`zip` 会在最后加上 .zip。
当你操作成百上千的文件时,为了减少终端中的输出,你可以使用 `-q` 参数来抑制 `zip` 命令中的输出:
```
zip -q myfiles.zip file1.txt file2.txt file3.txt
```
#### 递归压缩子文件夹
`zip` 命令的 `-r` 选项使你能够囊括所有子目录。这个选项会递归地遍历到一个目录结构的最后一个子目录,并将它们全部加入到压缩文件中。
下面的命令创建了一个包含 `my_folder` 内所有内容和子目录的压缩文件:
```
zip -r myfolder.zip my_folder
```
你也可以使用通配符(`*`)在你的压缩文件中包含特定类型的文件:
```
zip -0 my_movies.zip *.mp4
```
#### 混合添加文件和目录到压缩文件
有了以上所有的选项,`zip` 命令允许你把文件和目录一起作为参数指定。
```
zip -r myfiles.zip file1.txt file2.txt file3.txt my_folder1 my_folder2
```
### 压缩算法
zip 压缩的默认输出包含两个不同的词,即 `deflate` 和 `store`。zip 默认使用的压缩方法是 `deflate`。如果它成功地压缩了文件,那么输出显示 `deflate`。而当它不能压缩一个文件时,它只是将它们原封不动地存储在 .zip 文件中。这些文件的输出显示为 `store`。
目前有许多压缩算法。其中一种是 bzip2 压缩法,在 Linux 中的 `zip` 命令支持它。你可以指定压缩算法作为一个命令选项来使用。使用选项 `-Z`,后面跟上算法名称,如下所示:
```
zip -r -Z bzip2 myfolder.zip my_folder
```
#### 压缩级别
`zip` 命令还允许你指定压缩级别。压缩级别是指你想让 zip 优化多少来减少包的大小。它是一个从 0 到 9 的数值范围。压缩级别为 9 的值是最高的压缩。默认值是 6。
记住,如果你用 zip 压缩成千上万个大小不一的文件,它可能会占用较多的系统资源,并花费大量的时间。所以,如果你在程序中使用它,或者用 shell 脚本处理大量的文件,请遵循正确的编程标准。
```
zip -9 -r myfolder.zip my_folder
```
#### 用密码保护一个压缩文件
你也可以用下面的 `-e` 选项对压缩文件进行密码保护:
```
zip -e -r myfolder.zip my_folder
```
运行该命令后,它将要求输入密码。
>
> 注意。尽量不要使用 zip 命令来对压缩文件进行密码保护。zip 的加密算法是使用流式加密的 PKZIP。而它很容易被破解。如果你想保护你的文件,请使用 7-Zip 或其他高级工具。
>
>
>
#### 分割较大的压缩文件
许多应用程序、服务器和文件共享可能包含固定大小的文件上传限制。例如,你有一个 10GB 的文件,但服务只允许每个文件 1GB。使用 `zip` 的 `-s` 选项,你可以将其压缩并分割成几块进行上传。
```
zip -s 1g -r myfolder.zip my_folder
```
### 总结
你学到了一些 `zip` 命令的基本知识。它对大多数本地情况很有用,在这些情况下,你需要通过即时压缩来进行快速备份。然而,对于更高级的选项,你应该使用 7-Zip 或其他命令,我将在接下来的几篇文章中分享。
同时,你可以在 [zip 手册](https://linux.die.net/man/1/zip) 中了解更多。
---
via: <https://www.debugpoint.com/zip-command-linux-examples/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,541 | 跟着我们的新指南学习开发 WebAssembly | https://opensource.com/article/23/2/webassembly-guide | 2023-02-15T20:40:36 | [
"WebAssembly"
] | https://linux.cn/article-15541-1.html | 
>
> 使用 WebAssembly 开发有很多不同的方向,这取决于你已经知道的东西和你想建立的东西。
>
>
>
在过去的几十年里,Web 浏览器作为最流行的跨平台应用经久不衰。从另一个角度看浏览器,它是最受欢迎的应用交付平台之一。想想你使用的所有网站,它们取代了你过去用桌面上运行的软件进行的活动。你仍然在使用软件,但你是通过浏览器来访问它,而且是在别人的 Linux 服务器上运行。在优化我们所有人使用的软件的永恒努力中,软件开发世界早在 2019 年就引入了 WebAssembly,作为通过 Web 浏览器运行编译代码的一种方式。应用的性能比以往任何时候都要好,而且可以生成 WebAssembly 编码的语言远不只是通常的 PHP、Python 和 JavaScript。
### 一个目标和一种语言
关于 WebAssembly 的一个强大但也最令人困惑的地方是,“WebAssembly” 这个词既指一种语言,也指一个目标。WebAssembly 是一种汇编语言,但没有多少人选择直接用汇编写代码。即使是汇编语言,最终也会被转换为二进制格式,这也是计算机运行代码的要求。这种二进制格式也被称为 WebAssembly。不过这很好,因为这意味着你可以用你选择的语言来写一些最终以 WebAssembly 交付的东西,包括 C、C++、Rust、Javascript 和其他许多语言。
进入 WebAssembly 的途径是 Emscripten,这是一个 LLVM 编译器工具链,可以从你的代码中产生 WebAssembly。
### 安装 Emscripten
要在你的 Linux 或 macOS 电脑上安装 Emscripten,请使用 Git:
```
$ git clone https://github.com/emscripten-core/emsdk.git
```
改变目录进入 `emsdk` 目录并运行安装命令:
```
$ ./emsdk install latest
$ ./emsdk activate latest
```
Emscripten 工具链中的所有内容都安装在 `emsdk` 目录下,对系统的其他部分没有影响。由于这个原因,在使用 `emsdk` 之前,你必须 <ruby> 源引 <rt> source </rt></ruby> 它的环境:
```
$ source ./emsdk_env.sh
```
如果你打算经常使用 `emsdk`,你也可以在 `.bashrc` 中加入环境设置脚本。
要在 Windows 上安装 Emscripten,你可以在 WSL 环境下运行 Linux。
请访问 [Emscripten 网站](https://emscripten.org/) 了解更多安装信息。
### Hello World
下面是一个用 C++ 编写的简单的 “Hello World” 应用。
```
#include <iostream>
using namespace std;
int main() {
cout << "Hello world";
return 0;
}
```
先把它作为你的系统的标准二进制文件来测试:
```
$ g++ hello.cpp -o world
$ ./world
Hello world
```
看到它像预期的那样工作,用 `emcc` 把它构建为 WebAssembly:
```
$ emcc hello.cpp -o world.html
```
最后,用 `emrun` 运行它:
```
$ emrun ./world.html
```
`emrun` 工具是一个用于本地测试的方便命令。当你在服务器上托管你的应用时,`emrun` 就没有必要了。
### 学习更多关于 WebAssembly 的知识
使用 WebAssembly 开发可以有很多不同的方向,这取决于你已经知道的东西和你想建立的东西。如果你了解 C 或 C++,那么你可以用这些来写你的项目。如果你正在学习 Rust,那么你可以使用 Rust。甚至 Python 代码也可以使用 Pyodide 模块来作为 WebAssembly 运行。你有很多选择,而且没有错误的开始方式(甚至有 COBOL 到 WebAssembly 的编译器)。如果你渴望开始使用 WebAssembly,
>
> **[请下载我们免费的电子书](https://opensource.com/downloads/webassembly-ebook)**
>
>
>
---
via: <https://opensource.com/article/23/2/webassembly-guide>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Over the past few decades, the web browser has endured as the most popular cross-platform application. Looking at the browser from a different angle, it is one of the most popular platforms for application delivery. Think of all the websites you use that take the place of activities you used to do with software running on your desktop. You're still using software, but you're accessing it through a browser, and it's running on somebody else's Linux server. In the eternal effort to optimize the software we all use, the world of software development introduced WebAssembly back in 2019 as a way to run compiled code through a web browser. Application performance is better than ever, and the options for coding go far beyond the usual list of PHP, Python, and JavaScript.
## A target and a language
One of the powerful but also most confusing things about WebAssembly is that the term "webassembly" refers to both a language and a target. WebAssembly is an assembly language, but not many people choose to write code directly in assembly. Even the assembly language is ultimately converted to a binary format, which is what a computer requires to run code. This binary format is also called WebAssembly. This is good, though, because it means that you can use your choice of languages to write something that's ultimately delivered in WebAssembly, including C, C++, Rust, Javascript, and many others.
The gateway into WebAssembly is Emscripten, an LLVM compiler toolchain that produces WebAssembly from your code.
## Install Emscripten
To install Emscripten on your Linux or macOS computer, use Git:
```
``````
$ git clone \
https://github.com/emscripten-core/emsdk.git
```
Change directory into the `emsdk`
directory and run the install command:
```
``````
$ ./emsdk install latest
$ ./emsdk activate latest
```
Everything in the Emscripten toolchain is installed within the `emsdk`
directory and has no effect on the rest of your system. For this reason, before you use `emsdk`
, you must source its environment:
```
````$ source ./emsdk_env.sh`
If you plan on using `emsdk`
often, you can also source its environment setup script in `.bashrc`
.
To install Emscripten on Windows, you can run Linux in the WSL environment.
Visit the [Emscripten website](https://emscripten.org/) for more information on installation.
## Hello world
Here's a simple "hello world" application in written in C++.
```
``````
#include <iostream>
using namespace std;
int main() {
cout << "Hello world";
return 0;
}
```
Test it as a standard binary for your system first:
```
``````
$ g++ hello.cpp -o world
$ ./world
Hello world
```
Seeing that it works as expected, use `emcc`
to build it as WebAssembly:
```
````$ emcc hello.cpp -o world.html`
Finally, run it with `emrun`
:
```
````$ emrun ./world.html`
The `emrun`
utility is a convenience command for local testing. When you host your application on a server, `emrun`
isn't necessary.
## Learning more about WebAssembly
Developing for WebAssembly can go in many different directions, depending on what you already know and what you're trying to build. If you know C or C++, then you can write your project using those. If you're learning Rust, then you can use Rust. Even Python code can use the Pyodide module to run as WebAssembly. You have lots of options, and there's no wrong way to start (there's even a COBOL-to-WebAssembly compiler). If you're keen to get started with WebAssembly, [download our complimentary eBook](https://opensource.com/downloads/webassembly-ebook).
## Comments are closed. |
15,543 | 我们是如何聘请开源开发人员的 | https://opensource.com/article/22/2/how-we-hired-open-source-developer | 2023-02-16T07:44:36 | [
"面试"
] | https://linux.cn/article-15543-1.html |
>
> 我的团队不再采用标准的算法编程笔试,而是采用一套能够产出更多相关成果的流程。
>
>
>

作为初创安全公司 [Profian](https://profian.com/) 的首席执行官和联合创始人,我参与了我们聘请开发人员从事 [Enarx](https://enarx.dev/) 的工作。Enarx 是一个处理机密信息计算的安全项目,几乎完全用 [Rust 语言](https://opensource.com/article/21/3/rust-programmer) 编写(少部分用汇编语言)。Profian 现在已经在这次招聘找到了所有要找的人,一些开发人员将在接下来的几周内开始工作。然而,Enarx 绝对欢迎新的贡献者,如果事情继续顺利,公司将来肯定会雇用更多的人。
招聘人员并不容易,加上 Profian 还有一系列特别的要求,这让招人变得更加困难。因此我认为分享我们如何解决这个问题应该还蛮有意思的,而且也会对社区有帮助。
### 我们寻找什么样的人才?
以下就是我前文提到的特别要求:
* **系统编程**:Profian 主要需要那些喜欢系统层编程的人。这一层面的编程已经处于栈的底层,有很多直接与硬件或操作系统的交互。例如,要创建客户端-服务器部分,我们必须编写相当多的协议、管理加密等等,而这方面的工具还不是很成熟(请参阅下面的 “Rust” 一节)。
* **Rust**:项目几乎都是用 Rust 语言编写的,那些不是的则是用汇编语言写的(目前只有 x86 平台,尽管随着我们添加更多平台情况可能会有所改变)。Rust 是一门很新、很酷同时也令人兴奋的编程语言,但它同时也很年轻,并且一些领域没有你想要的所有支持或者没有你希望的那么成熟 —— 这包括从密码学到多线程库到编译器/构建基本架构。
* **分散各地的团队**:Profian 正在建立一个能够及时通讯联系的团队。Profian 在德国、芬兰、荷兰、北卡罗来纳州(美国)、马萨诸塞州(美国)、弗吉尼亚州(美国)和乔治亚州(美国)都有开发人员。我在英国,我们的社区经理在巴西,我们有来自印度和尼日利亚的实习生。从一开始我们就知道团队很难聚集在一个地方工作,因此我们需要能够通过视频、聊天和(最不济的情况下)电子邮件与人交流和协作的成员。
* **安全**:Enarx 是一个安全项目。虽然我们并不是专门在寻找安全专家,但我们需要能够将安全放在首位去思考和工作,并设计和编写适用于安全环境的代码的人。
* **Git**:我们所有的代码都存储在 Git 中(主要是 [GitHub](https://github.com/enarx/),还有一些存在 GitLab)。我们围绕代码的大部分交互都是围绕 Git 进行的,因此任何加入我们团队的人都需要能自如使用它作为日常工作中的标准工具。
* **开源**:开源不仅仅是许可;更是一种心态,同时,这也是一种合作方式。大量开源软件是由不同地域的人创建的,他们甚至可能不认为彼此身处于一个团队。我们需要知道我们招的人不仅能在公司内部凝聚成一个紧密的团队,同时也能够与组织外部的人员协作,并接受 Profian 的“默认开放”文化,这里的开放不仅仅限于代码,还要有开放的讨论、沟通和文档。
### 我们是如何找到人才的?
正如我在其他地方提到的,[招聘很困难](https://aliceevebob.com/2021/11/09/recruiting-is-hard/)。Profian 使用多种方式寻找候选人,它们取得了不同程度的成功:
* 领英招聘广告
* 领英搜索
* 特定语言的讨论板和招聘板(例如,Reddit)
* 外部招募人员(特别致敬来自 [Interstem](https://www.interstem.co.uk/) 公司的 Gerald)
* 口耳相传/个人推荐
虽然很难从质量方面判断这些来源如何,但如果没有外部招聘人员,我们肯定会在数量上苦苦挣扎(我们也有一些来自该途径的优秀候选人)。
### 我们如何筛选出想要的人才?
我们需要按照上述的所有要求衡量所有候选人,但并非所有要求都是同等重要的。例如,虽然我们热衷于雇用 Rust 程序员,但那些在系统级别具有强大 C/C++ 技能的人也能成为团队里有用的一份子,因为他们能够很快掌握 Rust 语言。另一方面,熟悉使用 Git 是至关重要的,因为我们无法花时间去培养新团队成员,让他们跟上我们的工作方式。
你可能会觉得很惊讶,但强大的开源背景并不是必需的要求,在类似模式中工作的心态是必需的,而任何有开源参与历史的人都可能对 Git 有很好的了解。同理,在一个分散各地的团队中工作的能力这一条件上,我们认为有过任意开源社区的参与经历都会是个积极的指标,因为有如此多的开源项目都是由分散各地的人们完成的。至于安全这一条件,我们则一致决定这只是一个“锦上添花”的条件。
我们想让这个过程简单快捷。 Profian 没有设置专门的人力资源部门或人力职能,因为我们正忙于编写代码。以下是我们最终使用的招聘流程(实际流程中可能略有不同),我们试图在 1-2 周内完成招聘:
1. 初审:个人履历/简历/GitHub/GitLab/领英主页,决定是否面试
2. 我作为 CEO 和候选人进行一场 30-40 分钟的讨论,了解他们是否适合我们团队的文化,同时让他们有机会了解我们,并了解他们是否真的像在初审提交的材料中所说的那样精通技术
3. 由 Nathaniel 领导的有关技术方面的深入讨论,通常我也在场
4. 与团队其他成员谈话
5. 编码笔试
6. 快速决策(通常在 24 小时内)
编码笔试很关键,但我们决定不采用通常的方法。我们的观点是,许多科技公司钟爱的纯“算法编码”笔试对我们想要的几乎毫无用处:考察候选人是否可以快速理解一段代码,解决一些问题,并与团队合作完成以上的工作。我们创建了一个 GitHub 存储库,其中包含一些几乎可以正常运行的 Rust 代码(事实上,我们最终使用了两个,其中一个用于技术栈上层的人),然后让候选人修复它,在上面执行一些与 Git 相关的过程,并稍作改进,在此过程中添加测试。
测试中一个必不可少的部分是让候选人通过我们的聊天室与团队互动。我们安排了 15 分钟的视频通话时间用于设置和初始问题,两个小时用于做笔试(“开卷”——以及与团队交谈,鼓励候选人使用互联网上所有可用的资源),然后是 30 分钟的总结会议,在这个会议上团队可以提出问题,候选人可以思考任务。这个谈话,结合笔试期间的聊天互动,让我们了解了候选人与团队沟通的能力。候选人挂断电话之后我们通常会在 5-10 分钟内决定是否要雇用他们。
这种方法通常效果很好。一些候选人在任务上遇到困难,一些人沟通不畅,一些人在 Git 交互方面做得不好 —— 这些是我们没有雇佣的人。这并不意味着他们不是优秀的程序员或者以后不适合该项目或公司,但他们不符合我们现在需要的标准。在我们聘用的开发人员中,他们的 Rust 经验水平和与团队互动的需求各不相同,但 Git 专业知识水平以及他们在和我们讨论之后的反应始终足以让我们决定接受他们。
### 感想
总的来说,我不认为我们会对筛选过程进行大的改动 —— 尽管我很确定我们可以在搜寻过程环节做得更好。通过编码笔试,我们可以筛选掉相当多的候选人,而且很好地帮了我们挑选合适的人。希望通过了这次选拔的每个人都很适合这个项目并且产出出色的代码(以及测试和文档等等)。时间会证明一切!
---
本文最初发布于 [Alice、Eve 和 Bob – 安全博客](https://aliceevebob.com/) 上,经许可后重新发布。
---
via: <https://opensource.com/article/22/2/how-we-hired-open-source-developer>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 选题:[lujun9972](https://github.com/lujun9972) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As the CEO and co-founder of [Profian](https://profian.com/), a start-up security company, I've been part of our effort to hire developers to work on [Enarx](https://enarx.dev/), a security project that deals with confidential computing, written almost exclusively in [Rust](https://opensource.com/article/21/3/rust-programmer) (with a bit of Assembly). Profian has now found all the people it was looking for in this search, with a couple of developers due to start in the next few weeks. However, new contributors are absolutely welcome to Enarx, and if things continue to go well, the company will definitely want to hire more folks in the future.
Hiring people is not easy, and Profian had a set of specialized requirements that made the task even more difficult. I thought it would be useful and interesting for the community to share how we approached the problem.
## What were we looking for?
These are the specialized requirements I'm talking about:
-
**Systems programming:**Profian mainly needs people who are happy programming at the systems layer. This is pretty far down the stack, with lots of interactions directly with hardware or the OS. To create client-server pieces, for instance, we have to write quite a lot of the protocols, manage the crypto, and so forth, and the tools for this aren't all very mature (see "Rust" below). -
**Rust:**Almost all of the project is written in Rust, and what isn't is written in Assembly language (currently exclusively x86, though that may change as we add more platforms). Rust is new, cool, and exciting, but it's still quite young, and some areas don't have all the support you might like or aren't as mature as you'd hope—everything from cryptography through multithreading libraries and compiler/build infrastructure. -
**Distributed team:**Profian is building a team of folks where we can find them. Profian has developers in Germany, Finland, the Netherlands, North Carolina (US), Massachusetts (US), Virginia (US), and Georgia (US). I'm in the United Kingdom, our community manager is in Brazil, and we have interns in India and Nigeria. We knew from the beginning that we wouldn't have everyone in one place, and this required people who would be able to communicate and collaborate with people via video, chat, and (at worst) email. -
**Security:**Enarx is a security project. Although we weren't specifically looking for security experts, we need people who can think and work with security top of mind and design and write code that is applicable and appropriate for the environment. -
**Git:**All of our code is stored in git (mainly[GitHub](https://github.com/enarx/), with a bit of GitLab thrown in). so much of our interaction around code revolves around git that anybody joining us would need to be very comfortable using it as a standard tool in their day-to-day work. -
**Open source:**Open source isn't just a licence; it's a mindset and, equally important, a way of collaborating. A great deal of open source software is created by people who aren't geographically co-located and who might not even see themselves as a team. We needed to know that the people we hired, while gelling as a close team within the company, would be able to collaborate with people outside the organisation and embrace Profian's "open by default" culture, not just for code, but for discussions, communications, and documentation.
## How did we find them?
As I've mentioned elsewhere, [recruiting is hard](https://aliceevebob.com/2021/11/09/recruiting-is-hard/). Profian used a variety of means to find candidates, with varying levels of success:
- LinkedIn job adverts
- LinkedIn searches
- Language-specific discussion boards and hiring boards (e.g., Reddit)
- An external recruiter (shout out to Gerald at
[Interstem](https://www.interstem.co.uk/)) - Word-of-mouth/personal recommendations
It's difficult to judge between these sources in terms of quality, but without an external recruiter, we'd certainly have struggled with quantity (and we had some great candidates from that pathway, too).
## How did we select them?
We needed to measure all of the candidates against all of the requirements noted above, but not all of them were equal. For instance, although we were keen to hire Rust programmers, someone with strong C/C++ skills at the systems level would be able to pick up Rust quickly enough to be useful. On the other hand, a good knowledge of using git was absolutely vital, as we couldn't spend time working with new team members to bring them up to speed on our way of working.
A strong open source background was, possibly surprisingly, not a requirement, but the mindset to work in that sort of model was, and anyone with a history of open source involvement is likely to have a good knowledge of git. The same goes for the ability to work in a distributed team: So much of open source is distributed that involvement in almost any open source community was a positive indicator. Security, we decided, was a "nice-to-have" qualification.
We wanted to keep the process simple and quick. Profian doesn't have a dedicated HR or People function, and we're busy trying to get code written. This is what we ended up with (with slight variations), and we tried to complete it within 1-2 weeks:
- Initial CV/resume/GitHub/GitLab/LinkedIn review to decide whether to interview
- 30-40 minute discussion with me as CEO, to find out if they might be a good cultural fit, to give them a chance to find out about us, and to get an idea if they were as technically adept as they appeared in Step 1
- Deep dive technical discussion led by Nathaniel, usually with me there
- Chat with other members of the team
- Coding exercise
- Quick decision (usually within 24 hours)
The coding exercise was key, but we decided against the usual approach. Our view was that a pure "algorithm coding" exercise beloved by many tech companies was pretty much useless for what we wanted: to find out whether a candidate could quickly understand a piece of code, fix some problems, and work with the team to do so. We created a GitHub repository with some almost-working Rust code in it (in fact, we ended up using two, with one for people a little higher up the stack), then instructed candidates to fix it, perform some git-related processes on it, and improve it slightly, adding tests along the way.
An essential part of the test was to get candidates to interact with the team via our chat room(s). We scheduled 15 minutes on a video call for setup and initial questions, two hours for the exercise ("open book" – as well as talking to the team, candidates were encouraged to use all resources available to them on the Internet), followed by a 30-minute wrap-up session where the team could ask questions, and the candidate could reflect on the task. This conversation, combined with the chat interactions during the exercise, allowed us to get an idea of how well the candidate was able to communicate with the team. Afterwards, the candidate would drop off the call, and we'd most often decide within 5-10 minutes whether we wanted to hire them.
This method generally worked very well. Some candidates struggled with the task, some didn't communicate well, some failed to do well with the git interactions – these were the people we didn't hire. It doesn't mean they're not good coders or might not be a good fit for the project or the company later on, but they didn't meet the criteria we need now. Of the developers we hired, the level of Rust experience and need for interaction with the team varied, but the level of git expertise and their reactions to our discussions afterwards were always sufficient for us to decide to take them.
## Reflections
On the whole, I don't think we'd change a huge amount about the selection process—though I'm pretty sure we could do better with the search process. The route through to the coding exercise allowed us to filter out quite a few candidates, and the coding exercise did a great job of helping us pick the right people. Hopefully, everyone who's come through the process will be a great fit and produce great code (and tests and documentation and …) for the project. Time will tell!
This article originally appeared on [Alice, Eve and Bob – a security blog](https://aliceevebob.com/) and is republished with permission.
## Comments are closed. |
15,544 | 如何使用 journalctl 查看和分析 systemd 日志(附实例) | https://www.debugpoint.com/systemd-journalctl/ | 2023-02-16T08:52:00 | [] | /article-15544-1.html | 
>
> 本指南介绍了 [systemd](https://freedesktop.org/wiki/Software/systemd/) 的 journalctl 工具及其各种命令的基础知识。你可以使用这些命令对 Linux 中的桌面和服务器日志进行故障诊断。以下是如何使用 journalctl 查看和分析 systemd 日志的不同例子。
>
>
>
### 简介
很多人说 systemd 不好,它对系统的影响很大,这也是一个有争议的话题。但你不能否认的是,它提供了一套完善的工具来管理和排除系统故障。想象一下,当你遇到一个没有 GUI 的损坏系统时,你可能会把启动和 GRUB 弄得一团糟。在这种情况下,你可以从一个<ruby> 立付 <rt> Live </rt></ruby>系统启动,挂上你的 Linux 分区,然后浏览 systemd 的日志,找出问题所在。
systemd 有三个基本组件,如下所示:
* `systemd`:Linux 操作系统的系统和服务管理器。
* `systemctl` :该命令用于反观和控制 systemd 系统和服务管理器的状态。
* `systemd-analyze`:该命令提供系统启动时的性能统计,并从系统和服务管理器中检索其他状态和跟踪信息。
除了这三个服务外,systemd 还提供其他服务,如 journald、logind、networkd 等。在本指南中,我们将讨论 systemd 的 journald 服务。
### journald - systemd 日志服务
根据设计,systemd 提供了一个集中的方式来处理所有来自进程、应用程序等的操作系统日志。所有这些日志事件都由 systemd 的 journald 守护进程来处理。journald 守护进程收集所有来自 Linux 操作系统各处的日志,并将其作为二进制数据存储在文件中。
以二进制数据集中记录事件、系统问题的好处有很多。例如,由于系统日志是以二进制而不是文本形式存储的,你可以以文本、JSON 对象等多种方式进行转译,以满足各种需求。另外,由于日志是按顺序存储的,通过对日志的日期/时间操作,超级容易追踪到单个事件。
请记住,journald 收集的日志文件数以千行计,而且不断更新每次开机、每个事件。因此,如果你有一个长期运行的 Linux 操作系统,日志的大小应该以 GB 为单位。由于有着数以千计的日志,最好用基本命令进行过滤,以了解更多系统问题。
#### journald 配置文件
journald 的配置文件存在于以下路径中。它包含了关于如何进行日志记录的各种标志。你可以看一下这个文件,并进行必要的修改。但我建议不要修改这个文件,除非你知道自己在做什么。
```
/etc/systemd/journald.conf
```
#### journald 存储二进制日志文件的地方
journald 以二进制格式存储日志。它们被保存在这个路径下的一个目录中:
```
/var/log/journal
```
例如,在下面的路径中,有一个目录包含了迄今为止的所有系统日志。

不要使用 `cat` 命令,也不要使用 `nano` 或 `vi` 来打开这些文件。它们(是二进制的),无法正常显示。
### 使用 journalctl 来查看和分析 systemd 日志
#### journald 基本命令
查看 journald 日志的基本命令是:
```
journalctl
```

该命令提供了所有应用程序和进程的日志条目,包括错误、警告等。它显示的列表中,最旧的日志在顶部,当前的日志在底部。你需要不断按回车键来逐行滚动浏览。你也可以使用 `PAGE UP` 和 `PAGE DOWN` 键来滚动。按 `q` 键可以退出这个视图。
#### 如何以不同时区的时间查看日志条目
默认情况下,`journalctl` 以当前系统时区显示日志的时间。然而,你可以很容易地在命令中提供时区,将同一日志转换为不同的时区。例如,要以 UTC 查看日志,请使用以下命令:
```
journalctl --utc
```

#### 如何在日志中只查看错误、警告等信息
系统产生的日志有不同的优先级。有些日志可能是可以忽略的警告,有些可能是重要的错误。你可能想只看错误,不看警告。这也可以用下面的命令来实现。
要查看紧急系统信息,请使用:
```
journalctl -p 0
```

错误代码:
```
0: 紧急情况
1: 警报
2: 危急
3: 错误
4: 警告
5: 通知
6: 信息
7:调试
```
当你指定错误代码时,它显示该等级及更高的所有信息。例如,如果你指定下面的命令,它会显示所有优先级为 2、1 和 0 的信息:
```
journalctl -p 2
```
#### 如何查看特定启动的日志
当你运行 `journalctl` 命令时,它会显示当前启动的信息,即你正在运行的会话中的信息。但也可以查看过去的启动信息。
在每次重启时,日志都会持续更新。journald 会记录不同启动时的日志。要查看不同启动时的日志,请使用以下命令。
```
journalctl --list-boots
```

* 第一个数字显示的是 journald 的唯一的启动跟踪号码,你可以在下一个命令中使用它来分析该特定的启动。
* 第二个数字是启动 ID,你也可以在命令中指定。
* 接下来的两个日期、时间组合是存储在相应文件中的日志的时间。如果你想找出某个特定日期、时间的日志或错误,这就非常方便了。
要查看一个特定的启动号码,你可以选择第一个启动跟踪号码或启动 ID,如下所示。
```
journalctl -b -45
```
```
journalctl -b 8bab42c7e82440f886a3f041a7c95b98
```

你也可以使用 `-x` 选项,在显示屏上添加 systemd 错误信息的解释。在某些情况下,这是个救命稻草。
```
journalctl -xb -p 3
```

#### 如何查看某一特定时间、日期的日志记录
`journalctl` 功能强大,可以在命令中提供类似英语的参数,用于时间和日期操作。
你可以使用 `--since` 选项与 `yesterday`、`today`、`tomorrow` 或 `now` 组合。
下面是一些不同命令的例子。你可以根据你的需要修改它们。它们是不言自明的。以下命令中的日期、时间格式为 `"YYYY-MM-DD HH:MM:SS"`
```
journalctl --since "2020-12-04 06:00:00"
```
```
journalctl --since "2020-12-03" --until "2020-12-05 03:00:00"
```
```
journalctl --since yesterday
```
```
journalctl --since 09:00 --until "1 hour ago"
```

你也可以将上述内容与错误级别开关结合起来。
#### 如何查看内核特定的日志记录
Linux 内核信息也可以从日志中提取出来。要查看当前启动时的内核信息,请使用以下命令:
```
journalctl -k
```
#### 如何查看某个服务、PID 的日志
你可以从 journald 日志中过滤出某个 systemd 服务单元的特定日志。例如,如果要查看 NetworkManager 服务的日志,请使用下面的命令。
```
journalctl -u NetworkManager.service
```

如果你不知道服务名称,可以使用下面的命令来列出系统中的 systemd 服务。
```
systemctl list-units --type=service
```
#### 如何查看用户、组的日志
如果你正在分析服务器日志,在多个用户登录的情况下,这个命令很有帮助。你可以先用下面的命令从用户名中找出用户的 ID。例如,要找出用户 `debugpoint` 的 ID:
```
id -u debugpoint
```
然后使用 `_UID` 选项指定该 ID 与来查看该用户产生的日志。
```
journalctl _UID=1000 --since today
```

同样地,使用 `_GID` 选项也可以查到用户组的情况。
#### 如何查看一个可执行文件的日志
你也可以查看某个特定程序或可执行文件的日志。例如,如果你想找出 `gnome-shell` 的信息,你可以运行以下命令。
```
journalctl /usr/bin/gnome-shell --since today
```

### 结束语
希望本指南能帮助你使用 `journalctl` 查看分析 Linux 桌面或服务器上的 systemd 日志,排除故障。如果你知道如何使用这些命令,systemd 日志管理的功能非常强大,它能让你在调试时的生活变得轻松一些。现在所有主流的 Linux 发行版都使用 systemd。Ubuntu、Debian、Fedora、Arch 它们都使用 systemd 作为其默认的操作系统组件。如果你想了解不使用 systemd 的 Linux发行版,你可能想看看 [MX-Linux](https://www.debugpoint.com/tag/mx-linux)、Gentoo、Slackware、Void Linux。
---
via: <https://www.debugpoint.com/systemd-journalctl/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,545 | Rnote:一个用于笔记和注释的开源绘图应用 | https://itsfoss.com/rnote/ | 2023-02-16T13:57:33 | [
"笔记"
] | https://linux.cn/article-15545-1.html |
>
> Rnote 可以让你做笔记、绘图和注释文件。听起来你需要它?让我们来了解一下。
>
>
>
我们已经介绍了许多记笔记的应用,但支持手写笔记的选项却屈指可数。
Rnote 就是这样一个有用的应用,它可以让你做手写笔记并对文件/图片进行注释。当然,你需要一个绘图板或一个带有手写笔的设置来使用 Rnote。
### Rnote: 基于矢量的绘图应用,用于绘制草图和手写笔记

Rnote 是一个用 Rust 和 GTK 4 编写的令人印象深刻的开源应用。
它提供了一个专注于手写笔输入的自适应用户界面。它看起来很简约,但却提供了手写笔记所需的一些基本功能。
让我强调一下它能做的一些事情。
### Rnote 的特点

[Rnote](https://rnote.flxzt.net) 是一个简洁而有很多功能的绘图/记事应用程序。一些功能包括:
* 支持具有各种笔画风格的压敏笔输入
* 用形状工具添加不同的形状
* 一个选择工具,可以移动、旋转、调整大小和修改你添加/绘制的内容
* 文档扩展布局
* 可定制的页面格式
* 可定制的背景颜色、图案和尺寸
* 支持笔的反馈声音
* 可重新配置的手写笔按钮快捷键
* 集成的工作区浏览器可快速访问媒体文件
* 支持拖放
* 支持剪贴板
* 支持常见的页面格式(A6、A5、US letter 等)
* 从 PDF、位图和 SVG 文件导入
* 使用原生的 .rnote 文件来保存/加载文件
* 支持导出到 SVG 和 PDF
* 自动保存功能
* 深色/浅色模式
开发者指出,Rnote 使用的原生文件格式可能不够稳定,无法在较新版本的应用之间兼容。
因此,在将 Rnote 升级到最新版本之前,最好在完成工作后将其导出。
除了它的功能外,你还能通过可用的选项获得良好的用户体验。它不会让人感到压抑,你可以快速访问所有的工具。
一些自定义功能可以隐藏滚动条,改变光标,并调整绘图光标。
你还可以调整自动保存启动的时间间隔,这在各种使用情况下应该很方便。

### 在 Linux 上安装 Rnote
Rnote 在 [Flathub](https://flathub.org/apps/details/com.github.flxzt.rnote) 上以 Flatpak 的形式提供。因此,只要你的系统启用了 [Flatpak](https://itsfoss.com/flatpak-guide/),你就可以在任何 Linux 发行版上安装它。
你可以在你的软件中心找到它(如果 Flatpak 集成已被启用),或者输入以下命令来安装它:
```
flatpak install flathub com.github.flxzt.rnote
```
要探索更多关于 Rnote 的信息,请前往其 [GitHub 页面](https://github.com/flxzt/rnote)。
### 总结
Rnote 正在积极开发,并在其功能设置方面取得了良好的进展。如果你喜欢 Rnote,你可能想看看 [Xournal++](https://xournalpp.github.io),它是另一个能让你做手写笔记的应用。
你还知道其他像 Rnote 这样令人兴奋的应用吗?你觉得 Rnote 怎么样?请在下面的评论中分享你的想法。
---
via: <https://itsfoss.com/rnote/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief:**Rnote allows you to take notes, draw, and annotate documents. Sounds like you need it? Let us explore more.*
We have featured numerous note-taking applications, but options that support handwritten notes are a handful.
Rnote is one such helpful application that lets you take handwritten notes and annotate documents/pictures.
Of course, you need a drawing tablet or a setup with a stylus to use Rnote.
## Rnote: Vector-based Drawing App for Sketching and Handwritten Notes
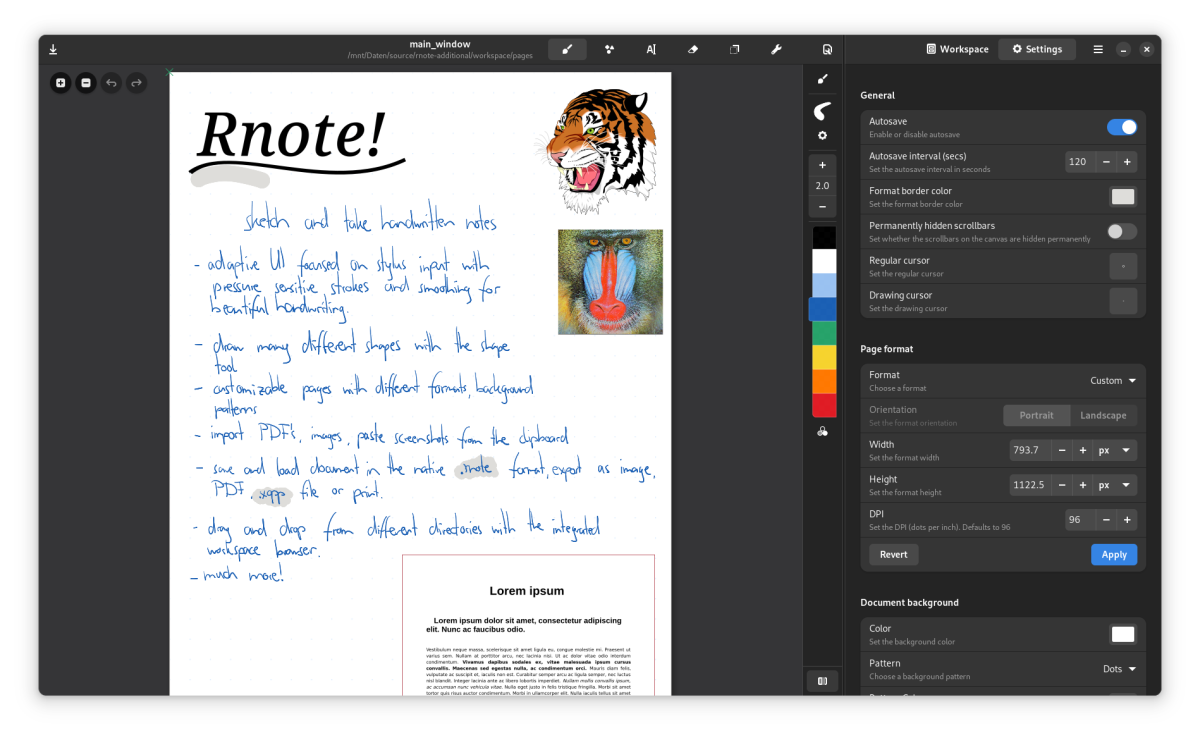
Rnote is an impressive open-source app written in Rust and GTK 4.
It provides an adaptive UI focused on stylus input. It looks pretty minimal and yet offers some of the essential features that one would need for handwritten notes.
Let me highlight some of the things it can do.
**Recommended Read**: **Best Note-Taking Apps for Linux Users**
## Features of Rnote
[Rnote](https://rnote.flxzt.net) is a simple yet capable sketching/note-taking app. Some features include:
- Supports pressure-sensitive stylus input with various stroke styles
- Add different shapes with the shape tool
- A selection tool to move, rotate, resize, and modify the content you add/draw.
- Document expand layouts
- Customizable page format
- Customizable background colors, patterns, and sizes
- Pen sound support for feedback
- Reconfigurable stylus button shortcuts
- Integrated workspace browser for quick media file access
- Drag and drop support
- Clipboard support
- Common page formats supported (A6, A5, US letter, etc)
- Import from PDF, bitmap, and SVG files.
- Native .rnote file to save/load documents.
- Export to SVG and PDF supported
- Autosave functionality
- Dark/Light mode
The developers note that the native file format used by Rnote may not be stable enough for compatibility between newer versions of the application.
So, it is best to export your work when you are done before upgrading Rnote to its latest version.
In addition to its features, you get a good user experience with the available options. It does not feel overwhelming, and you can access all the tools quickly.
Some customization is available to hide the scrollbars, change the cursor, and tweak the drawing cursor.
You can also adjust the time interval for autosave to kick in, which should come in handy for various use cases.
## Installing Rnote on Linux
Rnote is available as a Flatpak on [Flathub](https://flathub.org/apps/details/com.github.flxzt.rnote). So, as long as you have [Flatpak enabled on your system](https://itsfoss.com/flatpak-guide/), you can install it on any Linux distribution.
You can find it in your software center (if Flatpak integration has been enabled) or type in the following command to get it installed:
`flatpak install flathub com.github.flxzt.rnote`
To explore more about Rnote, head to its [GitHub page](https://github.com/flxzt/rnote).
## Wrapping Up
Rnote is actively developed and making good progress with its feature set. If you like Rnote, you might want to look at [Xournal++](https://xournalpp.github.io), another app that enables you to take handwritten notes.
*Do you know of any other exciting apps like Rnote? What do you think of Rnote? Share your thoughts in the comments down below.* |
15,547 | Opera 浏览器计划集成 ChatGPT | https://debugpointnews.com/opera-chatgpt-integration/ | 2023-02-17T09:12:00 | [
"Opera",
"ChatGPT"
] | /article-15547-1.html | 
>
> 据报道,Opera 浏览器正在寻求将语言模型 ChatGPT 集成到其桌面和移动产品中。
>
>
>
### 摘要
* 据报道,流行的桌面和移动网络浏览器 Opera 浏览器正在探索将语言模型 ChatGPT 集成到其产品中。
* 微软最近宣布将 ChatGPT 的制造商 OpenAI 技术集成到其 Edge 网络浏览器中,为用户添加人工智能功能。
### Opera 与 ChatGPT
[Opera](https://www.opera.com/),一个被广泛使用的桌面和移动网络浏览器,将把语言模型 ChatGPT 集成到它的软件产品中。Opera 的母公司昆仑科技是这一新闻的幕后推手,尽管这次集成的细节仍然有限。Opera 提供了一系列软件产品,包括桌面网络浏览器、移动网络浏览器以及其为 Chromebook 设计的浏览器版本。
最有可能整合 ChatGPT 的是 Opera 的主要桌面浏览器,包括 Opera 浏览器和 Opera GX(这是一款为游戏玩家设计的浏览器)。然而,也有可能集成到 Opera 的移动浏览器中,包括常规的 Opera 移动浏览器、Opera Mini 和 Opera Crypto 浏览器。
### 来自微软和谷歌的最新更新
微软上周宣布将 OpenAI 集成到其 Edge 网络浏览器中,成为头条新闻。这种集成将在未来为 Edge 用户带来两种人工智能功能,即 “<ruby> Chat <rt> 聊天 </rt></ruby>” 和 “<ruby> 撰写 <rt> Compose </rt></ruby>”。“聊天”功能可以让用户在浏览器中直接与人工智能交流。同时,“撰写”功能帮助用户进行文本撰写,包括使用不同的语气和长度撰写电子邮件和社交媒体帖子。
在最近的一次演示中,谷歌没有宣布将人工智能聊天机器人直接集成到其 Chrome 浏览器中,这一举措得到的回应并不热烈。
### 下一步是什么
据 Statcounter 统计,Opera 浏览器被数亿用户使用,在全球浏览器市场占有 2.4% 的份额。虽然它可能落后于谷歌 Chrome 的 65% 和 Safari 的 18%,但与 Mozilla Firefox 的 3% 相比,它仍然保持着自己的优势。
昆仑科技是一家在深圳证券交易所上市的北京公司。本周,中国搜索巨头百度宣布计划在其搜索产品中集成 ChatGPT 风格的机器人。
总之,ChatGPT 与 Opera 浏览器的集成代表着人工智能网络浏览向前迈出的重要一步。随着微软和百度等公司将人工智能技术融入其产品,Opera 将自己定位为该领域的领导者。
随着数亿用户和浏览器市场的日益增长,ChatGPT 与 Opera 的集成是一项备受期待的发展。
参考:[CNBC](https://www.cnbc.com/2023/02/09/web-browser-opera-is-planning-to-incorporate-chatgpt.html)
---
via: <https://debugpointnews.com/opera-chatgpt-integration/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed) 译者:[gpchn](https://github.com/gpchn) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,548 | 为什么企业应该选择平台即服务(PaaS) | https://www.opensourceforu.com/2022/09/why-enterprises-should-opt-for-platform-as-a-service/ | 2023-02-17T09:46:37 | [
"PaaS"
] | https://linux.cn/article-15548-1.html | 
>
> 平台即服务能够快速、轻松地创建网络应用,而无需购买和维护其下的软件和基础设施。本文解释了它为什么有用。
>
>
>
<ruby> 平台即服务 <rt> PaaS </rt></ruby>(以下简称 PaaS)指的是云计算服务,它为客户提供了开发、运行和管理应用程序的平台,而免去了建立和维护与开发和启动应用程序相关的基础设施的复杂工作。这是云原生应用和支持系统所依托的核心平台。
PaaS 通常包括不同的应用基础功能,包括应用平台、集成平台、业务分析平台、事件流服务和移动后端服务。此外,它还包括一套与监控、管理、部署相关的功能。
开发人员希望他们的开发环境不需要等待,而运营团队则更关心性能和稳定性。这经常引起两方间的冲突。PaaS 为这两方创造了和平的环境。一个作为服务交付的应用平台被称作 PaaS,它被用于部署用户代码。Cloud Foundry、Cloudify 和 OpenShift 这些开源环境都可用作 PaaS。
### PaaS 的采用模式
云计算必须满足五个基本特征:按需服务、接入网络、资源池化、弹性和可度量的服务。为此,云计算提供了三种服务模式:<ruby> 软件即服务 <rt> Software as a Service </rt></ruby>(SaaS)、<ruby> 平台即服务 <rt> Platform as a Service </rt></ruby>(PaaS)、<ruby> 基础设施即服务 <rt> Infrastructure as a Service </rt></ruby>(IaaS)。
业务选用 PaaS 的关键驱动力:
* 减少提供业务的资本支出和运营费用
* 通过减少应用程序的交付时间和提高开发和交付质量,最大限度地降低 IT 成本
* 增加中间件之间的灵活性和集成度
*简单 PaaS*:踏入 PaaS 领域的入口。它可以提供应用程序服务,并将它们暴露在自助服务的目录中;自动部署和计量服务使用的资源。
*管理 PaaS*:管理已配置应用程序的<ruby> 服务级别协议 <rt> SLA </rt></ruby>和<ruby> 服务质量 <rt> QoS </rt></ruby>,例如弹性、应用程序性能、安全性等。
*编程 PaaS*:允许应用程序与外部应用程序或公共云集成,并实现自动扩展和云爆发场景。
*面向流程 PaaS*:允许通过创建持续交付流程来实现<ruby> 开发运维 <rt> DevOps </rt></ruby>流程,该流程可以自动构建、测试应用程序并将其交付到云环境中。
除了这些采用模式之外,还有其他的 PaaS 变体如下,这些变化可能与上文的模式有一定重合:
*集成平台即服务(iPaaS)*:一套能够开发、执行和管理集成流的云服务。集成流可以是个人内部或跨多个组织连接的,可以包含任何企业内部或基于云的流程、服务、应用和数据。这些组合变化可能也符合上述的模式之一,例如 MuleSoft CloudHub 和 BizTalk。
*移动平台即服务(mPaaS)*:为开发移动应用提供的集成开发环境(IDE),并且支持多种移动平台。
*数据库平台即服务(dbPaas)*:一种按需的、安全且可扩展的自助式数据库平台,可自动配置和管理数据库。dbPaaS 使扩展数据库变得更加容易,并使它们更加可靠。
*物联网平台即服务(IoTPaaS)*:提供了实现异构物联网拓扑所需的通信、安全、分析和管理的通用基础架构。它为构建物联网解决方案提供了更简单、更敏捷的模型。
*业务流程管理平台即服务(bpmPaaS)*:一个完整的预集成业务流程管理平台,托管在云端并作为服务交付。它被用于开发和执行整个企业的业务流程和以工作流程为中心的应用程序。例如 Pega cloud 和 OpenText Cordys cloud。
PaaS 的一些基本特征:
* 在同一集成开发环境中开发、测试、部署、托管和维护应用程序的服务
* 多租户架构,即多个并发用户使用同样的开发程序
* 部署软件的内置可扩展性,包括负载平衡和故障转移
* 与异构平台和系统的集成
* 支持开发团队的协作
* 包含处理帐单和管理订阅的工具
### 主要的开源 PaaS
在选择 PaaS 之前,企业主要考虑关注以下几点:
* 部署灵活性
* 操作简便性
* 应用堆栈的选择
* 语言、数据库和框架支持
* 规模的可扩展性
* 服务质量(QoS)
* 开发和运营的工具
* 它有多适合你的业务
现在让我们快速浏览下流行的开源 PaaS。
*Cloud Foundry*:提供了多种云的选择、开发者框架和应用服务。Cloud Foundry 使构建、测试、部署和扩展应用程序变得更快、更容易。
它有不同的发行版本,其中比较流行的是 Pivotal 和 IBM。它包含应用<ruby> 运行时 <rt> runtime </rt></ruby>和容器运行时。在 Pivotal 上包含有应用服务和容器服务。
*OpenShift*:红帽的云计算 PaaS 产品。这是一个云端的应用平台,应用开发者和团队可以在这里构建、测试、部署和运行他们的应用程序。
*Cloudify*:在开放的原则下开发和设计,用以推动 IT 转型革命。它使组织能够在其上设计、建立和提供各种商业应用和网络服务。Cloudify 的最新版本为 4.3,它包含了先进的安全、控制和<ruby> 真自服务 <rt> true self-service </rt></ruby>等增强功能。Cloudify 4.3 还为 Kubernetes 容器编排引入了全新的概念。
| 功能 | Cloud Foundry | Cloudify | OpenShift |
| --- | --- | --- | --- |
| 核心功能 | Cloud controller | Manager | Broker |
| 提供第三方数据库服务 | Service broker | Agent | Cartridge |
| 传入流量的路由 | Router | Manager | REST API |
| 查询应用程序的状态 | Cloud controller | CLI client | Broker |
| 消息传递 | Message bus | Manager | Broker |
| 应用实例管理 | Droplet execution agent | Agent | Node |
| 应用程序状态管理 | Health manager | Manager | Broker |
| Broker | Warden | Agent | Gear |
| 用户请求的负载平衡 | Droplet execution agent | Manager | Broker |
| 框架提供者 | Blob store | Agent | Cartridge |
| 技术 | | | |
| 语言 | Java, Ruby, Scala, Node.js, Groovy, Grails, PHP, Go, Python | Java, PHP, Ruby | Java, Ruby, Node.js, PHP, Python, Perl, JavaScript |
| 数据库 | MongoDB,MySQL | | |
| MongoDB、MySQL、PostgreSQL | MySQL、MongoDB | MongoDB、MySQL、PostgreSQL | |
| 框架 | Spring, Rails, Grails, Play Sinatra | JavaScript, Node.js | Rails, Flask, Django, Drupal, Vertx |
| 水平扩展 | 是 | 是 | 是 |
| 垂直扩展 | 是 | 否 | 是 |
| 弹性伸缩 | 是 | 是 | 是 |
表 1 列出了 Cloud Foundry、Cloudify 和 OpenShift 的基本功能及其对应的架构组件。以上完全基于个人观点,所支持的功能的真实需求应与云供应商进行验证。
从行业统计数据中,我们可以清楚地看出 PaaS 的使用率正在迅速上升。PaaS 使企业应用程序可以是<ruby> 云无关 <rt> cloud-agnostic </rt></ruby>的,它们可以在任何云平台上运行——无论是公共的还是私有的。这意味着一个在亚马逊的 AWS 上开发的应用可以很容易地移植到微软 Azure、VMWare vSphere、Red Hat RHEV 等等其他平台。
当多个开发人员共同参与一个开发项目,或外部用户需要与开发过程协作时,PaaS 是很有用的。因此,PaaS 尤其适合于敏捷开发,因为它降低了围绕软件快速开发和迭代的难度。
### 鸣谢
作者感谢 Kiran M.R. 和 Wipro 有限公司的数字架构实践 Raju Alluri 为本文提供的支持。
---
via: <https://www.opensourceforu.com/2022/09/why-enterprises-should-opt-for-platform-as-a-service/>
作者:[Gopala Krishna Behara](https://www.opensourceforu.com/author/gopalakrishna-behara/) 选题:[lkxed](https://github.com/lkxed) 译者:[onionstalgia](https://github.com/onionstalgia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Platform as a Service enables quick and easy creation of Web applications without the necessity of buying and maintaining the software and infrastructure underneath it. This article explains why it’s useful.*
Platform as a Service (PaaS) refers to cloud computing services that provide a platform for customers to develop, run and manage applications without the complexity of building and maintaining the infrastructure associated with developing and launching them. This is the core platform on which cloud native applications and supporting systems are based.
PaaS typically involves diverse application software infrastructure capabilities including application platforms, integration platforms, business analytics platforms, event-streaming services and mobile back-end services. In addition, it includes a set of monitoring, management, deployment and related capabilities.
Developers are keen on getting their environments up without waiting, while operations teams care about performance and stability. This often gives rise to some conflict between them. PaaS creates a peaceful environment for both groups. An application platform delivered as a service is described as PaaS, and is used to deploy the user code. Cloud Foundry, Cloudify and OpenShift open source environments can be used as PaaS.
## PaaS adoption pattern
Cloud computing must satisfy five essential characteristics — on demand service, access network, resource pooling, elasticity and measured services. To achieve these, cloud computing provides three kinds of service models: Software as a Service (SaaS), Platform as a Service (PaaS) and Infrastructure as a Service (IaaS).
The key business drivers of PaaS adoption are:
- Reduction of capex and opex to deliver business services
- Minimising IT costs by improving the delivery time and quality of the application development and delivery
- Increasing the flexibility and integration between middleware components
** Simple PaaS** is the entry point into the PaaS space. It allows provisioning of application services and exposes them into a self-service catalogue; it automates the deployment and meters the resources used by this service.
* Manage PaaS* manages the SLA and QoS aspects of the provisioned applications such as resiliency, application performance, security, etc.
* Programming PaaS* allows applications to integrate with external applications or public clouds, and to implement auto-scaling and cloud-bursting scenarios.
* Process-oriented PaaS* allows implementation of a DevOps process by creating a continuous delivery flow that automates the build, test and delivery of applications into a cloud environment.
In addition to these adoption patterns, there are other variations of PaaS, as listed below. These variations might align to one of the patterns explained above.
**iPaaS:** Integration Platform as a Service (iPaaS) is a suite of cloud services that enables development, execution and governance of integration flows connecting any combination of on-premises and cloud-based processes, services, applications and data within individuals or across multiple organisations. Examples are MuleSoft CloudHub and BizTalk.
**mPaaS:** Mobile Platform as a Service (mPaaS) is a provision of an interactive development environment (IDE) for the creation of mobile apps. It supports multiple mobile operating platforms.
**dbPaaS:** Database Platform as a Service (dbPaas) is an on-demand, secure and scalable self-service database platform that automates the provisioning and administration of databases. dbPaaS makes it easier to scale databases and makes them more reliable.
**IoTPaaS:** This provides common infrastructure to enable communication, security, analytics and management for heterogeneous IoT topologies. It provides simpler and agile models for building IoT solutions.
**bpmPaaS:** Business process management PaaS (bpmPaaS) is a complete pre-integrated BPM platform hosted in the cloud and delivered as a service. It is leveraged for the development and execution of business processes and workflow-centric applications across enterprises. Examples are Pega cloud, and OpenText Cordys cloud.
Some basic characteristics of PaaS are:
- Services to develop, test, deploy, host and maintain applications in the same integrated development environment
- Multi-tenant architecture, in which multiple concurrent users use the same development application
- Built-in scalability of deployed software, including load balancing and failover
- Integration with heterogeneous platforms and systems
- Support for development team collaboration
- Tools to handle billing and subscription management
## Key open source Platforms as a Service
Before choosing a PaaS, enterprises must consider the following:
- Deployment flexibility
- Ease of operations
- Choice of application stacks
- Language, database and framework support
- Scaling capabilities
- QoS
- Tooling for development and operations
- How well it fits your business
Let’s now take a quick look at some popular open source PaaS.
**Cloud Foundry:** This PaaS provides a choice of clouds, developer frameworks and application services. Cloud Foundry makes it faster and easier to build, test, deploy and scale applications.
It has different distributions, of which the popular ones are Pivotal and IBM. It contains application runtime and container runtime. It also has Pivotal application service and Pivotal container service.
**OpenShift:** This is Red Hat’s cloud computing PaaS offering. It is an application platform in the cloud, where application developers and teams can build, test, deploy and run their applications.
**Cloudify:** Cloudify was developed and designed on the principles of openness to power the IT transformation revolution. It enables organisations to design, build and deliver various business applications and network services. The latest version of Cloudify is 4.3, which incorporates enhanced features like advanced security, control and true self-service. Cloudify 4.3 introduced a totally new concept for container orchestration with Kubernetes.
Functionality |
Cloud Foundry |
Cloudify |
OpenShift |
Core functionality | Cloud controller | Manager | Broker |
Providing third party database services | Service broker | Agent | Cartridge |
Routing of incoming traffic | Router | Manager | REST API |
Querying the state of apps | Cloud controller | CLI client | Broker |
Messaging | Message bus | Manager | Broker |
App instance management | Droplet execution agent | Agent | Node |
Application state management | Health manager | Manager | Broker |
Broker | Warden | Agent | Gear |
Load balancing of user requests | Droplet execution agent | Manager | Broker |
Framework provider | Blob store | Agent | Cartridge |
Technology |
|||
Languages | Java, Ruby, Scala, Node.js, Groovy, Grails, PHP, Go, Python | Java, PHP, Ruby | Java, Ruby, Node.js, PHP, Python, Perl, JavaScript |
Databases | MongoDB, MySQL, PostgreSQL |
MySQL, MongoDB | MongoDB, MySQL, PostgreSQL |
Frameworks | Spring, Rails, Grails, Play Sinatra | JavaScript, Node.js | Rails, Flask, Django, Drupal, Vertx |
Horizontal scaling | Yes | Yes | Yes |
Vertical scaling | Yes | No | Yes |
Auto scaling | Yes | Yes | Yes |
Table 1 lists the basic functionality and its corresponding Cloud Foundry, Cloudify and OpenShift architectural components. This is purely based on my views and the authenticity of the features supported needs to be validated with the cloud provider.
From the industry adoption statistics we can clearly make out that PaaS adoption is picking up very rapidly. PaaS enables enterprise applications to be cloud-agnostic, so that they can run on any cloud platform — whether public or private. This means that a PaaS application developed on Amazon AWS can easily be ported to Microsoft Azure, to VMWare vSphere, to Red Hat RHEV, etc.
PaaS is useful when multiple developers are working on a development project or when external users need to collaborate with the development process. So it is best suited for agile software development, because it eases the difficulties around rapid development and iteration of software.
## Acknowledgements
The author thanks Kiran M.R. and Raju Alluri of the digital architecture practice of Wipro Ltd for giving their time and support to this article. |
15,549 | 用 Penpot 弥合设计和代码之间的鸿沟 | https://opensource.com/article/23/1/merge-design-code-penpot | 2023-02-17T14:35:00 | [
"Penpot"
] | /article-15549-1.html | 
>
> 用 Penpot 这个开源的设计工作空间来弥合编程和设计之间的鸿沟。
>
>
>
在计算机编程的大部分历史中,在创建应用的代码的程序员和创建应用的用户体验(UX)的设计师之间一直存在着鸿沟。这两个学科接受的培训大不相同,他们使用的工具也不同。程序员使用文本编辑器或集成开发环境来编写代码,而设计师则经常绘制小部件布局和潜在交互的示意图。虽然一些 IDE,像 [Eclipse](https://opensource.com/article/20/12/eclipse) 和 [Netbeans](https://opensource.com/article/20/12/netbeans),有界面设计组件,但它们通常专注于小部件的位置而不是小部件的设计。开源设计应用 [Penpot](http://penpot.app) 是一个协作式设计和原型设计平台。它有一套新的功能,使设计师和开发者可以很容易地用熟悉的工作流程协同工作。Penpot 的设计界面可以让开发者在设计过程中和谐地编写代码,这是其他工具所无法做到的。自从我们 [上次介绍它](https://opensource.com/article/21/9/open-source-design) 以来,它已经有了长足的进步。它的最新功能不仅改善了你使用 Penpot 的体验,还推动了开源的 Penpot 应用超越类似的专有工具。
### 用 Penpot 做原型
在设计应用的最佳工作方式时,常见问题之一是在设计的时候这个应用还不存在。设计师可以通可视化和故事板来帮助设计团队和程序员了解目标是什么。但这是一个需要迭代和反馈的过程,当开发人员开始实施 UX 设计,设计会发生变化以应对对代码的实际变化。
使用 Penpot,你可以为你的网络或移动应用创建一个“可用”原型。你可以将按钮与特定的行动联系起来,根据用户的输入触发布局的变化。而这一切都可以在项目的代码存在之前完成。
但是,这方面最重要的不是模拟的能力。在 Penpot 中为应用的设计所做的一切都有可用的布局数据,开发人员可以在最终的项目中使用它们。Penpot 不仅仅是一个出色的绘图和布局工具。它为编码过程提供了信息。
Penpot 现在不仅仅是提供了一个设计师特定元素的视觉列表,如属性、颜色和排版,而是将代码输出直接整合到设计工作区(就像 Web 浏览器中的开发者工具)。设计师和开发人员共享设计和前端开发的相同空间,以他们需要的任何格式获得规格。

### 内存解锁
许多在线设计工具使用专有技术来提供一些花哨的功能,但代价是基本上成为一个应用,你只能运行它,而不能通过浏览器访问。不过 Penpot 使用开放的网络标准,并由你的网络浏览器渲染。这意味着 Penpot 可以访问浏览器可用的最大内存,使得 Penpot 成为第一个具有设计扩展性的在线原型和布局应用。你可以提供更多的选项、更多的模型,和更多的场地。此外,你可以向更多的并发协作者开放你的设计空间,而不必担心应用的内存耗尽。
### 自我托管和 SaaS
Penpot 是开源的,所以你不用必须在云上使用它,如果这不适合你的工作流程。你可以在一个容器中轻松地自我托管 Penpot,在你自己的工作站上作为一个本地应用使用,或者在你自己的服务器上为你的组织托管它。
### 开源设计
我以前写过一篇 [Penpot 的介绍性文章](https://opensource.com/article/21/12/open-source-design-penpot),自那以后,这个应用变得更好了。如果你想把程序员和相关人员带入你的设计过程中,那么请试试 Penpot。
---
via: <https://opensource.com/article/23/1/merge-design-code-penpot>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
15,551 | GNOME 正在(某种程度上)恢复在几年前删除的功能 | https://news.itsfoss.com/gnome-design-quick-access/ | 2023-02-18T16:37:49 | [
"GNOME"
] | https://linux.cn/article-15551-1.html |
>
> GNOME 的设计做了一些有意义的变化,它(某种程度上)带回了一个它早先删除的类似功能。
>
>
>

几年前,GNOME 移除了应用程序的菜单和指示器。
如果你不太清楚,应用程序指示器是一种从顶部面板与后台运行的应用程序进行交互的方式。
是的,你可以 [添加一个应用程序指示器的扩展](https://itsfoss.com/enable-applet-indicator-gnome/) 来获得同样的功能。但是,在使用 GNOME 桌面环境的发行版上,如 Fedora,你不再能找到默认的能力。
然而,Ubuntu,它的一些 [官方版本](https://itsfoss.com/which-ubuntu-install/),以及其他发行版如 Pop!\_OS,支持系统托盘图标,尽管 GNOME 放弃了它们。
现在,经过多年的设计变化,看起来我们可能会看到类似的东西。
### GNOME 将添加一个检查后台活动程序的简便方法
目前,在没有活动窗口的情况下,找出在后台运行的应用程序并没有简便的方法。
你必须使用 [任务管理器](https://itsfoss.com/task-manager-linux/) 或 [系统监控工具](https://itsfoss.com/linux-system-monitoring-tools/) 以获得更好的观测能力。
在未来的 GNOME 版本中(可能是 GNOME 44),你或许可以期待有一个功能可以直接从顶部面板的菜单面板上监控后台运行的应用程序。

[Allan Day](https://gitlab.gnome.org/aday) 的想法仍在讨论中,他分享了一个 [设计模拟图](https://gitlab.gnome.org/Teams/Design/os-mockups/-/issues/191)。不过,它很有可能会被接受。
这个想法也促使开发者 [Georges Basile Stavracas Neto](https://github.com/GeorgesStavracas) 披露了 Flatpak 的 xdg-desktop-portal 组件,它可以使得检测运行中的 Flatpak 应用程序变得容易。
>
> ? 检查后台应用程序这个功能的位置或设计仍在进行中;你在上面看到的内容可能会随着最终的实施而改变。
>
>
>
### 这是否也会使应用指示器回归?
并非如此。
通过这个功能,GNOME 旨在让你快速看到后台运行的应用程序,并对它们进行管理(关闭它们或访问特定的设置)。
然而,你仍需要少量点击来达到这一点 ?️。
小程序指示器或系统托盘图标是访问在后台运行的应用程序更快捷的方式,尽管不是每个后台应用程序都被列出。
毕竟,这总比没有好。
而最终,这些设计上的变化可能会产生一种直观的方式,以某种形式让应用指示器回归。
? 你对这个决定与即将发布的 GNOME 设计变化有何看法?请在下面的评论中分享你的想法。
参考:[Phoronix](https://www.phoronix.com/news/GNOME-Monitor-Background-Apps)
---
via: <https://news.itsfoss.com/gnome-design-quick-access/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed/) 译者:[SJFCS](https://github.com/SJFCS) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

GNOME removed the application menus and indicators a few years back.
If you are curious, app indicators were a way of interacting with the apps running in the background from the top panel.
Yes, you can [add an extension for app indicators](https://itsfoss.com/enable-applet-indicator-gnome/?ref=news.itsfoss.com) to get the same functionality. But, you will no longer find the ability by default on distributions using stock GNOME desktop environment, like Fedora.
However, Ubuntu, some of its [official flavors](https://itsfoss.com/which-ubuntu-install/?ref=news.itsfoss.com), and other distributions like Pop!_OS support the system tray icons even though GNOME dropped them.
Now, after years of design changes, it looks like we might be seeing something similar.
## GNOME to Add a Quick Way to Check Active Apps in the Background
Currently, there's no quick way to find out the apps running in the background without an active window.
You must use the [task manager](https://itsfoss.com/task-manager-linux/?ref=news.itsfoss.com) or [system monitoring tools](https://itsfoss.com/linux-system-monitoring-tools/?ref=news.itsfoss.com) for better insights.
With future GNOME releases (probably GNOME 44), you may expect **a feature to monitor background running apps** right from the **menu panel** of the top panel.
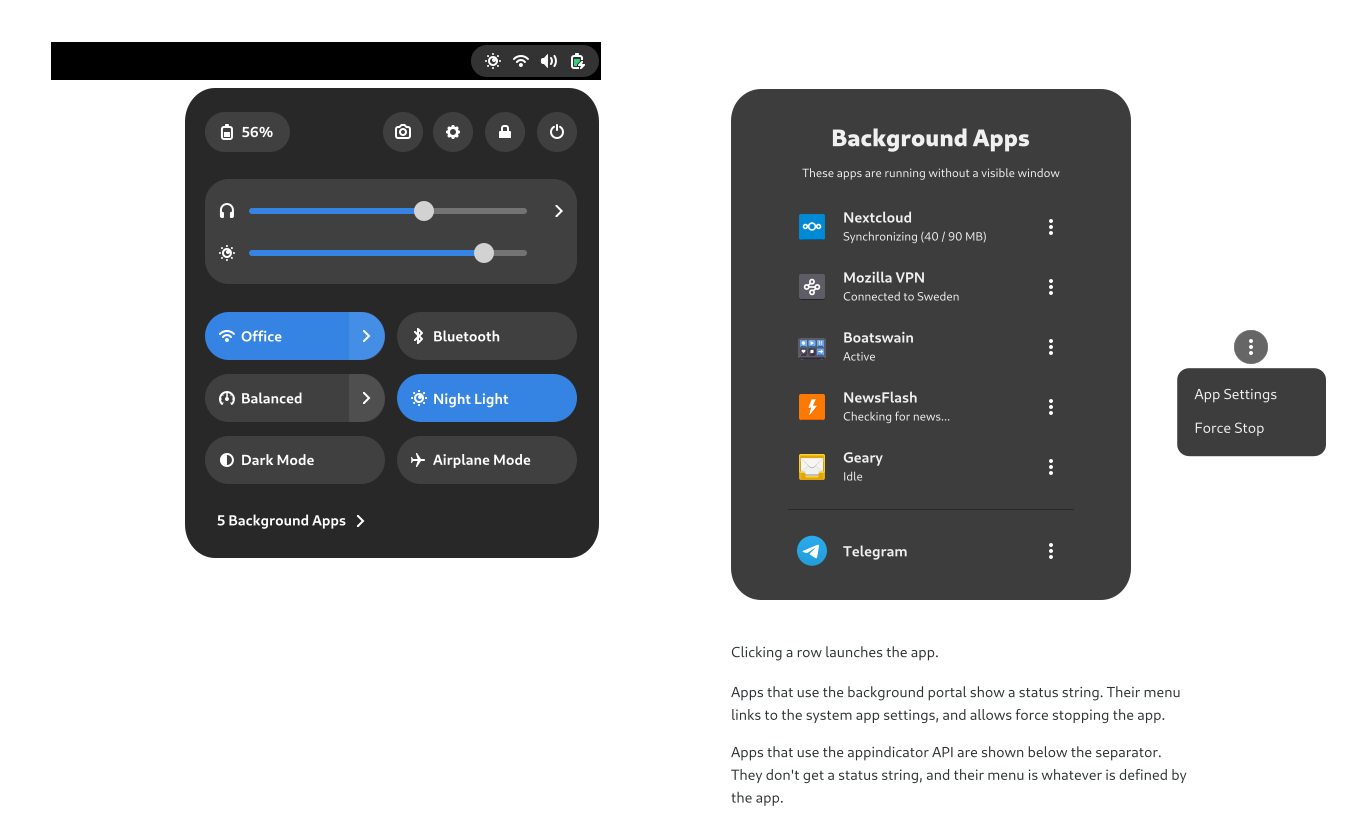
The idea by [Allan Day](https://gitlab.gnome.org/aday?ref=news.itsfoss.com) is still in discussion, and a [design mockup](https://gitlab.gnome.org/Teams/Design/os-mockups/-/issues/191?ref=news.itsfoss.com) has been shared. However, there is a good chance that it will be accepted.
This idea has also prompted developer [Georges Basile Stavracas Neto](https://github.com/GeorgesStavracas?ref=news.itsfoss.com) to expose Flatpak's xdg-desktop-portal component, making it easy to detect running Flatpak applications.
## Would This Bring Back App Indicators Too?
Not exactly.
With this feature, GNOME aims to allow you to quickly see the background running apps and manage them (close them or access specific settings).
However, you still have a few clicks to reach this point 🖱️
The applet indicators or the system tray icons were a faster way to access applications running in the background, even though not every background app was listed.
After all, it is better than nothing.
And eventually, these design changes could result in an intuitive way to get app indicators back in some form.
*💬 What do you think about this decision with GNOME design changes for upcoming releases? Share your thoughts in the comments below.*
**Via**: [Phoronix](https://www.phoronix.com/news/GNOME-Monitor-Background-Apps?ref=news.itsfoss.com)
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,552 | 借助开源软件开发包尝试量子计算编程 | https://opensource.com/article/21/6/qiskit | 2023-02-18T17:38:49 | [
"量子计算"
] | https://linux.cn/article-15552-1.html |
>
> Qiskit 是一个开源 SDK,借助它可以免费访问量子模拟器和硬件资源。
>
>
>

经典计算机是基于二进制数的,二进制数有 0 和 1 两种形式。这并不是由于二进制逻辑系统比有更多基本状态的逻辑系统(甚至包括模拟计算机)有内在优势。而是,对电路元件的开关操作很容易实现,而且借助先进的半导体技术,可以制造出体积小且价格低廉的计算机。
但它们并非没有局限性。经典计算机求解某些问题的效率并不高,主要是那些时间或内存成本随着问题的规模(O)呈指数级增长的问题。我们把这种问题称为 O(2<sup> n</sup>)([大 O 表示法](https://en.wikipedia.org/wiki/Big_O_notation))。
大部分现代加密方法甚至依赖这一特性。把两个大素数相乘,耗费的成本低(O(n<sup> 2</sup>)),但进行反向操作就非常耗时。所以只要使用的数字足够大,对它分解质因数就非常困难。
### 进入量子世界
量子计算的基础数学和力学知识不在本文的探讨范围内。然而,还是有一些基础知识需要预先说明。
量子计算机以 [量子比特](https://en.wikipedia.org/wiki/Qubit) 代替了二进制比特 —— 量子比特是体现量子属性的可控计算单元。构成量子比特的通常是超导元件,或自然界中存在的量子实物(例如电子)。量子比特可以以“<ruby> 叠加 <rt> superposition </rt></ruby>”状态存在,叠加态是 0 和 1 以某种方式组合起来的复杂状态。你可能听说过,量子比特既为 1 又为 0,这种说法并不准确。真实情况是,如果进行测量,量子比特的状态会坍缩为 0 或 1。在数学上,量子比特未测量的状态可以看作 <ruby> <a href="https://en.wikipedia.org/wiki/Bloch_sphere"> 布洛赫球面 </a> <rt> Bloch sphere </rt></ruby> 的几何表示上的一个点。
尽管对习惯使用经典计算机的任何人来说,叠加态是一个全新的概念,但一个量子比特本身并没有什么趣味性。量子计算的第二个概念是“<ruby> 干涉 <rt> interference </rt></ruby>”。真正的量子计算机本质上是统计性质的。量子算法对干涉图案进行编码,增加了可以测量编码方案的状态的概率。
叠加和干涉的概念虽然新颖,但在物理世界中也有对应的现象。而量子力学中的“<ruby> 纠缠 <rt> entanglement </rt></ruby>”却没有,但它是实现指数级量子加速的真正关键。借助量子纠缠,对一个微观粒子的测量可以影响后续对其他被纠缠的粒子的测量结果 —— 即使是那些物理上没有关联的粒子。
### 量子计算能做什么?
今天的量子计算机就其包含的量子比特的数量而言是相当小的,只有几十到几百个。因此,虽然人们不断开发新的算法,但比同级别经典计算机运行得快的硬件还未问世。
但是在很多领域,量子计算机能带来很大好处。例如,它能提供较好的方法来模拟自然界的量子系统,例如分子,其复杂程度超过了经典计算机的建模能力。量子计算也跟线性代数有关,它是机器学习和很多其他现代优化问题的基础。因此,我们有理由认为量子计算也可以很好地适用于此。
在量子算法相对于普通算法的优势方面,[Shor 算法](https://en.wikipedia.org/wiki/Shor%27s_algorithm) 是经常被提及的例子,它在较早时候就用于分解质因数。它由 MIT 的数学家 Peter Shor 于 1994 年发明,量子计算机目前还不能在较大的问题上运行该算法。但它已经被证明可以在 O(n<sup> 3</sup>) 时间内完成工作,而不像经典算法那样需要指数级的时间。
### 从使用 Qiskit 开始
你可能在想:“我身边没有量子计算机,但我很想尝试一下。能做到吗?”
我们来了解一下名称为 [Qiskit](https://qiskit.org/) 的开源项目(采用 Apache 2.0 许可证)。它是一个软件开发包(SDK),用于访问 IBM 量子实验室的量子计算模拟器和物理硬件(免费)。你只需要注册获得一个 API 密钥。
当然,如果要深入研究 Qiskit,需要很多其他方面的知识,线性代数只是其中一部分,这些都远远超出了本文的范围。如果你需要深入学习,网上有很多免费资源,其中也不乏完整的教科书。然而,体验一下也很简单,只需要一些 Python 和 Jupyter notebook 的基础知识即可。
为了增加趣味性,我们全程使用 [Qiskit 教程](https://qiskit.org/textbook/preface.html) 的 “Hello, World!” 程序:
首先,安装教程的相关工具和部件:
```
pip install git+https://github.com/qiskit-community/qiskit-textbook.git#subdirectory=qiskit-textbook-src
```
下一步,进行软件包的导入:
```
from qiskit import QuantumCircuit, assemble, Aer
from math import pi, sqrt
from qiskit.visualization import plot_bloch_multivector, plot_histogram
```
`Aer` 是本地模拟器。Qiskit 包括四个组件:`Aer`、基础组件 `Terra`、用于实际的量子系统上的噪音和错误处理的 `Ignis`,以及用于算法开发的 `Aqua`。
```
# Let's do an X-gate on a |0> qubit
qc = QuantumCircuit(1)
qc.x(0)
qc.draw()
```
虽然底层数学原理还涉及到矩阵乘法,量子计算机中 X 门也可以认为类似于经典计算机中的非门。(事实上,它经常被称为 "非门")。
现在,运行并测量它。结果跟你预期的一样,因为量子比特的初始状态是 `|0>`,接着反转,然后被测量。(使用 `|0>` 和 `|1>` 与经典计算机中的比特区分开来。)
```
# Let's see the result
svsim = Aer.get_backend('statevector_simulator')
qobj = assemble(qc)
state = svsim.run(qobj).result().get_statevector()
plot_bloch_multivector(state)
```

*布洛赫球体显示了预期的运行结果*
### 结论
在某些方面,你可以把量子计算看作用于经典计算机的一种独特的协处理器,跟 GPU 和 FPGA 一样。不同的是,在可预见的未来,量子计算机可以被用户像网络资源一样访问到。另一个差异是,它们的工作有本质的不同,所以不像很多其他你熟悉的加速器那样。因此,人们对算法开发如此感兴趣,并投入大量资源来研究量子在何时何地的性能最好。了解一下这些东西也无妨。
---
via: <https://opensource.com/article/21/6/qiskit>
作者:[Gordon Haff](https://opensource.com/users/ghaff) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cool-summer-021](https://github.com/cool-summer-021) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Classical computing is based on bits. Zeros and ones. This isn't because there's some inherent advantage to a binary logic system over logic systems with more states—or even over analog computers. But on-off switches are easy to make and, with modern semiconductor technology, we can make them very small and very cheap.
But they're not without limits. Some problems just can't be efficiently solved by a classical computer. These tend to be problems where the cost, in time or memory, increases exponentially with the scale (`n`
) of the problem. We say such problems are `O(2`
in n)[Big O notation](https://en.wikipedia.org/wiki/Big_O_notation).
Much of modern cryptography even depends on this characteristic. Multiplying two, even large, prime numbers together is fairly cheap computationally (`O(n`
). But reversing the operation takes exponential time. Use large enough numbers, and decryption that depends on such a factoring attack is infeasible.2)
## Enter quantum
A detailed primer on the mathematical and quantum mechanical underpinnings of quantum computing is beyond the scope of this article. However, here are some basics.
A quantum computer replaces bits with [qubits](https://en.wikipedia.org/wiki/Qubit)—controllable units of computing that display quantum properties. Qubits are typically made out of either an engineered superconducting component or a naturally occurring quantum object such as an electron. Qubits can be placed into a "superposition" state that is a complex combination of the 0 and 1 states. You sometimes hear that qubits are *both* 0 and 1, but that's not really accurate. What is true is that, when a measurement is made, the qubit state will collapse into a 0 or 1. Mathematically, the (unmeasured) quantum state of the qubit is a point on a geometric representation called the [Bloch sphere](https://en.wikipedia.org/wiki/Bloch_sphere).
While superposition is a novel property for anyone used to classical computing, one qubit by itself isn't very interesting. The next unique quantum computational property is "interference." Real quantum computers are essentially statistical in nature. Quantum algorithms encode an interference pattern that increases the probability of measuring a state encoding the solution.
While novel, superposition and interference do have some analogs in the physical world. The quantum mechanical property "entanglement" doesn't, and it's the real key to exponential quantum speedups. With entanglement, measurements on one particle can affect the outcome of subsequent measurements on any entangled particles—even ones not physically connected.
## What can quantum do?
Today's quantum computers are quite small in terms of the number of qubits they contain—tens to hundreds. Thus, while algorithms are actively being developed, the hardware needed to run them faster than their classical equivalents doesn't exist.
But there's considerable interest in quantum computing in many fields. For example, quantum computers may offer a good way to simulate natural quantum systems, like molecules, whose complexity rapidly exceeds the ability of classical computers to model them accurately. Quantum computing is also tied mathematically to linear algebra, which underpins machine learning and many other modern optimization problems. Therefore, it's reasonable to think quantum computing could be a good fit there as well.
One commonly cited example of an existing quantum algorithm likely to outperform classical algorithms is [Shor's algorithm](https://en.wikipedia.org/wiki/Shor%27s_algorithm), which can do the factoring mentioned earlier. Invented by MIT mathematician Peter Shor in 1994, quantum computers can't yet run the algorithm on larger than trivially sized problems. But it's been demonstrated to work in polynomial `O(n`
time rather than the exponential time required by classical algorithms.3)
## Getting started with Qiskit
At this point, you may be thinking: "But I don't have a quantum computer, and I really like to get hands-on. Is there any hope?"
Enter an open source (Apache 2.0 licensed) project called [Qiskit](https://qiskit.org/). It's a software development kit (SDK) for accessing both the quantum computing simulators and the actual quantum hardware (for free) in the IBM Quantum Experience. You just need to sign up for an API key.
Certainly, a deep dive into Qiskit, to say nothing of the related linear algebra, is far beyond what I can get into here. If you seek such a dive, there are [many free resources online](https://qiskit.org/learn), including a complete textbook. However, dipping a toe in the water is straightforward, requiring only some surface-level knowledge of Python and Jupyter Notebooks.
To give you a taste, let's do a "Hello, World!" program entirely within the [Qiskit textbook](https://qiskit.org/textbook/preface.html).
Begin by installing some tools and widgets specific to the textbook:
`pip install git+https://github.com/qiskit-community/qiskit-textbook.git#subdirectory=qiskit-textbook-src`
Next, do the imports:
```
from qiskit import QuantumCircuit, assemble, Aer
from math import pi, sqrt
from qiskit.visualization import plot_bloch_multivector, plot_histogram
```
Aer is the local simulator. Qiskit consists of four components: **Aer**, the **Terra** foundation, **Ignis** for dealing with noise and errors on real quantum systems, and **Aqua** for algorithm development.
```
# Let's do an X-gate on a |0> qubit
qc = QuantumCircuit(1)
qc.x(0)
qc.draw()
```
An **X-gate** in quantum computing is similar to a **Not gate** in classical computing, although the underlying math actually involves matrix multiplication. (It is, in fact, often called a **NOT-gate**.)
Now, run it and do a measurement. The result is as you would expect because the qubit was initialized in a `|0>`
state, then inverted, and measured. (Use `|0>`
and `|1>`
to distinguish from classic bits.)
```
# Let's see the result
svsim = Aer.get_backend('statevector_simulator')
qobj = assemble(qc)
state = svsim.run(qobj).result().get_statevector()
plot_bloch_multivector(state)
```
Bloch sphere showing the expected result. (Gordon Haff, CC-BY-SA 4.0)
## Conclusion
In some respects, you can think of quantum computing as a sort of exotic co-processor for classical computers in the same manner as graphics processing units (GPUs) and field-programmable gate arrays (FPGAs). One difference is that quantum computers will be accessed almost entirely as network resources for the foreseeable future. Another is that they work fundamentally differently, which makes them unlike most other accelerators you might be familiar with. That's why there's so much interest in algorithm development and significant resources going in to determine where and when quantum fits best. It wouldn't hurt to see what all the fuss is about.
## Comments are closed. |
15,554 | Live Captions:Linux 上的开源视频字幕应用 | https://opensource.com/article/23/2/live-captions-linux | 2023-02-19T10:58:00 | [
"字幕"
] | https://linux.cn/article-15554-1.html | 
>
> Live Captions 是一个用于 Linux 桌面的应用程序,为视频提供即时、本地和开源的字幕。
>
>
>
在一个完美的世界里,所有的视频都会有文字说明,直播视频也会有字幕。这不仅是没有听力的人能够参与流行文化和视频聊天的要求,对于有听力的人来说,这也是一种奢侈,他们只是喜欢阅读所说的内容。但并不是所有的软件都有内置的字幕,有些软件是依靠第三方的云服务来实现的。[Live Captions](https://github.com/abb128/LiveCaptions) 是 Linux 桌面上的一个应用,为视频提供即时、本地和开源的字幕。
### 安装 Live Captions
你可以通过 [Flatpak](https://opensource.com/article/21/11/install-flatpak-linux) 安装 Live Captions。
如果你的 Linux 发行版没有附带软件中心,请从终端手动安装它。首先,添加 [Flathub](https://flathub.org/apps/details/net.sapples.LiveCaptions) 仓库:
```
$ flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
接下来,安装应用:
```
$ flatpak install flathub net.sapples.LiveCaptions
```
### 启动 Live Captions
要启动 Live Captions,从你的应用菜单中启动它。
或者,你也可以使用 `flatpak` 命令从终端启动它:
```
$ flatpak run net.sapples.LiveCaptions
```
你也可以使用类似 [Fuzzpak](https://www.redhat.com/sysadmin/launch-flatpaks-terminal-fuzzpak) 的命令:
```
$ fuzzpak LiveCaptions
```
当 Live Captions 首次启动时,你会看到一个配置页面:

你可以设置字体、字体大小、颜色等。默认情况下,Live Captions 不是完全确定的文本会以更深的颜色呈现(LCTT 校注:因为有些语音识别结果不能确保完全正确)。如果你使用实时字幕是为了方便,这可能没有必要,但如果你听不到视频的声音,那么知道哪些文本可能不正确是有用的。
你可以随时返回偏好页面,所以你的选择不一定是最终的。
### 使用 Live Captions
当 Live Captions 开始运行,任何通过系统声音传来的英语单词都会被打印到 Live Captions 窗口中。
这不是一项云服务。不需要 API 密钥。没有遥测或间谍活动,也没有数据收集。事实上,它甚至不需要网络权限。Live Captions 是开源的,所以没有使用专有的服务或库。
要改变声音输入,请点击 Live Captions 窗口左上方的麦克风图标。要打开 “<ruby> 偏好 <rt> Preferences </rt></ruby>” 窗口,请点击 Live Captions 窗口左下方的齿轮图标。
### 开放访问
根据我的经验,Live Captions 的结果是好的。它们并不完美,但在小型的 [Jitsi 视频通话](https://opensource.com/article/21/9/alternatives-zoom)中,它很出色。即使是小众的视频(例如 Warhammer 40K 的激烈比赛),它也做得出奇地好,只在最虚构的科幻术语上磕磕碰碰。
让开源代码易于访问是至关重要的,最终它有可能使每个人受益。我个人不需要 Live Captions,但当我不想听视频的时候,我喜欢使用它。当我希望得到帮助以专注于我可能会分心的事情时,我也会使用它。Live Captions 不仅仅是一个有趣的开源项目,它也是一个重要的项目。
---
via: <https://opensource.com/article/23/2/live-captions-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In a perfect world, all videos would have transcripts, and live videos would have captioning. It's not just a requirement for people without hearing to be able to participate in pop culture and video chats, it's a luxury for people with hearing who just prefer to read what's been said. Not all software has captioning built-in though, and some that does relies on third-party cloud services to function. [Live Captions](https://github.com/abb128/LiveCaptions) is an application for the Linux desktop that provides instant, local, and open source captioning for video.
## Install Live Captions
You can install Live Captions as a [Flatpak](https://opensource.com/article/21/11/install-flatpak-linux).
If your Linux distribution doesn't ship with a software center, install it manually from a terminal. First, add the [Flathub](https://flathub.org/apps/details/net.sapples.LiveCaptions) repository:
```
``````
$ flatpak remote-add --if-not-exists flathub \
https://flathub.org/repo/flathub.flatpakrepo
```
Next, install the application:
```
````$ flatpak install flathub net.sapples.LiveCaptions`
## Launch Live Captions
To start Live Captions, launch it from your application menu.
Alternatively, you can start it from a terminal using the `flatpak`
command:
```
````$ flatpak run net.sapples.LiveCaptions`
You can also use a command like [Fuzzpak](https://www.redhat.com/sysadmin/launch-flatpaks-terminal-fuzzpak):
```
````$ fuzzpak LiveCaptions`
When Live Captions first starts, you're presented with a configuration screen.
(Seth Kenlon, CC BY-SA 4.0)
You can set the font, font size, colors, and more. By default, text that Live Captions isn't 100% confident about is presented in a darker color than your chosen font color. If you're using Live Captions as a convenience, this probably isn't necessary, but if you can't hear the video, then it's good to get an idea of words that may not be correct.
You can return to the preferences screen anytime, so your choices don't have to be final.
## Using Live Captions
Once Live Captions is running, any English words coming through your system sound are printed to the Live Captions window.
(Seth Kenlon, CC BY-SA 4.0)
This isn't a cloud service. There are no API keys required. There's no telemetry or spying and no data collection. In fact, it doesn't even require network permissions. Live Captions is open source, so there are no proprietary services or libraries in use.
To change the sound input, click the **Microphone** icon in the top left of the **Live Captions** window. To open the **Preferences** window, click on the **Gear** icon in the bottom left of the **Live **Captions window.
## Open access
In my experience, the results of Live Captions are good. They're not perfect, but in small [Jitsi video calls](https://opensource.com/article/21/9/alternatives-zoom), it's excellent. Even with niche videos (rowdy tournaments of Warhammer 40,000, for instance) it does surprisingly well, stumbling over only the most fictional of sci-fi terminology.
Making open source accessible is vital, and in the end it has the potential to benefit everyone. I don't personally require Live Captions, but I enjoy using it when I don't feel like listening to a video. I also use it when I want help to focus on something that I might otherwise be distracted away from. Live Captions isn't just a fun open source project, it's an important one.
## 2 Comments |
15,555 | “是时候为开源做贡献了” | https://www.opensourceforu.com/2022/06/its-time-to-contributing-to-open-source/ | 2023-02-19T14:11:31 | [
"开源"
] | https://linux.cn/article-15555-1.html | 
Nilesh Vaghela 是 AWS 的<ruby> 社区英雄 <rt> community hero </rt></ruby>,也是一家云计算开源公司 ElectroMech Corporation 的创始人。据 Nilesh 说,为开源做出贡献本身就是一种有意义的事。但是它需要人们的投入和奉献,而这个过程涉及许多步骤,从选择项目到确保你的贡献成果获得关注。在与 OSFY的 Abbinaya Kuzhanthaivel 的对话中,他分享了一些关于开发人员如何帮助提高印度对开源的贡献的技巧。

### 问:你能告诉我们一下你目前的角色和对开源的贡献吗?
**答:** 我目前是一名从事自动化工作的架构师。我领导着多个团队,并且同时主要在开源安全服务平台 Invinsense 上作出贡献。我在 1998 年初创建了开源小组,当时已经有大约 1500 名成员。我现在管理的一个小组 (<https://groups.google.com/g/vglug>) 自 2014-15 年以来一直非常活跃。
### 问:你是如何开始在开源项目中工作的?
**答:** 我是一名有着从业资格的机械工程师,当时我在我的公司 ElectroMech Corporation 负责调制解调器和 UPS 系统。我慢慢地被拖入负责 PC、网络和 Linux 等等。1996 年,我在核科学中心看到超过 150 台计算机服务器在 Linux 上运行时广受启发,之后便开始尝试。自此我将我的公司完全转变为专注于培训和支持的开源公司。
我可以自豪地说,我是最早一批使用开源的人 —— 帮助客户了解什么是开源、它有什么好处、什么是免费的、安全或代码问题等等。我们在 Vadodara 得到了至少四五个客户,并且最终通过黄页上的广告宣传自己。我们与 Red Hat 合作并且关系一直持续到现在。
### 问:自那以来你认为开源发展如何?
**答:** 我可以说,早些时候,开源是一种令人着迷的强烈爱好,吸引人们参与其中。当一些来自西伯利亚的贡献者致力于改善水资源短缺问题时,世界各地的用户都说他们的产品有多么简单易用,这给我留下了特别深刻的印象。它更像是一项企业社会责任(CSR)活动。人们和专家创建一个委员会来管理和推进项目。人们会因为对技术的热爱而加入进来,没有任何期望。
那时我并不相信开源可以商业化,但它是当今大多数创新和技术的驱动力,而且越来越多的企业正在采用它。我们期待在贡献和使用开源方面取得很好的平衡,因为我们有个人、社区和大公司参与进来。这才是开源真正的未来和力量。
### 问:你可以分享一些自己遇到的困难吗?
**答:** 最初我是单枪匹马干,但一旦人们知道我的意图是好的,他们就会加入我。我在没有任何期望的情况下创建了很多社区,但确实在声誉或名望方面间接地获得了回报;有人理解我是技术达人,并长期给我项目。在早期,人们刚开始加入社区并且不需要付出很多精力就可以做出贡献。因为我的目标不是做生意,因此可以说我没有真正面临什么障碍。
### 问:作为社区领袖,你的领导格言和经验教训是什么?
**答:** 首先,如果你想建立一个社区,那就保持中立,不要抱有偏见。虽然看起来好像是你作为领导者正在管理一个社区,但请记住,加入社区的人都是平等地做出贡献的。永远不要让成员失去动力。在发表评论和回答问题时要有礼貌。不管是什么问题,如果你不想回答,那就选择沉默。但别让人们停止提问,而是帮助他们建立专业知识。
第二,不要让社区掺杂商业。不要让社区的目标和你个人企业的目标产生混淆和互相匹配。将它们严格区分开来。
始终尝试鼓励人们参与,而不是作为专家提供指导。如果你发现人们有兴趣领导项目并采取主动,请给出舞台让他们发挥。邀请他们参与社区活动。这将帮助你培养更多的社区领袖。此外,让你的社区保持简单,不要在初始阶段让赞助商参与进来。
### 问:你从谁那里得到了灵感?
**答:** 开源运动之父 Richard Stallman 是我的灵感来源,我一直很钦佩他的项目。
除了他之外,我还有一个有趣的事要分享,它激励着我从事开源工作。在我开始从事开源工作的时候,核科学中心的大部分软件都是基于 Windows 操作系统的。然而,许多科学家希望使用基于 Linux 的软件。在两三个月内,他们实际上创建了 Linux 驱动程序。这就是让我着迷的地方——用户可以创建这些驱动程序,这在专有软件中是不太可能发生的。我真的很喜欢开源赋权用户这一点。
### 问:你对印度开源格局以及改进空间有什么看法?
**答:** 印度是使用开源的人最多的国家(LCTT 校注:或应加上“之一”),我们正致力于成为贡献者。有这么多开发者,印度却仍然没有软件巨头。我们拥有的主要是服务提供者,而不是创新者。更多的人应该成为开源的贡献者,去开发具有国际标签的东西。
为开源做贡献的想法应该从学校和大学抓起。幸运的是,古吉拉特邦政府已经在 8 年级到 10 年级里推出基于 Linux 的课程。教育年轻一代并让他们了解开源模型很重要。
其次,我们要培养好的导师。当人们开始贡献时,找到一位在这个项目中工作的开源导师很重要。导师给出了一个小任务,尝试代码然后提交。如果一切顺利,成员的贡献会逐渐增加。不幸的是,在印度导师很少。我们需要有很多导师,或者可以与世界各地的导师建立联系。
第三是要鼓励那些踊跃贡献的人。让人们发现,一旦你成为了一位广受认可的开发人员或为开源开发做出贡献的人,你在职业发展和业务上也会有所突破。
通过遵循这些简单的方法,印度可以成为开源的主要贡献者。
### 问:你如何看待为开源做出贡献时编程方面的要求?
**答:** 根据我的经验,如果你知道计算机内部的知识,如何开发应用程序,你应该维护什么样的代码标准,以及如何管理团队和其他最佳做法,你可能不必担心编程专业知识。
在设计、安全维护和整合方面还有其他角色可以担任。看看你合适什么。通过做你喜欢的事情来不断提升加强自己的技能。如果你仍然对编码感兴趣,那么你就在其他开发人员的支持下去学习。
### 问:你如何确定一个你想参与的项目?
**答:** 你需要了解你最感兴趣的几个领域,然后对围绕这些领域发生的项目进行研究。你需要弄清楚哪些领域有招募更多志愿者的需求或职位空缺。 你可以从小处着手练习,然后积累专业知识。
避免随大流;重要的是你的个人兴趣。例如,因为现在 DevOps(开发运维一体化)的需求量很大,你便可能更倾向于选择 DevOps 项目。不要犯这个错误。
你可以在云原生基金会([CNCF](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwib2vvv3dv3AhVa7XMBHfZSCsIQFnoECAgQAQ&url=https%3A%2F%2Fwww.cncf.io%2F&usg=AOvVaw2LnRyH4SZPDHntRLJU_b3q))、Apache、Fedora、Red Hat 等平台上找到开源项目。通过这种方式,你还可以找到已经在从事项目并可以给出适当指导的导师。
### 问:每个项目有自己的目的和目标受众,有时它们甚至与开源目标不一致。那么,在开始做出贡献之前要核实什么?
**答:** 我同意,当有人开始一个开源项目但随后又将其商业化时,你会感到为开源作出贡献也变得颇有难度。但这样的风险总是会有的,不应让你对此感到挫败。
首先试着去了解该小组 —— 小组中的贡献者有多受欢迎,他们贡献了多长时间,以及他们的声誉如何。一旦你加入,观察每一个人和每一件事是关键。尝试至少学习三到六个月,并了解一切是如何运作的。如果你发现他们的意图不对,你可以随时离开这个项目。但如果你觉得没问题,那就继续做贡献吧。

你可以看看他们是否有某些许可证,例如 GPLv3。你还可以查看未修改的许可证版本,例如 Apache 开源许可证。
### 问:你觉得大公司会接受应届生投稿吗?
**答:** 是的,当然。公司也喜欢指导新人。他们通常不允许你直接贡献,但可能先会给你一个小任务。导师会首先尝试了解你拥有什么技能以及你的能力如何。一旦他们认可你具备所需的技能,他们将继续指导你或根据你的技能将你分配给其他导师。初始阶段非常关键。很多公司都会做一些筛选,只有在你证明了自己的能力之后,你才会被允许做出贡献。
### 问:贡献者在接手项目时必须克服的最初挑战是什么?
**答:** 首先,你应该非常认真地对待你的贡献。没有书面承诺,贡献者可能倾向于对工作掉以轻心。这种想法是完全错误的。尝试每天投入 8-10 小时或任何可行的时间。如果你因为觉得没有立竿见影的回报而不愿投入其中,那么你就不是一个好的贡献者。
在最初阶段始终严格遵守导师的指导。这对于健康的贡献非常重要。有时你可能会认为自己擅长某事,而你的导师可能不会根据该技能给你分配项目。在这种情况下只需找你的导师,问他你应该做什么,你的角色是什么,以及你可以如何贡献。
### 问:许多开发人员在提交项目贡献后没有得到回复。如何让自己提交的东西被人注意到呢?
**答:** 写一篇关于你计划作出贡献的项目的小博客,包括你喜欢的方面,你不喜欢的地方,以及可以改进的地方。这种积极的推广方式可以帮到你很多。
成为小组的一员并参与与该项目相关的活动。作为贡献的替代,首先尝试参与到团队中去,这将增加你被采纳为贡献者的机会。
一旦你对项目有了更好的了解,你的工作不仅会被接受,而且你将能够更好地适应该项目。
### 问:你如何克服你的贡献不被接受的情况?
**答:** 就是理解发生这种情况的原因有很多 —— 也许你没有在合适的项目中,或者你没有做出正确的贡献。如果项目是国家驱动的,你的请求可能不会被接受。因此,如前所述,请记得列个清单。如果你的贡献没有被接受,请不要担心,因为要么你不适合该项目,要么该项目不适合你。
我会建议尝试找四到五个项目,并且至少有一个项目会接受你所做的工作。
### 问:你对我们的读者有何想说的?
**答:** 开源是当今大多数创新背后的驱动力。让我们根据自己的能力和技能试着做出贡献,而不是仅仅使用开源。贡献可以是代码、文档、测试、博客、金钱等。是时候做出贡献了。
### 问:ElectroMech 公司有招人的计划吗?
**答:** 我们在云计算 DevOps(开发运维一体化)方面有需求,正在招聘云架构师、Python 开发人员、Linux 架构师和安全专业人员。
---
via: <https://www.opensourceforu.com/2022/06/its-time-to-contributing-to-open-source/>
作者:[Abbinaya Kuzhanthaivel](https://www.opensourceforu.com/author/abbinaya-swath/) 选题:[lkxed](https://github.com/lkxed) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Nilesh Vaghela is an AWS community hero and founder, ElectroMech Corporation, a cloud and open source company. According to him, contributing to open source is a rewarding act in itself. However, it needs commitment and there are many steps involved in the process, right from selecting a project to ensuring your contribution is noticed. In a conversation with Abbinaya Kuzhanthaivel of OSFY, he shares a few tips on how developers can help to improve India’s contributions to open source.*
#### Q. Can you tell us a bit about your current role and contributions to open source.
**A.** I am currently an architect working on automation. I lead multiple teams and also contribute majorly to Invinsense, an open source security service platform. I started open source groups in early 1998 and had around 1500 members even then. A group (https://groups.google.com/g/vglug) I am handling now has been very active since 2014-15.
#### Q. How did you start working with open source projects?
**A.** I am a mechanical engineer by qualification, and was dealing with modems and UPS systems at my firm ElectroMech Corporation. I slowly got dragged into handling PCs, networking and Linux. I started experimenting in 1996 after getting inspired by seeing over 150 computer servers running on Linux at a Nuclear Science Centre. That’s when I converted my company entirely, focusing on open source for training and support.
I can proudly say that I was one of the first and early adopters of open source — helping customers to understand what is open source, what are its benefits, what’s available for free, security or code issues, and so on. We got at least four or five customers in Vadodara supporting us, and we eventually promoted ourselves through advertisements in the Yellow Pages. We partnered with Red Hat and the journey continues till now.
#### Q. How do you think open source has evolved since then?
A. I can say that, earlier, open source was a passion that fascinated and attracted people to participate. I was particularly impressed hearing user-friendly stories across the world when some Siberian contributors were working to improve water scarcity. It was more like a corporate social responsibility (CSR) activity. A board would be created by people and experts to govern and take projects forward. People would come in for the love of technology without expectations.
I did not believe then that open source could get commercial, but it is the driving force for most of the innovation and technology today, and many more enterprises are adopting it. We are looking forward to a great balance in contribution to and use of open source, as we have people, communities and big companies coming into play. This is the real future and power of open source.
#### Q. Could you share some of your challenges?
A. Initially, I walked alone but people joined once they knew my intentions were good. I created a lot of communities without any expectation, but did get paid indirectly in terms of reputation or fame; some people understood that I was a technical expert and gave projects in the long term. As it was very early days, people started joining the community and contributing without much effort. The goal wasn’t to get business and hence I can say I didn’t really face any hurdles.
#### Q. What are your leadership mantras and lessons from being a community leader?
**A.** First, if you want to start a community, then be neutral and don’t harbour a biased opinion. It may look like you are running a community as a leader, but remember those joining you are contributing equally. And never demotivate anyone. Be polite while making comments and addressing queries. Whatever the question, if you don’t want to give an answer, then choose to be quiet. But don’t stop anyone from asking. Help them build expertise.
Second, don’t involve the community in business. Do not mix and match the goals of your business and community. Have a clear differentiation.
Always try to encourage people to participate instead of delivering instructions as an expert. If you find people are interested to lead and take initiatives, then give them the stage. Invite and engage them in the community. That will help you to make more community leaders. Also, keep your community simple and don’t involve sponsors in the initial stages.
#### Q. Who do you look up to for inspiration?
**A.** Richard Stallman, the father of the open source movement, is my inspiration and I have always admired his projects.
Apart from him, I have an interesting incident to share that inspired me to work on open source. At the time when I started working on open source, most of the software for the Nuclear Science Centre was based on the Windows OS. However, many scientists wanted to work with Linux based software. And within two or three months, they actually created Linux drivers. This is what fascinated me – that the user can create these drivers which may not be possible in the case of proprietary software. I really liked the fact that open source empowered the user.
#### Q. Your thoughts on the open source landscape in India and the scope for improvement.
**A.** India is the largest consumer of open source and we are focusing on becoming a contributor. With so many developers around, we still do not have software giants in India. What we have mostly are service providers and not innovators. More people should become contributors to open source and develop something with international labels.
The very thought of contributing to open source should begin from the level of schools and colleges. Fortunately, the Gujarat government has already introduced lessons based on Linux from Class 8 to Class 10. It is important to educate and make youngsters aware of open source models.
Second, we have to develop good mentors. When people start contributing, it is important to find an open source mentor working in that particular project. The mentor gives a small assignment, tries the code and then commits it. If everything goes fine, the contribution is increased gradually. Unfortunately, we have very few mentors available in India. We need to prepare a lot of mentors or maybe connect to those across the world.
Third, we need to encourage those who come forward to contribute. Once you are a recognised developer or a person contributing to open source development, you also progress in your career and business.
India can be a major contributor to open source by following such simple methods.
#### Q. What do you think about the coding requirements to contribute to open source?
**A.** From my experience, if you know the internal parts, how to develop the application, what code standard you should maintain, and how to manage the team and other best practices, you may not have to actually worry about coding expertise.
There are other roles too with respect to designing, security maintenance and integration. See what works for you. Develop and strengthen your skill in what you like to do. If you feel coding still interests you, then take the support of fellow developers to learn it.
#### Q. How do you shortlist a project you would like to contribute to?
A. You need to understand your top few interest areas and then do your research on the projects happening around them. You need to figure out the area of requirements or openings for contributors and more volunteers. You can start small to practice and then build expertise.
Avoid going by the trendy topics; what’s important is your individual interest. For instance, DevOps is in high demand now and you may tend to go for a DevOps project. Do not make this mistake.
You can find open source projects on Cloud Native Computing Foundation ([CNCF](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwib2vvv3dv3AhVa7XMBHfZSCsIQFnoECAgQAQ&url=https%3A%2F%2Fwww.cncf.io%2F&usg=AOvVaw2LnRyH4SZPDHntRLJU_b3q)), Apache, Fedora, Red Hat, and so on. This way you can also find mentors who are already working on projects and can get proper guidance.
#### Q. Projects have their own purpose and target audience. Sometimes they even misalign with open source goals. So, what does one check before contributing?
A. I agree it becomes challenging when somebody starts an open source project and then commercialises it. But this is always a risk, and should not discourage you.
First try to check out the group — how popular are the contributors working in the group, how long have they been contributing, and how reputed are they. And once you join, observing everyone and everything is the key. Try to learn at least for three to six months, and understand how everything works. You can always leave the project if you find the intention is wrong. But if you feel it’s all right, then go ahead and contribute.


There are certain licence checks that you can do, say, like GPL version 3. You can also look at unmodified licence versions like the Apache open source licence.
#### Q. Do you think big companies will accept contributions from freshers?
A. Yes, of course. Companies also like mentoring. They usually don’t allow you to contribute directly, but may give you a small assignment initially. A mentor will first try to understand what skill you have and how good you are at it. Once they recognise you have the kind of skill that is needed, they will continue to guide you or assign you to some other mentor based on your skill. The initial stages are very crucial. Many companies do some sort of screening, and you may be allowed to contribute only after you have proved your ability.
#### Q. What are the initial challenges that contributors have to overcome when picking up projects?
A. First, you should be very serious about your contribution. There are no written commitments and contributors may tend to take the work lightly. That’s totally wrong. Try to dedicate 8-10 hours or whatever is feasible each day. If you are skipping this commitment because you feel there are no immediate returns, then you will not be a good contributor.
Always adhere to a mentor’s guidance strictly at the initial stages. This is very crucial for a healthy contribution. Sometimes it may happen that you believe you are good at something, while your mentor may not assign a project based on that skill. Simply approach your mentor in such scenarios and ask him what you should do, what is your role, and how you can contribute.
#### Q. Many developers do not get replies after submitting the contribution to a project. How does one make a submission noticeable?
A. Write a small blog on the project you are planning to contribute to, covering aspects like what you like in it, what you don’t like, and what can be improved. Such a positive and promotional approach can greatly help you.
Be a part of the group and be involved in activities related to that particular project. Instead of contributing, first try to engage with the group, and this will increase the chances for you to get adopted as a contributor.
Once you have a better understanding of the project, not only will your work be accepted but you will be able to better align yourself with that project.
#### Q. How do you overcome a situation where your contribution is not accepted?
A. Just understand that this can happen for many reasons — maybe you are not in the right project or you have not contributed correctly. If the project is country driven, your request may not be accepted. Hence, remember to have a checklist as stated earlier. Don’t worry if your contribution is not accepted because either you are not fit for the project or the project is not fit for you.
All I would recommend is try to identify four or five projects, and at least one among those projects you work on will probably be accepted.
#### Q. What is your message for our readers?
A. Open source is the driving force behind most of the innovation happening today. Instead of just using open source, let us try to contribute according to our capacity and skills. Contributions can be in terms of code, documentation, testing, blogs, money, etc. It’s time to contribute.
#### Q. Any hiring plans for ElectroMech Corporation — what are the roles and skill expectations?
We have requirements in cloud DevOps, and are hiring cloud architects, Python developers, Linux architects and security professionals. |
15,556 | elementary OS 7 安装指南及截图 | https://www.linuxtechi.com/elementary-os-7-installation-guide/ | 2023-02-19T14:37:00 | [
"elementary OS"
] | https://linux.cn/article-15556-1.html | 
在这篇文章中,我们将介绍如何在笔记本电脑或台式机上一步一步地安装 elementary OS 7,并附有截图。它基于最新和稳定的 Ubuntu 22.04 LTS。
elementary OS 7 的代号为 “Horus”,并带来了很多改进,例如:
* 改进了 AppCenter 和安装所有需要的应用。
* 改进了侧载和可选商店(Flathub)的体验。
* 最新的 GNOME Web 43,支持创建网络应用。
* 快速获得操作系统和应用的更新
* 电源配置文件管理
* 应用描述的改进
### elementary OS 7 的系统要求
* 双核 64 位处理器
* 4GB 内存或更多
* 32GB 硬盘
* 互联网接入
* 可启动的 USB 驱动器(4GB 存储空间)
闲话少说,让我们进入安装步骤:
### 1)下载 elementary OS 7
使用下面的官方网址来下载 ISO 文件。
>
> **[下载 elementary OS 7 ISO](https://elementary.io/)**
>
>
>
ISO 文件下载完成后,将其刻录到 USB 驱动器,并使其可启动。
在 Windows 操作系统中,用 Rufus 制作可启动的 USB 驱动器。在 Linux 中,请参考以下网址:
>
> **[如何在 Ubuntu/Linux Mint 上创建可启动的 USB 驱动器](https://www.linuxtechi.com/create-bootable-usb-disk-dvd-ubuntu-linux-mint/)**
>
>
>
### 2)用可启动介质启动系统
现在用可启动的 USB 驱动器启动目标系统。从 BIOS 设置中把启动介质从硬盘改为 USB。当系统用 USB 驱动器启动时,我们将看到以下页面。

### 3)选择安装语言
选择你喜欢的语言,然后点击“<ruby> 选择 <rt> Select </rt></ruby>”。

### 4)选择键盘布局
在这一步,你将被要求选择键盘布局,然后点击“<ruby> 选择 <rt> Select </rt></ruby>”。

### 5)尝试或安装 elementary OS
我们将看到下面的页面,在这里我们必须选择安装类型。它给了我们以下选项:
* <ruby> 试用演示模式 <rt> Try Demo Mode </rt></ruby> – 试用 elementary OS 7 而不安装
* <ruby> 擦除磁盘并安装 <rt> Erase disk and Install </rt></ruby> – 安装程序将擦除整个磁盘并自动创建所需分区。
* <ruby> 自定义安装(高级) <rt> Custom Install (Advanced) </rt></ruby> – 它将给我们一个选项来创建自定义分区。
在这篇文章中,我将使用第二个选项(擦除磁盘并安装)。

点击“<ruby> 擦除磁盘并安装 <rt> Erase disk and Install </rt></ruby>”。
在下面的屏幕上,选择要安装操作系统的驱动器,然后点击“<ruby> 擦除并安装 <rt> Erase and Install </rt></ruby>”。

如果你想对设备的驱动器进行加密,那么点击“<ruby> 选择密码 <rt> Choose Password </rt></ruby>”,否则点击“<ruby> 不加密 <rt> Don’t Encrypt </rt></ruby>”。

### 6)安装进度
正如我们在下面看到的,安装已经开始,并且正在进行中。

安装完成后,安装程序将提示重启系统。

点击“<ruby> 重启设备 <rt> Restart Device </rt></ruby>”,不要忘记从 BIOS 设置中改变启动介质,以便用磁盘启动。
### 7)创建本地用户并设置主机名
当系统在安装后启动时,系统会提示你输入本地用户的详细信息和系统的主机名。
根据你的要求指定这些细节。

点击“<ruby> 完成设置 <rt> Finish Setup </rt></ruby>”。
在下面的页面中,你将被提示输入你在上面创建的本地用户凭证。

输入凭证后,点击回车。
### 8)elementary OS 7 欢迎页
我们将看到下面的欢迎页。

选择“<ruby> 跳过所有 <rt> Skip All </rt></ruby>”。

点击“<ruby> 开始使用 <rt> Get Started </rt></ruby>”,然后我们会看到下面的桌面。

很好,这表明你已经成功地在系统上安装了 elementary OS 7。这就是本指南的全部内容,请探索这个令人兴奋的 Linux 发行版并享受其中的乐趣吧?。
---
via: <https://www.linuxtechi.com/elementary-os-7-installation-guide/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello techies, in this post, we will cover how to Install Elementary OS 7 step by step with screenshots on laptop or desktop. It is based on latest and stable Ubuntu 22.04 LTS.
Elementary OS 7 with code name “Horus” released with lot of improvements like :
- Improved AppCenter and install all application that one need.
- Improved sideloading and alt store (Flathub) experience
- Latest GNOME Web 43 support for creating web apps.
- Getting OS and Applicate Updates quickly
- Power Profile Management
- Improvement in App Description
#### System Requirements for Elementary OS 7
- Dual Core 64-bit processor
- 4 GB RAM or more
- 32 GB hard disk
- Internet Access
- Bootable USB Flash Drive ( 4 GB Storage)
Without any further delay, let’s jump into the installation steps
## 1) Download Elementary OS 7
Use below official URL to download ISO file,
Once ISO file is downloaded then burn it into USB flash drive and make it bootable.
On Windows operating use “Rufus” software to make bootable USB drive using ISO file. In Linux, refer the following URL:
## 2) Boot the system with bootable media
Now boot the target system with bootable USB drive. From bios settings change the boot medium from hard disk to USB. When the system boots up with USB drive then we will get the following screen,
## 3) Select Language for Installation
Choose your preferred language and then click select,
## 4) Choose Keyboard Layout
In this step, you will be requested to choose keyboard layout and then click on ‘Select’
## 5) Try or Install elementary OS
We will be presented the beneath screen, where we must our choose installation type. It gives us following options,
- Try Demo Mode – Try Elementary OS 7 without installing
- Erase disk and Install – Installer will erase the whole disk and will create required partitions automatically.
- Custom Install (Advanced) – It will give us the option to create custom partitions.
In this post, I will go with the 2nd option (Erase disk and install).
Click on “Erase Disk and Install”
In the following screen, select the drive on which OS will be installed and then click on “Erase and Install”
If you want to encrypt the device’s drive, then click on “Choose Password” else click on “Don’t Encrypt”.
## 6) Installation Progress
As we can see below, installation got started and is in progress.
Once the installation is completed, installer will prompt to reboot the system.
Click on “Restart Device” and don’t forget to change boot medium from bios settings so that it boots up with the disk.
## 7) Create Local User and Set Hostname
When the system boots up after the installation, you will be prompted to enter local user details and hostname of your system.
Specify the details as per your requirement,
Click on “Finish Setup”.
In the following screen, you will be prompted to enter your local user credentials that you have created above,
After entering the credentials, hit enter
## 8) Elementary OS 7 Welcome Screen
We will get the beneath welcome screen,
Choose “Skip All”
Click “Get Started” and then we will get following desktop screen,
Great, it confirms that you have successfully installed Elementary OS 7 on your system. That’s all from this guide, explore this exciting Linux distribution and have fun 😊.
r3mnantboots me into a red screen and on checking the power button it tells me I’m not logged in. |
15,558 | LibreOffice 简史 | https://opensource.com/article/23/2/libreoffice-history | 2023-02-20T19:13:35 | [
"LibreOffice"
] | https://linux.cn/article-15558-1.html | 
>
> LibreOffice 的起源故事,它是一个开源的办公解决方案,确保你总是能够访问你的数据并控制你的创造力。
>
>
>
在 2009 年初,[OpenOffice.org](http://OpenOffice.org)(OOo)还是微软 Office 在个人办公生产力套件市场的主要竞争对手。这个流行的开源办公套件的社区,期待着 11 月在意大利奥尔维耶托举行的研讨会。事情进展顺利,未来看起来很光明。
可这之后,同年 4 月,<ruby> 甲骨文公司 <rt> Oracle </rt></ruby> 宣布了对 <ruby> 太阳计算机系统公司 <rt> Sun Microsystems </rt></ruby> 的收购计划。
就个人而言,我觉得这对 [OpenOffice.org](http://OpenOffice.org) 来说是个坏消息。甲骨文对开源套件没有兴趣,我料想它会放弃这个项目。当然,我更希望在研讨会上被证明是我想错了。但到最后,甲骨文只派了一名代表来到奥尔维耶托,乏善可陈,含糊其辞地谈论了货币化和品牌重塑。我和其他社区成员们都觉得,最担心的事情成真了。
那一年,社区成员从奥尔维耶托返程之后决定采取行动。是时候兑现 [OpenOffice.org](http://OpenOffice.org) 项目的承诺了。我们决心创建一个独立的基金会来管理项目的资产,在社区的保护下促进套件的开发。[OpenOffice.org](http://OpenOffice.org) 将不再隶属于哪一家公司,而是属于它的用户和个人贡献者们。
### 建立基金会
当时,[OpenOffice.org](http://OpenOffice.org) 项目分布在世界各地,在语言社区帮助下进行本地化和推广,其中最主要的四个是:
* 德国:该软件诞生于德国,而且 Star Division(负责 [OpenOffice.org](http://OpenOffice.org) 的部门)的总部也在汉堡,因此开发者群体和德语支持者之间沟通顺畅。
* 法国:政府支持这个开源软件。
* 意大利:我所在的小组。
* 巴西。
2010 年初,在法国和德国语言社区的倡议下,最活跃的志愿者 —— 连同一些独立开发者和 SUSE 的开发者们 —— 着手建立了一个复刻项目,旨在作为一个额外的选择,让全球社区和投资 [OpenOffice.org](http://OpenOffice.org) 的企业能够同时参与进来。
我在国际商业咨询机构已有超过 30 年的工作经验了。在这个项目中负责市场营销和战略沟通。
随后的几个月里,活动越发忙碌。由于从 Star Division 传来的消息越来越负面,每周都得召开一次电话会议。
即使 [OpenOffice.org](http://OpenOffice.org) 的解散似乎迫在眉睫,我们还是通过发布文章征稿(CFP)的方式,确认了位于布达佩斯的研讨会仍将举办。当然,复刻项目的成员在做的也和往年别无二致。他们提交了演讲提案并制定了旅行计划。
### 一个安全的文件存放处
夏初,复刻项目几乎要完成了。我们的小组在布达佩斯开会评估 [OpenOffice.org](http://OpenOffice.org) 方面的境况,并召开了第一次面对面的组织会议。
布达佩斯的研讨会进行得很顺利,为期三天日程中举行了会议、主题演讲和技术研讨。一切似乎还算平常。
可其实并不平常。
当几位领头人没去参加会议的主要社交活动 —— 多瑙河上过夜巡游的时候,一些与会者开始有些疑虑了。其实我们没参加这次活动,是因为我们在餐厅开会敲定新基金会的最终细节,有太多事情要确保万无一失。我们必须定下公告日期,并且,为了协调基金会落地的各项任务,需要确定指导委员会的人员组成。
### LibreOffice
从这次会议到 LibreOffice 发布间隔了三周,我们紧锣密鼓地准备。我拟好了发布策略和新闻稿,开发者们为软件做准备。应用的名字甚至是在发布的前几天的一次电话会议上敲定的,那时我在格罗塞托,正在参加意大利开源软件社区会议。
2010 年 9 月 28 日,我把宣布“<ruby> 文档基金会 <rt> The Document Foundation </rt></ruby>”和 LibreOffice 的新闻稿分发到一个包含约 250 名记者的全球邮件列表中,这列表可是我根据供职过的公共关系机构的来信,花了很大力气整理的。
新闻稿是这样的:
>
> 开发和推广 [OpenOffice.org](http://OpenOffice.org) 的志愿者社区宣布将成立一个独立的基金会,推动项目的进一步发展。基金会将成为一个新的生态系统的基石,在这里,个人和组织都可以为一个真正免费的办公套件做出贡献,并从中受益。从用户的利益出发,这将带来更多的竞争和选择,并推动办公套件市场的创新。从现在开始,[OpenOffice.org](http://OpenOffice.org) 社区将被称为“<ruby> 文档基金会 <rt> The Document Foundation </rt></ruby>”。
>
>
>
我们邀请过 Oracle 成为基金会的成员,并捐赠社区在过去十年中发展起来的品牌。而在他们做出决定之前,我们选择了 LibreOffice 作为即将到来的软件的品牌。
媒体界对这一公告的反应非常积极。但另一方面,企业和分析师则倾向于对由社区管理的办公套件表示质疑,这是他们从未完全理解的实体,因为这个组织很扁平、任人唯贤。
公告发布后的两周内,就有 80 位新开发者加入这个项目,推翻了那些认为“仅凭 SUSE 和 Red Hat 的开发者来启动复刻项目并不现实”的预测。不出所料,大多数语言社区都转向了 LibreOffice。
LibreOffice 是基于 [OpenOffice.org](http://OpenOffice.org) 的源代码构建的。但新的功能被集成在 <ruby> Go-OO <rt> Go-Open Office </rt></ruby> 的源代码中,而不是在 [OpenOffice.org](http://OpenOffice.org)(OOo)上。
出于这个原因,LibreOffice 的第一个版本(于 2011 年 1 月 25 日发布)为 3.3,以保持与 [OpenOffice.org](http://OpenOffice.org) 的一致性。我们认为这对于从第一个版本迁移到新套件的用户很有帮助。由于还有必须解决的明显技术债务,该软件仍有点不成熟,这导致了一些问题和不稳定。这些问题预计将基本上通过 3.x 和 4.x 版本的代码清理和重构得到纠正。到了 5.x 和 6.x 版本,源代码应该已经稳定,并有条件改进用户界面,以及开发移动和云版本。
2011 年春天,甲骨文将 [OpenOffice.org](http://OpenOffice.org) 源代码转让给了 Apache 软件基金会。但该项目仅持续了三年,它的上一个新版本已经是将近十年前的事了。
### 未来是开放的
文档基金会的组建过程于 2012 年初结束,并于 2012 年 2 月 17 日在柏林有关部门完成注册。因为创始人希望该项目的志愿者成员们也可以根据贡献成为基金会成员,这让注册过程十分漫长。德国的法规并未考虑到基金会的这一细节,因此需要对章程进行多次修订才能满足现有状况。
基金会成立之初的前两项活动都是委员会成员的选举。这是从单纯的志愿者过渡到基于贡献的文档基金会成员所必经的规程。有委员五人,副委员三人。最后,负责在行政和战略方面领导基金会的董事会,由七名成员和三名副手组成。
2012 年底,基金会聘请了第一位雇员 Florian Effenberger,在后来他被提升为执行董事。今天,这个团队有十几个成员,他们负责日常活动,例如协调项目、行政管理、网络基础设施管理、软件发布、指导新的开发人员、协调质量保证、用户界面的演进、以及营销和沟通。
目前,基金会正在寻找开发人员满足企业客户需求,例如 RTL 语言管理和辅助功能。这些功能并不是由 LibreOffice 生态系统中的公司开发的,这些公司为他们提供功能开发服务、三级支持以及为企业需求优化的软件的长期支持版本。
在 LibreOffice 和文档基金会宣布成立已经过去 12 年之后,我们可以说,我们已经实现了开发一个独立的“<ruby> 自由和开源软件 <rt> free and open source </rt></ruby>(FOSS)”的项目目标。我们的项目是基于一个由个人志愿者和公司量力而行做出贡献的扩展社区。参与者们帮助创建了无与伦比的免费办公套件,并通过采用和发展现有市场上唯一真正的<ruby> 标准办公文档格式 <rt> Open Document Format </rt></ruby>(ODF)来支持开放标准。同时,该套件也确保了与专有的 OOXML 格式的出色兼容性。
这种模式的可持续性是一个日常问题。身处于与大型科技公司的激烈竞争下,我们一直在尝试,试图在“希望一切都免费”,和“希望每个用户都能力所能及做出贡献”之间达成一种平衡。不过无论如何,LibreOffice 都会是开源的办公套件,这提供了竞争之上的额外价值。
试试 LibreOffice 吧;捐赠;不论是工作还是业余,支持它;向你的朋友介绍它!LibreOffice 是一个开源的办公解决方案,它确保你总是能够访问你的数据,并掌控你的创造力。
---
via: <https://opensource.com/article/23/2/libreoffice-history>
作者:[Italo Vignoli](https://opensource.com/users/italovignoli) 选题:[lkxed](https://github.com/lkxed/) 译者:[onionstalgia](https://github.com/onionstalgia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In early 2009, OpenOffice.org was the main competitor to Microsoft Office in the individual office productivity suites market. The popular open source office suite's community looked forward to a November conference in Orvieto, Italy. Things were going well, and the future looked bright.
And then, in April of that year, Oracle announced its plans to acquire Sun Microsystems.
Personally, I knew it was bad news for OpenOffice.Org. Oracle had no interest in the open source suite, and I felt confident it would abandon the project. Of course, I hoped to be proved wrong at the upcoming conference. Instead, a single representative from Oracle, with no budget to speak of, arrived in Orvieto and talked vaguely about monetization and re-branding. I felt that my worst fears were confirmed, and my fellow community members agreed.
The community returned home from Orvieto that year and resolved to take action. The time had finally come to turn into reality what the OpenOffice.Org project had promised. We were determined to create an independent foundation to manage the project's assets and promote the development of the suite under the umbrella of the community. OpenOffice.org would no longer belong to a company but to its users and individual contributors.
## Building the foundation
At the time, the OpenOffice.org project had a presence on every continent, with language communities helping to localize and promote it. The four most important:
- German: The software was born in Germany, and StarDivision was based in Hamburg, so there was a natural link between the group of developers and German-speaking supporters.
- French: The government supported the open source software.
- Italian: The group to which I belonged.
- Brazilian
At the beginning of 2010, at the initiative of the French and German language communities, the most active volunteers—together with some independent and SUSE developers—started working on a fork project. The aim was to launch an alternative project involving both the global community and the companies invested in OpenOffice.org.
I have over 30 years of experience working in international business and consultancy agencies. The project brought me in to manage the marketing and communication strategy.
In the months that followed, activity became increasingly hectic. There was a weekly teleconference meeting, as the news coming in from Star Division (the department responsible for OpenOffice.org) was increasingly negative.
Even with the dissolution of OpenOffice.org seemingly imminent, a conference in Budapest was confirmed by the publication of a CFP (Call for Papers). Of course, the fork project members also did nothing different from previous years. They presented their talk proposals and made travel plans.
## A safe place for documents
At the beginning of the summer, the fork was almost ready. Our group met in Budapest to gauge the situation from the OpenOffice.org side and for a first face-to-face organizational meeting.
The Budapest conference ran smoothly, with meetings, keynotes, and technical sessions taking place over the three-day event. Everything seemed more or less normal.
Everything was not normal.
Some attendees were a little suspicious when several leading figures failed to attend the conference's main social event, an overnight cruise on the Danube. We didn't participate in this event because we were meeting in a restaurant to discuss the final details of a new foundation. There was a lot to get right. We had to determine an announcement date and the composition of the Steering Committee that would coordinate the tasks required to bring the foundation to life.
## LibreOffice
The three weeks between the conference and the announcement of LibreOffice were hectic. I prepared the launch strategy and the text of the press release. The developers prepared the software. The application's name had just been decided a few days earlier during a teleconference (which I'd joined from Grosseto, where I was attending the Italian open source software community meeting).
On September 28, 2010, I distributed the press release announcing The Document Foundation and LibreOffice to a global mailing list of about 250 journalists, which I painstakingly put together using input from the public relations agencies where I worked.
Here is the release:
The community of volunteers developing and promoting OpenOffice.Org announces an independent foundation to drive the further growth of the project. The foundation will be the cornerstone of a new ecosystem where individuals and organisations can contribute to and benefit from the availability of a truly free office suite. It will generate increased competition and choice for the benefit of customers and drive innovation in the office suite market. From now on the OpenOffice.Org community will be known as The Document Foundation.
We invited Oracle to become a member of the foundation and donate the brand the community had grown during the previous ten years. Pending the decision, we chose the brand LibreOffice for the software going forward.
Reactions to the announcement from the press were very positive. On the other hand, companies and analysts tended to be suspicious of an office suite governed by a community, an entity they never fully understood because of its flat, meritocratic organization.
In the two weeks following the announcement, 80 new developers joined the project, disproving the predictions of those who considered it unrealistic to launch a fork relying only on SUSE and Red Hat developers. Unsurprisingly, most of the language communities switched to LibreOffice.
LibreOffice is built from the source code of OpenOffice.org. The new functionalities are integrated in the source code of Go-OO and not on OOo.
For this reason, the first version of LibreOffice—announced on January 25, 2011—was 3.3 to maintain consistency with OpenOffice.org. This was useful for users who had migrated to the new suite since the first version. The software was still a little immature due to significant technical debt that had to be accounted for. This caused problems and instability that would largely be corrected through code cleaning and refactoring throughout the 3.x and 4.x versions. By versions 5.x and 6.x, the source code was considered stable, which allowed the user interface to be improved and the development of mobile and cloud versions.
In the spring of 2011, Oracle transferred the OpenOffice.org source code to the Apache Software Foundation. The project lasted for three years. The last new version was nearly a decade ago.
## The future is open
The formation process of The Document Foundation ended in early 2012, with registration by the Berlin authorities on February 17, 2012. This was a lengthy process because the founders wanted volunteer members of the project also to be members of the foundation based on contributions. This detail hadn't been foreseen for foundations under German law, so it required several revisions of statutes to comply with this condition.
The foundation's first two activities were the membership committee's election. This is the structure that decides on the transition from mere volunteer to member of The Document Foundation on the basis of contributions. There are five members and three deputies. Finally, there's a Board of Directors, which steers the foundation administratively and strategically, consisting of seven members and three deputies.
At the end of 2012, the foundation hired its first employee. This employee was Florian Effenberger, who was later promoted to executive director. Today, the team has a dozen members who take care of day-to-day activities such as coordinating projects, administration, network infrastructure management, software releases, mentoring of new developers, coordination of quality assurance, user interface evolution, and marketing and communications.
Right now, the foundation is looking for developers to handle tasks that do not fit the objectives of enterprise customers, such as RTL language management and accessibility. These features aren't developed by the companies in the LibreOffice ecosystem, which offer them feature development services, Level 3 support, and Long Term Support versions of the software optimized for enterprise needs.
More than 12 years after the announcement of LibreOffice and The Document Foundation, we can say that we have achieved our goal of developing an independent free and open source (FOSS) project. Our project is based on an extended community of individual volunteers and companies contributing according to their abilities. These participants help create the unmatched free office suite and support open standards by adopting and evolving the only true standard office document format on the market (Open Document Format, or ODF) while also ensuring excellent compatibility with the proprietary OOXML format.
The sustainability of this model is a day-to-day problem. There's severe competition from big tech firms. We're always searching for a balance between those who would like everything to be cost-free and those who would like each user to contribute according to their ability. No matter what, though, LibreOffice is an open source office suite, providing added value above and beyond its competition.
Try LibreOffice. Donate. Support it at home and work. Tell your friends about it. LibreOffice is the open source office solution that ensures you always have access to your data and control over your creativity.
## 4 Comments |
15,559 | KDE Connect 登陆苹果应用商店,轻松将你的 iPhone 与 Linux 连接起来 | https://news.itsfoss.com/kde-connect-ios/ | 2023-02-20T19:32:14 | [
"KDE Connect"
] | https://linux.cn/article-15559-1.html |
>
> 这是一个令人印象深刻的开源客户端,能帮你将手机与电脑连接起来,现在可用于 iPhone 和 iPad。快来试试看!
>
>
>

KDE Connect 是一种开源工具,可让你将手机与电脑连接起来。
最初,KDE Connect 支持安卓设备与 Linux 连接。渐渐地,他们增加了对 Windows 的支持。
现在,看起来你可以使用 KDE Connect 让你的 iOS 设备(iPhone 或 iPad)连接到你的 Windows/Linux 计算机。
需要注意的是 macOS 也在支持的平台列表中。但是,它仍然是早期发布版本。因此它可能不如在其他平台上那么好用。
### 苹果应用商店上的 KDE Connect

我们没有注意到任何官方公告。然而,一些用户发现 KDE Connect 在 [版本 0.2.1](https://invent.kde.org/network/kdeconnect-ios/-/commit/43d2ecbbb7e4e70274849f5ec987721318eb9f57) 发布后,就出现在了 [苹果应用商店](https://apps.apple.com/id/app/kde-connect/id1580245991) 上供 iOS 用户使用。
苹果应用商店上列出了所有基本功能,包括:
* 共享剪贴板:在设备之间复制/粘贴。
* 能够从任何应用程序将文件和 URL 共享到你的计算机。
* 将手机屏幕用作计算机的触摸板(可视触摸板)。
* 远程演示模式。
* 通过手机在计算机上运行命令
* 端到端 TLS 加密以确保安全。
虽然 KDE Connect 依然是一个开源应用程序,但为符合苹果应用商店的要求,该应用程序的许可与 [OMGUbuntu](https://www.omgubuntu.co.uk/2022/05/kde-connect-iphone-app-available) 所发现的有所不同。
同时值得注意的是,这里列出的功能可能与安卓版本不同,但至少我们终于为 iOS 用户提供了 KDE Connect,使其成为连接手机和计算机的真正开源跨平台解决方案。
我可以放心将 KDE Connect 推荐给任何想通过手机来对电脑进行操作的人。
点击下方的按钮即可前往应用程序商店开始安装。你还可以在其 [官方下载页面](https://kdeconnect.kde.org/download.html) 上找到针对不同支持平台的各种其他安装选项。
>
> **[KDE Connect(iOS)](https://apps.apple.com/id/app/kde-connect/id1580245991)**
>
>
>
你试过 iOS 上的 KDE Connect 了吗?在评论区中让我知道你的想法。
---
via: <https://news.itsfoss.com/kde-connect-ios/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:[XiaotingHuang22](https://github.com/XiaotingHuang22) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

KDE Connect is an open-source tool that lets you connect your mobile phone with your PC.
Originally, KDE Connect supported Android devices to connect with Linux. Gradually, they added support for Windows.
Now, it looks like you can use KDE Connect with your iOS device (iPhone or iPad) to connect to your Windows/Linux computer.
Note that macOS is also in the list of supported platforms. However, it is still an early release version for macOS. So, it may not work as good as it does with other platforms.
## KDE Connect on the App Store
We did not notice any official announcement for this. However, some users spotted KDE Connect being available on the [App Store for iOS users](https://apps.apple.com/id/app/kde-connect/id1580245991?ref=news.itsfoss.com) right after the release of [version 0.2.1](https://invent.kde.org/network/kdeconnect-ios/-/commit/43d2ecbbb7e4e70274849f5ec987721318eb9f57?ref=news.itsfoss.com).
The App Store lists all the essential features including:
**Shared clipboard: to copy/paste between devices.****Ability to share files and URLs to your computer from any app.****Use your phone screen as your computer’s touchpad (visual touchpad).****Remote presentation remote mode.****Run commands on your computer from your phone****End-to-end TLS encryption for security.**
While this remains as an open-source app, the app licensing is a bit different as spotted by [OMGUbuntu](https://www.omgubuntu.co.uk/2022/05/kde-connect-iphone-app-available?ref=news.itsfoss.com) to comply with App Store guidelines.
It is also worth noting that the feature set may not be the same as its Android counterpart, but at least we finally have KDE Connect for iOS users, making it a truly open-source cross-plaform solution to connect mobiles with computers.
I’d be comfortable recommending KDE Connect to anyone who wants to keep things in check with their mobile through computers.
Head to the app store from the button below to get started installing it. You can also find various other installation options for different supported platforms on its [official download page](https://kdeconnect.kde.org/download.html?ref=news.itsfoss.com).
*Have you tried KDE Connect on iOS yet? Let me know your thoughts in the comments.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,561 | 如何在 Arch Linux 中安装 MATE 桌面 | https://www.debugpoint.com/mate-desktop-arch-linux-install/ | 2023-02-21T10:44:00 | [
"MATE",
"Arch Linux"
] | /article-15561-1.html | 
>
> 本指南将详细解释你在 Arch Linux 中安装 MATE 桌面所需的步骤。
>
>
>
本指南分为两部分。第一部分讨论安装基础 Arch 系统。第二部分是在 Arch Linux 上安装完整的 MATE 桌面环境。
本文在以下版本中进行了测试:MATE 1.24 和 MATE 1.26。
### 什么是 MATE 桌面?
当 GNOME 桌面从 GNOME 2 改变方向到 GNOME 3 时,改变了用户交互和界面,MATE 桌面仍然延续了“较旧的”或者说“传统的” GNOME 2 的开发方向。因此,MATE 桌面环境保留了 Linux 中的传统桌面体验。它速度快,内存消耗低。在我看来,MATE 桌面环境是一个被低估的桌面环境,需要更多的关注!
MATE 团队一直在继续开发,它是一个基于 GNOME 2 的流行桌面之一,但同时支持更新的技术。你可以在其 [官方网站](https://mate-desktop.org/) 上了解更多信息。
### 在 Arch Linux 中安装 MATE 桌面
#### 第一部分: 安装 Arch Linux
如果你已经安装了 Arch Linux,则可以跳过此步骤,直接转到下面的 MATE 桌面安装部分。
要快速安装 Arch Linux,请按照这个自动化的 [archinstall 指南](https://www.debugpoint.com/archinstall-guide/) 进行操作,该指南非常容易上手。安装完成后,继续至第二部分。
#### 第二部分:在 Arch Linux 中安装 MATE 桌面
重新启动后,从 GRUB 中选择 Arch Linux。在 Arch Linux 提示符下,按顺序运行以下命令。这些命令将安装 Xorg 服务器、显示管理器、MATE 桌面组件、控制器包以及其他应用程序。
对于所有命令,请使用默认值,即在询问时按 Enter 键。
安装 Xorg。安装大小大约为 80 MB。
```
sudo pacman -S --needed xorg
```
安装显示管理器和 MATE 桌面组件。安装大小大约为 380 MB。
```
sudo pacman -S --needed mate mate-extra ttf-freefont lightdm lightdm-gtk-greeter
```
>
> LCTT 译注:在 Arch Linux 中,很多时候 lightdm 显示管理器需要额外的配置才能正常启用。可以参考:[LightDM - ArchWiki](https://wiki.archlinux.org/title/LightDM)。除此之外,可以安装 lightdm-gtk-greeter-settings 来对 lightdm-gtk-greeter 进行配置。
>
>
>

安装应用软件:
这只是一个参考。你也可以安装你所需要的内容。
```
sudo pacman -S --needed firefox vlc filezilla leafpad xscreensaver archlinux-wallpaper
```
现在是时候以服务的方式启用显示管理器和网络管理器了。这样,下次登录时,它们就可以通过 systemd 自动运行了。
```
systemctl enable lightdm
systemctl enable NetworkManager
```
使用重启命令重启系统:
```
reboot
```
如果一切顺利,你应该在 MATE 桌面上看到登录提示。
现在你可以使用刚刚创建的用户 ID 和密码登录。一个超快速和传统的 MATE 桌面将欢迎你的到来。

我希望本指南能帮助你从头开始创建自己的 Arch Linux 环境,并使用传统的 MATE 桌面。
---
via: <https://www.debugpoint.com/mate-desktop-arch-linux-install/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,562 | 好奇心帮我解决了一个硬件问题 | https://opensource.com/article/22/1/troubleshoot-hardware-sysadmin | 2023-02-21T16:43:20 | [
"好奇心"
] | https://linux.cn/article-15562-1.html |
>
> 好奇心能激发人们对于知识和真理的渴求,无论是对于硬件、开源软件、编程、组装个人电脑、优化系统设置,还是只是学习使用一个新软件。
>
>
>

我通常在家架设运行一个由一打计算机组成的家庭网络 —— 没错,正好 12 台计算机。同时我还负责其它地方的一些计算机维护工作。由于计算机很多,总会出现各种各样的故障,其中有很多最终确诊为硬件问题。但是要判定出是哪个硬件设备引发的故障却是一件难事。
就在这周,我的主工作站上出现了一个棘手的问题,导致我两次误判了问题的原因。本文将带你跟随我排查问题的过程。我将告诉你我在哪一步做了错误的判断以及为什么,还有误判是多么容易发生。
### 最初的症状
我手上一直有好几个项目。最近,我在几台台式机上打开了很多应用程序,我刚开始工作,突然就黑屏了。主工作站的大多数(不是全部)风扇都停了,这让我倒吸一口凉气。我从来没有遇到过这种情况,但显然我的系统出问题了。
我有两条主要线索可以跟进:一是显示黑屏,二是有些风扇不转了。但是前面板上的电源和磁盘活动指示灯还是亮的,只是比平常要暗一点。大多数安装在主板、内存条和风扇上的 RGB 装饰灯也都灭了。
我试过按电源键和重启键,都没有反应。我直接按供电单元的船型开关关闭了电源。重新供电后还是出现了刚才的症状。
### 最初的猜想
问题的现象和我数十年处理各类故障的经验将原因指向了供电问题。
我将供电单元拆了下来并用电源测试仪对它进行了检查。结果是供电单元没有任何问题,各项电压都符合规范。当然测试仪的结果也可能是错误的。测试仪并没有在满负荷状态下进行测试,比如计算机运行中耗电几百瓦的情况。我凭直觉更换了一个一千瓦的备用电源。
由于我的家庭网络中有 12 台计算机,我已经习惯准备了一些备用配件在身边。这样当有配件损坏时,我就不必非得跑一趟附近的电脑城或者网购后等快递了。由于计算机这么多,配件损坏是经常的事。
虽然电源测试仪告诉我电源没有问题,但更换电源后问题确实消失了。即便检测仪在过去都是正确的,我的经验、知识和直觉告诉我就是电源问题。
不幸的是,我的直觉错了。
### 第二个猜想
没过多久我的工作站再次又了相同的问题。但两个不同的供电单元有相同问题的可能性太低了。
我马上想到那一定是主板出问题了。我没有备用的主板,所以网购了一块新主板。我想到其实可以用上手上多余的内存条,然后把 CPU 连同一体水冷单元一起装到新主板上。
### 专业的故障排查
新主板需要几天天才能送到,所以我决定先将工作站上的旧主板拆下来。就在拔掉主板供电之前,我的好奇心显现,并驱使我给只剩主板、CPU 和内存的系统开机。我已经把其它的部分都拆掉了。
好的故障排除过程需要分离所有潜在变量,目前我只是对供电单元进行了测试。我需要对每个组件都进行测试。
这需要我先拔掉前面板上的扬声器和多功能面板连接线。多功能面板上集成了各种 USB、SATA 和内存卡插槽。
令人惊讶的是,当只有主板通电时竟然一切正常。
计算机本身无法开机,因为根本没有连接存储器。也不会有显示输出,因为我已经把显卡拆掉了。但是没有电源或主板故障的迹象。这进一步激发了我的好奇心。如果主板真的有问题的话,故障现象应该仍然存在才对。
所以我开始一系列的重复试验:断电,安装一个已经拆掉的配件,重新上电。
最终发现问题上由前置多功能面板引发的。
我拆除了多功能面板并将其它零件全部装了回去。工作站开机正常,运行良好。终于让我逮到罪魁祸首了。
### 起因
弄清真正的问题之后,我立刻就明白了问题的根本原因。这还要从几天前说起。那时我正在测试一些外接 USB 设备,包括几种摄像头、几个用于备份的存储设备和一个外接 USB 集线器。
我把一根 USB 连接线插到了多功能面板上的一个 USB 2.0 插口中。所有东西都停摆了,大部分灯熄灭了,风扇也不转了。USB 连接线发热很严重,我拔掉它时还把手指烫伤了。原来我不小心将连接线的 C 型插头插到了一个 USB 3.0 A 型插口里,导致了供电短路。
拔掉 USB 连接线之后,一切都恢复了“正常” —— 但事实并非如此。我粗心的错误对多功能面板造成了损伤,它在坚持了几天之后彻底短路了。
### 妄下结论
知识和经验有时候比电源测试仪之类的工具更重要。当然知识跟经验有时候也不管用。我最终找到了问题的真正原因,但其实我本该早就发现的。
尽管我在问题跟供电有关这一点上是对的,但还是误入歧途了。原因是我没能正确解读问题现象并根据线索调查得出逻辑结论导致的。我本可以更早找出问题的根本原因的,这样就不至于在修好主工作站之前浪费那么多时间在将我的笔记本变成临时主要设备上了。
系统管理员总与复杂的设备打交道,过早下结论在所难免。我有超过 50 年的从业经验,还是犯了这样的错误。我只需记住做几个 [深呼吸](https://opensource.com/article/21/11/linux-yoga),然后刨根问底直到找到问题的根本原因。
### 好奇心
至少在等待新主板到货期间,我遵循了自己的好奇心。这让我比等新主板到货要早得多将事情恢复正常。同时也避免了我在没有充分测试的情况下把一块完好的主板丢掉。
谚语说好奇心害死猫。我讨厌这个谚语,因为它被家长、学校、见识短浅的老板、老师和那些不想被我们这种好奇宝宝干扰的人用得太多了。事实上,好奇心激发了对于人们对于知识和真理的渴求。这可能是关于硬件、开源软件、编程、组装个人电脑、优化系统设置或者学习使用新软件。满足你的好奇心吧!
---
via: <https://opensource.com/article/22/1/troubleshoot-hardware-sysadmin>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I typically have a dozen computers up and running on my home network—yes, 12. And I am responsible for several more in other locations. With so many computers, there are always failures of various types, and I ultimately diagnose many of them as hardware problems. But it can be difficult to diagnose which hardware component is causing the issue.
Just this week, I had a perplexing problem that I misdiagnosed the cause of on my primary workstation—twice. This article takes you through the process I followed. I show you where and why I went down the wrong path and how easy it can be to do so.
## The first symptoms
I have been working on several projects. Recently, I had many applications open on multiple desktops and was just starting to work when the display went blank. Most (not all) of the fans in my primary workstation came to a stop, and I sucked in a deep breath. I'd never seen anything quite like this before, but I did know that my system was in trouble.
There were two primary clues I had to work with. The display went dark, and several fans had stopped. However, the front-panel power and disk activity LEDs were still on, although at a lower brightness level than usual. Most of the decorative RGB LED lights on my motherboard, memory DIMMs, and fans also went out.
I tried the power and reset buttons with no results. I turned off the power supply directly using the PSU rocker switch. Powering it back on resulted in the same set of symptoms.
## Initial thoughts
These symptoms and decades of experience with all kinds of failures pointed me to the power supply.
I removed the power supply and used my PSU tester to check it. The tester indicated that the PSU was good, and all voltages were within specs. However, I knew the tester could be wrong. PSU testers do not test under full load conditions such as those that exist when the computer is running and drawing a few hundred watts of power. I went with my gut and installed my spare 1000W power supply.
With an average of 12 computers in my home network, I have learned to keep plenty of spare parts on hand. It saves a lot of frustration that I don't have to run to the local computer store or order online and wait for delivery when things break—and things are always breaking with that many computers around.
That replacement power supply solved the problem despite the result I got from the PSU tester. Even though the tester has been correct many times in the past, my experience, my knowledge, and my gut told me differently.
Unfortunately, my gut instinct was wrong.
## Second thoughts
My workstation was exhibiting the same symptoms again. It is very unlikely that two different PSUs would fail exactly the same way.
Next idea: It had to be the motherboard. I don't keep spare motherboards around, so I ordered a new one online and figured that I could use extra memory I already had and move the CPU to the new motherboard along with its all-in-one liquid cooling unit.
## Disciplined troubleshooting
The new motherboard would take a couple of days to arrive, so I decided to prepare by removing the old one from the workstation. But before I unplugged the power feeds to the motherboard, my curiosity took over and forced me to power on the system with only the motherboard, CPU, and memory installed. I had disconnected everything else.
Good troubleshooting demands that you isolate all potential variables, and all I'd done so far was test the PSU. I had to test every component.
This process required me to disconnect the front panel cables for sound and the dashboard media panel that includes various USB, SATA, and memory card slots.
With just the motherboard connected, I got a surprise: Everything worked as normal!
The computer itself wouldn't boot because there were no connected storage drives, and nothing was displayed because I had removed the display adapter. But there were no symptoms of either power or motherboard failure. That piqued my curiosity even more. If the motherboard were truly bad, the symptoms would still exist.
So I started a sequence of powering off, reinstalling one of the removed components, and powering back on.
It turns out that the front panel media dashboard caused the symptoms.
I removed the media dashboard and plugged everything else back in. My workstation booted up properly and performed as expected. I had identified the culprit.
## How it started
Having figured out the actual problem, I immediately understood the root cause. It had started a couple of days previously. I was working with and testing several external USB devices, including various cameras, storage devices that I use for backups, and an external USB hub.
I picked up one USB cable and plugged it into a USB 2.0 slot on the media dashboard. Everything ground to a halt, and most of the lights and fans went out. I unplugged the USB cable, which was now very hot, and burned my fingers. I had inadvertently plugged the type C end into the USB 3.0 type A socket, which had shorted the power.
After unplugging the USB cable, everything went back to "normal"—except it didn't. The media dashboard lasted a few more days and then shorted out completely, having been weakened by my careless mistake.
## Jumping to conclusions
Knowledge and experience can sometimes count for more than tools like PSU testers. Except when they don't. I eventually found the actual cause of the problem, but I should have seen it sooner.
Although I was correct about this being a power problem, I was sidetracked by not correctly reading the symptoms and following that line of inquiry to its logical conclusion. I could have isolated the true cause of the problem sooner than I did and saved the time I spent configuring my laptop to be a temporary primary device until I could fix my primary workstation.
Sysadmins work with complex devices, and it can be easy to jump to conclusions. I have over 50 years of experience in the computer industry, and I still do it. I just need to remember to take a few deep [yoga breaths](https://opensource.com/article/21/11/linux-yoga) and keep digging until I isolate the root cause of the problem.
## Curiosity
At least I followed my curiosity while waiting for the replacement motherboard to arrive. That allowed me to return things to normal much sooner than had I waited until the new motherboard arrived. And I might have discarded a perfectly good motherboard by not testing it further.
There is a saying about curiosity killing the cat. I hate that saying because it is all too frequently used by parents, colleagues, pointy-haired bosses, teachers, and others who just want us curious folk to leave them alone. In reality, curiosity fuels the quest for knowledge and truth, whether it's about hardware, open source software, programming, building a PC, optimizing settings, or just learning a new application. Feed your curiosity!
## 1 Comment |
15,564 | 怎么用微分分析仪(来杀人) | https://twobithistory.org/2020/04/06/differential-analyzer.html | 2023-02-22T11:20:00 | [
"计算机",
"微分分析仪"
] | https://linux.cn/article-15564-1.html | 
微分分析仪是一种能够求解微分方程的机械式模拟计算机。它已经不再使用了,因为如今最便宜的笔记本电脑都能更快地解决相同的问题,并且你还可以同时在线刷剧。然而在数字计算机发明之前,微分分析仪使数学家能够完成一些用其它工具不可能完成的计算。
现如今很难想象一台不是由印刷的数字电路组成的计算机竟然是可以正常运作的。机械计算机听起来就像是从蒸汽朋克小说里跑出来的一样。事实证明微分分析仪不但能用,而且还是一些研究领域中必不可少的工具。它最为人所知的应用是曾被美国陆军用于编制火炮射表。如果没有射表辅助瞄准,口径再大的火炮也无法充分发挥效能。所以理论上来说,微分分析仪在帮助同盟国赢得二战上发挥了重要作用。
要弄清微分分析仪是如何做到这些的,你首先得知道什么是微分方程。已经还给学校了?没事,我也一样。
### 微分方程
你首次接触微分方程应该是在大学《微积分 I》的最后几周。在学期的这个阶段,你那薪资低微的兼职教授应该已经教授过极限、导数和积分这些概念了。在这些概念之上再引入等号,现在你就得到了一个微分方程。
微分方程描述了一个变量相对于另一个(或多个)变量的变化率。形如  的常见代数式表示变量 y 与 变量 x 之间的关系。形如  或  的微分方程表示变化率与其它变量间的关系。本质上微分方程就是用纯数学方式来描述变化率。前面第一个方程表示 “变量 y 相对于变量 x 的变化率刚好等于 x 。”第二个方程表示“无论 x 的值是多少, y 相对于 x 的变化率总是 2。”
微分方程非常有用,因为在现实世界中,描述复杂系统从一个瞬间到下一个瞬间的变化往往比想出一个描述系统在所有可能的瞬间的方程要容易。因此,微分方程被广泛应用于物理和工程领域。一个著名的微分方程是<ruby> 热传导方程 <rt> heat equation </rt></ruby>。它能描述热量在物体中的扩散过程。要提出一个完全地描述物体在某时刻 t 的热量分布的函数很困难,但推理热量从某时刻到下一个时刻的扩散过程不太可能会让你绞尽脑汁——近冷者变热,近热者变冷。所以尽管热传导方程在形式上比起前面的例子要复杂得多,它也只是变化率的描述而已。它描述了在给定与周围的温差时,物体上任意一点的温度随时间的变化。
再来举一个更具体的例子。假如我在真空中竖直向上抛出一个网球,在我窒息之前它会落回来吗?这是我在高中物理课上被问到的问题,解决它只需要基本的牛顿运动方程。现在暂且假设我已经忘记了牛顿运动方程,只记得物体以恒定的加速度 g (大约为 )向地球加速运动。那么如何用微分方程来解决这个问题呢?
现在把我对高中物理仅存的记忆表示成微分方程。网球在离手后会向地球以 g 加速运动。也就是说网球的速度相对于时间的变化率为 g(在负方向上)。进一步,我们可以说球离地高度的变化率(也就是速度)随时间的变化率是负方向的 g 。其微分方程形式如下,其中 h 表示高度, t 表示时间:

它跟前面的微分方程看起来略有差别,因为这是所谓的二阶微分方程。我们讨论的是变化率的变化率,也许你还记得微积分课讲过,这需要用到二阶导数。这是方程左边部分看上去像被平方了的原因。但是该方程也仅仅表示了球向下以恒定的加速度 g 加速运动这一事实。
到这里,我可以选择使用微积分来求解微分方程。解微分方程并不是要找满足指定关系的值,而是要找满足关系的函数。对上面的微分方程的另一种理解是存在这样的函数,它的二阶导数为 -g 。我们想要找到这个函数,因为它能告诉我们球在任意时刻的高度。好在这个微分方程恰巧是容易求解的。通过这样,我们可以重新推导出那些被我遗忘了的运动方程,从而轻松地计算出球落回来所花的时间。
但是大部分情况下微分方程是很难求解的。有时甚至是无法求解的。假设我在大学时把更多的精力花在了计算机科学上,那么我的另一种选择就是用微分方程来做模拟。如果已知球的初速度和加速度,我可以轻易用 Python 写一个 `for` 循环来逐秒迭代计算球在离手后 t 时刻的速度。在此基础上对循环程序稍加修改,就可以用算出的速度迭代计算出球的高度。运行这个 Python 模拟程序,它就可以计算出球什么时候落回来了。这个模拟并不是完全精确的,但是我可以通过减小计算用的时间步长来提升精度。总之我要做的只是搞清楚当球落回来时我是否还活着。
这就是微分方程的数值解法。这也是大多数领域中求解微分方程时实际采用的方法。对于用数值方法求解微分方程,计算机是必不可少的,因为模拟的精度取决于在微小步长上进行的大量计算。手工计算容易出错并且太耗时。
那如果将这个问题的背景时间设定在 1936 年呢?我仍然希望实现计算过程的自动化。但是此时离 <ruby> 克劳德·香农 <rt> Claude Shannon </rt></ruby> 完成他的硕士论文还有一年时间。在这篇论文中香农用数字电路实现了 <ruby> 布尔代数 <rt> boolean algebra </rt></ruby>。没有数字计算机可用,恐怕就只能寄希望于于模拟计算机了。
### 微分分析仪
首台微分分析仪是由 <ruby> 范内瓦·布什 <rt> Vannevar Bush </rt></ruby> 和 <ruby> 哈罗德·哈森 <rt> Harold Hazen </rt></ruby> 于 1928 年到 1931 年在 MIT 建造的。他们两人都是工程师。制造它是为了解决应用数学和物理领域中的实际问题。正如布什在 [1931 年的一篇论文](http://worrydream.com/refs/Bush%20-%20The%20Differential%20Analyzer.pdf) 中所说,微分分析仪是为了解决那些“不断为他们所用方程的复杂性而不是深刻性所困扰的”的数学家的所面临的当代问题。
微分分析仪是一台由传动轴、齿轮和转盘组成的复杂仪器,它能够求解高达六阶的微分方程。它是一台由简单部件通过复杂组合而成的神奇机器。在这一点上它和数字计算机很像。不同点是,数字计算机通过在电路中实现布尔代数来模拟代数问题,而微分分析仪通过传动轴、齿轮和转盘直接模拟微分方程问题。微分分析仪的本质就是对实际问题的直接机械类比。
那到底怎么用齿轮和转盘来计算微积分呢?其实这是最容易解释的部分。微分分析仪最重要的构件是六个积分器,每一个对应一阶的微分方程。机械积分器的历史可以追溯到 19 世纪,它是一个相对简单的装置,能够对单个简单函数进行积分运算的。下面我们将了解积分器的工作原理,但顺便说一句,布什的巨大成就不是发明了机械积分器,而是发现了一种将积分器串联起来解决高阶微分方程的方法。
机械积分器由一个大转盘和一个小得多的转轮组成。转盘像唱片机的转台一样平行于地面平放。它由电机驱动匀速转动。转轮竖直的轻放于转盘表面上,其压力既要足够让转盘驱动转轮,又不能太大以致于阻碍转轮相对于转盘自由侧向滑动。总之当转盘转动时,转轮也跟着转动。
转轮的转速由它距离转盘中心的距离决定。转盘的中心部分自然转动得比边缘部分慢。转轮的位置是固定不动的,而转盘被安装在一个可以来回滑动的底座上。这样就可以调节转轮相对转盘中心的位置。下面就是积分器工作的关键原理:转盘底座的位置由积分器的输入函数控制。积分器输出取决于转轮的转动量。所以输入函数驱动了输出函数的变化率,这就是将某个函数的导数转换成了这个函数本身。这不就是积分运算吗?
如果刚才的解释还没有让你理解积分器的原理,那么直接看到机械积分器实际工作的样子应该对你有所帮助。其实它的原理出乎意料的简单,看一遍它的运行过程你肯定就能窥见其运作机制。因此我制作了一个 [运行中的机械积分器动态原理图](https://sinclairtarget.com/differential-analyzer/),强烈建议你看一看。它展示了通过各个部件的旋转和移动求函数 f(x) 的 <ruby> 不定积分 <rt> antiderivative </rt></ruby> F(x) 的过程。这可太有趣了。

现在我们有了可以做积分运算的组件,但是只靠它还不足以解决微分方程。为了解释求解微分方程的全过程,我将使用布什在他 1931 年的论文中所举的例子。这个例子恰巧跟前面考虑的微分方程是在本质上是一样的。(真是奇妙的巧合!)布什使用下面的微分方程来表示下落物体的运动:

这跟前面的网球运动的方程基本上是一样的,只不过布什使用 x 代替了 h ,并且增加了一项来表示空气阻力的减速作用。这个新增项采用了最简单的形式来描述空气阻力的作用:空气减慢球速的比率正比于球的速度(这里 k 是一个常比例系数,我并不关心它的具体取值)。也就说是球运动得越快,空气阻力就越大,对球的减速作用越显著。
为了配置微分分析仪来解决这个微分方程,我们需要从布什称之为“输入面板”的东西开始。输入面板其实就是一张安装在支架上的坐标纸。如果想要解更复杂的方程,首先需要操作员在坐标纸上绘制好输入函数图像,然后在机器启动时用一个与机器主体相连的指针来跟踪函数图像的轨迹。在我们举的例子中,输入是常数 g ,所以我们只需将指针移动到正确的位置并让它保持不动即可。
剩下的变量 x 和 t 又是什么呢?变量 x 表示球的高度,是微分分析仪的输出。它会被绘制在输出面板上的坐标纸上。输出面板与输入面板类似,只是它没有指针,取而代之的是由微分分析仪驱动的绘图笔。变量 t 仅仅是按固定速率步进。(在前面模拟网球运动 Python 程序中,我们通过循环来增加 t 。)变量 t 来源于微分分析仪的电机,它通过匀速转动传动轴来驱动整个计算过程。
布什的原理图对于理解我下面要介绍的内容很有帮助。不过为了便于理解,需要先对微分方程再做一次变换。对方程两边同时进行一次积分,得到下式:

现在方程中的各项与微分分析仪运行中各部件转动量所表示的值之间有了更明确的对应关系。布什的原理图如下:

在原理图的顶部是输入面板,右下角是输出面板。
图中的输出面板被配置成同时绘制高度 x 和速度 。积分器在左下方,由于这是二阶微分方程,所以我们需要两个积分器。电机驱动顶部标注为 t 的传动轴。(有趣的是,布什将这些水平传动轴称为“总线”。)
现在原理图中还剩下两个部件没有解释了。里边标记了 k 的方框是<ruby> 乘法器 <rt> multiplier </rt></ruby>, k 是比例常数。它获取由 标记的传动轴的转动量,并通过齿轮组进行放缩。用 ∑ 标记的方框是<ruby> 加法器 <rt> adder </rt></ruby>。它通过巧妙的齿轮组合将两个传动轴的的转动叠加起来驱动第三个传动轴。我们的方程中涉及了求两项之和,所以需要引入加法器。这些额外组件的引入确保了微分分析仪有足够的灵活性来模拟由各种各样的项和系数组成的方程。
我发现以慢放的方式来推演电机启动时的级联因果过程对于理解微分分析仪的原理很有帮助。电机启动后立即驱动传动轴 t 匀速旋转。这样我们就有了时间的概念。这个传动轴有三个作用,分别由连接其上的三个竖直传动轴表示:它驱动了两个积分器的转盘的转动,同时带动输出面板的支架让绘图笔作图。
如果积分器的转轮被放置在转盘中心,那么传动轴 t 就不会带动其它传动轴转动。积分器的转盘会转动,但是放置在转盘中心的转轮不会被带动。这时输出图像将会是一条平坦的直线。出现这种情况是因为我们没有明确指定问题的初始条件。在上面的 Python 程序中,我们需要以常量或函数参数的形式用到网球的初始速度。在启动机器之前,我们通过将两个积分器的转盘调整到合适的位置来指定速度和加速度的初始值。
设置好这些之后,传动轴 t 的转动将会传导到整个系统之中。从物理上来说,许多部件会同时开始转动。但是我们可以认为转动首先传导到积分器 II,然后与基于 g 计算得到的加速度表达式求积分得到球的速度 。速度又反过来作为积分器 I 的输入,推动它的转盘让输出转轮以速率 转动。积分器 I 的输出作为最终结果将会被直接导向到输出面板上。
前面我有意避开了一个令人困惑的细节,那就是机器里有一个怪圈。积分器 II 以传动轴 为输入,但是该传动轴的转动又部分决定于积分器 II 的输出本身。这可能快把你绕吐了,但在物理上这并没有任何问题——因为所有部部件都是一同转动的。出现这种怪圈并没什么奇怪的,因为在用微分方程在描述某函数的变化率时,也经常会用该函数的函数的形式。(在这个例子中,加速度,即速度的变化率,取决于于速度。)
在将所有东西都正确配置好后,机器会输出球的高度和速度随时间变化的函数图像。这个图像是纸质的。用我们的现代数字化思维来看,这可能有点难以理解。画在纸上的函数图像能干什么?微分分析仪确实不能魔术般地给出解的简洁数学表达式,这是事实。但也请记住一点,很多的微分方程根本没有简洁的解析解。纸上的函数图像与前面模拟球下落的 Python 程序包含相同的信息:某时刻球的位置。它可以回答任何关于该问题的实际问题。
微分分析仪简直酷到爆。它虽然结构复杂,但是本质上只是一些传动轴和齿轮外的组合。要理解它的运作过程,你不必是电气工程师或者会制造芯片。然而它确实可以解微积分!它能够求解出那些靠你自己永远无法解决的微分方程问题。它证明建造计算机器的关键材料不是硅而是人类的创造力。
### 杀人
人类的创造力既能为善,也能为恶。正如我提到的,微分分析仪在历史上最知名的应用是为美国陆军计算火炮射表。鉴于二战是一场“正义的战争”,这是最好的结果。但是也不能忽视微分分析仪增强了大口径火炮的杀伤效能。火炮的确杀死了很多人。如果维基百科可信的话,在二战中死于炮火的士兵比被轻武器杀死的更多。
我们稍后再回到道德讨论上来,先快速解释一下为什么计算射表这么困难,以及微分分析仪是怎么帮助计算射表的。这是将微分分析仪应用于实际问题的很好的例子。射表能告诉炮手在射击某个距离外的目标时需要将炮口上抬多高。编制射表的一种方法是在不同的仰角下发射该火炮,并将结果记录下来。这种方法被用在靶场,比如位于马里兰的阿伯丁试验场。但是单纯通过实验观察的方式来编制射表即昂贵又耗时。在考虑到如天气状况或不同弹丸重量等其它因素时,需要进行的射击次数将会随组合爆增到无法实施的程度。所以基于少量观测数据建立数学模型,再基于该模型来填充出完整的射表是一个更好的方法。
我不想太深入讨论这些数学理论,它们实在太难了,我也不懂。但是你应该也想到了,支配飞行中的炮弹和向上抛出的网球运动的物理规律并没有什么不同。由于计算精度的需要,我们使用的微分方程不得不偏离其理想化的形式,并迅速变得面目狰狞起来。即便是最早的精确弹道理论中的公式,除其它因素外,还考虑了弹丸的重量、直径、形状、主风、海拔、大气密度以及地球自转 <sup class="footnote-ref"> <a href="#fn1" id="fnref1"> [1] </a></sup>。
虽然关于射表计算的方程很复杂,但它们跟前面的微分方程一样,都可以通过微分分析仪数值求解。1935 年微分分析仪被阿伯丁试验场用于求解弹道方程。这显著加快了计算射表的速度。<sup class="footnote-ref"> <a href="#fn2" id="fnref2"> [2] </a></sup> 然而,二战期间对于射表的需求增长太快了,以至于美国陆军计算射表的速度难以满足运往欧洲战场的武器装备的配套需求。这最终导致陆军资助了宾夕法尼亚大学的 ENIAC 项目。这促成了世界上第一台数字计算机的诞生。(LCTT 译注:严格来说 ENIAC 是第二台电子数字计算机。第一台电子计算机是<ruby> 阿塔纳索夫-贝瑞计算机 <rt> Atanasoff–Berry Computer </rt></ruby>,简称 ABC 计算机。)ENIAC 能够通过重新布线运行任意程序。但建造它的主要是为了以数倍于微分分析仪的速度来计算射表。
鉴于在微分分析仪之外,射表计算问题极大地推动了早期计算领域的发展,专门挑出微分分析仪的道德问题也许是不公正的。微分分析仪并没有局限于军事领域的应用,在二战期间和二战后的很大一段时间里,由于美国军方投入的大量的拨款,整个计算领域得到了发展。
总之,我认为微分分析仪更有趣的遗产是它告诉了我们计算的本质。我惊叹于于微分分析仪能做到这么多事情,我猜你也一样。我们很容易落入这样的思维陷阱:将计算看作是由快速数字电路实现的领域。事实上,计算是更抽象的过程,电子数字电路只是实现计算的典型手段罢了。在关于微分分析仪的论文中,布什说他的发明不过是在“运用复杂机械结构来类比复杂的推理过程这一影响深远的计划”上的微小贡献。他的总结很贴切。
---
1. Alan Gluchoff. “Artillerymen and Mathematicians: Forest Ray Moulton and Changes in American Exterior Ballistics, 1885-1934.” Historia Mathematica, vol. 38, no. 4, 2011, pp. 506–547., <https://www.sciencedirect.com/science/article/pii/S0315086011000279>. [↩︎](#fnref1)
2. Karl Kempf. “Electronic Computers within the Ordnance Corps,” 1961, accessed April 6, 2020, <https://ftp.arl.army.mil/~mike/comphist/61ordnance/index.html>. [↩︎](#fnref2)
---
via: <https://twobithistory.org/2020/04/06/differential-analyzer.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A differential analyzer is a mechanical, analog computer that can solve differential equations. Differential analyzers aren’t used anymore because even a cheap laptop can solve the same equations much faster—and can do it in the background while you stream the new season of Westworld on HBO. Before the invention of digital computers though, differential analyzers allowed mathematicians to make calculations that would not have been practical otherwise.
It is hard to see today how a computer made out of anything other than digital circuitry printed in silicon could work. A mechanical computer sounds like something out of a steampunk novel. But differential analyzers did work and even proved to be an essential tool in many lines of research. Most famously, differential analyzers were used by the US Army to calculate range tables for their artillery pieces. Even the largest gun is not going to be effective unless you have a range table to help you aim it, so differential analyzers arguably played an important role in helping the Allies win the Second World War.
To understand how differential analyzers could do all this, you will need to know what differential equations are. Forgotten what those are? That’s okay, because I had too.
## Differential Equations
Differential equations are something you might first encounter in the final few weeks of a college-level Calculus I course. By that point in the semester, your underpaid adjunct professor will have taught you about limits, derivatives, and integrals; if you take those concepts and add an equals sign, you get a differential equation.
Differential equations describe rates of change in terms of some other variable
(or perhaps multiple other variables). Whereas a familiar algebraic expression
like \(y = 4x + 3\) specifies the relationship between some variable quantity
\(y\) and some other variable quantity \(x\), a differential equation, which
might look like \(\frac{dy}{dx} = x\), or even \(\frac{dy}{dx} = 2\), specifies
the relationship between a *rate of change* and some other variable quantity.
Basically, a differential equation is just a description of a rate of change in
exact mathematical terms. The first of those last two differential equations is
saying, “The variable \(y\) changes with respect to \(x\) at a rate defined
exactly by \(x\),” and the second is saying, “No matter what \(x\) is, the
variable \(y\) changes with respect to \(x\) at a rate of exactly 2.”
Differential equations are useful because in the real world it is often easier to describe how complex systems change from one instant to the next than it is to come up with an equation describing the system at all possible instants. Differential equations are widely used in physics and engineering for that reason. One famous differential equation is the heat equation, which describes how heat diffuses through an object over time. It would be hard to come up with a function that fully describes the distribution of heat throughout an object given only a time \(t\), but reasoning about how heat diffuses from one time to the next is less likely to turn your brain into soup—the hot bits near lots of cold bits will probably get colder, the cold bits near lots of hot bits will probably get hotter, etc. So the heat equation, though it is much more complicated than the examples in the last paragraph, is likewise just a description of rates of change. It describes how the temperature of any one point on the object will change over time given how its temperature differs from the points around it.
Let’s consider another example that I think will make all of this more concrete. If I am standing in a vacuum and throw a tennis ball straight up, will it come back down before I asphyxiate? This kind of question, posed less dramatically, is the kind of thing I was asked in high school physics class, and all I needed to solve it back then were some basic Newtonian equations of motion. But let’s pretend for a minute that I have forgotten those equations and all I can remember is that objects accelerate toward earth at a constant rate of \(g\), or about \(10 \;m/s^2\). How can differential equations help me solve this problem?
Well, we can express the one thing I remember about high school physics as a
differential equation. The tennis ball, once it leaves my hand, will accelerate
toward the earth at a rate of \(g\). This is the same as saying that the
velocity of the ball will change (in the negative direction) over time at a
rate of \(g\). We could even go one step further and say that *the rate of
change in the height of my ball above the ground* (this is just its velocity)
will change over time at a rate of negative \(g\). We can write this down as
the following, where \(h\) represents height and \(t\) represents time:
This looks slightly different from the differential equations we have seen so far because this is what is known as a second-order differential equation. We are talking about the rate of change of a rate of change, which, as you might remember from your own calculus education, involves second derivatives. That’s why parts of the expression on the left look like they are being squared. But this equation is still just expressing the fact that the ball accelerates downward at a constant acceleration of \(g\).
From here, one option I have is to use the tools of calculus to solve the differential equation. With differential equations, this does not mean finding a single value or set of values that satisfy the relationship but instead finding a function or set of functions that do. Another way to think about this is that the differential equation is telling us that there is some function out there whose second derivative is the constant \(-g\); we want to find that function because it will give us the height of the ball at any given time. This differential equation happens to be an easy one to solve. By doing so, we can re-derive the basic equations of motion that I had forgotten and easily calculate how long it will take the ball to come back down.
But most of the time differential equations are hard to solve. Sometimes they are even impossible to solve. So another option I have, given that I paid more attention in my computer science classes that my calculus classes in college, is to take my differential equation and use it as the basis for a simulation. If I know the starting velocity and the acceleration of my tennis ball, then I can easily write a little for-loop, perhaps in Python, that iterates through my problem second by second and tells me what the velocity will be at any given second \(t\) after the initial time. Once I’ve done that, I could tweak my for-loop so that it also uses the calculated velocity to update the height of the ball on each iteration. Now I can run my Python simulation and figure out when the ball will come back down. My simulation won’t be perfectly accurate, but I can decrease the size of the time step if I need more accuracy. All I am trying to accomplish anyway is to figure out if the ball will come back down while I am still alive.
This is the numerical approach to solving a differential equation. It is how differential equations are solved in practice in most fields where they arise. Computers are indispensable here, because the accuracy of the simulation depends on us being able to take millions of small little steps through our problem. Doing this by hand would obviously be error-prone and take a long time.
So what if I were not just standing in a vacuum with a tennis ball but were standing in a vacuum with a tennis ball in, say, 1936? I still want to automate my computation, but Claude Shannon won’t even complete his master’s thesis for another year yet (the one in which he casually implements Boolean algebra using electronic circuits). Without digital computers, I’m afraid, we have to go analog.
## The Differential Analyzer
The first differential analyzer was built between 1928 and 1931 at MIT by
Vannevar Bush and Harold Hazen. Both men were engineers. The machine was
created to tackle practical problems in applied mathematics and physics. It was
supposed to address what Bush described, in [a 1931
paper](http://worrydream.com/refs/Bush%20-%20The%20Differential%20Analyzer.pdf)
about the machine, as the contemporary problem of mathematicians who are
“continually being hampered by the complexity rather than the profundity of the
equations they employ.”
A differential analyzer is a complicated arrangement of rods, gears, and
spinning discs that can solve differential equations of up to the sixth order.
It is like a digital computer in this way, which is also a complicated
arrangement of simple parts that somehow adds up to a machine that can do
amazing things. But whereas the circuitry of a digital computer implements
Boolean logic that is then used to simulate arbitrary problems, the
rods, gears, and spinning discs *directly* simulate the differential equation
problem. This is what makes a differential analyzer an analog computer—it is a
direct mechanical analogy for the real problem.
How on earth do gears and spinning discs do calculus? This is actually the easiest part of the machine to explain. The most important components in a differential analyzer are the six mechanical integrators, one for each order in a sixth-order differential equation. A mechanical integrator is a relatively simple device that can integrate a single input function; mechanical integrators go back to the 19th century. We will want to understand how they work, but, as an aside here, Bush’s big accomplishment was not inventing the mechanical integrator but rather figuring out a practical way to chain integrators together to solve higher-order differential equations.
A mechanical integrator consists of one large spinning disc and one much smaller spinning wheel. The disc is laid flat parallel to the ground like the turntable of a record player. It is driven by a motor and rotates at a constant speed. The small wheel is suspended above the disc so that it rests on the surface of the disc ever so slightly—with enough pressure that the disc drives the wheel but not enough that the wheel cannot freely slide sideways over the surface of the disc. So as the disc turns, the wheel turns too.
The speed at which the wheel turns will depend on how far from the center of the disc the wheel is positioned. The inner parts of the disc, of course, are rotating more slowly than the outer parts. The wheel stays fixed where it is, but the disc is mounted on a carriage that can be moved back and forth in one direction, which repositions the wheel relative to the center of the disc. Now this is the key to how the integrator works: The position of the disc carriage is driven by the input function to the integrator. The output from the integrator is determined by the rotation of the small wheel. So your input function drives the rate of change of your output function and you have just transformed the derivative of some function into the function itself—which is what we call integration!
If that explanation does nothing for you, seeing a mechanical integrator in
action really helps. The principle is surprisingly simple and there is no way
to watch the device operate without grasping how it works. So I have created [a
visualization of a running mechanical
integrator](https://sinclairtarget.com/differential-analyzer/) that I encourage
you to take a look at. The visualization shows the integration of some function
\(f(x)\) into its antiderivative \(F(x)\) while various things spin and move.
It’s pretty exciting.
*A nice screenshot of my visualization, but you should check out the real
thing!*
So we have a component that can do integration for us, but that alone is not enough to solve a differential equation. To explain the full process to you, I’m going to use an example that Bush offers himself in his 1931 paper, which also happens to be essentially the same example we contemplated in our earlier discussion of differential equations. (This was a happy accident!) Bush introduces the following differential equation to represent the motion of a falling body:
\[\frac{d^2x}{dt^2} = -k\,\frac{dx}{dt} - g\]This is the same equation we used to model the motion of our tennis ball, only Bush has used \(x\) in place of \(h\) and has added another term that accounts for how air resistance will decelerate the ball. This new term describes the effect of air resistance on the ball in the simplest possible way: The air will slow the ball’s velocity at a rate that is proportional to its velocity (the \(k\) here is some proportionality constant whose value we don’t really care about). So as the ball moves faster, the force of air resistance will be stronger, further decelerating the ball.
To configure a differential analyzer to solve this differential equation, we have to start with what Bush calls the “input table.” The input table is just a piece of graphing paper mounted on a carriage. If we were trying to solve a more complicated equation, the operator of the machine would first plot our input function on the graphing paper and then, once the machine starts running, trace out the function using a pointer connected to the rest of the machine. In this case, though, our input is just the constant \(g\), so we only have to move the pointer to the right value and then leave it there.
What about the other variables \(x\) and \(t\)? The \(x\) variable is our output as it represents the height of the ball. It will be plotted on graphing paper placed on the output table, which is similar to the input table only the pointer is a pen and is driven by the machine. The \(t\) variable should do nothing more than advance at a steady rate. (In our Python simulation of the tennis ball problem as posed earlier, we just incremented \(t\) in a loop.) So the \(t\) variable comes from the differential analyzer’s motor, which kicks off the whole process by rotating the rod connected to it at a constant speed.
Bush has a helpful diagram documenting all of this that I will show you in a second, but first we need to make one more tweak to our differential equation that will make the diagram easier to understand. We can integrate both sides of our equation once, yielding the following:
\[\frac{dx}{dt} = - \int \left(k\,\frac{dx}{dt} + g\right)\,dt\]The terms in this equation map better to values represented by the rotation of various parts of the machine while it runs. Okay, here’s that diagram:
*The differential analyzer configured to solve the problem of a falling body in
one dimension.*
The input table is at the top of the diagram. The output table is at the bottom-right. The output table here is set up to graph both \(x\) and \(\frac{dx}{dt}\), i.e. height and velocity. The integrators appear at the bottom-left; since this is a second-order differential equation, we need two. The motor drives the very top rod labeled \(t\). (Interestingly, Bush referred to these horizontal rods as “buses.”)
That leaves two components unexplained. The box with the little \(k\) in it is a multiplier respresnting our proportionality constant \(k\). It takes the rotation of the rod labeled \(\frac{dx}{dt}\) and scales it up or down using a gear ratio. The box with the \(\sum\) symbol is an adder. It uses a clever arrangement of gears to add the rotations of two rods together to drive a third rod. We need it since our equation involves the sum of two terms. These extra components available in the differential analyzer ensure that the machine can flexibly simulate equations with all kinds of terms and coefficients.
I find it helpful to reason in ultra-slow motion about the cascade of cause and effect that plays out as soon as the motor starts running. The motor immediately begins to rotate the rod labeled \(t\) at a constant speed. Thus, we have our notion of time. This rod does three things, illustrated by the three vertical rods connected to it: it drives the rotation of the discs in both integrators and also advances the carriage of the output table so that the output pen begins to draw.
Now if the integrators were set up so that their wheels are centered, then the rotation of rod \(t\) would cause no other rods to rotate. The integrator discs would spin but the wheels, centered as they are, would not be driven. The output chart would just show a flat line. This happens because we have not accounted for the initial conditions of the problem. In our earlier Python simulation, we needed to know the initial velocity of the ball, which we would have represented there as a constant variable or as a parameter of our Python function. Here, we account for the initial velocity and acceleration by displacing the integrator discs by the appropriate amount before the machine begins to run.
Once we’ve done that, the rotation of rod \(t\) propagates through the whole system. Physically, a lot of things start rotating at the same time, but we can think of the rotation going first to integrator II, which combines it with the acceleration expression calculated based on \(g\) and then integrates it to get the result \(\frac{dx}{dt}\). This represents the velocity of the ball. The velocity is in turn used as input to integrator I, whose disc is displaced so that the output wheel rotates at the rate \(\frac{dx}{dt}\). The output from integrator I is our final output \(x\), which gets routed directly to the output table.
One confusing thing I’ve glossed over is that there is a cycle in the machine: Integrator II takes as an input the rotation of the rod labeled \((k\,\frac{dx}{dt} + g)\), but that rod’s rotation is determined in part by the output from integrator II itself. This might make you feel queasy, but there is no physical issue here—everything is rotating at once. If anything, we should not be surprised to see cycles like this, since differential equations often describe rates of change in a function as a function of the function itself. (In this example, the acceleration, which is the rate of change of velocity, depends on the velocity.)
With everything correctly configured, the output we get is a nice graph, charting both the position and velocity of our ball over time. This graph is on paper. To our modern digital sensibilities, that might seem absurd. What can you do with a paper graph? While it’s true that the differential analyzer is not so magical that it can write out a neat mathematical expression for the solution to our problem, it’s worth remembering that neat solutions to many differential equations are not possible anyway. The paper graph that the machine does write out contains exactly the same information that could be output by our earlier Python simulation of a falling ball: where the ball is at any given time. It can be used to answer any practical question you might have about the problem.
The differential analyzer is a preposterously cool machine. It is complicated, but it fundamentally involves nothing more than rotating rods and gears. You don’t have to be an electrical engineer or know how to fabricate a microchip to understand all the physical processes involved. And yet the machine does calculus! It solves differential equations that you never could on your own. The differential analyzer demonstrates that the key material required for the construction of a useful computing machine is not silicon but human ingenuity.
## Murdering People
Human ingenuity can serve purposes both good and bad. As I have mentioned, the highest-profile use of differential analyzers historically was to calculate artillery range tables for the US Army. To the extent that the Second World War was the “Good Fight,” this was probably for the best. But there is also no getting past the fact that differential analyzers helped to make very large guns better at killing lots of people. And kill lots of people they did—if Wikipedia is to be believed, more soldiers were killed by artillery than small arms fire during the Second World War.
I will get back to the moralizing in a minute, but just a quick detour here to explain why calculating range tables was hard and how differential analyzers helped, because it’s nice to see how differential analyzers were applied to a real problem. A range table tells the artilleryman operating a gun how high to elevate the barrel to reach a certain range. One way to produce a range table might be just to fire that particular kind of gun at different angles of elevation many times and record the results. This was done at proving grounds like the Aberdeen Proving Ground in Maryland. But producing range tables solely through empirical observation like this is expensive and time-consuming. There is also no way to account for other factors like the weather or for different weights of shell without combinatorially increasing the necessary number of firings to something unmanageable. So using a mathematical theory that can fill in a complete range table based on a smaller number of observed firings is a better approach.
I don’t want to get too deep into how these mathematical theories work,
because the math is complicated and I don’t really understand it. But as you
might imagine, the physics that governs the motion of an artillery shell in
flight is not that different from the physics that governs the motion of a
tennis ball thrown upward. The need for accuracy means that the differential
equations employed have to depart from the idealized forms we’ve been using
and quickly get gnarly. Even the earliest attempts to formulate a rigorous
ballistic theory involve equations that account for, among other factors, the
weight, diameter, and shape of the projectile, the prevailing wind, the
altitude, the atmospheric density, and the rotation of the earth 1.
So the equations are complicated, but they are still differential equations
that a differential analyzer can solve numerically in the way that we have
already seen. Differential analyzers were put to work solving ballistics
equations at the Aberdeen Proving Ground in 1935, where they dramatically sped
up the process of calculating range tables. 2 Nevertheless, during the Second
World War, the demand for range tables grew so quickly that the US Army could
not calculate them fast enough to accompany all the weaponry being shipped to
Europe. This eventually led the Army to fund the ENIAC project at the
University of Pennsylvania, which, depending on your definitions, produced the
world’s first digital computer. ENIAC could, through rewiring, run any program,
but it was constructed primarily to perform range table calculations many times
faster than could be done with a differential analyzer.
Given that the range table problem drove much of the early history of computing even apart from the differential analyzer, perhaps it’s unfair to single out the differential analyzer for moral hand-wringing. The differential analyzer isn’t uniquely compromised by its military applications—the entire field of computing, during the Second World War and well afterward, advanced because of the endless funding being thrown at it by the United States military.
Anyway, I think the more interesting legacy of the differential analyzer is what it teaches us about the nature of computing. I am surprised that the differential analyzer can accomplish as much as it can; my guess is that you are too. It is easy to fall into the trap of thinking of computing as the realm of what can be realized with very fast digital circuits. In truth, computing is a more abstract process than that, and electronic, digital circuits are just what we typically use to get it done. In his paper about the differential analyzer, Vannevar Bush suggests that his invention is just a small contribution to “the far-reaching project of utilizing complex mechanical interrelationships as substitutes for intricate processes of reasoning.” That puts it nicely.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
*Previously on TwoBitHistory…*
Do you worry that your children are "BBS-ing"? Do you have a neighbor who talks too much about his "door games"?
— TwoBitHistory (@TwoBitHistory)
In this VICE News special report, we take you into the seedy underworld of bulletin board systems:[https://t.co/hBrKGU2rfB][February 2, 2020]
-
Alan Gluchoff. “Artillerymen and Mathematicians: Forest Ray Moulton and Changes in American Exterior Ballistics, 1885-1934.” Historia Mathematica, vol. 38, no. 4, 2011, pp. 506–547.,
[https://www.sciencedirect.com/science/article/pii/S0315086011000279](https://www.sciencedirect.com/science/article/pii/S0315086011000279).[↩](#fnref:1) -
Karl Kempf. “Electronic Computers within the Ordnance Corps,” 1961, accessed April 6, 2020,
[https://ftp.arl.army.mil/~mike/comphist/61ordnance/index.html](https://ftp.arl.army.mil/~mike/comphist/61ordnance/index.html).[↩](#fnref:2) |
15,565 | 修复 Ubuntu 中的 “Key is stored in legacy trusted.gpg keyring” 问题 | https://itsfoss.com/key-is-stored-in-legacy-trusted-gpg/ | 2023-02-22T14:32:37 | [
"排错"
] | https://linux.cn/article-15565-1.html | 
如果你在 Ubuntu 22.04 及以后的版本中使用 PPA 或添加外部仓库,你有可能会看到这样的信息:
```
W: https://packagecloud.io/slacktechnologies/slack/debian/dists/jessie/InRelease: Key is stored in legacy trusted.gpg keyring (/etc/apt/trusted.gpg), see the DEPRECATION section in apt-key(8) for details.
```

首先,这不是一个错误,而是一个警告信息。警告并不会导致程序停止工作。即使你在更新过程中看到这个警告信息,你也可以继续升级你的系统。
如果你不想看到这个警告信息,你可以采取一些手动步骤来摆脱它。
有两种方法;正确的方法和快速而不优雅的方法。阅读这两种方法,看看你对哪一种感到满意。
### 方法 1:导入密钥(正确但复杂的方法)
首先,列出所有添加到你系统中的 GPG 密钥。
```
sudo apt-key list
```
这将显示一个存储在你系统中的巨大的密钥列表。你在这里要做的是寻找与警告信息相关的密钥。
```
abhishek@itsfoss:~$ sudo apt-key list
[sudo] password for abhishek:
Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)).
/etc/apt/trusted.gpg
--------------------
pub rsa4096 2014-01-13 [SCEA] [expired: 2019-01-12]
418A 7F2F B0E1 E6E7 EABF 6FE8 C2E7 3424 D590 97AB
uid [ expired] packagecloud ops (production key) <abhishek@itsfoss>
pub rsa4096 2016-02-18 [SCEA]
DB08 5A08 CA13 B8AC B917 E0F6 D938 EC0D 0386 51BD
uid [ unknown] https://packagecloud.io/slacktechnologies/slack (https://packagecloud.io/docs#gpg_signing) <abhishek@itsfoss>
sub rsa4096 2016-02-18 [SEA]
/etc/apt/trusted.gpg.d/audio-recorder-ubuntu-ppa.gpg
----------------------------------------------------
pub rsa4096 2015-08-30 [SC]
42EF 41ED 9813 B713 D4F1 F06D 5CF1 2638 ACF9 669F
uid [ unknown] Launchpad PPA for Team audio-recorder
/etc/apt/trusted.gpg.d/danielrichter2007-ubuntu-grub-customizer.gpg
-------------------------------------------------------------------
pub rsa1024 2010-10-08 [SC]
59DA D276 B942 642B 1BBD 0EAC A8AA 1FAA 3F05 5C03
```
你要怎么做?仔细阅读该信息:
```
W: https://packagecloud.io/slacktechnologies/slack/debian/dists/jessie/InRelease: Key is stored in legacy
```
在我的例子中,仓库有 `packagecloud`、`slacktechnologies` 等关键词。它显示在 `apt-key` 列表输出的顶部。在你的情况下,你可能需要滚动一下。
在这种罕见的情况下,由 Slack 添加的外部仓库,有两个 GPG 密钥。其中一个已经过期,我会忽略它。你可能不会有这样的情况。
你应该看到 `pub` 后一行的最后 8 个字符(不包括空格):
```
/etc/apt/trusted.gpg
--------------------
pub rsa4096 2014-01-13 [SCEA] [expired: 2019-01-12]
418A 7F2F B0E1 E6E7 EABF 6FE8 C2E7 3424 D590 97AB
uid [ expired] packagecloud ops (production key) <abhishek@itsfoss>
pub rsa4096 2016-02-18 [SCEA]
DB08 5A08 CA13 B8AC B917 E0F6 D938 EC0D 0386 51BD
uid [ unknown] https://packagecloud.io/slacktechnologies/slack (https://packagecloud.io/docs#gpg_signing) <abhishek@itsfoss>
```
因此,从 `DB08 5A08 CA13 B8AC B917 E0F6 D938 EC0D 0386 51BD` 这行中,我将提取最后8个字符 `0386 51BD`,去掉空格,然后用它来导入 `/etc/apt/trusted.gpg.d` 目录下专用文件中的 GPG 密钥:
```
sudo apt-key export 038651BD | sudo gpg --dearmour -o /etc/apt/trusted.gpg.d/slack.gpg
```
我在这里创建了一个新的文件 `slack.gpg`,以防你没有注意到它。我把它命名为 `slack.gpg` 是因为它与我之前安装的 Slack 应用有关。文件名并不重要,但它对识别有好处。
如果命令运行成功,你将不会看到任何信息。你可以通过检查新创建的 gpg 文件是否存在来验证。

再次运行更新,现在你应该不会再看到警告信息了。
### 方法 2:复制到 trusted.gpd.d 目录中(快速而不优雅的方法)
如果你觉得手动做上面的事情不舒服,那么,你可以忽略这个警告信息。我的意思是,忽略它总是一种选择。
另一个选择是把 `/etc/apt/trusted.gpg` 文件复制到 `/etc/apt/trusted.gpg.d` 目录。毕竟,Ubuntu 只是抱怨说它需要 `/etc/apt/trusted.gpg.d` 目录下的 GPG 密钥。
你仍然要使用终端。打开它并使用以下命令:
```
sudo cp /etc/apt/trusted.gpg /etc/apt/trusted.gpg.d
```
现在,如果你运行更新,你就不会再看到 “Key is stored in legacy trusted.gpg keyring” 的警告信息。

### 总结
我曾经写过一篇关于 [弃用 apt-key](https://itsfoss.com/apt-key-deprecated/) 的详细文章。显然,那篇文章让一些读者感到困惑,因此我写了这篇文章,给他们提供摆脱该信息的直接步骤。
正如我之前所说,这是一个警告信息,目前可以忽略。解决这个问题的责任在于外部软件开发者和 Ubuntu 开发者。外部软件开发者应该确保他们的 GPG 密钥不再被添加到 `/etc/apt/trusted.gpg` 文件中。
终端用户不应该为他们的懒惰而承担痛苦。
那么,你是用哪种方法来摆脱 “key is stored in legacy” 的警告信息的呢?第一个方法还是第二个方法?
---
via: <https://itsfoss.com/key-is-stored-in-legacy-trusted-gpg/>
作者:[Abhishek Prakash](https://itsfoss.com/) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you use a PPA or add an external repository in Ubuntu 22.04 and later versions, chances are that you will see a message like this:
`W: https://packagecloud.io/slacktechnologies/slack/debian/dists/jessie/InRelease: Key is stored in legacy trusted.gpg keyring (/etc/apt/trusted.gpg), see the DEPRECATION section in apt-key(8) for details.`
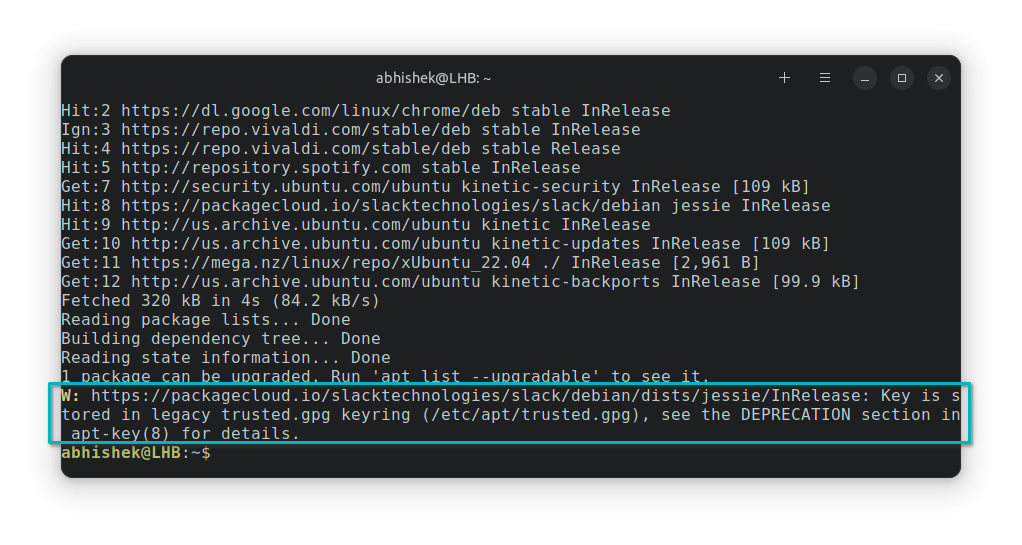
First thing first. It is not an error, it is a warning message. A warning does not stop the procedure. You can continue upgrading your system even if you see this warning message during an update.
If you don’t like seeing the warning message, you can take some manual steps to get rid of it.
There are two ways; the proper way and the quick and dirty way. Read both methods and see which one you feel comfortable with.
## Method 1: Import the key [Proper but complicated way]
First, list all the GPG keys added to your system.
`sudo apt-key list`
This will show a huge list of keys stored in your system. What you have to do here is to look for the keys associated with the warning message.
```
abhishek@itsfoss:~$ sudo apt-key list
[sudo] password for abhishek:
Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)).
/etc/apt/trusted.gpg
--------------------
pub rsa4096 2014-01-13 [SCEA] [expired: 2019-01-12]
418A 7F2F B0E1 E6E7 EABF 6FE8 C2E7 3424 D590 97AB
uid [ expired] packagecloud ops (production key) <
```[[email protected]](/cdn-cgi/l/email-protection)>
pub rsa4096 2016-02-18 [SCEA]
DB08 5A08 CA13 B8AC B917 E0F6 D938 EC0D 0386 51BD
uid [ unknown] https://packagecloud.io/slacktechnologies/slack (https://packagecloud.io/docs#gpg_signing) <[[email protected]](/cdn-cgi/l/email-protection)>
sub rsa4096 2016-02-18 [SEA]
/etc/apt/trusted.gpg.d/audio-recorder-ubuntu-ppa.gpg
----------------------------------------------------
pub rsa4096 2015-08-30 [SC]
42EF 41ED 9813 B713 D4F1 F06D 5CF1 2638 ACF9 669F
uid [ unknown] Launchpad PPA for Team audio-recorder
/etc/apt/trusted.gpg.d/danielrichter2007-ubuntu-grub-customizer.gpg
-------------------------------------------------------------------
pub rsa1024 2010-10-08 [SC]
59DA D276 B942 642B 1BBD 0EAC A8AA 1FAA 3F05 5C03
How do you do that? Read the message carefully.
`W: https://packagecloud.io/slacktechnologies/slack/debian/dists/jessie/InRelease: Key is stored in legacy`
In my case, the repository has keywords like packagecloud, slacktechnologies. It is shown at the top of the apt-key list output. You may have to scroll a bit in your case.
In this rare case, the external repository added by Slack, has two GPG keys. One of them is expired and I’ll ignore it. You may not have such a situation.
You should get the last 8 characters (excluding the space) under the line after pub.
```
/etc/apt/trusted.gpg
--------------------
pub rsa4096 2014-01-13 [SCEA] [expired: 2019-01-12]
418A 7F2F B0E1 E6E7 EABF 6FE8 C2E7 3424 D590 97AB
uid [ expired] packagecloud ops (production key) <
```[[email protected]](/cdn-cgi/l/email-protection)>
pub rsa4096 2016-02-18 [SCEA]
DB08 5A08 CA13 B8AC B917 E0F6 D938 EC0D 0386 51BD
uid [ unknown] https://packagecloud.io/slacktechnologies/slack (https://packagecloud.io/docs#gpg_signing) <[[email protected]](/cdn-cgi/l/email-protection)>
So from the line “DB08 5A08 CA13 B8AC B917 E0F6 D938 EC0D 0386 51BD”, I’ll take the last 8 characters “0386 51BD”, remove the space and then use it to import the GPG key in its dedicated file under the /etc/apt/trusted.gpg.d directory:
`sudo apt-key export 038651BD | sudo gpg --dearmour -o /etc/apt/trusted.gpg.d/slack.gpg`
I created a new file slack.gpg here, in case you didn’t notice it. I named it slack.gpg because it is associated with Slack application I installed earlier. The filename does not matter but it’s good for identification.
If the command runs successfully, you won’t see any message. You can verify that by checking if the newly created gpg file exists or not.
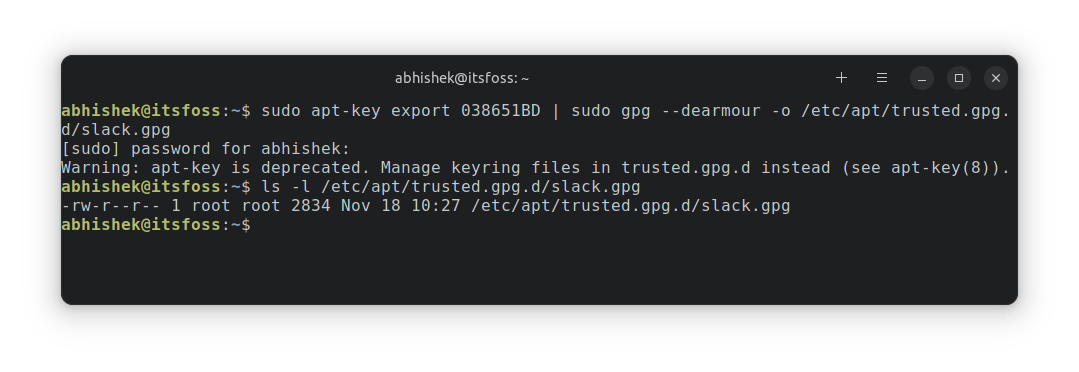
Run the update again and now you should not see the warning message anymore.
## Method 2: Copy to the trusted.gpd.d directory [Quick and dirty way]
If you don’t feel comfortable doing all the above stuff manually, well, you can ignore the warning message. I mean, ignoring it is always an option.
Another option is to copy the /etc/apt/trusted.gpg file to /etc/apt/trusted.gpg.d directory. After all, Ubuntu only complains that it needs the GPG keys in /etc/apt/trusted.gpg.d directory.
You’ll still have to use the terminal. Open it and use the following command:
`sudo cp /etc/apt/trusted.gpg /etc/apt/trusted.gpg.d`
Now, if you run the update, you won’t see the “Key is stored in legacy trusted.gpg keyring” warning message anymore.
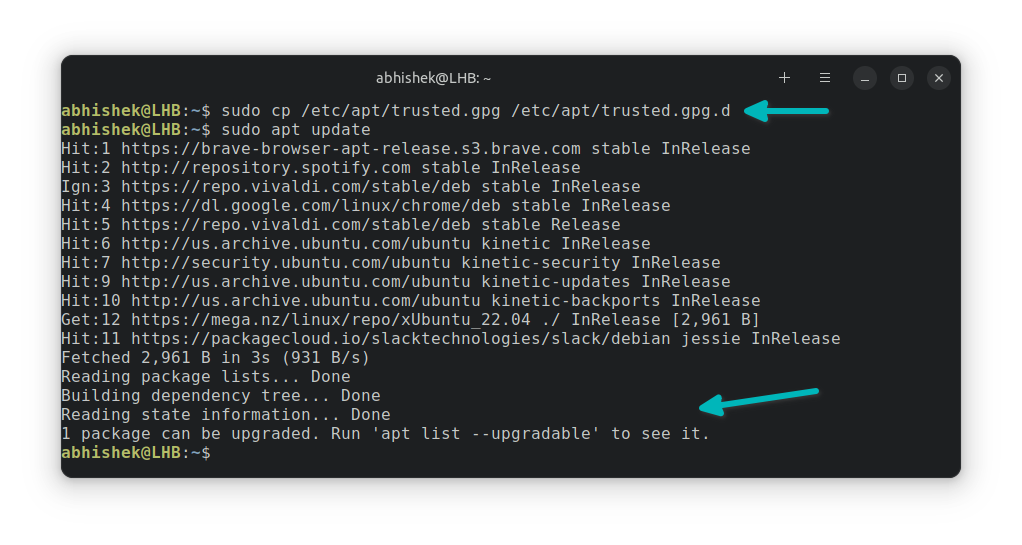
## Conclusion
I have written a detailed article on [apt-key deprecation](https://itsfoss.com/apt-key-deprecated/). Apparently, that article had some readers confused and hence I wrote this one to give them direct steps for getting rid of the message.
As I said before, it is a warning message and can be ignored for now. The onus to ‘fix’ this issue lies on the external software developers and Ubuntu developers. The external software developers should make sure that their GPG keys are no longer added in the /etc/apt/trusted.gpg file.
The end users should not take the pain for their laziness.
So, which method did you use to get rid of the ‘key is stored in legacy’ warning message? The first one or the second one? |
15,567 | 通过“猜数字”游戏学习 Tcl | https://opensource.com/article/23/2/learn-tcl-writing-simple-game | 2023-02-23T14:00:03 | [
"Tcl"
] | https://linux.cn/article-15567-1.html | 
>
> 探索 Tcl 的基本语言结构,包括用户输入、输出、变量、条件评估、循环和简单函数。
>
>
>
我的 Tcl 之旅始于最近需要将一个困难的基于 Java 的命令行配置工具自动化。我使用 Ansible 做了一些自动化编程,偶尔也会使用 `expect` 模块。坦率地说,我发现这个模块的作用有限,原因包括:难以对相同的提示进行排序,难以捕捉到额外步骤的值,控制逻辑的灵活性有限,等等。有时你可以用 `shell` 模块来代替。但有时你会遇到那种特立独行、过于复杂的命令行程序,似乎无法实现自动化。
就我而言,我正在自动安装我公司的一个程序。最后的配置步骤只能通过命令行来完成,通过几个不规范的、重复的提示和需要捕捉的数据输出。好在传统的 Expect 是唯一的答案。要使用 Expect 的基本功能,并不需要对 Tcl 有很深的了解,但你了解的越多,你就能从它那里得到更多的力量。这是后续文章的话题。现在,我探讨一下 Tcl 的基本语言结构,包括用户输入、输出、变量、条件判断、循环和简单函数。
### 安装 Tcl
在 Linux 系统上,我使用这个:
```
# dnf install tcl
# which tclsh
/bin/tclsh
```
在 macOS 上,你可以使用 [Homebrew](https://opensource.com/article/20/6/homebrew-mac) 来安装最新的 Tcl:
```
$ brew install tcl-tk
$ which tclsh
/usr/local/bin/tclsh
```
### 在 Tcl 中猜数字
从创建基本的可执行脚本 `numgame.tcl` 开始:
```
$ touch numgame.tcl
$ chmod 755 numgame.tcl
```
接着在你的文件中开始编码,标题是通常的 #!:
```
#!/usr/bin/tclsh
```
这里有一些关于 Tcl 的简单介绍,以便与本文一起追踪。
第一点是,Tcl 处理的都是字符串。变量通常被当作字符串处理,但可以自动切换类型和内部表示(这一点你通常无法看到)。函数可以把它们的字符串参数解释为数字(`expr`),并且只通过值传递。字符串通常使用双引号或大括号来划分。双引号允许变量扩展和转义序列,而大括号则完全没有扩展。
第二点是 Tcl 语句可以用分号隔开,但通常不这样。语句行可以用反斜杠字符来分割,然而,典型的做法是将多行语句放在大括号内,以避免需要这样做。大括号只是更简单,下面的代码格式也反映了这一点。大括号允许对字符串进行延迟求值。在 Tcl 进行变量替换之前,值被传递给函数。
最后,Tcl 使用方括号进行命令替换。方括号之间的任何东西都会被送到 Tcl 解释器的一个新的递归调用中进行求值。这对于在表达式中间调用函数或为函数生成参数是很方便的。
### 过程
虽然在这个游戏中没有必要,但我先举一个在 Tcl 中定义函数的例子,你可以在以后使用:
```
proc used_time {start} {
return [expr [clock seconds] - $start]
}
```
使用 `proc` 将其设定为一个函数(或过程)定义。接下来是函数的名称。然后是一个包含参数的列表;在本例中是一个参数 `{start}` ,然后是函数主体。注意,主体的大括号在这一行开始,它不能在下面一行。该函数返回一个值。返回值是一个复合求值(方括号),它从读取系统时钟 `[clock seconds]` 开始,并进行数学运算以减去 `$start` 参数。
### 设置、逻辑和完成
你可以在这个游戏的其余部分增加更多的细节,进行一些初始设置,对玩家的猜测进行迭代,然后在完成后打印结果:
```
set num [expr round(rand()*100)]
set starttime [clock seconds]
set guess -1
set count 0
puts "Guess a number between 1 and 100"
while { $guess != $num } {
incr count
puts -nonewline "==> "
flush stdout
gets stdin guess
if { $guess < $num } {
puts "Too small, try again"
} elseif { $guess > $num } {
puts "Too large, try again"
} else {
puts "That's right!"
}
}
set used [used_time $starttime]
puts "You guessed value $num after $count tries and $used elapsed seconds"
```
前面的 `set` 语句建立变量。前两个求值表达式用于识别 1 到 100 之间的随机数,下一个保存系统时钟启动时间。
`puts` 和 `gets` 命令用于来自玩家的输出和输入。我使用的 `puts` 暗示输出是标准输出。`gets` 需要定义输入通道,所以这段代码指定 `stdin` 作为用户的终端输入源。
当 `puts` 省略行末终止符时,需要 `flush stdout` 命令,因为 Tcl 缓冲了输出,在需要下一个 I/O 之前可能不会被显示。
从这里开始,`while` 语句说明了循环控制结构和条件逻辑,需要给玩家反馈并最终结束循环。
最后的 `set` 命令调用我们的函数来计算游戏的耗时秒数,接着是收集到的统计数字来结束游戏。
### 玩吧!
```
$ ./numgame.tcl
Guess a number between 1 and 100
==> 100
Too large, try again
==> 50
Too large, try again
==> 25
Too large, try again
==> 12
Too large, try again
==> 6
Too large, try again
==> 3
That's right!
You guessed value 3 after 6 tries and 20 elapsed seconds
```
### 继续学习
当我开始这个练习时,我怀疑回到 90 年代末的流行语言对我有多大的帮助。一路走来,我发现 Tcl 有几处让我非常喜欢的地方,我最喜欢的是方括号内的命令求值。与其他许多过度使用复杂闭包结构的语言相比,它似乎更容易阅读和使用。我以为它是一种 [已消亡的语言](https://opensource.com/article/19/6/favorite-dead-language),但实际上它仍在蓬勃发展,并在多个平台上得到支持。我学到了一些新的技能,并对这种古老的语言有了新的认识。
在 <https://www.tcl-lang.org> 上查看官方网站。你可以找到最新的源代码、二进制发行版、论坛、文档,以及仍在进行的会议信息的参考。
---
via: <https://opensource.com/article/23/2/learn-tcl-writing-simple-game>
作者:[James Farrell](https://opensource.com/users/jamesf) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | My path to Tcl started with a recent need to automate a difficult Java-based command-line configuration utility. I do a bit of automation programming using Ansible, and I occasionally use the expect module. Frankly, I find this module has limited utility for a number of reasons including: difficulty with sequencing identical prompts, capturing values for use in additional steps, limited flexibility with control logic, and so on. Sometimes you can get away with using the shell module instead. But sometimes you hit that ill-behaving and overly complicated command-line interface that seems impossible to automate.
In my case, I was automating the installation of one of my company's programs. The last configuration step could only be done through the command-line, through several ill-formed, repeating prompts and data output that needed capturing. The good old traditional Expect was the only answer. A deep understanding of Tcl is not necessary to use the basics of Expect, but the more you know, the more power you can get from it. This is a topic for a follow-up article. For now, I explore the basic language constructs of Tcl, which include user input, output, variables, conditional evaluation, looping, and simple functions.
## Install Tcl
On a Linux system, I use this:
```
``````
# dnf install tcl
# which tclsh
/bin/tclsh
```
On macOS, you can use [Homebrew ](https://opensource.com/article/20/6/homebrew-mac)to install the latest Tcl:
```
``````
$ brew install tcl-tk
$ which tclsh
/usr/local/bin/tclsh
```
## Guess the number in Tcl
Start by creating the basic executable script `numgame.tcl`
:
```
``````
$ touch numgame.tcl
$ chmod 755 numgame.tcl
```
And then start coding in your file headed up by the usual shebang script header:
```
````#!/usr/bin/tclsh`
Here are a few quick words about artifacts of Tcl to track along with this article.
The first point is that all of Tcl is considered a series of strings. Variables are generally treated as strings but can switch types and internal representations automatically (something you generally have no visibility into). Functions may interpret their string arguments as numbers ( `expr`
) and are only passed in by value. Strings are usually delineated using double quotes or curly braces. Double quotes allow for variable expansion and escape sequences, and curly braces impose no expansion at all.
The next point is that Tcl statements can be separated by semicolons but usually are not. Statement lines can be split using the backslash character. However, it's typical to enclose multiline statements within curly braces to avoid needing this. Curly braces are just simpler, and the code formatting below reflects this. Curly braces allow for deferred evaluation of strings. A value is passed to a function before Tcl does variable substitution.
Finally, Tcl uses square brackets for command substitution. Anything between the square brackets is sent to a new recursive invocation of the Tcl interpreter for evaluation. This is handy for calling functions in the middle of expressions or for generating parameters for functions.
## Procedures
Although not necessary for this game, I start with an example of defining a function in Tcl that you can use later:
```
``````
proc used_time {start} {
return [expr [clock seconds] - $start]
}
```
Using `proc`
sets this up to be a function (or procedure) definition. Next comes the name of the function. This is then followed by a list containing the parameters; in this case 1 parameter `{start}`
and then followed by the function body. Note that the body curly brace starts on this line, it cannot be on the following line. The function returns a value. The returned value is a compound evaluation (square braces) that starts by reading the system clock `[clock seconds]`
and does the math to subtract out the `$start`
parameter.
## Setup, logic, and finish
You can add more details to the rest of this game with some initial setup, iterating over the player's guesses, and then printing results when completed:
```
``````
set num [expr round(rand()*100)]
set starttime [clock seconds]
set guess -1
set count 0
puts "Guess a number between 1 and 100"
while { $guess != $num } {
incr count
puts -nonewline "==> "
flush stdout
gets stdin guess
if { $guess < $num } {
puts "Too small, try again"
} elseif { $guess > $num } {
puts "Too large, try again"
} else {
puts "That's right!"
}
}
set used [used_time $starttime]
puts "You guessed value $num after $count tries and $used elapsed seconds"
```
The first `set`
statements establish variables. The first two evaluate expressions to discern a random number between 1 and 100, and the next one saves the system clock start time.
The `puts`
and `gets`
command are used for output to and input from the player. The `puts`
I've used imply standard out for output. The `gets`
needs the input channel to be defined, so this code specifies `stdin`
as the source for terminal input from the user.
The `flush stdout`
command is needed when `puts`
omits the end-of-line termination because Tcl buffers output and it might not get displayed before the next I/O is needed.
From there the `while`
statement illustrates the looping control structure and conditional logic needed to give the player feedback and eventually end the loop.
The final `set`
command calls our function to calculate elapsed seconds for gameplay, followed by the collected stats to end the game.
## Play it!
```
``````
$ ./numgame.tcl
Guess a number between 1 and 100
==> 100
Too large, try again
==> 50
Too large, try again
==> 25
Too large, try again
==> 12
Too large, try again
==> 6
Too large, try again
==> 3
That's right!
You guessed value 3 after 6 tries and 20 elapsed seconds
```
## Continue learning
When I started this exercise, I doubted just how useful going back to a late 1990s fad language would be to me. Along the way, I found a few things about Tcl that I really enjoyed — my favorite being the square bracket command evaluation. It just seems so much easier to read and use than many other languages that overuse complicated closure structures. What I thought was a [dead language](https://opensource.com/article/19/6/favorite-dead-language) was actually still thriving and supported on several platforms. I learned a few new skills and grew an appreciation for this venerable language.
Check out the official site over at [https://www.tcl-lang.org](https://www.tcl-lang.org). You can find references to the latest source, binary distributions, forums, docs, and information on conferences that are still ongoing.
## Comments are closed. |
15,568 | 时隔两年,Transmission 4.0 升级版来了 | https://news.itsfoss.com/transmission-4-release/ | 2023-02-23T14:29:47 | [
"BitTorrent",
"Transmission"
] | https://linux.cn/article-15568-1.html |
>
> BitTorrent 客户端 Transmission 4.0 版本已经发布,带来了急需的功能升级和改进。
>
>
>

BitTorrent 是一种流行的 HTTP 的替代方式,用于在互联网上分享或下载文件。你可能知道,有许多各具特色的 BitTorrent 客户端。
Transmission 就是这样一个开源的、轻量级的 BitTorrent 客户端。
该应用程序的上一个稳定版本是近两年前发布的。虽然在此期间没有看到新的版本,但该项目仍在积极开发中。
### Transmission 4.0 有什么新内容?
新版本带来了大量的新功能和改进。这包括 IPv6 封锁、BitTorrent v2支持、改版的网络客户端等等。
以下是一些重要的亮点:
#### 对 BitTorrent v2 和混合 Torrent 的支持
BitTorrent v2 是现有 BitTorrent 协议的更新版本,带来了一些有用的技术进步。
另一方面,混合 Torrent 确保了与旧版 BitTorrent v1 的向后兼容性。
请注意,这个版本只能让你使用 v2 和混合 Torrent。而要创建 v2 和混合 Torrent ,你需要等待下一个版本。
#### 默认跟踪器的使用
用户现在应该发现,通过设置默认的跟踪器,可以更容易地公布或请求公开的 Torrent。
#### IPv6 封锁列表
现在包括对 IPv6 封锁的支持。
如果你遇到网络问题而想默认使用 IPv4,这很有用。
在某些情况下,VPN 用户可能也喜欢这个功能,因为许多 VPN 服务器可能不能很好地支持 IPv6,这可能导致数据泄露。
#### 新的隐私友好功能
用户有时喜欢在创建 Torrent 时不包括用户身份或相关信息。
有一个新的选项正是为了这个目的而添加的,它排除了这些细节信息。
#### ?️其他变化和改进
除了上面列出的变化外,考虑到他们已经开发了一年多,还有大量的改进!
其中一些值得注意的改进包括:
* 更好的资源利用。
* 将代码从 C 语言迁移到 C++ 语言。
* 在创建新 Torrent 时能够指定片断大小。
* 支持 Qt 6。
* 基于 GTKMM 的 GTK 客户端。
* 更好的网络客户端用户界面,包括对移动屏幕的支持。
* 支持 macOS 苹果芯片。
你可以前往其 [GitHub 发布区](https://github.com/transmission/transmission/releases/tag/4.0.0) 了解完整的发布说明。
### 下载 Transmission 4.0
官方资源库和 Flathub 还没有最新的版本可用。
因此,你必须从其 [官方下载页面](https://transmissionbt.com/download) 或 [GitHub 发布部分](https://github.com/transmission/transmission/releases/tag/4.0.0) 下载并解压 tar.xz 文件。
然后,从源码构建它以获得安装。
>
> **[Transmission 4.0](https://transmissionbt.com/download)**
>
>
>
你可以在同一页上找到其他平台的软件包。
---
via: <https://news.itsfoss.com/transmission-4-release/>
作者:[Rishabh Moharir](https://news.itsfoss.com/author/rishabh/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

BitTorrent is a popular alternative to HTTP to share or download files over the internet. You may know that numerous BitTorrent clients are available with different features and configurations.
**Transmission** is one such BitTorrent client that is open-source and lightweight.
The app's latest release arrives nearly two years after its last stable release. While no new releases were seen during this time, the project was in active development.
## Transmission 4.0: What's New?
The new release brings in a load of new features and improvements. This includes IPv6 blocking, BitTorrent v2 support, a revamped web client, and many more.
Some of the significant highlights are mentioned below.
**Suggested Read **📖
[Top 7 Torrent Clients for Ubuntu & Other Linux DistributionsLooking for the best torrent client for Ubuntu? Indeed, there are a number of torrent clients available for Linux. Even though I’ve primarily mentioned Ubuntu, you can get most of them working on any other Linux distribution out there. You can also check the best download managers for Ubuntu](https://itsfoss.com/best-torrent-ubuntu/?ref=news.itsfoss.com)

### Support for BitTorrent v2 and Hybrid Torrent
BitTorrent v2 is a newer version of the existing BitTorrent protocol, bringing in some helpful technical advancements.
On the other hand, hybrid torrents ensure backward compatibility with the older v1 torrents.
Do note that this release only allows using v2 and hybrid torrents. To be able to create v2 and hybrid torrents, you need to wait for the next release.
### Use of default trackers
Users should now find it easier to announce or request public torrents by setting up default trackers.
### IPv6 blocklists
Support for IPv6 blocking is now included.
This is useful if you're experiencing network problems and want to use IPv4 by default.
In some cases, VPN users might also prefer this feature since many VPN servers may not flawlessly support IPv6, which may lead to data leaks.
### New Privacy-Friendly Feature
Users sometimes prefer not to include user-identifying or relevant information when creating torrents.
There's a new option added precisely for this purpose that excludes such details.
### 🛠️Other Changes and Improvements
Apart from the changes listed above, there are loads of refinements considering that they have been preparing it for more than a year now!
Some of the noteworthy betterment include:
**Better resource efficiency****Migration of code from C to C++****Ability to specify piece size when creating new torrents****Support for Qt 6****GTK client based on GTKMM****Better Web client UI, including support for mobile screens****macOS Apple silicon support**
You can head to its [GitHub release section](https://github.com/transmission/transmission/releases/tag/4.0.0?ref=news.itsfoss.com) for full release notes.
## Download Transmission 4.0
The official repositories and Flathub do not have the latest version available yet.
So, you will have to download and extract the **tar.xz** file from its [official download page](https://transmissionbt.com/download?ref=news.itsfoss.com) or the [GitHub releases section](https://github.com/transmission/transmission/releases/tag/4.0.0?ref=news.itsfoss.com).
And, build it from the source to get it installed.
You can find packages for other platforms on the same page.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
15,570 | 所有官方的 Ubuntu 特色版决定默认不预装 Flatpak | https://debugpointnews.com/ubuntu-flavours-flatpak/ | 2023-02-24T08:17:00 | [
"Ubuntu",
"Flatpak"
] | /article-15570-1.html | 
>
> Ubuntu 各特色版已同意停止使用 Flatpak 作为其操作系统的默认打包系统,而选择替代的打包管理器。
>
>
>
这是一个令人惊讶的举动,Canonical 宣布,所有官方的 Ubuntu 特色版将不会默认支持 Flatpak。这个决定是在与所有官方 Ubuntu 特色版的团队/维护者达成一致后做出的。这一变化计划从 2023 年 4 月发布的 “Lunar Lobster” 开始,该版本将在几周后发布。
### Ubuntu 官方特色版将停止默认安装 Flatpak
基于 Ubuntu 的官方特色版(Kubuntu、Lubuntu、Xubuntu 等)将不再将 Flatpak 作为其默认的打包解决方案,而选择其他方案,如 Snap 和本地 deb 格式。这样做是为了 “在尊重现有用户个性化他们自己的体验方式的同时,改善新用户开箱即用的 Ubuntu 体验”。
虽然这个决定得到了 Canonical 的支持,为了提供更好的用户体验,阻止软件包生态系统的碎片化,并给用户一个稳定的应用产品的选择。但显然,有几个问题冒了出来。
为什么是现在?Flatpak 和 Snap 都已经存在多年了。Flatpak 正变得越来越流行,它作为一种包格式在积极开发和维护,一些现代功化的功能也正在开发中,比如即将出现的 “经过验证的应用程序”。而同时,由于 Snap 的 “启动时间慢”,以及被 Canonical 的封闭服务器所控制等其他原因,它在桌面应用部署领域无法得到很大普及。
Ubuntu 发行版本身从来没有默认提供过 Flatpak。但是特色版的维护者应该有选择自己的产品的自由,并在 Ubuntu 基础上进行创新。这也是成为一个特色版的主要原因,而不只是一个不同的桌面环境。
### 给用户造成的困难
虽然你总是可以手动安装 Flatpak 并配置 Flathub,但显然,这可能会给用户带来一些问题。我相信这个公告是彻底阻止 Flatpak 安装方式的第一步。
还记得 Firefox Snap 的情况吗?要删除 Firefox Snap,你必须做复杂的命令行操作,才能安装 deb 版本。这些对于普通的 Ubuntu 用户来说是非常复杂的。此外,一些流行的桌面应用程序在发布后会立即推出 Flatpak 软件包。对于许多流行的 Linux 桌面应用程序来说,有时甚至没有提供 Snap 软件包。
我相信让用户来决定哪种打包格式是容易和遵循的。Canonical 应该通过解决 Snap 的核心问题、应用程序的可用性和闭门造车的性质来自行改进 Snap,而不是强行做出决定。此外,在为一个社区贡献的发行版推送决定之前,应该与特色版维护者一起发起投票,以获得来自社区的反馈。
### 结束语
如果我们曾经从历史中吸取教训的话,它永远不会以好的方式结束。也就是说,这一变化将从 2023 年 4 月 23 日 Ubuntu 23.04 “Lunar Lobster” 发布时开始。
让我用 Ubuntu 的座右铭来结束这篇文章,在这一举措之后,这听起来很奇怪:
>
> “Ubuntu 是一个古老的非洲语单词,意思是‘<ruby> 以人道善待他人 <rt> Humanity to Others </rt></ruby>’。它经常被描述为提醒我们,‘群在故我在’。我们把 Ubuntu 的精神带到了计算机和软件的世界里。Ubuntu 发行版代表了世界软件社区与世界分享的最好的东西。”
>
>
> —— [关于 Ubuntu](https://ubuntu.com/about)
>
>
>
新闻引自 [Joey @ OMG! Ubuntu!](https://www.omgubuntu.co.uk/2023/02/ubuntu-flavors-no-flatpak) 和 [discourse](https://discourse.ubuntu.com/t/ubuntu-flavor-packaging-defaults/34061)。
---
via: <https://debugpointnews.com/ubuntu-flavours-flatpak/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,571 | 用这个开源工具在 React 中建立一个交互式时间轴 | https://opensource.com/article/22/11/react-timeline-planby | 2023-02-24T09:22:41 | [
"时间线"
] | https://linux.cn/article-15571-1.html | 
>
> Planby 是一个 JavaScript 组件,用于帮助创建流媒体服务、音乐和体育赛事等的时间表、时间线和电子节目指南(EPG)。
>
>
>
几年来,我在电视在线和视频点播(VOD)行业工作。在开发一个调度器网络应用时,我意识到在电子节目指南(EPG)和调度方面没有好的解决方案。诚然,对于大多数网络开发者来说,这是一个小众的功能,但对于电视应用来说,这是一个常见的需求。我看到并分析了许多网站实现了他们自己的 EPG 或时间表,我经常想,为什么每个人似乎都在发明他们自己的解决方案,而不是致力于开发一个大家都能使用的共享解决方案。这就是我开始开发 Planby 的时候。
[Planby](https://github.com/karolkozer/planby) 是一个 React(JavaScript)组件,帮助你为在线电视和视频点播(VOD)服务、音乐和体育赛事等创建计划、时间线和电子节目指南(EPG)。Planby 使用自定义的虚拟视图,允许你对大量的数据进行操作,并以友好和有用的方式呈现给你的观众。
Planby 有一个简单的 API,你可以与第三方 UI 库集成。组件的主题是根据应用设计的需要定制的。
### 时间线性能
实现时间线功能时,最重要的是性能。你有可能在许多不同频道处理无穷无尽的数据流。应用可能不断地在刷新、移动和滚动。你希望用户与内容的互动是流畅的。
还有一个潜在的问题是设计不当。有时,一个应用以列表的形式实现 EPG 时间线,你必须垂直滚动,这意味着你必须点击按钮在时间上左右移动,这很快就会变得很累。更重要的是,有时与 EPG 互动的自定义功能(如评级、选择你最喜欢的频道、从右到左(RTL)阅读等)根本无法使用,或者即便它们可用,也会导致性能问题。
我经常面临的另一个问题是,应用的数据传输过于冗长。当一个应用在你滚动浏览 EPG 的时候请求数据,时间线会感觉很慢,甚至会崩溃。
### 什么是 Planby?
这就是 Planby 的作用。Planby 是从头开始建立的,使用 React 和 Typescript 以及少量的资源。它使用一个自定义的虚拟视图,允许你对大量的数据进行操作。它向用户显示节目和频道,并根据时间和指定频道自动定位所有元素。当一个资源不包含任何内容时,Planby 会计算定位,使时间段正确对齐。
Planby 有一个简单的界面,包括所有必要的功能,如侧边栏、时间轴本身、愉快的布局和实时节目刷新。此外,还有一个可选的功能,允许你隐藏任何你不想包括在布局中的元素。
Planby 有一个简单的 API,允许你作为开发者实现你自己的项目以及用户的偏好。你可以使用 Planby 的主题来开发新的功能,也可以制作自定义的样式来配合你选择的设计。你可以很容易地整合其他功能,如日历、评级选项、用户最喜欢的列表、滚动、“现在” 按钮、录制计划、追播内容等等。更重要的是,你可以添加自定义的全局样式,包括 RTL 功能。
最重要的是,它在 MIT 许可下开源。
### 尝试 Planby
如果你想尝试一下 Planby,或者只是想了解一下它,请访问 [Git 仓库](https://github.com/karolkozer/planby)。在那里,我已经有了一些例子,你可以阅读文档了解详情。该软件包也可以通过 `npm` 获得。
---
via: <https://opensource.com/article/22/11/react-timeline-planby>
作者:[Karol Kozer](https://opensource.com/users/karolkozer) 选题:[lkxed](https://github.com/lkxed) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For several years, I worked in the TV online and video-on-demand (VOD) industry. While working on a scheduler web application, I realized that there were no good solutions for electronic program guides (EPG) and scheduling. Admittedly, this is a niche feature for most web developers, but it's a common requirement for TV applications. I've seen and analyzed a number of websites that have implemented their own EPG or timeline, and I often wondered why everyone seemed to be inventing their own solutions instead of working on a shared solution everyone could use. And that's when I started developing Planby.
[Planby](https://github.com/karolkozer/planby) is a React (JavaScript) component to help you create schedules, timelines, and electronic program guides (EPG) for online TV and video-on-demand (VOD) services, music and sporting events, and more. Planby uses a custom virtual view, allowing you to operate on a lot of data, and present it to your viewers in a friendly and useful way.
Planby has a simple API that you can integrate with third party UI libraries. The component theme is customised to the needs of the application design.
## Timeline performance
The most significant thing when implementing a timeline feature is performance. You're potentially handling basically an endless stream of data across many many different channels. Applications can struggle with refreshing, moving, and scrolling. You want the user's interactions with the content to be fluid.
There's also the potential for poor design. Sometimes, an app implements an EPG timeline in the form of a list that you must scroll vertically, meaning you must click on buttons to move left and right through time, which quickly becomes tiring. What's more, sometimes customization for interacting with an EPG (such as rating, choosing your favorite channels, reading right-to-left (RTL), and so on) aren't available at all, or when they are, they cause performance issues.
Another problem I often face is that an app is too verbose in its data transfer. When an app requests data *while* you scroll through the EPG, the timeline feels slow and can even crash.
## What is Planby?
This is where Planby comes in. Planby is built from scratch, using React and Typescript and a minimal amount of resources. It uses a custom virtual view, allowing you to operate on vast amounts of data. It displays programs and channels to the user, and automatically positions all elements according to hours and assigned channels. When a resource contains no content, Planby calculates the positioning so the time slots are properly aligned.
Planby has a simple interface and includes all necessary features, such as a sidebar, the timeline itself, a pleasant layout, and live program refreshing. In addition, there's an optional feature allowing you to hide any element you don't want to include in the layout.
Planby has a simple API that allows you as the developer to implement your own items along with your user preferences. You can use Planby's theme to develop new features, or you can make custom styles to fit in with your chosen design. You can easily integrate with other features, like a calendar, rating options, a list of user favorites, scroll, "now" buttons, a recording schedule, catch-up content, and much more. What's more, you can add custom global styles, including register-transfer level (RTL) functionality.
And best of all, it uses the open source MIT licensed.
## Try Planby
If you would like to try Planby, or just to learn more about it, visit the [Git repository](https://github.com/karolkozer/planby). There, I've got some examples of what's possible and you can read the documentation for the details. The package is also available with `npm`
.
## Comments are closed. |
15,572 | Firefox 110 发布,带来 GPU 沙盒、WebGL 改进功能 | https://debugpointnews.com/firefox-110/ | 2023-02-25T11:15:00 | [
"Firefox"
] | /article-15572-1.html | 
>
> Firefox 110 现在可以下载了,带来了以下新功能。
>
>
>
上周发布的 Firefox 110 是今年的第二个版本,现在可以通过官方发布渠道下载和升级。
这个月度版本是在 [Firefox 109](https://debugpointnews.com/firefox-109/) 版本之后发布的,后者是在 1 月份发布的。
总的来说,新的功能和错误修复很少,特别是对 Linux 来说。下面是一个快速点评。

### Firefox 110 的最佳新功能
对于 Windows 用户来说,这个版本有一些好消息。期待已久的安全功能 “GPU 沙盒” 现在在 Windows 中的 Firefox 中可用。从理论上讲,沙盒可以隔离一个进程,使其他恶意程序无法攻击或访问系统中的其他进程。有了这个功能,GPU 进程会被隔离,在 Windows 中可以给你一个更安全的浏览体验。
你可以使用以下步骤检查沙盒功能。
* 从地址栏打开 `about:support`。
* 在页面底部搜索(`CTRL+F`)“sandbox”。
* 并验证设置。
不知道这项功能何时会到达 Linux 或 macOS。
除上述内容外,现在还可以从 Opera 和 Vivaldi 网络浏览器中导入书签、浏览历史和密码。这使那些想迁移到 Firefox 的人更加方便。
此外,Firefox 浏览器现在启用了阻止第三方模块注入 Firefox 浏览器的选项。企业级大规模的 Firefox 浏览器部署得到了一个与上述阻止相一致的新策略,名为 `DisableThirdPartyModuleBlocking`。然而,它在 Firefox ESR 部署中不可用。
在 macOS、Linux 和 Windows 中进行了一些可用性改进,在按下 `CTRL` + `backspace`/`delete`或 `Cmd` + `backspace` 时,可以清除本地化的日期时间字段。除此之外,Firefox 现在在 Windows 的非英特尔 GPU 中叠加了硬件解码的视频,改善了视频播放性能和缩放质量。
这些是主要的变化,除了开发者特定的 CSS、HTML 更新,你可以在更新日志页面找到更多变化的说明(见下文)。
### 下载和更新
对于 Linux 发行版,如果你通过你的发行版的官方仓库使用 Firefox,那么你应该在几天内得到这个更新。
然而,你也可以从下面的页面下载这个版本的压缩版本。对于其他下载选项,请访问我们的 [Firefox 浏览器下载指南](https://www.debugpoint.com/download-firefox/)。
>
> **[下载 Firefox 浏览器110](https://ftp.mozilla.org/pub/firefox/releases/110.0/)**
>
>
>
祝你浏览愉快!
* [正式发布说明](https://www.mozilla.org/en-US/firefox/110.0/releasenotes/)
* [Beta110 发布说明](https://www.mozilla.org/en-US/firefox/110.0beta/releasenotes/)
* [开发者发布说明](https://developer.mozilla.org/en-US/docs/Mozilla/Firefox/Releases/110)
---
via: <https://debugpointnews.com/firefox-110/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,574 | 轻量化发行版 LegacyOS 历经九年后发布 2023 版本 | https://debugpointnews.com/legacy-os-2023-release/ | 2023-02-25T15:18:00 | [
"Legacy OS"
] | /article-15574-1.html | 
>
> 在将近十年后,基于 Debian 的 Legacy OS 2023 发布了,并带来了新的应用程序。
>
>
>

在此之前,Legacy OS 的最后一个版本发布于 2014 年。它旨在成为一个基于 Puppy Linux 的通用轻量级发行版,具有完整的应用程序、软件包、媒体编解码器等。目的是为旧电脑提供完整的操作系统。但是,该发行版在 2014 年之后停止了发布,直到现在。
### Legacy OS 2023 发布
基于 antiX 的新版 Legacy OS 2023 发布有了根本性的变化。它现在基于 Debian 的稳定分支(版本 11 “bullseye”),而不是 Puppy Linux。因此,你可以期望它更加稳定,其提供 Ice WM 作为默认窗口管理器。那些使用 IceWM 的人知道它有多快。这个版本也不例外。
除了 IceWM,Legacy OS 还预装了大量的默认应用程序。默认的文件管理器是 PCManFM,还包括 ROX 文件管理器。此外,所有 antiX 原生应用程序都也预装了,其中包括 antiX 更新程序和用户管理器。Synaptic 软件管理器以及一个单独的 CLI 包管理器也被预装在内。
图形软件包括用于高级绘图工作的 GIMP 和 Inkscape。此外,MyPaint、mtPaint、Peek 屏幕录制器、屏幕截图和 ImageMagick 库也默认安装。
如果你需要办公软件的话,Legacy OS 预装了 OnlyOffice 套件,Scribus 排版工具和 Dia 图表编辑器。

网络软件包括 Firefox ESR 浏览器、Thunderbird 邮件客户端、gFTP 客户端、Transmission 种子客户端和 NetSurf 浏览器。
如果你是一个开发者的话,Geany 和 VIM 代码编辑器是默认安装的。此外,强大的笔记应用 Cherrytree、必不可少的记事本应用 Leafpad 和白板应用 Xournal 是一些主要的应用程序,这使得它成为一个全能的、轻量级的发行版。
这些只是一些主要的应用程序,系统预装了近 100 个应用程序,而只占用了 7 GB 的磁盘空间。
这个发行版的性能真的是轻量级的,因为它并未使用 systemd,并使用了 IceWM。它在空闲状态下只使用 200 MB 的内存,这让我感到惊讶。总体而言,桌面性能非常快。

它使用 Calamares 安装程序,非常适合旧版本。但是,它现在只提供 64 位版本,但团队正在开发 32 位版本,很快就会发布。
我认为这是一个很值得一试的发行版,我们很高兴它又回来了。团队承诺将来会有定期的发布。
你可以从下面的链接下载 ISO 镜像文件。请记住,<ruby> 立付 <rt> Live </rt></ruby>介质的默认用户 ID 是 “demo”,密码也是 “demo”。
>
> **[下载 Legacy OS](https://sourceforge.net/projects/legacyoslinux/files/LegacyOS_2023_x64/)**
>
>
>
* 参考自 [官方公告](https://wikka.puppylinux.com/LegacyOS)
---
via: <https://debugpointnews.com/legacy-os-2023-release/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[Cubik65536](https://github.com/Cubik65536) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
15,575 | Lua 循环:如何使用 while 和 repeat until | https://opensource.com/article/23/2/lua-loops-while-repeat-until | 2023-02-25T15:28:04 | [
"Lua",
"循环"
] | https://linux.cn/article-15575-1.html | 
>
> 学习如何以及何时在 Lua 中使用 while 和 repeat until 循环。
>
>
>
控制结构是编程语言的一个重要特征,因为它们使你能够根据通常在程序运行时动态建立的条件来指导程序的流程。不同的语言提供了不同的控制,在 Lua 中,有 `while` 循环、`for` 循环和 `repeat` `until` 循环。这篇文章涵盖了 `while` 和 `repeat until` 循环。由于它们的灵活性,我在一篇 [单独的文章](https://opensource.com/article/22/11/lua-for-loops) 中介绍 `for` 循环。
条件是由一个使用运算符的表达式来定义的,运算符是你在数学课上可能认识的符号的一个花哨的术语。Lua 中有效的运算符有:
* `==` 等于
* `~=`不等于
* `<` 小于
* `>` 大于
* `⇐`小于或等于
* `>=` 大于或等于
这些被称为关系运算符,因为它们比较两个值之间的关联。还有一些逻辑运算符,其含义与英语中的含义相同,可以纳入条件中,进一步描述你想检查的状态:
* `and`
* `or`
下面是一些条件的例子:
* `foo > 3`:变量 `foo` 是否大于 3?`foo` 必须是 4 或更大才能满足这个条件。
* `foo >= 3`:`foo` 是否大于或等于 3?`foo` 必须是 3 或更大才能满足这个条件。
* `foo > 3 and bar < 1`:`foo` 是否大于 3 而 `bar` 小于 1?要满足这个条件,`foo` 变量必须在 `bar` 为 0 的同时为 4 或更大。
* `foo> 3 or bar < 1`:`foo` 是否大于 3?或者,`bar` 是否小于 1?如果 `foo` 是 4 或更大,或者 `bar` 是 0,那么这个条件就是真的。如果 `foo` 是 4 或更大,而 `bar` 是 0,会怎样?答案出现在本文的后面。
### While 循环
只要满足某个条件,while 循环就会执行指令。例如,假设你正在开发一个应用来监测正在进行的僵尸末日。当没有剩余的僵尸时,就不再有僵尸末日了:
```
zombie = 1024
while (zombie > 0) do
print(zombie)
zombie = zombie-1
end
if zombie == 0 then
print("No more zombie apocalypse!")
end
```
运行代码,看僵尸消失:
```
$ lua ./while.lua
1024
1023
[...]
3
2
1
No more zombie apocalypse!
```
### until 循环
Lua 还有一个 `repeat` `until` 循环结构,本质上是一个带有 `catch` 语句的 `while` 循环。假设你在从事园艺工作,你想追踪还剩下什么可以收获的东西:
```
mytable = { "tomato", "lettuce", "brains" }
bc = 3
repeat
print(mytable[bc])
bc = bc - 1
until( bc == 0 )
```
运行代码:
```
$ lua ./until.lua
brains
lettuce
tomato
```
这很有帮助!
### 无限循环
一个无限循环有一个永远无法满足的条件,所以它无限地运行。这通常是一个由错误逻辑或你的程序中的意外状态引起的错误。例如,在本文的开头,我提出了一个逻辑难题。如果一个循环被设定为 `foo > 3 or bar < 1` 运行 ,那么当 `foo` 为 4 或更大而 `bar` 为 0 时,会发生什么?
下面是解决这个问题的代码,为了以防万一,还使用了 `break` 语句安全捕获:
```
foo = 9
bar = 0
while ( foo > 3 or bar < 1 ) do
print(foo)
foo = foo-1
-- safety catch
if foo < -800000 then
break
end
end
```
你可以安全地运行这段代码,但它确实模仿了一个意外的无限循环。有缺陷的逻辑是 `or` 运算符,它允许这个循环在 `foo` 大于 3 和 `bar` 小于 1 的情况下继续进行。`and` 运算符有不同的效果,但我让你去探索。
无限循环实际上有其用途。图形应用使用技术上的无限循环来保持应用程序窗口的开放。我们没有办法知道用户打算使用这个程序多久,所以程序无限地运行,直到用户选择**退出**。在这些情况下使用的简单条件显然是一个总是被满足的条件。下面是一个无限循环的例子,为了方便起见,还是内置了一个安全陷阱:
```
n = 0
while true do
print(n)
n = n+1
if n > 100 then
break
end
end
```
条件 `while true` 总是被满足,因为 `true` 总是为真。这是比写 `while 1 == 1` 或类似的永远为真的简洁方式。
### Lua 中的循环
从示例代码中可以看出,尽管有不同的实现方式,但循环基本上都是朝着同一个目标工作。选择一个对你来说有意义的,并且在你需要执行的处理过程中效果最好的。以防万一你需要它:终止失控循环的键盘快捷键是 `Ctrl+C`。
---
via: <https://opensource.com/article/23/2/lua-loops-while-repeat-until>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Control structures are an important feature of programming languages because they enable you to direct the flow of the program based on conditions that are often established dynamically as the program is running. Different languages provide different controls, and in Lua there's the while loop, for loop, and repeat* *until loop. This article covers the while and repeat until loops. Because of their flexibility, I cover for loops in a [separate article](https://opensource.com/article/22/11/lua-for-loops).
A condition is defined by an expression using an operator, which is a fancy term for symbols you may recognize from math classes. Valid operators in Lua are:
-
`==`
equal to -
`~=`
not equal to -
`<`
less than -
`>`
greater than -
`⇐`
less than or equal to -
`>=`
greater than or equal to
Those are known as relational operators because they prompt an investigation of how two values relate to one another. There are also logical operators, which mean the same as they mean in English and can be incorporated into conditions to further describe the state you want to check for:
-
`and`
-
`or`
Here are some example conditions:
-
`foo > 3`
: Is the variable`foo`
is greater than 3? The`foo`
must be 4 or more to satisfy this condition. -
`foo >= 3`
: Is`foo`
greater than or equal to 3? The`foo`
must be 3 or more to satisfy this condition. -
`foo > 3 and bar < 1`
: Is`foo`
greater than 3 while`bar`
is less than 1? For this condition to be true, the`foo`
variable must be 4 or more at the same moment that`bar`
is 0. -
`foo > 3 or bar < 1`
: Is`foo`
greater than 3? Alternately, is`bar`
less than 1? If`foo`
is 4 or more, or`bar`
is 0, then this condition is true. What happens if`foo`
is 4 or more while`bar`
is 0? The answer appears later in this article.
## While loop
A while loop executes instructions for as long as *some condition* is satisfied. For example, suppose you're developing an application to monitor an ongoing zombie apocalypse. When there are no zombies remaining, then there is no more zombie apocalypse:
```
``````
zombie = 1024
while (zombie > 0) do
print(zombie)
zombie = zombie-1
end
if zombie == 0 then
print("No more zombie apocalypse!")
end
```
Run the code to watch the zombies vanish:
```
``````
$ lua ./while.lua
1024
1023
[...]
3
2
1
No more zombie apocalypse!
```
## Until loop
Lua also has a repeat until loop construct that's essentially a while loop with a "catch" statement. Suppose you've taken up gardening and you want to track what's left to harvest:
```
``````
mytable = { "tomato", "lettuce", "brains" }
bc = 3
repeat
print(mytable[bc])
bc = bc - 1
until( bc == 0 )
```
Run the code:
```
``````
$ lua ./until.lua
brains
lettuce
tomato
```
That's helpful!
## Infinite loops
An infinite loop has a condition that can never be satisfied, so it runs infinitely. This is often a bug caused by bad logic or an unexpected state in your program. For instance, at the start of this article, I posed a logic puzzle. If a loop is set to run until `foo > 3 or bar < 1`
, then what happens when `foo`
is 4 or more while `bar`
is 0?
Here's the code to solve this puzzle, with a safety catch using the `break`
statement just in case:
```
``````
foo = 9
bar = 0
while ( foo > 3 or bar < 1 ) do
print(foo)
foo = foo-1
-- safety catch
if foo < -800000 then
break
end
end
```
You can safely run this code, but it does mimic an accidental infinite loop. The flawed logic is the `or`
operator, which permits this loop to continue both when `foo`
is greater than 3 and when `bar`
is less than 1. The `and`
operator has a different effect, but I leave that to you to explore.
Infinite loops actually do have their uses. Graphical applications use what are technically infinite loops to keep the application window open. There's no way of knowing how long your user intends to use the application, so the program runs infinitely until the user selects **Quit**. The simple condition used in these cases is one that is obviously always satisfied. Here's an example infinite loop, again with a safety catch built in for convenience:
```
``````
n = 0
while true do
print(n)
n = n+1
if n > 100 then
break
end
end
```
The condition `while true`
is always satisfied because `true`
is always true. It's the terse way of writing `while 1 == 1`
or something similarly eternally true.
## Loops in Lua
As you can tell from the sample code, although there are different implementations, loops all basically work toward the same goal. Choose the one that makes sense to you and that works best with the processing you need to perform. And just in case you need it: The keyboard shortcut to terminate a runaway loop is **Ctrl+C**.
## Comments are closed. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.