
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
16,050 | Fedora Linux 的家族(一):官方版本 | https://fedoramagazine.org/fedora-linux-editions-part-1-official-editions/ | 2023-07-31T09:14:00 | [
"Fedora"
] | https://linux.cn/article-16050-1.html | 
Fedora Linux 提供了多个变体以满足你的需求。你可以在我之前的文章《[Fedora Linux 的各种版本](/article-15003-1.html)》中找到所有 Fedora Linux 变体的概述。本文将对 Fedora Linux 官方版本进行更详细的介绍。共有五个 <ruby> 版本 <rt> Edition </rt></ruby>: Fedora Workstation、Fedora Server、Fedora IoT、Fedora CoreOS 和 Fedora Silverblue。Fedora Linux 下载页面目前显示其中三个为 *官方* 版本,另外两个为 *新兴* 版本。本文将涵盖所有五个版本。
### Fedora Workstation
如果你是笔记本电脑或台式计算机用户,则 Fedora Workstation 是适合你的操作系统。Fedora Workstation 非常易于使用。你可以用它满足日常工作、教育、爱好等需求。例如,你可以使用它创建文档,制作演示文稿,上网冲浪,处理图像,编辑视频等等。
这个 Fedora Linux 版本默认使用 GNOME 桌面环境。你可以使用这种环境舒适地工作和进行各种活动。你还可以根据个人喜好自定义 Fedora Workstation 的外观,让你在使用过程中更加舒适。如果你是 Fedora Workstation 的新用户,你可以阅读我之前的文章 [在安装 Fedora Workstation 之后要做的事](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/)。通过该文章,你将更容易上手 Fedora Workstation。
更多信息请参阅以下链接:
>
> **[Fedora Workstation](https://getfedora.org/en/workstation/)**
>
>
>
### Fedora Server
许多公司需要自己的服务器来支持基础设施。Fedora Server 版操作系统配备了一个强大的基于 Web 的管理界面称为 Cockpit,具有现代化的外观。Cockpit 可以让你轻松查看和监控系统性能和状态。
Fedora Server 包含一些开源世界中的最新技术,并得到一个活跃的社区的支持。它非常稳定可靠。然而,并不保证 Fedora 社区中的任何人都能够在你遇到问题时提供帮助。如果你运行的是关键任务的应用程序,并且可能需要技术支持,你可能要考虑使用 [Red Hat Enterprise Linux](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux)。
更多信息请访问以下链接:
>
> **[Fedora Server](https://getfedora.org/en/server/)**
>
>
>
### Fedora IoT
为物联网设备专门设计的操作系统越来越受欢迎。Fedora IoT 就是为了应对这一需求而创建的操作系统。Fedora IoT 是一个不可变操作系统,使用 OSTree 技术来进行原子更新。该操作系统专注于物联网设备的安全性,这非常重要。Fedora IoT 支持多种架构。它还配备了一个基于 Web 的配置控制台,因此可以在不需要键盘、鼠标或监视器物理连接到设备的情况下进行远程配置。
更多信息请访问以下链接:
>
> **[Fedora IoT](https://getfedora.org/en/iot/)**
>
>
>
### Fedora CoreOS
Fedora CoreOS 是一个面向容器的操作系统。该操作系统用于在任何环境中安全可靠地运行应用程序。它设计用于集群,但也可以作为独立系统运行。该操作系统与 Linux 容器配置具有高度兼容性。
更多信息请访问以下链接:
>
> **[Fedora CoreOS](https://getfedora.org/en/coreos?stream=stable)**
>
>
>
### Fedora Silverblue
这个版本是 Fedora Workstation 的一个变体,界面并没有太大区别。但是,Fedora Silverblue 是一个不可变的操作系统,采用以容器为中心的工作流程。这意味着每个安装的副本与同一版本的其他副本完全相同。其目标是使其更加稳定,更少出现错误,并更容易进行测试和开发。
更多信息请访问以下链接:
>
> **[Fedora Silverblue](https://silverblue.fedoraproject.org/)**
>
>
>
### 结论
Fedora Linux 的每个版本都有不同的目的。多个版本的可用性可以帮助你获得适合你需求的操作系统。本文讨论的 Fedora Linux 版本是在 Fedora Linux 的主要下载页面上提供的操作系统。你可以在 <https://getfedora.org/> 找到下载链接和更完整的文档说明。
*(题图:MJ/90ffba71-aee2-4429-a846-41f06997792c)*
---
via: <https://fedoramagazine.org/fedora-linux-editions-part-1-official-editions/>
作者:[Arman Arisman](https://fedoramagazine.org/author/armanwu/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora Linux provides several variants to meet your needs. You can find an overview of all the Fedora Linux variants in my previous article [Introduce the different Fedora Linux editions](https://fedoramagazine.org/introduce-the-different-fedora-linux-editions/). This article will go into a little more detail about the Fedora Linux official editions. There are five *editions* — Fedora Workstation, Fedora Server, Fedora IoT, Fedora CoreOS, and Fedora Silverblue. The Fedora Linux download page currently shows that three of these are *official* editions and the remaining two are *emerging* editions. This article will cover all five editions.
## Fedora Workstation
If you are a laptop or desktop computer user, then Fedora Workstation is the right operating system for you. Fedora workstation is very easy to use. You can use this for daily needs such as work, education, hobbies, and more. For example, you can use it to create documents, make presentations, surf the internet, manipulate images, edit videos, and many other things.
This Fedora Linux edition comes with the GNOME Desktop Environment by default. You can work and do activities comfortably using this appearance concept. You can also customize the appearance of this Fedora Workstation according to your preferences, so you will be more comfortable using it. If you are a new Fedora Workstation user, you can read my previous article [Things to do after installing Fedora 34 Workstation](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/). Through the article, you will find it easier to start with Fedora Workstation.
More information is available at this link: [https://getfedora.org/en/workstation/](https://getfedora.org/en/workstation/)
## Fedora Server
Many companies require their own servers to support their infrastructure. The Fedora Server edition operating system comes with a powerful web-based management interface called Cockpit that has a modern look. Cockpit enables you to easily view and monitor system performance and status.
Fedora Server includes some of the latest technology in the open source world and it is backed by an active community. It is very stable and reliable. However, there is no *guarantee* that anyone from the Fedora community will be available or able to help if you encounter problems. If you are running mission critical applications and you might require technical support, you might want to consider [Red Hat Enterprise Linux](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux) instead.
More information is available at this link: [https://getfedora.org/en](https://getfedora.org/en/server/)[/server/](https://getfedora.org/en/server/)
## Fedora IoT
Operating systems designed specifically for IoT devices have become popular. Fedora IoT is an operating system created in response to this. Fedora IoT is an immutable operating system that uses OSTree Technology with atomic updates. This operating system focuses on security which is very important for IoT devices. Fedora IoT has support for multiple architectures. It also comes with a web-based configuration console so that it can be configured remotely without requiring that a keyboard, mouse or monitor be physically connected to the device.
More information is available at this link: [https://getfedora.org/en/iot/](https://getfedora.org/en/iot/)
## Fedora CoreOS
Fedora CoreOS is a container-focused operating system. This operating system is used to run applications safely and reliably in any environment. It is designed for clusters but can also be run as a standalone system. This operating system has high compatibility with Linux Container configurations.
More information is available at this link: [https://getfedora.org/en/coreos/](https://getfedora.org/en/coreos?stream=stable)
## Fedora Silverblue
This edition is a variant of Fedora Workstation with an interface that is not much different. However, the difference is that Fedora Silverblue is an immutable operating system with a container-centric workflow. This means that each installation is exactly the same as another installation of the same version. The goal is to make it more stable, less prone to bugs, and easier to test and develop.
More information is available at this link: [https://silverblue.fedoraproject.org/](https://silverblue.fedoraproject.org/)
## Conclusion
Each edition of Fedora Linux has a different purpose. The availability of several editions can help you to get an operating system that suits your needs. The Fedora Linux editions discussed in this article are the operating systems available on the main download page for Fedora Linux. You can find download links and more complete documentation at [https://getfedora.org/](https://getfedora.org/).
## Alan W Shrock
Did you forget about Fedora Kinoite?
## Jesse
Isn’t Fedora Kinoite the Silverblue Edition but using KDE Plasma? KDE Plasma is one of the Fedora Spins, but not an official Fedora Release.
## Peter Boy
A good article that comes just at the right time for us. The docs team is currently planning a restructuring of the Fedora user documentation, away from a release related structure to a structuring according to the variants (see https://communityblog.fedoraproject.org/fedora-docs-is-about-to-change-significantly-check-it-out-still-in-statu-nascendi/) . The article helps to get a clearer view of this.
@Arman Arisman, maybe you could help us to describe in the docs the peculiarities of the variants briefly and accurately?
I am very aware of how difficult it is to describe the variants briefly and succinctly and, given the variety of characteristics, to hit on the most important features. Some things do come up short for me.
For example, the problem of a reliable, quasi enforceable support affects all variants, not only Server where this is explicitly stated. It is certainly especially important for professional server use, perhaps more important than for Workstations? But isn’t it just as important for e.g. CoreOS? Isn’t it equally important for all server variants? Or what makes it less important for one or the other?
Or the Workstation – Silverblue relationship. Is Silverblue really “more stable” than Workstation? Are there facts and figures that prove this? I would really love to know. And if it is, at what “cost”? Experience shows that “nothing is for free”. What can I perhaps no longer do or only with additional effort? What are possible criteria to decide between the two?
## Nelson
Regarding Workstation/Silverblue – its additional stability comes down to it being an immutable OS (much like IoT/CoreOS).
Not only it relies on atomic updates (OSTree acting as a “git for binaries”), everything in the /usr folder of the system is mounted as read-only; so it isn’t possible by default to simply edit a specific binary (example, SSH) unbeknownst to the system admin(s) – it requires either unlocking the current deployment (making it mutable) or overlaying an additional package to replace it. Those actions are, in turn, traced by OSTree and can be easily reverted, thus providing a safer, more reliable and reproducible environment to work with.
## Peter Boy
Yes, I know. That’s the theory. What about the empirics? Once in a time, Unix systems used to mount /usr read only for the same effect (regarding modification, not the other features). Over time, there was no additional security in addition to all the other security measurement introduced over the last decades.
## Gregory Bartholomew
Hi Peter. FYI, I (the editor) was the one who suggested the additional wording about RHEL being available if you wanted better support in the Fedora Server section. To my knowledge, Red Hat doesn’t offer paid-support for Fedora CoreOS. What made it worth mention for Fedora Server but not for the others was that there was another/better option. Just my 2¢. 🙂
## Peter Boy
Yeah, the other way around as I read it. There is a kind of update option. This is a distinguishing feature, indeed. And it is one of the practically most important features.
## Matthew Phillips
The comment recommending RHEL to server users made sense to me. People want fresher software for their personal computers, and often don’t mind doing a little troubleshooting if something breaks or is buggy. But for servers its often the other way around… you can’t even force some people to make updates, if it works they’d rather not touch it.
There is another option for CoreOS too, Red Hat Atomic. Uses rpm-ostree and everything.
## Jonatas Esteves
Just want to leave a heads-up to all the tinkerers out there that Silverblue is almost ready, it’s safe to make the jump! I’ve been on it since F35 and I’m very happy with it, and convinced this is the future. I wouldn’t install it on “grandpa’s PC” yet, but for a techie person, it’s time to be on the next-big-thing.
## Edd
Genial Buen contenido
## Kodden Tecnologia
Great post, Im in doubt about Fedora Silverblue, it’s worth install on workstation? Thanks
## SigmaSquadron
Absolutely. Silverblue is stable, and implements many technolgies considered the be the future of the Linux userland.
## Vijay
One of the good article to read about Open source development.
I would like to share it wilth my connection.
## Stephen
I have been running Fedora Silverblue since Fedora Linux 27 as my daily driver and wouldn’t turn back to traditional Workstation.
## Matthew Phillips
Just my opinion, but it’s getting to be the time where Silverblue and CoreOS should be official editions and not ’emerging’. I’ve been using Silverblue since F30 I believe… it was good enough to stay on back then and has only aged like a fine wine.
When I first read this article and was reminded of the emerging label, the thought “maybe I should be using the official edition until Silverblue is considered official” momentarily went through my head. The emerging label makes it sound a bit like a project which could be dropped Google-style, even if the Fedora Council wouldn’t do that.
## Abdul Hameed
I have been using Fedora since Fedora 2.
Today, I am using Fedora workstation 36 .
Your Post is very useful about other editions of Fedora. I like only Fedora Workstation. So I had no more knowledge about other editions, but today, I read your post and now I have useful knowledge.
Thanks.
## Ravi
I am using Fedora 36 KDE spin, does upgrading to future release work as reliably as official edition(Workstation) if proper upgrading procedure is followed?
Fedora 36 KDE is excellent so far.
## SigmaSquadron
Fedora KDE is a spin. It’s produced by the Fedora KDE Special Interest Group, but should be as reliable as official editions.
## eswgftwretgewr
We need
Fedora Hurd
Fedora Serenity
Fedora Minix
## Greg Zeng
Fedora was frightening in my tests. Wayland display server is default. However Wayland will not work with dinner applications.
Gnome display environment is too innovative, moving very far away from there usual Windows interface.
BTRFS is often recommended by Fedora, but it is not widely supported perhaps. Utilities for BTRFS seen lacking or hard to use.
## Peter Boy
You are not alone in this assessment. But, have you also tried Gnome Classic? That is now very mature, and you can effectively work with it again (not as flexible as Gnome 2, but it’s ok). You can select it in the login screen.
There was a discussion about it. It is the eternal belief in progress that whatever is new and advanced is thought to be always useful and practical. Nevertheless, the Anaconda installation program offers the option to configure another file system. Use the custom option in Installation target.
Shh! Some users install the Server Edition and a GUI of their choice on top of it (see the use case in their documentation). But that’s not really how it’s meant to be used. 🙂
## makosol
If you want a desktop that is way more Windows-like, I recommend you to use the Fedora KDE spin.
## SigmaSquadron
I’m not sure what a dinner application is, but XWayland does work with almost all X11 applications. It even works well for gaming, with only very legacy applications being left behind, but in those cases, you can just switch to an X11 session. The benefits Wayland brings are too great to simply ignore in favour of X, and are worth the occasional broken application.
GNOME is its own thing. You could just use a spin, and its not a bad thing that it moves away from Windows. Breaking convention in favour of new, good ideas is a good thing.
About BTRFS, it sounds like you just have little experience with it. The default btrfs-progs tools does everything the ext4 tools do, and so much more. On ext4, you’ll often need external tools, such as testdisk, to do simple recovery tasks, but on btrfs, it’s a simple
away.
Also, BTRFS is widely supported on enterprise environments. SUSE is a major contender for Enterprise Linux, and they use BTRFS by default.
## Arthur Bishop
Fedora is like a restaurant with 5 Michelin stars. I have a lot of fun with MATE DESKTOP anyway my computer is weak it’s hard for him to run something else Thank God there is MATE with Fedora
## Matt
MATE is a wonderful desktop, I use it on all the distros I test. Give yourself that 2010-era Fedora 14 look!
## Kevin "G"
This comment I don’t think has much to do with the topic, but that graphic at the top (official editions), should be incorporated in my view to the banner that shows up when you first boot Fedora. That powder blue and the Fedora logo, give it a much nice “entrance screen” imo. Again, sorry this doesn’t relate to the topic at hand, but I had to say something. I love Fedora, and I love how it’s starting to look. Thank you for your time and reading.
## Kevin "G"
Have the welcome banner be the same as above, with powder blue and white letters that read…
Fedora Linux-Workstation Edition-36 (*in white letters, would change )
Fedora logo right side, as you can tell I really like the banner someone made, and I think with the black or dark of Gnome, and the powder blue with white letters giving it a Fedora primary universal look would be very nice looking. But that’s just my opinion. I tend to think Fedora should have a universal look, that users can change if they want to.
## Gregory Bartholomew
FYI, in this case, the cover image was made by the author of the article.
Also, if you want to recommend enhancements to Fedora’s Workstation edition, you might have better luck reaching the right people by posting your comment here: https://discussion.fedoraproject.org/tag/workstation
## Kevin "G"
yeah I know it was created by the author, but it would look great in distro, IMO. Thanks for the link. |
16,053 | 终端基础:在 Linux 中复制文件和目录 | https://itsfoss.com/copy-files-directory-linux/ | 2023-07-31T22:08:49 | [
"终端"
] | https://linux.cn/article-16053-1.html | 
>
> 在终端基础知识系列的这一部分中,学习如何在 Linux 中使用命令行复制文件和目录。
>
>
>
复制文件是你经常执行的最基本但最重要的任务之一。
Linux 有一个专门的 `cp` 命令用于复制文件和目录(文件夹)。
在终端基础知识系列的这一部分中,你将学习在终端中复制文件和文件夹。
>
> ? 回想一下,以下是你迄今为止在本终端基础知识系列中所学到的内容:
>
>
> * [更改目录](https://itsfoss.com/change-directories/)
> * [创建新目录](/article-15595-1.html)
> * [列出目录内容](https://itsfoss.com/list-directory-content/)
> * [创建文件](/article-15643-1.html)
> * [读取文件](https://itsfoss.com/view-file-contents/)
> * [删除文件和目录](/article-15809-1.html)
>
>
>
让我们继续该系列的第七章。
### 在 Linux 命令行中复制文件
让我向你展示一些复制文件的示例。
#### 将文件复制到另一个目录
要将一个文件复制到另一目录,你所要做的就是遵循给定的命令语法:
```
cp 源文件 目标目录
```
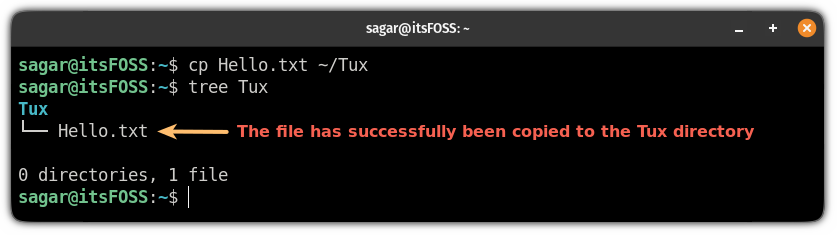
例如,在这里,我将名为 `Hello.txt` 的文件复制到名为 `Tux` 的目录中:

正如你所看到的,文件已成功复制到 `Tux` 目录中。
#### 复制文件但重命名
你可以选择在复制文件时重命名该文件。只需为“目标文件”指定一个不同的名称即可。
```
cp 源文件 改名的文件
```
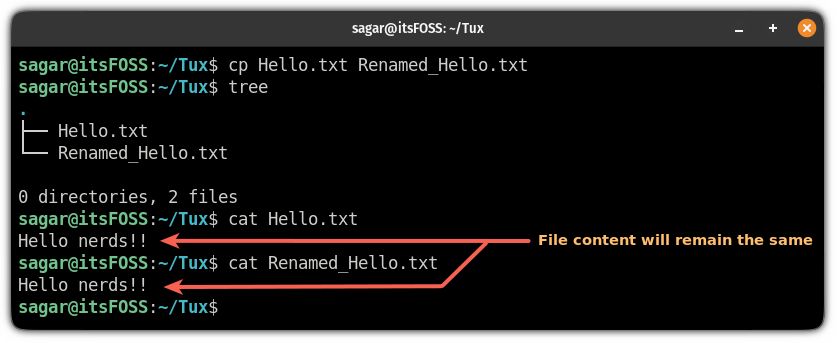
作为参考,在这里,我将名为 `Hello.txt` 的文件复制到同一目录,并将其重命名为 `Renamed_Hello.txt`:

为什么要这么做? 比如说,你必须编辑配置文件。一个好的做法是在编辑配置文件之前在同一位置对其进行备份。这样,如果事情没有按计划进行,你可以恢复到旧配置。
#### 将多个文件复制到另一个位置
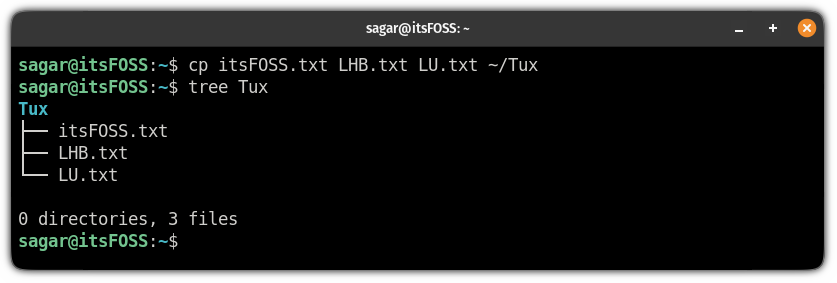
要将多个文件复制到另一个目录,请按以下方式执行命令:
```
cp File1 File2 File3 FileN Target_directory
```
在这里,我将多个文件复制到新位置。

>
> ? 当你复制多个文件时,仅使用 `cp` 命令无法重命名它们。
>
>
>
#### 复制时处理重复文件
默认情况下,如果目标目录中存在同名文件,`cp` 命令将覆盖该文件。
为了避免覆盖,你可以在 cp 命令中使用 `-n` 选项,它不会覆盖现有文件:
```
cp -n 源文件 目标目录
```
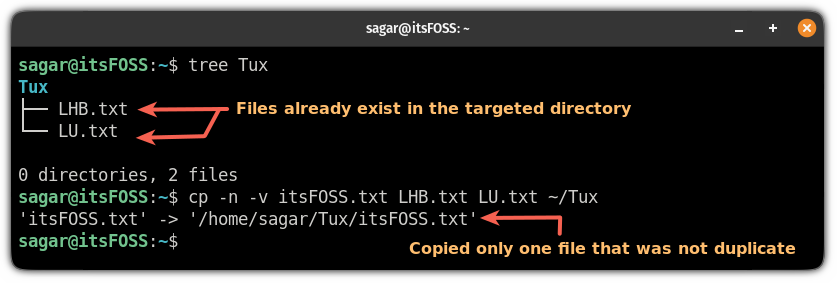
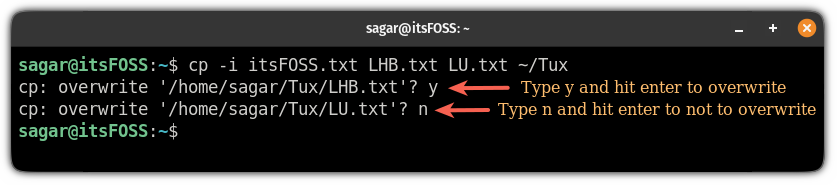
例如,在这里,我尝试复制目标目录中已有的两个文件,并使用 `-v` 选项来展示该命令正在执行的操作:
```
cp -n -v itsFOSS.txt LHB.txt LU.txt ~/Tux
```

#### 交互式复制文件
但是,当你想要覆盖某些文件,而某些文件应该保持不变时该怎么办?
好吧,你可以使用 `-i` 选项在交互模式下使用 `cp` 命令,它每次都会询问你是否应该覆盖该文件:
```
cp -i 源文件 目标目录
```

>
> ?️ 自己练习上述所有示例。你已经了解如何创建文件和文件夹,因此请重新创建所有内容。
>
>
>
### 在 Linux 命令行中复制目录
`mkdir` 命令用于创建新目录,`rmdir` 命令用于删除(空)目录。但没有用于复制目录的 `cpdir` 命令。
你必须使用相同的 `cp` 命令,但使用递归选项 `-r` 将目录及其所有内容复制到另一个位置:
```
cp -r 源目录 目标目录
```
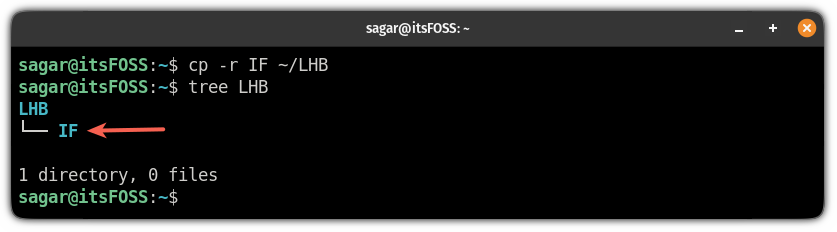
例如,在这里,我将名为 `IF` 的目录复制到 `LHB`:

但它复制了整个目录。?
那么,当你只想复制目录内容而不是目录本身时该怎么办?
你可以执行以下操作:
#### 仅复制目录的内容(不是目录)
要仅复制目录的内容,而不复制目录本身,请在源目录名称的末尾附加 `/.`:
```
cp -r 源目录/. 目标目录
```
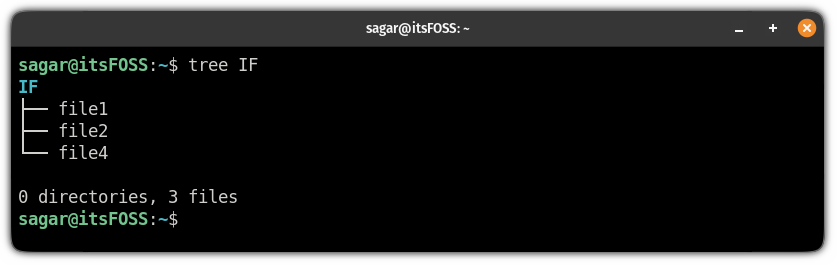
在这里,我想复制名为 `IF` 的目录的内容,其中包含以下三个文件:

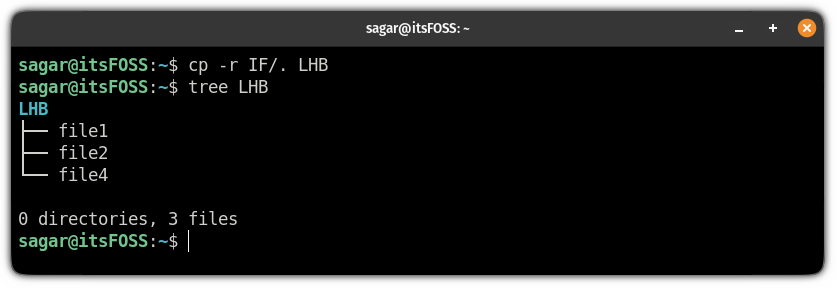
我将执行以下命令将 `IF` 目录的文件内容复制到 `LHB`:
```
cp -r IF/. LHB
```

你还可以在此处使用 `源目录/*` 。
#### 复制多个目录
要复制多个目录,你必须按以下方式执行命令:
```
cp -r 目录1 目录2 目录3 目录N 目标目录
```
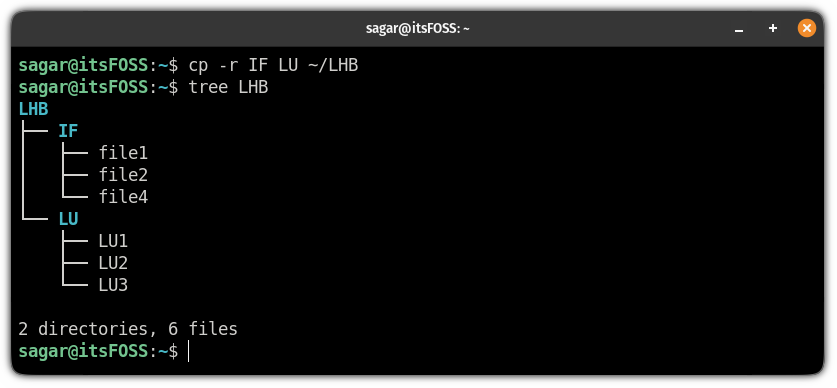
例如,在这里,我将两个名为 `IF` 和 `LU` 的目录复制到 `LHB`:
```
cp -r IF LU ~/LHB
```

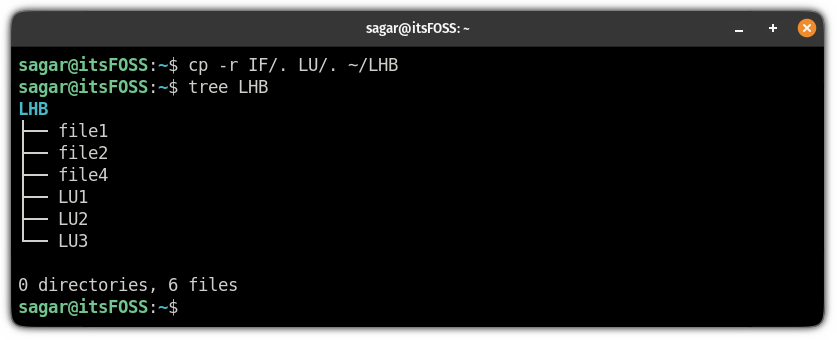
当你想要从多个目录复制文件但不复制目录本身时,你可以执行相同的操作:
```
cp -r 目录1/. 目录2/. 目录3/. 目录N/. 目标目录
```

>
> ?️ 你还可以像重命名文件一样重命名目录。
>
>
>
### 测试你的知识
现在,让我们看看你对到目前为止所学到的知识还记得多少。
* 创建一个名为 `copy_practice` 的目录。
* 将文件 `/etc/services` 复制到这个新创建的文件夹。
* 在此目录下创建一个名为 `secrets` 的文件夹,并将文件 `/etc/passwd` 和 `/etc/services` 复制到其中。
* 将 `copy_practice` 中的 `services` 文件复制到 `secrets` 文件夹中,但不要覆盖它。
* 将 `secrets` 文件夹复制到你的主目录。
* 删除 `secrets` 和 `copy_practice` 目录。
这会给你一些练习。
到目前为止进展顺利。你已经学到了很多东西。在下一章中,你将了解如何使用 `mv` 命令移动文件和文件夹。
---
via: <https://itsfoss.com/copy-files-directory-linux/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter 7: Copy Files and Directories in Linux
Learn how to copy files and directories in Linux using the command line in this part of the Terminal Basics series.
Copying files is one of the most basic yet crucial tasks you will be doing regularly.
Linux has a dedicated cp command for copying both files and directories (folders).
In this part of the Terminal Basics series, you'll learn to copy files and folders in the terminal.
-
[Change directories](https://itsfoss.com/change-directories/)
-
[Make new directories](https://itsfoss.com/make-directories/)
-
[List directory contents](https://itsfoss.com/list-directory-content/)
-
[Create files](https://itsfoss.com/create-files/)
-
[Reading files](https://itsfoss.com/view-file-contents/)
-
[Removing files and directories](https://itsfoss.com/delete-files-folders-linux/)
Let's go on with the seventh chapter in the series.
## Copying files in Linux command line
Let me show you a few examples of copying files.
### Copy a file to another directory
To copy one file to another directory, all you have to do is follow the given command syntax:
`cp Source_file Destination_directory`
For example, here, I have copied a file named `Hello.txt`
to the directory named `Tux`
:
And as you can see, the file has successfully been copied to the Tux directory.
### Copy the file but rename it
You can choose to rename the file while copying it. Just give a different name to the 'target file'.
`cp Source_file Renamed_file`
For reference, here, I have copied a file named `Hello.txt`
to the same directory by renaming it to `Renamed_Hello.txt`
:
Why would you do that? Say, you have to edit a config file. A good practice is to make a backup of the config file in the same location before editing it. This way, you can revert to the old configuration if things don't go as planned.
### Copy multiple files to another location
To copy multiple files to another directory, execute the command in the following fashion:
`cp File1 File2 File3 FileN Target_directory`
Here, I copy multiple files to a new location.
### Deal with duplicate files while copying
By default, the cp command will override the file if a file with the same name exists in the target directory.
To avoid overriding, you can use the `-n`
option with the cp command, and it won't override the existing files:
`cp -n Source_File Destination_directory`
For example, here, I have tried to copy two files that were already there in my targeted directory and used `-v`
option to showcase what is being done by the command:
`cp -n -v itsFOSS.txt LHB.txt LU.txt ~/Tux`
### Interactively copy files
But what about when you want to override some files, whereas some should be kept intact?
Well, you can use the cp command in the interactive mode using the `-i`
option, and it will ask you each time whether the file should be overridden or not:
`cp -i Source_file Destination_directory`
## Copy directories in Linux command line
There is mkdir command to make new directories, rmdir to remove (empty) directories. But there is no cpdir command for copying directories.
You'll have to use the same cp command but with the recursive option `-r`
to copy a directory with all its content to another location:
`cp -r Source_dir Target_dir`
For example, here, I have copied a directory named `IF`
to `LHB`
:
But it copied the entire directory 🤨
So, what do you do when you only want to copy the directory's contents, not the directory itself?
Here's what you can do:
### Copy only the contents of a directory (not the directory)
To copy only the contents of the directory, not the directory itself, you append `/.`
at the end of the source directory's name:
`cp -r Source_directory/. Destination_directory`
Here, I want to copy the contents of a directory named `IF`
which contains the following three files:
And I will execute the following command to copy the file contents of the `IF`
directory to `LHB`
:
`cp -r IF/. LHB`
You can also use Source_directory/* here.
### Copy multiple directories
To copy multiple directories, you will have to execute the command in the following way:
`cp -r Dir1 Dir2 Dir3 DirN Destiniation_directory`
For example, here, I have copied two directories named `IF`
and `LU`
to the `LHB`
:
`cp -r IF LU ~/LHB`
You can do the same when you want to copy files from multiple directories but not the directory itself:
`cp -r Dir1/. Dir2/. Dir3/. DirN/. Destination_directory`
## 📝 Test your knowledge
Now, let's see how much you remember the lessons learned so far.
- Create a directory called copy_practice
- Copy the file /etc/services to this newly created folder
- Create a folder named secrets under this directory and copy files /etc/passwd and /etc/services in it
- Copy the services file in copy_practice to the secrets folder but don't overwrite it
- Copy the secrets folder to your home directory
- Delete the secrets and copy_practice directories
That would give you some practice.
It's going well so far. You have learned quite a few things. In the next chapter, you'll see about [moving files and folders with mv command](https://itsfoss.com/move-files-linux/). |
16,055 | 使用 GoogleTest 和 CTest 进行单元测试 | https://opensource.com/article/22/1/unit-testing-googletest-ctest | 2023-08-02T11:15:50 | [
"单元测试"
] | /article-16055-1.html |
>
> 进行单元测试可以提高代码质量,并且它不会打断你的工作流。
>
>
>

本文是 [使用 CMake 和 VSCodium 设置一个构建系统](/article-14249-1.html) 的后续文章。
在上一篇文章中我介绍了基于 [VSCodium](https://vscodium.com/) 和 [CMake](https://cmake.org/) 配置构建系统。本文我将介绍如何通过 [GoogleTest](https://github.com/google/googletest) 和 [CTest](https://cmake.org/cmake/help/latest/manual/ctest.1.html) 将单元测试集成到这个构建系统中。
首先克隆 [这个仓库](https://github.com/hANSIc99/cpp_testing_sample),用 VSCodium 打开,切换到 `devops_2` 标签。你可以通过点击 `main` 分支符号(红框处),然后选择 `devops_2` 标签(黄框处)来进行切换:

或者你可以通过命令行来切换:
```
$ git checkout tags/devops_2
```
### GoogleTest
GoogleTest 是一个平台无关的开源 C++ 测试框架。单元测试是用来验证单个逻辑单元的行为的。尽管 GoogleTest 并不是专门用于单元测试的,我将用它对 `Generator` 库进行单元测试。
在 GoogleTest 中,测试用例是通过断言宏来定义的。断言可能产生以下结果:
* *成功*: 测试通过。
* *非致命失败*: 测试失败,但测试继续。
* *致命失败*: 测试失败,且测试终止。
致命断言和非致命断言通过不同的宏来区分:
* `ASSERT_*`: 致命断言,失败时终止。
* `EXPECT_*`: 非致命断言,失败时不终止。
谷歌推荐使用 `EXPECT_*` 宏,因为当测试中包含多个的断言时,它允许继续执行。断言有两个参数:第一个参数是测试分组的名称,第二个参数是测试自己的名称。`Generator` 只定义了 `generate(...)` 函数,所以本文中所有的测试都属于同一个测试组:`GeneratorTest`。
针对 `generate(...)` 函数的测试可以从 [GeneratorTest.cpp](https://github.com/hANSIc99/cpp_testing_sample/blob/main/Generator/GeneratorTest.cpp) 中找到。
#### 引用一致性检查
[generate(...)](https://github.com/hANSIc99/cpp_testing_sample/blob/main/Generator/Generator.cpp) 函数有一个 [std::stringstream](https://en.cppreference.com/w/cpp/io/basic_stringstream) 的引用作为输入参数,并且它也将这个引用作为返回值。第一个测试就是检查输入的引用和返回的引用是否一致。
```
TEST(GeneratorTest, ReferenceCheck){
const int NumberOfElements = 10;
std::stringstream buffer;
EXPECT_EQ(
std::addressof(buffer),
std::addressof(Generator::generate(buffer, NumberOfElements))
);
}
```
在这个测试中我使用 [std::addressof](https://en.cppreference.com/w/cpp/memory/addressof) 来获取对象的地址,并用 `EXPECT_EQ` 来比较输入对象和返回对象是否是同一个。
#### 检查元素个数
本测试检查作为输入的 `std::stringstream` 引用中的元素个数与输入参数中指定的个数是否相同。
```
TEST(GeneratorTest, NumberOfElements){
const int NumberOfElements = 50;
int nCalcNoElements = 0;
std::stringstream buffer;
Generator::generate(buffer, NumberOfElements);
std::string s_no;
while(std::getline(buffer, s_no, ' ')) {
nCalcNoElements++;
}
EXPECT_EQ(nCalcNoElements, NumberOfElements);
}
```
#### 乱序重排
本测试检查随机化引擎是否工作正常。如果连续调用两次 `generate` 函数,应该得到的是两个不同的结果。
```
TEST(GeneratorTest, Shuffle){
const int NumberOfElements = 50;
std::stringstream buffer_A;
std::stringstream buffer_B;
Generator::generate(buffer_A, NumberOfElements);
Generator::generate(buffer_B, NumberOfElements);
EXPECT_NE(buffer_A.str(), buffer_B.str());
}
```
#### 求和校验
与前面的测试相比,这是一个大体量的测试。它检查 1 到 n 的数值序列的和与乱序重排后的序列的和是否相等。 `generate(...)` 函数应该生成一个 1 到 n 的乱序的序列,这个序列的和应当是不变的。
```
TEST(GeneratorTest, CheckSum){
const int NumberOfElements = 50;
int nChecksum_in = 0;
int nChecksum_out = 0;
std::vector<int> vNumbersRef(NumberOfElements); // Input vector
std::iota(vNumbersRef.begin(), vNumbersRef.end(), 1); // Populate vector
// Calculate reference checksum
for(const int n : vNumbersRef){
nChecksum_in += n;
}
std::stringstream buffer;
Generator::generate(buffer, NumberOfElements);
std::vector<int> vNumbersGen; // Output vector
std::string s_no;
// Read the buffer back back to the output vector
while(std::getline(buffer, s_no, ' ')) {
vNumbersGen.push_back(std::stoi(s_no));
}
// Calculate output checksum
for(const int n : vNumbersGen){
nChecksum_out += n;
}
EXPECT_EQ(nChecksum_in, nChecksum_out);
}
```
你可以像对一般 C++ 程序一样调试这些测试。
### CTest
除了嵌入到代码中的测试之外,[CTest](https://cmake.org/cmake/help/latest/manual/ctest.1.html) 提供了可执行程序的测试方式。简而言之就是通过给可执行程序传入特定的参数,然后用 [正则表达式](https://en.wikipedia.org/wiki/Regular_expression) 对它的输出进行匹配检查。通过这种方式可以很容易检查程序对于不正确的命令行参数的反应。这些测试定义在顶层的 [CMakeLists.txt](https://github.com/hANSIc99/cpp_testing_sample/blob/main/CMakeLists.txt) 文件中。下面我详细介绍 3 个测试用例:
#### 参数正常
如果输入参数是一个正整数,程序应该输出应该是一个数列:
```
add_test(NAME RegularUsage COMMAND Producer 10)
set_tests_properties(RegularUsage
PROPERTIES PASS_REGULAR_EXPRESSION "^[0-9 ]+"
)
```
#### 没有提供参数
如果没有传入参数,程序应该立即退出并提示错误原因:
```
add_test(NAME NoArg COMMAND Producer)
set_tests_properties(NoArg
PROPERTIES PASS_REGULAR_EXPRESSION "^Enter the number of elements as argument"
)
```
#### 参数错误
当传入的参数不是整数时,程序应该退出并报错。比如给 `Producer` 传入参数 `ABC`:
```
add_test(NAME WrongArg COMMAND Producer ABC)
set_tests_properties(WrongArg
PROPERTIES PASS_REGULAR_EXPRESSION "^Error: Cannot parse"
)
```
#### 执行测试
可以使用 `ctest -R Usage -VV` 命令来执行测试。这里给 `ctest` 的命令行参数:
* `-R <测试名称>` : 执行单个测试
* `-VV`:打印详细输出
测试执行结果如下:
```
$ ctest -R Usage -VV
UpdatecTest Configuration from :/home/stephan/Documents/cpp_testing sample/build/DartConfiguration.tcl
UpdateCTestConfiguration from :/home/stephan/Documents/cpp_testing sample/build/DartConfiguration.tcl
Test project /home/stephan/Documents/cpp_testing sample/build
Constructing a list of tests
Done constructing a list of tests
Updating test list for fixtures
Added 0 tests to meet fixture requirements
Checking test dependency graph...
Checking test dependency graph end
```
在这里我执行了名为 `Usage` 的测试。
它以无参数的方式调用 `Producer`:
```
test 3
Start 3: Usage
3: Test command: /home/stephan/Documents/cpp testing sample/build/Producer
```
输出不匹配 `[^[0-9]+]` 的正则模式,测试未通过。
```
3: Enter the number of elements as argument
1/1 test #3. Usage ................
Failed Required regular expression not found.
Regex=[^[0-9]+]
0.00 sec round.
0% tests passed, 1 tests failed out of 1
Total Test time (real) =
0.00 sec
The following tests FAILED:
3 - Usage (Failed)
Errors while running CTest
$
```
如果想要执行所有测试(包括那些用 GoogleTest 生成的),切换到 `build` 目录中,然后运行 `ctest` 即可:

在 VSCodium 中可以通过点击信息栏的黄框处来调用 CTest。如果所有测试都通过了,你会看到如下输出:

### 使用 Git 钩子进行自动化测试
目前为止,运行测试是开发者需要额外执行的步骤,那些不能通过测试的代码仍然可能被提交和推送到代码仓库中。利用 [Git 钩子](https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks) 可以自动执行测试,从而防止有瑕疵的代码被提交。
切换到 `.git/hooks` 目录,创建 `pre-commit` 文件,复制粘贴下面的代码:
```
#!/usr/bin/sh
(cd build; ctest --output-on-failure -j6)
```
然后,给文件增加可执行权限:
```
$ chmod +x pre-commit
```
这个脚本会在提交之前调用 CTest 进行测试。如果有测试未通过,提交过程就会被终止:

只有所有测试都通过了,提交过程才会完成:

这个机制也有一个漏洞:可以通过 `git commit --no-verify` 命令绕过测试。解决办法是配置构建服务器,这能保证只有正常工作的代码才能被提交,但这又是另一个话题了。
### 总结
本文提到的技术实施简单,并且能够帮你快速发现代码中的问题。做单元测试可以提高代码质量,同时也不会打断你的工作流。GoogleTest 框架提供了丰富的特性以应对各种测试场景,文中我所提到的只是一小部分而已。如果你想进一步了解 GoogleTest,我推荐你阅读 [GoogleTest Primer](https://google.github.io/googletest/primer.html)。
*(题图:MJ/f212ce43-b60b-4005-b70d-8384f2ba5860)*
---
via: <https://opensource.com/article/22/1/unit-testing-googletest-ctest>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
16,056 | 如何访问虚拟机中的 GRUB 菜单 | https://itsfoss.com/access-grub-virtual-machine/ | 2023-08-02T11:30:00 | [
"虚拟机",
"GRUB"
] | https://linux.cn/article-16056-1.html | 
>
> 需要在虚拟机中访问 GRUB 菜单吗?以下是做法。
>
>
>
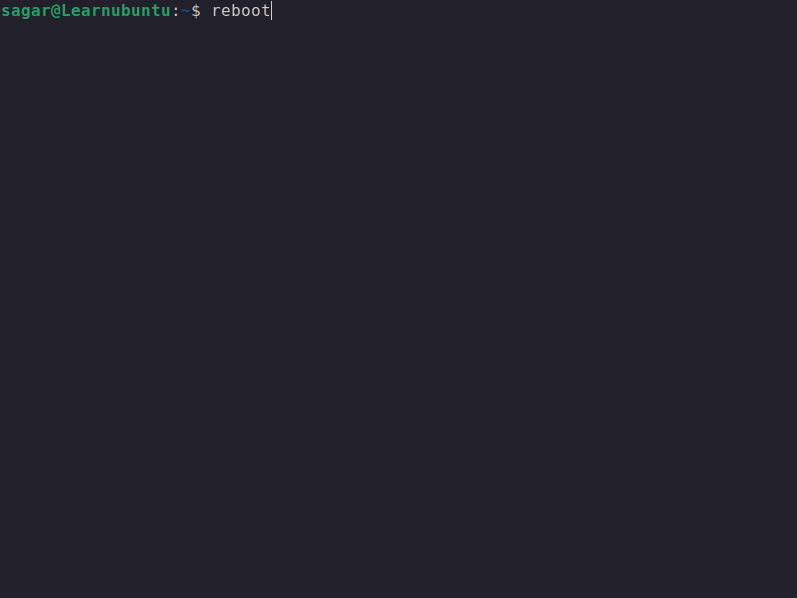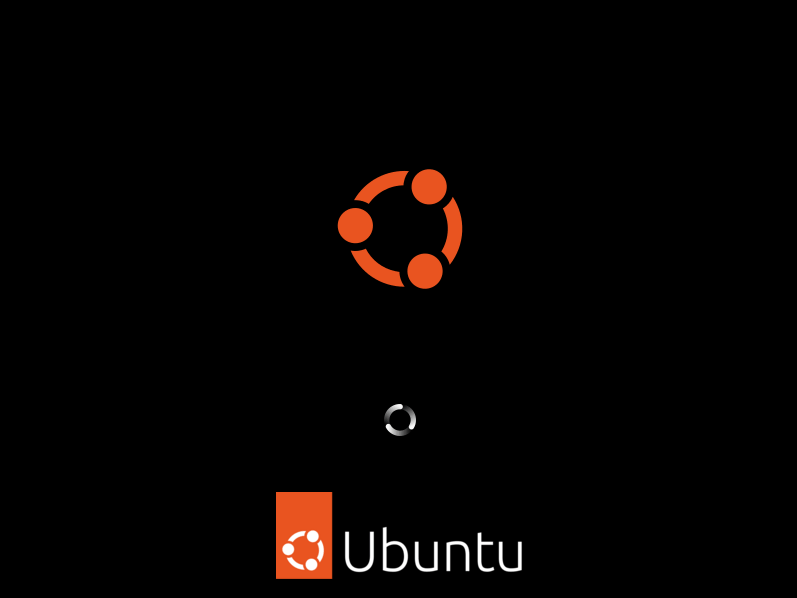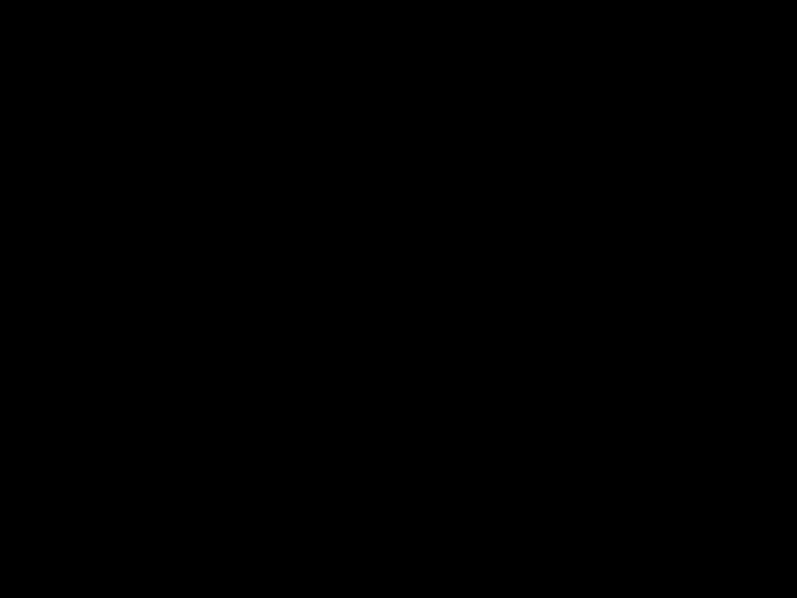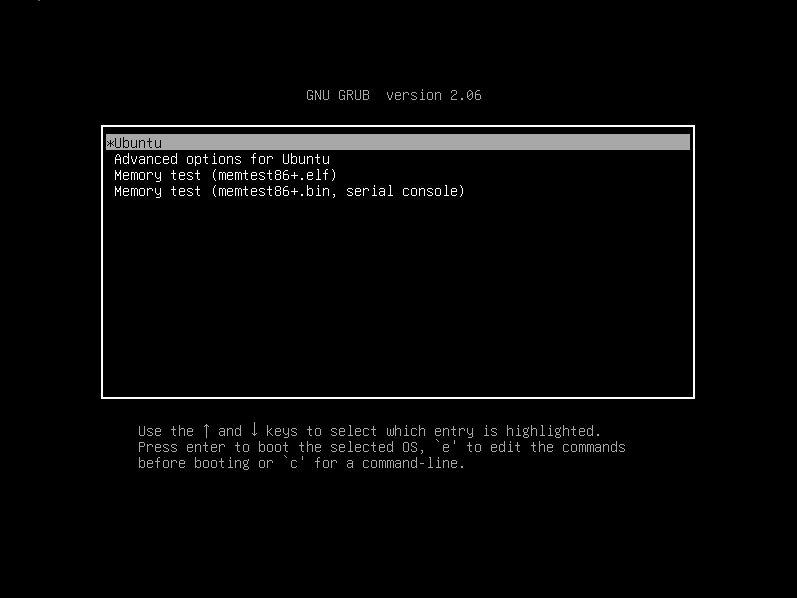
大多数现代虚拟机都配置为跳过 [GRUB 引导加载程序](https://itsfoss.com/what-is-grub/) 以获得无缝体验。
但是,你有时可能需要访问 GRUB 菜单。例如,如果你想切换回旧内核或进入恢复模式以 [重置密码](https://itsfoss.com/how-to-hack-ubuntu-password/)。
>
> ? TLDR:重启虚拟机并在再次启动时按住 `Shift` 键。这将为你提供 GRUB 菜单。
>
>
>
在这篇简短的文章中,我将向你展示两种访问虚拟机中运行的 Linux 中的 GRUB 菜单的方法:
* 临时方案(当你需要访问 GRUB 一两次时)
* 永久方案(每次启动时都会显示 GRUB)
由于大多数用户不会每天与 GRUB 交互,因此我将从一个临时解决方案开始,你可以无需任何调整即可访问 GRUB。
>
> ? 我在此处的教程中使用了 Ubuntu,但这些步骤也适用于其他 Linux 发行版。
>
>
>
### 在虚拟机中访问 GRUB 引导加载程序(快速方式)
如果你偶尔想访问 GRUB,这应该是最好的方法,因为它不需要任何配置。
只需重新启动系统并按住 `shift` 键即可。
就是这样!
你将拥有没有任何时间限制的 GRUB 菜单:

很简单的方法。不是吗?
但它仅适用于特定的启动。那么如果你想在每次启动时都进入 GRUB 该怎么办呢? 请参考下面的方法。
### 永久在虚拟机中启用 GRUB 菜单(如果你愿意)
>
> ? 此方法需要在命令行中更改 GRUB 配置文件。请确保你能够轻松地在终端中进行编辑。
>
>
>
如果你需要处理 GRUB 菜单来访问其他操作系统或经常更改 [从旧内核启动](https://itsfoss.com/boot-older-kernel-default/),那么此方法非常适合你。
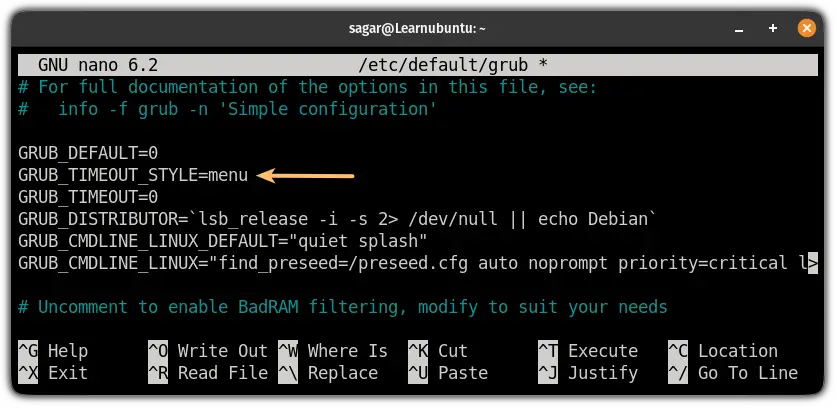
要使 GRUB 在每次引导时都可访问,你必须在配置文件中进行更改。
首先,使用以下命令打开 GRUB 配置文件:
```
sudo nano /etc/default/grub
```
在这里,将 `GRUB_TIMEOUT_STYLE=hidden` 更改为 `GRUB_TIMEOUT_STYLE=menu`:

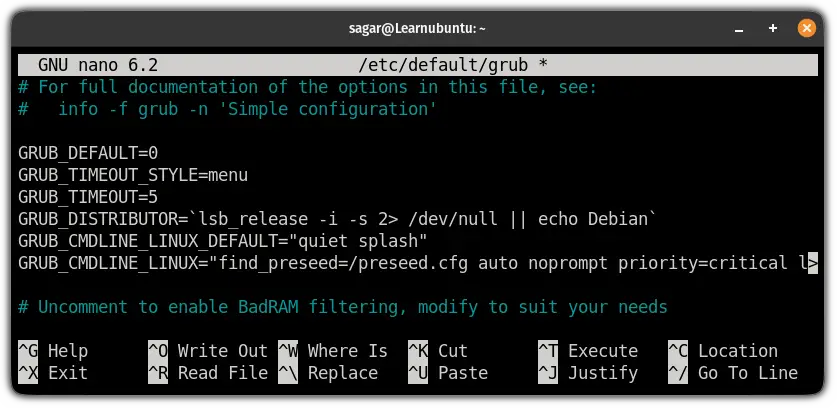
接下来,在同一个配置文件中,指定你希望 GRUB 显示的秒数。
我建议 5 秒,因为它似乎在太长和太短之间取得了平衡(是的,非常相关):
```
GRUB_TIMEOUT=5
```

最后,你可以 [保存更改并退出 nano](https://linuxhandbook.com/nano-save-exit/) 编辑器。
要激活对配置文件所做的更改,请使用以下命令更新 GRUB:
```
sudo update-grub
```
就是这样。重启系统,GRUB 应该会显示 5 秒钟。
### 将 GRUB 主题化如何?
大多数 Linux 发行版都会使用 GRUB 引导加载程序,因为它的配置非常简单,而且能完成工作。
但在默认情况下,除了黑色背景和纯文本外,它没什么样式。因此,我们制作了一份指南,教你如何让它看起来更漂亮:
>
> **[定制 GRUB 以获得更好的体验](https://itsfoss.com/customize-grub-linux/)**
>
>
>
希望本指南对你有所帮助,如果你有任何疑问,请在评论中告诉我。
*(题图:MJ/f75daf37-20c2-4bae-8a68-dc6a82ad0d61)*
---
via: <https://itsfoss.com/access-grub-virtual-machine/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Most modern VMs are configured to skip the [GRUB bootloader](https://itsfoss.com/what-is-grub/) for a seamless experience.
However, you might need to access the GRUB menu at times. For example, if you want to switch back to the older kernel or get into recovery mode for [resetting the password](https://itsfoss.com/how-to-hack-ubuntu-password/).
Reboot your VM and keep the Shift key pressed when it is booting up again. This should give you the GRUB menu.
In this quick article, I will be showing you two ways to access the GRUB menu in Linux running in a virtual machine:
- A temporary solution (when you have to access GRUB once or twice)
- A permanent solution (will show GRUB at every boot)
As most of the users are not going to interact with the grub on a daily basis, I will start with a temporary solution in which you can access the grub without any tweaks.
I have used Ubuntu in the tutorial here but the steps should be valid for other Linux distributions as well.
## Access the GRUB bootloader in VM (Quick way)
If you want to access the GRUB occasionally, this is supposed to be the best way as it does not require any configuration.
Just reboot your system and keep the `shift`
key pressed.
That's it!
You will have your grub menu without any time limit:
Pretty simple way. Isn't it?
But it will work for that specific boot only. So what if you want to have the grub on every boot? Refer to the given method.
## Enable Grub menu in virtual machines permanently (if you want to)
This method requires changing Grub config file in the command line. Please ensure that you are comfortable doing the edits in the terminal.
If you have to deal with the grub menu to access the other operating systems or change[ boot from the older kernels](https://itsfoss.com/boot-older-kernel-default/) often, this method is just for you.
To make the grub accessible at every boot, you must make changes in the configuration file.
First, open the grub config file using the following command:
`sudo nano /etc/default/grub`
Here, change the `GRUB_TIMEOUT_STYLE=hidden`
to the `GRUB_TIMEOUT_STYLE=menu`
:
Next, in the same config file, specify for how many seconds you want the grub to be displayed.
I would recommend 5 seconds as it seems to balance between not too long and short (yep, quite relatable):
`GRUB_TIMEOUT=5`
And finally, you can [save the changes and exit from the nano](https://linuxhandbook.com/nano-save-exit/) text editor.
To activate the changes you made to the config file, update the grub using the following command:
`sudo update-grub`
That's it. Reboot your system and the grub should be there for 5 seconds.
## How about theming GRUB?
You will get the grub bootloader in most of the Linux distros as it is quite simple to configure and gets the job done.
But by default, it's nothing apart from the black background and plain text. So we made a guide on how you can make it look dope:
[Customize Grub to Get a Better Experience With LinuxCouple of Grub configuration tweaks to get better experience with multi-boot Linux system using Grub Customizer GUI tool.](https://itsfoss.com/customize-grub-linux/)

I hope you will find this guide helpful and if you have any queries, let me know in the comments. |
16,058 | Fedora Linux 的家族(二):定制版 | https://fedoramagazine.org/fedora-linux-editions-part-2-spins/ | 2023-08-02T23:35:31 | [
"Fedora"
] | https://linux.cn/article-16058-1.html | 
使用 Linux 的一个好处是可以选择多种不同的桌面环境。Fedora Linux 官方的 Workstation 版本默认使用 GNOME 作为桌面环境,但是你可以通过 Fedora <ruby> 定制版 <rt> Spin </rt></ruby> 选择另一个桌面环境作为默认环境。本文将更详细地介绍 Fedora Linux 定制版。你可以在我之前的文章《[Fedora Linux 的各种版本](/article-15003-1.html)》中找到所有 Fedora Linux 变体的概述。
### KDE Plasma 桌面
这个 Fedora Linux 定制版使用 KDE Plasma 作为默认的桌面环境。KDE Plasma 是一个优雅的桌面环境,非常易于定制。因此,你可以根据自己的喜好自由地定制桌面的外观。你可以定制你喜欢的主题,安装所需的小部件,更换图标、字体,根据个人喜好定制面板,并从社区安装各种扩展功能。
Fedora Linux KDE Plasma 桌面预装了许多常用的应用程序。你可以使用 Firefox、Kontact、Telepathy、KTorrent 和 KGet 上网。LibreOffice、Okular、Dolphin 和 Ark 可满足你的办公需求。而针对多媒体需求,该版本提供了 Elisa、Dragon Player、K3B 和 GwenView 等多个应用程序。

更多信息请参考以下链接:
>
> **[Fedora Linux KDE Plasma 桌面](https://spins.fedoraproject.org/en/kde/)**
>
>
>
### XFCE 桌面
这个版本非常适合那些希望在外观定制和性能之间取得平衡的用户。XFCE 本身被设计为快速轻巧,但仍具有吸引人的外观。这个桌面环境逐渐受到老旧设备用户的欢迎。
Fedora Linux XFCE 安装了多种适合日常需求的应用程序,包括 Firefox、Pidgin、Gnumeric、AbiWord、Ristretto、Parole 等。Fedora Linux XFCE 还提供了一个系统设置菜单,让你更轻松地配置 Fedora Linux。

更多信息请访问此链接:
>
> **[Fedora Linux XFCE 桌面](https://spins.fedoraproject.org/en/xfce/)**
>
>
>
### LXQT 桌面
这个版本带有一个轻量级的 Qt 桌面环境,专注于现代经典的桌面体验,而不会降低系统性能。这个 Fedora Linux 版本包含基于 Qt5 工具包的应用程序,并采用 Breeze 主题。你可以通过内置的应用程序如 QupZilla、QTerminal、FeatherPad、qpdfview、Dragon Player 等来进行各种日常活动。

更多信息请访问此链接:
>
> **[Fedora Linux LXQT 桌面](https://spins.fedoraproject.org/en/lxqt/)**
>
>
>
### MATE-Compiz 桌面
Fedora Linux MATE Compiz 桌面是 MATE 和 Compiz Fusion 的组合。MATE 桌面环境使这个 Fedora Linux 版本能够通过优先考虑生产力和性能来发挥最佳效果。同时,Compiz Fusion 使用 Emerald 和 GTK+ 主题为系统提供了美观的 3D 外观。这个 Fedora Linux 版本还配备了各种流行的应用程序,如 Firefox、LibreOffice、Parole、FileZilla 等。

更多信息请访问此链接:
>
> **[Fedora Linux MATE Compiz 桌面](https://spins.fedoraproject.org/en/mate-compiz/)**
>
>
>
### Cinnamon 桌面
由于其用户友好的界面,Fedora Linux Cinnamon 桌面非常适合那些可能对 Linux 操作系统不太熟悉的用户。你可以轻松理解如何使用这个 Fedora Linux 版本。这个定制版内置了各种准备好供你日常使用的应用程序,如 Firefox、Pidgin、GNOME Terminal、LibreOffice、Thunderbird、Shotwell 等。你可以使用 Cinnamon 设置应用来配置你的操作系统。

更多信息请访问此链接:
>
> **[Fedora Linux Cinnamon 桌面](https://spins.fedoraproject.org/en/cinnamon/)**
>
>
>
### LXDE 桌面
Fedora Linux LXDE 桌面拥有一个快速运行的桌面环境,但设计旨在保持低资源使用。这个定制版专为低配置硬件设计,如上网本、移动设备和旧电脑。Fedora Linux LXDE 配备了轻量级和流行的应用程序,如 Midori、AbiWord、Osmo、Sylpheed 等。

更多信息请访问此链接:
>
> **[Fedora Linux LXDE 桌面](https://spins.fedoraproject.org/en/lxde/)**
>
>
>
### SoaS 桌面
SoaS 是 “Sugar on a Stick” 的缩写。Fedora Linux Sugar 桌面是一个面向儿童的学习平台,因此它具有非常简单的界面,易于儿童理解。这里的 “stick” 是指一个随身驱动器或存储“棒”。这意味着这个操作系统体积紧凑,可以完全安装在一个随身 U 盘上。学童可以将他们的操作系统携带在随身 U 盘上,这样他们可以在家、学校、图书馆和其他地方轻松使用。Fedora Linux SoaS 拥有各种有趣的儿童学习应用程序,如 Browse、Get Books、Read、Turtle Blocks、Pippy、Paint、Write、Labyrinth、Physic 和 FotoToon。

更多信息请访问此链接:
>
> **[Fedora Linux Sugar 桌面](https://spins.fedoraproject.org/en/soas/)**
>
>
>
### i3 Tiling WM
Fedora Linux 的 i3 Tiling WM 定制版与其他不太相同。这个 Fedora Linux 定制版不使用桌面环境,而只使用窗口管理器。所使用的窗口管理器是 i3,它是 Linux 用户中非常受欢迎的平铺式窗口管理器。Fedora i3 定制版适用于那些更注重使用键盘进行交互而非鼠标或触摸板的用户。这个 Fedora Linux 定制版配备了各种应用程序,如 Firefox、NM Applet、brightlight、azote、htop、mousepad 和 Thunar。

更多信息请访问此链接:
>
> **[Fedora Linux i3 Tiling WM](https://spins.fedoraproject.org/en/i3/)**
>
>
>
### 结论
Fedora Linux 通过 Fedora Linux 定制版提供了大量的桌面环境选择。你只需选择一个 Fedora 定制版,即可享受你选择的桌面环境以及其内置的即用应用程序。你可以在 <https://spins.fedoraproject.org/> 找到关于 Fedora 定制版的完整信息。
*(题图:MJ/6e7ea0c7-ccbe-4664-af60-61345a7c6617)*
---
via: <https://fedoramagazine.org/fedora-linux-editions-part-2-spins/>
作者:[Arman Arisman](https://fedoramagazine.org/author/armanwu/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the nice things about using Linux is the wide choice of desktop environments. Fedora Linux official Worksation edition comes with GNOME as default desktop environment, but you can choose another desktop environment as default via Fedora Spins. This article will go into a little more detail about the Fedora Linux Spins. You can find an overview of all the Fedora Linux variants in my previous article [Introduce the different Fedora Linux editions](https://fedoramagazine.org/introduce-the-different-fedora-linux-editions/).
## KDE Plasma Desktop
This Fedora Linux comes with KDE Plasma as the default desktop environment. KDE Plasma is an elegant desktop environment that is very easy to customize. Therefore, you can freely and easily change the appearance of your desktop as you wish. You can customize your favorite themes, install the widgets you want, change icons, change fonts, customize panels according to your preferences, and install various extensions from the community.
Fedora Linux KDE Plasma Desktop is installed with a variety of ready-to-use applications. You’re ready to go online with Firefox, Kontact, Telepathy, KTorrent, and KGet. LibreOffice, Okular, Dolphic, and Ark are ready to use for your office needs. Your multimedia needs will be met with several applications such as Elisa, Dragon Player, K3B, and GwenView.

More information is available at this link: [https://spins.fedoraproject.org/en/kde/](https://spins.fedoraproject.org/en/kde/)
## XFCE Desktop
This version is perfect for those who want a balance between ease of customizing appearance and performance. XFCE itself is made to be fast and light, but still has an attractive appearance. This desktop environment is becoming popular for those with older devices.
Fedora Linux XFCE is installed with various applications that suit your daily needs. These applications are Firefox, Pidgin, Gnumeric, AbiWord, Ristretto, Parole, etc. Fedora Linux XFCE also already has a System Settings menu to make it easier for you to configure your Fedora Linux.

More information is available at this link: [https://spins.fedoraproject.org/en/xfce/](https://spins.fedoraproject.org/en/xfce/)
## LXQT Desktop
This spin comes with a lightweight Qt desktop environment, and focuses on modern classic desktops without slowing down the system. This version of Fedora Linux includes applications based on the Qt5 toolkit and is Breeze themed. You will be ready to carry out various daily activities with built-in applications, such as QupZilla, QTerminal, FeatherPad, qpdfview, Dragon Player, etc.

More information is available at this link: [https://spins.fedoraproject.org/en/lxqt/](https://spins.fedoraproject.org/en/lxqt/)
## MATE-Compiz Desktop
Fedora Linux MATE Compiz Desktop is a combination of MATE and Compiz Fusion. MATE desktop allows this version of Fedora Linux to work optimally by prioritizing productivity and performance. At the same time Compiz Fusion provides a beautiful 3D look with Emerald and GTK + themes. This Fedora Linux is also equipped with various popular applications, such as Firefox, LibreOffice, Parole, FileZilla, etc.

More information is available at this link: [https://spins.fedoraproject.org/en/mate-compiz/](https://spins.fedoraproject.org/en/mate-compiz/)
## Cinnamon Desktop
Because of its user-friendly interface, Fedora Linux Cinnamon Desktop is perfect for those who may be new to the Linux operating system. You can easily understand how to use this version of Fedora Linux. This spin has built-in applications that are ready to use for your daily needs, such as Firefox, Pidgin, GNOME Terminal, LibreOffice, Thunderbird, Shotwell, etc. You can use Cinnamon Settings to configure your operating system.

More information is available at this link: [https://spins.fedoraproject.org/en/cinnamon/](https://spins.fedoraproject.org/en/cinnamon/)
## LXDE Desktop
Fedora Linux LXDE Desktop has a desktop environment that performs fast but is designed to keep resource usage low. This spin is designed for low-spec hardware, such as netbooks, mobile devices, and older computers. Fedora Linux LXDE has lightweight and popular applications, such as Midori, AbiWord, Osmo, Sylpheed, etc.

More information is available at this link: [https://spins.fedoraproject.org/en/lxde/](https://spins.fedoraproject.org/en/lxde/)
## SoaS Desktop
SoaS stands for Sugar on a Stick. Fedora Linux Sugar Desktop is a learning platform for children, so it has a very simple interface that is easy for children to understand. The word “stick” in this context refers to a thumb drive or memory “stick”. This means this OS has a compact size and can be completely installed on a thumb drive. Schoolchildren can carry their OS on a thumb drive, so they can use it easily at home, school, library, and elsewhere. Fedora Linux SoaS has a variety of interesting learning applications for children, such as Browse, Get Books, Read, Turtle Blocks, Pippy, Paint, Write, Labyrinth, Physic, and FotoToon.

More information is available at this link: [https://spins.fedoraproject.org/en/soas/](https://spins.fedoraproject.org/en/soas/)
## i3 Tiling WM
The i3 Tiling WM spin of Fedora Linux is a bit different from the others. This Fedora Linux spin does not use a desktop environment, but only uses a window manager. The window manager used is i3, which is a very popular tiling window manager among Linux users. Fedora i3 Spin is intended for those who focus on interacting using a keyboard rather than pointing devices, such as a mouse or touchpad. This spin of Fedora Linux is equipped with various applications, such as Firefox, NM Applet, brightlight, azote, htop, mousepad, and Thunar.
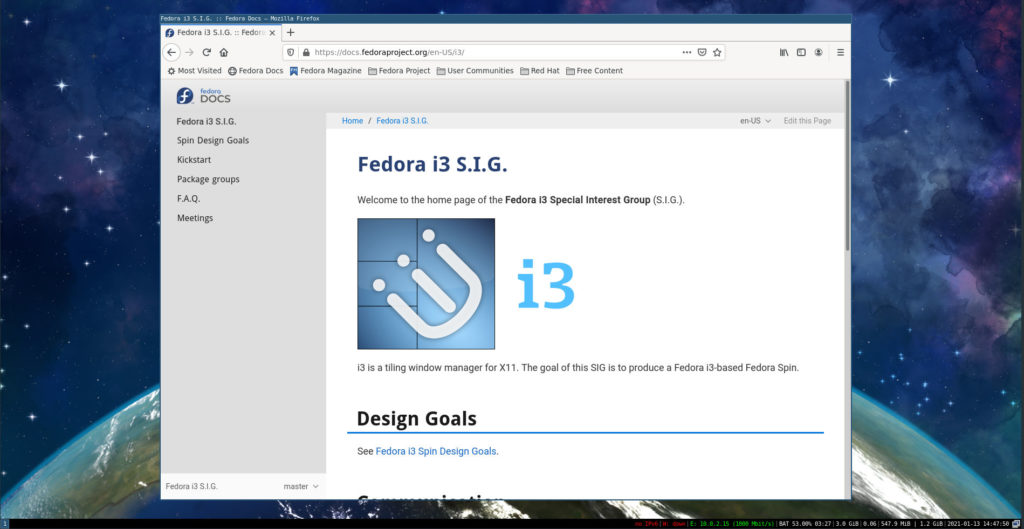

More information is available at this link: [https://spins.fedoraproject.org/en/i3/](https://spins.fedoraproject.org/en/i3/)
## Conclusion
Fedora Linux provides a large selection of desktop environments through Fedora Linux Spins. You can simply choose one of the Fedora Spins, and immediately enjoy Fedora Linux with the desktop environment of your choice along with its ready-to-use built-in applications. You can find complete information about Fedora Spins at [https://spins.fedoraproject.org/](https://spins.fedoraproject.org/).
## Darvond
I like Spins. They don’t confuse the user (especially the end user) into thinking that they’re disparate editions, but rather different starting points.
No thanks to Ubuntu and the many ___ntu editions, has that been a fine mess to explain over the years.## james
Great article, covers all the usual wms.
Will you cover fedora labs? I just downloaded comp-neuro and installed it in a vm and it had absolutely no installed applications, other than a base installation of fedora 36. No neuron, no brian, nothing… very disappointed
## james
it was my mistake, the packages were present after all.
## Cliff
The spins are grab and install then do. I had a major hard ware failure. Was back up running in just under 2 hours. Thanks to the spins.
## Hal Kristjan Stefansson
Thx for all the years together!! <3
I’ve used KDE for years now, and it’s awesome, but I’ll add I do miss the CUBE
love&light
Kristjan
## Vilius
Hi,
Does MATLAB install in the same way across all of the mentioned spins?
Can I have desktop shortcuts/icons on the original Fedora, i.e. GNOME?
Thanks a lot
## tsyang
Do you mean Octave, the freeware version of Matlab?
You can install it just like other package.
Open a terminal, then use this command
$ sudo dnf install octave
## robin
yes it does. But there is a carvet with fedora using a newer version of freetype and cairo. you have to make matlab default to system libraries for these and also for libstdc++ to be able to use your gpu.
## Richard Miller
What screenreader is used?
## Marcus
What’s the difference between “Fedora Spins” and “Fedora Labs”?
## Richard England
I refer you to the first article in Arman’s series:
https://fedoramagazine.org/introduce-the-different-fedora-linux-editions/
## Muhammed Yasin Özsaraç
Very good article. Thanks Arman !
## jtad
Don’t forget swaywm – along with i3 the best tiled wm for wayland. On Fedora, the version is almost the most up-to-date, and the repositories also contain up-to-date versions of the wayland utility like grim, fuzzel, and terminals like foot
## Sam
Thank you |
16,059 | Linux 中退出码的含义 | https://itsfoss.com/linux-exit-codes/ | 2023-08-03T15:50:00 | [
"退出码"
] | https://linux.cn/article-16059-1.html | 
>
> 揭开 Linux 中退出码的神秘面纱。了解什么是退出码,以及为什么和如何使用它们。
>
>
>
退出码(退出状态)可以告诉我们最后一次执行的命令的状态。在命令结束以后,我们可以知道命令是成功完成的还是以错误结束的。
**其基本思想是,程序返回退出代码 `0` 时表示执行成功,没有问题。代码 `1` 或 `0` 以外的任何代码都被视为不成功。**
退出码除了 0 和 1 外还有很多值,我将在本文介绍它们。
### Linux Shell 中的各种退出码
我们来快速了解一下 Linux Shell 中的主要退出码:
| 退出码 | 解释 |
| --- | --- |
| `0` | 命令成功执行 |
| `1` | 通用错误代码 |
| `2` | 命令(或参数)使用不当 |
| `126` | 权限被拒绝(或)无法执行 |
| `127` | 未找到命令,或 `PATH` 错误 |
| `128+n` | 命令被信号从外部终止,或遇到致命错误 |
| `130` | 通过 `Ctrl+C` 或 `SIGINT` 终止(*终止代码 2 或键盘中断*) |
| `143` | 通过 `SIGTERM` 终止(*默认终止*) |
| `255/*` | 退出码超过了 0-255 的范围,因此重新计算(LCTT 译注:超过 255 后,用退出码对 256 取模) |
>
> ? `130`(`SIGINT` 或 `^C`)和 `143`(`SIGTERM`)等终止信号是非常典型的,它们属于 `128+n` 信号,其中 `n` 代表终止码。
>
>
>
在简单了解了退出码之后,我们来看看它们的用法。
### 获取退出码
前一个命令执行的退出码存储在 [特殊变量](https://linuxhandbook.com:443/bash-special-variables/) `$?` 中。你可以通过运行以下命令来获取:
```
echo $?
```
我们在所有演示中都将使用它来获取退出代码。
请注意,`exit` 命令支持以带着前一条命令相同的退出码退出。
### 退出码 0
退出码 `0` 表示命令执行无误,这是完成命令的理想状态。
例如,我们运行这样一条基本命令
```
neofetch
echo $?
```

这个退出码 `0` 表示特定命令已成功执行,仅此而已。让我们再演示几个例子。
你可以尝试 [终止一个进程](https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/);它也会返回代码 `0`。
```
pkill lxappearance
```

查看文件内容也会返回退出码 0,这**仅**意味着 `cat` 命令执行成功。
### 退出码 1
退出码 `1` 也很常见。它通常表示命令以一般错误结束。
例如,在没有 sudo 权限的情况下使用 [软件包管理器](https://itsfoss.com/package-manager/),就会返回代码 `1`。在 Arch Linux 中,如果我运行下面的命令:
```
pacman -Sy
```
它会返回 `1`, 表示上一条命令运行出错。

>
> ? 如果你在基于 Ubuntu 的发行版中尝试这样做(不使用 `sudo` 执行 `apt update`),运行后会得到错误码 `100`,表示你是在没有权限的情况下运行 `apt`。`100` 不是标准错误码,而是 `apt` 特有的错误码。
>
>
>
虽然这是一般的理解,但我们也可以将其解释为 “不被允许的操作”。
除以 `0` 等操作也会返回错误码 `1`。

### 退出码 2
这个退出码出现在当执行的命令有语法错误时。滥用命令参数也会导致此错误。
一般来说,它表示由于使用不当,命令无法执行。
例如,我在一个本应只有一个连字符的选项上添加了两个连字符,那么此时会出现退出码 2。
```
grep --z file.txt
```

当权限被拒绝时,比如访问 `/root` 文件夹,就会出现错误码 `2`。

### 退出码 126
126 是一个特殊的退出码,它用于表示命令或脚本因权限错误而未被执行。
当你尝试执行没有执行权限的 Shell 脚本时,就会出现这个错误。

请注意,该退出码只出现在没有足够权限的脚本或命令的“*执行*”中,这与一般的**权限被拒绝**错误不同。
因此,不要把它与你之前看到的退出码为 `2` 的示例混淆。在那个示例中,运行的是 `ls` 命令,权限问题出自它试图执行的目录。而本例中权限问题来自脚本本身。
### 退出码 127
这是另一个常见的退出码。退出码 `127` 指的是“[未找到命令](https://itsfoss.com/bash-command-not-found/)”。它通常发生在执行的命令有错别字或所需的可执行文件不在 `$PATH` 变量中时。
例如,当我尝试执行一个不带路径的脚本时,经常会看到这个错误。

当你想运行的可执行文件不在 `$PATH` 变量中时,也会出现退出码 `127`。你可以通过 [在 PATH 变量中添加命令的目录](https://itsfoss.com/add-directory-to-path-linux/) 来纠正这种情况。
当你输入不存在的命令时,也会得到这样的退出码。

### 退出码 128+n 系列
当应用程序或命令因致命错误而终止或执行失败时,将产生 128 系列退出码(`128+n`),其中 `n` 为信号编号。
`n` 包括所有类型的终止代码,如 `SIGTERM`、`SIGKILL` 等。
#### 退出码 130 或 SIGINT
在通过终止信号 `2` 或按下 `Ctrl+C` 中断进程时,会发出 `SIGINT`(键盘中断信号)。
因为终止信号是 `2`,所以我们得到的退出码是 `130`(128+2)。下面的视频演示了 `lxappearance` 的中断信号。
#### 退出码 137 或 SIGKILL
`SIGKILL`(立即终止信号)表示终止信号 `9`。这是终止应用程序时最不应该使用的方法。
因为终止信号为 `9`,因此我们得到的退出代码为 `137`(128+9)。
#### 退出码 143 或 SIGTERM
`SIGTERM` 是进程在未指定参数的情况下被杀死时的默认行为。
`SIGTERM` 的终止信号为 `15`,因此该信号的退出码为 `143`(128+15)。
还有一些你以前可能不知道的终止信号,它们也有自己类似的退出码。你可以在这里查看它们:
>
> ? 请注意,如果进程在启动它的同一会话中终止,这些信号可能不会出现。如果要重现这些信号,请从不同的 shell 终止。
>
>
> 就个人而言,信号 `128` 是无法重现的。
>
>
>
### 当退出码超过了 255 会怎样?
最新版本的 Bash 甚至保留了超过 255 的原始退出码的值,但一般来说,如果代码超过 255,就会被重新计算。
也就是说,代码 `256` 会变成 `0`,`257` 会变成 `1`,`383` 会变成 `127`,以此类推。为确保更好的兼容性,请将退出码保持在 `0` 至 `255` 之间。
### 结语
希望你对 Linux Shell 中的退出码有所了解。在排查各种问题时,使用它们会非常方便。
如果你要在 Shell 脚本中使用这些代码,请确保你了解每个代码的含义,以便更容易地排除故障。
这就是本文的全部内容。如有遗漏,请在评论区告诉我。
*(题图:MJ/719ff711-1b9f-4aa9-a82e-980704acbdd8)*
---
via: <https://itsfoss.com/linux-exit-codes/>
作者:[Pranav Krishna](https://itsfoss.com/author/pranav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

An exit code or exit status tells us about the status of the last executed command. Whether the command was completed successfully or ended with an error. This is obtained after the command terminates.
**The basic ideology is that programs return the exit code 0 to indicate that it executed successfully without issues. Code 1 or anything other than 0 is considered unsuccessful. **
There are many more exit codes other than 0 and 1, which I'll cover in this article.
## Various exit codes in Linux shell
Let us take a quick look at the prominent exit codes in the Linux shell:
Exit code | Meaning of the code |
---|---|
`0` |
Command executed with no errors |
`1` |
Code for generic errors |
`2` |
Incorrect command (or argument) usage |
`126` |
Permission denied (or) unable to execute |
`127` |
Command not found, or PATH error |
`128+n` |
Command terminated externally by passing signals, or it encountered a fatal error |
`130` |
Termination by Ctrl+C or SIGINT (termination code 2 or keyboard interrupt) |
`143` |
Termination by SIGTERM (default termination) |
`255/*` |
Exit code exceeded the range 0-255, hence wrapped up |
The termination signals like `130`
(SIGINT or `^C`
) and `143`
(SIGTERM) are prominent, which are just `128+n`
signals with `n`
standing for the termination code.
Now that you are briefly familiar with the exit codes let's see about their usage.
## Retrieving the exit code
The exit code of the previously executed command is stored in the [special variable](https://linuxhandbook.com/bash-special-variables/) `$?`
. You can retrieve the exit status by running:
`echo $?`
This will be used in all our demonstrations to retrieve the exit code.
Note that the *exit* command supports carrying the same exit code of the previous command executed.
## Exit code 0
Exit code `0`
means that the command is executed without errors. This is ideally the best case for the completion of commands.
For example, let us run a basic command like this
```
neofetch
echo $?
```
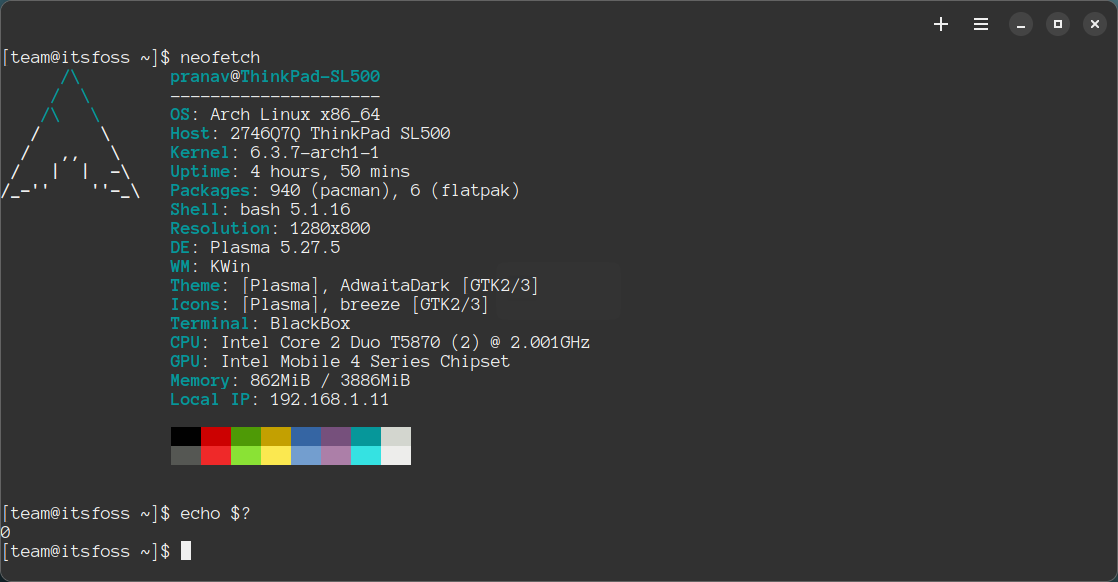
This exit code `0`
means that the particular command was executed successfully, nothing more or less. Let us demonstrate some more examples.
You may try [killing a process](https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/); it will also return the code `0`
.
`pkill lxappearance`

Viewing a file's contents will also return an exit code 0, which implies **only** that the 'cat' command executed successfully.
## Exit code 1
Exit code `1`
is also a common one. It generally means the command terminated with a generic error.
For example, using the [package manager](https://itsfoss.com/package-manager/) without sudo permissions results in code 1. In Arch Linux, if I try this:
`pacman -Sy `
It will give me exist code as 1 meaning the last command resulted in error.

If you try this in Ubuntu-based distros (`apt update`
without sudo), you get 100 as an error code for running 'apt' without permissions. This is not a standardized error code, but one specific to apt.
While this is a general understanding, we can also interpret this as "operation impermissible".
Operations like dividing by zero also result in code 1.

## Exit code 2
This exit code is given out when the command executed has a syntax error. Misusing the arguments of commands also results in this error.
It generally suggests that the command could not execute due to incorrect usage.
For example, I added two hyphens to an option that's supposed to have one hyphen. Code 2 was given out.
`grep --z file.txt`

When permission is denied, like accessing the /root folder, you get error code 2.
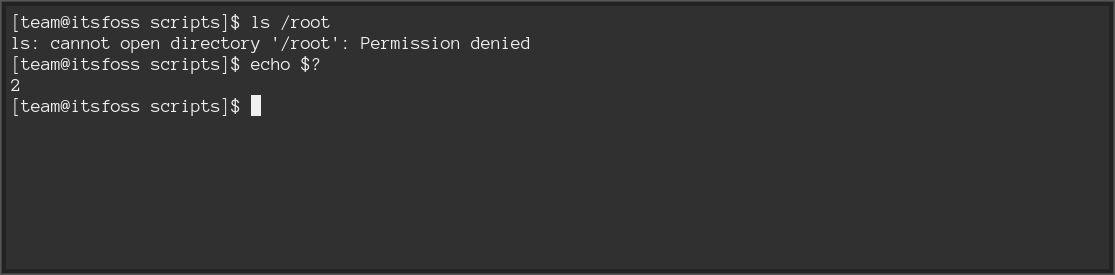
## Exit code 126
126 is a peculiar exit code since it is used to indicate a command or script was not executed due to a permission error.
This error can be found when you try executing a shell script without giving execution permissions.

Note that this exit code appears only for the '*execution*' of scripts/commands without sufficient permissions, which is different from a generic Permission Denied error.
So, on't confuse it with the previous example you saw with exit code 2. There, ls command ran and the permission issue came with the directory it was trying to execute. Here, the permission issues came from the script itself.
## Exit code 127
This is another common one. Exit code 127 refers to "[command not found](https://itsfoss.com/bash-command-not-found/)". It usually occurs when there's a typo in the command executed or the required executable is not in the $PATH variable.
For example, I often see this error when I try executing a script without its path.
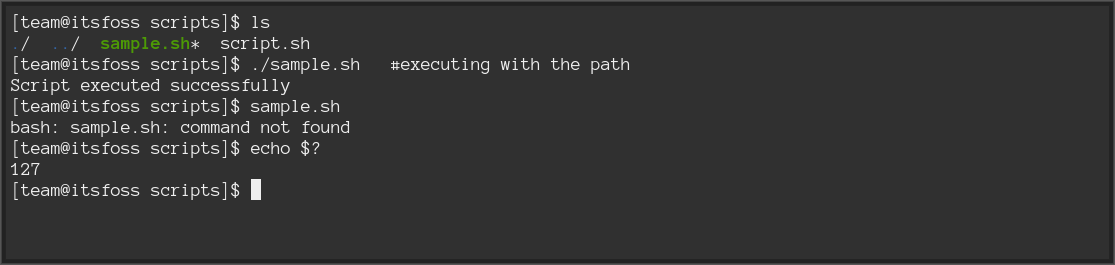
Or when the executable file you're trying to run, is not listed in the `$PATH`
variable. You can rectify this by [adding the parent directory to the PATH variable](https://itsfoss.com/add-directory-to-path-linux/).
[How to Add a Directory to PATH in LinuxLearn all the essential steps about adding a directory to the PATH in Linux and making those changes permanently.](https://itsfoss.com/add-directory-to-path-linux/)

You'll also get this exit code when you type commands that do not exist.

*is not a command, and*
*Unmount**is not installed*
*Screenfetch*## Exit code series 128+n
When an application or command is terminated or its execution fails due to a fatal error, the adjacent code to 128 is produced (128+n), where n is the signal number.
This includes all types of termination codes, like `SIGTERM`
, `SIGKILL`
, etc that apply to the value 'n' here.
### Code 130 or SIGINT
`SIGINT`
or **Sig**nal for Keyboard ** Int**errupt is induced by interrupting the process by termination signal 2, or by Ctrl+C.
Since the termination signal is 2, we get a code 130 (128+2). Here's a video demonstrating the interrupt signal for `lxappearance`
.
SIGINT(2) termination or Keyboard Interrupt (^C) that gives code 130
### Code 137 or SIGKILL
The `SIGKILL`
termination **sig**nal that **kill**s the process instantly has a termination signal 9. This is the last method one should use while terminating an application.
The exit code thrown is 137 since the termination signal is 9 (128+9).
SIGKILL(9) termination that gives code 137
### Code 143 or SIGTERM
`SIGTERM`
or **Sig**nal to **Term**inate is the default behavior when a process is killed without specifying arguments.
The termination code for SIGTERM is 15, hence this signal gets an exit code of 143 (128+15).
SIGTERM(15) termination that gives code 143
There are other termination signals that you may not have known before; they too have their own exit codes similar to these. You can check them out here:
[How to use SIGINT and other Termination Signals in LinuxTerminating executing process is more than just kill -9. Here are some of the prominent termination signals and their usage.](https://linuxhandbook.com/termination-signals/)

Note that these signals may not appear if terminated from the same session from which the process was started. If you're reproducing these, terminate from a different shell.
On a personal note, signal 128 was impossible to reproduce.
## What if the code exceeds 255?
Recent versions of Bash retain the original exit code value even beyond 255, but generally, if the code exceeds 255, then it is wrapped up.
That is, code 256 becomes '0', 257 becomes '1', 383 becomes '127', and so on and so forth. To ensure better compatibility, keep the exit codes between 0 and 255.
## Wrapping up
I hope you learned something about the exit codes in the Linux shell. Using them can come in handy for troubleshooting various issues.
If you are using these codes in a shell script, make sure you understand the meaning of each code in order to make it easier for troubleshooting.
In case you need a reference, check out the Bash series here:
[Bash Basics #1: Create and Run Your First Bash Shell ScriptStart learning bash scripting with this new series. Create and run your first bash shell script in the first chapter.](https://itsfoss.com/create-bash-script/)

That's all about the article. Feel free to let me know in the comments section if I have missed anything. |
16,061 | 你的旧电脑是 “过时” 了,还是使用 Linux 的机会? | https://opensource.com/article/22/10/obsolete-computer-linux-opportunity | 2023-08-04T09:37:44 | [
"旧电脑"
] | /article-16061-1.html | 
>
> 很多时候,老旧的电脑往往被打上 “过时” 的标签。Linux 改变了这一现状。翻新旧电脑,让它重新为需要它的人所用。
>
>
>
你可能经常听到有人说某个电脑、平板电脑或智能手机 “过时了”。当你听到这样的说法时,花一分钟问问自己:“这个人说的是个人观点还是事实?”
很多时候他们的陈述是主观观点。让我解释一下为什么。
当有人说一台电脑 “过时” 时,他们往往是从自己的角度出发的。因此,如果你是一名专业技术人员,一台使用了五年的电脑可能确实已经过时。但对于一个逃离战争或饥荒的难民家庭来说,这台五年前的电脑过时了吗?可能不会。对你来说过时的电脑,对别人来说可能是梦寐以求的电脑。
### 我是如何用 Linux 翻新旧电脑的
我在这方面有些经验。在过去的 25 年里,我一直把老旧电脑带给那些没有电脑的人。我的一名二年级学生,由祖母抚养长大,五年前从斯坦福大学毕业了。另一位学生,我在 2007 年给他送去了一台布满灰尘的 Windows XP 台式机,去年她从耶鲁大学毕业。这两名学生都利用捐赠的电脑实现了自我发展。后一位学生在中学毕业前,打字速度就超过了每分钟 50 个单词。我把捐赠电脑送到她家时,她还在读三年级,当时她的家庭还负担不起网络服务。因此,她有效地利用时间学习触摸打字技巧。我在这个 [YouTube 视频](https://www.youtube.com/watch?v=Ao_vOijz14U) 中记录了她的故事。
我再分享一件连我自己都难以相信的轶事。几年前,我在 eBay 上花 20 美元买了一台戴尔笔记本电脑。这台笔记本电脑是 2002 年的顶级笔记本电脑。我在上面安装了 Linux Mint,并添加了一个 USB WiFi 适配器,这台笔记本电脑就这样重生了。我把这个故事记录在 YouTube 视频中,名为 “[我的 20 美元 eBay 笔记本电脑](https://www.youtube.com/watch?v=UZiN6nm-PUU)”。
在视频中,你可以看到这台笔记本电脑正在上网。它的速度并不快,但比我们在 20 世纪 90 年代末使用的拨号上网电脑要快得多。我会将其描述为功能正常。有人可以用这台 2002 年的笔记本电脑撰写博士论文。论文读起来就像用昨天发布的电脑写的一样好。这台笔记本电脑应该摆放在公共场所,让人们近距离看到 2002 年的电脑仍然可以使用。眼见为实。这难道不是真理吗?
那么 2008 年、2009 年和 2010 年那些著名的 “上网本” 怎么样?它们肯定已经过时了吧?没那么快了吧!如果你在它们身上安装 32 位 Linux,它们就可以使用最新版本的 Chromium 网页浏览器上网冲浪,而 Chromium 浏览器仍然支持 32 位操作系统(不过谷歌 Chrome 浏览器不再支持 32 位操作系统)。使用这些上网本的学生可以观看<ruby> 可汗学院 <rt> Khan Academy </rt></ruby>的视频,使用<ruby> 谷歌文档 <rt> Google Docs </rt></ruby>提高写作能力。将这些上网本连接到更大的液晶屏幕上,学生就可以使用 [LibreOffice Draw](https://opensource.com/tags/libreoffice) 或 [Inkscape](https://opensource.com/downloads/inkscape-cheat-sheet) 这两个我最喜欢的开源图形程序来提高技能。如果你感兴趣,我有一个 [使用 Linux 重振上网本的视频](https://www.youtube.com/watch?v=GBYEclpvyGQ)。上网本也非常适合邮寄到海外,比如利比里亚的学校、海地的医院、索马里的食品分发点,或者其他任何捐赠技术可以发挥巨大作用的地方。
你知道翻新的上网本在哪里会受到欢迎吗?在那些向乌克兰难民敞开心扉和家园的社区。他们在尽自己的一份力量,我们也应该尽自己的一份力量。
### 开源让老旧电脑重获新生
许多技术专业人士生活在特权的泡沫中。当他们宣称某项技术 “过时” 时,可能并没有意识到他们把这种观点当作事实所造成的伤害。不了解开源如何让旧电脑重新焕发生机的人,正在宣判这些电脑的死刑。面对这种情况,我不会袖手旁观。你也不应该袖手旁观。
对于宣称电脑过时的人,一个简单的回答是:“有时旧电脑可以重获新生。我听说开源就是一种方法。”
如果你很了解对方,不妨分享本文列出的一些 YouTube 视频链接。如果有机会,请花点时间去见见那些无法获得所需技术的个人或家庭。这次会面将以你意想不到的方式丰富你的生活。
*(题图:MJ/cfd05206-dae4-4b14-a50c-38f2da342c95)*
---
via: <https://opensource.com/article/22/10/obsolete-computer-linux-opportunity>
作者:[Phil Shapiro](https://opensource.com/users/pshapiro) 选题:[lkxed](https://github.com/lkxed) 译者:[wcjjdlhws](https://github.com/wcjjdlhws) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
16,062 | 2023 年最佳 Linux 视频编辑软件 | https://www.debugpoint.com/linux-video-editors/ | 2023-08-04T10:35:00 | [
"视频编辑"
] | /article-16062-1.html | 
>
> 我们列出了最佳的 Linux 视频编辑器选项。请看一下。
>
>
>
视频编辑软件的确可能很昂贵,尤其是像 Adobe Premiere Pro 这样更高级的选项。但好消息是,有很多自由开源的视频编辑器可供选择。这些替代方案提供了出色的功能,而不需要付费。在这里,我们编制了一个由十个这样的免费 Linux 视频编辑器组成的列表,它们可能非常适合你的特定需求:
### 2023 年最佳 Linux 视频编辑器
#### 1、Blender
Blender 是这个列表中功能最强大的视频编辑器之一。值得注意的是,它是自由开源软件,同时也是一个 3D 建模工具。使用 Blender,你可以制作令人印象深刻的电影、动画电影、模拟以及进行动作追踪。
其多功能性使其成为许多用户的首选,包括工作室、个人艺术家、专业人士、爱好者、科学家、学生、视觉效果专家、动画师、游戏艺术家、改装者等等。
庞大的全球社区不断支持和丰富这个强大的编辑器,有众多贡献者不断增强其功能和能力。然而,由于它提供了一整套工具,新手可能需要一些时间来有效利用其全部潜能。但一旦掌握了它的功能,你将会对它能释放出无限创意而感到惊讶。

它的功能列表十分庞大,但以下是一些值得注意的功能:
* 建模
* 雕刻
* 动画与绑定
* <ruby> 油笔 <rt> Grease Pencil </rt></ruby>
* 渲染
* 模拟
* 视频编辑
* 脚本编写
* 视觉效果
* 用户界面
* 工作流程
>
> **[下载 Blender](https://www.blender.org/download/)**
>
>
>
#### 2、Lightworks
体验 [Lightworks](https://www.lwks.com/),一款多功能的<ruby> 免费增值 <rt> freemium </rt></ruby>的视频编辑器,可帮助你编辑社交媒体视频、4K 质量甚至完整的电影。非凡的是,这款非线性视频编辑器已在好莱坞电影编辑领域打下了自己的烙印,证明了其专业能力。
请记住,尽管免费版提供了丰富的工具和功能,但某些专业功能可能仅在付费版本中提供。
因此,无论你是渴望成为社交媒体影响者、专业电影制片人,还是喜欢制作高质量视频的人,Lightworks 可能成为你在视频编辑世界释放创造力的通行证。

以下是其功能的快速概述:
* 简单直观的用户界面
* 访问出色的免版税音频和视频内容
* 轻松进行时间轴编辑和修剪
* 用于 4K 的低分辨率代理工作流程
* 实时即用的音频和视频特效
* 导出适用于 YouTube/Vimeo、SD/HD 的视频,高达 4K
* 广泛的文件格式支持,包括可变帧率媒体
* 使用高达 32 位 GPU 精度和直方图工具专业地调整序列
>
> **[下载 Lightworks](https://lwks.com/)**
>
>
>
#### 3、Shotcut
介绍一下 [Shotcut](https://shotcut.org/),这是一款出色的自由开源的视频编辑器,能够在各种平台上无缝运行。Shotcut 具备许多功能,为用户带来了很多便利。其中一个突出的特点是其对各种格式的出色支持,让你可以轻松处理各种媒体文件。它的独特之处在于本地时间轴编辑,意味着你可以直接编辑文件,而无需进行耗时的导入操作。
Shotcut 的功能远不止于此;它还支持 Blackmagic Design,为你提供专业的输入和预览监控。无论你是内容创作者还是电影制片人,能够使用 4K 分辨率进行工作是 Shotcut 提供的巨大优势。你可以轻松使用该编辑器捕捉音频、视频甚至是摄像头画面。

Shotcut 的显著功能包括:
* 支持 4K 分辨率
* 音频、视频和摄像头捕捉
* 广泛的文件格式支持
* 4K 分辨率支持
* 插件
* 音频和视频滤镜
>
> **[下载 Shotcut](https://shotcut.org/download/)**
>
>
>
#### 4、Avidemux
对于初学者或仅作为业余爱好者的视频编辑者来说,Avidemux 是一个完美的选择。这款自由开源的视频编辑器专为简单的任务设计,如剪辑、应用滤镜和编码。它拥有用户友好的界面,为刚开始学习编辑的人提供流畅且易于操作的体验。
Avidemux 使用简单,并且支持广泛的文件格式,确保与各种媒体类型兼容。如果你有一些重复的任务或特定的工作流程,Avidemux 的项目和作业队列功能可以帮助你自动化编辑过程。
此外,Avidemux 还提供强大的脚本功能,适用于喜欢深入技术细节的用户,可以根据个人喜好自定义和微调编辑任务。
然而,需要注意的是,Avidemux 可能缺少一些其他专业级视频编辑器中的高级功能和复杂性。然而,对于初学者、学习者和业余爱好者来说,Avidemux 是一个直观且免费的解决方案,非常适合开始视频编辑之旅,为你的创作努力铺平道路。

>
> **[下载 Avidemux](https://avidemux.sourceforge.net/download.html)**
>
>
>
#### 5、HitFilm Express
寻找一个免费且出色的视频编辑器?试试 [HitFilm Express](https://fxhome.com/hitfilm-express),这是一款顶级的免费编辑软件。顾名思义,“express” 版本在功能上毫不逊色,非常适合初学者、YouTube 创作者和有抱负的电影制作者。有一支专业的开发团队支持,你可以期待无缝而精细的编辑体验。
HitFilm Express 集成了大量功能,让你释放创造力,制作出令人印象深刻的视频。无论你是刚开始视频编辑之旅还是希望提升你的 YouTube 内容,该软件提供了工具和灵活性,让你的想象变为现实。
然而,需要注意的是,目前 HitFilm Express 仅与 Windows 和 Mac 系统兼容。目前还没有 Linux 版本可用。开发团队根据用户群体做出了这个决定,因为在目前情况下,支持 Linux 可能在经济上不可行。(LCTT 译注:这个是怎么混进来的!)

>
> **[下载 HitFilm Express](https://fxhome.com/hitfilm-express)**
>
>
>
#### 6、DaVinci Resolve
DaVinci Resolve 是专业视频编辑的代表,具备精湛处理 8K 编辑的令人印象深刻能力。这款强大的软件跨越多个平台,使得 Linux、Mac 和 Windows 用户都能使用。然而,需要了解的是,DaVinci Resolve 是专有的商业软件。
凭借其全面的功能和出色的性能,DaVinci Resolve 是视频编辑爱好者和行业专业人士的强大选择。该软件提供了附加付费功能的工作室版本,包括许多插件和附加组件,以增强你的编辑能力。
如果你不想花费一分钱就能入门,也不必担心 - DaVinci Resolve 还提供免费版本。对于许多普通用户来说,免费版本已经完全足够满足他们的视频编辑需求。即使是免费版本,凭借其强大的工具和功能,也提供了丰富的选项,可以创建令人惊艳的视频,展现创意的想象力。

以下是一些主要功能的简介:
* 双时间轴
* 源磁带
* 专用修剪界面
* 智能编辑模式
* 快速回顾
* 变换、变速和稳定
* 快速导出
* 媒体导入
* 便携编辑
* 自定义时间轴设置
* 调整剪辑
* 人脸识别
* 速度加速变速
* 图像稳定
* 关键帧曲线编辑器
* 磁带式音频刮动
* 更快、更智能的编码
>
> **[下载 DaVinci Resolve](https://www.blackmagicdesign.com/in/products/davinciresolve)**
>
>
>
#### 7、OpenShot
如果你正在寻找一个简单强大、具有用户友好界面的免费视频编辑软件,那么 [OpenShot](https://www.openshot.org/) 是你的不二选择。这款出色的软件以简洁为设计理念,确保即使是初次接触视频编辑的人也能轻松上手。OpenShot 的直观设计提供了低学习曲线,适用于各个层次的用户。
最棒的是,OpenShot 适用于 Windows、Linux 和 Mac 等各种操作系统。因此,无论你喜欢哪个平台,都可以享受到 OpenShot 视频编辑能力带来的便利和强大功能。
因此,如果你正在寻找一个将用户友好功能与强大编辑能力相结合的免费视频编辑软件,OpenShot 应该是你的首选。拥抱其简洁性,投入编辑过程,轻松看到你的视频项目焕发生机。

>
> **[下载 OpenShot 视频编辑器](https://www.debugpoint.com)**
>
>
>
#### 8、KDenlive
认识一下 [KDenlive](https://kdenlive.org/),这是一款经过 15 年开发的经验丰富的视频编辑器。作为一款自由开源的应用程序,KDenlive 是社区合作和创新力量的典范。它基于 QT 框架构建,在 FFMpeg、frei0r、movie、ladspa 和 sox 等一流框架的支持下,确保了无缝可靠的编辑体验。
KDenlive 面向广泛的用户群体,非常适合想要尝试视频编辑的普通用户。它的独特之处在于考虑周到地包含了高级功能,实现了功能和易用性的完美平衡。你将找到丰富的工具,可以增强你的视频项目,而无需过多学习复杂的技术知识。
使用 KDenlive,你可以释放创造力,而无需被复杂的过程所困扰。这款编辑器使你能够制作引人入胜的视频,而无需掌握过多的技术知识。
以下是一些其功能的概述:
* 多轨视频编辑
* 使用任何音频/视频格式
* 可配置的界面和快捷键
* 使用带有 2D 标题的标题工具
* 多种效果和转场
* 音频和视频范围检测
* 代理编辑
* 自动备份
* 可在界面直接下载在线资源
* 时间轴预览
* 可关键帧化的效果
* 主题界面

>
> **[下载 KDenlive](https://kdenlive.org/en/download/)**
>
>
>
#### 9、Flowblade
“快速、精确、稳定” - 这正是最能概括 [Flowblade](https://jliljebl.github.io/flowblade/) 的标语,这是一款非线性视频编辑器,旨在以最高效的方式满足目标用户的需求。通过提供一种无缝快速的编辑体验,保证每个细节的精确性,并为你的创意努力提供稳定的平台,这款编辑器兑现了它的承诺。
Flowblade 在功能方面毫不保留。它配备了一套全面的工具,以促进你的编辑过程。从简化工作流程的编辑工具到平滑排序的时间轴功能,该编辑器应有尽有。
为了进一步提高你的编辑效率,Flowblade 包含了一个范围记录,方便你管理剪辑并精确选择所需的片段。此外,它支持代理编辑,这是一个有价值的功能,可在处理高分辨率媒体时优化性能。
以下是一些其功能的概述:
* 编辑工具
* 时间轴功能
* 合成器
* 滤镜
* 范围记录
* 代理编辑
* 批量渲染队列
* G'mic 特效工具
* 音频混音器
* 媒体链接处理
* 标题制作
* 其它功能
* 渲染
* 支持 MLT 视频和音频编解码器

该软件只适用于 Linux 系统,不适用于 Windows 或 Mac。
>
> **[下载 Flowblade](https://jliljebl.github.io/flowblade/download.html)**
>
>
>
#### 10、Olive
介绍一下 [Olive](https://www.olivevideoeditor.org/),这是一款非常出色的免费非线性视频编辑器,旨在成为高端专业视频编辑软件的全功能替代品。目前 Olive 处于活跃开发阶段,处于 ALPHA 阶段。尽管处于早期阶段,这个编辑器已经引起了广泛关注,并且已经在使用 Olive 进行视频创作的用户中表现出色。
凭借其雄心勃勃的目标和不断壮大的社区,Olive 展示出了成为视频编辑领域强大竞争对手的潜力。已经有用户开始使用这个新兴编辑器制作视频,他们的经验展示了它所具备的能力。

你可以通过下面的链接在 Windows、Linux 和 Mac 上下载。
>
> **[下载 Olive](https://www.olivevideoeditor.org/download.php)**
>
>
>
### 总结
在这个汇编中,我们重点介绍了 Linux 上的十大专业视频编辑器,为不同的编辑需求提供了多样化的选择。某些编辑器在熟练使用时甚至可以媲美甚至取代高价专业软件。
例如,Blender、KDenlive 和 DaVinci Resolve 是创建专业级视频甚至完整电影的出色选择。每个编辑器都具有独特的优势和功能,使它们成为有抱负的电影制作者和内容创作者的可靠工具。
现在轮到你了!你对这个 Linux 视频编辑器列表有何看法?你还有其他喜欢推荐的编辑器吗?请在评论框中告诉我。
*图片来源:各应用程序。*
*(题图:MJ/9b567ebc-e5ed-4cdc-a023-30bbdfa564e8)*
---
via: <https://www.debugpoint.com/linux-video-editors/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
16,064 | 分步指南:安装和访问 Kubernetes 仪表板 | https://www.linuxtechi.com/how-to-install-kubernetes-dashboard/ | 2023-08-05T13:25:00 | [
"Kubernetes"
] | https://linux.cn/article-16064-1.html | 
Kubernetes 是一个开源容器编排平台,已成为大规模管理容器化应用的首选解决方案。虽然 Kubernetes 提供了强大的命令行工具来管理集群,但有时可视化界面可以使监控和管理部署变得更加容易。Kubernetes 仪表板是一个基于 Web 的用户界面,可让你可视化 Kubernetes 集群并与之交互。
在这篇博文中,我们将逐步引导你完成安装和访问 Kubernetes Dashboard 的过程,使你能够简化 Kubernetes 管理任务。
先决条件:
在安装 Kubernetes Dashboard 之前,请确保你有一个正在运行的 Kubernetes 集群并具有必要的管理访问权限。
### 安装 Kubernetes 仪表板
为集群安装 Kubernetes 仪表板的简单方法是通过 Helm Chart。Kubernetes 仪表板现在依赖于 cert-manager 和 nginx-ingress-controller。幸运的是,可以使用 Helm Chart 自动安装这些依赖项。但是,如果你已经安装了这些组件,则可以在安装 Chart 时通过设置标志 `–set=nginx.enabled=false` 和 `–set=cert-manager.enabled=false` 来禁用它们的安装。
事不宜迟,让我们进入安装步骤。
#### 1)安装 Helm
使用终端或命令提示符访问集群的主节点。如果没有安装,请安装 helm。运行以下命令。
```
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
$ chmod 700 get_helm.sh
$ ./get_helm.sh
```

#### 2)添加 Kubernetes 仪表板 Helm 仓库
运行以下 `helm` 命令来添加仪表板仓库:
```
$ helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/
$ helm repo list
```

#### 3)安装 Kubernetes 仪表板
要使用 `helm` 安装 Kubernetes 仪表板,请运行以下命令:
```
$ helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard
```

上面的输出确认仪表板已部署在 `Kubernetes-dashboard` 命名空间中。因此,要访问仪表板,请运行:
```
$ kubectl -n kubernetes-dashboard port-forward svc/kubernetes-dashboard-nginx-controller 8443:443
```

现在,打开运行上述命令的系统的 Web 浏览器,输入以下 URL:
```
https://localhost:8443
```

点击“<ruby> 接受风险并继续 <rt> Accept the Risk and Continue </rt></ruby>”。

正如你在上面看到的,我们需要一个令牌才能登录。因此,让我们在下一步中生成所需的令牌。
#### 4)为 Kubernetes 仪表板生成令牌
再打开一个到主节点的 SSH 会话,创建一个服务帐户并使用以下 yaml 文件分配所需的权限:
```
$ vi k8s-dashboard-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kube-system
```
保存并退出文件。
接下来通过运行以下命令创建服务帐户:
```
$ kubectl create -f k8s-dashboard-account.yaml
serviceaccount/admin-user created
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
$
```
现在,为管理员用户生成令牌,运行:
```
$ kubectl -n kube-system create token admin-user
```

复制此令牌并返回浏览器,将其粘贴到“<ruby> 输入令牌 <rt> Enter token </rt></ruby>”字段中,如下所示:

点击“<ruby> 登录 <rt> Login </rt></ruby>”。
#### 5) 访问 Kubernetes 仪表板
当我们点击上面的“登录”时,我们将看到以下仪表板:

太好了,你现在已登录 Kubernetes 仪表板。以下是一些需要探索的关键特性和功能:
* 集群概览:获取集群运行状况、资源利用率和运行 Pod 的概览。
* 工作负载:查看和管理你的部署、副本集、有状态集和守护程序集。
* 服务:监控和管理你的服务,包括负载均衡器和外部端点。
* 配置:探索你的配置映射、密钥和持久卷声明。
* 存储:管理持久卷和存储类。
* 命名空间:在命名空间之间切换以查看和管理不同项目或团队的资源。
这就是这篇文章的全部内容,我希望你发现它有用且内容丰富。请在下面的评论部分发表你的疑问和反馈。
*(题图:MJ/1bd0efb0-d4ee-4c8b-854a-49dbf38c5dd7)*
---
via: <https://www.linuxtechi.com/how-to-install-kubernetes-dashboard/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this blog post, we will show you how to install Kubernetes dashboard using helm step-by-step, empowering you to streamline your Kubernetes management tasks.
Kubernetes, an open-source container orchestration platform, has become the go-to solution for managing containerized applications at scale. While Kubernetes provides powerful command-line tools for managing clusters, sometimes a visual interface can make monitoring and managing your deployments even easier. Kubernetes Dashboard is a web-based user interface that allows you to visualize and interact with your Kubernetes clusters.
#### Prerequisites
Before installing Kubernetes Dashboard, ensure that you have a running [Kubernetes cluster](https://www.linuxtechi.com/install-kubernetes-on-ubuntu-22-04/) and have the necessary administrative access.
## Installing Kubernetes Dashboard
The easy way to install [Kubernetes dashboard](https://github.com/kubernetes/dashboard) for your cluster is via helm chart. Latest Kubernetes dashboard now has a dependency on cert-manager and nginx-ingress-controller. Fortunately, these dependencies can be automatically installed using the Helm chart. However, if you already have these components installed, you can disable their installation by setting the flags —**set=nginx.enabled=false** and **–set=cert-manager.enabled=false** when installing the chart.
Without any further delay, let’s jump into Kubernetes dashboard installation steps,
#### 1) Install Helm
Access your cluster’s master node using a terminal or command prompt. Install helm if not installed. Run the following commands.
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 $ chmod 700 get_helm.sh $ ./get_helm.sh
#### 2) Add Kubernetes Dashboard Helm Repository
Run following helm command to add dashboard repository,
$ helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/ $ helm repo list
#### 3) Install Kubernetes Dashboard Using Helm
To install Kubernetes dashboard using helm, run following command,
$ helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard
Output above confirms dashboard has been deployed in Kubernetes-dashboard namespace. So, in order to access dashboard from the cluster locally, run
$ export POD_NAME=$(kubectl get pods -n kubernetes-dashboard -l "app.kubernetes.io/name=kubernetes-dashboard,app.kubernetes.io/instance=kubernetes-dashboard" -o jsonpath="{.items[0].metadata.name}") $ kubectl -n kubernetes-dashboard port-forward $POD_NAME 8443:8443
Now, open the web browser of system on which you have run above command, type following URL
https://localhost:8443
Click on “Accept the Risk and Continue”
As you can see above, we need a token to login. So, let’s generate the required token in the next step.
Accessing Kubernetes Dashboard from Outside
In case you want to access dashboard from outside of Kubernetes cluster then expose the Kubernetes-dashboard deployment using NodePort type, as show below:
$ kubectl expose deployment kubernetes-dashboard --name k8s-svc --type NodePort --port 8443 -n kubernetes-dashboard
Check the dashboard service, run
Next, try to access dashboard from outside of cluster using the URL:
https://<Worker-IP-Address>:31233
#### 4) Generate Token for Kubernetes Dashboard
Open one more ssh session to master node and create a service account and assign required permissions using following yaml file,
$ vi k8s-dashboard-account.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system
save and exit the file
Next create service account by running following command
$ kubectl create -f k8s-dashboard-account.yaml serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created $
Now, generate the token for admin-user, run
$ kubectl -n kube-system create token admin-user
Copy this token and head back to browser, paste it on “Enter Token” field as shown below,
Click on “Sign in”
#### 5) Access Kubernetes Dashboard
When we click on “Sign in” in above then we will get the following dashboard,
Great, you are now logged in to the Kubernetes Dashboard. Here are a few key features and functionalities to explore:
- Cluster Overview: Gain an overview of your cluster’s health, resource utilization, and running pods.
- Workloads: View and manage your deployments, replica sets, stateful sets, and daemon sets.
- Services: Monitor and manage your services, including load balancers and external endpoints.
- Configurations: Explore your config maps, secrets, and persistent volume claims.
- Storage: Manage persistent volumes and storage classes.
- Namespaces: Switch between namespaces to view and manage resources across different projects or teams.
That’s all from this post, I hope you have found it useful and informative. Kindly do post your queries and feedback in below comments section. |
16,065 | systemd:初学者如何理解其中的争议 | https://itsfoss.com/systemd-init/ | 2023-08-05T15:39:21 | [
"systemd"
] | https://linux.cn/article-16065-1.html | 
>
> 对于什么是 systemd,以及为什么它经常成为 Linux 世界争议的焦点,你可能仍然感到困惑。我将尝试用简单的语言来回答。
>
>
>
在 Linux 世界中,很少有争议能像传统的 System V [初始化](https://en.wikipedia.org:443/wiki/Init) 系统(通常称为 SysVinit)和较新的 [systemd](https://systemd.io:443/) 之间的斗争那样引起如此大的争议。
在这篇文章中,我将简要讨论什么是 systemd、它相对于传统初始化系统有哪些优点和缺点以及为什么它会引起争议。
### 什么是 systemd?
systemd 是一个系统和服务管理器,于 2010 年首次推出,用于取代传统的 System V 初始化系统。它旨在提高启动速度并更有效地管理系统服务。如今,systemd 是许多流行 Linux 发行版的默认初始化系统,包括 Ubuntu、Fedora 和 Red Hat Enterprise Linux(RHEL)。
### systemd 是守护进程吗?
尽管名字中带有 “d”,但 systemd 并不是一个守护进程。相反,它是一个为 Linux 提供许多系统组件的软件套件。其目标是标准化 Linux 发行版的服务配置和行为。
systemd 的主要组件是一个“系统和服务管理器”,它充当初始化系统来引导用户空间并管理用户进程。它还提供了各种守护程序和实用程序的替代品,从设备和登录管理到网络连接管理和事件记录。
### systemd 的主要特性
systemd 具有许多功能,例如它能够主动并行化操作、方便按需启动守护进程、使用 Linux 控制组监视进程、管理挂载点和自动挂载点,以及实现复杂的基于事务依赖的服务控制逻辑。
此外,systemd 支持 SysV 和 LSB 初始化脚本,作为 SysVinit 的替代品。它还提供了一个日志守护进程和用于管理基本系统配置的工具程序。

### systemd 与 SysVinit:争议
SysVinit 与 systemd 争论的核心围绕如何最好地管理基于 Linux 的系统。关注的范围从复杂性和兼容性到管理系统服务的最佳方式,涉及系统管理员和 Linux 爱好者面临的基本问题。
批评者认为 systemd 过于复杂和巨大化,使得故障排除变得更加困难。他们担心单点故障,因为所有服务都由一个守护进程管理,并且担心与 Linux 内核的紧密集成,这可能会限制向其他系统的可移植性。
这就是为什么有些人创建 [脱离 systemd 的发行版](https://itsfoss.com/systemd-free-distros/) 的原因。
然而,支持者称赞 systemd 提供了一种更高效、更现代的系统管理方法,其服务启动的并行性和守护进程的按需启动减少了启动时间并提高了系统响应能力。他们还赞扬其先进的日志记录功能。
尽管存在争议,systemd 已成为许多 Linux 发行版的默认初始化系统,系统管理员和开发人员已经开始欣赏它的高级特性和功能。
### systemd 与 SysVinit 的优点和缺点
优点:
| SysVinit 的优点 | systemd 的优点 |
| --- | --- |
| 简单且熟悉 | 提高启动速度 |
| 尊重 Unix 哲学 | 标准化日志系统 |
| 更直接地控制系统服务 | 一致的服务管理方法 |
| 系统成熟稳定 | 与现代 Linux 系统和应用程序的兼容性 |
| 与遗留系统和应用的兼容性 | 来自大型开发者和贡献者社区的积极开发和支持 |
缺点:
| SysVinit 的缺点 | systemd 的缺点 |
| --- | --- |
| 与新的初始化系统相比功能有限 | 复杂性和陡峭的学习曲线 |
| 缺乏对服务并行启动的内置支持 | 有侵入性,可能会破坏与传统 Unix 工具和程序的兼容性 |
| 可能比新的初始化系统效率低,尤其是在大型系统上 | 某些系统可能会出现不稳定和崩溃的情况 |
| 对现代 Linux 系统和应用的有限支持 | 与尚未支持 systemd 的遗留系统和应用的兼容性有限 |
### 总结:个人观点
作为一名来自 UNIX 早期的 Linux 用户,我更倾向于传统的初始化系统。然而,尽管我最初有所抵触,但我已经开始接受 systemd,并看到了它的一些好处。每个系统在 Linux 世界中都有自己的位置,了解这两个系统非常重要。
关于 systemd 的争论仍在继续。你对此有何看法?
*(题图:MJ/efce857c-2d1a-4bf0-a400-8eb60e9f3271)*
---
via: <https://itsfoss.com/systemd-init/>
作者:[Bill Dyer](https://itsfoss.com/author/bill/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

In the world of Linux, few debates have stirred as much controversy as the battle between the traditional System V [init](https://en.wikipedia.org/wiki/Init) system, often known as SysVinit, and the newer [ systemd](https://systemd.io/).
In this article, I'll briefly discuss what systemd is, what advantages and disadvantages it has over the traditional init systems and why it is controversial.
## What is systemd?
systemd is a system and service manager, first introduced in 2010 to replace the traditional System V init system. It was designed to improve boot-up speeds and manage system services more efficiently. Today, `systemd`
is the default `init`
system for many popular Linux distributions, including Ubuntu, Fedora, and Red Hat Enterprise Linux.
## Is systemd a Daemon?
Despite the name, `systemd`
is not a daemon. Instead, it's a software suite that provides a number of system components for Linux. Its goal: to standardize service configuration and behavior across Linux distributions.
The main component of `systemd`
is a "system and service manager", which serves as an `init`
system to bootstrap user space and manage user processes. It also offers replacements for various daemons and utilities, from device and login management to network connection management and event logging.
## Key Features of systemd
`systemd`
has many features, such as its ability to aggressively parallelize operations, facilitate the on-demand launching of daemons, monitor processes using Linux control groups, manage mount and automount points, and implement a sophisticated transactional dependency-based service control logic.
Additionally, `systemd`
supports SysV and LSB init scripts, serving as a substitute for SysVinit. It also offers a logging daemon and utilities for managing essential system configurations.
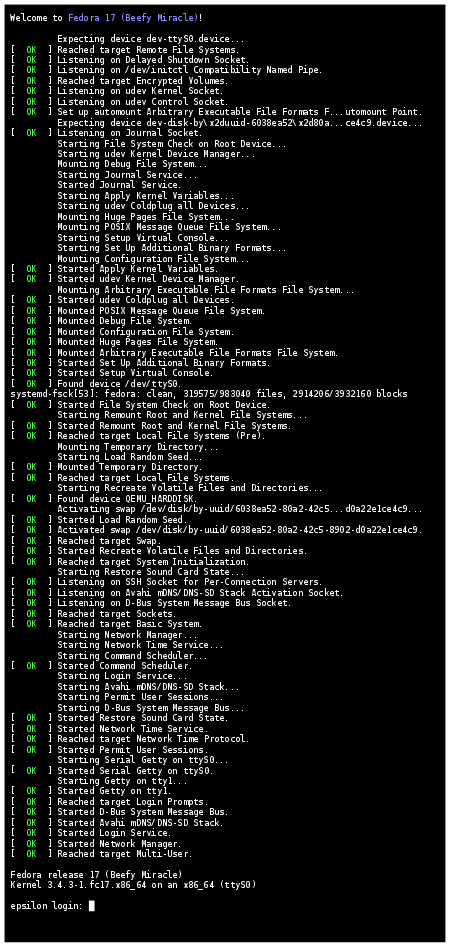
## systemd Vs SysVinit: The Controversy
The heart of the init vs systemd debate revolves around how best to manage Linux-based systems. Concerns range from complexity and compatibility to the optimal way to manage system services, touching on foundational questions facing system administrators and Linux enthusiasts.
Critics argue that `systemd`
is too complex and monolithic, making it harder to troubleshoot. They worry about a single point of failure, as all services are managed by one daemon, and voice concerns about tight integration with the Linux kernel, which could limit portability to other systems.
That's the reason why some people created [distributions free from systemd](https://itsfoss.com/systemd-free-distros/).
Proponents, however, praise `systemd`
for providing a more efficient and modern approach to system management, with its parallelization of service startup and on-demand starting of daemons reducing boot times and improving system responsiveness. They also commend its advanced logging capabilities.
Despite the controversy, `systemd`
has become the default `init`
system for many Linux distributions, and system administrators and developers have come to appreciate its advanced features and capabilities.
## Positives and Negatives of systemd Vs SysVinit
**Positives**
Positives of SysVinit | Positives of systemd |
---|---|
Simplicity and familiarity | Improved boot-up speed |
Respect for Unix philosophy | Standardized logging system |
More direct control over system services | Consistent approach to service management |
Mature and stable system | Compatibility with modern Linux systems and applications |
Compatibility with legacy systems and applications | Active development and support from a large community of developers and contributors |
**Negatives**
Negatives of SysVinit | Negatives of systemd |
---|---|
Limited functionality compared to newer `init` systems | Complexity and steep learning curve |
Lack of built-in support for parallel startup of services | Invasive nature and potential for breaking compatibility with traditional Unix tools and utilities |
Can be less efficient than newer `init` systems, especially on large systems | Potential for instability and crashes on some systems |
Limited support for modern Linux systems and applications | Limited compatibility with legacy systems and applications that have not been updated to work with `systemd` |
## Conclusion: A Personal Perspective
As a Linux user hailing from the older days of UNIX, my preference leans toward the traditional `init`
system. However, I've come to accept `systemd`
, seeing some of its benefits despite my initial resistance. Each system has its own place in the Linux world, and it's important to understand both.
The `systemd`
debate continues. What is your take on it? |
16,067 | 在启用安全启动的 Fedora 中安装英伟达驱动 | https://www.insidentally.com/articles/000034/ | 2023-08-05T18:41:44 | [
"Fedora",
"英伟达"
] | https://linux.cn/article-16067-1.html |
>
> 本文介绍如何在 Fedora 中自动签署英伟达内核模块。
>
>
>

### 背景信息
现在新出厂的电脑 UEFI 会默认开启<ruby> 安全启动 <rt> Secure Boot </rt></ruby>,它的作用是防止恶意软件侵入。当电脑的引导程序被病毒修改之后,它会给出提醒并拒绝启动,避免可能带来的进一步损失。不过它同样会阻止一些未经微软签名的 Linux 内核启动运行。虽然可以直接选择在主板设置中关闭安全启动来解决这些麻烦,但在近期微软公布的 Windows 11 最低硬件标准中可以看到,安全启动被微软看的越来越重。如果你的电脑是 Windows + Linux 双系统,最好还是让 Linux 本身支持安全启动。
而最好用的发行版之一 Fedora 更热衷于开源驱动。Fedora 其本身是支持安全启动的,但是当你通过 Rpmfusion 安装官方的英伟达驱动,会造成这些驱动的内核模块未签名。在 Linux 启动过程中因为安全启动校验签名,会阻止加载这些模块,进而无法正常驱动显卡。
用过 Ubuntu 的伙伴们应该知道,在安全启动开启的情况下,Ubuntu 安装程序会自动用自签密钥来签名英伟达驱动内核模块,并在开机过程中自动将该自签密钥导入 MOK List(安全启动机器主人信任密钥列表)。但 Fedora 只会保证自身内核签名有效,而对 Rpmfusion 中的第三方内核模块签名问题不予理会,导致无法正常加载英伟达驱动。
本文介绍如何在 Fedora 中自动签署英伟达内核模块
### 准备工作
在 Fedora 36 之前,要像 Ubuntu 那样自动签署内核模块有点困难。但从这个版本开始,你只需几个简单的步骤就能做到。
在开始之前,让我们先确认一些前提条件已经满足:
1. 已启用安全启动;
2. 尚未安装英伟达驱动程序(**非常关键**,如果你已经安装了专有的英伟达驱动,可能需要重装系统才行);
3. 以及安装了 Fedora 36 及以上版本。
本指南主要参考了以下资料:
1. [Rpmfusion 的官方英伟达文档](https://rpmfusion.org/Howto/NVIDIA)
2. [Rpmfusion 的官方安全启动文档](https://rpmfusion.org/Howto/Secure%20Boot)
3. [Andrei Nevedomskii 的博客教程](https://blog.monosoul.dev/2022/05/17/automatically-sign-nvidia-kernel-module-in-fedora-36/)
希望深入了解的朋友可以阅读上述资料进一步研究。
### 具体步骤
#### 1、安装自动签名所需的工具
```
sudo dnf install kmodtool akmods mokutil openssl
```
#### 2、生成签名密钥
```
sudo kmodgenca -a
```
该命令会在 `/etc/pki/akmods/certs/` 目录下生成密钥,运行正确的情况下**不会**有输出。
#### 3、启动密钥注册
这将使 Linux 内核信任使用你的密钥签名的驱动程序。
```
sudo mokutil --import /etc/pki/akmods/certs/public_key.der
```
你会被要求输入一个密码。请记住这个密码,在下面的第五步中还需要再次使用。
#### 4、重启以注册密钥
```
sudo reboot
```
#### 5、注册密钥
重启后,你将看到蓝色的 MOK 管理器界面,不要被这种类似 BSOD 的页面吓坏,按照以下步骤注册密钥。
>
> 如果你曾在启用安全启动的 Ubuntu 中安装过英伟达驱动程序,你可能见过这个界面。
>
>
>
1、首先要及时按任意建继续进入 MOK 管理(如果没有及时进入 MOK 管理,系统会重启)

2、首先选择 “Enroll MOK” 注册 MOK。
3、然后选择 “Continue”。
4、选择 “Yes” 并输入步骤 3 中的密码并回车(**密码不会在输入框中显示,输入密码直接回车就好了**)。

5、此时密钥已经注册,选择 “reboot”,设备将再次重启。

#### 6、安装英伟达驱动程序
现在只需正常安装英伟达驱动程序。
```
sudo dnf install gcc kernel-headers kernel-devel akmod-nvidia xorg-x11-drv-nvidia xorg-x11-drv-nvidia-libs
```
#### 7、确保内核模块已编译
```
sudo akmods --force
```
#### 8、确保启动镜像也已更新
```
sudo dracut --force
```
#### 9、重启设备
```
sudo reboot
```
### 验证是否成功
重启完成后,输入以下命令确认驱动是否加载:
```
lsmod | grep -i nvidia
```
如果有类似以下的输出,恭喜你,一切顺利,一切就绪!
```
$ lsmod | grep -i nvidia
nvidia_drm 94208 2
nvidia_modeset 1560576 2 nvidia_drm
nvidia_uvm 3493888 0
nvidia 62517248 118 nvidia_uvm,nvidia_modeset
video 73728 3 asus_wmi,i915,nvidia_modeset
```
现在,你可以愉快的在开启安全启动的情况下使用英伟达显卡了。
希望本文能够帮助到你。
---
作者简介:一个喜欢瞎鼓捣的外科医生
---
via: <https://www.insidentally.com/articles/000034/>
作者:[insidentally](https://www.insidentally.com) 编辑:[wxy](https://github.com/wxy)
本文由贡献者投稿至 [Linux 中国公开投稿计划](https://github.com/LCTT/Articles/),采用 [CC-BY-SA 协议](https://creativecommons.org/licenses/by-sa/4.0/deed.zh) 发布,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # 在启用安全启动的 Fedora 中安装 Nvidia 驱动
现在新出厂的电脑 UEFI 会默认开启安全启动,安全启动的作用是防止恶意软件侵入。当电脑引导器被病毒修改之后,它会给出提醒并拒绝启动,避免可能带来的进一步损失。不过它同样会阻止一些未经微软签名的 Linux 内核启动运行。虽然可以直接选择在主板设置中关闭安全启动来解决一系列麻烦,但就在近期微软公布的 Windows 11 最低硬件标准中可以看到,安全启动被微软看的越来越重。如果你的电脑是 Windows + Linux 双系统,最好还是让 Linux 本身支持安全启动。
而最好用的发行版之一 Fedora 更热衷于开源驱动。Fedora 其本身是支持安全启动的,但是当你通过 rpmfusion 安装官方的英伟达驱动,会造成这些驱动的内核模块未签名。在 Linux 启动过程中因为安全启动校验签名,会阻止加载这些模块,进而无法正常驱动显卡。用过 Ubuntu 的伙伴们应该知道,在安全启动开启的情况下 ,Ubuntu 安装程序会自动用自签密钥签名英伟达驱动内核模块,并在开机过程中自动将该自签密钥导入 MOK List(安全启动机器主人信任密钥列表)。而 Fedora 只会保证自身内核签名有效,对 rpmfusion 中的第三方内核模块签名问题不予理会,导致无法正常加载英伟达驱动。
本文介绍如何在 Fedora 中自动签署英伟达内核模块
### 准备工作
在 Fedora 36 之前,要像 Ubuntu 那样自动签署内核模块有点困难。但从这个版本开始,您只需几个简单的步骤就能做到。
在开始之前,让我们先确认一些前提条件已经满足:
- 已启用安全启动;
- 尚未安装英伟达驱动程序(
**非常关键**,如果你已经安装了专有的英伟达驱动,可能需要重装系统才行); - 以及安装了 Fedora 36 及以上版本。
本指南主要参考了以下资料:
不满足于本文的朋友可以阅读上述资料进一步深入研究。
### 具体步骤
#### 1. 安装自动签名所需的工具
1 | sudo dnf install kmodtool akmods mokutil openssl |
#### 2. 生成签名密钥
1 | sudo kmodgenca -a |
该命令会在 `/etc/pki/akmods/certs/`
目录下生成密钥,运行正确的情况下不会有输出。
#### 3. 启动密钥注册
这将使 Linux 内核信任使用你的密钥签名的驱动程序
1 | sudo mokutil --import /etc/pki/akmods/certs/public_key.der |
你会被要求输入一个密码。请记住这个密码,在第五步中还需要再次使用。
#### 4. 重启以注册密钥
1 | sudo reboot |
#### 5. 注册密钥
重启后,你将看到蓝色的 MOK 管理器界面,不要惊惶,按照以下步骤注册密钥。
如果你曾在启用安全启动的 Ubuntu 中安装过英伟达驱动程序,你可能见过这个界面。
- 首先要及时按任意建继续进入 MOK 管理(如果没有及时进入 MOK 管理,系统会重启)

-
接着选择“Enroll MOK”注册 MOK。
-
然后选择“Continue”。
-
选择“Yes”并输入步骤 3 中的密码并回车(
**密码不会在输入框中显示,输入密码直接回车就好了**)。

- 此时密钥已经注册,选择“reboot”,设备将再次重启。

#### 6. 安装英伟达驱动程序
现在只需正常安装英伟达驱动程序。
你需要提前配置好 rpmfusion 软件源。参看清华开源镜像站的
[教程]
1 | sudo dnf install gcc kernel-headers kernel-devel akmod-nvidia xorg-x11-drv-nvidia xorg-x11-drv-nvidia-libs |
#### 7. 确保内核模块已编译
1 | sudo akmods --force |
#### 8. 确保启动镜像也已更新
1 | sudo dracut --force |
#### 9. 重启设备
1 | sudo reboot |
### 确认是否成功
重启完成后,输入以下命令确认驱动是否加载:
1 | lsmod | grep -i nvidia |
如果有类似以下的输出,恭喜你,一切顺利,一切就绪!
1 | lsmod | grep -i nvidia |
现在,你可以愉快的在开启安全启动的情况下使用英伟达显卡了。
对于使用 Debian 的朋友,可以参考 Debian 关于安全启动的[官方教程](https://wiki.debian.org/SecureBoot#MOK_-_Machine_Owner_Key)。由于我没有在 Debian 上尝试过,无法为你提供帮助。
希望本文能够帮助到你。
[CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/)许可协议。转载请注明来自
[无妄当自持](https://www.insidentally.com)! |
16,068 | Linux 黑话解释:什么是 LUKS 加密? | https://itsfoss.com/luks/ | 2023-08-05T23:07:00 | [
"LUKS",
"黑话"
] | https://linux.cn/article-16068-1.html | 
>
> LUKS 是 Linux 用户中流行的磁盘加密机制。在这篇术语解析文章中,可以了解更多关于 LUKS 的信息。
>
>
>
计算机安全旨在保护私密信息。有许多方法可以保护系统。一些用户使用简单的用户名/密码登录方案进行基本保护。其他用户可能会通过加密以不同的方式增加额外的保护,如使用 VPN 和磁盘加密。
如果你的计算机上有敏感的客户数据(你可能在经营一家企业),或被视为知识产权的材料,或者你对隐私非常谨慎,你可能要考虑磁盘加密。
磁盘加密的一些好处包括:
* 保护系统免受黑客的攻击
* 防止数据泄露
* 保护你免受潜在的责任问题
磁盘加密软件可以防止台式机硬盘驱动器、便携式 USB 存储设备或笔记本电脑被访问,除非用户输入正确的身份验证数据。如果你的笔记本电脑丢失或被盗,加密会保护磁盘上的数据。
如今,新的 Windows 系统默认配备了 BitLocker 加密。在 Linux 上,LUKS 是最常用的磁盘加密方式。
想知道什么是 LUKS?我会为你简要介绍这个主题。
### 技术术语
在继续之前,需要定义一些术语。LUKS 有很多内容,因此将其拆解为细项将有助于你进一步了解。
<ruby> 卷 <rt> Volume </rt></ruby>:卷是一个逻辑存储区域,可用于存储数据。在磁盘加密的场景中卷指的是已加密以保护其内容的磁盘部分。
<ruby> 参数 <rt> Parameters </rt></ruby>:参数是控制加密算法运行方式的设置。参数可能包括所使用的加密算法、密钥大小以及有关如何执行加密的其他详细信息。
<ruby> 加密类型 <rt> Cipher type </rt></ruby>\*\*:它是指用于加密的数学算法。它指的是用于保护加密卷上数据的具体加密算法。
密钥大小Key size:密钥大小是衡量加密算法强度的指标:密钥大小越大,加密强度越高。通常以位数表示,例如 128 位加密或 256 位加密。
<ruby> 头部 <rt> Header </rt></ruby>:头部是加密卷开头的特殊区域,包含有关加密的信息,例如所使用的加密算法和加密密钥。
下一个定义对于新手来说可能有些棘手,但了解它还是很重要的,尤其在处理 LUKS 时,这会非常有用。
<ruby> 容器 <rt> Container </rt></ruby>:容器是一个特殊的文件,类似于虚拟加密卷。它可以用于存储加密数据,就像加密分区一样。不同之处在于容器是一个文件,可以存储在未加密的分区上,而加密分区是整个磁盘的一部分,已经完全加密。因此,容器是 *充当虚拟加密卷的文件*。
### LUKS 是什么以及它能做什么?
LUKS(<ruby> <a href="https://en.wikipedia.org/wiki/Linux_Unified_Key_Setup?ref=its-foss"> Linux 统一密钥设置 </a> <rt> Linux Unified Key Setup </rt></ruby>)是由 Clemens Fruhwirth 在 2004 年创建的磁盘加密规范,最初用于 Linux。它是一种知名的、安全的、高性能的磁盘加密方法,基于改进版本的 [cryptsetup](https://www.tutorialspoint.com/unix_commands/cryptsetup.htm?ref=its-foss),使用 [dm-crypt](https://www.kernel.org/doc/html/latest/admin-guide/device-mapper/dm-crypt.html?ref=its-foss) 作为磁盘加密后端。LUKS 也是网络附加存储(NAS)设备中常用的加密格式。
LUKS 还可以用于创建和运行加密容器。加密容器具有与 LUKS 全盘加密相同的保护级别。LUKS 还提供多种加密算法、多种加密模式和多种哈希函数,有 40 多种可能的组合。

任何文件系统都可以进行加密,包括交换分区。加密卷的开头有一个未加密的头部,它允许存储多达 8 个(LUKS1)或 32 个(LUKS2)加密密钥,以及诸如密码类型和密钥大小之类的加密参数。
这个头部的存在是 LUKS 和 dm-crypt 的一个重要区别,因为头部允许使用多个不同的密钥短语,并能轻松更改和删除它们。然而,值得提醒的是,如果头部丢失或损坏,设备将无法解密。
LUKS 有两个版本,LUKS2 具有更强的头部损坏抗击性,并默认使用 [Argon2](https://www.argon2.com/?ref=its-foss) 加密算法(LUKS1 使用 [PBKDF2](https://en.wikipedia.org/wiki/PBKDF2?ref=its-foss))。在某些情况下,可以在两个版本之间进行转换,但是 LUKS1 可能不支持某些功能。
### 希望了解更多信息?
希望本文有助于你对 LUKS 和加密有一些了解。关于使用 LUKS 创建和使用加密分区的确切步骤会因个人需求而异,因此我不会在此处涵盖安装和设置方面的内容。
如果你想要一份指南来帮助你设置 LUKS,可以在这篇文章中找到一个很好的指南:《[使用 LUKS 对 Linux 分区进行基本加密指南](https://linuxconfig.org/basic-guide-to-encrypting-linux-partitions-with-luks?ref=its-foss)》。如果你对此还不熟悉,并且想要尝试使用 LUKS,可以在虚拟机或闲置计算机上进行安全学习,以了解其工作原理。
*(题图:MJ/2c6b83e6-4bcb-4ce3-a49f-3cb38caad7d2)*
---
via: <https://itsfoss.com/luks/>
作者:[Bill Dyer](https://itsfoss.com/author/bill/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Computer security methods are designed to keep private things, well, private. There are many ways to secure a system. Some users use a simple username/password login scheme for basic protection. Other users may use extra protection through encryption in various ways like using VPN and disk encryption.
If you have sensitive client data on your machine (you might be running a business) or material deemed intellectual property or you are privacy cautious, you may want to consider disk encryption.
Some benefits of disk encryption are:
- Secure your system from hackers
- Prevent data leaks
- Protect you from potential liability issues
Disk encryption software prevents a desktop hard disk drive, a portable USB storage device, or laptop, from accessing unless the user inputs the correct authentication data. If your laptop is ever lost or stolen, encryption protects the data on the disk.
These days, new Windows-powered systems come with BitLocker encryption by default. On Linux, LUKS is the most popular way of employing disk encryption.
Wondering what is LUKS? I'll brief you on the topic.
## Technical jargons
Before going further, some terms should be defined. There is a lot to LUKS so it will help to break things down, especially if you're beginning to look into this.
**Volume**: A volume is a logical storage area that can be used to store data. In the context of disk encryption, a volume refers to a portion of a disk that has been encrypted to protect its contents.
**Parameters**: Parameters are settings that control how an encryption algorithm works. Parameters might include the encryption algorithm used, the key size, and other details about how the encryption should be performed.
**Cipher type**: A cipher is a mathematical algorithm used for encryption It refers to the specific encryption algorithm that is being used to protect the data on an encrypted volume.
**Key size**: The key size is a measure of the strength of an encryption algorithm: the larger the key size, the stronger the encryption. It is often expressed in bits, such as 128-bit encryption or 256-bit encryption.
**Header**: The header is a special area at the beginning of an encrypted volume that contains information about the encryption, such as the encryption algorithm used and the encryption keys.
The next definition can be tricky to a newcomer, but it's worth knowing about, especially when dealing with LUKS; it's quite handy.
**Container**: A container is a special file that acts like a virtual encrypted volume. It can be used to store encrypted data, just like an encrypted partition. The difference is that a container is a file that can be stored on an unencrypted partition, while an encrypted partition is a portion of a disk that has been encrypted as a whole. A container, then, is a file *that acts as a virtual encrypted volume*.
## What Is LUKS and What Can It Do?
[Linux Unified Key Setup - LUKS](https://en.wikipedia.org/wiki/Linux_Unified_Key_Setup) is a disk encryption specification created by Clemens Fruhwirth in 2004 and was originally intended for Linux. It is a well-known, secure, and high-performance disk encryption method based on an enhanced version of [cryptsetup](https://www.tutorialspoint.com/unix_commands/cryptsetup.htm), using [dm-crypt](https://www.kernel.org/doc/html/latest/admin-guide/device-mapper/dm-crypt.html) as the disk encryption backend. LUKS is also a popular encryption format in Network Attached Storage (NAS) devices.
LUKS can also be used to create and run encrypted containers. Encrypted containers feature the same level of protection as LUKS full-disk encryption. LUKS also offers multiple encryption algorithms, several modes of encryption, and several hash functions - a little over 40 possible combinations.
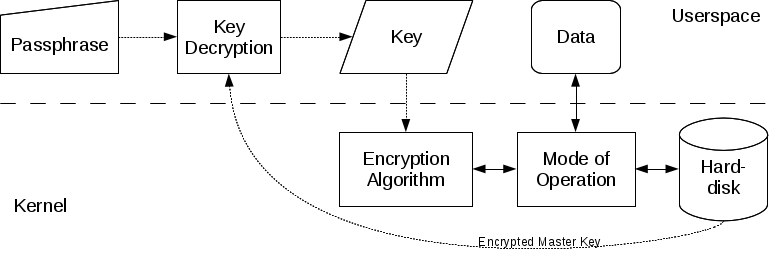
[SUSE WIKI](https://en.opensuse.org/SDB:Encrypted_filesystems)
Any filesystem can be encrypted, including the swap partition. There is an unencrypted header at the beginning of an encrypted volume, which allows up to 8 (LUKS1) or 32 (LUKS2) encryption keys to be stored along with encryption parameters such as cipher type and key size.
The existence of this header is a major difference between LUKS and dm-crypt, since the header allows multiple different passphrases to be used, with the ability to change and remove them easily. It is worth a reminder, however, that if the header is lost or corrupted, the device will no longer be decryptable.
There are two versions of LUKS, with LUKS2 having features such as greater resistance to header corruption, and the use of [Argon2](https://www.argon2.com/) encryption algorithm by default (LUKS1 uses [PBKDF2](https://en.wikipedia.org/wiki/PBKDF2)). Conversion between both versions of LUKS is possible in certain situations, but some features may not be available with LUKS1.
## Where Can I Learn More?
I am hopeful that this short article is a help in understanding a little about LUKS and encryption. The exact steps for creating and using an encrypted partition with LUKS varies, depending on an individual's specific needs, so I will not cover installation and setup here.
If you want a guide to lead you though setting up LUKS, an excellent guide can be found in this article: [Basic Guide To Encrypting Linux Partitions With LUKS](https://linuxconfig.org/basic-guide-to-encrypting-linux-partitions-with-luks). If you're new at this, and you want to try out LUKS, safe learning can be done on a virtual machine or a spare computer to get a feel for how it works. |
16,070 | Anytype:一款用于工作和生产力的一体化安全开源应用 | https://news.itsfoss.com/anytype-open-beta/ | 2023-08-07T15:14:16 | [
"Anytype"
] | https://linux.cn/article-16070-1.html |
>
> 一款适合所有人的新开源应用。尝试其公开测试版并查看它是否适合你。
>
>
>

Anytype 的口号是,“为那些崇尚信任和自主的人提供的一切应用”。它是一款新的**一体化安全开源个人 CRM 应用**,旨在提供一些令人印象深刻的功能。
他们联系我们来报道第一个公开测试版本,我们对此非常感兴趣。
请允许我带你了解一下。
### Anytype:概述 ⭐

Anytype 是一个**本地优先**、**点对点(P2P)的开源**工具,**可用于各种任务**,例如**项目管理**、**存储文档**、**每日笔记**、**管理任务**、**书籍/文章/网站收藏**以及**甚至作为个人 CRM 软件**。
他们还计划以后可以让你管理/创建博客、社区维基和讨论。
本地优先意味着 Anytype **可以在本地运行,无需连接到互联网**,从而实现更好的可靠性、速度,以及最重要的安全性。
>
> ? Anytype 的源码可以在其 [GitHub 页面](https://github.com/anyproto) 上找到。
>
>
>
不过,这**并不意味着它是一个仅限离线使用的工具**。你可以将其配置为通过互联网在多个平台上进行访问。
这之所以成为可能,是因为使用了 **Anysync 协议**,该协议**允许自托管**、**数据可移植性**和**实时 P2P 端到端加密协作**。
Anytype 作为模块化空间构建器和浏览器构建在 Anysync 之上,为用户提供了一套强大的工具来构建空间和基于图形的网站视图。
其背后的公司是一家**位于柏林的初创公司**,[其开源理念](https://blog.anytype.io/our-open-philosophy/) 似乎相当可靠。
除此之外,Anytype 的一些最显著的功能包括:
* 可互操作的空间。
* 无需代码即可构建空间。
* 能够创建公共/私人/共享空间。
* 设备上加密。
* 跨平台。
* 自我托管的能力。
#### 初步印象
我在我的 [Ubuntu 22.04 LTS](https://news.itsfoss.com/ubuntu-22-04-release/) 上尝试了 Anytype,使用体验非常好。
当你首次启动该应用时,你将看到一个“<ruby> 加入 <rt> Join </rt></ruby>”或“<ruby> 登录 <rt> Login </rt></ruby>”屏幕。我使用“加入”选项在本地创建一个新帐户。

之后,设置我的帐户并浏览欢迎屏幕。我被带到了一个**快速启动菜单**,其中有一堆**空间模板**可以开始使用。我选择了其中一个个人项目。

之后,它带我进入“<ruby> 我的主页 <rt> My Homepage </rt></ruby>”,在这里我可以访问侧边栏菜单和一个包含所有内容概述的页面。

从侧边栏菜单中,我进入“<ruby> 我的项目 <rt> My Projects </rt></ruby>”页面并选择了其中一个项目。它打开了一个块编辑器,让我可以直观地编辑文本。
>
> ? 它还具有用于跟踪多个任务的任务跟踪器。
>
>
>

之后,我测试了“<ruby> 我的笔记 <rt> My Notes </rt></ruby>”功能。它运行良好,并且符合你对 [笔记应用](https://itsfoss.com/note-taking-apps-linux/) 的期望。它还具有块编辑器,我在日常工作中对其进行了测试,效果非常好。
我所有的植物都喂饱了,我的猫也浇水了!?

最后,我看了一下“<ruby> 图表视图 <rt> Graph View </rt></ruby>”。我对它的详细程度感到惊讶。Anytype 能够通过这种方式非常有效地说明所有数据点。

那么,总结一下。
我可以看到 Anytype 成为我日常工作流程的一部分。它拥有的工具数量可以帮助管理一个人的日常工作甚至学习习惯。
除此之外,我很高兴 Monica 现在有了一个合适的竞争对手。我迫不及待地想看看 Anytype 对此有何反应。
你可以通过 [ProductHunt 上的公告帖子](https://www.producthunt.com/posts/anytype-2-0) 进行更深入的研究。
### ? 获取 Anytype
Anytype 可在 **Linux**、**Windows**、**Mac**、**iOS** 和 **安卓** 上使用。你可以前往[官方网站](https://anytype.io/)获取你选择的包。
>
> **[Anytype](https://anytype.io/)**
>
>
>
? 你会尝试 Anytype 吗? 让我们知道!
---
via: <https://news.itsfoss.com/anytype-open-beta/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

“The everything app for those who celebrate trust & autonomy”. The tagline of Anytype, a new **all-in-one secure open-source personal CRM app** that aims to deliver some pretty impressive features.
They reached out to us to cover the first open beta release, and we were pretty intrigued.
Allow me to take you through it.
## Anytype: Overview ⭐
Anytype is a **local-first**, **peer-2-peer (P2P)**, **open-source** tool that **can be used for a variety of tasks** such as **project management**, **storing documents**, **taking daily notes**, **managing tasks**, **collections of books/articles/websites,** and **even as a personal CRM software**.
They also plan to allow you to manage/create blogs, community wikis, and discussions in the future.
What it means to be local-first, is that Anytype **can run locally without the need to connect to the internet**, resulting in better reliability, speed, and most important of all, security.
[GitHub page](https://github.com/anyproto?ref=news.itsfoss.com).
Though, that **doesn't mean that it's an offline-only tool**. You can configure it for access via the internet over multiple platforms.
This was made possible due to using the **Anysync protocol** that **allows for self-hosting**, **data portability, **and **real-time P2P end-to-end encryption collaboration**.
Anytype is built on top of Anysync as a modular space builder and browser, providing users with a robust set of tools for building spaces, and graph-based views of websites.
The company behind it is a **Berlin-based startup**, and [its open-source philosophy](https://blog.anytype.io/our-open-philosophy/?ref=news.itsfoss.com) seems pretty solid.
Other than that, some of the most notable features of Anytype include:
**Interoperable Spaces.****Build spaces without code.****Ability to create Public/Private/Shared spaces.****On-device encryption.****Cross-platform.****Ability to self-host.**
### Initial Impressions
I tried Anytype on my [Ubuntu 22.04 LTS](https://news.itsfoss.com/ubuntu-22-04-release/) setup, and the usage experience was pretty neat.
When you first launch the app, you will be shown a screen to either 'Join', or 'Login'. I used the 'Join' option to create a new account locally.
After, setting up my account and going through the welcome screen. I was taken to a **quick-start menu**, where there were a bunch of **space templates** to get started. I chose the personal project one.
After that, it took me into '**My Homepage**', where I had access to the sidebar menu and a page with an overview of all the content.
From the sidebar menu, I went into the '**My Projects**' screen and selected one of the projects. It brought up a block editor that allowed me to edit the text intuitively.
After that, I tested out the '**My Notes**' feature. It worked well and is what you would expect from a [note-taking app](https://itsfoss.com/note-taking-apps-linux/?ref=news.itsfoss.com). It also features the block editor, I tested it out with my daily routine, and it worked quite well.
All my plants are now fed, and my cats are watered! 🤣
And finally, I took a look at the '**Graph-view'**. I was taken aback by the level of detail it had. Anytype was able to illustrate all the data points very effectively this way.
So, wrapping up.
I can see Anytype being a part of my daily workflow; the number of tools it has can be helpful in managing one's daily work or even study routine.
Other than that, I am glad Monica now has a proper competitor; I can't wait to see how Anytype fares against that.
[Monica: An Open-Source App for Personal Relationship ManagementYou probably know what CRM stands for – Customer Relationship Management. We already have a list of open-source CRM software that helps small businesses. Here, I talk about an interesting open-source web application that takes the same concept for personal relationships. Sounds unique, right?…](https://itsfoss.com/monica/?ref=news.itsfoss.com)

You may go through the [announcement post on ProductHunt](https://www.producthunt.com/posts/anytype-2-0?ref=news.itsfoss.com) to dive deeper.
## 📥 Get Anytype
Anytype is available on **Linux**, **Windows**, **Mac**, **iOS**, and **Android**. You can head to the [official website](https://anytype.io/?ref=news.itsfoss.com) to grab the package of your choice.
*💬 Will you be giving Anytype a try? Let us know!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,071 | 将 Linux 终端与 Nautilus 文件管理器结合起来 | https://itsfoss.com/terminal-nautilus-combination/ | 2023-08-07T15:57:48 | [
"Nautilus"
] | https://linux.cn/article-16071-1.html | 
>
> 这里有一些技巧和调整,通过将终端和文件管理器结合在一起,以节省你的时间。
>
>
>
Nautilus 是 GNOME 桌面环境中的图形化文件浏览器。你可以使用它来访问和管理系统中的文件和文件夹。
尽管并非所有人都喜欢使用终端来管理文件和目录,但你也可以通过终端进行文件和目录管理。
然而,你可能会遇到需要在终端和文件管理器之间切换的情况。
有多种方法可以在 Nautilus 文件管理器和终端之间进行交互。令人惊讶的是,并不是所有的 Linux 用户都知道这些方法。
例如,在 Nautilus 中,右键单击并选择“<ruby> 在终端中打开 <rt> Open in terminal </rt></ruby>”选项,将在终端中打开当前目录位置。

这只是我在本文中要与你分享的众多示例之一。
### 1、拖放获取绝对路径
如果你将文件夹或文件拖放到终端中,其绝对路径将被粘贴到终端屏幕上。

当你在文件浏览器中深入目录结构并且不想在终端中键入整个路径时,这样做很有帮助。
### 2、进入目录
这与上面看到的类似。如果你在目录结构中深入进入,并且不想为 [切换到该目录](https://itsfoss.com/change-directories/) 键入整个路径,这个技巧很有帮助。
在终端中键入 `cd` 命令,然后拖放以进入目录。

### 3、在编辑器中打开文件
类似地,你可以使用 Nano 或 Vim 编辑器打开文件进行 [编辑](https://itsfoss.com/nano-editor-guide/)。
将文件拖放到 `nano` 命令中以打开它进行编辑。

### 4、使用 sudo 权限打开文件进行编辑
与上述相同,但这次你可以使用 `sudo` 权限打开文件进行编辑。

### 5、拖放多个文件(如果命令支持多个参数)
你也可以拖放多个文件以获取它们的绝对路径。这可以与接受多个参数的命令一起使用。
例如,[diff 命令用于检查两个文件之间的差异](https://linuxhandbook.com/diff-command/)。输入 `diff`,然后拖放你想要检查差异的文件。

### 6、从文本文件复制粘贴
阅读文档并且需要在终端中运行其中提到的命令?你当然可以 [在终端中复制粘贴](https://itsfoss.com/copy-paste-linux-terminal/)。
然而,更快捷的方法是选中文本并将其拖放到终端。
这个技巧也适用于 [GNOME-Sushi](https://gitlab.gnome.org/GNOME/sushi) 预览。

### 7、从浏览器中拖放
与上述的文本文件类似,你也可以从浏览器中拖放文本。这有助于在进行教程操作时同时查看教程。

### 8、在 Nautilus 中嵌入终端
无法离开终端?直接将其嵌入到文件管理器中。这样,你无需单独 [打开一个终端](https://itsfoss.com/open-terminal-ubuntu/)。
这里的关键是,如果你在文件浏览器中切换到另一个目录,嵌入的终端会自动切换到相应的目录。
你也可以在 Nautilus 嵌入的终端中执行大部分上述的拖放操作。例如,通过拖放 `.bashrc` 文件并使用 `grep`,在 `.bashrc` 中搜索特定文本。

### 9、在嵌入的终端之间拖放文件标签
终端和文件管理器都支持选项卡视图。你可以在选项卡之间拖放文件。
例如,要 [检查 ISO 的 shasum 值](https://itsfoss.com/checksum-tools-guide-linux/),输入 `shasum` 命令,然后从另一个选项卡中拖放文件,如下所示。

### 更多关于 Nautilus 和终端的内容
喜欢这些技巧吗?也许你想学习更多类似的技巧。
如果你想更充分地利用 Nautilus 文件管理器,这里有一些技巧供你参考。
>
> **[调整你的 Nautilus 文件管理器的 13 种办法](https://itsfoss.com/nautilus-tips-tweaks/)**
>
>
>
这里还有一些探索的终端技巧:
>
> **[19 个你应该掌握的基本但重要的 Linux 终端技巧](https://itsfoss.com/basic-terminal-tips-ubuntu/)**
>
>
>
? 你是否了解其他将终端和文件管理器结合使用的酷炫技巧?不妨在下方的评论区与我们分享一下!
*(题图:MJ/ba1ee1c9-07e5-4fc8-bd2c-bde469ce095c)*
---
via: <https://itsfoss.com/terminal-nautilus-combination/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Nautilus is the graphical file browser in the GNOME desktop. You use it for accessing and managing files and folders on your system.
You can also manage files and directories from the terminal though not everyone prefers that.
However, you may encounter situations where you have to switch between the terminal and file manager.
There are various ways to interact between the Nautilus file manager and terminal. Surprisingly, not many Linux users know about them.
*For example, in Nautilus, right-click and choose 'Open in terminal' option and you'll open the current directory location in the terminal.*
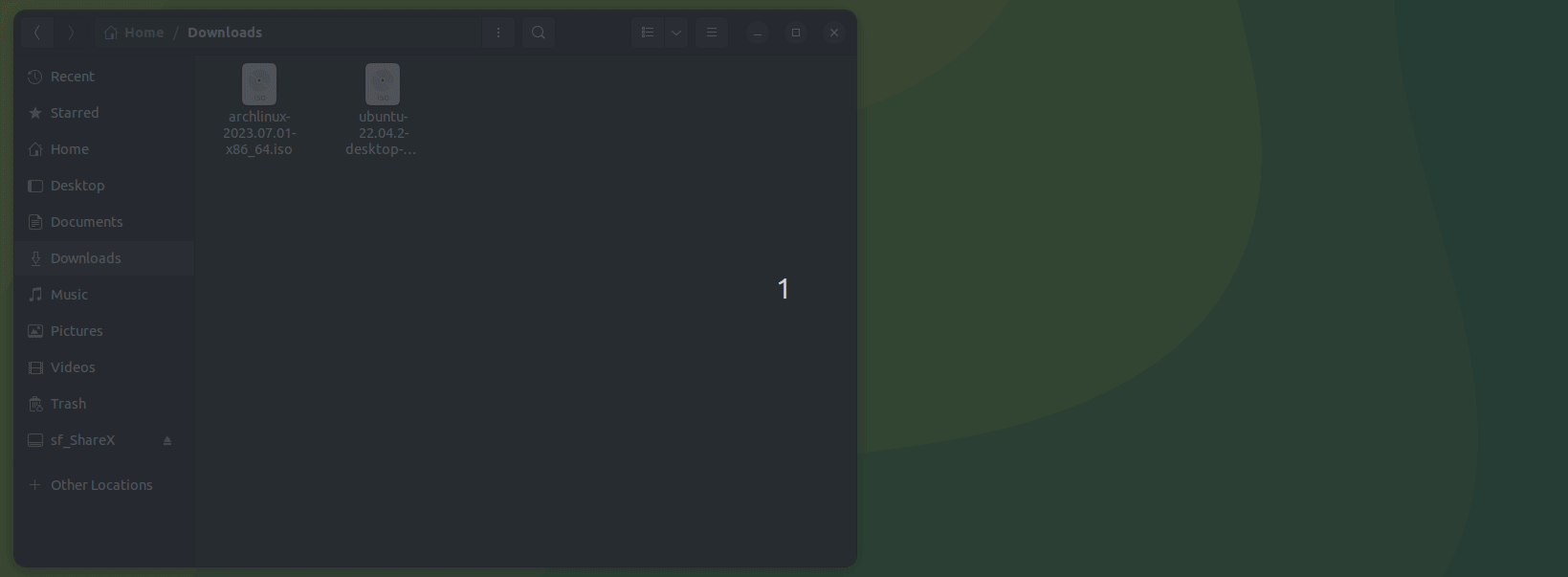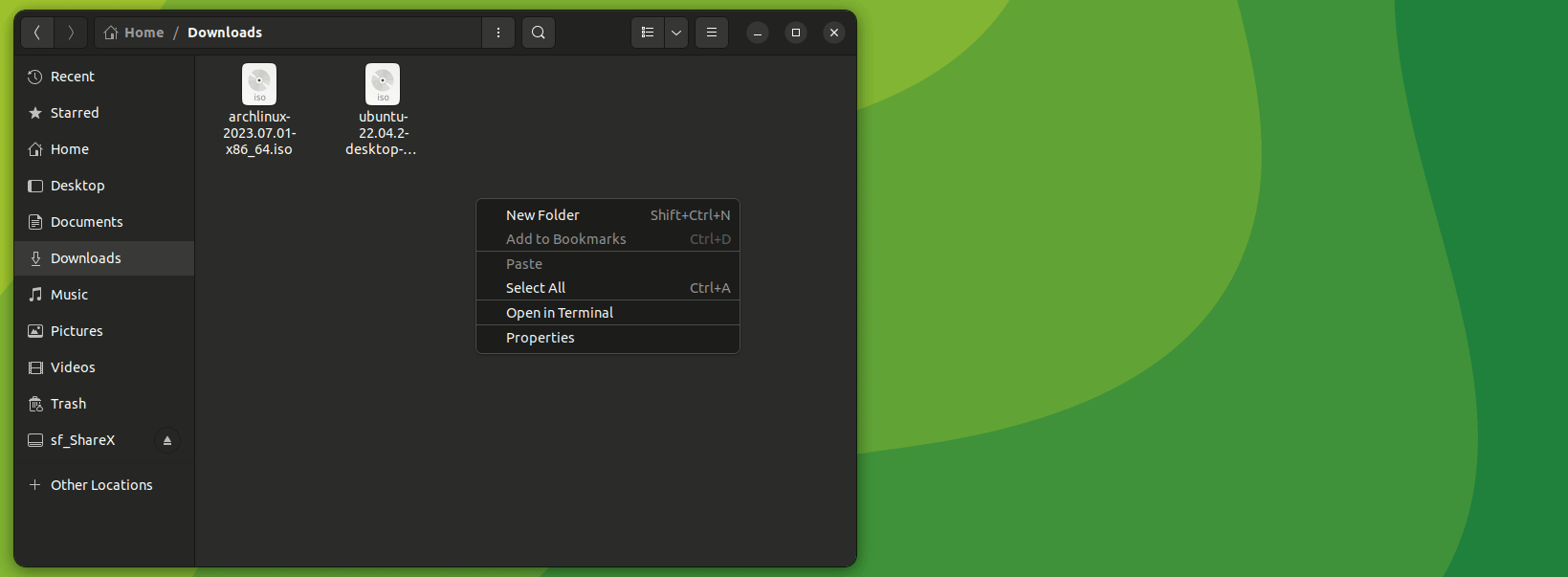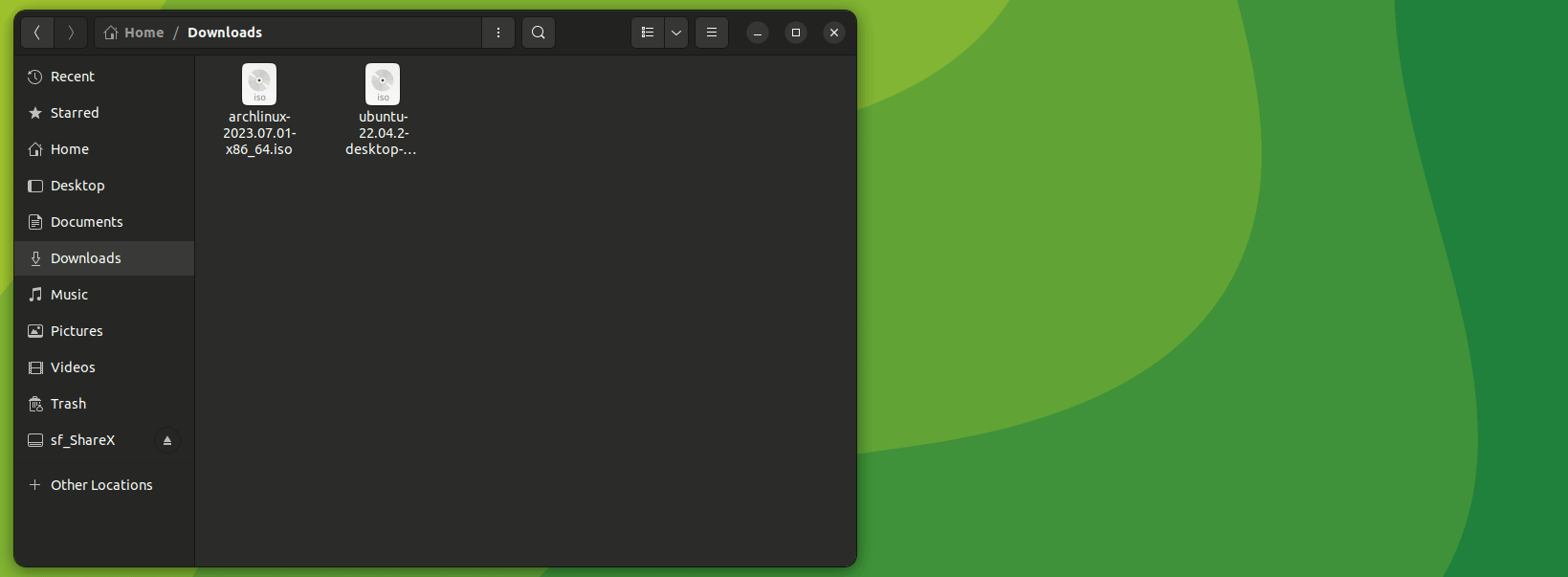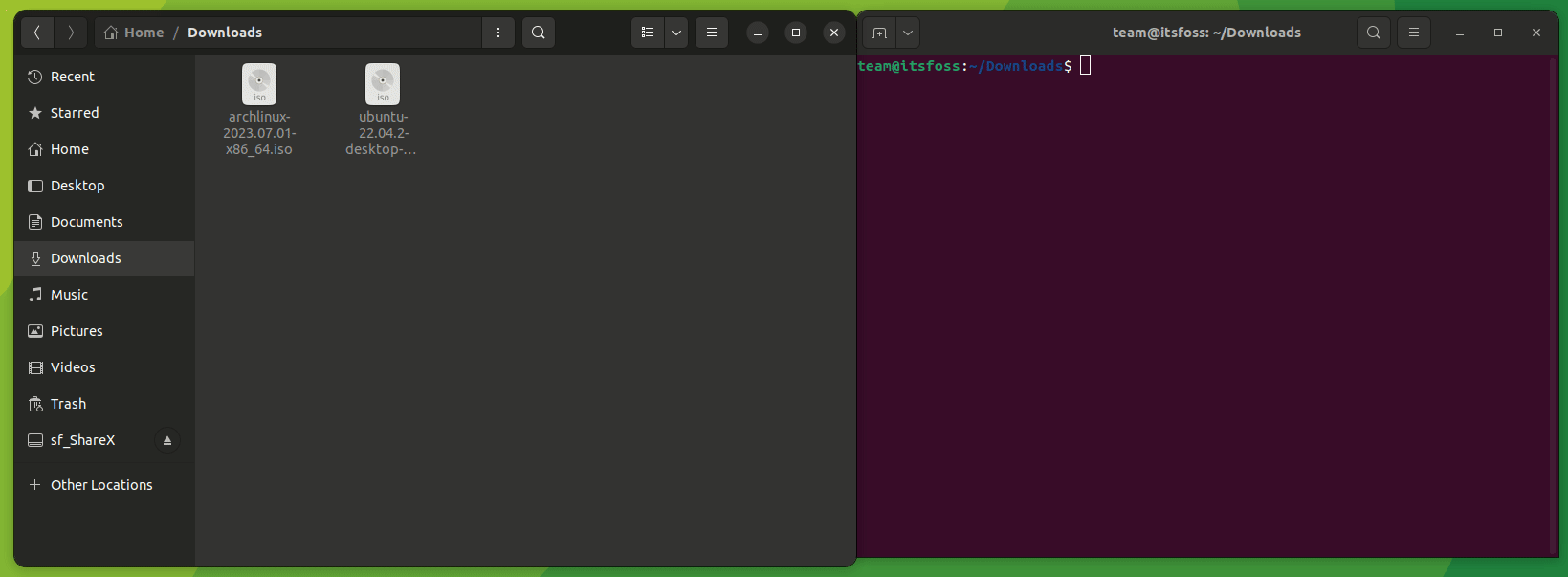
That's just one of the many examples I am going to share with you in this article.
## 1. Drag and drop to get the absolute path
If you drag and drop a folder or a file to a terminal, its absolute path will be pasted on the terminal screen.
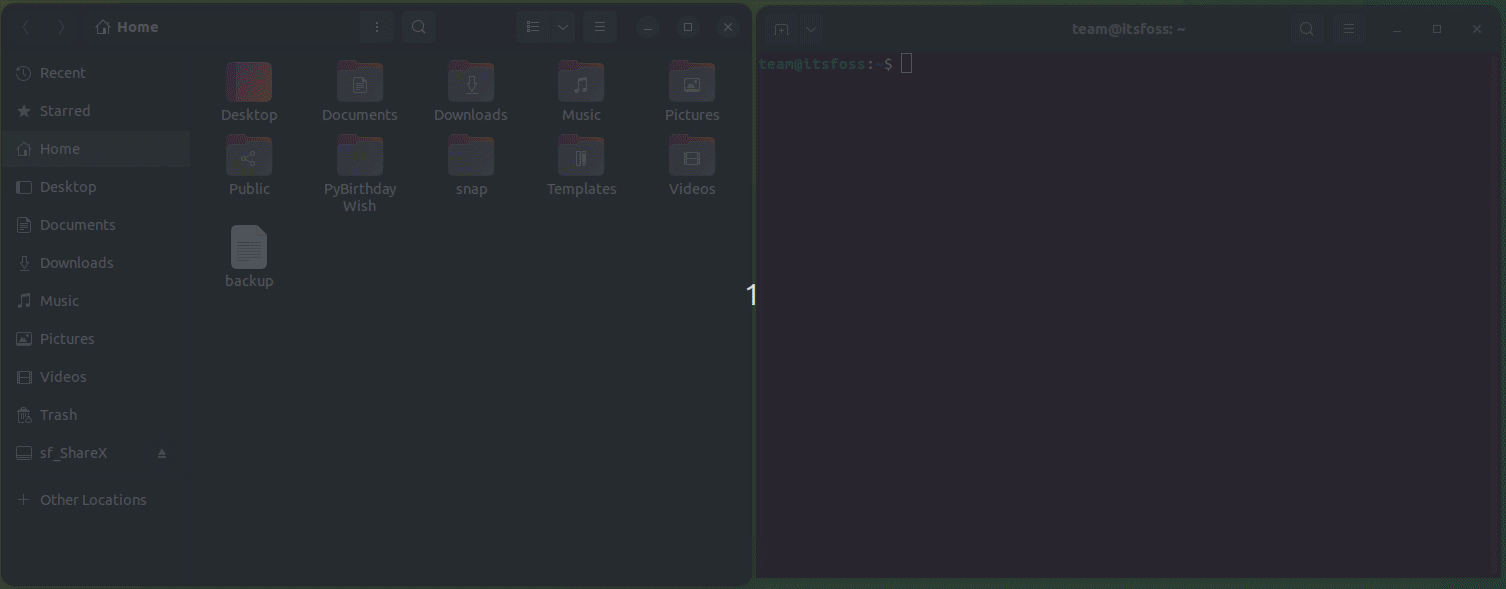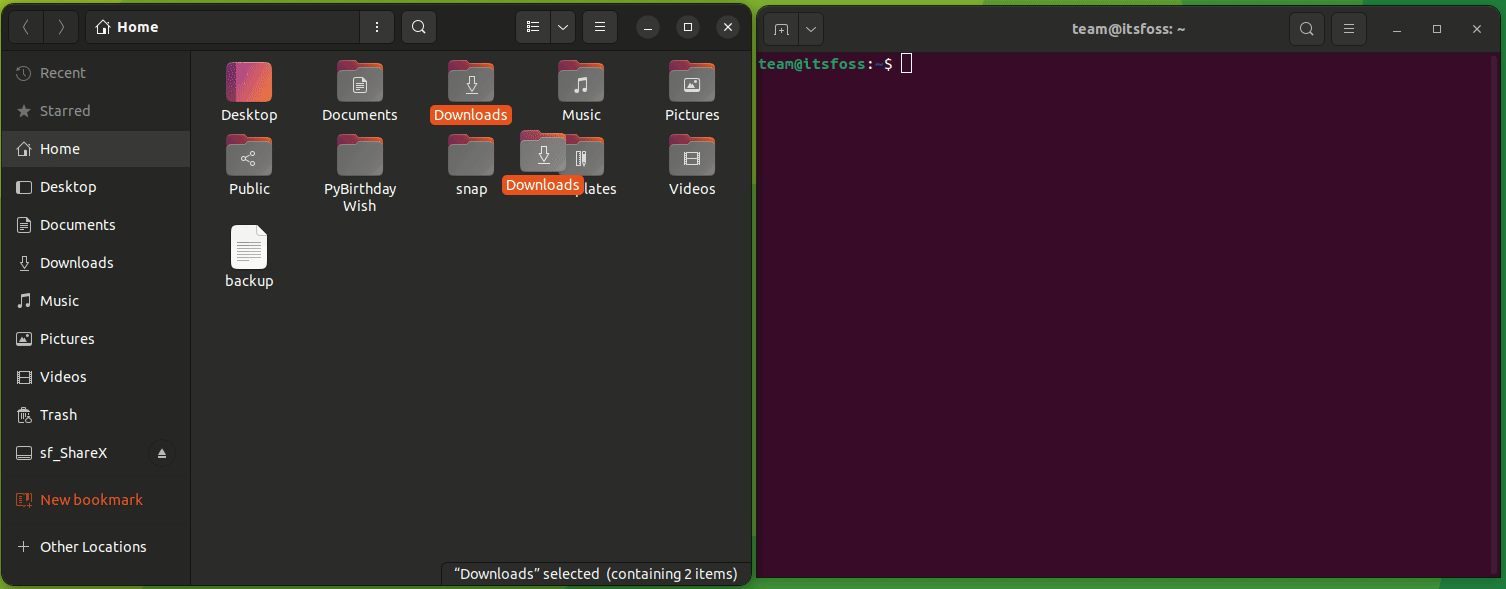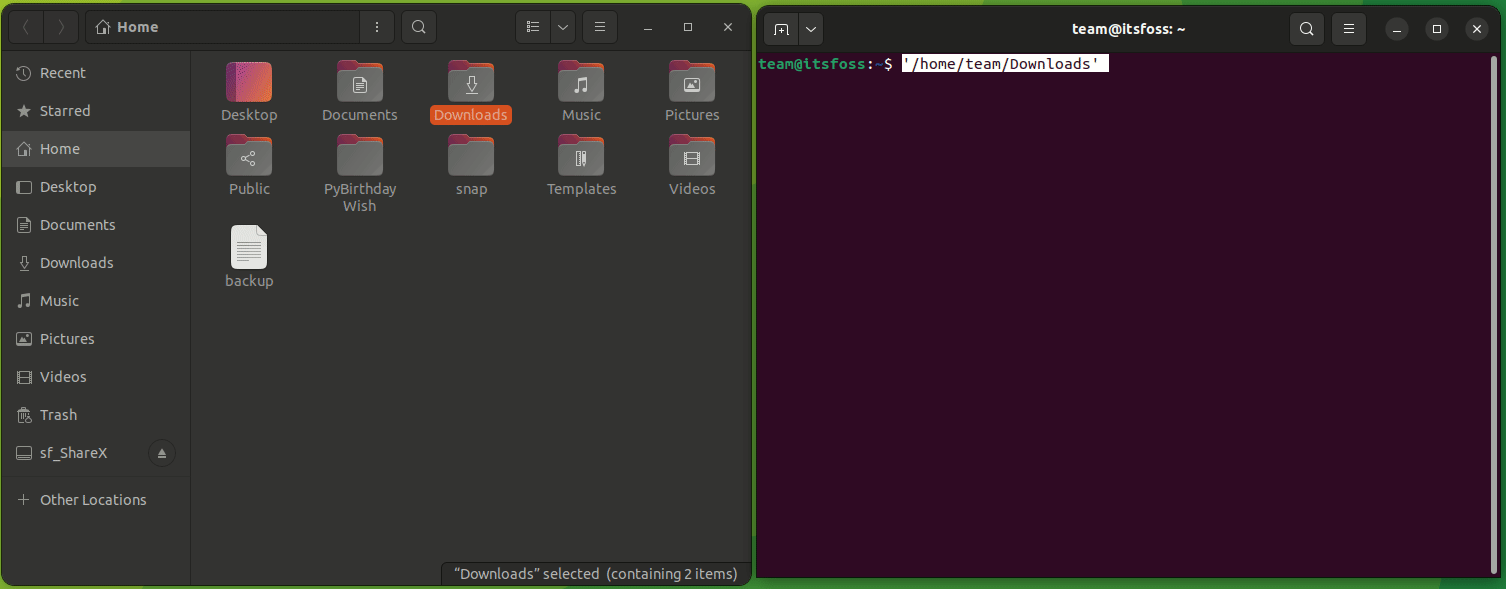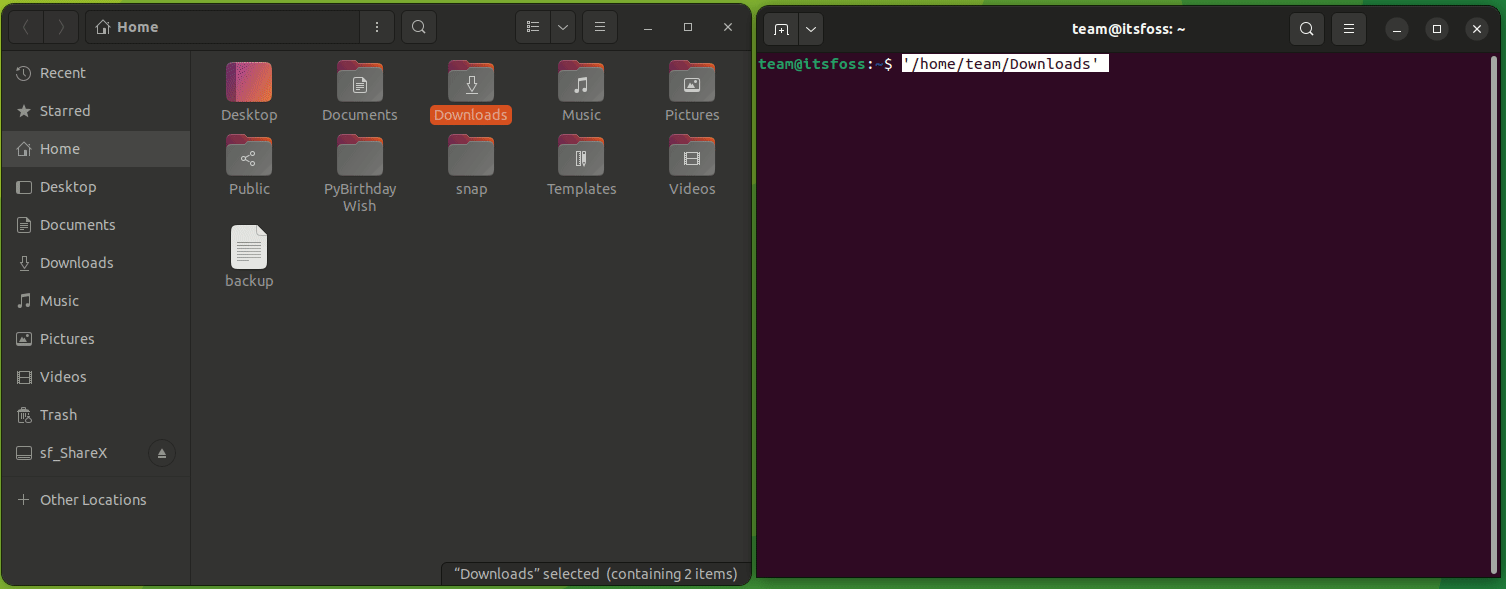
This helps when you are deep inside the directory structure in the file browser and don't want to type the entire path in the terminal.
## 2. Enter a directory
It's similar to what you saw above. If you are deep inside the directory structure and don't want to type the entire path for [switching to the directory](https://itsfoss.com/change-directories/), this trick helps.
Type the [cd command](https://itsfoss.com/cd-command/) in the terminal and then drag and drop to enter into the directory.
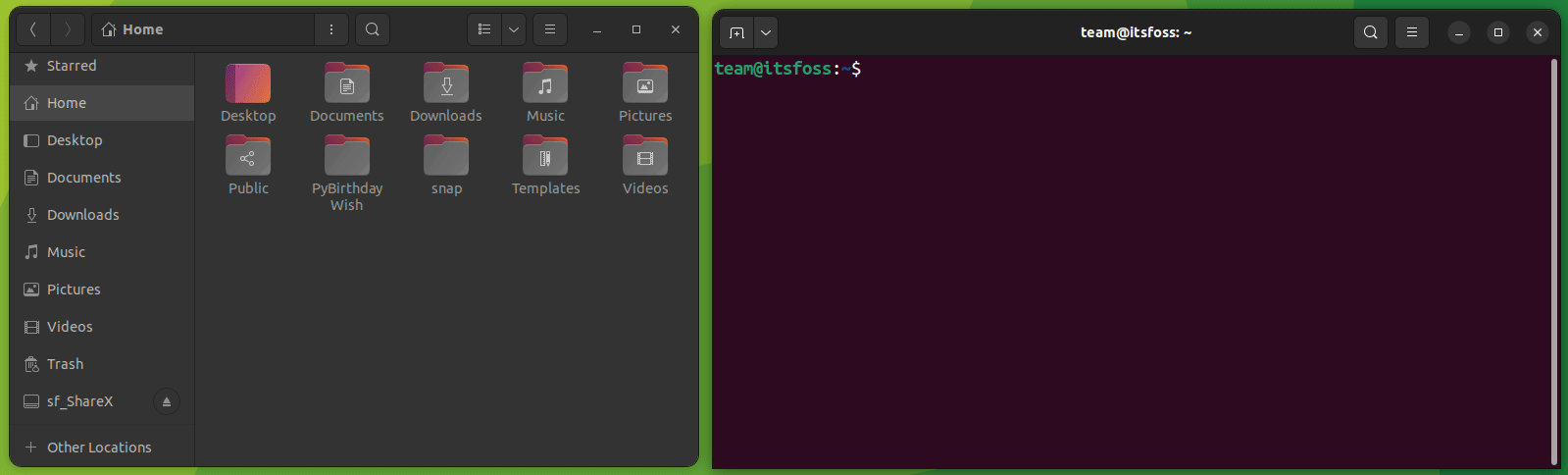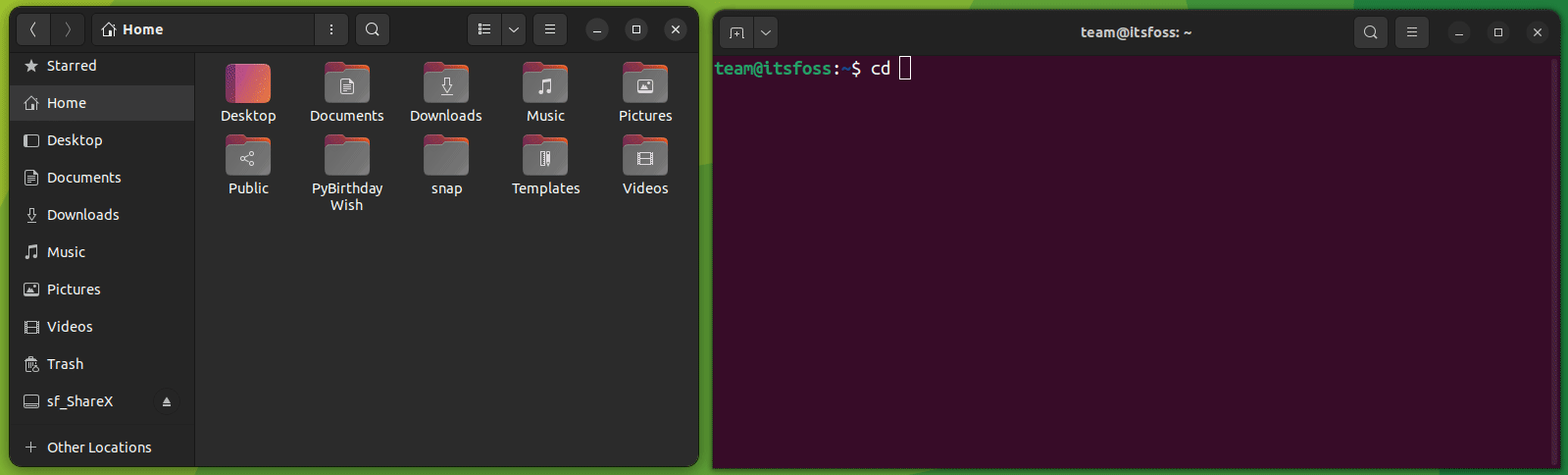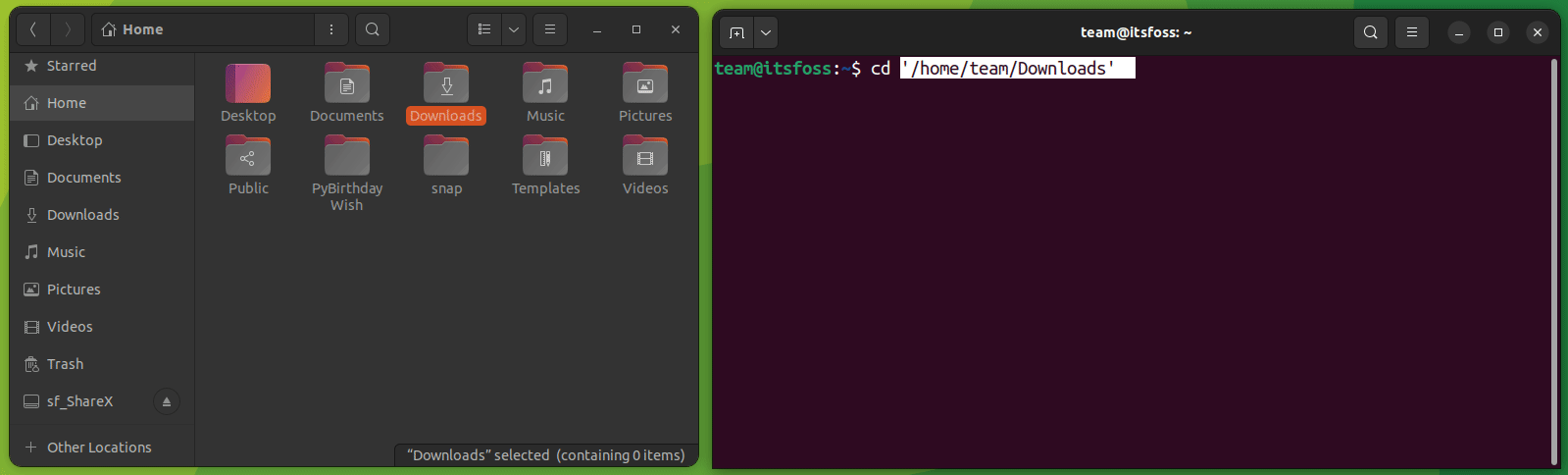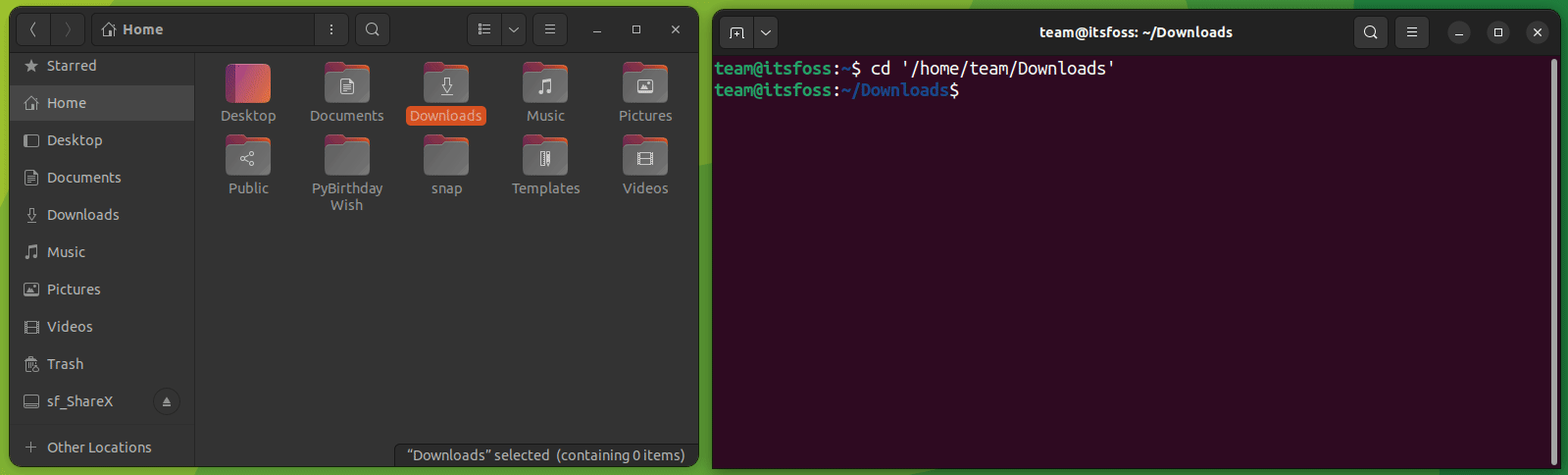
## 3. Open a file in editor
Similarly, you can open a file for [editing with Nano](https://itsfoss.com/nano-editor-guide/) or Vim editor.
Drag and drop a file to `nano`
command to open it for editing.
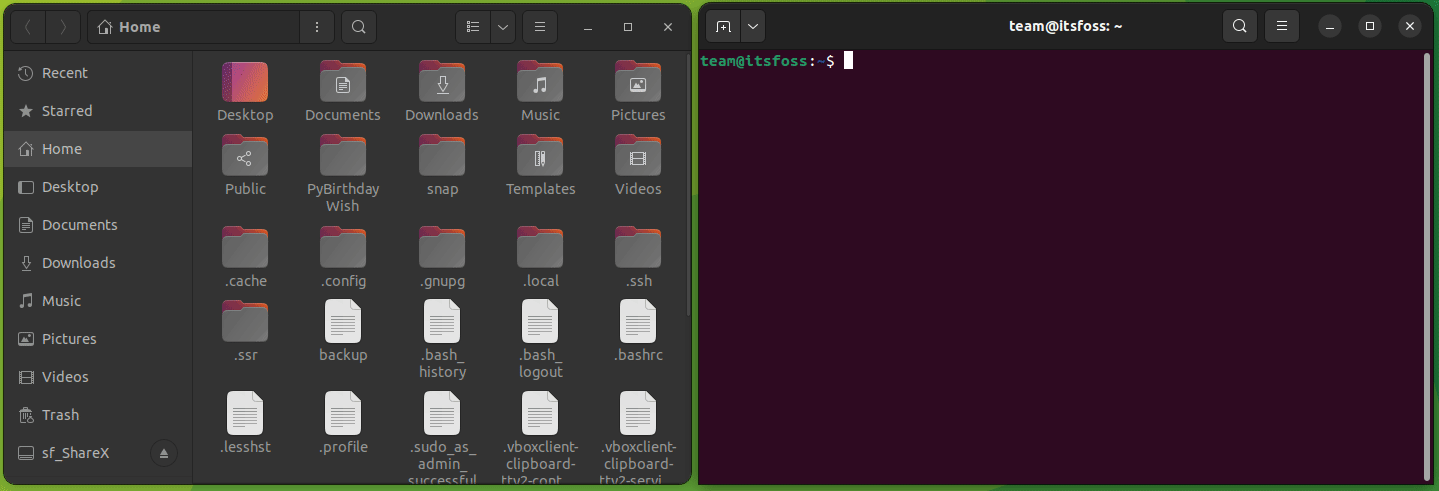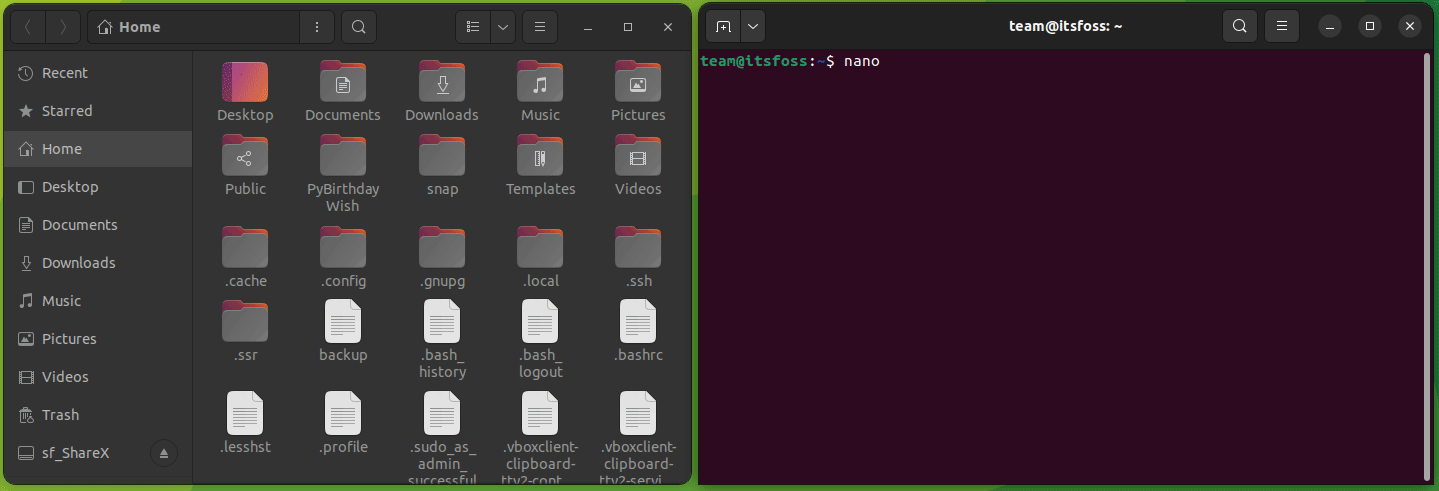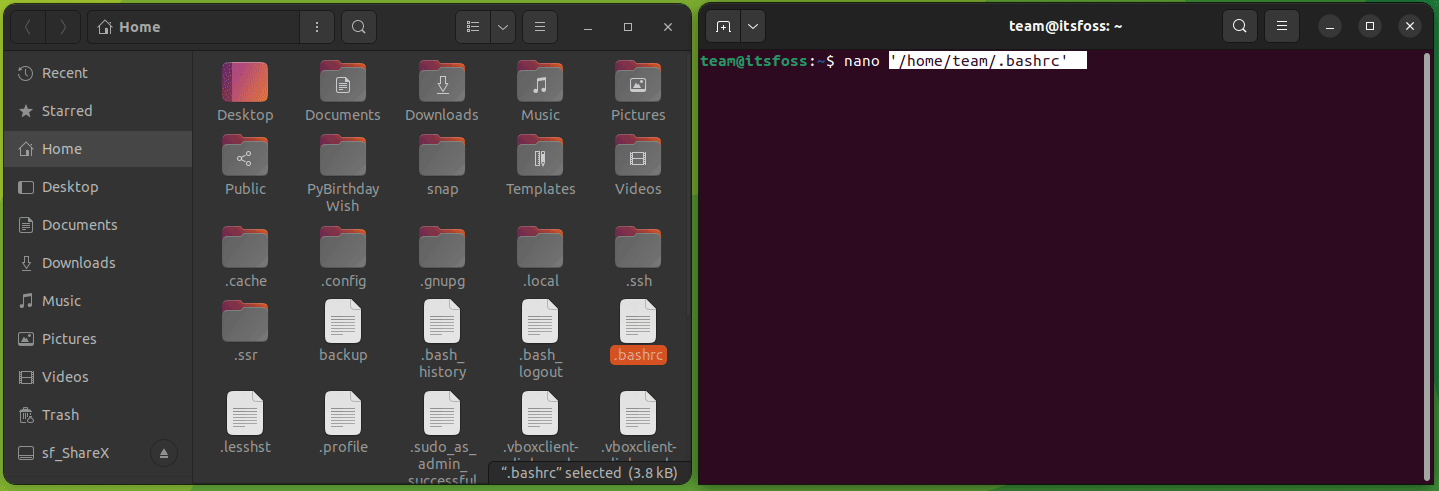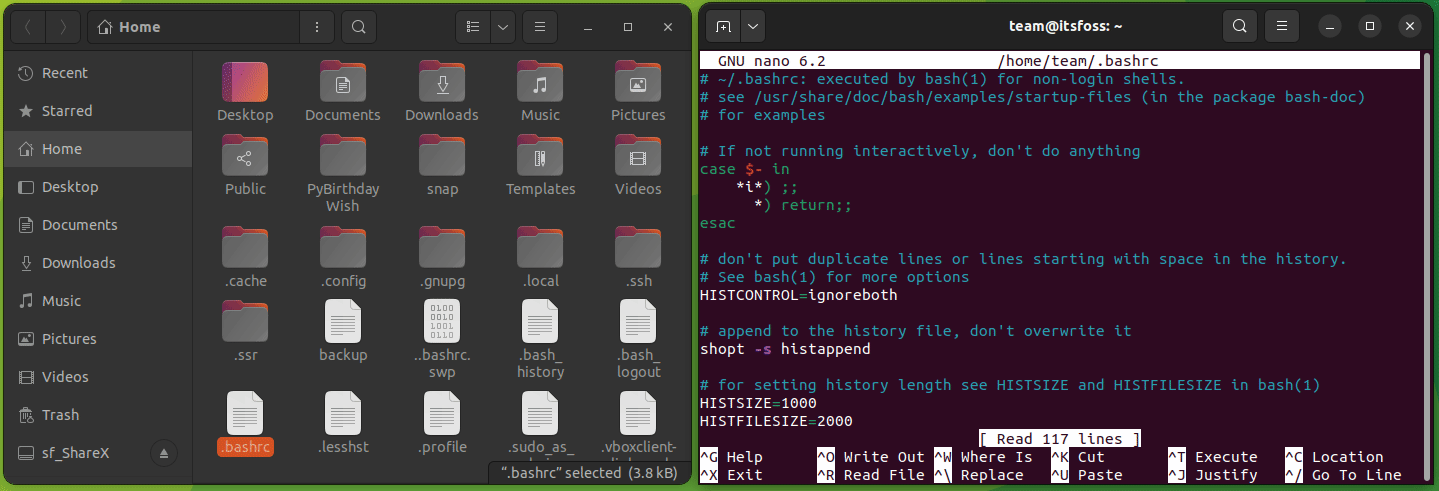
## 4. Open a file for editing with sudo
Same as above but this time, you open the file for editing with sudo access.
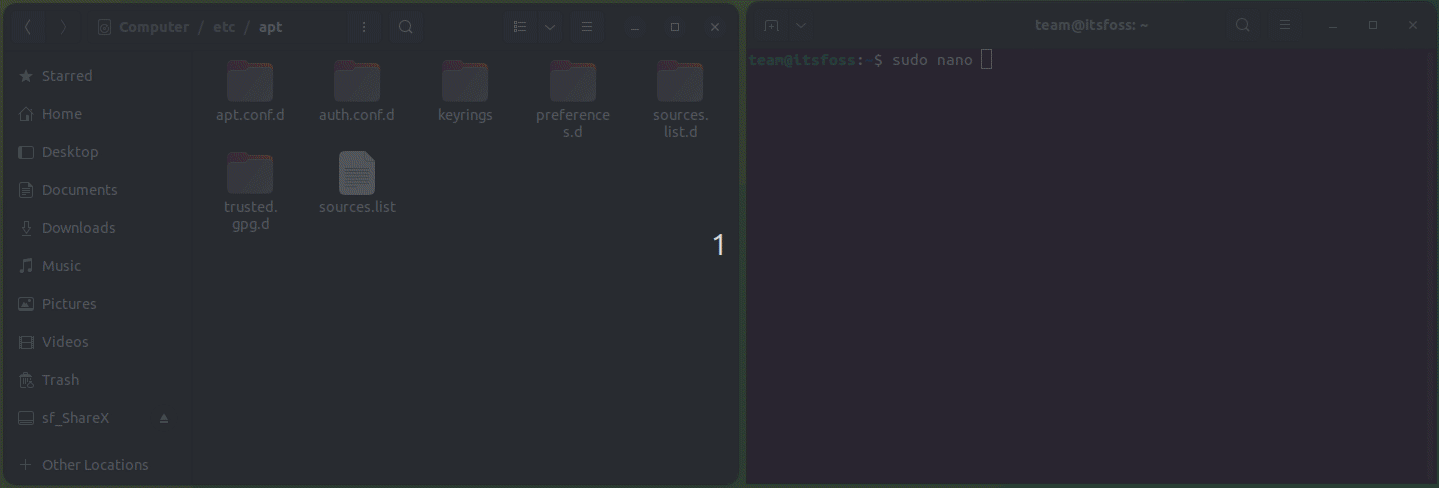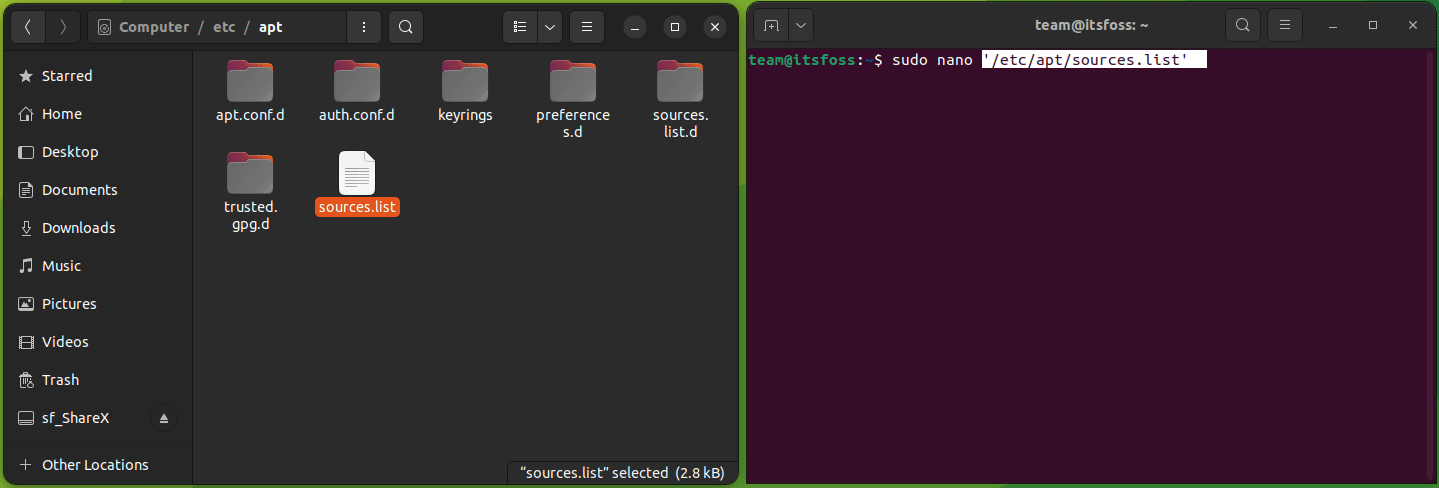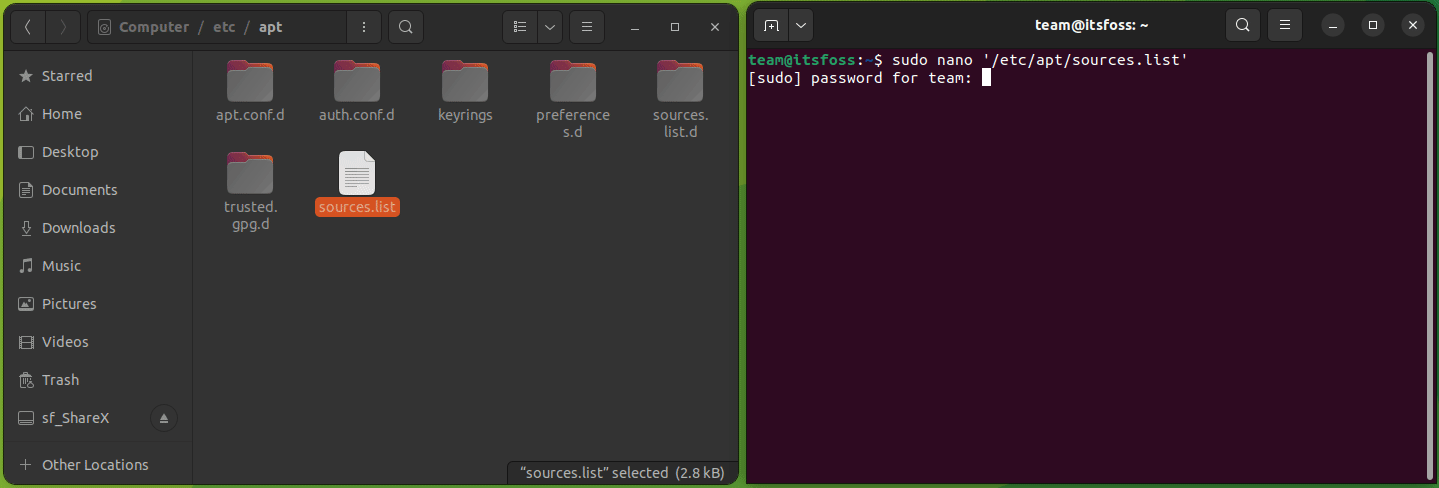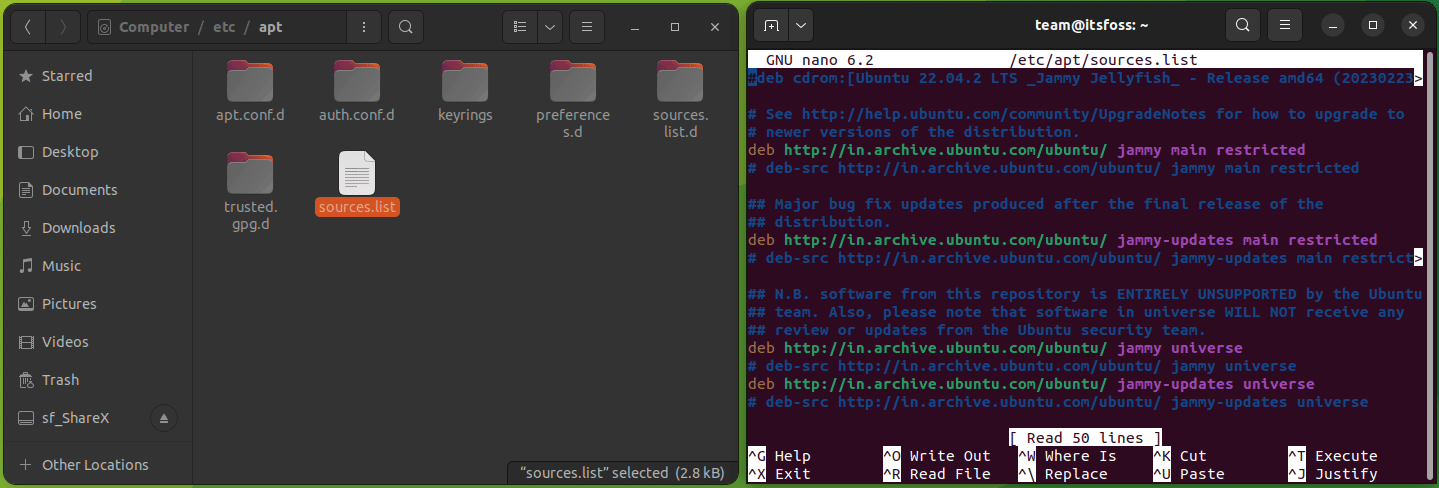
## 5. Drag multiple files, if the command supports multiple arguments
You can also drag and drop multiple files to get their absolute paths. This can be used with commands that accept more than one argument.
For example, the [diff command checks the difference between two files](https://linuxhandbook.com/diff-command/). Enter `diff`
and then drag and drop the files you want to check for differences.
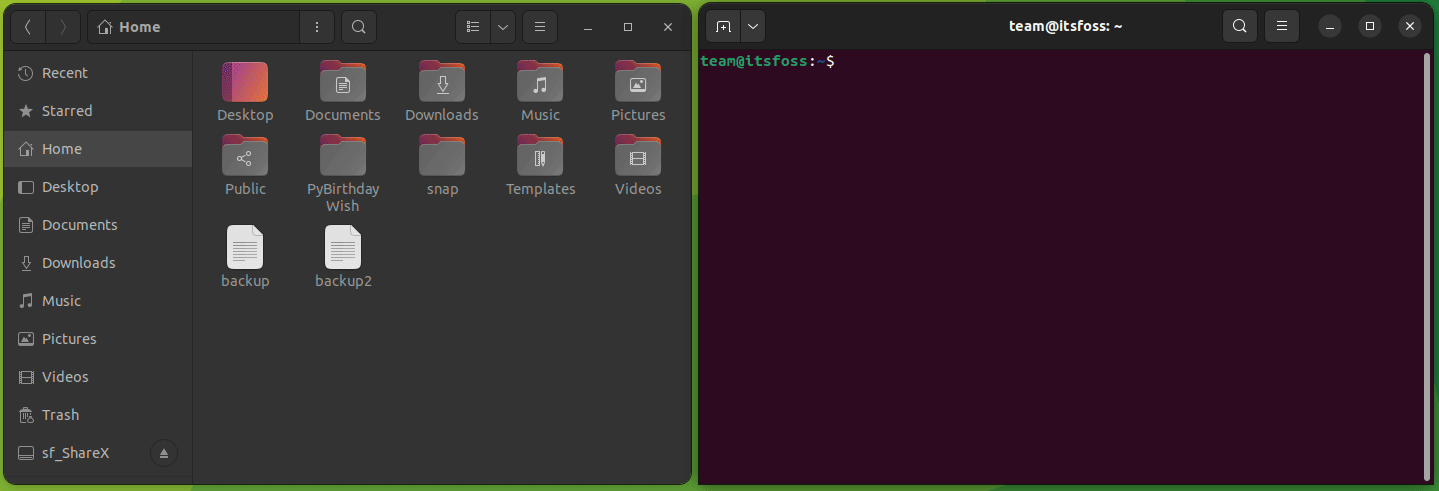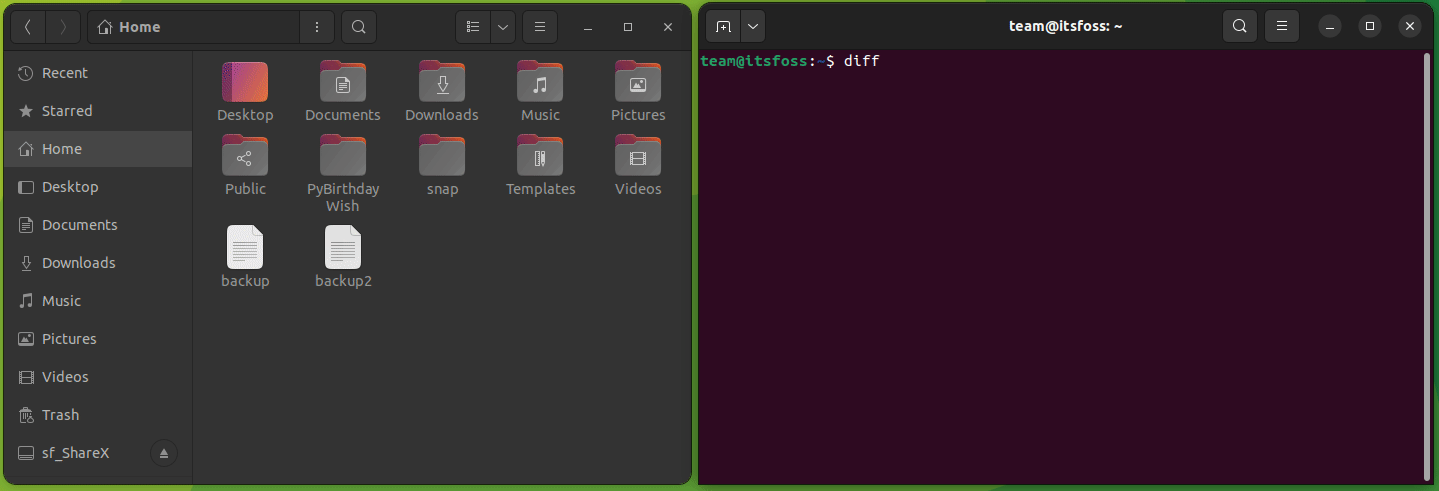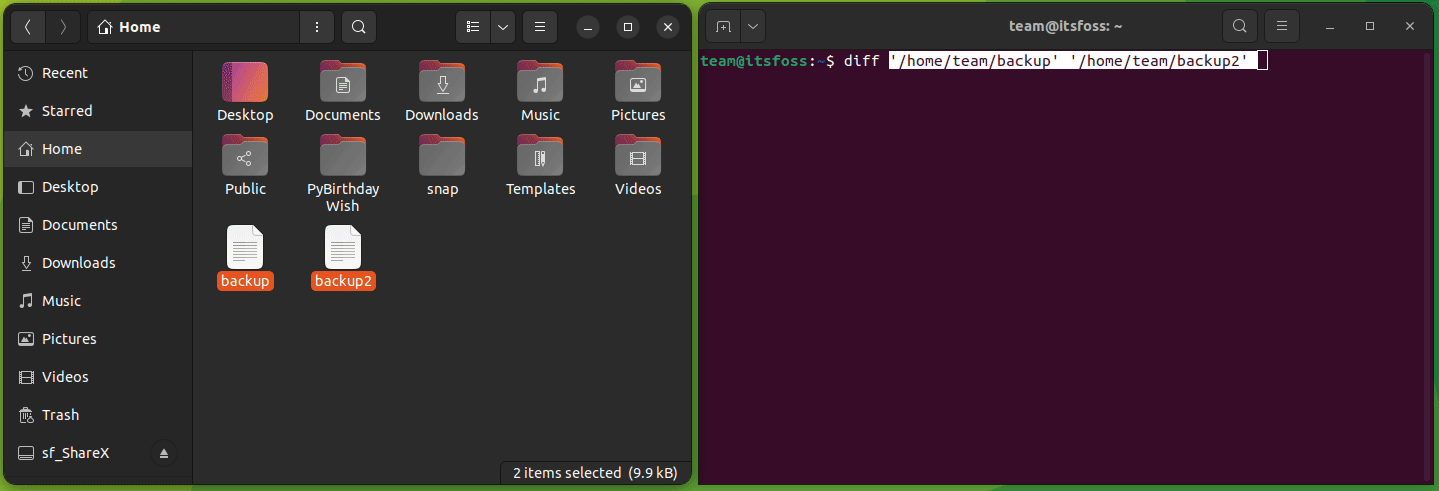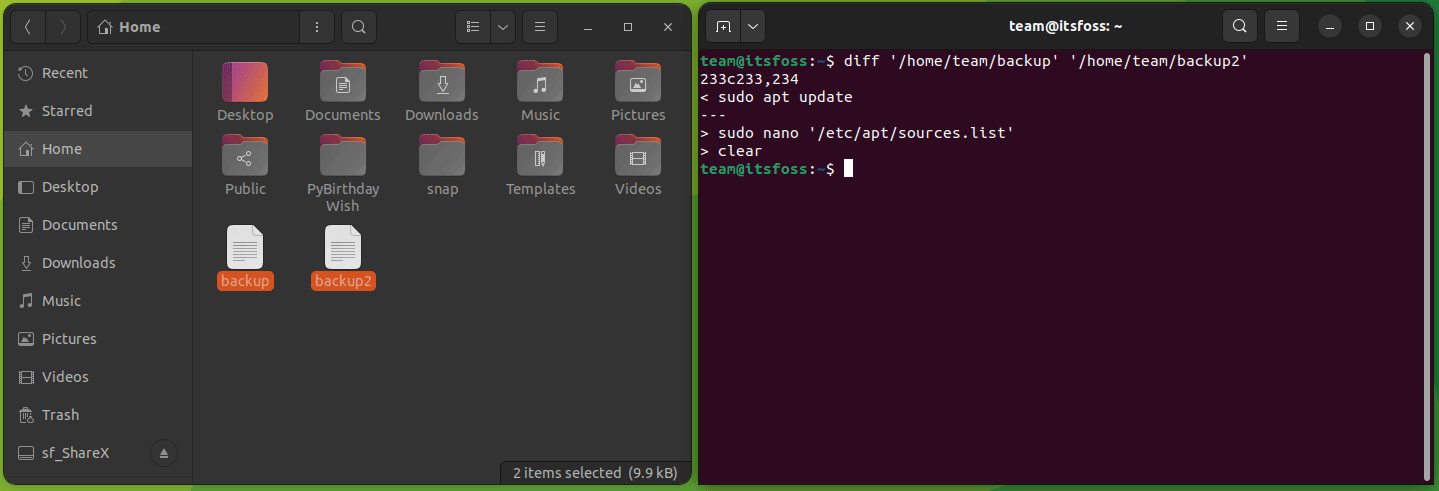
## 6. Copy and paste from text files
Reading a document and have to run a command mentioned in it? You can of course [copy paste in the terminal](https://itsfoss.com/copy-paste-linux-terminal/).
However, a quicker way is to select the text and drag and drop it to the terminal.
This trick works with [GNOME-Sushi](https://gitlab.gnome.org/GNOME/sushi) preview as well.
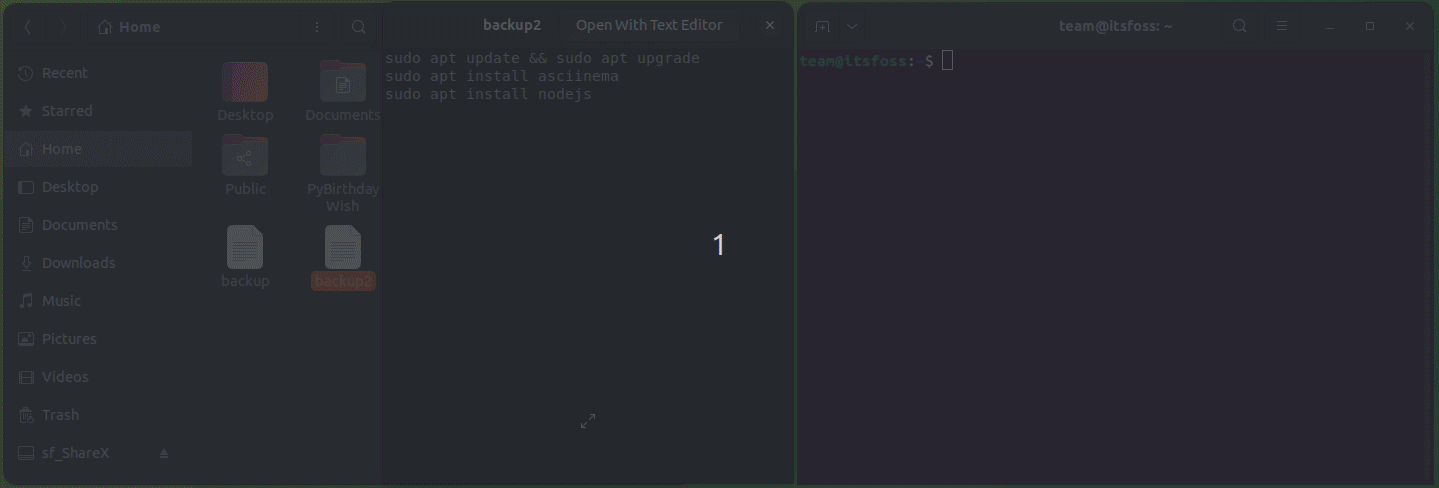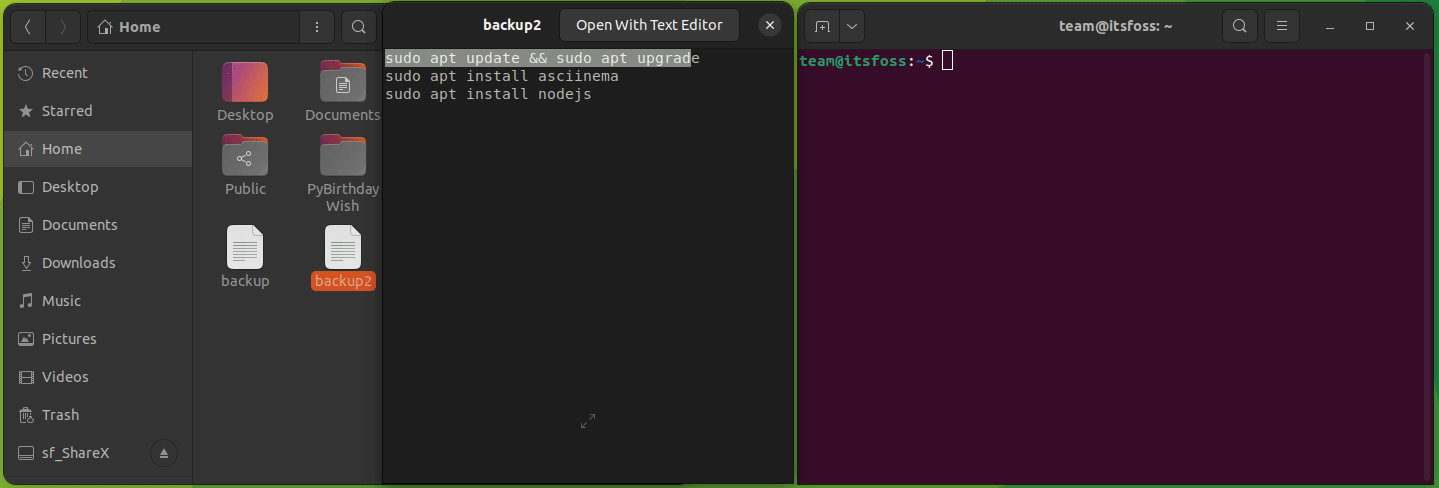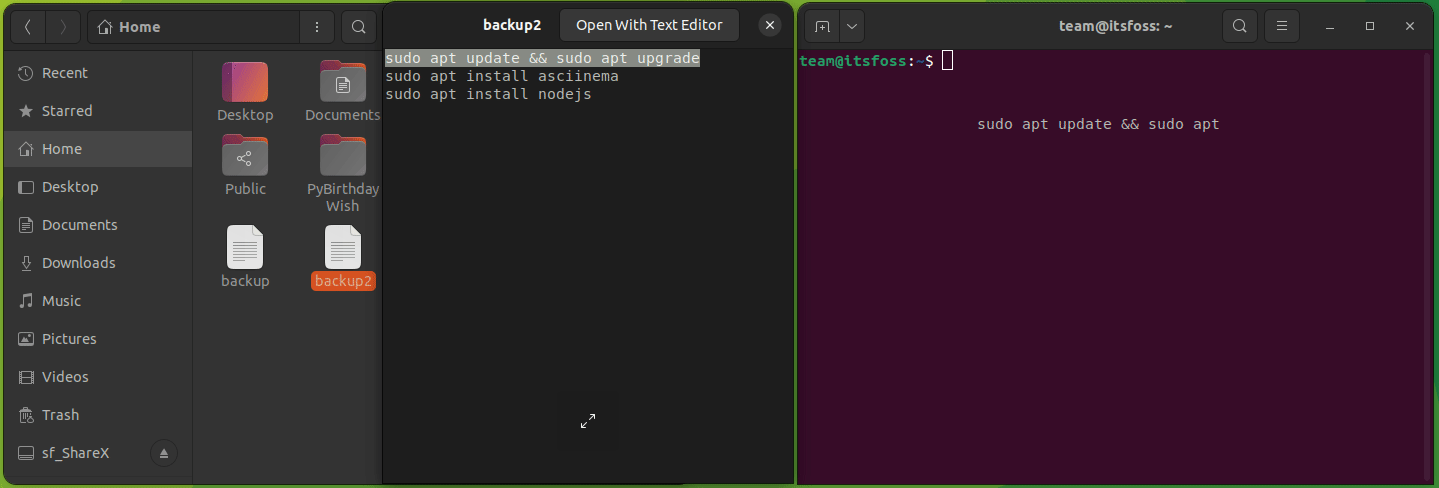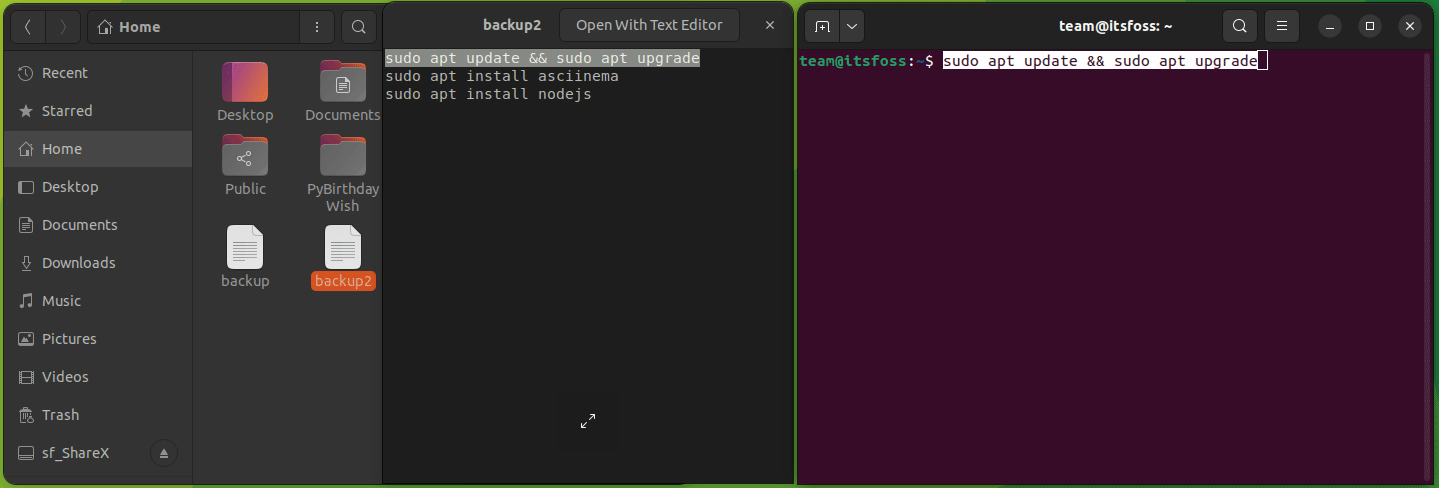
## 7. Drag and drop from browser
Like the text files above, you can also drag and drop text from browsers. This helps in following tutorials while doing it at the same time.
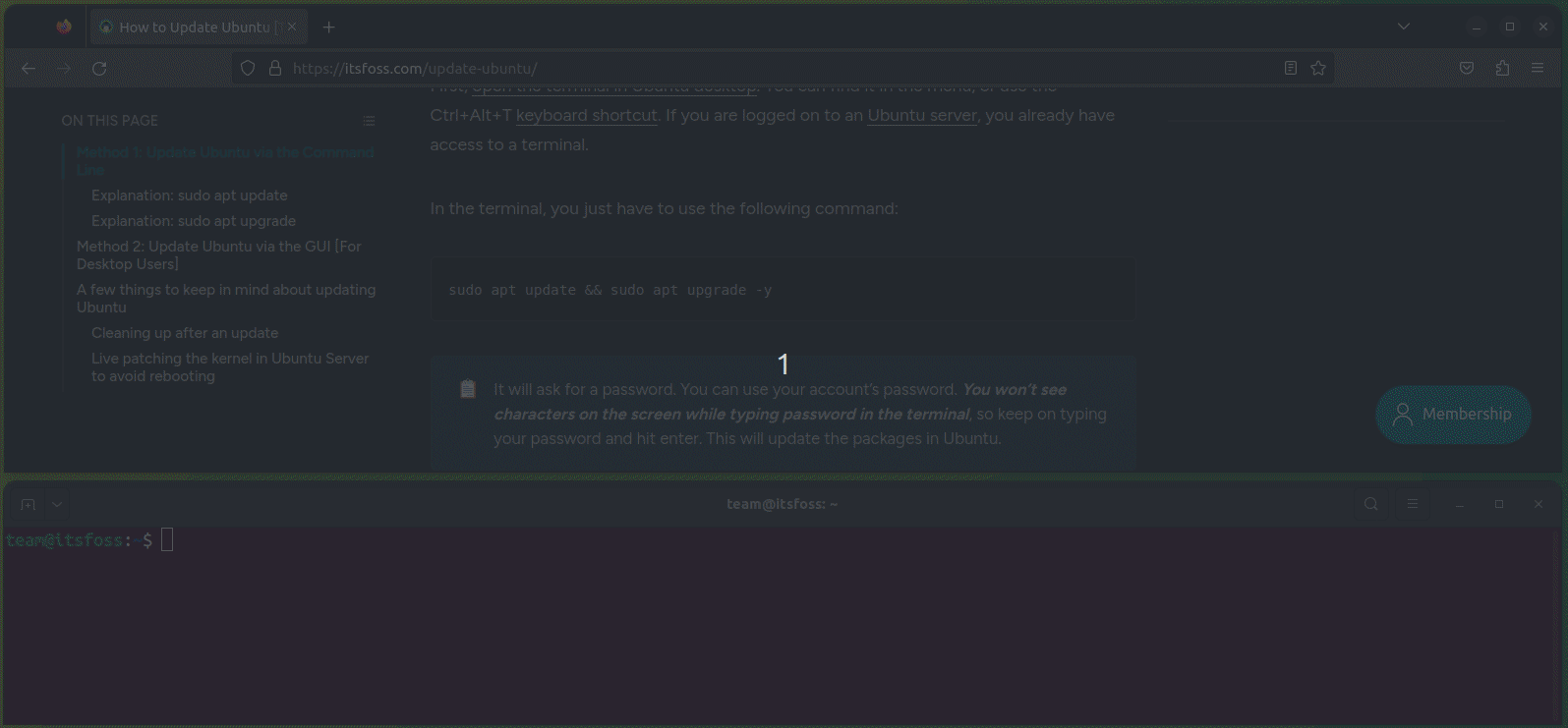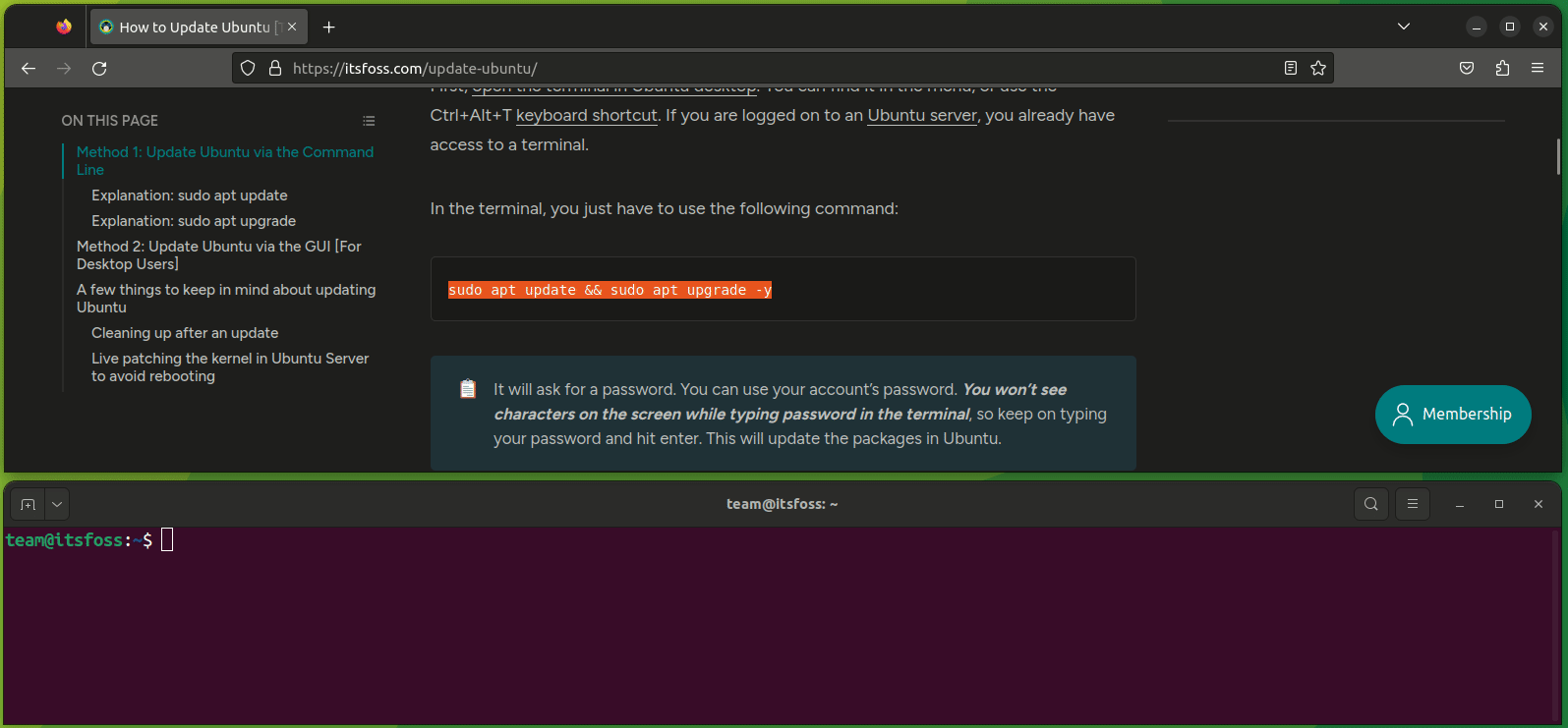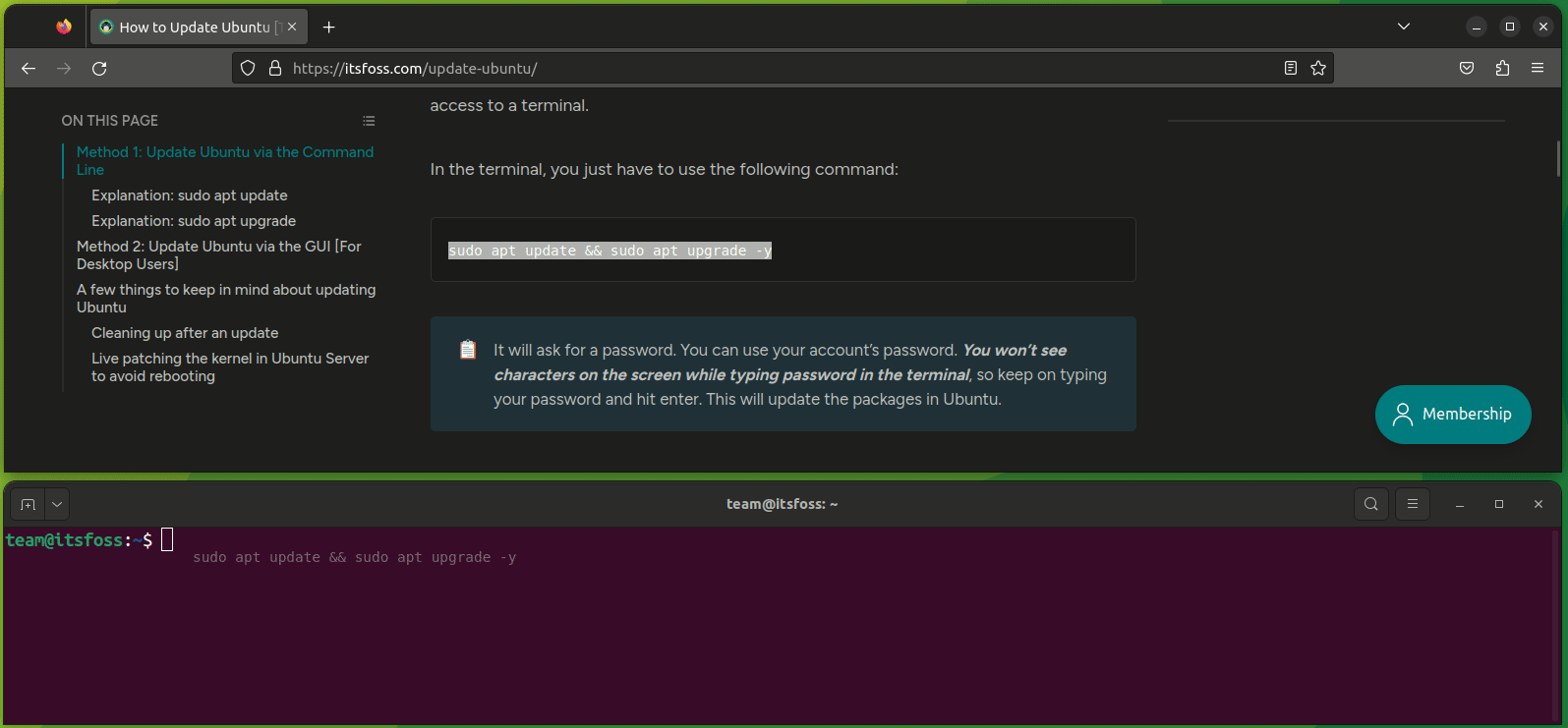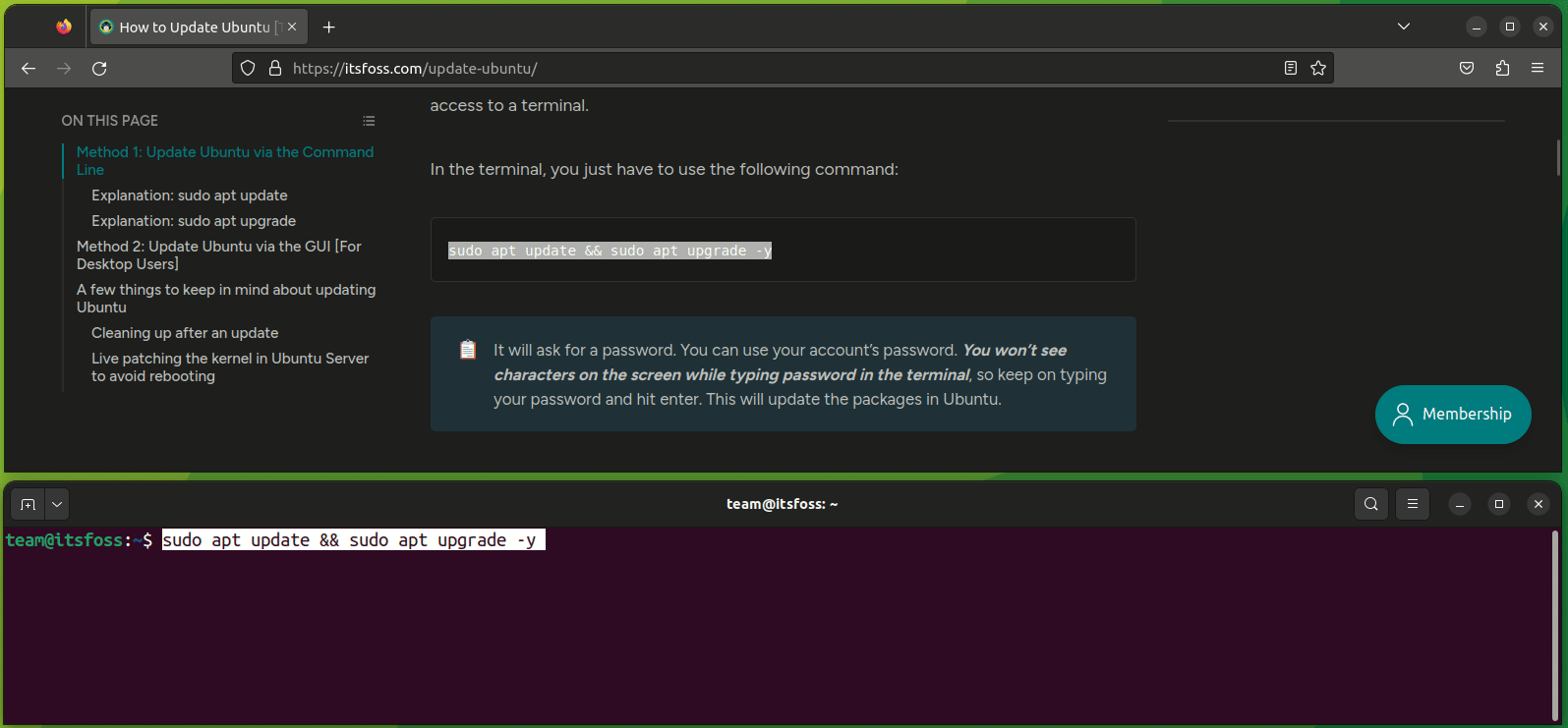
## 8. Embed terminal in Nautilus
Can't live without the terminal? Embed it directly in the file manager. This way you don't have to [open a terminal](https://itsfoss.com/open-terminal-ubuntu/) separately.
The thing here is that if you switch to another directory in the file browser, it automatically switches the directly in the embedded terminal also.
You can perform most of the above-mentioned drag and drop operations in the Nautilus embedded terminal also. For example, search for a specific text in bashrc, by dropping the `.bashrc`
file and using grep.
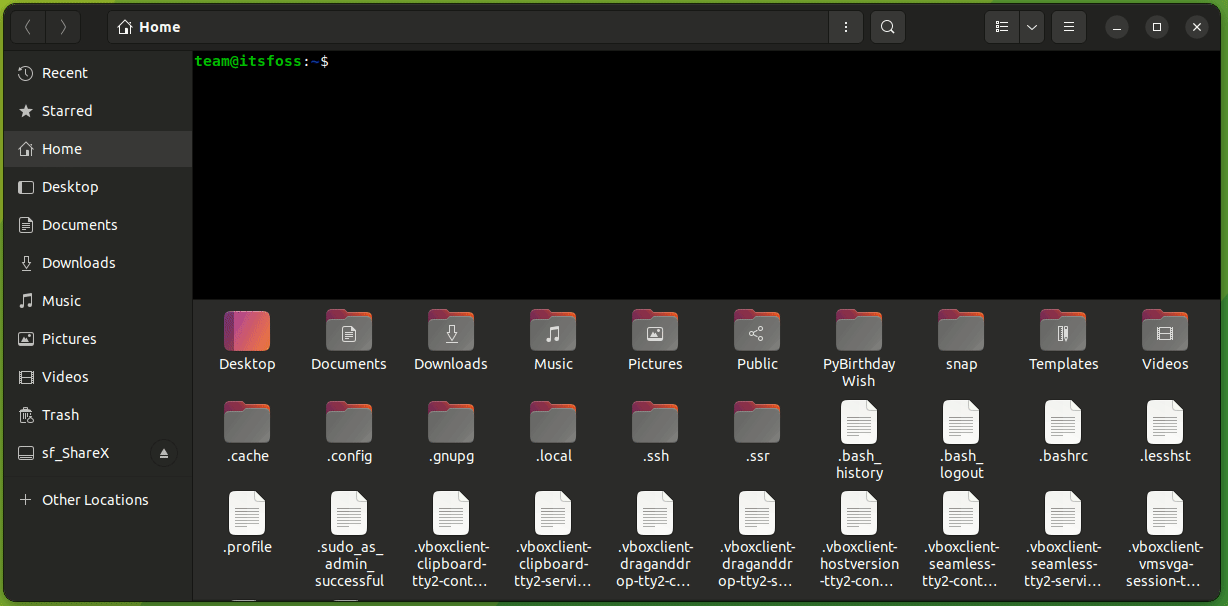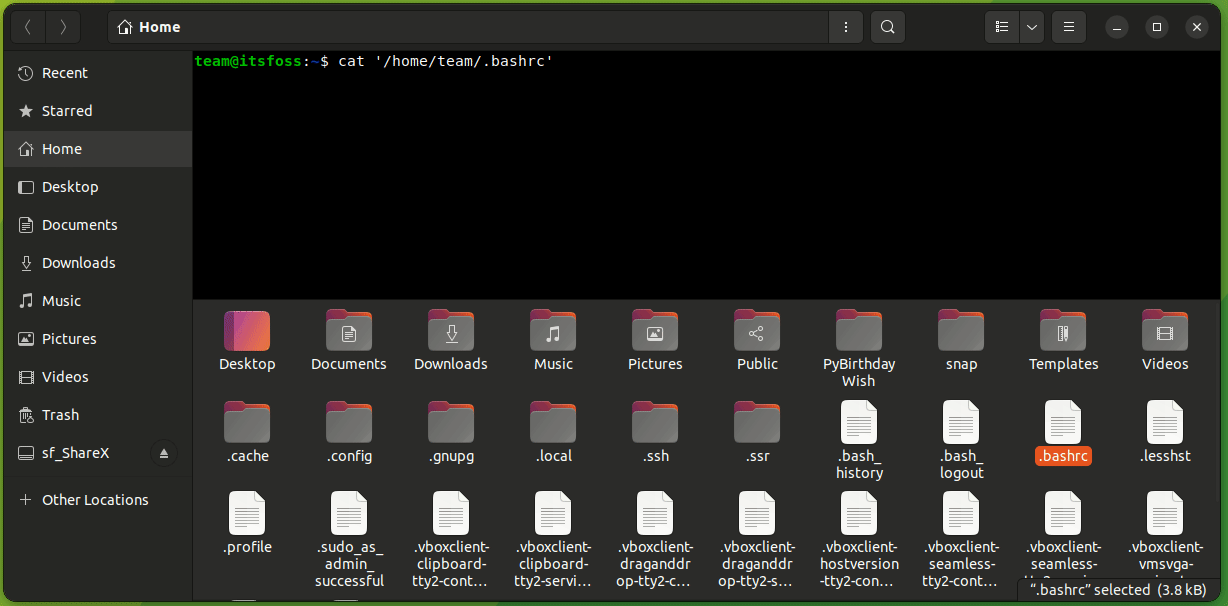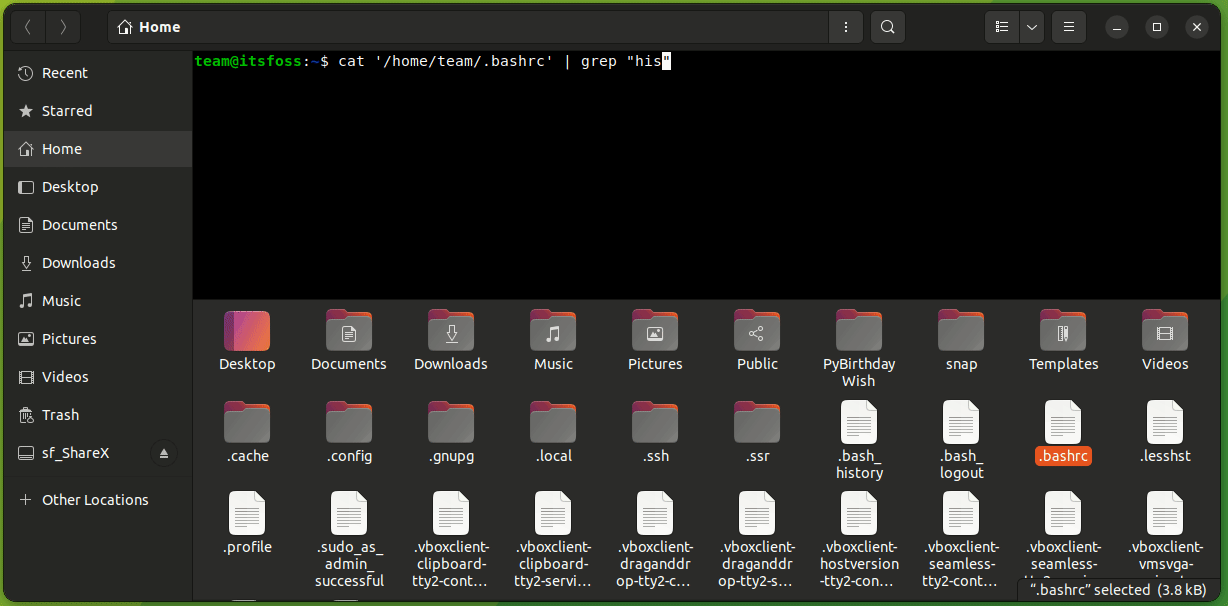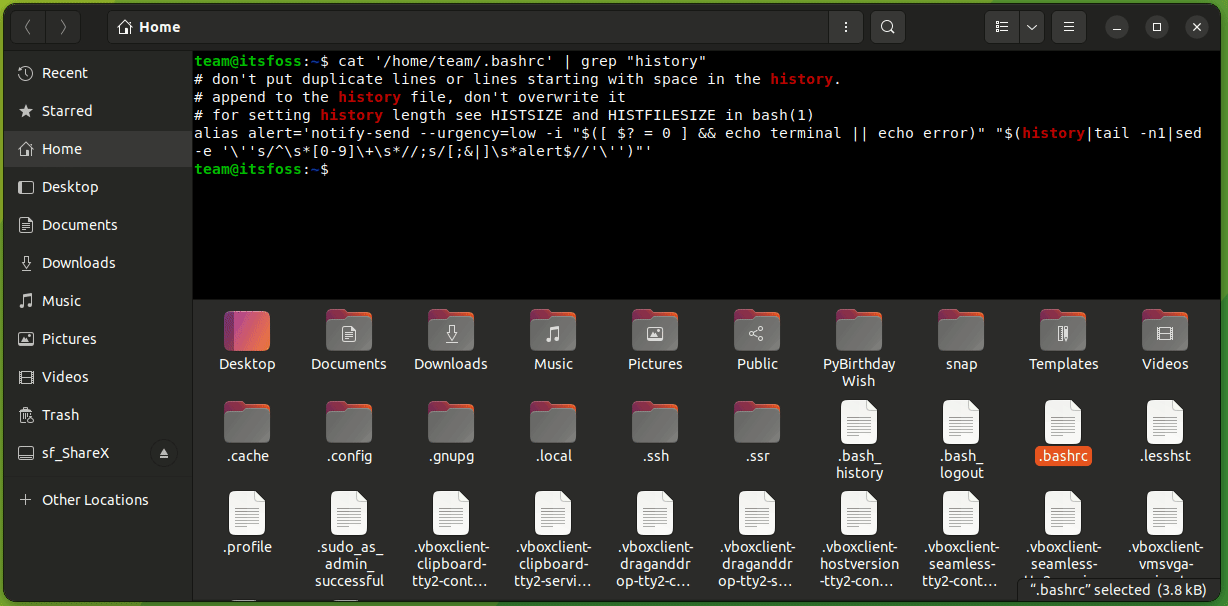
## 9. Drag files between tabs of the embedded terminal
Both terminal and file manager supports the tabbed view. You can drag and drop files from one tab to another.
For example, to [check the shasum](https://itsfoss.com/checksum-tools-guide-linux/) value for an ISO, enter shasum command, then, drag and drop the file from another tab, as shown below.
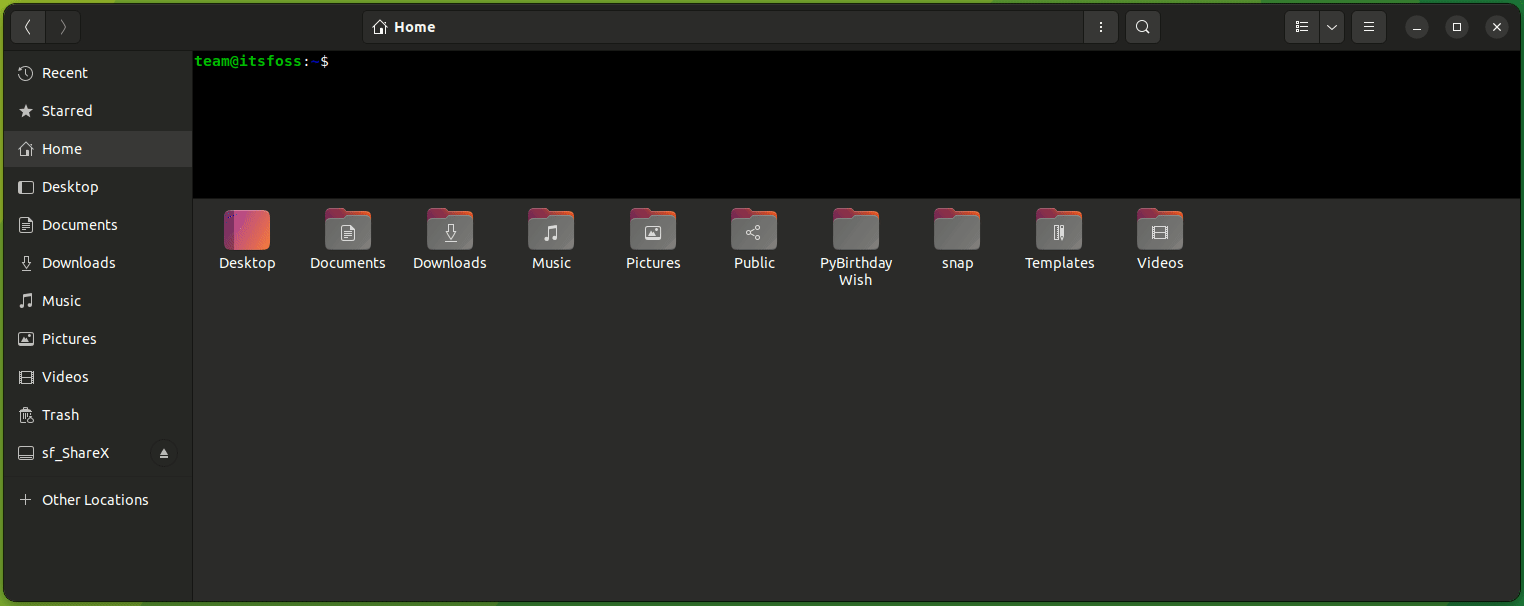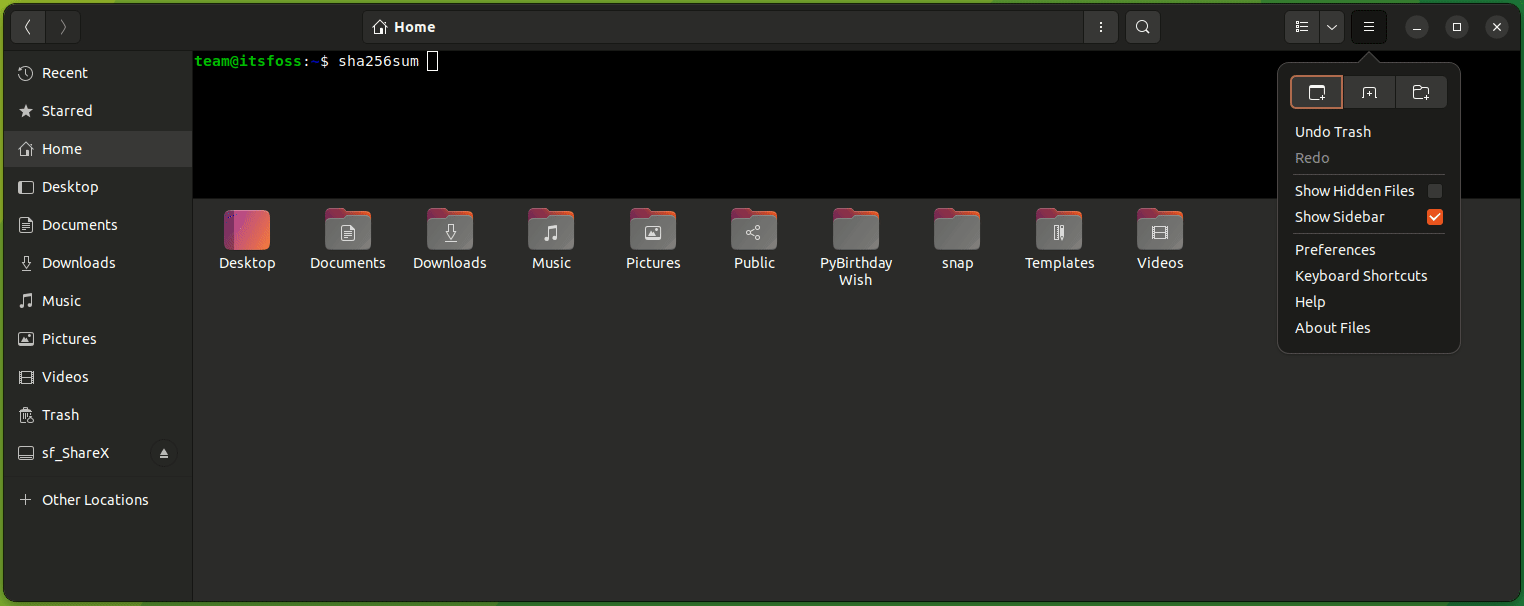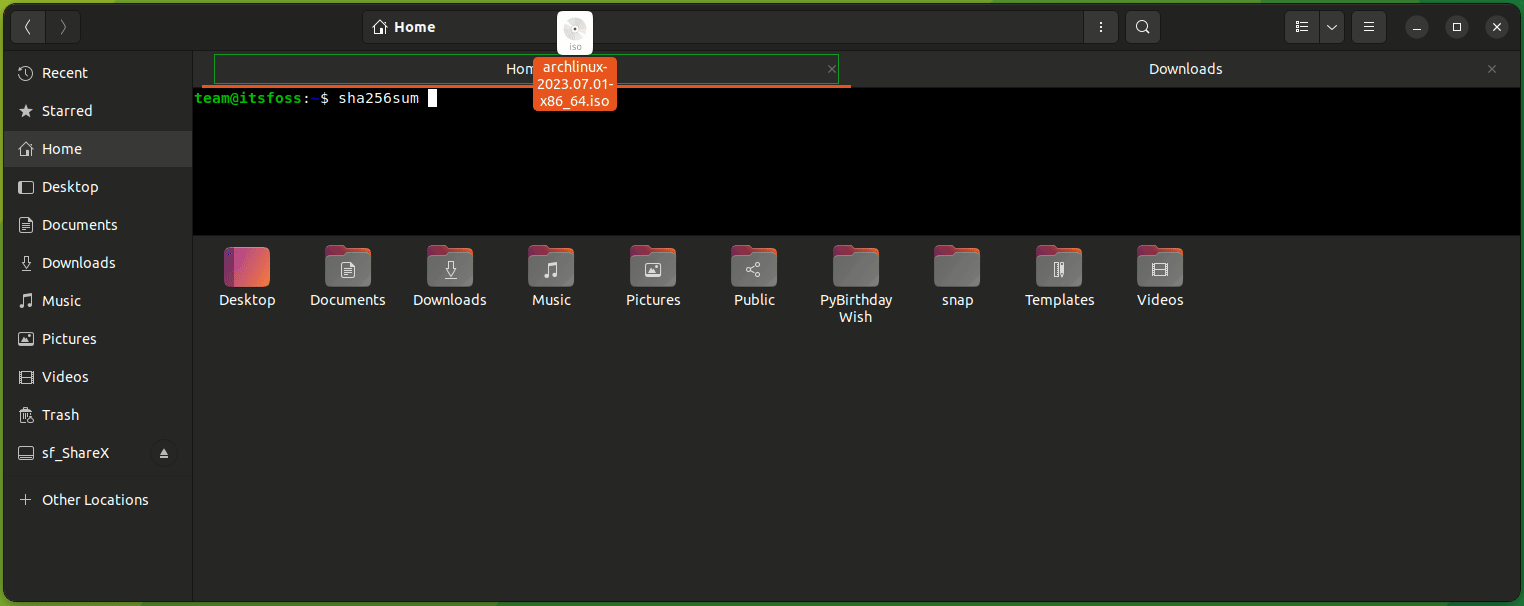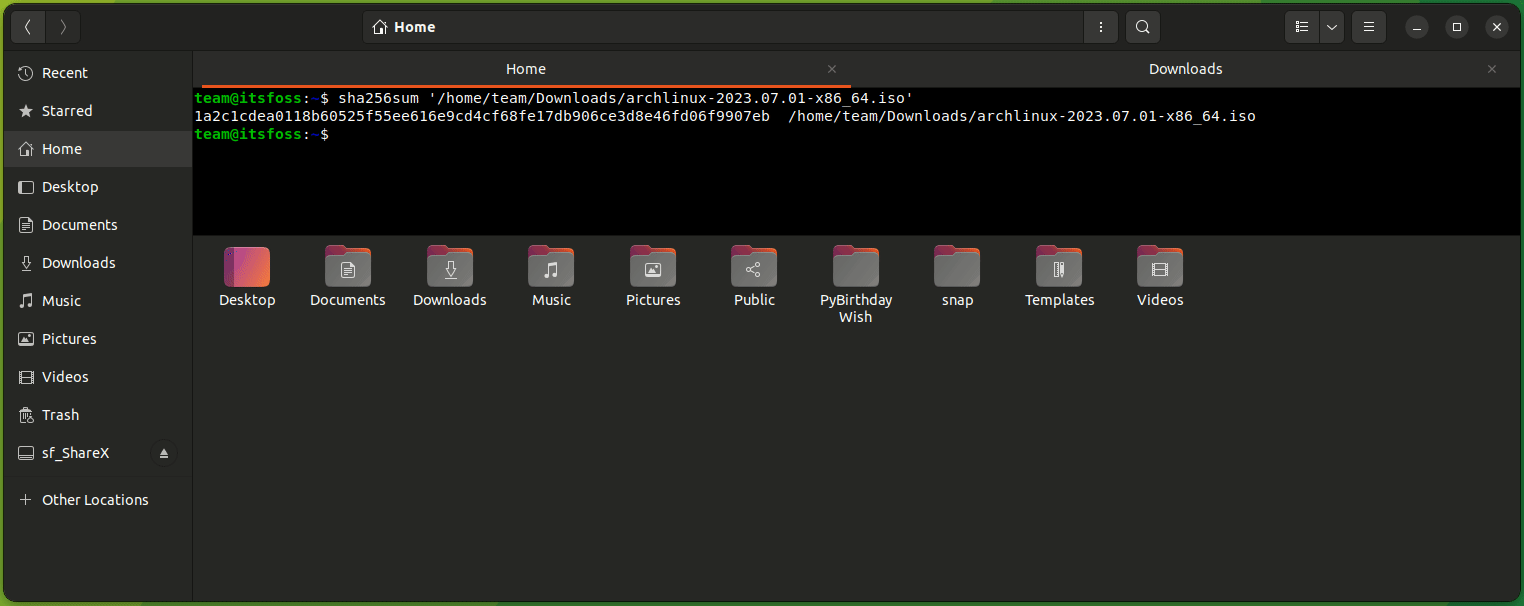
## More on Nautilus and terminal
Liked these tips? Maybe you would want to learn more such tips.
If you want to get more out of the Nautilus file manager, here are a few tips for you.
[13 Ways to Tweak Nautilus File Manager in LinuxNautilus, aka GNOME Files, is a good file manager with plenty of features. You can further enhance your experience by using these extensions, tweaks and tips.](https://itsfoss.com/nautilus-tips-tweaks/)

Here are some terminal tips to explore.
[19 Basic But Essential Linux Terminal Tips You Must KnowLearn some small, basic but often ignored things about the terminal. With the small tips, you should be able to use the terminal with slightly more efficiency.](https://itsfoss.com/basic-terminal-tips-ubuntu/)

💬 *Do you know any other such cool tip that combines the terminal and the file manager? Why not share it with us in the comment section below?* |
16,073 | 你喜欢哪种文档标记语言? | https://opensource.com/article/22/12/markup-languages-documentation | 2023-08-07T22:51:27 | [
"文档",
"文档标记语言",
"MarkDown"
] | https://linux.cn/article-16073-1.html | 
>
> 文档对于开源软件项目至关重要。我们询问了我们的贡献者,他们在文档编写中最喜欢使用的标记语言是什么。
>
>
>
文档很重要,而易读的文档更重要。在开源软件世界中,文档可以告诉我们如何使用或贡献一个应用程序,就像 [游戏](https://opensource.comttps://opensource.com/life/16/11/software-documentation-tabletop-gaming) 的规则书一样。
有很多不同类型的文档:
* 教程
* 操作指南
* 参考指南
* 软件架构
* 产品手册
我们向一些贡献者询问了他们的技术文档工作流程,他们更喜欢使用哪种标记语言,以及为什么会选择其中一种。以下是他们的回答。
### AsciiDoc
过去几年中,[Markdown](https://opensource.com/article/19/9/introduction-markdown) 一直是我的标准语言。但最近我决定尝试一下 [AsciiDoc](https://opensource.com/article/22/8/drop-markdown-asciidoc) 。这种语法并不难,我在 Linux 桌面上的 [Gedit](https://opensource.com/%20https%3A//opensource.com/article/20/12/gedit) 就支持它。我计划暂时坚持使用它一段时间。
—- [Alan Formy-Duval](https://opensource.com/users/alanfdoss)
就低语法标记语言而言,我更喜欢 AsciiDoc。我喜欢它,是因为其转换过程一致且可预测,没有令人困惑的“口味”变化 。我还喜欢将它输出为 [Docbook](https://opensource.com/article/17/9/docboo),这是一种我信任其持久性和灵活性的标记语言,它有大量的语法标记。
但“正确”的选择往往取决于项目已经在使用什么。如果项目使用某种口味的 Markdown,我就不会使用 AsciiDoc。嗯,公平地说,我可能会使用 AsciiDoc,然后使用 Pandoc 将其转换为草莓味的 Markdown。
当然,我认为 Markdown 有其应用的时间和场合。我发现它比 AsciiDoc 更易读。AsciiDoc 中的链接是这样:
```
http://example.com [Example website]
```
而 Markdown 中的链接是这样:
```
[Example.com](http://example.com)
```
Markdown 的语法直观,以读取 HTML 的方式呈现信息,大多数人都以相同的方式解析此类数据(“Example website……哦,那是蓝色的文本,我将悬停一下以查看它指向哪里……它指向 [example.com](http://example.com/)”)。
换句话说,当我的受众是人类读者时,我通常会选择 Markdown,因为它的语法简单,但仍具有足够的语法可以进行转换,因此仍然是一种可接受的存储格式。
虽然像 AsciiDoc 这样简洁的语法看起来更令人吃惊,但如果我的受众是要解析文件的计算机,我会选择 AsciiDoc。
—- [Seth Kenlon](https://opensource.com/users/seth)
### reStructuredText
我是 [代码即文档](https://opensource.com/article/22/10/docs-as-code) 的忠实支持者,它将开发者工具融入到内容流程中。这样可以更轻松地进行高效的审查和协作,尤其是如果工程师是贡献者。
作为一个标记语言的行家,我在 O'Reilly 写了整整一本关于 AsciiDoc 的书,还使用 Markdown 在各个平台上发布了上千篇博文。但目前,我转向使用 [reStructuredText](https://opensource.com/article/19/11/document-python-sphinx),并维护一些相关工具。
—— [Lorna Mitchell](https://opensource.com/users/lornajane)
不得不提到 reStructuredText。在我大量使用 Python 编程时,它已成为我的首选。它也是 Python 长期以来用于文档源码和代码注释的标准。
与 Markdown 相比,我喜欢它不会受到非标准规范的困扰。话虽如此,当我处理更复杂的文档时,确实还得使用许多 Sphinx 的功能和扩展。
—— [Jeremy Stanley](https://opensource.com/users/fungi)
### HTML
能不用标记语言我就不用。
不过,我发现 HTML 比其他标记语言更易于使用。
—— [Rikard Grossman-Nielsen](https://opensource.com/users/rikardgn)
对我来说,撰写文档有各种方式。这取决于文档将要放在何处,是作为网站的一部分、软件包的一部分,还是可下载的内容。
对于 [Scribus](https://opensource.com/article/21/12/desktop-publishing-scribus) 来说,其内部文档采用 HTML 格式,因为需要使用内部浏览器来访问。对于网站,可能需要使用维基语言。而对于可下载的内容,可以创建 PDF 或 EPUB 格式。
我倾向于在纯文本编辑器中编写文档。我可能会使用 XHTML,以便将这些文件导入到像 Sigil 这样的 EPUB 制作工具中。当然,对于创建 PDF,我会使用 Scribus,虽然我可能会导入用文本编辑器创建的文本文件。Scribus 具有包含图形并精确控制其布局的优势。
Markdown 从未吸引我,我也从未尝试过 AsciiDoc。
—— [Greg Pittman](https://opensource.com/users/greg-p)
我目前正在使用 HTML 撰写大量文档,所以我要为 HTML 代言一下。你可以使用 HTML 创建网站或创建文档。请注意,这两者实际上并不相同 —— 当你创建网站时,大多数设计师关注的是呈现。但是当你编写文档时,技术作者应该专注于内容。
当我用 HTML 撰写文档时,我遵循 HTML 定义的标签和元素,并不关心它的外观。换句话说,我用“未经样式化”的 HTML 编写文档。稍后我总是可以添加样式表。因此,如果我需要强调文本的某一部分(比如警告),或者给单词或短语加重语气,我可能会使用 `<strong>` 和 `<em>` 标签,像这样:
```
<p><strong>警告:激光!</strong>不要用你剩下的那只眼睛看向激光。</p>
```
或者在段落中提供一个简短的代码示例,我可能会这样写:
```
<p><code>puts</code> 函数将一些文本输出给用户。</p>
```
要在文档中格式化一段代码块,我使用 `<pre><code>..</code></pre>`,如下所示:
```
void
print_array(int *array, int size)
{
for (int i = 0; i < size; i++) {
printf("array[%d] = %d\n", i, array[i]);
}
}
```
HTML 的好处在于你可以立即在任何 Web 浏览器中查看结果。而你使用未经样式化的 HTML 编写的任何文档都可以通过添加样式表来美化。
—— [Jim Hall](https://opensource.com/users/jim-hall)
### 意料之外的答案:LibreOffice
在上世纪 80/90 年代,当我在 System V Unix、SunOS,最后是 Solaris 上工作时,我使用了 `nroff`、`troff` 和最终的 `groff` 与 `mm` 宏。你可以了解一下使用 `groff_mm` 的 MM(前提是你已经安装了它们)。
MM 并不是真正的标记语言,但它感觉像是。它是一套非常语义化的 troff 和 groff 宏。它具备标记语言用户所期望的大多数功能,如标题、有序列表等等。
我的第一台 Unix 机器上也安装了 “Writers' Workbench”,这对我们组织中需要撰写技术报告但没有特别进行“引人入胜”写作的许多人来说是一个福音。它的一些工具已经进入了 BSD 或 Linux 环境,比如样式(style)、用词检查(diction)和外观(look)。
我还记得早在上世纪 90 年代初期,Solaris 附带了一个标准通用标记语言(SGML)工具,也可能是我们购买了这个工具。我曾经使用它一段时间,这可能解释了为什么我不介意手动输入 HTML。
我使用过很多 Markdown,我应该说是“哪种 Markdown”,因为它有无数种风格和功能级别。正因为如此,我并不是 Markdown 的铁杆粉丝。我想,如果我有很多 Markdown 要处理,我可能会尝试使用一些 [CommonMark](https://commonmark.org/) 的实现,因为它实际上有一个正式的定义。例如,[Pandoc](https://opensource.com/downloads/pandoc-cheat-sheet) 支持 CommonMark(以及其他几种)。
我开始使用 AsciiDoc,相比于 Markdown,我更喜欢 AsciiDoc,因为它避免了“你使用的是哪个版本”的讨论,并提供了许多有用的功能。过去,让我对 AsciiDoc 感到困扰的是,有一段时间似乎需要安装 Asciidoctor,这是一个我不太想安装的 Ruby 工具链。但是现在,在我所用的 Linux 发行版中,有了更多的实现方式。奇怪的是,Pandoc 可以输出 AsciiDoc,但不支持读取 AsciiDoc。
那些嘲笑我不愿意为 AsciiDoc 安装 Ruby 工具链,却乐意安装 Pandoc 的 Haskell 工具链的人……我听到你们的笑声了。
我羞愧地承认,我现在主要使用 LibreOffice。
——[Chris Hermansen](https://opensource.com/users/clhermansen)
### 现在就编写文档吧!
文档编写可以通过多种不同的途径来完成,正如这里的作者们展示的那样。对于代码的使用方法,特别是在开源领域,进行文档编写非常重要。这确保其他人能够正确地使用和贡献你的代码。同时,告诉未来的用户你的代码提供了什么也是明智之举。
*(题图:MJ/9543e029-322d-479f-b609-442abc036b73)*
---
via: <https://opensource.com/article/22/12/markup-languages-documentation>
作者:[Opensource.com](https://opensource.com/users/admin) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Documentation is important for so many reasons. Readable documentation is even more so. In the world of open source software, documentation is how to use or contribute to an application. It's like the rulebook for a [game](ttps://opensource.com/life/16/11/software-documentation-tabletop-gaming).
There are many different types of documentation:
-
Tutorials
-
How-to guides
-
Reference guides
-
Software architecture
-
Product manuals
We asked some of the Opensource.com contributors about their technical documentation workflow, which markup language they preferred, and why they might use one over the other. Here's what they had to say.
## AsciiDoc
For the past several years, [Markdown](https://opensource.com/article/19/9/introduction-markdown) has been my standard language. But recently I decided to give [AsciiDoc](https://opensource.com/article/22/8/drop-markdown-asciidoc) a try. The syntax is not difficult and [Gedit](https://opensource.com/%20https%3A//opensource.com/article/20/12/gedit) on my Linux desktop supports it. I plan to stick with it for a while.
In terms of low-syntax markup, I prefer AsciiDoc. I like it because its conversion process is consistent and predictable, with no surprise "flavor" variations to confuse things. I also love that it outputs to [Docbook](https://opensource.com/article/17/9/docboo), which is a markup-heavy syntax that I trust for longevity and flexibility.
But the "right" choice tends to be what a project is already using. I wouldn't write in AsciiDoc if a project uses Strawberry-flavored Markdown. Well, to be fair, I might write in AsciiDoc and then convert it to Strawberry-flavored Markdown with Pandoc.
I do think there is a time and place for Markdown. I do find it more readable than AsciiDoc. Links in AsciiDoc:
```
````http://example.com[Example website]`
Links in Markdown:
```
````[Example.com](http://example.com)`
The Markdown syntax is intuitive, delivering the information in the same way that I think most of us parse the same data when reading HTML ("Example website…oh, that's blue text, I'll roll over it to see where it goes…it goes to [example.com](http://example.com/)").
In other words, when my audience is a human reader, I do often choose Markdown because its syntax is subtle but it's got enough of a syntax to make conversion possible, so it's still an OK storage format.
AsciiDoc, as minimal as it is, just looks scarier.
If my audience is a computer that's going to parse a file, I choose AsciiDoc.
## reStructuredText
I'm a big fan of [docs as code](https://opensource.com/article/22/10/docs-as-code) and how it brings developer tools into the content workflows. It makes it easier to have efficient reviews and collaboration, especially if engineers are contributors.
I'm also a bit of a markup connoisseur, having written whole books in AsciiDoc for O'Reilly, a lot of Markdown for various platforms, including a thousand posts on my blog. Currently, I'm a [reStructuredText](https://opensource.com/article/19/11/document-python-sphinx) convert and maintain some of the tooling in that space.
Obligatory mention of reStructuredText. That's my go-to these days as I do a lot of Python programming. It's also been Python's standard for documentation source and code comments for ages.
I like that it doesn't suffer quite so much from the proliferation of nonstandards that Markdown does. That said, I do use a lot of Sphinx features and extensions when working on more complex documentation.
## HTML
I rarely use markup languages if I don't have to.
I find HTML easier to use than other markup languages though.
For me, there are various ways to make documentation. It depends on where the documentation is going to be whether on a website, as part of the software package, or something downloadable.
For [Scribus](https://opensource.com/article/21/12/desktop-publishing-scribus), the internal documentation is in HTML, since an internal browser is used to access it. On a website, you might need to use a Wiki language. For something downloadable you might create a PDF or an EPUB.
I tend to write the documentation in a plain text editor. I might use XHTML, so that I can then import these files into an EPUB maker like Sigil. And, of course, Scribus is my go-to app for making a PDF, though I would probably be importing a text file created with a text editor. Scribus has the advantage of including and precisely controlling placement of graphics.
Markdown has never caught on with me, and I've never tried AsciiDoc.
I'm writing a lot of documentation in HTML right now, so I'll put in a plug for HTML. You can use HTML to create websites, or to create documentation. Note that the two are not really the same — when you're creating websites, most designers are concerned about presentation. But when you're writing documentation, tech writers should focus on content.
When I write documentation in HTML, I stick to the tags and elements defined by HTML, and I don't worry about how it will look. In other words, I write documentation in "unstyled" HTML. I can always add a stylesheet later. So if I need to make some part of the text stronger (such as a warning) or add emphasis to a word or phrase, I might use the <strong> and <em> tags, like this:
```
````<p><strong>Warning: Lasers!</strong> Do <em>not</em> look into laser with remaining eye.</p>`
Or to provide a short code sample within the body of a paragraph, I might write:
```
````<p>The <code>puts</code> function prints some text to the user.</p>`
To format a block of code in a document, I use <pre><code>..</code></pre> like this:
```
``````
void
print_array(int *array, int size)
{
for (int i = 0; i < size; i++) {
printf("array[%d] = %d\n", i, array[i]);
}
}
```
The great thing about HTML is you can immediately view the results with any web browser. And any documentation you write in unstyled HTML can be made prettier later by adding a stylesheet.
## Unexpected: LibreOffice
Back in the 80s and 90s when I worked in System V Unix, SunOS, and eventually Solaris, I used the mm macros with `nroff,`
`troff `
and finally `groff`
. Read about MM using groff_mm (provided you have them installed.)
MM isn't really a markup language, but it feels like one. It is a very semantic set of troff and groff macros. It has most things markup language users would expect—headings, numbered lists, and so on.
My first Unix machine also had Writers' Workbench available on it, which was a boon for many in our organization who had to write technical reports but didn't particularly write in an "engaging manner". A few of its tools have made it to either BSD or Linux—style, diction, and look.
I also recall a standard generalized markup language (SGML) tool that came with, or perhaps we bought for, Solaris in the very early 90s. I used this for awhile, which may explain why I don't mind typing in my own HTML.
I've used Markdown a fair bit, but having said that, I should also be saying "which Markdown", because there are endless flavors and levels of features. I'm not a huge fan of Markdown because of that. I guess if I had a lot of Markdown to do I would probably try to gravitate toward some implementation of [CommonMark](https://commonmark.org/) because it actually has a formal definition. For example, [Pandoc](https://opensource.com/downloads/pandoc-cheat-sheet) supports CommonMark (as well as several others).
I started using AsciiDoc, which I much prefer to Markdown as it avoids the "which version are you using" conversation and provides many useful things. What has slowed me down in the past with respect to AsciiDoc is that for some time it seemed to require installing Asciidoctor—a Ruby toolchain which I was not anxious to install. But these days there are more implementations at least in my Linux distro. Curiously, Pandoc emits AsciiDoc but does not read it.
Those of you laughing at me for not wanting a Ruby toolchain for AsciiDoc but being satisfied with a Haskell toolchain for Pandoc… I hear you.
I blush to admit that I mostly use LibreOffice these days.
## Document now!
Documentation can be achieved through many different avenues, as the writers here have demonstrated. It's important to document how to use your code, especially in open source. This ensures that other people can use and contribute to your code properly. It's also wise to tell future users what your code is providing.
## 4 Comments |
16,074 | 如何在 Ubuntu 上安装 GitLab | https://www.linuxtechi.com/how-to-install-gitlab-on-ubuntu/ | 2023-08-08T11:31:00 | [
"GitLab"
] | https://linux.cn/article-16074-1.html | 
GitLab 是一个开源平台,提供了强大且功能丰富的解决方案,用于管理仓库、问题、CI/CD 管道等。如果你是 Ubuntu 22.04 或 20.04 用户,并且想要设置自己的 [GitLab](https://about.gitlab.com/) 实例来简化你的 DevOps 工作流程,那么你来对地方了。
本分步指南将引导你完成 Ubuntu 22.04 或 20.04 上 GitLab 的安装过程。GItlab 提供企业版(Gitlab EE)和社区版(Gitlab CE)。在这篇文章中,我们将介绍社区版。
先决条件:
* 运行 Ubuntu 22.04 或 20.04 且具有 SSH 访问权限的虚拟或专用服务器。
* 静态主机名(`gitlab.linuxtechi.net`)
* 具有管理员权限的 Sudo 用户
* 2GB 内存或更多
* 2 个或更多 vCPU
* 互联网连接
### 1、更新系统包
让我们首先更新软件包列表并将任何现有软件包升级到最新版本。
```
$ sudo apt update
$ sudo apt upgrade -y
```
应用更新后重新启动系统。
```
$ sudo reboot
```
### 2、安装依赖项
GitLab 需要一些依赖项才能正常运行。使用以下命令安装它们:
```
$ sudo apt install -y curl openssh-server ca-certificates postfix
```
在 postfix 安装过程中,会出现一个配置窗口。选择 “Internet Site”并输入服务器的主机名作为邮件服务器名称。这将允许 GitLab 发送电子邮件通知。

选择 “Internet Site”,然后选择 “OK”。

检查系统的主机名并选择 “OK”。
### 3、添加 GitLab Apt 存储库
现在,我们将添加 GitLab 仓库,运行以下 `curl` 命令。它将自动检测你的 Ubuntu 版本并相应地设置仓库。
```
$ curl -sS https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/script.deb.sh | sudo bash
```

### 4、安装 Gitlab
运行以下命令在你的 ubuntu 系统上自动安装和配置 gitlab-ce,将服务器的主机名替换为你的设置,
```
$ sudo EXTERNAL_URL="http://gitlab.linuxtechi.net" apt install gitlab-ce
```
上述命令成功执行后,我们将得到如下输出。


上面的输出确认 GitLab 已成功安装。gitlab web 界面的用户名是 root,密码存储在 `/etc/gitlab/initial_root_password`。
注意:如果你的 ubuntu 系统上启用了操作系统防火墙,那请允许 80 和 443 端口。
```
$ sudo ufw allow http
$ sudo ufw allow https
```
### 5、访问 GitLab Web 界面
安装并配置 GitLab 后,打开 Web 浏览器并输入服务器的 IP 地址或主机名。
```
http://<Server-IP-Address-or-Hostname>
```
* 用户名:`root`
* 密码:从 `/etc/gitlab/initial_root_password` 获取密码

点击“<ruby> 登录 <rt> Sign in </rt></ruby>”。

很好,上面确认我们已经成功登录 Gitlab Web 界面。
目前我们的 GitLab 服务器运行在 http(80)协议上,如果你想为你的 GitLab 启用 https,请参考以下步骤。
### 6、为 GitLab Web 界面设置 HTTPS
为提高安全性,可使用自签名证书或 Let's Encrypt 为 GitLab 实例配置 HTTPS。Let's Encrypt 只适用于互联网上有 A 记录的公有域。但在本例中,我们使用的是私有域,因此将使用自签名证书来确保 GitLab 的安全。
现在,让我们创建以下文件夹并使用 `openssl` 命令生成自签名证书:
```
$ sudo mkdir -p /etc/gitlab/ssl
$ sudo chmod 755 /etc/gitlab/ssl
```
使用以下 `openssl` 命令生成私钥:
```
$ sudo openssl genrsa -des3 -out /etc/gitlab/ssl/gitlab.linuxtechi.net.key 2048
```
输入密码并记住它。
使用以下命令创建 CSR:
```
$ sudo openssl req -new -key /etc/gitlab/ssl/gitlab.linuxtechi.net.key -out /etc/gitlab/ssl/gitlab.linuxtechi.net.csr
```

从密钥中删除密码串,依次执行以下命令:
```
$ sudo cp -v /etc/gitlab/ssl/gitlab.linuxtechi.net.{key,original}
$ sudo openssl rsa -in /etc/gitlab/ssl/gitlab.linuxtechi.net.original -out /etc/gitlab/ssl/gitlab.linuxtechi.net.key
$ sudo rm -v /etc/gitlab/ssl/gitlab.linuxtechi.net.original
```
创建证书文件:
```
$ sudo openssl x509 -req -days 1460 -in /etc/gitlab/ssl/gitlab.linuxtechi.net.csr -signkey /etc/gitlab/ssl/gitlab.linuxtechi.net.key -out /etc/gitlab/ssl/gitlab.linuxtechi.net.crt
```
使用下面的 `rm` 命令删除 CSR 文件:
```
$ sudo rm -v /etc/gitlab/ssl/gitlab.linuxtechi.net.csr
```
设置密钥和证书文件的权限:
```
$ sudo chmod 600 /etc/gitlab/ssl/gitlab.linuxtechi.net.key
$ sudo chmod 600 /etc/gitlab/ssl/gitlab.linuxtechi.net.crt
```
Gitlab 服务器的所有重要配置均由文件 `/etc/gitlab/gitlab.rb` 控制,因此编辑此文件,搜索 `external_url` 并添加 `https://gitlab.linuxtechi.net`。
```
$ sudo vi /etc/gitlab/gitlab.rb
----------------------------------------------------------
external_url 'https://gitlab.linuxtechi.net'
----------------------------------------------------------
```
保存并退出文件,使用下面的命令重新配置 gitlab,以便其 Web 界面可以使用 HTTPS。
```
$ sudo gitlab-ctl reconfigure
```

成功执行上述命令后,你的 GitLab 界面应该可以通过 HTTPS 协议访问,在我的例子中,URL 为:`https://gitlab.linuxtechi.net/`
当你第一次访问它时,它会说你的连接不安全,点击“接受风险并继续”。

### 结论
恭喜! 你已在 Ubuntu 22.04 或 20.04 系统上成功安装 GitLab。随着 GitLab 的启动和运行,你现在可以创建仓库,与你的团队协作,并通过 GitLab 令人印象深刻的功能增强你的开发工作流程。享受无缝版本控制、持续集成等,一切尽在你的掌控之中!
*(题图:MJ/c6a3e27e-fe58-4184-b133-9e9c67224316)*
---
via: <https://www.linuxtechi.com/how-to-install-gitlab-on-ubuntu/>
作者:[Pradeep Kumar](https://www.linuxtechi.com/author/pradeep/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this blog post, we will explain how to install GitLab on Ubuntu 22.04 step-by-step. Gitlab comes with Enterprise edition (Gitlab EE) and Community edition (Gitlab CE). In this post , we will cover the community edition installation.
GitLab, an open-source platform, provides a robust and feature-rich solution for managing repositories, issues, CI/CD pipelines, and much more. If you’re an Ubuntu 22.04 user and want to set up your own [GitLab](https://about.gitlab.com/) instance to streamline your DevOps workflow, you’re in the right place.
#### Prerequisites
- A virtual or dedicated server running Ubuntu 22.04 with SSH access.
- Static Hostname (gitlab.linuxtechi.net)
- Sudo User with admin rights
- 2 GB RAM or more
- 2 vCPUs or more
- Internet Connectivity
## 1) Update System Packages
Let’s begin by updating the package lists and upgrading any existing packages to their latest versions.
$ sudo apt update $ sudo apt upgrade -y
Reboot the system after applying updates,
$ sudo reboot
## 2) Install Dependencies
GitLab requires some dependencies to function correctly. Install them using the following commands:
$ sudo apt install -y curl openssh-server ca-certificates postfix
During the postfix installation, a configuration window will appear. Choose “Internet Site” and enter your server’s hostname as the mail server name. This will allow GitLab to send email notifications.
Choose “Internet Site” and then slect OK.
Check system’s hostname and choose OK.
## 3) Add GitLab Apt Repository
Now, we’ll add the GitLab repository, run the following curl command. It will automatically detect your Ubuntu version and will set the repository accordingly.
$ curl -sS https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/script.deb.sh | sudo bash
## 4) Install Gitlab on Ubuntu 22.04
Run the beneath command to install and configure gitlab-ce on your ubuntu system automatically, replace the server’s hostname as your setup,
$ sudo EXTERNAL_URL="http://gitlab.linuxtechi.net" apt install gitlab-ce
Once the above the command is executed successfully, we will get output something like below,
Output above confirms that GitLab has been installed successfully. User name for gitlab web interface is root and password is stored at “/etc/gitlab/initial_root_password”
Note : If OS firewall is enabled on your ubuntu system, then allow 80 and 443 ports.
$ sudo ufw allow http $ sudo ufw allow https
## 5) Access GitLab Web Interface
With GitLab installed and configured, open your web browser and enter your server’s IP address or hostname.
http://<Server-IP-Address-or-Hostname>
- User Name: root
- Password : <<Get Password from /etc/gitlab/initial_root_password>>
click on “Sign in”
Great, above confirms that we have successfully login to Gitlab Web interface.
As of now our GitLab Server is working on http (80) protocol, if you want to enable https for your GitLab, then refer the below steps,
## 6) Secure GitLab Web Interface
For added security, you can configure HTTPS for your GitLab instance using self-signed certificate or Let’s Encrypt. We can use Let’s encrypt only for public domain whose A recorded available on internet. But in our case, we are using a private domain, so we will be using self-signed certificate to secure GitLab.
Now, let’s create following folder and generate self-sign certificates using openssl command
$ sudo mkdir -p /etc/gitlab/ssl $ sudo chmod 755 /etc/gitlab/ssl
Generate the private key using following openssl command,
$ sudo openssl genrsa -des3 -out /etc/gitlab/ssl/gitlab.linuxtechi.net.key 2048
Enter the passphrase and and remember it
Create the CSR using below command,
$ sudo openssl req -new -key /etc/gitlab/ssl/gitlab.linuxtechi.net.key -out /etc/gitlab/ssl/gitlab.linuxtechi.net.csr
Remove Passphrase from the key, execute the following commands one after the another
$ sudo cp -v /etc/gitlab/ssl/gitlab.linuxtechi.net.{key,original} $ sudo openssl rsa -in /etc/gitlab/ssl/gitlab.linuxtechi.net.original -out /etc/gitlab/ssl/gitlab.linuxtechi.net.key $ sudo rm -v /etc/gitlab/ssl/gitlab.linuxtechi.net.original
Create the Certificate file
$ sudo openssl x509 -req -days 1460 -in /etc/gitlab/ssl/gitlab.linuxtechi.net.csr -signkey /etc/gitlab/ssl/gitlab.linuxtechi.net.key -out /etc/gitlab/ssl/gitlab.linuxtechi.net.crt
Remove the CSR file using below [rm command](https://www.linuxtechi.com/rm-command-examples-for-beginners/),
$ sudo rm -v /etc/gitlab/ssl/gitlab.linuxtechi.net.csr
Set the permissions on key and certificate file
$ sudo chmod 600 /etc/gitlab/ssl/gitlab.linuxtechi.net.key $ sudo chmod 600 /etc/gitlab/ssl/gitlab.linuxtechi.net.crt
All the important configuration for Gitlab server is controlled by the file “/etc/gitlab/gitlab.rb” So edit this file, search “external_url” and add the “https://gitlab.linuxtechi.net”
$ sudo vi /etc/gitlab/gitlab.rb ---------------------------------------------------------- external_url 'https://gitlab.linuxtechi.net' ----------------------------------------------------------
Save and exit the file, reconfigure gitlab using beneath command so that it’s web interface start working https.
$ sudo gitlab-ctl reconfigure
Once above command is executed successfully, then your GitLab interface should be accessible over https protocol, In my case url will be: https://gitlab.linuxtechi.net/
When you access it first time, it will say something like your connection is not secure, click on “Accept the Risk and Continue”
#### Conclusion
Congratulations! You’ve successfully installed GitLab on your Ubuntu 22.04 system. With GitLab up and running, you can now create repositories, collaborate with your team, and enhance your development workflow through GitLab’s impressive features. Enjoy seamless version control, continuous integration, and more, all under your control!
Gerald BrownAfter running steps 1 & 2 above then running step 3 I get the following error
sudo apt install gitlab-ce returns Unable to locate package gitlab-ce
Pradeep KumarHi Gerald,
It seems like gitlab ce repository is not configured properly on your system that’s why you are getting the error.
To Fix this issue, please try to enable the repo using the step2 and then run “apt-get update” and after that try to install gitlab-ce packages. |
16,076 | GNOME 雄心勃勃的窗口管理改革 | https://debugpointnews.com/gnome-window-management-proposal/ | 2023-08-09T10:51:14 | [
"GNOME"
] | /article-16076-1.html | 
>
> 厌倦了窗口混乱和手动调整? GNOME 正在集体讨论一个自动化且用户友好的窗口管理系统。这是你需要了解的情况。
>
>
>
窗口管理是桌面计算的一个重要方面,几十年来一直是人们着迷和探索的话题。然而,尽管进行了多次尝试,仍然没有人能够破解完美的窗口管理解决方案的密码。GNOME 开发人员现在开始致力于彻底改变窗口管理,旨在提高生产力和用户体验。
GNOME 开发人员 Tobias Bernard 发表了一篇 [详细的文章](https://blogs.gnome.org/tbernard/2023/07/26/rethinking-window-management/),介绍了开发人员如何考虑为未来创新 GNOME 桌面。
### 传统窗口系统的挑战
传统的窗口系统为我们提供了很好的服务,允许应用生成可以手动移动和调整大小的矩形窗口。然而,随着窗口数量和尺寸的增加,问题开始出现。重叠的窗口很快就会变得一团糟,使得在不隐藏其他应用的情况下访问特定应序变得困难。最大化窗口可能会遮挡桌面上的其他所有内容,从而导致混乱和效率低下。
多年来,各种操作系统引入了工作区、任务栏和切换器等解决方法来处理这些问题。然而,窗口管理的核心问题仍未解决。特别是对于儿童和老年人等计算机新手来说,手动排列窗口可能会很麻烦且乏味。
### 引入平铺窗口管理器
平铺窗口管理器提供了防止窗口重叠的替代解决方案。虽然它们在某些情况下运行良好,但也有其局限性。平铺窗口可能会导致效率低下,因为应用通常是针对特定尺寸和纵横比设计的。此外,这些窗口管理器缺乏关于窗口内容和上下文的知识,需要额外的手动调整,并违背了简化工作流程的目的。更不用说记住很多键盘快捷键了。
### GNOME 当前的平铺功能
GNOME 已经在 GNOME 3 系列中尝试了基本的平铺功能。然而,现有的实现有一些局限性。这是一个手动过程,仅支持两个窗口,缺乏复杂布局的可扩展性,并且不会将平铺窗口分组到窗口栈中。
### 窗口管理的新愿景
该团队提出了一种新的窗口管理方法,重点关注符合用户期望和需求的自动化系统。他们的概念涉及窗口的三种潜在布局状态:马赛克、边缘平铺和浮动。
马赛克模式将成为默认行为,根据用户偏好和可用屏幕空间智能定位窗口并调整窗口大小。随着新窗口的打开,现有窗口将进行调整以适应新来者。如果窗口不适合当前布局,它将被放置在自己的工作区中。当屏幕接近布满时,窗口将自动平铺。
用户还可以通过将窗口拖动到现有窗口或空白区域上来手动平铺窗口。该系统提供了灵活性和便利性,使其更容易高效地执行多任务。
### 维护用户友好的浮动窗口
虽然平铺提供了多种好处,但 GNOME 开发人员明白,总会有用户更喜欢手动定位窗口的情况。因此,经典的浮动行为仍然适用于这些特定情况,但随着新的马赛克系统的引入,它可能不太常见。
### 利用窗口元数据增强性能
GNOME 旨在优化平铺体验,以从窗口收集有关其内容的更多信息。这包括窗口的最大所需尺寸以及应用最佳运行的理想尺寸范围等详细信息。通过使用这些元数据,系统可以定制窗口布局以满足用户的需求,从而提高整体可用性。
### 展望未来
虽然 GNOME 开发人员对这个新的窗口管理方向感到兴奋,但他们也承认与这种新颖方法相关的风险。他们计划进行用户研究以验证他们的假设并完善交互。尽管没有具体的实施时间表,但该项目可能会跨越多个开发周期,并成为 GNOME 46 或更高版本的一部分。
截至发布此内容时,还没有草案合并请求,你可以参与其中并提供反馈。
参考自 [Tobias 的博客](https://blogs.gnome.org/tbernard/2023/07/26/rethinking-window-management/)。
*(题图:MJ/04285b09-a074-4f6f-a32e-ae5af06f1d1f)*
---
via: <https://debugpointnews.com/gnome-window-management-proposal/>
作者:[arindam](https://debugpointnews.com/author/dpicubegmail-com/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
16,077 | Fedora Linux 的家族(三):实验室 | https://fedoramagazine.org/fedora-linux-editions-part-3-labs/ | 2023-08-09T14:56:00 | [
"Fedora"
] | https://linux.cn/article-16077-1.html | 
根据个人需求,每个人使用计算机的方式都不同。你可能是一位设计师,需要在计算机上安装各种设计软件。或者你可能是一位游戏玩家,所以需要一个支持你喜欢的游戏的操作系统。有时候我们没有足够的时间来准备一个支持我们需求的操作系统。Fedora Linux 实验室版本就是为了满足这个需求而存在的。Fedora 实验室是由 Fedora 社区成员精心策划和维护的用于特定目的的软件和内容的集合。本文将对 Fedora Linux 实验室版本进行更详细的介绍。
你可以在我之前的文章《Fedora Linux 的各种版本》中找到所有 Fedora Linux 变种的概述。
### Fedora 天文学版
Fedora <ruby> 天文学 <rt> Astronomy </rt></ruby> 版适用于业余和专业天文学家。你可以通过这个 Fedora Linux 版本进行各种与天文学相关的活动。Fedora 天文学版中包含的一些应用程序有 Astropy、Kstars、Celestia、Virtualplanet、Astromatic 等。Fedora 天文学版默认使用 KDE Plasma 作为其桌面环境。
有关所包含的应用程序的详细信息和下载链接,请访问此链接:
>
> **[Fedora 天文学版](https://labs.fedoraproject.org/en/astronomy/)**
>
>
>
### Fedora 计算神经科学版
Fedora <ruby> 计算神经科学 <rt> Comp Neuro </rt></ruby>版是由 NeuroFedora 团队创建的,旨在支持计算神经科学。Fedora Linux 中包含的一些应用程序有 Neuron、Brian、Genesis、SciPy、Moose、NeuroML、NetPyNE 等。这些应用程序可以支持你的工作,包括建模软件、分析工具和常规生产工具。
有关所包含的应用程序的详细信息和下载链接,请访问此链接:
>
> **[Fedora 计算神经科学版](https://labs.fedoraproject.org/en/comp-neuro/)**
>
>
>
### Fedora 设计套件版
如果你是一位设计师,那么这个 Fedora Linux 版本就适合你。你将获得一个完整的 Fedora Linux,其中包含各种设计工具,如 GIMP、Inkscape、Blender、Darktable、Krita、Pitivi 等。使用这些工具,你可以创建各种创意作品,如网页设计、海报、传单、3D 模型、视频和动画。这个 Fedora <ruby> 设计套件 <rt> Design Suite </rt></ruby>版是由设计师为设计师创建的。
有关所包含的应用程序的详细信息和下载链接,请访问此链接:
>
> **[Fedora 设计套件版](https://labs.fedoraproject.org/en/design-suite/)**
>
>
>
### Fedora 游戏版
玩游戏很有趣,你可以使用 Fedora <ruby> 游戏 <rt> Games </rt></ruby>版来尽情享受。这个 Fedora Linux 版本提供了各种游戏类型,如第一人称射击游戏、实时和回合制策略游戏以及益智游戏。Fedora Linux 上的一些游戏包括 Extreme Tux Racer、Wesnoth、Hedgewars、Colossus、BZFlag、Freeciv、Warzone 2011、MegaGlest 和 Fillets。
有关所包含的应用程序的详细信息和下载链接,请访问此链接:
>
> **[Fedora 游戏版](https://labs.fedoraproject.org/en/games/)**
>
>
>
### Fedora 音乐版
几乎每个人都喜欢音乐。你们中的一些人可能是音乐家或音乐制作人。或者你可能是喜欢玩音频的人。那么这个 Fedora <ruby> 音乐 <rt> Jam </rt></ruby>版就是为你而设计的,它带有 JACK、ALSA、PulseAudio 和各种音频和音乐支持。Fedora 音乐版中的一些默认应用程序包括 Ardor、Qtractor、Hydrogen、MuseScore、TuxGuitar、SooperLooper 等。
有关所包含的应用程序的详细信息和下载链接,请访问此链接:
>
> **[Fedora 音乐版](https://labs.fedoraproject.org/en/jam/)**
>
>
>
### Fedora Python 教室版
如果你是一位 Python 开发者、教师或讲师,Fedora <ruby> Python 教室 <rt> Python Classroom </rt></ruby>版将使你与 Python 相关的工作更加容易。Fedora Python 教室版预先安装了各种重要的内容。Fedora Linux 上的一些默认应用程序包括 IPython、Jupyter Notebook、git、tox、Python 3 IDLE 等。Fedora Python 教室版有三个变种,你可以以 GNOME 图形界面方式运行,也可以使用 Vagrant 或 Docker 容器。
有关所包含的应用程序的详细信息和下载链接,请访问此链接:
>
> **[Fedora Python 教室版](https://labs.fedoraproject.org/en/python-classroom/)**
>
>
>
### Fedora 安全实验室版
Fedora <ruby> 安全实验室 <rt> Security Lab </rt></ruby>版是为安全测试人员和开发人员打造的 Fedora Linux。Xfce 是默认的桌面环境,并进行了定制以满足安全审计、取证、系统救援等需求。这个 Fedora Linux 提供了一些默认安装的应用程序,以支持你在安全领域的工作,如 Etherape、Ettercap、Medusa、Nmap、Scap-workbench、Skipfish、Sqlninja、Wireshark 和 Yersinia。
有关所包含的应用程序的详细信息和下载链接,请访问此链接:
>
> **[Fedora 安全实验室版](https://labs.fedoraproject.org/en/security/)**
>
>
>
### Fedora 机器人套件版
Fedora <ruby> 机器人套件 <rt> Robotics Suite </rt></ruby>版是一款带有各种自由开源机器人软件包的 Fedora Linux。这个 Fedora Linux 版本适用于与机器人相关的专业人士或爱好者。一些默认应用程序包括 Player、SimSpark、Fawkes、Gazebo、Stage、PCL、Arduino、Eclipse 和 MRPT。
有关所包含的应用程序的详细信息和下载链接,请访问此链接:
>
> **[Fedora 机器人套件版](https://labs.fedoraproject.org/en/robotics/)**
>
>
>
### Fedora 科学版
Fedora <ruby> 科学 <rt> Scientific </rt></ruby>版将使你在科学和数值工作方面更加便利。这个 Fedora Linux 提供了各种有用的开源科学和数值工具。默认桌面环境为 KDE Plasma,配备了各种应用程序,包括 IPython、Pandas、Gnuplot、Matplotlib、R、Maxima、LaTeX、GNU Octave 和 GNU Scientific Library 等,这些应用程序将支持你的工作。
有关所包含的应用程序的详细信息和下载链接,请访问此链接:
>
> **[Fedora 科学版](https://labs.fedoraproject.org/en/scientific/)**
>
>
>
### 结论
你有许多 Fedora Linux 版本可供选择,以适应你的工作或爱好。Fedora 实验室使这一切变得轻松。你不需要从头开始进行许多配置,因为 Fedora 实验室将为你完成。你可以在 <https://labs.fedoraproject.org/> 找到有关 Fedora 实验室的完整信息。
*(题图:MJ/6ac3eb72-eeb5-45dc-af53-91b54d320638)*
---
via: <https://fedoramagazine.org/fedora-linux-editions-part-3-labs/>
作者:[Arman Arisman](https://fedoramagazine.org/author/armanwu/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
| 200 | OK | Everyone uses their computer in different ways, according to their needs. You may work as a designer, so you need various design software on your computer. Or maybe you’re a gamer, so you need an operating system that supports the games you like. Sometimes we don’t have enough time to prepare an operating system that supports our needs. Fedora Linux Lab editions are here for you for that reason. Fedora Labs is a selection of curated bundles of purpose-driven software and content curated and maintained by members of the Fedora Community. This article will go into a little more detail about the Fedora Linux Lab editions.
You can find an overview of all the Fedora Linux variants in my previous article [Introduce the different Fedora Linux editions](https://fedoramagazine.org/introduce-the-different-fedora-linux-editions/).
## Astronomy
Fedora Astronomy is made for both amateur and professional astronomers. You can do various activities related to astronomy with this Fedora Linux. Some of the applications in Fedora Astronomy are Astropy, Kstars, Celestia, Virtualplanet, Astromatic, etc. Fedora Astronomy comes with KDE Plasma as its default desktop environment.
Details about the applications included and the download link are available at this link: [https://labs.fedoraproject.org/en/astronomy/](https://labs.fedoraproject.org/en/astronomy/)
## Comp Neuro
Fedora Comp Neuro was created by the NeuroFedora Team to support computational neuroscience. Some of the applications included in Fedora Linux are Neuron, Brian, Genesis, SciPy, Moose, NeuroML, NetPyNE, etc. Those applications can support your work, such as modeling software, analysis tools, and general productivity tools.
Details about the applications included and the download link are available at this link: [https://labs.fedoraproject.org/en/comp-neuro/](https://labs.fedoraproject.org/en/comp-neuro/)
## Design Suite
This Fedora Linux is for you if you are a designer. You will get a complete Fedora Linux with various tools for designing, such as GIMP, Inkscape, Blender, Darktable, Krita, Pitivi, etc. You are ready to create various creative works with those tools, such as web page designs, posters, flyers, 3D models, videos, and animations. This Fedora Design Suite is created by designers, for designers.
Details about the applications included and the download link are available at this link: [https://labs.fedoraproject.org/en/design-suite/](https://labs.fedoraproject.org/en/design-suite/)
## Games
Playing games is fun, and you can do it with Fedora Games. This Fedora Linux is comes with various game genres, such as first-person shooters, real-time and turn-based strategy games, and puzzle games. Some of the games on Fedora Linux are Extreme Tux Racer, Wesnoth, Hedgewars, Colossus, BZFlag, Freeciv, Warzone 2011, MegaGlest, and Fillets.
Details about the applications included and the download link are available at this link: [https://labs.fedoraproject.org/en/games/](https://labs.fedoraproject.org/en/games/)
## Jams
Almost everyone likes music. Some of you may be a musician or music producer. Or maybe you are someone who likes to play with audio. Then this Fedora Jam is for you, as it comes with JACK, ALSA, PulseAudio, and various support for audio and music. Some of the default applications from Fedora Jam are Ardor, Qtractor, Hydrogen, MuseScore, TuxGuitar, SooperLooper, etc.
Details about the applications included and the download link are available at this link: [https://labs.fedoraproject.org/en/jam/](https://labs.fedoraproject.org/en/jam/)
## Python Classroom
Fedora Python Classroom will make your work related to Python easier, especially if you are a Python developer, teacher, or instructor. Fedora Python Classroom is supported by various important stuff pre-installed. Some of the default applications on Fedora Linux are IPython, Jypyter Notebook, git, tox, Python 3 IDLE, etc. Fedora Python Classroom has 3 variants, namely you can run it graphically with GNOME, or with Vagrant or Docker containers.
Details about the applications included and the download link are available at this link: [https://labs.fedoraproject.org/en/python-classroom/](https://labs.fedoraproject.org/en/python-classroom/)
## Security Lab
Fedora Security Lab is Fedora Linux for security testers and developers. Xfce comes as a default desktop environment with customizations to suit the needs of security auditing, forensics, system rescue, etc. This Fedora Linux provides several applications that are installed by default to support your work in the security field, such as Etherape, Ettercap, Medusa, Nmap, Scap-workbench, Skipfish, Sqlninja, Wireshark, and Yersinia.
Details about the applications included and the download link are available at this link: [https://labs.fedoraproject.org/en/security/](https://labs.fedoraproject.org/en/security/)
## Robotics Suite
Fedora Robotic Suite is Fedora Linux with a wide variety of free and open robotics software packages. This Fedora Linux is suitable for professionals or hobbyists related to robotics. Some of the default applications are Player, SimSpark, Fawkes, Gazebo, Stage, PCL, Arduino, Eclipse, and MRPT.
Details about the applications included and the download link are available at this link: [https://labs.fedoraproject.org/en/robotics/](https://labs.fedoraproject.org/en/robotics/)
## Scientific
Your scientific and numerical work will become easier with Fedora Scientific. This Fedora Linux features a variety of useful open source scientific and numerical tools. KDE Plasma is the default desktop environment along with various applications that will support your work, such as IPython, Pandas, Gnuplot, Matplotlib, R, Maxima, LaTeX, GNU Octave, and GNU Scientific Library.
Details about the applications included and the download link are available at this link: [https://labs.fedoraproject.org/en/scientific/](https://labs.fedoraproject.org/en/scientific/)
## Conclusion
You have many choices of Fedora Linux to suit your work or hobby. Fedora Labs makes that easy. You don’t need to do a lot of configuration from scratch because Fedora Labs will do it for you. You can find complete information about Fedora Labs at [https://labs.fedoraproject.org/](https://labs.fedoraproject.org/).
## Hank Lee
I settled in with Scientific lab for several months now. For analytics, Jupyter Notebook comes pre-installed. It cuts down my time to search for apps and install/tinker.
All essential tools for collaboration with the Fedora Project are also included. For me, they are git, Podman, and Docker. Preparation time to contribute is instant after first boot.
Scientific lab runs on my modest specced 4GB RAM laptop smoothly.
## Frederico Tavares
Thanks Arman!
Good info.
Regards!
## You Really Don't Want to Know
Corgis are better than Labs.
## Bob Patterson
Thank you. Great summation of the available Labs.
## Newton
aquilo que sentimos e a falta de facilidades para muitos mudar para o sistema Linux ,pós esta troca toda hora de sistema do computador pelo gigante ,nós da a change de trazer muitos jovens ou quem ama tecnologia livre e barata como nosso Fedora ,venha ajudar participar deste grande informativo ,obrigado
## Spencer
Thanks so much for this, I didn’t know Fedora has Labs.
I’m trying out the Security Lab version on a live USB. Now trying to figure out how to install packet tracer into it and have it stay across reboots……. |
16,079 | LibreOffice 和 OpenOffice 的相似与不同之处 | https://itsfoss.com/libreoffice-vs-openoffice/ | 2023-08-10T14:39:07 | [
"OpenOffice",
"LibreOffice"
] | https://linux.cn/article-16079-1.html | 
>
> 对两个最受欢迎的开源办公软件的比较。了解 LibreOffice 和 OpenOffice 之间的相似与不同之处。
>
>
>
LibreOffice 与 OpenOffice 是两个流行的微软办公套件的 [开源替代品](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/)。
如果你正在寻找一个具备文字处理、电子表格、演示和其他几个程序的开源办公套件,那么这两个办公软件都可以推荐。
然而,要充分利用这些办公套件,你应该了解它们之间的差异,以决定哪个最适合你。
你应该使用 LibreOffice 还是 OpenOffice?它们之间有什么区别?在这里,我将更详细地探讨这些问题。
### LibreOffice vs. OpenOffice:起源

OpenOffice 是由 <ruby> 昇阳微系统 <rt> Sun Microsystems </rt></ruby> 开发的项目。它是(他们最初收购的)与微软办公套件竞争的 StarOffice 的开源版本。
后来,<ruby> 甲骨文 <rt> Oracle </rt></ruby> 收购了昇阳微系统,并最终放弃了 [OpenOffice.org](http://OpenOffice.org)(OOo),将代码库交给了 Apache。
在 Apache 开始维护它时,该办公套件的名称被更改为 “OpenOffice” 或 “Apache OpenOffice”。
在这个过渡期间,出于担心 Oracle 会停止该项目,<ruby> 文档基金会 <rt> The Document Foundation </rt></ruby> 复刻了 [OpenOffice.org](http://OpenOffice.org),创建了 LibreOffice。
因此,LibreOffice 是作为 [OpenOffice.org](http://OpenOffice.org) 的替代品而创建的。
但是,现在 OpenOffice 仍然存在并得到积极维护(LCTT 译注:不是),为什么你应该选择 LibreOffice?OpenOffice 不够好吗?它们之间有什么相似之处?
### LibreOffice 和 Apache OpenOffice 有什么共同之处?
LibreOffice 和 Apache OpenOffice 有一些共同之处:
如果你只需要创建基本文档、电子表格或演示文稿,并不需要进行任何复杂操作或快捷方式来提高生产力,那么你可以使用它们中的任何一个。
简单来说,如果你在 Linux、Windows 和 macOS 上需要一个开源办公套件,这两个软件都可以胜任。
LibreOffice 和 Apache OpenOffice 都能够打开包括微软的 DOCX、PPT 等在内的各种文件格式。
但是,当你需要**不同的功能、用户界面、文件格式兼容性、导出能力**和其他特性时,它们之间的相似之处就会逐渐消失。
当然,如果你开始广泛使用它们,你将会注意到它们之间的差异。
为了节省你的麻烦,让我在这里重点指出这些差异:
### 安装和平台可用性
用户体验的第一步是安装过程和平台可用性。
如果安装复杂且不支持多个平台,那么这个程序就令人失望。
在这种情况下,LibreOffice 和 Apache OpenOffice 官方支持 **Linux、Windows 和 macOS**。
至于移动平台,你可以在谷歌 Play 商店(安卓)和苹果应用商店(iOS)上找到基于 LibreOffice 的 [Collabora Office](https://www.collaboraoffice.com/)。考虑到 Collabora 是 LibreOffice 的商业合作伙伴,它几乎可以视为 LibreOffice 的官方移植版。
而对于移动设备上的 OpenOffice,虽然你也可以使用其他社区/第三方移植版替代,**但它没有官方移植版可用**。
现在你已经了解了支持的平台,它们的安装是否容易?
**对于 Linux**,LibreOffice 在官方软件库中可用,并在软件中心和软件包管理器中列出。因此,你只需点击几下即可在 Linux 系统上安装它。

不幸的是,OpenOffice 的安装过程比较麻烦。它不在软件库中,软件中心中也找不到它。而且,如果你已经预先安装了 LibreOffice,则在尝试安装 OpenOffice 之前必须先删除任何痕迹(以避免安装冲突)。
你需要从其网站下载官方软件包(根据你的 Linux 发行版),然后解压缩,并使用一些命令来[在 Linux 上安装 OpenOffice](https://itsfoss.com/install-openoffice-ubuntu-linux/)。

**对于 Windows 和 macOS**,安装非常简单,你只需 [下载安装包](https://www.libreoffice.org/download/download/),然后按照屏幕上的指示进行操作即可。
[LibreOffice 还提供了另一种方式](https://www.libreoffice.org/download/libreoffice-from-microsoft-and-mac-app-stores/) 可供获取(通过合作伙伴),即通过微软商店和 Mac 应用商店。不过,你需要支付费用。其中的一部分将捐赠给文档基金会,一部分用于 LibreOffice 的开发。
还要注意,由于 [Collabora Office](https://www.collaboraoffice.com/press-releases/collabora-office-ships-for-chromebooks/),你也可以在 Chromebook 上使用 LibreOffice。
**总而言之,LibreOffice 提供了更好的平台可用性和更轻松的安装过程,这使得 OpenOffice 成为一个不太推荐的选择。**
### 用户体验
LibreOffice 提供了一个令人愉悦的用户界面,与现代标准相融合。LibreOffice 在大多数现代硬件上看起来都很好,不论你使用的是 2K 显示器还是 4K 显示器。

你可以从主启动器快速访问所有工具,这是一种良好的体验。Writer、Calc 和其他程序提供了一个易于使用且看起来井然有序的界面。

Apache OpenOffice 提供的是一个过时的用户界面。因此,如果你正在寻找一个现代化的开源办公套件,LibreOffice 是首选。

当然,一些用户喜欢经典的用户界面,因为他们对此很熟悉,并且在旧硬件上的使用受到限制。

换句话说,OpenOffice 仍然可用,但对于大多数现代用户来说可能不是一种直观的体验。
如果你仔细比较用户界面元素,这将取决于你阅读本文时可用的最新版本。因此,我们避免进行具体的视觉比较。
### 特点
强大的功能集的需求取决于你处理的文件类型。
默认情况下,OpenOffice 和 LibreOffice 均提供以下程序:
* Math(科学公式)
* Writer(文档)
* Impress(演示文稿)
* Draw(绘图、流程图等)
* Calc(电子表格)
* Base(数据库)
无论你使用文字处理器(Writer)、电子表格(Calc)还是演示文稿(Impress),你都可以获得相同的标准功能。
然而,如果你处理需要访问**更多模板、函数、导入/导出选项和高级格式设置**的复杂文档,LibreOffice 会更优秀一些。
### 文件格式兼容性

OpenOffice 支持几乎与 LibreOffice 相同的文件扩展名。
但是,LibreOffice 还支持一些 OpenOffice 不支持的文件格式导出。
例如,你可以在 OpenOffice 中打开 **.DOCX** 文件,但无法保留文件扩展名保存/导出该文件。
你只能将其保存为 .odt/.doc./.ott 等几种类似的文件格式。
同样,你无法得到对 .xslx 和 .pptx 的支持,这些是通常用于电子表格和演示文稿的现代文件格式。
当然,如果你不依赖于这些文件格式,可以尝试使用 OpenOffice。然而,与使用较新文件格式的用户进行协作时,你将遇到可能影响你工作的兼容性/格式设置问题。
考虑到 OpenOffice 缺乏许多功能,依赖它来访问较新的文件格式可能不明智;由于不良的兼容性,你可能会丢失重要的细节。
### 更新

为了提高你使用该程序的效率并获得增强的性能、新功能和安全修复,建议选择定期获得更新的软件工具。
从技术上讲,两者都会定期获得更新。但是,OpenOffice 仅限于修复错误和进行小型更新。
LibreOffice 的开发活动更加活跃,频繁修复错误/进行小型更新,定期进行较大的升级,增加新功能和改善用户体验。
难怪 [LibreOffice 给 Apache 写了一封公开信](https://itsfoss.com/libreoffice-letter-openoffice/),请求停止开发 OpenOffice 并将这些资源转用于帮助 LibreOffice 的开发。
### 企业支持和在线协作选项

有了 [Collabora Office](https://www.collaboraoffice.com/),你可以获得企业支持,并能够在工作场所使用 LibreOffice。通过 [Collabora Online](https://www.collaboraoffice.com/collabora-online/),你还可以在服务器上部署 LibreOffice 以实现协作工作空间。
遗憾的是,Apache OpenOffice 没有任何企业支持选项。因此,如果有的话,它最适合家庭用户使用。
### 许可
对于使用这些程序并无任何许可问题,也不会阻止或使你不愿使用它们。然而,这些信息对于项目的贡献者可能会有所帮助。
LibreOffice 使用 Mozilla Public License v2.0 许可证,而 Apache OpenOffice 则使用 Apache License 2.0 许可证。
### LibreOffice vs. OpenOffice:应该选择哪个?
基于现代设计、更多功能和对较新文件格式的支持,LibreOffice 是一个易于推荐的选择。
OpenOffice 可以是适用于熟悉旧版办公套件界面,且希望在 32 位系统中无障碍运行的用户的解决方案。在 LibreOffice 由于某些原因无法正常工作的情况下,OpenOffice 应该作为备选方案。
我们可以告诉你选择取决于个人喜好,但如果你经常处理文档,如果我不说 LibreOffice 是更好的选择,那么我显然不够诚恳。
*(题图:MJ/52f9aa1b-3529-492a-a5fb-7b24b62e2e8a)*
---
via: <https://itsfoss.com/libreoffice-vs-openoffice/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

LibreOffice and OpenOffice are two popular [open-source alternatives to Microsoft Office](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/).
They can be recommended if you want an open-source office suite with a word processor, spreadsheet, presentation, and a few other programs.
However, to make the best of an office suite, you should know their differences to decide what’s best for you.
Should you use LibreOffice or OpenOffice? What are the differences? Here, I explore more about that.
## LibreOffice vs. OpenOffice: Origins

OpenOffice.org was a project developed by Sun Microsystems. It was introduced as an open-source version of StarOffice (acquired by them initially) to compete with Microsoft Office.
Later, Oracle acquired Sun Microsystems and eventually ditched OpenOffice.org while submitting the code base to Apache.
When Apache started maintaining it, the name of the office suite was tweaked to “OpenOffice” or Apache OpenOffice.
During this transition period, The Document Foundation forked OpenOffice.org to create LibreOffice, fearing that Oracle would discontinue the project.
So, LibreOffice was created as a replacement for OpenOffice.org.
But, now that OpenOffice still exists and is actively maintained, why should you choose LibreOffice? Isn’t OpenOffice good enough? What are the similarities between them?
## What’s Common in LibreOffice and Apache OpenOffice?
LibreOffice and OpenOffice have a few things in common.
You can use any of them if all you need is to create a basic document, spreadsheet, or presentation without requiring any complex operations or shortcuts to improve productivity.
Simply put, you can count on both if you require an open-source office suite on Linux, Windows, and macOS.
LibreOffice and OpenOffice are capable enough to open various file formats that include Microsoft’s DOCX, PPT, and more.
Unfortunately, the similarities fade away as you look for **various features, user interface, file format compatibility, export capabilities**, and other characteristics.
Of course, if you start using them extensively, you shall notice the differences.
But, to save you from the trouble, let me highlight the differences here:
## Installation and Platform Availability
The first step to the user experience is the installation procedure and platform availability.
The program is a big let-down if it is tricky to install and not supported for multiple platforms.
In this case, LibreOffice and Apache OpenOffice are officially available for **Linux, Windows, and macOS**.
When it comes to mobile platforms, you can find [Collabora Office](https://www.collaboraoffice.com/?ref=itsfoss.com) (based on LibreOffice) on the Play Store (Android) and the App Store (iOS). It comes close to an official port of LibreOffice, considering Collabora is its commercial partner.
While you can also use them or any other community/third-party port as a replacement for OpenOffice on mobiles, **it has no official ports available**.
Now that you know the supported platforms, how easy is it to install them?
**For Linux, **LibreOffice is available in the official repositories and listed in the software center and package managers. So, you are a couple of clicks away from setting it up on your Linux system.
Unfortunately, OpenOffice is a hassle to install. It is not available in the repositories, nor you can find it in the software center. Moreover, if you already have LibreOffice pre-installed, you will have to remove any traces before attempting to install OpenOffice (to avoid installation conflict).
You will have to download the official packages (per your Linux distribution) from its website, extract it, and use a couple of commands to [install OpenOffice on Linux](https://itsfoss.com/install-openoffice-ubuntu-linux/).
**For Windows and macOS**, the installation is easy, where [you download the installer package](https://www.libreoffice.org/download/download/?ref=itsfoss.com) and follow the on-screen instructions.
[LibreOffice also offers an alternative way](https://www.libreoffice.org/download/libreoffice-from-microsoft-and-mac-app-stores/?ref=itsfoss.com) (through its partners) to get it, using the Microsoft Store and the Mac App Store. You will have to pay for them, though. Part of it is donated to the Document Foundation and part of it helps the development of LibreOffice.
Not to forget, LibreOffice can also be used on Chromebooks, thanks to [Collabora Office](https://www.collaboraoffice.com/press-releases/collabora-office-ships-for-chromebooks/?ref=itsfoss.com).
**To sum up, LibreOffice provides better platform availability and easier installation procedure, which can make OpenOffice a tough choice to recommend.**
## User Experience
LibreOffice presents a pleasing user interface that blends in with modern standards. LibreOffice should look fine on most modern hardware, whether you have a 2K display or a 4K display.
You can access all the tools quickly from its main launcher, which is a good experience. The Writer Document, Spreadsheet, and other programs offer an easy-to-use interface that looks well-organized.
Apache OpenOffice provides a dated user interface. So, if you are looking for a modern open-source office suite, LibreOffice takes the cake.
Of course, some users prefer the classic user interface, considering they are quite familiar with it, and their usage is limited on older hardware.
In other words, OpenOffice is still usable, but it may not be an intuitive experience for most modern users.
If you closely compare the user interface elements, it will vary based on the latest version available at the time you are reading this article; hence, we avoid making specific visual comparisons.
## Features
The need for a robust feature-set depends on the type of files you work with.
By default, you get the following programs with OpenOffice and LibreOffice:
- Math (Scientific formula)
- Writer (Documents)
- Impress (Presentations)
- Draw (Drawings, Flow Charts, etc.)
- Calc (Spreadsheets)
- Base (Database)
Whether you utilize the word processor (Writer), spreadsheet (Calc), or presentations, you get all the same standard features.
However, LibreOffice gets the edge if you work with complex documents requiring access to **more templates, functions, import/export options, and advanced formatting**.
## File Format Compatibility

OpenOffice supports almost all the same file extensions you can expect with LibreOffice.
However, LibreOffice also supports exporting in some of the same file formats, which OpenOffice does not.
For instance, you can open a **.DOCX** file with OpenOffice without hiccups, but you cannot save it/export the document preserving the file extension.
You can only save it as .odt/.doc./.ott and a few similar file formats.
Similarly, you do not get support for .xslx and .pptx, modern file formats usually used for spreadsheets and presentations.
Sure, if you do not rely on these file formats, you can try using OpenOffice. Still, when collaborating with a user with a newer file format, you will encounter compatibility/formatting issues that could affect your work.
Considering OpenOffice lacks numerous features, it may not be wise to depend on it to access newer file formats; you could lose significant details due to bad compatibility.
## Updates

To improve your productivity with the program and get enhanced performance, newer features, and security fixes, opting for a software tool that gets regular updates is recommended.
Technically, both receive regular updates. But, OpenOffice is limited to bug fixes and minor updates.
LibreOffice has more development activity, frequent bug fixes/minor updates, regular major upgrades with newer features, and improved user experience.
No wonder why [LibreOffice wrote an open letter to Apache](https://itsfoss.com/libreoffice-letter-openoffice/) to discontinue OpenOffice and divert those resources to help LibreOffice development.
## Enterprise Support and Online Collaboration Options

Thanks to [Collabora Office](https://www.collaboraoffice.com/?ref=itsfoss.com), you can get enterprise support while being able to use LibreOffice at your workplace. You can also deploy LibreOffice on your servers for a collaborative workspace, thanks to [Collabora Online](https://www.collaboraoffice.com/collabora-online/?ref=itsfoss.com).
Unfortunately, Apache OpenOffice does not have any enterprise support options. So, it is best suited for home users, if at all.
## Licensing
No licensing issues would stop you or discourage you from using any of these programs. However, this information could be useful for contributors to the project.
LibreOffice utilizes Mozilla Public License v2.0 while Apache OpenOffice is available under the Apache License 2.0.
## LibreOffice vs. OpenOffice: What Should You Pick?
LibreOffice is an easy choice to recommend for its modern design, more functionalities, and support for newer file formats.
OpenOffice can be a solution for users acquainted with older office suite interfaces and who want it to work without hiccups in their 32-bit systems. Otherwise, it should remain an alternative solution in cases where LibreOffice fails to work for some reason.
I could tell you that the choice depends on your personal preferences, but I’d be lying if I did not mention that LibreOffice is better if you regularly work with documents.
If you are looking for something other than the above two, try this list.
[6 Best Open Source Alternatives to Microsoft Office for LinuxLooking for Microsoft Office on Linux? Here are the best free and open-source alternatives to Microsoft Office for Linux.](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/)

Your opinion on LibreOffice and OpenOffice is welcome. |
16,080 | 在 Linux Mint 中安装 KDE Plasma 桌面环境 | https://www.debugpoint.com/kde-plasma-linux-mint/ | 2023-08-10T15:30:00 | [
"KDE",
"Linux Mint"
] | /article-16080-1.html | 
>
> 下面介绍如何在 Linux Mint 中安装 KDE Plasma 桌面环境,并进行了一些微调。
>
>
>
[Linux Mint](https://www.debugpoint.com/linux-mint) 是最流行的和用户友好的 Linux 发行版,以其易用性和稳定性而闻名。虽然 Linux Mint 中默认的 Cinnamon 桌面环境提供了友好愉快的体验,但也有一些用户可能想要探索其它的桌面环境,以进一步定制自己的 Linux 体验。KDE Plasma 是另一个著名的桌面环境,提供了一种现代化的特色功能丰富的界面。
然而,Linux Mint 从未正式提供过 KDE Plasma 。但是这里有一种在 Linux Mint 基础之上安装 KDE Plasma 桌面环境的方法。让我们一起尝试一下。
>
> **注意**: 不要在你的有重要数据的稳定系统中尝试这些步骤。有风险。
>
>
>

### 在 Linux Mint 中安装 KDE Plasma 桌面环境
在 Linux Mint 发行版中,有三种主要组件来安装 KDE Plasma 桌面环境。它们是 `kde-full`、`kde-standard` 和 `kde-plasma-desktop` 。
[kde-full](https://packages.ubuntu.com/kinetic/kde-full) 软件包集包含完整的 KDE Plasma 桌面环境。kde-standard 是最小的版本,kde-plasma-desktop 仅是桌面环境。
如果你将要尝试安装 KDE Plasma 桌面环境,我将建议安装 kde-full 软件包。
首先,打开一个终端,确保你的 Linux Mint 版本是已更新的。确保你执行了一次重新启动。
```
sudo apt update && sudo apt upgrade -y
```
```
reboot
```
其次,在终端中,运行下面的命令来安装完整的 KDE 软件包。由于 Linux Mint 是基于 Ubuntu LTS 版本的,所以,你应该会获取基于当前正在持续更新的 Kubuntu LTS Plasma 版本的 KDE Plasma 版本。
```
sudo apt install kde-full
```
完整的下载体积有点大。针对当前的 Linux Mint 版本,它大约是 1.5 GB ,整个安装过程可能需要 20 分钟。

在安装过程中,你需要选择显示管理器,因为 KDE Plasma 使用 SDDM 。出现提示时,在下面的屏幕中选择 SDDM 。

在安装完成后,你需要在 SDDM 配置文件中修改其中一个备选项以阻止在登录过程中弹出一个空的联机键盘。为此,使用 nano 或任意一个编辑器来打开下面的文件。
```
sudo nano /etc/sddm.conf
```
接下来,添加下面的行。保存并退出。
```
[General]InputMethod=
```
最后,重新启动系统。
```
reboot
```
在登录期间,你应该会看到 SDDM 登录窗口,而不是 Linux Mint 的原来的登录提示窗口。在窗口顶部,选择 “Plasma” 会话并登录。

### 移除 Cinnamon 、Xfce 或 MATE
在 KDE Plasma 安装后,你可以移除 Cinnamon 、Xfce 或 MATE 桌面环境组件。如果你看到你的 KDE Plasma 工作的很好,那么移除是安全的。使用下面的命令来移除它们,最后使用命令 `reboot` 来重新启动。
```
sudo apt purge cinnamon
```
```
sudo apt purge mate-desktop
```
```
sudo apt purge
xfce4-session
xfwm4
xfdesktop4
xfconf
xfce4-utils
exo-utils
xfce4-panel
xfce4-terminal
thunar
```
### 几点注意事项
* 你可能会发现:相比于 Cinnamon 桌面环境,KDE Plasma 的运行性能有一点慢,这是很明显的。
* Linux Mint 的壁纸、主题、图标和光标文件可能会保留在系统中。如果你想的话,你可以移除它们。
* Mint Plymouth 动画应该也会保留,你可以手动移除它。
* 如果你在一个虚拟机中的系统中使用上述步骤,在从待机状态唤醒时,SDDM 可能会崩溃。
### 总结
热烈庆贺!你已经在你的 Linux Mint 系统上成功的安装 Plasma 桌面环境。通过执行这些步骤,你现在可以访问一个功能丰富的、视觉震撼的、可高度自定义的桌面环境。请谨慎使用!
*(题图:MJ/8944ad54-b64c-4761-b848-801215c63b56)*
---
via: <https://www.debugpoint.com/kde-plasma-linux-mint/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
16,082 | 了解 Ubuntu 的软件存储库系统 | https://itsfoss.com/ubuntu-repository-mechanism/ | 2023-08-11T11:24:55 | [
"软件库",
"存储库"
] | https://linux.cn/article-16082-1.html | 
>
> 了解 Ubuntu 软件仓库系统的基本机制,更好地处理软件包管理问题,避免常见的更新错误。
>
>
>
当你开始使用 Ubuntu 或者其它基于 Ubuntu 的发行版时,你很快就会学会使用 `apt` 命令安装软件包:
```
sudo apt install package_name
```
你可能还会使用这三条 PPA 命令安装其它软件:
```
sudo add-apt-repository ppa:PPA_Name/ppa
sudo apt update
sudo apt install package_from_ppa
```
但当你添加一些外部的软件存储库时,很可能会遇到一些更新错误。
尽管你可以在互联网上搜索到同样的报错以及对应的解决方案,*但在大多数情况下,你并不知道这些错误为什么会出现,也不知道它们是怎么被解决的。*
**如果你了解了 Ubuntu 软件存储库的运行机制,你就会很清楚这些问题的根源是什么**,进而对症下药地给出处理方式。
在技术论坛上,你可以找到很多相关的零散内容,但那些碎片化的信息并不能让你对其产生一个全面的理解。
因此我写出了这篇文章,以便让你全面了解软件存储库是如何运作的。
本文的内容适用于 Linux Mint、Elementary OS 以及其它基于 Ubuntu 的发行版(Debian 或许也适用)。
>
> 本文主要面向终端用户而不是开发者,我只会介绍维护系统软件存储库所需要的知识,不会展示如何在 Ubuntu 中打包应用程序。
>
>
>
我们会先从关键部分开始,了解软件包管理器和软件存储库的基本概念。这可以为了解它们的底层运作方式奠定基础。
### 1、什么是包管理器?
简单地说,包管理器就是让用户在操作系统上安装、移除、升级、配置、管理软件包的工具。
Ubuntu 通过软件存储库为用户提供软件。软件存储库中包含了各种不同类型的软件包以及它们的元数据文件,元数据文件中记录了软件包的信息,包括软件包名称、版本号、软件包描述和软件存储库名称等。
软件包管理器与元数据进行交互,并在你的系统上创建本地的元数据缓存。当你需要安装软件时,软件包管理器会引用这些缓存来获取信息,通过互联网连接到对应的存储库下载软件包,然后再将软件包安装到系统上。

下面这篇文章详细介绍了软件包管理器的工作原理,欢迎查阅。
>
> **[Linux 上的软件包管理器](https://itsfoss.com/package-manager/)**
>
>
>
### 2、Ubuntu 的默认软件存储库
在上一节中,你可能已经对软件存储库有了一些认识。
你可能已经猜到,没有哪个软件存储库会包含所有软件包。因为软件包会被分类放置在不同的软件存储库中,这样就可以方便地启用或禁用部分软件存储库。
每个 Ubuntu 版本都有自己的一组四个官方存储库:
* **Main** – Canonical 支持的自由开源软件
* **Universe** – 社区维护的自由开源软件
* **Restricted** – 设备的专有驱动程序
* **Multiverse** – 受版权或法律问题限制的软件
下面这篇文章介绍了如何在 Ubuntu 中启用 Universe 和 Multiverse 软件存储库。
>
> **[如何启用 Universe 和 Multiverse 软件存储库](https://itsfoss.com/ubuntu-repositories/)**
>
>
>
### 3、了解 sources.list
`sources.list` 是 Ubuntu 软件存储库机制的一个组成部分。`sources.list` 文件中存在的错误条目常常是引发一些与更新问题的根本原因。
因此,了解 `sources.list` 很重要。
`sources.list` 是一个记录了软件存储库信息的文本文件,每一行未被注释的内容都代表一个单独的软件存储库。

但这些内容需要遵循特定的格式,并且不应出现重复的行。下面这篇文章中介绍了 `sources.list` 的更多详细内容。
>
> **[sources.list 的用法](https://itsfoss.com/sources-list-ubuntu/)**
>
>
>
### 4、深入了解 PPA
尽管 Ubuntu 最近在大力推广 Snap,但 PPA 仍然是获取 Ubuntu 最新软件的一个可靠途径。
然而很多 Ubuntu 用户都只是刻板地直接运行上面的三条命令来使用 PPA,自然很容易会遇到诸如“repository does not have release file”这样的问题。
下面这篇文章是一篇深入详尽的 PPA 指南。
>
> **[PPA 详尽指南](https://itsfoss.com/ppa-guide/)**
>
>
>
### 5、添加外部软件存储库
除了默认软件存储库和 PPA,你还可以从第三方软件存储库中添加软件。比如 Brave 浏览器、Docker 等软件都专门为 Ubuntu 提供了软件存储库。
你可以通过下面这篇文章了解使用外部软件存储库的机制。
>
> **[通过外部存储库安装软件](https://itsfoss.com/adding-external-repositories-ubuntu/)**
>
>
>
### 6、排查常见错误
现在你已经了解了底层机制,现在可以熟悉一下在使用 Ubuntu 时可能遇到的典型更新错误了。
当你看到出现错误之后,你会得到一些关于它的根本原因的提示。在了解根本原因后,你就能知道某个解决方案是如何解决问题的了。
这就是本文的目的。让你充分了解软件包管理系统的底层知识,从而避免常见错误或者直接有效修复这些错误。
**你不仅要知其然,还要知其所以然。**
#### 下载软件存储库信息失败
如果遇到了这种情况,就可以开始调查了。

在某些情况下,可能是网络连接的问题,但也有可能是因为你自行添加了某些软件存储库,或者 `sources.list` 中的条目有误。
这个时候应该在终端中尝试刷新软件包缓存。
```
sudo apt update
```
检查输出结果的最后几行,它会给出错误信息(也就是以 “E:” 开头的行)。有了错误信息之后,就可以开始故障排除了。
#### 软件存储库中没有发布文件
如果 Ubuntu 用户未检查某个 PPA 是否支持其 Ubuntu 版本,就盲目向系统中添加该 PPA 时,就很可能会遇到这样的错误。
```
E: The repository ‘http://ppa.launchpad.net/numix/ppa/ubuntu focal Release’ does not have a Release file.
```
原因很可能就是这个软件存储库没有针对所使用的 Ubuntu 版本进行配置。
下面这篇文章对此做了详细解释。
>
> **[软件存储库中没有发布文件](https://itsfoss.com/repository-does-not-have-release-file-error-ubuntu/)**
>
>
>
#### MergeList 问题
如果你看到这样的错误:
```
E:Encountered a section with no Package: header,
E:Problem with MergeList /var/lib/apt/lists/archive.ubuntu.com_ubuntu_dists_precise_universe_binary-i386_Packages,
E:The package lists or status file could not be parsed or opened.
```
这表明第二行中提到的缓存文件已经损坏。对应的解决方法是清空缓存并重试。
下面这篇文章对此做了详细解释。
>
> **[MergeList 问题](https://itsfoss.com/how-to-fix-problem-with-mergelist/)**
>
>
>
#### 目标软件包被多次配置
好吧!严格来说,这不是一个错误。它只是一个警告。但它仍然很常见,可能会给许多 Ubuntu 新用户带来麻烦。
这是一个能让你把新学到的知识用在这里的好例子。
出现这个问题是因为 `sources.list` 文件中有重复的条目。解决办法是将所有重复的行删除至只保留一行。
下面这篇文章对此做了详细解释。
>
> **[目标软件包被多次配置](https://itsfoss.com/fixing-target-packages-configured-multiple-times/)**
>
>
>
### 7、继续学习
在读完这篇文章后,希望你对 Ubuntu 的软件存储库机制能有更深入的了解。下一次当你遇到错误并寻找解决方案时,你就更有可能理解发生了什么。
接下来,你应该学会使用 `apt` 的各种命令管理软件包,不仅仅只是 `apt install` 或 `apt remove`。
>
> **[apt 命令详尽指南](https://itsfoss.com/apt-command-guide/)**
>
>
>
你还可以详细了解一下关于软件包管理的其它知识。
>
> **[完全指南:在 Ubuntu 安装和删除软件](https://itsfoss.com/remove-install-software-ubuntu/)**
>
>
>
由于 Ubuntu 比以往任何时候都更推崇 Snap,所以你也应该学习一些必要的 Snap 命令。
>
> **[完全指南:在 Ubuntu 上使用 Snap 安装包](https://itsfoss.com/use-snap-packages-ubuntu-16-04/)**
>
>
>
Flatpak 应用程序也越来越受欢迎,你也很可能会接触到它们。
>
> **[在 Ubuntu 上安装和使用 Flatpak](https://itsfoss.com/flatpak-ubuntu/)**
>
>
>
希望你喜欢学习软件存储库的机制,并对软件包管理有更清晰的认识。欢迎在评论区分享你的想法。
*(题图:MJ/6878226c-f6b0-40e7-aae7-d64932b36464)*
---
via: <https://itsfoss.com/ubuntu-repository-mechanism/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you start using Ubuntu or an Ubuntu-based distribution, soon you’ll find yourself using apt commands to install software like this:
`sudo apt install package_name`
You’ll probably also install additional software using the 3-step PPA command:
```
sudo add-apt-repository ppa:PPA_Name/ppa
sudo apt update
sudo apt install package_from_ppa
```
And when you start adding random external repositories, you’ll encounter update errors sooner or later.
Now, you can search for the error on the internet and perhaps fix it as well. *Most of the time, you won’t understand what causes the problem and how it was fixed.*
But **if you understand the repository mechanism in Ubuntu, you’ll understand the root cause of the problem** and fix it accordingly.
You might find all this information in fragments on It’s FOSS and various forums. But the fragmented information is not easy to understand.
Hence, I created this page to give you a comprehensive understanding of how the repository system works.
This guide also benefits the users of Linux Mint, elementary OS and other distributions based on Ubuntu (and perhaps Debian).
Let's start with the essentials first. Understands the basic concept of the package manager and the repositories. This will build a foundation for you to understand how things work underneath.
## Chapter 1: What is a Package Manager?
In simpler words, a package manager is a tool that allows users to install, remove, upgrade, configure and manage software packages on an operating system.
Ubuntu provides the software through repositories. The repositories contain software packages of different kinds. They also have metadata files that contain information about the packages such as the name of the package, version number, description of package and the repository name etc.
The package manager interacts with the metadata and creates a local metadata cache on your system. When you ask it to install a software, the package manager refers to this cache to get the information and then uses the internet to connect to the appropriate repository and downloads the package first before installing it on your system.
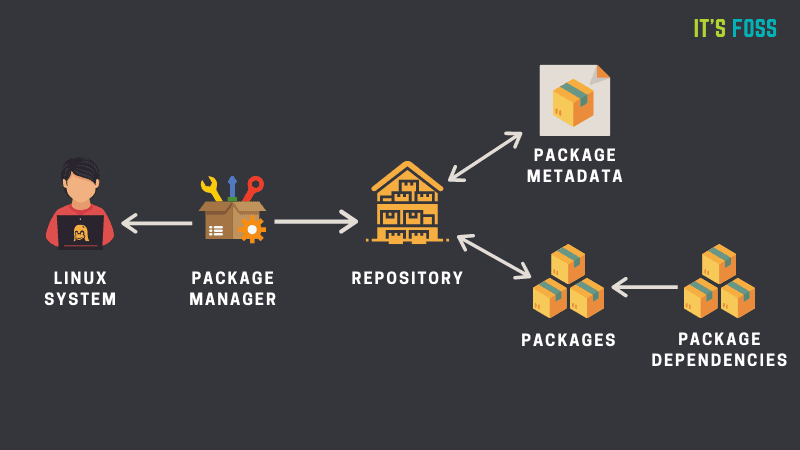
This article explains the working of the package manager in a bit more detail. Do check it out.
[What is a Package Manager in Linux?Learn about packaging system and package managers in Linux. You’ll learn how do they work and what kind of package managers available.](https://itsfoss.com/package-manager/)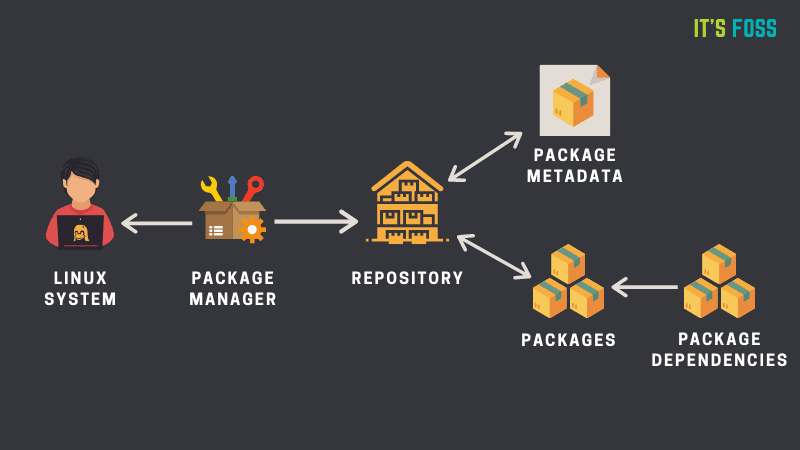

## Chapter 2: Ubuntu’s Default Repositories
From the previous section, you have some idea of the repositories.
You may have guessed that there is not a single repository that contains all the packages. Why not? Because it is categorized to have the packages in different repositories so that they can be enabled or disabled accordingly.
Each Ubuntu version has its own official set of four repositories:
**Main**– Canonical-supported free and open-source software.**Universe**– Community-maintained free and open-source software.**Restricted**– Proprietary drivers for devices.**Multiverse**– Software restricted by copyright or legal issues.
[How to Enable Universe and Multiverse Repositories in UbuntuThis detailed article tells you about various repositories like universe, multiverse in Ubuntu and how to enable or disable them.](https://itsfoss.com/ubuntu-repositories/)

## Chapter 3: Understanding sources.list
The sources.list is an integral part of Ubuntu's repository mechanism. Several update-related issues find their root cause in the incorrect entries in the sources.list file.
This is why it is important to understand it.
Sources.list is basically a text file that contains the repository details. Each uncommented line represents a separate repository.
But these entries follow a specific format and should not have duplicate entries. Read more about them in the article below.
[What is the Use of sources.list File in Ubuntu Linux?Understanding the concept of sources.list in Ubuntu will help you understand and fix common update errors in Ubuntu.](https://itsfoss.com/sources-list-ubuntu/)

## Chapter 3: Going in-depth with PPA
Though Snaps are pushed by Ubuntu a lot these days, PPAs are still a reliable way to get newer software in Ubuntu.
Many Ubuntu users blindly run three commands to use the PPA and naturally end up with issues like 'repository does not have release file'.
This is an in-depth and one-of-a-kind guide on PPA. It will improve your knowledge tremendously.
[Understanding PPA in Ubuntu Linux [Ultimate Guide]An in-depth article that covers almost all the questions around using PPA in Ubuntu and other Linux distributions.](https://itsfoss.com/ppa-guide/)

## Chapter 4: Adding External Repositories
Apart from the default repositories and PPAs, you will also add software from their party repositories. Softwares like Brave browser, Docker and many more provide dedicated repositories for Ubuntu.
Understand the mechanism of using external repositories.
[Installing Packages From External Repositories in UbuntuLearn the logic behind each step you have to follow for adding an external repository in Ubuntu and installing packages from it.](https://itsfoss.com/adding-external-repositories-ubuntu/)

## Chapter 5: Troubleshooting Common Errors
Now that you are familiar with the underlying mechanism, it's time to get familiar with the typical update errors you might encounter while using Ubuntu.
When you see go through the error, you may start getting the hint about the root cause. And when you go through the root cause, you will understand how the specific solution fixes it.
And that's the aim of this page. To give you enough under-the-hood knowledge on the package management system so that you can avoid common errors or effectively fix them.
**You'll understand the why along with the how.**
### Failed to Download Repository Information
If you encounter this error, it's just the beginning of your investigation.
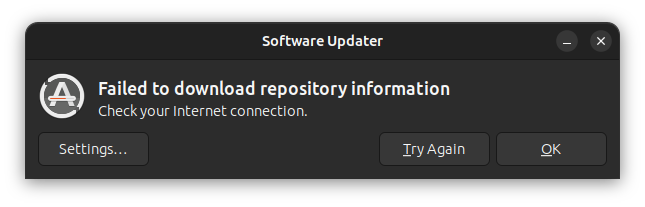
While the internet connection could be the issue in some cases, chances are that you have an issue because of some repository you added or wrong entries in the sources.list.
You should jump into the terminal and (try to) refresh the package cache.
`sudo apt update`
Look at the last few lines of the output. It will give you the error message (lines starting with E:). When you have the error message, your troubleshooting begins.
### Repository Does Not Have a Release File
A common error Ubuntu users encounter while blindly adding PPAs to the system without checking if the PPA exists for their Ubuntu version or not.
`E: The repository ‘http://ppa.launchpad.net/numix/ppa/ubuntu focal Release’ does not have a Release file.`
Let me give you a hint. The repository is not configured for the Ubuntu version being used.
[What to do When You See “Repository does not have a release file” Error in UbuntuOne of the several ways of installing software in Ubuntu is by using PPA or adding third-party repositories. A few magical lines give you easy access to a software or its newer version that is not available by default in Ubuntu. All thing looks well and good until you get](https://itsfoss.com/repository-does-not-have-release-file-error-ubuntu/)

### Problem With MergeList
If you see an error like this:
```
E:Encountered a section with no Package: header,
E:Problem with MergeList /var/lib/apt/lists/archive.ubuntu.com_ubuntu_dists_precise_universe_binary-i386_Packages,
E:The package lists or status file could not be parsed or opened.
```
It indicates that somehow the cached file mentioned in the second line got corrupted. The fix is to empty the cache and repopulate it.
[How To Fix Ubuntu Update Error: Problem With MergeListOne of the most common error a user encounters while updating is Problem with MergeList. The error could be encountered while using both Ubuntu Update Manager and using the sudo apt-get update in terminal. The complete error looks something like this: E:Encountered a section with no Packag…](https://itsfoss.com/how-to-fix-problem-with-mergelist/)

### Target Packages is configured multiple times
Alright! Technically, not an error. It's just a warning. But it is still quite common and could trouble many new Ubuntu users.
This is a good example for putting your newly acquired knowledge here.
There are duplicate entries in the sources.list files and that's causing the issue. The solution is to delete all the duplicate lines keeping just one.
[[Solved] Target Packages is configured multiple times ErrorSeeing repository configured multiple times error while updating your system with apt update command? Here’s what you can do about it.](https://itsfoss.com/fixing-target-packages-configured-multiple-times/)

## Continue Learning
I hope you have a slightly better understanding of the repository mechanism in Ubuntu. The next time you encounter an error and come across a solution, you are more likely to understand what's going on.
Next, you should learn to use the apt command for package management. There's more than just apt install or apt remove.
[Using apt Commands in Linux [Ultimate Guide]This guide shows you how to use apt commands in Linux with examples so that you can manage packages effectively.](https://itsfoss.com/apt-command-guide/)

You may also go a bit into detail about package management.
[How To Install And Remove Software In Ubuntu [Complete Guide]Brief: This detailed guide shows you various ways to install applications on Ubuntu Linux, and it also demonstrates how to remove installed software from Ubuntu. When you switch to Linux, the experience could be overwhelming at the start. Even basic things like installing applications on Ubuntu…](https://itsfoss.com/remove-install-software-ubuntu/)

Since Ubuntu is pushing for Snaps more than ever, learn the essential Snap commands.
[Using Snap Packages In Ubuntu & Other Linux [Complete Guide]Ubuntu’s new universal package Snaps are now everywhere. You should learn the essential snap commands to master this new packaging system.](https://itsfoss.com/use-snap-packages-ubuntu-16-04/)

Flatpak applications are also gaining popularity and you may come across them sooner or later.
[Install and Use Flatpak on UbuntuUbuntu may come with Snap by default but you could still enjoy the Flatpak universal packages on it.](https://itsfoss.com/flatpak-ubuntu/)

💬 I hope you enjoyed learning about the repository mechanism and has more clarity on package management. Do share your thoughts in the comment section. |
16,083 | Bash 基础知识系列 #7:If Else 语句 | https://itsfoss.com/bash-if-else/ | 2023-08-11T14:06:14 | [
"Bash",
"脚本"
] | https://linux.cn/article-16083-1.html | 
>
> 如果这样,那就那样,否则就……。还不明白吗?了解了 Bash Shell 脚本中的 if-else 语句后就明白了。
>
>
>
Bash 支持 if-else 语句,以便你可以在 shell 脚本中使用逻辑推理。
通用的 if-else 语法如下:
```
if [ expression ]; then
## 如果条件为真则执行此块,否则转到下一个
elif [ expression ]; then
## 如果条件为真则执行此块,否则转到下一个
else
## 如果以上条件都不成立,则执行此块
fi
```
正如你所注意到的:
* `elif` 用于 “否则如果” 类型的条件。
* if-else 条件始终以 `fi` 结尾。
* 使用分号 `;` 和 `then` 关键字
在展示 if 和 else-if 的示例之前,我先分享一下常见的比较表达式(也称为测试条件)。
### 测试条件
以下是可用于数字比较的测试条件运算符:
| 条件 | 当满足以下条件时为真 |
| --- | --- |
| `$a -lt $b` | `$a < $b`(`$a` **小于** `$b`) |
| `$a -gt $b` | `$a > $b`(`$a` **大于** `$b`) |
| `$a -le $b` | `$a <= $b`(`$a` **小于等于** `$b` ) |
| `$a -ge $b` | `$a >= $b` (`$a` **大于等于** `$b`) |
| `$a -eq $b` | `$a == $b` |
| `$a -ne $b` | `$a != $b` |
如果你要比较字符串,可以使用以下测试条件:
| 条件 | 当满足以下条件时为真 |
| --- | --- |
| `"$a" = "$b"` | `$a` 与 `$b` 相同 |
| `"$a" == "$b"` | `$a` 与 `$b` 相同 |
| `"$a" != "$b"` | `$a` 与 `$b` 不同 |
| `-z "$a"` | `$a` 为空字符串 |
文件类型检查也有条件:
| 条件 | 当满足以下条件时为真 |
| --- | --- |
| `-f $a` | `$a` 是一个文件 |
| `-d $a` | `$a` 是一个目录 |
| `-L $a` | `$a` 是一个链接 |
现在你已经了解了各种比较表达式,让我们在各种示例中看看它们的实际应用。
### 在 Bash 中使用 if 语句
让我们创建一个脚本来告诉你给定的数字是否为偶数。
这是我的脚本,名为 `even.sh`:
```
#!/bin/bash
read -p "Enter the number: " num
mod=$(($num%2))
if [ $mod -eq 0 ]; then
echo "Number $num is even"
fi
```
当模数运算(`%`)整除给定数字(本例中为 2)时,它返回零。
>
> ? 特别注意空格。左括号和右括号与条件之间必须有空格。同样,条件运算符(-le、== 等)前后必须有空格。
>
>
>
这是我运行脚本时显示的内容:

你是否注意到,当数字为偶数时,脚本会告诉你,但当数字为奇数时,脚本不会显示任何内容? 让我们使用 else 来改进这个脚本。
### 使用 if else 语句
现在我在前面的脚本中添加了一条 `else` 语句。这样,当你得到一个非零模数(因为奇数不能除以 2)时,它将进入 `else` 块。
```
#!/bin/bash
read -p "Enter the number: " num
mod=$(($num%2))
if [ $mod -eq 0 ]; then
echo "Number $num is even"
else
echo "Number $num is odd"
fi
```
让我们用相同的数字再次运行它:

正如你所看到的,该脚本更好,因为它还告诉你该数字是否为奇数。
### 使用 elif(否则如果)语句
这是一个检查给定数字是正数还是负数的脚本。在数学中,0 既不是正数也不是负数。该脚本也检查了这一事实。
```
#!/bin/bash
read -p "Enter the number: " num
if [ $num -lt 0 ]; then
echo "Number $num is negative"
elif [ $num -gt 0 ]; then
echo "Number $num is positive"
else
echo "Number $num is zero"
fi
```
让我运行它来涵盖这里的所有三种情况:

### 用逻辑运算符组合多个条件
到目前为止,一切都很好。但是你是否知道通过使用与(&&)、或(||)等逻辑运算符可以在一个条件中包含多个条件? 它使你能够编写复杂的条件。
让我们编写一个脚本来告诉你给定的年份是否是闰年。
你还记得闰年的条件吗? 它应该被 4 整除,但如果它能被 100 整除,那么它就不是闰年。但是,如果能被 400 整除,则为闰年。
这是我的脚本。
```
#!/bin/bash
read -p "Enter the year: " year
if [[ ($(($year%4)) -eq 0 && $(($year%100)) != 0) || ($(($year%400)) -eq 0) ]]; then
echo "Year $year is leap year"
else
echo "Year $year is normal year"
fi
```
>
> ? 注意上面双括号 `[[ ]]` 的使用。如果你使用逻辑运算符,则这是强制性的。
>
>
>
通过使用不同的数据运行脚本来验证脚本:

### ?️ 练习时间
让我们做一些练习吧 ?
**练习 1**:编写一个 Bash Shell 脚本,检查作为参数提供给它的字符串的长度。如果未提供参数,它将打印 “empty string”。
**练习 2**:编写一个 Shell 脚本来检查给定文件是否存在。你可以提供完整的文件路径作为参数或直接在脚本中使用它。
**提示**:文件使用 -f 选项
**练习 3**:通过检查给定文件是否是常规文件、目录或链接或者是否不存在来增强之前的脚本。
**提示**:使用 -f、-d 和 -L
**练习 3**:编写一个接受两个字符串参数的脚本。脚本应检查第一个字符串是否包含第二个参数的子串。
**提示**:请参阅上一章 [Bash 字符串](https://itsfoss.com/bash-strings/)
我希望你喜欢 Bash 基础知识系列。在下一章中,你将了解如何在 Bash 中使用循环。继续编写 Bash!
*(题图:MJ/1e8f2f5c-9e47-4c84-b8c1-072808e9cf70)*
---
via: <https://itsfoss.com/bash-if-else/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter #7: If Else Statement
If this, then that else something else. Doesn't make sense? It will after you learn about the if-else statements in bash shell scripting.
Bash supports if-else statements so that you can use logical reasoning in your shell scripts.
The generic if-else syntax is like this:
```
if [ expression ]; then
## execute this block if condition is true else go to next
elif [ expression ]; then
## execute this block if condition is true else go to next
else
## if none of the above conditions are true, execute this block
fi
```
As you can notice:
`elif`
is used for "else if" kind of condition- The if else conditions always end with
`fi`
- the use of semicolon
`;`
and`then`
keyword
Before I show the examples of if and else-if, let me share common comparison expressions (also called test conditions) first.
## Test conditions
Here are the test condition operators you can use for numeric comparison:
Condition | Equivalent to true when |
---|---|
$a -lt $b | $a < $b ($a is less than $b) |
$a -gt $b | $a > $b ($a is greater than $b) |
$a -le $b | $a <= $b ($a is less or equal than $b) |
$a -ge $b | $a >= $b ($a is greater or equal than $b) |
$a -eq $b | $a is equal to $b |
$a -ne $b | $a is not equal to $b |
If you are comparing strings, you can use these test conditions:
Condition | Equivalent to true when |
---|---|
"$a" = "$b" | $a is same as $b |
"$a" == "$b" | $a is same as $b |
"$a" != "$b" | $a is different from $b |
-z "$a" | $a is empty |
There are also conditions for file type check:
Condition | Equivalent to true when |
---|---|
-f $a | $a is a file |
-d $a | $a is a directory |
-L $a | $a is a link |
Now that you are aware of the various comparison expressions let's see them in action in various examples.
## Use if statement in bash
Let's create a script that tells you if a given number is even or not.
Here's my script named `even.sh`
:
```
#!/bin/bash
read -p "Enter the number: " num
mod=$(($num%2))
if [ $mod -eq 0 ]; then
echo "Number $num is even"
fi
```
The modulus operation (%) returns zero when it is perfectly divided by the given number (2 in this case).
Here's what it shows when I run the script:
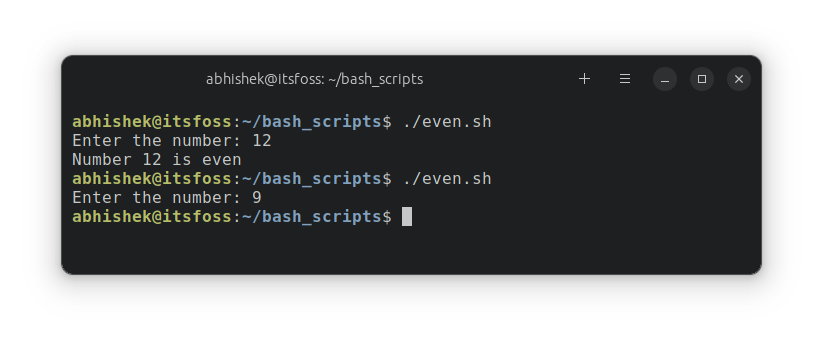
Did you notice that the script tells you when a number is even but it doesn't display anything when the number is odd? Let's improve this script with the use of else.
## Use if else statement
Now I add an else statement in the previous script. This way when you get a non-zero modulus (as odd numbers are not divided by 2), it will enter the else block.
```
#!/bin/bash
read -p "Enter the number: " num
mod=$(($num%2))
if [ $mod -eq 0 ]; then
echo "Number $num is even"
else
echo "Number $num is odd"
fi
```
Let's run it again with the same numbers:
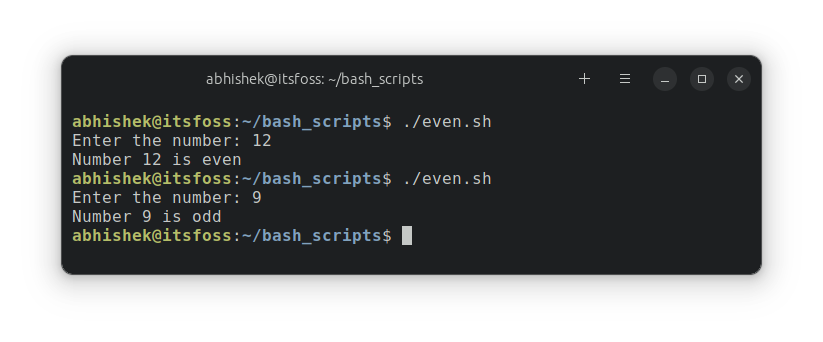
As you can see, the script is better as it also tells you if the number is odd.
## Use elif (else if) statement
Here's a script that checks whether the given number is positive or negative. In mathematics, 0 is neither positive nor negative. This script keeps that fact in check as well.
```
#!/bin/bash
read -p "Enter the number: " num
if [ $num -lt 0 ]; then
echo "Number $num is negative"
elif [ $num -gt 0 ]; then
echo "Number $num is positive"
else
echo "Number $num is zero"
fi
```
Let me run it to cover all three cases here:
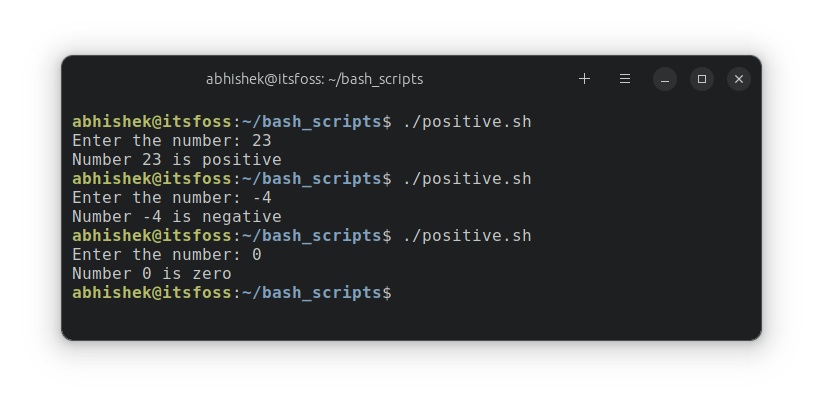
## Combine multiple conditions with logical operators
So far, so good. But do you know that you may have multiple conditions in a single by using logical operators like AND (&&), OR (||) etc? It gives you the ability to write complex conditions.
Let's write a script that tells you whether the given year is a leap year or not.
Do you remember the conditions for being a leap year? It should be divided by 4 but if it is divisible by 100, it's not a leap year. However, if it is divisible by 400, it is a leap year.
Here's my script.
```
#!/bin/bash
read -p "Enter the year: " year
if [[ ($(($year%4)) -eq 0 && $(($year%100)) != 0) || ($(($year%400)) -eq 0) ]]; then
echo "Year $year is leap year"
else
echo "Year $year is normal year"
fi
```
`[[ ]]`
above. It is mandatory if you are using logical operators.Verify the script by running it with different data:
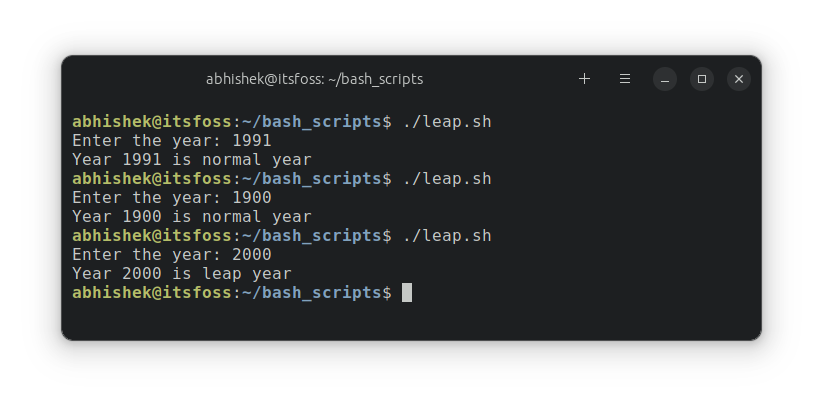
## 🏋️ Exercise time
Let's do some workout :)
**Exercise 1**: Write a bash shell script that checks the length of the string provided to it as an argument. If no argument is provided, it prints 'empty string'.
**Exercise 2**: Write a shell script that checks whether a given file exists or not. You can provide the full file path as the argument or use it directly in the script.
**Hint**: Use -f for file
**Exercise 3**: Enhance the previous script by checking if the given file is regular file, a directory or a link or if it doesn't exist.
**Hint**: Use -f, -d and -L
**Exercise 4**: Write a script that accepts two string arguments. The script should check if the first string contains the second argument as a substring.
**Hint**: Refer to the previous chapter on [bash strings](https://itsfoss.com/bash-strings/)
You may discuss your solution in the Community:
[Practice Exercise in Bash Basics Series #7: If Else StatementsIf you are following the Bash Basics series on It’s FOSS, you can submit and discuss the answers to the exercise at the end of the chapter: Fellow experienced members are encouraged to provide their feedback to new members. Do note that there could be more than one answer to a given problem.](https://itsfoss.community/t/practice-exercise-in-bash-basics-series-7-if-else-statements/10926)

I hope you are enjoying the Bash Basics Series. In the next chapter, you'll learn about [using loops in Bash](https://itsfoss.com/bash-loops/).
[Bash Basics #8: For, While and Until LoopsIn the penultimate chapter of the Bash Basics series, learn about for, while and until loops.](https://itsfoss.com/bash-loops/)

Keep on bashing! |
16,085 | 如何在命令行上舒适地生存? | https://jvns.ca/blog/2023/08/08/what-helps-people-get-comfortable-on-the-command-line-/ | 2023-08-12T10:18:28 | [
"命令行"
] | https://linux.cn/article-16085-1.html | 
有时我与一些害怕使用命令行的朋友交谈,我感到自己给不出好的建议(我已经使用命令行太长时间了),因此我向一些 [Mastodon](https://social.jvns.ca/@b0rk/110842645317766338) 上的人提出了以下问题:
>
> 如果在过去一到三年内,你刚刚不再害怕使用命令行了,是什么帮助了你?
>
>
> (如果你不记得,或者你已经使用命令行舒适地工作了 15 年,则无需回答——这个问题不适用于你 ?)
>
>
>
这个列表还不如我希望的那么长,但我希望通过发布它来收集更多的答案。显然,并没有一个单一的方法适用于所有人,不同的人会选择不同的路径。
我认为舒适使用命令行有三个方面:**减少风险**、**动机**和**资源**。我将先谈谈减少风险,然后是一些动机,并列出一些资源。
### 减少风险的方式
很多人(没错!)对在命令行上意外执行了一些无法撤销的破坏性操作感到担心。
以下是一些人们提到的帮助他们减少风险的策略:
* 定期备份(有人提到他们在上周的一个命令行错误中意外删除了整个家目录,但很幸运他们有备份)。
* 对于代码,尽可能多地使用 `git`。
* 将 `rm` 设置为类似 `safe-rm` 或 `rmtrash` 这样的工具的别名,这样你就不会意外删除不应删除的内容(或者就设置别名到 `rm -i`)。
* 尽量避免使用通配符,使用制表符键补全代替(我的 Shell 会使用 `TAB` 键补全 `rm *.txt` 并显示我将要删除的内容)。
* 使用精美的终端提示符,可以显示当前目录、计算机名称、`git` 分支和你是否具有 root 权限。
* 如果你计划对文件运行未经测试或危险的命令,先备份文件副本。
* 拥有一台专用的测试机器(如便宜的旧 Linux 计算机或树莓派)进行特别危险的测试,例如测试备份软件或分区。
* 对于危险命令,如果有的话,使用 `--dry-run` 选项来查看执行结果而不实际执行操作。
* 在你的 Shell 脚本中构建自己的 `--dry-run` 选项。
这些策略有助于降低在命令行上引发不可逆操作的风险。
### 杀手级应用程序
一些人提到了一个“杀手级命令行应用程序”,这激励他们开始花更多时间在命令行上。例如:
* [ripgrep](https://github.com/BurntSushi/ripgrep)
* jq
* wget / curl
* git(一些人发现他们更喜欢使用 git 命令行界面而不是使用图形界面)
* ffmpeg(用于视频处理)
* yt-dlp
* 硬盘数据恢复工具(来自 [这个精彩的故事](https://github.com/summeremacs/public/blob/main/20230629T180135--how-i-came-to-use-emacs-and-other-things__emacs_explanation_linux_origin_raspberrypi_story_terminal.org))
还有一些人提到他们对图形界面工具感到失望(例如使用了所有内存,并使计算机崩溃的重型集成开发环境),并因此有动机用更轻量级的命令行工具替代它们。
### 激发人们的命令行技巧
有人提到被其他人在命令行上展示的酷炫功能所激励,例如:
* [命令行工具可以比你的 Hadoop 集群快 235 倍](https://adamdrake.com/command-line-tools-can-be-235x-faster-than-your-hadoop-cluster.html)
* [Gary Bernhardt 的这个“命令行链锯”演讲](https://www.youtube.com/watch?v=ZQnyApKysg4&feature=youtu.be)
### explainshell
有几个人提到了 [explainshell](https://explainshell.com/),它可以让你粘贴任何命令行指令,并将其分解成不同的部分解释。
### 命令历史、制表符补全等等
有很多小技巧和窍门可以使在命令行上工作更容易,例如:
* 使用向上箭头查看先前的命令
* 使用 `Ctrl+R` 搜索你的 Bash 历史记录
* 使用快捷键在行内导航:`Ctrl+w` (删除一个单词)、`Ctrl+a`(跳转到行首)、`Ctrl+e`(跳转到行尾),以及 `Ctrl+left arrow` / `Ctrl+right arrow`(向前/向后跳转一个单词)
* 将 Bash 历史记录设置为无限制
* 使用 `cd -` 返回上一个目录
* 文件名和命令名的制表符自动补全
* 学习如何使用像 `less` 这样的分页工具阅读手册页或其他大型文本文件(如搜索、滚动等)
* 在 macOS 上使用 `pbcopy`/`pbpaste` 将剪贴板内容复制/粘贴到 stdout/stdin
* 在编辑配置文件之前备份它们
### fzf
很多人提到使用 [fzf](https://github.com/junegunn/fzf) 作为模糊搜索 Shell 历史记录的更好方法。除了作为更好的模糊搜索 Shell 历史记录的工具,人们还提到了一些其他用途:
* 选择 `git` 分支(`git checkout $(git for-each-ref --format='%(refname:short)' refs/heads/ | fzf)`)
* 快速查找要编辑的文件(`nvim $(fzf)`)
* 切换 Kubernetes 上下文(`kubectl config use-context $(kubectl config get-contexts -o name | fzf --height=10 --prompt="Kubernetes Context> ")`)
* 从测试套件中选择要运行的特定测试
一般的模式是使用 `fzf` 来选择某个对象(文件、`git` 分支、命令行参数),`fzf` 将所选对象输出到标准输出,然后将其插入作为另一个命令的命令行参数。
你还可以将 `fzf` 用作工具,自动预览输出并快速迭代,例如:
* 自动预览 `jq` 的输出(`echo '' | fzf --preview "jq {q} < YOURFILE.json"`)
* 自动预览 `sed` 的输出(`echo '' | fzf --preview "sed {q} YOURFILE"`)
* 自动预览 `awk` 的输出(`echo '' | fzf --preview "awk {q} YOURFILE"`)
你可以参考这个思路。
通常,人们会为 `fzf` 的使用定义别名,比如输入 `gcb` 或其他命令,以快速选择要检出的 `git` 分支。
### 树莓派
一些人开始使用树莓派,这样可以更安全地进行实验,而不必担心损坏计算机(只需擦除 SD 卡然后重新开始即可!)。
### 漂亮的 Shell 环境
很多人说,当他们开始使用像 [oh-my-zsh](https://ohmyz.sh/) 或 [Fish](https://fishshell.com/) 这样更用户友好的 Shell 环境时,他们在命令行上感到更舒适。我非常同意这一点 – 我已经使用 Fish 十年了,我非常喜欢它。
在这里还有一些其他的事情可以做:
* 有些人说,让他们的终端更漂亮可以帮助他们感到更舒适(“让它变成粉色!”)。
* 设置一个漂亮的 Shell 提示符来提供更多信息(例如,当命令失败时,可以将提示符设置为红色)。特别是 [transient prompts](https://www.reddit.com/r/zsh/comments/dsh1g3/new_powerlevel10k_feature_transient_prompt/)(在当前命令设置一个非常花哨的提示符,但在之前的命令中设置一个简单得多的提示符)看起来非常好。

一些用于美化终端的工具:
* 我使用 [base16-shell](https://github.com/chriskempson/base16-shell)
* [powerlevel10k](https://github.com/romkatv/powerlevel10k) 是一个流行的漂亮的 Zsh 主题,具有 transient prompts
* [starship](https://github.com/starship/starship) 是一个漂亮的提示符工具
* 在 Mac 上,我认为 [iTerm2](https://iterm2.com/) 比默认的终端更容易自定义。
### 漂亮的文件管理器
一些人提到了像 [ranger](https://github.com/ranger/ranger) 或 [nnn](https://github.com/jarun/nnn) 这样的漂亮的终端文件管理器,这是我之前没有听说过的。
### 一个有帮助的朋友或同事
一个可以回答初学者问题并给你指点的人是无价的。
### 通过肩并肩地观察学习
有人提到观察更有经验的人使用终端 - 有很多经验丰富的用户甚至没有意识到自己在做什么,你可以从中学到很多小技巧。
### 别名
很多人说,为常用任务创建自己的别名或脚本就像是一个神奇的“灵光一现”时刻,因为:
* 他们不必记住语法
* 然后他们就有了一份自己常用命令的列表,可以轻松调用
### 查找示例的备忘单
很多手册页没有示例,例如 [openssl s\_client](https://linux.die.net/man/1/s_client) 的手册页就没有示例。这使得起步变得更加困难!
人们提到了一些备忘单工具,比如:
* [tldr.sh](https://tldr.sh/)
* [cheat](https://github.com/cheat/cheat)(还可以进行编辑 - 你可以添加自己的命令以供以后参考)
* [um](http://ratfactor.com/cards/um)(一个非常精简的需要自己构建的系统)
例如,[openssl 的备忘单](https://github.com/cheat/cheatsheets/blob/master/openssl) 非常棒 - 我认为它几乎包含了我在实际中使用 `openssl` 时用过的所有内容(除了 `openssl s_client` 的 `-servername` 选项)。
有人说他们配置了他们的 `.bash_profile`,这样每次登录时都会打印出一张备忘单。
### 不要试图背诵
一些人说他们需要改变自己的方法 - 他们意识到不需要试图记住所有的命令,只需按需查找命令,随着时间的推移,他们会自然而然地记住最常用的命令。
(我最近对学习阅读 x86 汇编有了完全相同的体会 - 我正在上一门课程,讲师说“是的,刚开始时可以每次都查找,最终你会记住最常见的指令。”)
还有一些人说相反的观点 - 他们使用间隔重复应用程序(如 Anki)来记忆常用的命令。
### Vim
有人提到他们开始在命令行上使用 Vim 编辑文件,一旦他们开始使用终端文本编辑器,使用命令行处理其他事情也变得更自然。
此外,显然有一个名为 [micro](https://micro-editor.github.io/) 的新编辑器,像是更好的 `pico`/`nano`,适用于那些不想学习 Emacs 或 Vim 的人。
### 桌面上使用 Linux
有人说他们开始使用 Linux 作为他们的日常主力系统,而需要修复 Linux 问题可以帮助他们学习。这也是我在大约 2004 年熟悉命令行的方式(我非常喜欢安装各种不同的 Linux 发行版,以找到我最喜欢的那个),但我猜这不是如今最受欢迎的策略。
### 被迫仅使用终端
有些人说他们参加了一门大学课程,教授让他们在终端上做所有事情,或者他们自己制定了一个规则,一段时间内必须在终端上完成所有工作。
### 工作坊
有几个人说像 [Software Carpentry](https://software-carpentry.org/) 这样的工作坊(面向科学家的命令行、Git 和 Python/R 编程简介)帮助他们更熟悉命令行。
你可以在这里查看 [Software Carpentry 课程](https://software-carpentry.org/lessons/)。
### 书籍和文章
一些提到的材料:
文章:
* 《[终端](https://furbo.org/2014/09/03/the-terminal/)》
* 《[命令行功夫](http://blog.commandlinekungfu.com/)》(包含 UNIX 和 Windows 命令行技巧)
书籍:
* 《[Effective Linux at The Command Line](https://www.oreilly.com/library/view/efficient-linux-at/9781098113391/)》
* 《Unix Power Tools》(可能有些过时)
* 《The Linux Pocket guide》
视频:
* Mindy Preston 的 [CLI tools aren’t inherently user-hostile](https://www.youtube.com/watch?v=IcV9TVb-vF4)
* Gary Bernhardt 的 [destroy all software screencasts](https://www.destroyallsoftware.com/screencasts)
* [DistroTube](https://www.youtube.com/@DistroTube)
*(题图:MJ/c0dc082a-a477-434b-b826-77a42c8f61c3)*
---
via: <https://jvns.ca/blog/2023/08/08/what-helps-people-get-comfortable-on-the-command-line-/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sometimes I talk to friends who need to use the command line, but are
intimidated by it. I never really feel like I have good advice (I’ve been using
the command line for too long), and so I asked some people [on Mastodon](https://social.jvns.ca/@b0rk/110842645317766338):
if you just stopped being scared of the command line in the last year or three — what helped you?
(no need to reply if you don’t remember, or if you’ve been using the command line comfortably for 15 years — this question isn’t for you :) )
This list is still a bit shorter than I would like, but I’m posting it in the hopes that I can collect some more answers. There obviously isn’t one single thing that works for everyone – different people take different paths.
I think there are three parts to getting comfortable: **reducing risks**, **motivation** and **resources**. I’ll
start with risks, then a couple of motivations and then list some resources.
### ways to reduce risk
A lot of people are (very rightfully!) concerned about accidentally doing some destructive action on the command line that they can’t undo.
A few strategies people said helped them reduce risks:
- regular backups (one person mentioned they accidentally deleted their entire home directory last week in a command line mishap, but it was okay because they had a backup)
- For code, using git as much as possible
- Aliasing
`rm`
to a tool like[safe-rm](https://launchpad.net/safe-rm)or[rmtrash](https://github.com/PhrozenByte/rmtrash)so that you can’t accidentally delete something you shouldn’t (or just`rm -i`
) - Mostly avoid using wildcards, use tab completion instead. (my shell will tab complete
`rm *.txt`
and show me exactly what it’s going to remove) - Fancy terminal prompts that tell you the current directory, machine you’re on, git branch, and whether you’re root
- Making a copy of files if you’re planning to run an untested / dangerous command on them
- Having a dedicated test machine (like a cheap old Linux computer or Raspberry Pi) for particularly dangerous testing, like testing backup software or partitioning
- Use
`--dry-run`
options for dangerous commands, if they’re available - Build your own
`--dry-run`
options into your shell scripts
### a “killer app”
A few people mentioned a “killer command line app” that motivated them to start spending more time on the command line. For example:
[ripgrep](https://github.com/BurntSushi/ripgrep)- jq
- wget / curl
- git (some folks found they preferred the git CLI to using a GUI)
- ffmpeg (for video work)
[yt-dlp](https://github.com/yt-dlp/yt-dlp)- hard drive data recovery tools (from
[this great story](https://github.com/summeremacs/public/blob/main/20230629T180135--how-i-came-to-use-emacs-and-other-things__emacs_explanation_linux_origin_raspberrypi_story_terminal.org))
A couple of people also mentioned getting frustrated with GUI tools (like heavy IDEs that use all your RAM and crash your computer) and being motivated to replace them with much lighter weight command line tools.
### inspiring command line wizardry
One person mentioned being motivated by seeing cool stuff other people were doing with the command line, like:
[Command-line Tools can be 235x Faster than your Hadoop Cluster](https://adamdrake.com/command-line-tools-can-be-235x-faster-than-your-hadoop-cluster.html)[this “command-line chainsaw” talk by Gary Bernhardt](https://www.youtube.com/watch?v=ZQnyApKysg4&feature=youtu.be)
### explain shell
Several people mentioned [explainshell](https://explainshell.com/) where you
can paste in any shell incantation and get it to break it down into different
parts.
### history, tab completion, etc:
There were lots of little tips and tricks mentioned that make it a lot easier to work on the command line, like:
- up arrow to see the previous command
- Ctrl+R to search your bash history
- navigating inside a line with
`Ctrl+w`
(to delete a word),`Ctrl+a`
(to go to the beginning of the line),`Ctrl+e`
(to go to the end), and`Ctrl+left arrow`
/`Ctrl+right arrow`
(to jump back/forward a word) - setting bash history to unlimited
`cd -`
to go back to the previous directory- tab completion of filenames and command names
- learning how to use a pager like
`less`
to read man pages or other large text files (how to search, scroll, etc) - backing up configuration files before editing them
- using pbcopy/pbpaste on Mac OS to copy/paste from your clipboard to stdout/stdin
- on Mac OS, you can drag a folder from the Finder into the terminal to get its path
### fzf
Lots of mentions of using [fzf](https://github.com/junegunn/fzf) as a better
way to fuzzy search shell history. Some other things people mentioned using fzf for:
- picking git branches (
`git checkout $(git for-each-ref --format='%(refname:short)' refs/heads/ | fzf)`
) - quickly finding files to edit (
`nvim $(fzf)`
) - switching kubernetes contexts (
`kubectl config use-context $(kubectl config get-contexts -o name | fzf --height=10 --prompt="Kubernetes Context> ")`
) - picking a specific test to run from a test suite
The general pattern here is that you use fzf to pick something (a file, a git branch, a command line argument), fzf prints the thing you picked to stdout, and then you insert that as the command line argument to another command.
You can also use fzf as an tool to automatically preview the output and quickly iterate, for example:
- automatically previewing jq output (
`echo '' | fzf --preview "jq {q} < YOURFILE.json"`
) - or for
`sed`
(`echo '' | fzf --preview "sed {q} YOURFILE"`
) - or for
`awk`
(`echo '' | fzf --preview "awk {q} YOURFILE"`
)
You get the idea.
In general folks will generally define an alias for their `fzf`
incantations so
you can type `gcb`
or something to quickly pick a git branch to check out.
### raspberry pi
Some people started using a Raspberry Pi, where it’s safer to experiment without worrying about breaking your computer (you can just erase the SD card and start over!)
### a fancy shell setup
Lots of people said they got more comfortable with the command line
when they started using a more user-friendly shell setup like
[oh-my-zsh](https://ohmyz.sh/) or [fish](https://fishshell.com/). I really
agree with this one – I’ve been using fish for 10 years and I love it.
A couple of other things you can do here:
- some folks said that making their terminal prettier helped them feel more comfortable (“make it pink!”).
- set up a fancy shell prompt to give you more information (for example you can
make the prompt red when a command fails). Specifically
[transient prompts](https://www.reddit.com/r/zsh/comments/dsh1g3/new_powerlevel10k_feature_transient_prompt/)(where you set a super fancy prompt for the current command, but a much simpler one for past commands) seem really nice.
Some tools for theming your terminal:
- I use
[base16-shell](https://github.com/chriskempson/base16-shell) [powerlevel10k](https://github.com/romkatv/powerlevel10k)is a popular fancy zsh theme which has transient prompts[starship](https://github.com/starship/starship)is a fancy prompt tool- on a Mac, I think
[iTerm2](https://iterm2.com/)is easier to customize than the default terminal
### a fancy file manager
A few people mentioned fancy terminal file managers like
[ranger](https://github.com/ranger/ranger) or
[nnn](https://github.com/jarun/nnn), which I hadn’t heard of.
### a helpful friend or coworker
Someone who can answer beginner questions and give you pointers is invaluable.
### shoulder surfing
Several mentions of watching someone more experienced using the terminal – there are lots of little things that experienced users don’t even realize they’re doing which you can pick up.
### aliases
Lots of people said that making their own aliases or scripts for commonly used tasks felt like a magical “a ha!” moment, because:
- they don’t have to remember the syntax
- then they have a list of their most commonly used commands that they can summon easily
### cheat sheets to get examples
A lot of man pages don’t have examples, for example the [openssl s_client](https://linux.die.net/man/1/s_client) man page has no examples.
This makes it a lot harder to get started!
People mentioned a couple of cheat sheet tools, like:
[tldr.sh](https://tldr.sh/)[cheat](https://github.com/cheat/cheat)(which has the bonus of being editable – you can add your own commands to reference later)[um](http://ratfactor.com/cards/um)(an incredibly minimal system that you have to build yourself)
For example the [cheat page for openssl](https://github.com/cheat/cheatsheets/blob/master/openssl) is really
great – I think it includes almost everything I’ve ever actually used openssl
for in practice (except the `-servername`
option for `openssl s_client`
).
One person said that they configured their `.bash_profile`
to print out a cheat
sheet every time they log in.
### don’t try to memorize
A couple of people said that they needed to change their approach – instead of trying to memorize all the commands, they realized they could just look up commands as needed and they’d naturally memorize the ones they used the most over time.
(I actually recently had the exact same realization about learning to read x86 assembly – I was taking a class and the instructor said “yeah, just look everything up every time to start, eventually you’ll learn the most common instructions by heart”)
Some people also said the opposite – that they used a spaced repetition app like Anki to memorize commonly used commands.
### vim
One person mentioned that they started using vim on the command line to edit files, and once they were using a terminal text editor it felt more natural to use the command line for other things too.
Also apparently there’s a new editor called
[micro](https://micro-editor.github.io/) which is like a nicer version of
pico/nano, for folks who don’t want to learn emacs or vim.
### use Linux on the desktop
One person said that they started using Linux as their main daily driver, and having to fix Linux issues helped them learn. That’s also how I got comfortable with the command too back in ~2004 (I was really into installing lots of different Linux distributions to try to find my favourite one), but my guess is that it’s not the most popular strategy these days.
### being forced to only use the terminal
Some people said that they took a university class where the professor made them do everything in the terminal, or that they created a rule for themselves that they had to do all their work in the terminal for a while.
### workshops
A couple of people said that workshops like [Software Carpentry](https://software-carpentry.org/)
workshops (an introduction to the command line, git, and Python/R programming
for scientists) helped them get more comfortable with the command line.
You can see the [software carpentry curriculum here](https://software-carpentry.org/lessons/).
### books & articles
a few that were mentioned:
articles:
[The Terminal](https://furbo.org/2014/09/03/the-terminal/)[command line kung fu](http://blog.commandlinekungfu.com/)(has a mix of Unix and Windows command line tips)
books:
[effective linux at the command line](https://www.oreilly.com/library/view/efficient-linux-at/9781098113391/)- unix power tools (which might be outdated)
- The Linux Pocket guide
videos:
[CLI tools aren’t inherently user-hostile](https://www.youtube.com/watch?v=IcV9TVb-vF4)by Mindy Preston- Gary Bernhardt’s
[destroy all software screencasts](https://www.destroyallsoftware.com/screencasts) [DistroTube](https://www.youtube.com/@DistroTube) |
16,086 | 在 Linux 中使用 cp 命令 | https://itsfoss.com/cp-command/ | 2023-08-12T13:52:00 | [
"cp"
] | https://linux.cn/article-16086-1.html | 
>
> 熟悉在 Linux 命令行中复制文件和目录的 cp 命令。
>
>
>
`cp` 命令是 Linux 中一个重要的命令,你可能经常会用到它。
正如名称所示,`cp` 代表 <ruby> 复制 <rt> copy </rt></ruby>,它被用于 [在 Linux 命令行中复制文件和目录](https://itsfoss.com/copy-files-directory-linux/)。
这是一个相对简单的命令,只有几个选项,但你仍有必要深入了解它。
在展示 `cp` 命令的实际示例之前,我更建议你先熟悉绝对路径和相对路径的概念,将文件从一个位置复制到另一个位置时,你需要用到它们。
>
> [Linux 中的绝对路径和相对路径的不同之处](https://linuxhandbook.com/absolute-vs-relative-path/)
>
>
>
### 复制单个文件
`cp` 命令最简单和最常见的用途是复制文件,只需指定源文件和要“粘贴”文件的目标目录即可。
```
cp 源文件 目标目录
```

### 在复制文件的同时重命名它
你将文件复制到另一个位置时可以同时进行 [重命名](https://learnubuntu.com:443/rename-files/)。这有点类似于文本编辑器中的“另存为”选项。
为此,你必须在路径中给出新的文件名。
```
cp 源文件 目标目录/新文件名
```

### 复制多个文件
你还可以将多个文件复制到另一个位置。
```
cp 文件1 文件2 文件3 目标目录
```

在这种情况下,你无法重命名文件。
你还可以使用通配符扩展,将特定后缀的文件复制到另一个位置:
```
cp *.txt 目标目录
```

### 复制文件时避免覆盖现有文件
如果你将 `file1.txt` 复制到一个已经存在名为 `file1.txt` 文件的目录中,它会将原有的文件覆盖掉。
如果你不希望这样,`cp` 命令还提供了几个选项来处理文件覆盖的情况。
首先是使用选项 `-i` 的交互模式。在交互模式下,它会询问是否确认或放弃覆盖目标文件。
```
cp -i 源文件 目标目录
cp:覆盖 '目标目录/源文件' ?
```
按 `Y` 覆盖文件,按 `N` 跳过复制该文件。


选项 `-n` 代表完全取消覆盖。使用此选项时目标文件不会被覆盖。
```
cp -n 源文件 目标目录
```

还有一个选项 `-b`,在目标目录的文件将被覆盖时自动为其创建备份。我猜这里 `b` 代表 <ruby> 备份 <rt> backup </rt></ruby>。
```
cp -b 源文件 目标目录
```

最后,还有一个“<ruby> 更新 <rt> update </rt></ruby>”选项 `-u`,如果目标文件比源文件旧,或者目标文件不存在,就会被覆盖掉。
```
cp -u 源文件 目标目录
```

### 复制目录(文件夹)
cp 命令也用来[在 Linux 命令行中复制目录](https://linuxhandbook.com:443/copy-directory-linux/)。
在复制目录时,你需要使用递归选项 `-r`。
```
cp -r 源目录 目标目录
```

你还可以将多个目录复制到另一个位置:
```
cp -r 目录1 目录2 目录3 目标目录
```

### 在复制时保留属性
当你将文件复制到另一个位置时,它的 [时间戳](https://linuxhandbook.com:443/file-timestamps/)、[文件权限](https://linuxhandbook.com:443/linux-file-permissions/) 甚至所有权都会发生变化。
这是正常的行为。但在某些情况下,你可能希望在复制文件时保留其原始属性。
要保留属性,请使用选项 `-p`:
```
cp -p 源文件 目标目录
```

>
> ? 还有一个 `-a` 选项用于存档模式。它将连 ACL 也保留下来。
>
>
>
### ?️ 练习时间
想要练习一下 `cp` 命令吗?以下是一些简单的练习题供你尝试。
* 打开终端并创建一个名为 `practice_cp` 的目录。
* 现在,将 `/etc/services` 文件复制到这个新创建的目录中。
* 在 `practice` 目录中对复制的 `services` 文件进行一些小的更改。
* 现在,使用更新模式再次复制 `/etc/services` 文件。有什么变化吗?观察一下。
* 查看 `/var/log` 目录,并将以 `mail` 开头的日志文件复制到你的联系目录下。
* 现在,返回到你的家目录,并创建一个名为 `new_dir` 的新目录(好吧,我想不出更好的名字)。
* 将 `practice_cp` 目录复制到 `new_dir` 目录中。
对你来说这些练习足够用了。希望你能喜欢在这里学习 Linux 命令。
*(题图:MJ/07b35a39-826e-4904-9f85-25257831ce9d)*
---
via: <https://itsfoss.com/cp-command/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lkxed](https://github.com/lkxed/) 译者:[onionstalgia](https://github.com/onionstalgia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The cp command is one of the essential Linux commands you probably will be using on a regular basis.
As the name indicates, cp stands for copy and it is used for [copying files and directories in Linux command line](https://itsfoss.com/copy-files-directory-linux/).
It's one of the simpler commands with only a few options but that doesn't mean you cannot know more about it.
Before you see some practical examples of the cp command, I advise getting familiar with the concept of absolute and relative paths because you'll need to use them while copying files from one place to another.
[Absolute vs Relative Path in Linux: What’s the Difference?In this essential Linux learning chapter, know about the relative and absolute paths in Linux. What’s the difference between them and which one should you use.](https://linuxhandbook.com/absolute-vs-relative-path/?ref=itsfoss.com)

## Copy a file
The simplest and most common use of the cp command is for copying files. For that, you just have to specify the source file and the destination where you want to 'paste' the file.
`cp source_file destination_directory`
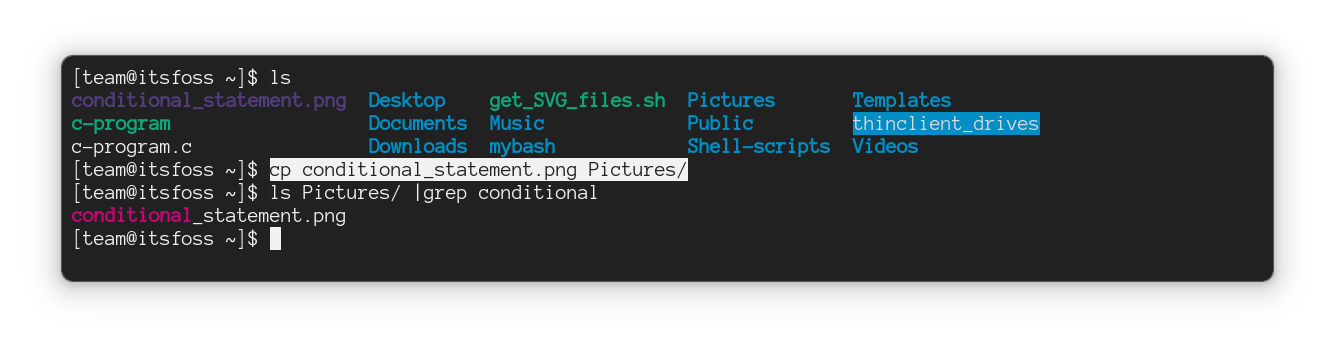
## Rename the file while copying it
You can also [rename the file](https://learnubuntu.com/rename-files/) while copying it to another location. This is like those 'save as' options you see in text editors.
For this, you must mention the new file name along with the path.
`cp source_file destination_directory/new_filename`
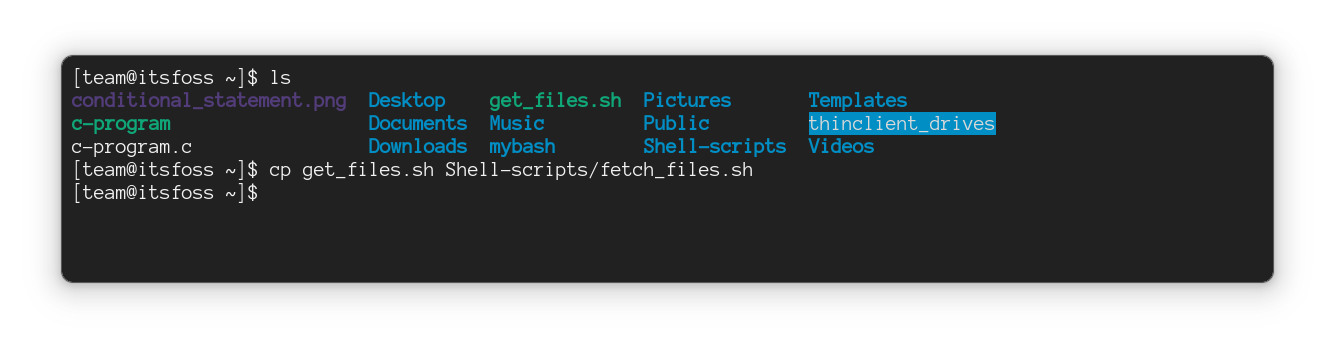
## Copy multiple files
You can also copy multiple files to another location.
`cp file1 file2 file3 destination_directory`
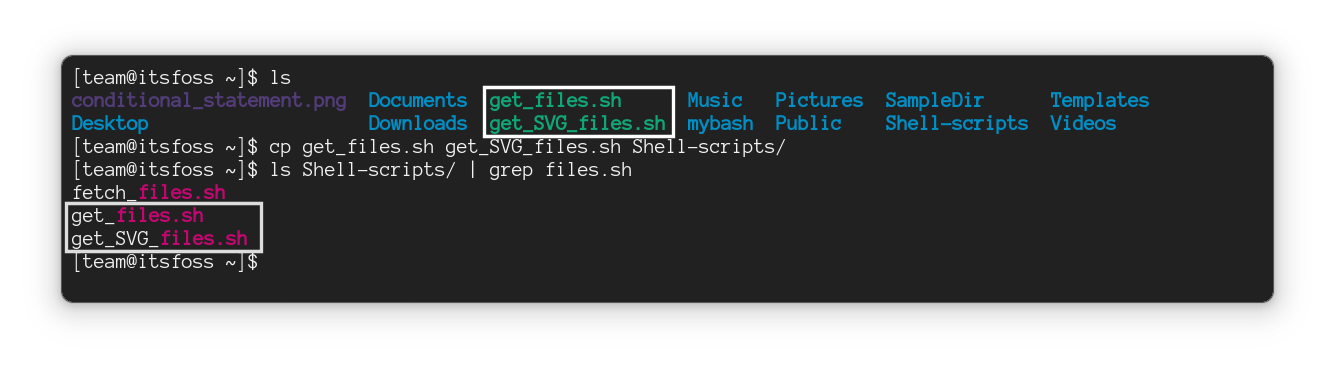
You cannot rename files in this case.
Of course, you can use wildcard expansion and copy files of a certain type to another location:
`cp *.txt destination_directory`
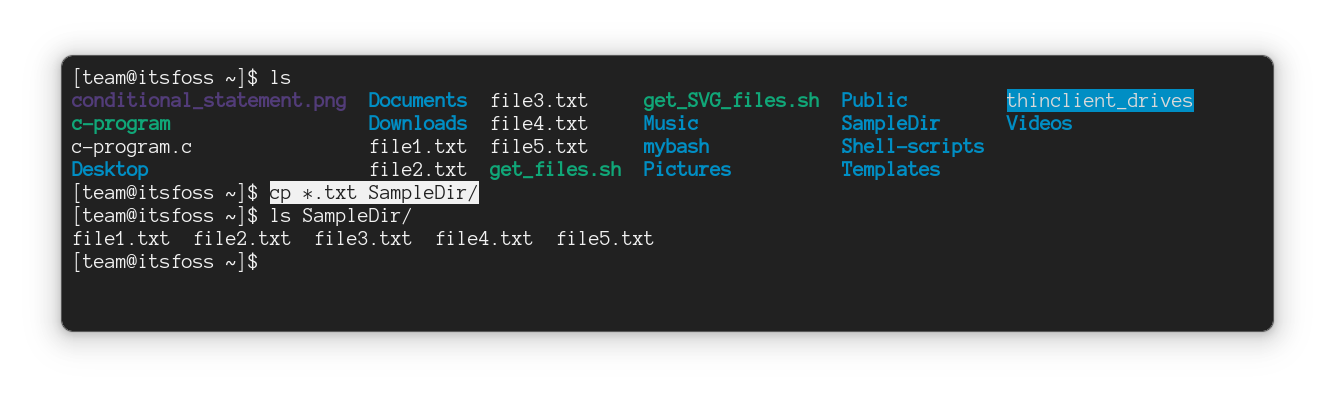
## Avoid overwriting while copying files
If you are copying file1.txt to a directory where there already exists a file named file1.txt, it will be overwritten with the file you are copying.
You may not always want that. This is why the cp command provides several options to deal with overwriting.
The firstmost is the interactive mode with the option `-i`
. In the interactive mode, it will ask you to confirm or deny the overwriting of the destination file.
```
cp -i source_file destination_directory
cp: overwrite 'destination_directory/source_file'?
```
Press Y to overwrite and N to skip copying the file.
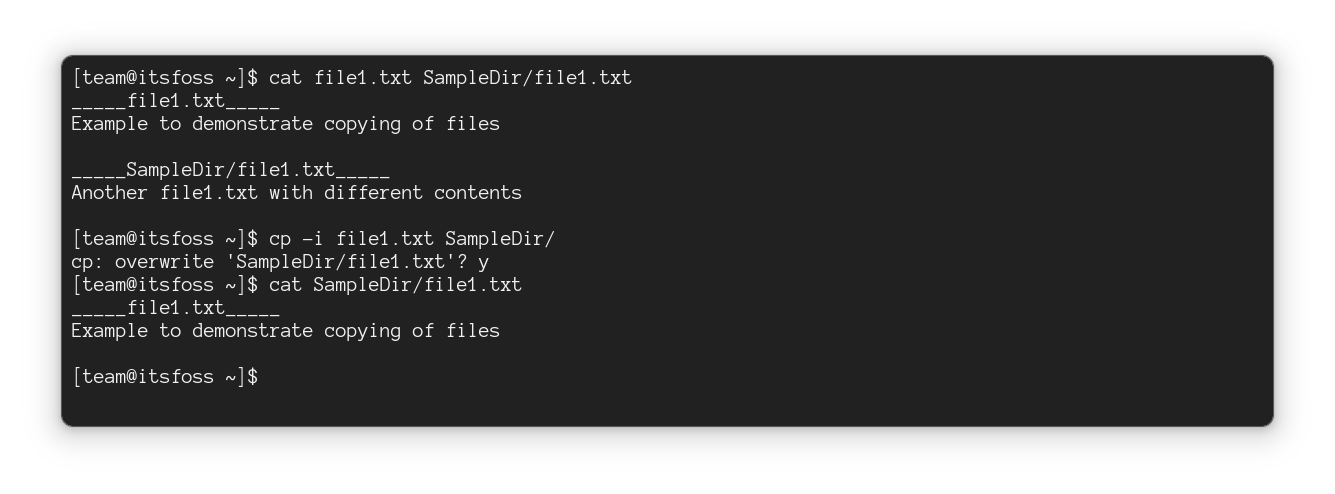
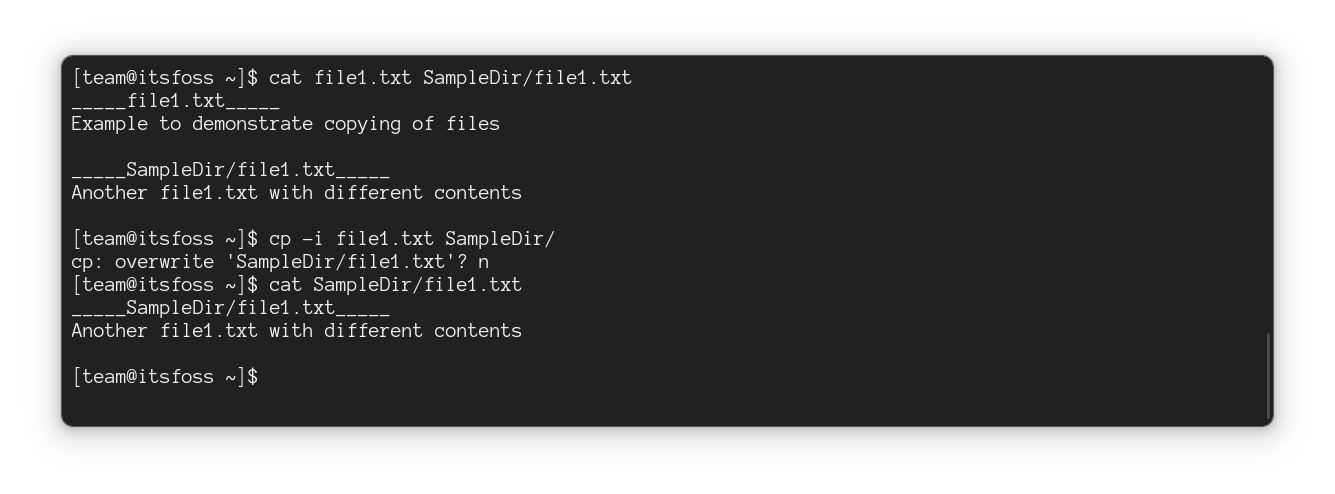
The option `-n`
negates overwriting completely. Destination files won't be overwritten with this option.
```
cp -n source_file destination_directory
```
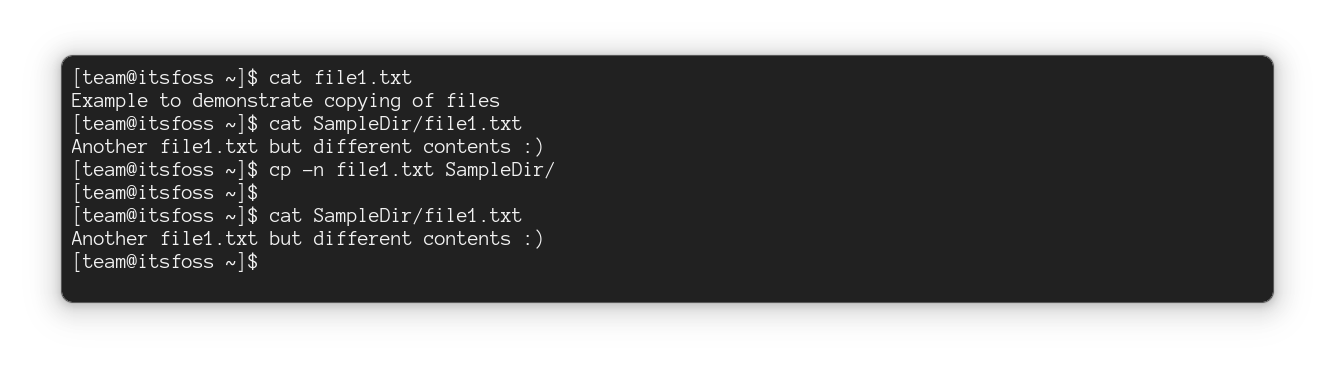
There is also an option `-b`
for automatically creating a backup if the destination file is going to be overwritten. B stands for backup, I presume.
```
cp -b source_file destination_directory
```
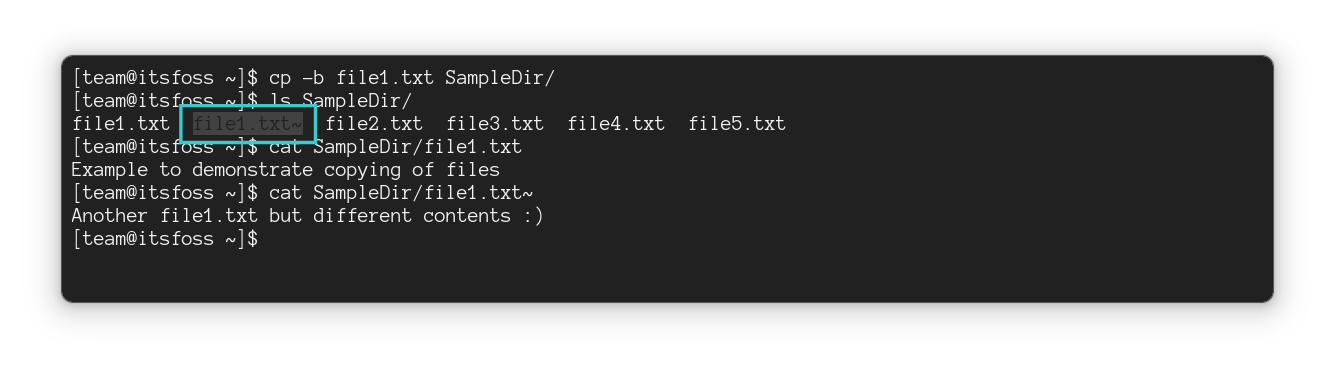
And lastly, there is the 'update' option `-u`
which will overwrite the destination file if it is older than the source file or if it destination file does not exist.
`cp -u source_file destination_directory`
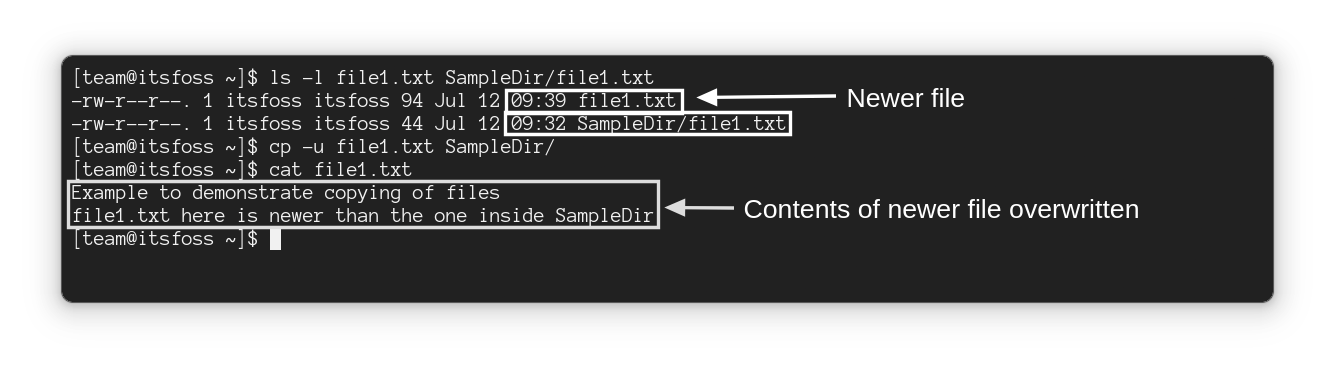
## Copy directories (folders)
The cp command is also used for [copy directories in the Linux command line](https://linuxhandbook.com/copy-directory-linux/).
You need to use the recursive option `-r`
for copying directories.
`cp -r source_dir destination_dir`
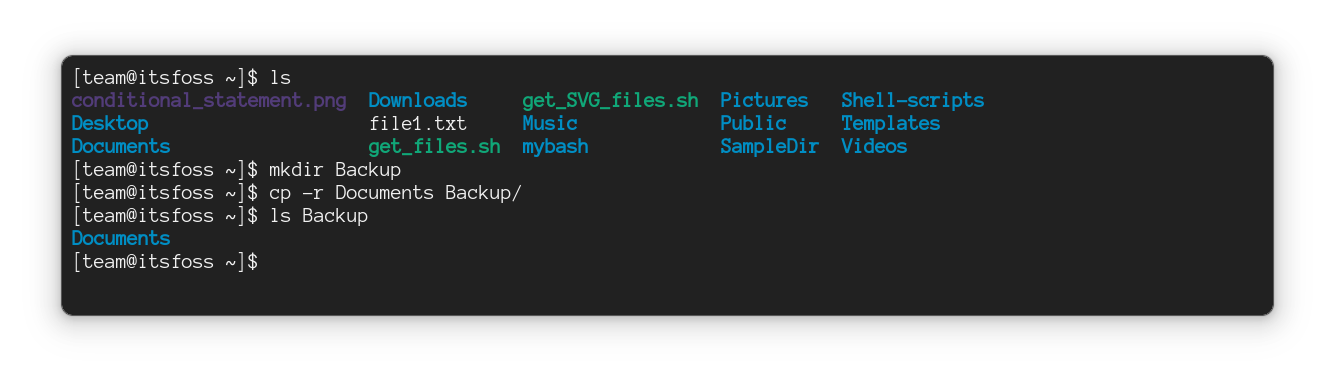
You can also copy multiple directories to another location:
`cp -r dir1 dir2 dir3 target_directory`
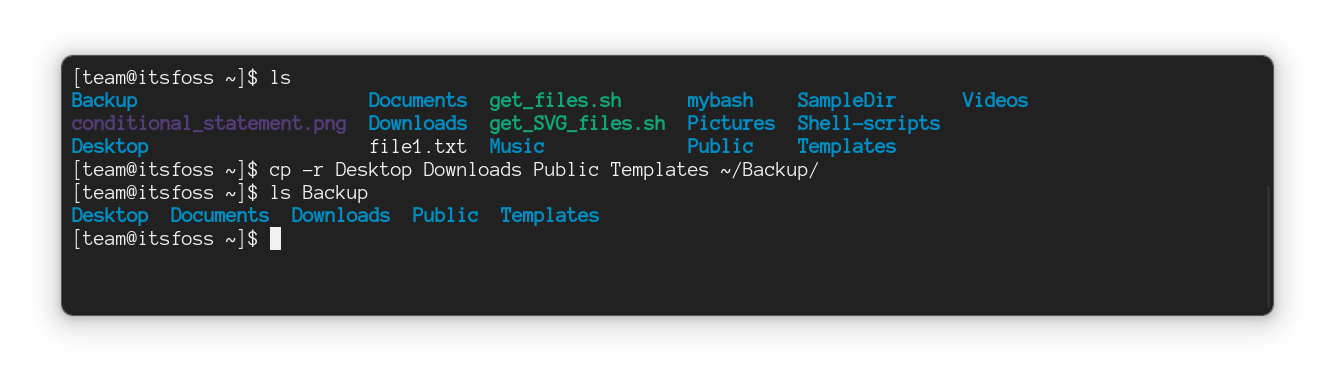
## Preserve attributes while copying
When you copy a file to another location, its [timestamp](https://linuxhandbook.com/file-timestamps/), [file permission](https://linuxhandbook.com/linux-file-permissions/) and even ownership gets changed.
That's the normal behavior. But in some cases, you may want to preserve the original attribute even when you are copying the file.
To preserve the attributes, use the option `-p`
:
`cp -p source_file destination_directory`
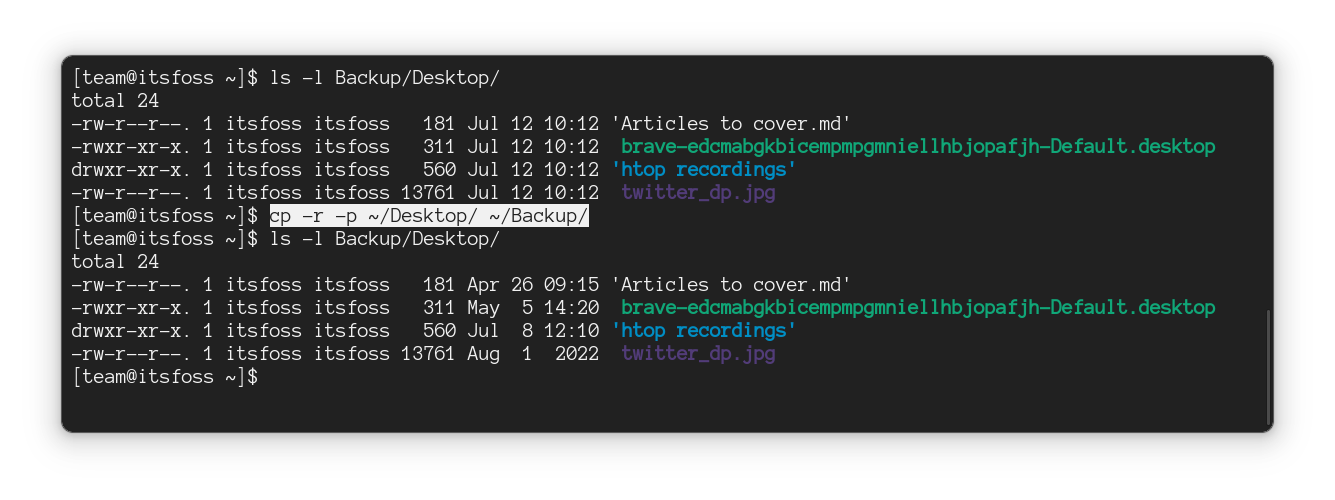
There is also `-a`
option for archive mode. It will preserve even the ACLs.
## 🏋️ Exercise time
Want to practice the cp command a little? Here are some simple exercises for you.
- Open a terminal and create a directory named
`practice_cp`
- Now, copy the /etc/services file in this newly created directory.
- Make some minor changes to the copied services file in practice directory.
- Now, copy /etc/services file again but in update mode. Does it change anything? Observe.
- Look into /var/log directory and copy the log files that start with mail into your practice directory
- Now, go back to your home directory and create a new directory named new_dir (well, I couldn't think of any better)
- Copy the practice_cp directory to new_dir
That should be good enough exercise for you. Enjoy learning Linux commands with It's FOSS. |
16,088 | Gherkin 语言如何弥合客户和开发人员之间的差距 | https://opensource.com/article/23/2/gherkin-language-developers | 2023-08-13T10:01:00 | [
"Gherkin",
"Cucumber"
] | https://linux.cn/article-16088-1.html | 
>
> Gherkin 语法可以帮助你思考技术事务的过程,然后帮助你将其转化为程序员逻辑的形式写下来。
>
>
>
与软件开发人员沟通通常是一项繁重的任务,尤其是当人们缺乏技术知识和技术词汇时。这就是为什么项目经理经常使用 [用户故事](https://softwareplanetgroup.co.uk/user-stories-bridging-the-gap-between-customers-and-developers-updated/) 和多功能系统隐喻。
你可以利用旨在促进项目利益相关者和开发人员之间讨论的技术,进一步协助沟通。
### Cucumber 框架
Cucumber 是一个开源框架,可以使用易于编写的通用语言创建自动化软件测试。它基于 [行为驱动开发(BDD)](https://opensource.com/article/19/2/behavior-driven-development-tools) 的概念,该概念规定创建软件应定义用户希望应用在特定条件成立时如何表现。
(LCTT 译注:Gherkin 和 Cucumber 都是黄瓜,其中 Gherkin 一种用来腌制的小黄瓜。顺便说一句,黄瓜原名胡瓜,因其由汉朝张骞出使西域时带回,后因石勒禁称“胡”字,更名为黄瓜。)
Cucumber 框架并不是现代意义上的“技术”。它不是位和字节的集合。相反,它是一种用自然语言(在本文中为英语,但到目前为止 Gherkin 已被翻译成 70 多种语言)的写作方式。使用 Cucumber 框架时,你不需要知道如何读取或编写代码。你只需要能够写下你对工作方式的想法即可。你还应该使用一组特定术语和指南来记录你希望技术如何为你服务。
### Gherkin 语言是什么?
Cucumber 使用 Gherkin 作为定义用例的方法。它主要用于生成明确的项目需求。换句话说,其目的是允许用户准确地描述他们需要软件做什么,不留任何解释或例外的空间。它帮助你思考技术事务的过程,然后帮助你以可转化为程序员逻辑的形式将其写下来。
这是一个例子:
```
功能:活期账户持有人取款
场景:有关账户并不缺少资金
假如账户余额为 200 英镑
借记卡有效
取款机里有足够的钱
当活期账户持有人申请 50 英镑时
则取款机支付 50 英镑
账户余额为 150 英镑
借记卡被退回
```
正如你所看到的,这是一个非常具体的场景,其中假设用户请求 50 英镑,取款机提供 50 英镑并相应地调整用户的帐户余额。此场景只是取款机用途的一部分,它仅代表人与取款机交互的特定组成部分。当程序员被赋予对机器进行编程以响应用户请求的任务时,这清楚地表明了涉及哪些因素。
#### Gherkin 关键字是什么?
Gherkin 语法使用五个不可或缺的语句来描述执行任务所需的操作:
* <ruby> 功能 <rt> Feature </rt></ruby>:表示任何给定软件功能的高层次描述
* <ruby> 场景 <rt> Scenario </rt></ruby>:描述具体\_示例\_
* <ruby> 假如 <rt> Given </rt></ruby>:解释系统的初始上下文
* <ruby> 当 <rt> When </rt></ruby>:指定事件或操作
* <ruby> 则 <rt> Then </rt></ruby>:描述预期输出或结果
* <ruby> 而且 <rt> And </rt></ruby>(或者 <ruby> 但是 <rt> But </rt></ruby>):增加文本流畅性
(LCTT 译注:这些关键字可以使用任何语言,请参照:<https://cucumber.io/docs/gherkin/languages/>)
通过使用这些简单的关键字,客户、分析师、测试人员和软件程序员能够使用所有人都能识别的术语来交换想法。
### 可执行的需求和自动化测试
更好的是,*Gherkin 要求也是可执行的*。这是通过将每个关键字映射到其预期(且明确说明)的功能来完成的。因此,为了与上面的示例保持一致,任何已经实现的内容都可以自动显示为绿色:
```
当活期账户持有人申请 50 英镑时
则取款机支付 50 英镑
账户余额为 150 英镑
借记卡被退回
```
通过扩展,Gherkin 使开发人员能够将需求转换为可测试的代码。在实践中,你可以使用特定的短语来检查你的软件方案!如果你当前的代码无法正常工作,或者新的更改意外导致软件错误(或两个或三个),那么你可以轻松查明问题,然后再继续修复它们。
### 结论
得益于 Gherkin 语法,你的客户将不再陷入困境。你可以弥合企业和开发人员之间的鸿沟,并比以往更有信心地交付出色的产品。
通过访问 [Cucumber 网站](https://cucumber.io/docs/gherkin/) 或其 [Git 仓库](https://github.com/cucumber/docs) 了解有关 Gherkin 的更多信息。
*(题图:MJ/b717cd4f-0a6b-4b28-a895-b9688b289551)*
---
via: <https://opensource.com/article/23/2/gherkin-language-developers>
作者:[David Blackwood](https://opensource.com/users/david-blackwood) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Communicating with software developers can often be a burdensome task, especially when people lack technical knowledge and technical vocabulary. This is why project managers often use [user stories](https://softwareplanetgroup.co.uk/user-stories-bridging-the-gap-between-customers-and-developers-updated/) and the versatile system metaphor*.*
You can assist communication further by utilizing technology designed to facilitate discussions between a project's stakeholders and developers.
## The Cucumber framework
Cucumber is an open source framework that enables the creation of automated software tests using an easy-to-write and common language*.* It's based on the concept of [behavior-driven development (BDD)](https://opensource.com/article/19/2/behavior-driven-development-tools), which dictates that creating software should define how a user wants an application to behave when specific conditions are true.
The Cucumber framework isn't "technology" in the modern sense. It's not a collection of bits and bytes. Instead, it's a way of writing in natural language (English, in the case of this article, but so far Gherkin has been translated to over 70 languages). When using the Cucumber framework, you aren't expected to know how to read or write code. You only need to be able to write down ideas you have about how you work. You should also document how you want technology to work for you, using a set of specific terms and guidelines.
## What is the Gherkin language?
Cucumber uses Gherkin as a means to define use cases. It's primarily used to generate unambiguous project requirements*.* In other words, its purpose is to allow users to describe precisely what they require software to do, leaving no room for interpretation or exception. It helps you think through the process of a transaction with technology and then helps you write it down in a form that translates into programmer logic.
Here's an example:
```
``````
Feature: The Current Account Holder withdraws money
Scenario: The account in question is not lacking in funds
Given that the account balance is £200
And the debit card is valid
And the cash machine contains enough money
When the Current Account Holder requests £50
Then the cash machine dispenses £50
And the account balance is £150
And the debit card is returned
```
As you can see, this is a highly specific scenario in which an imaginary user requests £50, and the ATM provides £50 and adjusts the user's account balance accordingly. This scenario is just one part of an ATM's purpose, and it only represents a specific component of a person's interaction with a cash machine. When a programmer is given the task to program the machine to respond to a user request, this clearly demonstrates what factors are involved.
### What are Gherkin keywords?
The Gherkin syntax makes use of five indispensable statements describing the actions needed to perform a task:
-
**Feature**: denotes a high-level description of any given software function -
**Scenario**: describes a concrete*example* -
**Given**: explains the initial context of the system -
**When**: specifies an event or action -
**Then**: describes an expected outcome, or a result -
**And (or but)**: increases text fluidity
By making use of these simple keywords, customers, analysts, testers, and software programmers are empowered to exchange ideas with terminology that's recognizable by all.
## Executable requirements and automated testing
Even better,* Gherkin requirements are also executable.* This is done by mapping each* *and every keyword to its intended (and clearly stated) functionality. So, to keep with the example above, anything already implemented could automatically be displayed in green:
```
``````
When the Current Account Holder requests £50*
Then the cash machine dispenses £50*
And the account balance is £150
And the debit card is returned
```
By extension, Gherkin enables developers to translate requirements into testable code. In practice, you can use specific phrases to check in on your software solutions! If your current code isn't working properly, or a new change has accidentally caused a software error (or two or three) then you can easily pinpoint problems before proceeding to repair them.
## Conclusion
Thanks to the Gherkin syntax, your customers will no longer be in a pickle. You can bridge the divide between businesses and developers and deliver outstanding products with greater confidence than ever before.
Find out more about Gherkin by visiting the [Cucumber website](https://cucumber.io/docs/gherkin/) or its [Git repository](https://github.com/cucumber/docs).
## Comments are closed. |
16,089 | 为什么 DNS 仍然难以学习? | https://jvns.ca/blog/2023/07/28/why-is-dns-still-hard-to-learn/ | 2023-08-13T12:17:00 | [
"DNS"
] | https://linux.cn/article-16089-1.html | 
我经常写关于我发现难以学习的技术的文章。不久前,我的朋友 Sumana 向我提出了一个有趣的问题 - 为什么这些东西学起来那么难?为什么它们看起来如此神秘?
以 DNS 为例。我们从 [80 年代](https://www.ietf.org/rfc/rfc1034.txt) 开始使用 DNS(已经超过 35 年了!)。它在互联网上的每个网站中都使用。而且它相当稳定 - 在很多方面,它的工作方式与 30 年前完全相同。
但是我花了好几年的时间才弄清楚如何自信地调试 DNS 问题,我也见过很多其他程序员在调试 DNS 问题上苦苦挣扎。那么到底发生了什么呢?
以下是关于为什么学习排除 DNS 问题很困难的几点思考。
(我不会在这篇文章中详细解释 DNS,更多关于 DNS 如何工作的信息,请参阅 《[用一个周末实现一个 DNS](https://implement-dns.wizardzines.com/)》 或 [我的 DNS 方面的博文](https://jvns.ca/categories/dns/))
### 并不是因为 DNS 非常难
当我最终学会如何排除 DNS 问题时,我的反应是“什么,就这样吗???这并不难!”我感觉有点被骗了!我可以在 [几个小时](https://wizardzines.com/zines/dns) 内向你解释关于 DNS 令我感到困惑的一切事情。
那么 - 如果 DNS 并不是那么复杂,为什么我花了这么多年的时间才弄清楚如何排除相当基本的 DNS 问题(比如“即使我已经正确设置了,我的域名仍无法解析”或者“`dig` 命令和我的浏览器的 DNS 结果不一致,为什么?”)?
而且,在发现 DNS 学习困难方面,我并不孤单!我与许多经验丰富的程序员朋友讨论过多年来的 DNS 问题,其中很多人要么:
* 不敢轻易对其网站进行简单的 DNS 更改
* 或对 DNS 工作原理的基本事实感到困惑(比如记录是 [拉取的而非推送的](https://jvns.ca/blog/2021/12/06/dns-doesn-t-propagate/))
* 或对 DNS 基础知识了解得很好,但却和我一样存在一些知识盲点(负缓存和 `dig` 命令及浏览器如何以不同方式进行 DNS 查询的细节)
因此,如果我们都面临着 DNS 的相同困扰,到底发生了什么?为什么对许多人来说学习 DNS 如此困难?
以下是我的一些看法。
### 很多系统是隐藏的
当你在计算机上发起 DNS 请求时,基本的过程如下:
1. 你的计算机向一个名为“解析器”的服务器发起请求。
2. 解析器检查其缓存,并向一些称为“权威名称服务器”的其它服务器发起请求。
以下是你看不到的一些内容:
* 解析器的**缓存**。里面有什么内容?
* 在你的计算机上进行 DNS 请求的**库代码**是哪个(是否是 libc 的 `getaddrinfo` 函数?如果是,它是来自 glibc、musl 还是苹果?是你的浏览器的 DNS 代码吗?还是其他自定义的 DNS 实现?)所有这些选项的行为略有不同,并且有不同的配置、缓存方法、可用功能等等。例如,musl DNS 直到 [2023 年初](https://www.theregister.com/2023/05/16/alpine_linux_318/) 才支持 TCP。
* 解析器与权威名称服务器之间的**对话**。如果你能够神奇地获得一个准确记录你的请求期间向下游查询的每个权威名称服务器以及它们的响应的追踪,我认为很多 DNS 问题将变得非常简单。(比如,如果你能运行 `dig +debug google.com` 并获得一些额外的调试信息会怎么样?)
### 如何和隐藏系统打交道
以下是几个处理隐藏系统的方法:
* 向人们传授隐藏系统的知识会产生重大影响。很长一段时间里,我不知道我的计算机有多个不同的 DNS 库,它们在不同情况下使用,我对此感到困惑了好几年。这是我的重要排错方法。
* 通过 [Mess With DNS](https://messwithdns.net/),我们尝试了一种“鱼缸”的方法,展示了通常隐藏的系统(与解析器和权威名称服务器的对话)的一些部分。
* 我觉得将 DNS 扩展以包括一个“调试信息”部分会非常酷。(注:似乎这已经有了!它被称为“[扩展 DNS 错误](https://blog.nlnetlabs.nl/extended-dns-error-support-for-unbound/)”,即 EDE,各种工具正在逐渐添加对它的支持。)
### 扩展 DNS 错误看起来不错
扩展 DNS 错误是 DNS 服务器提供额外调试信息的一种新方式。以下是一个示例:
```
$ dig @8.8.8.8 xjwudh.com
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 39830
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
; EDE: 12 (NSEC Missing): (Invalid denial of existence of xjwudh.com/a)
;; QUESTION SECTION:
;xjwudh.com. IN A
;; AUTHORITY SECTION:
com. 900 IN SOA a.gtld-servers.net. nstld.verisign-grs.com. 1690634120 1800 900 604800 86400
;; Query time: 92 msec
;; SERVER: 8.8.8.8#53(8.8.8.8) (UDP)
;; WHEN: Sat Jul 29 08:35:45 EDT 2023
;; MSG SIZE rcvd: 161
```
这里我请求了一个不存在的域名,并收到了扩展错误信息 `EDE: 12 (NSEC Missing): (Invalid denial of existence of xjwudh.com/a)`。我不太确定这是什么意思(它与 DNSSEC 有关),但能看到这样额外的调试信息真的很酷。
为了能看到上述内容,我确实需要安装更新版本的 `dig`。
### 令人困惑的工具
尽管很多 DNS 的细节被隐藏起来,但你可以通过使用 `dig` 工具来找出发生了什么事情。
例如,你可以使用 `dig +norecurse` 来确定给定的 DNS 解析器是否在其缓存中具有特定的记录。如果响应没有被缓存,`8.8.8.8` 看起来会返回 `SERVFAIL` 响应。
以下是对 `google.com` 进行该操作的示例:
```
$ dig +norecurse @8.8.8.8 google.com
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 11653
;; flags: qr ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;google.com. IN A
;; ANSWER SECTION:
google.com. 21 IN A 172.217.4.206
;; Query time: 57 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Fri Jul 28 10:50:45 EDT 2023
;; MSG SIZE rcvd: 55
```
这是对 `homestarrunner.com` 的示例:
```
$ dig +norecurse @8.8.8.8 homestarrunner.com
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 55777
;; flags: qr ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;homestarrunner.com. IN A
;; Query time: 52 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Fri Jul 28 10:51:01 EDT 2023
;; MSG SIZE rcvd: 47
```
在这里,你可以看到我们对于 `google.com` 得到了一个正常的 `NOERROR` 响应(`8.8.8.8` 的缓存中有该记录),但对于 `homestarrunner.com` 得到了 `SERVFAIL` 响应(没有缓存)。这并不意味着 `homestarrunner.com` 没有 DNS 记录(实际上有!),它只是没有被缓存。
但如果你不熟悉这样的输出,它确实很难阅读!以下是我认为其中一些奇怪的地方:
1. 标题很奇怪(有 `->>HEADER<<-`、`flags:`、`OPT PSEUDOSECTION:`、`QUESTION SECTION:`、`ANSWER SECTION:`)。
2. 空格排版很奇怪(`OPT PSEUDOSECTION` 和 `QUESTION SECTION` 之间为什么没有换行符?)。
3. `MSG SIZE rcvd: 47` 很奇怪(`MSG SIZE` 中是否还有其他字段,而不仅仅是 `rcvd`?它们是什么?)。
4. 它说有 1 个记录在 `ADDITIONAL` 部分,但没有显示它,你必须以某种方式神奇地知道`OPT PSEUDOSECTION` 记录实际上在 `ADDITIONAL` 部分。
总的来说,`dig` 的输出给人的感觉是一个以临时方式编写并随着时间的推移逐渐发展起来的脚本,而不是经过有意设计的东西。
### 处理令人困惑的工具的一些想法:
* **解释输出结果**。例如,我写了一篇 [如何使用 dig](https://jvns.ca/blog/2021/12/04/how-to-use-dig/) 的文章,解释了 `dig` 的输出结果以及如何配置它以默认给出更简短的输出。
* **创建新的、更友好的工具**。例如,在 DNS 方面,有 [dog](https://github.com/ogham/dog)、[doggo](https://github.com/mr-karan/doggo) 和 [我的 DNS 查询工具](https://dns-lookup.jvns.ca/)。我认为这些工具非常酷,但我个人不使用它们,因为有时我想做一些稍微高级一点的操作(比如使用 `+norecurse`),据我所知,无论是 `dog` 还是 `doggo` 都不支持 `+norecurse`。我更愿意使用一个工具来完成所有任务,所以我坚持使用 `dig`。要替换 `dig`,其功能广度是一项庞大的工作。
* **使 dig 的输出更加友好**。如果我在 C 编程方面更好一些,我可能会尝试编写一个 `dig` 的拉取请求,添加一个 `+human` 标志以以更结构化和易读的方式格式化长格式的输出,可能类似于以下形式:
```
$ dig +human +norecurse @8.8.8.8 google.com
HEADER:
opcode: QUERY
status: NOERROR
id: 11653
flags: qr ra
records: QUESTION: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
QUESTION SECTION:
google.com. IN A
ANSWER SECTION:
google.com. 21 IN A 172.217.4.206
ADDITIONAL SECTION:
EDNS: version: 0, flags:; udp: 512
EXTRA INFO:
Time: Fri Jul 28 10:51:01 EDT 2023
Elapsed: 52 msec
Server: 8.8.8.8:53
Protocol: UDP
Response size: 47 bytes
```
这样可以更清晰地呈现 DNS 响应的结构-包括标题、问题、答案和附加部分。
而且它并不是“简化”了什么!它是完全相同的信息,只是以更结构化的方式进行了格式化。我对替代的 DNS 工具最大的不满是它们经常为了清晰起见而删除信息。虽然这些工具肯定有其用武之地,但我想要看到所有的信息!我只是希望它能够以清晰明了的方式呈现。
在过去的 40 年中,我们已经学到了很多关于如何设计更用户友好的命令行工具的知识,我认为将其中一些知识应用到我们那些有些陈旧的工具中将会很棒。
### dig +yaml
关于 `dig` 的一个简单备注:较新版本的 `dig` 支持 `+yaml` 输出格式,对我来说更加清晰,但有些冗长(一个相当简单的 DNS 响应都无法在屏幕上完整显示)。
### 一些奇怪的陷阱
DNS 存在一些相对常见但很难通过自学了解到的奇怪问题。以下是一些例子(有更多可在 [导致 DNS 中断的一些方式](https://jvns.ca/blog/2022/01/15/some-ways-dns-can-break/) 中找到):
* 负缓存:我在 [这篇演讲](https://jvns.ca/blog/2023/05/08/new-talk-learning-dns-in-10-years/) 中提到过,我大约花了 5 年时间才意识到不应该访问没有 DNS 记录的域名,因为该记录的 **不存在** 信息将被缓存,并且该缓存在几个小时内不会被更新,这真的很烦人。
* `getaddrinfo` 实现的差异:直到 [2023 年初](https://www.theregister.com/2023/05/16/alpine_linux_318/),`musl` 不支持 TCP DNS。
* 忽略 TTL 的解析器:如果你在 DNS 记录上设置了 TTL(比如“5 分钟”),一些解析器完全会忽略这些 TTL 设置,并将记录缓存更长时间,比如可能是 24 小时。
* 如果你错误地配置了 Nginx([像这样](https://jvns.ca/blog/2022/01/15/some-ways-dns-can-break/#problem-nginx-caching-dns-records-forever)),它将永久缓存 DNS 记录。
* [ndots](https://pracucci.com/kubernetes-dns-resolution-ndots-options-and-why-it-may-affect-application-performances.html) 如何导致 Kubernetes DNS 缓慢。
### 如何应对奇怪的陷阱
对此,我没有像我希望的那样完美的答案。对奇怪陷阱的了解非常难以获得(再次强调,我花了多年的时间才弄清楚负缓存!),对我而言,人们不得不一次又一次地自己重新发现它们感觉很愚蠢。
以下是一些想法:
* 当有人在解释一个主题时提到了一些棘手的问题,这是非常有帮助的。例如(离开 DNS 一下),Josh Comeau 的 Flexbox 入门解释了这个 [最小尺寸的陷阱](https://www.joshwcomeau.com/css/interactive-guide-to-flexbox/#the-minimum-size-gotcha-11),在找到解释之前,我多年来遇到过很多次这个问题。
* 我希望看到更多的社区整理的常见陷阱。比如说,对于 Bash,[shellcheck](https://www.shellcheck.net/) 是一个非常不错的常见陷阱集合。
关于记录 DNS 陷阱的一个棘手问题是,不同的人会遇到不同的陷阱。如果你只是每三年为个人域名配置一次 DNS,你可能会遇到不同的问题,而那些管理高流量域名的人则可能会遇到其他问题。
还有一些更简单的原因:
### 不经常接触
很多人非常少接触 DNS。如果你只在每三年才处理一次 DNS,学习起来就会更加困难!
我认为备忘单(比如“这是更改你的名称服务器的步骤”)可以在这方面起到很大的帮助。
### 难以进行实验
DNS 在进行实验时可能会让人感到害怕,因为你不想搞砸自己的域名。我们建立了 [Mess With DNS](https://messwithdns.net/) 来使这个过程变得更容易一些。
### 目前就这些
我很想听听其他关于什么让 DNS(或你最喜欢的神秘技术)难以学习的想法。
*(题图:MJ/96c5d8fb-f4a5-4710-8f91-c71617120675)*
---
via: <https://jvns.ca/blog/2023/07/28/why-is-dns-still-hard-to-learn/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I write a lot about technologies that I found hard to learn about. A while back my friend Sumana asked me an interesting question – why are these things so hard to learn about? Why do they seem so mysterious?
For example, take DNS. We’ve been using DNS since the [80s](https://www.ietf.org/rfc/rfc1034.txt) (for more than 35 years!). It’s
used in every website on the internet. And it’s pretty stable – in a lot of
ways, it works the exact same way it did 30 years ago.
But it took me YEARS to figure out how to confidently debug DNS issues, and I’ve seen a lot of other programmers struggle with debugging DNS problems as well. So what’s going on?
Here are a couple of thoughts about why learning to troubleshoot DNS problems is hard.
(I’m not going to explain DNS very much in this post, see [Implement DNS in a Weekend](https://implement-dns.wizardzines.com/) or [my DNS blog posts](https://jvns.ca/categories/dns/) for more about how DNS works)
### it’s not because DNS is super hard
When I finally learned how to troubleshoot DNS problems, my reaction was “what,
that was it???? that’s not that hard!”. I felt a little bit cheated! I could
explain to you everything that I found confusing about DNS in [a few hours](https://wizardzines.com/zines/dns).
So – if DNS is not all that complicated, why did it take me so many years to
figure out how to troubleshoot pretty basic DNS issues (like “my domain doesn’t
resolve even though I’ve set it up correctly” or “`dig`
and my browser have
different DNS results, why?”)?
And I wasn’t alone in finding DNS hard to learn! I’ve talked to a lot of smart friends who are very experienced programmers about DNS of the years, and many of them either:
- didn’t feel comfortable making simple DNS changes to their websites
- or were confused about basic facts about how DNS works (like that records are
[pulled and not pushed](https://jvns.ca/blog/2021/12/06/dns-doesn-t-propagate/)) - or did understand DNS basics pretty well, but had the some of the same
knowledge gaps that I’d struggled with (negative caching and the details of
how
`dig`
and your browser do DNS queries differently)
So if we’re all struggling with the same things about DNS, what’s going on? Why is it so hard to learn for so many people?
Here are some ideas.
### a lot of the system is hidden
When you make a DNS request on your computer, the basic story is:
- your computer makes a request to a server called
**resolver** - the resolver checks its cache, and makes requests to some other servers called
**authoritative nameservers**
Here are some things you don’t see:
- the resolver’s
**cache**. What’s in there? - which
**library code**on your computer is making the DNS request (is it libc`getaddrinfo`
? if so, is it the getaddrinfo from glibc, or musl, or apple? is it your browser’s DNS code? is it a different custom DNS implementation?). All of these options behave slightly differently and have different configuration, approaches to caching, available features, etc. For example musl DNS didn’t support TCP until[early 2023](https://www.theregister.com/2023/05/16/alpine_linux_318/). - the
**conversation**between the resolver and the authoritative nameservers. I think a lot of DNS issues would be SO simple to understand if you could magically get a trace of exactly which authoritative nameservers were queried downstream during your request, and what they said. (like, what if you could run`dig +debug google.com`
and it gave you a bunch of extra debugging information?)
### dealing with hidden systems
A couple of ideas for how to deal with hidden systems
- just teaching people what the hidden systems are makes a huge difference. For a long time I had no idea that my computer had many different DNS libraries that were used in different situations and I was confused about this for literally years. This is a big part of my approach.
- with
[Mess With DNS](https://messwithdns.net/)we tried out this “fishbowl” approach where it shows you some parts of the system (the conversation with the resolver and the authoritative nameserver) that are normally hidden - I feel like it would be extremely cool to extend DNS to include a “debugging
information” section. (edit: it looks like this already exists! It’s called
[Extended DNS Errors](https://blog.nlnetlabs.nl/extended-dns-error-support-for-unbound/), or EDE, and tools are slowly adding support for it.
### Extended DNS Errors seem cool
Extended DNS Errors are a new way for DNS servers to provide extra debugging information in DNS response. Here’s an example of what that looks like:
```
$ dig @8.8.8.8 xjwudh.com
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 39830
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
; EDE: 12 (NSEC Missing): (Invalid denial of existence of xjwudh.com/a)
;; QUESTION SECTION:
;xjwudh.com. IN A
;; AUTHORITY SECTION:
com. 900 IN SOA a.gtld-servers.net. nstld.verisign-grs.com. 1690634120 1800 900 604800 86400
;; Query time: 92 msec
;; SERVER: 8.8.8.8#53(8.8.8.8) (UDP)
;; WHEN: Sat Jul 29 08:35:45 EDT 2023
;; MSG SIZE rcvd: 161
```
Here I’ve requested a nonexistent domain, and I got the extended error `EDE: 12 (NSEC Missing): (Invalid denial of existence of xjwudh.com/a)`
. I’m not
sure what that means (it’s some DNSSEC Thing), but it’s cool to see an extra
debug message like that.
I did have to install a newer version of `dig`
to get the above to work.
### confusing tools
Even though a lot of DNS stuff is hidden, there are a lot of ways to figure out
what’s going on by using `dig`
.
For example, you can use `dig +norecurse`
to figure out if a given DNS resolver
has a particular record in its cache. `8.8.8.8`
seems to return a `SERVFAIL`
response if the response isn’t cached.
here’s what that looks like for `google.com`
```
$ dig +norecurse @8.8.8.8 google.com
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 11653
;; flags: qr ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;google.com. IN A
;; ANSWER SECTION:
google.com. 21 IN A 172.217.4.206
;; Query time: 57 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Fri Jul 28 10:50:45 EDT 2023
;; MSG SIZE rcvd: 55
```
and for `homestarrunner.com`
:
```
$ dig +norecurse @8.8.8.8 homestarrunner.com
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 55777
;; flags: qr ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;homestarrunner.com. IN A
;; Query time: 52 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Fri Jul 28 10:51:01 EDT 2023
;; MSG SIZE rcvd: 47
```
Here you can see we got a normal `NOERROR`
response for `google.com`
(which is
in `8.8.8.8`
’s cache) but a `SERVFAIL`
for `homestarrunner.com`
(which isn’t).
This doesn’t mean there’s no DNS record `homestarrunner.com`
(there is!), it’s
just not cached).
But this output is really confusing to read if you’re not used to it! Here are a few things that I think are weird about it:
- the headings are weird (there’s
`->>HEADER<<-`
,`flags:`
,`OPT PSEUDOSECTION:`
,`QUESTION SECTION:`
,`ANSWER SECTION:`
) - the spacing is weird (why is the no newline between
`OPT PSEUDOSECTION`
and`QUESTION SECTION`
?) `MSG SIZE rcvd: 47`
is weird (are there other fields in`MSG SIZE`
other than`rcvd`
? what are they?)- it says that there’s 1 record in the ADDITIONAL section but doesn’t show it, you have to somehow magically know that the “OPT PSEUDOSECTION” record is actually in the additional section
In general `dig`
’s output has the feeling of a script someone wrote in an adhoc
way that grew organically over time and not something that was intentionally
designed.
### dealing with confusing tools
some ideas for improving on confusing tools:
**explain the output**. For example I wrote[how to use dig](https://jvns.ca/blog/2021/12/04/how-to-use-dig/)explaining how`dig`
’s output works and how to configure it to give you a shorter output by default**make new, more friendly tools**. For example for DNS there’s[dog](https://github.com/ogham/dog)and[doggo](https://github.com/mr-karan/doggo)and[my dns lookup tool](https://dns-lookup.jvns.ca/). I think these are really cool but personally I don’t use them because sometimes I want to do something a little more advanced (like using`+norecurse`
) and as far as I can tell neither`dog`
nor`doggo`
support`+norecurse`
. I’d rather use 1 tool for everything, so I stick to`dig`
. Replacing the breadth of functionality of`dig`
is a huge undertaking.**make dig’s output a little more friendly**. If I were better at C programming, I might try to write a`dig`
pull request that adds a`+human`
flag to dig that formats the long form output in a more structured and readable way, maybe something like this:
```
$ dig +human +norecurse @8.8.8.8 google.com
HEADER:
opcode: QUERY
status: NOERROR
id: 11653
flags: qr ra
records: QUESTION: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
QUESTION SECTION:
google.com. IN A
ANSWER SECTION:
google.com. 21 IN A 172.217.4.206
ADDITIONAL SECTION:
EDNS: version: 0, flags:; udp: 512
EXTRA INFO:
Time: Fri Jul 28 10:51:01 EDT 2023
Elapsed: 52 msec
Server: 8.8.8.8:53
Protocol: UDP
Response size: 47 bytes
```
This makes the structure of the DNS response more clear – there’s the header, the question, the answer, and the additional section.
And it’s not “dumbed down” or anything! It’s the exact same information, just formatted in a more structured way. My biggest frustration with alternative DNS tools that they often remove information in the name of clarity. And though there’s definitely a place for those tools, I want to see all the information! I just want it to be presented clearly.
We’ve learned a lot about how to design more user friendly command line tools in the last 40 years and I think it would be cool to apply some of that knowledge to some of our older crustier tools.
### dig +yaml
One quick note on dig: newer versions of dig do have a `+yaml`
output format
which feels a little clearer to me, though it’s too verbose for my taste (a
pretty simple DNS response doesn’t fit on my screen)
### weird gotchas
DNS has some weird stuff that’s relatively common to run into, but pretty hard
to learn about if nobody tells you what’s going on. A few examples (there are more in [some ways DNS can break](https://jvns.ca/blog/2022/01/15/some-ways-dns-can-break/):
- negative caching! (which I talk about in
[this talk](https://jvns.ca/blog/2023/05/08/new-talk-learning-dns-in-10-years/)) It took me probably 5 years to realize that I shouldn’t visit a domain that doesn’t have a DNS record yet, because then the**nonexistence**of that record will be cached, and it gets cached for HOURS, and it’s really annoying. - differences in
`getaddrinfo`
implementations: until[early 2023](https://www.theregister.com/2023/05/16/alpine_linux_318/),`musl`
didn’t support TCP DNS - resolvers that ignore TTLs: if you set a TTL on your DNS records (like “5 minutes”), some resolvers will ignore those TTLs completely and cache the records for longer, like maybe 24 hours instead
- if you configure nginx wrong (
[like this](https://jvns.ca/blog/2022/01/15/some-ways-dns-can-break/#problem-nginx-caching-dns-records-forever)), it’ll cache DNS records forever. - how
[ndots](https://pracucci.com/kubernetes-dns-resolution-ndots-options-and-why-it-may-affect-application-performances.html)can make your Kubernetes DNS slow
### dealing with weird gotchas
I don’t have as good answers here as I would like to, but knowledge about weird gotchas is extremely hard won (again, it took me years to figure out negative caching!) and it feels very silly to me that people have to rediscover them for themselves over and over and over again.
A few ideas:
- It’s incredibly helpful when people call out gotchas when explaining a topic. For example (leaving
DNS for a moment), Josh Comeau’s Flexbox intro explains this
[minimum size gotcha](https://www.joshwcomeau.com/css/interactive-guide-to-flexbox/#the-minimum-size-gotcha-11)which I ran into SO MANY times for several years before finally finding an explanation of what was going on. - I’d love to see more community collections of common gotchas. For bash,
[shellcheck](https://www.shellcheck.net/)is an incredible collection of bash gotchas.
One tricky thing about documenting DNS gotchas is that different people are going to run into different gotchas – if you’re just configuring DNS for your personal domain once every 3 years, you’re probably going to run into different gotchas than someone who administrates DNS for a domain with heavy traffic.
A couple of more quick reasons:
### infrequent exposure
A lot of people only deal with DNS extremely infrequently. And of course if you only touch DNS every 3 years it’s going to be harder to learn!
I think cheat sheets (like “here are the steps to changing your nameservers”) can really help with this.
### it’s hard to experiment with
DNS can be scary to experiment with – you don’t want to mess up your domain.
We built [Mess With DNS](https://messwithdns.net/) to make this one a little easier.
### that’s all for now
I’d love to hear other thoughts about what makes DNS (or your favourite mysterious technology) hard to learn. |
16,091 | 在 Fedora Linux 上使用 FIDO U2F 安全密钥 | https://fedoramagazine.org/use-fido-u2f-security-keys-with-fedora-linux/ | 2023-08-13T23:40:51 | [
"FIDO",
"YubiKey",
"密钥"
] | https://linux.cn/article-16091-1.html | 
FIDO U2F 安全密钥是一种小型的基于 USB/NFC 的设备。它是一种硬件安全令牌,具有多个安全相关的用途模块。FIDO U2F 标准兼容的密钥品牌有多种,包括 NitroKey、SoloKey v2 和 YubiKey。与类似 Yubico OTP 的专有协议相比,FIDO 协议是不依赖特定硬件令牌的,并且使用的工具也不依赖特定制造商。
本文介绍了 FIDO 协议,并展示了如何安装和启用 FIDO U2F 安全密钥作为替代身份验证因素,以用于登录终端、GDM 或进行 sudo 认证。
对于 YubiKey,特别是其不支持 FIDO2/U2F 的旧版设备,请参阅之前的文章:
>
> **[如何在 Fedora Linux 上使用 YubiKey](https://fedoramagazine.org/how-to-use-a-yubikey-with-fedora-linux/)**
>
>
>
本文不涵盖存储 OpenPGP 密钥或 X.509 证书的操作,因为这些功能与硬件相关,不属于 FIDO U2F 标准的一部分。
### 保留备用安全密钥
一旦你开始使用安全令牌,就必须考虑到自己可能会被锁定在与这些令牌相关联的账户之外的情况。由于硬件安全令牌是独特的,并且被设计为非常难以复制,你不能像在使用 KeePass 或 AndOTP 等软件保险库时那样制作备份。因此,你使用主要密钥进行的所有注册都应立即使用第二个备份密钥重复进行,并将其存储在安全的位置,甚至可能是保险箱中。
在实践中,这意味着你需要将两个硬件令牌注册到你的 Linux 和 Web 账户中,并生成两份 OpenSSH 私钥,并将这两份 OpenSSH 公钥上传到你使用的服务器和服务(例如 GitHub)中。
如果你丢失了一个密钥,你将需要使用第二个密钥登录与密钥注册的每个服务,删除丢失的密钥,并注册一个新密钥。对于使用 FIDO2 协议的无密码登录尤其如此。
### FIDO2、U2F 和 FIDO 联盟
FIDO2 是由 [FIDO 联盟](https://fidoalliance.org) 维护的一系列标准。FIDO 联盟希望最终完全摒弃密码,并提供通过多个因素安全验证用户身份的过程,而无需使用密码。
该标准包括万维网联盟(W3C)的 <ruby> 网页认证 <rt> Web Authentication </rt></ruby>(WebAuthn)和 FIDO 联盟的 <ruby> 客户端到认证器协议 <rt> Client-to-Authenticator Protocol </rt></ruby>(CTAP)。WebAuthn 是一种用于请求和处理公钥挑战进行认证的标准 API。通过这个标准,浏览器会向客户端发送一个 <ruby> 挑战 <rt> challenge </rt></ruby>,然后客户端使用私钥生成一个 <ruby> 响应 <rt> response </rt></ruby>,挑战者再使用之前交换的公钥进行验证。如何生成挑战答案对于服务来说是不可知的,而是由 CTAP 控制。用户可能会被要求使用多种验证方法,如生物识别、PIN 或存在性检查(或这些方法的组合)。这些验证方式在认证时与注册密钥时的方式相同。
为了保护与硬件令牌的任何交互,可以选择设置一个访问 PIN,并且默认情况下未设置。大多数密钥在连续八次输入访问 PIN 失败后将自动失效。恢复失效的密钥并设置新 PIN 的唯一方法是重置密钥。然而,当密钥重置时,所有其服务注册将丢失!
FIDO2 密钥还支持 FIDO U2F 协议(现已更名为 CTAP1)。该协议旨在提供第二或多因素(但非无密码)认证。Linux 的 PAM 认证系统也可以配置为使用 U2F 协议。虽然 FIDO U2F 不是为无密码认证设计的,但 U2F PAM 模块允许无密码认证。
### 安全影响
FIDO2 / U2F 通过将安全密钥与用户账户绑定来工作。大多数密钥默认启用/使用基本的存在性检查。它们通常通过点亮并提示你触摸密钥来进行存在性检查。FIDO2 PIN 是可选的,默认情况下未设置。当密钥用于登录 Linux 帐户或用于使用 sudo 时,只需确保设备和密钥物理上存在即可。FIDO2 PIN 是一个重要的附加验证步骤,用于确保只有你才能使用密钥进行身份验证。
>
> 等一下!现在我还要记住额外的 PIN 吗?这不就是一个更短的密码吗?
>
>
> —— 担心的读者
>
>
>
FIDO2 PIN 不是密码,它是一个简短、容易记住的短语。这并不是一个问题,因为:
1. 你需要物理访问密钥 *且* 需要知道 PIN。
2. 输入 PIN 错误达到八次会使密钥失效,这使得暴力破解变得困难。
相反地,现在你可以使用存储在密码管理器中的安全密码,而无需记住它。
谷歌在 2016 年进行的一项案例研究,题为 《安全密钥:现代网络的实用密码学第二因素》,显示了安全密钥有效地保护用户免受密码重用、钓鱼和中间人攻击的影响。
### 使用 PAM 进行用户认证
本地系统认证使用 [可插拔认证模块(PAM)](https://www.redhat.com/sysadmin/pluggable-authentication-modules-pam)。U2F 设备的 PAM 模块(因此进行认证)是 `pam_u2f`。你的密钥是否支持 FIDO2 或 FIDO U2F 取决于其固件版本和硬件型号。
设置如下:
1. 安装 PAM 模块。
2. 将密钥注册到你的用户账户上。
3. 使用 `authselect` 在 PAM 中激活智能卡支持。
[authselect](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/configuring_authentication_and_authorization_in_rhel/configuring-user-authentication-using-authselect_configuring-authentication-and-authorization-in-rhel) 是一个用于配置带有可重现配置文件的 PAM 的工具。使用 `authselect` 的配置文件可以避免手动修改 `/etc/pam.d` 目录下的配置文件。
### 依赖项
所需的软件包可在官方仓库中获取。
```
[…]$ sudo dnf install pam-u2f pamu2fcfg fido2-tools
```
#### 在密钥上设置 FIDO2 PIN
FIDO2 标准定义了一种用于访问保护的可选 PIN。如果 PIN 丢失或失效,没有 PUK 或其他恢复方式,请确保你有一种备用的身份验证方法。如果通过连续输入无效的 PIN 使 PIN 失效,恢复的唯一方法是重置密钥。然而,重置密钥会删除其所有凭据,并将其与以前注册的所有服务断开连接。
`fido2-tools` 包含一个用于设置密钥的 FIDO2 PIN 的工具: `fido2-token`。使用 `fido2-token -L` 获取当前连接的 FIDO2 设备列表,并使用 `fido2-token -C </path/to/device>` 设置一个新的 PIN:
```
[…]$ fido2-token -L
/dev/hidraw1: vendor=0x1050, product=0x0407 (Yubico YubiKey OTP+FIDO+CCID)
[…]$ fido2-token -C /dev/hidraw1
Enter current PIN for /dev/hidraw1:
Enter new PIN for /dev/hidraw1:
```
#### 将安全密钥注册到本地账户
使用工具 `pamu2fcfg` 检索一个配置行,该行将放入 `~/.config/Yubico/u2f_keys` 中。`pam_u2f` 是由 Yubico 提供的通用 U2F 密钥模块,因此使用 Yubico 特定的默认配置路径。该文件中的每个配置行由用户名和密钥特定的凭据/配置部分以冒号分隔。确保每个用户仅使用一行。
```
fedora-user:owBYtPIH2yzjlSQaRrVcxB...Pg==,es256,+presence+pin[:该用户另外的密钥]
```
如果密钥受 PIN 保护,你将被要求输入 PIN 来进行此操作。对于第一个密钥的初始注册,请使用以下命令:
```
[…]$ mkdir -p ~/.config/Yubico
[…]$ pamu2fcfg --pin-verification > ~/.config/Yubico/u2f_keys
```
要将另一个密钥(例如备份密钥)添加到此单用户配置中,请使用以下命令:
```
[…]$ pamu2fcfg --nouser --pin-verification >> ~/.config/Yubico/u2f_keys
```
`pam_u2f` 还支持使用一个中心身份验证文件。在这种情况下,请确保每个用户使用一行,并将给定用户的所有密钥保持在同一行上。如果两行引用相同的用户名,那么只有最后一行将被使用!请参阅 [pam\_u2f 手册页](https://manpages.org/pam_u2f/8) 获取所有可用选项的详细信息。
### 使用 authselect 配置 PAM
[authselect](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/configuring_authentication_and_authorization_in_rhel/configuring-user-authentication-using-authselect_configuring-authentication-and-authorization-in-rhel) 是一个用于控制系统 PAM 配置的工具。它引入了配置文件作为额外的抽象层。一个 `authselect` 配置文件可以更改多个 PAM 配置文件。配置文件具有控制附加功能和行为的参数,例如启用 FIDO U2F 安全密钥。有关 `authselect` 的详细介绍计划在未来的文章中进行。
显示当前活动的 `authselect` 配置文件。如果选择了 SSSD(系统安全服务守护程序)配置文件并启用了 U2F 支持,则输出可能类似于以下内容:
```
[…]$ authselect current
Profile ID: sssd
Enabled features:
- with-pam-u2f
```
使用 `authselect` 和 `with-pam-u2f` 标志,在 PAM 中激活 FIDO U2F 支持:
```
[…]$ sudo authselect select sssd with-pam-u2f
```
如果你还想使用指纹读取器,必须同时启用这两个功能:
```
[…]$ sudo authselect select sssd with-pam-u2f with-fingerprint
```
这会在 PAM 中激活具有 `pam_u2f` 和指纹读取器支持的 SSSD 配置文件。例如,当使用上述 `authselect` 配置文件在终端上使用 sudo 时,首先会要求你提供指纹,如果指纹识别失败,则使用 U2F 密钥。然而,GDM 将首先使用 U2F 密钥。
### 解锁 GNOME 钥匙环守护程序
当使用生物识别、U2F 密钥或任何其他不需要密码短语登录 GNOME 的方法时,无法自动解锁“登录”钥匙环。这是因为,默认情况下,钥匙环的密码短语设置为与你的登录密码短语相同。通常,PAM 将你的登录密码短语传递给钥匙环守护程序。由于你在通过生物识别或 U2F 密钥进行身份验证时不需要输入密码短语,因此 PAM 没有密码短语可以传递给钥匙环守护程序。这个问题没有简单直接的解决方法。
如果你为家目录使用 LUKS 加密并且操作的是单用户系统,你可以从钥匙环中移除密码短语。这将使你的 GNOME 钥匙环在文件级别上保持未加密。但它仍然在块级别上由 LUKS 加密,因为 LUKS 加密与单用户系统上的默认基于文件的钥匙环加密等效。由于钥匙环的加密仅旨在保护其内容免受离线访问,钥匙环在登录后将被解密/解锁,任何运行时应用程序或恶意软件在解锁后都有可能访问钥匙环的内容。由于 LUKS 也是一种离线保护机制,因此可以认为它是钥匙环正常基于文件的加密的替代选择。
如果你的系统被多个用户使用,则 LUKS 加密和钥匙环的正常基于文件的加密不是等效的。在具有只由 LUKS 保护的钥匙环的多用户系统中,具有解密磁盘和引导系统授权的任何用户都能够访问同一系统上的任何其他用户的钥匙环。
移除 GNOME “登录”钥匙环密码短语非常简单。只需设置一个新的空密码,钥匙环将被解锁,并且其内容将以未加密的方式存储在文件级别上。可以使用图形实用程序 Seahorse(也称为“密码和密钥”)来在 GNOME “登录”钥匙环上设置一个空密码。
### 警惕和其他用例
即将发布的文章将探讨如何使用 U2F Dracut 插件使用 FIDO2/U2F 密钥解锁 LUKS 加密的磁盘。
OpenSSH 8.2+ 支持使用 `ed25519-sk` 安全密钥。这个主题已经在之前的文章《[如何在 Fedora Linux 上使用 YubiKey](https://fedoramagazine.org/how-to-use-a-yubikey-with-fedora-linux/)》中涉及到。
需要注意的是,FIDO2/U2F 是一种认证标准。还有其他用于安全令牌的用例(主要由 Yubico 建立),例如 (T)OTP、PIV(用于 x509 密钥管理)或 OpenPGP,这些用例不是一般性的,而是具体硬件上的用例。
*(题图:MJ/4bd195dc-130b-4ef2-af6c-9a6ef5d54223)*
---
via: <https://fedoramagazine.org/use-fido-u2f-security-keys-with-fedora-linux/>
作者:[Alexander Wellbrock](https://fedoramagazine.org/author/w4tsn/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A FIDO U2F security key is a small USB and/or NFC based device. It is a hardware security token with modules for many security related use-cases. There are several brands of FIDO compliant keys, including NitroKey, SoloKey v2, and YubiKey. FIDO, in contrast to proprietary protocols like Yubico OTP, is hardware token agnostic and the tools used are manufacturer independent.
This post introduces the FIDO protocol(s) and shows how to install and enable a FIDO U2F security key as an alternative authentication factor for logging into a terminal, GDM, or authenticating for sudo.
For YubiKeys, especially older ones *without* FIDO2/U2F support, see the previous post titled “[How to use a YubiKey with Fedora Linux](https://fedoramagazine.org/how-to-use-a-yubikey-with-fedora-linux/)“.
This post will not cover storing OpenPGP keys or X.509 certificates because those features are hardware dependent and not part of the FIDO U2F standard.
## Keep a backup security key
As soon as you start working with security tokens you have to account for the potential to lock yourself out of accounts tied to these tokens. As hardware security tokens are unique and designed to be extremely hard to copy you cannot just make a backup of it like you can with software vaults like KeePass or AndOTP. Consequently, all registrations you make with your primary key you should immediately repeat with a second backup key that you will store in a secure location, maybe even a safe.
In practice this means you will need to register both hardware tokens with your Linux and web accounts, generate OpenSSH private keys twice, and upload both OpenSSH public keys to the servers and services you use (for example, GitHub).
Should you lose a key, you’ll want to use your second key to sign in on every service the keys are registered with, remove the lost key, and register a new one. This is especially true for password-less logins using a FIDO2 protocol.
## FIDO2, U2F and the FIDO Alliance
FIDO2 is a collection of standards maintained by the [FIDO Alliance](https://fidoalliance.org). The FIDO Alliance hopes to eventually get rid of passwords altogether and instead provide procedures to authenticate users securely through multiple factors but without the need for passwords.
The standard consists of the World Wide Web Consortium’s (W3C) Web Authentication (WebAuthn) and the FIDO Alliance’s Client-to-Authenticator Protocol (CTAP). WebAuthn is a standard API to request and process public key challenges for authentication. With this, browsers send a challenge to a client which then produces a response with a private key that the challenger then verifies using a previously exchanged public key. How the challenge answer is produced is unknown to the service and it is controlled by the CTAP. The user might be prompted for several verification methods like biometrics, PIN, or presence check (or some combination of these methods). These checks are the same for authentication as they are when registering the key with the service.
A access PIN to protect any interaction with the hardware token is optional and it is unset by default. Most keys will self-invalidate after eight sequential failed attempts at entering the access PIN. The only way to recover an invalidated key and set a new PIN is to reset the key. However, when a key is reset, all its service registrations will be lost!
A FIDO2 key also supports the FIDO U2F protocol (now renamed CTAP1). This protocol is designed for second- or multi-factor (but not password-less) authentication. Linux’s PAM authentication system can also be configured to use the U2F protocol. Although FIDO U2F is not designed for password-less authentication, the U2F PAM module does allow password-less authentication.
## Security implications
FIDO2 / U2F works by tying the security key to your user account. Most keys have a basic presence-check which is enabled / used by default. They typically perform a presence-check by lighting up and prompting you to touch the key. A FIDO2 PIN is optional and it will be unset by default. When the key is registered for signing in to your Linux account or for using sudo, it is sufficient to have the device and key physically present. A FIDO2 PIN is an important additional verification step to ensure that only you can use the key for authentication.
Wait! Now I have to keep track of an additional PIN? Isn’t this just a shorter password?
The concerned reader
A FIDO2 PIN is not a password. It is a short, easy-to-remember phrase. This is not a problem because:
- You need physical access to the key
*and*you need to know the PIN. - Failing to enter the PIN eight times will invalidate the key which makes it hard to brute-force.
On the contrary, you can now use a secure password stored in a password manager that you don’t need to remember.
A 2016 case study by Google, titled “* Security Keys: Practical Cryptographic Second Factors for the Modern Web*“, shows security keys effectively protect users from password reuse, phishing and man-in-the-middle attacks.
## User authentication using PAM
Local system authentication uses [Pluggable Authentication Modules (PAM)](https://www.redhat.com/sysadmin/pluggable-authentication-modules-pam). The PAM module for U2F devices (and hence authentication) is *pam_u2f*. Whether your key supports FIDO2 or FIDO U2F will depend on its firmware version and hardware model.
The setup is as follows:
- Install the PAM module.
- Register a key with your user account.
- Use
*authselect*to activate smart card support in PAM.
[Authselect](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/configuring_authentication_and_authorization_in_rhel/configuring-user-authentication-using-authselect_configuring-authentication-and-authorization-in-rhel) is a tool for configuring PAM with reproducible profiles. By using authselect’s profiles, manually altering configuration files under the /etc/pam.d directory can be avoided.
## Dependencies
The required packages are available in the official repositories.
[…]$ sudo dnf install pam-u2f pamu2fcfg fido2-tools
### Set a FIDO2 PIN on your key
The FIDO2 standard defines an optional PIN for access protection. There is no PUK or other way to restore a lost or invalidated PIN so make sure you have a backup approach for authentication. If the PIN is invalidated through sequential entry of invalid PINs, the only way to recover is to reset the key. However, resetting your key removes all its credentials and disconnects it from all previously registered services.
The *fido2-tools* package contains a tool to set the FIDO2 PIN of your key: *fido2-token*. Get a list of currently connected FIDO2 devices with `fido2-token -L` and set a new pin with `fido2-token -C </path/to/device>`:
[…]$ fido2-token -L /dev/hidraw1: vendor=0x1050, product=0x0407 (Yubico YubiKey OTP+FIDO+CCID) […]$ fido2-token -C /dev/hidraw1 Enter current PIN for /dev/hidraw1: Enter new PIN for /dev/hidraw1:
**Register the security key with your local account(s)**
Use the tool *pamu2fcfg* to retrieve a configuration line that goes into ~/.config/Yubico/u2f_keys. *pam_u2f* is a Yubico-provided, generic module for U2F keys, hence the Yubico specific default configuration path. Each configuration line in this file consists of a username and a key-specific credential / config part separated by colons. Be sure to only use one line per user.
fedora-user:owBYtPIH2yzjlSQaRrVcxB...Pg==,es256,+presence+pin[:another key for this user]
If the key is PIN protected you’ll be asked to enter the PIN for this operation. Use the following for the initial registration of your first key:
[…]$ mkdir -p ~/.config/Yubico […]$ pamu2fcfg --pin-verification > ~/.config/Yubico/u2f_keys
To add another key (for example, your backup key) to this single-user configuration, use the following command:
[…]$ pamu2fcfg --nouser --pin-verification >> ~/.config/Yubico/u2f_keys
*pam_u2f* also supports the use of a central authentication file. In that case, be sure to use one line per user and to keep all the keys of a given user on the same line. If two lines reference the same username only the last one will be used! Have a look at the [pam_u2f man page](https://manpages.org/pam_u2f/8) for all available options.
## Configure PAM with authselect
** authselect** is a tool for controling your system’s PAM configuration. It introduces profiles as an additional layer of abstraction. One authselect profile can change several PAM configuration files. Profiles have parameters that control additional features and behaviors like enabling FIDO U2F security keys. A detailed tour of
*authselect*is planned for a future article.
Display the currently active *authselect* profile. With the SSSD (System Security Service Daemon) profile selected and U2F support enabled, the output might resemble the following:
[…]$ authselect current Profile ID: sssd Enabled features: - with-pam-u2f
Activate FIDO U2F support in PAM using *authselect* with the *with-pam-u2f* flag:
[…]$ sudo authselect select sssd with-pam-u2f
If you also want to use your fingerprint reader you have to enable both features:
[…]$ sudo authselect select sssd with-pam-u2f with-fingerprint
This activates the *sssd* profile with *pam_u2f* and fingerprint reader support. For example, when using sudo on a terminal with the above authselect profile configuration, you’ll first be asked for a fingerprint and if that fails for the U2F key. GDM, however, will use the U2F key first.
## Unlocking the GNOME keyring daemon
When using biometrics, a U2F key, or any other method that does not require a passphrase to sign in to GNOME, the *Login* keyring cannot be unlocked automatically. This is because, by default, the keyring passphrase is set to the same value as your login passphrase. Normally, PAM passes your login passphrase to the keyring daemon. Since you are not entering a passphrase when authenticating via methods such as biometrics or U2F keys, there is no passphrase for PAM to pass to the keyring daemon. There is no straight forward solution to this problem.
If you use LUKS encryption for your home partition and operate a single-user system, you could remove the passphrase from your keyring. This will leave your gnome keyring unencrypted at the file level. But it will still be encrypted at the block level by LUKS. LUKS encryption is equivalent to the default file-based keyring encryption on a single-user system since the keyring’s encryption is only designed to protect its contents from offline access. The keyring will be decrypted / unlocked after login either way and any runtime application or malware can potentially access the keyring’s contents after it is unlocked. Since LUKS is also an offline protection mechanism, it can be considered an equivalent alternative to the keyring’s normal file-based encryption.
LUKS encryption and the keyring’s normal file-based encryption are not equivalent if your system is used by multiple users. In the case of a multi-user system with the keyrings protected only by LUKS, any user with authorization to decrypt the disk and boot the system will be able to access any other user’s keyring on that same system.
Removing the GNOME *Login* keyring passphrase is straight forward. Just set a new empty password and the keyring will be unlocked and it will be stored unencrypted at the file level. The graphical utility *seahorse* (also called *Passwords and Keys*) can be used to set a blank password on your GNOME *Login* keyring.
## Lookout and other use-cases
Upcoming articles will explore how to use FIDO2/U2F keys for unlocking LUKS-encrypted disks using the U2F Dracut plugin.
OpenSSH 8.2+ supports the use of *ed25519-sk* security keys. This topic has already been touched upon in the previous article titled “[How to use a YubiKey with Fedora Linux](https://fedoramagazine.org/how-to-use-a-yubikey-with-fedora-linux/)“.
Note that FIDO2/U2F is an authentication standard. There are other use-cases for security tokens (primarily established by Yubico) like (T)OTP, PIV (for x509 key management) or OpenPGP which are not covered in general but on a hardware by hardware basis.
## Aaron
I think removing the password from your GNOME keyring is
alwaysa bad idea, no matter the usecase.Yes, a LUKS-encrypted drive / home partition protects against offline-attacks. But that’s it. Once you are logged in, you have no protection whatsoever.
Imagine running some bad script or malicious program in your own user context. It can read (and probably write) all your files under ~. So it can easily get a copy of your keyring file from ~/.local/share/keyrings/ and submit it to some external server or whatever. You wouldn’t even notice, as these files are so small…
This can happen no matter if you have a passphrase set or or onto the keyring file itself.
The difference is that a keyring file without any passphrase is readable by anyone, so an attacker would now have all your saved credentials. If the file itself was protected with a passphrase, so its contents being encrypted, even if someone got read access, the only way would be to brute-force the passphrase, which is considerably more work than just opening an unencrypted file.
It’s a misconception that a password-protected but already unlocked keyfile would be unencrypted and as such easily read some malicious software. The keyfile
nevergets saved unencrypted onto the drive unless you remove the passphrase. As long as it has a passphrase set, the file itself isalwaysstill encrypted, the unencrypted data itself is just stored in the RAM while the keyring is in unlocked state, never written to disk. So even if someone takes a copy of your keyring file while it was unlocked by a passphrase earlier, the file itself is still encrypted.## Alexander Wellbrock
I have to object until proven wrong. If an attacker manages to infiltrate the system and gain user-level access the unlocked keyring is available through the dbus API org.freedesktop.secrets. Any (potentially malicious) process could read secrets from an unlocked keyring that way.
## Aaron
That’s correct; that’s why I was specifically speaking about copying the keyring-file(s).
If I were to write malware, that would be the first thing I’d try, because it’s the most simple one.
Copying the file(s) will surely be unnoticed, whereas querying data from an unlocked keyring
might(depending on the way the user has configured the system) trigger some notification, or even confirmation dialog to allow access to the keyring / wallet.Yes, it’s only a different approach of a malicious software trying to steal sensitive data, but wouldn’t you want to make it as hard as possible? There is no 100% perfect security, but shouldn’t you at least try to deny as many possible ways of accessing the data as possible?
I mean, this is not the right place to propose some not very well thought out changes to the way the keyring(-access) works, I know this… But some quick thoughts would be:
1. mandatory user-confirmation (OK / Deny Buttons, nothing too fancy) each and every time some application wants to access data from the keyring. Except:
2. an option for the user to generally allow specific processes from the (several) systemwide /bin and /sbin folders to access the keyring without any kind of user-confirmation (which would minimize the impact of 1 on the user experience, as only user-programs / scripts which reside in any other location would trigger the popup). This would assume that the system itself is uncompromised; if one would get root-access to your system, you surely have bigger problems than the GNOME keyring). This way, things like your email-client or accessing a network ressource or letting the ssh client access the private key passphrase and so on would still work, but some random script from the internet would not be able to query your unlocked keyring unnoticed…
Finally, because I forgot to say it in my first comment: thanks for your article, it’s well written and very understandable.
## Alexander Wellbrock
I follow your line of thought and I’m with you that it’s best to do as much as you can. The decision to propose to unlock the keyring is based on the convenience trade-off which helps in implementing this login technology. I think the benefits of the security key with good UX outweigh the risk of an unencrypted keyring, something which is more security-by-obscurity than security-by-design. If there would be a way to still encrypt the keyring while unlocking it without an extra password prompt it would be a no-brainer to keep it encrypted – e.g. by a pam module that uses the pam_u2f authentication also for unlocking the keyring which is exactly what happens right now with the pam password prompt and gnome keyring unlock modules.
I also forgot to thank you for your constructive comment. You caught me at a bad angle by saying “it’s always a bad idea”, because I think that the concept of “principle” mostly results in unwarranted disregard of viable approaches / use-cases / trade offs
## Jason Barbier
You make a good point, but counter point, Im a malware maker, Im already on your machine, I could take the files and scrape the keys out of memory, or swipe the passkey as you logon. All of those would be as equally unnoticed as copying your keyring file.
As Alexander points out really the key ring encryption is to help with offline attacks, the only way it would help with online attacks would be to do the same thing most password managers let you do, aggressively expire your session and lock the keyring, and if youre doing that chances are you dont care your keyring doesnt automatically unlock, infact its probably a feature for you not a bug.
We could get into affirmative consent for key ring access, and keep trust lists, and all of that, and that would be a step up but ultimately we will still have a problem of this key has to be in memory some time.
But I will say, your head and heart are in the right place and thanks for being constructive.
## Gregory Bartholomew
Why couldn’t malware run a command like the following to retrieve passwords from an unlocked keyring?
The GNOME keyring seems like an absolutely horrible idea. Security keys that use public-private-key encryption and store the private key in a way that cannot be retrieved definitely seem like the way to go.
## Ernest N. Wilcox Jr.
I’d prefer that the Fedora team take steps to accommodate and simplify the implementation of passwordless authentication using FIDO0 passkeys (the coming security technology) to login securely with my fingerprint scanner at boot time as well as to use it to enable me to log into websites where I have set up passwordless login. While passwordless authentication is not yet universally adopted, it will be the most secure login option available after its implementation is completed. By setting up a passkey on my computer, and using a FIDO0 compliant biometric fingerprint scanner, I should be able to log into any website with which I have an account and with which I have configured passwordless authentication, and that should include logging into my Fedora computer, and root authentication using sudo, etc. I have read that this protocol may become broadly mainstream within the coming year and I want to be able to use it in my Fedora workstation as easily as I can in my Windows systems.
My2Cents,
Ernie
## Alexandra
You actually have made a mistake in this configuration you will fallback on “password” if the key is missing or fail and password only will allow the login.
in my case i do
sudo authselect select sssd #remove useless thing
After in both /etc/pam.d/system-auth and sudo nano /etc/pam.d/gdm-password
auth [success=done default=die] pam_u2f.so prompt cue interactive sufficient required
success=done mean if successful ignore other auth, default die mean if a user have not set it will fail, prompt cue interactive make it blink will to push enter key before starting (like that if the key is not there you have time to plug it),
sufficient also allow the log when he’s the only one, required make it mandatory if it fail it do not use password as fallback.
## Alexander Wellbrock
If I omit the option –with-pam-u2f all entries about pam_u2f disappear from /etc/pam.d and the key is not used anymore. Tested on Fedora 38 Workstation GNOME edition.
## Nikos
In my machine there are other profiles enabled. It is ok to remove them? i don’t use fingeprint reader and others don’t know why are there:
Profile ID: sssd
Enabled features:
– with-fingerprint
– with-silent-lastlog
– with-mdns4
I kept them and if i remove yubikey i can also login with my password.
## Joe
I am using a trustkey g310 for log into fedora on all my devices for as long as Lennard Poetterings article https://0pointer.net/blog/unlocking-luks2-volumes-with-tpm2-fido2-pkcs11-security-hardware-on-systemd-248.html was posted.
It is really only the fact that gnome-keyring does not transparently work with it that is a little anoying, but bearable.
Great stuff! |
16,092 | 我的 Linux 团队使用 Penpot 的 3 个原因 | https://opensource.com/article/23/3/linux-penpot | 2023-08-14T11:08:00 | [
"Penpot"
] | https://linux.cn/article-16092-1.html | 
>
> Penpot 是一个设计师和开发人员使用的开源设计工作空间。
>
>
>
使用 Fedora 会让你接触到许多不同的开源软件。Fedora 网站的重大改造始于一年多前,目标是提高设计美感、创建风格指南、规划网站策略以及选择用于交付 Fedora Linux 产品网站的技术栈。从设计的角度来看,团队需要一个创建模型的工具、一个保存资源库的地方,以及完成后适合移交给开发人员的东西。
### 选择 Penpot
Figma 是许多人推荐的流行界面设计工具,但由于该公司最近对其免费计划施加了限制,因此被认为不合适。这种担忧在 Adobe 收购 Figma 之前就已经出现,所以现在回想起来,不使用它的决定更加重要!
团队研究了 Penpot,发现它符合每个人的要求。Penpot 是第一个面向跨领域团队的开源设计和原型平台。Kaleidos 内的一个团队创建了 Penpot。Kaleidos 是一家成立于 2011 年的科技公司,完全专注于开源项目。
Fedora 网站和应用程序团队通过三种方式使用 Penpot:
* 线框图和模型
* UX 测试和反馈
* 协作
我将在下面详细介绍这些用途。虽然示例讨论了 Fedora 项目,但 Penpot 可以为任何开源社区带来好处。
### 1、线框和模型
设计网页草图是我们团队使用 Penpot 的主要方式。草图可以实现快速协作并减少贡献者之间的沟通问题。开发人员和设计师可以在同一空间自由协作。
社区反馈很重要。正确地共享模型可能有点困难。Penpot 基于网络,可在任何平台上轻松访问。当在原型上进入 <ruby> 查看模式 <rt> View Mode </rt></ruby> 时,该工具会生成一个可共享的链接。如果你不再希望共享链接,还可以修改权限或销毁链接。

### 2、UX 测试和反馈
此次改造与 Fedora 社区密切合作。通过对原型进行可用性测试并共享设计进度,我们使用 Penpot 让社区参与每一步。
### 3、协作
在改造过程中,我们的开发和设计团队使用 Penpot 来产生想法、组织会议并直观地测试新概念。
我们的团队在早期规划会议中将 Penpot 用作白板,让开发人员在参与讨论的同时以异步方式贡献想法。这种方法减轻了压力,确保每个人的想法都能被听到,帮助我们看到模式,并调解分歧,达成良好的妥协。Penpot 有助于在每个人之间建立一种理解感。
团队使用 Penpot 作为素材来源。用户可以将元素和其他内容存储在资源库中,以便可以重复使用它们。Penpot 可以存储组件、图形、版式、调色板等。

共享这些库使整个团队都可以访问它们。当与定期访问相同源文件的团队合作时,这会很有帮助。如果新成员加入,他们开始为项目构建模型所需的所有素材都将随时可用。用户可以直接从 Penpot 文件导出这些素材。

开发人员可以在任何浏览器上查看原型的全部内容。这种功能让网站建设变得更容易,因为你可以与原型同时进行编码。如果设计人员同时在处理文件,他们所做的更改可以通过**查看模式**刷新查看,如果是在实际文件中,则可以实时查看。

### 开源价值观
Penpot 符合 Fedora 项目的“四大基础”:自由、朋友、功能和第一。在回顾这些价值观时,请考虑该工具如何与你自己的开源计划保持一致。
#### 自由
我们选择开源和自由来替代专有的代码和内容,并限制专有代码对项目和项目内的影响。Penpot 是第一个开源设计和原型平台。Penpot 基于网络,独立于操作系统,并采用开放网络标准。这确保了与 Web 浏览器和 Inkscape 等外部应用的兼容性。
#### 朋友
我的社区由各行各业的人们组成,他们共同努力推进自由软件的发展。Penpot 的使命是相似的。其目标是提供开源和开放标准工具,将设计人员和开发人员之间的协作提升到新的水平。使用 Penpot 可以顺利地向开发人员移交,并使我们能够高效地合作。无需来回寻找文件或素材,因为他们需要的一切都在 Penpot 文件中。
#### 功能
Fedora 关注优秀的软件。它的功能开发总是公开透明地进行,并鼓励参与。任何人都可以在任何问题上开始工作,也可以加入任何他们感兴趣的团队。Penpot 赞同这一理念。任何人都可以合作!代码和贡献者指南可从项目的 Git 仓库获取。
#### 第一
Fedora 采用的策略是通过持续的前进动力来推动自由软件的发展。这种方法通常遵循“早发布、勤发布”的工作流程。Penpot 也经常更新。它向社区发布每日开发博客,重点介绍已完成的工作。它在网站上写道:“我们也有这种紧迫感,我们需要快速行动,这关系到太多的事情”。
### 总结
该项目即将完成,第一个截止日期与 Fedora Linux 38 的发布日期一致。事实证明,Penpot 是一个非常有价值的工具,它为开源设计爱好者提供了更多的资源。最近,该平台庆祝了它的正式发布,下一步的发展令人兴奋。
Penpot 改变了我们团队的工作方式。它能为你的组织和社区做些什么?
本文改编自 Ashlyn Knox 和 Emma Kidney 在创意自由峰会上的演讲:《模型和动作 - Fedora 设计团队如何使用 Penpot》。该演讲的录音可 [在 PeerTube 上观看](https://peertube.linuxrocks.online/w/5H22PH66kYwiTKcKR1p2kJ)。
*(题图:MJ/fc248c3c-08e9-4e35-a389-8c88009a7110)*
---
via: <https://opensource.com/article/23/3/linux-penpot>
作者:[Emma Kidney](https://opensource.com/users/ekidney) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Working with Fedora exposes you to a lot of different open source software. A major Fedora website revamp started over a year ago, with the goal of improving design aesthetics, creating a style guide, planning the website strategy, and choosing the tech stack for delivering the Fedora Linux offerings website. From a design perspective, the team needed a tool to create mock-ups, a place to hold the asset libraries, and something suitable to hand off to developers once complete.
## Choosing Penpot
Figma is a popular interface designing tool recommended by many, but it wasn't deemed suitable because the company had recently imposed restrictions on their free plan. This concern arose before Adobe acquired Figma, so the decision not to use it was even more significant in retrospect!
The team looked into Penpot and found that it matched everyone's requirements. Penpot is the first open source design and prototyping platform for cross-domain teams. A team within Kaleidos creates Penpot. Kaleidos is a technology company started in 2011 that fully focuses on open source projects.
There are three ways the Fedora Websites and Apps team uses Penpot:
- Wireframes and mock-ups
- UX testing and feedback
- Collabloration
I expand on these uses below. While the example discusses the Fedora Project, Penpot offers benefits to any open source community.
## 1. Wireframes and mock-ups
Drafting webpage designs is the primary way our team uses Penpot. Drafting enables quick collaboration and lessens communication issues between contributors. Developers and designers can collaborate freely and in the same space.
Community feedback is important. It can be a bit difficult to share mock-ups properly. Penpot is web-based and easily accessible on any platform. When entering **View Mode** on a prototype, the tool generates a shareable link. You can also modify the permissions or destroy the link if you no longer want it shared.
(Emma Kidney, CC BY-SA 4.0)
## 2. UX testing and feedback
This revamp works closely with the Fedora community. By running usability testing sessions on prototypes and sharing design progress, we use Penpot to keep the community involved every step of the way.
## 3. Collaboration
During the revamp, our development and design teams used Penpot to generate ideas, organize meetings, and test new concepts visually.
Our teams used Penpot as a whiteboard in early planning sessions and enabled the developers to contribute ideas asynchronously while engaging in the discussion. This method reduced stress, made sure everyone's ideas could be heard, helped us see patterns, and mediated disagreements for a good compromise. Penpot helped create a sense of understanding between everyone.
The team used Penpot as a source of assets. Uses can store elements and other content in an asset library so that one can use them repeatedly. Penpot stores components, graphics, typographies, color palettes, and more.

(Emma Kidney, CC BY-SA 4.0)
Sharing these libraries enables the whole team to access them. This can be helpful when working with a team that regularly accesses the same source files. If a new member joins, all assets they need to start building mock-ups for the project would be readily available. Users can export these assets directly from the Penpot file.
(Emma Kidney, CC BY-SA 4.0)
Developers can view the prototype in full on any browser. This capability makes building the website easier as you can code side by side with the prototype. If a designer is working on the file at the same time, changes they make can be seen by refreshing in **View Mode** or in real-time if in the actual file.
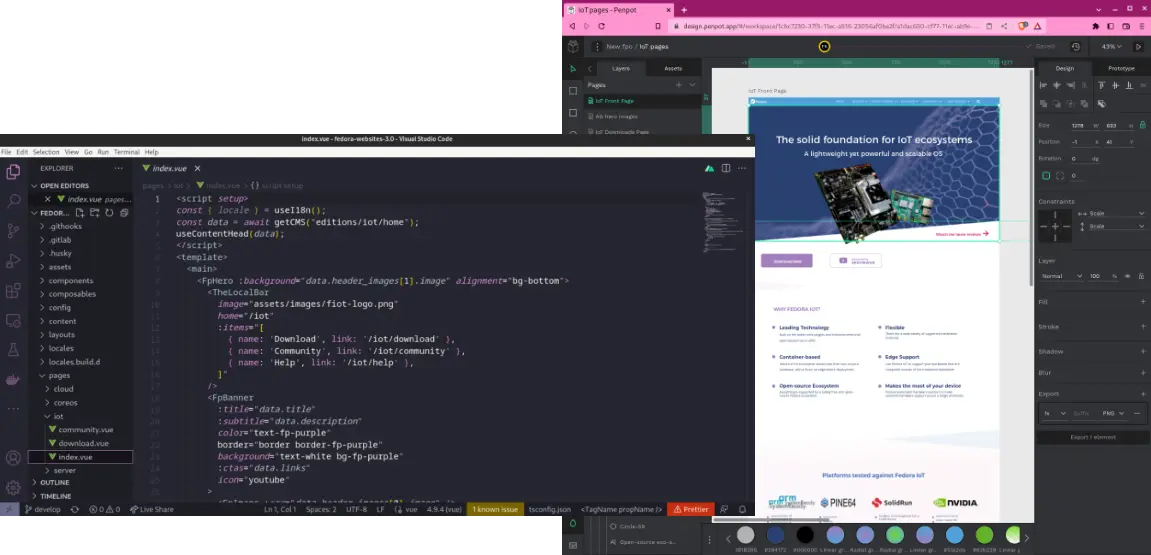
(Emma Kidney, CC BY-SA 4.0)
## Open source values
Penpot aligns with the Fedora Project's "Four Foundations" of Freedom, Friends, Features, and First. As you review these values, consider how the tool might align with your own open source initiative.
### Freedom
We choose open source and free alternatives to proprietary code and content and limit the effects of proprietary code on and within the Project. Penpot is the first open source design and prototyping platform. Penpot is web-based, independent of operating systems, and works with open web standards. This ensures compatibility with web browsers and external applications like Inkscape.
### Friends
My community consists of people from all walks of life working together to advance free software. Penpot's mission is similar. Its goal is to provide an open source and open standards tool to bring collaboration between designers and developers to the next level. Using Penpot has allowed for a smooth handoff to developers and has allowed us to work productively together. There's no back-and-forth looking for files or assets, as everything they need is in the Penpot file.
### Features
Fedora cares about excellent software. Its feature development is always done openly and transparently, and it encourages participation. Anyone can start working on any issue or as part of any team that interests them. Penpot shares this ethos. Anyone can collaborate! The code and a contributor guide are available on the project's Git repository.
### First
Fedora adopts a strategy of advancing free software through consistent forward momentum. This approach usually follows a "release early, release often" workflow. Penpot also updates frequently. It publishes a Dev Diary blog to the community, highlighting the work that has been done. It states on its website, "We also have this sense of urgency, we need to act fast, there's too much at stake."
## Wrap up
The project is coming close to completion, with the first deadline aligning with the release of Fedora Linux 38. Penpot has proven to be a valuable tool and is expanding the resources available to Open Source Design enthusiasts. With the platform celebrating its official launch recently, it's exciting to see what's next.
Penpot has changed the way the our team works. What can it do for your organization and community?
This article has been adapted from the talk: *Mock-ups and Motions—How the Fedora Design Team uses Penpot* by Ashlyn Knox and Emma Kidney, given at the Creative Freedom Summit. A recording of the talk is available to [watch on PeerTube](https://peertube.linuxrocks.online/w/5H22PH66kYwiTKcKR1p2kJ).
## 1 Comment |
16,094 | Linux 桌面上的 Firefox 面临着大问题 | https://www.osnews.com/story/136653/desktop-linux-has-a-firefox-problem/ | 2023-08-15T11:35:00 | [
"Firefox"
] | https://linux.cn/article-16094-1.html | 
毫无疑问,无论是在桌面、笔记本电脑还是移动设备上,**浏览器都是任何操作系统中最重要的应用之一**。如果没有一个功能强大、快速且稳定的浏览器,操作系统的实用性将大幅度降低,以至于我相当确定,**如果一个操作系统没有浏览器,几乎没有人会将其用于常规、正常的使用**。拥有一个起码可用的浏览器是将操作系统从娱乐玩具升级到你可以使用超过 10 分钟的有趣新奇物品的关键。
但问题在于,开发一个功能强大的浏览器实际上非常困难,因为浏览器本身已经成为一个功能丰富的平台。承担起从零开始构建浏览器的巨大任务并不是很多人感兴趣的事情——[除了那些疯狂的人](https://www.ladybird.dev/)——而这一切被恶化的原因是,由于市场的合并和垄断,与剩下来的三个浏览器引擎竞争基本上是无济于事的。Chrome 和其各种衍生产品的[占据统治地位](https://gs.statcounter.com/browser-market-share),其次是 iOS 上的 Safari,原因仅仅是因为你在 iOS 上不能使用任何其他浏览器(引擎)。然后就是 Firefox,作为一个**远远落后的第三名**而存在——且份额还在下滑。
这就是 Linux 桌面发行版所处的环境。长期以来,**Linux 桌面几乎完全依赖于 Firefox**(和之前的 Mozilla 套件)作为它们的浏览器,一些用户选择在安装后下载 Chrome。尽管 GNOME 和 KDE 名义上都有自己的两个浏览器,[GNOME Web](https://wiki.gnome.org/Apps/Web) 和 [Falkon](https://www.falkon.org/),但其用户数量有限,发布的版本也寥寥无几。例如,没有一个主要的 Linux 发行版会将 GNOME Web 作为其默认浏览器,并且它缺少用户对浏览器期待的许多功能。相比之下,Falkon 只会偶尔更新,往往几年才发布一个新版本。更糟糕的是,Falkon 通过 [QtWebEngine](https://wiki.qt.io/QtWebEngine) 使用的是 Chromium 引擎,而 GNOME Web 使用的是 WebKit(它们独立于浏览器更新,所以浏览器版本并不总是一个可靠的指标!),所以**两者都依赖于世界上最无情的两个公司——谷歌和苹果的善意**。
即使是 Firefox 本身,尽管它显然是 Linux 发行版和 Linux 用户的首选浏览器,也并**不将 Linux 视为一线平台**。**Firefox 首先是一个 Windows 浏览器,然后是 macOS,最后是 Linux。**Linux 世界对 Firefox 的热爱并没有得到 Mozilla 同样的回应,这种情况在许多地方表现出来,**那些在 Windows 端修复和解决的问题在 Linux 端被忽视了好几年甚至更久。**
**这种情况最好、最明显的例子就是硬件视频加速。**这个功能从一开始就是 Windows 版本的默认部分,但是直到 2023 年 7 月初发布的 [Firefox 115](https://www.omgubuntu.co.uk/2023/07/firefox-115-intel-gpu-video-decoding-on-linux),才在 Linux 上默认启用。即使是这样,这个功能也只是默认为英特尔显卡用户开启,并没有 AMD 和英伟达用户什么事。这种视频加速功能的缺失(对于 AMD 和英伟达用户来说,仍旧如此),是 **Linux 笔记本电脑在电池寿命上与 Windows 对手差距严重的一个主要因素。**
然后,要走上这条路一直都是漫长、艰巨、且充满颠簸。长久以来,要让硬件视频加速在 Linux 的 Firefox 上工作一直复杂而不稳定,每一个浏览器版本可能都会改变你需要设置的标志。有时候无论你怎么做,它可能都会在连续几个版本中停止工作。论坛消息、博客帖子和网站文章中充满了过时的指令和像 [Hail Mary](https://en.wikipedia.org/wiki/Hail_Mary) 一样的建议,供那些试图让它运行的用户参考。你以往的成功经验会随着每个版本的发布而变化,而跟踪所有这些都是一种**噩梦**。
不仅仅是硬件加速视频解码。手势支持在 Linux 版本上的推出比在 Windows 版本上要晚得多——比如使用滑动来前进和后退,或者在图片上捏合来进行缩放。同样,触摸屏支持也在 Linux 版本的 Firefox 上晚了一段时间才出现。通常,此类功能可能在默认启用之前几年就可以通过 `about:config` 指令启用,但这远非理想情况。
桌面 Linux 的普及率落后于 Windows 和 macOS,**这并不是什么意想不到的情况,或出于恶意的结果。**前几段的重点并不是抱怨 Linux 版 Firefox 的状态,或者建议 Mozilla 将 Windows 和 macOS 版本的宝贵资源转移到 Linux 版本。虽然如果他们这么做的话,我显然不会抱怨这些,但这并没有多大意义。我强调这些问题的真正原因是,如果今天在 Mozilla 现有的财力和资源下,Linux 版的 Firefox 已经被视为第三级平台,那么**如果 Mozilla 的财力和资源急剧减少,将会发生什么?**
Firefox 的状况并不太好。它的市场份额在这些年里急剧下滑,现在在桌面和笔记本电脑上仅占有微薄的 3%,而在移动设备上更是微不足道的 0.5%。Chrome 和稍少的 Safari 已经完全压倒了这个曾经威猛的浏览器,以至于它对于 Linux/BSD 用户和其他平台上的更多极客来说,基本上就是一个附带的产品。我说这个并不是为了贬低那些使用 Firefox 的人——我就是其中之一——而是为了强调 Firefox 当前市场位置的糟糕程度。**这种市场份额的缩小已经对 Firefox 的开发和未来前景构成了伤害**,尤其是如果这种滑坡还在继续的话。
然而,市场份额的下滑远非最大的问题。摆在 Firefox 头顶的达摩克利斯之剑是 **Mozilla 非常奇怪且失衡的收入来源**。大多数人可能都知道,Mozilla 的大部分收入来自与谷歌的搜索合作。大约 80% 的 Mozilla 的收入 [来自谷歌](https://www.bloomberg.com/news/newsletters/2023-05-05/why-google-keeps-paying-mozilla-s-firefox-even-as-chrome-dominates),后者支付给这个浏览器制造商费用,以将谷歌搜索设为默认搜索引擎。
这份协议还会持续多久?无论 Firefox 陷入多么糟糕的情况,它还会一直续约吗?合作的规模会缩小,还是会完全结束?什么时候,谷歌会觉得每年在本质上是对竞争对手的慈善上投入数亿美元已经不再值得,或者根本不需要?谷歌与苹果的类似搜索交易已经面临 [法律审查](https://www.businessinsider.com/google-apple-search-deal-doj-antitrust-suit-2020-10?op=1&r=US&IR=T);那么这种审查会对与 Mozilla 的交易产生影响吗?
只需问自己这个问题:如果由于 Firefox 的市场份额进一步下滑,与谷歌的交易泡汤,两者结合起来,或甚至这里未提到的其他因素,导致 **Mozilla 的资金短缺,哪个版本的 Firefox 将首先感受到削减?**Mozilla 会采取什么措施来缓解困境?当 Mozilla 日益绝望时,我们是否会看到与其他公司的肮脏交易?不靠谱的加密货币概念?允许广告以换取收入?更多的推荐的网站和扩展,需要付费?还是 Linux 版本将被全部削减,让社区接管?
**这就是 [Thunderbird](https://www.osnews.com/story/26159/mozilla-to-cease-development-on-thunderbird/) 所经历的。**Thunderbird 花了近十年的时间才完全恢复。这也可能发生在 Linux 的 Firefox 上。
这就是桌面 Linux 的 Firefox 所面临的问题。这个最重要的桌面 Linux 应用程序已经处于**非常困难的境地**,而且似乎不可避免的是,事态只会逐渐变得更糟。然而,我并**没有看到有人在谈论这个问题**,或者考虑 Firefox 最终可能的消亡,这对 Linux 桌面意味着什么,以及如何避免或减轻这种情况。
在理想的世界里,Linux 桌面的主要利益相关者 —— KDE、GNOME,各种主要的发行版 —— 会聚在一起,严肃地考虑一项行动计划。在我看来,最好的可能解决方案是复刻一个主要的浏览器引擎(或选择一个并大幅投入),并修改这个引擎,并专门为 Linux 桌面进行定制。**停止生活在 Windows 和 macOS 浏览器制造商的残羹冷炙中**,完全专注于制作一个完全为 Linux 及其图形堆栈和桌面优化的浏览器引擎。让主要的利益相关者共同在一个 Linux 首选—— 或甚至仅限于 Linux —— 的浏览器引擎上共同努力,而将图形前端留给各种工具箱和桌面环境。
显然,这并不容易,需要在时间、资源和人员方面进行重大投资。然而,通过仅专注于 Linux,你不会真正与 Blink 和 WebKit 竞争,因为他们完全不重视桌面 Linux(Chrome 在 Linux 上仍然没有硬件视频加速)。让其他引擎去为各种专有平台争夺——Linux 需要一个独立于谷歌(和苹果)的浏览器引擎,并且**认真将 Linux 作为一个平台对待。**
我真的很担心 Linux 上浏览器的状态,特别是 Firefox 在 Linux 上的未来。我认为桌面 Linux 社区的各种主要参与者,从 GNOME 到 KDE,从 Ubuntu 到 Fedora,**显然对于 Firefox 出问题或死亡完全没有应急计划**,尽管我们都知道当前的浏览器市场状态、Mozilla 的财务状况和两者的未来前景。这种行为实在是太不负责任了。
**Linux 桌面的 Firefox 面临着大问题,但似乎没有人愿意承认它。**
*(题图:MJ/0c6cebcc-3c94-4ac1-86cc-ecfa828d33e7)*
---
via: <https://www.osnews.com/story/136653/desktop-linux-has-a-firefox-problem/>
作者:[Thom Holwerda](https://www.osnews.com/story/author/thom-holwerda/) 选题:[wxy](https://github.com/wxy) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-16092-1.html) 荣誉推出
| 200 | OK | There’s no denying that the browser is the single-most important application on any operating system, whether that be on desktops and laptops or on mobile devices. Without a capable, fast, and solid browser, the usefulness of an operating system decreases exponentially, to the point where I’m quite sure virtually nobody’s going to use an operating system for regular, normal use if it doesn’t have a browser. Having an at least somewhat useable browser is what elevates an operating system from a hobby toy to something you could use for more than 10 minutes as a fun novelty.
The problem here is that making a capable browser is actually incredibly hard, as the browser has become a hugely capable platform all of its own. Undertaking the mammoth task of building a browser from scratch is not something a lot of people are interested in – [save for the crazy ones](https://www.ladybird.dev/) – made worse by the fact that competing with the three remaining browser engines is basically futile due to market consolidation and monopolisation. Chrome and its various derivatives are [vastly dominant](https://gs.statcounter.com/browser-market-share), followed by Safari on iOS, if only because you can’t use anything else on iOS. And then there’s Firefox, trailing far behind as a distant third – and falling.
This is the environment desktop Linux distributions find themselves in. For the longest time now, desktop Linux has relied virtually exclusively on shipping Firefox – and the Mozilla suite before that – as their browser, with some users opting to download Chrome post-install. While both GNOME and KDE nominally invest in their own two browsers, [GNOME Web](https://wiki.gnome.org/Apps/Web) and [Falkon](https://www.falkon.org/), their uptake is limited and releases few and far between. For instance, none of the major Linux distributions ship GNOME Web as their default browser, and it lacks many of the features users come to expect from a browser. Falkon, meanwhile, is updated only sporadically, often going years between releases. Worse yet, Falkon uses Chromium through [QtWebEngine](https://wiki.qt.io/QtWebEngine), and GNOME Web uses WebKit (which are updated separately from the browser, so browser releases are not always a solid metric!), so both are dependent on the goodwill of two of the most ruthless corporations in the world, Google and Apple respectively.
Even Firefox itself, even though it’s clearly the browser of choice of distributions and Linux users alike, does not consider Linux a first-tier platform. Firefox is first and foremost a Windows browser, followed by macOS second, and Linux third. The love the Linux world has for Firefox is not reciprocated by Mozilla in the same way, and this shows in various places where issues fixed and addressed on the Windows side are ignored on the Linux side for years or longer.
The best and most visible example of that is hardware video acceleration. This feature has been a default part of the Windows version since forever, but it wasn’t enabled by default for Linux until [Firefox 115](https://www.omgubuntu.co.uk/2023/07/firefox-115-intel-gpu-video-decoding-on-linux), released only in early July 2023. Even then, the feature is only enabled by default for users of Intel graphics – AMD and Nvidia users need not apply. This lack of video acceleration was – and for AMD and Nvidia users, still is – a major contributing factor to Linux battery life on laptops taking a serious hit compared to their Windows counterparts.
The road to even getting here has been a long, hard, and bumpy one. For years and years now, getting video acceleration to work on Firefox for Linux was complicated and unreliable, with every release of the browser possibly changing what flags you needed to set, and sometimes it would just stop working for several releases in a row altogether, no matter what you did. There’s a venerable encyclopaedia of forum messages, blog posts, and website articles with outdated instructions and [Hail Mary](https://en.wikipedia.org/wiki/Hail_Mary)-like suggestions for users trying to get it to work. Conventional wisdom would change with every release, and keeping track of it all was a nightmare.
It’s not just hardware accelerated video decoding. Gesture support has taken much longer to arrive on the Linux version than it did on the Windows version – things like using swipes to go back and forward, or pinch to zoom on images. Similarly, touchscreen support took a longer time to arrive on the Linux version of Firefox, too. Often, such features could be enabled with about:config incantations for years before becoming enabled by default, at least, but that’s far from an ideal situation.
With desktop Linux trailing both Windows and macOS in popularity, there’s nothing unexpected or inherently malicious about this, and the point of the previous few paragraphs is not to complain about the state of Firefox for Linux or to suggest Mozilla transfers precious resources from the Windows and macOS versions to the Linux version. While I obviously wouldn’t complain if they did so, it wouldn’t make much sense. The real reason I’m highlighting these issues is that if Firefox for Linux is already treated as a third wheel today, with Mozilla’s current financial means and resources, what would happen if Mozilla saw a drastic reduction in its financial means and resources?
Firefox is not doing well. Its market share has dropped radically over the years, and now sits at a meagre 3% on desktops and laptops, and a negligible 0.5% on mobile. Chrome and to a lesser extent Safari have trampled all over the venerable browser, to a point where it’s effectively an also-ran for Linux/BSD users, and a few more nerds on other platforms. I’m not saying this to disparage those who use Firefox – I’m one of them – but to underline just how dire Firefox’ current market position really is. This shrinking market share must already be harming the development and future prospects of Firefox, especially if the slide continues.
The declining market share is far from the biggest problem, however. The giant sword of Damocles dangling above Firefox’ head are Mozilla’s really odd and lopsided revenue sources. As most of us are probably aware, Mozilla makes most of its money from a search deal with Google. [Roughly 80% of Mozilla’s revenue comes from Google](https://www.bloomberg.com/news/newsletters/2023-05-05/why-google-keeps-paying-mozilla-s-firefox-even-as-chrome-dominates), who pays the browser maker to set Google Search as the default search engine.
How long will this deal continue? Will it be renewed indefinitely, regardless of how much farther Firefox slides into irrelevance? Will the size of the deal drop, or will it end altogether? When will Google decide that spending hundreds of millions of dollars every year in what is essentially charity for a competitor is no longer worth it, or needed? Google’s similar search deal with Apple is [already facing legal scrutiny](https://www.businessinsider.com/google-apple-search-deal-doj-antitrust-suit-2020-10?op=1&r=US&IR=T); will that scrutiny have consequences for the deal with Mozilla, too?
Just ask yourself this question – if Mozilla’s funding dries up because Firefox’ market share declines further, the Google deal falls through, a combination of the two, or even other factors not mentioned here – *which version of Firefox is going to feel the cuts first*? What will Mozilla do to soften the blow? Are we going to see sleazy deals with other companies as Mozilla grows increasingly desperate? Shady crypto nonsense? “Allowed” ads in exchange for revenue? More suggested websites and extensions, for a price? Or will the Linux version just get cut entirely, left to the community to take over?
Exactly this [happened to Thunderbird](https://www.osnews.com/story/26159/mozilla-to-cease-development-on-thunderbird/). It took Thunderbird almost a decade to fully recover. This could happen to Firefox for Linux, too.
This is desktop Linux’ Firefox problem. The single most important desktop Linux application is already in dire straits, and it seems inevitable that things are only going to get worse from here on out. Yet, I don’t see anyone talking about this problem, or planning for the eventual possible demise of Firefox, what that would mean for the Linux desktop, and how it can be avoided or mitigated.
In an ideal world, the major stakeholders of the Linux desktop – KDE, GNOME, the various major distributions – would get together and seriously consider a plan of action. The best possible solution, in my view, would be to fork one of the major browser engines (or pick one and significantly invest in it), and modify this engine and tailor it specifically for the Linux desktop. Stop living off the scraps and leftovers thrown across the fence from Windows and macOS browser makers, and focus entirely on making a browser engine that is optimised fully for Linux, its graphics stack, and its desktops. Have the major stakeholders work together on a Linux-first – or even Linux-only – browser engine, leaving the graphical front-end to the various toolkits and desktop environments.
Obviously, this won’t be easy, and will take serious investments in time, resources, and people. However, by focusing entirely on Linux alone, you wouldn’t really be competing with Blink and WebKit, who don’t take desktop Linux seriously at all (Chrome still doesn’t have hardware video acceleration on Linux). Let those other engines fight for the various proprietary platforms – Linux needs a browser engine that is independent of Google (and Apple), and takes Linux seriously as a platform.
I’m genuinely worried about the state of browsers on Linux, and the future of Firefox on Linux in particular. I think it’s highly irresponsible of the various prominent players in the desktop Linux community, from GNOME to KDE, from Ubuntu to Fedora, to seemingly have absolutely zero contingency plans for when Firefox enshittifies or dies, despite everything we know about the current state of the browser market, the state of Mozilla’s finances, and the future prospects of both.
Desktop Linux has a Firefox problem, but nobody seems willing to acknowledge it.
The problem isn’t the software. Its the dummies in charge….. they made FirefoxOS and then abandoned it.
Today there are 170million KaiOS devices in use, if they made even $1 per phone that’d be rolling in cash enormous amounts of cash anyway you look at it… it would have been a non search revenue source of cash of in excess of several million a year.
> The problem isn’t the software. Its the dummies in charge…..
You’re right, but only partially.
> Today there are 170million KaiOS devices in use
Absolutely. And they have the licence: they can legally compel this.
Licence author: Mitch Baker, Mozilla CEO.
But also, don’t neglect Rust.
Mozilla invented *the* hottest new programming language. Then, in cutbacks, they killed it and laid off the team.
While Ms Baker took home a 6 digit paycheque.
Absolutely at least Rust is now a foundation…. probably better off that way.
Actually I’d say the problem is on the side of Linux but the SECOND you mention it the “Cult of FOSS” also known as the FOSSies, have a royal screaming REE! fest…its the lack of a stable ABI. Look even Linus Torvalds himself puts out some software that he only supports on Apple and Windows because of this and the reason why is obvious, trying to keep stuff running on Linux is like trying to hit a running dog with a live bee.
Try getting some driver or program from even 6-7 years ago running on an up to date Linux? I hope you have a CS degree, meanwhile last year I found a disc I burned full of software I figured I’d need for the new hotness, the Windows XP RTM so for the hell of it I tried installing them on Windows 11…and they all “just worked”, hell even my old jukebox/MP3 ripper which I thought for sure wouldn’t work…nope, it worked.
If you want companies to support you? Ya gotta meet them half way and making software releases on Linux a life time job just don’t cut it. And as we saw with Thunderbird the FOSSies can’t scream “Give us the code and we’ll do the work” because that is exactly what happened to TBird and it still hasn’t recovered and last I used it Thunderbird felt like a relic of the early 00s, certainly nothing near what pro email software offers in 2023.
So either accept you need what the other 2 has had for years, a stable ABI, or don’t be surprised when what is happening with FF on Linux is the state all software not made exclusively for Linux ends up.
bassbeast,
I HAVE a CS degree, and honestly there’s been lots of drivers that I couldn’t get to work
on windows, so although I agree there’s some truth to linux dependency issues, the new self contained packages are improving this. Meanwhile windows users shouldn’t throw rocks when their own house is made of glass. Seriously, there is SO muchwindows hardwareI’ve had to throw away over the years because windows stopped supporting it. Sometimes it’s even the case that linux will run it and windows won’t. It’s not always rosy for linux support either, but methinks these one-sided linux attackers need to step back and look at the whole situation.Is this supposed to be a criticism for linux? Windows users use thunderbird too. In fact it was my email client when I was a windows user.. MS outlook express was the inferior product for me. When I migrated to linux thunderbird was one of the applications I didn’t have to switch out. You can be critical of it if you like, but there aren’t many alternatives with the same level of features. Gmail has monopolized email, but for users who still prefer a full email application, thunderbird is still a top contender despite the project’s lack of resources.
Be careful not to conflate issues, when we talk about stable ABI in terms of linux we’re usually referring to the kernel’s internal ABI, which isn’t something that impacts userspace stability. The linux userspace ABI has been exceptionally stable and you can run software from decades ago. The linux userspace compatibility issues do not stem from linux stable ABI, but rather the stability of 3rd party userspace dependencies, which generally have no affiliation with the linux kernel. This is somewhat equivalent to the DLL hell issue on windows, and linux has it too. Generally the solution for this is either not to build software using 3rd party resources, or to bundle those resources with the software. This works on both windows and linux, but linux has historically not done this because the repositories were used to keep software dependencies in sync – something that windows simply didn’t have. But linux can support bundled dependencies as well, you can take a look at android, appimage, snap, flatpak for examples of this. There is a lot of debate over whether this is better or worse than the distro repository model and both approaches have some compelling justifications.
So I think there is a lot of merit in having an informed discussion around these topics, but we’ve got to look much deeper than these “linux sucks” rants that do little to advance the discussion.
khtml vibe…
It’s a huge task but there is also https://servo.org/ a quite active rust web engine.
Problem is that WebKit/chromium and firefox are too confortable and good enough right now and people lazy. That’s why we need crazy people or forward thinking people/companies.
CosmicWeb ?
I wouldn’t call servo quite active… it can’t even properly render the most essential pages. There appears to be no succesful effort to get it into a usable state probably because there anybody on a payroll to push it forward.
Even the ladybird browser is doing that very well at this point… probably mainly because it has someone pushing it forward in the right direction.
Checking commits:
https://github.com/servo/servo/commits/master
is visible that Igalia (OSS contributor specialists) is working on it…
and this recent presentation, the situation doesn’t looks so bad:
https://www.youtube.com/watch?v=pfk8s5OD99A
Servo seemed like an attempt to rebuild all parts of Firefox at first, but the spreadsheets killed it off. Now it’s barely a proving ground for new tech ideas (I don’t even know if it’s still active). We did get a couple of pretty cool projects out of it though, Stylo and WebRender (not sure what else), which are integrated in Firefox now.
Arc (built on Blink, not WebKit – don’t get me started on Safari/WebKit) is showing that people are willing to trade up for value. But Firefox isn’t providing any value more than an 1:1 alternative for Chrome.
Thom, there are literally several dozen things you got wrong in your post.
Video HW acceleration: Firefox has had troubles with it because HW video acceleration has always been in a terribly fucked up state.
NVIDIA was the first to offer the community open source VDPAU but since the community was obsessed with the NIH syndrome, VAAPI followed. Too bad NVIDIA didn’t quite care. Then they eventually gave up on VDPAU, it started to trail the other implementation with no AV1 support, NVIDIA told everyone to start using NVDEC instead, it didn’t see any significant uptake, and then they eventually implemented AV1 decoding support in VDPAU. Now we still have VAAPI which sort of works and fully incompatible VDPAU. Mozilla decided not to support VDPAU in any shape or form.
Gesture support: I cannot comment on that because I’m not aware of any significant number of users who need or use this feature. 1 in 100 maybe? IMO it’s not really worth talking about.
Lastly.
Web engine development is hard and expensive, like really hard. Microsoft gave up on Edge and started using Chrome instead.
You’re talking about Linux as if some organizations with very deep pockets are standing behind it ready to pick up any development and support whatever necessary for Linux to succeed on the desktop.
The issue is, not a single organization in the world cares or is working to make the Linux desktop a competitive OS. None.
Main offers from RedHat, Ubuntu and Suse are RHEL, Ubuntu LTS and SLES all intended for enterprise/server use.
Linux on the desktop has been and remains a complete joke both in terms of money invested and the number of active users (fewer than 20 million). There’s no market for it either, as the vast majority of Linux users expect to get everything for free, they won’t spend a penny supporting anything for Linux.
How do you reconcile all those facts? A hobby OS, with few users and you ask Mozilla to spend more money properly supporting ~5% of its users? Why would they do so?
Your first need to have an actual well-supported OS, which can be used by your grandma, for which people can create proprietary software which can work for decades without recompilation and such. Windows is such an OS. Linux is a bug-ridden hobby OS where the knowledge of CLI and computing are a must to maintain your system. Once we have such an OS, guess what, even Chrome will support it better!
Lastly, Chromium supports HW video acceleration out of the box. I feel like you’ve forgotten it exists.
The truth Linux has an OS problem. It’s never become an actual OS outside of RHEL which is primarily a server OS. RHEL doesn’t use the mainline kernel (which doesn’t give a fuck about stable APIs/ABIs and breaks them regularly), doesn’t include modern software (for stability sake), doesn’t support modern HW.
/. has talked about this just today: https://linux.slashdot.org/story/23/08/12/1835204/should-there-be-an-official-version-of-linux
Your entire reply is a rambling jumble of nonsense, and a clear sign you haven’t read anything in the article. At all. We know you hate Linux. That’s fine. Why you, then, insist on always barging in with this gibberish is beyond me. Wouldn’t your life be more fun and mellow if you didn’t rage-bait like this?
Been contributing to Linux for over 20 years, using it as a primary OS on all of my computers, got mentioned in the kernel commit log at least a dozen times, initiated the resolution of OOM situation which resulted in systemd-oomd being written and incorporated by default which made Linux usable in low memory situations where it used to crap out hard before and … you call me a Linux hater and my comment a “rambling jumble of nonsense”?
OK, then, if you start with personal insults, then I’ll see myself out. You may as well delete/block my account on OSNews if you really believe I’m a Linux hater. Never expected something like that from you.
I can vouch for every sentence in my comment. Nothing in it was “nonsense” or “trolling”. I feel like someone has taken a huge dump on me. Sorry, I’ll just log out.
Well, for a start, your post is factually incorrect:
VA-API was developed by Intel and not ‘the community’ – see https://lwn.net/Articles/338581/
Later AST. I’m sure there are many Feecebook groups that have like minded people for you.
No more “here we go again” and tiring rebuttals to read.
Nice one Thom. Your article has hit Slashdot as well.
It’s very low of you to insult someone who brings forward very valid points about desktop Linux usability like that. The real-world stats speak for themselves and Linux doesn’t need die-hard fanatics with religious like attitude to succeed.
Artem S. Tashkinov,
That might have been true decades ago, but linux desktop has become much more usable on the desktop today. Canonical, despite controversies, deserve a lot of credit for making the desktop more user friendly. Also steam is making absolutely huge inroads for linux gamers. Linux isn’t as popular as the more dominant platforms, but clearly organizations are working on Linux desktop. I would say that Linux isn’t a one-size-fits-all OS, but that’s ok. It is extremely popular among developers, so much so that even microsoft have put aside their hatred and are supporting linux distros on windows.
You’re hatred of linux makes you ignorant to the fact that some of us are using it productively on the desktop today. Many of us are former windows users too, yet we found linux was a better OS
for us.Yes, I second Thom Holwerda, you are full of linux hate and it’s really tiresome to hear the thoughtless hater arguments over and over again. If linux doesn’t do it for you, that’s fine, stick with windows, macos, whatever…if you’ve got an OS that makes you happy then I’ll happy for you! IMHO it’s fine to criticize linux, especially when those criticisms are insightful! But too your arguments stem from anger issues more than rational considerations, and that just doesn’t create a good discussion.
Name one technology that cannonical has developed that has made Linux better on the desktop I’ll wait.
It certainly isn’t MIR.
upstart. It was replaced with SystemD, but it served as an improvement over sysv and showed the most conservative change wasn’t sufficient and the more radical SystemD was required to handle init.
I’ll also thank them for ubuntu tablet, that was the best linux tablet OS. Which isn’t saying much, and is just abandoned right now, but good effort no real hardware support which wasn’t completely their fault.
But their real contribution was in packaging and defaults. Ubuntu, especially the early versions made usb drives, dvd roms, media codec support easy as cake from first install with no headaches.
Fedora soon adopted many of those, and now its difficult to recommended over Fedora, but they deserve some credit.
A free LTM Desktop OS is also a nice contribution, that few others have done well.
Bill Shooter of Bul,
Upstart and Unity came to mind for me as well, though IMHO ubuntu had a positive impact on linux desktop earlier than these.
cb88,
Well, you’re asking for a specific home grown technology, and while canonical does have some to it’s name, I was thinking more about how Ubuntu contributed to making the linux desktop a well rounded experience in general Admittedly now days we take it more for granted, but originally most linux distros were quite hard to install and configure for non-hackers. Getting X configured and running was confusing and painful. Ubuntu took debian’s massive software collection and made it more accessible and streamlined for new users with live CDs & DVD that could easily be used to run and/or install a full desktop in a strait forward manor.
I suppose maybe we could haven gotten here without ubuntu, but I used to get tons of distros via “Linux Format” magazine and others, and IMHO ubuntu really was really one of the exceptional ones at that time. I believe without them linux adoption would have slowed. These days I actually prefer Mint though.
> There’s no market for it either, as the vast majority of Linux users expect to get everything for free, they won’t spend a penny supporting anything for Linux.
This is simply false. Valve, a company with extremely little patience for fruitless endeavors, has turned consumer Linux into a product that sells like hotcakes. Before that, people who run desktop Linux were already paying real money for games that run well on their OS, either natively or through Proton, which Valve also develops. According to Valve’s official surveys, there are more people running Steam on Linux than on MacOS (I doubt there are many people who bother to use Steam despite having no games on their account).
Not only that, but the Humble Bundle people have consistently reported Linux users as paying *more* on average: https://www.omgubuntu.co.uk/2011/08/linux-users-pay-more-humble-indie-bundle-3
Sure, it’s just games, which are inexpensive compared to professional software. But there is still a difference between inexpensive and free.
Besides, when was the last time you or anyone you know paid for a web browser? Of course people expect them for free! That has been the status quo since the late 90s.
Linux users are not even asking for something they do not have. It is not 2004 anymore, desktop Linux is not the self inflicted torture it used to be. They are lamenting the gradual loss of something they DO have, which is a functional and dependable web browser. Firefox is not merely being neglected on Linux, it’s gone to hell in general because of Mozilla’s gross incompetence–Linux users are affected disproportionately, but everyone is affected. Chrome and its reskins are a joke, and I lament the inevitable day I have to give in and switch simply to get my most used sites to work correctly.
fr4nk,
Me too. I don’t think it will be a sudden switch, rather the incompatibilities will gradually cause more websites to break over time. Just this month, I was forced to use chrome to register a new credit card since the process failed under firefox. I didn’t investigate further, but obviously the company hadn’t tested it and didn’t care about alternatives. I see this all too often even with my own clients 🙁
The uncomfortable truth for me is that running alternatives is increasingly becoming an empty symbolic gesture: I cheat and run chrome when websites force me to. Ergo, the market is proving that websites don’t have to support alternatives, we’ll just give in to the monopolists anyway. Many will ride FF until it becomes truly defunct, but then what? Can FOSS projects get enough donations or free labor to develop them independently without becoming stale? I don’t know and have never had a good answer here. Sometimes corporate subsidies work, like a free base product with charges for corporate upgrades. But this hasn’t panned out great for browsers when more dominant browsers get bundled for free.
To be completely clear eyed – Steam on macOS is VERY HOBBLED.
It can’t run Windows games at all (no proton support on macOS), and even most macOS games won’t run because they are 32-bit and current versions of macOS can’t run 32-bit apps (which is one of those radically stupid things that Apple regularly does). (As a side note, it’s EASIER to run 32-bit Windows games on M1 hardware, than it is to run 32-bit macOS games… this is stupid, and Apple deserves every ounce of blame for it.)
Anyway, it’s not an apt comparison – Steam isn’t well supported on macOS. Games are – you can run games on macOS, including the Windows version of Steam. But it’s not an adequate comparison to compare the macOS version of Steam to really anything else. It’s just not well supported (I do hope that changes, but I don’t see a lot of incentive for Valve to poor resources in to proton on macOS, even though it should be technically possible for them to get it up and running on the latest versions of Metal and Rosetta 2).
CaptainN-,
Agreed, the lack of 32bit is apple’s fault.
Rosetta 2 is and always was a stop gap measure for macos, just like rosetta 1. Unless apple were prepared to open source and/or license Rosetta’s ARM emulation to 3rd parties, it would make little sense for steam to target it only for it to disappear in a few years.
While developing an emulator like apple’s is technically possible, I think it could be beyond the current scope of wine/proton, as the acronym states “wine is not an emulator”.
I did a search and came up with two projects that might help here…appearently these can run x86 steam games on ARM SBCs like RPI.
https://github.com/ptitSeb/box86
https://github.com/ptitSeb/box64
Alas 32bit applications still wouldn’t work on apple’s latest macs…
Yeah, it wouldn’t surprise me if Apple turns off Rosetta 2 at some point (probably sooner, rather than later), because they do incredibly stupid things ALL THE TIME. For a lot of reasons, they really shouldn’t EVER turn it off (or at least give a stated long horizon of like 10 years). But I know they will, because they are Apple. And that makes building something on it a risky proposition.
I’m not sure if they could conceivably implement their own performant x86 emulation. From what I understand, Apple’s implementation in Rosetta 2 uses a hidden x86 memory model implemented in the m1 architecture, to radically improve the speed of their emulation vs. what is available to everyone else. I don’t know if they have documented that anywhere, or if they’d even allow anyone else to use that in their own code. I also am not certain they’d keep that around forever. They might remove that along with Rosetta 2 in some revision in the future (or likely remove Rosetta 2 long before they remove that support in hardware). This would be entirely stupid, but it’s Apple.
Somebody does not like Linux…
The first thing that is I want to say is that, while 20 million users may not be enough to sustain a viable commercial desktop, one of the great things about Open Source is that 20 million is still a huge number of users and more than enough to drive a viable community. That should be clear to somebody quoting /. as a source as I doubt that site has ever seen half that many users and the peak was long ago. /. is pre-Digg, pre-Fark, pre-Reddit, and now pre-Lemmy. I miss the /, effect. Blast from the past.
You are not wrong that the big money in Linux is in enterprise and the server. Behind that is certainly its absolute domination in the embedded market. Linux is the de-facto standard in the SBC market ( itself not that big ). “Desktop” Linux is probably behind all of those in absolute numbers. That said, you certainly cannot call Linux a “hobby OS” in my view. Linux is not cobbled together by a half-dozen enthusiasts.
First, Desktop Linux is still Linux and requires very little dedicated “operating system” work to be done as it inherits the Linux kernel. While you may not like Desktop Linux and for lots of valid reasons, even Microsoft has trouble competing with the features and performance of Linux because of all the kernel investment. Second, even desktop specific technologies get a lot of corporate backing. Obviously we have companies like Canonical ( Ubuntu ) which hopefully goes without saying. You say ( and are correct ) that Red Hat cares about Linux for RHEL but they are also authoring or sponsoring a bunch of decidedly desktop tech such as HDR ( high dynamic range colour ). One of the biggest drivers on the desktop these days is gaming and, on Linux, you have Valve ( the makers of Steam ) investing hugely in the Linux Desktop for gaming. Finally, like with the Apple ecosystem, there are hardware vendors that contribute to Desktop Linux to support their hardware business ( eg. System 76 ). The point here is that there are a lot of devs building Linux desktop tech as their day-job ( not as a hobby ).
A desktop is defined by its applications and Linux is the standard Open Source desktop. It is hard to find a class of application that is not available on Linux. There are typically numerous high-quality options. Often the best software in any given category is Open Source these days and, if that is the case, it probably runs best on Linux. On the distro I am typing this on, I think I have access to something close to 90,000 packages. That is a pretty deep bench of applications for a “hobby OS”.
There are even a fair number of commercial and proprietary applications available for Linux as well. This article is about web browsers. Both Google and Microsoft seem to think it is worth their time to make their browsers available for Linux. Why? Part of it may be because, while a smaller audience, it is who the Linux Desktop audience is made up of that makes it attractive. Why did Microsoft go to all the trouble of building WSL ( running Linux applications in Windows ) if nobody wanted to do that? It is clearly to keep developers from adopting Linux. Many were and many are. One of the biggest forces in tech is still “the cloud” and the standard “cloud architecture” is containerization ( micro-services, K8S, Docker, Podman ) and containers are native to Linux.
Which is to say that, while you may see it as “a joke”, it is totally viable to use Linux as your primary desktop. I do. I use it personally and professionally. Nothing that I have to do cannot be done and done well on Linux. Ironically, for your point and the point of Thom’s editorial, I can only say that because I use Microsoft Edge instead of Firefox sometimes as some video conferencing ( and other ) applications do not work well ( or at all ) on Firefox. So, thank God for the “non-hobby” desktop stuff Linux Desktop users have access to.
Now, all that said, there is no doubt that Desktop Linux is not displacing Windows or even MacOS anytime soon. It is also true that , relatively speaking, fewer commercial applications target Linux. Why is that? The /. article you link to does not posit that the problem is quality, as you have implied, but rather a lack of standardization. I buy this. There is no “Linux Desktop”. There is no dominant RHEL-like standard that application developers can target. At least, there did not used to be. I see Flatpak as finally addressing that problem. Instead of having to support 30 different “desktop” distributions, you can now just target Flatpak. It is not perfect yet but it is, in many ways, the standard, unified version of desktop Linux that the article you link to is asking for. On the gaming side, we finally have a stable ABI and a single “standardized” environment to target. Thanks to Proton, it is DirectX and Win32. It may not be what Richard Stallman had in mind but, as a practical matter, that is what is happening. So, the “application” side is starting to dial-in.
You do not have to like and certainly do not have to adopt desktop Linux. I am not here saying that it is awesome or better and that you are a fool if you do not use it. You made a lot of good points that I agree with. I certainly agree that, beyond the apps, the Linux desktop is pretty fragmented and even any given distro still introduces more “change” than most desktop users want. However, I cannot agree that desktop Linux is a “hobby OS” or “a joke”. The latter seems more subjective so I care to argue about it less. The level of commercial ( non-hobby ) involvement in making the Linux desktop viable is hard to ignore so completely though.
As you can probable guess, I am typing this on a Linux Desktop which also happens to be an old Macbook Pro. The reason that this particular machine is running a Linux desktop is that Linux provides a much more modern and vastly more capable desktop than Apple makes available to me on this hardware. But I guess I cannot expect that much from Apple as they do not have dramatically higher desktop market share than Linux does ( especially if you consider ChromeOS to be desktop Linux – which I do not ). Based on that, perhaps you consider ChromeOS ( or even MacOS ) to be a “hobby OS” as well.
> The issue is, not a single organization in the world cares or is working to make the Linux desktop a competitive OS.
Except ChromeOS. Which outsells Macs.
In $ terms, and note, each Mac is 3-4x the price of the average Chromebook, meaning ChromeBooks outsell Macs more than 4-5x times over.
Chromebooks have an average support lifespan of about 3 years. Over the last 3 years, ITRO of 100 million Chromebooks have sold.
https://www.statista.com/statistics/749890/worldwide-chromebook-unit-shipments/
Out of the box, they run nothing but ChromeOS, which is a Linux, based on Gentoo.
That is ~100 million Linux users. Counting in people on older machines and premium models with longer support, that’s 120-150 million, conservatively.
For contrast Ubuntu has more users than all other distros put together and it has maybe 40M users.
https://truelist.co/blog/linux-statistics/#:~:text=How%20many%20people%20use%20Ubuntu,of%20all%20Linux%2Dpowered%20websites.
That means ChromeOS is 3-4x Ubuntu, and that means that desktop Linux is over 150M people. That is quite significant.
Are you sure?
https://gs.statcounter.com/os-market-share/desktop/worldwide
https://gs.statcounter.com/os-market-share
I’ve made this point a lot of time – Linux is not an operating system the way folks understand that term (most define it as the complete stack – something comparable to Windows or macOS). Distros are more like an operating system on those terms.
Folks also don’t understand what goes in to adding a feature to Linux. It’s not the same as hacking some half-baked solution in to Windows, then never touching it again. There’s a great youtube channel by an engineer that used to work at Microsoft (Dave’s Garage) where he talks about some features he added in the 80s or 90s, that hasn’t been updated since (or has just barely been maintained). This is how commercial software is built, something is rapidly added to the point where it’s “just good enough”, then it sits there, often with all it’s bugs, which later become features that have to be maintained. That is why Windows’ multiple monitor support is still absolute trash in 2023, and why their color management and HDR support is laughably inadequate (macOS to Apple’s credit gets a lot of this right).
In Linux though, a proper spec has to be created, and then multiple distributed teams need to agree to that spec, probably write 9 more, before get the right one, and then it needs to get implemented correctly by all those teams. Watching the effort unfold around HDR has been a perfect example of this effort. All of that without a single (or often, without ANY) actual business model. The result will eventually be that Linux has the absolute best, most complete implementation of color management and HDR support, bar none. This has happened repeatedly with lots of other feature sets. Once Linux gets it, it’s the most solid implementation out there. But it takes TIME (especially for complex features, like color management/HDR, or a web browser).
App vendors like Mozilla with Firefox can’t just wave a magic wand and get the platform support they need for all this to work. Case in point, Firefox HAS (or at least did a few years ago) the best support for Wayland out of all the browsers. They have true 1st tier support for it, not just support through xwayland, like most of everyone else. It’s amazing fast, and amazingly responsive. But it’s buggy – because wayland itself isn’t quite ready yet (or wasn’t last I checked, I really gotta try out a recent version – my weekend project, just decided, it’s been too long).
I do wish Mozilla would more aggressively support the “desktop-ish” platforms that are being delivered to the market by vendors like Valve with Steam OS. There should be a top tier gaming mode Firefox implementation there. I do understand why they don’t – they’ve been burned by that type of effort before. I’d still like to see it.
The web has a Firefox problem. Open Source has a Firefox problem. It is not a Linux problem.
Yes, the web is in a dangerous spot with Blink ( Chrome ) having almost exclusive control of the web and with the only real alternative being the WebKit engine ( older Chrome ).
We need a viable Open Source web engine that is not controlled by a corporation. Obviously Blink ( Google ) and WebKit ( Apple ) are not that. To be honest though, Firefox is not really that either anymore as Mozilla is showing signs of being no better steward than the other two. I am really glad that you mentioned Ladybird as it could be a saviour here. They have a long way to go obviously but have actually made outstanding progress. I read this article the first time on Ladybird on Linux.
This editorial confuses me though. The success of Firefox is not really a Linux problem. As the editorial itself states, Firefox itself is not even Linux first. Firefox is a Windows browser that works on Linux. Although Firefox is my browser of choice, by the metric of being Linux specific, Firefox is no better than Google Chrome or Microsoft Edge. Both Chrome and Edge are available for Linux and work great. In fact, I have to use Edge all the time ( on Linux ) for situations where Firefox does not work. Losing Firefox would be a tragedy but not because Linux has any worse browser support or options than Windows and MacOS.
I do not think that a Linux specific browser engine makes sense actually. Browser engines should be cross-platform. I am happy that Ladybird has gone this way instead of just being the browser for SerenityOS. We can have Linux specific browsers but they should be based on cross-platform browser engines.
Anyway, I agree that Firefox is in trouble. I also agree that the web is in a bad spot without an Open Source browser engine from “the community” instead of a corporation. Neither of those are really Linux problems though. At least, not in my view.
tanishaj,
I agree with your premise that the loss of firefox is not just a linux problem. Becoming dependent on a monopoly is a problem for everyone. Also I see nothing wrong with browsers being portable. Although I do have an example of how a dominant platform could negatively effect web browsers on other platforms: remember MS active-x, where MS were deliberately shoving windows specific technology into the browser? Had that succeeded, it would have been catastrophic for the open web, turning it into a platform for proprietary OS specific technology. Thankfully that failed.
Yes, thank God MS Active-X failed ( not that it has totally gone away sadly ). Cross-platform protects against the OS monopoly but not against the applications monopoly and, as Thom correctly states, the web browser is the most important application as it has the potential to provide a monopoly over the web. Google is certainly doing its best to use their dominance against us with nonsense like manifest v3 and now the Web Integrity API. Our only protection against this is to avoid monopolies. Sadly, network effects and economics work to create natural monopolies in tech.
I was going to say that Linux, despite its small share, plays an important role in preventing things like Active-X. Microsoft wants to run Edge on Linux and MacOS. If it was just one competitor, perhaps it would be worth trying to force them out. In that sense, Open Source acts a bit like what proponents hope for the Fediverse. It is ok if we all use the same instance as long as there are viable alternatives. It is ok if some of these alternatives have barely any adoption as long as it is enough to keep them going. That way, if the dominant instance starts to flex and act against the community interest, it is possible for us to credibly move to something else. Firefox, even with 5% market share, plays an important role in keeping Chrome honest but only as long as Firefox is good enough to credibly adopt. In many ways, desktop Linux plays the same role. One of the great things about Open Source is that 20 million users is more than enough to keep it viable even if 3% market share would never attract a viable commercial competitor.
tanishaj,
I totally agree, a project doesn’t necessarily have to be dominant to keep competition honest! It just needs to be viable such that users have the opportunity to switch. Linux isn’t going anywhere, thanks in part to how much investment it is getting from corporations using it in servers and appliances. Firefox on the other hand…well, I am more concerned about it. Mozilla don’t have a stable conflict-free business model. They have no reliable revenue once they exclude google. A ~3% market share wouldn’t actually be so bad for mozilla
as long as it were sustainable. This is still a fairly large market, but I’m not sure that mozilla’s user base are adequate for mozilla’s long term survival without wealthy corporate sponsors like those feeding linux.I hope so. They have a good browser for now IMHO. But to date mozilla’s hasn’t succeeded in diversifying their revenue stream from google and that’s troubling. I feel that a risk of failure is still in the cards.
I think the real issue is Open Source has a scaling problem. It’s very common to see one or two people launch a project. It’s very rare to see projects with hundreds of active contributors (the kernel being a single exception.) A browser requires hundreds of active contributors due to the scale of the task, and a community development effort of that scale just hasn’t materialized. Plenty has been written about how “we need” it, but the issue is lack of people willing to devote time to actually do it.
Serious question/thought experiment: if there were hundreds of active volunteer developers on Mozilla in 2002-2004, would MozillaCo even exist? Any attempt to go commercial would just cause the volunteers to move to their own fork, and we’d see something like the LibreOffice/OpenOffice split, where the active fork is the one that gains users.
The problem is that Open Source, like almost everything humanity does, requires leadership and organization. We like to tell ourselves that successful Open Source projects are an emergent property of self-interested engineers or users. This is only partially true.
The reason that I think that Ladybird may succeed is because of Andreas Kling and the community / culture he has built. It looks like it may actually grow and sustain large enough and long enough to get the job done.
As you say, Firefox is mostly a product of Mozilla ( the company ) and there is not a lot of evidence that it will survive without them ( hope I am wrong ). Mozilla started off as a foundation in 1998 and did not become a corporation until 2005. But it has never really been independent of a corporation, first Netscape, then AOL, and of course Mozilla Corp itself.
Have we ever really seen a truly independent web engine? I mean Blink ( Chrome ) used to be WebKit ( old Chrome, current Safari ) but it was KHTML before that ( part of the KDE project ). The truth is though that KHTML never had the required number of devs behind it as a community effort. It was not until Apple got involved that it became a viable alternative to Gecko ( Mozilla ), Trident ( old Microsoft ), or even Presto ( old Opera ). Even though Apple was pretty heavy handed with the KHTML effort when they created WebKit, WebKit is the closest we came to a viable web engine community maybe. At one point, we had quite a few entities collaborating on a single engine: Apple, Google, SONY, Nokia, BlackBerry, and others. No one company dominated that group. That changed when Google forked WebKit to create Blink. Now, even though there are many Blink based browsers, Google is totally in control of Blink and Apple dominates WebKit.
The danger for web engines seems to be getting dominated by a single company regardless of if that happens out of the gate or at some later time. There has to be enough of a “community” to thrive even when a major corporation is participating or, even harder, when that corp forks the project.
Not to open this can of worms but, by my observation, it is not the license but rather the vibrancy of the community that determines which projects will thrive and how easily the can resist being dominated by a corporation. And community appears to be about the leader and the culture they create more than anything. There is no web engine equivalent to “Linux” because there is no “Linus”. Again, I am holding out hope for Ladybird because I think maybe Andreas can be that guy. What is it with Scandinavians?
Thom Holwerda,
Are you talking about the media? Because we actually do talk about this quite a lot even here in the osnews comments. We’re no strangers to this discussion, but what can we really do about it?
If mozilla & firefox fail, some of us will look for forks of course, these will probably be chrome derivatives. What concerns me greatly is the browser DRM that google are developing right now. DRM is a drug for media companies, they’re eager to get on board any DRM train. Advertisers have an incentive. Banks, governments, other service providers, even porn sites could start using google’s DRM too. So browser DRM really could be the nail in the coffin for FOSS browser alternatives.
For their parts google, microsoft, and apple will say “we just provide the DRM API, it’s not our fault service providers are blocking alternative.s”, and from a legal perspective this argument might carry weight.
I don’t think that’s true, I think most of us in the industry do acknowledge it, but we don’t have an answer for it. Marketshare is driven by the ignorant masses; they use what’s bundled without concerning themselves about monopolization in the least.
If love to see a return of Opera (of old). Current Opera is a different beast, no longer really aimed at power users. And it’s heir (Vivaldi) is great but based on Chrome like all the others.
Would I pay £20/£30 for it? Yeah, I think I would. But that’s the catch. Open source, by its nature is a difficult beast to monetize. “Why pay for something I can get for free”?. And something that isn’t free (beer) won’t be included in any distro as a result.
I wonder if there is an engine already floating around that the community could really around though. Khtml was obviously absorbed and rebranded. But I wonder what else is out there.
Adurbe,
Yeah. I’m sure thousands of developers would be willing and able to do the work if only they could answer the question of making a living and getting paid. The irony is that silicon valley has so much money that it shouldn’t be a problem, but the bulk of it is going to the very top while the rest make a pittance. Capitalism has not produced a balanced economy.
Alfman, you always provide a great read and it was overdue to tip my hat.
However, I don’t think that money or funding was a problem. I’d rather ask: what exactly is missing from a practical perspective? What problem are we going to solve? Right now I only assess an Uncomfortable Feeling in the Guts for Google playing an important role. However, the source code is available. If the issue becomes pressing, we will fork and remain the status quo.
Andreas Reichel,
You are too kind sir 🙂
That’s a fair point, money isn’t necessarily the end all be all for FOSS. But as a developer myself I’ve dedicated most of my working life to paid contracts and I don’t know how to change this. I concede that my experience may not be representative, but personally I would struggle to support myself and my family working on FOSS without income. In all my years I haven’t come across even a single business taking an interest in sponsoring FOSS projects. I’ve probably been looking and working at the wrong places for this, but as someone who is not independently wealthy, I guess I need more guidance as to how one should make a living working on FOSS.
Honestly, working on a browser would be intriguing technical challenge, which is something I do enjoy. But doing it for free feels irresponsible to my family given cost of living expenses that don’t disappear when I donate my time. From where I’m sitting with my connections independent FOSS development doesn’t cover my cost of living. Maybe I could use better connections though? I really don’t know, but if I could find a way to support myself independently doing pure FOSS work I would seriously consider it.
I’m with you. As a paid professional myself (who values work life balance too!) It’s very hard to find an “in” to open source projects sometimes. If more organisations paid to work on opensource work then it would be great. But more often than not, the proprietary bit the company builds on top is the focus as that’s what makes them the money!
Seconded. I couldn’t support myself on FOSS. No way. It seems at least in my generation many were essentially working two full time jobs, one that paid money and another one for fun that was FOSS. Then eventually a company stepped up and paid for the FOSS work. Or A company had a need in a FOSS app, and paid their devs to add it. My contributions have been rather small I must admit, my few contributions to various seldom used utilities and games took so much longer to submit and get reviewed than it took to write them it was very discouraging.
Honestly I think Ladybird, that Thom linked to, is about the best bet that we have.
Agreed. But it actually would need FireFox to vanish and Google doing something stupid for LadyBird to grow and to mature. Big trees need to fall for small sprouts to grow.
You think so? I am not arguing with the wisdom of your big trees / sprouts analogy in general. I think that is true of commercial efforts as it is just not viable to fund a commercial effort without market share. Certainly, it makes sense that it may also be hard to create a viable Open Source community around a project where other, larger, and good enough options exist.
I think though that the only pre-requisite for success in Open Source is community. If you can create one, you can succeed. The number of users relative to your “competition” is really not relevant.
The Ladybird community is interesting. Mostly, it is an offshoot of the SerenityOS project and involves the same people. The motivation for creating a web browser was simply that SerenityOS needed one and they have a preference for building all the core stuff from scratch themselves in a mono repo. For a good while, there was only the SerenityOS web browser and it only ran on SerenityOS. Andreas created Ladybird as a cross-platform browser that leverages the libraries in SerenityOS that were being used for the browser. My guess is that a good chunk of the reason for going cross-platform is that it dev on such a massive project was just faster if he could do it on Linux and not have to rebuild the OS every commit. Of course, it also raises awareness and interest in the project. There are now Ladybird contributors that were not part of SerenityOS. There has even been some commercial sponsorship lately and at least one person has been hired to work on Ladybird. Andreas himself is full time on SerenityOS / Ladybird / Jakt through Patreon and other sponsorships. The profile of Ladybird must be helping with that. SerenityOS / Ladybird do such a good job of building community. In addition to Discord and GitHub, there are regular YouTube videos, “office hours” live stream sessions, and participation in conferences. The Ladybird project especially seems to understand the importance of showing off real-world results and prioritizing dev by what is required to make real sites work. Contrast that to something like Servo ( which could not really render anything the last I looked ) or projects like ReactOS ( which does not care if users see results it seems ). Ladybird is still a very young project. Yet, I can read OSnews in it already. In fact, I first saw this editorial and read it the first time inside Ladybird ( I build it sometimes and test a few sites to see how they do — including OSnews ).
The Ladybird community is building a web browser for themselves with the the goal of being able to “surf the real web”. They are doing this as they do not see any of the existing browsers as meeting their needs. As long as they stay engaged with that mission, I do not think it matters what market share they have or how successful the other browsers are. To be clear though, I am not trying to predict what market share Ladybird will eventually have ( probably low ). Rather, I am wondering if they have the momentum and community-strength to create a viable alternative to Firefox and Chrome. While it is too soon to tell, I am thinking that they can.
Greetings Thom.
From my perspective, you look at it way too negative.
Yes, the current browser market has room for only 1 or 2 implementations of a rendering engine and more competition was always a good thing. However, both implementation are OPEN and there are a few alternative projects which only don’t pick up because there is no real need or demand since the existing solutions are just good enough.
As a programmer I find it easier to solve a problem when there is a real demand and maybe even a sponsor. Motivation is much harder when there is no immediate improvement to achieve. What problem exactly would you want to solve right now? (Seriously, nobody cares about HW acceleration, Gestures and all of that. JavaScript performance maybe, for continuously abusing browsers as OS Container for JS applications.)
So lets say, I give you 100 Mill USD for developing a browser for the Linux/Unix market and you can burn that money whatever way you want — what exactly would you do and which problems would you want to solve?
Andreas Reichel,
Ah, you are just posturing 🙂 Still, it’s an interesting question.
Many years ago I had ideas for how the web should work, and if I had the resources to work on it I might have given it a shot. I’ve never liked the HTTP postback model used by web pages. It still bugs me to this day. So much of our work as web devs goes into working around the web browser’s postback model: collecting posted fields and regenerating an HTML pages over and over again. This is inefficient on multiple levels: network traffic, latency, server cpu overhead, client cpu overhead, etc. My vision for the web was more data oriented. Database sources could be distributed and the interface would automatically update based on realtime updates to the database without relying on all these inefficient HTTP postbacks. .net “viewstate” kind of gives developers a way to hide the postback model, but it does so in an extremely inefficient manor build on top of HTTP/HTML and doesn’t support data streaming. What I wanted was a stronger framework to make this all transparent and work out of the box.
I wouldn’t t mind talking about this in more detail if anyone is interested 🙂 I for one am not confident that a small independent developer would be able to promote it effectively though even if it worked.
“.net viewstate” as in Webforms? Old school.
Since you mention .NET, what do you think of SignalR? How does that compare to your vision?
I just would hire full time devs to work on Firefox for Linux. I guess it would be better than creating new browser from scratch if there is FF already.
Would not be surprised if, some distant day, Thunderbird turned out to be Mozilla’s “marquee” program and Firefox became the charity case.
Speaking for my family, Thunderbird ( on macOS and on FreeBSD) has been the most reliable way to deal with the email “firehose” and with managing calendars.
Firefox’s (and Mozilla’s) biggest problem is that folks don’t use their product, even on Windows, the primary platform target. If I were them, I’d focus on questions about why more people don’t prefer Firefox – and especially devs (for me, it’s one very specific problem – their JS stack traces are harder to deal with than Chrome’s – that’s it.)
For non-developer users, I think the main problem is mostly that users now have their Browser data stored in Google’s cloud, and the 1 time mechanism for copying browser stuff from Chrome to Firefox is laughably insufficient for users either trying the browser out, or willing to try both for a while. Mozilla can put all the innovative UX in to Firefox they want (though they haven’t in a while), but it won’t matter if switching is going to cause users to lose all their browser settings.
Loss aversion is a real thing in browser land. Users don’t even close their tabs (seriously, its insane). Arc is a browser who’s entire selling point is that it’ll safely close your tabs for you. I’ll never understand this, as someone who just closes my tabs, but this is a real thing for end users. If Mozilla can figure out how to to satisfy a concern over loss aversion (the way Arc has) they might be able to claw back some market share.
On the subject of platform support – I get where Mozilla is coming from, with their prioritization of the commercial platforms (Windows in particular). It’s also worth noting that on the Linux Desktop side, it’s actually quite difficult to support that, and there are a lot of things in flux all the time. Linux Desktops don’t even have things like a stable HW accelerated interface (wayland isn’t there yet – even after all these years, though it seems close! Other things like HDR aren’t supported at all, though that’s not too important for web browsers just yet – color profiles ARE important, and no support for that either). Firefox BTW, DOES have 1st class support for Wayland, which is more than its competitors, but since Wayland itself isn’t complete, it’s not complete in Firefox, so you have to enable it in the advanced configs. But it’s REALLY fast when it’s enabled. Other browsers (at least last time I checked, which admittedly, was a while ago) use xwayland, which is mostly the thing that’s slow that folks complain about when when talk about wayland.
I’d love to see Mozilla and Firefox coordinate with vendors who are actively trying to expand the desktop Linux market share. It’s a travesty that they haven’t worked with Valve to produce something that works seemlessly in Steam OS. At the end of the day, Firefox is an old crusty code base, that seems hard and time consuming to work on (I’ve watched many bugs languish in their bloated bug tracker for years), and they haven’t prioritized making the core easier to work on, the way that Google has with Blink. That’s a real shame. There are parts in there that would make an excellent dev target. Like I’d love to see a React Native like target that uses their WebRender without JS – expose a DOM like API through to Rust, and then maybe implement a higher level React or Svelte like API on top of a scripting language like Rhai. There just doesn’t seem to be an appetite for creating new ways to use their tech at Mozilla, even though they’ve got quite the winner with Rust. They are in this hunkered down maintenance mode posture on Firefox. That’s what happens when your company is run by spreadsheets I guess. 80% of revenue comes from this thing (Firefox on Windows), so we have to spend our effort on just this thing, rather than creating new product categories (there seem to be so many opportunities). Maybe they’ll figure it out.
CaptainN-,
The cause is extremely simple: the vast majority of owners never change the bundled browsers. Unless there are serious problems, what’s bundled is what they’ll use. Unfortunately for mozilla, they don’t have the benefit of a successful hardware platform to bundle their browser with. To be fair, they did think of this already and built FF OS, but like everyone else, they failed to compete against android and IOS.
https://www.zdnet.com/article/firefox-os-is-dead-mozilla-kills-off-open-source-iot-project-with-50-layoffs/
Users switching browsers is not only rare but also some other browsers don’t play nice and steal the defaults back, like microsoft edge has been doing. So microsoft has a viable path for market inroads, whereas mozilla have to go against the grain.
I do think your ideas have merit, but I don’t think it would matter anyway. The firefox browser is completely off user’s radar, the vast majority of users are not even making a conscious decision not to use it. That’s the reality mozilla are up against. If mozilla were willing to spend money, they could grow their market share like google did by paying software developers to bundle chrome (tons of software devs did this back in the day, they’d get paid while google got marketshare). Another idea, which I’m not advocating for since it goes against the FOSS grain, is the Opera browser model. Mozilla could theoretically pay for ads like Opera does. They have a business model and use it to pay streamers/youtubers to advertise the Opera browser. I don’t know how well that’s working out?
I agree that being the default on OEM products is an advantage, but on Windows that is still Edge, yet they haven’t managed to gain much market share. Folks are downloading Chrome – but that probably has to do with how aggressive Google pushes that in Google search results (like they used to do for Firefox). So it’s not so much that users don’t have an interest, it’s a question of exposure, which I think is pretty close to your point. I’m not sure what Firefox could do on that front. I do like that they are the default on most Linux distros. We just need more people deciding to use Linux, which has the same problem (plus a few more)!
CaptainN-,
I would say have gained a lot of market share in just a few year…
https://www.neowin.net/news/microsoft-edge-now-has-more-than-10-of-the-desktop-browser-market-share/
I wish we had more data to work with publicly, but I wouldn’t be surprised if the upticks in edge correspond with users buying new hardware. It certainly seems plausible.
I concede it’s only speculation, but if mozilla’s browser were being bundled instead of edge, I think it’s likely that FF would be at 10-15% today and would have a positive projection over time.
OEMs bundling deals are quite common and the browser is no different. Google do bundling deals with some manufactures so that they were the default browser out of the box. I’ve seen it personally where chrome is preinstalled on windows. Also they obviously have android and chromebooks.
Then there’s crap like this…
https://www.engadget.com/2018-09-12-windows-10-to-discourage-chrome-firefox-installs.html
https://www.engadget.com/2018-03-16-windows-10-preview-forces-mail-links-to-open-in-edge.html
I think the EU may have cracked down on it and I don’t know if this is currently happening, but it’s not been a fair fight when this is what mozilla has had to face.
Yeah, I agree it would help. Linux uptake is not really something mozilla’s controls though.
Maybe more websites could recommend linux/firefox and use scare tactics for windows & edge users, haha. The thought of microsoft getting a taste of their own medicine is funny, but it’s unlikely to actually happen.
Thom is 100% right in his observation that we are on the brink of losing Firefox support on Linux. If Chrome/Chromium are going the same way is hard to tell, due to technological platform choices for their services, I suspect Google has quite many engineers preferring using Linux on their desktops too; this is only a guess from my own personal perspective, but if I am right, they are probably more willing to allocate resources for a marginal platform for their own browser. Hence if we lose Firefox there will probably be something chrome flavoured for fulfilling our browser needs.
There are two killer features of Chrome, same bookmarks on all devices and it is installed by default in Android and on most corporate Windows desktops I know of. Internet explorer used to be bad enough for IT departments to rather install something else and Google seems to be a dependable provider…
Regarding the assertion that graphics acceleration is a needed tool for day to day work, I humbly beg to differ. First and foremost I have neither managed to get it to work on Windows, nor on Linux and regardless of that, I am still in good health ,-)
I am using my browser as much as anyone else, the only circumstance where I have been forced to try this acceleration, has been to optimize MS Teams, first on linux when the pandemic hit and I was forced to move my lessons to this platform. Since Teams worked (but with problems) without acceleration and crashed the browser with acceleration enabled. Disabling acceleration was an easy choice on Linux. More or less the same result regardless if I used a computer with a discrete Nvidia GPU, AMD:s integrated GPU, or Intel’s integrated graphics.
After two years I was forced, by my employer to switch to Windows, and I soon found out that Teams and graphics support in the browser worked as bad in Windows as on linux; tried both Edge and Chrome there. The real killer seems to be if one of the students is running an animated background picture, then the my browser goes belly up if my acceleration is enabled. Same thing on Windows regardless of that platform being “better supported” in many ways; I have tested on various hardware platforms, same result regardless.
Teams is a moving target, this may well work flawlessly, right now. But that is not the point, the point is that this part of the basic set of capabilities that we may expect from a browser does not seem to work well anywhere, or there are certainly problems with it that makes this technology less useful. If my choice is between a browser that works and a browser that potentially would use less energy, but saving amperes while behaving erroneously, I would rather go for more power consumption and a more predictable behaviour.
There may be other web applications where the video acceleration feature of modern browsers is needed, unfortunately I have only seen one such app, and even if this feature was supposed to be required, it turned out not to work. Hence I believe that the video acceleration is quite an unusual requirement and regardless of platform choices, it is not mature enough to be trusted.
Almost like Chat GPT, which can be plenty of fun, but rather not something to depend on in your day to day life.
Thanks for a nice site,
B-man
there are, right now, as i write this, at least 10 forks of chromium and firefox for linux
palemoon, waterfox, librefox, icewolf, brave, de-googled chromium, opera, vivaldi, otter browser,
‘linux’ is several thousand people all working on different projects, statements like ‘linux has a firefox problem’ are bizarre and confusing since there’s over 100 distros of linux and at least half of them dont come with firefox except the corporate ones which don’t care at all about enshittification of the web
hazbot,
While it’s understandable why the existence of many forks may give the impression that the market is good for redundancy How many of them are genuinely doing the heavy lifting versus applying basic patches on the back of someone else’s work to scratch an itch? It’s pretty easy to create a fork and give it a name. For example osnews could realistically create a fork and call it the “osnews deluxe browser”, but it doesn’t mean they could maintain it in the absence of mozilla’s upstream developers.
At least if mozilla fails, developers will still be able to fork Chromium, so at least there’s that. But even so google’s dominant control over the market means google shapes the internet and forks are mostly along for the ride without much say themselves – especially if google’s DRM initiative catches on.
I have been using Firefox since version 0.9, but in the last year I have gradually switched to Chromium. I am a frequent user of the Raspberry Pi 4, and the Pi’s moderate hardware exposes Firefox’s problems very well. Mozilla on the Pi is a near-unusable resource hog, while Chromium performs adequately on this hardware.
The Brave browser is a good option. It is available for arm64, can sync across multiple devices, and has hardware acceleration that is good enough for YouTube and similar platforms. Brave still has some problems with DRM media on the Pi, but you can always use vanilla Chromium as a “player” exclusively for DRM content (you don’t need to sync). And despite recent claims, hardware acceleration for arm64 Linux in Firefox 116 only works barely.
The aggressive political agenda and stupid design decisions (including the latest unremovable “extensions” icon) are another issue, but I can live with the latter since Brave has a much less customizable UI anyway.
As for the Firefox itself I think we need an independent alternative to Chrome (including the reendering engine) so perhaps the next big reset “2003-style” is needed. Today’s Mozilla is a far worse resource hog than Netscape was back then.
Some time ago I`ve set up VM with Windows 11 and 4gb ram. Edge was slow as turtle, and Firefox just fly |
16,095 | Linux 窗口管理器 Compiz 简史 | https://itsfoss.com/compiz/ | 2023-08-15T14:27:00 | [
"Compiz"
] | https://linux.cn/article-16095-1.html | 
>
> 你会在 Linux 讨论中听到 Compiz 这个词。在此简要介绍一下 Compiz。
>
>
>
今天,我们听到人们谈论 “[发行版快闪](/article-15949-1.html)”。我们中的一些人可能对此深有感触。尝试具有新功能的新 Linux 发行版是很难抗拒的。即使我也不能幸免,我有几台笔记本电脑,我经常在上面尝试新的操作系统(如果我怀旧的话,可以尝试旧的操作系统)。
但曾经有一段时间,发行版快闪并不常见,因为在 Linux 诞生之初,发行版较少。我们许多早期用户所做的就是使用不同的窗口管理器。

[Compiz](https://code.launchpad.net/compiz) 是这些窗口管理器之一,于 2006 年发布。它是 [X Window 系统](https://en.wikipedia.org/wiki/X_Window_System) 最古老的合成窗口管理器之一,在当时相当先进。窗口管理器不再像以前那样流行,但 Compiz 仍然在维护中,仍然具有出色的性能和大量的功能。
### Compiz 是什么?
Compiz 是一个开源 [X 窗口管理器](https://en.wikipedia.org/wiki/X_window_manager),可实现高级视觉效果和桌面增强。它提供了广泛的功能,包括窗口管理、窗口装饰、桌面效果、动画等等,并以可加载插件的形式实现。Compiz 可以用作大多数其他桌面的默认窗口管理器和合成器的直接替代品。

### Compiz 的历史
在其早期阶段,Compiz 专门与 [Xgl](https://en.wikipedia.org/wiki/Xgl) 支持的 3D 硬件一起运行。与 Xgl 一起使用时,大多数 [英伟达](https://en.wikipedia.org/wiki/NVIDIA) 和 [ATI](https://en.wikipedia.org/wiki/ATI_(brand)) 显卡与 Compiz 兼容。从 2006 年 5 月 22 日开始,Compiz 通过利用 [AIGLX](https://en.wikipedia.org/wiki/AIGLX) 与标准 [X.Org 服务器](https://en.wikipedia.org/wiki/X.Org_Server) 兼容。
在 2000 年代初期,[ATI](https://en.wikipedia.org/wiki/ATI_Technologies) 和 [英伟达](https://en.wikipedia.org/wiki/Nvidia) 驱动程序在 Linux 上变得越来越流行,这使得先进的 [OpenGL](https://en.wikipedia.org/wiki/OpenGL) 开发能够扩展到昂贵的 UNIX 工作站之外。大约在同一时间,Xgl、Xegl 和 AIGLX 使 Xorg 能够利用 OpenGL 进行窗口转换和效果。
Compiz 于 2006 年 2 月由 [Novell](https://en.wikipedia.org/wiki/Novell)([SUSE](https://en.wikipedia.org/wiki/SUSE))作为自由软件推出,成为 X 的早期合成窗口管理器之一。到 2006 年 3 月,[红帽](https://en.wikipedia.org/wiki/Red_Hat) 将 Compiz 移植到了 AIGLX。
对 Compiz 的早期评论大多是正面的,称赞其性能、视觉吸引力和创新性。同时开发的还有 Metisse 和 Project Looking Glass 等项目,但没有一个项目获得了与 Compiz 相同的认可或广泛采用。后来,合成效果也被集成到窗口管理器中,例如 [GNOME Shell](https://en.wikipedia.org/wiki/GNOME_Shell) 和 [KWin](https://en.wikipedia.org/wiki/KWin)。
Wayland 于 2010 年左右出现,将合成器和图形服务器的功能合并到一个程序中,从而使单独的窗口管理器和合成器变得过时。因此,Compiz 不再被广泛使用,但这并不意味着它的时代已经结束。继续包含 Compiz 的发行版通常只启用一些实用的插件,同时禁用更多视觉上奢侈的插件。此外,发行版越来越多地将 [KDE](https://en.wikipedia.org/wiki/KDE) 和 [GNOME](https://en.wikipedia.org/wiki/GNOME) 与其默认窗口管理器结合在一起。最后一个以 Compiz 作为 Unity 桌面管理器的 Ubuntu 版本是 Ubuntu 16.04,此后其开发基本陷入停滞。
Compiz 仍然得到维护,有两个现有版本:Compiz 0.9 和 Compiz 0.8。Compiz 0.9 是用 C++ 重写的,而 Compiz 0.8 继续使用原始 C 版本。Ubuntu 维护和开发 Compiz 0.9,而 Debian 中的软件包是 Compiz 0.8 “Reloaded”。两个版本都很相似,但区别在于插件支持的级别,因为 0.9 重写版不得不排除了某些功能。Compiz 0.8 被认为更快、更稳定。
### 总结
我在使用时,Compiz 的所有功能和效果确实让我付出了很多时间。我记得我花费了大量的时间以独特的方式改造我的工作空间。然而,随着时间的推移,我发现自己花越来越多的时间在 Compiz 上修修补补,而不是专注于我的工作。虽然其视觉奇观的吸引力是不可否认的,但它也成为了分散注意力的来源:我摆弄 Compiz 的次数越多,我未完成的任务就越长。最终,我不得不更换窗口管理器才能完成工作。
对我来说,Compiz 在桌面环境的历史上占有特殊的地位。这证明了其开发人员和社区的独创性,将技术推向了极限。
如果你想了解 Compiz 的一些功能,请观看以下视频:[Compiz Fusion:快速演示](https://youtu.be/E4Fbk52Mk1w)。对于“旧代码”来说,它确实可以做很多事情并且有点领先。
顺便说一句,如果你对复古的东西感兴趣,我写了几篇文章来带你回忆起来。
我想你会喜欢它们的。
>
> **[怀旧 Coherent 操作系统](https://itsfoss.com/coherent-operating-system/)**
>
>
>
>
> **[在现代 Linux 发行版上体验 CDE](https://itsfoss.com/common-desktop-environment/)**
>
>
>
---
via: <https://itsfoss.com/compiz/>
作者:[Bill Dyer](https://itsfoss.com/author/bill/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Today, we hear of people "[distro hopping](https://itsfoss.com/distrohopping-issues/)." Some of us may be guilty of it. It's hard to resist, trying out that new Linux distro with the new features. Even I am not immune, and I have a couple of laptops that I routinely try a new OS (or older if I'm feeling nostalgic) on.
There was a time though, when distro hopping wasn't common as there were fewer distros in the beginning days of Linux. What many of us early users did instead was to play around with different window managers.
[Compiz](https://code.launchpad.net/compiz) was one of those window managers, released in 2006. It is one of the oldest compositing window managers for the [X Window System](https://en.wikipedia.org/wiki/X_Window_System) and it was quite advanced for its day. Window managers aren't as popular as they once were, but Compiz is still maintained, still has remarkable performance and a large number of features.
## What is Compiz?
Compiz is an open-source [X window manager](https://en.wikipedia.org/wiki/X_window_manager) that enables advanced visual effects and desktop enhancements. It provides a wide range of features, including window management, window decorations, desktop effects, animations, and much more, implemented as loadable plugins. Compiz can be used as a drop-in substitute for the default window managers and compositors of most other desktops.

## History of Compiz
In its early stages, Compiz exclusively functioned with 3D hardware supported by [Xgl](https://en.wikipedia.org/wiki/Xgl). Most [NVIDIA](https://en.wikipedia.org/wiki/NVIDIA) and [ATI](https://en.wikipedia.org/wiki/ATI_(brand)) graphics cards were compatible with Compiz when used alongside Xgl. Starting from May 22, 2006, Compiz became compatible with the standard [X.Org Server](https://en.wikipedia.org/wiki/X.Org_Server) through the utilization of [AIGLX](https://en.wikipedia.org/wiki/AIGLX).
During the early 2000s, both [ATI](https://en.wikipedia.org/wiki/ATI_Technologies) and [Nvidia](https://en.wikipedia.org/wiki/Nvidia) drivers became increasingly prevalent on Linux, which allowed advanced [OpenGL](https://en.wikipedia.org/wiki/OpenGL) development to extend beyond expensive UNIX workstations. Roughly during this same time, Xgl, Xegl, and AIGLX enabled Xorg to leverage OpenGL for window transformation and effects.
Compiz, introduced by [Novell](https://en.wikipedia.org/wiki/Novell) ([SUSE](https://en.wikipedia.org/wiki/SUSE)) as free software in February 2006, emerged as one of the pioneering compositing window managers for X. By March 2006, [Red Hat](https://en.wikipedia.org/wiki/Red_Hat) ported Compiz to AIGLX.
Early reviews of Compiz were mostly positive, lauding its performance, visual appeal, and innovative nature. Other projects such as Metisse and Project Looking Glass were developed at the same time, but none gained the same recognition or widespread adoption as Compiz. Later on, compositing effects were also integrated into window managers like [GNOME Shell](https://en.wikipedia.org/wiki/GNOME_Shell) and [KWin](https://en.wikipedia.org/wiki/KWin).
The emergence of Wayland around 2010 merged the functionalities of the compositor and graphics server into a single program, making separate window managers and compositors obsolete. Because of this, Compiz isn't used much anymore, but that doesn't mean that its days are over. Distributions that continued to include Compiz typically enabled only a few practical plugins while disabling more visually extravagant ones. Additionally, distributions increasingly incorporated [KDE](https://en.wikipedia.org/wiki/KDE) and [GNOME](https://en.wikipedia.org/wiki/GNOME) with their default window managers. The last version of Ubuntu to feature Compiz as the Unity desktop manager was Ubuntu 16.04, after which its development mostly stagnated.
Compiz is still maintained, with two existing versions: Compiz 0.9 and Compiz 0.8. Compiz 0.9 is a C++ rewrite, while Compiz 0.8 continues to utilize the original C version. Ubuntu maintains and develops Compiz 0.9, whereas the package in Debian is the Compiz 0.8 "Reloaded" version. Both versions are similar, but the distinction lies in the level of plugin support, as the 0.9 rewrite had to exclude certain features. Compiz 0.8 is considered to be faster and more stable.
## Conclusion
Compiz, with all of its features and effects certainly kept me busy when I used it. I can remember spending an inordinate amount of time transforming my workspace in unique ways. As time went on, however, I found myself spending more and more time tinkering with Compiz rather than focusing on my work. While the allure of its visual spectacle was undeniable, it also became a source of distraction - the more I played with Compiz, the longer my unfinished tasks became. Eventually, I had to change window managers in order to get any work done.
To me, Compiz holds a special place in the history of desktop environments - a testament to the ingenuity of its developers and the community that pushed technology to its limits.
If you would like to see some of what Compiz can do, here is a video: [Compiz Fusion: A Quick Demonstration](https://youtu.be/E4Fbk52Mk1w). For "old code," it really could do a lot and was a bit ahead.
By the way, if you are interested in retro stuff, I have written a couple of articles to take you down memory lane.
[Getting Nostalgic With the Coherent Operating SystemThe 90s was a wonderful decade. Apart from great music, you also had interesting tech. Coherent was part of the 90s UNIX-like operating systems.](https://itsfoss.com/coherent-operating-system/)

[Trying Common Desktop Environment on a Modern Linux DistroBill shares his re-experience with Common Desktop Environment (CDE), the de-facto standard windowing environment on UNIX systems in the 90s.](https://itsfoss.com/common-desktop-environment/)

I think you'll enjoy them. |
16,098 | 安装和使用额外的 Gedit 颜色主题 | https://itsfoss.com/gedit-themes/ | 2023-08-16T16:29:00 | [] | https://linux.cn/article-16098-1.html | 
>
> 不喜欢 Gedit 文本编辑器的默认外观?当然可以尝试更改颜色主题。以下是更改方法。
>
>
>
Gedit 是 Linux 世界中最流行的文本编辑器之一。它主要是一个文本编辑器,但 [经过一些调整](https://itsfoss.com/gedit-tweaks/),你也可以使用它进行编写程序。
现在,程序员通常更喜欢较暗的主题,Gedit 对此并不陌生。它有很多主题可供选择。
但是,如果你对它们不满意,你也可以安装第三方配色方案。如果需要,你甚至可以创建自己的配色方案,使其完全独一无二。
首先让我向你展示如何更改默认的 Gedit 主题,然后我将分享如何安装其他第三方主题。
### 更改默认的 Gedit 主题
正如我之前提到的,Gedit 带有一些自己的配色方案。你可以轻松切换到它们。
转到右上角的菜单并选择 “<ruby> 首选项 <rt> Preferences </rt></ruby>”。

现在,转到字体和颜色选项卡。

在这里,你可以更改配色方案。你可以在下面的截图中看到所有配色方案的外观。









不喜欢你所看到的? 让我们探索一下第三方 Gedit 主题。
### 安装第三方配色方案
你需要先从互联网下载所需的配色方案文件,然后从首选项将它们添加到 Gedit 或将它们放在 `.local/share/gedit/styles` 文件夹中。
#### 步骤 1:下载配色方案文件
第三方 Gedit 主题可在各种 GitHub 仓库中找到。为了你的方便,我列出了一些仓库,你可以在其中找到很多方案文件。
* [Mig 的方案](https://github.com:443/mig/gedit-themes)(更好看)
* [gmate 的方案](https://github.com:443/gmate/gmate/tree/master/styles)
* [GNOME Wiki](https://wiki.gnome.org:443/Projects/GtkSourceView/StyleSchemes)
* [其他仓库](https://github.com:443/topics/gedit-theme)
* [Gnome 外观](https://www.gnome-look.org:443/browse?cat=279&ord=latest)
在上面的仓库中,你可以找到 XML 文件。打开主题 XML 文件并使用 *将文件另存为原始数据* 选项下载它们,如下所示。

#### 步骤 2:安装单独的主题文件
如果你精心挑选了一些主题文件,你可以使用 Gedit 添加方案功能一一安装它们。为此,请打开 “<ruby> 首选项 <rt> Preferences </rt></ruby> > <ruby> 字体和颜色 <rt> Fonts & Colors </rt></ruby>” 选项卡。现在,单击左下角的 “+” 符号:

从文件浏览器中,选择下载的主题文件,然后单击“<ruby> 确定 <rt> OK </rt></ruby>”。

该主题现在将在同一“字体和颜色”选项卡上可见,你可以通过单击它进行切换。
#### 步骤 2 替代:批量安装主题
你是否下载了整个 GitHub 主题仓库? 那么一一安装主题就不方便了。不用担心,Gedit 有可用于批量安装的颜色主题目录。
你必须将所有 XML 文件复制并粘贴到 `.local/share/gedit/styles`。
之后,你将在“字体和颜色”选项卡上获得所有主题的缩略图。

如果没有 `styles` 目录,请创建一个。现在,主题将可供该特定用户使用。
>
> ? 在 Linux Mint 上,你可以将 XML 文件复制到 `/usr/share/gtksourceview-3.0` 目录,Gedit 和 Xed 编辑器都可以访问该目录。
>
>
>
### 删除 Gedit 主题
如果你不喜欢某些主题,可以从该位置删除这些文件。或者,转到字体和颜色部分。现在选择你要删除的主题,然后按左下角的 “-” 号。

这将删除该特定的配色方案。
### 一些好看的 Gedit 主题
下面的截图给出了我的一些建议。
Blackboard:

[Catppuccin](https://github.com:443/catppuccin/gedit) 是一个深色的 Gedit,如果你使用任何类似的 GTK 主题,那就太合适了:

Lowlight:

Midnight:

Monakai:

Neopro:

Plastic Code Wrap:

Slate:

Vibrant Fun:

你可以通过搜索 [GitHub 话题](https://github.com:443/topics/gedit-theme) 和仓库来获取更多主题。
### 更多 Gedit 调整
这只是众多 [调整 Gedit 的方法](https://itsfoss.com/gedit-tweaks/) 之一。这里还有更多内容供你探索。
享受更多颜色的 Gedit ?
*(题图:MJ/3a36db2e-6da6-4bdc-bf80-0aa0e6481f8e)*
---
via: <https://itsfoss.com/gedit-themes/>
作者:[Sreenath](https://itsfoss.com/author/sreenath/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Gedit is one of the most popular text editors in the Linux world. It is primarily a text editor but [with some tweaks](https://itsfoss.com/gedit-tweaks/), you can use it for programming as well.
Now, programmers often prefer a darker theme and Gedit is no stranger to that. It comes with a bunch of themes to choose from.
However, if you are not satisfied with them, you may also install third-party color schemes. If you want, you can even create your own color scheme to make it completely unique.
Let me show you how to change the default Gedit theme first and then I'll share how you can install additional, third-party themes.
## Change the default Gedit theme
As I mentioned earlier, Gedit comes with a few color schemes of its own. You can easily switch to them.
Go to the top right hamburger menu and select* Preferences.*
Now, go to Fonts & Color Tab.
From there, you can change the color scheme. You can see how all these color schemes look in the screenshots below.
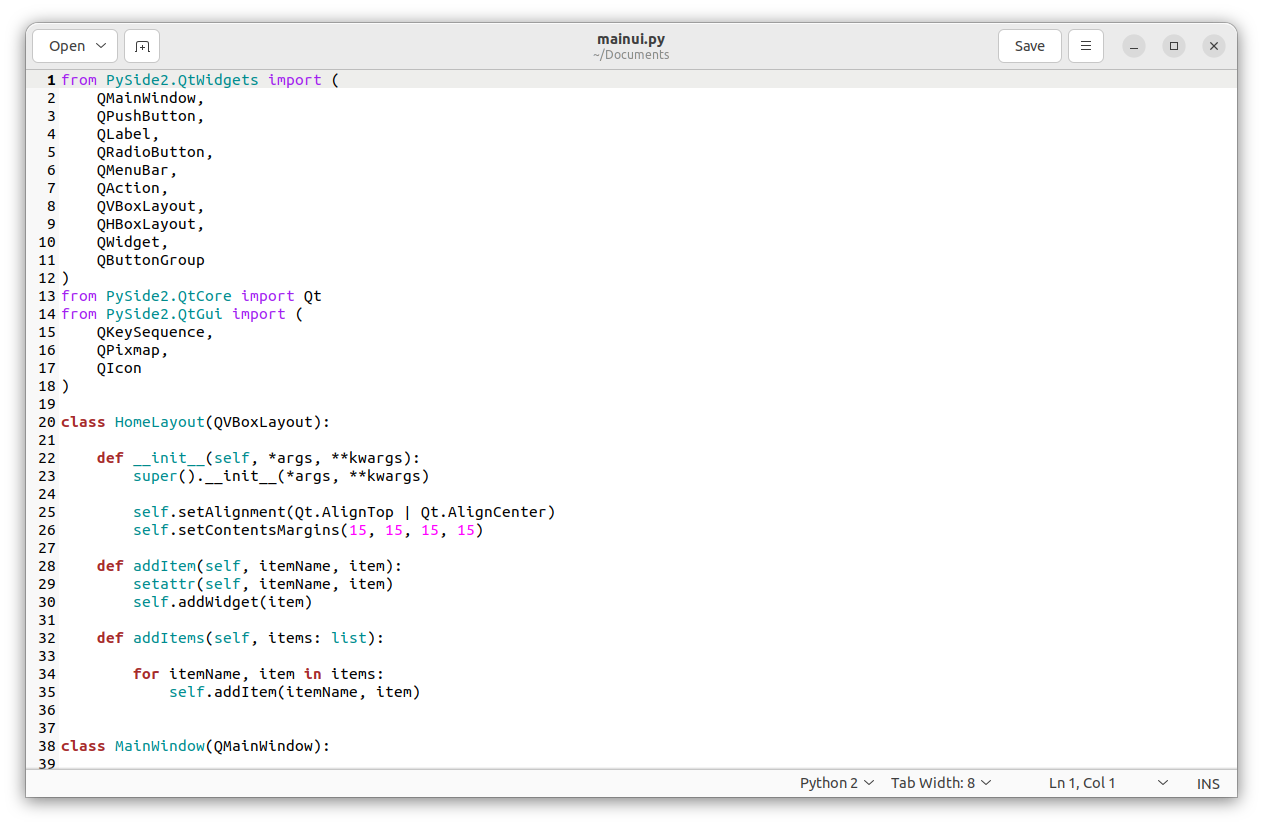
Classic, Cobalt, Kate, Oblivion, Solarized Dark, Solarized Light, Tango, Yaru, Yaru Dark
Don't like what you see? Let's explore third-party Gedit themes.
## Installing third-party color schemes
You need to download the required color scheme files from the internet first and then add them to Gedit from the Preferences or put them in .local/share/gedit/styles folder.
### Step 1: Download color Scheme Files
Third-party Gedit themes are available on various GitHub repositories. For your convenience, I am listing some repos where you can find a lot of scheme files.
[Schemes by Mig](https://github.com/mig/gedit-themes)(better looking)[Schemes by gmate](https://github.com/gmate/gmate/tree/master/styles)[GNOME Wiki](https://wiki.gnome.org/Projects/GtkSourceView/StyleSchemes)[Other repos](https://github.com/topics/gedit-theme)[Gnome-Look](https://www.gnome-look.org/browse?cat=279&ord=latest)
On the above repos, you can find XML files. Open the theme XML files and download them by using the *Save File as Raw Data* option, as shown below.
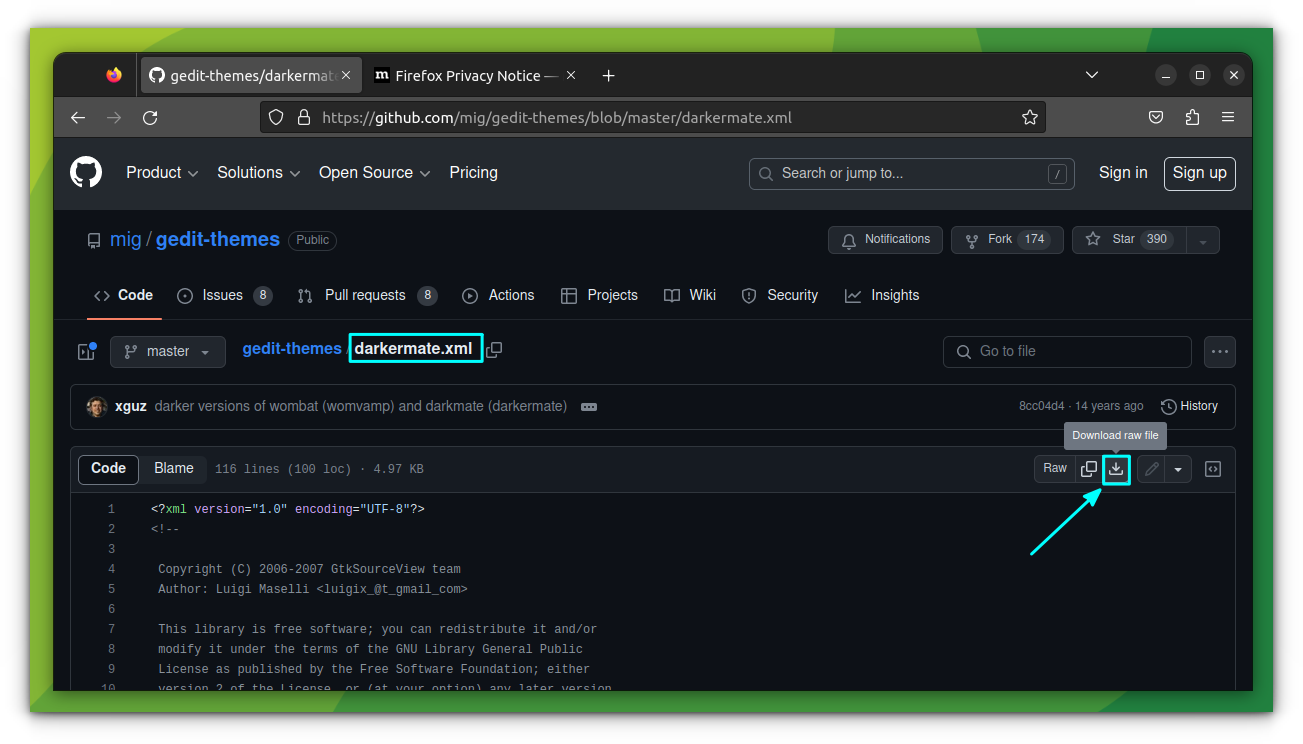
### Step 2: Install Individual Theme Files
If you have handpicked some theme files, you can install them one by one using Gedit Add scheme feature. For this, open the *Preferences > Fonts & Colors* tab. Now, click on the "+" symbol on the bottom left:
From the resulting file browser, select the downloaded theme file and click OK.
This theme will now be visible on the same Fonts & Colors tab, and you can switch by clicking on it.
### Alternative step 2: Install Themes in Bulk
Did you download an entire GitHub repo of themes? Then it is not convenient to install themes one by one. Do not worry; Gedit has color theme directories that can be used for bulk installs.
You have to copy and paste all the XML files to `.local/share/gedit/styles`
.
After that you will get a thumbnail of all the themes on the *Fonts & Colors* tab.
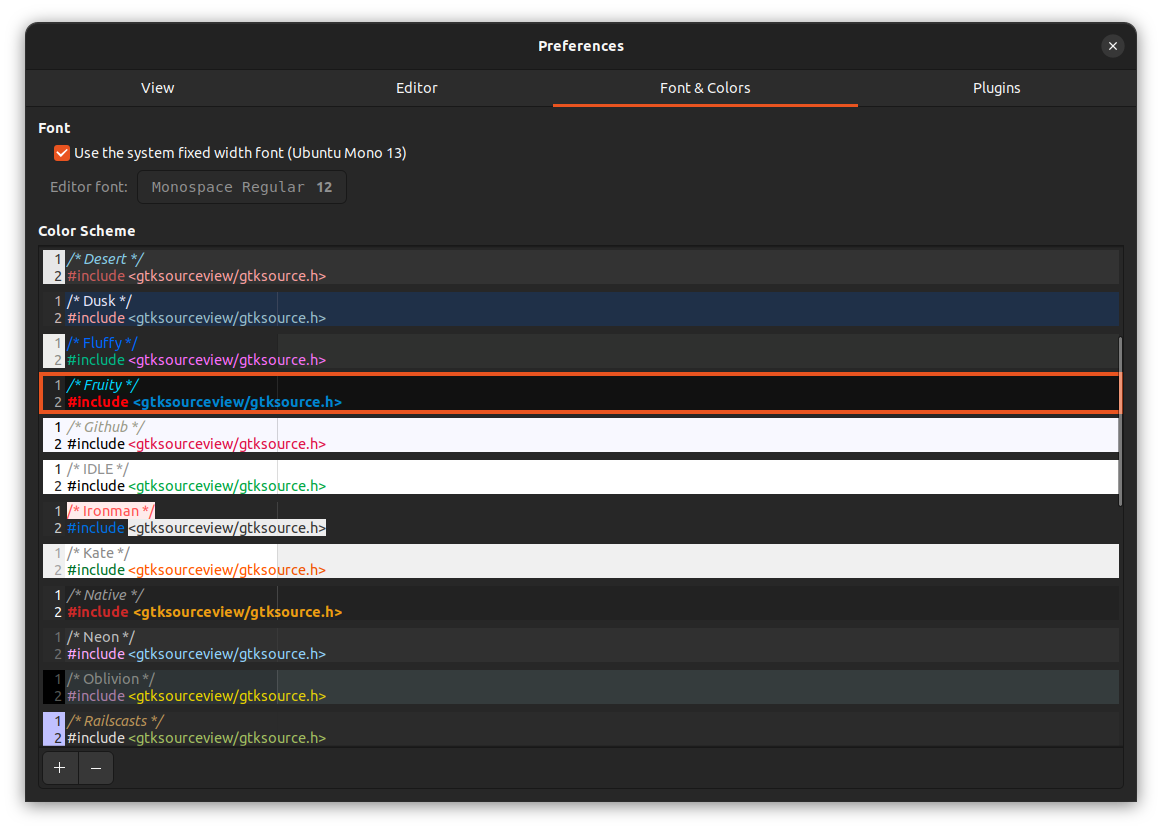
If there is no *Styles* directory, create one. Now, the themes will be available for that particular user.
On Linux Mint, you can copy the XML files to `/usr/share/gtksourceview-3.0`
directory, which will be accessible for both Gedit and Xed editor.
## Remove a Gedit theme
If you don't like some themes, you can delete those files from the location. Or, go to the Fonts & Colors section. Now select the theme that you want to delete and press the "-" sign on the bottom left.
This will delete that particular color scheme.
## Some good looking Gedit themes
The below screenshots give some suggestions from my side.
### Blackboard
### Catppuccin
[Catppuccin](https://github.com/catppuccin/gedit) is a dark Gedit them, good if you use any similar GTK theme.
### Lowlight
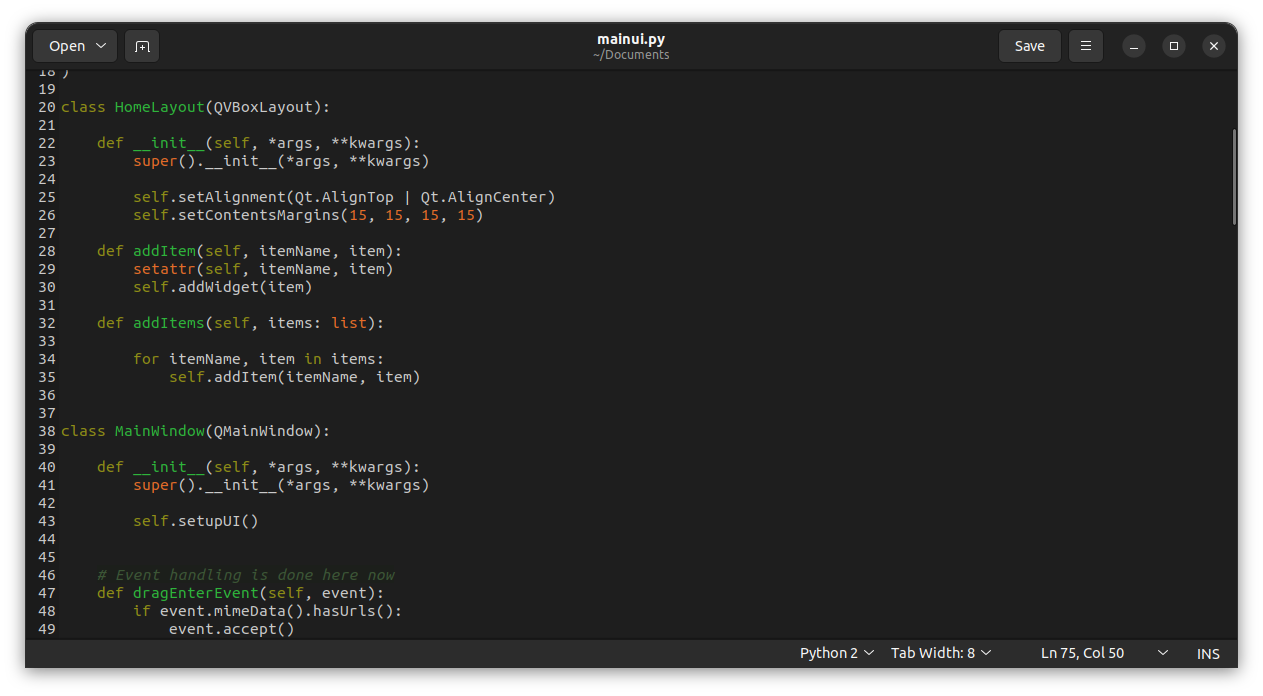
### Midnight
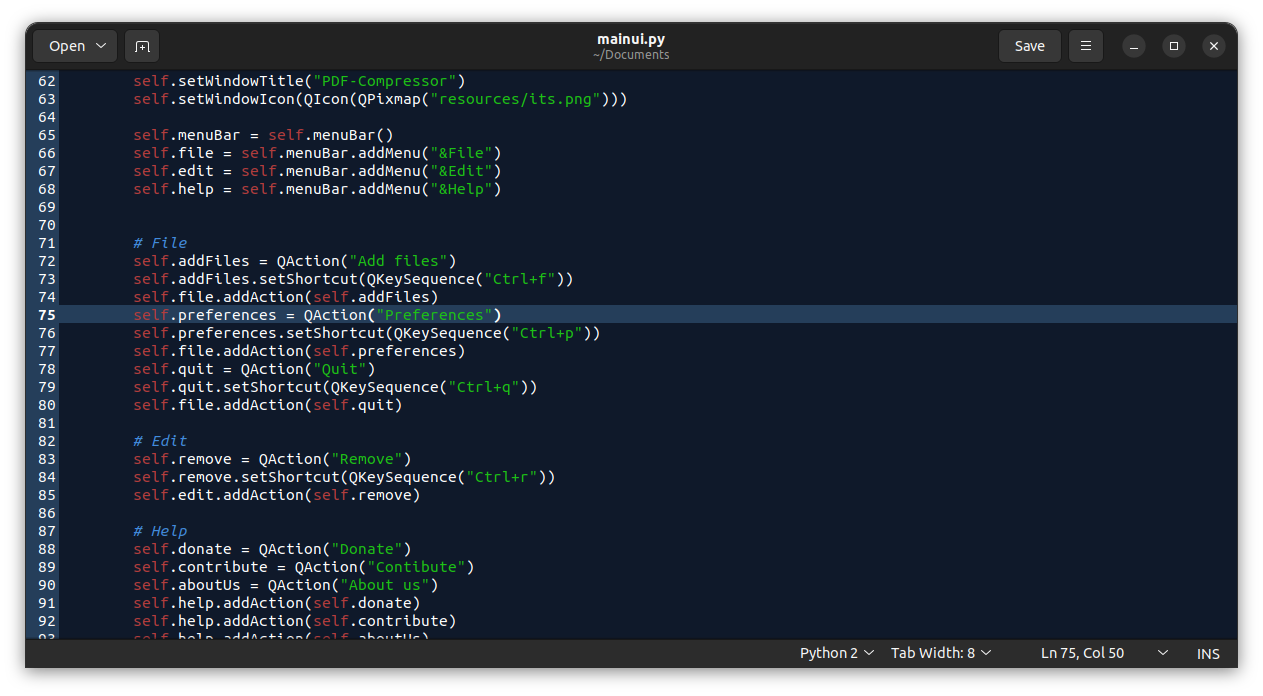
### Monakai
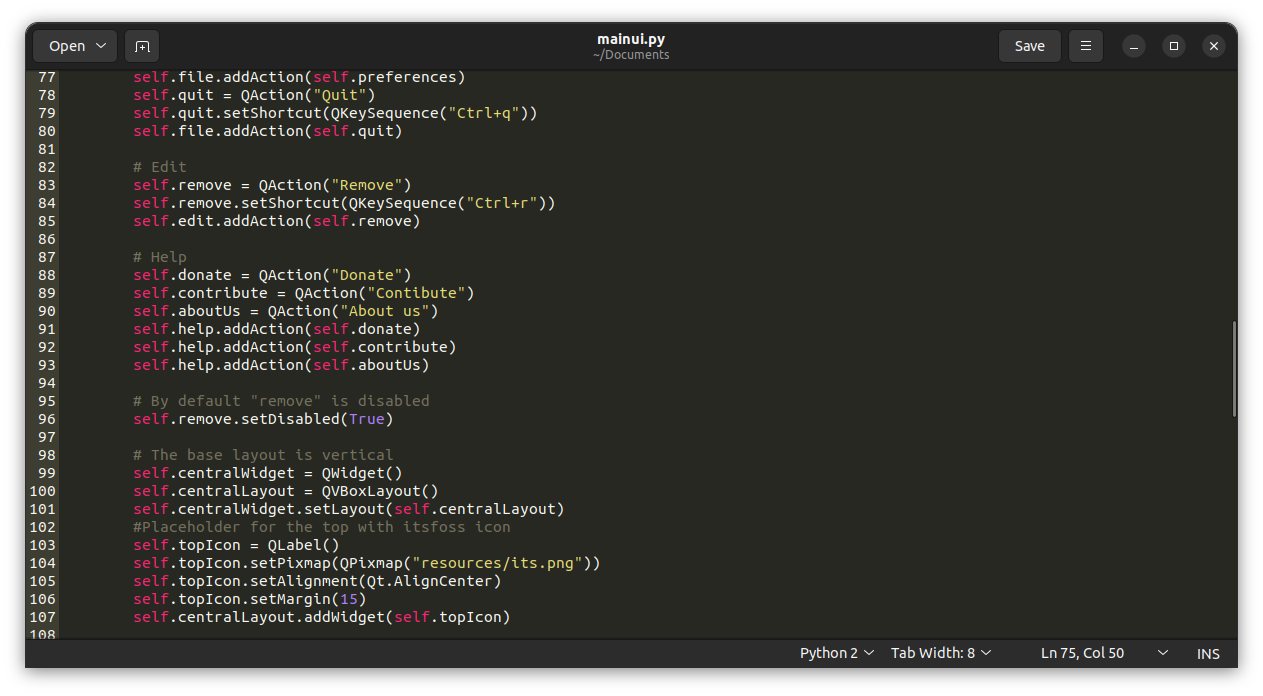
### Neopro
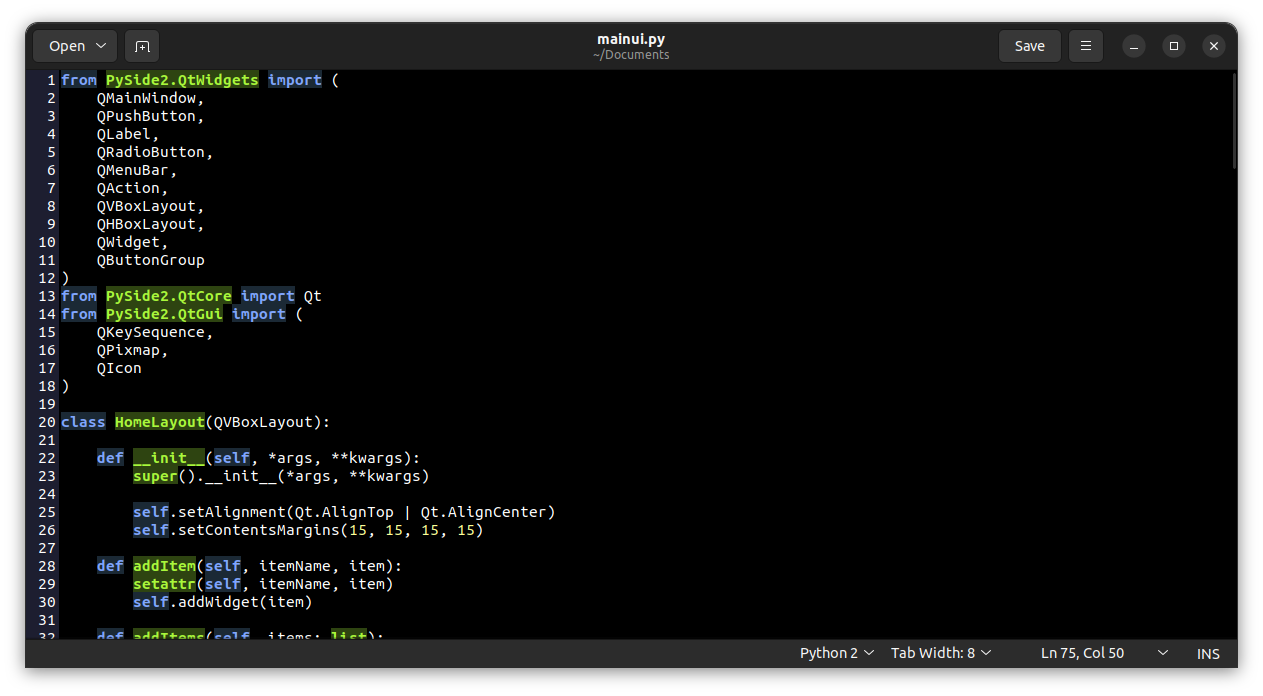
### Plastic Code Wrap
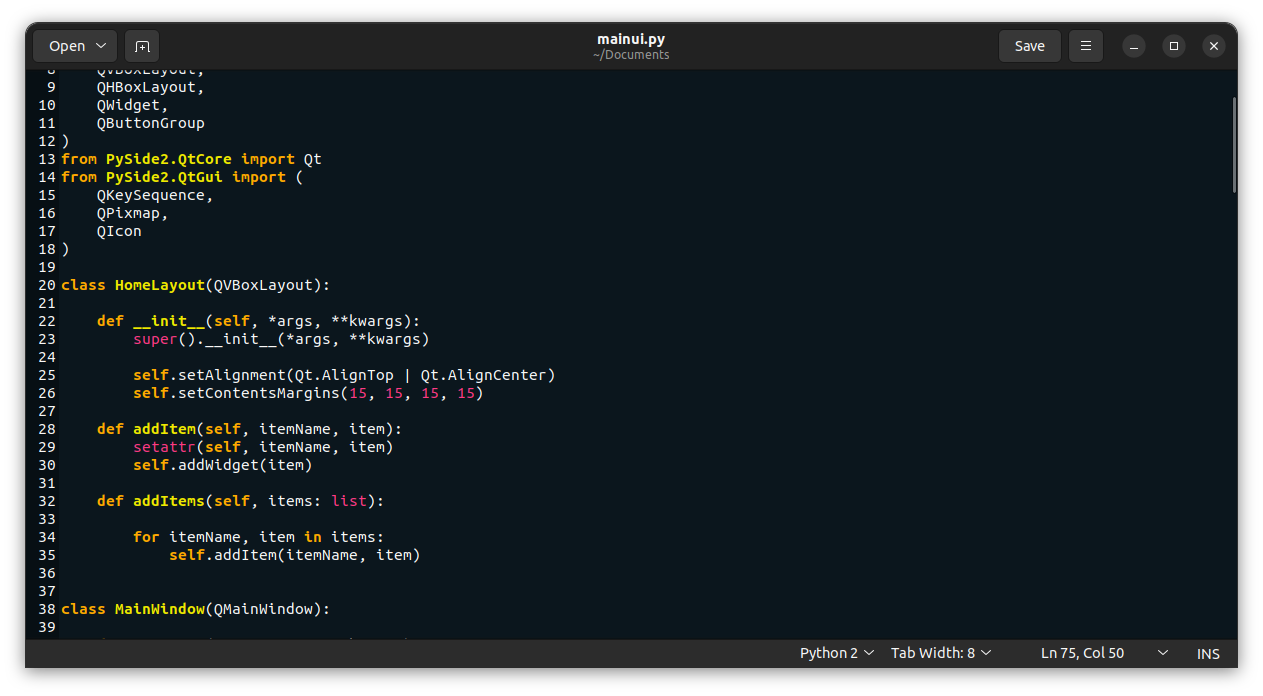
### Slate
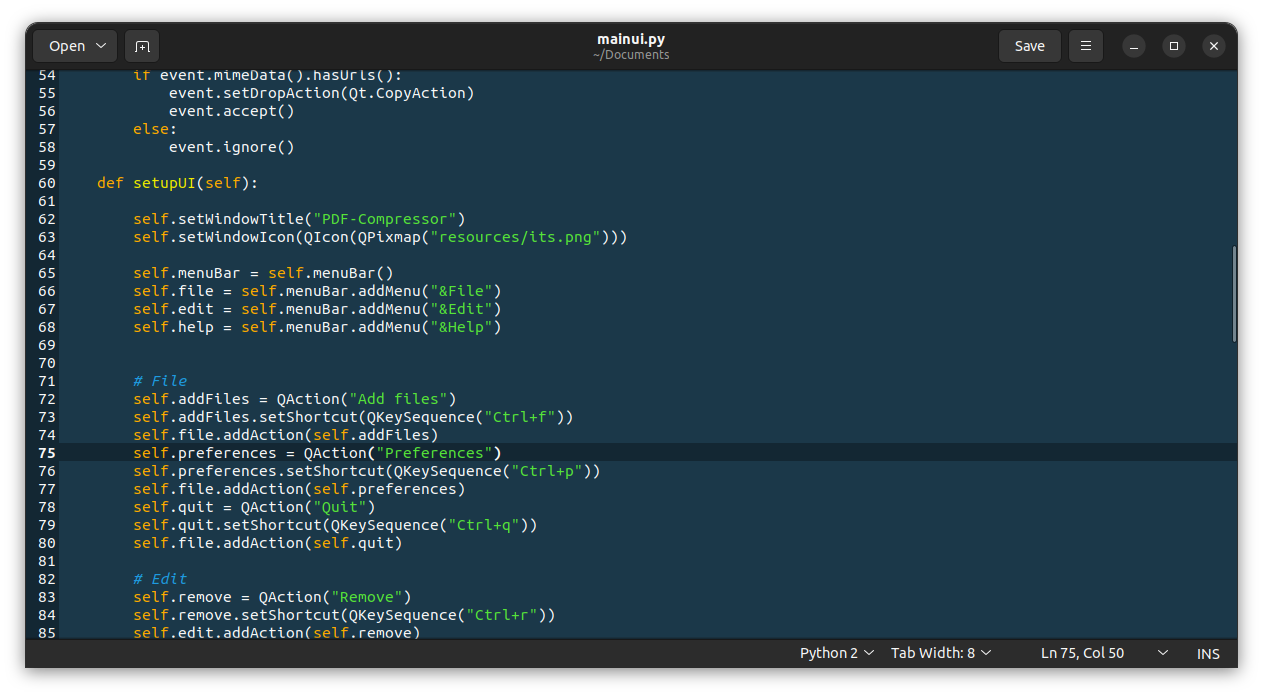
### Vibrant Fun
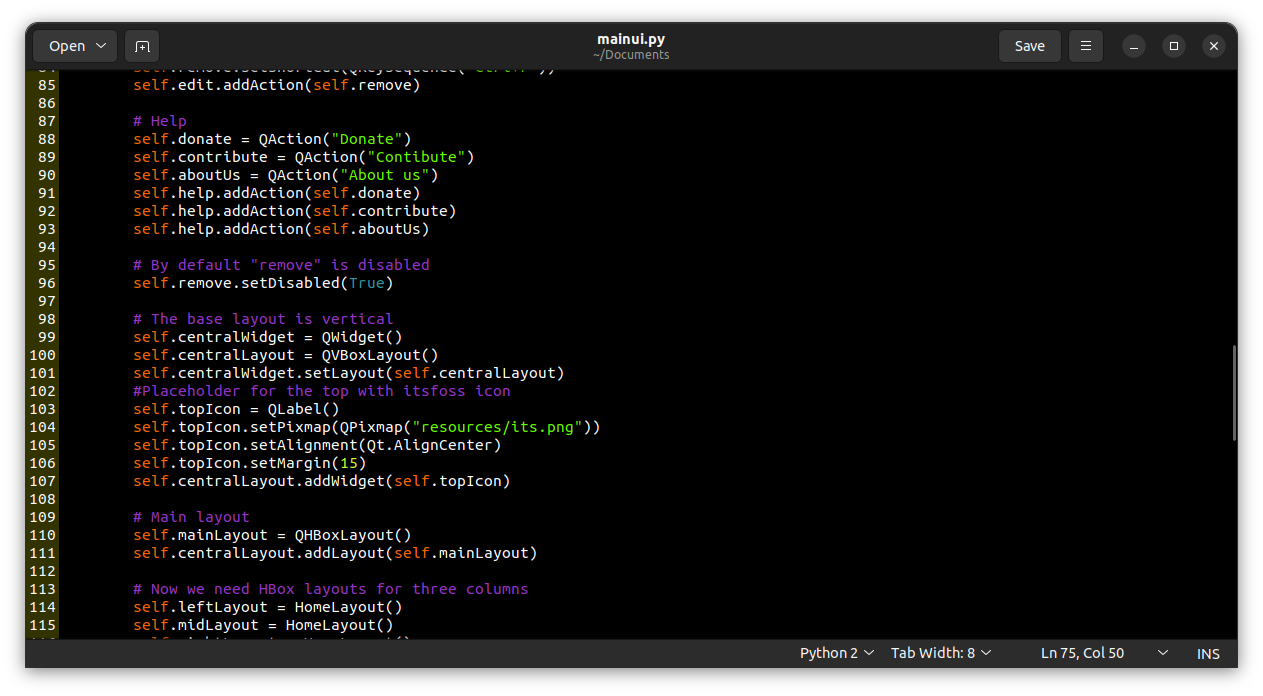
You can get more themes by searching on [GitHub topics](https://github.com/topics/gedit-theme) and repositories.
## More Gedit tweaks
That's just one of the many [ways you can tweak Gedit](https://itsfoss.com/gedit-tweaks/). Here are some more for you to explore.
[10 Tweaks to Supercharge Gedit as Code EditorGedit is a good text editor. Turn it into a good code editor with these tips, tricks and tweaks.](https://itsfoss.com/gedit-tweaks/)

Enjoy Gedit in more colors :) |
16,099 | Fedora Linux 的家族(四):替代下载 | https://fedoramagazine.org/fedora-linux-editions-part-4-alt-downloads/ | 2023-08-16T17:18:45 | [
"Fedora"
] | https://linux.cn/article-16099-1.html | 
Fedora 替代下载是 Fedora 项目提供的一项非常出色的资源,为寻求特定需求或独特用例的用户提供了替代的发行选项。本文将深入探讨 Fedora 替代下载的多样化选择,重点介绍它们的重要性以及它们如何满足 Fedora 社区中的不同需求。你可以在我之前的文章 [介绍不同的 Fedora Linux 版本](https://fedoramagazine.org/introduce-the-different-fedora-linux-editions/) 中找到所有 Fedora Linux 变种的概述。
### 网络安装器
Fedora 网络安装器是一个安装 Fedora Linux 的高效灵活的工具。这是 Fedora 的在线安装器。与主版本使用的封装在立付镜像中的方式不同,该安装器允许你在安装时自定义哪些软件包将被安装。然而,由于要安装的软件包并未封装在此安装器镜像中,因此在安装时需要网络访问以下载选定的软件包。
不要将这个与网络启动混淆,后者是从小型的 [预启动执行环境](https://en.wikipedia.org/wiki/Preboot_Execution_Environment) 启动操作系统或操作系统安装器的一种方法。(尽管这种 [引导程序](https://en.wikipedia.org/wiki/Bootloader) 有可能 [链式加载](https://en.wikipedia.org/wiki/Chain_loading) Fedora 的网络安装器。)
### Torrent 下载
Fedora Torrent 下载利用了 BitTorrent 协议,这是一种点对点的文件共享协议。BitTorrent 使用户可以同时从多个来源下载 Fedora Linux 镜像,而不是依赖于中央服务器进行下载。这种去中心化的方式提高了下载速度,减轻了单个服务器的负担,从而带来了更快、更可靠的下载体验。Fedora Torrent 下载提供了一种快速、可靠、由社区驱动的获取 Fedora Linux 镜像的方式。通过利用 BitTorrent 协议的力量,Fedora 利用了全球用户的集体带宽和资源,从而实现了更快的下载和提高了可靠性。
详细信息可在此链接查看:
>
> **[Torrent 下载](https://torrent.fedoraproject.org/)**
>
>
>
### 替代架构
Fedora 替代架构是 Fedora 项目的一项倡议,旨在通过提供一系列架构选项,扩大 Fedora Linux 操作系统的兼容性。除了标准的 x86\_64 架构外,Fedora 替代架构还为其他架构提供支持,包括 ARM AArch64,Power 和 s390x。该倡议使你可以根据硬件需求选择最适合的架构,使 Fedora Linux 能在多种设备和系统上运行。无论你是拥有树莓派、配备 Power 处理器的服务器,还是其他专用硬件,Fedora 替代架构都确保你能获得满足特定需求的定制 Fedora Linux 体验。
详细信息可在此链接查看:
>
> **[替代架构](https://alt.fedoraproject.org/alt/)**
>
>
>
### Fedora Cloud
在我写完介绍主要 Fedora Linux 版本的这个系列的初始帖子后,[Fedora Cloud 镜像已恢复为完整版状态](https://fedoraproject.org/wiki/Changes/RestoreCloudEdition)。Fedora 替代下载页面上仍有一些指向 Fedora Cloud 镜像的链接。但是它们将很快被移除。现在获取最新的 Fedora Cloud 镜像的正确地点是:
>
> **[Fedora Cloud 镜像](https://fedoraproject.org/cloud/download/)**
>
>
>
Fedora Cloud 镜像是 Fedora 项目为云环境使用提供的镜像集合。Fedora Cloud 镜像特别设计用于在云中以高效和最佳性能运行应用程序。使用 Fedora Cloud 镜像,你可以快速部署并在云中运行应用程序,而无需花费时间从头开始配置操作系统。Fedora Cloud 镜像也在可扩展性方面提供了灵活性,允许你根据应用程序的需求轻松调整资源的大小和容量。
### 测试镜像
Fedora 测试镜像是一系列专为测试和贡献 Fedora Linux 开发而设计的专用系统镜像。这些镜像允许你测试最新的特性,探索 Fedora Linux 的最近更改,并报告遇到的任何问题。使用 Fedora 测试镜像,你可以通过提供有价值的反馈和贡献,积极参与 Fedora Linux 的开发。
你参与测试和贡献 Fedora 测试镜像在维护和提高 Fedora Linux 的质量和可靠性方面起着至关重要的作用。通过汇报问题,测试软件和提供反馈,你可以帮助 Fedora 开发者修复漏洞,增强性能,确定需要进一步改进和开发的领域。Fedora 测试镜像为你提供了一个方便且安全的方式直接参与 Fedora Linux 的开发,从而加强社区,为所有 Fedora 用户带来更好、更可靠的操作系统。
### Rawhide
Fedora Rawhide 是 Fedora Linux 操作系统的开发分支。它提供了一个持续演进和尖端的 Fedora Linux OS 版本。它作为新特性、增强和软件更新的测试场地,这些更新都是针对包含在未来 Fedora Linux 稳定版本中的。Fedora Rawhide 提供了对最新软件包的早期访问,让用户能够走在技术的前沿,并参与到 Fedora Linux 的测试和完善中。
使用 Fedora Rawhide 既有好处也有考量因素。一方面,它为早期采用者、开发者和贡献者提供了一个平台,他们可以在此测试和对即将到来的特性和变更提供反馈。这有助于在将它们包含在稳定版本之前识别和解决问题。另一方面,由于 Fedora Rawhide 持续处于开发中,可能会遇到 bugs、不稳定和兼容性问题。因此,只推荐给熟悉排错并积极为 Fedora 社区贡献的经验用户。
详细信息可在此链接查看:
>
> **[Fedora Rawhide](https://docs.fedoraproject.org/en-US/releases/rawhide/)**
>
>
>
### 结论
Fedora 替代下载提供了一系列令人印象深刻的替代发行版,满足了 Fedora 社区内多样化的需求。无论是通过 Fedora 定制版、Fedora 实验室、Fedora 重混版、Fedora Silverblue 还是 ARM 版本,用户可以找到满足他们需求、偏好和用例的专门分发。这种灵活性和社区驱动的方式使 Fedora 替代下载成为 Fedora Linux 爱好者的宝贵资源,促进了 Fedora 生态系统内的创新和定制。你可以在下面找到关于 Fedora 替代下载的完整信息:
>
> **[Fedora 替代下载](https://alt.fedoraproject.org/)**
>
>
>
*(题图:MJ/c93c33ec-79e4-4815-ac65-d78b422b854f)*
---
via: <https://fedoramagazine.org/fedora-linux-editions-part-4-alt-downloads/>
作者:[Arman Arisman](https://fedoramagazine.org/author/armanwu/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
| 200 | OK | Fedora Alt Downloads is a remarkable resource provided by the Fedora Project, offering alternative distribution options for users seeking specific requirements or unique use cases. This article will delve into the diverse selection of Fedora Alt Downloads, highlighting their significance and how they cater to different needs within the Fedora community. You can find an overview of all the Fedora Linux variants in my previous article [Introduce the different Fedora Linux editions](https://fedoramagazine.org/introduce-the-different-fedora-linux-editions/).
## Network Installer
The Fedora Network Installer is an efficient and flexible tool for installing Fedora Linux. This is Fedora’s online installer. Unlike the baked-in Live images that the main editions use, this installer allows you to customize which software packages will be installed at installation time. However, because the packages to be installed are not baked into this installer image, network access will be required at installation time to download the selected packages.
Don’t confuse this with network booting which is a method of initiating an operating system or operating system installer from a small [Preboot Execution Environment](https://en.wikipedia.org/wiki/Preboot_Execution_Environment). (Though it is possible for that sort of [bootloader](https://en.wikipedia.org/wiki/Bootloader) to [chain-load](https://en.wikipedia.org/wiki/Chain_loading) Fedora’s network installer.)
## Torrent Downlods
Fedora Torrent Downloads utilize the BitTorrent protocol, which is a peer-to-peer file sharing protocol. Instead of relying on a central server for downloads, BitTorrent enables users to download Fedora Linux images from multiple sources simultaneously. This decentralized approach enhances download speeds and reduces strain on individual servers, resulting in a faster and more reliable download experience. Fedora Torrent Downloads offer a fast, reliable, and community-driven method for obtaining Fedora Linux images. By harnessing the power of the BitTorrent protocol, Fedora leverages the collective bandwidth and resources of users worldwide, resulting in faster downloads and improved reliability.
Details are available at this link: [https://torrent.fedoraproject.org/](https://torrent.fedoraproject.org/)
## Alternate Architectures
Fedora Alternate Architectures is an initiative by the Fedora Project that aims to expand the compatibility of the Fedora Linux operating systems by offering a range of architecture options. In addition to the standard x86_64 architecture, Fedora Alternate Architectures provides support for alternative architectures, including ARM AArch64, Power, and s390x. This initiative allows you to select the architecture that best suits their hardware requirements, enabling Fedora Linux to run on a diverse range of devices and systems. Whether you have a Raspberry Pi, a server with Power processors, or other specialized hardware, Fedora Alternate Architectures ensures that you have a tailored Fedora Linux experience that meets your specific needs.
Details are available at this link: [https://alt.fedoraproject.org/alt/](https://alt.fedoraproject.org/alt/)
## Fedora Cloud
After I wrote my initial post in this series that introduced the main Fedora Linux editions, [Fedora Cloud was restored to full edition status](https://fedoraproject.org/wiki/Changes/RestoreCloudEdition). There are still some links to the Fedora Cloud images on the Fedora Alt Downloads page. But they will be removed soon. The correct place to get the latest Fedora Cloud images is now [https://fedoraproject.org/cloud/download/](https://fedoraproject.org/cloud/download/).
Fedora Cloud images are a collection of images provided by the Fedora Project for use in cloud environments. Fedora Cloud images are specifically designed to run applications in the cloud with efficiency and optimal performance. By using Fedora Cloud images, you can quickly deploy and run applications in the cloud without the need to spend time configuring the operating system from scratch. Fedora Cloud images also provide flexibility in terms of scalability, allowing you to easily adjust the size and capacity of resources according to the needs of your applications.
## Testing Images
Fedora Testing Images are a collection of specialized system images designed for testing and contributing to the development of Fedora Linux. These images allow you to test the latest features, explore the recent changes in Fedora Linux, and report any issues encountered. By using Fedora Testing Images, you can actively participate in the development of Fedora Linux by providing valuable feedback and contributions.
Your participation in testing and contributing to Fedora Testing Images plays a vital role in maintaining and improving the quality and reliability of Fedora Linux. By reporting issues, testing software, and providing feedback, you can assist Fedora developers in fixing bugs, enhancing performance, and identifying areas for further improvement and development. Fedora Testing Images provide an easy and secure way for you to engage directly in the development of Fedora Linux, strengthening the community and resulting in a better and more reliable operating system for all Fedora users.
## Rawhide
Fedora Rawhide is the development branch of the Fedora Linux operating system. It provides a continuously evolving and cutting-edge version of the Fedora Linux OS. It serves as a testing ground for new features, enhancements, and software updates that are targeted for inclusion in future stable releases of Fedora Linux. Fedora Rawhide offers early access to the latest software packages, allowing users to stay at the forefront of technology and contribute to the testing and refinement of Fedora Linux.
Using Fedora Rawhide comes with both benefits and considerations. On one hand, it provides a platform for early adopters, developers, and contributors to test and provide feedback on upcoming features and changes. This helps identify and address issues before they are included in stable releases. On the other hand, since Fedora Rawhide is constantly under development, it may encounter bugs, instability, and compatibility issues. Therefore, it is recommended only for experienced users who are comfortable with troubleshooting and actively contributing to the Fedora community.
Details are available at this link: [https://docs.fedoraproject.org/en-US/releases/rawhide/](https://docs.fedoraproject.org/en-US/releases/rawhide/)
## Conclusion
Fedora Alt Downloads provides an impressive array of alternative distributions, catering to diverse needs within the Fedora community. Whether it’s through Fedora Spins, Fedora Labs, Fedora Remixes, Fedora Silverblue, or ARM editions, users can find specialized distributions that suit their requirements, preferences, and use cases. This versatility and community-driven approach makes Fedora Alt Downloads a valuable resource for Fedora Linux enthusiasts, fostering innovation, and customization within the Fedora ecosystem. You can find complete information about Fedora Alt Downloads at [https://alt.fedoraproject.org/](https://alt.fedoraproject.org/)
## Cornel Panceac
‘ including ARM, AArch64, ‘
You meant ‘ARM AArch64’ (without the comma), right?
Also: ‘ including ARM, AArch64, Power, and s390x.’
What means ‘including’ ? Is there anything else beside ARM AArch64, Power and S390x ?
## Gregory Bartholomew
Thanks for pointing out that typo Cornel. I’ve removed the extra comma.
There is RISC-V. But I don’t think it is officially supported yet.
## Paul A. Gureghian
I think it might be ARM 32 bit
## Gregory Bartholomew
According to the wiki page (https://fedoraproject.org/wiki/Changes/RetireARMv7) Fedora stopped supporting ARM 32 bit in June of 2023.
## iqk2d0r6r5
Love the alternative downloads and have been using them as well as the spins for a long time.
Really wish there was one additional alternative download that just contained a minimal fedora install’s entire filesystem packaged as some kind of tar/tar.xz/etc archive, similar to what Arch does.
This would be great for the use-case of doing manual partition setup with cli-tools and then manually installing to said partitions. Haven’t tried the new web-based Anaconda yet but I know the old GTK-based one makes doing this sort of thing next to impossible and due to the way BLS entries are handled in Anaconda, things like Fedora + Fedora dual-boot are very difficult to do under Anaconda (there are tickets mentioning it).
## Gregory Bartholomew
If you are formatting your drive manually from another Fedora OS, then
dnf ‐‐installroot=<target-partition-mountpoint> group install “Minimal Install”
dnf ‐‐installroot=<target-partition-mountpoint> install dnf5 kernel
should give you something
closeto what the Fedora Minimal image has.If you want to be a little more exact, you could examine the following kickstart scripts that are used to generate the Fedora Minimal image.
https://pagure.io/fedora-kickstarts/blob/main/f/fedora-disk-base.ks
https://pagure.io/fedora-kickstarts/blob/main/f/fedora-minimal-common.ks
https://pagure.io/fedora-kickstarts/blob/main/f/fedora-disk-minimal.ks
## iqk2d0r6r5
Thanks Gregory
Those are decent suggestions. I have tried the –installroot option before but if I recall correctly, I had run into some odd behavior with it on occasion (system not booting after install usually). Kickstart might be an option but had seemed a bit involved when I had attempted to decipher it in the past.
All the same, I still wish that the minimal install as a tar file existed as one of the alt download options as that would be far simpler than either the –installroot or kickstart approaches, usable from any live disc (not just fedora ones), and likely significantly faster since it would simply be unpacking a system. No clue where the proper place to propose such a thing would be but I assume it would be a moot point unless I had the time and know-how to build it and was willing to maintain it myself.
My current solution is to do a minimal install, then tar the filesystem myself. This works for reinstalls on the same pc but I haven’t tried it across hw builds (I suspect it would run into issues). Even this is a bit of a chore though so I don’t really bother with it every release, only when I have the time and energy to mess with different setups; even then I tend to reuse the one capture and then just do an in-place upgrade if I can get away with it.
## Gregory Bartholomew
Yes, configuring the bootloader is a separate (and complex) step from downloading/unpacking the root filesystem. That would be true of a tar archive as well, which is probably why Fedora doesn’t normally distribute their OS that way. They are adding official support for sd-boot in the upcoming release, however, and that might simplify the steps required to create the “bootloader” partition enough that people could do installs from simple file archives as you suggest. |
16,101 | 近乎零边际成本的社会及其对我们为何工作的影响 | https://opensource.com/open-organization/22/5/near-zero-marginal-cost-societies-and-impact-why-we-work | 2023-08-17T11:12:57 | [
"写作共享"
] | https://linux.cn/article-16101-1.html | 
>
> 随着我们的工作与生活环境已经物联网化,能源消耗将会接近于零,而社区协作将成为关键。
>
>
>
我拜读了 <ruby> 杰里米·里夫金 <rt> Jeremy Rifkin </rt></ruby> 的书籍《<ruby> <a href="https://www.goodreads.com/book/show/18594514-the-zero-marginal-cost-society"> 零边际成本社会——一个物联网、合作共赢的新经济时代 </a> <rt> The Zero Marginal Cost Society: The Internet of Things, the Collaborative Commons, and the Eclipse of Capitalism </rt></ruby>》(LCTT 译注:中文出版信息可以在 [此处](https://www.bkpcn.com/Book/Bk_OneBook.aspx?id=2014000629) 获取),该书主要讨论开放组织原则,尤其是社区创建。里夫金还在书中讨论了绿色能源时代的未来以及能源在物流中的使用。本文是三篇系列文章中的第二篇。在我先前的文章中,我讨论了 <ruby> 协作共享 <rt> Collaborative Commons </rt></ruby>。本文,我将讨论它对能源生产与供给的影响。
里夫金相信,接下来的 25 年间,家庭供暖、电气设备、电力行业、车辆驾驶、整体经济运行等各行各业中的大部分都将采用近乎免费的在地太阳能、风能与地热能。这一过程已经在个人及微型电站领域开始了,估计会在 2 - 8 年后收回投资。
管理几乎免费的绿色能源的最优组织架构是什么样的呢?此外,通过智能化的通讯与能源系统,组织可以在世界各地发展自己的业务,并且通过洲际能源互联网共享能源。最重要的是,可以仅以目前全球制造业巨头的一点儿零头生产和销售产品。
### 物联网已近
如里夫金所言,物联网(IoT)能够连接每一台设备、每一项业务、每一幢住处、每一辆交通工具,将所有这些连接在一张智能网络中,这一网络不仅包括目前所见的通讯网络,还包括未来的能源网络以及物流网络。所有这些网络将集成在单一的运行系统中。能源利用将被完全监控。里夫金相信 10 年内(到 2025 年)大量的智能化的能源测量设备将投入使用。所有这些投资将至少能够降低当前工业系统中 10% 的浪费。
由于设备集成的传感器与制动器的成本的降低,所有这些都将成为可能。射频识别(RFID)芯片的价格在 2012-2013 年间已经下降了 40%。微机电系统(MEMS),包括陀螺仪、加速度计、压力传感器等,的价格也在过去的 5 年间(直至 2015 年本书出版时)降低了 80-90%。
这将会使单个个体的个人设备设备连接数量提升到大约 1000 个。这种连接正是现在的年轻人所钟爱的,完全融入一个虚拟的全球公共广场中来分享他们的一切。他们在透明、协作与包容中茁壮成长,并注意保持适当的隐私水平。因此,可以想见,协作共享正当其时。
### 指数曲线增长
问题:你是想一次性拿到 1,000,000 美元还是想拿能够在接下来的 30 天内每一天都翻倍的 1 美元?(30 天后,1 美元将变成 536,870,912 美元,是 1,000,000 美元的 500 倍还多)31 天后,这笔钱将超过十亿美元。指数增长速度惊人。里夫金认为这正是成本如此快速降低的原因。这将导致整个化石能源工业投资都变成搁浅资产。鉴于这一境况将是协作共享的理想场景,我们应当现在就开始计划使用所有的开放组织原则进行协作共享。
### 未来,免费的能源网络
当前,互联网上充满了可供学习的免费信息,只要你尝试寻找它。下一步将是能源免费(太阳能、风能、地热能、生物质能、水能)。里夫金认为,在初始投资(研究、开发与部署)之后,免费能源的单位成本将快速降低。信息互联网与近乎零成本的可再生性也会引入能源互联网,为家庭、办公场所以及厂区等提供电力。理想情况下,能源可以提供给建筑并部分以氢能的形式存储,分布在绿色电网中,并与插电式零排放交通工具相连接。可再生能源的发展建立了一个由五大支柱组成的结构,这有助于让数以亿计的人口在物联网时代的世界中以接近零边际成本的方式共享能源。
### 太阳能
如果你开始收集来自太阳的能量,能量收集设施仅仅需要获取到达地球的太阳能量的 0.1%,就可以提供六倍于目前全球能量消耗的能量。
<ruby> <a href="https://us.sunpower.com"> 太阳动力公司 </a> <rt> SunPower Corporation </rt></ruby> 开展以上业务。它支持家庭能源生产者。太阳能光伏电池的价格随着工业产能的翻番大概会降低 20%。太阳能板的数量正在上升,而单片太阳能板的捕获效率则也在上升。将来也期待会开发出更薄的太阳能板,如纸般纤薄的太阳能片。最终将来将会出现太阳能工厂以及太阳能窗户。
生成超出的能量后,必须将其售出、存储在电池中亦或者是用于制氢。这一技术已经引入市场,并将在不久的将来占据市场的主导地位。仅仅依靠这一技术,零边际成本的电力已经触手可及。
### 风力发电
自上世纪 90 年代始,风力发电经历了指数形增长,目前(截止 2015 年)已经接近化石能源与核能的发电水平。随着风力发电机的生产、安装与维护成本的不断降低,风电容量大约每两年半翻一番。因此随着太阳能与风能资源的增加,政府将不再需要以关税资助风电与太阳能发电行业。
<ruby> <a href="https://www.energywatchgroup.org"> 能源观察组 </a> <rt> Energy Watch Group </rt></ruby> 正在跟踪这一趋势。根据里夫金的说法,地热能、生物质能、波浪与潮汐能将可能在下一个十年里进入它们各自指数增长过程中的陡峭上升阶段。他相信这些都将在 21 世纪上半叶发生。如果到 2028 年,新能源装机容量可以翻八番或者更多,能源生产中的 80% 都将来自可再生资源。
### 协作时代不久即将到来
基于上述能源的发展,社会工作环境与居住环境正在改变。摘引 <ruby> <a href="https://www.forbes.com/sites/ricoheurope/2020/02/06/moving-from-the-information-age-to-the-collaboration-age"> 协作时代 </a> <rt> collaborative age </rt></ruby> 的说法:
>
> 这一方式可以保证人们之间无障碍的进行任务协作。人员与机器可以无缝协作。而自动化,也即机器之间的协作,也会成为关键。正确地应用这些要素的行业将能够扩大员工的满足感,并吸引最好的人材。由于日常任务的自动化以及更小的办公空间需求,这将降低运营成本。
>
>
>
### 实现转型
这听起来很好,但商业如何才能从信息时代过渡到合作时代?一个途径将是通过3D 打印技术实现的去中心化生产 <ruby> <a href="https://en.wikipedia.org/wiki/3D_printing"> 增材制造 </a> <rt> additive manufacturing </rt></ruby>,不需要去除材料,造成浪费。
不通过商品输送,未来很多商品都可以实现在地制造,只需要传输相应的软件。这可以完全避免物流成本,而且可以使得产品制造可以在靠近终端市场的地区就地完成。就此而言,新开发的熔融塑料、熔融金属以及其他的打印耗材将可以用于制造。这赋予了 3D 打印机制造成千上万产品的能力(比如珠宝、飞机零部件以及假肢)。
### 中心化制造与分布式制造,里夫金项目的到来
里夫金相信:通过物联网经济以及几乎零边际成本的全球互联网站点,低商业成本是可能的。
1. 在地 3D 生产过程几乎不需要人力参与(基于 “<ruby> 信息制造 <rt> infofacture </rt></ruby>” 而不是工业制造)。人们收发在地制造所需的信息,就像日常下载音乐一样,你接收的仅仅是代码而已。
2. 3D 打印所需的代码是开源的,人们可以学习并改进设计,在更广泛的程度上成为一名自助生产者(不存在知识产权保护的藩篱)。这在接下来的几十年里将带来指数式的增长,以更低的价格以及近乎为零的边际成本提供更复杂的产品。
3. 减材制造过程(目前的制造过程)存在很大的浪费,在每一道工序中都产生了大量的废料。(仅有 1/10 的材料是所需要的。这些材料可以在地化地在任何地方从基本粒子合成出来,比如再生玻璃、纤维产品、陶瓷以及不锈钢等。复合纤维混凝土挤出后可以自由成型,其强度足以构建承重墙[有望在 20 年内实现]。)
4. 3D 打印工艺需要更少的移动部件,且几乎不需要备件。因此,昂贵的重组与产线转换所占用的时间延迟所带来的影响将会更加有限。
5. 材料将会更加耐用,更加可回收利用,且污染更小。
6. 由于其低物流成本与低能耗的特点,基于物联网的在地化分布式生产将以指数速率在世界范围内传播。
里夫金引用了 [Etsy][<https://www.etsy.com/>] 作为这种模式的一个例子。你可以找到你感兴趣的事物,并利用他们的网络在当地制造它。他们出售相应的代码,而你可以在当地供应这些产品。
里夫金认为未来,中小规模的 3D 公司可以通过信息制造生产更复杂的产品,它们因而可能在在地的技术园区内形成合适供应链规模的产业集群(另一种形式的社区开发)。下面是目前的案例:
1. [RepRap](https://reprap.org/wiki/RepRap): 一种能够制造自身以及自身所有零件的 3D 打印制造设备。
2. [Thingiverse](https://www.thingiverse.com): 最大的 3D 打印社区。基于 GPL 与 CC 许可共享 3D 打印模型。
3. Fab Lab: 开源的制造业点对点学习网站。它已经引入到发展中国家当地的偏远社区。
4. 3D 打印的汽车([Urbee vehicle](https://www.popularmechanics.com/cars/a9645/urbee-2-the-3d-prinhttps://www.popularmechanics.com/cars/a9645/urbee-2-the-3d-printed-car-that-will-drive-across-the-country-16119485))已经在测试了。
5. [KOR EcoLogic](https://phys.org/news/2013-02-kor-ecologic-urbee-car-d.html) 有一种城市电动汽车。
### 创客的行动准则
下面是这些生态系统所遵循的原则:
1. 它们使用开源共享软件。
2. 它们推崇合作学习文化。
3. 它们相信可以构建一个自给自足的社区。
4. 它们致力于可持续生产实践。
### 工作与协作共享的未来
当技术取代了工人,资本投入也就取代了劳动投入。2007 年相比 20 年前,商业公司使用的计算机与计算机软件的数量已经增长了 6 倍,单位时间内雇用劳动所使用的资本量也翻了一番。机器人劳动力的应用正在上升。中国、印度、墨西哥以及其他的新兴经济体已经认识到世界上最廉价的劳动力也没有像可以取代它们的信息技术、机器人技术以及人工智能技术那样廉价、高效和具有生产力。
回到里夫金的观点,第一次工业革命结束了奴隶制与农奴制,第二次工业革命造成了农业劳动与手工业劳动的极大萎缩。里夫金认为第三次工业革命将导致制造业、服务业中的大规模雇用劳动力的降低,也会导致大部分知识部门中雇用的专业劳动力的减少。
里夫金相信充沛的零边际成本的经济将会改变我们对经济运行过程的认知。他认为传统的资方与雇方、卖方与买方的范式将会崩溃。消费者将开始自行制造产品(同时也为有限的其他人),从而消除消费者之间的区别。在边际成本逐渐降低到零的共享协作中,这样既是生产者又是消费者的产消者将很快能生产、消费以及互相分享他们自己的商品与服务,从而带来超越传统的资本主义市场模式的组织未来的经济生活的全新方式。
里夫金预测未来,更加重要地是共享协作,并且在市场经济中这将会和努力工作一样重要(一个人的能力在于合作能力,而不仅仅是努力工作)。社交资本的积累将和市场资本的积累同等重要。社区的依赖以及对超越与价值的探索将成为对个人的物质财富的衡量标准。我们以上列明的 [开放组织原则](https://theopenorganization.org/definition/open-organization-definition/) 在未来将指数化的变得愈发重要。
物联网将把人类从资本主义市场经济中解放出来,让人们在共享协作中追求非物质的共享利益。在近乎零边际成本的社会中,虽然不是所有的基础物质需求,但是我们的大量基础物质需求几乎都将可以零成本满足。这个未来社会将会超乎想象的物质丰富。
### 产消者与智能社会的到来
里夫金在文中认为,随着资本主义经济在一些全球性的大宗货物上的没落,在共享协作的社会中,买卖双方将让位于 <ruby> 产消者 <rt> prosumer </rt></ruby>,所有权将让位于开源共享,使用权将比所有权更加重要,市场将由网络所取代,信息供应、能源生产、产品生产、学生教育的边际成本将几乎为零。
### 能源互联网已经在路上
物联网金融不是来自于富有的资本家或者企业股东,而是来自于成千上万的消费者与纳税人。互联网不为任何人独有。互联网之所以能够运行,仅仅是因为建立了一套商定的协议允许网络中的计算机可以互相通信。这对于每一个已经支付了网络使用费用的人来说就像是一个虚拟的公共广场。接下来的分布式可再生能源也会像类似的方式分布。在入网收费以及其他融资方式下,政府将承担初始的研究费用,但是在这一固定投资之后,大众将能够免费接入并使用它。一旦发生,政府中心化的运营方式将会转向分布式所有。[美国电力科学研究院](https://www.epri.com) 正在研究如何在接下来的 20 年间建立一个国家能源互联网。
这不仅仅是电力供应那样简单。每一幢建筑中的每一台设备都将装备连接到物联网的传感器与软件,提供产消者以及网络上其他人的实时的用电信息。这一能源互联网将能够感知每一台设备任一时刻的用电数据——空调、洗衣机、洗碗机、电视、吹风机、烤箱、烤炉以及冰箱等等。
这不是将会到来的情景,而是正在发生。它不仅仅是正在考虑当中,而且是正在践行当中。[Intwine Energy](https://www.intwineconnect.com) 已经可以提供上述过程。一批年轻的 [社会企业家](https://www.cleanweb.co) 现在正在使用社交媒体来鼓励他们的同龄人创造、运营和使用这个能源互联网。
### 物资充沛超出我们需求的新世界
里夫金认为我们必须开始展望一个完全不同的新世界。想像一下在这个世界里,你可以放弃那些你曾经必须付费购买的或者是必须以一定利润出售的东西。没有人会向我们收取互联网电话费用。他相信这些放弃的商品需要无法像电信、公路、桥梁、公立学校与公立医院那样由政府提供,也不能完全当作私人财产来买卖。这些商品必须由以一定规则、责任以及共同利益(信息、能源、在地生产与在线教育)凝聚的社区来供应。这些商品的交换不应由市场或者政府主导,而应基于 [公地悲剧](https://blogs.pugetsound.edu/econ/2018/03/09/comedy-of-the-commons) 的原因,由网络中的共同体负责,它管理和执行分布式、点对点、横向扩展的经济活动。
里夫金感到共享协作作为管理主体是极其重要的。这正是在地(项目)发挥领导力之处。目标、过程、任务以及责任都必须在同意以及确认后成功执行。进一步而言,“社会资本”也是主要因素,必须要广泛引进并深化质量。社区内部的交换、交互以及贡献远比向遥远的资本市场进军更加重要。如果情况如此,那么我们的 [开组织领导力](https://github.com/open-organization/open-org-leaders-manual/raw/master/second-edition/open_org_leaders_manual_2_3.pdf) 将会十分重要。
### 公共广场与私有权
“至少在互联网之前,公共广场是我们交流,社交,陶醉于彼此陪伴,建立公共纽带以及创造社会资本与信任的地方。”历史上,日本的乡村就是这样建立的,以应对像台风、地震这样的自然、经济或者政治灾难。他们将公共利益置于个人利益之上。这正是社区的开源组织原则的全部。
被接纳的权利,互相接触的权利,也就是共同参与的权利是所有参与者的基础权利。私有财产,即圈占、拥有和排除的权利,只是对标准规范的一种有限制的偏离。由于一些原因,在当前的现代社会中获取大量的私有财产的权利是重要的,里夫金认为在接下来的时间这将会得到反转。
里夫金在书中写道,世界将在下列领域公共化。
1. 公共广场公共化
2. 土地公共化
3. 虚拟公共化
4. 知识公共化(语言、文化、人类的知识与智慧)
5. 能源公共化
6. 电磁频谱公共化
7. 海洋公共化
8. 淡水公共化
9. 大气公共化
10. 生物圈公共化
过去 200 年的资本主义,市场的封闭化、私有化和商品化必须审视。 在透明、无等级和协作的文化中,他们如何才能最有效? 归结为两种观点,资本主义(我拥有,属于我的,你不能用)和协作主义(任何人可用,有相应的使用规则与使用指南,因而任何人有享有公平份额)。 今天的合作社在这方面很擅长,比如 [国际合作社联盟(ICA)](https://www.ica.coop/en)。 合作社必须为更大的社区利益生成动力,而且这种动力必须大于任何利润动机。 这是他们面临的挑战,但这并不新鲜,因为现在地球上七分之一的人都在某种合作社中。
正如我在本文中所展示的,物联网将成为我们的工作和生活环境。 此外,能源成本预计将接近于零。 随着这些变化,社区协作与合作将变得比努力工作更加重要。 在本系列的最后一部分中,我将探讨物流和其他经济活动中的协作共享。
*(题图:MJ/00ed9931-0d49-4cbe-82d1-ebd28b758880)*
---
via: <https://opensource.com/open-organization/22/5/near-zero-marginal-cost-societies-and-impact-why-we-work>
作者:[Ron McFarland](https://opensource.com/users/ron-mcfarland) 选题:[lkxed](https://github.com/lkxed) 译者:[CanYellow](https://github.com/CanYellow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I have read Jeremy Rifkin's book [The Zero Marginal Cost Society: The Internet of Things, the Collaborative Commons, and the Eclipse of Capitalism](https://www.goodreads.com/book/show/18594514-the-zero-marginal-cost-society), which has a strong connection to open organization principles, particularly community building. Rifkin also writes about the future of green energy generation and energy use in logistics. This is the second of three articles in this series. In my previous article, I examined the Collaborative Commons. In this article, I look at its impact on energy production and supply.
Within the next 25 years, Rifkin believes most of our energy for home heating, running appliances, powering businesses, driving vehicles, and operating the whole economy will be nearly free with on-site power solar, wind and geothermal energy generation. This is starting already, through both individual and micropower plants. The payback is around two to eight years.
What would be the best organizational structure to manage nearly free green energy? Furthermore, through an intelligent communication and energy system, an organization could generate business anywhere in the world, and share energy across a continental energy internet. On top of that, it could produce and sell goods at a fraction charged by global manufacturing giants.
## The Internet of Things is on the way
According to Rifkin, the Internet of Things (IoT) will connect every machine, business, residence, and vehicle in an intelligent network that consists of not just a communications internet like now, but in the future an energy internet, and a logistics internet. They will all be embedded in a single operating system. Energy use will be completely monitored. Rifkin believes that within 10 years, many smart energy meters will be in use (by 2025). All this investment will reduce at least 10% of the waste in the current industrial system.
All this will be possible with the reduction of costs of sensors and actuators embedded in devices. Radio-frequency identification (RFID) chip prices have fallen by 40% in around 2012-2013. Micro-electromechanical system (MEMS), including gyroscopes, accelerometers, and pressure sensors, have also dropped by 80-90% in price over the past five years (up to 2015 when this book was published).
This will increase device connections, to as many as 1,000 connections on one person's devices, appliances, and facilities. This connection is what young people love, total inclusion in a global virtual public square to share everything. They thrive on transparency, collaboration, and inclusivity with care taken to an appropriate level of privacy. So, you can see, the time is right for the growth of a Collaborative Commons in society.
## Exponential curve
Question: Would you accept US $1,000,000 today or US $1.00 that doubled every day for 30 days? (In 30 days it will be US $536,870,912. That is 500 times more). In 31 days, over one billion. Exponential growth is deceptively fast. That is how fast costs are coming down according to Rifkin. This will turn the entire fossil fuel industry investments into stranded assets. We should be planning for the Collaborative Commons using all open organization principles now, as the situation will be ideal for them very soon.
## Next, a free energy internet
At this point in time there is free information for learning if you look for it. The next step is free energy (solar, wind, geothermal, biomass, hydro). After initial investments (research, development, deployment), Rifkin forecasts that unit costs will rapidly come down. The information internet and near zero-cost renewables will merge into the energy internet, powering homes, offices, and factories. Ideally, there will be energy that's loaded into buildings and partially stored in the form of hydrogen, distributed over a green-electricity internet, and connected to plug-in, zero-emission transportation. The development of renewable energy establishes a five pillar mechanism that will allow billions of people to share energy at near zero marginal cost in the IoT world
## Solar energy
If you start collecting energy from the sun, facilities only need to obtain 00.1% of the sun's energy that reaches the Earth. That would provide six times the energy we now use globally.
[SunPower Corporation](https://us.sunpower.com) is one company doing that. It supports making homes energy producers. The price of solar photovoltaic (PV) cells tends to drop by 20% for every doubling of industry capacity. Solar panels are increasing, and their ability to capture more energy per panel is increasing. Expect to see the development of thinner solar panels, and paper thin solar sheets. Eventually there will be solar energy paint and solar energy windows in the future.
When too much energy is generated, it must be sold elsewhere or stored in batteries or used to produce hydrogen. This technology is coming to the market and will dominate it very soon. With these technologies alone, electricity is on the way to have zero marginal cost.
## Wind power generation
Wind power has been growing exponentially since the 1990s, and is now nearing fossil fuel and nuclear power generation levels (as of 2015). With the lowering costs of windmill production, installation, and maintenance, wind power is doubling every 2-½ years. With the increase of solar and wind energy sources, governments do not need to subsidize them with tariffs any longer.
[Energy Watch Group](https://www.energywatchgroup.org) is tracking this. According to Rifkin geothermal energy, biomass, and wave and tidal power will likely reach their own exponential takeoff stage within the next decade. He believes that all this will happen in the first half of the twenty-first century. If this capacity doubles eight more times, by 2028, 80% of all energy generation will be from these renewables.
## The collaborative age will soon be here
With all the above developments, society's working and living environment are changing. According to the [collaborative age](https://www.forbes.com/sites/ricoheurope/2020/02/06/moving-from-the-information-age-to-the-collaboration-age): "This means ensuring that people can collaborate on tasks without friction. That humans and machines work seamlessly together. And automation — machine to machine collaboration — will be crucial. Those businesses that get these elements right will be able to boost employee satisfaction and attract the best talent. They will reduce costs by automating mundane tasks and by requiring a smaller office footprint. The social impact-focused organizations that [Laura Hilliger](http://www.zythepsary.com/author/admin) and [Heather Leson](https://ch.linkedin.com/in/heatherleson) write about how it will take advantage of this new age. Download the PDF of their article here: [Opening up social impact-focused organizations](https://raw.githubusercontent.com/open-organization/open-perspectives/main/opening-up-social-impact-focused-organizations/opening-up-social-impact-focused-organizations.pdf).
## Making the transition
It sounds good, but how do businesses transition from the information age to the collaboration age? One area will be in decentralized production through 3D printing technology ([additive manufacturing](https://en.wikipedia.org/wiki/3D_printing), not cutting away and creating waste).
Instead of shipping goods, in the future, software will be shipped for many items to be manufactured locally, avoiding all shipping costs and making manufacturing become on-site near where the market need is. Locally, newly developed molten plastics, molten metal, or other feedstock inside a printer will be used for fabrication. This will give one 3D printer the ability to produce tens of thousands of products (like jewelry, airplane parts, and human prostheses).
## Centralized manufacturing vs local production which Rifkin projects will come
Rifkin believes lower marketing costs are possible by using the IoT economy and using global internet marketing sites at almost zero marginal cost.
-
There is little human involvement in the local 3D process (giving the name "infofacture" rather than manufacture. They ship the information required for local manufacturing, like downloading music today. It is just code that you receive.
-
The code for 3D printing is open source, so people can learn and improve designs, becoming further prosumers in a wide range of items (no intellectual-property protection barriers). This will lead to exponential growth over the next several decades, offering more complicated products at lower prices and near zero marginal cost.
-
There is great waste with subtraction processes (current manufacturing processes) producing great waste with each process. (1/10 the materials required. This material could be developed from subatomic particles that are available anywhere in the local environment, like recycled glass, fabrics, ceramics, and stainless steel. Composite-fiber concrete could be extruded form-free and be strong enough for building construction walls [probably available in two decades].)
-
3D printing processes have fewer moving parts and less spare parts. Therefore, expensive retooling and changeover delays will be less extensive.
-
Materials will be more durable, recyclable, and less polluting.
-
Local distributed production, through IoT, will spread globally at an exponential rate with little shipping cost and less use of energy.
Rifkin cites Etsy as an example of this model. You can find things you are interested in, and have them produced locally using their network. They sell the code, and you can have it supplied in your area.
Rifkin feels that in the future, small and medium sized 3D businesses, infofacturing more sophisticated products, will likely cluster in local technology parks to establish an optimum lateral scale (another form of community development). Here are current examples:
-
[RepRap](https://reprap.org/wiki/RepRap): This is a manufacturing machine that can produce itself and all its parts. -
[Thingiverse](https://www.thingiverse.com)The largest 3D printing community. They share under the General Public Licenses (GPL) and Creative Commons Licenses. -
Fab Lab: Open source peer-to-peer learning in manufacturing. It is being provided to local, distant communities in developing countries.
-
3D Printed automobiles (
[Urbee vehicle](https://www.popularmechanics.com/cars/a9645/urbee-2-the-3d-prinhttps://www.popularmechanics.com/cars/a9645/urbee-2-the-3d-printed-car-that-will-drive-across-the-country-16119485)) is already being tested. -
[KOR EcoLogic](https://phys.org/news/2013-02-kor-ecologic-urbee-car-d.html)has an urban electric vehicle.
## The makers' movement principles
Here are the principles that these ecosystems follow:
-
They use open source shared software.
-
They promote a collaborative learning culture.
-
They believe that it will build a self-sufficient community.
-
They are committed to sustainable production practices.
## The future of work and collaborative commons
When technology replaces workers, capital investments replace labor investments. In 2007, companies used 6 times more computers and software than 20 years before, doubling the amount of capital used per hour of employee work. The robot workforce is on the rise. China, India, Mexico, and other emerging nations are learning that the cheapest workers in the world are not as cheap, efficient, or productive as the information technology, robotics, and artificial intelligence that replaces them.
Going back to Rifkin, the first industrial revolution ended slave and serf labor. The second industrial revolution will dramatically shrink agricultural and craft labor. Rifkin believes the third industrial revolution will be a decline in mass wage labor in the manufacturing, service industries, and salaried professional labor in large parts of the knowledge sector.
Rifkin believes that an abundance, zero marginal cost economy, will change our notion of economic processes. He thinks the old paradigm of owners and workers, sellers and consumers will break down. Consumers will start producing for themselves (and a few others), eliminating their distinction. Prosumers will increasingly be able to produce, consume, and share their own goods and services with one another on the Collaborative Commons at diminishing marginal costs approaching zero, bringing to the fore new ways of organizing economic life beyond the traditional capitalist market mode.
Rifkin forecasts that in the future, greater importance will be placed on the Collaborative Commons and be as important as hard work was in the market economy (one's ability to cooperate and collaborate as opposed to just working hard). The amassing of social capital will become as valued as the accumulation of market capital. Attachment to community and the search for transcendence and meaning comes to define the measure of one's material wealth. All the [open organization principles](https://theopenorganization.org/definition/open-organization-definition/) we write about will be exponentially more important in the future.
The IoT will free human beings from the capitalist market economy to pursue nonmaterial shared interests on the Collaborative Commons. Many — but not all — of our basic material needs will be met for nearly free in a near zero marginal cost society. It will be abundance over scarcity.
## Prosumer and the entry of the smart economy
Rifkin writes that as capitalist economies step aside in some global commodities, in the Collaborative Commons, sellers and buyers will give way to prosumers, property rights will make room for open source sharing, ownership will be less important than access, markets will be superseded by networks, and the marginal cost of supplying information, generating energy, manufacturing products, and teaching students will become nearly zero.
## Internet of energy is on the way
Financing of the IoT will not come from wealthy capitalists and corporate shareholders, but from hundreds of millions of consumers and taxpayers. No one owns the internet. It is only in operation because a set of agreed-upon protocols were established that allows computer networks to communicate with each other. It is a virtual public square for all who pay for a connection to use it. Next comes distributed renewable energies that will be distributed in the same way. Supported by feed-in tariffs and other fund-raising methods, governments will pay for the initial research, but after that fixed investment, the public will be able to connect and use it freely. Once underway, governmental centralized operations will move to distributed ownership. The [Electric Power Research Institute](https://www.epri.com) (EPRI), is studying how to build a national energy internet over the next 20 years.
This is not just supplying electricity. Every device in every building will be equipped with sensors and software that connect to the IoT, feeding real-time information on electricity use to both the on-site prosumer and the rest of the network. The entire network will know how much electricity is being used by every appliance at any moment — thermostats, washing machines, dishwashers, televisions, hair dryers, toasters, ovens, and refrigerators.
This is not happening in the future, but now. It is not just being considered but being done now. [Intwine Energy](https://www.intwineconnect.com) can supply the above process now. The issue is getting it into the greater global population. A group of young [social entrepreneurs](https://www.cleanweb.co) are now using social media to mobilize their peers to create, operate and use the energy internet.
## A new world of abundance beyond our needs
Rifkin thinks society has to start envisioning an entire different living environment. Imagine a world in which you can just give away things you once had to pay for, or had to sell at a profit. No one charges us for each internet connected phone call. He believes these give-away goods need not be covered by governments, like telecommunication, roads, bridges, public schools or hospitals. They need not be considered totally private property to be sold and bought, either. These goods have to be supplied in communities with rules, responsibilities and joint benefits (information, energy, local production, and online education). Not governed by the markets or governments, but by networked commons because of the [tragedy of the commons](https://blogs.pugetsound.edu/econ/2018/03/09/comedy-of-the-commons). It governs and enforces distributed, peer-to-peer, laterally scaled economic activities.
Rifkin feels the Collaborative Commons as a governing body is extremely important. This is where local (project) leadership comes in. The goals, processes, tasks and responsibilities must be successfully executed, after they have been decided and agreed on. Furthermore, "social capital" is a major factor. It must be widely introduced and deepened in quality. Community exchange, interaction and contribution is far more important than selling to distant capital markets. If that is the case, our [open organization leadership](https://github.com/open-organization/open-org-leaders-manual/raw/master/second-edition/open_org_leaders_manual_2_3.pdf) will be extremely important.
## The public square versus private ownership
"The public square at — least before the Internet, is where we communicate, socialize, revel in each other's company, establish communal bonds, and create social capital and trust. These are all indispensable elements for a nurturing community." Historically, Japanese villages were built like that to survive natural, economic and political disasters like earthquakes and typhoons. They put common interests over self-interests. This is what the open organization principle of community is all about.
The right to be included, to have access to one another, which is the right to participate together, is a fundamental right of all. Private property, the right to enclose, own, and exclude is merely a qualified deviation from the norm. For some reason, having massive private property rights have gained in importance in more recent modern times. This will all be reversed in the years ahead according to Rifkin.
Rifkin writes that the world will move to these commons:
-
Public square commons
-
Land commons
-
Virtual commons
-
Knowledge commons (languages, cultures, human knowledge and wisdom)
-
Energy Commons
-
Electromagnetic spectrum commons
-
Ocean commons
-
Fresh water commons
-
Atmosphere commons
-
Biosphere commons.
The past 200 years of capitalism, the enclosed, privatized, and commodification of the market must be put under review. How would they be most effective in a transparent, non-hierarchical and collaborative culture? It comes down to two views, the capitalist (I own it. It is mine, and you can't use it) and the collaborationist (This is for everyone to use, and there are rules and guidelines to use it, so everyone can get their fair share). Today's cooperatives are good at this, like the [International Co-operative Alliance (ICA)](https://www.ica.coop/en). Cooperatives have to generate motivation for the greater community good, and that motivation must be greater than any profit motive. That is their challenge but this is not new, as one in seven people on the earth are in some kind of cooperative now.
As I've presented in this article, the IoT will become our working and living environment. Also, energy costs are projected to go to near zero. With those changes, community collaboration and cooperation will become ever more important over hard work. In the last part of this series I will look at Collaborative Commons in logistics and other economic activity.
## 1 Comment |
16,102 | Omnivore:一个类似 Pocket 的开源稍后阅读应用 | https://news.itsfoss.com/omnivore/ | 2023-08-17T13:51:57 | [
"稍后阅读"
] | https://linux.cn/article-16102-1.html | 
>
> 一款具有令人兴奋的功能的,Mozilla 的 Pocket 的开源替代品。
>
>
>
如果我告诉你有一个解决你所有稍后阅读需求的一站式解决方案,你会怎么想?
当你遇到了你想看却没时间阅读的有趣文章的时候。
这就是稍后阅读解决方案的作用。在这篇文章中,我们将看看一个名为 “**Omnivore**” 的跨平台,开源稍后阅读平台,它可以实现这样的任务。
让我向你展示它可以提供的东西。
### Omnivore:概览 ⭐

它主要由 **HTML** 和 **TypeScript** 驱动,Omnivore **的目标是成为满足你所有阅读需求的一站式解决方案**。
它听起来像是非常热门的 Mozilla 的 [Pocket](https://getpocket.com/en/) 应用的替代品。
你可以跨很多平台使用它,比如 **Web**、**安卓** 和 **iOS**。
你也可以在服务器上自己托管它,尽管 Omnivore 最初被设计为在 [GCP](https://cloud.google.com/)(谷歌云平台)上部署。幸运的是,开发者正在研发更具包容性的部署系统,这将使它更便携。
那么,让我们先来看看 Omnivore 的一些重要亮点:
* 支持全键盘导航。
* 在长文章中自动保存进度。
* 支持各种插件。
* 提供离线阅读功能。
#### 初次体验 ??
我在免费托管的 Omnivore 版本上进行了测试,这需要创建一个账户。
创建账号后,我将一些稍后阅读的文章添加到了它里面,结果就是这个 **组织良好的主页** 。

它具有一个侧边栏菜单,包括 <ruby> 收件箱 <rt> Inbox </rt></ruby>、<ruby> 继续阅读 <rt> Continue Reading </rt></ruby>、<ruby> 稍后阅读 <rt> Read Later </rt></ruby>、<ruby> 无标签的 <rt> Unlabeled </rt></ruby> 等分类选项。
主网格布局储存了所有保存的文章;它还有另一种列表式的视图,但我选择了网格视图。
下面,让我告诉你 **如何向 Omnivore 添加文章** 。
在 Omnivore 上保存稍后阅读的文章主要有两种方法。
一种是 **通过用户菜单** ,你需要点击 “<ruby> 添加链接 <rt> Add Link </rt></ruby>”,然后在你点击它时弹出的文本框中粘贴 URL。

但另一种方法更为直观;它是 **通过浏览器扩展** 完成的。我使用 [Chrome 网上应用店](https://chrome.google.com/webstore/detail/omnivore/blkggjdmcfjdbmmmlfcpplkchpeaiiab/) 的 Omnivore 扩展在 Vivaldi 上进行了测试。
安装后,你只需访问你感兴趣的文章,并点击浏览器扩展栏中显示的 Omnivore 图标。

文章将被添加到你的 Omnivore 账户;你还可以利用可用选项来 **添加注释、标签、编辑标题** 等。
别担心;这不仅仅是 Chromium 的独有方式。你也可以为 [Firefox](https://addons.mozilla.org/en-US/firefox/addon/omnivore/) 和 [Safari](https://apps.apple.com/us/app/omnivore-read-highlight-share/id1564031042) 获取浏览器扩展,这是很好的。
之后,我看了一下 Omnivore 上的 “<ruby> 标签 <rt> Labels </rt></ruby>” 系统。我创建了两个标签,并相应地将它们分配给了保存的文章。
它允许我按标签对它们进行排序。我只需要点击我想要访问的那个。

要创建新标签,点击侧边栏菜单中 “<ruby> 标签 <rt> Labels </rt></ruby>” 旁边的三点菜单,然后进行编辑。

接下来,你可以通过添加标签或修改已有的标签来开始,为它们设置一个名称和颜色。

要将它们分配给现有的文章,将鼠标悬停在一个文章卡片上,进入三点菜单,然后选择 “<ruby> 设置标签 <rt> Set Labels </rt></ruby>”。
然后,我看了一下 **文章阅读的体验** ,我并没有感到失望。文章查看器有一个干净的布局,一个浮动的侧边栏菜单允许各种功能。
第一个选项是设置文章的标签;第二个选项会打开一个笔记本,让你为特定的文章添加注释。

然后有 “<ruby> 编辑信息 <rt> Edit Info </rt></ruby>” 按钮,该按钮会打开一个编辑窗口,用于编辑已保存文章的关键细节。最后,最后两个按钮用于删除或归档已保存的文章。

然后,我转而去检查了 **在 Omnivore 上** 的插件支持。它支持几种不同的插件,允许你从各个地方导出内容。
你可以将其连接到 [Logseq](https://logseq.com/)、[Obsidian](https://obsidian.md/)、[Readwise](https://readwise.io/),甚至是 Mozilla 的 [Pocket](https://getpocket.com/en/)。
这种互操作性对我来说总是一个加分项!?

而这最后一点对我来说是一个惊喜。
Omnivore **支持创建电子邮件别名**,然后可以用该别名注册各种新闻简报。官方支持来自 [Substack](https://substack.com/)、[beehiv](https://www.beehiiv.com/)、[Axios](https://www.axios.com/) 等的新闻简报。

但是,结果证明,它也适用于其他新闻简报。我在 **[我们的新闻简报](https://itsfoss.com/newsletter/)** 上进行了测试,它集成得很好!
### ? 获取 Omnivore
如果你像我一样,希望方便地开始使用,我建议你访问 [官方网站](https://omnivore.app/)。
然而,如果你更喜欢自己托管,我建议你看一看 [官方文档](https://docs.omnivore.app/) 和它的 [GitHub 仓库](https://github.com/omnivore-app/omnivore)。
>
> **[Omnivore](https://omnivore.app/)**
>
>
>
**对于他们的定价结构**,目前,Omnivore 是完全免费的。开发者还没有决定一个合适的定价计划,但是他们有一些他们打算追求的主意。
目前,他们完全依赖社区的捐款。
? 你对此有什么看法?你会尝试一下吗?
*(题图:MJ/ed3cc6ff-cc45-4895-9733-3145bef84b48)*
---
via: <https://news.itsfoss.com/omnivore/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

What if I told you there's a one-stop solution to all your read-it-later needs?
You know, when you come across interesting articles you want to read but don't have the time to read them right then.
That is where a read-it-later solution comes in. In this article, we will look at a cross-platform, open-source read-it-later platform called '**Omnivore**' that facilitates such tasks.
Allow me to show you what it has to offer.
## Omnivore: Overview ⭐
Powered primarily by **HTML**, and **TypeScript**, Omnivore **aims to be an all-in-one solution** for all your reading needs.
It sounds like an alternative to the ever-popular [Pocket](https://getpocket.com/en/?ref=news.itsfoss.com) app by Mozilla.
You can use it across many platforms, such as **Web**, **Android**, and **iOS**.
You can also self-host it on a server, though Omnivore was initially designed to be deployed on [GCP](https://cloud.google.com/?ref=news.itsfoss.com) (Google Cloud Platform). Luckily, the developers are working on a more inclusive deployment system, that will make it more portable.
So, let us begin by taking a look at some key highlights of Omnivore:
**Support for full-keyboard navigation.****Autosave of progress in long articles.****Support for various plugins.****Offline reading functionality.**
### Initial Impressions 👨💻
I tested the free-hosted version of Omnivore, where you have to create an account.
After account creation, I set it up with a few articles to read later, and the result was this **well-organized homepage**.
It features a sidebar menu comprising category options like **Inbox, Continue Reading, Read Later, Unlabeled** and more.
The main grid layout houses all the saved articles; it also had an alternate list-style view, but I opted for the grid view.
So, moving on. Let me show you **how to add articles to Omnivore**.
There are two main ways of saving articles for reading later on Omnivore.
One is **through the user menu**, where you have to click on “**Add Link**”, and then paste the URL into the text box that appears when you click on it.
But the other way is far more intuitive; it is** via browser extensions**. I tested it on Vivaldi using the Omnivore extension from the [Chrome Web Store](https://chrome.google.com/webstore/detail/omnivore/blkggjdmcfjdbmmmlfcpplkchpeaiiab/?ref=news.itsfoss.com).
After installing it, you simply have to visit an article of interest and click on the Omnivore logo that shows up in the extensions bar of your browser.
The article will then be added to your Omnivore account; you can also make use of the available options to **add notes, labels, edit titles**, and more.
Don't worry; this is not a Chromium-only affair. You can get browser extensions for [Firefox](https://addons.mozilla.org/en-US/firefox/addon/omnivore/?ref=news.itsfoss.com) and [Safari](https://apps.apple.com/us/app/omnivore-read-highlight-share/id1564031042?ref=news.itsfoss.com) too, which is a good thing.
Post that, I went on to take a look at **the “Labels” system on Omnivore**. I had created two labels and assigned them to the saved articles accordingly.
It allowed me to sort them by label. I just had to click on the one I wanted to access.
For creating new labels, click on the three-dot menu beside “**Labels**” on the sidebar menu and proceed to edit.
Next, you can get started by adding a label or modifying the existing ones, giving them a name and color.
To assign them to existing articles, hover over an article card, go into the three-dot menu, and choose “**Set Labels**.”
I then proceeded to see the **article-reading experience**, and I was not disappointed. The article viewer had a clean layout with a floating sidebar menu that allowed for a range of functionality.
The first option was to set labels to the article; the second one opens up a notebook that lets you add notes to the specific article.
Then there's the “Edit Info” button that opens up an editing window for editing critical details of a saved article. And finally, the last two buttons are for deleting or archiving the saved article.
I then moved on to check out the plugin's support** on Omnivore**. It supports quite a few, allowing you to export content from there.
You can connect it to [Logseq](https://logseq.com/?ref=news.itsfoss.com), [Obsidian](https://obsidian.md/?ref=news.itsfoss.com), [Readwise](https://readwise.io/?ref=news.itsfoss.com), and even Mozilla's [Pocket](https://getpocket.com/en/?ref=news.itsfoss.com).
This level of interoperability is always a plus in my books! 🤓
And this last one came as a surprise to me.
Omnivore **supports the creation of email aliases** that can then be used to sign up for various newsletters. Officially, they support newsletters from [Substack](https://substack.com/?ref=news.itsfoss.com), [beehiv](https://www.beehiiv.com/?ref=news.itsfoss.com), [Axios](https://www.axios.com/?ref=news.itsfoss.com), and more.
But, as it turns out, it works on other newsletters too. I tested it out on ** our newsletter**, and it integrated well!
## 📥 Get Omnivore
If you are like me and want to get started conveniently, I suggest you visit the [official website](https://omnivore.app/?ref=news.itsfoss.com).
However, if you are more into self-hosting it, I recommend you take a look at the [official documentation](https://docs.omnivore.app/?ref=news.itsfoss.com) and its [GitHub repo](https://github.com/omnivore-app/omnivore?ref=news.itsfoss.com).
**As for their pricing structure**, currently, Omnivore is entirely free. The developers have not decided on a proper pricing plan but have a few ideas in the pipeline they intend to pursue.
Presently, they rely entirely on donations from the community.
*💬 What are your thoughts on this? Will you be giving this a try?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,104 | 终端基础:Linux 终端入门 | https://itsfoss.com/linux-terminal-basics/ | 2023-08-18T09:17:32 | [
"终端基础"
] | https://linux.cn/article-16104-1.html | 
>
> 想了解 Linux 命令行的基础知识吗? 这是一个带有实践方法的教程系列。
>
>
>
Linux 终端可能令人生畏。这块黑色的屏幕只能使用命令。很容易让人感到迷失。
问题是 Linux 命令行是一个很大的话题。你只需使用命令即可管理整个系统。我的意思是,这就是系统管理员、网络工程师和许多其他工作的角色。
**本教程集的目的不是让你做好工作准备。它旨在为你提供 Linux 命令行之旅的起点。** 它将为你提供足够的能力来使用终端并了解一些基本知识,例如读取文件和编辑文件。
由于这只是开始,所以大部分教程都属于“文件操作”类别。这是大多数 Linux 书籍和课程的起点。
>
> ? 最好的学习方法就是自己动手。我以“实践模式”编写了这些教程,以便你可以在 Linux 系统上参照这些示例。本系列的每一章都包含一些示例练习来锻炼。跟着学、多练习,你很快就能熟练掌握 Linux 命令行。
>
>
>
### 第 0 章:熟悉终端和术语
当你对终端完全陌生时,即使在阅读教程时你也会发现自己迷失了方向。那是因为你应该知道至少你得理解最简单的术语。
下面的文章将帮助你解决其中的一些问题。虽然我分享的一些技巧可能对你来说有点超前或不太有用,但你会发现很多有用的东西。
>
> **[19 个基础而重要的 Linux 终端技巧](https://itsfoss.com/basic-terminal-tips-ubuntu/)**
>
>
>
### 第 1 章:更改目录
在第一章中,学习使用绝对路径和相对路径切换目录(文件夹)。这样,你就可以在 Linux 命令行中切换。
>
> **[在 Linux 终端更改目录](https://itsfoss.com/change-directories/)**
>
>
>
### 第 2 章:创建目录
现在你已经了解了如何切换目录,接下来了解如何创建新目录。
>
> **[在 Linux 终端创建目录](/article-15595-1.html)**
>
>
>
### 第 3 章:列出目录中的内容
你已经很好地掌握了目录。学习查看目录内部并查看它们有哪些文件和子目录。
>
> **[在 Linux 终端列出目录](https://itsfoss.com/list-directory-content/)**
>
>
>
### 第 4 章:创建文件
关于目录已经足够了。了解在 Linux 命令行中创建新文件。
>
> **[在 Linux 终端创建文件](/article-15643-1.html)**
>
>
>
### 第 5 章:读取文件
文件里面有什么?在本章中学习阅读文本文件。
>
> **[在 Linux 终端读取文件](https://itsfoss.com/view-file-contents/)**
>
>
>
### 第 6 章:删除文件和目录
现在你已经学会了创建新文件和文件夹,是时候删除它们了。
>
> **[在 Linux 终端删除文件和目录](/article-15809-1.html)**
>
>
>
### 第 7 章:复制文件和目录
在终端基础知识系列的本期中,继续进行文件操作并学习复制文件和目录。
>
> **[在 Linux 终端复制文件和目录](/article-16053-1.html)**
>
>
>
### 第 8 章:移动文件和目录
移动文件操作就像剪切粘贴一样。你也可以使用相同的方法重命名文件和目录。
>
> **[在 Linux 终端移动文件和目录](https://itsfoss.com/move-files-linux/)**
>
>
>
### 第 9 章:编辑文件
作为最后一个主要的文件操作,学习在命令行中编辑文本文件。
>
> **[在 Linux 终端编辑文件](https://itsfoss.com/edit-files-linux/)**
>
>
>
### 第 10 章:获取帮助
现在你已经了解了大量基本的 Linux 命令行操作,是时候了解如何在终端本身中获取帮助了。
>
> **[在 Linux 终端获取帮助](https://itsfoss.com/linux-command-help/)**
>
>
>
### 从这往哪儿走?
现在你已经更熟悉终端并了解命令行中的基本文件操作,你可能想知道接下来要怎么做。
我建议你购买一本 Linux 书籍,例如《How Linux Works》。不过,你可以从你遇到的任何 Linux 书籍开始。这里有一些 [我喜欢的几本 Linux 书籍](https://itsfoss.com/best-linux-books/)。
还不想花钱买书吗? 不用担心! 这里有一些 [你可以下载的免费 Linux 电子书](https://itsfoss.com/learn-linux-for-free/)。
Bash 脚本也是 Linux 学习中不可或缺的一部分。即使你不必编写 Shell 脚本,如果你了解基础知识,你也应该能够理解使用 Linux 时遇到的脚本。
>
> **[Bash 基础知识系列](https://itsfoss.com/tag/bash-basics/)**
>
>
>
学无止境。不可能面面俱到。但是,如果你至少了解基础知识,就能帮助你更有效地使用系统。
? 希望你喜欢这个 Linux 终端教程系列。请在评论部分分享你的反馈。
---
via: <https://itsfoss.com/linux-terminal-basics/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Getting Started With Linux Terminal
Want to know the basics of the Linux command line? Here's a tutorial series with a hands-on approach.
The Linux terminal could be intimidating. The dark screen with just commands to use. It's easy to feel lost.
The thing is that Linux command line is a vast topic. You can manage the entire system using just the commands. I mean that's the role of sysadmins, network engineers and many other jobs.
**The aim of this tutorial collection is not to make you job-ready. It intends to give you the starting point of your Linux command line journey.** It will give you enough to navigate the terminal and understand a few basic things like reading files and editing them.
Since it's just the beginning, most of the tutorials are in the 'file operation' category. That's where most Linux books and courses begin.
## Prerequisite
When you are absolutely new to the terminal, you'll find yourself lost even while reading the tutorials. That's because you may not always understand even the simplest of terms.
The article below will help you with some of that. While some of the tips I shared may be a little advance or not-so-useful for you at this moment, you'll find plenty of useful stuff.
[19 Basic But Essential Linux Terminal Tips You Must KnowLearn some small, basic but often ignored things about the terminal. With the small tips, you should be able to use the terminal with slightly more efficiency.](https://itsfoss.com/basic-terminal-tips-ubuntu/)

## What will you learn here?
**Changing directories**: In the first chapter, learn to switch directories (folders) using absolute and relative paths. This way, you can navigate in the Linux command line.**Making directories**: Now that you know about switching directories, learn about creating new ones.**Listing directory content**: You are getting a good grasp of the directories. Learn to see inside directories and see what files and subdirectories do they have.**Creating files**: Enough about directories. Learn to create new files in the Linux command line.**Reading files**: What's inside the file? Learn to read text files in this chapter.**Deleting files and directories**: Now that you have learned to create new files and folders, it's time to delete them.**Copying files and directories**: Keep on with the file operations and learn to copy files and directories in this installment of the terminal basics series.**Moving files and directories**: Moving file operation is like cut-paste. You can use the same method for renaming files and directories as well.**Editing files**: As the last major file operation, learn to edit text files in the command line.**Getting help**: Now that you have learned plenty of the basic Linux command line operation, it's time to know how you can get help in the terminal itself.
## Where to go from here?
Now that you are more comfortable with the terminal and know the basic file operations in the command line, you may wonder what comes next.
I will suggest getting a Linux book like How Linux Works. However, you can start with any Linux book you come across. Here are a [few Linux books I love](https://itsfoss.com/best-linux-books/).
[Best Linux Books For Beginners to Advanced Linux UsersHere are some Linux book recommendations to improve your knowledge. These books cater to the need of beginners and experts and help you master Linux concepts.](https://itsfoss.com/best-linux-books/)

Don't want to spend money on books yet? No worries! Here are some [free Linux ebooks you can download](https://itsfoss.com/learn-linux-for-free/).
[20 Best Linux Books You Can Download For Free LegallyLet me share the best resource to learn Linux for free. This is a collection of Linux PDFs that you can download for free to learn Linux.](https://itsfoss.com/learn-linux-for-free/)

Bash scripting is also an integral part of Linux learning. Even if you don't have to write shell scripts, if you know the basics, you should be able to understand scripts you come across while using Linux.
[Learn Bash Scripting For Free With This Tutorial SeriesNew to bash? Start learning bash scripting with this series in am organized manner. Each chapter also includes sample exercises to practice your learning.](https://itsfoss.com/tag/bash-basics/)

There is no limit to learning. It's impossible to know it all. Yet, if you know at least the basics, it helps you in using the system more effectively.
*🗨 I hope you like this Linux terminal tutorial series. Do share your feedback in the comments section.* |
16,105 | 在 GitLab 上构建 CI 流水线 | https://opensource.com/article/22/2/setup-ci-pipeline-gitlab | 2023-08-18T09:45:11 | [
"连续集成",
"CI"
] | https://linux.cn/article-16105-1.html |
>
> <ruby> 连续集成 <rt> continuous integration </rt></ruby>(CI)是指代码变更会被自动构建和测试。以下是我为自己的 C++ 项目构建 CI 流水线的过程。
>
>
>

本文介绍如何在 [GitLab](https://gitlab.com/) 上配置 CI 流水线。我在前面的文章中介绍了 [基于 CMake 和 VSCodium 的构建系统](/article-14249-1.html) 和 [基于 GoogleTest 和 CTest 的单元测试](/article-16055-1.html)。本文将在此基础上进一步配置 CI 流水线。我会先演示如何布设和运行 CI 流水线,然后再介绍如何配置它。
CI 是指提交到代码仓库的代码变更会被自动构建和测试。在开源领域,GitLab 是一个流行的 CI 流水线平台。除了作为中心 Git 仓库外,GitLab 还提供 CI/CD 流水线、<ruby> 问题跟踪 <rt> issue tracking </rt></ruby> 和 <ruby> 容器注册表 <rt> container registry </rt></ruby>功能。
### 相关术语
在进入正题之前,我先介绍在本文和 [GitLab 文档](https://docs.gitlab.com/) 中会遇到的常见术语。
* <ruby> 持续交付 <rt> continuous delivery </rt></ruby>(CD):自动化供应软件,以供随时交付
* <ruby> 持续部署 <rt> continuous deployment </rt></ruby>(CD):自动化软件发布
* <ruby> 流水线 <rt> pipeline </rt></ruby>: CI/CD 的直接构件,它由阶段和作业构成
* <ruby> 阶段 <rt> stage </rt></ruby>:一组作业
* <ruby> 作业 <rt> job </rt></ruby>:某项需要执行的具体任务,比如编译、单元测试等
* <ruby> 执行器 <rt> runner </rt></ruby>:实际执行作业的服务
### 布设 CI 流水线
在下面的章节中,我将复用以前的 [示例工程](https://gitlab.com/hANSIc99/cpp_testing_sample)。点击 GitLab 仓库页面右上角的 <ruby> 复刻 <rt> Fork </rt></ruby> 按钮复刻代码仓库。

#### 设置执行器
为了让你对整个流程有所了解,我们先从在本地安装执行器讲起。
参照执行器服务 [安装指南](https://docs.gitlab.com/runner/install/) 安装好服务,然后注册执行器。
1、选择 GitLab 项目页面左侧的 <ruby> 设置 <rt> Settings </rt></ruby>,再选择 **CI/CD**。

2、展开 <ruby> 执行器 <rt> Runners </rt></ruby> 区域,关闭 <ruby> 共享的执行器 <rt> Shared runners </rt></ruby> 选项(黄框处)。特别注意令牌和 URL(绿框处),下一步会用到它们。

3、在终端中运行 `gitlab-runner register`,根据提示输入以下注册信息:
* GitLab 实例: <https://gitlab.com/> (如上图)
* 注册令牌:从执行器区域中获取 (如上图)
* 描述:按需自由填写
* 标签:可以不填
* 执行环境:选 **Shell**
如果有需要,你可以在 `~/.gitlab-runner/config.toml` 中修改这些配置。
4、用命令 `gitlab-runner run` 启动执行器。你可以在 GitLab 的项目设置界面执行器区域看到执行器的状态:

### 运行流水线
前面已经提过,流水线就是一组由执行器执行的作业。每个推送到 GitLab 的提交都会生成一个附加到该提交的流水线。如果多个提交被一起推送,那么只会为最后一个提交生成流水线。为了演示,我直接在 GitLab 在线编辑器中提交和推送修改。
打开 `README.md` 文件,添加一行数据:

现在提交修改。
这里注意默认的行为是为提交新建一个分支,为了简便起见,我们择提交到主分支。

提交后一会儿后,你就应该改能看到 GitLab 执行器执行的控制台中有输出消息:
```
Checking for jobs... received job=1975932998 repo_url=<https://gitlab.com/hANSIc99/cpp\_testing\_sample.git> runner=Z7MyQsA6
Job succeeded duration_s=3.866619798 job=1975932998 project=32818130 runner=Z7MyQsA6
```
在 GitLab 项目概览界面左侧选择 CI/CD --> <ruby> 管道 <rt> Pipelines </rt></ruby>,查看最近执行的流水线:

选中流水线可以在详情界面看到哪些作业失败了,并能查看各个作业的输出。
当遇到非零返回值是就认为作业执行失败了。在下面的例子中我通过调用 `exit 1` 强制让作业执行失败:

### CI 配置
阶段、流水线和作业的配置都在仓库根目录的 [.gitlab-ci.yml](https://gitlab.com/hANSIc99/cpp_testing_sample/-/blob/main/.gitlab-ci.yml) 文件中。我建议使用 GitLab 内置的流水线编辑器,它会自动对配置进行检查。
```
stages:
- build
- test
build:
stage: build
script:
- cmake -B build -S .
- cmake --build build --target Producer
artifacts:
paths:
- build/Producer
RunGTest:
stage: test
script:
- cmake -B build -S .
- cmake --build build --target GeneratorTest
- build/Generator/GeneratorTest
RunCTest:
stage: test
script:
- cmake -B build -S .
- cd build
- ctest --output-on-failure -j6
```
文件中定义了两个阶段:`build` 和 `test`,以及三个作业:`build`、`RunGTest` 和 `RunCTest`。其中作业 `build` 属于一个同名的阶段,另外两个作业属于阶段 `test`。
`script` 小节下的命令就是一般的 Shell 命令。你可以认为是将它们逐行输入到 Shell 中。
我要特别提及 <ruby> 产物artifact</ruby> 这个特性。在示例中我定义了二进制的 `Producer` 为作业 `build` 的产物。产物会被上传到 GitLab 服务器,并且可以从服务器的这个页面上被下载:

默认情况下,后续阶段的作业会自动下载先前阶段作业生成的所有产物。
你可以在 [docs.gitlab.com](https://docs.gitlab.com/ee/ci/yaml/) 上查看 `gitlab-ci.yml` 参考指南。
### 总结
上面只是一个最基本的例子,让你对持续集成的一般原则有一个了解。再演示中我禁用了共享执行器,然而这才是 GitLab 的优势所在。你可以在一个干净的容器化的环境中构架、测试和部署程序。除了使用 GitLab 提供的免费执行器,你也可以用自己的容器作为执行器。当然还有更高阶的用法:用 Kubernetes 来协调调度执行者容器,让流水线适应大规模使用的使用场景。如需进一步了解,可以查看 [about.gitlab.com](https://about.gitlab.com/solutions/kubernetes/)。
如果你使用的是 Fedora,需要注意的一点是目前 GitLab 执行者还不支持用 Podman 作为容器引擎。(LCTT 译注:Podman 是 Fedora 自带的容器引擎。)根据 <ruby> 议题 <rt> issue </rt></ruby> [#27119](https://gitlab.com/gitlab-org/gitlab-runner/-/issues/27119),对 Podman 支持已将列上日程。(LCTT 译注:Podman 4.2 及以上版本增加了对于 GitLab 执行器的支持。)
把重复性的操作描述成作业,并将作业合并成流水线和阶段,可以让你跟踪它们的质量而不增加额外工作。。特别是在大型社区项目中,适当配置的 CI 可以告诉你提交的代码是否对项目有改善,为你接受或拒绝合并请求提供依据。
*(题图:MJ/fb711c48-251a-4726-a41c-247370e5df25)*
---
via: <https://opensource.com/article/22/2/setup-ci-pipeline-gitlab>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article covers the configuration of a CI pipeline for a C++ project on [GitLab](https://gitlab.com/). My previous articles covered how to set up a build system based on [CMake and VSCodium](https://opensource.com/article/22/1/devops-cmake) and how to integrate unit tests based on [GoogleTest and CTest](https://opensource.com/article/22/1/unit-testing-googletest-ctest). This article is a follow-up on extending the configuration by using a CI pipeline. First, I demonstrate the pipeline setup and then its execution. Next comes the CI configuration itself.
Continuous integration (CI) simply means that code changes, which get committed to a central repository, are built and tested automatically. A popular platform in the open source area for setting up CI pipelines is GitLab. In addition to a central Git repository, GitLab also offers the configuration of CI/CD pipelines, issue tracking, and a container registry.
## Terms to know
Before I dive deeper into this area of the DevOps philosophy, I'll establish some common terms encountered in this article and the [GitLab documentation](https://docs.gitlab.com/):
- Continuous delivery (CD): Automatic provisioning of applications with the aim of deploying them.
- Continuous deployment (CD): Automatic publishing of software
- Pipelines: The top-level component for CI/CD, defines stages and jobs
- Stages: A collection of jobs that must execute successfully
- Jobs: Definition of tasks (e.g., compile, performing unit test)
- Runners: Services that are actually executing the Jobs
## Set up a CI pipeline
I will reuse the example projects from previous articles, which are available on GitLab. To follow the steps described in the coming chapters, fork the [example project](https://gitlab.com/hANSIc99/cpp_testing_sample) by clicking on the *Fork* button, which is found on the top right:
Stephan Avenwedde (CC BY-SA 4.)
### Set up a runner
To get a feeling for how everything works together, start at the bottom by installing a runner on your local system.
Follow the [installation instructions](https://docs.gitlab.com/runner/install/) for the GitLab runner service for your system. Once installed, you have to register a runner.
1. On the GitLab page, select the project and in the left pane, navigate to **Settings** and select **CI/CD**.
Stephan Avenwedde (CC BY-SA 4.0)
2. Expand the Runners section and switch **Shared runners** to off (yellow marker). Note the token and URL (green marker); we need them in the next step.
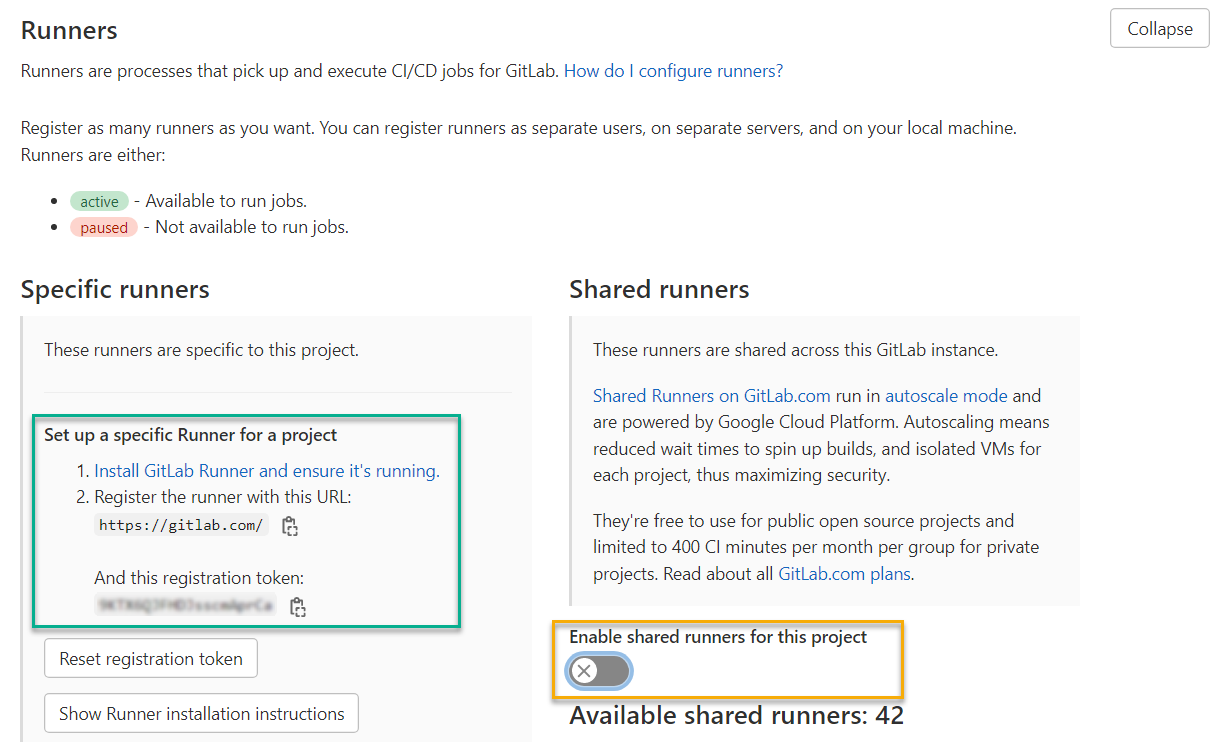
Stephan Avenwedde (CC BY-SA 4.0)
3. Now open a terminal and enter `gitlab-runner register`
. The command invokes a script that asks for some input. Here are the answers:
- GitLab instance:
[https://gitlab.com/](https://gitlab.com/)(screenshot above) - Registration token: Pick it from the
**Runners**section (screenshot above) - Description: Free selectable
- Tags: This is optional. You don't need to provide tags
- Executor: Choose
**Shell**here
If you want to modify the configuration later, you can find it under `~/.gitlab-runner/config.toml`
.
4. Now, start the runner with the command `gitlab-runner run`
. The runner is now waiting for jobs. Your runner is now available in the **Runners** section of the project settings on GitLab:
Stephan Avenwedde (CC BY-SA 4.0)
## Execute a pipeline
As previously mentioned, a pipeline is a collection of jobs executed by the runner. Every commit pushed to GitLab generates a pipeline attached to that commit. If multiple commits are pushed together, a pipeline is created for the last commit only. To start a pipeline for demonstration purposes, commit and push a change directly over GitLab's web editor.
For the first test, open the `README.md`
and add a additional line:
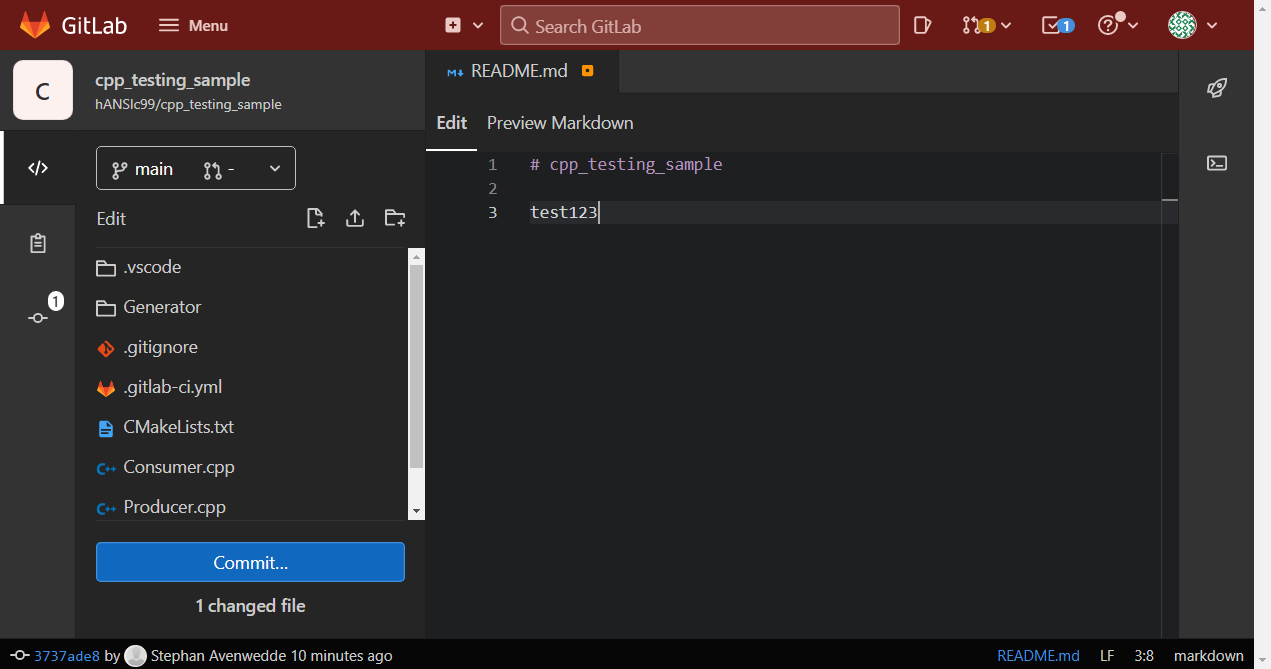
Stephan Avenwedde (CC BY-SA 4.0)
Now commit your changes.
Note that the default is **Create a new branch**. To keep it simple, choose **Commit to main branch**.
Stephan Avenwedde (CC BY-SA 4.0)
A few seconds after the commit, you should notice some output in the console window where the GitLab runner executes:
```
Checking for jobs... received job=1975932998 repo_url=https://gitlab.com/hANSIc99/cpp_testing_sample.git runner=Z7MyQsA6
Job succeeded duration_s=3.866619798 job=1975932998 project=32818130 runner=Z7MyQsA6
```
In the project overview in GitLab, select on the right pane **CI/CD --> Pipelines**. Here you can find a list of recently executed pipelines.
Stephan Avenwedde (CC BY-SA 4.0)
If you select a pipeline, you get a detailed overview where you can check which job failed (in case the pipeline failed) and see the output of individual jobs.
**A job is considered to have failed if a non-zero value was returned**. In the following case, I just invoked the bash command `exit 1`
(line 26) to let the job fail:
Stephan Avenwedde (CC BY-SA 4.0)
## CI configuration
The stages, pipelines, and jobs configurations are made in the file [.gitlab-ci.yml](https://gitlab.com/hANSIc99/cpp_testing_sample/-/blob/main/.gitlab-ci.yml) in the root of the repository. I recommend editing the configuration with GitLab's build-in Pipeline editor as it automatically checks for accuracy during editing.
```
stages:
- build
- test
build:
stage: build
script:
- cmake -B build -S .
- cmake --build build --target Producer
artifacts:
paths:
- build/Producer
RunGTest:
stage: test
script:
- cmake -B build -S .
- cmake --build build --target GeneratorTest
- build/Generator/GeneratorTest
RunCTest:
stage: test
script:
- cmake -B build -S .
- cd build
- ctest --output-on-failure -j6
```
The file defines the stages **build** and **test**. Next, it defines three jobs: **build**, **RunGTest** and **RunCTest**. The **build** job is assigned to the eponymous stage, and the other jobs are assigned to the *test* stage.
The commands under the **script** section are ordinary shell commands. You can read them as if you were typing them line by line in the shell.
I want to point out one special feature: **artifacts**. In this case, I define the *Producer* binary as an artifact of the **build** job. Artifacts are uploaded to the GitLab server and can be downloaded from there:
Stephan Avenwedde (CC BY-SA 4.0)
By default, jobs in later stages automatically download all the artifacts created by jobs in earlier stages.
A `gitlab-ci.yml`
reference is available on [docs.gitlab.com](https://docs.gitlab.com/ee/ci/yaml/).
## Wrap up
The above example is an elementary one, but it shows the general principle of continuous integration. In the above section about setting up a runner I deactivated shared runners, although this is the actual strength of GitLab. You can build, test, and deploy your application in clean, containerized environments. In addition to the freely available runners for which GitLab provides a free monthly contingent, you can also provide your own container-based, self-hosted runners. Of course, there is also a more advanced way: You can orchestrate container-based runners using Kubernetes, which allows you to scale the processing of pipelines freely. You can read more about it on [about.gitlab.com](https://about.gitlab.com/solutions/kubernetes/).
As I'm running Fedora, I have to mention that Podman is not yet supported as a container engine for GitLab runners. According to gitlab-runner issue [#27119](https://gitlab.com/gitlab-org/gitlab-runner/-/issues/27119), Podman support is already on the list.
Describing the recurring steps as jobs and combining them in pipelines and stages enables you to keep track of their quality without causing additional work. Especially in large community projects where you have to decide whether merge requests get accepted or declined, a properly configured CI approach can tell you if the submitted code will improve or worsen the project.
## Comments are closed. |
16,107 | Ubuntu 23.10 将首次推出基于 Flutter 的新 Ubuntu 商店 | https://news.itsfoss.com/ubuntu-23-10-ubuntu-store/ | 2023-08-18T22:38:00 | [
"Ubuntu",
"软件商店"
] | https://linux.cn/article-16107-1.html | 
>
> Ubuntu 正在升级其软件商店以提供顺滑的体验!
>
>
>
随着不断发展,Canonical 似乎全力以赴,将基于 Flutter 的元素整合到 Ubuntu 中。
在前段时间 [Ubuntu 23.04](https://news.itsfoss.com/ubuntu-23-04-release/) 发布后,**我们见到了基于 Flutter 的安装程序** ,现在,Ubuntu 的另一个重要工具也接受了 Flutter 改造:一款新的软件商店应用。
不过,现有的“软件中心”并不会现在就被取代。相反,Ubuntu 将有一个新的商店,目标是经典的软件中心与由社区构建的 Flutter 商店的进化版。
但是,你看,去年我们第一次看到了由 Canonical 的许多贡献者开发的 [非官方的基于 Flutter 软件中心](https://news.itsfoss.com/unofficial-flutter-ubuntu-software/) 时,就预见到了这一点。
而且,通过 Canonical 的 [Tim Holmes-Mitra](https://github.com/tim-hm?ref=news.itsfoss.com) 最近的更新,我们现在已经可以一窥新商店的风采了。
让我带你瞧瞧这个。
### Ubuntu 商店值得期待的地方?

最初,它被称为 “<ruby> 应用商店 <rt> App Store </rt></ruby>”,但为了避免与已经注册了该商标的苹果公司产生任何法律问题,这个名字将需要改变。
目前最受欢迎的似乎是 “<ruby> Ubuntu 商店 <rt> Ubuntu Store </rt></ruby>” ,我个人认为这个名字会很好地融入到该发行版中。不过,这个新的基于 Flutter 的软件中心的名称尚未最终确定,所以我们还必须等待。
Tim 也提到了:
>
> 这个项目仍然在建设中,现在我们的重点在于核心功能。我很乐观的认为到 23.10 的发布时,我们的新的评级功能和对 deb 的支持以及更多的改进将会落地。
>
>
>
这表明,如果事情进展顺利,我们可能会在 Ubuntu 23.10 最终发布的前期就看到 **新的基于 Flutter 的软件中心集成到其中** 。
不仅限于此,你可以在接下来的一两周内在 Ubuntu 23.10(Mantic Minotaur)的每日构建版本中找到作为**默认设置**的新 Ubuntu 商店 。
你可以参考 Tim 的 [公告](https://discourse.ubuntu.com/t/an-update-on-app-store-ubuntu-store/37770?ref=news.itsfoss.com) 获取更详细的细节。
### 但是等等,还有更多!\*\* ?
**我在我的 Ubuntu 22.04 LTS 系统上测试了新的基于 Flutter 的商店** ,我必须说,用户体验远超我们现有的软件中心。
**主页现在被整齐地划分为三个独特的部分**:一个是包含搜索菜单的页头,另一个是包含应用类别和设置菜单的侧边栏菜单,最后是包含应用本身的中心部分。

**搜索功能已经得到了大幅度的提升** ,我在输入搜索查询的过程中就已经开始显示结果了。

**应用视图也得到了大幅度的提升** ,在 Snap 和 Debian 包之间有了明显的源切换器。我很高兴看到这一点,因为并不是很多人喜欢 Snap ?

### 想在你的 Ubuntu 22.04 / 23.04 系统上试试看吗?
在开始之前,记住它仍然在积极开发中,随着开发的进展,事物将会发生改变。
你将需要切换到 Snap 商店的 <ruby> 预览/边缘 <rt> preview/edge </rt></ruby> 频道才能获得它。运行以下命令:
```
sudo snap refresh snap-store --channel=preview/edge
```
>
> ? 如果它抛出了一个 “snap-store” 有正在运行的应用的错误,那么使用 `sudo kill -9 PID` 杀死它,然后重新运行该命令。
>
>
>
然后,你可以从应用启动器运行 “软件” 应用来测试它。
要恢复到原生软件中心,请运行以下命令:
```
sudo snap refresh snap-store --channel=latest/stable
```
对于新的“软件中心”是如何工作以及查看源代码的更多细节,我建议你去查看它的 [GitHub 仓库](https://github.com/ubuntu/app-store?ref=news.itsfoss.com)。
参考自:[FOSTips](https://fostips.com/ubuntu-23-10-adopt-flutter-software-app/?ref=news.itsfoss.com)
*(题图:MJ/6f701cd5-fe15-4a70-bebc-9087c14af338)*
---
via: <https://news.itsfoss.com/ubuntu-23-10-ubuntu-store/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

As things stand now, Canonical seems to be going full-steam ahead for integrating Flutter-based elements into Ubuntu.
After the relatively recent release of [Ubuntu 23.04](https://news.itsfoss.com/ubuntu-23-04-release/), which **saw the introduction of a Flutter-based installer**, we now have another important utility of Ubuntu receiving the Flutter treatment; a new software store app.
No, the software center is not going anywhere for now. Instead, Ubuntu will have a new store that will aim to act as an evolution of the classic software center and the community-built Flutter store.
But, you see, we saw this coming last year when we first looked at the [unofficial Flutter-based software center](https://news.itsfoss.com/unofficial-flutter-ubuntu-software/) that was being worked on by many contributors from Canonical.
And, with a recent update by [Tim Holmes-Mitra](https://github.com/tim-hm?ref=news.itsfoss.com) of Canonical, we now have a sneak peek at the new store.
Let me take you through this.
## Ubuntu Store: What to Expect?
Initially, it was supposed to be called the “**App Store**”, but the name will need to be changed to avoid any legal issues with Apple, which has trademarked that term.
The favorite so far seems to be “**Ubuntu Store**,” and I personally think that this would blend in quite well with the rest of the distro. But, the name for the new Flutter-based software center has still not been finalized, so we will have to wait it out.
Tim also mentioned that:
This project is still very much under construction and right now our focus is on core features. I am optimistic that by 23.10’s launch our new approach to ratings and deb support will have landed as well as many more improvements.
That confirms that, if things go well, we will see the **new Flutter-based software center being integrated with Ubuntu 23.10's final launch**.
As of now, it is available as the **default in Ubuntu 23.10 (Mantic Minotaur) daily builds.**
You can go through Tim's [announcement](https://discourse.ubuntu.com/t/an-update-on-app-store-ubuntu-store/37770?ref=news.itsfoss.com) for the finer details.
**But wait, there's more! **🤓
**I tested the new Flutter-based store** on my **Ubuntu 22.04 LTS** system, and I must say, the user experience is far superior to what we have with the existing software center.
The **homepage is now** **neatly divided into three distinct sections**; one houses the header with the search menu, the other houses the sidebar menu with app categories and the settings menu, and finally, the center section that houses the apps itself.
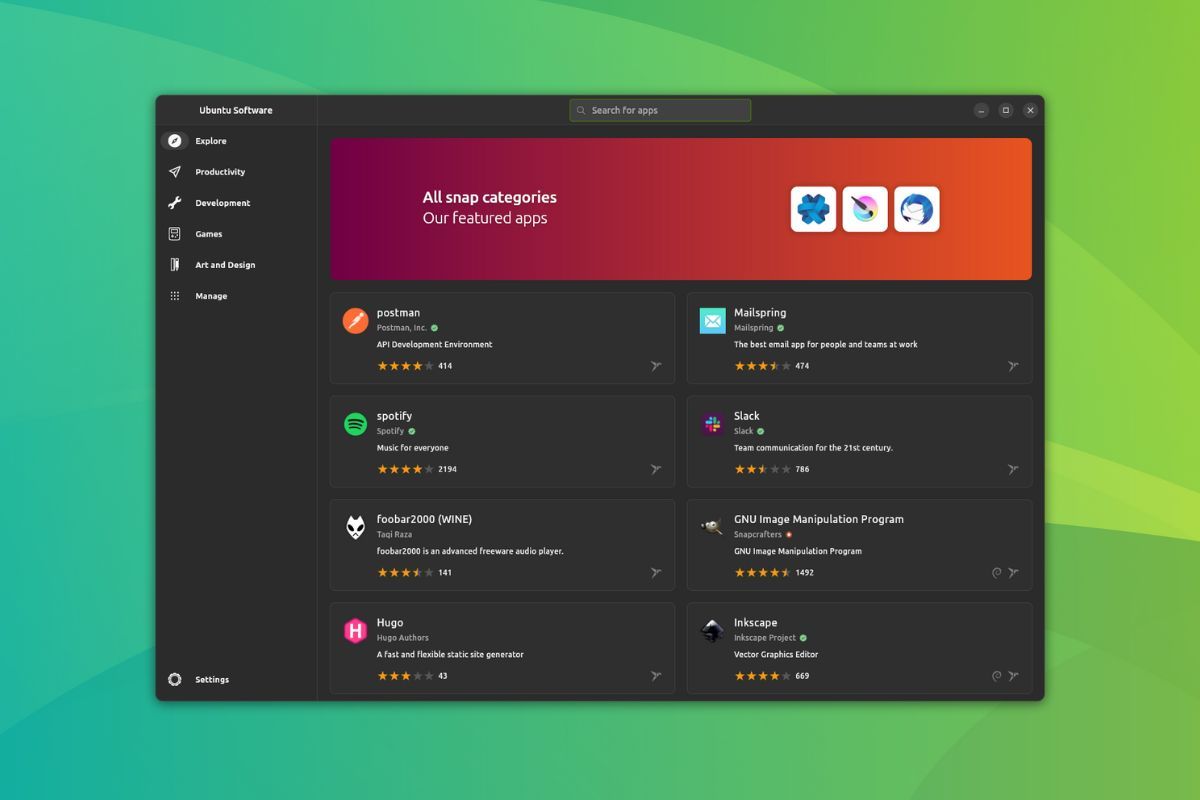
The **search functionality has been greatly improved**, already showing results as I started typing in the search query.
The **application view has also been greatly improved**, with a distinct source switcher between Snap and Debian packages. I was glad to see that, as not many people prefer snap 🤭
**Want to try it out on your Ubuntu 22.04/23.04 system?**
Before we start, remember that this is still in active development, and things will change as development progresses.
You will have to switch to the preview/edge channel of the Snap Store to get it. Run the following command:
```
sudo snap refresh snap-store --channel=preview/edge
```
You can then run “Software” from the app launcher to test it out.
To revert to the vanilla software center, run the following command:
```
sudo snap refresh snap-store --channel=latest/stable
```
For more details on how the new software center works or to look at the source code, I suggest you head over to its [GitHub repo](https://github.com/ubuntu/app-store?ref=news.itsfoss.com).
*Via: FOSTips*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,108 | ls 命令输出的颜色:它们意味着什么? | https://itsfoss.com/ls-color-output/ | 2023-08-19T09:38:25 | [
"ls"
] | https://linux.cn/article-16108-1.html | 
>
> 想知道 ls 命令输出中的颜色是什么?它们从何而来,又该如何设置?本文将为您一一解答。
>
>
>
相信你一定使用过 `ls` 命令来 [列出目录的内容](https://itsfoss.com/list-directory-content/)。在 Ubuntu 和许多其他发行版中,你将看到不同颜色的 `ls` 命令输出。
如果你没有看到过,你可以这样获得如下所示的彩色输出:
```
ls --color=auto
```
但是你有没有想过这些颜色在 `ls` 命令输出中意味着什么?
我将回答本文中的问题。**如果你的终端默认情况下不显示它,我还将展示如何使用 `ls` 命令获取彩色输出**。
### Ubuntu 中 ls 命令中使用的颜色的含义
>
> ? ls 命令输出的颜色没有固定的标准。不同的终端和发行版使用不同的颜色编码,你也可以根据自己的喜好进行修改。换句话说,不要依赖颜色。
>
>
>
**我在本节中使用默认的 Ubuntu 终端及其颜色配置文件。**
当你 [使用 ls 命令列出文件](https://itsfoss.com/ls-command/) 时,它会使用不同的颜色来指示不同类型的文件。
大多数终端都会以不同的颜色显示可执行文件、链接、常规文件和目录,以便你可以轻松区分它们。
有些终端(例如 Ubuntu 中的默认终端)将其提升到一个新的水平,并为音乐文件、图像和视频添加更多颜色。
为了演示,我列出了来自不同目录的文件,这些文件在 Ubuntu 中用不同的颜色填充了我的终端窗口:

看起来很混乱? 让我一一为你解密吧!
| 颜色 | 描述 |
| --- | --- |
| **粗体蓝色** | 目录 |
| **无色** | 文件或硬链接 |
| **粗体青色** | 指向文件的符号链接。 |
| **粗体绿色** | 可执行文件(`.sh` 扩展名的脚本) |
| **粗体红色** | 归档文件(主要是 tarball 或 zip 文件) |
| **洋红色** | 表示图像和视频文件 |
| **青色** | 音频文件 |
| **黄色配黑色背景** | 管道文件(称为 FIFO) |
| **粗体红色配黑色背景** | 损坏的符号链接 |
| **无色(白色)配红色背景** | 表示设置用户 ID 文件 |
| **黑色配黄色背景** | 表示设置组 ID 文件 |
| **白色与蓝色背景** | 显示粘滞位目录 |
| **蓝色配绿色背景** | 指向其他可写目录 |
| **黑色配绿色背景** | 当目录同时具有粘滞位和其他可写目录的特征时 |
>
> ? 再次强调,上述颜色数据基于终端的默认设置,如果更改调色板,将不会得到类似的结果。
>
>
>
但是如果你的终端不显示任何颜色怎么办? 好吧,这是有原因和解决方案的。
### 如果 ls 命令不显示彩色输出怎么办?
事情是这样的。默认情况下,`ls` 命令不应在输出中显示颜色。如果你使用 `--color=auto` 标志,它将显示颜色。
```
ls --color=auto
```
那么为什么 `ls` 命令在 Ubuntu 和其他一些发行版中默认添加颜色呢? 这是因为你的发行版为 `ls` 命令设置了别名,以便在执行 `ls` 命令时使用 `--color=auto` 标志:
```
alias
```

因此,如果 `ls` 命令未显示彩色输出,则是因为默认情况下没有设置别名。
现在,每当你使用 `ls` 命令时,你都可以使用 `--color=auto` 标志。

但这不太方便。相反,你应该创建别名并将其添加到 `.bashrc` 中,以便 `ls` 命令默认显示颜色。
#### 为 ls 创建一个永久别名来显示颜色
要创建永久别名,首先,使用以下命令打开 `.bashrc` 文件:
```
nano ~/.bashrc
```
使用 `Alt + /` [跳到文件末尾](https://linuxhandbook.com/beginning-end-file-nano/) 并 [粘贴如下行到终端](https://itsfoss.com/copy-paste-linux-terminal/):
```
alias ls='ls --color=auto'
```
完成后,[保存更改并退出 nano](https://linuxhandbook.com/nano-save-exit/) 文本编辑器。
要使你刚刚所做的更改生效,请 <ruby> 源引 <rt> source </rt></ruby> `.bashrc` 文件:
```
source ~/.bashrc
```
就是这样! 从现在开始,你可以使用彩色输出。
### ls 命令从哪里获取颜色?
现在有趣的部分来了。`ls` 命令的颜色在哪里定义? 答案是 `LS_COLORS` 环境变量。
是的。这是名为 `LS_COLORS` 的特殊环境变量,它定义 `ls` 命令使用的颜色。

这很好,但是谁定义了这个变量呢? 如果你想做出一些改变怎么办? 我也来回答一下这些问题。
实际上,你有一个专门的 `dircolors` 命令来为 `ls` 命令设置颜色。
不同的 Shell 有不同的颜色配置文件格式。这就是为什么在使用此命令时应指定 Shell。

如你所见,它定义了 `LS_COLORS` 环境变量并将其导出,以便该变量可用于子 Shell。
现在,如果你想使用它,你可以将其复制粘贴到你的 `.bashrc` 文件或像这样重定向输出:
```
dircolors -b >> .bashrc
```
并 <ruby> 源引 <rt> source </rt></ruby> 该文件,以便效果立即可见。你只需要做一次。
#### 理解颜色配置文件
`LS_COLORS` 包含由冒号(`:`)分隔的键值对数据。如果该值有多个部分,则它们之间用分号(`;`)分隔。
键通常是预定义的。值部分代表颜色。
因此,如果显示 `ln=01;36`,则表示对于符号链接,字体为粗体,颜色(`36`)为青色。
`00` 为正常,`01` 为粗体,`4` 为下划线。`31` 代表红色,32 代表绿色等。颜色代码遵循 [ANSI 转义代码](https://en.wikipedia.org/wiki/ANSI_escape_code)。
另一个例子。`or=40;31;01` 表示链接到不存在的文件(键为 `or`),使用黑色背景(颜色代码 `40`)、红色(`31`)和粗体字体(代码 `01`)。
我认为顺序并不重要,因为代码不重叠。`31` 是前景色红色的代码,`41` 是背景红色的颜色。因此,如果使用 `41`,你就知道它用于背景颜色。
### 使用 ls 命令执行更多操作
`ls` 命令可以做更多的事情,为此,我们制作了有关如何使用 `ls` 命令的详细教程:
>
> **[在 Linux 中使用 ls 命令](https://itsfoss.com/ls-command/)**
>
>
>
Abhishek Prakash 提供资料。
*(题图:MJ/4d0f1f66-259f-4671-a3a8-158f61a38b10)*
---
via: <https://itsfoss.com/ls-color-output/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I'm sure you must have used the ls command to [list the contents of a directory](https://itsfoss.com/list-directory-content/). In Ubuntu and many other distributions, you'll see the ls command output in different colors.
If you don't see it, you can get colored output like this:
`ls --color=auto`
But have you ever wondered what those colors mean in the ls command output?
I'll answer the questions in this article. **I'll also show how to get colored output with ls command** if your terminal does not show it by default.
## Meaning of colors used in the ls command in Ubuntu
**I am using the default Ubuntu terminal and its color profile in this section.**
When you [list files using the ls command](https://itsfoss.com/ls-command/), it will use different colors to indicate different kinds of files.
Most terminals will show the executable files, links, regular files and directories in different colors so that you can easily distinguish between them.
Some terminals, like the default one in Ubuntu, take it to the next level and add more colors for music files, images and videos.
For the demonstrations, I've listed files from different directories which filled my terminal window with different colors in Ubuntu:
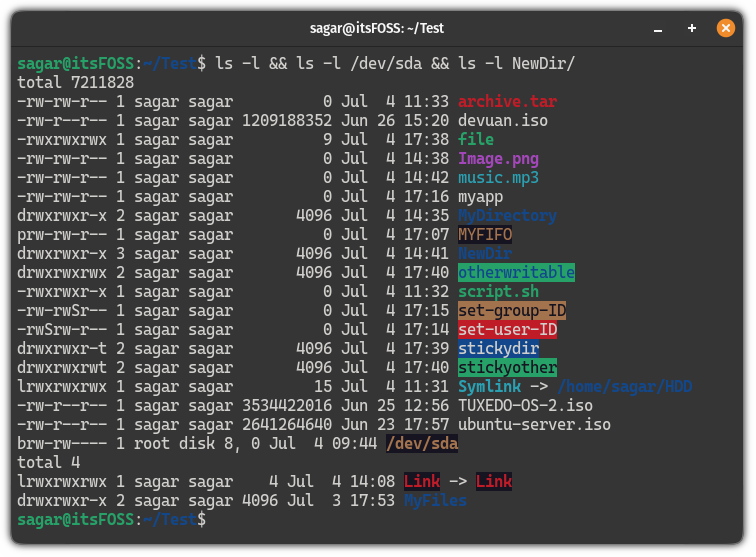
Looks confusing? Let me decode each one for you!
Color | Description |
---|---|
Bold Blue |
Directories. |
Uncolored |
File or multi-hard link. |
Bold Cyan |
A symbolic link pointing to a file. |
Bold Green |
An executable file (scripts with having an `.sh` extension). |
Bold Red |
Archive file (mostly a tarball or zip file). |
Magenta |
Indicates images and video files. |
Cyan |
Audio files. |
Yellow with black bg |
A pipe file (known as FIFO). |
Blod red with black bg |
A broken symbolic link. |
Uncolored (white) with red bg |
Indicates set-user-ID file. |
Black with yellow bg |
Indicates set-group-ID file. |
White with blue bg |
Shows a sticky directory. |
Blue with green bg |
Points to Other-writable directory |
Black with green bg |
When a directory has characteristics of both sticky and other-writable directories. |
But what if your terminal doesn't show any colors? Well, there's a reason and solution for that.
## What if the ls command does not show colored output?
Here's the thing. The ls command is not supposed to display colors in output by default. It will show the colors if you use the `--color=auto`
flag.
`ls --color=auto`
Then why does the ls command add colors by default in Ubuntu and some other distributions? That's because your distribution has an alias set for the ls command to use the `--color=auto`
flag when you execute the ls command:
`alias`
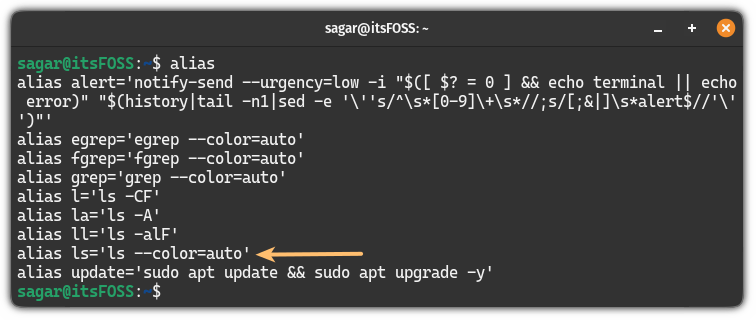
So if the ls command is not showing the colorful output, the alias is not set by default.
Now, you may use `--color=auto`
flag whenever you use the ls command
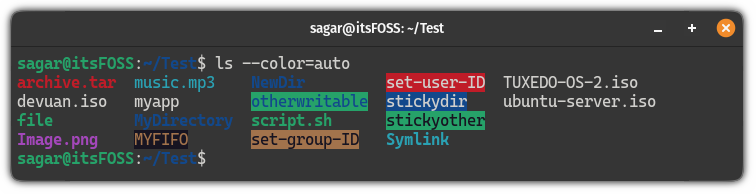
But that's not very convenient. Instead, you should create alias and add it to your bashrc so that ls command displays colors by default.
### Create a permanent alias for ls to display colors
To create a permanent alias, first, open the `.bashrc`
file using the following command:
`nano ~/.bashrc`
[Go to the end of the file](https://linuxhandbook.com/beginning-end-file-nano/) using `Alt + /`
and [paste the following line in the terminal](https://itsfoss.com/copy-paste-linux-terminal/):
`alias ls='ls --color=auto'`
Once done, [save changes and exit from the nano](https://linuxhandbook.com/nano-save-exit/) text editor.
To take effect from the changes you've just made, source the `.bashrc`
file:
`source ~/.bashrc`
That's it! From now on, you can use the colored output.
## Where does the ls command gets the color from?
Now comes the interesting part. Where are the colors for the ls command defined? The answer is LS_COLORS.
Yes. That's the special environment variable called LS_COLORS that defines the colors used by the ls command.
That's good but who defines this variable? What if you wanted to make some changes? I'll answer these questions as well.
Actually, you have a dedicated `dircolors`
command to setup color for the ls command.
Different shells have different formats for the color profile. This is why you should indicate the shell when you use this command.
As you can see, it defines the LS_COLORS environment variable and exports it so that the variable is available for the subshell.
Now, if you want to use it, you can either copy-paste it to your bashrc file or redirect the output like this:
`dircolors -b >> .bashrc`
And source the file so that the effects are immediately visible. You have to do it only once.
### Understanding the color profile
The LS_COLORS has data in key-value pair separated by a colon (:). If the value has more than one part, they are separated by a semicolon (;).
The key is usually predefined. The value part represents the colors.
So, if it says `ln=01;36`
, it means for symbolic links, the font is bold and the color (36) is cyan.
0 is for normal, 1 is for bold, 4 is for underlined. 31 is for red, 32 is for green etc. The color codes follow the [ANSI escape code](https://en.wikipedia.org/wiki/ANSI_escape_code).
Another example. `or=40;31;01`
means that link to a non-existent file (key is or) uses black background (color code 40), red color and bold font (code 01).
I think the order doesn't matter because the codes don't overlap. 31 is the code for the foreground red color and 41 is the color for the background red color. So if 41 is used, you know it is for the background color.
## Do more with the ls command
The ls command can do a lot more and for that purpose, we made a detailed tutorial on how to use the ls command:
[Using ls Command in Linuxls is one of the simplest and most frequently used commands is Linux. Learn to use it effectively in this tutorial.](https://itsfoss.com/ls-command/)

**This **
**tutorial was requested**by an It's FOSS member in our community forum. If you have suggestions or tutorial requests, please
**use our Community platform**.
*With inputs from Abhishek Prakash.* |
16,110 | 一直在期待的基于 Ubuntu 的滚动发布 Rhino Linux 终于来了 | https://news.itsfoss.com/rhino-linux-release/ | 2023-08-19T22:53:00 | [
"Rhino Linux"
] | https://linux.cn/article-16110-1.html | 
>
> Rhino Linux 绝对值得关注!
>
>
>
你可能还记得我们 [去年](https://news.itsfoss.com/rhino-linux/) 报道过,Rhino Linux 将会接替现已停止开发的 “[Rolling Rhino Remix](https://github.com/rollingrhinoremix)”。
经过漫长的等待,它的首个稳定版本终于发布了!
现在我们就一起来看看 Rhino Linux 有哪些值得特别关注的地方。
### Rhino Linux 到底是什么? ?

Rhino Linux 是一个基于 Ubuntu,使用了改版的 XFCE 4.18 以及 Pacstall 作为核心,提供了无忧用户体验的滚动发布版系统。
>
> ? 滚动发布的系统能接收到规律的软件升级,而不只是负责维护修复。
>
>
>
采用 XFCE 4.18 使得 Rhino Linux 能利用各种新优化,比如 Thunar 文件管理器的提升,增强的桌面/面板 等等。
你可以查看我们的相关报道以了解更多。
>
> [Xfce 4.18 版本发布:令人印象深刻](https://news.itsfoss.com/xfce-4-18-release/)
>
>
>
接着我们来说说 [Pacstall](https://pacstall.dev/),一个受到 AUR 启发的包管理器,它可以处理从内核安装到安装网页浏览器的所有任务。
所有与 Rhino Linux 相关的包都打包成 [pacscript](https://github.com/pacstall/pacstall/wiki/Pacscript-101),任何操作系统的更新都可以通过 Pacstall 来完成。
**那么,这个发行版的感觉和表现如何?**
首次启动 Rhino Linux 时,你会遇到一个使用 Rust 构建的简洁现代的快速设置向导。

>
> ? 我们的网站上有一份新的 [Rust 基础教程系列](https://itsfoss.com/tag/rust/)。你可以查看,学习一下 Rust 编程语言。
>
>
>
当你进行下一步时,你可以在三种不同的包管理器中进行选择:Flatpak ,Snap,以及 AppImage。

这样的功能得益于他们自创的定制包管理包装器 rhino-pkg,它可以让你从各种支持的仓库中搜索、安装、移除和更新包。
相比于最新的官方 Ubuntu 版本,你可以自由选择从开箱即用的 Flatpak 开始。
然后还有一些额外设置你可以选择启用。
其中一个是启用这个精妙的基于 Python 的 apt 包管理前端,,[Nala](https://itsfoss.com/nala/)。

另一个是 [Apport](https://wiki.ubuntu.com/Apport),这是一个崩溃报告系统,在系统崩溃的情况下可以让开发者知道你的安装有任何问题。
完成这些设置后,你看见的是一个非常简洁的桌面布局,包括一个干净的壁纸和一个悬浮的程序坞。

他们将自家桌面称为 “<ruby> 独角兽桌面 <rt> Unicorn Desktop </rt></ruby>”,这是一个基于大幅修改过的 XFCE 构建的桌面。
它的目标是将现代和传统的最佳实践结合在一起,为桌面用户体验提供包含两者优点的体验。

独角兽桌面还包含了一些附加的免费软件解决方案,如 [uLauncher](https://ulauncher.io/)(替代了 spotlight 的搜索工具)、lightpad(作为新的应用启动器)以及许多其他功能。

可以 [在这里](https://rhinolinux.org/unicorn.html) 阅读更多关于他们定制桌面体验的信息。
总的来说,用户体验相对直观,而且 Rhino 主题的壁纸看起来很漂亮。
**还有其他亮点吗?**
当然有!
本次发布还包含了一个我很期待看到的引人注目的版本。
这是一个**用于 PinePhone 设备(原版/Pro 版)的 Rhino Linux 移植版**,基于最新的 **Ubuntu Touch(20.04)**,它是首个基于 XFCE 的移动环境。
正如你可以从负责这个移植的 Oren Klopfer 分享的视频中看到的,它还处在非常初步的状态。
他打算在 XFCE 4.20 发布时就进行切换,以获得 Wayland 的支持并摒弃 X11。
我迫不及待地想看到结果了!
在 [发布博客](https://rhinolinux.org/news-6.html) 上你可以找到更多关于 Rhino Linux 的细节。
### ? 获取 Rhino Linux
有三个不同版本供你选择,一个是通用 ISO,适用于 x86\_64/ARM64 ,提到的PinePhone ISO,还有Raspberry Pi ISO。
你可以在 [此处](https://rhinolinux.org/download.html) 下载对应的 ISO。
>
> **[Rhino Linux](https://rhinolinux.org/download.html)**
>
>
>
你还可以使用其 [GitHub 仓库](https://github.com/rhino-linux) 中的源代码从头构建。
我非常期待看到 Rhino Linux 在未来能做出什么。⭐
*(题图:MJ/c6cb42de-7196-4759-a9a6-10db8adbc058)*
---
via: <https://news.itsfoss.com/rhino-linux-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You might remember us covering [last year](https://news.itsfoss.com/rhino-linux/) that Rhino Linux would be the successor of the now-defunct '[Rolling Rhino Remix](https://github.com/rollingrhinoremix?ref=news.itsfoss.com)'.
After much waiting, its first stable release is here!
Let's dig in and see what Rhino Linux has to offer.
## Rhino Linux: What is it? 🦏
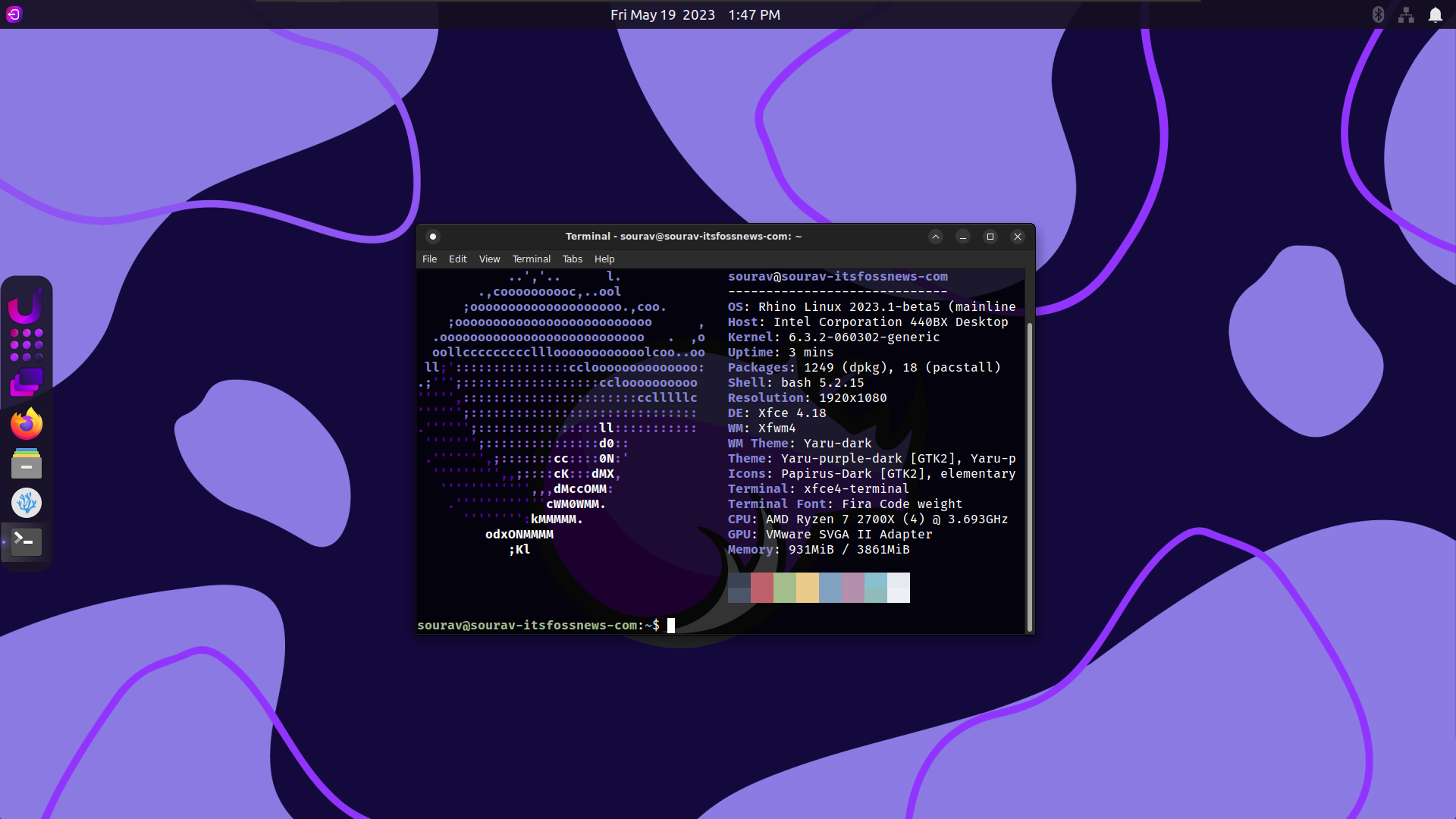
Rhino Linux is an Ubuntu-based, **rolling release distro** that uses a **modified version of XFCE 4.18**, alongside **Pacstall** at its core, for a hassle-free user experience.
The inclusion of XFCE 4.18 enables Rhino Linux to take advantage of the various improvements on offer, such as **improvements to the Thunar file manager**, **enhanced desktop/panel**, and more.
You can check out our coverage on the same to know more.
[XFCE 4.18 Release Looks Impressive!Xfce 4.18 is here with interesting feature additions and subtle changes.](https://news.itsfoss.com/xfce-4-18-release/)

Then there's '[Pacstall](https://pacstall.dev/?ref=news.itsfoss.com)', which is an AUR-inspired package manager that handles everything starting from kernel installs, all the way to installing a web browser.
As all Rhino Linux-related packages are packaged as '[pacscript](https://github.com/pacstall/pacstall/wiki/Pacscript-101?ref=news.itsfoss.com)', any OS updates can be done through Pacstall.
**So, how does the distro feel and behave?**
Well, when you first boot up into Rhino Linux, you are greeted with a very **clean and modern-looking quick-setup wizard** built using Rust.
**on It's FOSS. You may check it out to explore Rust programming language.**
[Rust Basics Series](https://itsfoss.com/tag/rust/?ref=news.itsfoss.com)When you proceed, you are given the option to choose from three distinct package managers: **Flatpak**, **Snap,** and **AppImage**.
Such functionality is thanks to implementing their **custom package management wrapper**, 'rhino-pkg'. Which allows you to search, install, remove, and update packages from the various supported repositories.
In contrast to the latest official Ubuntu flavors, you have the freedom to have Flatpak enabled out-of-the-box.
Then there are the extra settings that you can opt to enable.
One is to enable the wonderful Python-based frontend for apt package management, '[Nala](https://itsfoss.com/nala/?ref=news.itsfoss.com)'.
**Suggested Read **📖
[Apt++? Nala is Like Apt in Ubuntu but BetterNala is a Python-based frontend for apt package management. Inspired by the DNF package manager, Nala seems like a promising tool for Ubuntu and Debian users.](https://itsfoss.com/nala/?ref=news.itsfoss.com)

The other is '[Apport](https://wiki.ubuntu.com/Apport?ref=news.itsfoss.com)', a crash reporting system, that lets the developers know of any issues with your installation in the event of a system crash.
When you finish that, you get to see a **very clean desktop layout** with a neat wallpaper, and a floating dock.
They have dubbed their desktop as '**The Unicorn Desktop**' which has been built in-house with a heavily modified version of XFCE.
It aims to combine the best of both traditional and modern approaches for the desktop user experience.
The Unicorn desktop also features a few free add-on software solutions, such as [ uLauncher](https://ulauncher.io/?ref=news.itsfoss.com),
**a**
**replacement for spotlight search**,
**lightpad as the new app launcher**, and
**many other features**.

You can read more about their customized desktop experience ** here**.
Overall, the user experience seems relatively straightforward, and the Rhino-themed wallpaper looks lovely.
**Any other highlights?**
Yes!
This release has an interesting variant that I am excited to see.
It is a **Rhino Linux port for PinePhone devices** (the original one/Pro), based on the latest version of **Ubuntu Touch (20.04)**, it is the first XFCE-based mobile environment.
As you can see from the video shared by Oren Klopfer, who is working on this port, it's in a very work-in-progress state.
He intends to switch to XFCE 4.20 when it releases to get Wayland's support and do away with X11.
I can't wait to see how this turns out!
You can check out the [announcement blog](https://rhinolinux.org/news-6.html?ref=news.itsfoss.com) for more details on Rhino Linux.
## 📥 Get Rhino Linux
Three distinct editions are on offer; one is a **Generic ISO for x86_64/ARM64**, the aforementioned **PinePhone ISO**, and finally, the **Raspberry Pi ISO**.
Head over to the [official site](https://rhinolinux.org/download.html?ref=news.itsfoss.com) to get the ISO of your choice.
You can also build it from scratch using the source code in its [GitHub repo](https://github.com/rhino-linux?ref=news.itsfoss.com).
I am excited to see what Rhino Linux can achieve in the future ⭐
*Follow us on*
[Mastodon](https://mastodon.social/@itsfoss?ref=news.itsfoss.com), and join our[Telegram channel](https://t.me/itsfoss_official?ref=news.itsfoss.com)for news like this.## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,111 | 使用开源工具监控 Kubernetes 云成本 | https://opensource.com/article/23/3/kubernetes-cloud-cost-monitoring | 2023-08-20T13:34:18 | [
"Kubernetes"
] | https://linux.cn/article-16111-1.html | 
>
> OpenCost 是一款与 Kubernetes 无缝集成的云成本监控工具,可让您实时跟踪云支出,从而相应地优化资源。
>
>
>
[Kubernetes](https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=7013a000002qLH8AAM) 是一个强大的平台,用于管理云中的动态容器化应用,但可能很难理解成本发生在哪里。管理 Kubernetes 资源的成本效率可能是一个挑战。这就是 [OpenCost](https://www.opencost.io/) 的用武之地。OpenCost 是一种云成本监控工具,与 Kubernetes 无缝集成,让你可以实时跟踪云支出,以便相应地优化资源。
OpenCost 是一个开源 [CNCF 沙盒项目](https://www.cncf.io/projects/opencost/) 和 [规范](https://github.com/opencost/opencost/blob/develop/spec/opencost-specv01.md),用于实时监控与 Kubernetes 部署相关的云成本。该规范按服务、部署、命名空间、标签等对当前和历史 Kubernetes 云支出和资源分配进行建模。这些数据对于理解和优化 Kubernetes 从应用到基础设施的成本和性能至关重要。
### 要求和安装
开始使用 OpenCost 是一个相对简单的过程。OpenCost 使用 [Prometheus](https://prometheus.io/) 进行监控和指标存储。你可以从 [Prometheus 社区的 Kubernetes Helm Chart](https://prometheus-community.github.io/helm-charts) 安装它。
#### 安装 Prometheus
首先使用以下命令安装 Prometheus:
```
$ helm install my-prometheus --repo https://prometheus-community.github.io/helm-charts prometheus \
--namespace prometheus --create-namespace \
--set pushgateway.enabled=false --set alertmanager.enabled=false -f \
https://raw.githubusercontent.com/opencost/opencost/develop/kubernetes/prometheus/extraScrapeConfigs.yaml
```
#### 安装 OpenCost
接下来,使用 `kubectl` 命令安装 OpenCost:
```
$ kubectl apply --namespace opencost -f \
https://raw.githubusercontent.com/opencost/opencost/develop/kubernetes/opencost.yaml
```
此命令将 OpenCost 部署到你的集群并开始收集数据。这就是大多数安装所需的全部内容。你可以[使用你自己的 Prometheus](https://www.opencost.io/docs/install#providing-your-own-prometheus) 安装或使用 [OpenCost Helm Chart](https://github.com/opencost/opencost-helm-chart/) 自定义部署。
#### 测试和访问
OpenCost 会自动检测它是否在 AWS、Azure 还是 GCP 上运行,你可以将其配置为为本地 Kubernetes 部署提供定价。首先转发 API 和 UI 访问的端口:
```
$ kubectl port-forward --namespace opencost service/opencost 9003 9090
```
大约五分钟内,你可以验证 UI 和服务器是否正在运行,并且你可以通过 **<http://localhost:9090>** 访问 OpenCost UI。
### 监控成本
你已准备好开始使用部署到 Kubernetes 集群的 OpenCost 来监控云成本。OpenCost 仪表板提供对云支出的实时可见性,使你能够识别成本异常并优化云资源。你可以按节点、命名空间、pod、标签等查看云支出。

[kubectl cost](https://github.com/kubecost/kubectl-cost) 插件提供了对 Kubernetes 成本分配指标的简单 CLI 查询。它允许开发人员、运营商和其他人快速确定任何 Kubernetes 工作负载的成本和效率。
```
$ kubectl cost --service-port 9003 \
--service-name opencost --kubecost-namespace opencost \
--allocation-path /allocation/compute pod \
--window 5m --show-efficiency=true
+-------+---------+-------------+----------+---------------+
|CLUSTER|NAMESPACE|POD |MONTH RATE|COST EFFICIENCY|
+-------+---------+-------------+----------+---------------+
|cl-one |kube-syst|coredns-db...| 1.486732 | 0.033660 |
| | |coredns-...dm| 1.486732 | 0.032272 |
| | |kube-prox...7| 1.359577 | 0.002200 |
| | |kube-prox...x| 1.359577 | 0.002470 |
| |opencost |opencost...5t| 0.459713 | 0.187180 |
| |kube-syst|aws-node-cbwl| 0.342340 | 0.134960 |
| | |aws-node-gbfh| 0.342340 | 0.133760 |
| |prometheu|my-prome...pv| 0.000000 | 0.000000 |
| | |my-prome...hn| 0.000000 | 0.000000 |
| | |my-prome...89| 0.000000 | 0.000000 |
+-------+---------+-------------+----------+---------------+
| SUMMED| | | 6.837011 | |
+-------+---------+-------------+----------+---------------+
```
你还可以集成 API,以编程方式将数据提取到你选择的平台中。
### Kubernetes 优化策略
现在你已经掌握了云成本,是时候优化你的 Kubernetes 环境了。优化是一个迭代过程。从栈的顶部(容器)开始并遍历每一层。每一步的效率都会复合。有很多方法可以优化 Kubernetes 以提高成本效率,例如:
* 查找废弃的工作负载和未申明的卷:不再使用或断开连接的容器荚和存储会继续消耗资源而不提供价值。
* 调整你的工作负载大小:确保你为你的工作负载使用正确大小的容器。调查分配过多和分配不足的容器。
* 自动扩展:自动扩展可以帮助你仅在需要时使用资源来节省成本。
* 调整集群大小:节点过多或过大可能会导致效率低下。在容量、可用性和性能之间找到适当的平衡可能会大大降低成本。
* 研究更便宜的节点类型:CPU、RAM、网络和存储有很多变化。切换到 ARM 架构可能会带来更大的节省。
* 投资 FinOps 团队:组织内的专门团队可以通过协调预留实例、现货实例和节省计划来寻找实现更大节省的方法。
### 从今天开始
监控 Kubernetes 环境中的成本可能具有挑战性,但使用 OpenCost 则不必如此。要开始使用 OpenCost 并控制你的云支出,请访问 [OpenCost](https://opencost.io/) 网站,在 [GitHub](https://github.com/opencost) 中获取代码,查看 [OpenCost 文档](https://www.opencost.io/docs/),并参与 [CNCF Slack](https://slack.cncf.io/) 中的 **#opencost** 频道。
*(题图:MJ/5de557f1-464c-480c-8698-130748f60b20)*
---
via: <https://opensource.com/article/23/3/kubernetes-cloud-cost-monitoring>
作者:[Matt Ray](https://opensource.com/users/mattray-0) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Kubernetes](https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=7013a000002qLH8AAM) is a powerful platform for managing dynamic containerized applications in the cloud, but it may be difficult to understand where costs are incurred. Managing the cost efficiency of Kubernetes resources can be a challenge. That's where [OpenCost](https://www.opencost.io/) comes in. OpenCost is a cloud cost monitoring tool that integrates seamlessly with Kubernetes, allowing you to track your cloud spend in real-time so you can optimize your resources accordingly.
**[ Also read How to measure the cost of running applications ]**
OpenCost is an open source [CNCF Sandbox project](https://www.cncf.io/projects/opencost/) and [specification](https://github.com/opencost/opencost/blob/develop/spec/opencost-specv01.md) for the real-time monitoring of cloud costs associated with Kubernetes deployments. The specification models current and historical Kubernetes cloud spend and resource allocation by service, deployment, namespace, labels, and much more. This data is essential for understanding and optimizing Kubernetes for both cost and performance from the applications down through the infrastructure.
## Requirements and installation
Getting started with OpenCost is a relatively straightforward process. OpenCost uses [Prometheus](https://prometheus.io/) for both monitoring and metric storage. You can install it from the [Prometheus Community Kubernetes Helm Chart](https://prometheus-community.github.io/helm-charts).
### Install Prometheus
Begin by installing Prometheus using the following command:
```
``````
$ helm install my-prometheus --repo https://prometheus-community.github.io/helm-charts prometheus \
--namespace prometheus --create-namespace \
--set pushgateway.enabled=false --set alertmanager.enabled=false -f \
https://raw.githubusercontent.com/opencost/opencost/develop/kubernetes/prometheus/extraScrapeConfigs.yaml
```
### Install OpenCost
Next, install OpenCost using the `kubectl`
command:
```
``````
$ kubectl apply --namespace opencost -f \
https://raw.githubusercontent.com/opencost/opencost/develop/kubernetes/opencost.yaml
```
This command deploys OpenCost to your cluster and starts collecting data. That is all that most installations require. You can [use your own Prometheus](https://www.opencost.io/docs/install#providing-your-own-prometheus) installation or customize the deployment with the [OpenCost Helm Chart](https://github.com/opencost/opencost-helm-chart/).
### Testing and access
OpenCost automatically detects whether it runs on AWS, Azure, or GCP, and you can configure it to provide pricing for on-premises Kubernetes deployments. Begin by forwarding ports for API and UI access:
```
````$ kubectl port-forward --namespace opencost service/opencost 9003 9090`
Within about five minutes, you can verify the UI and server are running, and you may access the OpenCost UI at ** http://localhost:9090**.
## Monitor costs
You are ready to start monitoring your cloud costs with OpenCost deployed to your Kubernetes cluster. The OpenCost dashboard provides real-time visibility into your cloud spend, allowing you to identify cost anomalies and optimize your cloud resources. You can view your cloud spend by nodes, namespaces, pods, tags, and more.
(Matthew Ray, CC BY-SA 4.0)
The [kubectl cost](https://github.com/kubecost/kubectl-cost) plugin provides easy CLI queries to Kubernetes cost allocation metrics. It allows developers, operators, and others to determine the cost and efficiency for any Kubernetes workload quickly.
```
``````
$ kubectl cost --service-port 9003 \
--service-name opencost --kubecost-namespace opencost \
--allocation-path /allocation/compute pod \
--window 5m --show-efficiency=true
+-------+---------+-------------+----------+---------------+
|CLUSTER|NAMESPACE|POD |MONTH RATE|COST EFFICIENCY|
+-------+---------+-------------+----------+---------------+
|cl-one |kube-syst|coredns-db...| 1.486732 | 0.033660 |
| | |coredns-...dm| 1.486732 | 0.032272 |
| | |kube-prox...7| 1.359577 | 0.002200 |
| | |kube-prox...x| 1.359577 | 0.002470 |
| |opencost |opencost...5t| 0.459713 | 0.187180 |
| |kube-syst|aws-node-cbwl| 0.342340 | 0.134960 |
| | |aws-node-gbfh| 0.342340 | 0.133760 |
| |prometheu|my-prome...pv| 0.000000 | 0.000000 |
| | |my-prome...hn| 0.000000 | 0.000000 |
| | |my-prome...89| 0.000000 | 0.000000 |
+-------+---------+-------------+----------+---------------+
| SUMMED| | | 6.837011 | |
+-------+---------+-------------+----------+---------------+
```
You can also integrate an API to extract the data programmatically into your platform of choice.
## Kubernetes optimization strategies
Now that you have a handle on your cloud costs, it's time to optimize your Kubernetes environment. Optimization is an iterative process. Start at the top of the stack (containers) and work through each layer. The efficiencies compound at each step. There are many ways to optimize Kubernetes for cost efficiency, such as:
- Look for abandoned workloads and unclaimed volumes: Pods and storage that are no longer in use or are disconnected continue to consume resources without providing value.
- Right-size your workloads: Ensure you're using the right size containers for your workloads. Investigate over- and under-allocated containers.
- Autoscaling: Autoscaling can help you save costs by only using resources when needed.
- Right-size your cluster: Too many or too-large nodes may be inefficient. Finding the right balance between capacity, availability, and performance may greatly reduce costs.
- Investigate cheaper node types: There's a lot of variation in CPU, RAM, networking, and storage. Switching to ARM architectures may unlock even greater savings.
- Invest in a FinOps team: A dedicated team within your organization can look for ways to unlock greater savings by coordinating reserved instances, spot instances, and savings plans.
## Get started today
Monitoring costs in a Kubernetes environment can be challenging, but with OpenCost, it doesn't have to be. To get started with OpenCost and take control of your cloud spend, visit the [OpenCost](https://opencost.io/) website, get the code in [GitHub](https://github.com/opencost), check out the [OpenCost documentation](https://www.opencost.io/docs/), and get involved in the **#opencost** channel in the [CNCF Slack](https://slack.cncf.io/).
**[ Related read How to prioritize cloud spending ]**
## Comments are closed. |
16,113 | Fedora Linux Flatpak 八月推荐应用 | https://fedoramagazine.org/fedora-linux-flatpak-cool-apps-to-try-for-august/ | 2023-08-21T09:34:48 | [
"Flatpak"
] | https://linux.cn/article-16113-1.html | 
>
> 本文介绍了 Flathub 中可用的项目以及安装说明。
>
>
>
[Flathub](https://flathub.org) 是获取和分发适用于所有 Linux 的应用的地方。它由 Flatpak 提供支持,允许 Flathub 应用在几乎任何 Linux 发行版上运行。
请阅读 “[Flatpak 入门](https://fedoramagazine.org/getting-started-flatpak/)”。要启用 Flathub 作为你的 Flatpak 提供商,请使用 [Flatpak 站点](https://flatpak.org/setup/Fedora) 上的说明。
### Authenticator
[Authenticator](https://flathub.org/apps/com.belmoussaoui.Authenticator) 是一个简单的应用,可让你生成双因素身份验证代码。它有一个非常简单和优雅的界面,支持很多算法和方法。它的一些特点是:
* 支持基于时间/基于计数器/Steam 方法
* 支持 SHA-1/SHA-256/SHA-512 算法
* 使用相机或截图扫描二维码
* 使用密码锁定应用
* 从已知应用备份/恢复,如 FreeOTP+、Aegis(加密/纯文本)和 OTP、谷歌验证器
你可以通过单击站点上的安装按钮或手动使用以下命令来安装 Authenticator:
```
flatpak install flathub com.belmoussaoui.Authenticator
```
### Secrets
[Secrets](https://flathub.org/apps/org.gnome.World.Secrets) 是一个与 GNOME 集成的密码管理器。它易于使用,并使用 KeyPass 文件格式。它的一些特点是:
* 支持的加密算法:
+ AES 256 位
+ Twofish 256 位
+ ChaCha20 256 位
* 支持的衍生算法:
+ Argon2 KDBX4
+ Argon2id KDBX4
+ AES-KDF KDBX 3.1
* 创建或导入 KeePass safes 数据库
* 将附件添加到你的加密数据库
* 生成高强度加密的密码
* 快速搜索你喜爱的条目
* 不活动时自动锁定数据库
* 支持双因素认证
你可以通过单击站点上的安装按钮或手动使用以下命令来安装 Secrets:
```
flatpak install flathub org.gnome.World.Secrets
```
### Flatsweep
[Flatsweep](https://flathub.org/apps/io.github.giantpinkrobots.flatsweep) 是一个简单的应用,用于在 Flatpak 卸载后删除残留文件。它使用 GTK4 和 Libadwaita 提供一致的用户界面,与 GNOME 很好地集成,但你可以在任何桌面环境中使用它。
你可以通过单击站点上的安装按钮或手动使用以下命令来安装 Flatsweep:
```
flatpak install flathub io.github.giantpinkrobots.flatsweep
```
### Solanum
Solanum 是一款使用 [番茄工作法](https://en.wikipedia.org/wiki/Pomodoro_Technique) 的时间跟踪应用。它使用 GTK4,其界面与 GNOME 很好地集成。
你可以通过单击站点上的安装按钮或手动使用以下命令来安装 Solanum:
```
flatpak install flathub org.gnome.Solanum
```
*(题图:MJ/3e95393e-6dc5-4328-b0f9-27031c8848a2)*
---
via: <https://fedoramagazine.org/fedora-linux-flatpak-cool-apps-to-try-for-august/>
作者:[Eduard Lucena](https://fedoramagazine.org/author/x3mboy/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article introduces projects available in Flathub with installation instructions.
[Flathub](https://flathub.org) is the place to get and distribute apps for all of Linux. It is powered by Flatpak, allowing Flathub apps to run on almost any Linux distribution.
Please read “[Getting started with Flatpak](https://fedoramagazine.org/getting-started-flatpak/)“. In order to enable flathub as your flatpak provider, use the instructions on the [flatpak site](https://flatpak.org/setup/Fedora).
## Authenticator
[Authenticator](https://flathub.org/apps/com.belmoussaoui.Authenticator) is a simple app that allows you to generate Two-Factor authentication codes. It has a very simple and elegant interface with support for a a lot of algorithms and methods. Some of its features are:
- Time-based/Counter-based/Steam methods support
- SHA-1/SHA-256/SHA-512 algorithms support
- QR code scanner using a camera or from a screenshot
- Lock the application with a password
- Backup/Restore from/into known applications like FreeOTP+, Aegis (encrypted / plain-text), andOTP, Google Authenticator
You can install “Authenticator” by clicking the install button on the site or manually using this command:
flatpak install flathub com.belmoussaoui.Authenticator
## Secrets
[Secrets](https://flathub.org/apps/org.gnome.World.Secrets) is a password manager that integrates with GNOME. It’s easy to use and uses the KeyPass file format. Some of its features are:
- Supported Encryption Algorithms:
- AES 256-bit
- Twofish 256-bit
- ChaCha20 256-bit
- Supported Derivation algorithms:
- Argon2 KDBX4
- Argon2id KDBX4
- AES-KDF KDBX 3.1
- Create or import KeePass safes
- Add attachments to your encrypted database
- Generate cryptographically strong passwords
- Quickly search your favorite entries
- Automatic database lock during inactivity
- Support for two-factor authentication
You can install “Secrets” by clicking the install button on the site or manually using this command:
flatpak install flathub org.gnome.World.Secrets
## Flatsweep
[Flatsweep](https://flathub.org/apps/io.github.giantpinkrobots.flatsweep) is a simple app to remove residual files after a flatpak is unistalled. It uses GTK4 and Libadwaita to provide a coherent user interface that integrates nicely with GNOME, but you can use it on any desktop environment.
You can install “Flatsweep” by clicking the install button on the site or manually using this command:
flatpak install flathub io.github.giantpinkrobots.flatsweep
## Solanum
Solanum is a time tracking app that uses the [pomodoro technique](https://en.wikipedia.org/wiki/Pomodoro_Technique). It uses GTK4 and it’s interface integrates nicely with GNOME.
You can install “Solanum” by clicking the install button on the site or manually using this command:
flatpak install flathub org.gnome.Solanum
## bo
Many thanks, useful selection!
## Darvond
So between Google-Authenticator, totpcgi, Numberstaton and this one, what would be the vying pull for the double library bloat of Flatpaks?
Also Secrets is also in the main package repository, why bring it up?
The latter two aren’t in the repos, but Pomodoro timers aren’t hard to find. There’s 8 on Fdroid, probably countless more on the mainline app stores.
## Joerg
Thank you for the information about recommended apps. I’ve been using Fedora for about a year now and I’m impressed by its up-to-dateness, stability, and speed. The regular news from the Fedora community is very interesting.
## sepples
Helpful article as always! Minor typo in the last entry 😀 Change “Flatsweep” to “Solanum”.
## Axel
Great article! One addition that could be made is FlatSeal, a tool used to manage directory access and permissions other flatpaks have.
## T
Why do we need multiple app distribution mechanisms?
## Darvond
Mostly to solve the issue that people think that to make Linux appealing for “regular” people, something needs to be done to make the “Padded Cell” take place. I don’t think changing the distribution methodology is near the top of the actual issues.
## Phoenix
@hf, interesting content from these links. Did not know (too much) about it.
For my part I usually install everything from the package manager (DNF). The only exception here are Wine-based applications (through Lutris and Steam), where I indeed use flatpak for. The purpose here, however, is less about the security aspect than separating the many 32-bit components from my otherwise pure 64-bit host system in hopes to have it run smoother or with less problems. Whether this is perceived or real should likely be discussed elsewhere.
Though after having taken in the content of these links, I also agree with the suggested changes proposed in “Is Flatpak Fixable?” from the second link. It would provide a good future to flatpak and its applications. While it may put some load on the developers, the result would be a tremendously better user experience on the long run and as a user myself can only plea to the flatpak developers to reconsider. It will surely pay off.
## GroovieMan
Better create an rpm, i do not like packaging formats, that reminds me of windows.
## james sparks
thanks for today’s upgrade to the wifi driver!
## Till
What’s the reason that the flatpak commands do not properly uninstall packages but create the need for another app to clean up after them?
## Don Joe
Would love to hear why flatpaks dont get unistalled completley to use Flatsweep ?
As well as why should we use Flatseal permissions…
Why devs dont lock down flatpak app permissions for user ? |
16,114 | Bash 基础知识系列 #8:For、While 和 Until 循环 | https://itsfoss.com/bash-loops/ | 2023-08-21T10:08:12 | [
"Bash",
"脚本"
] | https://linux.cn/article-16114-1.html | 
>
> 在 Bash 基础知识系列的倒数第二章节,学习 `for`、`while` 和 `until` 循环。
>
>
>
循环是任何编程语言中的一个强大功能。如果你还不知道,循环其实是一种根据某些条件重复代码的方式。
例如,想象一下你需要打印从 1 到 10 的数字。你可以使用 `echo` 命令写十次,但那太原始了。你使用一个循环,在 3 到 4 行代码内,就能完成。
这是我能想到的最简单的例子。我将在讨论 Bash 循环时,分享一些实际有用的例子。
在 Bash 中有三种类型的循环:
* `for`
* `while`
* `until`
我将在教程中展示所有三种类型的循环。让我们从最常见的一种开始。
### Bash 中的 For 循环
以下是 Bash 中的 `for` 循环语法:
```
for arg in LIST; do
commands
done
```
这里的 `LIST` 可能是一个数组或者一个项目列表。[括号扩展](https://linuxhandbook.com/brace-expansion/?ref=itsfoss.com) 也是进行循环的常用手段。
考虑一下我在开始提到的最简单的场景。让我们使用 `for` 循环打印从 1 到 10 的数字:
```
#!/bin/bash
for num in {1..10}; do
echo $num
done
```
如果你运行它,你应该会看到像这样的输出:
```
$ ./for-loop.sh
1
2
3
4
5
6
7
8
9
10
```
你也可以使用 `for num in 1 2 3 4 5 6 7 8 9 10; do` ,但是使用括号扩展使得代码看起来更短且更智能。
`{..}` 是用于扩展模式的。你使用 `{d..h}` ,它等同于 `d e f g h` 。关于括号扩展的更多信息,可以在这篇文章中找到。
>
> **[在 Bash 中使用括号扩展](https://linuxhandbook.com/brace-expansion/?ref=itsfoss.com)**
>
>
>
>
> ? 如果你熟悉 C 语言编程,你可能会喜欢在 bash 中使用 C 风格的 for 循环:
>
>
>
> ```
> for ((i = 0 ; i < 10 ; i++)); do
> echo $i
> done
>
> ```
>
>
让我们看另一个例子,显示 [Bash 数组](https://itsfoss.com/bash-arrays/) 的所有内容:
```
#!/bin/bash
distros=(Ubuntu Fedora Debian Alpine)
for i in "${distros[@]}"; do
echo $i
done
```
如果你运行脚本,它将显示数组中定义的所有发行版:
```
Ubuntu
Fedora
Debian
Alpine
```
### Bash 中的 While 循环
`while` 循环测试一个条件,然后只要条件为真,就继续循环。
```
while [ condition ]; do
commands
done
```
如果你考虑前一个例子,它可以使用 `while` 循环进行重写:
```
#!/bin/bash
num=1
while [ $num -le 10 ]; do
echo $num
num=$(($num+1))
done
```
如你所见,你首先需要将变量 `num` 定义为 1,然后在循环体内,你增加 `num` 的值。只要 `num` 小于或等于 10,while 循环就会检查条件并运行脚本。
因此,现在运行脚本将会显示出和之前 `for` 循环中看到的完全相同的结果。
```
1
2
3
4
5
6
7
8
9
10
```
让我们看另一个例子。这是一个 [Bash 脚本,它接受一个数字作为参数](https://itsfoss.com/bash-pass-arguments/) 并显示该表。
```
#!/bin/bash
echo "Table for $1 is:"
index=1
while [ $index -le 10 ]; do
echo $(($1*$index))
index=$(($index+1))
done
```
如果你对 `$1` 的使用感到困惑,它代表传递给脚本的第一个参数。更多的细节可以参考这个系列的 [第三章](https://itsfoss.com/bash-pass-arguments/)。
如果你运行这个脚本,它应该会显示以下的输出:
```
$ ./table.sh 2
Table for 2 is:
2
4
6
8
10
12
14
16
18
20
```
### Bash 中的 Until 循环
这是一个使用较少的循环格式。它的行为和 `while` 循环类似。这里的区别是,循环运行直到它检查的条件为真为止。意味着为了在循环中执行代码,`[ ]` 中的条件必须为假。
我马上会解释一下。让我们先看一下它的语法。
```
until [ condition ]; do
commands
done
```
现在,如果我要使用相同的示例,即使用 `until` 循环打印从 1 到 10 的数字,它看起来会是这样:
```
#!/bin/bash
num=1
until [ $num -gt 10 ]; do
echo $num
num=$(($num+1))
done
```
区别在于条件;其余部分保持不变。
* 当变量 `num` 小于或等于 10 时,while 循环就会运行。`[ ]` 中的条件必须为真,循环才会执行。
* 知道变量 `num` 变得大于 10 时,until 循环才会运行。`[ ]` 中的条件必须为假,循环才会执行。
这都是做同样事情的两种不同方式。`while` 更受欢迎,因为你会在大多数编程语言中找到类似 `while` 的循环语法。
### ?️ 练习时间
那是有趣的。现在是做一些练习的时候了。
**练习 1**:编写一个脚本,该脚本接受一个数字作为参数并打印其表格。如果脚本在没有参数的情况下运行,你的脚本还应显示一个消息。
**预期输出**:
```
$: ./table.sh
You forgot to enter a number
$: ./table.sh 3
3
6
9
12
15
18
21
24
27
30
```
**练习 2** : 编写一个脚本,列出目录 `/var` 中的所有文件。
**提示** : 对于循环,使用 `/var/*` 作为 “列表”。
Bash 基础知识系列即将结束。作为该系列的最后一章,你将在下周学习在 Bash 脚本中使用函数。敬请期待。
*(题图:MJ/945241d6-6a73-432c-9bcd-e0948b3fadc0)*
---
via: <https://itsfoss.com/bash-loops/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter #8: For, While and Until Loops
In the penultimate chapter of the Bash Basics series, learn about for, while and until loops.
Loops are a powerful feature in any programming language. If you do not know already, the loops are a way to repeat the code based on certain criteria.
For example, imagine that you have to print the numbers from 1 to 10. You can write the echo command ten times but that's very primitive. You use a loop and in 3-4 lines of code, it can be done.
That's the simplest of the examples I could think of. I am going to share actual useful examples while I discuss the bash loops with you.
There are three types of loops in Bash:
- For
- While
- Until
I'll show all three kinds of looping in the tutorial. Let's start with the most common one.
## For loop in bash
Here's the syntax for 'for loop' in bash:
```
for arg in LIST; do
commands
done
```
The LIST here could be an array or a list of items. [Brace expansions](https://linuxhandbook.com/brace-expansion/) are also popular for looping.
Take the simplest scenario I mentioned in the beginning. Let's print numbers from 1 to 10 using for loop:
```
#!/bin/bash
for num in {1..10}; do
echo $num
done
```
If you run it, you should see an output like this:
```
abhishek@itsfoss:~/bash_scripts$ ./for-loop.sh
1
2
3
4
5
6
7
8
9
10
```
You could have also used `for num in 1 2 3 4 5 6 7 8 9 10; do`
but using the brace expansion makes the code look shorter and smarter.
`{..}`
is used for expanding on a pattern. You use `{d..h}`
and it is equivalent to `d e f g h`
. More on brace expansion can be found in this article.
[Using Brace Expansion in Bash ShellBrace expansion in the bash shell is a lesser known but an awesome feature. Learn about using them like a Pro Linux user with practical examples.](https://linuxhandbook.com/brace-expansion/)

for ((i = 0 ; i < 10 ; i++)); do
echo $i
done
Let's see another example that displays all the contents of an [array in bash](https://itsfoss.com/bash-arrays/):
```
#!/bin/bash
distros=(Ubuntu Fedora Debian Alpine)
for i in "${distros[@]}"; do
echo $i
done
```
If you run the script, it will display all the distros defined in the array:
```
Ubuntu
Fedora
Debian
Alpine
```
## While loop in bash
The while loop tests a condition and then keeps on looping as long as the condition is true.
```
while [ condition ]; do
commands
done
```
If you take the previous example, it can be rewritten using the while loop like this:
```
#!/bin/bash
num=1
while [ $num -le 10 ]; do
echo $num
num=$(($num+1))
done
```
As you can see, you had to define the variable `num`
to 1 first and then in the loop body, you increase the value of `num`
by 1. The while loop checks the condition and runs it as long as `num`
is less than or equal to 10.
Thus, running the script now will show the exact result you saw earlier with for loop.
```
1
2
3
4
5
6
7
8
9
10
```
Let's see another example. Here's a [bash script that takes a number as an argument](https://itsfoss.com/bash-pass-arguments/) and displays its table.
```
#!/bin/bash
echo "Table for $1 is:"
index=1
while [ $index -le 10 ]; do
echo $(($1*$index))
index=$(($index+1))
done
```
If you are confused about the use of $1, it represents the first argument passed to the script. Check out [chapter 3 of this series](https://itsfoss.com/bash-pass-arguments/) for more details.
If you run the script, it should show this output:
```
abhishek@itsfoss:~/bash_scripts$ ./table.sh 2
Table for 2 is:
2
4
6
8
10
12
14
16
18
20
```
## Until loop in bash
This is the lesser-used loop format. It behaves similarly to the while loop. The difference here is that the loop runs until the condition it checks is true. This means for the code in the loop to execute, the condition in `[ ]`
has to be false.
I'll explain it in a bit. Let's see its syntax first.
```
until [ condition ]; do
commands
done
```
Now, if I have to use the same example of printing numbers from 1 to 10 using until loop, it would look like this:
```
#!/bin/bash
num=1
until [ $num -gt 10 ]; do
echo $num
num=$(($num+1))
done
```
The difference is in the condition; the rest remains the same.
- The while loop ran while the variable
`num`
was less than or equal to 10. The condition in`[ ]`
has to be true for the loop to execute. - The until loop runs until the variable
`num`
becomes greater than 10. The condition in `[ ]` has to be false for the loop to execute.
Both are different ways of doing the same thing. While is more popular as you'll find a while loop equivalent in most programming languages.
## 🏋️ Exercise time
That was fun. Time to do some exercise now.
**Exercise 1**: Write a script that takes a number as an argument and prints its table. Your script should also show a message if the script is run without an argument.
**Expected output**:
```
$: ./table.sh
You forgot to enter a number
$: ./table.sh 3
3
6
9
12
15
18
21
24
27
30
```
**Exercise 2**: Write a script that lists all the files in the directory /var
**Hint**: Use for loop with /var/* as the 'list'.
You can discuss your answers in this dedicated thread in the Community:
[Practice Exercise in Bash Basics Series #8: For, While and Until LoopsIf you are following the Bash Basics series on It’s FOSS, you can submit and discuss the answers to the exercise at the end of the chapter: Fellow experienced members are encouraged to provide their feedback to new members. Do note that there could be more than one answer to a given problem.](https://itsfoss.community/t/practice-exercise-in-bash-basics-series-8-for-while-and-until-loops/10960)

The bash basics series is coming to an end. As the final chapter in the series, you'll learn to use functions in bash scripting next week. Stay tuned. |
16,116 | Bash 基础知识系列 #9:Bash 中的函数 | https://itsfoss.com/bash-function/ | 2023-08-22T11:43:00 | [
"脚本",
"Bash"
] | https://linux.cn/article-16116-1.html | 
>
> 在 Bash 基础系列的最后一章中学习函数的全部知识。
>
>
>
大多数编程语言都支持函数的概念。
函数帮助你避免在同一个程序中反复编写同一段代码。你只需将代码写为一个函数,然后在需要特定代码片段的地方使用这个函数。
在 Bash 基础知识系列的最后一章中,你将学习在 Bash 脚本中使用函数。
### Bash 中的函数
下面是声明 Bash 函数的通用语法:
```
function_name() {
commands
}
```
只有在 “调用函数” 的脚本中,函数内的命令才会被执行。
这里有一个伪代码来演示这个情况:
```
function_name() {
commands
}
some_other_commands
# 函数调用
function_name argument;
```
>
> ? 函数定义必须在你调用函数之前。
>
>
>
让我们通过一个简单的例子来看看这个:
```
#!/bin/bash
fun() {
echo "This is a function"
}
echo "This is a script"
fun
```
当你运行脚本时,你应该看到这样的输出:
```
This is a script
This is a function
```
函数是在没有任何参数的情况下被调用的。接下来,让我们看看在 bash 中如何处理函数的参数。
### 向函数传递参数
向函数传递参数和向 Bash 脚本传递参数是一样的。你在调用函数时,可以在函数名旁边写上参数。
```
function_name argument;
```
让我们用一个例子来看看这个:
```
#!/bin/bash
sum() {
sum=$(($1+$2))
echo "The sum of $1 and $2 is: $sum"
}
echo "Let's use the sum function"
sum 1 5
```
如果你运行这个脚本,你会看到以下输出:
```
Let's use the sum function
The sum of 1 and 5 is: 6
```
请记住,传递给脚本的参数和传递给函数的参数是不同的。
在下面的例子中,我在调用函数时交换了参数。
```
#!/bin/bash
arg() {
echo "1st argument to function is $1 and 2nd is $2"
}
echo "1st argument to script is $1 and 2nd is $2"
arg $2 $1
```
当你运行这个脚本时,你会看到这样的交换:
```
$ ./function.sh abhi shek
1st argument to script is abhi and 2nd is shek
1st argument to function is shek and 2nd is abhi
```
### Bash 中的递归函数
一个递归函数会调用它自己。这就是递归的含义。这个梗图可能会帮助你理解它。

递归功能非常强大,可以帮助你编写复杂的程序。
让我们用一个计算阶乘的样本脚本来看看它的应用。如果你忘记了,阶乘的定义是这样的。
n 的阶乘:
```
(n!) = 1 * 2 * 3 * 4 *... * n
```
所以,5 的阶乘是 1 \* 2 \* 3 \* 4 \* 5,计算结果是 120。
这是我用递归计算给定数字的阶乘的脚本。
```
#!/bin/bash
factorial() {
if [ $1 -gt 1 ]; then
echo $(( $1 * $(factorial $(( $1 -1 ))) ))
else
echo 1
fi
}
echo -n "Factorial of $1 is: "
factorial $1
```
注意到 `echo $(( $1 * $(factorial $(( $1 -1 ))) ))`,代码使用比输入值小 1 的值调用了函数自身。这个过程会一直持续到值变为 1。所以,如果你运行脚本并输入参数 5,它最终会返回 5 \* 4 \* 3 \* 2 \*1 的结果。
```
$ ./factorial.sh 5
Factorial of 5 is: 120
```
非常好。现在,让我们来做些练习吧。
### ?️ 练习时间
以下是一些示例编程挑战,用来帮助你实践你所学。
练习 1:写一个 Bash 脚本,使用一个名为 `is_even` 的函数来检查给定的数字是否是偶数。
练习 2:类似的练习,你需要编写一个脚本,该脚本具有一个名为 `is_prime` 的函数,并检查给定数字是否是质数。如果你还不知道,质数只能被 1 和它自身整除。
练习 3:编写一个生成给定数字的斐波那契序列的脚本。序列从 1 开始,脚本必须接受大于 3 的数字。
所以,如果你运行 `fibonacci.sh 5`,它应该输出 “1 1 2 3 5”。
就这些了,伙计们!这是 Bash 基础系列的最后一节。当然,你在这里学到的只是冰山一角;Bash 编程还有更多需要学习的内容。
但是现在,你应该对 Bash Shell 有了一定的理解。你应该能够理解大多数 Bash 脚本,并能编写简单的脚本,即便不能编写复杂的。
如果你想深入学习,没有什么比阅读 GNU Bash 手册更好的了。
>
> **[GNU Bash 手册](https://www.gnu.org/software/bash/manual/)**
>
>
>
? 希望你喜欢这个 Bash 基础知识系列。我们正在创建更多的教程系列,以给你提供更流畅的学习体验。请提供你的反馈,帮助我们帮助其他人学习 Linux。
*(题图:MJ/f0022a50-85fe-40cc-afdd-285d976ec98c)*
---
via: <https://itsfoss.com/bash-function/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Chapter #9: Functions in Bash
Learn all about functions in the final chapter of the Bash Basics series.
Most programming languages support the concept of functions.
Functions help you avoid writing the same piece of code again and again in the same program. You write the code once as function and then use this function where you need the specific code piece.
In the last chapter of the Bash Basics series, you'll learn about using functions in bash scripts.
## Functions in bash
Here's the generic syntax for declaring a bash function:
```
function_name() {
commands
}
```
The commands inside the function will only be executed if you 'call the function' in the script.
Here's a dummy code to demonstrate that:
```
function_name() {
commands
}
some_other_commands
#FUNCTION CALL
function_name argument;
```
Let's see this with a simple example:
```
#!/bin/bash
fun() {
echo "This is a function"
}
echo "This is a script"
fun
```
When you run the script, you should see an output like this:
```
This is a script
This is a function
```
The function is called without any arguments. Let's see about handling arguments with functions in bash.
## Passing arguments to functions
Passing arguments to functions is the same as passing arguments to bash scripts. You mention the arguments with the function name when you call the function.
`function_name argument;`
Let's see this with an example:
```
#!/bin/bash
sum() {
sum=$(($1+$2))
echo "The sum of $1 and $2 is: $sum"
}
echo "Let's use the sum function"
sum 1 5
```
If you run the script, you'll see the following output:
```
Let's use the sum function
The sum of 1 and 5 is: 6
```
Keep in mind that the argument passed to the scripts are not the same as arguments passed to the function.
In the example below, I have interchanged the arguments while calling the function.
```
#!/bin/bash
arg() {
echo "1st argument to function is $1 and 2nd is $2"
}
echo "1st argument to script is $1 and 2nd is $2"
arg $2 $1
```
And when you run the script, you'll see the interchange:
```
abhishek@itsfoss:~/bash_scripts$ ./function.sh abhi shek
1st argument to script is abhi and 2nd is shek
1st argument to function is shek and 2nd is abhi
```
## Recursive function in bash
A recursive function calls itself. That's what recursion is. This meme may help you understand it.

Now, the recursive functionality is quite powerful and could help you write complicated programs.
Let's see it in action with a sample script that computes the factorial of a number. In case you don't remember, the factorial is defined like this.
```
factorial of n (n!) = 1 * 2 * 3 * 4 *... * n
```
So, factorial of 5 is 1 * 2 * 3 * 4 * 5 which computes to 120.
Here's my script for computing the factorial of a given number using recursion.
```
#!/bin/bash
factorial() {
if [ $1 -gt 1 ]; then
echo $(( $1 * $(factorial $(( $1 -1 ))) ))
else
echo 1
fi
}
echo -n "Factorial of $1 is: "
factorial $1
```
Pay attention to `echo $(( $1 * $(factorial $(( $1 -1 ))) ))`
. The code is calling the function itself with 1 value less. The process goes in until the value equals 1. So if you run the script with argument 5, it will eventually result in 5 * 4 * 3 * 2 *1.
```
abhishek@itsfoss:~/bash_scripts$ ./factorial.sh 5
Factorial of 5 is: 120
```
That's nice. How about some practice?
## 🏋️ Exercise time
Here are some sample scripting challenges to practice your learning.
Exercise 1: Write a bash script that uses a function called is_even to check whether the given number is even or not.
Exercise 2: A similar exercise where you have to write a script that has a function is_prime and it check whether the given number is prime or not. If you didn't know already, a prime number is only divisible by 1 and the number itself.
Exercise 3: Write a script that generates the Fibonacci sequence of the given number. The sequence starts at 1 and the script must accept numbers greater than 3.
So, if you do `fibonacci.sh 5`
, it should generate 1 1 2 3 5.
And that's it, folks! This is the end of the Bash Basics Series. Of course, this is just the tip of the iceberg; there is much more to bash scripting than what you learned here.
But you should have a decent idea about bash shell by now. You should be able to understand most bash scripts and write simple, if not complicated ones.
If you want to dive deeper, nothing is better than the GNU Bash Manual.
[GNU Bash manual - GNU Project - Free Software Foundation](https://www.gnu.org/software/bash/manual/)

*🗨 I hope you liked this Bash Basics Series. We are creating more tutorial series to give you a more streamlined learning experience. Please provide your feedback and help us help others with Linux.* |
16,117 | Warp:一款可跨平台运行的开源安全文件共享应用 | https://news.itsfoss.com/warp-file-sharing/ | 2023-08-22T13:58:08 | [
"共享",
"Warp"
] | https://linux.cn/article-16117-1.html | 
>
> 在 Linux 和 Windows 之间安全共享文件的无缝方式? 试试这个!
>
>
>
在我们撰写《[First Look](https://news.itsfoss.com/tag/first-look/)》系列文章的过程中,我们找到了一种在 Linux 和 Windows 系统之间传输文件的安全且高效的方法。
一个名为 “**Warp**” 的工具,它是 [GNOME Circle](https://circle.gnome.org/) 的一部分,其中包含扩展 GNOME 生态系统的应用。Warp 有助于通过互联网或本地网络无缝传输文件。
我们来看一下。
### Warp:概述 ⭐

Warp 主要用 **Rust 编程语言** 编写,是一个**基于 GTK** 的文件传输应用,它使用 “[Magic Wormhole](https://github.com/magic-wormhole/magic-wormhole#magic-wormhole)” 协议使通过互联网/本地网络的文件传输成为可能。
所有文件传输均经过加密,接收者必须 **使用基于单词的传输码来访问文件**,以防止任何滥用。
**请允许我向你展示它是如何工作的。**
当你第一次启动该应用时,你会看到欢迎屏幕和关于 Warp 的简短介绍。

继续后,你将进入 “<ruby> 发送 <rt> Send </rt></ruby>” 菜单,你可以在其中选择要发送的文件或文件夹。
>
> ? 你还可以将文件和文件夹拖放到应用中。
>
>
>

之后,屏幕上将显示文本和二维码形式的传输码。你必须将其安全地发送给接收者,他们才能开始下载文件。
>
> ? 由于 Warp 是一个**跨平台应用**,你可以在 Linux 和 Windows 系统之间发送文件。
>
>
>

**那么,接收方看起来怎么样?**
好吧,他们必须进入 “<ruby> 接收 <rt> Receive </rt></ruby>” 菜单并将传输码粘贴到文本框中。他们还可以扫描二维码,将准确的文本复制到他们的设备上。

粘贴代码并单击 “<ruby> 接收文件 <rt> Receive File </rt></ruby>” 后,Warp 将开始连接到发送者的设备。

如果成功,将会显示 “<ruby> 已连接到对等点 <rt> Connected to Peer </rt></ruby>” 状态。如果不是,则表明发送者或接收者的系统/网络出现问题。

连接成功后,接收者可以选择 “<ruby> 接受 <rt> Accept </rt></ruby>” 将其保存到系统的“<ruby> 下载 <rt> Downlaods </rt></ruby>” 文件夹中,也可以选择 “<ruby> 另存为 <rt> Save As </rt></ruby>” 将其保存在他们选择的位置。
就是这样。文件传输完成后,接收方将显示以下页面:

用户还可以进入菜单图标下的 “<ruby> 首选项 <rt> Preferences </rt></ruby>” 菜单来访问高级设置,例如设置 “<ruby> 集合点/中转服务器 URL <rt> Rendezvous/Transit Server URL </rt></ruby>” 或将 “<ruby> 传输码字数 <rt> Code Word Count </rt></ruby>” 设置为更长的字数来增强安全性。

这就是 Warp 的全部内容。**它简单且工作良好**。
### ? 获取 Warp
Warp 可用于 **Linux** 和 **Windows**。你可以获取你选择的软件包或查看其 [GitLab 页面](https://gitlab.gnome.org/World/warp)上的源代码。
**对于 Linux 用户**,你可以从 [Flathub](https://flathub.org/apps/app.drey.Warp) 获取它。
>
> **[Warp (Flathub)](https://flathub.org/apps/app.drey.Warp)**
>
>
>
---
via: <https://news.itsfoss.com/warp-file-sharing/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

In our adventure with [First Look](https://news.itsfoss.com/tag/first-look/) series of articles, we found a secure and efficient method of transferring files between Linux and Windows systems.
A tool called '**Warp**', a part of [ GNOME Circle](https://circle.gnome.org/?ref=news.itsfoss.com) featuring apps that extend the GNOME ecosystem. Warp facilitates the seamless transfer of files via the Internet or across a local network.
Let's take a look at it.
## Warp: Overview ⭐

Written primarily in the **Rust programming language**, Warp is a **GTK-based** file transfer app that uses the '[Magic Wormhole](https://github.com/magic-wormhole/magic-wormhole?ref=news.itsfoss.com#magic-wormhole)' protocol to make file transfers over the internet/local networks possible.
All file transfers are encrypted, and the receiver must **use a word-based code to access the files**, preventing any misuse.
**Allow me to show you how it works.**
When you launch the app for the first time, you are greeted with a welcome screen and a short intro to Warp.

After proceeding, you are taken to the 'Send' menu, where you can select a file or folder to be sent.
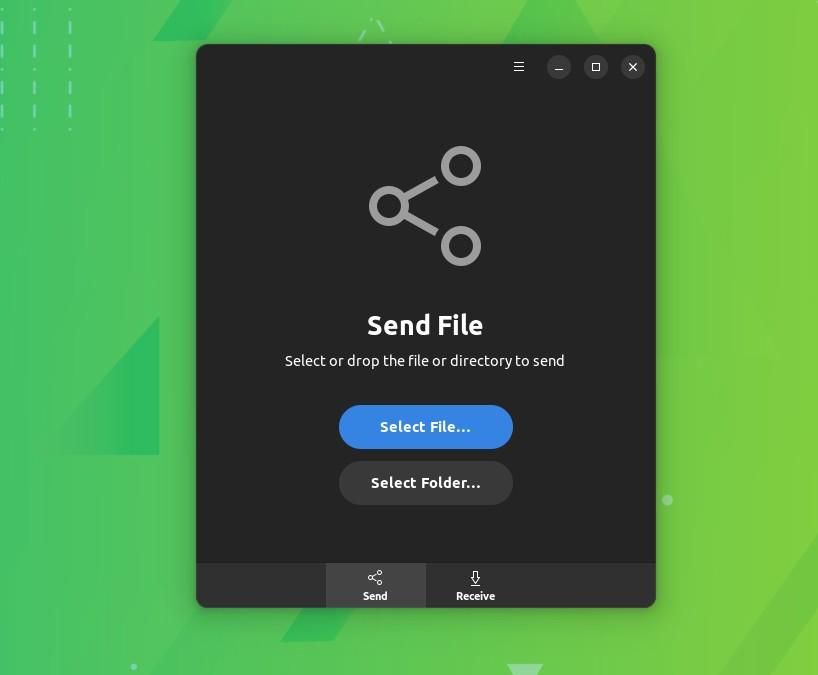
After processing, a screen will show up with the transfer code in text and QR code form. You have to send it securely to the receiver, and they can start downloading the files.
**cross-platform app**, you can send files to and from Linux and Windows systems.
**Suggested Read **📖
[Exodia OS is a Linux Distro for Cybersecurity EnthusiastsA new alternative to Kali Linux fans. What do you think?](https://news.itsfoss.com/exodia-os/)

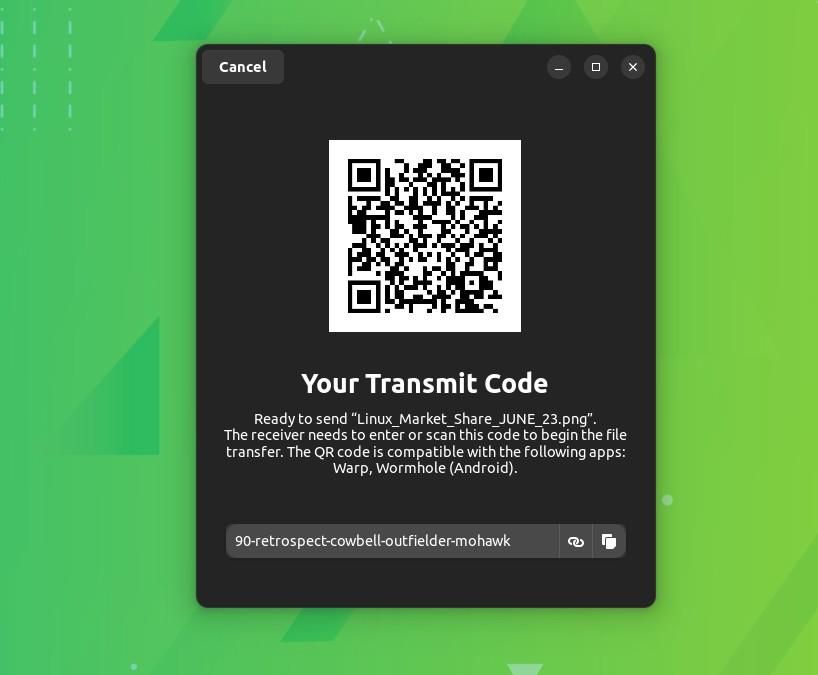
**So, how does it look on the receiver's side?**
Well, they must go into the '**Receive**' menu and paste the transmit code into the text box. They can also scan the QR code to copy the exact text onto their device.
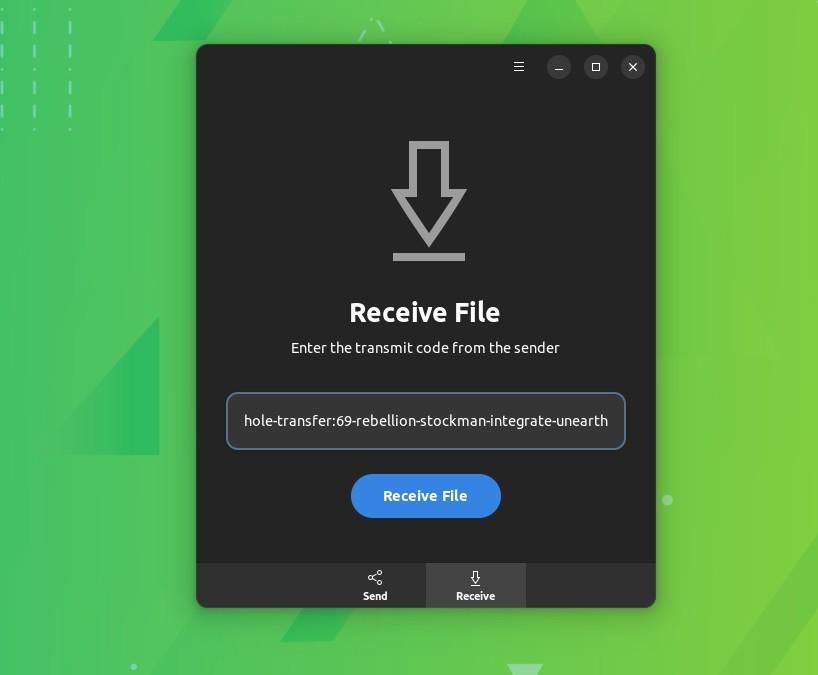
After they paste the code and click on '**Receive File**,' Warp will start connecting to the sender's device.
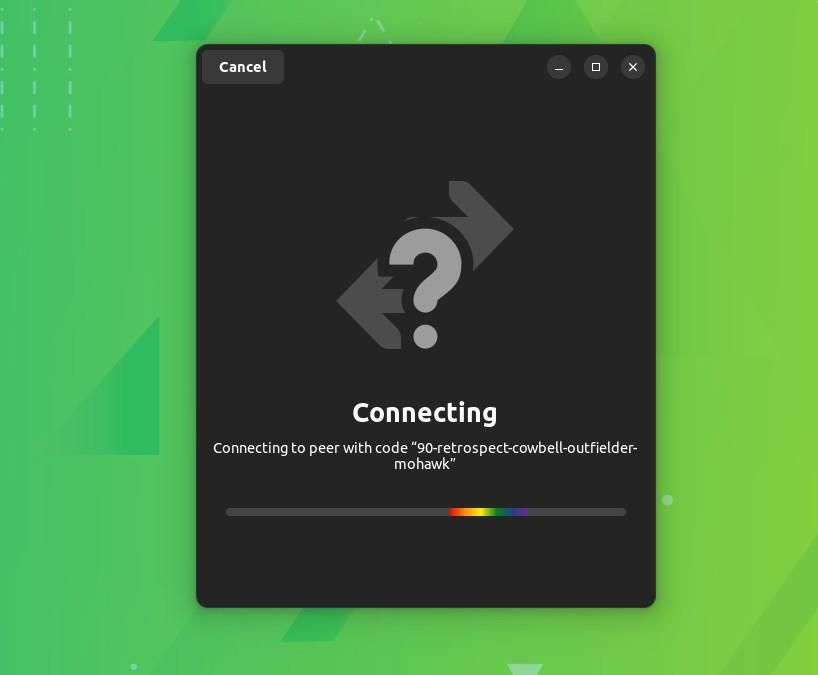
If it is successful, you will be shown a '**Connected to Peer**' status. If not, something is wrong with the sender's or receiver's system/network.
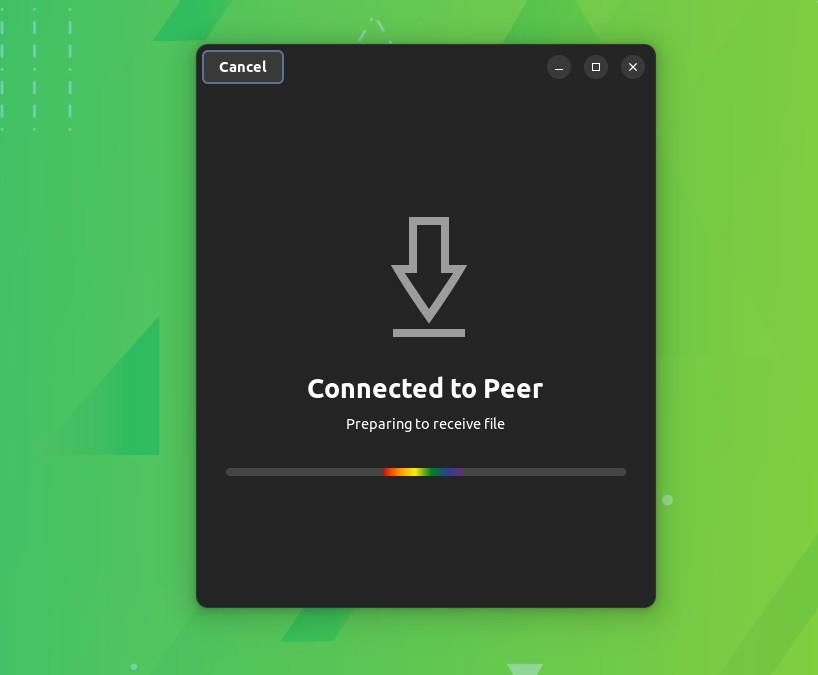
After a successful connection, the receiver can either choose '**Accept**' to save it to the '**Downloads**' folder of the system, or they can select '**Save as**' to save it in a location of their choice.
**Suggested Read **📖
[Meet ‘Clipboard’: An Open-Source App That Aims to Turn Up Your ProductivityThe clipboard app is a useful open-source tool with lots of features to improve your productivity.](https://news.itsfoss.com/clipboard/)

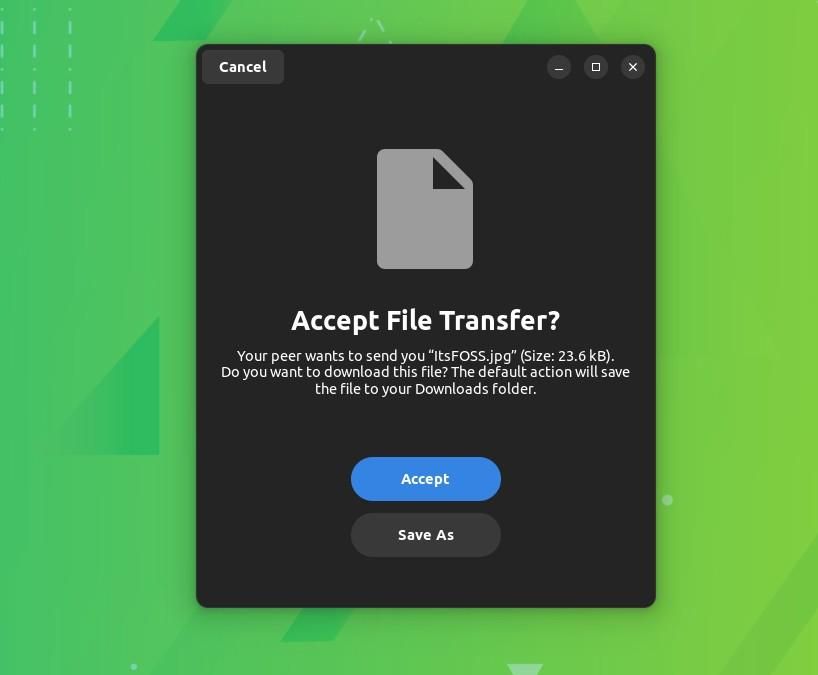
And that's it. The receiver will be shown the following screen when a file transfer is complete:
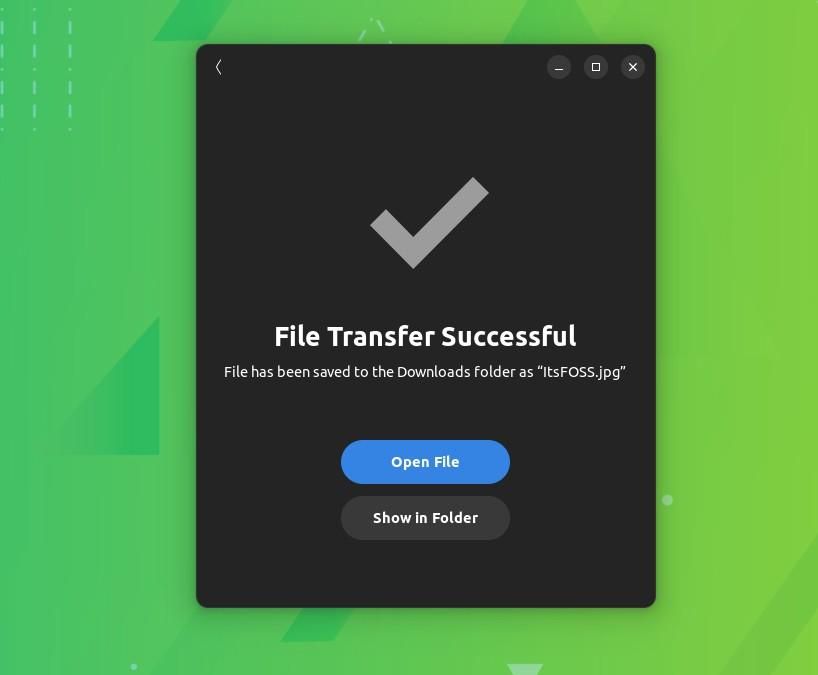
Users can also go into the '**Preferences**' menu under the three-ribbon icon to access advanced settings such as **setting the Rendezvous/Transit Server URL** or **setting the Code Words to a longer word count **for enhanced security.
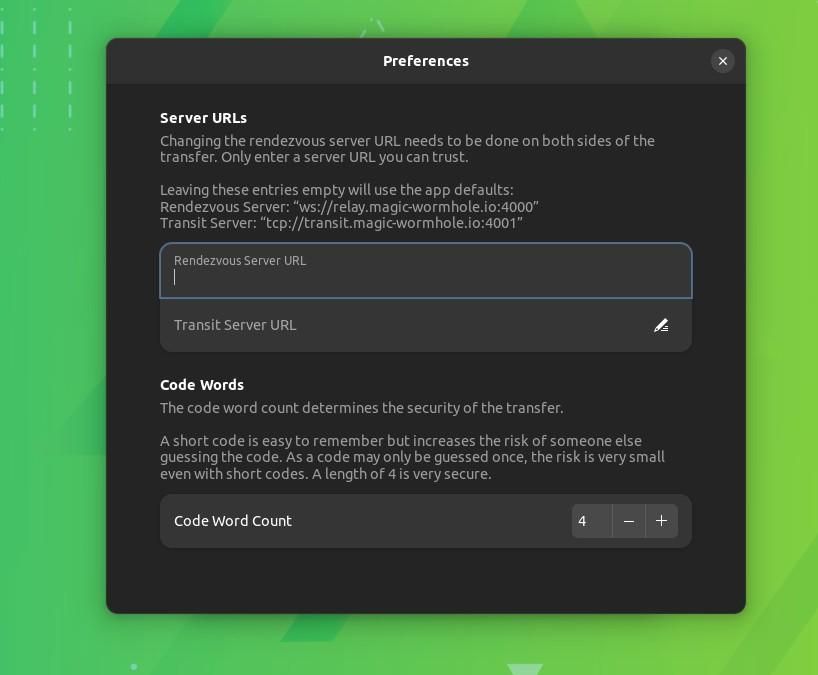
That's about it for Warp; it is **effortless and does the job well**.
**Learn Rust Programming **📖
[Rust - It’s FOSSStart learning Rust, the programming language that is C like but better than C. No wonder Linus Torvalds liked it and allowed it to be included in Linux Kernel. The series makes you familiar with the basic Rust concepts with simple to follow examples.](https://itsfoss.com/tag/rust/?ref=news.itsfoss.com)

## 📥 Get Warp
Warp is available both for **Linux** and **Windows; **You can get the package of your choice or look at the source code on its [GitLab page](https://gitlab.gnome.org/World/warp?ref=news.itsfoss.com).
**For Linux users, **you can get it from [Flathub](https://flathub.org/apps/app.drey.Warp?ref=news.itsfoss.com).
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,119 | UbuntuDDE Remix 23.04 登场! | https://news.itsfoss.com/ubuntudde-remix-23-04-release/ | 2023-08-23T11:02:00 | [
"UbuntuDDE"
] | https://linux.cn/article-16119-1.html |
>
> UbuntuDDE Remix 23.04 带着最新的深度桌面环境登场。
>
>
>

我们在 [去年](/article-15076-1.html) 介绍过 UbuntuDDE Remix,当时他们发布了一个新的 LTS 版本。现在,大约一年后,我们有了一款新的 **非 LTS 发行版**,名为 **UbuntuDDE Remix 23.04**,**它基于最近发布的 Ubuntu 23.04**。
如果你还不知道,Ubuntu DDE Remix 是一个上面运行 [深度](https://www.deepin.org/index/en?ref=news.itsfoss.com) 桌面环境(DDE)的 Ubuntu 发行版,旨在提供独特的用户体验。
对于那些因为其缓慢的服务器和其源于中国而产生的其他担忧,从而不喜欢深度操作系统(但喜欢他们的桌面体验)的用户来说,UbuntuDDE 是一个不错的替代品。
让我们来看看他们在这个版本中提供了什么。
### ? UbuntuDDE Remix 23.04:都有些什么新东西?

除了配备了 [Linux 内核 6.2](https://news.itsfoss.com/linux-kernel-6-2-release/),这个版本的 UbuntuDDE Remix 提供了一些不错的改进。
这个版本最明显的亮点包括:
* 深度桌面 23
* 更新的软件套件
* 新的壁纸
### 最新的深度桌面环境

UbuntuDDE Remix 23.04 **采用了最新的深度操作系统 23 的桌面环境(2023 年 5 月更新)**,使其能够利用所有对用户界面、控制中心、设置以及你可能预期的即将发布的 [深度操作系统发行版 23](https://news.itsfoss.com/deepin-23/) 的改进。
如果你有兴趣,UbuntuDDE 与上游和 [深度桌面环境](https://github.com/linuxdeepin/dde?ref=news.itsfoss.com) 的贡献者合作,使你能够完全领略改该桌面。
### 更新的软件套件

然后是更新的软件套件,它 **具有之前安装的,基于 DDE 的原生应用程序的升级版本**,例如:
* 深度音乐
* 深度影院
* 深度计算器
* 深度日志查看器
* 深度文本编辑器
* 等等
### 新的壁纸

最后,我们得到了来自 UbuntuDDE Remix 团队和深度操作系统的 **新壁纸和素材**。这些壁纸看起来非常不错,尤其是在使用浅色显示模式时。
开发者在 [官方公告](https://ubuntudde.com/blog/ubuntudde-remix-23-04-lunar-release-note/?ref=news.itsfoss.com) 博客中也提到,将在不久的将来通过 OTA 更新 **推送更多的软件更新**,进一步增强了整体的包装。
### ? 下载 UbuntuDDE Remix 23.04
你可以去 [官方网站](https://ubuntudde.com/download/?ref=news.itsfoss.com) 下载 UbuntuDDE Remix 23.04。你可以从 **官方仓库**、**SourceForge 镜像**,或以 **种子下载方式** 获取。
>
> **[UbuntuDDE Remix 23.04](https://ubuntudde.com/download/?ref=news.itsfoss.com)**
>
>
>
---
via: <https://news.itsfoss.com/ubuntudde-remix-23-04-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

We looked at UbuntuDDE Remix [last year](https://news.itsfoss.com/ubuntudde-remix-22-04-released/) when they released a new LTS release. And now, almost a year later, we have **a new non-LTS release** in the form of **UbuntuDDE Remix 23.04** **based on the recently released Ubuntu 23.04 release**.
If you didn't know, Ubuntu DDE Remix is a distro that features [Deepin](https://www.deepin.org/index/en?ref=news.itsfoss.com) desktop environment (DDE) on top of Ubuntu to give a unique user experience.
UbuntuDDE is a nice alternative for users who dislike Deepin for its slow servers and other concerns because of its Chinese origin (yet like the desktop experience).
Let's see what they are offering with this release.
**Suggested Read **📖
[Ubuntu 23.04 Releases With New Installer, A New Flavour, and GNOME 44Ubuntu 23.04 adds the magic of GNOME 44 with its own tweaks and improvements. Check it out here.](https://news.itsfoss.com/ubuntu-23-04-release/)

## 🆕 UbuntuDDE Remix 23.04: What's New?
Equipped with ** Linux Kernel 6.2**, this release of UbuntuDDE Remix has some neat improvements on offer.
Some of the most notable highlights of this release include:
**Deepin 23****Updated Software Suite****New Wallpapers**
### Latest Deepin Desktop Environment
UbuntuDDE Remix 23.04 **features the latest Deepin 23 desktop environment (May 2023 update), **allowing it to take advantage of all the improvements to the UI, control center, settings, and some of the things that you may expect with the upcoming [Deepin 23 distribution](https://news.itsfoss.com/deepin-23/).
If you are curious, UbuntuDDE works with the upstream and contributors from [Deepin Desktop Environment](https://github.com/linuxdeepin/dde?ref=news.itsfoss.com) to give you access to the desktop in its full glory.
### Updated Software Suite
Then there's the updated software suite that **features upgraded versions of the pre-installed, DDE-based native applications** such as:
- Deepin Music
- Deepin Movie
- Deepin Calculator
- Deepin Log Viewer
- Deepin Text Editor
- And More.
### New Wallpapers
And finally, we have the **new wallpapers and assets** from the UbuntuDDE Remix team and Deepin. These look pretty good, mainly when used with the 'Light' display mode.
The developers have also mentioned in the [official announcement](https://ubuntudde.com/blog/ubuntudde-remix-23-04-lunar-release-note/?ref=news.itsfoss.com) blog that **more software updates will be pushed through OTA updates** in the near future, further enhancing the overall package.
## 📥 Download UbuntuDDE Remix 23.04
You can head over to the [official website](https://ubuntudde.com/download/?ref=news.itsfoss.com) to download UbuntuDDE Remix 23.04, where you can get it from the **official repo**, a **SourceForge mirror**, and as a **Torrent**.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,120 | Bash 脚本编程入门 | https://itsfoss.com/bash-scripting-tutorial/ | 2023-08-23T11:37:25 | [
"Bash",
"脚本"
] | https://linux.cn/article-16120-1.html | 
>
> 初学者们,让我们在这个大型的教程中来认识一下 Bash 脚本编程。
>
>
>
Shell 是 Linux 的核心部分,它允许你使用各种诸如 `cd`、`ls`、`cat` 等的命令与 Linux 内核进行交互。
Bash 是 Linux 上众多可用的 Shell 中的一个。这些 Shell 主要的语法基本相同,但并非完全一样。Bash 是目前最受欢迎的 Shell,并在大多数 Linux 发行版中被设为默认 Shell。
当你打开一个终端或 SSH 会话时,即使你无法真切地看到它,你其实已经在运行着一个 Shell。

当你输入一个命令,它会被 Shell 解释。如果命令和语法是正确的,它就会被执行,否则你会看到一个错误。
### 当你可以直接运行 Linux 命令时,为什么还需要 Bash 脚本?
你可以直接在终端输入命令,它们就会被执行。
```
$ echo "hello world"
hello world
```
并且,同样的操作也可以在脚本中进行:
```
$ cat >> script.sh
#!/bin/bash
echo "hello world"
$ bash script.sh
hello world
```
那么,为什么我们需要 Shell 脚本呢?因为你不必一遍又一遍地输入同一个命令,你只需运行 Shell 脚本即可。
此外,如果你的脚本中有复杂的逻辑,把所有的命令都输入到终端中可能并不是一个好主意。
例如,如果你输入下面的命令,它会奏效,但这并不容易理解。不断地输入相同的命令(甚至要在 Bash 历史记录中搜索)会造成困扰。
```
if [ $(whoami) = 'root' ]; then echo "root"; else echo "not root"; fi
```
相反,你可以把命令放进 shell 脚本中,这样就更容易理解并且可以轻松运行了:
```
#!/bin/bash
if [ $(whoami) = 'root' ]; then
echo "You are root"
else
echo "You are not root"
fi
```
这还是比较简单的情况。尝试想象一下,一个复杂的脚本可能有五十行或一百行!
### 你将会学到什么?
在这个 Bash 脚本教程中,有九个部分。你将会学到:
* 创建并运行你的第一个 Bash Shell 脚本
* 使用变量
* 在你的 Bash 脚本中传递参数和接受用户输入
* 进行数学计算
* 操作字符串
* 使用条件语句,例如 `if-else`
* 使用 `for`、`while` 和 `until` 循环
* 创建函数
>
> ? 所有的部分都会给你一个简单的例子。如果你愿意,你可以通过访问每个部分的详细章节来更深入地学习。这些章节也都包含了实践练习。
>
>
>
### 这个教程的目标读者是谁?
这个教程适合任何想要开始学习 Bash Shell 脚本的人。
如果你是一名学生,而你的课程里包括了 Shell 脚本,那么这个系列就是为你准备的。
如果你是一个常规的桌面 Linux 用户,这个系列将会帮助你理解在探索各种软件和修复问题时遇到的大多数 Shell 脚本。你也可以使用它来自动化一些常见的、重复的任务。
在这个 Bash 脚本教程结束时,你应该可以编写简单的 Bash 脚本。
>
> ? 希望你已经拥有 Linux 命令行和编程语言的基础知识。
>
>
>
如果你对 Linux 命令行完全不熟悉,我建议你先掌握基础知识。
>
> **[19 个你应该知道的基础而重要的 Linux 终端技巧](https://itsfoss.com/basic-terminal-tips-ubuntu/)**
>
>
>
你应该了解如何在命令行中进入特定的位置。为了做到这一点,你需要理解 Linux 文件系统中的路径是如何工作的。
>
> **[Linux 中的绝对路径和相对路径有什么不同](https://linuxhandbook.com/absolute-vs-relative-path/)**
>
>
>
接下来,这个教程系列会给你介绍目录导航和文件操作的基本知识。
>
> **[终端基础:Linux 终端入门](/article-16104-1.html)**
>
>
>
### 1、编写你的第一个 Bash Shell 脚本
创建一个名为 `hello.sh` 的新文件:
```
nano hello.sh
```
这将在终端中打开 nano 编辑器。在其中输入以下几行代码:
```
#!/bin/bash
echo "Hello World"
```
通过按 `Ctrl+X` 键可以保存并退出 nano 编辑器。
现在,你可以以以下方式运行 Bash Shell 脚本:
```
bash hello.sh
```
你应该可以看到以下的输出:
```
Hello World
```
另一种方式是首先赋予脚本执行权限:
```
chmod u+x hello.sh
```
然后这样运行它:
```
./hello.sh
```
>
> ? 你也可以使用基于图形用户界面的文本编辑器来编写脚本。这可能更适合编写较长的脚本。然而,你需要切换到保存脚本的目录中才能运行它。
>
>
>
恭喜!你刚刚运行了你的第一个 Bash 脚本。
>
> **[Bash 基础知识系列 #1:创建并运行你的第一个 Bash Shell 脚本](/article-15921-1.html)**
>
>
>
### 2、在 Bash 脚本中使用变量
变量的声明方式如下:
```
var=some_value
```
然后可以像这样访问变量:
```
$var
```
>
> ? 在声明变量时,等号(`=`)前后不能有空格。
>
>
>
我们通过添加一个变量来修改前面的脚本。
```
#!/bin/bash
message="Hello World"
echo $message
```
如果运行这个脚本,输出仍然会保持不变。
```
Hello World
```
>
> **[Bash 基础知识系列 #2:在 Bash 中使用变量](/article-15991-1.html)**
>
>
>
### 3、向 Bash 脚本传递参数
你可以在运行 Bash 脚本时以以下方式传递参数:
```
./my_script.sh arg1 arg2
```
在脚本中,你可以使用 `$1` 来代表第 1 个参数,用 `$2` 来代表第 2 个参数,以此类推。`$0` 是一个特殊变量,它代表正在运行的脚本的名字。
现在,创建一个新的 shell 脚本,命名为 `arguments.sh`,并向其中添加以下几行代码:
```
#!/bin/bash
echo "Script name is: $0"
echo "First argument is: $1"
echo "Second argument is: $2"
```
使其可执行并像这样运行它:
```
$ ./argument.sh abhishek prakash
Script name is: ./argument.sh
First argument is: abhishek
Second argument is: prakash
```
让我们快速看一下特殊变量:
| 特殊变量 | 描述 |
| --- | --- |
| `$0` | 脚本名称 |
| `$1`、`$2`...`$9` | 脚本参数 |
| `${n}` | 10 到 255 的脚本参数 |
| `$#` | 参数数量 |
| `$@` | 所有参数一起 |
| `$$` | 当前 shell 的进程 id |
| `$!` | 最后执行命令的进程 id |
| `$?` | 最后执行命令的退出状态 |
你也可以通过接受键盘输入使你的 Bash 脚本变得交互式。
为此,你必须使用 `read` 命令。你还可以使用 `read -p` 命令提示用户进行键盘输入,而不需要 `echo` 命令。
```
#!/bin/bash
echo "What is your name, stranger?"
read name
read -p "What's your full name, $name? " full_name
echo "Welcome, $full_name"
```
现在,如果你运行这个脚本,当系统提示你输入“参数”时,你必须输入。
```
$ ./argument.sh
What is your name, stranger?
abhishek
What's your full name, abhishek? abhishek prakash
Welcome, abhishek prakash
```
>
> **[Bash 基础知识系列 #3:传递参数和接受用户输入](/article-16001-1.html)**
>
>
>
### 4、执行算术运算
在 Bash Shell 中执行算术运算的语法是这样的:
```
$((arithmetic_operation))
```
下面是你可以在 Bash 中执行的算术运算的列表:
| 操作符 | 描述 |
| --- | --- |
| `+` | 加法 |
| `-` | 减法 |
| `*` | 乘法 |
| `/` | 整数除法(没有小数) |
| `%` | 模运算(只余) |
| `**` | 指数(a 的 b 次方) |
以下是在 Bash 脚本中进行加法和减法的示例:
```
#!/bin/bash
read -p "Enter first number: " num1
read -p "Enter second number: " num2
sum=$(($num1+$num2))
sub=$(($num1-$num2))
echo "The summation of $num1 and $num2 is $sum"
echo "The substraction of $num2 from $num1 is $sub"
```
你可以执行 Shell 脚本,使用你选择的任意数字作为参数。

如果你尝试除法,会出现一个大问题。Bash 只使用整数。默认情况下,它没有小数的概念。因此,你会得到 10/3 的结果为3,而不是 3.333。
对于浮点数运算,你需要这样使用 `bc` 命令:
```
#!/bin/bash
num1=50
num2=6
result=$(echo "$num1/$num2" | bc -l)
echo "The result is $result"
```
这个时候,你将看到准确的结果。
```
The result is 8.33333333333333333333
```
>
> **[Bash 基础知识系列 #4:算术运算](/article-16006-1.html)**
>
>
>
### 5、在 Bash 脚本中使用数组
你可以使用 Bash 中的数组来存储同一类别的值,而不是使用多个变量。
你可以像这样声明一个数组:
```
distros=(Ubuntu Fedora SUSE "Arch Linux" Nix)
```
要访问一个元素,使用:
```
${array_name[N]}
```
像大多数其他的编程语言一样,数组的索引从 0 开始。
你可以像这样显示数组的所有元素:
```
${array[*]}
```
这样获取数组长度:
```
${#array_name[@]}
```
>
> **[Bash 基础知识系列 #5:在 Bash 中使用数组](/article-16016-1.html)**
>
>
>
### 6、Bash 中的基础字符串操作
Bash 能够执行许多字符串操作。
你可以使用这种方式获取字符串长度:
```
${#string}
```
连接两个字符串:
```
str3=$str1$str2
```
提供子字符串的起始位置和长度来提取子字符串:
```
${string:$pos:$len}
```
这里有一个例子:

你也可以替换给定字符串的一部分:
```
${string/substr1/substr2}
```
并且你也可以从给定字符串中删除一个子字符串:
```
${string/substring}
```
>
> **[Bash 基础知识系列 #6:处理字符串操作](/article-16047-1.html)**
>
>
>
### 7、在 Bash 中使用条件语句
你可以通过使用 `if` 或 `if-else` 语句为你的 Bash 脚本添加条件逻辑。这些语句以 `fi` 结束。
单个 `if` 语句的语法是:
```
if [ condition ]; then
your code
fi
```
注意使用 `[ ... ];` 和 `then` 。
`if-else` 语句的语法是:
```
if [ expression ]; then
## execute this block if condition is true else go to next
elif [ expression ]; then
## execute this block if condition is true else go to next
else
## if none of the above conditions are true, execute this block
fi
```
这里有一个使用 `if-else` 语句的 Bash 脚本示例:
```
#!/bin/bash
read -p "Enter the number: " num
mod=$(($num%2))
if [ $mod -eq 0 ]; then
echo "Number $num is even"
else
echo "Number $num is odd"
fi
```
运行它,你应该能看到这样的结果:

`-eq` 被称为测试条件或条件操作符。有许多这样的操作符可以给你不同类型的比较:
这些是你可以用来进行数值比较的测试条件操作符:
| 条件 | 当...时,等同于 true |
| --- | --- |
| `$a -lt $b` | `$a < $b` (`$a` 是小于 `$b`) |
| `$a -gt $b` | `$a > $b` (`$a` 是大于 `$b`) |
| `$a -le $b` | `$a <= $b` (`$a` 是小于或等于 `$b`) |
| `$a -ge $b` | `$a >= $b` (`$a` 是大于或等于 `$b`) |
| `$a -eq $b` | `$a == $b` (`$a` 等于 `$b`) |
| `$a -ne $b` | `$a != $b` (`$a` 不等于 `$b`) |
如果你在进行字符串比较,你可以使用以下这些测试条件:
| 条件 | 当...时,等同于 true |
| --- | --- |
| `"$a" = "$b"` | `$a` 等同于 `$b` |
| `"$a" == "$b"` | `$a` 等同于 `$b` |
| `"$a" != "$b"` | `$a` 不同于 `$b` |
| `-z "$a"` | `$a` 是空的 |
还有些条件用于检查文件类型:
| 条件 | 当...时,等同于 true |
| --- | --- |
| `-f $a` | `$a` 是一个文件 |
| `-d $a` | `$a` 是一个目录 |
| `-L $a` | `$a` 是一个链接 |
>
> ? 要特别注意空格。开括号和闭括号、条件之间必须有空格。同样地,条件操作符(`-le`、`==` 等)之前和之后必须有空格。
>
>
>
>
> **[Bash 基础知识系列 #7:If-Else 语句](/article-16083-1.html)**
>
>
>
### 8、使用 Bash 脚本中的循环
Bash 支持三种类型的循环:`for`、`while` 和 `until`。
这是 `for` 循环的一个例子:
```
#!/bin/bash
for num in {1..10}; do
echo $num
done
```
运行它,你将看到以下输出:
```
1
2
3
4
5
6
7
8
9
10
```
如果你选择使用上面的示例,可以使用 `while` 循环这样重写:
```
#!/bin/bash
num=1
while [ $num -le 10 ]; do
echo $num
num=$(($num+1))
done
```
同样,可以使用 `until` 循环来重写:
```
#!/bin/bash
num=1
until [ $num -gt 10 ]; do
echo $num
num=$(($num+1))
done
```
>
> ? `while` 循环和 `until` 循环非常相似。区别在于:`while` 循环在条件为真时运行,而 `until` 循环在条件为假时运行。
>
>
>
>
> **[Bash 基础知识系列 #8:For、While 和 Until 循环](/article-16114-1.html)**
>
>
>
### 9、在 Bash 脚本中使用函数
Bash Shell 支持使用函数,这样你不必反复编写相同的代码片段。
这是声明 Bash 函数的通用语法:
```
function_name() {
commands
}
```
这是一个使用带参数的函数的 Bash 脚本样例:
```
#!/bin/bash
sum() {
sum=$(($1+$2))
echo "The sum of $1 and $2 is: $sum"
}
echo "Let's use the sum function"
sum 1 5
```
如果你运行该脚本,你将看到以下输出:
```
Let's use the sum function
The sum of 1 and 5 is: 6
```
>
> **[Bash 基础知识系列 #9:Bash 中的函数](/article-16116-1.html)**
>
>
>
### 接下来呢?
这只是一个初窥。这个 Bash 脚本教程只是一篇引言。Bash 脚本的内容还有很多,你可以慢慢地、逐渐地探索。
GNU Bash 参考是一份优秀的在线资源,可以解答你的 Bash 疑问。
>
> **[GNU Bash 参考](https://www.gnu.org/software/bash/manual/bash.html)**
>
>
>
除此之外,你可以下载这本免费书籍来学习更多在此未涵盖的 Bash 内容:
>
> **[下载 Bash 初学者指南](https://tldp.org/LDP/Bash-Beginners-Guide/Bash-Beginners-Guide.pdf)**
>
>
>
一旦你具有足够的 Bash 基础知识,你可以通过这本免费书籍来学习高级 Bash 脚本:
>
> **[下载高级 Bash 编程指南](https://tldp.org/LDP/abs/abs-guide.pdf)**
>
>
>
这两本书至少都有十年的历史,但你仍然可以使用它们来学习 Bash。
? 希望你喜欢这个作为学习 Bash 脚本起点的教程。请在评论区提供你的反馈。
*(题图:MJ/98f47121-7426-4297-9242-8683ccf0496d)*
---
via: <https://itsfoss.com/bash-scripting-tutorial/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Shell is the core part of Linux. It allows you to interact with the Linux kernel by using various commands like cd, ls, cat etc.
Bash is one of the many available shells for Linux. They have mostly common but not identical syntax. Bash is the most popular shell out there and is the default on most Linux distributions.
You open a terminal or SSH session and you have a shell running in it even if you cannot really visualize it.
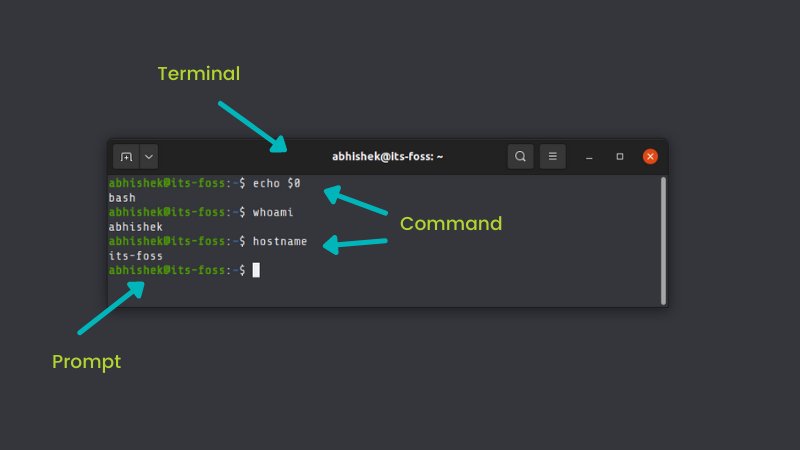
When you type a command, it is interpreted by the shell. If the command and syntax are correct, it will be executed otherwise you'll see an error.
## Why bash scripts when you can just run Linux commands?
You can enter the commands directly in the terminal and they will be executed.
```
abhishek@itsfoss:~$ echo "hello world"
hello world
```
And the same can be done in a script as well:
```
abhishek@itsfoss:~$ cat >> script.sh
#!/bin/bash
echo "hello world"
abhishek@itsfoss:~$ bash script.sh
hello world
```
Why do you need shell scripts then? Because you don't have to type the same command again and again. You just run the shell script.
Also, if you have complicated logic in your script, typing it all in the terminal won't be a good idea.
For example, if you enter the command below, it will work. But it is not easy to understand and typing it again and again (or even searching for it in the bash history) is a pain.
`if [ $(whoami) = 'root' ]; then echo "root"; else echo "not root"; fi`
Instead, you can put in a shell script so that it is easier to understand and run it effortlessly:
```
#!/bin/bash
if [ $(whoami) = 'root' ]; then
echo "You are root"
else
echo "You are not root"
fi
```
This was still simple. Imagine a complicated script with fifty or a hundred lines!
## What will you learn?
There are nine sections in this bash scripting tutorial. You'll learn to:
- Create and run your first bash shell script
- Use variables
- Pass arguments and accept user inputs in your bash scripts
- Perform mathematical calculations
- Manipulate strings
- Use conditional statements like if-else
- Use for, while and until loops
- Create functions
## 1. Writing your first bash shell script
Create a new file named `hello.sh`
:
`nano hello.sh`
This will open the nano editor in the terminal. Enter the following lines to it:
```
#!/bin/bash
echo "Hello World"
```
Save and exit the nano editor by pressing the Ctrl+X key.
Now, you can run the bash shell script in the following manner:
`bash hello.sh`
And you should see the following output:
`Hello World`
Another way is to give the script execute permission first:
`chmod u+x hello.sh`
And then run it in this manner:
`./hello.sh`
Congratulations! You just ran your first bash script.
[Bash Basics #1: Create and Run Your First Bash Shell ScriptStart learning bash scripting with this new series. Create and run your first bash shell script in the first chapter.](https://itsfoss.com/create-bash-script/)

## 2. Using variables in bash scripts
Variables are declared in the following manner:
`var=some_value`
And then the variable is accessed like this:
`$var`
`=`
while declaring variable.Let's modify the previous script by adding a variable.
```
#!/bin/bash
message="Hello World"
echo $message
```
The output will still remain the same if you run this script:
`Hello World`
[Bash Basics #2: Use Variables in Bash ScriptsIn this chapter of the Bash Basics series, learn about using variables in Bash scripts.](https://itsfoss.com/bash-use-variables/)

## 3. Passing arguments to bash script
You can pass arguments to a bash script while running it in the following manner:
```
./my_script.sh arg1 arg2
```
Inside the script, you can use $1 for the 1st argument, $2 for the 2nd argument and so on. $0 is a special variable that holds the name of the script being executed.
Now, create a new shell script named `arguments.sh`
and add the following lines to it:
```
#!/bin/bash
echo "Script name is: $0"
echo "First argument is: $1"
echo "Second argument is: $2"
```
Make it executable and run it like this:
```
abhishek@itsfoss:~$ ./argument.sh abhishek prakash
Script name is: ./argument.sh
First argument is: abhishek
Second argument is: prakash
```
Here's a quick look at the special variables:
Special Variable | Description |
---|---|
$0 | Script name |
$1, $2...$9 | Script arguments |
${n} | Script arguments from 10 to 255 |
$# | Number of arguments |
$@ | All arguments together |
$$ | Process id of the current shell |
$! | Process id of the last executed command |
$? | Exit status of last executed command |
You can also make your bash script interactive by accepting user input from the keyboard.
For that, you'll have to use the read command. You can also use `read -p`
command to prompt the user for the keyboard input without echo command.
```
#!/bin/bash
echo "What is your name, stranger?"
read name
read -p "What's your full name, $name? " full_name
echo "Welcome, $full_name"
```
Now if you run this script, you'll have to enter the 'arguments' when you are prompted for it.
```
abhishek@itsfoss:~$ ./argument.sh
What is your name, stranger?
abhishek
What's your full name, abhishek? abhishek prakash
Welcome, abhishek prakash
```
[Bash Basics #3: Pass Arguments and Accept User InputsLearn how to pass arguments to bash scripts and make them interactive in this chapter of the Bash Basics series.](https://itsfoss.com/bash-pass-arguments/)

## 4. Perform arithmetic operation
The syntax for arithmetic operations in the bash shell is this:
`$((arithmetic_operation))`
Here's the list of the arithmetic operations you can perform in bash:
Operator | Description |
---|---|
+ | Addition |
- | Subtraction |
* | Multiplication |
/ | Integer division (without decimal) |
% | Modulus division (only remainder) |
** | Exponentiation (a to the power b) |
Here's an example of performing summation and subtraction in bash script:
```
#!/bin/bash
read -p "Enter first number: " num1
read -p "Enter second number: " num2
sum=$(($num1+$num2))
sub=$(($num1-$num2))
echo "The summation of $num1 and $num2 is $sum"
echo "The substraction of $num2 from $num1 is $sub"
```
You can execute the shell script with random number of your choice.
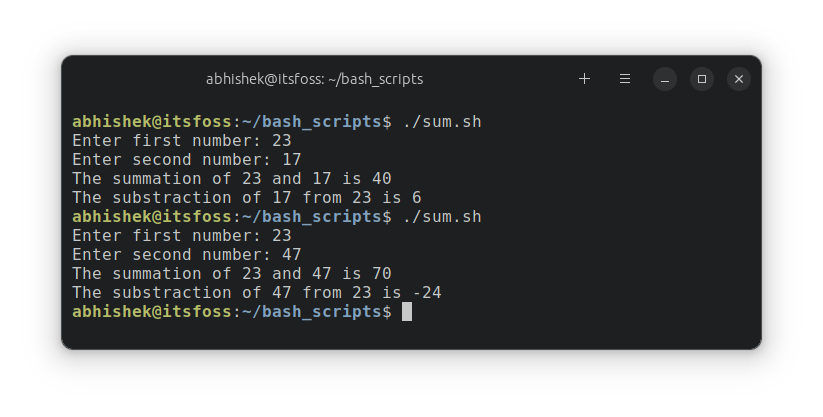
There is a big problem if you try the divison. Bash only works with integers. It doesn't have the concept of decimal numbers by default. And thus you'll get 3 as the result of 10/3 instead of 3.333.
For floating point operations, you'll have to use the bc command in this manner:
```
#!/bin/bash
num1=50
num2=6
result=$(echo "$num1/$num2" | bc -l)
echo "The result is $result"
```
And this time, you'll see accurate result.
```
The result is 8.33333333333333333333
```
[Bash Basics Series #4: Arithmetic OperationsIn the fourth chapter of the series, learn to use basic mathematics in Bash.](https://itsfoss.com/bash-arithmetic-operation/)

## 5. Using arrays in bash scripts
Instead of using multiple variables, you can use arrays in bash to store values in the same category.
You can declare an array like this:
```
distros=(Ubuntu Fedora SUSE "Arch Linux" Nix)
```
To access an element, use:
```
${array_name[N]}
```
Like most other programming languages, the array index starts at 0.
You can display all the elements of an array like this:
```
${array[*]}
```
And get the array length like this:
```
${#array_name[@]}
```
[Bash Basics Series #5: Using Arrays in BashTime to use arrays in bash shell scripts in this chapter. Learn to add elements, delete them and get array length.](https://itsfoss.com/bash-arrays/)

## 6. Basic string operation in Bash
Bash is capable of performing a number of string operations.
You can get the string length in this manner:
```
${#string}
```
Join two strings:
```
str3=$str1$str2
```
Extract a substring by providing the starting position of the substring and its length:
```
${string:$pos:$len}
```
Here's an example:
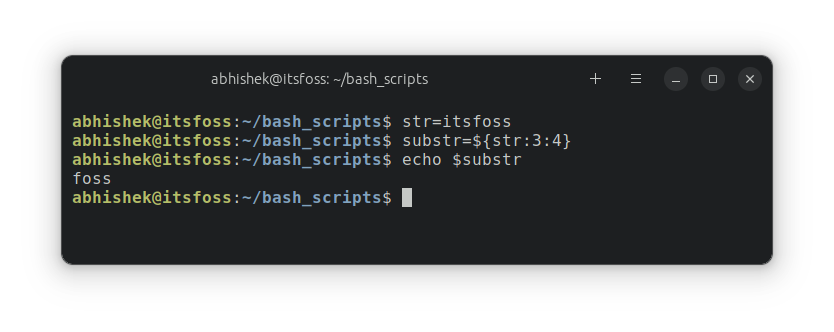
You can also replace a portion of the given string:
```
${string/substr1/substr2}
```
And you can also delete a substring from the given string:
```
${string/substring}
```
[Bash Basics Series #6: Handling String OperationsIn this chapter of the Bash Basics series, learn to perform various common string operations like extracting, replacing and deleting substrings.](https://itsfoss.com/bash-strings/)

## 7. Use conditional statements in Bash
You can add conditional logic to your bash scripts by using if or if-else statements. These statements end with `fi`
.
The syntax for a single if statement is:
```
if [ condition ]; then
your code
fi
```
Pay attention to the use `[ ... ];`
and `then`
.
The syntax for if-else statement is:
```
if [ expression ]; then
## execute this block if condition is true else go to next
elif [ expression ]; then
## execute this block if condition is true else go to next
else
## if none of the above conditions are true, execute this block
fi
```
Here's a sample bash script that uses if-else statement:
```
#!/bin/bash
read -p "Enter the number: " num
mod=$(($num%2))
if [ $mod -eq 0 ]; then
echo "Number $num is even"
else
echo "Number $num is odd"
fi
```
Run it and you should see a result like this:

The `-eq`
is called test condition or conditional operator. There are many such operators to give you different types of comparison:
Here are the test condition operators you can use for numeric comparison:
Condition | Equivalent to true when |
---|---|
$a -lt $b | $a < $b ($a is less than $b) |
$a -gt $b | $a > $b ($a is greater than $b) |
$a -le $b | $a <= $b ($a is less or equal than $b) |
$a -ge $b | $a >= $b ($a is greater or equal than $b) |
$a -eq $b | $a is equal to $b |
$a -ne $b | $a is not equal to $b |
If you are comparing strings, you can use these test conditions:
Condition | Equivalent to true when |
---|---|
"$a" = "$b" | $a is same as $b |
"$a" == "$b" | $a is same as $b |
"$a" != "$b" | $a is different from $b |
-z "$a" | $a is empty |
There are also conditions for file type check:
Condition | Equivalent to true when |
---|---|
-f $a | $a is a file |
-d $a | $a is a directory |
-L $a | $a is a link |
[Bash Basics Series #7: If Else StatementIf this, then that else something else. Doesn’t make sense? It will after you learn about the if-else statements in bash shell scripting.](https://itsfoss.com/bash-if-else/)

## 8. Using loops in bash scripts
Bash support three types of loops: for, while and until.
Here's an example of the **for loop**:
```
#!/bin/bash
for num in {1..10}; do
echo $num
done
```
Run it and you'll see the following output:
```
1
2
3
4
5
6
7
8
9
10
```
If you take the previous example, it can be rewritten using the **while loop** like this:
```
#!/bin/bash
num=1
while [ $num -le 10 ]; do
echo $num
num=$(($num+1))
done
```
And the same can be rewritten using the **until loop**:
```
#!/bin/bash
num=1
until [ $num -gt 10 ]; do
echo $num
num=$(($num+1))
done
```
[Bash Basics #8: For, While and Until LoopsIn the penultimate chapter of the Bash Basics series, learn about for, while and until loops.](https://itsfoss.com/bash-loops/)

## 9. Using functions in bash scripts
Bash shell does support the use of functions so that you don't have to write the same piece of code again and again.
Here's the generic syntax for declaring a bash function:
```
function_name() {
commands
}
```
Here's a sample bash script that uses function with arguments:
```
#!/bin/bash
sum() {
sum=$(($1+$2))
echo "The sum of $1 and $2 is: $sum"
}
echo "Let's use the sum function"
sum 1 5
```
If you run the script, you'll see the following output:
```
Let's use the sum function
The sum of 1 and 5 is: 6
```
[Bash Basics Series #9: Functions in BashLearn all about functions in the final chapter of the Bash Basics series.](https://itsfoss.com/bash-function/)

## Where to go from here?
This is just a glimpse. This bash scripting tutorial is just a primer. There is a lot more to bash scripting and you can explore it slowly and gradually.
The GNU bash reference is an excellent online resource to clear your bash doubts.
[Bash Reference ManualBash Reference Manual](https://www.gnu.org/software/bash/manual/bash.html)
##Apart from that, you can download this free book to learn more bash stuff that is not covered here:
Once you have enough knowledge of the bash basics, you can learn advanced bash scripting with this free book:
Both of these books are at least a decade old but you can still use them to learn bash.
💬 I hope you like this tutorial as the starting point of your bash script learning. Please provide your feedback in the comments section. |
16,122 | 如何在 GitLab 执行器中使用 Podman | https://opensource.com/article/23/3/podman-gitlab-runners | 2023-08-24T09:32:15 | [
"Podman",
"GitLab"
] | https://linux.cn/article-16122-1.html | 
>
> 使用 Podman 启动 GitLab 执行器有多种方法,我在本文中概述了其中两种。
>
>
>
GitLab <ruby> 执行器 <rt> Runner </rt></ruby> 是一个与 GitLab CI/CD 配合使用的应用,可在 GitLab 基础设施上的流水线中运行作业。它们通常用于在提交代码后自动编译应用或在代码库上运行测试。你可以将它们视为基于云的 [Git 钩子](https://www.redhat.com/sysadmin/git-hooks?intcmp=7013a000002qLH8AAM)。
主要的公共 [GitLab 实例](https://gitlab.com) 提供了许多易于访问的共享执行器,可供你在 CI 流水线中使用。你可以在 GitLab 上仓库的 <ruby> 设置 <rt> Settings </rt></ruby> -> CI/CD -> <ruby> 执行器 <rt> Runners </rt></ruby> 中找到共享执行器的列表。

你可能不想依赖共享执行器,而是选择自己的执行器,原因有很多。例如,控制执行器运行的基础设施以实现额外的安全性和/或隐私、灵活的执行器配置或分配给你的 GitLab 用户帐户的有限 CI 分钟数。
GitLab 执行器依赖于 <ruby> <a href="https://docs.gitlab.com/runner/executors/"> 执行环境 </a> <rt> executor </rt></ruby> 工具来运行 CI 作业。执行环境有许多选项可用:Docker、Kubernetes、VirtualBox 等。
那么,Podman 作为执行环境呢?
自 [v4.2.0](https://github.com/containers/podman/releases/tag/v4.2.0) 起,Podman 对 GitLab 执行器提供了原生支持。以下是使用 Podman 作为 GitLab 执行器的 [执行环境](https://docs.gitlab.com/runner/executors/docker.html) 的两种方法的快速浏览。
### Docker 执行环境
你可以在 GitLab 执行器中使用 Podman 作为 Docker 的直接替代品。就是这样:
本示例使用 2023 年 2 月的 CentOS Stream 9 环境,使用 Podman v4.4.0。它应该可以在任何具有足够新的 Podman 的 RHEL/CentOS Stream/Fedora 环境中正常工作。查看 [GitLab 文档](https://docs.gitlab.com/runner/executors/docker.html#use-podman-to-run-docker-commands) 了解先决条件。
首先,安装 Podman:
```
$ sudo dnf -y install podman
```
接下来安装 **gitlab-runner** 包:
```
# 添加 GitLab 执行器仓库
$ curl -L "https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.rpm.sh" | sudo bash
# 安装 gitlab-runner 包
$ sudo dnf -y install gitlab-runner
```
最后,允许用户在注销后执行任务:
```
$ sudo loginctl enable-linger gitlab-runner
```
#### 配置并注册执行器
使用以下步骤配置 Docker 运行环境。
安装 **gitlab-runner** 包会创建一个 **gitlab-runner** 用户帐户,但你需要 root 访问权限才能操作该用户帐户。**gitlab-runner** 可以在用户模式下运行,但需要一些手动干预来进行构建处理。在此示例中,我使用 `sudo` 在系统模式下运行它。它看起来是这样的:
```
$ sudo gitlab-runner register
Runtime platform arch=amd64 os=linux pid=7978 revision=d540b510 version=15.9.1
Running in system-mode.
Enter the GitLab instance URL (for example, https://gitlab.com/):
https://gitlab.com
Enter the registration token:
xxxxxxxxxxxxxxxxx
Enter a description for the runner:
[lmandvek-c9s-gitlab-runner]:
Enter tags for the runner (comma-separated):
Enter optional maintenance note for the runner:
WARNING: Support for registration tokens and runner parameters in the 'register' command has been deprecated in GitLab Runner 15.6 and will be replaced with support for authentication tokens. For more information, see https://gitlab.com/gitlab-org/gitlab/-/issues/380872
Registering runner... succeeded runner=GR13489419oEPYcJ8
Enter an executor: custom, docker, ssh, docker-ssh+machine, docker-ssh, parallels, shell, virtualbox, docker+machine, instance, kubernetes:
docker
Enter the default Docker image (for example, ruby:2.7):
registry.gitlab.com/rhcontainerbot/pkg-builder
Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!
Configuration (with the authentication token) was saved in "/etc/gitlab-runner/config.toml"
```
你将需要一些额外的配置才能使用 Podman。配置执行器为每个作业创建一个网络。有关更多信息,请参阅 [GitLab 文档](https://docs.gitlab.com/runner/executors/docker.html#create-a-network-for-each-job)。
首先,启用 Podman 系统服务并修改 `/etc/gitlab-runner/config.toml` 中的环境:
```
[[runners]]
environment = ["FF_NETWORK_PER_BUILD=1"]
[runners.docker]
host = "unix:///run/user/1001/podman/podman.sock"
```
重启执行器以实施更改:
```
$ sudo gitlab-runner restart
```
验证新的执行器在 GitLab 项目的 <ruby> 设置 <rt> Settings </rt></ruby> -> CI/CD -> <ruby> 执行器 <rt> Runners </rt></ruby> 中可见:

接下来,验证你的 CI 流水线正在使用执行器。你的 CI 任务日志将提及正在使用的执行器的名称以及任何其他配置信息,例如 执行器的执行环境的功能标志和容器镜像。

### Podman-in-Podman(pipglr)
[Chris Evich](https://gitlab.com/cevich) 创建了 [pipglr](https://gitlab.com/qontainers/pipglr),这是一个 Podman-in-Podman 设置,用于使用免 root 的 Podman 来支持你自己的免 root 的 GitLab 执行器。此方法不需要对 `.gitlab-ci.yaml` 配置进行任何更改,因此你可以继续按原样使用现有设置。
以下是帮助你运行此程序的快速设置指南。
#### 配置步骤
容器镜像是从 [pipglr Containerfile](https://gitlab.com/qontainers/pipglr) 自动构建的,因此将镜像设置为该仓库:
```
$ IMAGE="registry.gitlab.com/qontainers/pipglr:latest"
```
接下来,使用你的 GitLab 注册令牌创建 Podman 密钥:
```
$ echo '<actual registration token>' | podman secret create REGISTRATION_TOKEN -
```
创建一个空白的 `config.toml`,稍后将包含你的所有执行器设置。你必须执行此步骤才能使以下 `podman container register runlabel $IMAGE` 步骤成功:
```
$ touch ./config.toml # 重要:文件必须存在,即使是空的。
```
注册你的执行器。你可以重复此步骤来注册多个执行器。如果你想使用可能不同的标签或配置选项集并行运行多个 CI 任务,这非常有用。
```
$ podman container runlabel register $IMAGE
```
使用你选择的编辑器编辑 `config.toml`。这是可选的,但通常需要更改用于实际 CI 任务的容器镜像。默认情况下,镜像设置为:`registry.fedoraproject.org/fedora:latest`。
```
$ $EDITOR ./config.toml # if desired
```
最后,配置对卷的访问。容器卷内使用多个用户,因此你必须专门配置它们以允许访问。再次使用 `runlabel` 来完成:
```
$ podman container runlabel setupstorage $IMAGE
$ podman container runlabel setupcache $IMAGE
```
#### 测试执行器
是时候检查配置了。首先启动 GitLab 执行器容器:
```
$ podman container runlabel run $IMAGE
```
允许执行器用户在注销后运行服务:
```
$ sudo loginctl enable-linger $(id -u)
```
验证你的新执行器在 GitLab 项目的 <ruby> 设置 <rt> Settings </rt></ruby> -> CI/CD -> <ruby> 执行器 <rt> Runners </rt></ruby> 中可见:

最后,验证你的 CI 流水线正在使用你的执行器:

### 总结
使用 Podman 启动 GitLab 执行器有多种方法,我在此处概述了其中两种。尝试一下,然后让我知道哪一个最适合你。如果 Docker 执行环境方法有任何问题,请登录并通过 [Podman 上游](https://github.com/containers/podman/issues/new/choose) 或 [GitLab 支持](https://about.gitlab.com/support/#contact-support) 提交问题。如果 pipglr 方法出现问题,请在 pipglr 上游 [提交问题](https://gitlab.com/qontainers/pipglr/-/issues/new)。
GitLab 与 Podman 一起运行愉快 ?
*(题图:MJ/97e0ff4d-b769-4e20-990f-8c1e89e48434)*
---
via: <https://opensource.com/article/23/3/podman-gitlab-runners>
作者:[Lokesh Mandvekar](https://opensource.com/users/lsm5) 选题:[lkxed](https://github.com/lkxed/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A GitLab Runner is an application that works with GitLab CI/CD to run jobs in a pipeline on GitLab's infrastructure. They're often used to automatically compile applications after code has been committed or to run tests on a code base. You can think of them as cloud-based [Git hooks](https://www.redhat.com/sysadmin/git-hooks?intcmp=7013a000002qLH8AAM).
The main public [GitLab instance](https://gitlab.com) provides many easily accessible shared runners ready for use in your CI pipeline. You can find a list of shared runners in your repository's **Settings** -> **CI/CD** -> **Runners** on GitLab.
(Lokesh Mandvekar, CC BY-SA 4.0)
There are many reasons you may not want to depend on shared runners and instead stand up your own runners. For example, control over the infrastructure where the runners operate for additional security and/or privacy, flexible runner configuration, or limited CI minutes allotted to your GitLab user account.
GitLab runners depend on an [executor](https://docs.gitlab.com/runner/executors/) tool to run CI jobs. Many options are available for executors: Docker, Kubernetes, VirtualBox, and so on.
So, what about Podman as an executor?
Since [v4.2.0](https://github.com/containers/podman/releases/tag/v4.2.0), Podman has native support for GitLab runners. Here's a quick look at two approaches for using Podman as an [executor](https://docs.gitlab.com/runner/executors/docker.html) for GitLab runners.
## Docker executor
You can use Podman as a drop-in replacement for Docker in your GitLab Runner. Here's how:
This example used a CentOS Stream 9 environment in February 2023 using Podman v4.4.0. It should work just as well on any RHEL/CentOS Stream/Fedora environment with a new enough Podman. Check out the [GitLab documentation](https://docs.gitlab.com/runner/executors/docker.html#use-podman-to-run-docker-commands) for prerequisites.
First, install Podman:
```
````$ sudo dnf -y install podman`
Install the **gitlab-runner** package next:
```
``````
# Add the GitLab runner repository
$ curl -L "https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.rpm.sh" | sudo bash
# Install the gitlab-runner package
$ sudo dnf -y install gitlab-runner
```
Finally, allow the user to execute tasks after logout:
```
````$ sudo loginctl enable-linger gitlab-runner`
### Configure and register the runner
Use the following steps to configure the Docker executor.
Installing the **gitlab-runner** package creates a **gitlab-runner** user account, but you need root access to manipulate the user account. **gitlab-runner** can be run in user-mode but requires some manual intervention for build processing. In this example, I run it in system-mode with `sudo`
. This is what it looks like:
```
``````
$ sudo gitlab-runner register
Runtime platform arch=amd64 os=linux pid=7978 revision=d540b510 version=15.9.1
Running in system-mode.
Enter the GitLab instance URL (for example, https://gitlab.com/):
https://gitlab.com
Enter the registration token:
xxxxxxxxxxxxxxxxx
Enter a description for the runner:
[lmandvek-c9s-gitlab-runner]:
Enter tags for the runner (comma-separated):
Enter optional maintenance note for the runner:
WARNING: Support for registration tokens and runner parameters in the 'register' command has been deprecated in GitLab Runner 15.6 and will be replaced with support for authentication tokens. For more information, see https://gitlab.com/gitlab-org/gitlab/-/issues/380872
Registering runner... succeeded runner=GR13489419oEPYcJ8
Enter an executor: custom, docker, ssh, docker-ssh+machine, docker-ssh, parallels, shell, virtualbox, docker+machine, instance, kubernetes:
docker
Enter the default Docker image (for example, ruby:2.7):
registry.gitlab.com/rhcontainerbot/pkg-builder
Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!
Configuration (with the authentication token) was saved in "/etc/gitlab-runner/config.toml"
```
You will need some additional configuration to use Podman. Configure the runner to create a network for each job. See the [GitLab documentation](https://docs.gitlab.com/runner/executors/docker.html#create-a-network-for-each-job) for more information.
First, enable the Podman system service along with Env change in `/etc/gitlab-runner/config.toml`
:
```
``````
[[runners]]
environment = ["FF_NETWORK_PER_BUILD=1"]
[runners.docker]
host = "unix:///run/user/1001/podman/podman.sock"
```
Restart the runner to implement the change:
```
````$ sudo gitlab-runner restart`
Verify the new runner is visible in your GitLab project's **Settings** -> **CI/CD** -> **Runners**:

(Lokesh Mandvekar, CC BY-SA 4.0)
Next, verify your CI pipelines are using the runner. Your CI task logs will mention the name of the runner being used along with any additional configuration information, such as feature flags and container image used with the runner executor.

(Lokesh Mandvekar, CC BY-SA 4.0)
## Podman-in-Podman (pipglr)
[Chris Evich](https://gitlab.com/cevich) has created [pipglr](https://gitlab.com/qontainers/pipglr), a Podman-in-Podman setup to stand up your own rootless GitLab Runners using rootless Podman. This approach does not require any changes to your `.gitlab-ci.yaml`
configuration, so you can continue using your existing setup as is.
The following is a quick setup guide to help you get this running.
### Configuration steps
The container image is built automatically from the [pipglr Containerfile](https://gitlab.com/qontainers/pipglr), so set the image to that repo:
```
````$ IMAGE="registry.gitlab.com/qontainers/pipglr:latest"`
Next, create a Podman secret using your GitLab registration token:
```
````$ echo '<actual registration token>' | podman secret create REGISTRATION_TOKEN -`
Create a blank `config.toml`
that will later contain all your runner settings. You must do this step for the following `podman container register runlabel $IMAGE`
step to succeed:
```
````$ touch ./config.toml # important: file must exist, even if empty.`
Register your runner. You can repeat this step to register multiple runners. This is useful if you'd like to run several CI tasks in parallel with possibly different sets of tags or configuration options.
```
````$ podman container runlabel register $IMAGE`
Edit the `config.toml `
using your editor of choice. Editing is optional but often necessary to change the container image used for the actual CI task. By default, the image is set to: **registry.fedoraproject.org/fedora:latest**
```
````$ $EDITOR ./config.toml # if desired`
Finally, configure access to volumes. Several users are utilized inside the container volumes, so you must specifically configure them to permit access. Runlabels again to the rescue:
```
``````
$ podman container runlabel setupstorage $IMAGE
$ podman container runlabel setupcache $IMAGE
```
### Test the Runner
It's time to check the configurations. Begin by launching the GitLab Runner container:
```
````$ podman container runlabel run $IMAGE`
Allow the runner user to run services after logout:
```
````$ sudo loginctl enable-linger $(id -u)`
Verify your new runner is visible in your GitLab project's **Settings** -> **CI/CD** -> **Runners**:

(Lokesh Mandvekar, CC BY-SA 4.0)
Finally, verify your CI pipelines are using your runner:

(Lokesh Mandvekar, CC BY-SA 4.0)
## Wrap up
There are multiple ways to spin up GitLab runners using Podman, two of which I have outlined here. Try them out, and let me know which works best for you. In case of any problems with the docker executor approach, please log in to file an issue with [Podman upstream](https://github.com/containers/podman/issues/new/choose) or with [GitLab support](https://about.gitlab.com/support/#contact-support). In case of trouble with the pipglr method, please [file an issue](https://gitlab.com/qontainers/pipglr/-/issues/new) on pipglr upstream.
Happy GitLab Running with Podman 🙂
## 1 Comment |
16,123 | LibreOffice 7.6 发布,下一个版本 24.2 | https://news.itsfoss.com/libreoffice-7-6/ | 2023-08-24T11:54:15 | [
"LibreOffice"
] | https://linux.cn/article-16123-1.html | 
>
> LibreOffice 7.6 版本已经到来,这个版本为我们带来了众多优秀的改进。
>
>
>
LibreOffice 7.6 是这款优秀的开源办公套件的最新重要升级。
在其上一次的 [LibreOffice 7.5 版本发布](https://news.itsfoss.com/libreoffice-7-5-release/) 中,开发者们发布了新的应用图标和一系列的功能提升。而这一次,它为我们带来了一套全新的功能组合。
>
> ? 从 **2024** 年开始,文档基金会将实行基于日历的版本编号,意即,计划于 2024 年 2 月发布的下一个版本将以 **LibreOffice 24.2** 的形式呈现给大家。
>
>
>
让我们看一下这次发布的新版本有哪些新添的亮点。
### LibreOffice 7.6:有哪些亮点?
保持一贯的预期,所有工具都带来了显著的改良,对 Writer、Calc 和 Impress 的改进更是明显,包括以下几点:
* 对文档主题的全面支持
* 对帮助功能的升级改进
* 在兼容性上进行的改善
* 新的页码向导功能(Writer)
* 幻灯片的导航面板功能(Impress)
* 色彩排序的自动过滤器支持(Calc)
#### 对于 Writer 的优化
此次更新中的主要亮点是提供了对文档主题的支持。简单来说,当需要的时候,你可以为你的文档标题、正文和副标题挑选一套预设的颜色搭配。

你可以通过菜单 “<ruby> 格式 <rt> Format </rt></ruby> → <ruby> 主题 <rt> Themes </rt></ruby>” 来找到这项功能。
一个细微但重大的改进是在 “<ruby> 插入 <rt> Insert </rt></ruby>” 菜单中新增了一个向导,可以使用它在页眉/页脚添加页码。
新增了一个选项,使你能够通过聚光灯功能在文本中高亮显示段落样式或直接格式。

在面向用户体验的改进方面,你在编辑文档时可以从侧边栏方便快捷地找 到 “<ruby> 无障碍检查 <rt> Accesbility Check </rt></ruby>” 选项。

其他改动包括:
* 依靠段落样式,现可以更加灵活地创建图表了
* 现在能够直接在关联表格中编辑参考文献条目了
* 如果你无意间试图删除文档中的隐藏部分,Writer 会发出警告提醒
* Writer 现在接受用于短语检查的自定义词典了
#### Calc 的改进

新的颜色排序功能使得排序变得更为容易。
除此之外,还有一个用于数据透视表的紧凑的新布局。其他细微和技术层面的改进包括:
* 复制到另一个文件的电子表格保留了用户定义的打印范围
* 可以自定义新注释的默认外观
* 会保存求解器设置
* 如果表格为空,则在删除时不会显示确认
* 超链接格式已经进行改善,使其看起来更为醒目
#### Impress 与 Draw 的改进
现在,当你播放一个演示文稿时,会出现便于快速浏览的导航按钮。这是个小改动,但是应该可以帮助你轻松地在幻灯片之间进行导航。
其他的改进包括:
* 增加了对多图片 tiff 文件的支持
* 可以在导航器中按照从前到后的顺序列出对象
#### 其他变化

除了之前的亮点,你还可以得到一个已有所改进的 “<ruby> 帮助 <rt> Help </rt></ruby>” 部分。这里将展示关于改变布局或快速完成许多任务所需的命令/快捷键信息。
如果你想深入了解, 可以查阅 [LibreOffice 7.6 发行备注](https://wiki.documentfoundation.org/ReleaseNotes/7.6)。
### 如何升级/安装?
对于大部分用户来说,LibreOffice 可能已经预安装好了。如果是这样的话,你应该等待来自你的系统仓库、LibreOffice 的 PPA,或者 Flathub 的更新。这通常需要几天时间。
>
> ? 你也可以选择从你的系统中卸载 LibreOffice,并通过以下步骤获取新版本。但如果你能等待,我们建议你等待。
>
>
>
如果你还没有安装它并想要获取新版本,只需要根据你的需求(DEB/RPM)简单地 [下载 tar 包](https://www.libreoffice.org/download/download-libreoffice/)。

接下来,解压这个包,并在 `DEBS` 或 `RPMS` 文件夹下找到所有 .deb/.rpm 文件。

当你进入这个文件夹,在终端中使用右键菜单打开它(如图所示)并根据你的包输入以下命令之一(适用于 Fedora 和基于 Debian 的发行版):

```
sudo dnf install *.rpm
sudo dpkg -i *.deb
```
? 你对最新的 LibreOffice 发行版本有什么想法?请在下方的评论区分享你的看法。
*(题图:MJ/1afe80f6-a7dd-4e9e-ac77-f8581492b08a)*
---
via: <https://news.itsfoss.com/libreoffice-7-6/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

LibreOffice 7.6 is the next major upgrade for the open-source office suite.
With its previous [LibreOffice 7.5 release](https://news.itsfoss.com/libreoffice-7-5-release/), the developers unveiled new app icons and feature upgrades. And, this time, it includes a good set of new abilities.
**2024**, The Document Foundation will follow calendar-based numbering, i.e., the next version scheduled for Feb 2024 will be identified as
**LibreOffice**
**24.2.**
Let us take a look at what's new with the release.
## LibreOffice 7.6: What's New?
As expected, there are refinements across all the tools, with highlights for the Writer, Calc, and Impress; they are:
**Support for document themes****Improvements to Help****Compatibility improvements****New Page Number Wizard (Writer)****Navigation panel for slides (Impress)****Auto-filter support for sorting by color (Calc)**
### Writer Improvements
The highlight feature update is the support for document themes. In other words, when needed, you can select a preset of color combinations for your document's title, text, and subheadings.
You can find the option via **Format → Themes**.
A subtle but significant addition is adding a page number to the header/footer using a new wizard under the **Insert** menu.
You also get a new option to enable the spotlight for the paragraph styles or direct formatting in text.
For a UX-focused improvement, you can find the "**Accesbility Check**" from the sidebar for quick access while editing a document.
Other changes include:
- Table of figures can now be generated more flexibly using a paragraph-based style
- Bibliography entries can now be directly edited from its tables
- Writer warns if you try accidentally to delete a hidden section from your document
- Custom dictionaries for phrase checking are accepted
### Calc Improvements
Sorting has been made easy with the new ability to sort things by color.
In addition to this, you get a compact new layout for pivot tables. Other subtle and technical refinements include:
- Spreadsheets copied to another file retain a user-defined print range
- Ability to customize the default look of new comments
- Solver settings are saved
- If the sheet is empty, no confirmation is shown to delete it
- Hyperlink formatting has been improved to make it look distinct
### Impress & Draw Improvements
When you play a presentation now, you will get navigation buttons to go through them quickly. It is a small addition, but it should help you easily navigate through the slides.
Other refinements include:
- Added support for multi-image tiff files
- Objects can be listed in front-to-back order in the navigator
### Other Changes
Along with the highlights, you also get an improved "**Help**" section, which displays information about commands/shortcuts you need to change layout or do many things quicker.
To dive in deeper, you can check out [LibreOffice 7.6 release notes](https://wiki.documentfoundation.org/ReleaseNotes/7.6?ref=news.itsfoss.com).
## How to Upgrade/Install?
LibreOffice should already be pre-installed for most users. If so, you should wait for the update from your system repository, LibreOffice's PPA, or Flathub. It should take a few days.
If you do not have it installed and want to get the new version, simply [download the tar package](https://www.libreoffice.org/download/download-libreoffice/?ref=news.itsfoss.com) as per your requirements (DEB/RPM).
Next, extract the package, and find all the .deb/.rpm files under a "DEBS" or "RPMS" folder.
Once you are in that folder, use the right-click menu to open it in the terminal (as shown in the image above) and type one of the following commands as per the package (Fedora and Debian-based distros):
`sudo dnf install *.rpm`
`sudo dpkg -i *.deb`
*💬 What do you think about the latest LibreOffice release? Let us know your thoughts in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,125 | TransFLAC:将 FLAC 转换为有损格式 | https://fedoramagazine.org/transflac-convert-flac-to-lossy-formats/ | 2023-08-25T14:25:03 | [
"FLAC"
] | https://linux.cn/article-16125-1.html | 
### FLAC:无损音频压缩格式
自由无损音频编解码器([FLAC](https://xiph.org/flac/))是一种无损音频压缩格式,可保留所有原始音频数据。这意味着 FLAC 文件可以解码成与原始音频文件完全相同的副本,而不会有任何质量上的损失。不过,无损压缩通常会比有损压缩的文件大小更大,这就是为什么需要一种将 FLAC 转为有损格式的方法。而这就是 TransFLAC 可以提供帮助的地方。
FLAC 是一种流行的数字音频文件存档格式,也可用于在家用电脑上存储音乐收藏。音乐流媒体服务也越来越普遍地提供 FLAC 作为高品质音频的一种选择。
对于存储空间有限的便携设备,通常使用 MP3、AAC 和 OGG Vorbis 等有损音频格式。这些格式的文件大小比无损格式小得多,但音质仍然很好。
一般来说,FLAC 是对无损音频质量要求较高的应用(如存档、母带制作和 <ruby> 鉴定聆听 <rt> critical listening </rt></ruby>)的不错选择。对于文件大小更为重要的应用,如在便携设备上存储音乐或通过互联网串流音乐,有损格式是不错的选择。
### TransFLAC:将 FLAC 转换为有损格式
[TransFLAC](https://bitbucket.org/gbcox/transflac/wiki/Home) 是一款命令行应用,可将 FLAC 音频文件转换为指定质量级别的有损格式。它能使 FLAC 和存储有损格式的音乐库保持部分或完全同步。TransFLAC 还能同步目录结构中存储的专辑封面、专辑封底和文件夹文件。你可以在终端窗口中交互式运行 TransFLAC,也可以使用 cron 或 systemd 等应用安排其自动运行。
必须指定以下四个参数:
1. **输入 FLAC 目录**:要递归搜索 FLAC 音频文件的目录。目录名大小写敏感。TransFLAC 会将目录树中的所有 FLAC 音频文件转换为指定的有损编解码格式。程序将解决遇到的任何符号链接,并显示物理路径。
2. **输出有损目录**:有损音频文件的存储目录。目录名大小写敏感。程序将解析遇到的任何符号链接并显示物理路径。
3. **有损编解码器**:用于转换 FLAC 音频文件的编解码器。编解码器名称的大小写并不重要。对于给定的文件大小或比特率,OPUS 通常能提供最佳音质,是推荐的编解码器。有效值为 [opus](https://opus-codec.org/) | [ogg](https://xiph.org/vorbis/) | [aac](https://en.wikipedia.org/wiki/Fraunhofer_FDK_AAC) | [mp3](https://lame.sourceforge.io/)
4. **编解码器质量**: 用于编码有损音频文件的质量预设。质量名称的大小写并不重要。**OPUS STANDARD** 质量提供全带宽、立体声音乐、良好的音频质量和透明度,是推荐的设置。有效值为 低 | 中 | 标准 | 高 | 优质
**TransFLAC** 允许对配置中的某些项目进行 [自定义](https://bitbucket.org/gbcox/transflac/wiki/src-tf-conf-override.sh)。项目 [维基](https://bitbucket.org/gbcox/transflac/wiki/TransFLAC) 提供了更多信息。
在 [Fedora Linux](https://fedoraproject.org/) 上安装:
```
$ sudo dnf install transflac
```

---
via: <https://fedoramagazine.org/transflac-convert-flac-to-lossy-formats/>
作者:[Gerald B. Cox](https://fedoramagazine.org/author/gbcox/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **FLAC: The Lossless Audio Compression Format**
[FLAC](https://xiph.org/flac/), or Free Lossless Audio Codec, is a lossless audio compression format that preserves all the original audio data. This means that FLAC files can be decoded to an identical copy of the original audio file, without any loss in quality. However, lossless compression typically results in larger file sizes than lossy compression, which is why a method to convert FLAC to lossy formats is desirable. This is where TransFLAC can help.
FLAC is a popular format for archiving digital audio files, as well as for storing music collections on home computers. It is also becoming increasingly common for music streaming services to offer FLAC as an option for high-quality audio.
For portable devices, where storage space is limited, lossy audio formats such as MP3, AAC, and OGG Vorbis are often used. These formats can achieve much smaller file sizes than lossless formats, while still providing good sound quality.
In general, FLAC is a good choice for applications where lossless audio quality is important, such as archiving, mastering, and critical listening. Lossy formats are a good choice for applications where file size is more important, such as storing music on portable devices or streaming music over the internet.
## TransFLAC: Convert FLAC to lossy formats
[TransFLAC](https://bitbucket.org/gbcox/transflac/wiki/Home) is a command-line application that converts FLAC audio files to a lossy format at a specified quality level. It can keep both the FLAC and lossy libraries synchronized, either partially or fully. TransFLAC also synchronizes album art stored in the directory structure, such as cover, albumart, and folder files. You can run TransFLAC interactively in a terminal window, or you can schedule it to run automatically using applications such as cron or systemd.
The following four parameters must be specified:
**Input FLAC Directory**: The directory to recursively search for FLAC audio files. The case of the directory name matters. TransFLAC will convert all FLAC audio files in the directory tree to the specified lossy codec format. The program will resolve any symlinks encountered and display the physical path.**Output Lossy Directory:**The directory to store the lossy audio files. The case of the directory name matters. The program will resolve any symlinks encountered and display the physical path.**Lossy Codec:**The codec used to convert the FLAC audio files. The case of the codec name does not matter. OPUS generally provides the best sound quality for a given file size or bitrate, and is the recommended codec.
Valid values are:[OPUS](https://opus-codec.org/)|[OGG](https://xiph.org/vorbis/)|[AAC](https://en.wikipedia.org/wiki/Fraunhofer_FDK_AAC)|[MP3](https://lame.sourceforge.io/)**Codec Quality:**The quality preset used to encode the lossy audio files. The case of the quality name does not matter.**OPUS STANDARD**quality provides full bandwidth, stereo music, good audio quality approaching transparency, and is the recommended setting.
Valid values are: LOW | MEDIUM | STANDARD | HIGH | PREMIUM
**TransFLAC** allows for [customization](https://bitbucket.org/gbcox/transflac/wiki/src-tf-conf-override.sh) of certain items in the configuration. The project [wiki](https://bitbucket.org/gbcox/transflac/wiki/TransFLAC) provides additional information.
**Installation** on [Fedora Linux](https://fedoraproject.org/):
$ sudo dnf install transflac
## Gregory Bartholomew
If the animated SVG at the end doesn’t autoplay, try refreshing the page by pressing the F5 key. (Sorry, it’s the first time we’ve tried to use an animated SVG in an article.)
## Chris Moller
sox does flac conversion out of the box.
## Gerald B. Cox
AFAIK: SOX cannot convert FLAC files to OPUS or AAC formats. TransFLAC, on the other hand, can recursively scan a directory and convert all FLAC files found, using multiple threads to speed up the process.
## SigmaSquadron
have you heard about the magical artefact that is ffmpeg?
## Gerald B. Cox
See response to @darvond
## Darvond
Aside from a pretty text interface, what might this offer over the tried, tested, code mature ffmpeg?
Don’t get me wrong, the chrome on this is neat, but this is also just akin to showing someone who has a workflow based around ImageMagick/GraphicsMagick a bespoke gif converter.
## Gerald B. Cox
I’m well aware of ffmpeg. In fact, TransFLAC uses it for the conversion to MP3 and AAC files. However, what you are missing is that ffmpeg only provides a small subset of the entire functionality. For more information, refer to the wiki mentioned in the article.
## Grandpa Leslie
Congratulations on a very well done presentation.
Not many people (very very few people) could do better
## Cornel Panceac
In the .srpm:
$ file gbcox-transflac-884f17e71b29.tar.bz2
gbcox-transflac-884f17e71b29.tar.bz2: Zip archive data, at least v1.0 to extract, compression method=store
If it’s .zip, maybe it should be called .zip 🙂
(as opposed to .tar.bz2)
## Richard England
A “tar.bz2” file is a compressed archive file created using the tar command in Unix/Linux and the opensource patent free bzip2 compression algorithm.
https://sourceware.org/bzip2/
## Gregory Bartholomew
The contents of the file are independent of the file name:
## Richard England
That is true, but the bz2 extension tells the user what compression was used. This might be useful if someone wishes to un-compress the tar file but not extract the contents of the tar file. I’ve had a need to do that in the past.
## Gerald Cox
Thanks for reporting. It was due to a difference in the way Bitbucket handles downloads. Odd it didn’t seem to cause any errors in the build process. In any event, it is fixed in v1.2.4, If you notice any further problems/concerns, please report in fedora bugzilla or in the bitbucket transflac repo under issues.
## Cornel Panceac
The truth is TransFLAC is an amazing piece of software. It’s living proof things can still be simple in this very complex world.
## Patrick Perkins
Not sure why, but i get ZERO output using this tool. ffmpeg -i works perfectly. Unfortunately, I have music library of over 2800 flac files and was hoping to use this tool to convert about 500 of them to be used in my watch for when I ride my bike..
I suspect the tool is sensitive to spaces or other characters in my files
‘Disc 1 – 05 – All Along the Watchtower (live).flac’
Ill keep searching for a tool that works for me.
## Gerald B. Cox
Interesting, I tried with renaming a track to “Disc 1 – 05 – All Along the Watchtower (live).flac” and it encoded to mp3 with no problem. If you are still having an issue with this or the aac format, please open a bug report. Thanks!
## Patrick Perkins
Some additional infofor my comment above.
This works great when converting to MP3 format.
I get no output when attempting to convert to an AAC format.
I guess I am either missing an rpm or have an incorrect rpm installed.
## Vijay
So this allows more lossy formats that just mp3? Do they occupy volume space or does it do it on the fly in a virtual filesystem like mp3fs?
## Gerald B. Cox
opusenc is used to convert to opus
oggenc is used to convert to ogg
ffmpeg is used to convert to mp3 and aac
## Patrick Perkins
After reviewing the source code, I found that I don’t have the version of ffmpeg that allows the libfdk-aac codec which is used by transflac.
But the built-in ffmpeg aac codec works fine for what I want.
Was considering modifying transflac to use aac and then found a very sweet one line terminal command that converts all the files in a directory to the aac format that I am looking for.
Still, transflac is a very kewl tool for converting flac files to other formats.
## Gerald B. Cox
> After reviewing the source code, I found that I don’t have the version of ffmpeg that allows
> the libfdk-aac codec which is used by transflac.
Really? Where are you getting your version of ffmpeg. Fedora has ffmpeg-free which contains all the codecs needed by TransFLAC, as does most 3rd party repositories, e.g. freshrpms, negativo, etc. Since libfdk-aac is free now, I can’t imaging why anyone would exclude it from their ffmpeg build.
## Patrick Perkins
I have a couple of astronomical apps (Siril and Stellarium) that I believe pulled ffmpeg in as a dependency from rpm-fusion
I’ll do some clean up and see if i can get the ffmpeg-free installed and working with my astro-imaging apps.
I apologize for all the troubles I’ve caused you, Gerald.
And I thank you for your kindness and support
## Gregory Bartholomew
Just my 2¢, but it might be worth checking at installation time anyway. e.g.: if ! ffmpeg -encoders |& grep -qi "\saac\s\+AAC (Advanced Audio Coding)$"; then echo "warning: aac encoding support not detected"; fi
## Patrick Perkins
This is actually VERY fast too. I converted 2583 (70.7 GB) flac files to AAC Standard in less than 5 minutes.
Fedora 38, AMD Ryzen 5900X (4.25GHZ clock).
Very very nice! |
16,127 | Roblox 返回 Linux,携手 Wine,欢迎玩家们! | https://news.itsfoss.com/roblox-wine-support-linux/ | 2023-08-25T14:50:35 | [
"Roblox",
"Wine"
] | https://linux.cn/article-16127-1.html | 
>
> 现在,所有人都能再次享受 Roblox 了!
>
>
>
Roblox 即将重新登陆 Linux 平台。
不久前,我们曾 [报道](https://news.itsfoss.com/roblox-linux-end/) Roblox 的新反作弊软件 Hyperion 将默认阻断 [Wine](https://www.winehq.org/?ref=news.itsfoss.com) 的使用,这无疑让人失望。
然而,随着最近的开发进展,这一状况将有所改观。以下是整个情况的介绍。
发生了什么: 你看,早在 5 月,Roblox 推出了新的反作弊软件,成为了默认阻止 Wine 使用的工具,然而 **这一变化并非失误,而是故意为之**。
那时,一名 Roblox 员工在论坛中彻底否定了在 Linux 原生支持或找到变通方法运行 Roblox 的可能。
然而,事情并没有因此结束。
几天前,Roblox 的一名员工回复了论坛上的一篇帖子,称:
>
> 向 Grapejuice 社区大声疾呼 - 这是特别为你们准备的。
>
>
>
随后,他展示了一张截图,揭示了 **Roblox 在 Manjaro Linux 上运行** 的信息。

如果你还不知道,[Grapejuice](https://gitlab.com/brinkervii/grapejuice?ref=news.itsfoss.com) 是一个管理应用程序,可以帮助你在 Linux 上正确设置 Wine 和 Roblox。
尽管新的反作弊软件已经发布,但这显示了 Roblox 也能重新在 Linux 上运行。对我来说,这听起来很棒!
期待何时: 目前来看,这项整合工作仍在进行中,同样的,上文提到的员工表示:
>
> 我们将发布关于 Wine 的非官方支持的正式声明。至于何时,就说在不久之后™。
>
>
>
没错,Linux 上的 Roblox 玩家可能还需要稍作等待。
然而,玩家们现在应该会感到高兴,认识到至少 **Roblox 在 Linux 上的非官方支持即将到来**。

你可以查看 [这里](https://devforum.roblox.com/t/why-did-roblox-stop-supporting-linux-users/2444335/61?u=sirsquiddybob&ref=news.itsfoss.com) 的讨论以获取关于这个实施情况的更多详细信息。(需要登录)。
参考来源:[GamingOnLinux](https://www.gamingonlinux.com/2023/08/roblox-support-is-coming-back-to-wine-on-linux/?ref=news.itsfoss.com)
---
via: <https://news.itsfoss.com/roblox-wine-support-linux/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Roblox is making a comeback to Linux!
Just a few months prior, we [reported ](https://news.itsfoss.com/roblox-linux-end/)that Roblox's new anti-cheat software, '**Hyperion**' was all set to block [Wine](https://www.winehq.org/?ref=news.itsfoss.com) usage by default, a bummer indeed.
However, that is all set to change in light of recent developments. Allow me to take you through the situation.
**What's Happening: **You see, back in May, Roblox introduced a new anti-cheat software that blocked Wine usage by default, and **the change was not a mistake but intentional**.
Back then, even a Roblox staff member shut out any chances of Linux being supported natively or being able to run Roblox with workarounds on their forums.
But, as it turns out, that was not the end.
A few days back, one of Roblox's staff members replied to a post on their forum saying:
Shoutout to the Grapejuice community - this one is for you.
With the following screenshot attached, which shows **Roblox running on Manjaro Linux**.
If you did not know, [Grapejuice](https://gitlab.com/brinkervii/grapejuice?ref=news.itsfoss.com) is a management application that allows you to configure Wine and Roblox to run correctly on Linux.
And that there is proof that Roblox can run on Linux again, despite the new anti-cheat software. Sounds good to me!
**When to Expect: **As things stand now, the integration is still undergoing work, and the same staff member has mentioned that:
There will be an official announcement regarding unofficial support for Wine. As for an ETA, let’s just say soon™.
Yes, Roblox players on Linux will have to wait it out a bit more.
However, the players should be happy now, considering that at least **unofficial support for Roblox on Linux is coming soon**.
You can check out the discussion [here](https://devforum.roblox.com/t/why-did-roblox-stop-supporting-linux-users/2444335/61?u=sirsquiddybob&ref=news.itsfoss.com) for more details on this implementation. (requires login).
**Via**: [GamingOnLinux](https://www.gamingonlinux.com/2023/08/roblox-support-is-coming-back-to-wine-on-linux/?ref=news.itsfoss.com)
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,128 | Bodhi 7.0 版发布,基于 Ubuntu 22.04 LTS | https://news.itsfoss.com/bodhi-7-0-0-release/ | 2023-08-25T15:13:00 | [
"Bodhi"
] | https://linux.cn/article-16128-1.html | 
>
> Bodhi Linux 7.0 版终于发布! 此版本包含了一系列重要的升级和增强措施。
>
>
>
Bodhi Linux 是一款受大众喜爱的 [轻量级发行版](https://itsfoss.com/lightweight-linux-beginners/?ref=news.itsfoss.com),其特色在于采用了 [Moksha](https://itsfoss.com/bodhi-linux-introduces-moksha-desktop/?ref=news.itsfoss.com) 桌面环境,为用户提供了独一无二的体验。(“Bodhi” 的意思是菩提树。)
其上一个主要版本 [Bodhi Linux 6.0](https://news.itsfoss.com/bodhi-linux-6-release/) 已经是两年多前的事情了,它带来了显著的改进。
Bodhi Linux 7.0 版已经计划很久了,但是因为创建者出现了一些健康问题,开发工作暂时停滞。我们希望开发人员现在情况好转;让我们一起来关注其下一个升级版。
### ? Bodhi Linux 7.0:新功能有哪些?

本次发布的 Bodhi Linux 是基于 [Ubuntu 22.04](https://news.itsfoss.com/ubuntu-22-04-release/) LTS,这提供了一个非常稳定的基础。因此,无论是在硬件支持,还是在性能和安全性增强方面,都有着良好的表现。
Bodhi Linux 7.0 版现在引入了一款全新的默认主题,叫做 MokshaGreen。它包含了一款 **动态背景**、**全新的 Plymouth 引导屏幕**,以及 **全新的登录屏幕主题**。

所以,就算可能不是很多,我们还是可以期待一些视觉上的新鲜体验。
在桌面环境方面,也进行了几次重大的更新。**Moksha 0.4.0** 带来了一系列的改进,包括:
* 重构了一些模块,移除了对一些已经弃用的库的依赖。
* 添加了一个通过 `Super + F1` 访问的 Moksha 基础快捷方式查看器。
* 解决了“应用”语言设置的按钮问题。
* 增加了对贴边窗口的支持。
* 为 MokshaGreen 主题提供了 GTK 主题和图标集。
此外,在**模块**方面,添加了一系列改进,包括:
* 对电池模块的改进带来了更好的充电状态弹窗。
* 修复了浮动菜单段错误。
* 在时钟模块中添加了日期/时间设置。
* 在 iBar 模块中添加了一个应用程序实例菜单。
除此之外,Bodhi Linux 的软件栈也进行了更新,采用了非 Snap 版本的 **Chromium 115**、**Terminology 1.13.1** 以及 **Slick-greeter 1.8.1**。
你可以查阅 [发布备注](https://www.bodhilinux.com/release/7-0-0/?ref=news.itsfoss.com) 和 [公告博客](https://www.bodhilinux.com/2023/08/21/introducing-bodhi-linux-7-0-a-landmark-release/?ref=news.itsfoss.com),以对这个版本有更详细的了解。
### ? 获取 Bodhi Linux 7.0
对于这个发布版本,可选择三个不同的内核版本:
* 标准 ISO 版本包含 Linux 内核 5.15 LTS,
* 更新增强版的 HWE ISO 提供更近期的 Linux 内核 6.2,
* S76 ISO 版使用 System76 的 6.2.6 版本的 Linux 内核。
你可以从 Bodhi Linux 的 [官方网站](https://www.bodhilinux.com/download/?ref=news.itsfoss.com) 下载。
>
> **[Bodhi 7.0版](https://www.bodhilinux.com/download/?ref=news.itsfoss.com)**
>
>
>
(题图:[freeimages](https://www.freeimages.com/photo/bodhi-leaf-1392651))
---
via: <https://news.itsfoss.com/bodhi-7-0-0-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Bodhi Linux is a popular [lightweight distro](https://itsfoss.com/lightweight-linux-beginners/?ref=news.itsfoss.com) that features the [Moksha](https://itsfoss.com/bodhi-linux-introduces-moksha-desktop/?ref=news.itsfoss.com) desktop environment, which provides a unique user experience.
The last major release was [Bodhi Linux 6.0](https://news.itsfoss.com/bodhi-linux-6-release/), which came more than two years back with impressive improvements.
Bodhi Linux 7.0 has been on the roadmap for a while, but the development was stalled because the creator had some health issues. Hoping that the developer is doing better now; Let us look at the next upgrade.
## 🆕 Bodhi Linux 7.0: What's New?

This release of Bodhi Linux is based on [Ubuntu 22.04](https://news.itsfoss.com/ubuntu-22-04-release/) LTS, which is a **pretty solid foundation**. Resulting in some good hardware support alongside performance and security enhancements.
Bodhi Linux 7.0 now features a **new default theme** called '**MokshaGreen**', which features an **animated background**, a **new boot Plymouth boot screen**, and a **new login screen theme**.
So, some visual bling to watch out for, even if it may not be much.
The desktop environment side of things has also received several significant updates, with **Moksha 0.4.0** bringing in a host of improvements that include:
- Refactor several modules to remove dependence on depreciated libraries.
- A keybindings viewer for basic Moksha shortcuts that can be accessed using “Super + F1”.
- Fix the language settings 'Apply' button.
- Added Support for window snapping to the edge of the screen.
- GTK theme and Icon set for MokshaGreen.
**Suggested Read **📖
[7 Super Lightweight Linux DistrosLight as a feather! These super small, lightweight Linux distributions should be interesting to try.](https://itsfoss.com/super-lightweight-distros/?ref=news.itsfoss.com)

Whereas, on the **Modules** side of things, a load of improvements were added that include:
- Improvements to the battery module resulted in a better-charging status popup.
- Fix for float menu segfault.
- Date/Time settings added to the clock module.
- An application instances menu was added to the iBar module.
Other than that, the software stack of Bodhi Linux has also been updated with the non-snap version of **Chromium 115**, **Terminology 1.13.1**, and **Slick-greeter 1.8.1.**
You can go through the [release notes](https://www.bodhilinux.com/release/7-0-0/?ref=news.itsfoss.com) and the [announcement blog](https://www.bodhilinux.com/2023/08/21/introducing-bodhi-linux-7-0-a-landmark-release/?ref=news.itsfoss.com) for a more detailed outlook on this release.
## 📥 Get Bodhi Linux 7.0
With this release, three distinct kernel versions are available:
**Standard ISO features Linux Kernel 5.15 LTS****An****HWE ISO with the more recent Linux Kernel 6.2**,**An****S76 ISO that uses System76's 6.2.6 Linux Kernel**.
You can grab these from Bodhi Linux's [official website](https://www.bodhilinux.com/download/?ref=news.itsfoss.com).
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,129 | 如何使用 VLC 媒体播放器旋转视频 | https://itsfoss.com/rotate-video-vlc/ | 2023-08-26T11:02:00 | [
"VLC"
] | https://linux.cn/article-16129-1.html | 
>
> 这个多功能的 VLC 媒体播放器还可以旋转视频方向。在桌面上观看智能手机录制的视频相当方便。
>
>
>
有时,你会遇到以显示方向错误的视频。使用智能手机摄像头拍摄的视频很可能会以这种方式出现。
如果你可以将其旋转到方便的方向,那么效果会更好。
功能丰富的 VLC 媒体播放器提供了一种旋转视频的方法。你可以:
* 暂时旋转视频(下次播放时需要再次旋转)
* 永久旋转视频(视频将始终以新方向播放)
让我们看看如何实现这两者之一。
### 在 VLC 中暂时旋转视频
让我们看看如何在 VLC 中临时旋转视频。也就是说,完成该过程后,它不会反映在实际文件上。这对于查看文件或测试文件很有用。
#### 使用预设值旋转视频
在此方法中,你可以将视频旋转 90 度、180 度和 270 度。这是你大多数时候所需要的。
打开 VLC 并选择要旋转的视频。

单击主菜单上的 “<ruby> 工具 <rt> Tools </rt></ruby>”,然后转到 “<ruby> 效果和滤镜 <rt> Effects and Filters </rt></ruby>”。你也可以按快捷键 `CTRL + E`。

在 “效果和滤镜” 页面上,选择 “<ruby> 视频效果 <rt> Video Effects </rt></ruby>” 选项卡,然后进入 “<ruby> 几何 <rt> Geometry </rt></ruby>”。现在,选中 “<ruby> 变换 <rt> Transform </rt></ruby>” 复选框。

这将激活一个下拉菜单。从那里,选择你需要的适当旋转,如 90 度、180 度、水平翻转等。你可以在 VLC 窗口中查看变化。
对更改感到满意后,按 “<ruby> 保存 <rt> Save </rt></ruby>” 按钮以所选方向保存配置。
#### 使用自定义值旋转视频
需要将视频旋转到可用预设以外的方向? VLC 也有一个选项。
首先,像上一步一样,打开媒体,然后转到 “工具 > 效果和滤镜 > 视频效果 > 几何”。
现在,单击 “<ruby> 旋转 <rt> Rotate </rt></ruby>” 复选框,你可以看到交互式圆形滑块现已激活。
>
> ? 对于不规则的旋转值(例如 230 度等),某些部分都会从视频中删除。
>
>
>

移动滑块以获得正确的旋转。你可以在 VLC 窗口中看到视频出现的变化。确定更改后,请按 “保存” 按钮保存该配置。
>
> ? 请记住,此配置在此阶段不会永久应用于视频。但是,如果你按 “保存”,方向也会暂时应用于 VLC 中播放的其他视频。
>
>
>
### 永久旋转视频
你知道了如何临时旋转文件。永久保存视频文件更改也需要该步骤。
#### 第 1 步:转换视频
这是前一部分。打开视频文件,然后进行所需的旋转。确认特定视频所需的旋转后,按照上一步中的说明保存该配置。
#### 第 2 步:保存视频
现在,打开 VLC 并单击 “<ruby> 媒体 <rt> Media </rt></ruby> > <ruby> 转换/保存 <rt> Convert/Save </rt></ruby>”。这可以在没有打开任何视频文件的情况下进行,因为无论如何我们都不会处理当前打开的视频。

在下一个对话框中,使用 “添加Add” 按钮选择要旋转的文件(在上一步中测试以确认所需旋转的文件)。然后按 “<ruby> 转换并保存 <rt> Convert and Save </rt></ruby>”。

接下来,选择所需的视频输出,然后单击相邻的设置按钮,如下所示。

出现了配置文件设置窗口。在其上,进入 “<ruby> 视频编解码器 <rt> Video Codec </rt></ruby>”,然后转到 “<ruby> 过滤器 <rt> Filters </rt></ruby>” 选项卡。在这里,你必须根据需要应用过滤器。一个是 “<ruby> 旋转视频过滤器 <rt> Rotate Video Filter </rt></ruby>”,另一个是 “<ruby> 视频转换过滤器 <rt> Video transformation Filter </rt></ruby>”。
如果你已使用 “变换” 按钮对视频应用固定变换,请选择 “<ruby> 视频变换过滤器 <rt> Video transformation Filter </rt></ruby>”。另一方面,如果你对视频进行了一些不规则的旋转,请选择 “旋转视频过滤器”。

检查后,按 “保存”按钮。
现在,选择输出文件位置,我们要在其中保存转换后的文件。

应给出一个新的文件名,这可以通过进入你选择的目录并只需在顶部栏上输入你选择的名称来完成。
>
> ? 建议提供一个新的唯一名称,以避免文件覆盖和数据丢失。
>
>
>

按 “<ruby> 开始 <rt> Start </rt></ruby>” 开始转换。
转换将需要一些时间,具体取决于你的视频。完成后,你将获得旋转的视频,可以在任何视频播放器上查看。
>
> ? 转换视频后(无论是永久的还是临时的),最好在 “工具 > 效果和滤镜 > 视频效果 > 几何” 中关闭应用的旋转。否则,以后使用 VLC 播放的视频将出现旋转。
>
>
>
我希望你喜欢这个 VLC 技巧。欢迎你提出建议和反馈。
同时,你还可以学习这个很酷的 VLC 自动下载字幕的技巧。
>
> **[在 VLC 中自动下载字幕](https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/)**
>
>
>
*(题图:MJ/b604f181-660a-4f05-bdd2-49b5b6da0bae)*
---
via: <https://itsfoss.com/rotate-video-vlc/>
作者:[Sreenath](https://itsfoss.com/author/sreenath/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Sometimes, you come across videos displayed in the wrong orientation. Most probably, the videos taken using smartphone cameras may appear this way.
It's better viewed if you can rotate it to a convenient orientation.
The versatile VLC media player provides a method for rotating the videos. You can:
- Rotate videos temporarily (you'll have to rotate again when you play it the next time)
- Rotate videos permanently (videos will always be played in the new orientation)
Let's see how to achieve either of the two.
## Rotate the Video Temporarily in VLC
Let us see about rotating videos temporarily inside VLC. That is, after you have completed the process, it won't reflect on the actual file. This will be good for just viewing a file or testing it.
### Rotate videos using preset values
In this method, you can rotate the video at 90, 180 and 270 degrees. This is what you would need most of the time.
Open VLC and select the video you want to rotate.
Click on **Tools** on the Main menu and go to **Effects and Filters**. You can also press the shortcut CTRL + E.
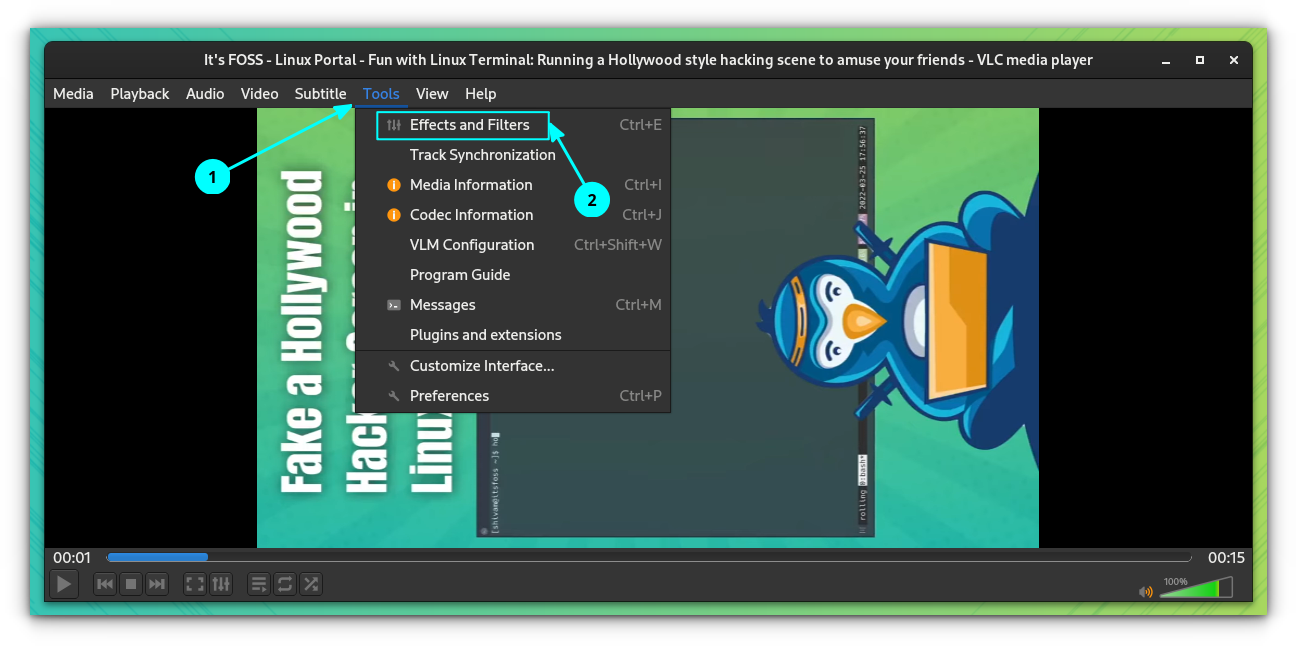
On the Effects and Filters page, select the **Video Effects** tab and inside that, go to **Geometry**. Now, check the transform checkbox.
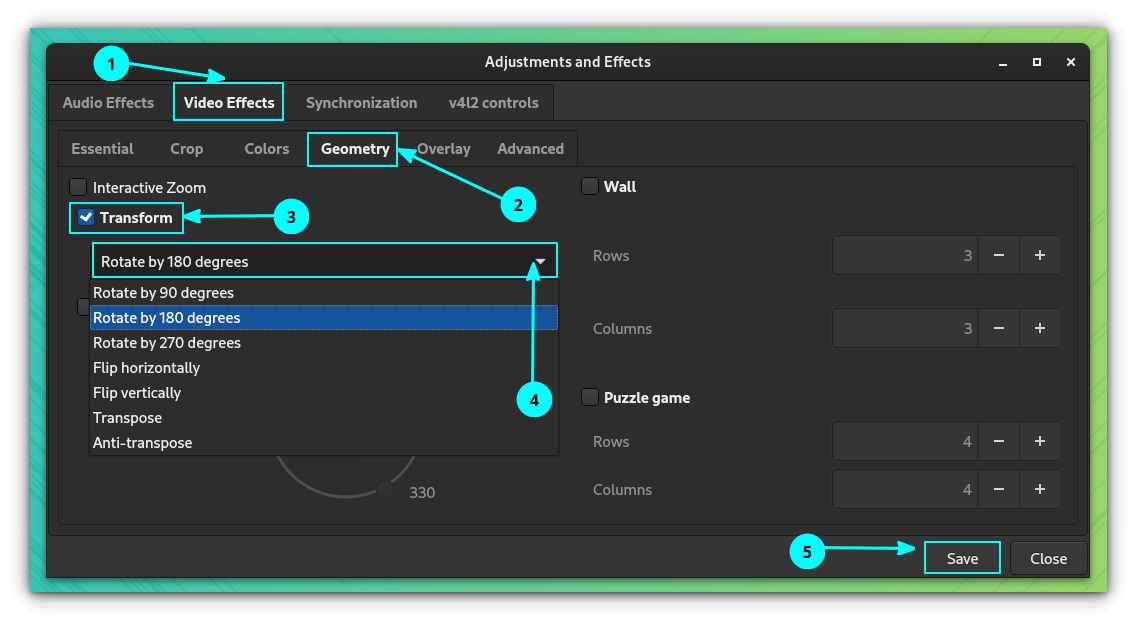
A drop-down menu will be activated. From there, select the appropriate rotation you need, like 90 degrees, 180 degrees, horizontal flip, etc. It is possible to view the changes on VLC window.
Once satisfied with the changes, press **the Save** button to save the configuration with the selected orientation.
### Rotate videos using custom values
Need to rotate the video to an orientation other than the available preset? VLC has an option for that too.
First, like in the previous step, open the media and then go to **Tools > Effects and Filters > Video Effects > Geometry**.
Now, click on the **rotate** checkbox, and you can see that an interactive circle slider has now been activated.
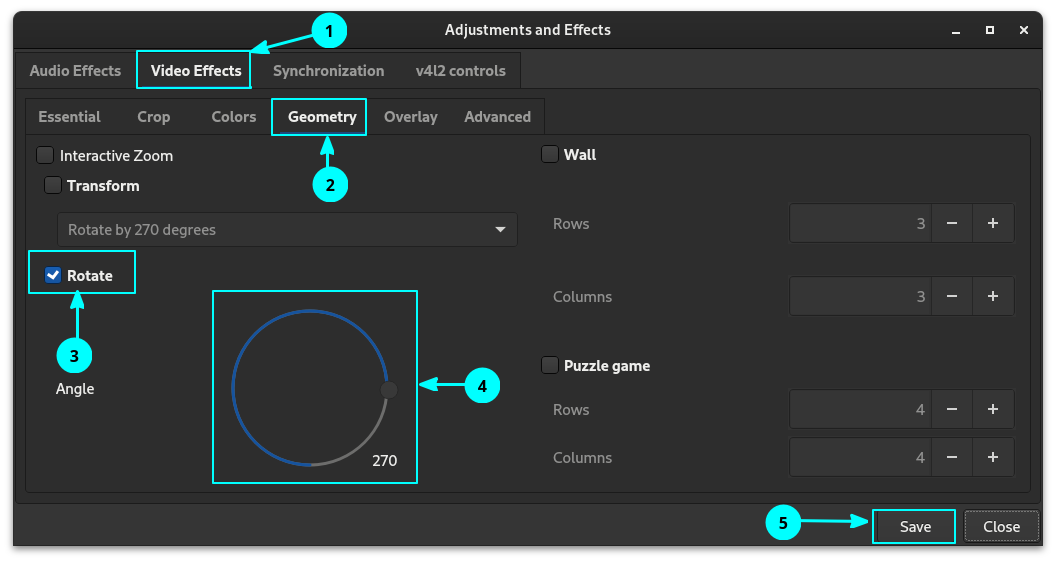
Move the slider so that you get the correct rotation. You can see the changes appearing to the video on VLC window. Press the **Save** button to save that configuration once you are OK with your changes.
## Permanently rotate a video
You know how to rotate a file temporarily. That step is also required to permanently save the video file changes.
### Step 1: Transform the Video
This is the previous part. Open a video file and then make the rotation that you wanted. Once you confirm the rotation needed for a particular video, save that configuration as explained in the previous step.
### Step 2: Save the Video
Now, open VLC and click on **Media > Convert/Save**. This can be without any video file opened, because we are not working on the currently opened video anyway.
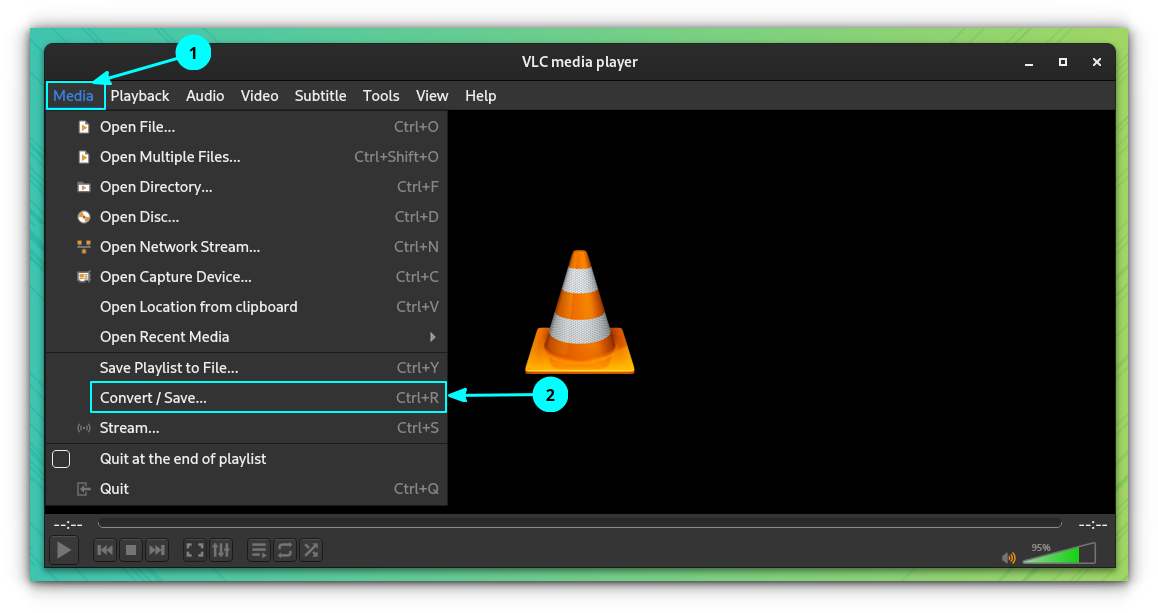
On the next dialog box, select the file you want to rotate (the one you tested to confirm the required rotation in the previous step) using the **Add** button. Then press **Convert and Save**.
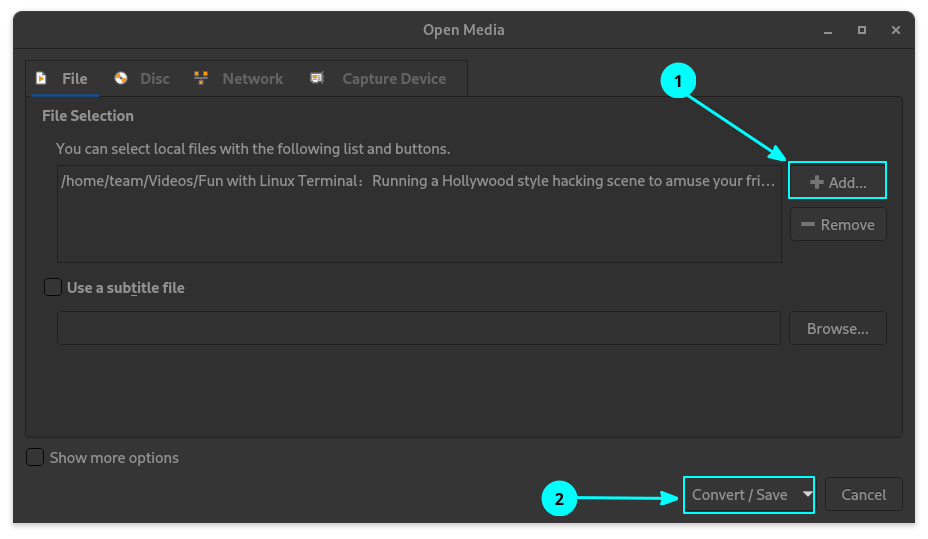
Next, select the video output you want and then click on the adjacent settings button as shown below.
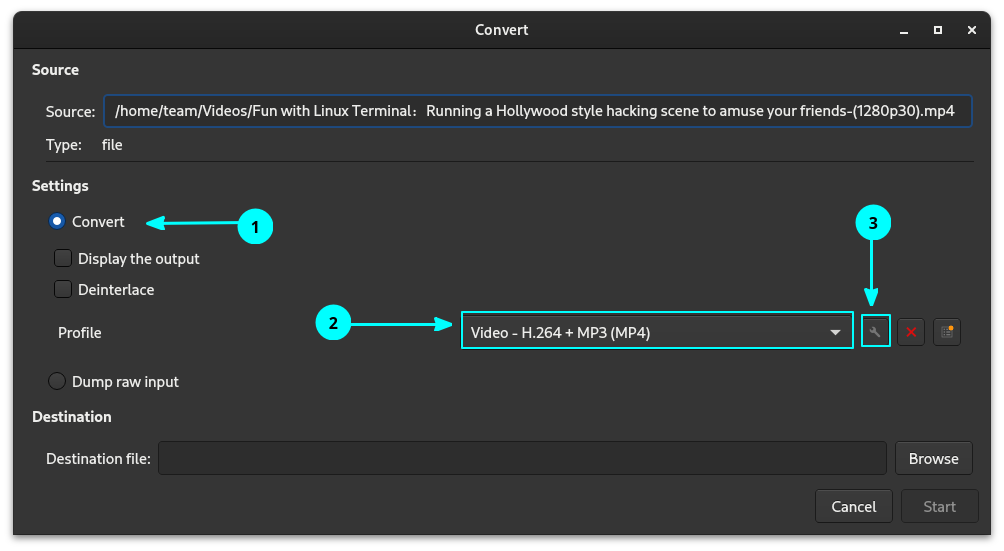
A profile settings window appears. On it, go to **Video Codec** and then **Filters** tab. Here, you have to apply filters as needed. One is **Rotate Video Filter** and another **Video transformation Filter**.
If you have applied fixed transformation to a video using the transform button, select the **Video transformation Filter**. On the other hand, if you have done some irregular rotation to the video, select **Rotate Video Filter**.
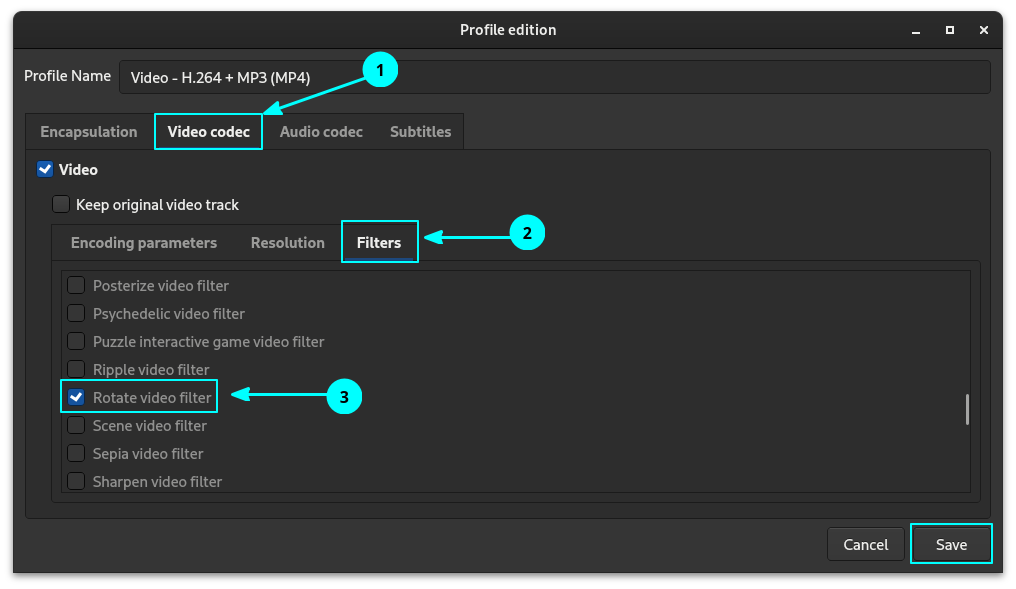
Once checked, press the **Save** button.
Now, select an output file location, where we want to save the converted file.
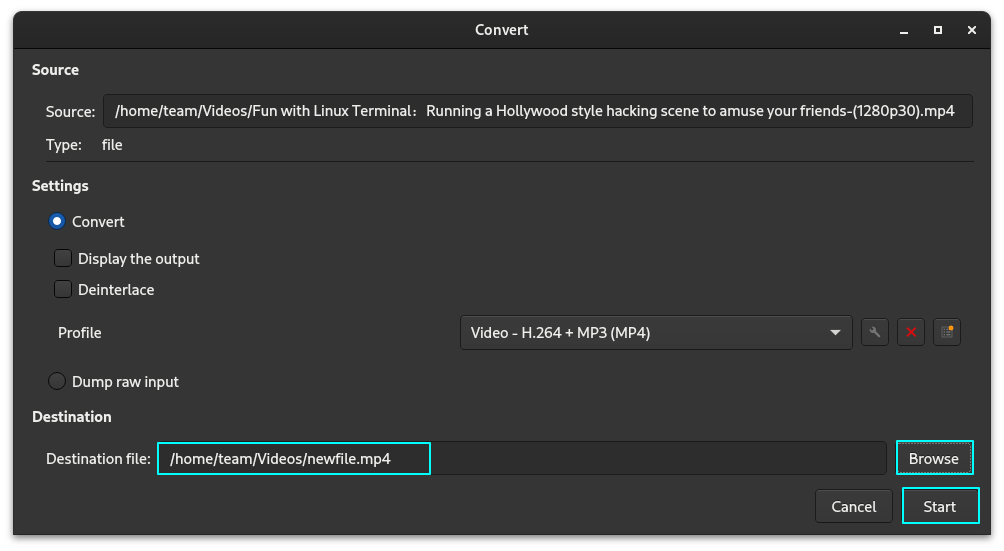
A new file name should be given, which can be done by going into a directory of your choice and simply enter the name of your choice on the top bar.
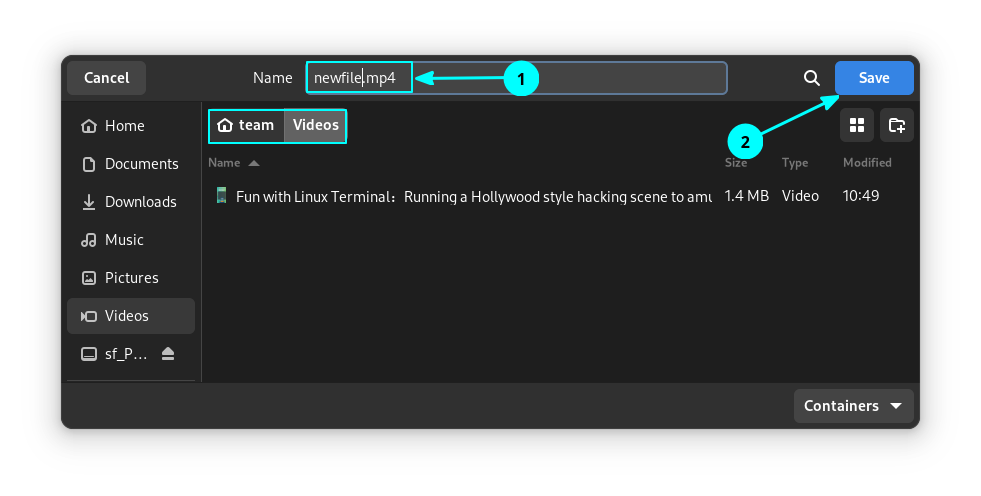
Press **Start** to start the conversion.
The conversion will take some time depending on your video. Once finished, you will get the rotated video to view on any video player.
**. Otherwise, the future videos played using VLC will appear rotated.**
**Tools > Effects and Filters > Video Effects > Geometry**I hope you liked this VLC tip. Your suggestions and feedback are welcome.
Meanwhile, you can also learn this cool VLC tip and download subtitles automatically.
[Download Subtitles Automatically With VLC Media PlayerVLC is a versatile media player. One of the lesser known features is the automatic subtitle download. Here’s how to use it.](https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/)
 |
16,130 | 更好地利用 Xfce 的 Thunar 文件管理器的 7 个技巧 | https://itsfoss.com/thunar-tweaks/ | 2023-08-26T16:52:17 | [
"Thunar",
"Xfce",
"文件管理器"
] | https://linux.cn/article-16130-1.html | 
>
> Thunar 是 Xfce 提供的一款优秀文件管理器,通过这些技巧和调整,你的使用体验可以得到提升。
>
>
>
Thunar 是 Xfce 桌面环境的默认文件管理器,它实现了轻量级与优秀的用户体验的完美平衡。
但是,像其他任何尚未深入探索的工具一样,你对 Thunar 的掌握会在你深入了解它之后变得更多。
我大胆地说,一系列的特性将会改善你的 Linux 体验。
在这个指南中,我会分享可以让 Thunar 体验更上一层楼的以下技巧:
* Thunar 的通用快捷键
* 添加 Thunar 插件
* 从你上次离开的地方继续
* 使用图标进行更好的识别
* 高亮显示文件/文件夹
* 在双窗口模式下轻松复制或移动文件
* 自定义操作
那就让我们从第一条开始吧。
### 1、利用键盘快捷键
毫无疑问,利用键盘快捷键可以提升你的工作效率。
以下是一些在 Thunar 中使用的简单快捷键,可以帮助减少鼠标点击操作:
| 快捷键 | 描述 |
| --- | --- |
| `Ctrl + T` | 新加标签页 |
| `Ctrl + N` | 新建窗口 |
| `F3` | 切换至双窗格模式 |
| `Alt + ←` | 后退 |
| `Alt + →` | 前进 |
| `Ctrl + F` | 搜索文件 |
| `Ctrl + S` | 按模式选取文件 |
| `Ctrl + H` | 显示隐藏文件 |
| `Ctrl + E` | 侧边栏启用树视图 |
| `Alt + ↑` | 打开父目录 |
| `Alt + Home` | 前往主目录 |
虽然看似简单,但请相信我,这些快捷键一旦融入你的日常工作流,你就会离不开它。
### 2、从你离开的地方重新打开 Thunar
>
> ? 此功能只在 Thunar 4.18 或更高版本中可用。
>
>
>
打开文件管理器时,默认打开上次关闭时的所有标签页,这是一个令人振奋的功能。
我就是那种喜欢深入 Linux 目录进行探索的人,所以从我离开的地方重新打开 Thunar 是一项重要功能。
若要启用此功能,只需遵循以下三个简单的步骤:
* 点击 “<ruby> 编辑 <rt> Edit </rt></ruby>” 菜单并选择 “<ruby> 偏好设定 <rt> Preferences </rt></ruby>”
* 切换至 “<ruby> 行为 <rt> Behavior </rt></ruby>” 标签页
* 勾选 “<ruby> 启动时还原标签 <rt> Restore tabs on startup </rt></ruby>” 选项

### 3、为文件或文件夹添加徽章
你可以把徽章看作是一个特殊标记,它可以帮助你更快地识别出特定的文件或文件夹。
另外,你也可以通过添加徽章使目录名更加直观。例如,将一个 “▶️” 徽章添加到“视频”目录上。
要添加徽章,遵循下面的步骤:
* 右键点击需要添加徽章的文件/文件夹,从上下文菜单中选择 “<ruby> 属性 <rt> Properties </rt></ruby>”
* 进入 “<ruby> 徽章 <rt> Emblem </rt></ruby>” 标签页,为选定项选择一个或多个徽章

我添加徽章后的样子就像这样:

### 4、使用突出颜色高亮文件/文件夹
>
> ? 这项功能只在 Thunar 4.18 及更高版本中可用。
>
>
>
如果仅通过添加徽章仍无法使文件/文件夹在众多文件中突显出来,你可以改变它的背景或前景颜色。
**注意:改变前景颜色只会改变选定项目的字体颜色。**
要突出高亮一个文件或文件夹,你需要按照以下步骤操作:
* 将鼠标悬停在需要高亮的项目上,右键并选择 “属性”。
* 进入 “<ruby> 高亮 <rt> Highlight </rt></ruby>” 部分,选择改变前景或背景(或两者都选,但要一次进行一项操作)。
* 接着,选择你想要的颜色,它会展示结果。如果满意,点击 “<ruby> 应用 <rt> Apply </rt></ruby>” 按钮,不满意就通过 “<ruby> 重置 <rt> Reset </rt></ruby>” 按钮恢复默认设置。

### 5、探索 Thunar 插件
不同于那些知名的文件管理器,Thunar 的插件相对较少,因为很多操作都可以通过自定义动作实现,其他的功能如内置一样与生俱来。
但是,也有一些实用的插件供你选择。
如要了解更多,你可以 [访问官方网站](https://goodies.xfce.org/projects/thunar-plugins/start?ref=itsfoss.com) 查看详情。
在这里,我将向你展示如何添加一个归档插件,让你可直接在右键菜单中创建和解压归档文件:

在 Ubuntu 中安装 Thunar 归档插件,可以使用以下命令:
```
sudo apt install thunar-archive-plugin
```
在 Fedora 中安装:
```
sudo dnf install thunar-archive-plugin
```
在 Arch Linux 中安装:
```
sudo pacman -S thunar-archive-plugin
```
### 6、利用双窗格特性进行文件传输
这是几乎所有的文件管理器都具备、而又被大多数人所忽视的一个重要特性。
那为什么我要将此特性列为 Thunar 的优化建议呢?答案很简单。因为 Thunar 的双窗格特性非常好用,它使得文件的复制和移动变得轻而易举。
#### 移动文件
接下来我们看一下如何将文件从一个目录动态一个目录:
* 首先,按下 `F3` 键开启双窗格模式。
* 打开两边窗格中的目录。一边导航到需要被移动的文件所在,另一边则打开目标位置。
* 接着,选中需要移动的项目。
* 移动文件很简单,只需选中它们,并拖动到另一侧窗格中(即你已打开的目标位置)。

#### 复制文件
复制文件的操作非常类似移动文件,只是在拖曳并释放文件时需要按下 `Ctrl` 键。
* 使用 `F3` 键切换到双窗格模式。
* 打开两边窗格中的源文件和目标位置。
* 选中需要复制的文件,然后按下 `Ctrl` 键,将它们拖到第二窗格中,释放鼠标后再放开 `Ctrl` 键。

如果你仔细看,会发现在移动文件时,鼠标指针呈现一个箭头 “↗”,而在复制文件时,它会显示一个加号 “➕”。
### 7、在 Thunar 中使用自定义操作(针对进阶用户)
到现在为止,Thunar 中最实用的功能无疑是你能创建属于自己的行为,比如使选定的文件变为可执行文件,以 root 用户身份打开 Thunar 等等。
因此,这也意味着这将是本教程中最详细的一节!
首先,点击 “编辑” 菜单,你会找到一个 “<ruby> 配置自定义操作 <rt> configure custom actions </rt></ruby>” 的选项,这是倒数第二个:

如你所见,所有可用的操作都在列表中显示。
要添加操作,点击加号 “➕” 按钮,你会看到多个选项:

这些选项包括:
* “<ruby> 名称 <rt> Name </rt></ruby>”:为自定义操作命名。
* “<ruby> 描述 <rt> Description </rt></ruby>”:该操作的信息说明(以帮助用户理解该操作的功能)。
* “<ruby> 子菜单 <rt> Submenu </rt></ruby>”:用于将多个操作整合到一起。
* “<ruby> 命令 <rt> Command </rt></ruby>”:关键的一步,你需要为这个操作分配一条命令使其可以工作。
如果你仔细看,你会发现还有另一个名为 “<ruby> 出现条件 <rt> Appearance Conditions </rt></ruby>” 的选项卡,在这里你可以指定在哪些文件(以及目录)类型的右键菜单中这个动作会出现。
例如,如果一个动作只应在所选文件是文本文件时才显示,那么你就需要勾选 “文本文件Text Files” 选项:

接下来,我要向你展示如何设置一个以 root 身份打开 Thunar 的自定义动作。
#### 创建自定义操作以 root 身份打开 Thunar
你一定经历过这种情况:你想操作一个文件,但是只有 root 用户能够访问。于是你打开终端,执行命令以 root 身份启动文件管理器。
但如果用这个自定义操作,只需轻点一下鼠标就可以了。
具体方法是,在 “<ruby> 基本 <rt> Basic </rt></ruby>” 选项卡的数据区域输入以下内容:
* 名称:以 root 身份打开 Thunar
* 命令:`pkexec thunar %F`
你能选择任何相关的图标,我在这里选择了一个简单的终端图标。
接着,在 “出现条件” 区域,输入如下内容:
* 如果所选内容包含:<ruby> 目录 <rt> Directories </rt></ruby>
完成后,数据区域会如下所示:

看一下最后的结果:

看起来很酷,对吧?
以下是一些其他可能有用的自定义操作:
#### 创建创建符号链接的自定义操作
[创建符号链接](https://linuxhandbook.com/symbolic-link-linux/?ref=itsfoss.com) 是访问深度嵌套在文件系统中的文件的一种简便手段。它同时也被用来重定向到特定的包的路径。
要创建一个创建符号链接的自定义操作,你可以输入以下指令:
* 名称:创建链接
* 描述:创建一个符号链接
* 命令:`ln -s %f 'Link to %n'`
* 若选择包含:框全部都要勾选

#### 直接查找文件
点击一个目录,选择搜索,输入你想要查找的内容。
这是在目录内搜索文件最为手边的方式了。
首先,在你的系统中安装 `catfish`,如果你是 Ubuntu/Debian 系的用户,可以使用如下命令:
```
sudo apt install catfish
```
然后,创建一个自定义操作,输入以下信息:
* 名称:在该目录中查找文件
* 描述:在选中的目录中搜索文件
* 命令:`catfish %f`
* 若选择包含:仅勾选 “目录”。

#### 一键安装多个图像转换的自定义操作
在我写作的过程中,我找到了一款令人惊艳的包,着包中包含了以下几种自定义操作:
* 旋转图像
* 缩小图像
* 图像灰度处理
* 将图像转换为 PDF
* 将图像转换为任意格式
* [合并 PDF 文件](https://itsfoss.com/merge-pdf-linux/)
* 缩小 PDF 文件的大小
* 创建符号链接
* 显示校验和
* 往图像的透明区域填充颜色
* 加密/解密文件
首先,在你的系统中安装以下软件包:
```
sudo apt install make imagemagick gnupg2 m4 build-essential pandoc gettext python3-lxml ubuntu-dev-tools git
```
接着,克隆这个库并切换到这个新的目录:
```
git clone https://gitlab.com/nobodyinperson/thunar-custom-actions.git && cd thunar-custom-actions
```
然后,运行以下命令来确认所有的依赖项都已就绪:
```
./configure --prefix=$HOME/.local PASSWDFILE=/etc/passwd
```
如果提示你缺少某个包,那你可能需要手动安装它(但大部分情况下不需要)。
接着,运行以下命令从源代码建立这个包:
```
make
```
然后,运行以下命令安装这个包:
```
sudo make install
```
要将更改合并进 Thunar,使用以下命令:
```
uca-apply update
```
完成以上操作后,**记得登出并重新登录以使改变生效。**
这样你就会看到系统中增加了多种新的自定义操作:

如果你觉得这些太多了,你也可以通过选择它并点击减号按钮来去除不需要的操作。
只要你有足够的想象力,你就可以创造出无数的自定义操作。欢迎你分享你最喜欢的(和命令),这样新用户也能受益。
### 进一步自定义 Xfce
有人可能觉得 Xfce 显示得有些传统。实际上,你完全可以为它带来现代化的感受。
>
> **[使 Xfce 看起来现代化和漂亮的四种方法](https://itsfoss.com/customize-xfce/)**
>
>
>
进行主题设计是最主要的自定义方式。这里有一些 [Xfce 主题建议](https://itsfoss.com/best-xfce-themes/) 你可以参考。
>
> **[使 Xfce 看起来现代化和漂亮的 11 个主题](https://itsfoss.com/best-xfce-themes/)**
>
>
>
我希望你觉得这些关于 Thunar 的改进很有用。
你能在 Linux 桌面上尝试到更多的乐趣,不妨开始你的探索之旅吧 ?
*(题图:MJ/0bd19051-a95f-41f8-839a-47c1ce84ac83)*
---
via: <https://itsfoss.com/thunar-tweaks/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Thunar is the default file manager in the Xfce desktop environment, which is a balanced blend of lightweight and good user experience.
But like any other unexplored tool, you won't find much until you scratch the surface and that's what I did with Thunar.
And behind my bold statement, a variety of features will surely enhance your Linux experience.
In this tutorial, I will share the following tricks that you can use to levitate the Thunar experience:
- General shortcuts for Thunar
- Add Thunar plugins
- Open from where you left off last time
- Emblem for better recognition
- Highlight file/folder
- Copy or move files easily in dual pane mode
- Custom actions
So let's start with the first one.
## 1. Use keyboard shortcuts
It is a no-brainer that by using keyboard shortcuts, you can increase your productivity.
So here are some easy shortcuts that you can use in Thunar to reduce the usage of the mouse:
Shortcut | Description |
---|---|
`Ctrl + T` |
New tab |
`Ctrl + N` |
New window |
`F3` |
Switch to dual pane mode |
`Alt + ⬅` |
Back |
`Alt + ➡` |
Forward |
`Ctrl + F` |
Search for files |
`Ctrl + S` |
Select a file by pattern |
`Ctrl + H` |
Show hidden files |
`Ctrl + E` |
Enable tree view in the side pane |
`Alt + ⬆` |
Open parent directory |
`Alt + home` |
Go to the home directory |
While it looks like nothing, trust me, implement these shortcuts to your daily workflow and you'd want more!
## 2. Open Thunar from where you left off
Opening your file manager with the same tabs opened that you closed last time is a big feature and should be celebrated.
I'm one of those guys who loves to explore Linux by diving deep into the Linux directories. And to open the Thunar from where I left off is a great feature.
To enable this, follow three simple steps:
- Click on the
`Edit`
menu and choose`Preferences`
- Go to the
`Behavior`
tab - And check the
`Restore tabs on startup`
option
## 3. Add emblem to file or folder
Think of emblems as a special sticker for that file or folder that you want to identify as soon as possible.
Also, you can add emblems to make directory names more relatable. For example, you can add an emblem of ▶️ to the Videos directory.
To add an emblem, you have to follow the given steps:
- Right-click on the file/folder and select
`Properties`
from the context menu - Go to the
`Emblem`
tab and choose one or more emblems for the selected item
Mine looks like this:
## 4. Highlight file/folder with an accent color
If adding emblems is not enough to stand that file/folder among others, then you can change its background color or even foreground color.
**Note: Changing the foreground color will only affect the font color of the selected item.**
To highlight a file or folder, you need to follow the given simple steps:
- Hover to the item that needs to be highlighted, right click and select
`Preferences`
. - Go to
`Highlight`
and choose between foreground or background (or even both but one at a time). - Then, select the color and it will show how will it look. If satisfied, hit the
`Apply`
button and if not, then reset to default by pressing the`Reset`
button.
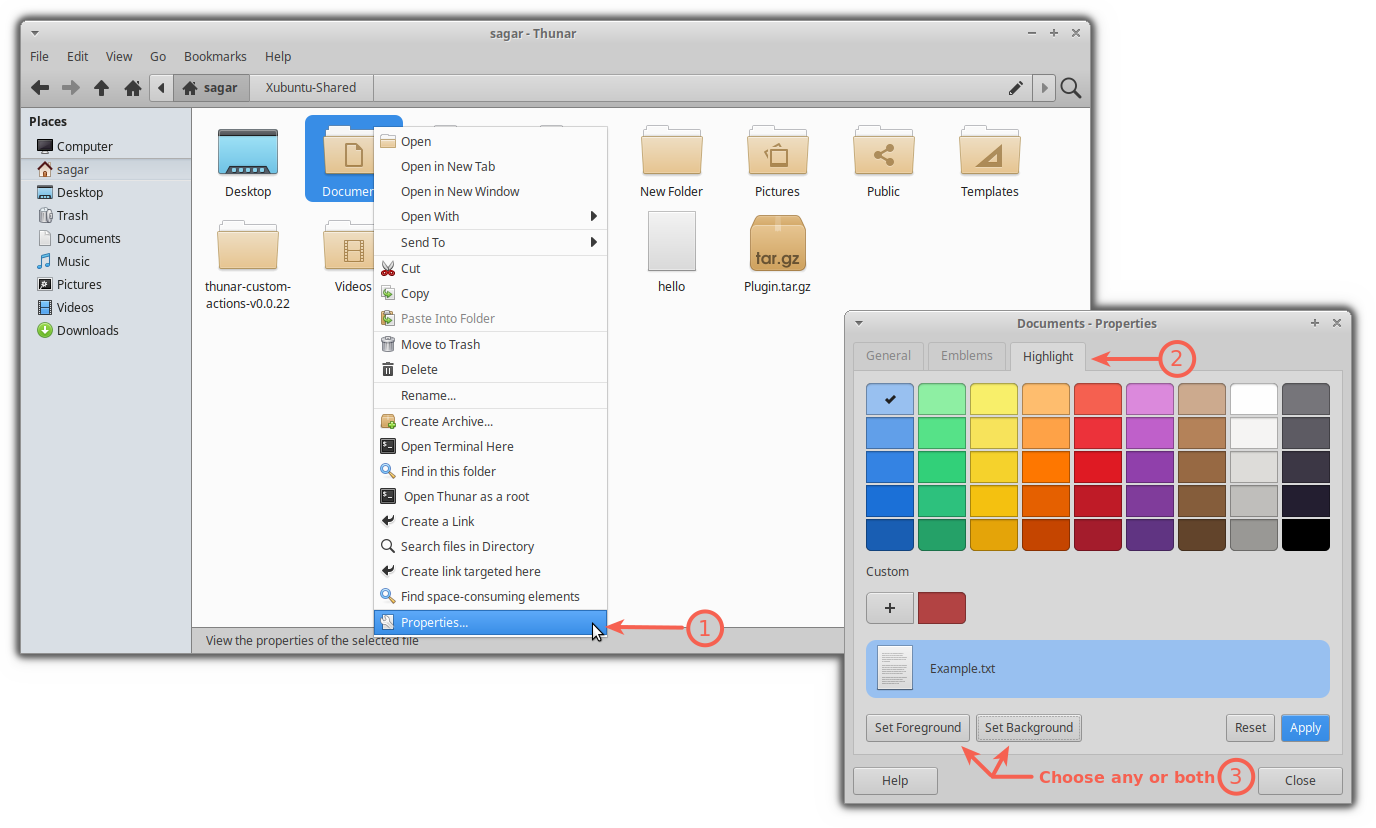
## 5. Explore Thunar plugins
Unlike famous file managers, Thunar has comparatively fewer plugins as everything can be done through custom actions and other features are inbuilt. (cough fanboy cough).
But some useful plugins are there.
To learn more about them, you can [head over to their official site.](https://goodies.xfce.org/projects/thunar-plugins/start)
And in this section, I will show you how you can add an archive plugin by which you can create and extract archives from the context menu only:
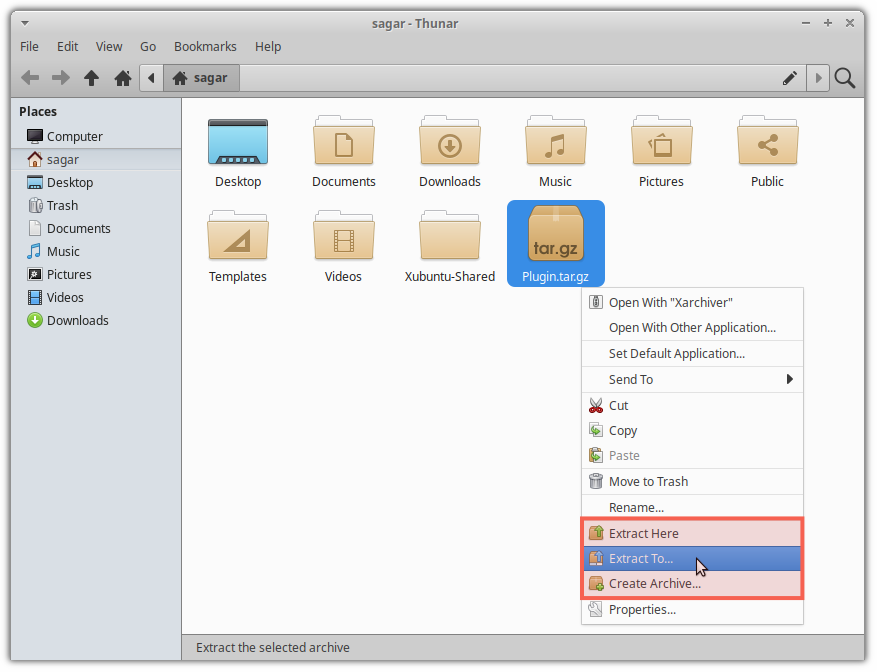
To install the Thunar archive plugin in Ubuntu, use the following command:
`sudo apt install thunar-archive-plugin`
For Fedora:
`sudo dnf install thunar-archive-plugin`
For Arch:
`sudo pacman -S thunar-archive-plugin`
## 6. Use dual pane feature for moving and copying files
This is one of those generous tips available to almost every file manager, but most people are unaware of that.
Then why am I adding this as a tip for Thunar? The answer is simple. The dual-pane feature of Thunar is outstanding and copying/moving files is the easiest task.
### Moving files
Let's have a look at how you can move files from one directory to another:
- First, press the
`F3`
to enable dual pane mode. - Navigate to directories on both sides. On one, navigate to the file that needs to be copied, and on the other side, navigate to the destination where it needs to be copied.
- Now, select the items that need to be moved.
- To move a file, simply select the items and drag them to the next pane (where you've opened the directory to paste the file).
Moving files
### Copying files
Copying is almost the same as moving. But here, you need to press `Ctrl`
key while dragging and dropping the file.
- Switch to dual pane mode using
`F3`
. - Navigate to the target and destination on both sides.
- Now, select the files, press the
`Ctrl`
key, drag them to the 2nd pan, release the mouse key first, and then Ctrl.
Copying files
If you notice carefully, the mouse cursor indicated an arrow ↗ whereas when you copy the file, it shows a plus ➕.
## 7. Use custom actions in Thunar (for advanced users)
By far, this is the most useful feature of Thunar where you can create your own action like creating a selected file executable, opening Thunar as a root user, and a lot more.
This means this will be the longest section of this tutorial!
First, click on the `Edit`
menu and you will find the second last option to configure custom actions:
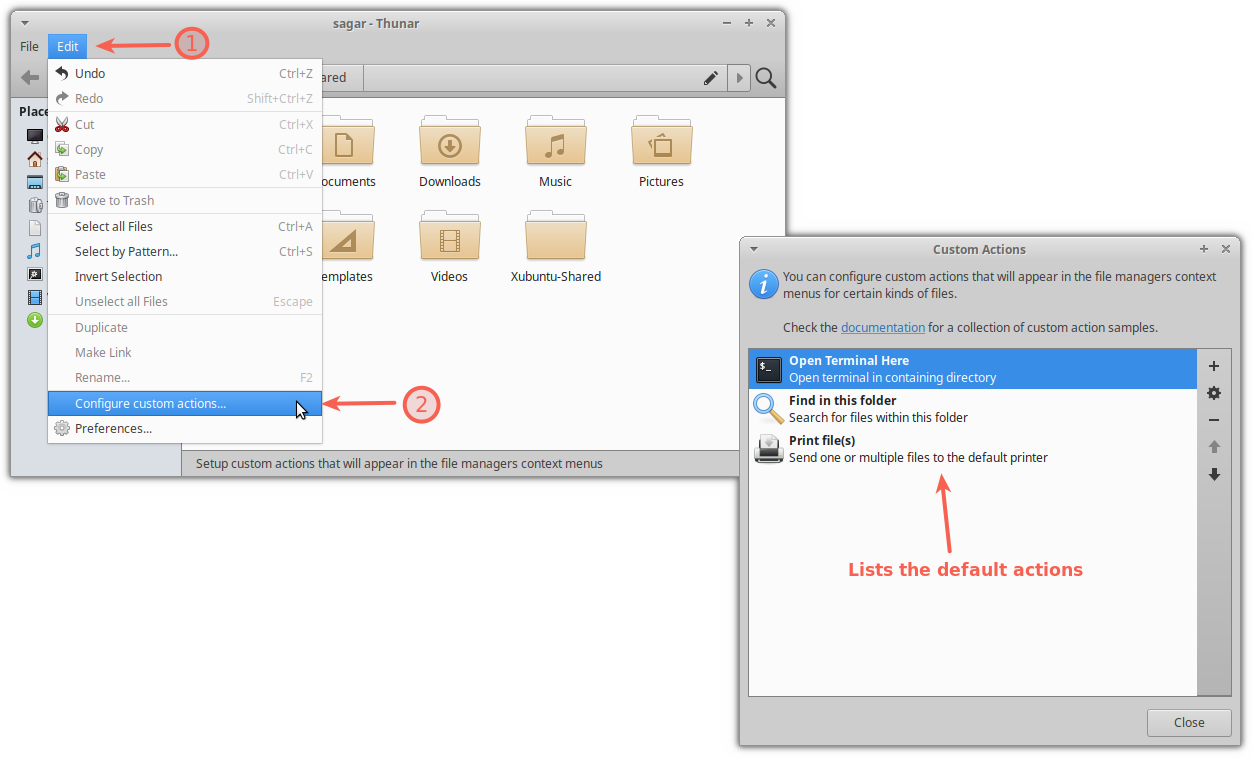
And as you can see, it listed all the actions available.
To add the action, click on the plus ➕ button and you'll see multiple options:
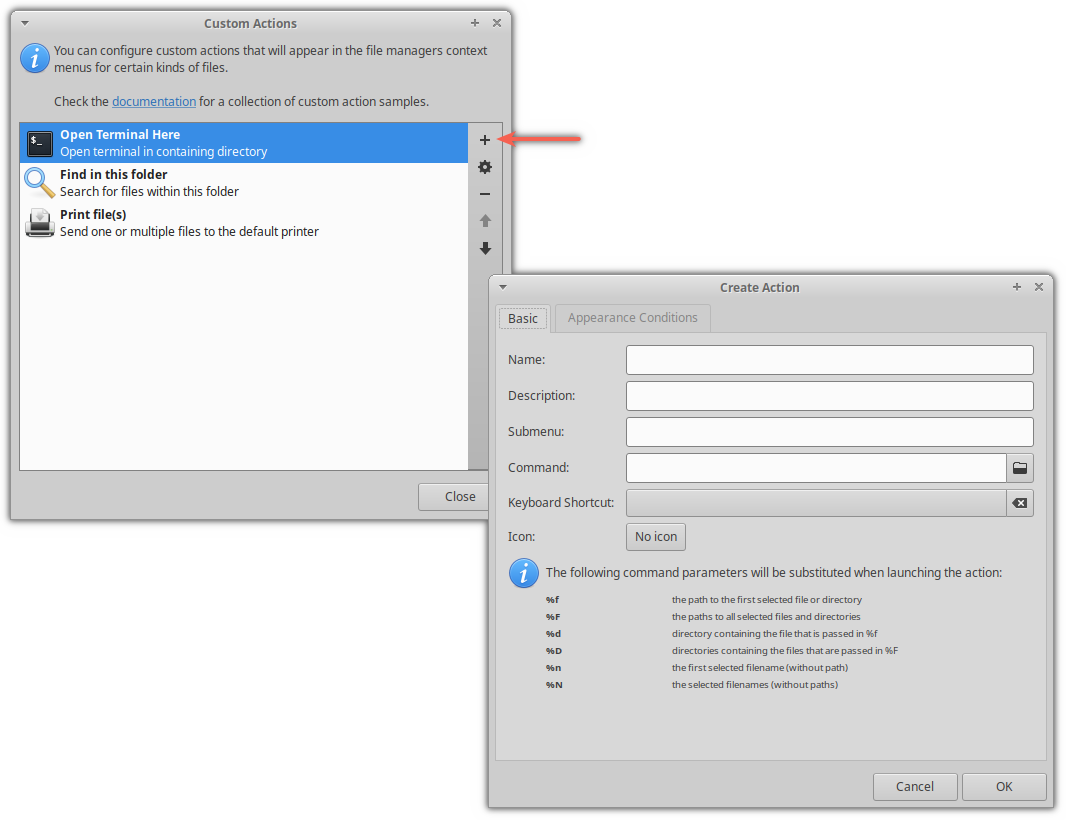
Here,
`Name`
: Name your custom action.`Description`
: Info on what this action is all about (for the user's understanding).`Submenu`
: To group multiple actions into one.`Command`
: The key part where you'll assign a command to make this action work.
But if you notice carefully, there's another tab named `Appearance Conditions`
where you specify what types of files (and directories) this action should appear in the context menu.
For example, if the action should only be visible when the selected file is a text file, then you tick mark the `Text Files`
box:
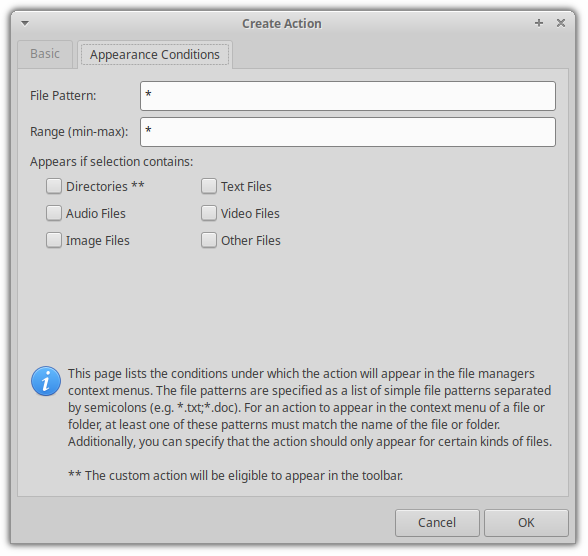
Now, let me show you the custom action for opening Thunar as a root.
### Creating custom action to open Thunar as a root
You must have encountered a situation where you wanted to work with a file but only the root user can access it so you open the terminal and then execute the command to start the file manager as a root.
But using this action, it can be done with a single click.
To do so, enter the following in the data fields of the `Basic`
tab:
- Name: Open Thunar as a root
- Command:
`pkexec thunar %F`
You can select any relatable icon. I'm going with a simple terminal icon here.
Now, click on the `Appearance Conditions`
section and enter the following:
- Appears if selection contains: Directories
In the end, data fields should look like this:
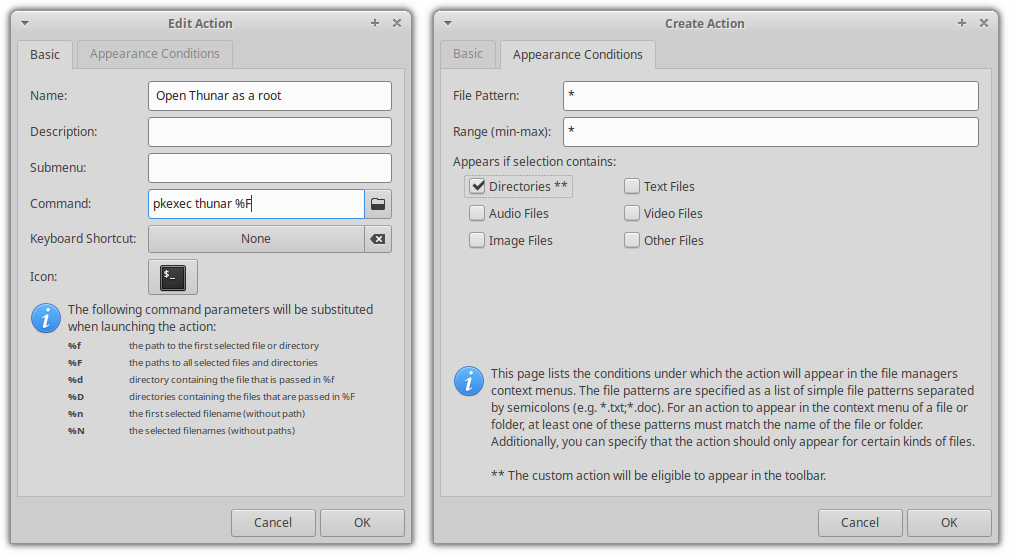
And here's the end result:
Opening Thunar as a root
Pretty cool. Right?
Here are some more that can be useful:
### Custom action for creating a symlink
[Creating symbolic links](https://linuxhandbook.com/symbolic-link-linux/) is one of the easiest ways to access files that are located deep inside the filesystem. Sure, it is also used to redirect paths to packages.
And to create a custom action to create a symlink, enter the following:
- Name: Create a Link
- Description: Create a symlink
- Command:
`ln -s %f 'Link to %n'`
- Appears if selection contains: check all the boxes.
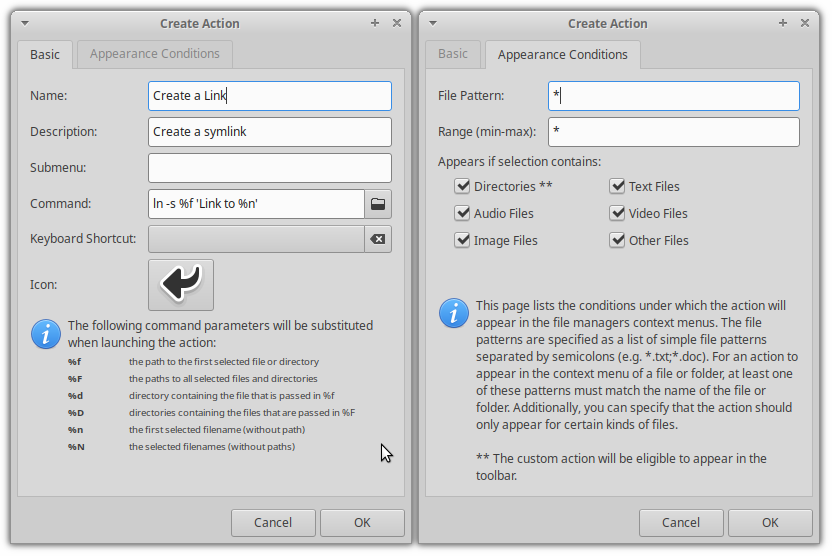
### Search files directly
Click on a directory, select search, and type whatever you want to search.
The most convenient way to search files within the directory.
First, install catfish in your system and if you're using Ubuntu/Debian base, then the following command will get the job done:
`sudo apt install catfish`
Now, create a custom action and add the following:
- Name: Search files in the directory
- Description: Look for files in the selected directory
- Command:
`catfish %f`
- Appears if selection contains: Check
`Directories`
only
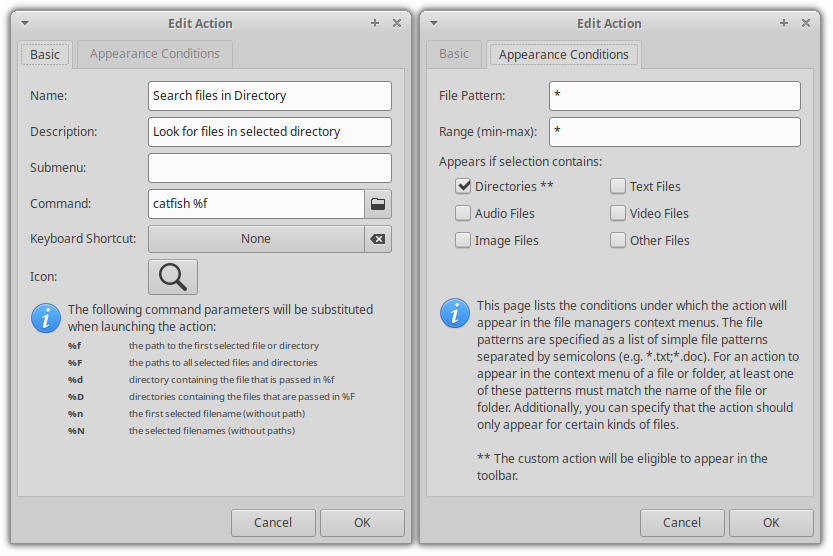
### Install multiple image conversion actions at once
While writing, I found an amazing package that includes custom actions for the following:
- Rotate images
- Shrink images
- Grayscale images
- Convert images to PDF
- Convert images to arbitrary formats
[Merge PDF files](https://itsfoss.com/merge-pdf-linux/)- Shrink PDF files in size
- Creating symbolic links
- Showing checksums
- Fill color to the transparent area of an image
- Encrypt/decrypt files
First, install the following packages to your system:
`sudo apt install make imagemagick gnupg2 m4 build-essential pandoc gettext python3-lxml ubuntu-dev-tools git`
Now, clone the repository and change your directory to it:
`git clone https://gitlab.com/nobodyinperson/thunar-custom-actions.git && cd thunar-custom-actions`
Next, check the dependency satisfaction using the following:
`./configure --prefix=$HOME/.local PASSWDFILE=/etc/passwd`
If it shows any missing package, then you may need to install that package manually (in most cases, it won't).
Then, build the package from the source:
`make`
After that, install the package:
`sudo make install`
To merge changes to Thunar, use the following:
`uca-apply update`
Now, **log out and log back in to take effect from the changes you've made.**
Once you do that, you'd see various custom actions installed in the system:
But if that's too much for your use case, then you can also remove any unnecessary action by selecting it and hitting the minus button:
And with your imagination, you can create endless variations of custom actions. Please share your favorites (with commands) so new users can benefit from it.
## More on Xfce, more on customization
Some people think Xfce has a retro feel. You can surely give it a modern touch.
[4 Ways You Can Make Xfce Look Modern and BeautifulXfce is a great lightweight desktop environment but it looks old. Let’s see how you can customize Xfce to give it a modern and beautiful look.](https://itsfoss.com/customize-xfce/)

Theming is the predominant method of customization. Here are [some Xfce theme suggestions](https://itsfoss.com/best-xfce-themes/).
[11 Themes to Make Xfce Look Modern and BeautifulXfce desktop looks outdated? No worries. Here are some of the best themes to make your Xfce desktop look beautiful.](https://itsfoss.com/best-xfce-themes/)

I hope you liked the Thunar tweaks. We have similar articles for GNOME's Nautilus and Cinnamon's Nemo file managers.
[13 Ways to Tweak Nautilus File Manager in LinuxNautilus, aka GNOME Files, is a good file manager with plenty of features. You can further enhance your experience by using these extensions, tweaks and tips.](https://itsfoss.com/nautilus-tips-tweaks/)

[15 Tweaks to Make Nemo File Manager Even BetterNemo is a good file manager with plenty of features. You can further enhance your experience by using these extensions, tweaks and tips.](https://itsfoss.com/nemo-tweaks/)

Enjoy exploring new things in your Linux desktop with It's FOSS :) |
16,132 | 如何解决服务器存储 inode 耗尽的问题 | http://www.yanjun.pro/?p=128 | 2023-08-27T11:34:00 | [
"分区",
"inode"
] | /article-16132-1.html | 
今天群里一朋友遇到这样一个问题,明明硬盘只用了 30% 左右的空间,但是却无法写入文件。使用 `df -iT` 命令查看文件系统使用情况时,发现根目录的 inode 使用率竟然是 100%。后来通过聊天得知,原来他的服务器主要用于存储 1KB 左右的小文件,这一下就破案了。
inode 主要用来记录文件的属性,及此文件的数据所在的块编号。每一个文件会占用一个 inode,因此如果都是小文件的话,那么就会出现 inode 已经耗尽,但文件系统还有很大的空闲空间,从而无法写入新文件。
### 如何获得更多的 inode
其实在创建 ext4 文件系统时,我们可以使用 `-T small` 参数来获得更多的 inode,从而优化对小文件的存储。接下来我们通过一个示例来看看效果。
这是两块相同大小的硬盘:
```
root@debian:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sdb 8:16 0 1G 0 disk
└─sdb1 8:17 0 1023M 0 part
sdc 8:32 0 1G 0 disk
└─sdc1 8:33 0 1023M 0 part
```
首先使用默认参数给 `/dev/sdb1` 创建文件系统:
```
root@debian:~# /sbin/mkfs.ext4 /dev/sdb1
mke2fs 1.47.0 (5-Feb-2023)
Creating filesystem with 261888 4k blocks and 65536 inodes
Filesystem UUID: 8935c902-df71-4808-b547-c85b6fd37a46
Superblock backups stored on blocks:
32768, 98304, 163840, 229376
Allocating group tables: done
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
```
从输出中可见,该文件系统有 261888 个 4KB 大小的块和 65536 个 inode。
然后使用 `-T` 参数对 `/dev/sdc1` 创建文件系统:
```
root@debian:~# /sbin/mkfs.ext4 -T small /dev/sdc1
mke2fs 1.47.0 (5-Feb-2023)
Creating filesystem with 1047552 1k blocks and 262144 inodes
Filesystem UUID: f521096d-a5a1-41c9-bbf7-e6102e74e87a
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729, 204801, 221185, 401409, 663553,
1024001
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
```
从输出中可见,该文件系统有 1047552 个 1KB 大小的块和 262144 个 inode。
也可以通过以下方式对比两个文件系统的 inode 数量:
```
root@debian:~# mkdir default small
root@debian:~# mount /dev/sdb1 default/
root@debian:~# mount /dev/sdc1 small/
root@debian:~# df -iT
Filesystem Type Inodes IUsed IFree IUse% Mounted on
/dev/sdb1 ext4 65536 11 65525 1% /root/default
/dev/sdc1 ext4 262144 11 262133 1% /root/small
```
从以上示例中我们可以看出,在使用 `-T small` 参数后,inode 数量多了近 20 万个!
**注意:** 这样做也是有代价的。在使用默认参数创建 ext4 文件系统时,默认数据块大小为 4KB,而使用 `-T small` 参数后,数据块大小为 1KB。这就意味着我们存储一个同样大小的文件,使用 `-T small` 参数创建的文件系统存储该数据时,占用的数据块更多,数据更分散,如果文件较大,会直接影响文件的读取速度
>
> `mke2fs`(`mkfs.ext4`)的 `-T` 参数指定了如何使用该文件系统,以便 `mke2fs` 可以为该用途选择最佳的文件系统参数,其支持的使用类型在配置文件 `/etc/mke2fs.conf` 中定义,可以使用逗号分隔指定一个或多个使用类型
>
>
>
### inode 不足的解决方法
当你已有的文件系统上出现 inode 不足的问题时,除了备份数据、重建分区并恢复分区数据外,还有两种临时解决方案:
1、删除文件大小为 0 的空文件,可以使用如下命令查找:
```
find PATH -name "*" -type f -size 0c
```
**注意:** 使用 `-size` 参数时,不要用 `-size 1k`,这个表示占用空间为 1KB,而不是文件大小为 1KB,应该使用 `-size 1024c` 才表示文件大小为 1KB。
2、可以定期对历史小文件进行打包、归档,以减少文件数量。
---
作者简介:一个喜欢瞎折腾的 IT 技术人员,懂得不多,但是喜欢和有共同兴趣爱好的朋友交流、学习
*(题图:MJ/9a66155a-772e-41f1-b29d-c3d4161f7853)*
---
via: <http://www.yanjun.pro/?p=128> 作者:[老颜随笔](http://www.yanjun.pro) 编辑:[wxy](https://github.com/wxy)
本文由贡献者投稿至 [Linux 中国公开投稿计划](https://github.com/LCTT/Articles/),采用 [CC-BY-SA 协议](https://creativecommons.org/licenses/by-sa/4.0/deed.zh) 发布,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPConnectionPool(host='www.yanjun.pro', port=80): Max retries exceeded with url: /?p=128 (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x7b83275ce530>, 'Connection to www.yanjun.pro timed out. (connect timeout=10)')) | null |
16,133 | 如何在 Linux 中注释 PDF | https://itsfoss.com/annotate-pdf-linux/ | 2023-08-27T14:10:27 | [
"PDF"
] | https://linux.cn/article-16133-1.html | 
>
> 你不需要专门的 PDF 编辑器来添加注释和高亮文本。下面介绍如何在 Linux 中使用 GNOME 的文档查看器来注释 PDF。
>
>
>
阅读一些 PDF 格式的有趣内容,并觉得需要添加评论或高亮显示某些文本?也许你在 PDF 文档上留一些反馈?
[Linux 用户可以使用多种 PDF 编辑器](https://itsfoss.com/pdf-editors-linux/)。但你不需要专门的 PDF 编辑器来完成这个简单的任务。
大多数 PDF 阅读器都具有内置注释功能,你可以使用它来快速轻松地高亮显示文本并添加注释。
我最近在审阅 O'Reilly 即将出版的第四版 [《Linux Pocket Guide》一书](https://www.oreilly.com/library/view/linux-pocket-guide/9780596806347/?ref=itsfoss.com)时“发现”了它。出版商请求对 PDF 文件本身提出建议。
让我分享一下如何在 Linux 中使用 Evince(GNOME 中的默认 PDF 阅读器)对 PDF 进行注释。使用 Okular(KDE 中默认的 PDF 阅读器)也可以实现同样的效果。
大多数 Linux 发行版都应该附带上述工具之一。如果没有,你可以轻松安装它们。我不会介绍安装过程。请在你的发行版的软件管理器中查找它们。
### 使用 Evince 文档查看器注释 PDF
使用 Evince(在 GNOME 中也称为“<ruby> 文档查看器 <rt> Document Viewer </rt></ruby>”)打开所需的 PDF 文件。
你将在文档查看器的左上角看到一个“编辑”选项。点击它会出现以下两个选项:
* 备注文本(用于添加评论)
* 高亮显示文本(用于高亮显示选定的文本)

让我详细介绍这是如何工作的。
#### 在 PDF 中添加注释
要添加评论,单击 “<ruby> 注释文本 <rt> Note text </rt></ruby>” 选项。
你会注意到光标变成了 “+” 号。你可以单击文档中的任意位置,它会立即添加注释图标并打开另一个窗口以添加注释。

我建议单击该行的末尾,以便注释图标位于空白区域,并且不会遮挡文件的实际文本。
添加所需注释后,你可以 **单击注释区域的 “X” 按钮来关闭** 注释文本窗口。
>
> ? 你可以通过在屏幕上拖动注释图标来移动注释图标。
>
>
>
#### 在 PDF 中高亮显示文本
同样,你可以选择 “<ruby> 高亮显示文本 <rt> Highlight text </rt></ruby>” 选项来高亮显示 PDF 文件中的特定文本。
之后,只需选择要高亮显示的文本即可。当你开始移动光标,它就会开始高亮显示。

>
> ? 你还可以在高亮显示的文本上添加注释,以提供有关高亮显示的一些上下文。要添加文本,请单击高亮显示的文本(现在它可点击了)。
>
>
>
#### 保存带注释的文件
你可能已在 PDF 上添加注释,但更改尚未保存。
保存更改很简单。按 `Ctrl+S` 键,你可以选择保存文件的位置。
你可以覆盖现有 PDF 文件或将其另存为新文件。

>
> ? 注释、评论和高亮被附加到 PDF 文件中,即使你使用其他可以读取注释的工具打开 PDF 文件,它们也应该可以看到。
>
>
>
#### 阅读注释
要阅读文本注释或评论,只需将鼠标悬停在注释图标或高亮显示的文本上即可。它将立即显示注释。

不要单击图标来阅读文本。单击将打开它进行编辑。
#### 编辑现有注释
假设你注意到需要向现有笔记添加更多详细信息。你所要做的就是单击“注释”图标。
它将打开添加的文本。你可以阅读它,如果你愿意,也可以编辑它。对于高亮显示的文本部分中的注释也是如此。
但是,编辑高亮显示的文本时它不是很完善。如果你认为必须高亮显示现有文本周围的更多文本,那么它会起作用。但如果你想缩短高亮显示的文本,那就不行了。
为此,你必须删除高亮显示并再次添加。
#### 删除现有注释
删除注释非常简单,只需右键单击注释并选择 “<ruby> 删除注释 <rt> Remove Annotation </rt></ruby>” 选项即可。

这对于高亮显示的文本也同样有效。
#### 修改注释的外观
不喜欢默认的黄色或注释图标?这一切都是可以改变的。
右键单击现有注释并选择 “<ruby> 注释属性 <rt> Annotation Properties... </rt></ruby>” 选项。

你可以更改评论的作者、注释的颜色和不透明度。你还可以更改注释的图标和高亮显示的标记类型(删除线、下划线等)。

这仅适用于现有注释。我找不到一种方法来更改所有未来注释的默认属性。
### 更多 PDF 编辑选项
如果你需要的不仅仅是简单的文本注释和高亮显示,可以使用专门的 PDF 编辑器。
>
> **[11 最好的 Linux 上的 PDF 编辑器](https://itsfoss.com/pdf-editors-linux/)**
>
>
>
这些工具可能允许你重新排列或合并 PDF 文件。
>
> **[如何在 Linux 上合并 PDF 文件](https://itsfoss.com/merge-pdf-linux/)**
>
>
>
如果需要,你还可以 [压缩 PDF 文件](https://itsfoss.com/compress-pdf-linux/)。
>
> **[如何在 Linux 上压缩 PDF 文件](https://itsfoss.com/compress-pdf-linux/)**
>
>
>
PDF 编辑永无止境。我希望你喜欢这篇有关 Linux 中 PDF 注释的初学者技巧。
KDE 的 Okular 还提供 PDF 注释选项。也许我可以写一篇关于 Okul 的类似文章。
请在评论栏留下你的反馈。
*(题图:MJ/a5318540-0b82-4ef6-a0bb-532505a17458)*
---
via: <https://itsfoss.com/annotate-pdf-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Reading something interesting in PDF format and feel the need of adding a comment or highlight certain text? Perhaps you want to provide feedback on the PDF document?
There are [several PDF editors available for Linux users](https://itsfoss.com/pdf-editors-linux/). But you don't need a dedicated PDF editor just for this simple task.
Most PDF readers have built-in annotation features and you can use it to quickly and easily highlight text and add comments.
I recently 'discovered' it when I was reviewing the upcoming 4th edition of the [Linux Pocket Guide book by O'Reilly](https://www.oreilly.com/library/view/linux-pocket-guide/9780596806347/). The publisher requested suggestions on the PDF file itself.
Let me share how you can annotate PDFs in Linux using Evince (the default PDF reader in GNOME). The same can be achieved with Okular (the default PDF reader in KDE) too.
Most Linux distributions should come with either of the above tools. If not, you can easily install them. I am not going into the installation process. Please look for them in your distribution's software manager.
## Annotating PDFs with Evince Document Viewer
Open the desired PDF file with Evince (also known as Document Viewer in GNOME).
You'll see an edit option in the top left side of the Document Viewer application. Click on it and the following two options will appear:
- Note text (for adding comments)
- Highlight text (for highlighting selected text)
Let me share their workings in detail.
### Adding comments in PDF
To add a comment, **click on Note text** option.
You'll notice that the cursor gets changed into a **+** sign. You can click anywhere in the document and it will immediately add a note icon and open another window for adding your notes.
I suggest clicking at the end of the line so that the note icon is on the white space and doesn't obstruct the actual text of the file.
Once you have added the desired note, you can **click the x button on the note field to close** the note text window.
### Highlight text in PDF
Similarly, you can choose the Highlight text option to highlight specific text in the PDF file.
After that, just select the text you want to highlight. It will start highlighting as soon as you start moving the cursor.
### Saving the annotated file
You might have added the note on the PDF but the changes are not saved yet.
Saving the change is simple. Press the `Ctrl+S`
keys and it will give you the option of where you want to save the file.
You can overwrite the existing PDF file or save it as a new one.
### Reading the annotations
To read a text note or comment, just hover over the note icon or highlighted text. It will show the notes immediately.
Don't click the icons to read the text. Clicking will open it for editing.
### Edit an existing annotation
Let's say you noticed that you need to add more details to an existing note. All you have to do is to click the Note icon.
It will open the added text. You can read it and you can also edit it if you like. The same works for the notes in the highlighted text section.
However, it won't work completely for editing the highlighted text. It will work if you think you have to highlight more text around an existing one. But if you want to shorten the highlighted text, it won't work.
For that, you have to delete the highlight and add it again.
### Delete an existing annotation
Deleting annotations is as simple as right-clicking on the annotation and selecting the 'Remove Annotation' option.
The same is valid for highlighted text too.
### Modifying the look and feel of the annotations
Don't like the default yellow color or the notes icon? All this can be changed.
Right-click on an existing annotation and select the 'Annotation Properties...' option.
You can change the author of the comment, color and opacity of the annotation. You can also change the icons for the notes and markup type for highlights (strikeout, underline etc).
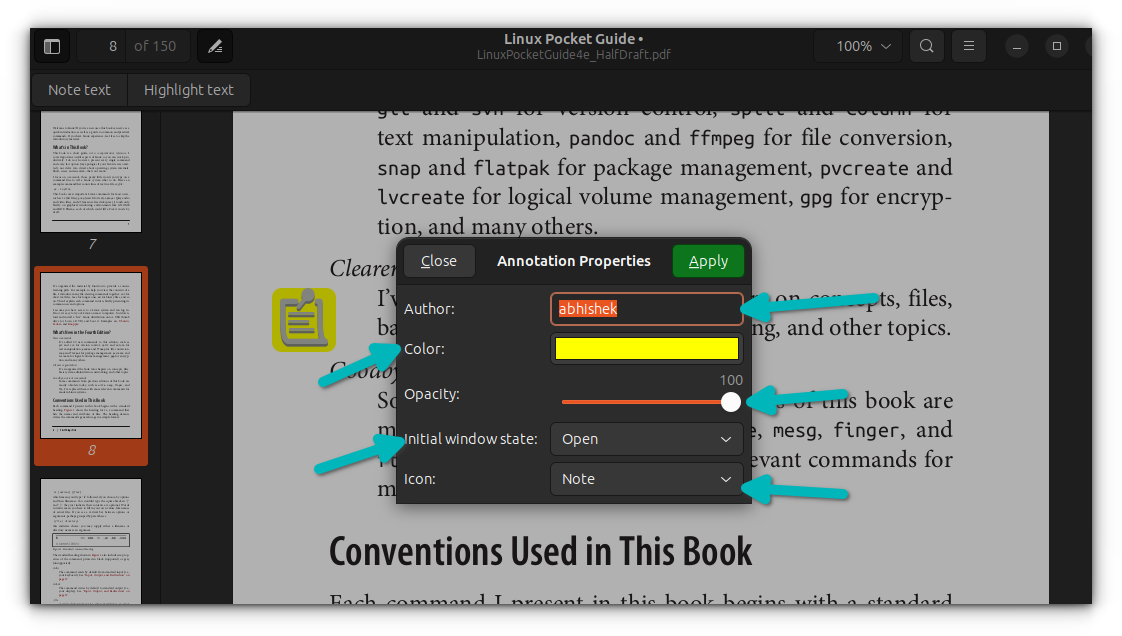
This is for existing annotations only. I could not find a way to change the properties by default for all future annotations.
## More PDF edition options
Dedicated PDF editors are available if you need more than simple text notes and highlighting.
[11 Best Linux PDF Editors You Can Use in 2023Looking for the best PDF editing options? You should find some awesome options here!](https://itsfoss.com/pdf-editors-linux/)

These tools may allow you to rearrange or merge PDF files.
[How to Merge PDF Files in LinuxGot several PDFs on the same subject and now you want to combine them into a single PDF? Or perhaps you need to upload a single file consisting of different files? Many government and academic portals require that. As a Linux user, if you are in a situation where you](https://itsfoss.com/merge-pdf-linux/)

You can also [compress the PDF files](https://itsfoss.com/compress-pdf-linux/) if you want.
[How to Compress PDF in Linux [GUI & Terminal]Brief: Learn how to reduce the size of a PDF file in Linux. Both command line and GUI methods have been discussed. I was filling some application form and it asked to upload the necessary documents in PDF format. Not a big issue. I gathered all the scanned images and](https://itsfoss.com/compress-pdf-linux/)

There is no end to PDF editing. I hope you liked this beginner's tip on PDF annotation in Linux.
KDE's Okular also provides PDF annotation options. Perhaps I could do a similar article on Okular some other day.
Please provide your feedback in the comment section. |
16,135 | Kali Linux 2023.3 版本:技术革新与新工具的全新结合 | https://news.itsfoss.com/kali-linux-2023-3-release/ | 2023-08-28T11:21:00 | [
"Kali Linux"
] | https://linux.cn/article-16135-1.html | 
>
> 最新发行的 Kali Linux 版本,注重于底层技术更迭和部分全新工具的推出。
>
>
>
作为全球渗透测试人员的优选,Kali Linux 作为 [注重于渗透测试的](https://itsfoss.com/linux-hacking-penetration-testing/) 发行版,为各种使用情景提供了丰富的工具库。
就在 [几个月之前](https://news.itsfoss.com/kali-linux-2023-2-release/),我们介绍过 Kali Linux 2023.2 版本,该版本中包含一系列显著改进。
现如今,我们迎来了 **Kali Linux 2023.3** 的更新发布,这一版本在更大程度上 **关注了后端技术**。
让我们详细探索此次更新中的新亮点。
? Kali Linux 2023.3:有哪些新鲜事?
---------------------------

借助 [Linux 内核 6.3](https://news.itsfoss.com/linux-kernel-6-3/),Kali Linux 2023.3 版本作为一次高度专注的发布,聚焦于几项关键更新。主要亮点包括:
* 全新的打包工具
* 内部基础设施优化
* 新增加网络工具
### 全新的打包工具
Kali Linux 已经添加了新功能、各项生活质量改良以及新脚本,全面扩充了他们开放的 [自制脚本库](https://gitlab.com/kalilinux/tools/packaging)。
打包工具中包含:
* [Britney2](http://repo.kali.org/britney)
* [Build-Logs](http://repo.kali.org/build-logs/)
* [Package Tracker](https://pkg.kali.org/)
* [AutoPkgTest](https://autopkgtest.kali.org/)
* 以及其他工具。
### 内部基础设施优化
得益于最近发布的 Debian 12,Kali Linux 的开发者得以全面改造、重新设计自己的基础设施。
这是一项宏大的工程,通过采用单一的软件处理 Kali Linux 的重要组成部分,**使得他们得以简化自己的软件栈**。
因此,**以 Debian 12 为基础**,使用 [Cloudflare](https://www.cloudflare.com/) 作为 CDN / WAF,Web 服务器服务采用 [Nginx](https://www.nginx.com/),并且选用了 [Ansible](https://www.ansible.com/) 作为 <ruby> 基础设施即代码 <rt> Infrastructure as Code </rt></ruby>的工具。
更多的优化将会在即将推出的更新中进行。
### 新增网络工具
伴随着 **Linux 内核的升级至 6.3.7**,Kali Linux 2023.3 版本 **推出了一系列专门针对网络操作的新工具**,这些新工具已经在网络仓库中对用户开放。
新工具包括:
* [kustomize](https://www.kali.org/tools/kustomize/) - Kubernetes YAML 配置的定制工具。
* [Rekono](https://www.kali.org/tools/rekono-kbx/) - 完整的渗透测试过程自动化平台。
* [rz-ghidra](https://www.kali.org/tools/rz-ghidra/) - 用于 rizin 的深度 ghidra 反编译器以及 sleigh 反汇编器的集成工具。
* [Calico](https://www.kali.org/tools/calico/) - 云原生网络和网络安全解决方案。
* [ImHex](https://www.kali.org/tools/imhex/) - 适应各种使用场景的 Hex 编辑器。
* [Villain](https://www.kali.org/tools/villain/) - 可以处理多个反向 Shell 的 C2 框架。
### ?️ 其它变动与提升
除了以上提及的要点,还有一些显著的变动值得注意:
* 两个包 [king-phisher](https://www.kali.org/tools/king-phisher/) 和 [plecost](https://www.kali.org/tools/plecost/) 已经舍弃,转而选择其他代替方案。
* 当在增强会话模式下使用 Hyper-V 时,引入了 PipeWire 的支持。
* 对 Kali Purple 进行了多项改进。
你可以阅读 [官方发布说明](https://www.kali.org/blog/kali-linux-2023-3-release/) 以获取这次版本更新的更细致信息。
? 获取 Kali Linux 2023.3
----------------------
你可以在官方网站获取 Kali Linux 的最新发布版本。
>
> **[Kali Linux 2023.3](https://www.kali.org/get-kali/)**
>
>
>
对于现有用户,你可以运行以下命令进行更新到最新版本:
```
sudo apt update && sudo apt full-upgrade
```
? 你是否打算在新版本中尝试新的工具?欢迎在评论区中分享你的想法。
*(题图:MJ/6539fac3-8d3d-47b8-8566-a9ce376b53d3)*
---
via: <https://news.itsfoss.com/kali-linux-2023-3-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[译者ID](https://github.com/%E8%AF%91%E8%80%85ID) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Kali Linux is the go-to option for pen testers worldwide, being a [penetration-testing-focused](https://itsfoss.com/linux-hacking-penetration-testing/?ref=news.itsfoss.com) distro, it offers a sizeable library of tools that cover a variety of use cases.
Just a [few months prior](https://news.itsfoss.com/kali-linux-2023-2-release/), we had covered the 2023.2 release of Kali Linux that offered some neat improvements.
And now, we have yet another release in the form of **Kali Linux 2023.3** that **focuses more on the back-end**.
Let's dive in and see what's on offer.
## 🆕 Kali Linux 2023.3: What's New?
Powered by [Linux Kernel 6.3](https://news.itsfoss.com/linux-kernel-6-3/), Kali Linux 2023.3 is a very focused release that touches on a few key things. Some highlights include:
**Refreshed Packaging Tools****Improved Internal Infrastructure****New Networking Tools**
### Refreshed Packaging Tools
Kali Linux has expanded on their publicly available [home-made scripts](https://gitlab.com/kalilinux/tools/packaging?ref=news.itsfoss.com) by adding new functionality, various quality-of-life improvements, and new scripts.
The packaging tools include:
### Improved Internal Infrastructure
Due to the recent release of Debian 12, the developers of Kali Linux were able to re-work, re-design, and re-architecture their infrastructure.
It is a massive undertaking that has **allowed them to simplify their software stack**, by using one piece of software for important elements of how they handle Kali Linux.
So, **Debian 12 as its base**,** Cloudflare **as CDN/WAF,
**Web server service -**, and
[Nginx](https://www.nginx.com/?ref=news.itsfoss.com)**for Infrastructure as Code, it is**
[Ansible](https://www.ansible.com/?ref=news.itsfoss.com).Further adjustments on the way with upcoming updates.
**Suggested Read **📖
[Debian 12 “Bookworm” Has LandedDebian’s next big release is here. Learn more about it.](https://news.itsfoss.com/debian-12-release/)

### New Networking Tools
With the **Linux Kernel bump to 6.3.7**, Kali Linux 2023.3 **features a number of new networking-specific tools** that are now available on the networking repositories.
The new tools include:
[kustomize](https://www.kali.org/tools/kustomize/?ref=news.itsfoss.com)- Customizer for Kubernetes YAML configs.[Rekono](https://www.kali.org/tools/rekono-kbx/?ref=news.itsfoss.com)- Automation platform for complete pentesting processes.[rz-ghidra](https://www.kali.org/tools/rz-ghidra/?ref=news.itsfoss.com)- A Deep ghidra decompiler and sleigh disassembler integration for rizin.[Calico](https://www.kali.org/tools/calico/?ref=news.itsfoss.com)- Cloud native networking and network security.[ImHex](https://www.kali.org/tools/imhex/?ref=news.itsfoss.com)- A Hex editor for various types of use cases.[Villain](https://www.kali.org/tools/villain/?ref=news.itsfoss.com)- C2 framework that can handle multiple reverse shells.
### 🛠️ Other Changes and Improvements
Other than the above-mentioned, here are some changes worth noting:
- Two packages,
[king-phisher](https://www.kali.org/tools/king-phisher/?ref=news.itsfoss.com)and[plecost](https://www.kali.org/tools/plecost/?ref=news.itsfoss.com)were dropped in favor of alternatives. - Introduction of PipeWire support when using Hyper-V in enhanced session mode.
- Various improvements for Kali Purple.
You may go through the [official release notes](https://www.kali.org/blog/kali-linux-2023-3-release/?ref=news.itsfoss.com) to for the finer details of this release.
## 📥 Get Kali Linux 2023.3
The latest release of Kali Linux can be sourced from the official website.
For existing users, you can update to the latest release by running the following command:
`sudo apt update && sudo apt full-upgrade`
*💬 Are you going to try the new tools with the release? Share your thoughts in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,136 | 在 RHEL 上配置网络绑定(成组) | https://www.2daygeek.com/configure-network-bonding-nic-teaming-rhel/ | 2023-08-28T12:25:34 | [
"绑定"
] | https://linux.cn/article-16136-1.html | 
网络 <ruby> <a href="https://www.kernel.org/doc/Documentation/networking/bonding.txt"> 绑定 </a> <rt> Bonding </rt></ruby>(<ruby> 成组 <rt> Teaming </rt></ruby>) 是 Linux 的一项内核特性,它让我们可以将多个网络接口(例如 `ens192`、`ens224`)聚合为一个专有的虚拟网络接口,被称为通道绑定(`bond0`)。这样做能够提升吞吐量并增加冗余备份。
网络绑定一共支持 7 种模式,你可以根据实际需求进行设置。<ruby> 链接聚合控制协议 <rt> Link Aggregation Control Protocol </rt></ruby>(LACP), 即模式 4(802.3ad)因其支持链接聚合与冗余而被广泛应用。
在本篇文章中,我们将引导你学习如何在 RHEL 系统中配置网卡(网络)绑定。
### LACP 绑定的前置条件
* 网络团队需要在网络交换机的端口上开启 LACP(802.3ad)来实现链接的聚合。
* 一个 Linux 系统应该配备至少两个网络接口。
* 对于物理服务器,我们推荐在板载接口与 PCI 接口间进行绑定配置,以避免在主机端的网络卡出现单点故障。
### Bonding 模块
你可以使用 `lsmod` 命令来确认你的 Linux 系统是否已经加载了 `bonding` 模块。
```
lsmod | grep -i bonding
bonding 12451 0
```
系统应该默认已加载。如果未看到,可以运用 `modprobe` 命令进行加载。
```
modprobe bonding
```
### 创建绑定接口
在 `/etc/sysconfig/network-scripts/` 路径下,创建一个名为 `ifcfg-bond0` 的绑定接口文件。依据你的网络情况,你可能需要修改诸如 `IP`、`MASK` 以及 `GATEWAY` 等值。
```
vi /etc/sysconfig/network-scripts/ifcfg-bond0
```
```
TYPE=Bond
DEVICE=bond0
NAME=bond0
BONDING_MASTER=yes
BOOTPROTO=none
ONBOOT=yes
IPADDR=192.168.1.100
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
BONDING_OPTS="mode=4 miimon=100 lacp_rate=1"
```
| 参数 | 描述 |
| --- | --- |
| `BONDING_MASTER=yes` | 表示设备是一个绑定主设备。 |
| `mode=4` | 绑定模式是 IEEE 802.3ad 动态链接聚合(LACP)。 |
| `miimon=100` | 定义以毫秒单位的 MII 链路监测频率,这决定了多久检查每个从属链路的状态一次以寻找失败的链路。`0` 值将禁用 MII 链路监测。`100` 是个不错的初始值。 |
| `lacp_rate=1` | 一个设置项,规定我们将以何种频率要求我们的链路伙伴每秒钟发送 LACPDU。默认为慢,即 `0`。 |
### 配置第一个子接口
修改你希望添加到绑定中的第一个子接口。请根据你的实际环境使用合适的接口名。
```
vi /etc/sysconfig/network-scripts/ifcfg-ens192
```
```
TYPE=Ethernet
BOOTPROTO=none
DEVICE=ens192
ONBOOT=yes
MASTER=bond0
SLAVE=yes
```
### 配置第二个子接口
修改你希望添加到绑定中的第二个子接口。请根据你的实际环境使用合适的接口名。
```
vi /etc/sysconfig/network-scripts/ifcfg-ens224
```
```
TYPE=Ethernet
BOOTPROTO=none
DEVICE=ens224
ONBOOT=yes
MASTER=bond0
SLAVE=yes
```
### 重启网络服务
重启网络服务以激活绑定接口。
```
systemctl restart network
```
### 验证绑定配置
你可以借助 [ip 命令](https://www.2daygeek.com/linux-ip-command-configure-network-interface/) 来查看绑定接口以及其子接口的情况。可以看到,`bond0` 现在已启动并在运行。

### 查阅绑定接口状态
检查以下文件,你可以看到绑定接口及其子接口的详细信息。输出结果应该看起来很不错,我们能看到诸如绑定模式,MII 状态,MII 轮询间隔,LACP 速率,端口数量等信息。
```
cat /proc/net/bonding/bond0
```
```
Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011)
Bonding Mode: IEEE 802.3ad Dynamic link aggregation
Transmit Hash Policy: layer (0)
MII Status: up
MII Polling Interval (ms): 100
Up Delay (ms): 0
Down Delay (ms): 0
802.3ad info
LACP rate: fast
Min links: 0
Aggregator selection policy (ad_select): stable
System priority: 65535
System MAC address: c8:5b:76:4d:d4:5c
Active Aggregator Info:
Aggregator ID: 1
Number of ports: 2
Actor Key: 15
Partner Key: 32773
Partner Mac Address: e4:a7:a0:32:fc:e9
Slave Interface: ens192
MII Status: up
Speed: 10000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: c8:5b:76:4d:d4:5c
Slave queue ID: 0
Aggregator ID: 1
Actor Churn State: none
Partner Churn State: none
Actor Churned State: 0
Partner Churned State: 0
details actor lacp pdu:
system priority: 65535
system mac address: c8:5b:76:4d:d4:5c
port key: 15
port priority: 255
port number: 1
port state: 63
details Partner lacp pdu:
system priority: 32667
system mac address: e4:a7:a0:32:fc:e9
oper key: 32773
port priority: 32768
port number: 290
port state: 61
Slave Interface: ens224
MII Status: up
Speed: 10000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: e4:a7:a0:32:fc:e9
Slave queue ID: 0
Aggregator ID: 1
Actor Churn State: none
Partner Churn State: none
Actor Churned State: 0
Partner Churned State: 0
details actor lacp pdu:
system priority: 65535
system mac address: e4:a7:a0:32:fc:e9
port key: 15
port priority: 255
port number: 2
port state: 63
details Partner lacp pdu:
system priority: 32667
system mac address: c8:5b:76:4d:d4:5c
oper key: 32773
port priority: 32768
port number: 16674
port state: 61
```
### 容错/冗余测试
为了验证容错性和连接速度,你可以逐个断开接口,然后检查服务器是否仍旧可达。
* 测试用例-1:当两个子接口都启动并运行时,使用 [ethtool 命令](https://www.2daygeek.com/view-change-ethernet-adapter-settings-nic-card-linux/) 检查链路速度。
* 测试用例-2:断开第一个子接口,然后尝试访问系统。
* 测试用例-3:断开第二个子接口,然后尝试访问系统。
#### 测试用例-1:
如果你想检测下连接速度:没错,我在 `bond0` 上看到了 `20 Gbps` 的速度,因为每个子接口支持 10 Gbps。
```
ethtool bond0
```
```
Settings for bond0:
Supported ports: [ ]
Supported link modes: Not reported
Supported pause frame use: No
Supports auto-negotiation: No
Supported FEC modes: Not reported
Advertised link modes: Not reported
Advertised pause frame use: No
Advertised auto-negotiation: No
Advertised FEC modes: Not reported
Speed: 20000Mb/s
Duplex: Full
Port: Other
PHYAD: 0
Transceiver: internal
Auto-negotiation: off
Link detected: yes
```
#### 测试用例-2:
现在我们将关闭第一个子接口。
```
ifdown ens192
```
```
Device 'ens192' successfully disconnected.
```
通过 `ssh` 尝试访问系统。没问题,系统现在是可以访问的。
```
ssh [email protected]
```
由于已经有一个子接口关闭,你现在在 `bond0` 上只能看到 10 Gbps 的速度。
```
ethtool bond0 | grep -i speed
```
```
Speed: 10000Mb/s
```
现在,我们再次查看绑定接口的状态。可以看出,只有一个子接口处于活跃状态。
```
cat /proc/net/bonding/bond0
```
#### 测试用例-3:
我们来关闭第二个子接口,并进行类似测试用例-2 的测试:
```
ifdown ens224
```
```
Device 'ens224' successfully disconnected.
```
### 结语
我希望你已经掌握了在 RHEL 上配置 LACP 绑定的方法。
在本教程中,我们为你展示了在 RHEL 系统配置网络绑定或网卡聚合的最简单方式。
如果你有任何疑问或者反馈,欢迎在下面留言。
*(题图:MJ/939f6ba6-eb46-480d-8879-3a422c7425d2)*
---
via: <https://www.2daygeek.com/configure-network-bonding-nic-teaming-rhel/>
作者:[Jayabal Thiyagarajan](https://www.2daygeek.com/author/jayabal/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
16,138 | Linux 下“Hello World”的幕后发生了什么 | https://jvns.ca/blog/2023/08/03/behind--hello-world/ | 2023-08-29T14:36:53 | [
"Hello World"
] | https://linux.cn/article-16138-1.html | 
今天我在想 —— 当你在 Linux 上运行一个简单的 “Hello World” Python 程序时,发生了什么,就像下面这个?
```
print("hello world")
```
这就是在命令行下的情况:
```
$ python3 hello.py
hello world
```
但是在幕后,实际上有更多的事情在发生。我将描述一些发生的情况,并且(更重要的是)解释一些你可以用来查看幕后情况的工具。我们将用 `readelf`、`strace`、`ldd`、`debugfs`、`/proc`、`ltrace`、`dd` 和 `stat`。我不会讨论任何只针对 Python 的部分 —— 只研究一下当你运行任何动态链接的可执行文件时发生的事情。
### 0、在执行 execve 之前
要启动 Python 解释器,很多步骤都需要先行完成。那么,我们究竟在运行哪一个可执行文件呢?它在何处呢?
### 1、解析 python3 [hello.py](http://hello.py)
Shell 将 `python3 hello.py` 解析成一条命令和一组参数:`python3` 和 `['hello.py']`。
在此过程中,可能会进行一些如全局扩展等操作。举例来说,如果你执行 `python3 *.py` ,Shell 会将其扩展到 `python3 hello.py`。
### 2、确认 python3 的完整路径
现在,我们了解到需要执行 `python3`。但是,这个二进制文件的完整路径是什么呢?解决办法是使用一个名为 `PATH` 的特殊环境变量。
**自行验证**:在你的 Shell 中执行 `echo $PATH`。对我来说,它的输出如下:
```
$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
```
当执行一个命令时,Shell 将会依序在 `PATH` 列表中的每个目录里搜索匹配的文件。
对于 `fish`(我的 Shell),你可以在 [这里](https://github.com/fish-shell/fish-shell/blob/900a0487443f10caa6539634ca8c49fb6e3ce5ba/src/path.cpp#L31-L45) 查看路径解析的逻辑。它使用 `stat` 系统调用去检验是否存在文件。
**自行验证**:执行 `strace -e stat bash`,然后运行像 `python3` 这样的命令。你应该会看到如下输出:
```
stat("/usr/local/sbin/python3", 0x7ffcdd871f40) = -1 ENOENT (No such file or directory)
stat("/usr/local/bin/python3", 0x7ffcdd871f40) = -1 ENOENT (No such file or directory)
stat("/usr/sbin/python3", 0x7ffcdd871f40) = -1 ENOENT (No such file or directory)
stat("/usr/bin/python3", {st_mode=S_IFREG|0755, st_size=5479736, ...}) = 0
```
你可以观察到,一旦在 `/usr/bin/python3` 找到了二进制文件,搜索就会立即终止:它不会继续去 `/sbin` 或 `/bin` 中查找。
#### 对 execvp 的补充说明
如果你想要不用自己重新实现,而运行和 Shell 同样的 `PATH` 搜索逻辑,你可以使用 libc 函数 `execvp`(或其它一些函数名中含有 `p` 的 `exec*` 函数)。
### 3、stat 的背后运作机制
你可能在思考,Julia,`stat` 到底做了什么?当你的操作系统要打开一个文件时,主要分为两个步骤:
1. 它将 **文件名** 映射到一个包含该文件元数据的 **inode**
2. 它利用这个 **inode** 来获取文件的实际内容
`stat` 系统调用只是返回文件的 inode 内容 —— 它并不读取任何的文件内容。好处在于这样做速度非常快。接下来让我们一起来快速了解一下 inode。(在 Dmitry Mazin 的这篇精彩文章 《[磁盘就是一堆比特](https://www.cyberdemon.org/2023/07/19/bunch-of-bits.html)》中有更多的详细内容)
```
$ stat /usr/bin/python3
File: /usr/bin/python3 -> python3.9
Size: 9 Blocks: 0 IO Block: 4096 symbolic link
Device: fe01h/65025d Inode: 6206 Links: 1
Access: (0777/lrwxrwxrwx) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2023-08-03 14:17:28.890364214 +0000
Modify: 2021-04-05 12:00:48.000000000 +0000
Change: 2021-06-22 04:22:50.936969560 +0000
Birth: 2021-06-22 04:22:50.924969237 +0000
```
**自行验证**:我们来实际查看一下硬盘上 inode 的确切位置。
首先,我们需要找出硬盘的设备名称:
```
$ df
...
tmpfs 100016 604 99412 1% /run
/dev/vda1 25630792 14488736 10062712 60% /
...
```
看起来它是 `/dev/vda1`。接着,让我们寻找 `/usr/bin/python3` 的 inode 在我们硬盘上的确切位置(在 debugfs 提示符下输入 `imap` 命令):
```
$ sudo debugfs /dev/vda1
debugfs 1.46.2 (28-Feb-2021)
debugfs: imap /usr/bin/python3
Inode 6206 is part of block group 0
located at block 658, offset 0x0d00
```
我不清楚 `debugfs` 是如何确定文件名对应的 inode 的位置,但我们暂时不需要深入研究这个。
现在,我们需要计算硬盘中 “块 658,偏移量 0x0d00” 处是多少个字节,这个大的字节数组就是你的硬盘。每个块有 4096 个字节,所以我们需要到 `4096 * 658 + 0x0d00` 字节。使用计算器可以得到,这个值是 `2698496`。
```
$ sudo dd if=/dev/vda1 bs=1 skip=2698496 count=256 2>/dev/null | hexdump -C
00000000 ff a1 00 00 09 00 00 00 f8 b6 cb 64 9a 65 d1 60 |...........d.e.`|
00000010 f0 fb 6a 60 00 00 00 00 00 00 01 00 00 00 00 00 |..j`............|
00000020 00 00 00 00 01 00 00 00 70 79 74 68 6f 6e 33 2e |........python3.|
00000030 39 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |9...............|
00000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000060 00 00 00 00 12 4a 95 8c 00 00 00 00 00 00 00 00 |.....J..........|
00000070 00 00 00 00 00 00 00 00 00 00 00 00 2d cb 00 00 |............-...|
00000080 20 00 bd e7 60 15 64 df 00 00 00 00 d8 84 47 d4 | ...`.d.......G.|
00000090 9a 65 d1 60 54 a4 87 dc 00 00 00 00 00 00 00 00 |.e.`T...........|
000000a0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
```
好极了!我们找到了 inode!你可以在里面看到 `python3`,这是一个很好的迹象。我们并不打算深入了解所有这些,但是 [Linux 内核的 ext4 inode 结构](https://github.com/torvalds/linux/blob/fdf0eaf11452d72945af31804e2a1048ee1b574c/fs/ext4/ext4.h#L769) 指出,前 16 位是 “模式”,即权限。所以现在我们将看一下 `ffa1` 如何对应到文件权限。
* `ffa1` 对应的数字是 `0xa1ff`,或者 41471(因为 x86 是小端表示)
* 41471 用八进制表示就是 `0120777`
* 这有些奇怪 - 那个文件的权限肯定可以是 `777`,但前三位是什么呢?我以前没见过这些!你可以在 [inode 手册页](https://man7.org/linux/man-pages/man7/inode.7.html) 中找到 `012` 的含义(向下滚动到“文件类型和模式”)。这里有一个小的表格说 `012` 表示 “符号链接”。
我们查看一下这个文件,确实是一个权限为 `777` 的符号链接:
```
$ ls -l /usr/bin/python3
lrwxrwxrwx 1 root root 9 Apr 5 2021 /usr/bin/python3 -> python3.9
```
它确实是!耶,我们正确地解码了它。
### 4、准备复刻
我们尚未准备好启动 `python3`。首先,Shell 需要创建一个新的子进程来进行运行。在 Unix 上,新的进程启动的方式有些特殊 - 首先进程克隆自己,然后运行 `execve`,这会将克隆的进程替换为新的进程。
**自行验证:** 运行 `strace -e clone bash`,然后运行 `python3`。你应该会看到类似下面的输出:
```
clone(child_stack=NULL, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7f03788f1a10) = 3708100
```
`3708100` 是新进程的 PID,这是 Shell 进程的子进程。
这里有些工具可以查看进程的相关信息:
* `pstree` 会展示你的系统中所有进程的树状图
* `cat /proc/PID/stat` 会显示一些关于该进程的信息。你可以在 `man proc` 中找到这个文件的内容说明。例如,第四个字段是父进程的PID。
#### 新进程的继承
新的进程(即将变为 `python3` 的)从 Shell 中继承了很多内容。例如,它继承了:
1. **环境变量**:你可以通过 `cat /proc/PID/environ | tr '\0' '\n'` 查看
2. **标准输出和标准错误的文件描述符**:通过 `ls -l /proc/PID/fd` 查看
3. **工作目录**(也就是当前目录)
4. **命名空间和控制组**(如果它在一个容器内)
5. 运行它的**用户**以及**群组**
6. 还有可能是我此刻未能列举出来的更多东西
### 5、Shell 调用 execve
现在我们准备好启动 Python 解释器了!
**自行验证**:运行 `strace -f -e execve bash`,接着运行 `python3`。其中的 `-f` 参数非常重要,因为我们想要跟踪任何可能产生的子进程。你应该可以看到如下的输出:
```
[pid 3708381] execve("/usr/bin/python3", ["python3"], 0x560397748300 /* 21 vars */) = 0
```
第一个参数是这个二进制文件,而第二个参数是命令行参数列表。这些命令行参数被放置在程序内存的特定位置,以便在运行时可以访问。
那么,`execve` 内部到底发生了什么呢?
### 6、获取该二进制文件的内容
我们首先需要打开 `python3` 的二进制文件并读取其内容。直到目前为止,我们只使用了 `stat` 系统调用来获取其元数据,但现在我们需要获取它的内容。
让我们再次查看 `stat` 的输出:
```
$ stat /usr/bin/python3
File: /usr/bin/python3 -> python3.9
Size: 9 Blocks: 0 IO Block: 4096 symbolic link
Device: fe01h/65025d Inode: 6206 Links: 1
...
```
该文件在磁盘上占用 0 个块的空间。这是因为符号链接(`python3.9`)的内容实际上是存储在 inode 自身中:在下面显示你可以看到(来自上述 inode 的二进制内容,以 `hexdump` 格式分为两行输出)。
```
00000020 00 00 00 00 01 00 00 00 70 79 74 68 6f 6e 33 2e |........python3.|
00000030 39 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |9...............|
```
因此,我们将需要打开 `/usr/bin/python3.9` 。所有这些操作都在内核内部进行,所以你并不会看到其他的系统调用。
每个文件都由硬盘上的一系列的 **块** 构成。我知道我系统中的每个块是 4096 字节,所以一个文件的最小大小是 4096 字节 —— 甚至如果文件只有 5 字节,它在磁盘上仍然占用 4KB。
**自行验证**:我们可以通过 `debugfs` 找到块号,如下所示:(再次说明,我从 Dmitry Mazin 的《[磁盘就是一堆比特](https://www.cyberdemon.org/2023/07/19/bunch-of-bits.html)》文章中得知这些步骤)。
```
$ debugfs /dev/vda1
debugfs: blocks /usr/bin/python3.9
145408 145409 145410 145411 145412 145413 145414 145415 145416 145417 145418 145419 145420 145421 145422 145423 145424 145425 145426 145427 145428 145429 145430 145431 145432 145433 145434 145435 145436 145437
```
接下来,我们可以使用 `dd` 来读取文件的第一个块。我们将块大小设定为 4096 字节,跳过 `145408` 个块,然后读取 1 个块。
```
$ dd if=/dev/vda1 bs=4096 skip=145408 count=1 2>/dev/null | hexdump -C | head
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............|
00000010 02 00 3e 00 01 00 00 00 c0 a5 5e 00 00 00 00 00 |..>.......^.....|
00000020 40 00 00 00 00 00 00 00 b8 95 53 00 00 00 00 00 |@.........S.....|
00000030 00 00 00 00 40 00 38 00 0b 00 40 00 1e 00 1d 00 |[email protected]...@.....|
00000040 06 00 00 00 04 00 00 00 40 00 00 00 00 00 00 00 |........@.......|
00000050 40 00 40 00 00 00 00 00 40 00 40 00 00 00 00 00 |@.@.....@.@.....|
00000060 68 02 00 00 00 00 00 00 68 02 00 00 00 00 00 00 |h.......h.......|
00000070 08 00 00 00 00 00 00 00 03 00 00 00 04 00 00 00 |................|
00000080 a8 02 00 00 00 00 00 00 a8 02 40 00 00 00 00 00 |..........@.....|
00000090 a8 02 40 00 00 00 00 00 1c 00 00 00 00 00 00 00 |..@.............|
```
你会发现,这样我们得到的输出结果与直接使用 `cat` 读取文件所获得的结果完全一致。
```
$ cat /usr/bin/python3.9 | hexdump -C | head
00000000 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 |.ELF............|
00000010 02 00 3e 00 01 00 00 00 c0 a5 5e 00 00 00 00 00 |..>.......^.....|
00000020 40 00 00 00 00 00 00 00 b8 95 53 00 00 00 00 00 |@.........S.....|
00000030 00 00 00 00 40 00 38 00 0b 00 40 00 1e 00 1d 00 |[email protected]...@.....|
00000040 06 00 00 00 04 00 00 00 40 00 00 00 00 00 00 00 |........@.......|
00000050 40 00 40 00 00 00 00 00 40 00 40 00 00 00 00 00 |@.@.....@.@.....|
00000060 68 02 00 00 00 00 00 00 68 02 00 00 00 00 00 00 |h.......h.......|
00000070 08 00 00 00 00 00 00 00 03 00 00 00 04 00 00 00 |................|
00000080 a8 02 00 00 00 00 00 00 a8 02 40 00 00 00 00 00 |..........@.....|
00000090 a8 02 40 00 00 00 00 00 1c 00 00 00 00 00 00 00 |..@.............|
```
#### 关于魔术数字的额外说明
这个文件以 `ELF` 开头,这是一个被称为“<ruby> 魔术数字 <rt> magic number </rt></ruby>”的标识符,它是一种字节序列,告诉我们这是一个 ELF 文件。在 Linux 上,ELF 是二进制文件的格式。
不同的文件格式有不同的魔术数字。例如,gzip 的魔数是 `1f8b`。文件开头的魔术数字就是 `file blah.gz` 如何识别出它是一个 gzip 文件的方式。
我认为 `file` 命令使用了各种启发式方法来确定文件的类型,而其中,魔术数字是一个重要的特征。
### 7、寻找解释器
我们来解析这个 ELF 文件,看看里面都有什么内容。
**自行验证**:运行 `readelf -a /usr/bin/python3.9`。我得到的结果是这样的(但是我删减了大量的内容):
```
$ readelf -a /usr/bin/python3.9
ELF Header:
Class: ELF64
Machine: Advanced Micro Devices X86-64
...
-> Entry point address: 0x5ea5c0
...
Program Headers:
Type Offset VirtAddr PhysAddr
INTERP 0x00000000000002a8 0x00000000004002a8 0x00000000004002a8
0x000000000000001c 0x000000000000001c R 0x1
-> [Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
...
-> 1238: 00000000005ea5c0 43 FUNC GLOBAL DEFAULT 13 _start
```
从这段内容中,我理解到:
1. 请求内核运行 `/lib64/ld-linux-x86-64.so.2` 来启动这个程序。这就是所谓的**动态链接器**,我们将在随后的部分对其进行讨论。
2. 该程序制定了一个入口点(位于 `0x5ea5c0`),那里是这个程序代码开始的地方。
接下来,让我们一起来聊聊动态链接器。
### 8、动态链接
好的!我们已从磁盘读取了字节数据,并启动了这个“解释器”。那么,接下来会发生什么呢?如果你执行 `strace -o out.strace python3`,你会在 `execve` 系统调用之后观察到一系列的信息:
```
execve("/usr/bin/python3", ["python3"], 0x560af13472f0 /* 21 vars */) = 0
brk(NULL) = 0xfcc000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=32091, ...}) = 0
mmap(NULL, 32091, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f718a1e3000
close(3) = 0
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libpthread.so.0", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0 l\0\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=149520, ...}) = 0
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f718a1e1000
...
close(3) = 0
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libdl.so.2", O_RDONLY|O_CLOEXEC) = 3
```
这些内容初看可能让人望而生畏,但我希望你能重点关注这一部分:`openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libpthread.so.0" ...`。这里正在打开一个被称为 `pthread` 的 C 语言线程库,运行 Python 解释器时需要这个库。
**自行验证**:如果你想知道一个二进制文件在运行时需要加载哪些库,你可以使用 `ldd` 命令。下面展示的是我运行后的效果:
```
$ ldd /usr/bin/python3.9
linux-vdso.so.1 (0x00007ffc2aad7000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f2fd6554000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f2fd654e000)
libutil.so.1 => /lib/x86_64-linux-gnu/libutil.so.1 (0x00007f2fd6549000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f2fd6405000)
libexpat.so.1 => /lib/x86_64-linux-gnu/libexpat.so.1 (0x00007f2fd63d6000)
libz.so.1 => /lib/x86_64-linux-gnu/libz.so.1 (0x00007f2fd63b9000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f2fd61e3000)
/lib64/ld-linux-x86-64.so.2 (0x00007f2fd6580000)
```
你可以看到,第一个列出的库就是 `/lib/x86_64-linux-gnu/libpthread.so.0`,这就是它被第一个加载的原因。
#### 关于 LD\_LIBRARY\_PATH
说实话,我关于动态链接的理解还有些模糊,以下是我所了解的一些内容:
* 动态链接发生在用户空间,我的系统上的动态链接器位于 `/lib64/ld-linux-x86-64.so.2`. 如果你缺少动态链接器,可能会遇到一些奇怪的问题,比如这种 [奇怪的“文件未找到”错误](https://jvns.ca/blog/2021/11/17/debugging-a-weird--file-not-found--error/)
* 动态链接器使用 `LD_LIBRARY_PATH` 环境变量来查找库
* 动态链接器也会使用 `LD_PRELOAD` 环境变量来覆盖你想要的任何动态链接函数(你可以使用它来进行 [有趣的魔改](https://jvns.ca/blog/2014/11/27/ld-preload-is-super-fun-and-easy/),或者使用像 jemalloc 这样的替代品来替换默认内存分配器)
* `strace` 的输出中有一些 `mprotect`,因为安全原因将库代码标记为只读
* 在 Mac 上,不是使用 `LD_LIBRARY_PATH`(Linux),而是 `DYLD_LIBRARY_PATH`
你可能会有疑问,如果动态链接发生在用户空间,我们为什么没有看到大量的 `stat` 系统调用在 `LD_LIBRARY_PATH` 中搜索这些库,就像 Bash 在 `PATH` 中搜索那样?
这是因为 `ld` 在 `/etc/ld.so.cache` 中有一个缓存,因此所有之前已经找到的库都会被记录在这里。你可以在 `strace` 的输出中看到它正在打开缓存 - `openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3`。
在 [完整的 strace 输出](https://gist.github.com/jvns/4254251bea219568df9f43a2efd8d0f5) 中,我仍然对动态链接之后出现的一些系统调用感到困惑(什么是 `prlimit64`?本地环境的内容是如何介入的?`gconv-modules.cache` 是什么?`rt_sigaction` 做了什么?`arch_prctl` 是什么?以及 `set_tid_address` 和 `set_robust_list` 是什么?)。尽管如此,我觉得已经有了一个不错的开头。
#### 旁注:ldd 实际上是一个简单的 Shell 脚本!
在 Mastodon 上,有人 [指出](https://octodon.social/@lkundrak/110832640058459399),`ldd` 实际上是一个 Shell 脚本,它设置了 `LD_TRACE_LOADED_OBJECTS=1` 环境变量,然后启动程序。因此,你也可以通过以下方式实现相同的功能:
```
$ LD_TRACE_LOADED_OBJECTS=1 python3
linux-vdso.so.1 (0x00007ffe13b0a000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f01a5a47000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f01a5a41000)
libutil.so.1 => /lib/x86_64-linux-gnu/libutil.so.1 (0x00007f2fd6549000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f2fd6405000)
libexpat.so.1 => /lib/x86_64-linux-gnu/libexpat.so.1 (0x00007f2fd63d6000)
libz.so.1 => /lib/x86_64-linux-gnu/libz.so.1 (0x00007f2fd63b9000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f2fd61e3000)
/lib64/ld-linux-x86-64.so.2 (0x00007f2fd6580000)
```
事实上,`ld` 也是一个可以直接运行的二进制文件,所以你也可以通过 `/lib64/ld-linux-x86-64.so.2 --list /usr/bin/python3.9` 来达到相同的效果。
#### 关于 init 和 fini
让我们来谈谈这行 `strace` 输出中的内容:
```
set_tid_address(0x7f58880dca10) = 3709103
```
这似乎与线程有关,我认为这可能是因为 `pthread` 库(以及所有其他动态加载的库)在加载时得以运行初始化代码。在库加载时运行的代码位于 `init` 区域(或者也可能是 `.ctors` 区域)。
**自行验证**:让我们使用 `readelf` 来看看这个:
```
$ readelf -a /lib/x86_64-linux-gnu/libpthread.so.0
...
[10] .rela.plt RELA 00000000000051f0 000051f0
00000000000007f8 0000000000000018 AI 4 26 8
[11] .init PROGBITS 0000000000006000 00006000
000000000000000e 0000000000000000 AX 0 0 4
[12] .plt PROGBITS 0000000000006010 00006010
0000000000000560 0000000000000010 AX 0 0 16
...
```
这个库没有 `.ctors` 区域,只有一个 `.init`。但是,`.init` 区域都有些什么内容呢?我们可以使用 `objdump` 来反汇编这段代码:
```
$ objdump -d /lib/x86_64-linux-gnu/libpthread.so.0
Disassembly of section .init:
0000000000006000 <_init>:
6000: 48 83 ec 08 sub $0x8,%rsp
6004: e8 57 08 00 00 callq 6860 <__pthread_initialize_minimal>
6009: 48 83 c4 08 add $0x8,%rsp
600d: c3
```
所以它在调用 `__pthread_initialize_minimal`。我在 glibc 中找到了 [这个函数的代码](https://github.com/bminor/glibc/blob/a78e5979a92c7985eadad7246740f3874271303f/nptl/nptl-init.c#L100),尽管我不得不找到一个较早版本的 glibc,因为在更近的版本中,libpthread [不再是一个独立的库](https://developers.redhat.com/articles/2021/12/17/why-glibc-234-removed-libpthread)。
我不确定这个 `set_tid_address` 系统调用是否实际上来自 `__pthread_initialize_minimal`,但至少我们知道了库可以通过 `.init` 区域在启动时运行代码。
这里有一份关于 .init 区域的 elf 手册的笔记:
```
$ man elf
```
`.init` 这个区域保存着对进程初始化代码有贡献的可执行指令。当程序开始运行时,系统会安排在调用主程序入口点之前执行该区域中的代码。
在 ELF 文件中也有一个在结束时运行的 `.fini` 区域,以及其他可以存在的区域 `.ctors` / `.dtors`(构造器和析构器)。
好的,关于动态链接就说这么多。
### 9、转到 \_start
在动态链接完成后,我们进入到 Python 解释器中的 `_start`。然后,它将执行所有正常的 Python 解析器会做的事情。
我不打算深入讨论这个,因为我在这里关心的是关于如何在 Linux 上运行二进制文件的一般性知识,而不是特别针对 Python 解释器。
### 10、写入字符串
不过,我们仍然需要打印出 “hello world”。在底层,Python 的 `print` 函数调用了 libc 中的某个函数。但是,它调用了哪一个呢?让我们来找出答案!
**自行验证**:运行 `ltrace -o out python3 hello.py`:
```
$ ltrace -o out python3 hello.py
$ grep hello out
write(1, "hello world\n", 12) = 12
```
看起来它确实在调用 `write` 函数。
我必须承认,我对 `ltrace` 总是有一些疑虑 —— 与我深信不疑的 `strace` 不同,我总是不完全确定 `ltrace` 是否准确地报告了库调用。但在这个情况下,它似乎有效。并且,如果我们查阅 [cpython 的源代码](https://github.com/python/cpython/blob/400835ea1626c8c6dcd967c7eabe0dad4a923182/Python/fileutils.c#L1955),它似乎在一些地方确实调用了 `write()` 函数,所以我倾向于相信这个结果。
#### 什么是 libc?
我们刚刚提到,Python 调用了 libc 中的 `write` 函数。那么,libc 是什么呢?它是 C 的标准库,负责许多基本操作,例如:
* 用 `malloc` 分配内存
* 文件 I/O(打开/关闭文件)
* 执行程序(像我们之前提到的 `execvp`)
* 使用 `getaddrinfo` 查找 DNS 记录
* 使用 `pthread` 管理线程
在 Linux 上,程序不一定需要使用 libc(例如 Go 就广为人知地未使用它,而是直接调用了 Linux 系统调用),但是我常用的大多数其他编程语言(如 node、Python、Ruby、Rust)都使用了 libc。我不确定 Java 是否也使用了。
你能通过在你的二进制文件上执行 `ldd` 命令,检查你是否正在使用 libc:如果你看到了 `libc.so.6` 这样的信息,那么你就在使用 libc。
#### 为什么 libc 重要?
你也许在思考 —— 为何重要的是 Python 调用 libc 的 `write` 函数,然后 libc 再调用 `write` 系统调用?为何我要着重提及 `libc` 是调用过程的一环?
我认为,在这个案例中,这并不真的很重要(根据我所知,libc 的 `write` 函数与 `write` 系统调用的映射相当直接)。
然而,存在不同的 libc 实现,有时它们的行为会有所不同。两个主要的实现是 glibc(GNU libc)和 musl libc。
例如,直到最近,[musl 的 `getaddrinfo` 并不支持 TCP DNS](https://www.openwall.com/lists/musl/2023/05/02/1),[这是一篇关于这个问题引发的错误的博客文章](https://christoph.luppri.ch/fixing-dns-resolution-for-ruby-on-alpine-linux)。
#### 关于 stdout 和终端的小插曲
在我们的程序中,stdout(`1` 文件描述符)是一个终端。你可以在终端上做一些有趣的事情!例如:
1. 在终端中运行 `ls -l /proc/self/fd/1`。我得到了 `/dev/pts/2` 的结果。
2. 在另一个终端窗口中,运行 `echo hello > /dev/pts/2`。
3. 返回到原始终端窗口。你应会看到 `hello` 被打印出来了!
### 暂时就到这儿吧!
希望通过上文,你对 `hello world` 是如何打印出来的有了更深的了解!我暂时不再添加更多的细节,因为这篇文章已经足够长了,但显然还有更多的细节可以探讨,如果大家能提供更多的细节,我可能会添加更多的内容。如果你有关于我在这里没提到的程序内部调用过程的任何工具推荐,我会特别高兴。
### 我很期待看到一份 Mac 版的解析
我对 Mac OS 的一个懊恼是,我不知道如何在这个级别上解读我的系统——当我打印 “hello world”,我无法像在 Linux 上那样,窥视背后的运作机制。我很希望看到一个深度的解析。
我所知道的一些在 Mac 下的对应工具:
* `ldd` -> `otool -L`
* `readelf` -> `otool`
* 有人说你可以在 Mac 上使用 `dtruss` 或 `dtrace` 来代替 `strace`,但我尚未有足够的勇气关闭系统完整性保护来让它工作。
* `strace` -> `sc_usage` 似乎能够收集关于系统调用使用情况的统计信息,`fs_usage` 则可以收集文件使用情况的信息。
### 延伸阅读
一些附加的链接:
* [快速教程:如何在 Linux 上创建超小型 ELF 可执行文件](https://www.muppetlabs.com/~breadbox/software/tiny/teensy.html)
* [在 FreeBSD 上探索 “hello world”](https://people.freebsd.org/~brooks/talks/asiabsdcon2017-helloworld/helloworld.pdf)
* [微观视角下的 Windows 中 “Hello World”][23A]
* 来自 LWN 的文章:[如何运行程序](https://lwn.net/Articles/630727/) ([以及第二部分](https://lwn.net/Articles/631631/))详尽介绍了 `execve` 的内部机制
* Lexi Mattick 的文章,[赋予 CPU “你” 的存在](https://cpu.land/how-to-run-a-program)
* [从零开始在 6502 上实现 “Hello, World”](https://www.youtube.com/watch?v=LnzuMJLZRdU) (来自 Ben Eater 的视频)
*(题图:MJ/b87ed0a2-80d6-49cd-b2bf-1ef822485e3f)*
---
via: <https://jvns.ca/blog/2023/08/03/behind--hello-world/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
16,140 | Linux 内核 6.5 发布,首次支持 Wi-Fi 7 和 USB4 | https://news.itsfoss.com/linux-kernel-6-5-release/ | 2023-08-30T10:13:20 | [
"内核"
] | https://linux.cn/article-16140-1.html | 
>
> Linux 内核 6.5 进行了一系列的改善,阅读此文以了解详情。
>
>
>
新版的 Linux 内核已经发布!
**Linux 6.5 内核** 已经推出,此次更新在 Linux 6.4 内核的基础上进行了进一步的开发,带来了值得注意的改变和新特性。
Linus Torvalds 表示,这是一次相对顺畅的发布:
>
> 上周并没有发生任何异常或惊人的事情,因此没有理由延迟 6.5 版的发布。
>
>
> 我仍有这样一个担忧,似乎是因为许多人都在度假,部分导致整体状态比较平静。但目前这次发布进展顺利,所以这可能只是我多虑了。上周的最大更新就仅仅是对我们自我测试的几次修订。
>
>
>
### ? Linux 内核 6.5:新增了哪些功能?
需要说明的是,这次发布的版本不是长期支持(LTS)版本。如果你期望使用最新的功能,那么这个版本就是为你准备的。否则,除非此版本解决了你关心的特定问题或者能有效提升性能,否则没有升级的必要。
以下是新版内核发布的主要亮点:
* AMD FreeSync 视频的即插即用支持
* AMD CPU 默认启用 P-State 主动模式
* 对 USB4 v2 和 WiFi 7 的初步支持
* ASUS ROG Ally 音效优化
### 开箱即用的 AMD FreeSync 视频支持

在这次发布中,重新引入的一项优秀功能是默认开启的 AMD FreeSync 视频模式支持。此特性在 Linux 内核 5.8 版本中首次引入,后因错误而被回滚。
启用 AMD FreeSync 模式后,通过将显示器的刷新率与显卡的帧率相匹配,可以显著减少游戏及视频中的屏幕撕裂和迟滞现象。
用技术词汇来描述,当它在 Linux 内核 5.8 版本中首次发布时,它的描述是:
>
> 这个补丁集启用了 FreeSync 视频模式的使用场景,这样用户空间可以请求一个 FreeSync 兼容的视频模式,因此,切换到此模式不会触发屏幕黑屏。
>
>
>
这对内容创作者和游戏玩家都非常有用。
但请注意,你需要一个兼容 FreeSync 的显示器和显卡才能充分利用它。
### AMD CPU 默认启用 P-State 主动模式
现代 AMD CPU,特别是那些基于 Zen 2 及更新架构构建的,将默认采用 amd-pstate 作为 CPU 性能调整驱动。之前,CPU 的频率调整机制默认由 CPUFreq 负责。
现在,amd-pstate 提供了三种模式:主动、被动和引导式自主模式。在这次发布中,默认启用了主动模式,从而取代了之前 Linux 内核 6.4 版本中使用的引导式自主模式。
据 Phoronix 的一些 [基准测试](https://www.phoronix.com/review/amd-pstate-epp-ryzen-mobile) 结果显示,发现 amd-pstate 的性能优于 CPUFreq。
你可以参考这个 [提交](https://lore.kernel.org/lkml/CAJZ5v0iQk8ytZ0953_HCWU6Vr62J9UeC8Z9pirOHAfjpbvcOfg@mail.gmail.com/) 了解更多详情。
### ASUS ROG Ally 声音优化

ASUS ROG Ally 是一款使用 AMD Z1 和 Z1 Extreme SoCs 驱动的 Windows 手持式游戏电脑,直接竞争的对手是非常知名的 Steam Deck。它在今年七月发布。
使用 Linux 的游戏玩家如果拥有 ASUS ROG Ally,可以期待看到一个针对系统音频设备的修补发布,感谢这个 [提交](https://git.kernel.org/pub/scm/linux/kernel/git/tiwai/sound.git/commit/?h=for-next&id=724418b84e6248cd27599607b7e5fac365b8e3f5)。
### 对 USB4 v2 & WiFi 7 的初始支持

下一代无线标准 - WiFi 7 - 的开发工作已经进行了一段时间。WiFi 7 支持 6Ghz 频段,最大数据传输速率达到 23 Gbps!
与此同时,下一代 USB4 标准的开发工作也已开始。USB4 支持 80 Gbps 的数据传输速率!
通过对 WiFi 的这个 [合并](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=3a8a670eeeaa40d87bd38a587438952741980c18) 和对 WiFi 7 的 [拉取请求](https://lore.kernel.org/lkml/[email protected]/),对二者的早期支持已经被嵌入到 Linux 6.5 内核中。
### ?️ 其他改动与提升
除了主要的亮点外,还有一些值得一提的更新:
* 对英特尔 P-State 的 CPU 进行了缩放修复
* 对 Btrfs 的性能进行了改进,以及其他存储优化
* 对最新的 Xbox 控制器增加了 Rumble 支持
* 对 AMD Radeon RX 7000 系列显卡进行了超频支持
* 对 AMD 和英特尔图形驱动进行了各种优化和改进
* 和以往一样,更多的 Rust 代码转换
[官方发布公告](https://lore.kernel.org/lkml/CAHk-=wgmKhCrdrOCjp=5v9NO6C=PJ8ZTZcCXj09piHzsZ7qqmw@mail.gmail.com/) 将给出自从上一个候选版释放以后的摘要。如果你对技术细节有兴趣,不妨参考 [变更日志](https://cdn.kernel.org/pub/linux/kernel/v6.x/ChangeLog-6.5)。
### 安装 Linux 内核 6.5
如果你使用像 Arch 这样的滚动更新发行版,可以很容易地升级至 Linux 内核 6.5。在新版本发布后的一段时间,这些发行版本会提供最新的内核。
另一方面,使用 Ubuntu 及其衍生版本的用户,可以期待在 Ubuntu 23.10 版本中看到这次的 Linux 内核发布。如果你使用的是像 Pop OS 和 Linux Lite 这样的发行版,可能会更早的见到这版内核发布。
但是如果你希望在基于 Ubuntu 的系统里快速尝试,可以按照我们的指南进行(请注意,这是自行承担风险!?)。
你可以在它的 [官方网站](https://www.kernel.org/) 上下载最新的 Linux 内核 的 Tarball(*发布之后可能需要一段时间才能下载到*)。
? 欢迎在评论区分享你对最新内核发布的看法。
---
via: <https://news.itsfoss.com/linux-kernel-6-5-release/>
作者:[Rishabh Moharir](https://news.itsfoss.com/author/rishabh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It's a new Linux kernel release time!
**Linux 6.5 kernel **is here and builds upon the work of the previous Linux 6.4 kernel, along with some notable changes and additions.
Linus Torvalds mentioned that this was a smooth release overall:
So nothing particularly odd or scary happened this last week, so there is no excuse to delay the 6.5 release.
I still have this nagging feeling that a lot of people are on vacation and that things have been quiet partly due to that. But this release has been going smoothly, so that's probably just me being paranoid. The biggest patches this last week were literally just to our selftests.
**Suggested Read **📖
[Linux Kernel 6.4 Released: Embracing Apple M2, New Hardware, and More Rust CodeIt’s a new Linux Kernel release day! Hardware enthusiast? Dive in to learn more what Linux Kernel 6.4 brings in.](https://news.itsfoss.com/linux-kernel-6-4/)

## 🆕 Linux Kernel 6.5: What's New?
Users should be aware that this is a non-LTS release. If you want to get your hands on the latest features, this release is for you. Otherwise, upgrading is unnecessary unless it fixes particular issues or improves performance.
Here are the major highlights of the new kernel release:
**Out-of-the-box Support for AMD FreeSync Video****Default P-State "Active" Mode for AMD CPUs****Initial Support for USB4 v2 & WiFi 7****ASUS ROG Ally Sound Optimizations**
### Out-of-the-box Support for AMD FreeSync Video

A neat feature re-introduced in this release is the support for AMD FreeSync Video mode enabled by default. It was earlier introduced in the Linux Kernel 5.8 but reverted due to bugs.
When AMD FreeSync mode is enabled, screen-tearing and stuttering in games and videos are heavily reduced by matching the monitor's refresh rate to the framerate of the graphics card.
In technical terms, here's how it was described when it was being released back in Linux 5.8 kernel:
This patchset enables freesync video mode usecase where the userspace can request a freesync compatible video mode such that switching to this mode does not trigger blanking.
This is quite useful for content creators and gamers alike.
But note that you will need a FreeSync-compatible monitor and graphics card to utilize it.
### Default P-State "Active "Mode for AMD CPUs
Modern AMD CPUs, specifically those built with Zen 2 and above architecture, will now use amd-pstate as the default CPU performance scaling driver. Earlier, the CPU scaling mechanism was managed by CPUFreq by default.
Now, amd-pstate offers three modes: active, passive, and guided autonomous. The "active" mode has been enabled by default in this release and thus replaces the guided autonomous mode used in the previous Linux Kernel 6.4.
It has been found that amd-pstate performs better than CPUFreq, as seen in some [benchmarks](https://www.phoronix.com/review/amd-pstate-epp-ryzen-mobile?ref=news.itsfoss.com) by Phoronix.
You can refer to this [commit](https://lore.kernel.org/lkml/CAJZ5v0iQk8ytZ0953_HCWU6Vr62J9UeC8Z9pirOHAfjpbvcOfg@mail.gmail.com/?ref=news.itsfoss.com) to learn more.
### ASUS ROG Ally Sound Optimizations

A direct competitor to the vastly famous Steam Deck, ASUS ROG Ally is a Windows handheld gaming computer powered by the AMD Z1 and Z1 Extreme SoCs. It was released back in July of this year.
Linux gamers owning an ASUS ROG Ally should expect to see a patch release for the system's audio device, thanks to this [commit](https://git.kernel.org/pub/scm/linux/kernel/git/tiwai/sound.git/commit/?h=for-next&id=724418b84e6248cd27599607b7e5fac365b8e3f5&ref=news.itsfoss.com).
### Initial Support for USB4 v2 & WiFi 7

Work for the next-generation wireless standard - WiFi 7 - has been in development for quite some time. As a quick fact, WiFi 7 supports the 6Ghz band with a max data rate of 23 Gbps!
Also along this line, development work for the next-generation USB4 standard has begun. USB4 supports an 80 Gbps data transfer rate!
Early support for both has been baked into the Linux 6.5 kernel via this [merge](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=3a8a670eeeaa40d87bd38a587438952741980c18&ref=news.itsfoss.com) for WiFi and [pull request](https://lore.kernel.org/lkml/[email protected]/?ref=news.itsfoss.com) for WiFi 7.
### 🛠️ Other Changes & Improvements
Here are some more things to be mentioned apart from the major highlights:
- CPU scaling fixes for Intel P-State
- Performance improvements for Btrfs and other storage optimizations
- Rumble support for the latest Xbox controllers
- Overclocking support for AMD Radeon RX 7000 series graphics cards
- Various improvements and optimizations for AMD and Intel graphics drivers
- And as always, more Rust code transitions
The [official release announcement](https://lore.kernel.org/lkml/CAHk-=wgmKhCrdrOCjp=5v9NO6C=PJ8ZTZcCXj09piHzsZ7qqmw@mail.gmail.com/?ref=news.itsfoss.com) would give you a short log since its last release candidate. And, if you are curious about technical details, refer to the [changelog](https://cdn.kernel.org/pub/linux/kernel/v6.x/ChangeLog-6.5?ref=news.itsfoss.com).
## Installing Linux Kernel 6.5
You can easily upgrade to Linux Kernel 6.5 using a rolling-release distro like Arch or Fedora. These distros offer the latest kernel sometime after the release.
On the other hand, folks using Ubuntu and its derivates should expect to see this Linux Kernel release in action via Ubuntu 23.10. You can expect this kernel release sooner using distros like Pop OS and Linux Lite.
But if you want to try it out quickly on an Ubuntu-based system, you can do so by following our guide (at your own risk! 👀)
[Install the Latest Mainline Linux Kernel Version in UbuntuThis article shows you how to upgrade to the latest Linux kernel in Ubuntu. There are two methods discussed. One is manually installing a new kernel and the other uses a GUI tool providing even easier way.](https://itsfoss.com/upgrade-linux-kernel-ubuntu/?ref=news.itsfoss.com)

You can download the tarball for the latest Linux Kernel from its [official website](https://www.kernel.org/?ref=news.itsfoss.com) (*it takes time for it to be available after release*).
*💬 Share your thoughts about the latest kernel release in the comments.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,141 | 在 Firefox 和 Chrome 中轻松截取完整网页截图 | https://itsfoss.com/firefox-screenshot/ | 2023-08-30T13:28:00 | [
"浏览器",
"截屏"
] | https://linux.cn/article-16141-1.html | 
>
> Firefox 浏览器内置了截屏工具,你可以用它对整个网页进行截屏。Chrome 浏览器也有同样的功能。
>
>
>
截屏来捕获信息是很常见的。
但你知道你可以在 Firefox 中截取整个网页的截图吗?Firefox 附带一个内置的截图工具,允许你截取选定区域、可见屏幕区域甚至整个网页的截图。
这意味着如果你想保存网页供以后参考,你可以快速捕获整个网页。
Chrome 也有截图功能,但稍微复杂一些。
在本教程中,我将引导你完成以下内容:
* 如何在 Firefox 中截图
* 如何在 Chrome 中截图
* 使用 Nimbus 扩展获得比内置的截屏更多的功能
那么让我们从第一个开始。
### 在 Firefox 中截取网页截图
Firefox 的内置工具可让你通过单击选择整个屏幕、整个页面,甚至特定段落。
#### 步骤 1:访问截图工具
要启动截图程序,请在使用 Firefox 时按 `Ctrl + Shift + s`。
如果你不总是能记住快捷方式,也可以从右键单击菜单访问该工具。

如果你经常截图,那么将该程序添加到工具栏将是一个好主意。为此,你只需执行三个简单步骤:
1. 首先,右键单击工具栏并选择 “<ruby> 自定义工具栏 <rt> Customize Toolbar </rt></ruby>” 选项
2. 找到 “<ruby> 截图 <rt> Screenshot </rt></ruby>” 程序并将其拖至工具栏
3. 点击 “<ruby> 完成 <rt> Done </rt></ruby>” 按钮即可
还困惑吗? 操作方法如下:

启用后,你可以单击刚刚拖动到工具栏的截图图标。
#### 步骤 2:在 Firefox 中截图
当你启动截图工具时,它会提示两个选项:“<ruby> 保存整页 <rt> Save full page </rt></ruby>” 和 “<ruby> 保存可见 <rt> Save visible </rt></ruby>”。这里:
* 保存整页将捕获整个网页
* 保存可见只会捕获当前帧中可见的内容
但如果你想捕获特定部分,你可以使用鼠标光标选择该部分并保存:

如你所见,有两个选项:<ruby> 下载 <rt> Download </rt></ruby> 或 <ruby> 复制 <rt> Copy </rt></ruby>(到剪贴板,以便你可以将其粘贴到文档或编辑工具中)。你可以根据你的场景使用其中之一。
### 在 Chrome 中截取网页截图
在 Chrome 中截取全部网页截图比在 Firefox 中要复杂一些,因为它隐藏在开发人员选项下。
不用担心!你将通过以下步骤做到:
* 打开菜单,进入 “<ruby> 更多工具 <rt> More Tools </rt></ruby>-><ruby> 开发者工具 <rt> Developer tools </rt></ruby>”。或者,你可以按 `Ctrl + Shift + l` 进入开发者工具目录。
* 按 `Ctrl + Shift + p` 并输入 `screenshot`(LCTT 译注:在中文环境中请输入 “屏幕截图”)
* 选择区域或整个页面,然后回下载截图。
让我向你展示如何做到这一点:

Chrome 基本提供的就是这些。
### 如何使用扩展程序截图
>
> ✋ 非自由和开源软件警告!这里讨论的 Nimbus 扩展不是开源的。
>
>
>
如果你想要更多功能,例如添加延迟、水印或符号,那么你必须使用扩展程序。
为此,我建议使用 Nimbus,它几乎可以让你执行任何本地安装的截图工具可以执行的所有操作。
下载 Firefox 版 Nimbus:
>
> **[Firefox 版 Nimbus](https://addons.mozilla.org/en-US/firefox/addon/nimbus-screenshot/?utm_source=addons.mozilla.org&utm_medium=referral&utm_content=search)**
>
>
>
下载 Chrome 版 Nimbus:
>
> **[Chrome 版 Nimbus](https://chrome.google.com/webstore/detail/nimbus-screenshot-screen/bpconcjcammlapcogcnnelfmaeghhagj)**
>
>
>
>
> ? 只有 Nimbus 的 Chrome 扩展具有视频录制功能。
>
>
>
完成安装后,**请务必注册 Nimbus 以启用所有功能。**
单击 Nimbus 扩展图标,你会看到多个选项:

你可以选择任何显示的功能,完成后,根据捕获后进行的操作(我选择编辑),它将直接下载截图,打开编辑器或将其发送到任何选定的云提供商。
如果你也将 “<ruby> 编辑 <rt> Edit </rt></ruby>” 作为捕获后的操作,那么它将打开一个编辑器,你可以在其中对捕获的截图进行编辑:

如果你想添加水印、了解/更改快捷方式、更改截图的格式等,请打开 Nimbus 并点击小齿轮按钮:

只是一个扩展却有非常酷的功能。不是吗?
>
> ? 如果你经常截屏,你可能需要将 Nimbus 扩展固定到任务栏。
>
>
>
### 想要更多功能吗?使用截图工具
如果你不想受到扩展功能的束缚,那么需要尝试具有更多功能的截图工具,这些工具可以在整个系统的任何地方使用。
如果你是 Linux 用户,那么我们有一份关于 [Linux 中截取和编辑截图的最佳工具](https://itsfoss.com/take-screenshot-linux/) 的专门指南:
>
> **[Linux 中截取和编辑截图的最佳工具](https://itsfoss.com/take-screenshot-linux/)**
>
>
>
我希望你喜欢这个快速技巧。
(题图:MJ/76cc0d02-fb37-4bd0-94ec-fc249c1f537e)
---
via: <https://itsfoss.com/firefox-screenshot/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Taking screenshots to capture information is pretty common.
But did you know you can take screenshots of an entire webpage in Firefox?
Firefox comes with an in-built screen capture tool that allows you to take screenshots of selected areas, visible screen areas, or even entire web pages.
This means if you want to save a webpage for later reference, you can quickly capture the entire webpage.
Chrome also has the screenshot feature but it is slightly more complicated.
In this tutorial, I will walk you through the following:
- How to take screenshots in Firefox
- How to capture screenshots in Chrome
- Using the Nimbus extension to get more features than the in-built one
So let's start with the first one.
## Taking full-page screenshots in Firefox
Firefox's in-built tool lets you select the whole screen, the complete page, or even a specific paragraph with a single click.
### Step 1: Access the screenshot tool
To start the screenshot utility, you press `Ctrl + Shift + s`
while using Firefox.
If you don't always remember shortcuts, you can access the tool from the right-click menu as well.
If you regularly take screenshots, adding the utility to the toolbar would be a good idea. And to do so, you follow the simple three steps:
- First, Right-click on the toolbar and select the option
`Customize Toolbar`
- Find the
`Screenshot`
utility and drag it to the toolbar - Hit the
`Done`
button and that's it
Still confused? Here's how you do it:

Once enabled, you can click on the screenshot logo that you just dragged to the toolbar.
### Step 2: Take a screenshot in Firefox
When you start the screenshot tool, it will prompt with two options: `Save full page`
and `Save visible`
. Here,
- Save full page will capture the entire webpage
- Save Visible will only capture what is visible in the current frame
But if you want to capture a specific part, you can select that part using the mouse cursor and save it:
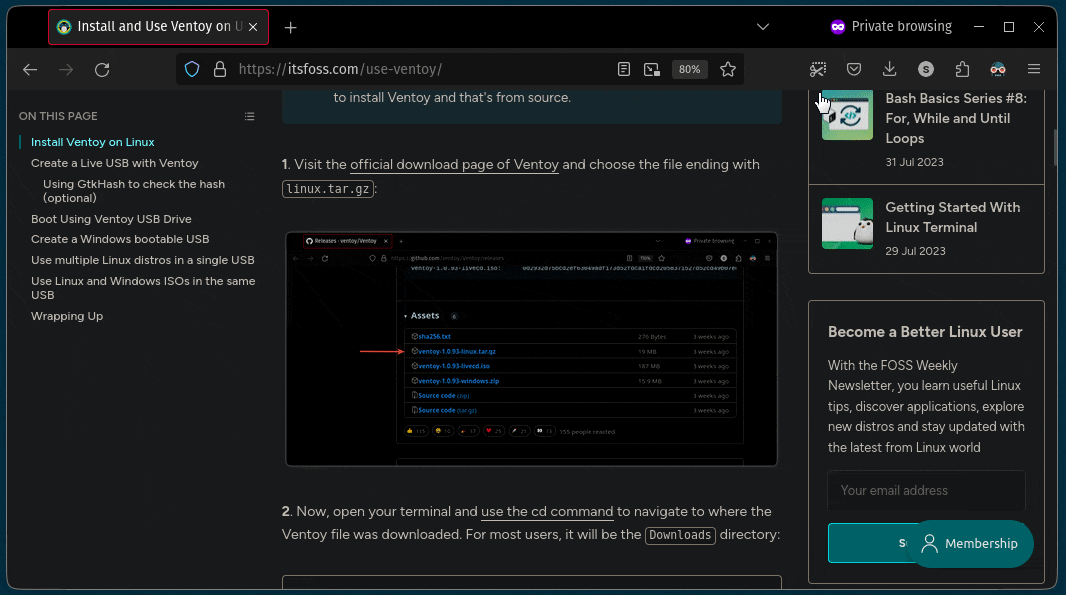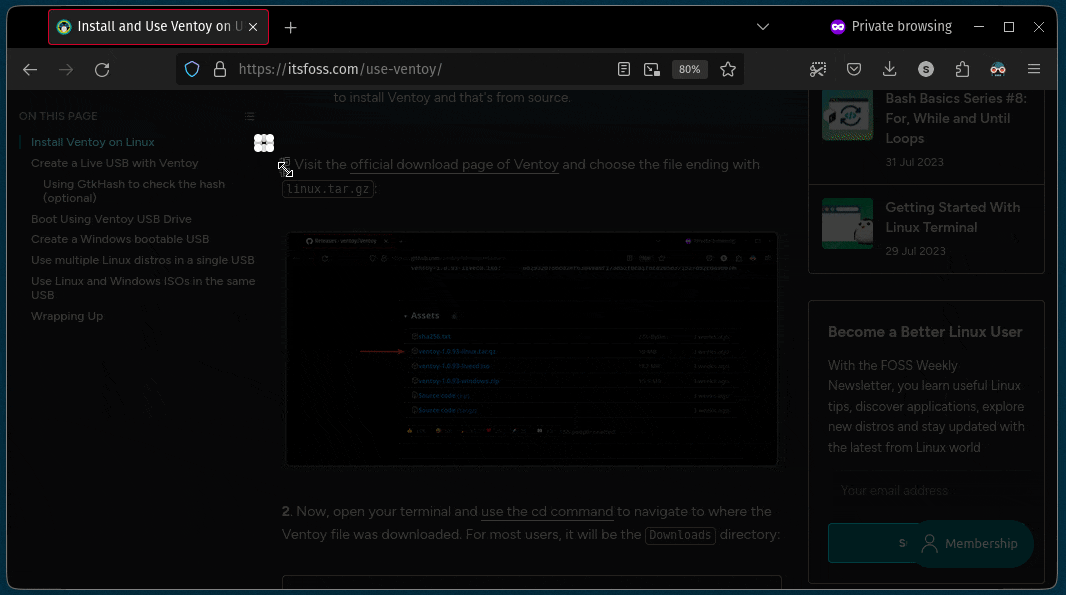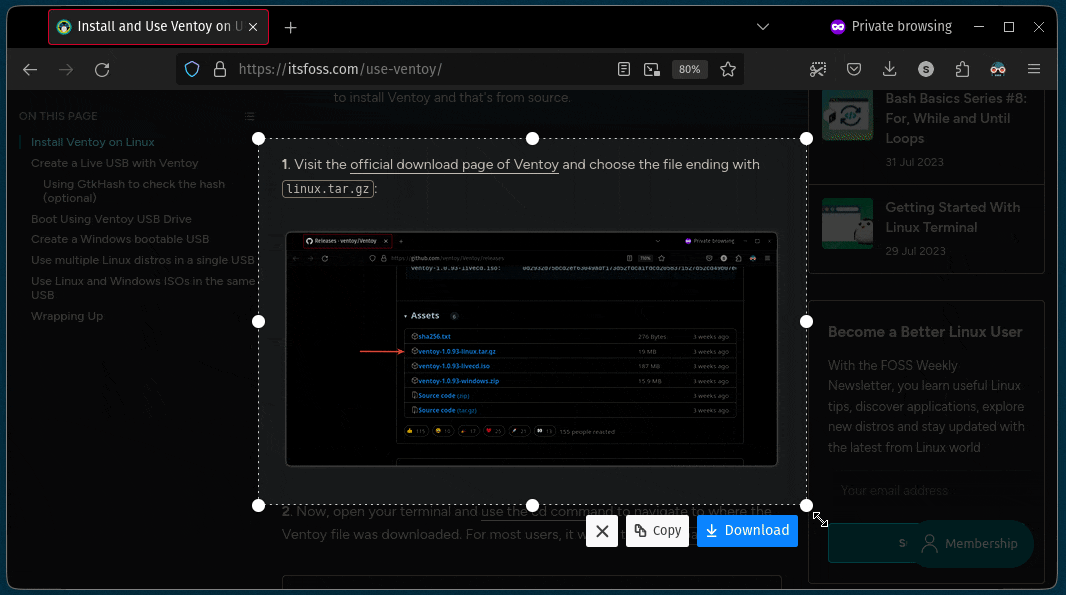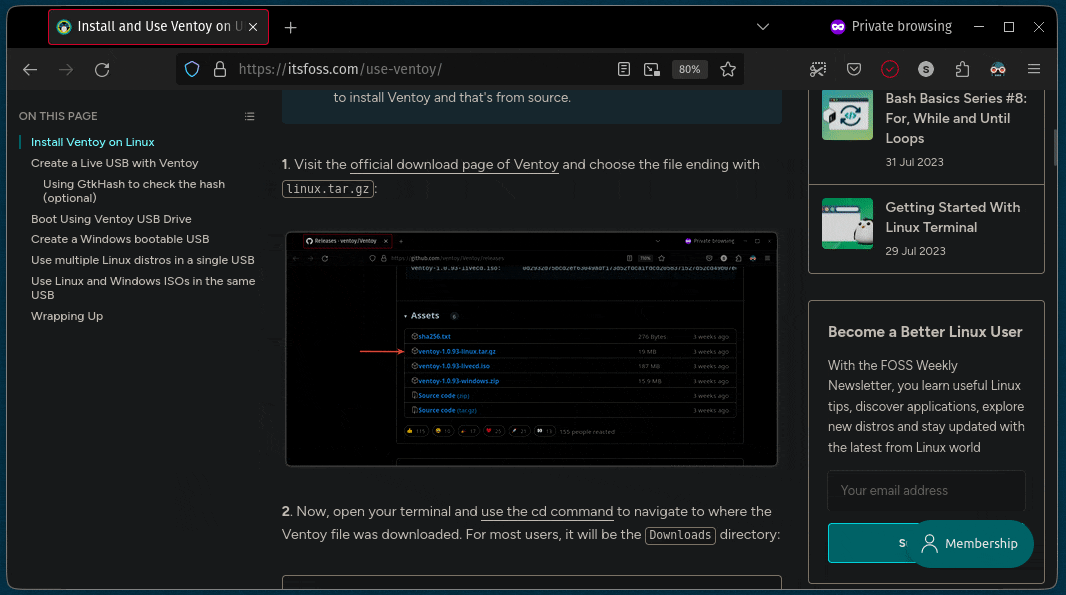
As you can see, there are two options: Save or copy (to clipboard so that you can paste it to a document or editing tool). You can use either as per your use case.
## Take full-page screenshots in Chrome
Taking full-page screenshots in Chrome is a little trickier than in Firefox because it is hidden under the developer options.
Worry not! You'll get there in the following steps:
- Open the menu and go to More Tools-> Developer tools. Alternatively, you can press
`Ctrl + Shift + l`
to directory get into Developer tools. - Press
`Ctrl + Shift + p`
and type**screenshot.** - Select the area or the entire page and a screenshot will be downloaded.
Let me show you how you do it:
That's pretty much all you get with Chrome.
## How to take screenshots using an extension
**The Nimbus extension discussed here is not open source.**
**Non-FOSS Warning!**If you want more features like adding a delay, watermark, or notations, then you have to use an extension.
And for that purpose, I would recommend using Nimbus which lets you do almost everything that any locally installed screenshot tool lets you do.
Download Nimbus for Firefox:
Download Nimbus for Chrome:
Once you're done with the installation, **make sure to sign-up for Nimbus to enable all the features.**
Click on the Nimbus extension logo and you'd see multiple options:
You can choose any of the shown features and once done, based on the action after the capture (mine is an edit) it will download the screenshot directly, open the editor or send it to any of the selected cloud providers.
If you too went with the `Edit`
as an action after capture, then it will open an editor where you can make nominal edits to the screenshot you've captured:
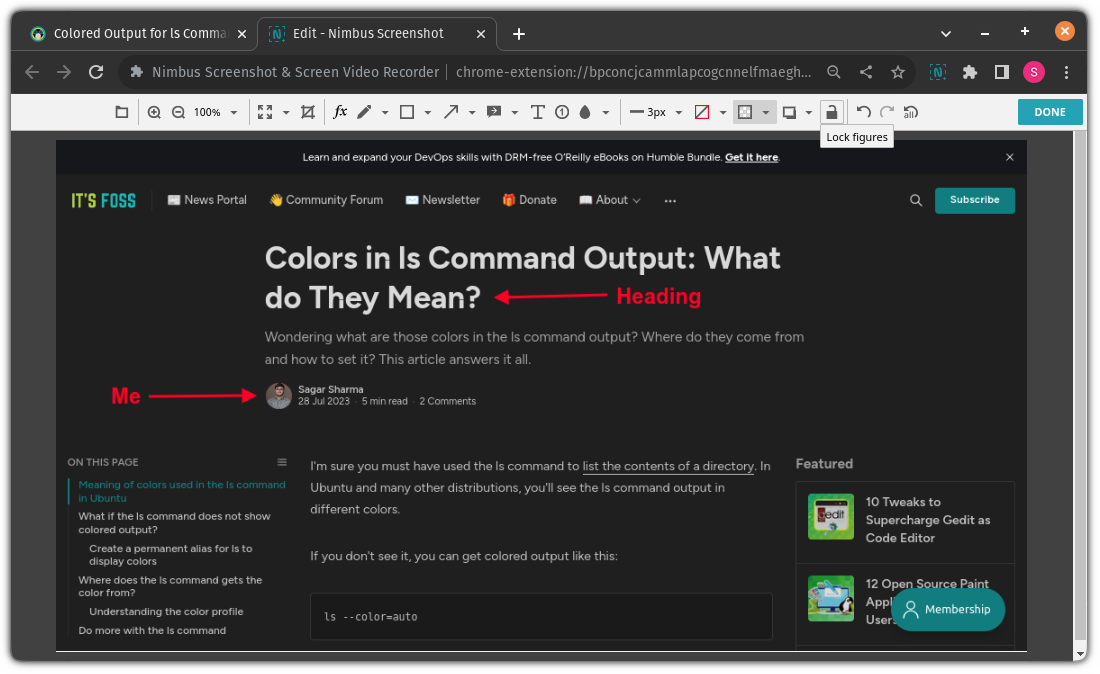
And if you want to add a watermark, know/change shortcuts, change the format of screenshots, and more, then open the Nimbus and hit the little gear button:
Pretty cool features being just an extension. Isn't it?
## Want more features? Checkout screenshot tools
If you don't want to be bound by the extension features, you have to try screenshot tools with more features that can be used anywhere across the system.
If you're a Linux user, then we have a dedicated guide on the [best tools for taking and editing screenshots for Linux](https://itsfoss.com/take-screenshot-linux/):
[Best Tools For Taking and Editing Screenshots in LinuxHere are several ways you can take screenshots and edit the screenshots by adding text, arrows etc. Instructions and mentioned screenshot tools are valid for Ubuntu and other major Linux distributions.](https://itsfoss.com/take-screenshot-linux/)

I hope you liked this quick Firefox trick. Keep visiting It's FOSS for more such learnings. |
16,143 | 如何关闭 KDE 钱包? | https://itsfoss.com/disable-kde-wallet/ | 2023-08-31T09:41:05 | [
"KDE 钱包",
"密码"
] | https://linux.cn/article-16143-1.html | 
>
> 不喜欢 KDE 钱包不时弹出?这里教你如何禁用它。
>
>
>
KDE <ruby> 钱包管理器 <rt> Wallet Manager </rt></ruby> 是 KDE Plasma 桌面默认包含的一个应用,用于存储和管理密码。
无论是存储网站凭据还是 SSH 密钥密码,你都可以使用 KDE 钱包来完成这一切。它与系统的其余部分集成良好,没有任何麻烦。你可以将其配置执行更多操作(或与更多应用和窗口管理器集成)。
既然 KDE 钱包是一个有用的程序,为什么要关闭它呢?
有时,当你与处理密码/凭据的操作交互时,KDE 钱包可能会弹出。因此,如果你遇到这种情况,我们的指南可以帮助你禁用钱包。

### 禁用 KDE 钱包的最快方法
幸运的是,你不需要使用终端或任何类型的命令来禁用它。你可以使用图形用户界面(GUI)直接从系统设置中执行此操作。
请注意,我在 **KDE Plasma 27.4** 上尝试过此操作。
首先,从应用坞或搜索栏打开 <ruby> 系统设置 <rt> System Settings </rt></ruby> 应用。

接下来,从左侧边栏中的菜单中,单击 “<ruby> KDE 钱包 <rt> KDE Wallet </rt></ruby>”。
>
> ? 如果你运行的是旧版本的 KDE Plasma,并且找不到下面的设置,那么需要手动安装 KDE <ruby> 钱包管理器 <rt> Wallet Manager </rt></ruby>(kwalletmanager)。
>
>
> 你可以通过 KDE 的软件中心(<ruby> 发现 <rt> Discover </rt></ruby> 应用)执行此操作,然后返回系统设置以查找所需的选项。
>
>
> 
>
>
>
这里,你可以访问钱包首选项,其中默认启用 KDE 钱包。
你所要做的就是取消选中 “<ruby> 启用 KDE 钱包子系统 <rt> Enable the KDE wallet subsystem </rt></ruby>” 选项。

完成后,点击 “<ruby> 应用 <rt> Apply </rt></ruby>” 使更改生效。系统可能会提示你使用密码验证操作。

确实,并不是每个 KDE Plasma 用户都使用这个钱包应用。如果它困扰你或与其他应用冲突,你只需将其禁用即可。
此外,你可以探索一些适用于 Linux 的 [最佳密码管理器](https://itsfoss.com/password-managers-linux/):
>
> **[5 个 Linux 上的最佳密码管理器](https://itsfoss.com/password-managers-linux/)**
>
>
>
? 你对 KDE 钱包有何看法? 你经常使用它吗? 之前有让你烦恼吗? 除了默认钱包之外,你更喜欢使用什么? 在下面的评论中分享你的想法。
*(题图:MJ/45d57fcd-72c3-489d-9051-2a1ad1b5eb96)*
---
via: <https://itsfoss.com/disable-kde-wallet/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

KDE Wallet Manager is an app included by default with KDE Plasma desktop to store and manage passwords.
Whether it is about storing a website credential or an SSH key passphrase, you can do all that with KDE Wallet. It integrates well with the rest of the system without any hassle. You can configure it to do more (or integrate with more applications and window managers).
Considering it is a useful utility, why would you want to turn off the KDE wallet?
Sometimes KDE Wallet can pop up when you interact with an action that deals with a password/credentials. So, if that happens to you, our guide here can help you disable the wallet.
**Suggested Read 📖**
[11 Ways to Customize KDE Desktop in LinuxKDE Plasma can confuse a beginner by the degree of customization it offers. Learn the key points of KDE Plasma customization that you should be aware of.](https://itsfoss.com/kde-customization/)

## Quickest Way to Disable KDE Wallet
Fortunately, you do not need to use the terminal or any sort of commands to disable it. You can do it right from the system settings using the graphical user interface (GUI).
Note that I tried this on **KDE Plasma 27.4**.
First, open the **System Settings **app from the dock or search bar.
Next, from the menu in the left sidebar, click on "**KDE Wallet**".
You can do this via the software center of KDE (Discover) and then head back to the system settings to find the required option.
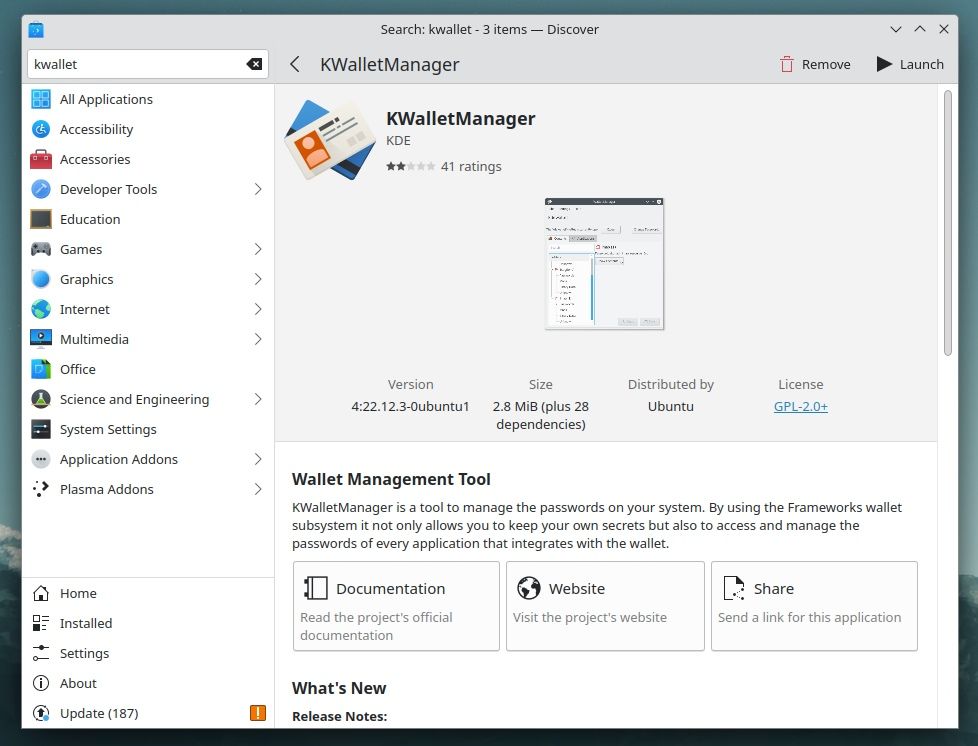
Here, you can access the wallet preferences, where the KDE wallet is enabled by default.
All you have to do is uncheck the "**Enable the KDE wallet subsystem**" option.
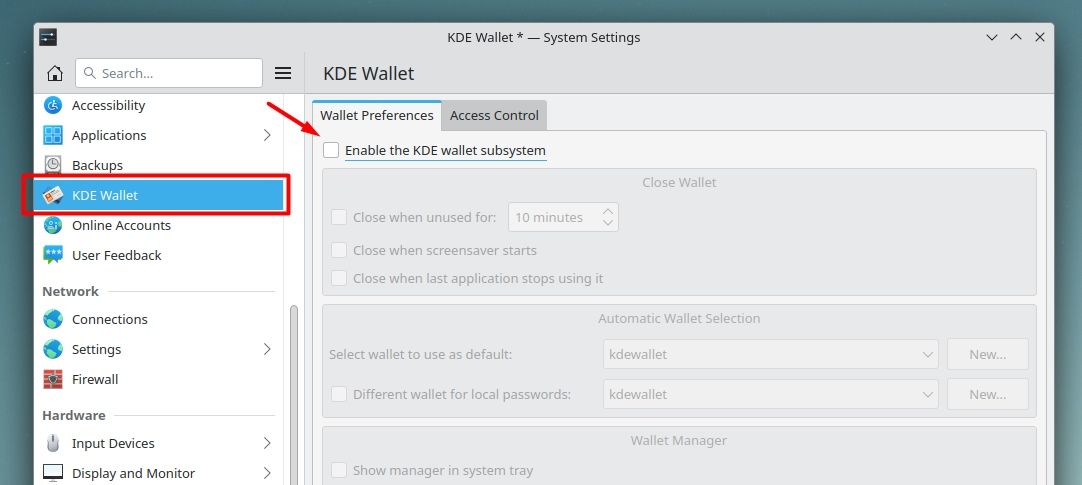
Once done, hit "**Apply**" to have the changes in effect. You might be prompted to authenticate the action using the password.
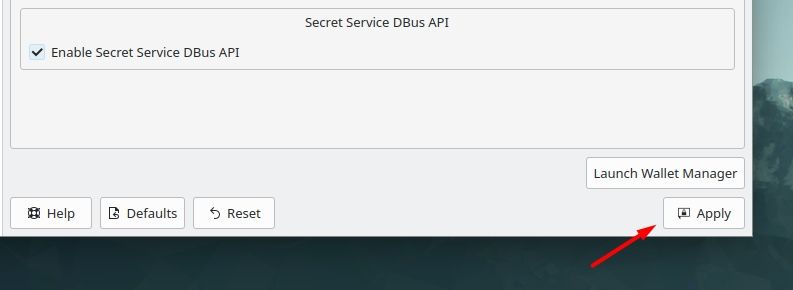
Sure, not every KDE Plasma user utilizes the wallet. But, if it bothers you or conflicts with other applications, you can simply disable it.
Furthermore, you can explore some of the [best password managers](https://itsfoss.com/password-managers-linux/) available for Linux:
[Top 5 Best Password Managers for Linux [2023]Linux Password Managers to the rescue!](https://itsfoss.com/password-managers-linux/)

*💬 What do you think about KDE Wallet? Do you use it often? Did it annoy you before? What do you prefer using instead of the default wallet? Share your thoughts in the comments down below.* |
16,144 | Mageia 9 发布:搭载 Linux 内核 6.4,支持 PulseAudio | https://news.itsfoss.com/mageia-9-released/ | 2023-08-31T10:20:28 | [
"Mageia"
] | https://linux.cn/article-16144-1.html | 
>
> 最新的 Mageia 主要版本已经推出,赶快来试试看吧。
>
>
>
Mageia 最初是 [Mandriva Linux](https://en.wikipedia.org/wiki/Mandriva_Linux) 的一个分支,但现在已经发展成全面的 [独立 Linux 发行版](https://itsfoss.com/independent-linux-distros/)。
从 2010 年以来,Mageia 已经成为一个用于桌面或服务器的稳定且安全的操作系统,并且定期更新。
它的近期的发布公告揭示了 Mageia 9 带来的众多核心改进。
下面就让我为你介绍一下这些改进。
### ? Mageia 9:新亮点是什么?

由最新发布的 [Linux 内核 6.4](https://news.itsfoss.com/linux-kernel-6-4/) 驱动的 Mageia 9,与前一个版本相比,有了大量的提升。
以下是一些主要的亮点:
* 改善了内核与硬件的支持
* 更新了软件套件
* 升级了桌面环境
### 改善了内核与硬件的支持
得益于 Linux 内核 6.4,Mageia 9 配备了 [Mesa 3D 23.1](https://docs.mesa3d.org/relnotes/23.1.0.html),这使得图形支持达到了新的高度。
在硬件方面,**Mageia 9 使用了针对 AMD/ATI 显卡的自由视频驱动程序,AMDGPU**,能同时支持新旧显卡。不过,似乎专有驱动程序不能用于这个版本。
另外,**对于英伟达显卡** ,与 Mageia 8 相比,Xorg Nouveau 驱动的表现得到了提升,并且在非自由仓库中还提供了专有的英伟达驱动程序。
因此,Mageia 9 能够同时支持新款和旧款的英伟达 GPU。
还有,Mageia 9 提供了 **[X.Org](http://X.Org) 21.1.8** 和 **XWayland 22.1.9**,这些都已从 Xserver 分离出来,以便进行更加方便的维护。
### 更新的软件套件
Mageia 9 特色之一是它丰富的应用策略,所有这些应用都已经升级至新版本。
包含如下内容:
* [LibreOffice 7.5](https://news.itsfoss.com/libreoffice-7-5-release/)
* Blender 3.3.4
* VirtualBox 7.0.10
* NeoVim 0.9.1
* Xen 4.17.0
* Ruby 3.1.4
* QEmu 7.2
* RPM 4.18
* Vim 9.0
* PHP 8.2
### 桌面环境升级

首先,由于 Mageia 的默认桌面是 KDE Plasma,让我们先从这个开始。
Mageia 9 带有基于 **Qt 5.15.7** 构建的 **KDE Plasma 5.27.5**、**KDE Frameworks 5.105** 和 **KDE Applications 23.04.1**。
然后,对于 **GNOME 版** ,Mageia 9 提供了 **GNOME 44.2** ,现在默认在启动时运行 Wayland,同时提供了 “GNOME on Xorg” 的备选会话选项。
对于 **Xfce** ,Mageia 9 发行了 [Xfce 4.18](https://news.itsfoss.com/xfce-4-18-release/),现在有专门的 32 位 / 64 位的立付 DVD。
最后,我们还有 **MATE 1.26.0** 、**Cinnamon 5.6**、**LXQt 1.3.0** ,这些都是 Mageia 9 提供的其它版本。
### ?️ 其他技术性变化
总结一下,以下是一些值得强调的其他更改:
* 同时支持 PulseAudio 和 PipeWire 声音服务器。
* 如果禁用了推荐软件包,将减少安装占用。
* RPM 数据库现在采用 SQLite 记录,已不再使用 Berkeley DB。
* 对 [Nvidia Optimus](https://en.wikipedia.org/wiki/Nvidia_Optimus) 笔记本进行了重大性能提升。
要了解此版本更多详情,可翻阅 [发布说明](https://wiki.mageia.org/en/Mageia_9_Release_Notes)。
### ? 下载 Mageia 9
Mageia 9 现已可以下载,欢迎访问 [官方网站](https://www.mageia.org/en/downloads/) 进行下载。
>
> **[Mageia 9](https://www.mageia.org/en/downloads/)**
>
>
>
**针对现有用户**,你可以按照官方提供的 [方便的指南](https://wiki.mageia.org/en/How_to_choose_the_right_Mageia_upgrade_method) 进行升级。
? 你对新变化有何感想?你是否一直期待着这次发布?欢迎在下方留言分享你的观点。
---
via: <https://news.itsfoss.com/mageia-9-released/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

What started as a fork of [Mandriva Linux](https://en.wikipedia.org/wiki/Mandriva_Linux?ref=news.itsfoss.com), now has grown into a fully-fledged [independent Linux distro](https://itsfoss.com/independent-linux-distros/?ref=news.itsfoss.com).
Started back in 2010, Mageia has come a long way since. It is now a stable and secure operating system for desktop/server use that gets regular updates.
With a recent announcement, Mageia 9 was introduced with plenty of key improvements.
Allow me to take you through those.
## 🆕 Mageia 9: What's New?
Powered by the recently released [Linux Kernel 6.4](https://news.itsfoss.com/linux-kernel-6-4/), Mageia 9 offers a plethora of improvements over its predecessor.
Some key highlights include:
**Better Kernel and Hardware Support****Updated Software Suite****Desktop Environment Upgrades**
### Better Kernel and Hardware Support
Thanks to Linux Kernel 6.4, Mageia 9 is equipped with ** Mesa 3D 23.1**, that has resulted in better graphics support than ever before.
In the case of hardware, **Mageia 9 uses free video drivers for AMD/ATI graphics cards, AMDGPU**, to support both newer and older cards. But, proprietary drivers don't seem to work with this release.
Similarly, **in the case of Nvidia**, the performance of the Xorg Nouveau driver has been enhanced compared to Mageia 8, and proprietary Nvidia drivers are provided via the non-free repositories.
This has allowed for supporting both, older, and newer Nvidia GPUs.
Furthermore, Mageia 9 is offered with **X.Org 21.1.8 **and **XWayland 22.1.9, **they have been split from Xserver for easier maintenance.
### Updated Software Suite
Mageia 9 features an extensive suite of applications, that have been updated to newer versions.
Some include:
[LibreOffice 7.5](https://news.itsfoss.com/libreoffice-7-5-release/)**Blender 3.3.4****VirtualBox 7.0.10****NeoVim 0.9.1****Xen 4.17.0****Ruby 3.1.4****QEmu 7.2****RPM 4.18****Vim 9.0****PHP 8.2**
**Suggested Read **📖
[LibreOffice 7.5 Unveils Stunning New App Icons and Cool FeaturesLibreOffice 7.5 seems to have a new personality with its brand-new app icons and other improvements.](https://news.itsfoss.com/libreoffice-7-5-release/)

### Desktop Environment Upgrades
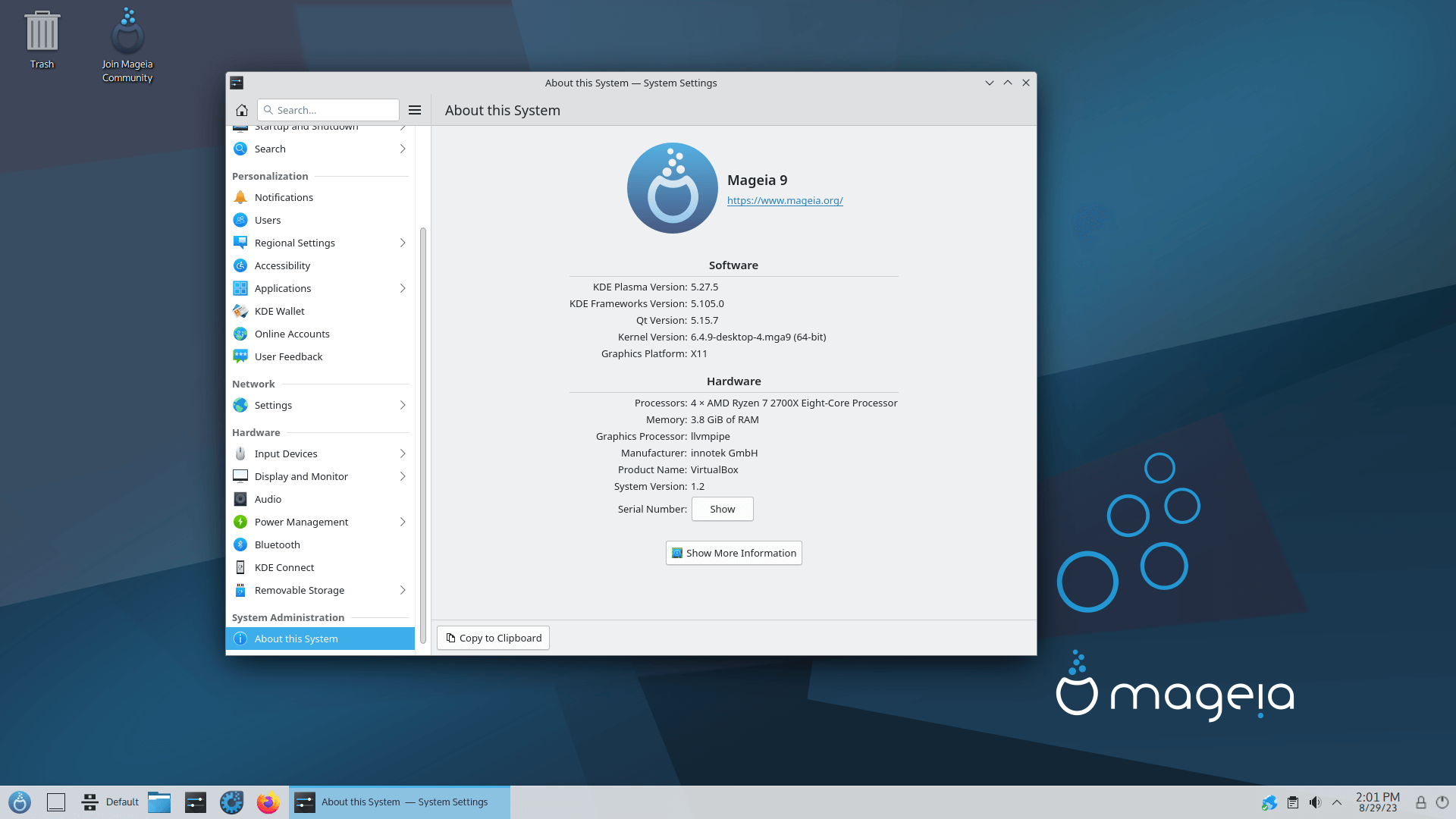
First things first, as Mageia's default desktop is KDE Plasma, we start with that.
Mageia 9 features **KDE Plasma 5.27.5**, that has been built on top of **Qt 5.15.7**, **KDE Frameworks 5.105**, and **KDE Applications 23.04.1**.
**Suggested Read **📖
[💕Valentine’s Gift for KDE Users Arrive in the Form of Plasma 5.27 ReleaseKDE Plasma 5.27 has landed with plenty of improvements.](https://news.itsfoss.com/kde-plasma-5-27-release/)

Then, for **GNOME edition**, Mageia 9 features **GNOME 44.2**, that now defaults to running Wayland on boot with an alternative “GNOME on Xorg” session available.
**In the case of Xfce**, Mageia 9 features [ Xfce 4.18](https://news.itsfoss.com/xfce-4-18-release/), that now has dedicated 32-bit/64-bit Live DVDs.
And finally, to sum it up, we have **MATE 1.26.0**, **Cinnamon 5.6**, and **LXQt 1.3.0 **as other variants being offered with Mageia 9.
### 🛠️ Other Technical Changes
To conclude, here are some other changes that are worth mentioning:
- Support for both PulseAudio and PipeWire sound servers.
- Lower install footprint if disabling the recommended packages.
- The RPM database now uses SQLite instead of Berkeley DB.
- Major performance improvements for
[Nvidia Optimus](https://en.wikipedia.org/wiki/Nvidia_Optimus?ref=news.itsfoss.com)laptops.
You may go through the [release notes](https://wiki.mageia.org/en/Mageia_9_Release_Notes?ref=news.itsfoss.com) to know more about this release.
**Suggested Read **📖
[13 Independent Linux Distros That are Built From ScratchUnique and independent Linux distributions that are totally built from scratch. Sounds interesting? Check out the list here.](https://itsfoss.com/independent-linux-distros/?ref=news.itsfoss.com)

## 📥 Download Mageia 9
Mageia 9 is available for download right now, head over to the [official website](https://www.mageia.org/en/downloads/?ref=news.itsfoss.com) to get started.
**For existing users:** You can follow the official [handy guide](https://wiki.mageia.org/en/How_to_choose_the_right_Mageia_upgrade_method?ref=news.itsfoss.com) to upgrade.
*💬 What do you think about the new changes? Were you waiting for this release? Share your thoughts in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,146 | FreeBSD 现在能在 25 毫秒内完成启动 | https://www.theregister.com/2023/08/29/freebsd_boots_in_25ms/ | 2023-08-31T16:28:00 | [
"微虚拟机",
"FreeBSD"
] | https://linux.cn/article-16146-1.html |
>
> 这是运行在 AWS Firecracker 上的,当然,同时也有其他的新兴微<ruby> 虚拟机 <rp> ( </rp> <rt> microVM </rt> <rp> ) </rp></ruby>引擎可供选择。
>
>
>

在更换了 FreeBSD 内核中的排序算法后,其启动速度提高了 100 倍以上……虽然这是专门针对 <ruby> 微虚拟机 <rt> microVM </rt></ruby> 的优化,但所有人都应能从中受益。
过去五年,微虚拟机在科技研发领域中备受关注。其核心理念是重新包装和创新了 IBM 在 1960 年代随着 <ruby> 虚拟机管理程序 <rt> hypervisor </rt></ruby> 诞生所发明的 [一些概念和技术](https://www.theregister.com/2011/07/14/brief_history_of_virtualisation_part_2/):设计专门作为另一个操作系统上的访客系统运行的操作系统。这意味着该操作系统必须专门构建在虚拟机内执行,并与特定的管理程序提供的资源进行交互,而不是模拟硬件。
这就意味着访客操作系统几乎不需要针对真实硬件的支持,只需要 [VirtIO](https://wiki.osdev.org/Virtio) 驱动,它们可以直接和宿主机的管理程序提供的功能进行交互。反过来说,管理程序无需提供模拟的 PCI 总线、模拟的电源管理、模拟的显卡、模拟的网卡等等。结果就是,管理程序本身可以变得更加微型和简化。
通过无情地缩减虚拟机监视器和运行在其内部的操作系统,这让两端都能更小、更简洁。意味着虚拟机能更少的使用资源,并能更快速地启动。
目前,这个商业目标是提供 “<ruby> 无服务器 <rt> serverless </rt></ruby>” 的计算能力。实际上,“无服务器” 是一种市场双关语:当然,真实世界中的服务器仍存在于某个数据中心中。但这与提供“基础设施即服务(IaaS)”模型不同,而是提供“[函数即服务(FaaS)](https://www.theregister.com/2018/12/19/serverless_computing_study/)”的模式。这就代表着你不需要了解任何有关基础设施的知识 —— 你的程序直接调用另一个程序,然后管理工具会运行所需的特定操作,返回结果,然后删除用于执行计算的虚拟机。你根本不需要知道这过程在何处,如何进行。
对消费者来说,这种技术的优势在于其快速和易用性。而对服务提供商而言,因为能够更快地回收和再利用资源,使得相同的硬件能服务更多的客户,这是一个巨大的优势。
AWS 通过一项名为 Lambda 的服务提供 FaaS,这个名称是来源于一个深奥的函数式编程术语。Lambda 由亚马逊自家研发的 [Firecracker](https://www.theregister.com/2018/11/27/aws_sets_firecracker/) 管理程序提供支持,Firecracker 同样也支撑着 [Fargate](https://www.theregister.com/2020/04/09/aws_revamps_fargate_serverless_containers/) 这一无服务器服务。
Firecracker 基于 Linux 内核的内建 KVM 管理程序:这本身就有别于之前 AWS [基于 Xen 管理程序](https://www.theregister.com/2017/11/07/aws_writes_new_kvm_based_hypervisor_to_make_its_cloud_go_faster/) 的实践。这也就意味着它本质上是一个 Linux-on-Linux 的解决方案。这听起来对 FreeBSD 内核开发者 Colin Percival 来说像是一个挑战,正如我们 [一年前的报道](https://www.theregister.com/2022/10/19/freebsd_comes_to_amazons_lightweight/):他决定在 Firecracker 上运行 FreeBSD。然而就如同大部分的计算任务一样,优化的过程大致上是:首先,让它可以运行;然后,提高其运行速度。
根据他本周稍早的一则 [推文](https://twitter.com/cperciva/status/1693127769901969772),他最新的性能优化成果相当令人震惊:替换排序算法使 FreeBSD 内核启动过程加速了约一百倍,将内核加载时间降至了惊人的 25 毫秒。换言之,只有四十分之一秒的时间。
>
> FreeBSD(HEAD)现已不再执行其 SYSINIT 上的冒泡排序。如今,我们运行的是更高效、速度大概快了 100 倍的归并排序:<https://cgit.freebsd.org/src/commit/?id=9a7add6d01f3c5f7eba811e794cf860d2bce131d>
>
>
>
> >
> > 当 FreeBSD 内核在 Firecracker (配备 1 CPU,128 MB 内存)中启动时,现在有大约 7% 的时间用于执行其 SYSINIT 上的冒泡排序。
> >
> >
> > 当你需要对上千个条目进行排序时,`O(N^2)` 的复杂度可能会带来较大的影响。因此,是时候将冒泡排序替换为更高效的算法了。
> >
> >
> >
>
>
>
这一调整只是一系列优化措施中的最新一个环节,两天后,他进一步 [详细](https://www.usenix.org/publications/loginonline/freebsd-firecracker) 阐述了这些优化。这包括了引导所需的初始更改:消除了假定在 Xen 下引导的一些初始化步骤,然后查询 ACPI 获取处理器的类型和数量。这一步出现了问题,因为 Firecracker 并未提供 ACPI。接着,对其仿真的唯一的硬件,串行控制台,进行初始化也失败了。
在内核成功启动之后,内存的使用迅速成为了一个问题:Firecracker 默认只给客户端分配了 128MB 的内存,原因在于一个必须修改的假设。之后是一整套的优化清单,每一项都为减少时间作出了一部分贡献。
即便你不是特别懂技术,阅读这篇文章也会很有趣。一些步骤更改了在专用硬件上引导的合理选择,在虚拟环境中,这些选择在机器产生、做工作、然后在几秒钟内再次被删除的情况下,已经无法适用。
Percival [评论](https://news.ycombinator.com/item?id=37205578) 称:
>
> 我相信在相同的环境下,Linux 的引导时间是 75-80 毫秒,而我已经让 FreeBSD 在 25 毫秒内引导。
>
>
>
他 [接着](https://news.ycombinator.com/item?id=37205475) 说道:
>
> 当我开始研究提速引导的过程时,内核大约需要 10 秒钟的时间来引导,所以现在我拥有的内核引导速度,比我几年前快约 400 倍。
>
>
>
目前,已经优化的系统内核是 FreeBSD 14 版的,运行在 x86-64 架构上,但也正在进行适配到 Arm64 的工作 —— AWS 是世界上 [最大的 Arm 服务器用户](https://www.theregister.com/2023/08/08/amazon_arm_servers/)。
Firecracker 是众多备受瞩目的微虚拟机中的一员,但也有其他的微虚拟机,而且它的成功也激励了 QEMU 开发者增加了一个 [微虚拟机](https://qemu.readthedocs.io/en/v8.1.0/system/i386/microvm.html) 平台。Canonical 的开发者 Christian Erhardt 在 [博客](https://cpaelzer.github.io/blogs/009-microvm-in-ubuntu/) 上介绍了如何在 Ubuntu 中使用这种技术,并且在线代码开发环境供应商 Hocus 最近 [解释](https://hocus.dev/blog/qemu-vs-firecracker/) 了为什么它从 Firecracker 转移到了 QEMU 等价物。
我们可以看到微虚拟机有很多潜在的使用场景,不仅仅是在云场景中。能够在一个完全不同的 OS 上运行为另一个 OS 构建的单个程序,而不需要始终运行完整的模拟环境,可能在各种情况下都非常方便。
容器是一个非常有用的工具,但在容器中你只能运行与宿主 OS 相同的二进制文件。运行任何其他的东西 —— 比如在 macOS 上运行 Docker Linux 容器 —— 意味着有一些模拟和一个访客操作系统被隐藏在堆栈的某个位置。这个 VM 能够越小,并且使用的资源越少,无论是对容器还是整个机器的整体性能来说都会更好。
*(题图:MJ/a5910e84-656d-4a5c-abad-bb0b0ffcb3fc)*
---
via: <https://www.theregister.com/2023/08/29/freebsd_boots_in_25ms/>
作者:[Liam Proven](https://www.theregister.com/Author/Liam-Proven) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-16144-1.html) 荣誉推出
| 200 | OK | This article is more than **1 year old**
# FreeBSD can now boot in 25 milliseconds
## On AWS Firecracker – but there are other new micro-VM engines around, too
Replacing a sort algorithm in the FreeBSD kernel has improved its boot speed by a factor of 100 or more… and although it's aimed at a micro-VM, the gains should benefit everyone.
MicroVMs are a hot area of technology R&D in the last half decade or so. The core idea is a re-invention of some of concepts and technology that [IBM invented along with the hypervisor](https://www.theregister.com/2011/07/14/brief_history_of_virtualisation_part_2/) in the 1960s: designing OSes specifically to run as guests under another OS. This means building the OS specifically to run inside a VM, and to talk to resources provided by a specific hypervisor rather than to fake hardware.
This means that the guest OS needs next to no support for real hardware, just [VirtIO](https://wiki.osdev.org/Virtio) drivers which talk directly to facilities provided by the host hypervisor. In turn, the hypervisor doesn't have to provide an emulated PCI bus, emulated power management, emulated graphics card, emulated network interface cards, and so on. The result is that the hypervisor itself can be much smaller and simpler.
The result of ruthlessly chopping down both the hypervisor, and the OS that runs inside it, is that both ends can be much smaller and simpler. That means that VMs can use much fewer resources, and start up much quicker.
At the moment, the commercial goal of this is providing "serverless" compute power. "Serverless" computing is marketing double-speak, really: of course there really are servers, somewhere in a datacenter. But rather than providing Infrastructure as a Service, the famed IaaS model, this is [Function as a Service instead](https://www.theregister.com/2018/12/19/serverless_computing_study/). The idea is that you don't need to know anything about the infrastructure: your program calls another program, and the management tooling spawns as many instances as needed to run that specific operation, return the result, and then delete the VMs used to run the calculations. You never need to know where it happened or how.
For the customer, it's good because it's fast and it's easy. For the providers, it's good because it means the resources are freed up again much more quickly, so they can reused immediately, which means supporting more customers on the same amount of hardware.
AWS is offering FaaS via a service called Lambda, after an arcane bit of functional programming terminology. Lambda is powered by Amazon's home-grown [Firecracker hypervisor](https://www.theregister.com/2018/11/27/aws_sets_firecracker/) which also powers its [Fargate serverless offering](https://www.theregister.com/2020/04/09/aws_revamps_fargate_serverless_containers/).
Firecracker is based on the Linux kernel's built-in KVM hypervisor: in itself, something of a departure, as up until then, [AWS was based on the Xen hypervisor](https://www.theregister.com/2017/11/07/aws_writes_new_kvm_based_hypervisor_to_make_its_cloud_go_faster/). This means it's inherently a Linux-on-Linux offering. That sounded like a challenge to FreeBSD kernel developer Colin Percival, as we [reported on a year ago](https://www.theregister.com/2022/10/19/freebsd_comes_to_amazons_lightweight/): he decided to get FreeBSD running on Firecracker. As with most of computing in general, though, the overall optimization process is: first, get it working at all; then, make it go fast.
According to his [tweet](https://twitter.com/cperciva/status/1693127769901969772) earlier this week, his latest performance optimization is impressive: replacing a sort algorithm made part of the FreeBSD kernel startup process around a *hundred times* faster, bringing the kernel loading time down to an impressive 25 milliseconds. That's a quarter of one-tenth of a second.
FreeBSD (HEAD) no longer spends time running a bubblesort on its SYSINITs. We're now running a mergesort which is ~100x faster:
— Colin Percival (@cperciva)[https://t.co/1F8Yodedh3][https://t.co/AvmVVwz9G5][August 20, 2023]
This tweak is just the latest in a long series, which he described in much more [detail](https://www.usenix.org/publications/loginonline/freebsd-firecracker) a couple of days later. It describes the preliminary changes needed to get it booting at all: removing several initialization steps which assumed it was booting under Xen, then querying ACPI for the type and number of processors. That failed, as Firecracker doesn't provide ACPI. Then, initialization of one of the only bits of hardware it does emulate, a serial console, failed.
After the kernel was successfully starting, memory usage quickly became a problem: Firecracker defaults to assigning the guest a mere 128MB of RAM, due to an assumption which had to be changed. What follows is a whole laundry list of optimizations, each of which contributed a small time saving.
It's an interesting read, even if you're not super technical. Some of the steps change things that were quite reasonable choices for booting on dedicated hardware, which no longer make sense in a virtual environment where a machine is spawned, does some work, and is deleted again within a matter of a few seconds.
Percival [commented](https://news.ycombinator.com/item?id=37205578):
I believe Linux is at 75-80 ms for the same environment where I have FreeBSD booting in 25 ms.
And [continued](https://news.ycombinator.com/item?id=37205475):
When I started working on speeding up the boot process, the kernel took about 10 seconds to boot, so I have a kernel booting about 400x faster now than I did a few years ago.
For now, the optimized kernel is the FreeBSD 14 one, on x86-64, but work is underway to bring it to Arm64 as well — AWS is [the biggest user of Arm servers](https://www.theregister.com/2023/08/08/amazon_arm_servers/) in the world.
[Spotted in the wild: Chimera – a Linux that](https://www.theregister.com/2023/02/13/chimera_non_gnu_linux/)*isn't*GNU/Linux[helloSystem 0.8: A friendly, all-graphical FreeBSD](https://www.theregister.com/2023/01/31/hellosystem_08/)[Double BSD birthday bash beckons – or triple, if you count MidnightBSD 3.0](https://www.theregister.com/2023/04/13/freebsd_132_openbsd_73/)[FreeBSD comes to Amazon's lightweight hypervisor](https://www.theregister.com/2022/10/19/freebsd_comes_to_amazons_lightweight/)
Firecracker is one of the higher-profile microVMs around, but there are others, and its success has inspired the QEMU developers to add a [microvm](https://qemu.readthedocs.io/en/v8.1.0/system/i386/microvm.html) virtual platform as well. Canonical developer Christian Erhardt has [blogged](https://cpaelzer.github.io/blogs/009-microvm-in-ubuntu/) about how to use this in Ubuntu, and online-code-development-environment vendor Hocus recently [explained](https://hocus.dev/blog/qemu-vs-firecracker/) why it switched from Firecracker to the QEMU equivalent instead.
We can see a lot of potential uses for microVMs, not just in cloud scenarios. The ability to run a single program built for one OS on top of a totally different OS, without the overhead of running a full emulated environment all the time, could be very handy in all kinds of situations.
Containers are a very useful tool, but in containers you can only run binaries for the same host OS. Running anything else – such as Docker Linux containers on macOS – means that some emulation and a guest OS have been hidden away somewhere in the stack. The smaller that VM can be, and the fewer resources it uses, the better the overall performance, not only of the containers but of the whole machine. ®
80 |
16,147 | 如何使用 grubby 更改 RHEL 8 和 9 的默认内核 | https://www.2daygeek.com/changing-default-kernel-rhel-8-rhel-9/ | 2023-09-01T10:51:29 | [
"内核"
] | https://linux.cn/article-16147-1.html | 
通常 Linux 系统会默认引导系统进入最新安装的内核,并保留最新的 3 个 Linux 内核引导条目。
假设你已经执行了 `yum update`,并且新的内核作为更新的一部分已经安装了。这时,由于这个新内核与应用程序不兼容,它会阻止应用程序启动。
想要暂时解决这个问题,你应该还是引导系统进入旧内核。
在本文中,我们将向您展示如何使用 `grubby` 工具将旧的内核版本设置为 RHEL 8 和 RHEL 9 系统上的默认版本。
### grubby 是什么
`grubby` 是一个命令行工具,用于在多个架构上更新和显示引导加载配置文件的信息。
### 检查当前引导的内核
你可以使用如下的 `uname` 命令来检查当前引导/加载的内核。
```
# uname -r
4.18.0-477.13.1.el8_8.x86_64
```
### 列出默认内核
使用 `grubby` 验证默认内核版本,运行以下命令:
```
# grubby --default-kernel
/boot/vmlinuz-4.18.0-477.13.1.el8_8.x86_64
```
要获取当前默认内核的索引号,请运行以下命令:
```
# grubby --default-index
0
```
### 检查已安装的内核
要检查已安装的内核的列表,请运行以下命令:
我们来解释以下的输出信息。最新安装的内核的**条目索引**为 `0`,接下来的 **较旧的内核** 版本将会是 `1`,第二个更旧的内核版本将会是 `2`,而 **救援内核** 的条目索引将会是 `3`。
```
# grubby --info=ALL | egrep -i 'index|title'
index=0
title="Red Hat Enterprise Linux (4.18.0-477.13.1.el8_8.x86_64) 8.8 (Ootpa)"
index=1
title="Red Hat Enterprise Linux (4.18.0-425.19.2.el8_7.x86_64) 8.7 (Ootpa)"
index=2
title="Red Hat Enterprise Linux (4.18.0-425.13.1.el8_7.x86_64) 8.7 (Ootpa)"
index=3
title="Red Hat Enterprise Linux (0-rescue-13iu76884ec5490puc67j8789s249b0c) 8.2 (Ootpa)"
```
### 更改默认内核引导条目
我们可以用两种方式,使用 “内核文件名”,或者使用 “内核条目索引”。我们设置索引号为 `1` 的 `4.18.0-425.19.2.el8_7.x86_64` 为默认内核,以此满足应用程序的依赖关系。
语法:
```
# grubby --set-default [kernel-filename]
```
```
# grubby --set-default /boot/vmlinuz-4.18.0-425.19.2.el8_7.x86_64
```
或者
```
# grubby --set-default vmlinuz-4.18.0-425.19.2.el8_7.x86_64
```
使用内核条目索引更改默认的内核引导:
语法:
```
# grubby --set-default-index=[kernel-entry-index]
```
```
# grubby --set-default-index=1
```
### 重启系统
重启系统,检查旧内核是否持久更改。
```
# reboot
```
或者
```
# init 6
```
### 验证更改
让我们检查一下在上一步中添加的内核是否生效了。好了,按我们的预期使用了较旧的内核 “N-1” 进行引导了。
```
# uname -r
4.18.0-425.19.2.el8_7.x86_64
# grubby --default-kernel
/boot/vmlinuz-4.18.0-425.19.2.el8_7.x86_64
```
要检查所有内核的详细信息,请运行以下命令:
```
# grubby --info=ALL
```

### 总结
在本教程中,我们展示了如何使用 `grubby` 工具在 RHEL 8 和 RHEL 9 系统上将旧版本内核设置为默认。
如果有任何问题或反馈,欢迎在下方发表评论。
*(题图:MJ/9204b9c1-c1ad-4694-b2f6-a7d983976d22)*
---
via: <https://www.2daygeek.com/changing-default-kernel-rhel-8-rhel-9/>
作者:[Rasool Cool](https://www.2daygeek.com/author/rasool/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[onionstalgia](https://github.com/onionstalgia) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
16,148 | PyCharm 和 Android Studio 为 Linux 版本增加 Wayland 支持 | https://news.itsfoss.com/intellij-wayland-support/ | 2023-09-01T15:55:48 | [
"Wayland",
"PyCharm",
"IntelliJ"
] | https://linux.cn/article-16148-1.html | 
>
> 如果你是在 Linux 或 WSL 环境下进行开发的开发者,以下这个好消息会让你兴奋起来。
>
>
>
JetBrains 平台近日宣布,基于 IntelliJ 的 IDE 最终将实现对 Wayland [显示服务器](https://itsfoss.com/display-server/) 协议的支持。可能你并不知道,PyCharm 和 IntelliJ IDEA 就是搭建在 IntelliJ 平台之上的出色 IDE,而由谷歌打造的 Android Studio 也是同样的应用。
Wayland 协议逐步成为 Linux 发行版的默认选择,与 X11 相比,它可以提供更快、更安全和更稳定的体验。如果你使用的编程环境能够支持 Wayland,那么用户体验会得到显著提升。
但是,具体表现在哪些方面有所增强,他们怎么实现这个目标的呢?下文有详细解说。
### 分数缩放和 WSL 集成
使用 [Linux 版本的 IntelliJ IDEA](https://itsfoss.com/install-intellij-ubuntu-linux/) 等 IDE 的用户,终将借助分数缩放,可以在高分辨率显示屏上自定义字体、图标的大小。
无论是多屏幕环境,还是高清显示屏,都可以通过 Wayland 的支持享受到提升的 IDE 体验。
你不再需要担心 IDE 的文本显示模糊的问题。
不仅仅局限于原生的 Linux 环境,同样适用于使用 Windows 的 Linux 子系统(WSL),即那些 “[Bash on Windows](https://itsfoss.com/install-bash-on-windows/)” 用户。
Wayland 的支持将确保你可以无缝集成 WSL。
此外,作为用户,你还将享受到 Wayland 带来的以下新特性:
* 弹出式窗口
* HiDPI 支持
* 窗口的交互式缩放
总的说来,通过实现 Wayland 的支持,基于 IntelliJ 的 IDE 将会更具响应速度,实现更高的稳定性和安全性。
### 构建 Wayland 工具集
让 Java 支持 Wayland 是件颇具挑战性的任务,但 IntelliJ 已经找到了应对之策。
JetBrains 和 Oracle 的桌面团队共同开发出一个基于 OpenJDK 21 的 **Wayland 工具集**。
由于拥有该工具集,你将获得一系列能力,包括:
* 基于软件的渲染。
* 极简的窗口装饰。
* 弹出窗口,包括应用于顶层菜单的窗口。
* 提供包括不同每台监视器比例的 HiDPI 和多监视器支持。
此外,他们还计划添加剪贴板**拖放支持**、**基于 Vulkan 的加速渲染**,以及**使用快捷键在窗口间切换**的功能。
你可以通过访问 [OpenJDK 维基](https://wiki.openjdk.org/display/wakefield/Work+breakdown) 来关注 Wayland 工具集的开发进程。
至于 Wayland 支持的具体实现时间并未明确,但可以肯定的是,这项工作正在进行中,而且这也表明 IntelliJ 平台也正在关注以 Linux 为主的用户群。
如需获取更多信息,你可以访问 [官方公告](https://blog.jetbrains.com/platform/2023/08/wayland-support/) 进行查阅。
?对于 IntelliJ 决定在其 IDE 加入 Wayland 原生支持你有什么看法呢?欢迎在评论区分享你的意见。
*(题图:MJ/dbd4f013-3c11-4c2d-83c1-c11df7c8c17b)*
---
via: <https://news.itsfoss.com/intellij-wayland-support/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Good news for developers using Linux!
The Jet Brains platform announced that IntelliJ-based IDEs will finally support the Wayland [display server](https://itsfoss.com/display-server/?ref=news.itsfoss.com) protocol. If you did not know, PyCharm and IntelliJ IDEA are some impressive IDEs based on the IntelliJ platform, and Android Studio is also an example (built by Google).
The Wayland protocol is gradually becoming the default for Linux distributions to provide a faster, secure, and stable experience compared to X11. And, if the coding environments you use support it, the user experience will be enhanced.
But what are the enhancements, and how do they plan to do it? Let me tell you.
**Suggested Read **📖
[Linux Jargon Buster: What is a Display Server in Linux? What is it Used for?In Linux related articles, news and discussions, you’ll often come across the term display server, Xorg, Wayland etc. In this explainer article, I’ll discuss display servers in Linux. What is display server in Linux? A display server is a program which is responsible for the input an…](https://itsfoss.com/display-server/?ref=news.itsfoss.com)

## Fractional Scaling and WSL Integration
Users utilizing an IDE like [IntelliJ IDEA for Linux](https://itsfoss.com/install-intellij-ubuntu-linux/?ref=news.itsfoss.com) can finally benefit from fractional scaling to customize the size of fonts/icons on a high-resolution display.
Multi-monitor setups and high-resolution displays both get an enhanced IDE experience with Wayland support.
You do not have to worry about blurry texts on your IDE anymore.
Not just limited to the native Linux experience but also for users who rely on Windows Subsystem for Linux or, if you would like to call it, '[Bash on Windows](https://itsfoss.com/install-bash-on-windows/?ref=news.itsfoss.com)'.
The Wayland support will ensure that you get a seamless WSL integration.
In addition, you should have the following new benefits with Wayland:
- Pop-up windows
- HiDPI support
- Interactive resizing of windows
Overall, IntelliJ based IDEs should have more responsiveness, stability, and security by introducing the Wayland support.
**Suggested Read **📖
[How to Install Linux Bash Shell on Windows [Step-by-Step Guide]Step-by-step screenshot guide to show you how to install bash on Windows 11 and 10.](https://itsfoss.com/install-bash-on-windows/?ref=news.itsfoss.com)

## Building a Wayland Toolkit
Wayland support on Java is not easy, but IntelliJ has a solution.
Jet Brains and the Oracle desktop team built a **Wayland toolkit** based on OpenJDK 21 to achieve this.
With the toolkit, you get some abilities like:
- Software-based rendering.
- Minimal window decorations.
- Popup windows, including those that are used for top-level menus.
- HiDPI and multi-monitor support, including different per-monitor scales.
Furthermore, they plan to add clipboard **drag and drop support**, **Vulkan-based accelerated rendering**, and **switching between windows** using a shortcut.
You can keep an eye on the Wayland toolkit's progress on the [OpenJDK wiki](https://wiki.openjdk.org/display/wakefield/Work+breakdown?ref=news.itsfoss.com).
There's no particular timeline to expect the Wayland support. But, it is good to hear that it is an ongoing effort, and IntelliJ as a platform also cares about its Linux-focused users.
You can learn more about it in its [official announcement post](https://blog.jetbrains.com/platform/2023/08/wayland-support/?ref=news.itsfoss.com).
*💬 What do you think about IntelliJ's decision to add Wayland native support to its IDEs? Share your thoughts in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,150 | GNOME 45 引入激动人心的更新 | https://news.itsfoss.com/gnome-45/ | 2023-09-02T12:03:59 | [
"GNOME"
] | https://linux.cn/article-16150-1.html | 
>
> 这里列出了在 GNOME 45 中你可以期待的新特性和改进。
>
>
>
每次 GNOME 的主要版本更新对我来说都充满了激动。
你可以始终期待看到 **以 UI 为中心的变化**、**功能增强**,以及**核心应用的更新**。
[GNOME 44](https://news.itsfoss.com/gnome-44-release/) 引入了一些有趣的新功能,比如能够检查正在后台运行的应用、在文件选择器中的缩略图视图等等。
GNOME 45 计划于 **9 月 20 日** 发布,但你已经可以在其 beta 版本中预览到更新的功能集。现在,让我们一起看看在 GNOME 45 中有哪些你可以期待的新内容。
### GNOME 45:有哪些新变化?

主要的亮点包括:
* 新的核心应用
* 系统设置中的新隐私中心
* 系统设置中新的“<ruby> 关于 <rt> About </rt></ruby>”面板
* 日历应用的新图标
* 对 Nautilus 文件管理器 UI 的微调
我将对所有这些改变进行分类,以帮助你更好的理解。那么,让我们立即开始:
#### Nautilus 的改善

在过去,Nautilus 文件管理器没有进行过任何 UI 调整。但是,在 GNOME 45 中,它做了一些微妙的 UI 改版,在侧边栏中你可以看到汉堡菜单。
总的来说,左侧边栏和窗口的其他部分更具区分度。
你还可以期待其性能提升和搜索功能的改善。
#### 系统设置的变更
自 GNOME 43 和 44 版本起,GNOME 在努力改进并清理<ruby> 系统设置 <rt> Settings </rt></ruby>,以便在简化系统设置选项的访问性的同时,简化所有的可用选项。
在这里,“<ruby> 隐私 <rt> Privacy </rt></ruby>”菜单已经改版,选项的展示更加有条理且易于访问。

接下来,“<ruby> 关于 <rt> About </rt></ruby>”区域也进行了调整,以便通过“<ruby> 系统详细信息 <rt> System Details </rt></ruby>”菜单展示技术信息,如下图所示。

你需要点击“系统详细信息”来获取关于操作系统和硬件的所有必要技术信息。

另外,为了让 Linux 新手更轻松上手:
* 在“<ruby> 用户 <rt> User </rt></ruby>”面板中增加了弹出的说明,用于解释自动登录设置。
* 向“<ruby> 分享 <rt> Sharing </rt></ruby>”面板中的选项添加了说明,帮助用户理解可用选项。
* “<ruby> 在线账户 <rt> Online Accounts </rt></ruby>”面板进行了一些改进,以提供更细粒度的控制。
#### 新增的核心应用
GNOME 45 使用了全新的 [Loupe 图像查看器](https://news.itsfoss.com/loupe-image-viewer/) 应用,替代了“<ruby> GNOME 之眼 <rt> Eye of GNOME </rt></ruby>”。

除此之外,你还可以期待出现“[Snapshot](https://news.itsfoss.com/gnome-snapshot/)”,这是一个新的摄像应用。它将替代“<ruby> 茄子 <rt> Cheese </rt></ruby>”并重新命名为“<ruby> 相机 <rt> Camera </rt></ruby>” 应用。
同时,GNOME <ruby> 图像 <rt> Photos </rt></ruby>应用已被移除。
#### GNOME “软件”应用的升级
虽然 GNOME <ruby> 软件 <rt> Software </rt></ruby>应用在初始阶段并未呈现出明显的 UI 变化,但它的价值实实在在地提升了。

包括以下一些值得注意的变化:
* 当卸载 Flatpak 包时,会提示你是否移除相关联的应用数据。
* 又新增了一项指示器,用于通知哪些更新中包含了安全修复。
* 系统更新下载时,会有通知提示。
#### 核心应用的改进
各种应用都已进行了更新。首先是“<ruby> 地图 <rt> Maps </rt></ruby>”应用,其中一些微妙的变化包括将缩放按钮从标题栏移动到地图的覆盖层。

重构“变更路径”的侧边栏,使其能够适应触摸屏显示器,以及其它一般性的功能。
接下来是“<ruby> 天气 <rt> Weather </rt></ruby>”应用,其增大了默认窗口大小以容纳所有温度计小部件。这款应用还可以记住你最后一次设定的窗口大小,便于在你下次打开时,直接展示该大小。

新的“<ruby> 控制台 <rt> Console </rt></ruby>”应用现在让你可以选择自定义字体,并设有新的设置窗口。

总的来说,控制台在多项技术层面进一步优化。
“<ruby> 连接 <rt> Connections </rt></ruby>”应用现在可以通过 RDP 连接复制/粘贴文本、图像和文件。
同时,“<ruby> 计算器 <rt> Calculator </rt></ruby>”现在支持更多货币,包括尼日利亚奈拉、牙买加元等。
#### 其他改变
许多其他改变可能并不很明显,但确实存在。这些包括:
* 文档扫描应用已迁移至 GTK4。
* 核心应用如文本编辑器、联系人、文件、网络、日历等的新应用样式和 [自适应行为](https://blogs.gnome.org/alicem/2023/06/15/rethinking-adaptivity/)。
* 性能提升。
* 在初次设置过程中对数据收集信息的改进。
如果需要更深入的了解 GNOME 45 的改变,可以查阅 [发布说明](https://gitlab.gnome.org/Teams/Design/release-notes/-/issues/36)。
### 如何立即体验 GNOME 45?
可以在 **Fedora 39 预发布版** 中获得体验。较安全的方式是通过 GNOME Boxes 尝试 **[GNOME OS](https://os.gnome.org/) 夜间构建版**。
**Ubuntu 23.10** 的日常构建可能很快就会(如果你正在阅读这篇文章,则可能已经提供)集成 GNOME 45。
当然,最佳的体验方式是等待 Fedora 39 的稳定版发布,或者在 GNOME 45 发布后立即在 Arch Linux 上进行安装。
*(题图:MJ/7a0bb088-81f1-4763-9281-b4a3b762841f)*
---
via: <https://news.itsfoss.com/gnome-45/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Every major GNOME release is exciting to me.
You can always expect **UI-focused changes**, **feature improvements**, and **updates to the core apps**.
[GNOME 44](https://news.itsfoss.com/gnome-44-release/) introduced some interesting abilities like being able to check running background apps, thumbnail view in the file chooser, and more.
Now that GNOME 45 has released! Let us look at what's new!
## GNOME 45: What's New?
The key highlights include:
**New core apps****New workspace indicator****New privacy hub in system settings****A new "About" panel in the system settings****New icon for Calendar app****UI tweaks to the Nautilus file manager**
I shall categorize all such changes to help you understand better. So, let me get to that now:
### New Workspace Indicator

The “Activities” button to navigate the workspace has been replaced with dot indicators.
It certainly looks neat, and serves a better purpose of letting you know the number of workspaces you have and when you scroll through it.
### Improvements to Nautilus
The Nautilus file manager did not receive any UI tweaks last time. But, with GNOME 45, a subtle UI makeover was added where you can see the hamburger menu in the sidebar.
Overall, the left sidebar is more distinguishable from the rest of the window.
You can also expect refinements to its performance and search improvements.
### System Setting Changes
GNOME has been hard at work since GNOME 43 and 44 to make the system setting options easy to access while uncluttering all that is available.
Here, the "**Privacy**" menu has been revamped, with the options that look organized and accessible.
Next, the "About" section has also been tweaked to display the technical information via "**System Details**" menu, as shown below.

You have to click on the system details to get all the required technical information about the OS and hardware.
In addition, to make things easier for new Linux users:
- An information popup was added to the Users panel to explain the autologin setting.
- Descriptions were added to help users understand the options available in the Sharing panel.
- Improvements to the online accounts panel for refined control.
### New Core Apps
GNOME 45 replaces the "**Eye of GNOME**" with its new [Loupe Image Viewer](https://news.itsfoss.com/loupe-image-viewer/) app.
Along with this, you can also expect "[Snapshot](https://news.itsfoss.com/gnome-snapshot/)", which is a new camera app. It will replace "Cheese" and be labelled as "Camera".
Additionally, GNOME Photos has been removed.
### GNOME Software Upgrades
GNOME Software does not feature any visible UI changes from the get-go, but it gets more valuable.
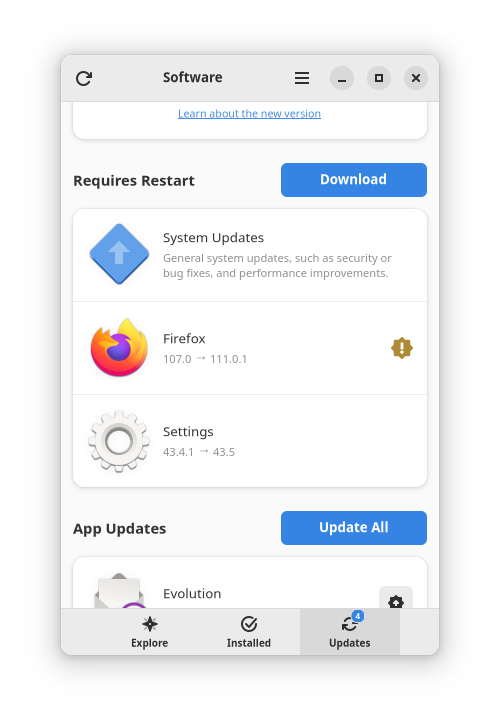
[GitLab](https://gitlab.gnome.org/GNOME/gnome-software/-/merge_requests/1676?ref=news.itsfoss.com)
Some notable changes include:
- When uninstalling a Flatpak package, you will get a prompt to remove associated app data.
- An indicator to inform which updates include security fixes.
- A notification when downloading system updates.
### Improvements to Core Apps
Various applications have been updated. Starting with **Maps**, there are some subtle changes, like zoom buttons moved from the header bar to an overlay on the map.
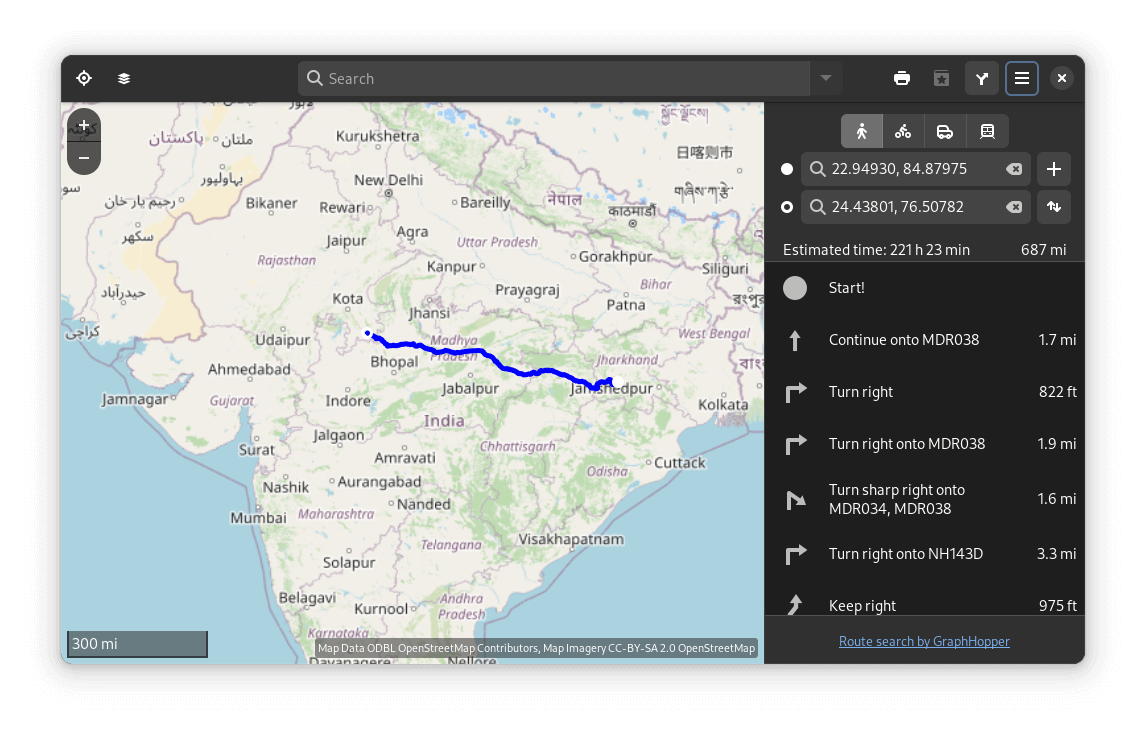
Rework the reroute sidebar to adapt to touchscreen displays, and everything else in general.
Next, we have the **Weather** app, where the default window size is bigger to accommodate all thermometer widgets. The app also remembers the window size when you re-launch it.
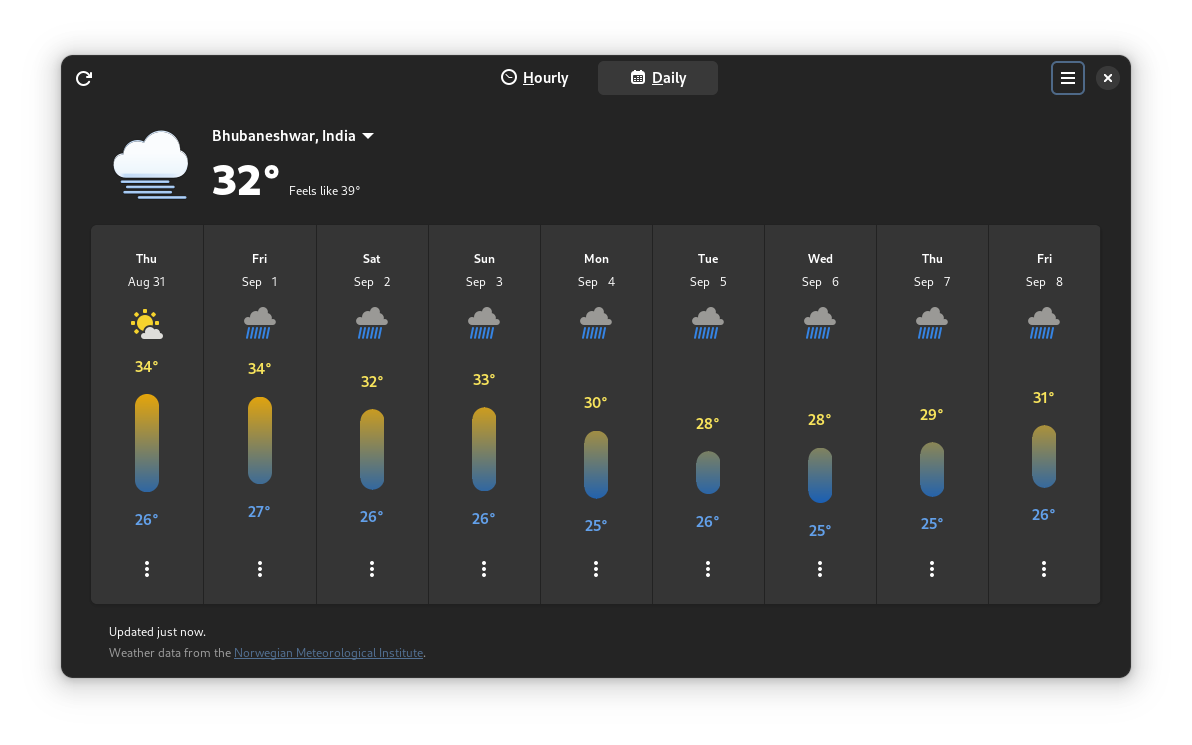
Not to forget, the new **Console **app now lets you choose a custom font and has a new preferences window.
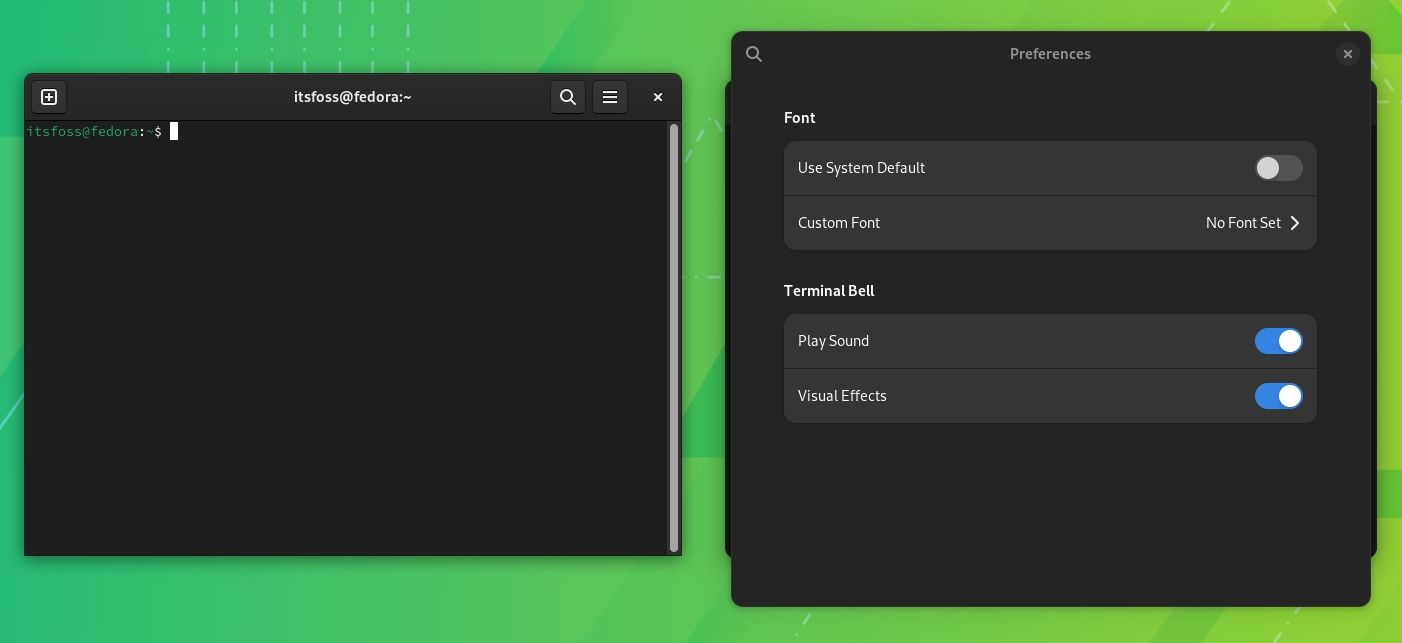
Overall, the Console gets better with a few other technical improvements.
The **Connections** app can now copy/paste text, images, and files with RDP connections.
Furthermore, the **Calculator** now supports more currencies, including the Nigerian Naira, the Jamaican Dollar, and others.
### Other Changes
Plenty of other changes may not be noticeable, but it is there. Some of those include:
- Document Scanner app ported to GTK4
- New app styling and
[adaptive behavior](https://blogs.gnome.org/alicem/2023/06/15/rethinking-adaptivity/?ref=news.itsfoss.com)for core apps like Text Editor, Contacts, Files, Web, Calendar, etc - Performance improvements
- Improved information about data collection in the initial setup process
If you want more technical insights into GNOME 45 changes, you can refer to the [release notes](https://gitlab.gnome.org/Teams/Design/release-notes/-/issues/36?ref=news.itsfoss.com).
## How Can You Try GNOME 45 Now?
You can experience it on **Fedora 39 pre-release edition **or wait for Ubuntu 23.10 and Fedora 39 stable releases.
**A safer way would be to try**
**via GNOME Boxes.**
[GNOME OS](https://os.gnome.org/?ref=news.itsfoss.com)Nightly**Ubuntu 23.10** daily builds might feature it soon (if not already when you read this).
Of course, the best way is to wait to experience it with Fedora 39 stable release or install it on Arch Linux right after GNOME 45 releases.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,151 | 简单技巧:从 Ubuntu 桌面上删除主文件夹图标 | https://itsfoss.com/ubuntu-remove-home-icon/ | 2023-09-02T15:38:53 | [
"主文件夹"
] | https://linux.cn/article-16151-1.html | 
>
> 对于不想在桌面上看到主文件夹图标的 Ubuntu 用户,这里有一个简单技巧。
>
>
>
Ubuntu 使用定制的 GNOME 版本,由于侧边启动器,它的外观与旧的 Unity 桌面有些相似。
普通 GNOME 和 Ubuntu 的 GNOME 之间的另一个区别是桌面上主文件夹和回收站的使用。这些图标就在那里,以便你可以快速访问它们。

如果你觉得不美观,可以从桌面视图中删除主文件夹。
让我分享一下 GUI 和命令行方法。
### 在 Ubuntu 中隐藏桌面上的主文件夹图标
你只需要这样做:
**在 Ubuntu 中按 `Super + D` [键盘快捷键](https://itsfoss.com/ubuntu-shortcuts/)访问桌面**。
现在**右键单击桌面上的空白区域**。
从右键单击上下文菜单中,**选择<ruby> 桌面图标设置 <rt> Desktop Icons Settings </rt></ruby>**。

它将在“<ruby> 设置 <rt> Settings </rt></ruby>”应用中打开 <ruby> Ubuntu 桌面 <rt> Ubuntu Desktop </rt></ruby>设置选项。你也可以通过打开“设置”应用并转到侧边栏中的“Ubuntu 桌面”选项来访问它。
在这里,你将看到\*\*<ruby> 显示个人文件夹 <rt> Show Personal folder </rt></ruby>的切换选项\*\*。将其关闭以禁用桌面上的主文件夹图标。

>
> ? 想要恢复主文件夹图标吗? 再次切换它。
>
>
>
### 使用命令行禁用主文件夹图标
是的,你可以从命令行完全禁用主文件夹图标。
打开终端并使用以下命令。
```
gsettings set org.gnome.shell.extensions.ding show-home false
```
效果将是立竿见影的。
要恢复图标,请使用相同的命令,但使用 `true` 而不是 `false`:
```
gsettings set org.gnome.shell.extensions.ding show-home true
```
看到那有多简单了吗? 也可以采取类似的步骤来删除回收站图标。
>
> **[如何在 Ubuntu 中移走桌面的回收站图标](https://itsfoss.com/remove-trash-icon-ubuntu-desktop/)**
>
>
>
*(题图:MJ/84c2e427-a8b3-40b7-a753-22f020800242)*
---
via: <https://itsfoss.com/ubuntu-remove-home-icon/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Ubuntu uses a customized GNOME version which has a somewhat similar look to the old Unity desktop thanks to the side launcher.
Another difference between the vanilla GNOME and Ubuntu's GNOME is the use of Home folder and tash on the desktop. The icons are there so that you can quickly access them.
If you do not find that aesthetically pleasing, you can remove the home folder from the desktop view.
Let me share both GUI and command line methods for that.
## Hide home folder icon from desktop in Ubuntu
Here's what you have to do.
**Access the desktop** by pressing the Super + D [keyboard shortcut in Ubuntu](https://itsfoss.com/ubuntu-shortcuts/).
Now **right click on an empty space** on the desktop.
From the right-click context menu, **select Desktop Icons Settings**.
It will open the Ubuntu Desktop settings option in the Settings application. You could have accessed it by opening Settings app and going to Ubuntu Desktop option in sidebar as well.
Here, you'll see a **toggle option for Show Personal folder**. Toggle it off to disable the home folder icon from the desktop.
## Disable the home folder icon using command line
Yes, you can totally disable the home folder icon from the command line.
Open a terminal and use the following command.
```
gsettings set org.gnome.shell.extensions.ding show-home false
```
The effects will be immediate.
To bring the home icon back, use the same command but with `true`
instead of `false`
:
`gsettings set org.gnome.shell.extensions.ding show-home true`
See how simple that was? Similar steps can be taken to remove the trash icon as well.
[How to Remove Trash Icon From Desktop in UbuntuThis simple quick tip shows how to remove trash icon from the desktop in Ubuntu. Both graphical and command line methods have been discussed.](https://itsfoss.com/remove-trash-icon-ubuntu-desktop/)
 |
16,153 | 什么是虚拟机? | https://itsfoss.com/virtual-machine/ | 2023-09-02T22:17:00 | [
"虚拟机"
] | https://linux.cn/article-16153-1.html | 
>
> 这是终端用户需要知道的所有关于虚拟机的信息,包括它的工作方式及其必要性。
>
>
>
**虚拟机(VM)是一个模拟版的物理计算机,它在虚拟环境中模拟各种功能并分配资源。**
简言之,你可以在你当前的操作系统中运行另一个操作系统,就像运行媒体播放器或网络浏览器一样。

你可以在 VM 中执行与裸机(例如你的笔记本电脑或个人电脑)相同的操作,例如连接到网络、下载软件、更新操作系统等等。
当然,根据使用场景,VM 的体验可能会与实体计算机有所不同。
让我们来探索虚拟机,它们的应用场景,以及它们的工作原理。
### 虚拟机:起源

虚拟机是最重要的基于软件的创新之一。它的起源可以追溯到 **1966 年的 IBM CP-40 和 CP-67** 虚拟机操作系统,那时候人们在研究和测试虚拟内存和资源的概念。
快进到我们发表此文的 2023 年,虚拟机已经无处不在,涵盖从个人电脑,到大型企业,再到小型企业。每个人以某种或其他方式都在使用虚拟机。
考虑到所有这些,显然,虚拟机非常有用。但是,它是如何工作的,我们具体用它来做什么?
>
> ?
>
>
> * 裸机 = 实体的物理电脑,例如你的 PC 或笔记本电脑
> * 宿主操作系统 = 安装在你实体电脑上的操作系统
> * 客户操作系统 = 在虚拟机内运行的操作系统
> * 虚拟机(VM)= 是虚拟化应用的通用术语
>
>
>
### 虚拟机如何运作

理解虚拟化的概念会有助于你弄清楚虚拟机是如何运作的。
回顾我们在一篇文章中的描述:
>
> “虚拟化为你提供了计算机硬件的抽象概念,以便你创建虚拟机(VM)、网络、存储等。”
>
>
>
**虚拟化**允许用户在虚拟环境中利用物理系统的资源。这使得一个进程可以单独地使用资源,而不会影响物理计算机。
而**虚拟机就是运用这一能力的过程**,在此你会得到以虚拟磁盘、内存,及其他配置文件形式的虚拟资源,让你能在其上运行操作系统。
你或许已经熟悉一些能帮助你创建这些虚拟机的 [专为 Linux 的虚拟化软件](https://itsfoss.com/virtualization-software-linux/)。
为了详细展示虚拟机和物理计算机之间的技术差异,这里提供一张图帮助你理解:

### 我们为什么需要使用虚拟机?
虚拟机已经成为一种多功能的概念,对于几乎每一个小任务都十分实用,这也是你应该 [在虚拟机中运行 Linux](https://itsfoss.com/why-linux-virtual-machine/) 的其中一个理由。
不仅对个人用户有帮助,虚拟机在云计算的领域中也起着重要的作用,而云计算是构成互联网必不可少的一部分。

下面是虚拟机能够帮助你完成的一些任务:
* 软件测试
* 操作系统测试
* 为临时的网络浏览会话增强你的在线隐私
* 在不影响物理计算机的情况下进行网络安全研究
* 利用虚拟机作为服务器,使同一硬件上可以托管更多的虚拟机,(从而让硬件资源使用更加高效)
* 各种开发活动,拥有了更强大的迁移、复制等功能
* 利用虚拟机在云中复制系统
因此,虚拟机的隔离能力使我们能采用它进行测试和开发,也使其成为服务器可扩展性和灵活性的核心。
**建议阅读 ?**
>
> [在虚拟机中运行 Linux 的十大原因](https://itsfoss.com/why-linux-virtual-machine/)
>
>
>
无论你是学生、专业人员,还是企业,你都会发现虚拟机在某个时间点会发挥出重要的作用。
### 虚拟机消耗系统资源吗?
当你创建一个虚拟机在其中运行另一个操作系统时,你会为它分配一些系统资源,主要包括:
* 处理器:只有当在虚拟机中运行操作系统时才消耗
* 内存:只有当在虚拟机中运行操作系统时才消耗
* 磁盘空间:创建虚拟机时预留,无论虚拟机是否运行,都会占据一定的空间。
有些人认为处理器和内存会一直被虚拟机占用,这并不正确。它们只在虚拟机运行操作系统时才会被使用。
然而,无论虚拟机是否在运行,磁盘空间始终会被占用。
### 使一切成为可能的虚拟化类型
如果你对能够帮助创建虚拟机的虚拟化概念感兴趣,那么我将列举并简要解释所有的不同类型。
<ruby> 管理程序 <rt> Hypervisor </rt></ruby> 管理着硬件,并将系统资源从虚拟环境中隔离出来。它在技术上被标记为 “<ruby> 虚拟机监视器 <rt> Virtual Machine Monitor </rt></ruby>(VMM)”。
而管理程序就是那个**能让我们创建和运行虚拟机的软件**。
管理程序有两种类型:
* **一级管理程序** :它直接连接到物理机,用于管理虚拟机的资源。一个很好的例子就是 [KVM](https://www.linux-kvm.org/page/Main_Page?ref=itsfoss.com),它直接集成在 Linux 系统里。
* **二级管理程序** :它存在于操作系统上,在操作系统上运行,让你能够管理虚拟机资源等等。例如 [VirtualBox](https://www.virtualbox.org/?ref=itsfoss.com)。
虽然管理程序使虚拟化成为可能,但是各种虚拟化类型则能使你在使用虚拟机时带来更多便利和功能。
一些相关的类型包括:
* **存储虚拟化** :这能通过将可用的磁盘空间划分为小块,以被虚拟机使用,从而创建虚拟磁盘。
* **网络虚拟化** :允许物理网络连接通过虚拟网络(或者适配器)路由到虚拟机。
* **桌面虚拟化** :通过该方式,你可以同时向多台物理设备部署多个虚拟桌面环境。可以从一个中心点配置和管理所有虚拟桌面。
为了深入了解所有的技术细节,我建议你查阅 [AWS 关于虚拟化的文档](https://aws.amazon.com/what-is/virtualization/?ref=itsfoss.com)。
### 虚拟机的优势

虽然你已经通过其使用案例了解到了一些虚拟机带给你的好处,但是我还是想再补充一些你需要知道的要点:
* 虚拟机能够让你充分地利用硬件资源,而不影响宿主机
* 有了虚拟机,你可以自由地进行测试或者做任何你想做的事情。无论是一个极老的应用,或是一个有风险的软件,你都可以完全依赖虚拟机来完成一切,并且不会对你宿主机产生影响
* 你可以在一个地方运行多个操作系统,而不需要面对双启动或增加额外的物理驱动器来使用其它操作系统的麻烦。这样可以帮你节省成本,时间,同时避免管理的困扰
* 有了虚拟机,你可以在不需增加任何硬件的情况下快速地克隆你的配置。
### 虚拟机的劣势

虽然虚拟机在许多场景中都非常有帮助,但是它也有可能带来什么不利影响吗?
嗯,实际上,使用虚拟机并没有直接的缺点,但是你仍然需要对一些虚拟机可能带来的影响持谨慎态度:
* 尽管虚拟机被认为能够有效地利用资源,但是如果你不监控它们或者粗心大意地运行多个虚拟机,它们还是有可能会耗尽系统的资源
* 虚拟机永远无法替代裸机的体验和性能。无论宿主机有多么强大,虚拟机的运行速度总是比你在物理计算机上预期的要慢
* 虚拟机虽然与宿主机隔离,但你必须要注意文件共享可能会将恶意软件暴露给你的宿主机系统
### 虚拟机的利用广泛
虚拟机的概念让许多事情变得可能。
如果没有虚拟机,你认为云计算行业会如何发展?如果每次尝试不同的操作系统都需要重新安装,这将带来多大的不方便?
? 无论是哪种形式,每个电脑用户或服务器用户都需要虚拟机。你对虚拟机有什么看法呢?你会如何定义它?
*(题图:MJ/be913487-080e-4869-98d9-ccd996f68a7f)*
---
via: <https://itsfoss.com/virtual-machine/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

**A virtual machine (VM) is an emulated version of a physical computer that mimics the functions and allocates the resources in a virtual environment.**
Simply put, you have another operating system running as a regular application like a media player or web browser in your current operating system.
You can do the same things in a VM compared to a bare metal machine (a real computer like your laptop or PC). For instance, connecting to a network, downloading software, updating the operating system, and more.
Of course, depending on the use case, the experience will be different from a physical computer.
Let us explore virtual machines, their use-cases, and how they work.
## Virtual Machines: The Origins

Virtual Machine is one of the most significant software-based innovation. It has its roots as early as **1966 **with **IBM CP-40 and CP-67** virtual machine operating systems, where the concept of virtual memory and resources was researched/tested.
Fast forward to 2023, when we publish this article, VMs are everywhere, from personal computers to enterprises and small businesses. Everyone uses a VM in one form or the other.
Considering all of that, it is evident that Virtual Machines (VMs) are immensely useful. But how does it work, and what exactly do we use it for?
Host OS = The operating system on your actual computer
Guest OS = The operating system running inside VM
VM = Virtual Machine, the generic term for the virtualization application
## Here's How Virtual Machines Work
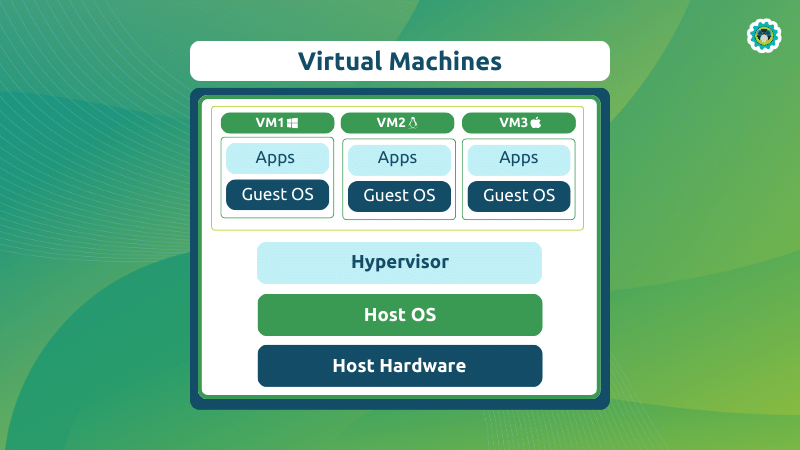
The concept of virtualization should help you clarify how virtual machines work.
To give you a quick reminder from one of our articles:
"* Virtualization provides an abstract concept of computer hardware to help you create virtual machines (VMs), networks, storage, and more.*"
**Virtualization** lets a user utilize physical system resources in a virtual environment. This enables a process to use the resources separately without tampering with the physical computer.
And **Virtual Machine is the process** that uses this ability, where you get virtual resources in the form of a virtual disk, RAM, and other configuration files to allow you to run an operating system on top of it.
You might already know some [virtualization software for Linux](https://itsfoss.com/virtualization-software-linux/) that help you create these virtual machines.
**Suggested Read 📖**
[Top 9 Best Virtualization Software for Linux [2023]We take a look at some of the best virtualization programs that make things easy for users creating/managing VMs.](https://itsfoss.com/virtualization-software-linux/)

To give you a technical difference between a virtual machine and a physical computer, here's a diagram to help you learn:
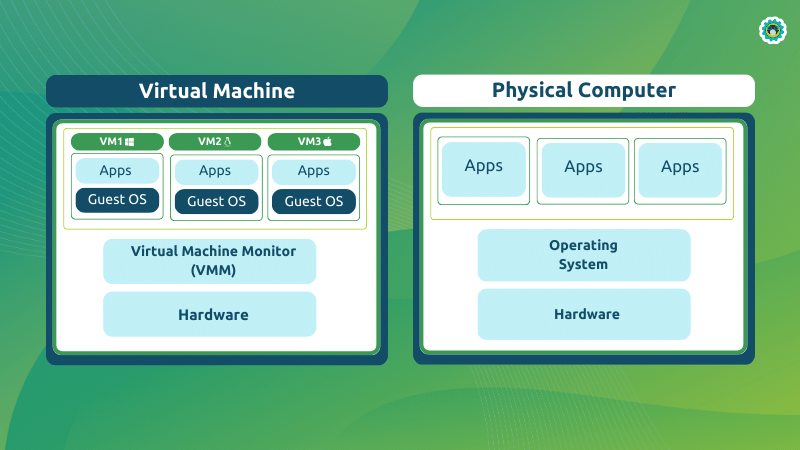
## Why Do We Use Virtual Machines?
Virtual Machines have become a versatile concept that comes in handy for almost every little thing—one of the reasons why you should [run Linux in virtual machines](https://itsfoss.com/why-linux-virtual-machine/).
Not just for individual users, but it is also a key highlight in cloud computing, which is a massive part of the internet.

Some of the tasks that VMs help achieve include:
- Software testing
- Operating system testing
- Enhancing your online privacy for temporary web browsing sessions
- Cybersecurity research without tampering physical computer
- Using VMs as servers to host more VMs (thereby making efficient use of hardware resources) on the same hardware
- All kinds of development activity with great flexibility of migration, cloning, etc.
- Replicating systems in the cloud using VMs
So, the virtual machine's isolation capability helps us use it for testing and development and use it as the core for server scalability and flexibility.
**Suggested Read 📖**
[10 Reasons to Run Linux in Virtual MachinesYou can run any operating system as a virtual machine to test things out or for a particular use case. When it comes to Linux, it is usually a better performer as a virtual machine when compared to other operating systems. Even if you hesitate to install Linux on bare](https://itsfoss.com/why-linux-virtual-machine/)

No matter whether you are a student, professional, or an enterprise, you will find the use of a virtual machine handy at one point of time.
## Do Virtual Machines Consume System Resources?
When you create a virtual machine to run another operating system in it, you allocate some system resources to it. They are primarily:
- CPU: Consumed only when the operating system is running in the VM
- RAM: Consumed only when the operating system is running in the VM
- Disk space: Reserved when you create the VM. Occupied irrespective of whether the VM is running or not.
A few people think the CPU and RAM will be utilized all the time. That's not true. RAM and CPUs are consumed only when the VM is running an operating system.
However, disk space is always reserved even when the VMs are not running.
## Types of Virtualization That Make it All Possible
If you are curious about the virtualization concept responsible for helping create a virtual machine, let me highlight all the different types of it and briefly explain it.
A hypervisor manages the hardware while separating the system resources from the virtual environment. It is technically labeled as a "**Virtual Machine Monitor (VMM)**"
And the hypervisor is the **software responsible for letting**An excellent** you create and run virtual machines.**
There are two types of hypervisors including:
**Type 1 hypervisor**: This is directly connected to the physical machine for managing resources for the VM. An excellent example for it is[KVM](https://www.linux-kvm.org/page/Main_Page), which comes baked with Linux.**Type 2 hypervisor:**This exists on top of an operating system as an application that lets you manage VM resources and more—for instance,[VirtualBox](https://www.virtualbox.org).
While the hypervisor makes virtualization possible, the types of virtualization available make your experience hassle-free facilitating the features you get with a VM.
Some of the relevant types include:
**Storage virtualization**: This helps creating a virtual disk by splitting the available disk space to small chunks reserved to be used by a virtual machine.**Network virtualization**allows the physical network connection to be routed through virtual networks (or adapters) to the virtual machines.**Desktop virtualization**:
To explore all the technical details, I recommend checking out [AWS's documentation on virtualization](https://aws.amazon.com/what-is/virtualization/).
## Advantages of Virtual Machines

While their use cases already give you an idea of the benefits they give you, let me add some pointers for you to know better:
- Virtual Machines let you use the hardware resources fully without tampering with the host.
- With VMs, you get the freedom to test or break whatever you want. Whether it is a super old application or a risky software, you can rely on the VM to do it all without affecting your host.
- You can run multiple operating systems from a single place without needing the hassle of dual-boot or adding extra physical drives to use other operating systems. Thereby saving you cost, time, and management trouble.
- With VMs, you can clone your configurations quickly without needing additional hardware.
## Disadvantages of Virtual Machines

Considering VMs are helpful in many scenarios, how can they be harmful?
Well, not precisely drawbacks to using them, but you need to be cautious about some of the things they can do:
- Even though virtual machines are known to use resources efficiently, they can still overwhelm the system resources if you do not monitor them or run multiple VMs without thinking about it.
- Virtual Machines can never replace bare metal experience and performance. No matter how mighty the host is, VMs run slower than you would expect with a physical computer.
- Virtual Machines are isolated from the host, but you must be careful about file sharing that might expose malware to your host system.
## Virtual Machines Are Super Useful
The concept of VMs made a lot of things happen.
What do you think would have happened to the cloud computing industry? How inconvenient would it be to always re-install operating systems to try a different one?
💬* In one form or the other, every computer user or server user does need it. What are your thoughts on a virtual machine? How would you define it?* |
16,154 | 如何在 Linux 中映射 SAN LUN、磁盘和文件系统 | https://www.2daygeek.com/map-san-lun-physical-disk-filesystem-linux/ | 2023-09-03T09:21:00 | [
"LUN",
"SAN"
] | https://linux.cn/article-16154-1.html | 
对于某些需求,你可能需要找到映射到逻辑单元号(LUN)和文件系统(FS)的块设备,以进行文件系统扩展或灾难恢复(DR)活动。
当你管理更大的基础设施时,类似的活动可能会经常发生。假设有超过 1000 台服务器托管各种应用。
**参考以下类似文章:**
* **[如何在 Linux 中查找 SAN 磁盘 LUN](https://www.2daygeek.com/find-san-disk-lun-id-linux/)**
* **[如何在 Linux 中将 ASM 磁盘映射到物理磁盘](https://www.2daygeek.com/shell-script-map-oracle-asm-disks-physical-disk-lun-in-linux/)**
在本文中,我们将向你展示如何在 Linux 中映射物理磁盘、存储 LUN 和文件系统(FS)。
### 将物理磁盘映射到 Linux 中的存储 LUN 和文件系统的 Shell 脚本
这个小 shell 脚本可帮助你识别哪些 SAN 磁盘映射到 Linux 上的哪些块设备和文件系统。
```
vi block_device_mapping_with_LUN_FS.sh
```
```
#!/bin/bash
for lunmap in `lsblk | grep disk | grep ^s | awk '{print $1}'`; do
for mpoint in `lsblk /dev/$lunmpa | grep lvm | awk '{print $NF}'`; do
echo "$lunmap --> $mpoint --> $(smartctl -a /dev/$lunmap | grep "Logical Unit id" | awk -F":" '{print $2}')"
done
done
```
设置 `block_device_mapping_with_LUN_FS.sh` 文件的可执行权限。
```
chmod +x block_device_mapping_with_LUN_FS.sh
```
最后运行脚本查看结果。
```
sh block_device_mapping_with_LUN_FS.sh
```

**注意:** 在上面的输出中,设备 `sda` 不会显示任何 LUN 信息,因为它是从 VMWare 端添加的虚拟磁盘,没有任何 LUN。其他 3 个磁盘是从存储映射的,这就是我们能够看到 LUN 信息的原因。
如果你想即时运行该脚本,请使用下面的一行脚本。
```
for lunmap in `lsblk | grep disk | grep ^s | awk '{print $1}'`; do
for mpoint in `lsblk /dev/$lunmpa | grep lvm | awk '{print $NF}'`; do
echo "$lunmap --> $mpoint --> $(smartctl -a /dev/$lunmap | grep "Logical Unit id" | awk -F":" '{print $2}')"
done
done
```
```
sda --> /
sda --> /usr
sda --> /opt
sda --> /tmp
sda --> /var
sda --> /home
sdb --> /data --> 0x3600d0230000000000e1140463955737c
sdc --> /app --> 0x3600d0230000000000e114046395577cd
sdd --> /backup --> 0x3600d0230000000000e11404639558cc5
```
### 总结
在本教程中,我们向你展示了如何在 Linux 上检查 SAN 提供的 LUN 以及底层操作系统磁盘和关联的文件系统。
如果你有任何问题或反馈,请随时在下面发表评论。
*(题图:MJ/09a00c62-f6a1-48b0-bf43-dc1bcb3c7861)*
---
via: <https://www.2daygeek.com/map-san-lun-physical-disk-filesystem-linux/>
作者:[Rasool Cool](https://www.2daygeek.com/author/rasool/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
16,155 | 上古纯文本社交网络 USENET 涅槃重生 | https://www.theregister.com/2023/08/30/usenet_revival/ | 2023-09-03T10:43:49 | [
"USENET"
] | https://linux.cn/article-16155-1.html |
>
> 考虑到它已经如此之老,它的活力令人惊讶。
>
>
>

USENET 管理委员会已经重新召开,这个早于万维网的原创社交网络上出现了增长的新苗头。
USENET(或 NetNews)是一个纯文本的社交讨论平台,或者说,是一系列的被称为“<ruby> 新闻组 <rt> newsgroup </rt></ruby>”的讨论组,这些讨论组部署在遍布世界各地的服务器上。虽然其原始开发者在 2010 年 [关闭](https://www.theregister.com/2010/05/20/usenet_duke_server/) 了他们的服务器,但那只是几百个服务器中的一个,在全球范围内,还有许多服务器运行得很好。USENET 并没有消失,它仍然活着,你可以免费加入,而且大多数操作系统都有协助你使用它的各种客户端应用程序。
尽管 USENET 是去中心化的 P2P 网络,但 Big-8 理事会仍是其最接近中央的管理机构。理事会成员 Tristan Miller 说:“我和 Jason Evans 在 2020 年 [重建](https://www.big-8.org/wiki/Press_releases/2020-11) 了这个理事会,此后,Rayner Lucas 几个月后加入了我们。”
包括其他事项在内,理事会开始重新管理新闻组列表。他们应版主的要求删除了一些过时的群组,并添加了多年来的首个新新闻组,这是一个用于 [Gemini 协议](https://www.theregister.com/2022/01/27/gemini_protocol/) 的新闻组。如果你有新闻客户端,你应该可以打开 `news:comp.infosystems.gemini`。此外,理事会也对网站进行了全新改版,举办了 [Reddit AMA](https://www.reddit.com/r/IAmA/comments/nn4vp8/were_the_usenet_big8_management_board_ask_us/)(在线问我任何事)活动,更新了版主所用的 [GNU Stump](https://www.algebra.com/~ichudov/stump/) 和 WebStump 软件包等。
USENET 比万维网更早,并且它运行的方式更类似与电子邮件:服务器会保存一份新闻组列表,并与其他服务器同步信息。
(USENET 之所以走向衰败,其原因之一是人们发现了如何发布二进制文件的方式 —— 将其编码为多段的 ASCII 文本。它仍然存在 [盗版问题](https://www.theregister.com/2019/07/12/a_pair_of_usenet_pirates_get_66_months_behind_bars/),但你可以选择忽略。这也是互联网历史上 [首次出现垃圾信息](https://www.campaignlive.co.uk/article/history-advertising-no-195-canter-siegels-green-card-spam/1441026) 的地方。)
连上 USENET 其实非常简单。你只需在 USENET 服务器上创建一个账户,安装一个客户端并告知它服务器地址。下载群组列表,选择订阅一些群组,新的消息便会传递到你的客户端,就这么简单。
The Register 的 FOSS 部门使用的是一个名为 “[Eternal September](https://www.eternal-september.org/)” 的服务器,该名字源自当年 AOL 向其互联网客户端引入 USENET 访问功能,导致大量的网络新手涌入但不了解其规则的 [事件](https://en.wikipedia.org/wiki/Eternal_September)。这里我们可以给出一条建议:请严格遵循 [纯文本、底部回复](https://www.theregister.com/2023/08/23/email_like_a_pro/) 的电子邮件“网络礼仪”。
“Eternal September” 只有文本新闻组,不接受二进制文件,但它提供完全免费的账户。而另一些大容量的服务器如 [Eweka](https://www.eweka.nl/en)、[Giganews](https://giganews.com/) 等则会收取访问费。
至于客户端 —— 如我们在新的 [Thunderbird ESR](https://www.theregister.com/2023/05/26/new_betas_of_firefox_and_tbird/) 版本的介绍中所提到的,我们选用了 Thunderbird。它是免费的,易用,并能运行在所有主流的桌面操作系统上。当然,市面上还有许多其他的客户端可供选择。甚至 [谷歌的网上论坛](https://groups.google.com/) 都还在运营,尽管显得有些被忽视。
作为一位重度科幻读者,我乐于深入研究 `rec.arts.sf.written` 和 `rec.arts.sf.fandom` 等群组。计算机历史群组 `alt.folklore.computers` 依然活跃。在一些复古计算频道中依然充满生机,我们也在这些频道中愉快地讨论了 Acorn RISC OS 和 Fortran 等诸多主题。
*(题图:MJ/97691bbe-858c-47d2-b47a-b4ca460016d6)*
---
via: <https://www.theregister.com/2023/08/30/usenet_revival/>
作者:[Liam Proven](https://www.theregister.com/Author/Liam-Proven) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-16153-1.html) 荣誉推出
| 200 | OK | This article is more than **1 year old**
# USENET, the OG social network, rises again like a text-only phoenix
## Alive and still quite vigorous considering its age
The USENET management committee has reconvened and there are green shoots of growth in the original, pre-World Wide Web social network.
USENET, or NetNews, is a text-only social discussions forum, or rather a set of a great many forums, called "newsgroups," carried by multiple servers around the world. Although the original developers [closed down](https://www.theregister.com/2010/05/20/usenet_duke_server/) their instance in 2010, that was just one server out of hundreds, and many are still running just fine. It never went away – it's still alive, you can get on it for free, and there is a choice of client apps for most OSes to help you navigate.
Although USENET is a decentralized, peer-to-peer network, the Big-8 board is the closest thing it has to a central governing authority. Board member [Tristan Miller](https://www.big-8.org/wiki/User:Tristan_Miller) told *The Reg*: "[Jason Evans](https://www.big-8.org/wiki/User:Jason_Evans) and I [re-established the Board](https://www.big-8.org/wiki/Press_releases/2020-11) in 2020, after a long period of dormancy. We were joined a few months later by [Rayner Lucas](https://www.big-8.org/wiki/User:Rayner_Lucas)."
Among other things, the board manages the list of newsgroups, and now that there's an active board again, it has been busy. It deleted some very old groups at the moderators' request, and added the first new newsgroup in many years for [the Gemini protocol](https://www.theregister.com/2022/01/27/gemini_protocol/). If you have a News client, news:comp.infosystems.gemini ought to open it. The board has also revamped the website, run a Reddit [Ask Me Anything session](https://www.reddit.com/r/IAmA/comments/nn4vp8/were_the_usenet_big8_management_board_ask_us/), updated the [GNU Stump](https://www.algebra.com/~ichudov/stump/) and WebStump packages used by moderators, and more.
USENET is older than the web, and works more like email: servers carry a list of newsgroups, and sync messages with each other.
(One of the things that contributed to the downfall of USENET was when people worked out how to post binary files, encoded as multi-part blocks of ASCII text. It still [has piracy problems](https://www.theregister.com/2019/07/12/a_pair_of_usenet_pirates_get_66_months_behind_bars/) but you can just ignore that stuff. It was also the venue for the [first spam message](https://www.campaignlive.co.uk/article/history-advertising-no-195-canter-siegels-green-card-spam/1441026) in internet history.)
[Want tech cred? Learn how to email like a pro](https://www.theregister.com/2023/08/23/email_like_a_pro/)[Computer graphics pioneer John Warnock dies at 82](https://www.theregister.com/2023/08/21/john_warnock_obituary/)[Why you might want an email client in the era of webmail](https://www.theregister.com/2023/05/26/new_betas_of_firefox_and_tbird/)[Founder of FreeDOS recounts the story so far, and the future](https://www.theregister.com/2023/01/18/retro_tech_week_freedos/)
Getting online is pretty easy. Get an account on a USENET server. Install a client, tell it the server address. Download the list of groups, subscribe to some, and new messages get delivered to your client. That's it.
*The Reg* FOSS desk uses a service called [Eternal September](https://www.eternal-september.org/), after the [event](https://en.wikipedia.org/wiki/Eternal_September) when AOL added USENET access to its internet client and tens of thousands of newbies flooded in without knowing the rules. We'll give you one hint: scrupulously follow the "netiquette" of [plain-text, bottom-posted email](https://www.theregister.com/2023/08/23/email_like_a_pro/).
Eternal September only carries text groups, no binaries, but it offers totally free accounts, whereas some higher-capacity servers such as [Eweka](https://www.eweka.nl/en) or [Giganews](https://giganews.com/) charge for access.
As for a client – well, as we mentioned [when introducing their new ESR versions](https://www.theregister.com/2023/05/26/new_betas_of_firefox_and_tbird/), we use Thunderbird. It's free, it works, and it runs on all the big desktop OSes. There are lots out there, though. Even [Google Groups](https://groups.google.com/) is still alive, if woefully neglected.
As a big science fiction reader, this vulture enjoys dipping into `rec.arts.sf.written`
and `rec.arts.sf.fandom`
. The computer history group `alt.folklore.computers`
is still pretty busy. There is life in several retrocomputing channels, and we've been enjoying talking about Acorn RISC OS and Fortran among other things. ®
122 |
16,157 | Murena Fairphone 5 发布:搭载去谷歌化的 /e/OS 系统 | https://news.itsfoss.com/murena-fairphone-5/ | 2023-09-04T09:30:25 | [
"Fairphone",
"/e/OS",
"安卓"
] | https://linux.cn/article-16157-1.html | 
>
> Murena Fairphone 5 现已接受预订,其特色在于搭载了备受瞩目的、以隐私保护为中心的移动操作系统 /e/OS。
>
>
>
[Murena](https://murena.com/?sld=5) 是一家在欧洲的智能手机和云服务供应商,凭借其去谷歌化的产品,受到了越来越多的关注。他们和智能手机制造商合作,提供开箱即用的隐私关注体验。
在近期的发布中,他们公布了其最新款产品;这款 **定制版 Fairphone 5** ,最初由 [Fairphone](https://www.fairphone.com/) 制造,其突出特点是预装了以隐私保护为重点的开源移动操作系统 /e/OS。
**推荐阅读** ?
>
> **[五款去谷歌化的基于安卓的操作系统](https://itsfoss.com/android-distributions-roms/)**
>
>
>
>
> ? 这款智能手机可能并不适合每一个人,各位在决定是否购买前,最好先做好研究,了解如何适应一种定制的安卓使用体验。这篇文章并非对该设备的背书,也不是我们的赞助内容。
>
>
>
### ? 对 Murena Fairphone 5,有何期待?

Murena Fairphone 5 是一款 **支持 5G 的智能手机**,**运行着** [/e/OS](https://e.foundation/e-os/)\*\*,这是一个去谷歌化的,**开源的手机操作系统**,系统内精选了多款软件,以取代各类谷歌应用。
这款操作系统 **基于安卓 13 开发**,而这款手机则是 **通过环保的方式制造出来**。
Murena Fairphone 5 的外壳使用了回收材料,并且凭借其模块化设计,着重强调了 **维修的便利性**。
你也许会问;**这款手机的硬件配置如何?**

事实上,Murena Fairphone 5 是一款 **配置非常全面的智能手机**,拥有以下硬件规格:
* **CPU:[Qualcomm QCM 6490](https://www.qualcomm.com/products/internet-of-things/industrial/building-enterprise/qcm6490)**
* **RAM:8 GB**
* **储存空间:256 GB**
* **可扩展存储:最高能达 2 TB(SDXC)**
* **显示屏:90hz 6.46" 的 POLED**
* **电池:4200 mAH 的锂离子电池**
* **网络连接:支持 2G、3G、4G、5G**
* **Wi-Fi:支持 802.11 a/b/g/n/ac/ax**
* **蓝牙:5.2 + LE**
* **NFC:有**
你可以在 [官方公告](https://murena.com/murena-fairphone-5-is-now-available-for-pre-order-at-murena-com/) 中了解更多有关这款去掉谷歌化的智能手机的信息。
### ? 获取 Murena Fairphone 5
Murena Fairphone 5 提供了三种不同的颜色选择:**黑色、蓝色和透明色**,而 RAM 和存储容量均为同样的 8 GB/256 GB 组合。
它 **目前在部分国家已开始接受预订**,可以通过 [官方网站](https://murena.com/shop/smartphones/brand-new/murena-fairphone-5/?sld=5) 预购,并且还有 “选择你最喜欢的手机壳” 的优惠。预计将在九月底开始发货。
>
> **[Murena Fairphone 5](https://murena.com/shop/smartphones/brand-new/murena-fairphone-5/?sld=5)**
>
>
>
? 我个人很喜欢 “透明色” 这款,它有点像 Nothing 手机,因为这款颜色可以让人看见 Murena Fairphone 5 的内部构造。你更喜欢哪一款颜色呢?
---
via: <https://news.itsfoss.com/murena-fairphone-5/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[译者ID](https://github.com/%E8%AF%91%E8%80%85ID) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Murena](https://murena.com/?sld=5&ref=news.itsfoss.com) is a Europe-based provider of smartphones and cloud services that has been growing in popularity thanks to its de-Googled offerings. They partner with smartphone manufacturers to provide privacy-focused experiences out of the box.
In a recent announcement, they unveiled their latest; **a customized Fairphone 5**, originally manufactured by [Fairphone](https://www.fairphone.com/?ref=news.itsfoss.com) packing a privacy-centric open-source mobile operating system /e/OS.
**Suggested Read **📖
[5 De-Googled Android-based Operating SystemsConcerned about your privacy or want to give another life to your smartphone? You could consider these Android distributions and custom ROMs.](https://itsfoss.com/android-distributions-roms/?ref=news.itsfoss.com)

## 📱 Murena Fairphone 5: What to Expect?

Murena Fairphone 5 is a **5G-enabled smartphone**, **powered by** ** /e/OS, **a de-Googled,
**open-source mobile operating system**that has been carefully packed with handpicked applications to replace various Google apps.
The operating system is **based on Android 13, **and the phone has been **manufactured using sustainable methods**.
The Murena Fairphone 5 uses recycled materials across its body, and has a **focus on repairability** thanks to its modular nature.
You may be wondering; **what's the hardware underneath?**

Well, the Murena Fairphone 5 is a **well-equipped smartphone** with the following hardware specifications:
**CPU:**[Qualcomm QCM 6490](https://www.qualcomm.com/products/internet-of-things/industrial/building-enterprise/qcm6490?ref=news.itsfoss.com)**RAM: 8 GB****Storage: 256 GB****Expandable Storage: Up to 2 TB (SDXC)****Display: 90hz 6.46**″**POLED****Battery: 4200 mAH Li-Ion****Network Connectivity: 2G, 3G, 4G, 5G****Wi-Fi: 802.11 a/b/g/n/ac/ax****Bluetooth: 5.2 + LE****NFC: Yes**
You can go through the [official announcement](https://murena.com/murena-fairphone-5-is-now-available-for-pre-order-at-murena-com/?ref=news.itsfoss.com) to know more about this de-Googled smartphone.
## 🛒 Get Murena Fairphone 5
The Murena Fairphone 5 is being offered in three different shades: **Black, Blue, and Transparent**, with RAM and storage capacity being the same 8 GB/256 GB combo.
It is **available to pre-order right now in selected countries** from the [official website](https://murena.com/shop/smartphones/brand-new/murena-fairphone-5/?sld=5&ref=news.itsfoss.com), with a “choose your favorite case” offer. Shipping will begin at the end of September.
*💬* *I love the 'Transparent' one, kind of like Nothing phone, as it gives a nice view into the components of the Murena Fairphone 5. Which one do you like?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,158 | Flarum:一个像 Discourse 一样的开源社区平台 | https://news.itsfoss.com/flarum/ | 2023-09-04T10:58:59 | [
"Flarum",
"Discourse",
"论坛"
] | https://linux.cn/article-16158-1.html | 
>
> Flarum 可能是一个更好、更简单,或者说更具创新性的 Discourse 替代品。更多信息可在此处获取。新的一天,再来一次初次尝试?。
>
>
>
这次,我们为你带来一个叫作 “**Flarum**” 的**开源论坛软件**,它可以作为 Discourse 的备选方案。它的目标是提供一个免费、快速且易于使用的**简洁而具有可定制性的讨论平台**。
Flarum 还**具有很高的可扩展性** ,允许进行大量的自定义。
当然,我们可以拥有的开源选项越多越好,对吧?
让我们一起来看看它能提供什么。
### Flarum 概述⭐

Flarum 是**现已中止运营的** [esoTalk](https://github.com/esotalk/esoTalk) 和 [FluxBB](https://github.com/fluxbb/fluxbb) 论坛软件套件的继任者。它以优化和快捷的性能为考量,提供了一整套良好的功能。
Flarum 主要使用 PHP 编程语言开发。它**由志愿者进行维护和管理**,并**依赖于社区的贡献来推动其发展**。
其主要亮点包括:
* **高度优化**
* **响应式用户接口**
* **移动优先设计**
* **非常的灵活性**
>
> ? Flarum 和 Discourse 使用了不同的技术栈,同时它们也有细微但实用的功能区别。
>
>
> 例如,Discourse 的时间线控制功能就是受到 Flarum 的启发。
>
>
>
### 初步印象 ??
我开始的测试是登录 Flarum 的 [官方论坛](https://discuss.flarum.org/),使用的是我的 GitHub 账户。
登录后我进入了 **首页**,那里展示了所有带有相关标签的讨论,并显示了各讨论的回复数。
**顶部菜单**具有通常的**搜索栏**,还有**查看草稿**、**通知**、**带有用户名/头像的菜单**以及一些**重要设定**的选项。

首页还包括一个**侧边栏菜单**,用户可以通过这个开始新的讨论、访问标签,或者查看私有讨论。
我必须说,我发现它和 Discourse 存在一些相似性,但这并不是什么坏事!
这里有一个让我熟悉的时间线滚动条,我可以用它跳转到帖子中的不同回复。

然后有一个 “<ruby> 关注 <rt> Follow </rt></ruby>” 按钮,允许使用者选择**三种独特的设置**。其中一项是默认设置(没有任何通知),另一个是获得帖子通知,最后一个则是忽略某个帖子。

此后,我关注到用户如何**互动回应某个帖子**,它提供了三种方式,即“<ruby> 回复 <rt> Reply </rt></ruby>”该帖子,“<ruby> 喜欢 <rt> Like </rt></ruby>”它或者“<ruby> 标记 <rt> Flag </rt></ruby>”它并让版主审阅。

**回帖体验**也很好,编辑器上方会显示实时预览。它还提供了保存回复至草稿、最小化编辑器、全屏编辑以及关闭编辑器等选项。

最后,我查看了**用户设置**,它完整地包括了通常的设置,并对通知提供了精细的控制。它还展示了与我的 Flarum 账户关联的第三方账户。

总的来说,Flarum 与广受欢迎的 Discourse 提供了相似的舒适体验,它具有**有益的特性差异,且其技术栈易于安装和管理。**
Flarum 经常更新,自从发布以来,已经取得了长足的发展。它也是 Linux 服务器上最好的 [开源论坛软件](https://itsfoss.com/open-source-forum-software/) 之一,事实已经证明了这一点。
**推荐阅读** ?
>
> **[11 个你可以部署在 Linux 服务器上的开源论坛软件](https://itsfoss.com/content/images/size/w256h256/2022/12/android-chrome-192x192.png)**
>
>
>
### ? 获取 Flarum
你既可以选择遵循 [官方文档](https://docs.flarum.org/install) 中所述的指南**自托管 Flarum**,也可以选择使用 [Free Flarum](https://freeflarum.com/),这是一项与 Flarum 团队无关的**免费社区服务**。
目前,他们并未提供任何付费托管方案。
>
> **[Flarum](https://flarum.org/)**
>
>
>
你同样可以通过访问其 [GitHub 仓库](https://github.com/flarum/flarum) 来查阅源代码。
? 你对于 Flarum 有什么看法?你会试一试吗?
---
via: <https://news.itsfoss.com/flarum/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[译者ID](https://github.com/%E8%AF%91%E8%80%85ID) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Another day, another first look 😎
This time, we have an **alternative to the open-source forum software Discourse** called “**Flarum**.” It aims to offer a **simple (yet customizable) discussion platform for websites** that is free, fast, and easy to use.
Flarum is also **highly extensible**, allowing for significant customization.
Of course, the more open-source options we have, the better, right?
Let's take a look at it and see what it offers.
## Flarum: Overview ⭐

Flarum is a **combined successor of the now-defunct ****esoTalk**** and ****FluxBB**** forum software** suites. It offers a good feature-set while keeping optimization and fast performance in mind.
Written primarily in the PHP programming language. It is **maintained/governed by volunteers** and **relies on contributions from the community** to fuel its development.
Some of its key highlights include:
**Highly optimized****Responsive User Interface****Mobile-First approach****Very flexible**
For instance, Discourse timeline control functionality was inspired by Flarum.
## Initial Impressions 👨💻
I started testing by visiting Flarum's [official forum](https://discuss.flarum.org/?ref=news.itsfoss.com) by using my GitHub account to log in.
Post login, I was brought to the **homepage** which featured all the discussions with their relevant tags, and the number of replies on them.
The **header menu** had the usual **search bar**, with options to **check drafts**, **notifications**, **a menu with the username/avatar**, and a **few important settings**.
The homepage also featured a **sidebar menu** with options to start a new discussion, access tags, and view private discussions.
I must say I did find some similarities to Discourse. But, that's not a bad thing at all!
There was a familiar timeline scroller that allowed me to jump to different replies in the post.
Then there's the “**Follow**” button that allows for **three distinct settings**. One was the default, with no notifications, the other was for getting post notifications, and the last one was to ignore a post.
Thereafter, I looked at how one could **interact with a post reply**. It had three options, one was to 'Reply' to the post, one was to 'Like' it, and the last one was to 'Flag' it for the moderators to take a look at.
The **post-replying experience** was also quite neat, with a live preview being shown above the editor. It also showed options to save the reply as a draft, minimize the editor, go into full-screen editing, and close the editor.
Finally, I took a look at the **user settings**, and it includes all the usual settings with fine control over notifications. It also showed what third-party accounts were linked to my Flarum account.
Overall, it mimics the comfort that you get with the already-popular Discourse with **useful feature differences and a tech stack that is easy to install and manage.**
Flarum receives updates regularly, and its development has come a long way since it all began. It is also one of the best [open-source forum software](https://itsfoss.com/open-source-forum-software/?ref=news.itsfoss.com) for Linux servers, and that shows.
**Suggested Read **📖
[11 Open-Source Forum Software That You Can Deploy on Your Linux ServersLooking to have a community forum or customer support portal? Here are some of the best open-source forum software you can deploy on your servers. Just like our It’s FOSS Community forum, it is important to always build a platform where like-minded people can discuss, interact, and seek support…](https://itsfoss.com/open-source-forum-software/?ref=news.itsfoss.com)

## 📥 Get Flarum
You can either **self-host Flarum** by following the instructions mentioned in the [official documentation](https://docs.flarum.org/install?ref=news.itsfoss.com), or you could opt for '[Free Flarum](https://freeflarum.com/?ref=news.itsfoss.com)', a **free community service** that is not affiliated with the Flarum team.
At the moment, they do not offer any premium hosting plans.
You could also take a look at the source code by visiting its [GitHub repo](https://github.com/flarum/flarum?ref=news.itsfoss.com).
Seeing that we are on the topic of forums, why don't you consider joining ours?
[It’s FOSS CommunityA place for desktop Linux users and It’s FOSS readers](https://itsfoss.community/?ref=news.itsfoss.com)

The folks over here are helpful, and there's a vast number of topics that you can go through.
*💬 What are your thoughts on Flarum? Will you be giving it a try?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,160 | 如何在 Linux 中映射 LUN、磁盘、LVM 和文件系统 | https://www.2daygeek.com/map-san-lun-physical-disk-filesystem-lvm-info-linux/ | 2023-09-05T15:07:08 | [
"磁盘",
"LUN"
] | https://linux.cn/article-16160-1.html | 
在某些情况下,你需要映射存储 LUN(逻辑单元号)、块设备、LVM(LV 和 VG 名称)和文件系统(FS)信息以进行文件系统扩展或灾难恢复(DR)操作。
这是大多数 Linux 管理员的例行活动,我们通常使用一些脚本来显示针对 SAN LUN 的块设备映射,然后我们将手动添加 LVM 和文件系统信息来完成操作。
今后,你无需手动干预此活动,因为这些信息可以通过 Shell 脚本进行映射,如下所示。
参考以下类似文章:
* [如何在 Linux 中查找 SAN 磁盘 LUN id](https://www.2daygeek.com/find-san-disk-lun-id-linux/)
* [如何在 Linux 中将 ASM 磁盘映射到物理磁盘](https://www.2daygeek.com/shell-script-map-oracle-asm-disks-physical-disk-lun-in-linux/)
* [如何在 Linux 中映射 SAN LUN、磁盘和文件系统](https://www.2daygeek.com/map-san-lun-physical-disk-filesystem-linux/)
### 在 Linux 中映射 LUN、磁盘、LVM 和文件系统的 Shell 脚本
这个 Shell 脚本可帮助你识别哪些 SAN 磁盘映射到 Linux 上的哪些块设备、LV、VG 和文件系统。
**请注意:** 我们排除了 `sda` 磁盘,因为这是操作系统(OS)盘,它有多个分区。
```
vi block_device_mapping_with_LUN_FS_LVM.sh
```
```
#!/bin/bash
for bdevice in `lsblk | grep disk | awk '{print $1}' | grep -v 'sda'`; do
for mpoint in `lsblk /dev/$bdevice | grep lvm | awk '{print $NF}'`; do
LVM_INFO=`lvs -o +devices | grep -i $bdevice | awk '{print $1,$2}'`
LUN_ID=`lsscsi --scsi | grep $bdevice | awk '{print $NF}'`
echo "$bdevice --> $mpoint --> $LVM_INFO --> $LUN_ID"
done
done
```
设置 `block_device_mapping_with_LUN_FS_LVM.sh` 文件的可执行权限。
```
chmod +x block_device_mapping_with_LUN_FS_LVM.sh
```
最后运行脚本查看结果。
```
sh block_device_mapping_with_LUN_FS_LVM.sh
```

**注意:** 在上面的输出中,设备 `sdb` 不会显示任何 LUN 信息,因为它是从 VMWare 端添加的虚拟磁盘,没有任何 LUN。其他 3 块磁盘是从存储映射的,这就是为什么可以看到 LUN 信息。
如果你想即时运行上述脚本,请使用下面的一行脚本。
```
for bdevice in `lsblk | grep disk | awk '{print $1}' | grep -v 'sda'`; do for mpoint in `lsblk /dev/$bdevice | grep lvm | awk '{print $NF}'`; do LVM_INFO=`lvs -o +devices | grep -i $bdevice | awk '{print $1,$2}'`; LUN_ID=`lsscsi --scsi | grep $bdevice | awk '{print $NF}'`; echo "$bdevice --> $mpoint --> $LVM_INFO --> $LUN_ID"; done; done
```
```
sdb --> [SWAP] --> swap2lv swapvg --> -
sdc --> /appserver --> appserver_lv appserver_vg --> 360000670000415600477312020662021
sdd --> /data --> data_lv data_vg --> 360000670000415600477312020662022
sde --> /backup --> backup_lv backup_vg --> 360000670000415600477312020662023
```
### 总结
在本教程中,我们向你展示了如何在 Linux 上检查 SAN 提供的 LUN 以及底层操作系统磁盘、LV 名称、VG 名称和关联的文件系统。
如果你有任何问题或反馈,请随时在下面发表评论。
*(题图:MJ/f5da2270-4e5a-4b2c-8998-fae974214384)*
---
via: <https://www.2daygeek.com/map-san-lun-physical-disk-filesystem-lvm-info-linux/>
作者:[Rasool Cool](https://www.2daygeek.com/author/rasool/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
16,161 | Linux 用户注意!GNOME 45 将影响所有扩展! | https://news.itsfoss.com/gnome-45-extensions/ | 2023-09-05T15:32:00 | [
"GNOME"
] | https://linux.cn/article-16161-1.html | 
>
> GNOME 45 是一次重要的升级,但对扩展的影响并不令人满意!
>
>
>
每当 GNOME 升级,总会有一些扩展遭遇问题,这点并不新鲜。但如今,到了 GNOME 45,每个扩展都将面临问题! ?
那么,究竟是什么原因呢?让我为你解释一番。
### GNOME 45 扩展的变化
每次升级,都意味着某种技术上的提升或者变化。
而 [GNOME 45](https://news.itsfoss.com/gnome-45/) 带来了许多激动人心的更新,除了这一项。
>
> **[GNOME 45 引入激动人心的更新](/article-16150-1.html)**
>
>
>
**GNOME Shell 的 JavaScript 部分发生了变化**。如果你还不清楚的话,你需要知道的是,JavaScript(以及相关的模块)负责扩展的用户界面,包括面板、菜单、对话框等。
技术上的变更主要在于,GNOME Shell 和扩展开始使用 ESModules,而不是 GJS 的自定义导入系统。
虽然这个变革旨在鼓励开发人员用更加标准化的方式来处理 GNOME Shell 和扩展的代码,但可能会造成大量困扰。
**为什么呢?**
那是因为旧有系统与新的模块系统存在不兼容问题。
以下是 **Florian Müllner** 在谈及这个技术问题时 [提到](https://blogs.gnome.org/shell-dev/2023/09/02/extensions-in-gnome-45/) 的:
>
> 模块加载的方式与脚本有所不同,有些语句,特别是 `import` 和 `export`,只在模块中有效。这就意味着,如果一个模块使用了这些语句(几乎是必然的),那么用旧系统导入这个模块就会出现语法错误。
>
>
>
那么问题影响范围呢?**所有 GNOME 扩展都将受影响。**
* 所有针对老版本 GNOME 设计的扩展将无法在 GNOME 45 上运行(除非迁移)。
* 专门为 GNOME 45 设计的新扩展,也无法在老版本上运行。
好消息是,GNOME 扩展的开发人员可以支持多版本的 GNOME,但他们将需要付出更多努力,为 GNOME 45 之前和之后的版本分别上传新的版本。
因此,即使开发人员选择了这样做,并使用 [迁移指南](https://gjs.guide/extensions/upgrading/gnome-shell-45.html#esm) 将他们的扩展移植到新系统中,这仍将花费他们更多的时间,而在此期间,终端用户(也就是我们)在使用 GNOME 45 时会遇到扩展无法运行的情况。
**这并不是一个好的用户体验,对不对?** ?
GNOME 的升级从未能完美处理扩展的兼容问题,现在,**情况变得更糟**。
虽然我并不太依赖现有的任何 [GNOME 扩展](https://itsfoss.com/gnome-shell-extensions/),但很多用户在日常使用中都会用到。对他们来说,一个可能破坏使用体验的升级绝非喜事。
? 你如何看待 GNOME 45 中对扩展的变动?在下方评论中分享你的想法吧。
*(题图:MJ/d67e0592-2395-4a7d-bda6-0ec3136e40db)*
---
via: <https://news.itsfoss.com/gnome-45-extensions/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

With every GNOME upgrade, some extensions break; that's not new. But, with GNOME 45, every extension will break 😱
And why is that? Let me tell you more about it.
## GNOME 45 Extension Changes
With every upgrade, there is always a technical improvement or change.
And, [GNOME 45](https://news.itsfoss.com/gnome-45/) comes with pretty exciting changes, except this one.
[GNOME 45 Packs in Exciting Upgrades: Here’s What’s NewThe features and improvements that you can expect with GNOME 45. We’ve listed them here.](https://news.itsfoss.com/gnome-45/)

**GNOME Shell's JavaScript has had a change**. If you are curious, the JavaScript part (and the modules) is responsible for the extension's user interface, including the panel, menus, dialogs, etc.
The technical change is that GNOME Shell and Extensions use ESModules instead of GJS' custom import system.
While this modification was intended to encourage developers to use a more standardized approach for GNOME Shell and Extensions codebase, it might have added a big hassle.
**Why?**
This is because the legacy system and the new modules approach are incompatible.
Here's what **Florian Müllner** had to [mention](https://blogs.gnome.org/shell-dev/2023/09/02/extensions-in-gnome-45/?ref=news.itsfoss.com) for the technical bits:
Modules are loaded differently than scripts, and some statements — namely`import`
and`export`
— are only valid in modules. That means that trying to import a module with the legacy system will result in a syntax error if the module uses one of those statements (about as likely as a pope being Catholic).
And the hassle? **All GNOME extensions break.**
- All the extensions targeted for older GNOME versions will no longer work on GNOME 45 (unless ported).
- New extensions tailored for GNOME 45 will not work on older versions.
The good thing is that a GNOME extension developer can support multiple versions of GNOME. But they will have more work to do and re-upload versions for pre and post-GNOME 45.
So, even if a developer chooses to do that and utilizes the [porting guide](https://gjs.guide/extensions/upgrading/gnome-shell-45.html?ref=news.itsfoss.com#esm) to migrate to the new system, it will take extra time for them while the end-users (us) encounter broken extensions when using GNOME 45.
**Not a pretty user experience. Is it? **😒
GNOME upgrades were not perfect for extension compatibility; now, **it is worse**.
While I do not rely much on any available [GNOME extensions](https://itsfoss.com/gnome-shell-extensions/?ref=news.itsfoss.com), many users do. And, for them, an upgrade that breaks the experience is not good news.
📰 **Want our news updates on your Google News feed? Follow us here:**
[It’s FOSS - Google NewsRead full articles from It’s FOSS and explore endless topics, magazines and more on your phone or tablet with Google News.](https://news.google.com/publications/CAAiENHoh-T8yP9Q8Qywor2dwGkqFAgKIhDR6Ifk_Mj_UPEMsKK9ncBp?ref=itsfoss.com)
*💬 What do you think about the change for extensions in GNOME 45? Share your thoughts on it in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,163 | Nitrux 3.0 发布:优化了更新工具及其它功能 | https://news.itsfoss.com/nitrux-3-0-release/ | 2023-09-06T08:14:25 | [
"Nitrux"
] | https://linux.cn/article-16163-1.html | 
>
> Nitrux 3.0 正式发布,带来核心级别的改进。在这查看详情。
>
>
>
作为 [Linux 发行版中最美观的系统](https://itsfoss.com/beautiful-linux-distributions/) 之一,Nitrux 以其精美的用户界面和强大的不变性功能吸引着大家。
自我们上一次了解 Nitrux已经过了 [一段时间](https://news.itsfoss.com/nitrux-2-7-release/)。根据最近的公告,Nitrux 3.0 在系统底层加入了许多优化。
下面我们简单回顾一下这次的更新内容。
### ? Nitrux 3.0:有何新亮点?

Nitrux 3.0 基于 **Linux 内核 6.4.12-2-liquorix**,这是一个旨在提升系统响应速度的 Linux 内核,Nitrux 3.0 专注于 **提升性能**、**硬件兼容性**以及 **核心应用的更新**。
本次发布的重点改进包括:
* MauiKit 的更新
* 系统更新的优化
* 桌面环境的升级
### MauiKit 的更新

Nitrux 3.0 版本中包括了最近发布有许多性能提升,以及为 Qt6 迁移打基础的 **MauiKit 和 Maui 框架 3.0.1**。
这也包括了 **更新后的应用**,如 MauiKit FileBrowsing、MauiKit TextEditor、MauiKit Calendar、MauiKit Documents 和 MauiKit Terminal。
他们也 **针对 MauiKit 3.0.1 调整了 Maui Apps 和 NX 软件中心**。你可以在 [此处](https://mauikit.org/blog/maui-release-briefing-3/) 查看更多关于 MauiKit 的更新信息。
**推荐阅读** ?
>
> **[11 个面向未来、不可变 Linux 发行版](https://itsfoss.com/content/images/size/w256h256/2022/12/android-chrome-192x192.png)**
>
>
>
### OS 更新的优化
**[Nitrux 更新工具系统](https://github.com/Nitrux/nuts) 更新到了 1.1.3 版本**。这次更新带来了两个主要变化:
首先,kexec 相关的代码被移除,因为现在有了 “<ruby> 内核引导 <rt> Kernel Boot </rt></ruby>”。
其次是新的 “急救” 功能,作为一种在没有意料到的事件中,如导致根目录不一致和无法使用的中断,确保备份冗余的方式。
这项新功能旨在让用户在活动会话中恢复根分区,以便于从这种情况中恢复。
### 桌面环境升级

在桌面环境方面,Nitrux 3.0 集成了 [KDE Plasma 5.27.7](https://news.itsfoss.com/kde-plasma-5-27-release/) 并进行了一些优化。
现在,NX 桌面新增了一个可以重启 Plasma 的选项,修复了与 “自动登录” 功能相关的一些问题,并且现在英伟达 X 服务器设置能正确显示 GPU 的信息了。
### ?️ 其它的变更和优化
除此之外,本版本还包括一些其它的更新,最显著的有:
* 集成了 [Firefox 117](https://news.itsfoss.com/firefox-117-release/)
* 更新至 **MESA 23.3~git2309020600.1ae3c4~oibaf~j**,这是一个测试版的版本。
* 针对影响英特尔和 AMD 处理器的 Downfall 和 Inception 硬件漏洞的 **安全补丁**。
* 加入了一个检查以 **确认英伟达专有驱动的存在**,从而在使用英伟达硬件的设备上不使用“内核引导”功能。
* **Nitrux 的 Calamares 配置进行了优化**,比如移除了一个已弃用的内核参数,为默认的图形会话启用 “自动登录” 等等。
请查阅官方 [公告博客](https://nxos.org/changelog/release-announcement-nitrux-3-0-0/),和 [发布说明](https://nxos.org/notes/notes-nitrux-3-0-0/) 了解更多关于本版本以及如何更新已有安装的详情。
### ? 下载 Nitrux 3.0
如果你需要新安装,你可以从 [官方网站](https://nxos.org/) 下载 ISO,或者使用以下的官方链接:
* [直接下载](https://nxos.org/get/latest)
* [FOSS Torrents](https://fosstorrents.com/distributions/nitrux/)
* [SourceForge 镜像](https://sourceforge.net/projects/nitruxos/files/Release/ISO)
>
> **[Nitrux 3.0](https://nxos.org/get/latest)**
>
>
>
---
via: <https://news.itsfoss.com/nitrux-3-0-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Being one of the [best-looking Linux distros](https://itsfoss.com/beautiful-linux-distributions/?ref=news.itsfoss.com) around, Nitrux is a very intriguing offering that features a beautiful user interface coupled with the power of immutability.
It's been [some time](https://news.itsfoss.com/nitrux-2-7-release/) since we last took a look at Nitrux. With a recent announcement, Nitrux 3.0 has added many improvements under the hood.
Let's take a brief look at the release.
## 🆕 Nitrux 3.0: What's New?
Powered by **Linux Kernel 6.4.12-2-liquorix**, an enthusiast-grade Linux Kernel designed for outright system responsiveness, Nitrux 3.0 aims for **better performance**, **hardware support**, and **updated core applications**.
Some key highlights of this release include:
**Updated MauiKit****Improved OS Updates****Desktop Environment Upgrade**
### Updated MauiKit
Nitrux 3.0 features **MauiKit and MauiKit Frameworks 3.0.1** which were released recently with various performance improvements, as well as ongoing groundwork for the Qt6 migration.
This has included** updated apps** such as MauiKit FileBrowsing, MauiKit TextEditor, MauiKit Calendar, MauiKit Documents, and MauiKit Terminal.
They have also **tweaked Maui Apps and NX Software Center** to build against MauiKit 3.0.1. You can read more about MauiKit-specific updates [here](https://mauikit.org/blog/maui-release-briefing-3/?ref=news.itsfoss.com).
**Suggested Read **📖
[11 Future-Proof Immutable Linux DistributionsImmutability is a concept in trend. Take a look at what are the options you have for an immutable Linux distribution.](https://itsfoss.com/immutable-linux-distros/?ref=news.itsfoss.com)

### Improved OS Updates
The ** Nitrux Update Tool System was updated to version 1.1.3**. This has resulted in two major changes:
First, the code related to 'kexec' was removed since 'Kernel Boot' exists now.
The second one is a new '**rescue**' operation that acts as a way to ensure backup redundancy during unexpected events, such as interruptions that cause the root directory to be inconsistent and unusable.
This new operation is intended to allow users to recover the root partition from a live session, allowing for recovery from such situations.
### Desktop Environment Upgrade
On the desktop environment side, Nitrux 3.0 comes with ** KDE Plasma 5.27.7 **and a few tweaks.
NX Desktop now has an option to restart Plasma, a few bugs were fixed related to the 'autologin' functionality, and NVIDIA X Server settings now display GPU information correctly.
### 🛠️ Other Changes and Improvements
As for some of the other changes that have arrived with this release, here are the most notable ones:
- Inclusion of
[Firefox 117](https://news.itsfoss.com/firefox-117-release/) - An upgrade to
**MESA 23.3~git2309020600.1ae3c4~oibaf~j**, that is a bleeding-edge version. - Various
**security patches for the “Downfall” and “Inception” hardware flaws**affecting Intel and AMD processors. - A check was added to
**verify the presence of NVIDIA proprietary drivers**, so Kernel Boot is not used in devices using NVIDIA hardware. - The
**Calamares config for Nitrux has been improved**by removing a deprecated kernel parameter, enabling 'autologin' for the default graphical session, and more.
Go through the official [announcement blog](https://nxos.org/changelog/release-announcement-nitrux-3-0-0/?ref=news.itsfoss.com), and the [release notes](https://nxos.org/notes/notes-nitrux-3-0-0/?ref=news.itsfoss.com) for more info about this release and how to update existing installations.
**Suggested Read **📖
[Firefox 117 Release Adds Automated Translation Feature SupportFirefox 117 release brings along necessary improvements and a new feature support for the upcoming upgrade.](https://news.itsfoss.com/firefox-117-release/)

## 📥 Download Nitrux 3.0
For new installations, you can either grab the ISO from the [official website](https://nxos.org/?ref=news.itsfoss.com), or use the following official sources:
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,164 | 如何在 Linux 中查找映射到 VxVM 磁盘的 SAN LUN | https://www.2daygeek.com/find-san-lun-mapping-with-vxvm-disk-veritas-linux/ | 2023-09-06T15:00:19 | [
"LUN"
] | https://linux.cn/article-16164-1.html | 
我们过去写过几篇文章来查找映射到块设备/磁盘的 LUN ID,但是当你管理 [VCS 集群](https://www.2daygeek.com/category/veritas-cluster/)时,在某些情况下你可能需要映射 LUN 用于 VxFS 文件系统扩展的 VxVM(Veritas 卷管理器)磁盘的 ID。
这篇短文介绍了如何在 Linux 中查找与 VxVM 磁盘关联的 LUN 号。
**推荐阅读:**
* **[如何在 Linux 中查找 SAN 磁盘 LUN id](https://www.2daygeek.com/find-san-disk-lun-id-linux/)**
* **[如何在 Linux 中将 ASM 磁盘映射到物理磁盘](https://www.2daygeek.com/shell-script-map-oracle-asm-disks-physical-disk-lun-in-linux/)**
* **[如何在 Linux 中映射 SAN LUN、磁盘和文件系统](https://www.2daygeek.com/map-san-lun-physical-disk-filesystem-linux/)**
* **[如何在 Linux 中映射 LUN、磁盘、LVM 和文件系统](https://www.2daygeek.com/map-san-lun-physical-disk-filesystem-lvm-info-linux/)**
### 在 Linux 中查找映射到 VxVM 磁盘的 LUN 号的 Shell 脚本
这个方便的 Shell 脚本可帮助你识别哪个存储 LUN 与 Linux 上的哪个 VxVM 磁盘关联。
#### 这个脚本是如何工作的
该脚本按照以下步骤收集和打印这些信息。
* 它收集系统上活动 “磁盘组”(DG)的列表
* 查找与相应 DG 关联的 “设备名称”。
* 接下来,它列出了与各个设备映射的 “块设备”。
* 最后收集与这些块设备关联的 **LUN ID** 并将它们全部打印在一起,如 DG 名称、块设备名称和 LUN 编号。
```
vi VxVM_disk_mapping_with_LUN_number.sh
```
```
#!/bin/bash
###########################################################
# Purpose: Mapping LUN Number to VxVM Disk in Linux
# Author: 2DayGeek
# Version: v1.0
###########################################################
echo "DG_Name Block_Device LUN_Number"
echo "-------------------------------------------------------------------"
for dg_name in `vxdg list | awk '{print $1}' | grep -v NAME`
do
for d_name in `vxdisk -e list | grep -i $dg_name | awk '{print $1}'
do
for b_device in `vxdisk list $d_name | grep -w state=enabled | awk '{print $1}' | head -1`
do
echo "$dg_name --> $b_device --> $(lsscsi --scsi | grep $b_device | awk '{print $NF}'"
done
done
done | column -t
```
设置 Shell 脚本文件的可执行权限。
```
chmod +x VxVM_disk_mapping_with_LUN_number.sh
```
最后执行脚本查看结果。
```
sh VxVM_disk_mapping_with_LUN_number.sh
```
你的输出将类似于此。但是,DG 名称、块设备和 LUN 会与此不同。

如果你想即时运行上述脚本,请使用下面的单行脚本。
```
# for dg_name in `vxdg list | awk '{print $1}' | grep -v NAME`; do for d_name in `vxdisk -e list | grep -i $dg_name | awk '{print $1}'; do for b_device in `vxdisk list $d_name | grep -w state=enabled | awk '{print $1}' | head -1`; do echo "$dg_name --> $b_device --> $(lsscsi --scsi | grep $b_device | awk '{print $NF}'"; done; done; done | column -t
```
```
apachedg --> sde --> 3600d0230000000000e11404639558823
apachedg --> sdf --> 3600d0230000000000e11404639558824
apachedg --> sdg --> 3600d0230000000000e11404639558825
sftpdg --> sdh --> 3600d0230000000000e11404639558826
sftpdg --> sdi --> 3600d0230000000000e11404639558827
```
### 总结
在本教程中,我们向你展示了如何在 Linux 中查找与 VxVM 磁盘映射的 LUN 号。
如果你有任何问题或反馈,请随时在下面发表评论。
*(题图:MJ/251ada36-41d9-4a1b-b857-a1def52f27f2)*
---
via: <https://www.2daygeek.com/find-san-lun-mapping-with-vxvm-disk-veritas-linux/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
16,165 | 如何创建 Ubuntu 持久化立付 U 盘 | https://itsfoss.com/ubuntu-persistent-live-usb/ | 2023-09-06T16:26:00 | [
"U 盘",
"立付"
] | https://linux.cn/article-16165-1.html | 
>
> 体验带有持久化的立付 U 盘,你在立付会话中做出的所有改动都会被保存。在此教程中,你将学习如何创建一个持久化的 U 盘。
>
>
>
如果我告诉你,你能将完整的 Ubuntu 系统装载在一个可移动的 U 盘上,你会有何感想?
在外置 U 盘上 [安装 Ubuntu](https://itsfoss.com/intsall-ubuntu-on-usb/) 过程相当复杂。一种更容易的方法是制作一个带有持久化存储的 <ruby> 立付 <rt> Live </rt></ruby> U 盘,这样你对 U 盘做出的改动都会被保存下来。
请相信我,这个过程跟使用 [BalenaEtcher](https://itsfoss.com/install-etcher-linux/) 或其他任何刻录工具创建可引导驱动器的过程十分相似。
然而,我们在开始之前,让我们先弄清楚持久化立付 U 盘是什么。
### 什么是持久化立付 U 盘?
当你使用立付 Linux U 盘时,你在 <ruby> 立付会话 <rt> Live session </rt></ruby> 中做出的所有更改,在重启以后都将丢失。比如,你必须重新连接 Wi-Fi,并且你下载的文件及安装的应用均不会被保留。而持久化立付 U 盘将会为你保存这些所有的更改。
这样,你就可以将该 U 盘作为一个外置操作系统使用,它将会保存你所做出的所有更改,比如创建用户账号,安装软件包,和一切你通常在电脑上做的事情。
当然,保存的文件数量将取决于你使用的 U 盘的大小!
但你已经明白我要表达的意思了吧。那么,我们开始学习如何创建一个带有持久性的 Ubuntu 立付 U 盘吧。
### 如何创建一个持久化的 Ubuntu U 盘
在这个教程中,我将引导你完成一个持久化的 Ubuntu U 盘的制作过程:
* 通过在 Windows 上的 Rufus 工具
* 或者,通过在 Linux 上的 mkusb 工具
你可以参照教程中的适合你的部分。
>
> ? 本教程中,你将会创建一个 Ubuntu 的持久化 U 盘。并非所有的 Linux 发行版都支持数据的持久化存储,所以这个方法可能并非所有的发行版本适用。
>
>
>
### 方法 1:在 Windows 上创建持久化的 Ubuntu U 盘
在 Windows 上创建一个持久化的 Ubuntu U 盘,我会使用 Rufus,这是一款自由开源工具,专门用于将 ISO 文件刻录到 U 盘上。
请访问 [Rufus 的官方下载页面](https://rufus.ie/en/),获取 Windows 版本的可执行文件:

然后,打开 Rufus,它将要求以管理员身份运行;请授予该权限,因为你即将在外部驱动器上做改动,需要相应的权限。
接下来,根据以下步骤使用 Rufus 创建持久化 U 盘:
* 选中 U 盘设备(如果只有一个 U 盘,它将默认被选中)。
* 点击 “<ruby> 选择 <rt> Select </rt></ruby>” 按钮,在文件管理器中选择 ISO 文件。
* 你可以使用滑块或直接设定持久化分区的大小(可以放心地设定为最大值)。
* 其他选项保持默认设置(除非你清楚在做什么)。
* 点击 “<ruby> 开始 <rt> Start </rt></ruby>” 按钮,开始进行刻录。

该程序你会告诉你,选中的驱动器上的所有数据将会被删除,所以你可以放心忽略这个警告。
完成后,我们可以来瞧瞧如何在 Windows 中直接启动到 UEFI 设置。
#### 通过 U 盘启动(简化版)
这个方法应适用于大多数用户,如果无效,你总是可以选择传统的方式,那就是重新启动系统并按下 `Esc`、`Delete`、`F1`、`F2`、`F10`、`F11` 或 `F12` 等按键。
步骤如下:按 `Win + X`,然后以管理员身份启动 Windows PowerShell:

一旦你看见提示符,直接运行以下命令:
```
shutdown.exe /r /fw
```
这将会计划一个关机动作,稍后,你会进入到 UEFI 固件设置。
到了这步,选择 U 盘作为首选的启动选项并保存设置:

你会看到一个正常的 GRUB 屏幕:

当你启动后,选择试用 Ubuntu 的选项,然后你所做的任何改动都可以被保存下来,即使你重新启动了电脑也无所谓。
### 方法 2:在 Ubuntu Linux 上创建持久化 Ubuntu U 盘
>
> ? 请注意,这种方法主要适用于 Ubuntu 和 Debian 的 ISO。
>
>
>
如果你还不知道,`mkusb` 是一个带有 GUI 的工具,让你能够将 ISO 文件刷到磁盘驱动器上,并且有附加功能,例如在 Ubuntu 上创建持久化驱动器。
你需要添加 `mkusb` 的 PPA 来进行安装,具体命令如下:
```
sudo add-apt-repository ppa:mkusb/ppa
```
要使改变生效,需要更新软件库索引:
```
sudo apt update
```
最后,安装 `mkusb` 以及其他相关软件包:
```
sudo apt install --install-recommends mkusb mkusb-nox usb-pack-efi
```
就这样!
首先,从系统菜单启动 `mkusb` 工具,它会提示你输入超级用户密码:

操作完成后,它会提示你所有驱动器上的数据将会被新数据覆盖。
只需简单地点击 “OK” 按钮即可:

然后它会显示 `mkusb` 工具能执行的多项操作,你需要选择第一选项 “<ruby> 安装(制作一个启动设备) <rt> Install (make a boot device) </rt></ruby>”:

接下来,它会显示许多安装选项,你需要选择第三个选项 “<ruby> 持久化立付(仅针对 Debian 和 Ubuntu) <rt> 'Persistent live' - only Debian and Ubuntu </rt></ruby>”:

在下一个步骤中,它会让你在多种方法/工具中选择一个,如果没有使用特定类型的版本,例如超精简版本,建议使用第一个名为 “dus-Iso2usb” 的方法:

接着,它会让你从文件管理器中选择你需要的 ISO 文件:

工具会显示已选 ISO 文件的名称,以及创建持久化 U 盘所要使用的工具:

下一步,你需要选择驱动器将之前选择的 ISO 文件刷入:

以上全部完成后,将会有 3 个选项供你选择。如果你不确定使用哪一个,那么就点击 “<ruby> 使用默认 <rt> Use defaults </rt></ruby>” 按钮,但是大多数用户选择第二个选项 “grold” 即可(我也是选择这个):

检查一切都无误后,点击 “<ruby> 开始 <rt> Go </rt></ruby>” 开始刷新过程:

现在,刷入过程已经开始了!

**注意,这个刷入过程会比你使用 BalenaEtcher 刷入要长一些时间!**
完成后,会有通知告诉你,过程已经完成,此时你可以取下 U 盘,然后重新插上,以查看更改的内容:

#### 从持久化 U 盘启动
如果你要从 U 盘启动,通常可以重启你的系统,连续按下对应的按钮即可,但这已经是旧方法了!
在 Linux 中,有一种更为简便的方式访问 BIOS,你只需在终端执行以下命令:
```
systemctl reboot --firmware-setup
```
然后,进入启动菜单并将 U 盘设置为首选的启动选项:

一旦你从 U 盘启动,你将有两个选项:
* 带有持久化模式的 ISO
* 以实时模式进行启动
如其名,你需要选择第一个选项以启动进入 Ubuntu 的持久化模式:

现在,你可以进行各种修改,如安装你喜欢的软件包,[创建新用户](https://learnubuntu.com/add-delete-users/) 等等!
我希望这个指南对你有所帮助。
*(题图:MJ/423c72d6-d6eb-4146-acd5-1e58eed11f41)*
---
via: <https://itsfoss.com/ubuntu-persistent-live-usb/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

What if I tell you you can carry a complete Ubuntu system in a removable disk drive?
[Installing Ubuntu on an external USB](https://itsfoss.com/intsall-ubuntu-on-usb/) is a complicated process. The simpler option is to make a live USB but with persistent storage that will save all the changes you make to it.
And trust me; the process is similar to [using BalenaEtcher](https://itsfoss.com/install-etcher-linux/) or any flashing tool to make a bootable drive.
But before that, let's have a look at what persistent live USB means.
## What is a persistent live USB?
When you use a live Linux USB, any changes you made in the live session are lost. If you boot from it again, you'll have to connect to WiFi again, your downloaded files and installed apps won't be there. A persistent live USB will save all those changes.
This way, you can keep using that USB drive as an external operating system that saves all the changes you've made like creating a user account, installing packages, and all sorts of things that you generally do with a normal computer.
Of course, the number of files would depend on the size of the disk you use!
But you got the point. Right? Let's see about creating a live Ubuntu USB with persistence.
## How to create a persistent Ubuntu drive
In this tutorial, I will walk you through the process of creating a persistent Ubuntu USB:
- On Windows using Rufus tool
- On Linux using mkusb tool
You can follow the appropriate section of the tutorial.
### Method 1: Create a persistent Ubuntu drive on Windows
To create a persistent Ubuntu drive on Windows, I will be using Rufus, a free and open-source tool to flash ISO files on USB drives.
[Visit the official download page of Rufus](https://rufus.ie/en/) to get the executable file for Windows:
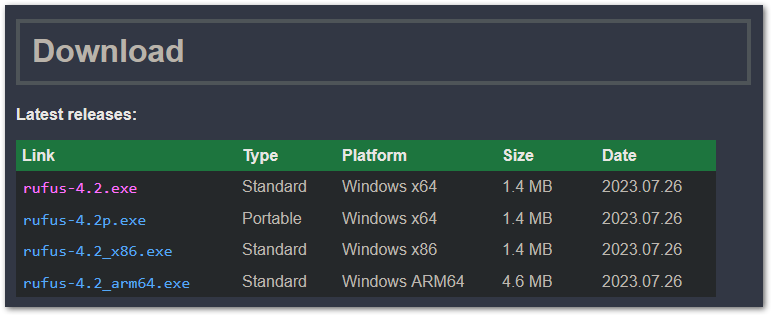
Now, open the Rufus and it will ask you to run as an administrator; grant the permissions as you're about to make changes in the external drive and permissions are necessary for that.
Next, follow the given steps to use Rufus to make a persistent USB drive:
- Select the USB device (if there's only one USB stick, it will be selected by default).
- Hit the
`Select`
button to select the ISO file from the file manager. - You can either use the slider or specify the size of the persistent drive directly (you can go to the max, no worries).
- Leave the other options to default (unless you know what you are up to).
- Hit the
`Start`
button to start the flashing.
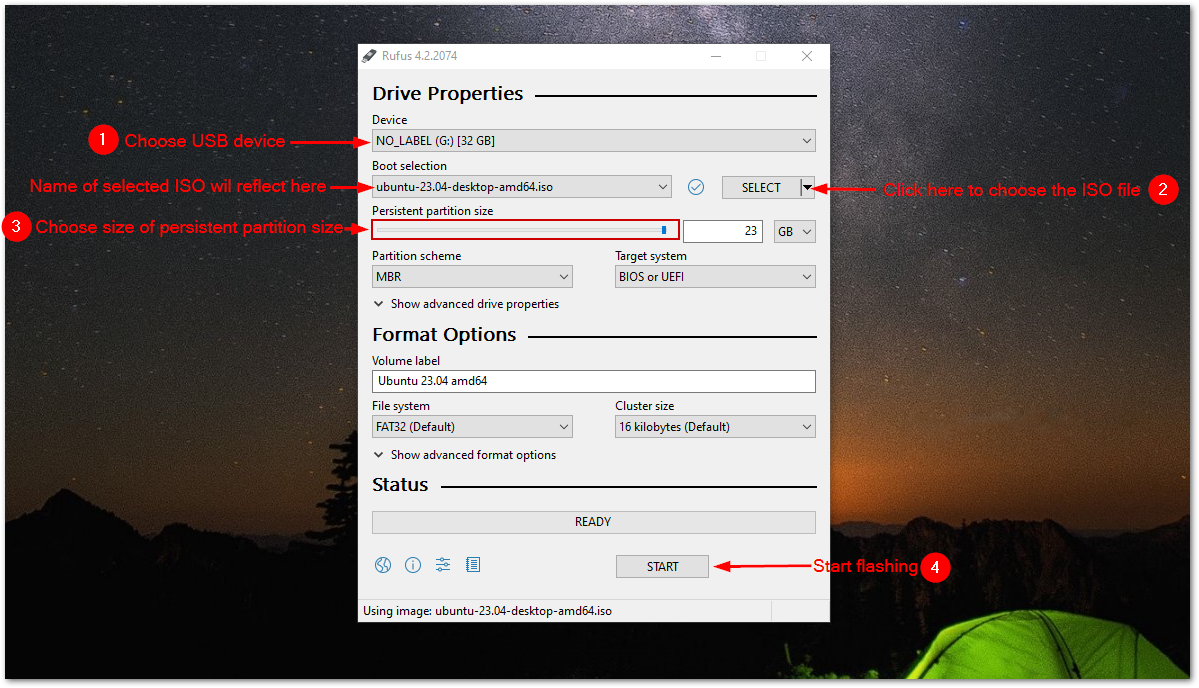
It will show you warnings that the data on the selected drive will be removed, so you can easily ignore them.
Once done, let's have a look at how you can directly boot to the UEFI settings in Windows.
#### Boot from the USB drive (the easy way)
This method should work for most users and if not, you can always use the traditional way by rebooting the system and pressing Esc, Delete, F1, F2, F10, F11, or F12 keys.
To follow the easy method, press `Win + X`
and start Windows PowerShell as an admin:
Once you see the prompt, simply execute the following command:
`shutdown.exe /r /fw`
It will schedule the shutdown and in a moment, you'll be booted into the UEFI firmware setup.
From there, choose the USB as a first preference to boot from and save changes:
You will see a normal grub screen:
Once you boot, select the option to test Ubuntu and from there you can save changes and they won't be removed even if you reboot the system.
### Method 2: Create a persistent Ubuntu drive on Ubuntu Linux
For those who don't know, mkusb is a GUI tool that lets you flash ISO on a disk drive but with additional features like creating a persistent drive on Ubuntu.
And for the installation, you have to add mkusb PPA using the following:
`sudo add-apt-repository ppa:mkusb/ppa`
To take effect from the changes, update the repository index:
`sudo apt update`
Finally, install mkusb and other packages:
`sudo apt install --install-recommends mkusb mkusb-nox usb-pack-efi`
That's it!
First, start what mkusb tool from the system menu. It will ask you to enter your superuser password:
Once done, it will show you the warning of all the data in the drive will be wiped with the new data.
Simply, press the `OK`
button:
And it will show you multiple actions that can be performed with the mkusb tool. From which, you have to select the first option "Install (make a boot device)":
After that, it will show you multiple options for the installation. From there, you select the third option `'Persistent live' - only Debian and Ubuntu`
:
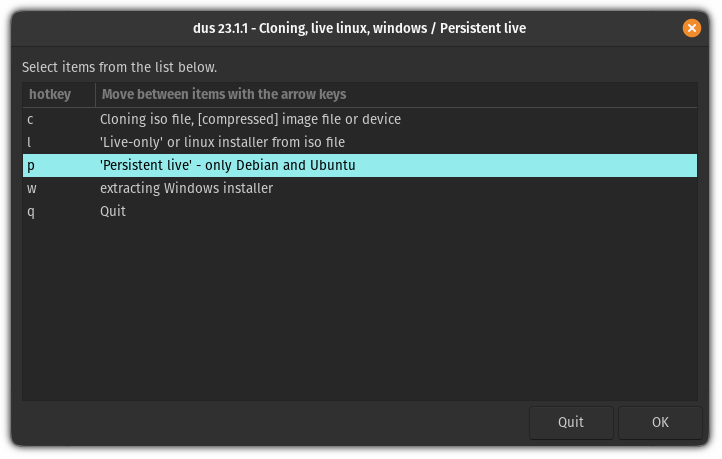
In the next step, it will ask you to choose between multiple methods.
And unless you're using something specific like an extremely stripped-down version, go with the first method named `dus-Iso2usb`
:
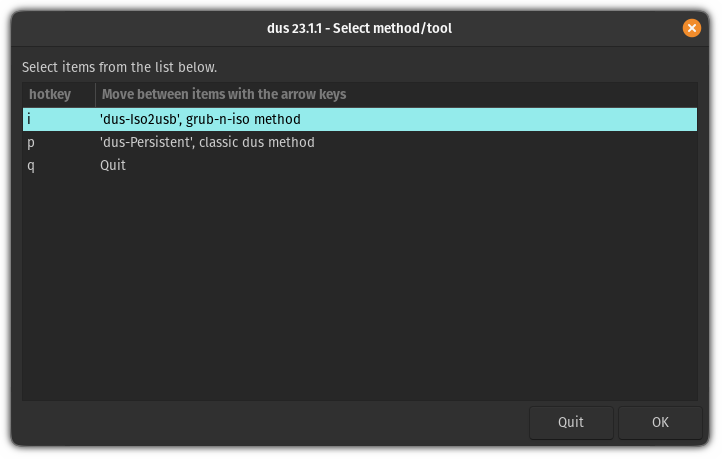
Next, it will ask you to select the ISO file from the file manager:
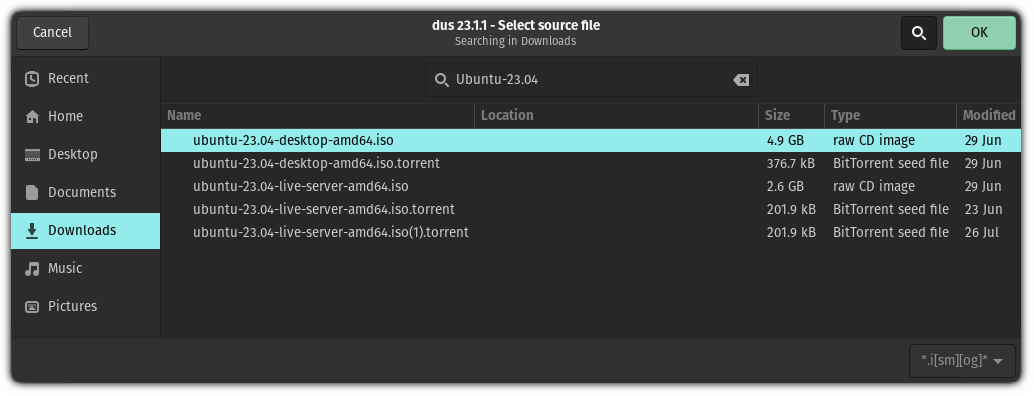
It will show you the name of the selected ISO file along with what tools it will be using to create a persistent USB drive:
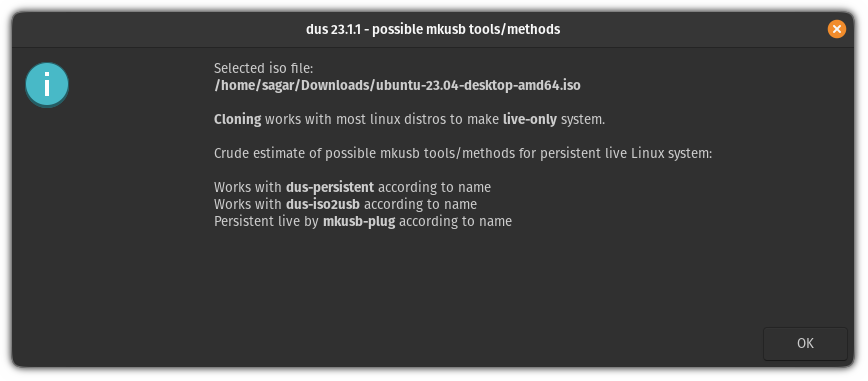
Next, you have to select the drive that needs to be flashed with the previously selected ISO file:
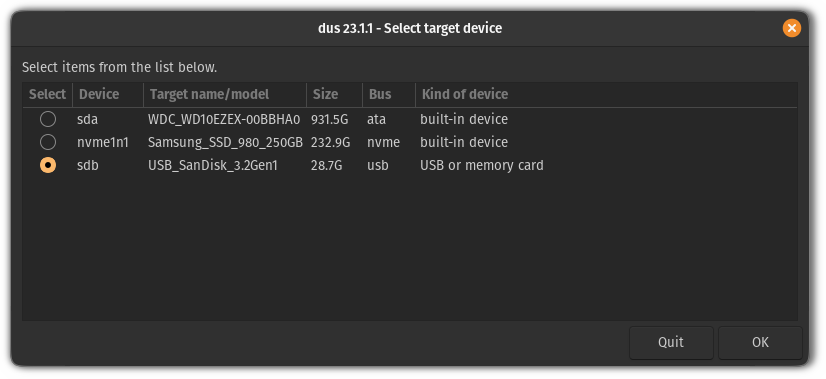
Once done, you will be given 3 choices. If you don't know which one to use, then press the `Use defaults`
button but for most users, going with the 2nd option `grold`
will get the job done (I'm going with the same):
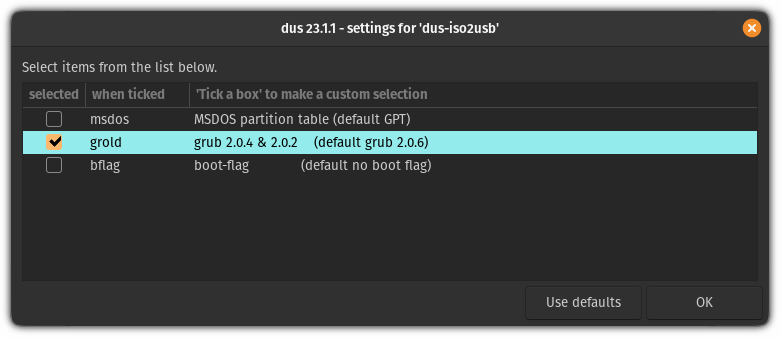
After everything is correct, choose `Go`
option to start the flashing process:
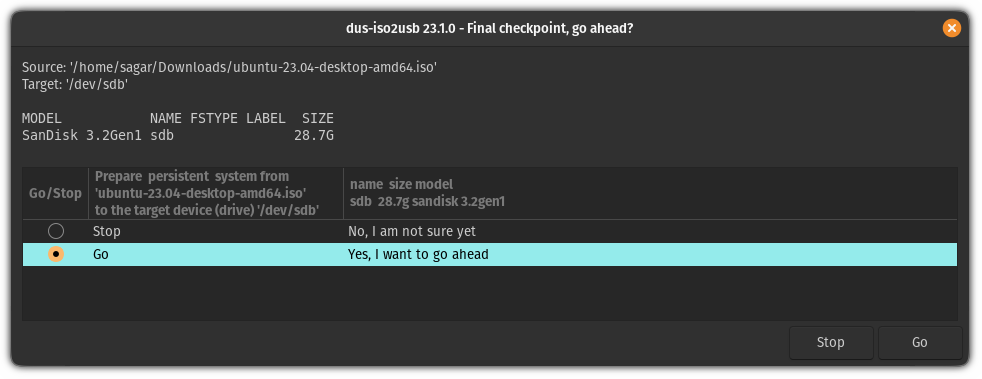
And it will start the flashing process!
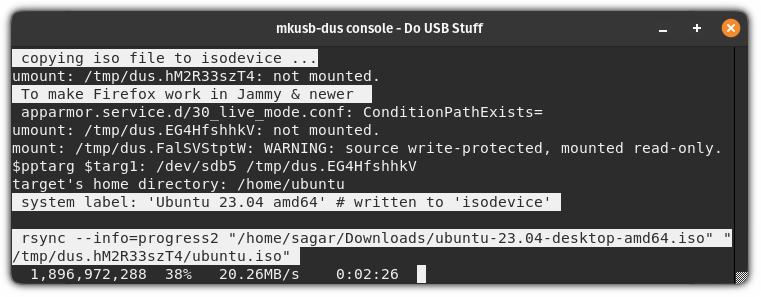
**Remember, it will take longer compared to the usual flashing that you do using BalenaEtcher!**
Once done, you'll be notified that the process has been completed and you can unplug and re-plug the drive to see changes:
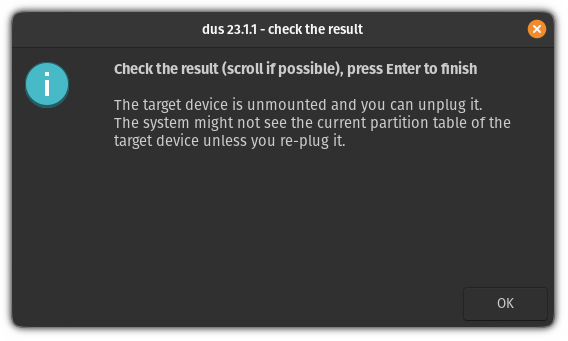
#### Boot from persistent USB drive
To boot from the USB drive, you can reboot your system, press the respective key multiple times, and get there but NO!
That's a decade-old method.
There's[ a simple way to access BIOS in Linux](https://itsfoss.com/access-uefi-from-linux/) where all you have to do is execute the following command in your terminal:
`systemctl reboot --firmware-setup`
Here, go to the Boot menu and select the USB drive as a first priority to boot from:
Once you boot from the USB, you'll have two options:
- ISO with persisted mode
- Booting from live mode
As the name suggests, you go with the first option to boot into the Ubuntu persisted mode:
And now, you can make changes like installing your favorite packages, [creating a new user](https://learnubuntu.com/add-delete-users/), and a lot more!
## Carry multiple ISOs in one drive!
Did you know that you can carry multiple ISOs in a single drive and those ISOs could be any Linux distro or even a Windows ISO file? Ventoy is an awesome tool for that.
[Install and Use Ventoy on Ubuntu [Complete Guide]Tired of flashing USB drives for every ISO? Get started with Ventoy and get the ability to easily boot from ISOs.](https://itsfoss.com/use-ventoy/)

[How to Install Multiple Live Linux Distros on One USBThis tutorial shows the steps you can take to create a live USB stick that allows you to boot into more than Linux distributions without needing to re-image the drive.](https://itsfoss.com/multiple-linux-one-usb/)

I hope you will find this guide helpful. |
16,167 | Fedora Linux Flatpak 九月推荐应用 | https://fedoramagazine.org/fedora-linux-flatpak-cool-apps-to-try-for-september/ | 2023-09-07T10:53:09 | [
"Flatpak"
] | https://linux.cn/article-16167-1.html | 
>
> 本文介绍了 Flathub 中可用的项目以及安装说明。
>
>
>
[Flathub](https://flathub.org) 是获取和分发适用于所有 Linux 的应用的地方。它由 Flatpak 提供支持,允许 Flathub 应用在几乎任何 Linux 发行版上运行。
请阅读 “[Flatpak 入门](https://fedoramagazine.org/getting-started-flatpak/)”。为了启用 Flathub 作为你的 Flatpak 提供商,请参照 [Flatpak 站点](https://flatpak.org/setup/Fedora) 上的说明。
### Flatseal
[Flatseal](https://flathub.org/apps/com.github.tchx84.Flatseal) 是一个图形程序,用于检查和修改 Flatpak 应用的权限。这是 Flatpak 世界中最常用的应用之一,它允许你提高 Flatpak 应用的安全性。然而,它需要谨慎使用,因为会让你的权限过于开放。
使用起来非常简单:只需启动 Flatseal,选择一个应用,然后修改其权限即可。进行更改后重新启动应用。如果出现任何问题,只需按重置按钮即可。
你可以通过单击网站上的安装按钮或手动使用以下命令来安装 Flatseal:
```
flatpak install flathub com.github.tchx84.Flatseal
```
你也可以在 Fedora 的仓库中找到它的 RPM 包。
### Reco
[Reco](https://flathub.org/apps/com.github.ryonakano.reco) 是一款录制应用,可帮助你回忆和收听之前听过的内容。
一些功能包括:
* 同时录制麦克风和系统的声音。
* 支持 ALAC、FLAC、MP3、Ogg Vorbis、Opus 和 WAV 等格式。
* 定时录制。
* 自动保存或始终询问保存位置的工作流程。
* 应用退出时保存录制。
我经常用它来帮助我录制 [Fedora Podcast](https://fedoraproject.org/podcast/) 的采访。
你可以单击网站上的安装按钮或手动使用以下命令来安装 Reco:
```
flatpak install flathub com.github.ryonakano.reco
```
### Mini Text
[Mini Text](https://flathub.org/apps/io.github.nokse22.minitext) 是一个非常小且简约的文本查看器,具有最少的编辑功能。它是一个对要粘贴的文本的进行编辑地方,它没有保存功能。它使用 GTK4,其界面与 GNOME 很好地集成。
我发现这对于保留我想要粘贴到任何地方的数据非常有用,它没有不需要的和/或不需要的富文本功能,只是具有最少编辑功能的纯文本。
你可以通过单击网站上的安装按钮或使用以下命令手动安装 Mini Text:
```
flatpak install flathub io.github.nokse22.minitext
```
### Tagger
[Tagger](https://flathub.org/apps/org.nickvision.tagger) 是一个音乐标签编辑器,适合我们这些仍然在本地保存音乐的人。
其中一些功能是:
* 一次编辑多个文件的标签和专辑封面,甚至跨子文件夹。
* 支持多种音乐文件类型(mp3、ogg、flac、wma 和 wav)。
* 轻松将文件名转换为标签,将标签转换为文件名。
你可以通过单击网站上的安装按钮或手动使用以下命令来安装 Tagger:
```
flatpak install flathub org.nickvision.tagger
```
*(题图:MJ/1d2d2ed0-a1c9-4cd6-954b-8ac76ddb8912)*
---
via: <https://fedoramagazine.org/fedora-linux-flatpak-cool-apps-to-try-for-september/>
作者:[Eduard Lucena](https://fedoramagazine.org/author/x3mboy/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article introduces projects available in Flathub with installation instructions.
[Flathub](https://flathub.org) is the place to get and distribute apps for all of Linux. It is powered by Flatpak, allowing Flathub apps to run on almost any Linux distribution.
Please read “[Getting started with Flatpak](https://fedoramagazine.org/getting-started-flatpak/)“. In order to enable flathub as your flatpak provider, use the instructions on the [flatpak site](https://flatpak.org/setup/Fedora).
## Flatseal
[Flatseal](https://flathub.org/apps/com.github.tchx84.Flatseal) is a graphical utility to review and modify permissions from your Flatpak applications. This is one of the most used apps in the flatpak world, it allows you to improve security on flatpak applications. However, it needs to be used with caution because you can make your permissions be too open.
It’s very simple to use: Simply launch Flatseal, select an application, and modify its permissions. Restart the application after making the changes. If anything goes wrong just press the reset button.
You can install “Flatseal” by clicking the install button on the web site or manually using this command:
flatpak install flathub com.github.tchx84.Flatseal
*Also available as rpm on fedora’s repositories*
## Reco
[Reco](https://flathub.org/apps/com.github.ryonakano.reco) is an audio recording app that helps you recall and listen to things you listened to earlier.
Some of the features include:
- Recording sounds from both your microphone and system at the same time.
- Support formats like ALAC, FLAC, MP3, Ogg Vorbis, Opus, and WAV
- Timed recording.
- Autosaving or always-ask-where-to-save workflow.
- Saving recording when the app quits.
I used it a lot to help me record interviews for the [Fedora Podcast](https://fedoraproject.org/podcast/)
You can install “Reco” by clicking the install button on the web site or manually using this command:
flatpak install flathub com.github.ryonakano.reco
## Mini Text
[Mini Text](https://flathub.org/apps/io.github.nokse22.minitext) is a very small and minimalistic text viewer with minimal editing capabilities. It’s meant as a place to edit text to be pasted, it doesn’t have saving capabilities. It uses GTK4 and it’s interface integrates nicely with GNOME.
I found this to be very useful just to keep data that I want to paste anywhere, it doesn’t have unwanted and/or unneeded rich text capabilities, just plain text with minimal editing features.
You can install “Mini Text” by clicking the install button on the web site or manually using this command:
flatpak install flathub io.github.nokse22.minitext
## Tagger
[Tagger](https://flathub.org/apps/org.nickvision.tagger) is a tag editor for those of us that still save the music locally.
Some of the features are:
- Edit tags and album art of multiple files, even across subfolders, all at once
- Support for multiple music file types (mp3, ogg, flac, wma, and wav)
- Convert filenames to tags and tags to filenames with ease
You can install “Tagger” by clicking the install button on the web site or manually using this command:
flatpak install flathub org.nickvision.tagger
## hf
imagine installing a GiB of runtimes to for an mp3 tagger app…
## lf
The runtime is already shared among apps. If you install only this app, then yes an app = a GB. If you have many apps on your daily use computer then an app = few MB.
## Darvond
The thing, why waste Flatpak on minor applications like this? Flatpak should be used for unweildly, rapidly updating things, which I honestly can’t really think of examples for. And for unweildly stability based distros with obstinate policies.
Flatpak feels like it’s enabling laziness of SiGs and packaging groups to shrug and go, “Oh, it’s in COPR/Flatland, we don’t need to mainline it.”, which doesn’t bear a great sign towards their overall health or future.
And I can’t imagine that “go find this on flathub” is going to do wonders for discoverability.
Fedora’s Modules already got the axe, what next?
## Adriaan
1. Package once for every single distro that supports flatpak
2. Make it easily usable for those of us like me who use immutable OS (Fedora Silverblue/Kinoite/etc, or OpenSUSE Aeon/Kalpa…)
There’s no reason not to package an application on flathub, basically.
## Misha Ramendik
“unweildly, rapidly updating things, which I honestly can’t really think of examples for” – Kdenlive is, in y view, a perfecr representative of this kind of software. Unwieldy, rapidly updating, and (if one does video editing) very much needed.
## nikita
Since flatpaks share runtimes it’s fine if all your apps are flatpak
And you get easily configurable sanboxing too
## SjoerdS93
I could say the same for installing it with traditional packages. Imagine installing a GiB of dependencies for an mp3 tagger. Especially since I already have said runtimes installed from other Flatpaks. So it’s just a few MiB extra for the Flatpak, but a GiB for the regular package.
## Anaconda Installer
There used to be only RPM packages. Had to compile from the source code all the time and it always didn’t work there were errors with the compiler. But everything was running faster, Fedora was very fast, today it feels very heavy.
## Darvond
None of these really appeal nor justify the idea behind having all the runtimes to run things that look small enough to self-compile.
Here’s sensible alternatives for sensible people:
1) Throw it out and use traditional filesystem permissions.
2) krecorder. I’m picking KDE applications out of spite.
3) Wordgrinder, Focus Writer, nano, there’s tons of text editors without distractions or rich text formatting.
4) Kid3. Picard. Puddletag. Demlo. There’s plenty to choose from because it’s a spreadsheet for audio pedants.
And one of these is for Flatpaks themselves, which feels like it should have these management tools built in by now.
## J
Agree!
## aqua
the runtimes help saving space and bandwidth when you have multiple apps installed.
you only need to download them once, and then the same runtime is shared between multiple apps, meaning apps don’t need to include everything themselves.
complaining about the fact you need to download the runtime to run the app is like complaining about the fact you need to download hundreds of libraries to install an app on a system with no packages installed.
i only use flatpaks exclusively to install software, and it doesn’t take up any significant space thanks to its deduplication technology.
flatpak solves multiple problems such as dependency hell, backwards compatibility, apps not running on certain systems while running on others, developers having to repackage the same app for every single distro, fragmentation, apps being extremely outdated on systems such as debian, and more.
## Darvond
Well, that’s great if that’s the extremely specific scenario you’ve boxed in as a criteria; but Fedora is
supposedto be the technological hotbed where new ideas and ventures are on the proving ground. Just as Arch, Tumbleweed SuSE and other rolling distros, but with a set upgrade point.POSIX compliance means that all software (within reason) should be portable.
## anon
You’re going to run into the same problems Android has – vulnerable libraries that don’t get updated with the Flatpak (think openssl), permissions hell rather than dependency hell, code that can’t be trusted, sandbox (immutable) escapes, and perhaps the biggest of all: proprietary code running on Linux… Arch Linux suddenly seems very attractive.
## Darvond
And you know, Apps that just plain vanish without a codebase of recourse.
Timely was probably one of the best alarm clocks, but the devs were swallowed up into a mothership and last year, the app finally vanished. Oops!
Flatpaks also have something of an increased bus factor.
## Pablo
Yes, I’ll install 3 GB of runtimes for minimalistic text editor
## Marco
Enough of misinforming Pablo!
Flatpak applications share some libraries. If you have already installed other apps, the “minimalistic text editor” only weighs 16.9kb (I just installed it).
## Test
The only one I found relevant was flatseal, and that was to easier manage and possibly delete flatpaks
## Matthew Phillips
Who is really sweating the runtime size. I’ve got a base Silverblue image and only Flatpaks, including Steam and several games installed (all work great I’m happy to say). I’ve used 105GB of a 256GB NVMe.
## me
I dont know why people complain about flatpak sizes. If you have a fresh gnome based system and install the first KDE app it will download hundreds of libraries. same goes other way around. In my machine tagger was a 40 MB download and MiniText was a 20 KB.
## Adriaan
… that would and is certainly a great usecase for flatpak to begin with. Mixing GNOME and KDE libraries on a system can become problematic rather quickly, so even before I moved to Kinoite I used flatpak for those so I didn’t have to worry about that.
## Baron von Lederhosen
Fedora is only getting better with flatpacks. It gets more accessible for newbies and it just works. Much better than Snaps under Ubuntu. What do you want more ? If you don’t like it there are still enough RPM’s. And if you’re really autistic, you just compile an entire app yourself. Why would you be so negative about progress ? |
16,168 | 将手机作为你的 Linux 桌面的摄像头和麦克风 | https://itsfoss.com/ubuntu-phone-camera-mic/ | 2023-09-07T15:53:11 | [
"手机",
"OBS"
] | https://linux.cn/article-16168-1.html | 
>
> 当你的桌面系统缺乏网络摄像头和专用麦克风时,你可以考虑使用智能手机。这里将教你如何在 Ubuntu Linux 中完成这个设置。
>
>
>
我和许多 Linux 用户一样,使用的是台式机。相较于笔记本电脑,并没有预装摄像头和麦克风。
若要获得与现代智能手机相媲美的画质,你可能需要购买一款高端的网络摄像头。
在此教程中,我将逐步指导你如何将你的手机用作麦克风和摄像头,这将非常适用于在线会议场景。
### Ubuntu 下使用手机的摄像头和麦克风
>
> ? 本教程采用第三方网站 <https://vdo.ninja/> 来托管音频和视频,因此,这并不是一项完全的开源方案。
>
>
>
我将指引你完成以下步骤:
* 安装 OBS (如果你还未安装)
* 通过 `vdo.ninja` 生成邀请链接
* 设置虚拟音频线缆(用于音频输出)
* 配置 OBS 以便从 `vdo.ninja` 重定向音视频流
首先,我们来看第一步。
>
> ? 虽然本教程是在 Ubuntu 系统下完成的,但我相信,这些同样可以在其他 Linux 发行版上实现。你只需为你的发行版安装所需的包即可。你可以自行尝试,看看效果如何。
>
>
>
#### 1、在 Ubuntu 中安装 OBS
OBS(Open Broadcaster Software)是众多用于录制和直播视频的优秀软件之一,许多直播者都选择使用 OBS 在各个数字化平台进行直播。
幸运的是,OBS 已经包含在 Ubuntu 的默认仓库中,你可以通过以下命令来安装:
```
sudo apt install obs-studio
```
#### 2、通过 VDO.ninja 生成直播邀请
在这一节,我将教你如何在 vdo.ninja 上生成一个直播邀请,进而从你的手机上开始直播音频和视频。
首先,访问 [VDO.ninja](https://vdo.ninja/) 并点击 “<ruby> 创建可重用的邀请 <rt> Create Reusable Invite </rt></ruby>”:

接下来你会看到很多选项,包括质量设置,添加视频效果等。我推荐你使用默认设置,因为高质量视频需要更快的处理速度和更多的带宽。
为了创建一个链接,你只需要点击 “<ruby> 生成邀请链接 <rt> GENERATE THE INVITE LINK </rt></ruby>” 按钮:

完成后你会看到:
* 你需要用你的手机扫描的二维码(当然,你也可以选择使用链接)。
* OBS 的链接。
**稍后我会在本教程中继续介绍 OBS 配置,所以请暂时别关闭这个窗口。**
首先,用你的手机扫描二维码,它会将你跳转到 VDO.ninja 的另一个页面,此时你需要:
* 选择 “<ruby> 共享你的相机 <rt> Share your Camera </rt></ruby>” 选项。
* 在视频源中选择使用前置或后置摄像头(默认为前置)。
* 点击 “<ruby> 开始 <rt> Start </rt></ruby>” 按钮后,它将开始在 OBS 连接的页面上进行直播。

#### 3、在 Ubuntu 上为 OBS 配置虚拟线缆
>
> ? 这种设置方法仅适用于 PulseAudio,并且在重启系统后虚拟线缆将被撤销。
>
>
>
首先,我们来解释一下“<ruby> 虚拟线缆 <rt> virtual cable </rt></ruby>”的概念,以及为何我们需要它来将手机做为摄像头和麦克风使用。
虚拟线缆是一种用于将音频流从一个应用传输到另一个应用的软件。
然而遗憾的是,它只支持 Windows 和 macOS。
啥?!那我为什么还要介绍这个呢?
答案其实很简单。我找到了一种变通方法,你可以在**当前的会话**中获得与虚拟线缆类似的功能。
要设置虚拟线缆,首先需要使用以下命令加载 `module-null-sink` 模块:
```
pactl load-module module-null-sink sink_name=Source
```
然后,执行下面的命令创建一个名为 `VirtualMic` 的虚拟音源:
```
pactl load-module module-virtual-source source_name=VirtualMic master=Source.monitor
```
这两个命令将返回一些数字,但无需对其过多关注。
接下来,前往系统“<ruby> 设置 <rt> Settings </rt></ruby>”,找到“<ruby> 声音 <rt> Sound </rt></ruby>”部分的设置:

然后进入 “<ruby> 输入 <rt> Input </rt></ruby>” 部分,在此你会找到选择输入设备的选项。
将 “VirtualMic” 设为输入设备:

这样就设置完了!
不过,如我之前所述,一旦你重启电脑,虚拟音频的设置就会被撤销,如果你打算经常使用手机作为摄像头和麦克风,这可能会造成一定的不便。
为了解决这个问题,你可以为这两个命令 [创建别名](https://linuxhandbook.com/linux-alias-command/),例如,为命令创建别名:`vc1` 和 `vc2`。
完成后,你就可以像这样 [一次执行两个命令](https://linuxhandbook.com/run-multiple-commands/):`vc1 && vc2`。
#### 4、配置 OBS 从手机直播音视频
开始阶段,你需要打开我之前告诉你不要关闭的 VDO.ninja 标签页,并复制 OBS 链接:

然后启动 OBS,在 “<ruby> 源 <rt> Sources </rt></ruby>” 区域你会看到一个 “➕(加号)”按钮,点击这个按钮并选择 “<ruby> 浏览 <rt> Browser </rt></ruby>”。
接着会弹出一个对话框,让你创建或选择一个源,你只需按下 “OK” 按钮即可:

最后,将已经复制的链接粘贴进 “URL” 字段:

然后你将能看到 OBS 正在使用你手机的摄像头:

不过为了从你的手机接收音频,还有一些额外步骤需要执行。
首先,在菜单中点击 “<ruby> 文件 <rt> File </rt></ruby>” 并选择 “<ruby> 设置 <rt> Settings </rt></ruby>”:

在出现的设置选项中选择 “<ruby> 音频 <rt> Audio </rt></ruby>”,然后寻找到 “<ruby> 高级 <rt> Advanced </rt></ruby>” 区域。
在 “高级” 区域里,你能找到 “<ruby> 监控设备 <rt> Monitoring Device </rt></ruby>” 的选项,这里你需要选择 “Source Audio/Sink sink”:

点击 “<ruby> 应用 <rt> Apply </rt></ruby>” 保存更改。
对于大部分用户,此时音频应该已经能够正常工作了。如果你的音频依然无法工作,那么你可以按照以下步骤操作。
在 “<ruby> 音频混音器 <rt> Audio Mixer </rt></ruby>” 区域,可能显示的是 “<ruby> 浏览 <rt> Browser </rt></ruby>” 或 “<ruby> 桌面音频 <rt> Desktop Audio </rt></ruby>”,也可能两者都显示。
点击 “桌面音频” 或 “浏览” 旁边的三个点(在我这个例子中,是 “桌面音频”),并选择 “<ruby> 高级音频属性 <rt> Advanced Audio Properties </rt></ruby>”:

然后,对于 “浏览” 和 “桌面音频”,都选择 “<ruby> 监控和输出 <rt> Monitor and Output </rt></ruby>”:

这样就可以了!现在你可以从你的手机上享受摄像头和麦克风的功能了。
#### 5、测试所有设置
为了测试这个设置,我在我们读书俱乐部的周会上用我的手机做为摄像头和麦克风,效果极佳。

你可以看到,上图显示摄像头和麦克风都在正常工作,这真的让我笑容满面 ?。
视频质量会取决于你的网络带宽,所以在开始重要的会议前,确保你有稳定的网络连接。
### 结语
作为一个没有摄像头和麦克风的台式计算机用户,我必须依靠笔记本或手机来参加工作会议,这让我感到非常烦躁。
需要注意的是,每次重启机器后,你都需要重新配置虚拟线缆,但这并不费时,因为只需要执行两条命令即可。
我已经多次使用这种解决方案,每一次都顺利运行。我真的希望你也能得到同样的结果。
*(题图:MJ/223b56b7-ffcc-4311-bfa6-8a25bfd5ad11)*
---
via: <https://itsfoss.com/ubuntu-phone-camera-mic/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Like many other Linux users, I use a desktop and unlike a laptop, you don't get a camera and mic pre-installed.
And you have to invest in a premium webcam to match the quality of your modern smartphone.
Well, in this tutorial, I will walk you through step-by-step how you can use your phone as a mic and camera which can be used in online meetings.
## Use the phone's camera and mic in Ubuntu
Here, I will guide you through the following:
- Installation of OBS (if you haven't)
- Generate invite through
`vdo.ninja`
- Setup virtual audio cable (for audio output)
- Configure OBS to redirect audio and video from
`vdo.ninja`
So let's start with the first one.
### 1. Install OBS in Ubuntu
OBS (Open Broadcaster Software) is one of the best software for recording and streaming videos and most streamers use OBS to live stream on digital platforms.
The good thing is OBS is available in the default repository of Ubuntu and can be installed using the following command:
`sudo apt install obs-studio`
### 2. Generate an invite through VDO.ninja
In this section, I will show you how you can generate an invite to stream your audio and video over vdo.ninja and how you can start streaming from your phone.
First, go to [VDO.ninja](https://vdo.ninja/) and click on `Create Reusable Invite`
:
It will show you multiple options such as quality settings, adding video effects, etc. I recommend using the default settings as you may need faster processing and more bandwidth for high-quality videos:
And to create a link, all you have to do is click on `GENERATE THE INVITE LINK`
button:
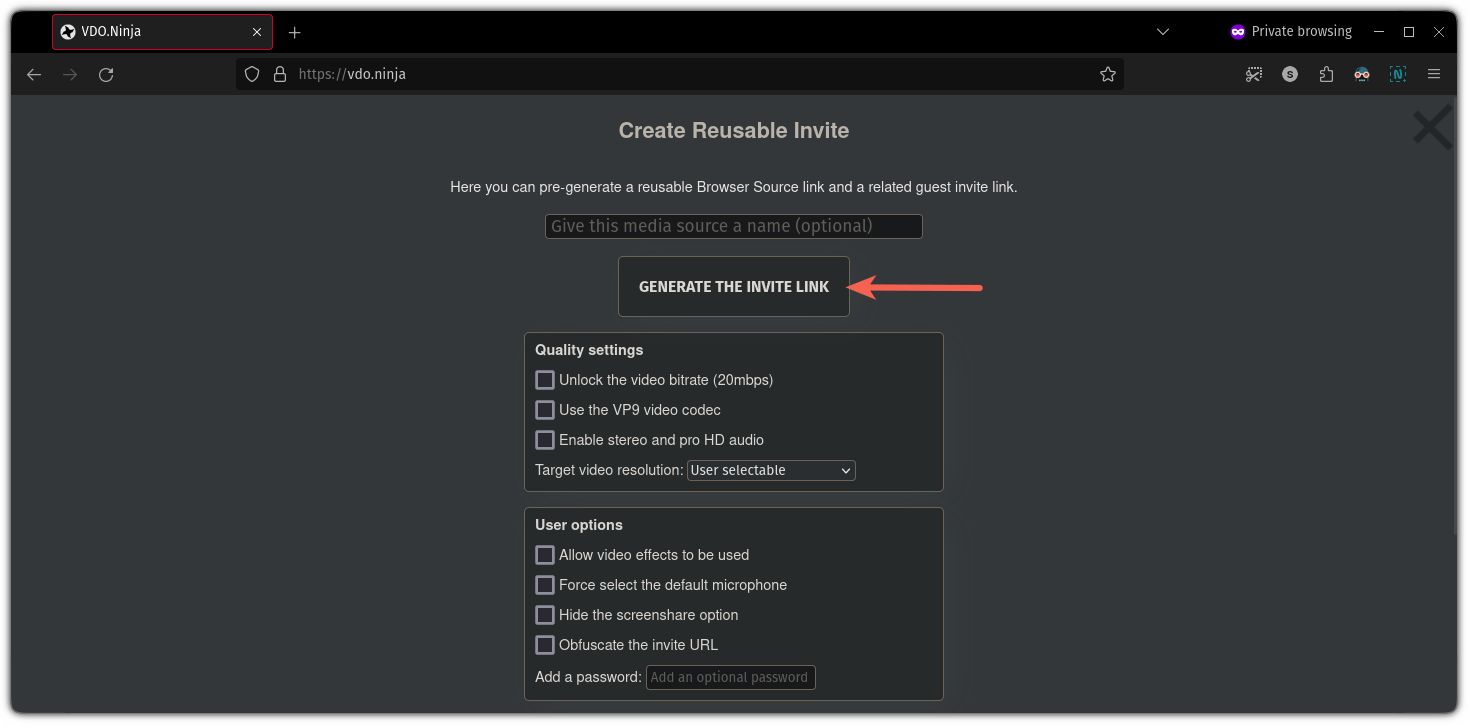
And it will show you the following:
- A QR code that you have to scan through your phone (alternatively, you can also use the link).
- Link for the OBS.
**I will cover the OBS part later on this tutorial so please don't close the window.**
First, scan the QR code from your smartphone and it will redirect you to another page of the VDO.ninja where you have to select the following:
- Select
`Share your Camera`
option. - You can choose a front or rear camera from the video source (the front will be selected by default).
- Hit the
`Start`
button and it will start the streaming on the OBS link.
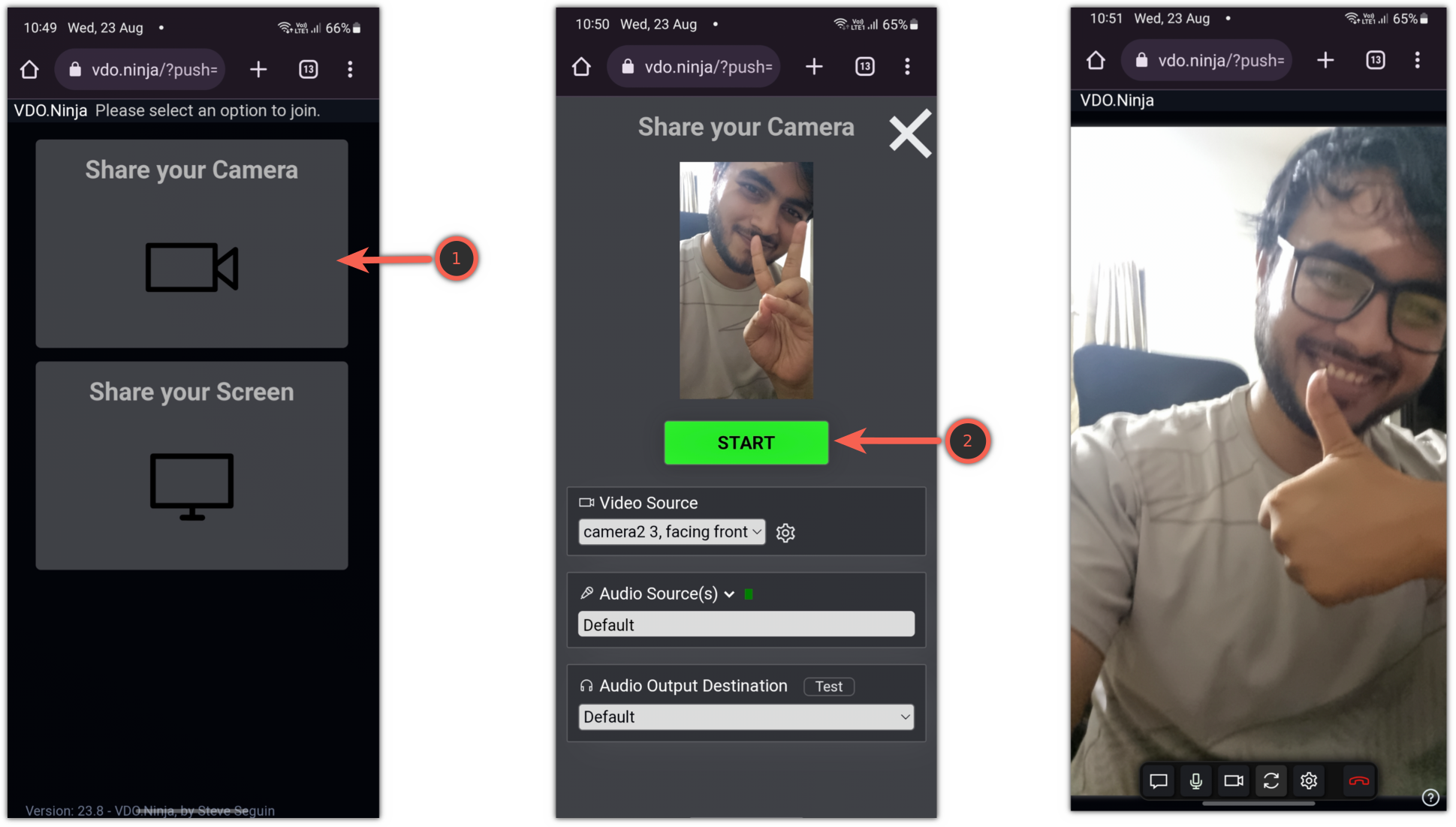
### 3. Setup a virtual cable for OBS on Ubuntu
First, let's talk about what is virtual cable and why you need it to use your phone as a camera and mic.
The virtual cable is software used for transfering audio streams from one application to another.
But the sad part is that it is only available for Windows and macOS.
Hmmmm???? So why am I writing this?
The answer is simple. I found a workaround to this where you can have the same functionality as a virtual cable for** the current session**.
To set up a virtual cable, first, you have to load the `module-null-sink`
module using the following command:
`pactl load-module module-null-sink sink_name=Source`
And then, execute the given command to create a virtual audio source named `VirtualMic`
:
`pactl load-module module-virtual-source source_name=VirtualMic master=Source.monitor`
Both commands will return some numbers that you don't have to worry about.
Now, go to the system settings, and there you will find settings for sound:
Next, go to the `Input`
section and there, you will find the option to choose an input device.
Chose `VirtualMic`
as an input device:
That's it!
But as I said earlier, once you reboot the effect of virtual audio will be flushed and if you regularly want to use your phone as a camera and mic, it can be inconvenient.
To cater to this, you can [create an alias](https://linuxhandbook.com/linux-alias-command/) for those two commands. For example, you can create aliases for both commands: vc1 and vc2.
Once done, you can [execute both commands at once](https://linuxhandbook.com/run-multiple-commands/) like this: `vc1 && vc2`
.
### 4. Setup OBS to stream audio and video from the phone
First, open the VDO.ninja tab that I told you not to close and copy the OBS link:
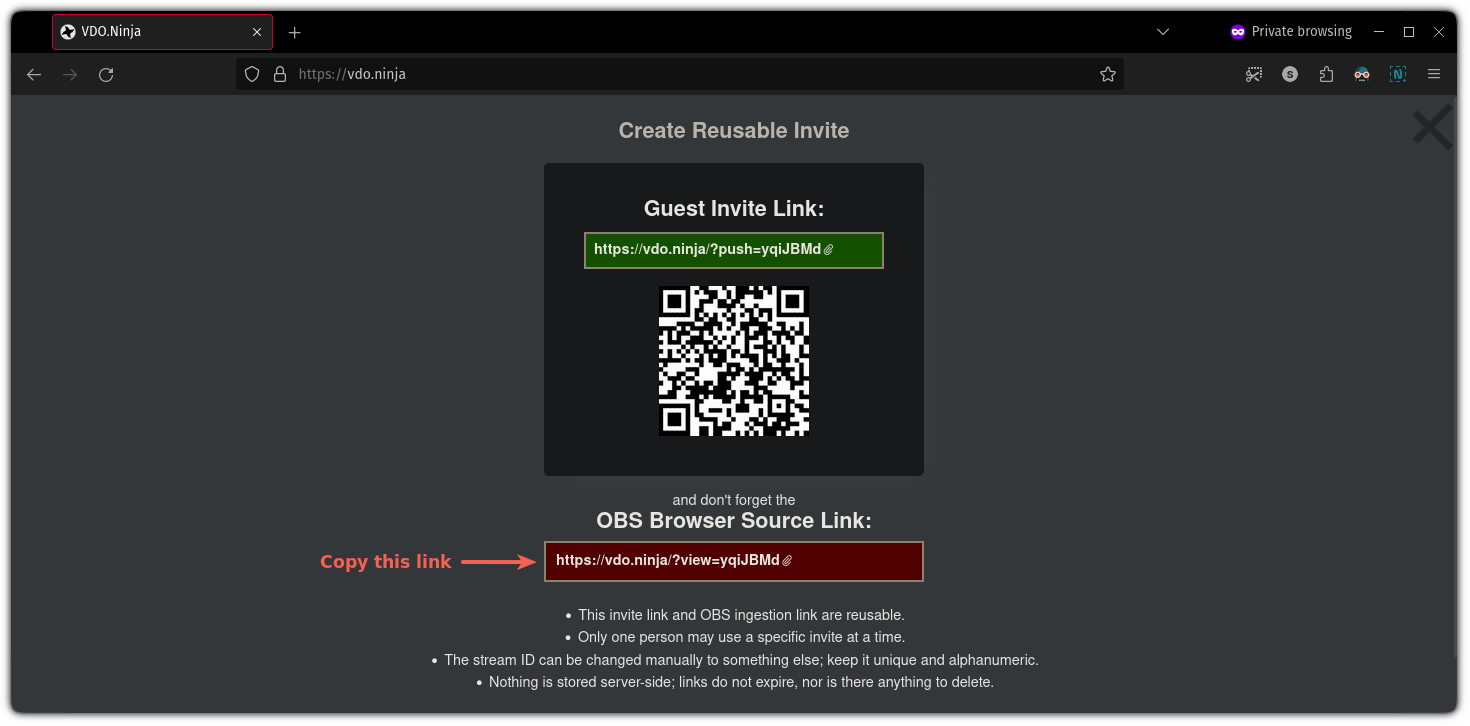
Once copied, open OBS, and under the `Sources`
section, you will find a ➕ (plus) button. Click that button and select `Browser`
.
It will open a little prompt to create/select a source. Simply press the `OK`
button:
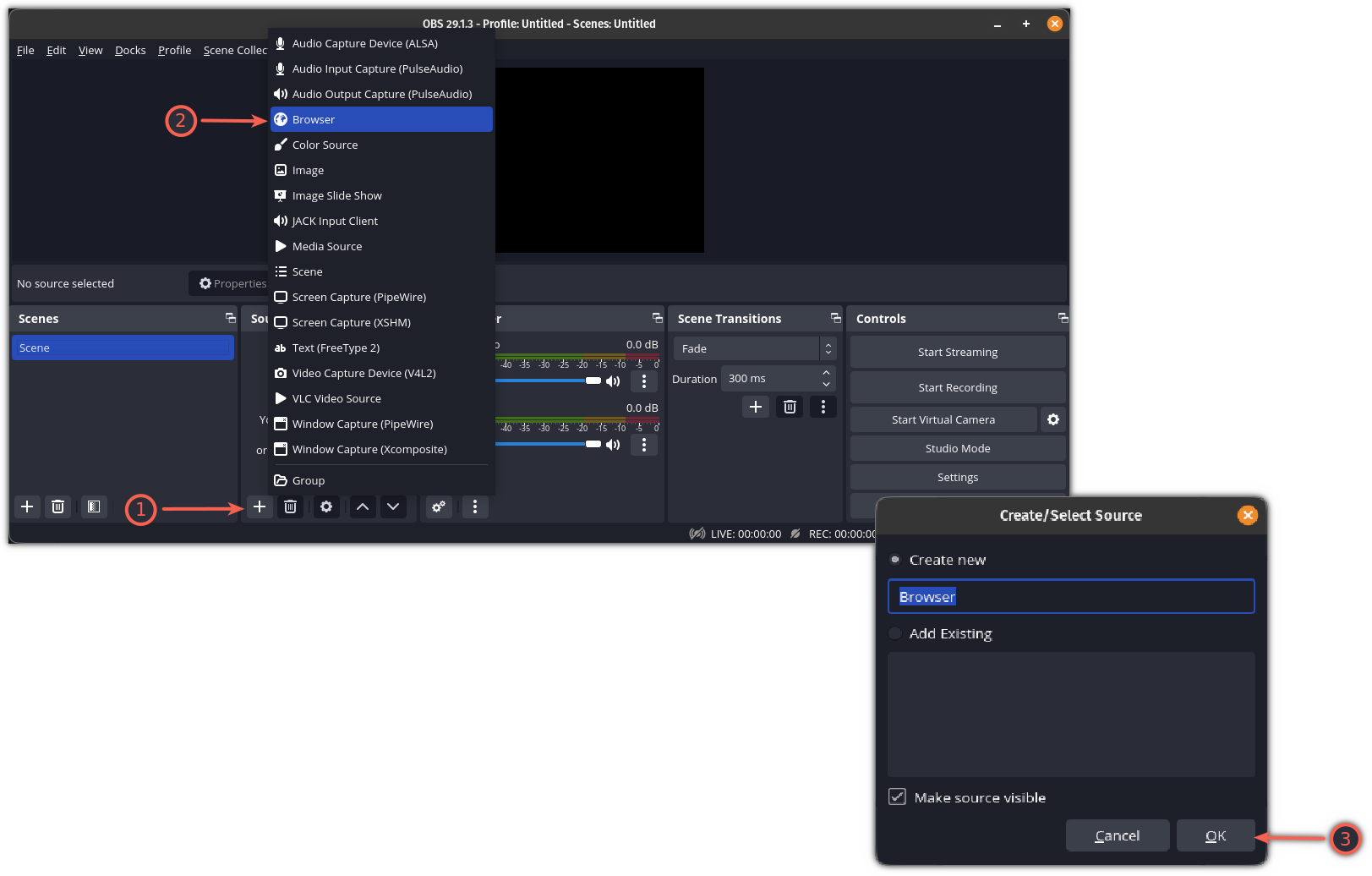
Finally, paste the link in the `URL`
field:
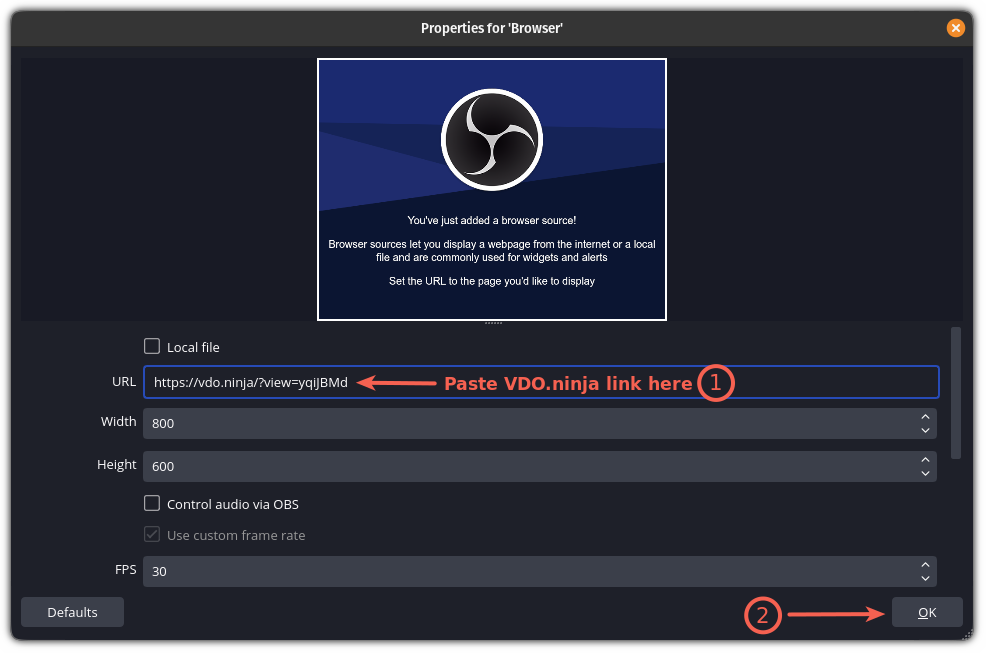
And soon, you will see OBS using your phone's camera:
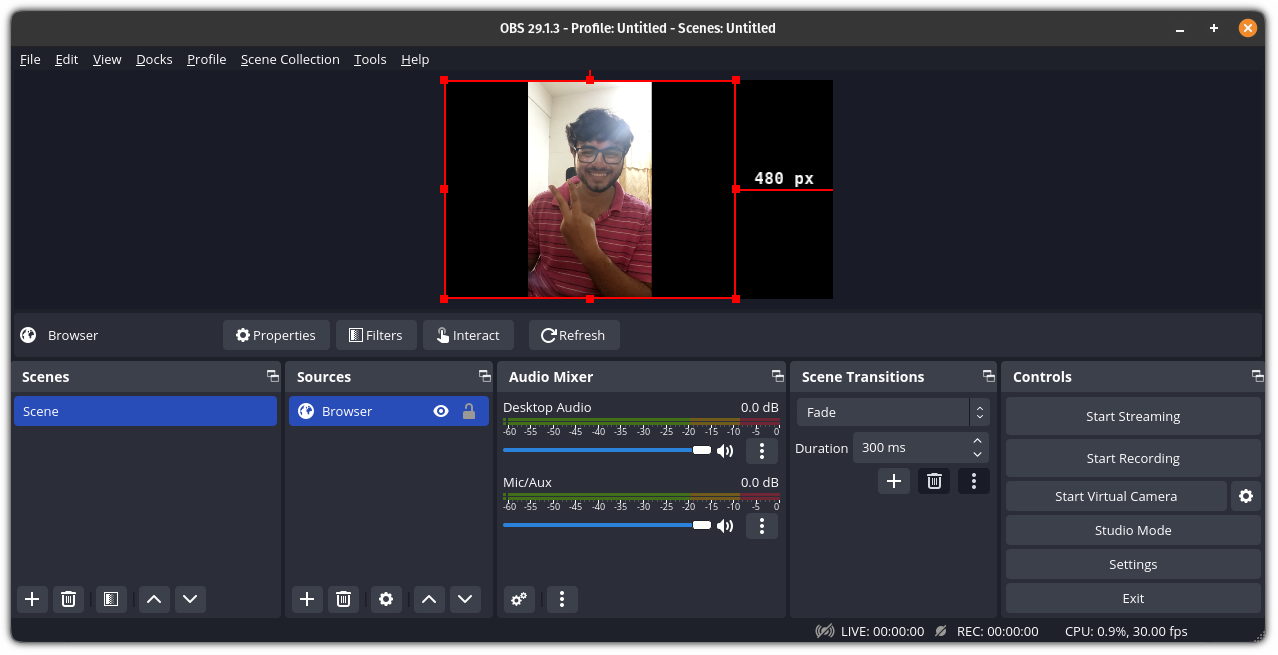
But there are a few extra steps to get audio from your phone.
First, click on the `File`
and choose `Settings`
:
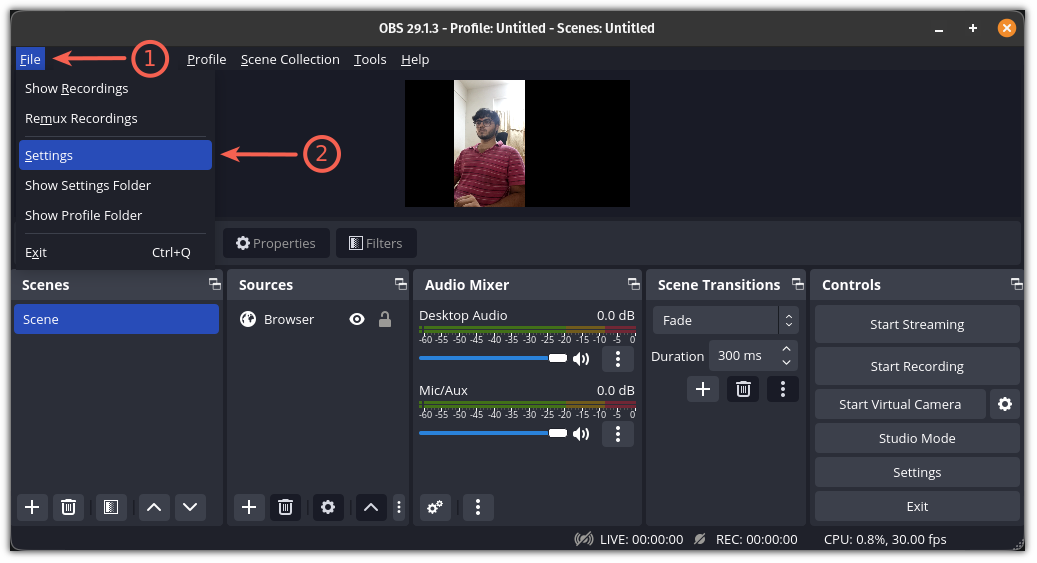
There, Choose `Audio`
and look for the `Advanced`
section.
In the Advanced section, you will find an option for `Monitoring Device`
and there you have to choose `Souce Audio/Sink sink`
:
Apply the changes.
For most users, the audio should be working by now. But if yours don't then here's how you can make it work.
In the Audio Mixer section, it will be either the `Browser`
or the `Desktop Audio`
, or you may also see both of them.
Click on those three dots for Desktop Audio or Browser (in my case, it's Desktop Audio) and choose `Advanced Audio Properties`
:
From there, choose `Monitor and Output`
for the Browser and Desktop Audio:
And that's it! You can enjoy the camera and mic from your phone.
### 5. Test the whole setup
To test this, I used my phone as a camera and mic in our book club's weekly meeting and it worked flawlessly.
As you can see, the above image indicates a working mic and camera (which brought a smile to my face 😸).
The video quality depends on the internet bandwidth so make sure you have a good connection before starting an important meeting.
## Wrapping Up...
I'm one of those desktop users who don't have access to a camera and mic and have to rely on a laptop or mobile for office meetings and I was irritated by that.
Remember, you have to create a virtual cable every time you reboot, but it won't take much time as it takes two command executions.
Have used this solution multiple times and it worked every time I put it to the test. I really hope you will have the same output. |
16,170 | 通过这个简单的游戏学习 Tcl/Tk 和 Wish | https://opensource.com/article/23/4/learn-tcltk-wish-simple-game | 2023-09-07T23:17:46 | [
"Tcl",
"Tcl/Tk",
"猜数字"
] | https://linux.cn/article-16170-1.html | 
>
> 以下是一个简单的编程项目,能够帮助你开始学习 Tcl/Tk。
>
>
>
探索 Tcl/Tk 的基础构造,包括用户输入、输出、变量、条件评估、简单函数和基础事件驱动编程。
我写这篇文章的初衷源于我想更深入地利用基于 Tcl 的 Expect。这让我写下了以下两篇文章:[通过编写一个简单的游戏学习 Tcl](https://opensource.com/article/23/2/learn-tcl-writing-simple-game) 和 [通过编写一个简单的游戏学习 Expect](https://opensource.com/article/23/2/learn-expect-automate-simple-game)。
我进行了一些 [Ansible](https://www.redhat.com/en/technologies/management/ansible/what-is-ansible?intcmp=7013a000002qLH8AAM) 自动化工作,逐渐积累了一些本地脚本。有些脚本我频繁使用,以至于以下循环操作变得有些烦人:
* 打开终端
* 使用 `cd` 命令跳转至合适的目录
* 输入一条带有若干选项的长命令启动所需的自动化流程
我日常使用的是 macOS。实际上我更希望有一个菜单项或者一个图标,能够弹出一个简单的界面接受参数并执行我需要的操作,[这就像在 Linux 的 KDE 中一样](https://opensource.com/article/23/2/linux-kde-desktop-ansible)。
经典的 Tcl 类书籍都包含了关于流行的 Tk 扩展的文档。既然我已经深入研究了这个主题,我尝试着对其(即 `wish`)进行编程。
虽然我并非一名 GUI 或者前端开发者,但我发现 Tcl/Tk 脚本编写的方式相当直接易懂。我很高兴能重新审视这个 UNIX 历史的古老且稳定的部分,这种技术在现代平台上依然有用且可用。
### 安装 Tcl/Tk
对于 Linux 系统,你可以按照下面的方式安装:
```
$ sudo dnf install tcl
$ which wish
/bin/wish
```
而在 macOS 上,你可以通过 [Homebrew](https://opensource.com/article/20/6/homebrew-mac) 来安装最新版的 Tcl/Tk:
```
$ brew install tcl-tk
$ which wish
/usr/local/bin/wish
```
### 编程理念
许多编写游戏的教程都会介绍到典型的编程语言结构,如循环、条件判断、变量、函数和过程等等。
在此篇文章中,我想要介绍的是 [事件驱动编程](https://developers.redhat.com/topics/event-driven/all?intcmp=7013a000002qLH8AAM)。当你的程序使用事件驱动编程,它会进入一个特殊的内置循环,等待特定的事件发生。当这个特定的事件发生时,相应的代码就会被触发,产生预期的结果。
这些事件可以包括键盘输入、鼠标移动、点击按钮、定时器触发,甚至是任何你的电脑硬件能够识别的事件(可能来自特殊的设备)。你的程序中的代码决定了用户看到了什么,以及程序需要监听什么输入,当这些输入被接收后程序会怎么做,然后进入事件循环等待输入。
这篇文章的理念并没有脱离我之前的 Tcl 文章太远。这里最大的不同在于用 GUI 设置和用于处理用户输入的事件循环替代了循环结构。其他的不同则是 GUI 开发需要采取的各种方式来制作一个可用的用户界面。在采用 Tk GUI 开发的时候,你需要了解两个基础的概念:<ruby> 部件 <rt> widget </rt></ruby>和<ruby> 几何管理器 <rt> geometry manager </rt></ruby>。
部件是构成可视化元素的 UI 元素,通过这些元素用户可以与程序进行交互。这其中包括了按钮、文本区域、标签和文本输入框。部件还包括了一些选项选择,如菜单、复选框、单选按钮等。最后,部件也包括了其他的可视化元素,如边框和线性分隔符。
几何管理器在放置部件在显示窗口中的位置上扮演着至关重要的角色。有一些不同的几何管理器可以供你使用。在这篇文章中,我主要使用了 `grid` 几何来让部件在整齐的行中进行布局。我会在这篇文章的结尾地方解释一些几何管理器的不同之处。
### 用 wish 进行猜数字游戏
这个示例游戏代码与我其他文章中的示例有所不同,我将它分解为若干部分以方便解释。
首先创建一个基本的可执行脚本 `numgame.wish` :
```
$ touch numgame.wish
$ chmod 755 numgame.wish
```
使用你喜欢的文本编辑器打开此文件,输入下列代码的第一部分:
```
#!/usr/bin/env wish
set LOW 1
set HIGH 100
set STATUS ""
set GUESS ""
set num [expr round(rand()*100)]
```
第一行定义了该脚本将通过 `wish` 执行。接下来,创建了几个全局变量。这里我使用全部大写字母定义全局变量,这些变量将绑定到跟踪这些值的窗口小部件(`LOW`、`HIGH`等等)。
全局变量 `num` 是游戏玩家要猜测的随机数值,这个值是通过 Tcl 的命令执行得到并保存到变量中的:
```
proc Validate {var} {
if { [string is integer $var] } {
return 1
}
return 0
}
```
这是一个验证用户输入的特殊函数,它只接受整数并拒绝其他所有类型的输入:
```
proc check_guess {guess num} {
global STATUS LOW HIGH GUESS
if { $guess < $LOW } {
set STATUS "What?"
} elseif { $guess > $HIGH } {
set STATUS "Huh?"
} elseif { $guess < $num } {
set STATUS "Too low!"
set LOW $guess
} elseif { $guess > $num } {
set STATUS "Too high!"
set HIGH $guess
} else {
set LOW $guess
set HIGH $guess
set STATUS "That's Right!"
destroy .guess .entry
bind all <Return> {.quit invoke}
}
set GUESS ""
}
```
这是主要的猜数逻辑循环。`global` 语句让我们能够修改在文件开头创建的全局变量(关于此主题后面将会有更多解释)。这个条件判断寻找入力范围在 1 至 100 之外以及已经被用户猜过的值。有效的猜测和随机值进行比较。`LOW` 和 `HIGH` 的猜测会被追踪,作为 UI 中的全局变量进行报告。在每一步,全局 `STATUS` 变量都会被更新,这个状态信息会自动在 UI 中显示。
对于正确的猜测,`destroy` 语句会移除 “Guess” 按钮以及输入窗口,并重新绑定回车键,以激活 “Quit” 按钮。
最后的语句 `set GUESS ""` 用于在下一个猜测之前清空输入窗口。
```
label .inst -text "Enter a number between: "
label .low -textvariable LOW
label .dash -text "-"
label .high -textvariable HIGH
label .status -text "Status:"
label .result -textvariable STATUS
button .guess -text "Guess" -command { check_guess $GUESS $num }
entry .entry -width 3 -relief sunken -bd 2 -textvariable GUESS -validate all \
-validatecommand { Validate %P }
focus .entry
button .quit -text "Quit" -command { exit }
bind all <Return> {.guess invoke}
```
这是设置用户界面的部分。前六个标签语句在你的 UI 上创建了不同的文本展示元素,`-textvariable` 选项监控给定的变量,并自动更新标签的值,这展示了全局变量 `LOW`、`HIGH`、`STATUS` 的绑定。
`button` 行创建了 “Guess” 和 “Quit” 按钮, `-command` 选项设定了当按钮被按下时要执行的操作。按下 “Guess” 按钮执行了上面的 `check_guess` 函数以检查用户输入的值。
`entry` 部件更有趣。它创建了一个三字符宽的输入框,并将输入绑定到 `GUESS` 全局变量。它还通过 `-validatecommand` 选项设置了验证,阻止输入部件接收除数字以外的任何内容。
`focus` 命令是用户界面的一项改进,使程序启动时输入部件处于激活状态。没有此命令,你需要先点击输入部件才可以输入。
`bind` 命令允许你在按下回车键时自动点击 “Guess” 按钮。如果你记得 `check_guess` 中的内容,猜测正确之后会重新绑定回车键到 “Quit” 按钮。
最后,这部分设定了图形用户界面的布局:
```
grid .inst
grid .low .dash .high
grid .status .result
grid .guess .entry
grid .quit
```
`grid` 几何管理器被逐步调用,以逐渐构建出预期的用户体验。它主要设置了五行部件。前三行是显示不同值的标签,第四行是 “Guess” 按钮和 `entry` 部件,最后是 “Quit” 按钮。
程序到此已经初始化完毕,`wish` shell 进入事件循环,等待用户输入整数并按下按钮。基于其在被监视的全局变量中找到的变化,它会更新标签。
注意,输入光标开始就在输入框中,而且按下回车键将调用适当且可用的按钮。
这只是一个初级的例子,Tcl/Tk 有许多可以让间隔、字体、颜色和其他用户界面方面更具有吸引力的选项,这超出了本文中简单 UI 的示例。
运行这个应用,你可能会注意到这些部件看起来并不很精致或现代。这是因为我正在使用原始的经典部件集,它们让人回忆起 X Windows Motif 的时代。不过,还有一些默认的部件扩展,被称为主题部件,它们可以让你的应用程序有更现代、更精致的外观和感觉。
### 启动游戏!
保存文件之后,在终端中运行它:
```
$ ./numgame.wish
```
在这种情况下,我无法给出控制台的输出,因此这里有一个动画 GIF 来展示如何玩这个游戏:

### 进一步了解 Tcl
Tcl 支持命名空间的概念,所以在这里使用的变量并不必须是全局的。你可以把绑定的部件变量组织进不同的命名空间。对于像这样的简单程序,可能并不太需要这么做。但对于更大规模的项目,你可能会考虑这种方法。
`proc check_guess` 函数体内有一行 `global` 代码我之前没有解释。在 Tcl 中,所有变量都按值传递,函数体内引用的变量的范围是局部的。在这个情况下,我希望修改的是全局变量,而不是局部范围的版本。Tcl 提供了许多方法来引用变量,在执行堆栈的更高级别执行代码。在一些情况下,像这样的简单引用可能带来一些复杂性和错误,但是调用堆栈的操作非常有力,允许 Tcl 实现那些在其他语言中实现起来可能较为复杂的新的条件和循环结构。
最后,在这篇文章中,我没有提到几何管理器,它们用于以特定的顺序展示部件。只有被某种几何管理器管理的部件才能显示在屏幕上。grid 管理器相当简洁,它按照从左到右的方式放置部件。我使用了五个 grid 定义来创建了五行。另外还有两个几何管理器:place 和 pack。pack 管理器将部件围绕窗口边缘排列,而 place 管理器允许固定部件的位置。除这些几何管理器外,还有一些特殊的部件,如 `canvas` ,`text` 和 `panedwindow`,它们可以容纳并管理其他部件。你可以在经典的 Tcl/Tk 参考指南,以及 [Tk 命令](https://tcl.tk/man/tcl8.7/TkCmd/index.html) 文档页上找到这些部件的全面描述。
### 继续学习编程
Tcl 和 Tk 提供了一个简单有效的方法来构建图形用户界面和事件驱动应用程序。这个简单的猜数游戏只是你能用这些工具做到的事情的起点。通过继续学习和探索 Tcl 和 Tk,你可以打开构建强大且用户友好的应用程序的无数可能性。继续尝试,继续学习,看看你新习得的 Tcl 和 Tk 技能能带你到哪里。
*(题图:MJ/40621c50-6577-4033-9f3c-8013bd0286f1)*
---
via: <https://opensource.com/article/23/4/learn-tcltk-wish-simple-game>
作者:[James Farrell](https://opensource.com/users/jamesf) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Explore the basic language constructs of Tcl/Tk, which include user input, output, variables, conditional evaluation, simple functions, and basic event driven programming.
My path to writing this article started with a desire to make advanced use of Expect which is based on Tcl. Those efforts resulted in these two articles: [Learn Tcl by writing a simple game](https://opensource.com/article/23/2/learn-tcl-writing-simple-game) and [Learn Expect by writing a simple game](https://opensource.com/article/23/2/learn-expect-automate-simple-game).
I do a bit of [Ansible](https://www.redhat.com/en/technologies/management/ansible/what-is-ansible?intcmp=7013a000002qLH8AAM) automation and, over time have collected a number of local scripts. Some of them I use often enough that it becomes annoying to go through the cycle of:
- Open terminal
- Use
`cd`
to get to the right place - Type a long command with options to start the desired automation
I use macOS on a daily basis. What I really wanted was a menu item or an icon to bring up a simple UI to accept parameters and run the thing I wanted to do, [like in KDE on Linux](https://opensource.com/article/23/2/linux-kde-desktop-ansible).
The classic Tcl books include documentation on the popular Tk extensions. Since I was already deep into researching this topic, I gave programming it (that is `wish`
) a try.
I've never been a GUI or front-end developer, but I found the Tcl/Tk methods of script writing fairly straight forward. I was pleased to revisit such a venerable stalwart of UNIX history, something still available and useful on modern platforms.
## Install Tcl/Tk
On a Linux system, you can use this:
```
``````
$ sudo dnf install tcl
$ which wish
/bin/wish
```
On macOS, use [Homebrew](https://opensource.com/article/20/6/homebrew-mac) to install the latest Tcl/Tk:
```
``````
$ brew install tcl-tk
$ which wish
/usr/local/bin/wish
```
## Programming concepts
Most game-writing articles cover the typical programming language constructs such as loops, conditionals, variables, functions and procedures, and so on.
In this article, I introduce [event-driven programming](https://developers.redhat.com/topics/event-driven/all?intcmp=7013a000002qLH8AAM). With event-driven programming, your executable enters into a special built-in loop as it waits for something specific to happen. When the specification is reached, the code is triggered to produce a certain outcome.
These events can consist of things like keyboard input, mouse movement, button clicks, timing triggers, or nearly anything your computer hardware can recognize (perhaps even from special-purpose devices). The code in your program sets the stage from what it presents to the end user, what kinds of inputs to listen for, how to behave when these inputs are received, and then invokes the event loop waiting for input.
The concept for this article is not far off from my other Tcl articles. The big difference here is the replacement of looping constructs with GUI setup and an event loop used to process the user input. The other differences are the various aspects of GUI development needed to make a workable user interface. With Tk GUI development, you need to look at two fundamental constructs called widgets and geometry managers.
Widgets are UI elements that make up the visual elements you see and interact with. These include buttons, text areas, labels, and entry fields. Widgets also offer several flavors of option selections like menus, check boxes, radio buttons, and so on. Finally, widgets include other visual elements like borders and line separators.
Geometry managers play a critical role in laying out where your widgets sit in the displayed window. There are a few different kinds of geometry managers you can use. In this article, I mainly use `grid`
geometry to lay widgets out in neat rows. I explain some of the geometry manager differences at the end of this article.
## Guess the number using wish
This example game code is different from the examples in my other articles. I've broken it up into chunks to facilitate the explanation.
Start by creating the basic executable script `numgame.wish`
:
```
``````
$ touch numgame.wish
$ chmod 755 numgame.wish
```
Open the file in your favorite text editor. Enter the first section of the code:
```
``````
#!/usr/bin/env wish
set LOW 1
set HIGH 100
set STATUS ""
set GUESS ""
set num [expr round(rand()*100)]
```
The first line defines that the script is executable with `wish`
. Then, several global variables are created. I've decided to use all upper-case variables for globals bound to widgets that watch these values (`LOW`
, `HIGH`
and so on).
The `num`
global is the variable set to the random value you want the game player to guess. This uses Tcl's command execution to derive the value saved to the variable:
```
``````
proc Validate {var} {
if { [string is integer $var] } {
return 1
}
return 0
}
```
This is a special function to validate data entered by the user. It accepts integer numbers and rejects everything else:
```
``````
proc check_guess {guess num} {
global STATUS LOW HIGH GUESS
if { $guess < $LOW } {
set STATUS "What?"
} elseif { $guess > $HIGH } {
set STATUS "Huh?"
} elseif { $guess < $num } {
set STATUS "Too low!"
set LOW $guess
} elseif { $guess > $num } {
set STATUS "Too high!"
set HIGH $guess
} else {
set LOW $guess
set HIGH $guess
set STATUS "That's Right!"
destroy .guess .entry
bind all <Return> {.quit invoke}
}
set GUESS ""
}
```
This is the main loop of the value guessing logic. The `global`
statement allows you to modify the global variables created at the beginning of the file (more on this topic later). The conditional looks for input that is out of bounds of 1 through 100 and also outside of values the user has already guessed. Valid guesses are compared against the random value. The `LOW`
and `HIGH`
guesses are tracked as global variables reported in the UI. At each stage, the global `STATUS`
variable is updated. This status message is automatically reported in the UI.
In the case of a correct guess, the `destroy`
statement removes the "Guess" button and the entry widget, and re-binds the **Return** (or **Enter**) key to invoke the **Quit** button.
The last statement `set GUESS ""`
is used to clear the entry widget for the next guess:
```
``````
label .inst -text "Enter a number between: "
label .low -textvariable LOW
label .dash -text "-"
label .high -textvariable HIGH
label .status -text "Status:"
label .result -textvariable STATUS
button .guess -text "Guess" -command { check_guess $GUESS $num }
entry .entry -width 3 -relief sunken -bd 2 -textvariable GUESS -validate all \
-validatecommand { Validate %P }
focus .entry
button .quit -text "Quit" -command { exit }
bind all <Return> {.guess invoke}
```
This is the section where the user interface is set up. The first six label statements create various bits of text that display on your UI. The option `-textvariable`
watches the given variable and updates the label's value automatically. This displays the bindings to global variables `LOW`
, `HIGH`
, and `STATUS`
.
The `button`
lines set up the **Guess** and **Quit** buttons, with the `-command`
option specifying what to do when the button is pressed. The **Guess** button invokes the `check_guess`
procedure logic above to check the users entered value.
The `entry`
widget gets more interesting. It sets up a three-character wide input field, and binds its input to `GUESS`
global. It also configures validation with the `-validatecommand`
option. This prevents the entry widget from accepting anything other than numbers.
The `focus`
command is a UI polish that starts the program with the entry widget active for input. Without this, you need to click into the entry widget before you can type.
The `bind`
command is an additional UI polish that automatically clicks the **Guess** button when the **Return** key is pressed. If you remember from above in `check_guess`
, guessing the correct value re-binds **Return** to the "Quit" button.
Finally, this section defines the GUI layout:
```
``````
grid .inst
grid .low .dash .high
grid .status .result
grid .guess .entry
grid .quit
```
The `grid`
geometry manager is called in a series of steps to incrementally build up the desired user experience. It essentially sets up five rows of widgets. The first three are labels displaying various values, the fourth is the **Guess** button and `entry`
widget, then finally, the **Quit** button.
At this point, the program is initialized and the `wish`
shell enters into the event loop. It waits for the user to enter integer values and press buttons. It updates labels based on changes it finds in watched global variables.
Notice that the input cursor starts in the entry field and that pressing **Return** invokes the appropriate and available button.
This was a simple and basic example. Tcl/Tk has a number of options that can make the spacing, fonts, colors, and other UI aspects much more pleasing than the simple UI demonstrated in this article.
When you launch the application, you may notice that the widgets aren't very fancy or modern. That is because I'm using the original classic widget set, reminiscent of the X Windows Motif days. There are default widget extensions, called themed widgets, which can give your application a more modern and polished look and feel.
## Play the game!
After saving the file, run it in the terminal:
```
````$ ./numgame.wish`
In this case, I can't give console output, so here's an animated GIF to demonstrate how the game is played:
(James Farrell, CC BY-SA 4.0)
## More about Tcl
Tcl supports the notion of namespaces, so the variables used here need not be global. You can organize your bound widget variables into alternate namespaces. For simple programs like this, it's probably not worth it. For much larger projects, you might want to consider this approach.
The `proc check_guess`
body contains a `global`
line I didn't explain. All variables in Tcl are passed by value, and variables referenced within the body are in a local scope. In this case, I wanted to modify the global variable, not a local scoped version. Tcl has a number of ways of referencing variables and executing code in execution stacks higher in the call chain. In some ways, it makes for complexities (and mistakes) for a simple reference like this. But the call stack manipulation is very powerful and allows for Tcl to implement new forms of conditional and loop constructs that would be cumbersome in other languages.
Finally, in this article, I skipped the topic of geometry managers which are used to take widgets and place them in a specific order. Nothing can be displayed to the screen unless it is managed by some kind of geometry manager. The grid manager is fairly simple. It places widgets in a line, from left to right. I used five grid definitions to create five rows. There are two other geometry managers: place and pack. The pack manager arranges widgets around the edges of the window, and the place manager allows for fixed placement. In addition to these geometry managers, there are special widgets called `canvas`
, `text`
, and `panedwindow`
that can hold and manage other widgets. A full description of all these can be found in the classic Tcl/Tk reference guides, and on the [Tk commands](https://tcl.tk/man/tcl8.7/TkCmd/index.html) documentation page.
## Keep learning programming
Tcl and Tk provide a straightforward and effective approach to building graphical user interfaces and event-driven applications. This simple guessing game is just the beginning when it comes to what you can accomplish with these tools. By continuing to learn and explore Tcl and Tk, you can unlock a world of possibilities for building powerful, user-friendly applications. Keep experimenting, keep learning, and see where your newfound Tcl and Tk skills can take you.
## Comments are closed. |
16,171 | Arch Linux 下全面使用 Wayland 的配置指南 | https://www.debugpoint.com/wayland-arch-linux/ | 2023-09-08T09:02:00 | [
"Wayland",
"Arch Linux"
] | /article-16171-1.html | 
>
> 我们能否在 Arch Linux 中通过主流的桌面环境或窗口管理器来全面运行 Wayland?一起来探索答案。
>
>
>
Wayland 是一种针对 Linux 运行图形应用的高效、现代化的协议。相较之下,它在安全、稳定和图形性能方面相较老旧的 [X.Org](http://X.Org) 显示服务器表现更出色。
尽管 [X.Org](http://X.Org) 多年来一直是默认的显示服务器,但其年代漫长且复杂度高,导致了许多问题,包括安全漏洞和对新型硬件的兼容性问题。而 Wayland 提供了一个更简洁和安全的显示协议,用以解决这些问题。
虽然向 Wayland 转型已经有近十年的时间,但这是可以理解的。大型 Linux 发行版,例如 Ubuntu 和 Fedora,自 2021 年起就默认使用 Wayland,因为该协议现已逐渐稳定。
然而,对 Arch Linux 用户来说,使用 Wayland 进行自定义安装可能会比较复杂。在所有主流桌面环境中,只有 KDE Plasma 和 GNOME 有最新的 Wayland 支持。Xfce、LXQt 及其他桌面环境正在开发支持 Wayland 的功能,但现在还没有做好准备。
在窗口管理器方面,Sway 在 Arch Linux 中已经全面支持 Wayland。尽管如此,我还是希望能测试 Wayland 在 Arch 中的表现,并给你提供一个截至今日的状态报告。
让我们来尝试在 Arch Linux 中配置 KDE Plasma 和 GNOME 以全面支持 Wayland。
### Arch Linux 中的 Wayland 设置
在理想的情况下,你应已经安装了 [基础的 wayland 包](https://archlinux.org/packages/extra/x86_64/wayland/)。打开一个终端,并通过运行下列命令进行核实:
```
pacman -Qi wayland
```
如果你尚未安装,则可以使用以下命令进行安装:
```
sudo pacman -S --needed wayland
```
#### KDE Plasma 桌面环境
接下来的步骤设定的前提条件是你拥有一个没有安装任何桌面环境或窗口管理器的裸机 Arch Linux 环境。你可以通过使用 [高效的 archinstall 脚本](https://www.debugpoint.com/archinstall-guide/) 进行 Arch Linux 的裸机安装。
在 Arch Linux 中,为了设置标准的 KDE Plasma,我们需要对 Wayland 进行一些调整。因此,该过程中需要从 AUR 安装一些包进来,这就要求你已经 [设置了 Yay](https://www.debugpoint.com/install-yay-arch/) 或者其他的 AUR 辅助工具。
首先,利用以下命令从 AUR 安装一个定制的 sddm 显示管理器 Wayland 软件包。请注意,这个 `sddm` 包与 Arch Extra 仓库中的 `sddm` 包并不相同。根据 [ArchWiki](https://wiki.archlinux.org/title/wayland#Display_managers) 的指南,只有 GDM 和 `sddm-git` 在 Arch Linux 中提供了完善的 Wayland 支持。
```
yay -S sddm-git
```
安装完成后,执行下述命令来安装更多 Wayland 包。
* `xorg-xwayland`:使得 xclients 能在 Wayland 下运行
* `xorg-xlsclients`:列出正在一个显示端口上运行的客户端应用(可选)
* `qt5-wayland`:为 Wayland 提供的 Qt API
* `glfw-wayland`:供 Wayland 使用的 GUI 应用开发包
```
pacman -S --needed xorg-xwayland xorg-xlsclients qt5-wayland glfw-wayland
```
然后,执行以下命令以安装 Plasma 和与 Wayland 会话关联的应用。请保持以下的安装顺序。
```
pacman -S --needed plasma kde-applications
```
```
pacman -S --needed plasma-wayland-session
```
**注意**:如果你是英伟达用户,你可能需要考虑安装 `egl-wayland` 包,但需要说明的是,我没有尝试过此操作。
我们现在来安装 Firefox 和 Chromium,这样能够帮助我们测试 Wayland 是否正常运行。
```
pacman -S --needed firefox chromium
```
安装完成后,启动 sddm 显示管理器和 NetworkManager 服务。
```
sudo systemctl enable sddm
sudo systemctl enable NetworkManager
```
另外,sddm 显示管理器需要做一些额外设置。使用你喜欢的文本编辑器,打开 sddm 的配置文件,然后在 `[Theme]` 下面添加 `Current=breeze`。
```
sudo nano /usr/lib/sddm/sddm.conf.d/default.conf
```
```
[Theme]
# current theme name
Current=breeze
```
设置完成后,保存并关闭文件,然后进行重启。
```
reboot
```
重启后,在登录屏幕上,你应该可以看到 Wayland 的选项。选择并登录 KDE Plasma 的 Wayland 会话。

你还能通过查看 `$XDG_SESSION_TYPE` 变量来 [核实你是否在运行 Wayland](https://www.debugpoint.com/check-wayland-or-xorg/)。

如果你希望强制让 Firefox 以 Wayland 运行,那么就在 `/etc/environment` 中添加以下行。
```
MOZ_ENABLE_WAYLAND=1
```
然后重新启动或执行下方的命令使其生效。
```
source /etc/environment
```
打开 Firefox,进入 `about:support` 页面来校验 “Window protocol” 的值。你也可以通过在终端中运行 `xlsclients` 来查看哪些外部应用正在运行在 Wayland 下。

至此,你已经完成了在 Arch Linux 中使用 Wayland 安装配置 KDE Plasma 的全部步骤。
#### Wayland KDE Plasma 在 Arch 中的性能表现
总体而言,Arch Linux 下的 KDE Plasma 配合 Wayland 运行得相当顺畅,未出现任何中断使用或重大问题的情形。截图和屏幕录制应用 Spectacle 功能一切正常。尽管如此,我在测试过程中还是注意到了几个小问题。
首先,在开启如 Dolphin 这类应用程序时,底部面板时不时会出现闪烁,这主要是在 VirtualBox 会话中观察到的。
其次,鼠标指针的变化行为有点奇怪。它无法适時地从指针状态切换到操作手柄状态(详见下图)。

最后,当从待机/屏幕关闭状态恢复在线时(在没有安装客户机插件的 VirtualBox 中),KWin 会崩溃。虽然这可能只是虚拟机特有的现象,但仍然需要进行硬重启才能返回到桌面。
在 Arch Linux 的 Wayland 会话闲置状态下,内存消耗大约为 2GB。
### GNOME
在 Arch Linux 中,GDM 显示管理器已经完全支持 Wayland。首先,我们通过下列命令安装 GDM:
```
pacman -S --needed gdm
```
安装完毕后,使用以下命令安装几个 Wayland 需要的包。
* `xorg-xwayland`:使得 xclients 能在 Wayland 下运行
* `xorg-xlsclients`:用于列出在显示器上运行的应用程序(可选)
* `glfw-wayland`:Wayland 的图形用户界面应用开发包
```
pacman -S --needed xorg-xwayland xorg-xlsclients glfw-wayland
```
接下来,你可以用下面的一系列命令来安装 GNOME 和一些与 Wayland 会话相关的应用。请确保按照下列给出的顺序来执行这些命令。
```
sudo pacman -S --needed gnome gnome-tweaks nautilus-sendto gnome-nettool gnome-usage gnome-multi-writer adwaita-icon-theme xdg-user-dirs-gtk fwupd arc-gtk-theme
```
**注意**:如果你正在使用英伟达,你可能需要安装 `egl-wayland` 软件包,但我并未亲自试过此方法。
接下来,我们还要安装 Firefox 和 Chromium,这样你就能测试 Wayland 是否在 GNOME 中正常运行。
```
pacman -S --needed firefox chromium
```
一旦这项任务完成,就启动 GDM 显示管理器和 NetworkManager 服务。
```
sudo systemctl enable gdm
sudo systemctl enable NetworkManager
```
保存并关闭文件之后,进行重启。
```
reboot
```
在登录界面,你能看到 “GNOME (Wayland)” 选项。选择并登录到 GNOME 的 Wayland 会话中,以进入 Arch Linux。

#### GNOME 的性能
如果将 GNOME 和 KDE Plasma 进行对比,你会发现 GNOME 在 Arch Linux 的 Wayland 下的表现更胜一筹。没有遇到重大问题或应用屏幕闪烁。这可能源于 GNOME 44 针对 Wayland 的最新改进已普及至 Arch Linux。
此外,Firefox 是在 GNOME 上直接在 Wayland 上运行,而不是使用 xwayland 包装器。

### 解决常见 Wayland 问题
虽然 Wayland 提供了众多优点,但在使用过程中你可能会遇到一些挑战。以下列出了几个常见的问题以及可能的解决方案:
* **处理不兼容的应用程序**:部分较旧或不常用的应用可能还未完全支持 Wayland。你可以考虑寻找专为 Wayland 设计的替代应用,或利用 XWayland 作为兼容性层。
* **解决性能相关问题**:如果你在特定的应用程序中遇到性能问题,确保你已经安装了最新的图形驱动。另外,也可以查看是否有特定的合成器设置或适用于特定应用程序的优化措施。
* 在 [这个页面](https://wiki.archlinux.org/title/wayland#Troubleshooting) 中,也有**更多**疑难解答的建议。
### 结论
在 Arch Linux 中将 Wayland 设置为默认的显示服务器可以大大提升安全性、稳定性和图形性能。遵循本指南的安装和配置步骤,你能够从 Xorg 平稳过渡到 Wayland,享受一个更为现代高效的显示体验。
然而,对于 Arch Linux 加 Wayland 的组合来说,整个过程可能会显得稍微复杂一些,因为许多问题崩溃时都需要额外的注意。
这个指南并没包括在 Arch 使用 Wayland 游戏的测试,所以你可能需要在配置完成后自行试验。我希望这篇教程能帮助你在 Arch Linux 中配置 Wayland。
如果你有任何进展,欢迎在下面的评论框中告诉我。
*(题图:MJ/188e0c86-ed52-4185-b583-23814fb72ce7)*
---
via: <https://www.debugpoint.com/wayland-arch-linux/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
16,173 | Linux Lite 6.6 发布:更新了欢迎应用和图标主题 | https://news.itsfoss.com/linux-lite-6-6-release/ | 2023-09-09T09:09:31 | [
"Linux Lite"
] | https://linux.cn/article-16173-1.html | 
>
> Linux Lite 6.6 可能没有大的变化,但看起来它专注于有用的部分。
>
>
>
Linux Lite 是 [最好的轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/) 之一,提供 [类似 Windows](https://itsfoss.com/windows-like-linux-distributions/) 的体验。
我们上次了解它是在今年早些时候,当时 [Linux Lite 6.4](https://news.itsfoss.com/linux-lite-6-4-released/) 添加了一些重大更改。现在,他们又发布了一个小版本,承诺进行大量改进。
### ? Linux Lite 6.6:有什么新变化?

该版本被称为 2012 年以来最大的 Linux Lite 版本之一,增加了数千行新代码。Linux Lite 6.6 由可靠的 [Linux 内核 5.15](https://news.itsfoss.com/linux-kernel-5-15-release/) 提供支持,是一个适度的更新。
一些亮点包括:
* **改进了 Lite 欢迎应用**
* **免费 AI 聊天机器人**
* **支持新语言**
### 改进的 Lite Welcome

“Lite Welcome” 应用已更新,当未安装 Linux Lite 时,在立付会话中显示 “<ruby> 立即安装 <rt> Install Now </rt></ruby>” 按钮。现在它将检查它是否在立付环境中运行并相应地显示按钮。
这将是直接将 Linux Lite 安装到系统上的便捷方法。此次更新还为欢迎应用添加了另一个选项。下面有更多内容。
### Free A.I. Chatbot

欢迎应用程序中的一个新链接可直接前往 Linux Lite 的网络聊天机器人,名为 “Free A.I. Chatbot”。
用户可以使用它来获得与 Linux Lite 相关的支持。尽管我希望这是系统中内置的专用应用,但拥有它仍然很有趣。
你还可以使用网络浏览器直接 [访问](https://www.linuxliteos.com/chatai/) 它。
### 支持新语言

这是上述代码行的主要部分,Linux Lite 6.6 中添加了对 **22 种语言**的支持。
我用“印地语”测试了它,效果很好。尽管某些选项仍然以英语显示,但很高兴看到它们**试图更具包容性**,提供更广泛的语言选项。
**提供这些语言的区域**包括主菜单、右键单击菜单、文件夹名称、Linux Lite 应用名称、桌面图标和“我的电脑”菜单名称。
### ?️ 其他更改和改进
其余的变化包括新壁纸和应用更新。其中一些是:
* Chrome 116
* VLC 3.0.16
* Gimp 2.10.30
* LibreOffice 7.5.6
* Thunderbird 102.15
* 新壁纸
* 包含最新的 Papirus 图标主题。
* 硬件数据库目前拥有超过 85,000 条提交内容。
有关这些变化的更详细的展望,请访问其 [公告](https://www.linuxliteos.com/forums/release-announcements/linux-lite-6-6-final-released/)。
### ? 下载 Linux Lite 6.6
你可以前往 [官方网站](https://www.linuxliteos.com/download.php) 获取此版本或单击下面的按钮。
>
> **[Linux Lite 6.6](https://www.linuxliteos.com/download.php)**
>
>
>
? 你对 Linux Lite 6.6 版本有何看法?
---
via: <https://news.itsfoss.com/linux-lite-6-6-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux Lite is one of the [best lightweight Linux distros](https://itsfoss.com/lightweight-linux-beginners/?ref=news.itsfoss.com) that offers a [Windows-like](https://itsfoss.com/windows-like-linux-distributions/?ref=news.itsfoss.com) experience.
We last looked at it earlier this year when [Linux Lite 6.4](https://news.itsfoss.com/linux-lite-6-4-released/) added some significant changes. Now, we have yet another point release that promises a slew of improvements.
## 🆕 Linux Lite 6.6: What's New?
Dubbed one of the largest releases of Linux Lite since 2012, this release consists of 1000 new lines of code. Powered by the reliable [ Linux Kernel 5.15](https://news.itsfoss.com/linux-kernel-5-15-release/), Linux Lite 6.6 is a modest update.
Some highlights include:
**Improved Lite Welcome app****Free A.I. Chatbot****Support for New Languages**
### Improved Lite Welcome
The '**Lite Welcome**' app has been updated to show an “**Install Now**” button in live sessions when Linux Lite is not installed. It will now check if it is running in a live environment and display the button accordingly.
This will be a handy way of directly installing Linux Lite onto your system. The update has also added another option to the welcome app; more on that below.
**Suggested Read **📖
[16 Best Lightweight Linux Distributions for Older ComputersDon’t throw your old computer just yet. Use a lightweight Linux distro and revive that decades-old system.](https://itsfoss.com/lightweight-linux-beginners/?ref=news.itsfoss.com)

### Free A.I. Chatbot
A new link in the welcome app to directly head to Linux Lite's web chatbot called “Free A.I. Chatbot”.
Users can use that to get support related to Linux Lite; though I hoped this to be a dedicated application built into the system, it is interesting to have nonetheless.
You can also [access it](https://www.linuxliteos.com/chatai/?ref=news.itsfoss.com) directly using a web browser.
### Support for New Languages
This has been the major contributor to the aforementioned lines of code i.e support for **22 languages **has been added to Linux Lite 6.6.
I tested it out in 'Hindi,' and it worked pretty well; though some options were still displayed in English, it was nice to see that they are **trying to be more inclusive **with a broader selection of language options.
The **areas that feature these languages** include the main menu, right-click menu, folder names, Linux Lite application names, desktop icons, and My Computer Menu names.
**Suggested Read **📖
[7 Linux Distributions to Replace Windows 11 & 10Looking for a Windows-like Linux? Here are the best Linux distributions that look like Windows.](https://itsfoss.com/windows-like-linux-distributions/?ref=news.itsfoss.com)

### 🛠️ Other Changes and Improvements
The rest of the changes include new wallpapers and app updates. Some of those are:
- Chrome 116
- VLC 3.0.16
- Gimp 2.10.30
- LibreOffice 7.5.6
- Thunderbird 102.15
- New Wallpapers
- Inclusion of the latest Papirus icon theme.
- The hardware database now has over 85,000 submissions.
For a more detailed outlook of these changes, head over to its [announcement](https://www.linuxliteos.com/forums/release-announcements/linux-lite-6-6-final-released/?ref=news.itsfoss.com).
## 📥 Download Linux Lite 6.6
You can head to the [official website](https://www.linuxliteos.com/download.php?ref=news.itsfoss.com) to grab this release or by clicking on the button below.
*💬 What are your thoughts on the Linux Lite 6.6 release? *
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,174 | Librum:为你打造在线图书馆的新兴开源电子书阅读器 | https://news.itsfoss.com/librum-reader/ | 2023-09-09T10:13:51 | [
"电子书"
] | https://linux.cn/article-16174-1.html | 
>
> Librum,这是一个全新的,配备云图书馆功能的电子书阅读器。
>
>
>
你是不是酷爱阅读?或者正在逐渐沦为书虫?
放心,我们为你准备了绝佳的解决方案!
Librum 阅读器,这是一个全新的电子阅读器产品,它打造的阅读环境 “能让每个人都发现阅读的乐趣,轻松愉快地阅读”。
尽管它并非你通常会使用的那种离线阅读器应用,但在 [Linux 最佳电子阅读器](https://itsfoss.com/best-ebook-readers-linux/) 的榜单上,很可能是候选之一。因为有了 Librum,你可以 **充分发挥云技术的优势**,任何时候,无论使用哪个设备,都能随时访问个人图书馆。
下面,就让我来为你详细介绍一下。
### Librum:概览 ⭐

Librum 基本上是通过 **QML** 和 **C++** 构建的,这款 **开源的电子书阅读器** 允许你以直观的界面将内容同步到云端。
你可以免费开始使用,初次注册便有 **2GB 的云存储空间**。此外,一些尚未最终确定的高级套餐也即将推出。
>
> ? Librum 阅读器目前正在积极开发中,尚未发布稳定版。
>
>
>
Librum 还配有丰富的功能,其中一些突出之处包括:
* **图书馆的个性化定制**
* **书籍的元数据编辑**
* **云同步**
* **现代化的界面**
**推荐阅读** ?
>
> **[8 个 Linux 上的最佳电子书阅读器](https://itsfoss.com/best-ebook-readers-linux/)**
>
>
>
#### 初步体验 ??
我首次尝试在我的 [Ubuntu 22.04](https://news.itsfoss.com/ubuntu-22-04-release/) 系统上运行 Librum。但是,在我使用该应用之前,我 **必须先创建一个账户**,提供电子邮件地址和密码。
虽然 Librum 的主打功能是基于云的体验,但我 **还是希望它能有一个专门的离线模式**,可以让我在注册之前做一些试用,或者作为一种可选择的备用模式。
不过,我还是继续前进,并登录了这款应用。我使用 “<ruby> 添加书籍 <rt> Add books </rt></ruby>” 功能导入了一些书籍,然后它们就在主页标签下被整齐地排列好,提供了对其排序、过滤或添加标签的选项。

**电子书的阅读体验** 几乎与你对现代阅读器应用的期待一致,拥有最简界面,还有放大文本、进入全屏模式等功能。

**汉堡菜单的选项内含有一些基本功能**。最上面三个选项可以让你打印、保存或分享当前打开的电子书。
此外的选项还包括:**文本转语音功能**、**连续/垂直显示页面**、**反转颜色**、**同步书籍**,以及**访问设置菜单**。

我也试用了一下 **搜索功能**:我可以快速地查找特定的词汇,并可以高亮显示所有结果、区分大小写或搜索整个单词。

**目录功能** 也相当方便使用,你可以使用搜索栏查找特定章节。

以上就是我使用 Librum 阅读器的电子书阅读体验。
但是等一下,这还没完,**还有更多的东西等着你去发现!**
#### 未来计划的功能 ?

我注意到还有很多功能正在开发中。
其中一个是 **一个在应用内部的免费书店**,**计划将提供超过 70,000 本的电子书籍**;另一个是 **统计页面**,将会显示 **个人的阅读统计信息**。
最后一个是 **插件页面**,应该是提供 **进一步增强 Librum 功能的插件**。

预计在接下来的几个月内会发布稳定版本。
**开发者们还没有明确说明即将推出的付费计划具体会提供什么**。我个人猜测可能会提供更多的云存储空间和接入更多新奇的功能。
我推荐你关注他们的 [新闻页面](https://librumreader.com/news),以便获取有关 Librum 阅读器的最新信息。
### ? 获取 Librum
目前,Librum **以 Flatpak 形式提供给 Linux 用户**,并且还在为 **Windows** 和 **macOS** 用户开发对应版本。
转到 [官方网站](https://librumreader.com/) 或 [Flathub 商店](https://flathub.org/apps/com.librumreader.librum) 就可以获取下载。
>
> **[Librum (Flathub)](https://flathub.org/apps/com.librumreader.librum)**
>
>
>
? 在 Linux 上,你最喜爱的电子书阅读器应用是哪个?在下方的评论框里留言分享你的观点吧。
*(题图:MJ/9b52d578-ae83-4401-ae57-eb342d8bcfd6)*
---
via: <https://news.itsfoss.com/librum-reader/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Are you a bookworm? Or turning into one?
Well, we have just the thing for you!
Librum Reader is a new eBook reader offering meant to “*make reading enjoyable and straightforward for everyone*.”
While this is not your usual offline reader app, it can be one of the [best eBook readers for Linux](https://itsfoss.com/best-ebook-readers-linux/?ref=news.itsfoss.com). With Librum, you can **take advantage of the cloud** by having a personal library that can be accessed from any device, anytime.
Allow me to show you around it.
## Librum: Overview ⭐
Built primarily using **QML** and **C++**, Librum is an **open-source e-book reader** that allows you to sync your content to the cloud with a pretty straightforward interface.
It is free to get started with **2 GB of cloud storage **and plans to offer some premium tiers (not yet finalized).
Librum is also packed with plenty of features, with some of the highlights including:
**Customizable library****Metadata editing of books****Cloud syncing****Modern interface**
**Suggested Read **📖
[8 Best eBook Readers for LinuxHave a look at some of the best ebook readers for Linux. These apps give a better reading experience and some will even help in managing your ebooks.](https://itsfoss.com/best-ebook-readers-linux/?ref=news.itsfoss.com)

### Initial Impressions 👨💻
I set out to test Librum on my [Ubuntu 22.04](https://news.itsfoss.com/ubuntu-22-04-release/)-powered system. But, before I could use the app, I **had to create an account** by providing an email address and password.
Even though Librum focuses on providing a cloud experience, I **would've liked a dedicated offline-only mode **as an alternative or a trial mode to check Librum out before signing up.
Anyway, I moved on and signed in to the application. I imported a few books by using the '**Add books**' option, and it then arranged them in the home tab neatly, with options to sort, filter, or add tags to them.
The** eBook reading experience** was just about what you would expect from a modern reader application, with a minimal interface and options to scale the text, go into full-screen mode, and more.
The **three-ribbon menu houses a few essential options**. The top three options allow you to print, save, or share the currently opened eBook.
The options include the **text-to-speech functionality**, **displaying pages continuously/vertically**, **inverting the colors**, **syncing the book**, and **accessing the settings menu.**
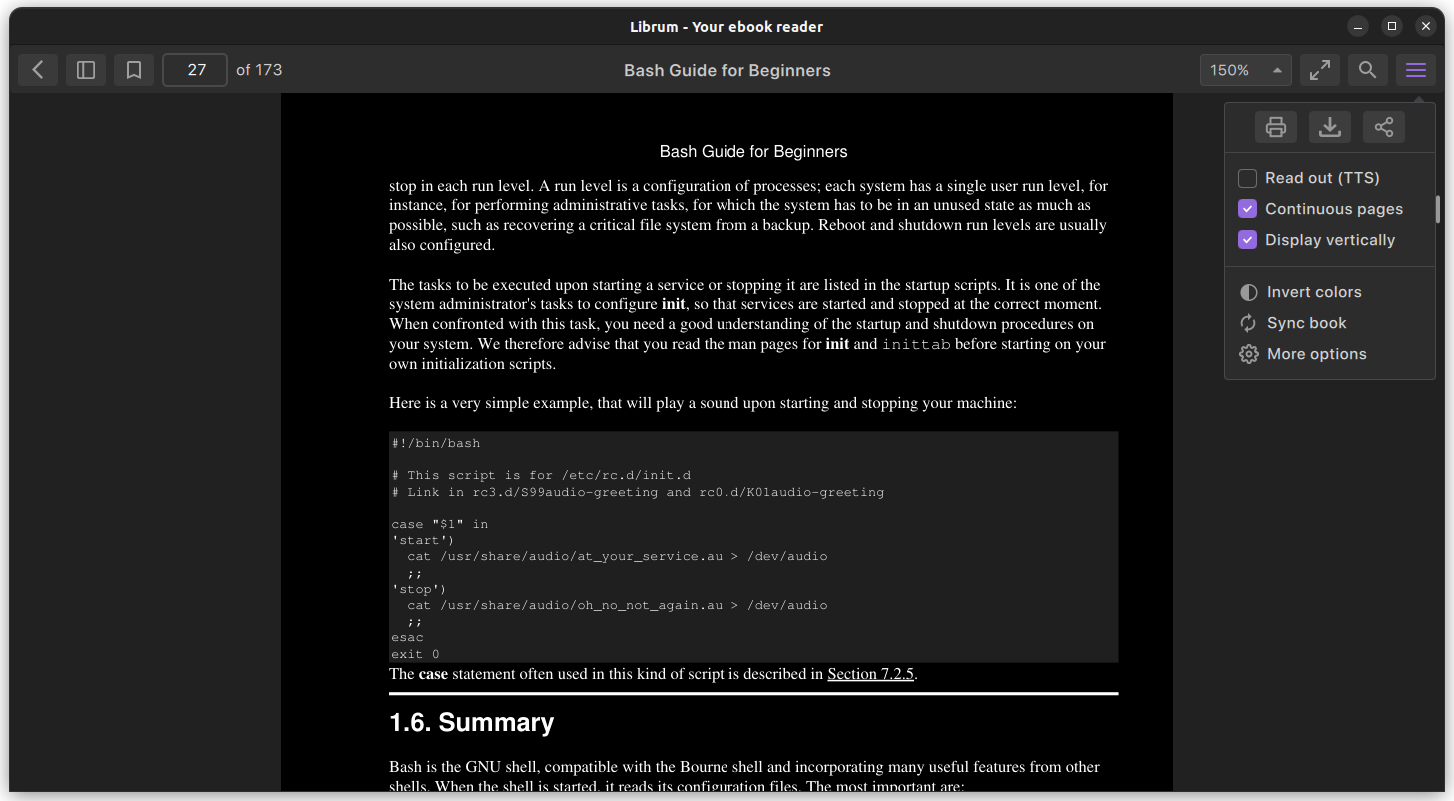
I also tested out **the** **search functionality;** I could quickly find specific words, with options to highlight them all, set it to be case-sensitive, and search for whole words.

The **table of contents** feature also worked quite well, with the option to search for specific chapters using the search bar.
That was it for my eBook reading experience on Librum Reader.
But wait, **there's more to look out for!**
### Proposed Upcoming Features 📝
I noticed that there were plenty of features that were still being worked on.
One of those is **a free in-app bookstore** that is** set to house over 70,000 eBooks; **the other is a '**Statistics Page**' that will contain **personalized reading statistics.**
The last one is an '**Add-ons Page**' that will most likely feature **add-ons that further enhance the functionality of Librum**.
The stable release is set to arrive in the coming months.
The **developers have not yet clarified what the upcoming paid plans will offer**. My best guess would be that they will offer more cloud storage and access to novelty features.
I suggest you watch their [news page](https://librumreader.com/news?ref=news.itsfoss.com) for up-to-date information regarding Librum Reader.
## 📥 Get Librum
Librum is **available as a Flatpak for Linux** right now, with **Windows** and **macOS** variants under development.
Head over to the [official website](https://librumreader.com/?ref=news.itsfoss.com) or the [Flathub store](https://flathub.org/apps/com.librumreader.librum?ref=news.itsfoss.com) to grab it.
*💬 What's your favorite e-book reader app on Linux? Share your thoughts in the comments box below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,176 | 在基于 Arm 的 Thinkpad X13S 笔记本上运行 Linux | https://www.theregister.com/2023/09/08/linux_on_the_thinkpad_x13s/ | 2023-09-10T09:47:00 | [
"Linux 笔记本电脑",
"Armbian",
"Arm"
] | https://linux.cn/article-16176-1.html | 
>
> Armbian 23.08 版本已出炉,初步开始为这款轻薄的 Snapdragon 笔记本提供支持。
>
>
>
最新发布的 Armbian 有助于解决在 Arm 计算机上安装并运行 Linux 发行版的困难 —— 这是一项不小的挑战。
今年 3 月我们 [评测](https://www.theregister.com/2023/03/21/lenovo_thinkpad_x13s_the_stealth/) 的联想 Thinkpad X13S 第一代,是我们评估的首款主流 Arm 驱动笔记本电脑。当然,市面上确实还有其他的 Arm 笔记本,如 Pine64 的 [Pinebook Pro](https://www.theregister.com/2022/08/02/pinebook_pro_finally_starts_shipping/) 和多款基于 Arm 的 ChromeBook 等。然而,X13S 更接近常规的基于 x86 的笔记本电脑:具备优质的配置,配有 16GB 内存和 256GB 的 NVMe SSD,更重要的是,它搭载了 PC 行业标准的 UEFI 固件,这在消费级 Arm 计算机上尚属罕见。另一个好消息是,你可以禁用安全启动,这是许多 Arm 设备不支持的。十年前,这是最初的微软 Surface RT 的一个 [关键问题](https://www.theregister.com/2013/11/14/microsoft_surface_rt_stockpile/):Windows RT 一团糟,而它的固件不让你运行其他的系统。
虽然 X13S 从 2022 年 5 月就开始发售,但要让这个机器支持运行 Linux,却花费了一段不短的时间。一篇 [博客文章](https://openwebcraft.com/linux-on-thinkpad-x13s-gen-1/) 列出一些相关问题,文章副标题 “拥抱苦难” 已经透露出难度之大。这篇文章链接了一篇有关如何在该机器上安装 Debian 的 [很老的指南](https://docs.google.com/document/d/1WuxE-42ZeOkKAft5FuUk6C2fonkQ8sqNZ56ZmZ49hGI/edit#heading=h.d1689esafsky)。我们按照指南操作,尝试安装中间版的 Debian,定制内核,看起来安装成功了。
将其从 SSD 启动,着实需要巨大的努力,这涉及到进入 UEFI 固件 Shell,并手动逐个查阅 30 到 40 个条目才能找出并启用正确的 UEFI 启动条目,但经过数小时的寻找和无数次的重启,它成功工作了,Debian 能够启动。不幸的是,在启动已经安装的操作系统时,屏幕在输出几行以后就变黑了,再也没亮过。虽然操作系统还在运行,例如,按下电源键会在几秒后干净地关闭电源,但由于没有显示,甚至是文本显示也没有,我们无法配置 Wi-Fi 连接,而且该机器并没有内建的以太网接口。

*随着最新固件和更新的支持,现在已经能在基于 Arm 的 Thinkpad 上使用 Ubuntu Lunar 的 GNOME 桌面环境。*
此外,尚有一种 “概念版” 的 Ubuntu 23.04 “Lunar Lobster”,其开发并未完成,该公司要求我们不公开相关链接。自从我们拿到这台机器以来,已经进行了多次固件更新:最初其固件版本为 1.25,如今已经更新至 1.57。在固件版本更新到 [1.49](https://download.lenovo.com/pccbbs/mobiles/n3huj12w.txt) 时,固件设置程序增加了一个处于测试阶段的 “Linux” 选项,并随着下一次更新,机器首次成功通过我们的 Ubuntu USB 启动盘启动。但引导过程极慢,开机至少需要 10-15 分钟,甚至更久,而且当它运行在<ruby> 立付 <rt> Live </rt></ruby>系统模式下时,设备功能有显著限制:比如无法发出声音,Wi-Fi 仅支持 2.4GHz 等。尽管如此,它的运行效果尚可,足以完成安装。初次启动进入的是空白屏幕,然而,你可以切换到虚拟控制台,登录并从 Shell 提示符下更新操作系统。在更新并重启后,图形登录界面出现,此时我们可以正常登录,5GHz Wi-Fi 也开始正常工作。
在固件 1.56 更新阶段,Ubuntu 在这款硬件上仍有诸多限制:无声音,仅支持 Wayland,不支持 X.org。按照我们的惯例,我们安装时将 `/home` 挂载在独立的磁盘分区中,Ubuntu 在一个只读的主目录上启动,但这导致 Ubuntu 无法保存任何设置,也未能创建常用的文件夹(如 `~/Documents` 等)。然而,执行了一条手动的 `chown` 命令后,权限问题得以解决,`/home` 目录也得以写入。

*全面更新后,就连 X.org 也能正常运行,这意味着非 GNOME 桌面可能最终也能被成功运行。*
固件版本 1.57 出现在上个月,重新安装并更新 Ubuntu “Lunar” 后,声音和 X11 功能得以正常工作,这意味着非 Wayland 桌面现在也变得可行。尽管仍有一些困难,但是配备一个 USB-C 以太网适配器会有很大帮助,现在的 X13S 笔记本已经可以很好地运行 Ubuntu。相较于 Windows 运行下的状态,一个显著的差异在于,没有了 x86 模拟环境,只有原生的 Arm64 应用,机器的运行状况变得没那么热了。尽管底座会变热,但它可以放在白白的大腿上使用而不会烫到你。

*甚至连声音芯片也得到了支持,我们可以播放音频并调整音量。*
### 一个(相对)更加简单的选择是——Armbian
在 Arm 笔记本上运行 Linux 的问题在于,基于 Arm 的计算机并不仅仅是一台 CPU 类型不同的 x86 个人电脑。标准的主板和芯片组以及可替换的 GPU 是相当稀有的。大部分机器都是围绕一种高度集成的 SoC 构建的,它包含了 CPU、GPU 以及所有其他组件。
在 x86 个人电脑上,操作系统可以依赖标准固件来启动计算机,但并非所有的 Arm 设备都拥有这样的固件。制造商为每种 Arm 设备打造适合运行特定操作系统的设备,替换为另一种操作系统可能非常棘手。这就是为什么树莓派计算机系列成功的原因之一:不是因为它们特别简单,它们并不是,而是因为它们的销售量大,因此得到广泛的支持。
Armbian 项目就是对这个问题的答案。它为大量的单板计算机(SBC)——主要是 Arm 架构的,正如名字暗示的那样,虽然并非只有这些——编译了特殊的内核。在 [23.08 版本](https://docs.armbian.com/Release_Changelog/#v23081-2023-09-01)(代号为 [Colobus](https://www.armbian.com/newsflash/armbian-23-8/))的发布时,已经列出了支持的 59 个 Arm64 设备,以及 8 个 RISC-V 的板卡,还有一个 [通用的 x86-64/UEFI](https://www.armbian.com/uefi-x86/) 版本。我们在去年 3 月时点评了 [Armbian 22.02](https://www.theregister.com/2022/03/03/armbian_project_releases_version_2202/),但我们重新回顾它,是因为这次发布包含了一个在 X13S 上的 [版本](https://www.armbian.com/lenovo-x13s/),即使支持仍在 [持续进行](https://armbian.atlassian.net/browse/AR-1842)。
对于 x86 PC 来说,你通常从安装介质启动,然后将操作系统安装到机器的内部硬盘上。但对于 SBC 来说,更常见的是将镜像写入内存卡,然后从内存卡启动电脑,因此并无特定的安装进程。Armbian 为 X13S 提供的下载压缩后只有大约 2GB,但它包含了一个完全安装的系统,因此你至少需要一个 16GB 的 U 盘。第一次启动时,它会进入文本模式提示并要求 root 密码、用户账户的凭据,时区以及地区信息。只有在这些信息输入完毕之后,它才会加载图形桌面。

*Armbian 的 Cinnamon 桌面实际上是专为 Arm64 设计的 Debian 12.1,额外附加的驱动及微调使其符合 X13s 的需要。*
这套方案成功地创建了一个工作正常的系统,包括屏幕亮度调节等功能。系统重启后,我们可以连接 2.4GHz 和 5GHz 的 Wi-Fi,并以典型的 Debian 方式进行更新:使用 `sudo apt update && sudo apt full-upgrade -y` 命令。然而,系统没有声音,而且电池支持也尚未到位:不能充电,并且电量指示器不能工作。而且,我们的 Planet Computers USB-C 集线器上的以太网端口也未被检测到。我们试图使用 armbian-installer 脚本将 Armbian 安装到 SSD,但尽管 Ubuntu 找到并将其添加到 GRUB 菜单中,Armbian 仍无法从 SSD 启动。
### 总结
随着时间推移,高通 Snapdragon 8cx Gen 3 平台的 Linux 支持得到了改善。在最新版本上,Ubuntu 在 X13S(内核版本 6.2)上已经可用,我们预期,随着下个月 Ubuntu 新版的发布,这种设备可能变成一个受到支持的平台。
与此同时,一些其他的发行版也在进行支持工作。虽然 Fedora 有一个 [内核镜像](https://copr.fedorainfracloud.org/coprs/jforbes/fedora-x13s/),但目前只是停留在这个阶段。另外,openSUSE Tumbleweed 也有一个预发布 [镜像](https://en.opensuse.org/HCL:ThinkpadX13s),但还没有安装程序,对声音以及电池也尚无支持。
OpenBSD 可以直接支持高通芯片,但是这个操作系统的常规限制,如蓝牙的全面缺失仍然存在。我们已经验证了其可以从 USB 启动并成功配置 Wi-Fi 及 USB 以太网卡,但我们并未深入尝试,因为对于删除我们当时唯一能够完全运行的操作系统——Windows,我们持保守态度。

*在 Windows 11 Arm64 上的 Ubuntu 22.04 上运行的 GNOME 网络浏览器 Epiphany*
当然,还有 <ruby> Windows 的 Linux 服务 <rt> Windows Services for Linux </rt></ruby>(WSL)。这目前是最快捷到达可工作的 Linux 系统的途径:我们试验了在 Windows 11 下的 WSL2 中运行 Ubuntu,它工作得相当完美——且带来附加优势,你明确知道你正在运行的是原生 Arm 应用,而非在耗电的模拟环境下运行的 x86 代码。然而,要注意运行 Windows 本身并不高效,如果你在后台有一些 X86 的应用,你的电池续航会严重受影响。
如果你乐意从 U 盘启动——此处我们推荐使用一个高速 USB-C 盘——那么 Armbian 就能很轻松地帮你启动,虽然有一些限制。随着新内核支持的提升,Armbian 的功能也将随之增强。
X13S 并未准备好全面采纳任何自由和开源的操作系统——例如,网络摄像头尤其仍未得到支持——但 Ubuntu 已经差不多准备好了。目前的镜像并非官方版本,但你可以在你信任的搜索引擎上找到它。如果这个方式失败,那么 Armbian 将是你的第二选择。
*(题图:MJ/701d8523-f00b-4ac4-b559-428a9ab2746f)*
---
via: <https://www.theregister.com/2023/09/08/linux_on_the_thinkpad_x13s/>
作者:[Liam Proven](https://www.theregister.com/Author/Liam-Proven) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-16174-1.html) 荣誉推出
| 200 | OK | This article is more than **1 year old**
# Linux on the Arm-based Thinkpad X13S: It's getting there
## Armbian 23.08 is out, and adds preliminary support for this ultralight Snapdragon laptop
Review The latest release of Armbian helps with the non-trivial problem of installing and running an arbitrary Linux distro on Arm computers.
The Lenovo Thinkpad X13S Generation 1 which we [reviewed back in March](https://www.theregister.com/2023/03/21/lenovo_thinkpad_x13s_the_stealth/) is the first mainstream Arm-powered laptop that the Reg FOSS Desk has got to evaluate. There are other Arm-based laptops out there, such as [Pine64's Pinebook Pro](https://www.theregister.com/2022/08/02/pinebook_pro_finally_starts_shipping/) and various Arm-powered ChromeBooks, but the X13S is closer to an ordinary X86-based laptop: it has a decent spec, with 16GB of RAM, a 256GB NVMe SSD – plus PC-industry-standard UEFI firmware, which is still relatively unusual on consumer Arm computers. Better still, you can disable Secure Boot, which many Arm-powered devices don't allow. A decade ago, this [was a critical problem](https://www.theregister.com/2013/11/14/microsoft_surface_rt_stockpile/) with the original Microsoft Surface RT: Windows RT was a flop, and the firmware wouldn't let you run anything else.
Although the X13S went on sale in May 2022, it took some time for the machine to get any Linux support. This [blog post](https://openwebcraft.com/linux-on-thinkpad-x13s-gen-1/) lists some of the issues, and its subtitle "Embrace the Suck" should give you a general hint. The post points to this lengthy [how-to](https://docs.google.com/document/d/1WuxE-42ZeOkKAft5FuUk6C2fonkQ8sqNZ56ZmZ49hGI/edit#heading=h.d1689esafsky) guide for getting Debian onto the machine. We tried that, and the interim Debian build, with a custom kernel, *did* install.
Getting it to boot from SSD is an epic undertaking, involving entering a UEFI firmware shell and manually going through 30 or 40 entries to find and enable the right UEFI boot entry, but after hours of searching and countless reboots, it worked, and Debian would start. Unfortunately, when booting the installed OS, the screen blanked after just a few lines of output, never to return. The OS was running – for instance, pressing the power button led to a clean shutdown after a few seconds – but with no display, not even a text one, we couldn't configure a Wi-Fi connection, and the machine has no built-in Ethernet port.
There is also a "concept" build of Ubuntu 23.04 "Lunar Lobster", but it's unfinished and the company asked us not to share the link. Since we've had this machine, there have been multiple firmware updates: it came with version 1.25 and it's now on 1.57. Around firmware [version 1.49](https://download.lenovo.com/pccbbs/mobiles/n3huj12w.txt), the firmware setup program gained a beta "Linux" option, and with the next update, it successfully booted our Ubuntu USB key for the first time. The bootup process is extremely slow: the machine takes 10-15 minutes or more to start up, and when it's running the live system, there are significant limitations: no sound, only 2.4GHz Wi-Fi, and so on. However, it does just about work well enough to install it. The first boot goes to a blank screen, but you can switch to a virtual console, log in, and update the OS from a shell prompt. Once updated and rebooted, the graphical login screen appears, and we could log in. 5GHz Wi-Fi starts working, too.
Around the time that firmware 1.56 was current, Ubuntu still had significant limitations on this hardware: no sound, and only Wayland working – no X.org. As is our standard practice, we installed with `/home`
on a separate disk partition, and Ubuntu started with a read-only home directory, meaning that it couldn't save any settings and none of the standard directories (`~/Documents`
and so on) were created. A manual `chown`
command fixed the permissions error and made our home directory writeable.
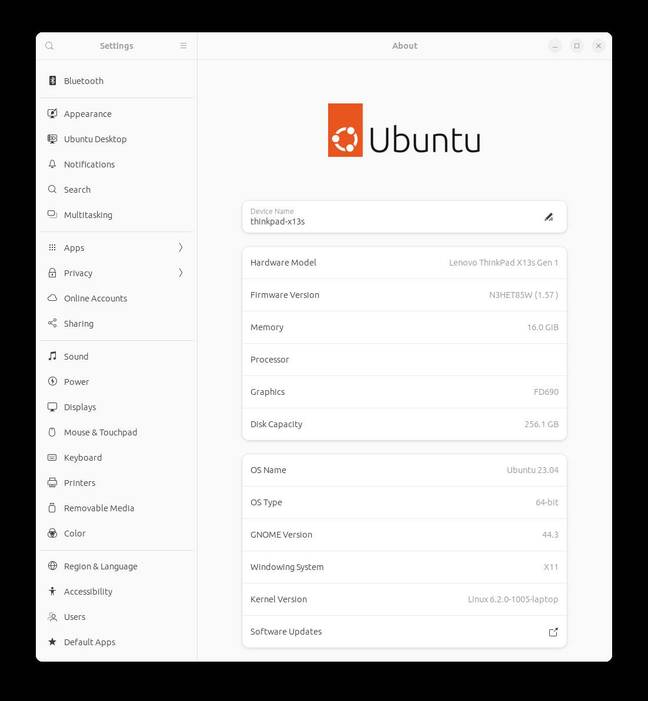
Fully updated, even X.org works, so non-GNOME desktops should finally be feasible too
Firmware version 1.57 appeared last month, and reinstalling and updating Ubuntu "Lunar" yielded working sound and X11, so non-Wayland desktops are now feasible. It's still not easy, and a USB-C Ethernet adaptor is a useful thing to have around, but the X13S is now usable as an Ubuntu laptop. A noticeable difference from running under Windows is that, with no x86 emulation and only native Arm64 apps, the machine runs cooler. Although its base does become warm, it's usable on bare legs without discomfort.
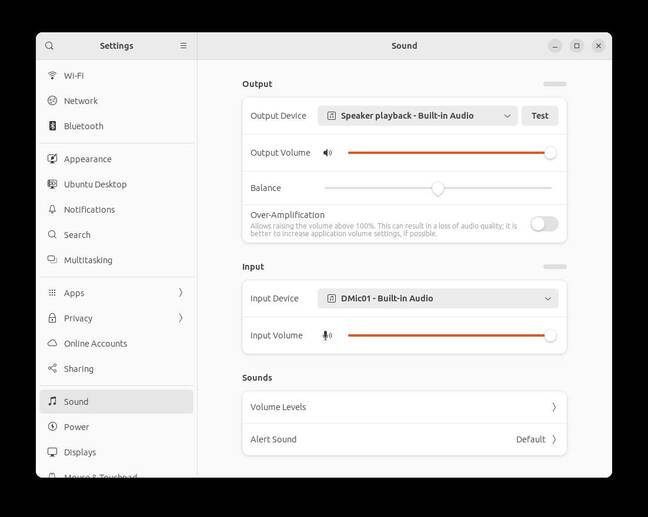
Even the sound chip is supported, and we were able to play audio and adjust the volume
### A (somewhat) easier option: Armbian
The problem with Linux on an Arm laptop is that Arm-powered computers are *not* just x86 PCs with a different kind of CPU. Standard motherboards and chipsets, and interchangeable GPUs, are rare. Most machines are based around a highly-integrated System-on-a-Chip, containing CPU, GPU, and all the other components.
On an x86 PC, the OS can rely on the presence of standard firmware to start the computer, but not all Arm kit has that. Manufacturers build each Arm device to run one specific OS, and replacing that OS with a different one can be a very tricky thing to do. This is one of the reasons for the success of the Raspberry Pi line of computers: not because they are especially simple machines – they aren't – but simply because they have sold in such large quantities that they're widely supported.
The Armbian project is a response to this. It builds specially-configured kernels tailored for a wide variety of single-board computers (SBCs) – mostly Arm based ones, as the name implies, but not exclusively. As of the [23.08 release](https://docs.armbian.com/Release_Changelog/#v23081-2023-09-01), codenamed [Colobus](https://www.armbian.com/newsflash/armbian-23-8/), it lists 59 Arm64 devices supported, but also eight RISC-V boards – and a generic [x86-64/UEFI version](https://www.armbian.com/uefi-x86/). We [looked at Armbian 22.02](https://www.theregister.com/2022/03/03/armbian_project_releases_version_2202/) in March last year, but we are revisiting it because this release includes a [version](https://www.armbian.com/lenovo-x13s/) for the X13S – although the support is still [work-in-progress](https://armbian.atlassian.net/browse/AR-1842).
With an x86 PC, you generally boot from an installation medium and then install the OS onto the machine's internal drive. With an SBC, though, it's more common to write the image onto a memory card, then boot the computer from the card; there's no installation process as such. The Armbian download for the X13S is only some 2GB compressed, but it contains a complete installed system, so you'll need at least a 16GB USB key. On the first boot, it drops to a text-mode prompt, and asks for a root password, some credentials for a user account, timezone and locale information. Only then does it load the graphical desktop.
The result was a working system, with screen brightness controls and so on. After a reboot, we could connect to Wi-Fi – both 2.4GHz and 5GHz – and run an update in the usual Debian way: `sudo apt update && sudo apt full-upgrade -y`
. However, there was no sound, and battery support isn't there yet: it doesn't charge, and the indicator doesn't work. It also didn't detect the Ethernet port on our Planet Computers USB-C hub. We tried installing Armbian to the SSD using the `armbian-installer`
script, but although Ubuntu found the resulting OS and added it to its GRUB menu, Armbian wouldn't boot from the SSD.
### Summing up
Linux support for the Qualcomm Snapdragon 8cx Gen 3 is visibly improving with time. As of the latest updates, Ubuntu on the X13S is usable with kernel 6.2, and we suspect the machine *might* become a supported platform when the next release of Ubuntu appears next month.
Some of the other distros are working on support, as well. There's a [kernel image](https://copr.fedorainfracloud.org/coprs/jforbes/fedora-x13s/) for Fedora, but so far, that's about it. There's also a pre-release [image](https://en.opensuse.org/HCL:ThinkpadX13s) for openSUSE Tumbleweed, but there's no installer, and no support for sound or battery yet.
[Had enough of Android? First 'Focal' based Ubuntu Touch is out](https://www.theregister.com/2023/03/29/first_focal_based_ubuntu_touch/)[Not all vendors' Arm-powered kit is created equally, benchmark fan finds](https://www.theregister.com/2022/12/06/arm64_laptops/)[Juno offering Linux-powered tablet PC for pre-order](https://www.theregister.com/2022/10/17/juno_tablet/)[End-of-life smartphone? Penguins at postmarketOS aim to revive it](https://www.theregister.com/2022/06/15/postmarketos_2206/)
OpenBSD directly supports the Qualcomm chip, with the usual caveats around that OS – such as no Bluetooth support whatsoever. We've verified that it can boot from USB and configure both Wi-Fi and USB Ethernet successfully, but so far, not much more, as we were nervous about removing Windows, the only completely-working OS on the machine at the time.
And, of course, there's Windows Subsystem for Linux. That's currently the easiest route to a working Linux system: we tried Ubuntu in WSL2 under Windows 11, and it works perfectly fine – with the added benefit that you know you're running native Arm apps, not x86 code under power-sapping emulation. However, running under Windows isn't very efficient, and if you have some X86 stuff in the background, it will badly impact battery life.
If you're content to run from a USB key – we suggest a fast USB-C one – then Armbian will get you up and running easily, with some limitations. As support in newer kernels improves, then so will Armbian's functionality.
The X13S is not yet ready for prime time with any FOSS OS – notably, the webcam remains unsupported – but Ubuntu is very nearly there. The image isn't official yet, but your preferred search engine will find it. Failing that, Armbian is close behind. ®
41 |
16,179 | 成功举办黑客马拉松的 10 步指南 | https://opensource.com/article/23/2/hackathon-guide | 2023-09-11T09:19:21 | [
"黑客马拉松",
"hackathon"
] | /article-16179-1.html | 
>
> 想要规划、主办及管理一次成功的黑客马拉松,请遵循以下蓝图。
>
>
>
初看起来,<ruby> 黑客马拉松 <rt> hackathon </rt></ruby>是很简单的事情。你需要为它投入多少准备呢?仅设置一个日期,人们便会自动参与。然而,实际上并非如此!
虽然你可以依靠这种方式碰碰运气,但实际情况是,黑客马拉松是科技行业中的基石体验,参与者都有自己的期待。不仅如此,你的组织也有特定的需求,并应该为黑客马拉松设定目标。那么,你应该如何保障黑客马拉松对你的组织和参与者都有益呢?
成功的黑客马拉松,取决于一系列可能会反复出现的决定。关于你想达成什么目标的决定,将影响你使用哪些资源以及采用何种沟通方式。这些决定将影响你是选择线上还是线下进行,而这个决定又将反过来影响你需要的资源以及如何沟通。对齐黑客马拉松的计划并非只是让人们达成共识那么简单。你需要一整套内在的决策来达成一致。例如,一场技术难度较高的黑客马拉松可能无法吸引大量观众(你可以问我怎么知道!),并需要一种需要特殊资源的招募策略。
这些年来,我主办过很多次黑客马拉松,包括最近几个月中,在我所在的组织主办的一次黑客马拉松,由此催生了我们将融入到我们的开源产品 Traefik Proxy 3.0 下一版本中的新特性。因此,相信我,策划一个能丰富参与者体验,同时为你的项目创造有价值成果的黑客马拉松,不仅仅需要期待、披萨,和混乱!
本文以最近的 Traefik Labs 黑客马拉松为蓝图。我分享了一个清单,提供了一些技巧和窍门,帮你确定目标,规划比赛,管理报酬,分享你的成果,以及处理黑客马拉松的长期效应(黑客马拉松结束后的工作并未结束!)
这个指南充当了你规划最佳实践的模板,让你也能成功举办一场有大量目标受众并能带来实效的黑客马拉松!
### 1、确定目标的三个问题
首要且至关重要的步骤就是设定你的目标。这可不简单,设立目标前你需要在多个方面进行内部整合,提出如下问题:
* 你为何想举办一场黑客马拉松?
* 你期望谁来参加?
* 你将如何衡量你的成功程度?
#### 确定你的内部利益相关者并设立期望
**黑客马拉松涉及到多个功能部门**。没有一个黑客马拉松是由一个社区人员独自进行的。确保每个人对目标的理解、实现这些目标所需的要求相互呼应,以及必要的资源能得到投入,这些都是重要的。听起来可能有点过于“公司化”,但即使在最小的项目中,这些功能也是必不可少的。一个项目需要广泛的接受度和代码支持。它还需要根据使用者的来做出价值判断。当然,无论何种项目都需要热情的贡献者。
**黑客马拉松需要跨各功能部门的资源投入**。单一团队拥有的一整套资源并不能成功地运行一场黑客马拉松。组织必须投放各种资源,包括:
* 市场营销部门进行规划和拓展。
* 产品管理部门提供产品和行业特定的洞察。
* 工程部门提供深度的技术知识和社区参与。
出于这些原因,黑客马拉松通常会支持满足跨功能部门的目标。例如,你的社区团队可能希望建立归属感并将用户转变为活跃的社区成员。营销团队可能希望提高知名度并吸引新用户。工程团队可能需要特定需求或挑战的新视角。产品团队可能对社区应该知道的目标或禁止行为有特定的设想。
最后但同样重要的点,黑客马拉松的预算也需要各部门共同承担。很抱歉告诉你,黑客马拉松并非天上掉下来的!你最大的支出始终是你团队成员的用心投入。
### 2、你为什么要这么做?
设定你的目标是举办成功黑客马拉松的核心部分。如果你对自己想要做什么或黑客马拉松为何重要都不清楚的话,最好情况下,它会浪费大量的潜力;最糟情况下,它将会变成一团混乱。
社区以归属感为动力。你需要决定自己期望从社区得到什么以及你希望社区成员拥有哪些归属感。如果没有清楚的理解这些,你的黑客马拉松可能无法最大程度地赋权于你的社区。
你需要特别关注你的黑客马拉松的设计和目标。不同类型的黑客马拉松吸引了不同技能水平的人。如果你期待的代码很深奥,那么花费额外的时间来倾听合适的受众,并认识到这样会降低整体的参与度。如果你期待的贡献在技能和经验上可以变化,那么你可能需要拓宽接纳的范围。
#### 你是否举办黑客马拉松来获取代码并推进你的项目?
* 有时,项目处于关键时刻或者围绕它有很多兴奋点,你希望利用这股力量共同创造一些事情。黑客马拉松正是一个达成这个目标的好方式!
* 如果你拥有一个活跃的用户社区,黑客马拉松可以将每个人同一时间共聚一堂,以此激发团队的创造能量。
**注意**:较小的,彼此互相关联并共享项目经验的团队确实更易实现这一目标。你还需要仔细评估构建你的项目所需的技能.
#### 你举办黑客马拉松的目的是建设你的社区或者重新唤起他们的热情吗?
* 可能你正在建设你的社区,或者你注意到你的社区需要一些新的活力。黑客马拉松带有激动人心的氛围,它们可以帮助恢复这种活跃度。
* 正如我在上文所说,“社区是以归属感为动力的。” 如果社区成员感觉他们在这个社区中没有足够的归属感,或是他们的需求和声音没有被重视,他们将会渐渐疏离。这在项目逐步扩大并更加正式化时往往会发生。随着参与的门槛不断提高,社区成员归属感的下降,项目对用户而言就更像是一种产品。提高社区参与感的一种方式是,举办引入用户并降低参与门槛的活动:比如错误修复活动、轻型需求、及长期的活动时间线。
* 或许正如你的用户社区在壮大,但由于技术日益复杂,与之相应的贡献者社区也变得更为专业化。在这种情况下,你需要吸引理解你的技术和使用者的复杂技术领域的人才。你应该寻找那些在工作中使用你技术的社区成员 —— 尤其在有大型或复杂部署的公司。这些人更有可能理解用户的需求以及技术本身的要求。他们也会对重大且有价值的优化提出建议。
* 你可以选择那些能建设你的社区,同时符合你的团队和社区成员的能量和时间的目标。例如,对于 Traefik Labs 来说,一个面向热心人士的、需要较小时间投入的黑客马拉松可能会针对我们的插件目录。然而,当我们在寻找较大贡献或是需要深度专业知识的贡献者时,我们可能会关注高级技术人才 —— 特别是我们认识的人。
#### 你是以庆祝某个事情为目的来举办黑客马拉松吗?
* 黑客马拉松是庆祝新产品发布和激发社区热情的有效方式。例如,这正是我们举办 [Traefik Proxy 3.0 Hackaethon](https://traefik.io/blog/announcing-traefik-proxy-3-0-hackaethon/) 的原因。
* 黑客马拉松也适合推广新产品的功能。在此,[Traefik Plugin Hackaethon](https://traefik.io/blog/announcing-the-inaugural-traefik-hackaethon-2020-in-october/) 便是一个很好的例子。
* 或许你想要举办一个活动来纪念你的顶级贡献者。那就用黑客马拉松来做吧!瞧瞧 [HackerOne 组织的这场黑客马拉松](https://www.youtube.com/watch?v=9VZCD9TirCg&list=PLxhvVyxYRvibM_KJBPtPsfEcjnP5oGS8H) 吧。如果你在思索:“但这并非与开源软件相关,这怎么能算是黑客马拉松呢?”我要告诉你的消息是 —— 黑客马拉松不只是为了开源软件!黑客马拉松是为了与广大的社区共创。
#### 你是为了提升知名度而举办黑客马拉松吗?
如果你刚起步并想提高你的产品/品牌知名度,黑客马拉松无疑是个好的开端。然而,请注意一些条件。
* 在这个阶段,期望目标高度集中或收到大贡献是不太可能的。你应追求更广泛而温和的焦点,并尽量减少参与者所需的工作。
* 尝试接触新的社区成员、经验相对较少的用户,以及对你特定项目接触不多的用户。
#### 你是为了与用户建立联系而举办黑客马拉松吗?
我认为没有比举办黑客马拉松更好的办法来将新用户引入你的项目。用户不仅会对你的项目有深入的了解,黑客马拉松也具有一种独特的方式,能够营造出一种难以通过其它类型活动实现的归属感。
### 3、你的目标观众是谁?
假设你已经确定为何要举办黑客马拉松以及你期望实现的目标,那么接下来该评估参与者需要具备哪些特性才能成功了。根据你设定的目标,明确你的目标受众,搞清楚哪一类社区成员能帮你实现这些目标。你可以根据以下几个对比进行考虑:
* 高级技能 vs. 混合技能 vs. 初级技能
* 专门技能 vs. 广泛技能
* 高强度时间投入 vs. 低强度时间投入
* 个人贡献 vs. 团队贡献
你最活跃的社区成员应该在某种程度上与你的目标观众有所呼应。
如果你能吸引到的观众和你的目标观众至少有 80% 的不符合,你可能需要重新考虑你的目标。准确识别你的目标受众对于构筑你的黑客马拉松及相关沟通策略,并让你的黑客马拉松更加成功极其重要。
### 4、你计划如何衡量目标的实现程度?
很好,你已经回答了前两个重大问题并明确了你的目标,接下来要考虑的是第三个重大问题 —— 你打算如何评估目标的实现程度?激励内部团队与社区一同构建你的项目的未来,激发归属感和提升参与度,这些都十分重要,但你无法断定成功与否,如果你没有评估目标的方法。
#### 活动结束后,什么标志着成功?
* 显然,首要的成功标志是你的参与者整体获得良好的体验,并且愿意更加积极地参与你的项目。
* 如果你在寻求扩大影响力,你可以设定一个参与者人数的目标,并且设定一个在活动后或三个月后再次参与的人数目标。
+ 成功的一大标志是参与者是否在黑客马拉松期间互相连接、交互、共享知识,并组建团队。
+ 是否形成了指导关系?通过合作,是否有许多新的用户转变为熟练的中级用户,或者中级用户升级为专家级用户?这是成功的关键标志。
+ 你的合作机构(比如大学)是否要求在未来举办更多的黑客马拉松或其他活动?
* 如果你在提升知名度,也可以关注活动后的讨论情况。有谁写了博客文章?参与者在社交媒体上谈论了吗?
* 如果你在寻找贡献,贡献是否在你预期范围内?这些是你需要的贡献吗?它们是否影响了你的团队对问题的思维方式?你会和这些贡献者建立持久的合作关系吗?
#### 活动过后三个月,什么标志着成功?
设定长期成功的基准也同样重要。以下是可能显示长期成功的一些例子:
* 你的黑客马拉松应当增多持续为你的项目做出贡献的人。目标在于让人们对你的项目保持热情。如果新来的人从黑客马拉松开始并保留下来成为用户,或者你的现有用户变得更加活跃,你就算赢了。
* 黑客马拉松作为单独的事件很棒,但作为营销内容,它更具价值。这些活动在社区中建立了信任,彰显了你的反应以及你重视社区的投入。它们运营的趣味性成为了社区成员的聚焦点,并激发他们对未来的期待。人们喜欢看到他人被庆祝,并计划在将来取得这种成绩。
* 当你围绕你的黑客马拉松制作营销内容时(或最好,别人为你的黑客马拉松制作内容),你就可以扩大你在二度联系人群中的影响力。
* 以羡慕他人为耻的现象是令人遗憾的。黑客马拉松是个绝佳的机会,可以邀请那些表现杰出的参与者去做更酷的事情,并宣传你的项目。
### 5、决定是线下活动还是线上活动
我猜你可能在思考 —— 线下活动是否还在我们的选择范围内?在后疫情时代,我们已经习惯于线上进行所有活动。那么,线下活动的时代就此结束了吗?我会争论说,不,线下活动依然在。只要我们采取适当的防护措施,线下活动仍然是黑客马拉松的精髓。(LCTT 译注:此文发表于半年前。)
* 线下活动意味着无干扰、丰富的披萨,以及充足的能量饮料激发的友谊。
* 线下活动更倾向于促进团队参与,而不仅仅是个人参与。
* 线下活动无论规模大小都适应:对大规模群体组织线下活动会带来高能量和奖励。但这会造成较高的成本。如果你计划举办大规模黑客马拉松,相对经验较少的开发者(如学生、社团、新入职者)将是更好的目标,因为这些人有更多的时间,并且在展示他们的技能和热情时有着更大的收获。
* 线下活动也很适合小的团队,非常适合紧张的计划和迭代 —— 和新老朋友一起度过的长夜,通常是吃着食物和喝着啤酒!
当然,虽然线下黑客马拉松有很多优势,但这并不是说线上体验只有缺点。诚然,没有什么能替代深夜聚会佐以披萨,即兴的评论让你改变整个项目方向,以及你正在测试或调试时,一双友好的眼睛注视着你的感觉。然而...
* 线上活动意味你可以吸引更广泛的参与者群体,且成本大幅减低。
* 线上活动尊重残障人士。
* 线上活动不受地理位置约束。
* 线上活动为个人做出更多贡献提供了更大可能。
* 线上活动在活动形式和时间长度上提供了更多灵活性 —— 毕竟你不能办一个持续一个月的线下活动!
#### 线上黑客马拉松的时间安排
决定举办线上黑客马拉松了?很好!现在你需要确定你期望的线上黑客马拉松类型。你是想要一个持续时间长的还是一个强度大的?请记住,你选择的 [线上黑客马拉松](https://opensource.com/article/20/8/virtual-hackathon) 的类型会在某种程度决定你的目标观众和沟通策略。
**延长的时间线:**
* 允许参与者在工作之外的时间投入,因此开发者可以不请假就参加。
* 提供更多时间来征求贡献。
* 对于组织者和参与者都需要较少的资源投入。
* 延长的时间线需要较少的实时资源。
**紧凑的时间线:**
* 重现了那种在线下黑客马拉松中通常体验到的紧张感。
* 在短时间内需要大量的资源。
* 需要严格的管理和沟通平台。
* 需要清晰的一对一沟通,但也可以促进群体对群体或社区内部的沟通。
### 6、构筑你的沟通策略
谈及沟通,确定了目标后,你需要决定**谁**将与参与者沟通以及**如何**进行沟通。通常,我们需要在流行应用中进行选择。你的选择将对活动的氛围产生影响。不同的 [聊天应用](https://opensource.com/alternatives/slack) 和 [协作平台](https://opensource.com/article/21/9/alternatives-zoom) 都具有各自的文化和优势。你在初期关于如何举办你的黑客马拉松(线下或线上,长期或紧凑)的决策,可能会对你的沟通策略产生最显著的影响。
#### 线下沟通计划
如果你正在举办一个线下的黑客马拉松,可以将其视为一个重要的活动 —— 它几乎感觉如同一场会议。线下的黑客马拉松通常包括以下活动:
* **研讨会 / 圆桌讨论**:意在教育并建立面对当前需求的新一代标准 / 最佳实践。这些环节可以作为 6 至 10 人间的限时讨论,他们会一致同意研究结果并向所有参与者公开记录的内容。
* **规划会议**:常用于产出非编程类的项目,比如制定更新标准。
* **编程会议**:用于需要持续工作以持续进步的编程类项目。
以上每一环节都有各自的沟通需求:
* 有人准备来引导,但不主导研讨会中的对话。
* 记录者以及确保笔记整理为可发布内容的人。
* 对于研讨会:
+ 项目经理来保证所有工作的执行。
+ 管理活动的通用沟通(如食物、清洁、资源管理)。
+ 主持人负责推动活动议程。
要完成所有这一切,需求来自于你的社区,产品经理和技术团队的资源和专门知识。从过去的经验来看,,要管理如此规模的活动,需要一个由社区成员和员工组成的团队。为了成功,你的团队将需要专业特长的人员。
你还需要决定你想要鼓励的沟通类型,以及谁应该负责:
* 多个团队可能需要轮班以提供全方位的支持。
* 开发者关系团队、工程或支持团队需负责管理与参与者和中间环节之间的技术沟通。
* 社区团队通常会花费很多时间建立与参与者的联系,以帮助他们强化技能或观点,这也是确保黑客马拉松魔力的一种方式。
* 社区团队还需要支持市场营销活动,以吸引参与者并进行后续管理。
#### 线上沟通方案
对于网络虚拟的黑客马拉松,选择沟通平台主要取决于你想实现的目标,你为黑客马拉松选择的时间表(延长或密集),以及你希望促进的沟通方式(同步或异步)。
**在 Git 主机上使用拉取请求和议题(异步):**
* 选择通过 Git 拉取请求和你项目的议题进行交流,可以把对项目的讨论保留在你当前的流程中,让你的团队更专注响应,而不用自发去引导沟通,这将会节省技术团队的资源。
* 如果你的黑客马拉松团队规模较小,或者预期的贡献相对较少,且你没有计划协助参与者组建团队,那么这种方式非常合适。
* 对于持续时间较长的黑客马拉松,使用已有的流程尤其有益,因为它们不需要额外的管理,也不需要你的团队去监控另外的应用。
* 然而,缺点在于你只是促进了已经协同工作的个别贡献者或贡献者团队的沟通。连接孤立工作的参与者比较困难,参与者们自行寻找彼此也不容易,这就失去了黑客马拉松参与者在公开的讨论中自发交流的魅力。
**使用聊天应用(同步):**
* 选择专用聊天服务器对于密集型的黑客马拉松是必须的。
* 聊天促进了团队的组建和对于有快速时间线的复杂项目必要的沟通,并激发了在做出了一些很棒的贡献前的头脑风暴。
* 再者,你的目标是要建立社区。人们想要加入一个他们可以有归属感、有朋友、感到舒适的社区。如果你希望他们长期留存,给参与者提供一个可以相互联系的地方是必要的。
* 事件结束后聊天服务器依然存在,可以持续促进社区的参与活动。
不论你选取哪一个平台,你都需要一个沟通方案来确定你的团队每个人何时在线。管理一个线上黑客马拉松可能会有点复杂,主要是因为不同的时区的问题 —— 人们可以在任何他们想要的时间、任何他们想要的地方参加。你必须计划安排在所有时区的人和每一个场合的参与者。排列好一个计划,清楚在下列情况下谁负责以及何时负责:
* 确定响应 SLA。
* 活跃你的虚拟空间(一个死气沉沉的空间会导致沟通质量降低)。
* 鼓励团队建设。
* 解答技术问题。
* 查询参与者的进度。
* 检查空间以确保参与者的安全。
### 7、确定奖项
你的黑客马拉松是一个竞赛形式的活动吗?通常,黑客马拉松的参与者对于优秀贡献者能获得大奖和丰富的礼品会感到非常满意。但在你决定这些令人兴奋的奖励(实物奖品)之前,你必须确定你的竞赛所重视的价值。
* 是什么因素让一个贡献变得更出色?如果你的参与者了解你对此的态度,他们可能更有可能全力以赴。
* 你重视什么?这是你向参与者阐明你希望看到什么样的参赛作品的机会,你可以通过把奖品挂在它旁边来做到这一点。例如,在上次的 Traefik 黑客马拉松中,我们为最受欢迎的特性提供了奖赏,实际上,这些特性确实是大多数人最努力的部分。
* 参赛作品是否有不同的分类?你需要为每个分类都设定奖项。
* 创造一个评分标准(定义和排名成绩的表格或网格,[像这个例子](https://www.isothermal.edu/about/assessment/assets/rubric-present.pdf))。这样一来,参与者会知道你在评估他们时重视什么。这也是我们在 HackerOne 提高提交质量的一种方式。
另一方面,有些人可能认为竞争被高估了。如果你的目标是鼓励参与,那么你有权奖励每一个参与者,只因他们为社区的回馈 就是这种方法的一个好例子。
### 8、准备炫酷的礼品
每个人都喜欢炫酷的礼品!无论是在线活动还是线下活动,你的参与者肯定会欣然接受能够纪念这次活动的礼品。礼品有两个目的:
* 礼品表示你对参与者的赞赏:贡献者花费时间投入在与你的紧密合作中,用一份礼品感谢他们就显示出了你对他们贡献的价值认同。
* 礼品增加了知名度:给参与者分发礼品,帮助他们传播他们对于社区的喜爱,并通过分享他们的收获和经验,提升你的社区的认知度。
社区成员喜爱礼品,但他们不喜欢单调的礼品!也许你在其他活动中已经发放过你现有的 T 恤和贴纸了。想让你的黑客马拉松给人留下深刻印象,就需要寻找新的、有趣的、专有的设计。T 恤固然好,但卫衣则更胜一筹。但是,你可以考虑一下参与者可能还没有的独特礼品。想象一下有什么可以成为他们的新宠,比如后备电池或帽子(这两样在 HackerOne 很流行)。对我个人来说,我家里就有一些来自黑客马拉松的毛巾和拖鞋!
### 9、进行宣传
设定目标和决定惊人的大奖和炫酷的礼品都是非常重要的步骤。但如果你不进行广泛的宣传,怎么能让人们知道你的黑客马拉松正在进行呢?你需要仔细调查可用的各类渠道,并要大胆地推广你的活动。这里说的包括博客、视频博客、电子邮件、社交媒体 —— 任何你能够利用的平台。
然而,依据你的目标定位,你需要在适当的渠道上进行投入。你进行广告的地方,取决于你想邀请谁来参加你的黑客马拉松。
* 如果你想吸引更有经验的用户,那么就将重点放在正在使用你的项目的大型组织上。在这种情况下,领英和电子邮件推广可能会更有效。
* 如果你希望吸引新的和经验较少的用户,那么你最好瞄准大学和培训营。在基于社区的媒体上宣传活动,如 Mastodon、Matrix、Mattermost、Reddit、Discourse、Discord,以及你的目标听众常去的任何地方,将是更好的选择。
### 10、后期管理
恭喜,黑客马拉松结束了!现在所有与黑客马拉松相关的活动都可以暂时停下,我们也不再需要投入资源了,对吗?错!你要把黑客马拉松视为你在软件开发和社区构建一系列活动中的一个环节。为了让你的黑客马拉松成功,你必须准备好进行活动后的各项工作。
* 传达你的成果:别忘了向内部和外部通报黑客马拉松的结果。在黑客马拉松期间,社区成员获取的成果可以增加对你的社区和项目的信任。
* 社区建设:依赖你的黑客马拉松参与者进行未来的社区活动。
* 编制回顾:什么做得好,什么做得糟糕,哪些事情让你感到平淡无奇,又有什么事情让你感到惊讶?这个分析是你如何成长,变化和迭代的方式。在可能的情况下,尽快做一个无责任的回顾,这样所有的事情还鲜活在你的记忆里。
### 总结
如果你一开始读这篇文章时,认为举办黑客马拉松并不难,那么我很遗憾要打破你的幻想!虽然我深信黑客马拉松是一个极好的方式,可以在多个层面上与社区进行交流和互动,但只有意图并不能保证结果。
为了使一个黑客马拉松成功,你需要非常周到,并准备投入大量的资源和努力来妥善规划和执行。
感谢你的阅读,我希望这个清单能帮助你成功地组织你的下一场黑客马拉松!
*(题图:MJ/954f2da1-8a3a-4039-9695-b7ea7e3dea95)*
---
via: <https://opensource.com/article/23/2/hackathon-guide>
作者:[Tiffany Long](https://opensource.com/users/tiffany-long) 选题:[lkxed](https://github.com/lkxed/) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
16,180 | 如何检查 VLC 日志文件 | https://itsfoss.com/vlc-check-log/ | 2023-09-11T10:05:41 | [] | https://linux.cn/article-16180-1.html | 
>
> 解决 VLC 的视频播放问题?以下是检查 VLC 日志文件的方法。
>
>
>
在 VLC 上观看你喜爱的视频时,你可能会遇到与编解码器、时间戳、视频播放等相关的问题。
但好消息是,就像 [检查防火墙的日志](https://learnubuntu.com/check-firewall-logs/) 一样,你可以使用 VLC 执行相同的操作来跟踪错误的根本原因。
>
> ? 与 Linux 不同,VLC 不会自动保存日志,一旦关闭,所有日志都会自动删除,因此你必须手动保存它们。
>
>
>
因此,请确保在关闭 VLC 播放器之前保存或读取日志文件。
### 检查并保存 VLC 日志文件
虽然听起来很复杂,但这是最简单的方法,它不仅允许你保存日志,还可以让你读取日志而不将其保存到文件中。
首先,从顶部菜单栏转到“<ruby> 工具 <rt> Tools </rt></ruby>”菜单,然后选择“<ruby> 消息 <rt> Messages </rt></ruby>”,或者,你也可以按 `Ctrl + M` 达到相同的效果:

它将显示与当前播放的视频文件相关的日志。
在这里,你有两种选择:你可以仅读取日志,也可以保存日志。
单击“消息”选项卡后,你会注意到 “<ruby> 冗余 <rt> Verbosity </rt></ruby>” 选项,因此让我们看一下多个详细程度选项的效果。
* <ruby> 错误 <rt> Errors </rt></ruby>: 只会记录错误信息
* <ruby> 警告 <rt> Warnings </rt></ruby>: 它将总结错误和警告消息
* <ruby> 调试 <rt> Debug </rt></ruby>:此级别将包括错误、警告和调试消息
选择适当的详细程度选项后,你很快就会看到与所选选项相关的日志。

正如你所看到的,当我选择 “调试” 选项时,它还包含警告日志。
要保存日志,请点击 “<ruby> 另存为 <rt> Save as... </rt></ruby>” 按钮,它将打开文件管理器,在这选择保存文件的位置并为其指定适当的名称:

现在,你可以使用任何文本编辑器打开日志文件:

从这里,你可以识别导致错误的罪魁祸首。
### 有关 VLC 的更多信息
你是否知道你可以使用 VLC 下载 YouTube 视频或使用 YouTube 链接来流式传输视频而无需广告?
嗯,VLC 能做的远不止这些。如果你有兴趣,请查看我们详细的 [让 VLC 更出色的技巧指南](https://itsfoss.com/simple-vlc-tips/)。
我希望本指南对你有所帮助。
*(题图:MJ/f614be05-cc16-40ef-9b2d-8f7a6864400f)*
---
via: <https://itsfoss.com/vlc-check-log/>
作者:[Sagar Sharma](https://itsfoss.com/author/sagar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

While watching your favorite videos on VLC, you might encounter issues related to codecs, timestamps, video playback, and a lot more.
But the good news is like you [check the logs of your firewall](https://learnubuntu.com/check-firewall-logs/), you can do the same with VLC to trace the root cause of the error.
So make sure you save or read the log file before closing the VLC player.
## Check and save VLC log files
While it sounds complex, this is the easiest method that not only allows you to save logs but also lets you read them without saving them to a file.
First, go to the `Tools`
menu from the top menubar and select choose `Messages`
, alternatively, you can also press `Ctrl + M`
to save the same effect:
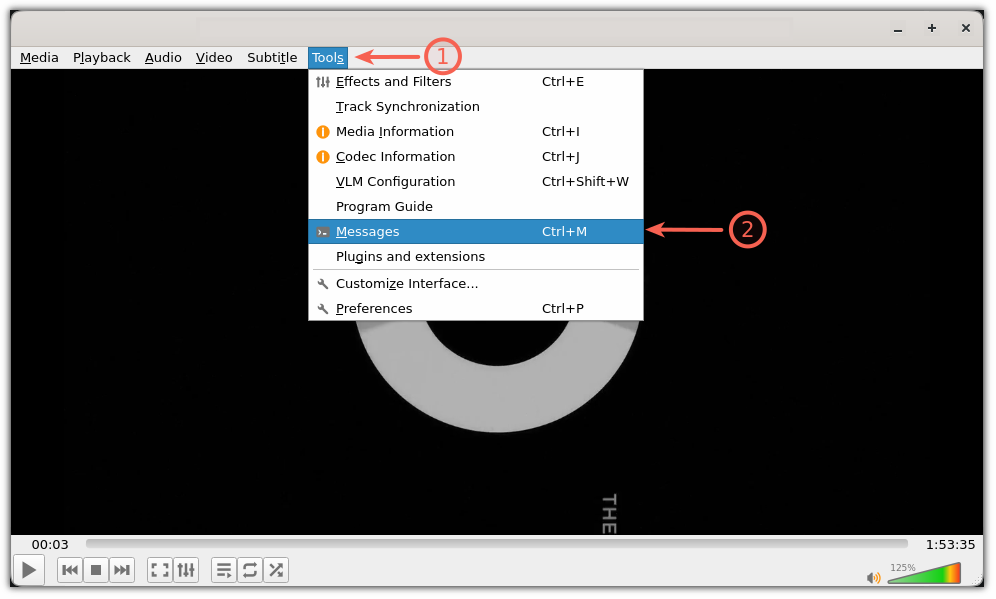
And it will show logs related to the currently playing video file.
Here, you have two choices: You can either read logs only or you can save them as well.
Once you click on the `Messages`
, you will notice a tab for the **Verbosity** so let's take a look at the effect of multiple verbosity options you have.
`Errors`
: This will only record the error messages only`Warnings`
: It will conclude error and warning messages`Debug`
: This level will include errors, warnings, and debug messages
After choosing the appropriate verbosity option, soon you will see logs related to the chosen option.
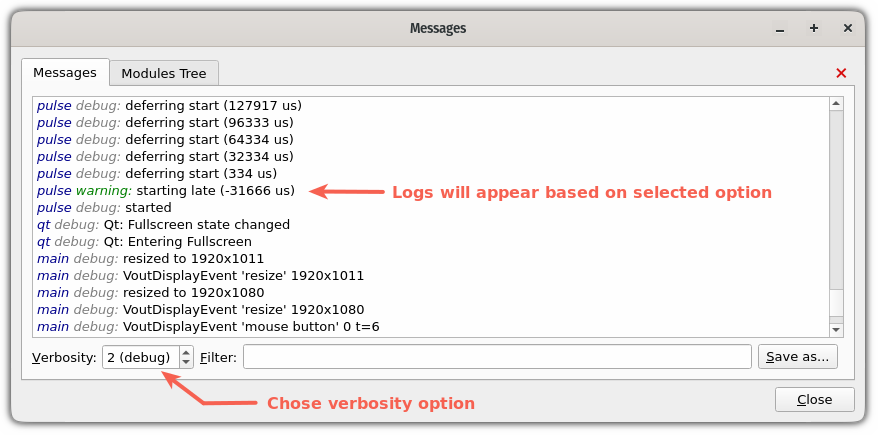
As you can see when I choose the `debug`
option, it also included the warning logs.
To save logs, hit the `Save as...`
button and it will open the file manager, from there, choose where you can to save the file and give it the appropriate name:
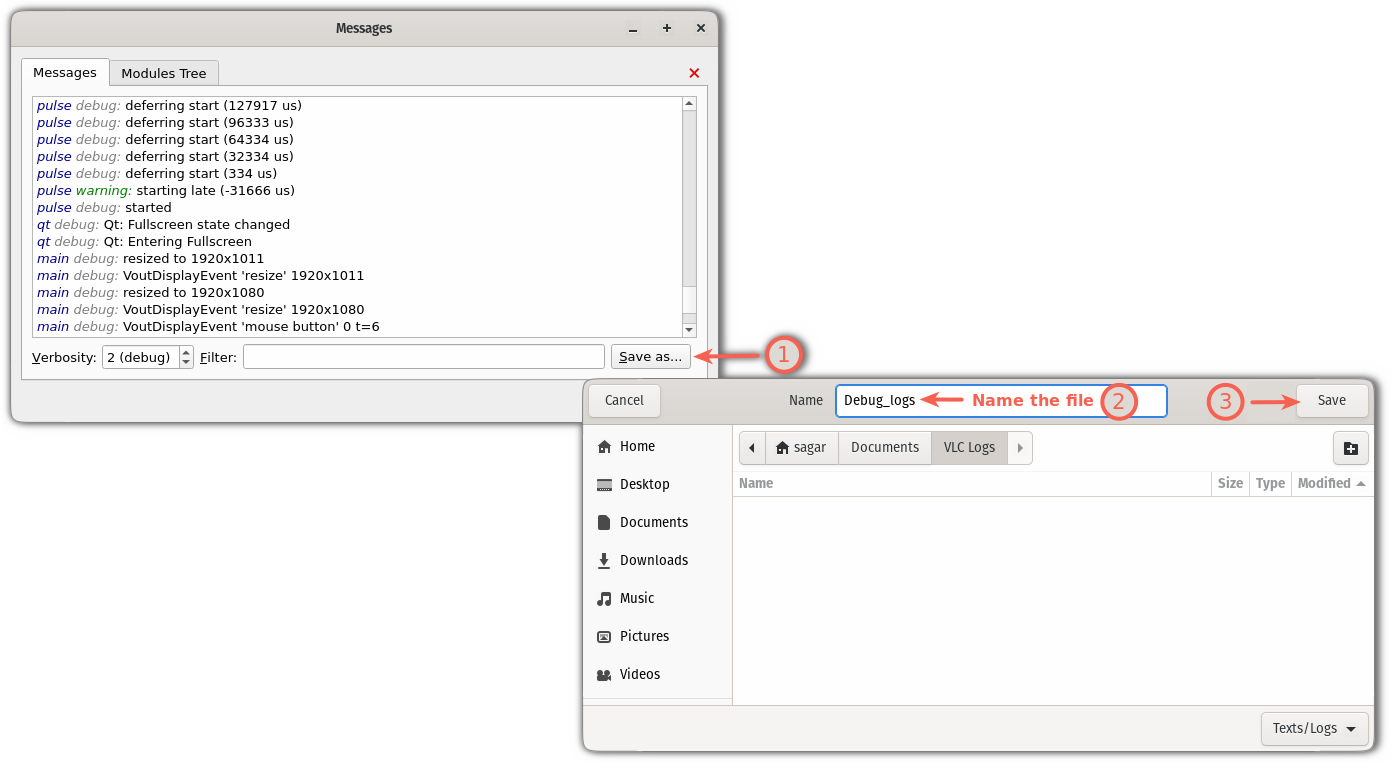
And now, you can open the log file using any text editor:
From here, you can identify the culprit causing errors.
## More on VLC
Did you know that you can download YouTube videos using VLC or use YouTube links to stream videos without ads?
Well, VLC can do a lot more than that. And if you're interested, check out our detailed [guide on tips to make VLC awesome](https://itsfoss.com/simple-vlc-tips/):
[Make VLC More Awesome With These Simple TipsVLC is one of the best open source video players, if not the best. What most people don’t know about it is that it is a lot more than just a video player. You can do a lot of complex tasks like broadcasting live videos, capturing devices etc. Just](https://itsfoss.com/simple-vlc-tips/)

Want to [download VLC subtitles automatically](https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/)? Here's how you do it:
[Download Subtitles Automatically With VLC Media PlayerVLC is a versatile media player. One of the lesser known features is the automatic subtitle download. Here’s how to use it.](https://itsfoss.com/download-subtitles-automatically-vlc-media-player-ubuntu/)

I hope you will find this guide helpful. |
16,181 | Linux 爱好者线下沙龙:LLUG 2023 深圳 - 活动预告 | https://jinshuju.net/f/VJkeMZ | 2023-09-11T19:04:00 | [
"LLUG"
] | https://linux.cn/article-16181-1.html | 
经历过 [6 月北京场](/article-15929-1.html)、[7 月上海场](/article-16052-1.html),一个月的休整之后,这次 LLUG 来到大陆的南端,美丽的鹏城 —— 深圳。
**2023 年 9 月 24 日下午,我们将在深圳举行 LLUG 2023 · 深圳场,**欢迎大家来到现场,和我们一起交流技术,分享自己工作过程中的所思所想。
本次活动依然由 Linux 中国和龙蜥社区(OpenAnolis)联合主办,华章出版社、《Linux 就该这么学》提供了支持。
> 龙蜥社区(OpenAnolis)是国内的顶尖 Linux 发行版社区,我们希望在普及 Linux 知识的同时,也能让中国的 Linux 发行版,为更多人知晓,推动国产发行版的发展和进步。
本次活动,我们将设常规的技术分享和闪电演讲两种不同分享的形态。技术分享会邀请来自 Linux 社区的开发者,分享自己在 Linux 中的技术实践,并配合 Q&A 的环节,帮助大家理解技术难点和实践。闪电演讲则不设定主题,每个人有 5 分钟时间来分享自己与 Linux、技术、开源有关的话题,共计 6 个闪电演讲名额。
如果你有想分享的,或者是想听别人分享的,欢迎通过评论告诉我们,我们来帮你邀请专家分享~

**提前剧透**:Linux 中国的负责人硬核老王,也会来到现场和大家一起交流!
如果你对分享感兴趣,欢迎填写下方问卷来提交你的议题:<https://jinshuju.net/f/VJkeMZ>
*(题图:MJ/b85cec6e-6646-4033-8f1d-914740e5e49f)*
| 302 | Found | null |
16,183 | Firefox 117 版本增加自动翻译功能支持 | https://news.itsfoss.com/firefox-117-release/ | 2023-09-12T08:38:10 | [
"Firefox"
] | https://linux.cn/article-16183-1.html | 
>
> Firefox 117 版本为即将到来的升级带来了必要的改进和新功能支持。
>
>
>
Firefox 是一款被许多人喜爱、却被少数人讨厌的浏览器。但是,作为**基于 Chromium 的浏览器**(例如 Chrome 和 Opera)的开源替代品,它不断发展以为其武器库添加新功能。
这一次,随着 **Firefox 117** 的发布,我们添加了一个有趣的附加功能,它已经准备了相当长一段时间了。
请允许我在本文中向你介绍这一点以及更多内容。让我们开始。
### ? Firefox 117:有什么新变化?

与大多数 Firefox 版本一样,它也提供了很多功能。一些值得注意的亮点包括:
* 新的注重隐私的本地翻译功能(正在进行)。
* 将信用卡自动填充功能扩展到更多地区。
* YouTube 视频列表现在可以使用屏幕阅读器正确滚动。
虽然功能听起来不错,但让我们关注翻译功能。
### 注重隐私的翻译
如上面的演示,Firefox 现在具有内置翻译工具。
它的主要卖点是**所有语言翻译都在本地进行**,无需将你的数据发送到任何服务器进行处理。
该功能本来已经存在于 Firefox 中,由名为 “[Firefox Translations](https://addons.mozilla.org/en-US/firefox/addon/firefox-translations/)” 的附加组件提供。
但是,[当时](https://hacks.mozilla.org/2022/06/neural-machine-translation-engine-for-firefox-translations-add-on/) 在 Mozilla 对引擎代码库进行内部安全审查后,由于其第三方依赖性,放弃将其直接将其集成到 Firefox 中。
幸运的是,现在我们有了合适的原生功能。**但是,有一个问题。**
>
> ? 感谢 [Ghack](https://www.ghacks.net/2023/08/29/firefox-117-native-language-translations-last-firefox-102-update-and-security-fixes/),我发现**翻译功能在 Firefox 117 上默认处于禁用状态。他们计划逐步向用户推出该功能,并在下一个版本更新时默认禁用**。
>
>
>
因此,为了测试它,我必须进入 `about:config` 手动启用它,然后在高级首选项中启用 `browser.translations.enable` 标志。

### ?️ 其他更改和改进
除此之外,还有一些值得注意的变化:
* 各种安全更新。
* macOS 用户现在可以控制控件和链接的选项卡功能。
* 新的 CSS 兼容性工具提示增强了 Web 兼容性检查。(对网络开发人员有用)
* 一个新的首选项,允许禁用按 Shift+右键单击时出现的上下文菜单。
你可以浏览 [发行说明](https://www.mozilla.org/en-US/firefox/117.0/releasenotes/) 以更深入地了解此版本。
### ? 获取 Mozilla Firefox 117
你可以从 [FTP 门户](https://ftp.mozilla.org/pub/firefox/releases/117.0/) 获取最新版本的 Firefox。如果尚未提供,它应该很快就会在 [官方网站](https://www.mozilla.org/firefox/download/thanks/) 上提供。
>
> **[Mozilla Firefox 117](https://www.mozilla.org/firefox/download/thanks/)**
>
>
>
**对于现有安装:** 你可以通过在设置菜单中搜索“**更新**”,然后单击“**检查更新**”来更新它。
? 你对 Firefox 117 新的自动翻译功能支持有何看法? 在下面的评论中分享你的想法。
*(题图:MJ/e604e69e-3cf0-4306-8f3f-1dac6f1f9220)*
---
via: <https://news.itsfoss.com/firefox-117-release/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Firefox is a browser loved by many, hated by few. But, as **an open-source alternative to Chromium-based browsers** such as Chrome and Opera, it constantly evolves to add new features to its arsenal.
And this time around, with the **Firefox 117** release, we have an interesting addition that was in the making for quite some time now.
**Suggested Read **📖
[7 Open Source Chrome Alternative Web Browsers for LinuxGoogle Chrome might rule the world of browsers, but you don’t need to keep using it. Here are some free and open-source web browsers for Linux.](https://itsfoss.com/open-source-browsers-linux/?ref=news.itsfoss.com)

Allow me to take you through that, and more in this article. Let's begin.
## 🆕 Firefox 117: What's New?

Like most Firefox releases, this too has a lot to offer. Some notable highlights include:
**New privacy-focused native translation feature**(*a work in progress*)**Expansion of the credit card autofill feature to more locales.****YouTube video lists now scroll correctly with a screen reader.**
While the feature set sounds good, let us focus on the translation feature.
### Privacy-Focused Translations
As shown in the demo above, Firefox now features an in-built translation tool.
Its main selling point is that **all language translations happen locally**, without your data being sent to any server for processing.
This kind of functionality already existed in Firefox thanks to an add-on called '[Firefox Translations](https://addons.mozilla.org/en-US/firefox/addon/firefox-translations/?ref=news.itsfoss.com)'.
But, [back then](https://hacks.mozilla.org/2022/06/neural-machine-translation-engine-for-firefox-translations-add-on/?ref=news.itsfoss.com), integrating this directly into Firefox was discarded owing to its third-party dependencies after Mozilla's internal security review of the engine codebase.
Luckily, now we have proper native functionality. **But, there's a catch.**
[Ghack](https://www.ghacks.net/2023/08/29/firefox-117-native-language-translations-last-firefox-102-update-and-security-fixes/?ref=news.itsfoss.com), I found that
**the translation feature was disabled by default on Firefox 117. They plan to gradually roll it out to users, and by default on its next version update**.
So, to test it out, I had to manually enable it by going into '**about:config**', then enabling the 'b**rowser.translations.enable**' flag among advanced preferences.
### 🛠️ Other Changes and Improvements
Other than that, here are a few other changes that are worth noting:
- Various security updates.
- macOS users can now control the tabability of controls and links.
- Web compatibility inspection has been enhanced for their new CSS compatibility tooltip. (useful for web developers)
- A new preference to allow for the disabling of the context menu that appears when pressing shift+right-click.
You can go through the [release notes](https://www.mozilla.org/en-US/firefox/117.0/releasenotes/?ref=news.itsfoss.com) to dive deeper into this release.
## 📥 Get Mozilla Firefox 117
You can grab the latest release of Firefox from its [FTP portal](https://ftp.mozilla.org/pub/firefox/releases/117.0/?ref=news.itsfoss.com). It should be available on the [official website](https://www.mozilla.org/firefox/download/thanks/?ref=news.itsfoss.com) shortly, if it is not yet available.
**For existing installations:** You can update it by searching for '**Update**', in the settings menu, and clicking on '**Check for Updates**'.
*💬 What do you think about the new automated translation feature support with Firefox 117? Share your thoughts in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,184 | 7 个独特的非主流网页浏览器等待你的探索 | https://itsfoss.com/unique-web-browsers/ | 2023-09-12T09:38:55 | [
"浏览器"
] | https://linux.cn/article-16184-1.html | 
>
> 想要尝试一些新奇的东西吗?这些与众不同的网页浏览器或许能为你的浏览体验带来新的乐趣。
>
>
>
网页浏览器是我们浏览互联网的重要工具。因此,对于大多数用户来说,浏览器的用户体验和功能集是至关重要的因素。
考虑到各种因素,包括安全性问题,用户往往会选择 [最受欢迎的网页浏览器](https://itsfoss.com/best-browsers-ubuntu-linux/)。
理所当然,为了便捷性,你可能不愿意轻易尝试一个新的或是实验阶段的网页浏览器。但是,如果你打算切换一种不同的用户体验,又或者是想要尝试一款独特的网页浏览器,那又该如何呢?
无需担忧,我们为你准备了一些你可能愿意一探究竟的选项。
### 1、Nyxt

[Nyxt](https://nyxt.atlas.engineer/) 是一款专为那些大量使用键盘的用户设计的网页浏览器。
你可以在这款浏览器上使用键盘快捷键进行网页浏览,完全不需要使用鼠标。这能够让你节省时间,让你更少地分心去适应可能会让人感到困扰的用户界面。
[Nyxt 浏览器](https://itsfoss.com/nyxt-browser/) 目前以 Flatpak 形式提供,并有计划提供对 macOS/Windows 的支持。你可以按照其 [官方网站](https://nyxt.atlas.engineer/download) 上的说明进行安装,并在其 [GitHub 页面](https://github.com/atlas-engineer/nyxt) 了解更多信息。
亮点:
* 主打键盘操作
* 可进行个性化定制
>
> **[Nyxt](https://nyxt.atlas.engineer/)**
>
>
>
### 2. Epiphany(GNOME Web 应用)

如果你是那些寻求具备基础功能且用户体验质感洁净的用户,那么 GNOME Web 应用(也被称为 Epiphany)将会是你的理想选择。
尽管该浏览器并未装饰众多现代化的浏览器功能,但其外观和使用体验绝对不会令你失望。值得注意的是,Epiphany 是一款专门为 Linux 用户设计的浏览器,此外,它还支持 Firefox 的同步功能。
亮点:
* 极简而精致的用户体验
* 具备必要的功能
* 支持 Firefox 同步
>
> **[GNOME Web](https://apps.gnome.org/zh-CN/Epiphany/)**
>
>
>
### 3. Tor

[Tor 浏览器](https://www.torproject.org/) 在隐私保护领域的爱好者中享有盛名。而且,它也是一款可以提供安全和私密网络体验的独特解决方案。
Tor 浏览器基于 Mozilla 的 Firefox 进行开发,同时也加入了一些旨在提升隐私保护能力和 Tor 网络集成的新特点。
此款浏览器可以在 Linux、Windows、macOS 以及 Android 平台上使用。
亮点:
* 专注于隐私保护
* 集成 Tor 网络的连接
>
> **[Tor 浏览器](https://www.torproject.org/)**
>
>
>
### 4、Mullvad 浏览器

[Mullvad 浏览器](https://mullvad.net/en/download/browser/linux) 是一个专注于隐私保护的解决方案,与 Tor 类似但没有集成 Tor 网络。在编写本文时,这是一个非常新的选择,其开发是与 Tor 项目合作进行的。
如果你想尝试 Mullvad 的 VPN 服务或想要体验一下私密的网络浏览,你可以尝试一下这款浏览器。
此浏览器适用于 Linux、Windows 和 macOS。
亮点:
* 以隐私为中心
* 开箱即用的 VPN 集成
>
> **[Mullvad 浏览器](https://mullvad.net/en/download/browser/linux)**
>
>
>
### 5、Min

Min 非常类似于 Epiphany,但更为极简。如其名称所示,Min 的目标是为你营造一个无干扰的用户体验,让你能够专注于当前的页面。
你可以将你的页面进行分组并快速访问。同时,它也内置了隐私保护功能。
亮点:
* 用户体验为中心
* 高效
>
> **[Min](https://minbrowser.org/)**
>
>
>
### 6、Konqueror

[Konqueror](https://apps.kde.org/konqueror/) 是 KDE 的网页浏览器,具有管理和预览文件的功能。
它的用户界面简洁有效,内置了基本的隐私保护选项。
如果你是 KDE Plasma 桌面的用户,你可以试试这款浏览器,它能带给你简洁易用的浏览体验。
亮点:
* 专为 KDE 用户打造
* 简约的用户体验
>
> **[Konqueror](https://apps.kde.org/konqueror/)**
>
>
>
### 7、Falkon

Falkon 是另一款专为 KDE 用户设计的浏览器。如果你正在寻找一款 [轻量级的开源浏览器](https://itsfoss.com/lightweight-web-browsers-linux/),这是你的一个选择。
Falkon 是一款基于 QtWebEngine 的浏览器,拥有基本的隐私保护功能。
你可能无法得到丰富的功能集,但如果你只需要一些基础的网络导航功能,如查看邮件、观看 YouTube,Falkon 将是你的一个不错的选择。
Falkon 适用于 Linux 和 Windows。
>
> **[Falkon](https://www.falkon.org/)**
>
>
>
### 非自由开源软件:Opera One

[Opera One](https://www.opera.com/one) 是 Opera 开发者的一项全新尝试,旨在推出经典 Opera 网页浏览器的继任者。如果你并不追求一个颠覆性的浏览器,但希望能有独特的使用体验,Opera One 或许是你的一个理想选择,只需要你对这款专有软件持开放态度。
这款浏览器尝试以一种全新的方式处理浏览器标签,并且保持其设计的模块化。更重要的是,它完全集成了原生的 AI 技术。
Opera One 适用于 Linux 以及包括 macOS 和 Windows 在内的其他平台。
### 那么,你的选择是?
我列出了一些与众不同,相较于普遍认知的选择提供独特体验的网页浏览器。此外,如果你喜欢在终端操作,你还可以探索如 [Carbonyl](https://github.com/fathyb/carbonyl) 这样的 [命令行浏览器](https://itsfoss.com/terminal-web-browsers/)。
[Beaker 浏览器](https://github.com/beakerbrowser) 作为一项实验性尝试曾经颇受欢迎,但现已停止更新。
? 如果你在寻求各种特性的平衡,希望获得特别的浏览体验,我建议你可以尝试 GNOME Web、Min 或是 Nyxt(这是我个人的偏好)。你有意愿尝试哪个呢?
请在下方评论区分享你的想法。
---
via: <https://itsfoss.com/unique-web-browsers/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Web browsers help us navigate the internet. So, the user experience and feature set of a browser is essential to most users.
Considering all the factors along with security, users tend to choose the [most popular web browsers](https://itsfoss.com/best-browsers-ubuntu-linux/).
**Of course, for convenience, you would rather not take a leap of faith with a new or experimental web browser.** But what if you want to have a different user experience and want to try a unique web browser for a change?
Fret not; we have some options that you might like to explore.
## 1. Nyxt
[Nyxt](https://nyxt.atlas.engineer) is a web browser for people who like to use their keyboard a lot.
You can use keyboard shortcuts, and totally rely on them to navigate the web on this browser. This can help you save time, and focus less on adjusting to the user interface, which could be confusing for some.
[Nyxt browser](https://itsfoss.com/nyxt-browser/) is available as a Flatpak and planned to be available for macOS/Windows. You can follow the official instructions on their [website](https://nyxt.atlas.engineer/download?ref=itsfoss.com) to get it installed and explore its [GitHub page](https://github.com/atlas-engineer/nyxt).
**Highlights:**
- Keyboard-focused
- Customizable
[Nyxt: Keyboard-oriented Web Browser Inspired by Emacs & VimThis is not your regular web browser. This is intended for power users who like to use their keyboard more than their mouse. Learn more about it.](https://itsfoss.com/nyxt-browser/)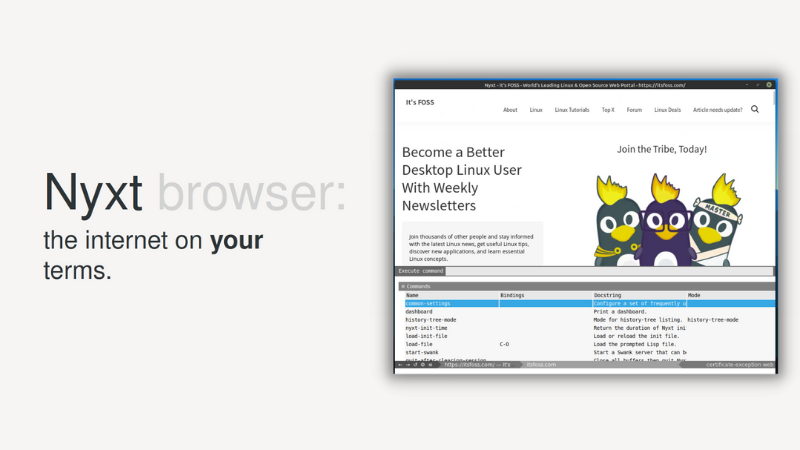

## 2. Web or Epiphany
GNOME Web or Epiphany is a good web browser for users who want essential features with clean user experience.
It looks great, even without the usual bells and whistles of a modern web browser. Epiphany is a Linux-only web browser, but it does support Firefox sync integration.
**Highlights:**
- Minimal but elegant user experience
- Includes essential features
- Supports Firefox Sync
## 3. Tor
[Tor browser](https://www.torproject.org) is a well-known option for privacy enthusiasts. However, it remains as a unique solution to a secure and private web experience.
The browser is based on Mozilla's Firefox, with several tweaks to provide an enhanced privacy protection and Tor network integration.
It is available for Linux, Windows, macOS, and Android.
**Highlights:**
- Privacy-focused
- Tor network connection
[Proton Mail: Get a private, secure, and encrypted email account | ProtonProton Mail is the world’s largest secure email service with over 100 million users. Available on Web, iOS, Android, and desktop. Protected by Swiss privacy law.](https://go.getproton.me/aff_c?offer_id=26&aff_id=1173&url_id=267)

Partner Link
## 4. Mullvad Browser

[Mullvad Browser](https://mullvad.net/en/download/browser/linux?ref=news.itsfoss.com) is yet another privacy-focused solution built similarly without the Tor network integration. It is a fairly new option at the time of writing the article made in collaboration with the Tor Project.
If you want to use Mullvad's VPN service or a private web experience, you can give it a try.
It is available for Linux, Windows, and macOS.
**Highlights:**
- Privacy focused
- VPN integration out of the box
## 5. Min
Similar to Epiphany, but extremely minimal. As the name suggests, Min aims to provide you a distraction-free user experience, letting you focus to work on the current tab.
You can group your tabs and quickly access them. It comes with built-in privacy protection as well.
**Highlights:**
- Focused user experience
- Fast performance
## 6. Konqueror

[Konqueror](https://apps.kde.org/konqueror/) is KDE's web browser with the ability to manage and preview files.
The user interface is simple, and effective. It features basic privacy protection options.
If you are on KDE Plasma desktop, you should give it a try for a simple browsing experience.
**Highlights:**
- Tailored for KDE users
- Simple UX
[pCloud - Europe’s Most Secure Cloud StoragepCloud is Europe’s most secure encrypted cloud storage, where you can store your personal files or backup your PC or share your business documents with your team!](https://partner.pcloud.com/r/1935)

Partner Link
## 7. Falkon

Falkon is yet another browser tailored for KDE. If you are looking for [lightweight open-source browsers](https://itsfoss.com/lightweight-web-browsers-linux/), this is one of the options.
It is a QtWebEngine based browser with basic privacy protection features in place.
You may not get the best feature set, but if you don't need much and need some traditional web navigation like checking email, and accessing YouTube, you can go with it.
Falkon is available for Linux, and Windows.
**Suggested Read 📖**
[10 Open Source Lightweight Web Browsers for LinuxDo you think your web browser consumes too much system resources? Try these light web browsers in Linux.](https://itsfoss.com/lightweight-web-browsers-linux/)

## Non-FOSS entry: Opera One
[Opera One](https://www.opera.com/one) is a fairly new initiative by the developers of Opera to pitch the successor to the classic Opera web browser. If you do not want a wildly different browser but still want some unique aspect, Opera One could be a choice if you can give a pass to this proprietary product.
The browser tries to offer a new way to approach the browser tabs, and keep the design modular. And all of this, with its native AI fully integrated into the browser.
It is available for Linux, and other platforms, including macOS and Windows.
## So, What's Your Pick?
I listed some of the web browsers that offer unique traits compared to the popular options. Furthermore, you can also explore [command-line browsers](https://itsfoss.com/terminal-web-browsers/) like [Carbonyl](https://github.com/fathyb/carbonyl) if you are a fan of the terminal.
[Beaker Browser](https://github.com/beakerbrowser) was a nice take as an experiment, but it is now discontinued.
*💬 If you want a balance of everything, and want a unique experience, I suggest trying GNOME Web, Min, or Nyxt (as per my personal preferences). What would you try?*
*Let me know your thoughts in the comments below.* |
16,186 | 让你的 Windows 系统为虚拟机做好准备 | https://itsfoss.com/windows-enable-virtualization/ | 2023-09-13T10:07:30 | [
"虚拟机"
] | https://linux.cn/article-16186-1.html | 
>
> 以下是确保 Windows 系统已准备好运行虚拟机的必要条件。
>
>
>
在 VirtualBox 中看到了“<ruby> 无法打开虚拟机会话 <rt> failed to open a session for the virtual machine </rt></ruby>”错误?
你的系统上可能没有启用虚拟化。
这是在 Windows 系统上创建虚拟机所需执行的几件事之一。
简单来说,你需要了解:
* 在你的 PC 上启用虚拟化支持
* 使用虚拟机程序创建/管理虚拟机
* 确保某些系统资源要求以无缝使用虚拟机
下面是第一件事:
### 在 Windows PC 上启用虚拟化
如果你的系统预装了 Windows 10/11,那么你很可能已经启用了虚拟化。你不需要额外的设置。
但如果你在系统上手动安装了 Windows,那么可能需要检查 BIOS 设置以查看它是否支持虚拟化。如果禁用,虚拟机程序将无法运行并给出错误。
这是使用 VirtualBox 程序时出现的错误:

你怎么能这么做呢? 以下是基本步骤:

1. 前往 UEFI 固件设置(或 BIOS 菜单)。你通常可以通过按 `Del` 按钮或 `F1`、`F2`、`F10` 或 `F12` 来访问它。
2. 根据主板制造商的不同,用户界面会有所不同。但是,在大多数情况下,你必须进入到其中的“<ruby> 高级 <rt> Advance </rt></ruby>”选项,并访问“<ruby> CPU 配置 <rt> CPU Configuration </rt></ruby>”设置。
3. 在 CPU 配置中,你必须启用 “Intel (VMX) Virtualization Technology” 或 “SVM Mode”(适用于 AMD 处理器)。
下一步是什么? 考虑到你已经启用了虚拟化支持,你需要使用 [虚拟化程序](https://itsfoss.com/virtualization-software-linux) 来帮助你完成工作。
### 使用虚拟化程序
你可以选择第三方应用以方便使用,也可以选择使用 Windows 自带的 Hyper-V。
#### Hyper-V
我们不会详细介绍如何使用 Hyper-V,但为了节省你一些时间,你可以按照以下步骤启用它,然后按照其[文档](https://learn.microsoft.com/en-us/virtualization/hyper-v-on-windows/about/)使用它。
>
> ? Hyper-V 不适用于 Windows 10/11 家庭版。
>
>
>
考虑到你的系统上安装了 Windows 专业版/教育版/企业版,可以通过**控制面板**或使用 **PowerShell** 轻松启用它。

我更喜欢控制面板,只需在搜索栏中搜索 “Windows 功能”或通过 “控制面板 → 程序 → 打开或关闭 Windows 功能” 打开。
接下来,单击 “Hyper-V” 并点击 “OK”。就是这样。

它将通过获取所需的文件来应用更改。你只需要等待。
完成后,它会要求你**重启系统**以使新功能生效。

#### 第三方虚拟化程序
虽然使用 Hyper-V 可以让虚拟机获得更好的性能,但它使用起来却并不那么简单。
因此,建议终端用户使用第三方虚拟机程序。
最好的选择之一是 [VirtualBox](https://www.virtualbox.org/)。我们还有一个指南可以帮助你使用 [VirtualBox 安装 Linux](https://itsfoss.com/install-linux-in-virtualbox/)。

它是一个开源程序,具有一系列功能和用户友好的界面。你也可以在 Windows、Linux 和 macOS 上使用它。
你还可以选择专有(但流行)的选项,例如 [VMware Workstation](https://www.vmware.com/products/workstation-player.html)。
想了解这些程序吗?你可以查看 Linux 下的一些可用选项,了解有哪些解决方案:
>
> **[9 个最佳虚拟化软件](https://itsfoss.com/virtualization-software-linux/)**
>
>
>
### 检查系统资源和要求
创建和使用虚拟机并不完全是一个非常占用资源的过程。但是,你可能需要注意一些变量。
其中一些包括:
* 确保你的系统至少有 4 GB 内存(越多越好)
* 双核或以上 64 位处理器
如果你不知道,即使虚拟机是孤立的机器,也会占用你系统的资源。大多数最低规格建议 4 GB RAM,但**我建议使用 8 GB**。
如果你想要**运行两个虚拟机**,你可能需要在 Windows 上拥有**超过 8GB 的内存**。
除了内存,你应该有一个**多核**处理器。这样,一些内核可以自由地让你在主机上做其他事情,而另一些内核则用于处理虚拟机。
当确定了处理器和内存,接下来就是**磁盘空间**。
对于虚拟机来说,磁盘通常是动态分配的,也就是说,物理存储驱动器的空间会随着操作系统及其文件的增加而消耗。
在某些类型的虚拟磁盘中,它保留你指定的整个空间。因此,执行此操作时,请在启动之前检查可用磁盘空间。通常最好选择一个未安装 Windows 系统的单独驱动器。
**如果你遵循了上述所有提示,你的 Windows 系统就可以运行和管理虚拟机了。现在,你可以 [在 Windows 的虚拟机中轻松地安装 Linux](https://itsfoss.com/install-linux-in-virtualbox/)**。
? 那么,你喜欢用什么方式来处理虚拟机?请在下面的评论中告诉我们你的想法。
*(题图:MJ/c1690724-a797-442b-8fb5-b6d41ef0c45c)*
---
via: <https://itsfoss.com/windows-enable-virtualization/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Seeing a '**failed to open a session for the virtual machine**' error with VirtualBox?
Chances are that you do not have virtualization enabled on your system.
And that's one of the several things you need to do to create a virtual machine on any of your Windows-powered systems.
To give you an overview, you need to learn about:
**Enabling virtualization support on your PC****Using a virtual machine program to create/manage VMs****Ensuring certain system resource requirements to seamlessly use virtual machines**
Here's the first thing:
## Enabling virtualization on Windows PC
If you have a system with Windows 10/11 pre-installed, chances are, you already have virtualization enabled. So you do not need to fiddle around with unnecessary settings.
But if you installed Windows manually on your system, you might have to check the BIOS settings to see if it supports virtualization. If disabled, the virtual machine program will not work and give you an error.
Here's what the error looks like when using VirtualBox program:
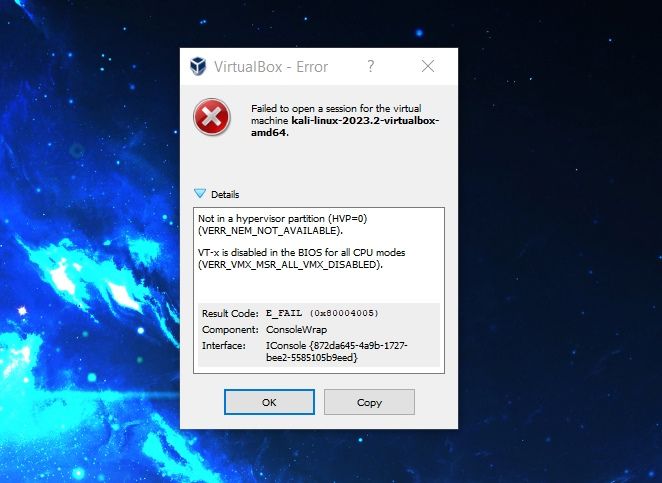
How can you do that? Here are the basic steps:
- Head to the UEFI Firmware settings (or BIOS menu). You can usually access it by pressing the "
**Del**" button or**F1, F2, F10, or F12**. - Depending on the motherboard manufacturer, the user interface will differ. However, in most cases, you have to navigate to the "
**Advanced**" options in that, and access "**CPU Configuration**" settings. - In the CPU configuration, you will have to enable "
**Intel (VMX) Virtualization Technology**" or "**SVM Mode**" (for AMD processors).
What's next? Considering you already enabled the virtualization support, you need to use [virtualization programs](https://itsfoss.com/virtualization-software-linux) to help you finish the job.
## Using virtualization programs
You can opt for third-party applications for ease of use, or choose to use Hyper-V that comes baked in with Windows.
### Hyper-V
We will not be detailing how to use Hyper-V, but to save you some time, you can follow the steps below to enable it and then follow its [documentation](https://learn.microsoft.com/en-us/virtualization/hyper-v-on-windows/about/) to use it.
Considering you have a Windows Pro/Education/Enterprise edition installed on your system, it is easy to enable it from the **control panel** or using the **PowerShell**.
I prefer the control panel, just search for “Windows features” in the search bar or navigate your way through **Control Panel → Programs → Turn Windows features on or off**
Next, click on** “Hyper-V” **and hit** “OK”**.** **That's it.
It will apply the changes by fetching the files needed for it. You just have to wait it out.
Once done, it will ask you to **restart the system **to put the new feature in effect.
### Third-party virtualization programs
While using Hyper-V allows you to get better performance for virtual machines, it is not as simple to use.
So, third-party virtual machine programs are recommended for end-users.
One of the best bets is [VirtualBox](https://www.virtualbox.org). We also have a guide to help you use [VirtualBox to install Linux](https://itsfoss.com/install-linux-in-virtualbox/).
It is an open-source program with a range of features, and a user-friendly interface. You can use it on Windows, Linux, and macOS as well.
You can also opt for proprietary (but popular) options like [VMware Workstation](https://www.vmware.com/products/workstation-player.html).
Want to get an idea on programs like these? You can check out some options available for Linux to see what kind of solutions are available:
[Top 9 Best Virtualization Software for Linux [2023]We take a look at some of the best virtualization programs that make things easy for users creating/managing VMs.](https://itsfoss.com/virtualization-software-linux/)

## Checking system resources and requirements
Creating and using a virtual machine is not entirely a super intensive process. However, there are a couple of variables that you might have to keep an eye on.
Some of those include:
- Making sure that you have at least 4 GB RAM in your system (the more, the merrier)
- 64-bit processor with dual-core or more
If you did not know, VMs use up resources of your system even if they are isolated machines. Most minimum specification recommendations include 4 GB of RAM, but **I would recommend 8 GB** instead.
If you want to **run two virtual machines**, you might need **more than 8 GB of RAM** on Windows.
Coupled with the memory, you should have a **processor with multiple cores**. So, some cores can freely let you do other things on your host while some are busy with the virtual machines.
Once you are sure about the processor and memory, next comes the **disk space**.
For virtual machines, the disk is usually dynamically allocated, meaning, the space from your physical storage drive is consumed as much as the OS and its files add up with time.
In some type of virtual disk, it reserves the entire space you specify. So, when you do that, check the free disk space before you initiate it. It is typically a good idea to choose a separate drive where you do not have Windows system installed.
**Considering you follow all the above-mentioned tips, your Windows system will be ready to run and manage virtual machines. Now, you can **
**easily install Linux in a virtual machine on Windows**.
[How to Install Linux Inside Windows Using VirtualBoxUsing Linux in a virtual machine allows you to try Linux within Windows. This step-by-step guide shows you how to install Linux inside Windows using VirtualBox.](https://itsfoss.com/install-linux-in-virtualbox/)

💬* So, what would be your preferred way to handle virtual machines? Let us know your thoughts in the comments below.* |
16,187 | Ubuntu 23.10 将提供实验性 TPM 支持的全磁盘加密 | https://news.itsfoss.com/ubuntu-23-10-disk-encryption/ | 2023-09-13T10:43:17 | [
"TPM",
"全磁盘加密"
] | https://linux.cn/article-16187-1.html | 
>
> 展望未来,Ubuntu 将允许你利用 TPM 支持的全磁盘加密。但是,这是你想要的吗?
>
>
>
Ubuntu 23.10 每日构建不断增加令人兴奋的新功能!
早些时候,我们介绍了 [主要的 PPA 变化](https://news.itsfoss.com/ubuntu-23-10-ppa/) 和新的 [基于 Flutter 的商店](https://news.itsfoss.com/ubuntu-23-10-ubuntu-store/)(也随最新的每日构建一起发布)。
现在,我们又看到了另一项重大更改,通过更改用户处理磁盘加密的方式(如果启用),增强 Ubuntu 系统的安全性。
该功能的初始支持将在 Ubuntu 23.10 中提供,并将在未来的 Ubuntu 版本中得到改进。
### Ubuntu 23.10:TPM 支持的全磁盘加密

TPM 支持的<ruby> 全磁盘加密 <rt> Full Disk Encryption </rt></ruby>(FDE)作为**一项实验性功能**引入,是 Ubuntu 过去 15 年处理 FDE 方式的重大变化。
**在现有系统中**,采用了密码机制,该机制将通过接受用户设置的密码来对用户进行身份验证,然后使用该密码提供对磁盘的访问。
所有这一切都是由于集成了 <ruby> <a href="https://en.wikipedia.org/wiki/Linux_Unified_Key_Setup"> Linux 统一密钥设置 </a> <rt> Linux Unified Key Setup </rt></ruby>(LUKS)框架而成为可能,该框架在块级别处理磁盘加密。
**使用 TPM 支持的系统**,主板上的 TPM 芯片将用于提供全磁盘加密,而无需密码。
**芯片将处理锁定完整 EFI 状态的密钥** 以及内核命令行的解密。只有当设备使用已定义为“**授权**”来访问机密数据的软件启动时,才有可能实现这一点。
>
> ? TPM <ruby> <a href="https://en.wikipedia.org/wiki/Trusted_Platform_Module"> 可信平台模块 </a> <rt> Trusted Platform Module </rt></ruby> 的缩写。
>
>
>
**但是,有一个问题。**
TPM 支持的 FDE 基于与 [Ubuntu Core](https://ubuntu.com/core) [相同的架构](https://ubuntu.com/core/docs/uc20/full-disk-encryption),这导致了许多关键组件的共享,这些组件 **以 Snap 包的形式提供**。因此,**引导加载程序**(shim/GRUB)和**内核文件**等内容是通过 Snap 交付的。
幸运的是,这种新的 **TPM 支持的 FDE 并不是加密磁盘的唯一方法**。对于那些不想使用新系统的人来说,**传统密码系统仍将存在**。
用户还可以使用新系统和密码来进一步增强安全性。
有关 TPM 支持的磁盘加密如何工作的技术细节,我建议你阅读 Ubuntu 的[官方博客](https://ubuntu.com/blog/tpm-backed-full-disk-encryption-is-coming-to-ubuntu)。
**有兴趣测试一下吗?** ?
>
> ? 测试任何实验功能都可能导致全部数据丢失。因此,请自行承担风险。
>
>
>
好吧,TPM 支持的 FDE 已推出到 **Ubuntu 23.10** 的 [每日构建](https://cdimage.ubuntu.com/daily-live/current/) 中,你只需在安装过程中进行设置,如本文中的截图所示。
在 Ubuntu 安装程序中选择安装类型时,可在“**高级功能**”下使用新的 FDE 选项。
? 你对这个新的实验性功能有何看法? 在下面的评论中分享你的想法。
*(题图:MJ/d89e5b66-af24-4a2f-b351-9257239819cd)*
---
via: <https://news.itsfoss.com/ubuntu-23-10-disk-encryption/>
作者:[Sourav Rudra](https://news.itsfoss.com/author/sourav/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Ubuntu 23.10 daily builds keep getting exciting new additions!
Earlier we had covered the [major PPA changes](https://news.itsfoss.com/ubuntu-23-10-ppa/), and the new [Flutter-based store](https://news.itsfoss.com/ubuntu-23-10-ubuntu-store/) (which also landed with the latest daily builds).
Now, we have yet another major change that is set to enhance the security of Ubuntu systems; by changing how users handle the encrypting of their disks (if enabled).
The initial support for the feature is set to arrive with Ubuntu 23.10 and will be improved in future Ubuntu releases.
**Suggested Read **📖
[Ubuntu 23.10: Release Date and New FeaturesUbuntu’s next latest and greatest. Here’s what it is expected to pack in.](https://news.itsfoss.com/ubuntu-23-10/)

## Ubuntu 23.10: TPM-backed Full Disk Encryption
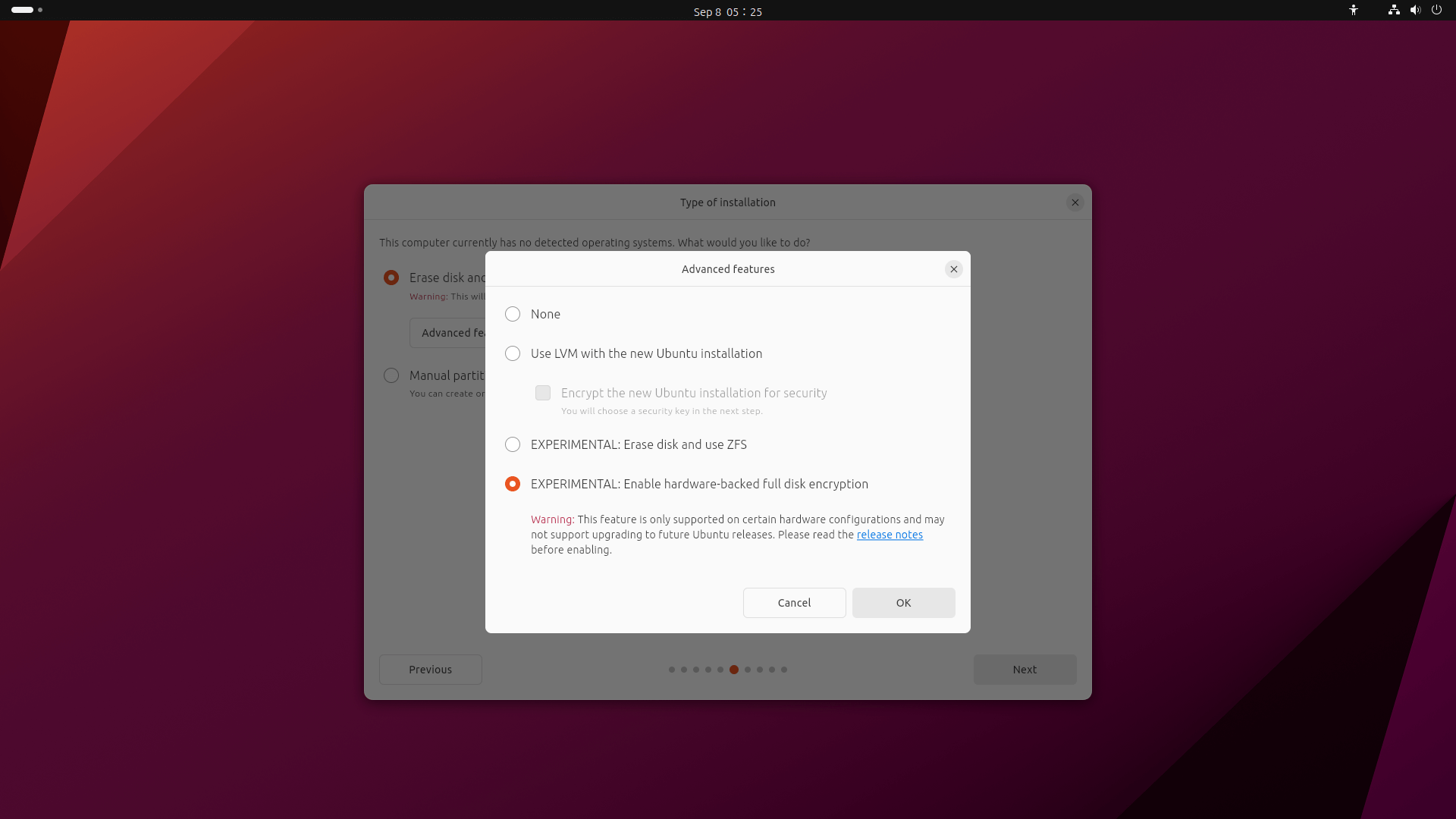
Introduced as **an experimental feature**, TPM-backed Full Disk Encryption (FDE) is a major change from how Ubuntu has been handling FDE for the past 15 years.
**In the existing system**, a passphrase mechanism was in place, that would authenticate users by accepting a user-set phrase that would then be used to provide access to the disk.
All of this was made possible due to the integration of the ** Linux Unified Key Setup** (LUKS) framework, which handles disk encryption at the block level.
**With the TPM-backed system**, the TPM chip on your motherboard will be used to provide full disk encryption, doing away with the need for a passphrase.
The **chip will handle the decryption of the secret key** that locks the full EFI state, and the kernel command line. That is only possible when the device boots with software that has been defined as '**authorized**' to access confidential data.
[Trusted Platform Module](https://en.wikipedia.org/wiki/Trusted_Platform_Module?ref=news.itsfoss.com).
**But, there's a catch.**
TPM-backed FDE is based on the [same architecture](https://ubuntu.com/core/docs/uc20/full-disk-encryption?ref=news.itsfoss.com) as [Ubuntu Core](https://ubuntu.com/core?ref=news.itsfoss.com), this has resulted in the sharing of many key components that are **delivered as snap packages**. So, things such as the **bootloader** (shim/GRUB) and **kernel assets** are delivered via snap.
Luckily, this new **TPM-backed FDE is not the only way of encrypting disks**. The **conventional passphrases system will still be in place**, for those who don't want to use the new system.
Users can also use the new system alongside passphrases to further bolster their security.
For technical details on how TPM-backed disk encryption works, I suggest you go through Ubuntu's [official blog](https://ubuntu.com/blog/tpm-backed-full-disk-encryption-is-coming-to-ubuntu?ref=news.itsfoss.com) post.
**Interested in testing this out? **🤔
Well, TPM-backed FDE has been rolled out into the [ daily builds](https://cdimage.ubuntu.com/daily-live/current/?ref=news.itsfoss.com) of
**Ubuntu 23.10**, you just have to set it up during installation as shown in the screenshot in the article.
The new FDE option is available under '**Advanced Features**' during the selection of the type of install on the Ubuntu installer.
*💬 What do you think of this new experimental feature? Share your thoughts in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,189 | Btrfs 详解:基础概念 | https://fedoramagazine.org/working-with-btrfs-general-concepts/ | 2023-09-13T23:51:00 | [
"Btrfs"
] | https://linux.cn/article-16189-1.html | 
这篇文章是《Btrfs 详解》系列文章中的一篇。从 Fedora Linux 33 开始,Btrfs 就是 Fedora Workstation 和 Fedora Silverblue 的默认文件系统。
### 介绍
文件系统是现代计算机的基础之一。它是任何操作系统必不可少的一部分,且通常不为人注意。但是,像 Btrfs 这样的现代文件系统提供了许多很棒的特性,使计算机的使用更加方便。例如,它可以无感地为你压缩文件,或者为增量备份建立可靠的基础。
这篇文章将带你高屋建瓴地了解 Btrfs 文件系统是如何工作的,有什么特性。本文既不会过多涉及技术细节,也不会研究其底层实现,系列后续的文章会详细介绍一些重要特性。
### 什么是文件系统
如果你基本了解过文件系统是如何工作的,那么下面的内容对你应该是不陌生的,你可以直接跳到下一节。否则,请先阅读下面对文件系统的简短介绍。
简单来说,文件系统允许你的 PC 去寻找存储在磁盘上的数据。这听起来像是微不足道的工作,但实际上时至今日各种类型的非易失性存储设备(比如机械硬盘、固态硬盘、SD 卡等等)仍然与 1970 年代 PC 被发明时基本相同:一个(巨大的)存储块集合。
“<ruby> 块 <rt> Block </rt></ruby>” 是最小的可寻址存储单元。PC 上的每个文件内容被存储在多个块中。一个块通常是 4096 字节的大小。这取决于你的硬件和在这之上的软件(即文件系统)。
文件系统允许我们从海量的存储块中查找文件的内容,这是通过所谓的 *inode* 去实现的。一个 inode 在特殊格式的存储块里记录了文件的信息。这包含文件的大小,哪里去寻找组成文件内容的存储块,访问规则(即谁可读,可写,可执行)等等。
下面是 inode 的示意图:

inode 的结构对文件系统的功能有巨大的影响,因此它是各种文件系统诸多的重要数据结构之一。出于这个原因,每个文件系统有各自的 inode 结构。如果你想了解更多信息,看看下面 [链接](https://btrfs.wiki.kernel.org/index.php/Data_Structures#btrfs_inode_item) 关于 Btrfs 文件系统 inode 结构的内容。如需更详细地了解各个字段的含义,你可以 [参考](https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Inode_Table) ext4 文件系统的 inode 结构。
### 写时复制(CoW)文件系统
相比 ext4,Btrfs 拥有的杰出特性之一是,它是一个 <ruby> 写时复制 <rt> Copy-on-Write </rt></ruby>(CoW)文件系统。当一个文件被改变和回写磁盘,它不会故意写回它原来的位置,而是被复制和存储在磁盘上的新位置。从这个意义上,可以简单地认为 Cow 是一种 “重定向”,因为文件写入被重定向到不同的存储块上。
这听起来很浪费,但实际上并不是。这是因为被修改的数据无论如何一定会被写到磁盘上,不管文件系统是如何工作的。Btrfs 仅仅是确保了数据被写入在之前没被占据的块上,所以旧数据保持完整。唯一真正的缺点就是这种行为会导致文件碎片化比其他文件系统要快。在日常的电脑使用中,你不太可能会注意到这点差异。
CoW 的优势在哪里?简单的说:文件被修改和编辑的历史被保存了下来。Btrfs 保存文件旧版本的引用(inode)可以轻易地被访问。这个引用就是快照:文件系统在某个时间点的状态镜像。这将是这系列文章里的单独的一篇,所以暂时留到后面介绍。
除了保存文件历史,CoW 文件系统永远处于一致的状态,即使之前的文件系统事务(比如写入一个文件)由于断电等原因没有完成。这是因为文件系统的元数据更新也是写时复制的:文件系统本身永远不会被覆写,所以中断不会使其处于部分写入的状态。
### 对文件的写时复制
你可以将文件名视为对 inode 的指针。在写入文件的时候,Btrfs 创建一个被修改文件内容(数据)的拷贝,和一个新的 inode(元数据),然后让文件名指向新的 inode,旧的 inode 保持不变。下面是一个假设示例来阐述这点:

这里 `myfile.txt` 增加了三个字节。传统的文件系统会更新中间的 `Data` 块去包含新的内容。CoW 文件系统不会改变旧的数据块(图中灰色),写入(复制)更改的数据和元数据在新的地方。值得注意的是,只有被改变的数据块被复制,而不是全部文件。
如果没有空闲的块去写入新内容,Btrfs 将从被旧文件版本占据的数据块中回收空间(除非它们是快照的一部分,本系列后续文章会看到)。
### 对目录的写时复制
从文件系统的角度看,目录只是特殊类型的文件。与常规文件不同,文件系统直接解释数据块的内容。一个目录有自身的元数据(inode,就像上面说的文件一样)去记录访问权限或修改时间。最简单的形式,存在目录里的数据(被叫作目录项)是一个 inode 引用的列表,每个 inode 又是另外的文件或目录。但是,现代文件系统在目录项中至少会存储一个文件名和对应的 inode 引用。
之前已经指出,写入一个文件会创建之前 inode 的副本,并相应修改其内容。从根本上,这产生了一个和之前无关的新的 inode 。为了让被修改的文件对文件系统可见,所有包含这个文件引用的目录项都会被更新。
这是一个递归的过程!因为一个目录本身是一个带有 inode 的文件。修改目录里的任何一项都会为这个目录文件创建新的 inode 。这会沿着文件系统树递归直到文件系统的根。
所以,只要保留对任何旧目录的引用,并且这些目录没有被删除和覆写,就可以遍历之前旧状态的文件系统树。这就是快照的功能。
### 后续文章可以期待的内容
Btrfs 不只是一个 Cow 文件系统。它目标是实现高级特性的同时关注容错、修复和易于管理(参见 [文档](https://btrfs.readthedocs.io/en/latest/Introduction.html))。本系列未来的文章将会专门介绍这些特性。
* 子卷 – 文件系统中的文件系统
* 快照 – 回到过去
* 压缩 – 透明节省存储空间
* 配额组 – 限制文件系统大小
* RAID – 替代 mdadm 配置
这远非 Btrfs 特性的详尽列表。如果你想全面地了解可用特性,查看 [维基](https://btrfs.wiki.kernel.org/index.php/Main_Page) 和 [文档](https://btrfs.readthedocs.io/en/latest/Introduction.html)。
### 总结
我希望我已能激起你进一步了解计算机文件系统的兴趣。如果目前你有任何疑问,请在评论区留言讨论以便在日后文章中探讨,同时,你也可以自行学习文中提供的相关资源。如果你发现 Btrfs 中某项特别有趣的功能,也欢迎在评论区提出。如果某个主题收到足够的关注,我可能会在系列文章中新增相关内容。下一篇文章再见!
*(题图:MJ/35fa1970-1806-4026-8d58-095a56206ec9)*
---
via: <https://fedoramagazine.org/working-with-btrfs-general-concepts/>
作者:[Andreas Hartmann](https://fedoramagazine.org/author/hartan/) 选题:[lkxed](https://github.com/lkxed) 译者:[A2ureStone](https://github.com/A2ureStone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article is part of a series of articles that takes a closer look at Btrfs. This is the default filesystem for Fedora Workstation and Fedora Silverblue since Fedora Linux 33.
## Introduction
Filesystems are one of the foundations of modern computers. They are an essential part of every operating system and they usually work unnoticed. However, modern filesystems such as Btrfs offer many great features that make working with computers more convenient. Next to other things they can, for example, transparently compress your files for you or build a solid foundation for incremental backups.
This article gives you a high-level overview of how the Btrfs filesystem works and some of the features it has. It will not go into much technical detail nor look at the implementation. More detailed explanations of some highlighted features follow in later articles of this series.
## What is a filesystem?
If you’ve heard before how filesystems work on the most basic level, then this isn’t new to you and you can skip to the next section. Otherwise, read ahead for a short introduction into what makes a filesystem in the first place.
In simple terms, a filesystem allows your PC to find the data that it stores on disk. This sounds like a trivial task, but in essence any type of non-volatile storage device today (such as HDDs, SSDs, SD cards, etc…) is still mostly what it was back in 1970 when PCs were being invented: A (huge) collection of storage blocks.
Blocks are the most granular addressable storage unit. Every file on your PC is stored across one or more blocks. A block is typically 4096 bytes in size. This depends on the hardware you have and the software (i.e. the filesystem) on top of it.
Filesystems allow us to find the contents of our files from the vast amount of available storage blocks. This is done via so-called *inodes*. An inode contains information about a file in a specially formatted storage block. This includes the file’s size, where to find the storage blocks that make up the file contents, its access rules (i.e. who can read, write or execute the file) and much more.
Below is an example of what this looks like:


The structure of an inode has big implications on a filesystem’s capabilities, so it is one of the central datastructures for any file system. For this reason every filesystem has its own inode structure. If you want to know more about this, have a look at the inode structure of the Btrfs filesystem linked below [[1]](#sources). For a more detailed explanation of what the individual fields mean, you can refer to the inode structure of the ext4 filesystem [[2]](#sources).
## Copy-on-Write filesystems
One of the outstanding features of Btrfs, compared to ext4, for example, is that it is a CoW (Copy-on-Write) filesystem. When a file is changed and written back to disk, it intentionally is not written back to where it was before. Instead, it is copied and stored in an entirely new location on disk. In this sense, it may be simpler to think of CoW as a kind of “redirection”, because the file write is redirected to different storage blocks.
This may sound wasteful, but in practice it isn’t. This is because the modified data must be written back to the disk in any case, regardless of how the filesystem works. Btrfs merely makes sure that the data is written to previously unoccupied blocks, so the old data remains intact. The only real drawback is that this behavior can lead to file fragmentation quicker than on other filesystems. In regular desktop usage scenarios it is unlikely you will notice a difference.
What is the advantage of CoW? In simple terms: a history of the modified and edited files can be kept. Btrfs will keep the references to the old file versions (inodes) somewhere they can be easily accessed. This reference is a *snapshot*: An image of the filesystem state at some point in time. This will be the topic of a separate article in this series, so it will be left at that for now.
Beyond keeping file histories, CoW filesystems are always in a consistent state, even if a previous filesystem transaction (like writing to a file) didn’t complete due to e.g. power loss. That is because filesystem metadata updates are also CoW: The file system itself is never overwritten, so an interruption can’t leave it in a partially written state
## Copy-on-Write for files
You can think of filenames as pointers to the inodes of the file they belong to. Upon writing to a file, Btrfs creates a copy of the modified file content (the data), along with a new inode (the metadata), and then makes your filename point to this new inode. The old inode remains untouched. Below you see another hypothetical example to illustrate this:
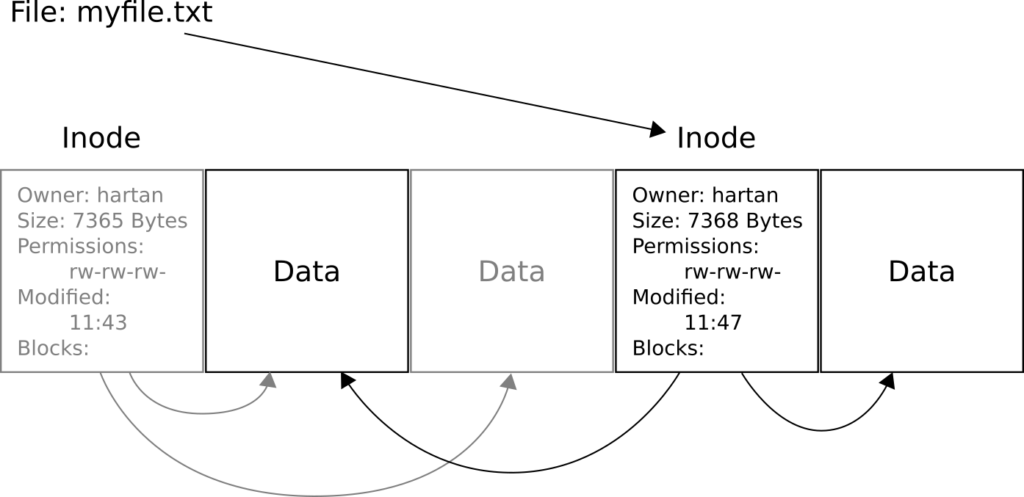

Here “myfile.txt” has had three bytes appended. A traditional filesystem would have updated the “Data” block in the middle to contain the new contents. A CoW filesystem keeps the old blocks intact (greyed out) and writes (copies) changed data and metadata somewhere new. It is important to note that only changed data blocks are copied, and not the whole file.
If there are no more unused blocks to write new contents to, Btrfs will reclaim space from data blocks occupied by old file versions (Unless they are part of a snapshot, see later article in this series).
## Copy-on-Write for folders
From a filesystem’s point of view, a folder is a special type of file. In contrast to regular files, the filesystem interprets the underlying contents directly. A folder has some metadata associated with it (an inode, as seen for files above) that governs access permissions or modification time. In the simplest case, the data stored in a folder (so called “directory entries”) is a list of references to inodes, where each inode is in turn another file or folder. However, modern filesystems store at least a filename, together with a reference to an inode of the file in question, in a directory entry.
Earlier it was pointed out that writing to a file creates a copy of the previous inode and modifies the contents accordingly. In essence, this yields a new inode that isn’t related to its predecessor. To make the modified file show up in the filesystem, all the directory entries containing a reference to it are updated as well.
This is a recursive process! Since a folder is itself a file with an inode, modifying any of its folder entries creates a new inode for the folder file. This recursion occurs all the way up the filesystem tree, until it arrives at the filesystem root.
As a consequence, as long as a reference is kept to any of the old directories and they are not deleted or overwritten, the filesystem tree can be traversed in it’s previous state. This, again, is exactly what snapshots do.
## What to expect in future articles
Btrfs is more than just a CoW filesystem. It aims to implement “advanced features while also focusing on fault tolerance, repair and easy administration” (See [[3]](#sources)). Future articles of this series will have a look at these features in particular:
- Subvolumes – Filetrees within your filetree
- Snapshots – Going back in time
- Compression – Transparently saving storage space
- Qgroups – Limiting your filesystem size
- RAID – Replace your mdadm configuration
This is by far not an exhaustive list of Btrfs features. If you want the full overview of available features, check out the Wiki [[4]](#sources) and Docs [[3]](#sources).
## Conclusion
I hope that I managed to whet your appetite for getting to know your PC filesystem. If you have questions so far, please leave a comment about what you come up with so they can be discussed in future articles. In the meantime, feel free to study the linked resources in the text. If you stumble over a Btrfs feature that you find particularly intriguing, please add a comment below, too. If there’s enough interest in a particular topic, maybe I’ll add an article to the series. See you in the next article!
## Sources
[1]: [https://btrfs.wiki.kernel.org/index.php/Data_Structures#btrfs_inode_item](https://btrfs.wiki.kernel.org/index.php/Data_Structures#btrfs_inode_item)
[2]: [https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Inode_Table](https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Inode_Table)
[3]: [https://btrfs.readthedocs.io/en/latest/Introduction.html](https://btrfs.readthedocs.io/en/latest/Introduction.html)
[4]: [https://btrfs.wiki.kernel.org/index.php/Main_Page](https://btrfs.wiki.kernel.org/index.php/Main_Page)
## Oscar
I’d like Stratis could be a real competitor in a near future
## Chris Murphy
Congrats on this first article, Andreas! Good work! Looking forward to reading the rest of the series – keep writing!
## Simon
Very informative and clear! I’m looking forward to further articles about btrfs.
## lol
“For a more detailed explanation of what the individual fields mean, you can refer to the inode structure of the ext4 filesystem” …
## John
You’ve got a great writing style! Thanks for sharing!
## Matthew
This article is fantastic, love the style and the explanation is great! I’m looking forward to the rest of the series!
## Benjamin
Nice intro! now I need the rest of this series 😉
## Chamseddine
You will be surprised to know XFS or Ext4 do not require defragmentation.
## Heliosstyx
A very good description of the btrfs concepts and similar files-ystems. Perhaps can you write also an article about btrfs automated clean-up mechanisms? It would help newcomers to administer btrfs in a right way. Thank you.
## Andreas Hartmann
Thank you for the suggestion!
I’m not sure I understand what you mean here, could you try to explain a little more? If you’re referring to the automated removal of “old file copies” (files that aren’t referenced any longer), that is automatically handled by Btrfs. There is no manual intervention needed.
## David Brownburg
Nice job!
## Satheesaran
Also, it would be good to know the advantage of using BTRFS over XFS, and the reason why Fedora chose to use BTRFS
## Benjamin
If I recal correctly, XFS partition are not shrinkable. While I’m fine with it on a data disk (and it’s probably the best for a media server!), I don’t want an unshrinkable partition near a disk that hold boot and/or home partition! It had already bite me in the past, and it being the defaut on a distro whould be a dealbreaker for me.
## C.
XFS is definitely not shrinkable. It also doesn’t have file checksumming, so bit rot can be an issue.
Overall, XFS is a decent filesystem, but btrfs just is better than it in many ways. btrfs brings with it built in compression (lzo, zstd), but you can use a utility like duperemove for offline deduplication, and the nice thing about how dedupe is implemented in btrfs is that it requires no additional RAM. Yes, the dedupe process will take up memory when running, but the btrfs filesystem will not need RAM to decode dedupe tables like ZFS and VDO do.
People bash btrfs, but Synology has been using it as their main filesystem in their low-midrange NAS appliances, implemented on top of md-raid. If there were any show-stopping bugs, people would be screaming everywhere.
The biggest reason why btrfs is stable these days is that Facebook/Meta has thrown a lot of development effort into ensuring the filesystem can handle petabytes of their own data, likely NoSQL based, and a filesystem that handles this needs to be able to have a lot of intrinsic data protection measures like file checksumming, COW, online scrubbing, snapshots, etc.
## b
We have many use-cases but btrfs isn’t a ZFS Holy Grail. To be clear and nuanced, there are different risk tolerances and expectations between client machines (grandma’s laptop vs. developer machine), stateless web services, stateful database servers, and stateful specialized loads. We have 10^5-ish Linux desktop users where Fedora (N-1) is the only officially-supported choice.
At home, I use AlmaLinux 9 + XFS on mdraid on my NAS because I had a terrible experience with ZFS (ZoL). It was permanently read-only and there was zero support. That’s what happens with ripping production code out of Solaris, trying to transplant it, and work without corporate backing.
Btrfs and ZoL are never going to be production stable because they don’t get used in critical corporate infrastructure and/or mass market use the ways Ext4, XFS, NTFS, APFS, F2FS, and Solaris ZFS did.
One can live on the bleeding edge with fancy features but they should expect to enjoy fixing it themselves when it breaks. If you want (data + metadata) integrity, snapshots, or encryption, do it at the block device level. It’s not as fine-grained as distributed, ft, ha fses but it’s simpler and is fs-independent. The key with block device snapshots (and most backup/restore operations) is orchestrating quiescence of stateful workloads, flushing fs buffers, and pausing any scrub-/repair-type crons.
## Bernd
Thanks for the article! I’m still on a continuous upgrade from before Fedora switched to btrfs, so I’m wondering, how does this play together with LVM? Or are these two completely separate things?
## Gregory Bartholomew
There is a “Btrfs on LVM” section at the end of this earlier article.
## Edier
Wow thank you. I want to read all the BTRFS series that you will write here.
I always wanted to know technical features of this filesystem
## Renich Bon Ćirić
Very informative. Thanks a ton! 😀
## Mr Leslie Satenstein, Montreal,Que
Well done Andreas. Btrfs is today a great file system. I use it as a preference file system for Fedora (gnome and kde) and for another distribution that heavily promotes it’s use.
I also discovered a utility that collects disposed blocks, as otherwise, the partition could after some heavy file creation and deletion, create many “discarded blocks” that are no loner of interest.
I am looking forward to your follow up presentation
## Audun Nes
Thanks for a very well written article. I’ve heard about btrfs for years, but never looked into how it worked. It was also news to me that btrfs is now the default filesystem on Fedora Workstation. I hadn’t noticed the change.
## Spunkie
I’m interested to get to the snapshot and qgroup posts.
I only know qgroups as that thing that would completely freeze my machine every hour when making a snapshot. I had to outright disable qgroups system wide to make it workable and even after the bug stuck around in timeshift for over a year they eventually ripped out an entire feature set rather than fixing the underlying qgroups issue.
Also, when I made the switch to linux, I was so excited about btrfs snapshots + timeshift-autosnap-manjaro + grub, and it turned out to be exactly the kind of easy to use pre OS boot magic safety net I imagined with snapshots.
But I’ve since switched to arch with systemd-boot and haven’t found a replacement yet. 🥲
## mlll
Pretty good writeup, it’d be great that seeing this series continued.
## Darvond
How about things such as “Scheduling a filesystem check”?
“Verifying data integrity”?
## Stuart Gathman
man btrfs check
## Stuart Gathman
“CoW filesystems are always in a consistent state, even if a previous filesystem transaction (like writing to a file) didn’t complete due to e.g. power loss. That is because filesystem metadata updates are also CoW: The file system itself is never overwritten, so an interruption can’t leave it in a partially written state.”
This is not actually true – because the disk drive controller doesn’t necessarily write blocks to the media in the order they were sent to the drive controller.
To make it so, you can disable write cache on the drive at a loss of performance. Or buy drives with battery backed controller memory so it can finish queued writes on system power loss ($$$).
There are also write cache algorithms that preserve write ordering (such as used by DRBR queue software).
## b
Don’t conflate uncommitted dirty data loss with previously stored data loss/corruption from partial writes. Most CoW and log-structured fses are immune to the latter while some old-school fses aren’t to the former. If the power goes out, a battery fails, the kernel panics, or a meteor hits, there are edge-cases of data loss that cannot be prevented. It’s the behavior of partial writes that is the make-or-break. ZFS supposedly wrote data blocks to preferring unallocated space and wrote metadata last in such a way that it was crash fail-safe.
## klaatu
This is the clearest article on BtrFS I’ve read. Thank you for this.
## Buyer
Thanks for the article.
I know about BTRFS and ZFS (ZoL in particular) more than a decade.
I use ZFS on my NAS since 2011.
What I missing in ZFS are reflinks and a real O_DIRECT support (WIP now).
IMHO the main showstopper for BTRFS usage on the NAS is absent of production ready RAID 5 and 6 support.
## Stuart Gathman
mdraid has been production ready for many years now, and is filesystem independent. I recommend layering LVM on top of mdraid with classic (NOT “thin”) volumes for btrfs. This is because LVs work much better with KVM, allow easy resizing, and classic LV performance with no active snapshots is basically equivalent to a partition.
## Buyer
Many different layers are less handy than ZFS “all in one”.
Sure both has a pros&cons. E.g. ZFS provides “send/receive” feature which is not possible with stack of mdraid or LVM and FS above.
## Kristian
Sorry to be the odd one out amongst all the experts above, on top of being not a pro of filesystem. Reading the above sentence out loud, I still need more information for clarification. I’m still wondering whether it’s only the modified part of a file content that is copied. Then, the modified part(s) of the file content (new block Z) is kept along with the original (unmodified) file content (block Y) metadata-wise in a new inode. The filename then points to this new inode, which refers back to the original unmodified file and the modified portion of the file. Unless, I’m completely of track…
## Andreas Hartmann
No need to apologize, sorry if I confused you!
I think you got it right, yes. All the parts of the file that aren’t changed aren’t copied either. It’s important to keep in mind that the old inode is kept, too, and only the old inode points to block Y from your example. The new inode points to Z. All the rest of the file contents (data blocks A-X) is pointed to by both inodes.
## Anders Ö
Waiting for more good write-ups on btrfs!
## gianluca
when f37 comes out i try to install a clean revision with btrfs, but i remember was slow compare to ext4… |
16,190 | 如果你使用过 “Free Download Manager”,必读! | https://news.itsfoss.com/free-download-manager-malware/ | 2023-09-14T08:03:37 | [
"恶意软件"
] | https://linux.cn/article-16190-1.html | 
>
> 无论如何,保持谨慎总是上策!
>
>
>
对于 Linux 的恶意软件,我们并不常提及,这是因为它常会被迅速修复,并且与 Windows/macOS 相比,在现实中被利用的情况相对较少。
然而,一款颇受欢迎的跨平台下载管理器 **Free Download Manager**,最近引起了一些关注。
虽然在我们的 [下载管理器列表](https://itsfoss.com/best-download-managers-linux/) 中,并未将其列为 Linux 的推荐选项,但我们的一些读者以及我自己在过去的 Windows 使用体验中,都曾选择了它。
那么,问题来了,这究竟是怎么回事?
### 伪装成 Linux 版 Free Download Manager 的恶意软件
**Free Download Manager 本身并非恶意软件**。但问题在于,研究人员发现了一个恶意 Linux 程序包,而这个包,正是假冒 Free Download Manager 的。
安全研究公司卡巴斯基的研究员们 [发现](https://securelist.com/backdoored-free-download-manager-linux-malware/110465/),这个恶意程序包已经存在了至少两年(**2020-2022年**)的时间,而在此期间,大部分使用者并未意识到他们所安装的软件包,含有恶意组件。
许多恶意程序包都试图伪装成市场上受欢迎的程序;那么,*这件事究竟是怎么回事呢?*
**问题的核心在于**:这个恶意程序包是通过 **Free Download Manager 的官方网站** ? 和其他非官方渠道分发的,一直持续到 2022 年。
>
> ? Free Download Manager 的官方网站是 `freedownloadmanager.org`,正式的下载 URL 是 `files2.freedownloadmanager.org`。
>
>
>
而恶意程序包下载的域名是 `deb.fdmpkg.org`。
换言之,这表明开发者并未察觉其官方网站已被恶意破坏,用户已被重定向,下载安装来自另一个域名的带有恶意的 Linux 程序包。
**需要注意的是**:并非所有用户在 2020 年至 2022 年期间,都被从官方网站重定向,下载了恶意程序包。然而,这并不能让情况改观,对吧?
你可能下载了,也可能没有下载安装过这个具有感染性的程序包 ?
**这个恶意软件究竟干了什么** ?
卡巴斯基的报告在描述这个恶意软件时,称其为 “一种 bash 窃取器”,这种窃取器可以收集系统信息、浏览记录、已保存的密码、加密货币钱包的文件,以及云服务的凭据,包括 AWS、Google Cloud、Oracle Cloud Infrastructure 以及 Azure 等。
考虑到在现实世界中很少看到 Linux 版的恶意软件,因此验证你下载工具的来源和可靠程度是至关重要的,这需要你始终保持谨慎态度。
尽管我们并未明确了解有多少的 Linux 用户习惯使用 Free Download Manager,但这的确是令人警惕的新闻。你应当遵循所有 [提高隐私保护的建议](https://itsfoss.com/improve-privacy/),确保你的在线体验安全无忧。
### 现在,你应该怎么做?
在软件的开发者就此问题做出正式公开回应之前,我会建议你转而使用其他下载管理器:
>
> **[6 个最好的 Linux 下载管理器](https://itsfoss.com/best-download-managers-linux/)**
>
>
>
如果你不记得(或无法确认你下载源的准确位置),我会建议你移除该下载管理器。
另外,我建议你阅读卡巴斯基发表的 [研究报告](https://securelist.com/backdoored-free-download-manager-linux-malware/110465/),找出可能的系统遭受损害的迹象。如果你的系统中存在相同的文件路径,且 Debian 程序包的恶意校验和与之相吻合,那么你应该手动移除它们。
即使你想要重新下载该软件,在安装包到你的 Linux 系统之前,你也必须核对下载 URL 的准确性。
? 你如何看待 Linux 用户如何保护自己避免受到恶意软件的攻击?欢迎在评论中留言分享你的想法。
*(题图:MJ/6b1e3b3f-a880-4342-b38b-500468c72052)*
---
via: <https://news.itsfoss.com/free-download-manager-malware/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

We do not often talk about Linux malware because it is often quickly patched up and not exploited much in the wild compared to Windows/macOS.
However, there has been a concern regarding the **Free Download Manager** (a decently popular cross-platform download manager).
While we do not recommend it on our [list of download managers](https://itsfoss.com/best-download-managers-linux/?ref=news.itsfoss.com) available for Linux, some of our readers have suggested it in the past. And I have used it as well until now on Windows.
So, what is the issue?
## Malware Disguised as Free Download Manager Linux Package
**Free Download Manager is not malware**. However, a malicious package for Linux was found, distributed as Free Download Manager.
Security researchers at **Kaspersky** [discovered](https://securelist.com/backdoored-free-download-manager-linux-malware/110465/?ref=news.itsfoss.com) that it existed for at least two years (**2020-2022**) without users knowing what they were installing.
Many malicious packages are disguised as popular programs.; *what's new here?*
**The problem**: The malicious package was found to be **distributed through the official website of Free Download Manager** 😱 along with any other unofficial sources until 2022.
**freedownloadmanager.org,**with
**files2.freedownloadmanager.org**as the correct download URL.
The domain from which the infected package was downloaded was
**deb.fdmpkg[.]org.**
In other words, the official website was compromised without the developers realizing and redirected its users to download a malware-infected package for Linux from another domain.
**The catch is**: that not every user was redirected to download the malware package between 2020 and 2022 from the official website. However, it does not make things any better, right?
You may or may not have downloaded the infected package 😕
**What is the malware all about? **🤖
Kaspersky's report describes it as “**a bash stealer**” that *collects data such as system information, browsing history, saved passwords, cryptocurrency wallet files, as well as credentials for cloud services (AWS, Google Cloud, Oracle Cloud Infrastructure, Azure).*
Considering Linux malware is rarely observed in the wild, it is important to stay cautious to verify the sources and the credibility of tools you download.
While we do not know how many Linux users utilize Free Download Manager, it is indeed alarming news. You should follow all the [tips to improve privacy](https://itsfoss.com/improve-privacy/?ref=news.itsfoss.com) and secure your online experience.
**Suggested Read **📖
[11 Ways to Improve Your Privacy in Online WorldBring your A game to improve your privacy online, whether you are a Linux user or not. Follow these tips for a secure experience!](https://itsfoss.com/improve-privacy/?ref=news.itsfoss.com)

## What Should You Do Now?
**UPDATE**: The developers have published an [official statement](https://www.freedownloadmanager.org/blog/?p=664&ref=news.itsfoss.com) on their site **with instructions to use a script to help identify if you were affected by the malwar**e.
As per the announcement, they are working towards reinforcing the site security to prevent security breaches in the near future.
You can also try switching to other download managers available:
[Top 6 Best Download Managers for Linux DesktopExplore some of the best download managers for Linux to make things easy!](https://itsfoss.com/best-download-managers-linux/?ref=news.itsfoss.com)

**It is essential** that you should remove the download manager if you do not remember (or cannot verify the source of your download).
Additionally, I would recommend you go through the [research report](https://securelist.com/backdoored-free-download-manager-linux-malware/110465/?ref=news.itsfoss.com) by Kaspersky to check indicators of compromise. If you have the same file path on your system and the malicious checksum for the Debian package matches, you should get rid of them manually.
Not to forget, if you downloaded the malicious package, **change your passwords** immediately, preferably using a [password manager.](https://itsfoss.com/password-managers-linux/?ref=news.itsfoss.com)
Even if you want to re-download it, you should check the download URL before installing the package on your Linux system.
*💬 What are your thoughts on staying protected from malware on Linux? Share your thoughts in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,192 | 在 Linux 文件系统中使用 attr 添加扩展属性 | https://opensource.com/article/22/6/linux-attr-command | 2023-09-15T08:13:00 | [
"attr"
] | https://linux.cn/article-16192-1.html | 
>
> 我使用开源的 XFS 文件系统是为了其扩展属性带来的小小便利。扩展属性是一种为我的数据添加上下文的独特方式。
>
>
>
“文件系统” 是一个描述你的计算机怎样跟踪你创建的所有文件的完美词语。你的计算机存储有大量的数据,无论是文档、配置文件还是数以千计的照片。这需要一种对人和机器都友好的方式。诸如 Ext4、XFS、JFS、BtrFS 的文件系统是你的计算机用来跟踪文件的“语言”。
你的桌面或终端可以帮助你快速查找文件。例如,你的文件管理器可能有过滤功能,以便让你可以快速查看家目录内的图片,它也可能带有搜索功能以让你使用文件名定位文件。这些特性被称作*文件属性*,正如其名,它们是由文件头或者文件系统代码定义的文件对象的属性。大多数的文件系统记录了标准的文件属性,例如文件名、文件大小、文件类型、创建时间、上次访问时间等。
我在我的计算机上使用开源的 XFS 文件系统,不是为了其稳定性和高性能,而是为了其扩展属性带来的小小便利。
### 常见的文件属性
当你保存一个文件,文件相关的数据也会随同保存。常见的属性会告诉操作系统是否更新访问时间,什么时间同步数据到硬盘等逻辑细节。哪些属性被保存取决于底层文件系统的功能和特性。
在标准文件属性(如果有标准属性的话)之外,XFS、Ext4 和 BtrFS 文件系统都可以使用扩展属性。
### 扩展属性
XFS、Ext4 和 BtrFs 允许你创建自己的任意文件属性。由于是自己创建的,操作系统不会有内建支持,不过我以“标签”的方式使用它们,就像图片的 EXIF 数据一样。开发者们也许会选择使用扩展属性去开发应用内的自定义的功能。
XFS 中的属性有两个“命名空间”:用户(`user`)和根(`root`)。当创建属性时,你必须将其加入其中一个命名空间。要将属性添加到根命名空间,必须使用 `sudo` 命令或以 `root` 身份登录。
### 增加一个属性
你可以使用 `attr` 和 `setfattr` 命令在 XFS 文件系统中为文件增加属性。
`attr` 命令默认在 `user` 命名空间下进行,所以你只需要为属性设置一个名字(`-s`)和值(`-V`)。
```
$ attr -s flavor -V vanilla example.txt
Attribute "flavor" set to a 7 byte value for example.txt:
vanilla
```
`setfattr` 命令需要你指定目标命名空间:
```
$ setfattr --name user.flavor --value chocolate example.txt
```
### 列出扩展文件属性
使用 `attr` 或者 `getfattr` 命令可以看已添加到文件上的扩展属性。`attr` 命令默认使用 `user` 空间,使用 `-g` 以获取扩展属性:
```
$ attr -g flavor example.txt
Attribute "flavor" had a 9 byte value for example.txt:
chocolate
```
`getfattr` 命令需要属性的命名空间和名字:
```
$ getfattr --name user.flavor example.txt
# file: example.txt
user.flavor="chocolate"
```
### 列出所有扩展属性
要看一个文件的所有扩展属性,你可以使用 `attr -l`:
```
$ attr -l example.txt
Attribute "md5sum" has a 32 byte value for example.txt
Attribute "flavor" has a 9 byte value for example.txt
```
或者,你也可以使用 `getfattr -d`:
```
$ getfattr -d example.txt
# file: example.txt
user.flavor="chocolate"
user.md5sum="969181e76237567018e14fe1448dfd11"
```
扩展文件属性可以使用 `attr` 和 `setfattr` 更新,就像你创建这些属性一样:
```
$ setfattr --name user.flavor --value strawberry example.txt
$ getfattr -d example.txt
# file: example.txt
user.flavor="strawberry"
user.md5sum="969181e76237567018e14fe1448dfd11"
```
### 其他文件系统上的属性
使用扩展属性最大的风险是忘记这些属性是特定于某个文件系统的。这意味着当你从一个磁盘或分区复制文件到另外一个磁盘或分区时,这些属性都会丢失,**即使**目标位置的文件系统也支持扩展属性。
为了避免丢失扩展属性,你需要使用支持保留这些属性的工具,例如 `rsync` 命令。
```
$ rsync --archive --xattrs ~/example.txt /tmp/
```
但无论你使用什么工具,如果你传输文件到一个不知道如何处理扩展属性的文件系统,这些属性都会被丢弃。
### 搜索属性
与扩展属性交互的机制并不多,所以使用这些添加的文件属性的方法也有限。我使用扩展属性作为标签机制,这让我可以将没有明显关系的文件联系起来。例如,假设我需要在一个项目中用“知识共享”的图形。假如我预见性地将 `license` 属性添加到了我的图形库中,我就可以使用 `find` 和 `getfattr` 在图形文件夹中寻找:
```
find ~/Graphics/ -type f \
-exec getfattr \
--name user.license \
-m cc-by-sa {} \; 2>/dev/null
# file: /home/tux/Graphics/Linux/kde-eco-award.png
user.license="cc-by-sa"
user.md5sum="969181e76237567018e14fe1448dfd11"
```
### 文件系统的秘密
文件系统一般不会引起你的注意。它们实际是定义文件的系统。这不是计算机做的最让人兴奋的任务,也不是用户应该关心的东西。但是有些文件系统可以给你有趣、安全的特殊能力,扩展文件属性就是一个好例子。它的用途可能有限,但是扩展属性是你为数据增加上下文的独特方法。
*(题图:MJ/06c0c478-7af7-49e4-836b-a9923db9dc0c)*
---
via: <https://opensource.com/article/22/6/linux-attr-command>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lkxed](https://github.com/lkxed) 译者:[wznmickey](https://github.com/wznmickey) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The term *filesystem* is a fancy word to describe how your computer keeps track of all the files you create. Whether it's an office document, a configuration file, or thousands of digital photos, your computer has to store a lot of data in a way that's useful for both you and it. Filesystems like Ext4, XFS, JFS, BtrFS, and so on are the "languages" your computer uses to keep track of data.
Your desktop or terminal can do a lot to help you find your data quickly. Your file manager might have, for instance, a filter function so you can quickly see just the image files in your home directory, or it might have a search function that can locate a file by its filename, and so on. These qualities are known as *file attributes* because they are exactly that: Attributes of the data object, defined by code in file headers and within the filesystem itself. Most filesystems record standard file attributes such as filename, file size, file type, time stamps for when it was created, and time stamps for when it was last visited.
I use the open source XFS filesystem on my computers not for its reliability and high performance but for the subtle convenience of extended attributes.
## Common file attributes
When you save a file, data about it are saved along with it. Common attributes tell your operating system whether to update the access time, when to synchronize the data in the file back to disk, and other logistical details. Which attributes get saved depends on the capabilities and features of the underlying filesystem.
In addition to standard file attributes (insofar as there are standard attributes), the XFS, Ext4, and BtrFS filesystems can all use extending filesystems.
## Extended attributes
XFS, Ext4, and BtrFS allow you to create your own arbitrary file attributes. Because you're making up attributes, there's nothing built into your operating system to utilize them, but I use them as "tags" for files in much the same way I use EXIF data on photos. Developers might choose to use extended attributes to develop custom capabilities in applications.
There are two "namespaces" for attributes in XFS: **user** and **root**. When creating an attribute, you must add your attribute to one of these namespaces. To add an attribute to the **root** namespace, you must use the `sudo`
command or be logged in as root.
## Add an attribute
You can add an attribute to a file on an XFS filesystem with the `attr`
or `setfattr`
commands.
The `attr`
command assumes the `user`
namespace, so you only have to set (`-s`
) a name for your attribute followed by a value (`-V`
):
```
``````
$ attr -s flavor -V vanilla example.txt
Attribute "flavor" set to a 7 byte value for example.txt:
vanilla
```
The `setfattr`
command requires that you specify the target namespace:
```
````$ setfattr --name user.flavor --value chocolate example.txt`
## List extended file attributes
Use the `attr`
or `getfattr`
commands to see extended attributes you've added to a file. The `attr`
command defaults to the **user** namespace and uses the `-g`
option to *get* extended attributes:
```
``````
$ attr -g flavor example.txt
Attribute "flavor" had a 9 byte value for example.txt:
chocolate
```
The `getfattr`
command requires the namespace and name of the attribute:
```
``````
$ getfattr --name user.flavor example.txt
# file: example.txt
user.flavor="chocolate"
```
## List all extended attributes
To see all extended attributes on a file, you can use `attr -l`
:
```
``````
$ attr -l example.txt
Attribute "md5sum" has a 32 byte value for example.txt
Attribute "flavor" has a 9 byte value for example.txt
```
Alternately, you can use `getfattr -d`
:
```
``````
$ getfattr -d example.txt
# file: example.txt
user.flavor="chocolate"
user.md5sum="969181e76237567018e14fe1448dfd11"
```
Any extended file attribute can be updated with `attr`
or `setfattr`
, just as if you were creating the attribute:
```
``````
$ setfattr --name user.flavor --value strawberry example.txt
$ getfattr -d example.txt
# file: example.txt
user.flavor="strawberry"
user.md5sum="969181e76237567018e14fe1448dfd11"
```
## Attributes on other filesystems
The greatest risk when using extended attributes is forgetting that these attributes are specific to the filesystem they're on. That means when you copy a file from one drive or partition to another, the attributes are lost *even if the target filesystem supports extended attributes*.
To avoid losing extended attributes, you must use a tool that supports retaining them, such as the `rsync`
command.
```
````$ rsync --archive --xattrs ~/example.txt /tmp/`
No matter what tool you use, if you transfer a file to a filesystem that doesn't know what to do with extended attributes, those attributes are dropped.
## Search for attributes
There aren't many mechanisms to interact with extended attributes, so the options for using the file attributes you've added are limited. I use extended attributes as a tagging mechanism, which allows me to associate files that have no obvious relation to one another. For instance, suppose I need a Creative Commons graphic for a project I'm working on. Assume I've had the foresight to add the extended attribute **license** to my collection of graphics. I could search my graphic folder with `find`
and `getfattr`
together:
```
``````
find ~/Graphics/ -type f \
-exec getfattr \
--name user.license \
-m cc-by-sa {} \; 2>/dev/null
# file: /home/tux/Graphics/Linux/kde-eco-award.png
user.license="cc-by-sa"
user.md5sum="969181e76237567018e14fe1448dfd11"
```
## Secrets of your filesystem
Filesystems aren't generally something you're meant to notice. They're literally systems for defining a file. It's not the most exciting task a computer performs, and it's not something users are supposed to have to be concerned with. But some filesystems give you some fun, and safe, special abilities, and extended file attributes are a good example. Its use may be limited, but extended attributes are a unique way to add context to your data.
## Comments are closed. |
16,193 | 使用 R 语言构建一个可交互的 Web 应用 | https://www.opensourceforu.com/2022/10/using-r-for-building-an-interactive-web-app/ | 2023-09-15T09:19:58 | [
"R 语言"
] | https://linux.cn/article-16193-1.html | 
数据分析已成为企业的当务之急,并且对具有用户友好界面的数据驱动应用程序有巨大的需求。本文介绍如何使用 R 语言中的 Shiny 包开发交互式 Web 应用程序,R 语言是一种流行的数据科学编程语言。
如今,世界各地几乎所有企业都以某种形式依赖于数据。数据科学通过使用数据驱动的应用程序帮助许多企业实现转型,无论是在金融、银行、零售、物流、电子商务、运输、航空还是任何其他领域。
高性能计算机和低成本存储使我们现在能够在几分钟内预测结果,而不是像以前一样以前需要花费很多时间。数据科学家着眼于未来,正在开发具有高性能和多维可视化的便捷应用。这一切都始于大数据,它由三个组成部分组成:数量、多样性和速度。算法和模型都是根据这些数据提供的。机器学习和人工智能领域最前沿的数据科学家正在创建能够自我改进、检测错误并从中学习的模型。
在数据科学领域,统计和计算用于将数据转化为有用的信息,通常称为数据驱动科学。数据科学是来自各个领域的方法的综合,用于收集、分析和解释数据,以形成新的见解并做出选择。构成数据科学的技术学科包括统计学、概率、数学、机器学习、商业智能和一些编程。
数据科学可以应用于各个领域(图 1)。对大型、复杂数据集的分析是数据科学的重点。它帮助我们创建了一个以全新方式看待数据的新宇宙。亚马逊、谷歌和 Facebook 等科技巨头利用数据科学原理进行商业智能和商业决策。

### R 语言:为数据科学量身打造的语言
由于海量的可用信息,我们迫切需要数据分析以得到新的见解,在多种技术的帮助下,原始数据转化为成品数据产品。在数据研究、处理、转换和可视化方面,没有比 R 语言更好的工具了。
R 语言用于数据科学的主要功能包括:
* 数据预处理
* 社交媒体数据获取和分析
* 对数据结构的各种操作
* 提取、转换、加载(ETL)
* 连接到各种数据库,包括 SQL 和电子表格
* 与 NoSQL 数据库交互
* 使用模型进行训练和预测
* 机器学习模型
* 聚类
* 傅里叶变换
* 网页抓取
R 语言是一种强大的编程语言,常用于统计计算和数据分析。有关优化 R 语言用户界面的努力由来已久。从简单的文本编辑器到更现代的交互式 R Studio 和 Jupyter Notebooks,世界各地的多个数据科学小组都在关注 R 语言的发展。
只有全世界 R 用户的贡献才使这一切成为可能。R 语言中包含的强大软件包使其日益强大。许多开源软件包使处理大型数据集和可视化数据变得更加容易和高效。
### 使用 Shiny 在 R 语言中开发交互式 Web 应用
你可以使用 Shiny 包在 R 语言中构建交互式 Web 应用程序。应用程序可以托管在网站上、嵌入 R Markdown 文档中,或用于开发控制面板板和可视化。CSS 主题、HTML 小部件和 JavaScript 操作都可以用于进一步自定义你的 Shiny 应用程序。
Shiny 是一款 R 语言工具,它可以轻松创建交互式的 Web 应用程序。它允许你将你的 R 代码扩展到 Web 上,从而使更多的人能够使用它,从中获益。
除了 Shiny 内置的功能外,还有许多第三方扩展包可用,例如 shinythemes、shinydashboard 和 shinyjs。
使用 Shiny 可以开发各种应用程序。以下是其中一些:
* 基于 Web 应用的机器学习
* 具有动态控件的 Web 应用程序
* 数据驱动的仪表盘
* 多重数据集的交互式应用
* 实时数据可视化面板
* 数据收集表单
Shiny Web 应用程序可以分为以下几类:
* 用户接口
* 服务功能逻辑
* Shiny 应用逻辑
获取更深理解,请访问以下网站 <https://shiny.rstudio.com/gallery/> 。
其中某个用 Shiny 开发的应用如图 2(<https://shiny.rstudio.com/gallery/radiant.html> )。

### 销售仪表盘的生成
下面是一个与销售仪表盘相关的 Web 应用程序的代码片段。该仪表板具有多个控件和用户界面模块,用于查看数据。
首先,安装 Shiny 包,然后在代码中调用它,以便将输出呈现为 Web 页面的形式。
```
library(shiny)
library(dplyr)
sales <- vroom::vroom(“salesdata.csv”, na = “”)
ui <- fluidPage(
titlePanel(“Dashboard for Sales Data”),
sidebarLayout(
sidebarPanel(
selectInput(“territories”, “territories”, choices = unique(sales$territories)),
selectInput(“Customers”, “Customer”, choices = NULL),
selectInput(“orders”, “Order number”, choices = NULL, size = 5, selectize = FALSE),
),
mainPanel(
uiOutput(“customer”),
tableOutput(“data”)
)
)
)
server <- function(input, output, session) {
territories <- reactive({
req(input$territories)
filter(sales, territories == input$territories)
})
customer <- reactive({
req(input$Customers)
filter(territories(), Customers == input$Customers)
})
output$customer <- renderUI({
row <- customer()[1, ]
tags$div(
class = “well”,
tags$p(tags$strong(“Name: “), row$customers),
tags$p(tags$strong(“Phone: “), row$contact),
tags$p(tags$strong(“Contact: “), row$fname, “ “, row$lname)
)
})
order <- reactive({
req(input$order)
customer() %>%
filter(ORDER == input$order) %>%
arrange(OLNUMBER) %>%
select(pline, qty, price, sales, status)
})
output$data <- renderTable(order())
observeEvent(territories(), {
updateSelectInput(session, “Customers”, choices = unique(territories()$Customers), selected = character())
})
observeEvent(customer(), {
updateSelectInput(session, “order”, choices = unique(customer()$order))
})
}
shinyApp(ui, server)
```
运行 Shiny 应用程序的代码后,生成了图 3 所示的输出,可以在任何 Web 浏览器上查看。销售仪表盘具有多个控件,并且具有不同的用户界面模块,非常互动。

通过使用 Shiny Cloud,可以将这个应用程序部署和托管在云上,以便随时随地在互联网上使用。

Shiny Cloud 的免费版本允许在 25 个活动小时内部署五个应用程序。研究人员和数据科学家可以使用 R 的 Shiny 库开发基于实时数据驱动的用户友好应用程序。这个库也可以用于在 Web 平台上部署他们的机器学习应用程序。
*(题图:MJ/1a76ad20-e56d-480b-b28b-8cf74d2230a1)*
---
via: <https://www.opensourceforu.com/2022/10/using-r-for-building-an-interactive-web-app/>
作者:[Dr Kumar Gaurav](https://www.opensourceforu.com/author/dr-gaurav-kumar/) 选题:[lkxed](https://github.com/lkxed) 译者:[Charonxin](https://github.com/Charonxin) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Data analysis has become imperative for companies, and there is a huge demand for data-driven applications with user friendly interfaces. This article tells you how to develop an interactive web app using the Shiny package in R, which is a popular programming language for data science.*
Nearly every business across the world relies on data today, in some way or the other. In fact, data science has helped transform many businesses by using data-driven applications, whether in the field of finance, banking, retail, logistics, e-commerce, transportation, airlines, or any other.
High performance computers and low-cost storage allow us to predict results in minutes today rather than the many hours it used to take earlier. Data scientists focused on the future are developing easy to use applications with high performance and multi-dimensional visualisation. It all starts with Big Data, which consists of three components: quantity, diversity, and velocity. Algorithms and models are fed from this data. The most cutting-edge data scientists working in machine learning and AI are creating models that self-improve, detecting and learning from their errors.
Statistics and computing are used to turn data into useful information in the field of data science, often termed as data-driven science. Data science is a synthesis of methods from a variety of fields to gather, analyse, and interpret data in order to develop new insights and make choices. The technological disciplines that constitute data science include statistics, probability, mathematics, machine learning, business intelligence, and some programming.
Data science can be applied in various areas (Figure 1). The analysis of large, complicated data sets is the focus of data science. It has helped to create a new universe in which data is seen in whole new ways. Tech giants like Amazon, Google, and Facebook use data science principles for business intelligence and decision making.
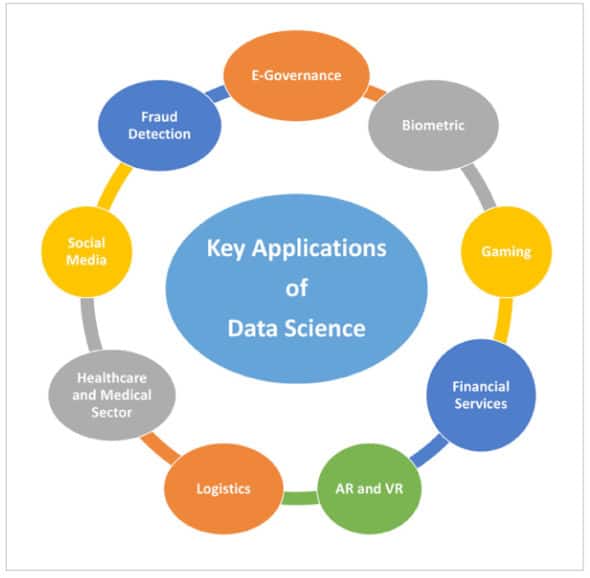

## R: The language for data science
Data analysis and insights are urgently needed because of the volume of information available. Raw data is transformed into finished data products with the help of a number of technologies. When it comes to research, processing, transformation, and visualisation of data, there are few better tools than R.
The key features in R for data science are:
- Data pre-processing
- Social media fetching and analysis
- Assorted operations on data frames
- Extract, transform, load (ETL)
- Connection to a variety of databases, including SQL and spreadsheets
- Interaction with NoSQL databases
- Training and prediction with models
- Machine learning models
- Clustering
- Fourier transform
- Web scraping
R is a robust programming language commonly used in statistical computation and data analysis. Efforts to enhance R’s user interface have been going on since long. Several data science groups throughout the world have followed the development of R from a simple text editor to the more current interactive R Studio and Jupyter Notebooks.
Only the contributions of R users throughout the world have made this possible. The inclusion of strong packages in R has made it increasingly powerful over time. Numerous open source packages have made it easier and more efficient to work with large data sets and visualise data.
## Developing interactive web applications in R using Shiny
You can construct interactive web apps in R using the Shiny package. Apps can be hosted on a website, embedded in R Markdown documents, or used to develop dashboards and visualisations. CSS themes, HTML widgets, and JavaScript actions can all be used to customise your Shiny apps further.
Shiny is an R tool that makes it simple to create interactive web apps. It allows you to extend your R code to the web so that it may benefit from the larger community of people who can use it.
In addition to Shiny’s built-in features, there are a number of third-party extension packages available, such as shinythemes, shinydashboard, and shinyjs.
There are various apps that can be developed using Shiny. Here is a list of a few of them.
- Machine learning based web apps
- Web apps with dynamic controls
- Data-driven dashboards
- Interactive apps for multiple data sets
- Real-time data visualisation panels
- Data collection forms
- Shiny web apps can be divided into the following:
- User interface
- Server function
- Shiny app function
For better understanding, you can refer to the examples and use cases available at https://shiny.rstudio.com/gallery/.
One of the apps developed using Shiny is shown in Figure 2 (https://shiny.rstudio.com/gallery/radiant.html).

## Generation of a sales dashboard
The code snippet for a web app related to a sales dashboard is given below. This dashboard has multiple controls and user interface modules to view the data.
First, the Shiny package is installed and then it is called in the code so that the output can be presented in the form of a web page.
library(shiny) library(dplyr) sales <- vroom::vroom(“salesdata.csv”, na = “”) ui <- fluidPage( titlePanel(“Dashboard for Sales Data”), sidebarLayout( sidebarPanel( selectInput(“territories”, “territories”, choices = unique(sales$territories)), selectInput(“Customers”, “Customer”, choices = NULL), selectInput(“orders”, “Order number”, choices = NULL, size = 5, selectize = FALSE), ), mainPanel( uiOutput(“customer”), tableOutput(“data”) ) ) ) server <- function(input, output, session) { territories <- reactive({ req(input$territories) filter(sales, territories == input$territories) }) customer <- reactive({ req(input$Customers) filter(territories(), Customers == input$Customers) }) output$customer <- renderUI({ row <- customer()[1, ] tags$div( class = “well”, tags$p(tags$strong(“Name: “), row$customers), tags$p(tags$strong(“Phone: “), row$contact), tags$p(tags$strong(“Contact: “), row$fname, “ “, row$lname) ) }) order <- reactive({ req(input$order) customer() %>% filter(ORDER == input$order) %>% arrange(OLNUMBER) %>% select(pline, qty, price, sales, status) }) output$data <- renderTable(order()) observeEvent(territories(), { updateSelectInput(session, “Customers”, choices = unique(territories()$Customers), selected = character()) }) observeEvent(customer(), { updateSelectInput(session, “order”, choices = unique(customer()$order)) }) } shinyApp(ui, server)
On running the code of the Shiny app, the output shown in Figure 3 is generated which can be viewed on any web browser. The sales dashboard has multiple controls and is quite interactive with different user interface modules.

With the use of Shiny cloud, this app can be deployed and hosted on the cloud for anytime anywhere availability on the internet.

The free variant of Shiny cloud allows five applications to be deployed within 25 active hours.
Researchers and data scientists can develop user-friendly apps driven with real-time data using the Shiny library of R. This library can also be used for deploying their machine learning apps on web platforms. |
16,195 | openSUSE 将用新产品取代 Leap | https://news.itsfoss.com/opensuse-leap-replacement/ | 2023-09-16T10:58:28 | [
"openSUSE"
] | https://linux.cn/article-16195-1.html | 
>
> openSUSE Leap 将被新产品取代。怎么回事?
>
>
>
openSUSE 项目的长期贡献者 Richard Brown 分享了最近贡献者调查的一些结果。
这是关于用新的社区构建的产品取代 openSUSE Leap 的兴趣和可行性。哦?一个 openSUSE Leap 的替代品?
有趣的消息,对吧? ?
这并不令人震惊。随着 <ruby> 适应性 Linux 平台 <rt> Adaptable Linux Platform </rt></ruby> (ALP) 的推出,openSUSE 团队曾 [暗示](https://lists.opensuse.org/archives/list/[email protected]/thread/N6TTE7ZBY7GFJ27XSDTXRF3MVLF6HW4W/) Leap 将于 **2022** 停止运营。所以,这是预料之中的。
但是,有哪些选择可以替代 openSUSE Leap?
### Tumbleweed 衍生版可能取代 Leap
根据这份更换提案,我们有两种选择:
* **Linarite**:一个普通的老式桌面发行版,软件包的选择范围可能比我们习惯的 Leap 更小,除非我们找到更多的贡献者来支持所有的软件包。
* **Slowroll** :是 Tumbleweed 的衍生版本,尽可能地自动构建,使用自动化和度量标准仅在特定条件(最大周期、X 周无变化等)后才从 Tumbleweed 复制软件包。基本上,它试图提供比全速运行的 Tumbleweed 不那么风险的东西。
>
> 作为这件事的后继,openSUSE 现在为 Slowroll 做了一个 [页面](https://en.opensuse.org/openSUSE:Slowroll) 供你测试。
>
>
>
然而,调查结果显示意见不一。
大多数**用户**选择 “**Slowroll**” 作为未来可行的替代方案,他们愿意为此做出贡献。
相比之下,**贡献者**们则投票不取代 openSUSE Leap 或使用 Tumbleweed 替代它。
但是,在选择一个选项时,贡献者选择了 “**Linarite**”。
因此,用户和现有贡献者有不同的选择。
openSUSE 决定按照**用户**的喜好使用滚动发行版 Slowroll。它需要比调查中表示感兴趣的更多的贡献者。
Richard 还透露,**两个替代方案中的任何一个都需要比 Leap** 付出更多的努力,而且截至目前,对这两个选项感兴趣的 **贡献者数量比 Leap** 少。
>
> 即使有 61 个人直接为代码库和 backports/PackageHub 做出贡献,Leap 仍然举步维艰。这时我们就可以借用 SLE 代码库,这大大减少了所需的工作。
>
>
> Slowroll 或 Linarite 都比 Leap 需要更多的打包和维护工作。
>
>
>
他还强调,**任何 Leap 替代品都应该专注于桌面场景**,而不是试图同时兼顾服务器和桌面的需求。
### 换还是不换?
[调查结果公告](https://lists.opensuse.org/archives/list/[email protected]/thread/KJMMAZFTP2MPKWKFZCYUROZFJ44BNVB5/) 要求社区回答 openSUSE 是否应该继续替换 Leap。
而且,如果他们继续这样做,社区可以帮助他们支持吗?
? 你认为 openSUSE 的最终决定应该是什么? 请在下面的评论部分告诉我你的想法。
(题图:MJ/f0fcd9d7-dcae-493f-83db-4a0338eece3b)
---
via: <https://news.itsfoss.com/opensuse-leap-replacement/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Richard Brown, a long-time contributor to the openSUSE project, shared some results from a recent contributor survey.
It was about the interest and feasibility of replacing openSUSE Leap with a new community-built offering. Yes? A replacement to openSUSE Leap?
Interesting news, right? 😳
It's not shocking. The openSUSE team [hinted](https://lists.opensuse.org/archives/list/[email protected]/thread/N6TTE7ZBY7GFJ27XSDTXRF3MVLF6HW4W/?ref=news.itsfoss.com) at Leap being discontinued in **2022** with the introduction of the **Adaptable Linux Platform** (ALP). So, it was expected.
But, what are the options to replace openSUSE Leap with?
## A Derivative of Tumbleweed Likely to Replace Leap
As per the replacement proposal, we have two options:
**Linarite**:*A regular old-fashioned release desktop distribution, likely with a narrower package selection than we're used to with Leap unless we find significantly more contributors to be able to support everything***Slowroll**:*A derivative of Tumbleweed, built automatically as much as possible, using automation and metrics to copy packages from Tumbleweed only after certain conditions (max age, X weeks without change, etc). Basically an attempt to provide something less scary than full speed Tumbleweed.*
[webpage for Slowroll](https://en.opensuse.org/openSUSE:Slowroll?ref=news.itsfoss.com)for you to test.
However, the survey results show a mixed bag of opinions.
Most **users** choose "**Slowroll**" as a viable replacement going forward, which they would like to contribute to.
In contrast, **contributors** voted not to replace openSUSE Leap or use Tumbleweed instead.
But, when choosing one option, the contributors chose "**Linarite**".
So, the users and existing contributors have different choices.
OpenSUSE decides to go with the users' preference as Slowroll, a rolling release distro. It would need more contributors than what the survey highlights as interested.
Richard also revealed that either of the **two replacements will need more effort than Leap**, and as of now, the **contributors interested in both options are fewer in number when compared to Leap**.
Leap has struggled even with 61 folk contributing directly to the codebase and backports/PackageHub. And this is when we've had the SLE codebase to borrow from, which dramatically reduced the work required.
Either Slowroll or Linarite would require considerably more packaging and maintenance work than Leap.
He also emphasized that **any Leap replacement should focus on desktop use cases** rather than trying to cater to both server and desktop.
## To Replace or Not?
The [announcement of survey results](https://lists.opensuse.org/archives/list/[email protected]/thread/KJMMAZFTP2MPKWKFZCYUROZFJ44BNVB5/?ref=news.itsfoss.com) challenges the community to answer if openSUSE should proceed with replacing Leap or not.
And, if they go ahead, can the community help them support it?
*💬* *What do you think should be the final decision for openSUSE? Let me know your thoughts in the comments section below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
16,196 | DevOps 文档成熟度的四个层次 | https://opensource.com/article/22/2/devops-documentation-maturity | 2023-09-16T14:00:09 | [
"DevOps",
"文档"
] | https://linux.cn/article-16196-1.html | 
>
> 提升 DevOps 文档成熟度的过程与达到 DevOps 或 DevSecOps 成熟化的历程是类似的。
>
>
>
为了能在软件迭代交付周期内按时交付优质的文档,DevOps 和 DevSecOps 的文档实践也需要是敏捷的。这与实现 DevOps 类似,只是更偏向自动化和敏捷的内容处理方法。如果文档现在才进入你的机构的 DevOps 讨论,那么是时候让文档实践追上 DevOps 的步伐了。
下面是 DevOps 文档成熟度的四个层次:
### 第一层:临时且孤立
在最低一级成熟度(最不成熟),文档编制工作没有和 DevOps 开发对齐。开发团队和文档团队按照各自的路线开展工作,常常导致文档落后于开发。在竞争激烈的“云”世界里,因为文档问题而推迟产品发布是不可接受的。
#### 人员
这个阶段的文档编制人员还没有摆脱传统的工作方式。<ruby> 技术写作 <rt> technical writer </rt></ruby>人员隶属于一个中心化的单独团队,与开发团队是脱节的。技术写作组和开发团队之间的鸿可能是由多方面原因造成的:
* 造成团队分裂和孤立的公司政治
* 团队只是将技术文档视为项目验收清单上的检查项,而不是推动项目成功的资产
* 事后才雇佣技术写作人员
* 技术写作的优先级与开发团队的实际情况不匹配
这个阶段,另一个在人员配置上的挑战是如何“界定工作完成”。刚接触敏捷实践的技术写作可能难以适应 CI/CD 工具链和流程。
#### 文档工具和流程
这个阶段的技术写作仍习惯于使用传统的办公工具,比如办公套件和布局程序。这些工具不够敏捷,没有版本控制和内容管理的要求。它们无法与 DevOps 工具链高效集成,不能支撑快速开发。在这个成熟度,技术写作仍然参照遗留的模板和流程。
#### 成果
这个级别交付的文档可能是过时的,甚至缺乏技术准确性的。如果开发团队以 DevOps 的速度推进工作,而技术文档编制却遵循传统的非敏捷流程(使用专有的工具和交付格式),这就很难让文档迭代速度并跟上应用程序的变化。
### 第二层:实验和试点
DevOps 文档成熟度的第二层是实验/试验阶段。这个阶段是 DevOps 团队主管和技术写作采取行动打造更敏捷的文档实践和工具的第一步。
理想的情况下,这些实验是<ruby> 相关方 <rt> stakeholder </rt></ruby>支持的试点项目的一部分。他们能够从文档交付流程的改善以及其与 DevOps 实践的集成中获益。
#### 人员
本阶段的人员可能来自以下三种形式:
1. 有远见的技术写作为了更好地完成工作,用自己的时间来实验更敏捷的工具。并且向领导层提出更敏捷的文档编制过程的想法。
2. DevOps 负责人或工程师试用 Hugo 和 Jekyll 等工具,并将这些工具集成到 CI/CD 流水线中。然后 DevOps 小组教授技术写作如何使用它们。
3. 团队引入了第三方承包商或顾问,他们在 DevOps 文档工具方面具有专业知识,并且了解文档工具适合嵌入到 CI/CD 工具链和 DevOps 生命周期的位置。
#### 文档工具和实践
[Hugo](https://opensource.com/article/18/3/start-blog-30-minutes-hugo) 和 [Jekyll](https://opensource.com/article/17/4/getting-started-jekyll) 是本阶段开始出现的工具。在这个阶段也出现新的内容策略和技术写作方法。
#### 成果
实验试点阶段理想的成果应该能够“<ruby> 落地并推广 <rt> land and expand </rt></ruby>”。也就是说其它项目组也可以将其付诸实践。
这个阶段的实验也包括内容策略和发布流程上的根本性变化。其它非试点项目组的技术写作可以学习和使用它们。
试点带来的另一个可能的产出是 [技术写作招聘流程](https://opensource.com/article/19/11/hiring-technical-writers-devops) 的变化。你需要针对 DevOps 和你新引入的文档工具对内部编写人员进行培训。
新的文档工具和流程是此阶段的关键成果,你需要通过演示、状态报告和内部案例研究等方式,将这一成果推给领导层、相关方和其它团队。
### 第三层:部分自动化和扩展
DevOps 文档成熟度的第三层(部分自动化和扩展)就是“落地并推广”的进一步行动。在这个阶段,其它 DevOps 团队借用试点项目中产生的 DevOps 文档工具和流程,吸取其中的经验教训。
#### 人员
在这个成熟度,技术写作和 DevOps 团队开始更紧密的协作。招聘新的技术写作主要关注具有 DevOps 环境经验的人选。
#### 工具和文档实践
技术写作开始从抛弃传统的工具和流程,转到更敏捷的文档工具上,比如:
* [docToolchain](http://doctoolchain.org/)
* [Docbook](https://opensource.com/article/17/9/docbook)
* Hugo
* Jekyll
在这个成熟度,技术写作也负责调整遗留的文档实践。
#### 成果
DevOps 文档工具和实践超越试点项目,成为标准实践。在这个成熟度,随着新团队使用新的文档工具和流程,持续学习是必不可少的。
### 第四层:完全采用
在最高一级的 DevOps 文档成熟度(完全采用且自动化)所有工具、实践和流程已经到位,以支持将文档为项目中的高优先级事项。要达到这一成熟度,需要不断实验、迭代和团队协作。
#### 人员
完全自动化使 DevOps 团队与技术写作之间的协作更紧密。这一阶段的标志是,技术写作牢牢地融入到项目团队的工作流程中。文档工具的维护工作由一些大型企业负责,它们拥有专职维护 DevOps 工具链的工程师。
#### 文档工具和实践
在这个成熟度,技术写作统一采用 Markdown 语言和自动化工具。
#### 成果
本阶段的成果是一套完整的工具和实践,它们支持自动化在线文档发布。技术写作者可以按需发布和重新发布文档,以支持迭代开发流程。
持续学习是这个阶段的另一项成果。技术写作和工具链维护者寻找改进自动化和流程的方法,以帮助文档实践。
### 总结
提升 DevOps 文档成熟度的过程跟达到 DevOps 或 DevSecOps 成熟化的历程是类似的。我希望行业能够将更灵活的文档实践和工具作为公司推进 DevOps 进程中的一个部分。提高 DevOps 文档成熟度应该作整体 DevOps 成熟化甚至 [DevOps 到 DevSecOps 转型](https://opensource.com/article/21/10/devops-to-devsecops)的一部分。
*(题图:MJ/154429b7-bdfc-4b34-9a81-55d9fe33ab07)*
---
via: <https://opensource.com/article/22/2/devops-documentation-maturity>
作者:[Will Kelly](https://opensource.com/users/willkelly) 选题:[lujun9972](https://github.com/lujun9972) 译者:[toknow-gh](https://github.com/toknow-gh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | DevOps and DevSecOps require agile documentation practices to deliver quality documentation on time with an iterative software delivery cycle. It's a similar journey to DevOps with a move to automation and a more agile approach to content. If documentation is only now entering your organization's DevOps discussions, it's time to catch your documentation practices up to DevOps.
Here are the four levels of DevOps documentation maturity:
## Level 1: Ad hoc and siloed
In the first level of DevOps documentation maturity (most immature), documentation efforts do not align with DevOps efforts. DevOps development follows their path while the documentation team follows a separate path, which often causes the documentation to be behind the development. Delaying a product launch because of documentation is not an option in the hyper-competitive cloud world.
### Staffing
The documentation staffing at this level hasn't deviated from the old way of doing things. Technical writers still work in a centralized team detached from the development teams. A gulf between the technical writing group and development teams happens for a variety of reasons, including:
- Corporate politics that create team divisions and silos
- The team sees technical documentation as a checkmark, not an asset that creates project success
- The hiring of technical writers in an afterthought
- Misalignment of technical writer priorities with development team realities
Another sign of staffing challenges at this phase is the "definition of done." This is where technical writers new to the agile experience may find it challenging working with applications developed through the iteration that continuous integration/continuous development (CI/CD) toolchains and processes.
### Documentation tools and processes
Technical writers in this phase use tools they're used to from traditional office work, such as office suites and layout programs. The tools aren't agile and require version control, and content management requirements don't integrate efficiently with DevOps toolchains or support development velocity. Technical writers still follow legacy templates and processes at this level.
### Outcomes
The documentation deliverables at this level may not be current or even lack technical accuracy. When a development team moves at the velocity of DevOps and their technical writer support follows a legacy non-agile process (using proprietary tools and delivery formats), it is difficult to iterate the documentation and keep pace with application changes.
## Level 2: Experimentation and pilot
The second level of DevOps documentation maturity (experimentation phase) is where DevOps leads and technical writers make the first moves to implement more agile documentation practices and tools.
Ideally, experimentation is part of a pilot project with support from stakeholders who have the most to gain from improved documentation delivery and its integration with DevOps practices.
### Staffing
The staffing at the experimental phase can take one of three forms:
- A forward-thinking technical writer experimenting with more agile tools on their own time brings their findings to work because they want a better way to do their job. The writer pitches the idea of a more agile documentation process to their leadership.
- The DevOps lead or engineer is experimenting with tools such as Hugo and Jekyll and integrating the tool into the CI/CD pipeline. The DevOps team teaches the tooling to the technical writer.
- The team brings in third-party contractors or consultants with expertise in DevOps documentation tools and knowledge of where documentation tools fit into the CI/CD toolchain and DevOps lifecycle.
### Documentation tools & practices
[Hugo](https://opensource.com/article/18/3/start-blog-30-minutes-hugo) and [Jekyll](https://opensource.com/article/17/4/getting-started-jekyll) are among the tools that appear during this phase. This phase also sees new approaches to content strategy and technical writing.
### Outcomes
An outcome of a successful experimentation phase should be "land and expand" and set up DevOps documentation practices that other project teams can put into practice.
Experimentation in this phase also includes fundamental changes to content strategy and publishing processes, which technical writers outside the pilot project can learn and adopt.
A change in [technical writer hiring practices](https://opensource.com/article/19/11/hiring-technical-writers-devops) is another potential outcome of this phase based on the pilot's success. It's essential to bring your in-house writers along by offering them training about DevOps and your newly implemented documentation tools.
New documentation tooling and processes are the critical outcomes for this phase. You'll also need to sell this outcome to your leadership, stakeholders, and other teams through presentations, status reports, and internal case studies.
## Level 3: Partial automation and expansion
The third level of DevOps documentation maturity (partial automation and expansion) is the next step in the "land and expand" outcome. In this phase, other DevOps teams adopt the DevOps documentation tools, practices, and lessons learned from the pilot project.
### Staffing
Technical writers and DevOps teams begin a much closer collaboration at this level. Hiring new technical writers at this level focuses on writers with experience in DevOps environments.
### Tools and documentation practices
Technical writers begin to migrate away from their legacy tools and processes and adopt more agile documentation tools during this phase, such as:
[docToolchain](http://doctoolchain.org/)[Docbook](https://opensource.com/article/17/9/docbook)- Hugo
- Jekyll
Technical writers also work to adjust their legacy practices at this level.
### Outcomes
DevOps documentation tools and practices expand beyond the pilot project(s) to become standard practices. Continuous learning is essential at this level as new teams go live with new documentation tools and processes.
## Level 4: Full adoption
The highest level of DevOps documentation maturity (full adoption and automation) is where the tools, practices, and processes are in place to support documentation as a top-level project priority. Reaching this level of maturity requires experimentation, iteration, and collaboration.
### Staffing
Full automation brings together the closest collaboration between the DevOps team and technical writers. A mark of this phase is that your technical writers become firmly embedded into the project team's workflow. Large enterprises with engineers assigned to maintain DevOps toolchains assume maintenance duties over the documentation tools.
### Documentation tools and practices
Technical writers at this level of maturity are standardized on markdown language and automated tools.
### Outcomes
The outcomes at this phase are a complete suite of tools and practices that support the automation of online documentation publishing. Technical writers can publish and republish documentation as needed to support an iterative development process.
Continuous learning is another outcome of this phase. Technical writers and toolchain maintainers seek ways to improve automation and processes that help documentation practices.
## Final thoughts
DevOps documentation requires a similar journey as you went through to reach DevOps or DevSecOps maturity. I hope to reach a point across industries where moving to more agile documentation practices and tools becomes part of an organization's overall DevOps journey. There is still work to be done. Advancing your DevOps documentation maturity should come as part of your overall DevOps maturity or even [DevOps to DevSecOps transformation](https://opensource.com/article/21/10/devops-to-devsecops).
## Comments are closed. |
16,198 | 在 Git 仓库中,文件究竟被存储在哪里? | https://jvns.ca/blog/2023/09/14/in-a-git-repository--where-do-your-files-live-/ | 2023-09-16T23:02:30 | [
"Git"
] | https://linux.cn/article-16198-1.html | 
大家好!今天我和一个朋友讨论 Git 的工作原理,我们感到奇怪,Git 是如何存储你的文件的?我们知道它存储在 `.git` 目录中,但具体到 `.git` 中的哪个位置,各个版本的历史文件又被存储在哪里呢?
以这个博客为例,其文件存储在一个 Git 仓库中,其中有一个文件名为 `content/post/2019-06-28-brag-doc.markdown`。这个文件在我的 `.git` 文件夹中具体的位置在哪里?过去的文件版本又被存储在哪里?那么,就让我们通过编写一些简短的 Python 代码来探寻答案吧。
### Git 把文件存储在 .git/objects 之中
你的仓库中,每一个文件的历史版本都被储存在 `.git/objects` 中。比如,对于这个博客,`.git/objects` 包含了 2700 多个文件。
```
$ find .git/objects/ -type f | wc -l
2761
```
>
> 注意:`.git/objects` 包含的信息,不仅仅是 “仓库中每一个文件的所有先前版本”,但我们暂不详细讨论这一内容。
>
>
>
这里是一个简短的 Python 程序([find-git-object.py](https://gist.github.com/jvns/ff884dceef7660402fe1eca697cfbf51)),它可以帮助我们定位在 `.git/objects` 中的特定文件的具体位置。
```
import hashlib
import sys
def object_path(content):
header = f"blob {len(content)}\0"
data = header.encode() + content
sha1 = hashlib.sha1()
sha1.update(data)
digest = sha1.hexdigest()
return f".git/objects/{digest[:2]}/{digest[2:]}"
with open(sys.argv[1], "rb") as f:
print(object_path(f.read()))
```
此程序的主要操作如下:
* 读取文件内容
* 计算一个头部(`blob 16673\0`),并将其与文件内容合并
* 计算出文件的 sha1 校验和(此处为 `e33121a9af82dd99d6d706d037204251d41d54`)
* 将这个 sha1 校验和转换为路径(如 `.git/objects/e3/3121a9af82dd99d6d706d037204251d41d54`)
运行的方法如下:
```
$ python3 find-git-object.py content/post/2019-06-28-brag-doc.markdown
.git/objects/8a/e33121a9af82dd99d6d706d037204251d41d54
```
### 术语解释:“内容寻址存储”
这种存储策略的术语为“<ruby> 内容寻址存储 <rt> content addressed storage </rt></ruby>”,它指的是对象在数据库中的文件名与文件内容的哈希值相同。
内容寻址存储的有趣之处就是,假设我有两份或许多份内容完全相同的文件,在 Git 的数据库中,并不会因此占用额外空间。如果内容的哈希值是 `aabbbbbbbbbbbbbbbbbbbbbbbbb`,它们都会被存储在 `.git/objects/aa/bbbbbbbbbbbbbbbbbbbbb` 中。
### 这些对象是如何进行编码的?
如果我尝试在 `.git/objects` 目录下查看这个文件,显示的内容似乎有一些奇怪:
```
$ cat .git/objects/8a/e33121a9af82dd99d6d706d037204251d41d54
x^A<8D><9B>}s<E3>Ƒ<C6><EF>o|<8A>^Q<9D><EC>ju<92><E8><DD><9C><9C>*<89>j<FD>^...
```
这是怎么回事呢?让我们来运行 `file` 命令检查一下:
```
$ file .git/objects/8a/e33121a9af82dd99d6d706d037204251d41d54
.git/objects/8a/e33121a9af82dd99d6d706d037204251d41d54: zlib compressed data
```
原来,它是压缩的!我们可以编写一个小巧的 Python 程序—— `decompress.py`,然后用 `zlib` 模块去解压这些数据:
```
import zlib
import sys
with open(sys.argv[1], "rb") as f:
content = f.read()
print(zlib.decompress(content).decode())
```
让我们来解压一下看看结果:
```
$ python3 decompress.py .git/objects/8a/e33121a9af82dd99d6d706d037204251d41d54
blob 16673---
title: "Get your work recognized: write a brag document"
date: 2019-06-28T18:46:02Z
url: /blog/brag-documents/
categories: []
---
... the entire blog post ...
```
结果显示,这些数据的编码方式非常简单:首先有 `blob 16673\0` 标识,其后就是文件的全部内容。
### 这里并没有差异性数据(diff)
这里有一件我第一次知道时让我感到惊讶的事:这里并没有任何差异性数据!那个文件是该篇博客文章的第 9 个版本,但 Git 在 `.git/objects` 目录中存储的版本是完整文件内容,而并非与前一版本的差异。
尽管 Git 实际上有时候会以差异性数据存储文件(例如,当你运行 `git gc` 时,为了提升效率,它可能会将多个不同的文件封装成 “打包文件”),但在我个人经验中,我从未需要关注这个细节,所以我们不在此深入讨论。然而,关于这种格式如何工作,Aditya Mukerjee 有篇优秀的文章 《[拆解 Git 的打包文件](https://codewords.recurse.com/issues/three/unpacking-git-packfiles)》。
### 博客文章的旧版本在哪?
你可能会好奇:如果在我修复了一些错别字之前,这篇博文已经存在了 8 个版本,那它们在 `.git/objects` 目录中的位置是哪里?我们如何找到它们呢?
首先,我们来使用 `git log` 命令来查找改动过这个文件的每一个提交:
```
$ git log --oneline content/post/2019-06-28-brag-doc.markdown
c6d4db2d
423cd76a
7e91d7d0
f105905a
b6d23643
998a46dd
67a26b04
d9999f17
026c0f52
72442b67
```
然后,我们选择一个之前的提交,比如 `026c0f52`。提交也被存储在 `.git/objects` 中,我们可以尝试在那里找到它。但是失败了!因为 `ls .git/objects/02/6c*` 没有显示任何内容!如果有人告诉你,“我们知道有时 Git 会打包对象来节省空间,我们并不需过多关心它”,但现在,我们需要去面对这个问题了。
那就让我们去解决它吧。
### 让我们开始解包一些对象
现在我们需要从打包文件中解包出一些对象。我在 Stack Overflow 上查找了一下,看起来我们可以这样进行操作:
```
$ mv .git/objects/pack/pack-adeb3c14576443e593a3161e7e1b202faba73f54.pack .
$ git unpack-objects < pack-adeb3c14576443e593a3161e7e1b202faba73f54.pack
```
这种直接对库进行手术式的做法让人有些紧张,但如果我误操作了,我还可以从 Github 上重新克隆这个库,所以我并不太担心。
解包所有的对象文件后,我们得到了更多的对象:大约有 20000 个,而不是原来的大约 2700 个。看起来很酷。
```
find .git/objects/ -type f | wc -l
20138
```
### 我们回头再看看提交
现在我们可以继续看看我们的提交 `026c0f52`。我们之前说过 `.git/objects` 中并不都是文件,其中一部分是提交!为了弄清楚我们的旧文章 `content/post/2019-06-28-brag-doc.markdown` 是在哪里被保存的,我们需要深入查看这个提交。
首先,我们需要在 `.git/objects` 中查看这个提交。
### 查看提交的第一步:找到提交
经过解包后,我们现在可以在 `.git/objects/02/6c0f5208c5ea10608afc9252c4a56c1ac1d7e4` 中找到提交 `026c0f52`,我们可以用下面的方法去查看它:
```
$ python3 decompress.py .git/objects/02/6c0f5208c5ea10608afc9252c4a56c1ac1d7e4
commit 211tree 01832a9109ab738dac78ee4e95024c74b9b71c27
parent 72442b67590ae1fcbfe05883a351d822454e3826
author Julia Evans <[email protected]> 1561998673 -0400
committer Julia Evans <[email protected]> 1561998673 -0400
brag doc
```
我们也可以用 `git cat-file -p 026c0f52` 命令来获取相同的信息,这个命令能起到相同的作用,但是它在格式化数据时做得更好一些。(`-p` 选项意味着它能够以更友好的方式进行格式化)
### 查看提交的第二步:找到树
这个提交包含一个**树**。树是什么呢?让我们看一下。树的 ID 是 `01832a9109ab738dac78ee4e95024c74b9b71c27`,我们可以使用先前的 `decompress.py` 脚本查看这个 Git 对象,尽管我不得不移除 `.decode()` 才能避免脚本崩溃。
```
$ python3 decompress.py .git/objects/01/832a9109ab738dac78ee4e95024c74b9b71c27
```
这个输出的格式有些难以阅读。主要的问题在于,该提交的哈希(`\xc3\xf7$8\x9b\x8dO\x19/\x18\xb7}|\xc7\xce\x8e…`)是原始字节,而没有进行十六进制的编码,因此我们看到 `\xc3\xf7$8\x9b\x8d` 而非 `c3f76024389b8d`。我打算切换至 `git cat-file -p` 命令,它能以更友好的方式显示数据,我不想自己编写一个解析器。
```
$ git cat-file -p 01832a9109ab738dac78ee4e95024c74b9b71c27
100644 blob c3f76024389b8d4f192f18b77d7cc7ce8e3a68ad .gitignore
100644 blob 7ebaecb311a05e1ca9a43f1eb90f1c6647960bc1 README.md
100644 blob 0f21dc9bf1a73afc89634bac586271384e24b2c9 Rakefile
100644 blob 00b9d54abd71119737d33ee5d29d81ebdcea5a37 config.yaml
040000 tree 61ad34108a327a163cdd66fa1a86342dcef4518e content <-- 这是我们接下来的目标
040000 tree 6d8543e9eeba67748ded7b5f88b781016200db6f layouts
100644 blob 22a321a88157293c81e4ddcfef4844c6c698c26f mystery.rb
040000 tree 8157dc84a37fca4cb13e1257f37a7dd35cfe391e scripts
040000 tree 84fe9c4cb9cef83e78e90a7fbf33a9a799d7be60 static
040000 tree 34fd3aa2625ba784bced4a95db6154806ae1d9ee themes
```
这是我在这次提交时库的根目录中所有的文件。看起来我曾经不小心提交了一个名为 `mystery.rb` 的文件,后来我删除了它。
我们的文件在 `content` 目录中,接下来让我们看看那个树:`61ad34108a327a163cdd66fa1a86342dcef4518e`
### 查看提交的第三步:又一棵树
```
$ git cat-file -p 61ad34108a327a163cdd66fa1a86342dcef4518e
040000 tree 1168078878f9d500ea4e7462a9cd29cbdf4f9a56 about
100644 blob e06d03f28d58982a5b8282a61c4d3cd5ca793005 newsletter.markdown
040000 tree 1f94b8103ca9b6714614614ed79254feb1d9676c post <-- 我们接下来的目标!
100644 blob 2d7d22581e64ef9077455d834d18c209a8f05302 profiler-project.markdown
040000 tree 06bd3cee1ed46cf403d9d5a201232af5697527bb projects
040000 tree 65e9357973f0cc60bedaa511489a9c2eeab73c29 talks
040000 tree 8a9d561d536b955209def58f5255fc7fe9523efd zines
```
还未结束……
### 查看提交的第四步:更多的树……
我们要寻找的文件位于 `post/` 目录,因此我们需要进一步探索:
```
$ git cat-file -p 1f94b8103ca9b6714614614ed79254feb1d9676c
.... 省略了大量行 ...
100644 blob 170da7b0e607c4fd6fb4e921d76307397ab89c1e 2019-02-17-organizing-this-blog-into-categories.markdown
100644 blob 7d4f27e9804e3dc80ab3a3912b4f1c890c4d2432 2019-03-15-new-zine--bite-size-networking-.markdown
100644 blob 0d1b9fbc7896e47da6166e9386347f9ff58856aa 2019-03-26-what-are-monoidal-categories.markdown
100644 blob d6949755c3dadbc6fcbdd20cc0d919809d754e56 2019-06-23-a-few-debugging-resources.markdown
100644 blob 3105bdd067f7db16436d2ea85463755c8a772046 2019-06-28-brag-doc.markdown <-- 我们找到了!!!
```
在此,`2019-06-28-brag-doc.markdown` 之所以位于列表最后,是因为在发布时它是最新的博文。
### 查看提交的第五步:我们终于找到它!
经过努力,我们找到了博文历史版本所在的对象文件!太棒了!它的哈希值是 `3105bdd067f7db16436d2ea85463755c8a772046`,因此它位于 `git/objects/31/05bdd067f7db16436d2ea85463755c8a772046`。
我们可以使用 `decompress.py` 来查看它:
```
$ python3 decompress.py .git/objects/31/05bdd067f7db16436d2ea85463755c8a772046 | head
blob 15924---
title: "Get your work recognized: write a brag document"
date: 2019-06-28T18:46:02Z
url: /blog/brag-documents/
categories: []
---
... 文件的剩余部分在此 ...
```
这就是博文的旧版本!如果我执行命令 `git checkout 026c0f52 content/post/2019-06-28-brag-doc.markdown` 或者 `git restore --source 026c0f52 content/post/2019-06-28-brag-doc.markdown`,我就会获取到这个版本。
### 这样遍历树就是 git log 的运行机制
我们刚刚经历的整个过程(找到提交、逐层遍历目录树、搜索所需文件名)看似繁琐,但实际上当我们执行 `git log content/post/2019-06-28-brag-doc.markdown` 时,背后就是这样在运行。它需要逐个检查你历史记录中的每一个提交,在每个提交中核查 `content/post/2019-06-28-brag-doc.markdown` 的版本(例如在这个案例中为 `3105bdd067f7db16436d2ea85463755c8a772046`),并查看它是否自上一提交以来有所改变。
这就是为什么有时 `git log FILENAME` 会执行的有些缓慢 —— 我的这个仓库中有 3000 个提交,它需要对每个提交做大量的工作,来判断该文件是否在该提交中发生过变化。
### 我有多少个历史版本的文件?
目前,我在我的博客仓库中跟踪了 1530 个文件:
```
$ git ls-files | wc -l
1530
```
但历史文件有多少呢?我们可以列出 `.git/objects` 中所有的内容,看看有多少对象文件:
```
$ find .git/objects/ -type f | grep -v pack | awk -F/ '{print $3 $4}' | wc -l
20135
```
但并不是所有这些都代表过去版本的文件 —— 正如我们之前所见,许多都是提交和目录树。不过,我们可以编写一个小小的 Python 脚本 `find-blobs.py`,遍历所有对象并检查是否以 `blob` 开头:
```
import zlib
import sys
for line in sys.stdin:
line = line.strip()
filename = f".git/objects/{line[0:2]}/{line[2:]}"
with open(filename, "rb") as f:
contents = zlib.decompress(f.read())
if contents.startswith(b"blob"):
print(line)
```
```
$ find .git/objects/ -type f | grep -v pack | awk -F/ '{print $3 $4}' | python3 find-blobs.py | wc -l
6713
```
于是,看起来在我的 Git 仓库中存放的旧文件版本有 `6713 - 1530 = 5183` 个,Git 会为我保存这些文件,以备我想着要恢复它们时使用。太好了!
### 就这些啦!
在 [这个 gist](https://gist.github.com/jvns/ff884dceef7660402fe1eca697cfbf51) 中附上了全部的此篇文章所用代码,其实没多少。
我以为我已经对 Git 的工作方式了如指掌,但我以前从未真正涉及过打包文件,所以这次探索很有趣。我也很少思考当我让 `git log` 跟踪一个文件的历史时,它实际上有多大的工作量,因此也很开心能深入研究这个。
作为一个有趣的后续:我提交这篇博文后,Git 就警告我仓库中的对象太多(我猜 20,000 太多了!),并运行 `git gc` 将它们全部压缩成打包文件。所以现在我的 `.git/objects` 目录已经被压缩得十分小了:
```
$ find .git/objects/ -type f | wc -l
14
```
*(题图:MJ/319a396c-6f3f-4891-b051-261312c8ea9a)*
---
via: <https://jvns.ca/blog/2023/09/14/in-a-git-repository--where-do-your-files-live-/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello! I was talking to a friend about how git works today, and we got onto the
topic – where does git store your files? We know that it’s in your `.git`
directory, but where exactly in there are all the versions of your old files?
For example, this blog is in a git repository, and it contains a file called
`content/post/2019-06-28-brag-doc.markdown`
. Where is that in my `.git`
folder?
And where are the old versions of that file? Let’s investigate by writing some
very short Python programs.
### git stores files in `.git/objects`
Every previous version of every file in your repository is in `.git/objects`
.
For example, for this blog, `.git/objects`
contains 2700 files.
```
$ find .git/objects/ -type f | wc -l
2761
```
note: `.git/objects`
actually has more information than “every previous version
of every file in your repository”, but we’re not going to get into that just yet
Here’s a very short Python program
([find-git-object.py](https://gist.github.com/jvns/ff884dceef7660402fe1eca697cfbf51)) that
finds out where any given file is stored in `.git/objects`
.
```
import hashlib
import sys
def object_path(content):
header = f"blob {len(content)}\0"
data = header.encode() + content
digest = hashlib.sha1(data).hexdigest()
return f".git/objects/{digest[:2]}/{digest[2:]}"
with open(sys.argv[1], "rb") as f:
print(object_path(f.read()))
```
What this does is:
- read the contents of the file
- calculate a header (
`blob 16673\0`
) and combine it with the contents - calculate the sha1 sum (
`e33121a9af82dd99d6d706d037204251d41d54`
in this case) - translate that sha1 sum into a path (
`.git/objects/e3/3121a9af82dd99d6d706d037204251d41d54`
)
We can run it like this:
```
$ python3 find-git-object.py content/post/2019-06-28-brag-doc.markdown
.git/objects/8a/e33121a9af82dd99d6d706d037204251d41d54
```
### jargon: “content addressed storage”
The term for this storage strategy (where the filename of an object in the database is the same as the hash of the file’s contents) is “content addressed storage”.
One neat thing about content addressed storage is that if I have two files (or
50 files!) with the exact same contents, that doesn’t take up any extra space
in Git’s database – if the hash of the contents is `aabbbbbbbbbbbbbbbbbbbbbbbbb`
, they’ll both be stored in `.git/objects/aa/bbbbbbbbbbbbbbbbbbbbb`
.
### how are those objects encoded?
If I try to look at this file in `.git/objects`
, it gets a bit weird:
```
$ cat .git/objects/8a/e33121a9af82dd99d6d706d037204251d41d54
x^A<8D><9B>}s<E3>Ƒ<C6><EF>o|<8A>^Q<9D><EC>ju<92><E8><DD>\<9C><9C>*<89>j<FD>^...
```
What’s going on? Let’s run `file`
on it:
```
$ file .git/objects/8a/e33121a9af82dd99d6d706d037204251d41d54
.git/objects/8a/e33121a9af82dd99d6d706d037204251d41d54: zlib compressed data
```
It’s just compressed! We can write another little Python program called `decompress.py`
that uses the `zlib`
module to decompress the data:
```
import zlib
import sys
with open(sys.argv[1], "rb") as f:
content = f.read()
print(zlib.decompress(content).decode())
```
Now let’s decompress it:
```
$ python3 decompress.py .git/objects/8a/e33121a9af82dd99d6d706d037204251d41d54
blob 16673---
title: "Get your work recognized: write a brag document"
date: 2019-06-28T18:46:02Z
url: /blog/brag-documents/
categories: []
---
... the entire blog post ...
```
So this data is encoded in a pretty simple way: there’s this
`blob 16673\0`
thing, and then the full contents of the file.
### there aren’t any diffs
One thing that surprised me here is the first time I learned it: there aren’t
any diffs here! That file is the 9th version of that blog post, but the version
git stores in the `.git/objects`
is the whole file, not the diff from the
previous version.
Git actually sometimes also does store files as diffs (when you run `git gc`
it
can combine multiple different files into a “packfile” for efficiency), but I
have never needed to think about that in my life so we’re not going to get into
it. Aditya Mukerjee has a great post called [Unpacking Git packfiles](https://codewords.recurse.com/issues/three/unpacking-git-packfiles) about how the format works.
### what about older versions of the blog post?
Now you might be wondering – if there are 8 previous versions of that blog
post (before I fixed some typos), where are they in the `.git/objects`
directory? How do we find them?
First, let’s find every commit where that file changed with `git log`
:
```
$ git log --oneline content/post/2019-06-28-brag-doc.markdown
c6d4db2d
423cd76a
7e91d7d0
f105905a
b6d23643
998a46dd
67a26b04
d9999f17
026c0f52
72442b67
```
Now let’s pick a previous commit, let’s say `026c0f52`
. Commits are also stored
in `.git/objects`
, and we can try to look at it there. But the commit isn’t
there! `ls .git/objects/02/6c*`
doesn’t have any results! You know how we
mentioned “sometimes git packs objects to save space but we don’t need to worry
about it?”. I guess now is the time that we need to worry about it.
So let’s take care of that.
### let’s unpack some objects
So we need to unpack the objects from the pack files. I looked it up on Stack Overflow and apparently you can do it like this:
```
$ mv .git/objects/pack/pack-adeb3c14576443e593a3161e7e1b202faba73f54.pack .
$ git unpack-objects < pack-adeb3c14576443e593a3161e7e1b202faba73f54.pack
```
This is weird repository surgery so it’s a bit alarming but I can always just clone the repository from Github again if I mess it up, so I wasn’t too worried.
After unpacking all the object files, we end up with way more objects: about 20000 instead of about 2700. Neat.
```
find .git/objects/ -type f | wc -l
20138
```
### back to looking at a commit
Now we can go back to looking at our commit `026c0f52`
. You know how we said
that not everything in `.git/objects`
is a file? Some of them are commits! And
to figure out where the old version of our post
`content/post/2019-06-28-brag-doc.markdown`
is stored, we need to dig pretty
deep into this commit.
The first step is to look at the commit in `.git/objects`
.
### commit step 1: look at the commit
The commit `026c0f52`
is now in
`.git/objects/02/6c0f5208c5ea10608afc9252c4a56c1ac1d7e4`
after doing some
unpacking and we can look at it like this:
```
$ python3 decompress.py .git/objects/02/6c0f5208c5ea10608afc9252c4a56c1ac1d7e4
commit 211tree 01832a9109ab738dac78ee4e95024c74b9b71c27
parent 72442b67590ae1fcbfe05883a351d822454e3826
author Julia Evans <[email protected]> 1561998673 -0400
committer Julia Evans <[email protected]> 1561998673 -0400
brag doc
```
We can also get same information with `git cat-file -p 026c0f52`
, which does the same thing but does a better job of formatting the data. (the `-p`
option means “format it nicely please”)
### commit step 2: look at the tree
This commit has a **tree**. What’s that? Well let’s take a look. The tree’s ID
is `01832a9109ab738dac78ee4e95024c74b9b71c27`
, and we can use our
`decompress.py`
script from earlier to look at that git object. (though I had to remove the `.decode()`
to get the script to not crash)
```
$ python3 decompress.py .git/objects/01/832a9109ab738dac78ee4e95024c74b9b71c27
b'tree 396\x00100644 .gitignore\x00\xc3\xf7`$8\x9b\x8dO\x19/\x18\xb7}|\xc7\xce\x8e:h\xad100644 README.md\x00~\xba\xec\xb3\x11\xa0^\x1c\xa9\xa4?\x1e\xb9\x0f\x1cfG\x96\x0b
```
This is formatted in kind of an unreadable way. The main display issue here is that
the commit hashes (`\xc3\xf7$8\x9b\x8dO\x19/\x18\xb7}|\xc7\xce\`
…) are raw
bytes instead of being encoded in hexadecimal. So we see `\xc3\xf7$8\x9b\x8d`
instead of `c3f76024389b8d`
. Let’s switch over to using `git cat-file -p`
which
formats the data in a friendlier way, because I don’t feel like writing a
parser for that.
```
$ git cat-file -p 01832a9109ab738dac78ee4e95024c74b9b71c27
100644 blob c3f76024389b8d4f192f18b77d7cc7ce8e3a68ad .gitignore
100644 blob 7ebaecb311a05e1ca9a43f1eb90f1c6647960bc1 README.md
100644 blob 0f21dc9bf1a73afc89634bac586271384e24b2c9 Rakefile
100644 blob 00b9d54abd71119737d33ee5d29d81ebdcea5a37 config.yaml
040000 tree 61ad34108a327a163cdd66fa1a86342dcef4518e content <-- this is where we're going next
040000 tree 6d8543e9eeba67748ded7b5f88b781016200db6f layouts
100644 blob 22a321a88157293c81e4ddcfef4844c6c698c26f mystery.rb
040000 tree 8157dc84a37fca4cb13e1257f37a7dd35cfe391e scripts
040000 tree 84fe9c4cb9cef83e78e90a7fbf33a9a799d7be60 static
040000 tree 34fd3aa2625ba784bced4a95db6154806ae1d9ee themes
```
This is showing us all of the files I had in the root directory of the
repository as of that commit. Looks like I accidentally committed some file
called `mystery.rb`
at some point which I later removed.
Our file is in the `content`
directory, so let’s look at that tree: `61ad34108a327a163cdd66fa1a86342dcef4518e`
### commit step 3: yet another tree
```
$ git cat-file -p 61ad34108a327a163cdd66fa1a86342dcef4518e
040000 tree 1168078878f9d500ea4e7462a9cd29cbdf4f9a56 about
100644 blob e06d03f28d58982a5b8282a61c4d3cd5ca793005 newsletter.markdown
040000 tree 1f94b8103ca9b6714614614ed79254feb1d9676c post <-- where we're going next!
100644 blob 2d7d22581e64ef9077455d834d18c209a8f05302 profiler-project.markdown
040000 tree 06bd3cee1ed46cf403d9d5a201232af5697527bb projects
040000 tree 65e9357973f0cc60bedaa511489a9c2eeab73c29 talks
040000 tree 8a9d561d536b955209def58f5255fc7fe9523efd zines
```
Still not done…
### commit step 4: one more tree….
The file we’re looking for is in the `post/`
directory, so there’s one more tree:
```
$ git cat-file -p 1f94b8103ca9b6714614614ed79254feb1d9676c
.... MANY MANY lines omitted ...
100644 blob 170da7b0e607c4fd6fb4e921d76307397ab89c1e 2019-02-17-organizing-this-blog-into-categories.markdown
100644 blob 7d4f27e9804e3dc80ab3a3912b4f1c890c4d2432 2019-03-15-new-zine--bite-size-networking-.markdown
100644 blob 0d1b9fbc7896e47da6166e9386347f9ff58856aa 2019-03-26-what-are-monoidal-categories.markdown
100644 blob d6949755c3dadbc6fcbdd20cc0d919809d754e56 2019-06-23-a-few-debugging-resources.markdown
100644 blob 3105bdd067f7db16436d2ea85463755c8a772046 2019-06-28-brag-doc.markdown <-- found it!!!!!
```
Here the `2019-06-28-brag-doc.markdown`
is the last file listed because it was
the most recent blog post when it was published.
### commit step 5: we made it!
Finally we have found the object file where a previous version of my blog post
lives! Hooray! It has the hash `3105bdd067f7db16436d2ea85463755c8a772046`
, so
it’s in `git/objects/31/05bdd067f7db16436d2ea85463755c8a772046`
.
We can look at it with `decompress.py`
```
$ python3 decompress.py .git/objects/31/05bdd067f7db16436d2ea85463755c8a772046 | head
blob 15924---
title: "Get your work recognized: write a brag document"
date: 2019-06-28T18:46:02Z
url: /blog/brag-documents/
categories: []
---
... rest of the contents of the file here ...
```
This is the old version of the post! If I ran `git checkout 026c0f52 content/post/2019-06-28-brag-doc.markdown`
or `git restore --source 026c0f52 content/post/2019-06-28-brag-doc.markdown`
, that’s what I’d get.
### this tree traversal is how `git log`
works
This whole process we just went through (find the commit, go through the
various directory trees, search for the filename we wanted) seems kind of long
and complicated but this is actually what’s happening behind the scenes when we
run `git log content/post/2019-06-28-brag-doc.markdown`
. It needs to go through
every single commit in your history, check the version (for example
`3105bdd067f7db16436d2ea85463755c8a772046`
in this case) of
`content/post/2019-06-28-brag-doc.markdown`
, and see if it changed from the previous commit.
That’s why `git log FILENAME`
is a little slow sometimes – I have 3000 commits in this
repository and it needs to do a bunch of work for every single commit to figure
out if the file changed in that commit or not.
### how many previous versions of files do I have?
Right now I have 1530 files tracked in my blog repository:
```
$ git ls-files | wc -l
1530
```
But how many historical files are there? We can list everything in `.git/objects`
to see how many object files there are:
```
$ find .git/objects/ -type f | grep -v pack | awk -F/ '{print $3 $4}' | wc -l
20135
```
Not all of these represent previous versions of files though – as we saw
before, lots of them are commits and directory trees. But we can write another little Python
script called `find-blobs.py`
that goes through all of the objects and checks
if it starts with `blob`
or not:
```
import zlib
import sys
for line in sys.stdin:
line = line.strip()
filename = f".git/objects/{line[0:2]}/{line[2:]}"
with open(filename, "rb") as f:
contents = zlib.decompress(f.read())
if contents.startswith(b"blob"):
print(line)
```
```
$ find .git/objects/ -type f | grep -v pack | awk -F/ '{print $3 $4}' | python3 find-blobs.py | wc -l
6713
```
So it looks like there are `6713 - 1530 = 5183`
old versions of files lying
around in my git repository that git is keeping around for me in case I ever
want to get them back. How nice!
### that’s all!
[Here’s the gist](https://gist.github.com/jvns/ff884dceef7660402fe1eca697cfbf51) with all
the code for this post. There’s not very much.
I thought I already knew how git worked, but I’d never really thought about
pack files before so this was a fun exploration. I also don’t spend too much
time thinking about how much work `git log`
is actually doing when I ask it to
track the history of a file, so that was fun to dig into.
As a funny postscript: as soon as I committed this blog post, git got mad about
how many objects I had in my repository (I guess 20,000 is too many!) and
ran `git gc`
to compress them all into packfiles. So now my `.git/objects`
directory is very small:
```
$ find .git/objects/ -type f | wc -l
14
``` |
16,199 | 如何在 Linux 中扩展 Veritas 文件系统(VxFS) | https://www.2daygeek.com/extend-increase-vxvm-volume-vxfs-filesystem-linux/ | 2023-09-17T09:52:25 | [
"VxFX"
] | https://linux.cn/article-16199-1.html | 
扩展 VxFX 文件系统是 Linux/Unix 管理员的一项日常任务,可以通过以下文章中描述的几个步骤在线完成此任务:
在此,磁盘组没有足够的可用空间,因此我们将在现有磁盘组(DG)中添加新磁盘,然后调整其大小。
**相关文章:**
* **[如何在 Linux 中创建 VxVM 卷和文件系统](https://www.2daygeek.com/create-vxvm-volume-vxfs-filesystem-linux/)**
* **[如何在 Linux 上创建共享 VxFS 文件系统](https://www.2daygeek.com/create-veritas-shared-vxfs-file-system-linux/)**
### 步骤 1:识别文件系统
使用 [df 命令](https://www.2daygeek.com/linux-check-disk-space-usage-df-command/) 检查要增加/扩展的文件系统,并记下以下输出中的磁盘组(DG)和卷名称,稍后在运行 `vxdg` 和 `vxresize` 命令时将使用这些名称。
```
# df -hP /data
Filesystem Size Used Avail Use% Mounted on
/dev/vx/dsk/testdg/testvol 9.0G 8.4G 0.6G 95% /data
```
根据上面的输出,VxFS 文件系统大小为 9.0 GB,我们希望额外扩展 5 GB 并发布此活动,VxFS 大小将为 14 GB。
在本例中,DG 名称为 `testdg`,卷名称为 `testvol`。
### 步骤 2:获取新磁盘/LUN
新磁盘必须由存储团队映射到主机,这可能需要 CR 批准,因此提出 CR 并向相关团队添加必要的任务,并且还包括此活动的回滚计划。
### 步骤 3:扫描磁盘/LUN
存储团队将新 LUN 映射到主机后,获取 LUN id 并将其保存。
使用以下命令扫描 LUN 以在操作系统级别发现它们。
```
for disk_scan in `ls /sys/class/scsi_host`; do
echo "Scanning $disk_scan…Completed"
echo "- - -" > /sys/class/scsi_host/$disk_scan/scan
done
```
```
Scanning host0...Completed
Scanning host1...Completed
.
.
Scanning host[N]...Completed
```
扫描完成后,使用以下命令查看是否在操作系统级别找到给定的 LUN。
```
lsscsi --scsi | grep -i [Last_Five_Digit_of_LUN]
```
### 步骤 4:在 VxVM 中查找磁盘
默认情况下,所有可用磁盘对 Veritas 卷管理器(VxVM)都是可见的,可以使用 `vxdisk` 命令列出这些磁盘,如下所示。
```
# vxdisk -e list
DEVICE TYPE DISK GROUP STATUS OS_NATIVE_NAME ATTR
emc_01 auto:cdsdisk disk1 testdg online sdd -
emc_02 auto:cdsdisk disk2 testdg online sde -
emc_03 auto:none - - online invalid sdf -
sda auto:LVM - - LVM sda -
sdb auto:LVM - - LVM sdb -
```
磁盘 `sdf` 的状态显示为 `Online invalid` 表示该磁盘不受 VxVM 控制。但是,请使用 `smartctl` 命令仔细检查 LUN id,以确保你选择了正确的磁盘。
```
smartctl -a /dev/sd[x]|grep -i unit
```
如果磁盘未填充到 VxVM,请执行以下命令扫描操作系统设备树中的磁盘设备。
```
vxdisk scandisks
```
### 步骤 5:在 VxVM 中初始化磁盘
当磁盘在**步骤 4** 中对 VxVM 可见,那么使用 `vxdisksetup` 命令初始化磁盘,如下所示:
```
vxdisksetup -i sdf
```
上面的命令将磁盘 `sdf` 带到 Veritas 卷管理器(VxVM),并且磁盘状态现在更改为 `online`。

### 步骤 6:将磁盘添加到 VxVM 中的磁盘组(DG)
`vxdg` 命令对磁盘组执行各种管理操作。在此示例中,我们将使用它向现有磁盘组(DG)添加新磁盘。
```
vxdg -g [DG_Name] adddisk [Any_Name_to_Disk_as_per_Your_Wish=Device_Name]
```
```
vxdg -g testdg adddisk disk3=emc_03
```
运行上述命令后,磁盘名称为 `disk3` 且磁盘组名称为 `testdg` 已针对 `emc_03` 设备进行更新 如下所示:
```
# vxdisk -e list
DEVICE TYPE DISK GROUP STATUS OS_NATIVE_NAME ATTR
emc_01 auto:cdsdisk disk1 testdg online sdd -
emc_02 auto:cdsdisk disk2 testdg online sde -
emc_03 auto:none disk3 testdg online sdf -
sda auto:LVM - - LVM sda -
sdb auto:LVM - - LVM sdb -
```
### 步骤 7:检查磁盘组(DG)中的可用空间
要确定连接卷有多少可用空间,请运行:
```
vxassist -g testdg maxsize
```
### 步骤 8:扩展 VxVM 卷和 VxFS 文件系统
我们为此活动添加了 5GB LUN,因此额外扩展了 VxVM 卷和 VxFS 文件系统 `5GB`,如下所示:
```
vxresize -b -g [DG_Name] [Volume_Name] +[Size_to_be_Increased]
```
```
vxresize -b -g testdg testvol +5g
```
这里:
* `vxresize`:命令
* `-b`:在后台执行调整大小操作(可选)。
* `-g`:将命令的操作限制为给定磁盘组,由磁盘组 ID 或磁盘组名称指定。
* `testdg`:我们的磁盘组(DG)名称
* `test`vol`:我们的卷名称
* `+5g`:此卷将额外增加 5GB。
### 步骤 9:检查扩展 VxFS 文件系统
最后,使用 `df` 命令检查 `/data` 的扩展 VxFS:
```
# df -hP /data
Filesystem Size Used Avail Use% Mounted on
/dev/vx/dsk/testdg/testvol 14G 8.4G 5.6G 68% /data
```
### 总结
在本教程中,我们向你展示了如何向现有磁盘组(DG)添加新磁盘,以及如何通过几个简单步骤在 Linux 中扩展 VxVM 卷和 VxFS 文件系统。
如果你有任何问题或反馈,请随时在下面发表评论。
*(题图:MJ/3fe4fdb7-99da-4b8f-a818-0ae232e6fbcc)*
---
via: <https://www.2daygeek.com/extend-increase-vxvm-volume-vxfs-filesystem-linux/>
作者:[Jayabal Thiyagarajan](https://www.2daygeek.com/author/jayabal/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
16,201 | Linux 如何挽救老旧电脑(和地球) | https://opensource.com/article/22/4/how-linux-saves-earth | 2023-09-17T23:40:52 | [
"旧电脑"
] | https://linux.cn/article-16201-1.html | 
>
> 请不要丢弃你的旧电脑。让我们跳过填埋场,利用 Linux 为它注入新的活力。
>
>
>
我的两位孙子,Mint 和 Kasen,请求我帮助他们搭建游戏电脑。他们的请求让我感到非常欣喜。这不仅给了我一个与他们共度时光的美好机会,也让我能够帮助他们了解科技。同时,我能深入探讨电脑对环境产生的影响。
等一下!这似乎有些离题,对吧?其实并非如此,本文就是为了阐述这个问题。
### 旧电脑的命运是什么?
关于旧电脑的处理(以及处理的原因)是我们讨论的核心。首先,普通电脑通常在提供服务五年左右后被替换。理由何在?
我在一个名为《CHRON》的面向小企业的刊物的在线文章中找到 [这样一篇文章](https://smallbusiness.chron.com/life-span-average-pc-69823.html),电脑的寿命被建议在三至五年。这个建议的部分原因是,假定电脑在生命周期的这个阶段开始变慢。这篇文章,以及其他的一些文章,都在鼓励人们在大约同样的时间段内更换更新、速度更快的电脑。当然,这些压力主要来源于电脑和芯片的厂商,他们想要保持收入的增长。
再者,美国国税局也通过规定电脑所能完全折旧的时间是五年,以此间接强化了这个服务寿命的观念。
我们首先来讨论一下关于电脑会变慢的迷思。电脑实际上是不会变慢的,恒定的时钟速度一直在运作。无论是 2.8GHz 还是 4.5GHz,当电脑忙碌时,它们总是以那个速度运行。当然,当电脑闲置或事情不多时,将会有意识地降低它的时钟速度以节省电力。
电脑变慢并不是因为它们变老了。装有 Windows 系统的电脑在使用过程中,会积累大量的恶意软件、间谍软件、广告软件和恐吓软件。这些垃圾软件拖慢了电脑的运行。电脑用户逐渐认为这是正常的,安于电脑性能下降的境况。
### Linux 驰骋救援
作为朋友和熟人心目中的电脑专家,人们有时会将他们不再需要的旧电脑送给我。他们认为电脑运行速度慢,因此选择交给我,并让我在将它们带到我家附近几个街区的电子设备回收中心之前清除硬盘数据。我总是建议他们,那些三到五年的老电脑其实仍然可用,但他们似乎更倾向于花费金钱换新,而非学习一个新的操作系统。
我已经收到过几台他人赠送的旧电脑。其中一个十分特别的是一台 Dell Optiplex 755,它配备了一个 2.33 GHz 的 Core 2 Duo 处理器以及 8GB 的 RAM。它的 BIOS 日期为 2010 年,所以现在大约应有 12 岁。这是我拥有的最老的电脑,我总是让它忙个不停。我已经使用它好几年了,且它从未变慢,这是因为我在它上面运行的是 Linux —— 如今是 Fedora 35。
如果你认为那是例外,那么我给你更多例子。十年前的 2012 年,我为自己组装了三台电脑,然后在它们所有上安装了 Fedora。至今,它们还在顺利运行,速度一如往昔。
这里没有例外,只有 Linux 系统在旧电脑上的正常运作。
使用 Linux 至少可以将电脑的使用寿命延长一倍,同时不需要任何额外花费。这就使得这些电脑在进入垃圾填埋场(最差情况)或回收中心(最好情况)之前,可以额外使用五到七年或更久。
只要我能找到这些电脑的替换零件,就可以使它们继续运行,远离任何垃圾处理或回收途径。有些电脑的问题在于找到合适的零部件。
### 非标准硬件
让我们讨论一下非标准硬件,以及你能在一些知名公司买到的电脑。正如我之前提到的,我有一台旧电脑是 Dell 的。Dell 是一家历史悠久的企业。尽管我不会购买 Dell 的台式机或塔式电脑,但是我会接受捐赠或者作为礼物赠予的 Dell 电脑。我可以在这些旧电脑上安装 Linux,去除 Windows,让它们重新发挥作用。它们在我的家庭实验室里作为测试计算机使用,等等。
然而,Dell 使用了一些你无法轻松替换的非标准零部件。当你能找到零部件(如电源和主板)时,它们并不便宜。原因在于,这些制造商设计了搭载非标准电源和主板的系统,只适配他们自家的非标准机箱。这是一种保持收入增长的策略。如果你在市场上找不到这些零部件,你就得去原厂买,并且价格通常非常高。
举例来说,我拥有的那台 Dell Optiplex 就使用了不符合通用标准的主板、机箱和电源。换句话说,Dell 的主板或电源可能无法适配我在当地电脑店或亚马逊上购买的标准机箱。这些部件也不适合我孙子们会使用的游戏机箱。主板和电源的安装孔不会与标准机箱对齐。电源适配器不符合标准机箱中可用的空间。而主板上的 PCI 插槽和后板接口在标准机箱中的位置会不对,电源的连接器也与标准主板上的不匹配。
最后,那些非标准部件中的一个或多个终究会出现故障,你可能完全找不到替代品,或者至少找不到价格合理的替代品。在这种情况下,处理旧电脑并采购新电脑就变得合情合理了。
### 标准件组装
让我们探讨一下使用标准化部件进行电脑组装,以及它们的长寿耐用如何适用于我正在帮助孙子们制造的游戏电脑。
大部分主板采用的设计是标准化的,包括微型 ATX、ATX,以及扩展版的 ATX。这些主板在规定的位置上设置了安装孔。许多孔位是重叠的,也就是说 ATX 主板上的孔位会和扩展版 ATX 主板的许多孔位对齐。这就意味着你可以在任何预钻了用于标准主板孔位的机箱中安装这些主板。这些主板都有标准的电源连接器,这意味着你可以配套使用任何标准电源。
在他们生日那天,我两个孙子都送给了一款有标准主板安装孔位的游戏电脑机箱。这些孔位的螺纹是标准的,因此他们可以使用任何主板配套提供的黄铜支架螺丝在这些主板安装孔位中。支架螺丝锁定入主板,并且自身设有适配标准主板锁定螺丝的标准螺纹孔。
这一切的结果就是他们可以在任何标准电脑机箱内,使用标准固定件和标准电源,安装任何标准主板。
需要注意的是,内存、处理器以及插卡设备都是标准化的,但是它们需要和主板兼容。所以旧款主板配套的内存可能已经买不到了。在这种情况下,你需要新的主板、内存和处理器。然而,电脑的其他部分仍然可以完好使用。
如我所告诉 Mint 和 Kasen 的那样,用全套标准部件组装(或购买)电脑就意味着你永远不需要买新电脑。我送给他们的这款优质机箱永远不必更换。随着时间的推移,可能有一些部件会出故障,但他们只需要换掉那些有缺陷的部件。这样一来,通过不断更新换代的标准部件,这些电脑将能经久耐用,且维护成本极低。如果有一个部件出故障,只需更换这一个部件,然后将故障部件回收。
这也极大地减少了你需要回收或者填入垃圾场的材料总量。
### 回收旧电脑配件
我很幸运,生活在一个提供路边回收服务的地方。这个服务虽然不包含电子设备,但周围的多个地方都可以接受电子设备回收,我便住在其中一个地方附近。我已经把很多旧的、不能使用的电子设备送去回收,包括出了故障的电脑配件,但我从未送过整机。
我会将这些出了故障的部件分类,用旧的纸箱存起来。按类别分类——一箱是电子设备,另一箱是金属,第三箱是电池,等等。这些箱子的内容与回收中心的分类相对应。等到一两个箱子满了,我就会送去回收。
### 结语
即使在为这篇文章和我之前的自我教育做了大量的研究,仍难以确定回收的电脑和电脑配件最终会去哪里。我所在附近的回收中心的网站指出,每种回收物料的运用都会依据它的经济价值来决定。电脑含有大量有价值的金属和稀土元素,因此总会被回收。
而这种回收是否以一种健康、环保的方式进行,这就是另一个话题了。到现在为止,我还无法追踪到送去回收的电子设备最后都去了哪里。我决定让自己尽自己的一份力,同时也要尽量保证回收链的其他环节也要设置得当,高效运行。
为了地球,我们最好让电脑尽可能长地运行。只更换故障的部件,能让一台电脑比目前承认的寿命还要运行得更久,这显著减少了我们需要填埋或回收的电子垃圾量。
当然,还要使用 Linux,这样你的电脑就不会变慢了。
*(题图:MJ/7ac9becc-f966-49f4-86a9-29fb41a5fd38)*
---
via: <https://opensource.com/article/22/4/how-linux-saves-earth>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lkxed](https://github.com/lkxed) 译者:ChatGPT 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Mint and Kasen, two of my grandkids, asked me to help them build gaming computers. I am ecstatic that they asked. This gives me a great opportunity to help them learn about technology while being a part of their lives. Both of those things make me happy. There are many ways to approach the ecological impact of computers.
Wait! That's quite a non-sequitur—right? Not really, and this article is all about that.
## What happens to old computers?
What happens to old computers (and why) is a big part of this discussion. Start with the typical computer getting replaced after about five years of service. Why?
Online articles such as [this one](https://smallbusiness.chron.com/life-span-average-pc-69823.html) I found on CHRON, a publication aimed at small businesses suggest a three-to-five-year lifespan for computers. This is partly based on the alleged fact that computers slow down around that time in their life cycle. I find the pressure to get a newer, faster computer within that same time frame in this and other articles. Of course, much of that pressure comes from the computer and chip vendors who need to keep their income streams growing.
The United States Internal Revenue Service reinforces this five-year service life by specifying that time frame for full depreciation of computers.
Let's start with the myth of computer slowdowns. Computers don't slow down—ever. Computers always run at their designed clock speeds. Whether that is 2.8GHz or 4.5GHz, they will always run at that speed when busy. Of course, the clock speeds get intentionally reduced when the computer has little or nothing to do, saving power.
Computers don't slow down because they are old. Computers with Windows installed produce less legitimate work as they grow older because of the massive amount of malware, spyware, adware, and scareware they accumulate over time. Computer users have come to believe that this is normal, and they resign themselves to life with all of this junk dragging down the performance of their computers.
## Linux to the rescue
As a known computer geek among my friends and acquaintances, people sometimes gift me with their old computers. They no longer want them because they are slow, so they give them to me and ask me to wipe their hard drives before taking them to the electronics recycling center a few blocks from my house. I always suggest that their three-to-five-year-old computers are still good, but they seem intent on spending money rather than learning a new operating system.
I have several old computers gifted to me. One, in particular, a Dell Optiplex 755 with a 2.33 GHz Core 2 Duo processor and 8GB of RAM, is particularly interesting. Its BIOS is dated 2010, so it is around 12 years old. It is the oldest computer I have, and I keep it quite busy. I have had it for several years, and it never slows down because I use Linux on it—Fedora 35 right now.
If that is an exception, here are more. I built three computers for myself in 2012, ten years ago, and installed Fedora on all of them. They are all still running with no problems and as fast as they ever did.
There are no exceptions here, just normal operations for old computers on Linux.
Using Linux will at least double the usable lifetime of a computer and at no cost. This keeps those computers out of the landfill (at worst) and out of the recycling centers (at best) for an additional five-to-seven years or more.
So long as I can find replacement parts for these computers, I can keep them running and out of any disposal or recycling path. The problem with some computers is finding parts.
## Non-standard hardware
Let's talk about non-standard hardware and some of the computers that you can buy from some well-known companies. As I mentioned above, one of my old computers is a Dell. Dell is a respectable company that has been around for a long time. I will never purchase a Dell desktop or tower computer, although I will take them as donations or gifts. I can install Linux, get rid of Windows, and make these old computers useful again. I use them in my home lab as test computers, among other things.
However, Dell uses some non-standard parts that you can't easily replace. When you can find parts (like power supplies and motherboards), they are not cheap. The reason is that those vendors create systems with non-standard power supplies and motherboards that only fit within their own non-standard cases. This is a strategy used to keep revenues up. If you can't find these parts on the open market, you must go to the original manufacturer and pay inflated, if not exorbitant, prices.
As one example, the Dell Optiplex I have uses a motherboard, case, and power supply that do not meet generally accepted standards for physical compatibility. In other words, a Dell motherboard or power supply would not fit in a standard case that I can purchase at the local computer store or Amazon. Those parts would not fit in a gaming case that my grandkids would use. The holes for mounting the motherboard and power supply would not align. The power supply would not fit the space available in the standard case. The PCI card slots and back panel connectors on the motherboard would be in the wrong place for a standard case, and the power supply connectors would not match those on a standard motherboard.
Eventually, one or more of those non-standard parts will fail, and you won't be able to find a replacement at all, or at least not for a reasonable price. At that point, it makes sense to dispose of the old computer and purchase a new one.
## Standard builds
Let's explore what using standardized parts can do for building computers, their longevity, and how that applies to the gaming computers that I am helping my grandkids with.
Most motherboards are standardized. They have standard forms such as micro ATX, ATX, and extended ATX. All of these have mounting holes in standard locations. Many of the locations overlap, so holes for ATX motherboards align with many of the mounting holes used on extended ATX motherboards. This means that you can always use a case that has holes drilled for standard motherboard hole locations for any of those motherboards. These motherboards have standard power connectors, which means you can use them with any standard power supply.
I sent both of my grandkids a gaming computer case that has standardized mounting holes for the motherboards for their birthdays. These holes have standard threads so that they can use the brass standoffs that come with any motherboard in those motherboard mounting holes. The standoffs screw into the motherboard, and themselves have standard threaded holes that fit standard motherboard mounting screws.
The result of all this is that they can install any standard motherboard in any standard case using standard fasteners with any standard power supply.
Note that memory, processors, and add-in cards are all standardized, but they must be compatible with the motherboard. So memory for an old motherboard may no longer be available. You would need a new motherboard, memory, and processor in such a case. But the rest of the computer is still perfectly good.
As I have told Mint and Kasen, building (or purchasing) a computer with standard parts means never having to buy a new computer. The good case I gave them will never need replacement. Over time components may fail, but they only need to replace any defective parts. This continuous renewal of standardized parts will allow those computers to last a lifetime with minimal cost. If one component fails, just replace that one part and recycle the defective one.
This also significantly reduces the amount of material you need to recycle or otherwise add to the landfills.
## Recycling old computer parts
I am fortunate to live in a place that provides curbside recycling pickup. Although that curbside pickup does not include electronic devices, multiple locations around the area do take electronics for recycling, and I live close to one. I have taken many loads of old, unusable electronics to that recycling center, including my computers' defective parts. But never an entire computer.
I collect those defective parts in old cardboard boxes, sorted by type—electronics in one, metal in another, batteries in a third, and so on. This corresponds to the collection points at the recycling center. When a box or two get full, I take them for recycling.
## Some final thoughts
Even after a good deal of research for this article and my own edification in the past, it is very difficult to determine where the recycled computers and computer parts will go. The website for our recycling center indicates that the outcomes for each type of recycled material get based on its economic value. Computers have relatively large amounts of valuable metals and rare earth elements, so they get recycled.
The issue of whether such recycling gets performed in ways that are healthy for the people involved and the planet itself is another story. So far, I have been unable to determine where electronics destined for recycling go from here. I have decided that I need to do my part while working to ensure the rest of the recycling chain gets set up and functions appropriately.
The best option for the planet is to keep computers running as long as possible. Replacing only defective components as they go bad can keep a computer running for years longer than the currently accepted lifespan and significantly reduces the amount of electronic waste that we dump in landfills or that needs recycling.
And, of course, use Linux so your computers won't slow down.
## 10 Comments |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.