
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
13,419 | 抛弃 Autotools 向 CMake 迈进吧 | https://opensource.com/article/21/5/cmake | 2021-05-24T18:35:39 | [
"CMake",
"make",
"Autotools"
] | https://linux.cn/article-13419-1.html |
>
> CMake 是一个跨平台的编译、测试和打包软件,即使你以前从来没有使用过构建系统,也可以轻松上手。
>
>
>

在我以前的文章 [Autotools 入门](https://opensource.com/article/19/7/introduction-gnu-autotools) 一文中,我说明了如何使用 Autotools 来管理和打包代码。这是一个强大且通用的平台,可轻松集成到许多打包系统中,包括 RPM、APT、[pkgsrc](https://opensource.com/article/19/11/pkgsrc-netbsd-linux) 等等。它的语法和结构可能会令人困惑,但幸运的是,我们还有其他选择,开源的 [CMake](http://cmake.org) 就是其中一个。
CMake 是一个用于构建、测试和打包软件的跨平台套件。它使用简单而清晰的语法,因此即使你以前从未使用过构建系统,也很容易开始使用。
### 安装 CMake
CMake 可能已经安装在你的 Linux 系统上。如果没有,你可以使用发行版的程序包管理器进行安装:
```
$ sudo dnf install cmake
```
在 Debian 或者其他相似的系统上:
```
$ sudo apt install cmake
```
在 Mac 上,你可以使用 [MacPorts](https://opensource.com/article/20/11/macports) 或者 [Homebrew](https://opensource.com/article/20/6/homebrew-linux) 来安装:
```
$ sudo port install cmake
```
在 Windows 上,你可以使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey) 或者直接从 [CMake 网站](https://cmake.org/download) 下载二进制来安装。
### 使用 CMake
对于想要从源代码构建软件的开发人员或用户来说,CMake 是一种快速简便的编译和安装方法。 CMake 分阶段工作:
1. 首先,在 `cmake` 步骤中,CMake 扫描计算机查看一些默认设置。默认设置包括库的位置以及在系统上安装软件的位置。
2. 接下来,使用系统上的 `make` 命令(在 Linux 上是 GUN Make,在 [NetBSD](https://opensource.com/article/19/3/netbsd-raspberry-pi) 上是 NetBSD Make)来编译程序。这个过程通常是将人类可读的源代码转换成机器语言。
3. 最后,在 `make install` 一步中,那些编译过的文件将被拷贝到(在 `cmake` 步骤中扫描出来的)计算机上合适的位置。
这看起来很简单,当你使用 CMake 时就是这样。
### CMake 的可移植性
CMake 在设计时就考虑了可移植性。虽然它不能使你的项目在所有 POSIX 平台上都能正常工作(这取决于作为开发者的你),但它可以确保将标记为要安装的文件安装到已知平台上最合适的位置。而且由于有了 CMake 之类的工具,对于高级用户而言,根据其系统需求自定义和覆盖任何不合适的选项都很容易。
使用 CMake,你只需要知道将哪些文件安装到哪个常规位置即可。它会照顾其他一切。不再需要自定义安装脚本,它们有可能在任何未经测试的操作系统上失败。
### 打包
像 Autotools 一样,CMake 也得到了很好的打包支持。无论它们是打包成 RPM 还是 DEB 或 TGZ(或其他任何东西),将带有 CMake 的项目交给打包者,他们的工作既简单又直接。打包工具支持 CMake,因此可能不需要进行任何修补或者调整。在许多情况下,可以自动将 CMake 项目整合到工作流中。
### 如何使用 CMake
要在项目中使用 CMake,只需在项目目录中创建 `CMakeLists.txt` 文件。首先,声明最低要求的 CMake 版本以及项目名称和版本。CMake 会努力在尽可能长时间内保持兼容性,但是随着你使用的时间越长,并且关注它最新的开发动态,你就会知道哪些特性是你所依赖的。
```
cmake_minimum_required(VERSION 3.10)
project(Hello VERSION 1.0)
```
如你可能已经看到的那样,CMake 的语法是一个带有括号和参数的命令。大写的 `VERSION` 字符串不是任意的,也不只是格式。它们是 `project` 命令中的有效参数。
在继续之前,先写一个简单的 C 或者 C++ 的 `hello world` 程序。为了简单,我就写了六行 C 代码,并把它保存在 `hello.c` 中(为了匹配我在 `CMakeLists.txt` 中可执行文件的名字)。
```
#include <stdio.h>
int main() {
printf("Hello open source\n");
return 0;
}
```
不过,不要搞错了,CMake 不仅适用于 C 和 C++。它可以处理任意文件,并且有许多可用的命令,因此它可以帮助你维护许多不同形式的项目。
CMake 网站中记录了所有有效的内置命令及其可用参数,因此无论你要做什么,都可以轻松发现所需的功能。不过,这是一个简单的示例,因此,你需要的下一个命令是必不可少的 —— 你必须为 CMake 定义要构建的代码:
```
add_executable(Hello hello.c)
```
这个命令指定了你编译后的二进制文件的名字为 `Hello`。因此,它与你在终端中执行带有 `-o Hello` 的 `gcc` 命令是一样的。
在一些比较复杂的项目中,你可能还需要使用库文件,你可以使用 `add library` 命令来链接库文件。
在你设置了你想要构建和标记为安装的文件之后,你必须要告诉 CMake 一旦用户安装了程序,最终的应用程序应该在哪个位置。
在这个简单的例子里,你仅需要做的一件事就是在你的 `CMakeLists.txt` 文件里添加 `install` 命令。`install` 命令接受几个参数。但是在这个例子中,你仅需要使用 `TARGET` 命令来指定你要安装文件的名字。
```
install(TARGETS Hello)
```
### 向 CMake 工程添加一些文件
一个软件项目向用户交付的往往不仅仅只有代码,还有一些其他的文件数据,例如手册或者是信息页、示例项目,或者是配置文件。你可以使用与包含编译文件时类似的工作流程,将任意数据包含在 CMake 项目中:在 `CMakelists.txt` 文件中使用 `file` 命令,然后说明一下这些文件要安装在哪里。
例如,你可以在这个项目中包含一个 `assets` 目录,你可以使用 `file` 命令,后面跟上 `COPY` 和 `DESTINATION` 参数来告诉 CMake 将这些额外的文件复制到你的分发包中。
```
file(COPY assets DESTINATION "${CMAKE_CURRENT_BINARY_DIR}")
```
这个 `${CMAKE_CURRENT_BINARY_DIR}` 变量是一个特殊的 CMake 内置变量,表示 CMake 正在处理的目录。换句话说,你的任何文件都会被复制到编译目录(在你运行 `cmake` 命令后,这个过程会更加清晰,到时候回过头来看一下)。
因为这些额外的数据文件有些杂乱不堪(如果你不信的话,可以看一下 `/usr/share` 这个目录)。对于你自己的项目创建一个子文件夹对谁都有好处。最好也带上版本名字。你可以通过在 `CMAKE_CURRENT_BINARY_DIR` 中指定一个新的目录,使用你选择的项目名称,后面跟一个为你的项目命名的特殊变量和你在项目声明中为它设置的 `VERSION`。
```
file(COPY assets DESTINATION "${CMAKE_CURRENT_BINARY_DIR}/Hello-${Hello_VERSION}")
```
### 定义安装位置
你已经定义你要编译的文件,因此现在你要告诉 CMake 你的程序要安装在哪个位置。比如你的主程序,这个要程使用 `install` 命令:
```
install(DIRECTORY "${CMAKE_CURRENT_BINARY_DIR}/Hello-${Hello_VERSION}" TYPE DATA)
```
这里有一些新的参数。`DIRECTORY` 参数指定了数据文件是一个目录,而不是一个文件(`FILE`)或者脚本(`SCRIPT`)。你使用的参数和复制一些额外文件到编译目录时是一样。另外,在 `install` 命令中 `TYPE` 或者 `DESTINATION` 必须要指定其一。`TYPE` 参数指定了通用的文件类型,这些文件通常将会被放到合适的位置。在 Linux 系统上,`TYPE DATA` 一般是 `/usr/local/share` 或者 `/usr/share`,除非用户定义了其他的位置。
这是诸如 CMake 之类的良好构建系统的强大功能之一。你不必担心文件的确切位置,因为你知道用户可以更改 CMake 的首选默认设置,并且 CMake 将构建代码以使其正常工作。
### 运行 CMake
CMake 有多种方式来让你执行命令,你可以在终端或者在一个可交互的程序上执行命令,或者你也可以使用它的图形界面(GUI)。我比较偏向于使用终端命令,但是我也喜欢使用一些其他的方式(相比与在 `Makefile` 中查找那些晦涩的变量然后去修改它们更胜一筹)。
对于编译过开源 C++ 项目的任何人,都熟悉的第一步是创建一个 `build` 目录,进入到该目录,然后运行 `cmake ..` 命令。 我是一个懒惰的打字员,所以我将构建目录命名为 `b`,但是你可以使用最合适的方式:
```
$ mkdir b
$ cd b
$ cmake ..
-- The C compiler identification is GNU 11.1.1
-- The CXX compiler identification is GNU 11.1.1
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/cc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done
-- Generating done
-- Build files have been written to: /var/home/seth/demo-hello/b
$
```
这或多或少相当于经典的 `./configure; make; make install` 中的 `./configure`。看一下你的构建目录,CMake 已经帮你生成了几个新的文件,来让你的项目更完整。这里生成了 CMake 的数据文件、一个常规的 `Makefile` 文件(这是一个免费提供的 247 行的文件,但对于越复杂的项目,行数要多得多),还有一个包含这个示例程序的任意非编译数据的 `Hello-1.0` 目录。
```
$ ls
CMakeCache.txt
CMakeFiles
Makefile
Hello-1.0
cmake_install.cmake
```
接下来,你可以进行构建。你可以使用 CMake 的 `--build` 选项来做这件事,使用当前的构建目录作为源目录。
```
$ cmake --build .
Scanning dependencies of target Hello
[ 50%] Building C object CMakeFiles/Hello.dir/hello.c.o
[100%] Linking C executable Hello
[100%] Built target Hello
```
或者你可以运行 `make` 命令。这将读取由 CMake 生成的 `Makefile` 文件。在这个例子中,`make` 默认的行为就是由源程序 `hello.c` 生成目标文件。
```
$ make
Scanning dependencies of target Hello
[ 50%] Building C object CMakeFiles/Hello.dir/hello.c.o
[100%] Linking C executable Hello
[100%] Built target Hello
$
```
如你所料,`Hello` 二进制可执行文件现在存在于当前的构建目录中。因为它是一个简单的自包含应用程序,所以你可以运行它进行测试:
```
$ ./Hello
Hello open source
$
```
最后,你可以用 `--install` 选项进行安装。因为我不希望我的简单的 “hello world” 应用程序真的被安装到我的系统上,我设置了 `--prefix` 选项,将 CMake 的目标从根目录(`/`)重定向到 `/tmp` 的一个子目录。
```
$ cmake --install . --prefix /tmp/hello/
-- Install configuration: ""
-- Installing: /tmp/dist-hello/usr/local/bin/Hello
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0/assets/file0
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0/assets/file1
```
另外,你也可以运行 `make install` 来调用 `Makefile` 的安装动作。同样,为了避免在我的系统上安装一个演示程序,我在这个例子中设置了 `DESTDIR` 变量,将安装目标重定向到 `/tmp` 的一个子目录:
```
$ mkdir /tmp/dist-hello
$ make install DESTDIR=/tmp/dist-hello
[100%] Built target Hello
Install the project...
-- Install configuration: ""
-- Installing: /tmp/dist-hello/usr/local/bin/Hello
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0/assets/file0
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0/assets/file1
```
看一下输出的内容,来确定它具体的安装位置,这个程序已经安装好了。
### 快速自定义
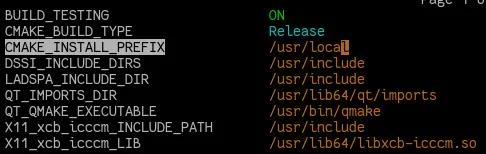
CMake 的安装前缀(由 `CMAKE_INSTALL_PREFIX` 变量指定)默认是在 `/usr/local` 这个位置,但是所有的 CMake 变量都可以在你运行 `cmake` 命令的时候,加一个 `-D` 选项来改变它。
```
$ cmake -DCMAKE_INSTALL_PREFIX=/usr ..
$ make install DESTDIR=/tmp/dist-hello
$ make install DESTDIR=/tmp/dist-hello
[100%] Built target Hello
Install the project...
-- Install configuration: ""
-- Installing: /tmp/dist-hello/usr/bin/Hello
-- Installing: /tmp/dist-hello/usr/share/Hello-1.0
-- Installing: /tmp/dist-hello/usr/share/Hello-1.0/assets/file0
-- Installing: /tmp/dist-hello/usr/share/Hello-1.0/assets/file1
```
所有由 CMake 使用的变量都可以通过这种方式来修改。
### 交互式的 CMake
CMake 的交互模式是一种用于配置安装环境的友好而有用的方法。要让用户知道该项目使用的所有可能的 CMake 变量是一件工作量很大的事,因此 CMake 交互式界面是他们无需查看 `Makefile` 和 `CMakeLists` 即可发现自定义选项的简便方法。
为了调用这个交互式的 CMake,使用 `ccmake` 命令,在这个简单的项目里没有太多的东西。但是对于像 [Rosegarden](https://opensource.com/article/18/3/make-sweet-music-digital-audio-workstation-rosegarden) 这样的大型项目,这将非常有用。

### CMake 的更多知识
还有很多很多的 CMake 知识需要去了解。作为一个开发者,我非常喜欢它简洁的语法、详尽的文档、可扩展性以及便捷性。作为一个用户我非常喜欢 CMake 友好且实用的错误提示信息还有它的用户界面,如果你的项目还未开始使用构建系统,请了解一下 CMake 吧。你以及以后尝试打包你应用程序的任何人都不会后悔。
---
via: <https://opensource.com/article/21/5/cmake>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my [introduction to Autotools](https://opensource.com/article/19/7/introduction-gnu-autotools), I demonstrated how to manage building and packaging code with GNU Autotools. It's a robust and common platform that integrates easily into many packaging systems, including RPM, APT, [pkgsrc](https://opensource.com/article/19/11/pkgsrc-netbsd-linux), and more. Its syntax and structure can be confusing, but luckily there are alternatives, including the open source [CMake](http://cmake.org) framework.
CMake is a cross-platform suite for building, testing, and packaging software. It uses simple and clearly documented syntax, so it's easy to start using even if you've never used a build system before.
## Install CMake
CMake may already be installed on your Linux system. If not, you can install it with your distribution's package manager:
`$ sudo dnf install cmake`
On Debian or similar:
`$ sudo apt install cmake`
For Mac, you can use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-linux):
`$ sudo port install cmake`
On Windows, you can use [Chocolatey](https://opensource.com/article/20/3/chocolatey) or download a binary directly from the [CMake website](https://cmake.org/download).
## CMake at work
For developers or users who want to build software from source code, CMake is a quick and easy way to compile and install it. CMake works in stages:
- First, during the
`cmake`
step, CMake scans the host system (the computer it's being run on) to discover the default settings. Default settings include where support libraries are located and where new software should be placed on the system. - Next, you use your system's
`make`
command (usually GNU Make on Linux, NetBSD Make on[NetBSD](https://opensource.com/article/19/3/netbsd-raspberry-pi), and so on) to build the application, usually by converting human-readable source code into machine language. - Finally, during the
`make install`
step, the built files are copied to the appropriate locations (as detected during the`cmake`
stage) on your computer.
It seems simple, and it is when you use CMake.
## CMake portability
CMake is designed with portability in mind. While it can't make your project work across all POSIX platforms (that's up to you, as the coder), it can ensure that the files you've marked for installation get installed to the most sensible locations on a known platform. And because of tools like CMake, it's trivial for power users to customize and override any non-optimal value according to their system's needs.
With CMake, all you have to know is which files need to be installed to what general location. It takes care of everything else. No more custom install scripts that break on any untested operating system.
## Packaging
Like Autotools, CMake is well-supported. Hand a project with CMake over to a distro packager, whether they're packaging an RPM or a DEB or a TGZ (or anything else), and their job is simple and direct. Packaging tools know CMake, so it's likely there will not be any patching, hacking, or adjustments required. In many cases, incorporating a CMake project into a pipeline can be automated.
## How to use CMake
To start using CMake with your project, you need only to create a `CMakeLists.txt`
file in your project directory. First, declare the minimum required version of CMake and a project title and version. CMake strives to retain compatibility for as long as possible, but the more you use it and follow its development, the better you'll know what features you rely upon.
```
cmake_minimum_required(VERSION 3.10)
project(Hello VERSION 1.0)
```
As you may already be detecting, the syntax of CMake is a command followed by parameters in parentheses. The capitalized `VERSION`
strings aren't arbitrary or just for style; they're valid parameters for the `project`
command.
Before continuing, generate a sample `hello world`
application in C or C++. For simplicity, I wrote six lines of C code and saved it as `hello.c`
(to match the executable I list in `CMakeLists.txt`
):
```
#include <stdio.h>
int main() {
printf("Hello open source\n");
return 0;
}
```
Make no mistake, though, CMake is useful beyond just C and C++. It can handle arbitrary files and has lots of commands available to it, so it can help you maintain projects in many different forms.
The CMake website documents all valid built-in commands and their available parameters, so it's easy to uncover the functions you need, no matter what you're trying to do. This is a simple example, though, so the next command you need is essential—you must define for CMake what code you're building:
`add_executable(Hello hello.c)`
This sets the name of your compiled binary to `Hello`
, so functionally, it's the same as running `gcc`
with `-o Hello`
in your terminal.
In a complex project, you likely have libraries as well as executables. You can add libraries with the `add_library`
command.
After you've set what files you want built and marked for installation, you must tell CMake where the finished product should end up once a user installs your application.
In this simple example, only one thing is marked for installation, so you only have to add one `install`
line to your `CMakeLists`
. The `install`
command accepts a few parameters, but in this case, all that's necessary is the `TARGETS`
parameter followed by the name of the file to install:
`install(TARGETS Hello)`
### Adding files to a CMake project
A software project rarely just delivers code to its users. There's usually some additional data, such as manual or info pages, example projects, or configuration files. You can include arbitrary data in a CMake project using a similar workflow to when you include compiled files: first, add the file to `CMakeLists.txt`
and then describe how it is to be installed.
For example, to include a directory called `assets`
with your sample application, you use the `file`
command, followed by the `COPY`
and `DESTINATION`
parameters to tell CMake to copy your additional files into your distributable package:
`file(COPY assets DESTINATION "${CMAKE_CURRENT_BINARY_DIR}")`
The `${CMAKE_CURRENT_BINARY_DIR}`
is a special built-in CMake variable representing the path to the directory currently being processed by CMake. In other words, your arbitrary data gets copied to the build directory (this becomes even clearer after you run `cmake`
, so watch for this to come up again later).
Because data directories tend to be crowded places (take a look in `/usr/share`
if you don't believe me), it's to everyone's benefit for you to create a subdirectory for your own project, preferably with versioning. You can do this by specifying a new directory within `CMAKE_CURRENT_BINARY_DIR`
using your chosen project name followed by a special variable named for your project and the `VERSION`
you set for it in your project declaration:
`file(COPY assets DESTINATION "${CMAKE_CURRENT_BINARY_DIR}/Hello-${Hello_VERSION}")`
## Defining install locations
You've defined the file for the build process, so now you must tell CMake where to put it during the install process. Like your main executable, this uses the `install`
command:
`install(DIRECTORY "${CMAKE_CURRENT_BINARY_DIR}/Hello-${Hello_VERSION}" TYPE DATA)`
There are some new parameters here. The `DIRECTORY`
parameter identifies the data source as a directory (rather than `FILE`
or `SCRIPT`
, for instance). You're using the same variables as you used when copying the data files into the build location. Additionally, either a `TYPE`
or a `DESTINATION`
must be provided for `install`
(not both). The `TYPE`
argument specifies a generic file type, which is placed into a location appropriate to the target system. On Linux, a `TYPE DATA`
directory usually gets placed into `/usr/local/share`
or `/usr/share`
, unless the user or packager has defined a different data location.
That's one of the powerful things about a good build system like CMake. You don't have to worry about exactly where files end up because you know that the user can alert CMake of their preferred defaults and that CMake will build the code to make that work.
## Running CMake
CMake has several interfaces. You can use it from your terminal as a command or an interactive application, or you can use its graphical user interface (GUI) front end. I tend to use the terminal command, but I enjoy the other user experiences just as much (they definitely beat scrubbing through Makefiles in search of obscure variables to redefine).
The first step, familiar to anyone who's built their fair share of open source C++ projects, is to create a `build`
directory, change to it, and then run the `cmake ..`
command. I'm a lazy typist, so I name my build directory `b`
, but you can use whatever makes the most sense to you:
```
$ mkdir b
$ cd b
$ cmake ..
-- The C compiler identification is GNU 11.1.1
-- The CXX compiler identification is GNU 11.1.1
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /usr/bin/cc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Configuring done
-- Generating done
-- Build files have been written to: /var/home/seth/demo-hello/b
$
```
This is, more or less, the equivalent of `./configure`
in the classic `./configure; make; make install`
incantation. A look into your build directory reveals that CMake has generated several new files to help your project come together. There's some CMake data, a regular Makefile (that's 247 lines of code for free, but quite a lot more for complex projects), and the `Hello-1.0`
data directory containing the arbitrary non-compiled data distributed with this example application:
```
$ ls
CMakeCache.txt
CMakeFiles
Makefile
Hello-1.0
cmake_install.cmake
```
Next, you can build. You can do this with CMake using the `--build`
option, using the current build directory as the source directory:
```
$ cmake --build .
Scanning dependencies of target Hello
[ 50%] Building C object CMakeFiles/Hello.dir/hello.c.o
[100%] Linking C executable Hello
[100%] Built target Hello
```
Or you can run the `make`
command. This reads the `Makefile`
generated by CMake. In this example, the default action for Make is to compile its target, `hello.c`
:
```
$ make
Scanning dependencies of target Hello
[ 50%] Building C object CMakeFiles/Hello.dir/hello.c.o
[100%] Linking C executable Hello
[100%] Built target Hello
$
```
As you might expect, the `Hello`
binary executable now exists in your current build directory. Because it's a simple self-contained application, you can run it for testing purposes:
```
$ ./Hello
Hello open source
$
```
Finally, you can install with the `--install`
option. Because I don't want my simple "hello world" application to actually get installed on my system, I set the `--prefix`
option to redirect CMake's target from the root directory (`/`
) to a subdirectory in `/tmp`
:
```
$ cmake --install . --prefix /tmp/hello/
-- Install configuration: ""
-- Installing: /tmp/dist-hello/usr/local/bin/Hello
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0/assets/file0
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0/assets/file1
```
Alternately, you can run `make install`
to invoke the install actions of the Makefile. Again, to avoid a demo application to be installed on my system, I set the `DESTDIR`
variable in this example to redirect the install target to a subdirectory in `/tmp`
:
```
$ mkdir /tmp/dist-hello
$ make install DESTDIR=/tmp/dist-hello
[100%] Built target Hello
Install the project...
-- Install configuration: ""
-- Installing: /tmp/dist-hello/usr/local/bin/Hello
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0/assets/file0
-- Installing: /tmp/dist-hello/usr/local/share/Hello-1.0/assets/file1
```
The output confirms its actions, and the application is installed.
## Quick customization
CMake's install prefix (the `CMAKE_INSTALL_PREFIX`
variable) defaults to `/usr/local`
, but any CMake variable can be customized when you run `cmake`
with the `-D`
option:
```
$ cmake -DCMAKE_INSTALL_PREFIX=/usr ..
$ make install DESTDIR=/tmp/dist-hello
$ make install DESTDIR=/tmp/dist-hello
[100%] Built target Hello
Install the project...
-- Install configuration: ""
-- Installing: /tmp/dist-hello/usr/bin/Hello
-- Installing: /tmp/dist-hello/usr/share/Hello-1.0
-- Installing: /tmp/dist-hello/usr/share/Hello-1.0/assets/file0
-- Installing: /tmp/dist-hello/usr/share/Hello-1.0/assets/file1
```
Any variable used by CMake can be customized in this way.
## Interactive CMake
CMake's interactive mode is a friendly and useful method to configure an installation environment. It's a lot to ask your users to know all the possible CMake variables your project uses, so the CMake interactive interface is an easy way for them to discover customization options without looking at Makefiles and CMakeLists.
To invoke an interactive CMake session, use the `ccmake`
command. There's not much to see for this simple example project, but a big project like the digital audio workstation [Rosegarden](https://opensource.com/article/18/3/make-sweet-music-digital-audio-workstation-rosegarden) makes the user interface invaluable.
(Seth Kenlon, CC BY-SA 4.0)
## More CMake
There's much, much more to CMake. As a developer, I enjoy CMake for its simple syntax and extensive [documentation](https://cmake.org/cmake/help/latest/), extensibility, and expediency. As a user, I appreciate CMake for its friendly and helpful error messages and user interfaces. If you're not using a build system for your project, take a look at CMake. You, and anyone trying to package your application later, won't be sorry.
## 3 Comments |
13,420 | 4 款值得一试的 Linux 终端多路复用器 | https://opensource.com/article/21/5/linux-terminal-multiplexer | 2021-05-24T20:51:09 | [
"终端",
"多路复用器"
] | https://linux.cn/article-13420-1.html |
>
> 比较 tmux、GNU Screen、Konsole 和 Terminator,看看哪个最适合你。
>
>
>

Linux 用户通常需要大量的虚拟视觉空间。一个终端窗口是永远不够的,所以终端有了标签。一个桌面太受限制了,所以有了虚拟桌面。当然,应用程序窗口可以堆叠,但当它们堆叠起来时,又有多大的好处呢?哎呀,即使是后台文本控制台也有 `F1` 到 `F7`,可以在任务之间来回翻转。
有了这么多的多任务处理方式,有人发明了终端 *多路复用器* 的概念就不奇怪了。诚然,这是一个令人困惑的术语。在传统的电子学中,“<ruby> 多路复用器 <rt> multiplexer </rt></ruby>”是一个接收多个输入信号并将选定的信号转发到单一输出的部件。终端多路复用器的作用正好相反。它从一个输入(人类在键盘上向一个终端窗口打字)接收指令,并将该输入转发给任意数量的输出(例如,一组服务器)。
然后,“多路复用器”一词在美国也是一个流行的术语,指的是有许多屏幕的电影院(与“<ruby> 影城 <rt> cineplex </rt></ruby>”一词一个意思)。在某种程度上,这很好地描述了终端复用器的作用。它可以在一个框内提供许多屏幕。
不管这个词是什么意思,任何尝试过它的人都有自己的喜好的某一种多路复用器。因此,我决定考察一些流行的终端多路复用器,看看每一个都怎么样。就我的评估标准而言,最低限度,我需要每个多路复用器能够分割*和*堆叠终端窗口。
### tmux

据我所知,是从 tmux 开始使用“多路复用器”这个术语的。它工作的很出色。
它作为一个守护程序运行,这样即使你关闭了正在查看的终端模拟器,你的终端会话仍然处于活动状态。它将你的终端屏幕分割成多个面板,这样你就可以在每个面板上打开独特的终端提示符。
推而广之,这意味着你也可以远程连接到任何数量的系统,并在你的终端中打开它们。利用 tmux 的能力,将输入镜像(或者以电子学术语说是“反向多路复用”)到其他打开的窗格,就能从一个中央命令窗格同时控制几台计算机。
tmux 在 GNU Screen 还只能水平分割的时候就有了垂直分割能力,这吸引了追求最大灵活性的粉丝。而灵活性正是用户在 tmux 中得到的。它可以分割、堆叠、选择和提供服务;几乎没有什么是它做不到的。
#### ? 软件包大小
从软件包中安装 tmux 大约需要 700K,这还不算它所依赖的十几个共享库。
#### ?️ 控制键
tmux 的默认触发键是 `Ctrl+B`,尽管很容易在其配置文件中重新定义。
#### ⌨️ 黑客因子
即使你只是在学习如何使用终端,你也一定会觉得使用 tmux 的人很像黑客。它看起来很复杂,但一旦你了解了正确的键绑定,就很容易使用。它为你提供了很多有用的技巧,让你玩的飞起,而且它是一种快速构建 HUD(抬头显示器)的超简单方法,可以把你需要的所有信息摆在你面前。
### GNU Screen

像 tmux 一样,GNU Screen 也运行一个守护程序,所以即使你关闭了用来启动它的终端,你的 shell 仍然可用。你可以从不同的计算机上连接并共享屏幕。它可以将你的终端屏幕分割成水平或垂直的窗格。
与 tmux 不同的是,GNU Screen 可以通过串行连接进行连接(`screen 9600 /dev/ttyUSB0` 就可以了),通过按键绑定可以方便地发出 `XON` 和 `XOFF` 信号。
与 SSH 会话相比,在串行连接中需要多路复用器的情况可能并不常见,所以大多数用户并不了解 Screen 这个真正特殊的功能。不过,GNU Screen 是一个很棒的多路复用器,有很多有用的选项。而如果你真的需要同时向多个服务器发送信号,还有专门的工具,比如 ClusterSSH 和 [Ansible](https://opensource.com/article/19/2/quickstart-guide-ansible)。
#### ? 软件包大小
从软件包中安装 GNU Screen 大约需要 970K,这还不算它所依赖的十几个共享库。
#### ?️ 控制键
GNU Screen 的默认触发键是 `Ctrl+A`,这对于熟悉 Bash 快捷键的人来说可能特别烦人。幸运的是,你可以在配置文件中轻松地重新定义这个触发键。
#### ⌨️ 黑客因子
当使用 Screen 通过串行连接到你的路由器或你的原型电路板时,你会成为你所有硬件黑客朋友羡慕的对象。
### Konsole

对于没有标榜自己是多路复用器的 Konsole 来说,令人惊讶的是它也是其中一个。它可以使用 Qt 窗格和标签进行必要的窗口分割和堆叠,但它也可以通过“编辑(将输入复制到)”菜单中的一个选项将输入从一个窗格传到另一个(或全部)。
然而,它所最明显缺乏的功能是作为一个守护程序运行以进行远程重新连接的能力。与 tmux 和 GNU Screen 不同,你不能远程连接到运行 Konsole 的机器并加入会话。对于一些管理员来说,这可能不是一个问题。许多管理员用 [VNC](https://en.wikipedia.org/wiki/Virtual_Network_Computing) 连接到机器的次数比用 [SSH](https://en.wikipedia.org/wiki/Secure_Shell_Protocol) 还要多,所以“重新加入”一个会话就像在 VNC 客户端上点击 Konsole 窗口一样简单。
使用 Konsole 作为多路复用器是 KDE 极客们的大招。Konsole 是我使用的第一个 Linux 终端(直到今天,我有时也会按 `Ctrl+N` 来切换新标签),所以有能力使用这个熟悉的终端作为多路复用器是一个很大的便利。这绝不是必要的,因为无论如何 tmux 和 Screen 都可以在 Konsole 里面运行,但是通过让 Konsole 处理窗格,我就不必调整肌肉记忆。这种微妙的功能包容正是 [KDE 的伟大之处](https://opensource.com/article/19/12/linux-kde-plasma)。
#### ? 软件包大小
Konsole 本身大约是 11KB,但它依赖于 105 个 KDE 和 Qt 库,所以实际上,它至少有 50MB。
#### ?️ 控制键
大多数重要的 Konsole 快捷键以 `Shift+Ctrl` 开始,分割屏幕、打开新标签、复制输入到其他窗格等都是如此。这是 KDE 里的主控台,所以如果你对 Plasma 桌面很熟悉,会感觉快捷键很熟悉。
#### ⌨️ 黑客因子
使用 Konsole 作为你的多路复用器让你有资格称自己为 KDE 高级用户。
### Terminator

对于 GNOME 用户来说,Terminator 多路复用器是为他们原本极简的 GNOME 终端增加功能的一个简单方法。除了必要的多路复用功能外,Terminator 还可以向所有打开的窗格广播输入,但和 Konsole 一样,它不会在后台运行以便你可以通过 SSH 重新连接到它。话说回来,由于 GNOME 和 Wayland 让 VNC 变得如此简单,你有可能会觉得没有必要通过 SSH 来恢复终端会话。
如果你愿意,Terminator 可以完全由鼠标驱动。Konsole 通过其主菜单也有同样的能力。有了 Terminator,你可以在 Shell 的任何地方点击右键,弹出相关选项,以水平或垂直分割窗口,将窗格分组作为广播目标,广播输入,关闭窗格,等等。你还可以为所有这些动作配置键盘快捷键,所以在许多方面,你可以形成自己的体验。
我认为自己主要是一个 KDE 用户,所以当我说 Terminator 感觉像一个 KDE 应用时,我其实是一种极大的赞美。Terminator 是一个令人惊讶的可配置的和灵活的应用程序。在许多方面,它体现了开源的力量,把简陋的 GNOME 终端变成了一个强大的多路复用器。
#### ? 软件包大小
Terminator 的安装容量为 2.2MB,其中大部分是 Python 模块。但它依赖于 GTK3 和 GNOME,所以如果你没有运行完整的 GNOME 桌面,可以预料你需要一个更大的安装来拉入这些依赖。
#### ?️ 控制键
Terminator 的默认控制键没有什么一致性。你可以用 `Alt` 键来执行一些命令,用 `Ctrl` 来执行其他命令,还可以用 `Shift+Ctrl`、`Ctrl+Alt`、`Shift+Super` 等等,还有鼠标。话说回来,这是我试过的最可配置的多路复用器之一,所以只要有想法,稍加努力,你就能设计出适合你的模式。
#### ⌨️ 黑客因子
当你使用 Terminator 时,你会觉得自己是最现代、最务实的黑客。由于它的各种极客选项,它是多路复用的最佳选择,而且由于它非常灵活,无论你的手是在键盘上,还是键盘和鼠标并用,你都可以同样轻松地使用它。
### 我全要
还有更多的多路复用器和一些具有类似多路复用能力的应用。你不必非要找到*一个*完全按照你想要的方式完成你需要的所有工作的多路复用器。你可以使用不止一个。事实上,你甚至可以同时使用多个,因为 tmux 和 Screen 实际上是 shell,而 Konsole 和 Terminator 是显示 shell 的终端。对唾手可得的工具感到舒适,而且它们能帮助你管理你的工作空间,使你能有效地工作,才是最重要的。
去尝试一下多路复用器,或者在你喜欢的应用程序中发现类似多路复用器的功能。它可能会改变你看待计算的方式。
---
via: <https://opensource.com/article/21/5/linux-terminal-multiplexer>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux users generally need a lot of virtual visual space. One terminal window is never enough, so terminals have tabs. One desktop is too constraining, so there are virtual desktops. And sure, application windows can stack, but how much better is it when they tile? Heck, even the back-end text console has F1 to F7 available for flipping back and forth between tasks.
With this much multitasking going on, it's no surprise that somebody invented the concept of a terminal *multiplexer*. This is admittedly a confusing term. In traditional electronics, a "multiplexer" is a component that receives several input signals and forwards the selected one to a single output. A terminal multiplexer does the opposite. It receives instructions from one input (the human at the keyboard typing into one terminal window) and forwards that input to any number of outputs (for example, a group of servers).
Then again, the term "multiplex" is also a term popular in the US for a cinema with many screens (sharing mindshare with the term "cineplex"). In a way, that's pretty descriptive of what a terminal multiplexer can do: It can provide lots of screens within one frame.
Whatever the term means, anybody who's tried a multiplexer has a favorite. So, I decided to take a look at a few of the popular ones to see how each one measures up. In terms of my evaluation criteria, at the bare minimum, I needed each multiplexer to split *and* stack terminal windows.
## Tmux
(Seth Kenlon, CC BY-SA 4.0)
As far as I know, it was tmux that started using the "multiplexer" term. It's great at what it does.
It runs as a daemon so that your terminal session remains active even after you close the terminal emulator you're viewing it in. It splits your terminal screen into panes so that you can open unique terminal prompts in each.
By extension, this means you can also connect remotely to any number of systems and have them open in your terminal, too. Using tmux's ability to mirror (or reverse multiplex, in electronics terms) input to other open panes, it's possible to control several computers at once from one central command pane.
Tmux had vertical splits back when GNU Screen only had horizontal splits, which attracted fans looking for maximum flexibility. And flexibility is what users get with tmux. It can split, stack, select, and serve; there's practically nothing it can't do.
### ? Size
Installing tmux from a package occupies roughly 700K, not counting the dozen shared libraries it depends upon.
### ?️ Control
The default trigger key for tmux is **Ctrl+B**, although it's easy to redefine this in its configuration file.
### ⌨️ Hacker factor
Even if you're just learning how to use the terminal, you're sure to feel every bit like the hacker you are by using tmux. It looks complex, but once you get to know the right key bindings it's easy to use. It provides you with lots of useful tricks to keep yourself busy, and it's a pretty easy way to construct a quick HUD with all the information you need in front of you.
## GNU Screen
(Seth Kenlon, CC BY-SA 4.0)
Like tmux, GNU Screen runs a daemon, so your shell is available even after you close the terminal you use to launch it. You can connect from separate computers and share Screen. It splits your terminal screen into horizontal or vertical panes.
And unlike tmux, GNU Screen can connect over a serial connection (`screen 9600 /dev/ttyUSB0`
is all it takes), with key bindings for easy XON and XOFF signals.
It's probably less common to need a multiplexer over a serial connection than over an SSH session, so Screen's really special feature is lost on most users. Still, GNU Screen is a great multiplexer with many useful options, and if you really really need to send signals to multiple servers at once, there are always dedicated tools like ClusterSSH and [Ansible](https://opensource.com/article/19/2/quickstart-guide-ansible).
### ? Size
Installing GNU Screen from a package occupies roughly 970K, not counting the dozen shared libraries it depends upon.
### ?️ Control
The default trigger key for GNU Screen is **Ctrl+A**, which can be particularly annoying for anyone familiar with Bash shortcuts. Luckily, you can easily redefine this trigger in the configuration file.
### ⌨️ Hacker factor
You'll be the envy of all your hardware hacker friends when using Screen to connect over a serial connection to your router or your prototype circuit board.
## Konsole
(Seth Kenlon, CC BY-SA 4.0)
For not billing itself as a multiplexer, Konsole is a surprisingly effective one. It can do the requisite splitting and stacking of windows using Qt panes and tabs, but it can also echo input from one pane to another (or all) through an option in the **Edit (Copy input to)** menu.
The most notable feature that it lacks, however, is the ability to run as a daemon for remote reconnection. Unlike Tmux and GNU Screen, you can't connect remotely to a machine running Konsole and join the session. For some admins, this may not be an issue. Many admins [VNC](https://en.wikipedia.org/wiki/Virtual_Network_Computing) to machines more often than they [SSH](https://en.wikipedia.org/wiki/Secure_Shell_Protocol), so "rejoining" a session is as trivial as clicking on the Konsole window in a VNC client.
Using Konsole as a multiplexer is a power move for KDE geeks. Konsole was the first Linux terminal I used (to this day, I sometimes press **Ctrl+N** for a new tab), so having the ability to use this familiar terminal as a multiplexer is a great convenience. It's by no means necessary because tmux and Screen both run inside Konsole anyway, but by letting Konsole handle panes, I don't have to adjust my muscle memory. This kind of subtle feature inclusion is exactly [what makes KDE so great](https://opensource.com/article/19/12/linux-kde-plasma).
### ? Size
Konsole itself is roughly 11KB, but it relies on 105 KDE and Qt libraries, so effectively, it's more like 50MB at minimum.
### ?️ Control
Most important Konsole shortcuts start with **Shift+Ctrl**, and that's the case with splitting screens, opening new tabs, copying input to other panes, and so on. It's just Konsole, so if you're comfortable with the Plasma desktop, this feels familiar.
### ⌨️ Hacker factor
Using Konsole as your multiplexer gives you the right to call yourself a KDE power user.
## Terminator
(Seth Kenlon, CC BY-SA 4.0)
For GNOME users, the Terminator multiplexer is an easy way to add power to their otherwise minimal GNOME terminal. In addition to the requisite multiplex features, Terminator can broadcast input to all open panes, but like Konsole, it can't run in the background so that you can reattach to it over SSH. Then again, with GNOME and Wayland making VNC so easy, it's possible that you won't feel the need to SSH in to continue a terminal session.
If you want it to be, Terminator can be entirely mouse-driven. Konsole has the same ability through its main menu. With Terminator, you can right-click anywhere in your shell and bring up relevant options to split the window horizontally or vertically, group panes together to target them for broadcasts, broadcast input, close panes, and so on. You can also configure keyboard shortcuts for all of these actions, so in many ways, you can build your own experience.
I consider myself mostly a KDE user, so when I say Terminator feels like a K-app, I mean that as a great compliment. Terminator is a surprisingly configurable and flexible application. In many ways, it exemplifies the power of open source by taking the humble GNOME Terminal and transforming it into a powerful multiplexer.
### ? Size
Terminator is 2.2MB to install, most of which are Python modules. It relies on GTK3 and GNOME, though, so if you're not running the full GNOME desktop, you can expect a much larger install for pulling in these dependencies.
### ?️ Control
There's not much consistency in Terminator's default controls. You use the **Alt** key for some commands, **Ctrl** for others, **Shift+Ctrl**, **Ctrl+Alt**, **Shift+Super**, and the mouse. Then again, it's one of the most configurable multiplexers I tried, so with an opinion and a little effort, you can design a schema that works for you.
### ⌨️ Hacker factor
You'll feel like the most modern and pragmatic of hackers when you use Terminator. With all of its geeky options, it's a great choice for multiplexing, and because it's so flexible you can use it just as easily whether your hands are on your keyboard or split between your keyboard and mouse.
## Choose them all
There are more multiplexers out there and several applications with multiplex-like abilities. You don't have to find the *one* multiplexer that does everything you need it to do exactly the way you want it done. You're allowed to use more than one. In fact, you can even use more than one at the same time because tmux and Screen are effectively shells, while Konsole and Terminator are terminals that display a shell. The important things are that you feel comfortable with the tools at your fingertips, and they help you manage your workspace so that you can work efficiently.
Go try a multiplexer, or discover multiplex-like features in your favorite application. It might just change the way you view computing.
## 11 Comments |
13,422 | Git 中上下文切换的 4 种方式 | https://opensource.com/article/21/4/context-switching-git | 2021-05-25T09:18:00 | [
"Git",
"分支"
] | https://linux.cn/article-13422-1.html |
>
> 比较 Git 中四种切换分支的方法的优缺点。
>
>
>

所有大量使用 Git 的人都会用到某种形式的上下文切换。有时这只会给你的工作流程增加少量的开销,但有时,这可能是一段痛苦的经历。
让我们用以下这个例子来讨论一些常见的上下文切换策略的优缺点:
>
> 假设你在一个名为 `feature-X` 的分支中工作。你刚刚发现你需要解决一个无关的问题。这不能在 `feature-X` 分支中完成。你需要在一个新的分支 `feature-Y` 中完成这项工作。
>
>
>
### 方案 1:暂存 + 分支
解决此问题最常见的工作流程可能如下所示:
1. 停止分支 `feature-X` 上的工作
2. `git stash`
3. `git checkout -b feature-Y origin/main`
4. 一顿鼓捣,解决 `feature-Y` 的问题
5. `git checkout feature-X` 或 `git switch -`
6. `git stash pop`
7. 继续在 `feature-X` 中工作
**优点:** 这种方法的优点在于,对于简单的更改,这是一个相当简单的工作流程。它可以很好地工作,特别是对于小型仓库。
**缺点:** 使用此工作流程时,一次只能有一个工作区。另外,根据你的仓库的状态,使用暂存是一个麻烦的环节。
### 方案 2:WIP 提交 + 分支
这个解决方案和前一个非常相似,但是它使用 WIP(<ruby> 正在进行的工作 <rt> Work in Progress </rt></ruby>)提交而不是暂存。当你准备好切换回来,而不是弹出暂存时,`git reset HEAD~1` 会展开 WIP 提交,你可以自由地继续,就像之前的方案一样,但不会触及暂存。
1. 停止分支 `feature-X` 上的工作
2. `git add -u`(仅仅添加修改和删除的文件)
3. `git commit -m "WIP"`
4. `git checkout -b feature-Y origin/master`
5. 一顿鼓捣,解决 `feature-Y` 的问题
6. `git checkout feature-X` 或 `git switch -`
7. `git reset HEAD~1`
**优点:** 对于简单的更改,这是一个简单的工作流,也适合于小型仓库。你不需要使用暂存。
**缺点:** 任何时候都只能有一个工作区。此外,如果你或你的代码审阅者不够谨慎,WIP 提交可能会合并到最终产品。
使用此工作流时,你**永远**不要想着将 `--hard` 添加到 `git reset`。如果你不小心这样做了,你应该能够使用 `git reflog` 恢复提交,但是你最好完全避免这种情况发生,否则你会听到心碎的声音。
### 方案 3:克隆一个新仓库
在这个解决方案中,不是创建新的分支,而是为每个新的功能分支创建存储库的新克隆。
**优点:** 你可以同时在多个工作区中工作。你不需要 `git stash` 或者是 WIP 提交。
**缺点:** 需要考虑仓库的大小,因为这可能会占用大量磁盘空间(浅层克隆可以帮助解决这种情况,但它们可能并不总是很合适。)此外,你的仓库克隆将互不可知。因为他们不能互相追踪,所以你必须手动追踪你的克隆的源仓库。如果需要 git 钩子,则需要为每个新克隆设置它们。
### 方案 4:git 工作树
要使用此解决方案,你可能需要了解 `git add worktree`。如果你不熟悉 Git 中的工作树,请不要难过。许多人多年来都对这个概念一无所知。
#### 什么是工作树?
将工作树视为仓库中属于项目的文件。本质上,这是一种工作区。你可能没有意识到你已经在使用工作树了。开始使用 Git 时,你将自动获得第一个工作树。
```
$ mkdir /tmp/foo && cd /tmp/foo
$ git init
$ git worktree list
/tmp 0000000 [master]
```
你可以在以上代码看到,甚至在第一次提交前你就有了一个工作树。接下来去尝试再添加一个工作树到你的项目中吧。
#### 添加一个工作树
想要添加一个新的工作树你需要提供:
1. 硬盘上的一个位置
2. 一个分支名
3. 添加哪些分支
```
$ git clone https://github.com/oalders/http-browserdetect.git
$ cd http-browserdetect/
$ git worktree list
/Users/olaf/http-browserdetect 90772ae [master]
$ git worktree add ~/trees/oalders/feature-X -b oalders/feature-X origin/master
$ git worktree add ~/trees/oalders/feature-Y -b oalders/feature-Y e9df3c555e96b3f1
$ git worktree list
/Users/olaf/http-browserdetect 90772ae [master]
/Users/olaf/trees/oalders/feature-X 90772ae [oalders/feature-X]
/Users/olaf/trees/oalders/feature-Y e9df3c5 [oalders/feature-Y]
```
与大多数其他 Git 命令一样,你需要在仓库路径下使用此命令。一旦创建了工作树,就有了隔离的工作环境。Git 仓库会跟踪工作树在磁盘上的位置。如果 Git 钩子已经在父仓库中设置好了,那么它们也可以在工作树中使用。
请注意到,每个工作树只使用父仓库磁盘空间的一小部分。在这种情况下,工作树需要只大约三分之一的原始磁盘空间。这这非常适合进行扩展。如果你的仓库达到了千兆字节的级别,你就会真正体会到工作树对硬盘空间的节省。
```
$ du -sh /Users/olaf/http-browserdetect
2.9M
$ du -sh /Users/olaf/trees/oalders/feature-X
1.0M
```
**优点:** 你可以同时在多个工作区中工作。你不需要使用暂存。Git 会跟踪所有的工作树。你不需要设置 Git 钩子。这也比 `git clone` 更快,并且可以节省网络流量,因为你可以在飞行模式下执行此操作。你还可以更高效地使用磁盘空间,而无需借助于浅层克隆。
**缺点:** 这是个需要你额外学习和记忆的新东西,但是如果你能养成使用这个功能的习惯,它会给你丰厚的回报。
#### 额外的小技巧
有很多方式可以清除工作树,最受欢迎的方式是使用 Git 来移除工作树:
```
git worktree remove /Users/olaf/trees/oalders/feature-X
```
如果你喜欢 RM 大法,你也可以用 `rm -rf` 来删除工作树。
```
rm -rf /Users/olaf/trees/oalders/feature-X
```
但是,如果执行此操作,则可能需要使用 `git worktree prune` 清理所有剩余的文件。或者你现在可以跳过清理,这将在将来的某个时候通过 `git gc` 自行完成。
#### 注意事项
如果你准备尝试 `git worktree`,请记住以下几点:
* 删除工作树并不会删除该分支。
* 可以在工作树中切换分支。
* 你不能在多个工作树中同时签出同一个分支。
* 像其他命令一样,`git worktree` 需要从仓库内运行。
* 你可以同时拥有许多工作树。
* 要从同一个本地仓库签出创建工作树,否则它们将互不可知。
#### git rev-parse
最后一点注意:在使用 `git worktree` 时,仓库根所在的位置可能取决于上下文。幸运的是,`git rev parse` 可以让你区分这两者。
* 要查找父仓库的根目录,请执行以下操作:
```
git rev-parse --git-common-dir
```
* 要查找你当前所在仓库的根目录,请执行:
```
git rev-parse --show-toplevel
```
### 根据你的需要选择最好的方法
就像很多事情一样,TIMTOWDI(<ruby> 条条大道通罗马 <rt> there's more than one way to do it </rt></ruby>)。重要的是你要找到一个适合你需要的工作流程。你的需求可能因手头的问题而异。也许你偶尔会发现自己将 `git worktree` 作为版本控制工具箱中的一个方便工具。
---
via: <https://opensource.com/article/21/4/context-switching-git>
作者:[Olaf Alders](https://opensource.com/users/oalders) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Anyone who spends a lot of time working with Git will eventually need to do some form of context switching. Sometimes this adds very little overhead to your workflow, but other times, it can be a real pain.
Let's discuss the pros and cons of some common strategies for dealing with context switching using this example problem:
Imagine you are working in a branch called
`feature-X`
. You have just discovered you need to solve an unrelated problem. This cannot be done in`feature-X`
. You will need to do this work in a new branch,`feature-Y`
.
## Solution #1: stash + branch
Probably the most common workflow to tackle this issue looks something like this:
- Halt work on the branch
`feature-X`
`git stash`
`git checkout -b feature-Y origin/main`
- Hack, hack, hack…
`git checkout feature-X`
or`git switch -`
`git stash pop`
- Resume work on
`feature-X`
**Pros:** The nice thing about this approach is that this is a fairly easy workflow for simple changes. It can work quite well, especially for small repositories.
**Cons:** When using this workflow, you can have only one workspace at a time. Also, depending on the state of your repository, working with the stash can be non-trivial.
## Solution #2: WIP commit + branch
A variation on this solution looks quite similar, but it uses a WIP (Work in Progress) commit rather than the stash. When you're ready to switch back, rather than popping the stash, `git reset HEAD~1`
unrolls your WIP commit, and you're free to continue, much as you did in the earlier scenario but without touching the stash.
- Halt work on the branch
`feature-X`
`git add -u`
(adds only modified and deleted files)`git commit -m "WIP"`
`git checkout -b feature-Y origin/master`
- Hack, hack, hack…
`git checkout feature-X`
or`git switch -`
`git reset HEAD~1`
**Pros:** This is an easy workflow for simple changes and also good for small repositories. You don't have to work with the stash.
**Cons:** You can have only one workspace at any time. Also, WIP commits can sneak into your final product if you or your code reviewer are not vigilant.
When using this workflow, you *never* want to add a `--hard`
to `git reset`
. If you do this accidentally, you should be able to restore your commit using `git reflog`
, but it's less heartstopping to avoid this scenario entirely.
## Solution #3: new repository clone
In this solution, rather than creating a new branch, you make a new clone of the repository for each new feature branch.
**Pros:** You can work in multiple workspaces simultaneously. You don't need `git stash`
or even WIP commits.
**Cons:** Depending on the size of your repository, this can use a lot of disk space. (Shallow clones can help with this scenario, but they may not always be a good fit.) Additionally, your repository clones will be agnostic about each other. Since they can't track each other, you must track where your clones live. If you need git hooks, you will need to set them up for each new clone.
## Solution #4: git worktree
To use this solution, you may need to learn about `git add worktree`
. Don't feel bad if you're not familiar with worktrees in Git. Many people get by for years in blissful ignorance of this concept.
### What is a worktree?
Think of a worktree as the files in the repository that belong to a project. Essentially, it's a kind of workspace. You may not realize that you're already using worktrees. When using Git, you get your first worktree for free.
```
$ mkdir /tmp/foo && cd /tmp/foo
$ git init
$ git worktree list
/tmp 0000000 [master]
```
As you can see, the worktree exists even before the first commit. Now, add a new worktree to an existing project.
### Add a worktree
To add a new worktree, you need to provide:
- A location on disk
- A branch name
- Something to branch from
```
$ git clone https://github.com/oalders/http-browserdetect.git
$ cd http-browserdetect/
$ git worktree list
/Users/olaf/http-browserdetect 90772ae [master]
$ git worktree add ~/trees/oalders/feature-X -b oalders/feature-X origin/master
$ git worktree add ~/trees/oalders/feature-Y -b oalders/feature-Y e9df3c555e96b3f1
$ git worktree list
/Users/olaf/http-browserdetect 90772ae [master]
/Users/olaf/trees/oalders/feature-X 90772ae [oalders/feature-X]
/Users/olaf/trees/oalders/feature-Y e9df3c5 [oalders/feature-Y]
```
Like with most other Git commands, you need to be inside a repository when issuing this command. Once the worktrees are created, you have isolated work environments. The Git repository tracks where the worktrees live on disk. If Git hooks are already set up in the parent repository, they will also be available in the worktrees.
Don't overlook that each worktree uses only a fraction of the parent repository's disk space. In this case, the worktree requires about one-third of the original's disk space. This can scale very well. Once your repositories are measured in the gigabytes, you'll really come to appreciate these savings.
```
$ du -sh /Users/olaf/http-browserdetect
2.9M
$ du -sh /Users/olaf/trees/oalders/feature-X
1.0M
```
**Pros:** You can work in multiple workspaces simultaneously. You don't need the stash. Git tracks all of your worktrees. You don't need to set up Git hooks. This is also faster than `git clone`
and can save on network traffic since you can do this in airplane mode. You also get more efficient disk space use without needing to resort to a shallow clone.
**Cons:** This is yet another thing to remember. However, if you can get into the habit of using this feature, it can reward you handsomely.
## A few more tips
When you need to clean up your worktrees, you have a couple of options. The preferable way is to let Git remove the worktree:
`git worktree remove /Users/olaf/trees/oalders/feature-X`
If you prefer a scorched-earth approach, `rm -rf`
is also your friend:
`rm -rf /Users/olaf/trees/oalders/feature-X`
However, if you do this, you may want to clean up any remaining files with `git worktree prune`
. Or you can skip the `prune`
now, and this will happen on its own at some point in the future via `git gc`
.
## Notable notes
If you're ready to get started with `git worktree`
, here are a few things to keep in mind.
- Removing a worktree does not delete the branch.
- You can switch branches within a worktree.
- You cannot simultaneously check out the same branch in multiple worktrees.
- Like many other Git commands,
`git worktree`
needs to be run from inside a repository. - You can have many worktrees at once.
- Create your worktrees from the same local checkout, or they will be agnostic about each other.
## git rev-parse
One final note: When using `git worktree`
, your concept of where the root of the repository lives may depend on context. Fortunately, `git rev-parse`
allows you to distinguish between the two.
- To find the parent repository's root:
`git rev-parse --git-common-dir`
- To find the root of the repository you're in:
`git rev-parse --show-toplevel`
## Choose the best method for your needs
As in many things, TIMTOWDI (there's more than one way to do it). What's important is that you find a workflow that suits your needs. What your needs are may vary depending on the problem at hand. Maybe you'll occasionally find yourself reaching for `git worktree`
as a handy tool in your revision-control toolbelt.
## Comments are closed. |
13,423 | 对 JavaScript 构建工具的 6 个预测 | https://opensource.com/article/20/11/javascript-build-tools | 2021-05-25T11:21:48 | [
"JavaScript"
] | /article-13423-1.html |
>
> JavaScript 前端工具的生态系统充满着变数和竞争,且只有最好的工具才会存活下来。
>
>
>

生产中使用的代码与开发中的有所不同. 在生产中,我们需要构建一些能运行得够快、能管理各种依赖关系、能自动执行任务、能加载外部模块等功能的包。而那些将开发中的代码转为生产代码的 [JavaScript](https://www.javascript.com/) 工具我们就称之为 *构建工具。*
我们可以通过各个构建步骤以及其重要性来解释前端代码需要被“构建”的原因。
### 前端代码构建步骤
前端代码的构建涉及下面的四个步骤:
#### 1、转译
通过<ruby> 转译 <rt> Transpiling </rt></ruby>,开发者可以使用到语言最新、最热门的更新和扩展,并保持浏览器的兼容性等。下面是使用 [Babel](https://babeljs.io/) 的一个例子:
```
// 数组映射中的箭头函数语法
const double = [1, 2, 3].map((num) => num * 2);
// 转译后
const double = [1, 2, 3].map(function(num) {
return num * 2;
});
```
#### 2、分包
<ruby> 分包 <rt> Bundling </rt></ruby>是处理所有 `import` 与`require` 语句的过程;找到相匹配的 JavaScript 代码片段、包和库;将它们添加到适当的域中;然后将它们打包到一个大的 JavaScript 文件中。常用的分包器包括 Browserify、Webpack 与 Parcel。
#### 3、压缩
<ruby> 压缩 <rt> Minifing </rt></ruby>是通过删除空白和代码注释来减少最终的文件大小。在压缩过程中,我们还可以更进一步添加代码混淆步骤,混淆会更改变量名和方法名,使代码变得晦涩难懂,因此一旦代码交付到客户端,它就不是那么容易能让人读懂。下面是一个使用 Grunt 的例子:
```
// 压缩前
const double = [1, 2, 3].map(function(num) {
return num * 2;
});
// 压缩后
const double=[1,2,3].map(function(num){return num*2;});
```
#### 4、打包
完成上面的所有步骤之后, 我们需要将这些具有兼容性、且经过分包、压缩/混淆过的文件放置到某个地方。<ruby> 打包 <rt> Packaging </rt></ruby>正是这样一个过程,它将上述步骤所产生的结果放置到开发者指定的某个位置上,这通常是通过打包器完成的。
### 前端构建工具
前端工具及构建工具可以分为以下几类:
* 包管理: NPM、Yarn
* 转译器: Babel 等
* 打包器: Webpack、Parcel、Browserify
* 压缩混淆: UglifyJS、Packer、Minify 等
JavaScript 生态系统中有各种各样的构建工具可以使用,包括下面的这些:
#### Grunt 和 Bower
[Grunt](https://gruntjs.com/) 是作为命令行工具引入的,它仅提供一个脚本来指定和配置相关构建任务。[Bower](https://bower.io/) 作为包管理器,提供了一种客户端包的管理方法而紧追其后。这两者,再加上 NPM,它们经常在一起使用,它们看上去似乎可以满足大多数的自动化需求,但 Grunt 的问题在于它无法提供给开发者配置更复杂任务的自由,而 Bower 使开发者管理的程序包是平常的两倍,因为它将前端包、后台包分开了(例如,Bower 组件与 Node 模块)。
**Grunt 与 Bower 的未来:** Grunt 与 Bower 正在退出 JavaScript 工具生态,但是还有一些替代品。
#### Gulp 和 Browserify
[Gulp](https://gulpjs.com/) 是在 Grunt 发布一年半之后才发布的。但 Gulp 却让大家感到很自然、舒服。用 JavaScript 来写构建脚本与用 JSON 来写相比更自由。你可以在 Gulp 的构建脚本中编写函数、即时创建变量、在任何地方使用条件语句 —— 但就这些,并不能说让我们的感觉变得特别自然和舒适,只能说这只是其中的一个可能的原因。[Browserify](http://browserify.org/) 和 Gulp 可以配合使用,Browserify 允许 NPM 包(用于后端 Node 服务器)被直接带入到前端,就这一点已经直接让 Bower 废了。而正是这种用一个包管理器来处理前后端包的方式让人感到更自然和更好。
**Gulp 的未来:** Gulp 可能会被改进,以便匹配当前流行的构建工具,但这完全取决于创造者的意愿。Gulp 仍在使用中,只是不再像以前那么流行了。
#### Webpack 和 NPM/Yarn 脚本
[Webpack](https://webpack.js.org/) 是现代前端开发工具中最热门的宠儿,它是一个开源的 JavaScript 模块打包器。Webpack 主要是为处理 JavaScript 而创造的,但如果包含相应的加载器,它也可以转换 HTML、CSS 和图片等前端资源。通过 Webpack,你也可以像 Gulp 一样编写构建脚本,并通过 [NPM/Yarn](https://github.com/yarnpkg/yarn) 来执行它们。
**Webpack 的未来:** Webpack 是目前 JavaScript 工具生态系统中最热门的工具,最近几乎所有的 JavaScript 库都在使用 React 和 Webpack。Webpack 目前处于第四个版本,不会很快消失。(LCTT 译注:Webpack 目前已经发布了第五个版本了,且还在火热更新中)
#### Parcel
[Parcel](https://parceljs.org/) 是一个 Web 应用打包器,于 2018 年推出,因其开发者体验而与众不同。Parcel 能利用处理器多核功能提供极快的打包性能,且还零配置。但 Parcel 还是一个新星,对于一些大型应用,其采用率并不高。相比之下,开发人员更喜欢使用 Webpack,因为 Webpack 有更广泛的支持和可定制性。
**Parcel 的未来:** Parcel 非常容易使用,如果你统计打包和构建时间,它会比 Webpack 更快,而且它还提供了更好的开发者体验。Parcel 没有被大量采用的原因可能是它仍然比较新。在前端构建工具的生态系统中,Parcel 的前景会非常光明,它将会存在一段时间。
#### Rollup
[Rollup](https://rollupjs.org/guide/en/) 是 JavaScript 的一个模块分包器,它可将一小段代码编译为更大更复杂的库或应用。Rollup 一般建议用来构建 JavaScript 库,特别是那种导入和依赖的第三方库较少的那种库。
**Rollup 的未来:** Rollup 很酷,且正在被迅速采用。它有很多强大的功能,将在很长一段时间内作为前端工具生态系统的一个组成部分而存在。
### 了解更多
JavaScript 前端工具的生态系统充满着变数和竞争,且只有最好的工具才能存活下来。在不久的将来,我们的构建工具将具有更少(或没有)的配置,更方便的定制化,更好的扩展性的和更好的构建速度。
该用什么样的构建工具用于你的前端项目,你需要根据具体的项目需求来做出决定。至于选择什么样的工具,才是最合适自己的,大多数时候,需要我们自己作出取舍。
更多信息, 请看:
* [JavaScript tooling: The evolution and future of JS/frontend build tools](https://qmo.io/blog/javascript-tooling-the-evolution-and-future-of-js-front-end-build-tools/)
* [Tools and modern workflow for frontend developers](https://blog.logrocket.com/tools-and-modern-workflow-for-front-end-developers-505c7227e917/)
* [Modern frontend: The tools and build process explained](https://medium.com/@trevorpoppen/modern-front-end-the-tools-and-build-process-explained-36641b5c1a53)
* [Best build tools in frontend development](https://www.developerdrive.com/best-build-tools-frontend-development/)
*这篇文章最初发表在 [Shedrack Akintayo 的博客](https://www.sheddy.xyz/posts/javascript-build-tools-past-and-beyond) 上,经许可后重新发表。*
---
via: <https://opensource.com/article/20/11/javascript-build-tools>
作者:[Shedrack Akintayo](https://opensource.com/users/shedrack-akintayo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ywxgod](https://github.com/ywxgod) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,425 | 使用开源工具进行 Linux 内存取证 | https://opensource.com/article/21/4/linux-memory-forensics | 2021-05-26T11:20:06 | [
"内存",
"转储",
"取证"
] | https://linux.cn/article-13425-1.html |
>
> 利用 Volatility 找出应用程序、网络连接、内核模块、文件等方面的情况。
>
>
>

计算机的操作系统和应用使用主内存(RAM)来执行不同的任务。这种易失性内存包含大量关于运行应用、网络连接、内核模块、打开的文件以及几乎所有其他的内容信息,但这些信息每次计算机重启的时候都会被清除。
<ruby> 内存取证 <rt> Memory forensics </rt></ruby>是一种从内存中找到和抽取这些有价值的信息的方式。[Volatility](https://github.com/volatilityfoundation/volatility) 是一种使用插件来处理这类信息的开源工具。但是,存在一个问题:在你处理这些信息前,必须将物理内存转储到一个文件中,而 Volatility 没有这种能力。
因此,这篇文章分为两部分:
* 第一部分是处理获取物理内存并将其转储到一个文件中。
* 第二部分使用 Volatility 从这个内存转储中读取并处理这些信息。
我在本教程中使用了以下测试系统,不过它可以在任何 Linux 发行版上工作:
```
$ cat /etc/redhat-release
Red Hat Enterprise Linux release 8.3 (Ootpa)
$
$ uname -r
4.18.0-240.el8.x86_64
$
```
>
> **注意事项:** 部分 1 涉及到编译和加载一个内核模块。不要担心:它并不像听起来那么困难。
>
>
> 一些指南:
>
>
> * 按照以下的步骤。
> * 不要在生产系统或你的主要计算机上尝试任何这些步骤。
> * 始终使用测试的虚拟机(VM)来尝试,直到你熟悉使用这些工具并理解它们的工作原理为止。
>
>
>
### 安装需要的包
在开始之前安装必要的工具。如果你经常使用基于 Debian 的发行版,可以使用 `apt-get` 命令。这些包大多数提供了需要的内核信息和工具来编译代码:
```
$ yum install kernel-headers kernel-devel gcc elfutils-libelf-devel make git libdwarf-tools python2-devel.x86_64-y
```
### 部分 1:使用 LiME 获取内存并将其转储到一个文件中
在开始分析内存之前,你需要一个内存转储供你使用。在实际的取证活动中,这可能来自一个被破坏或者被入侵的系统。这些信息通常会被收集和存储来分析入侵是如何发生的及其影响。由于你可能没有可用的内存转储,你可以获取你的测试 VM 的内存转储,并使用它来执行内存取证。
<ruby> Linux 内存提取器 <rt> Linux Memory Extractor </rt></ruby>([LiME](https://github.com/504ensicsLabs/LiME))是一个在 Linux 系统上获取内存很常用的工具。使用以下命令获得 LiME:
```
$ git clone https://github.com/504ensicsLabs/LiME.git
$
$ cd LiME/src/
$
$ ls
deflate.c disk.c hash.c lime.h main.c Makefile Makefile.sample tcp.c
$
```
#### 构建 LiME 内核模块
在 `src` 文件夹下运行 `make` 命令。这会创建一个以 .ko 为扩展名的内核模块。理想情况下,在 `make` 结束时,`lime.ko` 文件会使用格式 `lime-<your-kernel-version>.ko` 被重命名。
```
$ make
make -C /lib/modules/4.18.0-240.el8.x86_64/build M="/root/LiME/src" modules
make[1]: Entering directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
<< 删节 >>
make[1]: Leaving directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
strip --strip-unneeded lime.ko
mv lime.ko lime-4.18.0-240.el8.x86_64.ko
$
$
$ ls -l lime-4.18.0-240.el8.x86_64.ko
-rw-r--r--. 1 root root 25696 Apr 17 14:45 lime-4.18.0-240.el8.x86_64.ko
$
$ file lime-4.18.0-240.el8.x86_64.ko
lime-4.18.0-240.el8.x86_64.ko: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), BuildID[sha1]=1d0b5cf932389000d960a7e6b57c428b8e46c9cf, not stripped
$
```
#### 加载LiME 内核模块
现在是时候加载内核模块来获取系统内存了。`insmod` 命令会帮助加载内核模块;模块一旦被加载,会在你的系统上读取主内存(RAM)并且将内存的内容转储到命令行所提供的 `path` 目录下的文件中。另一个重要的参数是 `format`;保持 `lime` 的格式,如下所示。在插入内核模块之后,使用 `lsmod` 命令验证它是否真的被加载。
```
$ lsmod | grep lime
$
$ insmod ./lime-4.18.0-240.el8.x86_64.ko "path=../RHEL8.3_64bit.mem format=lime"
$
$ lsmod | grep lime
lime 16384 0
$
```
你应该看到给 `path` 命令的文件已经创建好了,而且文件大小与你系统的物理内存(RAM)大小相同(并不奇怪)。一旦你有了内存转储,你就可以使用 `rmmod` 命令删除该内核模块:
```
$
$ ls -l ~/LiME/RHEL8.3_64bit.mem
-r--r--r--. 1 root root 4294544480 Apr 17 14:47 /root/LiME/RHEL8.3_64bit.mem
$
$ du -sh ~/LiME/RHEL8.3_64bit.mem
4.0G /root/LiME/RHEL8.3_64bit.mem
$
$ free -m
total used free shared buff/cache available
Mem: 3736 220 366 8 3149 3259
Swap: 4059 8 4051
$
$ rmmod lime
$
$ lsmod | grep lime
$
```
#### 内存转储中是什么?
这个内存转储文件只是原始数据,就像使用 `file` 命令可以看到的一样。你不可能通过手动去理解它;是的,在这里边有一些 ASCII 字符,但是你无法用编辑器打开这个文件并把它读出来。`hexdump` 的输出显示,最初的几个字节是 `EmiL`;这是因为你的请求格式在上面的命令行中是 `lime`:
```
$ file ~/LiME/RHEL8.3_64bit.mem
/root/LiME/RHEL8.3_64bit.mem: data
$
$ hexdump -C ~/LiME/RHEL8.3_64bit.mem | head
00000000 45 4d 69 4c 01 00 00 00 00 10 00 00 00 00 00 00 |EMiL............|
00000010 ff fb 09 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 b8 fe 4c cd 21 44 00 32 20 00 00 2a 2a 2a 2a 2a |..L.!D.2 ..*****|
00000030 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a |****************|
00000040 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 20 00 20 |************* . |
00000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000080 00 00 00 00 00 00 00 00 00 00 00 00 70 78 65 6c |............pxel|
00000090 69 6e 75 78 2e 30 00 00 00 00 00 00 00 00 00 00 |inux.0..........|
000000a0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
$
```
### 部分 2:获得 Volatility 并使用它来分析你的内存转储
现在你有了要分析的示例内存转储,使用下面的命令获取 Volatility 软件。Volatility 已经用 Python 3 重写了,但是本教程使用的是用 Python 2 写的原始的 Volatility 包。如果你想用 Volatility 3 进行实验,可以从合适的 Git 仓库下载它,并在以下命令中使用 Python 3 而不是 Python 2:
```
$ git clone https://github.com/volatilityfoundation/volatility.git
$
$ cd volatility/
$
$ ls
AUTHORS.txt contrib LEGAL.txt Makefile PKG-INFO pyinstaller.spec resources tools vol.py
CHANGELOG.txt CREDITS.txt LICENSE.txt MANIFEST.in pyinstaller README.txt setup.py volatility
$
```
Volatility 使用两个 Python 库来实现某些功能,所以使用以下命令来安装它们。否则,在你运行 Volatility 工具时,你可能看到一些导入错误;你可以忽略它们,除非你正在运行的插件需要这些库;这种情况下,工具将会报错:
```
$ pip2 install pycrypto
$ pip2 install distorm3
```
#### 列出 Volatility 的 Linux 配置文件
你将要运行的第一个 Volatility 命令列出了可用的 Linux 配置文件,运行 Volatility 命令的主要入口点是 `vol.py` 脚本。使用 Python 2 解释器调用它并提供 `--info` 选项。为了缩小输出,查找以 Linux 开头的字符串。正如你所看到的,并没有很多 Linux 配置文件被列出:
```
$ python2 vol.py --info | grep ^Linux
Volatility Foundation Volatility Framework 2.6.1
LinuxAMD64PagedMemory - Linux-specific AMD 64-bit address space.
$
```
#### 构建你自己的 Linux 配置文件
Linux 发行版是多种多样的,并且是为不同架构而构建的。这就是为什么配置文件是必要的 —— Volatility 在提取信息前必须知道内存转储是从哪个系统和架构获得的。有一些 Volatility 命令可以找到这些信息;但是这个方法很费时。为了加快速度,可以使用以下命令构建一个自定义的 Linux 配置文件:
移动到 Volatility 仓库的 `tools/linux`目录下,运行 `make` 命令:
```
$ cd tools/linux/
$
$ pwd
/root/volatility/tools/linux
$
$ ls
kcore Makefile Makefile.enterprise module.c
$
$ make
make -C //lib/modules/4.18.0-240.el8.x86_64/build CONFIG_DEBUG_INFO=y M="/root/volatility/tools/linux" modules
make[1]: Entering directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
<< 删节 >>
make[1]: Leaving directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
$
```
你应该看到一个新的 `module.dwarf` 文件。你也需要 `/boot` 目录下的 `System.map` 文件,因为它包含了所有与当前运行的内核相关的符号:
```
$ ls
kcore Makefile Makefile.enterprise module.c module.dwarf
$
$ ls -l module.dwarf
-rw-r--r--. 1 root root 3987904 Apr 17 15:17 module.dwarf
$
$ ls -l /boot/System.map-4.18.0-240.el8.x86_64
-rw-------. 1 root root 4032815 Sep 23 2020 /boot/System.map-4.18.0-240.el8.x86_64
$
$
```
要创建一个自定义配置文件,移动回到 Volatility 目录并且运行下面的命令。第一个参数提供了一个自定义 .zip 文件,文件名是你自己命名的。我经常使用操作系统和内核版本来命名。下一个参数是前边创建的 `module.dwarf` 文件,最后一个参数是 `/boot` 目录下的 `System.map` 文件:
```
$
$ cd volatility/
$
$ zip volatility/plugins/overlays/linux/Redhat8.3_4.18.0-240.zip tools/linux/module.dwarf /boot/System.map-4.18.0-240.el8.x86_64
adding: tools/linux/module.dwarf (deflated 91%)
adding: boot/System.map-4.18.0-240.el8.x86_64 (deflated 79%)
$
```
现在自定义配置文件就准备好了,所以在前边给出的位置检查一下 .zip 文件是否被创建好。如果你想知道 Volatility 是否检测到这个自定义配置文件,再一次运行 `--info` 命令。现在,你应该可以在下边的列出的内容中看到新的配置文件:
```
$
$ ls -l volatility/plugins/overlays/linux/Redhat8.3_4.18.0-240.zip
-rw-r--r--. 1 root root 1190360 Apr 17 15:20 volatility/plugins/overlays/linux/Redhat8.3_4.18.0-240.zip
$
$
$ python2 vol.py --info | grep Redhat
Volatility Foundation Volatility Framework 2.6.1
LinuxRedhat8_3_4_18_0-240x64 - A Profile for Linux Redhat8.3_4.18.0-240 x64
$
$
```
#### 开始使用 Volatility
现在你已经准备好去做一些真正的内存取证了。记住,Volatility 是由自定义的插件组成的,你可以针对内存转储来获得信息。命令的通用格式是:
```
python2 vol.py -f <memory-dump-file-taken-by-Lime> <plugin-name> --profile=<name-of-our-custom-profile>
```
有了这些信息,运行 `linux_banner` 插件来看看你是否可从内存转储中识别正确的发行版信息:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_banner --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
Linux version 4.18.0-240.el8.x86_64 ([[email protected]][4]) (gcc version 8.3.1 20191121 (Red Hat 8.3.1-5) (GCC)) #1 SMP Wed Sep 23 05:13:10 EDT 2020
$
```
#### 找到 Linux 插件
到现在都很顺利,所以现在你可能对如何找到所有 Linux 插件的名字比较好奇。有一个简单的技巧:运行 `--info` 命令并抓取 `linux_` 字符串。有各种各样的插件可用于不同的用途。这里列出一部分:
```
$ python2 vol.py --info | grep linux_
Volatility Foundation Volatility Framework 2.6.1
linux_apihooks - Checks for userland apihooks
linux_arp - Print the ARP table
linux_aslr_shift - Automatically detect the Linux ASLR shift
<< 删节 >>
linux_banner - Prints the Linux banner information
linux_vma_cache - Gather VMAs from the vm_area_struct cache
linux_volshell - Shell in the memory image
linux_yarascan - A shell in the Linux memory image
$
```
使用 `linux_psaux` 插件检查内存转储时系统上正在运行哪些进程。注意列表中的最后一个命令:它是你在转储之前运行的 `insmod` 命令。
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_psaux --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
Pid Uid Gid Arguments
1 0 0 /usr/lib/systemd/systemd --switched-root --system --deserialize 18
2 0 0 [kthreadd]
3 0 0 [rcu_gp]
4 0 0 [rcu_par_gp]
861 0 0 /usr/libexec/platform-python -Es /usr/sbin/tuned -l -P
869 0 0 /usr/bin/rhsmcertd
875 0 0 /usr/libexec/sssd/sssd_be --domain implicit_files --uid 0 --gid 0 --logger=files
878 0 0 /usr/libexec/sssd/sssd_nss --uid 0 --gid 0 --logger=files
<< 删节 >>
11064 89 89 qmgr -l -t unix -u
227148 0 0 [kworker/0:0]
227298 0 0 -bash
227374 0 0 [kworker/u2:1]
227375 0 0 [kworker/0:2]
227884 0 0 [kworker/0:3]
228573 0 0 insmod ./lime-4.18.0-240.el8.x86_64.ko path=../RHEL8.3_64bit.mem format=lime
228576 0 0
$
```
想要知道系统的网络状态吗?运行 `linux_netstat` 插件来找到在内存转储期间网络连接的状态:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_netstat --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
UNIX 18113 systemd/1 /run/systemd/private
UNIX 11411 systemd/1 /run/systemd/notify
UNIX 11413 systemd/1 /run/systemd/cgroups-agent
UNIX 11415 systemd/1
UNIX 11416 systemd/1
<< 删节 >>
$
```
接下来,使用 `linux_mount` 插件来看在内存转储期间哪些文件系统被挂载:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_mount --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
tmpfs /sys/fs/cgroup tmpfs ro,nosuid,nodev,noexec
cgroup /sys/fs/cgroup/pids cgroup rw,relatime,nosuid,nodev,noexec
systemd-1 /proc/sys/fs/binfmt_misc autofs rw,relatime
sunrpc /var/lib/nfs/rpc_pipefs rpc_pipefs rw,relatime
/dev/mapper/rhel_kvm--03--guest11-root / xfs rw,relatime
tmpfs /dev/shm tmpfs rw,nosuid,nodev
selinuxfs /sys/fs/selinux selinuxfs rw,relatime
<< 删节 >>
cgroup /sys/fs/cgroup/net_cls,net_prio cgroup rw,relatime,nosuid,nodev,noexec
cgroup /sys/fs/cgroup/cpu,cpuacct cgroup rw,relatime,nosuid,nodev,noexec
bpf /sys/fs/bpf bpf rw,relatime,nosuid,nodev,noexec
cgroup /sys/fs/cgroup/memory cgroup ro,relatime,nosuid,nodev,noexec
cgroup /sys/fs/cgroup/cpuset cgroup rw,relatime,nosuid,nodev,noexec
mqueue /dev/mqueue mqueue rw,relatime
$
```
好奇哪些内核模块被加载了吗?Volatility 也为这个提供了一个插件 `linux_lsmod`:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_lsmod --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
ffffffffc0535040 lime 20480
ffffffffc0530540 binfmt_misc 20480
ffffffffc05e8040 sunrpc 479232
<< 删节 >>
ffffffffc04f9540 nfit 65536
ffffffffc0266280 dm_mirror 28672
ffffffffc025e040 dm_region_hash 20480
ffffffffc0258180 dm_log 20480
ffffffffc024bbc0 dm_mod 151552
$
```
想知道哪些文件被哪些进程打开了吗?使用 `linux_bash` 插件可以列出这些信息:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_bash --profile=LinuxRedhat8_3_4_18_0-240x64 -v
Volatility Foundation Volatility Framework 2.6.1
Pid Name Command Time Command
-------- -------------------- ------------------------------ -------
227221 bash 2021-04-17 18:38:24 UTC+0000 lsmod
227221 bash 2021-04-17 18:38:24 UTC+0000 rm -f .log
227221 bash 2021-04-17 18:38:24 UTC+0000 ls -l /etc/zzz
227221 bash 2021-04-17 18:38:24 UTC+0000 cat ~/.vimrc
227221 bash 2021-04-17 18:38:24 UTC+0000 ls
227221 bash 2021-04-17 18:38:24 UTC+0000 cat /proc/817/cwd
227221 bash 2021-04-17 18:38:24 UTC+0000 ls -l /proc/817/cwd
227221 bash 2021-04-17 18:38:24 UTC+0000 ls /proc/817/
<< 删节 >>
227298 bash 2021-04-17 18:40:30 UTC+0000 gcc prt.c
227298 bash 2021-04-17 18:40:30 UTC+0000 ls
227298 bash 2021-04-17 18:40:30 UTC+0000 ./a.out
227298 bash 2021-04-17 18:40:30 UTC+0000 vim prt.c
227298 bash 2021-04-17 18:40:30 UTC+0000 gcc prt.c
227298 bash 2021-04-17 18:40:30 UTC+0000 ./a.out
227298 bash 2021-04-17 18:40:30 UTC+0000 ls
$
```
想知道哪些文件被哪些进程打开了吗?使用 `linux_lsof` 插件可以列出这些信息:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_lsof --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
Offset Name Pid FD Path
------------------ ------------------------------ -------- -------- ----
0xffff9c83fb1e9f40 rsyslogd 71194 0 /dev/null
0xffff9c83fb1e9f40 rsyslogd 71194 1 /dev/null
0xffff9c83fb1e9f40 rsyslogd 71194 2 /dev/null
0xffff9c83fb1e9f40 rsyslogd 71194 3 /dev/urandom
0xffff9c83fb1e9f40 rsyslogd 71194 4 socket:[83565]
0xffff9c83fb1e9f40 rsyslogd 71194 5 /var/log/messages
0xffff9c83fb1e9f40 rsyslogd 71194 6 anon_inode:[9063]
0xffff9c83fb1e9f40 rsyslogd 71194 7 /var/log/secure
<< 删节 >>
0xffff9c8365761f40 insmod 228573 0 /dev/pts/0
0xffff9c8365761f40 insmod 228573 1 /dev/pts/0
0xffff9c8365761f40 insmod 228573 2 /dev/pts/0
0xffff9c8365761f40 insmod 228573 3 /root/LiME/src/lime-4.18.0-240.el8.x86_64.ko
$
```
#### 访问 Linux 插件脚本位置
通过读取内存转储和处理这些信息,你可以获得更多的信息。如果你会 Python,并且好奇这些信息是如何被处理的,可以到存储所有插件的目录,选择一个你感兴趣的,并看看 Volatility 是如何获得这些信息的:
```
$ ls volatility/plugins/linux/
apihooks.py common.py kernel_opened_files.py malfind.py psaux.py
apihooks.pyc common.pyc kernel_opened_files.pyc malfind.pyc psaux.pyc
arp.py cpuinfo.py keyboard_notifiers.py mount_cache.py psenv.py
arp.pyc cpuinfo.pyc keyboard_notifiers.pyc mount_cache.pyc psenv.pyc
aslr_shift.py dentry_cache.py ld_env.py mount.py pslist_cache.py
aslr_shift.pyc dentry_cache.pyc ld_env.pyc mount.pyc pslist_cache.pyc
<< 删节 >>
check_syscall_arm.py __init__.py lsmod.py proc_maps.py tty_check.py
check_syscall_arm.pyc __init__.pyc lsmod.pyc proc_maps.pyc tty_check.pyc
check_syscall.py iomem.py lsof.py proc_maps_rb.py vma_cache.py
check_syscall.pyc iomem.pyc lsof.pyc proc_maps_rb.pyc vma_cache.pyc
$
$
```
我喜欢 Volatility 的理由是他提供了许多安全插件。这些信息很难手动获取:
```
linux_hidden_modules - Carves memory to find hidden kernel modules
linux_malfind - Looks for suspicious process mappings
linux_truecrypt_passphrase - Recovers cached Truecrypt passphrases
```
Volatility 也允许你在内存转储中打开一个 shell,所以你可以运行 shell 命令来代替上面所有命令,并获得相同的信息:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_volshell --profile=LinuxRedhat8_3_4_18_0-240x64 -v
Volatility Foundation Volatility Framework 2.6.1
Current context: process systemd, pid=1 DTB=0x1042dc000
Welcome to volshell! Current memory image is:
file:///root/LiME/RHEL8.3_64bit.mem
To get help, type 'hh()'
>>>
>>> sc()
Current context: process systemd, pid=1 DTB=0x1042dc000
>>>
```
### 接下来的步骤
内存转储是了解 Linux 内部情况的好方法。试一试 Volatility 的所有插件,并详细研究它们的输出。然后思考这些信息如何能够帮助你识别入侵或安全问题。深入了解这些插件的工作原理,甚至尝试改进它们。如果你没有找到你想做的事情的插件,那就写一个并提交给 Volatility,这样其他人也可以使用它。
---
via: <https://opensource.com/article/21/4/linux-memory-forensics>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[RiaXu](https://github.com/ShuyRoy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A computer's operating system and applications use the primary memory (or RAM) to perform various tasks. This volatile memory, containing a wealth of information about running applications, network connections, kernel modules, open files, and just about everything else is wiped out each time the computer restarts.
Memory forensics is a way to find and extract this valuable information from memory. [Volatility](https://github.com/volatilityfoundation/volatility) is an open source tool that uses plugins to process this type of information. However, there's a problem: Before you can process this information, you must dump the physical memory into a file, and Volatility does not have this ability.
Therefore, this article has two parts:
- The first part deals with acquiring the physical memory and dumping it into a file.
- The second part uses Volatility to read and process information from this memory dump.
I used the following test system for this tutorial, but it will work on any Linux distribution:
```
$ cat /etc/redhat-release
Red Hat Enterprise Linux release 8.3 (Ootpa)
$
$ uname -r
4.18.0-240.el8.x86_64
$
```
A note of caution:Part 1 involves compiling and loading a kernel module. Don't worry; it isn't as difficult as it sounds. Some guidelines:
- Follow the steps.
- Do not try any of these steps on a production system or your primary machine.
- Always use a test virtual machine (VM) to try things out until you are comfortable using the tools and understand how they work.
## Install the required packages
Before you get started, install the requisite tools. If you are using a Debian-based distro, use the equivalent `apt-get`
commands. Most of these packages provide the required kernel information and tools to compile the code:
`$ yum install kernel-headers kernel-devel gcc elfutils-libelf-devel make git libdwarf-tools python2-devel.x86_64-y`
## Part 1: Use LiME to acquire memory and dump it to a file
Before you can begin to analyze memory, you need a memory dump at your disposal. In an actual forensics event, this could come from a compromised or hacked system. Such information is often collected and stored to analyze how the intrusion happened and its impact. Since you probably do not have a memory dump available, you can take a memory dump of your test VM and use that to perform memory forensics.
Linux Memory Extractor ([LiME](https://github.com/504ensicsLabs/LiME)) is a popular tool for acquiring memory on a Linux system. Get LiME with:
```
$ git clone https://github.com/504ensicsLabs/LiME.git
$
$ cd LiME/src/
$
$ ls
deflate.c disk.c hash.c lime.h main.c Makefile Makefile.sample tcp.c
$
```
### Build the LiME kernel module
Run the `make`
command inside the `src`
folder. This creates a kernel module with a .ko extension. Ideally, the `lime.ko`
file will be renamed using the format `lime-<your-kernel-version>.ko`
at the end of `make`
:
```
$ make
make -C /lib/modules/4.18.0-240.el8.x86_64/build M="/root/LiME/src" modules
make[1]: Entering directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
<< snip >>
make[1]: Leaving directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
strip --strip-unneeded lime.ko
mv lime.ko lime-4.18.0-240.el8.x86_64.ko
$
$
$ ls -l lime-4.18.0-240.el8.x86_64.ko
-rw-r--r--. 1 root root 25696 Apr 17 14:45 lime-4.18.0-240.el8.x86_64.ko
$
$ file lime-4.18.0-240.el8.x86_64.ko
lime-4.18.0-240.el8.x86_64.ko: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), BuildID[sha1]=1d0b5cf932389000d960a7e6b57c428b8e46c9cf, not stripped
$
```
### Load the LiME kernel module
Now it's time to load the kernel module to acquire the system memory. The `insmod`
command helps load the kernel module; once loaded, the module reads the primary memory (RAM) on your system and dumps the memory's contents to the file provided in the `path`
directory on the command line. Another important parameter is `format`
; keep the format `lime`
, as shown below. After inserting the kernel module, verify that it loaded using the `lsmod`
command:
```
$ lsmod | grep lime
$
$ insmod ./lime-4.18.0-240.el8.x86_64.ko "path=../RHEL8.3_64bit.mem format=lime"
$
$ lsmod | grep lime
lime 16384 0
$
```
You should see that the file given to the `path`
command was created, and the file size is (not surprisingly) the same as the physical memory size (RAM) on your system. Once you have the memory dump, you can remove the kernel module using the `rmmod`
command:
```
$
$ ls -l ~/LiME/RHEL8.3_64bit.mem
-r--r--r--. 1 root root 4294544480 Apr 17 14:47 /root/LiME/RHEL8.3_64bit.mem
$
$ du -sh ~/LiME/RHEL8.3_64bit.mem
4.0G /root/LiME/RHEL8.3_64bit.mem
$
$ free -m
total used free shared buff/cache available
Mem: 3736 220 366 8 3149 3259
Swap: 4059 8 4051
$
$ rmmod lime
$
$ lsmod | grep lime
$
```
### What's in the memory dump?
This dump file is just raw data, as you can see using the `file`
command below. You cannot make much sense out of it manually; yes, there are some ASCII strings in there somewhere, but you can't open the file in an editor and read it out. The hexdump output shows that the initial few bytes are `EmiL`
; this is because your request format was "lime" in the command above:
```
$ file ~/LiME/RHEL8.3_64bit.mem
/root/LiME/RHEL8.3_64bit.mem: data
$
$ hexdump -C ~/LiME/RHEL8.3_64bit.mem | head
00000000 45 4d 69 4c 01 00 00 00 00 10 00 00 00 00 00 00 |EMiL............|
00000010 ff fb 09 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 b8 fe 4c cd 21 44 00 32 20 00 00 2a 2a 2a 2a 2a |..L.!D.2 ..*****|
00000030 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a |****************|
00000040 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 20 00 20 |************* . |
00000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000080 00 00 00 00 00 00 00 00 00 00 00 00 70 78 65 6c |............pxel|
00000090 69 6e 75 78 2e 30 00 00 00 00 00 00 00 00 00 00 |inux.0..........|
000000a0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
$
```
## Part 2: Get Volatility and use it to analyze your memory dump
Now that you have a sample memory dump to analyze, get the Volatility software with the command below. Volatility has been rewritten in Python 3, but this tutorial uses the original Volatility package, which uses Python 2. If you want to experiment with Volatility 3, download it from the appropriate Git repo and use Python 3 instead of Python 2 in the following commands:
```
$ git clone https://github.com/volatilityfoundation/volatility.git
$
$ cd volatility/
$
$ ls
AUTHORS.txt contrib LEGAL.txt Makefile PKG-INFO pyinstaller.spec resources tools vol.py
CHANGELOG.txt CREDITS.txt LICENSE.txt MANIFEST.in pyinstaller README.txt setup.py volatility
$
```
Volatility uses two Python libraries for some functionality, so please install them using the following commands. Otherwise, you might see some import errors when you run the Volatility tool; you can ignore them unless you are running a plugin that needs these libraries; in that case, the tool will error out:
```
$ pip2 install pycrypto
$ pip2 install distorm3
```
### List Volatility's Linux profiles
The first Volatility command you'll want to run lists what Linux profiles are available. The main entry point to running any Volatility commands is the `vol.py`
script. Invoke it using the Python 2 interpreter and provide the `--info`
option. To narrow down the output, look for strings that begin with Linux. As you can see, not many Linux profiles are listed:
```
$ python2 vol.py --info | grep ^Linux
Volatility Foundation Volatility Framework 2.6.1
LinuxAMD64PagedMemory - Linux-specific AMD 64-bit address space.
$
```
### Build your own Linux profile
Linux distros are varied and built for various architectures. This why profiles are essential—Volatility must know the system and architecture that the memory dump was acquired from before extracting information. There are Volatility commands to find this information; however, this method is time-consuming. To speed things up, build a custom Linux profile using the following commands.
Move to the `tools/linux`
directory within the Volatility repo, and run the `make`
command:
```
$ cd tools/linux/
$
$ pwd
/root/volatility/tools/linux
$
$ ls
kcore Makefile Makefile.enterprise module.c
$
$ make
make -C //lib/modules/4.18.0-240.el8.x86_64/build CONFIG_DEBUG_INFO=y M="/root/volatility/tools/linux" modules
make[1]: Entering directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
<< snip >>
make[1]: Leaving directory '/usr/src/kernels/4.18.0-240.el8.x86_64'
$
```
You should see a new `module.dwarf`
file. You also need the `System.map`
file from the `/boot`
directory, as it contains all of the symbols related to the currently running kernel:
```
$ ls
kcore Makefile Makefile.enterprise module.c module.dwarf
$
$ ls -l module.dwarf
-rw-r--r--. 1 root root 3987904 Apr 17 15:17 module.dwarf
$
$ ls -l /boot/System.map-4.18.0-240.el8.x86_64
-rw-------. 1 root root 4032815 Sep 23 2020 /boot/System.map-4.18.0-240.el8.x86_64
$
$
```
To create a custom profile, move back to the Volatility directory and run the command below. The first argument provides a custom .zip with a file name of your choice. I used the operating system and kernel versions in the name. The next argument is the `module.dwarf`
file created above, and the final argument is the `System.map`
file from the `/boot`
directory:
```
$
$ cd volatility/
$
$ zip volatility/plugins/overlays/linux/Redhat8.3_4.18.0-240.zip tools/linux/module.dwarf /boot/System.map-4.18.0-240.el8.x86_64
adding: tools/linux/module.dwarf (deflated 91%)
adding: boot/System.map-4.18.0-240.el8.x86_64 (deflated 79%)
$
```
Your custom profile is now ready, so verify the .zip file was created at the location given above. If you want to know if Volatility detects this custom profile, run the `--info`
command again. This time, you should see the new profile listed below:
```
$
$ ls -l volatility/plugins/overlays/linux/Redhat8.3_4.18.0-240.zip
-rw-r--r--. 1 root root 1190360 Apr 17 15:20 volatility/plugins/overlays/linux/Redhat8.3_4.18.0-240.zip
$
$
$ python2 vol.py --info | grep Redhat
Volatility Foundation Volatility Framework 2.6.1
LinuxRedhat8_3_4_18_0-240x64 - A Profile for Linux Redhat8.3_4.18.0-240 x64
$
$
```
### Start using Volatility
Now you are all set to do some actual memory forensics. Remember, Volatility is made up of custom plugins that you can run against a memory dump to get information. The command's general format is:
`python2 vol.py -f <memory-dump-file-taken-by-Lime> <plugin-name> --profile=<name-of-our-custom-profile>`
Armed with this information, run the **linux_banner** plugin to see if you can identify the correct distro information from the memory dump:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_banner --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
Linux version 4.18.0-240.el8.x86_64 ([email protected]) (gcc version 8.3.1 20191121 (Red Hat 8.3.1-5) (GCC)) #1 SMP Wed Sep 23 05:13:10 EDT 2020
$
```
### Find Linux plugins
That worked well, so now you're probably curious about how to find all the names of all the Linux plugins. There is an easy trick: run the `--info`
command and `grep`
for the `linux_`
string. There are a variety of plugins available for different uses. Here is a partial list:
```
$ python2 vol.py --info | grep linux_
Volatility Foundation Volatility Framework 2.6.1
linux_apihooks - Checks for userland apihooks
linux_arp - Print the ARP table
linux_aslr_shift - Automatically detect the Linux ASLR shift
<< snip >>
linux_banner - Prints the Linux banner information
linux_vma_cache - Gather VMAs from the vm_area_struct cache
linux_volshell - Shell in the memory image
linux_yarascan - A shell in the Linux memory image
$
```
Check which processes were running on the system when you took the memory dump using the **linux_psaux** plugin. Notice the last command in the list: it's the `insmod`
command you ran before the dump:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_psaux --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
Pid Uid Gid Arguments
1 0 0 /usr/lib/systemd/systemd --switched-root --system --deserialize 18
2 0 0 [kthreadd]
3 0 0 [rcu_gp]
4 0 0 [rcu_par_gp]
861 0 0 /usr/libexec/platform-python -Es /usr/sbin/tuned -l -P
869 0 0 /usr/bin/rhsmcertd
875 0 0 /usr/libexec/sssd/sssd_be --domain implicit_files --uid 0 --gid 0 --logger=files
878 0 0 /usr/libexec/sssd/sssd_nss --uid 0 --gid 0 --logger=files
<<< snip >>>
11064 89 89 qmgr -l -t unix -u
227148 0 0 [kworker/0:0]
227298 0 0 -bash
227374 0 0 [kworker/u2:1]
227375 0 0 [kworker/0:2]
227884 0 0 [kworker/0:3]
228573 0 0 insmod ./lime-4.18.0-240.el8.x86_64.ko path=../RHEL8.3_64bit.mem format=lime
228576 0 0
$
```
Want to know about the system's network stats? Run the **linux_netstat** plugin to find the state of the network connections during the memory dump:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_netstat --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
UNIX 18113 systemd/1 /run/systemd/private
UNIX 11411 systemd/1 /run/systemd/notify
UNIX 11413 systemd/1 /run/systemd/cgroups-agent
UNIX 11415 systemd/1
UNIX 11416 systemd/1
<< snip>>
$
```
Next, use the **linux_mount** plugin to see which filesystems were mounted during the memory dump:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_mount --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
tmpfs /sys/fs/cgroup tmpfs ro,nosuid,nodev,noexec
cgroup /sys/fs/cgroup/pids cgroup rw,relatime,nosuid,nodev,noexec
systemd-1 /proc/sys/fs/binfmt_misc autofs rw,relatime
sunrpc /var/lib/nfs/rpc_pipefs rpc_pipefs rw,relatime
/dev/mapper/rhel_kvm--03--guest11-root / xfs rw,relatime
tmpfs /dev/shm tmpfs rw,nosuid,nodev
selinuxfs /sys/fs/selinux selinuxfs rw,relatime
<< snip>>
cgroup /sys/fs/cgroup/net_cls,net_prio cgroup rw,relatime,nosuid,nodev,noexec
cgroup /sys/fs/cgroup/cpu,cpuacct cgroup rw,relatime,nosuid,nodev,noexec
bpf /sys/fs/bpf bpf rw,relatime,nosuid,nodev,noexec
cgroup /sys/fs/cgroup/memory cgroup ro,relatime,nosuid,nodev,noexec
cgroup /sys/fs/cgroup/cpuset cgroup rw,relatime,nosuid,nodev,noexec
mqueue /dev/mqueue mqueue rw,relatime
$
```
Curious what kernel modules were loaded? Volatility has a plugin for that too, aptly named **linux_lsmod**:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_lsmod --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
ffffffffc0535040 lime 20480
ffffffffc0530540 binfmt_misc 20480
ffffffffc05e8040 sunrpc 479232
<< snip >>
ffffffffc04f9540 nfit 65536
ffffffffc0266280 dm_mirror 28672
ffffffffc025e040 dm_region_hash 20480
ffffffffc0258180 dm_log 20480
ffffffffc024bbc0 dm_mod 151552
$
```
Want to find all the commands the user ran that were stored in the Bash history? Run the **linux_bash** plugin:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_bash --profile=LinuxRedhat8_3_4_18_0-240x64 -v
Volatility Foundation Volatility Framework 2.6.1
Pid Name Command Time Command
-------- -------------------- ------------------------------ -------
227221 bash 2021-04-17 18:38:24 UTC+0000 lsmod
227221 bash 2021-04-17 18:38:24 UTC+0000 rm -f .log
227221 bash 2021-04-17 18:38:24 UTC+0000 ls -l /etc/zzz
227221 bash 2021-04-17 18:38:24 UTC+0000 cat ~/.vimrc
227221 bash 2021-04-17 18:38:24 UTC+0000 ls
227221 bash 2021-04-17 18:38:24 UTC+0000 cat /proc/817/cwd
227221 bash 2021-04-17 18:38:24 UTC+0000 ls -l /proc/817/cwd
227221 bash 2021-04-17 18:38:24 UTC+0000 ls /proc/817/
<< snip >>
227298 bash 2021-04-17 18:40:30 UTC+0000 gcc prt.c
227298 bash 2021-04-17 18:40:30 UTC+0000 ls
227298 bash 2021-04-17 18:40:30 UTC+0000 ./a.out
227298 bash 2021-04-17 18:40:30 UTC+0000 vim prt.c
227298 bash 2021-04-17 18:40:30 UTC+0000 gcc prt.c
227298 bash 2021-04-17 18:40:30 UTC+0000 ./a.out
227298 bash 2021-04-17 18:40:30 UTC+0000 ls
$
```
Want to know what files were opened by which processes? Use the **linux_lsof** plugin to list that information:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_lsof --profile=LinuxRedhat8_3_4_18_0-240x64
Volatility Foundation Volatility Framework 2.6.1
Offset Name Pid FD Path
------------------ ------------------------------ -------- -------- ----
0xffff9c83fb1e9f40 rsyslogd 71194 0 /dev/null
0xffff9c83fb1e9f40 rsyslogd 71194 1 /dev/null
0xffff9c83fb1e9f40 rsyslogd 71194 2 /dev/null
0xffff9c83fb1e9f40 rsyslogd 71194 3 /dev/urandom
0xffff9c83fb1e9f40 rsyslogd 71194 4 socket:[83565]
0xffff9c83fb1e9f40 rsyslogd 71194 5 /var/log/messages
0xffff9c83fb1e9f40 rsyslogd 71194 6 anon_inode:[9063]
0xffff9c83fb1e9f40 rsyslogd 71194 7 /var/log/secure
<< snip >>
0xffff9c8365761f40 insmod 228573 0 /dev/pts/0
0xffff9c8365761f40 insmod 228573 1 /dev/pts/0
0xffff9c8365761f40 insmod 228573 2 /dev/pts/0
0xffff9c8365761f40 insmod 228573 3 /root/LiME/src/lime-4.18.0-240.el8.x86_64.ko
$
```
### Access the Linux plugins scripts location
You can get a lot more information by reading the memory dump and processing the information. If you know Python and are curious how this information was processed, go to the directory where all the plugins are stored, pick one that interests you, and see how Volatility gets this information:
```
$ ls volatility/plugins/linux/
apihooks.py common.py kernel_opened_files.py malfind.py psaux.py
apihooks.pyc common.pyc kernel_opened_files.pyc malfind.pyc psaux.pyc
arp.py cpuinfo.py keyboard_notifiers.py mount_cache.py psenv.py
arp.pyc cpuinfo.pyc keyboard_notifiers.pyc mount_cache.pyc psenv.pyc
aslr_shift.py dentry_cache.py ld_env.py mount.py pslist_cache.py
aslr_shift.pyc dentry_cache.pyc ld_env.pyc mount.pyc pslist_cache.pyc
<< snip >>
check_syscall_arm.py __init__.py lsmod.py proc_maps.py tty_check.py
check_syscall_arm.pyc __init__.pyc lsmod.pyc proc_maps.pyc tty_check.pyc
check_syscall.py iomem.py lsof.py proc_maps_rb.py vma_cache.py
check_syscall.pyc iomem.pyc lsof.pyc proc_maps_rb.pyc vma_cache.pyc
$
$
```
One reason I like Volatility is that it provides a lot of security plugins. This information would be difficult to acquire manually:
```
linux_hidden_modules - Carves memory to find hidden kernel modules
linux_malfind - Looks for suspicious process mappings
linux_truecrypt_passphrase - Recovers cached Truecrypt passphrases
```
Volatility also allows you to open a shell within the memory dump, so instead of running all the commands above, you can run shell commands instead and get the same information:
```
$ python2 vol.py -f ~/LiME/RHEL8.3_64bit.mem linux_volshell --profile=LinuxRedhat8_3_4_18_0-240x64 -v
Volatility Foundation Volatility Framework 2.6.1
Current context: process systemd, pid=1 DTB=0x1042dc000
Welcome to volshell! Current memory image is:
file:///root/LiME/RHEL8.3_64bit.mem
To get help, type 'hh()'
>>>
>>> sc()
Current context: process systemd, pid=1 DTB=0x1042dc000
>>>
```
## Next steps
Memory forensics is a good way to learn more about Linux internals. Try all of Volatility's plugins and study their output in detail. Then think about ways this information can help you identify an intrusion or a security issue. Dive into how the plugins work, and maybe even try to improve them. And if you didn't find a plugin for what you want to do, write one and submit it to Volatility so others can use it, too.
## Comments are closed. |
13,426 | 将 Fedora Linux 系统添加到企业域中 | https://fedoramagazine.org/join-fedora-linux-enterprise-domain/ | 2021-05-26T12:01:53 | [
"活动目录"
] | https://linux.cn/article-13426-1.html | 
在企业互联网场景中,一般情况下最广泛使用的基于 Linux 的操作系统是 Red Hat Enterprise Linux(RHEL),它主要用于服务器,但也可以用作工作站。Fedora linux 其实也是工作站系统的一个很好的选择,它提供了许多在企业环境中工作的特性,使管理成为一项简单的任务。
当你的工作网络中有许多机器时,你需要一种以集中方式管理用户和机器的方法。[FreeIPA](https://www.freeipa.org/page/Main_Page) 和 <ruby> <a href="https://en.wikipedia.org/wiki/Active_Directory"> 活动目录 </a> <rt> Active Directory </rt></ruby> 就是用于这个任务的技术。它们允许系统管理员使用网络中所有实体的目录来管理大量的机器。
### Fedora 中的活动目录
活动目录在公司环境中非常常见。Fedora 和 RHEL 通过使用 SSSD (<ruby> 系统安全服务守护进程 <rt> System Security Services Daemon </rt></ruby>)与 FreeIPA 或活动目录等服务很好地集成。SSSD 是一种访问远程目录和身份验证机制的系统服务。使用此软件的计算机能够使用远程凭据进行身份验证,并访问该目录网络中可用的其他服务。
要加入域网络,你需要域管理员的权限才能添加计算机。可以通过在域凭据上设置特殊权限或代表你对该计算机进行预配置。Fedora Linux 有一个在安装时配置机器的选项,叫做<ruby> 企业登录 <rt> Enterprise Login </rt></ruby>。如果你的计算机网络自动配置为企业域网络,那么你可以直接使用域凭据登录。

如果你的配置不是自动的,或者你已经安装了 Fedora Linux,你可以通过以下几个配置步骤加入一个活动目录域:
1. 设置此计算机的 DNS。要连接到目录服务,首先需要能够解析目录域名。如果你的网络使用 DHCP 设置正确的 DNS,则可以跳过此步骤。
2. 更改你的计算机名称,以反映它将是新域的一部分。编辑文件 `/etc/hostname`,并将机器名更改为 `machinename.my_domain`。
3. 通过执行以下命令加入域:`sudo realm join my_domain -v`( 用域名称替换 `my_domain`)。
运行此命令后,系统将请求允许加入该域中新计算机的用户的凭据。如果进程中没有错误,则机器将成为域的一部分。

现在,此计算机已成为你的域的一部分,你可以:
* 使用域用户名登录到计算机
* 获取 kerberos 票据以访问域网络中的不同服务
* 访问其他服务,具体取决于域的配置方式
### 使用 Fleet Commander 管理 Fedora Linux
现在这台计算机已经是你的域的一部分了,你可以使用活动目录的域管理员工具来管理它。由于你的计算机没有运行 Windows,因此你只能进行身份验证以及访问网络和目录服务。无法在此计算机上设置与桌面相关的配置。
幸运的是,Fedora 有个工具叫 [Fleet Commander](https://fleet-commander.org/)。
#### 创建配置
Fleet Commander 是一个管理工具,允许你为网络中的所有 Fedora Linux 机器设置桌面配置文件。
这意味着,你可以简单地为 GNOME 桌面、Firefox、Chrome、LibreOffice 和其他支持的软件设置任何配置,然后在登录到选定的用户/组/计算机时以细粒度的方式应用该配置。

要使用这个工具首先安装 `fleet-commander-admin` 软件包:
```
sudo dnf install fleet-commander-admin
```
然后,用浏览器访问 [http://localhost:9090](http://localhost:9090/) 来登录。在左边的菜单中,点击 “Fleet Commander”。
Fleet Commander 有一个工具,可以使用“实时会话”机制直观地设置配置概要文件。它运行一个虚拟机,作为基本机器的模板。你需要手动进行所需的配置更改。然后检查所有配置更改,选择要添加到配置文件中的更改,然后部署它。
#### 管理客户端
在每个 Fedora Linux 或 RHEL 机器中,你都需要安装 Fleet Commander 客户端服务。此服务在用户登录时激活。它在域中搜索应用于当前用户/计算机的配置文件,并应用这个配置。
安装 `fleet-commander-client`:
```
sudo dnf install fleet-commander-client
```
软件将自动检测机器是否是域的一部分。当用户登录时,它将使用应用于该用户的配置文件来设置会话。
---
via: <https://fedoramagazine.org/join-fedora-linux-enterprise-domain/>
作者:[ogutierrez](https://fedoramagazine.org/author/ogutierrez/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you think about corporate networks, the most widely used Linux-based operating system that comes to mind is Red Hat Enterprise Linux (RHEL), used mostly on servers, but also as workstations. Fedora Linux is also a very good choice for a workstation, and comes packed with lots of features to work in the corporate environment and makes management an easy task.
When you work with many machines in your network you need a way to manage users and machines in a centralized way. That’s why [FreeIPA](https://www.freeipa.org/page/Main_Page) and [Active Directory](https://en.wikipedia.org/wiki/Active_Directory) are the technologies of choice for this task. They allow a sysadmin to manage a huge amount of machines using a directory of all the entities in their network.
## Fedora and Active Directory
Active Directory is very common in corporate environments. Fedora and RHEL integrate well with services such as FreeIPA or Active Directory by using the System Security Services Daemon (SSSD). SSSD is a system service to access remote directories and authentication mechanisms. A machine using this software is able to authenticate with remote credentials and access other services available in that directory network.
To join a domain network, you need the domain administrator’s permission to add the machine. Maybe by setting special permissions on your domain credentials or doing the pre-configuration of that machine on your behalf. Fedora Linux has an option to configure a machine during installation called *Enterprise Login*. If your machine network is automatically configured for the enterprise domain network, then you can login with your domain credentials directly.
In the case your configuration is not automated—or you have Fedora Linux already installed—you can join an Active Directory domain with a few configuration steps:
- Set up the DNS for this machine. To connect to a directory service, you need first to be able to resolve the directory domain name. If your network sets up the correct DNS using DHCP, you can skip this step.
- Change your machine name to reflect it will be part of the new domain. Edit the file
*/etc/hostname*and change the machine name to “machinename.my_domain” - Join the domain by executing this command:
*sudo realm join my_domain -v*(replace “my_domain” with the name of your domain)
After running this command, the system will ask for the credentials of a user allowed to join new machines in that domain. If there are no errors in the process, the machine will become part of the domain.
Now that this machine is part of your domain you can:
- Login with a domain username into the machine
- Get kerberos tickets to access different services in the domain network
- Access other services, depending on how the domain is configured
## Manage Fedora Linux with Fleet Commander
Now the machine is part of your domain, you can manage it with the domain administrator tools for Active Directory. Since your machine is not running Windows, you are limited to authentication and access to network and directory services. You cannot set up things like desktop-related configuration on this machine.
Luckily, Fedora has a tool called [Fleet Commander](https://fleet-commander.org/).
### Create configuration
Fleet Commander is a management tool that allows you to set up desktop configuration profiles for all Fedora Linux machines across your network.
This means, you can set up any configuration for GNOME desktop, Firefox, Chrome, LibreOffice, and other supported software in an easy way, and then make that configuration to be applied on login to the selected users/groups/machines in a granular way.
To use this tool, install the fleet-commander-admin package
sudo dnf install fleet-commander-admin
Next, visit [http://localhost:9090](http://localhost:9090/) in your browser to log in. On the menu to the left, click on *Fleet Commander*.
Fleet Commander has a tool to set up the configuration profiles intuitively using a “live session” mechanism. It runs a VM that serves as a template of your base machines. You have to manually make the configuration changes you want. Then you review all the configuration changes, select the ones you want to add to the profile, and deploy it.
### Manage clients
In each of your Fedora Linux or RHEL machines, you will need to install the Fleet Commander client service. This service activates when a user logs in. It searches the domain for the profiles that apply to current user/machine, and applies the configuration for the session.
To install the fleet-commander-client:
sudo dnf install fleet-commander-client
The software will detect if the machine is part of a domain automatically. When a user logs in, it will set up the session with the profiles that apply to the user.
## Marcelo
Congratulations on the article, very useful to know these resources, thank you.
## Os
Very useful information.
Thanks.
## LavaCreeperKing
Wow did not know about all of this. I don’t have a Windows server(Windows is terrible) to create an active directory with, but there is a tool to create Linux domains with. So I now need to play with setting up a Linux domain.
## MT
I tested it on a stock Fedora 34 Workstation Installation and a Windows Server 2016 Standard Edition.
I have to add “rc4-hmac” in the file “/etc/krb5.conf.d/crypto-policies” on my Fedora Workstation. Then the join succeeded. Without “rc4-hmac” it did not work.
## Muhammad Zamri Bin Muhamad Suharini
Thanks for the info
## René Genz
re-adding “rc4-hmac” is a bad solution considering security, see:
https://bugzilla.redhat.com/show_bug.cgi?id=1839414#c4
better enable AES in Active Directory
## DDG
What would happen if i install this on my laptop, bring said laptop outside with no connection to my FreeIPA/AD boxes at home? Can i still login?
## James
Yes, SSSD caches the last-seen good credentials.
## René Genz
SSSD supports offline login: https://fedoraproject.org/wiki/Features/SSSD#Benefit_to_Fedora
First log in with directory-based account must happen on-site. Fleet Commander client not required for offline login.
## Oliver
Yes. SSSD caches the login information so you can login offline. Fleet Commander Client is not required for login. It just fires after login, and in the case of Active Directory, checks if the directory services are present, downloads the profiles for that user and then apply them. In the case of FreeIPA, the profiles are downloaded and cached by SSSD.
If Fleet Commander is not able to download the profiles in Active Directory and there was a previous login, if will reuse the cached profiles.
## Mike
Yes, SSSD allows for cached credentials. Well it did for my test when I was playing with it a couple years ago.
## Torsten Nielsen
Joining a machine during installation went without a hitch, but I’m wondering how to get admin/root/sudo priviledges after the installation is complete. I didn’t create any local admin account. Logging in with AD-credentials work, but I don’t have sudo rights. Do I have to manage sudo via AD? or am I missing something obvious?
## ogutierrez
We are working on that.
https://gitlab.gnome.org/GNOME/gnome-initial-setup/-/issues/80
## Torsten Nielsen
Thanks! |
13,428 | 用开源软件保护你的文件的 5 种方法 | https://opensource.com/article/21/4/secure-documents-open-source | 2021-05-27T00:08:00 | [
"文件保护"
] | https://linux.cn/article-13428-1.html |
>
> 控制你自己的数据,使未经授权的用户无法访问它。
>
>
>

用户完全有权利关心他们数据的安全和保障。当你在计算机上创建数据时,希望对其进行独家控制是合理的。
有许多方法保护你的文件。在文件系统层面,你可以 [加密你的硬盘](https://opensource.com/article/21/3/encryption-luks) 或 [只是加密一个文件](https://opensource.com/article/21/3/luks-truecrypt)。不过,一个好的办公套件为你提供了更多的选择,我收集了五种我用开源软件保护文件的方法。
### 5 种保护你的文件的方法
#### 1、将文件保存在安全的云存储服务中
自托管一个开源的内容管理系统(CMS)平台可以让你完全控制你的数据。你的所有数据都留在你的服务器上,你可以控制谁可以访问它。
**选项:** [Nextcloud](https://nextcloud.com/)、[ownCloud](https://owncloud.com/)、[Pydio](https://pydio.com/) 和 [Seafile](https://www.seafile.com/en/home/)
所有这些都提供了存储、同步和共享文件和文件夹、管理内容、文件版本等功能。它们可以很容易地取代 Dropbox、Google Drive 和其他专有的云存储,不用将你的数据放在你不拥有、不维护、不管理的服务器上。
上面列出的开源的自托管方式符合 GDPR 和其他保护用户数据的国际法规。它们提供备份和数据恢复选项、审计和监控工具、权限管理和数据加密。

*Pydio 细胞中的审计控制。(来源:[Pydio.com](http://pydio.com))*
#### 2、启用静态、传输和端到端的加密功能
我们经常笼统地谈论数据加密,但在加密文件时有几个方面需要考虑:
* 通过**静态加密**(或磁盘加密),你可以保护存储在你的基础设施内或硬盘上的数据。
* 在使用 HTTPS 等协议时,**传输加密**会保护流量形式的数据。它可以保护你的数据在从一个地方移动到另一个地方时不被拦截和转换。当你把文件上传到你的云端时,这很重要。
* **端到端加密**(E2EE)通过在一端加密,在另一端解密来保护数据。除非有解密密钥,否则任何第三方都无法读取你的文件,即使他们干扰了这个过程并获得了这个文件的权限。
**选项:** CryptPad、ownCloud、ONLYOFFICE 工作区、Nextcloud 和 Seafile
ownCloud、ONLYOFFICE 工作区、Nextcloud 和 Seafile 支持所有三层的加密。但它们在实现端到端加密的方式上有所不同。
* 在 ownCloud 中,有一个 E2EE 插件,允许你对文件夹共享进行加密。
* 在 Nextcloud 中,桌面客户端有一个文件夹级别的选项。
* Seafile 通过创建加密库来提供客户端的 E2EE。
* [ONLYOFFICE 工作区](https://www.onlyoffice.com/workspace.aspx) 不仅允许你在存储和共享文件时对其进行加密,而且还允许你在“私人房间”中实时安全地共同编辑文件。加密数据是自动生成和传输的,并且是自己加密的 —— 你不需要保留或记住任何密码。
* 正如其名称所示,[CryptPad](https://cryptpad.fr/) 是完全私有的。所有的内容都是由你的浏览器进行加密和解密的。这意味着文件、聊天记录和文件在你登录的会话之外是无法阅读的。即使是服务管理员也无法得到你的信息。

*加密的 CryptPad 存储。(来源:[Cryptpad.fr](http://cryptpad.fr))*
#### 3、使用数字签名
数字签名可以让你验证你是文件内容的原作者,并且没有对其进行过修改。
**选项:** LibreOffice Writer、ONLYOFFICE 桌面编辑器、OpenESignForms 和 SignServer
[LibreOffice](https://www.libreoffice.org/) 和 [ONLYOFFICE](https://www.onlyoffice.com/desktop.aspx) 套件提供了一个对文件数字签名的集成工具。你可以添加一个在文档文本中可见的签名行,并允许你向其他用户请求签名。
一旦你应用了数字签名,任何人都不能编辑该文件。如果有人修改文档,签名就会失效,这样你就会知道内容被修改了。
在 ONLYOFFICE 中,你可以在 LibreOffice 中签名 OOXML 文件(例如,DOCX、XLSX、PPTX)作为 ODF 和 PDF。如果你试图在 LibreOffice 中签名一个 OOXML 文件,该签名将被标记为“只有部分文件被签署”。

*ONLYOFFICE 中的数字签名。 (来源:[ONLYOFFICE帮助中心](http://helpcenter.onlyoffice.com))*
[SignServer](https://www.signserver.org/) 和 [Open eSignForms](https://github.com/OpenESignForms) 是免费的电子签名服务,如果你不需要在编辑器中直接签名文件,你可以使用它们。这两个工具都可以让你处理文档,SignServer 还可以让你签名包括 Java 在内的代码,并应用时间戳。
#### 4、添加水印
水印可避免你的内容在未经授权的情况下被重新分发,并保护你的文件可能包含的任何机密信息。
**选项:**Nextcloud 中的 Collabora Online 或 ONLYOFFICE Docs
当与 Nextcloud 集成时,[ONLYOFFICE Docs](https://www.onlyoffice.com/office-for-nextcloud.aspx) 和 [Collabora](https://www.collaboraoffice.com/) 允许你在文件、电子表格和演示文稿中嵌入水印。要激活水印功能,必须以管理员身份登录你的 Nextcloud 实例,并在解决方案的设置页面上进入**安全视图设置**。
你可以使用占位符将默认的水印替换成你自己的文本。在打开文件时,水印将针对每个用户单独显示。你也可以定义组来区分将看到水印的用户,并选择必须显示水印的共享类型。

*水印 (Ksenia Fedoruk, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
你也可以在 LibreOffice 和 ONLYOFFICE 桌面应用程序中的文档中插入水印。然而,在这种情况下,它只是一个放置在主文本层下的文本或图像,任何人都可以轻易地删除它。
#### 5、用密码保护文件
密码保护允许你安全地存储和交换本地文件。如果有人访问你的桌面或通过电子邮件或其他方法得到受保护的文件,他们不知道密码就无法打开它。
**选项:** Apache OpenOffice、LibreOffice 和 ONLYOFFICE 桌面编辑器
所有这三种解决方案都提供了为你的敏感文件设置密码的能力。
如果一个受保护的文档对你很重要,强烈建议你使用密码管理器保存密码或记住它,因为 LibreOffice、ONLYOFFICE 和 [OpenOffice](https://www.openoffice.org/) 不提供密码恢复选项。因此,如果你忘记或丢失了密码,就没有办法恢复或重置密码并打开文件。
### 你的数据属于你
使用这些方法中的一种或多种来保护你的文件,以保持更安全的在线活动。现在是 21 世纪,计算机太先进了,不能冒险把你的数据交给你无法控制的服务。使用开源,掌握你的数字生活的所有权。
你最喜欢的安全使用文档的工具是什么?请在评论中分享它们。
---
via: <https://opensource.com/article/21/4/secure-documents-open-source>
作者:[Ksenia Fedoruk](https://opensource.com/users/ksenia-fedoruk) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Users have every right to be concerned about the safety and security of their data. When you create data on a computer, it's reasonable to want exclusive control over it.
There are many ways to protect your documents. At the filesystem level, you can [encrypt your hard drive](https://opensource.com/article/21/3/encryption-luks) or [just a file](https://opensource.com/article/21/3/luks-truecrypt). A good office suite affords you many more options, though, and I've gathered five of the methods I use to secure my documents with open source software.
## 5 ways to secure your docs
### 1. Keeping documents in secure cloud storage services
Self-hosting an open source content management system (CMS) platform gives you complete control over your data. All your data stays on your server, and you control who has access to it.
**Options:** [Nextcloud](https://nextcloud.com/), [ownCloud](https://owncloud.com/), [Pydio](https://pydio.com/), and [Seafile](https://www.seafile.com/en/home/)
All of these offer functionality for storing, syncing, and sharing documents and folders, managing content, file versioning, and so on. They can easily replace Dropbox, Google Drive, and other proprietary cloud storage that place your data on servers you don't own, maintain, or govern.
The open source self-hosted options listed above are compliant with GDPR and other international regulations that protect user data. They offer backup and data recovery options, auditing and monitoring tools, permissions management, and data encryption.
Audit control in Pydio Cells. (©2020, Pydio.com)
### 2. Enabling encryption at rest, in transit, and end-to-end
We often speak of data encryption in general terms, but there are several aspects to consider when encrypting files:
- With
**encryption at rest**(or disk encryption), you can protect data stored within your infrastructure or on your hard drive. **Encryption in transit**protects data as traffic when it's using protocols like HTTPS. It protects your data from being intercepted and transformed as it moves from one location to another. This is important when you upload documents to your cloud.**End-to-end encryption**(E2EE) protects data by encrypting it on one end and decrypting it on the other. No third party can read your documents, even if they interfere in the process and get access to the files unless they have the decryption key.
**Options:** CryptPad, ownCloud, ONLYOFFICE Workspace, Nextcloud, and Seafile
ownCloud, ONLYOFFICE Workspace, Nextcloud, and Seafile support all three layers of encryption. They differ in how they implement end-to-end encryption:
- In ownCloud, there's an E2EE plugin that allows you to encrypt folder sharing.
- In Nextcloud, there's a folder-level option available in the desktop client.
- Seafile provides client-side E2EE by creating encrypted libraries.
[ONLYOFFICE Workspace](https://www.onlyoffice.com/workspace.aspx)not only allows you to encrypt your documents while storing and sharing them, but it also permits you to securely co-edit them in real time in Private Rooms. The encryption data is automatically generated and transferred and is encrypted itself—you don't have to keep or remember any passwords.[CryptPad](https://cryptpad.fr/), as its name suggests, is completely private. All content is encrypted and decrypted by your browser. This means documents, chats, and files are unreadable outside the session where you are logged in. Even the service administrators can't get your information.
Encrypted CryptPad storage. ( Cryptpad.fr)
### 3. Using digital signatures
Digital signatures allow you to verify that you originated a document's content and no alterations have been made to it.
**Options:** LibreOffice Writer, ONLYOFFICE Desktop Editors, OpenESignForms, and SignServer
[LibreOffice](https://www.libreoffice.org/) and [ONLYOFFICE](https://www.onlyoffice.com/desktop.aspx) suites provide an integrated tool to digitally sign documents. You can add a signature line that is visible in the document text and allows you to request signatures from other users.
Once you apply a digital signature, no one can edit the document. If someone changes the document, the signature becomes invalid, so you'll know the content was modified.
In ONLYOFFICE, you can sign OOXML files (e.g., DOCX, XLSX, PPTX) in LibreOffice as ODFs and PDFs. If you try to sign an OOXML document in LibreOffice, the signature will be marked with "only parts of the document are signed."

Digital signature in ONLYOFFICE. (Source: ONLYOFFICE Help Center)
[SignServer](https://www.signserver.org/) and [Open eSignForms](https://github.com/OpenESignForms) are free electronic signature services that you can use if you don't need to sign a document right in the editor. Both tools allow you to work with documents, and SignServer also enables you to sign code, including Java, and apply time stamping.
### 4. Watermarking
Watermarks avoid unauthorized redistribution of your content and protect any confidential information your files might contain.
**Options:** Collabora Online in Nextcloud or ONLYOFFICE Docs in Nextcloud
[ONLYOFFICE Docs](https://www.onlyoffice.com/office-for-nextcloud.aspx) and [Collabora](https://www.collaboraoffice.com/), when integrated with Nextcloud, allow you to embed a watermark in your documents, spreadsheets, and presentations. To activate watermarking, you have to log into your Nextcloud instance as an admin and go to **Secure view settings** on the solution's Settings page.
You can replace the default watermark with your own text using the placeholders. The watermark will be displayed individually for each user when opening a file. You can also define groups to differentiate users who will see the watermark and select the types of shares that must show the watermark.
Watermarking (Ksenia Fedoruk, CC BY-SA 4.0)
You can also insert watermarks in your docs in the LibreOffice and ONLYOFFICE desktop apps. However, in this case, it's just a text or an image placed under the main text layer, so anyone can remove it easily.
### 5. Protecting documents with passwords
Password protection allows you to store and exchange local files securely. If someone accesses your desktop or gets the protected file via email or another method, they won't be able to open it without knowing the password.
**Options:** Apache OpenOffice, LibreOffice, and ONLYOFFICE Desktop Editors
All three solutions offer you the ability to set a password for your sensitive documents.
If a protected doc is important to you, it is strongly recommended you save the password using a password manager or memorize it because LibreOffice, ONLYOFFICE, and [OpenOffice](https://www.openoffice.org/) don't offer a password-recovery option. So, if you forget or lose the password, there is no ability to restore or reset it and open the file.
## Your data belongs to you
Protect your documents using one or more of these methods to stay safer online. It's the 21st century, and computing is too advanced to risk giving your data to a service outside your control. Use open source and take ownership of your digital life.
What are your favorite tools for working securely with docs? Please share them in the comments.
## 1 Comment |
13,429 | 什么是 Java 的无服务器化? | https://opensource.com/article/21/5/what-serverless-java | 2021-05-27T08:59:00 | [
"Java",
"serverless",
"无服务器"
] | /article-13429-1.html |
>
> Java 仍是开发企业应用程序最流行的语言之一。那么,为什么<ruby> 无服务器 <rt> serverless </rt></ruby>开发人员对它望而却步?
>
>
>

几十年来,企业已经在各类平台上开发了关键业务应用程序,包括物理服务器、虚拟机和云环境。这些应用程序在各行各业都有一个共同点,那就是无论需求如何,它们都需要持续可用(24x7x365),保证稳定性、可靠性和性能。因此,即使实际资源利用率低于 50%,每个企业都必须付出高额成本维护基础架构(如 CPU、内存、磁盘、网络等)。
无服务器架构是为了帮助解决这些问题而产生的。无服务器允许开发人员按需构建和运行应用程序,保证高可用性,不必在多云和混合云环境中管理服务器。在幕后,无服务器拓扑中仍有很多服务器,但它们是从应用程序开发中抽象出来的。相反,云提供商使用无服务器进行资源管理,例如配置、维护、联网和扩展服务器实例。
由于其高效性,无服务器开发模式现在是一些企业的需求,这些企业希望按需启动服务,而不是一直运行服务。
许多新建的开源项目用来在 [Kubernetes](https://opensource.com/article/19/6/reasons-kubernetes) 集群上通过 Linux 容器包来管理无服务器应用程序。CNCF 的《[交互式无服务器全景](https://landscape.cncf.io/serverless?zoom=150)》 是一份关于开源项目、工具、框架和公共云平台的指南,帮助 DevOps 团队处理无服务器应用程序。

开发人员可以编写代码,然后将其快速部署到各种无服务器环境中。然后,无服务器应用程序响应需求,并根据需要自动伸缩扩展。
你可能想知道什么编程语言和运行环境最适合无服务器应用程序开发,以便与上图中的技术集成。这个问题不只一个答案,但是让我们退一步来讨论在企业生产环境中开发业务应用程序最流行的应用程序运行环境:Java。
据 [Developer Economics](https://developereconomics.com/) 称,截至 2020 年第三季度,仍有 800 多万家企业开发人员在使用 Java 来实现其业务需求。然而,根据 2020 年的一项调查,Java(占比 6%)显然不是有前瞻意识的开发人员的首选,他们使用当前云服务做开发。

*来自 NewRelic 无服务器基准报告的数据(Daniel Oh, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
资源使用、响应时间和延迟在无服务器开发中至关重要。公有云提供商提供的无服务器产品通常是按需计量的,只有在无服务器应用程序启动时,才会通过事件驱动的执行模式收费。因此,当无服务器应用程序闲置或缩减为零时,企业无需支付任何费用。
### 带有容器的 Java 状态
在这种背景下,你可能会问:“*既然现有业务应用程序很可能是在 Java 技术上开发的,那么开发人员为什么不尝试使用 Java 栈进行无服务器应用程序开发呢?*”
隐藏的真相是:很难在新的不可变更的基础设施(例如 Kubernetes 这样的容器平台)中优化 Java 应用程序。

该图描述了 Java 进程与竞争的语言、框架(如 [Node.js](https://nodejs.org/) 和 [Go](https://golang.org/))之间内存资源使用的差异。Java HotSpot 占用资源最大,其中包括每个<ruby> Java 虚拟机 <rt> Java Virtual Machine </rt></ruby>(JVM)实例分配的堆内存。中间显示了 Node.js 每个进程要比 Java 小得多。最后,Go 是一种流行的云服务编程语言,因为它的内存消耗最低。
如你所见,当你在这张图从左到右走,你会看到更密的节点。这就是开发人员在云、容器和 Kubernetes 上编写无服务器应用程序时回避 Java(包括 [Spring Boot](https://spring.io/projects/spring-boot),一种顽固的微服务 Java 框架)的原因。
### 下一步是什么?
企业可以通过实现无服务器应用程序获得明显的好处,但是资源密度问题导致他们避免使用 Java 堆栈在 Kubernetes 上开发无服务器应用程序开发。但是选择其他语言会给全球数百万 Java 开发人员带来学习负担。因此,在本系列的下一篇文章中,我将指导你如何开始使用 Java 无服务器函数,而不是使用其他语言。
---
via: <https://opensource.com/article/21/5/what-serverless-java>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,432 | 3 个值得使用的在 Python 3.1 中发布的特性 | https://opensource.com/article/21/5/python-31-features | 2021-05-27T22:51:34 | [
"Python"
] | /article-13432-1.html |
>
> 探索一些未被充分利用但仍然有用的 Python 特性。
>
>
>

这是 Python 3.x 首发特性系列文章的第二篇。Python 3.1 于 2009 年首次发布,尽管它已经发布了很长时间,但它引入的许多特性都没有被充分利用,而且相当酷。下面是其中的三个。
### 千位数格式化
在格式化大数时,通常是每三位数放置逗号,使数字更易读(例如,1,048,576 比 1048576 更容易读)。从 Python 3.1 开始,可以在使用字符串格式化函数时直接完成:
```
"2 to the 20th power is {:,d}".format(2**20)
```
```
'2 to the 20th power is 1,048,576'
```
`,d` 格式符表示数字必须用逗号格式化。
### Counter 类
`collections.Counter` 类是标准库模块 `collections` 的一部分,是 Python 中的一个秘密超级武器。它经常在 Python 的面试题的简单解答中首次遇到,但它的价值并不限于此。
例如,在 [Humpty Dumpty 的歌](http://www2.open.ac.uk/openlearn/poetryprescription/humpty-dumptys-recitation.html) 的前八行中找出五个最常见的字母:
```
hd_song = """
In winter, when the fields are white,
I sing this song for your delight.
In Spring, when woods are getting green,
I'll try and tell you what I mean.
In Summer, when the days are long,
Perhaps you'll understand the song.
In Autumn, when the leaves are brown,
Take pen and ink, and write it down.
"""
```
```
import collections
collections.Counter(hd_song.lower().replace(' ', '')).most_common(5)
```
```
[('e', 29), ('n', 27), ('i', 18), ('t', 18), ('r', 15)]
```
### 执行软件包
Python 允许使用 `-m` 标志来从命令行执行模块。甚至一些标准库模块在被执行时也会做一些有用的事情;例如,`python -m cgi` 是一个 CGI 脚本,用来调试网络服务器的 CGI 配置。
然而,直到 Python 3.1,都不可能像这样执行 *软件包*。从 Python 3.1 开始,`python -m package` 将执行软件包中的 `__main__` 模块。这是一个放调试脚本或命令的好地方,这些脚本主要是用工具执行的,不需要很短。
Python 3.0 在 11 年前就已经发布了,但是在这个版本中首次出现的一些功能是很酷的,而且没有得到充分利用。如果你还没使用,那么将它们添加到你的工具箱中。
---
via: <https://opensource.com/article/21/5/python-31-features>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,433 | 用这个开源项目在 Linux 上玩复古视频游戏 | https://opensource.com/article/21/4/scummvm-retro-gaming | 2021-05-28T06:20:30 | [
"复古游戏",
"游戏"
] | https://linux.cn/article-13433-1.html |
>
> ScummVM 是在现代硬件上玩老式视频游戏的最直接的方法之一。
>
>
>

玩冒险游戏一直是我使用计算机经验的一个重要部分。从最早的基于文本的冒险游戏到 2D 像素艺术、全动态视频和 3D 游戏,冒险游戏类型为我提供了很多美好的回忆。
有时我想重温那些老游戏,但它们很多都是在 Linux 出现之前发布的,那么我如何去重玩这些游戏呢?我使用 [ScummVM](https://www.scummvm.org/),说实话,这是我最喜欢的开源项目之一。
### 什么是 ScummVM

ScummVM 是一个设计用来在现代硬件上玩老式冒险游戏的程序。ScummVM 最初是为了运行使用<ruby> 卢卡斯艺术 <rt> LucasArt </rt></ruby>的<ruby> 疯狂豪宅脚本创作工具 <rt> Script Creation Utility for Maniac Mansion </rt></ruby>(SCUMM)开发的游戏,现在支持许多不同的游戏引擎。它可以支持几乎所有经典的<ruby> 雪乐山娱乐 <rt> Sierra On-Line </rt></ruby>和卢卡斯艺术的冒险游戏,以及其他发行商的大量冒险游戏。ScummVM 并不支持所有的冒险游戏(目前),但它可以用来玩数百种冒险游戏。ScummVM 可用于多个平台,包括 Windows、macOS、Linux、Android、iOS 和一些游戏机。
### 为什么使用 ScummVM
有很多方法可以在现代硬件上玩老游戏,但它们往往比使用 ScummVM 更复杂。[DOSBox](https://www.dosbox.com/) 可以用来玩 DOS 游戏,但它需要调整设置,使其以正确的速度进行游戏。Windows 游戏可以用 [WINE](https://www.winehq.org/) 来玩,但这需要游戏及其安装程序都与 WINE 兼容。
即使游戏可以在 WINE 下运行,一些游戏仍然不能在现代硬件上很好地运行,因为硬件的速度太快了。这方面的一个例子是《<ruby> 国王密使 6 <rt> King's Quest VI </rt></ruby>》中的一个谜题,它涉及将点燃的鞭炮带到某个地方。在现代硬件上,鞭炮爆炸的速度太快了,这使得在角色不死很多次的情况下不可能到达正确的位置。
ScummVM 消除了其他玩复古冒险游戏的方法中存在的许多问题。如果是 ScummVM 支持的游戏,那么它的配置和玩都很简单。在大多数情况下,将游戏文件从原始游戏光盘复制到一个目录,并在 ScummVM 中添加该目录,就可以玩该游戏了。对于多张光盘上的游戏,可能需要重命名一些文件以避免文件名冲突。需要哪些数据文件的说明以及任何重命名的说明都记录在 [每个支持的游戏](https://wiki.scummvm.org/index.php?title=Category:Supported_Games) 的 ScummVM 维基页面上。
ScummVM 的一个奇妙之处在于,每一个新版本都会增加对更多游戏的支持。ScummVM 2.2.0 增加了对十几种互动小说解释器的支持,这意味着 ScummVM 现在可以玩数百种基于文本的冒险游戏。ScummVM 的开发分支应该很快就会变成 2.3.0 版本,它整合了 [ResidualVM](https://www.residualvm.org/) 对 3D 冒险游戏的支持,所以现在 ScummVM 可以用来玩《<ruby> 冥界狂想曲 <rt> Grim Fandango </rt></ruby>》、《神秘岛 3:放逐者Myst III: Exile》和《<ruby> 最长的旅程 <rt> The Longest Journey </rt></ruby>》。其开发分支最近还增加了对使用 [Adventure Game Studio](https://www.adventuregamestudio.co.uk/) 创建的游戏的支持,这为 ScummVM 增加了成百上千的游戏。
### 如何安装 ScummVM
如果你想从你的 Linux 发行版的仓库中安装 ScummVM,过程非常简单。你只需要运行一个命令。然而,你的发行版可能会提供一个旧版本的 ScummVM,它不像最新版本那样支持许多游戏,所以要记住这一点。
在 Debian/Ubuntu 上安装 ScummVM:
```
sudo apt install scummvm
```
在 Fedora 上安装 ScummVM:
```
sudo dnf install scummvm
```
#### 使用 Flatpak 或 Snap 安装 ScummVM
ScummVM 也可以以 Flatpak 和 Snap 的形式提供。如果你使用这些方式之一,你可以使用以下命令来安装相关的版本,它应该总是 ScummVM 的最新版本。
```
flatpak install flathub org.scummvm.ScummVM
```
或
```
snap install scummvm
```
#### 编译 ScummVM 的开发分支
如果你想尝试 ScummVM 尚未稳定的开发分支中的最新和主要的功能,你可以通过编译 ScummVM 的源代码来实现。请注意,开发分支是不断变化的,所以事情可能不总是正确的。如果你仍有兴趣尝试开发分支,请按照下面的说明进行。
首先,你需要为你的发行版准备必要的开发工具和库,这些工具和库在 ScummVM 维基上的 [编译 ScummVM/GCC](https://wiki.scummvm.org/index.php/Compiling_ScummVM/GCC) 页面列出。
一旦你安装了先决条件,运行以下命令:
```
git clone <https://github.com/scummvm/scummvm.git>
cd scummvm
./configure
make
sudo make install
```
### 向 ScummVM 添加游戏
将游戏添加到 ScummVM 是你在游戏前需要做的最后一件事。如果你的收藏集中没有任何支持的冒险游戏,你可以从 [ScummVM 游戏](https://www.scummvm.org/games/) 页面下载 11 个精彩的游戏。你还可以从 [GOG.com](https://www.gog.com/) 购买许多 ScummVM 支持的游戏。如果你从 [GOG.com](http://GOG.com) 购买了游戏,并需要从 GOG 下载中提取游戏文件,你可以使用 [innoextract](https://constexpr.org/innoextract/) 工具。
大多数游戏需要放在自己的目录中(唯一的例外是由单个数据文件组成的游戏),所以最好先创建一个目录来存储你的 ScummVM 游戏。你可以使用命令行或图形化文件管理器来完成这个工作。在哪里存储游戏并不重要(除了 ScummVM Flatpak,它是一个沙盒,要求游戏存储在 `~/Documents` 目录中)。创建这个目录后,将每个游戏的数据文件放在各自的子目录中。
一旦文件被复制到你想要的地方,运行 ScummVM,并通过点击“Add Game…”将游戏添加到收藏集中,在打开的文件选择器对话框中选择适当的目录,并点击“Choose”。如果 ScummVM 正确检测到游戏,它将打开其设置选项。如果你想的话,你可以从各个标签中选择高级配置选项(也可以在以后通过使用“Edit Game…”按钮进行更改),或者你可以直接点击“OK”,以默认选项添加游戏。如果没有检测到游戏,请查看 ScummVM 维基上的 [支持的游戏](https://wiki.scummvm.org/index.php/Category:Supported_Games) 页面,以了解特定游戏的数据文件可能需要的特殊说明的细节。
现在唯一要做的就是在 ScummVM 的游戏列表中选择游戏,点击“Start”,享受重温旧爱或首次体验经典冒险游戏的乐趣。
---
via: <https://opensource.com/article/21/4/scummvm-retro-gaming>
作者:[Joshua Allen Holm](https://opensource.com/users/holmja) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Playing adventure games has always been a big part of my experience with computers. From the earliest text-based adventure games to 2D pixel art, full-motion video, and 3D games, the adventure game genre has provided me with a lot of fond memories.
Sometimes I want to revisit those old games, but many were released before Linux was even a thing, so how do I go about replaying those games? I use [ScummVM](https://www.scummvm.org/), which is honestly one of my favorite open source projects.
## What is ScummVM
(Joshua Allen Holm, CC BY-SA 4.0)
ScummVM is a program designed to play old adventure games on modern hardware. Originally designed to run games developed using LucasArt's Script Creation Utility for Maniac Mansion (SCUMM), ScummVM now supports many different game engines. It can play almost all of the classic Sierra On-Line and LucasArts adventure games as well as a wide selection of adventure games from other publishers. ScummVM does not support *every* adventure game (yet), but it can be used to play hundreds of them. ScummVM is available for multiple platforms, including Windows, macOS, Linux, Android, iOS, and several game consoles.
## Why use ScummVM
There are plenty of ways to play old games on modern hardware, but they tend to be more complicated than using ScummVM. [DOSBox](https://www.dosbox.com/) can be used to play DOS games, but it requires tweaking to get the settings right so that the game plays at the right speed. Windows games can be played using [WINE](https://www.winehq.org/), but that requires both the game and the game's installer to be compatible with WINE.
Even if a game runs under WINE, some games still do not work well on modern hardware because the hardware is too fast. One example of this is a puzzle in King's Quest VII that involves taking a lit firecracker somewhere. On modern hardware, the firecracker explodes way too quickly, which makes it impossible to get to the right location without the character dying multiple times.
ScummVM eliminates many of the problems present in other methods for playing retro adventure games. If ScummVM supports a game, it is straightforward to configure and play. In most cases, copying the game files from the original game discs to a directory and adding that directory in ScummVM is all that is needed to play the game. For games that came on multiple discs, it might be necessary to rename some files to avoid file name conflicts. The instructions for what data files are needed and any renaming instructions are documented on the ScummVM Wiki page for [each supported game](https://wiki.scummvm.org/index.php?title=Category:Supported_Games).
One of the wonderful things about ScummVM is how each new release adds support for more games. ScummVM 2.2.0 added support for a dozen interactive fiction interpreters, which means ScummVM can now play hundreds of text-based adventure games. The development branch of ScummVM, which should become version 2.3.0 soon, integrates [ResidualVM](https://www.residualvm.org/)'s support for 3D adventure games, so now ScummVM can be used to play Grim Fandango, Myst III: Exile, and The Longest Journey. The development branch also recently added support for games created using [Adventure Game Studio](https://www.adventuregamestudio.co.uk/), which adds hundreds, possibly thousands, of games to ScummVM's repertoire.
## How to install ScummVM
If you want to install ScummVM from your Linux distribution's repositories, the process is very simple. You just need to run one command. However, your distribution might offer an older release of ScummVM that does not support as many games as the latest release, so do keep that in mind.
**Install ScummVM on Debian/Ubuntu:**
`sudo apt install scummvm`
**Install ScummVM on Fedora:**
`sudo dnf install scummvm`
### Install ScummVM using Flatpak or Snap
ScummVM is also available as a Flatpak and as a Snap. If you use one of those options, you can use one of the following commands to install the relevant version, which should always be the latest release of ScummVM:
`flatpak install flathub org.scummvm.ScummVM`
or
`snap install scummvm`
### Compile the development branch of ScummVM
If you want to try the latest and greatest features in the not-yet-stable development branch of ScummVM, you can do so by compiling ScummVM from the source code. Do note that the development branch is constantly changing, so things might not always work correctly. If you are still interested in trying out the development branch, follow the instructions below.
To start, you will need the required development tools and libraries for your distribution, which are listed on the [Compiling ScummVM/GCC page](https://wiki.scummvm.org/index.php/Compiling_ScummVM/GCC) on the ScummVM Wiki.
Once you have the prerequisites installed, run the following commands:
```
git clone https://github.com/scummvm/scummvm.git
cd scummvm
./configure
make
sudo make install
```
## Add games to ScummVM
Adding games to ScummVM is the last thing you need to do before playing. If you do not have any supported adventure games in your collection, you can download 11 wonderful games from the [ScummVM Games page](https://www.scummvm.org/games/). You can also purchase many of the games supported by ScummVM from [GOG.com](https://www.gog.com/). If you purchase a game from GOG.com and need to extract the game files from the GOG download, you can use the [innoextract](https://constexpr.org/innoextract/) utility.
Most games need to be in their own directory (the only exceptions to this are games that consist of a single data file), so it is best to begin by creating a directory to store your ScummVM games. You can do this using the command line or a graphical file manager. Where you store your games does not matter (except in the case of the ScummVM Flatpak, which is a sandbox and requires the games to be stored in the `~/Documents`
directory). After creating this directory, place the data files for each game in their own subdirectories.
Once the files are copied to where you want them, run ScummVM and add the game to the collection by clicking **Add Game…**, selecting the appropriate directory in the file-picker dialog box that opens, and clicking **Choose**. If ScummVM properly detects the game, it will open its settings options. You can select advanced configuration options from the various tabs if you want (which can also be changed later by using the **Edit Game…** button), or you can just click **OK** to add the game with the default options. If the game is not detected, check the [Supported Games pages](https://wiki.scummvm.org/index.php/Category:Supported_Games) on the ScummVM Wiki for details about special instructions that might be needed for a particular game's data files.
The only thing left to do now is select the game in ScummVM's list of games, click on **Start**, and enjoy replaying an old favorite or experiencing a classic adventure game for the first time.
## Comments are closed. |
13,435 | 3 个到今天仍然有用的 Python 3.2 特性 | https://opensource.com/article/21/5/python-32 | 2021-05-28T20:20:00 | [
"Python"
] | /article-13435-1.html |
>
> 探索一些未被充分利用但仍然有用的 Python 特性。
>
>
>

这是 Python 3.x 首发特性系列文章中的第三篇。其中一些 Python 版本已经推出了一段时间。例如,Python 3.2 是在 2011 年首次发布的,但其中引入的一些很酷、很有用的特性仍然没有被使用。下面是其中的三个。
### argparse 子命令
`argparse` 模块首次出现在 Python 3.2 中。有许多用于命令行解析的第三方模块。但是内置的 `argparse` 模块比许多人认为的要强大。
要记录所有的 `argparse` 的特性,那需要专门写系列文章。下面是一个例子,说明如何用 `argparse` 做子命令。
想象一下,一个命令有两个子命令:`negate`,需要一个参数,`multiply`,需要两个参数:
```
$ computebot negate 5
-5
$ computebot multiply 2 3
6
```
```
import argparse
parser = argparse.ArgumentParser()
subparsers = parser.add_subparsers()
```
`add_subparsers()` 方法创建一个对象,你可以向其添加子命令。唯一需要记住的技巧是,你需要添加通过 `set_defaults()` 调用的子命令:
```
negate = subparsers.add_parser("negate")
negate.set_defaults(subcommand="negate")
negate.add_argument("number", type=float)
```
```
multiply = subparsers.add_parser("multiply")
multiply.set_defaults(subcommand="multiply")
multiply.add_argument("number1", type=float)
multiply.add_argument("number2", type=float)
```
我最喜欢的一个 `argparse` 功能是,因为它把解析和运行分开,测试解析逻辑特别令人愉快。
```
parser.parse_args(["negate", "5"])
```
```
Namespace(number=5.0, subcommand='negate')
```
```
parser.parse_args(["multiply", "2", "3"])
```
```
Namespace(number1=2.0, number2=3.0, subcommand='multiply')
```
### contextlib.contextmanager
上下文是 Python 中一个强大的工具。虽然很多人 *使用* 它们,但编写一个新的上下文常常看起来像一门黑暗艺术。有了 `contextmanager` 装饰器,你所需要的只是一个一次性的生成器。
编写一个打印出做某事所需时间的上下文,就像这样简单:
```
import contextlib, timeit
@contextlib.contextmanager
def timer():
before = timeit.default_timer()
try:
yield
finally:
after = timeit.default_timer()
print("took", after - before)
```
你可以这样使用:
```
import time
with timer():
time.sleep(10.5)
```
```
took 10.511025413870811`
```
### functools.lru\_cache
有时,在内存中缓存一个函数的结果是有意义的。例如,想象一下经典的问题:“有多少种方法可以用 25 美分、1 美分、2 美分和 3 美分可以来换取 1 美元?”
这个问题的代码可以说是非常简单:
```
def change_for_a_dollar():
def change_for(amount, coins):
if amount == 0:
return 1
if amount < 0 or len(coins) == 0:
return 0
some_coin = next(iter(coins))
return (
change_for(amount, coins - set([some_coin]))
+
change_for(amount - some_coin, coins)
)
return change_for(100, frozenset([25, 10, 5, 1]))
```
在我的电脑上,这需要 13ms 左右:
```
with timer():
change_for_a_dollar()
```
```
took 0.013737603090703487`
```
事实证明,当你计算有多少种方法可以做一些事情,比如用 50 美分找钱,你会重复使用相同的硬币。你可以使用 `lru_cache` 来避免重复计算。
```
import functools
def change_for_a_dollar():
@functools.lru_cache
def change_for(amount, coins):
if amount == 0:
return 1
if amount < 0 or len(coins) == 0:
return 0
some_coin = next(iter(coins))
return (
change_for(amount, coins - set([some_coin]))
+
change_for(amount - some_coin, coins)
)
return change_for(100, frozenset([25, 10, 5, 1]))
```
```
with timer():
change_for_a_dollar()
```
```
took 0.004180959425866604`
```
一行的代价是三倍的改进。不错。
### 欢迎来到 2011 年
尽管 Python 3.2 是在 10 年前发布的,但它的许多特性仍然很酷,而且没有得到充分利用。如果你还没使用,那么将他们添加到你的工具箱中。
---
via: <https://opensource.com/article/21/5/python-32>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,436 | 将操作系统移植到新的芯片架构的经验 | https://opensource.com/article/21/5/port-chip-architectures | 2021-05-28T22:19:33 | [
"移植",
"芯片",
"架构"
] | https://linux.cn/article-13436-1.html |
>
> 在将嵌入式系统操作系统移植到不同的芯片架构时,RT-Thread 的维护者们从中学到了什么。
>
>
>

曾经有人问我,为什么计算机被称为“计算机”,它们做的事情可远不止计算数字。一台现代的个人电脑可以浏览互联网、播放音频和视频、为视频游戏和电影生成漂亮的图形、模拟和预测复杂的天气模式和流行病风险、将建筑和工程蓝图变为现实等等。
计算机之所以能做到这些,是因为所有这些问题都可以归结为数字方程,而计算机的 CPU —— 其中央处理单元 —— 实际上不过是一个简单的计算器。
为了让 CPU 向硬盘驱动器发送信号以写入数据,或向显示器发送信号以显示图像,它必须接收指令。这些指令是以 “代码” 的形式出现的,这是一种简明的说法,即必须有人写一个 *程序* ,与CPU “说” 同样的语言。CPU 理解的是 *机器语言*,这是一个大多数人都无法理解的比特阵列,大多数人都不可能手动写出来。相反,我们使用像 C、C++、Java、Python 等编程语言。这些语言被解析并编译成机器语言,然后交付给 CPU。
如果你试图用一种它不理解的语言来指示 CPU,它不知道该怎么做。你可以通过尝试用 [x86\_64 RHEL](https://www.redhat.com/en/store/red-hat-enterprise-linux-developer-suite) 镜像启动 [树莓派](https://opensource.com/resources/raspberry-pi) 来体验这种误传尝试的尴尬结果。如果它能工作就好了,但是不能。
### 将一个操作系统移植到一个新的架构上
[RT-Thread 项目](https://opensource.com/article/20/6/open-source-rtos) 为嵌入式系统程序员提供了一个开源的操作系统(OS)。嵌入式领域是非常多样化的,有很多物联网(IoT)、定制工业和业余设备。RT-Thread 的目标是使嵌入式编程对每个人来说都很容易,无论你使用什么设备。有时,这意味着要将一个操作系统移植到一个新的架构上,不管是用于相同架构但指令集略有不同的的芯片,还是用于全新的架构。
一开始处理这个问题可能会有点吓人 —— 你可能不知道从哪里开始或如何开始。这篇文章收集了 RT-Thread 维护者在将 [RTOS](https://www.rt-thread.io/) 移植到新的芯片架构时学到的经验。
### 你在开始之前需要知道什么
这里是一个看似难以逾越的过程的高屋建瓴的观点。这对你的项目来说可能有所不同,但从概念上来说,这是相对普遍的,即使一些具体的细节是不同的:
1. 准备好一个 C 语言的执行环境
2. 确认可以通过串行端口发送和接收字符
3. 确认上下文切换代码可以工作
4. 获取支持的硬件定时器
5. 确认中断程序可以通过串口接收和解析数据
### 执行模式
对于大多数先进的体系结构,操作系统和用户应用程序运行在不同的权限级别上。这可以防止有功能故障的代码影响操作系统的集成和安全。例如,在 ARMv7-A 架构中,操作系统通常在系统模式下运行,而在 ARMv8-A 中,操作系统可以在 EL2 或 EL3 权限级别上运行。
通常情况下,芯片在通电时以最高权限级别执行启动代码。但在此之后,操作系统会将特权级别切换到其目标模式。
#### 1、执行 C 代码
这一步的关键动作是将 <ruby> <a href="https://en.wikipedia.org/wiki/.bss"> 块起始符号 </a> <rt> block starting symbol </rt></ruby>(.bss)部分设置为零,并设置堆栈指针。
在 C 语言的实现中,未初始化的全局变量和静态变量通常存储在 .bss 部分,它不占用存储设备的任何空间。当程序被加载时,相应的空间被分配到内存中,并被初始化为零。当操作系统启动时,它必须自己做这项工作。
另一方面,操作系统必须初始化堆栈空间并设置堆栈指针。由于 C 语言程序在进入和退出函数时在堆栈上保存和恢复局部变量,所以在调用任何 C 函数之前必须设置堆栈指针。RT-Thread 必须为每个新创建的线程做这个步骤。
#### 2、至少使用一个串行驱动器
RT-Thread 通过串口输出信息和日志,这也有助于在移植过程中对代码进行调试。在这个阶段,通过串口 *接收* 数据是不必要的。当我们第一次在串口上看到我们友好的、熟悉的 RT-Thread 的标志时,我们就知道我们走对了路!
#### 3、确认上下文切换逻辑
一个任务的上下文是它的整个执行环境,它包含通用寄存器、程序计数器、堆栈帧的位置等等。当一个新的线程被创建时,RT-Thread 必须手动分配和设置它的上下文,这样调度器就可以切换到新的线程,就像它对其他线程一样。
有三件事需要注意:
* 首先,当 RT-Thread 启动时,默认情况下中断是禁用的。当任务调度器第一次被启用时,它们就会被启用;这个过程是在上下文切换期间用汇编语言实现的。
* 第二,当一个线程退出时,下一个调度将开始,这时拥有的资源会被空闲的线程回收。
* 第三,数据被推入堆栈的顺序必须与从堆栈中弹出数据的顺序一致。
一般来说,你希望正常进入主函数和 msh 控制台。然而,在这个阶段无法实现输入控制,因为串行输入中断还没有实现。当串行中断实现后,就可以进行 msh 输入了。
#### 4、设置定时器
RT-Thread 需要一个定时器来定期产生中断;它被用来计算自系统启动以来所经过的“滴答”。计数器的编号用于提供软件中断功能,并指示内核何时开始调度一个任务。
设置时间片的值可能是一件棘手的事情。它通常是 10ms 到 1ms。如果你在一个慢速的 CPU 上选择一个小的时间片,大部分时间就会花在任务切换上 —— 不利于完成其他事情。
#### 5、确认串口工作正常
在这一步,我们通过串口与 RT-Thread msh 进行交互。我们发送命令,按回车键,然后看着 msh 执行命令并显示结果。
这个过程通常不难实现。不过,有一点要提醒大家。在某些平台上,在处理完串口中断后,别忘了清除中断标志。
一旦串口工作正常,移植过程基本上就完成了。
### 实践
为了将你的项目移植到不同的芯片架构上,你需要非常清楚地了解你所针对的芯片的架构。熟悉你的项目中最关键的部分的底层代码。通过对照芯片的手册结合大量的实际工作经验,你会了解芯片的特权模式、寄存器和编译方法。
如果你没有需要移植到新芯片的项目,请加入我们;RT-Thread 项目总是需要帮助将 RTOS 移植到新的芯片上!作为一个开源项目,RT-Thread 正在改变开源嵌入式编程的面貌。请在 [RT-Thread 俱乐部](https://club.rt-thread.io/)介绍你自己并寻求帮助!
---
本文基于 DEV 社区上的 [如何将操作系统移植到不同的芯片架构上?](https://dev.to/abby06/how-to-port-operating-system-to-different-chip-architecture-3od9),并经许可转载。
---
via: <https://opensource.com/article/21/5/port-chip-architectures>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I was once asked why computers are called "computers" when they do so much more than compute numbers. A modern PC browses the internet, plays audio and video, generates beautiful graphics for video games and movies, simulates and predicts complex weather patterns and epidemiological risks, brings architectural and engineering blueprints to life, and much more.
The reason computers can do all of this because all these problems can be expressed as numerical equations, and the computer's CPU—its central processing unit—is actually little more than a simple calculator.
To get a CPU to send signals to a hard drive to write data or to a monitor to show an image, it must receive instructions. These instructions come in the form of "code," which is a terse way of saying someone must write a *program* that "speaks" the same language as the CPU. A CPU understands *machine language*, a mostly incomprehensible array of bits that most humans don't bother writing out manually. Instead, we use programming languages like C, C++, Java, Python, and so on. These languages are parsed and compiled into machine language, which is delivered to the CPU.
If you try to instruct a CPU in a language it doesn't understand, the CPU won't know what to do. You can experience the rather unspectacular results of such an attempt at miscommunication by trying to boot a [Raspberry Pi](https://opensource.com/resources/raspberry-pi) from an [x86_64 RHEL](https://www.redhat.com/en/store/red-hat-enterprise-linux-developer-suite) image. It would be nice if it could work, but it doesn't.
## Porting an OS to a new architecture
The [RT-Thread project](https://opensource.com/article/20/6/open-source-rtos) offers an open source operating system (OS) for embedded-systems programmers. The embedded space is extremely diverse, with lots of Internet of Things (IoT), custom industrial, and hobbyist devices. RT-Thread's goal is to make embedded programming easy for *everyone*, regardless of what device you're using. Sometimes, that means porting an OS to a new architecture, whether for a chip of the same architecture but with slightly different instruction sets or new architectures altogether.
Approaching this problem can be a little intimidating at first—you may not know where or how to start. This article collects the lessons RT-Thread maintainers learned as we ported [RTOS](https://www.rt-thread.io/) to new chip architectures.
## What you need to know before beginning
Here's a high-level view of a seemingly insurmountable process. This could differ for your project, but conceptually this is relatively universal, even if some of the specifics are different:
- Prepare a C-language execution environment
- Confirm that characters can be sent and received over a serial port
- Confirm that the context switch code works
- Get the hardware timers supported
- Confirm that the interrupt routine can receive and parse data over the serial port
## The execution model
For most advanced architectures, the OS and user applications run at different privilege levels. This prevents malfunctioning code from affecting the OS's integration and safety. For example, in the ARMv7-A architecture, the OS usually runs in the System mode, while in ARMv8-A, an OS can run at the EL2 or EL3 privilege level.
Usually, a chip executes bootup code at the highest privilege level when it's powered on. After that, though, the OS switches the privilege level to its target mode.
### 1. Execute C code
The key action in this step is to set the [block starting symbol](https://en.wikipedia.org/wiki/.bss) (.bss) section to zero and set up the stack pointers.
In C-language implementations, the uninitialized global variables and static variables are usually stored in the .bss section, which doesn't occupy any space in the storage device. When the program is loaded, the corresponding space is allocated in memory and initialized to zero. When the OS boots up, it has to do this work by itself.
On the other hand, the OS has to initialize the stack space and set up the stack pointer. Since C-language programs save and restore local variables on the stack when entering and exiting a function, the stack pointer must be set before invoking any C functions. RT-Thread has to do this step for each newly created thread.
### 2. Use at least one serial drive
RT-Thread outputs information and logs through the serial port, which also helps debug the code during the transplantation process. At this stage, *receiving* data over serial ports is not required. We knew we were on the right track when we first saw our friendly, familiar RT-Thread logo over the serial port!
### 3. Confirm context switching logic
The context of a task is its whole execution environment, which contains generic registers, the program counter, the location of the stack frame, and so on. When a new thread is created, RT-Thread has to allocate and set up its context manually so that the scheduler can switch to the new thread, as it does with others.
There are three things to pay attention to:
- First, when RT-Thread starts up, interrupts are disabled by default. They are enabled when the task scheduler is enabled for the first time; this process is implemented in assembly language during the context-switch period.
- Second, the next scheduling will start when a thread exits, which is when the resources owned are reclaimed by the idle thread.
- Third, the order that data is pushed into the stack must be consistent with the order of popping data out of the stack.
Generally, you want to enter the main function and the msh console normally. However, input control can't be achieved at this stage because serial input interrupts are not implemented. When serial interrupts are implemented, msh inputs can be made.
### 4. Set the timer
RT-Thread requires a timer to generate interrupts periodically; this is used to count the ticks that elapse since the system startup. The tick number is used to provide software interrupt functions and instruct the kernel when to start scheduling a task.
Setting the value of a time slice can be a tricky business. It's usually 10ms to 1ms. If you choose a small time slice on a slow CPU, most of the time is spent on task switching—to the detriment of getting anything else done.
### 5. Confirm serial port works correctly
In this step, we interacted with RT-Thread msh over the serial port. We sent commands, pressed Enter, and watched as msh executed the command and displayed the results.
This process is usually not difficult to implement. A word of warning, though: Don't forget to clear the interrupt flag on some platforms after the serial port interrupt is handled.
Once the serial port works correctly, the porting process is essentially done!
## Get busy
To port your project to different chip architectures, you need to be very clear about the architecture of the chip you're targeting. Get familiar with the underlying code in the most critical points of your project. By cross-referencing the chip's manual combined with a lot of practical working experience, you'll learn the chip privilege mode, register, and compilation method.
If you don't have a project you need to port to a new chip, please join us; the RT-Thread project can always use help porting RTOS to new chips! As an open source project, RT-Thread is changing the landscape of open source embedded programming. Please introduce yourself and ask for help at [RT-Thread Club](https://club.rt-thread.io/)!
*This article is based on How to Port Operating System to Different Chip Architecture?*
*on the DEV Community and is republished with permission.*
## Comments are closed. |
13,439 | Python 3.3 为改进代码中的异常处理所做的工作 | https://opensource.com/article/21/5/python-33 | 2021-05-29T22:14:07 | [
"Python"
] | https://linux.cn/article-13439-1.html |
>
> 探索异常处理和其他未被充分利用但仍然有用的 Python 特性。
>
>
>

这是 Python 3.x 首发特性系列文章的第四篇。Python 3.3 于 2012 年首次发布,尽管它已经发布了很长时间,但它引入的许多特性都没有得到充分利用,而且相当酷。下面是其中的三个。
### yield from
`yield` 关键字使 Python 更加强大。可以预见的是,人们都开始使用它来创建整个迭代器的生态系统。[itertools](https://docs.python.org/3/library/itertools.html) 模块和 [more-itertools](https://more-itertools.readthedocs.io/en/stable/) PyPI 包就是其中两个例子。
有时,一个新的生成器会想要使用一个现有的生成器。作为一个简单的(尽管有点故意设计)的例子,设想你想枚举所有的自然数对。
一种方法是按照“自然数对的和,自然数对的第一项”的顺序生成所有的自然数对。用 `yield from` 来实现这个方法是很自然的。
`yield from <x>` 关键字是以下的简称:
```
for item in x:
yield item
```
```
import itertools
def pairs():
for n in itertools.count():
yield from ((i, n-i) for i in range(n+1))
```
```
list(itertools.islice(pairs(), 6))
```
```
[(0, 0), (0, 1), (1, 0), (0, 2), (1, 1), (2, 0)]
```
### 隐式命名空间包
假设有一个叫 Parasol 的虚构公司,它制造了一堆东西。它的大部分内部软件都是用 Python 编写的。虽然 Parasol 已经开源了它的一些代码,但其中一些代码对于开源来说过于专有或专业。
该公司使用内部 [DevPI](https://opensource.com/article/18/7/setting-devpi) 服务器来管理内部软件包。对于 Parasol 的每个 Python 程序员来说,在 PyPI 上找一个未使用的名字是没有意义的,所以所有的内部包都被称为 `parasol.<business division>.<project>`。遵守最佳实践,开发人员希望包的名字能反映出这个命名系统。
这一点很重要!如果 `parasol.accounting.numeric_tricks` 包安装了一个名为 `numeric_tricks` 的顶层模块,这意味着依赖这个包的人将无法使用名为 `numeric_tricks` 的 PyPI 包,不管它写的有多好。
然而,这给开发者留下了一个两难的选择:哪个包拥有 `parasol/__init__.py` 文件?从 Python 3.3 开始,最好的解决办法是把 `parasol`,可能还有 `parasol.accounting`,变成没有 `__init__.py` 文件的 [命名空间包](https://www.python.org/dev/peps/pep-0420/)。
### 抑制异常的上下文
有时,在从异常中恢复的过程中出现的异常是一个问题,有上下文来跟踪它是很有用的。然而,有时却不是这样:异常已经被处理了,而新的情况是一个不同的错误状况。
例如,想象一下,在字典中查找一个键失败后,如果不能分析它,则希望失败并返回 `ValueError()`。
```
import time
def expensive_analysis(data):
time.sleep(10)
if data[0:1] == ">":
return data[1:]
return None
```
这个函数需要很长的时间,所以当你使用它时,想要对结果进行缓存:
```
cache = {}
def last_letter_analyzed(data):
try:
analyzed = cache[data]
except KeyError:
analyzed = expensive_analysis(data)
if analyzed is None:
raise ValueError("invalid data", data)
cached[data] = analyzed
return analyzed[-1]
```
不幸的是,当出现缓存没有命中时,回溯看起来很难看:
```
last_letter_analyzed("stuff")
```
```
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-16-a525ae35267b> in last_letter_analyzed(data)
4 try:
----> 5 analyzed = cache[data]
6 except KeyError:
KeyError: 'stuff'
```
在处理上述异常的过程中,发生了另一个异常:
```
ValueError Traceback (most recent call last)
<ipython-input-17-40dab921f9a9> in <module>
----> 1 last_letter_analyzed("stuff")
<ipython-input-16-a525ae35267b> in last_letter_analyzed(data)
7 analyzed = expensive_analysis(data)
8 if analyzed is None:
----> 9 raise ValueError("invalid data", data)
10 cached[data] = analyzed
11 return analyzed[-1]
ValueError: ('invalid data', 'stuff')
```
如果你使用 `raise ... from None`,你可以得到更多可读的回溯:
```
def last_letter_analyzed(data):
try:
analyzed = cache[data]
except KeyError:
analyzed = expensive_analysis(data)
if analyzed is None:
raise ValueError("invalid data", data) from None
cached[data] = analyzed
return analyzed[-1]
```
```
last_letter_analyzed("stuff")
```
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-21-40dab921f9a9> in <module>
----> 1 last_letter_analyzed("stuff")
<ipython-input-20-5691e33edfbc> in last_letter_analyzed(data)
5 analyzed = expensive_analysis(data)
6 if analyzed is None:
----> 7 raise ValueError("invalid data", data) from None
8 cached[data] = analyzed
9 return analyzed[-1]
ValueError: ('invalid data', 'stuff')
```
### 欢迎来到 2012 年
尽管 Python 3.3 在十年前就已经发布了,但它的许多功能仍然很酷,而且没有得到充分利用。如果你还没有,就把它们添加到你的工具箱中吧。
---
via: <https://opensource.com/article/21/5/python-33>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the fourth in a series of articles about features that first appeared in a version of Python 3.x. Python 3.3 was first released in 2012, and even though it has been out for a long time, many of the features it introduced are underused and pretty cool. Here are three of them.
## yield from
The `yield`
keyword made Python much more powerful. Predictably, everyone started using it to create a whole ecosystem of iterators. The [itertools](https://docs.python.org/3/library/itertools.html) module and the [more-itertools](https://more-itertools.readthedocs.io/en/stable/) PyPI package are just two examples.
Sometimes, a new generator will want to use an existing generator. As a simple (if somewhat contrived) example, imagine you want to enumerate all pairs of natural numbers.
One way to do it is to generate all pairs in the order of `sum of pair, first item of pair`
. Implementing this with `yield from`
is natural.
The `yield from <x>`
keyword is short for:
```
for item in x:
yield item
```
```
import itertools
def pairs():
for n in itertools.count():
yield from ((i, n-i) for i in range(n+1))
```
`list(itertools.islice(pairs(), 6))`
` [(0, 0), (0, 1), (1, 0), (0, 2), (1, 1), (2, 0)]`
## Implicit namespace packages
Imagine a fictional company called Parasol that makes a bunch of stuff. Much of its internal software is written in Python. While Parasol has open sourced some of its code, some of it is too proprietary or specialized for open source.
The company uses an internal [DevPI](https://opensource.com/article/18/7/setting-devpi) server to manage the internal packages. It does not make sense for every Python programmer at Parasol to find an unused name on PyPI, so all the internal packages are called `parasol.<business division>.<project>`
. Observing best practices, the developers want the package names to reflect that naming system.
This is important! If the package `parasol.accounting.numeric_tricks`
installs a top-level module called `numeric_tricks`
, this means nobody who depends on this package will be able to use a PyPI package that is called `numeric_tricks`
, no matter how nifty it is.
However, this leaves the developers with a dilemma: Which package owns the `parasol/__init__.py`
file? The best solution, starting in Python 3.3, is to make `parasol`
, and probably `parasol.accounting`
, to be [namespace packages](https://www.python.org/dev/peps/pep-0420/), which don't have the `__init__.py`
file.
## Suppressing exception context
Sometimes, an exception in the middle of a recovery from an exception is a problem, and having the context to trace it is useful. However, sometimes it is not: the exception has been handled, and the new situation is a different error condition.
For example, imagine that after failing to look up a key in a dictionary, you want to fail with a `ValueError()`
if it cannot be analyzed:
```
import time
def expensive_analysis(data):
time.sleep(10)
if data[0:1] == ">":
return data[1:]
return None
```
This function takes a long time, so when you use it, you want to cache the results:
```
cache = {}
def last_letter_analyzed(data):
try:
analyzed = cache[data]
except KeyError:
analyzed = expensive_analysis(data)
if analyzed is None:
raise ValueError("invalid data", data)
cached[data] = analyzed
return analyzed[-1]
```
Unfortunately, when there is a cache miss, the traceback looks ugly:
`last_letter_analyzed("stuff")`
```
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-16-a525ae35267b> in last_letter_analyzed(data)
4 try:
----> 5 analyzed = cache[data]
6 except KeyError:
KeyError: 'stuff'
```
During handling of the above exception, another exception occurs:
```
ValueError Traceback (most recent call last)
<ipython-input-17-40dab921f9a9> in <module>
----> 1 last_letter_analyzed("stuff")
<ipython-input-16-a525ae35267b> in last_letter_analyzed(data)
7 analyzed = expensive_analysis(data)
8 if analyzed is None:
----> 9 raise ValueError("invalid data", data)
10 cached[data] = analyzed
11 return analyzed[-1]
ValueError: ('invalid data', 'stuff')
```
If you use `raise ... from None`
, you can get much more readable tracebacks:
```
def last_letter_analyzed(data):
try:
analyzed = cache[data]
except KeyError:
analyzed = expensive_analysis(data)
if analyzed is None:
raise ValueError("invalid data", data) from None
cached[data] = analyzed
return analyzed[-1]
```
`last_letter_analyzed("stuff")`
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-21-40dab921f9a9> in <module>
----> 1 last_letter_analyzed("stuff")
<ipython-input-20-5691e33edfbc> in last_letter_analyzed(data)
5 analyzed = expensive_analysis(data)
6 if analyzed is None:
----> 7 raise ValueError("invalid data", data) from None
8 cached[data] = analyzed
9 return analyzed[-1]
ValueError: ('invalid data', 'stuff')
```
## Welcome to 2012
Although Python 3.3 was released almost a decade ago, many of its features are still cool—and underused. Add them to your toolkit if you haven't already.
## Comments are closed. |
13,440 | Btrfs 文件系统入门 | https://opensource.com/article/20/11/btrfs-linux | 2021-05-30T07:02:32 | [
"Btrfs",
"文件系统"
] | https://linux.cn/article-13440-1.html |
>
> B-tree 文件系统(Btrfs)融合了文件系统和卷管理器。它为 Linux 操作系统提供了高级文件系统应当拥有的诸多不错的功能特性。
>
>
>

好几年前 Btrfs 就已经可以在 Linux 中使用了,所以你可能已经熟悉它了。如果没有,你可能对它尚有疑虑,尤其是如果你使用的是 Fedora 工作站 (Btrfs 现在是它的默认文件系统)。本文旨在帮助你熟悉它及其高级功能,例如 [写时复制](https://en.wikipedia.org/wiki/Copy-on-write) 和 [校验和](https://en.wikipedia.org/wiki/Checksum)。
Btrfs 是 “B-Tree Filesystem” 的缩写,实际上是文件系统和卷管理器的结合体。它通常被视为对 ZFS 的回应,ZFS 早在 2005 年就被引入 Sun 微系统的 Solaris 操作系统中,现在基本上被一个名为 OpenZFS 的开源实现所取代。Ubuntu 和 FreeBSD 常常使用 OpenZFS。其他具有类似特性的示例有红帽的 Stratis 和 Linux <ruby> 逻辑卷管理器 <rt> Logical Volume Manager </rt></ruby>(LVM)。
### 安装
为了尝试 Btrfs,我下载了 Fedora 33 工作站 [ISO 文件](https://getfedora.org/en/workstation/download/) 并将其安装到一个新的虚拟机(VM)中。安装过程与以前的版本没有变化。我没有自定义任何设置,包括驱动器分区和格式化,以保持本教程的准确“开箱即用”设置。当虚拟机启动并运行后,我安装并运行了 GNOME 分区编辑器([GParted](https://gparted.org/)),以获得一个良好的、工厂级的驱动器布局视图。

从安装这一点来说,与你以前所习惯的情况没什么不同;事实上,你可以正常使用该系统,甚至可能没有注意到文件系统是 Btrfs。然而,拥有这个新的默认文件系统使你能够利用几个很酷的特性。
### 检查 Btrfs 文件系统
我暂时没有找到特定于 Btrfs 的图形工具,尽管它的一些功能已经被合并到现有的磁盘管理工具中。
在命令行中,你可以更仔细地查看 Btrfs 格式:
```
# btrfs filesystem show
Label: 'fedora_localhost-live' uuid: f2bb02f9-5c41-4c91-8eae-827a801ee58a
Total devices 1 FS bytes used 6.36GiB
devid 1 size 10.41GiB used 8.02GiB path /dev/vda3
```
### 修改 Btrfs 标签
我首先注意到的是安装程序设置的文件系统标签:`fedora_localhost-live`。这是不准确的,因为它现在是一个已安装的系统,不再是 [livecd](https://en.wikipedia.org/wiki/Live_CD)。所以我使用 `btrfs filesystem label` 命令对其进行了更改。
修改 Btrfs 标签非常的简单:
```
# btrfs filesystem label /
fedora_localhost-live
# btrfs filesystem label / fedora33workstation
# btrfs filesystem label /
fedora33workstation
```
### 管理 Btrfs 子卷
子卷看起来像是可以由 Btrfs 管理的标准目录。我的新 Fedora 33 工作站上有几个子卷:
```
# btrfs subvolume list /
ID 256 gen 2458 top level 5 path home
ID 258 gen 2461 top level 5 path root
ID 265 gen 1593 top level 258 path var/lib/machines
```
使用 `btrfs subvolume Create` 命令创建新的子卷,或使用 `btrfs subvolume delete` 删除子卷:
```
# btrfs subvolume create /opt/foo
Create subvolume '/opt/foo'
# btrfs subvolume list /
ID 256 gen 2884 top level 5 path home
ID 258 gen 2888 top level 5 path root
ID 265 gen 1593 top level 258 path var/lib/machines
ID 276 gen 2888 top level 258 path opt/foo
# btrfs subvolume delete /opt/foo
Delete subvolume (no-commit): '/opt/foo'
```
子卷允许设置配额、拍摄快照以及复制到其他位置和其他主机等操作。那么系统管理员如何利用这些功能?用户主目录又是如何操作的呢?
#### 添加用户
就像从前一样,添加一个新的用户帐户会创建一个主目录供该帐户使用:
```
# useradd student1
# getent passwd student1
student1:x:1006:1006::/home/student1:/bin/bash
# ls -l /home
drwx------. 1 student1 student1 80 Oct 29 00:21 student1
```
传统上,用户的主目录是 `/home` 的子目录。所有权和操作权是为所有者量身定制的,但是特殊功能来没有管理它们。而企业服务器环境是另外一种情况。通常,目录是为特定的应用程序及其用户保留的。你可以利用 Btrfs 来管理和应用对这些目录的约束。
为了将 Btrfs 子卷作为用户主页,在 `useradd` 命令中有一个新选项:`--Btrfs-subvolume-home`。尽管手册页尚未更新(截至本文撰写之时),但你可以通过运行 `useradd --help` 来查看该选项。通过在添加新用户时传递此选项,将创建一个新的 Btrfs 子卷。它的功能与创建常规目录时的 `-d` 选项类似:
```
# useradd --btrfs-subvolume-home student2
Create subvolume '/home/student2'
```
使用 `getent passwd student2` 验证用户,它将显示为正常。但是,运行 `btrfs subvolume` 命令列出子卷,你将看到一些有趣的内容:新用户的主目录!
```
# btrfs subvolume list /
ID 256 gen 2458 top level 5 path home
ID 258 gen 2461 top level 5 path root
ID 265 gen 1593 top level 258 path var/lib/machines
ID 272 gen 2459 top level 256 path home/student2
```
探索企业服务器环境的第二个场景。假设你需要在 `/opt` 中安装一个 [WildFly](https://www.wildfly.org/) 服务器并部署一个 Java web 应用程序。通常,你的第一步是创建一个 `wildfly` 用户。使用新的 `--btrfs-subvolume-home` 选项和 `-b` 选项来指定 `/opt` 作为基本目录:
```
# useradd -b /opt --btrfs-subvolume-home wildfly
Create subvolume '/opt/wildfly'
```
于是,`wildfly` 用户可以使用了,并且主目录设置在了 `/opt/wildfly`。
#### 删除用户
删除用户时,有时需要同时删除该用户的文件和主目录。`userdel` 命令有 `-r` 选项,它可以同时删除 Btrfs 子卷:
```
# userdel -r student2
Delete subvolume (commit): '/home/student2'
```
#### 设置磁盘使用配额
在我的一节计算机科学课上,一个学生运行了一个失控的 C 程序,然后写进了磁盘,将我们院的 Unix 系统上整个 `/home` 目录都填满了!在管理员终止失控进程并清除一些空间之前,服务器将无法使用。上述情况也是如此;那个 Wildfly 企业应用程序将为其用户提供越来越多的日志文件和内容存储。如何防止服务器因磁盘已满而死机?设置磁盘使用限制是个好主意。幸运的是,Btrfs 通过设置配额的方式支持这一点。
配置配额需要几个步骤。第一步是在 Btrfs 文件系统上启用配额:
```
# btrfs quota enable /
```
确保你知道每个子卷的配额组(qgroup)ID 号,该编号由 `btrfs subvolume list` 命令显示。每个子卷都需要基于 ID 号码来关联配额组。这可以通过 `btrfs qgroup create` 单独完成,但是,btrfs 维基提供了以下命令来加快为文件系统上的子卷创建配额组:
```
> btrfs subvolume list \<path> | cut -d' ' -f2 | xargs -I{} -n1 btrfs qgroup destroy 0/{} \<path>
```
在新安装的 Fedora 33 工作站系统中,你在根文件系统路径上操作,`/`。用根路径替换 `\<path>`:
```
# btrfs subvolume list / | cut -d' ' -f2 | xargs -I{} -n1 btrfs qgroup create 0/{} /
```
然后运行 `btrfs quota rescan`,查看新的配额组:
```
# btrfs quota rescan /
quota rescan started
# btrfs qgroup show /
qgroupid rfer excl
-------- ---- ----
0/5 16.00KiB 16.00KiB
0/256 272.04MiB 272.04MiB
0/258 6.08GiB 6.08GiB
0/265 16.00KiB 16.00KiB
0/271 16.00KiB 16.00KiB
0/273 16.00KiB 16.00KiB
```
于是现在,你可以将配额分配给其中一个配额组,然后将配额应用于其关联的子卷。因此,如果要将 `student3` 的主目录使用限制为 1 GB,请使用 `btrfs qgroup limit` 命令:
```
# btrfs qgroup limit 1G /home/student3
```
查看特定子卷的配额:
```
# btrfs qgroup show -reF /home/student3
qgroupid rfer excl max_rfer max_excl
-------- ---- ---- -------- --------
0/271 16.00KiB 16.00KiB 1.00GiB none
```
稍有不同的选项参数将显示所有配额组和设置的所有配额:
```
# btrfs qgroup show -re /
qgroupid rfer excl max_rfer max_excl
-------- ---- ---- -------- --------
0/5 16.00KiB 16.00KiB none none
0/256 272.04MiB 272.04MiB none none
0/258 6.08GiB 6.08GiB none none
0/265 16.00KiB 16.00KiB none none
0/271 16.00KiB 16.00KiB 1.00GiB none
0/273 16.00KiB 16.00KiB none none
```
### 其他特性
这些例子提供了 Btrfs 特性的一些思考。运行 `btrfs --help` 查看命令的完整列表。还有许多其他值得注意的功能;例如,快照和发送/接收是两个值得学习的功能。
### 总结讨论
Btrfs 为向 Linux 提供高级文件系统特性集贡献了很多特性。这不是第一次;我知道 ZFS 在大约 15 年前引入了这种类型的文件系统,但是 Btrfs 是完全开源的,不受专利的限制。
如果你想探索这个文件系统,我建议从虚拟机或备用系统开始。
我想能够出现一些图形化的管理工具,为那些喜欢用图形工具的系统管理员提供便利。幸运的是,Btrfs 具有强大的开发活动,Fedora 33 项目决定将其设置为工作站上的默认值就证明了这一点。
---
via: <https://opensource.com/article/20/11/btrfs-linux>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Btrfs has been available for Linux for several years, so you may already be familiar with it. If not, you may have questions about it, especially if you use Fedora Workstation (Btrfs is now its default filesystem). This article aims to help you get familiar with it and its advanced features, such as [copy-on-write](https://en.wikipedia.org/wiki/Copy-on-write) and [checksums](https://en.wikipedia.org/wiki/Checksum).
Btrfs, short for B-Tree Filesystem, is actually a filesystem and volume manager rolled into one. It's often seen as a response to ZFS, introduced in Sun Microsystem's Solaris OS back in 2005, now largely replaced by an open source implementation called OpenZFS. Ubuntu Linux and FreeBSD often feature OpenZFS. Other examples with similar features are Red Hat's Stratis and the Linux Logical Volume Manager (LVM).
## Setup
To try Btrfs, I [downloaded](https://getfedora.org/en/workstation/download/) the Fedora 33 Workstation ISO file and installed it into a new virtual machine (VM). The installation process has not changed from previous versions. I did not customize any settings, including drive partitioning and formatting, to maintain an accurate "out of the box" setup for this tutorial. Once the VM was up and running, I installed and ran the GNOME Partition Editor ([GParted](https://gparted.org/)) for a nice, factory-fresh view of the drive layout.
(Alan Formy-Duvall, CC BY-SA 4.0)
From this point, it's not much different from what you're used to; in fact, you can use the system normally, and you might not even notice that the filesystem is Btrfs. However, having this new default enables you to leverage several cool features.
## Examine the Btrfs filesystem
I am not aware of any Btrfs-specific graphical tools, although some of its functions have been incorporated into existing disk-management tools.
From the command line, you can get a closer look at the Btrfs format:
```
# btrfs filesystem show
Label: 'fedora_localhost-live' uuid: f2bb02f9-5c41-4c91-8eae-827a801ee58a
Total devices 1 FS bytes used 6.36GiB
devid 1 size 10.41GiB used 8.02GiB path /dev/vda3
```
## Change Btrfs labels
The first thing I noticed was the filesystem label set by the installer: `fedora_localhost-live`
. This is inaccurate because it is now an installed system and no longer a [live CD](https://en.wikipedia.org/wiki/Live_CD). So I changed it using the `btrfs filesystem label`
command.
Changing a Btrfs filesystem label is simple:
```
# btrfs filesystem label /
fedora_localhost-live
# btrfs filesystem label / fedora33workstation
# btrfs filesystem label /
fedora33workstation
```
## Manage Btrfs subvolumes
A subvolume appears to be a standard directory that can be managed by Btrfs. There are several subvolumes on my new Fedora 33 Workstation:
```
# btrfs subvolume list /
ID 256 gen 2458 top level 5 path home
ID 258 gen 2461 top level 5 path root
ID 265 gen 1593 top level 258 path var/lib/machines
```
Create a new subvolume using the `btrfs subvolume create`
command, or delete a subvolume with `btrfs subvolume delete`
:
```
# btrfs subvolume create /opt/foo
Create subvolume '/opt/foo'
# btrfs subvolume list /
ID 256 gen 2884 top level 5 path home
ID 258 gen 2888 top level 5 path root
ID 265 gen 1593 top level 258 path var/lib/machines
ID 276 gen 2888 top level 258 path opt/foo
# btrfs subvolume delete /opt/foo
Delete subvolume (no-commit): '/opt/foo'
```
Subvolumes allow actions like setting a quota, taking a snapshot, and replicating to other locations and hosts. How can system administrators take advantage of these capabilities? How about for user home directories?
### Add a user
As has been the case since olden times, adding a new user account creates a home directory for the account to use:
```
# useradd student1
# getent passwd student1
student1:x:1006:1006::/home/student1:/bin/bash
# ls -l /home
drwx------. 1 student1 student1 80 Oct 29 00:21 student1
```
Traditionally, a user's home directory is a subdirectory of `/home`
. Ownership and privileges are tailored to the owner, but there are no special functions for managing them. The enterprise server environment is another scenario. Often, a directory is reserved for use by a particular application and its user. You can take advantage of Btrfs to manage and apply constraints to these directories.
To accommodate Btrfs subvolumes as user homes, there is a new option to the `useradd`
command: `--btrfs-subvolume-home`
. Although the man pages have not been updated (as of this writing), you can see the option by running `useradd --help`
. By passing this option when adding a new user, a new Btrfs subvolume will be created. It functions just like the `-d`
option does for creating a regular directory:
```
# useradd --btrfs-subvolume-home student2
Create subvolume '/home/student2'
```
Verify the user with `getent passwd student2`
, and it will appear normal. However, run the `btrfs subvolume`
command to list subvolumes, and you will see something interesting: the new user's home directory!
```
# btrfs subvolume list /
ID 256 gen 2458 top level 5 path home
ID 258 gen 2461 top level 5 path root
ID 265 gen 1593 top level 258 path var/lib/machines
ID 272 gen 2459 top level 256 path home/student2
```
Explore the second scenario of an enterprise server environment. Suppose you need to install a [WildFly](https://www.wildfly.org/) server in `/opt`
and deploy a Java web application. Often, your first step is to create a `wildfly`
user. Do this using the new `--btrfs-subvolume-home `
option along with the `-b`
option to specify `/opt`
as the base directory:
```
# useradd -b /opt --btrfs-subvolume-home wildfly
Create subvolume '/opt/wildfly'
```
Now, the `wildfly`
user can log in and complete the installation in `/opt/wildfly`
.
### Delete a user
When you delete a user, sometimes you want to delete that user's files and the home directory at the same time. The `userdel`
command has the `-r`
option for this, and it also deletes Btrfs subvolumes:
```
# userdel -r student2
Delete subvolume (commit): '/home/student2'
```
### Set disk-usage quotas
In one of my computer science classes, a student ran a C program that went out of control and wrote to the disk until the entire `/home`
was filled on the department's Unix system! The server became unavailable until the admin killed the runaway process and cleared some space. The same is true for the scenario above; that Wildfly enterprise application will have a growing number of log files and content stores for its users. How can you prevent a server from grinding to a halt because the disk has filled up? Setting disk-usage constraints is a good idea. Fortunately, Btrfs supports this by way of quotas.
There are several steps required to configure quotas. The first step is to enable `quota`
on the Btrfs filesystem:
`# btrfs quota enable /`
Make sure you know each subvolume's quota group (qgroup) ID number, which is displayed by the `btrfs subvolume list`
command. Each subvolume needs an associated qgroup based on its ID number. This can be done on an individual basis with `btrfs qgroup create`
, but, conveniently, the Btrfs wiki provides the following command to expedite creating qgroups for subvolumes on a filesystem:
`>btrfs subvolume list \<path> | cut -d' ' -f2 | xargs -I{} -n1 btrfs qgroup destroy 0/{} \<path>`
In a freshly installed Fedora 33 workstation system, you are operating on the root filesystem path, `/`
. Substitute `\<path>`
with the root path:
`# btrfs subvolume list / | cut -d' ' -f2 | xargs -I{} -n1 btrfs qgroup create 0/{} /`
Then run `btrfs quota rescan`
and take a look at the new qgroups:
```
# btrfs quota rescan /
quota rescan started
# btrfs qgroup show /
qgroupid rfer excl
-------- ---- ----
0/5 16.00KiB 16.00KiB
0/256 272.04MiB 272.04MiB
0/258 6.08GiB 6.08GiB
0/265 16.00KiB 16.00KiB
0/271 16.00KiB 16.00KiB
0/273 16.00KiB 16.00KiB
```
Now you can assign a quota to one of the qgroups, which, in turn, is applied to its associated subvolume. So, if you want to limit student3's home directory usage to 1GB, use the `btrfs qgroup limit`
command:
`# btrfs qgroup limit 1G /home/student3`
Confirm the quota for the specific subvolume:
```
# btrfs qgroup show -reF /home/student3
qgroupid rfer excl max_rfer max_excl
-------- ---- ---- -------- --------
0/271 16.00KiB 16.00KiB 1.00GiB none
```
Slightly different options will show all qgroups and any quotas that are set:
```
# btrfs qgroup show -re /
qgroupid rfer excl max_rfer max_excl
-------- ---- ---- -------- --------
0/5 16.00KiB 16.00KiB none none
0/256 272.04MiB 272.04MiB none none
0/258 6.08GiB 6.08GiB none none
0/265 16.00KiB 16.00KiB none none
0/271 16.00KiB 16.00KiB 1.00GiB none
0/273 16.00KiB 16.00KiB none none
```
## Other features
These examples provide some idea of Btrfs' features. Run `btrfs --help`
to see the full list of commands. Many other notable capabilities exist; for instance, snapshots and send/receive are two worth learning.
## Final thoughts
Btrfs offers a lot of promise for delivering an advanced filesystem feature set to Linux. It wasn't the first; I credit ZFS for my introduction to this type of filesystem some 15 years ago, but Btrfs is fully open source and unencumbered by patents.
I advise starting with a virtual machine or spare system if you want to explore this filesystem.
I would like to see some graphical management utilities produced for system administrators who like to operate in the GUI world. Fortunately, Btrfs has strong development activity, as evidenced by the Fedora project's decision to make it default on Workstation 33.
## 5 Comments |
13,442 | 体验 /e/ OS:开源的去谷歌化的安卓 | https://itsfoss.com/e-os-review/ | 2021-05-30T22:26:27 | [
"安卓",
"谷歌"
] | https://linux.cn/article-13442-1.html | 
/e/ 安卓操作系统是一个以隐私为导向的去谷歌化的移动操作系统,是 Lineage OS 的复刻,由 Mandrake Linux(现在的 [Mandriva Linux](https://en.wikipedia.org/wiki/Mandriva_Linux))的创建者 [Gaël Duval](https://en.wikipedia.org/wiki/Ga%C3%ABl_Duval) 于 2018 年中期创立。
尽管安卓在 2007 年成为了一个开源项目,但当安卓得到普及时,谷歌使用专有软件取代了一些操作系统元素。/e/ 基金会用 [MicroG](https://en.wikipedia.org/wiki/MicroG) 取代了其中的专有的应用程序和服务,这是一个开源的替代框架,可以最大限度地减少跟踪和设备活动。
我们收到的 [Fairphone 3](https://esolutions.shop/shop/e-os-fairphone-3-fr/) 预装了 /e/ OS,这是一个来自 /e/ 基金会的 [以道德的方式创造的智能手机](https://www.fairphone.com/en/story/?ref=header)。我使用了一个月这个设备,然后把它返还给了他们,我将分享我对这个隐私设备的体验。我忘了截图,所以我将分享来自官方网站的通用图片。
### 在道德的 Fairphone 设备上体验 /e/ 移动操作系统
在我进一步说明之前,让我澄清一下,Fairphone 3 并不是使用 /e/ 的唯一选择。如果你要从他们那里购买设备,/e/ 基金会会给你 [一些智能手机的选择](https://esolutions.shop/shop/)。
你不需要购买设备来使用 /e/ OS。按照 /e/ 基金会的说法,你可以 [在 100 多个支持的设备上使用它](https://doc.e.foundation/devices/)。
尽管我很喜欢使用 Fairphone 3,而且我的个人信仰与 Fairphone 的宣言一致,但我不会把注意力放在设备上,而只是放在 /e/ OS 上。
#### 有评级隐私的应用程序

我把 Fairphone 3 作为我的日常使用设备用了几天时间,以比较与我的“普通”安卓手机在现实中的使用情况。
首先,我想看看我使用的所有应用程序是否都可以在 /e/ 基金会创建的“[应用商店](https://e.foundation/e-os-available-applications/)”上找到。/e/ 应用商店包含有隐私评级的应用程序。

我可以找到许多应用程序,包括来自谷歌的应用程序。这意味着,如果有人真的想使用一些谷歌的服务,它仍然可以作为一个选项来下载。尽管与其他安卓设备不同,没有强行将谷歌服务塞进你的嘴里。
虽然有很多应用程序,但我无法找到我在英国使用的手机银行应用程序。我不得不承认,手机银行应用程序可以在一定程度上促进便利。作为替代方案,我不得不在需要时进入电脑使用网上银行平台。
从可用性的角度来看,/e/ OS 可以取代我的“标准”安卓操作系统,但会有一些小插曲,比如银行应用程序。
#### 如果不是谷歌的,那是什么?
想知道 /e/ OS 使用哪些基本的应用程序,而不是谷歌的那些?这里有一个快速列表:
* [魔法地球](https://www.magicearth.com/) —— 逐向道路导航
* 浏览器 —— Chromium 的一个非谷歌复刻版本
* 邮件 —— [K9-mail](https://k9mail.app/) 的一个复刻
* 短信 —— QKSMS 的一个复刻
* 照相机 —— OpenCamera 的一个复刻
* 天气 —— GoodWeather 的一个复刻
* OpenTasks —— 任务组织者
* 日历:[Etar calendar](https://github.com/Etar-Group/Etar-Calendar) 的一个复刻
#### Bliss Launcher 和整体设计

/e/ OS 的默认启动程序被称为 “Bliss Launcher”,其目的是为了获得有吸引力的外观和感觉。对我来说,这个设计感觉与 iOS 相似。
通过向左滑动面板,你可以访问 /e/ 选择的一些有用的小工具。

* 搜索:快速搜索预装的应用程序或搜索 Web
* APP 建议:前 4 个最常用的应用程序将出现在这个小部件上
* 天气:天气小部件显示的是当地的天气。它不会自动检测位置,需要进行配置。
* 编辑:如果你想在屏幕上有更多的小部件,你可以通过点击“编辑”按钮添加它们。
总而言之,用户界面是干净整洁的简单明了,增强了愉快的用户体验。 \* 天气。天气小部件显示的是当地的天气。它不会自动检测位置,需要进行配置。
* 编辑:如果你想在屏幕上有更多的小部件,你可以通过点击编辑按钮添加它们。
总而言之,用户界面干净整洁、简单明了,增强了愉快的用户体验。
#### 去谷歌化和面向隐私的操作系统
如前所述,/e/ 操作系统是一个去谷歌化的操作系统,它基于 [Lineage OS](https://lineageos.org/) 的开源核心。所有的谷歌应用程序已经被删除,谷歌服务已经被 MicroG 框架所取代。/e/ OS 仍然与所有的安卓应用兼容。
主要的隐私功能:
* 谷歌搜索引擎已被 DuckDuckGo 等替代品取代
* 谷歌服务已被 microG 框架所取代
* 使用替代的默认应用程序,而不是谷歌应用程序
* 取消了对谷歌服务器的连接检查
* NTP 服务器已被替换为标准的 NTP 服务:[pool.ntp.org](http://pool.ntp.org)
* DNS 默认服务器由 9.9.9.9 取代,可以根据用户的选择进行编辑
* 地理定位是在 GPS 的基础上使用 Mozilla 定位服务
>
> 隐私声明
>
>
> 请注意,使用由 /e/ 基金会提供的智能手机并不自动意味着无论你做什么都能保证你的隐私。分享你的个人信息的社交媒体应用程序应在你的意识下使用。
>
>
>
### 结论
我成为安卓用户已经超过十年了。/e/ OS 给我带来了积极的惊喜。关注隐私的用户可以发现这个解决方案非常吸引人,而且根据所选择的应用程序和设置,可以再次感觉到使用智能手机的安全。
如果你是一个有隐私意识的技术专家,并且能够自己找到解决问题的方法,我向你推荐它。对于那些习惯于谷歌主流服务的人来说,/e/ 生态系统可能会让他们不知所措。
你使用过 /e/ OS 吗?你的使用经验如何?你怎么看这些关注隐私的项目?
---
via: <https://itsfoss.com/e-os-review/>
作者:[Dimitrios](https://itsfoss.com/author/dimitrios/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | /e/ Android operating system is a privacy oriented, Google-free mobile operating system, fork of Lineage OS and was founded in mid-2018 by [Gaël Duval](https://en.wikipedia.org/wiki/Ga%C3%ABl_Duval), creator of Mandrake Linux (now [Mandriva Linux)](https://en.wikipedia.org/wiki/Mandriva_Linux).
Despite making Android an open source project in 2007, Google replaced some OS elements with proprietary software when Android gained popularity. /e/ Foundation has replaced the proprietary apps and services with [MicroG](https://en.wikipedia.org/wiki/MicroG), an open source alternative framework which minimizes tracking and device activity.
It’s FOSS received [Fairphone 3](https://esolutions.shop/shop/e-os-fairphone-3-fr/) with /e/ OS preinstalled, an [ethically created smartphone](https://www.fairphone.com/en/story/?ref=header) from the /e/ Foundation. I used the device for a month before returning it to them and I am going to share my experience with this privacy device. I forgot to take screenshots so I’ll be sharing the generic images from the official website.
## Experiencing the /e/ mobile operating system on the ethical Fairphone device
Before I go any further, let me clear that Fairphone 3 is not the only option to get /e/ in your hands. The /e/ foundation gives you [a few smartphone options to choose](https://esolutions.shop/shop/) if you are buying a device from them.
You don’t have to buy a device to use /e/ OS. As per the /e/ Foundation, you can [use it on over 100 supported devices](https://doc.e.foundation/devices/).
Despite I enjoyed using the Fairphone 3, and my personal beliefs are in line with the Fairphone manifesto, I won’t focus my attention on the device but to the /e/ operating system only.
### Apps with rated privacy
I used Fairphone 3 as my daily driver for a couple of days, to compare the usage with my “ordinary” Android phone in reality.
First and foremost I wanted to see if all the apps that I use, are available at the “[App Store](https://e.foundation/e-os-available-applications/)” /e/ foundation has created. The /e/ App Store contains apps with privacy ratings.
I could find many applications, including apps from Google. This means that if someone really wants to use some Google service, it is still available as an option to download. Though unlike other Android devices, Google services are not forced down your throat.
Though there are lot of apps available, I could not find the mobile banking app I use in the UK. I have to admit that the mobile banking app can contribute to a level of convenience. As an alternative, I had to access a computer to use the online banking platform if needed.
From a usability point of view, /e/ OS could replace my “standard” Android OS with minor hiccups like the banking apps.
### If not Google, then what?
Wondering what essential apps /e/ OS uses instead of the ones from Google? Here’s a quick list:
[Magic Earth](https://www.magicearth.com/)– Turn by turn navigation- Web-browser – an ungoogled fork of Chromium
- Mail – a fork of
[K9-mail](https://k9mail.app/) - SMS – a fork of QKSMS
- Camera – a fork of OpenCamera
- Weather – a fork of GoodWeather
- OpenTasks – Task organizer
- Calendar -Calendar: a fork of
[Etar calendar](https://github.com/Etar-Group/Etar-Calendar)
### Bliss Launcher and overall design

The default launcher application of /e/ OS is called “Bliss Launcher” which aims to an attractive look and feel. To me, the design felt similar to iOS.
By Swiping to the left panel, you can access a few useful widgets /e/ has selected.
- Search: Quick search of pre-installed apps or search the web
- APP Suggestions: The top 4 most used apps will appear on this widget
- Weather: The weather widget is showing the local weather. It doesn’t automatically detect the location and it needs to be configured.
- Edit: If you want more widgets on the screen, you can add them by clicking the edit button
All in all, the user interface is clean and neat. Being simple and straightforward enhances a pleasant user experience.
### DeGoogled and privacy oriented OS
As mentioned earlier /e/ OS is a Google-free operating system which is based on an open source core of [Lineage OS](https://lineageos.org/). All the Google apps have been removed and the Google services have been replaced with the Micro G framework. The /e/ OS is still compatible with all Android apps.
#### Key privacy features:
- Google search engine has been replaced with alternatives such as DuckDuckGo
- Google Services have been replaced by microG framework
- Alternative default apps are used instead of Google Apps
- Connectivity check against Google servers is removed
- NTP servers have been replaced with the standard NTP service: pool.ntp.orgs
- DNS default servers are replaced by 9.9.9.9 and can be edited to user’s choice
- Geolocation is using Mozilla Location Services on top of GPS
Privacy notice
Please be mindful that using a smartphone, provided by /e/ foundation doesn’t automatically mean that your privacy is guaranteed no matter what you do. Social media apps that share your personal information should be used under your awareness.
### Conclusion
I have been an Android user for more than a decade. /e/ OS surprised me positively. A privacy concerned user can find this solution very appealing, and depending on the selected apps and settings can feel secure again using a smartphone.
I could recommend it to you if you are a privacy aware tech-savvy and can find your way around things on your own. The /e/ ecosystem is likely to be overwhelming for people who are used to of mainstream Google services.
Have you used /e/ OS? How was your experience with it? What do you think of projects like these that focus on privacy? |
13,443 | 回顾一下 Python 3.4 中的枚举 | https://opensource.com/article/21/5/python-34-features | 2021-05-30T23:10:26 | [
"Python"
] | https://linux.cn/article-13443-1.html |
>
> 另外探索一些未被充分利用但仍然有用的 Python 特性。
>
>
>

这是 Python 3.x 首发特性系列文章的第五篇。Python 3.4 在 2014 年首次发布,尽管它已经发布了很长时间,但它引入的许多特性都没有被充分利用,而且相当酷。下面是其中的三个。
### 枚举
我最喜欢的逻辑谜题之一是自我描述的 [史上最难的逻辑谜题](https://en.wikipedia.org/wiki/The_Hardest_Logic_Puzzle_Ever)。在其中,它谈到了三个“神”,他们被称为 A、B 和 C,他们的身份是真、假和随机,按一定顺序排列。你可以问他们问题,但他们只用神的语言回答,其中 “da” 和 “ja” 表示 “是” 和 “不是”,但你不知道哪个是哪个。
如果你决定使用 Python 来解决这个问题,你将如何表示神的名字和身份以及神的语言中的词语?传统的答案是使用字符串。然而,字符串的拼写错误可能会带来灾难性的后果。
如果在解题的关键部分,你用字符串 “jaa” 而不是 “ja” 进行比较,你就会得到一个错误的答案。虽然谜题没有说明风险是什么,但这可能是最好的避免方式。
`enum` 模块让你能够以一种可调试但安全的方式来定义这些东西:
```
import enum
@enum.unique
class Name(enum.Enum):
A = enum.auto()
B = enum.auto()
C = enum.auto()
@enum.unique
class Identity(enum.Enum):
RANDOM = enum.auto()
TRUE = enum.auto()
FALSE = enum.auto()
@enum.unique
class Language(enum.Enum):
ja = enum.auto()
da = enum.auto()
```
枚举的一个好处是,在调试日志或异常中,枚举的呈现方式是有帮助的:
```
name = Name.A
identity = Identity.RANDOM
answer = Language.da
print("I suspect", name, "is", identity, "because they answered", answer)
```
```
I suspect Name.A is Identity.RANDOM because they answered Language.da
```
### functools.singledispatch
在开发游戏的“基础设施”层时,你想通用地处理各种游戏对象,但仍然允许这些对象自定义动作。为了使这个例子更容易解释,假设这是一个基于文本的游戏。当你使用一个对象时,大多数情况下,它只会打印 `You are using <x>`。但是使用一把特殊的剑可能需要随机滚动,否则会失败。
当你获得一个物品时,它通常会被添加到库存中。然而,一块特别重的石头会砸碎一个随机物品。如果发生这种情况,库存中会失去该物体。
处理这个问题的一个方法是在物品上设置 `use` 和 `acquire` 方法。随着游戏复杂性的增加,这些方法会越来越多,使游戏对象变得难以编写。
相反,`functools.singledispatch` 允许你以安全和尊重命名空间的方式追溯性地添加方法。
你可以定义没有行为的类:
```
class Torch:
name="torch"
class Sword:
name="sword"
class Rock:
name="rock"
```
```
import functools
@functools.singledispatch
def use(x):
print("You use", x.name)
@functools.singledispatch
def acquire(x, inventory):
inventory.add(x)
```
对于火炬来说,这些通用的实现已经足够了:
```
inventory = set()
def deploy(thing):
acquire(thing, inventory)
use(thing)
print("You have", [item.name for item in inventory])
deploy(Torch())
```
```
You use torch
You have ['torch']
```
然而,剑和石头需要一些专门的功能:
```
import random
@use.register(Sword)
def use_sword(sword):
print("You try to use", sword.name)
if random.random() < 0.9:
print("You succeed")
else:
print("You fail")
deploy(sword)
```
```
You try to use sword
You succeed
You have ['sword', 'torch']
```
```
import random
@acquire.register(Rock)
def acquire_rock(rock, inventory):
to_remove = random.choice(list(inventory))
inventory.remove(to_remove)
inventory.add(rock)
deploy(Rock())
```
```
You use rock
You have ['sword', 'rock']
```
岩石可能压碎了火炬,但你的代码更容易阅读。
### pathlib
从一开始,Python 中文件路径的接口就是“智能字符串操作”。现在,通过 `pathlib`,Python 有了一种面向对象的方法来操作路径。
```
import pathlib
```
```
gitconfig = pathlib.Path.home() / ".gitconfig"
text = gitconfig.read_text().splitlines()
```
诚然,用 `/` 作为操作符来生成路径名有点俗气,但在实践中却不错。像 `.read_text()` 这样的方法允许你从小文件中获取文本,而不需要手动打开和关闭文件句柄。
这使你可以集中精力处理重要的事情:
```
for line in text:
if not line.strip().startswith("name"):
continue
print(line.split("=")[1])
```
```
Moshe Zadka
```
### 欢迎来到 2014 年
Python 3.4 大约在七年前就发布了,但是在这个版本中首次出现的一些功能非常酷,而且没有得到充分利用。如果你还没使用,那么将他们添加到你的工具箱中。
---
via: <https://opensource.com/article/21/5/python-34-features>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the fifth in a series of articles about features that first appeared in a version of Python 3.x. Python 3.4 was first released in 2014, and even though it has been out for a long time, many of the features it introduced are underused and pretty cool. Here are three of them.
## enum
One of my favorite logic puzzles is the self-descriptive [Hardest Logic Puzzle Ever](https://en.wikipedia.org/wiki/The_Hardest_Logic_Puzzle_Ever). Among other things, it talks about three gods who are called A, B, and C. Their identities are True, False, and Random, in some order. You can ask them questions, but they only answer in the god language, where "da" and "ja" mean "yes" and "no," but you do not know which is which.
If you decide to use Python to solve the puzzle, how would you represent the gods' names and identities and the words in the god language? The traditional answer has been to use strings. However, strings can be misspelled with disastrous consequences.
If, in a critical part of your solution, you compare to the string `jaa`
instead of `ja`
, you will have an incorrect solution. While the puzzle does not specify what the stakes are, that's probably best avoided.
The `enum`
module gives you the ability to define these things in a debuggable yet safe manner:
```
import enum
@enum.unique
class Name(enum.Enum):
A = enum.auto()
B = enum.auto()
C = enum.auto()
@enum.unique
class Identity(enum.Enum):
RANDOM = enum.auto()
TRUE = enum.auto()
FALSE = enum.auto()
@enum.unique
class Language(enum.Enum):
ja = enum.auto()
da = enum.auto()
```
One advantage of enums is that in debugging logs or exceptions, the enum is rendered helpfully:
```
name = Name.A
identity = Identity.RANDOM
answer = Language.da
print("I suspect", name, "is", identity, "because they answered", answer)
```
` I suspect Name.A is Identity.RANDOM because they answered Language.da`
## functools.singledispatch
While developing the "infrastructure" layer of a game, you want to deal with various game objects generically but still allow the objects to customize actions. To make the example easier to explain, assume it's a text-based game. When you use an object, most of the time, it will just print `You are using <x>`
. But using a special sword might require a random roll, and it will fail otherwise.
When you acquire an object, it is usually added to the inventory. However, a particularly heavy rock will smash a random object; if that happens, the inventory will lose that object.
One way to approach this is to have methods `use`
and `acquire`
on objects. More and more of these methods will be added as the game's complexity increases, making game objects unwieldy to write.
Instead, `functools.singledispatch`
allows you to add methods retroactively—in a safe and namespace-respecting manner.
You can define classes with no behavior:
```
class Torch:
name="torch"
class Sword:
name="sword"
class Rock:
name="rock"
```
```
import functools
@functools.singledispatch
def use(x):
print("You use", x.name)
@functools.singledispatch
def acquire(x, inventory):
inventory.add(x)
```
For the torch, those generic implementations are enough:
```
inventory = set()
def deploy(thing):
acquire(thing, inventory)
use(thing)
print("You have", [item.name for item in inventory])
deploy(Torch())
```
```
You use torch
You have ['torch']
```
However, the sword and the rock need some specialized functionality:
```
import random
@use.register(Sword)
def use_sword(sword):
print("You try to use", sword.name)
if random.random() < 0.9:
print("You succeed")
else:
print("You fail")
deploy(sword)
```
```
You try to use sword
You succeed
You have ['sword', 'torch']
```
```
import random
@acquire.register(Rock)
def acquire_rock(rock, inventory):
to_remove = random.choice(list(inventory))
inventory.remove(to_remove)
inventory.add(rock)
deploy(Rock())
```
```
You use rock
You have ['sword', 'rock']
```
The rock might have crushed the torch, but your code is much easier to read.
## pathlib
The interface to file paths in Python has been "smart-string manipulation" since the beginning of time. Now, with `pathlib`
, Python has an object-oriented way to manipulate paths:
`import pathlib`
```
gitconfig = pathlib.Path.home() / ".gitconfig"
text = gitconfig.read_text().splitlines()
```
Admittedly, using `/`
as an operator to generate path names is a little cutesy, but it ends up being nice in practice. Methods like `.read_text()`
allow you to get text out of small files without needing to open and close file handles manually.
This lets you concentrate on the important stuff:
```
for line in text:
if not line.strip().startswith("name"):
continue
print(line.split("=")[1])
```
` Moshe Zadka`
## Welcome to 2014
Python 3.4 was released about seven years ago, but some of the features that first showed up in this release are cool—and underused. Add them to your toolkit if you haven't already.
## Comments are closed. |
13,445 | 不是程序员?那就找到自己的定位 | https://opensource.com/article/21/2/advice-non-technical | 2021-05-31T19:26:56 | [
"非技术"
] | https://linux.cn/article-13445-1.html |
>
> 无论你是已经工作了几十年的还是刚开始从业的非工程型技术人,此建议都可以帮助你确定你的位置归属。
>
>
>

在 [本系列第一篇文章](/article-13168-1.html) 中 ,我解释了将人员和角色分为“技术”或“非技术”类别的问题。在 [第二篇文章](/article-13178-1.html) 中,我为不写代码的人分享了一些技术岗位角色。这一次,我将把这次探索总结为——“技术或非技术意味着什么”,并提供一些能够在职业发展上帮到你的建议。
无论你是已经从事技术工作数十年,或是刚刚起步,还是正在寻求职业变更,请考虑本文中来自非技术人员但在技术角色方面取得成功的人士的建议。
>
> “不要把你的工作和身份捆绑起来 —— 把它们分开。”
>
>
> —— Adam Gordon Bell,Earthly Technologies 开发者关系部
>
>
>
转换角色,并不意味着你的技能会消失且你不再具有价值。如果你担任了新角色,则需要专注于该角色的关键技能。培养技能是需要时间的。花点时间,找出新职位的重要技能。
如果你管理工程师们,请鼓励他们提升技术技能的同时发展非工程技能,这些技能往往能比编程能力和技术技能对职业发展和成功产生更显著的变化。
### 做你自己
>
> “不要让其他人定义你是技术人员还是非技术人员。什么是技术人员,什么不是技术人员,以及这是否重要,是人们必须自己搞清楚的事情。”
>
>
> —— Adam Gordon Bell
>
>
>
>
> “永远不要用‘我不是技术人员’为开头进行对话。因为很可能让对方产生‘这点我需要提醒你’的想法,这在面试的时候可从来不会留下好印象,而且还有可能会让人觉得你对自己技能缺乏信心。”
>
>
> —— Mary Thengvall,Camunda 开发者关系总监
>
>
>
避免刻板成见;不是所有的工程师都喜欢《星球大战》或《星际迷航》。不是所有工程师都穿连帽卫衣。工程师也可以和别人交流。
>
> “单单就你的行为举止,旁人就有很多关于技术或非技术方面的看法。在办公室工作的时候,我会穿裙子,因为只有这样我才能舒服一点。”
>
>
> —— Shailvi Wakhlu,Strava 高级数据总监
>
>
>
### 了解你的价值
正如我在第一篇文章中讨论的那样,被打上“非技术”的标签会导致 [冒充者综合症](https://opensource.com/business/15/9/tips-avoiding-impostor-syndrome)。承认自己的价值,不要在自己身上贴上“非技术”标签,因为它会限制你的收入潜力和职业发展。
>
> “人们之所以把我重新包装成其他东西,是因为他们认为我和工程师的刻板印象不一样。我很高兴我没有听这些人的话,因为他们本质上是在告诉我,在我拥有的技能之外,去找一份低薪的工作。”
>
>
> —— Shailvi Wakhlu
>
>
>
>
> “年轻的或者女性技术人,特别是刚接触技术的女性,更容易患上冒名综合症,认为自己技术不够好。比如,‘哦,我只会前端。’,什么叫你*只会*前端?前端也很难的好吧。”
>
>
> —— Liz Harris
>
>
>
### 寻找那些可以提升价值并帮到人们的地方
你不需要创建 PR 就可以参与开源。
>
> “当有人想为开源项目做点贡献时,我总是对他说,‘不要想着,得是一个提交才行、得提一个 PR 才可以。’这就好像,‘不行。怎么才能为那个项目贡献点价值呢?’ 如果你没时间提交 PR,那你是不是提个议题并把要点写下来?”
>
>
> —— Eddie Jaoude,Jaoude Studios 开源程序员
>
>
>
### 思维的多样性有助于事业成功
看看所有角色和人员的价值和贡献。不要根据头衔将人归到同能力的一组。
>
> “要认识到,所有人(包括自己在内),在任何时候,以及事情全貌的重要性。创造力这个事儿不应该由自我驱动。要知道,对于你所做的事情,你可以做的更好,也可以做的更糟。不要害怕寻求帮助,知道到我们在一起。”
>
>
> —— Therese Eberhard,电影/广告和视频场景画师
>
>
>
>
> “在我参加过的黑客马拉松中,我们都是技术人员,组建了一支四五个硬核程序员组成的强大团队,但我们输了。我不骗你,我们输了。在新冠疫情之前,我赢了前六次的黑客马拉松,而且当时团队中一半的人属于其他领域的专家。在我们赢过的比赛中,大多数人会认为团队一半人是非技术的,尽管我不喜欢这个术语,因为这像是给团队/项目贴金。我们之所以获胜,是因为我们对所构建的东西有很多不同的看法。”
>
>
> —— Eddie Jaoude
>
>
>
>
> “我们越能摆脱‘技术/非技术’、‘开发人员/非开发人员’的标签,并理解到一个连续统一的整体存在,我们就越能全力以赴地雇用到合适的人来做这项工作,只要不被你需要‘技术团队’的假设所困扰。”
>
>
> —— Mary Thengvall
>
>
>
我们的社区和团队越多样化,它们的包容性就越大。
>
> “老实说,无论是从社区角度还是从产品角度,我认为,总的来说,最重要的事情都是,我们应该确保我们建立的是一个包容性的社区,这不仅是为了我们的产品,也不仅是为了我们正在使用的技术,还为了整个人类社会,我想……我敢打赌,如果我们做到了这一点,那么作为人类,我们就比过去更进步了。”
>
>
> —— Leon Stigter,Lightbend 高级产品经理
>
>
>
如果你以非程序员的技术身份工作,你会给那些认为自己“非技术”的人(或被他人认为是“非技术”的人)提供什么建议? 在评论中分享你的见解。
---
via: <https://opensource.com/article/21/2/advice-non-technical>
作者:[Dawn Parzych](https://opensource.com/users/dawnparzych) 选题:[lujun9972](https://github.com/lujun9972) 译者:[max27149](https://github.com/max27149) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the [first article in this series](https://opensource.com/article/21/2/what-does-it-mean-be-technical), I explained the problems with dividing people and roles into "technical" or "non-technical" categories. In the [second article](https://opensource.com/article/21/2/non-engineering-jobs-tech), I shared some of the tech roles for people who don't code. Here, I'll wrap up this exploration into what it means to be technical or non-technical with some recommendations to help you on your journey.
Whether you've been working in tech for decades, are just starting, or are looking to change careers, consider the advice in this article from people who have been labeled as non-technical but are succeeding in tech roles.
"Don't tie up what you do and your identity. Get them separate."
—Adam Gordon Bell, Developer Relations, Earthly Technologies
Switching roles doesn't mean your skills will disappear and you no longer have value. If you take on a new role, you need to focus on that role's critical skills. It takes time to develop skills. Take your time, and figure out the important skills for the new position.
If you manage engineers, encourage them to develop their non-engineering skills and their technical skills. These skills often make a more significant difference in career growth and success than coding and technical skills.
## Be yourself
"Don't let other people define whether you are technical or not-technical. "What's technical and what's not, and whether that's important or not is something the people have to figure out for themselves."
—Adam Gordon Bell
"Don't ever start a conversation with, 'I'm not technical.' It can come across as, 'I need to warn you about this thing,' which is never a good impression to make for an interview, but it also has the potential to come across as a lack of confidence in your skills."
—Mary Thengvall, Director of Developer Relations, Camunda
Avoid the stereotypes; not all engineers like Star Wars or Star Trek. Not all engineers wear hoodies. Engineers can speak to people.
"People have a lot of perceptions about the technical, non-technical piece, in terms of how you present. When I was working in the office, I would wear a dress because that's how I feel comfortable."
—Shailvi Wakhlu, Senior Director of Data, Strava
## Know your worth
As I discussed in the first article, being labeled non-technical can lead to [impostor syndrome](https://opensource.com/business/15/9/tips-avoiding-impostor-syndrome). Recognize your value, and don't apply the non-technical label to yourself because it can limit earning potential and career growth.
"People kept reboxing me into something else because they thought I was different from the normal stereotype that they had for an engineer. I'm so glad that I didn't listen to any of those people because inherently they were also telling me to go for a lesser-paying job on the basis of something that was in addition to the skills that I had."
—Shailvi Wakhlu
"It is more likely the younger and … the woman in tech, especially new to tech, who's going to have imposter syndrome, who's going to consider themselves not technical enough. Like, 'oh, I only do front-end.' What do you mean you
onlydo front-end? Front-end is incredibly hard."
—Liz Harris
## Find where you can add value and help people
You don't need to create a pull request to participate in open source.
"I always say to people when they try to contribute to open source projects, 'don't think, it's got to be a commit, it's got to be a pull request.' It's like, 'No. How can you add value to that project?' If you haven't got time to do the pull request, are you raising an issue and putting the points down?"
—Eddie Jaoude, Open Source Developer, Jaoude Studios
## Diversity of thought leads to success
See the value and contributions of all roles and people. Don't pigeonhole them into a set of abilities based on their title.
"Realize how important everybody is, including yourself at all times, and the overall picture of things. Being creative shouldn't be ego-driven. Realize that you can always be better. You can also be worse at what you do. Don't be afraid to ask for help, and realize that we're in there together."
—Therese Eberhard, scenic painter for film, commercials, and video
"The hackathons that I have attended where we've all been technical, we've built a great team of four or five hardcore coders, we've lost. I kid you not, we've lost. And before COVID, I won six previous hackathons, and half the team was focused on other areas. In the hackathons we won, half the team would be considered non-technical by most people, although I do not like this term, as it is about adding value to the team/project. We won because we had so many different perspectives on what we were building."
—Eddie Jaoude
"The more we can move away from those labels of technical/not technical, developer/not developer, and understand that there's a continuum, the better off we're all going to be as far as hiring the right people for the job, instead of letting ourselves get hung up by the presumption that you need a technical team."
—Mary Thengvall
The more diverse our communities and teams are, the more inclusive they are.
"I honestly think the most important thing, whether it's from a community perspective or whether it's from a product perspective, just in general, we have to make sure that we built an inclusive community, not just for our products, not just for the technology that we're working on, but as a human society in general. And I'm going to guess… I'm going to wager that if we do that, as a human species, we will actually be better than what we were yesterday."
—Leon Stigter, Senior Product Manager, Lightbend
If you work in a non-coding tech role, what advice would you give people who consider themselves "non-technical" (or are considered by others to be so)? Share your insights in the comments.
## Comments are closed. |
13,446 | 在 Flutter 移动应用程序中创建一个列表 | https://opensource.com/article/20/11/flutter-lists-mobile-app | 2021-05-31T20:15:21 | [
"Flutter"
] | https://linux.cn/article-13446-1.html |
>
> 了解如何创建 Flutter 应用的界面以及如何在它们之间进行数据传递。
>
>
>

Flutter 是一个流行的开源工具包,它可用于构建跨平台的应用。在文章《[用 Flutter 创建移动应用](/article-12693-1.html)》中,我已经向大家展示了如何在 Linux 中安装 [Flutter](https://flutter.dev/) 并创建你的第一个应用。而这篇文章,我将向你展示如何在你的应用中添加一个列表,点击每一个列表项可以打开一个新的界面。这是移动应用的一种常见设计方法,你可能以前见过的,下面有一个截图,能帮助你对它有一个更直观的了解:

Flutter 使用 [Dart](https://dart.dev/) 语言。在下面的一些代码片段中,你会看到以斜杠开头的语句。两个斜杠(`//`)是指代码注释,用于解释某些代码片段。三个斜杠(`///`)则表示的是 Dart 的文档注释,用于解释 Dart 类和类的属性,以及其他的一些有用的信息。
### 查看Flutter应用的主要部分
Flutter 应用的典型入口点是 `main()` 函数,我们通常可以在文件 `lib/main.dart` 中找到它:
```
void main() {
runApp(MyApp());
}
```
应用启动时,`main()` 会被调用,然后执行 `MyApp()`。 `MyApp` 是一个无状态微件(`StatelessWidget`),它包含了`MaterialApp()` 微件中所有必要的应用设置(应用的主题、要打开的初始页面等):
```
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Flutter Demo',
theme: ThemeData(
primarySwatch: Colors.blue,
visualDensity: VisualDensity.adaptivePlatformDensity,
),
home: MyHomePage(title: 'Flutter Demo Home Page'),
);
}
}
```
生成的 `MyHomePage()` 是应用的初始页面,是一个有状态的微件,它包含包含可以传递给微件构造函数参数的变量(从上面的代码看,我们传了一个 `title` 变量给初始页面的构造函数):
```
class MyHomePage extends StatefulWidget {
MyHomePage({Key key, this.title}) : super(key: key);
final String title;
@override
_MyHomePageState createState() => _MyHomePageState();
}
```
有状态微件(`StatefulWidget`)表示这个微件可以拥有自己的状态:`_MyHomePageState`。调用 `_MyHomePageState` 中的 `setState()` 方法,可以重新构建用户界面:
```
class _MyHomePageState extends State<MyHomePage> {
int _counter = 0; // Number of taps on + button.
void _incrementCounter() { // Increase number of taps and update UI by calling setState().
setState(() {
_counter++;
});
}
...
}
```
不管是有状态的,还是无状态的微件,它们都有一个 `build()` 方法,该方法负责微件的 UI 外观。
```
@override
Widget build(BuildContext context) {
return Scaffold( // Page widget.
appBar: AppBar( // Page app bar with title and back button if user can return to previous screen.
title: Text(widget.title), // Text to display page title.
),
body: Center( // Widget to center child widget.
child: Column( // Display children widgets in column.
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
Text( // Static text.
'You have pushed the button this many times:',
),
Text( // Text with our taps number.
'$_counter', // $ sign allows us to use variables inside a string.
style: Theme.of(context).textTheme.headline4,// Style of the text, “Theme.of(context)” takes our context and allows us to access our global app theme.
),
],
),
),
// Floating action button to increment _counter number.
floatingActionButton: FloatingActionButton(
onPressed: _incrementCounter,
tooltip: 'Increment',
child: Icon(Icons.add),
),
);
}
```
### 修改你的应用
一个好的做法是,把 `main()` 方法和其他页面的代码分开放到不同的文件中。要想将它们分开,你需要右击 `lib` 目录,然后选择 “New > Dart File” 来创建一个 .dart 文件:

将新建的文件命名为 `items_list_page`。
切换回到 `main.dart` 文件,将 `MyHomePage` 和 `_MyHomePageState` 中的代码,剪切并粘贴到我们新建的文件。然后将光标放到 `StatefulWidget` 上(下面红色的下划线处), 按 `Alt+Enter` 后出现下拉列表,然后选择 `package:flutter/material.dart`:

经过上面的操作我们将 `flutter/material.dart` 包添加到了 `main.dart` 文件中,这样我们就可以使用 Flutter 提供的默认的 material 主题微件。
然后, 在类名 `MyHomePage` 右击,“Refactor > Rename...”将其重命名为 `ItemsListPage`:

Flutter 识别到你重命名了 `StatefulWidget` 类,它会自动将它的 `State` 类也跟着重命名:

回到 `main.dart` 文件,将文件名 `MyHomePage` 改为 `ItemsListPage`。 一旦你开始输入, 你的 Flutter 集成开发环境(可能是 IntelliJ IDEA 社区版、Android Studio 和 VS Code 或 [VSCodium](https://opensource.com/article/20/6/open-source-alternatives-vs-code)),会给出自动代码补完的建议。

按回车键即可完成输入,缺失的导入语句会被自动添加到文件的顶部。

到此,你已经完成了初始设置。现在你需要在 `lib` 目录创建一个新的 .dart 文件,命名为 `item_model`。(注意,类命是大写驼峰命名,一般的文件名是下划线分割的命名。)然后粘贴下面的代码到新的文件中:
```
/// Class that stores list item info:
/// [id] - unique identifier, number.
/// [icon] - icon to display in UI.
/// [title] - text title of the item.
/// [description] - text description of the item.
class ItemModel {
// class constructor
ItemModel(this.id, this.icon, this.title, this.description);
// class fields
final int id;
final IconData icon;
final String title;
final String description;
}
```
回到 `items_list_page.dart` 文件,将已有的 `_ItemsListPageState` 代码替换为下面的代码:
```
class _ItemsListPageState extends State<ItemsListPage> {
// Hard-coded list of [ItemModel] to be displayed on our page.
final List<ItemModel> _items = [
ItemModel(0, Icons.account_balance, 'Balance', 'Some info'),
ItemModel(1, Icons.account_balance_wallet, 'Balance wallet', 'Some info'),
ItemModel(2, Icons.alarm, 'Alarm', 'Some info'),
ItemModel(3, Icons.my_location, 'My location', 'Some info'),
ItemModel(4, Icons.laptop, 'Laptop', 'Some info'),
ItemModel(5, Icons.backup, 'Backup', 'Some info'),
ItemModel(6, Icons.settings, 'Settings', 'Some info'),
ItemModel(7, Icons.call, 'Call', 'Some info'),
ItemModel(8, Icons.restore, 'Restore', 'Some info'),
ItemModel(9, Icons.camera_alt, 'Camera', 'Some info'),
];
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text(widget.title),
),
body: ListView.builder( // Widget which creates [ItemWidget] in scrollable list.
itemCount: _items.length, // Number of widget to be created.
itemBuilder: (context, itemIndex) => // Builder function for every item with index.
ItemWidget(_items[itemIndex], () {
_onItemTap(context, itemIndex);
}),
));
}
// Method which uses BuildContext to push (open) new MaterialPageRoute (representation of the screen in Flutter navigation model) with ItemDetailsPage (StateFullWidget with UI for page) in builder.
_onItemTap(BuildContext context, int itemIndex) {
Navigator.of(context).push(MaterialPageRoute(
builder: (context) => ItemDetailsPage(_items[itemIndex])));
}
}
// StatelessWidget with UI for our ItemModel-s in ListView.
class ItemWidget extends StatelessWidget {
const ItemWidget(this.model, this.onItemTap, {Key key}) : super(key: key);
final ItemModel model;
final Function onItemTap;
@override
Widget build(BuildContext context) {
return InkWell( // Enables taps for child and add ripple effect when child widget is long pressed.
onTap: onItemTap,
child: ListTile( // Useful standard widget for displaying something in ListView.
leading: Icon(model.icon),
title: Text(model.title),
),
);
}
}
```
为了提高代码的可读性,可以考虑将 `ItemWidget` 作为一个单独的文件放到 `lib` 目录中。
现在唯一缺少的是 `ItemDetailsPage` 类。在 `lib` 目录中我们创建一个新文件并命名为 `item_details_page`。然后将下面的代码拷贝进去:
```
import 'package:flutter/material.dart';
import 'item_model.dart';
/// Widget for displaying detailed info of [ItemModel]
class ItemDetailsPage extends StatefulWidget {
final ItemModel model;
const ItemDetailsPage(this.model, {Key key}) : super(key: key);
@override
_ItemDetailsPageState createState() => _ItemDetailsPageState();
}
class _ItemDetailsPageState extends State<ItemDetailsPage> {
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text(widget.model.title),
),
body: Center(
child: Column(
children: [
const SizedBox(height: 16),
Icon(
widget.model.icon,
size: 100,
),
const SizedBox(height: 16),
Text(
'Item description: ${widget.model.description}',
style: TextStyle(fontSize: 18),
)
],
),
),
);
}
}
```
上面的代码几乎没什么新东西,不过要注意的是 `_ItemDetailsPageState` 里使用了 `widget.item.title` 这样的语句,它让我们可以从有状态类中引用到其对应的微件(`StatefulWidget`)。
### 添加一些动画
现在让我们来添加一些基础的动画:
1. 找到 `ItemWidget` 代码块(或者文件)
2. 将光标放到 `build()` 方法中的 `Icon()` 微件上
3. 按 `Alt+Enter`,然后选择“Wrap with widget...”

输入 `Hero`,然后从建议的下拉列表中选择 `Hero((Key key, @required this, tag, this.create))`:

下一步, 给 Hero 微件添加 `tag` 属性 `tag: model.id`:

最后我们在 `item_details_page.dart` 文件中做相同的修改:

前面的步骤,其实我们是用 `Hero()` 微件对 `Icon()` 微件进行了封装。还记得吗?前面我们定义 `ItemModel` 类时,定义了一个 `id field`,但没有在任何地方使用到。因为 Hero 微件会为其每个子微件添加一个唯一的标签。当 Hero 检测到不同页面(`MaterialPageRoute`)中存在相同标签的 Hero 时,它会自动在这些不同的页面中应用过渡动画。
可以在安卓模拟器或物理设备上运行我们的应用来测试这个动画。当你打开或者关闭列表项的详情页时,你会看到一个漂亮的图标动画:

### 收尾
这篇教程,让你学到了:
* 一些符合标准的,且能用于自动创建应用的组件。
* 如何添加多个页面以及在页面间传递数据。
* 如何给多个页面添加简单的动画。
如果你想了解更多,查看 Flutter 的 [文档](https://flutter.dev/docs)(有一些视频和样例项目的链接,还有一些创建 Flutter 应用的“秘方”)与 [源码](https://github.com/flutter),源码的开源许可证是 BSD 3。
---
via: <https://opensource.com/article/20/11/flutter-lists-mobile-app>
作者:[Vitaly Kuprenko](https://opensource.com/users/kooper) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ywxgod](https://github.com/ywxgod) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Flutter is a popular open source toolkit for building cross-platform apps. In "[Create a mobile app with Flutter](https://opensource.com/article/20/9/mobile-app-flutter)," I demonstrated how to install [Flutter](https://flutter.dev/) on Linux and create your first app. In this article, I'll show you how to add a list of items in your app, with each item opening a new screen. This is a common design method for mobile apps, so you've probably seen it before, but here's a screenshot to help you visualize it:
(Vitaly Kuprenko, CC BY-SA 4.0)
Flutter uses the [Dart](https://dart.dev/) language. In some of the code snippets below, you'll see statements beginning with slashes. Two slashes (`/ /`
) is for code comments, which explain certain pieces of code. Three slashes (`/ / /`
) denotes Dart's documentation comments, which explain Dart classes and their properties and other useful information.
## Examine a Flutter app's main parts
A typical entry point for a Flutter application is a `main()`
function, usually found in a file called `lib/main.dart`
:
```
void main() {
runApp(MyApp());
}
```
This method is called when the app is launched. It runs `MyApp()`
, a StatelessWidget containing all necessary app settings in the `MaterialApp()`
widget (app theme, initial page to open, and so on):
```
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Flutter Demo',
theme: ThemeData(
primarySwatch: Colors.blue,
visualDensity: VisualDensity.adaptivePlatformDensity,
),
home: MyHomePage(title: 'Flutter Demo Home Page'),
);
}
}
```
The initial page generated is called `MyHomePage()`
. It's a stateful widget that contains variables that can be passed to a widget constructor parameter (take a look at the code above, where you pass the variable `title`
to the page constructor):
```
class MyHomePage extends StatefulWidget {
MyHomePage({Key key, this.title}) : super(key: key);
final String title;
@override
_MyHomePageState createState() => _MyHomePageState();
}
```
StatefulWidget means that this page has its own state: `_MyHomePageState`
. It lets you call the `setState()`
method there to rebuild the page's user interface (UI):
```
class _MyHomePageState extends State<MyHomePage> {
int _counter = 0; // Number of taps on + button.
void _incrementCounter() { // Increase number of taps and update UI by calling setState().
setState(() {
_counter++;
});
}
...
}
```
A `build()`
function in stateful and stateless widgets is responsible for UI appearance:
```
@override
Widget build(BuildContext context) {
return Scaffold( // Page widget.
appBar: AppBar( // Page app bar with title and back button if user can return to previous screen.
title: Text(widget.title), // Text to display page title.
),
body: Center( // Widget to center child widget.
child: Column( // Display children widgets in column.
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
Text( // Static text.
'You have pushed the button this many times:',
),
Text( // Text with our taps number.
'$_counter', // $ sign allows us to use variables inside a string.
style: Theme.of(context).textTheme.headline4,// Style of the text, “Theme.of(context)” takes our context and allows us to access our global app theme.
),
],
),
),
// Floating action button to increment _counter number.
floatingActionButton: FloatingActionButton(
onPressed: _incrementCounter,
tooltip: 'Increment',
child: Icon(Icons.add),
),
);
}
```
## Modify your app
It's good practice to separate the `main()`
method and other pages' code into different files. To do so, you need to create a new .dart file by right-clicking on the **lib** folder then selecting **New > Dart File**:
(Vitaly Kuprenko, CC BY-SA 4.0)
Name the file `items_list_page`
.
Switch back to your `main.dart`
file, cut the `MyHomePage`
and `_MyHomePageState`
code, and paste it into your new file. Next, set your cursor on `StatefulWidget`
(underlined below in red), press Alt+Enter, and select `package:flutter/material.dart`
:
(Vitaly Kuprenko, CC BY-SA 4.0)
This adds `flutter/material.dart`
to your file so that you can use the default material widgets Flutter provides.
Then, right-click on **MyHomePage class > Refactor > Rename…** and rename this class to `ItemsListPage`
:
(Vitaly Kuprenko, CC BY-SA 4.0)
Flutter recognizes that you renamed the StatefulWidget class and automatically renames its State class:
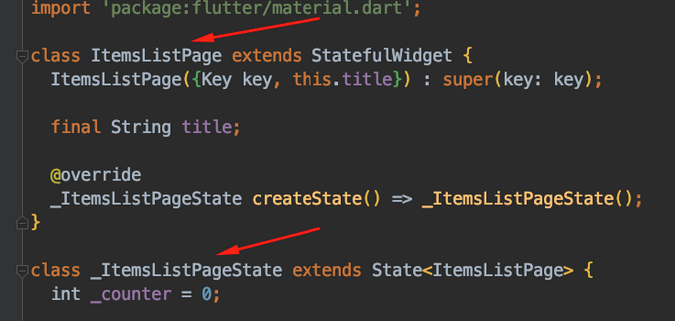
(Vitaly Kuprenko, CC BY-SA 4.0)
Return to the `main.dart`
file and change the name `MyHomePage`
to `ItemsListPage`
. Once you start typing, your Flutter integrated development environment (probably IntelliJ IDEA Community Edition, Android Studio, and VS Code or [VSCodium](https://opensource.com/article/20/6/open-source-alternatives-vs-code)) suggests how to autocomplete your code:
(Vitaly Kuprenko, CC BY-SA 4.0)
Press Enter to complete your input. It will add the missing import to the top of the file automatically:

(Vitaly Kuprenko, CC BY-SA 4.0)
You've completed your initial setup. Now you need to create a new .dart file in the **lib** folder and name it `item_model`
. (Note that classes have UpperCamelCase names, but files have snake_case names.) Paste this code into the new file:
```
/// Class that stores list item info:
/// [id] - unique identifier, number.
/// [icon] - icon to display in UI.
/// [title] - text title of the item.
/// [description] - text description of the item.
class ItemModel {
// class constructor
ItemModel(this.id, this.icon, this.title, this.description);
// class fields
final int id;
final IconData icon;
final String title;
final String description;
}
```
Return to `items_list_page.dart`
, and replace the existing `_ItemsListPageState`
code with:
```
class _ItemsListPageState extends State<ItemsListPage> {
// Hard-coded list of [ItemModel] to be displayed on our page.
final List<ItemModel> _items = [
ItemModel(0, Icons.account_balance, 'Balance', 'Some info'),
ItemModel(1, Icons.account_balance_wallet, 'Balance wallet', 'Some info'),
ItemModel(2, Icons.alarm, 'Alarm', 'Some info'),
ItemModel(3, Icons.my_location, 'My location', 'Some info'),
ItemModel(4, Icons.laptop, 'Laptop', 'Some info'),
ItemModel(5, Icons.backup, 'Backup', 'Some info'),
ItemModel(6, Icons.settings, 'Settings', 'Some info'),
ItemModel(7, Icons.call, 'Call', 'Some info'),
ItemModel(8, Icons.restore, 'Restore', 'Some info'),
ItemModel(9, Icons.camera_alt, 'Camera', 'Some info'),
];
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text(widget.title),
),
body: ListView.builder( // Widget which creates [ItemWidget] in scrollable list.
itemCount: _items.length, // Number of widget to be created.
itemBuilder: (context, itemIndex) => // Builder function for every item with index.
ItemWidget(_items[itemIndex], () {
_onItemTap(context, itemIndex);
}),
));
}
// Method which uses BuildContext to push (open) new MaterialPageRoute (representation of the screen in Flutter navigation model) with ItemDetailsPage (StateFullWidget with UI for page) in builder.
_onItemTap(BuildContext context, int itemIndex) {
Navigator.of(context).push(MaterialPageRoute(
builder: (context) => ItemDetailsPage(_items[itemIndex])));
}
}
// StatelessWidget with UI for our ItemModel-s in ListView.
class ItemWidget extends StatelessWidget {
const ItemWidget(this.model, this.onItemTap, {Key key}) : super(key: key);
final ItemModel model;
final Function onItemTap;
@override
Widget build(BuildContext context) {
return InkWell( // Enables taps for child and add ripple effect when child widget is long pressed.
onTap: onItemTap,
child: ListTile( // Useful standard widget for displaying something in ListView.
leading: Icon(model.icon),
title: Text(model.title),
),
);
}
}
```
Consider moving `ItemWidget`
to a separate file in the **lib** folder to improve the readability of your code.
The only thing missing is the `ItemDetailsPage`
class. Create a new file in the **lib** folder and name it `item_details_page`
. Then copy and paste this code there:
```
import 'package:flutter/material.dart';
import 'item_model.dart';
/// Widget for displaying detailed info of [ItemModel]
class ItemDetailsPage extends StatefulWidget {
final ItemModel model;
const ItemDetailsPage(this.model, {Key key}) : super(key: key);
@override
_ItemDetailsPageState createState() => _ItemDetailsPageState();
}
class _ItemDetailsPageState extends State<ItemDetailsPage> {
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text(widget.model.title),
),
body: Center(
child: Column(
children: [
const SizedBox(height: 16),
Icon(
widget.model.icon,
size: 100,
),
const SizedBox(height: 16),
Text(
'Item description: ${widget.model.description}',
style: TextStyle(fontSize: 18),
)
],
),
),
);
}
}
```
Almost nothing new here. Notice that `_ItemDetailsPageState`
is using the `widget.item.title`
code. It enables referring to the `StatefulWidget`
fields in its `State`
class.
## Add some animation
Now, it's time to add some basic animation:
- Go to
`ItemWidget`
code. - Put the cursor on the
`Icon()`
widget in the`build()`
method. - Press Alt+Enter and select "Wrap with widget…"
(Vitaly Kuprenko, CC BY-SA 4.0)
Start typing "Hero" and select the suggestion for `Hero((Key key, @required this, tag, this.create))`
:
(Vitaly Kuprenko, CC BY-SA 4.0)
Next, add the tag property `tag: model.id`
to the Hero widget:
(Vitaly Kuprenko, CC BY-SA 4.0)
And the final step is to make the same change in the `item_details_page.dart`
file:
(Vitaly Kuprenko, CC BY-SA 4.0)
The previous steps wrapped the `Icon()`
widget with the `Hero()`
widget. Do you remember in `ItemModel`
you added the `id field`
but didn't use it anywhere? The Hero widget takes a unique tag for the child widget. If Hero detects that different app screens (MaterialPageRoute) have a Hero widget with the same tag, it'll automatically animate the transition between these pages.
Test it out by running the app on an Android emulator or physical device. When you open and close the item details page, you'll see a nice animation of the icon:

(Vitaly Kuprenko, CC BY-SA 4.0)
## Wrapping up
In this tutorial, you learned:
- The components of a standard, automatically created app
- How to add several pages that pass data among each other
- How to add a simple animation for those pages
If you want to learn more, check out Flutter's [docs](https://flutter.dev/docs) (with links to sample projects, videos, and "recipes" for creating Flutter apps) and the [source code](https://github.com/flutter), which is open source under a BSD 3-Clause License.
## Comments are closed. |
13,448 | Python 3.5 带给我们的方便的矩阵以及其他改进 | https://opensource.com/article/21/5/python-35-features | 2021-06-01T20:20:01 | [
"Python"
] | https://linux.cn/article-13448-1.html |
>
> 探索一些未被充分利用但仍然有用的 Python 特性。
>
>
>

这是 Python 3.x 首发特性系列文章的第六篇。Python 3.5 在 2015 年首次发布,尽管它已经发布了很长时间,但它引入的许多特性都没有被充分利用,而且相当酷。下面是其中的三个。
### @ 操作符
`@` 操作符在 Python 中是独一无二的,因为在标准库中没有任何对象可以实现它!它是为了在有矩阵的数学包中使用而添加的。
矩阵有两个乘法的概念。元素积是用 `*` 运算符完成的。但是矩阵组合(也被认为是乘法)需要自己的符号。它是用 `@` 完成的。
例如,将一个“八转”矩阵(将轴旋转 45 度)与自身合成,就会产生一个四转矩阵。
```
import numpy
hrt2 = 2**0.5 / 2
eighth_turn = numpy.array([
[hrt2, hrt2],
[-hrt2, hrt2]
])
eighth_turn @ eighth_turn
```
```
array([[ 4.26642159e-17, 1.00000000e+00],
[-1.00000000e+00, -4.26642159e-17]])
```
浮点数是不精确的,这比较难以看出。从结果中减去四转矩阵,将其平方相加,然后取其平方根,这样就比较容易检查。
这是新运算符的一个优点:特别是在复杂的公式中,代码看起来更像基础数学:
```
almost_zero = ((eighth_turn @ eighth_turn) - numpy.array([[0, 1], [-1, 0]]))**2
round(numpy.sum(almost_zero) ** 0.5, 10)
```
```
0.0
```
### 参数中的多个关键词字典
Python 3.5 使得调用具有多个关键字-参数字典的函数成为可能。这意味着多个默认值的源可以与更清晰的代码”互操作“。
例如,这里有个可笑的关键字参数的函数:
```
def show_status(
*,
the_good=None,
the_bad=None,
the_ugly=None,
fistful=None,
dollars=None,
more=None
):
if the_good:
print("Good", the_good)
if the_bad:
print("Bad", the_bad)
if the_ugly:
print("Ugly", the_ugly)
if fistful:
print("Fist", fistful)
if dollars:
print("Dollars", dollars)
if more:
print("More", more)
```
当你在应用中调用这个函数时,有些参数是硬编码的:
```
defaults = dict(
the_good="You dig",
the_bad="I have to have respect",
the_ugly="Shoot, don't talk",
)
```
从配置文件中读取更多参数:
```
import json
others = json.loads("""
{
"fistful": "Get three coffins ready",
"dollars": "Remember me?",
"more": "It's a small world"
}
""")
```
你可以从两个源一起调用这个函数,而不必构建一个中间字典:
```
show_status(**defaults, **others)
```
```
Good You dig
Bad I have to have respect
Ugly Shoot, don't talk
Fist Get three coffins ready
Dollars Remember me?
More It's a small world
```
### os.scandir
`os.scandir` 函数是一种新的方法来遍历目录内容。它返回一个生成器,产生关于每个对象的丰富数据。例如,这里有一种打印目录清单的方法,在目录的末尾跟着 `/`:
```
for entry in os.scandir(".git"):
print(entry.name + ("/" if entry.is_dir() else ""))
```
```
refs/
HEAD
logs/
index
branches/
config
objects/
description
COMMIT_EDITMSG
info/
hooks/
```
### 欢迎来到 2015 年
Python 3.5 在六年前就已经发布了,但是在这个版本中首次出现的一些特性非常酷,而且没有得到充分利用。如果你还没使用,那么将他们添加到你的工具箱中。
---
via: <https://opensource.com/article/21/5/python-35-features>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the sixth in a series of articles about features that first appeared in a version of Python 3.x. Python 3.5 was first released in 2015, and even though it has been out for a long time, many of the features it introduced are underused and pretty cool. Here are three of them.
## The @ operator
The `@`
operator is unique in Python in that there are no objects in the standard library that implement it! It was added for use in mathematical packages that have matrices.
Matrices have two concepts of multiplication; point-wise multiplication is done with the `*`
operator. But matrix composition (also considered multiplication) needed its own symbol. It is done using `@`
.
For example, composing an "eighth-turn" matrix (rotating the axis by 45 degrees) with itself results in a quarter-turn matrix:
```
import numpy
hrt2 = 2**0.5 / 2
eighth_turn = numpy.array([
[hrt2, hrt2],
[-hrt2, hrt2]
])
eighth_turn @ eighth_turn
```
```
array([[ 4.26642159e-17, 1.00000000e+00],
[-1.00000000e+00, -4.26642159e-17]])
```
Floating-point numbers being imprecise, this is harder to see. It is easier to check by subtracting the quarter-turn matrix from the result, summing the squares, and taking the square root.
This is one advantage of the new operator: especially in complex formulas, the code looks more like the underlying math:
```
almost_zero = ((eighth_turn @ eighth_turn) - numpy.array([[0, 1], [-1, 0]]))**2
round(numpy.sum(almost_zero) ** 0.5, 10)
```
` 0.0`
## Multiple keyword dictionaries in arguments
Python 3.5 made it possible to call functions with multiple keyword-argument dictionaries. This means multiple sources of defaults can "co-operate" with clearer code.
For example, here is a function with a ridiculous amount of keyword arguments:
```
def show_status(
*,
the_good=None,
the_bad=None,
the_ugly=None,
fistful=None,
dollars=None,
more=None
):
if the_good:
print("Good", the_good)
if the_bad:
print("Bad", the_bad)
if the_ugly:
print("Ugly", the_ugly)
if fistful:
print("Fist", fistful)
if dollars:
print("Dollars", dollars)
if more:
print("More", more)
```
When you call this function in the application, some arguments are hardcoded:
```
defaults = dict(
the_good="You dig",
the_bad="I have to have respect",
the_ugly="Shoot, don't talk",
)
```
More arguments are read from a configuration file:
```
import json
others = json.loads("""
{
"fistful": "Get three coffins ready",
"dollars": "Remember me?",
"more": "It's a small world"
}
""")
```
You can call the function from both sources together without having to construct an intermediate dictionary:
`show_status(**defaults, **others)`
```
Good You dig
Bad I have to have respect
Ugly Shoot, don't talk
Fist Get three coffins ready
Dollars Remember me?
More It's a small world
```
## os.scandir
The `os.scandir`
function is a new way to iterate through directories' contents. It returns a generator that yields rich data about each object. For example, here is a way to print a directory listing with a trailing `/`
at the end of directories:
```
for entry in os.scandir(".git"):
print(entry.name + ("/" if entry.is_dir() else ""))
```
```
refs/
HEAD
logs/
index
branches/
config
objects/
description
COMMIT_EDITMSG
info/
hooks/
```
## Welcome to 2015
Python 3.5 was released over six years ago, but some of the features that first showed up in this release are cool—and underused. Add them to your toolkit if you haven't already.
## Comments are closed. |
13,449 | Nyxt 浏览器:一个受 Emacs 和 Vim 启发的面向键盘的网页浏览器 | https://itsfoss.com/nyxt-browser/ | 2021-06-01T21:26:17 | [
"Nyxt",
"键盘",
"Vim",
"浏览器"
] | https://linux.cn/article-13449-1.html | 你可以得到很多适用于 Linux 的开源网页浏览器,不只是基于 Chrome 的浏览器,而且还有 [其它的替代品](https://itsfoss.com/open-source-browsers-linux/)。
它们大多数都侧重于提供漂亮的用户体验,并同时兼顾隐私功能。
然而,Nyxt 浏览器可能不是为最好的用户体验而建立的,而是为资深用户喜欢的某些东西而打造的。
### Nyxt 浏览器:专注于键盘快捷键和命令的开源浏览器

[Nyxt](https://nyxt.atlas.engineer/) 是一个面向键盘的开源网页浏览器,可在 Linux 和 macOS 上使用。
当然,不是每个资深用户都会去使用键盘快捷键,但这旨在满足那些喜欢通过键盘导航的用户的需求。
它的灵感来自于 Vim 和 Emacs 中的键盘快捷键的工作方式 —— 所以如果你对这些编辑器很熟悉,那么你也会对这些快捷键感到熟悉。
与主流的网页浏览器不同,你不必在多个设置和菜单中导航,只需一个快速快捷键或一个命令,你就会获得所有你需要访问的功能。
如果你想知道的话,它不特定于某种网页引擎,它目前支持 WebEngine 和 WebKit。
因此,如果你是一个喜欢使用键盘导航的人,它可以节省时间并改善你的浏览体验。
它提供了相当多的有用功能,我将在下面指出。
### Nyxt 浏览器的特点

你会发现这里提供了许多非常规的功能。在探索这里提到的每一个关键亮点之前,你可能想先浏览一下官方文档(按 `F1` 找到它),你可以在欢迎屏幕中可以找到链接。
* 无损的树形的历史记录(跟踪你的浏览历史的确切层次,并轻松回忆你导航到的内容)
* 剪贴板历史,帮助你快速找到你之前复制的内容
* 开始输入命令的键盘快捷方式(`CTRL+Space`)
* 使用键盘快捷键在冗长的文件中导航,可以跳到一个特定的标题
* 缓冲区替代了标签,它将每个标签的行为和设置相互隔离
* 通过将多个标签映射到一个共同的元素来一同关闭
* 无鼠标导航
* 使用搜索快速找到一个缓冲区,而不是在许多标签中寻找它
* 能够根据你的工作流程运行简短的脚本
* 可定制的自动填写功能,你也可以在表单中自动填写当前日期
* 内置的广告拦截器
除了上面提到的功能外,你还可以切换**黑暗模式**、**HTTPS 模式**,以及在命令菜单中有大量的选项。
此外,它是完全可定制和可编程的。因此,你可以选择为自己量身定做。
### 在 Linux 中安装 Nyxt 浏览器

对于基于 Ubuntu 的发行版,你可以从 [官方下载页面](https://nyxt.atlas.engineer/download) 找到一个 deb 包。
如果你还不会,你可能想读一下 [安装 deb 文件的方法](https://itsfoss.com/install-deb-files-ubuntu/)。
它也为 Arch Linux 用户提供了 [AUR](https://itsfoss.com/aur-arch-linux/),并为 Alpine Linux、Nix 和 Guix 提供了包。
如果你需要编译它,你也可以在 [GitHub 页面](https://github.com/atlas-engineer/nyxt) 中找到源代码。
* [下载 Nyxt 浏览器](https://nyxt.atlas.engineer/download)
### 总结
虽然 Nyxt 浏览器可能不是最友好的浏览体验,但对于能够充分利用键盘快捷键和命令的用户来说,它肯定是一个特殊的选择。
如果你想要一个无鼠标的导航体验,这是一个值得尝试的浏览器。我建议你尝试一下 —— 但如果你一般不使用键盘快捷键来导航,这对你来说将是一个复杂的体验。
你尝试过 Nyxt 浏览器吗?请在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/nyxt-browser/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You get plenty of [web browsers available for Linux](https://itsfoss.com/best-browsers-ubuntu-linux/). Not just limited to Chrome-based options, but [Chrome alternatives](https://itsfoss.com/open-source-browsers-linux/) as well.
Most of the options available focus on a pretty user experience while offering privacy features.
However, the Nyxt browser may not be built for the best user experience in mind, but is something that power users love.
## Nyxt Browser: Open-Source Browser That Focuses on Keyboard Shortcuts and Commands
[Nyxt](https://nyxt.atlas.engineer/?ref=itsfoss.com) is a keyboard-oriented open-source web browser available for Linux and macOS and Windows, while the later two are still in development.
Of course, not every power user utilizes keyboard shortcuts, but this aims to cater to the needs of users who prefer to navigate via the keyboard.
It is inspired by how the keyboard shortcuts in Vim and Emacs work — so if you are comfortable with those editors, the shortcuts will feel familiar to you.
Unlike mainstream web browsers, you do not have to navigate your way inside multiple settings and menus, you will get all the functionality that you need to access with a quick shortcut or a command.
In case you were wondering, it is web engine agnostic, but it currently supports WebEngine and WebKit.
So, it saves time and improves your browsing experience if you are a fan of navigating around using the keyboard.
It offers a fair share of useful features, which I shall highlight below.
## Features of Nyxt Browser
You will find many non-conventional features offered here. Before exploring each of the key highlights mentioned here, you might want to go through the official documentation (press **F1 + r** to find it). It is also linked on the welcome screen:
- Lossless tree-based history (track the exact hierarchy of your history and easily recall what you navigated to)
- Clipboard history to help you quickly find what you copied earlier
- Keyboard shortcut to start entering commands (
**CTRL+ Space**) - Navigate your way through lengthy documents using keyboard shortcuts to jump to a specific heading
- Buffers instead of tabs, which isolates behaviour and settings of every tab from one another
- Ability to close multiple tabs by mapping them with a common element
- Mouseless navigation
- Link hinting for hyperlinks
- In-built adblocker
- Customizable autofill feature with which you can also have the current date filled in automatically in a form
- Ability to run short scripts as per your workflow
- Quickly find a buffer using search instead of looking for it among many tabs
In addition to the features highlighted above, you will get the ability to toggle a **dark mode**, **HTTPS mode**, and a ton of options from the command menu.
Moreover, it is completely customizable and programmable. So, you can choose to tailor it for yourself.
## Install Nyxt Browser in Linux
For Arch Linux users, it is available in the Extra repositories. To install, open a terminal and run:
`sudo pacman -S nyxt`
Also, for other systems, Nyxt is available as a Flatpak application. If your system has [Flatpak support enabled](https://itsfoss.com/flatpak-guide/), run the following command:
`flatpak install flathub engineer.atlas.Nyxt`
You should also find the source in the [GitHub page](https://github.com/atlas-engineer/nyxt?ref=itsfoss.com) if you need to compile it.
## Wrapping Up
While Nyxt browser may not be the most user-friendly browsing experience out there, it is certainly a special option for users who can make the most out of keyboard shortcuts and commands.
If you want a mouseless navigation experience, this is the browser to try. I’d suggest you to try it anyway – but if you do not generally use keyboard shortcuts to navigate, this would be a complicated experience for you.
Have you tried Nyxt browser ever before? Let me know your thoughts in the comments below.
**Suggested Read 📖**
Here are some light-weight web browsers for Linux.
[10 Open Source Lightweight Web Browsers for LinuxDo you think your web browser consumes too much system resources? Try these light web browsers in Linux.](https://itsfoss.com/lightweight-web-browsers-linux/)

Or, want to try some lesser known browsers?
[7 Lesser Known but Unique Web Browsers For You to ExploreLooking for something different? These unique web browsers can help you make things interesting.](https://itsfoss.com/unique-web-browsers/)

Have a look at these terminal-based web browsers for command line fans.
[Best Terminal-based Web Browsers for Linux UsersYou can do a lot in the Linux command line. Browsing the internet is one of them. Here are some of the best terminal based browsers.](https://itsfoss.com/terminal-web-browsers/)
 |
13,451 | Make 命令未找到?这是修复它的方法 | https://itsfoss.com/make-command-not-found-ubuntu/ | 2021-06-02T20:30:58 | [
"make"
] | https://linux.cn/article-13451-1.html | 
有一天,我试图在一个新的 Ubuntu 系统上编译一个程序,当我试图使用 `make` 命令时,它向我抛出一个错误:
```
The program 'make' is currently not installed. You can install it by typing:
sudo apt install make
```
这表明 `make` 命令还没有安装。你可以用这些命令在 Ubuntu 上逐步安装 `make`:
```
sudo apt update
sudo apt install make
```
第一个命令是更新本地的软件包缓存。如果是一个新安装的 Ubuntu 系统,这是很有必要的。有了刷新的软件包缓存,你的系统就会知道应该从哪个仓库下载 `make` 包。
并验证 `make` 是否已经正确安装:
```
make --version
```

### 在 Ubuntu 上安装 make 的更好方法
安装 `make` 命令的一个更好的方法是使用 `build-essential` 包。这个包包含 `make`、`gcc`、`g++` 和其他一些编译器和开发工具。
```
sudo apt install build-essential
```

安装了这个 `build-essential` 包后,你就可以[在 Linux 中轻松地运行 C/C++ 程序](https://itsfoss.com/c-plus-plus-ubuntu/)。
### 如果 make 已经安装了,但它没有工作怎么办?
在一些罕见的情况下,可能会发生 `make` 已经安装了,但却无法工作的情况。
其原因是 `make` 命令不在 `$PATH` 变量中。你可以用这个命令重新安装 `make`:
```
sudo apt install --reinstall make
```
如果这不起作用,你可以尝试 [手动添加二进制文件到你的 PATH 中](https://itsfoss.com/add-directory-to-path-linux/),但这应该不需要手动。
我希望这个快速提示能帮助你。仍然有问题或对相关主题有疑问?请随时在评论区留言。
---
via: <https://itsfoss.com/make-command-not-found-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The other day I was trying to compile a program on a fresh new Ubuntu system and it threw me an error when I tried to use the make command:
```
The program 'make' is currently not installed. You can install it by typing:
sudo apt install make
```
One of the reasons you see the [bash: command not found error](https://itsfoss.com/bash-command-not-found/) is because the command is not installed on the system. You may install make on Ubuntu using these commands one by one:
```
sudo apt update
sudo apt install make
```
The first command updates the local package cache. It is necessary specially if it is a freshly installed Ubuntu system. With the refreshed package cache, your system would know about the repository from where make package should be downloaded.
And verify that make has been properly installed:
`make --version`
## A better way to install make on Ubuntu
An even better way to install make command is to [use the build essential package](https://itsfoss.com/build-essential-ubuntu/). This package contains make, gcc, g++ and several other compilers and developer tools.
`sudo apt install build-essential`
With this build-essential package installed, you can [easily run C/C++ programs in Linux](https://itsfoss.com/c-plus-plus-ubuntu/).
## What if make is installed but it doesn’t work
In some rare cases, it may happen that make is installed and yet it doesn’t work.
The reason is that make command is not in the $PATH variable. You can either reinstall make with this command:
`sudo apt install --reinstall make`
If that doesn’t work, you may try to [manually add the binary to your PATH](https://itsfoss.com/add-directory-to-path-linux/) but it shouldn’t come to this manual effort.
I hope this quick tip helped you. Still have the problem or question on the related topic? Feel free to use the comment section. I’ll try to help you in my capacity. If you want an even more rapid response, you may [join It’s FOSS Community forum](https://itsfoss.community/). Enjoy :) |
13,452 | 使用 systemd 作为问题定位工具 | https://opensource.com/article/20/5/systemd-troubleshooting-tool | 2021-06-02T21:43:51 | [
"systemd",
"故障定位"
] | /article-13452-1.html |
>
> 虽然 systemd 并非真正的故障定位工具,但其输出中的信息为解决问题指明了方向。
>
>
>

没有人会认为 systemd 是一个故障定位工具,但当我的 web 服务器遇到问题时,我对 systemd 和它的一些功能的不断了解帮助我找到并规避了问题。
我遇到的问题是这样,我的服务器 yorktown 为我的家庭办公网络提供名称服务 、DHCP、NTP、HTTPD 和 SendMail 邮件服务,它在正常启动时未能启动 Apache HTTPD 守护程序。在我意识到它没有运行之后,我不得不手动启动它。这个问题已经持续了一段时间,我最近才开始尝试去解决它。
你们中的一些人会说,systemd 本身就是这个问题的原因,根据我现在了解的情况,我同意你们的看法。然而,我在使用 SystemV 时也遇到了类似的问题。(在本系列文章的 [第一篇](https://opensource.com/article/20/4/systemd) 中,我探讨了围绕 systemd 作为旧有 SystemV 启动程序和启动脚本的替代品所产生的争议。如果你有兴趣了解更多关于 systemd 的信息,也可以阅读 [第二篇](https://opensource.com/article/20/4/systemd-startup) 和 [第三篇](https://opensource.com/article/20/4/understanding-and-using-systemd-units) 文章。)没有完美的软件,systemd 和 SystemV 也不例外,但 systemd 为解决问题提供的信息远远多于 SystemV。
### 确定问题所在
找到这个问题根源的第一步是确定 httpd 服务的状态:
```
[root@yorktown ~]# systemctl status httpd
● httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
Active: failed (Result: exit-code) since Thu 2020-04-16 11:54:37 EDT; 15min ago
Docs: man:httpd.service(8)
Process: 1101 ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND (code=exited, status=1/FAILURE)
Main PID: 1101 (code=exited, status=1/FAILURE)
Status: "Reading configuration..."
CPU: 60ms
Apr 16 11:54:35 yorktown.both.org systemd[1]: Starting The Apache HTTP Server...
Apr 16 11:54:37 yorktown.both.org httpd[1101]: (99)Cannot assign requested address: AH00072: make_sock: could not bind to address 192.168.0.52:80
Apr 16 11:54:37 yorktown.both.org httpd[1101]: no listening sockets available, shutting down
Apr 16 11:54:37 yorktown.both.org httpd[1101]: AH00015: Unable to open logs
Apr 16 11:54:37 yorktown.both.org systemd[1]: httpd.service: Main process exited, code=exited, status=1/FAILURE
Apr 16 11:54:37 yorktown.both.org systemd[1]: httpd.service: Failed with result 'exit-code'.
Apr 16 11:54:37 yorktown.both.org systemd[1]: Failed to start The Apache HTTP Server.
[root@yorktown ~]#
```
这种状态信息是 systemd 的功能之一,我觉得比 SystemV 提供的任何功能都要有用。这里的大量有用信息使我很容易得出逻辑性的结论,让我找到正确的方向。我从旧的 `chkconfig` 命令中得到的是服务是否在运行,以及如果它在运行的话,进程 ID(PID)是多少。这可没多大帮助。
该状态报告中的关键条目显示,HTTPD 不能与 IP 地址绑定,这意味着它不能接受传入的请求。这表明网络启动速度不够快,因为 IP 地址还没有设置好,所以 HTTPD 服务还没有准备好与 IP 地址绑定。这是不应该发生的,所以我查看了我的网络服务的 systemd 启动配置文件;在正确的 `after` 和 `requires` 语句下,所有这些似乎都没问题。下面是我服务器上的 `/lib/systemd/system/httpd.service` 文件:
```
# Modifying this file in-place is not recommended, because changes
# will be overwritten during package upgrades. To customize the
# behaviour, run "systemctl edit httpd" to create an override unit.
# For example, to pass additional options (such as -D definitions) to
# the httpd binary at startup, create an override unit (as is done by
# systemctl edit) and enter the following:
# [Service]
# Environment=OPTIONS=-DMY_DEFINE
[Unit]
Description=The Apache HTTP Server
Wants=httpd-init.service
After=network.target remote-fs.target nss-lookup.target httpd-init.service
Documentation=man:httpd.service(8)
[Service]
Type=notify
Environment=LANG=C
ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND
ExecReload=/usr/sbin/httpd $OPTIONS -k graceful
# Send SIGWINCH for graceful stop
KillSignal=SIGWINCH
KillMode=mixed
PrivateTmp=true
[Install]
WantedBy=multi-user.target
```
`httpd.service` 单元文件明确规定,它应该在 `network.target` 和 `httpd-init.service`(以及其他)之后加载。我试着用 `systemctl list-units` 命令找到所有这些服务,并在结果数据流中搜索它们。所有这些服务都存在,应该可以确保在设置网络 IP 地址之前,httpd 服务没有加载。
### 第一个解决方案
在互联网上搜索了一下,证实其他人在 httpd 和其他服务也遇到了类似的问题。这似乎是由于其中一个所需的服务向 systemd 表示它已经完成了启动,但实际上它却启动了一个尚未完成的子进程。通过更多搜索,我想到了一个规避方法。
我搞不清楚为什么花了这么久才把 IP 地址分配给网卡。所以我想,如果我可以将 HTTPD 服务的启动推迟合理的一段时间,那么 IP 地址就会在那个时候分配。
幸运的是,上面的 `/lib/systemd/system/httpd.service` 文件提供了一些方向。虽然它说不要修改它,但是它还是指出了如何操作:使用 `systemctl edit httpd` 命令,它会自动创建一个新文件(`/etc/systemd/system/httpd.service.d/override.conf`)并打开 [GNU Nano](https://www.nano-editor.org/) 编辑器(如果你对 Nano 不熟悉,一定要看一下 Nano 界面底部的提示)。
在新文件中加入以下代码并保存:
```
[root@yorktown ~]# cd /etc/systemd/system/httpd.service.d/
[root@yorktown httpd.service.d]# ll
total 4
-rw-r--r-- 1 root root 243 Apr 16 11:43 override.conf
[root@yorktown httpd.service.d]# cat override.conf
# Trying to delay the startup of httpd so that the network is
# fully up and running so that httpd can bind to the correct
# IP address
#
# By David Both, 2020-04-16
[Service]
ExecStartPre=/bin/sleep 30
```
这个覆盖文件的 `[Service]` 段有一行代码,将 HTTPD 服务的启动时间推迟了 30 秒。下面的状态命令显示了等待时间里的服务状态:
```
[root@yorktown ~]# systemctl status httpd
● httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/httpd.service.d
└─override.conf
/usr/lib/systemd/system/httpd.service.d
└─php-fpm.conf
Active: activating (start-pre) since Thu 2020-04-16 12:14:29 EDT; 28s ago
Docs: man:httpd.service(8)
Cntrl PID: 1102 (sleep)
Tasks: 1 (limit: 38363)
Memory: 260.0K
CPU: 2ms
CGroup: /system.slice/httpd.service
└─1102 /bin/sleep 30
Apr 16 12:14:29 yorktown.both.org systemd[1]: Starting The Apache HTTP Server...
Apr 16 12:15:01 yorktown.both.org systemd[1]: Started The Apache HTTP Server.
[root@yorktown ~]#
```
这个命令显示了 30 秒延迟过后 HTTPD 服务的状态。该服务已经启动并正常运行。
```
[root@yorktown ~]# systemctl status httpd
● httpd.service - The Apache HTTP Server
Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/httpd.service.d
└─override.conf
/usr/lib/systemd/system/httpd.service.d
└─php-fpm.conf
Active: active (running) since Thu 2020-04-16 12:15:01 EDT; 1min 18s ago
Docs: man:httpd.service(8)
Process: 1102 ExecStartPre=/bin/sleep 30 (code=exited, status=0/SUCCESS)
Main PID: 1567 (httpd)
Status: "Total requests: 0; Idle/Busy workers 100/0;Requests/sec: 0; Bytes served/sec: 0 B/sec"
Tasks: 213 (limit: 38363)
Memory: 21.8M
CPU: 82ms
CGroup: /system.slice/httpd.service
├─1567 /usr/sbin/httpd -DFOREGROUND
├─1569 /usr/sbin/httpd -DFOREGROUND
├─1570 /usr/sbin/httpd -DFOREGROUND
├─1571 /usr/sbin/httpd -DFOREGROUND
└─1572 /usr/sbin/httpd -DFOREGROUND
Apr 16 12:14:29 yorktown.both.org systemd[1]: Starting The Apache HTTP Server...
Apr 16 12:15:01 yorktown.both.org systemd[1]: Started The Apache HTTP Server.
```
我本来可以实验下更短的延迟时间是否也能奏效,但是我的系统并不用那么严格,所以我觉得不这样做。目前系统的工作状态很可靠,所以我很高兴。
因为我收集了所有这些信息,我将其作为 Bug[1825554](https://bugzilla.redhat.com/show_bug.cgi?id=1825554) 报告给红帽 Bugzilla。我相信报告 Bug 比抱怨 Bug 更有有用。
### 更好的解决方案
把这个问题作为 bug 上报几天后,我收到了回复,表示 systemd 只是一个管理工具,如果 httpd 需要在满足某些要求之后被拉起,需要在单元文件中表达出来。这个回复指引我去查阅 `httpd.service` 的手册页。我希望我能早点发现这个,因为它是比我自己想出的更优秀的解决方案。这种方案明确的针对了前置目标单元,而不仅仅是随机延迟。
来自 [httpd.service 手册页](https://www.mankier.com/8/httpd.service#Description-Starting_the_service_at_boot_time):
>
> **在启动时开启服务**
>
>
> `httpd.service` 和 `httpd.socket` 单元默认是 *禁用* 的。为了在启动阶段开启 httpd 服务,执行:`systemctl enable httpd.service`。在默认配置中,httpd 守护进程会接受任何配置好的 IPv4 或 IPv6 地址的 80 口上的连接(如果安装了 mod\_ssl,就会接受 443 端口上的 TLS 连接)。
>
>
> 如果 httpd 被配置成依赖任一特定的 IP 地址(比如使用 `Listen` 指令),该地址可能只在启动阶段可用,又或者 httpd 依赖其他服务(比如数据库守护进程),那么必须配置该服务,以确保正确的启动顺序。
>
>
> 例如,为了确保 httpd 在所有配置的网络接口配置完成之后再运行,可以创建一个带有以下代码段的 drop-in 文件(如上述):
>
>
>
> ```
> [Unit]
> After=network-online.target
> Wants=network-online.target
>
> ```
>
>
我仍然觉得这是个 bug,因为在 `httpd.conf` 配置文件中使用 Listen 指令是很常见的,至少在我的经验中。我一直在使用 Listen 指令,即使在只有一个 IP 地址的主机上,在多个网卡和 IP 地址的机器上这显然也是有必要的。在 `/usr/lib/systemd/system/httpd.service` 默认配置文件中加入上述几行,对不使用 `Listen` 指令的不会造成问题,对使用 `Listen` 指令的则会规避这个问题。
同时,我将使用建议的方法。
### 下一步
本文描述了一个我在服务器上启动 Apache HTTPD 服务时遇到的一个问题。它指引你了解我在解决这个问题上的思路,并说明了我是如何使用 systemd 来协助解决问题。我也介绍了我用 systemd 实现的规避方法,以及我按照我的 bug 报告得到的更好的解决方案。
如我在开头处提到的那样,这有很大可能是一个 systemd 的问题,特别是 httpd 启动的配置问题。尽管如此,systemd 还是提供了工具让我找到了问题的可能来源,并制定和实现了规避方案。两种方案都没有真正令我满意地解决问题。目前,这个问题根源依旧存在,必须要解决。如果只是在 `/usr/lib/systemd/system/httpd.service` 文件中添加推荐的代码,那对我来说是可行的。
在这个过程中我发现了一件事,我需要了解更多关于定义服务启动顺序的知识。我会在下一篇文章中探索这个领域,即本系列的第五篇。
### 资源
网上有大量的关于 systemd 的参考资料,但是大部分都有点简略、晦涩甚至有误导性。除了本文中提到的资料,下列的网页提供了跟多可靠且详细的 systemd 入门信息。
* Fedora 项目有一篇切实好用的 [systemd 入门](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html),它囊括了几乎所有你需要知道的关于如何使用 systemd 配置、管理和维护 Fedora 计算机的信息。
* Fedora 项目也有一个不错的 [备忘录](https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet),交叉引用了过去 SystemV 命令和 systemd 命令做对比。
* 关于 systemd 的技术细节和创建这个项目的原因,请查看 [Freedesktop.org](http://Freedesktop.org) 上的 [systemd 描述](http://www.freedesktop.org/wiki/Software/systemd)。
* [Linux.com](http://Linux.com) 的“更多 systemd 的乐趣”栏目提供了更多高级的 systemd [信息和技巧](https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/)。
此外,还有一系列深度的技术文章,是由 systemd 的设计者和主要开发者 Lennart Poettering 为 Linux 系统管理员撰写的。这些文章写于 2010 年 4 月至 2011 年 9 月间,但它们现在和当时一样具有现实意义。关于 systemd 及其生态的许多其他好文章都是基于这些文章:
* [Rethinking PID 1](http://0pointer.de/blog/projects/systemd.html)
* [systemd for Administrators,Part I](http://0pointer.de/blog/projects/systemd-for-admins-1.html)
* [systemd for Administrators,Part II](http://0pointer.de/blog/projects/systemd-for-admins-2.html)
* [systemd for Administrators,Part III](http://0pointer.de/blog/projects/systemd-for-admins-3.html)
* [systemd for Administrators,Part IV](http://0pointer.de/blog/projects/systemd-for-admins-4.html)
* [systemd for Administrators,Part V](http://0pointer.de/blog/projects/three-levels-of-off.html)
* [systemd for Administrators,Part VI](http://0pointer.de/blog/projects/changing-roots)
* [systemd for Administrators,Part VII](http://0pointer.de/blog/projects/blame-game.html)
* [systemd for Administrators,Part VIII](http://0pointer.de/blog/projects/the-new-configuration-files.html)
* [systemd for Administrators,Part IX](http://0pointer.de/blog/projects/on-etc-sysinit.html)
* [systemd for Administrators,Part X](http://0pointer.de/blog/projects/instances.html)
* [systemd for Administrators,Part XI](http://0pointer.de/blog/projects/inetd.html)
---
via: <https://opensource.com/article/20/5/systemd-troubleshooting-tool>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tt67wq](https://github.com/tt67wq) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,454 | 你使用过 Python 3.6 中针对文件系统的这个神奇方法吗? | https://opensource.com/article/21/5/python-36-features | 2021-06-03T16:44:11 | [
"Python"
] | https://linux.cn/article-13454-1.html |
>
> 探索 os.fspath 和其他两个未被充分利用但仍然有用的 Python 特性。
>
>
>

这是 Python 3.x 首发特性系列文章中的第七篇。Python 3.6 首次发布于 2016 年,尽管它已经发布了一段时间,但它引入的许多特性都没有得到充分利用,而且相当酷。下面是其中的三个。
### 分隔数字常数
快回答哪个更大,`10000000` 还是 `200000`?你在看代码时能正确回答吗?根据当地的习惯,在写作中,你会用 10,000,000 或 10.000.000 来表示第一个数字。问题是,Python 使用逗号和句号是用于其他地方。
幸运的是,从 Python 3.6 开始,你可以使用下划线来分隔数字。这在代码中和使用字符串的 `int()` 转换器时都可以使用:
```
import math
math.log(10_000_000) / math.log(10)
```
```
7.0
```
```
math.log(int("10_000_000")) / math.log(10)
```
```
7.0
```
### Tau 是对的
45 度角用弧度表示是多少?一个正确的答案是 `π/4`,但这有点难记。记住 45 度角是一个八分之一的转角要容易得多。正如 [Tau Manifesto](https://tauday.com/tau-manifesto) 所解释的,`2π`,称为 `Τ`,是一个更自然的常数。
在 Python 3.6 及以后的版本中,你的数学代码可以使用更直观的常数:
```
print("Tan of an eighth turn should be 1, got", round(math.tan(math.tau/8), 2))
print("Cos of an sixth turn should be 1/2, got", round(math.cos(math.tau/6), 2))
print("Sin of a quarter turn should be 1, go", round(math.sin(math.tau/4), 2))
```
```
Tan of an eighth turn should be 1, got 1.0
Cos of an sixth turn should be 1/2, got 0.5
Sin of a quarter turn should be 1, go 1.0
```
### os.fspath
从 Python 3.6 开始,有一个神奇的方法表示“转换为文件系统路径”。当给定一个 `str` 或 `bytes` 时,它返回输入。
对于所有类型的对象,它寻找 `__fspath__` 方法并调用它。这允许传递的对象是“带有元数据的文件名”。
像 `open()` 或 `stat` 这样的普通函数仍然能够使用它们,只要 `__fspath__` 返回正确的东西。
例如,这里有一个函数将一些数据写入一个文件,然后检查其大小。它还将文件名记录到标准输出,以便追踪:
```
def write_and_test(filename):
print("writing into", filename)
with open(filename, "w") as fpout:
fpout.write("hello")
print("size of", filename, "is", os.path.getsize(filename))
```
你可以用你期望的方式来调用它,用一个字符串作为文件名:
```
write_and_test("plain.txt")
```
```
writing into plain.txt
size of plain.txt is 5
```
然而,可以定义一个新的类,为文件名的字符串表示法添加信息。这样可以使日志记录更加详细,而不改变原来的功能:
```
class DocumentedFileName:
def __init__(self, fname, why):
self.fname = fname
self.why = why
def __fspath__(self):
return self.fname
def __repr__(self):
return f"DocumentedFileName(fname={self.fname!r}, why={self.why!r})"
```
用 `DocumentedFileName` 实例作为输入运行该函数,允许 `open` 和 `os.getsize` 函数继续工作,同时增强日志:
```
write_and_test(DocumentedFileName("documented.txt", "because it's fun"))
```
```
writing into DocumentedFileName(fname='documented.txt', why="because it's fun")
size of DocumentedFileName(fname='documented.txt', why="because it's fun") is 5
```
### 欢迎来到 2016 年
Python 3.6 是在五年前发布的,但是在这个版本中首次出现的一些特性非常酷,而且没有得到充分利用。如果你还没使用,那么将他们添加到你的工具箱中。
---
via: <https://opensource.com/article/21/5/python-36-features>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the seventh in a series of articles about features that first appeared in a version of Python 3.x. Python 3.6 was first released in 2016, and even though it has been out for a while, many of the features it introduced are underused and pretty cool. Here are three of them.
## Separated numeral constants
Quick, which is bigger, `10000000`
or `200000`
? Would you be able to answer correctly while scanning through code? Depending on local conventions, in prose writing, you would use 10,000,000 or 10.000.000 for the first number. The trouble is, Python uses commas and periods for other reasons.
Fortunately, since Python 3.6, you can use underscores to separate digits. This works both directly in code and when using the `int()`
convertor from strings:
```
import math
math.log(10_000_000) / math.log(10)
```
` 7.0`
`math.log(int("10_000_000")) / math.log(10)`
` 7.0`
## Tau is right
What's a 45-degree angle expressed in radians? One correct answer is `π/4`
, but that's a little hard to remember. It's much easier to remember that a 45-degree angle is an eighth of a turn. As the [Tau Manifesto](https://tauday.com/tau-manifesto) explains, `2π`
, called `Τ`
, is a more natural constant.
In Python 3.6 and later, your math code can use the more intuitive constant:
```
print("Tan of an eighth turn should be 1, got", round(math.tan(math.tau/8), 2))
print("Cos of an sixth turn should be 1/2, got", round(math.cos(math.tau/6), 2))
print("Sin of a quarter turn should be 1, go", round(math.sin(math.tau/4), 2))
```
```
Tan of an eighth turn should be 1, got 1.0
Cos of an sixth turn should be 1/2, got 0.5
Sin of a quarter turn should be 1, go 1.0
```
## os.fspath
Starting in Python 3.6, there is a magic method that represents "convert to a filesystem path." When given an `str`
or `bytes`
, it returns the input.
For all types of objects, it looks for an `__fspath__`
method and calls it. This allows passing around objects that are "filenames with metadata."
Normal functions like `open()`
or `stat`
will still be able to use them, as long as `__fspath__`
returns the right thing.
For example, here is a function that writes some data into a file and then checks its size. It also logs the file name to standard output for tracing purposes:
```
def write_and_test(filename):
print("writing into", filename)
with open(filename, "w") as fpout:
fpout.write("hello")
print("size of", filename, "is", os.path.getsize(filename))
```
You can call it the way you would expect, with a string for a filename:
`write_and_test("plain.txt")`
```
writing into plain.txt
size of plain.txt is 5
```
However, it is possible to define a new class that adds information to the string representation of filenames. This allows the logging to be more detailed, without changing the original function:
```
class DocumentedFileName:
def __init__(self, fname, why):
self.fname = fname
self.why = why
def __fspath__(self):
return self.fname
def __repr__(self):
return f"DocumentedFileName(fname={self.fname!r}, why={self.why!r})"
```
Running the function with a `DocumentedFileName`
instance as input allows the `open`
and `os.getsize`
functions to keep working while enhancing the logs:
`write_and_test(DocumentedFileName("documented.txt", "because it's fun"))`
```
writing into DocumentedFileName(fname='documented.txt', why="because it's fun")
size of DocumentedFileName(fname='documented.txt', why="because it's fun") is 5
```
## Welcome to 2016
Python 3.6 was released about five years ago, but some of the features that first showed up in this release are cool—and underused. Add them to your toolkit if you haven't already.
## Comments are closed. |
13,456 | 在 2021 年你需要知道 Quarkus 些什么? | https://opensource.com/article/21/5/quarkus | 2021-06-04T22:18:23 | [
"Quarkus"
] | https://linux.cn/article-13456-1.html |
>
> Quarkus 受益于 20 多年的 Java 开发历史,使开发应用变得更快、更容易。
>
>
>

在云上发布服务部分是为了通过简单可靠的方式为用户和开发者提供对这些服务的便捷访问。与在线应用对接的最流行的方法之一是通过应用编程接口(API),这是一个花哨的术语,意味着你允许用户通过代码与你的应用进行互动。
API 的概念很重要,因为它可以帮助其他人在你的应用基础上进行开发。假设你设计了一个网站,当用户点击一个按钮时返回一个随机数字。通常情况下,这需要用户打开你的网站并点击一个按钮。网站可能是有用的,但只是在一定程度上。如果你包含一个 API,用户可以直接向你的服务器发送一个信号,要求一个随机数,或者他们可以自己编程,“调用”你的服务器来获取一个数字,而不需要点击或手动交互。开发者可以使用你的随机数作为游戏的数值,或作为密码生成器的一部分,或其他任何开发者需要随机数的地方(总是有的)。一个好的 API 可以解锁你的应用,让其他人使用你的代码结果,本质上,将你在网络上的工作转变为一个软件库。
### 什么是 Quarkus?
[Quarkus](https://quarkus.io) 是一个原生 Kubernetes Java 栈,为无服务器应用交付而设计。与有 20 年历史的 Java 相比,[Quarkus](https://developers.redhat.com/blog/2019/03/07/quarkus-next-generation-kubernetes-native-java-framework/) 相对年轻,但受益于这 20 年的发展,用该项目的话说,是 “超音速的亚原子 Java”。可能没有人知道这句话的确切含义,但你肯定可以通过一下午使用 Quarkus 来感受到它对你的开发生活的意义。
Quarkus 让你用一个有用的 API 开发应用,几乎不需要配置,也不用担心启动一个复杂的环境。你不需要学习关于云计算或边缘计算的所有知识,就可以学习并擅长使用 Quarkus。了解 Quarkus 可以使你的开发更快,它可以帮助你为现代计算机网络制作灵活的应用。
下面是我们最近的一些涉及 Quarkus 的文章。
### 开始使用 Quarkus
在 Saumya Singh 的《[如何创建你的第一个 Quarkus 应用](https://opensource.com/article/21/4/quarkus-tutorial)》中,你可以了解 Quarkus 和无服务器交付的好处,并在大约 10 分钟内创建了一个简单的演示应用。事实上,*10* 分钟以内更准确,因为在 Maven 和 Quarkus 之间,几乎没有你想象中的那么多设置。它几乎感觉不到像 Java 一样的坏处,而感觉像 Java 一样好。
### 边缘开发
Linux 是创建物联网 (IoT) [边缘应用](https://opensource.com/article/17/9/what-edge-computing) 的一个流行平台。这有很多原因,包括安全性、编程语言和开发模型的广泛选择以及协议支持。不出所料,Quarkus 对物联网的处理非常好。Quarkus 的内存效率高,启动快,并且有快速的运行时,所以它不仅是物联网的可行解决方案,而且是理想的解决方案。你可以通过 Daniel Oh 的《[在 Linux 上使用开源的边缘开发入门](https://opensource.com/article/21/5/edge-quarkus-linux)》来开始使用 Quarkus 和物联网。
### Quarkus 和 VS Code
当你处理代码时,一个集成开发环境(IDE)会有很大的不同。微软的开源 [VS Code](https://github.com/microsoft/vscode)(或无品牌标志的 [VSCodium](https://opensource.com/article/20/6/open-source-alternatives-vs-code))是一个伪装成 IDE 的流行文本编辑器(或者说是伪装成文本编辑器的 IDE?),它有很多扩展,可以使它成为几乎任何编程语言的专门环境。如果你正在使用或考虑使用 VS Code,那么请阅读 Daniel Oh 的《[Quarkus in VS Code](https://opensource.com/article/20/4/java-quarkus-vs-code)》使用指南,了解一些关于 Maven、Quarkus 和 VS Code 如何协同工作的专业技巧。
### 获得 Quarkus
使用 Quarkus 开发,可以像 Python 一样简单地设置环境,但它为你提供了强大的 Java 语言及其众多的库。它是进入云计算、[Knative](https://www.openshift.com/learn/topics/quarkus) 和边缘计算的一个重要入口。获取 Quarkus 并开始编码。
---
via: <https://opensource.com/article/21/5/quarkus>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Part of publishing services on the cloud is providing users and developers easy access to those services through easy and reliable means. One of the most popular methods of interfacing with applications online is through an application programming interface (API), a fancy term that means you allow users to interact with your app through code.
The API concept is significant because it helps others build upon your app. Suppose you design a website that returns a random number when a user clicks a button. Normally, that would require a user to navigate to your site and click a button. The site might be useful, but only to a point. If you included an API, a user could just send a signal to your server requesting a random number, or they could program something of their own that "calls" your server for a number with no clicking or manual interaction required. A developer could use your random number as a value for a game or as part of a passphrase generator or whatever else developers need random numbers for (there's always something). A good API unlocks your application for others to use your code's results, transforming your work on the web into, essentially, a software library.
## What is Quarkus?
[Quarkus](https://quarkus.io) is a Kubernetes Native Java stack designed for serverless application delivery. Compared to Java, which is 20 years old, [Quarkus is relatively young](https://developers.redhat.com/blog/2019/03/07/quarkus-next-generation-kubernetes-native-java-framework/) but benefits from those two decades of development to produce, in the project's terms, "Supersonic Subatomic Java." Probably nobody knows exactly what that phrase means, but you can certainly get a feel for what Quarkus can mean to your development life just by using it for an afternoon.
Quarkus lets you develop applications with a useful API with little to no configuration and without worrying about bootstrapping a complex environment. You don't have to learn everything there is to know about the cloud or about edge computing to learn and excel at Quarkus. Getting to know Quarkus makes your development faster, and it helps you produce flexible applications for the modern computer network.
Here are some of our recent articles covering Quarkus.
## Getting started with Quarkus
In Saumya Singh's * How to create your first Quarkus application*, you learn about the benefits of Quarkus and serverless delivery and create a simple demo application in about 10 minutes. In fact,
*under*10 minutes is more accurate because between Maven and Quarkus, there's not nearly as much setup as you might expect. It barely feels like Java (I mean that in the bad way), but it feels so much like Java (and I mean that in the good way.)
## Edge development
Linux is a popular platform for creating Internet of Things (IoT) [edge applications](https://opensource.com/article/17/9/what-edge-computing). There are many reasons for this, including security, the wide choices for programming languages and development models, and protocol support. Unsurprisingly, Quarkus handles IoT really well. Quarkus is efficient with memory, is quick to launch, and uses a fast runtime, so it's not just a viable solution for IoT; it's ideal. You can get started with Quarkus and the Internet of Things with Daniel Oh's * Getting started with edge development on Linux using open source*.
## Quarkus and VS Code
An integrated development environment (IDE) makes all the difference when you're working on code. Microsoft's open source [VS Code](https://github.com/microsoft/vscode) (or the non-branded [VSCodium](https://opensource.com/article/20/6/open-source-alternatives-vs-code)) is a popular text editor disguised as an IDE (or is it an IDE disguised as a text editor?) with lots of extensions that can make it into a specialized environment for nearly any programming language. If you're using, or considering using, VS Code, then read Daniel Oh's walkthrough for using [Quarkus in VS Code](https://opensource.com/article/20/4/java-quarkus-vs-code) for some pro tips on how Maven, Quarkus, and VS Code work together.
## Get Quarkus
Developing with Quarkus makes setting up your environment as easy as Python, but it provides you with the power of the Java language and its many, many libraries. It's a great entry point to the cloud, [Knative](https://www.openshift.com/learn/topics/quarkus), and edge computing. Get Quarkus and get coding.
## Comments are closed. |
13,459 | 用这个 Python 3.7 的特性来切片无限生成器 | https://opensource.com/article/21/5/python-37-features | 2021-06-05T23:10:07 | [
"Python"
] | https://linux.cn/article-13459-1.html |
>
> 了解更多关于这个和其他两个未被充分利用但仍然有用的 Python 特性。
>
>
>

这是关于 Python 3.x 首发特性系列文章的第八篇。[Python 3.7](https://opensource.com/downloads/cheat-sheet-python-37-beginners) 于 2018 年首次发布,尽管它已经发布了几年,但它引入的许多特性都未被充分利用,而且相当酷。下面是其中的三个。
### 注解推迟评估
在 Python 3.7 中,只要激活了正确的 `__future__` 标志,注解在运行时就不会被评估:
```
from __future__ import annotations
def another_brick(wall: List[Brick], brick: Brick) -> Education:
pass
```
```
another_brick.__annotations__
```
```
{'wall': 'List[Brick]', 'brick': 'Brick', 'return': 'Education'}
```
它使递归类型(指向自己的类)和其他有趣的事情成为了可能。然而,这意味着如果你想做自己的类型分析,你需要明确地使用 `ast`。
```
import ast
raw_type = another_brick.__annotations__['wall']
[parsed_type] = ast.parse(raw_type).body
```
```
subscript = parsed_type.value
f"{subscript.value.id}[{subscript.slice.id}]"
```
```
'List[Brick]'
```
### itertools.islice 支持 **index**
Python 中的序列切片长期以来一直接受各种 *类 int 对象*(具有 `__index__()` 的对象)作为有效的切片部分。然而,直到 Python 3.7,`itertools.islice`,即核心 Python 中对无限生成器进行切片的唯一方法,才获得了这种支持。
例如,现在可以用 `numpy.short` 大小的整数来切片无限生成器:
```
import numpy
short_1 = numpy.short(1)
short_3 = numpy.short(3)
short_1, type(short_1)
```
```
(1, numpy.int16)
```
```
import itertools
list(itertools.islice(itertools.count(), short_1, short_3))
```
```
[1, 2]
```
### functools.singledispatch() 注解注册
如果你认为 [singledispatch](https://opensource.com/article/19/5/python-singledispatch) 已经很酷了,你错了。现在可以根据注解来注册了:
```
import attr
import math
from functools import singledispatch
@attr.s(auto_attribs=True, frozen=True)
class Circle:
radius: float
@attr.s(auto_attribs=True, frozen=True)
class Square:
side: float
@singledispatch
def get_area(shape):
raise NotImplementedError("cannot calculate area for unknown shape",
shape)
@get_area.register
def _get_area_square(shape: Square):
return shape.side ** 2
@get_area.register
def _get_area_circle(shape: Circle):
return math.pi * (shape.radius ** 2)
get_area(Circle(1)), get_area(Square(1))
```
```
(3.141592653589793, 1)
```
### 欢迎来到 2017 年
Python 3.7 大约是四年前发布的,但是在这个版本中首次出现的一些特性非常酷,而且没有得到充分利用。如果你还没使用,那么将它们添加到你的工具箱中。
---
via: <https://opensource.com/article/21/5/python-37-features>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the eighth in a series of articles about features that first appeared in a version of Python 3.x. [Python 3.7](https://opensource.com/downloads/cheat-sheet-python-37-beginners) was first released in 2018, and even though it has been out for a few years, many of the features it introduced are underused and pretty cool. Here are three of them.
## Postponed evaluation of annotations
In Python 3.7, as long as the right `__future__`
flags are activated, annotations are not evaluated during runtime:
```
from __future__ import annotations
def another_brick(wall: List[Brick], brick: Brick) -> Education:
pass
```
`another_brick.__annotations__`
` {'wall': 'List[Brick]', 'brick': 'Brick', 'return': 'Education'}`
This allows recursive types (classes that refer to themselves) and other fun things. However, it means that if you want to do your own type analysis, you need to use `ast`
explictly:
```
import ast
raw_type = another_brick.__annotations__['wall']
[parsed_type] = ast.parse(raw_type).body
```
```
subscript = parsed_type.value
f"{subscript.value.id}[{subscript.slice.id}]"
```
` 'List[Brick]'`
## itertools.islice supports __index__
Sequence slices in Python have long accepted all kinds of *int-like objects* (objects that have `__index__()`
) as valid slice parts. However, it wasn't until Python 3.7 that `itertools.islice`
, the only way in core Python to slice infinite generators, gained this support.
For example, now it is possible to slice infinite generators by `numpy.short`
-sized integers:
```
import numpy
short_1 = numpy.short(1)
short_3 = numpy.short(3)
short_1, type(short_1)
```
` (1, numpy.int16)`
```
import itertools
list(itertools.islice(itertools.count(), short_1, short_3))
```
` [1, 2]`
## functools.singledispatch() annotation registration
If you thought [singledispatch](https://opensource.com/article/19/5/python-singledispatch) couldn't get any cooler, you were wrong. Now it is possible to register based on annotations:
```
import attr
import math
from functools import singledispatch
@attr.s(auto_attribs=True, frozen=True)
class Circle:
radius: float
@attr.s(auto_attribs=True, frozen=True)
class Square:
side: float
@singledispatch
def get_area(shape):
raise NotImplementedError("cannot calculate area for unknown shape",
shape)
@get_area.register
def _get_area_square(shape: Square):
return shape.side ** 2
@get_area.register
def _get_area_circle(shape: Circle):
return math.pi * (shape.radius ** 2)
get_area(Circle(1)), get_area(Square(1))
```
` (3.141592653589793, 1)`
## Welcome to 2017
Python 3.7 was released about four years ago, but some of the features that first showed up in this release are cool—and underused. Add them to your toolkit if you haven't already.
## Comments are closed. |
13,461 | 在 Linux 终端将图像转换成 ASCII 艺术 | https://itsfoss.com/ascii-image-converter/ | 2021-06-06T21:08:00 | [
"ASCII"
] | https://linux.cn/article-13461-1.html | 
想在 Linux 终端中做一些有趣的事情吗?把一张普通的图片转换成 ASCII 艺术怎么样?
你知道 [什么是 ASCII](https://www.computerhope.com/jargon/a/ascii.htm) 么?它是一个标准,在 8 位码中的 256 个空位上分配字母、数字和其他字符。ASCII 艺术是一个由可打印的 ASCII 字符组成的图形。基本上,它是由一堆字母、数字和特殊字符组成的。
你可能见过有人 [以 ASCII 格式显示他们发行版的标志](https://itsfoss.com/display-linux-logo-in-ascii/),像这样:

这很酷,对吗?把一张普通的图片转换成 ASCII 艺术怎么样?这就是在这篇文章中要探讨的问题。
### Ascii Image Converter
顾名思义,[Ascii Image Converter](https://github.com/TheZoraiz/ascii-image-converter) 是一个将图片转换为 ASCII 艺术的工具。它是一个用 Go 语言编写的基于命令行的工具,它打印出提供给它的图片的ASCII版本。
你可能认不出我,但下面的图片中的 ASCII 版就是我。那是我的 8 位头像。

该工具支持以下格式的输入图像:
* JPEG/JPG
* PNG
* BMP
* WEBP
* TIFF/TIF
让我们看看如何安装和使用它。
### 在 Linux 上安装 Ascii Image Converter
这个有趣的工具也可以在 Windows 上使用,但我不打算这么做。在本教程中,让我们坚持使用 Linux。
如果你的发行版中启用了 [Snap](https://itsfoss.com/enable-snap-support-linux-mint/),你可以用下面的命令轻松地安装它的 snap 包:
```
sudo snap install ascii-image-converter
```
你也可以从它的发布页面下载 Linux 的可执行文件,并把可执行文件放在 `/usr/local/bin/` 目录下。这样,你就能像普通的 Linux 命令一样运行它。如果你想知道为什么会这样,请了解一下 [Linux 目录层次结构](https://linuxhandbook.com/linux-directory-structure/)。
### 使用 Ascii Image Converter
使用很简单。安装后,你只需要提供你想转换的图像的路径。
```
ascii-image-converter path_to_image
```
你也可以提供图片的 URL,直接从网上把图片转换成 ASCII。
这是我的个人资料照片转换成 ASCII 格式。我把我的原始照片放在这里供大家参考。

你也可以转换成彩色的 ASCII。
```
ascii-image-converter -C path_to_image
```

你可以通过提供它们的路径将多个图像转换为 ASCII。它将在终端显示器上一个接一个地打印 ASCII 版本。
也有一个选项可以保存生成的 ASCII 艺术。在旧版本中,它只会被保存为文本文件,而不是图像。开发者 Zoraiz Hassan 发布了一个新版本,现在该工具默认将生成的 ASCII 图像保存为 PNG 格式。
```
ascii-image-converter path_to_image -s .
```
还有一些可用的选项,比如给输出一个特定的尺寸,使用更多的 ASCII 字符,或者使用你自己的字符集来打印 ASCII 艺术。你可以在 [项目的仓库](https://github.com/TheZoraiz/ascii-image-converter) 上阅读相关内容。
### 喜欢它吗?
你喜欢更多的 ASCII 相关的东西吗?那么 [在 Linux 上玩 ASCII 游戏](https://itsfoss.com/best-ascii-games/) 怎么样?是的,你完全可以这么做。
如果你喜欢在终端做实验,你可能会喜欢这个工具。虽然我不知道 ASCII 转换后的图像能有什么好的实际用途。有什么想法吗?
---
via: <https://itsfoss.com/ascii-image-converter/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Want to do some fun stuff in the Linux terminal? How about converting a regular image into an ASCII art?
You know [what’s ASCII](https://www.computerhope.com/jargon/a/ascii.htm?ref=itsfoss.com)? It’s a standard that assigns letters, numbers and other characters in the 256 slots available in the 8-bit code. The ASCII art is a graphics composed of the printable ASCII characters. Basically, it is composed of a bunch of letters, numbers and special characters.
You might have seen people [displaying their distribution’s logo in ASCII format](https://itsfoss.com/display-linux-logo-in-ascii/) like this:
That’s cool, right? How about converting a normal picture into ASCII art? That’s what you are going to explore in this article.
## Ascii Image Converter
As the name suggests, [Ascii Image Converter](https://github.com/TheZoraiz/ascii-image-converter?ref=itsfoss.com) is a tool that converts an image into ASCII art. It is a command line based tool written in Go and it prints the ASCII version of the image supplied to it.
You probably won’t recognize me, but that’s me in ASCII in the image below. That’s my 8-bit avatar.
The tool supports input images in the following format:
- JPEG/JPG
- PNG
- BMP
- WEBP
- TIFF/TIF
Let’s see about installing and using it.
## Installing Ascii Image Converter on Linux
This nifty tool is also available on Windows but I am not going that way. Let’s stick to Linux in this tutorial.
If you have [Snap enabled in your distribution](https://itsfoss.com/enable-snap-support-linux-mint/), you can easily install its snap package using the following command:
`sudo snap install ascii-image-converter`
You may also download the Linux executable file from its release page and put the executable in the /usr/local/bin/ directory. This way, you’ll be able to run it like a regular Linux command. If you wonder why so, please learn about [Linux directory hierarchy](https://linuxhandbook.com/linux-directory-structure/?ref=itsfoss.com).
## Using Ascii Image Converter
The usage is simple. Once installed, you just have to provide the path of the image you want to convert.
`ascii-image-converter path_to_image`
You may also provide the URL of the image to convert an image into ASCII directly from the web.
Here is my profile picture converted into ASCII. I have put my original photo for the reference.
You may also have a colored ASCII conversion.
`ascii-image-converter -C path_to_image`
You may convert multiple images into ASCII by providing their paths. It will print the ASCII version one after another on the terminal display.
There is also an option to save the generated ASCII art. In the older version, it would be saved only as a text file, not as an image. The developer, Zoraiz Hassan, released a new version and now the tool saves the generated ASCII image in PNG format by default.
`ascii-image-converter path_to_image -s .`
There are a few more options available such as giving the output a specific dimension, use more ASCII characters, or use your own set of characters for printing the ASCII art. You can read about it on the [project’s repository](https://github.com/TheZoraiz/ascii-image-converter?ref=itsfoss.com).
## Like it?
Would you like [more ASCII stuff in the Linux terminal](https://itsfoss.com/ascii-art-linux-terminal/)? How about [playing ASCII games on Linux](https://itsfoss.com/best-ascii-games/)? Yes, you can totally do that.
If you like experimenting in the terminal, you may like this tool. However, I wonder what could be a good practical use of an ASCII-converted image. Any ideas? |
13,462 | 使用开源工具识别 Linux 的性能瓶颈 | https://opensource.com/article/21/3/linux-performance-bottlenecks | 2021-06-07T08:00:00 | [
"性能"
] | https://linux.cn/article-13462-1.html |
>
> 不久前,识别硬件瓶颈还需要深厚的专业知识。今天的开源 GUI 性能监视器使它变得相当简单。
>
>
>

计算机是一个集成的系统,它的性能取决于最慢的硬件组件。如果一个组件的能力比其他组件差,性能落后而不能跟上,它就会拖累你的整个系统。这就是一个 *性能瓶颈*。消除一个严重的瓶颈可以使你的系统飞起来。
本文解释了如何识别 Linux 系统中的硬件瓶颈。这些技术同时适用于个人的电脑和服务器。我强调的是个人电脑 —— 我不会涉及局域网管理或数据库系统等领域的服务器特定的瓶颈。这些通常涉及专门的工具。
我也不会多谈解决方案。这对本文来说是个太大的话题。相反,我将写一篇关于性能调整的后续文章。
我将只使用开源的图形用户界面(GUI)工具来完成这项工作。大多数关于 Linux 瓶颈的文章都相当复杂。它们使用专门的命令,并深入研究神秘的细节。
开源提供的 GUI 工具使得识别许多瓶颈变得简单。我的目标是给你一个快速、简单的方法,你可以在任何地方使用。
### 从哪里开始
一台计算机由六个关键的硬件资源组成。
* 处理器
* 内存
* 存储器
* USB 端口
* 互联网连接
* 图形处理器
如果任何一个资源表现不佳,就会产生一个性能瓶颈。为了识别瓶颈,你必须监测这六种资源。
开源提供了大量的工具来完成这项工作。我会使用 [GNOME 系统监视器](https://wiki.gnome.org/Apps/SystemMonitor)。它的输出很容易理解,而且你可以在大多数软件库中找到它。
启动它并点击“资源”标签。你可以马上发现许多性能问题。

*图 1. 系统监控器发现问题。(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
在“资源”面板上显示三个部分:CPU 历史、内存和交换历史,以及网络历史。一眼就能看出你的处理器是否不堪负荷了,还是你的电脑没有内存了,抑或你的网络带宽被用光了。
我将在下面探讨这些问题。现在,当你的电脑速度变慢时,首先检查系统监视器。它可以立即为你提供最常见的性能问题的线索。
现在让我们来探讨一下如何识别特定方面的瓶颈。
### 如何识别处理器的瓶颈
要发现瓶颈,你必须首先知道你有什么硬件。开源为这个目的提供了几个工具。我喜欢 [HardInfo](https://itsfoss.com/hardinfo/),因为它的屏幕显示很容易阅读,而且广泛流行。
启动 HardInfo。它的“计算机->摘要”面板可以识别你的 CPU 并告诉你它的核心数、线程数和速度。它还能识别你的主板和其他计算机部件。

*图 2. HardInfo 显示了硬件细节。(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
HardInfo 显示,这台计算机有一个物理 CPU 芯片。该芯片包含两个处理器(或称为核心)。每个核心支持两个线程(或称为逻辑处理器)。这就是总共四个逻辑处理器 —— 正是图 1 中系统监控器的 CPU 历史部分所显示的。
当处理器不能在其时间内对请求做出反应时,就会出现 *处理器瓶颈*,说明它们已经很忙了。
当系统监控器显示逻辑处理器的利用率持续在 80% 或 90% 以上时,你就可以确定这一点。这里有一个例子,四个逻辑处理器中有三个被淹没在 100% 的利用率中。这是一个瓶颈,因为它没有留下多少 CPU 用于其他工作。

*图 3. 一个处理器的瓶颈。(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
#### 哪个程序导致了这个问题?
你需要找出是哪个程序在消耗所有的 CPU。点击系统监视器的“进程”标签。然后点击“CPU 百分比”标头,根据它们消耗的 CPU 的多少对进程进行排序。你将看到哪些应用程序正在扼杀你的系统。

*图 4. 识别违规的进程。(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
前三个进程各消耗了 *总 CPU 资源的 24%*。由于有四个逻辑处理器,这意味着每个进程消耗了一整个处理器。这就像图 3 所示。
在“进程”面板上,一个名为“analytical\_AI”的程序被确定为罪魁祸首。你可以在面板上右键单击它,以查看其资源消耗的更多细节,包括内存使用、它所打开的文件、其输入/输出细节,等等。
如果你的登录会话有管理员权限,你可以管理这个进程。你可以改变它的优先级,并停止、继续、结束或杀死它。因此,你可以在这里立即解决你的瓶颈问题。

*图 5. 右键点击一个进程来管理它。(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
如何解决处理瓶颈问题?除了实时管理违规的进程外,你也可以防止瓶颈的发生。例如,你可以用另一个应用程序来代替违规进程,绕过它,改变你使用该应用程序的行为,将该应用程序安排在非工作时间,解决潜在的内存问题,对该应用程序或你的系统软件进行性能调整,或升级你的硬件。这里涉及的内容太多,所以我将在下一篇文章中探讨这些方式。
#### 常见的处理器瓶颈
在用系统监控器监控你的 CPU 时,你会遇到几种常见的瓶颈问题。
有时一个逻辑处理器出现瓶颈,而其他所有的处理器都处于低利用率。这意味着你有一个应用程序,它的代码不够智能,无法利用一个以上的逻辑处理器,而且它已经把正在使用的那个处理器耗尽了。这个应用程序完成的时间将比使用更多的处理器要长。但另一方面,至少它能让你的其他处理器腾出手来做别的工作,而不会接管你的电脑。
你也可能看到一个逻辑处理器永远停留在 100% 的利用率。要么它非常忙,要么是一个进程被挂起了。判断它是否被挂起的方法是,是看该进程是否从不进行任何磁盘活动(正如系统监视器“进程”面板所显示的那样)。
最后,你可能会注意到,当你所有的处理器都陷入瓶颈时,你的内存也被完全利用了。内存不足的情况有时会导致处理器瓶颈。在这种情况下,你要解决的是根本的内存问题,而不是体现出症状的 CPU 问题。
### 如何识别内存瓶颈
鉴于现代 PC 中有大量的内存,内存瓶颈比以前要少得多。然而,如果你运行内存密集型程序,特别是当你的计算机没有很多的随机存取内存(RAM)时,你仍然可能遇到这些问题。
Linux [使用内存](https://www.networkworld.com/article/3394603/when-to-be-concerned-about-memory-levels-on-linux.html) 既用于程序,也用于缓存磁盘数据。后者加快了磁盘数据的访问速度。Linux 可以在它需要的任何时候回收这些内存供程序使用。
系统监视器的“资源”面板显示了你的总内存和它被使用的程度。在“进程”面板上,你可以看到单个进程的内存使用情况。
下面是系统监控器“资源”面板中跟踪总内存使用的部分。

*图 6. 一个内存瓶颈。(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
在“内存”的右边,你会注意到 [交换空间](https://opensource.com/article/18/9/swap-space-linux-systems)。这是 Linux 在内存不足时使用的磁盘空间。它将内存写入磁盘以继续操作,有效地将交换空间作为你的内存的一个较慢的扩展。
你要注意的两个内存性能问题是:
1. 内存被大量使用,而且你看到交换空间的活动频繁或不断增加。
2. 内存和交换空间都被大量使用。
情况一意味着更慢的性能,因为交换空间总是比内存更慢。你是否认为这是一个性能问题,取决于许多因素(例如,你的交换空间有多活跃、它的速度、你的预期,等等)。我的看法是,对于现代个人电脑来说,交换空间任何超过象征性的使用都是不可接受的。
情况二是指内存和交换空间都被大量使用。这是一个 *内存瓶颈*。计算机变得反应迟钝。它甚至可能陷入一种“咆哮”的状态,在这种状态下,除了内存管理之外,它几乎不能完成其他任务。
上面的图 6 显示了一台只有 2GB 内存的旧电脑。当内存使用量超过 80% 时,系统开始向交换空间写入,响应速度下降了。这张截图显示了内存使用量超过了 90%,而且这台电脑已经无法使用。
解决内存问题的最终答案是要么少用内存,要么多买内存。我将在后续文章中讨论解决方案。
### 如何识别存储瓶颈
如今的存储有固态和机械硬盘等多个品种。设备接口包括 PCIe、SATA、雷电和 USB。无论有哪种类型的存储,你都要使用相同的程序来识别磁盘瓶颈。
从系统监视器开始。它的“进程”面板显示各个进程的输入/输出率。因此,你可以快速识别哪些进程做了最多的磁盘 I/O。
但该工具并不显示每个磁盘的总数据传输率。你需要查看特定磁盘上的总负载,以确定该磁盘是否是一个存储瓶颈。
要做到这一点,使用 [atop](https://opensource.com/life/16/2/open-source-tools-system-monitoring) 命令。它在大多数 Linux 软件库中都有。
只要在命令行提示符下输入 `atop` 即可。下面的输出显示,设备 `sdb` 达到 `busy 101%`。很明显,它已经达到了性能极限,限制了你的系统完成工作的速度。

*图 7. atop 命令识别了一个磁盘瓶颈。(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
注意到其中一个 CPU 有 85% 的时间在等待磁盘完成它的工作(`cpu001 w 85%`)。这是典型的存储设备成为瓶颈的情况。事实上,许多人首先看 CPU 的 I/O 等待时间来发现存储瓶颈。
因此,要想轻松识别存储瓶颈,请使用 `atop` 命令。然后使用系统监视器上的“进程”面板来识别导致瓶颈的各个进程。
### 如何识别 USB 端口的瓶颈
有些人整天都在使用他们的 USB 端口。然而,他们从不检查这些端口是否被最佳地使用。无论你是插入外部磁盘、U 盘,还是其他东西,你都要确认你是否从 USB 连接的设备中获得了最大性能。
这个图表显示了原因。潜在的 USB 数据传输率差异 *很大*。

*图 8. USB 速度变化很大。(Howard Fosdick,根据 [Tripplite](https://www.samsung.com/us/computing/memory-storage/solid-state-drives/) 和 [Wikipedia](https://en.wikipedia.org/wiki/USB) 提供的数字,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
HardInfo 的“USB 设备”标签显示了你的计算机支持的 USB 标准。大多数计算机提供不止一种速度。你怎么知道一个特定端口的速度呢?供应商对它们进行颜色编码,如图表中所示。或者你可以在你的计算机的文档中查找。
要看到你得到的实际速度,可以使用开源的 [GNOME 磁盘](https://wiki.gnome.org/Apps/Disks) 程序进行测试。只要启动 GNOME 磁盘,选择它的“磁盘基准”功能,然后运行一个基准测试。这将告诉你在一个端口插入特定设备时,你将得到的最大实际速度。
你可能会得到不同的端口传输速度,这取决于你将哪个设备插入它。数据速率取决于端口和设备的特定组合。
例如,一个可以以 3.1 速度运行的设备如果使用 2.0 端口就会以 2.0 的速度运行。(而且它不会告诉你它是以较慢的速度运行的!)相反,如果你把一个 USB 2.0 设备插入 3.1 端口,它能工作,但速度是 2.0 的速度。所以要获得快速的 USB,你必须确保端口和设备都支持它。GNOME 磁盘为你提供了验证这一点的方法。
要确定 USB 的处理瓶颈,使用你对固态和硬盘所做的同样程序。运行 `atop` 命令来发现 USB 存储瓶颈。然后,使用系统监视器来获取违规进程的详细信息。
### 如何识别互联网带宽瓶颈
系统监控器的“资源”面板会实时告诉你互联网连接速度(见图 1)。
有 [很好的 Python 工具](https://opensource.com/article/20/1/internet-speed-tests) 可以测试你的最大网速,但你也可以在 [Speedtest](https://www.speedtest.net/)、[Fast.com](https://fast.com/) 和 [Speakeasy](https://www.speakeasy.net/speedtest/) 等网站进行测试。为了获得最佳结果,关闭所有东西,只运行 *速度测试*;关闭你的虚拟私有网络;在一天中的不同时间运行测试;并比较几个测试网站的结果。
然后将你的结果与你的供应商声称的下载和上传速度进行比较。这样,你就可以确认你得到的是你所付费的速度。
如果你有一个单独的路由器,在有和没有它的情况下进行测试。这可以告诉你,你的路由器是否是一个瓶颈。如果你使用 WiFi,在有 WiFi 和没有 WiFi 的情况下进行测试(通过将你的笔记本电脑直接与调制解调器连接)。我经常看到人们抱怨他们的互联网供应商,而实际上他们只是有一个 WiFi 瓶颈,可以自己解决。
如果某些程序正在消耗你的整个互联网连接,你想知道是哪一个。通过使用 `nethogs` 命令找到它。它在大多数软件库中都有。
有一天,我的系统监视器突然显示我的互联网访问量激增。我只是在命令行中输入了 `nethogs`,它立即确定带宽消耗者是 Clamav 防病毒更新。

*图 9. Nethogs 识别带宽用户。(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
### 如何识别图形处理瓶颈
如果你把显示器插在台式电脑后面的主板上,你就在使用 *板载显卡*。如果你把它插在后面的卡上,你就有一个专门的图形子系统。大多数人称它为 *视频卡* 或 *显卡*。对于台式电脑来说,附加显卡通常比主板上的显卡更强大、更昂贵。笔记本电脑总是使用板载显卡。
HardInfo 的“PCI 设备”面板告诉你关于你的图形处理单元(GPU)。它还显示你的专用视频内存的数量(寻找标有“可预取”的内存)。

*图 10. HardInfo提供图形处理信息。(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
CPU 和 GPU [非常密切地](https://www.wepc.com/tips/cpu-gpu-bottleneck/) 一起工作。简而言之,CPU 为 GPU 准备渲染的帧,然后 GPU 渲染这些帧。
当你的 CPU 在等待 100% 繁忙的 GPU 时,就会出现 *GPU 瓶颈*。
为了确定这一点,你需要监控 CPU 和 GPU 的利用率。像 [Conky](https://itsfoss.com/conky-gui-ubuntu-1304/) 和 [Glances](https://opensource.com/article/19/11/monitoring-linux-glances) 这样的开源监控器,如果它们的扩展插件支持你的图形芯片组,就可以做到这一点。
看一下 Conky 的这个例子。你可以看到,这个系统有很多可用的 CPU。GPU 只有 25% 的使用率。想象一下,如果这个 GPU 的数量接近 100%。那么你就会知道 CPU 在等待 GPU,你就会有一个 GPU 的瓶颈。

*图 11. Conky 显示 CPU 和 GPU 的利用率。 (图片来源:[AskUbuntu论坛](https://askubuntu.com/questions/387594/how-to-measure-gpu-usage))*
在某些系统上,你需要一个供应商专属的工具来监控你的 GPU。它们可以从 GitHub 上下载,并在 [GPU 监控和诊断命令行工具](https://www.cyberciti.biz/open-source/command-line-hacks/linux-gpu-monitoring-and-diagnostic-commands/) 这篇文章中有所描述。
### 总结
计算机由一系列集成的硬件资源组成。如果它们中的任何一个在工作量上远远落后于其他资源,就会产生性能瓶颈。这可能会拖累你的整个系统。你需要能够识别和纠正瓶颈,以实现最佳性能。
不久前,识别瓶颈需要深厚的专业知识。今天的开源 GUI 性能监控器使它变得相当简单。
在我的下一篇文章中,我将讨论改善你的 Linux 电脑性能的具体方法。同时,请在评论中分享你自己的经验。
---
via: <https://opensource.com/article/21/3/linux-performance-bottlenecks>
作者:[Howard Fosdick](https://opensource.com/users/howtech) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Computers are integrated systems that only perform as fast as their slowest hardware component. If one component is less capable than the others—if it falls behind and can't keep up—it can hold your entire system back. That's a *performance bottleneck*. Removing a serious bottleneck can make your system fly.
This article explains how to identify hardware bottlenecks in Linux systems. The techniques apply to both personal computers and servers. My emphasis is on PCs—I won't cover server-specific bottlenecks in areas such as LAN management or database systems. Those often involve specialized tools.
I also won't talk much about solutions. That's too big a topic for this article. Instead, I'll write a follow-up article with performance tweaks.
I'll use only open source graphical user interface (GUI) tools to get the job done. Most articles on Linux bottlenecking are pretty complicated. They use specialized commands and delve deep into arcane details.
The GUI tools that open source offers make identifying many bottlenecks simple. My goal is to give you a quick, easy approach that you can use anywhere.
## Where to start
A computer consists of six key hardware resources:
- Processors
- Memory
- Storage
- USB ports
- Internet connection
- Graphics processor
Should any one resource perform poorly, it can create a performance bottleneck. To identify a bottleneck, you must monitor these six resources.
Open source offers a plethora of tools to do the job. I'll use the [GNOME System Monitor](https://wiki.gnome.org/Apps/SystemMonitor). Its output is easy to understand, and you can find it in most repositories.
Start it up and click on the **Resources** tab. You can identify many performance problems right off.
Fig. 1. System Monitor spots problems (Howard Fosdick, CC BY-SA 4.0)
The **Resources** panel displays three sections: **CPU History**, **Memory and Swap History**, and **Network History**. A quick glance tells you immediately whether your processors are swamped, or your computer is out of memory, or you're using up all your internet bandwidth.
I'll explore these problems below. For now, check the System Monitor first when your computer slows down. It instantly clues you in on the most common performance problems.
Now let's explore how to identify bottlenecks in specific areas.
## How to identify processor bottlenecks
To spot a bottleneck, you must first know what hardware you have. Open source offers several tools for this purpose. I like [HardInfo](https://itsfoss.com/hardinfo/) because its screens are easy to read and it's widely popular.
Start up HardInfo. Its **Computer -> Summary** panel identifies your CPU and tells you about its cores, threads, and speeds. It also identifies your motherboard and other computer components.
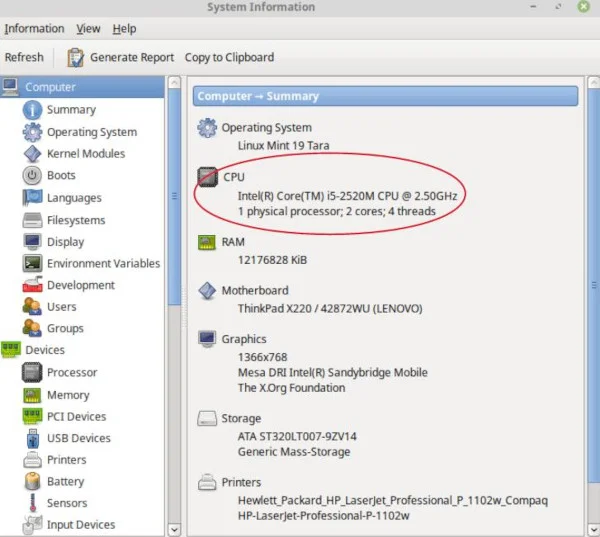
Fig. 2. HardInfo shows hardware details (Howard Fosdick, CC BY-SA 4.0)
HardInfo reveals that this computer has one physical CPU chip. That chip contains two processors, or cores. Each core supports two threads, or logical processors. That's a total of four logical processors—exactly what System Monitor's CPU History section showed in Fig. 1.
A *processor bottleneck* occurs when processors can't respond to requests for their time. They're already busy.
You can identify this when System Monitor shows logical processor utilization at over 80% or 90% for a sustained period. Here's an example where three of the four logical processors are swamped at 100% utilization. That's a bottleneck because it doesn't leave much CPU for any other work.
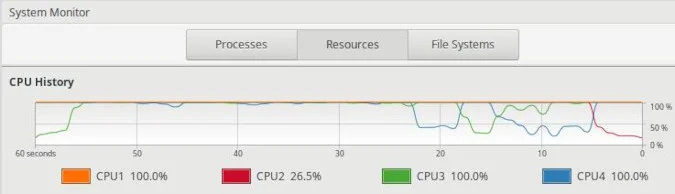
Fig. 3. A processor bottleneck (Howard Fosdick, CC BY-SA 4.0)
### Which app is causing the problem?
You need to find out which program(s) is consuming all that CPU. Click on System Monitor's **Processes** tab. Then click on the **% CPU** header to sort the processes by how much CPU they're consuming. You'll see which apps are throttling your system.
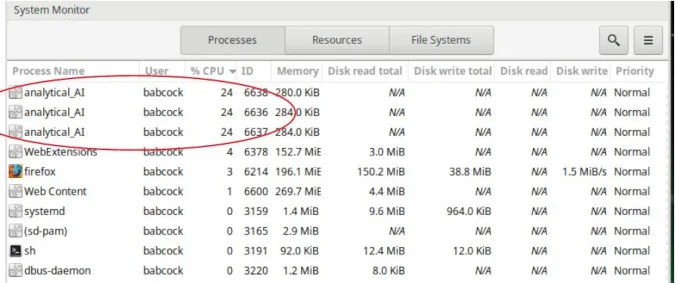
Fig. 4. Identifying the offending processes (Howard Fosdick, CC BY-SA 4.0)
The top three processes each consume 24% of the *total* CPU resource. Since there are four logical processors, this means each consumes an entire processor. That's just as Fig. 3 shows.
The **Processes** panel identifies a program named **analytical_AI** as the culprit. You can right-click on it in the panel to see more details on its resource consumption, including memory use, the files it has open, its input/output details, and more.
If your login has administrator privileges, you can manage the process. You can change its priority and stop, continue, end, or kill it. So, you could immediately resolve your bottleneck here.
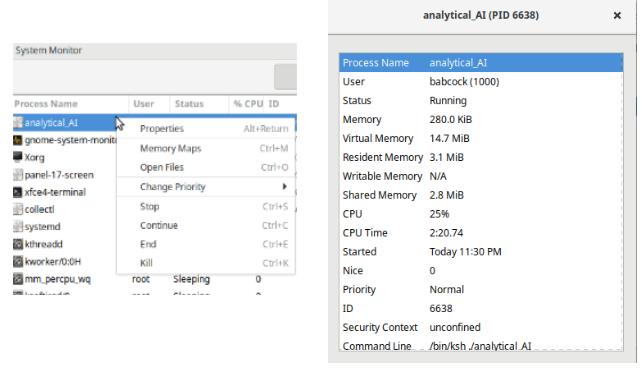
Fig. 5. Right-click on a process to manage It (Howard Fosdick, CC BY-SA 4.0)
How do you fix processing bottlenecks? Beyond managing the offending process in real time, you could prevent the bottleneck from happening. For example, you might substitute another app for the offender, work around it, change your behavior when using that app, schedule the app for off-hours, address an underlying memory issue, performance-tweak the app or your system software, or upgrade your hardware. That's too much to cover here, so I'll explore those options in my next article.
### Common processor bottlenecks
You'll encounter several common bottlenecks when monitoring your CPUs with System Monitor.
Sometimes one logical processor is bottlenecked while all the others are at low utilization. This means you have an app that's not coded smartly enough to take advantage of more than one logical processor, and it's maxed out the one it's using. That app will take longer to finish than it would if it used more processors. On the other hand, at least it leaves your other processors free for other work and doesn't take over your computer.
You might also see a logical processor stuck forever at 100% utilization. Either it's very busy, or a process is hung. The way to tell if it's hung is if the process never does any disk activity (as the System Monitor **Processes** panel will show).
Finally, you might notice that when all your processors are bottlenecked, your memory is fully utilized, too. Out-of-memory conditions sometimes cause processor bottlenecks. In this case, you want to solve the underlying memory problem, not the symptomatic CPU issue.
## How to identify memory bottlenecks
Given the large amount of memory in modern PCs, memory bottlenecks are much less common than they once were. Yet you can still run into them if you run memory-intensive programs, especially if you have a computer that doesn't contain much random access memory (RAM).
Linux [uses memory](https://www.networkworld.com/article/3394603/when-to-be-concerned-about-memory-levels-on-linux.html) both for programs and to cache disk data. The latter speeds up disk data access. Linux can reclaim that memory any time it needs it for program use.
The System Monitor's **Resources** panel displays your total memory and how much of it is used. In the **Processes** panel, you can see individual processes' memory use.
Here's the portion of the System Monitor **Resources** panel that tracks aggregate memory use:
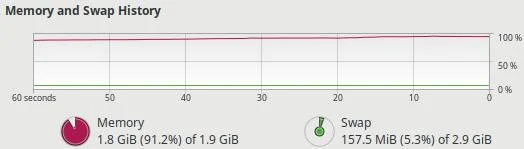
Fig. 6. A memory bottleneck (Howard Fosdick, CC BY-SA 4.0)
To the right of Memory, you'll notice [Swap](https://opensource.com/article/18/9/swap-space-linux-systems). This is disk space Linux uses when it runs low on memory. It writes memory to disk to continue operations, effectively using swap as a slower extension to your RAM.
The two memory performance problems you'll want to look out for are:
- Memory appears largely used, and you see frequent or increasing activity on the swap space.
- Both memory and swap are largely used up.
Situation 1 means slower performance because swap is always slower than memory. Whether you consider it a performance problem depends on many factors (e.g., how active your swap space is, its speed, your expectations, etc.). My opinion is that anything more than token swap use is unacceptable for a modern personal computer.
Situation 2 is where both memory and swap are largely in use. This is a *memory bottleneck.* The computer becomes unresponsive. It could even fall into a state of *thrashing*, where it accomplishes little more than memory management.
Fig. 6 above shows an old computer with only 2GB of RAM. As memory use surpassed 80%, the system started writing to swap. Responsiveness declined. This screenshot shows over 90% memory use, and the computer is unusable.
The ultimate answer to memory problems is to either use less of it or buy more. I'll discuss solutions in my follow-up article.
## How to identify storage bottlenecks
Storage today comes in several varieties of solid-state and mechanical hard disks. Device interfaces include PCIe, SATA, Thunderbolt, and USB. Regardless of which type of storage you have, you use the same procedure to identify disk bottlenecks.
Start with System Monitor. Its **Processes** panel displays the input/output rates for individual processes. So you can quickly identify which processes are doing the most disk I/O.
But the tool doesn't show the *aggregate data transfer rate per disk.* You need to see the total load on a specific disk to determine if that disk is a storage bottleneck.
To do so, use the [atop](https://opensource.com/life/16/2/open-source-tools-system-monitoring) command. It's available in most Linux repositories.
Just type `atop`
at the command-line prompt. The output below shows that device `sdb`
is `busy 101%`
. Clearly, it's reached its performance limit and is restricting how fast your system can get work done.
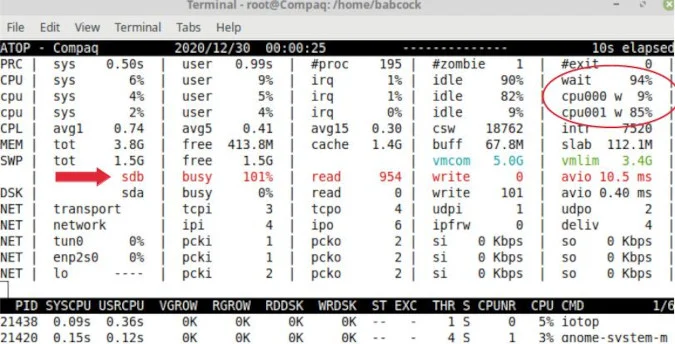
Fig. 7. The atop command identifies a disk bottleneck (Howard Fosdick, CC BY-SA 4.0)
Notice that one of the CPUs is waiting on the disk to do its job 85% of the time (`cpu001 w 85%`
). This is typical when a storage device becomes a bottleneck. In fact, many look first at CPU I/O waits to spot storage bottlenecks.
So, to easily identify a storage bottleneck, use the `atop`
command. Then use the **Processes** panel on System Monitor to identify the individual processes that are causing the bottleneck.
## How to identify USB port bottlenecks
Some people use their USB ports all day long. Yet, they never check if those ports are being used optimally. Whether you plug in an external disk, a memory stick, or something else, you'll want to verify that you're getting maximum performance from your USB-connected devices.
This chart shows why. Potential USB data transfer rates vary *enormously*.
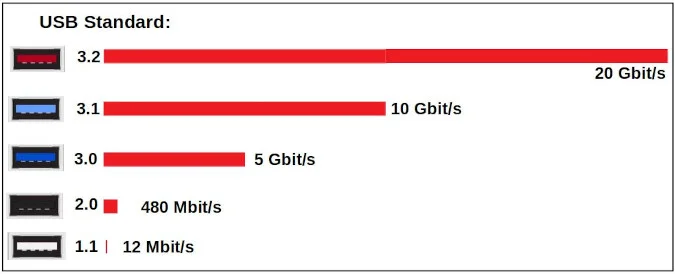
Fig. 8. USB speeds vary a lot (Howard Fosdick, based on figures provided by Tripplite and Wikipedia, CC BY-SA 4.0)
HardInfo's **USB Devices** tab displays the USB standards your computer supports. Most computers offer more than one speed. How can you tell the speed of a specific port? Vendors color-code them, as shown in the chart. Or you can look in your computer's documentation.
To see the actual speeds you're getting, test by using the open source [GNOME Disks](https://wiki.gnome.org/Apps/Disks) program. Just start up GNOME Disks, select its **Benchmark Disk** feature, and run a benchmark. That tells you the maximum real speed you'll get for a port with the specific device plugged into it.
You may get different transfer speeds for a port, depending on which device you plug into it. Data rates depend on the particular combination of port and device.
For example, a device that could fly at 3.1 speed will use a 2.0 port—at 2.0 speed—if that's what you plug it into. (And it won't tell you it's operating at the slower speed!) Conversely, if you plug a USB 2.0 device into a 3.1 port, it will work, but at the 2.0 speed. So to get fast USB, you must ensure both the port and the device support it. GNOME Disks gives you the means to verify this.
To identify a USB processing bottleneck, use the same procedure you did for solid-state and hard disks. Run the `atop`
command to spot a USB storage bottleneck. Then, use System Monitor to get the details on the offending process(es).
## How to identify internet bandwidth bottlenecks
The System Monitor **Resources** panel tells you in real time what internet connection speed you're experiencing (see Fig. 1).
There are [great Python tools out there](https://opensource.com/article/20/1/internet-speed-tests) to test your maximum internet speed, but you can also test it on websites like [Speedtest](https://www.speedtest.net/), [Fast.com](https://fast.com/), and [Speakeasy](https://www.speakeasy.net/speedtest/). For best results, close everything and run *only* the speed test; turn off your VPN; run tests at different times of day; and compare the results from several testing sites.
Then compare your results to the download and upload speeds that your vendor claims you're getting. That way, you can confirm you're getting the speeds you're paying for.
If you have a separate router, test with and without it. That can tell you if your router is a bottleneck. If you use WiFi, test with it and without it (by directly cabling your laptop to the modem). I've often seen people complain about their internet vendor when what they actually have is a WiFi bottleneck they could fix themselves.
If some program is consuming your entire internet connection, you want to know which one. Find it by using the `nethogs`
command. It's available in most repositories.
The other day, my System Monitor suddenly showed my internet access spiking. I just typed `nethogs`
in the command line, and it instantly identified the bandwidth consumer as a Clamav antivirus update.
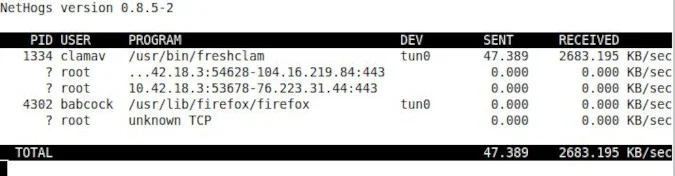
Fig. 9. Nethogs identifies bandwidth consumers (Howard Fosdick, CC BY-SA 4.0)
## How to identify graphics processing bottlenecks
If you plug your monitor into the motherboard in the back of your desktop computer, you're using *onboard graphics*. If you plug it into a card in the back, you have a dedicated graphics subsystem. Most call it a *video card* or *graphics card.* For desktop computers, add-in cards are typically more powerful and more expensive than motherboard graphics. Laptops always use onboard graphics.
HardInfo's **PCI Devices** panel tells you about your graphics processing unit (GPU). It also displays the amount of dedicated video memory you have (look for the memory marked "prefetchable").
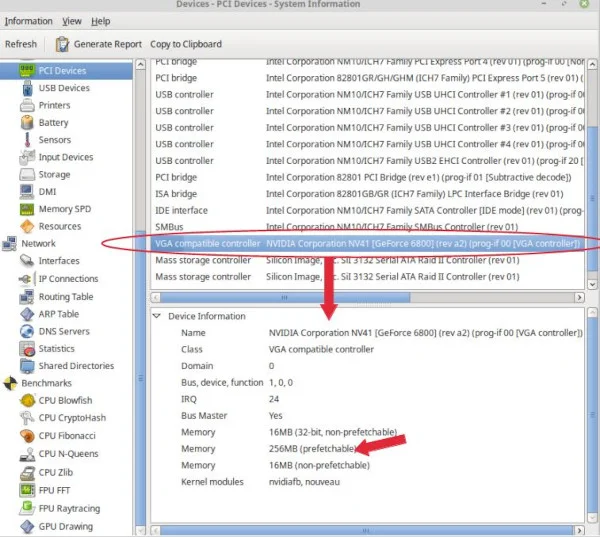
Fig. 10. HardInfo's graphics processing information (Howard Fosdick, CC BY-SA 4.0)
CPUs and GPUs work [very closely](https://www.wepc.com/tips/cpu-gpu-bottleneck/) together. To simplify, the CPU prepares frames for the GPU to render, then the GPU renders the frames.
A *GPU bottleneck* occurs when your CPUs are waiting on a GPU that is 100% busy.
To identify this, you need to monitor CPU and GPU utilization rates. Open source monitors like [Conky](https://itsfoss.com/conky-gui-ubuntu-1304/) and [Glances](https://opensource.com/article/19/11/monitoring-linux-glances) do this if their extensions work with your graphics chipset.
Take a look at this example from Conky. You can see that this system has a lot of available CPU. The GPU is only 25% busy. Imagine if that GPU number were instead near 100%. Then you'd know that the CPUs were waiting on the GPU, and you'd have a GPU bottleneck.
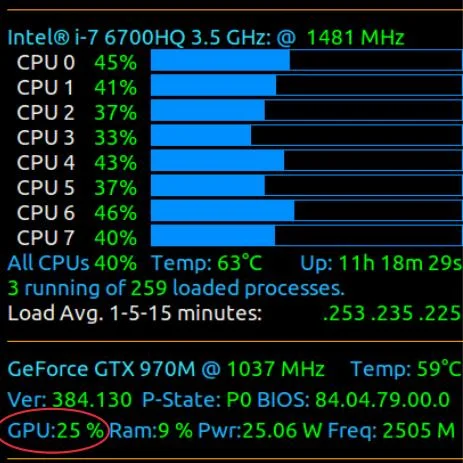
Fig. 11. Conky displaying CPU and GPU utilization (Image courtesy of AskUbuntu forum)
On some systems, you'll need a vendor-specific tool to monitor your GPU. They're all downloadable from GitHub and are described in this article on [GPU monitoring and diagnostic command-line tools](https://www.cyberciti.biz/open-source/command-line-hacks/linux-gpu-monitoring-and-diagnostic-commands/).
## Summary
Computers consist of a collection of integrated hardware resources. Should any of them fall way behind the others in its workload, it creates a performance bottleneck. That can hold back your entire system. You need to be able to identify and correct bottlenecks to achieve optimal performance.
Not so long ago, identifying bottlenecks required deep expertise. Today's open source GUI performance monitors make it pretty simple.
In my next article, I'll discuss specific ways to improve your Linux PC's performance. Meanwhile, please share your own experiences in the comments.
## Comments are closed. |
13,463 | 如何在 Ubuntu 上安装和使用 XRDP 进行远程桌面连接 | https://itsfoss.com/xrdp-ubuntu/ | 2021-06-07T09:38:25 | [
"XRDP",
"RDP",
"远程桌面"
] | https://linux.cn/article-13463-1.html | 
>
> 这是一份初学者指南,展示了在基于 Ubuntu 的 Linux 发行版上设置 XRDP 所需要遵循的步骤。有了它,你就可以从不同的电脑上访问你的 Ubuntu 系统,并以图形方式使用它。
>
>
>
微软的 [远程桌面协议](https://en.wikipedia.org/wiki/Remote_Desktop_Protocol)(RDP) 是一个允许从一台计算机到另一台计算机进行图形化远程桌面连接的协议。RDP 的工作原理是让一台主机运行软件,允许其他几台计算机连接到它。
[XRDP](https://en.wikipedia.org/wiki/Xrdp) 是 RDP 的一个开源实现,不需要运行任何专有程序。XRDP 不仅试图遵循 RDP,而且还与常规的 RDP 客户端兼容,如 [Remmina](https://remmina.org/) 和 [GNOME Boxes](https://wiki.gnome.org/Apps/Boxes)。
下面是 XRDP 连接屏幕的样子。

### 使用 XRDP 需要注意的事项
虽然 XRDP 对于机器的远程访问非常好用,但重要的是要知道 XRDP **不** 适合什么。
#### 如果你需要一个安全的连接,请不要使用 XRDP
通过 XRDP 建立的连接可以被攻击者查看和修改,因此应避免任何敏感信息。这一点可以通过使用 SSH 连接或证书来缓解,但这两者都需要更复杂的设置,这里就不一一介绍了。
#### XRDP 在默认情况下不能很好地应用主题
在我的测试中,XRDP 默认似乎从未应用过 [Ubuntu](https://ubuntu.com/) 主题。在文章的结尾处有关于解决这个问题的说明。
#### 如果你只想/需要一个 CLI 环境,就不要使用 XRDP
XRDP 是为在 GUI 环境中使用而设计和制造的。如果你打算在 CLI 环境中使用它,比如在服务器上,你应该看看其他工具,比如 SSH。
### 在 Ubuntu 上安装和使用 XRDP
下面是这个远程连接设置正常工作所需的设置:
* 一个安装了 XRDP 服务器的 Linux 系统。这是一个将被远程访问的系统。
* 远程系统应该和你的系统在同一个网络上,或者它应该有一个 [公共 IP 地址](https://itsfoss.com/check-ip-address-ubuntu/)。
* 远程 Linux 系统的用户名和密码。
* 安装有 RDP 客户端的另一个系统(无论是 Linux、macOS 还是 Windows)。

#### 第 1 步:在远程计算机上安装 XRDP
安装 XRDP 只需几个步骤,而且是相当直接的操作。
>
> 备注:在访问任何地方之前,请注意,这里说的 “远程机器” 是其他人连接到的机器。
>
>
>
XRDP 包含在大多数发行版的软件库中。在 Ubuntu 上,你可以在 universe 库中找到它。
你可以用下面的命令来安装它:
```
sudo apt install xrdp
```
#### 第 2 步:连接到远程机器
好消息是,XRDP 开箱就能使用!
要连接到你安装了 XRDP 的机器上,你首先需要在本地机器上安装一个 RDP 客户端。
我将使用 GNOME Boxes,它可以通过以下方式安装:
```
sudo apt install gnome-boxes
```
GNOME Boxes 更多的是以虚拟机使用而闻名,但它也支持其他各种协议,包括 XRDP。
如果由于某种原因你不想使用 Boxes,你也可以使用一个叫做 Remmina 的客户端。
```
sudo apt install remmina
```
不过,请注意,在本教程的其余部分,我将使用 Boxes。
首先,启动 GNOME Boxes,并点击 “+” 号,选择 “连接到远程计算机…”。

接下来,输入你要连接的机器的 IP 地址,前缀为 `rdp://`,然后按下图连接:
>
> **不确定你的 IP 地址是什么?**
>
>
> 你可以用 `ip address` 命令找到你的 IP 地址。你需要寻找一个看起来像分成四组的数字的东西:
>
>
>
> ```
> abhishek@its-foss:~$ ip address
> 1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
> link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
> inet 127.0.0.1/8 scope host lo
> valid_lft forever preferred_lft forever
> 2: wlp0s20f3: mtu 1500 qdisc noqueue state UP group default qlen 1000
> link/ether dc:46:b9:fb:7a:c5 brd ff:ff:ff:ff:ff:ff
> inet 192.168.0.107/24 brd 192.168.0.255 scope global dynamic noprefixroute wlp0s20f3
> valid_lft 6183sec preferred_lft 6183sec
>
> ```
>
>
避免任何名为 `127.0.0.1` 的 IP 地址,因为那个地址指向你运行命令的机器。输出中应该有更多的 IP 地址,如上图所示。

然后,你应该会看到一个登录页面。将“会话”设置为 “Xorg”,只需输入你的用户名和密码,然后点击 “OK”。

之后,你应该看到远程主机的桌面:

至此,一切都会像机器在你面前时一样表现。
### 故障排除:修复 XRDP 连接的主题问题
在我对 Ubuntu 20.04 的测试中,默认的 Yaru 主题似乎在连接时没有应用。这可以通过一些努力来解决。
首先,在远程计算机上运行这个命令:
```
sudo apt install gnome-tweaks gnome-shell-extensions dconf-editor -y
```
接下来,打开 “扩展” 应用,并打开如下开关:

接下来,关闭你的远程桌面会话并重新登录。现在,打开 Tweaks,按照下面的截图配置:

最后,打开 dconf 编辑器,并进入 `/org/gnome/shell/extensions/dash-toock/`。设置如下所示的值:
* `custom-theme-shrink`:`On`
* `dock-fixed`:`On`
* `transparency-mode`:`FIXED`
### 总结
至此,一切都准备好了,可以做你需要做的事了。
如果有什么地方做得不太对,或者你有什么问题或意见,请在下面留言。我会尽力帮助你的。
---
via: <https://itsfoss.com/xrdp-ubuntu/>
作者:[Hunter Wittenborn](https://itsfoss.com/author/hunter/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: This tutorial goes over setting up XRDP on Ubuntu, which will allow for GUI connections to a remote computer.*
[Microsoft Remote Desktop Protocol](https://en.wikipedia.org/wiki/Remote_Desktop_Protocol) (RDP) is a protocol that allows for graphical remote desktop connections from one computer to another. RDP works by having a main machine run software that allows several other computers to connect to it.
[XRDP](https://en.wikipedia.org/wiki/Xrdp) is an open-source implementation of RDP, removing the need to run any proprietary programs. XRDP not only tries to follow in the direction of RDP, but is also compatible with regular RDP clients such as [Remmina](https://remmina.org/) and [GNOME Boxes](https://wiki.gnome.org/Apps/Boxes).
XRDP features a simple one-page interface, after which you’ll be right at your desktop:
## Things to keep in mind about using XRDP
While XRDP works great for getting remote access to machine, it’s important to know what XRDP ** isn’t** good at.
### Do not use XRDP if you need a secure connection
Connections made over XRDP can be viewed and modified by attackers, and should thus be avoided for any sensitive information. This can be alleviated through the use of an SSH connection or with certificates, but both require a more complex setup and will not be covered here.
### XRDP doesn’t work well with theming by default
In my testing, XRDP didn’t ever seem to apply the theming [Ubuntu](https://ubuntu.com/) comes with by default. Instructions for fixing this are available at the end of the article.
### Don’t use XRDP if you only want/need a CLI environment
XRDP is designed and made to use in a GUI environment. If you plan on using it for a CLI environment, such as on a server, you should look at other tools, such as [SSH](https://ubuntu.com/server/docs/service-openssh).
## Installing and Setting Up XRDP on Ubuntu
This tutorial assumes the following setup to get everything working properly.
- A Linux system with the XRDP server software installed on it. This is the system which will be accessed remotely.
- If the remove machine isn’t on your local network, the machine will need a
[public IP address](https://itsfoss.com/check-ip-address-ubuntu/)with port forwarding enabled. - The username
password of the remote system.**and** - Another system (be it Linux, Windows, or macOS) with an RDP client installed.
### Step 1: Install XRDP on the remote machine
Installing XRDP is just a couple of steps, and is pretty straightforward to do.
Note
Before going anywhere, note that the “remote machine” will be the machine that all others connect to.
XRDP is included in most distributions’ repositories. On Ubuntu, it is available in the universe repository.
You can install it with the following command:
`sudo apt install xrdp`
### Step 2: Connecting to the remote machine
Good news is XRDP works right out of the box!
To connect to the machine you installed XRDP on, you’ll first need to install an RDP client on your local machine.
I’ll be using GNOME Boxes, which can be installed with the following:
`sudo apt install gnome-boxes`
GNOME Boxes is known more for virtual machine use, but it also supports a variety of other protocols, including XRDP.
If for whatever reason you don’t want to use Boxes, you can also use a client called Remmina:
`sudo apt install remmina`
Again though, note that I’ll be using Boxes throughout the rest of the tutorial.z
First off, Start GNOME Boxes, and click on the + sign and select “**Connect to a Remote Computer…**“.
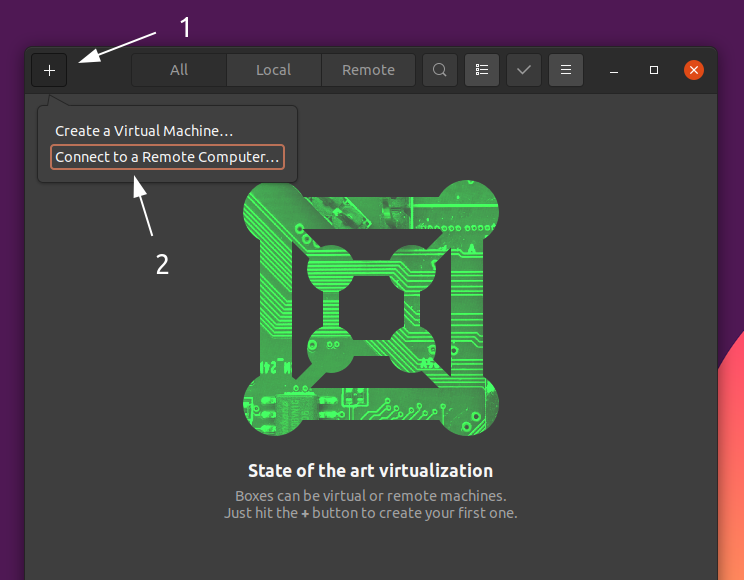
Next, enter the IP address of the machine you’re connecting to, prefixed with `rdp://`
, and then connect as shown below:
Not sure what your IP address is?
You can [find your IP address](https://itsfoss.com/check-ip-address-ubuntu/) with the `ip address`
command. You’ll need to look for something that looks like a number split into four groups:
abhishek@its-foss:~$ ip address
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: wlp0s20f3: mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether dc:46:b9:fb:7a:c5 brd ff:ff:ff:ff:ff:ff
inet ** 192.168.0.107**/24 brd 192.168.0.255 scope global dynamic noprefixroute wlp0s20f3
valid_lft 6183sec preferred_lft 6183sec
Avoid any IP addresses named `127.0.0.1`
, as that one points back to the machine you ran the command on. There should be more IP addresses in the output, as shown above.
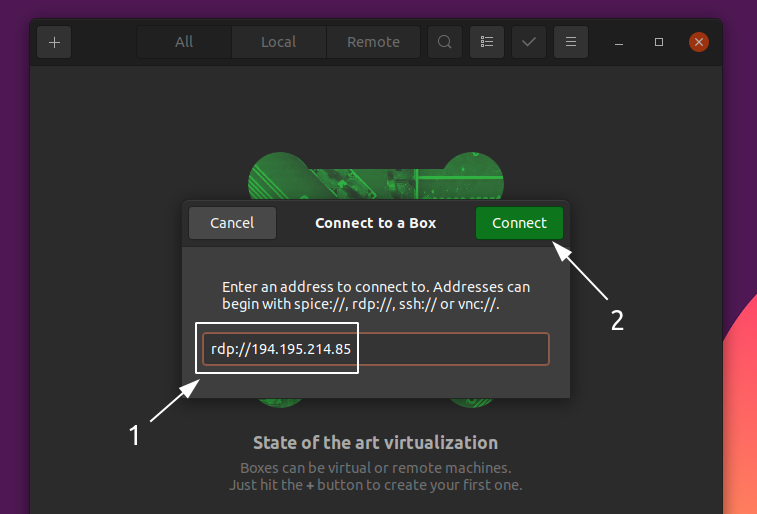
You should then be presented with a login screen. Keep “Session” set to “Xorg”, and just enter your username and password, then click “OK”:

After, you should be presented with the desktop of the remote machine:
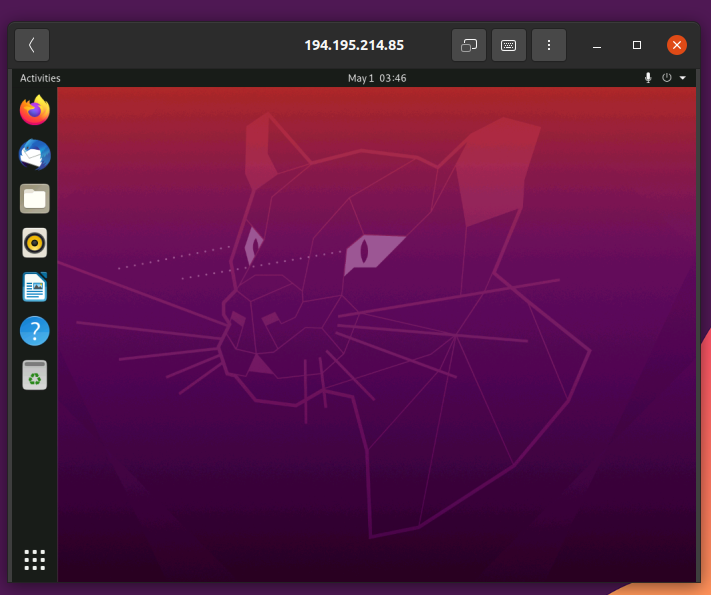
And now you’re good to go! Everything will behave just the same as if the machine was right in front of you.
## Troubleshooting: Fixing theming issues
XRDP never seemed to get the theming correct for me. This can be fixed with a few steps.
First, on the **remote computer**, run the following command:
`sudo apt install gnome-tweaks gnome-shell-extensions dconf-editor -y`
Next, open the Extensions app, and turn on the toggles shown below:
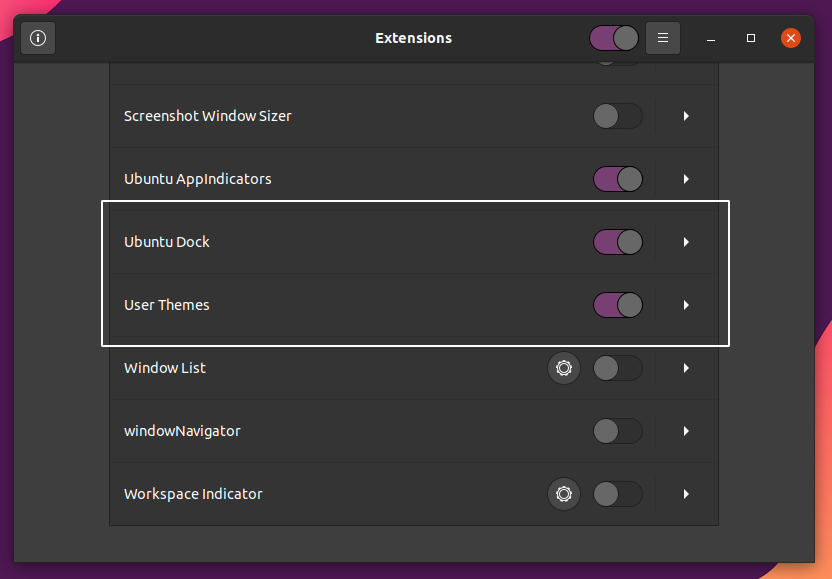
Now, close your remote desktop session and log back in. Next, open up Tweaks and configure everything per the screenshot below:
Lastly, open up dconf Editor, and navigate to `/org/gnome/shell/extensions/dash-to-dock/`
, and set the values that are shown below:
`custom-theme-shrink`
: On`dock-fixed`
: On`transparency-mode`
: FIXED
## Wrapping Up
And there you go! Everything is good to go, ready to do what you need to.
If something isn’t working quite right, or you have any questions or comments, feel free to leave them below. |
13,466 | 用 Python 3.8 中的这个位置技巧让你的 API 变得更好 | https://opensource.com/article/21/5/python-38-features | 2021-06-07T16:49:35 | [
"Python"
] | https://linux.cn/article-13466-1.html |
>
> 探索只接受位置参数和其他两个未被充分利用但仍然有用的 Python 特性。
>
>
>

这是 Python 3.x 首发特性系列文章的第九篇。Python 3.8 于 2019 年首次发布,两年后,它的许多很酷的新特性仍然没有被使用。下面是其中的三个。
### importlib.metadata
[入口点](https://packaging.python.org/specifications/entry-points/) 在 Python 包中被用来做各种事情。大多数人熟悉的是 [console\_scripts](https://python-packaging.readthedocs.io/en/latest/command-line-scripts.html) 入口点,不过 Python 中的许多插件系统都使用它们。
在 Python 3.8 之前,从 Python 中读取入口点的最好方法是使用 `pkg_resources`,这是一个有点笨重的模块,它是 `setuptools` 的一部分。
新的 `importlib.metadata` 是一个内置模块,它允许访问同样的东西:
```
from importlib import metadata as importlib_metadata
distribution = importlib_metadata.distribution("numpy")
distribution.entry_points
```
```
[EntryPoint(name='f2py', value='numpy.f2py.f2py2e:main', group='console_scripts'),
EntryPoint(name='f2py3', value='numpy.f2py.f2py2e:main', group='console_scripts'),
EntryPoint(name='f2py3.9', value='numpy.f2py.f2py2e:main', group='console_scripts')]
```
入口点并不是 `importlib.metadata` 允许访问的唯一东西。可以调试、报告,或者(在极端情况下)触发兼容模式,你也可以在运行时检查依赖的版本!
```
f"{distribution.metadata['name']}=={distribution.version}"`[/code] [code]` 'numpy==1.20.1'
```
### 只接受位置参数
强制关键字的参数在传达 API 作者的意图方面取得巨大成功之后,另一个空白被填补了:只接受位置参数。
特别是对于那些允许使用任意关键字的函数(例如,生成数据结构),这意味着对允许的参数名称的限制更少:
```
def some_func(prefix, /, **kwargs):
print(prefix, kwargs)
```
```
some_func("a_prefix", prefix="prefix keyword value")
```
```
a_prefix {'prefix': 'prefix keyword value'}`
```
注意,令人困惑的是,*变量* `prefix` 的值与 `kwargs["prefix"]` 的值不同。就像在很多地方一样,要注意小心使用这个功能。
### 自我调试表达式
50 多年来,`print()` 语句(及其在其他语言中的对应语句)一直是快速调试输出的最爱。
但是我们在打印语句方面取得了很大的进展,比如:
```
special_number = 5
print("special_number = %s" % special_number)
```
```
special_number = 5
```
然而,自我记录的 f-strings 使它更容易明确:
```
print(f"{special_number=}")
```
```
special_number=5`
```
在 f-string 插值部分的末尾添加一个 `=`,可以保留字面部分,同时添加数值。
当更复杂的表达式在该部分内时,这就更有用了:
```
values = {}
print(f"{values.get('something', 'default')=}")
```
```
values.get('something', 'default')='default'
```
### 欢迎来到 2019 年
Python 3.8 大约在两年前发布,它的一些新特性非常酷,而且没有得到充分利用。如果你还没使用,那么将他们添加到你的工具箱中。
---
via: <https://opensource.com/article/21/5/python-38-features>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the ninth in a series of articles about features that first appeared in a version of Python 3.x. Python 3.8 was first released in 2019, and two years later, many of its cool new features remain underused. Here are three of them.
## importlib.metadata
[Entry points](https://packaging.python.org/specifications/entry-points/) are used for various things in Python packages. The most familiar are [console_scripts](https://python-packaging.readthedocs.io/en/latest/command-line-scripts.html) entrypoints, but many plugin systems in Python use them.
Until Python 3.8, the best way to read entry points from Python was to use `pkg_resources`
, a somewhat clunky module that is part of `setuptools`
.
The new `importlib.metadata`
is a built-in module that allows access to the same thing:
```
from importlib import metadata as importlib_metadata
distribution = importlib_metadata.distribution("numpy")
distribution.entry_points
```
```
[EntryPoint(name='f2py', value='numpy.f2py.f2py2e:main', group='console_scripts'),
EntryPoint(name='f2py3', value='numpy.f2py.f2py2e:main', group='console_scripts'),
EntryPoint(name='f2py3.9', value='numpy.f2py.f2py2e:main', group='console_scripts')]
```
Entry points are not the only thing `importlib.metadata`
permits access to. For debugging, reporting, or (in extreme circumstances) triggering compatibility modes, you can also check the version of dependencies—at runtime!
`f"{distribution.metadata['name']}=={distribution.version}"`
` 'numpy==1.20.1'`
## Positional-only parameters
After the wild success of keywords-only arguments at communicating API authors' intentions, another gap was filled: positional-only arguments.
Especially for functions that allow arbitrary keywords (for example, to generate data structures), this means there are fewer constraints on allowed argument names:
```
def some_func(prefix, /, **kwargs):
print(prefix, kwargs)
```
`some_func("a_prefix", prefix="prefix keyword value")`
` a_prefix {'prefix': 'prefix keyword value'}`
Note that, confusingly, the value of the *variable* `prefix`
is distinct from the value of `kwargs["prefix"]`
. As in many places, take care to use this feature carefully.
## Self-debugging expressions
The `print()`
statement (and its equivalent in other languages) has been a favorite for quickly debugging output for over 50 years.
But we have made much progress in print statements like:
```
special_number = 5
print("special_number = %s" % special_number)
```
` special_number = 5`
Yet self-documenting f-strings make it even easier to be clear:
`print(f"{special_number=}")`
` special_number=5`
Adding an `=`
to the end of an f-string interpolated section keeps the literal part while adding the value.
This is even more useful when more complicated expressions are inside the section:
```
values = {}
print(f"{values.get('something', 'default')=}")
```
` values.get('something', 'default')='default'`
## Welcome to 2019
Python 3.8 was released about two years ago, and some of its new features are cool—and underused. Add them to your toolkit if you haven't already.
## Comments are closed. |
13,469 | openSUSE Leap 15.3 版本缩小了与 SUSE Linux 企业版的差距 | https://news.itsfoss.com/opensuse-leap-15-3-release/ | 2021-06-08T18:49:27 | [
"openSUSE"
] | https://linux.cn/article-13469-1.html | 
>
> 随着 openSUSE 15.3 的发布,与 SUSE Linux 企业版的差距终于缩小了。对于开发团队来说,这应该是一个令人兴奋的用于测试的更新。
>
>
>
去年,在 [openSUSE Leap 15.2 发行版](https://itsfoss.com/opensuse-leap-15-2-release/) 中他们希望通过使用与企业版相同二进制软件包来构建 openSUSE Leap,从而缩小 openSUSE Leap 与 SUSE Linux 企业版之间的差距。
这样一来的话,如果有人在使用 openSUSE 测试后切换到 SUSE Linux 企业版,部署的迁移过程都将大大简化。此外,openSUSE Leap 将是开发团队进行测试的一个轻松选择。
随着 openSUSE Leap 15.3 的发布,这个构想成为了现实。本文我将重点介绍这次发布的主要变化。
### openSUSE Leap 15.3: 最新变化
最重要的变化是,它使用与 SUSE Linux 企业版相同的二进制软件包构建。
并且,[发布公告](https://news.opensuse.org/2021/06/02/opensuse-leap-bridges-path-to-enterprise/) 中提到了这一巨大变化的好处:
>
> 此版本对于迁移项目和用户验收测试非常有益,使用 openSUSE leap 15.3 进行运行调优和测试工作负载的大型开发团队将会获得最大的好处,因为这些工作负载可以轻松提升并转移到 SUSE Linux 企业版 15 SP3 上进行长期维护。
>
>
>
除了这个巨大的变化,还有其他几个重要的变化使它成为一个令人激动的版本。

对于 Xfce 4.16 桌面,有一些视觉变化,包括新的图标和调色板。设置管理器还增加了一个视觉刷新功能,提供了更清晰的外观。
如果有需要,KDE Plasma 5.18 也可以作为 LTS 选项与此版本一起提供。而且,GNOME 3.34 在某些应用程序的外观和感觉上有一些细微的变化。虽然 Cinnamon 没有大的变化,但是你会发现它有了一个新的模式。
在这个版本中,你将发现 gnu health 3.8 添加了一些新特性供你探索。
DNF 包管理器有一个更新计划,但是当前没有释放出来,你可以通过后续的维护更新获得它。

IBM Z 和 LinuxONE(s390x)是 Leap 15.3 中新支持的两种架构。
所包含的容器技术仍然保持不变,但是它们在本版本中收到了安全更新。当然,你需要去找 Linode 等托管解决方案提供的最新云镜像。
几个应用程序升级包括 Ononishare 2.2、Chromium 89 等。你可以在 [官方特性列表](https://en.opensuse.org/Features_15.3) 中找到更多详细信息。
### 下载 openSUSE Leap 15.3
需要注意的是,从今天起,Leap 15.2 将有六个月的寿命(EOL)。
在尝试升级到 Leap 15.3 之前,你必须确保运行的是 Leap 15.2。你可以在他们的 [官方发行说明](https://en.opensuse.org/Release_announcement_15.3) 中找到有关升级过程的更多信息。
从下面的按钮链接的官方下载页面获取最新的 ISO。
* [下载 openSUSE Leap 15.3](https://get.opensuse.org/leap/)
---
via: <https://news.itsfoss.com/opensuse-leap-15-3-release/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Last year, with [openSUSE Leap 15.2 release](https://itsfoss.com/opensuse-leap-15-2-release/?ref=news.itsfoss.com) they aimed to close the gap between SUSE Linux Enterprise by building it with the same binary packages used in the enterprise version.
This would ease up the migration process for the deployments if anyone switches to the SUSE Linux Enterprise after testing with openSUSE. Also, openSUSE Leap will be the easy choice for development teams for testing.
Finally, with openSUSE Leap 15.3 release, that is a reality. Here, I shall highlight the key changes of this release.
## openSUSE Leap 15.3: What’s New?
The most considerable change is that it is built with the same binary packages as you’d find in SUSE Enterprise Linux.
However, the [release announcement](https://news.opensuse.org/2021/06/02/opensuse-leap-bridges-path-to-enterprise/?ref=news.itsfoss.com) mentions the benefit of this massive change as:
This release is hugely beneficial for migration projects and user acceptance testing. Large development teams gain added value by using openSUSE Leap 15.3 to optimally run and test workloads that can be lifted and shifted to SUSE Linux Enterprise Linux 15 SP3 for long-term maintenance.
In addition to this big change, there are several other essential changes that makes it an exciting release.

With Xfce 4.16 desktop, there are visual changes that include new icons and palette. The Settings Manager also received a visual refresh providing a cleaner look.
KDE Plasma 5.18 is also available with this release as an LTS option if you need. And, GNOME 3.34 includes some subtle changes in the look and feel for certain applications. While Cinnamon has no major changes, you will find a new pattern for it.
You will find the addition of GNU Health 3.8 in this release with new features for you to explore.
An update to DNF package manager was planned, but it looks like you will be getting it with a maintenance update following this release.
IBM Z and LinuxONE (s390x) are two of the new architecture support added with Leap 15.3.
The container technologies included still remain the same, but they have received security updates with this release. Of course, you should find the latest cloud images available with the hosting solutions like Linode.
Several application upgrades include OnionShare 2.2, Chromium 89, and more. You can find more details in the [official feature list](https://en.opensuse.org/Features_15.3?ref=news.itsfoss.com).
## Download openSUSE Leap 15.3
It is worth noting that from today onwards, Leap 15.2 will have six months until its End of Life (EOL).
You will have to ensure that you are running Leap 15.2 before trying to upgrade to Leap 15.3. You can find more information about the upgrade process in their [official release notes](https://en.opensuse.org/Release_announcement_15.3?ref=news.itsfoss.com).
Get the latest ISO from the official download page linked in the button below.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,472 | 使用开源工具升级你的 Linux PC 硬件 | https://opensource.com/article/21/4/upgrade-linux-hardware | 2021-06-09T20:44:52 | [
"硬件",
"升级",
"瓶颈"
] | https://linux.cn/article-13472-1.html |
>
> 升级你的电脑硬件来提升性能,以获得最大的回报。
>
>
>

在我的文章《[使用开源工具识别 Linux 性能瓶颈](/article-13462-1.html)》中,我解释了一些使用开源的图形用户界面(GUI)工具监测 Linux 性能的简单方法。我的重点是识别 *性能瓶颈*,即硬件资源达到极限并阻碍你的 PC 性能的情况。
你会如何解决性能瓶颈问题呢?你可以调整应用程序或系统软件。或者你可以运行更高效的应用程序。你甚至可以改变你使用电脑的行为,例如,将后台程序安排在非工作时间。
你也可以通过硬件升级来提高电脑的性能。本文重点介绍可以给你带来最大回报的升级。
开源工具是关键。GUI 工具可以帮助你监控你的系统,预测哪些硬件改进会有效。否则,你可能买了硬件后发现它并没有提高性能。在升级之后,这些工具也有助于验证升级是否产生了你预期的好处。
这篇文章概述了一种简单的 PC 硬件升级的方法,其“秘诀”是开源的 GUI 工具。
### 如何升级内存
几年前,升级内存是不用多想的。增加内存几乎总是能提高性能。
今天,情况不再是这样了。个人电脑配备了更多的内存,而且 Linux 能非常有效地使用它。如果你购买了系统用不完的内存,就浪费了钱。
因此,你要花一些时间来监测你的电脑,看看内存升级是否会有助于提升它的性能。例如,在你进行典型的一天工作时观察内存的使用情况。而且一定要检查在内存密集型工作负载中发生了什么。
各种各样的开源工具可以帮助你进行这种监测,不过我用的是 [GNOME 系统监视器](https://vitux.com/how-to-install-and-use-task-manager-system-monitor-in-ubuntu/)。它在大多数 Linux 软件库中都有。
当你启动系统监视器时,它的“资源”面板会显示这样的输出:

*图 1. 用 GNOME 系统监视器监控内存 (Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
屏幕中间显示了内存的使用情况。[交换空间](https://opensource.com/article/18/9/swap-space-linux-systems) 是 Linux 在内存不足时使用的磁盘空间。Linux 通过使用交换空间作为内存的一个较慢的扩展来有效地增加内存。
由于交换空间比内存慢,如果内存交换活动变得显著,增加内存将改善你的计算机的性能。你会得到多大的改善取决于交换活动的数量和交换空间所在的设备的速度。
如果使用了大量的交换空间,你通过增加内存会得到比只使用了少量交换空间更多的性能改善。
如果交换空间位于慢速的机械硬盘上,你会发现增加内存比将交换空间放在最快的固态硬盘上改善更多。
下面是一个关于何时增加内存的例子。这台电脑在内存利用率达到 80% 后显示交换活动在增加。当内存利用率超过 90% 时,它就变得失去反应了。

*图 2. 内存升级会有帮助(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
#### 如何进行内存升级
在升级之前,你需要确定你有多少个内存插槽,有多少个是空的,它们需要什么样的内存条,以及你的主板所允许的最大内存。
你可以阅读你的计算机的文档来获得这些答案。或者,你可以直接输入这些 Linux 命令行:
| 问题 | 命令 |
| --- | --- |
| 已安装的内存条有什么特点? | `sudo lshw -short -C memory` |
| 这台计算机允许的最大内存是多少? | `sudo dmidecode -t memory | grep -i max` |
| 有多少个内存插槽是空的?(没有输出意味着没有可用的) | `sudo lshw -short -C memory | grep -i empty` |
与所有的硬件升级一样,事先拔掉计算机的电源插头。在你接触硬件之前,将自己接地 —— 即使是最微小的电涌也会损坏电路。将内存条完全插入主板的插槽中。
升级后,启动系统监视器。运行之前使你的内存超载的相同程序。
系统监控器应该显示出你扩充的内存,而且你应该发现性能更好了。
### 如何升级存储
我们正处在一个存储快速改进的时代。即使是只用了几年的计算机也可以从磁盘升级中受益。但首先,你要确保升级对你的计算机和工作负载是有意义的。
首先,要找出你有什么磁盘。许多开源工具会告诉你。[Hardinfo](https://itsfoss.com/hardinfo/) 或 [GNOME 磁盘](https://en.wikipedia.org/wiki/GNOME_Disks) 是不错的选择,因为它们都是广泛可用的,而且它们的输出很容易理解。这些应用程序会告诉你磁盘的品牌、型号和其他细节。
接下来,通过基准测试来确定你的磁盘性能。GNOME 磁盘让这一切变得简单。只要启动该工具并点击它的“磁盘基准测试”选项。这会给出你磁盘的读写率和平均磁盘访问时间。

*图 3. GNOME 磁盘基准输出(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
有了这些信息,你可以在 [PassMark Software](https://www.harddrivebenchmark.net/) 和 [UserBenchmark](https://www.userbenchmark.com/) 等基准测试网站上将你的磁盘与其他人进行比较。这些网站提供性能统计、速度排名,甚至价格和性能数字。你可以了解到你的磁盘与可能的替代品相比的情况。
下面是你可以在 UserBenchmark 找到的一些详细磁盘信息的例子。

*图 4. 在 [UserBenchmark](https://ssd.userbenchmark.com/) 进行的磁盘比较*
#### 监测磁盘利用率
就像你对内存所做的那样,实时监控你的磁盘,看看更换磁盘是否会提高性能。[atop 命令行](https://opensource.com/life/16/2/open-source-tools-system-monitoring) 会告诉你一个磁盘的繁忙程度。
在它下面的输出中,你可以看到设备 `sdb` 是 `busy 101%`。其中一个处理器有 85% 的时间在等待该磁盘进行工作(`cpu001 w 85%`)。

*图 5. atop 命令显示磁盘利用率(Howard Fosdick, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
很明显,你可以用一个更快的磁盘来提高性能。
你也会想知道是哪个程序使用了磁盘。只要启动系统监视器并点击其“进程”标签。
现在你知道了你的磁盘有多忙,以及哪些程序在使用它,所以你可以做出一个有根据的判断,是否值得花钱买一个更快的磁盘。
#### 购买磁盘
购买新的内置磁盘时,你会遇到三种主流技术:
* 机械硬盘(HDD)
* SATA 接口的固态硬盘(SSD)
* PCIe 接口的 NVMe 固态磁盘(NVMe SSD)
它们的速度差异是什么?你会在网上看到各种不同的数字。这里有一个典型的例子。

*图 6. 内部磁盘技术的相对速度([Unihost](https://unihost.com/help/nvme-vs-ssd-vs-hdd-overview-and-comparison/))*
* **红色柱形图:** 机械硬盘提供最便宜的大容量存储。但就性能而言,它们是迄今为止最慢的。
* **绿色柱形图:** 固态硬盘比机械硬盘快。但如果固态硬盘使用 SATA 接口,就会限制其性能。这是因为 SATA 接口是十多年前为机械硬盘设计的。
* **蓝色柱形图:** 最快的内置磁盘技术是新的 [PCIe 接口的 NVMe 固态盘](https://www.trentonsystems.com/blog/pcie-gen4-vs-gen3-slots-speeds)。这些可以比 SATA 连接的固态硬盘大约快 5 倍,比机械硬盘快 20 倍。
对于外置 SSD,你会发现 [最新的雷电接口和 USB 接口](https://www.howtogeek.com/449991/thunderbolt-3-vs.-usb-c-whats-the-difference/) 是最快的。
#### 如何安装一个内置磁盘
在购买任何磁盘之前,请确认你的计算机支持必要的物理接口。
例如,许多 NVMe 固态硬盘使用流行的新 M.2(2280)外形尺寸。这需要一个量身定做的主板插槽、一个 PCIe 适配器卡,或一个外部 USB 适配器。你的选择可能会影响你的新磁盘的性能。
在安装新磁盘之前,一定要备份你的数据和操作系统。然后把它们复制到新磁盘上。像 Clonezilla、Mondo Rescue 或 GParted 这样的开源 [工具](https://www.linuxlinks.com/diskcloning/) 可以完成这项工作。或者你可以使用 Linux 命令行,如 `dd` 或 `cp`。
请确保在最有影响的情况下使用你的快速新磁盘。把它用作启动盘、存储操作系统和应用程序、交换空间,以及最常处理的数据。
升级之后,运行 GNOME 磁盘来测试你的新磁盘。这可以帮助你验证你是否得到了预期的性能提升。你可以用 `atop` 命令来验证实时运行。
### 如何升级 USB 端口
与磁盘存储一样,USB 的性能在过去几年中也有了长足的进步。许多只用了几年的计算机只需增加一个廉价的 USB 端口卡就能获得很大的性能提升。
这种升级是否值得,取决于你使用端口的频率。很少使用它们,如果它们很慢也没有关系。经常使用它们,升级可能真的会影响你的工作。
下面是不同端口标准的最大 USB 数据速率的巨大差异。

*图 7. USB 速度差别很大(Howard Fosdick,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/),基于 [Tripplite](https://www.tripplite.com/products/usb-connectivity-types-standards) 和 [维基](https://en.wikipedia.org/wiki/USB) 的数据*
要查看你得到的实际 USB 速度,请启动 GNOME 磁盘。GNOME 磁盘可以对 USB 连接的设备进行基准测试,就像对内部磁盘一样。选择其“磁盘基准测试”选项。
你插入的设备和 USB 端口共同决定了你将得到的速度。如果端口和设备不匹配,你将体验到两者中较慢的速度。
例如,将一个支持 USB 3.1 速度的设备连接到一个 2.0 端口,你将得到 2.0 的数据速率。你的系统不会告诉你这一点,除非你用 GNOME 磁盘这样的工具来检查)。反之,将 2.0 设备连接到 3.1 端口,你也会得到 2.0 的速度。因此,为了获得最好的结果,总是要匹配你的端口和设备的速度。
要实时监控 USB 连接的设备,请使用 `atop` 命令和系统监控器,就像你监控内部磁盘一样。这可以帮助你看到是否碰到了当前设置的限制,并可以通过升级而受益。
升级你的端口很容易。只要购买一个适合你的空闲的 PCIe 插槽的 USB 卡。
USB 3.0 卡的价格只有 25 美元左右。较新、较贵的卡提供 USB 3.1 和 3.2 端口。几乎所有的 USB 卡都是即插即用的,所以 Linux 会自动识别它们。但在购买前一定要核实。
请确保在升级后运行 GNOME 磁盘以验证新的速度。
### 如何升级你的互联网连接
升级你的互联网带宽很容易。只要给你的 ISP 写一张支票即可。
问题是,应该升级吗?
系统监控器显示了你的带宽使用情况(见图 1)。如果你经常遇到你从 ISP 购买的带宽限额,你会从购买更高的限额中受益。
但首先,要确认你是否有一个可以自己解决的问题。我见过很多案例,有人认为他们需要从 ISP 那里购买更多的带宽,而实际上他们只是有一个可以自己解决的连接问题。
首先在 [Speedtest](https://www.speedtest.net/) 或 [Fast.com](https://fast.com/) 等网站测试你的最大网速。为了获得准确的结果,关闭所有程序,只运行速度测试;关闭你的虚拟私有网络;在一天中的不同时间运行测试;并比较几个测试网站的结果。如果你使用 WiFi,在有 WiFi 和没有 WiFi 的情况下进行测试(将你的笔记本电脑直接与调制解调器连接)。
如果你有一个单独的路由器,在有它和没有它的情况下进行测试。这将告诉你路由器是否是瓶颈。有时,只是重新定位你家里的路由器或更新其固件就能提高连接速度。
这些测试将验证你是否得到了你从 ISP 购买的带宽速度。它们也会暴露出任何你可以自己解决的本地 WiFi 或路由器问题。
只有在你做了这些测试之后,你才应该得出结论,你需要购买更多的网络带宽。
### 你应该升级你的 CPU 还是 GPU?
升级你的 CPU(中央处理单元)或 GPU(图形处理单元)呢?
笔记本电脑用户通常不能升级这两个单元,因为它们被焊接在主板上。
大多数台式机主板支持一系列的 CPU,并且是可以升级的 —— 假设你还没有使用该系列中最顶级的处理器。
使用系统监视器观察你的 CPU,并确定升级是否有帮助。它的“资源”面板将显示你的 CPU 负载。如果你的所有逻辑处理器始终保持在 80% 或 90% 以上,你可以从更多的 CPU 功率中受益。
这是一个升级 CPU 的有趣项目。只要小心谨慎,任何人都可以做到这一点。
不幸的是,这几乎没有成本效益。大多数卖家对单个 CPU 芯片收取溢价,比他们卖给你的新系统要高。因此,对许多人来说,升级 CPU 并不具有经济意义。
如果你将显示器直接插入台式机的主板,你可能会通过升级图形处理器而受益。只需添加一块显卡。
诀窍是在新显卡和你的 CPU 之间实现平衡的工作负荷。这个 [在线工具](https://www.gpucheck.com/gpu-benchmark-comparison) 能准确识别哪些显卡能与你的 CPU 最好地配合。[这篇文章](https://helpdeskgeek.com/how-to/see-how-much-your-cpu-bottlenecks-your-gpu-before-you-buy-it/) 详细解释了如何去升级你的图形处理。
### 在升级前收集数据
个人电脑用户有时会根据直觉来升级他们的 Linux 硬件。一个更好的方法是先监控性能并收集一些数据。开源的 GUI 工具使之变得简单。它们有助于预测硬件升级是否值得你花时间和金钱。然后,在你升级之后,你可以用它们来验证你的改变是否达到了预期效果。
这些是最常见的硬件升级。只要稍加努力并使用正确的开源工具,任何 Linux 用户都可以经济有效地升级一台 PC。
---
via: <https://opensource.com/article/21/4/upgrade-linux-hardware>
作者:[Howard Fosdick](https://opensource.com/users/howtech) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my article on [identifying Linux performance bottlenecks using open source tools](https://opensource.com/article/21/3/linux-performance-bottlenecks), I explained some simple ways to monitor Linux performance using open source graphical user interface (GUI) tools. I focused on identifying *performance bottlenecks*, situations where a hardware resource reaches its limits and holds back your PC's performance.
How can you address a performance bottleneck? You could tune the applications or system software. Or you could run more efficient apps. You could even alter your behavior using your computer, for example, by scheduling background programs for off-hours.
You can also improve your PC's performance through a hardware upgrade. This article focuses on the upgrades that give you the biggest payback.
Open source tools are the key. GUI tools help you monitor your system to predict which hardware improvements will be effective. Otherwise, you might buy hardware and find that it doesn't improve performance. After an upgrade, these tools also help verify that the upgrade produced the benefits you expected.
This article outlines a simple approach to PC hardware upgrades. The "secret sauce" is open source GUI tools.
## How to upgrade memory
Years ago, memory upgrades were a no-brainer. Adding memory nearly always improved performance.
Today, that's no longer the case. PCs come with much more memory, and Linux uses it very efficiently. If you buy memory your system doesn't need, you've wasted money.
So you'll want to spend some time monitoring your computer to see if a memory upgrade will help its performance. For example, watch memory use while you go about your typical day. And be sure to check what happens during memory-intensive workloads.
A wide variety of open source tools can help with this monitoring, but I'll use the [GNOME System Monitor](https://vitux.com/how-to-install-and-use-task-manager-system-monitor-in-ubuntu/). It's available in most Linux repositories.
When you start up the System Monitor, its **Resources** panel displays this output:
Fig. 1. Monitoring memory with GNOME System Monitor (Howard Fosdick, CC BY-SA 4.0)
The middle of the screen shows memory use. [Swap](https://opensource.com/article/18/9/swap-space-linux-systems) is disk space that Linux uses when it runs low on memory. Linux effectively increases memory by using swap as a slower extension to memory.
Since swap is slower than memory, if swap activity becomes significant, adding memory will improve your computer's performance. How much improvement you'll get depends on the amount of swap activity and the speed of your swap device.
If a lot of swap space is used, you'll get a bigger performance improvement by adding memory than if only a small amount of swap is used.
And if swap resides on a slow mechanical hard drive, you'll see a greater improvement by adding memory than you will if swap resides on the fastest available solid-state disk.
Here's an example of when to add memory. This computer shows increased swap activity after memory utilization hits 80%. It becomes unresponsive as memory use surpasses 90%:
Fig. 2. A memory upgrade will help (Howard Fosdick, CC BY-SA 4.0)
### How to perform a memory upgrade
Before you upgrade, you need to determine how many memory slots you have, how many are open, the kinds of memory sticks they require, and your motherboard's maximum allowable memory.
You can read your computer's documentation to get those answers. Or, you can just enter these Linux line commands:
What are the characteristics of the installed memory sticks? |
`sudo lshw -short -C memory` |
What is the maximum allowable memory for this computer? |
`sudo dmidecode -t memory | grep -i max` |
How many memory slots are open? (A null response means none are available) |
`sudo lshw -short -C memory | grep -i empty` |
As with all hardware upgrades, unplug the computer beforehand. Ground yourself before you touch your hardware—even the tiniest shock can damage circuitry. Fully seat the memory sticks into the motherboard slots.
After the upgrade, start System Monitor. Run the same programs that overloaded your memory before.
System Monitor should show your expanded memory, and you should see better performance.
## How to upgrade storage
We're in an era of rapid storage improvements. Even computers that are only a few years old can benefit from disk upgrades. But first, you'll want to make sure an upgrade makes sense for your computer and workload.
Start by finding out what disk you have. Many open source tools will tell you. [Hardinfo](https://itsfoss.com/hardinfo/) or [GNOME Disks](https://en.wikipedia.org/wiki/GNOME_Disks) are good options because both are widely available, and their output is easy to understand. These apps will tell you your disk's make, model, and other details.
Next, determine your disk's performance by benchmarking it. GNOME Disks makes this easy. Just start the tool and click on its **Benchmark Disk** option. This gives you disk read and write rates and the average disk access time:
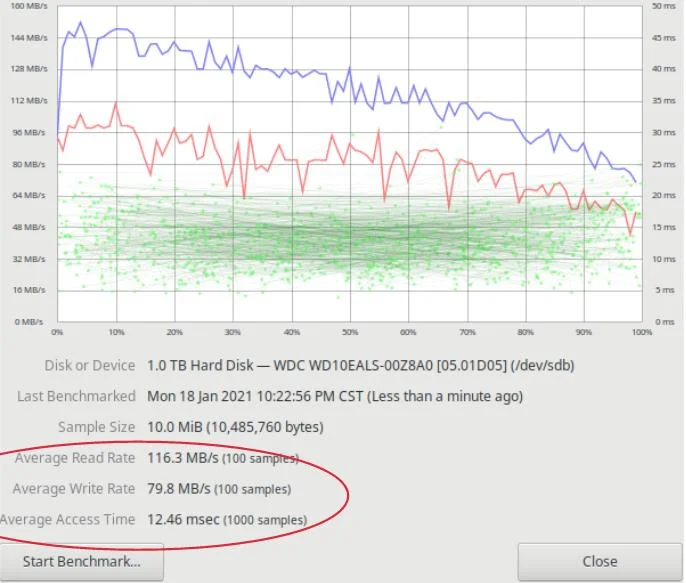
Fig. 3. GNOME disks benchmark output (Howard Fosdick, CC BY-SA 4.0)
With this information, you can compare your disk to others at benchmarking websites like [PassMark Software](https://www.harddrivebenchmark.net/) and [UserBenchmark](https://www.userbenchmark.com/). Those provide performance statistics, speed rankings, and even price and performance numbers. You can get an idea of how your disk compares to possible replacements.
Here's an example of some of the detailed disk info you'll find at UserBenchmark:
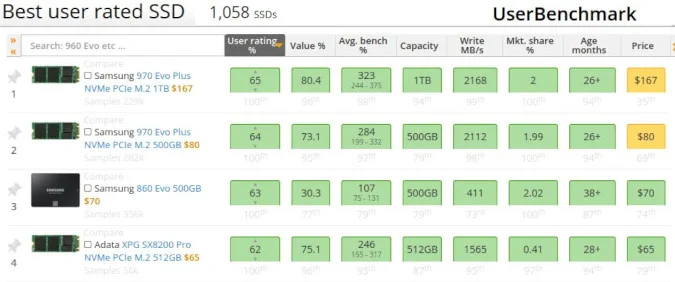
Fig. 4. Disk comparisons at UserBenchmark (Howard Fosdick, CC BY-SA 4.0)
### Monitor disk utilization
Just as you did with memory, monitor your disk in real time to see if a replacement would improve performance. The [ atop line command](https://opensource.com/life/16/2/open-source-tools-system-monitoring) tells you how busy a disk is.
In its output below, you can see that device `sdb`
is `busy 101%`
. And one of the processors is waiting on that disk to do its work 85% of the time (`cpu001 w 85%`
):
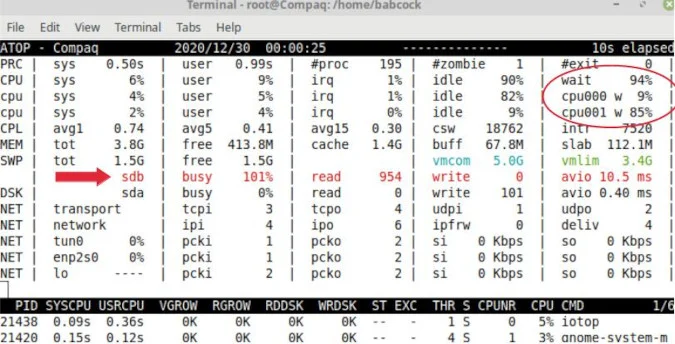
Fig. 5. atop command shows disk utilization (Howard Fosdick, CC BY-SA 4.0)
Clearly, you could improve performance with a faster disk.
You'll also want to know which program(s) are causing all that disk usage. Just start up the System Monitor and click on its **Processes** tab.
Now you know how busy your disk is and what program(s) are using it, so you can make an educated judgment whether a faster disk would be worth the expense.
### Buying the disk
You'll encounter three major technologies when buying a new internal disk:
- Mechanical hard drives (HDDs)
- SATA-connected solid-state disks (SSDs)
- PCIe-connected NVMe solid-state disks (NVMe SSDs)
What are their speed differences? You'll see varying numbers all over the web. Here's a typical example:
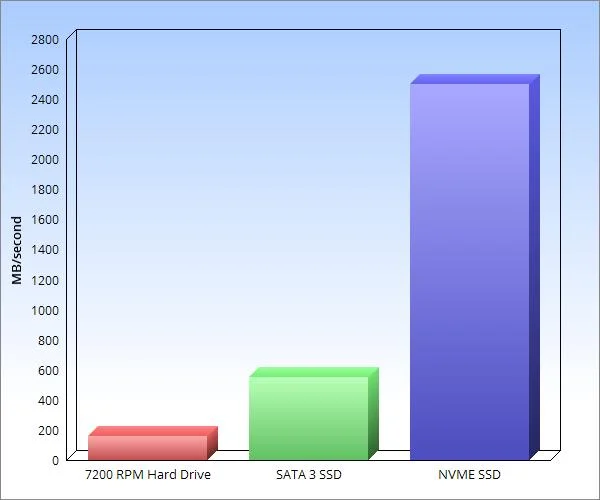
opensource.com
**Red bar:**Mechanical hard disks offer the cheapest bulk storage. But in terms of performance, they're slowest by far.**Green bar:**SSDs are faster than mechanical hard drives. But if an SSD uses a SATA interface, that limits its performance. This is because the SATA interface was designed over a decade ago for mechanical hard drives.**Blue bar:**The fastest technology for internal disks is the new[PCIe-connected NVMe solid-state disk](https://www.trentonsystems.com/blog/pcie-gen4-vs-gen3-slots-speeds). These can be roughly five times faster than SATA-connected SSDs and 20 times faster than mechanical hard disks.
For external SSDs, you'll find that the [latest Thunderbolt and USB interfaces](https://www.howtogeek.com/449991/thunderbolt-3-vs.-usb-c-whats-the-difference/) are the fastest.
### How to install an internal disk
Before purchasing any disk, verify that your computer can support the necessary physical interface.
For example, many NVMe SSDs use the popular new M.2 (2280) form factor. That requires either a tailor-made motherboard slot, a PCIe adapter card, or an external USB adapter. Your choice could affect your new disk's performance.
Always back up your data and operating system before installing a new disk. Then copy them to the new disk. Open source [tools](https://www.linuxlinks.com/diskcloning/) like Clonezilla, Mondo Rescue, or GParted can do the job. Or you could use Linux line commands like `dd`
or `cp`
.
Be sure to use your fast new disk in situations where it will have the most impact. Employ it as a boot drive, for storing your operating system and apps, for swap space, and for your most frequently processed data.
After the upgrade, run GNOME Disks to benchmark your new disk. This helps you verify that you got the performance boost you expected. You can verify real-time operation with the `atop`
command.
## How to upgrade USB ports
Like disk storage, USB performance has shown great strides in the past several years. Many computers only a few years old could get a big performance boost simply by adding a cheap USB port card.
Whether the upgrade is worthwhile depends on how frequently you use your ports. Use them rarely, and it doesn't matter if they're slow. Use them frequently, and an upgrade might really impact your work.
Here's how dramatically maximum USB data rates vary across port standards:
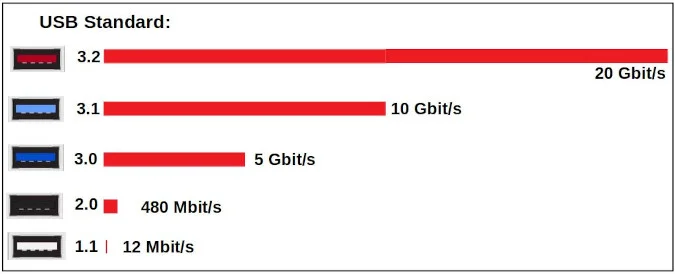
Fig. 7. USB speeds vary greatly (Howard Fosdick, CC BY-SA 4.0, based on data from Tripplite and Wikipedia)
To see the actual USB speeds you're getting, start GNOME Disks. GNOME Disks can benchmark a USB-connected device just like it can an internal disk. Select its **Benchmark Disk** option.
The device you plug in and the USB port together determine the speed you'll get. If the port and device are mismatched, you'll experience the slower speed of the two.
For example, connect a device that supports USB 3.1 speeds to a 2.0 port, and you'll get the 2.0 data rate. (And your system won't tell you this unless you investigate with a tool like GNOME Disks.) Conversely, connect a 2.0 device to a 3.1 port, and you'll also get the 2.0 speed. So for best results, always match your port and device speeds.
To monitor a USB-connected device in real time, use the `atop`
command and System Monitor together, the same way you did to monitor an internal disk. This helps you see if you're bumping into your current setup's limit and could benefit by upgrading.
Upgrading your ports is easy. Just buy a USB card that fits into an open PCIe slot.
USB 3.0 cards are only about $25. Newer, more expensive cards offer USB 3.1 and 3.2 ports. Nearly all USB cards are plug-and-play, so Linux automatically recognizes them. (But always verify before you buy.)
Be sure to run GNOME Disks after the upgrade to verify the new speeds.
## How to upgrade your internet connection
Upgrading your internet bandwidth is easy. Just write a check to your ISP.
The question is: should you?
System Monitor shows your bandwidth use (see Figure 1). If you consistently bump against the limit you pay your ISP for, you'll benefit from buying a higher limit.
But first, verify that you don't have a problem you could fix yourself. I've seen many cases where someone thinks they need to buy more bandwidth from their ISP when they actually just have a connection problem they could fix themselves.
Start by testing your maximum internet speed at websites like [Speedtest](https://www.speedtest.net/) or [Fast.com](https://fast.com/). For accurate results, close all programs and run *only* the speed test; turn off your VPN; run tests at different times of day; and compare the results from several testing sites. If you use WiFi, test with it and without it (by directly cabling your laptop to the modem).
If you have a separate router, test with and without it. That will tell you if your router is a bottleneck. Sometimes just repositioning the router in your home or updating its firmware will improve connection speed.
These tests will verify that you're getting the speeds you're paying your ISP for. They'll also expose any local WiFi or router problem you could fix yourself.
Only after you've done these tests should you conclude that you need to purchase more internet bandwidth.
## Should you upgrade your CPU or GPU?
What about upgrading your CPU (central processing unit) or GPU (graphics processing unit)?
Laptop owners typically can't upgrade either because they're soldered to the motherboard.
Most desktop motherboards support a range of CPUs and are upgradeable—assuming you're not already using the topmost processor in the series.
Use System Monitor to watch your CPU and determine if an upgrade would help. Its **Resources** panel will show your CPU load. If all your logical processors consistently stay above 80% or 90%, you could benefit from more CPU power.
It's a fun project to upgrade your CPU. Anyone can do it if they're careful.
Unfortunately, it's rarely cost-effective. Most sellers charge a premium for an individual CPU chip versus the deal they'll give you on a new system unit. So for many people, a CPU upgrade doesn't make economic sense.
If you plug your display monitor directly into your desktop's motherboard, you might benefit by upgrading your graphics processing. Just add a video card.
The trick is to achieve a balanced workload between the new video card and your CPU. This [online tool](https://www.gpucheck.com/gpu-benchmark-comparison) identifies exactly which video cards will best work with your CPU. [This article](https://helpdeskgeek.com/how-to/see-how-much-your-cpu-bottlenecks-your-gpu-before-you-buy-it/) provides a detailed explanation of how to go about upgrading your graphics processing.
## Gather data before you upgrade
Personal computer users sometimes upgrade their Linux hardware based on gut feel. A better way is to monitor performance and gather some data first. Open source GUI tools make this easy. They help predict whether a hardware upgrade will be worth your time and money. Then, after your upgrade, you can use them to verify that your changes had the intended effect.
These are the most popular hardware upgrades. With a little effort and the right open source tools, any Linux user can cost-effectively upgrade a PC.
## 4 Comments |
13,477 | Python 3.9 如何修复装饰器并改进字典 | https://opensource.com/article/21/5/python-39-features | 2021-06-12T11:53:21 | [
"Python"
] | https://linux.cn/article-13477-1.html |
>
> 探索最近版本的 Python 的一些有用的特性。
>
>
>

这是 Python 3.x 首发特性系列文章中的第十篇,其中一些版本已经发布了一段时间。Python 3.9 在 2020 年首次发布,具有很酷的新特性,但仍未被充分利用。下面是其中的三个。
### 添加字典
假设你有一个 `defaults` 字典,而你想更新它的参数。在 Python 3.9 之前,最好的办法是复制 `defaults` 字典,然后使用 `.update()` 方法。
Python 3.9 为字典引入了联合运算符:
```
defaults = dict(who="someone", where="somewhere")
params = dict(where="our town", when="today")
defaults | params
```
```
{'who': 'someone', 'where': 'our town', 'when': 'today'}
```
注意,顺序很重要。在这种情况下,正如预期,来自 `params` 的 `where` 值覆盖了默认值。
### 删除前缀
如果你用 Python 做临时的文本解析或清理,你会写出这样的代码:
```
def process_pricing_line(line):
if line.startswith("pricing:"):
return line[len("pricing:"):]
return line
process_pricing_line("pricing:20")
```
```
'20'
```
这样的代码很容易出错。例如,如果字符串被错误地复制到下一行,价格就会变成 `0` 而不是 `20`,而且会悄悄地发生。
从 Python 3.9 开始,字符串有了一个 `.lstrip()` 方法:
```
"pricing:20".lstrip("pricing:")
```
```
'20'
```
### 任意的装饰器表达式
以前,关于装饰器中允许哪些表达式的规则没有得到充分的说明,而且很难理解。例如:虽然
```
@item.thing
def foo():
pass
```
是有效的,而且:
```
@item.thing()
def foo():
pass
```
是有效的,相似地:
```
@item().thing
def foo():
pass
```
产生一个语法错误。
从 Python 3.9 开始,任何表达式作为装饰器都是有效的:
```
from unittest import mock
item = mock.MagicMock()
@item().thing
def foo():
pass
print(item.return_value.thing.call_args[0][0])
```
```
<function foo at 0x7f3733897040>
```
虽然在装饰器中保持简单的表达式仍然是一个好主意,但现在是人类的决定,而不是 Python 分析器的选择。
### 欢迎来到 2020 年
Python 3.9 大约在一年前发布,但在这个版本中首次出现的一些特性非常酷,而且没有得到充分利用。如果你还没使用,那么将它们添加到你的工具箱中。
---
via: <https://opensource.com/article/21/5/python-39-features>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the tenth in a series of articles about features that first appeared in a version of Python 3.x. Some of these versions have been out for a while. Python 3.9 was first released in 2020 with cool new features that are still underused. Here are three of them.
## Adding dictionaries
Say you have a dictionary with "defaults," and you want to update it with parameters. Before Python 3.9, the best option was to copy the defaults dictionary and then use the `.update()`
method.
Python 3.9 introduced the union operator to dictionaries:
```
defaults = dict(who="someone", where="somewhere")
params = dict(where="our town", when="today")
defaults | params
```
` {'who': 'someone', 'where': 'our town', 'when': 'today'}`
Note that the order matters. In this case, the `where`
value from `params`
overrides the default, as it should.
## Removing prefixes
If you have done ad hoc text parsing or cleanup with Python, you will have written code like:
```
def process_pricing_line(line):
if line.startswith("pricing:"):
return line[len("pricing:"):]
return line
process_pricing_line("pricing:20")
```
` '20'`
This kind of code is prone to errors. For example, if the string is copied incorrectly to the next line, the price will become `0`
instead of `20`
, and it will happen silently.
Since Python 3.9, strings have a `.removeprefix()`
method:
```
>>> "pricing:20".removeprefix("pricing:")
'20'
```
## Arbitrary decorator expressions
Previously, the rules about which expressions are allowed in a decorator were underdocumented and hard to understand. For example, while:
```
@item.thing
def foo():
pass
```
is valid, and:
```
@item.thing()
def foo():
pass
```
is valid, the similar:
```
@item().thing
def foo():
pass
```
produces a syntax error.
Starting in Python 3.9, any expression is valid as a decorator:
```
from unittest import mock
item = mock.MagicMock()
@item().thing
def foo():
pass
print(item.return_value.thing.call_args[0][0])
```
` <function foo at 0x7f3733897040>`
While keeping to simple expressions in the decorator line is still a good idea, it is now a human decision, rather than the Python parser's option.
## Welcome to 2020
Python 3.9 was released about one year ago, but some of the features that first showed up in this release are cool—and underused. Add them to your toolkit if you haven't already.
## Comments are closed. |
13,478 | RTFM!如何阅读(和理解)Linux 中神奇的手册页 | https://itsfoss.com/linux-man-page-guide/ | 2021-06-12T16:18:12 | [
"手册页",
"man"
] | https://linux.cn/article-13478-1.html | 
<ruby> 手册页 <rt> man pages </rt></ruby>,即<ruby> 参考手册页 <rt> reference manual pages </rt></ruby>的简称,是你进入 Linux 的钥匙。你想知道的一切都在那里,包罗万象。这套文档永远不会赢得普利策奖,但这套文档是相当准确和完整的。手册页是主要信源,其权威性是众所周知的。
虽然它们是源头,但阅读起来并不是最令人愉快的。有一次,在很久以前的哲学课上,有人告诉我,阅读 [亚里士多德](https://www.britannica.com/biography/Aristotle) 是最无聊的阅读。我不同意:说到枯燥的阅读,亚里士多德远远地排在第二位,仅次于手册页。
乍一看,这些页面可能看起来并不完整,但是,不管你信不信,手册页并不是为了隐藏信息 —— 只是因为信息量太大,这些页面必须要有结构,而且信息是以尽可能简短的形式给出的。这些解释相当简略,需要一些时间来适应,但一旦你掌握了使用它们的技巧,你就会发现它们实际上是多么有用。
### Linux 中的手册页入门
这些页面是通过一个叫做 `man` 的工具查看的,使用它的命令相当简单。在最简单的情况下,要使用 `man`,你要在命令行上输入 `man`,后面加一个空格和你想查询的命令,比如 `ls` 或 `cp`,像这样:
```
man ls
```
`man` 会打开 `ls` 命令的手册页。

你可以用方向键上下移动,按 `q` 退出查看手册页。通常情况下,手册页是用 `less` 打开的,所以 `less` 命令的键盘快捷键在 `man` 中也可以使用。
例如,你可以用 `/search_term` 来搜索一个特定的文本,等等。
有一个关于手册页的介绍,这是一篇值得阅读介绍。它非常详细地说明了手册页是如何布局和组织的。
要看这个页面,请打开一个终端,然后输入:
```
man man
```

### 节
在你开始更深入地研究手册页之前,知道手册页有一个固定的页面布局和一个归档方案会有帮助。这可能会让新手感到困惑,因为我可以说:“看手册页中关于 `ls` 的 NAME <ruby> 节 <rt> section </rt></ruby>”,我也可以说:“看第 5 <ruby> 节 <rt> section </rt></ruby>中的 `passwd` 的手册页。”
我把 “<ruby> 节 <rt> section </rt></ruby>” 这个词用斜体字表示,是为了显示混淆的来源。这个词,“节” 被用于两种不同的方式,但并不总是向新人解释其中的区别。
我不确定为什么会出现这种混淆,但我在培训新用户和初级系统管理员时看到过几次这种混淆。我认为这可能是隧道视野,专注于一件事会使一个人忘记另一件事。一叶障目,不见泰山。
对于那些已经知道其中的区别的人,你可以跳过这一小节。这一部分是针对那些刚接触到手册页的人。
这就是区别:
#### 对于手册页
单独的手册页是用来显示信息块的。例如,每个手册页都有一个“NAME”节,显示命令的名称和简短的描述。还会有另一个信息块,称为“SYNOPSIS”,显示该命令是如何使用的,以此类推。

每个手册页都会有这些,以及其他的标题。这些在各个手册页上的节,或者说标题,有助于保持事情的一致性和信息的分工。
#### 对于手册
使用“节”,如 “查看第 5 节中的 `passwd` 的手册页”,是指整个手册的内容。当我们只看一页时,很容易忽略这一点,但是 `passwd` 手册页是同一本手册的一部分,该手册还有 `ls`、`rm`、`date`、`cal` 等的手册页。
整个 Linux 手册是巨大的;它有成千上万的手册页。其中一些手册页有专门的信息。有些手册页有程序员需要的信息,有些手册页有网络方面的独特信息,还有一些是系统管理员会感兴趣的。
这些手册页根据其独特的目的被分组。想想看,把整个手册分成几个章节 —— 每章有一个特定的主题。有 9 个左右的章节(非常大的章节)。碰巧的是,这些章节被称为“节”。
总结一下:
* 手册中单页(我们称之为“手册页”)的节是由标题定义的信息块。
* 这个大的手册(所有页面的集合)中的章节,刚好被称为“节”。
现在你知道区别了,希望本文的其余部分会更容易理解。
### 手册页的节
你将会看到不同的手册页,所以让我们先研究一下各个页面的布局。
手册页被分成几个标题,它们可能因提供者不同而不同,但会有相似之处。一般的分类如下:
* `NAME`(名称)
* `SYNOPSIS`(概要)
* `DESCRIPTION`(描述)
* `EXAMPLES`(例子)
* `DIAGNOSTICS`(诊断)
* `FILES`(文件)
* `LIMITS`(限制)
* `PORTABILITY`(可移植性)
* `SEE ALSO`(另见)
* `HISTORY`(历史)
* WARNING`(警告)或`BUGS`(错误)
* `NOTES`(注意事项)
`NAME` - 在这个标题下是命令的名称和命令的简要描述。
`SYNOPSIS` - 显示该命令的使用方法。例如,这里是 `cal` 命令的概要:
```
cal [Month] [Year]
```
概要以命令的名称开始,后面是选项列表。概要采用命令行的一般形式;它显示了你可以输入的内容和参数的顺序。方括号中的参数(`[]`)是可选的;你可以不输入这些参数,命令仍然可以正常工作。不在括号内的项目必须使用。
请注意,方括号只是为了便于阅读。当你输入命令时,不应该输入它们。
`DESCRIPTION` - 描述该命令或工具的作用以及如何使用它。这一节通常以对概要的解释开始,并说明如果你省略任何一个可选参数会发生什么。对于长的或复杂的命令,这一节可能会被细分。
`EXAMPLES` - 一些手册页提供了如何使用命令或工具的例子。如果有这一节,手册页会尝试给出一些简单的使用例子,以及更复杂的例子来说明如何完成复杂的任务。
`DIAGNOSTICS` - 本节列出了由命令或工具返回的状态或错误信息。通常不显示不言自明的错误和状态信息。通常会列出可能难以理解的信息。
`FILES` - 本节包含了 UNIX 用来运行这个特定命令的补充文件的列表。这里,“补充文件”是指没有在命令行中指定的文件。例如,如果你在看 `passwd` 命令的手册,你可能会发现 `/etc/passwd` 列在这一节中,因为 UNIX 是在这里存储密码信息。
`LIMITS` - 本节描述了一个工具的限制。操作系统和硬件的限制通常不会被列出,因为它们不在工具的控制范围内。
`PORTABILITY` - 列出其他可以使用该工具的系统,以及该工具的其他版本可能有什么不同。
`SEE ALSO` - 列出包含相关信息的相关手册页。
`HISTORY` - 提供命令的简要历史,如它第一次出现的时间。
`WARNING` - 如果有这个部分,它包含了对用户的重要建议。
`NOTES` - 不像警告那样严重,但也是重要的信息。
同样,并不是所有的手册都使用上面列出的确切标题,但它们足够接近,可以遵循。
### 手册的节
整个 Linux 手册集合的手册页传统上被划分为有编号的节:
**第 1 节**:Shell 命令和应用程序 **第 2 节**:基本内核服务 - 系统调用和错误代码 **第 3 节**:为程序员提供的库信息 **第 4 节**:网络服务 - 如果安装了 TCP/IP 或 NFS 设备驱动和网络协议 **第 5 节**:文件格式 - 例如:显示 `tar` 存档的样子 **第 6 节**:游戏 **第 7 节**:杂项文件和文档 **第 8 节**:系统管理和维护命令 **第 9 节**:不知名的内核规格和接口
将手册页分成这些组,可以使搜索更有效率。在我工作的地方,我有时会做一些编程工作,所以我花了一点时间看第 3 节的手册页。我也做一些网络方面的工作,所以我也知道要涉足网络部分。作为几个实验性机器的系统管理员,我在第 8 节花了很多时间。
将手册网归入特定的节(章节),使搜索信息更加容易 —— 无论是对需要搜索的人,还是对进行搜索的机器。
你可以通过名称旁边的数字来判断哪个手册页属于哪个部分。例如,如果你正在看 `ls` 的手册页,而页面的最上面写着。 `LS(1)`,那么你正在浏览第 1 节中的 `ls` 页面,该节包含关于 shell 命令和应用程序的页面。
下面是另一个例子。如果你在看 `passwd` 的手册页,页面的顶部显示: `PASSWD(1)`,说明你正在阅读第 1 节中描述 `passwd` 命令如何更改用户账户密码的手册页。如果你看到 `PASSWD(5)`,那么你正在阅读关于密码文件和它是如何组成的的手册页。

`passwd` 恰好是两个不同的东西:一个是命令的名称,一个是文件的名称。同样,第 1 节描述了命令,而第 5 节涉及文件格式。
括号中的数字是重要的线索 —— 这个数字告诉你正在阅读的页面来自哪一节。
### 搜索一个特定的节
基本命令:
```
man -a name
```
将在每一节中搜索由 `name` 标识的手册页,按数字顺序逐一显示。要把搜索限制在一个特定的部分,请在 `man` 命令中使用一个参数,像这样:
```
man 1 name
```
这个命令将只在手册页的第 1 节中搜索 `name`。使用我们前面的 `passwd` 例子,这意味着我们可以保持搜索的针对性。如果我想阅读 `passwd` 命令的手册页,我可以在终端输入以下内容:
```
man 1 passwd
```
`man` 工具将只在第 1 节中搜索 `passwd` 并显示它。它不会在任何其他节中寻找 `passwd`。
这个命令的另一种方法是输入: `man passwd.1`。
### 使用 man -k 来搜索包含某个关键词的所有手册页
如果你想获得包含某个关键词的手册页的列表,`man` 命令中的 `-k` 选项(通常称为标志或开关)可以派上用场。例如,如果你想看一个关于 `ftp` 的手册列表,你可以通过输入以下内容得到这个列表:
```
man -k ftp
```
在接下来的列表中,你可以选择一个特定的手册页来阅读:

在某些系统上,在 `man -k` 工作之前,系统管理员需要运行一个叫做 `catman` 的工具。
### 使用 whatis 和 whereis 命令来了解手册的各个节
有两个有趣的工具可以帮助你搜索信息:`whatis`和 `whereis`。
#### whatis
有的时候,我们完全可以得到我们需要的信息。我们需要的信息有很大的机会是可以找到的 —— 找到它可能是一个小问题。
例如,如果我想看关于 `passwd` 文件的手册页,我在终端上输入:
```
man passwd
```
我就会看到关于 `passwd` 命令所有信息的手册页,但没有关于 `passwd` 文件的内容。我知道 `passwd` 是一个命令,也有一个 `passwd` 文件,但有时,我可能会忘记这一点。这时我才意识到,文件结构在手册页中的不同节,所以我输入了:
```
man 4 passwd
```
我得到这样的答复:
```
No manual entry for passwd in section 4
See 'man 7 undocumented' for help when manual pages are not available.
```
又是一次健忘的失误。文件结构在 System V UNIX 页面的第 4 节中。几年前,当我建立文件时,我经常使用 `man 4 ...`;这仍然是我的一个习惯。那么它在 Linux 手册中的什么地方呢?
现在是时候调用 `whatis` 来纠正我了。为了做到这一点,我在我的终端中输入以下内容:
```
whatis passwd
```
然后我看到以下内容:
```
passwd (1) - change user password
passwd (1ssl) - compute password hashes
passwd (5) - the password file
```
啊!`passwd` 文件的页面在第 5 节。现在没问题了,可以访问我想要的信息了:
```
man 5 passwd
```
然后我被带到了有我需要的信息的手册页。
`whatis` 是一个方便的工具,可以用简短的一句话告诉你一个命令的作用。想象一下,你想知道 `cal` 是做什么的,而不想查看手册页。只要在命令提示符下键入以下内容。
```
whatis cal
```
你会看到这样的回应:
```
cal (1) - displays a calendar and the date of Easter
```
现在你知道了 `whatis` 命令,我可以告诉你一个秘密 —— 有一个 `man` 命令的等价物。为了得到这个,我们使用 `-f` 开关:`man -f ...`。
试试吧。在终端提示下输入 `whatis cal`。执行后就输入:`man -f cal`。两个命令的输出将是相同的:

#### whereis
`whereis` 命令的名字就说明了这一点 —— 它告诉你一个程序在文件系统中的位置。它也会告诉你手册页的存放位置。再以 `cal` 为例,我在提示符下输入以下内容:
```
whereis cal
```
我将看到这个:

仔细看一下这个回答。答案只在一行里,但它告诉我两件事:
* `/usr/bin/cal` 是 `cal` 程序所在的地方,以及
* `/usr/share/man/man1/cal.1.gz` 是手册页所在的地方(我也知道手册页是被压缩的,但不用担心 —— `man` 命令知道如何即时解压)。
`whereis` 依赖于 `PATH` 环境变量;它只能告诉你文件在哪里,如果它们在你的 `PATH` 环境变量中。
你可能想知道是否有一个与 `whereis` 相当的 `man` 命令。没有一个命令可以告诉你可执行文件的位置,但有一个开关可以告诉你手册页的位置。在这个例子中使用 `date` 命令,如果我们输入:
```
whereis date
```
在终端提示符下,我们会看到:

我们看到 `date` 程序在 `/usr/bin/` 目录下,其手册页的名称和位置是:`/usr/share/man/man1/date.1.gz`。
我们可以让 `man` 像 `whereis` 一样行事,最接近的方法是使用 `-w` 开关。我们不会得到程序的位置,但我们至少可以得到手册页的位置,像这样:
```
man -w date
```
我们将看到这样的返回:

你知道了 `whatis` 和 `whereis`,以及让 `man` 命令做同样(或接近)事情的方法。我展示了这两种方法,有几个不同的原因。
多年来,我使用 `whatis` 和 `whereis`,因为它们在我的培训手册中。直到最近我才了解到 `man -f ...` 和 `man -w ...`。我确信我看了几百次 `man` 的手册页,但我从未注意到 `-f` 和 `-w` 开关。我总是在看手册页的其他东西(例如:`man -k ...`)。我只专注于我需要找到的东西,而忽略了其他的东西。一旦我找到了我需要的信息,我就会离开这个页面,去完成工作,而不去注意这个命令所提供的其他一些宝贝。
这没关系,因为这部分就是手册页的作用:帮助你完成工作。
直到最近我向别人展示如何使用手册页时,我才花时间去阅读 —— “看看还有什么可能” —— 我们才真正注意到关于 `man` 命令的 `-f` 和 `-w` 标记可以做什么的信息。
不管你使用 Linux 多久了,或者多么有经验,总有一些新东西需要学习。
手册页会告诉你在完成某项任务时可能需要知道的东西 —— 但它们也有很多内容 —— 足以让你看起来像个魔术师,但前提是你要花时间去读。
### 结论
如果你花一些时间和精力在手册页上,你将会取得胜利。你对手册页的熟练程度,将在你掌握 Linux 的过程中发挥巨大作用。
---
via: <https://itsfoss.com/linux-man-page-guide/>
作者:[Bill Dyer](https://itsfoss.com/author/bill/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The * man pages*, short for
*, are your keys to Linux. Everything you want to know is there – take it all in an run with it. The collection of documents will never win a Pulitzer prize, but the set is quite accurate and complete. The man pages are*
*reference manual pages**primary source and that authority is well-known.*
*the*While they are the “go to” source, they aren’t the most pleasant to read. Once, in a long past philosophy class, I was told that reading [Aristotle](https://www.britannica.com/biography/Aristotle?ref=itsfoss.com) was the most boring read around. I disagreed: when it comes to dry reading, Aristotle comes in at a distant second to man pages.
At first glance, the pages may look incomplete but, believe it or not, the man pages aren’t designed to hide information from you – it’s just that there is so much information that the pages have to be structured and information is given in the most brief form possible. The explanations are rather spartan and they will take some getting used to, but once you get the hang of using them, you’ll see how useful they actually are.
## Getting Started with the man Pages in Linux
The pages are viewed through a utility called, `man`
, and the command to use it is rather easy. In the simplest form, to use `man`
, you type `man`
on the command line, followed by a `space`
and the command that you want to look up, such as `ls`
or `cp`
, like so:
`man ls`
man opens the manual page of the `ls`
command.
You can move up and down with the arrow keys and press `q`
to quit viewing the man page. Usually, the man pages are opened with less so the keyboard shortcuts for less command work in man as well.
For example, you can search for a specific text using /search_term and so on.
There is an introduction to the man pages and it’s important that you read this one. It spells out, in great detail, how the man pages are laid out and organized.
To see this page, open a terminal and type:
`man man`
## Section What?
Before you begin to look at man pages much deeper, it will be helpful to know that man pages have a set page layout * and* a filing scheme. This can be confusing to a newcomer since I can say: “Look at the NAME
*of the man page for*
*section*`ls`
.” I can also say, “Look at the man page for `passwd`
in *5.”*
*section*I italicized the word, * section* to try to show a source of confusion. The word,
*is being used in two different ways, but the difference isn’t always explained to newcomers.*
*section*I am not sure why this confusion sets in, but I have seen it happen a few times back when I trained new users and entry-level sysadmins. I think it might be tunnel vision. Focusing on one thing can make a person forget about another. It’s a lot like not being able to see the forest because the trees are in the way.
To those who know the difference already, you can skip this sub-section. This part is directed to the people new to man pages.
Here is the difference:
### The man page
Individual man pages are made to show blocks of information. For example, every man page has a **NAME** section to show the name of the command along with a brief description. There will be another block of information, called **SYNOPSIS** to show how the command is used, and so on.
Every man page will have these, and other headings. These sections, or headings, on individual man pages, helps keep things consistent and information compartmentalized.
### The Manual
The use of * section*, as in “Look at the man page for
`passwd`
in *5” speaks of the manual as a whole. When we look at only one page, it can be easy to overlook that, but the man page for*
*section*`passwd`
is part of the same manual that has a man page for `ls`
, `rm`
, `date`
, `cal`
, and others.The entire Linux manual is huge; it has thousands of pages. Some of those pages have specialized information. Some pages have information that programmers need, while others have information unique to networking, and others that system administrators would be interested in.
These pages are grouped according to their unique purpose. Think of splitting the entire manual into several chapters – each chapter having a specific topic. There are 9 or so chapters (very large ones at that). It just so happens that these chapters are called * sections*.
To sum this up:
- Sections of a single page of the manual (what we call the man page) are blocks of information defined by the headings and
- Sections of the manual-at-large (the collection of all of the pages) are chapters which happen to be called
.*sections*
Now you know the difference and, hopefully, the rest of this article will be easier to follow.
## man Page Sections
You will be looking at different man pages so let’s study the individual page layout first.
Manual pages are split into several headings and they may vary from vendor to vendor, but they will be similar. The general breakdown is as follows:
- NAME
- SYNOPSIS
- DESCRIPTION
- EXAMPLES
- DIAGNOSTICS
- FILES
- LIMITS
- PORTABILITY
- SEE ALSO
- HISTORY WARNING (or Bugs)
- NOTES
**NAME** – Under this heading is the command name and a brief description of the command.
**SYNOPSIS** – Shows how the command is used. For instance, here is a synopsis of the `cal`
command:
`cal [Month] [Year]`
The synopsis begins with the name of the command, with a list of options following. The synopsis takes the general form of a command line; it shows what you can type and the order of the arguments. Arguments in square brackets (`[]`
) are optional; you can leave these arguments out and the command will still work correctly. Items not in brackets must be used.
Take note that brackets are for readability only. They should not be typed when you enter a command.
**DESCRIPTION** – Describes the command or utility as to what it does and how you can use it. This section usually starts off with an explanation of the synopsis as well as telling what happens if you omit any of the optional arguments. This section may be subdivided for long or complex commands.
**EXAMPLES** – Some man pages provide examples of how the command or utility can be used. If this section is present, the page tries to give a few simple usage examples, as well as more complex examples to show how complex tasks can be completed.
**DIAGNOSTICS** – This section lists status or error messages returned by the command or utility. Self-explanatory error and status messages aren’t usually shown. Messages that may be hard to understand are usually listed.
**FILES** This section contains a list of supplementary files used by UNIX to run this specific command. Here, * supplementary* files are files not specified on the command line. For example, if you were looking at a man page for the
`passwd`
command, you may find `/etc/passwd`
listed in this section since that is where UNIX stores password information.**LIMITS** – This section describes any limitations of a utility. Operating system and hardware limitations are usually not listed as they are outside of the utility’s control.
**PORTABILITY** – Lists other systems where the utility is available, along with how other versions of the utility may differ.
**SEE ALSO** – lists related man pages that contain relevant information.
**HISTORY** – Gives a brief history of the command such as when it first appeared.
**WARNING** – If this section is present, it contains important advice for users.
**NOTES** – Not as severe as a warning, but important information.
Again, not all man pages use the exact headings listed above, but they’re close enough to follow.
## The Manual’s Sections
The entire Linux manual collection of pages are traditionally divided into numbered sections:
**Section 1**: Shell commands and applications**Section 2**: Basic kernel services – system calls and error codes**Section 3**: Library information for programmers**Section 4**: Network services – if TCP/IP or NFS is installed Device drivers and network protocols**Section 5**: Standard file formats – for example: shows what aarchive looks like.*tar***Section 6**: Games**Section 7**: Miscellaneous files and documents**Section 8**: System administration and maintenance commands**Section 9**: Obscure kernel specs and interfaces
The grouping of pages into these groups makes for more efficient searching. I sometimes do a little programming where I work, so I spend a little time look at section 3 man pages. I also do a little work in networking, so I’ve been known to wade through the networking section, and as a system administrator of several experimental machines, I spend a good deal of time in section 8.
Grouping pages into specific (chapters) sections make searching for information easier – both for the human needing it, and for the machine doing the searching.
You can tell which page belongs to which section by the number next to the name. For example, if you’re looking at a man page for `ls`
and the very top of the page says this: `LS(1)`
, you are viewing the `ls`
page in section 1, which contains the pages about shell commands and applications.
Here is another example. If you’re looking at a man page for `passwd`
and the top of the page shows: `PASSWD(1)`
, you are reading the page from section 1 that describes how the `passwd`
command changes passwords for user accounts. If you see `PASSWD(5)`
, you are reading about the the password file and how it is made up.
`passwd`
happens to be be two different things: it is the name of a command and a name of a file. Again, section 1 describes the command, while section 5 covers file formats.
The number in the parenthesis is the big clue – that number tells you what section that the page you’re reading, came from.
## Searching for a Specific Section
The basic command:
` man name`
will search for the man page identified by * name* in every section, displaying them one at a time, in numerical order. To limit your search to a specific section, use an argument with the
`man`
command, like so:` man 1 name`
This command will only search section 1, of the man pages, for * name*. Using our
`passwd`
example earlier, this means that we can keep the search targeted. If I want to read about the `passwd`
command, I can type this in the terminal:`man 1 passwd`
The `man`
utility will only search through section 1 for `passwd`
and display it. It will not look through any other section for `passwd`
.
An alternative method for this command is to type: `man passwd.1`
## Using man -k to Search all man Pages Containing a Certain Keyword
The * man* command, with the
*option (often called a*
*k**or*
*flag**) can come in handy if you want a listing of man pages containing a certain keyword. For example, if you want to see a list of man pages that deal with, say,*
*switch*`ftp`
, you can get this list by typing:` man -k ftp`
From the listing that will follow, you’ll be able to pick a specific man page to read:
On some systems, before `man -k`
will work, the system administrator will need to run a utility called `catman`
.
## Using whatis and whereis Commands to Know the Manual’s Sections
There are two nifty utilities that can be helpful in your search for information: whatis and whereis.
### whatis
There are times when we can quite get the information we need. Chances are great that the information we need is available – finding it can be a small problem.
For example, if I want to look at the man page about the `passwd`
file, and I type this on the terminal:
`man passwd`
I would see the page that tells me all about the `passwd`
command, but nothing about the `passwd`
file. I know that `passwd`
is a command and there’s also a `passwd`
file, but sometimes, I might forget that. It’s then that I realize that file structures are in a different section in the man pages, so I type:
`man 4 passwd`
and I get this reply:
```
No manual entry for passwd in section 4
See 'man 7 undocumented' for help when manual pages are not available.
```
Another lapse of forgetfulness. File structures are in section 4 of System V UNIX pages. Years ago, when I built files, I used `man 4...`
* a lot*; it’s still a habit with me. So where is it in the Linux manual?
It’s time to call `whatis`
to straighten me out. To do this, I type this in my terminal:
`whatis passwd`
and I see the following:
```
passwd (1) - change user password
passwd (1ssl) - compute password hashes
passwd (5) - the password file
```
Ah! the page for the `passwd`
file is in section 5. Now I am set straight and can access the information I want:
`man 5 passwd`
and I am brought to the man page that has the information I need.
`whatis`
is handy utility that can tell you, in a brief one-liner, what a command does. Imagine that you want to know what `cal`
does without having to view the man page. Just type this at the command prompt:
`whatis cal`
and you will see this in response:
`cal (1) - displays a calendar and the date of Easter`
Now that you know about the `whatis`
command, I can let you in on a secret – there is a `man`
command equivalent. To get this, we use the `-f`
switch: `man -f ...`
Try it out. Type: `whatis cal`
at a terminal prompt. Once that executes, type: `man -f cal`
. The output of both commands will be identical.

### whereis
The very name of the `whereis`
command explains itself – it tells you where a program is within the filesystem. It will also tell you where the man page is stored too. Using `cal`
as an example again, I type this at the prompt:
`whereis cal`
I will see this:

Look carefully at the reply. The answer is on one line, but it tells me two things:
`/usr/bin/cal`
is where the `cal`
program is and
`/usr/share/man/man1/cal.1.gz`
is where the man page resides (I’m also clued into the fact that the man page is compressed, but not to worry – the man command knows how to decompress it on the fly)
`whereis`
is PATH dependent; it can only tell you where files are if they are in your PATH environment.
You may be wondering if there is an equivalent `man`
command for `whereis`
. There isn’t one that will tell you where the executable file is, but there is a switch you can use that will tell you where the man page is. Using the `date`
command in this example, if we type:
`whereis date`
at a terminal prompt, we will see:

We see that the `date`
program is in the `/usr/bin/`
directory and the name and location of its man page is: `/usr/share/man/man1/date.1.gz`
The closest we can get man to act like `whereis`
is to use the `-w`
switch. We won’t get the location of the program, but we can at least get the location of the man page, like this:
`man -w date`
and we will see this returned:

You know about `whatis`
and `whereis`
as well as a method to get the `man`
command to do the same (or close) thing. I showed both ways for a couple of different reasons.
For years, I used `whatis`
and `whereis`
since they were in my training manuals. I didn’t learn about `man -f ...`
and `man -w ...`
until fairly recently. I’m sure I looked at the man page for `man`
hundreds of times, but I never noticed the `-f`
and `-w`
switches. I was always looking at the man page for something else (i.e. `man -k ...`
). I concentrated only on what I needed to find and ignored the rest. Once I found the information I needed, I would leave the page and get the work done, not paying attention to some of the other gems the command had to offer.
This is okay since this is partly what the man pages are for: to help you get work done.
It wasn’t until I was recently showing someone how to use man pages, that I took the time to just read – “to see what else was possible” – and we took real notice of the information about what the `man`
command’s `-f`
and `-w`
flags can do.
No matter how long you have been using Linux, or how experienced, there is always something new to learn.
The man pages will tell you what you may need to know to work through a certain task – but they also hold a lot more – enough to make you look like a magician – but only if you take the time to read.
## Conclusion
If you spend some time and effort with the man pages, you will come out on top. Your proficiency of the man pages, will play a huge part in your mastery over Linux. |
13,480 | 4 位技术专家谈少数族群的技术职业 | https://opensource.com/article/20/2/careers-tech-minorities | 2021-06-13T09:10:45 | [
"黑人"
] | https://linux.cn/article-13480-1.html |
>
> 了解 BHM 对他们意味着什么,什么影响了他们的职业生涯,为想要进入科技领域的少数族群提供资源,等等。
>
>
>

为了纪念 BHM,我收集了一些我最喜欢的技术专家和开源贡献者的意见。这四位正在为下一代铺路,同时也在为他们在科技行业所做的工作铺路。了解 BHM 对他们意味着什么,是什么影响了他们的职业生涯,为想要进入科技领域的少数族群提供资源,等等。
**[Tameika Reed](https://www.linkedin.com/in/tameika-reed-1a7290128/),Women In Linux 创始人**
自 Women In Linux 发起以来,Tameika 一直致力于探索基础设施、网络安全、DevOps 和物联网领域的职业生涯,并致力于领导力和持续技能的培养。作为一个自学成才的系统管理员,Tameika 相信学习技术的最好方法就是深入其中。为了给女性一个全面的角度来看技术,Tameika 每周都会举办一次线上会议来探讨 Hyperledger、Kubernetes、微服务和高性能计算等 Linux 常规之外的技术。Tameika 的职业生涯包括与 OSCon、LISA 2018、Seagl、HashiCorp EU 2019 不同的会议以及各种当地活动进行会议发言。
**[Michael Scott Winslow](https://twitter.com/michaelswinslow),Comcast 公司核心应用与平台总监**
“我是一个父亲、丈夫、兄弟、儿子。我出生在一个小家庭,所以我很乐于把朋友们变成一个大家庭。当我把我的名字附在某件事上时,我就非常希望它能成功,所以我很在意我参与的事情。噢,在我的职业生涯中我已经做了数十年的软件开发。我解决问题,和别人合作一起帮助解决大问题,我带领、引导和指导年轻的软件工程师的同时观察我想要学习的人。”
**[Bryan Liles](https://twitter.com/bryanl),VMware 资深工程师**
“我正在和我们的团队一起重新思考开发人员如何与 Kubernetes 进行交互。当我不工作的时候,我就制造机器人和在社区里努力激励下一代的软件工程师。”
**[Mutale Nkonde](https://twitter.com/mutalenkonde),AI For the People(AFP)首席执行官**
AFP 是一家非营利性的创意机构。在创办非营利组织之前,Nkonde 从事人工智能治理工作。在此期间,她是向美国众议院提出《算法和深度伪造算法法案》以及《无生物识别障碍住房法案》的团队成员之一。Nkonde 的职业生涯中最开始是做广播记者,曾在英国广播公司(BBC)、美国有线电视新闻网(CNN)和美国广播公司(ABC)工作。她还广泛从事种族和科技方面的写作,并在哈佛大学和斯坦福大学获得奖学金。
### 是什么影响了你选择技术领域的职业?
当我回到大学的时候,我害怕电脑。我害怕电脑是因为我从大学辍学了。之后我又回去了,我就把尽我所能学习作为自己的任务。这是我至今的座右铭,学习永不停止。— Tameika Reed
我不会拐弯抹角,我小时候是个极客!在我 10 岁的时候,我就从印刷杂志上读到的代码开始每天写 GW-BASIC。在我上高中的时候,我给了自己一点喘息的时间来享受生活,但是当到了为大学选择专业的时候,这是一个很容易做出的选择。我留在了科技行业,这得感谢我一路走来遇到的了不起的导师和同事。— Michael Scott Winslow
我从中学就开始写软件了。我喜欢告诉电脑去做事情并看到结果。长大后,我很快就意识到,拥有一份让我满意、收入高的工作才是正确的选择。— Bryan Liles
我想知道为什么科技公司雇佣的黑人女性这么少。 — Mutale Nkonde
### 在开源技术领域有没有某个特别的人给了你启发?
我从很多其他人和项目中得到启发。比如我喜欢看到其他人来到 [Women In Linux](https://twitter.com/WomenInLinux),并确定他们想去哪里。我试着让人们从更全面的角度来看科技,这样他们就可以决定自己喜欢什么。说自己想在科技行业工作很容易,但要入手并坚持下去很难。你不必仅仅是一个程序员,你也可以成为一个云计算架构师。— Tameika Reed
[Kelsey Hightower](https://twitter.com/kelseyhightower)、[Bryan Liles](https://twitter.com/bryanl) 和 Kim Scott 激励了我。他们是如此真实!他们说的都是我每天的感受和经历。做好你的工作!别抱怨了!承认你的行为,并明白你是如何促成你的处境的 也给了我很大的启发。作为 DevOps 运动的领导者,我看到自己在追随和模仿他做的很多事情。 — Michael Scott Winslow
不,我没有看到我想要的灵感,所以我努力成为 20 年前那个给我启发的人。 — Bryan Liles
太多了!我最喜欢的一个是:[Dorothy Vaughan](https://en.wikipedia.org/wiki/Dorothy_Vaughan),她是美国第一个为 IBM 沃森电脑编程的人。她的故事被记录在电影《Hidden Figures》中。 — Mutale Nkonde
### 你有什么特别的资源可以推荐给那些想要加入科技行业的少数人吗?
有,我建议你在 Twitter 上交一些朋友,然后提问。以下是我在科技界关注和欣赏的一些人: — Tameika Reed
* [@techgirl1908](https://twitter.com/techgirl1908)
* [@bryanl](https://twitter.com/bryanl)
* [@kelseyhightower](https://twitter.com/kelseyhightower)
* [@kstewart](https://twitter.com/kstewart)
* [@tiffani](https://twitter.com/tiffani)
* [@EricaJoy](https://twitter.com/EricaJoy)
* [@womeninlinux](https://twitter.com/WomenInLinux)
* [@ArlanWasHere](https://twitter.com/ArlanWasHere)
* [@blkintechnology](https://twitter.com/blkintechnology)
* [@digundiv](https://twitter.com/digundiv)
受重视的新人训练营确实缩短了人们加入科技行业的时间。我遇到过几位经过培训的专业人士,他们都比 4 年制学校的同行更出色。我认为我们可以真正开始尊重人们创造的成果,而不是技术的熟练。 — Michael Scott Winslow
我不确定我能推荐什么具体的东西。科技是一个很大的整体,所以没有一个简单的答案。我的建议是选择你认为会感兴趣的东西,并努力成为这个方面的专家。从问为什么开始,而不是怎么做,并且开始理解事物是如何一起运作的。 — Bryan Liles
这取决于他们想做什么工作。对于那些在科技和社会公正的交汇处工作的人,我推荐 Safiya Noble 的《[Algorithms of Oppression](http://algorithmsofoppression.com/)》一书。 —Mutale Nkonde
### 你对有色人种将科技作为他们的职业有什么建议?
我建议你学习自己的技能。你将是一个永远的学习者。总会有人或事挡在你的路上,你的反应和行动将取决于你自己。永远不要拒绝第一个提议,要知道自己的价值。我看技术就像看艺术一样。发展需要时间,所以要对自己有耐心,拔掉插头说不也没关系。 — Tameika Reed
作为一个有点像行业保护者一样的人,我不想要不适合技术的人。所以要真正判断自己是否适合科技。你是一个能解决问题的人吗?你是否理性多于感性?你是否经常发现自己在创造过程?如果是这样,无论你的背景如何,我认为你都可以在科技行业找到一个家。— Michael Scott Winslow
事情不会那么简单。你的进步会因为你的族群而减慢。你必须更努力工作。把逆境当作动力。你要比周围的人准备的更充分,这样当机会出现时你就能够应对它。找一个与你相似的人的网络,私下发泄不满,公开展示实力。你属于这里,你就能成功。 — Bryan Liles
除了为一家公司工作,也在发展公共利益技术领域,我们的工作中心是技术如何影响真实的人。许多领导这项工作的人是有色人种妇女,黑人妇女正在取得巨大的进步。— Mutale Nkonde
### BHM 对你来说意味着什么?
意味着永不停止,为你永远不会忘记。 —Tameika Reed
BHM 对我来说意味着关注塔斯克基飞行队而不是奴隶制。强调我们如何为历史做出贡献,而不是如何成为历史的受害者。我希望人们理解我们的骄傲来自哪里,而不是我们的愤怒。在我们的人民身上发生了很多非常糟糕的事情,但我们还站在这里。坚强!— Michael Scott Winslow
BHM 是一个反思被遗忘的美国黑人历史的日子。我把它当作是感谢我的祖先所做的牺牲的时刻。— Bryan Liles
这是一个集中体现全球黑人所作贡献的时刻。我喜欢它,这是我一年中最喜欢的时间之一。 — Mutale Nkonde
---
via: <https://opensource.com/article/20/2/careers-tech-minorities>
作者:[Shilla Saebi](https://opensource.com/users/shillasaebi) 选题:[lujun9972](https://github.com/lujun9972) 译者:[M4Xrun](https://github.com/M4Xrun) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In honor of Black History Month, I've garnered the opinions of a few of my favorite technology professionals and open source contributors. These four individuals are paving the way for the next generation alongside the work they're doing in the technology industry. Learn what Black History Month means to them, what influences their career, resources for minorities wanting to break into tech, and more.
[Tameika Reed](https://www.linkedin.com/in/tameika-reed-1a7290128/), founder of Women In Linux
Since its launch, Tameika leads initiatives with a focus on exploring careers in infrastructure, cybersecurity, DevOps and IoT, pivoting into leadership and continuous skill-building. As a self-taught system administrator, Tameika believes the best way to learn tech is by just diving in. In efforts to give women a 360° view of tech, Tameika hosts a weekly virtual meetup to explore outside the norm of just Linux but introducing hyperledger, Kubernetes, microservices, and high-performance computing. Tameika’s career includes different conference talks from OSCon, LISA 2018, Seagl, HashiCorp EU 2019, and various local events.
[Michael Scott Winslow](https://twitter.com/michaelswinslow), Director, Core Applications and Platforms, Comcast
"I'm a father, husband, brother, and son. I come from a small family so I have fun turning friends into an extended family. When I attach my name to something, I obsess over its success, so I am very careful what I agree to be a part of. Oh, so as far as my career I have been involved with software development for decades. I solve problems. I work with others to help solve large problems. I lead, guide and mentor newer software engineers while observing others that I want to learn from."
[Bryan Liles](https://twitter.com/bryanl), senior staff engineer, VMware
"I’m working with our team to rethink how developers interact with Kubernetes. When not working, I’m out in the community trying to inspire the next generation of software engineers and building robots."
[Mutale Nkonde](https://twitter.com/mutalenkonde), founding CEO of AI For the People (AFP)
AFP is a nonprofit creative agency. Prior to starting a nonprofit she worked in AI Governance. During that time she was part of the team that introduced the Algorithmic and Deep Fakes Algorithmic Acts, as well as the No Biometric Barriers to Housing Act to the US House of Representatives. Nkonde started her career as a broadcast journalist and worked at the BBC, CNN & ABC. She also writes widely on race and tech, as well as holding fellowships at Harvard and Stanford.
## What influenced you to pursue a career in technology?
My fear of the computer when I went back to college. I was afraid of the computer because I dropped out of college. After and going back, I made it my mission to learn all I can. This is still my motto to this day, learning never stops. —Tameika Reed
I won’t mince words, I was a child geek! At 10 years old I started writing GW-BASIC from code that I read in printed magazines. Every single day. I gave it a bit of a break to have a life while I went to high school, but when it came time to pick a major for college, it was an easy choice. I stayed in technology thanks to the amazing mentors and colleagues I’ve had along the way. —Michael Scott Winslow
I’ve been writing software since I was in middle school. I like being able to tell computers to do things and seeing the results. As an adult, I quickly realized that having a job that gave me satisfaction and paid well was the way to go. —Bryan Liles
I wanted to explore the questions around why so few black women were being hired by tech companies. —Mutale Nkonde
## Is there a particular person or people in open source and the tech world who have inspired you?
I get inspired by a lot of other people and projects. For example, I love seeing others come to [Women In Linux](https://twitter.com/WomenInLinux) and are sure where they want to go. I try to give people a 360-view of tech so they can make a decision on what they like. Its easy to say I want to be in tech but it’s hard to get started and stay. You don’t have to be just a coder/programmer but you can be a cloud architect. —Tameika Reed
[Kelsey Hightower](https://twitter.com/kelseyhightower), [Bryan Liles](https://twitter.com/bryanl), and Kim Scott inspire me very much. They are so REAL! They say things that I feel and experience every day. Get your job done! Stop complaining! Own your actions and understand how you contribute to your situation! [Gene Kim](https://twitter.com/RealGeneKim) is a big inspiration as well. As a leader in the DevOps movement, I see myself following and emulating a lot of things he does. —Michael Scott Winslow
No. I didn’t see the inspiration I wanted, so I’ve worked hard to be the inspiration I needed 20 years ago. —Bryan Liles
There are so many! One of my favorites is [Dorothy Vaughan](https://en.wikipedia.org/wiki/Dorothy_Vaughan): She was the first person in the US to program an IBM Watson computer. Her story is captured in the movie Hidden Figures. —Mutale Nkonde
## Are there particular resources you would recommend for minorities wanting to break into tech?
Yes, I recommend finding folks on Twitter and just ask questions. Here is a list of people I follow and admire in tech: —Tameika Reed
[@techgirl1908](https://twitter.com/techgirl1908)[@bryanl](https://twitter.com/bryanl)[@kelseyhightower](https://twitter.com/kelseyhightower)[@kstewart](https://twitter.com/kstewart)[@tiffani](https://twitter.com/tiffani)[@EricaJoy](https://twitter.com/EricaJoy)[@womeninlinux](https://twitter.com/WomenInLinux)[@ArlanWasHere](https://twitter.com/ArlanWasHere)[@blkintechnology](https://twitter.com/blkintechnology)[@digundiv](https://twitter.com/digundiv)
Respected bootcamps are really cutting down the time it takes to break into the tech industry. I’ve met several professionals who went through bootcamps who have outshined their 4-year institution counterparts. I think we can really start respecting everything that people bring to the table, rather than technical fluency. —Michael Scott Winslow
I’m not sure I can recommend anything specific. Tech is a big thing and there isn’t an easy answer. My advice is to pick something you think will be interested in and work to become an expert on the topic. Start asking why instead of how, and also start understanding how things work together. — Bryan Liles
It really depends on the type of work they want to do. For people working at the intersection of tech and social justice, I would recommend the book [Algorithms of Oppression](http://algorithmsofoppression.com/) by Safiya Noble. —Mutale Nkonde
## What advice would you give to a person of color considering technology as their career?
I suggest you study your craft. You will be a forever learner. There will always be someone or something in your way how you respond and move will be on you. Never take the first offer push back and know your worth. I look at tech like I look at art. It takes time to develop so be patient with yourself. It's okay to unplug and say no. —Tameika Reed
As someone who is a bit of a protector of the industry, I don’t want people who are not suited for technology. So really decide if you have the personality for tech. Are you a problem solver? Are you more logical than emotional? Do you constantly find yourself creating processes? If so, no matter your background, I think you can find a home in tech. —Michael Scott Winslow
It is not going to be simple. Your progress will be slowed because of your race. You will have to work harder. Use this adversity as a strength. You will be better prepared than those around you and when the opportunity arises, you will be able to tackle it. Find a network of those who look like you. Air grievances in private and show strength in public. You belong and you can succeed. —Bryan Liles
To think beyond working for a company, the field of public interest tech is growing, our work centers on how technology impacts real people. Many of the people leading this work are women of color and Black women are making huge strides. Mutale Nkonde
## What does Black History Month mean to you?
It means never stop because you can never forget. —Tameika Reed
Black History Month to me means focusing on the Tuskegee Airmen and not slavery. Highlighting how we contributed to history and not how were victims of it. I want people to understand where our pride comes from and not our anger. There are a lot of really bad things that happened to our people and we are still right here. Strong! —Michael Scott Winslow
Black History Month is a time to reflect on the forgotten history of black people in the United States. I take it as a time to be thankful for the sacrifices my ancestors made. —Bryan Liles
It is a time to center the contributions black people have made across the globe. I love it, it is one of my favorite times of year. —Mutale Nkonde
## 1 Comment |
13,481 | 15 个提高工作效率的 VS Code 键盘快捷键 | https://itsfoss.com/vs-code-shortcuts/ | 2021-06-13T12:38:15 | [
"快捷键",
"VSCode"
] | https://linux.cn/article-13481-1.html | 
毫无疑问,微软的 [VS Code是最好的开源代码编辑器之一](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/)。它与传说中的 Vim 不同,VS Code 不需要你是一个快捷键大师(LCTT 译注:以下都指键盘快捷键),开发者们对它大部分的功能都及其熟悉,且推崇备至。
但这并不意味着你不能成为快捷键大师,或者说你在 VS Code 中不应该使用快捷键。
在敲代码的时候,你可能需要用鼠标去执行其他的动作,比如在 VS Code 编辑器中切换终端,而此时你的代码流程会被打断,这是不是很讨厌?如果是的,那么你应该立即熟记下面这些 VS Code 有用的快捷键。
它不仅能帮助你摆脱鼠标,还能使你的生产力和工作效率得到提高。
那么,让我们来了解一下如何通过使用快捷键快速进行代码导航来进行快速编码。
### 有用的 VS Code 快捷键
免责声明。下面的这些快捷键是我在 VS Code 的使用中发现的较为有用的,你可以根据你的需要来发现更多有用的快捷键。
下面我还给出了 MacOS 用户的键盘快捷键。
#### 1、显示所有命令
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + SHIFT + P` 或 `F1` | `SHIFT + ⌘ + P` 或 `F1` |
我们从最有用的快捷键开始,这个快捷键能打开命令面板(列表),它提供了对 VS Code 所有功能的访问。

这是一个非常重要的 VS Code 快捷键,因为即使你忘记了或不想记起其他任何快捷键,但你记得这个,那么你仍然可以使用命令面板进行各种操作,如创建新文件、打开设置、改变主题,还可以查看所有快捷键。
#### 2、垂直和水平拆分 VS Code 编辑器
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + \` | `⌘ + \` |
为了提高效率,但你又没有安装多个显示器,那么你可以通过水平或垂直分割 VS Code 的编辑器来一次查看多个文件的代码。

要在多个编辑区间切换焦点,你可以使用数字键或箭头键。
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + 1`/`2`/`3` | `⌘ + 1`/`2`/`3` |
| `CTRL + K` `CTRL + ←`/`→` | `⌘ + K` `⌘ + ←`/`→` |
#### 3、切换集成终端
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + `` | `⌘ + `` |
VS Code 中的集成终端是一个非常方便的功能,它可以让你在不切换窗口的情况下快速执行任务。要在编辑器中显示/隐藏终端,下面的快捷键会非常方便。

但是,如果你跟我一样觉得 CTRL + ` 在键盘的角落位置而比较难按到,你可以打开命令面板执行`View: Toggle Terminal` 命令来切换终端。

#### 4、转到文件
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + P` | `⌘ + P` |
随着项目的壮大,查找文件可能会变得困难。因此,我建议,即使你使用鼠标,这个命令也能为你节省很多搜索和导航到版本库中的文件的时间。

#### 5、转到行
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + G` | `^ + G` |
当你找到文件,你可能需要去到文件中指定的行增加或编辑代码,而如果这个文件包含了数千行代码,那么滚动代码将会浪费你大量的时间。而 `CTRL + G` 或 `^ + G` 快捷键能让你快速的去掉指定的行。

另外,你也可以使用上面的转到文件的快捷键,在输入框中输入冒号 `:` 加行号,结果就跟转到行是一样的。
#### 6、在整个项目中搜索
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + SHIFT + F` | `⌘ + SHIFT + F` |
很可能你需要在整个项目中搜索一个文本、变量或函数,在这种情况下,上面的命令就非常方便,它会在侧边栏显示一个搜索输入框。

我们还可以在搜索的时候添加一些过滤器,比如使用 `ALT+C` 来启用大写匹配,`ALT+W` 用于匹配整个单词,`ALT+R` 用于启用正则表达式。
#### 7、禅模式
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + K Z` | `⌘ + K Z` |
想要在不受干扰的环境中工作以保持更专注? 你可以试试禅模式(先按下 `CTRL + K`,再按下 `Z`),它会隐藏所有 UI(状态栏、活动栏、面板和侧边栏)并仅在全屏上显示编辑器。

要启用禅模式,你可以使用上面的快捷键或者打开命令面板执行 `View: Toggle Zen Mode`,要退出禅模式,你可以按两次 `Esc` 键。
#### 8、将选择添加到下一次匹配中
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + D` | `⌘ + D` |
这条命令能让你选择所选文本的下一个出现的地方,从而进行编辑。如果下一个匹配出现的位置与第一个相离较远,那这将会很方便处理。

#### 9、切换行注释
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + /` | `⌘ + /` |
将光标移到行的开头,然后添加双斜杠进行注释,这种麻烦的操作我们可以用上面的快捷键来代替了。

甚至,如果你想注释多行代码,你可以先通过 `SHIFT+UP`/`Down` 快捷键来选中多行,然后按 `CTRL+/` 快捷键进行注释。
#### 10、转到文件的开头或结尾
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + HOME`/`END` | `⌘ + ↑`/`↓` |
如果你迷失在文件的中间位置,该命令可以让你快速达到文件的起点或终点。
#### 11、代码折叠或打开
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + SHIFT + [`/`]` | `⌥ + ⌘ + [`/`]` |
这也是最有用的快捷键之一,它可以帮助你折叠/取消折叠一个区域的代码。通过这种方式,你可以隐藏不必要的代码,每次只查看所需的部分代码,以便更加专注和快速编码。

#### 12、窥视执行
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + SHIFT + F12` | `⌘ + SHIFT + F12` |
这个快捷键最有可能的作用是帮助你进行代码分析,或修复 bug 时了解函数和变量的运行情况。

#### 13、删除当前行
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + SHIFT + K` | `SHIFT + ⌘ + K` |
这是一条可以快速执行,选中当前行并按删除/退格键,这两个任务的简单命令。
#### 14、查找与替换
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + F` | `⌘ + F` |
| `CTRL + H` | `⌥ + ⌘ + F` |
用一个新的文本替换文件中所有出现的该文本的最好方法是什么?如果你手动一个一个的通过滚动代码来处理,且如果需要替换的地方又很多,那么你可能会花费大量的时间。

而使用查找和替换功能我们能在几秒内完成相同的任务。你可以用两个快捷键来打开它,其中一个实际上是打开用于查找文本的输入框,另一个用于输入新的文本。
#### 15、VS Code 的全部键盘快捷键
| Windows/Linux | macOS |
| --- | --- |
| `CTRL + K CTRL + S` | `⌘ + K ⌘ + S` |
最后,如果你还在为记住上述所有的快捷键而苦恼,你大可不必。因为你可以使用上面的快捷键查看编辑器所有可用的命令。

你还可以根据自己的喜好编辑命令的绑定键。
### 想要为 VS Code 添加更多快捷键?
如果你想对 VS Code 的快捷键有完整的了解,你可以查看 VS Code 的 [文档](https://code.visualstudio.com/docs/getstarted/keybindings)。
或者,如果你想在纸上将所有快捷键打印出来慢慢看,下面这些是各个系统对应的快捷键速查表: [Linux](https://code.visualstudio.com/shortcuts/keyboard-shortcuts-linux.pdf)、[macOS](https://code.visualstudio.com/shortcuts/keyboard-shortcuts-macos.pdf) 和 [Windows](https://code.visualstudio.com/shortcuts/keyboard-shortcuts-windows.pdf)。
---
via: <https://itsfoss.com/vs-code-shortcuts/>
作者:[Sarvottam Kumar](https://itsfoss.com/author/sarvottam/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ywxgod](https://github.com/ywxgod) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

There is no doubt that Microsoft’s [VS Code is one of the best open source code editor](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) out there. Unlike the legendary Vim, VS Code doesn’t need you to be a keyboard ninja and has tons of features that developers swear by.
But this doesn’t mean you cannot, or you should not use keyboard shortcuts in [Visual Studio Code](https://itsfoss.com/install-visual-studio-code-ubuntu/).
Do you hate breaking your coding flow and move your hand to a mouse for performing an action like toggling terminal in your Visual Studio Code (VS Code) editor? If yes, then you should immediately get yourself familiar and memorize these useful keyboard shortcuts for VS Code.
It will not just help you to get rid of a mouse, but also make you highly productive and efficient.
So, let’s get to know how you can code fast by quickly navigating through the code editor using keyboard shortcuts.
## Useful VS Code Keyboard Shortcuts
I have also mentioned keyboard shortcuts for macOS users.
### 1. Show All Commands
Windows/Linux | macOS |
---|---|
CTRL + SHIFT + P or F1 | SHIFT + ⌘ + P or F1 |
Starting with the most helpful shortcut, it opens the Command Palette that provides access to all the functionality of VS Code.
It is a very important VS Code Shortcut because even if you forget or don’t want to remember any shortcut except this one, you can still perform various operations using Command Palette like create a new file, open settings, change theme, and view all keyboard shortcuts as well.
### 2. Split VS Code Editor Vertically Or Horizontally
Windows/Linux | macOS |
---|---|
CTRL + \ | ⌘ + \ |
If you don’t have a multi-monitor setup for high productivity, you can still view codes of multiple files at once by splitting the editor either horizontally or vertically.
To change focus into editor group, you can either use number or arrow keys.
Windows/Linux | macOS |
---|---|
CTRL + 1/2/3 | ⌘ + 1/2/3 |
CTRL + K CTRL + ←/→ | ⌘ + K ⌘ + ←/→ |
### 3. Toggle Integrated Terminal
Windows/Linux | macOS |
---|---|
CTRL + ` | ⌘ + ` |
Integrated terminal in VS Code is a very convenient feature that lets you execute the task quickly without switching windows. To hide/unhide the terminal in the editor, this keyboard shortcut comes in very handy.
However, like me, if you find pressing "**CTRL+`**" difficult to use due to its weird corner location, you can still open Command Palette and execute `View: Toggle Terminal`
command.

### 4. Go To File
Windows/Linux | macOS |
---|---|
CTRL + P | ⌘ + P |
As the project grows, looking for a file might become a very difficult task. Hence, I would suggest even you use a mouse, this command can save you a lot of time in searching and navigating to a file in a repository.
### 5. Go To Line
Windows/Linux | macOS |
---|---|
CTRL + G | ^ + G |
Once you search a file, you may now want to jump to a specific line for adding or editing code. If a file contains thousands of lines of code, scrolling can definitely eat up your time. Hence, CTRL+G or ^+G VS Code Keyboard Shortcut can quickly take you to a line you want.

Alternatively, you can also use the fourth shortcut for ‘Go To File,’ where appending `:`
colon with line number in the input box works as ‘Go To Line.’
### 6. Search Complete Project
Windows/Linux | macOS |
---|---|
CTRL + SHIFT + F | ⌘ + SHIFT + F |
Most probably, you may also want to search for a text, variable, or function in your whole project. In such a case, this command is very convenient that shows search input in the sidebar.
You can also add filters to your search using ALT+C to match case, ALT+W to match the whole word, and ALT+R to use regular expression.
### 7. Zen Mode
Windows/Linux | macOS |
---|---|
CTRL + K Z | ⌘ + K Z |
Want to work in a distraction-free environment to stay more focused? Zen mode is a feature in a VS Code that hides all UI (Status Bar, Activity Bar, Panel, and Sidebar) and displays only the editor on a full screen.
To enable Zen Mode, you can either use the above shortcut or open Command Palette and execute “View: Toggle Zen Mode.” To exit Zen mode, you need to press `Esc`
button twice.
### 8. Add Selection To Next Find Match
Windows/Linux | macOS |
---|---|
CTRL + D | ⌘ + D |
This command enables you to select the next occurrences of a selected text for editing. It comes very handy if the next match is located far away from the first match.
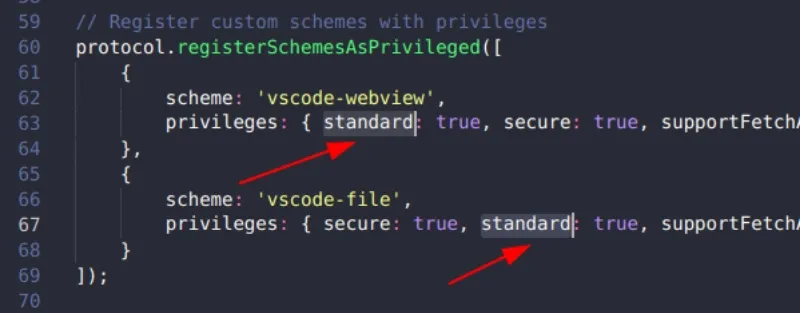
### 9. Toggle Line Comment
Windows/Linux | macOS |
---|---|
CTRL + / | ⌘ + / |
The struggle to reach the start of a line and then add a double forward slash to the comment line can be replaced with this quick keyboard shortcut.
Even if you want to comment out multiple lines, you can select all lines using `SHIFT+UP/Down`
and then press `CTRL+/`
.
### 10. Jump To The Beginning Or End Of File
Windows/Linux | macOS |
---|---|
CTRL + HOME/END | ⌘ + ↑/↓ |
If you get lost in the middle of your codes, the command can help to quickly reach either start or end of the file.
### 11. Code Folding Or Unfolding
Windows/Linux | macOS |
---|---|
CTRL + SHIFT + [ or ] | ⌥ + ⌘ + [ or ] |
It is one of the most useful shortcuts that can help you collapse/uncollapse a region of code. In this way, you can hide unnecessary code and view only the required section of code at a time to focus more and code fast.
### 12. Peek Implementation
Windows/Linux | macOS |
---|---|
CTRL + SHIFT + F12 | ⌘ + SHIFT + F12 |
The shortcut is most likely to help you in your code analysis or bug fixing where you want to understand the working of functions and variables.
### 13. Delete Current Line
Windows/Linux | macOS |
---|---|
CTRL + SHIFT + K | SHIFT + ⌘ + K |
A single quick command can sum up two tasks of selecting a current line and pressing the delete/backspace button.
### 14. Find And Replace
Windows/Linux | macOS |
---|---|
CTRL + F | ⌘ + F |
CTRL + H | ⌥ + ⌘ + F |
What could be the best way to replace all occurrences of a text in a file with a new one? If you go for one by one manually by scrolling down the code, no wonder how much time it will take if text occurrence is large.
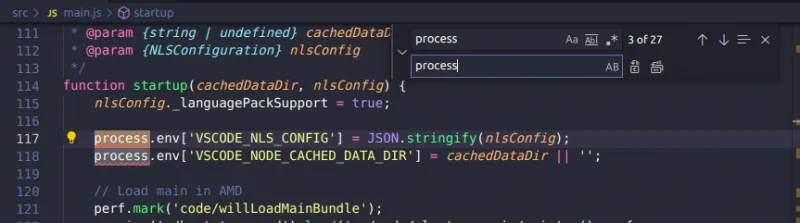
While using Find and Replace do the same task within seconds. You can open it using two shortcuts where one actually opens the input box for finding text and the other for replacing text.
### 15. VS Code Keyboard Shortcuts
Windows/Linux | macOS |
---|---|
CTRL + K CTRL + S | ⌘ + K ⌘ + S |
At last, if you still struggle with remembering all the above keyboard shortcuts, you still don’t have to worry. This is because you can view all available commands for your editor using the above shortcut.
You can also edit keybinding for the command as per your comfort.
Here is a summary of all the keyboard shortcuts discussed above.
Usage | Linux/Windows | macOS |
---|---|---|
Opens Command Palette | CTRL + SHIFT + P or F1 | SHIFT + ⌘ + P or F1 |
Split Editor Vertically Or Horizontally | CTRL + \ | ⌘ + \ |
Change focus into editor group | CTRL + 1/2/3 | ⌘ + 1/2/3 |
CTRL + K CTRL + ←/→ | ⌘ + K ⌘ + ←/→ | |
Toggle Integrated Terminal | CTRL + ` | ⌘ + ` |
Searching and navigating to a file in a repository | CTRL + P | ⌘ + P |
Jump to a specific line | CTRL + G | ^ + G |
Search for a text, variable, or function in your whole project | CTRL + SHIFT + F | ⌘ + SHIFT + F |
Zen Mode (distraction-free environment) | CTRL + K Z | ⌘ + K Z |
Select the next occurrences of a selected text | CTRL + D | ⌘ + D |
Toggle Line Comment | CTRL + / | ⌘ + / |
Jump To The Beginning Or End Of File | CTRL + HOME/END | ⌘ + ↑/↓ |
Code Folding Or Unfolding | CTRL + SHIFT + [ or ] | ⌥ + ⌘ + [ or ] |
Peek Implementation to understand the working of functions and variables. | CTRL + SHIFT + F12 | ⌘ + SHIFT + F12 |
Delete Current Line | CTRL + SHIFT + K | SHIFT + ⌘ + K |
Find And Replace | CTRL + F | ⌘ + F |
CTRL + H | ⌥ + ⌘ + F | |
VS Code Keyboard Shortcuts | CTRL + K CTRL + S | ⌘ + K ⌘ + S |
## Want More on VS Code?
If you want to have complete knowledge of VS Code keyboard shortcuts, you can check out the [documentation](https://code.visualstudio.com/docs/getstarted/keybindings?ref=itsfoss.com) of Visual Studio Code.
Or, if you want all available shortcuts in a single piece of paper, get the above cheat sheet for [Linux](https://code.visualstudio.com/shortcuts/keyboard-shortcuts-linux.pdf?ref=itsfoss.com), [macOS](https://code.visualstudio.com/shortcuts/keyboard-shortcuts-macos.pdf?ref=itsfoss.com), and [Windows](https://code.visualstudio.com/shortcuts/keyboard-shortcuts-windows.pdf?ref=itsfoss.com). You can have a quick look whenever you forget.
Once you learn keyboard shortcuts on VS Code, see how to make your code neat with [VS Code auto intend feature](https://itsfoss.com/auto-indent-vs-code/).
[How to Automatically Indent Your Code in Visual Studio CodeFormat your code correctly. Learn how to automatically indent code in Visual Studio Code.](https://itsfoss.com/auto-indent-vs-code/)

I think you already know to connect VS Code with GitHub?
[How to Connect GitHub to VS Code [Step by Step]Take your coding experience to the next level of ease by integrating GitHub into VS Code.](https://itsfoss.com/vs-code-github/)

If the built-in telemetry is holding you back from using VS Code, try VSCodium.
[VSCodium: 100% Open Source Version of Microsoft VS CodeBrief: VSCodium is a clone of Microsoft’s popular Visual Studio Code editor. It’s identical to VS Code with the single biggest difference that unlike VS Code, VSCodium doesn’t track your usage data. Microsoft’s Visual Studio Code is an excellent editor not only for web developers but](https://itsfoss.com/vscodium/)

Let me know your favorite shortcut in the comment section. |
13,483 | 完善的 API 的 4 个基本特征 | https://opensource.com/article/21/5/successful-apis | 2021-06-14T15:56:06 | [
"API"
] | https://linux.cn/article-13483-1.html |
>
> 创建一个 API(应用程序接口),我们所要做的远远不止是让它能“正常工作”。
>
>
>

如果你正在构建基于 C/S 模型的应用程序,那么你需要一个应用程序接口(API)。API 就是一种非常清晰而又明确的定义,它是一个<ruby> 进程 <rt> process </rt></ruby>与另一个进程之间明确定义的边界。Web 应用中我们常见的边界定义就是 REST/JSON API。
虽然很多开发者可能主要关注在如何让 API 正常工作(或功能正常),但却还有一些“非功能性”的要求也是需要他们注意的。所有的 API *必须具备* 的 4 个非功能性的要求是:
* 安全
* 文档
* 验证
* 测试
### 安全
在软件开发中,安全是最基本的要求。对于 API 开发者来说,API 的安全性主要包含以下 4 个方面:
1. HTTPS/SSL 证书
2. 跨域资源共享
3. 身份认证与 JSON Web 令牌
4. 授权与作用域
#### 1、HTTPS/SSL 证书
Web 应用的黄金标准是使用 SSL 证书的 HTTPS 协议。[Let's Encrypt](https://letsencrypt.org/) 可以帮你达到这一目的。Let's Encrypt 来自于非营利性的互联网安全研究小组(ISRG),它是一个免费的、自动化的、开放的证书颁发机构。
Let's Encrypt 的软件会为你的域(LCTT 译注:包含域名、IP 等信息)生成中央授权证书。而正是这些证书确保了从你的 API 到客户端的数据载荷是点对点加密的。
Let's Encrypt 支持证书管理的多种部署方案。我们可以通过查看 [文档](https://letsencrypt.org/docs/) 来找出最适合自己需要的方案。
#### 2、跨域资源共享
<ruby> 跨域资源共享 <rt> Cross-origin resource sharing </rt></ruby>(CORS)是一个针对浏览器的安全策略预检。如果你的 API 服务器与发出请求的客户端不在同一个域中,那么你就要处理 CORS。例如,如果你的服务器运行在 `api.domain-a.com` 并且接到一个来自 `domain-b.com` 的客户端的请求,那么 CORS 就会(让浏览器)发送一个 HTTP 预检请求,以便查看你的 API 服务是否会接受来自此客户域的客户端请求。
[来自 MDN 的定义](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS):
>
> “跨域资源共享(CORS)是一种基于 HTTP 头的机制,这种机制允许服务器标记除自身源外的其他任何来源(域、方案或端口)。而对于这些被服务器标识的源,浏览器应该允许我们从它们加载资源。”
>
>
>

*([MDN文档](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS), [CC-BY-SA 2.5](https://creativecommons.org/licenses/by-sa/2.5/))*
另外,有很多用于 [Node.js](https://nodejs.org) 的辅助库来 [帮助 API 开发者处理 CORS](https://www.npmjs.com/search?q=CORS)。
#### 3、身份认证与 JSON Web 令牌
有多种方法可以验证你的 API 中的认证用户,但最好的方法之一是使用 JSON Web 令牌(JWT),而这些令牌使用各种知名的加密库进行签名。
当客户端登录时,身份管理服务会向客户端提供一个 JWT。然后,客户端可以使用这个令牌向 API 发出请求,API 收到请求后,从服务器读取公钥或私密信息来验证这个令牌。
有一些现有的库,可以帮助我们对令牌进行验证,包括 [jsonwebtoken](https://github.com/auth0/node-jsonwebtoken)。关于 JWT 的更多信息,以及各种语言中对其的支持库,请查看 [JWT.io](https://jwt.io)。
```
import jwt from 'jsonwebtoken'
export default function (req, res, next) {
// req.headers.authorization Bearer token
const token = extractToken(req)
jwt.verify(token, SECRET, { algorithms: ['HS256'] }, (err, decoded) => {
if (err) { next(err) }
req.session = decoded
next()
})
}
```
#### 4、授权与作用域
认证(或身份验证)很重要,但授权同样很重要。也就是说,经过验证的客户端是否有权限让服务器执行某个请求呢?这就是作用域的价值所在。当身份管理服务器对客户端进行身份认证,且创建 JWT 令牌时,身份管理服务会给当前客户提供一个作用域,这个作用域将会决定当前经过验证的客户的 API 请求能否被服务器执行。这样也就免去了服务器对访问控制列表的一些不必要的查询。
作用域是一个文本块(通常以空格分隔),用于描述一个 API 端点的访问能力。一般来说,作用域被分为资源与动作。这种模式对 REST/JSON API 很有效,因为它们有相似的 `RESOURCE:ACTION` 结构。(例如,`ARTICLE:WRITE` 或 `ARTICLE:READ`,其中 `ARTICLE` 是资源,`READ` 和 `WRITE` 是动作)。
作用域的划分让我们的 API 能够专注于功能的实现,而不是去考虑各种角色和用户。身份访问管理服务可以将不同的角色和用户分配不同的权限范围,然后再将这些不同的作用域提供给不同的 JWT 验证中的客户。
#### 总结
当我们开发和部署 API 时,安全应该一直是最重要的要求之一。虽然安全性是一个比较宽泛的话题,但如果能解决上面四个方面的问题,这对于你的 API 来说,在生产环境中将会表现得更好。
### 文档
*有什么能比没有文档更糟糕?过期的文档。*
开发者对文档真的是又爱又恨。尽管如此,文档仍然是 API 定义是否完善的一个关键部分。开发者需要从文档中知道如何使用这些 API,且你创建的文档对于开发者如何更好地使用 API 也有着非常巨大的作用。
创建 API 文档,我们需要关注下面三个方面:
1. 开发者入门文档(自述文件/基本介绍)
2. 技术参考(规范/说明书)
3. 使用方法(入门和其他指南)
#### 1、入门文档
在构建 API 服务的时候,你需要明确一些事情,比如:这个 API 是做什么的?如何建立开发者环境?如何测试该服务?如何提交问题?如何部署它?
通常我们可以通过自述(`README`)文件来回答上面的这些问题,自述文件一般放在你的代码库中,用于为开发者提供使用你项目的最基本的起点和说明。
自述文件应该包含:
* API 的描述
* 技术参考与指南的链接
* 如何以开发者的身份设置你的项目
* 如何测试这个项目
* 如何部署这个项目
* 依赖管理
* 代码贡献指南
* 行为准则
* 许可证
* 致谢
你的自述文件应该简明扼要;你不必解释每一个方面,但要提供足够的信息,以便开发者在熟悉你的项目后可以进一步深入研究。
#### 2、技术参考
在 REST/JSON API 中, 每一个具体的<ruby> 端点 <rt> endpoint </rt></ruby>都对应一个特定的功能,都需要一个具体的说明文档,这非常重要。文档中会定义 API 的描述,输入和可能的输出,并为各种客户端提供使用示例。
[OpenAPI](https://spec.openapis.org/oas/v3.1.0) 是一个创建 REST/JSON 文档的标准, 它可以指导你完成编写 API 文档所需的各种细节。OpenAPI 还可以为你的 API 生成演示文档。
#### 3、使用方法
对于 API 的用户来说,仅仅只有技术说明是不够的。他们还需要知道如何在一些特定的情况和场景下来使用这些 API,而大多数的潜在用户可能希望通过你的 API 来解决他们所遇到的问题。
向用户介绍 API 的一个好的方法是利用一个“开始”页面。“开始”页面可以通过一个简单的用例引导用户,让他们迅速了解你的 API 能给他们能带来的益处。
#### 总结
对于任何完善的 API,文档都是一个很关键的组成部分。当你在创建文档时,你需要关注 API 文档中的如何入门、技术参考以及如何快速开始等三个方面,这样你的 API 才算是一个完善的 API。
### 验证
API 开发过程中经常被忽视的一个点就是验证。它是一个验证来自外部来源的输入的过程。这些来源可以是客户端发送过来的 JSON 数据,或者是你请求别人的服务收到的响应数据。我们不仅仅要检查这些数据的类型,还要确保这些数据确实是我们要的数据,这样可以消除很多潜在的问题。了解你的边界以及你能控制的和不能控制的东西,对于 API 的数据验证来说是一个很重要的方面。
最好的策略是在进入数据逻辑处理之前,在你能控制的边界的边缘处进行数据的验证。当客户端向你的 API 发送数据时,你需要对该数据做出任何处理之前应用你的验证,比如:确保 Email 是真实的邮件地址、日期数据有正确的格式、字符串符合长度要求。
这种简单的检查可以为你的应用增加安全性和一致性。还有,当你从某个服务接收数据时,比如数据库或缓存,你需要重新验证这些数据,以确保返回的结果符合你的数据检查。
你可以自己手写这些校验逻辑,当然也可以用像 [Lodash](https://lodash.com) 或 [Ramda](https://ramdajs.com/) 这样的函数库,它们对于一些小的数据对象非常有用。像 [Joi](https://joi.dev/)、[Yup](https://github.com/jquense/yup) 或 [Zod](https://github.com/colinhacks/zod/tree/v3) 这样的验证库效果会更好,因为它们包含了一些常见的验证方法,可以节省你的时间和精力。除此,它们还能创建一个可读性强的模式。如果你需要看看与语言无关的东西,请看 [JSON Schema](https://json-schema.org/)。
#### 总结
数据验证虽然并不显眼和突出(LCTT 译注:跟 API 的功能实现以及其他几个方面比),但它可以帮你节省大量的时间。如果不做验证,这些时间将可能被用于故障排除和编写数据迁移脚本。真的不要相信你的客户端会发送干净的数据给你,也不要让验证不通过的数据渗入到你的业务逻辑或持久数据存储中去。花点时间验证你的 API 收到的数据和请求到的响应数据,虽然在前期你可能会感到一些挫折和不适,但这总比你在后期花大量时间去做各种数据收紧管制、故障排除等要容易得多。
### 测试
测试是软件开发中的最佳实践,它应该是最主要的非功能性的要求。对于包括 API 在内的任何项目,确定测试策略都是一个挑战,因为你自始至终都要掌握各种约束,以便相应的来制定你的测试策略。
<ruby> 集成测试 <rt> Integration testing </rt></ruby>是测试 API 的最有效的方法之一。在集成测试模式中,开发团队会创建一个测试集用来覆盖应用流程中的某些部分,从一个点到另一个点。一个好的集成测试流程包括测试 API 的入口点以及模拟请求到服务端的响应。搞定这两点,你就覆盖了整个逻辑,包括从 API 请求的开始到模拟服务器的响应,并返回数据给 API。
虽然使用的是模拟,但这种方法让能我们专注于代码逻辑层,而不需要去依赖后端服务和展示逻辑来进行测试。没有依赖的测试会更加可靠、更容易实现自动化,且更容易被接入持续集成管道流。
集成测试的实施中,我会用 [Tape](https://github.com/substack/tape)、[Test-server](https://github.com/twilson63/test-server) 和 [Fetch-mock](http://www.wheresrhys.co.uk/fetch-mock/)。这些库让我们能够从 API 的请求到数据的响应进行隔离测试,使用 Fetch-mock 还可以将出站请求捕获到持久层。
#### 总结
虽然其他的各种测试和类型检查对 API 也都有很好的益处,但集成测试在流程效率、构建和管理时间方面却有着更大的优势。使用 Fetch-mock 这样的工具,可以在服务边界提供一个干净的模拟场景。
### 专注于基础
不管是设计和构建应用程序还是 API,都要确保包含上面的四个基本要素。它们并不是我们唯一需要考虑的非功能性需求,其他的还包括应用监控、日志和 API 管理等。即便如此,安全、文档、验证和测试这四个基本点,对于构建任何使用场景下的完善 API 都是至关重要的关注点。
---
via: <https://opensource.com/article/21/5/successful-apis>
作者:[Tom Wilson](https://opensource.com/users/tomwillson4014) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ywxgod](https://github.com/ywxgod) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you are building an application that uses some variation of a client/server model, you need an application programming interface (API). An API is a clearly defined boundary between one process and another. A common boundary in web applications is a REST/JSON API.
While developers may be mainly focused on making the API work (or function), there are some "non-functional" requirements that need their attention. Four *must-have* non-functional requirements for all APIs are:
- Security
- Documentation
- Validation
- Testing
## Security
Security is an essential requirement in software development. There are four areas for API developers to include regarding security:
- HTTPS/SSL certificates
- Cross-origin resource sharing
- Authentication and JSON Web Tokens
- Authorizations and scopes
### 1. HTTPS/SSL certificates
The gold standard for the web is HTTPS using SSL certificates, and [Let's Encrypt](https://letsencrypt.org/) can help you achieve this. It is a free, automated, and open certificate authority from the non-profit Internet Security Research Group (ISRG).
Let's Encrypt's software generates central authority certificates for your domain. These certificates ensure payloads of data from your API to the client are encrypted from point to point.
Let's Encrypt supports several deployment options for certificate management; check out its [documentation](https://letsencrypt.org/docs/) to find the right solution for your needs.
### 2. Cross-origin resource sharing
CORS is a browser-specific security policy preflight check. If your API server is not in the same domain as the requesting client's domain, you will need to deal with CORS. For example, if your server is running on **api.domain-a.com **and gets a client request from **domain-b.com**, CORS sends an HTTP precheck request to see if your API service will accept client-side requests from the client's domain.
"Cross-origin resource sharing (CORS) is an HTTP-header based mechanism that allows a server to indicate any other origins (domain, scheme, or port) than its own from which a browser should permit loading of resources."
There are many helper libraries for [Node.js](https://nodejs.org) to [help API developers with CORS](https://www.npmjs.com/search?q=CORS).
### 3. Authentication and JSON Web Tokens
There are several approaches to validate an authenticated user in your API, but one of the best ways is to use JSON Web Tokens (JWT). These tokens are signed using various types of well-known cryptographic libraries.
When a client logs in, an identity-management service provides the client with a JWT. The client can then use this token to make requests to the API. The API has access to a public key or a secret that it uses to verify the token.
There are several libraries available to help verify tokens, including [jsonwebtoken](https://github.com/auth0/node-jsonwebtoken). For more information about JWT and the libraries that support it in every language, check out [JWT.io](https://jwt.io).
```
import jwt from 'jsonwebtoken'
export default function (req, res, next) {
// req.headers.authorization Bearer token
const token = extractToken(req)
jwt.verify(token, SECRET, { algorithms: ['HS256'] }, (err, decoded) => {
if (err) { next(err) }
req.session = decoded
next()
})
}
```
### 4. Authorizations and scopes
Authentication (or identity verification) is important, but so is authorization, i.e., *does the verified client have the privilege to execute this request?* This is where **scopes** are valuable. When the client authenticates with the identity management server and a JWT token is created, having the identity management service provide the scopes for the given authenticated client can enable the API service to determine if this verified client request can be performed without having to perform an additional costly lookup to an access control list.
A scope is a text block (usually space-delimited) that describes the access capability of an API endpoint. Normally, scopes are broken down between Resources and Actions. This pattern works well for REST/JSON APIs since they are very similarly structured in a RESOURCE:ACTION format (e.g., ARTICLE:WRITE or ARTICLE:READ, where ARTICLE is the resource and READ and WRITE are the actions).
This allows the API to focus on function and not roles or users. The identity access management service can relate roles and users to scopes, then provide the scopes to the client in a verified JWT.
### Summary
When building and deploying APIs, security should always be one of the most important requirements. While security is a broad topic, addressing these four areas will position your API well for production environments.
## Documentation
*What's worse than no documentation? Outdated documentation.*
Developers have a love–hate relationship with documentation. Still, documentation is a crucial part of an API's definition of success. Developers need to know how to use the API, and the documentation you create plays a huge role in educating developers on how to best use it.
There are three areas to focus on in API documentation:
- Developer onboarding (READMEs)
- Technical reference (Specifications)
- Usage (Getting started and other guides)
### 1. Developer onboarding
When building an API service, you need to specify things like: What does the API do? How do you set up a developer environment? How do you test the service? How do you submit an issue? How do you deploy it?
The usual way to answer these questions is with a README file. It is the file in your code repository that gives developers a starting point for working with your project.
A README should contain:
- A description of the API
- Links to technical references and guides
- How to set up the project as a developer
- How to test the project
- How to deploy the project
- Dependency management
- Contribution guide
- Code of conduct
- License
- Gratitude
Be concise in your README; you do not have to explain every aspect but give enough information so that developers can drill deeper as they become familiar with your project.
### 2. Technical reference
In a REST/JSON API, every endpoint is a specific function with a purpose. It is important to have technical documentation that specifies each endpoint; defines the description, inputs, and outputs that can occur; and provides examples for various clients.
REST/JSON has a specification standard called [OpenAPI](https://spec.openapis.org/oas/v3.1.0), which can guide you through the details required to document an API. OpenAPI can also generate presentation documentation for your API.
### 3. Usage
Your API's users want more than just technical specifications. They want to know how to use your API in specific situations or cases. Most potential users have a problem and they are looking to your API to solve it.
A great way to introduce users to your API is with a "getting started" page. This can walk the user through a simple use case that gets them up to speed quickly on the benefits of your API.
### Summary
Documentation is a key component of any successful API. When creating documentation, think about the three areas of focus—onboarding, technical, and usage—cover those bases, and you will have a well-documented API.
## Validation
One of the most often overlooked aspects of API development is validation. Validation is the process of verifying input from external sources. These sources might be a client sending JSON or a service responding to your request. More than just checking types, ensuring that the data is what it is supposed to be can eliminate many potential problems. Understanding your boundaries and what you do and don't have control over is an important aspect of validation.
The best strategy is to validate at the edges before your logic takes place. When a client sends your API some data, apply validation before you do anything else with that data. Make sure an email is an actual email address, a date is properly formatted, a string meets length requirements.
This simple check will add safety and consistency to your application. Also, when you receive data from a service, like a database or a cache, revalidate it to make sure the returned result meets your data checks.
You can always validate by hand or use utility function libraries like [Lodash](https://lodash.com) or [Ramda](https://ramdajs.com/). These work great for small data objects. Validation libraries like [Joi](https://joi.dev/), [Yup](https://github.com/jquense/yup), or [Zod](https://github.com/colinhacks/zod/tree/v3) work even better, as they contain common validations that can save time and effort and create a very readable schema. If you need something language-agnostic, look at [JSON Schema](https://json-schema.org/).
### Summary
Validation is not sexy, but it can save a ton of time that would otherwise be spent troubleshooting and writing data migration scripts. Don't make the mistake of trusting your client to send clean data; you don't want bad data leaked into your business logic or persistent data store. Take the time and validate your API endpoints and service responses. While it may cause some frustration upfront, it is much easier to loosen the reigns than to tighten them later.
## Testing
Testing is a best practice for software development and should be a primary non-functional requirement. Defining a test strategy can be a challenge for any project, including APIs. Always understand your constraints and define your strategy accordingly.
Integration testing is one of the most effective methods for testing APIs. In this pattern, the development team creates a test to cover some part of the application flow, from one specific point to another. A great integration test flow includes testing the API's entry point and mocking the request point to the service. By picking those two points, you cover the entire logic, from the beginning of the API request to the service request, and the mock service gives you a response to hand back to the API response.
Although it uses mocks, this method allows you to focus on the code in the logic layer and not depend on back-end services or presentation logic to run the test. Having no dependencies makes running the test much more reliable, easier to automate, and simpler to include in your continuous integration pipeline.
One setup I use for integration testing uses [Tape](https://github.com/substack/tape), [Test-server](https://github.com/twilson63/test-server), and [Fetch-mock](http://www.wheresrhys.co.uk/fetch-mock/). These libraries enable me to run isolated tests against API endpoints from the request to the response, with Fetch-mock catching the outbound request to the persistence layer.
### Summary
While all types of testing and type checking are beneficial to APIs, integration testing offers the largest benefit in terms of effectiveness vs. time to build and manage. Using tools like Fetch-mock can provide clean mocking scenarios at the service boundary.
## Focus on the fundamentals
As you design and build your application and API, make sure to include these four fundamentals. These are not the only non-functional requirements to consider; others include application monitoring, logging, and API management. Even so, security, documentation, validation, and testing are crucial focus points for designing and building a successful API for any use case.
## Comments are closed. |
13,484 | 如何在 Ubuntu Linux 上安装 Code Blocks IDE | https://itsfoss.com/install-code-blocks-ubuntu/ | 2021-06-14T16:48:14 | [
"IDE"
] | https://linux.cn/article-13484-1.html | 
Code Blocks 是一个用 C++ 编写的开源 IDE,非常适合 C、C++ 和 Fortran 开发。它是跨平台的,可以在 Linux、macOS 和 Windows 上运行。
Code Blocks 是轻量级和快速的。它支持工作区、多目标项目、工作区内的项目间依赖关系。
你可以得到语法高亮、代码折叠、标签式界面、类浏览器、智能缩进等功能。你还可以通过插件扩展 IDE 的功能。
在本教程中,你将学习如何在基于 Ubuntu 的 Linux 发行版上安装 Code Blocks。
>
> 注意
>
>
> Code Blocks 也可以在 Ubuntu 软件中心找到。然而,从 Ubuntu 21.04 开始,从 Ubuntu 软件中心以图形方式安装 Code Blocks 会安装一个 codeblocks-common 软件包,而不是图形化 IDE。因而你不能看到安装在你系统上的 Code Blocks 以运行。由于这个原因,我建议采取终端的方式在 Ubuntu 上安装 Code Blocks。
>
>
>
### 在基于 Ubuntu 的 Linux 发行版上安装 Code Blocks
[Code Blocks IDE](https://www.codeblocks.org/) 在所有 Ubuntu 版本的 universe 库中都有。虽然它通常是默认启用的,但先[启用 universe 仓库](https://itsfoss.com/ubuntu-repositories/)也无妨:
```
sudo add-apt-repository universe
```
更新软件包缓存,这样系统就能知道新添加的仓库中的额外软件包的可用性:
```
sudo apt update
```
最后,你可以使用 `apt install` 命令在基于 Ubuntu 的发行版上安装 Code Blocks:
```
sudo apt install codeblocks
```

建议你也安装额外的插件,以便从 Code Blocks IDE 中获得更多。你可以使用 `codeblocks-contrib` 包来安装它们:
```
sudo apt install codeblocks-contrib
```
### 如何使用 Code Blocks
在系统菜单中搜索 “Code Blocks”。这是在 Ubuntu 默认的 GNOME 版本中的样子:

当你第一次启动 Code Blocks 时,它会寻找你系统中所有可用的编译器,并将其添加到路径中,这样你就不用自己去配置它了。
在我的例子中,我的 Ubuntu 系统上已经安装了 gcc,Code Blocks 很好地识别了它。

Code Blocks 的用户界面绝对不够现代,但请记住,这个 IDE 是轻量级的,它几乎消耗不到 50MB 的内存。
如果你曾经使用过像 Eclipse 这样的其他 IDE,你就不会觉得使用 Code Block 有什么困难。你可以写你的代码并把它们组织在项目中。
构建、运行并构建和运行按钮一起放在顶部。

当你运行代码时,它会打开一个新的终端窗口来显示输出。

这就是你需要的关于 Code Blocks 的最少信息。剩下的留给你,你可以通过浏览它的 [维基](https://wiki.codeblocks.org/index.php/Main_Page) 和[用户手册](https://www.codeblocks.org/user-manual/) 来进一步探索它。
拥有一个 IDE 可以使 [在 Linux 上运行 C 或 C++ 程序](https://itsfoss.com/c-plus-plus-ubuntu/) 更容易。Eclipse 是一个很好的 IDE,但它比 Code Blocks 要消耗更多的系统资源。当然,最后,重要的是你的选择。
---
via: <https://itsfoss.com/install-code-blocks-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Code Blocks is an open source IDE written in C++ and ideal for C, C++ and Fortran development. It is cross-platform and runs on Linux, macOS and Windows.
Code Blocks is lightweight and fast. It supports workspaces, multi-target projects, inter project dependencies inside workspace.
You get syntax highlighting, code folding, tabbed interface, class browser, smart indentation and more. You can also extend the feature of the IDE via plugins.
In this tutorial, you’ll learn to install Code Blocks on Ubuntu-based Linux distributions.
Note
Code Blocks is also available in Ubuntu Software Center. However, as of Ubuntu 21.04, installing Code Blocks graphically from the Ubuntu Software Center installs a codeblocks-common package, not the graphical IDE. And thus you don’t see the Code Blocks installed on your system to run. For this reason, I recommend taking the terminal approach for installing Code Blocks on Ubuntu.
## Install Code Blocks on Ubuntu-based Linux distributions
The [Code Blocks IDE](https://www.codeblocks.org/) is available in the universe repository of all Ubuntu releases. Though it is usually enabled by default, it won’t harm to [enable universe repository](https://itsfoss.com/ubuntu-repositories/) first:
`sudo add-apt-repository universe`
Update the package cache so that system knows about the availability of the additional packages from the newly added repository:
`sudo apt update`
And finally, you can install Code Blocks on Ubuntu-based distributions using the apt install command:
`sudo apt install codeblocks`
It is advised to also install additional plugins to get more out of the Code Blocks IDE. You can install them using the codeblocks-contrib package:
`sudo apt install codeblocks-contrib`
## How to use Code Blocks
Search for Code Blocks in the system menu. This is what it looks like in Ubuntu’s default GNOME version:
When you first start Code Blocks, it looks for all the available compilers on your system and adds it to the path so you don’t have to configure it on your own.
In my case, I already had gcc installed on my Ubuntu system and it was well recognized by Code Blocks.
The user interface of Code Blocks is definitely not modern but keep in mind that the IDE is lightweight and it hardly consumes 50 MB of RAM.
If you have ever used another IDE like Eclipse, you won’t find it difficult to use Code Block. You can write your code and organize them in projects.
The buttons to build, run and build and run together is right their on the top.
When you run the code, it opens a new terminal window to display the output.
That’s the bare minimum information you need about Code Blocks. I leave it up to you to explore it further by going through its [wiki](https://wiki.codeblocks.org/index.php/Main_Page) and [user manual](https://www.codeblocks.org/user-manual/).
Having an IDE makes [running C or C++ programs on Linux](https://itsfoss.com/c-plus-plus-ubuntu/) easier. Eclipse is a good IDE for that job but it consumes more system resources than Code Blocks. Of course, in the end, it’s your choice that matters. |
13,486 | 《代码英雄》第四季(4):软盘 —— 改变世界的磁盘 | https://www.redhat.com/en/command-line-heroes/season-4/floppies | 2021-06-15T10:57:00 | [
"软盘",
"代码英雄"
] | https://linux.cn/article-13486-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》第四季(4):软盘 —— 改变世界的磁盘](https://www.redhat.com/en/command-line-heroes/season-4/floppies)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/2a8eaecd-092f-424b-ba65-83ac5c59dc87/clh-s4e4-floppies-v2_tc.mp3)脚本。
>
> 导语:软盘是计算机领域最伟大的突破之一。它以一种盛行几十年的格式助推了软件行业的发展。在某些情况下,它保存了曾经被认为是永远失去了的珍宝。
>
>
> 在软盘出现之前,计算机背负着打孔卡和磁带缓慢前行。Steven Vaughan-Nichols 描述了软盘所带来的巨大变化。Dave Bennet 解释了对永久存储(和便于邮寄)的需求,如何导致了第一批 8 英寸驱动器的出现。George Sollman 回顾了他是如何受命制造出更小的软盘的,以及哪些意想不到的来源激发了他的下一个设计的灵感。而当 Sollman 把它展示给<ruby> 自制计算机俱乐部 <rt> HomeBrew Computer Club </rt></ruby>时,这一季的几位常客请他展示更多的内容。接下来发生的事,就众所周知了。
>
>
> Matthew G. Kirschenbaum 指出,软盘在一些意想不到的地方仍然在使用。Jason Scott 和 Tony Diaz 告诉我们他们是如何将一些源代码从“跑腿网络”中带到云端的。
>
>
>
**00:00:00 - Saron Yitbarek**:
Jordan Mechner 是个收藏爱好者。他是《<ruby> 空手道 <rt> Karateka </rt></ruby>》和《<ruby> 波斯王子 <rt> The Prince of Persia </rt></ruby>》等游戏的开发者。他精心保存下了开发过程中的一切细节,比如日记、素描和情节提要等所有的一切。因此,当他找不到自己保存的某样东西时,多少会让他有点吃惊,而这也确实是一件大事。
**00:00:26**:
早在 2002 年, Mechner 就在做《<ruby> 波斯王子:时之沙 <rt> Prince of Persia: The Sands of Time </rt></ruby>》的开发。程序员们希望将该游戏的经典版本作为复活节彩蛋加入到他们的 PlayStation 2 版本中。因此,他们向他索要原始的源代码。但是当 Mechner 查看他的归档时,他找不到这份源代码了。他四处寻找。这份源代码是在他的老旧 Apple II 上写的,他肯定自己保存过的这些代码,消失了。
**00:00:58**:
快进 10 年。Mechner 的父亲正在打扫房间,有一个看上去很破旧的鞋盒藏在壁橱后面,里面装着一堆满是灰尘的 3.5 英寸旧软盘。其中一张被标记为“《波斯王子》的源代码。版权所有 1989 年”,括号里用全大写字母写着 “原版” 一词。这份丢失了很长时间的代码,终于被找到了。它在那个盒子里待了四分之一个世纪,然后像考古发现一样被发掘出来。
**00:01:36**:
但那是 2012 年。他要怎样把信息从那些旧磁盘上取出来,数据是否还完好无损?事实上,现在去挽救他的工作已经为时已晚了吗?
**00:01:54**:
挽救(保存)我们的工作,现如今这个过程经常是自动发生的。随着程序定期向云端推送内容,我们再也无需费心去手动保存东西了。事实上,全新的一代人甚至不知道那个保存图标表示什么意思。旁注:这不是自动售货机。
**00:02:16**:
但是几十年来,保存、存储和传输我们的数据都必须使用某种物理介质。当个人计算机革命开始后(我们在有关 Altair 8800 的上一集中讲过),有一项技术成为了保存的代名词 —— 软盘。如今看起来这是如此的简单。但是软盘改变了我们的历史进程,因为它们帮助将<ruby> 微型计算机 <rt> microcomputer </rt></ruby>转变成了<ruby> 个人电脑 <rt> personal computer </rt></ruby>。
**00:02:50**:
我是 Saron Yitbarek。这里是《代码英雄》,一档来自<ruby> 红帽 <rt> Red Hat </rt></ruby>的原创播客节目。
**00:02:58**:
让我们暂且把 Jordan Mechner 发现软盘的故事搁在一边。我们之后会回过头来谈论它。首先,我想先了解一下软盘最初是怎样诞生的,以及近 40 年以来它是如何成为技术界如此至关重要的一部分的。
**00:03:18**:
我们的第一站是 1890 年。在电子计算机出现之前,就已经有了机械的电子计算设备。数据输入输出的方法是通过一美元钞票大小的打孔卡实现的。电子计算机在上世纪 50 年代问世时,IBM 用 80 列 12 行的打孔卡进行了标准化。所打的孔就会形成一种字符,没有打孔则意味着另一种。
**00:03:50**:
长期以来,这些打孔卡是数据输入的主要方式。但是为更大、更复杂的程序处理数以百计的打孔卡非常麻烦。必须要有一种更好的方法来保存和传输数据。
**00:04:08**:
紧接着是 20 世纪 50 年代问世的纸带。要了解纸带如何在个人计算机的起源中扮演了核心角色,请收听我们的上一集节目。纸带与打孔卡具有同样的用于读取数据的打孔方式。但是因为这都在一卷纸带上,人们没必要担心卡片会混起来。它可以携带更多的数据,并且使用起来更快。但是随着微型计算机容量的增加,存储程序需要越来越多的纸带。就像打孔卡一样,纸带最终遇到了它的瓶颈。
**00:04:47**:
让我们进入到磁带阶段。其关键成分是聚酯薄膜,一种坚韧、有弹性的材料,表面涂有磁性氧化物来使得磁带能够记录。每盘磁带的九条磁道最多可以存储 175 MB。这在上世纪 50 和 60 年代是一件大事。10.5 英寸卷轴的磁带驱动器成了企业的标准配置。
**00:05:11 - Steven Vaughan-Nichols**:
但是磁带的问题在于,尽管其很方便将大量数据从一个位置移动到另一个位置,但要在磁带上搜索以找到某些特定的东西着实不易。我们会使用磁带在微型计算机和大型机上安装软件,但是对于小型便携的数据或者涉及数据交互的事情,磁带确实没那么好用。
**00:05:40 - Saron Yitbarek**:
这位是 CBS Interactive 的特约编辑 Steven Vaughan-Nichols。当然,磁带可以存储更多的数据。但是它太大、太慢了。确实,这仅仅在大型机领域可行。又一次,需要有一个更好的存储方法了。
**00:05:58**:
更好的方法出现在 1956 年,当时 IBM 推出了其首个<ruby> 磁盘驱动器 <rt> disk drive </rt></ruby> —— IBM 350 磁盘存储单元。它是 305 RAMAC 大型计算机的组成部分,这台机器整整占满了一个房间。这位是前 IBM 磁盘和存储产品工程师 Dave Bennet。
**00:06:23 - Dave Bennet**:
存储在核心内存中。事实上,RAMAC 中的磁盘存储设备是第一个允许随机访问给定的记录的存储设备,而不是磁带驱动器。
**00:06:39 - Saron Yitbarek**:
很有趣。那款磁盘驱动器差点没有问世,因为它威胁到了 IBM 的打孔卡生意。但是这个项目最终还是获得了批准。问题在于,该驱动器包含由固体金属制成的磁碟。RAMAC 重达一吨,它必须由叉车搬运,并且用大型货运飞机运输。这不是最方便的存储方式,但除此之外,还有更好的解决方案。
**00:07:10 - Dave Bennet**:
尽管<ruby> 软盘 <rt> floppy disk </rt></ruby>最初是为了满足一个新需求而开发的。原因在于有一种中间类型的存储方式。最初的存储方式是计算机代码,然后是计算机内存,即工作内存。但是随着 System 360 的出现,它们之间出现了一类新的内存,它们称之为<ruby> 固件 <rt> firmware </rt></ruby>。在 System 360 中,有着独特的各种形式的固件技术,要么是一种特殊的打孔卡,要么是一种所谓的<ruby> 转换器只读存储 <rt> transformer read-only storage </rt></ruby>。
**00:07:51**:
但是,新的需求是在半导体技术瞬息万变的时代,从这些技术转向半导体技术。这意味着在切断电源后,半导体中所存储的内容都会消失。因此,必须要有一种再次充入的方式,在电力恢复后将程序存回到内存中,以加载所谓的<ruby> 微程序 <rt> micro program </rt></ruby>或<ruby> 中间存储器 <rt> intermediate memory </rt></ruby>。
**00:08:28**:
对这种设备的需求是导致软盘驱动器发展的原因。
**00:08:37 - Saron Yitbarek**:
因此在 1967 年,一小队由 David Noble 领导的工程师开始着手开发一款廉价的系统,用于将这些微程序载入到大型计算机。他们项目的代号是 “Minnow”。
**00:08:53 - Dave Bennet**:
Noble 能想到的所有东西,包括各种形式的打孔卡、盒式磁带,他都亲自实验了一遍。我不知道他还实验过什么。但是他想到了使用基于柔性磁盘的廉价磁盘驱动器,和成本非常廉价的只读机制。
**00:09:19 - Saron Yitbarek**:
Minnow 团队希望能够把他们的微程序邮寄到需要加载它的各个地方。因此这款用于发送该程序的产品必须足够耐用,才能够在不损坏其数据的情况下实现邮寄。这是某种外壳包装方式。
**00:09:38 - Dave Bennet**:
现在,为了使它能够被邮寄,他们实际上必须要做的是,把它放进一个相当坚固的塑料容器里。实际上,他们会在磁盘还放在这个塑料容器(像一个信封、塑料信封)里的时候读写该磁盘。当磁盘上有涂层而且有一个刚性的磁头时,必定会有磨损。而一旦有磨损,就会产生磨损颗粒。
**00:10:06**:
他们所遇到的问题是,随着磨损颗粒的堆积,会引起雪崩效应。这些颗粒会充当额外的磨料。然后很快,颗粒散在那里,记录轨道会被磨损,就不再能用了。
**00:10:28**:
参与该项目的一个名叫 Herb Thompson 的家伙非常聪明,他提出了一项方案,该方案基于 3M 卖给家庭主妇用于家具除尘的家用除尘织物。他在信封和磁盘之间放了这样的一张布。这种材料吸收了磨损颗粒,并将其嵌入到除尘织物中,从而防止了雪崩效应,真正解决了这个问题。
**00:11:00 - Saron Yitbarek**:
柔性 8 英寸聚酯薄膜磁盘,甚至可以称它们为<ruby> 软盘 <rt> floppy disk </rt></ruby>。它完全被装在一个很薄但是很坚固的信封中,并带有再利用的除尘装置。总之,它很容易被拿起,也很容易邮寄。每张新的软盘有 80 KB 的存储容量,可以容纳与 3000 张打孔卡相当的数据量。这是存储容量上一个巨大的飞跃。
**00:11:29**:
IBM 在 1971 年发布了他们的 8 英寸软盘。Minnow 团队做得很好,但他们不知道有多好。他们的突破即将演变成一种完全改变游戏规则的技术。
**00:11:49**:
IBM 的直接访问存储产品的负责人是一个名叫 Alan Shugart 的人。 Minnow 项目是他的宝贝。 Shugart 很有个性,天生具有企业家精神。他的日常制服是夏威夷衬衫,从来不穿夹克和领带。在发布 8 英寸软盘不久后,Shugart 离开了 IBM,并于 1969 年加入了 Memorex,然后在 1973 年成立了自己的公司 Shugart Associates,专门从事计算机外围设备。
**00:12:23**:
Don Massaro 从 IBM 就跟随 Shugart,他成为了 Shugart Associates 的运营副总裁。在那工作了几年之后,Massaro 收到了一个名叫王安的人的需求。他是<ruby> 王安电脑公司 <rt> Wang Laboratories </rt></ruby>的负责人,这是当时领先的计算机公司之一。王安想出了一种磁芯存储器的方法,这是计算机在未来 20 年内使用的方法。
**00:12:51**:
当 1975 年王安接触 Massaro 时,他给了 Massaro 一个挑战。当时 Shugart 的一名工程师 George Sollman 还记得这件事。
**00:13:03 - George Sollman**:
王博士说:“我真的很想做小型商业系统和文字处理器,但是现在的磁盘驱动器 —— 你的 8 英寸大的磁盘驱动器太大了。我们需要几个小型的存储设备。它们可以被安置在 CRT 显像管旁边,但我们不能用 8 英寸大的,因为磁场会破坏图像。”因此,他认为我们可以采用 8 英寸的软盘并且把它缩小。我们知道必须设计出低成本而且可行的东西来。我们整理了一张普通老套的挂图来描述它是什么,然后拿回来和王博士见了面。王博士说:“我喜欢它,但是你不能在里面使用交流电动机,因为这会扭曲图像。”
**00:13:52 - George Sollman**:
所以他说:“为什么不找找看谁在制造磁带机的电动机,比如通用汽车公司?”因此,我们回过头来,实现了一些很小的电动机,这些电动机适合微型软盘,可以驱动皮带,并转动软盘。
**00:14:10 - Saron Yitbarek**:
George Sollman 必须确定这种新软盘的规格,它应该变得有多小,以及应该容纳什么。
**00:14:19 - George Sollman**:
我们所做的是,查看了当时所有的磁带机,并计算了它们的平均尺寸。完成了全部的工作后,最终选择了 5.25 英寸的软盘尺寸。我们知道我们可能只有一次机会。我记得那是在王博士把 Don 和我拉进他办公室时说的:“我给你们看一下,你们的磁盘驱动器装在我们的新文字处理器上。”他们还想向我们订购大量的磁盘驱动器,有 10000 个。因此这就好像,哇,我们成功了。
**00:14:54 - Saron Yitbarek**:
现如今,在历史上的技术传说中,有关 5.25 英寸这一尺寸是如何形成的,有几个不同的说法。一种说法是让软盘比口袋的尺寸大,以避免不幸的弯曲和折断。最受欢迎的民间版本是,Al Shugart 在酒吧里喝了几杯酒,然后当他弄脏了一块恰巧 5.25 平方英寸的酒吧餐巾纸时,灵光一动。这位是 Teri Shugart,Al 的女儿。
**00:15:26 - Teri Shugart**:
他喜欢喝酒,我可以告诉你的是,他所创办的所有公司的大部分计划都确实是在酒吧里做出的。因此,这件事并非不可能,实际上很可能就是这样。
**00:15:43 - Saron Yitbarek**:
但是,真正改变了 Shugart 和他团队的游戏规则的,坦率地说也是改变了所有计算机历史的关键时刻,是 George Sollman 和 Don Massaro 决定在自制计算机俱乐部展示他们的 5.25 英寸软盘。
**00:16:00 - George Sollman**:
有一个自制计算机俱乐部的会议在斯坦福的线性加速器中心的会议室举行,离我们住的地方大约有一英里。因此,我们带了我们的微型软盘过去并做了演示,观众里有个名叫<ruby> 史蒂夫•沃兹尼亚克 <rt> Steve Wozniak </rt></ruby>的家伙,他想就我们的产品和我谈谈,并说:“我得让某些人关注到它。”
**00:16:24 - Saron Yitbarek**:
演示之后,George 和 Don 回归了他们的常规事务,但是几天后,在办公室里,Don 把他叫到了一边。
**00:16:33 - George Sollman**:
并说道:“你是营销人员,你应当保持前厅整洁,George。”然后我说:“嗯,Don 你想说什么?”他说:“我们的前厅里有个流浪汉,我们应该把他弄出去。”所以我走了出去,和这个家伙握了握手。他有着一双最为锐利的眼睛,我又和他聊了一会儿,他的谈话非常有趣,他说:“我想和你去实验室看看 Steve 说的这个东西是什么。”我不知道这样是否合法,但他是我所遇到过的最有趣的人之一,很显然他有着很高的智商和极大的好奇心,他就是<ruby> 史蒂夫•乔布斯 <rt> Steve Jobs </rt></ruby>。
**00:17:19 - Saron Yitbarek**:
史蒂夫•乔布斯讨厌苹果早期计算机中的盒式磁带驱动器。它们总是出现故障,要花很长时间大费周折获取信息。对于 Apple II,他想要一个软盘驱动器,史蒂夫•沃兹尼亚克想要制造它,但尺寸是关键因素。必须缩小软盘的尺寸,从而使得这款计算机更能吸引消费者。因此,在 1997 年圣诞节假期的两周时间里,沃兹尼亚克靠着天天吃麦当劳开发了原型。在新的一年的<ruby> 拉斯维加斯 <rt> Las Vegas </rt></ruby><ruby> 消费电子展 <rt> Consumer Electronics Show </rt></ruby>之前及时完成了。
**00:17:57**:
沃兹尼亚克很喜欢开发那款软盘驱动器,并将其描述为他参与过的最好的工程。乔布斯雇佣了 Shugart 来制造 Apple 软盘。Disk II 成为了 Apple 的主打产品,助推了 Apple II 计算机的销售并改变了行业。这位是 Steven Vaughan-Nichols。
**00:18:20 - Steven Vaughan-Nichols**:
如果你买了一台 Apple II,Disk II 是一个很快就会大受欢迎的选择。确实,你可以将史蒂夫•乔布斯誉为将软盘驱动器引入到个人计算机领域的人。人们正在运行名为 CPM 80 的操作系统,实际上还有数十家小型制造商和一些像 DEC 之类的大型制造商在制造 CPM 80 计算机,而所有这些计算机都使用 5.25 英寸的软盘驱动器。然后,当 IBM 在 1981 年推出第一台 IBM PC 时,每个人都清楚这不再是一个业余市场了。
**00:19:04**:
这是一个真正的商业市场,而这将由新流行的 5.25 英寸软盘驱动器驱动。
**00:19:14 - Saron Yitbarek**:
软盘和个人计算机革命是共生的。它们一个驱动着另一个,反之亦然。它们一起进化。由于有了软盘,公司可以编写程序,将程序复制到磁盘里,然后通过邮寄或在商店里出售。它对早期个人电脑的作用就像应用商店对智能手机的作用一样,为开发人员提供了便利。事实上,软盘使得软件行业成为可能,并且随着这些软件程序变得越来越大、越来越复杂,软盘再一次发生了变化。1981 年,<ruby> 索尼 <rt> Sony </rt></ruby>推出了将软盘缩小到 3.5 英寸的新版本。
**00:19:59**:
较小的同类产品用硬塑料包裹,并内置金属遮板,以防止灰尘进入。它们更加坚固,可以存储更多的数据。有趣的是,尽管它们的外壳很硬,但它们仍被称为软盘,而当苹果公司在 1984 年发布其新 Macintosh 计算机时,又一次使得 3.5 英寸软盘成为新标准。
**00:20:25 - Steven Vaughan-Nichols**:
好吧,我们都知道<ruby> 史蒂夫•乔布斯 <rt> Steve Jobs </rt></ruby>和<ruby> 史蒂夫•沃兹尼亚克 <rt> Steve Wozniak </rt></ruby>。像 Shugart 这些软盘驱动器的创造者,却不是家喻户晓的名字,但是他们所做的工作绝对至关重要。如果没有他们的话,个人计算机被采用的速度将会慢得多。我无法想象,如果没有这些早期的驱动器,个人计算机革命会如何发生。它使得数据输入输出计算机比其它方式更容易。
**00:21:06 - Saron Yitbarek**:
由于软盘尺寸适中且易于分享,因此它们具有一种社交性,就像早期的社交媒体形式一样。你可以和人们见面并交易软盘。这是在人们可以轻松访问调制解调器、互联网尚未出现之前的事情。人们分享装满了程序的软盘,就像分享装满 Cyndi Lauper 曲目的混合磁带一样。而且这种数据传输的方式甚至有个名字,即<ruby> 跑腿网络 <rt> Sneakernet </rt></ruby>,从字面上看,你必须用你的双脚将数字信息从一台机器传输到另外一台,而人们在这些分享的磁盘上所存放的内容可以是任何东西,当然有软件,但是还有更多,尤其是随着新兴的数字创作工具的出现。
**00:21:55**:
Jaime Levy 是上世纪 80 年代后期那些新兴的数字创作者之一。她如今是<ruby> 南加州大学 <rt> the University of Southern California </rt></ruby>的教授,也是《UX Strategy》的作者。
**00:22:07 - Jaime Levy**:
我当然也认为这很神奇,你可以在软盘上制作出交互式的、非线性的东西。我当时正在制作后来被称之为<ruby> 磁盘杂志 <rt> diskzine </rt></ruby>的杂志。那是在桌面出版的同一时期。我想当时 PageMaker 已经问世。人们刚购买了 Macintosh,正逐渐被吸引到数字技术上来。
**00:22:32 - Saron Yitbarek**:
此前从来都没有人听说过交互式的杂志,甚至连 Jamie 也没有,但是她结合了动画、艺术、声音以及交互式界面,并使得它们适合放在软盘上。她制作了一堆副本,将它们打包并运送到了当地的一家书店。
**00:22:48**:
在大多数情况下,人们没有 Macintosh 甚至不能看它们的内容,他们不知道上面有什么。所以我说,在这里放 10 个副本,你拿一个回家看看,如果喜欢它的话,就把它们卖出去。他们会把它们放在前台,因为它们没法很好地被放在架子上,然后立即就有人买了它们。只要有 Mac 的人走进那里,看到这个东西只要 6 美元,他们就会说:“是的,我想要那东西。”
**00:23:15**:
书店里不断售空。Jaime 收到了来自世界各地的来信,并且开始引起了全国媒体的注意。不久后,她通过邮购贩卖她的磁盘来做生意。然后,她作为界面设计师的职业生涯开始了。她的故事是软盘和跑腿网络力量的证明。曾经有一段时间,你可以使用单个 160 KB 的软盘驱动器运行一个完整的操作系统,但是到了上世纪 90 年代中期,你需要多张软盘才能运行任何东西,文件变得越来越大,而把软盘从你的计算机来回放入和取出实在是很烦人。
**00:23:57**:
1998 年,iMac 成了第一款不带软盘驱动器的个人计算机,这是一个不祥之兆。当调制解调器变得越来越好,互联网更加易于使用,人们从软盘转移到了更新的存储技术,比如 CD ROM,从 CD 我们又转到了 DVD、SD 卡、USB 闪存驱动器。回过身来,我们的身后有一整个废弃的存储技术坟墓。现如今,我们有了云。可怜的老软盘,它们不再有机会了。但是,重要的是,软盘仍然苟延残喘。它们有持久的生命力。首先,仍然有供初学者使用的“保存”图标。
**00:24:43**:
人们仍然有着装满了它们的鞋盒。实际上,事实证明,软盘是最具弹性的技术之一。你可能会惊讶地发现它们仍然被用来维护<ruby> 美国洲际弹道导弹系统 <rt> the US Intercontinental Ballistic Missile System </rt></ruby>等遗留机器。直到最近,该系统一直依赖于 8 英寸的软盘驱动器。 Matthew Kirschenbaum 是<ruby> 马里兰大学 <rt> the University of Maryland </rt></ruby>的英语和数字研究教授。
**00:25:17 - Matthew Kirschenbaum**:
因此,有一个关于美国空军从其核指挥和控制系统中逐步淘汰 8 英寸软盘的故事正在流传。伴随着的是人们在导弹发射井中将软盘插入某种老式大型计算机中的照片。我认为着实令人惊讶,因为看到某些东西,比如核武器仍然通过 8 英寸软盘控制着。政府、军方最终将淘汰这些系统。我当然认为那是一件好事,但也要记住,作为存储介质,软盘往往非常耐用且具有弹性。它们的面积密度低,这意味着与当今的硬盘驱动器相比,它们相对粗糙或低保真。实际上,这使得它们更具弹性,也更可靠。由于年代久远,它们也是那些计算机系统的过时之处。具有讽刺意味的是,它们可以更好地保护我们免受当今以病毒、黑客攻击和类似形式出现的网络威胁。人们所使用的术语是“<ruby> 气隙 <rt> air gap </rt></ruby>”,软盘没有以任何方式连接到互联网,并且可以将其视为非常理想的安全功能。即使这使得人们有些许不安。但它们被使用了这么长时间,并不完全是没道理的。
**00:26:53 - Saron Yitbarek**:
当然。现在看软盘,它们看起来很脆弱,而且有点儿可笑,但是借助正确的设备,几十年前的磁盘如今仍然可以被读取。谁知道在那些数据被检索时能发现什么样的宝藏呢。
**00:27:09 - Matthew Kirschenbaum**:
几年前,有新闻说发现了十几张 Andy Warhol 的图片。实际上这些图片是 20 世纪 80 年代 Andy Warhol 在一台 Amiga 计算机上创造的。
**00:27:26**:
他得到了一台 Amiga,并进行了实验,开始将其用于他的一些艺术作品,所得到的图像被保存到位于<ruby> 匹兹堡 <rt> Pittsburgh </rt></ruby> Warhol 博物馆的软盘上。<ruby> 卡内基·梅隆大学 <rt> Carnegie Mellon University </rt></ruby>的一个团队抢救了这些文件,所以现在我们又有 Andy Warhol 的十几件艺术品。
**00:27:53 - Saron Yitbarek**:
说到宝藏,是时候了解一下 Jordan Mechner 和他丢失多年的源代码到底发生了什么了。前情回顾, Jordan 丢失了《<ruby> 波斯王子 <rt> Prince of Persia </rt> <rt> </rt></ruby>》的源代码。多年之后,他的父亲在壁橱后面发现了一个鞋盒,里面装着一堆满是灰尘的 3.5 英寸软盘。其中一张被标记为“源代码”,但是源代码真的在那张磁盘上吗?他能够恢复他《<ruby> 波斯王子 <rt> Prince of Persia </rt> <rt> </rt></ruby>》作品吗?
**00:28:23**:
为了找到答案,我们和 Jordan 招募的拯救源代码小组的两个成员进行了交谈。Jordan 联系的第一个人是 Jason Scott,他是<ruby> 互联网档案馆 <rt> Internet Archive </rt></ruby>的放养档案管理员。
**00:28:38 - Jason Scott**:
这可能行得通,但也可能不行,但是你总是希望能对最坏的结果做好准备。我认识一个人,他的名字叫 Tony,而 Tony 与苹果公司的关系非常密切。他对他们无所不知。我称他为“Apple II 耳语者”。
**00:28:59 - Saron Yitbarek**:
通过一个长期运行的 IRC 频道,Jason 找到了 Tony Diaz,并招募了他来担任这份工作。 Jordan 邀请了这对计算机考古学家到他位于 Hollywood Hills 的家中。Tony 将一堆装备装进了卡车的后部,准备从 Oceanside 长途开车到洛杉矶。
**00:29:19 - Tony Diaz**:
我拿了几套闲置的 Apple IIe 系统,打包装箱,各种东西装满了半个皮卡车斗,并且还有用于读取困难的软盘的改装磁盘驱动器和各种类似的工具。磁盘驱动器控制器的功能有所不同,还有一些更为现代化的计算机上的东西,有些可以帮助处理软盘(如果有必要的话)。是的,把它们全部装载起来然后上路。
**00:29:43 - Saron Yitbarek**:
在 Jordan 的起居室里。Tony 建立了一个令人印象深刻的由老式 Apple II 计算机和 3.5 英寸磁盘驱动器组成的阵列。然后 Jordan 把一个装在塑料袋里的鞋盒拿了出来,就仿佛它是个圣杯一样。这个圣杯周围有橡皮筋,以防止鞋盒盖子掉落。
**00:30:03 - Tony Diaz**:
我曾多次遇到这种情况,刚刚打开旧的磁盘盒,它们都有同样的那种霉味。我不知道该怎么说,这很难描述,但是对于那些曾经在海军舰船上的人来说,它们气味相同,和你去到飞机后面闻到的都一样。软盘有它自己的独特的,那个词怎么说来着,光泽。
**00:30:25 - Saron Yitbarek**:
Tony 取出了几个磁盘,看看它们的状况。如果需要的话,他准备着取下保护套,并用 Joy 洗碗皂清洗它们。这些磁盘已经很久没有转动过了。因此,他把手指放在中间,摇晃了一下并旋转了一下,以检查是否发霉。然后他和 Jason 分成了两队。
**00:30:49 - Jason Scott**:
我要去做<ruby> 磁通量读数 <rt> flux reading </rt></ruby>,也就是磁信息,从软盘上拉取下来每一个磁性波动信息,这会产生非常巨大且难以解码的软盘镜像。这样的想法是,如果发生其他任何错误或者我们在某种单一方式受到阻碍,那么未来我们能够使用这些信息。
**00:31:16**:
Tony 知道这些磁盘上的信息是什么,他在计算机上使用实用工具来读取磁盘,就像早在 1990 年时候那样,这些数据对他来说是有意义的。我们去找那些很明显是标准文件副本的磁盘。试图确保在我们知道面对的是什么之前,我们不会处理任何只有单张的磁盘。这些最初的简单磁盘上的一些是诸如 《Death Bounce》之类的东西。这是他制作的一款从未问世的游戏,还有 Asteroids Clone。它们能运行,我们能够在机器上玩它们,他看着他几十年来都没想起来过的游戏,它们正运行良好。
**00:32:06 - Saron Yitbarek**:
到目前为止,一切都很顺利。现在轮到被标记着《<ruby> 波斯王子 <rt> Prince of Persia </rt></ruby>》的那张磁盘了。Tony 开始分析它,并且意识到它是一个硬盘驱动器的备份,被分成了五份放在了五张软盘里。他需要把整个东西重新整合在一起。
**00:32:23 - Tony Diaz**:
因此,要想还原这些镜像,你必须有一个与写入时大小相同的硬盘驱动器卷。当然,我带来了硬盘,但是怎么可能正好有完全相同的大小呢?因为你并不见得总能这么巧。没关系,我将在我的卡上创建了一个 10M 的分区,并制作了这些磁盘的副本,然后告诉它是从 10M 的驱动器上进行的备份。我们继续还原它,然后得到了一个完美的硬盘驱动器,装满了待查看的源代码文件。
**00:32:50 - Saron Yitbarek**:
重大的发现出现在当他们完成了第一个目录并查看文件的时候。
**00:32:55 - Tony Diaz**:
是的,就是它。Merlin 文件,它们都以 “.s” 结尾,还有 OBJ 文件,用于编译或汇编时 —— 都在这里了。哦,我的天哪,它有如此之多的不同版本,我们不得不把这些弄清楚,但是所有人的头基本上都转向了右后方的显示器和计算机上,多少有点儿沉默,好吧,让我们来瞧瞧这上面有什么?那个呢?我记得这个。
**00:33:20 - Jason Scott**:
当他开始这么做,并且我们开始滚动浏览那张磁盘上的文本文件,Jordan 立即识别出来它们是他的原始源代码。因此,即使我们知道我们有了重大发现,我们也还是继续浏览所有的磁盘,以确保我们不会错过一些其他的版本。在我们发现的东西中,有《波斯王子》中其他正在进行的工作,他曾尝试过不同的图形等等。
**00:33:48 - Saron Yitbarek**:
令人惊讶。当团队看到可识别的源代码文件那一刻,长长地松了一口气。《波斯王子:时之沙》已经从时间的流沙中获救。不过他们的工作还没有完全完成。
**00:34:09 - Saron Yitbarek**:
Jason 将抢救回来的代码上传到了 GitHub,世界各地的粉丝立刻就能获取到它。这件事的消息已经散布出去,人们登录并等待着。
**00:34:22 - Tony Diaz**:
我们那天的主要目的是尽快将其上传到 GitHub 上的一个仓库里。我们一直都连接在同一个 IRC 聊天室,有各种各样的人问我们问题。“这是什么?你看到的是什么?你获得了什么?”而且我们在进行时得到了现场反馈。
**00:34:38 - Jason Scott**:
曾开发过《<ruby> 毁灭战士 <rt> Doom </rt></ruby>》和《<ruby> 雷神 <rt> Quake </rt></ruby>》的 John Romero 说,他在看源代码时学到了一些技巧,而其他一些人当然完全搞不懂他们在看什么,因为在 20 世纪 80 年代后期所写的代码和今日相比相当不一样。事实上他逐个字节地移动内存,试图清理空间以使得“精灵”看起来像预期的一样。那是完全不同的一个世界。
**00:35:09 - Saron Yitbarek**:
自从 2012 年那重大的一天以来,《波斯王子》的源代码一直被研究、分享、评论和珍藏。这里是 Matthew G. Kirschenbaum 的一些总结。
**00:35:23 - Matthew Kirschenbaum**:
这是另一个例子,有关我们会认为是数字文化、有点像当今艺术作品的方式,我们当下的创造性表达方式。很多东西都被锁在了这些陈旧过时、满是灰尘的软盘里,但是凭借一点运气和工程学工作,发生了一些我们如何把东西弄回来的非常了不起的故事。
**00:35:49 - Saron Yitbarek**:
如今,“保存”图标是我们中的一些人离软盘最近的地方,但是当你们看到它时,我希望你们能够记住,它是这段神奇历史的一部分,我们不应该将其视为理所当然。这是一段有关分享和拯救我们所创造的东西的历史,一段有关保存的历史。
**00:36:09 - Saron Yitbarek**:
《代码英雄( Command Line Heroes )》是红帽( Red Hat )的一档原创播客节目。请到 [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) 查看我们的软盘研究笔记。顺便说一句,如果我们保存了这一集(大约 51.5 MB ),我们估计它会占用 36 张 3.5 英寸的软盘。我是 Saron Yitbarek,直到下一次,继续写代码吧。
**附加剧集**
从打孔卡和纸带到软盘并不是简单的事情。听听王安的故事,他推动了计算机存储技术的发展。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-4/floppies>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[JonnieWayy](https://github.com/JonnieWayy) 校对:[wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
The floppy disk was one of the greatest breakthroughs in computing. It helped spin up the software industry with a format that endured for decades. And in some cases, it’s conserved treasures once thought to be lost forever.
Before floppy disks came along, computing was weighed down by punch cards and magnetic tapes. Steven Vaughan-Nichols describes the magnitude of the changes brought by the floppy disk. Dave Bennet explains how the need for permanent storage, which was also easily mailable, led to the first 8-inch drives. George Sollman recalls how he was tasked with creating a smaller floppy, and what unexpected sources inspired the next design. And when Sollman showed it to the HomeBrew Computer Club, a couple of this season’s usual suspects asked him to see more. And the rest is history.
Or is it? Matthew G. Kirschenbaum points out that floppy disks are still in use in some unexpected places. And Jason Scott and Tony Diaz tell us how they brought some source code from the sneakernet to the cloud.

**00:00** - *Saron Yitbarek*
Jordan Mechner is a pack rat. He's the creator of games like Karateka and The Prince of Persia. He meticulously saved everything along the way. Journals, sketches, and storyboards. All of it. So it came as a bit of a shock to him when he couldn't find something he'd saved, and that something was a pretty big deal.
**00:26** - *Saron Yitbarek*
Back in 2002, Mechner was working on Prince of Persia: The Sands of Time. The programmers wanted to add the classic version of the game to their PlayStation 2 update as an Easter egg. So they asked him for the original source code. But when Mechner looked in his archives, he couldn't find it. He searched everywhere. The source code that he'd written on his old Apple II, the code he was positive he saved, had vanished.
**00:58** - *Saron Yitbarek*
Fast forward 10 years. Mechner's dad is cleaning house, and buried at the back of a closet is a ratty looking shoebox holding a bunch of dusty old 3.5-inch floppy disks. One is labeled, "Prince of Persia source code. Copyright 1989." And in brackets, in all caps, the word, "Original." The long lost code, found at last. It had sat in that box for a quarter century, before being unearthed like some archeological discovery.
**01:36** - *Saron Yitbarek*
But this was 2012. How would he be able to get it off those old disks, and would the data still be intact? Was it, in fact, too late to save his work?
**01:54** - *Saron Yitbarek*
Saving our work. These days it often happens automatically. With programs regularly pushing stuff into the cloud. We don't worry about manually saving things anymore. In fact, a whole new generation doesn't even know what that save icon represents. Side note: it is not a vending machine.
**02:16** - *Saron Yitbarek*
But for many decades, saving, storing, and transferring our data had to be done using some physical medium. When the personal computing revolution took off, which we heard about in our last episode on the Altair 8800, there was one piece of technology that became synonymous with saving. The floppy disk. It seems so simple now. But floppies changed the course of our history. Because they helped turn microcomputers into personal computers.
**02:50** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is Command Line Heroes. An original podcast from Red Hat.
**02:58** - *Saron Yitbarek*
Let's put a pin in Jordan Mechner's floppy disk discovery for a moment. We'll come back to it. First though, I want to learn how the floppy disk was born in the first place, and how it became such a crucial part of the tech world for almost 40 years.
**03:18** - *Saron Yitbarek*
Our first stop, 1890. Before electronic computers existed, there were electrical mechanical computing devices. The method for getting data in and out of them was through punch cards the size of a dollar bill. When electronic computers came along in the '50s, IBM standardized those punch cards with 80 columns, and 12 rows. A punched hole would form one type of character. No hole meant another.
**03:50** - *Saron Yitbarek*
For a long while, those punch cards were the main method for data input. But handling hundreds of cards for bigger, more complex programs, was hugely cumbersome. There had to be a better way to save and transfer information.
**04:08** - *Saron Yitbarek*
Next up, paper tape. Which came along in the 1950s. To hear how paper tape played a central role in the origin of personal computing, listen to our last episode. Paper tape had the same punched hole method of reading data as punch cards. But because it's all one tape, no one had to worry about getting cards mixed up. It could carry more data, and was much faster to use. But as minicomputers grew in capacity, they needed more and more tape to store programs. Like punch cards, paper tape eventually met its limit.
**04:47** - *Saron Yitbarek*
Enter magnetic tape. The key ingredient was mylar, a tough, flexible material coated with magnetic oxide to make the tape recordable. Nine tracks could store up to 175 megabytes per tape. That was a big deal in the '50s and '60s. Magnetic tape drives of 10.5-inch reels became standard issue for businesses.
**05:11** - *Steven Vaughan-Nichols*
But the problem with tape is that while it's great for moving large chunks of data from one place to another, it's really hard to search on them to find anything in particular. We would install software on our minicomputers and mainframes using tape, but it really wasn't that good for anything small and portable or if we wanted to do anything interactive with our data.
**05:40** - *Saron Yitbarek*
That's Steven Vaughan-Nichols, contributing editor at CBS Interactive. Sure, magnetic tape could store a lot more data. But it was too big and slow. It was only practical for the mainframe world, really. Again, there had to be a better way.
**05:58** - *Saron Yitbarek*
That better way came along in 1956, when IBM launched its very first disk drive—the IBM 350 disk storage unit. It was a component of the 305 RAMAC mainframe computer, a machine that filled an entire room. Here's Dave Bennet, a former IBM disk and storage product engineer.
**06:23** - *Dave Bennet*
There was storage in core memory. In fact, the disk storage device, of which RAMAC was the first, was a storage device that permitted random access to a given record, as opposed to a tape drive.
**06:39** - *Saron Yitbarek*
Interesting thing. That disk drive almost didn't see the light of day, because it threatened IBM's punch card business. But the project was eventually approved. Problem was, the drive contained disks made of solid metal. RAMAC literally weighed a ton. It had to be moved with forklifts, and transported by large cargo planes. Not the most convenient storage method. But out of that, came a better solution.
**07:10** - *Dave Bennet*
While the floppy disk was originally developed for a new need. The reason was that there was an intermediate kind of storage. Originally there was the computer code, and then there was the computer memory, the working memory. But with System 360, there was a new class of memory in between, which they called firmware. In System 360, there was unique technology for the firmware in various forms. It was either a special kind of a punched card, or there was a thing called transformer read-only storage.
**07:51** - *Dave Bennet*
But the new need was the desire to go from these technologies, to semiconductor technology, in the days when semiconductor technology was volatile. That means that the memory in semiconductors went away when the power was removed. So there had to be a way of recharging. Bringing the program back into that memory when the power was restored, for loading what was called a micro program, or that intermediate memory.
**08:28** - *Dave Bennet*
The need for such a device is what caused the development of the floppy disk drive.
**08:37** - *Saron Yitbarek*
So in 1967, a small team of engineers, led by David Noble, started developing an inexpensive system for loading those micro programs into mainframe computers. The codename for their project was Minnow.
**08:53** - *Dave Bennet*
Noble personally went through all the things that he could think of, including various forms of punched cards. Including use of tape cassettes. I don't know what else he went through. But he hit on the idea of using an inexpensive form of disk drive based on a flexible disk, and a very inexpensive read-only mechanism.
**09:19** - *Saron Yitbarek*
The Minnow team wanted to be able to mail their micro program to various locations that needed to load it. So the product for sending that program around had to be durable enough to fly through the mail without having its data damaged. Some kind of casing.
**09:38** - *Dave Bennet*
Now what they actually had to do in order to make it mailable was, they decided to put it in a plastic container that was fairly rigid. They would actually read and write the disk while it was inside of this plastic container, like an envelope. A plastic envelope. When you have a coating on a disk and a rigid head, you're going to have wear. When you have wear, you have wear particles.
**10:06** - *Dave Bennet*
The problem that they had was that as the wear particles built up, it kind of caused an avalanche effect. The particles would act as additional abrasive. Then pretty soon, with the particles being loose in there, you'd wear the recording track out, and it didn't work anymore.
**10:28** - *Dave Bennet*
So a really smart guy that was on that program, a man named Herb Thompson, came up with a plan that was based on a household dusting fabric that 3M sold to housewives for dusting their furniture. He put a sheet of that in there, between the envelope and the disk. That material picked up the wear particles, and they embedded themselves in that fabric, and prevented the avalanche effect, and really saved the day.
**11:00** - *Saron Yitbarek*
Flexible 8-inch mylar disks. One could even call them floppy. It was all housed in a slim but sturdy envelope, with that repurposed, dust-wiping mechanism. Altogether, it was easy to pick up, easy to mail. With a storage capacity of 80 kilobytes, each new floppy disk could hold the same amount of data as 3000 punch cards. A huge leap forward in storage capacity.
**11:29** - *Saron Yitbarek*
IBM released their 8-inch floppy disk in 1971. The Minnow team had done good, but they had no idea how good. Their breakthrough was about to evolve into a totally game-changing technology.
**11:49** - *Saron Yitbarek*
The head of direct access storage products at IBM was a man named Alan Shugart. The Minnow project was his baby. Shugart was quite a character, and entrepreneurial by nature. He wore Hawaiian shirts as his daily uniform, never a jacket and tie. Shortly after the 8-inch floppy was released, Shugart left IBM, joined Memorex in 1969, and then founded his own company in 1973, Shugart Associates. Specializing in computer peripherals.
**12:23** - *Saron Yitbarek*
Don Massaro followed Shugart from IBM, becoming VP of operations at Shugart Associates. A couple of years into that gig, Massaro received a request from a man named An Wang. He was the head of Wang Laboratories, one of the leading computer companies at the time. Wang had come up with a method for magnetic core memory that computers would use for the next 20 years.
**12:51** - *Saron Yitbarek*
When Wang reached out to Massaro in 1975, he gave him a challenge. George Sollman, an engineer at Shugart at the time, remembers.
**13:03** - *George Sollman*
Dr. Wang said, “I really want to do the small business system and word processor, but the disk drives that are out there, your big 8-inch ones are too big. We want a couple of small storage devices. They'll sit next to the CRT, and we can't have the big 8-inch ones, because the magnetic fields will corrupt the image.” So he thought we could take the 8-inch floppy and condense it down. So we knew we had to come up with something that was low cost and we could execute. We put together a plain old garden variety flip chart that described what it was, and we took it back and met with Dr. Wang, who said, “I like it, but you cannot use a motor in it that uses AC current because you're going to distort the image.”
**13:52** - *George Sollman*
So he said, “Why don't you find out who makes the motors for the tape players in, say, the General Motors cars?” So we went back, we implemented some very small motors that would fit in the mini floppy that would drive a belt, that would rotate the diskette.
**14:10** - *Saron Yitbarek*
George Sollman had to figure out the specs of this new floppy disk, how much smaller it should be and what it should hold.
**14:19** - *George Sollman*
What we did is, we looked at all of the tape players at that time, and we figured out their average dimensions. When you get all done with it, you end up with a 5.25-inch diskette size. We knew we’d probably have one time at bat. I think it was when Dr. Wang pulled Don and I into his office said, “Let me show you your disk drives in our new word processor.” And they also wanted to give us an order for some significant amount, 10,000 disk drives. So it was like, wow. We were now there.
**14:54** - *Saron Yitbarek*
Now in historical tech lore, there are a few variations to the story of how that 5.25-inch size came to be. One states that weighing one of the floppy disk to be larger than pocket size to avoid unfortunate bends and breaks. The favorite folk tale takes place in a bar over several drinks with Al Shugart and a eureka moment when he spotted a bar napkin that happened to be 5.25 inches square. Here's Teri Shugart, Al's daughter.
**15:26** - *Teri Shugart*
He liked to drink and what I can tell you is most of his planning in any company he ever started always did take place in a bar. And so it's not unlikely that that might've actually been the case.
**15:43** - *Saron Yitbarek*
But what really changed the game for Shugart and his team, and frankly for all of computing history, came down to one key moment when George Sollman and Don Massaro decided to demonstrate their 5.25 floppy disk at the Homebrew Computer Club.
**16:00** - *George Sollman*
There was a Homebrew Computer Club meeting at the Stanford Linear Accelerator meeting room, which turned out to be about a mile from where we lived. So we brought our mini floppy over and demonstrated it and there was a guy named Steve Wozniak in the audience and Steve wanted to talk to me on it and said, “I've got to have some people pay attention to this.”
**16:24** - *Saron Yitbarek*
After the demo, George and Don went back to their regular routine, but a few days later in the office, Don called him aside.
**16:33** - *George Sollman*
And said, “You're the marketing guy. You're supposed to keep the front lobby clean, George.” And I said, “yes, Don. What's your point?” He said, “We have a bum in the front lobby, we should get him out of here.” So I went out and shook this guy's hands. And he had the most intense eyes, and I talked to him a little bit more and he was very interesting to talk with and he said, “I would like to walk out in the lab with you and see what this thing is that Steve talked about.” I didn't know whether it was legit, but he was one of the more interesting people I've met and it was pretty clear he had a high IQ and a huge curiosity and that was Steve Jobs.
**17:19** - *Saron Yitbarek*
Steve Jobs hated the cassette drives in Apple's early computers. They were always failing and took forever to go back and forth to get information. For the Apple II, he wanted a floppy disk drive and Steve Wozniak wanted to build it, but size was key. The floppy had to be shrunk down to make the computer more compelling to customers. So in a 2-week span over the Christmas holidays in 1977, subsisting mainly on a diet of McDonald's, Woz built the prototype. It was done in time for the new year's Consumer Electronics Show in Vegas.
**17:57** - *Saron Yitbarek*
Woz loved building that floppy drive, describing it as the finest piece of engineering he ever engaged in. Jobs hired Shugart to manufacture the Apple floppy. The disk II became a major hit for Apple, helping drive sales of the Apple II computer and changing the industry. Here's Steven Vaughan-Nichols.
**18:20** - *Steven Vaughan-Nichols*
If you bought an Apple II, this was an option that very quickly became wildly popular. Really, you can give Steve Jobs the credit for being the person to introduce the floppy drive to the PC world. People are running this operating system called CPM 80 and there are literally dozens of small manufacturers and some big ones like DEC making CPM 80 computers and all of these computers use the 5.25-inch floppy drive. And then when IBM comes along in 1981 with the first IBM PC, it has become clear to everyone that this is no longer a hobbyist market.
**19:04** - *Steven Vaughan-Nichols*
This is a real business market and that this business is going to be driven by the newfangled 5.25-inch floppy drives.
**19:14** - *Saron Yitbarek*
The floppy disk and the personal computer revolution were symbiotic. One fueled the other and vice versa. They evolved together. Thanks to the floppy, companies could write programs, copy them onto disks and sell them through the mail or in stores. It did for early PCs what app stores would do for smartphones, opening things up for developers. In fact, the floppy made the whole software industry possible, and as those software programs became larger and more complex, floppies changed again. In 1981, Sony introduced the next evolution of the floppy disk shrunk down to 3.5 inches.
**19:59** - *Saron Yitbarek*
The smaller siblings were encased in hard plastic with a built-in metal shutter to prevent dust from getting in. They were more sturdy and they could store more data. Funny thing, despite their hard case, they were still called floppies and once again it was Apple that made the 3.5s the new standard when they released their new Macintosh computer in 1984.
**20:25** - *Steven Vaughan-Nichols*
Well, we all know about Steve Jobs and Steve Wozniak. The creators of the floppy drives, like Shugart, are not household names by any means, but the work they did was absolutely vital. If it wasn't for that, PCs would have been adopted much more slowly. It's impossible for me to see how the PC revolution could have happened the way it did without these early drives. It just made getting data in and out of computers an order of magnitude easier than it would have been otherwise.
**21:06** - *Saron Yitbarek*
Because floppies were hand-sized and easily shareable, they had a social quality, like an early form of social media. You could meet up with people and trade disks. This was before people had easy access to modems and before the internet was even a thing. People shared floppies full of programs the same way they shared mixed tapes full of Cyndi Lauper tracks. And this way of transferring data even had a name, Sneakernet, because you literally have to use your feet to transport digital information from one machine to another and what people put on those shared disks could be anything, software sure, but so much more, especially with all the new digital creation tools that started to spring up.
**21:55** - *Saron Yitbarek*
Jaime Levy was one of those new digital creators back in the late '80s. She's now a professor at the University of Southern California and the author of the book UX Strategy.
**22:07** - *Jaime Levy*
I certainly thought it was amazing too, that you could make something that was interactive and nonlinear on a floppy disk. I was making what became a diskzine. It was at the same time as desktop publishing. I think PageMaker was coming out. People were just getting Macintoshs and people were slowly gravitating to digital.
**22:32** - *Saron Yitbarek*
No one had ever heard of an interactive zine before, not even Jamie, but she combined animation, art, and sound and an interactive interface and made them fit on a floppy. She made a bunch of copies, packaged them up and took them to a local bookstore.
**22:48** - *Saron Yitbarek*
In most cases, they did not have a Macintosh to even look at them, and so they didn't know what was on them. So I'd say, well here, take 10, take one home and check it out, and if you like it, then sell them. And they would keep them by the front counter because they didn't fit nicely on a rack and then immediately people bought them. As soon as anyone with a Mac walked in there and saw this thing for 6 bucks, they were like, “Yes, I want that thing.”
**23:15** - *Saron Yitbarek*
The bookstores kept selling out. Jaime received letters from around the world and started getting national media attention. Soon she made a business from selling her disks through mail order. Then her career as an interface designer took off. Her story is a testament to the floppy and the power of Sneakernet. There was a time when you could run an entire operating system off a single 160-kilobyte floppy drive, but by the mid '90s you needed multiple floppy disks to run anything. Files got bigger and bigger and it was annoying to do the floppy disk shuffle in and out of your machine.
**23:57** - *Saron Yitbarek*
The writing was on the wall when the 1998 iMac was the first personal computer to ship without a floppy drive. When modems got better and the internet was easier to get on, people moved away from floppies to newer storage technology like the CD ROM and from CDs we moved on to DVDs, SD cards, USB flash drives. Turn around, and there's a whole graveyard of obsolete storage technology behind us. And now we have the cloud. Poor old floppies, they didn't stand a chance. But here's the thing, floppies linger. They have staying power. There's still the save icon for starters.
**24:43** - *Saron Yitbarek*
People still have shoe boxes full of them. Floppies have in fact proven to be one of the most resilient pieces of technology out there. You might be surprised to learn they're still used to maintain the legacy machines like the US Intercontinental Ballistic Missile System. Up until recently, that system relied on 8-inch floppy drives for real. Matthew Kirschenbaum is a professor of English and Digital Studies at the University of Maryland.
**25:17** - *Matthew Kirschenbaum*
So there was a story that was making the rounds about the US Air Force phasing out 8-inch floppy disks from its nuclear command and control systems. And so this was accompanied by pictures of people down in the missile silos plugging floppy diskettes into sort of old style mainframe computers. And I think that surprised a lot of people to see that something like nuclear weaponry was still controlled by 8-inch floppy disks. The government, the military is finally phasing those systems out. And I certainly think that's a good thing, but it's worth remembering, too, that floppies tend to be pretty durable and resilient as storage media goes. They're low areal density, meaning that they're relatively coarse or low-fi as compared to hard drives nowadays. Which actually made them a little bit more resilient, and reliable. They were also, because of the very age, the very obsolescence of those computer systems. They were ironically more protected against some of the kinds of networked threats that we see nowadays in the forms of viruses, and hacking, and that sort of thing. The phrase people used was the “air gap,” and so the floppies were not physically connected to the internet in any way and there's a way to think of that as a pretty desirable security feature. Even though it made people a little bit queasy. It's not completely absurd that they've persisted in use for as long as they have.
**26:53** - *Saron Yitbarek*
Sure. When you look at floppies now, they look flimsy and a bit ridiculous, but with the right equipment, disks from decades ago are still readable today. Who knows what treasures can be found when that data is retrieved.
**27:09** - *Matthew Kirschenbaum*
A couple of years back, there was a press release that there had been a dozen new Andy Warhol images located. It turns out that the images in question were actually digital images that Andy Warhol had created on an Amiga computer back in the 1980s.
**27:26** - *Matthew Kirschenbaum*
He had gotten the Amiga and was experimenting with it and began to use it for some of his artwork and the resulting images were stored on floppies that were at the Warhol Museum in Pittsburgh. A team from Carnegie Mellon University was able to rescue those files, and we now have a dozen additional pieces of artwork by Andy Warhol.
**27:53** - *Saron Yitbarek*
Speaking of treasures, it's time to find out what happened to Jordan Mechner and his long-lost source code. To recap, Jordan lost the original source code for Prince of Persia. Years later, his dad unearthed a shoe box at the back of a closet with a bunch of dusty, 3.5-inch floppies. One was labeled “source code,” but was the source code really on that disk? Would he be able to recover his Prince of Persia work?
**28:23** - *Saron Yitbarek*
To find out, we talked to two people Jordan enlisted as his save-the-code crew. The first person Jordan contacted was Jason Scott. Free range archivist at the Internet Archive.
**28:38** - *Jason Scott*
It was going to work or it wasn't, but you'll always want to prepare for the worst. There's this guy I know and his name is Tony and Tony's relationship to Apple is astounding. He knows them inside and out. I would call him an “Apple II whisperer.”
**28:59** - *Saron Yitbarek*
Via a long running IRC channel, Jason tracked down Tony Diaz and recruited him for the job. Jordan invited this pair of computer archeologists to his home in Hollywood Hills. Tony loaded a bunch of gear into the back of his truck for the long drive from Oceanside to LA.
**29:19** - *Tony Diaz*
I took a couple of Apple IIe systems that I have sitting out, back them up, filled about half the pickup truck bed full of various stuff, and I got disk drives that are modified for reading difficult floppies and various tools like that. Disk drive controller that does things a little differently and some stuff on more modern computer that helps with the floppies if I have to do it. Yup, load it all up and hit the road.
**29:43** - *Saron Yitbarek*
In Jordan's living room. Tony set up an impressive array of vintage Apple II computers and 3.5-inch disk drives. Then Jordan brought out the shoe box in a plastic bag like it was the Holy grail. This grail had rubber bands around it to try to keep the cardboard lid from falling off.
**30:03** - *Tony Diaz*
I've been at the receiving end of this a lot of times where I just crack open the old box of disks, and it's all got that same kind of musty smell that. I don't know, it's hard to describe, but for those people who've been on a Navy ship, they all have the same smell. You go to an airport, the backside of it, they all smell the same. The floppy disks have their own unique, what's the word—luster—to them, anyway.
**30:25** - *Saron Yitbarek*
Tony pulled out a couple of the disks to see what condition they were in. He was ready to take off the protective cover if he had to and clean them with Joy dish soap. The disks hadn't been rotated for a long time. So he put his fingers in the center, gave it a wiggle and rotated it once to check for mold. Then he and Jason split off into two teams.
**30:49** - *Jason Scott*
I was going to do flux readings, which is where you take the magnetic information, pulling every single wavering of magnetic info off of a floppy and that produces a very large and hard-to-decode image of the floppy. The idea was that if anything else went wrong or we were stymied in any single way, that we'd be able to use that in the future.
**31:16** - *Jason Scott*
Tony understood what the information on these disks were and he was using utilities on a machine to read the disk as if it was back in 1990 and the data was something that made sense to him. We went after the disks that were very obviously standard copies of files. Trying to make sure we weren't touching any one-of-a-kind disks until we knew what we were up against. Some of the things that were on these initial simple disks were things like Death Bounce. A game that he made that never came out along with an Asteroids Clone. They worked, and we were able to make them play on the machine and he was looking at games he hadn't even thought about for decades and they were running fine.
**32:06** - *Saron Yitbarek*
So far, so good. Now for the disk labeled Prince of Persia. Tony started analyzing it and realized it was a backup of a hard drive that had been split across five floppies. He needed to put the whole thing back together.
**32:23** - *Tony Diaz*
So to restore those images, you have to have a hard drive volume the same size as the one that you wrote it from. Of course, I brought drives, but what are the odds we're going to have the exact same size because you didn't always. That's okay, I'll make a 10 meg partition on my card here, and I will make a copy of these disks, and I will tell it that you have been backed up from a 10-meg drive. We proceed to restore it and after that get a nice hard drive full of a source code files to go through.
**32:50** - *Saron Yitbarek*
The big reveal happened when they did the first catalog and looked at the files.
**32:55** - *Tony Diaz*
Yup. That's it. Merlin files, they all end in “.s” and there's the OBJ files for when it's compiling or when it's assembling—it's all here. Oh my gosh, there's so many different versions of it we have to figure these out, but all the heads basically turned pretty much concentrated right back towards the monitor and the computer and it was kind of silence more like, okay, here, let's see what's on this one? How about that one? I remember this.
**33:20** - *Jason Scott*
Once he did that, and we started scrolling through the text files that were on that disk, Jordan recognized them immediately as his original source code. So we just kept going through all of the disks even though we knew we had struck gold, just to make sure we weren't missing some other versions. Among the things we found were other work in progresses from Prince of Persia where he had tried different graphics and so on.
**33:48** - *Saron Yitbarek*
Amazing. The moment the team saw the directory with recognizable source code files, they let out a collective sigh of relief. Prince of Persia had been rescued from the sands of time. Their work was not quite done.
**34:09** - *Saron Yitbarek*
Jason uploaded the salvaged code to GitHub where it was instantly accessible to fans from around the world. Word of the event had leaked out and people were logged on and waiting.
**34:22** - *Tony Diaz*
Our main goal that day was to get it uploaded to a repository on GitHub as soon as possible. We were connected in that same IRC chat room the whole time, and we had all kinds of people asking us questions. "What is it? What are you seeing? What do you got?" And we're getting live feedback as we're going.
**34:38** - *Jason Scott*
John Romero who worked on Doom and Quake said that he learned a few tricks looking at the source code and a bunch of other people of course were completely confused as to what they're looking at because a code written in the late 1980s is a lot different than today. The fact that he is byte-by-byte moving memory, trying to clear space so that a Sprite looks like it's supposed to. That's a whole other world.
**35:09** - *Saron Yitbarek*
Since that eventful day back in 2012, the Prince of Persia source code has been studied, shared, commented on, and cherished. Here's Matthew G. Kirschenbaum with some final thoughts.
**35:23** - *Matthew Kirschenbaum*
It's another example of the way in which aspects of what we would think of as digital culture, sort of the artwork of today, the creative expression of our own moment. A lot of it is locked away on these dusty obsolescent floppies, but with a little bit of luck and engineering, there are some pretty remarkable stories that have emerged about how we've gotten things back.
**35:49** - *Saron Yitbarek*
The save icon is as close as some of us ever get to floppies these days, but when you see it, I hope you'll remember that it's part of this amazing history we should never take for granted. A history of sharing and rescuing the things we create. A history of saving.
**36:09** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Check out our floppy disk research notes at [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes). By the way, if we saved this episode, which is about 51.5-megabytes, we figured it would take 36 3.5-inch floppies. I'm Saron Yitbarek, until next time, keep on coding.
### Further reading
[ The History of Punched Cards](https://www.routledgehandbooks.com/doi/10.4324/9781315442686-3) by Robert S. Wahl
[ Alan Shugart: About the Floppy Disk](https://www.computerhistory.org/revolution/memory-storage/8/261/2276) at the Computer History Museum
[ Oral History Panel on 5.25 and 3.5 inch Floppy Drives](http://archive.computerhistory.org/resources/text/Oral_History/5.25_3.5_Floppy_Drive/5.25_and_3.5_Floppy_Panel.oral_history.2005.102657925.pdf) by Jim Porter
[ BUSINESS TECHNOLOGY; The Evolution of the Floppy Disk for PC's](https://www.nytimes.com/1990/03/14/business/business-technology-the-evolution-of-the-floppy-disk-for-pc-s.html) by Andrew Pollack
### Bonus episode
Moving from punch cards and paper tape to floppies wasn’t straightforward. Hear the story of An Wang, who pushed computer storage technology forward. |
13,487 | 使用 Cockpit 管理你的树莓派 | https://opensource.com/article/21/5/raspberry-pi-cockpit | 2021-06-15T14:41:00 | [
"树莓派",
"Cockpit"
] | https://linux.cn/article-13487-1.html |
>
> 用 Cockpit 建立你的树莓派的控制中心。
>
>
>

去年,我写了关于使用 [Cockpit 管理我的 Linux 服务器的文章](https://opensource.com/article/20/11/cockpit-server-management)。它是一个基于 Web 的工具,为管理多个服务器及其相关的服务和应用提供了一个简洁、强大的界面。它还简化了日常的管理任务。
在这篇文章中,我将会介绍如何在树莓派基金会提供的标准操作系统树莓派 OS 上安装用于 Linux 服务器的 Cockpit Web 控制台。我还会简要介绍它的特性。
### 在树莓派 OS 上安装 Cockpit
在 `sudo` 权限下使用一个账户通过 SSH 登录你的树莓派系统。如果你还没有建立一个账户:
```
$ ssh pibox
alan@pibox's password:
Linux pibox.someplace.org 5.10.17-v7+ #1403 SMP Mon Feb 22 11:29:51 GMT 2021 armv7l
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Tue May 4 09:55:57 2021 from 172.1.4.5
alan@pibox:~ $
```
在树莓派 OS 上安装 Cockpit Web 控制台和在 Linux 服务器上一样简单:
```
$ sudo apt install cockpit
```
Cockpit 只需要 60.4 KB 的磁盘空间。加上它的几个包依赖项,总使用量是 115MB。
安装过程将负责设置和启动服务。你可以使用 `systemctl` 命令来验证状态:
```
$ systemctl status cockpit.socket
● cockpit.socket - Cockpit Web Service Socket
Loaded: loaded (/lib/systemd/system/cockpit.socket; enabled; vendor preset: enabled)
Active: active (listening) since Tue 2021-05-04 10:24:43 EDT; 35s ago
Docs: man:cockpit-ws(8)
Listen: 0.0.0.0:9090 (Stream)
Process: 6563 ExecStartPost=/usr/share/cockpit/motd/update-motd localhost (code=exited, status=0/SUCCESS)
Process: 6570 ExecStartPost=/bin/ln -snf active.motd /run/cockpit/motd (code=exited, status=0/SUCCESS)
Tasks: 0 (limit: 2181)
CGroup: /system.slice/cockpit.socket
```
### 使用 Cockpit
#### 连接
默认的监听端口号是 9090。打开你最喜欢的 Web 浏览器并输入地址,例如: `https://pibox:9090`。

你现在可以使用你的普通账户登录。同样,这个账户上需要有使用 `sudo` 的权限 —— 很可能就是你用来 SSH 和运行 Apt 的那个账户。一定要勾选“为特权任务重用我的密码”。
#### 管理你的树莓派
Cockpit 的初始屏幕以 “System” 页开始,提供当前 CPU 和内存使用的详细信息和图表。

你可以从这个屏幕看到硬件细节。

通过点击每一项来展开左边的列(例如,日志、存储、服务等)。这些是标准的 Cockpit 部分,不言自明。让我快速描述一下每个部分。
#### 日志
这部分展示了日志。它们可以根据日期和严重程度来过滤。
#### 存储
存储部分展示了已经安装的物理驱动器和 RAID 设备。例如大小、序列号等细节都被展示了出来。还展示了读/写活动和实际空间使用的图表。存储的具体日志显示在底部。
#### 网络
这部分展示了发送和接收活动、IP 地址以及网络特定的日志。你还可以使用相应的按钮添加更多的网络设备,如绑定、网桥和 VLAN。
#### 账户
这里展示了已有的账户。点击每个账户来管理,或使用创建新账户按钮来添加用户。账户也可以被删除。
#### 服务
这部分可以让管理员查看系统所有服务的状态。点击任何服务都会转到一个包含启动、重启和禁用的标准任务的屏幕。
#### 应用程序
通常,这个屏幕提供了各种用于管理功能的应用程序,例如 389 目录服务器或创建 Podman 容器。但在我的树莓派 OS 上,这个屏幕只显示“没有安装或可用的应用程序”。在写这篇文章的时候,这个或许还没有实现。虽然,你可能会怀疑这类型的程序对于树莓派硬件来说是否太过沉重。
#### 软件更新
对任何系统管理员来说,保持软件最新是最重要的任务之一。Cockpit 的软件更新部分可以检查并进行更新。

#### 终端
Cockpit 最方便的特点之一是终端。你可以使用它,而不是打开一个单独的终端模拟器并使用 SSH。我使用终端来安装 [ScreenFetch](https://opensource.com/article/20/1/screenfetch-neofetch):
```
$ sudo apt install screenfetch
```
使用 ScreenFetch 生成了这张截图:

### 使用 Cockpit 的中心控制
Cockpit 在树莓派上的表现就像它在其他 Linux 系统上一样。你可以将它添加到仪表盘上进行集中控制。它允许企业在 Cockpit 作为管理仪表盘解决方案的任何地方,将基于树莓派的服务和系统整合到他们的整体 Linux 基础设施中。因为树莓派经常在高密度机架数据中心以<ruby> 无外接控制 <rt> headless </rt></ruby>方式运行,而这些数据中心通常会缺乏 KVM 访问方式,这是非常方便的。
---
via: <https://opensource.com/article/21/5/raspberry-pi-cockpit>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[RiaXu](https://github.com/ShuyRoy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I wrote about using [Cockpit to manage my Linux servers](https://opensource.com/article/20/11/cockpit-server-management). It is a web-based tool that gives you a clean, powerful interface for managing multiple servers and their associated services and applications. It also eases regular day-to-day administrative tasks.
In this article, I'll describe how to install the Cockpit web console for Linux servers on the Raspberry Pi operating system (OS), the standard OS provided by the Raspberry Pi Foundation. I'll also provide brief descriptions of its features.
## Installing Cockpit on Raspberry Pi OS
Log into your Raspberry Pi system using secure shell (SSH) using an account with sudo privileges. Set up an account if you haven't already done so:
```
$ ssh pibox
alan@pibox's password:
Linux pibox.someplace.org 5.10.17-v7+ #1403 SMP Mon Feb 22 11:29:51 GMT 2021 armv7l
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Tue May 4 09:55:57 2021 from 172.1.4.5
alan@pibox:~ $
```
The command to install the Cockpit web console is as simple on Raspberry Pi OS as it is on Linux servers:
`$ sudo apt install cockpit`
Cockpit only requires 60.4 kB of disk space. Together with its several package dependencies, total usage is 115MB.
The installation process will take care of setting up and starting the services. You can verify the status by using the `systemctl`
command:
```
$ systemctl status cockpit.socket
● cockpit.socket - Cockpit Web Service Socket
Loaded: loaded (/lib/systemd/system/cockpit.socket; enabled; vendor preset: enabled)
Active: active (listening) since Tue 2021-05-04 10:24:43 EDT; 35s ago
Docs: man:cockpit-ws(8)
Listen: 0.0.0.0:9090 (Stream)
Process: 6563 ExecStartPost=/usr/share/cockpit/motd/update-motd localhost (code=exited, status=0/SUCCESS)
Process: 6570 ExecStartPost=/bin/ln -snf active.motd /run/cockpit/motd (code=exited, status=0/SUCCESS)
Tasks: 0 (limit: 2181)
CGroup: /system.slice/cockpit.socket
```
## Using Cockpit
### Connecting
The default listening port is 9090. Open your favorite web browser and enter the address, e.g., `https://pibox:9090`
.
(Alan Formy-Duval, CC BY-SA 4.0)
You can now log in with your regular user account. Again, it is helpful to have sudo privileges on this account—most likely the same one you use to SSH and run Apt. Be sure to check the box for "Reuse my password for privileged tasks".
### Managing your Pi
Cockpit's initial screen starts with **System** and will provide details and graphs of current CPU and memory usage.
(Alan Formy-Duval, CC BY-SA 4.0)
You can view hardware details from this screen.
(Alan Formy-Duval, CC BY-SA 4.0)
Explore the column on the left by clicking each item (e.g., Logs, Storage, Services, etc.). These are the standard Cockpit sections and are fairly self explanatory. Let me quickly describe each.
### Logs
This section shows the logs. They can be filtered by date and severity.
### Storage
The storage section shows the physical drives and RAID devices that are installed. Details such as size and serial number are shown. Graphs for read/write activity and actual space usage are displayed. Storage specific logs are presented at the bottom.
### Networking
This section displays send and recieve activity, IP addresses, and network specific logs. You can also add more networking devices; such as bonds, bridges, and VLANs using the respective buttons.
### Accounts
Existing accounts are shown here. Click each to manage or use the *Create New Account* button to add users. Accounts can be deleted here also.
### Services
This section allows the administrator to view the status of all of the system services. Clicking any service takes you to a screen with the standard tasks of start, restart, and disable.
### Applications
Normally, this screen provides various applications for managing functions such as the 389 Directory Server or creation of Podman containers. On my Raspberry OS though, this screen only displayed the message, "No applications installed or available". At the time of writing, perhaps this has not yet been implemented. Although, you do have to wonder whether these types of processes would be too heavy for the Raspberry PI hardware.
### Software Updates
Keeping software up to date is one of the most important tasks for any system administrator. Cockpit's Software Updates section checks and applies updates.
(Alan Formy-Duval, CC BY-SA 4.0)
### Terminal
One of Cockpit's neatest features is the terminal. You can use it instead of opening a separate terminal emulator and using SSH. I used the terminal to install [ScreenFetch](https://opensource.com/article/20/1/screenfetch-neofetch):
`$ sudo apt install screenfetch`
And I used ScreenFetch to produce this screenshot:
(Alan Formy-Duval, CC BY-SA 4.0)
## Centralized control with Cockpit
Cockpit behaves on Raspberry Pi just like it does on any other Linux system. You can add it to a dashboard for centralized control. It allows organizations to integrate Raspberry Pi-based services and systems into their overall Linux infrastructure anywhere Cockpit is used as a management dashboard solution. This is highly convenient, given that Pis are often run headless in high-density racked data centers that generally lack KVM access.
## 8 Comments |
13,491 | 2021 年学习 Java 的三个理由 | https://opensource.com/article/21/5/java | 2021-06-16T12:20:25 | [
"Java"
] | /article-13491-1.html |
>
> Java 具有功能强大、多样化、可拓展、有趣的特点。这就是 Java 为什么被我们广泛使用,也是我们如何正确使用它的方式。
>
>
>

Java 是在 1995 年发布的,当我写这篇文章的时候,它已经 26 岁了。起初它是专有的,但在 2007 年,Java 基于 GPL 协议被开源发布了。如果想要理解是什么使得 Java 变得非常重要,你就必须理解它声称要解决的是什么样的问题,从而你就能理解它让开发者和用户受益的原因和方式。
理解 Java 解决了什么问题的最好方式就是进行软件开发,当然啦,如果不做开发,仅仅只是使用软件也会是一个很好的开始。作为一名开发人员,当你将在自己的本地计算机上运行良好的软件部署到其他计算机上运行时,一些稀奇古怪的麻烦可能就出现了,从而导致软件可能无妨正常运行。软件本应正常工作,但每个程序员都明白,一些问题总是会被忽视。当你在另一个操作系统上尝试运行该软件时,情况就变得更加复杂了。这也是为什么在每一个软件的获取页面上都会有针对不同的操作系统有对应下载按钮的原因:Windows 的、macOS 的、Linux 的、移动端的、甚至许多其他操作系统环境的下载选项。
作为一名用户,一个典型的场景是你想下载一些优秀的软件,但它却不适用于你的平台。遗憾的是这样的情况仍然发生在当下非常先进的计算机上,它们可以在计算机中运行虚拟机,通过仿真使老式视频游戏保持活力,甚至可以放在你的口袋里,但软件交付实际上相当困难。
有没有更好的办法?可能会有吧。
### 1、一次编码,任意环境都能跑通
令人惊讶甚至是失望的是,代码是特定于操作系统和环境的。代码需要从对人友好的高级程序设计语言编译成机器语言,即被设计可以用于让 CPU 响应的一系列二进制指令。在先进的计算机世界中,我们很难理解为什么不能仅仅只要编写代码,就能将它发送给任何一个想要运行它的平台,无需担忧它们正处在什么样的平台中。
Java 可以解决这种不协调的问题。它的代码是可以跨平台进行工作的,在任何运行它的系统上都执行相同的工作。Java 实现这一壮举的方法起初是有悖常理的。在某种程度上,Java 只与一台计算机兼容。奇怪的是,这台电脑实际上并不存在。Java 代码的目标计算机是Java 虚拟机(JVM)。这是一个由 Java 的创建者编写的程序,可用于你能想到的任何计算机设备。只要你安装了它,你运行的任何 Java 代码都会由你计算机中的这台“虚拟”计算机进行处理。Java 代码会由 JVM 执行,JVM 向你的计算机发送适当的特定于平台的指令,因此所有工作在每个操作系统和架构上都是一样的。
当然,Java 使用的方法并不是这里的真正的卖点。大多数用户和许多开发人员并不关心软件兼容性是如何实现的,只关心它是否具备兼容性。许多语言都承诺提供跨平台的功能,通常情况下,这个承诺最终都是真的,但是这个过程并不总是容易实现的。编程语言必须针对其目标平台进行编译,脚本语言需要特定于平台的解释器,而且两者都很难确保对底层系统资源的一致访问。跨平台支持变得越来越好,库可以帮助转换路径、环境变量和设置,并且一些框架(特别是 [Qt](http://qt.io))在弥补外设访问的差距方面做了很多工作。但是,Java 始终可靠地提供它的兼容性。
### 2、明智的代码
Java 的语法即使是在最好的方面也很无聊。如果你把所有流行的编程语言都放在一个摇滚杯中,那么你会得到 Java。通过观察 Java 编写的源代码,你或多或少会均匀地看到所有特定的编程表达方式。括号表示函数和流程控制的范围、变量在使用前被明确地声明和实例化,并且表达式具有清晰一致的结构。
我发现 Java 学习过程中通常会鼓励自学成才的程序员使用结构化程度较少的语言编写更精炼的代码。从网上学习的源代码中收集到的技术中,有许多“基本”编程经验是你无法学到的,比如以 Java 公开字段的风格进行全局变量声明、正确地预测和处理异常、使用类和函数、和许多其他的技术。从 Java 借鉴的一点小改动可以产生很大的不同。
### 3、脚手架和支持
流行的编程语言都有很好的支持系统,这也是使得其变成流行语言的原因。它们都有很多文档资料,有针对它们的集成开发环境或 IDE 扩展、示例代码、免费和付费培训和开发者社区。在另一方面,当你在尝试做某事遇到困难时,似乎没有任何编程语言有足够的支持。
我不能说 Java 可以摆脱这两个普遍但又相互矛盾的事实。尽管如此,我发现当我需要一个 Java 库时,我必然能为给定的任务找到多个选项。通常我不想使用一个库的原因是我不喜欢它的开发人员如何实现我需要的功能,它的许可证与我喜欢的有所不同,或者有其他琐碎的争议点。当一门语言得到大量支持时,我就会很多的选择性。我可以从许多合适的解决方案中选择一个最能满足我需求的,不论我的需求多么微不足道都能被最好得满足。
更好的是,围绕 Java 有一个健康的基础设施。像 [Apache Ant](https://ant.apache.org/)、[Gradle](https://gradle.org) 和 [Maven](https://spring.io/guides/gs/maven) 等工具可以帮助管理构建和交付的过程。像 [Sonatype Nexus](https://www.sonatype.com/products/repository-pro) 等服务帮助实现监控的安全性。[Spring](http://spring.io) 和 [Grails](https://grails.org) 使 Web 开发变得更加容易,而 [Quarkus](https://opensource.com/article/21/4/quarkus-tutorial) 和 [Eclipse Che](https://opensource.com/article/19/10/cloud-ide-che) 有助于云上的开发。
在接触 Java 语言本身时,你甚至可以选择使用什么样的版本。[OpenJDK](http://adoptopenjdk.net) 提供经典的、官方的 Java,而 [Groovy](https://opensource.com/article/20/12/groovy) 是一种类似于脚本语言的简化方法(你可以把它比作 Python),而 [Quarkus](https://developers.redhat.com/products/quarkus/getting-started) 提供了一个容器优先开发的框架。
还有很多,但现在已经足以说明 Java 是一个完整的生态了,无论你想在其中寻找什么。
### 此外,简单易学
事实证明,Java 对我和各行各业的许多开发人员来说是一个明智的解决方案。以下是我喜欢使用 Java 的一些原因。
你可能听说过或推断出 Java 是一种“专业”语言,只适用于笨重的政府网站,专供“真正的”开发人员使用。千万不要被 Java 25 年以来的各种名声所迷惑!它的可怕程度只有它名声的一半,这意思是,并不比其他任何语言更可怕。
编程很困难的这件事是无法回避的,它要求你基于逻辑进行思考,学习一种比母语表达方式更少的新语言,要你弄清楚如何解决困难的问题,使它们可以使用你的程序完成自动化的执行,没有语言可以避免这些问题。
然而,编程语言的学习曲线的差异令人惊讶。有些一开始很容易,但当你开始探索细节时就会变得复杂。换句话说,打印“hello world”可能只需要一行代码,但当你学习到了类和函数, 你相当于开始重新学习这门语言(或者至少是它的数据模型)。Java 从一开始就是 Java,一旦你学会了它,就可以使用它的许多技巧和便利。
简而言之: 去学习 Java 吧!它具有功能强大、多样化、可拓展、有趣的特点。为了给你提供帮助, [下载我们的 Java 备忘单](https://opensource.com/downloads/java-cheat-sheet), 它包含你在开发前十个项目时需要的所有基本语法。在那之后,你就不再需要它了,因为 Java 具有完美的一致性和可预测性。来享受它吧!
---
via: <https://opensource.com/article/21/5/java>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[PearFL](https://github.com/PearFL) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,492 | FreeDOS 入门 | https://opensource.com/article/21/6/get-started-freedos | 2021-06-16T12:36:02 | [
"FreeDOS",
"DOS"
] | https://linux.cn/article-13492-1.html |
>
> 它看起来像复古计算,但它是一个现代的操作系统,你可以用它来完成任务。
>
>
>

在整个 1980 年代和 1990 年代,我主要是一个 DOS 用户。我喜欢 DOS 提供的命令行环境,它随着每一个连续的版本变得更加强大。我甚至学会了如何用 C 语言编写自己的 DOS 程序,这样我就可以扩展 DOS 命令行,并为标准的 DOS 命令编写更强大的替代程序。我曾经试验过微软的 Windows,但如果你记得当时的 Windows 3,你就会知道它很慢,而且容易崩溃。但无论如何我更喜欢命令行,所以我坚持使用 DOS。
这一切在 1994 年发生了变化。流行的技术杂志谈到了即将到来的 Windows 版本,它将完全废除 DOS。我不想被迫使用 Windows。在我访问的 Usenet 讨论区中,其他人也有同样的感觉。所以在 [1994 年 6 月 29 日](https://groups.google.com/g/comp.os.msdos.apps/c/oQmT4ETcSzU/m/O1HR8PE2u-EJ),我认为如果我们想保留 DOS,我们需要自己编写。所以在 6 月 29 日,我宣布了一个小项目,这个项目后来成为 [FreeDOS 项目](https://www.freedos.org/)。
从那时起,我们已经发布了几个完整的 FreeDOS 发行版。我们从 1994 年到 1997 年的 alpha 系列开始,再到 1998 年到 2005 年的 beta 系列,最后在 2006 年发布了 FreeDOS 1.0 版本。从那时起,进展是缓慢但稳定的。在 1.0 之后,我们并没有真正急于发布每个新版本,因为 DOS 在 1995 年不再是一个变动的目标。
从 1.0 开始的每一个 FreeDOS 发行版都是对现代 DOS 的不断重新想象。我们已经包括了很多编译器和汇编器,供开发人员编写软件。我们还提供了许多“强大工具”,以便你可以做真正的工作。我们还提供了各种编辑器,因为每个人都有自己的最爱。
我们最近发布了 FreeDOS 1.3 RC4 发行版。从技术上讲,这是我们即将推出的 FreeDOS 1.3 发行版的候选版本,但它是一个全功能的发行版。我对 FreeDOS 1.3 RC4 的所有功能感到非常兴奋。
### 无需安装 FreeDOS 即可运行 FreeDOS
在我们以前所有的 FreeDOS 发行版中,我们把重点放在 *安装* FreeDOS 到电脑上。但我们认识到,大多数用户实际上已经不在实际硬件上运行 FreeDOS 了。他们在 [像 QEMU 或 VirtualBox 这样的虚拟机](https://opensource.com/article/20/8/virt-tools) 中运行 FreeDOS。所以在 FreeDOS 1.3 RC4 中,我们改进了 “LiveCD” 环境。
通过 FreeDOS 1.3 RC4,你可以在你喜欢的虚拟机中启动 LiveCD 镜像,并立即开始使用 FreeDOS。这就是我现在运行 FreeDOS 的方式。我有一个小的虚拟硬盘镜像,我把所有的文件都放在那里,但我从 LiveCD 启动并运行 FreeDOS。

*启动 FreeDOS 1.3 RC4 LiveCD (Jim Hall, [CC-BY SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
### 安装真的很简单
如果你不想从 LiveCD 上运行 FreeDOS,你也可以在你的硬盘上安装它。我们更新了 FreeDOS 的安装程序,所以它本身并不是一个真正的“程序”,而是一个非常聪明的 DOS “批处理”文件,它可以检测到各种情况并采取适当的行动,例如在没有 FreeDOS 分区的情况下为其创建一个新的磁盘分区。
旧的 FreeDOS 发行版会提示你各种问题,甚至选择个别程序来安装。新的安装程序非常精简。它只问你几个问题就开始了,然后就自己做其他事情。在一个空的虚拟机上安装 FreeDOS 只需要几分钟时间。

*安装FreeDOS 1.3 RC4 (Jim Hall, [CC-BY SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
### 你可以从软盘安装它
不是每个人都喜欢在虚拟机中运行 FreeDOS。现在有一个复古计算社区,他们收集并精心修复经典的 PC 硬件,如 Pentium 或 486 系统。你甚至可以在那里找到一些 XT(8088)或 AT(80286)系统,它由一个专门的用户社区运营。
虽然我们认为 FreeDOS 是一个现代的 DOS,但如果我们不在旧的 PC 硬件上运行,我们就不是 “DOS” 了。因此,在 FreeDOS 1.3 中,我们包含了一个纯软盘版!这个版本可以运行在任何硬件上。这个版本应该可以在任何可以运行 FreeDOS 的硬件上运行,并且有 EGA 或更好的图形。
你在运行 286 或其他没有 CD-ROM 驱动器的经典系统吗?从这些软盘安装 FreeDOS。你是否只有一个硬盘而没有 CD 或软盘驱动器?只要把软盘的内容复制到一个临时目录,然后从那里运行安装程序。想执行“无交互外设方式”安装到不同的 DOS 目录吗?用命令行选项就可以了。
纯软盘版使用一个完全不同的安装程序,并包含一套有限的 FreeDOS 程序,它们在经典的 PC 硬件上更有用。

*安装FreeDOS纯软盘版 (Jim Hall, [CC-BY SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
### 充满了开源应用和游戏
如果 FreeDOS 是一个闭源的 DOS,它就不是一个 *自由* 的 DOS。我们希望每个人都能使用和研究 FreeDOS,包括其源代码。当我们计划 FreeDOS 1.3 发行版时,我们仔细检查了每个软件包中的每一个许可证,并专注于只包括 *开源* 程序。(在以前的 FreeDOS 发行版中,有几个程序并不完全“开源”,还有一两个程序没有包括源码,但是可以“自由使用和发布”。在这个版本中,所有的东西都是开源的,以“开源定义”作为我们的模型。)
而且,这是一个多么棒的开源应用和游戏的集合。游戏是 FreeDOS 1.3 RC4 中我最喜欢的内容。许多人使用 FreeDOS 来玩经典的 DOS 游戏,但我们想提供我们自己的开源游戏给人们玩。
你可以发现 LiveCD 中已经安装了两个游戏:Simple Senet(可以追溯到古埃及的棋盘游戏)和 Floppy Bird(Flappy Bird 游戏的一个版本)。如果你安装了 FreeDOS,你还会发现很多其他游戏可以尝试,包括 Sudoku86(一个数独游戏)、Wing(一个太空射击游戏)和 Bolitaire(单人纸牌游戏)。

*玩 Floppy Bird 游戏 (Jim Hall, [CC-BY SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*

*古老的 Senet 游戏 (Jim Hall, [CC-BY SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
### 现在就试试 FreeDOS 1.3 RC4
你可以在 FreeDOS 的 [下载](https://www.freedos.org/download/) 页面上找到新的 FreeDOS 1.3 RC4。要安装 FreeDOS,你需要至少 20MB 的可用磁盘空间:20MB 用来安装一个普通的 FreeDOS 系统,或者 250MB 用来安装所有,包括应用和游戏。要安装源码,你将需要高达 450MB 的可用空间。
---
via: <https://opensource.com/article/21/6/get-started-freedos>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Throughout the 1980s and into the 1990s, I was primarily a DOS user. I loved the command line environment offered in DOS, which became more powerful with each successive release. I even learned how to write my own DOS programs in the C programming language so I could extend the DOS command line, and write more powerful replacements for the standard DOS commands. I'd experimented with Microsoft's Windows—but if you remember Windows 3 from that time, you know it was slow and tended to crash. But I preferred the command line anyway, so I stuck to DOS.
That all changed in 1994. Popular tech magazines talked about an upcoming version of Windows that would completely do away with DOS. I didn't want to be forced to Windows. On the discussion boards I visited on Usenet, others felt the same. So [on 29 June 1994](https://groups.google.com/g/comp.os.msdos.apps/c/oQmT4ETcSzU/m/O1HR8PE2u-EJ), I decided that if we wanted to keep DOS, we needed to write our own. So on June 29, I announced a small project that would become [The FreeDOS Project](https://www.freedos.org/).
Since then, we've released several full distributions of FreeDOS. We started with the alpha series from 1994 to 1997, the beta series from 1998 to 2005, before finally releasing the FreeDOS 1.0 distribution in 2006. Progress has been slow but steady since then. We haven't really been rushed to release each new version after 1.0, because DOS stopped being a moving target in 1995.
Each FreeDOS distribution since 1.0 has been a continual re-imagining of what a modern DOS might look like. We've included lots of compilers, assemblers for developers to write software. We also provide lots of "power tools" so you can do real work. And we offer a variety of editors because everyone has their favorite.
We recently released the FreeDOS 1.3 RC4 distribution. This is technically a release candidate towards our upcoming FreeDOS 1.3 distribution, but it's a full-featured distribution. I'm very excited about all the great features in FreeDOS 1.3 RC4.
## Run FreeDOS without installing FreeDOS
In all our previous FreeDOS distributions, we focused on *installing* FreeDOS to a computer. But we recognize that most users don't actually run FreeDOS on actual hardware anymore—they run FreeDOS in [a virtual machine like QEMU or VirtualBox](https://opensource.com/article/20/8/virt-tools). So in FreeDOS 1.3 RC4, we improved the "LiveCD" environment.
With FreeDOS 1.3 RC4, you can just boot the LiveCD image in your favorite virtual machine, and start using FreeDOS right away. That's how I run FreeDOS now; I have a small virtual hard drive image where I store all my files, but I boot and run FreeDOS from the LiveCD.
opensource.com
Booting the FreeDOS 1.3 RC4 LiveCD
## Installing is really easy
If you don't want to run FreeDOS from the LiveCD, you can also install it on your hard drive. We updated the installer in FreeDOS so it's not really a "program" per se, but instead is a very smart DOS "batch" file that detects all sorts of things and takes the appropriate action, like creating a new disk partition for FreeDOS if none exist already.
Older FreeDOS distributions used to prompt you for everything, even selecting individual programs to install. The new installer is very streamlined. It asks you a few questions to get started, then does everything else on its own. Installing FreeDOS on an empty virtual machine takes only a few minutes.
opensource.com
Installing FreeDOS 1.3 RC4
## You can install it from floppy
Not everyone prefers to run FreeDOS in a virtual machine. There's a retrocomputing community out there that collects and lovingly restores classic PC hardware like Pentium or '486 systems. You can even find some XT (8088) or AT (80286) systems out there, kept running by a dedicated user community.
And while we consider FreeDOS a *modern* DOS, we wouldn't be "DOS" if we didn't also run on the older PC hardware too. So with FreeDOS 1.3, we include a Floppy-Only Edition! This edition should run on any hardware that can run FreeDOS and has EGA or better graphics.
Are you running a '286 or another classic system without a CD-ROM drive? Install from these floppies to install FreeDOS. Do you have just one hard drive and no CD or floppy drive? Just copy the contents of the floppies to a temporary directory and run the installer from there. Want to perform a "headless" install to a different DOS directory? It's easy with the command-line options.
The Floppy-Only Edition uses a completely different installer and contains a limited FreeDOS set of programs that are more useful on classic PC hardware.
opensource.com
Installing the FreeDOS Floppy-Only Edition
## Filled with open source apps and games
FreeDOS isn't a *free* DOS if it's a closed source DOS. We want everyone to be able to use and study FreeDOS, including its source code. As we planned the FreeDOS 1.3 distribution, we took a close look at every license in every package and focused on including only *open source* programs. (A few programs in previous FreeDOS distributions were not quite "open source," and one or two programs didn't include source code but were otherwise "free to use and distribute." In this release, everything is open source, using the Open Source Definition as our model.)
And what a great collection of open source apps and games. The games are my favorite addition to FreeDOS 1.3 RC4. Many people use FreeDOS to play classic DOS games, but we wanted to provide our own open source games for people to play.
You can find two games already installed in the LiveCD: Simple Senet (a board game dating to ancient Egypt) and Floppy Bird (a version of the Flappy Bird game). If you install FreeDOS, you'll also find lots of other games to try, including Sudoku86 (a sudoku game), Wing (a space shooter), and Bolitaire (solitaire card game).

opensource.com
Playing the Floppy Bird game
opensource.com
The ancient game of Senet
## Try FreeDOS 1.3 RC4 now
You can find the new FreeDOS 1.3 RC4 from the FreeDOS website, on our [Downloads](https://www.freedos.org/download/) page. To install FreeDOS, you'll need at least 20MB of free disk space: 20MB to install a plain FreeDOS system, or 250MB to install everything, including applications and games. To install the source code too, you'll need up to 450MB of free space.
## Comments are closed. |
13,495 | Helix:高级 Linux 用户的终端文本编辑器 | https://itsfoss.com/helix-editor/ | 2021-06-17T13:17:01 | [
"编辑器",
"Helix"
] | https://linux.cn/article-13495-1.html |
说到 [基于终端的文本编辑器](https://itsfoss.com/command-line-text-editors-linux/),通常 Vim、Emacs 和 Nano 受到了关注。
这并不意味着没有其他这样的文本编辑器。Vim 的现代增强版 [Neovim](https://neovim.io/),是许多这样的例子之一。
按照同样的思路,我想介绍另一个基于终端的文本编辑器,叫做 Helix Editor。
### Helix,一个用 Rust 编写的现代文本编辑器

[Helix](https://helix-editor.com/) 是用 Rust 编写的,使用 Tree-sitter 进行语法高亮。开发者声称,它比正则表达式高亮更快,因为 Tree-sitter 像编译器一样将代码解析成语法树,从而给出更多的代码结构信息。
你可以跟踪局部变量,计算缩进和操作选择来选择语法节点。它足够强大,即使有语法错误也能产生结果。
Helix 的主要亮点是“多重选择”,这是基于 [Kakoune](http://kakoune.org/) 的。
内置的语言服务器支持提供上下文感知补全、诊断和代码操作。
### 在 Linux 上安装 Helix
对于 Arch 和 Manjaro 用户来说,Helix 在 AUR 中有两个包:
* [helix-bin](https://aur.archlinux.org/packages/helix-bin/): 包含来自 GitHub 发布的预构建二进制文件
* [helix-git](https://aur.archlinux.org/packages/helix-git/): 构建该仓库的主分支
作为一个 Arch 用户,我相信你可能已经知道 [如何使用 AUR 安装应用](https://itsfoss.com/aur-arch-linux/)。
对于其他 Linux 发行版,你必须使用 Cargo。Cargo 是 Rust 软件包管理器。有了它,你可以安装 Rust 包。可以认为它相当于 Python 的 PIP。
你应该能够使用你的发行版的包管理器来安装 Cargo。在基于 Ubuntu 的发行版上,可以这样安装 Cargo:
```
sudo apt install cargo
```
接下来,你要克隆 Helix 仓库:
```
git clone --recurse-submodules --shallow-submodules -j8 https://github.com/helix-editor/helix
```
进入克隆的目录中:
```
cd helix
```
现在用 `cargo` 来安装 Helix:
```
cargo install --path helix-term --features "embed_runtime"
```
最后一步是将 `hx` 二进制文件添加到 `PATH` 变量中,这样你就可以从任何地方运行它。这应该被添加到你的 `bashrc` 或 bash 配置文件中。
```
export PATH=”$HOME/.cargo/bin:$PATH”
```
现在都设置好了,你应该可以通过在终端输入 `hx` 来使用编辑器。
你可以在 Helix 的[文档页](https://docs.helix-editor.com/)上找到使用 Helix 的键盘快捷键:
* [Helix 键盘快捷键](https://docs.helix-editor.com/keymap.html)
它与 Vim 或 Neovim 相比如何?我无法说。我可以用 Vim 进行基本的编辑,但我不是 Vim 忍者。如果你是一个信奉 Vim(或 Emacs)的人,请你试试 Helix 并自己判断。
---
via: <https://itsfoss.com/helix-editor/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When it comes to [terminal based text editors](https://itsfoss.com/command-line-text-editors-linux/), it is usually Vim, Emacs and Nano that get the limelight.
That doesn’t mean there are not other such text editors. [Neovim](https://neovim.io/?ref=itsfoss.com), a modern enhancement to Vim, is one of many such examples.
Along the same line, I would like to introduce yet another terminal based text editor called Helix Editor.
## Helix, a modern text editor written in Rust
[Helix](https://helix-editor.com/?ref=itsfoss.com) is written in Rust and uses Tree-sitter for syntax highlighting. The developer claims that it is faster than regex highlighting because Tree-sitter parses code into syntax trees like a compiler and thus giving a lot more information about code structure.
You can track local variables, calculate indentations and manipulate selection to select syntax nodes. It is robust enough to produce results even with syntax error.
The main focus of Helix is on ‘multiple selection’. This is based on [Kakoune](http://kakoune.org/?ref=itsfoss.com).
The built-in language server support provides context aware completion, diagnostics and code actions.
## Installing Helix on Linux
For Arch and Manjaro users, Helix is available in the AUR in two packages:
[helix-bin](https://aur.archlinux.org/packages/helix-bin/?ref=itsfoss.com): contains prebuilt binary from GitHub releases[helix-git](https://aur.archlinux.org/packages/helix-git/?ref=itsfoss.com): builds the master branch of this repository
As an Arch user, you probably already know [how to install applications using AUR](https://itsfoss.com/aur-arch-linux/), I believe.
For other Linux distributions, you have to use Cargo. Cargo is a Rust package manager that allows you to [install Rust](https://itsfoss.com/install-rust-cargo-ubuntu-linux/) packages. Consider it Rust equivalent to PIP of Python.
You should be able to install Cargo using your distribution’s package manager. On Ubuntu based distributions, install cargo like this:
`sudo apt install cargo`
Next, you clone the Helix repository:
`git clone --recurse-submodules --shallow-submodules -j8 https://github.com/helix-editor/helix`
Move to the cloned directory:
`cd helix`
And now use cargo to install Helix:
`cargo install --path helix-term --features "embed_runtime"`
One last step is to add the hx binary to the PATH variable so that you can run it from anywhere. This should be added to your bashrc or bash profile.
` export PATH=”$HOME/.cargo/bin:$PATH”`
Now that everything is set, you should be able to use the editor by typing `hx`
in the terminal.
You can find the keyboard shortcuts for using Helix on its [documentation page](https://docs.helix-editor.com/?ref=itsfoss.com):
How does it compare with Vim or Neovim? I cannot say. I can use Vim for basic editing but I am not a Vim ninja. If you are someone who swears and live by Vim (or Emacs), I let you try Helix and judge it yourself. |
13,497 | 云原生软件的 6 个要求 | https://opensource.com/article/20/1/cloud-native-software | 2021-06-18T10:14:16 | [
"云原生",
"容器"
] | https://linux.cn/article-13497-1.html |
>
> 开发和实施云原生(容器优先)软件的检查清单。
>
>
>

许多年来,单体应用是实现业务需求的标准企业架构。但是,当云基础设施开始以规模和速度为业务加速,这种情况就发生了重大变化。应用架构也发生了转变,以适应云原生应用和 [微服务](https://opensource.com/resources/what-are-microservices)、[无服务器](https://opensource.com/article/18/11/open-source-serverless-platforms) 以及事件驱动的服务,这些服务运行在跨混合云和多云平台的不可变的基础设施上。
### 云原生与 Kubernetes 的联系
根据 [云原生计算基金会](https://github.com/cncf/toc/blob/master/DEFINITION.md) (CNCF) 的说法:
>
> “云原生技术使企业能够在现代动态环境中建立和运行可扩展的应用,如公共云、私有云和混合云。容器、服务网格、微服务、不可变的基础设施和声明式 API 就是这种方法的典范。”
>
>
> “这些技术使松散耦合的系统具有弹性、可管理和可观察性。与强大的自动化相结合,它们使工程师能够以最小的工作量频繁地、可预测地进行重要的改变。”
>
>
>
像 [Kubernetes](https://opensource.com/resources/what-is-kubernetes) 这样的容器编排平台允许 DevOps 团队建立不可变的基础设施,以开发、部署和管理应用服务。现在,快速迭代的速度与业务需求相一致。构建容器以在 Kubernetes 中运行的开发人员需要一个有效的地方来完成。
### 云原生软件的要求
创建云原生应用架构需要哪些能力,开发人员将从中获得哪些好处?
虽然构建和架构云原生应用的方法有很多,但以下是一些需要考虑的部分:
* **运行时:** 它们更多是以容器优先或/和 Kubernetes 原生语言编写的,这意味着运行时会如 Java、Node.js、Go、Python 和 Ruby。
* **安全:** 在多云或混合云应用环境中部署和维护应用时,安全是最重要的,应该是环境的一部分。
* **可观察性:** 使用 Prometheus、Grafana 和 Kiali 等工具,这些工具可以通过提供实时指标和有关应用在云中的使用和行为的更多信息来增强可观察性。
* **效率:** 专注于极小的内存占用、更小的构件大小和快速启动时间,使应用可跨混合/多云平台移植。
* **互操作性:** 将云原生应用与能够满足上述要求的开源技术相结合,包括 Infinispan、MicroProfile、Hibernate、Kafka、Jaeger、Prometheus 等,以构建标准运行时架构。
* **DevOps/DevSecOps:** 这些方法论是为持续部署到生产而设计的,与最小可行产品 (MVP) 一致,并将安全作为工具的一部分。
### 让云原生具体化
云原生似乎是一个抽象的术语,但回顾一下定义并像开发人员一样思考可以使其更加具体。为了使云原生应用获得成功,它们需要包括一长串定义明确的组成清单。
你是如何规划云原生应用的设计的?在评论中分享你的想法。
---
via: <https://opensource.com/article/20/1/cloud-native-software>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For many years, monolithic applications were the standard enterprise architecture for achieving business requirements. But that changed significantly once cloud infrastructure began treating business acceleration at scale and speed. Application architectures have also transformed to fit into the cloud-native applications and the [microservices](https://opensource.com/resources/what-are-microservices), [serverless](https://opensource.com/article/18/11/open-source-serverless-platforms), and event-driven services that are running on immutable infrastructures across hybrid and multi-cloud platforms.
## The cloud-native connection to Kubernetes
According to the [Cloud Native Computing Foundation](https://github.com/cncf/toc/blob/master/DEFINITION.md) (CNCF):
"Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
"These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil."
Container orchestration platforms like [Kubernetes](https://opensource.com/resources/what-is-kubernetes) allow DevOps teams to build immutable infrastructures to develop, deploy, and manage application services. The speed at which rapid iteration is possible now aligns with business needs. Developers building containers to run in Kubernetes need an effective place to do so.
## Requirements for cloud-native software
What capabilities are required to create a cloud-native application architecture, and what benefits will developers gain from it?
While there are many ways to build and architect cloud-native applications, the following are some ingredients to consider:
**Runtimes:**They are more likely to be written in the container-first or/and Kubernetes-native language, which means runtimes such as Java, Node.js, Go, Python, and Ruby.**Security:**When deploying and maintaining applications in a multi-cloud or hybrid cloud application environment, security is of utmost importance and should be part of the environment.**Observability:**Use tools such as Prometheus, Grafana, and Kiali that can enhance observability by providing realtime metrics and more information about how applications are being used and behave in the cloud.**Efficiency:**Focus on a tiny memory footprint, small artifact size, and fast boot time to make applications portable across hybrid/multi-cloud platforms.**Interoperability:**Integrate cloud-native apps with open source technologies that enable you to meet the requirements listed above, including Infinispan, MicroProfile, Hibernate, Kafka, Jaeger, Prometheus, and more, for building standard runtime architectures.**DevOps/DevSecOps:**These methodologies are designed for continuous deployment to production, in-line with the minimum viable product (MVP) and with security as part of the tooling.
## Making cloud-native concrete
Cloud-native can seem like an abstract term, but reviewing the definition and thinking like a developer can make it more concrete. In order for cloud-native applications to be successful, they need to include a long, well-defined list of ingredients.
How are you planning for cloud-native application design? Share your thoughts in the comments.
## Comments are closed. |
13,498 | C++ 类成员函数指针语法的友好指南 | https://opensource.com/article/21/2/ccc-method-pointers | 2021-06-18T10:42:09 | [
"指针"
] | https://linux.cn/article-13498-1.html |
>
> 一旦你理解了一般原则,C++ 类成员函数指针不再那么令人生畏。
>
>
>

如果你正在寻找性能、复杂性或许多可能的解决方法来解决问题,那么在涉及到极端的情况下,[C++](https://en.wikipedia.org/wiki/C++) 总是一个很好的选择。当然,功能通常伴随着复杂性,但是一些 C++ 的特性几乎难以分辨。根据我的观点,C++ 的 [类成员函数指针](https://en.wikipedia.org/wiki/Function_pointer#Method_pointers) 也许是我接触过的最复杂的表达式,但是我会先从一些较简单的开始。
文章中的例子可以在我的 [Github 仓库](https://github.com/hANSIc99/worst_possible_syntax) 里找到。
### C 语言:函数指针
让我们先从一些基础开始:假设你有一个函数接收两个整数作为参数返回一个整数:
```
int sum(int a, int b) {
return a+b;
}
```
在纯 C 语言中,你可以创建一个指向这个函数的指针,将其分配给你的 `sum(...)` 函数,通过解引用来调用它。函数的签名(参数、返回类型)必须符合指针的签名。除此之外,一个函数指针表现和普通的指针相同:
```
int (*funcPtrOne)(int, int);
funcPtrOne = ∑
int resultOne = funcPtrOne(2, 5);
```
如果你使用指针作为参数并返回一个指针,这会显得很丑陋:
```
int *next(int *arrayOfInt){
return ++arrayOfInt;
}
int *(*funcPtrTwo)(int *intPtr);
funcPtrTwo = &next;
int resultTwo = *funcPtrTwo(&array[0]);
```
C 语言中的函数指针存储着子程序的地址。
### 指向类成员函数的指针
让我们来进入 C++:好消息是你也许不需要使用类成员函数指针,除非在一个特别罕见的情况下,比如说接下来的例子。首先,你已经知道定义一个类和其中一个成员函数:
```
class MyClass
{
public:
int sum(int a, int b) {
return a+b;
}
};
```
#### 1、定义一个指针指向某一个类中一个成员函数
声明一个指针指向 `MyClass` 类成员函数。在此时,你并不知道想调用的具体函数。你仅仅声明了一个指向 `MyClass` 类中任意成员函数的指针。当然,签名(参数、返回值类型)需要匹配你接下想要调用的 `sum(...)` 函数:
```
int (MyClass::*methodPtrOne)(int, int);
```
#### 2、赋值给一个具体的函数
为了和 C 语言(或者 [静态成员函数](https://en.wikipedia.org/wiki/Static_(keyword)#Static_method))对比,类成员函数指针不需要指向绝对地址。在 C++ 中,每一个类中都有一个虚拟函数表(vtable)用来储存每个成员函数的地址偏移量。一个类成员函数指针指向 vtable 中的某个条目,因此它也只存储偏移值。这样的原则使得 [多态](https://en.wikipedia.org/wiki/Dynamic_dispatch) 变得可行。
因为 `sum(...)` 函数的签名和你的指针声明匹配,你可以赋值签名给它:
```
methodPtrOne = &MyClass::sum;
```
#### 3、调用成员函数
如果你想使用指针调用一个类成员函,你必须提供一个类的实例:
```
MyClass clsInstance;
int result = (clsInstance.*methodPtrOne)(2,3);
```
你可以使用 `.` 操作符来访问,使用 `*` 对指针解引用,通过提供两个整数作为调用函数时的参数。这是丑陋的,对吧?但是你可以进一步应用。
### 在类内使用类成员函数指针
假设你正在创建一个带有后端和前端的 [客户端/服务器](https://en.wikipedia.org/wiki/Client%E2%80%93server_model) 原理架构的应用程序。你现在并不需要关心后端,相反的,你将基于 C++ 类的前端。前端依赖于后端提供的数据完成初始化,所以你需要一个额外的初始化机制。同时,你希望通用地实现此机制,以便将来可以使用其他初始化函数(可能是动态的)来拓展你的前端。
首先定义一个数据类型用来存储初始化函数(`init`)的指针,同时描述何时应调用此函数的信息(`ticks`):
```
template<typename T>
struct DynamicInitCommand {
void (T::*init)(); // 指向额外的初始化函数
unsigned int ticks; // 在 init() 调用后 ticks 的数量
};
```
下面一个 `Frontend` 类示例代码:
```
class Frontend
{
public:
Frontend(){
DynamicInitCommand<Frontend> init1, init2, init3;
init1 = { &Frontend::dynamicInit1, 5};
init2 = { &Frontend::dynamicInit2, 10};
init3 = { &Frontend::dynamicInit3, 15};
m_dynamicInit.push_back(init1);
m_dynamicInit.push_back(init2);
m_dynamicInit.push_back(init3);
}
void tick(){
std::cout << "tick: " << ++m_ticks << std::endl;
/* 检查延迟初始化 */
std::vector<DynamicInitCommand<Frontend>>::iterator it = m_dynamicInit.begin();
while (it != m_dynamicInit.end()){
if (it->ticks < m_ticks){
if(it->init)
((*this).*(it->init))(); // 这里是具体调用
it = m_dynamicInit.erase(it);
} else {
it++;
}
}
}
unsigned int m_ticks{0};
private:
void dynamicInit1(){
std::cout << "dynamicInit1 called" << std::endl;
};
void dynamicInit2(){
std::cout << "dynamicInit2 called" << std::endl;
}
void dynamicInit3(){
std::cout << "dynamicInit3 called" << std::endl;
}
unsigned int m_initCnt{0};
std::vector<DynamicInitCommand<Frontend> > m_dynamicInit;
};
```
在 `Frontend` 完成实例化后,`tick()` 函数会被后端以固定的时间时间调用。例如,你可以每 200 毫秒调用一次:
```
int main(int argc, char* argv[]){
Frontend frontendInstance;
while(true){
frontendInstance.tick(); // 仅用于模拟目的
std::this_thread::sleep_for(std::chrono::milliseconds(200));
}
}
```
`Fronted` 有三个额外的初始化函数,它们必须根据 `m_ticks` 的值来选择调用哪个。在 ticks 等于何值调用哪个初始化函数的信息存储在数组 `m_dynamicInit` 中。在构造函数(`Frontend()`)中,将此信息附加到数组中,以便在 5、10 和 15 个 tick 后调用其他初始化函数。当后端调用 `tick()` 函数时,`m_ticks` 值会递增,同时遍历数组 `m_dynamicInit` 以检查是否必须调用初始化函数。
如果是这种情况,则必须通过引用 `this` 指针来取消引用成员函数指针:
```
((*this).*(it->init))()
```
### 总结
如果你并不熟悉类成员函数指针,它们可能会显得有些复杂。我做了很多尝试和经历了很多错误,花了一些时间来找到正确的语法。然而,一旦你理解了一般原理后,方法指针就变得不那么可怕了。
这是迄今为止我在 C++ 中发现的最复杂的语法。 你还知道更糟糕的吗? 在评论中发布你的观点!
---
via: <https://opensource.com/article/21/2/ccc-method-pointers>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you're looking for performance, complexity, or many possible solutions to solve a problem, [C ++](https://en.wikipedia.org/wiki/C++) is always a good candidate when it comes to extremes. Of course, functionality usually comes with complexity, but some C++ peculiarities are almost illegible. From my point of view, C++ [method pointers](https://en.wikipedia.org/wiki/Function_pointer#Method_pointers) may be the most complex expressions I've ever come across, but I'll start with something simpler.
The examples in this article are available in my [GitHub repository](https://github.com/hANSIc99/worst_possible_syntax).
## C: Pointer to functions
Let's begin with some basics: Assume you have a function that takes two integers as arguments and returns an integer:
```
int sum(int a, intb){
return a+b;
}
```
In plain C, you can create a pointer to this function, assign it to your `sum(...)`
function, and call it by dereferencing. The function's signature (arguments, return type) must comply with the pointer's signature. Aside from that, a function pointer behaves like an ordinary pointer:
```
int (*funcPtrOne)(int, int);
funcPtrOne = ∑
int resultOne = funcPtrOne(2, 5);
```
It gets a bit uglier if you take a pointer as an argument and return a pointer:
```
int *next(int *arrayOfInt){
return ++arrayOfInt;
}
int *(*funcPtrTwo)(int *intPtr);
funcPtrTwo = &next;
int resultTwo = *funcPtrTwo(&array[0]);
```
Function pointers in C store the address of a subroutine.
## Pointers to methods
Let's step into C++: The good news is that you probably won't need to use pointers to methods, except in a few rare cases, like the following one. First, define a class with member functions you already know:
```
class MyClass
{
public:
int sum(int a, int b) {
return a+b;
}
};
```
### 1. Define a pointer to a method of a certain class type
Declare a pointer to a method of the `MyClass`
type. At this point, you don't know the exact method you want to call. You've only declared a pointer to some arbitrary `MyClass`
method. Of course, the signature (arguments, return type) matches the `sum(…)`
method you want to call later:
`int (MyClass::*methodPtrOne)(int, int);`
### 2. Assign a certain method
In contrast to C (or [static member functions](https://en.wikipedia.org/wiki/Static_(keyword)#Static_method)), method pointers don't point to absolute addresses. Each class type in C++ has a virtual method table (vtable) that stores the address offset for each method. A method pointer refers to a certain entry in the vtable, so it also stores only the offset value. This principle also enables [dynamic dispatch](https://en.wikipedia.org/wiki/Dynamic_dispatch).
Because the signature of the `sum(…)`
method matches your pointer's declaration, you can assign the signature to it:
`methodPtrOne = &MyClass::sum;`
### 3. Invoke the method
If you want to invoke the method with the pointer, you have to provide an instance of the class type:
```
MyClass clsInstance;
int result = (clsInstance.*methodPtrOne)(2,3);
```
You can access the instance with the `.`
operator, dereference the pointer with a `*`
, and thus call the method by providing two integers as arguments. Ugly, right? But you can still go a step further.
## Using method pointers within a class
Assume you are creating an application with a [client/server](https://en.wikipedia.org/wiki/Client%E2%80%93server_model) principle architecture with a backend and a frontend. You don't care about the backend for now; instead, you will focus on the frontend, which is based on a C++ class. The frontend's complete initialization relies on data provided by the backend, so you need an additional initialization mechanism. Also, you want to implement this mechanism generically so that you can extend your frontend with other initialization methods in the future (maybe dynamically).
First, define a data type that can store a method pointer to an initialization method (`init`
) and the information describing when this method should be called (`ticks`
):
```
template<typename T>
struct DynamicInitCommand {
void (T::*init)(); // Pointer to additional initialization method
unsigned int ticks; // Number of ticks after init() is called
};
```
Here is what the `Frontend`
class looks like:
```
class Frontend
{
public:
Frontend(){
DynamicInitCommand<Frontend> init1, init2, init3;
init1 = { &Frontend::dynamicInit1, 5};
init2 = { &Frontend::dynamicInit2, 10};
init3 = { &Frontend::dynamicInit3, 15};
m_dynamicInit.push_back(init1);
m_dynamicInit.push_back(init2);
m_dynamicInit.push_back(init3);
}
void tick(){
std::cout << "tick: " << ++m_ticks << std::endl;
/* Check for delayed initializations */
std::vector<DynamicInitCommand<Frontend>>::iterator it = m_dynamicInit.begin();
while (it != m_dynamicInit.end()){
if (it->ticks < m_ticks){
if(it->init)
((*this).*(it->init))(); // here it is
it = m_dynamicInit.erase(it);
} else {
it++;
}
}
}
unsigned int m_ticks{0};
private:
void dynamicInit1(){
std::cout << "dynamicInit1 called" << std::endl;
};
void dynamicInit2(){
std::cout << "dynamicInit2 called" << std::endl;
}
void dynamicInit3(){
std::cout << "dynamicInit3 called" << std::endl;
}
unsigned int m_initCnt{0};
std::vector<DynamicInitCommand<Frontend> > m_dynamicInit;
};
```
After `Frontend`
is instantiated, the `tick()`
method is called at fixed intervals by the backend. For example, you can call it every 200ms:
```
int main(int argc, char* argv[]){
Frontend frontendInstance;
while(true){
frontendInstance.tick(); // just for simulation purpose
std::this_thread::sleep_for(std::chrono::milliseconds(200));
}
}
```
`Frontend`
has three additional initialization methods that must be called based on the value of `m_ticks`
. The information about which initialization method to call at which tick is stored in the vector `m_dynamicInit`
. In the constructor (`Frontend()`
), append this information to the vector so that the additional initialization functions are called after five, 10, and 15 ticks. When the backend calls the `tick()`
method, the value `m_ticks`
is incremented, and you iterate over the vector `m_dynamicInit`
to check whether an initialization method has to be called.
If this is the case, the method pointer must be dereferenced by referring to `this`
:
`((*this).*(it->init))()`
## Summary
Methods pointers can get a bit complicated if you're not familiar with them. I did a lot of trial and error, and it took time to find the correct syntax. However, once you understand the general principle, method pointers become less terrifying.
This is the most complex syntax I have found in C++ so far. Do you know something even worse? Post it in the comments!
## 3 Comments |
13,501 | 使用 cpulimit 来释放你的 CPU | https://fedoramagazine.org/use-cpulimit-to-free-up-your-cpu/ | 2021-06-19T08:40:00 | [
"CPU"
] | https://linux.cn/article-13501-1.html | 
在 Linux 系统上管理系统资源的推荐工具是 [cgroups](https://en.wikipedia.org/wiki/Cgroups)。虽然在可以调整的限制方面(CPU、内存、磁盘 I/O、网络等)非常强大,但配置 cgroups 并不简单。[nice](https://en.wikipedia.org/wiki/Nice_(Unix)) 命令从 1973 年起就可以使用了。但它只是调整在一个处理器上竞争时间的进程之间的调度优先级。`nice` 命令不会限制一个进程在单位时间内所能消耗的 CPU 周期的百分比。[cpulimit](https://github.com/opsengine/cpulimit) 命令提供了两个世界的最佳方案。它限制了一个进程在每单位时间内可以分配的 CPU 周期的百分比,而且相对容易调用。
`cpulimit` 命令主要对长期运行的和 CPU 密集型的进程有用。编译软件和转换视频是长期运行的进程的常见例子,它们可以使计算机的 CPU 使用率达到最大。限制这类进程的 CPU 使用率将释放出处理器时间,供计算机上可能运行的其他任务使用。限制 CPU 密集型进程也将减少功耗及热输出,并可能减少系统的风扇噪音。限制一个进程的 CPU 使用率的代价是,它需要更多的时间来完成运行。
### 安装 cpulimit
`cpulimit` 命令在默认的 Fedora Linux 仓库中可用。运行下面的命令,在 Fedora Linux 系统上安装 `cpulimit`:
```
$ sudo dnf install cpulimit
```
### 查看 cpulimit 的文档
`cpulimit` 软件包并没有附带的手册页。使用下面的命令来查看 `cpulimit` 的内置文档。输出结果在下面提供。但你可能需要在你自己的系统上运行该命令,以防止自本文编写以来选项发生变化。
```
$ cpulimit --help
Usage: cpulimit [OPTIONS…] TARGET
OPTIONS
-l, --limit=N percentage of cpu allowed from 0 to 800 (required)
-v, --verbose show control statistics
-z, --lazy exit if there is no target process, or if it dies
-i, --include-children limit also the children processes
-h, --help display this help and exit
TARGET must be exactly one of these:
-p, --pid=N pid of the process (implies -z)
-e, --exe=FILE name of the executable program file or path name
COMMAND [ARGS] run this command and limit it (implies -z)
```
### 演示
为了演示 `cpulimit` 命令的使用方式,下面提供了一个精心设计的、计算量很大的 Python 脚本。该脚本首先在没有限制的情况下运行,然后在限制为 50% 的情况下运行。它计算的是第 42 个 [斐波那契数](https://en.wikipedia.org/wiki/Fibonacci_number) 的值。该脚本在这两种情况下都作为 `time` 命令的子进程运行,以显示计算答案所需的总时间。
```
$ /bin/time -f '(computed in %e seconds)' /bin/python -c 'f = lambda n: n if n<2 else f(n-1)+f(n-2); print(f(42), end=" ")'
267914296 (computed in 51.80 seconds)
$ /bin/cpulimit -i -l 50 /bin/time -f '(computed in %e seconds)' /bin/python -c 'f = lambda n: n if n<2 else f(n-1)+f(n-2); print(f(42), end=" ")'
267914296 (computed in 127.38 seconds)
```
当运行第一个版本的命令时,你可能会听到电脑上的 CPU 风扇转动起来。但在运行第二个版本时,你应该不会。第一个版本的命令不受 CPU 的限制,但它不应该导致你的电脑陷入瘫痪。它是以这样一种方式编写的:它最多只能使用一个 CPU 核心。大多数现代 PC 都有多个 CPU 核心,当其中一个 CPU 100% 繁忙时,可以毫无困难地同时运行其他任务。为了验证第一条命令是否使你的一个处理器达到最大,在一个单独的终端窗口中运行 `top` 命令并按下 `1` 键。要退出 `top` 命令可以按 `Q` 键。
设置高于 100% 的限制只对能够进行 [任务并行化](https://en.wikipedia.org/wiki/Task_parallelism) 的程序有意义。对于这样的程序,高于 100% 的增量代表一个 CPU 的全部利用率(200%=2 个CPU,300%=3 个CPU,等等)。
注意,在上面的例子中,`-i` 选项已经传递给 `cpulimit` 命令。这是必要的,因为要限制的命令不是 `cpulimit` 命令的直接子进程。相反,它是 `time` 命令的一个子进程,而后者又是 `cpulimit` 命令的一个子进程。如果没有 `-i` 选项,`cpulimit` 将只限制 `time` 命令。
### 最后说明
如果你想限制一个从桌面图标启动的图形程序,请将该程序的 `.desktop` 文件(通常位于 `/usr/share/applications` 目录下)复制到你的 `~/.local/share/applications` 目录下,并相应修改 `Exec` 行。然后运行下面的命令来应用这些变化:
```
$ update-desktop-database ~/.local/share/applications
```
---
via: <https://fedoramagazine.org/use-cpulimit-to-free-up-your-cpu/>
作者:[Gregory Bartholomew](https://fedoramagazine.org/author/glb/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The recommended tool for managing system resources on Linux systems is [cgroups](https://en.wikipedia.org/wiki/Cgroups). While very powerful in terms of what sorts of limits can be tuned (CPU, memory, disk I/O, network, etc.), configuring cgroups is non-trivial. The [ nice](https://en.wikipedia.org/wiki/Nice_(Unix)) command has been available since 1973. But it only adjusts the scheduling priority among processes that are competing for time on a processor. The
*nice*command will not limit the percentage of CPU cycles that a process can consume per unit of time. The
*command provides the best of both worlds. It limits the percentage of CPU cycles that a process can allocate per unit of time and it is relatively easy to invoke.*
[cpulimit](https://github.com/opsengine/cpulimit)The *cpulimit* command is mainly useful for long-running and CPU-intensive processes. Compiling software and converting videos are common examples of long-running processes that can max out a computer’s CPU. Limiting the CPU usage of such processes will free up processor time for use by other tasks that may be running on the computer. Limiting CPU-intensive processes will also reduce the power consumption, heat output, and possibly the fan noise of the system. The trade-off for limiting a process’s CPU usage is that it will require more time to run to completion.
## Install cpulimit
The *cpulimit* command is available in the default Fedora Linux repositories. Run the following command to install *cpulimit* on a Fedora Linux system.
$sudo dnf install cpulimit
## View the documentation for cpulimit
The cpulimit package does not come with a man page. Use the following command to view cpulimit’s built-in documentation. The output is provided below. But you may want to run the command on your own system in case the options have changed since this article was written.
$cpulimit --helpUsage: cpulimit [OPTIONS…] TARGET OPTIONS -l, --limit=N percentage of cpu allowed from 0 to 800 (required) -v, --verbose show control statistics -z, --lazy exit if there is no target process, or if it dies -i, --include-children limit also the children processes -h, --help display this help and exit TARGET must be exactly one of these: -p, --pid=N pid of the process (implies -z) -e, --exe=FILE name of the executable program file or path name COMMAND [ARGS] run this command and limit it (implies -z)
## A demonstration
To demonstrate using the *cpulimit* command, a contrived, computationally-intensive Python script is provided below. The script is run first with no limit and then with a limit of 50%. It computes the value of the 42nd [Fibonacci number](https://en.wikipedia.org/wiki/Fibonacci_number). The script is run as a child process of the *time* command in both cases to show the total time that was required to compute the answer.
$/bin/time -f '(computed in %e seconds)' /bin/python -c 'f = lambda n: n if n<2 else f(n-1)+f(n-2); print(f(42), end=" ")'267914296 (computed in 51.80 seconds) $/bin/cpulimit -i -l 50 /bin/time -f '(computed in %e seconds)' /bin/python -c 'f = lambda n: n if n<2 else f(n-1)+f(n-2); print(f(42), end=" ")'267914296 (computed in 127.38 seconds)
You might hear the CPU fan on your PC rev up when running the first version of the command. But you should not when running the second version. The first version of the command is not CPU limited but it should not cause your PC to become bogged down. It is written in such a way that it can only use at most one CPU. Most modern PCs have multiple CPUs and can simultaneously run other tasks without difficulty when one of the CPUs is 100% busy. To verify that the first command is maxing out one of your processors, run the *top* command in a separate terminal window and press the **1** key. Press the **Q** key to quit the *top* command.
Setting a limit above 100% is only meaningful on a program that is capable of [task parallelism](https://en.wikipedia.org/wiki/Task_parallelism). For such programs, each increment of 100% represents full utilization of a CPU (200% = 2 CPUs, 300% = 3 CPUs, etc.).
Notice that the **-i** option has been passed to the *cpulimit* command in the above example. This is necessary because the command to be limited is not a direct child process of the *cpulimit* command. Rather it is a child process of the *time* command which in turn is a child process of the *cpulimit* command. Without the **-i** option, *cpulimit* would only limit the *time* command.
## Final notes
If you want to limit a graphical application that you start from a desktop icon, copy the application’s *.desktop* file (often located under the */usr/share/applications* directory) to your *~/.local/share/applications* directory and modify the *Exec* line accordingly. Then run the following command to apply the changes.
$update-desktop-database ~/.local/share/applications
## Thomas Mittelstaedt
Thanks for the ‘just-in-time’ hint. Will try that on the Android emulator virtual machine process qemu, which ran ‘wild’ yesterday.
## Ben
The version of CPU Limit you linked to in the article hasn’t been maintained in years. Most distributions/OSes (Debian, Ubuntu, openSUSE, FreeBSD) use the LimitCPU fork these days. LimitCPU does the same thing, has the same syntax, and features a manual page. Plus it’s still maintained and occasionally improved to provide more features/compiler tweaks. Its latest release was about a month ago.
http://limitcpu.sourceforge.net/
## Gregory Bartholomew
Thanks Ben. I didn’t know about LimitCPU.
## Gregory Bartholomew
For those who may be interested, here is a one-liner written in Perl that computes the 42nd Fibonacci number. It isn’t as useful for testing cpulimit though 😛.
## Ben
Thank you for this, very useful for my workloads (running long computations while keeping system interactive). I was wondering if you could comment on how this interacts with taskset[1] (cpu pinning).
From my understanding of your article cpulimit 100% would be equivalent to pinning to 1 CPU, but I’m wondering if that is 1 core (topology), or the equivalent (for the scheduler) of 1 CPU core. (assuming HT is disabled)
I tend(ed) to use taskset because it ensures while limiting overall CPU use, the running process would still be benefiting from the local caches bound to the selected (cores), but would be interesting to see if they can be combined.
Thanks!
[1]https://linux.die.net/man/1/taskset
## Ben
CPUlimit (or its modern fork LimitCPU) limits the target process(es) to an overall CPU resource limit.
Basically if you run “cpulimit -l 50 program-name” it means program-name won’t go above 50% of your CPU resources, as monitored by a system monitor like top.
It doesn’t limit a process to a specific CPU, just an overall consumption percentage of available resources.
## Gregory Bartholomew
Right. Sorry that I didn’t make that clear in the article. Thanks for the clarification. 🙂
## jama
I do use ‘taskset’ every once in while, and you can confirm the cpu pinning (topology) of your system with ‘lstopo’, which produces graphical image form your system.
Once you have identified the topology, you can assign the wanted cpu-pairs for your process, like ‘taskset –cpu-list 0,1,2,3’ or ‘taskset –cpu-list 0-3’ etc…
To verify, you may use ‘htop’ instead of ‘top’, as ‘htop’ displays the individual cpu core load as well.
## Ben
Thanks, lstopo is really neat!
## Raman Gupta
For others looking for this command, they are in Fedora package hwloc and hwloc-gui.
## Chris
Another command for this sort of thing, and will be more prevalent the more chiplets are employed is numactl.
numactl can limit processes and their children to a single node and direct which node they use.
But thanks for showing me another way.
## jama
Thank you for your excellent article, again, but in my opinion, this command, as well as ‘nice’, are not that much useful nowadays since the amount of cpu cores and memory have increased during the decades since 1973… What comes to the compiling, nowadays it in fact is possible to use ‘make -j <#cores>’ -flag to perform the compilation in parallel by distributing the compilation process among several cpus, making it faster, instead of using only one. In addition, the ‘oom-kill’ -process kills the processes it considers ‘unnecessary’, in order to keep the system stable.
This is my opinion. I would like to have processes to be finished as fast as possible, instead of having ‘nice’ queue of processes waiting to be finished.
The drawback might be, that even you ‘nice’, or otherwise ‘optimize’ a process, especially one having constant disk activity, like a compilation process, the disk activity in fact will not be affected that much, and each disk access (I/O) is taken away from other processes, making those more slower as they need to wait their share…
However, for some large-scale system administrators with 1000s of simultaneous users this kind of ‘optimization’ might be necessary.
## Cecille
Thanks for the article.
Bash does not seems to get limited:
fibonacci_42 () {
perl -e ‘use feature “signatures”; sub f($n) { $f[$n] //= ($n<2) ? $n : f($n-1) + f($n-2) }; print f(42), “\n”‘ 2>/dev/null
}
export -f fibonacci_42
$/bin/bash -E -c “fibonacci_42”
267914296
$cpulimit -i -l 1 /bin/bash -E -c “fibonacci_42”
267914296
## Gregory Bartholomew
It is because the Perl one-liner I provided in my comment does not require 100% CPU usage for any significant length of time. I think if you use the Python script it should work.
## Jesse
cpulimit maintainer here. In the example in your comment I wouldn’t expect limiting to work as I’m pretty sure the process doing the calculation is Perl, not bash. Bash is calling Perl in the function, but would probably just be waiting for Perl to return the answer if I’m reading your example correctly.
To use cpulimit (or LimitCPU) in this instance you’d want to do one of two things. Either run “cpulimit -l 10 perl -e ….” or “cpulimit -m -l 10 bash …”. The -m flag monitors child processes and limits them as well as the parent.
## newton
nosso Fedora ficou maravilhoso em nosso estilo plasma bem feito super rápido e bom demais para navegar ,parabéns
## Mark
Personally I find cpulimit only useful on machines with many cores. I have experienced issued on single core machines (yes, some VMs are setup that way) where using cpulimit to limit a process to 50% does work on the process, but cpulimit itself will use all remaining cpu itself; too much context switching in the OS between those two processes I guess.
However on multi core machines Some common utilities like ‘ffmpeg’ will happily span cores and drive them all to 100% busy.
Apart from the noise of spinning fans, utilities like lm_sensors or the extremely usefull ‘bpytop’ can show the core temperatures sitting at a point where they are probably considering shutting themselves down.
Using cpulimit with the flag to include child processes to throttle it resolves that; although as noted in an earlier reply things will take longer, a ffmpeg run that would take 30mins running hot can take over 2hrs when throttled; but in my opinion better than leaving the cores running at what they report as a critical temp for 30mins when you know in advance that is what will happen.
I have not looked at tasksets so thanks to the comment on that, if they are available on all OS’s I may look into that further.
cpulimit is a nice tool to know about as it is available everywhere, it is in most RedHat and Debian based package repositories and where it is not I have never had problems building it from the github source.
For those like me that do a lot of cpu intensive scheduled batch work it is worth knowing about and installing, or even if just for one annoying program you don’t care about that slows down your machine every day (thinking of you packagekit).
Gregory, thanks for the ‘final notes’ section on how to set it up within a desktop application setting. The ‘update-desktop-database’ command I wasn’t aware of and has probably solved a few unrelated issues :-).
## Gregory Bartholomew
Hi Mark!
FYI to everyone else — Mark is the one who originally suggested this article. Thanks for notifying us about this command. I didn’t use the ffmpeg example from your original proposal because it is not in the default Fedora repositories and we’ve been told in the past not to promote it on the Magazine because of its non-FOSS codecs. Hope that you don’t mind that I took your proposal and wrote up the article. It had been setting in our “approved specifications” category for over a year and we’ve been a little low on contributions lately.
The reason that I included that bit about how to use it with GUI applications at the end is because someone had asked that exact question a while ago on Fedora’s user support forum:
https://ask.fedoraproject.org/t/limit-cpu-utilisation-core/12816/2
I pointed them at the cpulimit command you had mentioned and they said that it worked to fix their problem. So your proposal has been very useful to lots of people. Thanks! And thanks also to Jesse who is maintaining the software of course. 🙂
## jama
Mark,
If you’re concerned about
…’Some common utilities like ‘ffmpeg’ will happily span cores and drive them all to 100% busy.
Apart from the noise of spinning fans, utilities like lm_sensors or the extremely usefull ‘bpytop’ can show the core temperatures sitting at a point where they are probably considering shutting themselves down.’…,
one option could be limiting the cpu frequency itself.
The available cpu frequencies can be checked with:
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_frequencies
3600000 2800000 2200000
Where we can see that the slowest supported speed is 2,2GHz.
By forcing this smallest value to each core, the temperatures will not get high, keeping the fans silent as well:
for i in {0..15} ; do echo 2200000 > /sys/devices/system/cpu/cpu$i/cpufreq/scaling_max_freq ; done
And the cpu frequencies will not exceed 2,2GHz.
To revert the setting, just replace the 2200000 with 3600000.
## Fionn Langhans
Thanks, that’s such a useful feature for background processes!
## Tom
I think it’s a very confusing to understand the CPU percentage help message.
Is 1 CPU core 100%, or is 100% all of the available cores? If 100% is all available cores/threads you should not be able to choose 800%.
If 1 core = 100%, what about hypterthreading cores?
If 100% is one HT core, can you only control a 4 core/ 8 HT thread CPU?
What if you have 16 cores available for example? It says maximum 800%
## Gregory Bartholomew
I think you’ll have to ask the developer to be sure. But, from the results of the demonstration in the article, it appears that 1 core = 100%. The Python script, unrestricted, will use 100% of 1 core. When limited to 50%, the script took twice as long to run (plus context switching overhead). If the 50 were out of a scale of 800 then it would have taken 800/50=16 times longer to compute the answer. My guess is that cpulimit isn’t capable of restricting processes across more than 8 cores.
## Ben
cpulimit judges usage by number of threads available. As it says in the manual page: “percentage of CPU allowed from 1 up. Usually 1 – 100, but can be higher on multi-core CPUs.”
## Andrew
A little new here. In the final notes section, where stated, “modify the Exec line accordingly”, do I just add the cpulimit -l N _name_of_program in that order?
I just want to make sure I’m doing this right.
## Gregory Bartholomew
In the simplest case, yes. If the program forks/spawns other programs that you also want limited, then you would need to add -i (include childern). And if the program is a flatpak then it is even more complicated. See fatka’s explanation here for an explanation of how to get it to work with flatpaks (his post was the reason I added that final note about using cpulimit with GUI programs to this article).
## Andrew
Thank you, that source made me understand a lot better on how to use this program!
The learning process is always appreciated! |
13,503 | FreeDOS 如何启动 | https://opensource.com/article/21/6/freedos-boots | 2021-06-20T14:08:18 | [
"FreeDOS",
"引导",
"启动"
] | https://linux.cn/article-13503-1.html |
>
> 概述你的计算机如何引导和启动一个像 FreeDOS 这样的简单操作系统。
>
>
>

在使用 DOS 计算机的过程中,我很欣赏的一点是,引导过程相对容易理解。在 DOS 中没有太多的变动组件。而今天,我想和大家分享一下电脑是如何引导和启动像 FreeDOS 这样的简单操作系统的概况。
### 初始引导
当你打开计算机的电源时,系统会进行一些自我检查,如验证内存和其他组件。这被称为<ruby> 开机自检 <rt> Power On Self Test </rt></ruby>(POST)。POST 之后,计算机使用一个硬编码指令,告诉它在哪里找到加载操作系统的指令。这就是“<ruby> 引导加载程序 <rt> boot loader </rt></ruby>”,通常它将试图找到硬盘上的<ruby> 主引导记录 <rt> Master Boot Record </rt></ruby>(MBR)。然后,MBR 加载主操作系统,在这里就是 FreeDOS。
这个定位一个信息以便计算机能够加载操作系统的下一个部分的过程被称为“<ruby> 引导 <rt> bootstrapping </rt></ruby>”,来自于“<ruby> 通过你自己的努力振作起来 <rt> picking yourself up by your bootstraps </rt></ruby>”的古老说法。正是从这个用法中,我们采用了“<ruby> 引导 <rt> boot </rt></ruby>”一词来表示启动你的计算机。
### 内核
当计算机加载 FreeDOS 内核时,内核所做的第一件事就是识别用户所表示要使用的任何参数。它被保存在一个叫做 `FDCONFIG.SYS` 的文件中,与内核保存在同一个根目录下。如果 `FDCONFIG.SYS` 不存在,那么 FreeDOS 的内核就会寻找一个叫做 `CONFIG.SYS` 的替代文件。
如果你在 20 世纪 80 年代或 90 年代使用过 DOS,你可能对 `CONFIG.SYS` 文件很熟悉。从 1999 年起,FreeDOS 首先寻找 `FDCONFIG.SYS`,以防你的 DOS 系统与其他 DOS(如 MS-DOS)做了 *双启动*。请注意,MS-DOS 只使用 `CONFIG.SYS` 文件。因此,如果你用同一个硬盘同时启动 FreeDOS 和 MS-DOS,MS-DOS 使用 `CONFIG.SYS` 来配置自己,而 FreeDOS 则使用 `FDCONFIG.SYS`。这样一来,双方都可以使用自己的配置。
`FDCONFIG.SYS` 可以包含一些配置设置,其中之一是 `SHELL=` 或 `SHELLHIGH=`。任何一个都会指示内核加载这个程序作为用户的交互式 shell。
如果 `FDCONFIG.SYS` 和 `CONFIG.SYS` 都不存在,那么内核就会假定几个默认值,包括在哪里找到 shell。如果你在启动 FreeDOS 系统时看到 “Bad or missing Command Interpreter” 的信息,这意味着 `SHELL=` 或 `SHELLHIGH=` 指向了一个在你系统中不存在的 shell 程序。

你可以通过查看 `SHELL=` 或 `SHELLHIGH=` 行来调试这个问题。如果做不到这一点,请确保你在 FreeDOS 系统的根目录下有一个名为 `COMMAND.COM` 的程序。它就是 *shell*,我接下来会讲到它。
### shell
在 DOS 系统中,“shell” 一词通常是指一个命令行解释器:一个交互式程序,它从用户那里读取指令,然后执行它们。在这里,FreeDOS 的 shell 与 Linux 的 Bash shell 相似。
除非你用 `SHELL=` 或 `SHELLHIGH=` 要求内核加载一个不同的 shell,否则 DOS 上的标准命令行 shell 被称为 `COMMAND.COM`。当 `COMMAND.COM` 启动时,它也寻找一个文件来配置自己。默认情况下,`COMMAND.COM` 会在根目录下寻找一个名为 `AUTOEXEC.BAT` 的文件。`AUTOEXEC.BAT` 是一个“批处理文件”,它包含一组启动时运行的指令,大致类似于 Linux 上 Bash 启动时读取的 `~/.bashrc` “资源文件”。
你可以在 `FDCONFIG.SYS` 文件中用 `SHELL=` 或 `SHELLHIGH=` 改变 shell 以及 shell 的启动文件。FreeDOS 1.3 RC4 安装程序将系统设置为读取 `FDAUTO.BAT` 而不是 `AUTOEXEC.BAT`。这与内核读取另一个配置文件的原因相同;你可以在硬盘上用另一个 DOS 双启动 FreeDOS。FreeDOS 将使用 `FDAUTO.BAT` 而 MS-DOS 将使用 `AUTOEXEC.BAT`。
如果没有像 `AUTOEXEC.BAT` 这样的启动文件,shell 将简单地提示用户输入日期和时间。

就是这些了。当 FreeDOS 加载了内核,而内核也加载了 shell,FreeDOS 就准备好让用户输入命令了。

---
via: <https://opensource.com/article/21/6/freedos-boots>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One thing I appreciate from growing up with DOS computers is that the boot process is relatively easy to understand. There aren't a lot of moving parts in DOS. And today, I'd like to share an overview of how your computer boots up and starts a simple operating system like FreeDOS.
## Initial bootstrapping
When you turn on the power to your computer, the system performs several self-checks, such as verifying the memory and other components. This is called the **Power On Self Test** or "POST." After the POST, the computer uses a hard-coded instruction that tells it where to find its instructions to load the operating system. This is the "boot loader," and usually it will try to locate a Master Boot Record or (MBR) on the hard drive. The MBR then loads the primary operating system; in this case, that's FreeDOS.
This process of locating one piece of information so the computer can load the next part of the operating system is called "bootstrapping," from the old expression of "picking yourself up by your bootstraps." It is from this usage that we adopted the term "boot" to mean starting up your computer.
## The kernel
When the computer loads the FreeDOS kernel, one of the first things the kernel does is identify any parameters the user has indicated to use. This is stored in a file called `FDCONFIG.SYS`
, stored in the same root directory as the kernel. If `FDCONFIG.SYS`
does not exist, then the FreeDOS kernel looks for an alternate file called `CONFIG.SYS`
.
If you used DOS in the 1980s or 1990s, you may be familiar with the `CONFIG.SYS`
file. Since 1999, FreeDOS looks for `FDCONFIG.SYS`
first in case you have a DOS system that is *dual booting* FreeDOS with some other DOS, such as MS-DOS. Note that MS-DOS only uses the `CONFIG.SYS`
file. So if you use the same hard drive to boot both FreeDOS and MS-DOS, MS-DOS uses `CONFIG.SYS`
to configure itself, and FreeDOS uses `FDCONFIG.SYS`
instead. That way, each can use its own configuration.
`FDCONFIG.SYS`
can contain a number of configuration settings, one of which is `SHELL=`
or `SHELLHIGH=`
. Either one will instruct the kernel to load this program as the interactive shell for the user.
If neither `FDCONFIG.SYS`
nor `CONFIG.SYS`
exist, then the kernel assumes several default values, including where to find the shell. If you see the message "Bad or missing Command Interpreter" when you boot your FreeDOS system, that means `SHELL=`
or `SHELLHIGH=`
is pointing to a shell program that doesn't exist on your system.
Image by Jim Hall, CC-BY SA 4.0
You might debug this by looking at the `SHELL=`
or `SHELLHIGH=`
lines. Failing that, make sure you have a program called `COMMAND.COM`
in the root directory of your FreeDOS system. This is the *shell*, which I'll talk about next.
## The shell
The term "shell" on a DOS system usually means a command-line interpreter; an interactive program that reads instructions from the user, then executes them. In this way, the FreeDOS shell is similar to the Bash shell on Linux.
Unless you've asked the kernel to load a different shell using `SHELL=`
or `SHELLHIGH=`
, the standard command-line shell on DOS is called `COMMAND.COM`
. And as `COMMAND.COM`
starts up, it also looks for a file to configure itself. By default, `COMMAND.COM`
will look for a file called `AUTOEXEC.BAT`
in the root directory. `AUTOEXEC.BAT`
is a "batch file" that contains a set of instructions that run at startup, and is roughly analogous to the `~/.bashrc`
"resource file" that Bash reads when it starts up on Linux.
You can change the shell, and the startup file for the shell, in the `FDCONFIG.SYS`
file, with `SHELL=`
or `SHELLHIGH=`
. The FreeDOS 1.3 RC4 installer sets up the system to read `FDAUTO.BAT`
instead of `AUTOEXEC.BAT`
. This is for the same reason that the kernel reads an alternate configuration file; you can dual-boot FreeDOS on a hard drive with another DOS. FreeDOS will use `FDAUTO.BAT`
while MS-DOS will use `AUTOEXEC.BAT`
..
Without a startup file like `AUTOEXEC.BAT`
, the shell will simply prompt the user to enter the date and time.
Image by Jim Hall, CC-BY SA 4.0
And that's it. Once FreeDOS has loaded the kernel, and the kernel has loaded the shell, FreeDOS is ready for the user to type commands.
Image by Jim Hall, CC-BY SA 4.0
## Comments are closed. |
13,504 | 我如何用 CircuitPython 和开源工具监控温室 | https://opensource.com/article/21/5/monitor-greenhouse-open-source | 2021-06-20T15:20:28 | [
"监控",
"微控制器"
] | https://linux.cn/article-13504-1.html |
>
> 使用微控制器、传感器、Python 以及 MQTT 持续追踪温室的温度、湿度以及环境光。
>
>
>

CircuitPython 提供了一种和微控制器板进行交互的革命性方式。这篇文章介绍了如何使用 CircuitPython 来监测温室的温度、湿度以及环境光,并且使用 CircuitPython MQTT 客户端将结果发布到一个 [MQTT](https://mqtt.org/) <ruby> 中介 <rt> broker </rt></ruby>。你可以在若干个程序中订阅 MQTT 队列并进一步处理信息。
这个项目使用一个简单的 Python 程序来运行 Web 服务器,它发布一个 Prometheus 格式的采集端点,拉取监控指标到 [Prometheus](https://prometheus.io/) 进行不间断的监控。
### 关于 CircuitPython
[CircuitPython](https://circuitpython.io/) 是一个由 [Adafruit](https://adafruit.com) 创建的开源 Python 发行版,用于运行在低成本微控制器开发板上。CircuitPython 为与 [兼容的开发板](https://circuitpython.org/downloads) 的交互提供了简单的开发体验。你可以在连接你的开发板时挂载的 `CIRCUITPYTHON` 根驱动器上创建一个 `code.py` 文件来启动你的程序。CircuitPython 还为开发板提供了一个串行连接,包含一个交互式解释器(REPL)会话,你可以使用 Python 代码实时和开发板进行交互。
Adafruit 的网站提供了大量的文档,可以帮助你开始使用 CircuitPython。首先,参考下《[欢迎来到 CircuitPython](https://learn.adafruit.com/welcome-to-circuitpython)》指南。这份指南能够帮助你开始使用 CircuitPython 在开发板上运行代码以及和 REPL 交互。它还记录了如何安装 Adafruit 的 CircuitPython 库合集和范例,可以用在它出售的许多开发板和传感器上。接下来,阅读《[CircuitPython 基础](https://learn.adafruit.com/circuitpython-essentials/circuitpython-essentials)》指南来学习更多关于其功能的信息,里面还有链接指向在特定及兼容的开发板上使用 CircuitPython 的相关信息。最后,就如所有开源软件一样,你可以深入 [CircuitPython 的源码](https://github.com/adafruit/circuitpython),发布议题,以及做出贡献。
### 微控制器设置
微控制器系统非常简单。要完成这个示例项目,你会需要:
* **树莓派 4**:你需要一台电脑来给微控制器系统编程,我用的是树莓派 4。
* **CircuitPython 兼容的微控制器**:我用的是 [Adafruit Feather S2](https://www.adafruit.com/product/4769),带有内置 WiFi,环境光传感器,Qwiic 线缆输入。
* **微控制器 WiFi**:Feather S2 内置了 WiFi。如果你的微控制器没有,你需要给开发板找个 WiFi 扩展板。
* **传感器**:Feather S2 有个内置的环境光传感器,所以我还需要一个温湿度传感器。有很多不同厂商的产品可以选择,包括 Adafruit、SparkFun、亚马逊。我用的是一个 [Adafruit 传感器](https://www.adafruit.com/product/3251),带有 Feather S2 输入兼容的 Qwiic 线缆。尽管多数 SparkFun 传感器可以在 Adafruit 库下工作,但如果你不是从 Adafruit 购买的传感器,你可能还是需要自己去找到它兼容 CircuitPython 的 Python 库。
* **跳线和线缆**:为了避免使用面包板或焊接,我使用 [Adafruit Qwiic 线缆](https://www.adafruit.com/product/4399)。SparkFun 销售的包含不同长度的[线缆套装](https://www.sparkfun.com/products/15081)中也有它。
在将微控制器连接到你的电脑之前,将传感器连接到微控制器上。

现在你可以将微控制器用 USB 数据线连接到你的电脑。
### MQTT 中介
你可以使用 [这份说明](https://pimylifeup.com/raspberry-pi-mosquitto-mqtt-server/) 来在树莓派的系统上安装 [Mosquitto MQTT 中介](https://mosquitto.org/) 和 Mosquitto 客户端。如果你想把树莓派做为长期服务器使用,在你的网络上给树莓派 4 设置一个静态 IP 地址。Mosquitto 中介运行起来之后,创建一份 [用户名/密码文件](https://mosquitto.org/documentation/authentication-methods/),设置客户端向中介发布和订阅消息时用的认证信息。
你可以用树莓派上的 Mosquitto 客户端来测试 MQTT 中介。打开两个终端(如果你是无界面运行的话打开两个 SSH 会话):
在终端一输入:
```
mosquitto_sub -h localhost -u $user -P $pass -t "mqtt/test"
```
这条命令会启动一个持续运行的进程,监听发布到 `mqtt/test` 队列的消息。
在终端二输入:
```
mosquitto_pub -h localhost -u $user -P $pass -t "mqtt/test" -m hello`
```
这条命令会向 `mqtt/test` 队列发布一条消息,它应该会显示在终端一的输出里。
现在你可以中止终端一运行的 `sub` 命令了。
Mosquitto 中介允许客户端发布消息到任何队列,甚至没有任何订阅的队列也可以。这些消息会永久丢失,但这不会阻止客户端继续发布消息。
打开第三个终端,订阅下列队列(你的控制器会发布消息到这些队列上):
* greenhouse/temperature
* greenhouse/light
* greenhouse/humidity
### 给微控制器编码
现在你已经准备好给微控制器编码,发布它的监测指标到树莓派 4 上运行的 MQTT 中介上了。
Adafruit 有 [出色的文档](https://learn.adafruit.com/mqtt-in-circuitpython),指导你使用 [CircuitPython 库合集](https://circuitpython.org/libraries) 的库来将你的微控制器连接到 WiFi 路由器,并发布监测指标到 MQTT 中介上。
安装下列库到 `CIRCUITPYTHON/lib` 目录,温室监控会用到它们。这些库在 Adafruit 的 CircuitPython 库合集中都有提供:
* `adafruit_bus_device`:一个带有多个 .mpy 文件的 Python 包文件夹(.mpy 是经过压缩的 Python 文件,用以节省空间)
* `adafruit_requests`:单个 .mpy 文件
* `adafruit_register`:一个包文件夹
* `adafruit_minimqtt`:一个包文件夹
* `adafruit_si7021`:单个 .mpy 文件,用来支持温湿度传感器
库装好了之后,将以下代码写入 `CIRCUITPYTHON` 文件夹的 `code.py` 文件中:
```
import time
import ssl
import socketpool
import wifi
import adafruit_minimqtt.adafruit_minimqtt as MQTT
import board
from digitalio import DigitalInOut, Direction, Pull
from analogio import AnalogIn
import adafruit_si7021
# Add a secrets.py to your filesystem that has a dictionary called secrets with "ssid" and
# "password" keys with your WiFi credentials. DO NOT share that file or commit it into Git or other
# source control.
# pylint: disable=no-name-in-module,wrong-import-order
try:
from secrets import secrets
except ImportError:
print("WiFi secrets are kept in secrets.py, please add them there!")
raise
print("Connecting to %s" % secrets["ssid"])
wifi.radio.connect(secrets["ssid"], secrets["password"])
print("Connected to %s!" % secrets["ssid"])
### Feeds ###
light_feed = "greenhouse/light"
temp_feed = "greenhouse/temperature"
humidity_feed = "greenhouse/humidity"
# Define callback methods which are called when events occur
# pylint: disable=unused-argument, redefined-outer-name
def connected(client, userdata, flags, rc):
# This function will be called when the client is connected
# successfully to the broker.
print("Connected to MQTT!")
def disconnected(client, userdata, rc):
# This method is called when the client is disconnected
print("Disconnected from MQTT!")
def get_voltage(pin):
return (pin.value * 3.3) / 65536
# Create a socket pool
pool = socketpool.SocketPool(wifi.radio)
# Set up a MiniMQTT Client
mqtt_client = MQTT.MQTT(
broker=secrets["broker"],
port=secrets["port"],
username=secrets["aio_username"],
password=secrets["aio_key"],
socket_pool=pool,
ssl_context=ssl.create_default_context(),
)
# Setup the callback methods above
mqtt_client.on_connect = connected
mqtt_client.on_disconnect = disconnected
# Connect the client to the MQTT broker.
print("Connecting to MQTT...")
mqtt_client.connect()
# Create library object using our Bus I2C port
sensor = adafruit_si7021.SI7021(board.I2C())
light_pin = AnalogIn(board.IO4)
while True:
# Poll the message queue
mqtt_client.loop()
# get the current temperature
light_val = get_voltage(light_pin)
temp_val = ((sensor.temperature * 9)/5) + 32
humidity_val = sensor.relative_humidity
# Send a new messages
mqtt_client.publish(light_feed, light_val)
mqtt_client.publish(temp_feed, temp_val)
mqtt_client.publish(humidity_feed, humidity_val)
time.sleep(0.5)
```
保存你的代码。然后连接到串行监视器,看程序连接到你的 MQTT 中介。你还可以将树莓派 4 上的终端切换到订阅了它的发布队列的终端来查看输出。
### 处理监测指标
像 MQTT 这样的发布/订阅工作流给微控制器系统提供了诸多好处。你可以有多个微控制器 + 传感器来回报同一个系统的不同指标或并行回报相同指标的若干读数。你还可以有多个不同进程订阅各个队列,并行地对这些消息进行回应。甚至还可以有多个进程订阅相同的队列,对消息做出不同的动作,比如数值过高时发送通知邮件或将消息发送到另一个 MQTT 队列上去。
另一个选项是让一个微控制器订阅一个外部队列,可以发送信号告诉微控制器做出动作,比如关闭或开始一个新会话。最后,发布/订阅工作流对低功耗微控制器系统更佳(比如那些使用电池或太阳能的系统),因为这些设备可以在更长的延迟周期后批量发布监测指标,并在回报的间隔期间关闭大量消耗电量的 WiFi 广播。
要处理这些监测指标,我创建了一个 Python 客户端,使用 [Paho Python MQTT 客户端](https://pypi.org/project/paho-mqtt/) 订阅监测指标队列。我还使用官方的 [Prometheus Python 客户端](https://pypi.org/project/prometheus-client) 创建了一个 Web 服务器,它产生一个符合 Prometheus 标准的采集端点,使用这些监测指标作为面板信息。[Prometheus 服务器](https://opensource.com/article/21/3/iot-measure-raspberry-pi)和 Mosquitto MQTT 中介我都是运行在同一个树莓派 4 上的。
```
from prometheus_client import start_http_server, Gauge
import random
import time
import paho.mqtt.client as mqtt
gauge = {
"greenhouse/light": Gauge('light','light in lumens'),
"greenhouse/temperature": Gauge('temperature', 'temperature in fahrenheit'),
"greenhouse/humidity": Gauge('humidity','relative % humidity')
}
try:
from mqtt_secrets import mqtt_secrets
except ImportError:
print("WiFi secrets are kept in secrets.py, please add them there!")
raise
def on_connect(client, userdata, flags, rc):
print("Connected with result code "+str(rc))
# Subscribing in on_connect() means that if we lose the connection and
# reconnect then subscriptions will be renewed.
client.subscribe("greenhouse/light")
client.subscribe('greenhouse/temperature')
client.subscribe('greenhouse/humidity')
def on_message(client, userdata, msg):
topic = msg.topic
payload = msg.payload
gauge[topic].set(payload)
client = mqtt.Client()
client.username_pw_set(mqtt_secrets["mqtt_user"],mqtt_secrets['mqtt_password'])
client.on_connect = on_connect
client.on_message = on_message
client.connect('localhost',1883,60)
if __name__ == '__main__':
# Start up the server to expose the metrics.
client = mqtt.Client()
client.username_pw_set('london','abc123')
client.on_connect = on_connect
client.on_message = on_message
client.connect('localhost',1883,60)
start_http_server(8000)
client.loop_forever()
```
然后我配置 Prometheus 服务器采集端点数据到 `localhost:8000`。
你可以在 Github 上访问 [温室 MQTT 微控制器](https://github.com/dmlond/greenhouse_mqtt_microcontroller) 这个项目的代码,项目采用 MIT 许可证授权。
---
via: <https://opensource.com/article/21/5/monitor-greenhouse-open-source>
作者:[Darin London](https://opensource.com/users/dmlond) 选题:[lujun9972](https://github.com/lujun9972) 译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | CircuitPython provides a revolutionary way to interact with microcontroller boards. This article explains how to use CircuitPython to measure a greenhouse's temperature, humidity, and ambient light and publish the results to an [ MQTT](https://mqtt.org/) broker using a CircuitPython MQTT client. You can subscribe any number of programs to the MQTT queues to process the information further.
This project uses a simple Python program that runs a web server that publishes a Prometheus-formatted scrape endpoint and pulls these metrics into [Prometheus](https://prometheus.io/) for ongoing monitoring.
## About CircuitPython
[CircuitPython](https://circuitpython.io/) is an open source Python distribution created by [ Adafruit](https://adafruit.com) to run on low-cost microcontroller boards. CircuitPython provides a simple development experience for interacting with [ compatible boards](https://circuitpython.org/downloads). You can start a program on the board by creating a `code.py`
file in the `CIRCUITPYTHON`
root drive that mounts when you connect your board. CircuitPython also provides a serial connection from your board that includes an interactive read-evaluate-print loop (REPL) session that you can use to interact with your board in real time using Python code.
Adafruit's website offers extensive documentation to help you get started with CircuitPython. First, consult the [ Welcome to CircuitPython](https://learn.adafruit.com/welcome-to-circuitpython) guide. This will get you started running code on your microcontroller with CircuitPython and interacting with the REPL. It also documents how to install Adafruit's bundle of CircuitPython libraries and examples for many of the boards and sensors it sells. Next, read the [ CircuitPython Essentials](https://learn.adafruit.com/circuitpython-essentials/circuitpython-essentials) guide to learn more about its capabilities and link to information about using CircuitPython with specific, compatible boards. Finally, as with all open source software, you can dig into [ CircuitPython's code](https://github.com/adafruit/circuitpython), post issues, and contribute.
## Microcontroller setup
The microcontroller system is very simple. To follow along with this demo, you will need:
**Raspberry Pi 4:**You need a computer to program the microcontroller system, and this is what I used.**A CircuitPython-compatible microcontroller:**I used the[Adafruit FeatherS2](https://www.adafruit.com/product/4769)with built-in WiFi, ambient light sensor, and Qwiic cable input.**Microcontroller WiFi:**The FeatherS2 has a built-in WiFi radio. If your microcontroller does not, you will need to find a WiFi expansion board for it.**Sensors:**The Feather S2 has a built-in ambient light sensor, so I needed to get a temperature and humidity sensor. A variety is available from vendors, including Adafruit, SparkFun, and Amazon. I used an[Adafruit sensor](https://www.adafruit.com/product/3251)with a Qwiic cable connection compatible with the Feather S2 input. You may have to find CircuitPython-compatible Python libraries for sensors not purchased from Adafruit, although many SparkFun sensors work with Adafruit libraries.**Jumpers and cables:**To avoid using a breadboard or soldering, I used an[Adafruit Qwiic cable](https://www.adafruit.com/product/4399). SparkFun also sells them in a[bundle of cables](https://www.sparkfun.com/products/15081)of different lengths.
Before plugging the microcontroller into your computer, connect the sensors to the microcontroller.

(Darin London, CC BY-SA 4.0)
Now you can plug the microcontroller into your computer using a USB data cable.
## The MQTT Broker
You can use [ these instructions](https://pimylifeup.com/raspberry-pi-mosquitto-mqtt-server/) to install the [ Mosquitto MQTT broker](https://mosquitto.org/) and Mosquitto clients on a Raspberry Pi 4 running Raspberry Pi OS. If you want to use the Raspberry Pi as a long-term server, set a static IP address for the Raspberry Pi 4 on your network. Once the Mosquitto broker is running, create a [ user/password file](https://mosquitto.org/documentation/authentication-methods/) that sets the authentication parameters for clients to use when publishing and subscribing to the broker.
You can test the MQTT broker using the Mosquitto clients on the Raspberry Pi. Open two terminals (or SSH sessions if you are running headless):
On Terminal 1, enter:
`mosquitto_sub -h localhost -u $user -P $pass -t "mqtt/test"`
This will start a long-running process that listens for messages published to the `mqtt/test`
queue.
On Terminal 2, enter:
`mosquitto_pub -h localhost -u $user -P $pass -t "mqtt/test" -m hello`
This will publish a message to the `mqtt/test`
queue, which should show up in Terminal 1's output.
You can then kill the `sub`
command running on Terminal 1.
The Mosquitto broker allows clients to publish messages to any queue, even if it has no subscribers. These messages will be lost forever, but they will not stop the client from publishing.
Start a third terminal and subscribe to the following queues (the queues your microcontroller will publish messages to):
- greenhouse/temperature
- greenhouse/light
- greenhouse/humidity
## Code the microcontroller
You are now ready to code your microcontroller to publish its metrics to the MQTT broker running on your Raspberry Pi 4.
Adafruit has [ excellent documentation](https://learn.adafruit.com/mqtt-in-circuitpython) on using the [ CircuitPython Library Bundle](https://circuitpython.org/libraries)'s libraries to connect your microcontroller to your WiFi router and get it publishing metrics to your MQTT broker.
Install the following libraries, which the greenhouse monitor will use, into the `CIRCUITPYTHON/lib`
directory. These are all available in the Adafruit CircuitPython Library Bundle:
**adafruit_bus_device:**A Python package directory with multiple .mpy files (.mpy is a compressed Python file that saves space on your microcontroller)**adafruit_requests:**A single .mpy file**adafruit_register:**Another package directory**adafruit_minimqtt:**Another package directory**adafruit_si7021:**A single .mpy file that works with the temperature and humidity sensors
Once these libraries are installed, write the following into `code.py`
in the `CIRCUITPYTHON`
directory:
```
import time
import ssl
import socketpool
import wifi
import adafruit_minimqtt.adafruit_minimqtt as MQTT
import board
from digitalio import DigitalInOut, Direction, Pull
from analogio import AnalogIn
import adafruit_si7021
# Add a secrets.py to your filesystem that has a dictionary called secrets with "ssid" and
# "password" keys with your WiFi credentials. DO NOT share that file or commit it into Git or other
# source control.
# pylint: disable=no-name-in-module,wrong-import-order
try:
from secrets import secrets
except ImportError:
print("WiFi secrets are kept in secrets.py, please add them there!")
raise
print("Connecting to %s" % secrets["ssid"])
wifi.radio.connect(secrets["ssid"], secrets["password"])
print("Connected to %s!" % secrets["ssid"])
### Feeds ###
light_feed = "greenhouse/light"
temp_feed = "greenhouse/temperature"
humidity_feed = "greenhouse/humidity"
# Define callback methods which are called when events occur
# pylint: disable=unused-argument, redefined-outer-name
def connected(client, userdata, flags, rc):
# This function will be called when the client is connected
# successfully to the broker.
print("Connected to MQTT!")
def disconnected(client, userdata, rc):
# This method is called when the client is disconnected
print("Disconnected from MQTT!")
def get_voltage(pin):
return (pin.value * 3.3) / 65536
# Create a socket pool
pool = socketpool.SocketPool(wifi.radio)
# Set up a MiniMQTT Client
mqtt_client = MQTT.MQTT(
broker=secrets["broker"],
port=secrets["port"],
username=secrets["aio_username"],
password=secrets["aio_key"],
socket_pool=pool,
ssl_context=ssl.create_default_context(),
)
# Setup the callback methods above
mqtt_client.on_connect = connected
mqtt_client.on_disconnect = disconnected
# Connect the client to the MQTT broker.
print("Connecting to MQTT...")
mqtt_client.connect()
# Create library object using our Bus I2C port
sensor = adafruit_si7021.SI7021(board.I2C())
light_pin = AnalogIn(board.IO4)
while True:
# Poll the message queue
mqtt_client.loop()
# get the current temperature
light_val = get_voltage(light_pin)
temp_val = ((sensor.temperature * 9)/5) + 32
humidity_val = sensor.relative_humidity
# Send a new messages
mqtt_client.publish(light_feed, light_val)
mqtt_client.publish(temp_feed, temp_val)
mqtt_client.publish(humidity_feed, humidity_val)
time.sleep(0.5)
```
Save your code. Then attach to the serial monitor and watch it connect to your MQTT broker. You can also see the output by switching to the terminals on your Raspberry Pi 4 subscribed to the queues where this publishes.
## Process the metrics
Publish/subscribe workflows like MQTT offer many advantages for microcontroller systems. You can have multiple microcontroller + sensor installations reporting different metrics about the same system or reporting many readings of the same metric in parallel. You can also have many different processes that subscribe to each queue to respond to these messages in parallel. It is even possible to have multiple different processes subscribed to the same queue for different actions, such as sending an email when a value gets too high or publishing a message to another MQTT queue.
Another option is to have a microcontroller subscribe to an external queue that sends signals to tell the microcontroller to perform an action, such as turning off or starting a new session. Finally, pub/sub workflows can be better for low-power microcontroller installations (such as those using battery or solar power) because these devices can send metrics in batches separated by long delays and turn off the power-hungry WiFi radio during the intervals between reports.
To process these metrics, I created a Python client that uses the [ Paho Python MQTT client](https://pypi.org/project/paho-mqtt/) to subscribe to the metrics queues. I also use the official [ Prometheus Python client](https://pypi.org/project/prometheus-client) to create a web server that produces a Prometheus-compliant scrape endpoint with these metrics as gauges. I run this, a [Prometheus server](https://opensource.com/article/21/3/iot-measure-raspberry-pi), and the Mosquitto MQTT broker on the same Raspberry Pi 4.
```
from prometheus_client import start_http_server, Gauge
import random
import time
import paho.mqtt.client as mqtt
gauge = {
"greenhouse/light": Gauge('light','light in lumens'),
"greenhouse/temperature": Gauge('temperature', 'temperature in fahrenheit'),
"greenhouse/humidity": Gauge('humidity','relative % humidity')
}
try:
from mqtt_secrets import mqtt_secrets
except ImportError:
print("WiFi secrets are kept in secrets.py, please add them there!")
raise
def on_connect(client, userdata, flags, rc):
print("Connected with result code "+str(rc))
# Subscribing in on_connect() means that if we lose the connection and
# reconnect then subscriptions will be renewed.
client.subscribe("greenhouse/light")
client.subscribe('greenhouse/temperature')
client.subscribe('greenhouse/humidity')
def on_message(client, userdata, msg):
topic = msg.topic
payload = msg.payload
gauge[topic].set(payload)
client = mqtt.Client()
client.username_pw_set(mqtt_secrets["mqtt_user"],mqtt_secrets['mqtt_password'])
client.on_connect = on_connect
client.on_message = on_message
client.connect('localhost',1883,60)
if __name__ == '__main__':
# Start up the server to expose the metrics.
client = mqtt.Client()
client.username_pw_set('london','abc123')
client.on_connect = on_connect
client.on_message = on_message
client.connect('localhost',1883,60)
start_http_server(8000)
client.loop_forever()
```
Then I configure the Prometheus server to scrape that endpoint on localhost:8000.
You can access all the code for this project in my MIT-licensed [ Greenhouse MQTT Microcontroller](https://github.com/dmlond/greenhouse_mqtt_microcontroller) repository on GitHub.
## Comments are closed. |
13,506 | 探索 Kubernetes 生态系统(2021 版) | https://opensource.com/article/21/6/kubernetes-ebook | 2021-06-21T16:26:22 | [
"Kubernetes"
] | /article-13506-1.html |
>
> 这份可下载的指南充满了有用的教程,让 SRE 和系统管理员使用 Kubernetes 获得便利。
>
>
>

Kubernetes 是容器编排的事实标准,在基础设施管理和应用开发方面已经迅速发展成为容器环境的主导。作为一个拥有庞大的爱好者和专业人士社区的开源平台,以及作为云原生计算基金会的一部分,Kubernetes 不仅成为一个强大而令人印象深刻的编排系统本身,而且它还促进了一个庞大的相关工具和服务的生态系统,使其更容易使用,并通过更强大和复杂的组件扩展其功能。
在这本新的电子书《[给 SRE 和系统管理员的 Kubernetes 指导](https://opensource.com/downloads/kubernetes-sysadmin)》中,[Jess Cherry](https://opensource.com/users/cherrybomb)(Ben Finkel 也有贡献)涵盖了一系列用于管理和整合 Kubernetes 的工具和服务。Cherry 和 Finkel 提供了一些有用的 *入门* 指南,包括 Kubernetes 和一些工具。他们甚至还分享了面试问题,以帮助读者为在这个快速增长的大规模生态系统中工作做好准备。
### 了解 Kubernetes
如果你刚开始接触 Kubernetes 和容器,Ben Finkel 的 《[Kubernetes 入门](https://opensource.com/article/17/11/getting-started-kubernetes)》文如其题,也是一篇对你需要了解的相关概念的出色介绍。它也是一本轻量级的快速入门指南,用于设置和使用单节点集群进行测试。没有什么比亲身体验技术并直接进入学习更好的方法了。什么是<ruby> 吊舱 <rt> Pod </rt></ruby>? 如何在集群上部署一个应用程序? Ben 一一为你做了介绍。
与集群交互的主要方式是 [kubectl](https://kubernetes.io/docs/reference/kubectl/kubectl/) 命令,这是一种 CLI 工具,它提供了一种与管理集群本身的 API 服务器交互的适合方式。例如,你可以使用 `kubectl get` 来列出上述的吊舱和部署,但正如你对 Kubernetes 这样复杂的东西所期望的那样,它的 CLI 界面有很强的功能和灵活性。Jess Cherry 的《[9 个系统管理员需要知道的 kubectl 命令](https://opensource.com/article/20/5/kubectl-cheat-sheet)》速查表是一个很好的介绍,是使用 `kubectl` 的入门好方法。
同样,Cherry 的《[给初学者的 Kubernetes 命令空间](https://opensource.com/article/19/12/kubernetes-namespaces)》也很好地解释了什么是命名空间以及它们在 Kubernetes 中的使用方式。
### 简化 Kubernetes 的工作
在一个复杂的系统中工作是很困难的,尤其是使用像 `kubectl` 这样强大而极简的 CLI 工具。幸运的是,在围绕 Kubernetes 的生态系统中,有许多工具可用于简化事情,使扩展服务和集群管理更容易。
可用于在 Kubernetes 上部署和维护应用和服务的 `kubectl` 命令主要使用的是 YAML 和 JSON。然而,一旦你开始管理更多应用,用 YAML 的大型仓库这样做会变得既重复又乏味。一个好的解决方案是采用一个模板化的系统来处理你的部署。[Helm](https://helm.sh/) 就是这样一个工具,被称为 “Kubernetes 的包管理器”,Helm 提供了一种方便的方式来打包和共享应用。Cherry 写了很多关于 Helm 的有用文章:创建有效的 《[Helm 海图](https://opensource.com/article/20/5/helm-charts)》和有用的《[Helm 命令](https://opensource.com/article/20/2/kubectl-helm-commands)》。
`kubectl` 也为你提供了很多关于集群本身的信息:上面运行的是什么,以及正在发生的事件。这些信息可以通过 `kubectl` 来查看和交互,但有时有一个更直观的 GUI 来进行交互是有帮助的。[K9s](https://k9scli.io/) 符合这两个世界的要求。虽然它仍然是一个终端应用,但它提供了视觉反馈和一种与集群交互的方式,而不需要长长的 `kubectl` 命令。Cherry 也写了一份很好的《[k9s 使用入门](https://opensource.com/article/20/5/kubernetes-administration)》的指南。
### 建立在 Kubernetes 的强大和灵活性之上的扩展
幸运的是,尽管 Kubernetes 是复杂而强大的,但它惊人的灵活并且开源。它专注于其核心优势:容器编排,并允许围绕它的爱好者和专业人士的社区扩展其能力,以承担不同类型的工作负载。其中一个例子是 [Knative](https://cloud.google.com/knative/),在 Kubernetes 之上提供组件,它为无服务器和事件驱动的服务提供工具,并利用 Kubernetes 的编排能力在容器中运行最小化的微服务。事实证明,这样做非常高效,既能提供在容器中开发小型、易于测试和维护的应用的好处,又能提供仅在需要时运行这些应用的成本优势,可以在特定事件中被触发,但在其他时候处于休眠。
在这本电子书中,Cherry 介绍了 Knative 和它的事件系统,以及为什么值得自己研究使用 Knative。
### 有一个完整的世界可以探索
通过 Jess Cherry 和 Ben Finkel 的这本新的[电子书](https://opensource.com/downloads/kubernetes-sysadmin),可以开始了解 Kubernetes 和围绕它的生态系统。除了上述主题外,还有一些关于有用的 Kubernetes 扩展和第三方工具的文章。
---
via: <https://opensource.com/article/21/6/kubernetes-ebook>
作者:[Chris Collins](https://opensource.com/users/clcollins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,507 | 用 Deskreen 将你的 Linux 屏幕镜像或串流到任何设备上 | https://itsfoss.com/deskreen/ | 2021-06-21T16:53:15 | [
"Deskreen",
"屏幕"
] | https://linux.cn/article-13507-1.html | 其它平台上的屏幕共享或屏幕镜像应用并不那么好。尽管大多数选项仅适用于 Windows/Mac,而你可能很难找到一个适用于 Linux 的开源解决方案。
有了这个应用,你可以与连接到网络的任何设备共享你的屏幕。
如果你有多显示器设置,你会意识到拥有多个屏幕的好处。而且,有了 Deskreen,你可以把任何设备变成你的副屏,多么令人激动啊!
### Deskreen:将任何设备变成你的 Linux 系统的副屏

[Deskreen](https://deskreen.com/lang-en) 是一个自由开源的应用,可以让你使用任何带有 Web 浏览器的设备来作为电脑的副屏。
如果你愿意,它还支持多个设备连接。
Deskreen 很容易使用,当你的所有设备都连接到同一个 Wi-Fi 网络时,它可以正常工作。
让我们来看看它的功能和工作原理。
### Deskreen 的功能
Deskreen 的功能包括以下要点:
* 分享整个屏幕的能力
* 选择一个特定的应用窗口进行串流
* 翻转模式,将你的屏幕作为提词器使用
* 支持多种设备
* 高级视频质量设置
* 提供端对端加密
* 最小的系统要求
* 黑暗模式
没有一个冗长的功能列表,但对大多数用户来说应该是足够的。
### 如何使用 Deskreen 应用?
Deskreen 使用分为三个简单的步骤,让我为你强调一下,以便你开始使用:
首先,当你启动该应用时,它会显示一个二维码和一个 IP 地址,以帮助你用 Web 浏览器连接其他设备,以串流你的屏幕。

你可以按你喜欢的方式,在你的辅助设备上的 Web 浏览器的帮助下建立连接。
当你扫描二维码或在浏览器的地址栏中输入 IP 地址,你会在 Deskreen 应用上得到一个提示,允许或拒绝连接。除非是你不认识它,否则就允许吧。

接下来,你将被要求选择你想要串流的内容(你的整个屏幕或特定的应用窗口):

你可以选择串流整个屏幕或选择你想串流的窗口。然而,并不是每个应用窗口都能被检测到。
在我的快速测试中,我没有检测到 Rocket.Chat 应用窗口,但它似乎能检测到 Slack 窗口、Deskscreen 窗口和终端。

你只需要选择源并确认,就可以了。你应该注意到它在你的副屏(手机/桌面)上开始串流。

这是它完成后的样子:

Deskreen 还为你提供了管理连接设备的能力。因此,如果你需要断开任何会话或所有会话的连接,你可以从设置中进行操作。
### 在 Linux 中安装 Deskreen
你会找到一个用于 Linux 机器的 DEB 包和 AppImage 文件。如果你不知道,可以通过我们的 [安装 DEB 包](https://itsfoss.com/install-deb-files-ubuntu/) 和 [使用 AppImage 文件](https://itsfoss.com/use-appimage-linux/) 指南来安装它。
你可以从 [官方网站](https://deskreen.com/lang-en) 下载它,或者从它的 [GitHub 页面](https://github.com/pavlobu/deskreen)探索更多的信息。
* [Deskreen](https://deskreen.com/lang-en)
### 结束语
考虑到它使用 Wi-Fi 网络工作,在串流方面绝对没有问题。这是一种奇妙的方式,可以与别人分享你的屏幕,或者出于任何目的将其串流到第二个设备上。
当然,它不能取代你的电脑的第二个显示器的优势,但在一些使用情况下,你可能不需要第二个屏幕。
现在,我想问你,你能想到哪些实际应用可以用到 Deskreen?
---
via: <https://itsfoss.com/deskreen/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It is a cool ability to be able to mirror your computer screen on to your smartphone. While that's not the best experience, you can choose to do that to keep an eye on a few things. If you have a multi-monitor setup, you realize the advantages of having multiple screens.
And, yes, you can do that on a Linux computer with the help of an open-source tool, i.e, **Deskreen**.
With Deskreen, you can turn any device into your secondary screen. It makes screen sharing just as easier as it is on Windows.
## Using Deskreen to Mirror Screen Content on Ubuntu
[Deskreen](https://deskreen.com/lang-en?ref=itsfoss.com) is a cross-platform tool popularly used to turn devices into a second computer screen. The application mirrors the screen to an interface accessible via a web browser; hence, it can be viewed by any device with a browser.
All you have to is make sure, your devices are connected to the same Wi-Fi network.
It uses [WebRTC](https://en.wikipedia.org/wiki/WebRTC?ref=itsfoss.com) API for communications via the browser, which enables it to stream the screen.
The initial interface shows a QR code and a web address that the client devices, such as a smartphone, could connect to. The interface looks like this:
Upon scanning the QR code through your phone, a dialog box appears asking whether to accept the connection, along with the device's IP and operating system.
Next, you get to select if you want to mirror the entire screen or a particular window. Select the one you need and hit Confirm.
Depending upon the choice, you can choose to mirror the available screens — more than one screen is shown if you have multiple displays or a virtual screen adapter is connected — or an application window that's in the same virtual desktop as deskreen.
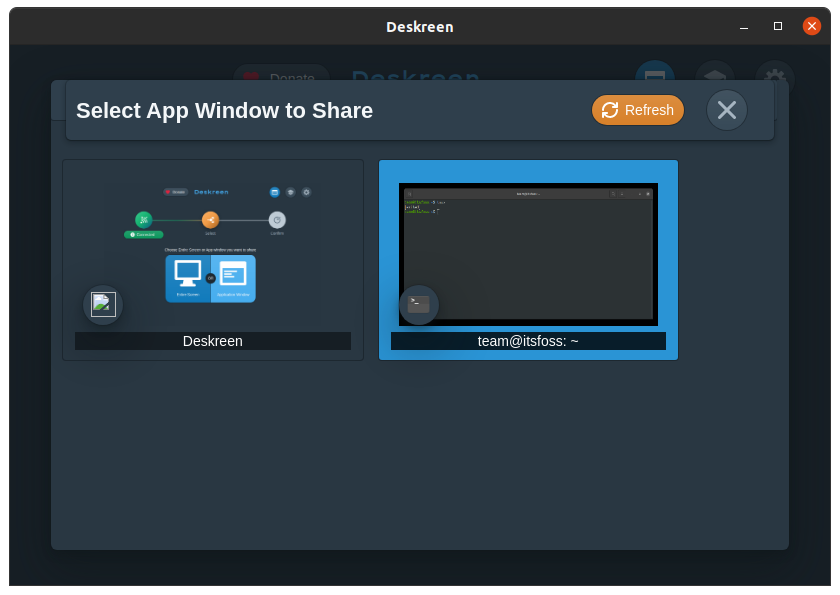
Here's how it looks when you want to share your entire screen:
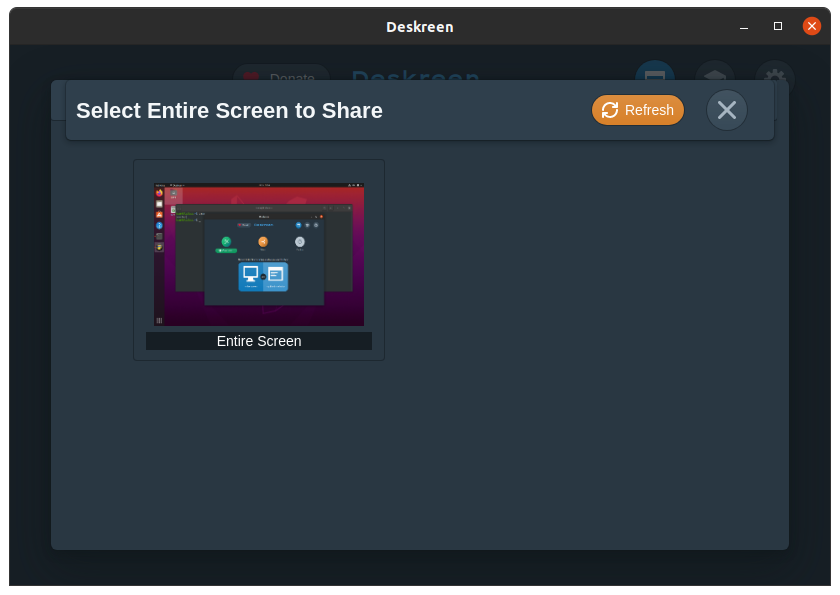
Once the choice is confirmed, the window or screen is streamed to the browser window. The client interface provides some basic controls over the streaming, like choosing the quality, flipping the contents, using the default video player for the stream, etc.
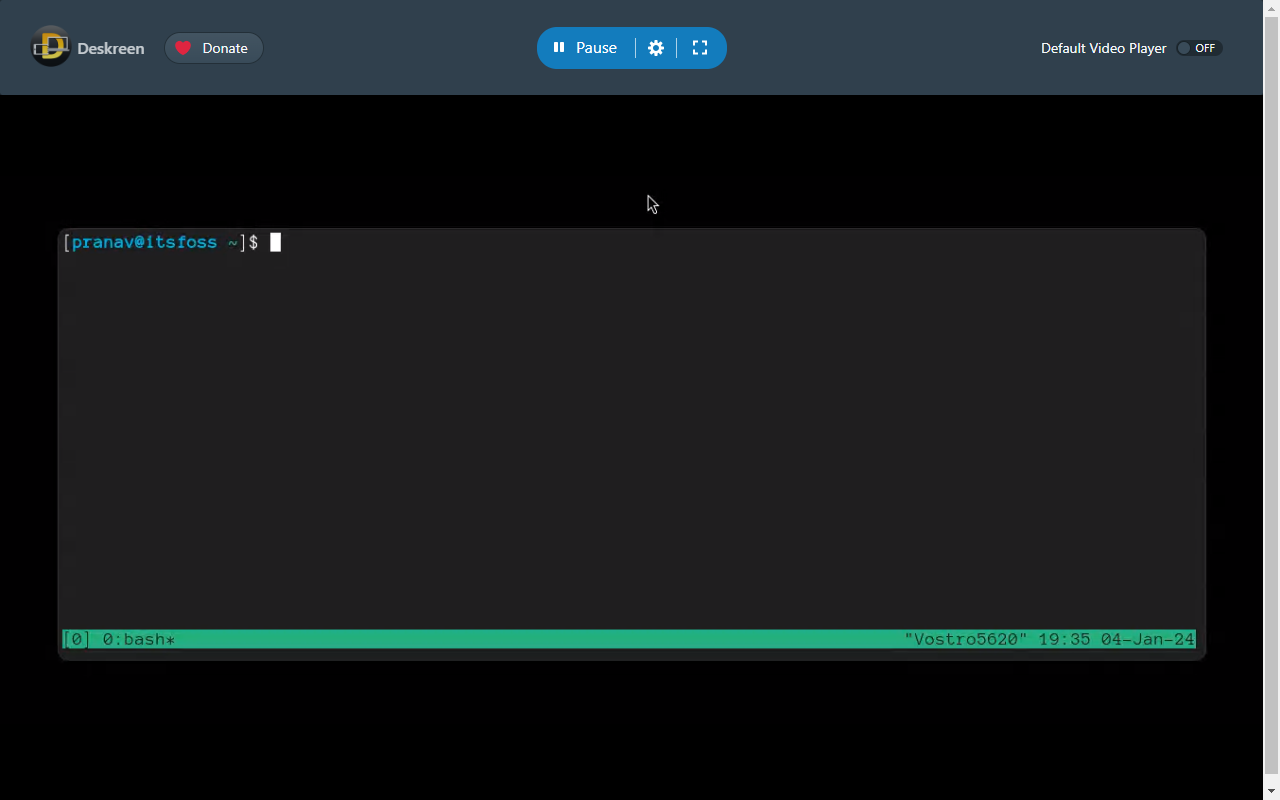
That's how simple it is to get Deskreen working.
## Download and Install Deskreen
To get started, you can download the *.deb* file from the [official site](https://deskreen.com/lang-en?ref=itsfoss.com) or its [GitHub page](https://github.com/pavlobu/deskreen). Alternatively, one could make use of the AppImage file as well.
You can follow [one of the available ways to install deb files](https://itsfoss.com/install-deb-files-ubuntu/). For an AppImage, you can make the file executable and run it as a program:
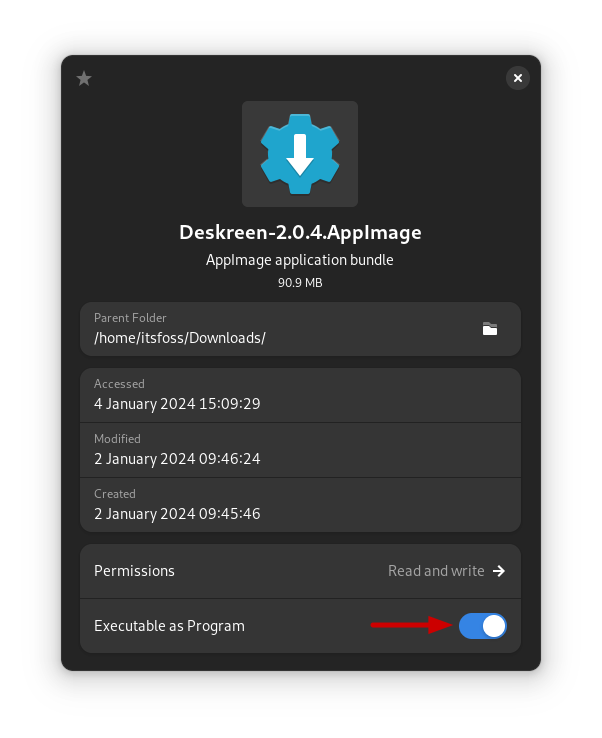
Deskreen is a handy tool to share your screen with a desired device instantly. It makes the job easier and quicker when compared to conventional methods of configuring [VNC or RDP](https://itsfoss.com/remote-desktop-tools/).
*Please let us know your thoughts about screen mirroring, and what is your favorite tool/method to do it?* |
13,509 | 《代码英雄》第四季(5):更智能的电话 —— 掌上电脑的旅程 | https://www.redhat.com/en/command-line-heroes/season-4/smarter-phones | 2021-06-22T12:35:00 | [
"智能手机",
"Palm"
] | https://linux.cn/article-13509-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》第四季(5):更智能的电话—— 掌上电脑的旅程](https://www.redhat.com/en/command-line-heroes/season-4/smarter-phones)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/1a47591d-3e71-49d7-89ac-acda1be1b39d/s4e5-smarter-phones-journey-to-the-palm-sized-computer-v1_tc.mp3)脚本。
>
> 导语:很少有人能想象到掌上电脑会是什么样子,甚至能做什么。但三个有远见的人看到了计算机的发展方向。不过,要在这个新领域取得成功,他们需要从头开始创造一切,并抛弃硬件方面的传统思维。
>
>
> 他们的创造 —— PalmPilot,后来打破了销售记录。它向世界展示了什么是可能的,它帮助人们认识到科技的价值再次发生了变化。但是,当科技泡沫破灭,新的竞争者进入市场时,Palm 对掌上电脑行业的控制力开始下滑。
>
>
>
**00:00:02 - Saron Yitbarek**:
在 20 世纪 90 年代初,一位心灵手巧的软件开发者将一堆木头切割成不同尺寸的小块。他仔细的比较了每个小块的重量。当他找到一个感觉像口袋大小的木块时,把一张打印着显示器图案的贴纸贴到了上面。然后把它装在上衣口袋里走来走去,感受随身携带一个这样的设备是什么体验。他畅想着在不久的将来,这样的设备会变为现实。如果你认为他的名字是<ruby> 史蒂夫•乔布斯 <rt> Steve Jobs </rt></ruby>,那么你就错了。他的名字是 Jeff Hawkins,曾合作创造了 PalmPilot 掌上电脑。2007 年,当 iPhone 上市时,评论家们和竞争对手们就曾经质疑智能手机是否能够成功。
**00:00:55**:
十年后,问题变成了,人怎么可能没有智能手机。智能手机无处不在,它的软件功能涵盖生活的方方面面,它硬件设备的好坏更成为了身份的象征。但是,尽管 iPhone 对我们移动生活的崛起起到了至关重要的作用,但它并不是一切的起点。我要分享早期掌上设备如何为智能手机铺路的史诗故事,故事的主人公是一个充满奉献精神的团队,自始至终坚信掌上设备会获得成功。我是 Saron Yitbarek,这里是<ruby> 代码英雄 <rt> Command Line Heros </rt></ruby>,一款红帽的原创播客。
**00:01:38**:
影视作品中很早就出现了智能机的概念,比如《<ruby> 星际迷航 <rt> Star Trek </rt></ruby>》中的<ruby> 三录仪 <rt> tricorder </rt></ruby>。而在现实生活中,直到 1984 年,人们才把手机称作智能机。那时的智能机像砖块一样笨重,后来在 90 年代智能机变得越来越小。到电视节目《<ruby> 救命下课铃 <rt> Saved by the Bell </rt></ruby>》播出时,主角 Zack Morris 已经可以随身携带。但这时智能机只用来打电话。还记得打电话么?所谓智能机上,没有任何“智能”的部分。与此同时,另一种技术备受青睐,那就是 PDA,一种<ruby> 个人数字助理 <rt> personal digital assistant </rt></ruby>,即一种可以扮演你的个人数据管家的移动电子设备。有关这种设备的故事我们一会儿再说,但是在那个时候,科技产业更多的关注在个人电脑上。这个故事我们已经在第三集讲 Altair 8800 时学习过了。
**00:02:33 - Ed Colligan**:
每个人都存在思维定势,认为个人电脑是一种放在桌子下面的巨大的、米黄色的大箱子。人们无法想象你可以将个人电脑装在自己的口袋中。
**00:02:43 - Saron Yitbarek**:
在 20 世纪 90 年代早期,Ed Colligan 还是 Plam 公司市场副总裁。这是一家由 Jeff Hawkins,那个揣着木块到处走的人,创建的移动软件公司。
**00:02:57 - Donna Dubinsky**:
这是一个宏大的愿景,也是计算的未来。在这个未来,人们用手持设备计算;在这个未来,手持式计算机的运算量将可能超越 PC。
**00:03:11 - Saron Yitbarek**:
欢迎 Donna Dubinsky,Plam 公司的时任 CEO。
**00:03:15 - Donna Dubinsky**:
我知道今天我说的东西听起来像 “不管怎样,这很合乎逻辑。”但是,请相信我,这在当时是不符合逻辑的。
**00:03:21 - Ed Colligan**:
我们很难体会为什么当时的人理解不了。因为你知道,计算技术发展如此迅速,对吧?它已经从占满整个房间的计算机变成了大型机,再到小型计算机,而小型计算机又被误称为个人计算机,再到台式计算机。这是<ruby> 摩尔定律 <rt> Moore's Law </rt></ruby>发展的必然结果,即计算机越来越强大,但是体积越来越小。
**00:03:48 - Saron Yitbarek**:
Plam 公司最开始为<ruby> 卡西欧 <rt> Casio </rt></ruby>公司生产的 PDA 设备开发一款名叫 Zoomer 的信息管理软件,以及为<ruby> 惠普 <rt> Hewlett Packard </rt></ruby>的设备研发一些同步软件。但是第一代 PDA 并没有获得成功。并且,随着苹果公司的高调失败,整个 PDA 的梦想似乎已经失去了存在的理由。苹果失败的原因在于 Apple Newton 这款 PDA 太大、太笨重、软件运行速度太慢。但是 Palm 团队想知道是否有一种新方法可以改变游戏。
**00:04:25 - Donna Dubinsky**:
我们最初的合作对象是操作系统公司 GeoWorks,和硬件供应商公司卡西欧。后来我们发现,工业级架构的硬件堆叠对于手持式计算并没有意义。使用高度集成的硬件和软件才是构建手持设备的正确方式,因此,从本质上讲,改变我们想法的东西是从失败中诞生的。
**00:04:55 - Saron Yitbarek**:
Palm 公司认识到,如果他们可以用自己生产的硬件,运行他们开发的软件,那么他们也许会创造一款成功的 PDA。
**00:05:04 - Ed Colligan**:
不,不,<ruby> 个人数字助理 <rt> personal digital assistant </rt></ruby>(PDA)这词不是我们的。
**00:05:09 - Saron Yitbarek**:
哎哟,对不起,Ed。
**00:05:11 - Ed Colligan**:
我们不想做一款 PDA。新产品的定位是与 PC 连接的记事簿。我们努力改变人们看待它的方式。让人们意识到,这不是一款你需要适应的全新设备,这只是 PC 的一个配件。
**00:05:29 - Saron Yitbarek**:
当 Ed 说 “连接” 时,他的意思是说将设备连接到电脑,而不是指连接到无线互联网。那时的设备还无法连接互联网。即便只是将 Palm 设备同步到个人电脑,这样的创意仍然比竞争对手棋高一着。
**00:05:46 - Donna Dubinsky**:
当时的 PDA 并不能与其他设备连接,你的 Sion 以及 Casio Wizard 中的地址簿,跟你电脑上的地址簿没有任何关联。我们并没有把它定位为独立的标准手持设备,相反的,我们把它定位为电脑的一个附属物。一个你电脑之上的窗口,让你能够把电脑的一部分随身携带,这样的定位让同步成为了该设备的核心功能。
**00:06:13 - Saron Yitbarek**:
除了设计手持设备外,Palm 公司还希望它有与其他设备配对的能力,比如说将其插入电脑就可以更新数据。
**00:06:24 - Rob Haitani**:
那时候要实现这样的目标非常困难。他们只有 25 个人,当时的硬件非常……昂贵,需要许多投资,需要时间,需要采购,坦白讲,这是非常大的挑战。
**00:06:40 - Saron Yitbarek**:
听完 Palm 公司的产品经理 Rob Haitani 的分享。接下来再听 Donna Dubinsky 介绍一下他对 Rob 团队的考验。
**00:06:47 - Donna Dubinsky**:
我们既想设计操作系统、又要开发应用软件、还得研究硬件协同软件,每项都够一个独立公司喝一壶。现在回想起来,一家小公司,要同时完成这些目标,是非常大胆的想法。
**00:07:14 - Rob Haitani**:
这就是人们来硅谷的原因。在这里你可以创造一个全新的行业。像 IBM、苹果和微软这样的公司在这方面都失败了,是什么让这 25 个人自信可以成功?要知道,对于硅谷人来说,没有什么比告诉他们无法做到某件事更能激励他们。我们坚信 Jeff 的愿景,而 Jeff 对他的愿景更是有清晰的规划。实际上,最让我产生共鸣的是他们“客户至上”的理念。他说,“不要构建技术给客户,客户需要个性化的解决方案。”
**00:07:45 - Saron Yitbarek**:
正是这种“客户至上”的理念激励了 Jeff Hawkins ,让他雕刻出了那个木块。
**00:07:54 - Rob Haitani**:
他把小木块放进口袋中,带着它参加会议。拿出木制的触控笔,模拟这种体验。我们假装在上面写字,人们会用奇怪的表情看他。Jeff,你知道的,因为他正在一块木头上写东西。我认为这使他有了深刻的领悟,关于使用移动设备的体验。
**00:08:16 - Saron Yitbarek**:
在这个小木块的启发下,我们有了一些核心设计标准。首先,它的大小必须适合放入衬衫口袋。其次,它的售价必须低于 300 美元。最后,它写东西必须比纸和笔更快。你可以立刻打开使用它。下面 Ed 和 Rob 将会把 Palm 的设计方法论与竞争对手进行的比较。
**00:08:41 - Ed Colligan**:
竞争对手都在设计独立设备,因此他们说:“噢,我们需要扩展卡来增加内存。” 或者他们会说:“我们必须得有一个键盘。” 而我们基本上在说:“不,我们把它连接到 PC 上,我们会快速的同步两者的数据。”
**00:09:00 - Rob Haitani**:
Jeff 采取了完全相反的观点。面对设备运行太慢的问题,传统的解决方案是换一个更快的处理器。但他会用其它方法,比如,如何让用户感觉更快?这不仅与硬件有关,事实是如果你让软件也变得轻量级,那么它就会成功并产生螺旋效应:体积越来越小,重量越来越轻,电池也越来越耐用。我们延续了这种精简步骤和效率至上的设计哲学。
**00:09:37 - Saron Yitbarek**:
他们甚至给自己的设计哲学起了个名字:“Palm 之禅”,并为之编写了完整的设计宣言。设计 Palm 操作系统涉及到了与设计大型机器截然不同的新概念和思维方式。对于 PC 来说,特性越多越好。但是掌机则是另一种不同的生物。根据 Palm 之禅的定义,掌机应该以用户为中心。功能应当更加聚焦,设备应当可以在任何地方使用。
**00:10:11 - Rob Haitani**:
这就好比,你不可能把整座大山装进茶杯,但你可以在上山找到钻石,把钻石装进去。我们的设计目标不是把整个 PC 的完整功能压缩填充到一块小屏幕上,而是把用户任何时候都要使用的核心功能实现在上面。为了实现这个目标,我们几乎把所有的功能讨论了个遍,最后决定哪些必须留在上面。
**00:10:41 - Saron Yitbarek**:
因为减少了页面上按钮的数量,所以屏幕可以设计的更小,与此同时 Rob 团队优化了操作流程,大大减少了点击次数。
**00:10:52 - Donna Dubinsky**:
他几乎亲自体验了所有的功能,绞尽脑汁的想要办法减少点击次数。举个例子:与其三次点击 —— 打开屏幕、点击日历应用、点击今天的日期 —— 这是你的常用操作。要是有一个“今日”按钮,点一下就会自动打开屏幕,打开日历并展示当前日期该有多好。如今,这些显而易见的事情,在当时是相当激进的设计。这不是人与设备交互的模式,因此,硬件和软件之间还存在巨大的协调空间。
**00:11:35 - Saron Yitbarek**:
短短 18 个月内,Palm 公司只用 300 万美元便完成了这看似不可能的任务。他们有了一台软硬件完美同步的原型机。但这也是他们仅有的 300 万美元,虽然他们有了令人惊叹的新型手持式计算机,但他们却濒临破产了。Palm 团队为继续融资而采取的孤注一掷的解决方案是,在 1995 年把公司卖给 US Robotics。这是他们让这个新型连接式记事簿(他们将其命名为 PalmPilot)面世的唯一途径。他们知道这很有市场。首席执行官 Donna Dubinsky 回忆起 Jeff Hawkins 在首次发布会上发布 PalmPilot 的情形。
**00:12:37 - Donna Dubinsky**:
Jeff 登上舞台向大家展示我们的新设备,当他拿出机座,把设备放在机座上,按下按钮时,我们几乎要站起来鼓掌了。你可以在屏幕上看到它正在与 PC 同步数据,台下响起了热烈的掌声。观众理解了我们产品的核心卖点,这让我们非常激动。
**00:13:13 - Saron Yitbarek**:
Palm 公司举办这场发布会的目的是,让用户感受他们的产品有多好用,但是他们没有足够的预算来请名人助阵,所以发布会必须要有创意。
**00:13:24 - Donna Dubinsky**:
我们想出了让老妈们来发布会帮忙的疯狂点子,我的妈妈、Jeff 的妈妈还有 Ed 的妈妈都来了,她们头戴 “<ruby> 飞行员妈妈 <rt> Moms for Pilot </rt></ruby>”字样的帽子,胸前别着“我女儿是 Donna”,“我儿子是 Ed”之类字样的胸针,妈妈们负责帮忙接受订单。直到今天,人们还会拦住我说,“我从你妈妈那里买的 Pilot。”是在是太有趣了。他们玩得很开心,这是一次难忘的发布会。
**00:14:06 - Saron Yitbarek**:
妈妈们签下的订单是掌上电脑发展的一大步。但是请记住,这发生在 1996 年。Ed Colligan 和 Rob Haitanihat 有话要说。
**00:14:18 - Ed Colligan**:
只要两节七号电池就能让设备用一个月,它有 128K 的内存。你可能从没听过用 K 做单位来说内存。它用于显示的显示屏是黑白的。
**00:14:38 - Rob Haitani**:
我们有 160 × 160 像素的超小屏幕,小到跟我之前设计的图标差不多大。我们的处理器功耗很低,内存很小。它的处理器是 16MHz,内存是 128K,我们必须让操作系统在有限的资源下工作。屏幕功耗也很低,它不是彩色的,甚至不是灰度的。是一个单色的,160 像素的屏幕,屏幕下方有一个看上去很像屏幕的<ruby> 数字化仪 <rt> digitizer </rt></ruby>,你可以在上面写字。
**00:15:16 - Saron Yitbarek**:
Palm 公司在其上预装了名叫 Graffiti 的手写识别软件,请记住,它没有键盘,你可以用手写笔在上面写字。
**00:15:29 - Rob Haitani**:
你可以在设备底部的矩形数字化仪上书写,每次在一个字母上面接着写另一个,你需要学习一个简化的字母表。
**00:15:39 - Saron Yitbarek**:
这项技术非常新颖和流畅,但也不是没有遇到问题。比如……
**00:15:45 - Donna Dubinsky**:
商品已经售卖了一段时间,我们忽然收到反馈说,我们的设备存在严重故障。设备一旦被关机,就再也开不了机。我们赶紧把设备送进我们的服务部门,看哪里出了问题。
**00:16:02 - Rob Haitani**:
这就是为什么创业公司不生产硬件。因为生产硬件非常难,我们遇到的问题是,人们丢失了数据,但我们不知道为什么。
**00:16:15 - Saron Yitbarek**:
研发团队梳理了所有的文档,回溯了他们的许多变更协议和订单,他们试图把它追溯到他们的流程中的一些变化。沮丧之下,Donna 把大家都召集起来了。
**00:16:32 - Donna Dubinsky**:
我把所有的高级员工都关在房间里,锁上门,对他们说:“要是查不出问题,大家都不能离开!”。
**00:16:41 - Saron Yitbarek**:
最终,研发团队意识这不是硬件问题,故障的原因是机器内部不符合预期的微小变更。
**00:16:53 - Donna Dubinsky**:
当你打开电池盖更换电池的时候,你会看到电池盖上有一张贴纸,上边写着警告之类的字样。
**00:17:03 - Saron Yitbarek**:
正是这个电池盖下写着警告字样的小贴纸,造成了这次大规模的故障。
**00:17:11 - Donna Dubinsky**:
贴纸与电池摩擦,有可能会导致断电。断电的时候,一个已经被加载的软件补丁就会丢失。
**00:17:27 - Saron Yitbarek**:
硬件团队将在设备上增加了支撑电池的弹簧,用这种超简单的方法,解决了这次灾难性的故障。
**00:17:35 - Donna Dubinsky**:
好消息是设备可以和电脑同步,所以数据都有备份。这场故障让人们意识到,真正有价值的并不是设备,而是存储在设备上的数据。
**00:17:49 - Saron Yitbarek**:
也许你正在用智能手机收听我们的播客,如果是的话,看一下你的手机,它比古老的 PalmPilots 先进太多,然而,很多基本功能 PalmPilots 上都有。接下来有请 Palm 公司的竞争分析总监 Chris Dunphy。
**00:18:10 - Donna Dubinsky**:
那是一个神奇的黄金时代。Palm 在 1996 年向市场推出了 PalmPilot,然后轰动一时。那个年代,口袋里装着 PalmPilot 这样小型大脑一样的设备,是非常酷的事情,Palm 公司后来推出开发者 SDK 作为辅助工具,然后又是大火。有了 SDK 的帮助,应用商店涌现了大量有趣的小程序。各行各业的人都爱上了他们的设备,爱上了他们的应用。
**00:18:43 - Saron Yitbarek**:
当时一群为 Mac 的台式机开发软件的开发者,转而开始为 Palm 创建应用生态系统。
**00:18:52 - Chris Dunphy**:
很多最初的 Palm 开发商都不是大公司,他们只是在业余时间做小项目的爱好者。他们有一些业余兴趣项目,当他们开始思考我们随身携带的小型电脑的本质时,他们灵感爆发,拓宽了我们的思路。越来越多的人在开发工具的帮助下,把自己的奇思妙想变为现实,这非常具有开创性。
**00:19:18 - Donna Dubinsky**:
我知道很多人认为,应用商店和手机应用是苹果发明的,但实际上初代 PalmPilot 就有一个非常早期的应用商店。那是一个第三方应用商店,早期的开发者开发了海量的创造性应用,人们借助应用商店将它们同步到设备上。
**00:19:37 - Saron Yitbarek**:
他们的计划是在第一年销售 10 万台。在前六个月,销售额一直稳定在每月 1 万台左右。但之后,销售量开始爆发。
**00:19:50 - Donna Dubinsky**:
实际上,短短 18 月的时间里,我们卖出了 100 万台,这是当时美国历史上销售量增长最快的产品。短短 18 个月内生产了 100 万台,这太不可思议了。
**00:20:01 - Saron Yitbarek**:
Palm 公司创造了全新的硬件类目。它本应是这场游戏的赢家。但随后,Palm 的母公司 US Robotics 出乎意料地被卖给了另一家名为 3Com 的公司。受微软业务模式的影响,3Com 负责人决定将 Palm OS 许可给想要创造自己的 PDA 的公司们。
**00:20:29 - Donna Dubinsky**:
很明显,这是微软在个人电脑领域取得成功的策略。我们不认为这是掌上电脑的正确策略。我们认为掌上电脑需要高度集成的设备。但他们始终认为这是一个错误的决定,认为我们应该将操作系统授权给所有的商业。我们不能认同他们的决定。
**00:20:53 - Saron Yitbarek**:
他们相信自己的愿景。于是,在他们帮母公司革新市场后,Jeff Hawkins、Donna Dubinsky、Ed Colligan 还有 Rob Haitani 等人离开了 Palm ,成立了一家新公司,名叫 Handspring。他们获得他们所创建的 Palm OS 的许可,把它安装到他们新的掌机上。他们曾创造巨人,现在,他们打算用自己的操作系统,以“大卫和歌利亚”的方式,以弱胜强打败它。Handspring 在 1999 年获得独立,并发布了新的硬件产品:名为 Visor 的全新系列 PDA。Visor 内置 Palm OS。Ed Colligan 还记得这款新设备大受欢迎。
**00:21:48 - Ed Colligan**:
果不其然,我们一夜之间就占据了 25% 的市场份额。
**00:21:53 - Saron Yitbarek**:
Palm 公司的硬件销量受到了这一举动的打击。讽刺的是,正是 3Com 决定将 Handspring 拆分为独立公司的,这正合他们心意。值得欣慰的是,当时 90% 以上的掌上电脑上,运行着 Palm 公司的操作系统。事实上,有很短的一段时间,Palm 的市值超过了福特和通用汽车的总和。人们认为它会成为下一个微软。当然,Handspring 这时也有自己的计划。
**00:22:23 - Donna Dubinsky**:
成立 Handspring 以后,我们意识到掌上电脑的终极形态会是通信设备。所以我们在产品上增加了一个硬件插槽,打算将来用以实验和整合多种类型的通信设备,比如可以插上一个呼机卡、语音卡什么的。这样我们就可以从中学习,深入了解通信领域。
**00:22:51 - Ed Colligan**:
未来是智能手机的天下,所有这些东西正朝着无线发展,我们的下一步是将 PDA 和手机集成起来。
**00:23:07 - Saron Yitbarek**:
然后,Handspring 开始开发智能手机。他们用键盘取代了手写笔,将他们的新产品命名为 TreoSo。Jeff、Donna 还有 Ed 一起会见了另一位科技企业家,他正在智能手机领域做一些有趣的事情。这人正是<ruby> 史蒂夫•乔布斯 <rt> Steve Jobs </rt></ruby>。
**00:23:28 - Ed Colligan**:
史蒂夫在白板上画了一台<ruby> 麦金塔计算机 <rt> Macintosh </rt></ruby>,然后在其周围像卫星一样画出照片、视频等各种附属功能。然后他说:“我们的战略是,麦金塔计算机将成为一切的中心。iTunes、iPhoto 等所有功能都围绕它设计”,然而,Jeff 反驳道:“不是这样的。人们将会有一台掌上电脑,所有这些东西都将以它为中心才对”。
**00:24:05 - Saron Yitbarek**:
我们都知道结果如何。Jeff Hawkins 的观点实际上更接近事实,但在21世纪初,乔布斯对此持怀疑态度。整个行业都对此持怀疑态度。
**00:24:18 - Ed Colligan**:
我曾经去游说 Sprint 和 Verizon 这些公司,试着说服他们未来是智能手机的时代。虽然今天很难相信,但实际上,会议上他们的反应就像在说:“嗯,这是些新奇的设备”,或者,你知道的……“谁会用口袋里的东西发邮件呢”,我会说:“嗯,我真的认为这将会发生”。
**00:24:40 - Saron Yitbarek**:
在们等待智能手机的时代到来时,他们有另一个更紧迫的问题。2001 年,科技泡沫破裂,股市暴跌,资金短缺,投资枯竭。这威胁到了 Handspring、Palm 以及几乎所有产品的未来。所以<ruby> 万福玛利亚 <rt> hail-Mary </rt></ruby>,为了制造 Treo,Handspring 又合并回了 Palm 公司。这来回的折腾也让我有点头晕。但 Treo 作为 Palm 的主力产品,成为了市场上最受欢迎的智能手机。当然,在那个时候,Palm OS 已经开始显露老态。新玩家也进入了这个市场,比如 RIM 公司的<ruby> 黑莓 <rt> Blackberry </rt></ruby>手机。
**00:25:29 - Saron Yitbarek**:
当无线成为一种潮流时,专家们开始严重怀疑 Palm 操作系统是否适合下一代设备。所以在 2005 年,Palm 公司发布了第一款不使用 Palm 操作系统的产品 Treo。Treo 使用的是 Windows mobile 操作系统。到 2007 年时,Palm 已经成了没有自研操作系统的纯硬件公司。Palm 团队想要建立的未来还在发展,但似乎不再需要与 Palm 公司同行了。
**00:26:03 - Saron Yitbarek**:
正当 Palm 公司需要帮助时,John Rubinstein 挺身而出。Rubinstein 在苹果公司开发了 iPod。在苹果公司 2007 年发布 iPhone 时,Rubinstein 加入了 Palm 公司,担任其产品开发的新主管。两年后,Palm 团队推出了他们的新设备:Palm Pre 和一款名为 Web OS 的新操作系统。它们于 2009 年在消费电子展(CES)上推出。有人认为这是有史以来最好的科技主题报告。Ed Colligan 在活动中说到:
**00:26:40 - Ed Colligan**:
它叫做 Palm Web OS,我们非常高兴今天能把它带给大家。它是为开发人员而构建的。这一切都建立在行业标准的 Web 工具之上。只要您了解 HTML、CSS 和 JavaScript,就可以为这个平台开发应用程序。
**00:27:03 - Saron Yitbarek**:
没人见过像 Web OS 这样的东西,它为我们现今智能手机的体验奠定了基础。实际上,iOS 和 Android 都从中汲取了很多东西。Web OS 的功能有:多个同步日历、统一的社交媒体和联系人管理、曲面显示器、无线充电、集成文本和 Web 消息、非侵入式通知等等。只需将其置于开发模式即可轻松升级,并且还支持无线更新。Web OS 是其他公司无法比拟的伟大成就,不过,这还不够。
**00:27:46 - Ed Colligan**:
我认为我们在这方面做得很出色,但还是太少,太迟了,因为那时苹果已经发布了 iPhone。他们执行得又快又好,所以市场被他们占领了,但我认为我们的设计对他们影响深远。我的意思是,直到今天,iPhone 和 OS X 才真正赶上 Web OS 的所有功能。
**00:28:12 - Saron Yitbarek**:
但是 Ed 认为真正的杀手锏是另一部手机.
**00:28:15 - Ed Colligan**:
导致他们失败的杀手锏其实是是谷歌和 Android。有了搜索业务的支撑,谷歌不需要通过卖手机赚钱。
**00:28:24 - Saron Yitbarek**:
谷歌基本上免费提供了 Android。这对微软的 Windows Phone 还有 Palm pre 的 Web OS 来说,是个大问题。
**00:28:34 - Ed Colligan**:
我们没有那样的商业模式,这对我们造成了巨大的影响,导致我们再也没办法从中恢复过来。
**00:28:48 - Saron Yitbarek**:
用 PalmPilot 创造了一个全新的技术类目,用 Palm OS 主导了移动软件,打造了第一款智能手机 Treo,并用 Web OS 重塑了移动操作系统,在所有这些创新和迭代之后,Palm 公司在 2010 年被惠普收购,后来又被 LG 收购。然后在 2012 年,惠普发布了基于 Linux 开源 Web OS。
**00:29:18 - Saron Yitbarek**:
一旦开源,Web OS 就成为其他智能设备、电视、手表和物联网的底层操作系统。关于硬件和软件融合的争论,让 Donna Dubinsky 来解决吧。
**00:29:36 - Donna Dubinsky**:
它们实际上是无法区分的。你不能在好硬件上运行坏软件,也不能用坏硬件来支持好软件。这个问题几乎毫无意义,两者必须保持一致。这些你随身携带的软硬件,被高度集成在一起。人们甚至不知道硬件在哪里结束,软件在哪里开始,事实就是如此。
**00:29:58 - Saron Yitbarek**:
在 Jeff Hawkins 的故事中,不管是硬件还是软件,都是从他衬衫口袋里的那块小木块开始的。25 年后,这个小木块演化成了数百万、甚至数十亿部智能手机。
**00:30:21 - Saron Yitbarek**:
《代码英雄》是红帽的原创播客。访问我们的网站[redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes%22redhat.com/commandlineheroes%22)了解更多有关 Palm 和 Web OS 的精彩故事。想要收到我们的简讯,记得注册哦,我是 Saron Yitbarek,下期之前,编码不止!
**附加剧集**
PalmOS 是 PalmPilot 成功的一个重要部分。听 Neil Rhodes 讲述为不多的几个公开提供的软件开发工具包之一进行开发是什么感觉。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-4/smarter-phones>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[2581543189](https://github.com/2581543189) 校对:[wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Few could imagine what a handheld computer would look like—or even do. But a trio of visionaries saw where computing was headed. To succeed in this new frontier, though, they would need to create everything from scratch, and throw out the conventional wisdom on hardware.
Their creation, the PalmPilot, went on to break sales records. It showed the world what was possible and it helped people realize that the value in tech was shifting once again. But when the tech bubble burst, and new competitors entered the market, Palm’s grip on the handheld computing industry began to slip.

**00:02** - *Saron Yitbarek*
In the early 90s, a handy software developer took a stack of wood, and carved it into small blocks of various sizes. He carefully compared the weight of each block. And when he found one that felt pocket-sized, he taped a printout of a tiny monitor onto it. Then he tucked the block in his shirt pocket, and walked around with it, to see how it would feel to be attached to a device. He was imagining, in a not so distant future, where we'd all be doing the same thing. If you think that guy's name was Steve Jobs, you're wrong. His name was Jeff Hawkins, and he co-created the PalmPilot. When the iPhone hit the market in 2007, critics and competitors questioned whether a smartphone would succeed.
**00:55** - *Saron Yitbarek*
A decade later, the question is, how can a person succeed without one? Smartphones are ubiquitous. Their apps allow us to do pretty much anything. And the hardware running them says a lot about who we are. But as central as the iPhone has been to the rise of our mobile lives, it wasn't the catalyst. This is the epic story of how an earlier handheld device paved the way for the smartphone. And it's the story of a devoted team that stuck with that device for its entire journey. I'm Saron Yitbarek, and this is Command Line Heroes, an original podcast from Red Hat.
**01:38** - *Saron Yitbarek*
The smartphone concept has been around since Star Trek’s tricorder. In real life though, the concept first translated into cell phones in 1984, bulky things that looked like bricks during the 90s they got a bit smaller, small enough for Zack Morris to carry on Saved by the Bell—but they were still just used for phone calls. Remember phone calls? Nothing “smart” was happening on mobile phones, but there was another piece of technology gaining traction. It was called a PDA, a personal digital assistant, a mobile electronic device that acted as your personal information manager. We'll get to that in a moment, but at the time, the tech industry was way more focused on the personal computer, which we learned about in episode 3 when we looked at the Altair 8800.
**02:33** - *Ed Colligan*
Everyone was so caught up in what a personal computer was, this huge, big beige box sitting under your desk. They couldn't imagine that you'd carry this thing around in your pocket.
**02:43** - *Saron Yitbarek*
Ed Colligan was VP of marketing at a nascent mobile software company called Palm in the early 90s. Palm was founded by Jeff Hawkins, the guy who walked around with a block of wood in his pocket.
**02:57** - *Donna Dubinsky*
It was a big vision. It was the future of computing, of personal computing as handheld computing and that there would be more transactions done on handheld computers in the future than on desktop computers.
**03:11** - *Saron Yitbarek*
That's Donna Dubinsky, Palm’s CEO at the time.
**03:15** - *Donna Dubinsky*
I know today when I say that it sounds like, “Whatever, that's logical.” But believe me, it was not logical at the time.
**03:21** - *Ed Colligan*
We didn't understand why other people didn't understand it, because you know, where had computing gone, right? It had gone from computers that filled a room to mainframe computers to minicomputers, which were kind of misnamed to personal computers to desktop computers. And we saw the inevitable march of Moore's Law and more and more power and smaller, smaller packages.
**03:48** - *Saron Yitbarek*
Palm started out developing information management software for a PDA that Casio was making, called the Zoomer. They also made some synchronization software for Hewlett Packard's devices, but those first-gen PDAs weren't taking off. And then the whole personal digital assistant dream looked like a lost cause after the high-profile failure of Apple's efforts. The Newton—they were all too big, too heavy, and the software was too slow. But the Palm team wondered whether a new approach could change the game.
**04:25** - *Donna Dubinsky*
The original deal we worked on was with an operating system company, GeoWorks, and a hardware provider, Casio. However, what happened along the way was we figured out that industry architecture, if you will, that stacked up didn't make sense for handheld computing. What we learned was the right way to build these was with highly integrated hardware and software products. So, what changed our mind was born out of failure, essentially.
**04:55** - *Saron Yitbarek*
Palm figured that if they could build their own hardware, something that ran their software, they might be able to build a winning PDA.
**05:04** - *Ed Colligan*
No, no personal digital assistant actually wasn't our term.
**05:09** - *Saron Yitbarek*
Whoops, sorry Ed.
**05:11** - *Ed Colligan*
We didn't like PDA. We literally positioned it as a connected organizer. We effectively tried to change the way people looked at it, from being a whole new device that you need to adapt to, to being an accessory to your PC.
**05:29** - *Saron Yitbarek*
When Ed says connected, he means connecting the device to the computer, not connected to the wireless internet. That wasn't happening yet, but even being able to sync your Palm device with your personal computer was a step above what the competition offered.
**05:46** - *Donna Dubinsky*
They didn't connect with anything, so if you had an address book in your Sion and your Casio Wizard, it had nothing to do with your address book on your computer. Instead of a standard handheld standalone computer, we positioned it as an appendage of your computer, a window onto your computer, a way to take a little piece of your computer with you, which put the synchronization function at the center of the positioning.
**06:13** - *Saron Yitbarek*
In addition to building a mobile organizer device, Palm wanted to pair it with a synchronization device that you could plug into your computer to update information.
**06:24** - *Rob Haitani*
Which seemed very intimidating at the time. There's 25 people, hardware is very... It's capital intensive, you need a lot of investments, you need time, you need procurement, and it was quite an intimidating challenge, frankly.
**06:40** - *Saron Yitbarek*
That's Rob Haitani, Palm’s product manager. And this was Donna Dubinsky’s challenge to Rob’s team.
**06:47** - *Donna Dubinsky*
And we wanted to create from scratch an operating system, application software, hardware synchronization software, any one of these was effectively a company. So, for a little company to take on all of that at one time, and have it all work together, was really audacious as I look back.
**07:14** - *Rob Haitani*
This is why people go to Silicon Valley. It's like, okay, you're going to create an entirely new industry. The people like IBM and Apple and Microsoft have failed at this. So, what makes you 25 people think you can succeed? And you know nothing inspires people in Silicon Valley more than telling them they can't do something. We believed in Jeff's vision, and Jeff had a very clear vision. And, what I really... what really resonated to me, was very customer focused. He said, "Don't build technology, build a solution for a customer."
**07:45** - *Saron Yitbarek*
It was that customer-first attitude that inspired Jeff Hawkins to carve himself that gadget-sized block of wood.
**07:54** - *Rob Haitani*
So, he’d carry this thing around in his pocket, and they would walk into meetings, and he had this little wooden stylus, and he would pretend that he was trying to simulate what the experience would be like. So, we'd pretend to be writing on it, and people would give him these funny looks cause he's, you know... you're writing on a piece of wood, Jeff. I think that really gave him some insights into what it would really... the experience would feel like.
**08:16** - *Saron Yitbarek*
That little block of wood inspired some core design criteria. First, it had to fit into a shirt pocket. Second, it had to have a price tag of less than $300. Third, it had to be faster than pen and paper. You could instantly turn it on and use it. Here's Ed and Rob comparing Palm's approach to design versus the competition’s.
**08:41** - *Ed Colligan*
Everybody else was trying to create this standalone device and so they said, “Oh, we need an expansion card for more memory,” or they'd say, “We have to have a keyboard,” and we basically said, “No, we're going to hook it to the PC, and we're going to synchronize the information between the PC and this device instantly.”
**09:00** - *Rob Haitani*
Jeff was a guy who took a completely contrarian point of view. He said, the problem you're trying to solve is it's too slow. Then the conventional wisdom is to add a faster processor. He took the other approach saying, well, how do you make it faster for the customer? It's not only about the hardware, it's about if you make the software slim and light, then that will succeed and then that will have its own spiraling effect of: that will be small, it'll be lighter, it will have longer battery life. So we developed this philosophy of stripping down the number of steps and being super critical about efficiency.
**09:37** - *Saron Yitbarek*
They even gave their philosophy a name: “the Zen of Palm.” They wrote a whole design manifesto and everything. Designing the Palm OS platform involved new concepts and new ways of thinking that were different from designing for bigger machines. With PCs, the more features the better. But handhelds are a different creature. According to the Zen of Palm, handhelds should be all about the user. Features should be tightly focused and the device should be usable anywhere.
**10:11** - *Rob Haitani*
How do you fit a mountain into a teacup? You want to find the diamond in the mountain and put that in the teacup. The purpose of a design for a small screen is not to take a desktop PC, full-functional design, and cram it and miniaturize it. It was to take the nuggets that you really needed at any time and put that on the screen. And the way we addressed that was, we literally would step through every task and say what absolutely has to be on the screen.
**10:41** - *Saron Yitbarek*
Reducing the amount of buttons on any given page allowed for a smaller screen, and Rob's team drastically reduced the number of taps it took to execute function.
**10:52** - *Donna Dubinsky*
He literally would go through every screen and every function and see how he could reduce the taps. An example I like to use is that rather than three-tap—turning on a device, hitting a calendar app, hitting the date for today—this was one of the most common things you wanted to do. What if you could just press one button, and this button would turn on the device, take you to the calendar app, and show you today? It was a “today button.” And now, again, these sorts of things seem obvious, but at the time, this was quite radical. That was not how you interacted with devices. So, that took tremendous coordination between the hardware and the software.
**11:35** - *Saron Yitbarek*
Within 18 months, Palm had done the seemingly impossible. They had a prototype with beautifully synchronized hardware and software. And they'd done it with only $3 million. But there was one problem. It was their last $3 million. Palm had an amazing new handheld computing device, and they were flat broke. The Palm team's hail-Mary solution to keep on financing their new product was to sell the company to US Robotics in 1995. It was the only way they could get this new connected organizer, which they dubbed the PalmPilot into the hands of customers. And they knew there'd be customers. Here's CEO Donna Dubinsky, remembering what happened when Jeff Hawkins unveiled the “PalmPilot” at a tech conference.
**12:37** - *Donna Dubinsky*
We had Jeff up there on the stage, showing the device, but the moment that was the most powerful, and that got us a near standing ovation was, he brought out the cradle, and he put the device in the cradle, and he pressed the button. And you could see on the screen it synchronizing with the PC. And that blew people away. And they just spontaneously applauded. So it was very exciting to see how they got the core value proposition of what we were trying to sell.
**13:13** - *Saron Yitbarek*
Palm's goal at that launch was to convey to people how simple the device was to use. But they didn't have a big budget to produce their reveal. So, they got creative.
**13:24** - *Donna Dubinsky*
We came up with this crazy idea to have our mothers come, and help us launch it. So we had my mom, Jeff's mom, and Ed's mom. They had little hats we made up that said “Moms for Pilot.” They had little pins that said “My daughter's Donna,” “My son is Ed,” or whatever. And we had them take orders for Pilots on the spot. I bought my Pilot from Jeff's mom, or from Ed's mom, or whatever. To this day, people stop me and say, "I bought my Pilot from your mom." It was really, really fun. They had a blast, and it made for a memorable launch.
**14:06** - *Saron Yitbarek*
What the moms were signing orders for was a huge step forward in handheld computing. But keep in mind, this is happening in 1996. Ed Colligan and Rob Haitani again.
**14:18** - *Ed Colligan*
The product ran on two AAA batteries, for a month, ok. It had 128K of memory. You've probably never heard a K of memory. It had a display screen that was a black and white, you know, display.
**14:38** - *Rob Haitani*
We had a screen that was 160x160 pixels, which is microscopic. I mean, I've designed icons almost that size. So we had a very low-powered processor, and a very small amount of memory. So it had a 16 megahertz processor, 128K of RAM, and we had to make an operating system work under those constraints. Low-powered screen. It was not color, it was not even grayscale. It was a monochrome, 160-pixel screen, and then below it, we had a digitizer that was not a screen, but it was a digitizer, so you could write on it.
**15:16** - *Saron Yitbarek*
Palm added its handwriting recognition software, called Graffiti to the PalmPilot. Remember, that it didn't have a keyboard. If you wanted to write something on it, you used a stylus.
**15:29** - *Rob Haitani*
You wrote on a rectangle at the bottom, and you wrote letters on top of each other, and you had to learn a simplified alphabet.
**15:39** - *Saron Yitbarek*
The technology was new and smooth, but it wasn't without its problems. For example...
**15:45** - *Donna Dubinsky*
We had been shipping for a little while, and we suddenly started getting catastrophic failures in the field. Devices that went off, and just couldn't go back on, and we started getting these into our service department, and had to try to figure out what was going wrong.
**16:02** - *Rob Haitani*
This is why startups don't typically make hardware. It's very difficult, and we had this problem where people were losing data, and we couldn't figure out what was happening.
**16:15** - *Saron Yitbarek*
The team combed through all their documentation, back through their many change agreements and orders. They tried tracing it back to something that changed with their process. Still, they couldn't figure it out. Out of frustration, Donna got everyone together.
**16:32** - *Donna Dubinsky*
I put all the senior people in one room and almost locked the door and said, "You're not leaving here until you figure out what's wrong with this thing. Why is this happening?"
**16:41** - *Saron Yitbarek*
Eventually, the team realized there'd been a tiny change inside the machine, but not the kind you'd expect. It had nothing to do with the hardware components at all.
**16:53** - *Donna Dubinsky*
You know how when you take a battery cover off, or you put in batteries on a device, so the inside cover there, somebody added a sticker with some kind of a warning or something.
**17:03** - *Saron Yitbarek*
The source of this giant headache was a little warning sticker that had been added to the underside of the battery cover.
**17:11** - *Donna Dubinsky*
That sticker caused friction with the batteries, and they could get depressed in a way that disconnected the power. And there had been a software patch that had been loaded on, and that patch was lost when the power was disconnected.
**17:27** - *Saron Yitbarek*
The hardware team swapped out connectors for springs to bolster the batteries, a super-simple fix for a catastrophic failure.
**17:35** - *Donna Dubinsky*
The good news was it was all synchronized, so it was all backed up. And you realized that for people, it's a real light-bulb moment. The data is the value, not the device.
**17:49** - *Saron Yitbarek*
Maybe you're listening to this podcast on a smartphone right now. Take a look at it. Your phone is light-years ahead of those old PalmPilots. And yet, the basics of what you're using were all there in the Palm. Chris Dunphy was Palm's Director of Competitive Analysis.
**18:10** - *Donna Dubinsky*
It was this kind of amazing golden age. Palm launched to the market in 1996, with the PalmPilot, and it was the buzz everywhere. It was the cool thing to have, this little thing in your pocket that was a portable brain, and Palm was smart enough that they'd put out a developer SDK as kind of, almost, a side effect, and that took off. All these little niche markets had really cool little apps popping up for them. From everything from doctors to knitters. And people were in love with their devices, in love with their apps.
**18:43** - *Saron Yitbarek*
There was an existing community of developers making similar apps for Mac's desktops, and they hopped over to build an app ecosystem for Palm.
**18:52** - *Chris Dunphy*
A lot of the original Palm developers weren't large companies. They were just small hobbyists who were doing projects in their spare time. They had some personal passion project, and their minds exploded when they started thinking, what is a computer, and a screen that you carry with you all the time? And it becomes an extension of your mind. And so many people had so many great ideas of how to take advantage of that software development kit, and write really, really cool things. And, it was really groundbreaking.
**19:18** - *Donna Dubinsky*
I mean, I know a lot of people think Apple invented the App Store, and the idea of apps on handheld, but actually the very first PalmPilot had a very early app store. It was a third-party app store, and very early developers who came in and did all sorts of creative applications that again, people could just sync onto their device.
**19:37** - *Saron Yitbarek*
The plan was to sell 100,000 units in the first year. And for the first six months, sales were stable. About 10,000 units a month. But then, things started to skyrocket.
**19:50** - *Donna Dubinsky*
And in fact by 18 months, we sold a million units, which was the fastest new product growth in American history at the time. I mean it was stunning growth. A million units in 18 months.
**20:01** - *Saron Yitbarek*
Palm had created an entirely new category of hardware. And the spoils were, theoretically, theirs for the taking. But then, unexpectedly, Palm's parent company, US Robotics was sold to another company, called 3Com. And the head of 3Com, who was influenced by the Microsoft business model, decided to license the Palm OS to companies that wanted to create PDAs of their own.
**20:29** - *Donna Dubinsky*
And obviously, it was a strategy that has succeeded very well from Microsoft in personal computers. We didn't think that was the right strategy for handheld computers. We felt they needed to be highly integrated devices, but they consistently felt that that was the wrong decision, and that what we should do is license the OS to all commerce. And we disagreed with that.
**20:53** - *Saron Yitbarek*
They believed in their vision. And so, right after they helped their parent company revolutionize the market, Jeff Hawkins, Donna Dubinsky, Ed Colligan, Rob Haitani, and others left Palm to form a new company. They called it Handspring. There, they would license the software they'd created, Palm OS, and load it onto their own handhelds. They had built a giant. And now, they were going to try to take it down, David-and-Goliath style, using its own OS. In 1999, the newly formed Handspring, free from those old parent companies released its own hardware, the Visor line of PDAs. And they ran on Palm OS. Ed Colligan remembers its public reception.
**21:48** - *Ed Colligan*
And sure enough, we took like 25% of the market, almost overnight.
**21:53** - *Saron Yitbarek*
Palm's hardware was hit by that move. So ironically, 3Com spun it off into the independent company the team had hoped for. In the meantime, the Palm OS was running on 90% of all handheld computers, not too shabby. In fact, for a short period, Palm was worth more than Ford and General Motors combined. People thought it'd become the next Microsoft. Meanwhile, Handspring had its own plans.
**22:23** - *Donna Dubinsky*
By the time we started Handspring, we started realizing that these devices ultimately would be communications devices and we built it with a hardware slot and the hardware slot was specifically with the idea to be able to experiment and integrate any kind of communication things—put in a pager card, put in a voice card, put in whatever, and that we would learn from that, and learn how to integrate communications and what would be important in the space.
**22:51** - *Ed Colligan*
We saw the smartphone coming, we saw that these things were all going wireless and we decided we wanted to figure out how to create that integrated device of both the PDA and the phone.
**23:07** - *Saron Yitbarek*
So Handspring got to work creating a smartphone. In the process, they replaced the stylus with the keyboard and named their new creation the Treo. While all this was in progress Jeff, Donna, and Ed met with another tech entrepreneur doing interesting things in the space. A guy by the name of Steve Jobs.
**23:28** - *Ed Colligan*
At that meeting, Steve got up on the board and drew out a Macintosh and he had all these things like photos and video and other things as satellite things off of the Macintosh and he said, "Our strategy is the Macintosh is going to be the center of everything and all these things are going to pivot around it." And that was iTunes, iPhoto, whatever. Right? And Jeff said, "Nope, that's not how it's going to work. How it's going to work is there's going to be a handheld computer and all these things are going to pivot off of it."
**24:05** - *Saron Yitbarek*
We know how this all turned out. Jeff Hawkins’ vision was actually closer to the truth, but at the time, early 2000s, Jobs was skeptical. The whole industry was skeptical.
**24:18** - *Ed Colligan*
I used to go into Sprint and Verizon, and these guys, and try to convince them that smartphones were going to be something. I know it's hard to believe today, but literally we'd sit down in meetings and they're like, eh, these new-fangled devices or you know ... who's going to do email on something in your pocket. And I'd go, "Well, I really think it's going to happen."
**24:40** - *Saron Yitbarek*
But while they waited for the world to catch up, they had another more pressing problem. It threatened the future of Handspring, Palm, and just about everything. In 2001, the tech bubble burst, stocks plummeted, money was suddenly scarce and investments dried up. So in another hail-Mary, this time to manufacture the Treo, Handspring merged back into Palm. I know all the back and forth is making me a little dizzy, too. The Treo became Palm's powerhouse product and the most popular smartphone on the market. But of course by that point, the Palm OS had started to show its age. New players had entered the market. Companies like RIM with its Blackberry.
**25:29** - *Saron Yitbarek*
Wireless was becoming a thing and experts seriously doubted whether the Palm operating system was a good fit for the next generation of devices. So in 2005, Palm shipped its first Treo without the Palm OS. They built that Treo around Windows mobile. By 2007, Palm had become a hardware company with no operating system of its own. The future that the Palm team wanted to build seemed to be rolling on without them.
**26:03** - *Saron Yitbarek*
Palm needed help and they got it in the form of John Rubinstein, the man who developed the iPod at Apple, just as Apple released the iPhone in 2007, Rubinstein came on board at Palm as their new head of product development. Two years later, the Palm team had a new device, the Palm Pre and a new OS called Web OS. They launched at CES in 2009. Some called it the best tech keynote ever. Here's Ed Colligan onstage at the event.
**26:40** - *Ed Colligan*
And it's called the Palm Web OS and we're very, very excited to bring it to you today. It was built with developers in mind. The whole thing is built on industry-standard web tools. If you know HTML, CSS, and JavaScript, you can develop applications for this platform.
**27:03** - *Saron Yitbarek*
No one had ever seen anything like Web OS, it laid the groundwork for the whole smartphone experience we take for granted today. In fact, iOS and Android gleaned a lot from its features. Features like multiple synchronized calendars, unified social media and contact management, curved displays, wireless charging, integrated text and web messaging, unintrusive notifications. You could upgrade it easily just by putting it into dev mode and you could receive over-the-air updates. Web OS was an amazing achievement that no other company could match. Unfortunately, it wasn't enough.
**27:46** - *Ed Colligan*
I think we did a phenomenal job with that, but it was just too little, too late, because at that point Apple had launched the iPhone. They executed really, really well and so all power to them, but I think they were hugely influenced by what we had done and to this day, I mean until, like, OS X or whatever on the iPhone, that was the first time they'd actually caught up with all the features that were in the Web OS.
**28:12** - *Saron Yitbarek*
But Ed thinks the real killer was another phone.
**28:15** - *Ed Colligan*
The killer blow was Google and Android and their ability to not have to make money off of it, other than search.
**28:24** - *Saron Yitbarek*
Google basically gave Android away for free. It was a problem for Microsoft's Windows phone and for the Palm pre/Web OS combo.
**28:34** - *Ed Colligan*
And we did not have that business model, and it just hugely undermined us and, and there was really no way to recover from that.
**28:48** - *Saron Yitbarek*
After creating a whole new tech category with the PalmPilot, dominating mobile software with Palm OS, building the first smartphone, the Treo, reinventing mobile OS with Web OS, after all those innovation and iterations, Palm was sold to HP in 2010 and then later to LG. In 2012, HP released open Web OS built on top of a Linux kernel.
**29:18** - *Saron Yitbarek*
Once it was open source Web OS became the underlying OS for tons of other smart devices, TVs, watches, and the Internet of Things. And that old debate over fusing hardware and software, well, I'll let Donna Dubinsky settle things.
**29:36** - *Donna Dubinsky*
They're virtually indistinguishable from each other. You can't have great hardware and terrible software and you can't have great software and terrible hardware. The question is almost nonsensical. They have to be together. You know, you carry these things on you all the time. It's a highly integrated device. People don't even know where the hardware ends and the software begins and that's as it should be.
**29:58** - *Saron Yitbarek*
In Jeff Hawkins’ case the hardware and the software began with that small block of wood tucked away in his shirt pocket. That simple block of the right shape and size has launched a fleet of millions, perhaps billions, of smartphones 25 years later.
**30:21** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Go to our website for some amazing bonus material we dug up on Palm and Web OS. [Redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes). And hey, while you're there, sign up for our newsletter. I'm Saron Yitbarek. Until next time. Keep on coding.
### Further reading
[ Palm: The Rise and Fall of a Legend](https://www.technobuffalo.com/palm-the-rise-and-fall-of-a-legend) by Chris Dunphy
[ The Zen of Palm (PDF)](https://designingmlearning.com/resources/ZenOfPalm.pdf) by PalmSource
[ The Whole World in Her Handheld](https://www.alumni.hbs.edu/stories/Pages/story-bulletin.aspx?num=4381) with Donna Dubinsky
[ Palm’s progress: The rise, fall—and rebirth—of a legendary brand](https://www.fastcompany.com/90246716/palms-progress-the-rise-fall-and-rebirth-of-a-legendary-brand) by Harry McCracken
### Bonus episode
The PalmOS was a big part of the PalmPilot’s success. Hear Neil Rhodes tell what it was like to develop for one of the few publicly available software developer’s kits. |
13,510 | Subtitld: 一个跨平台的开源字幕编辑器 | https://itsfoss.com/subtitld/ | 2021-06-22T14:58:33 | [
"字幕"
] | https://linux.cn/article-13510-1.html | 
字幕可以使观看视频的体验更加完美。你不需要一定理解视频的语言,字幕可以帮助你用你喜欢的文字来弄清楚正在发生什么。
你在流媒体平台上找到的大部分内容都有字幕,你可能需要为一些你在本地收藏的视频添加字幕。
虽然你可以通过简单地下载 SRT 文件并使用视频播放器加载它来做到这一点,但你如何编辑它,删除它,或转录一个视频?Subtitld 是一个开源的字幕编辑器,它可以帮助你。
### Subtitld: 创建、删除、切分和转录字幕
Subtitld 是一个自由开源的项目,可以让你充分利用你的字幕。

如果你没有字幕,就创建一个,如果你需要编辑它,就用这个吧。有了这个开源工具,你会有许多选项来处理字幕。
换句话说,它是字幕编辑器之一,也是一个成熟的字幕编辑器(就我所遇到的而言)。
在你决定试用它之前,让我强调一些关键功能。
### Subtitld 的功能

它提供了大量的功能,虽然不是每个人都需要所有的功能,但如果你是一个经常需要创建、编辑和处理字幕的人,它应该会很方便。
下面是它的功能列表:
* 创建字幕
* 编辑字幕
* 使用时间轴移动字幕,手动同步
* 放大/缩小功能,帮助处理拥挤的时间线
* 支持保存为 SRT 文件格式
* 支持各种其他格式的导入和导出(SSA、TTML、SBV、DFXP、VTT、XML、SCC 和 SAMI)
* 易于调整字幕大小或从时间轴上调整字幕的持续时间
* 与其他字幕合并,或从项目中切分字幕
* 能够启用网格,按帧、场景或秒进行可视化
* 在编辑器中回放以检查字幕情况
* 在时间轴上捕捉字幕以避免重叠
* 在字幕中添加/删除
* 启用安全边界,以确保字幕不会看起来不妥当
* 调整播放速度
* 键盘快捷键
* 自动转录
* 输出加入了字幕的视频
* 无限次撤消
除了这些功能外,音频波形的视觉提示也有一定的帮助。

总的来说,如果你是一个转录视频的人,想一次性地编辑视频,你可以用它做很多事情,也可以专业地使用它。
### 在 Linux 中安装 Subtitld
虽然它也适用于 Windows,但你可以在 Linux 上使用 [snap 包](https://snapcraft.io/subtitld) 轻松地安装它。你不会找到二进制包或 Flatpak,但你应该能够在任何 Linux 发行版上 [使用 snap](https://itsfoss.com/use-snap-packages-ubuntu-16-04/) 安装它。
* [Subtitld](https://subtitld.jonata.org)
如果你想深入探索,你可以在 [GitLab](https://gitlab.com/jonata/subtitld) 上找到源代码。
### 总结
它有视频同步或添加字幕的精细设置,我只是测试了一些导入、导出、添加或删除字幕的基本功能。
自动转录功能仍处于测试阶段(截至发布时),但用户界面可以再做一些改进。例如,当我把鼠标悬停在编辑器内的按钮上时,它没有告诉我它是做什么的。
总的来说,它是一个在 Linux 上的有用工具。你对它有什么看法?请不要犹豫,在下面的评论中让我知道你的想法。
---
via: <https://itsfoss.com/subtitld/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Subtitles make the experience of watching a video seamless. You do not need to necessarily understand the language of the video, the subtitle helps you figure out what’s happening with a text version of the audio in your preferred language.
You get subtitles for most of the content in streaming platforms you might have to add subtitles for some videos that you have in your local collection.
While you can do that by simply downloading SRT files and loading it up using the video player, how do you edit it, remove it, or transcribe a video? Subtitld is an open-source subtitle editor that comes to the rescue.
## Subtitld: Create, Remove, Slice, and Transcribe Subtitles
Subtitld is a free and open-source project that lets you make the most out of your subtitles.
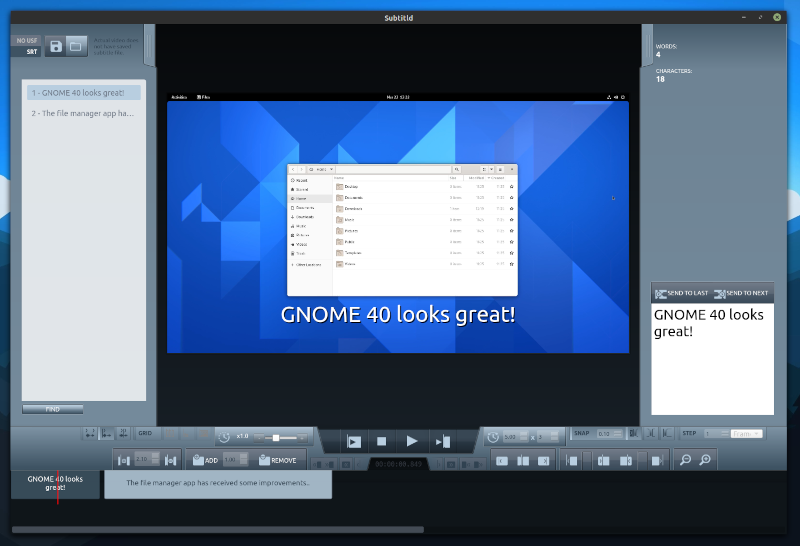
If you do not have a subtitle, create one, if you need to edit it, go ahead. With this open-source tool, you get many options to work with the subtitles.
In other words, it is a full-fledged subtitle editor and one of its kind (as far as I’ve come across).
Let me highlight some key features before you decide to try it.
## Features of Subtitld
It offers a great deal of functions, while not everyone needs all of them, but if you are someone who regularly creates, edits, and works with subtitles, it should come in pretty handy.
Here’s a list of them:
- Create subtitles
- Edit subtitles
- Move subtitles using a timeline to sync manually
- Zoom in/out function to help with a crowded timeline
- Supports saving to SRT file format
- Supports various other formats to import and export (SSA, TTML, SBV, DFXP, VTT, XML, SCC and SAMI)
- Easy to resize or adjust the duration of a subtitle from the timeline
- Merge with other subtitles or just slice a subtitle in a project
- Ability to enable grids to visualize by frames, scenes, or seconds
- Playback in the editor to check how the subtitles work
- Snap the subtitles in the timeline to avoid overlapping
- Add/remove among the subtitles
- Enable safety margins to ensure that the subtitles do not look improper
- Adjust the playback speed
- Keyboard shortcuts available
- Auto-transcribe
- Export videos with subtitles burned in
- Unlimited undo
In addition to these features, the visual clues for the audio waveform also help in a way.
Overall, you can do many things and use it professionally as well, if you are someone who transcribes videos and want to edit the video in one go.
**Recommended Read:**
## Installing Subtitld in Linux
While it is also available for Windows, you can easily install it on Linux using the [snap package](https://snapcraft.io/subtitld). You will not find any binary packages or Flatpak available, but you should be able to install it on any Linux distribution [using snap on Linux](https://itsfoss.com/use-snap-packages-ubuntu-16-04/).
You can find the source code on [GitLab](https://gitlab.com/jonata/subtitld) if you want to explore.
## Closing Thoughts
With fine-grained settings available to sync or add subtitles for a video, I just tested a few basic functions to import, export, add or remove subtitles.
The auto-transcribe feature is still something in beta (as of publishing this), but the user interface could use some improvements. For instance, when I hover over the buttons inside the editor, it does not tell me what it does.
Overall, it is a useful tool to have available on Linux. What do you think about it? Please don’t hesitate to let me know your thoughts in the comments down below. |
13,512 | 自由/开源软件如何保护在线隐私 | https://news.itsfoss.com/save-privacy-with-foss/ | 2021-06-23T15:40:00 | [
"自由软件",
"隐私"
] | https://linux.cn/article-13512-1.html | 
*多年来,我一直使用科技巨头提供的服务。大部分都是免费的,但是是以牺牲我的隐私为代价的。但那些日子已经过去了,现在我浏览、聊天、工作,没有任何人能跟踪、变现和审查我的数据。多亏了自由/开源软件。*
### 我开始担心大型科技公司了

我一直觉得机器应该按照我的意愿行事,而不是反过来。这就是为什么谷歌的 Android 操作系统在 2008 年首次上市时就立刻吸引了我。在当时,谷歌的开源方式确实令人耳目一新。我花了几个小时定制了我的 HTC Hero 手机。我对它是不是比我朋友的 iPhone 或塞班设备更丑并不在意。我的新玩意具有无限的通用性。
一跃十年,谷歌已经成为了科技巨头,使 iOS 相形见绌并且淘汰了塞班操作系统。如今,这个公司占据了 90% 以上的搜索流量,并主导着浏览器市场。这种惊人的增长是有代价的,谷歌删除了“不作恶”条款就说明了这一点。这家搜索巨头目前正陷入官司之中,比如关于 [数据收集和追踪不当行为](https://www.gizmodo.com.au/2021/05/google-location-services-lawsuit) 的案件。研究人员还在谷歌的联系人追踪应用程序中发现了 [隐私缺陷](https://blog.appcensus.io/2021/04/27/why-google-should-stop-logging-contact-tracing-data)。更重要的是,这家科技巨头宣布了一个颇具争议的 [可以追踪用户浏览行为](https://news.itsfoss.com/google-floc) 的新算法,从而更好地提供广告服务。
现在,我不想把责任推给谷歌。亚马逊刚刚建立了美国历史上最大的民用 [监控网络](https://www.theguardian.com/commentisfree/2021/may/18/amazon-ring-largest-civilian-surveillance-network-us) 。它让警方可以在未经许可的情况下使用数百万个家庭监控摄像头。于此同时,欧洲对亚马逊遵守 [隐私规定](https://edps.europa.eu/press-publications/press-news/press-releases/2021/edps-opens-two-investigations-following-schrems_en) 的情况进行了调查。微软也是如此。它也为顺带着促进 [工作场所监控](https://www.theguardian.com/technology/2020/dec/02/microsoft-apologises-productivity-score-critics-derided-workplace-surveillance) 功能而道歉。
有人可能认为,人们至少可以指望苹果来保护他们的隐私。这家科技巨头最近让他们选择知道应用程序是否会追踪他们的行为。事实证明,[只有 5%](https://www.flurry.com/blog/ios-14-5-opt-in-rate-att-restricted-app-tracking-transparency-worldwide-us-daily-latest-update) 的美国用户选择接受这种新的应用追踪透明度。与此同时,该公司从谷歌这样的数据经纪商的业务中获得了 [巨大的利益](https://www.nytimes.com/2020/10/25/technology/apple-google-search-antitrust.html)。更别提《堡垒之夜》开发商 Epic Games 和苹果之间的 [反垄断审判](https://www.nytimes.com/2021/05/25/business/dealbook/apple-epic-case.html) ,后者声称要保护其应用商店的隐私。当然,还有 Facebook。该公司的隐私不当行为在参议院就 [剑桥分析公司](https://en.wikipedia.org/wiki/Cambridge_Analytica) 丑闻举行的听证会上达到了高潮,失去了用户仅存的信任。
尽管如此 —— 或者因为 —— 这些有问题的做法,这些公司的总价值在 2021 年 3 月超过了 [7.5 万亿美元](https://en.wikipedia.org/wiki/List_of_public_corporations_by_market_capitalization#2021)。“科技巨头”们现在超过了德国和英国国内生产总值的总和!
### 为什么隐私很重要

我们都在使用大科技公司的服务。我们是 <ruby> <a href="https://en.wikipedia.org/wiki/Surveillance_capitalism"> 监控资本主义 </a> <rt> Surveillance Capitalism </rt></ruby> 的一部分,这是哈佛大学教授 Shoshana Zuboff 创造的一个术语,在 Cory Doctorow 的 [新书](https://www.goodreads.com/book/show/55134785-how-to-destroy-surveillance-capitalism)《监控资本主义》里也讨论了它。这是一个以技术垄断为中心的经济体系,通过收集个人数据来获取利润最大化。这一制度威胁到民主的核心,因为它导致了大规模监视,扰乱了选举程序,推动了思想的一致性和审查制度。
监视资本主义的基础是对我们生活的侵犯,令人深感不安。我们往往忘记隐私是一项基本权利。它被<ruby> 联合国人权理事会 <rt> UN Human Rights Council </rt></ruby>、《<ruby> 公民权利与政治权利国际公约 <rt> International Covenant on Civil and Political Rights </rt></ruby>》和一些条约所规定。我认为我们都能体会到:在我们的生活中有很多方面我们想要保持隐私,即使没有错误的行为。无论是为了自由地表达自己,探索自己的个性,而不被他人评判。还是为了保护我们不受监视、审查和操纵。这就是窗帘被发明的原因。还有银行保密、律师-客户特权,通信保密,投票保密,告解室保密或医疗保密。
解决网络隐私问题是一个广泛问题,它需要对我们的法律体系和社会习俗的全面改变。对技术垄断的监管是这个十年的主要挑战之一。最近科技巨头和政府之间的对峙就说明了这一点:[澳大利亚 vs. Facebook](https://www.bbc.com/news/world-australia-56163550)、 [中国 vs. 腾讯](https://www.nytimes.com/2021/06/02/technology/china-tencent-monopoly.html)、 [印度 vs. WhatsApp](https://www.theguardian.com/world/2021/may/26/whatsapp-sues-indian-government-over-mass-surveillance-internet-laws)、 [欧盟 vs. Facebook](https://nypost.com/2021/05/26/eu-reportedly-set-to-open-formal-antitrust-probe-into-facebook) 或者是 [美国 vs. 科技巨头](https://www.nytimes.com/interactive/2020/10/06/technology/house-antitrust-report-big-tech.html)。多年来,数字权利组织和软件基金会一直在倡导更好的隐私法律、用户权利和创新自由,如:<ruby> 电子前沿基金会 <rt> Electronic Frontier Foundation </rt></ruby>、<ruby> 自由软件基金会 <rt> Free Software Foundation </rt></ruby>、<ruby> 新闻自由基金会 <rt> Freedom of the Press Foundation </rt></ruby>、<ruby> 隐私国际 <rt> Privacy International </rt></ruby>、<ruby> 开放权利组织 <rt> Open Rights Group </rt></ruby>或<ruby> 欧洲数字权利 <rt> European Digital Rights </rt></ruby>。
### 这和自由/开源软件有什么关系?

自 1983 年成立以来,<ruby> <a href="https://itsfoss.com/what-is-foss"> 自由软件运动 </a> <rt> Free Software movement </rt></ruby> 已经成为一个相当多样化的社区。自由和开源软件通常被称为 FOSS、FLOSS、Libre Software 或 Free Software。 它包括一系列许可证,授权给用户 [使用、学习、分享并提高](https://fsfe.org/freesoftware/freesoftware.en.html) 这个软件的权力。以及 [维修](https://framatube.org/videos/watch/99069c5c-5a00-489e-97cb-fd5cc76de77c) 的权利。 <ruby> 自由软件 <rt> Free Software </rt></ruby>的“<ruby> 自由 <rt> Free </rt></ruby>”是指 “[言论自由](https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech)”的“自由”,有时也指 “免费啤酒”的“免费”。因此,自由/开源软件(FOSS)不仅仅是技术。它是关于社会、政治和经济解放的。
几年前,一场隐私争议震动了自由软件社区。Ubuntu 12.10(各种不同的 GHU/Linux 风格之一)开始在人们的电脑上建立互联网连接进行本地搜索。它为亚马逊提供广告服务,并与 Facebook 或 Twitter 共享私人数据。遭到了 [剧烈反弹](https://itsfoss.com/canonical-targets-website-crictical-ubuntu-privacy)。几年后, Canonical(Ubuntu 背后的公司)最终取消了在线搜索和亚马逊 Web 应用。最近 [Audacity 闹剧](https://github.com/audacity/audacity/pull/835) 是自由/开源软件如何保护隐私的另一个例子。新的项目管理层决定将谷歌的 Analytics 和 Yandex 添加到音频软件中,但由于公众的强烈抗议,最终放弃了这一计划。
尽管自由软件有很多优点,但它也不能免于批评。一种说法是自由/开源软件项目经常被放弃。然而最近在 [实证软件工程和测量会议](https://arxiv.org/abs/1906.08058) 上提出的一项研究表明,情况并非如此:在 1932 个流行的开源项目中,有 7%(128 个项目)在被忽视后由新的开发人员接管,使烂尾率降低到不到 10%(187 个项目)。
另一个常见的批评是自由/开源软件通过公布代码暴露了潜在的安全漏洞。另一方面,将源代码保密 [不一定会提高安全性](https://www.schneier.com/crypto-gram/archives/2002/0515.html#1)。认为封闭源代码要比自由/开源软件安全得多的观点,却忽略了一个事实,即专有堆栈越来越多地构建在 [开放源代码之上](https://www.bcg.com/publications/2021/open-source-software-strategy-benefits)。自由软件也倾向于去中心化,这有助于增强抵御监视、单点故障或大规模数据泄露。所以可以肯定的是,自由/开源软件并不能避免安全漏洞。但专有的解决方案也是如此,正如来自 Facebook、Linkedin 和 Clubhouse 的最新 [10 亿人的数据泄露](https://www.politico.eu/article/how-to-leak-data-and-get-away-with-it) 或者对 SolarWind 和 Colonial 管道公司的大规模 [安全攻击](https://theconversation.com/the-colonial-pipeline-ransomware-attack-and-the-solarwinds-hack-were-all-but-inevitable-why-national-cyber-defense-is-a-wicked-problem-160661) 所说明的那样。
总之,自由软件在促进网上隐私方面发挥了重要作用。近四十年来,自由/开源软件一直鼓励开发人员审计代码、修复问题并确保幕后没有任何可疑的事情发生。
### 使用自由/开源软件实现在线隐私的七个步骤

在等待更好的隐私法律出台的同时,还有很多事情可以让你的设备更隐私。以下是用尊重隐私、自由/开源软件取代大型科技公司的七个步骤。 根据你的 [威胁模型](https://www.eff.org/files/2015/11/24/3mod_threat-modeling-ssd_9-3-15.pdf),你可能想首先考虑步骤 1 到步骤 4,因为它们已经提供了一个合理的隐私水平。如果你有一些技术技能,想要更进一步,看看步骤 5 到步骤 7。
1. **[参与到隐私保护中来](https://www.gofoss.today/nothing-to-hide)**。关于在线隐私、数据利用、过滤泡沫、监控和审查,还有很多值得我们讨论和学习的地方。参与进来,传播信息。
2. **[选择一个安全和隐私的浏览器](https://www.gofoss.today/intro-browse-freely)**。切换到 Firefox。阻止追踪器、cookie 和广告。使用尊重隐私的搜索引擎。可能要用 Tor 或 VPN 加密你的通信。
3. **[保持交流的私密性](https://www.gofoss.today/intro-speak-freely)**。使用端到端加密保护你的电子邮件、消息和电话。抛弃传统的社交媒体,探索 fediversity ,这是一个由各种在线服务组成的联合家庭。
4. **[保护你的数据](https://www.gofoss.today/intro-store-safely)**。使用长且独特的密码。为你的每个账户和设备选择一个不同的密码。将它们安全地保存在加密的密码管理器中。考虑使用双因素身份验证。创建一个常规备份例程。并对敏感数据进行加密。
5. **[解绑你的电脑](https://www.gofoss.today/intro-free-your-computer)**。切换到 GNU/Linux ,并首选自由和开源的应用程序。根据你的需要,选择一个对初学者友好的发行版,如 Linux Mint 或 Ubuntu;对于更有经验的用户,选择 Debian、Manjaro、openSUSE、Fedora 或 Gentoo Linux。对于隐私爱好者,可以看看 Qubes OS、Whonix 或 Tails。
6. **[解绑你的手机](https://www.gofoss.today/intro-free-your-phone)**。切换到一个定制的移动操作系统,如 LineageOS、CalyxOS、GrapheneOS 或 /e/。首选社区维护的应用商店提供的自由及开源应用。
7. **[解绑你的云](https://www.gofoss.today/intro-free-your-cloud)**。选择尊重隐私的云服务商。或设置你自己的安全服务器和自托管服务,例如云存储、图库、任务和联系人管理,或媒体流。
### 结束

面对在线隐私没有一键式解决方案。用自由及开源软件取代大型科技公司是一个过程。有些改动很简单,比如安装 Firefox 或 Signal。其他方法需要更多的时间和技能。但它们绝对值得。你并不孤单,你可以依靠一个很棒的社区的支持。所以,请允许我引用《华盛顿邮报》在线专栏的 [Geoffrey A. Fowler](https://www.washingtonpost.com/technology/2019/12/31/how-we-survive-surveillance-apocalypse) 的话作为总结: “*隐私没有消亡,但你必须足够愤怒才能要求它*”。
---
### 关于作者

*Georg Jerska 是一个对保护公民隐私特别感兴趣的开源爱好者。他和他的小团队运营着 [GoFOSS](https://gofoss.today/),这是一个关于如何用尊重隐私的自由和开源软件取代大型科技公司的全面指南。*
*[开源](https://undraw.co/license) 插图 [Katerina Limpitsouni](https://undraw.co)。*
*所表达的观点只是作者的观点,并不一定反应我们的官方政策或立场。*
---
via: <https://news.itsfoss.com/save-privacy-with-foss/>
作者:[Team It's FOSS](https://news.itsfoss.com/author/team/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zz-air](https://github.com/zz-air) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

*I have used services from tech giants for years. Most were free of charge, at the expense of my privacy. But those days are over. Now I browse, chat and work without anyone tracking, monetizing or censoring my data. Thanks to free (libre) and open source software.*
## I start to worry about Big Tech

I’ve always felt machines should be doing what I want them to do, not the other way round. That’s why Google’s Android operating system immediately appealed to me when it first hit the market in 2008. At the time, Google’s open-source approach was genuinely refreshing. I spent hours customizing my HTC Hero phone. Little did I care that it was uglier than my friends’ iPhones or Symbian devices. My new gadget was infinitely more versatile.
Fast forward a decade. Google has become a tech giant, dwarfed iOS and killed Symbian OS. Today, the company captures over 90% of search traffic and dominates the browser market. This stellar growth came at a cost, as illustrated by the removal of Google’s “don’t be evil” clause. The search giant is entangled in court cases, such as the one over [data collection and tracking malpractices](https://www.gizmodo.com.au/2021/05/google-location-services-lawsuit?ref=news.itsfoss.com). Researchers also found [privacy flaws](https://blog.appcensus.io/2021/04/27/why-google-should-stop-logging-contact-tracing-data?ref=news.itsfoss.com) in Google’s contact tracing app. To top it off, the tech giant announced a controversial new algorithm that [tracks browsing behaviour](https://news.itsfoss.com/google-floc) to better serve ads.
Now, I don’t want to pass the buck to Google. Amazon just created the largest civilian [surveillance network](https://www.theguardian.com/commentisfree/2021/may/18/amazon-ring-largest-civilian-surveillance-network-us?ref=news.itsfoss.com) in US history. It provides the police with unwarranted access to millions of home security cameras. Meanwhile, Europe probes into Amazon’s compliance with [privacy rules](https://edps.europa.eu/press-publications/press-news/press-releases/2021/edps-opens-two-investigations-following-schrems_en?ref=news.itsfoss.com). Same goes for Microsoft, which incidentally also apologized for having facilitated [workplace surveillance](https://www.theguardian.com/technology/2020/dec/02/microsoft-apologises-productivity-score-critics-derided-workplace-surveillance?ref=news.itsfoss.com) feature.
One might think that users can at least count on Apple to protect their privacy. The tech giant recently gave them the choice to know whether apps track their behavior. As it turns out that [only 5%](https://www.flurry.com/blog/ios-14-5-opt-in-rate-att-restricted-app-tracking-transparency-worldwide-us-daily-latest-update?ref=news.itsfoss.com) of US users opt into this new app-tracking transparency. Meanwhile, the company [hugely benefits](https://www.nytimes.com/2020/10/25/technology/apple-google-search-antitrust.html?ref=news.itsfoss.com) from doing business with data brokers like Google. Not to mention the [antitrust trial](https://www.nytimes.com/2021/05/25/business/dealbook/apple-epic-case.html?ref=news.itsfoss.com) raging between Fortnite developer Epic Games and Apple, which claims to protect the privacy of its App Store. And of course, there’s Facebook. The company’s privacy misconducts culminated in a Senate hearing over the [Cambridge Analytica](https://en.wikipedia.org/wiki/Cambridge_Analytica?ref=news.itsfoss.com) scandal, wiping out what was left of user trust.
Yet in spite – or because – of these questionable practices, the total value of these companies reached over [7.5 trillion dollars](https://en.wikipedia.org/wiki/List_of_public_corporations_by_market_capitalization?ref=news.itsfoss.com#2021) in March 2021. “Big Tech” is now worth more than Germany’s and the UK gross domestic product – combined!
## Why privacy matters

We all use Big Tech’s services. We are part of [Surveillance Capitalism](https://en.wikipedia.org/wiki/Surveillance_capitalism?ref=news.itsfoss.com), a term coined by Harvard professor Shoshana Zuboff and discussed in Cory Doctorow’s [latest book](https://www.goodreads.com/book/show/55134785-how-to-destroy-surveillance-capitalism?ref=news.itsfoss.com), Surveillance Capitalism. It’s an economic system centered around tech monopolies which harvest personal data to maximize profit. This system threatens the very core of democracy, as it gives rise to mass surveillance, polarizes the political debate, interferes with the electoral process and drives uniformity of thought as well as censorship.
Surveillance Capitalism is based on a deeply troubling invasion of our lives. We tend to forget that privacy is a fundamental right. It’s enshrined by the UN Human Rights Council, the International Covenant on Civil and Political Rights and a number of treaties. I think we can all relate: there are more than a few aspects in our lives we’d like to keep private, even without wrongdoing. Whether it is to freely express ourselves and explore our personality without being judged by others. Or to shield us from surveillance, censorship and manipulation. That’s why curtains were invented. And things like banking secrecy, attorney-client privilege, secrecy of correspondence, secrecy of the ballot, confessional secret or medical confidentiality.
Tackling online privacy is a broad issue. It requires comprehensive changes to our legal systems and social conventions. Regulation of tech monopolies is one of the main challenges of this decade. As illustrated by the recent standoffs between tech giants and governments: [Australia vs. Facebook](https://www.bbc.com/news/world-australia-56163550?ref=news.itsfoss.com), [China vs. Tencent](https://www.nytimes.com/2021/06/02/technology/china-tencent-monopoly.html?ref=news.itsfoss.com), [India vs. WhatsApp](https://www.theguardian.com/world/2021/may/26/whatsapp-sues-indian-government-over-mass-surveillance-internet-laws?ref=news.itsfoss.com), the [EU vs. Facebook](https://nypost.com/2021/05/26/eu-reportedly-set-to-open-formal-antitrust-probe-into-facebook?ref=news.itsfoss.com) or the [US vs. Big Tech](https://www.nytimes.com/interactive/2020/10/06/technology/house-antitrust-report-big-tech.html?ref=news.itsfoss.com). For years, digital rights groups and software foundations have been advocating for better privacy laws, user rights and the freedom to innovate. Let’s only name a few: the Electronic Frontier Foundation, the Free Software Foundation, the Freedom of the Press Foundation, Privacy International, the Open Rights Group or the European Digital Rights.
## What’s this got to do with FOSS?

Since its inception in 1983, the [Free Software movement](https://itsfoss.com/what-is-foss?ref=news.itsfoss.com) has become quite a diverse community. Free and open source software is often referred to as FOSS, FLOSS, Libre Software or Free Software. It includes a whole range of licenses that give users the right to [use, study, share and improve](https://fsfe.org/freesoftware/freesoftware.en.html?ref=news.itsfoss.com) the software. As well as the [right to repair](https://framatube.org/videos/watch/99069c5c-5a00-489e-97cb-fd5cc76de77c?ref=news.itsfoss.com). Free Software is “free” as in “[free speech](https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech?ref=news.itsfoss.com)” — and sometimes as in “free beer”. As such, FOSS is not only about technology. It’s about social, political and economic emancipation.
A few years back, a privacy controversy shook up the Free Software community. Ubuntu 12.10 – one of the various GNU/Linux flavours – started establishing Internet connections for local searches on people’s computers. It served Amazon ads and shared private data with Facebook or Twitter. The [backlash was massive](https://itsfoss.com/canonical-targets-website-crictical-ubuntu-privacy?ref=news.itsfoss.com). A few years later, Canonical – the firm behind Ubuntu – ended up removing online searches and the Amazon web app. The more recent [Audacity drama](https://github.com/audacity/audacity/pull/835?ref=news.itsfoss.com) is another example of how FOSS protects privacy. The new project management decided to add Google Analytics and Yandex to the audio software, but ended up renouncing to its plans after public outcry.
For all its merits, Free Software is not free from criticism. One claim is that FOSS projects often get abandoned. A [study recently presented at the Empirical Software Engineering and Measurement conference](https://arxiv.org/abs/1906.08058?ref=news.itsfoss.com) suggests otherwise: out of 1.932 popular open source projects, 7% (128 projects) were taken over by new developers after being neglected, reducing the dropout rate to less than 10% (187 projects).
Another common criticism is that FOSS exposes potential security vulnerabilities by publishing the code. On the flip side, keeping the source code a secret [doesn’t necessarily increase security](https://www.schneier.com/crypto-gram/archives/2002/0515.html?ref=news.itsfoss.com#1). Arguing that closed source code is vastly more secure than FOSS conveniently omits the fact that proprietary stacks are increasingly built [on top of open source code](https://www.bcg.com/publications/2021/open-source-software-strategy-benefits?ref=news.itsfoss.com). Free Software also tends to be decentralized, which helps with resilience against surveillance, single points of failure or massive data leaks. So sure, FOSS is not immune to security breaches. But neither are proprietary solutions, as illustrated by the latest [leaks of a billion people’s data](https://www.politico.eu/article/how-to-leak-data-and-get-away-with-it?ref=news.itsfoss.com) from Facebook, LinkedIn and Clubhouse. Or the spectacular [security attacks](https://theconversation.com/the-colonial-pipeline-ransomware-attack-and-the-solarwinds-hack-were-all-but-inevitable-why-national-cyber-defense-is-a-wicked-problem-160661?ref=news.itsfoss.com) against SolarWind and Colonial Pipeline.
All in all, Free Software is instrumental in promoting online privacy. For nearly forty years, FOSS has been encouraging developers to audit the code, fix issues and ensure nothing shady goes on in the background.
## Seven steps to online privacy with FOSS
While waiting for better privacy laws, there’s a lot you can do to make your devices more private. Here are seven steps to replace Big Tech with privacy-respecting, free and open source software. Depending on your [threat model](https://www.eff.org/files/2015/11/24/3mod_threat-modeling-ssd_9-3-15.pdf?ref=news.itsfoss.com), you’ll likely want to consider steps 1 through 4 first, as they already provide a reasonable level of privacy. If you have some tech skills and want to go further, take a look at steps 5 to 7.
. There is much to be said and learned about online privacy, data exploitation, filter bubbles, surveillance and censorship. Get involved and spread the word.[Get involved in privacy](https://www.gofoss.today/nothing-to-hide?ref=news.itsfoss.com). Switch to Firefox. Block trackers, cookies and ads. Use privacy-respecting search engines. Possibly encrypt your traffic with Tor or VPN.[Choose a safe and private browser](https://www.gofoss.today/intro-browse-freely?ref=news.itsfoss.com). Use end-to-end encryption to secure your emails, messages and calls. Ditch classic social media and discover the Fediverse, a federated family of various online services.[Keep your conversations private](https://www.gofoss.today/intro-speak-freely?ref=news.itsfoss.com). Use long and unique passphrases. Choose a different one for each of your accounts and devices. Keep them safe in an encrypted password manager. Consider using two-factor authentication. Create a regular backup routine. And encrypt sensitive data.[Protect your data](https://www.gofoss.today/intro-store-safely?ref=news.itsfoss.com). Switch to GNU/Linux and favor free and open source apps. Depending on your needs, choose a beginner friendly distribution like Linux Mint or Ubuntu. For more experienced users, pick Debian, Manjaro, openSUSE, Fedora or Gentoo Linux. And for privacy buffs, have a look at Qubes OS, Whonix or Tails.[Free your computer](https://www.gofoss.today/intro-free-your-computer?ref=news.itsfoss.com). Switch to a custom mobile operating system like LineageOS, CalyxOS, GrapheneOS or /e/. Favor tracker-free open source apps from community maintained app stores.[Free your phone](https://www.gofoss.today/intro-free-your-phone?ref=news.itsfoss.com). Choose privacy-respecting cloud providers. Or set up your own secure server and self host services such as cloud storage, photo galleries, task and contact management, or media streaming.[Free your cloud](https://www.gofoss.today/intro-free-your-cloud?ref=news.itsfoss.com)
## Wrapping Up

There is no one-click solution for online privacy. Replacing Big Tech with free and open source software is a process. Some changes are simple – like installing Firefox or Signal. Other methods require more time and skills. But they are definitely worth it. And you’re not alone, you can count on the support of a wonderful community. So allow me to conclude by quoting [Geoffrey A. Fowler](https://www.washingtonpost.com/technology/2019/12/31/how-we-survive-surveillance-apocalypse?ref=news.itsfoss.com) from the Washington Post: “*Online privacy is not dead, but you have to be angry enough to demand it*“.
## About the author

*Georg Jerska is an open source enthusiast with a special interest in protecting the privacy of citizens. With his small team he runs GoFOSS, a comprehensive guide on how to replace Big Tech with privacy-respecting, free and open source software.*
[Open source](https://undraw.co/license?ref=news.itsfoss.com) illustrations by [Katerina Limpitsouni](https://undraw.co/?ref=news.itsfoss.com).
*The views and opinions expressed are those of the authors and do not necessarily reflect the official policy or position of It’s FOSS.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,513 | 用 Eleventy 建立一个静态网站 | https://opensource.com/article/21/6/static-site-builder | 2021-06-23T16:00:08 | [
"静态网站"
] | /article-13513-1.html |
>
> Eleventy 是一个基于 JavaScript 的 Jekyll 和 Hugo 的替代品,用于构建静态网站。
>
>
>

静态网站生成器是一种基于原始数据和一组模板生成完整的静态 HTML 网站的工具。它可以自动完成单个 HTML 页面的编码任务,并让这些页面准备好为用户服务。由于 HTML 页面是预先建立的,它们在用户的浏览器中加载得非常快。
静态网站对文档也很友好,因为静态网站很容易扩展,而且它们是生成、维护和部署项目文档的一种简单方法。由于这些原因,企业经常使用它们来记录应用编程接口 (API)、数据库模式和其他信息。文档是软件开发、设计和其他方面技术的一个重要组成部分。所有的代码库都需要某种形式的文档,选择范围从简单的 README 到完整的文档。
### Eleventy: 一个静态网站生成器
[Eleventy](https://www.11ty.dev/)(11ty)是一个简单的静态网站生成器,是 [Jekyll](https://opensource.com/article/17/4/getting-started-jekyll) 和 [Hugo](https://opensource.com/article/18/3/start-blog-30-minutes-hugo) 的替代品。它是用 JavaScript 编写的,它将一个(不同类型的)模板目录转化为 HTML。它也是开源的,在 MIT 许可下发布。
Eleventy 可以与 HTML、Markdown、Liquid、Nunjucks、Handlebars、Mustache、EJS、Haml、Pug 和 JavaScript Template Literals 协同工作。
它的特点包括:
* 易于设置
* 支持多种模板语言(如 Nunjucks、HTML、JavaScript、Markdown、Liquid)
* 可定制
* 基于 JavaScript,这是许多网络开发者所熟悉的,新用户也容易学习
### 安装 Eleventy
Eleventy 需要 Node.js。在 Linux 上,你可以使用你的包管理器安装 Node.js:
```
$ sudo dnf install nodejs
```
如果你的包管理器没有 Node.js,或者你不在 Linux 上,你可以从 Node.js 网站[安装它](https://nodejs.org/en/)。
Node.js 安装完毕后,就用它来安装 Eleventy:
```
$ npm install -g @11ty/eleventy
```
这就完成了!
### 为你的文档建立一个静态网站
现在你可以开始使用 Eleventy 来建立你的静态文档网站。以下是需要遵循的步骤。
#### 1、创建一个 package.json 文件
要将 Eleventy 安装到你的项目中,你需要一个 `package.json` 文件:
```
$ npm init -y
```
#### 2、将 Eleventy 安装到 package.json 中
安装 Eleventy 并保存到你的项目的 `package.json` 中。运行:
```
$ npm install-save-dev @11ty/eleventy
```
#### 3、运行 Eleventy
使用 `npx` 命令来运行你本地项目的 Eleventy 版本。在你确认安装完成后,尝试运行 Eleventy:
```
$ npx @11ty/eleventy
```
#### 4、创建一些模板
现在运行两个命令来创建两个新的模板文件(一个 HTML 和一个 Markdown 文件):
```
$ cat << EOF >> index.html
<!doctype html><html>
<head>
<title>Page title</title>
</head><body>
<p>Hello world</p>
</body></html>
EOF
$ echo '# Page header' > index.md
```
这就把当前目录或子目录中的任何内容模板编译到输出文件夹中(默认为 `_site`)。
运行 `eleventy --serve` 来启动一个开发网络服务器。
```
$ npx @11ty/eleventy-serve
```
在你的网络浏览器中打开 `http://localhost:8080/README/`,看你的 Eleventy 输出。
然后把 `_site` 中的文件上传到你的 Web 服务器,发布你的网站给世界看。
### 尝试 Eleventy
Eleventy 是一个静态网站生成器,它易于使用,有模板和主题。如果你已经在你的开发流程中使用 Node.js,Eleventy 可能比 Jekyll 或 Hugo 更自然。它能快速提供很好的结果,并使你免于复杂的网站设计和维护。要了解更多关于使用 Eleventy 的信息,请仔细阅读它的[文档](https://www.11ty.dev/docs/getting-started/)。
---
*本文基于 [为开源项目建立技术文档静态网站](https://wise4rmgodadmob.medium.com/building-a-technical-documentation-static-site-for-open-source-projects-7af4e73d77f0),首次发布在 Nwokocha Wisdom Maduabuchi 的 Medium 上,经授权转载。*
---
via: <https://opensource.com/article/21/6/static-site-builder>
作者:[Nwokocha Wisdom](https://opensource.com/users/wise4rmgod) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,516 | 在 Linux 上用 fd 代替 find | https://opensource.com/article/21/6/fd-linux | 2021-06-24T11:06:30 | [
"find",
"查找"
] | https://linux.cn/article-13516-1.html |
>
> fd 命令是一个流行的、用户友好的 find 命令的替代品。
>
>
>

许多 Linux 程序员在其工作中每天都在使用 `find` 命令。但是 `find` 给出的文件系统条目是有限的,如果你要进行大量的 `find` 操作,它甚至不是很快速。因此,我更喜欢使用 Rust 编写的 `fd` 命令,因为它提供了合理的默认值,适用于大多数使用情况。
正如它的 [README](https://github.com/sharkdp/fd) 所说,“`fd` 是一个在文件系统中寻找条目的程序。它是一个简单、快速和用户友好的 `find` 的替代品。”它的特点是目录的并行遍历,可以一次搜索多个目录。它支持正则表达式(regex)和基于通配符的模式。
### 安装 fd
在 Linux 上,你可以从你的软件库中安装 `fd`(可用的软件包列表可以在 [Repology 上的 fd 页面](https://repology.org/project/fd-find/versions) 找到)。 例如,在 Fedora 上:
```
$ sudo dnf install fd-find
```
在 macOS 上,可以使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac)。
另外,你也可以使用 Rust 的 Cargo 软件包管理器:
```
$ cargo install fd-find
```
### 使用 fd
要做一个简单的搜索,运行 `fd` 并在后面跟上要搜索的名字,例如:
```
$ fd sh
registry/src/github.com-1ecc6299db9ec823/cc-1.0.67/src/bin/gcc-shim.rs
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/completions/completions.bash
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/completions/completions.fish
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/completions/completions.zsh
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/xtests/run.sh
registry/src/github.com-1ecc6299db9ec823/git2-0.13.18/src/stash.rs
registry/src/github.com-1ecc6299db9ec823/libc-0.2.94/src/unix/solarish
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/cmake/SelectHashes.cmake
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/include/git2/stash.h
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/include/git2/sys/hashsig.h
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/script/backport.sh
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/script/leaks.sh
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/script/valgrind.sh
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/src/config_snapshot.c
[...]
```
如果你想搜索一个特定的目录,可以将目录路径作为 `fd` 的第二个参数,例如:
```
$ fd passwd /etc
/etc/pam.d/passwd
/etc/passwd
/etc/passwd-
/etc/security/opasswd
```
要搜索一个特定的文件扩展名,使用 `-e` 作为选项。例如:
```
$ fd . '/home/ssur/exa' -e md
/home/ssur/exa/README.md
/home/ssur/exa/devtools/README.md
/home/ssur/exa/man/exa.1.md
/home/ssur/exa/man/exa_colors.5.md
/home/ssur/exa/xtests/README.md
$
```
你也可以通过提供 `-x` 或 `-X` 来执行一个命令。
* `-x`/`--exec`:选项为每个搜索结果(并行)运行一个外部命令。
* `-X`/`--exec-batch`:选项将所有搜索结果作为参数启动一次外部命令。
例如,要递归地找到所有的 ZIP 档案并解压:
```
$ fd -e zip -x unzip
```
或者,要列出某个特定目录下在过去 *n* 天内改变的所有文件,使用`--changed-within` 选项:
```
$ fd . '/home/ssur/Work/' --changed-within 10d
/home/ssur/Work/wildfly/connector/src/main/java/org/jboss/as/connector/subsystems/data_sources/JdbcDriverAdd.java
/home/ssur/Work/wildfly/connector/src/main/java/org/jboss/as/connector/subsystems/data_sources/JdbcExample.java
[...]
```
而要搜索所有在特定天数之前被修改的文件,请使用 `--changed-before` *n* 选项:
```
$ fd . '/home/ssur/Work/' --changed-before 365d
```
这里,`.` 作为一个(正则)通配符,指示 `fd` 返回所有文件。
要了解更多关于 `fd` 的功能,请查阅 GitHub 上的 [文档](https://github.com/sharkdp/fd)。
### 总结
我特别喜欢 `fd` 的一点是,搜索模式默认是不区分大小写的,这使得它更容易找到东西,即使你对你要找的东西没有精确的认识。更好的是,如果模式包含一个大写的字符,它就会*自动*切换到大小写敏感。
另一个好处是,它使用颜色编码来突出不同的文件类型。
如果你已经在使用这个神奇的 Rust 工具,请在评论中告诉我们你的想法。
---
via: <https://opensource.com/article/21/6/fd-linux>
作者:[Sudeshna Sur](https://opensource.com/users/sudeshna-sur) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many Linux programmers use the `find`
command every single day of their career. But `find`
gives a limited set of filesystem entries, and if you have to do a large set of `find`
operations, it's not even very fast. So instead, I prefer to use the Rust `fd`
command because it provides sensible defaults that work for most use cases.
As its [README](https://github.com/sharkdp/fd) says, "`fd`
is a program to find entries in your filesystem. It is a simple, fast, and user-friendly alternative to `find`
." It features parallelized directory traversal, so it can search multiple directories at once. It supports regular expressions (regex) and glob-based patterns.
## Install fd
On Linux, you can install `fd`
from your software repository (a list of available packages can be found on the [fd page on Repology](https://repology.org/project/fd-find/versions).) For example, on Fedora:
`$ sudo dnf install fd-find`
On macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac).
Alternately, you can use Rust's Cargo package manager:
`$ cargo install fd-find`
## Use fd
To do a simple search, run `fd`
after any argument, such as:
```
$ fd sh
registry/src/github.com-1ecc6299db9ec823/cc-1.0.67/src/bin/gcc-shim.rs
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/completions/completions.bash
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/completions/completions.fish
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/completions/completions.zsh
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/xtests/run.sh
registry/src/github.com-1ecc6299db9ec823/git2-0.13.18/src/stash.rs
registry/src/github.com-1ecc6299db9ec823/libc-0.2.94/src/unix/solarish
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/cmake/SelectHashes.cmake
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/include/git2/stash.h
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/include/git2/sys/hashsig.h
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/script/backport.sh
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/script/leaks.sh
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/script/valgrind.sh
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/src/config_snapshot.c
[...]
```
If you want to search for a specific directory, provide the directory path as a second argument to `fd`
, such as:
```
$ fd passwd /etc
/etc/pam.d/passwd
/etc/passwd
/etc/passwd-
/etc/security/opasswd
```
To search for a particular file extension, use `-e`
as an option. For example:
```
$ fd . '/home/ssur/exa' -e md
/home/ssur/exa/README.md
/home/ssur/exa/devtools/README.md
/home/ssur/exa/man/exa.1.md
/home/ssur/exa/man/exa_colors.5.md
/home/ssur/exa/xtests/README.md
$
```
You can also execute a command by providing `-x`
or `-X`
.
- The
`-x/--exec`
option runs an external command for each search result (in parallel). - The
`-X/--exec-batch`
option launches the external command once with all search results as arguments.
For example, to recursively find all ZIP archives and unpack them:
`$ fd -e zip -x unzip`
Or, to list all files under a particular directory that were changed within the last *n* number of days, use the `--changed-within`
option:
```
$ fd . '/home/ssur/Work/' --changed-within 10d
/home/ssur/Work/wildfly/connector/src/main/java/org/jboss/as/connector/subsystems/data_sources/JdbcDriverAdd.java
/home/ssur/Work/wildfly/connector/src/main/java/org/jboss/as/connector/subsystems/data_sources/JdbcExample.java
[...]
```
And to search all files that were changed before a specific number of days, use the `--changed-before`
*n* option:
`$ fd . '/home/ssur/Work/' --changed-before 365d`
Here, `.`
acts as a wildcard entry to instruct `fd`
to return all files.
To learn about more the functionalities of `fd`
, consult its [documentation](https://github.com/sharkdp/fd) on GitHub.
## Conclusion
One thing I especially like about `fd`
is that the search pattern is case-insensitive by default, which makes it easier to find things even when you have imprecise knowledge about what you're looking for. Better yet, it *automatically *switches to case-sensitive if the pattern contains an uppercase character.
Another benefit is that it uses color-coding to highlight different file types.
If you are already using this amazing Rust tool, please let us know your thoughts in the comments.
## Comments are closed. |
13,517 | Cube.js:试试这个新的数据分析开源工具 | https://opensource.com/article/21/6/cubejs | 2021-06-24T11:49:53 | [
"数据分析"
] | https://linux.cn/article-13517-1.html |
>
> Cube.js 是一个开源的分析平台,可以作为数据源和应用之间的中间层。
>
>
>

数据分析是一个时髦的领域,有许多解决方案可供选择。其中之一是 [Cube.js](https://cube.dev/),这是一个开源的分析平台。你可以把 Cube.js 看作是你的数据源和应用之间的一个中间层。
如下图所示,Cube.js 支持无服务器数据仓库和大多数现代关系型数据库管理系统 (RDBMS)。你可以使用任何用于数据可视化的 JavaScript 前端库,而 Cube.js 将负责其他工作,包括访问控制、性能、并发性等。

### 主要优点
当我向我们的社区成员询问 Cube.js 的主要优点时,他们经常提到:
* **它的抽象层**:配置 Cube.js 后,人们说他们不再需要担心性能优化、资源管理、SQL 专业知识等问题。许多人把 Cube.js 称为 “黑盒”,因为它的抽象层帮助他们专注于理解数据,而不是实施细节。
* **易于定制**:由于 Cube.js 是可视化的,它很容易与前端框架集成,建立看起来像用户自己平台的解决方案。大多数商业平台(如 Looker、Tableau 等)需要更多的定制工作来与他们的基础设施整合。许多用户说,定制的便利性与抽象层相结合,使他们能够减少数据分析平台的开发时间。
* **社区支持**:在开始使用 Cube.js 时,人们通常会从社区成员那里得到帮助(特别是在我们的 [Slack](https://slack.cube.dev/)),许多人提到社区支持是一个关键的入门资源。
访问 [用户故事页面](https://cube.dev/blog/category/user-stories/),阅读更多关于人们使用 Cube.js 的经验以及他们如何使用它。
### 开始使用
如果你想了解 Cube.js:
* 进入我们的 [文档页面](https://cube.dev/docs/),点击**开始**,并按照指示在你的笔记本电脑或工作站上启动和运行 Cube.js。
* 当你进入 [Developer Playground](https://cube.dev/docs/dev-tools/dev-playground),你将能够生成数据模式,执行查询,并建立仪表盘,以看到 Cube.js 的运行。
在你启动和运行 Cube.js 之后,这里有一些有用的资源:
* [文档](https://cube.dev/docs/):我们把大量的精力放在我们的文档上,因为它是开源社区的重要资源。我们还在我们的文档页面和 YouTube 频道的 [入门播放列表](https://www.youtube.com/playlist?list=PLtdXl_QTQjpaXhVEefh7JCIdtYURoyWo9) 中添加了视频剪辑。
* [Discourse](https://forum.cube.dev/):Cube.js 论坛是最近增加的,社区成员可以在这里分享他们的使用案例、技巧和窍门等,这样我们就可以建立一个社区知识库。
* [GitHub](https://github.com/cube-js/cube.js): 你可以在这里找到 Cube.js 的代码,社区成员可以通过 [问题页面](https://github.com/cube-js/cube.js/issues) 提交错误或功能请求。我们还在 GitHub 上发布了我们的 [季度路线图](https://github.com/cube-js/cube.js/projects),以便每个人都能看到我们正在进行的工作。
* [每月社区电话会议](https://cube.dev/community-call/):我们在每个月的第二个星期三举行电话会议,讨论社区更新,展示功能演示,并邀请社区成员分享他们的使用案例。你可以在 [社区电话会议页面](https://cube.dev/community-call/) 上找到电话会议的日程,你也可以在我们 YouTube 频道的 [社区电话会议播放列表](https://www.youtube.com/playlist?list=PLtdXl_QTQjpb1dHZCM09qKTsgvgqjSvc9) 上找到过去的电话会议录音。
就像任何好的开源项目一样,Cube.js 有许多软件贡献者。如果你想查看社区的拉取请求(PR),请搜索带有 `pr:community` 标签的 PR。如果你想寻找你可以回答的问题,请搜索带有 `good first issue` 或者 `help wanted` 标签的问题。
我希望你试试 Cube.js。如果你有任何问题,请随时在下面留言或在 [Cube.js Slack](https://slack.cube.dev/) 上找我!
---
via: <https://opensource.com/article/21/6/cubejs>
作者:[Ray Paik](https://opensource.com/users/rpaik) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Data analytics is a trendy field with many solutions available. One of them is [Cube.js](https://cube.dev/), an open source analytical platform. You can think of Cube.js as a layer between your data sources and applications.
As the diagram below shows, Cube.js supports serverless data warehouses and most modern relational database management systems (RDBMS). You can work with any JavaScript front-end library for data visualization, and Cube.js will take care of the rest, including access control, performance, concurrency, and more.
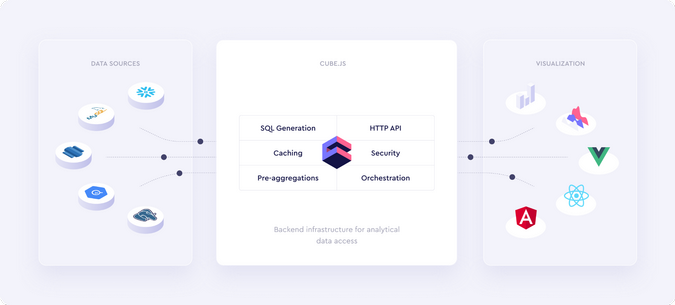
(©2021, Cube Dev, Inc.)
## Key benefits
When I ask our community members about Cube.js's key benefits, they frequently mention:
**Its abstraction layer:**After configuring Cube.js, people say they no longer have to worry about performance optimization, resource management, SQL expertise, etc. Many refer to Cube.js as a "black box" because its abstraction layer helps them focus on understanding the data rather than the implementation details.**Ease of customization:**Since Cube.js is visualization-agnostic, it's easy to integrate with front-end frameworks to build solutions that look like a user's own platform. Most commercial platforms (e.g., Looker, Tableau, etc.) require a lot more customization work to integrate with their infrastructure. Many users say that the ease of customization combined with the abstraction layer enables them to reduce development time for their data analytics platforms.**Community support:**When getting started with Cube.js, people usually get help from fellow community members (especially on our[Slack](https://slack.cube.dev/)), and many mention community support as a key onboarding resource.
Visit the [user stories page](https://cube.dev/blog/category/user-stories/) to read more about people's experience with Cube.js and how they use it.
## Get started
If you want to check out Cube.js:
- Go to our
[Documentation page](https://cube.dev/docs/), click on**Getting started**, and follow the instructions to get Cube.js up and running on your laptop or workstation. - Once you get to the
[developer playground](https://cube.dev/docs/dev-tools/dev-playground), you will be able to generate the data schema, execute queries, and build dashboards to see Cube.js in action.
After you get Cube.js up and running, here are some helpful resources:
[Documentation](https://cube.dev/docs/): We put a lot of focus on our documentation because it is a critical resource for open source communities. We're also adding video clips to our documentation pages and the[getting started playlist](https://www.youtube.com/playlist?list=PLtdXl_QTQjpaXhVEefh7JCIdtYURoyWo9)on our YouTube channel.[Discourse](https://forum.cube.dev/): The Cube.js forum is a recent addition where community members can share their use cases, tips & tricks, etc. so that we can build a community knowledge base.[GitHub](https://github.com/cube-js/cube.js): You'll find the Cube.js code here, and community members file bugs or feature requests via[issues](https://github.com/cube-js/cube.js/issues). We also publish our[quarterly roadmaps](https://github.com/cube-js/cube.js/projects)on GitHub so that everyone can see what we're working on.[Monthly community calls](https://cube.dev/community-call/): We have calls on the second Wednesday of each month to discuss community updates, showcase feature demos, and invite community members to share their use cases. You will find call logistics on the[community calls page](https://cube.dev/community-call/), and you can find recordings of past calls on the[community calls playlist](https://www.youtube.com/playlist?list=PLtdXl_QTQjpb1dHZCM09qKTsgvgqjSvc9)on our YouTube channel.
As with any good open source project, Cube.js has many contributors to the software. If you want to look at pull requests (PRs) from the community, search for PRs with the label `pr:community`
. If you are eager to look for issues that you can work on, search for issues with the labels `good first issue`
or `help wanted`
.
I hope you will give Cube.js a try. If you have any questions, please feel free to leave comments below or find me on the [Cube.js Slack](https://slack.cube.dev/)!
## Comments are closed. |
13,519 | 为什么在 2021 年我仍然推荐你使用 Linux | https://news.itsfoss.com/switch-to-linux-in-2021/ | 2021-06-25T10:41:31 | [
"Linux"
] | https://linux.cn/article-13519-1.html | 
在某些领域,Linux 确实要比 Windows 和 macOS 更加优秀。人们正在意识到这一点,而且 Linux 也在桌面操作系统市场上变得愈发流行。
当然,目前大多数桌面操作系统用户仍然对 Windows 或者 macOS 推崇备至,但是也有着越来越多的用户开始尝试新的 Linux 发行版,看看他们是否可以从原来的系统切换到 Linux 系统。
他们可能已经听过 [用 Linux 作为桌面操作系统](https://news.itsfoss.com/linux-foundation-linux-desktop/) 的一些优秀案例,又或者是仅仅想要去尝试一些与原先不同的事物,谁知道呢?
在这里,我将为你解释为什么在 2021 年我仍然推荐你使用 Linux。
### Linux 真棒,但是究竟是什么让其在 2021 年值得推荐呢?
如果已经知道了 [使用 Linux 的优点](https://itsfoss.com/reasons-switch-linux-windows-xp/),你可能就知道接下来我会说些什么。
#### 1、你不需要购买许可证

你必须付费才能获得 Windows 10 许可证。
虽然有更便宜的选择,如获得 OEM 密钥。但是,如果你不愿意通过一些地下网站,而是从官方网站获得许可证,那么仅授权使用 1 台 PC 的**家庭版**就至少需要花费 **140 美元**。
当然,macOS 是一个完全不同的模式(你需要购买先进的硬件才能使用 macOS)——所以我们才会一直使用微软的 Windows。
关键是,在失业的浪潮中,配置一台新电脑是一个挑战。此外,你还需要花钱购买操作系统的许可证,但是你却可以在多台计算机上免费使用 Linux。
是的,你不需要为 Linux 获取许可证密钥。你可以轻松下载 [Linux 发行版](https://itsfoss.com/what-is-linux-distribution/),并根据需要将其安装在尽可能多的设备上。
不要担心,如果你不了解 Linux 发行版,你可以看看我们的 [最好的 Linux 发行版](https://itsfoss.com/best-linux-distributions/) 列表。
#### 2、重新唤醒你的 PC 并节省资金
[全球芯片短缺](https://www.cnbc.com/2021/05/12/the-global-chip-shortage-could-last-until-2023-.html) 已经严重影响了电脑组件的价格,特别是**显卡**。并不是简单的价格上升,而是你不得不支付 **2 到 5 倍**的零售价来购得显卡。
当然,如果你没有电脑,现在配置一个新的电脑可能是难以置信的挑战,但如果你有一个旧电脑的话,选择在上面运行 Windows 10 将会是十分卡顿的。
如果你不想要 Windows 系统,那 macOS 呢?入门级 Mac 系统将会花费至少 **1100** 美金,甚至更多,这取决于你住在哪里。对许多人来说,这会是一笔昂贵的开销。
你肯定需要升级你的系统 —— 但是如果我说 Linux 可以让你的旧电脑重新派上用场,能为你省钱呢?
你将能够在你认为无法运行最新版本的微软 Windows 的电脑上运行 Linux。是的,就是这样的。
Linux 是一个资源高效型的操作系统,可在各种较旧的系统配置上运行。
所有你需要做的只是参考我们的列表 [轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/),并选择一个你喜欢的。
#### 3、通过再次利用系统来减少电子浪费

考虑到电子废物正在全球不断产生,尤其是由加密矿工产生的,我们可以尽量减少浪费。除非你真正需要新的硬件,否则最好将现有硬件设备重新用于新任务。
而且,多亏了 Linux,你可以将旧电脑或单片机转变成媒体服务器或个人 [Nextcloud](https://itsfoss.com/nextcloud/) 服务器。
你可以在现有硬件上使用 Linux 做更多工作。
因此,这将显著降低对新硬件的需求,并让你高效地重复使用现有的设备。
#### 4、远离病毒和恶意软件

在远程工作无处不在的时代,病毒和恶意软件显著增加。因此,即使你想平静地工作,你最终也可能受到恶意软件的影响。
Windows 和 macOS 比以往任何时候都更容易受到恶意软件的影响。但是,对于 Linux?这是不太可能的。
Linux 发行版会定期修补,以确保最佳安全性。
此外,正因为用户群体小,攻击者就不会花太多时间制作欺骗 Linux 用户的病毒或软件。因此,在使用 Linux 时遇到某种形式的恶意软件的机会较小。
#### 5、没有强制更新

在一个人们压力倍增的时代,强制更新然后发现计算机无法启动可能是一大烦恼。
至少,Windows 用户的情况就是这样。
但是,使用 Linux,你可以继续使用你的系统,而无需在后台强制下载任何更新。
你的操作系统只有你能决定。
当你想要更新你的 Linux 发行版本时,你可以选择更新,也可以不更新,它可以一直保持不更新的状态并且不会打扰你,除非你有很长一段时间没有更新。
### 总结
这些只是我能想到的几个原因之一,Linux 作为操作系统的选择在 2021 年比以往任何时候都更值得被推荐。
当然,这也取决于你的要求,这些好处可能不会体现在在你的用例中。但是,如果你确实不了解 Linux,至少,现在你可以评估你的需求,重新作出选择。
除了上述几点之外,你还能想到什么?请在下面的评论中告诉我。
---
via: <https://news.itsfoss.com/switch-to-linux-in-2021/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zepoch](https://github.com/zepoch) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux does have several benefits over Windows and macOS in certain areas. People are realizing it, and it is slowly gaining popularity in the desktop OS market.
Of course, the majority of desktop users still swear by Windows or macOS, but a greater number of users are trying out new Linux distributions to see if they can switch to Linux.
They may have heard good things about [Linux as a desktop choice](https://news.itsfoss.com/linux-foundation-linux-desktop/), or just want to try something different while confined to their homes. Who knows?
Here, I will be presenting you all the good reasons why Linux makes more sense in 2021.
## Linux is Great, But What Makes it Relevant in 2021?
If you already know the [advantages of using Linux](https://itsfoss.com/reasons-switch-linux-windows-xp/?ref=news.itsfoss.com), you may have an idea what follows next.
### 1. You Do Not Need to Purchase a License

You do have to pay to get a Windows 10 license.
While there are cheaper options available, such as getting an OEM key. But, if you want to avoid visiting shady websites and get a license from the official website instead, it will cost you at least **$140** for the **Home edition** that authorizes just 1 PC.
Of course, macOS is an entirely different story (you need to purchase premium hardware to access macOS) — so we will stick to Microsoft’s Windows here.
The point is – amid the pandemic with several people jobless, setting up a new computer is a challenge. Moreover, you need to spend money for an operating system’s license while you can use Linux for free on multiple computers.
Yes, you do not need to get a license key for Linux. You can easily download a [Linux distribution](https://itsfoss.com/what-is-linux-distribution/?ref=news.itsfoss.com) and install it on as many devices as you want.
Fret not, if you did not know about Linux distros, you can take a look at our list of the [best Linux distributions](https://itsfoss.com/best-linux-distributions/?ref=news.itsfoss.com).
### 2. Revive Your Existing PC and Save Money
The [global chip shortage situation](https://www.cnbc.com/2021/05/12/the-global-chip-shortage-could-last-until-2023-.html?ref=news.itsfoss.com) has significantly affected the price of PC components, especially the **graphics card**. Not just any hike, but you will have to **pay 2-5x times** of the retail price to get a graphics card for your computer.
Of course, if you do not have a PC, it is incredibly challenging to build one now, but what if you have an old system that cannot run Windows without crashing or stuttering?
Also, [Microsoft seems to be making hardware obsolete](https://news.itsfoss.com/windows-11-linux/) by not supporting Windows 11 on a wide range of systems.
If you do not want a Windows-powered system, what about macOS? Well, the entry-level Mac system will cost you upwards of **$1100** or more depending on where you live. It is an expensive endeavor for many.
You surely need an upgrade – but what if I say that Linux can revive your old system and save you money as well?
You will be able to run Linux on the very same system that you think is incapable of running the latest version of Microsoft’s Windows. Yes, that is correct.
Linux is resource-efficient and can run on a variety of older system configurations.
All you need to do is simply refer to our list of [lightweight Linux distributions](https://itsfoss.com/lightweight-linux-beginners/?ref=news.itsfoss.com) and pick one that you like.
### 3. Reduces e-waste by Reviving Systems

Considering that e-waste is being constantly generated all over the globe, especially by the miners, we can try not to follow the suit? Unless you really need new hardware, it is best to reuse and repurpose existing hardware for new tasks.
And, thanks to Linux, you can turn your old PC or a single board computer to a media server or your personal [Nextcloud](https://itsfoss.com/nextcloud/?ref=news.itsfoss.com) server.
You can do so much more with Linux on your existing hardware.
So, this will drop the need for new hardware significantly and let you efficiently reuse your existing system.
### 4. Stay Safe from Viruses and Malware

In a time where remote work is a thing everywhere, there has been a significant rise in viruses and malware. So, even if you wanted to work peacefully, you might end up getting affected by a malware.
Both Windows and macOS are susceptible to malware more than ever. But, for Linux? It is highly unlikely.
Linux distributions are regularly patched to ensure the best security.
Also, just because the userbase is small, the attackers do not spend much time crafting ways to fool Linux users. So, less chances of you to meet some form of malware while using Linux.
### 5. No Forced Updates

In a time where everyone is stressed out, getting a forced update and finding your computer to not boot can be a major annoyance.
At least, this is the case for Windows users.
But, with Linux, you can keep using your system without any updates forced to download in the background.
Your operating system, your decision.
Only if you want to update your Linux distro, you can – or else, it stays that way and will not bother you unless you haven’t updated in a long time.
## Wrapping Up
These are only some of the few reasons that I can think of where Linux as a choice of operating system makes sense in 2021 more than ever.
Of course, depending on your requirements, the benefits may not reflect with your use-case. But, if you did not know about Linux, at least, now you have a choice to make and evaluate your needs.
What else can you think of in addition to the points mentioned above? Please don’t hesitate to let me know in the comments below.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,520 | 用 Forklift 将虚拟机迁移到 Kubernetes 上 | https://opensource.com/article/21/6/migrate-vms-kubernetes-forklift | 2021-06-25T11:30:18 | [
"Kubernetes",
"虚拟机"
] | /article-13520-1.html |
>
> 用 Forklift 将你的虚拟化工作负载过渡到 Kubernetes。
>
>
>

2017 年,[KubeVirt](http://kubevirt.io/) 团队 [发起](https://kubevirt.io/2017/This-Week-in-Kube-Virt-1.html) 了一个在 [Kubernetes](https://opensource.com/resources/what-is-kubernetes) 中管理容器及相关的虚拟机(VM)的项目。这个开源项目的意图是让虚拟机成为这个环境中的一等公民。
自从在 [2018 年开源峰会](https://ossna18.sched.com/event/FAOR/kubevirt-cats-and-dogs-living-together-stephen-gordon-red-hat) 上推出以来,KubeVirt 一直在不断成熟和发展。它在 GitHub 上已经达到了 200 多颗星,甚至在 2021 年 2 月推出了自己的活动:[KubeVirt 峰会](https://kubevirt.io/summit/)。

*KubeVirt 架构(© 2020,[Red Hat OpenShift](https://www.openshift.com/learn/topics/virtualization/))*
KubeVirt 是 [OpenShift 虚拟化](https://openshift.com/virtualization/) 的基础,它帮助开发者将虚拟机带入容器化工作流程。
### 在 Kubernetes 中使用虚拟机
KubeVirt 使你能够在虚拟机上原生使用 Kubernetes。这意味着它们可以连接到使用标准 Kubernetes 方法(如服务、路由、管道等)访问的<ruby> 吊舱 <rt> Pod </rt></ruby>网络。应用于虚拟机吊舱的网络策略与应用于应用吊舱的方式相同,它提供一个一致的模型来管理虚拟机到吊舱(或反之)的通信。
这方面的一个真实例子是一家航空公司利用旧的模拟器软件的方式。它注入了人工智能和机器学习 (AI/ML) 的模型,然后在基于虚拟机的模拟器上自动部署和测试它们。这使得它能够使用 Kubernetes 和 [Kubeflow](https://www.kubeflow.org/) 完全自动化地获得测试结果和新的遥测训练数据。

*(Konveyor, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
[Konveyor.io](https://www.konveyor.io/) 是一个开源项目,帮助现有工作负载(开发、测试和生产)过渡到 Kubernetes。其工具包括将容器从一个 Kubernetes 平台转移到另一个平台的 [Crane](https://www.konveyor.io/crane);将工作负载从 Cloud Foundry 带到 Kubernetes的 [Move2Kube](https://move2kube.konveyor.io/);以及分析 Java 应用,使其对 Kubernetes 等容器化平台中的运行时更加标准和可移植,从而使其现代化的 [Tackle](https://www.konveyor.io/tackle)。
这些工具在转化模式中很有用,但许多项目希望在早期阶段利用 Kubernetes,以变得更加敏捷和富有成效。在基础设施方面,这些好处可能包括蓝/绿负载均衡、路由管理、声明式部署,或(取决于你的部署方式)由于不可变的基础设施而更容易升级。在开发方面,它们可能包括将持续集成/持续开发 (CI/CD) 管道与平台整合,使应用更快地投入生产,自我提供资源,或整合健康检查和监控。
KubeVirt 可以通过在 Kubernetes 环境中以虚拟机来运行工作负载帮助你。它能让你的工作负载迅速使用 Kubernetes,享受它的好处,并随着时间的推移稳步实现工作负载的现代化。但是,仍然有一个问题,就是把你的虚拟机从传统的虚拟化平台带到现代的 Kubernetes 平台。这就是 Konveyor 的 [Forklift](https://www.konveyor.io/forklift) 项目的意义所在。
### 关于 Forklift
Forklift 使用 KubeVirt 将不同来源的虚拟化工作负载迁移到 Kubernetes。它的设计目标是使任务变得简单,以便你可以从一两台机器到数百台机器迁移任何东西。
迁移是一个简单的、三阶段的过程:
1. 连接到一个现有的虚拟化平台(称为“源提供者”)和一个 Kubernetes 环境(“目标提供者”)。
2. 将网络和存储资源从源提供者映射到目标提供者,在两者中寻找等价的资源。
3. 选择要迁移的虚拟机,分配网络和存储映射,制定迁移计划。然后运行它。
### 如何开始
要开始使用 Forklift,首先,你需要一个兼容的源提供商。你还需要一个带有 KubeVirt 0.40 或更新版本的 Kubernetes 环境和裸机节点(尽管为了测试,你可以使用嵌套虚拟化)。用读-写-执行 (RWX) 功能配置你的存储类,并使用 [Multus](https://github.com/k8snetworkplumbingwg/multus-cni) 配置你的网络,以匹配你的虚拟机在源提供者中使用的网络。(如果你不能这样做,也不用担心。你也可以选择重新分配 IP 地址。)
最后,使用提供的操作器在你的 Kubernetes 上[安装 Forklift](https://www.youtube.com/watch?v=RnoIP3QjHww&t=1693s),并进入用户界面,开始运行你的第一次测试迁移。
Forklift 是 Red Hat 的 [虚拟化迁移工具套件](https://access.redhat.com/documentation/en-us/migration_toolkit_for_virtualization/2.0/) 的上游版本。因此,如果你想在生产环境中使用它,你可以考虑使用该工具的支持版本。
迁移愉快!
---
via: <https://opensource.com/article/21/6/migrate-vms-kubernetes-forklift>
作者:[Miguel Perez Colino](https://opensource.com/users/mperezco) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,522 | 用于调度任务的 systemd 定时器 | https://fedoramagazine.org/systemd-timers-for-scheduling-tasks/ | 2021-06-25T17:57:46 | [
"定时器",
"cron"
] | https://linux.cn/article-13522-1.html | 
systemd 提供定时器有一段时间了,定时器替代了 cron 功能,这一特性值得看看。本文将向你介绍在系统启动后如何使用 systemd 中的定时器来运行任务,并在此后重复运行。这不是对 systemd 的全面讨论,只是对此特性的一个介绍。
### 快速回顾:cron、anacron 与 systemd
cron 可以以几分钟到几个月或更长时间的粒度调度运行一个任务。设置起来相对简单,它只需要一个配置文件。虽然配置过程有些深奥,但一般用户也可以使用。
然而,如果你的系统在需要执行的时间没有运行,那么 cron 会失败。
anacron 克服了“系统没有运行”的问题。它确保任务将在你的系统再次启动时执行。虽然它旨在给管理员使用,但有些系统允许普通用户访问 anacron。
但是,anacron 的执行频率不能低于每天一次。
cron 和 anacron 都存在执行上下文一致性的问题。必须注意任务运行时有效的环境与测试时使用的环境完全相同。必须提供相同的 shell、环境变量和路径。这意味着测试和调试有时会很困难。
systemd 定时器提供了 cron 和 anacron 二者的优点,允许调度到分钟粒度。确保在系统再次运行时执行任务,即使在预期的执行时间内系统处于关闭状态。它对所有用户都可用。你可以在它将要运行的环境中测试和调试执行。
但是,它的配置更加复杂,至少需要两个配置文件。
如果你的 cron 和 anacron 配置可以很好地为你服务,那么可能没有理由改变。但是 systemd 至少值得研究,因为它可以简化任何当前的 cron/anacron 工作方式。
### 配置
systemd 定时器执行功能至少需要两个文件。这两个是“<ruby> 定时器单元 <rt> timer unit </rt></ruby>”和“<ruby> 服务单元 <rt> service unit </rt></ruby>”。(其执行的)“动作”不仅仅是简单的命令,你还需要一个“作业”文件或脚本来执行必要的功能。
定时器单元文件定义调度表,而服务单元文件定义执行的任务。有关的更多详细信息请参考 `man systemd.timer` 中提供的 .timer 单元。服务单元的详细信息可在 `man systemd.service` 中找到。
单元文件存放在几个位置(在手册页中有列出)。然而,对于普通用户来说,最容易找到的位置可能是 `~/.config/systemd/user`。请注意,这里的 `user` 是字符串 `user`。
### 示例
此示例是一个创建用户调度作业而不是(以 root 用户身份运行的)系统调度作业的简单示例。它将消息、日期和时间打印到文件中。
1、首先创建一个执行任务的 shell 脚本。在你的本地 `bin` 目录中创建它,例如在 `~/bin/schedule-test.sh` 中。
创建文件:
```
touch ~/bin/schedule-test.sh
```
然后将以下内容添加到你刚刚创建的文件中:
```
#!/bin/sh
echo "This is only a test: $(date)" >> "$HOME/schedule-test-output.txt"
```
记住赋予你的 shell 脚本执行权限。
2、创建 .service 单元调用上面的脚本。在以下位置创建目录与文件:`~/.config/systemd/user/schedule-test.service`:
```
[Unit]
Description=A job to test the systemd scheduler
[Service]
Type=simple
ExecStart=/home/<user>/bin/schedule-test.sh
[Install]
WantedBy=default.target
```
请注意 `<user>` 应该是你的家目录地址,但是单元文件路径名中的 `user` 实际上是字符串 `user`。
`ExecStart` 应该提供一个没有变量的绝对地址。例外情况是,对于用户单元文件,你可以用 `%h` 替换 `$HOME`。换句话说,你可以使用:
```
ExecStart=%h/bin/schedule-test.sh
```
这仅用于用户单元文件,而不适用于系统服务,因为在系统环境中运行时 `%h` 总是返回 `/root`。其他特殊符号可在 `man systemd.unit` 的 `SPECIFIERS` 中找到。因为它超出了本文的范围,所以这就是我们目前需要了解的关于特殊符号的全部内容。
3、创建一个 .timer 单元文件,该文件实际上调度你创建的 .service 单元文件。在 .service 单元文件相同位置创建它:`~/.config/systemd/user/schedule-test.timer`。请注意,文件名仅在扩展名上有所不同,例如一个是 `.service`,一个是 `.timer`。
```
[Unit]
Description=Schedule a message every 1 minute
RefuseManualStart=no # Allow manual starts
RefuseManualStop=no # Allow manual stops
[Timer]
#Execute job if it missed a run due to machine being off
Persistent=true
#Run 120 seconds after boot for the first time
OnBootSec=120
#Run every 1 minute thereafter
OnUnitActiveSec=60
#File describing job to execute
Unit=schedule-test.service
[Install]
WantedBy=timers.target
```
请注意,这个 .timer 单元文件使用了 `OnUnitActiveSec` 来指定调度表。`OnCalendar` 选项更加灵活。例如:
```
# run on the minute of every minute every hour of every day
OnCalendar=*-*-* *:*:00
# run on the hour of every hour of every day
OnCalendar=*-*-* *:00:00
# run every day
OnCalendar=*-*-* 00:00:00
# run 11:12:13 of the first or fifth day of any month of the year
# 2012, but only if that day is a Thursday or Friday
OnCalendar=Thu,Fri 2012-*-1,5 11:12:13
```
有关 `OnCalendar` 的更多信息参见 [这里](https://www.freedesktop.org/software/systemd/man/systemd.time.html#Calendar%20Events)。
4、所有的部件都已就位,但你应该进行测试,以确保一切正常。首先,启用该用户服务:
```
$ systemctl --user enable schedule-test.service
```
这将导致类似如下的输出:
```
Created symlink /home/<user>/.config/systemd/user/default.target.wants/schedule-test.service → /home/<user>/.config/systemd/user/schedule-test.service.
```
现在执行测试工作:
```
$ systemctl --user start schedule-test.service
```
检查你的输出文件(`$HOME/schedule-test-output.txt`),确保你的脚本运行正常。应该只有一个条目,因为我们还没有启动定时器。必要时进行调试。如果你需要更改 .service 单元文件,而不是更改它调用的 shell 脚本,请不要忘记再次启用该服务。
5、一旦作业正常运行,通过为服务启用、启动用户定时器来实时调度作业:
```
$ systemctl --user enable schedule-test.timer
$ systemctl --user start schedule-test.timer
```
请注意,你已经在上面的步骤 4 中启动、启用了服务,因此只需要为它启用、启动定时器。
`enable` 命令会产生如下输出:
```
Created symlink /home/<user>/.config/systemd/user/timers.target.wants/schedule-test.timer → /home/<user>/.config/systemd/user/schedule-test.timer.
```
`start` 命令将只是返回命令行界面提示符。
### 其他操作
你可以检查和监控服务。如果你从系统服务收到错误,下面的第一个命令特别有用:
```
$ systemctl --user status schedule-test
$ systemctl --user list-unit-files
```
手动停止服务:
```
$ systemctl --user stop schedule-test.service
```
永久停止并禁用定时器和服务,重新加载守护程序配置并重置任何失败通知:
```
$ systemctl --user stop schedule-test.timer
$ systemctl --user disable schedule-test.timer
$ systemctl --user stop schedule-test.service
$ systemctl --user disable schedule-test.service
$ systemctl --user daemon-reload
$ systemctl --user reset-failed
```
### 总结
本文以 systemd 定时器为出发点,但是 systemd 的内容远不止于此。这篇文章应该为你提供一个基础。你可以从 [Fedora Magazine systemd 系列](https://fedoramagazine.org/what-is-an-init-system/) 开始探索更多。
### 参考
更多阅读:
* `man systemd.timer`
* `man systemd.service`
* [Use systemd timers instead of cronjobs](https://opensource.com/article/20/7/systemd-timers)
* [Understanding and administering systemd](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/)
* <https://opensource.com/> 内有 systemd 速查表
---
via: <https://fedoramagazine.org/systemd-timers-for-scheduling-tasks/>
作者:[Richard England](https://fedoramagazine.org/author/rlengland/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[dcoliversun](https://github.com/dcoliversun) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Systemd has provided timers for a while and it is worth taking a look at this feature as an alternative to *cron*. This article will show you how to use timers with *systemd* to run a task after the system has booted and on a recurring basis after that. This is not a comprehensive discussion of *systemd*, only an introduction to this one feature.
## Cron vs anacron vs systemd: a quick review
*Cron* can schedule a task to be run at a granularity ranging from minutes to months or more. It is relatively simple to set up, requiring a single configuration file. Although the configuration line is somewhat esoteric. It can also be used by general users.
*Cron*, however, fails if your system happens to not be running when the appropriate execution time occurs.
*Anacron*, overcomes the “system not running” issue. It insures that the task will be executed when your system is again active. While it was intended to be used by administrators, some systems give general users access.
However, the *anacron* frequency of execution can be no less than daily.
Both *cron* and *anacron* have issues with consistency in execution context. Care must be taken that the environment in effect when the task runs is exactly that used when testing. The same shell, environment variables and paths must be provided. This means that testing and debugging can sometimes be difficult.
*Systemd* timers offer the best of both *cron* and *anacron*. Allows scheduling down to minute granularity. Assures that the task will be executed when the system is again running even if it was off during the expected execution time. Is available to all users. You can test and debug the execution in the environment it will run in.
However, the configuration is more involved, requiring at least two configuration files.
If your *cron* and *anacron* configuration is serving you well then there may not be a reason to change. But *systemd* is at least worth investigating since it may simplify any current *cron* /*anacron* work-arounds.
## Configuration
*Systemd* timer executed functions require, at a minimum, two files. These are the “timer unit” and the “service unit”. Actions consisting of more than a simple command, you will also need a “job” file or script to perform the necessary functions.
The timer unit file defines the schedule while the service unit file defines the task(s) performed. More details on the .timer unit is available in “man systemd.timer”. Details on the service unit are available in “man systemd.service”.
There are several locations where unit files exist (listed in the man page). Perhaps the easiest location for the general user, however, is “~/.config/systemd/user”. Note that “user” here, is the literal string “user”.
## Demo
This demo is a simple example creating a user scheduled job rather than a system schedule job (which would run as root). It prints a message, date, and time to a file.
- Start by creating a shell script that will perform the task. Create this in your local “bin” directory, for example, in
“~/bin/schedule-test.sh”
To create the file:touch ~/bin/schedule-test.sh
Then add the following content to the file you just created.
#!/bin/sh echo "This is only a test: $(date)" >> "$HOME/schedule-test-output.txt"
Remember to make your shell script executable.
- Create the .service unit that will call the script above. Create the directory and file in:
“~/.config/systemd/user/schedule-test.service”:
[Unit] Description=A job to test the systemd scheduler [Service] Type=simple ExecStart=/home/<user>/bin/schedule-test.sh [Install] WantedBy=default.target
Note that <user> should be your @HOME address but the “user” in the path name for the unit file is literally the string “user”.
The *ExecStart *line should provide an absolute address with no variables. An exception to this is that for *user* units you may substitute “%h” for $HOME. In other words you can use:
ExecStart=%h/bin/schedule-test.sh
This is only for user unit file use. It is not good for system units since “%h” will always return “/root” when run in the system environment. Other substitutions are found in “man systemd.unit” under the heading “SPECIFIERS”. As it is outside the scope of this article, that’s all we need to know about SPECIFIERS for now.
3. Create a .timer unit file which actually schedules the .service unit you just created. Create it in the same location as the .service file “~/.config/systemd/user/schedule-test.timer”. Note that the file names differ only in their extensions, that is ,”.service” versus “.timer”
[Unit] Description=Schedule a message every 1 minute RefuseManualStart=no # Allow manual starts RefuseManualStop=no # Allow manual stops [Timer] #Execute job if it missed a run due to machine being off Persistent=true #Run 120 seconds after boot for the first time OnBootSec=120 #Run every 1 minute thereafter OnUnitActiveSec=60 #File describing job to execute Unit=schedule-test.service [Install] WantedBy=timers.target
Note that the .timer file has used “OnUnitActiveSec” to specify the schedule. Much more flexible is the “OnCalendar” option. For example:
# run on the minute of every minute every hour of every day OnCalendar=*-*-* *:*:00 # run on the hour of every hour of every day OnCalendar=*-*-* *:00:00 # run every day OnCalendar=*-*-* 00:00:00 # run 11:12:13 of the first or fifth day of any month of the year # 2012, but only if that day is a Thursday or Friday OnCalendar=Thu,Fri 2012-*-1,5 11:12:13
More information on “OnCalendar” is available [here](https://www.freedesktop.org/software/systemd/man/systemd.time.html#Calendar%20Events).
4. All the pieces are in place but you should test to make certain everything works. First, enable the user service:
$ systemctl --user enable schedule-test.service
This should result in output similar to this:
Created symlink /home/<user>/.config/systemd/user/default.target.wants/schedule-test.service → /home/<user>/.config/systemd/user/schedule-test.service.
Now do a test run of the job:
$ systemctl --user start schedule-test.service
Check your output file ( $HOME/schedule-test-output.txt ) to insure that your script is
performing correctly. There should be a single entry since we have not started the timer yet. Debug as necessary. Don’t forget to enable the service again if you needed to change your .service file as opposed to the shell script it invokes.
5. Once the job works correctly, schedule it for real by enabling and starting the user timer for your service:
$ systemctl --user enable schedule-test.timer $ systemctl --user start schedule-test.timer
Note that you have already started and enabled the service in step 4, above, so it is only necessary to enable and start the timer for it.
The “enable” command will result in output similar to this:
Created symlink /home/<user>/.config/systemd/user/timers.target.wants/schedule-test.timer → /home/<user>/.config/systemd/user/schedule-test.timer.
and the “start” will simply return you to a CLI prompt.
## Other operations
You can check and monitor the service. The first command below is particularly useful if you receive an error from the service unit:
$ systemctl --user status schedule-test $ systemctl --user list-unit-files
Manually stop the service:
$ systemctl --user stop schedule-test.service
Permanently stop and disable the timer and the service, reload the daemon config and reset any failure notifications:
$ systemctl --user stop schedule-test.timer $ systemctl --user disable schedule-test.timer $ systemctl --user stop schedule-test.service $ systemctl --user disable schedule-test.service $ systemctl --user daemon-reload $ systemctl --user reset-failed
## Summary
This article will jump-start you with *systemd* timers, however, there is much more to *systemd* than covered here. This article should provide you with a foundation on which to build. You can explore more about it starting in the [Fedora Magazine systemd series ](https://fedoramagazine.org/what-is-an-init-system/).
References – Further reading:
- man systemd.timer
- man systemd.service
[Use systemd timers instead of cronjobs](https://opensource.com/article/20/7/systemd-timers)[Understanding and administering systemd](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/)- Also,
[https://opensource.com/](https://opensource.com/)has a good[systemd cheatsheet](https://opensource.com/downloads/linux-systemd-cheat-sheet)
## Ralf
Very nice article, but actually, I would prefer a graphical user interface or management platform for setting up timers, due to the amount of tasks one has to manage and the syntax you need to get used to.
I not dealing very often with the topic.
## Basil
This sounds like a good inclusion for cockpit
## Frank Theile
## Richard England
Indeed, and it has been corrected. Thank you for letting me know.
## Frank Theile
Good article to get rid of
, thanks!
One can also ommit
in the
file and rely on the implicit rule ”
controlls the start of
“, as recommended in the manage.
## Darvond
One thing of note; and something I’ve done for another Fedora install is using these timer services to automate Fedora updates. In fact, I feel there’s an article covering just that.
## Ralf Seidenschwang
There seems to be a option available for displaying timers in Cockpit, but you can’t create a timer from that view under services —> timer. I’ve found a bug from 2017 for that issue.
Ok, I’m unsure if I’m missing a button hidden somewhere else…
## Richard England
If you change your Cockpit session to “Administrative access” then the “timer” category under “Services” will include a “Create timer” button at the top of the page. This does not exist for “Limited access” so I believe the processes will not run as a user, only as root.
I do not have extensive experience with Cockpit so perhaps someone else will be able to elaborate on this.
## Ralf Seidenschwang
I have no root access for Cockpit right now, but will test that soon. Thanks a lot!
## iregognice
You wrote “OnCalender” but it should be “OnCalendar”.
## Richard England
Thank you. Corrections made. Cut’n’paste not necessarily your friend.
## rugk
Note that you can actually also use a CLI command (”systemctl edit –force –full –user schedule-test.service”) to create that service (or timer units etc.) without having to manually create and remember that compliacted file path. 😉
See https://unix.stackexchange.com/q/650484/146739
## Richard England
That’s great to know. Thanks for adding that to the conversation.
## Ralf
I haven’t found the cheat sheet on the first click in the menu, so that would be the direct link: https://opensource.com/downloads/linux-systemd-cheat-sheet
Fantastic website, which I wasn’t aware for whatever reason.
I’ve found a guide for inter-process communication there. I was long searching for an appropriate guide in an suitable length. Perfect!
## Richard England
Thanks, Ralf. I’ve added that more direct link.
## Ralf
Thanks Richard.
## Hugo Leonardo R. D. Lopes
Good evening! I really liked the article. Very well explained. Congratulations. However, there is a caveat that I would like to make and that I have been hitting on this key since 2000. For users who have technical knowledge of Linux it is easy to do, but the community has not yet seen the reality of the world we live in, nor who the people are with no programming or technical knowledge, I would like to use the much talked about Linux. The hotdog guy, the lawyer, the mechanic, the school cook, my grandmother and grandfather, the geography teacher (history, chemistry, physical education, etc…), people who barely know how to send an email or attach something to it. At this point, Windows and Microsoft come out ahead since Windows 95 in terms of the end user’s vision, that is, people without knowledge. As far as the Linux crowd doesn’t make difficult things easy and port everything to an intuitive and easy-to-use graphical interface for anyone. Linux will always play a supporting role in the world of operating systems for simple people. “Wow! Do you use Linux? I wanted to understand how you use it! I prefer Windows, it’s easier!”
## Gregory Bartholomew
The most straight-forward answer is that there are always trade-offs. If Linux were to remove all of those confusing “options” so that there were just a few “easier” things to point and click on, then it would no longer be Linux.
It is very true that not everyone is the same in terms of their computer skills. You might find this 2016 study by the Organisation for Economic Co-operation and Development interesting:The Distribution of Users’ Computer Skills: Worse Than You Think .
A one size fits all design really isn’t possible. Fedora Linux does try to accommodate the variety of users by offering a variety of “spins”. KDE, for example, tries to be more intuitive for people who are familiar with Windows. i3 is for people who do more work on the command line.
## Richard England
Thank you. I’m glad you liked the article.
The article, however, is written for someone that needs or wants to understand scheduling jobs with systemd. That task is something my grandmother, my mother, or the mechanic (don’t sell any of them short) has no need for in daily use on either OS.
Whether Windows is better than Linux really comes down to need and to a very large extent how trained and familiar you are with one or the other. From my experience teaching beginner Linux classes, I feel the opposite as you. I can teach someone who wants to learn how to use the GUI to be very proficient using either OS. There is typically no need for them to delve into the CLI unless they have the desire.
But Linux Desktop vs Windows is an old argument and this is probably not the place to try and solve it.
## Ralf
As a former windows user, I can confirm that the advanced scheduling features are somehow hidden from the user and I would say that most users never view (you will be overwhelmed by the amount of timers windows sets up by default), add or modify timers.
Some developers are working on a GUI here:
https://github.com/cockpit-project/cockpit/issues/15927
I haven’t tested the feature, but I would prefer it for that specific topic.
## mutant
great idea this article. this knowledge is a real life need.
my experience: systemd scheduling is a fat monster that needs to be learned well.
And it has some advantages cron can never catch up with.
So yes, I use both.
Each where apropriate.
Please do never tell one of these mechanismns is always advantageous or better than the other – that would be a stupid lie distracting from there are proper areas of use for each of them.
## Mallikarjungouda S Patil
It’s a very helpful article. Please post more like this on other Linux utilities. Thanks a lot! |
13,525 | FCC 的频谱拍卖是对 5G 普及的长期助推 | https://www.networkworld.com/article/3584072/fcc-auctions-should-be-a-long-term-boost-for-5g-availability.html | 2021-06-27T10:30:57 | [
"5G"
] | https://linux.cn/article-13525-1.html |
>
> FCC 制定新政策是为了让更多的频谱能够被用于通信以此来创造新的服务。
>
>
>

随着 5G 的发展,为了完全实现它的服务,显然需要更多的频谱来,FCC 显然对此当成重中之重。
FCC 近日完成了有关<ruby> 公民宽带无线电服务 <rt> Citizen’s Broadband Radio Service </rt></ruby>(CBRS)的 5G 频谱的[拍卖](https://www.networkworld.com/article/3572564/cbrs-wireless-yields-45b-for-licenses-to-support-5g.html),这些频谱是位于 3.5GHz 频段中的 70MHz 新带宽。它拍卖了 45.8 个亿,是近几年为无线传输释放更多频道的拍卖会之一。FCC 在 2011、2014 和 2015 年在中低频段(大致在 1.7GHz 至 2.2GHz)和 700MHz 上拍卖了 65MHz。
当前频谱可操作的范围是低于 6GHz 频段或是中频段的频谱,与 [CBRS](https://www.networkworld.com/article/3180615/faq-what-in-the-wireless-world-is-cbrs.html) 拍卖中出售的频谱处于同一区域。据专家称,即将举行的 C 频段拍卖将会是重要一环,将会有高达 280 MHz 频谱被拍卖。
IDC 的研究主管 Jasom leigh 说,“C 频段的拍卖将带来大笔资金。……美国的中频段频谱是稀缺的,这就是为什么你会看到这种巨大的紧迫性。”
虽然几大主要移动运营商仍有望抢到这次拍卖中的大部分可用的许可证,但频谱的一些最具创新性的用途将由企业实施,所以将会与运营商竞争一系列可用的频段。
[物联网](https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html)、资产追踪以及其他私人网络应用的专用网络早已可以通过私人 LTE 实现,但由于 5G 技术先进的频谱共享、低延迟和多连接的特性,它的成熟大大拓宽了它们的范围。广义上讲,能替代更多当前需要连线的应用,如工业自动化、设备管理等等。
### 重新分配频谱就意味着谈判
对于想要改变美国的频谱优先事项上的问题并不是小事,FCC 前主席 Tom Wheeler 对此绝对深有体会,过去 10 年里,美国政府一直在推动重新分配频段,而持有频段者的大多是政府机构或者是卫星网络运营商。
Wheeler 说,这些利益相关者必须被分配到不同频段,通常以纳税人出资补偿,而让各个相关方参与分享和进行分享经常是一个复杂的过程。
他指出,“FCC 现在面临的挑战之一是,频谱的分配是根据假定使用模拟信号做出的,而这些假定由于数字技术而被改写”。就像电视从模拟电视转变成数字电视。当模拟电视占用了 6MHz 频段,并需要两侧的保护带以避免干扰时,数字信号却能够在一个频段里容纳四到五个信号。
事实证明,这些假定是很难面对的。反对者公开反对 FCC 在中频段的动作,认为这样做没有足够的预防措施来避免对他们原有的设备和服务的干扰,而改变频率也意味着必须购买新的设备。
“我们和[美国国防部]还有卫星公司讨论过,事实上其中一个较大的原因是监管的挑战,没人想放弃现有体系下基于模拟信号假定下的安全地位。”Wheeler 说到,“我认为你也必须考虑周全,但我发现那些所谓宣声信号冲突的人,其实是将眼下当作避难所,根本没有竞争和威胁方面的意识。”
### 未来:更多的服务
Leigh 表示,无论开放频谱的确切方式如何,但广泛的观点认为将中频频段开放给运营商和企业,对美国商业会有潜在的优势。而当美国坚持以拍卖形式分配无线频谱时,其他国家,像德国,就已经专门预留了供企业使用的中频段频谱。
对于试图推出自己的私有 5G 网络的公司而言,可能会推高频谱拍卖价格。但是,只要最终有足够可用的频谱,就有服务足够可用,无论它们是内部提供的,还是由移动运营商或供应商销售的。
他说:“企业在 5G 方面做的事情,将推动真正的未来。”
---
via: <https://www.networkworld.com/article/3584072/fcc-auctions-should-be-a-long-term-boost-for-5g-availability.html>
作者:[Jon Gold](https://www.networkworld.com/author/Jon-Gold/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[littlebirdnest](https://github.com/littlebirdnest) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
13,526 | 如何维护关键的 Python 项目 | https://opensource.com/article/20/2/python-maintained | 2021-06-27T13:04:08 | [
"Python",
"开源"
] | https://linux.cn/article-13526-1.html |
>
> 一窥开源 Python 项目保持平稳运行的社区幕后。
>
>
>

Jannis Leidel 是 [Jazzband](https://jazzband.co/) 社区的一部分。Jazzband 是一个协作社区,共同承担维护基于 [Python](https://opensource.com/resources/python) 的项目。
Jazzband 的诞生源于长期独自维护一个开源项目的压力。Jannis 是“roadie”,这意味着他负责管理任务并确保团队中的人可以在他们想要的时候参与。
Jazzband 并不是他的第一个开源志愿者工作——他是前 [Django](https://opensource.com/article/18/8/django-framework) 核心开发人员,[Django 软件基金会](https://www.djangoproject.com/foundation/) 董事会成员,编写了许多 Django 应用程序和 Python 项目,曾是 [pip](https://opensource.com/article/19/11/python-pip-cheat-sheet) 和 [virtualenv](https://virtualenv.pypa.io/en/latest/) 核心开发人员和发布经理,共同创立了 <ruby> <a href="https://www.pypa.io/en/latest/"> Python 打包机构 </a> <rt> Python Packaging Authority </rt></ruby>,还担任过 [PyPI](https://pypi.org/) 管理员。在社区方面,他共同创立了德国 Django 协会,担任 [DjangoCon Europe](https://djangocon.eu/) 2010 联合主席,在多个会议上发言,并在去年担任了 [Python 软件基金会](https://www.python.org/psf/) 董事和联席主席。
### Moshe Zadka: 你是如何开始编程的?
Jannis Leidel:我开始接触编程是在高中的常规德国计算机科学课程中,在那里我涉猎了 Turbo Pascal 和 Prolog。我很快就进入了 Web 开发的世界,并使用 PHP3、[Perl5](http://opensource.com/article/18/1/why-i-love-perl-5) 和 [MySQL](https://opensource.com/life/16/10/all-things-open-interview-dave-stokes) 编写了一些小型网站。后来在大学里,我在从事媒体艺术项目时再次学习了编程,发现 [Ruby](http://opensource.com/business/16/4/save-development-time-and-effort-ruby)、Perl 和 Python 特别有用。我最终坚持使用 Python,因为它的多功能性和易用性。从那时起,我很高兴能够在我的职业生涯中使用 Python 和开放 Web 技术(HTML/JS/CSS)。
### Zadka: 你是如何开始接触开源的?
Leidel:作为大学艺术项目的一部分,我需要一种与各种 Web 服务对话并与一些电子设备交互的方法,但发现我之前的 PHP 技能无法胜任这项任务。因此,我参加了有关使用 Python 编程的课程,相比库,我对学习更多有关框架如何工作更感兴趣,因为它们进一步体现了我想了解的最佳实践。特别是,新生的 Django Web 框架对我很有吸引力,因为它倾向于一种务实的方法,并为如何开发 Web 应用程序提供了大量指导。 2007 年,我作为学生参与了 Google Summer of Code for Django,后来为 Django 及其可重用组件生态系统做出了更多贡献,不久我也成为了 Django 核心开发人员。在完成学位期间,我能够利用这些技能成为一名自由职业者,并花时间在 Django 社区的许多不同部分工作。在那时,横向移动到更广泛的 Python 社区不过是很自然的。
### Zadka: 你的日常工作是什么?
Leidel:我是 Mozilla 的一名软件工程师,致力于为 Firefox 数据管道开发数据工具。实际上,这意味着我在更广泛的 Firefox 工程团队中工作,从事各种内部和面向公众的基于 Web 的项目,这些项目帮助 Mozilla 员工和社区成员理解 Firefox Web 浏览器发送的遥测数据。我目前的部分重点是维护我们的数据分析和可视化平台,该平台基于开源项目 [Redash](https://redash.io/),并对其做出贡献。我参与的其他项目是我们的下一代遥测系统 [Glean](https://firefox-source-docs.mozilla.org/toolkit/components/telemetry/start/report-gecko-telemetry-in-glean.html) 和一个允许你在浏览器(包括 Scientific Python 堆栈)中进行数据科学的工具 [Iodide](https://alpha.iodide.io/)。
### Zadka: 你是如何参与 Jazzband 的?
Leidel:早在 2015 年,我就对单独维护很多人所依赖的项目感到沮丧,并看到我的许多社区同行都在为类似的问题苦苦挣扎。我不知道有什么好方法可以让社区中更多的人对长期维护感兴趣。在某些情况下,我觉得新的“社会编码”范式的社会性的不足,而且常常是孤立的,有时甚至对新老贡献者来说都是创伤。我相信在我们的社区中,我现在觉得无法容忍的不平等现象在当时更加猖獗,这使得为贡献者提供一个安全的环境变得困难——我们现在知道这对于稳定的项目维护至关重要。我想知道我们是否缺少一种更具协作性和包容性的软件开发方法。
Jazzband 项目的启动是为了降低进入维护的门槛,并简化其中一些较无聊的方面(例如,围绕 [CI](https://opensource.com/article/19/12/cicd-resources) 的最佳实践)。
### Zadka: 你最喜欢 Jazzband 的哪一点?
Leidel:我最喜欢 Jazzband 的一点是,我们确保了许多人所依赖的许多项目的维护,同时还确保任何经验水平的新贡献者都可以加入。
### Zadka: Jazzband 的“roadie”的工作是什么?
Leidel:“roadie”是指处理 Jazzband 幕后所有事务的人。这意味着,例如,处理新项目的进入、维护 Jazzband 网站以处理用户管理和项目发布、充当安全或行为准则事件的第一响应者等等。“roadie”这个词是从音乐和演出行业借来的,指的是支持人员,他们负责在巡回演出中几乎所有需要做的事情,除了实际的艺术表演。在 Jazzband,他们的存在是为了确保成员可以在项目中工作。这也意味着,在有意义的情况下,某些任务是部分或完全自动化的,并且最佳实践被应用于大多数 Jazzband 项目,如打包设置、文档托管或持续集成。
### Zadka: 作为 Jazzband 的“roadie”,你工作中最具挑战性的方面是什么?
Leidel:目前,我作为“roadie”的工作中最具挑战性的方面是实施社区成员提出的 Jazzband 改进,而不影响他们所依赖的工作流程。换句话说,Jazzband 越大,在概念级别上扩展项目变得越困难。具有讽刺意味的是,我是目前唯一的“roadie”,独自处理一些任务,而 Jazzband 却试图阻止其项目发生这种情况。这是 Jazzband 未来的一大担忧。
### Zadka: 对于有兴趣想知道能否加入 Jazzband 的人,你有什么想说的?
Leidel:如果你有兴趣加入一群相信协作工作比单独工作更好的人,或者如果你一直在为自己的维护负担而苦苦挣扎,并且不知道如何继续,请考虑加入 Jazzband。它简化了新贡献者的进入流程,提供了一个争议解决框架,并自动发布到 [PyPI](https://opensource.com/downloads/7-essential-pypi-libraries)。有许多最佳实践可以很好地降低项目无人维护的风险。
### Zadka: 你还有什么想告诉我们的读者的吗?
Leidel:我鼓励每个从事开源项目的人都考虑屏幕另一边的人。要有同理心,记住你自己的经历可能不是你同龄人的经历。要明白你是全球多元化社区的成员,这要求我们始终尊重我们之间的差异。
---
via: <https://opensource.com/article/20/2/python-maintained>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Jannis Leidel is part of the [Jazzband](https://jazzband.co/) community. Jazzband is a collaborative community that shares the responsibility of maintaining [Python](https://opensource.com/resources/python)-based projects.
Jazzband was born out of the stress of maintaining an open source project alone for a longer time. Jannis is a roadie, which means he does administrative tasks and makes sure the people in the band can play when they want.
Jazzband is not his first open source volunteer work—he is a former [Django](https://opensource.com/article/18/8/django-framework) core developer, [Django Software Foundation](https://www.djangoproject.com/foundation/) board member, has written many Django apps and Python projects, has been a [pip](https://opensource.com/article/19/11/python-pip-cheat-sheet) and [virtualenv](https://virtualenv.pypa.io/en/latest/) core developer and release manager, co-founded the [Python Packaging Authority](https://www.pypa.io/en/latest/), and been a [PyPI](https://pypi.org/) admin. On the community front, he co-founded the German Django Association, served as [DjangoCon Europe](https://djangocon.eu/) 2010 co-chairperson, has spoken at several conferences, and for the last year has served as a director and co-communication chair of the [Python Software Foundation](https://www.python.org/psf/).
### Moshe Zadka: How did you get started with programming?
Jannis Leidel: I got started with programming as part of the regular German computer science lessons in high school, where I dabbled with Turbo Pascal and Prolog. I quickly got drawn into the world of web development and wrote small websites with PHP3, [Perl5](http://opensource.com/article/18/1/why-i-love-perl-5), and [MySQL](https://opensource.com/life/16/10/all-things-open-interview-dave-stokes). Later at university, I picked up programming again while working on media arts projects and found [Ruby](http://opensource.com/business/16/4/save-development-time-and-effort-ruby), Perl, and Python to be particularly helpful. I eventually stuck with Python for its versatility and ease of use. I'm very happy to have been able to use Python and open web technologies (HTML/JS/CSS) in my career since then.
### Zadka: How did you get started with open source?
Leidel: As part of an art project at university, I needed a way to talk to various web services and interact with some electronics and found my prior PHP skills not up to the task. So I took a class about programming with Python and got interested in learning more about how frameworks work—compared to libraries—as they further enshrine best practices that I wanted to know about. In particular, the nascent Django Web Framework really appealed to me since it favored a pragmatic approach and provided lots of guidance for how to develop web applications. In 2007 I participated as a student in the Google Summer of Code for Django and later contributed more to Django and its ecosystem of reusable components—after a while as a Django core developer as well. While finishing my degree, I was able to use those skills to work as a freelancer and also spend time on many different parts of the Django community. Moving laterally to the broader Python community was only natural at that point.
### Zadka: What do you for your day job?
Leidel: I'm a Staff Software Engineer at Mozilla, working on data tools for the Firefox data pipeline. In practice, that means I'm working in the broader Firefox Engineering team on various internal and public-facing web-based projects that help Mozilla employees and community members to make sense of the telemetry data that the Firefox web browser sends. Part of my current focus is maintaining our data analysis and visualization platform, which is based on the open source project [Redash](https://redash.io/), and also contributing back to it. Other projects that I contribute to are our next-gen telemetry system [Glean](https://firefox-source-docs.mozilla.org/toolkit/components/telemetry/start/report-gecko-telemetry-in-glean.html) and a tool that allows you to do data science in the browser (including the Scientific Python stack) called [Iodide](https://alpha.iodide.io/).
### Zadka: How did you get involved with Jazzband?
Leidel: Back in 2015, I was frustrated with maintaining projects alone that a lot of people depended on and saw many of my community peers struggle with similar issues. I didn't know a good way to reach more people in the community who may also have an interest in long-term maintenance. On some occasions, I felt that the new "social coding" paradigm was rarely social and often rather isolating and sometimes even traumatic for old and new contributors. I believe the inequality in our community that I find intolerable nowadays was even more rampant at the time, which made providing a safe environment for contributors difficult—something which we now know is essential for stable project maintenance. I wondered if we were missing a more collaborative and inclusive approach to software development.
The Jazzband project was launched in an attempt to lower the barriers to entry for maintenance and simplify some of the more boring aspects of it (e.g., best practices around [CI](https://opensource.com/article/19/12/cicd-resources)).
### Zadka: What is your favorite thing about Jazzband?
Leidel: My favorite thing about Jazzband is the fact that we've secured the maintenance of many projects that a lot of people depend on while also making sure that new contributors of any level of experience can join.
### Zadka: What is the job of a "roadie" in Jazzband?
Leidel: A "roadie" is a go-to person when it comes to all things behind the scenes for Jazzband. That means, for example, dealing with onboarding new projects, maintaining the Jazzband website that handles user management and project releases, acting as a first responder to security or Code of Conduct incidents, and much more. The term "roadies" is borrowed from the music and event industry for support personnel that takes care of almost everything that needs to be done while traveling on tour, except for the actual artistic performance. In Jazzband, they are there to make sure the members can work on the projects. That also means that some tasks are partially or fully automated, where it makes sense, and that best practices are applied to the majority of the Jazzband projects like packaging setup, documentation hosting or continuous integration.
### Zadka: What is the most challenging aspect of your job as a roadie for Jazzband?
Leidel: At the moment, the most challenging aspect of my job as a roadie is to implement improvements for Jazzband that community members have proposed without risking the workflow that they have come to rely on. In other words, scaling the project on a conceptual level has become more difficult the bigger Jazzband gets. There is a certain irony in the fact that I'm the only roadie at the moment and handle some of the tasks alone while Jazzband tries to prevent that from happening for its projects. This is a big concern for the future of Jazzband.
### Zadka: What would you say to someone who is wondering whether they should join Jazzband?
Leidel: If you're interested in joining a group of people who believe that working collaboratively is better than working alone, or if you have struggled with maintenance burden on your own and don't know how to proceed, consider joining Jazzband. It simplifies onboarding new contributors, provides a framework for disputes, and automates releases to [PyPI](https://opensource.com/downloads/7-essential-pypi-libraries). There are many best practices that work well for reducing the risk of projects becoming unmaintained.
### Zadka: Is there anything else you want to tell our readers?
Leidel: I encourage everyone working on open source projects to consider the people on the other side of the screen. Be empathetic and remember that your own experience may not be the experience of your peers. Understand that you are members of a global and diverse community, which requires us always to take leaps of respect for the differences between us.
## Comments are closed. |
13,527 | 13 个 Linux 5.13 中最值得关注的变化 | https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.13-Features | 2021-06-27T16:04:37 | [
"Linux",
"内核"
] | https://linux.cn/article-13527-1.html | 
如果一切顺利的话,周日 Linus Torvalds 将会发布 Linux 5.13 稳定版,而不是发布 5.13-rc8 测试版并把最终版本再推后一个版本。不管是哪种情况,Linux 5.13 很快就会发布,而且会有很多新功能。
在合并窗口结束后,我们照例发布了 Linux 5.13 的功能概述。但是,对于那些不记得在 4 月底到 5 月初的合并窗口期间所有这些变化的人来说,这里回顾了这个下一个内核版本中最突出的变化:
* [对苹果 M1 SoC 和 2020 硬件平台的初步支持](https://www.phoronix.com/scan.php?page=news_item&px=Apple-M1-ARM-SoCs-In-Linux-5.13),尽管这种支持仍然是早期的,对苹果 M1 GPU 等还没有主线支持。
* 经过多年的开发,[Landlock Linux](https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.13-Landlock-Lands) 安全模块已经合并入主线,支持无特权的应用程序沙箱。
* [对 Alder Lake S 图形的初步支持](https://www.phoronix.com/scan.php?page=news_item&px=Intel-Alder-Lake-S-DRM-Next),以及许多使其进入 Linux 5.13 的 Alder Lake 启用代码,如对 Perf 和其他领域。
* [AMDGPU FreeSync HDMI 支持](https://www.phoronix.com/scan.php?page=news_item&px=AMDGPU-Linux-5.13-Aldebaran)现在进入了主线,允许在 HDMI(v2.1 之前)连接上实现 FreeSync,而不仅仅是通过 DisplayPort。
* 对 [Aldebaran](https://www.phoronix.com/scan.php?page=search&q=Aldebaran) 作为下一代 AMD CDNA 加速器的初步支持。
* [一个新的英特尔冷却驱动](https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.13-Intel-Cooling-Driver),允许在比系统默认温度更低的阈值下对 CPU 进行降频。
* [一个通用的 USB 显示驱动](https://www.phoronix.com/scan.php?page=news_item&px=Generic-USB-Display-GUD-5.13),用于将树莓派 Zero 变成一个基于 USB 的显示适配器。
* [对 IO\_uring 的更多性能增强](https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.13-More-IO_uring),它在整个开源生态系统中不断得到采用。
* 支持 [Realtek RTL8156 和 RTL8153D 网络适配器](https://www.phoronix.com/scan.php?page=news_item&px=Realtek-RTL8153-RTL8156-Linux)。同时在音频方面也有一些[新的 Realtek 硬件支持](https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.13-Sound)。
* 亚马逊的 [Luna 游戏控制器现在由 XPad 驱动支持](https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.13-Amazon-Game-Control)。
* 对[较新的微软 Surface 笔记本电脑的触摸板和键盘支持](https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.13-Surface-HID),以前需要使用树外的内核代码。
* 对主线内核的 [Clang 控制流完整性支持](https://www.phoronix.com/scan.php?page=news_item&px=Clang-CFI-Linux-5.13)(CFI),可以增强安全性而仅有少量运行时开销。
* 作为另一项内核安全改进,将每个[系统调用的内核堆栈偏移量随机化](https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.13-Rand-Offset-Sys-Call)。
---
via: <https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.13-Features>
作者:[Michael Larabel](https://www.phoronix.com/scan.php?page=michaellarabel) 选题:[wxy](https://github.com/wxy) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-13526-1.html) 荣誉推出
| 301 | Moved Permanently | null |
13,529 | 七个改变我生活的 Git 小技巧 | https://opensource.com/article/20/10/advanced-git-tips | 2021-06-28T11:00:36 | [
"Git"
] | https://linux.cn/article-13529-1.html |
>
> 这些有用的小技巧将改变你在当前最流行的版本控制系统下的工作方式。
>
>
>

Git 是当前最流行最普遍的版本控制系统之一,它被应用于私有系统和公开网站上各种各样的开发工作。不论我变得对 Git 有多熟悉,似乎总有些功能等待着被发掘。下面分享下和 Git 相关的改变我工作方式的一些小技巧。
### 1、Git 中的自动纠错
我们每个人都不时在输入时犯拼写错误,但是如果你使能了 Git 的自动纠错功能,你就能让 Git 自动纠正一些输入错误的子命令。
假如你想用命令 `git status` 来检查状态,但是你恰巧错误地输入了 `git stats`。通常情况下,Git 会告诉你 ‘stats’ 不是个有效的命令:
```
$ git stats
git: ‘stats’ is not a git command. See ‘git --help’.
The most similar command is
status
```
为了避免类似情形,只需要在你的 Git 配置中使能自动纠错功能。
```
$ git config --global help.autocorrect 1
```
如果你只想对当前的仓库生效,就省略掉选项 `--global`。
这个命令会使能自动纠错功能。在相应的 [Git 官方文档](https://git-scm.com/book/en/v2/Customizing-Git-Git-Configuration#_code_help_autocorrect_code) 中可以看到这个命令的详细说明,但是试着敲一下上面的错误命令会使你对这个设置干了什么有个直观的了解:
```
$ git stats
git: ‘stats’ is not a git command. See ‘git --help’.
On branch master
Your branch is up to date with ‘origin/master’.
nothing to commit, working tree clean
```
在上面的例子中,Git 直接运行了它建议命令的第一个,也就是 `git status`,而不是给你展示它所建议的子命令。
### 2、对提交进行计数
需要对提交进行计数的原因有很多。例如,一些开发人员利用提交计数来判断什么时候递增工程构建序号,也有一些开发人员用提交计数来对项目进展取得一个整体上的感观。
对提交进行计数相当简单而且直接,下面就是相应的 Git 命令:
```
$ git rev-list --count branch-name
```
在上述命令中,参数 `branch-name` 必须是一个你当前仓库里的有效分支名。
```
$ git rev-list –count master
32
$ git rev-list –count dev
34
```
### 3、仓库优化
你的代码仓库不仅对你来说很宝贵,对你所在的组织也一样。通过少数几个惯例你就能使自己的仓库整洁并且保持最新。[使用 .gitignore 文件](https://opensource.com/article/20/8/dont-ignore-gitignore) 就是这些最好的惯例之一。通过使用这个文件你可以告诉 Git 不要保存一些不需要记录的文件,如二进制文件、临时文件等等。
当然,你还可以使用 Git 的垃圾回收来进一步优化你的仓库。
```
$ git gc --prune=now --aggressive
```
这个命令在你和你的团队经常使用 `pull` 或者 `push` 操作的时候很有帮助。
它是一个内部工具,能清理掉你的仓库里没法访问或者说“空悬”的 Git 对象。
### 4、给未追踪的文件来个备份
大多数时候,删除所有未追踪的文件是安全的。但很多时候也有这么一种场景,你想删掉这些未追踪的文件同时也想做个备份防止以后需要用到。
Git 组合一些 Bash 命令和管道操作,可以让你可以很容易地给那些未追踪的文件创建 zip 压缩包。
```
$ git ls-files --others --exclude-standard -z |\
xargs -0 tar rvf ~/backup-untracked.zip
```
上面的命令就生成了一个名字为 `backup-untracked.zip` 的压缩包文件(当然,在 `.gitignore` 里面忽略了的文件不会包含在内)。
### 5、了解你的 .git 文件夹
每个仓库都有一个 `.git` 文件夹,它是一个特殊的隐藏文件夹。
```
$ ls -a
. … .git
```
Git 主要通过两个东西来工作:
1. 当前工作树(你当前检出的文件状态)
2. 你的 Git 仓库的文件夹(准确地说,包含版本信息的 `.git` 文件夹的位置)
这个文件夹存储了所有参考信息和一些其他的如配置、仓库数据、HEAD 状态、日志等更多诸如此类的重要细节。
一旦你删除了这个文件夹,尽管你的源码没被删,但是类似你的工程历史记录等远程信息就没有了。删除这个文件夹意味着你的工程(至少本地的复制)不再在版本控制的范畴之内了。这也就意味着你没法追踪你的修改;你没法从远程仓拉取或推送到远程仓了。
通常而言,你需要或者应当对你的 `.git` 文件夹的操作并不多。它是被 Git 管理的,而且大多数时候是一个禁区。然而,在这个文件夹内还是有一些有趣的工件,比如说当前的 HEAD 状态在内的就在其中。
```
$ cat .git/HEAD
ref: refs/heads/master
```
它也隐含着对你仓库地描述:
```
$ cat .git/description
```
这是一个未命名的仓库;通过编辑文件 ‘description’ 可以给这个仓库命名。
Git 钩子文件夹连同一些钩子文件例子也在这里。参考这些例子你就能知道 Git 钩子能干什么了。当然,你也可以 [参考这个 Seth Kenlon 写的 Git 钩子介绍](https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6)。
### 6、浏览另一个分支的文件
有时,你会想要浏览另一个分支下某个文件的内容。这其实用一个简单的 Git 命令就可以实现,甚至都不用切换分支。
设想你有一个命名为 [README.md](http://README.md) 的文件,并且它在 `main` 分支上。当前你正工作在一个名为 `dev` 的分支。
用下面的 Git 命令,在终端上就行。
```
$ git show main:README.md
```
一旦你执行这个命令,你就能在你的终端上看到 `main` 分支上该文件的内容。
### 7、Git 中的搜索
用一个简单的命令你就能在 Git 中像专业人士一样搜索了。更有甚者,尽管你不确定你的修改在哪次提交或者哪个分支上,你依然能搜索。
```
$ git rev-list --all | xargs git grep -F ''
```
例如,假设你想在你的仓库中搜索字符串 `“font-size: 52 px;"` :
```
$ git rev-list –all | xargs git grep -F ‘font-size: 52 px;’
F3022…9e12:HtmlTemplate/style.css: font-size: 52 px;
E9211…8244:RR.Web/Content/style/style.css: font-size: 52 px;
```
### 试试这些小技巧
我希望这些小技巧对你是有用的,或者增加你的生产力或者节省你的大量时间。
你也有一些喜欢的 [Git 技巧](https://acompiler.com/git-tips/) 吗?在评论区分享吧。
---
via: <https://opensource.com/article/20/10/advanced-git-tips>
作者:[Rajeev Bera](https://opensource.com/users/acompiler) 选题:[lujun9972](https://github.com/lujun9972) 译者:[BoosterY](https://github.com/BoosterY) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Git is one of the most common version control systems available, and it's used on private systems and publicly hosted websites for all kinds of development work. Regardless of how proficient with Git I become, it seems there are always features left to discover. Here are seven tricks that have changed the way I work with Git.
## 1. Autocorrection in Git
We all make typos sometimes, but if you have Git's auto-correct feature enabled, you can let Git automatically fix a mistyped subcommand.
Suppose you want to check the status with `git status`
but you type `git stats`
by accident. Under normal circumstances, Git tells you that 'stats' is not a valid command:
```
$ git stats
git: ‘stats’ is not a git command. See ‘git --help’.
The most similar command is
status
```
To avoid similar scenarios, enable Git autocorrection in your Git configuration:
`$ git config --global help.autocorrect 1`
If you want this to apply only to your current repository, omit the `--global`
option.
This command enables the autocorrection feature. An in-depth tutorial is available at [Git Docs](https://git-scm.com/book/en/v2/Customizing-Git-Git-Configuration#_code_help_autocorrect_code), but trying the same errant command as above gives you a good idea of what this configuration does:
```
$ git stats
git: ‘stats’ is not a git command. See ‘git --help’.
On branch master
Your branch is up to date with ‘origin/master’.
nothing to commit, working tree clean
```
Instead of suggesting an alternative subcommand, Git now just runs the top suggestion, which in this case was **git status**.
## 2. Count your commits
There are many reasons you might need to count your commits. Many developers count the number of commits to judge when to increment the build number, for instance, or just to get a feel for how the project is progressing.
To count your commits is really easy and straightforward; here is the Git command:
`$ git rev-list --count`
In the above command, the **branch-name** should be a valid branch name in your current repository.
```
$ git rev-list –count master
32
$ git rev-list –count dev
34
```
## 3. Optimize your repo
Your code repository is valuable not only for you but also for your organization. You can keep your repository clean and up to date with a few simple practices. One of the best practices is to [use the .gitignore file](https://opensource.com/article/20/8/dont-ignore-gitignore). By using this file, you are telling Git not to store many unwanted files like binaries, temporary files, and so on.
To optimize your repository further, you can use Git garbage collection.
`$ git gc --prune=now --aggressive`
This command helps when you or your team heavily uses **pull** or **push** commands.
This command is an internal utility that cleans up unreachable or "orphaned" Git objects in your repository.
## 4. Take a backup of untracked files
Most of the time, it's safe to delete all the untracked files. But many times, there is a situation wherein you want to delete, but also to create a backup of your untracked files just in case you need them later.
Git, along with some Bash command piping, makes it easy to create a zip archive for your untracked files.
```
$ git ls-files --others --exclude-standard -z |\
xargs -0 tar rvf ~/backup-untracked.zip
```
The above command makes an archive (and excludes files listed in .gitignore) with the name backup-untracked.zip
## 5. Know your .git folder
Every repository has a .git folder. It is a special hidden folder.
```
$ ls -a
. … .git
```
Git mainly works with two things:
- The working tree (the state of files in your current checkout)
- The path of your Git repository (specifically, the location of the .git folder, which contains the versioning information)
This folder stores all references and other important details like configurations, repository data, the state of HEAD, logs, and much more.
If you delete this folder, the current state of your source code is not deleted, but your remote information, such as your project history, is. Deleting this folder means your project (at least, the local copy) isn't under version control anymore. It means you cannot track your changes; you cannot pull or push from a remote.
Generally, there's not much you need to do, or should do, in your .git folder. It's managed by Git and is considered mostly off-limits. However, there are some interesting artifacts in this directory, including the current state of HEAD:
```
$ cat .git/HEAD
ref: refs/heads/master
```
It also contains, potentially, a description of your repository:
`$ cat .git/description`
This is an unnamed repository; edit this file 'description' to name the repository.
The Git hooks folder is also here, complete with example hook files. You can read these samples to get an idea of what's possible through Git hooks, and you can also [read this Git hook introduction by Seth Kenlon](https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6).
## 6. View a file of another branch
Sometimes you want to view the content of the file from another branch. It's possible with a simple Git command, and without actually switching your branch.
Suppose you have a file called [README.md](http://README.md), and it's in the **main** branch. You're working on a branch called **dev**.
With the following Git command, you can do it from the terminal.
`$ git show main:README.md`
Once you execute this command, you can view the content of the file in your terminal.
## 7. Search in Git
You can search in Git like a pro with one simple command. Better still, you can search in Git even if you aren't sure which commit—or even branch—you made your changes.
`$ git rev-list --all | xargs git grep -F ‘’`
For example, suppose you want to search for the string "font-size: 52 px;" in your repository:
```
$ git rev-list –all | xargs git grep -F ‘font-size: 52 px;’
F3022…9e12:HtmlTemplate/style.css: font-size: 52 px;
E9211…8244:RR.Web/Content/style/style.css: font-size: 52 px;
```
## Try these tips
I hope these advanced tips are useful and boost your productivity, saving you lots of time.
Do you have [Git tips](https://acompiler.com/git-tips/) you love? Share them in the comments.
## Comments are closed. |
13,530 | KTorrent:KDE 上的一个非常有用的 BitTorrent 应用 | https://itsfoss.com/ktorrent/ | 2021-06-28T12:00:36 | [
"BitTorrent"
] | https://linux.cn/article-13530-1.html | 
Linux 中有各种各样的 BitTorrent 应用。但是,找到一个好的、提供许多功能的应用将可以为你节省一些时间。
KDE 的 KTorrent 就是这样一个为 Linux 打造的 BitTorrent 应用。
虽然 [Linux 有好几个 torrent 客户端](https://itsfoss.com/best-torrent-ubuntu/),但我最近发现 KTorrent 对我而言很合适。
### KTorrent: 适用于 Linux 的开源 BitTorrent 客户端

KTorrent 是一个成熟的 torrent 客户端,主要为 KDE 桌面定制。无论你使用什么桌面环境,它都能很好地工作。
当然,使用 KDE 桌面,你可以得到一个无缝的用户体验。
让我们来看看它的所有功能。
### KTorrent 的功能

对于普通的 torrent 用户来说,拥有一套全面的功能使事情变得简单。而 KTorrent 也不例外。在这里,我将列出 KTorrent 的主要亮点:
* 在一个队列中添加 torrent 下载
* 能够控制每次下载(或整体)的速度限制
* 视频和音频文件预览选项
* 支持导入下载的文件(部分/全部)
* 在下载多个文件时,能够对 torrent 下载进行优先排序
* 为多文件 torrent 选择要下载的特定文件
* IP 过滤器,可选择踢走/禁止对端。
* 支持 UDP 跟踪器
* 支持 µTorrent 对端
* 支持协议加密
* 能够创建无跟踪器的 torrent
* 脚本支持
* 系统托盘集成
* 通过代理连接
* 增加了插件支持
* 支持 IPv6
KTorrent 看起来可以作为一个日常使用的 torrent 客户端,在一个地方管理所有的 torrent 下载。

除了上面提到的功能外,它还对客户端的行为提供了很大的控制。例如,调整下载/暂停/跟踪器的指示颜色。
如果你想禁用完成 torrent 下载时的声音或得到活动通知,你还可以设置通知。

虽然像协议加密支持这样的功能可能无法取代一些 [最好的私有专用网络](https://itsfoss.com/best-vpn-linux/) 服务,但它对桌面客户端来说是一个重要的补充。
### 在 Linux 中安装 KTorrent
KTorrent 应该可以通过包管理器(如 [Synaptic](https://itsfoss.com/synaptic-package-manager/))或默认的仓库获得。你也可以在你的软件中心找到它并轻松安装。
除此之外,它还在 [Flathub](https://flathub.org/apps/details/org.kde.ktorrent) 上提供了一个适用于任何 Linux 发行版的 [Flatpak](https://itsfoss.com/what-is-flatpak/) 官方包。如果你需要帮助,我们有一个 [Flatpak 指南](https://itsfoss.com/flatpak-guide/) 供参考。
如果你喜欢的话,你也可以尝试可用的 [snap包](https://snapcraft.io/ktorrent)。
要探索更多关于它和源码的信息,请前往它的 [官方 KDE 应用页面](https://apps.kde.org/ktorrent/)。
* [KTorrent](https://apps.kde.org/ktorrent/)
### 结束语
KTorrent 是 Linux 中一个出色的 torrent 客户端。我在我的 Linux Mint 系统的 Cinnamon 桌面上试用了它,它运行得很好。
我喜欢它的简单和可配置性。尽管我不是每天都在使用 torrent 客户端,但在我短暂的测试中,我没有发现 KTorrent 有什么奇怪的地方。
你认为 KTorrent 作为 Linux 的 torrent 客户端怎么样?你喜欢用什么呢?
---
via: <https://itsfoss.com/ktorrent/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are a variety of BitTorrent applications available for Linux. But finding a good application that offers many features should save you some time.
KTorrent by KDE is one such BitTorrent app built for Linux.
While there are [several torrent clients for Linux](https://itsfoss.com/best-torrent-ubuntu/), I recently found KTorrent interesting for my use-case.
## KTorrent: Open Source BitTorrent Client for Linux
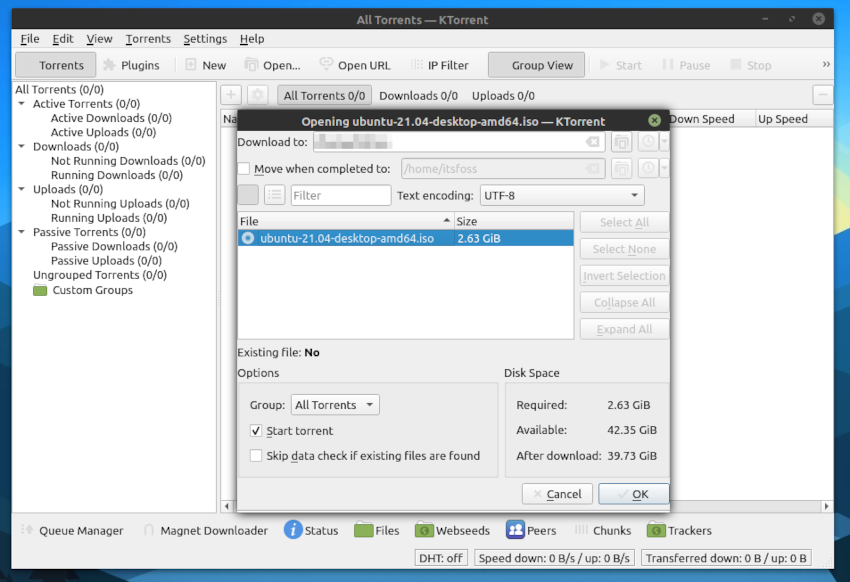
KTorrent is a full-fledged torrent client primarily tailored for KDE desktop. It should work simply fine no matter what desktop environment you use.
Of course, with KDE desktop, you may get a seamless user experience.
Let us look at the all the features offered.
## Features of KTorrent
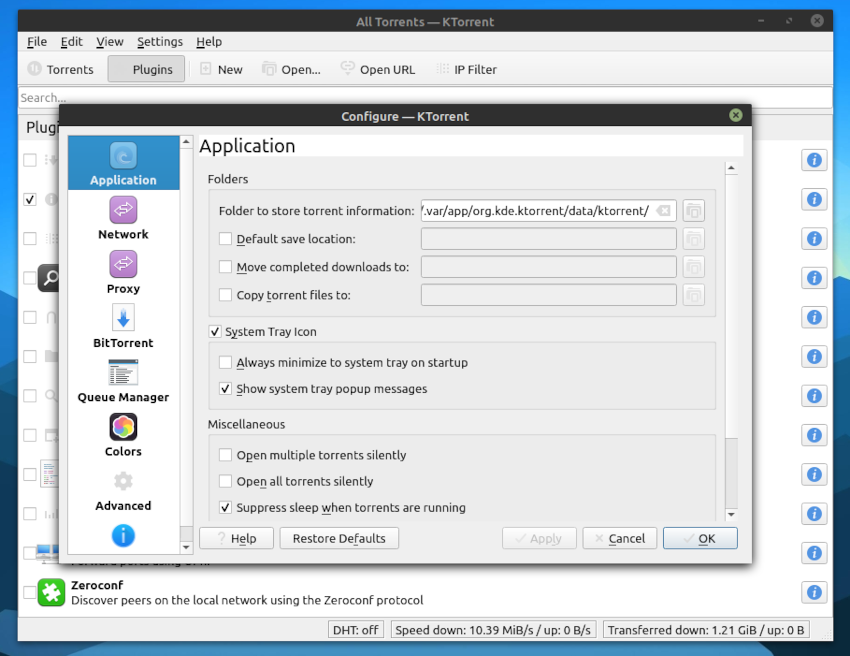
For regular torrent users, having an extensive set of features makes things easy. And KTorrent is no exception. Here, I’ll highlight the key highlights of KTorrent:
- Adding torrent downloads in a queue
- Ability to control the speed limits per download (or overall)
- Video and audio file preview option
- Supports importing of downloaded files (partial/full)
- Ability to prioritize torrent downloads when downloading multiple files
- Selection of specific files to download for multi-file torrents
- IP filter with the option of kicking/banning peers
- UDP tracker support
- µTorrent peer support
- Support for protocol encryption
- Ability to create trackerless torrent
- Scripting support
- System tray integration
- Connection through a proxy
- Added plugin support
- Supports IPv6
KTorrent sounds something useful as a torrent client that you can use daily with control to manage all your torrent downloads at one place.
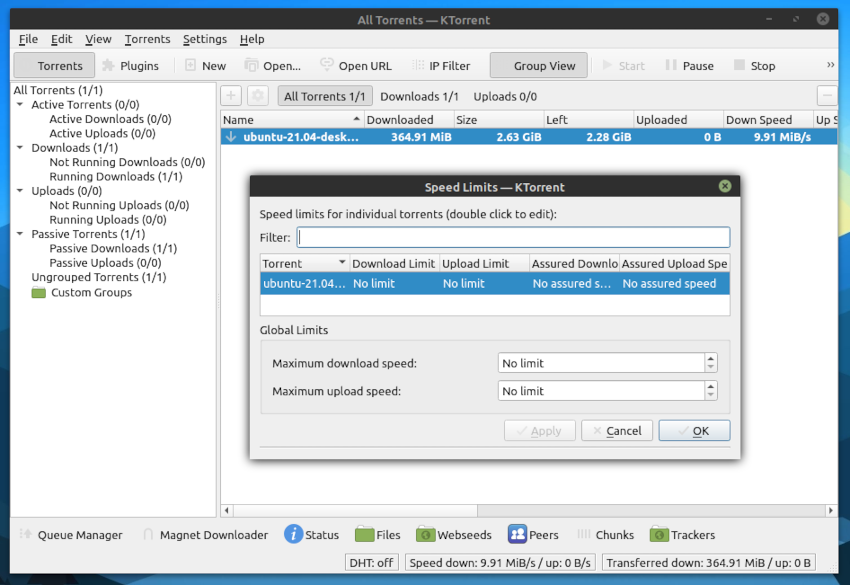
In addition to the features mentioned above, it offers great control over the behavior of the client as well. For instance, tweaking the color that indicates downloads/pause/trackers.
You also get the ability to set the notification if you want to disable the sound of completing a torrent download or getting notified of the activity.
While features like protocol encryption support may not be able to replace some of the [best VPN](https://itsfoss.com/best-vpn-linux/) services, it is an important addition for desktop clients.
## Installing KTorrent in Linux
KTorrent should be available through your package managers like [Synaptic](https://itsfoss.com/synaptic-package-manager/) or the default repositories. You can also find it listed in your software center for easy installation.
In addition to this, it also offers a [Flatpak](https://itsfoss.com/what-is-flatpak/) official package on [Flathub](https://flathub.org/apps/details/org.kde.ktorrent) for any Linux distribution. If you need help with that, we have a [Flatpak guide](https://itsfoss.com/flatpak-guide/) for reference.
You can also try the [snap package](https://snapcraft.io/ktorrent) available if you prefer that.
To explore more about it and the source code, head to its [official KDE app page](https://apps.kde.org/ktorrent/).
## Closing Thoughts
KTorrent is a phenomenal torrent client for Linux. I tried it on my Linux Mint system on top of Cinnamon desktop, and it worked great.
I like how simple, yet configurable it is. Even though I don’t use a torrent client every day, I did not see anything weird with KTorrent in my brief testing.
What do you think about KTorrent as a torrent client for Linux? What do you prefer to use it instead? |
13,532 | 在 Linux 上用 dust 代替 du | https://opensource.com/article/21/6/dust-linux | 2021-06-29T03:34:24 | [
"du"
] | https://linux.cn/article-13532-1.html |
>
> dust 命令是用 Rust 编写的对 du 命令的一个更直观实现。
>
>
>

如果你在 Linux 命令行上工作,你会熟悉 `du` 命令。了解像 `du` 这样的命令,可以快速返回磁盘使用情况,是命令行使程序员更有效率的方法之一。然而,如果你正在寻找一种方法来节省更多的时间,使你的生活更加容易,看看 [dust](https://github.com/bootandy/dust),它是用 Rust 重写的 `du`,具有更多的直观性。
简而言之,`dust` 是一个提供文件类型和元数据的工具。如果你在一个目录中运行了 `dust`,它将以几种方式报告该目录的磁盘利用率。它提供了一个信息量很大的图表,告诉你哪个文件夹使用的磁盘空间最大。如果有嵌套的文件夹,你可以看到每个文件夹使用的空间百分比。
### 安装 dust
你可以使用 Rust 的 Cargo 包管理器安装 `dust`:
```
$ cargo install du-dust
```
另外,你可以在 Linux 上的软件库中找到它,在 macOS 上,可以使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac)。
### 探索 dust
在一个目录中执行 `dust` 命令,会返回一个图表,以树状格式显示其内容和每个项目所占的百分比。
```
$ dust
5.7M ┌── exa │ ██ │ 2%
5.9M ├── tokei │ ██ │ 2%
6.1M ├── dust │ ██ │ 2%
6.2M ├── tldr │ ██ │ 2%
9.4M ├── fd │ ██ │ 4%
2.9M │ ┌── exa │ ░░░█ │ 1%
15M │ ├── rustdoc │ ░███ │ 6%
18M ├─┴ bin │ ████ │ 7%
27M ├── rg │ ██████ │ 11%
1.3M │ ┌── libz-sys-1.1.3.crate │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 0%
1.4M │ ├── libgit2-sys-0.12.19+1.1.0.crate │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 1%
4.5M │ ┌─┴ github.com-1ecc6299db9ec823 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 2%
4.5M │ ┌─┴ cache │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 2%
1.0M │ │ ┌── git2-0.13.18 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
1.4M │ │ ├── exa-0.10.1 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
1.5M │ │ │ ┌── src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
2.2M │ │ ├─┴ idna-0.2.3 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
1.2M │ │ │ ┌── linux │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
1.6M │ │ │ ┌─┴ linux_like │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
2.6M │ │ │ ┌─┴ unix │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
3.1M │ │ │ ┌─┴ src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
3.1M │ │ ├─┴ libc-0.2.94 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
1.2M │ │ │ ┌── test │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
2.6M │ │ │ ┌─┴ zlib-ng │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
904K │ │ │ │ ┌── vstudio │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
2.0M │ │ │ │ ┌─┴ contrib │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
3.4M │ │ │ ├─┴ zlib │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
6.1M │ │ │ ┌─┴ src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 2%
6.1M │ │ ├─┴ libz-sys-1.1.3 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 2%
1.6M │ │ │ ┌── pcre │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
2.5M │ │ │ ┌─┴ deps │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
3.8M │ │ │ ├── src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
7.4M │ │ │ ┌─┴ libgit2 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 3%
7.6M │ │ ├─┴ libgit2-sys-0.12.19+1.1.0 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 3%
26M │ │ ┌─┴ github.com-1ecc6299db9ec823 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░██████ │ 10%
26M │ ├─┴ src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░██████ │ 10%
932K │ │ ┌── .cache │ ░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓█ │ 0%
11M │ │ │ ┌── pack-c3e3a51a17096a3078196f3f014e02e5da6285aa.idx │ ░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓███ │ 4%
135M │ │ │ ├── pack-c3e3a51a17096a3078196f3f014e02e5da6285aa.pack│ ░░░░░░▓▓███████████████████████████ │ 53%
147M │ │ │ ┌─┴ pack │ ░░░░░░█████████████████████████████ │ 57%
147M │ │ │ ┌─┴ objects │ ░░░░░░█████████████████████████████ │ 57%
147M │ │ ├─┴ .git │ ░░░░░░█████████████████████████████ │ 57%
147M │ │ ┌─┴ github.com-1ecc6299db9ec823 │ ░░░░░░█████████████████████████████ │ 57%
147M │ ├─┴ index │ ░░░░░░█████████████████████████████ │ 57%
178M ├─┴ registry │ ███████████████████████████████████ │ 69%
257M ┌─┴ . │██████████████████████████████████████████████████ │ 100%
$
```
将 `dust` 应用于一个特定的目录:
```
$ dust ~/Work/
```

`-r` 选项以相反的顺序显示输出,“根”在底部:
```
$ dust -r ~/Work/
```
使用 `dust -d 3` 会返回三层的子目录和它们的磁盘利用率:
```
$ dust -d 3 ~/Work/wildfly/jaxrs/target/classes
4.0K ┌── jaxrs.xml │ █ │ 1%
4.0K ┌─┴ subsystem-templates │ █ │ 1%
4.0K │ ┌── org.jboss.as.controller.transform.ExtensionTransformerRegistration│ █ │ 1%
4.0K │ ├── org.jboss.as.controller.Extension │ █ │ 1%
8.0K │ ┌─┴ services │ █ │ 2%
8.0K ├─┴ META-INF │ █ │ 2%
4.0K │ ┌── jboss-as-jaxrs_1_0.xsd │ ░█ │ 1%
8.0K │ ├── jboss-as-jaxrs_2_0.xsd │ ░█ │ 2%
12K ├─┴ schema │ ██ │ 3%
408K │ ┌── as │ ████████████████████████████████████████ │ 94%
408K │ ┌─┴ jboss │ ████████████████████████████████████████ │ 94%
408K ├─┴ org │ ████████████████████████████████████████ │ 94%
432K ┌─┴ classes │██████████████████████████████████████████ │ 100%
$
```
### 总结
`dust` 的魅力在于它是一个小而简单的、易于理解的命令。它使用颜色方案来表示最大的子目录,使你的目录易于可视化。这是一个受欢迎的项目,欢迎大家来贡献。
你是否使用或考虑使用 `dust`?如果是,请在下面的评论中告诉我们你的想法。
---
via: <https://opensource.com/article/21/6/dust-linux>
作者:[Sudeshna Sur](https://opensource.com/users/sudeshna-sur) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you work on the Linux command line, you will be familiar with the `du`
command. Knowing commands like `du`
, which returns information about disk usage quickly, is one of the ways the command line makes programmers more productive. Yet if you're looking for a way to save even more time and make your life even easier, take a look at [dust](https://github.com/bootandy/dust), which is `du`
rewritten in Rust with more intuitiveness.
In short, `dust`
is a tool that provides a file's type and metadata. If you trigger `dust`
in a directory, it will report that directory's disk utilization in a couple of ways. It provides a very informative graph that tells you which folder is using the most disk space. If there is a nested folder, you can see the percentage of space used by each folder.
## Install dust
You can install `dust`
using Rust's Cargo package manager:
`$ cargo install du-dust`
Alternately, you might find it in your software repository on Linux, and on macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac).
## Explore dust
Issuing the `dust`
command on a directory returns a graph that shows its contents and what percentage each item holds in a tree format.
```
$ dust
5.7M ┌── exa │ ██ │ 2%
5.9M ├── tokei │ ██ │ 2%
6.1M ├── dust │ ██ │ 2%
6.2M ├── tldr │ ██ │ 2%
9.4M ├── fd │ ██ │ 4%
2.9M │ ┌── exa │ ░░░█ │ 1%
15M │ ├── rustdoc │ ░███ │ 6%
18M ├─┴ bin │ ████ │ 7%
27M ├── rg │ ██████ │ 11%
1.3M │ ┌── libz-sys-1.1.3.crate │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 0%
1.4M │ ├── libgit2-sys-0.12.19+1.1.0.crate │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 1%
4.5M │ ┌─┴ github.com-1ecc6299db9ec823 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 2%
4.5M │ ┌─┴ cache │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 2%
1.0M │ │ ┌── git2-0.13.18 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
1.4M │ │ ├── exa-0.10.1 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
1.5M │ │ │ ┌── src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
2.2M │ │ ├─┴ idna-0.2.3 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
1.2M │ │ │ ┌── linux │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
1.6M │ │ │ ┌─┴ linux_like │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
2.6M │ │ │ ┌─┴ unix │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
3.1M │ │ │ ┌─┴ src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
3.1M │ │ ├─┴ libc-0.2.94 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
1.2M │ │ │ ┌── test │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
2.6M │ │ │ ┌─┴ zlib-ng │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
904K │ │ │ │ ┌── vstudio │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
2.0M │ │ │ │ ┌─┴ contrib │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
3.4M │ │ │ ├─┴ zlib │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
6.1M │ │ │ ┌─┴ src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 2%
6.1M │ │ ├─┴ libz-sys-1.1.3 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 2%
1.6M │ │ │ ┌── pcre │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
2.5M │ │ │ ┌─┴ deps │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
3.8M │ │ │ ├── src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
7.4M │ │ │ ┌─┴ libgit2 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 3%
7.6M │ │ ├─┴ libgit2-sys-0.12.19+1.1.0 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 3%
26M │ │ ┌─┴ github.com-1ecc6299db9ec823 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░██████ │ 10%
26M │ ├─┴ src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░██████ │ 10%
932K │ │ ┌── .cache │ ░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓█ │ 0%
11M │ │ │ ┌── pack-c3e3a51a17096a3078196f3f014e02e5da6285aa.idx │ ░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓███ │ 4%
135M │ │ │ ├── pack-c3e3a51a17096a3078196f3f014e02e5da6285aa.pack│ ░░░░░░▓▓███████████████████████████ │ 53%
147M │ │ │ ┌─┴ pack │ ░░░░░░█████████████████████████████ │ 57%
147M │ │ │ ┌─┴ objects │ ░░░░░░█████████████████████████████ │ 57%
147M │ │ ├─┴ .git │ ░░░░░░█████████████████████████████ │ 57%
147M │ │ ┌─┴ github.com-1ecc6299db9ec823 │ ░░░░░░█████████████████████████████ │ 57%
147M │ ├─┴ index │ ░░░░░░█████████████████████████████ │ 57%
178M ├─┴ registry │ ███████████████████████████████████ │ 69%
257M ┌─┴ . │██████████████████████████████████████████████████ │ 100%
$
```
To apply `dust`
to a specific directory:
`$ dust ~/Work/`

(Sudeshna Sur, CC BY-SA 4.0)
The `-r`
option shows the output in reverse order, with root at the bottom:
`$ dust -r ~/Work/`
Using `dust -d 3`
returns three levels of subdirectories and their disk utilization:
`$ dust -d 3 ~/Work/wildfly/jaxrs/target/classes`
```
$ dust -d 3 ~/Work/wildfly/jaxrs/target/classes
4.0K ┌── jaxrs.xml │ █ │ 1%
4.0K ┌─┴ subsystem-templates │ █ │ 1%
4.0K │ ┌── org.jboss.as.controller.transform.ExtensionTransformerRegistration│ █ │ 1%
4.0K │ ├── org.jboss.as.controller.Extension │ █ │ 1%
8.0K │ ┌─┴ services │ █ │ 2%
8.0K ├─┴ META-INF │ █ │ 2%
4.0K │ ┌── jboss-as-jaxrs_1_0.xsd │ ░█ │ 1%
8.0K │ ├── jboss-as-jaxrs_2_0.xsd │ ░█ │ 2%
12K ├─┴ schema │ ██ │ 3%
408K │ ┌── as │ ████████████████████████████████████████ │ 94%
408K │ ┌─┴ jboss │ ████████████████████████████████████████ │ 94%
408K ├─┴ org │ ████████████████████████████████████████ │ 94%
432K ┌─┴ classes │██████████████████████████████████████████ │ 100%
$
```
## Conclusion
The beauty of `dust`
lies in being a small, simple, and easy-to-understand command. It uses a color scheme to denote the largest subdirectories, making it easy to visualize your directory. It's a popular project, and contributions are welcome.
Have you used or considered using `dust`
? If so, please let us know your thoughts in the comments below.
## 5 Comments |
13,533 | 为什么我们要开源我们的 Python 平台 | https://opensource.com/article/20/7/why-open-source | 2021-06-29T04:12:00 | [
"开源",
"Python"
] | /article-13533-1.html |
>
> 开源开发的理念使得 Anvil 的整个解决方案更加有用且值得信赖。
>
>
>

Anvil 团队最近开源了 [Anvil App Server](https://anvil.works/blog/open-source), 一个用于托管完全用 Python 构建的 Web 程序的运行时引擎。
社区的反应十分积极,我们 Anvil 团队已经将许多反馈纳入了我们的 [下一个版本](https://github.com/anvil-works/anvil-runtime)。但是我们不断被问到的问题是,“为什么你们选择开源这个产品的核心呢?”
### 我们为何创造 Anvil
[Anvil](https://anvil.works/) 是一个可以使得构建 Web 应用更加简单的工具。我们让你们有能力仅使用一种语言—— Python —— 就可以来构建你的整个应用。
在 Anvil 之前,如果你想要构建一个 Web app,你需要写很多代码,用很多的技术,比如 HTML、Javascript、CSS、Python、SQL、React、Redux、Bootstrap、Sass、Webpack 等。这需要花费很长时间来学习。对于一个简单的应用便是这样子;相信我,一般的应用其实 [更加复杂](https://github.com/kamranahmedse/developer-roadmap#introduction)。

*是的。对于一个简单的 web 应用便是需要如此多的技术。*
但即使如此,你还没有完成!你需要了解有关 Git 和云托管提供商的所有信息、如何保护(很有可能是)Linux 操作系统、如何调整数据库,然后随时待命以保持其运行。一直如此。
因此,我们开发出了 Anvil,这是一个在线 IDE,你可以在用 [拖放编辑器](https://anvil.works/docs/client/ui) 来设计你的 UI 界面,用 Python 编写你的 [逻辑](https://anvil.works/docs/client/python),然后 Anvil 会负责其余的工作。我们将所有的繁杂的技术栈进行了替换,只用 Python 就行啦!
### 简单的 Web 托管很重要,但还不够
Anvil 还可以为你托管你的应用程序。为什么不呢?部署 Web 应用程序非常复杂,因此运行我们自己的云托管服务是提供我们所需的简单性的唯一方法。在 Anvil 编辑器中构建一个应用程序,[单击按钮](https://anvil.works/docs/deployment),它就在网上发布了。
但我们不断听到有人说,“那太好了,但是……”
* “我需要在没有可靠互联网接入的海外平台上运行这个应用。”
* “我想要将我的应用程序嵌入到我售出的 IoT 设备中”
* "如果我把我的宝都压到你的 Anvil 上,我怎么能确定十年后我的应用仍然能够运行呢?”
这些都是很好的观点!云服务并不是适合所有人的解决方案。如果我们想为这些用户提供服务,就必须有一些方法让他们把自己的应用从 Anvil 中取出来,在本地运行,由他们自己完全控制。
### 开源是一个逃生舱,而不是弹射座椅
在会议上,我们有时会被问到,“我可以将它导出为 Flask+JS 的应用程序吗?” 当然,我们可以将 Anvil 项目分别导出为 Python 和 JavaScript —— 我们可以生成一个服务器包,将客户端中的 Python 编译为 Javascript,然后生成一个经典的 Web 应用程序。但它会有严重的缺点,因为:**代码生成是一个弹射座椅。**

生成的代码聊胜于无;至少你可以编辑它!但是在你编辑该代码的那一刻,你就失去了生成它的系统的所有好处。如果你使用 Anvil 是因为它的 [拖放编辑器](https://anvil.works/docs/editor) 和 [运行在浏览器中的 Python](https://anvil.works/docs/client),那么你为什么必须使用 vim 和 Javascript 才能在本地托管你的应用程序?
我们相信 [逃生舱,而不是弹射座椅](https://anvil.works/blog/escape-hatches-and-ejector-seats)。所以我们选择了一个正确的方式——我们 [开源了 Anvil 的运行引擎](https://anvil.works/blog/open-source),这与在我们的托管服务中为你的应用程序提供服务的代码相同。这是一个独立的应用程序;你可以使用文本编辑器编辑代码并在本地运行。但是你也可以将它直接用 `git` 推回到我们的在线 IDE。这不是弹射座椅;没有爆炸性的转变。这是一个逃生舱;你可以爬出来,做你需要做的事情,然后再爬回来。
### 如果它开源了,它还可靠吗
开源中的一个看似矛盾的是,它的免费可用性是它的优势,但有时也会产生不稳定的感觉。毕竟,如果你不收费,你如何保持这个平台的长期健康运行?
我们正在做我们一直在做的事情 —— 提供一个开发工具,使构建 Web 应用程序变得非常简单,尽管你使用 Anvil 构建的应用程序 100% 是你的。我们为 Anvil 应用程序提供托管,并为 [企业客户](https://anvil.works/docs/overview/enterprise) 提供整个现场开发和托管平台。这使我们能够提供免费计划,以便每个人都可以将 Anvil 用于业余爱好或教育目的,或者开始构建某些东西并查看它的发展。
### 得到的多,失去的少
开源我们的运行引擎并没有减少我们的业务 —— 它使我们的在线 IDE 在今天和未来变得更有用、更值得信赖。我们为需要它的人开放了 Anvil App Server 的源代码,并提供最终的安全保障。对于我们的用户来说,这是正确的举措 —— 现在他们可以放心地进行构建,因为他们知道开源代码 [就在那里](https://github.com/anvil-works/anvil-runtime),如果他们需要的话。
如果我们的开发理念与你产生共鸣,何不亲自尝试 Anvil?
---
这篇文章改编自 [Why We Open Sourced the Anvil App Server](https://anvil.works/blog/why-open-source),经许可重复使用。
---
via: <https://opensource.com/article/20/7/why-open-source>
作者:[Meredydd Luff](https://opensource.com/users/meredydd-luff) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zepoch](https://github.com/zepoch) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,535 | 为什么要为你的家庭自动化项目选择开源 | https://opensource.com/article/21/6/home-automation-ebook | 2021-06-29T21:54:00 | [
"开源"
] | https://linux.cn/article-13535-1.html |
>
> 家庭自动化是一个令人兴奋的技术分支。现在开始用开源工具为你的家庭自动化设计一套解决方案吧。
>
>
>

行动起来吧。科技的关键是让生活更加美好。
当然,“更好”的标准因人而异,取决于他们在特定时刻的需求。尽管如此,技术具有影响许多不同阶段生活的独特能力。对一些人来说,科技提供了一个轻松的下午娱乐,而对另一些人来说,它提供导航帮助、改善医疗保健或更精确的科学研究。
有趣的是,为一个目的开发的技术很少与用于另一个目的的技术完全无关。例如,运动相机的进步使得一个人可以记录她们在滑雪场上的滑雪过程,也可以使得人体摄像头来帮助防止警察侵犯人权。3D 打印的进步可以让一个人可以制作超级英雄的动作手办,也使得志愿者可以为体弱者制造氧气呼吸机成为可能。技术很重要,它影响着我们所有人。
开源的工作之一是确保每个人都能获得技术进步,无论种族、性别、国籍、身体能力、宗教信仰或财富如何。可悲的是,有些公司将技术视为一种工具来获取有关其客户(即你和我!)的数据,即使这些客户为该技术的研究和开发提供资金。不过,这不是开源的目标,开源项目保护其用户。
是的,家庭自动化是一种现代便利,它正在变得一天比一天好。但这是你的家。开源家庭自动化可以让生活变得更轻松,更像是所有科幻书籍和电影中承诺的未来。但它也可以改善那些身体能力与电器制造商计划不同的人的生活。一个简单的 Python 脚本对一个用户来说可能只是带来了一些便利,而对其他人来说却可能会改变生活。
家庭自动化是一个令人兴奋和有趣的技术分支。 借助这本 **[电子书](https://opensource.com/downloads/home-automation-ebook)**,立即开始设计你的家庭自动化解决方案,然后与他人分享你的创新,让每个人都能受益。
这就是开源的真正意义所在:可以帮助世界上的所有人。
---
via: <https://opensource.com/article/21/6/home-automation-ebook>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zepoch](https://github.com/zepoch) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Let's face it. The point of technology is to make life better.
Of course, what qualifies as "better" varies for people, depending on what they need at any given moment. Still, technology has the unique ability to affect lives at many different stages. For some people, technology offers a relaxing afternoon of entertainment, while for others, it provides navigational assistance, improved health care, or more precise scientific research.
Interestingly, technology developed for one purpose is rarely divorced from technology used for another. For example, progress made in sports cameras so one person can record their snowboard ride down a ski slope also enables bodycams to help prevent human rights violations by police. Progress made in 3D printing so one person can prototype superhero action figures also makes it possible for volunteers to create oxygen ventilators for the infirm. Technology matters, and it affects us all.
It's part of the job of open source to ensure that technological advancements are available to everyone, regardless of ethnicity, gender, nationality, physical abilities, religion, or wealth. Sadly, there are companies out there that view technology as a tool to farm data about its customers (that's you and me!), even while those customers finance the research and development of that technology. That's not what open source is about, though. Open source protects its users.
Yes, home automation is a modern convenience. It's getting better every day. But it's your home. Open source home automation can make life a little easier, a little more like the future promised in all the sci-fi books and movies. But it can also improve the lives of those with different physical abilities than what an appliance manufacturer planned for. A simple Python script written as a minor convenience for one user can be a life-changer for someone else.
Home automation is an exciting and fun branch of tech. Start designing your home automation solutions today with the help of this ** ebook**, and then share your innovation with others so everyone can benefit.
That's just what open source is really all about: taking care of each other.
## Comments are closed. |
13,536 | Fedora Linux 中的 Python 3.10 测试版 | https://fedoramagazine.org/python-3-10-beta-in-fedora-linux/ | 2021-06-29T22:16:01 | [
"Python"
] | https://linux.cn/article-13536-1.html | 
Python 开发者已经发布了 Python 3.10.0 的三个测试版本。现在,你可以在 Fedora Linux 中试用最新的版本尽早用 3.10 测试你的 Python 代码,为 10 月份的 3.10.0 最终版本做好准备。
### 在 Fedora Linux 上安装 Python 3.10
如果你运行 Fedora Linux,你可以用 `dnf` 从官方仓库安装 Python 3.10:
```
$ sudo dnf install python3.10
```
你可能需要启用 `updates-testing` 仓库来获得最新的预发布版本:
```
$ sudo dnf install --enablerepo=updates-testing python3.10
```
随着更多的测试版和候选版 [发布](https://www.python.org/dev/peps/pep-0619/),Fedora 包将得到更新。不需要编译你自己的 Python 开发版本,只要安装它就可以获得最新。从第一个测试版开始,Python 开发者不会再增加新的功能了。你已经可以享受所有的新东西了。
### 用 Python 3.10 测试你的项目
运行 `python3.10` 命令来使用 Python 3.10,或者用 [内置的 venv 模块 tox](https://developer.fedoraproject.org/tech/languages/python/multiple-pythons.html) 或用 [pipenv](https://fedoramagazine.org/install-pipenv-fedora/) 和 [poetry](https://python-poetry.org/) 创建虚拟环境。下面是一个使用 `tox` 的例子:
```
$ git clone https://github.com/benjaminp/six.git
Cloning into 'six'...
$ cd six/
$ tox -e py310
py310 run-test: commands[0] | python -m pytest -rfsxX
================== test session starts ===================
platform linux -- Python 3.10.0b3, pytest-6.2.4, py-1.10.0, pluggy-0.13.1
collected 200 items
test_six.py ...................................... [ 19%]
.................................................. [ 44%]
.................................................. [ 69%]
.................................................. [ 94%]
............ [100%]
================== 200 passed in 0.43s ===================
________________________ summary _________________________
py310: commands succeeded
congratulations :)
```
如果你在 Fedora Linux 上发现了 Python 3.10 的问题,请 [在 Fedora 的 bugzilla 上提交 bug 报告](https://bugzilla.redhat.com/buglist.cgi?component=python3.10&product=Fedora) 或在 [Python 的问题追踪](https://bugs.python.org/) 上提交。如果你不确定这是否是 Python 的问题,你可以 [通过电子邮件或 IRC 直接联系 Fedora 的 Python 维护者](https://fedoraproject.org/wiki/SIGs/Python#Communicate) 。
### Python 3.10 中的新内容
参见 [Python 3.10 的全部新闻列表](https://docs.python.org/3.10/whatsnew/3.10.html)。例如,你可以尝试一下 [结构模式匹配](https://www.python.org/dev/peps/pep-0634/):
```
$ python3.10
Python 3.10.0b3 (default, Jun 17 2021, 00:00:00)
[GCC 10.3.1 20210422 (Red Hat 10.3.1-1)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> point = (3, 10)
>>> match point:
... case (0, 0):
... print("Origin")
... case (0, y):
... print(f"Y={y}")
... case (x, 0):
... print(f"X={x}")
... case (x, y):
... print(f"X={x}, Y={y}")
... case _:
... raise ValueError("Not a point")
...
X=3, Y=10
>>> x
3
>>> y
10
```
敬请期待 [Fedora Linux 35 中的 python3 —— Python 3.10](https://fedoraproject.org/wiki/Changes/Python3.10)!
---
via: <https://fedoramagazine.org/python-3-10-beta-in-fedora-linux/>
作者:[Miro Hrončok](https://fedoramagazine.org/author/churchyard/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Python developers have already released three beta versions of Python 3.10.0. You can try the latest one in Fedora Linux today! Test your Python code with 3.10 early to be ready for the final 3.10.0 release in October.
## Install Python 3.10 on Fedora Linux
If you run Fedora Linux, you can install Python 3.10 from the official software repository with *dnf*:
$ sudo dnf install python3.10
You might need to enable the *updates-testing* repository to get the very latest pre-release:
$ sudo dnf install --enablerepo=updates-testing python3.10
As more betas and release candidates [will be released](https://www.python.org/dev/peps/pep-0619/), the Fedora package will receive updates. No need to compile your own development version of Python, just install it and have it up to date. The Python developers will add no new features starting with the first beta; you can already enjoy all the new things.
## Test your projects with Python 3.10
Run the *python3.10* command to use Python 3.10 or create virtual environments with the [builtin venv module, tox](https://developer.fedoraproject.org/tech/languages/python/multiple-pythons.html) or with
[pipenv](https://fedoramagazine.org/install-pipenv-fedora/)and
[poetry](https://python-poetry.org/). Here’s an example using
*tox*:
$ git clone https://github.com/benjaminp/six.git Cloning into 'six'... $ cd six/ $ tox -e py310 py310 run-test: commands[0] | python -m pytest -rfsxX ================== test session starts =================== platform linux -- Python 3.10.0b3, pytest-6.2.4, py-1.10.0, pluggy-0.13.1 collected 200 items test_six.py ...................................... [ 19%] .................................................. [ 44%] .................................................. [ 69%] .................................................. [ 94%] ............ [100%] ================== 200 passed in 0.43s =================== ________________________ summary _________________________ py310: commands succeeded congratulations :)
If you find a problem with Python 3.10 on Fedora Linux, please do [file bug reports at Fedora’s bugzilla](https://bugzilla.redhat.com/buglist.cgi?component=python3.10&product=Fedora) or in the [Python’s issue tracker](https://bugs.python.org/). If you aren’t sure if it is a problem in Python, you can [contact the Fedora’s Python maintainers](https://fedoraproject.org/wiki/SIGs/Python#Communicate) directly via email or IRC.
## What’s new in Python 3.10
See the [full list of news in Python 3.10](https://docs.python.org/3.10/whatsnew/3.10.html). You can, for example, try out [structural pattern matching](https://www.python.org/dev/peps/pep-0634/):
$ python3.10 Python 3.10.0b3 (default, Jun 17 2021, 00:00:00) [GCC 10.3.1 20210422 (Red Hat 10.3.1-1)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> point = (3, 10) >>> match point: ... case (0, 0): ... print("Origin") ... case (0, y): ... print(f"Y={y}") ... case (x, 0): ... print(f"X={x}") ... case (x, y): ... print(f"X={x}, Y={y}") ... case _: ... raise ValueError("Not a point") ... X=3, Y=10 >>> x 3 >>> y 10
And stay tuned for [Python 3.10 as python3 in Fedora Linux 35](https://fedoraproject.org/wiki/Changes/Python3.10)!
## Katsuharu Tanaka
Python3.10 doesn’t seem to be supported by Pandas, which is often used for Data Science, but I’m very interested in API stability and def method stability.
Thank you for providing me with a valuable news article.
## Janil Garcia
Have you tried using pandas with it?
I just successfully created a new virtualenv with Python 3.10 and pandas is working just fine for me.
I believe Python 3.10 is API compatible with 3.9, just changing internal details in some libraries and maybe adding new optional parameters. Most libraries will be unaffected by the change.
The new syntax constructs were also additive, so nothing should be broken by them.
## Václav Tengler
nejde to
## Alex
Why python3.10 is normal package instead of the module :(?
## Miro Hrončok
Because modules are generally not parallel installable and if we want to make them so we would be packaging a “normal package” like this one into a module for no benefit. Maintaining modular packages is needlessly complex and using them from other parts of the Fedora project is almost impossible.
## SergMx
It’s a shame they buried SCLO. This technology had no problem keeping five PYTHONs in one system.
But they went down the road of simplification. One module in one container …
## Miro Hrončok
You can have many different Pythons in Fedora on one system. See https://developer.fedoraproject.org/tech/languages/python/multiple-pythons.html
## Mx
Thank you. Good resource.
But why do you think there is a section about mod_wsgi?
With SCLO I had no problem using 2 and 3 at once.
venv = chroot only python.
sclo = system level chroot.
## Dilord
Me gustaría aprender algo básico sobre Python como lenguaje de programación y ver algunos ejemplos sencillos. |
13,538 | 如何在 Linux 上设置雷蛇设备的灯光效果和其他配置 | https://itsfoss.com/set-up-razer-devices-linux/ | 2021-06-30T16:06:30 | [
"雷蛇"
] | https://linux.cn/article-13538-1.html | 你有了一个闪亮的新雷蛇硬件,但你找不到 Linux 的 Razer Synapse 软件。而你最终没有正确 RGB 同步,也没有办法定制它。你会怎么做呢?
好吧,对于某些功能,比如给你的鼠标添加宏,你仍然需要(在 Windows 或 MacOS 上)访问 Razer Synapse。
但是,要调整其他一些选项,如键盘的宏,改变鼠标的 DPI,或灯光效果,你可以在 Linux 上轻松设置你的雷蛇外设。

这里有一些鼠标和鼠标垫的照片。这是同样的设置,但有不同的照明方案。点击图片可以看到更大的图片。



雷蛇 Basilisk 是一款不错的游戏鼠标。如果你想,你可以从亚马逊订购或从当地商店获得。
如果你已经拥有一个雷蛇设备,让我展示一下配置它的步骤,就像我在这里做的那样。
### 步骤 1:安装 OpenRazer
**OpenRazer** 是一个开源的驱动程序,使雷蛇硬件在 Linux 上工作。它支持几种功能来定制和控制你的设备,包括 RGB 鼠标垫。
虽然这不是官方 Linux 驱动,但它在各种设备上工作良好。
它为各种 Linux 发行版提供支持,包括 Solus、openSUSE、Fedora、Debian、Arch Linux、Ubuntu 和其他一些发行版。
在这里,我将重点介绍在任何基于 Ubuntu 的发行版上安装它的步骤,对于其他发行版,你可能想参考 [官方说明](https://openrazer.github.io/#download)。
你需要在 Ubuntu 上 [使用 PPA](https://itsfoss.com/ppa-guide/) 安装 OpenRazer,下面是如何做的:
```
sudo apt install software-properties-gtk
sudo add-apt-repository ppa:openrazer/stable
sudo apt update
sudo apt install openrazer-meta
```
它也提供了一个 [守护进程](https://itsfoss.com/linux-daemons/),你可以选择让它工作,你要把你的用户加入到 `plugdev` 组,它给了设备的特权访问:
```
sudo gpasswd -a $USER plugdev
```
我不需要用上述命令中配置/添加一个守护程序,但我仍然可以很好地使用这些设备。守护进程主要是确保驱动保持活跃。
* [下载 OpenRazer](https://openrazer.github.io/)
### 步骤 2:安装一个 GUI 来管理和调整选项
现在驱动已经安装完毕,你所需要的是一个图形用户界面 (GUI) 来帮助你定制你的雷蛇硬件。
你可以找到一些可用的选择,但我将推荐安装 [Polychromatic](https://polychromatic.app),它提供了一个有吸引力的用户界面,而且运行良好。

Polychromatic 是我能推荐的最接近 Razer Synapse 的应用,而且效果不错。
对于基于 Ubuntu 的发行版,你需要做的就是使用 PPA 安装它:
```
sudo add-apt-repository ppa:polychromatic/stable
sudo apt update
sudo apt install polychromatic
```
对于 Arch Linux 用户,你可以在 [AUR](https://itsfoss.com/aur-arch-linux/) 中找到它。关于更多的安装说明,你可以参考[官方下载页面](https://polychromatic.app/download/)。
* [下载 Polychromatic](https://polychromatic.app/)
你会得到不同设备的不同选项。在这里,我试着改变 DPI,自定义颜色周期,以及我的雷蛇 Basilisk v2 鼠标的轮询率,它完全正常。

如果你知道你想做什么,它还为你提供了轻松重启或停止 [守护进程](https://itsfoss.com/linux-daemons/)、改变小程序图标和执行高级配置选项的能力。
另外,你可以试试 [RazerGenie](https://github.com/z3ntu/RazerGenie)、[Snake](https://github.com/bithatch/snake) 或 [OpenRGB](https://itsfoss.com/openrgb/) (用于改变颜色)来调整鼠标的颜色或任何其他设置。
### 总结
现在你可以轻松地定制你的雷蛇硬件了,希望你能玩得开心!
虽然你可能会找到一些其他的选择来配置你的雷蛇设备,但我没有找到任何其他效果这么好的选择。
如果你遇到了一些有用的东西,值得在这里为所有的雷蛇用户提一下,请在下面的评论中告诉我。
---
via: <https://itsfoss.com/set-up-razer-devices-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You have a shiny new Razer hardware, but you cannot find the Razer Synapse software for Linux. And you end up with no proper RGB sync and do not get to customize it. What do you do?
Well, for certain functionalities, like adding macros to your mouse, you will still need access to Razer Synapse (on Windows or macOS).
But, to tweak a few other options like macros for the keyboard, changing the DPI of your mouse, or lighting effects, you can easily set up your Razer peripherals on Linux.

Here are some pictures of both the mouse and the mouse pad. It’s the same setup but with different lighting schemes. Click on the images to see bigger images.

Razer Basilisk is a good gaming mouse. If you want you can order it from [Amazon](https://www.amazon.com/dp/B081QXJLDN?tag=chmod7mediate-20&linkCode=osi&th=1&psc=1&keywords=razer+basilisk+v2&ref=itsfoss.com) or get it from your local store.
If you already own a Razer device, let me show the steps to configure it, just like what I did here.
## Step 1: Install OpenRazer
**OpenRazer** is an open-source driver to make Razer hardware work on Linux. It supports several functionalities to customize and control your devices, including RGB mousemats.
While this is not an official driver for Linux, it works quite well for a wide range of devices.
**It offers support for a variety of Linux distributions that include Solus, openSUSE, Fedora, Debian, Arch Linux, Ubuntu, and a few others.**
Here, I will be focusing on the steps to install it on any Ubuntu-based distro, you may want to refer to the [official instructions](https://openrazer.github.io/?ref=itsfoss.com#download) for other distros.
You need to install OpenRazer [using a PPA](https://itsfoss.com/ppa-guide/) on Ubuntu, here’s how to do that:
```
sudo apt install software-properties-gtk
sudo add-apt-repository ppa:openrazer/stable
sudo apt update
sudo apt install openrazer-meta
```
It also offers a [daemon](https://itsfoss.com/linux-daemons/) as well, you can choose to make it work, you will be adding your user to the **plugdev** group — which gives privileged access to the device:
`sudo gpasswd -a $USER plugdev`
I did not need to configure/add a daemon using the above command, but I can still use the devices just fine. The daemon mostly ensures that the driver stays active.
## Step 2: Install a GUI to Manage and Tweak Options
Now that the driver has been installed, all you need is a graphical user interface (GUI) to help you customize your Razer hardware.
You can find a few options available out there, but I will recommend installing [Polychromatic](https://polychromatic.app/?ref=itsfoss.com), which offers an attractive UI and works well as well.
Polychromatic app is the closest I could recommend to Razer Synapse, and it works good.
For Ubuntu-based distros, all you need to do is install it using PPA:
```
sudo add-apt-repository ppa:polychromatic/stable
sudo apt update
sudo apt install polychromatic
```
You can find it listed in [AUR](https://itsfoss.com/aur-arch-linux/) for Arch Linux users. For more installation instructions, you can refer to the [official download page](https://polychromatic.app/download/?ref=itsfoss.com).
While you will get a distinct set of options for various devices. Here, I tried changing the DPI, customizing the color cycle, and the polling rate of my Razer Basilisk v2 mouse, and it worked completely fine.
It also offers you the ability to easily restart or stop the [daemon](https://itsfoss.com/linux-daemons/), change the applet icon, and perform advanced configuration options if you know what you want to do.
Alternatively, you can try [RazerGenie](https://github.com/z3ntu/RazerGenie?ref=itsfoss.com), [Snake](https://github.com/bithatch/snake?ref=itsfoss.com), or [OpenRGB](https://itsfoss.com/openrgb/) (meant for changing the colors) to tweak the mouse color or any other settings.
## Wrapping Up
Now that you can easily customize your Razer hardware, hope you have fun!
While you may find some other options to configure your Razer devices, I did not find any other options that work very well.
If you have come across something that works and that deserves a mention here for all the Razer users, let me know in the comments below. |
13,539 | 使用开源工具创建私有的虚拟专用网络 | https://opensource.com/article/21/5/open-source-private-vpn | 2021-07-01T10:16:37 | [
"Wireguard",
"OpenWRT"
] | https://linux.cn/article-13539-1.html |
>
> 使用 OpenWRT 和 Wireguard 在路由器上创建自己的虚拟专用网络。
>
>
>

通过计算机网络从一个地方到另一个地方可能是一件棘手的事情。除了知道正确的地址和打开正确的端口之外,还有安全问题。 对于 Linux,SSH 是一种流行的默认方式,虽然你可以使用 SSH 做很多事情,但它仍然“只是”一个安全外壳(实际上,这就是 SSH 的含义)。用于加密流量的更广泛的协议是“虚拟专用网络”,它创建了一个独特的两点之间的虚拟的专用网络。有了它,你可以登录到另一个网络上的计算机并使用它的所有服务(文件共享、打印机等等),就像你坐在同一个房间里一样,并且全部的数据都是从点到点加密的。
通常,为了使虚拟专用网络连接成为可能,进入每个网络的网关必须接受虚拟专用网络流量,并且必须侦听目标网络上的某些计算机的虚拟专用网络流量。然而,你可以运行自己的带有虚拟专用网络服务器的路由器固件,使你能够连接到目标网络,而无需担心转发端口或考虑内部拓扑。我最喜欢的固件是 OpenWrt,在本文中我将演示如何设置它,以及如何启用虚拟专用网络。
### 什么是 OpenWrt?
[OpenWrt](https://openwrt.org/) 是一个使用 Linux 面向嵌入式设备的开源项目。它已经存在超过 15 年,拥有庞大而活跃的社区。
使用 OpenWrt 的方法有很多种,但它的主要用途是在路由器中。它提供了一个具有包管理功能的完全可写的文件系统,并且由于它是开源的,你可以查看和修改代码并为生态系统做出贡献。如果你想对路由器进行更多控制,这就是你想要使用的系统。
OpenWrt 支持很多路由器,包括 [思科](https://www.cisco.com/c/en/us/products/routers/index.html)、[华硕](https://www.asus.com/Networking-IoT-Servers/WiFi-Routers/All-series/)、[MikroTik](https://mikrotik.com/)、[Teltonika Networks](https://teltonika-networks.com/)、[D-Link](https://www.dlink.com/en/consumer)、[TP-link](https://www.tp-link.com/us/)、[Buffalo](https://www.buffalotech.com/products/category/wireless-networking)、[Ubiquiti](https://www.ui.com/) 等知名品牌和 [许多其他品牌](https://openwrt.org/toh/views/toh_fwdownload)。
### Wireguard 是什么?
[Wireguard](https://www.wireguard.com/) 是开源的虚拟专用网络软件,它比 OpenVPN 等其他选项更快、更简单且更安全。它使用最先进的密码学:用于对称加密的 ChaCha20;用于密钥协商的 Curve 25519(使用椭圆曲线),和用于散列的 BLAKE2。这些算法的设计方式在嵌入式系统上是高效的。Wireguard 也可用于各种操作系统 [平台](https://www.wireguard.com/install/)。
### 先决条件
对于这个项目,你需要:
* [Teltonika RUT955](https://teltonika-networks.com/product/rut955/) 或支持 OpenWrt 的其他路由器
* 一个公网 IP 地址,用于从外部网络连接到虚拟专用网络
* 一部安卓手机
### 安装 OpenWrt
首先,下载路由器的 OpenWrt 镜像。使用 [固件选择器](https://firmware-selector.openwrt.org/) 检查 OpenWrt 是否支持你的路由器并下载固件。输入你的路由器型号,将显示选项:

使用搜索框右侧的下拉输入选择要下载的固件版本。
下载出厂镜像。

许多路由器允许你从 Web 界面刷入未经授权的固件,但 Teltonika Networks 不允许。要将 OpenWrt 固件刷入这样的路由器,你需要使用引导加载器。为此,请按照下列步骤操作:
1. 拔掉路由器的电源线。
2. 按住重置按钮。
3. 插入路由器的电源线。
4. 插入电源线后,继续按住重置按钮 5 到 8 秒。
5. 将计算机的 IP 地址设置为 `192.168.1.15`,将网络掩码设置为 `255.255.255.0`。
6. 使用以太网电缆通过 LAN 端口连接路由器和计算机。
7. 打开网页浏览器并输入 `192.168.1.1:/index.html`。
8. 上传并刷写固件。
刷机过程可能占用三分钟。之后,你应该可以通过在浏览器中输入 `192.168.1.1` 来访问路由器的 Web 界面。 默认情况下没有设置密码

### 配置网络连接
网络连接是必要条件。如果你的 Internet 服务提供商(ISP) 使用 DHCP 自动分配你的 IP 地址,你只需将以太网电缆插入路由器的 WAN 端口。
如果你需要手动分配 IP 地址,导航至 “Network → Interfaces”。选择 “Edit” 编辑你的 WAN 接口。从 “Protocol” 字段中,选择 “Static address”,然后选择 “Switch protocol”。

在 “IPv4 address” 字段中,输入你的路由器地址。设置 “IPv4 netmask” 以匹配你的网络子网;输入你将用于连接到网络的 “IPv4 gateway” 地址; 并在 “Use custom DNS servers” 字段中输入 DNS 服务器的地址。保存配置。
就是这样!你已成功配置 WAN 接口以获得网络连接。
### 安装必要的包
默认情况下,该固件不包含很多包,但 OpenWrt 有一个包管理器和可选安装的软件包。导航到 “System → Software” 并通过选择 “Update list...” 更新你的包管理器。

在“Filter”输入中,键入 “Wireguard”,等待系统找到所有包含该关键字的包。找到并安装名为 “luci-app-wireguard” 的包。

该软件包包括一个用于配置 Wireguard 的 Web 界面,并安装 Wireguard 所必需的所有依赖项。
如果你在安装 Wireguard 软件包之前收到一个软件包丢失的警告并且在存储库中找不到,请忽略它并继续。
接下来,找到并安装名为 “luci-app-ttyd” 的包。这将用于稍后访问终端。
安装这些软件包后,重新启动路由器以使更改生效。
### 配置 Wireguard 接口
接下来,创建 Wireguard 接口。导航到 “Network → Interfaces” 并选择左下角的 “Add new interface...”。在弹出窗口中,输入你想要的接口名称,从下拉列表中选择 “WireguardVPN”,然后选择右下角的 “Create interface”。

在新弹出的窗口中,选择 “Generate Key” 为 Wireguard 接口生成私钥。在 “Listen Port” 字段中,输入所需的端口。我将使用默认的 Wireguard 端口,“51820”。在 “IP Addresses” 字段中,分配将用于 Wireguard 接口的 IP 地址。在这个例子中,我使用了 `10.0.0.1/24`。数字 “24” 表明我的子网的大小。

保存配置并重启接口。
导航到 “Services → Terminal”,登录到 shell,然后输入命令 `wg show`。你将看到有关 Wiregaurd 接口的一些信息,包括其公钥。复制公钥——稍后你将需要它来创建对等点。

### 配置防火墙
导航到 “Network → Firewall” 并选择 “Traffic Rules” 选项卡。在页面底部,选择 “Add”。在弹出窗口的 “Name” 字段中,为你的规则命名,例如 “Allow-wg”。接下来,将 “Destination zone” 从 “Lan” 更改为 “Device”,并将 “Destination port” 设置为 “51820”。

保存配置。
### 手机上配置 Wireguard
从 Google Play 在你的手机上安装 [Wireguard 应用程序](https://play.google.com/store/apps/details?id=com.wireguard.android&hl=lt&gl=US)。安装后,打开应用程序并从头开始创建一个新接口。在 “Name” 字段中,输入要用于接口的名称。在 “Private key” 字段中,按右侧的双向箭头图标生成密钥对。你将需要上面的公钥来在你的手机和路由器之间创建一个对等点。在 “Addresses” 字段中,分配你将用于通过虚拟专用网络访问电话的 IP 地址。我将使用 `10.0.0.2/24`。在 “Listen port” 中,输入端口;我将再次使用默认端口。

保存配置。
要向配置中添加对等点,请选择 “Add peer”。在 “Public key” 字段中,输入路由器的 Wireguard 公钥。在 “Endpoint” 字段中,输入路由器的公共 IP 地址和端口,以冒号分隔,例如 `12.34.56.78:51820`。在 “Allowed IP” 字段中,输入要通过 Wireguard 接口访问的 IP 地址。 (你可以输入路由器的虚拟专用网络接口 IP 地址和 LAN 接口地址。)IP 地址必须用逗号分隔。你还可以定义子网的大小。

保存配置。
配置中还剩下最后一步:在路由器上添加一个对等点。
### 在路由器上添加一个对等点
导航到 “Network → Interfaces” 并选择你的 Wireguard 接口。转到 “Peers” 选项卡并选择 “Add peer”。在 “Description” 字段中,输入对等方的名称。在 “Public Key” 字段中输入手机的 Wireguard 接口公钥,在 “Allowed IPs” 字段中输入手机的 Wireguard 接口 IP 地址。选中 “Route Allowed IPs” 复选框。

保存配置并重启接口。
### 测试配置
在手机上打开 Web 浏览器。在 URL 栏中,输入 IP 地址 `10.0.0.1` 或 `192.168.1.1`。你应该能够访问路由器的网站。

### 你自己的虚拟专用网络
这些天有很多虚拟专用网络服务商在做广告,但是拥有和控制自己的基础设施还有很多话要说,尤其是当该基础设施仅用于提高安全性时。无需依赖其他人为你提供安全的数据连接。使用 OpenWrt 和 Wireguard,你可以拥有自己的开源虚拟专用网络解决方案。
---
via: <https://opensource.com/article/21/5/open-source-private-vpn>
作者:[Lukas Janėnas](https://opensource.com/users/lukasjan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Getting from one place to another over a computer network can be a tricky thing. Aside from knowing the right address and opening the right ports, there's the question of security. For Linux, SSH is a popular default, and while there's a lot you can do with SSH it's still "just" a secure shell (that's what SSH stands for, in fact.) A broader protocol for encrypted traffic is VPN, which creates a unique, virtual private network between two points. With it, you can log in to a computer on another network and use all of its services (file shares, printers, and so on) just as if you were physically sitting in the same room, and every bit of data is encrypted from point to point.
Normally, in order to make a VPN connection possible, the gateways into each network must accept VPN traffic, and some computer on your target network must be listening for VPN traffic. However, it's possible to run your own router firmware that runs a VPN server, enabling you to connect to your target network without having to worry about forwarding ports or thinking at all about internal topography. My favorite firmware is OpenWrt, and in this article I demonstrate how to set it up, and how to enable VPN on it.
## What is OpenWrt?
[OpenWrt](https://openwrt.org/) is an open source project that uses Linux to target embedded devices. It's been around for more than 15 years and has a large and active community.
There are many ways to use OpenWrt, but its main purpose is in routers. It provides a fully writable filesystem with package management, and because it is open source, you can see and modify the code and contribute to the ecosystem. If you would like to have more control over your router, this is the system you want to use.
OpenWrt supports many routers, including famous brands such as [Cisco](https://www.cisco.com/c/en/us/products/routers/index.html), [ASUS](https://www.asus.com/Networking-IoT-Servers/WiFi-Routers/All-series/), [MikroTik](https://mikrotik.com/), [Teltonika Networks](https://teltonika-networks.com/), [D-Link](https://www.dlink.com/en/consumer), [TP-link](https://www.tp-link.com/us/), [Buffalo](https://www.buffalotech.com/products/category/wireless-networking), [Ubiquiti](https://www.ui.com/), and [many others](https://openwrt.org/toh/views/toh_fwdownload).
## What is Wireguard?
[Wireguard](https://www.wireguard.com/) is open source virtual private network (VPN) software that is much faster, simpler, and more secure than other options such as OpenVPN. It uses state-of-the-art cryptography: ChaCha20 for symmetric cryptography; Curve 25519 (which uses elliptic curves) for key agreement; and BLAKE2 for hashing. These algorithms are designed in a way that is efficient on embedded systems. WIreguard is also available on a wide variety of operating system [platforms](https://www.wireguard.com/install/).
## Prerequisites
For this project, you will need:
[Teltonika RUT955](https://teltonika-networks.com/product/rut955/)or another router supported by OpenWrt- A public IP address to connect to your VPN from outside your network
- An Android phone
## Install OpenWrt
To get started, download the OpenWrt image for your router. Use the [firmware selector](https://firmware-selector.openwrt.org/) to check if OpenWrt supports your router and download the firmware. Enter your router's model, and it will show your options:
(Lukas Janenas, CC BY-SA 4.0)
Select the firmware version you want to download by using the drop-down input on the right side of the search box.
Download the factory image.
(Lukas Janenas, CC BY-SA 4.0)
Many routers allow you to flash unauthorized firmware from the web interface, but Teltonika Networks does not. To flash the OpenWrt firmware to a router like this, you need to use the bootloader. To do so, follow these steps:
- Unplug the router's power cable.
- Press and hold the Reset button.
- Plug in the router's power cable.
- Continue holding the reset button for 5 to 8 seconds after you plug the power cable in.
- Set computer's IP address to
`192.168.1.15`
and the netmask to`255.255.255.0`
. - Connect the router and your computer with an Ethernet cable over a LAN port.
- Open a web browser and enter
`192.168.1.1:/index.html`
. - Upload and flash the firmware.
The flashing process can take up to three minutes. Afterward, you should be able to reach the router's web interface by entering `192.168.1.1`
in a browser. There is no password set by default.
(Lukas Janenas, CC BY-SA 4.0)
## Configure network connectivity
Network connectivity is a requirement. If your Internet service provider (ISP) assigns your IP address automatically using DHCP, you just need to plug your Ethernet cable into the WAN port of your router.
If you need to assign the IP address manually, navigate to **Network → Interfaces**. Select **Edit** to edit your WAN interface. From the **Protocol** field, select **Static address**, and select **Switch protocol**.
(Lukas Janenas, CC BY-SA 4.0)
In the **IPv4 address** field, enter your router's address. Set **IPv4 netmask** to match your network subnet; enter the **IPv4 gateway** address you will use to connect to the network; and enter the DNS server's address in the **Use custom DNS servers** field. Save the configuration.
That's it! You have successfully configured your WAN interface to get network connectivity.
## Install the necessary packages
The firmware doesn't include many packages by default, but OpenWrt has a package manager with a selection of packages you can install. Navigate to **System → Software** and update your package manager by selecting **Update lists…**

(Lukas Janenas, CC BY-SA 4.0)
In the Filter input, type **Wireguard**, and wait until the system finds all the packages that include this keyword. Find and install the package named **luci-app-wireguard**.
(Lukas Janenas, CC BY-SA 4.0)
This package includes a web interface to configure Wireguard and installs all the dependencies necessary for Wireguard to work.
If you get a warning that a package is missing and can't be found in the repositories before installing the Wireguard package, just ignore it and proceed.
Next, find and install the package named **luci-app-ttyd**. This will be used to access the terminal later.
After these packages are installed, reboot your router for the changes to take effect.
## Configure the Wireguard interface
Next, create the Wireguard interface. Navigate to **Network → Interfaces** and select **Add new interface…** on the bottom-left. In the pop-up window, enter your desired name for the interface, choose **Wireguard VPN** from the drop-down list, and select **Create interface** on the lower-right.
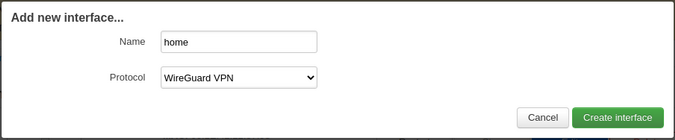
(Lukas Janenas, CC BY-SA 4.0)
In the new pop-up window, select **Generate Key** to generate a private key for the Wireguard interface. In the **Listen Port** field, enter your desired port. I will use the default Wireguard port, **51820**. In the **IP Addresses** field, assign the IP address which will be used for the Wireguard interface. In this example, I use `10.0.0.1/24`
. The number **24** indicates the size of my subnet.
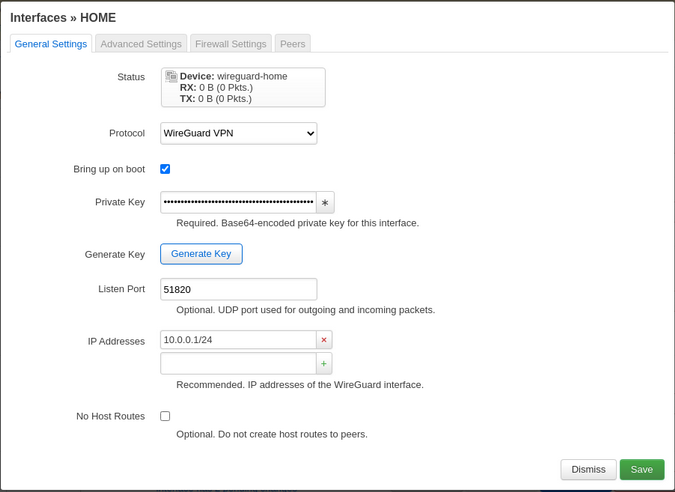
(Lukas Janenas, CC BY-SA 4.0)
Save the configuration and restart the interface.
Navigate to **Services → Terminal**, log into the shell, and enter the command `wg show`
. You will see some information about your Wiregaurd interface, including its public key. Copy down the public key—you will need it to create peers later.

(Lukas Janenas, CC BY-SA 4.0)
## Configure the firewall
Navigate to **Network → Firewall** and select the **Traffic Rules** tab. On the bottom of the page, select **Add**. In the **Name** field of the pop-up window, give your rule a name, e.g., **Allow-wg**. Next, change the **Destination zone** from **Lan** to **Device**, and set the **Destination port** to 51820.
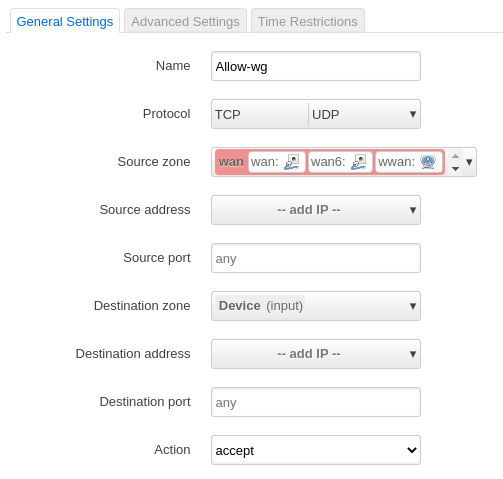
(Lukas Janenas, CC BY-SA 4.0)
Save the configuration.
## Configure Wireguard on an Android phone
Install the [Wireguard app](https://play.google.com/store/apps/details?id=com.wireguard.android&hl=lt&gl=US) on your phone from Google Play. Once it's installed, open the app and create a new interface from scratch. In the **Name** field, enter the name you want to use for your interface. In the **Private key** field, press the double-arrow icon on the right to generate a key pair. You will need the public key from above to create a peer between your phone and router. In the **Addresses** field, assign the IP address you will use to reach the phone over VPN. I will use `10.0.0.2/24`
. In **Listen port**, enter a port; I will again use the default port.
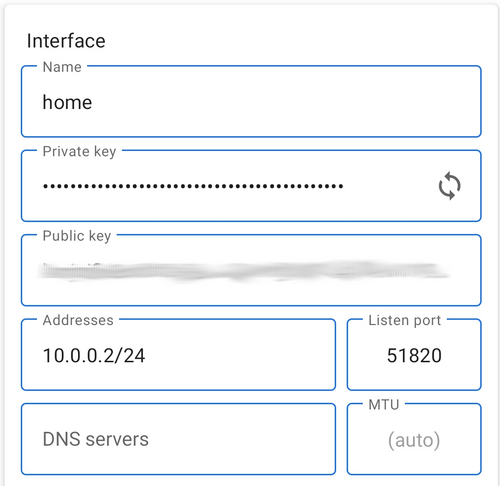
(Lukas Janenas, CC BY-SA 4.0)
Save the configuration.
To add a peer to the configuration, select **Add peer**. In the **Public key** field, enter your router's Wireguard public key. In the **Endpoint** field, enter your router's public IP address and port separated by a colon, e.g., `12.34.56.78:51820`
. In the **Allowed IPs** field, enter the IP addresses you want to reach through the Wireguard interface. (You can enter your router's VPN interface IP address and LAN interface address.) The IP addresses must be separated by commas. You can also define the size of the subnet.
(Lukas Janenas, CC BY-SA 4.0)
Save the configuration.
There's one last step left in the configuration: adding a peer on the router.
## Add a peer on the router
Navigate to **Network → Interfaces** and select your Wireguard interface. Go to the **Peers** tab and select **Add peer**. In the **Description** field, enter the peer's name. In the **Public Key** field, enter your phone's Wireguard interface public key, and in the **Allowed IPs** field, enter your phone's Wireguard interface IP address. Check the **Route Allowed IPs** checkbox.
(Lukas Janenas, CC BY-SA 4.0)
Save the configuration and restart the interface.
## Test the configuration
Open a web browser on your phone. In the URL bar, enter the IP address `10.0.0.1`
or `192.168.1.1`
. You should be able to reach your router's website.
(Lukas Janenas, CC BY-SA 4.0)
## Your very own VPN
There are lots of VPN services being advertised these days, but there's a lot to be said for owning and controlling your own infrastructure, especially when that infrastructure only exists to boost security. There's no need to rely on somebody else to provide you with a secure connection to your data. Using OpenWrt and Wireguard, you can have your own open source VPN solution.
## Comments are closed. |
13,541 | CI/CD 管道是什么? | https://opensource.com/article/21/6/what-cicd-pipeline | 2021-07-02T10:58:38 | [
"CI",
"CD"
] | https://linux.cn/article-13541-1.html |
>
> 你如何定义持续集成/持续部署管道取决于你组织的要求。
>
>
>

<ruby> 持续集成 <rt> continuous integration </rt></ruby>/<ruby> 持续部署 <rt> continuous deployment </rt></ruby>(CI/CD)管道是每个 DevOps 计划的基础。 CI/CD 管道打破了传统的开发孤岛,使开发和运营团队能够在整个软件开发生命周期中进行协作。
更好的是,转向 DevOps 和 CI/CD 管道可以帮助你的组织以更高的速度更安全地 [交付软件](https://techbeacon.com/devops/5-reasons-why-cicd-vital-your-organizations-value-stream)。
### 拆解 CI/CD 管道
CI/CD 管道有很多定义,所以我总是建议组织定义自己的 CI/CD 管道版本和其他 DevOps 概念,而不是使用其他人的。开源 CI/CD 工具为你提供构建满足组织要求的 CI/CD 管道的自由和选择。
形成 CI/CD 管道的阶段是将不同的任务子集分组为 *管道阶段*。典型的管道阶段包括:
* **构建**:开发人员编译应用程序代码。
* **测试**:质量保证(QA)团队使用自动化测试工具和策略测试应用程序代码。
* **发布**:开发团队将应用程序代码交付到代码库。
* **部署**:DevOps 团队将应用程序代码分阶段投入生产。
* **安全性和合规性**:QA 团队根据项目要求验证构建。这是组织部署容器扫描工具的阶段,这些工具根据<ruby> 常见漏洞和暴露 <rt> Common Vulnerabilities and Exposures </rt></ruby>(CVE)检查容器镜像的质量。
这些是 CI/CD 管道的标准阶段,但一些组织调整 CI/CD 管道模型以满足他们的要求。例如,为医疗保健市场构建应用程序的组织,具有严格的合规性标准,可以在整个工具链中分发测试、验证和合规性门槛。
其他示例可能是依赖于具有开源软件(OSS)的复杂软件供应链的组织。商业组件可能会设立一个门槛,开发团队成员可以在其中为 OSS 包生成 <ruby> <a href="https://www.ntia.gov/SBOM"> 软件物料清单 </a> <rt> software bill of materials </rt></ruby>(SBOM),或者外部商业软件供应商必须将 SBOM 作为其合同可交付成果的一部分进行交付。
### CI/CD 管道的障碍
实施 CI/CD 管道会改变团队的流程和文化。尽管许多开发人员愿意接受某些任务和测试的自动化,但人员可能成为采用 CI/CD 的障碍。
从瀑布式流程转向 CI/CD 可能会动摇某些组织中基本的和隐含的权力结构。由于 CI/CD 管道提高了软件交付速度,旧手动流程的“守门人”可能会受到这种变化的威胁。
### 整合机会
随着你在文化、流程和工具中达到更高的 DevOps 成熟度水平,包含 CI/CD 工具链的工具的开源根源为一些激动人心的集成创造了机会。
分析公司 Forrester 在 2020 年预测,<ruby> 即时学习 <rt> just-in-time learning </rt></ruby>将加入 CI/CD 管道。如果你考虑一下,会发现这是有道理的。在当前远程工作的时代,甚至对于新员工的远程入职,这更有意义。例如,组织可以将文档 wiki 与内部流程文档集成到其管道中。
更雄心勃勃的组织可以将学习管理系统(LMS)(例如 [Moodle](https://moodle.org/))集成到其 CI/CD 管道中。它可以使用 LMS 发布有关新 DevOps 工具链功能的简短视频,开发人员在加入时或在整个管道中更新工具时需要学习这些功能。
一些组织正在将群聊和其他协作工具直接集成到他们的 CI/CD 管道中。聊天平台提供警报并支持团队之间的协作和沟通。将 Mattermost、Rocket.Chat 或其他 [企业聊天](https://opensource.com/alternatives/slack) 平台集成到你的 CI/CD 管道中需要预先规划和分析,以确保管道用户不会被警报淹没。
另一个需要探索的集成机会是将分析和高级报告构建到你的 CI/CD 管道中。这有助于你利用通过管道传输的数据。
### 总结
CI/CD 管道是 DevOps 的基础。开源使其能够适应并灵活地满足你在 DevOps 之旅中实施的运营变更所产生的新需求。
我希望看到对统一 DevOps 平台趋势的开源响应,在这种趋势中,组织寻求端到端的 CI/CD 解决方案。这种解决方案的要素就在那里。毕竟,GitLab 和 GitHub 将他们的平台追溯到开源根源。
最后,不要忘记每一个成功的 CI/CD 工具链背后的教育和外展。记录你的工具链和相关流程将改善开发人员入职和持续的 DevOps 团队培训。
你和你的组织如何定义你的 CI/CD 工具链?请在评论中分享你的反馈。
---
via: <https://opensource.com/article/21/6/what-cicd-pipeline>
作者:[Will Kelly](https://opensource.com/users/willkelly) 选题:[lujun9972](https://github.com/lujun9972) 译者:[baddate](https://github.com/baddate) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A continuous integration/continuous deployment (CI/CD) pipeline is an anchor for every DevOps initiative. The CI/CD pipeline breaks down traditional silos and enables development and operations teams to collaborate throughout the entire software development lifecycle.
Better yet, moving to DevOps and a CI/CD pipeline can help your organization [deliver software](https://techbeacon.com/devops/5-reasons-why-cicd-vital-your-organizations-value-stream) more securely at a higher velocity.
## Breaking down the CI/CD pipeline
There are many definitions of CI/CD pipelines out there, so I always advise organizations to define their own version of a CI/CD pipeline and other DevOps concepts rather than using someone else's. Open source CI/CD tools give you the freedom and options to construct a CI/CD pipeline that meets your organization's requirements.
The stages that form a CI/CD pipeline are distinct subsets of tasks grouped into *pipeline stages*. Typical pipeline stages include:
**Build:**Developers compile the application code.**Test**: The quality assurance (QA) team tests the application code using automated testing tools and strategies.**Release:**The development team delivers the application code to the code repository.**Deploy**: The DevOps team stages application code to production.**Security and compliance**: The QA team validates a build based on the project's requirements. This is the stage where organizations deploy container-scanning tools that check the quality of images against Common Vulnerabilities and Exposures (CVEs).
These are standard stages for a CI/CD pipeline, yet some organizations adapt the CI/CD pipeline model to fit their requirements. For example, an organization building applications for the healthcare market, with its stringent compliance standards, may distribute the test, validation, and compliance gates throughout their toolchain.
Other examples might be an organization that depends on a complex software supply chain with open source software (OSS). Commercial components may institute a gate where development team members generate a [software bill of materials](https://www.ntia.gov/SBOM) (SBOM) for OSS packages or the outside commercial software vendor must deliver an SBOM as part of their contract deliverable.
## Barriers to CI/CD pipelines
Implementing a CI/CD pipeline changes a team's processes and culture. While many developers are receptive to automation of some tasks and testing, people can be a barrier to CI/CD adoption.
Moving from a waterfall process to CI/CD can shake up the fundamental and implied power structure in some organizations. Since a CI/CD pipeline increases software delivery velocity, the "gatekeepers" of your old manual process may feel threatened by this change.
## Integration opportunities
The open source roots of the tools comprising a CI/CD toolchain create opportunities for some exciting integrations as you achieve greater DevOps maturity levels in your culture, processes, and tooling.
Analyst firm Forrester predicted in 2020 that just-in-time learning will join the CI/CD pipeline. It makes sense if you think about it. It makes even more sense in the current era of remote work and even for remote onboarding of new employees. For instance, an organization could integrate a documentation wiki into its pipeline with documentation of internal processes.
A more ambitious organization can integrate a learning management system (LMS) such as [Moodle](https://moodle.org/) into its CI/CD pipeline. It could use the LMS to publish short videos about new DevOps toolchain features that developers need to learn as they onboard or when tools are updated across the pipeline.
Some organizations are integrating group chat and other collaboration tools directly into their CI/CD pipelines. The chat platform serves alerts and enables collaboration and communication among teams. Integrating Mattermost, Rocket.Chat, or another [enterprise chat](https://opensource.com/alternatives/slack) platform into your CI/CD pipeline requires upfront planning and analysis to ensure that pipeline users won't drown in alerts.
Another integration opportunity to explore is building analytics and advanced reporting into your CI/CD pipeline. This helps you harness the data that courses through your pipeline.
## Final thoughts
The CI/CD pipeline is foundational to DevOps. And open source makes it adaptable and flexible to new requirements resulting from operational changes you implement during your DevOps journey.
I hope to see an open source response to the unified DevOps platform trend, in which organizations seek an end-to-end CI/CD solution. The makings of such a solution are out there. After all, GitLab and GitHub trace their platforms back to open source roots.
Lastly, don't forget the education and outreach underlying every successful CI/CD toolchain. Documenting your toolchains and accompanying processes will improve developer onboarding and ongoing DevOps team training.
How do you and your organization define your CI/CD toolchain? Please share your feedback in the comments.
## 2 Comments |
13,542 | 使用 Python 来解决慈善机构的业务问题 | https://opensource.com/article/20/9/solve-problem-python | 2021-07-02T12:42:48 | [
"Python"
] | https://linux.cn/article-13542-1.html |
>
> 比较不同的编程语言如何解决同一个问题是一个很有趣的事情,也很有指导意义。接下来,我们就来讲一讲如何用 Python 来解决。
>
>
>

在我这一系列的 [第一篇文章](https://opensource.com/article/20/8/solving-problem-groovy) 里,我描述了这样子的一个问题,如何将一大批的救助物资分为具有相同价值的物品,并将其分发给社区中的困难住户。我也曾写过用不同的编程语言写一些小程序来解决这样子的小问题以及比较这些程序时如何工作的。
在第一篇文章中,我是使用了 [Groovy](https://groovy-lang.org/) 语言来解决问题的。Groovy 在很多方面都与 [Python](https://www.python.org/) 很相似,但是在语法上她更像 C 语言和 Java。因此,使用 Python 来创造一个相同的解决方案应该会很有趣且更有意义。
### 使用 Python 的解决方案
使用 Java 时,我会声明一个工具类来保存元组数据(新的记录功能将会很好地用于这个需求)。使用 Groovy 时,我就是用了该语言的映射功能,我也将在 Python 使用相同的机制。
使用一个字典列表来保存从批发商处批发来的货物:
```
packs = [
{'item':'Rice','brand':'Best Family','units':10,'price':5650,'quantity':1},
{'item':'Spaghetti','brand':'Best Family','units':1,'price':327,'quantity':10},
{'item':'Sardines','brand':'Fresh Caught','units':3,'price':2727,'quantity':3},
{'item':'Chickpeas','brand':'Southern Style','units':2,'price':2600,'quantity':5},
{'item':'Lentils','brand':'Southern Style','units':2,'price':2378,'quantity':5},
{'item':'Vegetable oil','brand':'Crafco','units':12,'price':10020,'quantity':1},
{'item':'UHT milk','brand':'Atlantic','units':6,'price':4560,'quantity':2},
{'item':'Flour','brand':'Neighbor Mills','units':10,'price':5200,'quantity':1},
{'item':'Tomato sauce','brand':'Best Family','units':1,'price':190,'quantity':10},
{'item':'Sugar','brand':'Good Price','units':1,'price':565,'quantity':10},
{'item':'Tea','brand':'Superior','units':5,'price':2720,'quantity':2},
{'item':'Coffee','brand':'Colombia Select','units':2,'price':4180,'quantity':5},
{'item':'Tofu','brand':'Gourmet Choice','units':1,'price':1580,'quantity':10},
{'item':'Bleach','brand':'Blanchite','units':5,'price':3550,'quantity':2},
{'item':'Soap','brand':'Sunny Day','units':6,'price':1794,'quantity':2}]
```
大米有一包,每包中有 10 袋大米,意大利面条有十包,每包中有一袋意大利面条。上述代码中,变量 `packs` 被设置为 Python 字典列表。这与 Groovy 的方法非常相似。关于 Groovy 和 Python 之间的区别,有几点需要注意:
1. 在 Python 中,无需关键字来定义变量 `packs`,Python 变量初始化时需要设置一个值。
2. Python 字典中的词键(例如,`item`、`brand`、`units`、`price`、 `quantity`)需要引号来表明它们是字符串;Groovy 假定这些是字符串,但也接受引号。
3. 在 Python 中,符号 `{ ... }` 表明一个字典声明; Groovy 使用与列表相同的方括号,但两种情况下的结构都必须具有键值对。
当然,表中的价格不是以美元计算的。
接下来,打开散装包。例如,打开大米的单个散装包装,将产出 10 单元大米; 也就是说,产出的单元总数是 `units * quantity`。 Groovy 脚本使用一个名为 `collectMany` 的方便的函数,该函数可用于展平列表列表。 据我所知,Python 没有类似的东西,所以使用两个列表推导式来产生相同的结果:
```
units = [[{'item':pack['item'],'brand':pack['brand'],
'price':(pack['price'] / pack['units'])}] *
(pack['units'] * pack['quantity']) for pack in packs]
units = [x for sublist in units for x in sublist]
```
第一个列表可理解为(分配给单元)构建字典列表列表。 第二个将其“扁平化”为字典列表。 请注意,Python 和 Groovy 都提供了一个 `*` 运算符,它接受左侧的列表和右侧的数字 `N`,并复制列表 `N` 次。
最后一步是将这些单元的大米之类的重新包装到篮子(`hamper`)中以进行分发。 就像在 Groovy 版本中一样,你需要更具体地了解理想的篮子数,当你只剩下几个单元时,你最好不要过度限制,即可以做一些随机分配:
```
valueIdeal = 5000
valueMax = valueIdeal * 1.1
```
很好! 重新打包篮子。
```
import random
hamperNumber = 0 # 导入 Python 的随机数生成器工具并初始化篮子数
while len(units) > 0: # 只要有更多可用的单元,这个 `while` 循环就会将单元重新分配到篮子中:
hamperNumber += 1
hamper = []
value = 0
canAdd = True # 增加篮子编号,得到一个新的空篮子(单元的列表),并将其值设为 0; 开始假设你可以向篮子中添加更多物品。
while canAdd: # 这个 `while` 循环将尽可能多地向篮子添加单元(Groovy 代码使用了 `for` 循环,但 Python 的 `for` 循环期望迭代某些东西,而 Groovy 则是为更传统的 C 形式的 `for` 循环形式):
u = random.randint(0,len(units)-1) # 获取一个介于 0 和剩余单元数减 1 之间的随机数。
canAdd = False # 假设你找不到更多要添加的单元。
o = 0 # 创建一个变量,用于从你正在寻找要放入篮子中的物品的起点的偏移量。
while o < len(units): # 从随机选择的索引开始,这个 `while` 循环将尝试找到一个可以添加到篮子的单元(再次注意,Python `for` 循环可能不适合这里,因为列表的长度将在迭代中中发生变化)。
uo = (u + o) % len(units)
unit = units[uo]
unitPrice = unit['price'] # 找出要查看的单元(随机起点+偏移量)并获得其价格。
if len(units) < 3 or not (unit in hamper) and (value + unitPrice) < valueMax:
# 如果只剩下几个,或者添加单元后篮子的价值不太高,你可以将此单元添加到篮子中。
hamper.append(unit)
value += unitPrice
units.pop(u) # 将单元添加到篮子中,按单价增加 篮子数,从可用单元列表中删除该单元。
canAdd = len(units) > 0
break # 只要还有剩余单元,你就可以添加更多单元,因此可以跳出此循环继续寻找。
o += 1 # 增加偏移量。
# 在退出这个 `while` 循环时,如果你检查了所有剩余的单元并且找不到单元可以添加到篮子中,那么篮子就完成了搜索; 否则,你找到了一个,可以继续寻找更多。
print('')
print('Hamper',hamperNumber,'value',value)
for item in hamper:
print('%-25s%-25s%7.2f' % (item['item'],item['brand'],item['price'])) # 打印出篮子的内容。
print('Remaining units',len(units)) # 打印出剩余的单元信息。
```
一些澄清如上面的注释。
运行此代码时,输出看起来与 Groovy 程序的输出非常相似:
```
Hamper 1 value 5304.0
UHT milk Atlantic 760.00
Tomato sauce Best Family 190.00
Rice Best Family 565.00
Coffee Colombia Select 2090.00
Sugar Good Price 565.00
Vegetable oil Crafco 835.00
Soap Sunny Day 299.00
Remaining units 148
Hamper 2 value 5428.0
Tea Superior 544.00
Lentils Southern Style 1189.00
Flour Neighbor Mills 520.00
Tofu Gourmet Choice 1580.00
Vegetable oil Crafco 835.00
UHT milk Atlantic 760.00
Remaining units 142
Hamper 3 value 5424.0
Soap Sunny Day 299.00
Chickpeas Southern Style 1300.00
Sardines Fresh Caught 909.00
Rice Best Family 565.00
Vegetable oil Crafco 835.00
Spaghetti Best Family 327.00
Lentils Southern Style 1189.00
Remaining units 135
...
Hamper 21 value 5145.0
Tomato sauce Best Family 190.00
Tea Superior 544.00
Chickpeas Southern Style 1300.00
Spaghetti Best Family 327.00
UHT milk Atlantic 760.00
Vegetable oil Crafco 835.00
Lentils Southern Style 1189.00
Remaining units 4
Hamper 22 value 2874.0
Sardines Fresh Caught 909.00
Vegetable oil Crafco 835.00
Rice Best Family 565.00
Rice Best Family 565.00
Remaining units 0
```
最后一个篮子在内容和价值上有所简化。
### 结论
乍一看,这个程序的 Python 和 Groovy 版本之间没有太大区别。 两者都有一组相似的结构,这使得处理列表和字典非常简单。 两者都不需要很多“样板代码”或其他“繁杂”操作。
此外,使用 Groovy 时,向篮子中添加单元还是一件比较繁琐的事情。 你需要在单元列表中随机选择一个位置,然后从该位置开始,遍历列表,直到找到一个价格允许的且包含它的单元,或者直到你用完列表为止。 当只剩下几件物品时,你需要将它们扔到最后一个篮子里。
另一个值得一提的问题是:这不是一种特别有效的方法。 从列表中删除元素、极其多的重复表达式还有一些其它的问题使得这不太适合解决这种大数据重新分配问题。 尽管如此,它仍然在我的老机器上运行。
如果你觉得我在这段代码中使用 `while` 循环并改变其中的数据感到不舒服,你可能希望我让它更有用一些。 我想不出一种方法不使用 Python 中的 map 和 reduce 函数,并结合随机选择的单元进行重新打包。 你可以吗?
在下一篇文章中,我将使用 Java 重新执行此操作,以了解 Groovy 和 Python 的工作量减少了多少,未来的文章将介绍 Julia 和 Go。
---
via: <https://opensource.com/article/20/9/solve-problem-python>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zepoch](https://github.com/zepoch) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my [first article](https://opensource.com/article/20/8/solving-problem-groovy) in this series, I described a problem of dividing bulk supplies into hampers of similar value to distribute to struggling neighbors in your community. I also wrote about how I enjoy solving small problems like this with small programs in various languages and comparing how they do it.
In the first article, I solved this problem with the [Groovy](https://groovy-lang.org/) programming language. Groovy is like [Python](https://www.python.org/) in many ways, but syntactically it's more like C and Java. Therefore, it should be interesting and instructive to create the same solution in Python.
## The Python solution
In Java, I declare utility classes to hold tuples of data (the new record feature is going to be great for that). In Groovy, I use the language support for maps, and I follow the same approach in Python.
Use a list of dictionaries to hold the bulk items picked up from the wholesaler:
```
packs = [
{'item':'Rice','brand':'Best Family','units':10,'price':5650,'quantity':1},
{'item':'Spaghetti','brand':'Best Family','units':1,'price':327,'quantity':10},
{'item':'Sardines','brand':'Fresh Caught','units':3,'price':2727,'quantity':3},
{'item':'Chickpeas','brand':'Southern Style','units':2,'price':2600,'quantity':5},
{'item':'Lentils','brand':'Southern Style','units':2,'price':2378,'quantity':5},
{'item':'Vegetable oil','brand':'Crafco','units':12,'price':10020,'quantity':1},
{'item':'UHT milk','brand':'Atlantic','units':6,'price':4560,'quantity':2},
{'item':'Flour','brand':'Neighbor Mills','units':10,'price':5200,'quantity':1},
{'item':'Tomato sauce','brand':'Best Family','units':1,'price':190,'quantity':10},
{'item':'Sugar','brand':'Good Price','units':1,'price':565,'quantity':10},
{'item':'Tea','brand':'Superior','units':5,'price':2720,'quantity':2},
{'item':'Coffee','brand':'Colombia Select','units':2,'price':4180,'quantity':5},
{'item':'Tofu','brand':'Gourmet Choice','units':1,'price':1580,'quantity':10},
{'item':'Bleach','brand':'Blanchite','units':5,'price':3550,'quantity':2},
{'item':'Soap','brand':'Sunny Day','units':6,'price':1794,'quantity':2}]
```
There is one bulk pack of 10 bags of rice and 10 bulk packs with one bag each of spaghetti. In the above, the variable `packs`
is set to a Python list of dictionaries. This turns out to be very similar to the Groovy approach. A few points worth noting about the difference between Groovy and Python:
- In Python, there is no keyword used to define the variable
`packs`
; Python expects the first use to set a value. - Python dictionary keys (e.g.,
`item`
,`brand`
,`units`
,`price`
,`quantity`
) require quotes to indicate they are strings; Groovy assumes these are strings, but accepts quotes as well. - In Python, the notation
`{ … }`
indicates a dictionary declaration; Groovy uses the same square brackets as a list, but the structure in both cases must have key-value pairs.
And, yes, those prices aren't in US dollars.
Next, unpack the bulk packages. Unpacking the single bulk package of rice, for example, will yield 10 units of rice; that is, the total number of units yielded is `units * quantity`
. The Groovy script uses a handy function called `collectMany`
that can be used to flatten out lists of lists. As far as I know, Python doesn't have anything similar, so use two list comprehensions to produce the same result:
```
units = [[{'item':pack['item'],'brand':pack['brand'],
'price':(pack['price'] / pack['units'])}] *
(pack['units'] * pack['quantity']) for pack in packs]
units = [x for sublist in units for x in sublist]
```
The first list comprehension (assignment to units) builds the list of lists of dictionaries. The second "flattens" that into just a list of dictionaries. Note that both Python and Groovy provide an `*`
operator that takes a list on the left and a number `N`
on the right and replicates the list `N`
times.
The final step is to repack the units into the hampers for distribution. As in the Groovy version, you need to get a bit more specific about the ideal hamper value, and you might as well not be overly restrictive when you get down to just a few units left:
```
valueIdeal = 5000
valueMax = valueIdeal * 1.1
```
OK! Repack the hampers:
```
import random
hamperNumber = 0 # [1]
while len(units) > 0: # [2]
hamperNumber += 1
hamper = []
value = 0
canAdd = True # [2.1]
while canAdd: # [2.2]
u = random.randint(0,len(units)-1) # [2.2.1]
canAdd = False # [2.2.2]
o = 0 # [2.2.3]
while o < len(units): # [2.2.4]
uo = (u + o) % len(units)
unit = units[uo]
unitPrice = unit['price'] # [2.2.4.1]
if len(units) < 3 or not (unit in hamper) and (value + unitPrice) < valueMax:
# [2.2.4.2]
hamper.append(unit)
value += unitPrice
units.pop(u) # [2.2.4.3]
canAdd = len(units) > 0
break # [2.2.4.4]
o += 1 # [2.2.4.5]
# [2.2.5]
print('')
print('Hamper',hamperNumber,'value',value)
for item in hamper:
print('%-25s%-25s%7.2f' % (item['item'],item['brand'],item['price'])) # [2.3]
print('Remaining units',len(units)) # [2.4]
```
Some clarification, with numbers in brackets in the comments above (e.g., *[1]*) corresponding to the clarifications below:
- 1. Import Python's random number generator facilities and initialize the hamper number.
- 2. This
`while`
loop will redistribute units into hampers as long as there are more available:
- 2.1 Increment the hamper number, get a new empty hamper (a list of units), and set its value to 0; start off assuming you can add more items to the hamper.
- 2.2 This
`while`
loop will add as many units to the hamper as possible (the Groovy code used a`for`
loop, but Python's`for`
loops expect to iterate over something, while Groovy has the more traditional C form of`for`
loop):
- 2.2.1 Get a random number between zero and the number of remaining units minus 1.
- 2.2.2 Assume you can't find more units to add.
- 2.2.3 Create a variable to be used for the offset from the starting point where you're looking for items to put in the hamper.
- 2.2.4 Starting at the randomly chosen index, this
`while`
loop will try to find a unit that can be added to the hamper (once again, note that the Python`for`
loop probably isn't suitable here since the length of the list will change during processing).
- 2.2.4.1. Figure out which unit to look at (random starting point + offset) and get its price.
- 2.2.4.2 You can add this unit to the hamper if there are only a few left or if the value of the hamper isn't too high once the unit is added.
- 2.2.4.3 Add the unit to the hamper, increment the hamper value by the unit price, remove the unit from the available units list.
- 2.2.4.4 As long as there are units left, you can add more, so break out of this loop to keep looking.
- 2.2.4.5 Increment the offset.
- 2.2.5 On exit from this
`while`
loop, if you inspected every remaining unit and could not find one to add to the hamper, the hamper is complete; otherwise, you found one and can continue looking for more.
- 2.3 Print out the contents of the hamper.
- 2.4 Print out the remaining units info.
When you run this code, the output looks quite similar to the output from the Groovy program:
```
Hamper 1 value 5304.0
UHT milk Atlantic 760.00
Tomato sauce Best Family 190.00
Rice Best Family 565.00
Coffee Colombia Select 2090.00
Sugar Good Price 565.00
Vegetable oil Crafco 835.00
Soap Sunny Day 299.00
Remaining units 148
Hamper 2 value 5428.0
Tea Superior 544.00
Lentils Southern Style 1189.00
Flour Neighbor Mills 520.00
Tofu Gourmet Choice 1580.00
Vegetable oil Crafco 835.00
UHT milk Atlantic 760.00
Remaining units 142
Hamper 3 value 5424.0
Soap Sunny Day 299.00
Chickpeas Southern Style 1300.00
Sardines Fresh Caught 909.00
Rice Best Family 565.00
Vegetable oil Crafco 835.00
Spaghetti Best Family 327.00
Lentils Southern Style 1189.00
Remaining units 135
…
Hamper 21 value 5145.0
Tomato sauce Best Family 190.00
Tea Superior 544.00
Chickpeas Southern Style 1300.00
Spaghetti Best Family 327.00
UHT milk Atlantic 760.00
Vegetable oil Crafco 835.00
Lentils Southern Style 1189.00
Remaining units 4
Hamper 22 value 2874.0
Sardines Fresh Caught 909.00
Vegetable oil Crafco 835.00
Rice Best Family 565.00
Rice Best Family 565.00
Remaining units 0
```
The last hamper is abbreviated in contents and value.
## Closing thoughts
At a glance, there isn't a whole lot of difference between the Python and Groovy versions of this program. Both have a similar set of constructs that make handling lists and dictionaries very straightforward. Neither requires a lot of "boilerplate code" or other "ceremonial" actions.
Also, as in the Groovy example, there is some fiddly business about being able to add units to the hamper. Basically, you pick a random position in the list of units and, starting at that position, iterate through the list until you either find a unit whose price allows it to be included or until you exhaust the list. Also, when there are only a few items left, you just toss them into the last hamper.
Another issue worth mentioning: This isn't a particularly efficient approach. Removing elements from lists, being careless about repeated expressions, and a few other things make this less suitable for a huge redistribution problem. Still, it runs in a blink on my old machine.
If you are shuddering at my use of `while`
loops and mutating the data in this code, you probably wish I made it more functional. I couldn't think of a way to use map and reduce features in Python in conjunction with a random selection of units for repackaging. Can you?
In the next article, I'll re-do this in Java just to see how much less effort Groovy and Python are, and future articles will cover Julia and Go.
## 2 Comments |
13,544 | 《Bash it out》书评:用这本谜题书学习 Bash | https://opensource.com/article/20/4/bash-it-out-book | 2021-07-03T15:41:41 | [
"Bash",
"书评"
] | https://linux.cn/article-13544-1.html |
>
> 《Bash it out》使用 16 个谜题,涵盖了基本、中级和高级 Bash 脚本。
>
>
>

计算机既是我的爱好,也是我的职业。我的公寓里散布着大约 10 台计算机,它们都运行 Linux(包括我的 Mac)。由于我喜欢升级我的电脑和提升我的电脑技能,当我遇到 Sylvain Leroux 的《[Bash it out](https://www.amazon.com/Bash-Out-Strengthen-challenges-difficulties/dp/1521773262/)》时,我抓住了购买它的机会。我在 Debian Linux 上经常使用命令行,这似乎是扩展我的 Bash 知识的好机会。当作者在前言中解释他使用 Debian Linux 时,我笑了,这是我最喜欢的两个发行版之一。
Bash 可让你自动执行任务,因此它是一种省力、有趣且有用的工具。在阅读本书之前,我已经有相当多的 Unix 和 Linux 上的 Bash 经验。我不是专家,部分原因是脚本语言非常广泛和强大。当我在基于 Arch 的 Linux 发行版 [EndeavourOS](https://endeavouros.com/) 的欢迎屏幕上看到 Bash 时,我第一次对 Bash 产生了兴趣。
以下屏幕截图显示了 EndeavourOS 的一些选项。你可能不相信,这些面板只指向 Bash 脚本,每个脚本都完成一些相对复杂的任务。而且因为它都是开源的,所以我可以根据需要修改这些脚本中的任何一个。


### 总有东西要学
我对这本书的印象非常好。虽然不长,但经过了深思熟虑。作者对 Bash 有非常广泛的了解,并且具有解释如何使用它的不可思议的能力。这本书使用 16 个谜题涵盖了基本、中级和高级 Bash 脚本,他称之为“挑战”。这教会了我将 Bash 脚本视为需要解决的编程难题,这让我玩起来更有趣。
Bash 的一个令人兴奋的方面是它与 Linux 系统深度集成。虽然它的部分能力在于它的语法,但它也很强大,因为它可以访问很多系统资源。你可以编写重复性任务或简单但厌倦了手动执行的任务的脚本。不管是大事还是小事,《Bash it out》可以帮助你了解可以做什么以及如何实现它。
如果我不提及 David Both 的发布在 [Opensource.com](http://Opensource.com) 的免费资源《[A sysadmin's guide to Bash scripting\_](https://opensource.com/downloads/bash-scripting-ebook)》,这篇书评就不会完整。这个 17 页的 PDF 指南与《Bash it out》不同,但它们共同构成了任何想要了解它的人的成功组合。
我不是计算机程序员,但《Bash it out》增加了我进入更高级 Bash 脚本水平的欲望——虽然没有这个打算,但我可能最终无意中成为一名计算机程序员。
我喜欢 Linux 的原因之一是因为它的操作系统功能强大且用途广泛。无论我对 Linux 了解多少,总有一些新东西需要学习,这让我更加欣赏 Linux。
在竞争激烈且不断变化的就业市场中,我们所有人都应该不断更新我们的技能。这本书帮助我以非常实际的方式学习了 Bash。几乎感觉作者和我在同一个房间里,耐心地指导我学习。
作者 Leroux 具有不可思议的能力去吸引读者。这是一份难得的天赋,我认为比他的技术专长更有价值。事实上,我写这篇书评是为了感谢作者预见了我自己的学习需求;虽然我们从未见过面,但我从他的天赋中受益匪浅。
---
via: <https://opensource.com/article/20/4/bash-it-out-book>
作者:[Carlos Aguayo](https://opensource.com/users/hwmaster1) 选题:[lujun9972](https://github.com/lujun9972) 译者:[baddates](https://github.com/baddates) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Computers are both my hobby and my profession. I have about 10 of them scattered around my apartment, all running Linux (including my Macs). Since I enjoy upgrading my computers and my computer skills, when I came across [ Bash it out](https://www.amazon.com/Bash-Out-Strengthen-challenges-difficulties/dp/1521773262/) by Sylvain Leroux, I jumped on the chance to buy it. I use the command line a lot on Debian Linux, and it seemed like a great opportunity to expand my Bash knowledge. I smiled when the author explained in the preface that he uses Debian Linux, which is one of my two favorite distributions.
Bash lets you automate tasks, so it's a labor-saving, interesting, and useful tool. Before reading the book, I already had a fair amount of experience with Bash on Unix and Linux. I'm not an expert, in part because the scripting language is so extensive and powerful. I first became intrigued with Bash when I saw it on the welcome screen of [EndeavourOS](https://endeavouros.com/), an Arch-based Linux distribution.
The following screenshots show some options from EndeavourOS. Beleieve it or not, these panels just point to Bash scripts, each of which accomplish some relatively complex tasks. And because it's all open source, I can modify any of these scripts if I want.
## Always something to learn
My impressions of this book are very favorable. It's not long, but it is well-thought-out. The author has very extensive knowledge of Bash and an uncanny ability to explain how to use it. The book covers basic, medium, and advanced Bash scripting using 16 puzzles, which he calls "challenges." This taught me to see Bash scripting as a programming puzzle to solve, which makes it more interesting to play with.
An exciting aspect of Bash is that it's deeply integrated with the Linux system. While part of its power lies in its syntax, it's also powerful because it has access to so much. You can script repetitive tasks, or tasks that are easy but you're just tired of performing manually. Nothing is too great or too small, and *Bash it out *helps you understand both what you can do, and how to achieve it.
This review would not be complete if I didn't mention David Both's free resource [ A sysadmin's guide to Bash scripting](https://opensource.com/downloads/bash-scripting-ebook) on Opensource.com. This 17-page PDF guide is different from
*Bash it out*, but together they make a winning combination for anyone who wants to learn about it.
I am not a computer programmer, but *Bash it out* has increased my desire to get into more advanced levels of Bash scripting—I might inadvertently end up as a computer programmer without planning to.
One reason I love Linux is because of how powerful and versatile the operating system is. However much I know about Linux, there is always something new to learn that makes me appreciate Linux even more.
In a competitive and ever-changing job market, it behooves all of us to continuously update our skills. This book helped me learn Bash in a very hands-on way. It almost felt as if the author was in the same room with me, patiently guiding me in my learning.
The author, Leroux, has an uncanny ability to engage readers. This is a rare gift that I think is even more valuable than his technical expertise. In fact, I am writing this book review to thank the author for anticipating my own learning needs; although we have never met, I have benefited in real ways from his gifts.
## 6 Comments |
13,545 | 在 WSL 上忘记了 Linux 密码?下面是如何轻松重设的方法 | https://itsfoss.com/reset-linux-password-wsl/ | 2021-07-03T15:58:24 | [
"WSL",
"密码"
] | https://linux.cn/article-13545-1.html | 对于那些想从舒适的 Windows 中享受 Linux 命令行的人来说,WSL(Windows Subsystem for Linux) 是一个方便的工具。
当你 [在 Windows 上使用 WSL 安装 Linux](https://itsfoss.com/install-bash-on-windows/) 时,会要求你创建一个用户名和密码。当你在 WSL 上启动 Linux 时,这个用户会自动登录。
现在的问题是,如果你有一段时间没有使用它,你可能会忘记 WSL 的账户密码。而如果你要使用 `sudo` 的命令,这将成为一个问题,因为这里你需要输入密码。

不要担心。你可以很容易地重置它。
### 在 Ubuntu 或任何其他 Linux 发行版上重置遗忘的 WSL 密码
要在 WSL 中重设 Linux 密码,你需要:
* 将默认用户切换为 `root`
* 重置普通用户的密码
* 将默认用户切换回普通用户
让我向你展示详细的步骤和截图。
#### 步骤 1:将默认用户切换为 root
记下你的普通/常规用户名将是明智之举。如你所见,我的普通帐户的用户名是 `abhishek`。

WSL 中的 `root` 用户是无锁的,没有设置密码。这意味着你可以切换到 `root` 用户,然后利用 `root` 的能力来重置密码。
由于你不记得帐户密码,切换到 `root` 用户是通过改变你的 Linux WSL 应用的配置,使其默认使用 `root` 用户来完成。
这是通过 Windows 命令提示符完成的,你需要知道你的 Linux 发行版需要运行哪个命令。
这个信息通常在 [Windows 商店](https://www.microsoft.com/en-us/store/apps/windows) 中的发行版应用的描述中提供。这是你首次下载发行版的地方。

从 Windows 菜单中,启动命令提示符:

在这里,以这种方式使用你的发行版的命令。如果你使用的是 Windows 商店中的 Ubuntu 应用,那么该命令将是:
```
ubuntu config --default-user root
```
截图中,我正在使用 Windows 商店中的 Ubuntu 20.04 应用。所以,我使用了 ubuntu2004 命令。

为了减少你的麻烦,我在这个表格中列出了一些发行版和它们各自的命令:
| 发行版应用 | Windows 命令 |
| --- | --- |
| Ubuntu | `ubuntu config –default-user root` |
| Ubuntu 20.04 | `ubuntu2004 config –default-user root` |
| Ubuntu 18.04 | `ubuntu1804 config –default-user root` |
| Debian | `debian config –default-user root` |
| Kali Linux | `kali config –default-user root` |
#### 步骤 2:重设帐户密码
现在,如果你启动 Linux 发行程序,你应该以 `root` 身份登录。你可以重新设置普通用户帐户的密码。
你还记得 WSL 中的用户名吗?(LCTT 译注:请使用你的“用户名”替换下列命令中的 `username`)如果没有,你可以随时检查 `/home` 目录的内容。当你有了用户名后,使用这个命令:
```
passwd username
```
它将要求你输入一个新的密码。\*\*当你输入时,屏幕上将不会显示任何内容。这很正常。只要输入新的密码,然后点击回车就可以了。\*\*你必须重新输入新的密码来确认,当你输入密码时,屏幕上也不会显示任何东西。

恭喜你。用户账户的密码已经被重置。但你还没有完成。默认用户仍然是 `root`。你应该把它改回你的普通用户帐户,否则它将一直以 `root` 用户的身份登录。
#### 步骤 3:再次将普通用户设置为默认用户
你需要你在上一步中用 [passwd 命令](https://linuxhandbook.com/passwd-command/) 使用的普通帐户用户名。
再次启动 Windows 命令提示符。**使用你的发行版命令**,方式与第 1 步中类似。然而,这一次,用普通用户代替 `root`。
```
ubuntu config --default-user username
```

现在,当你在 WSL 中启动你的 Linux 发行版时,你将以普通用户的身份登录。你已经重新设置了密码,可以用它来运行 `sudo` 命令。
如果你将来再次忘记了密码,你知道重置密码的步骤。
### 如果重设 WSL 密码如此简单,这难道不是一种安全风险吗?
并非如此。你需要有对计算机的物理访问权以及对 Windows 帐户的访问权。如果有人已经有这么多的访问权,他/她可以做很多事情,而不仅仅是改变 WSL 中的 Linux 密码。
### 你是否能够重新设置 WSL 密码?
我给了你命令并解释了步骤。我希望这对你有帮助,并能够在 WSL 中重置你的 Linux 发行版的密码。
如果你仍然遇到问题,或者你对这个话题有疑问,请随时在评论区提问。
---
via: <https://itsfoss.com/reset-linux-password-wsl/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Reset Forgotten Linux Password on WSL
Forgot the password of your Linux distribution app you installed in Windows via WSL? No worries. You can easily reset the Linux password in WSL.
WSL (Windows Subsystem for Linux) is a handy tool for people who want to enjoy the power of Linux command line from the comfort of Windows.
When you [install Linux using WSL on Windows](https://itsfoss.com/install-bash-on-windows/), you are asked to create a username and password. This user is automatically logged on when you start Linux on WSL.
Now, the problem is that if you haven’t used it for some time, you may forget the account password of WSL. And this will become a problem if you have to use a command with sudo because here you’ll need to enter the password.
Don’t worry. You can easily reset it.
## Reset forgotten password for Ubuntu or any other Linux distribution on WSL
To reset the Linux password in WSL, you have to:
- Switch the default user to root
- Reset the password for the normal user
- Switch back the default user to the normal user
Let me show you the steps in detail and with screenshots. If you want a video, you can watch that as well.
### Step 1: Switch to root as default user
It will be wise to note down your account’s normal/regular username. As you can see, my regular account’s username is abhishek.
The root user in WSL is unlocked and doesn’t have a password set. This means that you can switch to the root user and then use the power of root to reset the password.
Since you don’t remember the account password, switching to the root user is done by changing the configuration of your Linux WSL application and make it use root user by default.
This is done through Windows Command Prompt and you’ll need to know which command you need to run for your Linux distribution.
This information is usually provided in the description of the distribution app in the [Windows Store](https://www.microsoft.com/en-us/store/apps/windows). This is from where you had downloaded your distribution in the first place.
From the Windows menu, start the command prompt:
In here, use your distribution’s command in this fashion. If you were using the Ubuntu app from Windows store, the command would be:
`ubuntu config --default-user root`
In the screenshot, I am using Ubuntu 20.04 app from the Windows store. So, I have used `ubuntu2004`
command.
To save you the trouble, I am listing some distributions and their respective commands in this table:
Distribution App | Windows Command |
---|---|
Ubuntu | ubuntu config –default-user root |
Ubuntu 20.04 | ubuntu2004 config –default-user root |
Ubuntu 18.04 | ubuntu1804 config –default-user root |
Debian | debian config –default-user root |
Kali Linux | kali config –default-user root |
### Step 2: Reset the password for the account
Now, if you start the Linux distribution app, you should be logged in as root. You can reset the password for the normal user account.
Do you remember the username in WSL? If not, you can always check the contents of the /home directory. When you have the username, use this command:
`passwd username`
It will ask you to enter a new password. **When you type here, nothing will be displayed on the screen. That’s normal. Just type the new password and hit enter.** You’ll have to retype the new password to confirm and once again, nothing will be displayed on the screen while you type the password.
Congratulations. The password for the user account has been reset. But you are done just yet. The default user is still root. You should change it back to your regular account user, otherwise, it will keep on logging in as the root user.
### Step 3: Set regular user as default again
You’ll need the regular account username that you used with the [passwd command](https://linuxhandbook.com/passwd-command/) in the previous step.
Start the Windows command prompt once again. **Use your distribution’s command** in the similar manner you did in step 1. However, this time, replace root with the regular user.
`ubuntu config --default-user username`
Now when you start your Linux distribution app in WSL, you’ll be logged in as a regular user. You have reset the password fresh and can use it to run commands with sudo.
If you forgot the password again in the future, you know the steps to reset it.
## If resetting WSL password is this easy, is this not a security risk?
Not really. You need physical access to the computer and access to the Windows account. If someone already has this much access, they can do much more than just change the Linux password in WSL.
## Were you able to reset WSL password?
I gave you the commands and explained the steps. I hope this was helpful to you and you were able to reset the password of your Linux distribution in WSL.
If you are still facing issues or if you have a question on this topic, please feel free to ask in the comment section. |
13,547 | “MAGFest 先生”专访:用 Python 和 Linux 进行音乐创作 | https://opensource.com/article/20/2/linux-open-source-music | 2021-07-04T17:48:51 | [
"音乐"
] | /article-13547-1.html |
>
> 与 “MAGFest 先生” Brendan Becker 的对话。
>
>
>

1999 年,我在一家计算机商店工作时遇到了 Brendan Becker。我们都喜欢构建定制计算机并在其上安装 Linux。Brendan 一直在同时参与着从游戏编程到音乐创作的多个技术项目。从那之后快进几年,他继续编写 [pyDance](http://icculus.org/pyddr/),这是一个多舞种游戏的开源实现,然后成为了音乐和游戏项目 [MAGFest](http://magfest.org/) 的 CEO。他有时被称为 “MAGFest 先生”,因为他是该项目的负责人,Brendan 现在使用的音乐笔名是 “[Inverse Phase](http://www.inversephase.com/)”,是一位<ruby> 电子合音 <rt> chiptune </rt></ruby>(主要在 8 位计算机和游戏机上创作的音乐)作曲家。
我认为采访并询问他在整个职业生涯中如何从 Linux 和开源软件中受益的一些细节会很有趣。

### 你是如何开始接触计算机和软件的?
Brendan Becker:从我记事起,我家就有一台电脑。我父亲热衷于技术;在康柏便携式电脑刚刚上市时,他就带了一台回家,当他不在上面工作时,我就可以使用它。由于我两岁时就开始阅读,使用电脑就成了我的第二天性——只要阅读磁盘上的内容,按照说明进行操作,我就可以玩游戏了!有时我会玩一些学习和教育软件,我们有几张装满游戏的磁盘,我可以在其他时间玩。我记得有一张磁盘,里面有一些流行游戏的免费副本。后来,我父亲向我展示了我们可以呼叫其他计算机(我 5 岁时就上了 BBS!),我看到了一些游戏来自那儿。我喜欢玩的一款游戏是用 BASIC 编写的,当我意识到我可以简单地修改游戏,只需阅读一些内容并重新输入它们游戏就会更轻松,玩游戏就没意思了。
### 这是上世纪 80 年代?
Becker:康柏便携式电脑于 1983 年推出,这可以给你一些参考。我爸爸有一个那个型号的初代产品。
### 你是如何进入 Linux 和开源软件的?
Becker:在上世纪 90 年代初,我酷爱 MOD 和<ruby> 演示场景 <rt> demoscene </rt></ruby>之类的东西,我注意到 Walnut Creek(即 [cdrom.com](https://en.wikipedia.org/wiki/Walnut_Creek_CDROM);现已解散)在 FreeBSD 上开设了商店。总的来说,我对 Unix 和其他操作系统非常好奇,但没有太多的第一手资料,我认为是时候尝试一些东西了。当时 DOOM 刚刚发布,有人告诉我,我可以试着在计算机上运行它。在这与能够运行很酷的互联网服务器之间,我开始陷入两难取舍。有人看到我在阅读有关 FreeBSD 的文章,并建议我了解一下 Linux,这是一个为 x86 重新编写的新操作系统,与 BSD 不同,(他们说)后者存在一些兼容性问题。因此,我加入了 undernet IRC 上的 #linuxhelp 频道,询问如何开始使用 Linux,并表明我已经做了一些研究(我已经能问出 “Red Hat 和 Slackware 之间有什么区别?”这样的问题),想知道什么是最容易使用的。频道里唯一说话的人说他已经 13 岁了,他都能弄明白 Slackware,所以我应该不会有问题。学校的一个数学老师给了我一个硬盘,我下载了 “A” 盘组和一个启动盘,写入到软盘,安装了它,回头看也并没有花太多时间。
### 你是如何被称为 “MAGFest 先生”的?
Becker:嗯,这个很简单。在第一个活动后,我几乎立即成为了 MAGFest 的代理负责人。前任主席都各奔东西,我向负责人要求不要取消活动。解决方案就是自己运营它,当我慢慢地将项目塑造成我自己的时,这个昵称就成了我的。
### 我记得我在早期参加过,MAGFest 最终变得有多大?
Becker:第一届 MAGFest 是 265 人。现在它超大,有两万多名不同的参与者。
### 太棒了!你能简要描述一下 MAGFest 大会吗?
Becker:我的一个朋友 Hex 描述得非常好。他说:“就像是和你所有的朋友一起举办这个以电子游戏为主题的生日派对,那里恰好有几千人,如果你愿意,他们都可以成为你的朋友,然后还有摇滚音乐会。” 这很快被采用并缩短为 “这是一个为期四天的电子游戏派对,有多场电子游戏摇滚音乐会”。通常 “音乐和游戏节” 这句话就能让人们明白这个意思。
### 你是如何利用开源软件来运行 MAGFest 的?
Becker:当我成为 MAGFest 的负责人时,我已经用 Python 编写了一个游戏,所以我觉得用 Python 编写我们的注册系统最舒服。这是一个非常轻松的决定,因为不涉及任何费用,而且我已经有了经验。后来,我们的在线注册系统和拼车界面都是用 PHP/MySQL 编写的,我们的论坛使用了 Kboard。最终,这发展到我们用 Python 从头开始编写了自己的注册系统,我们也在活动中使用它,并在主网站上运行 Drupal。有一次,我还用 Python 编写了一个系统来管理视频室和邀请比赛站。哦,我们有一些游戏音乐收听站,你可以翻阅标志性的游戏 OST(原始音轨)的曲目和简介,和演奏 MAGFest 的乐队。
### 我知道几年前你减少了你在 MAGFest 的职责,去追求新的项目。你接下来的努力是什么?
Becker:我一直非常投入游戏音乐领域,并试图将尽可能多的音乐带到 MAGFest 中。随着我越来越多地成为这些社区的一部分,我想参与其中。我使用以前用过的自由开源版本的 DOS 和 Windows 演示场景工具编写了一些视频游戏曲调的混合曲、封面和编曲,我以前使用过的这种工具也是免费的,但不一定是开源的。我在运行 MAGFest 的最初几年发布了一些曲目,然后在 Jake Kaufman(也被称为 `virt`;在他的简历之外也叫 Shovel Knight 和 Shantae)的一些严厉的关爱和建议之后,我改变主题到我更擅长的电子和音。尽管我小时候就用我的康柏便携式电脑编写了 PC 扬声器发出的哔哔啵啵声,并在 90 年代的演示场景中写过 MOD 文件,但我在 2006 年发布了第一首 NES 规格的曲目,我真的能很自豪地称之为我自己的作品。随后还有几张流行音乐的作品和专辑。
2010 年,有很多人找我做游戏配乐工作。尽管配乐工作对它没有太大影响,但我开始更认真地缩减我在 MAGFest 的一些职责,并且在 2011 年,我决定更多地进入幕后。我会留在董事会担任顾问,帮助人们了解他们需要什么来管理他们的部门,但我不再掌舵了。与此同时,我的兼职工作,即给我支付账单的工作,解雇了他们所有的工人,我突然发现自己有了很多空闲时间。我开始写《 Pretty Eight Machine》,这是一首向《Nine Inch Nails》致敬的作品,我在这个事情和游戏配乐工作之间花了一年多,我向自己证明了我可以用音乐来(即便只是勉强)维持生计,这就是我接下来想做的。

*版权所有 Inverse Phase,经许可使用。*
### 就硬件和软件而言,你的工作空间是什么样的?
Becker:在我的 DOS/Windows 时代,我主要使用 FastTracker 2。在 Linux 中,我将其替换为 SoundTracker(不是 Karsten Obarski 的原始版本,而是 GTK 重写版本;参见 [soundtracker.org](http://soundtracker.org))。近来,SoundTracker 处于不断变化的状态——虽然我仍然需要尝试新的 GTK3 版本——但是当我无法使用 SoundTracker 时,[MilkyTracker](http://www.milkytracker.org) 是一个很好的替代品。如果我真的需要原版 FastTracker 2,虽然老旧但它也可以在 DOSBox 中运行起来。然而,那是我开始使用 Linux 的时候,所以这是我在 20-25 年前发现的东西。
在过去的十年里,我已经从基于采样的音乐转向了电子和音,这是由来自 8 位和 16 位游戏系统和计算机的旧声音芯片合成的音乐。有一个非常好的跨平台工具叫 [Deflemask](http://www.deflemask.com),可以为许多这些系统编写音乐。不过,我想为其创作音乐的一些系统不受支持,而且 Deflemask 是闭源的,因此我已经开始使用 Python 和 [Pygame](http://www.pygame.org) 从头开始构建自己的音乐创作环境。我使用 Git 维护我的代码树,并将使用开源的 [KiCad](http://www.kicad-pcb.org) 控制硬件合成器板。
### 你目前专注于哪些项目?
Becker:我断断续续地从事于游戏配乐和音乐委托工作。在此期间,我还一直致力于创办一个名为 [Bloop](http://bloopmuseum.com) 的电子娱乐博物馆。我们在档案和库存方面做了很多很酷的事情,但也许最令人兴奋的是我们一直在用树莓派构建展览。它们的用途非常广泛,而且我觉得很奇怪,如果我在十年前尝试这样做,我就不会有可以驱动我的展品的小型单板计算机;我可能会用把一个平板固定在笔记本电脑的背面!
### 现在有更多游戏平台进入 Linux,例如 Steam、Lutris 和 Play-on-Linux。你认为这种趋势会持续下去吗?这些会一直存在吗?
Becker:作为一个在 Linux 上玩了 25 年游戏的人——事实上,我 *是因为* 游戏才接触 Linux 的——我想我认为这个问题比大多数人认为的更艰难。我已经玩了 Linux 原生游戏几十年了,我甚至不得不对收回我当年说的“要么存在 Linux 解决方案,要么编写出来”这样的话,但最终,我做到了,我编写了一个 Linux 游戏。
说实话:Android 问世于 2008 年。如果你在 Android 上玩过游戏,那么你就在 Linux 上玩过游戏。Steam 在 Linux 已经八年了。Steambox/SteamOS 发布在 Steam 发布一年后。我没有听到太多 Lutris 或 Play-on-Linux 的消息,但我知道它们并希望它们成功。我确实看到 GOG 的追随者非常多,我认为这非常好。我看到很多来自 Ryan Gordon(icculus)和 Ethan Lee(flibitijibibo)等人的高质量游戏移植,甚至有些公司在内部移植。Unity 和 Unreal 等游戏引擎已经支持 Linux。Valve 已经将 Proton 纳入 Linux 版本的 Steam 已有两年左右的时间了,所以现在 Linux 用户甚至不必搜索他们游戏的 Linux 原生版本。
我可以说,我认为大多数游戏玩家期待并将继续期待他们已经从零售游戏市场获得的支持水平。就我个人而言,我希望这个水平是增长而不是下降!
*详细了解 Brendan 的 [Inverse Phase](https://www.inversephase.com) 工作。*
---
via: <https://opensource.com/article/20/2/linux-open-source-music>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,548 | 在 Linux 和 FreeDOS 之间复制文件 | https://opensource.com/article/21/6/copy-files-linux-freedos | 2021-07-04T18:13:31 | [
"FreeDOS"
] | /article-13548-1.html |
>
> 下面是我如何在我的 FreeDOS 虚拟机和 Linux 桌面系统之间传输文件。
>
>
>

我运行 Linux 作为我的主要操作系统,我在一个虚拟机中启动 FreeDOS。大多数时候,我使用 QEMU 作为我的 PC 模拟器,但有时我会用 GNOME Boxes(它使用 QEMU 作为后端虚拟机)或用 VirtualBox 运行其他实验。
我喜欢玩经典的 DOS 游戏,有时我也会调出一个最喜欢的 DOS 应用。我在管理信息系统(MIS)课上讲计算机的历史,有时我会用 FreeDOS 和一个传统的 DOS 应用录制一个演示,比如 As-Easy-As(我最喜欢的 DOS 电子表格,曾经作为“共享软件”发布,但现在可以 [从 TRIUS 公司免费获得](http://www.triusinc.com/forums/viewtopic.php?t=10))。
但是以这种方式使用 FreeDOS 意味着我需要在我的 FreeDOS 虚拟机和我的 Linux桌 面系统之间传输文件。让我来展示是如何做到这一点的。
### 用 guestmount 访问镜像
我曾经通过计算第一个 DOS 分区的偏移量来访问我的虚拟磁盘镜像,然后用正确的选项组合来调用 Linux 的 `mount` 命令来匹配这个偏移量。这总是很容易出错,而且不是很灵活。幸运的是,有一个更简单的方法可以做到这一点。来自 [libguestfs-tools](https://libguestfs.org/) 包的 `guestmount` 程序可以让你从 Linux 中访问或 *挂载* 虚拟磁盘镜像。你可以在 Fedora 上用这个命令安装 `libguestfs-tools`:
```
$ yum install libguestfs-tools libguestfs
```
使用 `guestmount` 并不像从 GNOME 文件管理器中双击文件那么简单,但命令行的使用并不难。`guestmount` 的基本用法是:
```
$ guestmount -a image -m device mountpoint
```
在这个用法中,`image` 是要使用的虚拟磁盘镜像。在我的系统中,我用 `qemu-img` 命令创建了 QEMU 虚拟磁盘镜像。`guestmount` 程序可以读取这种磁盘镜像格式,以及 GNOME Boxes 使用的 QCOW2 镜像格式,或者 VirtualBox 使用的 VDI 镜像格式。
`device` 选项表示虚拟磁盘上的分区。想象一下,把这个虚拟磁盘当作一个真正的硬盘使用。你可以用 `/dev/sda1` 访问第一个分区,用 `/dev/sda2` 访问第二个分区,以此类推。这就是 `guestmount` 的语法。默认情况下,FreeDOS 1.3 RC4 在一个空的驱动器上创建了一个分区,所以访问这个分区的时候要用 `/dev/sda1`。
而 `mountpoint` 是在你的本地 Linux 系统上“挂载” DOS 文件系统的位置。我通常会创建一个临时目录来工作。你只在访问虚拟磁盘时需要挂载点。
综上所述,我使用这组命令从 Linux 访问我的 FreeDOS 虚拟磁盘镜像:
```
$ mkdir /tmp/freedos
$ guestmount -a freedos.img -m /dev/sda1 /tmp/freedos
```
之后,我可以通过 `/tmp/freedos` 目录访问我的 FreeDOS 文件,使用 Linux 上的普通工具。我可以在命令行中使用 `ls /tmp/freedos`,或者使用桌面文件管理器打开 `/tmp/freedos` 挂载点。
```
$ ls -l /tmp/freedos
total 216
drwxr-xr-x. 5 root root 8192 May 10 15:53 APPS
-rwxr-xr-x. 1 root root 85048 Apr 30 07:54 COMMAND.COM
-rwxr-xr-x. 1 root root 103 May 13 15:48 CONFIG.SYS
drwxr-xr-x. 5 root root 8192 May 15 16:52 DEVEL
drwxr-xr-x. 2 root root 8192 May 15 13:36 EDLIN
-rwxr-xr-x. 1 root root 1821 May 10 15:57 FDAUTO.BAT
-rwxr-xr-x. 1 root root 740 May 13 15:47 FDCONFIG.SYS
drwxr-xr-x. 10 root root 8192 May 10 15:49 FDOS
-rwxr-xr-x. 1 root root 46685 Apr 30 07:54 KERNEL.SYS
drwxr-xr-x. 2 root root 8192 May 10 15:57 SRC
-rwxr-xr-x. 1 root root 3190 May 16 08:34 SRC.ZIP
drwxr-xr-x. 3 root root 8192 May 11 18:33 TEMP
```

*使用 GNOME 文件管理器来访问虚拟磁盘*
例如,要从我的 Linux `projects` 目录中复制几个 C 源文件到虚拟磁盘镜像上的 `C:\SRC`,以便我以后能在 FreeDOS 下使用这些文件,我可以使用 Linux `cp` 命令:
```
$ cp /home/jhall/projects/*.c /tmp/freedos/SRC
```
虚拟驱动器上的文件和目录在技术上是不分大小写的,所以你可以用大写或小写字母来引用它们。然而,我发现使用所有大写字母来输入 DOS 文件和目录更为自然。
```
$ ls /tmp/freedos
APPS CONFIG.SYS EDLIN FDCONFIG.SYS KERNEL.SYS SRC.ZIP
COMMAND.COM DEVEL FDAUTO.BAT FDOS SRC TEMP
$ ls /tmp/freedos/EDLIN
EDLIN.EXE MAKEFILE.OW
$ ls /tmp/freedos/edlin
EDLIN.EXE MAKEFILE.OW
```
### 用 guestmount 卸载
在你再次在虚拟机中使用虚拟磁盘镜像之前,你应该总是先 *卸载*。如果你在运行 QEMU 或 VirtualBox 时让镜像挂载,你有可能弄乱你的文件。
与 `guestmount` 配套的命令是 `guestunmount`,用来卸载磁盘镜像。只要给出你想卸载的挂载点就可以了:
```
$ guestunmount /tmp/freedos
```
请注意命令拼写与 Linux 的 `umount` 稍有不同。
---
via: <https://opensource.com/article/21/6/copy-files-linux-freedos>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,550 | 使用 GDB 查看程序的栈空间 | https://jvns.ca/blog/2021/05/17/how-to-look-at-the-stack-in-gdb/ | 2021-07-05T10:42:00 | [
"堆栈",
"gdb"
] | https://linux.cn/article-13550-1.html | 
昨天我和一些人在闲聊的时候,他们说他们并不真正了解栈是如何工作的,而且也不知道如何去查看栈空间。
这是一个快速教程,介绍如何使用 GDB 查看 C 程序的栈空间。我认为这对于 Rust 程序来说也是相似的。但我这里仍然使用 C 语言,因为我发现用它更简单,而且用 C 语言也更容易写出错误的程序。
### 我们的测试程序
这里是一个简单的 C 程序,声明了一些变量,从标准输入读取两个字符串。一个字符串在堆上,另一个字符串在栈上。
```
#include <stdio.h>
#include <stdlib.h>
int main() {
char stack_string[10] = "stack";
int x = 10;
char *heap_string;
heap_string = malloc(50);
printf("Enter a string for the stack: ");
gets(stack_string);
printf("Enter a string for the heap: ");
gets(heap_string);
printf("Stack string is: %s\n", stack_string);
printf("Heap string is: %s\n", heap_string);
printf("x is: %d\n", x);
}
```
这个程序使用了一个你可能从来不会使用的极为不安全的函数 `gets` 。但我是故意这样写的。当出现错误的时候,你就知道是为什么了。
### 第 0 步:编译这个程序
我们使用 `gcc -g -O0 test.c -o test` 命令来编译这个程序。
`-g` 选项会在编译程序中将调式信息也编译进去。这将会使我们查看我们的变量更加容易。
`-O0` 选项告诉 gcc 不要进行优化,我要确保我们的 `x` 变量不会被优化掉。
### 第一步:启动 GDB
像这样启动 GDB:
```
$ gdb ./test
```
它打印出一些 GPL 信息,然后给出一个提示符。让我们在 `main` 函数这里设置一个断点:
```
(gdb) b main
```
然后我们就可以运行程序:
```
(gdb) b main
Starting program: /home/bork/work/homepage/test
Breakpoint 1, 0x000055555555516d in main ()
(gdb) run
Starting program: /home/bork/work/homepage/test
Breakpoint 1, main () at test.c:4
4 int main() {
```
好了,现在程序已经运行起来了。我们就可以开始查看栈空间了。
### 第二步:查看我们变量的地址
让我们从了解我们的变量开始。它们每个都在内存中有一个地址,我们可以像这样打印出来:
```
(gdb) p &x
$3 = (int *) 0x7fffffffe27c
(gdb) p &heap_string
$2 = (char **) 0x7fffffffe280
(gdb) p &stack_string
$4 = (char (*)[10]) 0x7fffffffe28e
```
因此,如果我们查看那些地址的堆栈,那我们应该能够看到所有的这些变量!
### 概念:栈指针
我们将需要使用栈指针,因此我将尽力对其进行快速解释。
有一个名为 ESP 的 x86 寄存器,称为“<ruby> 栈指针 <rt> stack pointer </rt></ruby>”。 基本上,它是当前函数的栈起始地址。 在 GDB 中,你可以使用 `$sp` 来访问它。 当你调用新函数或从函数返回时,栈指针的值会更改。
### 第三步:在 `main` 函数开始的时候,我们查看一下在栈上的变量
首先,让我们看一下 main 函数开始时的栈。 现在是我们的堆栈指针的值:
```
(gdb) p $sp
$7 = (void *) 0x7fffffffe270
```
因此,我们当前函数的栈起始地址是 `0x7fffffffe270`,酷极了。
现在,让我们使用 GDB 打印出当前函数堆栈开始后的前 40 个字(即 160 个字节)。 某些内存可能不是栈的一部分,因为我不太确定这里的堆栈有多大。 但是至少开始的地方是栈的一部分。

我已粗体显示了 `stack_string`,`heap_string` 和 `x` 变量的位置,并改变了颜色:
* `x` 是红色字体,并且起始地址是 `0x7fffffffe27c`
* `heap_string` 是蓝色字体,起始地址是 `0x7fffffffe280`
* `stack_string` 是紫色字体,起始地址是 `0x7fffffffe28e`
你可能会在这里注意到的一件奇怪的事情是 `x` 的值是 0x5555,但是我们将 `x` 设置为 `10`! 那是因为直到我们的 `main` 函数运行之后才真正设置 `x` ,而我们现在才到了 `main` 最开始的地方。
### 第三步:运行到第十行代码后,再次查看一下我们的堆栈
让我们跳过几行,等待变量实际设置为其初始化值。 到第 10 行时,`x` 应该设置为 `10`。
首先我们需要设置另一个断点:
```
(gdb) b test.c:10
Breakpoint 2 at 0x5555555551a9: file test.c, line 11.
```
然后继续执行程序:
```
(gdb) continue
Continuing.
Breakpoint 2, main () at test.c:11
11 printf("Enter a string for the stack: ");
```
好的! 让我们再来看看堆栈里的内容! `gdb` 在这里格式化字节的方式略有不同,实际上我也不太关心这些(LCTT 译注:可以查看 GDB 手册中 `x` 命令,可以指定 `c` 来控制输出的格式)。 这里提醒一下你,我们的变量在栈上的位置:
* `x` 是红色字体,并且起始地址是 `0x7fffffffe27c`
* `heap_string` 是蓝色字体,起始地址是 `0x7fffffffe280`
* `stack_string` 是紫色字体,起始地址是 `0x7fffffffe28e`

在继续往下看之前,这里有一些有趣的事情要讨论。
### `stack_string` 在内存中是如何表示的
现在(第 10 行),`stack_string` 被设置为字符串`stack`。 让我们看看它在内存中的表示方式。
我们可以像这样打印出字符串中的字节(LCTT 译注:可以通过 `c` 选项直接显示为字符):
```
(gdb) x/10x stack_string
0x7fffffffe28e: 0x73 0x74 0x61 0x63 0x6b 0x00 0x00 0x00
0x7fffffffe296: 0x00 0x00
```
`stack` 是一个长度为 5 的字符串,相对应 5 个 ASCII 码- `0x73`、`0x74`、`0x61`、`0x63` 和 `0x6b`。`0x73` 是字符 `s` 的 ASCII 码。 `0x74` 是 `t` 的 ASCII 码。等等...
同时我们也使用 `x/1s` 可以让 GDB 以字符串的方式显示:
```
(gdb) x/1s stack_string
0x7fffffffe28e: "stack"
```
### `heap_string` 与 `stack_string` 有何不同
你已经注意到了 `stack_string` 和 `heap_string` 在栈上的表示非常不同:
* `stack_string` 是一段字符串内容(`stack`)
* `heap_string` 是一个指针,指向内存中的某个位置
这里是 `heap_string` 变量在内存中的内容:
```
0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x00
```
这些字节实际上应该是从右向左读:因为 x86 是小端模式,因此,`heap_string` 中所存放的内存地址 `0x5555555592a0`
另一种方式查看 `heap_string` 中存放的内存地址就是使用 `p` 命令直接打印 :
```
(gdb) p heap_string
$6 = 0x5555555592a0 ""
```
### 整数 x 的字节表示
`x` 是一个 32 位的整数,可由 `0x0a 0x00 0x00 0x00` 来表示。
我们还是需要反向来读取这些字节(和我们读取 `heap_string` 需要反过来读是一样的),因此这个数表示的是 `0x000000000a` 或者是 `0x0a`,它是一个数字 `10`;
这就让我把把 `x` 设置成了 `10`。
### 第四步:从标准输入读取
好了,现在我们已经初始化我们的变量,我们来看一下当这段程序运行的时候,栈空间会如何变化:
```
printf("Enter a string for the stack: ");
gets(stack_string);
printf("Enter a string for the heap: ");
gets(heap_string);
```
我们需要设置另外一个断点:
```
(gdb) b test.c:16
Breakpoint 3 at 0x555555555205: file test.c, line 16.
```
然后继续执行程序:
```
(gdb) continue
Continuing.
```
我们输入两个字符串,为栈上存储的变量输入 `123456789012` 并且为在堆上存储的变量输入 `bananas`;
### 让我们先来看一下 `stack_string`(这里有一个缓存区溢出)
```
(gdb) x/1s stack_string
0x7fffffffe28e: "123456789012"
```
这看起来相当正常,对吗?我们输入了 `12345679012`,然后现在它也被设置成了 `12345679012`(LCTT 译注:实测 gcc 8.3 环境下,会直接段错误)。
但是现在有一些很奇怪的事。这是我们程序的栈空间的内容。有一些紫色高亮的内容。

令人奇怪的是 **`stack_string` 只支持 10 个字节**。但是现在当我们输入了 13 个字符以后,发生了什么?
这是一个典型的缓冲区溢出,`stack_string` 将自己的数据写在了程序中的其他地方。在我们的案例中,这还没有造成问题,但它会使你的程序崩溃,或者更糟糕的是,使你面临非常糟糕的安全问题。
例如,假设 `stack_string` 在内存里的位置刚好在 `heap_string` 之前。那我们就可能覆盖 `heap_string` 所指向的地址。我并不确定 `stack_string` 之后的内存里有一些什么。但我们也许可以用它来做一些诡异的事情。
### 确实检测到了有缓存区溢出
当我故意写很多字符的时候:
```
./test
Enter a string for the stack: 01234567891324143
Enter a string for the heap: adsf
Stack string is: 01234567891324143
Heap string is: adsf
x is: 10
*** stack smashing detected ***: terminated
fish: Job 1, './test' terminated by signal SIGABRT (Abort)
```
这里我猜是 `stack_string` 已经到达了这个函数栈的底部,因此额外的字符将会被写在另一块内存中。
当你故意去使用这个安全漏洞时,它被称为“堆栈粉碎”,而且不知何故有东西在检测这种情况的发生。
我也觉得这很有趣,虽然程序被杀死了,但是当缓冲区溢出发生时它不会立即被杀死——在缓冲区溢出之后再运行几行代码,程序才会被杀死。 好奇怪!
这些就是关于缓存区溢出的所有内容。
### 现在我们来看一下 `heap_string`
我们仍然将 `bananas` 输入到 `heap_string` 变量中。让我们来看一下内存中的样子。
这是在我们读取了字符串以后,`heap_string` 在栈空间上的样子:

需要注意的是,这里的值是一个地址。并且这个地址并没有改变,但是我们来看一下指向的内存上的内容。
```
(gdb) x/10x 0x5555555592a0
0x5555555592a0: 0x62 0x61 0x6e 0x61 0x6e 0x61 0x73 0x00
0x5555555592a8: 0x00 0x00
```
看到了吗,这就是字符串 `bananas` 的字节表示。这些字节并不在栈空间上。他们存在于内存中的堆上。
### 堆和栈到底在哪里?
我们已经讨论过栈和堆是不同的内存区域,但是你怎么知道它们在内存中的位置呢?
每个进程都有一个名为 `/proc/$PID/maps` 的文件,它显示了每个进程的内存映射。 在这里你可以看到其中的栈和堆。
```
$ cat /proc/24963/maps
... lots of stuff omitted ...
555555559000-55555557a000 rw-p 00000000 00:00 0 [heap]
... lots of stuff omitted ...
7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
```
需要注意的一件事是,这里堆地址以 `0x5555` 开头,栈地址以 `0x7fffff` 开头。 所以很容易区分栈上的地址和堆上的地址之间的区别。
### 像这样使用 gdb 真的很有帮助
这有点像旋风之旅,虽然我没有解释所有内容,但希望看到数据在内存中的实际情况可以使你更清楚地了解堆栈的实际情况。
我真的建议像这样来把玩一下 gdb —— 即使你不理解你在内存中看到的每一件事,我发现实际上像这样看到我程序内存中的数据会使抽象的概念,比如“栈”和“堆”和“指针”更容易理解。
### 更多练习
一些关于思考栈的后续练习的想法(没有特定的顺序):
* 尝试将另一个函数添加到 `test.c` 并在该函数的开头创建一个断点,看看是否可以从 `main` 中找到堆栈! 他们说当你调用一个函数时“堆栈会变小”,你能在 gdb 中看到这种情况吗?
* 从函数返回一个指向栈上字符串的指针,看看哪里出了问题。 为什么返回指向栈上字符串的指针是不好的?
* 尝试在 C 中引起堆栈溢出,并尝试通过在 gdb 中查看堆栈溢出来准确理解会发生什么!
* 查看 Rust 程序中的堆栈并尝试找到变量!
* 在 [噩梦课程](https://github.com/guyinatuxedo/nightmare) 中尝试一些缓冲区溢出挑战。每个问题的答案写在 README 文件中,因此如果你不想被宠坏,请避免先去看答案。 所有这些挑战的想法是给你一个二进制文件,你需要弄清楚如何导致缓冲区溢出以使其打印出 `flag` 字符串。
---
via: <https://jvns.ca/blog/2021/05/17/how-to-look-at-the-stack-in-gdb/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I was chatting with someone yesterday and they mentioned that they don’t really understand exactly how the stack works or how to look at it.
So here’s a quick walkthrough of how you can use gdb to look at the stack of a C program. I think this would be similar for a Rust program, but I’m going to use C because I find it a little simpler for a toy example and also you can do Terrible Things in C more easily.
### our test program
Here’s a simple C program that declares a few variables and reads two strings from standard input. One of the strings is on the heap, and one is on the stack.
```
#include <stdio.h>
#include <stdlib.h>
int main() {
char stack_string[10] = "stack";
int x = 10;
char *heap_string;
heap_string = malloc(50);
printf("Enter a string for the stack: ");
gets(stack_string);
printf("Enter a string for the heap: ");
gets(heap_string);
printf("Stack string is: %s\n", stack_string);
printf("Heap string is: %s\n", heap_string);
printf("x is: %d\n", x);
}
```
This program uses the extremely unsafe function `gets`
which you should never
use, but that’s on purpose – we learn more when things go wrong.
### step 0: compile the program.
We can compile it with `gcc -g -O0 test.c -o test`
.
The `-g`
flag compiles the program with debugging symbols, which is going to
make it a lot easier to look at our variables.
`-O0`
tells gcc to turn off optimizations which I did just to make sure our `x`
variable didn’t get optimized out.
### step 1: start gdb
We can start gdb like this:
```
$ gdb ./test
```
It prints out some stuff about the GPL and then gives a prompt. Let’s create a breakpoint on the `main`
function.
```
(gdb) b main
Breakpoint 1 at 0x1171: file test.c, line 4.
```
Then we can run the program:
```
(gdb) run
Starting program: /home/bork/work/homepage/test
Breakpoint 1, main () at test.c:4
4 int main() {
```
Okay, great! The program is running and we can start looking at the stack
### step 2: look at our variables’ addresses
Let’s start out by learning about our variables. Each of them has an address in memory, which we can print out like this:
```
(gdb) p &x
$3 = (int *) 0x7fffffffe27c
(gdb) p &heap_string
$2 = (char **) 0x7fffffffe280
(gdb) p &stack_string
$4 = (char (*)[10]) 0x7fffffffe28e
```
So if we look at the stack at those addresses, we should be able to see all of these variables!
### concept: the stack pointer
We’re going to need to use the stack pointer so I’ll try to explain it really quickly.
There’s an x86 register called ESP called the “stack pointer”. Basically
it’s the address of the start of the stack for the current function. In gdb you can access it
with `$sp`
. When you call a new function or return from a function, the value
of the stack pointer changes.
### step 3: look at our variables on the stack at the beginning of `main`
First, let’s look at the stack at the start of the `main`
function. Here’s
the value of our stack pointer right now:
(gdb) p $sp $7 = (void *) 0x7fffffffe270
So the stack for our current function starts at `0x7fffffffe270`
. Cool.
Now let’s use gdb to print out the first 40 words (aka 160 bytes) of memory after the start of the current function’s stack. It’s possible that some of this memory isn’t part of the stack because I’m not totally sure how big the stack is here. But at least the beginning of this is part of the stack.
(gdb) x/40x $sp 0x7fffffffe270: 0x00000000 0x00000000 0x555552500x000055550x7fffffffe280:0x00000000 0x000000000x55555070 0x000055550x7fffffffe290:0xffffe390 0x00007fff0x00000000 0x00000000 0x7fffffffe2a0: 0x00000000 0x00000000 0xf7df4b25 0x00007fff 0x7fffffffe2b0: 0xffffe398 0x00007fff 0xf7fca000 0x00000001 0x7fffffffe2c0: 0x55555169 0x00005555 0xffffe6f9 0x00007fff 0x7fffffffe2d0: 0x55555250 0x00005555 0x3cae816d 0x8acc2837 0x7fffffffe2e0: 0x55555070 0x00005555 0x00000000 0x00000000 0x7fffffffe2f0: 0x00000000 0x00000000 0x00000000 0x00000000 0x7fffffffe300: 0xf9ce816d 0x7533d7c8 0xa91a816d 0x7533c789
I’ve bolded approximately where the `stack_string`
, `heap_string`
, and `x`
variables are and colour coded them:
`x`
is red and starts at`0x7fffffffe27c`
`heap_string`
is blue and starts at`0x7fffffffe280`
`stack_string`
is purple and starts at`0x7fffffffe28e`
I think I might have bolded the location of some of those variables a bit wrong here but that’s approximately where they are.
One weird thing you might notice here is that `x`
is the number `0x5555`
, but
we set `x`
to 10! That because `x`
doesn’t actually get set until after our
`main`
function starts, and we’re at the very beginning of `main`
.
### step 3: look at the stack again on line 10
Let’s skip a few lines and wait for our variables to actually get set to the
values we initialized them to. By the time we get to line 10, `x`
should be set to 10.
First, we need to set another breakpoint:
```
(gdb) b test.c:10
Breakpoint 2 at 0x5555555551a9: file test.c, line 11.
```
and continue the program running:
```
(gdb) continue
Continuing.
Breakpoint 2, main () at test.c:11
11 printf("Enter a string for the stack: ");
```
Okay! Let’s look at all the same things again! `gdb`
is formatting the bytes in
a slightly different way here and I don’t actually know why. Here’s a reminder of where to find our variables on the stack:
`x`
is red and starts at`0x7fffffffe27c`
`heap_string`
is blue and starts at`0x7fffffffe280`
`stack_string`
is purple and starts at`0x7fffffffe28e`
(gdb) x/80x $sp 0x7fffffffe270: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x7fffffffe278: 0x50 0x52 0x55 0x550x0a 0x00 0x00 0x000x7fffffffe280:0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x000x7fffffffe288: 0x70 0x50 0x55 0x55 0x55 0x550x73 0x740x7fffffffe290:0x61 0x63 0x6b 0x00 0x00 0x00 0x00 0x000x7fffffffe298: 0x00 0x80 0xf7 0x8a 0x8a 0xbb 0x58 0xb6 0x7fffffffe2a0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x7fffffffe2a8: 0x25 0x4b 0xdf 0xf7 0xff 0x7f 0x00 0x00 0x7fffffffe2b0: 0x98 0xe3 0xff 0xff 0xff 0x7f 0x00 0x00 0x7fffffffe2b8: 0x00 0xa0 0xfc 0xf7 0x01 0x00 0x00 0x00
There are a couple of interesting things to discuss here before we go further in the program.
### how `stack_string`
is represented in memory
Right now (on line 10) `stack_string`
is set to “stack”. Let’s take a look at
how that’s represented in memory.
We can print out the bytes in the string like this:
```
(gdb) x/10x stack_string
0x7fffffffe28e: 0x73 0x74 0x61 0x63 0x6b 0x00 0x00 0x00
0x7fffffffe296: 0x00 0x00
```
The string “stack” is 5 characters which corresponds to 5 ASCII bytes –
`0x73`
, `0x74`
, `0x61`
, `0x63`
, and `0x6b`
. `0x73`
is `s`
in ASCII, `0x74`
is
`t`
, etc.
We can also get gdb to show us the string with `x/1s`
:
```
(gdb) x/1s stack_string
0x7fffffffe28e: "stack"
```
### how `heap_string`
and `stack_string`
are different
You’ll notice that `stack_string`
and `heap_string`
are represented in very
different ways on the stack:
`stack_string`
has the contents of the string (“stack”)`heap_string`
is a pointer to an address somewhere else in memory
Here are the bytes on the stack for the `heap_string`
variable:
```
0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x00
```
These bytes actually get read backwards because x86 is little-endian, so the
memory address of `heap_string`
is `0x5555555592a0`
Another way to see the address of `heap_string`
in gdb is just to print it out
with `p`
:
```
(gdb) p heap_string
$6 = 0x5555555592a0 ""
```
### the bytes that represent the integer `x`
`x`
is a 32-bit integer, and the bytes that represent it are `0x0a 0x00 0x00 0x00`
.
We need to read these bytes backwards again (the same way reason we read the
bytes for `heap_string`
address backwards), so this corresponds to the number
`0x000000000a`
, or `0xa`
, which is 10.
That makes sense! We set `int x = 10;`
!
### step 4: read input from standard input
Okay, we’ve initialized the variables, now let’s see how the stack changes when this part of the C program runs:
```
printf("Enter a string for the stack: ");
gets(stack_string);
printf("Enter a string for the heap: ");
gets(heap_string);
```
We need to set another breakpoint:
```
(gdb) b test.c:16
Breakpoint 3 at 0x555555555205: file test.c, line 16.
```
and continue running the program
```
(gdb) continue
Continuing.
```
We’re prompted for 2 strings, and I entered `123456789012`
for the stack string
and `bananas`
for the heap.
### let’s look at `stack_string`
first (there’s a buffer overflow!)
```
(gdb) x/1s stack_string
0x7fffffffe28e: "123456789012"
```
That seems pretty normal, right? We entered `123456789012`
and now it’s set to `123456789012`
.
But there’s something weird about this. Here’s what those bytes look like on the stack. They’re highlighted in purple again.
0x7fffffffe270: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x7fffffffe278: 0x50 0x52 0x55 0x55 0x0a 0x00 0x00 0x00 0x7fffffffe280: 0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x00 0x7fffffffe288: 0x70 0x50 0x55 0x55 0x55 0x550x31 0x320x7fffffffe290:0x33 0x34 0x35 0x36 0x37 0x38 0x39 0x300x7fffffffe298:0x31 0x32 0x000x8a 0x8a 0xbb 0x58 0xb6 0x7fffffffe2a0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x7fffffffe2a8: 0x25 0x4b 0xdf 0xf7 0xff 0x7f 0x00 0x00 0x7fffffffe2b0: 0x98 0xe3 0xff 0xff 0xff 0x7f 0x00 0x00 0x7fffffffe2b8: 0x00 0xa0 0xfc 0xf7 0x01 0x00 0x00 0x00
The weird thing about this is that **stack_string was only supposed to be 10
bytes**. But now suddenly we’ve put 13 bytes in it? What’s happening?
This is a classic buffer overflow, and what’s happening is that `stack_string`
wrote over other data from the program. This hasn’t caused a problem yet in our
case, but it can crash your program or, worse, open you up to Very Bad Security
Problems.
For example, if `stack_string`
were before `heap_string`
in memory, then we
could overwrite the address that `heap_string`
points to. I’m not sure exactly
what’s in memory after `stack_string`
here but we could probably use this to do
some kind of shenanigans.
### something actually detects the buffer overflow
When I cause this buffer overflow problem, here’s
./test Enter a string for the stack: 01234567891324143 Enter a string for the heap: adsf Stack string is: 01234567891324143 Heap string is: adsf x is: 10 *** stack smashing detected ***: terminated fish: Job 1, './test' terminated by signal SIGABRT (Abort)
My guess about what’s happening here is that the `stack_string`
variable is
actually at the end of this function’s stack, and so the extra bytes are going into a
different region of memory.
When you do this intentionally as a security exploit it’s called “stack
smashing”, and somehow something is detecting that this is happening.
Originally I wasn’t sure how this was being detected, but a couple of people
emailed me to say that it’s a compiler feature called “stack protection”.
Basically it adds a “canary” value to the end of the stack and when the
function returns it checks to see if that value has been changed. Here’s an
[article about the stack smashing protector on the OSDev wiki](https://wiki.osdev.org/Stack_Smashing_Protector).
That’s all I have to say about buffer overflows.
### now let’s look at `heap_string`
We also read a value (`bananas`
) into the `heap_string`
variable. Let’s see what that
looks like in memory.
Here’s what `heap_string`
looks on the stack after we read the variable in.
(gdb) x/40x $sp 0x7fffffffe270: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x7fffffffe278: 0x50 0x52 0x55 0x55 0x0a 0x00 0x00 0x00 0x7fffffffe280:0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x000x7fffffffe288: 0x70 0x50 0x55 0x55 0x55 0x55 0x31 0x32 0x7fffffffe290: 0x33 0x34 0x35 0x36 0x37 0x38 0x39 0x30
The thing to notice here is that it looks exactly the same! It’s an address, and the address hasn’t changed. But let’s look at what’s at that address.
```
(gdb) x/10x 0x5555555592a0
0x5555555592a0: 0x62 0x61 0x6e 0x61 0x6e 0x61 0x73 0x00
0x5555555592a8: 0x00 0x00
```
Those are the bytes for `bananas`
! Those bytes aren’t in the stack at all,
they’re somewhere else in memory (on the heap)
### where are the stack and the heap?
We’ve talked about how the stack and the heap are different regions of memory, but how can you tell where they are in memory?
There’s a file for each process called `/proc/$PID/maps`
that shows you the
memory maps for each process. Here’s where you can see the stack and the heap
in there.
```
$ cat /proc/24963/maps
... lots of stuff omitted ...
555555559000-55555557a000 rw-p 00000000 00:00 0 [heap]
... lots of stuff omitted ...
7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
```
One thing to notice is that here the heap addresses start with `0x5555 `
and
the stack addresses start with `0x7fffff`
. So it’s pretty easy to tell the
difference between an address on the stack and an address on the heap.
### playing about with gdb like this is really helpful
This was kind of a whirlwind tour and I didn’t explain everything, but hopefully seeing what the data actually looks like in memory makes it a little more clear what the stack actually is.
I really recommend playing around with gdb like this – even if you don’t understand every single thing that you see in memory, I find that actually seeing the data in my program’s memory like this makes these abstract concepts like “the stack” and “the heap” and “pointers” a lot easier to understand.
### maybe lldb is easier to use
A couple of people suggested that lldb is easier to use than gdb. I haven’t
used it yet but I looked at it quickly, and it does seem like it might be
simpler! As far as I can tell from a quick inspection everything in this
walkthrough also works in lldb, except that you need to do `p/s`
instead of
`p/1s`
.
### ideas for more exercises
A few ideas (in no particular order) for followup exercises to think about the stack:
- try adding another function to
`test.c`
and make a breakpoint at the beginning of that function and see if you can find the stack from`main`
! They say that “the stack grows down” when you call a function, can you see that happening in gdb? - return a pointer from a function to a string on the stack and see what goes wrong. Why is it bad to return a pointer to a string on the stack?
- try causing a stack overflow in C and try to understand exactly what happens when the stack overflows by looking at it in gdb!
- look at the stack in a Rust program and try to find the variables!
- try some of the buffer overflow challenges in the
[nightmare course](https://github.com/guyinatuxedo/nightmare). The README for each challenge is the solution so avoid reading it if you don’t want to be spoiled. The idea with all of those challenges is that you’re given a binary and you need to figure out how to cause a buffer overflow to get it to print out the “flag” string. |
13,551 | 使用 Python 解析配置文件 | https://opensource.com/article/21/6/parse-configuration-files-python | 2021-07-05T11:36:00 | [
"配置文件"
] | https://linux.cn/article-13551-1.html |
>
> 第一步是选择配置文件的格式:INI、JSON、YAML 或 TOML。
>
>
>

有时,程序需要足够的参数,将它们全部作为命令行参数或环境变量既不让人愉快也不可行。 在这些情况下,你将需要使用配置文件。
有几种流行的配置文件格式。其中包括古老的(虽然有时定义不明确)INI 格式,虽然流行但有时难以手写的 JSON 格式,使用广泛但有时在细节方面令人意外的 YAML 格式,以及很多人还没有听说过的最新出现的 TOML。
你的首要任务是选择一种格式,然后记录该选择。解决了这个简单的部分之后就是时候解析配置了。
有时,在配置中拥有一个与“抽象“数据相对应的类是一个不错的想法。因为这段代码不会对配置做任何事情,所以这是展示解析逻辑最简单的方式。
想象一下文件处理器的配置:它包括一个输入目录、一个输出目录和要提取的文件。
配置类的抽象定义可能类似于:
```
from __future__ import annotations
```
```
import attr
@attr.frozen
class Configuration:
@attr.frozen
class Files:
input_dir: str
output_dir: str
files: Files
@attr.frozen
class Parameters:
patterns: List[str]
parameters: Parameters
```
为了使特定于格式的代码更简单,你还需要编写一个函数来从字典中解析此类。请注意,这假设配置将使用破折号,而不是下划线。 这种差异并不少见。
```
def configuration_from_dict(details):
files = Configuration.Files(
input_dir=details["files"]["input-dir"],
output_dir=details["files"]["output-dir"],
)
parameters = Configuration.Paraneters(
patterns=details["parameters"]["patterns"]
)
return Configuration(
files=files,
parameters=parameters,
)
```
### JSON
JSON(JavaScript Object Notation)是一种类似于 JavaScript 的格式。
以下是 JSON 格式的示例配置:
```
json_config = """
{
"files": {
"input-dir": "inputs",
"output-dir": "outputs"
},
"parameters": {
"patterns": [
"*.txt",
"*.md"
]
}
}
"""
```
解析逻辑使用 `json` 模块将 JSON 解析为 Python 的内置数据结构(字典、列表、字符串),然后从字典中创建类:
```
import json
def configuration_from_json(data):
parsed = json.loads(data)
return configuration_from_dict(parsed)
```
### INI
INI 格式,最初只在 Windows 上流行,之后成为配置标准格式。
这是与 INI 相同的配置:
```
ini_config="""
[files]
input-dir = inputs
output-dir = outputs
[parameters]
patterns = ['*.txt', '*.md']
"""
```
Python 可以使用内置的 `configparser` 模块解析它。解析器充当类似 `dict` 的对象,因此可以直接传递给 `configuration_from_dict`:
```
import configparser
def configuration_from_ini(data):
parser = configparser.ConfigParser()
parser.read_string(data)
return configuration_from_dict(parser)
```
### YAML
YAML(Yet Another Markup Language)是 JSON 的扩展,旨在更易于手动编写。为了实现了这一点,部分原因是有一个很长的规范。
以下是 YAML 中的相同配置:
```
yaml_config = """
files:
input-dir: inputs
output-dir: outputs
parameters:
patterns:
- '*.txt'
- '*.md'
"""
```
要让 Python 解析它,你需要安装第三方模块。最受欢迎的是`PyYAML`(`pip install pyyaml`)。 YAML 解析器还返回可以传递给 `configuration_from_dict` 的内置 Python 数据类型。但是,YAML 解析器需要一个字节流,因此你需要将字符串转换为字节流。
```
import io
import yaml
def configuration_from_yaml(data):
fp = io.StringIO(data)
parsed = yaml.safe_load(fp)
return configuration_from_dict(parsed)
```
### TOML
TOML(Tom's Own Markup Language)旨在成为 YAML 的轻量级替代品。其规范比较短,已经在一些地方流行了(比如 Rust 的包管理器 Cargo 就用它来进行包配置)。
这是与 TOML 相同的配置:
```
toml_config = """
[files]
input-dir = "inputs"
output-dir = "outputs"
[parameters]
patterns = [ "*.txt", "*.md",]
"""
```
为了解析 TOML,你需要安装第三方包。最流行的一种被简单地称为 `toml`。 与 YAML 和 JSON 一样,它返回基本的 Python 数据类型。
```
import toml
def configuration_from_toml(data):
parsed = toml.loads(data)
return configuration_from_dict(parsed)
```
### 总结
选择配置格式是一种微妙的权衡。但是,一旦你做出决定,Python 就可以使用少量代码来解析大多数流行的格式。
---
via: <https://opensource.com/article/21/6/parse-configuration-files-python>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zepoch](https://github.com/zepoch) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sometimes, a program needs enough parameters that putting them all as command-line arguments or environment variables is not pleasant nor feasible. In those cases, you will want to use a configuration file.
There are several popular formats for configuration files. Among them are the venerable (although occasionally under-defined) `INI`
format, the popular but sometimes hard to write by hand `JSON`
format, the extensive yet occasionally surprising in details `YAML`
format, and the newest addition, `TOML`
, which many people have not heard of yet.
Your first task is to choose a format and then to document that choice. With this easy part out of the way, it is time to parse the configuration.
It is sometimes a good idea to have a class that corresponds to the "abstract" data in the configuration. Because this code will do nothing with the configuration, this is the simplest way to show parsing logic.
Imagine the configuration for a file processor: it includes an input directory, an output directory, and which files to pick up.
The abstract definition for the configuration class might look something like:
`from __future__ import annotations`
```
import attr
@attr.frozen
class Configuration:
@attr.frozen
class Files:
input_dir: str
output_dir: str
files: Files
@attr.frozen
class Parameters:
patterns: List[str]
parameters: Parameters
```
To make the format-specific code simpler, you will also write a function to parse this class out of dictionaries. Note that this assumes the configuration will use dashes, not underscores. This kind of discrepancy is not uncommon.
```
def configuration_from_dict(details):
files = Configuration.Files(
input_dir=details["files"]["input-dir"],
output_dir=details["files"]["output-dir"],
)
parameters = Configuration.Paraneters(
patterns=details["parameters"]["patterns"]
)
return Configuration(
files=files,
parameters=parameters,
)
```
## JSON
JSON (JavaScript Object Notation) is a JavaScript-like format.
Here is an example configuration in JSON format:
```
json_config = """
{
"files": {
"input-dir": "inputs",
"output-dir": "outputs"
},
"parameters": {
"patterns": [
"*.txt",
"*.md"
]
}
}
"""
```
The parsing logic parses the JSON into Python's built-in data structures (dictionaries, lists, strings) using the `json`
module and then creates the class from the dictionary:
```
import json
def configuration_from_json(data):
parsed = json.loads(data)
return configuration_from_dict(parsed)
```
## INI
The INI format, originally popular on Windows, became a de facto configuration standard.
Here is the same configuration as an INI:
```
ini_config="""
[files]
input-dir = inputs
output-dir = outputs
[parameters]
patterns = ['*.txt', '*.md']
"""
```
Python can parse it using the built-in `configparser`
module. The parser behaves as a `dict`
-like object, so it can be passed directly to `configuration_from_dict`
:
```
import configparser
def configuration_from_ini(data):
parser = configparser.ConfigParser()
parser.read_string(data)
return configuration_from_dict(parser)
```
## YAML
YAML (Yet Another Markup Language) is an extension of JSON that is designed to be easier to write by hand. It accomplishes this, in part, by having a long specification.
Here is the same configuration in YAML:
```
yaml_config = """
files:
input-dir: inputs
output-dir: outputs
parameters:
patterns:
- '*.txt'
- '*.md'
"""
```
For Python to parse this, you will need to install a third-party module. The most popular is `PyYAML`
(`pip install pyyaml`
). The YAML parser also returns built-in Python data types that can be passed to `configuration_from_dict`
. However, the YAML parser expects a stream, so you need to convert the string into a stream.
```
import io
import yaml
def configuration_from_yaml(data):
fp = io.StringIO(data)
parsed = yaml.safe_load(fp)
return configuration_from_dict(parsed)
```
## TOML
TOML (Tom's Own Markup Language) is designed to be a lightweight alternative to YAML. The specification is shorter, and it is already popular in some places (for example, Rust's package manager, Cargo, uses it for package configuration).
Here is the same configuration as a TOML:
```
toml_config = """
[files]
input-dir = "inputs"
output-dir = "outputs"
[parameters]
patterns = [ "*.txt", "*.md",]
"""
```
In order to parse TOML, you need to install a third-party package. The most popular one is called, simply, `toml`
. Like YAML and JSON, it returns basic Python data types.
```
import toml
def configuration_from_toml(data):
parsed = toml.loads(data)
return configuration_from_dict(parsed)
```
## Summary
Choosing a configuration format is a subtle tradeoff. However, once you make the decision, Python can parse most of the popular formats using a handful of lines of code.
## Comments are closed. |
13,553 | 我在进入技术行业之前的奇怪工作 | https://opensource.com/article/21/5/weird-jobs-tech | 2021-07-06T11:23:45 | [
"技术"
] | /article-13553-1.html |
>
> 你永远不会知道从你的第一份工作会走到哪里!
>
>
>

在我从事技术工作之前,我做过一些奇怪的工作。
我是一家飞机修理厂的初级助理,这意味着我的工作要在溶剂中清洗肮脏的金属零件(哇,70 年代的事情可和现在不一样)。我在那里最有趣的工作是熨烫涤纶飞机的布料,放到一架正在修理中的漂亮的老式<ruby> 比奇交错式双翼机 <rt> Beechcraft Staggerwing </rt></ruby>的木制副翼和水平稳定器上。
在大学期间的一个夏天,我在同一个机场的一个团队工作,混合阻燃剂,然后把它注入灭火飞机(“<ruby> <a href="https://worldairphotography.wordpress.com/2016/08/22/air-tanker-history-in-canada-part-one/amp/"> 水轰炸机 </a> <rt> water bomber </rt></ruby>”)。那可能是我做过的最脏的工作了,但是给飞机装载还是挺酷的。有一个离地面约两米的小挡板,你可以在把填充软管连接到接头后把手指伸进去。然后泵上的人启动泵。当你觉得你的手指湿了,就挥手让管理泵的人停止泵。与此同时,在你前方几米处运行的右侧径向引擎噪音极大,螺旋桨吹掉了你身上因混合阻燃剂而积聚的红色粉尘。如果你搞砸了,让飞机装得太满,他们就得滑到一块地方,把货卸在那里,否则他们会太重而无法起飞。
另外两个夏天,我在当地的百事可乐、七喜、Orange Crush 经销商那里工作,给商店和餐馆送一箱箱的软饮料。这绝对是我做过的最重的体力活了。想想看,在一辆手推车上堆放着五层高的木箱,每个木箱里装着一打 750 毫升的软饮料玻璃瓶。想想把它搬到二楼的餐厅,想想那家餐厅每周要运 120 箱……爬 24 次楼,然后又带着所有的空瓶子下来。一辆小卡车上通常会有 300 箱左右的软饮料。我们的工资是按载重计算的,而不是按小时计算的,所以我们的目标是早点完工,然后去海滩。
### 我的技术工作
送苏打水是我大学期间最后一份暑期工作。第二年我毕业了,获得了数学学位,还修了很多计算机课程,尤其是数值分析。我在技术领域的第一份工作,是为一家小型电脑服务咨询公司工作。我用 SPSS 对一些运动钓鱼调查做了一些分析,写了几百行 PL/1,在我们按时间租来的服务部门的 IBM 3800 激光打印机上打印演唱会门票,并开始研究一些程序来分析森林统计数据。我最终为需要林业统计的客户工作,在 20 世纪 80 年代中期成为合伙人。那时我们已经不仅仅是测量树木,也不再使用<ruby> 分时服务部门 <rt> timesharing bureau </rt></ruby>来进行计算了。我们买了一台 UNIX 小型计算机,我们在 80 年代后期升级到 SUN 工作站网络。
我在一个大型开发项目上工作了一段时间,它的总部设在马来西亚吉隆坡。然后我们买了第一个地理信息系统,在 80 年代末和 90 年代,我的大部分时间都在和我们的客户一起工作,他们需要定制软件来满足他们的业务需求。到了 21 世纪初,我的三个老合伙人都准备退休了,我试图弄明白,我是如何融入我们这个不再是小公司的,大约 200 名员工的长期图景。我们新的员工老板也不明白这一点,2002 年,我来到智利,想看看智利-加拿大自由贸易协定,是否提供了一个合理的机会,把我们的部分业务转移到拉丁美洲。
该业务在 2004 年正式成立。与此同时,加拿大的母公司由于一些投资组合受到严重影响,在 2007-2009 年的经济衰退的情况下,这些投资似乎不再那么明智,它在 2011 年被迫倒闭。然而,那时候,智利子公司还在经营,所以我们原来的雇员和我成了合伙人,通过资产出售买下了它。直到今天,它仍在运行,在社会环境领域做了很多很酷的事情,我经常参与其中,特别是当我可靠的数学和计算背景有用的时候。
作为一个副业,我为一个在印度以买卖赛马为业的人开发和支持一个赛马信息系统。
---
via: <https://opensource.com/article/21/5/weird-jobs-tech>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MM-BCY](https://github.com/MM-BCY) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,554 | 使用 Tokei 查看有关代码的统计信息 | https://opensource.com/article/21/6/tokei | 2021-07-06T11:43:15 | [
"编程",
"统计"
] | https://linux.cn/article-13554-1.html |
>
> 了解有关项目编程语言的详细信息。
>
>
>

近来,GitHub 添加了一个小指标来展示项目的细节,包括项目使用的编程语言。在这之前,对一个新的贡献者来说,了解他们感兴趣的项目的信息是较为困难的。
这个补充很有帮助,但是如果您想知道有关本地存储库中项目的相同信息该怎么办呢? 这正是 [Tokei](https://github.com/XAMPPRocky/tokei) 派上用场的地方。这是一个当你想和精通不同语言的人想要构建一个项目时可以告诉你项目的代码数据的特别有用的工具。
### 探索 Tokei
据其 [README](https://github.com/XAMPPRocky/tokei/blob/master/README.md),“Tokei 是一个可以展示你的代码数据的程序。Tokei 将会展示文件的数量,和这些文件中不同语言的代码、注释、空白的行数。”它的 v.12.1.0 版本 [elaborates](https://github.com/XAMPPRocky/tokei/releases/tag/v12.1.0) 是这样子介绍的,“Tokei 是一个快速准确的代码分析 CLI 工具和库,可以使你轻松快速地在你的代码库中看到有多少空白、评论和代码行”。它能够识别超过 150 种编程语言。
```
$ ./tokei ~/exa/src ~/Work/wildfly/jaxrs
==================
Language Files Lines Code Comments Blank
Java 46 6135 4324 945 632
XML 23 5211 4839 473 224
---------------------------------
Rust
Markdown
-----------------------------------
Total
```
### 安装 Tokei
在 Fedora 上安装 Tokei:
```
$ sudo dnf install tokei
```
用 Rust's Cargo 包管理器安装:
```
$ cargo install tokei
```
### 使用 Tokei
要列出当前目录中的代码统计:
```
$ tokei
===============================================================================
Language Files Lines Code Comments Blanks
===============================================================================
Ada 10 2840 1681 560 599
Assembly 4 2508 1509 458 541
GNU Style Assembly 4 2751 1528 748 475
Autoconf 16 2294 1153 756 385
Automake 1 45 34 0 11
BASH 4 1895 1602 133 160
Batch 2 4 4 0 0
C 330 206433 150241 23402 32790
C Header 342 60941 24682 29143 7116
CMake 48 4572 3459 548 565
C# 9 1615 879 506 230
C++ 5 907 599 136 172
Dockerfile 2 16 10 0 6
Fish 1 87 77 5 5
HTML 1 545 544 1 0
JSON 5 8995 8995 0 0
Makefile 10 504 293 72 139
Module-Definition 12 1183 1046 65 72
MSBuild 1 141 140 0 1
Pascal 4 1443 1016 216 211
Perl 2 189 137 16 36
Python 4 1257 949 112 196
Ruby 1 23 18 1 4
Shell 15 1860 1411 222 227
Plain Text 35 29425 0 26369 3056
TOML 64 3180 2302 453 425
Visual Studio Pro| 30 14597 14597 0 0
Visual Studio Sol| 6 655 650 0 5
XML 1 116 95 17 4
YAML 2 81 56 12 13
Zsh 1 59 48 8 3
-------------------------------------------------------------------------------
Markdown 55 4677 0 3214 1463
|- C 1 2 2 0 0
|- Rust 19 336 268 20 48
|- TOML 23 61 60 0 1
(Total) 5076 330 3234 1512
-------------------------------------------------------------------------------
Rust 496 210966 188958 5348 16660
|- Markdown 249 17676 1551 12502 3623
(Total) 228642 190509 17850 20283
===============================================================================
Total 1523 566804 408713 92521 65570
===============================================================================
$
```
下面的命令打印出了支持的语言和拓展:
```
$ tokei -l
ABNF
ABAP
ActionScript
Ada
Agda
Alex
Alloy
Arduino C++
AsciiDoc
ASN.1
ASP
ASP.NET
Assembly
GNU Style Assembly
```
如果你在两个文件夹上运行 `tokei` 并指定其位置作为参数,它将以先入先出的规则打印单个文件的统计数据:

默认情况下,`tokei` 仅仅输出有关语言的数据,但是使用 `--files` 标记可提供单个文件统计信息:
```
$ tokei ~/exa/src --files
===========================================================================================
Language Files Lines Code Comments Blanks
===========================================================================================
Rust 54 9339 7070 400 1869
|- Markdown 33 1306 0 1165 141
(Total) 10645 7070 1565 2010
-------------------------------------------------------------------------------------------
/home/ssur/exa/src/theme/default_theme.rs 130 107 0 23
/home/ssur/exa/src/output/render/times.rs 30 24 0 6
/home/ssur/exa/src/output/render/users.rs 98 76 0 22
/home/ssur/exa/src/output/render/size.rs 182 141 3 38
/home/ssur/exa/src/output/render/octal.rs 116 88 0 28
/home/ssur/exa/src/output/render/mod.rs 33 20 3 10
/home/ssur/exa/src/output/render/inode.rs 28 20 0 8
/home/ssur/exa/src/output/render/links.rs 87 65 0 22
/home/ssur/exa/src/output/render/groups.rs 123 93 0 30
|ome/ssur/exa/src/output/render/filetype.rs 31 26 0 5
/home/ssur/exa/src/output/render/blocks.rs 57 40 0 17
/home/ssur/exa/src/output/render/git.rs 108 87 0 21
|/ssur/exa/src/output/render/permissions.rs 204 160 3 41
/home/ssur/exa/src/output/grid.rs 67 51 3 13
/home/ssur/exa/src/output/escape.rs 26 18 4 4
/home/ssur/exa/src/theme/lsc.rs 235 158 39 38
/home/ssur/exa/src/options/theme.rs 159 124 6 29
/home/ssur/exa/src/options/file_name.rs 46 39 0 7
/home/ssur/exa/src/options/flags.rs 84 63 6 15
/home/ssur/exa/src/fs/mod.rs 10 8 0 2
/home/ssur/exa/src/fs/feature/mod.rs 33 25 0 8
-- /home/ssur/exa/src/output/time.rs ---------------------------------------------------------------
|- Rust 215 170 5 40
|- Markdown 28 0 25 3
```
### 总结
我发现使用 `tokei` 来了解我的代码统计数据十分容易。另一个使用 `tokei` 的好处就是它可以用作为一个很容易集成到其他项目的库。访问 Tokei 的 [Crate.io page](https://crates.io/crates/tokei) 和 [Docs.rs](https://docs.rs/tokei/12.1.2/tokei/) 网站来了解其更多用法。如果你想参与其中,你也可以通过它的 [GitHub 仓库](https://github.com/XAMPPRocky/tokei) 来为 Tokei 作贡献。
你是否觉得 Tokei 很有用呢?可以在下方的评论区告诉我们。
---
via: <https://opensource.com/article/21/6/tokei>
作者:[Sudeshna Sur](https://opensource.com/users/sudeshna-sur) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zepoch](https://github.com/zepoch) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently, GitHub added a small indicator that shows details about projects, including what programming languages a project uses. Before this, it was hard for new contributors to know this type of information about the projects they were interested in.
This addition is helpful, but what if you want to know the same information about projects in your local repository? That's where [Tokei](https://github.com/XAMPPRocky/tokei) comes in handy. It's a tool that tells you code statistics about a project, which is especially useful when you want to build a project with people who are proficient in different languages.
## Exploring Tokei
According to its [README](https://github.com/XAMPPRocky/tokei/blob/master/README.md), "Tokei is a program that displays statistics about your code. Tokei will show the number of files, total lines within those files and code, comments, and blanks grouped by language." The introduction to its v.12.1.0 release [elaborates](https://github.com/XAMPPRocky/tokei/releases/tag/v12.1.0), "Tokei is a fast and accurate code analysis CLI tool and library, allowing you to easily and quickly see how many blank lines, comments, and lines of code are in your codebase." It can identify over 150 programming languages.
```
$ ./tokei ~/exa/src ~/Work/wildfly/jaxrs
==================
Language Files Lines Code Comments Blank
Java 46 6135 4324 945 632
XML 23 5211 4839 473 224
---------------------------------
Rust
Markdown
-----------------------------------
Total
```
## Install Tokei
To install Tokei in Fedora:
`$ sudo dnf install tokei`
To install it with Rust's Cargo package manager:
`$ cargo install tokei`
## Use Tokei
To list code statistics for the current directory:
```
$ tokei
===============================================================================
Language Files Lines Code Comments Blanks
===============================================================================
Ada 10 2840 1681 560 599
Assembly 4 2508 1509 458 541
GNU Style Assembly 4 2751 1528 748 475
Autoconf 16 2294 1153 756 385
Automake 1 45 34 0 11
BASH 4 1895 1602 133 160
Batch 2 4 4 0 0
C 330 206433 150241 23402 32790
C Header 342 60941 24682 29143 7116
CMake 48 4572 3459 548 565
C# 9 1615 879 506 230
C++ 5 907 599 136 172
Dockerfile 2 16 10 0 6
Fish 1 87 77 5 5
HTML 1 545 544 1 0
JSON 5 8995 8995 0 0
Makefile 10 504 293 72 139
Module-Definition 12 1183 1046 65 72
MSBuild 1 141 140 0 1
Pascal 4 1443 1016 216 211
Perl 2 189 137 16 36
Python 4 1257 949 112 196
Ruby 1 23 18 1 4
Shell 15 1860 1411 222 227
Plain Text 35 29425 0 26369 3056
TOML 64 3180 2302 453 425
Visual Studio Pro| 30 14597 14597 0 0
Visual Studio Sol| 6 655 650 0 5
XML 1 116 95 17 4
YAML 2 81 56 12 13
Zsh 1 59 48 8 3
-------------------------------------------------------------------------------
Markdown 55 4677 0 3214 1463
|- C 1 2 2 0 0
|- Rust 19 336 268 20 48
|- TOML 23 61 60 0 1
(Total) 5076 330 3234 1512
-------------------------------------------------------------------------------
Rust 496 210966 188958 5348 16660
|- Markdown 249 17676 1551 12502 3623
(Total) 228642 190509 17850 20283
===============================================================================
Total 1523 566804 408713 92521 65570
===============================================================================
$
```
The following command prints out the supported languages and extensions:
```
$ tokei -l
ABNF
ABAP
ActionScript
Ada
Agda
Alex
Alloy
Arduino C++
AsciiDoc
ASN.1
ASP
ASP.NET
Assembly
GNU Style Assembly
```
If you run `tokei`
on two files and specify their location as an argument, it prints the stats for individual files in a last-in-first-out format:
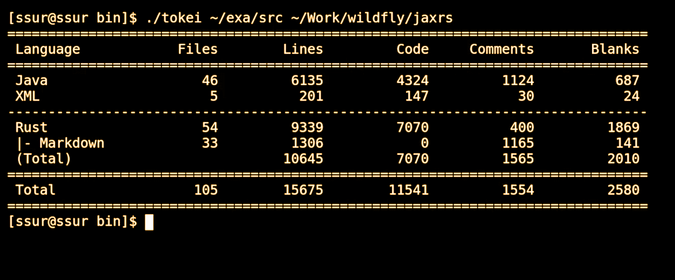
(Sudeshna Sur, CC BY-SA 4.0)
By default, `tokei`
outputs only data about the languages used, but using the `--files`
flag provides individual file statistics:
```
$ tokei ~/exa/src --files
===========================================================================================
Language Files Lines Code Comments Blanks
===========================================================================================
Rust 54 9339 7070 400 1869
|- Markdown 33 1306 0 1165 141
(Total) 10645 7070 1565 2010
-------------------------------------------------------------------------------------------
/home/ssur/exa/src/theme/default_theme.rs 130 107 0 23
/home/ssur/exa/src/output/render/times.rs 30 24 0 6
/home/ssur/exa/src/output/render/users.rs 98 76 0 22
/home/ssur/exa/src/output/render/size.rs 182 141 3 38
/home/ssur/exa/src/output/render/octal.rs 116 88 0 28
/home/ssur/exa/src/output/render/mod.rs 33 20 3 10
/home/ssur/exa/src/output/render/inode.rs 28 20 0 8
/home/ssur/exa/src/output/render/links.rs 87 65 0 22
/home/ssur/exa/src/output/render/groups.rs 123 93 0 30
|ome/ssur/exa/src/output/render/filetype.rs 31 26 0 5
/home/ssur/exa/src/output/render/blocks.rs 57 40 0 17
/home/ssur/exa/src/output/render/git.rs 108 87 0 21
|/ssur/exa/src/output/render/permissions.rs 204 160 3 41
/home/ssur/exa/src/output/grid.rs 67 51 3 13
/home/ssur/exa/src/output/escape.rs 26 18 4 4
/home/ssur/exa/src/theme/lsc.rs 235 158 39 38
/home/ssur/exa/src/options/theme.rs 159 124 6 29
/home/ssur/exa/src/options/file_name.rs 46 39 0 7
/home/ssur/exa/src/options/flags.rs 84 63 6 15
/home/ssur/exa/src/fs/mod.rs 10 8 0 2
/home/ssur/exa/src/fs/feature/mod.rs 33 25 0 8
-- /home/ssur/exa/src/output/time.rs ---------------------------------------------------------------
|- Rust 215 170 5 40
|- Markdown 28 0 25 3
```
## Conclusion
I found it very easy to use `tokei`
to learn more about my code statistics. Another good thing about `tokei`
is that it can be used as a library, which makes it easy to integrate into other projects. Visit Tokei's [Crate.io page](https://crates.io/crates/tokei) and [Docs.rs](https://docs.rs/tokei/12.1.2/tokei/) to learn more about its usage. If you would like to get involved, you can also contribute to Tokei through its [GitHub repository](https://github.com/XAMPPRocky/tokei).
Do you find Tokei useful? Let us know in the comments section below.
## 1 Comment |
13,557 | TIOBE 编程社区指数 20 年 | https://devclass.com/2021/07/05/20-years-of-tiobe-programming-community-index-go-gets-a-bounce/ | 2021-07-07T09:47:40 | [
"TIOBE",
"编程",
"榜单"
] | https://linux.cn/article-13557-1.html | 
2021 年 7 月版的 [TIOBE 编程社区指数](https://www.tiobe.com/tiobe-index/)已经出来了,榜单前几名有点拥挤。
该指数首次发布于 2001 年 7 月,当时 TIOBE 首席执行官 Paul Jansen 开始了“一个个人爱好项目,想看看哪些语言有需求”。从那时起,确定一种语言的受欢迎程度(也就是在该指数中的位置)的方法基本保持不变:通过计算列表中的热门搜索引擎的 “+<语言> programming” 的查询的点击率并将其标准化来计算评级。
2004 年,谷歌方式的改变使得 TIOBE 增加了更多的搜索引擎,以减少波动。然而,目前使用的大多数合格的引擎都属于谷歌家族,所以那里的变化仍然会影响整体结果。对该指数的批评往往归结为其意义不大,因为像新版本或临时问题这样的单一事件有可能大大改变排名的结果。
TIOBE 公司成立于 Eindhoven,主要以其 TICS 产品而闻名,这是一个测量软件代码质量的框架。它的名字是“The Importance Of Being Earnest”的缩写,意在反映该公司“真诚和专业的态度”(我们想,这也为奥斯卡•王尔德的鉴赏家提供了一点笑料)。
20 年前,TIOBE 指数的最高排名是由 Java、C 和 C++ 组成的。这与今天的情况没有太大区别,只是 Python 取代了 C++ 的位置,而且这三个顶级竞争者显然比以前更接近。
在连续 15 个月占据最高位置的 C 和排名第三的 Python 之间,这次的差距只有 0.67%。一年前,两者之间的差距约为 7.36%,因此 2020 年的年度语言似乎正处于一个清晰的轨道上。最新一期的 [PYPL 指数](https://pypl.github.io/PYPL.html)已经看到 Python 在那里牢牢占据榜首,它在过去五年中的受欢迎程度增长最快。同时,在 TIOBE 指数中排名第二的 Java 似乎正在继续失去地位。
Jansen [解释](https://www.tiobe.com/tiobe-index/)说 Python 的持续上升与“数据挖掘和人工智能领域的蓬勃发展”有关。然而,这不可能全部的原因,因为像 R、Matlab 和 Julia 这样的语言在该领域也很常见,目前在该榜单中略有回落,要么更多是停滞不前。拥有一个比较成熟的工具生态系统,包括像 NumPy、TensorFlow 和 PyTorch 这样的重量级工具,以及相对稳固的 IDE 支持,肯定有助于 Python 的排名攀升。
除了少数例外,前十名与去年的排名基本保持一致。R 从第 8 位下降到第 12 位,Swift 从第 10 位下降到第 16 位,为中坚力量 PHP 和 SQL 腾出了一点空间。
再往下看,前 30 名中还有一点有趣的变化,Go 从第 20 名爬升到 2 月份的第 13 名。
Rust 也有些许进步,从第 30 位跃升至第 27 位。除其他原因外,这可能是由于人们对 Rust for Linux 项目的兴趣越来越大,该项目旨在为 Linux 内核带来内存安全,并在[最近](https://www.memorysafety.org/blog/supporting-miguel-ojeda-rust-in-linux/)开始获得资金支持。
---
via: <https://devclass.com/2021/07/05/20-years-of-tiobe-programming-community-index-go-gets-a-bounce/>
作者: [Julia Schmidt](https://devclass.com/author/julia/) 选题:[wxy](https://github.com/wxy) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-13553-1.html) 荣誉推出
| 200 | OK | 
The July 2021 edition of the [TIOBE Programming Community Index](https://www.tiobe.com/tiobe-index/) is out, and things are a bit crowded at the top.
The Index was first published in July 2001, after TIOBE CEO Paul Jansen embarked on “a personal hobby project to see what languages were in demand”. The methodology to determine a language’s popularity — and therefore place on the index — has stayed pretty much the same since then: ratings are calculated by counting and normalising the hits for the query `+"<language> programming"` in a list of popular search engines.
A change in Google’s methods in 2004 led TIOBE to add more search engines to the mix to minimise fluctuations. However, most of the qualified engines currently used belong to the Google family, so a change there would still influence the overall outcome. Criticism of the Index often boils down to it not being very meaningful, since singular events like a new release or temporary problems can potentially change the outcome of the ranking significantly.
TIOBE, the company, was founded in Eindhoven, and is mostly known for its TICS product, a framework for measuring software code quality. Its name stands for “The Importance Of Being Earnest”, which is meant to reflect the company’s “sincere and professional attitude” (and provide Oscar Wilde connoisseurs with a bit of a chuckle, we suppose).
20 years ago, the top ranks of the TIOBE Index were populated by Java, C, and C++. This isn’t too different from the way things are today, except that Python has taken over C++’s position and the three top contenders are apparently closer than ever before.
Between C, which occupies the highest spot for the 15th straight month, and third-placed Python, there’s a difference of just 0.67 per cent this time. A year ago the gap was about 7.36 per cent between the two, so 2020’s language of the year seems to be on a clear trajectory towards the top. The latest edition of the [PYPL Index](https://pypl.github.io/PYPL.html) already sees Python settled there, ascribing it the most growth in popularity in the last five years. Meanwhile Java, the second on the TIOBE Index, appears to be continuing to lose ground.
Jansen [explains](https://www.tiobe.com/tiobe-index/) Python’s continuous rise with the “booming field of data mining and artificial intelligence”. This can’t be the whole story however, given that languages like R, Matlab, and Julia — which are also common in that area — are currently falling back down the list slightly or are stagnant at best. Having a somewhat established ecosystem of tools including heavyweights like NumPy, TensorFlow and PyTorch, as well as comparatively solid IDE support, surely helped Python climb up the ranks.
With few exceptions, the top 10 stayed pretty much the same since last year’s rankings. R dropped from #8 to #12, and Swift plunged from #10 to #16, making room for stalwarts PHP and SQL to shift a little.
Further down, the top 30 shows at least a bit of interesting movement, with [Go](https://devclass.com/2021/02/17/go-1_16_programming-language/) climbing back up from #20 to its February position of #13.
[Rust](https://devclass.com/2021/06/21/array-with-you-rust-1-53-lands-with-intoiterator-and-nested-or-allows-for-localised-code/) also got some tailwind and jumped from #30 to #27. Among other things, this might be down to growing interest in the Rust for Linux project, which is meant to bring memory safety to the Linux kernel and has started to receive financial support just [recently](https://www.memorysafety.org/blog/supporting-miguel-ojeda-rust-in-linux/).
[Ruby on Rails 8.0 first beta release: A big bet on SQLite in production ](https://devclass.com/2024/10/09/ruby-on-rails-8-0-first-beta-release-a-big-bet-on-sqlite-in-production/)
[OpenAI previews major update to ChatGPT visual interface for writing and coding](https://devclass.com/2024/10/07/openai-previews-major-update-to-chatgpt-visual-interface-for-writing-and-coding/)
[Python 3.13 delayed by 'drastic change' removal of incremental garbage collector](https://devclass.com/2024/10/04/python-3-13-delayed-by-drastic-change-removal-of-incremental-garbage-collector/)
[Why Windows 11 24H2 is a big yawn for developers](https://devclass.com/2024/10/03/why-windows-11-24h2-is-a-big-yawn-for-developers/)
[The SQLite team is preparing an efficient remote replication tool](https://devclass.com/2024/10/02/the-sqlite-team-is-preparing-an-efficient-remote-replication-tool/)
[Harness previews Cloud Development Environments, AI assistants, turns to Google for AI DevOps](https://devclass.com/2024/09/27/harness-previews-cloud-development-environments-and-ai-assistants-turns-to-google-for-ai-devops/)
[Survey: Ruby on Rails devs happy to go their own way, now prefer Stimulus.js over React](https://devclass.com/2024/09/25/survey-ruby-on-rails-devs-happy-to-go-their-own-way-now-prefer-stimulus-js-over-react/)
[GitHub adds Microsoft Azure-based EU data residency to Enterprise Cloud](https://devclass.com/2024/09/25/github-adds-microsoft-azure-based-eu-data-residency-to-enterprise-cloud/)
[Deno version 2.0 is nearly done – but after over 4 years, the project's big bets have yet to pay off](https://devclass.com/2024/09/23/deno-version-2-0-is-nearly-done-but-after-over-4-years-the-projects-big-bets-have-yet-to-pay-off/)
[Pulumi releases security management product, touts benefits of IaC using general-purpose programming...](https://devclass.com/2024/09/20/pulumi-releases-security-management-product-touts-benefits-of-iac-using-general-purpose-programming-languages/)
[Apple releases Swift 6 with improved concurrency, testing, cross-platform support – enough to lift i...](https://devclass.com/2024/09/19/apple-releases-swift-6-with-improved-concurrency-testing-cross-platform-support-enough-to-lift-it-out-of-its-niche/)
[RustConf speakers affirm Rust for Linux project despite challenges of unstable Rust, maintainer resi...](https://devclass.com/2024/09/18/rustconf-speakers-affirm-rust-for-linux-project-despite-challenges-of-unstable-rust-maintainer-resignation/) |
13,558 | Jim Hall,你觉得 Fedora 怎么样? | https://fedoramagazine.org/jim-hall-how-do-you-fedora/ | 2021-07-07T10:39:37 | [
"采访"
] | https://linux.cn/article-13558-1.html | 
我们最近采访了 Jim Hall,了解他是如何使用 Fedora 的。这个 Fedora 杂志 [系列](https://fedoramagazine.org/tag/how-do-you-fedora) 中的一篇。该系列介绍了 Fedora 用户以及他们如何使用 Fedora 来完成任务。如果你对本系列的后继采访感兴趣,请通过 [反馈表](https://fedoramagazine.org/submit-an-idea-or-tip) 与我们联系。
### Jim Hall 是谁?
Jim Hall 曾担任高等教育和政府部门的首席信息官超过 8 年,最近创办了咨询公司 [Hallmentum](https://hallmentum.com/)。他的大部分工作包括培训、研讨会和指导,帮助新的 IT 领导者发展领导技能,也帮助当前的 IT 领导者更好地发挥领导力。除了咨询,Jim 还担任大学的兼职教师,目前教授管理信息系统(MIS)和技术与专业写作课程。
Jim 是如何成长的? Jim 童年时代的英雄来自电视和电影,包括蝙蝠侠和汉索罗。Jim 长期以来最喜欢看的电影是《星球大战:新希望》。Jim 说:“我是一个星球大战迷。”Jim 最喜欢吃意大利菜,“我喜欢意大利菜!我最喜欢的意大利菜可能是炖鸡”。Jim 的观点是,诚实、创造力、想象力、好奇心和开放性是一个人所能拥有的五个好品质。
他喜欢写作,非常好的是他的日常工作主要是写作。他花了很多时间为像 [OpenSource.com](http://OpenSource.com)、 CloudSavvy IT 和 Linux Magazine 等网站撰写“如何”类文章。现在他正在写一本关于 C 编程的书。除了写作,他还玩电子游戏来放松。他有一台 PlayStation 4 游戏机,大多数周六下午他都会坐在电视机前玩游戏。
### Fedora 社区
Jim 从 1993 年开始使用 Linux。他的第一个 Linux 发行版是 Softlanding Linux System(SLS)1.03,运行 Linux 内核 0.99,补丁级别 11。“从那以后,我一直是家里的全职 Linux 用户”。Jim 在很久以前参加了 Fedora Core 时代的一个 Linux 会议之后,开始更多参与到 Fedora 中。Jim 在这遇见了 Tom “Spot” Callaway,他们开始谈论 Fedora。“Spot 鼓励我用另一种方式来做贡献:找到 bug 并报告它们。这就是我参与测试所有 Beta 版本的原因”。
Jim 想在 Fedora 改变什么? 他想在 [getfedora.com](http://getfedora.com) 上看到一个倒计时,告诉大家新的 Beta 版本或新的完整版本是什么时候发布的,这是 Fedora 项目的一个改变。并且 Jim 想让人们都知道,使用 Fedora 是多么容易。“对开源做出贡献最具挑战性的事情是,弄清楚如何做出他们的第一个贡献。”Jim 补充道,“我不知道我和其他开发人员一样是‘Fedora 项目成员’。我只是个用户。但是作为一个从 1993、1994 年就开始参与开发开源软件的人,我努力成为社区中一个有用的成员。因此,我利用一切机会尝试新的 Fedora 版本,甚至是 Beta 版,如果我发现问题,就会告诉大家。”
### 你用什么硬件?
Jim 目前正在运行一台 ThinkCentre M720 Tiny。它配置了第 8 代酷睿 i3-8100T(3.10GHz,6MB 缓存)、32GB(16GB + 16GB)DDR4 2666MHz、英特尔显卡、256GB 固态硬盘 PCIe-NVME Opal M.2、英特尔 8265 802.11AC 和 蓝牙 4.2。他的显示器是华硕 VE248H。 Jim 说:“这一切在Fedora上都很好用!”。
他使用 Perixx Periboard-512 人体工程学经典分体式键盘,它从 1998 年开始取代了他最初的微软 Natural Keyboard Elitee PS/2 键盘。Jim 说: “我有时候会把我的 Perixx 键盘换成 Unicomp 的 IBM Model M USB 克隆键盘。我很喜欢这种带有扣动式弹簧动作的点击式键盘。我的是‘灰白色’,所以它有种经典的外观和感觉”
### 你用什么软件?
Jim 目前运行的是 Fedora 33,之前是 Fedora 33 Beta 和 Fedora 32。Jim 说:“我使用 GNOME 3 作为我的桌面。我发现默认设置适合我的大多数需求,所以我没有加载任何 GNOME 扩展,但我确实使用‘设置’和 ‘GNOME Tweaks’ 调整了一些东西。所以我没有做什么大的改变。例如,我将默认用户界面字体改为使用 Droid Sans Regular 字体。并且我用‘设置’来改变键盘快捷键,用 `Alt-Tab` 键来切换窗口,而不是切换应用程序。我是在 `Alt-Tab` 工作流程中长大的,所以我已经习惯了。”他使用火狐和谷歌浏览器来作为他的 Web 浏览器。
为了经营他的咨询业务,Jim 依赖于一套应用程序:
* 使用 [LibreOffice](https://www.libreoffice.org/) 去写他的书。例如,他去年出版了 《[Coaching Buttons](https://www.amazon.com/Coaching-Buttons-Jim-Hall/dp/0359834930)》,他完全使用 LibreOffice 来写这本书。最近他写了一本关于 [用 C 语言编写 FreeDOS 程序的书](https://www.freedos.org/books/) 也用了 LibreOffice 。

* [INKSCAPE](https://inkscape.org/) 为他创建了矢量格式的公司标志。他的标志可以完美地放大缩小,从文件上的小角落图像到大幅面的海报或横幅。并且 INKSCAPE 允许他导出各种通用格式。Jim 说他的广告合作伙伴很欣赏 INKSCAPE 可以输出到EPS(Encapsulated Postscript),这使得在产品上打印他的标志变得很容易。
* [GIMP](https://www.gimp.org/) 用于其他图形,例如闪屏图片。“我的闪屏图片是我们公司的标志被放在了背景照片上,在我需要额外装饰的地方,比如印刷材料,我用它来替代普通标志。我也在我的网站上使用了闪屏图片的一个版本”。
* [QEMU](https://www.qemu.org/) 用来运行虚拟机,在他那里可以启动 [FreeDOS](https://www.freedos.org/)。“我喜欢使用 QEMU,因为我可以在命令行中设置所有需要的选项,这使我在配置虚拟机时有了很大的灵活性。为了更方便,我将所有选项放入到一个脚本中,用它来运行QEMU,每次都是相同的选项”。

* [Scribus](https://www.scribus.net/) 是用来打印产品的。Scribus 很容易用来创建具有“全出血”的印刷品,这意味着任何颜色的背景都会与纸张的边缘重叠。全出血需要一个特殊的打印准备文件,与打印区域重叠。它甚至还提供了切割标记,以便打印机准确地知道要修剪的位置。

---
via: <https://fedoramagazine.org/jim-hall-how-do-you-fedora/>
作者:[Karimi Hari Priya](https://fedoramagazine.org/author/haripriya21/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zz-air](https://github.com/zz-air) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We recently interviewed Jim Hall on how he uses Fedora. This is part of a [series ](https://fedoramagazine.org/tag/how-do-you-fedora)on the Fedora Magazine. The series profiles Fedora users and how they use Fedora to get things done. Contact us on the [feedback form ](https://fedoramagazine.org/submit-an-idea-or-tip)if you are interested in being interviewed for a further installment of this series.
**Who is Jim Hall?**
Jim Hall served as Chief Information Officer in higher education and government for over eight years and has recently started the consulting company [Hallmentum](https://hallmentum.com/). Most of his work includes training, workshops, and coaching to help new IT leaders develop leadership skills, also to help current IT leaders get better at leadership. Apart from consulting, Jim also serves as adjunct faculty at the university level, currently teaching courses in Management Information Systems (MIS) and Technical & Professional Writing.
How did Jim grow up? Jim’s childhood heroes were from TV and movies, including Batman and Han Solo. Jim’s long-time favorite go-to movie is Star Wars: A New Hope. Jim says, “I am a big Star Wars nerd.” Jim’s favorite meals are Italian. “I love Italian food! Probably my favorite Italian dish is chicken cacciatore.” Jim’s opinion is that Honesty, Creativity, Imagination, Curiosity, and Openness are the five greatest qualities someone can possess.
He loves writing, which is good because most of his day job is about writing. He spends a lot of time writing “how-to” articles for places like OpenSource.com, CloudSavvy IT, and Linux Magazine, and right now he is writing a book about C programming. Apart from writing, he also relaxes by playing video games. He owns a PlayStation 4 and can be found most Saturday afternoons in front of his TV playing a game.
**Fedora Community**
Jim started using Linux in 1993. His first Linux distribution was Softlanding Linux System (SLS) 1.03, running Linux kernel 0.99 patch level 11. “I’ve been a full-time Linux user at home ever since”. Jim became more involved in Fedora after attending a Linux conference long ago in the Fedora Core days. Jim met Tom “Spot” Callaway there, and they got talking about Fedora. “Spot encouraged me to contribute another way: by finding bugs and reporting them. And that’s how I got involved in testing for all the Beta releases”.
What would Jim like to change in Fedora? He would like to see a countdown on the getfedora.org website, that tells when the new Beta release or new full release is due out as a change in Fedora Project. And Jim wishes that other people know how easy it is to use Fedora. ”The most challenging thing in contributing to open source is to figure out how to make their first contribution.” Jim adds, “I don’t know that I’m a ‘Fedora Project member’ like other developers would be. I’m just a user. But as someone who’s been involved in developing open-source software since 1993 or 1994, I try to be a helpful member of the community. So I take every opportunity to experiment with new Fedora releases, even the Beta releases, and let people know if I find problems.”
**What hardware do you use?**
Jim is currently running a ThinkCentre M720 Tiny. It’s configured with 8th Generation Intel Core i3-8100T (3.10GHz, 6MB Cache), 32GB (16GB + 16GB) DDR4 2666MHz, Intel graphics, 256GB Solid State Drive PCIe-NVME Opal M.2, Intel 8265 802.11AC, and Bluetooth 4.2. His monitor is an Asus VE248H. “It all works great with Fedora!” says Jim.
He uses the Perixx Periboard-512 Ergonomic Classic Split Keyboard which replaced his original Microsoft Natural Keyboard Elite PS/2 keyboard from 1998. Jim says “I sometimes swap out the Perixx keyboard for my USB clone of the original IBM Model M keyboard, from Unicomp. I do love the clicky keyboard with the buckling spring action. And mine is in the ‘putty white’ color so it has that classic look and feel.”
**What software do you use?**
Jim is currently running Fedora 33 and previously Fedora 33 Beta, and Fedora 32. “I use GNOME 3 as my desktop. I find the defaults suit most of my needs, so I don’t have any GNOME Extensions loaded, but I do adjust a few things using Settings and GNOME Tweaks. So I’m not making any big changes. For example, I changed my default user interface font to use Droid Sans Regular. And I used Settings to change the keyboard shortcut so Alt-Tab switches windows instead of switching applications. I grew up with the Alt-Tab workflow, so I’m used to that,” says Jim. He uses Firefox and Google Chrome as his web browsers.
To run his consultancy business, Jim relies on a suite of applications:
[LibreOffice](https://www.libreoffice.org/)to write his books. For example, he published[Coaching Buttons](https://www.amazon.com/Coaching-Buttons-Jim-Hall/dp/0359834930)last year. He wrote this book entirely using LibreOffice. More recently, he wrote a book about[Writing Free DOS Programs in C](https://www.freedos.org/books/)and used LibreOffice for that too.[INKSCAPE](https://inkscape.org/)for creating his company logo in vector format. His logo scales up and down perfectly—from a small corner image on a document to a large-format poster or banner. And INKSCAPE lets him export to a variety of common formats. Jim says that his advertising partners appreciate that INKSCAPE can export to EPS (Encapsulated Postscript), which makes it a snap to print his logo on products.[GIMP](https://www.gimp.org/)for other graphics, such as a splash image. “My splash image is my company logo placed over a background image, and I use that in place of a plain logo where I need extra pizzazz, such as on printed materials. I also use a version of the splash image on my website.”[QEMU](https://www.qemu.org/)to run a virtual machine where he can boot[FreeDOS](https://www.freedos.org/). “I like using QEMU because I can set all the options I need at the command line, which gives me a lot of extra flexibility in configuring the virtual machine. To make this easier, I put all the options into a script, and use that to run QEMU with the same options every time.”[Scribus](https://www.scribus.net/)to print products. Scribus is easy to use to create print-ready materials with*full bleed*, meaning any color backgrounds overlap the edge of the paper. Full bleed requires a special print-ready file that overlaps the print area . It even provides cut marks so that the printer knows exactly where to trim.
**Scribus – Postcard**
**QEMU – running as easy as in FreeDOS**
**Libre Office Writer**
## rugk
“Don’t get nibbled to death by ducks”? 🤣
## Roger
I checked out the font ‘droid sans regular’ for the user interface…I like it.
## Anise Star
Try Red Hat Display
## Roger
Very good too, thank you.
## Michael
What is manufacturer of the microphone in the background?
## Grayson / computerkid
Looks like a blue yeti to me
## Jim Hall
Correct, that is a Blue Yeti microphone. Great sound quality.
## Helmy
I think that is rhode
## Gregory Zeng
Why was the Deb package manager avoided? RPM seems not so popular with 3rd party application creators, such as Flashpeak Slimjet. Even Red Hat seems to not prefer Fedora.
## Julius Schwartzenberg
Jim, have you considered running FreeDOS inside DOSEMU2 instead of QEMU?
Recently work was done specifically to provide FreeDOS also easily to DOSEMU2 users on Fedora:
https://github.com/dosemu2/dosemu2/wiki/Download-sites-for-dosemu2 |
13,559 | Fotoxx:用于管理和编辑大型照片集合的开源应用 | https://itsfoss.com/fotoxx/ | 2021-07-07T13:10:30 | [
"相片",
"图片"
] | https://linux.cn/article-13559-1.html | 
说到 [Linux 中的照片管理软件](https://itsfoss.com/linux-photo-management-software/),Shotwell 可能是其中最有名的。难怪它在许多发行版中都预装了。
但是,如果你正在寻找一个类似 Shotwell 而速度更快的应用,Fotoxx 可能是一个不错的选择。
它可能没有一个现代的用户界面,但它在处理大量照片集合时速度很快。这一点很重要,因为索引和显示成千上万张照片的缩略图可能需要相当多的时间和计算资源。
### 用 Fotoxx 在 Linux 中管理照片并编辑它们

正如你在上面的截图中看到的,它没有漂亮的界面。看起来更像是一个 2010 年左右的应用。它在视觉上的不足,在功能和性能上得到了弥补。
你可以导入大量的照片,包括 RAW 图像。这些图片保持原样。它们不会被复制或移动。它们只是在应用中被索引。
你可以编辑图像元数据,如标签、地理标签、日期、评级、标题等。你可以根据这些元数据来搜索图片。
它还有一个地图功能,可以分组并显示属于某个地点的图片(基于图片上的地理标签数据)。

由于它专注于管理大型照片集合,有几个批处理功能,可以重命名、调整大小、复制/移动、转换图像格式和编辑元数据。
你可以选择图片来创建相册和幻灯片,所有这些都是在去重图片的情况下进行的。照片可以组合成 360 度的全景图。
Fotoxx 还有几个编辑功能,可以用来修饰图片,添加效果(如素描、绘画)、修剪、旋转等。
还有一些选项可以去除旧的、扫描照片打印件上的红眼和尘斑。
我可以继续列举功能清单,但这太长了。它的网站描述了它的[全部功能](https://kornelix.net/fotoxx/fotoxx.html),你应该去看看。
### 在 Linux 上安装 Fotoxx
请记住,**Fotoxx 的开发者建议使用一台强大的计算机**,有 4 个以上的 CPU 核心,16GB 以上的内存,以便正常运行。较小的计算机可能会很慢,或可能无法编辑大型图像。
Fotoxx 在大多数 Linux 发行版中都有,如 Debian、Ubuntu、Fedora 和 Arch Linux。只需使用你的发行版的包管理器或软件中心来搜索 Fotoxx 并安装它。
在基于 Ubuntu 和 Debian 的发行版上,你可以使用 apt 命令来安装它,像这样:
```
sudo apt install fotoxx
```
当你第一次运行它时,它会要求搜索主目录中的图像。你可以继续使用它,或者将搜索位置限制在选定的文件夹。

我注意到,尽管在一分钟左右的时间内索引了 4700 多张,但它并没有立即开始显示图片。我不得不**点击 Gallery->All Folders,然后选择文件夹,然后它就显示了图片**。所以,这一点要记住。
Fotoxx 是一个功能广泛的工具,你需要一些时间来适应它并探索它的[所有功能](https://kornelix.net/fotoxx/fotoxx.html)。它的网站列出了几个例子,你应该看看。
正如我前面所说,它不是最漂亮的应用,但它大量的功能列表可以完成任务。如果你是一个摄影师或有大量的图片收藏,你可以试试 Fotoxx,看看它是否符合你的需要。当你试过后,请在评论区分享你的经验。
---
via: <https://itsfoss.com/fotoxx/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When it comes to [photo management software in Linux](https://itsfoss.com/linux-photo-management-software/), Shotwell is perhaps the most famous of them all. No wonder it comes preinstalled in many distributions.
But if you are looking for a Shotwell like application which is a bit faster, Fotoxx could be a good choice.
It may not have a modern user interface, but it is fast in handling a large collection of photos. And it matters because indexing and showing thumbnails for thousands of photos could take considerable time and computing resources.
## Manage photos and edit them in Linux with Fotoxx
As you can see in the screenshot above, it is not the nicest interface. Looks more like an application from around 2010. What it lacks in the visual department, it makes up with features and performance.
You can import a huge collection of photos, including RAW images. The images stay where they are. They are not copied or moved. They just get indexed in the application.
You can edit image metadata like tags, geotags, dates, ratings, captions etc. You can search images based on these matadata.
It also has a map feature that groups and displays images belonging to a certain location (based on geotag data on the images).
Since it focuses on managing large collection of photos, it has several batch functions to rename, resize, copy/move, convert image format and edit metadata.
You can select images to create albums and slideshows and all this happens without duplicating the images. Photos can be combined to create 360-degree panoramas.
Fotoxx also has several editing functions that can be used to retouch the images, add effect (like sketching, painting), trim, rotate and more.
There is also options for removing red eyes and dust spots from the old, scanned photo prints.
I can go on with the features list but it won’t end. Its website describes its full capabilities and you should check it out.
If it interests you, you can watch this video that demonstrates the features of Fotoxx:
## Installing Fotoxx on Linux
Please keep in mind that **Fotoxx developer recommends a strong computer** with 4+ CPU cores, 16+ GB memory for proper functioning. Lesser computers may be slow or may fail to edit large images.
Fotoxx is available in the repositories of most Linux distributions like Debian, Ubuntu, Fedora and Arch Linux. Just use your distribution’s package manager or software center to search for Fotoxx and install it.
On Ubuntu and Debian based distributions, you can use the apt command to install it like this:
`sudo apt install fotoxx`
When you first run it, it will ask to search the home directory for images. You may continue with it or limit the search location to selected folders.
I noticed that despite indexing over 4,700 in a minute or so, it didn’t start displaying the images immediately. I had to **click on Gallery->All Folders and the select the folder(s) and then it showed the images**. So, this is something to keep in mind.
Fotoxx is an extensive tool and it will take some time in getting used to it and explore all its features. Its webapge lists several examples that you should have a look at.
As I said earlier, it is not the prettiest application, but it gets the job done with a huge list of features. If you are a photographer or have a large collection of images, you may give Fotoxx a try and see if it fits your need. And when you do that, please do share your experience with it in the comment section. |
13,561 | 如何解析 Bash 程序的配置文件 | https://opensource.com/article/21/6/bash-config | 2021-07-08T16:36:38 | [
"配置"
] | /article-13561-1.html |
>
> 将配置文件与代码分离,使任何人都可以改变他们的配置,而不需要任何特殊的编程技巧。
>
>
>

将程序配置与代码分离是很重要的。它使非程序员能够改变配置而不需要修改程序的代码。如果是编译好的二进制可执行文件,这对非程序员来说是不可能的,因为它不仅需要访问源文件(我们在开源程序中会这样),而且还需要程序员的技能组合。很少有人有这种能力,而且大多数人都不想学习它。
对于像 Bash 这样的 shell 语言,由于 shell 脚本没有被编译成二进制格式,所以从定义上讲,源码是可以访问的。尽管有这种开放性,但对于非程序员来说,在 shell 脚本中钻研和修改它们并不是一个特别好的主意。即使是经验丰富的开发人员和系统管理员,也会意外地做出一些导致错误或更糟的改变。
因此,将配置项放在容易维护的文本文件中,提供了分离,并允许非程序员编辑配置,而不会有对代码进行意外修改的危险。许多开发者对用编译语言编写的程序都是这样做的,因为他们并不期望用户是开发者。由于许多相同的原因,对解释型 shell 语言这样做也是有意义的。
### 通常的方式
和其他许多语言一样, 你可以为 Bash 程序编写代码,来读取并解析 ASCII 文本的配置文件、读取变量名称并在程序代码执行时设置值。例如,一个配置文件可能看起来像这样:
```
var1=LinuxGeek46
var2=Opensource.com
```
程序将读取文件,解析每一行,并将值设置到每个变量中。
### 源引
Bash 使用一种更简单的方法来解析和设置变量, 叫做<ruby> 源引 <rt> sourcing </rt></ruby>。从一个可执行的 shell 程序中获取一个外部文件是一种简单的方法,可以将该文件的内容完整地引入 shell 程序中。在某种意义上,这很像编译语言的 `include` 语句,在运行时包括库文件。这样的文件可以包括任何类型的 Bash 代码,包括变量赋值。
(LCTT 译注:对于使用 `source` 或 `.` 命令引入另外一个文件的行为,我们首倡翻译为“源引”。)
像往常一样,演示比解释更容易。
首先,创建一个 `~/bin` 目录(如果它还不存在的话),并将其作为当前工作目录(PWD)。[Linux 文件系统分层标准](http://refspecs.linuxfoundation.org/fhs.shtml) 将 `~/bin` 定义为用户存储可执行文件的适当位置。
在这个目录下创建一个新文件。将其命名为 `main`,并使其可执行:
```
[dboth@david bin]$ touch main
[dboth@david bin]$ chmod +x main
[dboth@david bin]$
```
在这个可执行文件中添加以下内容:
```
#!/bin/bash
Name="LinuxGeek"
echo $Name
```
并执行这个 Bash 程序:
```
[dboth@david bin]$ ./main
LinuxGeek
[dboth@david bin]$
```
创建一个新的文件并命名为 `~/bin/data`。这个文件不需要是可执行的。在其中添加以下信息:
```
# Sourced code and variables
echo "This is the sourced code from the data file."
FirstName="David"
LastName="Both"
```
在 `main` 程序中增加三行,看起来像这样:
```
#!/bin/bash
Name="LinuxGeek"
echo $Name
source ~/bin/data
echo "First name: $FirstName"
echo "LastName: $LastName"
```
重新运行该程序:
```
[dboth@david bin]$ ./main
LinuxGeek
This is the sourced code from the data file.
First name: David
LastName: Both
[dboth@david bin]$
```
关于源引还有一件非常酷的事情要知道。你可以使用一个单点(`.`)作为 `source` 命令的快捷方式。改变 `main` 文件,用 `.` 代替 `source`。
```
#!/bin/bash
Name="LinuxGeek"
echo $Name
. ~/bin/data
echo "First name: $FirstName"
echo "LastName: $LastName"
```
并再次运行该程序。其结果应该与之前的运行完全相同。
### 运行 Bash
每一台使用 Bash 的 Linux 主机(几乎所有主机都是,因为 Bash 是所有发行版的默认 shell),都包括一些优秀的、内置的源引示例。
每当 Bash shell 运行时,它的环境必须被配置成可以使用的样子。有五个主要文件和一个目录用于配置 Bash 环境。它们和它们的主要功能如下:
* `/etc/profile`: 系统级的环境和启动程序
* `/etc/bashrc`: 系统级的函数和别名
* `/etc/profile.d/`: 包含系统级的脚本的目录,用于配置各种命令行工具,如 `vim` 和 `mc` 以及系统管理员创建的任何自定义配置脚本
* `~/.bash_profile`: 用户特定的环境和启动程序
* `~/.bashrc`: 用户特定的别名和函数
* `~/.bash_logout`: 用户特定的命令,在用户注销时执行
试着通过这些文件追踪执行顺序,确定它在非登录 Bash 初始化和登录 Bash 初始化中使用的顺序。我在我的 Linux 培训系列《[使用和管理 Linux:从零到系统管理员](http://www.both.org/?page_id=1183)》的第一卷第 17 章中这样做过。
给你一个提示。这一切都从 `~/.bashrc` 脚本开始。
### 总结
这篇文章探讨了在 Bash 程序中引用代码和变量的方法。这种从配置文件中解析变量的方法是快速、简单和灵活的。它提供了一种将 Bash 代码与变量赋值分开的方法,以使非程序员能够设置这些变量的值。
---
via: <https://opensource.com/article/21/6/bash-config>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,564 | 如何在 Go 中嵌入 Python | https://www.datadoghq.com/blog/engineering/cgo-and-python/ | 2021-07-09T12:33:00 | [
"Python",
"Go"
] | https://linux.cn/article-13564-1.html | 
如果你看一下 [新的 Datadog Agent](https://github.com/DataDog/datadog-agent/),你可能会注意到大部分代码库是用 Go 编写的,尽管我们用来收集指标的检查仍然是用 Python 编写的。这大概是因为 Datadog Agent 是一个 [嵌入了](https://docs.python.org/2/extending/embedding.html) CPython 解释器的普通 Go 二进制文件,可以在任何时候按需执行 Python 代码。这个过程通过抽象层来透明化,使得你可以编写惯用的 Go 代码而底层运行的是 Python。
在 Go 应用程序中嵌入 Python 的原因有很多:
* 它在过渡期间很有用;可以逐步将现有 Python 项目的部分迁移到新语言,而不会在此过程中丢失任何功能。
* 你可以复用现有的 Python 软件或库,而无需用新语言重新实现。
* 你可以通过加载去执行常规 Python 脚本来动态扩展你软件,甚至在运行时也可以。
理由还可以列很多,但对于 Datadog Agent 来说,最后一点至关重要:我们希望做到无需重新编译 Agent,或者说编译任何内容就能够执行自定义检查或更改现有检查。
嵌入 CPython 非常简单,而且文档齐全。解释器本身是用 C 编写的,并且提供了一个 C API 以编程方式来执行底层操作,例如创建对象、导入模块和调用函数。
在本文中,我们将展示一些代码示例,我们将会在与 Python 交互的同时继续保持 Go 代码的惯用语,但在我们继续之前,我们需要解决一个间隙:嵌入 API 是 C 语言,但我们的主要应用程序是 Go,这怎么可能工作?

### 介绍 cgo
有 [很多好的理由](https://dave.cheney.net/2016/01/18/cgo-is-not-go) 说服你为什么不要在堆栈中引入 cgo,但嵌入 CPython 是你必须这样做的原因。[cgo](https://golang.org/cmd/cgo/) 不是语言,也不是编译器。它是 <ruby> <a href="https://en.wikipedia.org/wiki/Foreign_function_interface"> 外部函数接口 </a> <rt> Foreign Function Interface </rt></ruby>(FFI),一种让我们可以在 Go 中使用来调用不同语言(特别是 C)编写的函数和服务的机制。
当我们提起 “cgo” 时,我们实际上指的是 Go 工具链在底层使用的一组工具、库、函数和类型,因此我们可以通过执行 `go build` 来获取我们的 Go 二进制文件。下面是使用 cgo 的示例程序:
```
package main
// #include <float.h>
import "C"
import "fmt"
func main() {
fmt.Println("Max float value of float is", C.FLT_MAX)
}
```
在这种包含头文件情况下,`import "C"` 指令上方的注释块称为“<ruby> 序言 <rt> preamble </rt></ruby>”,可以包含实际的 C 代码。导入后,我们可以通过“C”伪包来“跳转”到外部代码,访问常量 `FLT_MAX`。你可以通过调用 `go build` 来构建,它就像普通的 Go 一样。
如果你想查看 cgo 在这背后到底做了什么,可以运行 `go build -x`。你将看到 “cgo” 工具将被调用以生成一些 C 和 Go 模块,然后将调用 C 和 Go 编译器来构建目标模块,最后链接器将所有内容放在一起。
你可以在 [Go 博客](https://blog.golang.org/c-go-cgo) 上阅读更多有关 cgo 的信息,该文章包含更多的例子以及一些有用的链接来做进一步了解细节。
现在我们已经了解了 cgo 可以为我们做什么,让我们看看如何使用这种机制运行一些 Python 代码。

### 嵌入 CPython:一个入门指南
从技术上讲,嵌入 CPython 的 Go 程序并没有你想象的那么复杂。事实上,我们只需在运行 Python 代码之前初始化解释器,并在完成后关闭它。请注意,我们在所有示例中使用 Python 2.x,但我们只需做很少的调整就可以应用于 Python 3.x。让我们看一个例子:
```
package main
// #cgo pkg-config: python-2.7
// #include <Python.h>
import "C"
import "fmt"
func main() {
C.Py_Initialize()
fmt.Println(C.GoString(C.Py_GetVersion()))
C.Py_Finalize()
}
```
上面的例子做的正是下面 Python 代码要做的事:
```
import sys
print(sys.version)
```
你可以看到我们在序言加入了一个 `#cgo` 指令;这些指令被会被传递到工具链,让你改变构建工作流程。在这种情况下,我们告诉 cgo 调用 `pkg-config` 来收集构建和链接名为 `python-2.7` 的库所需的标志,并将这些标志传递给 C 编译器。如果你的系统中安装了 CPython 开发库和 pkg-config,你只需要运行 `go build` 来编译上面的示例。
回到代码,我们使用 `Py_Initialize()` 和 `Py_Finalize()` 来初始化和关闭解释器,并使用 `Py_GetVersion` C 函数来获取嵌入式解释器版本信息的字符串。
如果你想知道,所有我们需要放在一起调用 C 语言 Python API的 cgo 代码都是模板代码。这就是为什么 Datadog Agent 依赖 [go-python](https://github.com/sbinet/go-python) 来完成所有的嵌入操作;该库为 C API 提供了一个 Go 友好的轻量级包,并隐藏了 cgo 细节。这是另一个基本的嵌入式示例,这次使用 go-python:
```
package main
import (
python "github.com/sbinet/go-python"
)
func main() {
python.Initialize()
python.PyRun_SimpleString("print 'hello, world!'")
python.Finalize()
}
```
这看起来更接近普通 Go 代码,不再暴露 cgo,我们可以在访问 Python API 时来回使用 Go 字符串。嵌入式看起来功能强大且对开发人员友好,是时候充分利用解释器了:让我们尝试从磁盘加载 Python 模块。
在 Python 方面我们不需要任何复杂的东西,无处不在的“hello world” 就可以达到目的:
```
# foo.py
def hello():
"""
Print hello world for fun and profit.
"""
print "hello, world!"
```
Go 代码稍微复杂一些,但仍然可读:
```
// main.go
package main
import "github.com/sbinet/go-python"
func main() {
python.Initialize()
defer python.Finalize()
fooModule := python.PyImport_ImportModule("foo")
if fooModule == nil {
panic("Error importing module")
}
helloFunc := fooModule.GetAttrString("hello")
if helloFunc == nil {
panic("Error importing function")
}
// The Python function takes no params but when using the C api
// we're required to send (empty) *args and **kwargs anyways.
helloFunc.Call(python.PyTuple_New(0), python.PyDict_New())
}
```
构建时,我们需要将 `PYTHONPATH` 环境变量设置为当前工作目录,以便导入语句能够找到 `foo.py` 模块。在 shell 中,该命令如下所示:
```
$ go build main.go && PYTHONPATH=. ./main
hello, world!
```

### 可怕的全局解释器锁
为了嵌入 Python 必须引入 cgo ,这是一种权衡:构建速度会变慢,垃圾收集器不会帮助我们管理外部系统使用的内存,交叉编译也很难。对于一个特定的项目来说,这些问题是否是可以争论的,但我认为有一些不容商量的问题:Go 并发模型。如果我们不能从 goroutine 中运行 Python,那么使用 Go 就没有意义了。
在处理并发、Python 和 cgo 之前,我们还需要知道一些事情:它就是<ruby> 全局解释器锁 <rt> Global Interpreter Lock </rt></ruby>,即 GIL。GIL 是语言解释器(CPython 就是其中之一)中广泛采用的一种机制,可防止多个线程同时运行。这意味着 CPython 执行的任何 Python 程序都无法在同一进程中并行运行。并发仍然是可能的,锁是速度、安全性和实现简易性之间的一个很好的权衡,那么,当涉及到嵌入时,为什么这会造成问题呢?
当一个常规的、非嵌入式的 Python 程序启动时,不涉及 GIL 以避免锁定操作中的无用开销;在某些 Python 代码首次请求生成线程时 GIL 就启动了。对于每个线程,解释器创建一个数据结构来存储当前的相关状态信息并锁定 GIL。当线程完成时,状态被恢复,GIL 被解锁,准备被其他线程使用。
当我们从 Go 程序运行 Python 时,上述情况都不会自动发生。如果没有 GIL,我们的 Go 程序可以创建多个 Python 线程,这可能会导致竞争条件,从而导致致命的运行时错误,并且很可能出现分段错误导致整个 Go 应用程序崩溃。
解决方案是在我们从 Go 运行多线程代码时显式调用 GIL;代码并不复杂,因为 C API 提供了我们需要的所有工具。为了更好地暴露这个问题,我们需要写一些受 CPU 限制的 Python 代码。让我们将这些函数添加到前面示例中的 `foo.py` 模块中:
```
# foo.py
import sys
def print_odds(limit=10):
"""
Print odds numbers < limit
"""
for i in range(limit):
if i%2:
sys.stderr.write("{}\n".format(i))
def print_even(limit=10):
"""
Print even numbers < limit
"""
for i in range(limit):
if i%2 == 0:
sys.stderr.write("{}\n".format(i))
```
我们将尝试从 Go 并发打印奇数和偶数,使用两个不同的 goroutine(因此涉及线程):
```
package main
import (
"sync"
"github.com/sbinet/go-python"
)
func main() {
// The following will also create the GIL explicitly
// by calling PyEval_InitThreads(), without waiting
// for the interpreter to do that
python.Initialize()
var wg sync.WaitGroup
wg.Add(2)
fooModule := python.PyImport_ImportModule("foo")
odds := fooModule.GetAttrString("print_odds")
even := fooModule.GetAttrString("print_even")
// Initialize() has locked the the GIL but at this point we don't need it
// anymore. We save the current state and release the lock
// so that goroutines can acquire it
state := python.PyEval_SaveThread()
go func() {
_gstate := python.PyGILState_Ensure()
odds.Call(python.PyTuple_New(0), python.PyDict_New())
python.PyGILState_Release(_gstate)
wg.Done()
}()
go func() {
_gstate := python.PyGILState_Ensure()
even.Call(python.PyTuple_New(0), python.PyDict_New())
python.PyGILState_Release(_gstate)
wg.Done()
}()
wg.Wait()
// At this point we know we won't need Python anymore in this
// program, we can restore the state and lock the GIL to perform
// the final operations before exiting.
python.PyEval_RestoreThread(state)
python.Finalize()
}
```
在阅读示例时,你可能会注意到一个模式,该模式将成为我们运行嵌入式 Python 代码的习惯写法:
1. 保存状态并锁定 GIL。
2. 执行 Python。
3. 恢复状态并解锁 GIL。
代码应该很简单,但我们想指出一个微妙的细节:请注意,尽管借用了 GIL 执行,有时我们通过调用 `PyEval_SaveThread()` 和 `PyEval_RestoreThread()` 来操作 GIL,有时(查看 goroutines 里面)我们对 `PyGILState_Ensure()` 和 `PyGILState_Release()` 来做同样的事情。
我们说过当从 Python 操作多线程时,解释器负责创建存储当前状态所需的数据结构,但是当同样的事情发生在 C API 时,我们来负责处理。
当我们用 go-python 初始化解释器时,我们是在 Python 上下文中操作的。因此,当调用 `PyEval_InitThreads()` 时,它会初始化数据结构并锁定 GIL。我们可以使用 `PyEval_SaveThread()` 和 `PyEval_RestoreThread()` 对已经存在的状态进行操作。
在 goroutines 中,我们从 Go 上下文操作,我们需要显式创建状态并在完成后将其删除,这就是 `PyGILState_Ensure()` 和 `PyGILState_Release()` 为我们所做的。

### 释放 Gopher
在这一点上,我们知道如何处理在嵌入式解释器中执行 Python 的多线程 Go 代码,但在 GIL 之后,另一个挑战即将来临:Go 调度程序。
当一个 goroutine 启动时,它被安排在可用的 `GOMAXPROCS` 线程之一上执行,[参见此处](https://morsmachine.dk/go-scheduler) 可了解有关该主题的更多详细信息。如果一个 goroutine 碰巧执行了系统调用或调用 C 代码,当前线程会将线程队列中等待运行的其他 goroutine 移交给另一个线程,以便它们有更好的机会运行; 当前 goroutine 被暂停,等待系统调用或 C 函数返回。当这种情况发生时,线程会尝试恢复暂停的 goroutine,但如果这不可能,它会要求 Go 运行时找到另一个线程来完成 goroutine 并进入睡眠状态。 goroutine 最后被安排给另一个线程,它就完成了。
考虑到这一点,让我们看看当一个 goroutine 被移动到一个新线程时,运行一些 Python 代码的 goroutine 会发生什么:
1. 我们的 goroutine 启动,执行 C 调用并暂停。GIL 被锁定。
2. 当 C 调用返回时,当前线程尝试恢复 goroutine,但失败了。
3. 当前线程告诉 Go 运行时寻找另一个线程来恢复我们的 goroutine。
4. Go 调度器找到一个可用线程并恢复 goroutine。
5. goroutine 快完成了,并在返回之前尝试解锁 GIL。
6. 当前状态中存储的线程 ID 来自原线程,与当前线程的 ID 不同。
7. 崩溃!
所幸,我们可以通过从 goroutine 中调用运行时包中的 `LockOSThread` 函数来强制 Go runtime 始终保持我们的 goroutine 在同一线程上运行:
```
go func() {
runtime.LockOSThread()
_gstate := python.PyGILState_Ensure()
odds.Call(python.PyTuple_New(0), python.PyDict_New())
python.PyGILState_Release(_gstate)
wg.Done()
}()
```
这会干扰调度器并可能引入一些开销,但这是我们愿意付出的代价。
### 结论
为了嵌入 Python,Datadog Agent 必须接受一些权衡:
* cgo 引入的开销。
* 手动处理 GIL 的任务。
* 在执行期间将 goroutine 绑定到同一线程的限制。
为了能方便在 Go 中运行 Python 检查,我们很乐意接受其中的每一项。但通过意识到这些权衡,我们能够最大限度地减少它们的影响,除了为支持 Python 而引入的其他限制,我们没有对策来控制潜在问题:
* 构建是自动化和可配置的,因此开发人员仍然需要拥有与 `go build` 非常相似的东西。
* Agent 的轻量级版本,可以使用 Go 构建标签,完全剥离 Python 支持。
* 这样的版本仅依赖于在 Agent 本身硬编码的核心检查(主要是系统和网络检查),但没有 cgo 并且可以交叉编译。
我们将在未来重新评估我们的选择,并决定是否仍然值得保留 cgo;我们甚至可以重新考虑整个 Python 是否仍然值得,等待 [Go 插件包](https://golang.org/pkg/plugin/) 成熟到足以支持我们的用例。但就目前而言,嵌入式 Python 运行良好,从旧代理过渡到新代理再简单不过了。
你是一个喜欢混合不同编程语言的多语言者吗?你喜欢了解语言的内部工作原理以提高你的代码性能吗?
---
via: <https://www.datadoghq.com/blog/engineering/cgo-and-python/>
作者:[Massimiliano Pippi](https://github.com/masci) 译者:[Zioyi](https://github.com/Zioyi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you look at the [new Datadog Agent](https://github.com/DataDog/datadog-agent/), you might notice most of the codebase is written in Go, although the checks we use to gather metrics are still written in Python. This is possible because the Datadog Agent, a regular Go binary, [embeds](https://docs.python.org/2/extending/embedding.html) a CPython interpreter that can be called whenever it needs to execute Python code. This process can be made transparent using an abstraction layer so that you can still write idiomatic Go code even when there’s Python running under the hood.
There are a number of reasons why you might want to embed Python in a Go application:
- It is useful during a port; gradually moving portions of an existing Python project to the new language without losing any functionality during the process.
- You can reuse existing Python software or libraries without re-implementing them in the new language.
- You can dynamically extend your software by loading and executing regular Python scripts, even at runtime.
The list could go on, but for the Datadog Agent the last point is crucial: we want you to be able to execute custom checks or change existing ones without forcing you to recompile the Agent, or in general, to compile anything.
Embedding CPython is quite easy and well documented. The interpreter itself is written in C and a C API is provided to programmatically perform operations at a very low level, like creating objects, importing modules, and calling functions.
In this article we’ll show some code examples, and we’ll focus on keeping the Go code idiomatic while interacting with Python at the same time, but before we proceed we need to address a small gap: the embedding API is C but our main application is Go, how can this possibly work?
[Introducing cgo](#introducing-cgo)
There are [a number of good reasons](https://dave.cheney.net/2016/01/18/cgo-is-not-go) why you might not want to introduce cgo in your stack, but embedding CPython is one of those cases where you must. [Cgo](https://golang.org/cmd/cgo/) is not a language nor a compiler. It’s a [Foreign Function Interface](https://en.wikipedia.org/wiki/Foreign_function_interface) (FFI), a mechanism we can use in Go to invoke functions and services written in a different language, specifically C.
When we say “cgo” we’re actually referring to a set of tools, libraries, functions, and types that are used by the go toolchain under the hood so we can keep doing `go build`
to get our Go binaries. An absolutely minimal example of a program using cgo looks like this:
```
package main
// #include <float.h>
import "C"
import "fmt"
func main() {
fmt.Println("Max float value of float is", C.FLT_MAX)
}
```
The comment block right above the `import "C"`
instruction is called a “preamble” and can contain actual C code, in this case an header inclusion. Once imported, the “C” pseudo-package lets us “jump” to the foreign code, accessing the `FLT_MAX`
constant. You can build the example by invoking `go build`
, the same as if it was plain Go.
If you want to have a look at all the work cgo does under the hood, run `go build -x`
. You’ll see the “cgo” tool will be invoked to generate some C and Go modules, then the C and Go compilers will be invoked to build the object modules and finally the linker will put everything together.
You can read more about cgo on the [Go blog](https://blog.golang.org/c-go-cgo). The article contains more examples and few useful links to get further into details.
Now that we have an idea of what cgo can do for us, let’s see how we can run some Python code using this mechanism.
[Embedding CPython: a primer](#embedding-cpython-a-primer)
A Go program that, technically speaking, embeds CPython is not as complicated as you might expect. In fact, at the bare minimum, all we have to do is initialize the interpreter before running any Python code and finalize it when we’re done. Please note that we’re going to use Python 2.x throughout all the examples but everything we’ll see can be applied to Python 3.x as well with very little adaptation. Let’s look at an example:
```
package main
// #cgo pkg-config: python-2.7
// #include <Python.h>
import "C"
import "fmt"
func main() {
C.Py_Initialize()
fmt.Println(C.GoString(C.Py_GetVersion()))
C.Py_Finalize()
}
```
The example above does exactly what the following Python code would do:
```
import sys
print(sys.version)
```
You can see we put a `#cgo`
directive in the preamble; those directives are passed to the toolchain to let you change the build workflow. In this case, we tell cgo to invoke “pkg-config” to gather the flags needed to build and link against a library called “python-2.7” and pass those flags to the C compiler. If you have the CPython development libraries installed in your system along with pkg-config, this would let you keep using a plain `go build`
to compile the example above.
Back to the code, we use `Py_Initialize()`
and `Py_Finalize()`
to set up and shut down the interpreter and the `Py_GetVersion`
C function to retrieve the string containing the version information for the embedded interpreter.
If you’re wondering, all the cgo bits we need to put together to invoke the C Python API are boilerplate code. This is why the Datadog Agent relies on [go-python](https://github.com/sbinet/go-python) for all the embedding operations; the library provides a Go friendly thin wrapper around the C API and hides the cgo details. This is another basic embedding example, this time using go-python:
```
package main
import (
python "github.com/sbinet/go-python"
)
func main() {
python.Initialize()
python.PyRun_SimpleString("print 'hello, world!'")
python.Finalize()
}
```
This looks closer to regular Go code, no more cgo exposed and we can use Go strings back and forth while accessing the Python API. Embedding looks powerful and developer friendly. Time to put the interpreter to good use: let’s try to load a Python module from disk.
We don’t need anything complex on the Python side, the ubiquitous “hello world” will serve the purpose:
```
# foo.py
def hello():
"""
Print hello world for fun and profit.
"""
print "hello, world!"
```
The Go code is slightly more complex but still readable:
```
// main.go
package main
import "github.com/sbinet/go-python"
func main() {
python.Initialize()
defer python.Finalize()
fooModule := python.PyImport_ImportModule("foo")
if fooModule == nil {
panic("Error importing module")
}
helloFunc := fooModule.GetAttrString("hello")
if helloFunc == nil {
panic("Error importing function")
}
// The Python function takes no params but when using the C api
// we're required to send (empty) *args and **kwargs anyways.
helloFunc.Call(python.PyTuple_New(0), python.PyDict_New())
}
```
Once built, we need to set the `PYTHONPATH`
environment variable to the current working dir so that the import statement will be able to find the `foo.py`
module. From a shell, the command would look like this:
```
$ go build main.go && PYTHONPATH=. ./main
hello, world!
```
[The dreadful Global Interpreter Lock](#the-dreadful-global-interpreter-lock)
Having to bring in cgo in order to embed Python is a tradeoff: builds will be slower, the Garbage Collector won’t help us managing memory used by the foreign system, and cross compilation will be non-trivial. Whether or not these are concerns for a specific project can be debated, but there’s something I deem not negotiable: the Go concurrency model. If we couldn’t run Python from a goroutine, using Go altogether would make very little sense.
Before playing with concurrency, Python, and cgo, there’s something we need to know: it’s the Global Interpreter Lock, also known as the GIL. The GIL is a mechanism widely adopted in language interpreters (CPython is one of those) preventing more than one thread from running at the same time. This means that no Python program executed by CPython will be ever able to run in parallel within the same process. Concurrency is still possible and in the end, the lock is a good tradeoff between speed, security, and implementation simplicity. So why should this pose a problem when it comes to embedding?
When a regular, non-embedded Python program starts, there’s no GIL involved to avoid useless overhead in locking operations; the GIL starts the first time some Python code requests to spawn a thread. For each thread, the interpreter creates a data structure to store information about the current state and locks the GIL. When the thread has finished, the state is restored and the GIL unlocked, ready to be used by other threads.
When we run Python from a Go program, none of the above happens automatically. Without the GIL, multiple Python threads could be created by our Go program. This could cause a race condition leading to fatal runtime errors, and most likely a segmentation fault bringing down the whole Go application.
The solution to this problem is to explicitly invoke the GIL whenever we run multithreaded code from Go; the code is not complex because the C API provides all the tools we need. To better expose the problem, we need to do something CPU bounded from Python. Let’s add these functions to our foo.py module from the previous example:
```
# foo.py
import sys
def print_odds(limit=10):
"""
Print odds numbers < limit
"""
for i in range(limit):
if i%2:
sys.stderr.write("{}\n".format(i))
def print_even(limit=10):
"""
Print even numbers < limit
"""
for i in range(limit):
if i%2 == 0:
sys.stderr.write("{}\n".format(i))
```
We’ll try to print odd and even numbers concurrently from Go, using two different goroutines (thus involving threads):
```
package main
import (
"sync"
"github.com/sbinet/go-python"
)
func main() {
// The following will also create the GIL explicitly
// by calling PyEval_InitThreads(), without waiting
// for the interpreter to do that
python.Initialize()
var wg sync.WaitGroup
wg.Add(2)
fooModule := python.PyImport_ImportModule("foo")
odds := fooModule.GetAttrString("print_odds")
even := fooModule.GetAttrString("print_even")
// Initialize() has locked the the GIL but at this point we don't need it
// anymore. We save the current state and release the lock
// so that goroutines can acquire it
state := python.PyEval_SaveThread()
go func() {
_gstate := python.PyGILState_Ensure()
odds.Call(python.PyTuple_New(0), python.PyDict_New())
python.PyGILState_Release(_gstate)
wg.Done()
}()
go func() {
_gstate := python.PyGILState_Ensure()
even.Call(python.PyTuple_New(0), python.PyDict_New())
python.PyGILState_Release(_gstate)
wg.Done()
}()
wg.Wait()
// At this point we know we won't need Python anymore in this
// program, we can restore the state and lock the GIL to perform
// the final operations before exiting.
python.PyEval_RestoreThread(state)
python.Finalize()
}
```
While reading the example you might note a pattern, the pattern that will become our mantra to run embedded Python code:
- Save the state and lock the GIL.
- Do Python.
- Restore the state and unlock the GIL.
The code should be straightforward but there’s a subtle detail we want to point out: notice that despite seconding the GIL mantra, in one case we operate the GIL by calling `PyEval_SaveThread()`
and `PyEval_RestoreThread()`
, in another (look inside the goroutines) we do the same with `PyGILState_Ensure()`
and `PyGILState_Release()`
.
We said when multithreading is operated from Python, the interpreter takes care of creating the data structure needed to store the current state, but when the same happens from the C API, we’re responsible for that.
When we initialize the interpreter with go-python, we’re operating in a Python context. So when `PyEval_InitThreads()`
is called it initializes the data structure and locks the GIL. We can use `PyEval_SaveThread()`
and `PyEval_RestoreThread()`
to operate on already existing state.
Inside the goroutines, we’re operating from a Go context and we need to explicitly create the state and remove it when done, which is what `PyGILState_Ensure()`
and `PyGILState_Release()`
do for us.
[Unleash the Gopher](#unleash-the-gopher)
At this point we know how to deal with multithreading Go code executing Python in an embedded interpreter but after the GIL, another challenge is right around the corner: the Go scheduler.
When a goroutine starts, it’s scheduled for execution on one of the `GOMAXPROCS`
threads available—[see here](https://morsmachine.dk/go-scheduler) for more details on the topic. If a goroutine happens to perform a syscall or call C code, the current thread hands over the other goroutines waiting to run in the thread queue to another thread so they can have better chances to run; the current goroutine is paused, waiting for the syscall or the C function to return. When this happens, the thread tries to resume the paused goroutine, but if this is not possible, it asks the Go runtime to find another thread to complete the goroutine and goes to sleep. The goroutine is finally scheduled to another thread and it finishes.
With this in mind, let’s see what can happen to a goroutine running some Python code when a goroutine is moved to a new thread::
- Our goroutine starts, performs a C call, and pauses. The GIL is locked.
- When the C call returns, the current thread tries to resume the goroutine, but it fails.
- The current thread tells the Go runtime to find another thread to resume our goroutine.
- The Go scheduler finds an available thread and the goroutine is resumed.
- The goroutine is almost done and tries to unlock the GIL before returning.
- The thread ID stored in the current state is from the original thread and is different from the ID of the current thread.
- Panic!
Luckily for us, we can force the Go runtime to always keep our goroutine running on the same thread by calling the LockOSThread function from the runtime package from within a goroutine:
```
go func() {
runtime.LockOSThread()
_gstate := python.PyGILState_Ensure()
odds.Call(python.PyTuple_New(0), python.PyDict_New())
python.PyGILState_Release(_gstate)
wg.Done()
}()
```
This will interfere with the scheduler and might introduce some overhead, but it’s a price that we’re willing to pay to avoid random panics.
[Conclusions](#conclusions)
In order to embed Python, the Datadog Agent has to accept a few tradeoffs:
- The overhead introduced by cgo.
- The task of manually handling the GIL.
- The limitation of binding goroutines to the same thread during execution.
We’re happy to accept each of these for the convenience of running Python checks in Go. But by being conscious of the tradeoffs, we’re able to minimize their effect. Regarding other limitations introduced to support Python, we have few countermeasures to contain potential issues:
- The build is automated and configurable so that devs have still something very similar to
`go build`
. - A lightweight version of the agent can be built stripping out Python support entirely simply using Go build tags.
- Such a version only relies on core checks hardcoded in the agent itself (system and network checks mostly) but is cgo free and can be cross compiled.
We’ll re-evaluate our options in the future and decide whether keeping around cgo is still worth it; we could even reconsider whether Python as a whole is still worth it, waiting for the [Go plugin package](https://golang.org/pkg/plugin/) to be mature enough to support our use case. But for now the embedded Python is working well and transitioning from the old Agent to the new one couldn’t be easier.
Are you a polyglot who loves mixing different programming languages? Do you love learning about the inner workings of languages to make your code more performant? [Join us at Datadog!](https://careers.datadoghq.com/) |
13,567 | 如何在 FreeDOS 上归档文件 | https://opensource.com/article/21/6/archive-files-freedos | 2021-07-10T06:34:00 | [
"FreeDOS",
"zip"
] | https://linux.cn/article-13567-1.html |
>
> 虽然有一个 FreeDOS 版的 tar,但 DOS 上事实上的标准归档工具是 Zip 和 Unzip。
>
>
>

在 Linux 上,你可能熟悉标准的 Unix 归档命令:`tar`。FreeDOS 上也有 `tar` 的版本(还有其他一些流行的归档程序),但 DOS 上事实上的标准归档程序是 Zip 和 Unzip。Zip 和 Unzip 都默认安装在 FreeDOS 1.3 RC4 中。
Zip 文件格式最初是由 PKWARE 的 Phil Katz 在 1989 年为 PKZIP 和 PKUNZIP 这对 DOS 归档工具构思的。Katz 将 Zip 文件的规范作为一个开放标准发布,因此任何人都可以创建 Zip 档案。作为开放规范的结果,Zip 成为 DOS 上的一个标准归档格式。[Info-ZIP](http://infozip.sourceforge.net/) 项目实现了一套开源的 `ZIP` 和 `UNZIP` 程序。
### 对文件和目录进行压缩
你可以在 DOS 命令行中使用 `ZIP` 来创建文件和目录的归档。这是一个方便的方法,可以为你的工作做一个备份,或者发布一个“包”,在未来的 FreeDOS 发布中使用。例如,假设我想为我的项目源码做一个备份,其中包含这些源文件:

*我想把这些文件归档*
`ZIP` 有大量的命令行选项来做不同的事情,但我最常使用的命令行选项是 `-r` 来处理目录和子目录 *递归*,以及使用 `-9` 来提供可能的最大压缩。`ZIP` 和 `UNZIP` 使用类似 Unix 的命令行,所以你可以在破折号后面组合选项:`-9r` 将提供最大压缩并在 Zip 文件中包括子目录。

*压缩一个目录树*
在我的例子中,`ZIP` 能够将我的源文件从大约 33KB 压缩到大约 22KB,为我节省了 11KB 的宝贵磁盘空间。你可能会得到不同的压缩率,这取决于你给 `ZIP` 的选项,或者你想在 Zip 文件中存储什么文件(以及有多少)。一般来说,非常长的文本文件(如源码)会产生良好的压缩效果,而非常小的文本文件(如只有几行的 DOS “批处理”文件)通常太短,无法很好地压缩。
### 解压文件和目录
将文件保存到 Zip 文件中是很好的,但你最终会需要将这些文件解压到某个地方。让我们首先检查一下我们刚刚创建的 Zip 文件里有什么。为此,使用 `UNZIP`命令。你可以在 `UNZIP`中使用一堆不同的选项,但我发现我只使用几个常用的选项。
要列出一个 Zip 文件的内容,使用 `-l` (“list”) 选项。

*用 unzip 列出归档文件的内容*
该输出允让我看到 Zip 文件中的 14 个条目:13 个文件加上 `SRC` 目录。
如果我想提取整个 Zip 文件,我可以直接使用 `UNZIP` 命令并提供 Zip 文件作为命令行选项。这样就可以从我当前的工作目录开始提取 Zip 文件了。除非我正在恢复某个东西的先前版本,否则我通常不想覆盖我当前的文件。在这种情况下,我希望将 Zip 文件解压到一个新的目录。你可以用 `-d` (“destination”) 命令行选项指定目标路径。

*你可以用 -d 来解压到目标路径*
有时我想从一个 Zip 文件中提取一个文件。在这个例子中,假设我想提取一个 DOS 可执行程序 `TEST.EXE`。要提取单个文件,你要指定你想提取的 Zip 文件的完整路径。默认情况下,`UNZIP` 将使用 Zip 文件中提供的路径解压该文件。要省略路径信息,你可以添加 `-j`(“junk the path”) 选项。
你也可以组合选项。让我们从 Zip 文件中提取 `SRC\TEST.EXE` 程序,但省略完整路径并将其保存在 `TEMP` 目录下:

*unzip 组合选项*
因为 Zip 文件是一个开放的标准,所以我们会今天继续看到 Zip 文件。每个 Linux 发行版都可以通过 Info-ZIP 程序支持 Zip 文件。你的 Linux 文件管理器可能也支持 Zip 文件。在 GNOME 文件管理器中,你应该可以右击一个文件夹并从下拉菜单中选择“压缩”。你可以选择创建一个包括 Zip 文件在内的新的归档文件。
创建和管理 Zip 文件是任何 DOS 用户的一项关键技能。你可以在 Info-ZIP 网站上了解更多关于 `ZIP` 和 `UNZIP` 的信息,或者在命令行上使用 `h`(“帮助”)选项来打印选项列表。
---
via: <https://opensource.com/article/21/6/archive-files-freedos>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | On Linux, you may be familiar with the standard Unix archive command: `tar`
. There's a version of `tar`
on FreeDOS too (and a bunch of other popular archive programs), but the de facto standard archiver on DOS is Zip and Unzip. Both Zip and Unzip are installed in FreeDOS 1.3 RC4 by default.
The Zip file format was originally conceived in 1989 by Phil Katz of PKWARE, for the PKZIP and PKUNZIP pair of DOS archive utilities. Katz released the specification for Zip files as an open standard, so anyone could create Zip archives. As a result of the open specification, Zip became a standard archive on DOS. The [Info-ZIP](http://infozip.sourceforge.net/) project implements an open source set of `ZIP`
and `UNZIP`
programs.
## Zipping files and directories
You can use `ZIP`
at the DOS command line to create archives of files and directories. This is a handy way to make a backup copy of your work or to release a "package" to use in a future FreeDOS distribution. For example, let's say I wanted to make a backup of my project source code, which contains these source files:
`ZIP`
sports a ton of command-line options to do different things, but the command line options I use most are `-r`
to process directories and subdirectories *recursively*, and `-9`
to provide the maximum compression possible. `ZIP`
and `UNZIP`
use a Unix-like command line, so you can combine options behind the dash: `-9r`
will give maximum compression and include subdirectories in the Zip file.
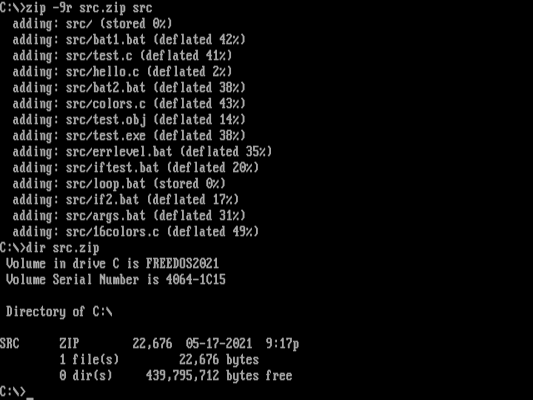
In my example, `ZIP`
was able to compress my source files from about 33 kilobytes down to about 22 kilobytes, saving me 11 kilobytes of valuable disk space. You might get different compression ratios depending on what options you give to `ZIP`
or what files (and how many) you are trying to store in a Zip file. Generally, very long text files (such as source code) yield good compression—very small text files (like DOS "batch" files of only a few lines) are usually too short to compress well.
## Unzipping files and directories
Saving files into a Zip file is great, but you'll eventually need to extract those files somewhere. Let's start by examining what's inside the Zip file we just created. For this, use the `UNZIP`
command. You can use a bunch of different options with `UNZIP`
, but I find I use just a few common options.
To list the contents of a Zip file, use the `-l`
("list") option:
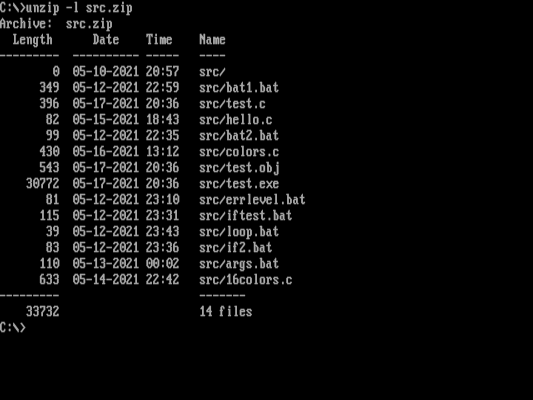
The output allows me to see the 14 entries in the Zip file: 13 files plus the `SRC`
directory entry.
If I want to extract the entire Zip file, I could just use the `UNZIP`
command and provide the Zip file as a command-line option. That extracts the Zip file starting at my current working directory. Unless I'm restoring a previous version of something, I usually don't want to overwrite my current files. In that case, I will want to extract the Zip file to a new directory. You can specify the destination path with the `-d`
("destination") command-line option:
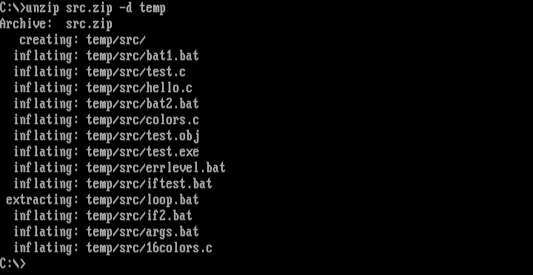
Sometimes I want to extract a single file from a Zip file. In this example, let's say I wanted to extract `TEST.EXE`
, a DOS executable program. To extract a single file, you specify the full path *from the Zip file* that you want to extract. By default, `UNZIP`
will extract this file using the path provided in the Zip file. To omit the path information, you can add the `-j`
("junk the path") option.
You can also combine options. Let's extract the `SRC\TEST.EXE`
program from the Zip file, but omit the full path and save it in the `TEMP`
directory:

Because Zip files are an open standard, we continue to see Zip files today. Every Linux distribution supports Zip files using the Info-ZIP programs. Your Linux file manager may also have Zip file support—on the GNOME file manager, you should be able to right-click on a folder and select "Compress" from the drop-down menu. You'll have the option to create a new archive file, including a Zip file.
Creating and managing Zip files is a key skill for any DOS user. You can learn more about `ZIP`
and `UNZIP`
at the Info-ZIP website, or use the `-h`
("help") option on the command line to print out a list of options.
## 1 Comment |
13,568 | 用开源移动应用 PlantNet 来识别花草和树木 | https://opensource.com/article/21/7/open-source-plantnet | 2021-07-10T06:54:37 | [
"识别",
"植物"
] | https://linux.cn/article-13568-1.html |
>
> PlantNet 将开源技术与众包知识结合起来,帮助你成为业余植物学家。
>
>
>

在我居住的地方很多小路和道路两旁都有花草树木。我所在的社区因其每年的枫树节而闻名,枫树对我来说很容易识别。然而,还有许多其他的树我无法识别名字。花也是如此:蒲公英很容易发现,但我不知道在我的步行道上的野花的名字。
最近,我的妻子告诉我了 PlantNet,一个可以识别这些花草和树木的移动应用。它可以在 iOS 和 Android 上使用,而且是免费的,所以我决定试试。
### 以开源的方式识别植物
我在手机上下载了这个应用程序,开始用它来识别我在村子周围散步时的一些花草和树木。随着我对这个应用的熟悉,我注意到我拍摄的图片(以及其他用户拍摄的图片)是以知识共享署名-相同方式共享(CC-BY-SA)的许可方式共享的。进一步的调查显示,PlantNet 是 [开源](https://github.com/plantnet) 的。如果你喜欢,你可以匿名使用该应用,或者成为社区的注册成员。
根据 [Cos4Cloud](https://cos4cloud-eosc.eu/citizen-science-innovation/cos4cloud-citizen-observatories/plntnet/) 公民科学项目,“PlantNet 是一个参与性的公民科学平台,用于收集、分享和审查基于自动识别的植物观察结果。它的目标是监测植物的生物多样性,促进公众对植物知识的获取”。它使用图像识别技术来清点生物多样性。
该项目的开发始于 2009 年,由法国的植物学家和计算机科学家进行。它最初是一个 [Web 应用](https://identify.plantnet.org/),而智能手机应用程序于 2013 年推出。该项目是 [Floris'Tic](http://floristic.org/) 倡议的一部分,这是法国的另一个项目,旨在促进植物科学的科学、技术和工业文化。
PlantNet 允许用户利用智能手机的摄像头来收集视觉标本,并由软件和社区进行识别。然后,这些照片将与全世界数百万加入 PlantNet 网络的人分享。
该项目说:“PlantNet 系统的工作原理是,比较用户通过他们寻求鉴定的植物器官(花、果实、叶……)的照片传送的视觉模式。这些图像被分析,并与每天协作制作和充实的图像库进行比较。然后,该系统提供一个可能的物种清单及其插图”。
### 使用 PlantNet
该应用很容易使用。从你的智能手机上的应用图标启动它。

当应用打开时,你会看到你已经在资料库中收集的标本。显示屏底部的相机图标允许你使用你的相机将图片添加到你的照片库。

选择“相机”选项,将手机的摄像头对准你想识别的树木或花草。拍完照后,点击与你想识别的标本相匹配的选项(叶、花、树皮、果实等)。

例如,如果你想通过叶子的特征来识别一个标本,请选择**叶子**。PlantNet 对其识别的确定程度进行了分配,从高到低的百分比不等。你还可以使用你的智能手机的 GPS 功能,将位置信息自动添加到你的数据收集中,你还可以添加注释。

你可以在你的智能手机上或通过你的用户 ID(如果你创建了一个账户)登录网站,访问你上传的所有观测数据,并跟踪社区是否批准了它们。从网站界面上,你也可以下载 CSV 或电子表格格式的观察记录。

### 很好的户外活动
我特别喜欢 PlantNet 与维基百科的链接,这样我就可以阅读更多关于我收集的植物数据的信息。
目前全球大约有 1200 万 PlantNet 用户,所以数据集一直在增长。该应用是免费使用的,每天最多可以有 500 个请求。它还有一个 API,以 JSON 格式提供数据,所以你甚至可以把 Pl antNet 的视觉识别引擎作为一个 Web 服务使用。
PlantNet 的一个非常好的地方是,它结合了众包知识和开源技术,将用户相互联系起来,并与很好的户外活动联系起来。没有比这更好的理由来支持开源软件了。
关于该应用及其开发者的完整描述可在 [YouTube](https://www.youtube.com/watch?v=W_cBqaPfRFE) 上找到(有法语、英文字幕)。你也可以在 [PlantNet](https://plantnet.org/) 的网站上了解更多该项目。
---
via: <https://opensource.com/article/21/7/open-source-plantnet>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Where I live, there are lots of trails and roads lined with flowers and trees. My community is famous for its annual maple festival, and maple trees are easy for me to identify. However, there are many other trees I cannot identify by name. Flowers are the same: dandelions are easy to spot, but I don't know the names of the wildflowers that line my walking path.
Recently my wife told me about PlantNet, a mobile application that can identify these flowers and trees. It's available on iOS and Android, and it's free, so I decided to try it out.
## Identifying plants the open source way
I downloaded the app on my phone and began using it to identify some of the flowers and trees on my walks around the village. As I became familiar with the app, I noticed that the pictures I took (and those taken by other users) are shared with a Creative Commons Attribution-ShareAlike (CC-BY-SA) license. Further investigation revealed that the back-end driving the app is [open source](https://github.com/plantnet). You can use the application anonymously if you like, or become a registered member of the community.
While the mobile apps themselves aren't open source, the data set and PlantNet are open source, with BSD, MIT, and GPL licensed code available on the project's [Github site](https://github.com/plantnet).
According to the [Cos4Cloud](https://cos4cloud-eosc.eu/citizen-science-innovation/cos4cloud-citizen-observatories/plntnet/) citizen science project, "PlantNet is a participatory citizen science platform for collecting, sharing, and reviewing plant observations based on automated identification. Its objective is to monitor plant biodiversity and facilitate access to plant knowledge by the general public." It uses image-recognition techniques to inventory biodiversity.
The project's development began in 2009 by botanists and computer scientists in France. It started out as a [web application](https://identify.plantnet.org/), and the smartphone app launched in 2013. The project is part of the [Floris'Tic](http://floristic.org/) initiative, another French project that aims to promote scientific, technical, and industrial culture in plant sciences.
PlantNet allows users to utilize a smartphone's camera to collect visual specimens, which are identified by software and the community. These photos are then shared with millions of people worldwide who are part of the PlantNet network.
The project says, "The PlantNet system works by comparing visual patterns transmitted by users via photos of plant organs (flowers, fruits, leaves …) that they seek to determine. These images are analyzed and compared to an image bank produced collaboratively and enriched daily. The system then offers a possible list of species with its illustrations."
## Using PlantNet
Using the website or the mobile application, you can add pictures to your photo library.
(Don Watkins, CC BY-SA 4.0)
Choose the Camera option, and point your phone's camera at a tree or flower you want to identify. After you take the picture, click on the option (leaf, flower, bark, fruit, and so on) that matches the specimen you want to identify.
(Don Watkins, CC BY-SA 4.0)
For example, if you're trying to identify a specimen by its leaf characteristics, choose **leaf**. PlantNet assigns a degree of certainty about its identification, ranging from a high to a low percentage. You can also use your smartphone's GPS function to add location information to your data collection automatically, and you can also add a note.
(Don Watkins, CC BY-SA 4.0)
You can access all the observations you have uploaded and keep track of whether the community has approved them either on your smartphone or by logging into the website with your user ID (if you create an account). From the web interface, you can also download a record of your observations in CSV or spreadsheet formats.
(Don Watkins, CC BY-SA 4.0)
## The great outdoors
I particularly enjoy that PlantNet links to Wikipedia so that I can read more information about the plant data I collect.
There are currently approximately 12 million PlantNet users worldwide, so the data set is growing all the time. The application is free to use for up to 500 requests per day. It also features an API that delivers data in JSON format, so you can even use Pl antNet's visual identification engine as a web service.
One very nice thing about PlantNet is that it combines crowdsourced knowledge and open source technology to connect users to each other and with the great outdoors. There's no better reason to support open source software than this.
A complete description of the application and its developers is available on [YouTube](https://www.youtube.com/watch?v=W_cBqaPfRFE) (in French with English subtitles). You can also learn more about the project on [PlantNet](https://plantnet.org/)'s website.
## 2 Comments |
13,570 | 在 Linux 上使用 Tealdeer 替代手册页 | https://opensource.com/article/21/6/tealdeer-linux | 2021-07-11T20:46:53 | [
"tldr",
"Tealder",
"rust"
] | https://linux.cn/article-13570-1.html |
>
> Tealder 是 Rust 版本的 tldr,对常用的命令提供了易于理解的说明信息。
>
>
>

手册页是我开始探索 Linux 时最常用的资源。当然,对于初学者熟悉命令行指令而言,`man` 是最频繁使用的指令。但是手册页中有大量的选项和参数列表,很难被解读,这使得你很难理解你想知道的东西。如果你想要一个更简单的解决方案,有基于例子的输出,我认为 [tldr](https://github.com/tldr-pages/tldr) (<ruby> 太长不读 <rt> too long dnot's read </rt></ruby>)是最好的选择。
### Tealdeer 是什么?
[Tealdeer](https://github.com/dbrgn/tealdeer) 是 tldr 的一个基于 Rust 的实现。它是一个社区驱动的手册页,给出了非常简单的命令工作原理的例子。Tealdeer 最棒的地方在于它几乎包含了所有你通常会用到的命令。
### 安装 Tealdeer
在 Linux 系统,你可以从软件仓库安装 Tealdeer,比如在 [Fedora](https://src.fedoraproject.org/rpms/rust-tealdeer) 上:
```
$ sudo dnf install tealdeer
```
在 macOS 可以使用 [MacPorts](https://opensource.com/article/20/11/macports) 或者 [Homebrew](https://opensource.com/article/20/6/homebrew-mac)。 同样,你可以使用 Rust 的 Cargo 包管理器来编译和安装此工具:
```
$ cargo install tealdeer
```
### 使用 Tealdeer
输入 `tldr-list` 返回 tldr 所支持的手册页,比如 `touch`、`tar`、`dnf`、`docker`、`zcat`、`zgrep` 等:
```
$ tldr --list
2to3
7z
7za
7zr
[
a2disconf
a2dismod
a2dissite
a2enconf
a2enmod
a2ensite
a2query
[...]
```
使用 `tldr` 跟上具体的命令(比如 `tar` )能够显示基于示例的手册页,描述了你可以用该命令做的所有选项。
```
$ tldr tar
Archiving utility.
Often combined with a compression method, such as gzip or bzip2.
More information: <https://www.gnu.org/software/tar>.
[c]reate an archive and write it to a [f]ile:
tar cf target.tar file1 file2 file3
[c]reate a g[z]ipped archive and write it to a [f]ile:
tar czf target.tar.gz file1 file2 file3
[c]reate a g[z]ipped archive from a directory using relative paths:
tar czf target.tar.gz --directory=path/to/directory .
E[x]tract a (compressed) archive [f]ile into the current directory [v]erbosely:
tar xvf source.tar[.gz|.bz2|.xz]
E[x]tract a (compressed) archive [f]ile into the target directory:
tar xf source.tar[.gz|.bz2|.xz] --directory=directory
[c]reate a compressed archive and write it to a [f]ile, using [a]rchive suffix to determine the compression program:
tar caf target.tar.xz file1 file2 file3
```
如需控制缓存:
```
$ tldr --update
$ tldr --clear-cache
```
你能够控制 Tealdeer 输出的颜色选项,有三种模式选择:一直、自动、从不。默认选项是自动,但我喜欢颜色提供的额外信息,所以我在我的 `~/.bashrc`文件中增加了这个别名:
```
alias tldr='tldr --color always'
```
### 结论
Tealdeer 的美妙之处在于不需要网络连接就可以使用,只有更新缓存的时候才需要联网。因此,即使你处于离线状态,依然能够查找和学习你新学到的命令。更多信息,请查看该工具的 [说明文档](https://dbrgn.github.io/tealdeer/intro.html)。
你会使用 Tealdeer 么?或者你已经在使用了?欢迎留言让我们知道。
---
via: <https://opensource.com/article/21/6/tealdeer-linux>
作者:[Sudeshna Sur](https://opensource.com/users/sudeshna-sur) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ddl-hust](https://github.com/ddl-hust) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Man pages were my go-to resource when I started exploring Linux. Certainly, `man`
is the most frequently used command when a beginner starts getting familiar with the world of the command line. But man pages, with their extensive lists of options and arguments, can be hard to decipher, which makes it difficult to understand whatever you wanted to know. If you want an easier solution with example-based output, I think [tldr](https://github.com/tldr-pages/tldr) is the best option.
## What's Tealdeer?
[Tealdeer](https://github.com/dbrgn/tealdeer) is a wonderful implementation of tldr in Rust. It's a community-driven man page that gives very simple examples of how commands work. The best part about Tealdeer is that it has virtually every command you would normally use.
## Install Tealdeer
On Linux, you can install Tealdeer from your software repository. For example, on [Fedora](https://src.fedoraproject.org/rpms/rust-tealdeer):
`$ sudo dnf install tealdeer`
On macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac).
Alternately, you can build and install the tool with Rust's Cargo package manager:
`$ cargo install tealdeer`
## Use Tealdeer
Entering `tldr --list`
returns the list of man pages tldr supports, like `touch`
, `tar`
, `dnf`
, `docker`
, `zcat`
, `zgrep`
, and so on:
```
$ tldr --list
2to3
7z
7za
7zr
[
a2disconf
a2dismod
a2dissite
a2enconf
a2enmod
a2ensite
a2query
[...]
```
Using `tldr`
with a specific command (like `tar`
) shows example-based man pages that describe all the options that you can do with that command:
```
$ tldr tar
Archiving utility.
Often combined with a compression method, such as gzip or bzip2.
More information: <https://www.gnu.org/software/tar>.
[c]reate an archive and write it to a [f]ile:
tar cf target.tar file1 file2 file3
[c]reate a g[z]ipped archive and write it to a [f]ile:
tar czf target.tar.gz file1 file2 file3
[c]reate a g[z]ipped archive from a directory using relative paths:
tar czf target.tar.gz --directory=path/to/directory .
E[x]tract a (compressed) archive [f]ile into the current directory [v]erbosely:
tar xvf source.tar[.gz|.bz2|.xz]
E[x]tract a (compressed) archive [f]ile into the target directory:
tar xf source.tar[.gz|.bz2|.xz] --directory=directory
[c]reate a compressed archive and write it to a [f]ile, using [a]rchive suffix to determine the compression program:
tar caf target.tar.xz file1 file2 file3
```
To control the cache:
```
$ tldr --update
$ tldr --clear-cache
```
You can give Tealdeer output some color with the `--color`
option, setting it to `always`
, `auto`
, and `never`
. The default is `auto`
, but I like the added context color provides, so I make mine permanent with this addition to my `~/.bashrc`
file:
`alias tldr='tldr --color always'`
## Conclusion
The beauty of Tealdeer is you don't need a network connection to use it, except when you're updating the cache. So, even if you are offline, you can still search for and learn about your new favorite command. For more information, consult the tool's [documentation](https://dbrgn.github.io/tealdeer/intro.html).
Would you use Tealdeer? Or are you already using it? Let us know what you think in the comments below.
## 1 Comment |
13,572 | 如何在 Ubuntu Linux 上安装 Zlib | https://itsfoss.com/install-zlib-ubuntu/ | 2021-07-12T09:55:57 | [
"zlib"
] | https://linux.cn/article-13572-1.html | 
[Zlib](https://zlib.net/) 是一个用于数据压缩的开源库。
作为使用者,你可能会遇到需要安装 zlib(或 zlib-devel 包)作为另一个应用程序的依赖项的情况。
但问题来了,如果你尝试在 Ubuntu 上安装 zlib,它会抛出 “unable to locate package zlib” 错误。
```
sudo apt install zlib
Reading package lists... Done
Building dependency tree
Reading state information... Done
E: Unable to locate package zlib
```
为什么会看到这个 [Ubable to locate package 错误](https://itsfoss.com/unable-to-locate-package-error-ubuntu/)呢?因为没有名为 zlib 的包。
如果你 [使用 apt search 命令](https://itsfoss.com/apt-search-command/),你会发现有几个包可以让你安装:zlib 1g 和 zlib 1g-dev。当你知道这些后,只需一个 `apt` 命令就可以安装它们。
### 在基于 Ubuntu 的 Linux 发行版上安装 Zlib
打开终端,使用以下命令:
```
sudo apt install zlib1g
```
请记住 `g` 前面的字母是数字 `1`,而不是小写的字母 `L`。很多人在输入命令时都会犯这个错误。
另一个包,zlib 1g-dev 是开发包。只有在你需要时才安装它,否则你应该使用 zlib 1g 包。
```
sudo apt install zlib1g-dev
```
你也可以 [Zlib 网站](https://zlib.net/) 下载源代码并安装它。但是,除非你有充分的理由,否则我不推荐使用源代码方式来安装 zlib。例如,如果你需要最新或特定版本的 zlib,但该版本在发行版的仓库中不可用。
有趣的是,像安装 zlib 这样看似很小的东西可能会变得很麻烦,有两个原因:一个是不同的包名;另一个是包含“隐藏”数字 1,它与小写 L 混淆了。
我希望这个快速提示能帮助到你。随意在评论部分留下你的问题、建议或简单的一句 “thank you”。
---
via: <https://itsfoss.com/install-zlib-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Zlib](https://zlib.net/) is an open source library for used for data compression.
As an end user, you are likely to encounter the need of installing Zlib (or zlib devel package) as a dependency of another application.
But here comes the problem. If you try installing Zlib on Ubuntu, it will throw “unable to locate package zlib” error.
```
sudo apt install zlib
Reading package lists... Done
Building dependency tree
Reading state information... Done
E: Unable to locate package zlib
```
Why do you see this [unable to locate package error](https://itsfoss.com/unable-to-locate-package-error-ubuntu/)? Because there is no package named zlib.
If you [use the apt search command](https://itsfoss.com/apt-search-command/), you’ll find that the there are a couple of packages that let you install zlib: **zlib1g and zlib1g-dev**. When you have that information, installing them is just one apt command away.
## Install Zlib on Ubuntu-based Linux distributions
Open a terminal and use the following command:
`sudo apt install zlib1g`
*Please keep in mind that the the letter before g is 1 (one), not lowercase L. Many people make this mistake while typing the command.*
The other package, zlib1g-dev is development package. Only install it if you require it otherwise you should be good with the main runtime zlib1g package.
`sudo apt install zlib1g-dev`
You may also download the source code of Zlib [from its website](https://zlib.net/) and install it. However, I won’t recommend going the source code way just for installing zlib unless you have a good reason to do so. For example, if you need the latest or a specific version of zlib which is not available in the distribution’s repository.
It is interesting how seemingly small stuff like installing zlib could become a pain for two reasons: a different package name and the package name containing a “hidden” numeral one (1) which is confused with a lowercase L.
I hope this quick tip helps you. Feel free to drop your questions, suggestions or a simple “thank you” in the comment section. |
13,573 | 在 Linux 命令行中收发 Gmail 邮件 | https://opensource.com/article/21/7/gmail-linux-terminal | 2021-07-12T10:50:01 | [
"Mutt",
"Gmail",
"邮件"
] | https://linux.cn/article-13573-1.html |
>
> 即使你用的是诸如 Gmail 的托管邮件服务,你也可以通过 Mutt 在终端里收发电子邮件。
>
>
>

我喜欢在 Linux 终端上读写电子邮件的便捷,因此我是 [Mutt](http://www.mutt.org/) 这个轻量简洁的电子邮件客户端的忠实用户。对于电子邮件服务来说,不同的系统配置和网络接入并不会造成什么影响。这个客户端通常隐藏在我 Linux 终端的 [某个标签页或者某个终端复用器的面板](https://opensource.com/article/21/5/linux-terminal-multiplexer) 上,需要用的时候随时可以调出来,不需要使用的时候放到后台,就不需要在桌面上一直放置一个电子邮件客户端的应用程序。
当今我们大多数人使用的都是托管电子邮件账号,在这种使用场景中并不会与电子邮件协议发生过多的直接交互。而 Mutt(以及更早的 ELM)是在更简单的时代创建的,那时候检查邮件只是对 `uucp` 的调用,以及对 `/var/mail` 的读取。当然 Mutt 也很与时俱进,随着各种流行的协议(如 POP、IMAP、LDAP)出现,它都实现了良好的支持。因此,即使我们使用的是 Gmail 这种邮件服务,也可以与 Mutt 无缝衔接。
如今在大多数情况下,用户都不会拥有自己的电子邮件服务器,大部分用户都会选择 Gmail,因此下文会以 Mutt + Gmail 为例作介绍。如果你比较注重电子邮件隐私,不妨考虑 [ProtonMail](https://protonmail.com) 或者 [Tutanota](https://tutanota.com),它们都提供完全加密的电子邮件服务。其中 Tutanota 包含很多 [开源组件](https://github.com/tutao/tutanota),而 ProtonMail 则为付费用户提供 [IMAP 桥接](https://protonmail.com/bridge/),简化了在非浏览器环境下的邮件访问。不过,很多公司、学校和组织都没有自己的电子邮件服务,而是使用 Gmail 提供的邮件服务,这样一来,大部分用户都会有一个 Gmail 邮箱。
当然,如果你自己就 [拥有电子邮件服务器](https://www.redhat.com/sysadmin/configuring-email-server),那么使用 Mutt 就更简单了。下面我们开始介绍。
### 安装 Mutt
在 Linux 系统上,一般可以直接从发行版提供的软件库中安装 Mutt,另外需要在家目录中创建一个 `.mutt` 目录以存放配置文件:
```
$ sudo dnf install mutt
$ mkdir ~/.mutt
```
在 MacOS 上,可以通过 [MacPorts](https://opensource.com/article/20/11/macports) 或者 [Homebrew](https://opensource.com/article/20/6/homebrew-mac) 安装;在 Windows 上则可以使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey) 安装。
Mutt 是一个<ruby> 邮件用户代理 <rt> Mail User Agent </rt></ruby>(MUA),因此它的作用是读取、编写以及向外部邮件池发送邮件。向邮件服务器实际传输邮件是其它应用或邮件服务的工作,尽管它们可以和 Mutt 进行协作,让我们看起来是 Mutt 完成了所有功能,但实际上并非如此。在弄懂了两者之间的区别之后,我们会对 Mutt 的配置更加清楚。
这也是为什么除了 Mutt 之外,我们还需要视乎进行通信的服务种类选择一些辅助应用程序。在本文中我使用的是 IMAP 服务,这可以让我本地的电子邮件副本与电子邮件服务提供商的远程邮件副本保持同步。如果你选择 POP 服务,配置的难度就更下一个台阶了,也无需依赖其它外部工具。我们需要 OfflineIMAP 这个 Python 应用程序来实现 IMAP 的集成,这个应用程序可以在 [它的 GitHub 存储库](https://github.com/OfflineIMAP/offlineimap3) 获取。
OfflineIMAP 目前仍然在从 Python 2 移植到 Python 3,目前需要手动安装,但以后你也可以通过 `python3 -m pip` 命令进行安装。
OfflineIMAP 依赖于 `imaplib2` 库,这个库也在努力开发当中,所以我更喜欢手动安装。同样地,也是通过 Git 将代码库克隆到本地,进入目录后使用 `pip` 安装。
首先安装 `rfc6555` 依赖:
```
$ python3 -m pip install --user rfc6555
```
然后从源码安装 `imaplib2`:
```
$ git clone [email protected]:jazzband/imaplib2.git
$ pushd imaplib2.git
$ python3 -m pip install --upgrade --user .
$ popd
```
最后从源码安装 OfflineIMAP:
```
$ git clone [email protected]:OfflineIMAP/offlineimap3.git
$ pushd offlineimap3.git
$ python3 -m pip install --upgrade --user .
$ popd
```
如果你使用的是 Windows 上的 Cygwin,那么你还需要安装 [Portlocker](https://pypi.org/project/portalocker)。
### 配置 OfflineIMAP
OfflineIMAP 默认使用 `~/.offlineimaprc` 这个配置文件,在它的代码库中会有一个名为 `offlineimap.conf` 的配置模板,可以直接将其移动到家目录下:
```
$ mv offlineimap3.git/offlineimap.conf ~/.offlineimaprc`
```
你可以使用任何文本编辑器打开浏览这个配置文件,它的注释很完善,便于了解各个可用的配置项。
以下是我的 `.offlineimaprc` 配置文件,为了清晰起见,我把其中的注释去掉了。对于你来说其中有些配置项的值可能会略有不同,但或许会为你的配置带来一些启发:
```
[general]
ui = ttyui
accounts = %your-gmail-username%
pythonfile = ~/.mutt/password_prompt.py
fsync = False
[Account %your-gmail-username%]
localrepository = %your-gmail-username%-Local
remoterepository = %your-gmail-username%-Remote
status_backend = sqlite
postsynchook = notmuch new
[Repository %your-gmail-username%-Local]
type = Maildir
localfolders = ~/.mail/%your-gmail-username%-gmail.com
nametrans = lambda folder: {'drafts': '[Gmail]/Drafts',
'sent': '[Gmail]/Sent Mail',
'flagged': '[Gmail]/Starred',
'trash': '[Gmail]/Trash',
'archive': '[Gmail]/All Mail',
}.get(folder, folder)
[Repository %your-gmail-username%-Remote]
maxconnections = 1
type = Gmail
remoteuser = %your-gmail-username%@gmail.com
remotepasseval = '%your-gmail-API-password%'
## remotepasseval = get_api_pass()
sslcacertfile = /etc/ssl/certs/ca-bundle.crt
realdelete = no
nametrans = lambda folder: {'[Gmail]/Drafts': 'drafts',
'[Gmail]/Sent Mail': 'sent',
'[Gmail]/Starred': 'flagged',
'[Gmail]/Trash': 'trash',
'[Gmail]/All Mail': 'archive',
}.get(folder, folder)
folderfilter = lambda folder: folder not in ['[Gmail]/Trash',
'[Gmail]/Important',
'[Gmail]/Spam',
]
```
配置文件里有两个可以替换的值,分别是 `%your-gmail-username%` 和 `%your-gmail-API-password%`。其中第一个值需要替换为 Gmail 用户名,也就是邮件地址中 `@gmail.com` 左边的部分。而第二个值则需要通过双因素身份验证(2FA)后从 Google 获取(即使你在查收邮件时不需要使用 2FA)。
### 为 Gmail 设置双因素身份验证(2FA)
Google 希望用户通过 Gmail 网站收发电子邮件,因此当你在 Gmail 网站以外操作电子邮件时,实际上是被 Google 作为“开发者”看待(尽管你没有进行任何开发工作)。也就是说,Google 会认为你正在创建一个应用程序。要获得开发者层面的应用程序密码,就必须设置双因素身份验证。完成了这个过程以后,就可以获得一个应用程序密码,Mutt 可以通过这个密码在浏览器以外的环境登录到你的电子邮箱中。
为了安全起见,你还可以在 Google 的 [账号安全](https://myaccount.google.com/security) 页面中添加一个用于找回的电子邮件地址。
在账号安全页面中,点击“<ruby> 两步验证 <rt> 2-step Verification </rt></ruby>”开始设置 2FA,设置过程中需要用到一部手机。
激活 2FA 之后,账号安全页面中会出现“<ruby> 应用程序密码 <rt> App Passwords </rt></ruby>”选项,点击就可以为 Mutt 创建一个新的应用程序密码。在 Google 生成密码之后,将其替换 `.offlineimaprc` 配置文件中的 `%your-gmail-API-password%` 值。
直接将应用程序密码记录在 `.offlineimaprc` 文件中,这种以纯文本形式存储的做法有一定的风险。长期以来我都是这样做的,而且感觉良好,因为我的家目录是加密的。但出于安全考虑,我现在已经改为使用 GnuPG 加密应用程序密码,这部分内容不在本文的讨论范围,关于如何设置 GPG 密码集成,可以参考我的 [另一篇文章](https://opensource.com/article/21/6/enter-invisible-passwords-using-python-module)。
### 在 Gmail 启用 IMAP
在你永远告别 Gmail 网页界面之前,还有最后一件事:你必须启用 Gmail 账户的 IMAP 访问。
在 Gmail 网站页面中,点击右上角的“cog”图标,选择“<ruby> 查看所有设置 <rt> See all settings </rt></ruby>”。在 Gmail 设置页面中,点击“POP/IMAP”标签页,并选中“<ruby> 启用 IMAP <rt> enable IMAP </rt></ruby>”,然后保存设置。
现在就可以在浏览器以外访问你的 Gmail 电子邮件了。
### 配置 Mutt
Mutt 的配置过程相对简单。和 [.bashrc](https://opensource.com/article/18/9/handy-bash-aliases)、[.zshrc](https://opensource.com/article/19/9/adding-plugins-zsh)、`.emacs` 这些配置文件一样,网络上有很多优秀的 .muttrc 配置文件可供参照。我自己的 `.muttrc` 配置文件则借鉴了 [Kyle Rankin](https://twitter.com/kylerankin)、[Paul Frields](https://twitter.com/stickster) 等人的配置项和想法。下面列出我的配置文件的一些要点:
```
set ssl_starttls=yes
set ssl_force_tls=yes
set from='[email protected]'
set realname='Tux Example'
set folder = imaps://imap.gmail.com/
set spoolfile = imaps://imap.gmail.com/INBOX
set postponed="imaps://imap.gmail.com/[Gmail]/Drafts"
set smtp_url="smtp://smtp.gmail.com:25"
set move = no
set imap_keepalive = 900
set record="imaps://imap.gmail.com/[Gmail]/Sent Mail"
# Paths
set folder = ~/.mail
set alias_file = ~/.mutt/alias
set header_cache = "~/.mutt/cache/headers"
set message_cachedir = "~/.mutt/cache/bodies"
set certificate_file = ~/.mutt/certificates
set mailcap_path = ~/.mutt/mailcap
set tmpdir = ~/.mutt/temp
set signature = ~/.mutt/sig
set sig_on_top = yes
# Basic Options
set wait_key = no
set mbox_type = Maildir
unset move # gmail does that
# Sidebar Patch
set sidebar_visible = yes
set sidebar_width = 16
color sidebar_new color221 color233
## Account Settings
# Default inbox
set spoolfile = "+example.com/INBOX"
# Mailboxes to show in the sidebar.
mailboxes +INBOX \
+sent \
+drafts
# Other special folder
set postponed = "+example.com/drafts"
# navigation
macro index gi "<change-folder>=example.com/INBOX<enter>" "Go to inbox"
macro index gt "<change-folder>=example.com/sent" "View sent"
```
整个配置文件基本是开箱即用的,只需要将其中的 `Tux Example`和 `example.com` 替换为你的实际值,并将其保存为 `~/.mutt/muttrc` 就可以使用了。
### 启动 Mutt
在启动 Mutt 之前,需要先启动 `offlineimap` 将远程邮件服务器上的邮件同步到本地。在首次启动的时候耗时可能会比较长,只需要让它整晚运行直到同步完成就可以了。
在同步完成后,启动 Mutt:
```
$ mutt
```
Mutt 会提示你打开用于管理电子邮件的目录权限,并展示收件箱的视图。

### 学习使用 Mutt
在学习使用 Mutt 的过程中,你可以找到最符合你使用习惯的 `.muttrc` 配置。例如我的 `.muttrc` 配置文件集成了使用 Emacs 编写邮件、使用 LDAP 搜索联系人、使用 GnuPG 对邮件进行加解密、链接获取、HTML 视图等等一系列功能。你可以让 Mutt 做到任何你想让它做到的事情,你越探索,就能发现越多。
---
via: <https://opensource.com/article/21/7/gmail-linux-terminal>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HankChow](https://github.com/HankChow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I'm a [Mutt](http://www.mutt.org/) user. I like viewing and composing emails in the convenience of my Linux terminal. With a lightweight and minimal client like Mutt, I know that I can have my email available regardless of system specifications or internet access. And because I have a Linux terminal open more often than not, my email client essentially has no footprint on my desktop real estate. It's hidden away in a [terminal tab or multiplexer pane](https://opensource.com/article/21/5/linux-terminal-multiplexer), so I can ignore it when I don't need it but get to it quickly when I do need it.
A commonly perceived problem with Mutt is that most of us use hosted email accounts these days and interact with actual email protocols only superficially. Mutt (and ELM before it) was created back in simpler times, when checking email was a call to `uucp`
and a glance at `/var/mail`
. However, it's adapted nicely to developing technology and works well with all sorts of modern protocols like POP, IMAP, and even LDAP, so you can use Mutt even if you're using Gmail as your email host.
Because it's relatively rare to run your own email server today, and because Gmail is very common, this tutorial assumes you're using Mutt with Gmail. If you're concerned about email privacy, consider opening an account with [ProtonMail](https://protonmail.com) or [Tutanota](https://tutanota.com), both of which provide fully encrypted email. Tutanota has many [open source components](https://github.com/tutao/tutanota), and ProtonMail provides an [IMAP bridge](https://protonmail.com/bridge/) for paid users so that you don't have to work around accessing your email outside a browser. However, many companies, schools, and organizations don't run their own email services and just use Gmail, so you may have a Gmail account whether you want one or not.
If you are [running your own email server](https://www.redhat.com/sysadmin/configuring-email-server), setting up Mutt is even easier than what I demonstrate in this article, so just dive right in.
## Install Mutt
On Linux, you can install Mutt from your distribution's software repository and then create a `.mutt`
directory to hold its configuration files:
```
$ sudo dnf install mutt
$ mkdir ~/.mutt
```
On macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac). On Windows, use [Chocolatey](https://opensource.com/article/20/3/chocolatey).
Mutt is a mail user agent (MUA), meaning its job is to read, compose, and send email to an outbound mail spool. It's the job of some other application or service to actually transfer a message to or from a mail server (although there's a lot of integration with Mutt so that it seems like it's doing all the work even when it's not.) Understanding this separation of tasks can help configuration make a little more sense.
It also explains why you must have helper applications (in addition to Mutt) depending on what service you need to communicate with. For this article, I use IMAP so that my local copy of email and my email provider's remote copy of mail remain synchronized. Should you decide to use POP instead, that configuration is even easier to configure and can be done without any external tools. IMAP integration, however, requires OfflineIMAP, a Python application available from [its GitHub repository](https://github.com/OfflineIMAP/offlineimap3).
Eventually, you'll be able to install it with the `python3 -m pip`
command, but as of this writing, you must install OfflineIMAP manually because it's still being ported from Python 2 to Python 3.
OfflineIMAP requires `imaplib2`
, which is also in heavy development, so I prefer doing a manual install of that, as well. The process is the same: clone the source code repository with Git, change into the directory, and install with `pip`
.
First, install the `rfc6555`
dependency:
`$ python3 -m pip install --user rfc6555`
Next, install `imaplib2`
from source:
```
$ git clone [email protected]:jazzband/imaplib2.git
$ pushd imaplib2.git
$ python3 -m pip install --upgrade --user .
$ popd
```
Finally, install OfflineIMAP from source:
```
$ git clone [email protected]:OfflineIMAP/offlineimap3.git
$ pushd offlineimap3.git
$ python3 -m pip install --upgrade --user .
$ popd
```
If you're using Cygwin on Windows, then you must also install [Portalocker](https://pypi.org/project/portalocker).
## Configure OfflineIMAP
OfflineIMAP reads the configuration file `~/.offlineimaprc`
by default. A template for this file, named `offlineimap.conf`
, is included in the Git repository you cloned to install OfflineIMAP. Move the example file to your home directory:
`$ mv offlineimap3.git/offlineimap.conf ~/.offlineimaprc`
Open the file in your favorite text editor and read through it. It's a well-commented file, and it's good to get familiar with the options available.
Here's my `.offlineimaprc`
as an example, with comments removed for brevity. Some values may be slightly different for you, but this gives you a reasonable idea of what your end product ought to look like:
```
[general]
ui = ttyui
accounts = %your-gmail-username%
pythonfile = ~/.mutt/password_prompt.py
fsync = False
[Account %your-gmail-username%]
localrepository = %your-gmail-username%-Local
remoterepository = %your-gmail-username%-Remote
status_backend = sqlite
postsynchook = notmuch new
[Repository %your-gmail-username%-Local]
type = Maildir
localfolders = ~/.mail/%your-gmail-username%-gmail.com
nametrans = lambda folder: {'drafts': '[Gmail]/Drafts',
'sent': '[Gmail]/Sent Mail',
'flagged': '[Gmail]/Starred',
'trash': '[Gmail]/Trash',
'archive': '[Gmail]/All Mail',
}.get(folder, folder)
[Repository %your-gmail-username%-Remote]
maxconnections = 1
type = Gmail
remoteuser = %your-gmail-username%@gmail.com
remotepasseval = '%your-gmail-API-password%'
## remotepasseval = get_api_pass()
sslcacertfile = /etc/ssl/certs/ca-bundle.crt
realdelete = no
nametrans = lambda folder: {'[Gmail]/Drafts': 'drafts',
'[Gmail]/Sent Mail': 'sent',
'[Gmail]/Starred': 'flagged',
'[Gmail]/Trash': 'trash',
'[Gmail]/All Mail': 'archive',
}.get(folder, folder)
folderfilter = lambda folder: folder not in ['[Gmail]/Trash',
'[Gmail]/Important',
'[Gmail]/Spam',
]
```
There are two replaceable values in this file: `%your-gmail-username%`
and `%your-gmail-API-password%`
. Replace the first with your Gmail user name. That's the part of your email address on the left of the `@gmail.com`
part. You must acquire the second value from Google through a two-factor authentication (2FA) setup process (even though you don't need to use 2FA to check email).
## Set up 2FA for Gmail
Google expects its users to use the Gmail website for email, so when you attempt to access your email outside of Gmail's interface, you're essentially doing so as a developer (even if you don't consider yourself a developer). In other words, you're creating what Google considers an "app." To obtain a developer-level *app password*, you must set up 2FA; through that process, you get an app password, which Mutt can use to log in outside the usual browser interface.
For safety, you can also add a recovery email address. To do that, go to Google's [Account Security page](https://myaccount.google.com/security) and scroll down to **Recovery email**.
To set up 2FA, go back to the Account Security page, and click on **2-step Verification** to activate and configure it. This requires a mobile phone for setup.
After activating 2FA, you get a new Google Account Security option: **App passwords**. Click on it to create a new app password for Mutt. Google generates the password for you, so copy it and paste it into your `.offlineimaprc`
file in the place of the `%your-gmail-API-password%`
value.
Placing your API password in your `.offlineimaprc`
file stores it in plain text, which can be dangerous. For a long while, I did this and felt fine about it because my home directory is encrypted. However, in the interest of better security, I now encrypt my API password with GnuPG. That's somewhat beyond the scope of this article, but I've written an article demonstrating how to [set up GPG password integration](https://opensource.com/article/21/6/enter-invisible-passwords-using-python-module).
## Enable IMAP in Gmail
There's one last thing before you can say goodbye to the Gmail web interface forever: You must enable IMAP access to your Gmail account.
To do this, go to the Gmail web interface, click the "cog" icon in the upper-right corner, and select **See all settings**. In Gmail **Settings**, click the **POP/IMAP** tab, and enable the radio button next to **Enable IMAP**. Save your settings.
Now Gmail is configured to give you access to your email outside a web browser.
## Configure Mutt
Now that you're all set up for Mutt, you'll be happy to learn that configuring Mutt is the easy part. As with [.bashrc](https://opensource.com/article/18/9/handy-bash-aliases), [.zshrc](https://opensource.com/article/19/9/adding-plugins-zsh), and .emacs files, there are many examples of very good .muttrc files available on the internet. For my configuration file, I borrowed options and ideas from [Kyle Rankin](https://twitter.com/kylerankin), [Paul Frields](https://twitter.com/stickster), and many others, so I've abbreviated my .muttrc file to just the essentials in the interest of simplicity:
```
set ssl_starttls=yes
set ssl_force_tls=yes
set from='[email protected]'
set realname='Tux Example'
set folder = imaps://imap.gmail.com/
set spoolfile = imaps://imap.gmail.com/INBOX
set postponed="imaps://imap.gmail.com/[Gmail]/Drafts"
set smtp_url="smtp://smtp.gmail.com:25"
set move = no
set imap_keepalive = 900
set record="imaps://imap.gmail.com/[Gmail]/Sent Mail"
# Paths
set folder = ~/.mail
set alias_file = ~/.mutt/alias
set header_cache = "~/.mutt/cache/headers"
set message_cachedir = "~/.mutt/cache/bodies"
set certificate_file = ~/.mutt/certificates
set mailcap_path = ~/.mutt/mailcap
set tmpdir = ~/.mutt/temp
set signature = ~/.mutt/sig
set sig_on_top = yes
# Basic Options
set wait_key = no
set mbox_type = Maildir
unset move # gmail does that
# Sidebar Patch
set sidebar_visible = yes
set sidebar_width = 16
color sidebar_new color221 color233
## Account Settings
# Default inbox
set spoolfile = "+example.com/INBOX"
# Mailboxes to show in the sidebar.
mailboxes +INBOX \
+sent \
+drafts
# Other special folder
set postponed = "+example.com/drafts"
# navigation
macro index gi "<change-folder>=example.com/INBOX<enter>" "Go to inbox"
macro index gt "<change-folder>=example.com/sent" "View sent"
```
Nothing in this file requires changing, but consider replacing the fake name `Tux Example`
and the fake address `example.com`
with something that applies to you. Copy and paste this text into a file and save it as `~/.mutt/muttrc`
.
## Launch Mutt
Before launching Mutt, run `offlineimap`
from a terminal to sync your computer with the remote server. The first run of this takes *a long time*, so leave it running overnight.
Once your account has synchronized, you can launch Mutt:
`$ mutt`
Mutt prompts you for permission to create the directories it needs to organize your email activity and then displays a view of your inbox.
## Learn Mutt
Learning Mutt is a mixture of exploring the application and finding your favorite hacks for your .muttrc config. For example, my config file integrates Emacs for composing messages, LDAP so that I can search through contacts, GnuPG so that I can encrypt and decrypt messages, link harvesting, HTML views, and much more. You can make Mutt anything you want it to be (as long as you want it to be an email client), and the more you experiment, the more you discover.
## Comments are closed. |
13,575 | 让你的大脑在这个夏天保持忙碌的 7 本开源指南 | https://opensource.com/article/21/7/open-source-guides | 2021-07-12T23:00:05 | [
"开源",
"电子书"
] | https://linux.cn/article-13575-1.html |
>
> 下载我们的免费指南之一:开发一个基于 Python 的电子游戏;使用开源工具来让你的生活井井有条;完成家庭自动化项目;或尝试你的树莓派家用实验室。
>
>
>

(LCTT 译注:[opensource.com](http://opensource.com) 的免费电子书需要免费注册一个用户才能下载。)
### 开启一个新的树莓派项目
近十年来,树莓派一直俘获着开源爱好者的心和手。你可以用树莓派做无数的项目,无论是 [监控你的花园](https://opensource.com/article/21/5/monitor-greenhouse-open-source)、[设置家长监控](https://opensource.com/article/21/3/raspberry-pi-parental-control)(尤其是在那些漫长的夏天),甚至从你自己的后院 [跟踪飞机](https://opensource.com/article/21/3/tracking-flights-raspberry-pi)。如果这些很酷的项目激起了你的兴趣,但你的树莓派仍在吃灰,那么你需要下载我们的指南来促使你开始行动。在你知道它之前,你需要学习 [如何管理它们](https://opensource.com/article/21/5/raspberry-pi-cockpit),因为你将与很多树莓派一起工作!
**下载:《[如何开始使用你的树莓派](https://opensource.com/downloads/raspberry-pi-guide)》**
### 设计你的开源智能家庭
一个聪明且有用的方式去使用树莓派的方式是去设计你的智能家庭。使用家庭助手或其他的开源工具,你的家可以按你自己的设置进行自动化而无需借助第三方平台。作者 [Steve Ovens](https://opensource.com/downloads/home-automation-ebook) 用这本家庭自动化集锦的手写电子书来指导你的每一步工作。
**下载:《[使用开源工具实现家庭自动化的实用指南](https://opensource.com/downloads/home-automation-ebook)》**
### 将事情梳理地井井有条
可能你并没做好准备使得你的家庭完全自动化,但是你可能会对梳理你的思维有兴趣。为什么不从你的 to-do 列表开始呢?在贡献者 [Kevin Sonney](https://opensource.com/users/ksonney) 的生产力指导下,你将会熟悉六个开源工具的使用,从而帮你把事情安排得井井有条。一旦你完成了他的教程,你就会感到事情井井有条,在这个夏天终于有时间放松了。
**下载:《[六个可以将事情梳理地井井有条的开源工具](https://opensource.com/downloads/organization-tools)》**
### 学习如何写代码
电脑无处不在。能吐槽一下很多编程语言对初学者不是很友好吗?
有许多为初学者设计的编程语言。Bash 是 Linux 和 macOS 终端中使用的相同的脚本语言,如果你新开始写代码,Bash 将会是一个伟大的开始。你可以以 [互动的方式学习它](https://opensource.com/article/19/10/learn-bash-command-line-games#bashcrawl),之后下载我们的电子书以了解更多。
**下载:《[Bash 编程指南](https://opensource.com/downloads/bash-programming-guide)》**
### 用 Python 写一个游戏
另一个初学者喜欢的编程语言是 Python。它不仅受到仅仅学习编码的中小学生的欢迎,还被专业程序员用来做 [网站开发](https://opensource.com/article/18/4/flask)、[视频编辑](https://opensource.com/article/21/2/linux-python-video) 以及 [云端自动化](https://opensource.com/article/19/2/quickstart-guide-ansible)。无论你最终的目标是什么,开始学习 Python 的一个有趣的方式是编写一个自己的游戏。
**下载:《[Python 游戏开发指南](https://opensource.com/downloads/python-gaming-ebook)》**
### 发现使用 Jpuyter 的巧妙方法
为了让 Python 具有交互性且易于分享,Jupyter 项目提供了基于 Web 的发展环境。你可以在“笔记本”文件中写代码,然后将其发送给其他用户,以便他们轻松复制和可视化你所做的。它是代码、文档和演示文稿的完美组合,而且非常灵活。下载 Moshe Zadka 的多方面指南了解更多关于 Jupyter。
**下载:《[使用 Jupyer 的六种惊艳方式](https://opensource.com/downloads/jupyter-guide)》**
### 在你的家庭实验室里尝试 Kubernetes
现在,你已经在你的树莓派上安装了 Linux,已经登录,已设置新用户并 [配置了 sudo](https://opensource.com/article/19/10/know-about-sudo) 使得能够进入管理员模式,你正在 [运行所有你需要的服务](https://opensource.com/article/20/5/systemd-units) 。之后呢?
如果你对 Linux 和服务器管理感到满意,你的下一步可能是云服务。可以读一下 Chris Collins 的电子书,从你的家庭实验室的舒适中了解所有关于容器,吊舱和集群的信息。
**下载: 《[在你的树莓派家庭实验室上运行 Kubernetes](https://opensource.com/downloads/kubernetes-raspberry-pi)》**
### 福利:书籍列表
只工作不休息是不健康的。夏天(或任何季节,它是在你的世界的一部分)假期是为了休息,没有什么比坐在门廊或海滩上读一本好书更休闲人心的。下面是一些最近列出的书,以激发一些想法:
* [8 本供开源技术专家读的书(2021)](https://opensource.com/article/21/6/2021-opensourcecom-summer-reading-list)
* [十几本适合所有年龄段的书](https://opensource.com/article/20/6/summer-reading-list)
* [8 本提升领导力的书籍](https://enterprisersproject.com/article/2021/5/8-leadership-books-self-improvement)
* [6 本必读的云架构书籍](https://www.redhat.com/architect/books-cloud-architects)
* 我们的第一份 [2010 年的书籍列表](https://opensource.com/life/10/8/open-books-opensourcecom-summer-reading-list)
---
via: <https://opensource.com/article/21/7/open-source-guides>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zepoch](https://github.com/zepoch) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ## Start a new Raspberry Pi project
The Raspberry Pi has been capturing the hearts and hands of open source enthusiasts for nearly a decade. There are endless options with what you can do with a Raspberry Pi, whether it's [monitoring your garden](https://opensource.com/article/21/5/monitor-greenhouse-open-source), [setting parental controls](https://opensource.com/article/21/3/raspberry-pi-parental-control) (especially handy on those long summer days), or even [tracking aircraft](https://opensource.com/article/21/3/tracking-flights-raspberry-pi) from your own backyard. If any of these cool projects perked your interest but your Raspberry Pi is still collecting dust, then you need to download our guide to nudge you to get started. Before you know it, you'll be working with so many Raspberry Pis, you'll need to learn [how to manage them all](https://opensource.com/article/21/5/raspberry-pi-cockpit)!
**Download: How to get started with your Raspberry Pi**
## Design your open source smart home
One clever and useful way to use your Raspberry Pi is to design your own smart home. Using Home Assistant and other open source tools, your home can be automated on your own terms without a third-party conglomerate. Author [Steve Ovens](https://opensource.com/downloads/home-automation-ebook) guides you through every step of the way with a collection of home automation found in this handy eBook.
**Download: A practical guide to home automation using open source tools**
## Get organized
Maybe you're not quite ready to automate everything in your home yet but are interested in sprucing up the place—your brain space. Why not start with your to-do list? With contributor [Kevin Sonney's](https://opensource.com/users/ksonney) productivity guide, you'll become familiar with 6 open source tools to help you stay organized. Once you're through with his tutorials, you'll be organized and have time to finally relax this summer.
**Download: 6 open source tools for staying organized**
## Learn how to code
Computers are everywhere. Wouldn't it be great to be able to talk their language?
There are lots of languages designed for beginners. Bash is the same scripting language used in the Linux and MacOS terminals, so it makes for a great start if you're new to code. You can [learn it interactively](https://opensource.com/article/19/10/learn-bash-command-line-games#bashcrawl), and then download our eBook to learn more.
**Download:** [An introduction to programming with Bash](https://opensource.com/downloads/bash-programming-guide)
## Build a video game with Python
Another programming language that beginners love is Python. It's equally as popular among school children just learning to code as it is with professional programmers [developing websites](https://opensource.com/article/18/4/flask) and [video editors](https://opensource.com/article/21/2/linux-python-video) or [automating the cloud](https://opensource.com/article/19/2/quickstart-guide-ansible). Regardless of what your eventual goal happens to be, a fun way to start with Python is by programming your own video game.
**Download: A guide to building a video game with Python**
## Discover clever ways to use Jupyter
To make Python interactive and easy to share, the Jupyter project provides a web-based development environment. You can write your code in "notebook" files, and then send them to other users to make it easy for them to replicate and visualize what you've done. It's the perfect combination of code, documentation, and presentation, and it's surprisingly flexible. Learn more by downloading Moshe Zadka's multifaceted tour through Jupyter.
**Download: 6 surprising ways to use Jupyter**
## Experiment with Kubernetes in your homelab
So you've installed Linux on your Pi, you've logged in, you've set up a new user and [configured sudo](https://opensource.com/article/19/10/know-about-sudo) to make administration painless, and you're [running all the services](https://opensource.com/article/20/5/systemd-units) you need. Now what?
If you're comfortable with Linux and server administration, the next step for you could be The Cloud. Get Chris Collins' eBook to learn all about containers, pods, and clusters, all from the comfort of your own homelab.
**Download: Running Kubernetes on your Raspberry Pi homelab**
## Bonus: Book lists
All work and no play isn't healthy. Summer (or whatever season it is in your part of the world) vacation is meant to be relaxing, and there's nothing quite like sitting back on the porch or beach with a good book. Here are a few recent book lists to spark some ideas:
## 1 Comment |
13,576 | 用 Groovy 解析 JSON 配置文件 | https://opensource.com/article/21/6/groovy-parse-json | 2021-07-12T23:24:38 | [
"JSON",
"Groovy"
] | https://linux.cn/article-13576-1.html |
>
> 抛开关于是否使用 JSON 作为配置格式的争论,只需学习如何用 Groovy 来解析它。
>
>
>

应用程序通常包括某种类型的默认或“开箱即用”的状态或配置,以及某种让用户根据自己的需要定制配置的方式。
例如,[LibreOffice Writer](https://www.libreoffice.org/discover/writer/) 通过其菜单栏上的**工具 > 选项**,可以访问诸如用户数据、字体、语言设置等(以及更多的)设置。一些应用程序(如 LibreOffice)提供了一个点选式的用户界面来管理这些设置。有些,像 [Tracker](https://gitlab.gnome.org/GNOME/tracker)(GNOME 的“任务”,用于索引文件)使用 XML 文件。还有一些,特别是基于 JavaScript 的应用,使用 JSON,尽管它有许多人抗议(例如,[这位作者](https://www.lucidchart.com/techblog/2018/07/16/why-json-isnt-a-good-configuration-language/) 和 [这位其他作者](https://medium.com/trabe/stop-using-json-config-files-ab9bc55d82fa))。
在这篇文章中,我将回避关于是否使用 JSON 作为配置文件格式的争论,并解释如何使用 [Groovy 编程语言](https://groovy-lang.org/) 来解析这类信息。Groovy 以 Java 为基础,但有一套不同的设计重点,使 Groovy 感觉更像 Python。
### 安装 Groovy
由于 Groovy 是基于 Java 的,它也需要安装 Java。你可能会在你的 Linux 发行版的软件库中找到最近的、合适的 Java 和 Groovy 版本。或者,你可以按照其网站上的 [说明](https://groovy.apache.org/download.html) 安装 Groovy。 Linux 用户的一个不错的选择是 [SDKMan](https://sdkman.io/),你可以使用它来获取 Java、Groovy 和许多其他相关工具的多个版本。 对于本文,我将使用我的发行版的 OpenJDK11 和 SDKMan 的 Groovy 3.0.7。
### 演示的 JSON 配置文件
在这个演示中,我从 [Drupal](https://www.drupal.org/node/2008800) 中截取了这个 JSON 文件,它是 Drupal CMS 使用的主要配置文件,并将其保存在文件 `config.json` 中:
```
{
"vm": {
"ip": "192.168.44.44",
"memory": "1024",
"synced_folders": [
{
"host_path": "data/",
"guest_path": "/var/www",
"type": "default"
}
],
"forwarded_ports": []
},
"vdd": {
"sites": {
"drupal8": {
"account_name": "root",
"account_pass": "root",
"account_mail": "[email protected]",
"site_name": "Drupal 8",
"site_mail": "[email protected]",
"vhost": {
"document_root": "drupal8",
"url": "drupal8.dev",
"alias": ["www.drupal8.dev"]
}
},
"drupal7": {
"account_name": "root",
"account_pass": "root",
"account_mail": "[email protected]",
"site_name": "Drupal 7",
"site_mail": "[email protected]",
"vhost": {
"document_root": "drupal7",
"url": "drupal7.dev",
"alias": ["www.drupal7.dev"]
}
}
}
}
}
```
这是一个漂亮的、复杂的 JSON 文件,有几层结构,如:
```
<>.vdd.sites.drupal8.account_name
```
和一些列表,如:
```
<>.vm.synced_folders
```
这里,`<>` 代表未命名的顶层。让我们看看 Groovy 是如何处理的。
### 用 Groovy 解析 JSON
Groovy 自带的 `groovy.json` 包,里面有各种很酷的东西。其中最好的部分是 `JsonSlurper` 类,它包括几个 `parse()` 方法,可以将 JSON 转换为 Groovy 的 `Map`,一种根据键值存储的数据结构。
下面是一个简短的 Groovy 程序,名为 `config1.groovy`,它创建了一个 `JsonSlurper` 实例,然后调用其中的 `parse()` 方法来解析文件中的 JSON,并将其转换名为 `config` 的 `Map` 实例,最后将该 map 输出:
```
import groovy.json.JsonSlurper
def jsonSlurper = new JsonSlurper()
def config = jsonSlurper.parse(new File('config.json'))
println "config = $config"
```
在终端的命令行上运行这个程序:
```
$ groovy config1.groovy
config = [vm:[ip:192.168.44.44, memory:1024, synced_folders:[[host_path:data/, guest_path:/var/www, type:default]], forwarded_ports:[]], vdd:[sites:[drupal8:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 8, site_mail:[email protected], vhost:[document_root:drupal8, url:drupal8.dev, alias:[www.drupal8.dev]]], drupal7:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 7, site_mail:[email protected], vhost:[document_root:drupal7, url:drupal7.dev, alias:[www.drupal7.dev]]]]]]
$
```
输出显示了一个有两个键的顶层映射:`vm` 和 `vdd`。每个键都引用了它自己的值的映射。注意 `forwarded_ports` 键所引用的空列表。
这很容易,但它所做的只是把东西打印出来。你是如何获得各种组件的呢?下面是另一个程序,显示如何访问存储在 `config.vm.ip` 的值:
```
import groovy.json.JsonSlurper
def jsonSlurper = new JsonSlurper()
def config = jsonSlurper.parse(new File('config.json'))
println "config.vm.ip = ${config.vm.ip}"
```
运行它:
```
$ groovy config2.groovy
config.vm.ip = 192.168.44.44
$
```
是的,这也很容易。 这利用了 Groovy 速记,这意味着:
```
config.vm.ip
```
在 Groovy 中等同于:
```
config['vm']['ip']
```
当 `config` 和 `config.vm` 都是 `Map` 的实例,并且都等同于在 Java 中的:
```
config.get("vm").get("ip")
```
仅仅是处理 JSON 就这么多了。如果你想有一个标准的配置并让用户覆盖它呢?在这种情况下,你可能想在程序中硬编码一个 JSON 配置,然后读取用户配置并覆盖任何标准配置的设置。
假设上面的配置是标准的,而用户只想覆盖其中的一点,只想覆盖 `vm` 结构中的 `ip` 和 `memory` 值,并把它放在 `userConfig.json` 文件中:
```
{
"vm": {
"ip": "201.201.201.201",
"memory": "4096",
}
}
```
你可以用这个程序来做:
```
import groovy.json.JsonSlurper
def jsonSlurper = new JsonSlurper()
// 使用 parseText() 来解析一个字符串,而不是从文件中读取。
// 这给了我们一个“标准配置”
def standardConfig = jsonSlurper.parseText("""
{
"vm": {
"ip": "192.168.44.44",
"memory": "1024",
"synced_folders": [
{
"host_path": "data/",
"guest_path": "/var/www",
"type": "default"
}
],
"forwarded_ports": []
},
"vdd": {
"sites": {
"drupal8": {
"account_name": "root",
"account_pass": "root",
"account_mail": "[email protected]",
"site_name": "Drupal 8",
"site_mail": "[email protected]",
"vhost": {
"document_root": "drupal8",
"url": "drupal8.dev",
"alias": ["www.drupal8.dev"]
}
},
"drupal7": {
"account_name": "root",
"account_pass": "root",
"account_mail": "[email protected]",
"site_name": "Drupal 7",
"site_mail": "[email protected]",
"vhost": {
"document_root": "drupal7",
"url": "drupal7.dev",
"alias": ["www.drupal7.dev"]
}
}
}
}
}
""")
// 打印标准配置
println "standardConfig = $standardConfig"
//读入并解析用户配置信息
def userConfig = jsonSlurper.parse(new File('userConfig.json'))
// 打印出用户配置信息
println "userConfig = $userConfig"
// 一个将用户配置与标准配置合并的函数
def mergeMaps(Map input, Map merge) {
merge.each { k, v ->
if (v instanceof Map)
mergeMaps(input[k], v)
else
input[k] = v
}
}
// 合并配置并打印出修改后的标准配置
mergeMaps(standardConfig, userConfig)
println "modified standardConfig $standardConfig"
```
以下列方式运行:
```
$ groovy config3.groovy
standardConfig = [vm:[ip:192.168.44.44, memory:1024, synced_folders:[[host_path:data/, guest_path:/var/www, type:default]], forwarded_ports:[]], vdd:[sites:[drupal8:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 8, site_mail:[email protected], vhost:[document_root:drupal8, url:drupal8.dev, alias:[www.drupal8.dev]]], drupal7:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 7, site_mail:[email protected], vhost:[document_root:drupal7, url:drupal7.dev, alias:[www.drupal7.dev]]]]]]
userConfig = [vm:[ip:201.201.201.201, memory:4096]]
modified standardConfig [vm:[ip:201.201.201.201, memory:4096, synced_folders:[[host_path:data/, guest_path:/var/www, type:default]], forwarded_ports:[]], vdd:[sites:[drupal8:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 8, site_mail:[email protected], vhost:[document_root:drupal8, url:drupal8.dev, alias:[www.drupal8.dev]]], drupal7:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 7, site_mail:[email protected], vhost:[document_root:drupal7, url:drupal7.dev, alias:[www.drupal7.dev]]]]]]
$
```
以 `modified standardConfig` 开头的一行显示,`vm.ip` and `vm.memory` 的值被覆盖了。
眼尖的读者会注意到,我没有检查畸形的 JSON,也没有仔细确保用户的配置是有意义的(不创建新字段,提供合理的值,等等)。所以用这个递归方法来合并两个映射在现实中可能并不那么实用。
好吧,我必须为家庭作业留下 *一些* 东西,不是吗?
### Groovy 资源
Apache Groovy 网站有很多很棒的 [文档](http://groovy-lang.org/documentation.html)。另一个很棒的 Groovy 资源是 [Mr. Haki](https://blog.mrhaki.com/)。学习 Groovy 的一个非常好的理由是继续学习 [Grails](https://grails.org/),它是一个非常高效的全栈 Web 框架,建立在 Hibernate、Spring Boot 和 Micronaut 等优秀组件之上。
---
via: <https://opensource.com/article/21/6/groovy-parse-json>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Applications typically include some type of default or "out-of-the-box" state or configuration, as well as some way for users to customize that configuration for their needs.
For example, [LibreOffice Writer](https://www.libreoffice.org/discover/writer/) gives access to stuff like user data, fonts, language settings, and (much) more through **Tools > Options** on its menu bar. Some applications (like LibreOffice) provide a point-and-click user interface to manage these settings. Some, like [Tracker](https://gitlab.gnome.org/GNOME/tracker) (the GNOME task that indexes files), use XML files. And some, especially JavaScript-based applications, use JSON, despite the protestations of many (for example, [this writer](https://www.lucidchart.com/techblog/2018/07/16/why-json-isnt-a-good-configuration-language/) and [this other writer](https://medium.com/trabe/stop-using-json-config-files-ab9bc55d82fa)).
In this article, I'll sidestep the debate about whether or not to use JSON as a configuration file format and explain how to parse this kind of information using the [Groovy programming language](https://groovy-lang.org/). Groovy is based on Java but with a different set of design priorities that make Groovy feel more like Python.
## Install Groovy
Since Groovy is based on Java, it also requires a Java installation. You might find recent and decent versions of Java and Groovy in your Linux distribution's repositories. Or you can install Groovy following the [instructions](https://groovy.apache.org/download.html) on its website. A nice alternative for Linux users is [SDKMan](https://sdkman.io/), which you can use to get multiple versions of Java, Groovy, and many other related tools. For this article, I'll use my distro's OpenJDK11 release and SDKMan's Groovy 3.0.7 release.
## The demo JSON configuration file
For this demonstration, I snagged this JSON from [Drupal](https://www.drupal.org/node/2008800)—it's the main configuration file used by the Drupal CMS—and saved it in the file `config.json`
:
```
{
"vm": {
"ip": "192.168.44.44",
"memory": "1024",
"synced_folders": [
{
"host_path": "data/",
"guest_path": "/var/www",
"type": "default"
}
],
"forwarded_ports": []
},
"vdd": {
"sites": {
"drupal8": {
"account_name": "root",
"account_pass": "root",
"account_mail": "[email protected]",
"site_name": "Drupal 8",
"site_mail": "[email protected]",
"vhost": {
"document_root": "drupal8",
"url": "drupal8.dev",
"alias": ["www.drupal8.dev"]
}
},
"drupal7": {
"account_name": "root",
"account_pass": "root",
"account_mail": "[email protected]",
"site_name": "Drupal 7",
"site_mail": "[email protected]",
"vhost": {
"document_root": "drupal7",
"url": "drupal7.dev",
"alias": ["www.drupal7.dev"]
}
}
}
}
}
```
This is a nice, complex JSON file with several levels of structure, like:
`<>.vdd.sites.drupal8.account_name`
and some lists like:
`<>.vm.synced_folders`
Here, `<>`
represents the unnamed top level. Let's see how Groovy handles that.
## Parsing JSON with Groovy
Groovy comes with the `groovy.json`
package, which is full of all sorts of cool stuff. One of the best parts is the `JsonSlurper`
class, which includes several `parse()`
methods that convert JSON to a Groovy `Map`
—a data structure with values stored against keys.
Here's a nice, short Groovy program named `config1.groovy`
that creates a `JsonSlurper`
instance, then calls one of its `parse()`
methods to parse the JSON in a file and convert it to a `Map`
instance called `config`
, and finally writes out that map:
```
import groovy.json.JsonSlurper
def jsonSlurper = new JsonSlurper()
def config = jsonSlurper.parse(new File('config.json'))
println "config = $config"
```
Run this program on the command line in a terminal:
```
$ groovy config1.groovy
config = [vm:[ip:192.168.44.44, memory:1024, synced_folders:[[host_path:data/, guest_path:/var/www, type:default]], forwarded_ports:[]], vdd:[sites:[drupal8:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 8, site_mail:[email protected], vhost:[document_root:drupal8, url:drupal8.dev, alias:[www.drupal8.dev]]], drupal7:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 7, site_mail:[email protected], vhost:[document_root:drupal7, url:drupal7.dev, alias:[www.drupal7.dev]]]]]]
$
```
The output shows a top-level map with two keys: `vm`
and `vdd`
. Each key references its own map of values. Notice the empty list referenced by the `forwarded_ports`
key.
Huh. That was easy, but all it did was print things out. How do you get at the various components? Here's another program that shows how to access the value stored at `config.vm.ip`
:
```
import groovy.json.JsonSlurper
def jsonSlurper = new JsonSlurper()
def config = jsonSlurper.parse(new File('config.json'))
println "config.vm.ip = ${config.vm.ip}"
```
Run it:
```
$ groovy config2.groovy
config.vm.ip = 192.168.44.44
$
```
Yup, that's easy, too. This takes advantage of Groovy shorthand that means:
`config.vm.ip`
in Groovy is equivalent to:
`config['vm']['ip']`
when `config`
and `config.vm`
are both instances of `Map`
, and both are equivalent to:
`config.get("vm").get("ip")`
in Java.
So much for just handling the JSON. What if you want to have a standard configuration and let the user override it? In that case, you might want to have a JSON configuration hard-coded in the program, then read the user configuration and override any of the standard configuration settings.
Say the above configuration is standard, and the user wants to override only a bit of it, just the `ip`
and `memory`
values in the `vm`
structure, and put that in the `userConfig.json`
file:
```
{
"vm": {
"ip": "201.201.201.201",
"memory": "4096",
}
}
```
You could do that using this program:
```
import groovy.json.JsonSlurper
def jsonSlurper = new JsonSlurper()
// use parseText() to parse a string rather than reading from a file
// this gives us the “standard configuration”
def standardConfig = jsonSlurper.parseText("""
{
"vm": {
"ip": "192.168.44.44",
"memory": "1024",
"synced_folders": [
{
"host_path": "data/",
"guest_path": "/var/www",
"type": "default"
}
],
"forwarded_ports": []
},
"vdd": {
"sites": {
"drupal8": {
"account_name": "root",
"account_pass": "root",
"account_mail": "[email protected]",
"site_name": "Drupal 8",
"site_mail": "[email protected]",
"vhost": {
"document_root": "drupal8",
"url": "drupal8.dev",
"alias": ["www.drupal8.dev"]
}
},
"drupal7": {
"account_name": "root",
"account_pass": "root",
"account_mail": "[email protected]",
"site_name": "Drupal 7",
"site_mail": "[email protected]",
"vhost": {
"document_root": "drupal7",
"url": "drupal7.dev",
"alias": ["www.drupal7.dev"]
}
}
}
}
}
""")
// print out the standard configuration
println "standardConfig = $standardConfig"
// read in and parse the user configuration information
def userConfig = jsonSlurper.parse(new File('userConfig.json'))
// print out the user configuration information
println "userConfig = $userConfig"
// a function to merge the user configuration with the standard
def mergeMaps(Map input, Map merge) {
merge.each { k, v ->
if (v instanceof Map)
mergeMaps(input[k], v)
else
input[k] = v
}
}
// merge the configurations and print out the modified
// standard configuration
mergeMaps(standardConfig, userConfig)
println "modified standardConfig $standardConfig"
```
Run this as:
```
$ groovy config3.groovy
standardConfig = [vm:[ip:192.168.44.44, memory:1024, synced_folders:[[host_path:data/, guest_path:/var/www, type:default]], forwarded_ports:[]], vdd:[sites:[drupal8:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 8, site_mail:[email protected], vhost:[document_root:drupal8, url:drupal8.dev, alias:[www.drupal8.dev]]], drupal7:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 7, site_mail:[email protected], vhost:[document_root:drupal7, url:drupal7.dev, alias:[www.drupal7.dev]]]]]]
userConfig = [vm:[ip:201.201.201.201, memory:4096]]
modified standardConfig [vm:[ip:201.201.201.201, memory:4096, synced_folders:[[host_path:data/, guest_path:/var/www, type:default]], forwarded_ports:[]], vdd:[sites:[drupal8:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 8, site_mail:[email protected], vhost:[document_root:drupal8, url:drupal8.dev, alias:[www.drupal8.dev]]], drupal7:[account_name:root, account_pass:root, account_mail:[email protected], site_name:Drupal 7, site_mail:[email protected], vhost:[document_root:drupal7, url:drupal7.dev, alias:[www.drupal7.dev]]]]]]
$
```
The line beginning `modified standardConfig`
shows that the `vm.ip`
and `vm.memory`
values were overridden.
Sharp-eyed readers will notice that I did not check for malformed JSON , nor was I careful to ensure that the user configuration makes sense (doesn't create new fields, provides reasonable values, and so on). So the cute little recursive method to merge the two maps probably isn't all that practical in the real world.
Well I had to leave *something* for homework, didn't I?
## Groovy resources
The Apache Groovy site has a lot of great [documentation](http://groovy-lang.org/documentation.html). Another great Groovy resource is [Mr. Haki](https://blog.mrhaki.com/). And a really great reason to learn Groovy is to go on and learn [Grails](https://grails.org/), which is a wonderfully productive full-stack web framework built on top of excellent components like Hibernate, Spring Boot, and Micronaut.
## Comments are closed. |
13,578 | 像查询数据库一样查询你的 Linux 操作系统信息 | https://opensource.com/article/21/6/osquery-linux | 2021-07-14T09:58:31 | [
"数据库",
"ps"
] | https://linux.cn/article-13578-1.html |
>
> 使用数据库查询操作轻松获取系统信息。
>
>
>

Linux 提供了很多帮助用户收集主机操作系统信息的命令:列出文件或者目录的属性信息;查询安装的软件包、正在执行的命令、开机时启动的服务;或者了解系统的硬件。
每个命令使用自己的输出格式列出系统的信息。你需要使用 `grep`、`sed`、`awk` 这样的工具过滤命令输出的结果,以便找到特定的信息。此外,很多这样的信息会频繁变动,导致系统状态的改变。
将所有的信息格式化为一个数据库的 SQL 查询的输出进行查看将会十分有益。想象一下,你能够像查询具有类似名称的 SQL 数据库表一样查询 `ps` 和 `rpm` 命令的输出。
幸运的是,有一个工具刚好实现了这个功能,而且功能更多:[Osquery](https://osquery.io/) 是一个 [开源的](https://github.com/osquery/osquery) “由 SQL 驱动的操作系统仪表、监控和分析框架”。
许多处理安全、DevOps、合规性的应用,以及仓储管理管理(仅举几例)在内部依赖 Osquery 提供的核心功能。
### 安装 Osquery
Osquery 适用于 Linux、macOS、Windows、FreeBSD。请按照 [指南](https://osquery.io/downloads/official) 为你的操作系统安装最新版本。(我会在下面的例子中使用 4.7.0 版本。)
安装完成后,确保 Osquery 可以工作:
```
$ rpm -qa | grep osquery
osquery-4.7.0-1.linux.x86_64
$
$ osqueryi --version
osqueryi version 4.7.0
$
```
### Osquery 组件
Osquery 有两个主要组件:
* `osqueri` 是一个交互式的 SQL 查询控制台,可以独立运行,不需要超级用户权限(除非要查询的表格需要访问权限)。
* `osqueryd` 像一个安装在主机的监控守护进程,可以定期调度查询操作执行,从底层架构收集信息。
可以在不运行 `osqueryd` 的情况下执行 `osqueri`。另一个工具,`osqueryctl`,控制守护进程的启动、停止,并检查其状态。
```
$ rpm -ql osquery-4.8.0-1.linux.x86_64 | grep bin
/usr/bin/osqueryctl
/usr/bin/osqueryd
/usr/bin/osqueryi
$
```
### 使用 osqueryi 交互式命令提示符
你和 Osquery 的交互与使用 SQL 数据库十分相似。事实上,`osqueryi` 是 SQList shell 的一个修改版。执行 `osqueryi` 命令进入交互式命令提示符 ,就可以执行 Osquery 的命令,通常以 `.` 开始:
```
$ osqueryi
Using a virtual database. Need help, type '.help'
osquery>
```
要退出交互式命令提示符,执行 `.quit` 命令回到操作系统的命令提示符:
```
osquery>
osquery> .quit
$
```
### 找出可用的表
如前所述,Osquery 像 SQL 查询一样输出数据,数据库中的信息通常保存在表中。但是如何在不知道表名的情况下查询这些表呢?你可以运行 `.tables` 命令列出所有可以查询的表。如果你是一个 Linux 长期用户或者一个系统管理员 ,就会对表名十分熟悉,因为你一直在使用操作系统命令获取同样的信息:
```
osquery> .tables
=> acpi_tables
=> apparmor_events
=> apparmor_profiles
=> apt_sources
<<裁剪>>
=> arp_cache
=> user_ssh_keys
=> users
=> yara
=> yara_events
=> ycloud_instance_metadata
=> yum_sources
osquery>
```
### 检查各个表的模式
知道表名后,可以查看每个表提供的信息。既然 `ps` 命令经常用于获取进程信息,就以 `processes` 为例。执行 `.schema` 命令加上表名查看表中保存的信息。如果要验证命令返回的结果,可以快速执行 `ps -ef` 或 `ps aux`,对比命令的输出和表中的内容:
```
osquery> .schema processes
CREATE TABLE processes(`pid` BIGINT, `name` TEXT, `path` TEXT, `cmdline` TEXT, `state` TEXT, `cwd` TEXT, `root` TEXT, `uid` BIGINT, `gid` BIGINT, `euid` BIGINT, `egid` BIGINT, `suid` BIGINT, `sgid` BIGINT, `on_disk` INTEGER, `wired_size` BIGINT, `resident_size` BIGINT, `total_size` BIGINT, `user_time` BIGINT, `system_time` BIGINT, `disk_bytes_read` BIGINT, `disk_bytes_written` BIGINT, `start_time` BIGINT, `parent` BIGINT, `pgroup` BIGINT, `threads` INTEGER, `nice` INTEGER, `is_elevated_token` INTEGER HIDDEN, `elapsed_time` BIGINT HIDDEN, `handle_count` BIGINT HIDDEN, `percent_processor_time` BIGINT HIDDEN, `upid` BIGINT HIDDEN, `uppid` BIGINT HIDDEN, `cpu_type` INTEGER HIDDEN, `cpu_subtype` INTEGER HIDDEN, `phys_footprint` BIGINT HIDDEN, PRIMARY KEY (`pid`)) WITHOUT ROWID;
osquery>
```
要进一步确认,可以使用下面的命令查看 RPM 包的结构信息,然后与操作系统命令 `rpm -qa` 和 `rpm -qi` 的输出比较:
```
osquery>
osquery> .schema rpm_packages
CREATE TABLE rpm_packages(`name` TEXT, `version` TEXT, `release` TEXT, `source` TEXT, `size` BIGINT, `sha1` TEXT, `arch` TEXT, `epoch` INTEGER, `install_time` INTEGER, `vendor` TEXT, `package_group` TEXT, `pid_with_namespace` INTEGER HIDDEN, `mount_namespace_id` TEXT HIDDEN, PRIMARY KEY (`name`, `version`, `release`, `arch`, `epoch`, `pid_with_namespace`)) WITHOUT ROWID;
osquery>
```
从 Osquery 的 [表格文档](https://osquery.io/schema/4.8.0/) 获取更多信息。
### 使用 PRAGMA 命令
或许模式信息对你来说太难看懂,还有另一种途径能够以详细的表格格式打印表中的信息:`PRAGMA` 命令。例如,我想通过 `PRAGMA` 用一种易于理解的格式查看 `rpm_packages` 表的信息:
```
osquery> PRAGMA table_info(rpm_packages);
```
这种表格式信息的一个好处是你可以关注想要查询的字段,查看命令提供的类型信息:
```
osquery> PRAGMA table_info(users);
+-----+-------------+--------+---------+------------+----+
| cid | name | type | notnull | dflt_value | pk |
+-----+-------------+--------+---------+------------+----+
| 0 | uid | BIGINT | 1 | | 1 |
| 1 | gid | BIGINT | 0 | | 0 |
| 2 | uid_signed | BIGINT | 0 | | 0 |
| 3 | gid_signed | BIGINT | 0 | | 0 |
| 4 | username | TEXT | 1 | | 2 |
| 5 | description | TEXT | 0 | | 0 |
| 6 | directory | TEXT | 0 | | 0 |
| 7 | shell | TEXT | 0 | | 0 |
| 8 | uuid | TEXT | 1 | | 3 |
+-----+-------------+--------+---------+------------+----+
osquery>
```
### 进行你的第一次查询
在你从表、模式、条目中获取到所有进行查询所需要的信息后,进行你的第一次 SQL 查询查看其中的信息。下面的查询返回系统中的用户和每个用户的用户 ID、组 ID、主目录和默认的命令行解释器。Linux 用户通过查看 `/etc/passwd` 文件的内容并执行 `grep`、`sed`、`awk` 命令获取同样的信息。
```
osquery>
osquery> select uid,gid,directory,shell,uuid FROM users LIMIT 7;
+-----+-----+----------------+----------------+------+
| uid | gid | directory | shell | uuid |
+-----+-----+----------------+----------------+------+
| 0 | 0 | /root | /bin/bash | |
| 1 | 1 | /bin | /sbin/nologin | |
| 2 | 2 | /sbin | /sbin/nologin | |
| 3 | 4 | /var/adm | /sbin/nologin | |
| 4 | 7 | /var/spool/lpd | /sbin/nologin | |
| 5 | 0 | /sbin | /bin/sync | |
| 6 | 0 | /sbin | /sbin/shutdown | |
+-----+-----+----------------+----------------+------+
osquery>
```
### 不进入交互模式的查询
如果你想要在不进入 `osqueri` 交互模式的情况下进行查询,该怎么办?要用查询操作写命令行解释器脚本,这种方式可能十分有用。这种情况下,可以直接从 Bash 解释器 `echo` SQL 查询,通过管道输出到 `osqueri` :
```
$ echo "select uid,gid,directory,shell,uuid FROM users LIMIT 7;" | osqueryi
+-----+-----+----------------+----------------+------+
| uid | gid | directory | shell | uuid |
+-----+-----+----------------+----------------+------+
| 0 | 0 | /root | /bin/bash | |
| 1 | 1 | /bin | /sbin/nologin | |
| 2 | 2 | /sbin | /sbin/nologin | |
| 3 | 4 | /var/adm | /sbin/nologin | |
| 4 | 7 | /var/spool/lpd | /sbin/nologin | |
| 5 | 0 | /sbin | /bin/sync | |
| 6 | 0 | /sbin | /sbin/shutdown | |
+-----+-----+----------------+----------------+------+
$
```
### 获悉系统启动时开始的服务
Osquery 还可以列出系统启动时开始的所有服务。例如,可以查询 `startup_items` 表获取启动时开始的前五项服务的名称、状态和路径:
```
osquery> SELECT name,type,status,path FROM startup_items LIMIT 5;
name = README
type = Startup Item
status = enabled
path = /etc/rc.d/init.d/README
name = anamon
type = Startup Item
status = enabled
path = /etc/rc.d/init.d/anamon
name = functions
type = Startup Item
status = enabled
path = /etc/rc.d/init.d/functions
name = osqueryd
type = Startup Item
status = enabled
path = /etc/rc.d/init.d/osqueryd
name = AT-SPI D-Bus Bus
type = Startup Item
status = enabled
path = /usr/libexec/at-spi-bus-launcher --launch-immediately
osquery>
```
### 查阅二进制文件的 ELF 信息
假如你想要弄清 `ls` 二进制文件的更多细节,通常会通过 `readelf -h` 命令,加上 `ls` 命令的路径。查询 Osquery 的 `elf_info` 表你可以得到同样的信息:
```
osquery> SELECT * FROM elf_info WHERE path="/bin/ls";
class = 64
abi = sysv
abi_version = 0
type = dyn
machine = 62
version = 1
entry = 24064
flags = 0
path = /bin/ls
osquery>
```
现在你应该初步了解如何使用 `osqueri` 查询自己想要的信息。然而,这些信息保存在数量巨大的表中;我查询过的一个系统中,有 156 个不同的表,这个数字可能是十分惊人的:
```
$ echo ".tables" | osqueryi | wc -l
156
$
```
要让事情变得更容易,可以从这些表开始获取你的 Linux 系统的信息:
**系统信息表:**
```
osquery> select * from system_info;
```
**系统限制信息:**
```
osquery> select * from ulimit_info;
```
**由各种进程打开的文件:**
```
osquery> select * from process_open_files;
```
**系统上开放的端口:**
```
osquery> select * from listening_ports;
```
**运行中的进程信息:**
```
osquery> select * from processes;
```
**已安装的包信息:**
```
osquery> select * from rpm_packages;
```
**用户登录信息:**
```
osquery> select * from last;
```
**系统日志信息:**
```
osquery> select * from syslog_events;
```
### 了解更多
Osquery 是一个强大的工具,提供了许多可以用于解决各种使用案例的主机信息。你可以阅读 [文档](https://osquery.readthedocs.io/en/latest/) 了解更多 Osquery 的信息。
---
via: <https://opensource.com/article/21/6/osquery-linux>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[YungeG](https://github.com/YungeG) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux offers a lot of commands to help users gather information about their host operating system: listing files or directories to check attributes; querying to see what packages are installed, processes are running, and services start at boot; or learning about the system's hardware.
Each command uses its own output format to list this information. You need to use tools like `grep`
, `sed`
, and `awk`
to filter the results to find specific information. Also, a lot of this information changes frequently, leading to changes in the system's state.
It would be helpful to view all of this information formatted like the output of a database SQL query. Imagine that you could query the output of the `ps`
and `rpm`
commands as if you were querying an SQL database table with similar names.
Fortunately, there is a tool that does just that and much more: [Osquery](https://osquery.io/) is an [open source](https://github.com/osquery/osquery) "SQL powered operating system instrumentation, monitoring, and analytics framework."
Many applications that handle security, DevOps, compliance, and inventory management (to name a few) depend upon the core functionalities provided by Osquery at their heart.
## Install Osquery
Osquery is available for Linux, macOS, Windows, and FreeBSD. Install the latest version for your operating system by following its [installation instructions](https://osquery.io/downloads/official). (I'll use version 4.7.0 in these examples.)
After installation, verify it's working:
```
$ rpm -qa | grep osquery
osquery-4.7.0-1.linux.x86_64
$
$ osqueryi --version
osqueryi version 4.7.0
$
```
## Osquery components
Osquery has two main components:
**osqueri**is an interactive SQL query console. It is a standalone utility that does not need super-user privileges (unless you are querying tables that need that level of access).**osqueryd**is like a monitoring daemon for the host it is installed on. This daemon can schedule queries to execute at regular intervals to gather information from the infrastructure.
You can run the osqueri utility without having the osqueryd daemon running. Another utility, **osqueryctl**, controls starting, stopping, and checking the status of the daemon.
```
$ rpm -ql osquery-4.8.0-1.linux.x86_64 | grep bin
/usr/bin/osqueryctl
/usr/bin/osqueryd
/usr/bin/osqueryi
$
```
## Use the osqueryi interactive prompt
You interact with Osquery much like you would use an SQL database. In fact, osqueryi is a modified version of the SQLite shell. Running the `osqueryi`
command drops you into an interactive shell where you can run commands specific to Osquery, which often start with a `.`
:
```
$ osqueryi
Using a virtual database. Need help, type '.help'
osquery>
```
To quit the interactive shell, run the `.quit`
command to get back to the operating system's shell:
```
osquery>
osquery> .quit
$
```
## Find out what tables are available
As mentioned, Osquery makes data available as the output of SQL queries. Information in databases is often saved in tables. But how can you query these tables if you don't know their names? Well, you can run the `.tables`
command to list all the tables that you can query. If you are a long-time Linux user or a sysadmin, the table names will be familiar, as you have been using operating system commands to get this information:
```
osquery> .tables
=> acpi_tables
=> apparmor_events
=> apparmor_profiles
=> apt_sources
<< snip >>
=> arp_cache
=> user_ssh_keys
=> users
=> yara
=> yara_events
=> ycloud_instance_metadata
=> yum_sources
osquery>
```
## Check the schema for individual tables
Now that you know the table names, you can see what information each table provides. As an example, choose `processes`
, since the `ps`
command is used quite often to get this information. Run the `.schema`
command followed by the table name to see what information is saved in this table. If you want to check the results, you could quickly run `ps -ef`
or `ps aux`
and compare the output with the contents of the table:
```
osquery> .schema processes
CREATE TABLE processes(`pid` BIGINT, `name` TEXT, `path` TEXT, `cmdline` TEXT, `state` TEXT, `cwd` TEXT, `root` TEXT, `uid` BIGINT, `gid` BIGINT, `euid` BIGINT, `egid` BIGINT, `suid` BIGINT, `sgid` BIGINT, `on_disk` INTEGER, `wired_size` BIGINT, `resident_size` BIGINT, `total_size` BIGINT, `user_time` BIGINT, `system_time` BIGINT, `disk_bytes_read` BIGINT, `disk_bytes_written` BIGINT, `start_time` BIGINT, `parent` BIGINT, `pgroup` BIGINT, `threads` INTEGER, `nice` INTEGER, `is_elevated_token` INTEGER HIDDEN, `elapsed_time` BIGINT HIDDEN, `handle_count` BIGINT HIDDEN, `percent_processor_time` BIGINT HIDDEN, `upid` BIGINT HIDDEN, `uppid` BIGINT HIDDEN, `cpu_type` INTEGER HIDDEN, `cpu_subtype` INTEGER HIDDEN, `phys_footprint` BIGINT HIDDEN, PRIMARY KEY (`pid`)) WITHOUT ROWID;
osquery>
```
To drive home the point, use the following command to see the schema for the RPM packages and compare the information with `rpm -qa`
and `rpm -qi`
operating system commands:
```
osquery>
osquery> .schema rpm_packages
CREATE TABLE rpm_packages(`name` TEXT, `version` TEXT, `release` TEXT, `source` TEXT, `size` BIGINT, `sha1` TEXT, `arch` TEXT, `epoch` INTEGER, `install_time` INTEGER, `vendor` TEXT, `package_group` TEXT, `pid_with_namespace` INTEGER HIDDEN, `mount_namespace_id` TEXT HIDDEN, PRIMARY KEY (`name`, `version`, `release`, `arch`, `epoch`, `pid_with_namespace`)) WITHOUT ROWID;
osquery>
```
You learn more in Osquery's [tables documentation](https://osquery.io/schema/4.8.0/).
## Use the PRAGMA command
In case that schema information is too cryptic for you, there is another way to print the table information in a verbose, tabular format: the `PRAGMA`
command. For example, I'll use `PRAGMA`
to see information for the `rpm_packages`
table in a nice format:
`osquery> PRAGMA table_info(rpm_packages);`
One benefit of this tabular information is that you can focus on the field you want to query and see the type of information that it provides:
```
osquery> PRAGMA table_info(users);
+-----+-------------+--------+---------+------------+----+
| cid | name | type | notnull | dflt_value | pk |
+-----+-------------+--------+---------+------------+----+
| 0 | uid | BIGINT | 1 | | 1 |
| 1 | gid | BIGINT | 0 | | 0 |
| 2 | uid_signed | BIGINT | 0 | | 0 |
| 3 | gid_signed | BIGINT | 0 | | 0 |
| 4 | username | TEXT | 1 | | 2 |
| 5 | description | TEXT | 0 | | 0 |
| 6 | directory | TEXT | 0 | | 0 |
| 7 | shell | TEXT | 0 | | 0 |
| 8 | uuid | TEXT | 1 | | 3 |
+-----+-------------+--------+---------+------------+----+
osquery>
```
## Run your first query
Now that you have all the required information from the table, the schema, and the items to query, run your first SQL query to view the information. The query below returns the users that are present on the system and each one's user ID, group ID, home directory, and default shell. Linux users could get this information by viewing the contents of the `/etc/passwd`
file and doing some `grep`
, `sed`
, and `awk`
magic.
```
osquery>
osquery> select uid,gid,directory,shell,uuid FROM users LIMIT 7;
+-----+-----+----------------+----------------+------+
| uid | gid | directory | shell | uuid |
+-----+-----+----------------+----------------+------+
| 0 | 0 | /root | /bin/bash | |
| 1 | 1 | /bin | /sbin/nologin | |
| 2 | 2 | /sbin | /sbin/nologin | |
| 3 | 4 | /var/adm | /sbin/nologin | |
| 4 | 7 | /var/spool/lpd | /sbin/nologin | |
| 5 | 0 | /sbin | /bin/sync | |
| 6 | 0 | /sbin | /sbin/shutdown | |
+-----+-----+----------------+----------------+------+
osquery>
```
## Run queries without entering interactive mode
What if you want to run a query without entering the osqueri interactive mode? This could be very useful if you are writing shell scripts around it. In this case, you could `echo`
the SQL query and pipe it to osqueri right from the Bash shell:
```
$ echo "select uid,gid,directory,shell,uuid FROM users LIMIT 7;" | osqueryi
+-----+-----+----------------+----------------+------+
| uid | gid | directory | shell | uuid |
+-----+-----+----------------+----------------+------+
| 0 | 0 | /root | /bin/bash | |
| 1 | 1 | /bin | /sbin/nologin | |
| 2 | 2 | /sbin | /sbin/nologin | |
| 3 | 4 | /var/adm | /sbin/nologin | |
| 4 | 7 | /var/spool/lpd | /sbin/nologin | |
| 5 | 0 | /sbin | /bin/sync | |
| 6 | 0 | /sbin | /sbin/shutdown | |
+-----+-----+----------------+----------------+------+
$
```
## Learn what services start when booting up
Osquery can also return all the services set to start at boot. For example, to query the `startup_items`
table and get the name, status, and path of the first five services that run at startup:
```
osquery> SELECT name,type,status,path FROM startup_items LIMIT 5;
name = README
type = Startup Item
status = enabled
path = /etc/rc.d/init.d/README
name = anamon
type = Startup Item
status = enabled
path = /etc/rc.d/init.d/anamon
name = functions
type = Startup Item
status = enabled
path = /etc/rc.d/init.d/functions
name = osqueryd
type = Startup Item
status = enabled
path = /etc/rc.d/init.d/osqueryd
name = AT-SPI D-Bus Bus
type = Startup Item
status = enabled
path = /usr/libexec/at-spi-bus-launcher --launch-immediately
osquery>
```
## Look up ELF information for a binary
Imagine you want to find out more details about the `ls`
binary. Usually, you would do it with the `readelf -h`
command followed by the `ls`
command's path. You can query the `elf_info`
table with Osquery and get the same information:
```
osquery> SELECT * FROM elf_info WHERE path="/bin/ls";
class = 64
abi = sysv
abi_version = 0
type = dyn
machine = 62
version = 1
entry = 24064
flags = 0
path = /bin/ls
osquery>
```
Now you have a taste of how to use osqueri to look for information of interest to you. However, this information is stored on a huge number of tables; one system I queried had 156 different tables, which can be overwhelming:
```
$ echo ".tables" | osqueryi | wc -l
156
$
```
To make things easier, you can start with these tables to get information about your Linux system:
**System information table**
`osquery> select * from system_info;`
**System limit information**
`osquery> select * from ulimit_info;`
**Files opened by various processes**
`osquery> select * from process_open_files;`
**Open ports on a system**
`osquery> select * from listening_ports;`
**Running processes information**
`osquery> select * from processes;`
**Installed packages information**
`osquery> select * from rpm_packages;`
**User login information**
`osquery> select * from last;`
**System log information**
`osquery> select * from syslog_events;`
## Learn more
Osquery is a powerful tool that provides a lot of host information that can be used to solve various use cases. You can learn more about Osquery by [reading its documentation](https://osquery.readthedocs.io/en/latest/).
## 2 Comments |
13,579 | 使用这个 Python 模块输入不可见的密码 | https://opensource.com/article/21/7/invisible-passwords-python | 2021-07-14T10:16:00 | [
"密码",
"gpg"
] | https://linux.cn/article-13579-1.html |
>
> 用 GPG 和 Python 的 getpass 模块给你的密码多一层安全保障。
>
>
>

密码对程序员来说尤其重要。你不应该在不加密的情况下存储它们,而且你也不应该在用户输入密码的时候显示出输入的内容。当我决定要提高我的笔记本电脑的安全性时,这对我来说变得特别重要。我对我的家目录进行了加密,但当我登录后,任何以纯文本形式存储在配置文件中的密码都有可能暴露在偷窥者面前。
具体来说,我使用一个名为 [Mutt](http://www.mutt.org/) 的应用作为我的电子邮件客户端。它可以让我在我的 Linux 终端中阅读和撰写电子邮件,但通常它希望在其配置文件中有一个密码。我限制了我的 Mutt 配置文件的权限,以便只有我可以看到它,我是我的笔记本电脑的唯一用户,所以我并不真的担心经过认证的用户会无意中看到我的配置文件。相反,我想保护自己,无论是为了吹嘘还是为了版本控制,不至于心不在焉地把我的配置发布到网上,把我的密码暴露了。此外,虽然我不希望我的系统上有不受欢迎的客人,但我确实想确保入侵者不能通过对我的配置上运行 `cat` 就获得我的密码。
### Python GnuPG
Python 模块 `python-gnupg` 是 `gpg` 应用的一个 Python 封装。该模块的名字是 `python-gnupg`,你不要把它和一个叫做 `gnupg` 的模块混淆。
[GnuPG](https://gnupg.org/)(GPG) 是 Linux 的默认加密系统,我从 2009 年左右开始使用它。我对它很熟悉,对它的安全性有很高的信任。
我决定将我的密码输入 Mutt 的最好方法是将我的密码存储在一个加密的 GPG 文件中,创建一个提示我的 GPG 密码来解锁这个加密文件,然后将密码交给 Mutt(实际上是交给 `offlineimap` 命令,我用它来同步我的笔记本和电子邮件服务器)。
[用 Python 获取用户输入](https://opensource.com/article/20/12/learn-python) 是非常容易的。对 `input` 进行调用,无论用户输入什么,都会被存储为一个变量:
```
print("Enter password: ")
myinput = input()
print("You entered: ", myinput)
```
我的问题是,当我根据密码提示在终端上输入密码时,我所输入的所有内容对任何从我肩膀上看过去或滚动我的终端历史的人来说都是可见的:
```
$ ./test.py
Enter password: my-Complex-Passphrase
```
### 用 getpass 输入不可见密码
正如通常的情况一样,有一个 Python 模块已经解决了我的问题。这个模块是 `getpass4`,从用户的角度来看,它的行为和 `input` 完全一样,只是不显示用户输入的内容。
你可以用 [pip](https://opensource.com/article/19/11/python-pip-cheat-sheet) 安装这两个模块:
```
$ python -m pip install --user python-gnupg getpass4
```
下面是我的 Python 脚本,用于创建密码提示:
```
#!/usr/bin/env python
# by Seth Kenlon
# GPLv3
# install deps:
# python3 -m pip install --user python-gnupg getpass4
import gnupg
import getpass
from pathlib import Path
def get_api_pass():
homedir = str(Path.home())
gpg = gnupg.GPG(gnupghome=os.path.join(homedir,".gnupg"), use_agent=True)
passwd = getpass.getpass(prompt="Enter your GnuPG password: ", stream=None)
with open(os.path.join(homedir,'.mutt','pass.gpg'), 'rb') as f:
apipass = (gpg.decrypt_file(f, passphrase=passwd))
f.close()
return str(apipass)
if __name__ == "__main__":
apipass = get_api_pass()
print(apipass)
```
如果你想试试,把文件保存为 `password_prompt.py`。如果你使用 `offlineimap` 并想在你自己的密码输入中使用这个方案,那么把它保存到某个你可以在 `.offlineimaprc` 文件中指向 `offlineimap` 的位置(我使用 `~/.mutt/password_prompt.py`)。
### 测试密码提示
要查看脚本的运行情况,你首先必须创建一个加密文件(我假设你已经设置了 GPG):
```
$ echo "hello world" > pass
$ gpg --encrypt pass
$ mv pass.gpg ~/.mutt/pass.gpg
$ rm pass
```
现在运行 Python 脚本:
```
$ python ~/.mutt/password_prompt.py
Enter your GPG password:
hello world
```
当你输入时没有任何显示,但只要你正确输入 GPG 口令,你就会看到该测试信息。
### 将密码提示符与 offlineimap 整合起来
我需要将我的新提示与 `offlineimap` 命令结合起来。我为这个脚本选择了 Python,因为我知道 `offlineimap` 可以对 Python 程序进行调用。如果你是一个 `offlineimap` 用户,你会明白唯一需要的“整合”是在你的 `.offlineimaprc` 文件中改变两行。
首先,添加一行引用 Python 文件的内容:
```
pythonfile = ~/.mutt/password_prompt.py
```
然后将 `.offlineimaprc`中的 `remotepasseval` 行改为调用 `password_prompt.py`中的 `get_api_pass()` 函数:
```
remotepasseval = get_api_pass()
```
配置文件中不再有密码!
### 安全问题
在你的个人电脑上考虑安全问题有时会让人觉得很偏执。你的 SSH 配置是否真的需要限制为 600?隐藏在名为 `.mutt` 的无关紧要的电子邮件密码真的重要吗?也许不重要。
然而,知道我没有把敏感数据悄悄地藏在我的配置文件里,使我更容易把文件提交到公共 Git 仓库,把片段复制和粘贴到支持论坛,并以真实好用的配置文件的形式分享我的知识。仅就这一点而言,安全性的提高使我的生活更加轻松。而且有这么多好的 Python 模块可以提供帮助,这很容易实现。
---
via: <https://opensource.com/article/21/7/invisible-passwords-python>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Passwords are particularly problematic for programmers. You're not supposed to store them without encrypting them, and you're not supposed to reveal what's been typed when your user enters one. This became particularly important to me when I decided I wanted to boost security on my laptop. I encrypt my home directory—but once I log in, any password stored as plain text in a configuration file is potentially exposed to prying eyes.
Specifically, I use an application called [Mutt](http://www.mutt.org/) as my email client. It lets me read and compose emails in my Linux terminal, but normally it expects a password in its configuration file. I restricted permissions on my Mutt config file so that only I can see it, but I'm the only user of my laptop, so I'm not really concerned about authenticated users inadvertently looking at my configs. Instead, I wanted to protect myself from absent-mindedly posting my config online, either for bragging rights or version control, with my password exposed. In addition, although I have no expectations of unwelcome guests on my system, I did want to ensure that an intruder couldn't obtain my password just by running `cat`
on my config.
## Python GnuPG
The Python module `python-gnupg`
is a Python wrapper for the `gpg`
application. The module's name is `python-gnupg`
, which you must not confuse with a module called `gnupg`
.
[GnuPG](https://gnupg.org/) (GPG) is the default encryption system for Linux, and I've been using it since 2009 or so. I feel comfortable with it and have a high level of trust in its security.
I decided that the best way to get my password into Mutt was to store my password inside an encrypted GPG file, create a prompt for my GPG password to unlock the encrypted file, and hand the password over to Mutt (actually to the `offlineimap`
command, which I use to synchronize my laptop with the email server).
[Getting user input with Python](https://opensource.com/article/20/12/learn-python) is pretty easy. You make a call to `input`
, and whatever the user types is stored as a variable:
```
print("Enter password: ")
myinput = input()
print("You entered: ", myinput)
```
My problem was when I typed a password into the terminal in response to my password prompt, everything I typed was visible to anyone looking over my shoulder or scrolling through my terminal history:
```
$ ./test.py
Enter password: my-Complex-Passphrase
```
## Invisible password entry with getpass
As is often the case, there's a Python module that's already solved my problem. The module is `getpass4`
, and from the user's perspective, it behaves exactly like `input`
except without displaying what the user is typing.
You can install both modules with [pip](https://opensource.com/article/19/11/python-pip-cheat-sheet):
```
$ python -m pip install --user \
python-gnupg getpass4
```
Here's my Python script to create a password prompt:
```
#!/usr/bin/env python
# by Seth Kenlon
# GPLv3
# install deps:
# python3 -m pip install --user python-gnupg getpass4
import gnupg
import getpass
from pathlib import Path
def get_api_pass():
homedir = str(Path.home())
gpg = gnupg.GPG(gnupghome=os.path.join(homedir,".gnupg"), use_agent=True)
passwd = getpass.getpass(prompt="Enter your GnuPG password: ", stream=None)
with open(os.path.join(homedir,'.mutt','pass.gpg'), 'rb') as f:
apipass = (gpg.decrypt_file(f, passphrase=passwd))
f.close()
return str(apipass)
if __name__ == "__main__":
apipass = get_api_pass()
print(apipass)
```
Save the file as `password_prompt.py`
if you want to try it out. If you're using `offlineimap`
and want to use this solution for your own password entry, then save it to some location you can point `offlineimap`
to in your `.offlineimaprc`
file (I use `~/.mutt/password_prompt.py`
).
## Testing the password prompt
To see the script in action, you first must create an encrypted file (I'll assume that you already have GPG set up):
```
$ echo "hello world" > pass
$ gpg --encrypt pass
$ mv pass.gpg ~/.mutt/pass.gpg
$ rm pass
```
Now run the Python script:
```
$ python ~/.mutt/password_prompt.py
Enter your GPG password:
hello world
```
Nothing displays as you type, but as long as you enter your GPG passphrase correctly, you will see the test message.
## Integrating the password prompt with offlineimap
I needed to integrate my new prompt with the `offlineimap`
command. I chose Python for this script because I knew that `offlineimap`
can make calls to Python applications. If you're an `offlineimap`
user, you'll appreciate that the only "integration" required is changing two lines in your `.offlineimaprc`
file.
First, add a line referencing the Python file:
`pythonfile = ~/.mutt/password_prompt.py`
And then replace the `remotepasseval`
line in `.offlineimaprc`
with a call to the `get_api_pass()`
function in `password_prompt.py`
:
`remotepasseval = get_api_pass()`
No more passwords in your config file!
## Security matters
It sometimes feels almost paranoid to think about security minutiae on your personal computer. Does your SSH config really need to be restricted to 600? Does it really matter that your email password is in an inconsequential config file buried within a hidden folder called, of all things, `.mutt`
? Probably not.
And yet knowing that I don't have sensitive data quietly hidden away in my config files makes it a lot easier for me to commit files to public Git repositories, to copy and paste snippets into support forums, and to share my knowledge in the form of actual, known-good configuration files. For that alone, improved security has made my life easier. And with so many great Python modules available to help, it's easy to implement.
## Comments are closed. |
13,581 | 在 Linux 命令行上编辑 PDF | https://opensource.com/article/21/7/qpdf-command-line | 2021-07-15T09:32:55 | [
"PDF"
] | https://linux.cn/article-13581-1.html |
>
> 使用 qpdf 和 poppler-utils 来分割、修改和合并 PDF 文件。
>
>
>

你收到的许多文件都是 PDF 格式的。有时这些 PDF 需要进行处理。例如,可能需要删除或添加页面,或者你可能需要签署或修改一个特定的页面。
不管是好是坏,这就是我们所处的现实。
有一些花哨的图形用户界面工具可以让你编辑 PDF,但我一直对命令行感到最舒服。在这个任务的许多命令行工具中,当我想修改一个 PDF 时,我使用的是 `qpdf` 和 `poppler-utils`。
### 安装
在 Linux 上,你可以用你的包管理器(如 `apt` 或 `dnf`)来安装 `qpdf` 和 `poppler-utils`。比如在 Fedora 上:
```
$ sudo dnf install qpdf poppler-utils
```
在 macOS 上,使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac)。在 Windows 上,使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey)。
### qpdf
`qpdf` 命令可以做很多事情,但我主要用它来:
1. 将一个 PDF 分割成不同的页面
2. 将多个 PDF 文件合并成一个文件
要将一个 PDF 分割成不同的页面:
```
qpdf --split-pages original.pdf split.pdf
```
这就会生成像 `split-01.pdf`、`split-02.pdf` 这样的文件。每个文件都是一个单页的 PDF 文件。
合并文件比较微妙:
```
qpdf --empty concatenated.pdf --pages split-*.pdf --
```
这就是 `qpdf` 默认的做法。`--empty` 选项告诉 qpdf 从一个空文件开始。结尾处的两个破折号(`--`)表示没有更多的文件需要处理。这是一个参数反映内部模型的例子,而不是人们使用它的目的,但至少它能运行并产生有效的 PDF!
### poppler-utils
这个软件包包含几个工具,但我用得最多的是 [pdftoppm](https://www.xpdfreader.com/pdftoppm-man.html),它把 PDF 文件转换为可移植的像素图(`ppm`)文件。我通常在用 `qpdf` 分割页面后使用它,并需要将特定页面转换为我可以修改的图像。`ppm` 格式并不为人所知,但重要的是大多数图像处理方法,包括 [ImageMagick](https://opensource.com/article/17/8/imagemagick)、[Pillow](https://opensource.com/article/20/8/edit-images-python) 等,都可以使用它。这些工具中的大多数也可以将文件保存为 PDF。
### 工作流程
我通常的工作流程是:
* 使用 `qpdf` 将 PDF 分割成若干页。
* 使用 `poppler-utils` 将需要修改的页面转换为图像。
* 根据需要修改图像,并将其保存为 PDF。
* 使用 `qpdf` 将各页合并成一个 PDF。
### 其他工具
有许多很好的开源命令来处理 PDF,无论你是 [缩小它们](https://opensource.com/article/20/8/reduce-pdf)、[从文本文件创建它们](https://opensource.com/article/20/5/pandoc-cheat-sheet)、[转换文档](https://opensource.com/article/21/3/libreoffice-command-line),还是尽量 [完全避免它们](https://opensource.com/article/19/3/comic-book-archive-djvu)。你最喜欢的开源 PDF 工具是什么?请在评论中分享它们。
---
via: <https://opensource.com/article/21/7/qpdf-command-line>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many of the documents you receive come in PDF format. Sometimes those PDFs need to be manipulated. For example, pages might need to be removed or added, or you might need to sign or change a specific page.
Whether good or bad, this is the reality we all live in.
There are some fancy graphical user interface tools that let you edit PDFs, but I have always been most comfortable with the command line. Of the many command-line tools for this task, the ones I use when I want to modify a PDF are `qpdf`
and `poppler-utils`
.
## Install
On Linux, you can install `qpdf`
and `poppler-utils`
using your package manager (such as `apt`
or `dnf`
.) For example, on Fedora:
`$ sudo dnf install qpdf poppler-utils`
On macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac). On Windows, use [Chocolatey](https://opensource.com/article/20/3/chocolatey).
## qpdf
The `qpdf`
command can do a lot, but I mostly use it for:
- Splitting a PDF into separate pages
- Concatenating, or combining, PDFs into one file
To split a PDF into separate pages:
`qpdf --split-pages original.pdf split.pdf`
This generates files like `split-01.pdf`
, `split-02.pdf`
, and so on. Each file is a single-page PDF file.
Concatenating files is a little subtler:
`qpdf --empty concatenated.pdf --pages split-*.pdf --`
This is what `qpdf`
does by default. The `--empty`
option tells qpdf to start with an empty file. The two dashes (`--`
) at the end signals that there are no more files to process. This is a case where the parameters reflect an internal model, rather than what people use it for, but at least it runs and produces valid PDFs!
## poppler-utils
This package contains several utilities, but the one I use the most is [pdftoppm](https://www.xpdfreader.com/pdftoppm-man.html), which converts PDF files to portable pixmap (`ppm`
) image files. I usually use it after I split pages with `qpdf`
and need to convert a specific page to an image that I can modify. The `ppm`
format is not well known, but the important thing about it is that most image manipulation methods, including [ImageMagick](https://opensource.com/article/17/8/imagemagick), [Pillow](https://opensource.com/article/20/8/edit-images-python), and many other options, work with it. Most of these tools can save files back to PDF, too.
## Workflow
My usual workflow is:
- Use
`qpdf`
to split the PDF into pages. - Use
`poppler-utils`
to convert the pages that need to be changed into images. - Modify the images as needed and save them to PDF.
- Use
`qpdf`
to concatenate the pages back into one PDF.
## Other tools
There are many great open source commands to deal with PDFs, whether you're [shrinking them](https://opensource.com/article/20/8/reduce-pdf), [creating them from text files](https://opensource.com/article/20/5/pandoc-cheat-sheet), [converting documents](https://opensource.com/article/21/3/libreoffice-command-line), or trying your best to [avoid them altogether](https://opensource.com/article/19/3/comic-book-archive-djvu). What are your favorite open source PDF utilities? Please share them in the comments.
## Comments are closed. |
13,582 | 在 Linux 命令行中生成密码 | https://opensource.com/article/21/7/generate-passwords-pwgen | 2021-07-15T09:47:15 | [
"密码"
] | https://linux.cn/article-13582-1.html |
>
> 在命令行上创建符合特定规范的密码。
>
>
>

大多数网站或应用都要求用户创建带有安全密码的账户,以便他们能够迎合用户体验。虽然这有利于网站开发者,但肯定不会让用户的生活更轻松。
有时,创建密码的规则是如此严格,以至于难以生成一个强壮且合规的组合。如果有一个工具可以生成符合网站或应用程序要求的任何规则的安全密码,那就容易多了。
这就是 `pwgen` 的用武之地。根据它的 [手册页](https://linux.die.net/man/1/pwgen):“pwgen 生成的密码是为了让人容易记住,同时又尽可能的安全。” 它返回符合你所提供的规则的多个密码选项,这样你就可以选择一个你喜欢的(而且可能更容易记住)。
### 安装 pwgen
在 Linux 上,你可以通过包管理器安装 `pwgen`。例如,在 Fedora 上:
```
$ sudo dnf install pwgen
```
在 macOS 上,可以使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac)。在 Windows 上,可以使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey)。
### 使用 pwgen 生成密码
有几种方式可以通过向 `pwgen` 传递参数来生成密码,这取决于你所需的参数。这里有一些例子。更多的参数选项请查阅手册页。
如果你需要一个安全的、难以记忆的特定长度的密码,请运行 `pwgen --secure`(或简写 `-s`),后面跟上你所需的密码长度:
```
$ pwgen -s 25
pnFBg9jB8AlKL3feOuS2ZwMGb xlmDRoaLssduXTdGV6jkQhUGY O3IUB3CH7ry2kD4ZrSoODzWez
dENuvhkF3mmeb4FfXd4VPU2dE EMCi1sHFKHUVmbVajXWleFBzD 4UXJIu3JztVzYz6qJktBB3KCv
AF9WM7hmG89cpTlg8PksI7jsL LSSaT7DD4IT8DUgRAgY8Zt06m Nths10uT0bIMGsPuE0XEHDxsj
6YjLRbg3VnGnrzkoQCmrneLmm Tam1Mftac5RxrZPoXJtXx1Qdy BPqePJW4LdTtFnuZOepKEj0o0
Ss8veqqf95zusqYPsfE7mLb93 4KuZdReO5lhKff7Xv1en1Hefs is7hjLnDrVCUJ7Hh6zYUzfppn
UXOfENPRJYWiroIWEt5IgAwdJ t8i4hM4cDuL8pN1rpFKHnx7yw Wr7gyuyU2br7aCbiH5M5ogvc6
evk90lUmK2rOUWGgnqmznn0a9 Lflyc9svJfaBRRMin24j0P9ec hIzyJIwCpklDjgOb5PrMkyPCI
bhYcaV7GXfUiCMZ1kvMnlmKLx v4EJew54u6s4ZCirOTAWjfPQ2 IdemhbOHOm4Qo70WGibaNTOpO
j6XkmdB3LBfqZf5mbL3GndliG PpZbeXfWOFCpNARyXt1FWPAb8 OLQS2HFuqkiSg56sdxNsg5vaJ
1g666HxJPQ6l2L0RlaDEMoi50 1t6au7VuTN9HVPpiVmd1Gurli 46OAWypvwtZZUdBEfaHSunjpw
0LiRj9dbtMuI4cbDES8O4gYRq 2HPiaq5AANvVT32fWqNIruu3R 3lT5B107WoUbHsELkKUjnEEih
gLmYUTp0XZJWvIVbA5rFvBT54 LEm6QVeTMinc056DC9c4V55cV ipV45Ewj704365byKhY8zn766
```
运行 `pwgen -symbols`(或简写 `-y`),再加上所需的密码长度,生成包含特殊字符的密码:
```
$ pwgen -y 25
Osh0chahxe0won9aech4ese?v pemoh2ohm9aim;iu4Eiy"ah0y Taiqu;o2aeSh+o4aedoagait3
Vei;phoh5owai5jui+t|ei3ot teu!w7mahxoh0Po7ohph8Iez6 quie#phooCeu2lohm5shaPaer
eTh5AechaexieToh9ez5eeZ;e nuloh1ico0Nool:eG<aiv`ah, Heeghuo8ahzii1Iep~ie_ch7p
oe6Xee6uchei7Oroothail~iL ahjie!Chee.W4wah[wuu]phoo ees7ieb!i[ibahhei1xoz2Woh
Atei9ooLu7lo~sh>aig@ae9No OVahh2OhNgahtu8iethaR@i7o ouFai8ahP@eil4Ieh5le5ipu5
eeT4tahW0ieng9fe?i5auM3ie seet0ohc4aiJei]koiGha2zu% iuh@oh4eix0Vuphi?o,hei9me
loh0Aeph=eix(ohghe6chee3z ahgh2eifiew8dahG_aeph8woo oe!B4iasaeHo`ungie3taekoh
cei!c<ung&u,shee6eir7Eigo va6phou8ooYuoquohghi-n6Qu eeph4ni\chi2shohg3Die1hia
uCagha8Toos2bahLai7phuph` Zue2thieng9ohhoo~shoh6ese Aet7Lio1ailee^qu4hiech5ie
dee]kuwu9OhTh3shoi2eijoGe daethahH6ahV3eekoo9aep$an aehiiMaquieHee9moh`l_oh4l
aec#ii6Chophu3aigh*ai#le4 looleihoog:uo4Su"thiediec eeTh{o7Eechah7eeJ2uCeish!
oi3jaiphoof$aiy;ieriexeiP Thozool3aipi|cahfu0Ha~e1e az/u8iel2Jaeph2vooshai9Wi
```
运行 `pwgen --capitalize`(或缩写 `-c`),后面跟上密码长度,生成包含大写字母的密码:
```
$ pwgen -c 25
pheipichusheta6ieJ4xai4ai seiLeiciev7ijoy5Uez7Iepee Foobeisheec7ooGahbicholo6
shenahsheevigh3pha1Ie5aev taiTheitahne3oong4joegh9d ooshieV0ooGhaelabuyahsh7t
ieniech0Uajeh8nieYaak0foh dohm5Pee3jeeshahm1eipei0a aemoob8Lequeesho8ahreiwee
keineeCh5ieZejafitith6Osh Tahn3nohl6iewaimee6oofied Aed2Woh7nae5ohgh2toh1ieph
le4agheeb0bieth0Ui7ielais Iunoo4lev1aiG4NohfoTh3ro5 iLai7eiQuohXosh8ooyiev6wu
eezib2zoh2ohsh0cooSahluK6 baekiew8bo5oeMouthi7taCee iep6Puungae0uushogah4rohw
chohm5leogae2zeiph1OL0uK2 oosieCaishievahvig3Iaphai ii9AemieYeepe1ahciSei8ees
ie3aighaiy9TaX6bae8soKe6t sooDaivi4mia8Eireech8ope9 moi9uk3bauv0ahY4to0aedie7
que8seHu4shu7Veib6noe7dai shuyuj9aiphoip2Ier4oole1u Thoaziebah1Ieph2Veec0Ohm8
auqua4Kaitie9sei6quoh7chi jeewaituH3Ohsaisahp0viequ ueh1quaibidoh6Bae6ri0Mee2
lae3aiJaiNgoh7yieghozev7o Di2vohfahr7uo7ohSh0voh5sh Jeurahxiedeiyoom3aechaS7d
thung2pheiy2tooBeenuN8ia3 foh0oge1athei0oowieZen0ai iexei0io1vohsieThuCoy5ogi
tohHe3uu2eXieheeQuoh7eit8 aiMieCeizeivu1ooch8aih0sh Riojei2yoah0AiWeiRoMieQu0
```
### 让它变得简单
由于人脑更倾向于选择模式,所以强壮的随机密码难以生成。通过使用 `pwgen`,你可以轻松生成密码。借助于优秀的 [开源密码管理器](https://opensource.com/article/16/12/password-managers),你可以完全从易于使用但难以猜测的密码中获益。
---
via: <https://opensource.com/article/21/7/generate-passwords-pwgen>
作者:[Sumantro Mukherjee](https://opensource.com/users/sumantro) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Most websites and applications ask users to create accounts with secure passwords so that they can provide tailored user experiences. While this tips the odds in favor of website developers, it certainly doesn't make life easier for users.
Sometimes the rules for creating passwords are so strict that it's hard to get a good and allowable combination. It would be much easier to have a tool that generates secure passwords that meet whatever rules the website or application requires.
This is where pwgen comes into play. According to its [man page](https://linux.die.net/man/1/pwgen), "the pwgen program generates passwords which are designed to be easily memorized by humans, while being as secure as possible." It returns multiple password options that meet the criteria you provide so that you can select the one that you prefer (and might be more likely to remember).
## Install pwgen
On Linux, you can install pwgen using your package manager. For instance, on Fedora:
`$ sudo dnf install pwgen`
On macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac). On Windows, use [Chocolatey](https://opensource.com/article/20/3/chocolatey).
## Generate passwords with pwgen
There are several ways to pass arguments to pwgen to generate passwords, depending on what parameters you need. Here are some examples; consult the man page for more options.
If you need a secure, hard-to-remember password of a specific length, run `pwgen --secure`
(or `-s`
for short) followed by the character length you need:
```
$ pwgen -s 25
pnFBg9jB8AlKL3feOuS2ZwMGb xlmDRoaLssduXTdGV6jkQhUGY O3IUB3CH7ry2kD4ZrSoODzWez
dENuvhkF3mmeb4FfXd4VPU2dE EMCi1sHFKHUVmbVajXWleFBzD 4UXJIu3JztVzYz6qJktBB3KCv
AF9WM7hmG89cpTlg8PksI7jsL LSSaT7DD4IT8DUgRAgY8Zt06m Nths10uT0bIMGsPuE0XEHDxsj
6YjLRbg3VnGnrzkoQCmrneLmm Tam1Mftac5RxrZPoXJtXx1Qdy BPqePJW4LdTtFnuZOepKEj0o0
Ss8veqqf95zusqYPsfE7mLb93 4KuZdReO5lhKff7Xv1en1Hefs is7hjLnDrVCUJ7Hh6zYUzfppn
UXOfENPRJYWiroIWEt5IgAwdJ t8i4hM4cDuL8pN1rpFKHnx7yw Wr7gyuyU2br7aCbiH5M5ogvc6
evk90lUmK2rOUWGgnqmznn0a9 Lflyc9svJfaBRRMin24j0P9ec hIzyJIwCpklDjgOb5PrMkyPCI
bhYcaV7GXfUiCMZ1kvMnlmKLx v4EJew54u6s4ZCirOTAWjfPQ2 IdemhbOHOm4Qo70WGibaNTOpO
j6XkmdB3LBfqZf5mbL3GndliG PpZbeXfWOFCpNARyXt1FWPAb8 OLQS2HFuqkiSg56sdxNsg5vaJ
1g666HxJPQ6l2L0RlaDEMoi50 1t6au7VuTN9HVPpiVmd1Gurli 46OAWypvwtZZUdBEfaHSunjpw
0LiRj9dbtMuI4cbDES8O4gYRq 2HPiaq5AANvVT32fWqNIruu3R 3lT5B107WoUbHsELkKUjnEEih
gLmYUTp0XZJWvIVbA5rFvBT54 LEm6QVeTMinc056DC9c4V55cV ipV45Ewj704365byKhY8zn766
```
Run `pwgen –symbols`
(or `-y`
for short) followed by the desired character length to generate a password that has special characters:
```
$ pwgen -y 25
Osh0chahxe0won9aech4ese?v pemoh2ohm9aim;iu4Eiy"ah0y Taiqu;o2aeSh+o4aedoagait3
Vei;phoh5owai5jui+t|ei3ot teu!w7mahxoh0Po7ohph8Iez6 quie#phooCeu2lohm5shaPaer
eTh5AechaexieToh9ez5eeZ;e nuloh1ico0Nool:eG<aiv`ah, Heeghuo8ahzii1Iep~ie_ch7p
oe6Xee6uchei7Oroothail~iL ahjie!Chee.W4wah[wuu]phoo ees7ieb!i[ibahhei1xoz2Woh
Atei9ooLu7lo~sh>aig@ae9No OVahh2OhNgahtu8iethaR@i7o ouFai8ahP@eil4Ieh5le5ipu5
eeT4tahW0ieng9fe?i5auM3ie seet0ohc4aiJei]koiGha2zu% iuh@oh4eix0Vuphi?o,hei9me
loh0Aeph=eix(ohghe6chee3z ahgh2eifiew8dahG_aeph8woo oe!B4iasaeHo`ungie3taekoh
cei!c<ung&u,shee6eir7Eigo va6phou8ooYuoquohghi-n6Qu eeph4ni\chi2shohg3Die1hia
uCagha8Toos2bahLai7phuph` Zue2thieng9ohhoo~shoh6ese Aet7Lio1ailee^qu4hiech5ie
dee]kuwu9OhTh3shoi2eijoGe daethahH6ahV3eekoo9aep$an aehiiMaquieHee9moh`l_oh4l
aec#ii6Chophu3aigh*ai#le4 looleihoog:uo4Su"thiediec eeTh{o7Eechah7eeJ2uCeish!
oi3jaiphoof$aiy;ieriexeiP Thozool3aipi|cahfu0Ha~e1e az/u8iel2Jaeph2vooshai9Wi
```
Run `pwgen --capitalize`
(or `-c`
for short) followed by the character length to generate a password with at least one capital letter:
```
$ pwgen -c 25
pheipichusheta6ieJ4xai4ai seiLeiciev7ijoy5Uez7Iepee Foobeisheec7ooGahbicholo6
shenahsheevigh3pha1Ie5aev taiTheitahne3oong4joegh9d ooshieV0ooGhaelabuyahsh7t
ieniech0Uajeh8nieYaak0foh dohm5Pee3jeeshahm1eipei0a aemoob8Lequeesho8ahreiwee
keineeCh5ieZejafitith6Osh Tahn3nohl6iewaimee6oofied Aed2Woh7nae5ohgh2toh1ieph
le4agheeb0bieth0Ui7ielais Iunoo4lev1aiG4NohfoTh3ro5 iLai7eiQuohXosh8ooyiev6wu
eezib2zoh2ohsh0cooSahluK6 baekiew8bo5oeMouthi7taCee iep6Puungae0uushogah4rohw
chohm5leogae2zeiph1OL0uK2 oosieCaishievahvig3Iaphai ii9AemieYeepe1ahciSei8ees
ie3aighaiy9TaX6bae8soKe6t sooDaivi4mia8Eireech8ope9 moi9uk3bauv0ahY4to0aedie7
que8seHu4shu7Veib6noe7dai shuyuj9aiphoip2Ier4oole1u Thoaziebah1Ieph2Veec0Ohm8
auqua4Kaitie9sei6quoh7chi jeewaituH3Ohsaisahp0viequ ueh1quaibidoh6Bae6ri0Mee2
lae3aiJaiNgoh7yieghozev7o Di2vohfahr7uo7ohSh0voh5sh Jeurahxiedeiyoom3aechaS7d
thung2pheiy2tooBeenuN8ia3 foh0oge1athei0oowieZen0ai iexei0io1vohsieThuCoy5ogi
tohHe3uu2eXieheeQuoh7eit8 aiMieCeizeivu1ooch8aih0sh Riojei2yoah0AiWeiRoMieQu0
```
## Make it easy
Good, randomized passwords are hard to invent, especially because the human brain tends to prefer patterns. Make password generation easier on yourself by using pwgen. With a good [open source password manager](https://opensource.com/article/16/12/password-managers), you can benefit from passwords that are hard to guess but easy to use from start to finish.
## 1 Comment |
13,584 | 包含新功能和工具的 Linux Mint 20.2 已经发布 | https://news.itsfoss.com/linux-mint-20-2-release/ | 2021-07-16T10:03:00 | [
"Mint"
] | https://linux.cn/article-13584-1.html |
>
> Linux Mint 20.2 是一次令人兴奋的升级,它有新的应用程序、更新提醒和桌面环境的升级。是时候升级了?
>
>
>

几周前,Linux Mint 20.2 beta 版 [发布](https://news.itsfoss.com/linux-mint-20-2-beta-release/)了。现在,Linux Mint 20.2 最终稳定版也发布了。
这个版本是基于 Ubuntu 20.04 的 LTS(长期支持版本),支持 2025 年截止。
来看下这个版本有什么新特性,以及如何获取它。
### Linux Mint 20.2: 有什么新特性?
这个版本主要两点是增加了更新通知。该功能鼓励用户更新系统,以确保安全性。
该功能不像 [Windows 系统那样强制更新](https://news.itsfoss.com/linux-mint-updates-notice/),但它会留意你多久没有更新系统,检查系统运行时间,然后提醒你更新。 
更棒的是,你可以配置更新通知。
其他主要升级还有:桌面环境 **Cinnamon 5**,新的**批量改名工具** Bulky,**用 Sticky Notes 取代 GNote** 作为默认笔记应用。

批量文件改名工具可以在所有桌面版本中使用,但不包括 Xfce。因为 Xfce 默认的文件管理器(Thunar)已经有该功能。
Cinnamon 5 不是很让人激动,不过有一些内在性能改进,并增加了限制内存使用的选项。

Sticky Notes 是用 GTK 3 开发的,支持 HiDPI,并提供了更多的功能。同时,与系统托盘整合得更好。

### 其他改进
在网络上共享文件的 [Warpinator 应用程序](https://news.itsfoss.com/warpinator-android-app/) 得到了一些升级,变得更有用。
其他桌面环境的升级包括 Xfce 4.16 和 MATE 1.24。除此之外,你还会发现一些细微的 UI 改进和错误修复。
特别是解决了 NVIDIA 显卡**对混合图形的支持**的问题,这对笔记本电脑用户来说是个好消息。
要了解更多变更详情,你可以参考任一桌面版本的 [官方公告](https://blog.linuxmint.com/?p=4102)。
### 下载或升级至 Linux Mint 20.2
你可以直接在官方网站 [下载页面](https://linuxmint.com/download.php) 找到稳定版本。
* [下载 Linux Mint 20.2](https://linuxmint.com/download.php)
如果已经安装了 Linux Mint 20 或者 20.1。你可以先检查所有可用更新,然后更新管理器会收到更新。
接下来,确保你做了备份(如果你想的话,可以使用 timeshift 工具),然后从**编辑**菜单种静茹更新管理器的系统升级选项,如下所示。

当你单击后,屏幕上会出现升级的提示。你也可以通过 [官方升级说明](https://blog.linuxmint.com/?p=4111) 获得进一步帮助。
*你完成升级了吗?你对最新版本有什么看法?欢迎在下面的评论中分享你的想法。*
---
via: <https://news.itsfoss.com/linux-mint-20-2-release/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lcf33](https://github.com/lcf33) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux Mint 20.2 beta [arrived](https://news.itsfoss.com/linux-mint-20-2-beta-release/) a few weeks ago. And now, the final stable release for Linux Mint 20.2 is here.
This release is an LTS upgrade based on Ubuntu 20.04 that is supported until 2025.
Let us take a quick look at what’s new with this release and how do you get it.
## Linux Mint 20.2: What’s New?
The key highlight of this release is the addition of update notification, which should encourage more users to keep their systems up-to-date to ensure best security.
It will [not force updates like Windows](https://news.itsfoss.com/linux-mint-updates-notice/), but it will keep an eye out for how long you don’t apply updates, check system’s uptime, and then prompt you with an update reminder notification.
You also get to configure the update notifications, which is great.
Other major upgrades include **Cinnamon 5** desktop environment, a new bulk **file renaming tool** (Bulky), and **Sticky Notes replacing GNote** as the default note application.
The file renaming tool is available for all the desktop editions, excluding Xfce, because its default file manager (Thunar) already supports the feature.
Cinnamon 5 is not exactly exciting, but there are some under-the-hood improvements to its performance and nice little option to limit its RAM usage.
And Sticky Notes is developed in GTK 3, supports HiDPI and offers more features, along with better integration with the system tray.
## Other Improvements
[Warpinator app](https://news.itsfoss.com/warpinator-android-app/) to share files across a network has received some upgrades making it more useful.
Other desktop environment upgrades include Xfce 4.16 and MATE 1.24. In addition to that, you will find certain subtle UI improvements and several bug fixes.
Especially addressing issues with NVIDIA graphics, along with the **support for hybrid graphics**, great news for Laptop users!
To know more about some of the detailed changes, you can refer to the [official announcement](https://blog.linuxmint.com/?p=4102&ref=news.itsfoss.com) for one of the desktop editions.
## Download or Upgrade to Linux Mint 20.2
You can find the stable releases directly from the official website’s [download page](https://linuxmint.com/download.php?ref=news.itsfoss.com).
If you have Linux Mint 20 or 20.1 installed, you can choose to first apply all the available updates and then an update to your Update Manager.
Next, make sure that you have a backup (use timeshift if you want) and then head to the Update Manager’s System Upgrade option from the **Edit** menu as shown below.
When you click on it, you will be greeted with the on-screen instructions to go ahead with the upgrade. You may also refer to the [official upgrade instructions](https://blog.linuxmint.com/?p=4111&ref=news.itsfoss.com) for further help.
*Have you upgraded yet? What do you think about the latest release? Feel free to share your thoughts in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,585 | 如何在 CentOS、RHEL、Rocky Linux 最小化安装中设置互联网 | https://www.debugpoint.com/2021/06/setup-internet-minimal-install-server/ | 2021-07-16T10:49:49 | [
"网络",
"连接"
] | /article-13585-1.html | 
在最小化服务器安装中,设置互联网或网络是非常容易的。在本指南中,我们将解释如何在 CentOS、RHEL、Rocky Linux 最小安装中设置互联网或网络。
当你刚刚完成任何服务器发行版的最小化安装时,你没有任何图形界面或桌面环境可以用于设置你的网络或互联网。因此,当你只能使用终端时,了解如何设置联网是很重要的。NetworkManager 以及 systemd 服务为完成这项工作提供了必要的工具。以下是具体使用方法。
### 在 CentOS、RHEL、Rocky Linux 最小化安装中设置互联网
完成安装后,启动服务器终端。理想情况下,你应该会看到提示符。使用 root 或 admin 账户登录。
然后,首先尝试使用 `nmcli` 检查网络接口的状态和细节。`nmcli` 是一个控制 NetworkManager 服务的命令行工具。使用以下命令进行检查。
```
nmcli device status
```
这将显示设备名称、状态等。

运行工具 `nmtui` 来配置网络接口。[nmtui](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/networking_guide/sec-configuring_ip_networking_with_nmtui) 是 NetworkManager 工具的一部分,它为你提供了一个漂亮的用户界面来配置网络。这是 NetworkManager-tui 包的一部分,当你完成最小服务器的安装时它应该默认安装。
```
nmtui
```
在 `nmtui` 窗口中点击编辑一个连接。

选择网口名称:

在编辑连接窗口,为 IPv4 和 IPv6 选择自动。并选择自动连接。完成后按 “OK”。

通过使用如下 [systemd systemctl](https://www.debugpoint.com/2020/12/systemd-systemctl-service/) 命令,重新启动 NetworkManager 服务。
```
systemctl restart NetworkManager
```
如果一切顺利,在 CentOS、RHEL、Rocky Linux 服务器的最小化安装中你应该可以连接到网络和互联网了,前提是你的网络有互联网连接。你可以用 `ping` 来验证它是否正常。

### 额外技巧:在最小化服务器中设置静态 IP
当你把网络配置设置为自动,当你连接到互联网时,网口会动态地分配 IP。在某些情况下,当你建立一个局域网 (LAN) 时,你可能想给你的网口分配静态 IP。这超级简单。
打开你的网络的网络配置脚本。根据你的设备修改高亮部分:
```
vi /etc/sysconfig/network-scripts/ifcfg-ens3
```
在上面的文件中,用 `IPADDR` 属性添加你想要的 IP 地址。保存该文件。
```
IPADDR=192.168.0.55
```
在 `/etc/sysconfig/network` 中为你的网络添加网关:
```
NETWORKING=yes
HOSTNAME=debugpoint
GATEWAY=10.1.1.1
```
在 `/etc/resolv.conf` 的 `resolv.conf` 中添加任意公共 DNS 服务器:
```
nameserver 8.8.8.8
nameserver 8.8.4.4
```
并重新启动网络服务:
```
systemctl restart NetworkManager
```
这样就完成了静态 IP 的设置。你也可以使用 `ip addr` 命令检查详细的 IP 信息。
我希望这个指南能帮助你在你的最小化服务器中设置网络、互联网和静态 IP。如果你有任何问题,请在评论区告诉我。
---
via: <https://www.debugpoint.com/2021/06/setup-internet-minimal-install-server/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,588 | Windows 11 能影响 Linux 发行版吗? | https://news.itsfoss.com/can-windows-11-influence-linux/ | 2021-07-17T11:38:12 | [
"Linux"
] | https://linux.cn/article-13588-1.html |
>
> Windows 11 正在为全球的桌面用户制造新闻。它会影响 Linux 发行版走向桌面用户吗?
>
>
>

微软的 Windows11 终于发布了。有些人将其与 macOS 进行比较,另一些人则比较其细枝末节发现与 GNOME 和 KDE 的相似之处(这没有多大意义)。
但是,在所有的热议当中,我对另一件事很好奇—— **微软的 Windows 11 能影响桌面 Linux 发行版未来的决策吗?**
在这里,我将提到一些我的想法,即如果它以前发生过,为什么会发生?以及 Linux 发行版未来会怎样。
### 一些 Linux 发行版已经关注类似 Windows 的体验:但是,为什么呢?
微软的 Windows 是最受欢迎的桌面操作系统,因其易操作、软件支持和硬件兼容占据了 88% 的市场分额。
相反, Linux 占有 **大约 2% 的市场分额,** [即使 Linux 比 Windows 有更多的优势](https://itsfoss.com/linux-better-than-windows/)。
那么 Linux 能做什么来说服更多的用户将 Linux 作为他们的桌面操作系统呢?
每个桌面操作系统的主要关注点应该是用户体验。当微软和苹果设法为大众提供舒适的用户体验时,Linux 发行版并没有设法在这方面取得巨大的胜利。
然而,你将会发现有几个 [Linux 发行版打算取代 Windows 10](https://itsfoss.com/windows-like-linux-distributions/)。这些 Linux 发行版试图提供一个熟悉的用户界面,鼓励 Windows 用户考虑切换到 Linux 。
而且,由于这些发行版的存在,[在 2021 年切换到 Linux](https://news.itsfoss.com/switch-to-linux-in-2021/) 比以往任何时候都更有意义。
因此,为了让更多的用户跳转到 Linux ,微软 Window 多年来已经影响了许多发行版。
### Windows 11 在某些方面比 Linux 好?
用户界面随着 Windows 的发展而不断的发展。即使这是主观的,它似乎是大多数桌面用户的选择。
所以我要说 Windows 11 在这方面做了一些有吸引力的改进。

不仅仅局限于 UI/UX ,比如在任务栏中集成微软团队的聊天功能,可以方便用户与任何人即时联系。
**虽然 Linux 发行版没有自己成熟的服务,但是像这样定制的更多开箱即用的集成,应该会使新用户更容易上手。**
并且这让我想起了 Windows 11 的另一个方面——个性化的新闻和信息提要。
当然,微软会为此收集数据,你可能需要使用微软账号登录。但这也减少了用户寻找独立应用程序来跟踪天气、新闻和其他日常信息的摩擦。
Linux 不会强迫用户做出这些选择,但是像这样的特性/集成可以作为额外的选项添加,可以以选择的形式呈现给用户。
**换句话说,在与操作系统集成的同时,使事物更容易访问,应该可以摆脱陡峭的学习曲线。**
而且,可怕的微软商店也在 Windows 11 上进行了重大升级。

不幸的是,对于 Linux 发行版,我没有看到对应用中心进行多少有意义的升级,来使其在视觉上更吸引人,更有趣。
elementaryOS 可能正努力专注于 UX/UI ,并不断发展应用中心的体验,但对于大多数其他发行版,没有重大的升级。

虽然我很欣赏深度 Linux 在这方面所做的,但它并不是许多用户第一次尝试 Linux 时的热门选择。
### Windows 11 引入了更多的竞争:Linux 必须跟上
随着 Windows 11 的推出,作为桌面选择的 Linux 将面临更多的竞争。
虽然在 Linux 世界中,我们确实有一些 Windows 10 经验的替代品,但还没有针对 Windows 11 的。
但这让我们看到了来自 Linux 社区的明显反击—— **一个针对 Windows 11 的 Linux 发行版**。
不管是讨厌还是喜欢微软最新的 Windows 11 设计方案,在接下来的几年里,大众将会接受它。
并且,为了使 Linux 成为一个引人注目的桌面替代品,Linux 发行版的设计语言也必须发展。
不仅仅是桌面市场,还有笔记本专用的设计选择也需要对 Linux 发行版进行重大改进。
像 [Pop!\_OS\_System 76](https://pop.system76.com) 这些选择一直试图为 Linux 提供这种体验,这是一个良好的开端。
我认为 Zorin OS 可以作为一个引入 “**Windows 11**” 布局的发行版,作为让更多用户尝试 Linux 的一个选择。
别忘了,在 Windows 11 将 Android 应用程序支持作为一项功能推向市场之后,[深度 Linux 就引入了 Android 应用程序支持。](https://news.itsfoss.com/deepin-linux-20-2-2-release/)
所以,你看,当微软的 Windows 采取行动时,对 Linux 也会产生连锁反应。而深度 Linux 的 Android 应用支持只是一个开始……让我们看看接下来还会出现什么。
*你对 Windows 11 影响 Linux 桌面的未来有什么看法?我们也需要进化吗?或者我们应该继续与众不同,不受大众选择的影响?*
---
via: <https://news.itsfoss.com/can-windows-11-influence-linux/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zz-air](https://github.com/zz-air) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Microsoft’s Windows 11 has been finally revealed. While some compare it to macOS, others compare the nitty-gritty details to find similarities with GNOME and KDE (which does not make much sense).
But, among all the buzz, I am curious about something else — **Can Microsoft’s Windows 11 influence the future design decisions of desktop Linux distributions?**
Here I shall mention some of my thoughts on why it might happen, if it has happened before, and what the future holds for Linux distributions.
## Some Linux Distributions Already Focus on Windows-like Experience: But, why?
Microsoft’s Windows is the most popular desktop operating system with **88% of the market share** for its ease of use, software support, and hardware compatibility.
On the contrary, Linux has **about 2% of the market share,** even with all the added [benefits of Linux over Windows](https://itsfoss.com/linux-better-than-windows/?ref=news.itsfoss.com).
So what can Linux do to convince more users to try Linux as their desktop operating system?
The main focus of every desktop operating system should be the user experience. While Microsoft and Apple have managed to provide a comfortable user experience for the masses, Linux distributions did not manage to get a big win on that front.
However, you will find several [Linux distributions that aim to replace Windows 10](https://itsfoss.com/windows-like-linux-distributions/?ref=news.itsfoss.com). These Linux distributions try to provide a familiar user interface that could encourage a Windows user to consider switching to Linux.
And, due to the existence of such distributions, [switching to Linux in 2021](https://news.itsfoss.com/switch-to-linux-in-2021/) makes more sense than ever.
Hence, to get more users to jump-ship to Linux, Microsoft Windows has influenced many distributions for years now.
## Is Windows 11 Better than Linux in Some Way?
The user interface is constantly evolving with Windows. Even if that’s subjective, it is what most desktop users seem to be going for.
So I’d say Windows 11 has made some attractive improvements on that front.

Not just limited to the UI/UX, things like integrating Microsoft Team’s chat features in the taskbar makes it convenient for users to instantly connect with anyone.
**While Linux distributions do not have their own full-fledged services, more out-of-the-box integrations tailored like this should make the onboarding experience easier for new users.**
And that brings me to another aspect of Windows 11—a personalized news and information feed.
Sure, Microsoft collects data for that, and you may have to sign in using a Microsoft account. But this is yet something that reduces friction for the users to go and look for a separate app to keep track of weather, news, and other daily information.
Linux does not force these choices for a user but features/integrations like this can be added as additional options which can be presented in the form of a choice to users.
**In other words, making things more accessible while integrated with the OS should get rid of a steep learning curve. **
And, the dreaded Microsoft Store has also got a serious upgrade with Windows 11.
Unfortunately, for Linux distributions, I don’t see much meaningful upgrade to the app centers to make it visually appealing, and something interesting.
elementaryOS is probably making a good effort to focus on the UX/UI, and the evolving the experience with app center but for the most other distros, no significant upgrade.
While I appreciate what Deepin Linux does in this regard, but it isn’t the popular choice for many users who try Linux for the first time.
## Windows 11 Introduces More Competition: Linux Has to Keep Up
With the launch of Windows 11, Linux as a desktop choice will get more competition.
While we do have some replacements for Windows 10 experience in the Linux world, there’s nothing that targets Windows 11, yet.
But this brings us to the obvious counter-response from the Linux community – **a Linux distribution that takes a dab at Windows 11**.
No matter whether you hate or love Microsoft’s latest design approach to Windows 11, the masses will adopt it over the next few years.
And to keep Linux as a compelling desktop alternative, the design language with Linux distributions must evolve as well.
Not just the desktop market—but laptop-exclusive design choices also need a significant improvement for Linux distributions.
Some options like [Pop!_OS by System76](https://pop.system76.com/?ref=news.itsfoss.com) have been trying to offer that experience for Linux, which is a good start.
I think Zorin OS can be one of the distributions to introduce a “**Windows 11**” layout as an option to get more users to try Linux.
Not to forget—[Deepin Linux introduced Android app support](https://news.itsfoss.com/deepin-linux-20-2-2-release/) right after Windows 11 marketed it as a feature.
So, you see when Microsoft’s Windows makes a move, it does have a ripple effect on Linux, too. And Deepin Linux’s Android app support is just the start…Let’s see what else comes up next.
*What do you think about Windows 11 influencing the future of Linux desktop? Do we need to evolve as well? Or should we continue being different and not get influenced by what the masses choose?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,589 | 我的 7 大 Rust 关键字 | https://opensource.com/article/20/10/keywords-rust | 2021-07-17T12:22:46 | [
"Rust"
] | https://linux.cn/article-13589-1.html |
>
> 从 Rust 标准库学习一些有用的关键字。
>
>
>

我使用 [Rust](https://www.rust-lang.org/) 已经有几个月了,写的东西比我预期的要多——尽管随着我的学习,我改进了所写的代码,并完成了一些超出我最初意图的更复杂的任务,相当多的东西已经被扔掉了。
我仍然喜欢它,并认为谈论一些在 Rust 中反复出现的重要关键字可能会有好处。我会提供我个人对它们的作用的总结:为什么你需要考虑如何使用它们,以及任何其他有用的东西,特别是对于刚接触 Rust 的新手或来自另一种语言的人(如 Java;请阅读我的文章 [为什么作为一个 Java 程序员的我喜欢学习 Rust](https://opensource.com/article/20/5/rust-java))。
事不宜迟,让我们开始吧。获取更多信息的好地方总是 Rust 官方文档 —— 你可能想从 [std 标准库](https://doc.rust-lang.org/std/)开始。
1. `const` – 你可以用 `const` 来声明常量,而且你应该这样做。虽然这不是造火箭,但请一定要用 `const` ,如果你要在不同的模块中使用常量,那请创建一个 `lib.rs` 文件(Rust 默认的),你可以把所有的常量放在一个命名良好的模块中。我曾经在不同模块的不同文件中发生过 `const` 变量名(和值)的冲突,仅仅是因为我太懒了,除了在不同文件中剪切和粘贴之外,我本可以通过创建一个共享模块来节省大量的工作。
2. `let` – 你并不 *总是* 需要用 `let` 语句声明一个变量,但当你这样做时你的代码会更加清晰。此外,如果可以,请一定要添加变量类型。Rust 会尽最大努力猜测它应该是什么类型的变量,但它不一定总能在运行时做到这一点(在这种情况下,编译器 [Cargo](https://doc.rust-lang.org/cargo/) 会提示你),它甚至可能做不到你期望的那样。在后一种情况下,对于 Cargo 来说,抱怨你所赋值的函数(例如)与声明不一致,总比 Rust 试图帮助你做错事,而你却不得不在其他地方花费大量时间来进行调试要简单。
3. `match` – `match` 对我来说是新鲜事物,我喜欢使用它。它与其他编程语言中的 `switch` 没有什么不同,但在 Rust 中被广泛使用。它使代码更清晰易读,如果你做了一些愚蠢的事情(例如错过一些可能的情况),Cargo 会很好地提示你。我一般的经验法则是,在管理不同的选项或进行分支时,如果可以使用 `match`,那就请一定要使用它。
4. `mut` – 在声明一个变量时,如果它的值在声明后会发生变化,那么你需要声明它是可变的(LCTT 译注:Rust 中变量默认是不可变的)。常见的错误是在某个变量 *没有* 变化的情况下声明它是可变的,这时编译器会警告你。如果你收到了 Cargo 的警告,说一个可变的变量没有被改变,而你认为它被 *改变* 了,那么你可能要检查该变量的范围,并确保你使用的是正确的那个。
5. `return` – 实际上我很少使用 `return`,它用于从函数中返回一个值,但是如果你只是在函数的最后一行提供值(或提供返回值的函数),通常会变得更简单,能更清晰地阅读。警告:在很多情况下,你 *会* 忘记省略这一行末尾的分号(`;`),如果你这样做,编译器会不高兴的。
6. `unsafe` – 如其意:如果你想做一些不能保证 Rust 内存安全的事情,那么你就需要使用这个关键字。我绝对无意在现在或将来的任何时候宣布我的任何 Rust 代码不安全;Rust 如此友好的原因之一是它阻止了这种黑客行为。如果你真的需要这样做,再想想,再想想,然后重新设计代码。除非你是一个非常低级的系统程序员,否则要 *避免* 使用 `unsafe`。
7. `use` – 当你想使用另一个 crate 中的东西时,例如结构体、变量、函数等,那么你需要在你要使用它的代码的代码块的开头声明它。另一个常见的错误是,你这样做了,但没有在 `Cargo.toml` 文件中添加该 crate (最好有一个最小版本号)。
我知道,这不是我写过的最复杂的文章,但这是我在开始学习 Rust 时会欣赏的那种文章。我计划在关键函数和其他 Rust 必知知识方面编写类似的文章:如果你有任何要求,请告诉我!
---
*本文最初发表于 [Alice, Eve, and Bob](https://aliceevebob.com/2020/09/01/rust-my-top-7-keywords/) 经作者许可转载。*
---
via: <https://opensource.com/article/20/10/keywords-rust>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 选题:[lujun9972](https://github.com/lujun9972) 译者:[mcfd](https://github.com/mcfd) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I've been using [Rust](https://www.rust-lang.org/) for a few months now, writing rather more of it than I expected—though quite a lot of that has been thrown away as I've learned, improved what I'm writing, and taken some more complex tasks beyond what I originally intended.
I still love it and thought it might be good to talk about some of the important keywords that come up again and again in Rust. I'll provide my personal summary of what they do, why you need to think about how you use them, and anything else that's useful, particularly for people who are new to Rust or coming from another language (such as Java; see my article [ Why I'm enjoying learning Rust as a Java programmer](https://opensource.com/article/20/5/rust-java)).
Without further ado, let's get going. A good place for further information is always the official Rust documentation—you'll probably want to start with the [std library](https://doc.rust-lang.org/std/).
**const**– You get to declare constants with const, and you should. This isn't rocket science, but do declare with const, and if you're going to use constants across different modules, then do the right thing and create a`lib.rs`
file (the Rust default) into which you can put all of them with a nicely named module. I've had clashes of const variable names (and values!) across different files in different modules simply because I was too lazy to do anything other than cut and paste across files when I could have saved myself lots of work simply by creating a shared module.**let**– You don't*always*need to declare a variable with a let statement, but your code will be clearer when you do. What's more, always add the type if you can. Rust will do its very best to guess what it should be, but it may not always be able to do so at runtime (in which case[Cargo](https://doc.rust-lang.org/cargo/), the compiler, will tell you), or it may even not do what you expect. In the latter case, it's always simpler for Cargo to complain that the function you're assigning from (for instance) doesn't match the declaration than for Rust to try to help you do the wrong thing, only for you to have to spend ages debugging elsewhere.**match**– match was new to me, and I love it. It's not dissimilar to "switch" in other languages but is used extensively in Rust. It makes for legible code, and Cargo will have a good go at warning you if you do something foolish (such as miss possible cases). My general rule of thumb, where I'm managing different options or doing branching, is to ask whether I can use match. If I can, I will.**mut**– When declaring a variable, if it's going to change after its initialisation, then you need to declare it mutable. A common mistake is to declare something mutable when it*isn't*changed—but the compiler will warn you about that. If you get a warning from Cargo that a mutable variable isn't changed when you think it*is*, then you may wish to check the scope of the variable and make sure that you're using the right version.**return**– I actually very rarely use return, which is for returning a value from a function, because it's usually simpler and clearer to read if you just provide the value (or the function providing the return value) at the end of the function as the last line. Warning: you*will*forget to omit the semicolon at the end of this line on many occasions; if you do, the compiler won't be happy.**unsafe**– This does what it says on the tin: If you want to do things where Rust can't guarantee memory safety, then you're going to need to use this keyword. I have absolutely no intention of declaring any of my Rust code unsafe now or at any point in the future; one of the reasons Rust is so friendly is because it stops this sort of hackery. If you really need to do this, think again, think yet again, and then redesign. Unless you're a seriously low-level systems programmer,*avoid*unsafe.**use**– When you want to use an item, e.g., struct, variable, function, etc. from another crate, then you need to declare it at the beginning of the block where you'll be using it. Another common mistake is to do this but fail to add the crate (preferably with a minimum version number) to the`Cargo.toml`
file.
This isn't the most complicated article I've ever written, I know, but it's the sort of article I would have appreciated when I was starting to learn Rust. I plan to create similar articles on key functions and other Rust must-knows: let me know if you have any requests!
*This article was originally published on Alice, Eve, and Bob and is reprinted with the author's permission.*
## Comments are closed. |
13,591 | Box64 模拟器发布 Arm64 Linux 版本 | https://news.itsfoss.com/box64-emulator-released/ | 2021-07-18T09:47:01 | [
"模拟器",
"ARM"
] | https://linux.cn/article-13591-1.html |
>
> 在 Box64 模拟器的帮助下,在 ARM 设备上运行 x64 Linux 程序。想试试吗?
>
>
>

[Box86](http://github.com/ptitseb/box86) 是一个流行的 X86 模拟器,刚进行了一次巨大的升级。发布了 [Box64](http://github.com/ptitseb/box64),也就是对应的 ARM64 版本。
可能你还不了解这个模拟器,Box64\_86 允许你在 ARM 系统上运行 32 或 64 位的 X86/64 Linux 程序。换句话说,它能让你在树莓派或者 [树莓派替代品](https://itsfoss.com/raspberry-pi-alternatives/) 上运行 Linux 桌面程序。
幸运的是,现在我们有 Box86 和 Box64 的支持,无论你的 ARM 系统是什么类型。
### Box64 是什么?

你可能听说过苹果的 Rosetta 2,它是一个翻译层,允许为老款 Mac(Intel X86 处理器)设计的应用程序在新的 M1(ARM 处理器)驱动的 Mac 上运行。Box64 与之类似,允许为 X86 设计的应用程序运行在 ARM Linux 设备上。
由于它的 Dynarec 模块,它能够做到这一点,同时又是 100% 开源的、免费的,而且速度惊人。它通过重新编译 ARM 程序来提升速度,这意味着和其他 ARM 原生应用一样快。
但是,即使 Box64 无法重新编译应用,它仍然可以使用即时模拟,也有令人印象深刻的结果。
许多树莓派用户很熟悉 Box86,这是一个大约一年前发布的类似程序。二者最大的区别是 Box86 只兼容 Arm32,而 Box64 只兼容 Arm64。
这就是 Box64,一个非常棒的兼容层,允许你在 ARM 电脑上运行 x86\_64 应用。
### 总结
如果你问我认为 Box64 怎么样,我会说这是一个绝对的游戏规则改变者。在难以置信的性能和巨大的潜力之间,这个兼容层肯定会在未来的 ARM 电脑中扮演一个重要角色。
如果你想知道它的工作原理,以及如何开始使用它,请查看其 [GitHub 页面](https://github.com/ptitseb/box64)。
就这样吧,现在你自己去潜入其中并测试吧。
你觉得 Box64 怎样?写下你的评论让我知道。
---
via: <https://news.itsfoss.com/box64-emulator-released/>
作者:[Jacob Crume](https://news.itsfoss.com/author/jacob/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zde200572](https://github.com/zd200572) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Box86](https://github.com/ptitseb/box86?ref=news.itsfoss.com), the popular x86 emulator, has just received a huge upgrade. This comes in the form of [Box64](https://github.com/ptitseb/box64?ref=news.itsfoss.com), the ARM64 equivalent.
If you did not know, Box64_86 lets you run 64-bit or 32-bit Linux programs on ARM systems. In other words, it makes it possible for you to access desktop Linux programs on your Raspberry Pi or [Raspberry Pi alternatives](https://itsfoss.com/raspberry-pi-alternatives/?ref=news.itsfoss.com).
Fortunately, now we have Box86 and Box64 to the rescue no matter what type of ARM system you’ve got.
## What is Box64?

You may have heard about Apple’s Rosetta 2, a translation layer that allows apps designed for older Macs to run on the new M1-powered Macs. Box64 is something similar that allows apps designed for x86 to run on ARM Linux devices.
It manages to do this all while being 100% open-source, free, and surprisingly fast, thanks to its Dynarec module. This improves speed by re-compiling the program for ARM, meaning that it runs the same as any other ARM-supported app.
However, even if Box64 is unable to recompile the app, it can still run it using on-the-fly emulation, with impressive results here too.
Many Raspberry Pi users will be familiar with Box86, a similar program that has been around for about a year now. The biggest difference is that Box86 is only compatible with Arm32, while Box64 is only compatible with Arm64.
So that’s Box64, the awesome compatibility layer that allows users to run x86_64 apps on your ARM-based PCs.
## Wrapping Up
If you were to ask me what I think about Box64, I would say it’s an absolute game changer. Between the incredible performance and massive potential, this compatibility layer is sure to play a huge role in the future ARM-based Linux PCs.
Check out its [GitHub page](https://github.com/ptitseb/box64?ref=news.itsfoss.com) if you are curious to know how it works, and how you can get started with it.
With that, I’ll leave you now to dive into and test for yourself.
*What do you think of Box64? Let me know down in the comments below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.