
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
13,746 | Debian 和 Ubuntu:有什么不同?应该选择哪一个? | https://itsfoss.com/debian-vs-ubuntu/ | 2021-09-02T23:08:31 | [
"Ubuntu",
"Debian"
] | https://linux.cn/article-13746-1.html | 
在 Debian 和 Ubuntu 系统中,你都可以 [使用 apt-get 命令](https://itsfoss.com/apt-get-linux-guide/) 来管理应用。你也可以在这两个发行版中安装 DEB 安装包。很多时候,你会在这两个发行版中发现同样的包安装命令。
它们两者是如此的相似,那么,它们两者之间有什么区别呢?
Debian 和 Ubuntu 属于同一系列的发行版。Debian 是由 Ian Murdock 在 1993 年创建的最初的发行版。Ubuntu 是 Mark Shuttleworth 在 2004 年基于 Debian 创建的发行版。
### Ubuntu 基于 Debian:这意味着什么?
Linux 发行版虽然有数百个,但其中只有少数是从零开始的独立发行版。 [Debian](https://www.debian.org/)、Arch、Red Hat 是其中几个不派生于其它发行版的使用最广的发行版。
Ubuntu 源自 Debian。这意味着 Ubuntu 使用与 Debian 相同的 APT 包管理系统,并共享来自 Debian 库中的大量包和库。它建立在 Debian 基础架构上。

这就是大多数“衍生”发行版所做的。它们使用相同的包管理器,并与基础发行版共享包。但它们也做了一些改变,添加了一些自己的包。这就是 Ubuntu 和 Debian 的不同之处,尽管它是从 Debian 衍生而来的。
### Ubuntu 和 Debian 的不同之处
因此,Ubuntu 构建在 Debian 架构和基础设施上,也与 Debian 一样是用 .DEB 格式的软件包。
这意味着使用 Ubuntu 和使用 Debian 是一样的吗?并不完全如此。有很多因素可以用来区分两个不同的发行版。
让我逐一讨论这些因素来比较 Ubuntu 和 Debian。请记住,有些比较适用于桌面版本,而有些比较适用于服务器版本。

#### 1、发布周期
Ubuntu 有两种发布版本:LTS(长期支持)和常规版本。[Ubuntu LTS 版本](https://itsfoss.com/long-term-support-lts/) 每两年发布一次,并且会提供五年的支持。你可以选择升级到下一个可用的 LTS 版本。LTS 版本被认为更稳定。
还有一个非 LTS 版本,每六个月发布一次。这些版本仅仅提供九个月的支持,但是它们会有一些新的软件版本和功能。在当前的版本到达维护年限时,你应当升级到下一个 Ubuntu 版本。
所以基本上,你可以根据这些版本在稳定性和新特性之间进行选择。
另一方面,Debian 有三个不同的版本:稳定版、测试版和非稳定版。非稳定版是为了实际测试,应该避免使用。
测试版不是那么不稳定。它是用来为下一个稳定版做准备。有一些 Debian 用户更倾向于使用测试版来获取新的特性。
然后是稳定版。这是 Debian 的主要版本。Debian 稳定版可能没有最新的软件和功能,但在稳定性方面毋庸置疑。
每两年 Debian 会发布一个稳定版,并且会提供三年的支持。此后,你应当升级到下一个可用的稳定版。
#### 2、软件更新

Debian 更关注稳定性,这意味着它并不总是使用最新版本的软件。例如,最新的 Debian 11 用的 GNOME 版本为 3.38,并不是最新版的 GNOME 3.40。
对于 GIMP、LibreOffice 等其它软件也是如此。这是你必须对 Debian 做出的妥协。这就是“Debian stable = Debian stale”笑话在 Linux 社区流行的原因。
Ubuntu LTS 版本也关注稳定性。但是它们通常拥有较新版本的常见软件。
你应该注意,对于某些软件,从开发者的仓库安装也是一种选择。例如,如果你想要安装最新版的 Docker,你可以在 Debian 和 Ubuntu 中添加 Docker 仓库。
总体来说,相比较于 Ubuntu ,Debian 稳定版的软件版本会更旧。
#### 3、软件可用性
Debian 和 Ubuntu 都拥有一个巨大的软件仓库。然而,[Ubuntu 还有 PPA](https://itsfoss.com/ppa-guide/)(<ruby> 个人软件包存档 <rt> Personal Package Archive </rt></ruby>)。通过 PPA,安装更新版本的软件或者获取最新版本的软件都将会变的更容易。

你可以在 Debian 中尝试使用 PPA,但是体验并不好。大多数时候你都会遇到问题。
#### 4、支持的平台
Ubuntu 可以在 64 位的 x86 和 ARM 平台上使用。它不再提供 32 位的镜像。
另一方面,Debian 支持 32 位和 64 位架构。除此之外,Debian 还支持 64 位 ARM(arm64)、ARM EABI(armel)、ARMv7(EABI hard-float ABI,armhf)、小端 MIPS(mipsel)、64 位小端 MIPS(mips64el)、64 位小端 PowerPC(ppc64el) 和 IBM System z(s390x)。
所以它也被称为 “<ruby> 通用操作系统 <rt> universal operating system </rt></ruby>”。
#### 5、安装
[安装 Ubuntu](https://itsfoss.com/install-ubuntu/) 比安装 Debian 容易得多。我并不是在开玩笑。即使对于有经验的 Linux 用户,Debian 也可能令人困惑。
当你下载 Debian 的时候,它默认提供的是最小化镜像。此镜像没有非自由(非开源)的固件。如果你继续安装它,你就可能会发现你的网络适配器和其它硬件将无法识别。
有一个单独的包含固件的非自由镜像,但它是隐藏的,如果你不知道,你可能会大吃一惊。

Ubuntu 在默认提供的镜像中包含专有驱动程序和固件时要宽容的多。
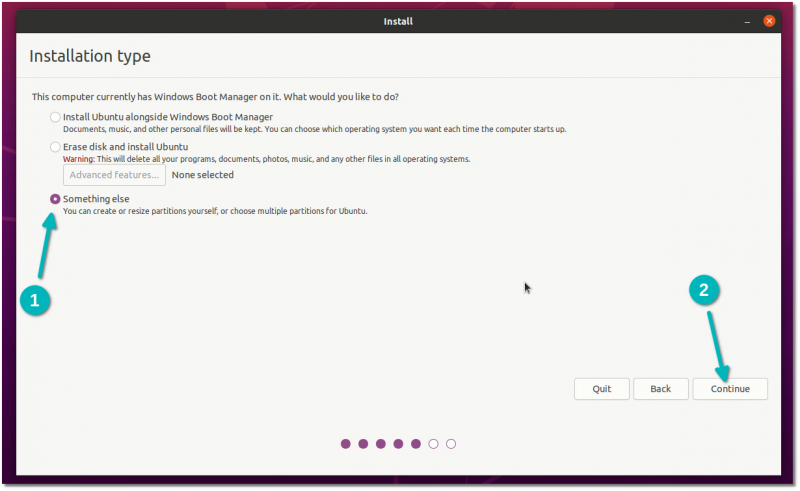
此外,Debian 安装程序看起来很旧,而 Ubuntu 安装程序看起来就比较现代化。Ubuntu 安装程序还可以识别磁盘上其它已安装的操作系统,并为你提供将 Ubuntu 与现有操作系统一起安装的选项(双引导)。但我在测试时并没有注意到 Debian 有此选项。

#### 6、开箱即用的硬件支持
就像之前提到的,Debian 主要关注 [FOSS](https://itsfoss.com/what-is-foss/)(自由和开源软件)。这意味着 Debian 提供的内核不包括专有驱动程序和固件。
这并不是说你无法使其工作,而是你必须添加/启动额外的存储库并手动安装。这可能令人沮丧,特别是对于初学者来说。
Ubuntu 并不完美,但在提供开箱即用的驱动程序和固件方面,它比 Debian 好得多。这意味着更少的麻烦和更完整的开箱即用体验。
#### 7、桌面环境选择
Ubuntu 默认使用定制的 GNOME 桌面环境。你可以在其上安装 [其它桌面环境](https://itsfoss.com/best-linux-desktop-environments/),或者选择 [各种不同桌面风格的 Ubuntu](https://itsfoss.com/which-ubuntu-install/),如 Kubuntu(使用 KDE 桌面)、Xubuntu(使用 Xfce 桌面)等。
Debian 也默认安装了 GNOME 桌面。但是它会让你在安装的过程中选择你要安装的桌面环境。

你还可以从其网站获取 [特定桌面环境的 ISO 镜像](https://cdimage.debian.org/debian-cd/current-live/amd64/iso-hybrid/)。
#### 8、游戏性
由于 Stream 及其 Proton 项目,Linux 上的游戏总体上有所改善。尽管如此,游戏在很大程度上取决于硬件。
在硬件兼容性上,Ubuntu 比 Debian 在支持专有驱动程序方面要好。
并不是说在 Debian 中不能做到这一点,而是需要一些时间和精力来实现。
#### 9、性能
性能部分没有明显的“赢家”,无论是在服务器版本还是在桌面版本。 Debian 和 Ubuntu 作为桌面和服务器操作系统都很受欢迎。
性能取决于你系统的硬件和你所使用的软件组件。你可以在你的操作系统中调整和控制你的系统。
#### 10、社区和支持
Debian 是一个真正的社区项目。此项目的一切都由其社区成员管理。
Ubuntu 由 [Canonical](https://canonical.com/) 提供支持。然而,它并不是一个真正意义上的企业项目。它确实有一个社区,但任何事情的最终决定权都掌握在 Canonical 手中。
就支持而言,Ubuntu 和 Debian 都有专门的论坛,用户可以在其中寻求帮助和提出建议。
Canonical 还为其企业客户提供收费的专业支持。Debian 则没有这样的功能。
### 结论
Debian 和 Ubuntu 都是桌面或服务器操作系统的可靠选择。 APT 包管理器和 DEB 包对两者都是通用的,因此提供了一些相似的体验。
然而,Debian 仍然需要一定程度的专业知识,特别是在桌面方面。如果你是 Linux 新手,坚持使用 Ubuntu 将是你更好的选择。在我看来,你应该积累一些经验,熟悉了一般的 Linux,然后再尝试使用 Debian。
并不是说你不能从一开始就使用 Debian,但对于 Linux 初学者来说,这并不是一种很好的体验。
欢迎你对这场 Debian 与 Ubuntu 辩论发表意见。
---
via: <https://itsfoss.com/debian-vs-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You can [use apt-get commands](https://itsfoss.com/apt-get-linux-guide/) for managing applications in both Debian and Ubuntu. You can install DEB packages in both distributions as well. Many times, you’ll find common package installation instructions for both distributions.
So, what’s the difference between the two, if they are so similar?
Debian and Ubuntu belong to the same side of the distribution spectrum. Debian is the original distribution created by Ian Murdock in 1993. Ubuntu was created in 2004 by Mark Shuttleworth and it is based on Debian.
## Ubuntu is based on Debian: What does it mean?
While there are hundreds of Linux distributions, only a handful of them are independent ones, created from scratch. [Debian](https://www.debian.org/?ref=itsfoss.com), Arch, Red Hat are some of the biggest distributions that do not derive from any other distribution.
Ubuntu is derived from Debian. It means that Ubuntu uses the same APT packaging system as Debian and shares a huge number of packages and libraries from Debian repositories. It utilizes the Debian infrastructure as base.
That’s what most ‘derived’ distributions do. They use the same package management system and share packages as the base distribution. But they also add some packages and changes of their own. And that is how Ubuntu is different from Debian despite being derived from it.
## Difference between Ubuntu and Debian
So, Ubuntu is built on Debian architecture and infrastructure and uses .DEB packages same as Debian.
Does it mean using Ubuntu is the same as using Debian? Not quite so. There are many more factors involved that distinguish one distribution from the other.
Let me discuss these factors one by one to compare Ubuntu and Debian. Please keep in mind that some comparisons are applicable to desktop editions while some apply to the server editions.

### 1. Release cycle
Ubuntu has two kinds of releases: LTS and regular. [Ubuntu LTS (long term support) release](https://itsfoss.com/long-term-support-lts/) comes out every two years and they get support for five years. You have the option to upgrade to the next available LTS release. The LTS releases are considered more stable.
There are also non-LTS releases every six months. These releases are supported for nine months only, but they have newer software versions and features. You have to upgrade to the next [Ubuntu version when the current one reaches end of life](https://itsfoss.com/end-of-life-ubuntu/).
So basically, you have the option to choose between stability and new features based on these releases.
On the other hand, Debian has three different releases: Stable, Testing and Unstable. Unstable is for actual testing and should be avoided.
The testing branch is not that unstable. It is used for preparing the next stable branch. Some Debian users prefer the testing branch to get newer features.
And then comes the stable branch. This is the main Debian release. It may not have the latest software and feature but when it comes to stability, Debian Stable is rock solid.
There is a new stable release every two years and it is supported for a total of five years. The first three years are by the Debian security team and the next two years by volunteers (in the form of the Debian LTS team). After that, you have to upgrade to the next available stable release.
### 2. Software freshness
Debian’s focus on stability means that it does not always aim for the latest versions of the software. For example, the latest Debian 11 features GNOME 3.38, not the latest GNOME 3.40.
The same goes for other software like GIMP, LibreOffice, etc. This is a compromise you have to make with Debian. This is why “Debian stable = Debian stale” joke is popular in the Linux community.
Ubuntu LTS releases also focus on stability. But they usually have more recent versions of the popular software.
You should note that for * some software*, installing from the developer’s repository is also an option. For example, if you want the latest Docker version, you can add Docker repository in both Debian and Ubuntu.
Overall, software in Debian Stable often have older versions when compared to Ubuntu.
### 3. Software availability
Both Debian and Ubuntu has a huge repository of software. However, [Ubuntu also has PPA](https://itsfoss.com/ppa-guide/) (Personal Package Archive). With PPA, installing newer software or getting the latest software version becomes a bit easier.

You may try using PPA in Debian but it won’t be a smooth experience. You’ll encounter issues most of the time.
### 4. Supported platforms
Ubuntu is available on 64-bit x86 and ARM platforms. It does not provide 32-bit ISO anymore.
Debian, on the other hand, supports both 32-bit and 64-bit architecture. Apart from that Debian also supports 64-bit ARM (arm64), ARM EABI (armel), ARMv7 (EABI hard-float ABI, armhf), little-endian MIPS (mipsel), 64-bit little-endian MIPS (mips64el), 64-bit little-endian PowerPC (ppc64el) and IBM System z (s390x).
No wonder it is called the ‘universal operating system’.
### 5. Installation
[Installing Ubuntu](https://itsfoss.com/install-ubuntu/) is a lot easier than [installing Debian](https://itsfoss.com/install-debian-easily/). I am not kidding. Debian could be confusing even for intermediate Linux user.
When you download Debian, it provides a minimal ISO by default. This ISO has no non-free (not open source) firmware. You go on to install it and realize that your network adapters and other hardware won’t be recognized.
There is a separate non-free ISO that contains firmware but it is hidden and if you do not know that, you are in for a bad surprise.
Ubuntu is a lot more forgiving when it comes to including proprietary drivers and firmware in the default ISO.
Also, the Debian installer looks old, whereas the Ubuntu installer is modern looking. Ubuntu installer also recognizes other installed operating systems on the disk and gives you the option to install Ubuntu alongside the existing ones (dual boot). I have not noticed it with Debian installer in my testing.
### 6. Out of the box hardware support
As mentioned earlier, Debian focuses primarily on [FOSS](https://itsfoss.com/what-is-foss/) (free and open source software). This means that the kernel provided by Debian does not include proprietary drivers and firmware.
It’s not that you cannot make it work but you’ll have to do add/enable additional repositories and install it manually. This could be discouraging, specially for the beginners.
Ubuntu is not perfect but it is a lot better than Debian for providing drivers and firmware out of the box. This means less hassle and a more complete out-of-the-box experience.
### 7. Desktop environment choices
Ubuntu uses a customized GNOME desktop environment by default. You may install [other desktop environments](https://itsfoss.com/best-linux-desktop-environments/) on top of it or opt for [various desktop based Ubuntu flavors](https://itsfoss.com/which-ubuntu-install/) like Kubuntu (for KDE), Xubuntu (for Xfce) etc.
Debian also installs GNOME by default. But its installer gives you choice to install desktop environment of your choice during the installation process.
You may also get [DE specific ISO images from its website](https://cdimage.debian.org/debian-cd/current-live/amd64/iso-hybrid/?ref=itsfoss.com).
### 8. Gaming
Gaming on Linux has improved in general thanks to Steam and its Proton project. Still, gaming depends a lot on hardware.
And when it comes to hardware compatibility, Ubuntu is better than Debian for supporting proprietary drivers.
Not that it cannot be done in Debian but it will require some time and effort to achieve that.
### 9. Performance
There is no clear ‘winner’ in the performance section, whether it is on the server or on the desktop. Both Debian and Ubuntu are popular as desktop as well as server operating systems.
The performance depends on your system’s hardware and the software component you use. You can tweak and control your system in both operating systems.
### 10. Community and support
Debian is a true community project. Everything about this project is governed by its community members.
Ubuntu is backed by [Canonical](https://canonical.com/?ref=itsfoss.com). However, it is not entirely a corporate project. It does have a community but the final decision on any matter is in Canonical’s hands.
As for support goes, both Ubuntu and Debian have dedicated forums where users can seek help and advice.
Canonical also offers professional support for a fee to its enterprise clients. Debian has no such features.
## Conclusion
Both Debian and Ubuntu are solid choices for desktop or server operating systems. The apt package manager and DEB packaging is common to both and thus give a somewhat similar experience.
However, Debian still needs a certain level of expertise, especially on the desktop front. If you are new to Linux, sticking with Ubuntu will be a better choice for you. In my opinion, you should gain some experience, get familiar with Linux in general and then try your hands on Debian.
It’s not that you cannot jump onto the Debian wagon from the start, but it is more likely to be an overwhelming experience for Linux beginners.
**Your opinion on this Debian vs Ubuntu debate is welcome.** |
13,747 | 我们离不开的 Linux 内核模块 | https://opensource.com/article/21/8/linux-kernel-module | 2021-09-03T06:57:01 | [
"内核",
"模块",
"Linux"
] | https://linux.cn/article-13747-1.html |
>
> 开源爱好者们对他们所喜爱的 Linux 内核模块进行了评价。
>
>
>

Linux 内核今年就要满 30 岁了! 如果你像我们一样对此特别重视,那么让我们本周用几个特别的文章来庆祝 Linux。
今天,我们先来看看来自社区对“**你不能没有哪个 Linux 内核模块?为什么?**”的回答,让我们听听这 10 位爱好者是怎么说的。
### #1
我猜一些内核开发者听到我的回答后会尖叫着跑开。不过,我还是在这里列出了两个最具争议性的模块:
* 第一个是 NVIDIA,因为我的工作笔记本和个人台式机上都有 NVIDIA 显卡。
* 另一个可能产生的仇恨较少。VMware 的 VMNET 和 VMMON 模块,以便能够运行 VMware Workstation。
— [Peter Czanik](https://opensource.com/users/czanik)
### #2
我最喜欢的是 [zram](https://en.wikipedia.org/wiki/Zram) 模块。它在内存中创建了一个压缩块设备,然后它可以作为交换分区使用。在内存有限的情况下(例如,在虚拟机上),还有如果你担心频繁的 I/O 操作会磨损你的 SSD 或者甚至更糟糕的基于闪存的存储,那么使用基于 zram 的交换分区是非常理想的。
— [Stephan Avenwedde](https://opensource.com/users/hansic99)
### #3
最有用的内核模块无疑是 snd-hda-intel,因为它支持大多数集成声卡。我可以一边听音乐,一边在 Linux 桌面上编码一个音频编曲器。
— [Joël Krähemann](https://opensource.com/users/joel2001k)
### #4
如果没有我用 Broadcom 文件生成的 kmod-wl,我的笔记本就没有价值了。我有时会收到关于内核污染的信息,但没有无线网络的笔记本电脑有什么用呢?
— [Gregory Pittman](https://opensource.com/users/greg-p)
### #5
我不能没有蓝牙。没有它,我的鼠标、键盘、扬声器和耳机除了用来挡住门板还有啥用?
— [Gary Smith](https://opensource.com/users/greptile)
### #6
我要冒昧地说 *全* 都是。 说真的,我们已经到了随机拿一块硬件,插入它,它就可以工作的地步。
* USB 串行适配器能正常工作
* 显卡可以使用(尽管可能不是最好的)
* 网卡正常工作
* 声卡正常工作
所有这些模块整体带来大量可以工作的驱动程序,令人印象深刻。我记得在过去那些糟糕的日子里,我们曾经大喊 xrandr 魔法字符串才能来使投影仪工作。而现在,是的,当设备基本不能正常工作时,才真的罕见。
如果我不得不把它归结为一个,那就是 raid6。
— [John 'Warthog9' Hawley](https://opensource.com/users/warthog9)
### #7
对于这个问题,我想回到 20 世纪 90 年代末。我是一家小公司的 Unix 系统管理员(兼任 IS 经理)。我们的磁带备份系统死了,由于“小公司”预算有限,我们没有急于更换或现场维修。所以我们必须得把它送去维修。
在那两个星期里,我们没有办法进行磁带备份。没有一个系统管理员愿意处于这种境地。
但后来我想起了读过的 [如何使用软盘磁带机](https://tldp.org/HOWTO/Ftape-HOWTO.html),我们刚好有一台刚换下来的塔式电脑,它有一个软盘磁带机。
于是我用 Linux 重新安装了它,设置了 ftape 内核驱动模块,进行了一些备份/恢复测试,然后将我们最重要的备份运行到 QIC 磁带上。在这两个星期里,我们依靠 ftape 备份重要数据。
所以,对于那些让软盘磁带机在 1990 年代的 Linux 上工作的无名英雄,你真是太厉害了!
— [Jim Hall](https://opensource.com/users/jim-hall)
### #8
嗯,这很简单。是 kvm 内核模块。就个人而言,我无法想象在没有虚拟机的情况下完成日常工作。我愿意相信我们大多数人都是这样。kvm 模块在使 Linux 成为云战略的核心方面也发挥了很大作用。
— [Gaurav Kamathe](https://opensource.com/users/gkamathe)
### #9
对我来说,是 dm-crypt,它是用于 LUKS 的。参见:
* <https://www.redhat.com/sysadmin/disk-encryption-luks>
* <https://manpages.debian.org/unstable/cryptsetup-bin/cryptsetup.8.en.html>
知道别人无法看到你的磁盘上的内容是非常棒的,例如,如果你的笔记本丢失或被盗时。
— [Maximilian Kolb](https://opensource.com/users/kolb)
### #10
对于密码学基础,很难超越 crypto 模块和它的 C API,它是如此简洁明了。
在日常生活中,还有什么比蓝牙提供的即插即用更有价值的吗?
— [Marty Kalin](https://opensource.com/users/mkalindepauledu)
在评论中与我们分享。你的生活中不能没有什么 Linux 内核模块?
---
via: <https://opensource.com/article/21/8/linux-kernel-module>
作者:[Jen Wike Huger](https://opensource.com/users/jen-wike) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Linux kernel is turning 30 this year! If you're like us, that's a big deal and we are celebrating Linux this week with a couple of special posts.
Today we start with a roundup of responses from around the community answering "What Linux kernel module can you not live without? And, why?" Let's hear what these 10 enthusiasts have to say.
I guess some kernel developers will run away screaming when they hear my answer. Still, I list here two of the most controversial modules:
- First is NVIDIA, as I have an NVIDIA graphics card on my work laptop and my personal desktop.
- The other one probably generates less hatred—the VMNET and VMMON modules from VMware to be able to run VMware Workstation. —
[Peter Czanik](https://opensource.com/users/czanik)
My favorite is the [zram](https://en.wikipedia.org/wiki/Zram) module. It creates a compressed block device in memory, which can then be used as a swap partition. Using a zram-based swap partition is ideal when memory is limited (for example, on virtual machines) and if you are worried about wearing out your SSD or, even worse, your flash-based storage because of frequent I/O operations. —[Stephan Avenwedde](https://opensource.com/users/hansic99)
The most useful kernel module is definitively snd-hda-intel since it supports most integrated sound cards. I listen to music while coding an audio sequencer on the Linux desktop. —[Joël Krähemann](https://opensource.com/users/joel2001k)
My laptop would be worthless without the kmod-wl that I generate with the Broadcom file. I sometimes get messages about tainting the kernel, but what good is a laptop without wireless? —[Gregory Pittman](https://opensource.com/users/greg-p)
I can't live without Bluetooth. Without it, my mouse, keyboard, speakers, and headset would be doorstops. —[Gary Smith](https://opensource.com/users/greptile)
I'm going to go out on a limb and say *all of them*. Seriously, we've gotten to the point where I grab a random piece of hardware, plug it in, and it just works.
- USB serial adapter just works
- Video card just works (though maybe not at its best)
- Network card just works
- Sound card just works
It's tough not to be utterly impressed with the broad scope of the driver work that all the modules bring to the whole. I remember the bad old days when we used to yell out xrandr magic strings to make projectors work, and now—yeah, it's a genuine rarity when stuff doesn't (mostly) just work.
If I had to nail it down to one, though, it'd be raid6. —[John 'Warthog9' Hawley](https://opensource.com/users/warthog9)
I'm going to go back to the late 1990s for this one. I was a Unix systems administrator (and double duty as IS manager) for a small company. Our tape backup system died, and because of "small company" limited budgets, we didn't have a rush replacement or onsite repair on it. So we had to send it in for repair.
During those two weeks, we didn't have a way to make tape backups. No systems administrator wants to be in that position.
But then I remembered reading the [Floppy Tape How-to](https://tldp.org/HOWTO/Ftape-HOWTO.html), and we happened to have a tower PC we'd just replaced that had a floppy tape drive.
So I reinstalled it with Linux, set up the **ftape** kernel driver module, ran a few backup/recovery tests, then ran our most important backups to QIC tapes. For those two weeks, we relied on **ftape** backups of critical data.
So to the unsung hero out there who made floppy tape drives work on 1990s Linux, you are awesome! —[Jim Hall](https://opensource.com/users/jim-hall)
Well, that's easy. It's the kvm kernel modules. On a personal front, I cannot imagine doing my day-to-day work without VMs. I'd like to believe that's the case with most of us. The kvm modules also play a big part in making Linux central to the cloud strategy. —[Gaurav Kamathe](https://opensource.com/users/gkamathe)
For me, it's dm-crypt, which is used for LUKS. See:
[https://www.redhat.com/sysadmin/disk-encryption-luks](https://www.redhat.com/sysadmin/disk-encryption-luks)[https://manpages.debian.org/unstable/cryptsetup-bin/cryptsetup.8.en.html](https://manpages.debian.org/unstable/cryptsetup-bin/cryptsetup.8.en.html)
It's fantastic to know others cannot see what's on your disk, for example, if you lose your notebook or it gets stolen. —[Maximilian Kolb](https://opensource.com/users/kolb)
For cryptography basics, it's hard to beat the crypto module and its C API, which is straightforward.
For day-to-day life, is there anything more valuable than the plug-and-play that Bluetooth provides? —[Marty Kalin](https://opensource.com/users/mkalindepauledu)
Share with us in the comments: What Linux kernel module can you not live without?
## 1 Comment |
13,749 | 安装 elementary OS 6 “Odin” 后要做的 10 件事 | https://www.debugpoint.com/2021/08/10-things-to-do-after-install-elementary-os-6/ | 2021-09-04T08:14:00 | [
"elementaryOS"
] | /article-13749-1.html |
>
> 一个精心准备的在安装 elementary OS 6 “Odin” 后要做的事情的列表。
>
>
>

在经过两年多的开发后 [elementary OS 6 “Odin”](https://www.debugpoint.com/2021/08/elementary-os-6/) 于不久前发布,此次版本更新在核心模块、 Pantheon 桌面、原生应用方面带来了一大批新特性。elementary OS 6 “Odin” 是基于 Ubuntu 20.04 LTS 的。
如果你完成了安装,你可能想要尝试通过一些特定的设置来使你的系统更加的个性化。这里描述的选项是通用的,在某些情况下可能对你没有用,但是我们觉得有必要列出一些基本的东西,让你有合适的方式来探索这个漂亮的 elementary OS。
### 安装完 elementary OS 6 “Odin” 后要做的事情
准备步骤:
首先确保你已经连上了互联网,你可以在顶部的通知区域查看可用的网络列表
#### 1、更改主机名
这可能不是你想做的第一件事。但是我不知道为什么在安装过程中没有给出更改主机名的选项。例如,见下图的终端提示, 这个主机名是 elementary OS 的默认硬件配置。在我看来这一点都不好。

打开终端并运行下列命令以更改主机名:
```
hostnamectl set-hostname your-new-hostname
```
示例:


#### 2、升级你的系统
在安装任何 Linux 发行版后,你应该做的第一件事就是确保系统处于最新的软件包和安全更新状态。
你可以通过打开应用中心来检查或者安装更新。
或者打开终端运行下列命令:
```
sudo apt update
sudo apt upgrade
```
#### 3、安装 Pantheon Tweaks
Pantheon Tweaks 是 elementary OS 的必备应用。它提供了一些无法通过系统原生设置程序修改的额外的设置和配置选项,请打开终端并运行以下命令以安装 Pantheon Tweaks。注意:先前版本的 Tweak 工具叫做 elementary Tweaks,从 Odin 版本开始更名为 Pantheon Tweaks。
```
sudo apt install software-properties-common
sudo add-apt-repository -y ppa:philip.scott/pantheon-tweaks
sudo apt install -y pantheon-tweaks
```
安装后打开系统设置,你可以在那里找到 “<ruby> 调整 <rt> Tweaks </rt></ruby>” 选项。
[这里](https://www.debugpoint.com/2021/07/elementary-tweaks-install/) 提供了更详细的安装指南(如果你需要了解更多信息)。
### 4、配置 Dock
Dock 是整个桌面的中心。老实说,Dock 中默认包含的应用并不常用,因此你可以通过以下步骤配置 Dock 中的项目。
* 移除:右键单击并取消 “<ruby> 在 Dock 中驻留 <rt> Keep in Dock </rt></ruby>” 选项。
* 添加新的项目:单击顶部的应用程序。然后右键单击你想要放在 Dock 的应用图标。选择 “<ruby> 添加到 Dock <rt> Add to Dock </rt></ruby>”。
在我看来,你应该至少把文件管理、截图工具、Firefox 、计算器,以及其他的一些应用添加到 Dock。然后移除 Dock 上那些你不需要的应用。
#### 5、更改外观
elementary OS 6 Odin 改进了桌面的整体外观,为整个桌面和应用程序提供了自带的强调色和原生的夜间模式,同时,系统自带了许多漂亮的壁纸。你可以通过 “应用 > 系统设置 > 桌面” 来定制壁纸、外观、面板和多任务视图。

按照你希望的样子来配置你系统的外观。
你也可以基于日出和日落的时间来设置夜间模式。
#### 6、安装其他的应用
自带的应用中心非常适合这个系统,我发现它是 Linux 桌面最好的应用商店之一。然而,有时候需要安装没有预装的必要应用(大多数是知名的应用)。下面是个新系统推荐安装的软件列表。(说真的,为什么 LibreOffice 没有预装?)
* firefox
* gimp
* gedit
* inkscape
* obs-studio
* libreoffice
#### 7、一些针对笔记本电脑的省电贴士
有许多方法可以配置你的 elementary OS(或者一般的 Linux 桌面),以达到延长电池寿命的目的。记住,电池寿命取决于你的笔记本硬件,以及电池和笔记本的使用年限。所以,遵循下面的一些建议,最大限度的利用你的笔记本电池。
* 安装 [tlp](https://linrunner.de/tlp/)。`tlp` 是一个简单易用的命令行程序,用来帮你在 Linux 上延长电池寿命。你只需要安装它,默认情况下,它会处理好其他的设置。安装命令:
```
sudo add-apt-repository ppa:linrunner/tlp
sudo apt update
sudo apt-get install tlp
sudo tlp start
```
* 关闭蓝牙,默认情况下,蓝牙是开启状态。在需要的时候再启动它。
* 通过下面的命令安装 `thermald`。这个实用程序(实际是个守护进程)控制着你的 CPU 的 P-States 和 T-States 的温度以及 CPU 发热。
```
sudo apt install thermald
```
* 根据你的需要将亮度调到最小。
#### 8、安装磁盘实用程序
在很多情况下,你发现你需要格式化 USB 或者向 USB 中写入一些东西。默认情况下,系统没有安装任何相关的应用。你可以安装以下这些易用的应用。
* gnome-disk-utility
* gparted
#### 9、启用最大化和最小化选项
许多用户喜欢在窗口标题栏左边或者右边使用最大化、最小化的按钮,elementary OS 默认只提供关闭和恢复两个选项。这没什么问题,因为这就是它的设计理念。然而你可以通过使用 Pantheon Tweaks 来开启最大化和最小化按钮,具体的方式是:“调整 > 外观 > 窗口控制”。

#### 10、在 Odin 中学习新的多点触控手势
如果你是笔记本用户,并且使用 elementary OS “Odin”,那么你一定要看看这些超酷的新触控手势。三根手指向上滑动,就会平滑的打开多任务视图,展示打开的应用程序和工作空间。用三根手指向左或向右滑动,就能在动态工作空间之间流畅的切换,使任务之间的切换更快。
用两根手指也可以在原生应用中实现类似的功能。
### 结束语
我希望这篇安装 elementary OS 6 “Odin” 后要做的 10 件事能帮助到你,让你可以上手使用 elementary OS 6 “Odin”,尽管这些事情完全是用户的偏好,因此这些事情有可能适合你也有可能不适用于你,但总的来说,这些都是一般用户喜欢的预期调整。
如果你觉得有更多的东西应该添加到列表中,请在下面的评论中告诉我。
---
via: <https://www.debugpoint.com/2021/08/10-things-to-do-after-install-elementary-os-6/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[anine09](https://github.com/anine09) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,750 | Zulip:一个不错的开源的 Slack 替代品 | https://itsfoss.com/zulip/ | 2021-09-04T08:37:51 | [
"Zulip",
"Slack"
] | https://linux.cn/article-13750-1.html |
>
> Zulip 是一个开源的协作平台,它把自己定位为一个更好的 Slack 替代品。让我们来了解一下。
>
>
>

当涉及到你的工作时,消息和协作平台有很大的不同。
虽然有几个选择,但 Slack 是许多组织使用的一个流行选择。但是,可以自托管的 Slack 的开源替代方案如何呢?
Zulip 就是这样一个软件。
### Zulip:开源的协作消息应用

如果你想多了解,我必须提到还有更多的 [Slack 开源替代品](https://itsfoss.com/open-source-slack-alternative/)。
但在这里,我重点介绍 Zulip。
Zulip 是一个自由而开源的消息应用,有付费托管选项和自托管的能力。
它旨在提供与 Slack 类似的体验,同时努力帮助你利用话题提高对话的有效性。
与 Slack 中的频道相比,Zulip 聊天添加了话题(类似标签),以快速过滤与你有关的对话。
### Zulip 的特点

你可以通过 Zulip 获得大部分的基本功能。这里列出主要的亮点,你可以发现:
* 支持 Markdown
* 频道的主题
* 支持拖放文件
* 代码块
* 集成 GitHub 来跟踪问题
* 支持电子邮件通知
* 自托管选项
* 信息编辑
* 集成 GIPHY
* 用 Zoom、Jitsi 或 BigBlueButton 进行视频通话
除了上述功能外,你可以预期得到你通常在 Slack 和其他方面得到的基本选项。
此外,如果你愿意,你还可以将它与 Matrix 和 IRC 整合。

在我简短的测试使用中,其用户界面对于有效的沟通来说是足够好的。然而,我没能找到任何黑暗模式或改变主题的能力。
它看起来比 Slack 更简单直白,这样可以改善用户体验方面的问题。
### 在 Linux 中安装 Zulip
Zulip 在其官方网站上以 AppImage 文件的形式提供。如果你需要帮助,可以参考我们关于 [在 Linux 中使用 AppImage](https://itsfoss.com/use-appimage-linux/) 的指南。
它也有一个 Snap 包。所以,你可以在任何一个 Linux 发行版上使用它们中的任何一个。
你也可以使用 APT 通过终端为基于 Ubuntu/Debian 的发行版安装它。如果你想这样做,请看它的 [官方说明](https://zulip.com/help/desktop-app-install-guide)。
Zulip 可用于 Windows、Mac 和 Linux。你也应该发现它可用于 Android 和 iOS 手机。
* [Zulip](https://zulip.com/)
你可以在网络、桌面和智能手机上使用 Zulip,所以可以把它当做 Slack 的合适替代品。
你试过了吗?你用什么消息平台来进行工作协作?欢迎在评论中分享你的想法。
---
via: <https://itsfoss.com/zulip/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief:** Zulip is an open-source collaboration platform that pitches itself as a better replacement to Slack. Let us take a closer look.
Messaging and collaboration platforms make a big difference when it comes to your work.
While there are several options available, Slack is a popular one used by many organizations. But, what about an open-source alternative to Slack that you can self-host?
Zulip is one such software.
## Zulip: Open Source Collaboration Messaging App
If you want to explore, I must mention that there are more [open-source alternatives to Slack](https://itsfoss.com/open-source-slack-alternative/) out there.
Here, I focus on Zulip.
Zulip is a free and open-source messaging application with paid hosted options and the ability to self-host.
It aims to provide a similar experience to Slack while striving to help you improve the effectiveness of conversations using topics.
In contrast to channels in Slack, Zulip chat adds topics (which are like tags) to quickly filter through the conversations that matter to you.
## Features of Zulip
You get most of the essential features with Zulip. To list the key highlights, you can find:
- Markdown support
- Topics for channels
- Drag and drop file support
- Code blocks
- GitHub integration to track issues
- Email notification support
- Self-host option
- Message editing
- GIPHY integration
- Video calls with Zoom, Jitsi, or BigBlueButton
In addition to the features mentioned, you should expect the basic options that you usually get with Slack and others.
Also, you can integrate it with Matrix and IRC if you want.
In my brief test usage, the user interface is good enough for effective communication. However, I failed to find any dark mode or the ability to change a theme.
It looks more straightforward than Slack so that it can improve the user experience side of things.
## Install Zulip in Linux
Zulip is available as an AppImage file from its official website. You may refer to our guide on[ using AppImage in Linux](https://itsfoss.com/use-appimage-linux/) in case you need help.
It is also available as a snap package. So, you can utilize either of them for any Linux distro.
You can also install it through the terminal for Ubuntu/Debian-based distros using APT. Take a look at its [official instructions](https://zulip.com/help/desktop-app-install-guide) if you want that.
Zulip is available for Windows, Mac, and Linux. You should also find it available for Android and iOS mobile phones.
Considering that you can use Zulip on the web, desktop, and smartphones, it is a suitable replacement for Slack.
*Have you tried it yet? What messaging platform do you use to collaborate for work? Feel free to share your thoughts in the comments.* |
13,752 | 通过 ftrace 来分析 Linux 内核 | https://opensource.com/article/21/7/linux-kernel-ftrace | 2021-09-05T15:20:00 | [
"strace",
"ftrace",
"追踪"
] | https://linux.cn/article-13752-1.html |
>
> 通过 `ftrace` 来了解 Linux 内核内部工作方式是一个好方法。
>
>
>

操作系统的内核是最难以理解的软件之一。自从你的系统启动后,它会一直在后台运行。尽管每个用户都不与内核直接交互,但他们在内核的帮助下完成自己的计算任务。与内核的交互发生在调用系统调用或者用户日常使用的各种库或应用间接调用了系统调用。
在之前的文章里我介绍了如何使用 [strace](/article-11545-1.html) 来追踪系统调用。然而,使用 `strace` 时你的视野是有限的。它允许你查看特定参数的系统调用。并在工作完成后,看到其返回值或状态,以表明是成功还是失败。但是你无法知道内核在这段时间内发生了什么。除了系统调用外,还有很多其他活动内核中发生,而你却视而不见。
### ftrace 介绍
本文的旨在通过使用一个名为 `ftrace` 的机制来阐明追踪内核函数的一些情况。它使得任何 Linux 用户可以轻松地追踪内核,并且了解更多关于 Linux 内核内部如何工作。
`ftrace` 默认产生的输出往往是巨大的,因为内核总是忙碌的。为了节省空间,很多情况下我会通过截断来给出尽量小的输出。
我使用 Fedora 来演示下面的例子,但是它们应该在其他最新的 Linux 发行版上同样可以运行。
### 启用 ftrace
`ftrace` 现在已经是内核中的一部分了,你不再需要事先安装它了。也就是说,如果你在使用最近的 Linux 系统,那么 `ftrace` 是已经启用了的。为了验证 `ftrace` 是否可用,运行 `mount` 命令并查找 `tracefs`。如果你看到类似下面的输出,表示 `ftrace` 已经启用,你可以轻松地尝试本文中下面的例子。下面有些命令需要在 root 用户下使用(用 `sudo` 执行是不够的)。
```
# mount | grep tracefs
none on /sys/kernel/tracing type tracefs (rw,relatime,seclabel)
```
要想使用 `ftrace`,你首先需要进入上面 `mount` 命令中找到的特定目录中,在那个目录下运行文章中的其他命令。
```
# cd /sys/kernel/tracing
```
### 一般的工作流程
首先,你需要理解捕捉踪迹和获取输出的一般流程。如果你直接运行 `ftrace`,不会运行任何特定的 `ftrace` 命令。相反的,基本操作是通过标准 Linux 命令来写入或读取一些文件。
一般的步骤如下:
1. 通过写入一些特定文件来启用/结束追踪
2. 通过写入一些特定文件来设置/取消追踪时的过滤规则
3. 从文件中读取基于第 1 和 2 步的追踪输出
4. 从文件中清除早期输出或缓冲区
5. 缩小到你的特定用例(你要追踪的内核函数),重复 1、2、3、4 步
### 可用的追踪器类型
有多种不同的追踪器可供使用。之前提到,在运行任何命令前,你需要进入一个特定的目录下,因为需要的文件在这些目录下。我在我的例子中使用了相对路径(而不是绝对路径)。
你可以查看 `available_tracers` 文件内容来查看所有可用的追踪器类型。你可以看下面列出了几个。不需要担心这些:
```
$ pwd
/sys/kernel/tracing
$ sudo cat available_tracers
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
```
在所有输出的追踪器中,我会聚焦于下面三个特殊的:启用追踪的 `function` 和 `function_graph`,以及停止追踪的 `nop`。
### 确认当前的追踪器
通常情况默认的追踪器设定为 `nop`。即在特殊文件中 `current_tracer` 中的 “无操作”,这意味着追踪目前是关闭的:
```
$ pwd
/sys/kernel/tracing
$ sudo cat current_tracer
nop
```
### 查看追踪输出
在启用任何追踪功能之前,请你看一下保存追踪输出的文件。你可以用 [cat](https://opensource.com/article/19/2/getting-started-cat-command) 命令查看名为 `trace` 的文件的内容:
```
# cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 0/0 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
```
### 启用 function 追踪器
你可以通过向 `current_tracer` 文件写入 `function` 来启用第一个追踪器 `function`(文件原本内容为 `nop`,意味着追踪是关闭的)。把这个操作看成是启用追踪的一种方式:
```
$ pwd
/sys/kernel/tracing
$ sudo cat current_tracer
nop
$ echo function > current_tracer
$
$ cat current_tracer
function
```
### 查看 function 追踪器的更新追踪输出
现在你已启用追踪,是时候查看输出了。如果你查看 `trace` 文件内容,你将会看到许多被连续写入的内容。我通过管道只展示了文件内容的前 20 行。根据左边输出的标题,你可以看到在某个 CPU 上运行的任务和进程 ID。根据右边输出的内容,你可以看到具体的内核函数和其父函数。中间显示了时间戳信息:
```
# sudo cat trace | head -20
# tracer: function
#
# entries-in-buffer/entries-written: 409936/4276216 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
<idle>-0 [000] d... 2088.841739: tsc_verify_tsc_adjust <-arch_cpu_idle_enter
<idle>-0 [000] d... 2088.841739: local_touch_nmi <-do_idle
<idle>-0 [000] d... 2088.841740: rcu_nocb_flush_deferred_wakeup <-do_idle
<idle>-0 [000] d... 2088.841740: tick_check_broadcast_expired <-do_idle
<idle>-0 [000] d... 2088.841740: cpuidle_get_cpu_driver <-do_idle
<idle>-0 [000] d... 2088.841740: cpuidle_not_available <-do_idle
<idle>-0 [000] d... 2088.841741: cpuidle_select <-do_idle
<idle>-0 [000] d... 2088.841741: menu_select <-do_idle
<idle>-0 [000] d... 2088.841741: cpuidle_governor_latency_req <-menu_select
```
请记住当追踪打开后,这意味着追踪结果会被一直连续写入直至你关闭追踪。
### 关闭追踪
关闭追踪是简单的。你只需要在 `current_tracer` 文件中用 `nop` 替换 `function` 追踪器即可:
```
$ sudo cat current_tracer
function
$ sudo echo nop > current_tracer
$ sudo cat current_tracer
nop
```
### 启用 function\_graph 追踪器
现在尝试第二个名为 `function_graph` 的追踪器。你可以使用和上面相同的步骤:在 `current_tracer` 文件中写入 `function_graph`:
```
$ sudo echo function_graph > current_tracer
$ sudo cat current_tracer
function_graph
```
### function\_tracer 追踪器的追踪输出
注意到目前 `trace` 文件的输出格式已经发生变化。现在,你可以看到 CPU ID 和内核函数的执行时长。接下来,一个花括号表示一个函数的开始,以及它内部调用了哪些其他函数:
```
# cat trace | head -20
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
6) | n_tty_write() {
6) | down_read() {
6) | __cond_resched() {
6) 0.341 us | rcu_all_qs();
6) 1.057 us | }
6) 1.807 us | }
6) 0.402 us | process_echoes();
6) | add_wait_queue() {
6) 0.391 us | _raw_spin_lock_irqsave();
6) 0.359 us | _raw_spin_unlock_irqrestore();
6) 1.757 us | }
6) 0.350 us | tty_hung_up_p();
6) | mutex_lock() {
6) | __cond_resched() {
6) 0.404 us | rcu_all_qs();
6) 1.067 us | }
```
### 启用追踪的设置来增加追踪的深度
你可以使用下面的步骤来调整追踪器以看到更深层次的函数调用。完成之后,你可以查看 `trace` 文件的内容并发现输出变得更加详细了。为了文章的可读性,这个例子的输出被省略了:
```
# cat max_graph_depth
0
# echo 1 > max_graph_depth ## or:
# echo 2 > max_graph_depth
# sudo cat trace
```
### 查找要追踪的函数
上面的步骤足以让你开始追踪。但是它产生的输出内容是巨大的,当你想试图找到自己感兴趣的内容时,往往会很困难。通常你更希望能够只追踪特定的函数,而忽略其他函数。但如果你不知道它们确切的名称,你怎么知道要追踪哪些进程?有一个文件可以帮助你解决这个问题 —— `available_filter_functions` 文件提供了一个可供追踪的函数列表:
```
$ sudo wc -l available_filter_functions
63165 available_filter_functions
```
### 查找一般的内核函数
现在试着搜索一个你所知道的简单内核函数。用户空间由 `malloc` 函数用来分配内存,而内核由 `kmalloc` 函数,它提供类似的功能。下面是所有与 `kmalloc` 相关的函数:
```
$ sudo grep kmalloc available_filter_functions
debug_kmalloc
mempool_kmalloc
kmalloc_slab
kmalloc_order
kmalloc_order_trace
kmalloc_fix_flags
kmalloc_large_node
__kmalloc
__kmalloc_track_caller
__kmalloc_node
__kmalloc_node_track_caller
[...]
```
### 查找内核模块或者驱动相关函数
在 `available_filter_functions` 文件的输出中,你可以看到一些以括号内文字结尾的行,例如下面的例子中的 `[kvm_intel]`。这些函数与当前加载的内核模块 `kvm_intel` 有关。你可以运行 `lsmod` 命令来验证:
```
$ sudo grep kvm available_filter_functions | tail
__pi_post_block [kvm_intel]
vmx_vcpu_pi_load [kvm_intel]
vmx_vcpu_pi_put [kvm_intel]
pi_pre_block [kvm_intel]
pi_post_block [kvm_intel]
pi_wakeup_handler [kvm_intel]
pi_has_pending_interrupt [kvm_intel]
pi_update_irte [kvm_intel]
vmx_dump_dtsel [kvm_intel]
vmx_dump_sel [kvm_intel]
$ lsmod | grep -i kvm
kvm_intel 335872 0
kvm 987136 1 kvm_intel
irqbypass 16384 1 kvm
```
### 仅追踪特定的函数
为了实现对特定函数或模式的追踪,你可以利用 `set_ftrace_filter` 文件来指定你要追踪上述输出中的哪些函数。这个文件也接受 `*` 模式,它可以扩展到包括具有给定模式的其他函数。作为一个例子,我在我的机器上使用 ext4 文件系统。我可以用下面的命令指定 ext4 的特定内核函数来追踪:
```
# mount | grep home
/dev/mapper/fedora-home on /home type ext4 (rw,relatime,seclabel)
# pwd
/sys/kernel/tracing
# cat set_ftrace_filter
#### all functions enabled ####
$
$ echo ext4_* > set_ftrace_filter
$
$ cat set_ftrace_filter
ext4_has_free_clusters
ext4_validate_block_bitmap
ext4_get_group_number
ext4_get_group_no_and_offset
ext4_get_group_desc
[...]
```
现在当你可以看到追踪输出时,你只能看到与内核函数有关的 `ext4` 函数,而你之前已经为其设置了一个过滤器。所有其他的输出都被忽略了:
```
# cat trace |head -20
## tracer: function
#
# entries-in-buffer/entries-written: 3871/3871 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
cupsd-1066 [004] .... 3308.989545: ext4_file_getattr <-vfs_fstat
cupsd-1066 [004] .... 3308.989547: ext4_getattr <-ext4_file_getattr
cupsd-1066 [004] .... 3308.989552: ext4_file_getattr <-vfs_fstat
cupsd-1066 [004] .... 3308.989553: ext4_getattr <-ext4_file_getattr
cupsd-1066 [004] .... 3308.990097: ext4_file_open <-do_dentry_open
cupsd-1066 [004] .... 3308.990111: ext4_file_getattr <-vfs_fstat
cupsd-1066 [004] .... 3308.990111: ext4_getattr <-ext4_file_getattr
cupsd-1066 [004] .... 3308.990122: ext4_llseek <-ksys_lseek
cupsd-1066 [004] .... 3308.990130: ext4_file_read_iter <-new_sync_read
```
### 排除要被追踪的函数
你并不总是知道你想追踪什么,但是,你肯定知道你不想追踪什么。因此,有一个 `set_ftrace_notrace` —— 请注意其中的 “no”。你可以在这个文件中写下你想要的模式,并启用追踪。这样除了所提到的模式外,任何其他东西都会被追踪到。这通常有助于删除那些使我们的输出变得混乱的普通功能:
```
$ sudo cat set_ftrace_notrace
#### no functions disabled ####
```
### 具有目标性的追踪
到目前为止,你一直在追踪内核中发生的一切。但是,它无法帮助你追踪与某个特定命令有关的事件。为了达到这个目的,你可以按需打开和关闭跟踪,并且在它们之间,运行我们选择的命令,这样你就不会在跟踪输出中得到额外的输出。你可以通过向 `tracing_on` 写入 `1` 来启用跟踪,写 `0` 来关闭跟踪。
```
# cat tracing_on
0
# echo 1 > tracing_on
# cat tracing_on
1
### Run some specific command that we wish to trace here ###
# echo 0 > tracing_on
# cat tracing_on
0
```
### 追踪特定的 PID
如果你想追踪与正在运行的特定进程有关的活动,你可以将该 PID 写入一个名为 `set_ftrace_pid` 的文件,然后启用追踪。这样一来,追踪就只限于这个 PID,这在某些情况下是非常有帮助的。
```
$ sudo echo $PID > set_ftrace_pid
```
### 总结
`ftrace` 是一个了解 Linux 内核内部工作的很好方式。通过一些练习,你可以学会对 `ftrace` 进行调整以缩小搜索范围。要想更详细地了解 `ftrace` 和它的高级用法,请看 `ftrace` 的核心作者 Steven Rostedt 写的这些优秀文章。
* [调试 Linux 内核,第一部分](https://lwn.net/Articles/365835/)
* [调试 Linux 内核,第二部分](https://lwn.net/Articles/366796/)
* [调试 Linux 内核,第三部分](https://lwn.net/Articles/370423/)
---
via: <https://opensource.com/article/21/7/linux-kernel-ftrace>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | An operating system's kernel is one of the most elusive pieces of software out there. It's always there running in the background from the time your system gets turned on. Every user achieves their computing work with the help of the kernel, yet they never interact with it directly. The interaction with the kernel occurs by making system calls or having those calls made on behalf of the user by various libraries or applications that they use daily.
I've covered how to trace system calls in an earlier article using
. However, with [strace](https://opensource.com/article/19/10/strace)`strace`
, your visibility is limited. It allows you to view the system calls invoked with specific parameters and, after the work gets done, see the return value or status indicating whether they passed or failed. But you had no idea what happened inside the kernel during this time. Besides just serving system calls, there's a lot of other activity happening inside the kernel that you're oblivious to.
## Ftrace Introduction
This article aims to shed some light on tracing the kernel functions by using a mechanism called `ftrace`
. It makes kernel tracing easily accessible to any Linux user, and with its help you can learn a lot about Linux kernel internals.
The default output generated by the `ftrace`
is often massive, given that the kernel is always busy. To save space, I've kept the output to a minimum and, in many cases truncated the output entirely.
I am using Fedora for these examples, but they should work on any of the latest Linux distributions.
## Enabling ftrace
`Ftrace`
is part of the Linux kernel now, and you no longer need to install anything to use it. It is likely that, if you are using a recent Linux OS, `ftrace`
is already enabled. To verify that the `ftrace`
facility is available, run the mount command and search for `tracefs`
. If you see output similar to what is below, `ftrace`
is enabled, and you can easily follow the examples in this article. These commands must be run as the root user (`sudo`
is insufficient.)
```
# mount | grep tracefs
none on /sys/kernel/tracing type tracefs (rw,relatime,seclabel)
```
To make use of `ftrace`
, you first must navigate to the special directory as specified in the mount command above, from where you'll run the rest of the commands in the article:
`# cd /sys/kernel/tracing`
## General work flow
First of all, you must understand the general workflow of capturing a trace and obtaining the output. If you're using `ftrace`
directly, there isn't any special `ftrace-`
specific commands to run. Instead, you basically write to some files and read from some files using standard command-line Linux utilities.
The general steps:
- Write to some specific files to enable/disable tracing.
- Write to some specific files to set/unset filters to fine-tune tracing.
- Read generated trace output from files based on 1 and 2.
- Clear earlier output or buffer from files.
- Narrow down to your specific use case (kernel functions to trace) and repeat steps 1, 2, 3, 4.
## Types of available tracers
There are several different kinds of tracers available to you. As mentioned earlier, you need to be in a specific directory before running any of these commands because the files of interest are present there. I use relative paths (as opposed to absolute paths) in my examples.
You can view the contents of the `available_tracers`
file to see all the types of tracers available. You can see a few listed below. Don't worry about all of them just yet:
```
# pwd
/sys/kernel/tracing
# cat available_tracers
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
```
Out of all the given tracers, I focus on three specific ones: `function`
and `function_graph`
to enable tracing, and `nop`
to disable tracing.
## Identify current tracer
Usually, by default, the tracer is set to `nop`
. That is, "No operation" in the special file `current_tracer`
, which usually means tracing is currently off:
```
# pwd
/sys/kernel/tracing
# cat current_tracer
nop
```
## View Tracing output
Before you enable any tracing, take a look at the file where the tracing output gets stored. You can view the contents of the file named `trace`
using the [cat](https://opensource.com/article/19/2/getting-started-cat-command) command:
```
# cat trace
# tracer: nop
#
# entries-in-buffer/entries-written: 0/0 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
```
## Enable function tracer
You can enable your first tracer called `function`
by writing `function`
to the file `current_tracer`
(its earlier content was `nop`
, indicating that tracing was off.) Think of this operation as a way of enabling tracing:
```
# pwd
/sys/kernel/tracing
# cat current_tracer
nop
# echo function > current_tracer
# cat current_tracer
function
```
## View updated tracing output for function tracer
Now that you've enabled tracing, it's time to view the output. If you view the contents of the `trace`
file, you see a lot of data being written to it continuously. I've piped the output and am currently viewing only the top 20 lines to keep things manageable. If you follow the headers in the output on the left, you can see which task and Process ID are running on which CPU. Toward the right side of the output, you see the exact kernel function running, followed by its parent function. There is also time stamp information in the center:
```
# sudo cat trace | head -20
# tracer: function
#
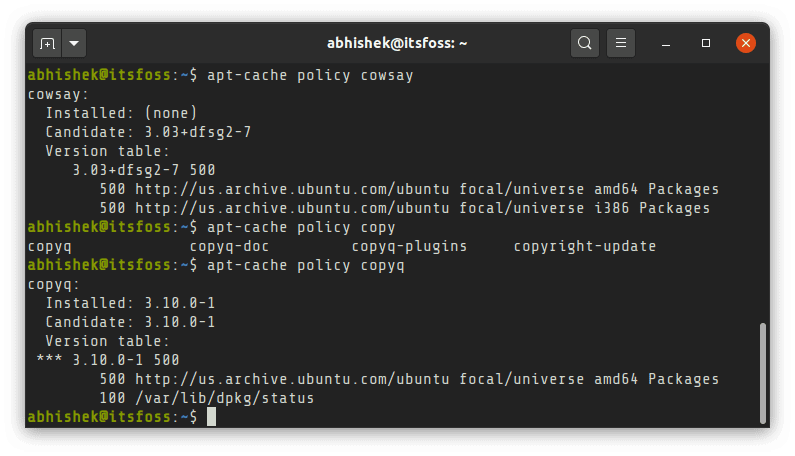
# entries-in-buffer/entries-written: 409936/4276216 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
<idle>-0 [000] d... 2088.841739: tsc_verify_tsc_adjust <-arch_cpu_idle_enter
<idle>-0 [000] d... 2088.841739: local_touch_nmi <-do_idle
<idle>-0 [000] d... 2088.841740: rcu_nocb_flush_deferred_wakeup <-do_idle
<idle>-0 [000] d... 2088.841740: tick_check_broadcast_expired <-do_idle
<idle>-0 [000] d... 2088.841740: cpuidle_get_cpu_driver <-do_idle
<idle>-0 [000] d... 2088.841740: cpuidle_not_available <-do_idle
<idle>-0 [000] d... 2088.841741: cpuidle_select <-do_idle
<idle>-0 [000] d... 2088.841741: menu_select <-do_idle
<idle>-0 [000] d... 2088.841741: cpuidle_governor_latency_req <-menu_select
```
Remember that tracing is on, which means the output of tracing continues to get written to the trace file until you turn tracing off.
## Turn off tracing
Turning off tracing is simple. All you have to do is replace `function`
tracer with `nop`
in the `current_tracer`
file and tracing gets turned off:
```
# cat current_tracer
function
# echo nop > current_tracer
# cat current_tracer
nop
```
## Enable function_graph tracer
Now try the second tracer, called `function_graph`
. You can enable this using the same steps as before: write `function_graph`
to the `current_tracer`
file:
```
# echo function_graph > current_tracer
# cat current_tracer
function_graph
```
## Tracing output of function_graph tracer
Notice that the output format of the `trace`
file has changed. Now, you can see the CPU ID and the duration of the kernel function execution. Next, you see curly braces indicating the beginning of a function and what other functions were called from inside it:
```
# cat trace | head -20
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
6) | n_tty_write() {
6) | down_read() {
6) | __cond_resched() {
6) 0.341 us | rcu_all_qs();
6) 1.057 us | }
6) 1.807 us | }
6) 0.402 us | process_echoes();
6) | add_wait_queue() {
6) 0.391 us | _raw_spin_lock_irqsave();
6) 0.359 us | _raw_spin_unlock_irqrestore();
6) 1.757 us | }
6) 0.350 us | tty_hung_up_p();
6) | mutex_lock() {
6) | __cond_resched() {
6) 0.404 us | rcu_all_qs();
6) 1.067 us | }
```
## Enable trace settings to increase the depth of tracing
You can always tweak the tracer slightly to see more depth of the function calls using the steps below. After which, you can view the contents of the `trace`
file and see that the output is slightly more detailed. For readability, the output of this example is omitted:
```
# cat max_graph_depth
0
# echo 1 > max_graph_depth ## or:
# echo 2 > max_graph_depth
# sudo cat trace
```
## Finding functions to trace
The steps above are sufficient to get started with tracing. However, the amount of output generated is enormous, and you can often get lost while trying to find out items of interest. Often you want the ability to trace specific functions only and ignore the rest. But how do you know which processes to trace if you don't know their exact names? There is a file that can help you with this—`available_filter_functions`
provides you with a list of available functions for tracing:
```
# wc -l available_filter_functions
63165 available_filter_functions
```
## Search for general kernel functions
Now try searching for a simple kernel function that you are aware of. User-space has `malloc`
to allocate memory, while the kernel has its `kmalloc`
function, which provides similar functionality. Below are all the `kmalloc`
related functions:
```
# grep kmalloc available_filter_functions
debug_kmalloc
mempool_kmalloc
kmalloc_slab
kmalloc_order
kmalloc_order_trace
kmalloc_fix_flags
kmalloc_large_node
__kmalloc
__kmalloc_track_caller
__kmalloc_node
__kmalloc_node_track_caller
[...]
```
## Search for kernel module or driver related functions
From the output of `available_filter_functions`
, you can see some lines ending with text in brackets, such as `[kvm_intel]`
in the example below. These functions are related to the kernel module `kvm_intel`
, which is currently loaded. You can run the `lsmod`
command to verify:
```
# grep kvm available_filter_functions | tail
__pi_post_block [kvm_intel]
vmx_vcpu_pi_load [kvm_intel]
vmx_vcpu_pi_put [kvm_intel]
pi_pre_block [kvm_intel]
pi_post_block [kvm_intel]
pi_wakeup_handler [kvm_intel]
pi_has_pending_interrupt [kvm_intel]
pi_update_irte [kvm_intel]
vmx_dump_dtsel [kvm_intel]
vmx_dump_sel [kvm_intel]
# lsmod | grep -i kvm
kvm_intel 335872 0
kvm 987136 1 kvm_intel
irqbypass 16384 1 kvm
```
## Trace specific functions only
To enable tracing of specific functions or patterns, you can make use of the `set_ftrace_filter`
file to specify which functions from the above output you want to trace.
This file also accepts the `*`
pattern, which expands to include additional functions with the given pattern. As an example, I am using the `ext4`
filesystem on my machine. I can specify `ext4`
specific kernel functions to trace using the following commands:
```
# mount | grep home
/dev/mapper/fedora-home on /home type ext4 (rw,relatime,seclabel)
# pwd
/sys/kernel/tracing
# cat set_ftrace_filter
#### all functions enabled ####
$
$ echo ext4_* > set_ftrace_filter
$
$ cat set_ftrace_filter
ext4_has_free_clusters
ext4_validate_block_bitmap
ext4_get_group_number
ext4_get_group_no_and_offset
ext4_get_group_desc
[...]
```
Now, when you see the tracing output, you can only see functions `ext4`
related to kernel functions for which you had set a filter earlier. All the other output gets ignored:
```
# cat trace |head -20
## tracer: function
#
# entries-in-buffer/entries-written: 3871/3871 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
cupsd-1066 [004] .... 3308.989545: ext4_file_getattr <-vfs_fstat
cupsd-1066 [004] .... 3308.989547: ext4_getattr <-ext4_file_getattr
cupsd-1066 [004] .... 3308.989552: ext4_file_getattr <-vfs_fstat
cupsd-1066 [004] .... 3308.989553: ext4_getattr <-ext4_file_getattr
cupsd-1066 [004] .... 3308.990097: ext4_file_open <-do_dentry_open
cupsd-1066 [004] .... 3308.990111: ext4_file_getattr <-vfs_fstat
cupsd-1066 [004] .... 3308.990111: ext4_getattr <-ext4_file_getattr
cupsd-1066 [004] .... 3308.990122: ext4_llseek <-ksys_lseek
cupsd-1066 [004] .... 3308.990130: ext4_file_read_iter <-new_sync_read
```
## Exclude functions from being traced
You don't always know what you want to trace but, you surely know what you don't want to trace. For that, there is this file aptly named `set_ftrace_notrace`
—notice the "no" in there. You can write your desired pattern in this file and enable tracing, upon which everything except the mentioned pattern gets traced. This is often helpful to remove common functionality that clutters our output:
```
# cat set_ftrace_notrace
#### no functions disabled ####
```
## Targetted tracing
So far, you've been tracing everything that has happened in the kernel. But that won't help us if you wish to trace events related to a specific command. To achieve this, you can turn tracing on and off on-demand and, and in between them, run our command of choice so that you do not get extra output in your trace output. You can enable tracing by writing `1`
to `tracing_on`
, and `0`
to turn it off:
```
# cat tracing_on
0
# echo 1 > tracing_on
# cat tracing_on
1
### Run some specific command that we wish to trace here ###
# echo 0 > tracing_on
# cat tracing_on
0
```
## Tracing specific PID
If you want to trace activity related to a specific process that is already running, you can write that PID to a file named `set_ftrace_pid`
and then enable tracing. That way, tracing is limited to this PID only, which is very helpful in some instances:
`# echo $PID > set_ftrace_pid`
## Conclusion
`Ftrace`
is a great way to learn more about the internal workings of the Linux kernel. With some practice, you can learn to fine-tune `ftrace`
and narrow down your searches. To understand `ftrace`
in more detail and its advanced usage, see these excellent articles written by the core author of `ftrace`
himself—Steven Rostedt.
## Comments are closed. |
13,753 | 如何使用 youtube-dl 只下载音频 | https://itsfoss.com/youtube-dl-audio-only/ | 2021-09-05T15:32:00 | [
"音频",
"youtube-dl"
] | https://linux.cn/article-13753-1.html | 
[youtube-dl](https://github.com/ytdl-org/youtube-dl) 是一个多功能的命令行工具,用于从 YouTube 和许多其他网站下载视频。我用它来做我自己的 YouTube 视频的备份。
默认情况下,你会 [使用 youtube-dl 下载视频](https://itsfoss.com/download-youtube-linux/)。用 youtube-dl 只提取音频怎么样? 其实很简单。让我告诉你步骤。
>
> **注意**
>
>
> 从网站下载视频可能违反他们的政策。这取决于你是否选择下载视频或音频。
>
>
>
### 使用 youtube-dl 只下载音频
请确保你已经在你的 Linux 发行版上安装了 `youtube-dl`。
```
sudo snap install youtube-dl
```
如果你只想从 YouTube 视频中下载音频,你可以使用 `youtube-dl` 的 `-x` 选项。这个提取音频的选项将视频文件转换为纯音频文件。
```
youtube-dl -x video_URL
```
该文件被保存在你运行 `youtube-dl` 命令的同一目录下。
这是我下载 Zorin OS 16 评论视频的画外音的示例:
```
youtube-dl -x https://www.youtube.com/watch?v=m_PmLG7HqbQ
[youtube] m_PmLG7HqbQ: Downloading webpage
[download] Destination: Zorin OS 16 Review - It's a Visual Masterpiece-m_PmLG7HqbQ.m4a
[download] 100% of 4.26MiB in 00:03
[ffmpeg] Correcting container in "Zorin OS 16 Review - It's a Visual Masterpiece-m_PmLG7HqbQ.m4a"
[ffmpeg] Post-process file Zorin OS 16 Review - It's a Visual Masterpiece-m_PmLG7HqbQ.m4a exists, skipping
```
你注意到音频格式了吗?它是 .m4a 格式。你可以把音频格式指定为你所选择的格式。
比如你想提取 MP3 格式的音频。你可以像这样使用它:
```
youtube-dl -x --audio-format mp3 video_URL
```
下面是我之前展示的同一个例子。你可以看到它 [使用 ffmpeg 转换](https://itsfoss.com/ffmpeg/) m4a 文件为 mp3:
```
youtube-dl -x --audio-format mp3 https://www.youtube.com/watch?v=m_PmLG7HqbQ
[youtube] m_PmLG7HqbQ: Downloading webpage
[download] Zorin OS 16 Review - It's a Visual Masterpiece-m_PmLG7HqbQ.m4a has already been downloaded
[download] 100% of 4.26MiB
[ffmpeg] Correcting container in "Zorin OS 16 Review - It's a Visual Masterpiece-m_PmLG7HqbQ.m4a"
[ffmpeg] Destination: Zorin OS 16 Review - It's a Visual Masterpiece-m_PmLG7HqbQ.mp3
Deleting original file Zorin OS 16 Review - It's a Visual Masterpiece-m_PmLG7HqbQ.m4a (pass -k to keep)
```
### 以 MP3 格式下载整个 YouTube 播放列表
是的,你完全可以这样做。最主要的是要在这里得到播放列表的 URL。它通常是以下格式:
```
https://www.youtube.com/playlist?list=XXXXXXXXXXXXXXXXXXX
```
要获得一个播放列表的 URL,当播放列表显示在右边栏时,点击其名称。

它将带你到播放列表页面,你可以在这里复制 URL。

现在你有了播放列表的 URL,你可以用它来下载 MP3 格式的音频文件,方法如下:
```
youtube-dl --extract-audio --audio-format mp3 -o "%(title)s.%(ext)s" playlist_URL
```
那个看起来很可怕的 `-o "%(title)s.%(ext)s"` 指定了输出文件(选项 `-o`),并指示它使用视频的标题和扩展名(本例为 mp3)来命名音频文件。

我希望你觉得这个技巧对你有帮助。享受音频文件吧。
---
via: <https://itsfoss.com/youtube-dl-audio-only/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[youtube-dl](https://github.com/ytdl-org/youtube-dl?ref=itsfoss.com) is a versatile command line tool for downloading videos from YouTube and many other websites. I use it for making back up of my own YouTube videos.
By default, you [use youtube-dl for downloading videos](https://itsfoss.com/download-youtube-linux/). How about extracting only the audio with youtube-dl? That’s very simple actually. Let me show you the steps.
## Install youtube-dl first
Please make sure that you have installed youtube-dl on your Linux distribution first.
Since 2021, the usual snap and default package manager installations of youtube-dl give a broken utility. So, you need to install the Nightly version of youtube-dl to make it work.
The Nightly release contains recent changes and fixes so that you can run it without any error. I will describe the easiest way to set it up. First go to the Nightly release GitHub page.
Here, you can get a python file, named `youtube-dl`
. Just download it. Once downloaded, copy that file to `/usr/local/bin/`
. For this, open a terminal where you downloaded the file and then run:
```
sudo cp youtube-dl /usr/local/bin/
```
Now, give the file execution permission using the `chmod`
command.
```
sudo chmod a+rx /usr/local/bin/youtube-dl
```
You cannot just run `youtube-dl`
now, because of issue with `python`
naming. It uses `python`
while in Ubuntu-based systems, it is `python3`
.
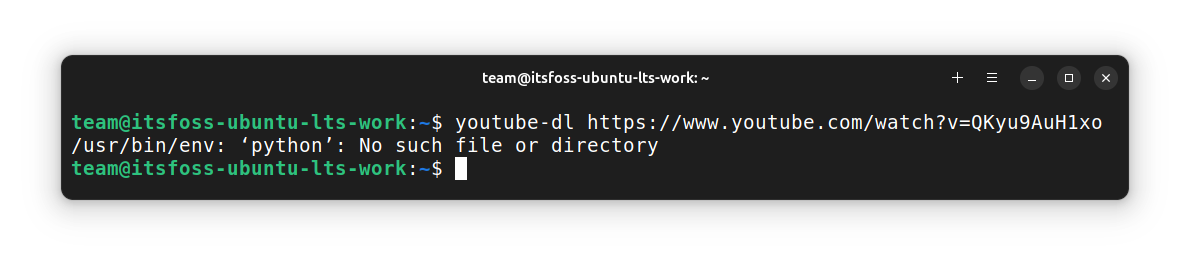
So, [you can create an alias](https://linuxhandbook.com/linux-alias-command/) for youtube-dl in your `.bashrc`
.
```
alias youtube-dl='python3 /usr/local/bin/youtube-dl'
```
That’s it. You have set up youtube-dl in your system.
**Remember**In order to download audio using youtube-dl, you should have
[FFMPEG installed on your system](https://itsfoss.com/ffmpeg/).
## Download only audio with youtube-dl
If you only want to download audio from a YouTube video, you can use the `-x`
option with youtube-dl. This extract-audio option converts the video files to audio-only files.
```
youtube-dl -x video_URL
```
The file is saved in the same directory from where you ran the youtube-dl command.
Here’s an example where I downloaded the voice-over of our [Install Google Chrome on Ubuntu 24.04](https://www.youtube.com/watch?v=Cfo5BR2FGEQ) video.
Did you notice the audio format? It is in .m4a format. You may specify the audio format to something of your choice.
Say you want to extract the audio in MP3 format. You can use it like this:
```
youtube-dl -x --audio-format mp3 video_URL
```
Here’s the same example I showed previously. You can see that it [uses ffmpeg to convert](https://itsfoss.com/ffmpeg/) the m4a file into MP3.
`-k`
option to preserve the old file along with the new one.## Download entire YouTube playlist in MP3 format
Yes, you can totally do that. The main thing is to get the URL of the playlist here. It is typically in the following format:
```
https://www.youtube.com/playlist?list=XXXXXXXXXXXXXXXXXXX
```
To get the URL of a playlist, click on its name when the playlist is being displayed in the right sidebar.
It will take you to the playlist page, and you can copy the URL here.
Now that you have the playlist URL, you can use it to download the audio files in MP3 format in the following fashion:
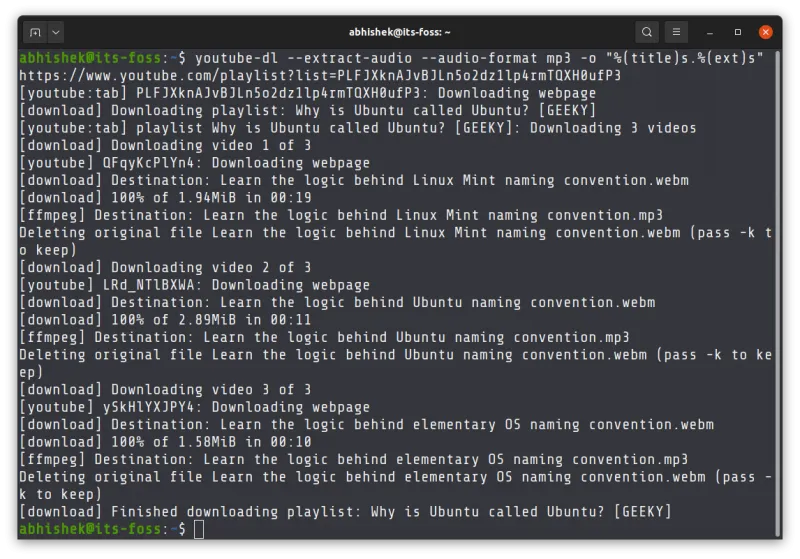
```
youtube-dl --extract-audio --audio-format mp3 -o "%(title)s.%(ext)s" playlist_URL
```
That scary looking `-o "%(title)s.%(ext)s"`
specifies the output file (with option -o) and instructs it to use the title of the video and the extension (MP3 in this case) for naming the audio files.
I hope you find this quick tip helpful. Enjoy the audio files 😄 |
13,755 | 满足日常需求的应用(二):办公套件 | https://fedoramagazine.org/apps-for-daily-needs-part-2-office-suites/ | 2021-09-05T23:20:36 | [
"办公套件"
] | https://linux.cn/article-13755-1.html | 
今天,几乎每个家庭都有一台台式电脑或笔记本电脑。这是因为计算机已经成为一个非常重要的要求。此外,不管是为了工作还是学习,许多人需要创建电子版的文档和演示文稿。因此,办公套件是几乎所有计算机上的必备应用程序。本文将介绍一些你可以在 Fedora Linux 上使用的开源办公套件。这些软件你可能需要安装。如果你不熟悉如何在 Fedora Linux 中添加软件包,请参阅我之前的文章 [安装 Fedora 34 工作站后要做的事情](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/)。下面是满足日常需求的办公套件类的应用程序列表。
### LibreOffice
LibreOffice 是 GNU/Linux 用户中最流行的办公套件。它的用户界面和用户体验类似于微软 Office。这使得 LibreOffice 对于那些刚刚从微软 Office 迁移过来的人来说很容易学习。LibreOffice 有完整的功能,可以满足你在文档和演示方面的工作需要。它由六个应用程序组成:Writer、Calc、Impress、Draw、Math 和 Base。
第一个应用程序是 Writer,用于创建各种类型的文档,如信件、传真、议程、会议记录等。它是一个全功能的文字处理和桌面出版工具。第二个应用程序是 Calc,它是一个电子表格程序,非常适合以表格形式呈现数据和记录数据。Calc 可以创建简单的表格或进行专业的数据分析。第三个应用程序是 Impress,它是一个易于使用的演示应用程序。你可以很容易地选择你在演示幻灯片中想要的功能,如文本、图像、表格、图表等。



前面提到的三个 LibreOffice 应用程序是创建文档和演示文稿中最常用的应用程序。然而,LibreOffice 提供的其他三个应用程序也非常有用。第一个是 Draw,它可以用来创建从简单到复杂的图纸和图表。下一个应用程序是 Math,它可以帮助我们做出完美格式的数学和科学公式。最后一个是 Base,这是一个用于处理数据库的应用程序。



更多信息请见此链接:<https://www.libreoffice.org/>
### ONLYOFFICE
ONLYOFFICE 是一款与微软 Office 高度兼容的办公套件应用程序。因此,我们与使用微软 Office 的同事协作时就不必担心了,因为它可以读取各种文件格式,如 docx、xlsx 和 pptx。
ONLYOFFICE 提供了三种具有简洁和现代外观的应用程序。我们可以很容易地找到我们需要的功能和工具。虽然功能没有 LibreOffice 那么齐全,但也足以帮助我们创建良好的文档和演示文稿。
第一个应用程序是文档编辑器,它的功能与 LibreOffice 的 Writer 相同。它具有文字处理器所需的所有基本功能,如管理字体和样式、格式化文本、调整行距和段距、插入页眉和页脚、自定义页面布局和设置页边距。第二个应用程序是电子表格编辑器,它是一个用于处理数据并将其创建为表格格式的文件的应用程序。它是一个具有与 Calc 相同功能的应用程序。最后一个是演示文稿编辑器,它是一个演示文稿应用程序,其功能类似于 Impress。
不幸的是,ONLYOFFICE 在官方的 Fedora Linux 软件库中并没有提供。但是你仍然可以使用 Flatpak 或 Appimages 在 Fedora Linux 上安装它。



更多信息请见此链接:<https://www.onlyoffice.com/desktop.aspx>
### Calligra
Calligra 是一个由 KDE 创建的办公套件。因此,这个应用程序实际上更适合于 KDE Plasma 桌面环境的用户。但它仍然可以在其他桌面环境中良好运行,例如使用 GNOME 的 Fedora 工作站。
Calligra 提供的几个应用程序的外观与 LibreOffice 或 ONLYOFFICE 略有不同。对于那些习惯于主流办公套件应用程序的人来说,可能需要一些适应。然而,Calligra 仍然是一个可靠的办公套件,足以支持我们的日常需求。
第一个应用程序是 Words,它是一个具有桌面出版功能的直观的文字处理器。它具有帮助我们进行文档创作的全面功能。第二个应用程序是 Sheets,它具有与 Calc 和电子表格编辑器相同的功能,是一个功能齐全的电子表格应用程序。第三个应用程序是 Stage,它可以帮助我们制作演示幻灯片。



这三个 Calligra 应用程序是创建文档和演示文稿最常用的应用程序。另外还有三个应用程序也非常有用。第一个是 Karbon,它可以用来创建从简单到复杂的图纸和图表。下一个应用程序是 Plan,这是一个项目管理应用程序,可以帮助管理具有多种资源的中等规模的项目。最后一个是 KEXI,它是一个可视化数据库应用程序的创建器。



更多信息请见此链接:<https://calligra.org/>
### 总结
这篇文章介绍了 3 个可以在 Fedora Linux 上使用的办公套件,以满足你的日常需要。如果你想拥有具有一套完整功能的办公套件,那么 LibreOffice 可能是正确的选择。如果想与微软 Office 有良好的兼容性,那么你可以选择 ONLYOFFICE。然而,如果你想要一个不同的用户界面和创建文档和演示文稿的体验,你可以试试 Calligra。希望这篇文章能帮助你选择合适的办公套件。如果你有使用这些应用程序的经验,请在评论中分享你的经验。
---
via: <https://fedoramagazine.org/apps-for-daily-needs-part-2-office-suites/>
作者:[Arman Arisman](https://fedoramagazine.org/author/armanwu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today, almost every family has a desktop computer or laptop. That’s because the computer has become a very important requirement. Moreover, many people have to create documents and presentations in digital format for work or study. Therefore, the office suites are must-have application on almost all computers. This article will introduce some of the open source office suites that you can use on Fedora Linux. You may need to install the software mentioned. If you are unfamiliar with how to add software packages in Fedora Linux, see my earlier article [Things to do after installing Fedora 34 Workstation](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/). Here is the list of apps for daily needs in the office suites category.
## LibreOffice
LibreOffice is the most popular office suite among GNU/Linux users. It has a user interface and user experience similar to Microsoft Office. This makes LibreOffice easy to learn for those who have just migrated from Microsoft Office. LibreOffice has complete features to meet your needs working on documents and presentations. It consists of six applications: Writer, Calc, Impress, Draw, Math, and Base.
The first application is Writer that is used to create various kinds of documents, such as letters, faxes, agendas, minutes, etc. It is a full-featured word processing and desktop publishing tool. The second application is Calc which is a spreadsheet program that is perfect for presenting data and documenting it in tabular format. Calc can create simple tables or do professional data analysis. The third application is Impress which is an easy-to-use presentation application. You can easily choose what you features want in your presentation slides, such as text, images, tables, diagrams, etc.
The three LibreOffice applications mentioned earlier are the most commonly used applications in creating documents and presentations. However, LibreOffice provides three other applications that are also very useful. The first is Draw which can be used to create drawings and diagrams, ranging from simple to complex. The next application is Math which can help us make perfectly formatted mathematical and scientific formulas. The last is Base which is an application for processing databases.
More information is available at this link: [https://www.libreoffice.org/](https://www.libreoffice.org/)
## ONLYOFFICE
ONLYOFFICE is an office suite application that is highly compatible with Microsoft Office. Therefore we do not have to worry about collaborating with colleagues who use Microsoft Office because it can read various file formats such as docx, xlsx, and pptx.
ONLYOFFICE provides three applications with a clean and modern look. We can easily find the features and tools that we need. Although the features are not as complete as LibreOffice, they are very sufficient to help us create good documents and presentations.
The first application is Documents Editor which has the same function as Writer from LibreOffice. It has all the basic features needed in a word processor, such as managing fonts and styles, formatting text, adjusting line and paragraph spacing, inserting headers and footers, customizing page layout, and setting margins. The second application is Spreadsheet Editor which is an application for processing data and creating it as a document in tabular format. It is an application with the same functionality as Calc. The last one is Presentations Editor which is a presentation application with functions similar to Impress.
Unfortunately ONLYOFFICE is not available in the official Fedora Linux repositories. But you can still install it on Fedora Linux using Flatpak or Appimages.
More information is available at this link: [https://www.onlyoffice.com/desktop.aspx](https://www.onlyoffice.com/desktop.aspx)
## Calligra
Calligra is an office suite created by KDE. Therefore, this application is actually more suitable for users of the KDE Plasma desktop environment. But it can still run well on other desktop environments, such as Fedora Workstation using GNOME.
Calligra provides several applications with a slightly different look from LibreOffice or ONLYOFFICE. It may take some adjustment for those who are used to mainstream office suite applications. However, Calligra is still a reliable office suite to support our daily needs.
The first application is Words which is an intuitive word processor with desktop publishing features. It has a full range of features to help us in document creation. The second application is Sheets which has the same functionality as Calc and Spreadsheet Editors as a fully-featured spreadsheet application. The third application is Stage which can help us in making presentation slides.
The three Calligra applications are the most commonly used applications for creating documents and presentations. There are three other applications that are also very useful. The first is Karbon which can be used to create drawings and diagrams, ranging from simple to complex. The next application is Plan which is project management application that can help in managing moderately large projects with multiple resources. The last is KEXI which is a visual database application creator.
More information is available at this link: [https://calligra.org/](https://calligra.org/)
## Conclusion
This article presented 3 office suites for your daily needs that you can use on Fedora Linux. If you want a complete set of features in your office suite, then LibreOffice may be the right choice. For good compatibility with Microsoft Office, then you may choose ONLYOFFICE. However, if you want a different user interface and experience in creating documents and presentations, you can try Calligra. Hopefully this article can help you to choose the right office suite. If you have experience in using these applications, please share your experience in the comments.
## dragontao
wps maybe another good choice 🙂
## Arman Arisman
Of course. But unfortunately WPS is not open source software 🙂
Thanks for adding information through your comments.
## Adam
Freeoffice – free version of SoftMaker office – https://www.freeoffice.com/en/download/applications
## Arman Arisman
Thanks for adding information for this article. I’ve never tried it. Is it open source software?
## Adam
(freeware/registerware)
## Arman Arisman
Oh I see. Thanks for your info 🙂
## HelloWorls
OpenOffice is also good.
## Arman Arisman
Of course. Thank you for completing my article 🙂
## Null_Pointer_00
Hello.
No, OpenOffice is no good at all.
https://itsfoss.com/libreoffice-letter-openoffice/
https://blog.documentfoundation.org/blog/2020/10/12/open-letter-to-apache-openoffice/
Regards.
## Arman Arisman
I think everyone has different preferences and needs. Thanks for the opinion 🙂
## PissedOff Veteran
Having tried all the above packages I/we have decided the only one that comes close to providing for our needs is LibreOffice.
Therefore we have cleaned our all others to avoid having people inadvertently using such as Calibreoffice etc and causing a ruckus.
Actually started using LibreOffice way before there was LibreOffice.
Started with it’s Great Grand Father, “Star office.”
Later used Open Office but there were problems. So tried LibreOffice which had just branched off Open Office. It had even more problems so stuck with Open Office for a while, then Libre Office cleaned up the problems that was incompatible with us and we have been with it ever since.
## Arman Arisman
Wow! You have a lot of experience related to the use of office applications in the Linux world. Thank you for sharing here. Nice info!
## Ralf Seidenschwang
I mainly need to concert documents into PDF files, and therefore LibreOffice is a very good choice.
The electronic paper file didn’t get around everywhere, so I still have to maintain a couple paper folders for mostly extremely unimportant things.
I often get the impression that a different format is chooses by intend to make the communications more difficult than needed and to provoke dispute. Our governments – that’s how they tick.
## Arman Arisman
Hi, Ralf. Yes, LibreOffice is a good choice. Agree with you. And thanks for your opinion too 🙂
## Ralf Seidenschwang
Opinions change from time to time, knowledge too.
Thanks for the nice article.
## Arman Arisman
Sure. You’re welcome, Ralf 🙂
## Bill
I’m curious to see if this series looks into other kinds of software I’ve always found very lacking on Linux. I couldn’t ever find a good todo list app, calendar app, note taking app, or email app. For that matter, I wouldn’t say that any of the apps mentioned in this series of articles so far are as good as their closed source counterparts. But I’ll keep reading. Maybe there are apps I’m not aware of out there. I’d love to use Linux as my full time OS, but as far as I can tell, the apps just aren’t there.
## Arman Arisman
Hi, Bill. Thank you for reading and giving your opinion 🙂
I think this goes back to our needs. In using office suites, I personally have had enough with open source software as I wrote in this article. But some of my friends have to use other applications because they have special needs.
To be honest there are still many fields that do not have good open source software.
## Eric
I like LibreOffice for work-related tasks, Thunderbird for email, and Chromium and Firefox for browsers on Linux. Oh, and Lollypop and Rhythmbox for managing music 🙂 But I do use Microsoft Office to do my work, as there are some things that LibreOffice doesn’t handle correctly, but I have a VirtualBox VM for that.
I just wish Wine worked more consistently with Blizzard’s launcher and games. It was doing well in Fedora 33, but now it seems to be broken in 34. Steam is consistently great, though, including at running Windows games via Proton.
I like that I can install Fedora or any other distro on a system I’ve built myself and get so much great functionality without paying money to Microshaft for an OS, or be locked into Apple’s strange and pricey hardware configurations. I even have a home-built Linux PC hooked to my TV instead of some set top box, and I wouldn’t have it any other way. On top of that, I have a Raspberry Pi with a 4-drive USB 3 enclosure hooked to it and running Open Media Vault acting as a NAS! So, bottom line, Linux has a lot of uses and flexibility, and it’s all free. It’s so nice to have available and can do a lot of things very well.
## Arman Arisman
Thanks for sharing here, Eric! 🙂
## Ralf Seidenschwang
I don‘t like the idea of running a VM with Office365 on my Linux Box and would be very interested if someone can imagine a solution with minimal overhead using some of the new technologies available.
I certainly would pay for the Office suite in a corporate environment, but I dislike my current approach to start virtual machine or a bare metal client to access Office 365 in the case I need some functionality.
Well, as already said: I‘m using OpenSource Office suites regularly and I‘m very happy with them, but there is no replacement for Outlook.
## Jared G
I used to think of LibreOffice as a second-rate MS Office clone. I’ve since discovered that with some configuration, it’s really quite competitive! Like so many things in Linux, the out-of-box situation is improved with a few personalized tweaks and some elbow grease.
As for the other gaps you mentioned, I recommend Thunderbird for email and calendaring, though Evolution is a more Outlook-like alternative. And nothing beats Vim or Emacs for note-taking, but I digress … 😉
## foshelan
For the Chinese users, Yozo Office is a very good choice. Especially for the convenience of the Chinese input. Whats more, it’s very small.
## Arman Arisman
Hi. Thank you for sharing and completing this list. To be honest, I never knew about Yozo. Thanks for your information.
## foshelan
I used to have intention of installing WPS at the beginning, but which presents some errors by missing some of the Chinese fonts in the system, what’s more, the WPS suite presents always some ads. Occasionnally, I have heard of the Yozo Office (whose name in Chinse is 永中OFFICE), which does not contain those annoying ads, and very simple to be installed: It has 2 versions for Linux, one is in .deb and another is .rpm.
## Arman Arisman
Thanks for the additional information 🙂
## svsv sarma
My preference is LibreOffice only. It has all the qualities I need for DTP. But nothing beats macros in MSOffice.
## Arman Arisman
Hi. Thanks for your opinion 🙂
## giuseppe
I do everything with LibreOffice, also its Draw package is awesome.
And, begin a scientist, I appreciate a lot the Latex support through the TexMaths extension. It should be used everywhere instead of paying licenses for other software!
## Arman Arisman
Sure, LibreOffice is indeed very complete. LaTeX is also very good. You can even find LaTeX as a default application in Fedora Scientific [0]. Thanks for your comment 🙂
[0] https://labs.fedoraproject.org/en/scientific/
## Vitor Gabriel
I use and recommend free office from softmaker. It’s really good!
## Arman Arisman
Hi, Vitor. Thanks for sharing. I’ve never tried it.
## Geir Jonsen
LaTeX for writing -> beautiful documents. Gnumeric for basic ( advanced? ) spreadsheet.
## Arman Arisman
Hi, Geir. Thanks for completing the list. Do you use LaTeX and Gnumeric? Maybe you can share your experience 🙂
## Doug
For those who find the LibreOffice Calc spreadsheet too heavy or slow, give Gnumeric a try, less features, but much snappier!
## Arman Arisman
Sure. Gnumeric is also a good app. Thanks for the comment 🙂
## JL
I also tried Abiword. What is your oppinion about it? In fact, Abiword + Gnumeric sometimes are known as “Gnome Office” (or at least, they were).
## Arman Arisman
Yes you’re right. In the past, Abiword, Gnumeric, and GNOME-DB were part of the GNOME Office package. But it seems we can’t find any information about GNOME Office at the moment on the GNOME website.
## Ralf Seidenschwang
I‘m not very sure how to use GTK 4 in a way like you use the QT-designer as a development environment for designing your apps with graphical elements constructed very easily and C++ for the logic.
I looked around and there is something like a widget factory, but probably that would be worth an additional article overwritten with something like: „How to get started with GTK 4 to construct useful applications“ or something like that…
## Renato Trevisan
Does any of theses suites have integration with OneDrive, just like LibreOffice has with Google Drive? |
13,756 | 使用 ncurses 在你的 Linux 屏幕上定位文本 | https://opensource.com/article/21/8/ncurses-linux | 2021-09-06T08:59:23 | [
"ncurses",
"终端"
] | https://linux.cn/article-13756-1.html |
>
> 使用 ncurses 在 Linux 屏幕上的特定位置放置文本,可以带来更友好的用户界面体验。
>
>
>

大多数的 Linux 实用程序仅仅只在屏幕的底部滚动文本。如果你想在屏幕中放置你的文本,例如一个游戏或者一个数据展示,你可以试试 ncurses。
curses 是一个旧的 Unix 库,它可以在文本终端界面控制光标。curses 的名称就来自于术语 “<ruby> 光标控制 <rt> cursor control </rt></ruby>”。多年以后,其他人编写了新的 curses 版本用来添加新的功能,新版本被叫做 “new curses” 或者 “ncurses”。你可以在每个流行的 Linux 发行版中找到 ncurses。尽管默认情况下可能未安装开发库、头文件和文档。例如,在 Fedora 上,你需要使用以下命令安装 `ncurses-devel` 包:
```
$ sudo dnf install ncurses-devel
```
### 在程序中使用 ncurses
要在屏幕上直接寻址,你首先需要初始化 `ncurses` 库。大部分程序会通过以下三行来做到这一点:
* `initscr()`:初始化窗口对象和 ncurses 代码,返回代表整个屏幕的窗口对象
* `cbreak()`:禁用缓冲并使键入的输入立即可用
* `noecho()`:关闭回显,因此用户输入不会显示在屏幕上
这些函数定义在 `curses.h` 头文件中,你需要在你的程序中通过以下方式将其包含进来:
```
#include <curses.h>
```
初始化终端后,你可以自由使用任何 ncurses 函数,我们将在示例程序中探讨其中的一些函数。
当你使用完 ncurses 并想返回到常规终端模式下时,使用 `endwin()` 重置一切。此命令可以重置任何屏幕颜色,将光标移动到屏幕的左下角,并使光标可见。通常在退出程序之前执行此操作。
### 在屏幕上寻址
关于 ncurses 首先需要知道的是屏幕的坐标分为行和列,左上角的是 `0,0` 点。ncurses 定义了两个全局变量来帮助你识别屏幕:`LINES` 是屏幕的行数,`COLS` 是屏幕的列数。屏幕右下角的位置是 `LINES-1,COLS-1`。
例如,如果你想要移动光标到第 10 行和第 30 列,你可以使用 `move()` 函数,移动到此坐标:
```
move(10, 30);
```
之后显示的任何文本都将从屏幕的该位置开始。要显示单个字符,请对单个字符使用 `addch(c)` 函数。要显示字符串,将对字符串使用 `addstr(s)` 函数。对于类似于 `printf` 的格式化输出,请使用带有常用选项的 `printw(fmt, ...)`。
移动到屏幕指定位置和显示文本是一件很常见的事情,ncurses 提供了同时执行这两项操作的快捷方式。`mvaddch(row, col, c)` 函数将在屏幕第 `row` 行,第 `col` 列的位置显示一个字符。而 `mvaddstr(row, col, s)` 函数将在屏幕第 `row` 行,第 `col` 列的位置显示一个字符串。举个更直接的例子,在程序中使用 `mvaddstr(10, 30, "Welcome to ncurses");` 函数将从屏幕的第 `10` 行和第 `30` 列开始显示文本 `Welcome to ncurses`。使用 `mvaddch(0, 0, '+')` 函数将在屏幕的左上角第 `0` 行和第 `0` 列处显示一个加号(`+`)。
在终端屏幕上绘制文本会对某些系统产生性能影响,尤其是在较旧的硬件终端上。因此 ncurses 允许你“堆叠”一堆文本以显示在屏幕上,然后使用 `refresh()` 函数使所有这些更改对用户可见。
让我们来看一个将以上所有内容整合在一起的简单示例:
```
#include <curses.h>
int
main()
{
initscr();
cbreak();
noecho();
mvaddch(0, 0, '+');
mvaddch(LINES - 1, 0, '-');
mvaddstr(10, 30, "press any key to quit");
refresh();
getch();
endwin();
}
```
程序的开始初始化了一个终端窗口,然后在屏幕的左上角打印了一个加号,在左下角打印了一个减号,在第 `10` 行和第 `30` 列打印了 `press any key to quit` 文本。程序通过使用 `getch()` 函数接收了键盘输入的单个字符,接着,使用 `endwin()` 函数在程序完全退出前重置了终端。
`getch()` 是一个很有用的函数,你可以使用它来做很多事情。我经常使用它在我退出程序前用来暂停。与大多数 ncurses 函数一样,还有一个名为 `mvgetch(row, col)` 的 `getch()` 版本,用于在等待字符输入之前移动到屏幕位置的第 `row` 行,第 `col` 列。
### 使用 ncurses 编译
如果你尝试以通常的方式编译该示例程序,例如 `gcc pause.c`,你可能会从链接器中获得大量错误列表。那是因为 GNU C 编译器不会自动链接 `ncurses` 库。相反,你需要使用 `-l ncurses` 命令行选项加载它以进行链接。
```
$ gcc -o pause pause.c -lncurses
```
运行新程序将打印一条简单的 `press any key to quit`消息,该消息差不多位于屏幕中央:

*图 1:程序中居中的 “press any key to quit” 消息。*
### 使用 ncurses 构建更好的程序
探索 `ncurses` 库函数以了解在屏幕上显示文本的其它方法。你可以在 `ncurses` 的手册页中找到所有 `ncurses` 函数的列表。这给出了 ncurses 的一般概述,并提供了不同 `ncurses` 函数的类似表格的列表,并参考了包含完整详细信息的手册页。例如,在 `curs_printw(3X)` 手册页中描述了 `printw`,可以通过以下方式查看:
```
$ man 3x curs_printw
```
更简单点:
```
$ man curs_printw
```
使用 ncurses,你可以创建更多有趣的程序。通过在屏幕上的特定位置打印文本,你可以创建在终端中运行的游戏和高级实用程序。
---
via: <https://opensource.com/article/21/8/ncurses-linux>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Most Linux utilities just scroll text from the bottom of the screen. But what if you wanted to position text on the screen, such as for a game or a data display? That's where **ncurses** comes in.
**curses** is an old Unix library that supports cursor control on a text terminal screen. The name *curses* comes from the term *cursor control*. Years later, others wrote an improved version of **curses** to add new features, called *new curses* or **ncurses**. You can find **ncurses** in every modern Linux distribution, although the development libraries, header files, and documentation may not be installed by default. For example, on Fedora, you will need to install the **ncurses-devel** package with this command:
`$ sudo dnf install ncurses-devel`
## Using ncurses in a program
To directly address the screen, you'll first need to initialize the **ncurses** library. Most programs will do that with these three lines:
- initscr(); Initialize the screen and the
**ncurses**code - cbreak(); Disable buffering and make typed input immediately available
- noecho(); Turn off echo, so user input is not displayed to the screen
These functions are defined in the **curses.h** header file, which you'll need to include in your program with:
`#include <curses.h>`
After initializing the terminal, you're free to use any of the **ncurses** functions, some of which we'll explore in a sample program.
When you're done with **ncurses** and want to go back to regular terminal mode, use **endwin();** to reset everything. This command resets any screen colors, moves the cursor to the lower-left of the screen, and makes the cursor visible. You usually do this right before exiting the program.
## Addressing the screen
The first thing to know about **ncurses** is that screen coordinates are *row,col*, and start in the upper-left at 0,0. **ncurses** defines two global variables to help you identify the screen size: LINES is the number of lines on the screen, and COLS is the number of columns. The bottom-right position is LINES-1,COLS-1.
For example, if you wanted to move the cursor to line 10 and column 30, you could use the move function with those coordinates:
`move(10, 30);`
Any text you display after that will start at that screen location. To display a single character, use the **addch(c)** function with a single character. To display a string, use **addstr(s)** with your string. For formatted output that's similar to **printf**, use **printw(fmt, …)** with the usual options.
Moving to a screen location and displaying text is such a common thing that **ncurses** provides a shortcut to do both at once. The **mvaddch(row, col, c)** function will display a character at screen location *row,col*. And the **mvaddstr(row, col, s)** function will display a string at that location. For a more direct example, using **mvaddstr(10, 30, "Welcome to ncurses");** in a program will display the text "Welcome to ncurses" starting at row 10 and column 30. And the line **mvaddch(0, 0, '+');** will display a single plus sign in the upper-left corner at row 0 and column 0.
Drawing text to the terminal screen can have a performance impact on certain systems, especially on older hardware terminals. So **ncurses** lets you "stack up" a bunch of text to display to the screen, then use the **refresh()** function to make all of those changes visible to the user.
Let's look at a simple example that pulls everything together:
```
#include <curses.h>
int
main()
{
initscr();
cbreak();
noecho();
mvaddch(0, 0, '+');
mvaddch(LINES - 1, 0, '-');
mvaddstr(10, 30, "press any key to quit");
refresh();
getch();
endwin();
}
```
The program starts by initializing the terminal, then prints a plus sign in the upper-left corner, a minus in the lower-left corner, and the text "press any key to quit" at row 10 and column 30. The program gets a single character from the keyboard using the getch() function, then uses **endwin()** to reset the terminal before the program exits completely.
**getch()** is a useful function that you could use for many things. I often use it as a way to pause before I quit the program. And as with most **ncurses** functions, there's also a version of **getch()** called **mvgetch(row, col)** to move to screen position *row,col* before waiting for a character.
## Compiling with ncurses
If you tried to compile that sample program in the usual way, such as `gcc pause.c`
, you'll probably get a huge list of errors from the linker. That's because the **ncurses** library is not linked automatically by the GNU C Compiler. Instead, you'll need to load it for linking using the `-l ncurses`
command-line option.
`$ gcc -o pause pause.c -lncurses`
Running the new program will print a simple "press any key to quit" message that's more or less centered on the screen:
Figure 1: A centered "press any key to quit" message in a program.
## Building better programs with ncurses
Explore the **ncurses** library functions to learn about other ways to display text to the screen. You can find a list of all **ncurses** functions in the man ncurses manual page. This gives a general overview of **ncurses** and provides a table-like list of the different **ncurses** functions, with a reference to the manual page that has full details. For example, **printw** is described in the *curs_printw(3X)* manual page, which you can view with:
`$ man 3x curs_printw`
or just:
`$ man curs_printw`
With **ncurses**, you can create more interesting programs. By printing text at specific locations on the screen, you can create games and advanced utilities to run in the terminal.
## Comments are closed. |
13,759 | 用户必会的 20 个 Linux 基础命令 | https://opensource.com/article/21/9/essential-linux-commands | 2021-09-07T08:25:33 | [
"Linux",
"命令"
] | https://linux.cn/article-13759-1.html |
>
> 无论新手老手,这 20 个 Linux 命令都能让你的操作更轻松。
>
>
>

在黝黑的终端窗口中输入命令,这样的方式对某些人群来说可能好像过时了,但对许多专业计算机人员来说,这几乎是计算机完成能够执行的所有任务的最有效、最简便和最清晰的方式。如今,一些项目将开源命令引入了 macOS 和 Windows 等非开放平台,因此终端命令不仅仅是针对 Linux 和 BSD 用户,更是与每个人都息息相关。你可能会惊讶地发现,在一台普通的 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 计算机上安装了数千个命令,当然,其中很多命令并不是真的有用,至少不是直接或经常性被使用。而其中的一部分命令虽然不是有效终端必须使用的命令,但相比其他命令而言使用频率较高,值得大家学习一下。
以下是终端用户最可能会使用的前 20 个命令:
### cd
在终端外,你可以单击图标从一个文件夹移动到另一个文件夹,但在终端中,你需要使用 `cd`。`cd` 命令代表<ruby> 变更目录 <rt> change directory </rt></ruby>,是用户在 Linux 系统中移动的方式。这是 Linux 中从一个地方到另一个地方最快、最直接的路线。
例如,在桌面上,当你想从你的主目录(你保存所有文件夹的地方)移动到一个名为 `presentations` 的文件夹时,你首先要打开你的 `Documents` 文件夹,然后打开一个名叫 `work` 的文件夹,然后是 `projects` 文件夹,然后是 `conference` 文件夹,最后是 `presentations` 文件夹,里面存放的是 LibreOffice Impress 幻灯片。这个过程包含了很多次的双击操作。同时屏幕上还需要许多鼠标移动动作,这取决于新窗口出现的位置,以及大脑需要跟踪的许多路径点。许多人通过将 *所有文件* 都放在桌面上来避免这个看似微不足道的任务。
而终端用户只需键入以下内容即可避免此问题:
```
$ cd ~/Documents/work/projects/conference/presentations
```
一些有经验的终端用户甚至都懒得输入所有这些,而是使用 `Tab` 键自动完成单词填充。更甚者,有时你都不必依赖自动完成,而是改用通配符:
```
$ cd ~/Doc*/work/*/conf*/p*
```
### pwd
用 Buckaroo Banzai 的话来说:“无论你走到哪里,你就在那里。”
当你想弄清楚确切位置时,就可以使用 `pwd` 命令。`pwd` 代表<ruby> 打印工作目录 <rt> print working directory </rt></ruby>,这正是它的作用。`--physical`(在某些情况时缩写为 `-P`)显示解析所有符号链接后的确切位置。
```
$ pwd
/home/tux/presentation
$ pwd --physical
/home/tux/Documents/work/projects/conference/presentations
```
### sed
流编辑器 `sed` 更广为人知的是一个强大的批量 *查找和替换* 命令,但它同时也是一个正当合理的文本编辑器。你可以通过阅读我的 [介绍性文章](https://opensource.com/article/20/12/sed) 来学习使用它,然后通过我的 [高级教程和备忘录](https://opensource.com/article/21/3/sed-cheat-sheet) 成为老手。
### grep
`grep` 命令使用很普遍,以至于经常被用作动词(例如 “我会对一些文件进行 grep”)和动名词(例如 “grep 一些输出”)。无论是查看日志文件还是解析其他命令的输出,它都是在 shell 中解析文本时的关键组件。这是忙碌的用户专注于特定信息的一种方式。考虑一下计算世界中的数据量,`grep` 命令的流行就见怪不怪了。你可以通过阅读我的 [介绍性文章](https://opensource.com/article/21/3/grep-cheat-sheet) 了解 `grep`,然后下载 [备忘录](https://opensource.com/downloads/grep-cheat-sheet) 学习。
### file
当你需要知道文件包含什么类型的数据时,请使用 `file` 命令:
```
$ file example.foo
example.foo: RIFF (little-endian) data, Web/P image [...]
$ file example.bar
example.bar: ELF 64-bit LSB executable, x86-64 [...]
```
当然,`file` 命令并不神奇。它只不过是根据文件如何标识自身而进行输出的,并且文件可能是错误的、损坏的或伪装的。使用 [hexdump](https://opensource.com/article/19/8/dig-binary-files-hexdump) 进行严格检查的方式确定性更强,但对于日常使用而言,`file` 命令非常方便。
### awk
`awk` 不仅仅是一个命令,它还是一种字面意义上的 [编程语言](https://opensource.com/article/21/1/learn-awk)。[点此下载我们的免费 Awk 电子书](https://opensource.com/article/20/9/awk-ebook) 进行学习,你可能会写出远超你想象的脚本。
### curl
`curl` 命令是用于终端的 [非交互式 Web 浏览器](https://opensource.com/article/20/5/curl-cheat-sheet)。它是面向 Web 和 API 开发人员的 [开发工具](https://www.redhat.com/sysadmin/use-curl-api)。它是一个复杂灵活的命令,但如果你想从你的终端顺利地与 Web 服务交互,该命令是很值得学习的。
下载我们免费的 [curl 备忘录](https://opensource.com/downloads/curl-command-cheat-sheet),你可以从中学会 `curl` 的许多选项。
### ps
管理系统资源主要由内核负责,当你更喜欢或更需要手动管理时,可以使用 `ps` 命令。读者可以在我的 [使用 procps-ng 监控 Linux 系统](https://opensource.com/article/21/8/linux-procps-ng) 文章中了解 `ps`。
### cat
[cat 命令](https://opensource.com/article/19/2/getting-started-cat-command) 是<ruby> 连接 <rt> concatenate </rt></ruby>的缩写,它曾因为能将若干小文件合并而显得非常有用,这些小文件可能是由于大小限制而(使用 `split` 命令)拆分的。如今,`cat` 主要是用来将文本文件的内容转储到终端中以供快速阅读,除非你为此专门去使用 `head`、`tail`、`more` 或 `less` 等命令。
尽管它的原始用途几乎已被弃用,并且其他几个命令也主要提供了其次要功能,但 `cat` 仍然是一个有用的工具。例如,它可以是复制(`cp`)命令的替代品:
```
$ cat myfile.ogg > /backups/myfile.ogg
```
它可以显示文件中不便观察的隐形字符。例如,使用 `--show-tabs` 选项,分割 [YAML](https://www.redhat.com/sysadmin/yaml-beginners) 的 `Tab` 字符就会显示为 `^I`:
```
$ cat --show-tabs my.yaml
---
- hosts: all
tasks:
- name: Make sure the current version of 'sysstat' is installed.
dnf:
name:
^I- sysstat
^I- httpd
^I- mariadb-server
state: latest
```
它还可以用 `--show-nonprinting` 显示非打印字符,用 `--show-ends` 标记行尾,用 `--number` 提供行号,等等。
### find
`find` 命令可以用来查找文件,但它还有许多选项,这些选项可以帮助你通过各种过滤器和参数查找文件。读者可以从我的 [介绍性文章](https://opensource.com/article/21/8/find-files-and-directories-find) 中学习该命令的基础知识。
如果你一直想知道为什么最基本的、不起眼的 [ls 命令](https://opensource.com/article/19/7/master-ls-command),不在本文列表中,那是因为 `find` 的灵活性。它不仅可以列表文件:
```
$ find .
./bar.txt
./baz.xml
./foo.txt
[...]
```
它还可以提供包含详细信息的长列表功能:
```
$ find . -ls
3014803 464 -rw-rw-r-- 1 tux users 473385 Jul 26 07:25 ./foo.txt
3014837 900 -rwxrwxr-x 1 tux users 918217 Nov 6 2019 ./baz.xml
3026891 452 -rw-rw-r-- 1 tux users 461354 Aug 10 13:41 ./foo.txt
[...]
```
这是一个技术问题,但也是很一个巧妙的技巧。
### tar
人们有时会引用 BSD 的 `tar` 语法来拿 Linux 命令开玩笑。尽管有这样的名声,但 `tar` 命令实际上非常直观。读者可以阅读我的 [如何解压缩 tar.gz 文件](https://opensource.com/article/17/7/how-unzip-targz-file) 文章,了解在需要时使用 `tar` 命令的简单知识。
### more、less 和 most
这些统称为分页命令。分页命令与 `cat` 类似,但前者会在屏幕底部暂停输出,直到你向下滚动查看更多内容。这些命令比较简单,但每个之间都有细微差别。用户是用箭头键还是空格键滚动?是必须手动退出,还是在显示的文件末尾自动退出?用户的首选搜索行为是什么样的?选择你最喜欢的分页命令并将其设置在 `.bashrc` 中吧!
### ssh 和 scp
OpenSSH 不仅有助于保护与远程系统的连接安全,还可以用于启用其他命令。例如,对于许多用户来说,有了 `.ssh` 目录,他们才能与 Git 存储库顺利交互、将更新发布到网站、登录云控制平台。
### mv
`mv` 命令有双重作用:它既可以 [移动文件](https://opensource.com/article/21/8/move-files-linux) 又可以 [重命名文件](https://opensource.com/article/21/8/rename-file-linux-terminal)。它有几个可用的保护措施,例如 `--interactive` 和 `--no-clobber` 选项避免破坏现有文件,`--backup` 命令确保数据在新位置验证之前被保留,以及 `--update` 选项确保旧版本不会替换新版本文件。
### sudo
当某个用户账户的用户名已知,且具有 *全部* 系统权限时,该用户很快就会成为黑客攻击的目标。`sudo` 命令消除了对字面上 `root` 用户的需求,从而优雅地移除了有关系统的重要信息。不过这还不是全部,使用 `sudo` 你还可以轻松地管理单个命令、用户和组的权限。你可以在选定的命令上启用无密码执行、记录用户会话、使用摘要验证来验证命令,[等等](https://opensource.com/article/19/10/know-about-sudo)。
### alias
使用 `alias` 命令将长命令变成易于记忆的快捷方式:
```
$ alias ls='ls --classify --almost-all --ignore-backups --color'
```
### clear
有时终端会显得很混乱,输入 `clear`(或在某些 shell 中按 `Ctrl+L`)后,你就能得到漂亮、刷新的屏幕了。
### setfacl
传统上,POSIX 文件权限由 `chown` 和 `chmod` 决定。然而,如今系统变得更加复杂,因此有一个灵活性更高的命令。`setfacl` 命令允许创建一个 [访问控制列表(ACL)](https://opensource.com/article/20/3/external-drives-linux),可以配置任意用户所需权限,并可以为文件夹及其中创建的内容设置默认权限。
### netcat
可能需要使用 `netcat`(`nc`)的人不多,但这些使用它的人确离不开它。`nc` 命令是一个通用的网络连接工具。
它可以连接到一个端口,类似于 `telnet` 命令:
```
$ nc -u 192.168.0.12 80
```
它可以 ping 一个端口,类似于 `ping` 命令:
```
$ nc -zvn 192.168.0.12 25
```
它可以探测开放端口,类似于 `nmap` 命令:
```
$ nc -zv 192.168.0.12 25-80
```
以上仅是该命令的一小部分用途。
### 你自己构建的命令
在某种程度上,Linux 终端是一个创造性解决问题的平台。当你学习命令时,你也在学习可用于创建自己的命令的组块。我的 [shell 历史](https://opensource.com/article/18/6/history-command) 中的许多命令都是自己编写的 shell 脚本,从而实现了根据自己想要的工作方式定制工作流程。你为自己的效率和舒适度而设计的命令也可以作为 shell 中的基本命令。花些时间了解一些很棒的命令,然后试着构建自己的命令吧。当你构建出的命令非常好用时,把它开源,这样就可以与他人分享你的想法啦!
---
via: <https://opensource.com/article/21/9/essential-linux-commands>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Typing commands into a darkened terminal window may seem antiquated to some, but for many computer users, it's the most efficient, most accessible, and clearest way to accomplish nearly any task a computer is capable of performing. These days, thanks to all the projects that bring open source commands to non-open platforms like macOS and Windows, terminal commands are relevant to everybody, not just Linux and BSD users. It may surprise you to learn that there are thousands of commands installed on an average [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) computer, but of course, a good many of those aren't really intended to be used, at least not directly or regularly. Some commands are more universally useful than others, and still fewer are absolutely essential for effective terminal use.
Here are the top 20 commands a terminal user might find themselves using:
## cd
Outside of a terminal, you click on icons to move from one folder to another, but in the terminal, you use `cd`
. The `cd`
command, which stands for *change directory*, is how you move through a Linux system. It's the fastest and most direct route from one place to another.
For instance, on the desktop, when you want to move from your home directory (the place you keep all of your folders) to a folder called `presentations`
, then you might first have to open your `Documents`
folder, then open a folder called `work`
, then a `projects`
folder, and then the `conference`
folder, and finally the `presentations`
folder, which contains your exciting LibreOffice Impress slideshow. That's a lot of double-clicking. It may also be a lot of moving around on the screen, depending on where new windows appear, and a lot of waypoints for your brain to track. Many people circumvent this seemingly minor task by keeping *everything *on their desktop.
Terminal users avoid this issue by just typing:
`$ cd ~/Documents/work/projects/conference/presentations`
Experienced terminal users don't even bother typing all of that. They use the **Tab** key to autocomplete the words for them. And sometimes, you don't even have to resort to autocompletion. You can use wildcards instead:
`$ cd ~/Doc*/work/*/conf*/p*`
## pwd
In the words of Buckaroo Banzai: "No matter where you go, there you are."
When you need to figure out where exactly that is, you use the `pwd`
command. The `pwd`
stands for *print working directory,* and that's exactly what it does. The `--physical`
(or just `-P`
in some implementations) shows your location with all symlinks resolved.
```
$ pwd
/home/tux/presentation
$ pwd --physical
/home/tux/Documents/work/projects/conference/presentations
```
## sed
Better known as `sed`
, the stream editor is a powerful bulk *find and replace *command, but it's also a legitimate text editor. You can learn to use it by reading my [introductory article](https://opensource.com/article/20/12/sed), and then become an expert with my [advanced tutorial and cheat sheet](https://opensource.com/article/21/3/sed-cheat-sheet).
## grep
The `grep`
command is so ubiquitous that it's often used as a verb ("I'll grep through some files") and a gerund ("grepping some output"). It's a key component when parsing text in your shell, whether you're looking through log files or parsing the output of some other command. It's a way for the busy user to focus on specific information. Given just how much data there is in the computing world, there's no wonder it's a popular command. Go grok grep by reading my [introductory article](https://opensource.com/article/21/3/grep-cheat-sheet), and then download the [cheat sheet](https://opensource.com/downloads/grep-cheat-sheet).
## file
Use the `file`
command when you need to know what type of data a file contains:
```
$ file example.foo
example.foo: RIFF (little-endian) data, Web/P image [...]
$ file example.bar
example.bar: ELF 64-bit LSB executable, x86-64 [...]
```
The `file`
command isn't magic, of course. It only reports based on how a file identifies itself, and files can be wrong, corrupted, or disguised. A rigorous inspection with [ hexdump](https://opensource.com/article/19/8/dig-binary-files-hexdump) provides more certainty, but for casual use, the
`file`
command is convenient.## awk
Awk isn't just a command; it's a literal [programming language](https://opensource.com/article/21/1/learn-awk). [Download our free Awk ebook](https://opensource.com/article/20/9/awk-ebook), learn it, and you'll be writing scripts you never thought possible.
## curl
The `curl`
command is a [non-interactive web browser](https://opensource.com/article/20/5/curl-cheat-sheet) for your terminal. It's a [development tool](https://www.redhat.com/sysadmin/use-curl-api) for web and API developers. It's a complex command for its flexibility, but it's worth learning if you want to interact with network services from your terminal smoothly.
Download our free [ curl cheat sheet](https://opensource.com/downloads/curl-command-cheat-sheet), so you can internalize its many options.
## ps
Managing your system's resources is mostly up to the kernel, but when you prefer or require a manual approach, there's the `ps`
command. Learn about `ps`
in my [monitor your Linux system with procps-ng](https://opensource.com/article/21/8/linux-procps-ng) article.
## cat
The [ cat command](https://opensource.com/article/19/2/getting-started-cat-command) is short for
*concatenate*, and it was very useful once for joining files that had been split (with a command intuitively called
`split`
) into several small files due to size limitations. Today, `cat`
is mostly used as a way to dump the contents of a text file into your terminal for quick reference, unless you use `head`
, `tail`
, `more`
, or `less`
for that.Despite its almost deprecated original purpose, and despite that several other commands also perform its secondary function, `cat`
is still a useful utility. For instance, it can be a stand-in for the copy (`cp`
) command:
`$ cat myfile.ogg > /backups/myfile.ogg`
It can reveal inconvenient invisible characters in files. The **Tab** character, which breaks [YAML](https://www.redhat.com/sysadmin/yaml-beginners), shows up as `^I`
with the `--show-tabs`
option:
```
$ cat --show-tabs my.yaml
---
- hosts: all
tasks:
- name: Make sure the current version of 'sysstat' is installed.
dnf:
name:
^I- sysstat
^I- httpd
^I- mariadb-server
state: latest
```
It can show non-printing characters with `--show-nonprinting`
, mark the ends of lines with `--show-ends`
, provide line numbers with `--number`
, and more.
## find
The `find`
command helps you find files, but thanks to its many options, it can help you find files with a variety of filters and parameters. Learn the basics from my [introductory article](https://opensource.com/article/21/8/find-files-and-directories-find).
And in case you've been wondering why the most fundamental command of all, the humble , isn't on this list, it's because of the flexibility of
`ls`command
`find`
. Not only can find list files:```
$ find .
./bar.txt
./baz.xml
./foo.txt
[...]
```
It can also provide long listings:
```
$ find . -ls
3014803 464 -rw-rw-r-- 1 tux users 473385 Jul 26 07:25 ./foo.txt
3014837 900 -rwxrwxr-x 1 tux users 918217 Nov 6 2019 ./baz.xml
3026891 452 -rw-rw-r-- 1 tux users 461354 Aug 10 13:41 ./foo.txt
[...]
```
It's a technicality, but a neat trick to know.
## tar
People sometimes joke about Linux commands by citing BSD's `tar`
syntax. In spite of its reputation, the `tar`
command can actually be very intuitive. Read my [how to unzip a tar.gz file](https://opensource.com/article/17/7/how-unzip-targz-file) article to learn the simple secret to rattling off a `tar`
command on demand.
## more or less or most
Pagers are like `cat`
, except they pause their output at the bottom of your screen until you scroll down for more. It's a simple application, but there's nuance to each implementation. Do you scroll with arrow keys or the spacebar? Do you have to quit manually, or does the pager exit at the end of the file it's displaying? What's your preferred search behavior? Choose your favorite pager and set it in your `.bashrc`
!
## ssh and scp
OpenSSH not only helps secure connections to remote systems it also enables other commands. For instance, for many users, it's their `.ssh`
directory that makes it possible for them to interact smoothly with Git repositories, post updates to a website, or log in to their cloud's control plane.
## mv
The `mv`
command does double-duty: It both [moves files](https://opensource.com/article/21/8/move-files-linux) and it [renames files](https://opensource.com/article/21/8/rename-file-linux-terminal). It has several available safeguards, including `--interactive`
and `--no-clobber`
options to avoid clobbering an existing file, a `--backup`
command to ensure data is preserved until it is verified at its new location, and the `--update`
option to ensure that an older version doesn't replace a newer file.
## sudo
When you have a single user with a known user name and *all* the privileges on a system, that user quickly becomes the target of attacks. By eliminating the need for a literal `root`
user, the `sudo`
command elegantly removes important information about your system from general knowledge. That's not all it does, though. With `sudo`
, you can easily manage privileges down to individual commands, users, and groups. You can enable password-less execution of select commands, record user sessions, verify commands with digest validation, [and more](https://opensource.com/article/19/10/know-about-sudo).
## alias
Turn long commands into easy-to-remember shortcuts by using the `alias`
command:
`$ alias ls='ls --classify --almost-all --ignore-backups --color'`
## clear
Sometimes your terminal gets cluttered. There's nothing like a nice, fresh screen after typing `clear`
(or pressing **Ctrl+L** in some shells).
## setfacl
Traditionally, POSIX file permissions were determined by `chown`
and `chmod`
. Systems have become more complex, though, so there's a command to provide a little more flexibility. The `setfacl`
command lets you create an [Access Control List (ACL)](https://opensource.com/article/20/3/external-drives-linux), granting permissions to arbitrary users and setting default permissions for folders and the contents created within them.
## netcat
Not every user needs netcat (`nc`
), but few who use it ever want to give it up. The `nc`
command is an all-purpose network connection tool.
It can connect to a port, similar to `telnet`
:
`$ nc -u 192.168.0.12 80`
It can ping a port, similar to `ping`
:
`$ nc -zvn 192.168.0.12 25`
It can probe for open ports, similar to `nmap`
:
`$ nc -zv 192.168.0.12 25-80`
And that's just a small sample.
## you
The Linux terminal is, in part, about creative problem-solving. When you learn commands, you're also learning building blocks you can use to create your own commands. Many of the commands in my [shell history](https://opensource.com/article/18/6/history-command) are shell scripts I've written myself. The result is that my workflow is customized to how I want to work. Essential commands in your shell can also be the ones you design for your own efficacy and comfort. Spend some time getting to know some great commands, and then build your own. And when you hit upon something really good, make it open source so you can share your ideas with others!
## 1 Comment |
13,761 | 满足日常需求的应用(三):图像编辑器 | https://fedoramagazine.org/apps-for-daily-needs-part-3-image-editors/ | 2021-09-07T18:39:21 | [
"图像编辑器"
] | https://linux.cn/article-13761-1.html | 
图像编辑器是许多人喜欢和需要的应用程序,从专业的设计师、学生,或那些有某些爱好的人。特别是在这个数字时代,越来越多的人因为各种原因需要图像编辑器。本文将介绍一些你可以在 Fedora Linux 上使用的开源图像编辑器。你可能需要安装提到的软件。如果你不熟悉如何在 Fedora Linux 中添加软件包,请参阅我之前的文章 [安装 Fedora 34 工作站后要做的事情](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/)。这里列出了图像编辑器类的一些日常需求的应用程序。
### GIMP
GIMP(<ruby> GNU 图像处理程序 <rt> GNU Image Manipulation Program </rt></ruby>)是一个光栅图像(位图)编辑器,用于照片修饰、图像合成和图像创作。它的功能几乎与 Adobe Photoshop 相同。你可以用 GIMP 做很多你可以用 Photoshop 做的事情。正因为如此,GIMP 作为 Adobe Photoshop 的开源替代品,已经成为最受欢迎的应用程序。
GIMP 有很多图像处理的功能,特别是针对光栅图像。你可以用 GIMP 修复或改变照片的颜色。你可以选择图像的一部分,裁剪它,然后与图像的其他部分合并。GIMP 还有许多你可以应用于你的图像的效果,包括模糊、阴影、噪音等等。许多人用 GIMP 来修复损坏的照片,提高图像质量,裁剪图像中不需要的部分,制作海报和各种图形设计作品,等等。此外,你还可以在 GIMP 中添加插件和脚本,使其功能更加全面。

更多信息请见此链接:: <https://www.gimp.org/>
### Inkscape
Inkscape 是一个流行的开源应用程序,用于创建和编辑矢量图。它是一个功能丰富的矢量图形编辑器,这使它可以与其他类似的专有应用程序(如 Adobe Illustrator 和 Corel Draw)相竞争。正因为如此,许多专业插画师使用它来创建基于矢量的艺术作品。
你可以用 Inkscape 制作艺术和技术插图,如标志、图表、图标、桌面壁纸、流程图、漫画等等。此外,Inkscape 可以处理各种图形文件格式。此外,你还可以添加附加组件,使你的工作更容易。

更多信息请见此链接: <https://inkscape.org/>
### Krita
Krita 乍一看像 GIMP 或 Inkscape。但实际上,它是一个完全不同的应用程序,尽管它有一些类似的功能。Krita 是一款用于创作像艺术家那样的数字绘画的应用程序。你可以用 Krita 来制作概念艺术、插图、漫画、纹理和哑光画。
Krita 有 100 多个预装的专业画笔。它还有一个画笔稳定器功能,有 3 种不同的方式来平滑和稳定你的画笔笔触。此外,你可以用 9 种以上的独特画笔引擎来定制你的画笔。Krita 是那些喜欢进行数字绘画的人的合适应用。

更多信息可在此链接获得:<https://krita.org/en/>
### darktable
darktable 是摄影师或那些想提高照片质量的人的完美选择。darktable 更侧重于图像编辑,特别是对 RAW 图像的非破坏性后期制作。因此,它提供专业的色彩管理,支持自动检测显示配置文件。此外,你还可以用 darktable 过滤和排序多张图片。所以你可以通过标签、评级、颜色标签等来搜索你的收藏。它可以导入各种图像格式,如 JPEG、CR2、NEF、HDR、PFM、RAF 等。

更多信息可在此链接中获得:<https://www.darktable.org/>
### 总结
这篇文章介绍了四个图像编辑器,你可以在 Fedora Linux 上使用它们满足你日常需求。每个应用程序都代表了图像编辑器应用程序的一个子类别。实际上,还有许多其他的图像编辑器可以在 Fedora Linux 上使用。你也可以使用 RawTherapee 或 Photivo 作为 dartkable 替代品。此外,还有 Pinta 作为 GIMP 的替代品,以及 MyPaint 作为 Krita 的替代品。希望这篇文章能帮助你选择正确的图像编辑器。如果你有使用这些应用程序的经验,请在评论中分享你的经验。
---
via: <https://fedoramagazine.org/apps-for-daily-needs-part-3-image-editors/>
作者:[Arman Arisman](https://fedoramagazine.org/author/armanwu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Image editors are applications that are liked and needed by many people, from professional designers, students, or for those who have certain hobbies. Especially in this digital era, more and more people need image editors for various reasons. This article will introduce some of the open source image editors that you can use on Fedora Linux. You may need to install the software mentioned. If you are unfamiliar with how to add software packages in Fedora Linux, see my earlier article [Things to do after installing Fedora 34 Workstation](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/). Here is a list of a few apps for daily needs in the image editors category.
## GIMP
GIMP (GNU Image Manipulation Program) is a raster graphics editor used for photo retouching, image composition, and image authoring. It has almost the same functionality as Adobe Photoshop. You can use GIMP to do a lot of the things you can do with Photoshop. Because of that, GIMP has become the most popular application as an open source alternative to Adobe Photoshop.
GIMP has a lot of features for manipulating images, especially for raster images. You can fix or change the color of your photos using GIMP. You can select a part of the image, crop it, and then merge it with other pieces of the image. GIMP also has many effects that you can apply to your images, including blur, shadow, noise, etc. Many people use GIMP to repair damaged photos, improve image quality, crop unwanted parts of images, create posters and various graphic design works, and much more. Moreover you can also add plugins and scripts in GIMP, making it even more fully featured.
More information is available at this link: [https://www.gimp.org/](https://www.gimp.org/)
## Inkscape
Inkscape is a popular open source application used to create and edit vector graphics. It is a feature-rich vector graphics editor which makes it competitive with other similar proprietary applications, such as Adobe Illustrator and Corel Draw. Because of that, many professional illustrators use it to create vector-based artwork.
You can use Inkscape for making artistic and technical illustrations, such as logos, diagrams, icons, desktop wallpapers, flowcharts, cartoons, and much more. Moreover, Inkscape can handle various graphic file formats. In addition, you can also add add-ons to make your work easier.
More information is available at this link: [https://inkscape.org/](https://inkscape.org/)
## Krita
Krita looks like GIMP or Inkscape at first glance. But actually it is an application that is quite different, although it has some similar functions. Krita is an application for creating digital paintings like those made by artists. You can use Krita for making concept art, illustration, comics, texture, and matte paintings.
Krita has over 100 professionally made brushes that come preloaded. It also has a brush stabilizer feature with 3 different ways to smooth and stabilize your brush strokes. Moreover, you can customize your brushes with over 9 unique brush engines. Krita is the right application for those of you who like digital painting activities.
More information is available at this link: [https://krita.org/en/](https://krita.org/en/)
## darktable
darktable is perfect for photographers or for those who want to improve the quality of their photos. darktable focuses more on image editing specifically on non-destructive post-production of raw images. Therefore, it provides professional color management that supports automatic display profile detection. In addition, you can also use darktable to handle multiple images with filtering and sorting features. So you can search your collections by tags, rating, color labels, and many more. It can import various image formats, such as JPEG, CR2, NEF, HDR, PFM, RAF, etc.
More information is available at this link: [https://www.darktable.org/](https://www.darktable.org/)
## Conclusion
This article presented four image editors as apps for your daily needs that you can use on Fedora Linux. Each application represents a sub-category of image editor applications. Actually there are many other image editors that you can use in Fedora Linux. You can also use RawTherapee or Photivo as a dartkable alternative. In addition there is Pinta as an alternative to GIMP, and MyPaint as an alternative to Krita. Hopefully this article can help you to choose the right image editors. If you have experience in using these applications, please share your experience in the comments.
## Reiza T.S
WowwI don’t know PS alternative other than Gimp. Maybe I will check Pinta later… Nice Write btw
## Arman Arisman
Thanks, Reiza 🙂
## Man
I live
## Rizqi N. Assyaufi
Nice post!
For daily use, I mostly use image manager applications like gThumb. gThumb is actually an image manager, but it already has handy image editing tools. For some light image editing needs, I prefer to use gThumb.
However, for complex image editing processes, GIMP, Inkscape, Krita and Darktable are really reliable and able to compete with their competitors.
## JLuis
I was thinking just the same. For me, gThumb is also great; and covers most of my needs about images in my job of web publishing.
## Arman Arisman
Thanks for reading and sharing 🙂
## Joao
Great series Arman. thxs for all your work!
I have been using GIMP+Inkscape on every OS I have used. They are great tools, even if sometimes I wonder if they have already too much functionality 😀 inside.
on the office apps, I Think that you should also mention that Office365 on the web is still available for Linux Users. It is not the best and practical option, but it might be the needed workaround for a lot of usecases. Remember we are displaying the better options for someone new to linux/fedora.
## Arman Arisman
Hi, Joao. Thanks for reading. And thanks for your opinion and suggestion 🙂
## David
Nice summary. Have used Darktable for a couple of years for post processing raw files and feel it has become better and better. Rather fast with openCL support too and as you note with various options for selections. One can setup their own toolbar (list of modules, which are the tools) and have different toolbars for different purposes if one wishes. Removing chromatic aberrations such as purple fringing, hot pixels in astro shots and dust spots is quite effective as well.
## Arman Arisman
Hi, David. Thanks for sharing 🙂
## x3mboy
I think is worth mentioning kolourpaint that is very useful for quick editions like putting a square in a screenshot (one of the most used characteristic in office’s environments)
## Arman Arisman
Thanks. I’ve never tried it. Your comments complete this article!
## svsv sarma
A good initiation for a debate. I use GIMP for image editing for DTP and it is my favourite. I tried inkspace but GIMP serves my purpose well and settled for it.
Krita and Darktable are new to me and I have to explore their advantages over Gimp.
Thank you.
## Arman Arisman
Thanks for sharing here 🙂
## Josh
Krita is fantastic. It and Inkscape have been life-savers for a non-artist such as myself. Bravo to the teams involved.
## Arman Arisman
Yup. Krita and Inkscape are very good apps 🙂
## Darvond
While I know the Gimp is the Defacto, it’s got a massive UX problem. Elephant sized. To the point where forks have been formed just to fix it, like Glimpse Editor. (Course, the name could do with a redo too.)
But hey, with GIMP 3.0 somewhere in the pipeline, maybe it’ll be time for them to launch a broad campaign to advertise that they finally jazzed it up. Because when I, and most others think of it, the thought is, “Something that was last redesigned in 2006”.
https://bloggeroctopus.com/wp-content/uploads/2018/03/gimp_talleres_de_software_libre.jpg
When I tell artists and painters about how good it is in the world of Linux now, I tend to mention The GIMP as an afterthought. That’s how bad the image was.
Myself, I go for things like GraFX2 (A clone of Deluxe Paint II), mtpaint, Kolourpaint, and Krita. As for viewing, I’m a simple lad: FEH is really all one needs.
Overall, there’s a good variety of artistic programs within the Fedora repos, so one can find what they seek without having to look far.
## Arman Arisman
Hi, Darvond. Thanks for reading this article. And also thanks for sharing and giving your opinion here. It’s completed my article. Cheers 🙂
## Kristofer
That’s great, I love Fedora, I use it as my daily driver, I’m a web dev, web design and I use gimp in every day to edit thousands of photos for the websites.
I’m really enjoying the new posts, keep them coming.
Cheers.
## Arman Arisman
Hi, Kristofer. Thanks for reading and sharing here 🙂
## Sirko Kemter
uups, I should have seen this before published, you throw image manipulation, vector editing, digital painting and RAW photo development programs under image editing. There are worlds between this just an example
Krita is a digital painting program, there is another one called MyPaint which is much simpler but good. The difference between this kind of digital painting vs. image manipulation is, the first ones concentrate on handling tablet usage and their pencil engines are way more pressure oriented as that of GIMP. Just make a pencil for GIMP and then for Mypaint or Krita, you will figure that out.
Sure you can do “image editing” in Inkscape except that you can easier crop pictures to complicated shapes, the pure image manipulation functions are rudimentary and limited to the Image Magick functions (Extensions > Raster)
It’s a bit like you buy a new Porsche and then open his trunk to shovel sand into its trunk, because you need to transport it. Each tool has a purpose or would you use pliers to hammer a nail into the wall? You can paint in Blender to 😉 and you can use the compositing editor to edit images 😀
## Gregory Bartholomew
@gnokii
Just FYI, there is still plenty of time to update your articles if you want to. I’ve moved them back to “draft” status so that you can edit them further if you want to.
## Arman Arisman
Hi, Sirko. Thanks for your opinion. I think that’s what the comments feature in Fedora Magazine is for. So we can complement and correct each other too 😉
Actually I use the word “image editors” to be easily accepted by common readers. I tried to explain the differences in each description.
But thanks a lot for the opinion. Your explanation completes this article. Cheers 😀
## jama
I think rawtherapee should be mentioned as well, as some might consider it better alternative to darktable…
## Eddy
for daily needs, gimp, Inkscape is always ready on the toolbar. sometimes I do myPaint for artwork instead of Krita.
Very good article. |
13,762 | 通过 ncurses 在 Linux 上写一个猜谜游戏 | https://opensource.com/article/21/8/guess-number-game-ncurses-linux | 2021-09-07T22:43:22 | [
"ncurses"
] | https://linux.cn/article-13762-1.html |
>
> 使用 ncurses 的灵活性和强大功能在 Linux 上创建一个猜数字游戏。
>
>
>

在我的 [上一篇文章](/article-13756-1.html),我简要介绍了使用 ncurses 库通过 C 语言编写文本模式交互式应用程序。使用 ncurses,我们可以控制文本在终端上的显示位置和方式。如果你通过阅读手册页探索 ncurses 库函数,你会发现显示文本有很多不同的方式,包括粗体文本、颜色、闪烁文本、窗口、边框、图形字符和其它功能,这些都可以使你的应用脱颖而出。
如果你想探索一个更高级的程序来演示其中一些有趣的功能,有一个简单的“猜数字”游戏,我已更新为使用 ncurses 编写的了。该程序在一个范围内选择一个随机数,然后要求用户进行重复猜测,直到他们猜到这个秘密数字。当用户进行猜测时,程序会告知他们猜测的数字是太低还是太高。
请注意,程序限定可能的数字范围是 0 到 7。将值保持在有限的个位数数字范围内,可以更轻松的使用 `getch()` 函数从用户读取单个数字。我还使用了 `getrandom` 内核系统调用来生成随机数,设定数字最大值为 7,以从 0 (二进制 `0000`)到 7 (二进制 `0111`)中选择一个随机数。
```
#include <curses.h>;
#include <string.h>; /* for strlen */
#include <sys/random.h>; /* for getrandom */
int
random0_7()
{
int num;
getrandom(&num, sizeof(int), GRND_NONBLOCK);
return (num & 7); /* from 0000 to 0111 */
}
int
read_guess()
{
int ch;
do {
ch = getch();
} while ((ch < '0') || (ch > '7'));
return (ch - '0'); /* turn into a number */
}
```
通过使用 ncurses,我们可以增加一些有趣的视觉体验。通过添加函数,我们可以在屏幕顶部显示重要的文本信息,在屏幕底部显示状态消息行:
```
void
print_header(const char *text)
{
move(0, 0);
clrtoeol();
attron(A_BOLD);
mvaddstr(0, (COLS / 2) - (strlen(text) / 2), text);
attroff(A_BOLD);
refresh();
}
void
print_status(const char *text)
{
move(LINES - 1, 0);
clrtoeol();
attron(A_REVERSE);
mvaddstr(LINES - 1, 0, text);
attroff(A_REVERSE);
refresh();
}
```
通过这些函数,我们就可以构建猜数字游戏的主要部分。首先,程序为 ncurses 设置终端,然后从 0 到 7 中选择一个随机数。显示数字刻度后,程序启动一个循环,询问用户的猜测。
当用户进行猜测时,程序会在屏幕上提供反馈。如果猜测太低,程序会在屏幕上的数字下方打印一个左方括号。如果猜测太高,程序会在屏幕上的数字下方打印一个右方括号。这有助于用户缩小他们的选择范围,直到他们猜出正确的数字。
```
int
main()
{
int number, guess;
initscr();
cbreak();
noecho();
number = random0_7();
mvprintw(1, COLS - 1, "%d", number); /* debugging */
print_header("Guess the number 0-7");
mvaddstr(9, (COLS / 2) - 7, "0 1 2 3 4 5 6 7");
print_status("Make a guess...");
do {
guess = read_guess();
move(10, (COLS / 2) - 7 + (guess * 2));
if (guess < number) {
addch('[');
print_status("Too low");
}
else if (guess > number) {
addch(']');
print_status("Too high");
}
else {
addch('^');
}
} while (guess != number);
print_header("That's right!");
print_status("Press any key to quit");
getch();
endwin();
return 0;
}
```
复制这个程序,自己尝试编译它。不要忘记你需要告诉 GCC 编译器链接到 ncurses 库:
```
$ gcc -o guess guess.c -lncurses
```
我留下了一个调试行,所以你可以看到屏幕右上角附近的秘密数字:

*图1:猜数字游戏。注意右上角的秘密数字。*
### 开始使用 ncurses
该程序使用了 ncurses 的许多其它函数,你可以从这些函数开始。例如,`print_header` 函数在屏幕顶部居中以粗体文本打印消息,`print_status` 函数在屏幕左下角以反向文本打印消息。使用它来帮助你开始使用 ncurses 编程。
---
via: <https://opensource.com/article/21/8/guess-number-game-ncurses-linux>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my [last article](https://opensource.com/article/21/8/ncurses-linux), I gave a brief introduction to using the **ncurses** library to write text-mode interactive applications in C. With **ncurses**, we can control where and how text gets displayed on the terminal. If you explore the **ncurses** library functions by reading the manual pages, you’ll find there are a ton of different ways to display text, including bold text, colors, blinking text, windows, borders, graphic characters, and other features to make your application stand out.
If you’d like to explore a more advanced program that demonstrates a few of these interesting features, here’s a simple “guess the number” game, updated to use **ncurses**. The program picks a random number in a range, then asks the user to make repeated guesses until they find the secret number. As the user makes their guess, the program lets them know if the guess was too low or too high.
Note that this program limits the possible numbers from 0 to 7. Keeping the values to a limited range of single-digit numbers makes it easier to use **getch()** to read a single number from the user. I also used the **getrandom** kernel system call to generate random bits, masked with the number 7 to pick a random number from 0 (binary 0000) to 7 (binary 0111).
```
#include <curses.h>
#include <string.h> /* for strlen */
#include <sys/random.h> /* for getrandom */
int
random0_7()
{
int num;
getrandom(&num, sizeof(int), GRND_NONBLOCK);
return (num & 7); /* from 0000 to 0111 */
}
int
read_guess()
{
int ch;
do {
ch = getch();
} while ((ch < '0') || (ch > '7'));
return (ch - '0'); /* turn into a number */
}
```
By using **ncurses**, we can add some visual interest. Let’s add functions to display important text at the top of the screen and a message line to display status information at the bottom of the screen.
```
void
print_header(const char *text)
{
move(0, 0);
clrtoeol();
attron(A_BOLD);
mvaddstr(0, (COLS / 2) - (strlen(text) / 2), text);
attroff(A_BOLD);
refresh();
}
void
print_status(const char *text)
{
move(LINES - 1, 0);
clrtoeol();
attron(A_REVERSE);
mvaddstr(LINES - 1, 0, text);
attroff(A_REVERSE);
refresh();
}
```
With these functions, we can construct the main part of our number-guessing game. First, the program sets up the terminal for **ncurses**, then picks a random number from 0 to 7. After displaying a number scale, the program then enters a loop to ask the user for their guess.
As the user makes their guess, the program provides visual feedback. If the guess is too low, the program prints a left square bracket under the number on the screen. If the guess is too high, the game prints a right square bracket. This helps the user to narrow their choice until they guess the correct number.
```
int
main()
{
int number, guess;
initscr();
cbreak();
noecho();
number = random0_7();
mvprintw(1, COLS - 1, "%d", number); /* debugging */
print_header("Guess the number 0-7");
mvaddstr(9, (COLS / 2) - 7, "0 1 2 3 4 5 6 7");
print_status("Make a guess...");
do {
guess = read_guess();
move(10, (COLS / 2) - 7 + (guess * 2));
if (guess < number) {
addch('[');
print_status("Too low");
}
else if (guess > number) {
addch(']');
print_status("Too high");
}
else {
addch('^');
}
} while (guess != number);
print_header("That's right!");
print_status("Press any key to quit");
getch();
endwin();
return 0;
}
```
Copy this program and compile it for yourself to try it out. Don’t forget that you need to tell GCC to link with the **ncurses** library:
`$ gcc -o guess guess.c -lncurses`
I’ve left the debugging line in there, so you can see the secret number near the upper-right corner of the screen:
Figure 1: Guess the number game. Notice the secret number in the upper right.
## Get yourself going with ncurses
This program uses a bunch of other features of **ncurses** that you can use as a starting point. For example, the print_header function prints a message in bold text centered at the top of the screen, and the print_status function prints a message in reverse text at the bottom-left of the screen. Use this to help you get started with **ncurses** programming.
## Comments are closed. |
13,763 | OpenWrt 21.02 发布,支持 Linux 内核 5.4 和 WPA3 | https://news.itsfoss.com/openwrt-21-02-release/ | 2021-09-08T09:46:56 | [
"OpenWrt"
] | https://linux.cn/article-13763-1.html | 
OpenWrt 社区宣布了该发行版的最新稳定版本:OpenWrt 21.02。
补充一句,OpenWrt 是一个帮助你创建嵌入式设备定制操作系统的项目。
它使用户能够根据他们的网络需求公开定制他们的设备,这是市面上销售的路由器的固件所没有的功能。除了路由器之外,OpenWrt 还可以在各种设备上运行,如智能手机、住宅网关,甚至是 32 位的个人电脑。
自从旧的 OpenWrt 19.07 以来,这个版本的发布带来了超过 5800 个新提交。
让我们来看看 OpenWrt 21.02 有哪些新功能。
### OpenWrt 21.02 有什么新内容?
虽然有一些技术上的变化和改进,但让我强调一下主要的新增内容。
#### WPA3 支持
虽然在 19.07 版本中就已经存在,但这个最新的 Wi-Fi 网络安全标准现在已默认包含在镜像中了。
WPA3 的意思是<ruby> Wi-Fi 受保护接入第三版 <rt> Wi-Fi Protected Access 3 </rt></ruby>,与流行的 WPA2 相比,在安全方面有很大的改进,也向后兼容。
#### TLS 和 HTTPS 支持
就像 WPA3 一样,它也默认包括了 TLS 和 HTTPS 支持,并且带有来自 Mozilla 的可信 CA 证书。
有了这个支持,无需其它工作,`wget` 和 `opkg` 现在可以通过 HTTPS 获取资源了。此外,除了 HTTP 之外,[LuCl](https://openwrt.org/docs/techref/luci) 也可以通过 HTTPS 获得。
#### 初步的 DSA 支持
正如其发布公告中所说:
>
> “DSA(<ruby> 分布式交换机架构 <rt> Distributed Switch Architecture </rt></ruby>)是关于可配置的以太网交换机的 Linux 标准。”
>
>
>
这取代了直到现在还在使用的 `swconfig` 系统,是对 VLAN 和交换机端口管理方式的一个明显变化。
#### 新的最低硬件要求
随着 OpenWrt 的众多新功能和更新,以及 Linux 内核的大小的普遍增加,其最低硬件要求也被提高。
现在设备需要至少 8MB 的闪存和 64MB 的内存来运行默认的构建版本,以确保适当的稳定性。
#### 软件包更新
该版本还包含了几个软件包的升级,其中一些是:
* Linux 内核 5.4.143
* gcc 8.4.0
* glibc 2.33
* binutils 2.34
* busybox 1.33.1
除了上述列出的软件包,还有许多其他软件包也得到了升级。你可以在 [官方发布公告](https://openwrt.org/releases/21.02/notes-21.02.0) 中了解完整的技术细节。
### 下载 OpenWrt 21.02
你可以前往其官方网站下载最新的稳定版,或者选择开发快照进行实验。
构建自己的软件包和固件的说明应该可以在其文档中找到。
可以使用 `sysupgrade` 命令将你的系统从 OpenWrt 19.07 升级到 OpenWrt 21.02。请注意,你无法从 18.06 升级。
* [OpenWrt 21.02](https://openwrt.org/downloads)
---
via: <https://news.itsfoss.com/openwrt-21-02-release/>
作者:[Rishabh Moharir](https://news.itsfoss.com/author/rishabh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The OpenWrt community announced the first stable update of their series, OpenWrt 21.02.
In case you did not know, OpenWrt is a project that helps create custom operating systems for embedded devices.
It enables users to openly customize their devices according to their networking needs, something that the stock router firmware doesn’t. Other than routers, OpenWrt can run on a variety of devices such as smartphones, residential gateways, and even 32 bit PCs!
With this release, they have over 5800 commits since the older OpenWrt 19.07.
Let us take a look at what is new with OpenWrt 21.02.
## OpenWrt 21.02: What’s New?
While there are several technical changes and improvements, let me highlight the key additions.
### WPA3 Support
Although present in the 19.07 release, the latest security standard for Wi-Fi networks is now included by default in the images.
WPA3 stands for Wi-Fi Protected Access 3 and is a major improvement in terms of security over the popular WPA2. Backward compatibility is also supported.
### TLS and HTTPS Support
Just like WPA3, TLS and HTTPS support is also included by default. This comes with the trusted CA certificates from Mozilla as well.
With this addition, *wget* and *opkg* should now support fetching resources over HTTPS out-of-the-box. Moreover, [LuCl](https://openwrt.org/docs/techref/luci?ref=news.itsfoss.com) is available over HTTPS in addition to HTTP.
### Initial DSA Support
As the release announcement states:
“DSA stands for Distributed Switch Architecture and is the Linux standard to deal with configurable Ethernet switches”
This has replaced the *swconfig* system which was being used until now. This is a notable change to how VLANs and switch ports are managed.
### New Minimum Hardware Requirements
With numerous new features and updates to OpenWrt, including the increase in the general size of the Linux kernel, the minimum requirements have been increased.
Devices now require at least 8 MB of flash and 64 MB memory to run the default build ensuring proper stability.
### Package Updates
The release also comes packed in with several package upgrades, some of them are:
- Linux kernel 5.4.143
- gcc 8.4.0
- glibc 2.33
- binutils 2.34
- busybox 1.33.1
Along with the above-listed packages, there are many others that have also received upgrades. You can get the full technical details in the [official release announcement](https://openwrt.org/releases/21.02/notes-21.02.0?ref=news.itsfoss.com).
## Download OpenWrt 21.02
You can head to its official website to download the latest stable builds or opt for development snapshots for experiments.
Instructions to build your own packages, and firmware should be available in their documentation.
The* sysupgrade* command can be used to upgrade your system from OpenWrt 19.07 to OpenWrt 21.02. Do note that you won’t be able to upgrade from 18.06.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,765 | 了解团队隐含价值观和需求的指南 | https://opensource.com/open-organization/21/8/leadership-cultural-social-norms | 2021-09-08T14:28:40 | [
"开放式组织"
] | https://linux.cn/article-13765-1.html |
>
> 为了增强团队动力,开放式领导可以研究指导成员行为和决策的隐性社会规范。
>
>
>

文化在 [开放式组织](https://theopenorganization.org/definition/) 很重要。但“文化”似乎是一个如此庞大而复杂的概念。我们该如何帮助开放式组织去理解它呢?
一个解决方案可能来自于《[Rule Makers, Rule Breakers](https://www.michelegelfand.com/rule-makers-rule-breakers)》的作者 [Michele J. Gelfand](https://www.michelegelfand.com/):紧密和松散的文化以及指导我们生活的秘密信号。Gelfand 把所有的国家和文化分成简单的两类:一类是“紧密的”文化,另一类是“松散的”。然后,她解释了两者的特点和社会规范,提供了它们的相对优势和劣势。通过研究两者,我们可以克服团队、组织和国家之间的分歧和冲突。
在这个分为两篇的《Rule Makers, Rule Breakers》的点评中, 我将解释 Gelfand 的论点,并讨论它对在开放性组织中工作的人们有用的方式。
### 了解你的社会规范
Gelfand 认为,我们的行为很大程度上取决于我们是生活在“紧密的”还是“松散的”社区文化中,因为每一种文化都有不同于其他文化的社会规范。这些规范 ——— 以及强制执行的严格程度 ——— 将决定我们在社会中的行为。它们给了我们身份,它们帮助我们彼此协调。简而言之,这些价值使社区团结在一起。
它们也会影响我们的世界观,影响我们构造环境的方式,甚至影响我们大脑的处理过程。 Gelfand 写道:“无数研究表明,社会规范对于将社区团结成合作、协调良好的团体,从而实现伟大成就至关重要。” 纵观历史,社区让其公民参加看似最疯狂的仪式,除了维持群体凝聚力和合作外,别无其他原因。 这些仪式产生了更紧密的联系,使人们得以生存(特别是在狩猎、觅食和战争时期)。
社会规范包括我们所有人都会自动遵守的规则, Gelfand 称之为一种 “规范性自动驾驶仪”。 这些是我们不需要思考就能做的事情————例如,在图书馆、电影院、电梯或飞机上保持安静。 我们会自动的做这些事。 “从表面看,” Gelfand 说, “我们的社会规范通常看起来很奇怪。但在内心深处,我们认为这是理所当然的。” 她解释到,社会规范可以被编入法规和法律(“遵守停车标志”和“不要偷窃”)。还有一些基本上是不言而喻的(“不要盯着火车上的人看”或“打喷嚏时捂住嘴”)。当然,它们因环境而异。
挑战在于大多数社会规范都是无形的,我们不知道这些社会规范在多大程度上控制着我们。在不知不觉中,我们常常只是跟随周围的人群。这被称为“群体思维”,在这种思维中,人们会跟随他们认同的群体,即使这个群体是错误的。他们不想站出来。
### 组织,有松有紧
Gelfand 将社会规范组织成不同的组别。她认为,一些规范具有“紧密”文化的特征,而另一些规范则具有“松散”文化的特征。为此, Gelfand 对来自五大洲 30 多个国家的约 7000 人进行了研究和抽样,他们具有广泛的职业、性别、年龄、宗教、教派,以及社会阶层,以了解这些社区将自己定位在何处(以及他们的社会规范在官方和社区/社区总体上的执行力度)。 紧密和松散文化之间的差异在国家之间、国家内部(如美国及其各个地区)、组织内部、社会阶层内部甚至家庭内部都有所不同。
因为组织有文化,它们也有自己的社会规范(毕竟,如果一个组织无法协调其成员并影响其行为,它将无法存在)。 因此,组织也可以反映和灌输 Gelfand 所描述的“紧密”或“松散”的文化特征。 并且如果我们有很强的能力识别这些差异,我们就能更成功地预测和解决冲突。然后,在对这些社会规范有了更高认识的情况下,我们可以将开放式组织原则付诸实践。
Gelfand 这样描述紧密和松散文化的区别:
>
> 从广义上讲,松散的文化倾向于开放,但它们也更加无序。另一方面,紧密的文化有令人欣慰的秩序和可预测性,但它们的容忍度较低。这就是紧与松的权衡:一个领域的优势与另一个领域的劣势并存。
>
>
>
她总结说,紧密的社会保持着严格的社会秩序、同步性和自律性;宽松的社会以高度宽容、富有创造力和对变化持开放态度而自豪。
虽然并非所有情况都是如此,但紧密和松散的文化通常会表现出一些权衡;每个人都有自己的长处和短处。参见下面的图 1 。

在这两种环境中成功应用五项开放式组织原则的工作可能会有很大的不同。要取得成功,社区承诺至关重要,如果社会规范不同,承诺的理由也会不同。组织领导者必须知道社区的价值观是什么。只有这样,这个人才能充分激励他人。
在本点评的下一部分中,我将更彻底地解释紧密文化和松散文化的特征,以便领导者能够更好地了解如何将开放式组织原则运用到团队中。
---
via: <https://opensource.com/open-organization/21/8/leadership-cultural-social-norms>
作者:[Ron McFarland](https://opensource.com/users/ron-mcfarland) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zz-air](https://github.com/zz-air) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Culture matters in [open organizations](https://theopenorganization.org/definition/). But "culture" seems like such a large, complicated concept to address. How can we help open organization teams better understand it?
One solution might come from [Michele J. Gelfand](https://www.michelegelfand.com/), author of *Rule Makers, Rule Breakers**: Tight and Loose Cultures and the Secret Signals That Direct Our Lives*. Gelfand organizes all countries and cultures into two very simple groups: those with "tight" cultures and those with "loose" ones. Then she explains the characteristics and social norms of both, offering their relative strengths and weaknesses. By studying both, one might overcome the divisions and conflicts that separate people in and across teams, organizations, and countries.
In this two-part review of *Rule Makers, Rule Breakers*, I'll explain Gelfand's argument and discuss the ways it's useful to people working in open organizations.
## Know your social norms
Gelfand believes that our behavior is very strongly dependent on whether we live in a "tight" or "loose" community culture, because each of these cultures has social norms that differ from the other. These norms—and the strictness with which they are enforced—will determine our behavior in the community. They give us our identity. They help us coordinate with each other. In short, they're the glue that holds communities together.
They also impact our worldviews, the ways we build our environments, and even the processing in our brains. "Countless studies have shown that social norms are critical for uniting communities into cooperative, well-coordinated groups that can accomplish great feats," Gelfand writes. Throughout history, communities have put their citizens through the seemingly craziest of rituals for no other reason than to maintain group cohesion and cooperation. The rituals result in greater bonding, which has kept people alive (particularly in times of hunting, foraging, and warfare).
Social norms include rules we all tend to follow automatically, what Gelfand calls a kind of "normative autopilot." These are things we do without thinking about them—for example, being quiet in libraries, cinemas, elevators, or airplanes. We do these things automatically. "From the outside," Gelfand says, "our social norms often seem bizarre, but from the inside, we take them for granted." She explains that social norms can be codified into regulations and laws ("obey stop signs" and "don't steal"). Others are largely unspoken ("don't stare at people on the train" or "cover your mouth when you sneeze"). And, of course, they vary by context.
The challenge is that most social norms are invisible, and we don't know how much these social norms control us. Without knowing it, we often just follow the groups in our surroundings. This is called "groupthink," in which people will follow along with their identifying group, even if the group is wrong. They don't want to stand out.
## Organizations, tight and loose
Gelfand organizes social norms into various groupings. She argues that some norms are characteristic of "tight" cultures, while others are characteristic of "loose" cultures. To do this, Gelfand researched and sampled approximately seven thousand people from more than 30 countries across five continents and with a wide range of occupations, genders, ages, religions, sects, and social classes in order to learn where those communities positioned themselves (and how strongly their social norms were enforced officially and by the communities/neighborhoods in general). Differences between tight and loose cultures vary between nations, within countries (like within the United States and its various regions), within organizations, within social classes and even within households.
Because organizations have cultures, they too have their own social norms (after all, if an organization is unable to coordinate its members and influence their behavior, it won't be able to survive). So organizations can also reflect and instill the "light" or "loose" cultural characteristics Gelfand describes. And if we have a strong ability to identify these differences, we can predict and address conflict more successfully. Then, armed with greater awareness of those social norms, we can put open organization principles to work.
Gelfand describes the difference between tight and loose cultures this way:
Broadly speaking, loose cultures tend to be open, but they're also much more disorderly. On the flip side, tight cultures have a comforting order and predictability, but they're less tolerant. This is the tight-loose trade-off: advantages in one realm coexist with drawbacks in another.
Tight societies, she concludes, maintain strict social order, synchrony and self-regulation; loose societies take pride in being highly tolerant, creative and open to change.
Although not true in every case, tight and loose cultures generally exhibit some trade-offs; each has its own strengths and weaknesses. See Figure 1 below.
*Figure 1: Characteristics of tight and loose cultures (from *Rule Makers, Rule Breakers*, pg. 56)*
The work of successfully applying the five open organization principles in these two environments can vary greatly. To be successful, community commitment is vital, and if the social norms are different, the reasons for commitment would be different as well. Organizational leaders must know what the community's values are. Only then can that person adequately inspire others.
In the next part of this review, I'll explain more thoroughly the characteristics of tight and loose cultures, so leaders can get a better sense of how they can put open organization principles to work on their teams.
## Comments are closed. |
13,766 | 什么是容器镜像? | https://opensource.com/article/21/8/container-image | 2021-09-08T15:27:42 | [
"容器",
"镜像",
"Docker"
] | https://linux.cn/article-13766-1.html |
>
> 容器镜像包含一个打包的应用,以及它的依赖关系,还有它在启动时运行的进程信息。
>
>
>

容器是当今 IT 运维的一个关键部分。<ruby> 容器镜像 <rt> container image </rt></ruby>包含了一个打包的应用,以及它的依赖关系,还有它在启动时运行的进程信息。
你可以通过提供一组特殊格式的指令来创建容器镜像,可以是提交给<ruby> 注册中心 <rt> Registry </rt></ruby>,或者是作为 Dockerfile 保存。例如,这个 Dockerfile 为 PHP Web 应用创建了一个容器:
```
FROM registry.access.redhat.com/ubi8/ubi:8.1
RUN yum --disableplugin=subscription-manager -y module enable php:7.3 \
&& yum --disableplugin=subscription-manager -y install httpd php \
&& yum --disableplugin=subscription-manager clean all
ADD index.php /var/www/html
RUN sed -i 's/Listen 80/Listen 8080/' /etc/httpd/conf/httpd.conf \
&& sed -i 's/listen.acl_users = apache,nginx/listen.acl_users =/' /etc/php-fpm.d/www.conf \
&& mkdir /run/php-fpm \
&& chgrp -R 0 /var/log/httpd /var/run/httpd /run/php-fpm \
&& chmod -R g=u /var/log/httpd /var/run/httpd /run/php-fpm
EXPOSE 8080
USER 1001
CMD php-fpm & httpd -D FOREGROUND
```
这个文件中的每条指令都会在容器镜像中增加一个<ruby> 层 <rt> layer </rt></ruby>。每一层只增加与下面一层的区别,然后,所有这些堆叠在一起,形成一个只读的容器镜像。
### 它是如何工作的?
你需要知道一些关于容器镜像的事情,按照这个顺序理解这些概念很重要:
1. 联合文件系统
2. 写入时复制(COW)
3. 叠加文件系统
4. 快照器
### 联合文件系统
<ruby> 联合文件系统 <rt> Union File System </rt></ruby>(UnionFS)内置于 Linux 内核中,它允许将一个文件系统的内容与另一个文件系统的内容合并,同时保持“物理”内容的分离。其结果是一个统一的文件系统,即使数据实际上是以分支形式组织。
这里的想法是,如果你有多个镜像有一些相同的数据,不是让这些数据再次复制过来,而是通过使用一个叫做<ruby> 层 <rt> layer </rt></ruby>的东西来共享。

每一层都是一个可以在多个容器中共享的文件系统,例如,httpd 基础层是 Apache 的官方镜像,可以在任何数量的容器中使用。想象一下,由于我们在所有的容器中使用相同的基础层,我们节省了多少磁盘空间。
这些镜像层总是只读的,但是当我们用这个镜像创建一个新的容器时,我们会在它上面添加一个薄的可写层。这个可写层是你创建、修改、删除或进行每个容器所需的其他修改的地方。
### 写时复制(COW)
当你启动一个容器时,看起来好像这个容器有自己的整个文件系统。这意味着你在系统中运行的每个容器都需要自己的文件系统副本。这岂不是要占用大量的磁盘空间,而且还要花费大量的时间让容器启动?不是的,因为每个容器都不需要它自己的文件系统副本!
容器和镜像使用<ruby> 写时复制 <rt> copy-on-write </rt></ruby>(COW)机制来实现这一点。写时复制策略不是复制文件,而是将同一个数据实例分享给多个进程,并且只在一个进程需要修改或写入数据时进行复制。所有其他进程将继续使用原始数据。
Docker 对镜像和容器都使用了写时复制的机制。为了做到这一点,在旧版本中,镜像和运行中的容器之间的变化是通过<ruby> 图驱动 <rt> graph driver </rt></ruby>来跟踪的,现在则是通过<ruby> 快照器 <rt> snapshotter </rt></ruby>来跟踪。
在运行中的容器中执行任何写操作之前,要修改的文件的副本被放在容器的可写层上。这就是发生 *写* 的地方。现在你知道为什么它被称为“写时复制”了么。
这种策略既优化了镜像磁盘空间的使用,也优化了容器启动时间的性能,并与 UnionFS 一起工作。
### 叠加文件系统
<ruby> 叠加文件系统 <rt> Overlay File System </rt></ruby>位于现有文件系统的顶部,结合了上层和下层的目录树,并将它们作为一个单一的目录来呈现。这些目录被称为<ruby> 层 <rt> layer </rt></ruby>。下层保持不被修改。每一层只增加与下一层的差异(计算机术语为 “diff”),这种统一的过程被称为<ruby> 联合挂载 <rt> union mount </rt></ruby>。
最低的目录或镜像层被称为<ruby> 下层目录 <rt> lowerdir </rt></ruby>,上面的目录被称为 <ruby> 上层目录 <rt> upperdir </rt></ruby>。最后的覆盖层或统一层被称为<ruby> 合并层 <rt> merged </rt></ruby>。

常见的术语包括这些层的定义:
* <ruby> 基础层 <rt> Base layer </rt></ruby>:是你的文件系统的文件所在的地方。就容器镜像而言,这个层就是你的基础镜像。
* <ruby> 叠加层 <rt> Overlay layer </rt></ruby>:通常被称为<ruby> 容器层 <rt> container layer </rt></ruby>,因为对运行中的容器所做的所有改变,如添加、删除或修改文件,都会写到这个可写层。对这一层所做的所有修改都存储在下一层,是基础层和差异层的联合视图。
* <ruby> 差异层 <rt> Diff layer </rt></ruby>包含了在叠加层所作的所有修改。如果你写的东西已经在基础层了,那么叠加文件系统就会把文件复制到差异层,并做出你想写的修改。这被称为写时复制。
### 快照器
通过使用层和图驱动,容器可以将其更改作为其容器文件系统的一部分来构建、管理和分发。但是使用<ruby> 图驱动 <rt> graph driver </rt></ruby>的工作真的很复杂,而且容易出错。<ruby> 快照器 <rt> SnapShotter </rt></ruby>与图驱动不同,因为它们不用了解镜像或容器。
快照器的工作方式与 Git 非常相似,比如有树的概念,并跟踪每次提交对树的改变。一个<ruby> 快照 <rt> snapshot </rt></ruby>代表一个文件系统状态。快照有父子关系,使用一组目录。可以在父级和其快照之间进行差异比较(`diff`),以创建一个层。
快照器提供了一个用于分配、快照和挂载抽象的分层文件系统的 API。
### 总结
你现在对什么是容器镜像以及它们的分层方法如何使容器可移植有了很好的认识。接下来,我将介绍容器的运行机制和内部结构。
本文基于 [techbeatly](https://medium.com/techbeatly/container-part-ii-images-4f2139194775) 的文章,经许可后改编。
---
via: <https://opensource.com/article/21/8/container-image>
作者:[Nived V](https://opensource.com/users/nivedv) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Containers are a critical part of today's IT operations. A *container image* contains a packaged application, along with its dependencies, and information on what processes it runs when launched.
You create container images by providing a set of specially formatted instructions, either as commits to a registry or as a Dockerfile. For example, this Dockerfile creates a container for a PHP web application:
```
FROM registry.access.redhat.com/ubi8/ubi:8.1
RUN yum --disableplugin=subscription-manager -y module enable php:7.3 \
&& yum --disableplugin=subscription-manager -y install httpd php \
&& yum --disableplugin=subscription-manager clean all
ADD index.php /var/www/html
RUN sed -i 's/Listen 80/Listen 8080/' /etc/httpd/conf/httpd.conf \
&& sed -i 's/listen.acl_users = apache,nginx/listen.acl_users =/' /etc/php-fpm.d/www.conf \
&& mkdir /run/php-fpm \
&& chgrp -R 0 /var/log/httpd /var/run/httpd /run/php-fpm \
&& chmod -R g=u /var/log/httpd /var/run/httpd /run/php-fpm
EXPOSE 8080
USER 1001
CMD php-fpm & httpd -D FOREGROUND
```
Each instruction in this file adds a *layer* to the container image. Each layer only adds the difference from the layer below it, and then, all these layers are stacked together to form a read-only container image.
## How does that work?
You need to know a few things about container images, and it's important to understand the concepts in this order:
- Union file systems
- Copy-on-Write
- Overlay File Systems
- Snapshotters
## Union File Systems (Aufs)
The Union File System (UnionFS) is built into the Linux kernel, and it allows contents from one file system to be merged with the contents of another, while keeping the "physical" content separate. The result is a unified file system, even though the data is actually structured in branches.
The idea here is that if you have multiple images with some identical data, instead of having this data copied over again, it's shared by using something called a *layer*.
Image CC BY-SA opensource.com
Each layer is a file system that can be shared across multiple containers, e.g., The httpd base layer is the official Apache image and can be used across any number of containers. Imagine the disk space we just saved since we are using the same base layer for all our containers.
These image layers are always read-only, but when we create a new container from this image, we add a thin writable layer on top of it. This writable layer is where you create/modify/delete or make other changes required for each container.
## Copy-on-write
When you start a container, it appears as if the container has an entire file system of its own. That means every container you run in the system needs its own copy of the file system. Wouldn't this take up a lot of disk space and also take a lot of time for the containers to boot? No—because every container does not need its own copy of the filesystem!
Containers and images use a copy-on-write mechanism to achieve this. Instead of copying files, the copy-on-write strategy shares the same instance of data to multiple processes and copies only when a process needs to modify or write data. All other processes would continue to use the original data. Before any write operation is performed in a running container, a copy of the file to be modified is placed on the writeable layer of the container. This is where the *write* takes place. Now you know why it's called *copy-on-write*.
This strategy optimizes both image disk space usage and the performance of container start times and works in conjunction with UnionFS.
## Overlay File System
An overlay sits on top of an existing filesystem, combines an upper and lower directory tree, and presents them as a single directory. These directories are called *layers*. The lower layer remains unmodified. Each layer adds only the difference (the *diff*, in computing terminology) from the layer below it, and this unification process is referred to as a *union mount*.
The lowest directory or an Image layer is called *lowerdir*, and the upper directory is called *upperdir*. The final overlayed or unified layer is called *merged.*
Image CC BY-SA opensource.com
Common terminology consists of these layer definitions:
- Base layer is where the files of your filesystem are located. In terms of container images, this layer would be your base image.
- Overlay layer is often called the
*container layer*, as all the changes that are made to a running container, as adding, deleting, or modifying files, are written to this writable layer. All changes made to this layer are stored in the next layer, and is a*union*view of the Base and Diff layers. - Diff layer contains all changes made in the Overlay layer. If you write something that's already in the Base layer, then the overlay file system copies the file to the Diff layer and makes the modifications you intended to write. This is called a
*copy-on-write*.
# Snapshotters
Containers can build, manage, and distribute changes as a part of their container filesystem using layers and graph drivers. But working with graph drivers is really complicated and is error-prone. SnapShotters are different from graph drivers, as they have no knowledge of images or containers.
Snapshotters work very similar to Git, such as the concept of having trees, and tracking changes to trees for each commit. A *snapshot* represents a filesystem state. Snapshots have parent-child relationships using a set of directories. A *diff can* be taken between a parent and its snapshot to create a layer.
The Snapshotter provides an API for allocating, snapshotting, and mounting abstract, layered file systems.
## Wrap up
You now have a good sense of what container images are and how their layered approach makes containers portable. Next up, I'll cover container runtimes and internals.
*This article is based on a techbeatly article and has been adapted with permission.*
## Comments are closed. |
13,768 | 在 Linux 上使用 stat 命令查看文件状态 | https://opensource.com/article/21/8/linux-stat-file-status | 2021-09-10T07:29:19 | [
"stat",
"文件"
] | https://linux.cn/article-13768-1.html |
>
> 获取到任何文件或文件系统的所有信息,仅需要一条 Linux 命令。
>
>
>

在 GNU `coreutils` 软件包中包含 `stat` 命令,它提供了关于文件和文件系统包括文件大小、节点位置、访问权限和 SELinux 上下文,以及创建和修改时间等各种元数据。通常情况下,你需要多个不同命令获取的信息,而这一个命令就可以实现。
### 在 Linux 上安装 stat 命令
在 Linux 系统中,可能已经预装了 `stat` 命令,因为它属于核心功能软件包,通常默认包含在 Linux 发行版里。
如果系统中没有安装 `stat` 命令,你可以使用包管理器安装 `coreutils` 软件包。
另外,你可以 [通过源码编译安装 coreutils 包](https://www.gnu.org/software/coreutils/)。
### 获取文件状态
运行 `stat` 命令可以获取指定文件或目录易读的状态信息。
```
$ stat planets.xml
File: planets.xml
Size: 325 Blocks: 8 IO Block: 4096 regular file
Device: fd03h/64771d Inode: 140217 Links: 1
Access: (0664/-rw-rw-r--) Uid: (1000/tux) Gid: (100/users)
Context: unconfined_u:object_r:user_home_t:s0
Access: 2021-08-17 18:26:57.281330711 +1200
Modify: 2021-08-17 18:26:58.738332799 +1200
Change: 2021-08-17 18:26:58.738332799 +1200
Birth: 2021-08-17 18:26:57.281330711 +1200
```
输出的信息易懂,但是包含了很多的信息,这里是 `stat` 所包含的项:
* `File`:文件名
* `Size`:文件大小,以字节表示
* `Blocks`:在硬盘驱动器上为文件保留的数据块的数量
* `IO Block`:文件系统块大小
* `regular file`:文件类型(普通文件、目录、文件系统)
* `Device`:文件所在的设备
* `Inode`:文件所在的 Inode 号
* `Links`:文件的链接数
* `Access`、`UID`、`GID`:文件权限、用户和组的所有者
* `Context`:SELinux 上下文
* `Access`、`Modify`、`Change`、`Birth`:文件被访问、修改、更改状态以及创建时的时间戳
### 精简输出
对于精通输出或者想要使用其它工具(例如:[awk](https://opensource.com/article/20/9/awk-ebook))解析输出的人,这里可以使用 `--terse`(短参数为 `-t`)参数,实现没有标题或换行符的格式化输出。
```
$ stat --terse planets.xml
planets.xml 325 8 81b4 100977 100 fd03 140217 1 0 0 1629181617 1629181618 1629181618 1629181617 4096 unconfined_u:object_r:user_home_t:s0
```
### 自定义格式
你可以使用 `--printf` 参数以及与 [printf](https://opensource.com/article/20/8/printf) 类似的语法定义自己的输出格式。`stat` 的每一个属性都有一个格式序列(`%C` 表示 SELinux 上下文,`%n` 表示文件名等等),所以,你可以定义输出格式。
```
$ stat --printf="%n\n%C\n" planets.xml
planets.xml
unconfined_u:object_r:user_home_t:s0
$ $ stat --printf="Name: %n\nModified: %y\n" planets.xml
Name: planets.xml
Modified: 2021-08-17 18:26:58.738332799 +1200
```
下面是一些常见的格式序列:
* `%a` 访问权限
* `%F` 文件类型
* `%n` 文件名
* `%U` 用户名
* `%u` 用户 ID
* `%g` 组 ID
* `%w` 创建时间
* `%y` 修改时间
在 `stat` 手册和 `coreutils` 信息页中都有完整的格式化序列列表。
### 文件信息
如果你曾尝试解析过 `ls -l` 的输出,那么,你会很喜欢 `stat` 命令的灵活性。你并不是每次都需要 `stat` 提供的所有信息,但是,当你需要其中一些或全部的时候它是非常有用的。不管你是读取默认输出,还是你自己创建的查询输出,`stat` 命令都可以查看所需的数据。
---
via: <https://opensource.com/article/21/8/linux-stat-file-status>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[New-World-2019](https://github.com/New-World-2019) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The `stat`
command, included in the GNU `coreutils`
package, provides a variety of metadata, including file size, inode location, access permissions and SELinux context, and creation and modification times, about files and filesystems. It's a convenient way to gather information that you usually need several different commands to acquire.
## Installing stat on Linux
On Linux, you probably already have the `stat`
command installed because it's part of a core utility package that's generally bundled with Linux distributions by default.
In the event that you don't have `stat`
installed, you can install `coreutils`
with your package manager.
Alternately, you can [compile coreutils from source code](https://www.gnu.org/software/coreutils/).
## Getting the status of a file
Running `stat`
provides easy to read output about a specific file or directory.
```
$ stat planets.xml
File: planets.xml
Size: 325 Blocks: 8 IO Block: 4096 regular file
Device: fd03h/64771d Inode: 140217 Links: 1
Access: (0664/-rw-rw-r--) Uid: (1000/tux) Gid: (100/users)
Context: unconfined_u:object_r:user_home_t:s0
Access: 2021-08-17 18:26:57.281330711 +1200
Modify: 2021-08-17 18:26:58.738332799 +1200
Change: 2021-08-17 18:26:58.738332799 +1200
Birth: 2021-08-17 18:26:57.281330711 +1200
```
It may be easy to read, but it's still a lot of information. Here's what `stat`
is covering:
**File**: the file name**Size**: the file size in bytes**Blocks**: the number of blocks on the hard drive reserved for this file**IO Block**: the size of a block of the filesystem**regular file**: the type of file (regular file, directory, filesystem)**Device**: the device where the file is located**Inode**: the inode number where the file is located**Links**: the number of links to the file**Access, UID, GID**: file permissions, user, and group owner**Context**: SELinux context**Access, Modify, Change, Birth**: the timestamp of when the file was accessed, modified, changed status, and created
## Terse output
For people who know the output well, or want to parse the output with other utilities like [awk](https://opensource.com/article/20/9/awk-ebook), there's the `--terse`
(`-t`
for short) option, which formats the output without headings or line breaks.
```
$ stat --terse planets.xml
planets.xml 325 8 81b4 100977 100 fd03 140217 1 0 0 1629181617 1629181618 1629181618 1629181617 4096 unconfined_u:object_r:user_home_t:s0
```
## Choosing your own format
You can define your own format for output using the `--printf`
option and a syntax similar to [printf](https://opensource.com/article/20/8/printf). Each attribute reported by `stat`
has a format sequence (`%C`
for SELinux context, `%n`
for file name, and so on), so you can choose what you want to see in a report.
```
$ stat --printf="%n\n%C\n" planets.xml
planets.xml
unconfined_u:object_r:user_home_t:s0
$ $ stat --printf="Name: %n\nModified: %y\n" planets.xml
Name: planets.xml
Modified: 2021-08-17 18:26:58.738332799 +1200
```
Here are some common format sequences:
**%a**access rights**%F**file type**%n**file name**%U**user name**%u**user ID**%g**group ID**%w**time of birth**%y**modification time
A full listing of format sequences is available in the `stat`
man page and the `coreutils`
info pages.
## File information
If you've ever tried to parse the output of `ls -l`
, then you'll appreciate the flexibility of the `stat`
command. You don't always need every bit of the default information that `stat`
provides, but the command is invaluable when you do need some or all of it. Whether you read its output in its default format, or you create your own queries, the `stat`
command gives you easy access to the data about your data.
## 2 Comments |
13,769 | 在 Java 中使用外部库 | https://opensource.com/article/20/2/external-libraries-java | 2021-09-10T07:57:59 | [
"Java"
] | https://linux.cn/article-13769-1.html |
>
> 外部库填补了 Java 核心库中的一些功能空白。
>
>
>

Java 自带有一组核心库,其中包含了定义常用数据类型和相关行为的库(例如 `String` 和 `Date`)、与主机操作系统交互的实用程序(例如 `System` 和 `File`),以及一些用来管理安全性、处理网络通信、创建或解析 XML的有用的子系统。鉴于核心库的丰富性,程序员通常很容易在其中找到有用的组件,以减少需要编写的代码量。
即便如此,核心库仍有一些功能上的不足,因此发现这些不足的程序员们还额外创建了很多有趣的 Java 库。例如,[Apache Commons](https://commons.apache.org/)“是一个专注于可重用 Java 组件所有方面的 Apache 项目”,提供了大约 43 个开源库的集合(截至撰写本文时),涵盖了 Java 核心库之外的一系列功能 (例如 [geometry](https://commons.apache.org/proper/commons-geometry/) 或 [statistics](https://commons.apache.org/proper/commons-statistics/)),并增强或替换了 Java 核心库中的原有功能(例如 [math](https://commons.apache.org/proper/commons-math/) 或 [numbers](https://commons.apache.org/proper/commons-numbers/))。
另一种常见的 Java 库类型是系统组件的接口(例如数据库系统接口),本文会着眼于使用此类接口连接到 [PostgreSQL](https://opensource.com/article/19/11/getting-started-postgresql) 数据库,并得到一些有趣的信息。首先,我们来回顾一下库的重要部分。
### 什么是库?
<ruby> 库 <rt> library </rt></ruby>里自然包含的是一些有用的代码。但为了发挥用处,代码需要以特定方式进行组织,特定的方式使 Java 程序员可以访问其中组件来解决手头问题。
可以说,一个库最重要的部分是它的应用程序编程接口(API)文档。这种文档很多人都熟悉,通常是由 [Javadoc](https://en.wikipedia.org/wiki/Javadoc) 生成的。Javadoc 读取代码中的结构化注释并以 HTML 格式输出文档,通常 API 的 <ruby> 包 <rt> package </rt></ruby> 在页面左上角的面板中显示,<ruby> 类 <rt> class </rt></ruby> 在左下角显示,同时右侧会有库、包或类级别的详细文档(具体取决于在主面板中选择的内容)。例如,[Apache Commons Math 的顶级 API 文档](https://commons.apache.org/proper/commons-math/apidocs/index.html) 如下所示:

单击主面板中的包会显示该包中定义的 Java 类和接口。例如,[org.apache.commons.math4.analysis.solvers](https://commons.apache.org/proper/commons-math/apidocs/org/apache/commons/math4/analysis/solvers/package-summary.html) 显示了诸如 `BisectionSolver` 这样的类,该类用于使用二分算法查找单变量实函数的零点。单击 [BisectionSolver](https://commons.apache.org/proper/commons-math/apidocs/org/apache/commons/math4/analysis/solvers/BisectionSolver.html) 链接会列出 `BisectionSolver` 类的所有方法。
这类文档可用作参考文档,不适合作为学习如何使用库的教程。比如,如果你知道什么是单变量实函数并查看包 `org.apache.commons.math4.analysis.function`,就可以试着使用该包来组合函数定义,然后使用 `org.apache.commons.math4.analysis.solvers` 包来查找刚刚创建的函数的零点。但如果你不知道,就可能需要更多学习向的文档,也许甚至是一个实际例子,来读懂参考文档。
这种文档结构还有助于阐明 <ruby> 包 <rt> package </rt></ruby>(相关 Java 类和接口定义的集合)的含义,并显示特定库中捆绑了哪些包。
这种库的代码通常是在 [.jar 文件](https://en.wikipedia.org/wiki/JAR_(file_format)) 中,它基本上是由 Java 的 `jar` 命令创建的 .zip 文件,其中还包含一些其他有用的信息。.jar 文件通常被创建为构建过程的端点,该构建过程编译了所定义包中的所有 .java 文件。
要访问外部库提供的功能,有两个主要步骤:
1. 确保通过类路径(或者命令行中的 `-cp` 参数或者 `CLASSPATH` 环境变量),库可用于 Java 编译步骤([javac](https://en.wikipedia.org/wiki/Javac))和执行步骤(`java`)。
2. 使用恰当的 `import` 语句访问程序源代码中的包和类。
其余的步骤就与使用 `String` 等 Java核心类相同,使用库提供的类和接口定义来编写代码。很简单对吧?不过也没那么简单。首先,你需要了解库组件的预期使用模式,然后才能编写代码。
### 示例:连接 PostgreSQL 数据库
在数据库系统中访问数据的典型使用步骤是:
1. 访问正在使用的特定数据库软件代码。
2. 连接到数据库服务器。
3. 构建查询字符串。
4. 执行查询字符串。
5. 针对返回的结果,做需要的处理。
6. 断开与数据库服务器的连接。
所有这些面向程序员的部分由接口包 [java.sql](https://docs.oracle.com/javase/8/docs/api/java/sql/package-summary.html) 提供,它独立于数据库,定义了核心客户端 Java 数据库连接(JDBC)API。`java.sql` 包是 Java 核心库的一部分,因此无需提供 .jar 文件即可编译。但每个数据库提供者都会创建自己的 `java.sql` 接口实现(例如 `Connection` 接口),并且必须在运行步骤中提供这些实现。
接下来我们使用 PostgreSQL,看看这一过程是如何进行的。
#### 访问特定数据库的代码
以下代码使用 [Java 类加载器](https://en.wikipedia.org/wiki/Java_Classloader)(`Class.forName()` 调用)将 PostgreSQL 驱动程序代码加载到正在执行的虚拟机中:
```
import java.sql.*;
public class Test1 {
public static void main(String args[]) {
// Load the driver (jar file must be on class path) [1]
try {
Class.forName("org.postgresql.Driver");
System.out.println("driver loaded");
} catch (Exception e1) {
System.err.println("couldn't find driver");
System.err.println(e1);
System.exit(1);
}
// If we get here all is OK
System.out.println("done.");
}
}
```
因为类加载器可能失败,失败时会抛出异常,所以将对 `Class.forName()` 的调用放在 `try-catch` 代码块中。
如果你使用 `javac` 编译上面的代码,然后用 `java` 运行,会报异常:
```
me@mymachine:~/Test$ javac Test1.java
me@mymachine:~/Test$ java Test1
couldn't find driver
java.lang.ClassNotFoundException: org.postgresql.Driver
me@mymachine:~/Test$
```
类加载器要求类路径中有包含 PostgreSQL JDBC 驱动程序实现的 .jar 文件:
```
me@mymachine:~/Test$ java -cp ~/src/postgresql-42.2.5.jar:. Test1
driver loaded
done.
me@mymachine:~/Test$
```
#### 连接到数据库服务器
以下代码实现了加载 JDBC 驱动程序和创建到 PostgreSQL 数据库的连接:
```
import java.sql.*;
public class Test2 {
public static void main(String args[]) {
// Load the driver (jar file must be on class path) [1]
try {
Class.forName("org.postgresql.Driver");
System.out.println("driver loaded");
} catch (Exception e1) {
System.err.println("couldn't find driver");
System.err.println(e1);
System.exit(1);
}
// Set up connection properties [2]
java.util.Properties props = new java.util.Properties();
props.setProperty("user","me");
props.setProperty("password","mypassword");
String database = "jdbc:postgresql://myhost.org:5432/test";
// Open the connection to the database [3]
try (Connection conn = DriverManager.getConnection(database, props)) {
System.out.println("connection created");
} catch (Exception e2) {
System.err.println("sql operations failed");
System.err.println(e2);
System.exit(2);
}
System.out.println("connection closed");
// If we get here all is OK
System.out.println("done.");
}
}
```
编译并运行上述代码:
```
me@mymachine:~/Test$ javac Test2.java
me@mymachine:~/Test$ java -cp ~/src/postgresql-42.2.5.jar:. Test2
driver loaded
connection created
connection closed
done.
me@mymachine:~/Test$
```
关于上述的一些注意事项:
* 注释 `[2]` 后面的代码使用系统属性来设置连接参数(在本例中参数为 PostgreSQL 用户名和密码)。代码也可以从 Java 命令行获取这些参数并将所有参数作为参数包传递,同时还有一些其他 `Driver.getConnection()` 选项可用于单独传递参数。
* JDBC 需要一个用于定义数据库的 URL,它在上述代码中被声明为 `String database` 并与连接参数一起传递给 `Driver.getConnection()` 方法。
* 代码使用 `try-with-resources` 语句,它会在 `try-catch` 块中的代码完成后自动关闭连接。[Stack Overflow](https://stackoverflow.com/questions/8066501/how-should-i-use-try-with-resources-with-jdbc) 上对这种方法进行了长期的讨论。
* `try-with-resources` 语句提供对 `Connection` 实例的访问,并可以在其中执行 SQL 语句;所有错误都会被同一个 `catch` 语句捕获。
#### 用数据库的连接处理一些有趣的事情
日常工作中,我经常需要知道为给定的数据库服务器实例定义了哪些用户,这里我使用这个 [简便的 SQL](https://www.postgresql.org/message-id/[email protected]) 来获取所有用户的列表:
```
import java.sql.*;
public class Test3 {
public static void main(String args[]) {
// Load the driver (jar file must be on class path) [1]
try {
Class.forName("org.postgresql.Driver");
System.out.println("driver loaded");
} catch (Exception e1) {
System.err.println("couldn't find driver");
System.err.println(e1);
System.exit(1);
}
// Set up connection properties [2]
java.util.Properties props = new java.util.Properties();
props.setProperty("user","me");
props.setProperty("password","mypassword");
String database = "jdbc:postgresql://myhost.org:5432/test";
// Open the connection to the database [3]
try (Connection conn = DriverManager.getConnection(database, props)) {
System.out.println("connection created");
// Create the SQL command string [4]
String qs = "SELECT " +
" u.usename AS \"User name\", " +
" u.usesysid AS \"User ID\", " +
" CASE " +
" WHEN u.usesuper AND u.usecreatedb THEN " +
" CAST('superuser, create database' AS pg_catalog.text) " +
" WHEN u.usesuper THEN " +
" CAST('superuser' AS pg_catalog.text) " +
" WHEN u.usecreatedb THEN " +
" CAST('create database' AS pg_catalog.text) " +
" ELSE " +
" CAST('' AS pg_catalog.text) " +
" END AS \"Attributes\" " +
"FROM pg_catalog.pg_user u " +
"ORDER BY 1";
// Use the connection to create a statement, execute it,
// analyze the results and close the result set [5]
Statement stat = conn.createStatement();
ResultSet rs = stat.executeQuery(qs);
System.out.println("User name;User ID;Attributes");
while (rs.next()) {
System.out.println(rs.getString("User name") + ";" +
rs.getLong("User ID") + ";" +
rs.getString("Attributes"));
}
rs.close();
stat.close();
} catch (Exception e2) {
System.err.println("connecting failed");
System.err.println(e2);
System.exit(1);
}
System.out.println("connection closed");
// If we get here all is OK
System.out.println("done.");
}
}
```
在上述代码中,一旦有了 `Connection` 实例,它就会定义一个查询字符串(上面的注释 `[4]`),创建一个 `Statement` 实例并用其来执行查询字符串,然后将其结果放入一个 `ResultSet` 实例。程序可以遍历该 `ResultSet` 实例来分析返回的结果,并以关闭 `ResultSet` 和 `Statement` 实例结束(上面的注释 `[5]`)。
编译和执行程序会产生以下输出:
```
me@mymachine:~/Test$ javac Test3.java
me@mymachine:~/Test$ java -cp ~/src/postgresql-42.2.5.jar:. Test3
driver loaded
connection created
User name;User ID;Attributes
fwa;16395;superuser
vax;197772;
mbe;290995;
aca;169248;
connection closed
done.
me@mymachine:~/Test$
```
这是在一个简单的 Java 应用程序中使用 PostgreSQL JDBC 库的(非常简单的)示例。要注意的是,由于 `java.sql` 库的设计方式,它不需要在代码中使用像 `import org.postgresql.jdbc.*;` 这样的 Java 导入语句,而是使用 Java 类加载器在运行时引入 PostgreSQL 代码的方式,也正因此无需在代码编译时指定类路径。
---
via: <https://opensource.com/article/20/2/external-libraries-java>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Java comes with a core set of libraries, including those that define commonly used data types and related behavior, like **String** or **Date**; utilities to interact with the host operating system, such as **System** or **File**; and useful subsystems to manage security, deal with network communications, and create or parse XML. Given the richness of this core set of libraries, it's often easy to find the necessary bits and pieces to reduce the amount of code a programmer must write to solve a problem.
Even so, there are a lot of interesting Java libraries created by people who find gaps in the core libraries. For example, [Apache Commons](https://commons.apache.org/) "is an Apache project focused on all aspects of reusable Java components" and provides a collection of some 43 open source libraries (as of this writing) covering a range of capabilities either outside the Java core (such as [geometry](https://commons.apache.org/proper/commons-geometry/) or [statistics](https://commons.apache.org/proper/commons-statistics/)) or that enhance or replace capabilities in the Java core (such as [math](https://commons.apache.org/proper/commons-math/) or [numbers](https://commons.apache.org/proper/commons-numbers/)).
Another common type of Java library is an interface to a system component—for example, to a database system. This article looks at using such an interface to connect to a [PostgreSQL](https://opensource.com/article/19/11/getting-started-postgresql) database and get some interesting information. But first, I'll review the important bits and pieces of a library.
## What is a library?
A library, of course, must contain some useful code. But to be useful, that code needs to be organized in such a way that the Java programmer can access the components to solve the problem at hand.
I'll boldly claim that the most important part of a library is its application programming interface (API) documentation. This kind of documentation is familiar to many and is most often produced by [Javadoc](https://en.wikipedia.org/wiki/Javadoc), which reads structured comments in the code and produces HTML output that displays the API's packages in the panel in the top-left corner of the page; its classes in the bottom-left corner; and the detailed documentation at the library, package, or class level (depending on what is selected in the main panel) on the right. For example, the [top level of API documentation for Apache Commons Math](https://commons.apache.org/proper/commons-math/apidocs/index.html) looks like:
Clicking on a package in the main panel shows the Java classes and interfaces defined in that package. For example, ** org.apache.commons.math4.analysis.solvers** shows classes like
**BisectionSolver**for finding zeros of univariate real functions using the bisection algorithm. And clicking on the
[BisectionSolver](https://commons.apache.org/proper/commons-math/apidocs/org/apache/commons/math4/analysis/solvers/BisectionSolver.html)link lists all the methods of the class
**BisectionSolver**.
This type of documentation is useful as reference information; it's not intended as a tutorial for learning how to use the library. For example, if you know what a univariate real function is and look at the package **org.apache.commons.math4.analysis.function**, you can imagine using that package to compose a function definition and then using the **org.apache.commons.math4.analysis.solvers** package to look for zeros of the just-created function. But really, you probably need more learning-oriented documentation to bridge to the reference documentation. Maybe even an example!
This documentation structure also helps clarify the meaning of *package*—a collection of related Java class and interface definitions—and shows what packages are bundled in a particular library.
The code for such a library is most commonly found in a [ .jar file](https://en.wikipedia.org/wiki/JAR_(file_format)), which is basically a .zip file created by the Java
**jar**command that contains some other useful information.
**.jar**files are typically created as the endpoint of a build process that compiles all the
**.java**files in the various packages defined.
There are two main steps to accessing the functionality provided by an external library:
- Make sure the library is available to the Java compilation step—
—and the execution step—**javac****java**—via the classpath (either the**-cp**argument on the command line or the**CLASSPATH**environment variable). - Use the appropriate
**import**statements to access the package and class in the program source code.
The rest is just like coding with Java core classes, such as **String**—write the code using the class and interface definitions provided by the library. Easy, eh? Well, maybe not quite that easy; first, you need to understand the intended use pattern for the library components, and then you can write code.
## An example: Connect to a PostgreSQL database
The typical use pattern for accessing data in a database system is:
- Gain access to the code specific to the database software being used.
- Connect to the database server.
- Build a query string.
- Execute the query string.
- Do something with the results returned.
- Disconnect from the database server.
The programmer-facing part of all of this is provided by a database-independent interface package, ** java.sql**, which defines the core client-side Java Database Connectivity (JDBC) API. The
**java.sql**package is part of the core Java libraries, so there is no need to supply a
**.jar**file to the compile step. However, each database provider creates its own implementation of the
**java.sql**interfaces—for example, the
**Connection**interface—and those implementations must be provided on the run step.
Let's see how this works, using PostgreSQL.
### Gain access to the database-specific code
The following code uses the [Java class loader](https://en.wikipedia.org/wiki/Java_Classloader) (the **Class.forName()** call) to bring the PostgreSQL driver code into the executing virtual machine:
```
import java.sql.*;
public class Test1 {
public static void main(String args[]) {
// Load the driver (jar file must be on class path) [1]
try {
Class.forName("org.postgresql.Driver");
System.out.println("driver loaded");
} catch (Exception e1) {
System.err.println("couldn't find driver");
System.err.println(e1);
System.exit(1);
}
// If we get here all is OK
System.out.println("done.");
}
}
```
Because the class loader can fail, and therefore can throw an exception when failing, surround the call to **Class.forName()** in a try-catch block.
If you compile the above code with **javac** and run it with Java:
```
me@mymachine:~/Test$ javac Test1.java
me@mymachine:~/Test$ java Test1
couldn't find driver
java.lang.ClassNotFoundException: org.postgresql.Driver
me@mymachine:~/Test$
```
The class loader needs the **.jar** file containing the PostgreSQL JDBC driver implementation to be on the classpath:
```
me@mymachine:~/Test$ java -cp ~/src/postgresql-42.2.5.jar:. Test1
driver loaded
done.
me@mymachine:~/Test$
```
### Connect to the database server
The following code loads the JDBC driver and creates a connection to the PostgreSQL database:
```
import java.sql.*;
public class Test2 {
public static void main(String args[]) {
// Load the driver (jar file must be on class path) [1]
try {
Class.forName("org.postgresql.Driver");
System.out.println("driver loaded");
} catch (Exception e1) {
System.err.println("couldn't find driver");
System.err.println(e1);
System.exit(1);
}
// Set up connection properties [2]
java.util.Properties props = new java.util.Properties();
props.setProperty("user","me");
props.setProperty("password","mypassword");
String database = "jdbc:postgresql://myhost.org:5432/test";
// Open the connection to the database [3]
try (Connection conn = DriverManager.getConnection(database, props)) {
System.out.println("connection created");
} catch (Exception e2) {
System.err.println("sql operations failed");
System.err.println(e2);
System.exit(2);
}
System.out.println("connection closed");
// If we get here all is OK
System.out.println("done.");
}
}
```
Compile and run it:
```
me@mymachine:~/Test$ javac Test2.java
me@mymachine:~/Test$ java -cp ~/src/postgresql-42.2.5.jar:. Test2
driver loaded
connection created
connection closed
done.
me@mymachine:~/Test$
```
Some notes on the above:
- The code following comment [2] uses system properties to set up connection parameters—in this case, the PostgreSQL username and password. This allows for grabbing those parameters from the Java command line and passing all the parameters in as an argument bundle. There are other
**Driver.getConnection()**options for passing in the parameters individually. - JDBC requires a URL for defining the database, which is declared above as
**String database**and passed into the**Driver.getConnection()**method along with the connection parameters. - The code uses try-with-resources, which auto-closes the connection upon completion of the code in the try-catch block. There is a lengthy discussion of this approach on
[Stack Overflow](https://stackoverflow.com/questions/8066501/how-should-i-use-try-with-resources-with-jdbc). - The try-with-resources provides access to the
**Connection**instance and can execute SQL statements there; any errors will be caught by the same**catch**statement.
### Do something fun with the database connection
In my day job, I often need to know what users have been defined for a given database server instance, and I use this [handy piece of SQL](https://www.postgresql.org/message-id/[email protected]) for grabbing a list of all users:
```
import java.sql.*;
public class Test3 {
public static void main(String args[]) {
// Load the driver (jar file must be on class path) [1]
try {
Class.forName("org.postgresql.Driver");
System.out.println("driver loaded");
} catch (Exception e1) {
System.err.println("couldn't find driver");
System.err.println(e1);
System.exit(1);
}
// Set up connection properties [2]
java.util.Properties props = new java.util.Properties();
props.setProperty("user","me");
props.setProperty("password","mypassword");
String database = "jdbc:postgresql://myhost.org:5432/test";
// Open the connection to the database [3]
try (Connection conn = DriverManager.getConnection(database, props)) {
System.out.println("connection created");
// Create the SQL command string [4]
String qs = "SELECT " +
" u.usename AS \"User name\", " +
" u.usesysid AS \"User ID\", " +
" CASE " +
" WHEN u.usesuper AND u.usecreatedb THEN " +
" CAST('superuser, create database' AS pg_catalog.text) " +
" WHEN u.usesuper THEN " +
" CAST('superuser' AS pg_catalog.text) " +
" WHEN u.usecreatedb THEN " +
" CAST('create database' AS pg_catalog.text) " +
" ELSE " +
" CAST('' AS pg_catalog.text) " +
" END AS \"Attributes\" " +
"FROM pg_catalog.pg_user u " +
"ORDER BY 1";
// Use the connection to create a statement, execute it,
// analyze the results and close the result set [5]
Statement stat = conn.createStatement();
ResultSet rs = stat.executeQuery(qs);
System.out.println("User name;User ID;Attributes");
while (rs.next()) {
System.out.println(rs.getString("User name") + ";" +
rs.getLong("User ID") + ";" +
rs.getString("Attributes"));
}
rs.close();
stat.close();
} catch (Exception e2) {
System.err.println("connecting failed");
System.err.println(e2);
System.exit(1);
}
System.out.println("connection closed");
// If we get here all is OK
System.out.println("done.");
}
}
```
In the above, once it has the **Connection** instance, it defines a query string (comment [4] above), creates a **Statement** instance and uses it to execute the query string, then puts its results in a **ResultSet** instance, which it can iterate through to analyze the results returned, and ends by closing both the **ResultSet** and **Statement** instances (comment [5] above).
Compiling and executing the program produces the following output:
```
me@mymachine:~/Test$ javac Test3.java
me@mymachine:~/Test$ java -cp ~/src/postgresql-42.2.5.jar:. Test3
driver loaded
connection created
User name;User ID;Attributes
fwa;16395;superuser
vax;197772;
mbe;290995;
aca;169248;
connection closed
done.
me@mymachine:~/Test$
```
This is a (very simple) example of using the PostgreSQL JDBC library in a simple Java application. It's worth emphasizing that it didn't need to use a Java import statement like **import org.postgresql.jdbc.*;** in the code because of the way the **java.sql** library is designed. Because of that, there's no need to specify the classpath at compile time. Instead, it uses the Java class loader to bring in the PostgreSQL code at run time.
## Comments are closed. |
13,771 | 满足日常需求的应用(四):音频编辑器 | https://fedoramagazine.org/apps-for-daily-needs-part-4-audio-editors/ | 2021-09-10T11:31:21 | [
"音频"
] | https://linux.cn/article-13771-1.html | 
在过去,音频编辑应用或<ruby> 数字音频工作站 <rt> digital audio workstation </rt></ruby>(DAW)只提供给专业人士使用,如唱片制作人、音响工程师和音乐家。但现在很多不是专业人士的人也需要它们。这些工具被用于演示文稿解说、视频博客,甚至只是作为一种爱好。现在尤其如此,因为有这么多的在线平台,方便大家分享音频作品,如音乐、歌曲、播客等。本文将介绍一些你可以在 Fedora Linux 上使用的开源音频编辑器或 DAW。你可能需要安装提到的软件。如果你不熟悉如何在 Fedora Linux 中添加软件包,请参阅我之前的文章[安装 Fedora 34 工作站后要做的事情](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/)。这里列出了音频编辑器或 DAW 类的一些日常需求的应用。
### Audacity
我相信很多人已经知道 Audacity 了。它是一个流行的多轨音频编辑器和录音机,可用于对所有类型的音频进行后期处理。大多数人使用 Audacity 来记录他们的声音,然后进行编辑,使其成品更好。其成品可以作为播客或视频博客的解说词。此外,人们还用 Audacity 来创作音乐和歌曲。你可以通过麦克风或调音台录制现场音频。它还支持 32 位的声音质量。
Audacity 有很多功能,可以支持你的音频作品。它有对插件的支持,你甚至可以自己编写插件。Audacity 提供了许多内置效果,如降噪、放大、压缩、混响、回声、限制器等。你可以利用实时预览功能在直接聆听音频的同时尝试这些效果。内置的插件管理器可以让你管理经常使用的插件和效果。

详情请参考此链接: <https://www.audacityteam.org/>
### LMMS
LMMS(即 <ruby> Linux 多媒体工作室 <rt> Linux MultiMedia Studio </rt></ruby>)是一个全面的音乐创作应用。你可以从头使用 LMMS 用你的电脑开始制作你的音乐。你可以根据自己的创意创造旋律和节拍,并通过选择声音乐器和各种效果使其更加完美。有几个与乐器和效果有关的内置功能,如 16 个内置合成器、嵌入式 ZynAddSubFx、支持插入式 VST 效果插件、捆绑图形和参数均衡器、内置分析器等等。LMMS 还支持 MIDI 键盘和其他音频外围设备。

详情请参考此链接: <https://lmms.io/>
### Ardour
Ardour 作为一个全面的音乐创作应用,其功能与 LMMS 相似。它在其网站上说,Ardour 是一个 DAW 应用,是来自世界各地的音乐家、程序员和专业录音工程师合作的结果。Ardour 拥有音频工程师、音乐家、配乐编辑和作曲家需要的各种功能。
Ardour 提供了完整的录音、编辑、混音和输出功能。它有无限的多声道音轨、无限撤销/重做的非线性编辑器、一个全功能的混音器、内置插件等。Ardour 还包含视频播放工具,所以使用它为视频项目创建和编辑配乐也很有帮助。

详情请参考此链接: <https://ardour.org/>
### TuxGuitar
TuxGuitar 是一款指法谱和乐谱编辑器。它配备了指法编辑器、乐谱查看器、多轨显示、拍号管理和速度管理。它包括弯曲、滑动、颤音等各种效果。虽然 TuxGuitar 专注于吉他,但它也可以为其他乐器写乐谱。它也能够作为一个基本的 MIDI 编辑器。你需要对指法谱和乐谱有一定的了解才能使用它。

详情请参考此链接: <http://www.tuxguitar.com.ar/>
### 总结
本文章介绍了四款音频编辑器,可以满足你在 Fedora Linux 上日常使用的需求。其实,在 Fedora Linux 上还有很多音频编辑器或者 DAW 供你选择。你也可以使用 Mixxx、Rosegarden、Kwave、Qtractor、MuseScore、musE 等等。希望本文为你调查和选择合适的音频编辑器或者 DAW 提供帮助。如你有使用这些应用的经验,请在评论中分享你的经验。
---
via: <https://fedoramagazine.org/apps-for-daily-needs-part-4-audio-editors/>
作者:[Arman Arisman](https://fedoramagazine.org/author/armanwu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Audio editor applications or digital audio workstations (DAW) were only used in the past by professionals, such as record producers, sound engineers, and musicians. But nowadays many people who are not professionals also need them. These tools are used for narration on presentations, video blogs, and even just as a hobby. This is especially true now since there are so many online platforms that facilitate everyone sharing audio works, such as music, songs, podcast, etc. This article will introduce some of the open source audio editors or DAW that you can use on Fedora Linux. You may need to install the software mentioned. If you are unfamiliar with how to add software packages in Fedora Linux, see my earlier article [Things to do after installing Fedora 34 Workstation](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/). Here is a list of a few apps for daily needs in the audio editors or DAW category.
## Audacity
I’m sure many already know Audacity. It is a popular multi-track audio editor and recorder that can be used for post-processing all types of audio. Most people use Audacity to record their voices, then do editing to make the results better. The results can be used as a podcast or a narration for a video blog. In addition, people also use Audacity to create music and songs. You can record live audio through a microphone or mixer. It also supports 32 bit sound quality.
Audacity has a lot of features that can support your audio works. It has support for plugins, and you can even write your own plugin. Audacity provides many built-in effects, such as noise reduction, amplification, compression, reverb, echo, limiter, and many more. You can try these effects while listening to the audio directly with the real-time preview feature. The built in plugin-manager lets you manage frequently used plugins and effects.
More information is available at this link: [https://www.audacityteam.org/](https://www.audacityteam.org/)
## LMMS
LMMS or Linux MultiMedia Studio is a comprehensive music creation application. You can use LMMS to produce your music from scratch with your computer. You can create melodies and beats according to your creativity, and make it better with selection of sound instruments and various effects. There are several built-in features related to musical instruments and effects, such as 16 built-in sythesizers, embedded ZynAddSubFx, drop-in VST effect plug-in support, bundled graphic and parametric equalizer, built-in analyzer, and many more. LMMS also supports MIDI keyboards and other audio peripherals.
More information is available at this link: [https://lmms.io/](https://lmms.io/)
## Ardour
Ardour has capabilities similar to LMMS as a comprehensive music creation application. It says on its website that Ardour is a DAW application that is the result of collaboration between musicians, programmers, and professional recording engineers from around the world. Ardour has various functions that are needed by audio engineers, musicians, soundtrack editors, and composers.
Ardour provides complete features for recording, editing, mixing, and exporting. It has unlimited multichannel tracks, non-linear editor with unlimited undo/redo, a full featured mixer, built-in plugins, and much more. Ardour also comes with video playback tools, so it is also very helpful in the process of creating and editing soundtracks for video projects.
More information is available at this link: [https://ardour.org/](https://ardour.org/)
## TuxGuitar
TuxGuitar is a tablature and score editor. It comes with a tablature editor, score viewer, multitrack display, time signature management, and tempo management. It includes various effects, such as bend, slide, vibrato, etc. While TuxGuitar focuses on the guitar, it allows you to write scores for other instruments. It can also serve as a basic MIDI editor. You need to have an understanding of tablature and music scoring to be able to use it.
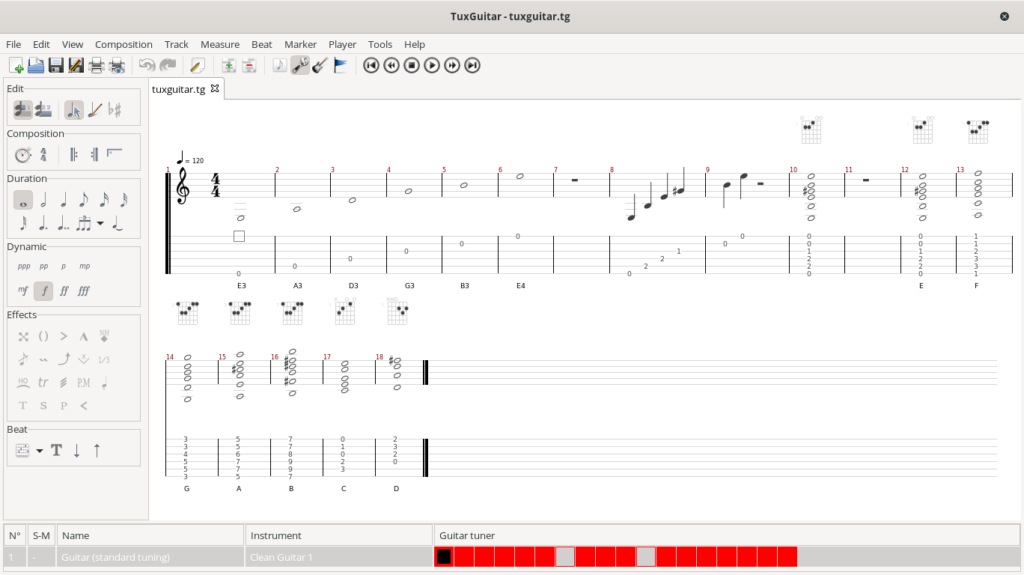
More information is available at this link: [http://www.tuxguitar.com.ar/](http://www.tuxguitar.com.ar/)
## Conclusion
This article presented four audio editors as apps for your daily needs and use on Fedora Linux. Actually there are many other audio editors, or DAW, that you can use on Fedora Linux. You can also use Mixxx, Rosegarden, Kwave, Qtractor, MuseScore, musE, and many more. Hopefully this article can help you investigate and choose the right audio editor or DAW. If you have experience using these applications, please share your experiences in the comments.
## JaspEr
If article is called “something” part 4, it would really help if it linked to at least parts 1-3.
I know there’s search, but being nice doesn’t hurt.
## Gregory Bartholomew
There should be links to previous articles in the series in the left-hand sidebar.
## tgc
No in the mobile view, because there is no left-hand sidebar.
## JaspEr
Exactly, No left sidebar in mobile version + some of us use feed readers instead of browsers.
## Taras
New versions of Audacity violate our privacy. We must ignore this audio editor as a community.
## Frederik
Could you elaborate?
## Darvond
Here’s a summation: Muse purchased Audacity, and are doing what they did to other projects while using licensing terms that are not favorable to contributors.
They also tried to install telemetry which backfired.
## LWinterberg
They do not. Especially not on Linux, where it’s being built by the repo maintainers, which have all the problematic stuff (error reporting, update checking) disabled on build time
## X
Fake news. The building-in of telemetry was cancelled due to backlash from the community.
## Angel
This is great , please there should be a link to Go part 1 and 3 , that will be helpful
## Gregory Bartholomew
You should be able to click on the author’s name in the upper-left corner to get a list of all articles by this author.
## Darvond
I feel it goes without saying that Audacity should be vetoed in favor of forks such as Tenacity, which are taking massive strides to introduce nice things like build sanity.
Not actually ready to ship due to the need to debrand the code, but the Fedora Packaging Team should keep an eye on it.
https://github.com/tenacityteam/tenacity/issues/90#issuecomment-901585714
## Trowa
kwave is also a very nice alternative for something simple.
## Vincent Chernin
EasyEffects (PipeWire only audio effects app) is also quite handy. It is available on Flathub. https://flathub.org/apps/details/com.github.wwmm.easyeffects
## Bruno
I knew about https://gitlab.freedesktop.org/ryuukyu/helvum but not about EasyEffects.
It is interesting to see that plugins (LSP, ZAM, … ) are being packaged for FlatHub.
Seems to me that this work regarding Audio support in Flatpak deserve more visibility https://github.com/flathub/org.freedesktop.LinuxAudio.BaseExtension
## x3mboy
Audicity doesn’t need to be vanished. It’s a great software, and everyone can make mistakes. Now the privacy note is been updated:
https://www.audacityteam.org/about/desktop-privacy-notice/
And the concerns have been corrected: versions 3.0.2 and bellow aren’t affected (3.0.2 it’s the one in the fedora repositories) and newer versions can turn off the infamous telemetry.
Great article, I’ve used all of the mentioned software and I can recommend all of them!
## Darvond
This doesn’t change what they’ve done to their contribution policy, nor does it prevent them from turning the switches back on later. The trust is broken. The build system is pants. There are enough problems that a clean break would be just what it needs.
Like how MATE was the best thing to happen to GNOME.
## X
How was MATE the best thing to happen to GNOME? MATE forked GNOME 2 because GNOME moved ahead with its redesign. I quite like modern GNOME as do many other people.
## Kristofer
This is awesome, I’m aiming to get back on playing electric guitar and record some songs I’ve wrote long ago… Thanks for this article.
## Joy
Wonderful I will love to Go part 1 and 2 any Available Liklnks
## Gregory Bartholomew
You should be able to click on the author’s name in the upper-left corner to get a list of all articles by this author.
## Bruno
You can find a huge list of audio apps here https://audinux.github.io/packages/index.html (work in progress)
A big difference between Audacity and Ardour is that Ardour is non-destructive: You can always roll-back all your changes.
A big common point is that they all use the same plugins more or less. |
13,772 | 什么是容器运行时? | https://opensource.com/article/21/9/container-runtimes | 2021-09-11T11:01:13 | [
"容器"
] | https://linux.cn/article-13772-1.html |
>
> 通过深入了解容器运行时,理解容器环境是如何建立的。
>
>
>

在学习 [容器镜像](https://opensource.com/article/21/8/container-fundamentals-2) 时,我们讨论了容器的基本原理,但现在是深入研究容器<ruby> 运行时 <rt> runtime </rt></ruby>的时候了,从而了解容器环境是如何构建的。本文的部分信息摘自 <ruby> 开放容器计划 <rt> Open Container Initiative </rt></ruby>(OCI)的 [官方文档](https://github.com/opencontainers),所以无论使用何种容器引擎,这些信息都是一致的。
### 容器运行机制
那么,当你运行 `podman run` 或 `docker run` 命令时,在后台到底发生了什么?一个分步的概述如下:
1. 如果本地没有镜像,则从镜像<ruby> 登记仓库 <rt> registry </rt></ruby>拉取镜像
2. 镜像被提取到一个写时复制(COW)的文件系统上,所有的容器层相互堆叠以形成一个合并的文件系统
3. 为容器准备一个挂载点
4. 从容器镜像中设置元数据,包括诸如覆盖 `CMD`、来自用户输入的 `ENTRYPOINT`、设置 SECCOMP 规则等设置,以确保容器按预期运行
5. 提醒内核为该容器分配某种隔离,如进程、网络和文件系统(<ruby> 命名空间 <rt> namespace </rt></ruby>)
6. 提醒内核为改容器分配一些资源限制,如 CPU 或内存限制(<ruby> 控制组 <rt> cgroup </rt></ruby>)
7. 传递一个<ruby> 系统调用 <rt> syscall </rt></ruby>给内核用于启动容器
8. 设置 SELinux/AppArmor
容器运行时负责上述所有的工作。当我们提及容器运行时,想到的可能是 runc、lxc、containerd、rkt、cri-o 等等。嗯,你没有错。这些都是容器引擎和容器运行时,每一种都是为不同的情况建立的。
<ruby> 容器运行时 <rt> Container runtime </rt></ruby>更侧重于运行容器,为容器设置命名空间和控制组(cgroup),也被称为底层容器运行时。高层的容器运行时或容器引擎专注于格式、解包、管理和镜像共享。它们还为开发者提供 API。
### 开放容器计划(OCI)
<ruby> 开放容器计划 <rt> Open Container Initiative </rt></ruby>(OCI)是一个 Linux 基金会的项目。其目的是设计某些开放标准或围绕如何与容器运行时和容器镜像格式工作的结构。它是由 Docker、rkt、CoreOS 和其他行业领导者于 2015 年 6 月建立的。
它通过两个规范来完成如下任务:
#### 1、镜像规范
该规范的目标是创建可互操作的工具,用于构建、传输和准备运行的容器镜像。
该规范的高层组件包括:
* [镜像清单](https://github.com/opencontainers/image-spec/blob/master/manifest.md) — 一个描述构成容器镜像的元素的文件
* [镜像索引](https://github.com/opencontainers/image-spec/blob/master/image-index.md) — 镜像清单的注释索引
* [镜像布局](https://github.com/opencontainers/image-spec/blob/master/image-layout.md) — 一个镜像内容的文件系统布局
* [文件系统布局](https://github.com/opencontainers/image-spec/blob/master/layer.md) — 一个描述容器文件系统的变更集
* [镜像配置](https://github.com/opencontainers/image-spec/blob/master/config.md) — 确定镜像层顺序和配置的文件,以便转换成 [运行时捆包](https://github.com/opencontainers/runtime-spec)
* [转换](https://github.com/opencontainers/image-spec/blob/master/conversion.md) — 解释应该如何进行转换的文件
* [描述符](https://github.com/opencontainers/image-spec/blob/master/descriptor.md) — 一个描述被引用内容的类型、元数据和内容地址的参考资料
#### 2、运行时规范
该规范用于定义容器的配置、执行环境和生命周期。`config.json` 文件为所有支持的平台提供了容器配置,并详细定义了用于创建容器的字段。在详细定义执行环境时也描述了为容器的生命周期定义的通用操作,以确保在容器内运行的应用在不同的运行时环境之间有一个一致的环境。
Linux 容器规范使用了各种内核特性,包括<ruby> 命名空间 <rt> namespace </rt></ruby>、<ruby> 控制组 <rt> cgroup </rt></ruby>、<ruby> 权能 <rt> capability </rt></ruby>、LSM 和文件系统<ruby> 隔离 <rt> jail </rt></ruby>等来实现该规范。
### 小结
容器运行时是通过 OCI 规范管理的,以提供一致性和互操作性。许多人在使用容器时不需要了解它们是如何工作的,但当你需要排除故障或优化时,了解容器是一个宝贵的优势。
本文基于 [techbeatly](https://medium.com/techbeatly/container-runtimes-deep-dive-77eb0e511939) 的文章,并经授权改编。
---
via: <https://opensource.com/article/21/9/container-runtimes>
作者:[Nived V](https://opensource.com/users/nivedv) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my examination of [container images](https://opensource.com/article/21/8/container-fundamentals-2), I discussed container fundamentals, but now it's time to delve deeper into container runtimes so you can understand how container environments are built. The information in this article is in part extracted from the [official documentation](https://github.com/opencontainers) of the Open Container Initiative (OCI), the open standard for containers, so this information is relevant regardless of your container engine.
## Container runtimes
So what really happens in the backend when you run a command like `podman run`
or `docker run`
command? Here is a step-by-step overview for you:
- The image is pulled from an image registry if it not available locally
- The image is extracted onto a copy-on-write filesystem, and all the container layers overlay each other to create a merged filesystem
- A container mount point is prepared
- Metadata is set from the container image, including settings like overriding CMD, ENTRYPOINT from user inputs, setting up SECCOMP rules, etc., to ensure container runs as expected
- The kernel is alerted to assign some sort of isolation, such as process, networking, and filesystem, to this container (namespaces)
- The kernel is also alerted to assign some resource limits like CPU or memory limits to this container (cgroups)
- A system call (syscall) is passed to the kernel to start the container
- SELinux/AppArmor is set up
Container runtimes take care of all of the above. When we think about container runtimes, the things that come to mind are probably runc, lxc, containerd, rkt, cri-o, and so on. Well, you are not wrong. These are container engines and container runtimes, and each is built for different situations.
*Container runtimes* focus more on running containers, setting up namespace and cgroups for containers, and are also called lower-level container runtimes. Higher-level container runtimes or container engines focus on formats, unpacking, management, and image-sharing. They also provide APIs for developers.
## Open Container Initiative (OCI)
The Open Container Initiative (OCI) is a Linux Foundation project. Its purpose is to design certain open standards or a structure around how to work with container runtimes and container image formats. It was established in June 2015 by Docker, rkt, CoreOS, and other industry leaders.
It does this using two specifications:
### 1. Image Specification (image-spec)
The goal of this specification is to enable the creation of interoperable tools for building, transporting, and preparing a container image to run.
The high-level components of the spec include:
[Image Manifest](https://github.com/opencontainers/image-spec/blob/master/manifest.md)— a document describing the elements that make up a container image[Image Index](https://github.com/opencontainers/image-spec/blob/master/image-index.md)— an annotated index of image manifests[Image Layout](https://github.com/opencontainers/image-spec/blob/master/image-layout.md)— a filesystem layout representing the contents of an image[Filesystem Layer](https://github.com/opencontainers/image-spec/blob/master/layer.md)— a changeset that describes a container’s filesystem[Image Configuration](https://github.com/opencontainers/image-spec/blob/master/config.md)— a document determining layer ordering and configuration of the image suitable for translation into a[runtime bundle](https://github.com/opencontainers/runtime-spec)[Conversion](https://github.com/opencontainers/image-spec/blob/master/conversion.md)— a document explaining how this translation should occur[Descriptor](https://github.com/opencontainers/image-spec/blob/master/descriptor.md)— a reference that describes the type, metadata, and content address of referenced content
### 2. Runtime specification (runtime-spec)
This specification aims to define the configuration, execution environment, and lifecycle of a container. The config.json file provides the container configuration for all supported platforms and details the field that enables the creation of a container. The execution environment is detailed along with the common actions defined for a container’s lifecycle to ensure that applications running inside a container have a consistent environment between runtimes.
The Linux container specification uses various kernel features, including namespaces, cgroups, capabilities, LSM, and filesystem jails to fulfill the spec.
## Now you know
Container runtimes are managed by the OCI specifications to provide consistency and interoperability. Many people use containers without the need to understand how they work, but understanding containers is a valuable advantage when you need to troubleshoot or optimize how you use them.
*This article is based on a techbeatly article and has been adapted with permission.*
## Comments are closed. |
13,773 | 如何在 Ubuntu Linux 上安装 Dropbox | https://itsfoss.com/install-dropbox-ubuntu/ | 2021-09-11T11:28:00 | [
"Dropbox"
] | https://linux.cn/article-13773-1.html | 
Dropbox 是 [最受欢迎的云存储服务之一,可用于 Linux](https://itsfoss.com/cloud-services-linux/) 和其他操作系统。
事实上,Dropbox 是最早提供原生 Linux 应用的服务之一。它仍然 [支持 32 位 Linux 系统](https://itsfoss.com/32-bit-linux-distributions/),这也是一项值得称赞的工作。
在这个初学者的教程中,我将展示在 Ubuntu 上安装 Dropbox 的步骤。这些步骤其实很简单,但有些网站把它弄得不必要的复杂。
### 在 Ubuntu 桌面上安装 Dropbox
让我们来看看安装步骤,一步一步来。
#### 第一步:获取 Ubuntu 的 Dropbox 安装程序
Dropbox 为其安装程序提供 DEB 文件。进入网站的下载页面:
* [下载 Dropbox](https://www.dropbox.com/install-linux)
下载相应的 DEB 文件。考虑到你使用的是 64 位的 Ubuntu,请获取 64 位版本的 DEB 文件。

#### 第二步:安装 Dropbox 安装程序
你下载的 deb 文件只是 Dropbox 的一个安装程序。实际的 Dropbox 安装稍后开始,类似于 [在 Ubuntu 上安装 Steam](https://itsfoss.com/install-steam-ubuntu-linux/)。
要 [安装下载的 deb 文件](https://itsfoss.com/install-deb-files-ubuntu/),可以双击它,或者右击并选择用软件安装打开。

它将打开软件中心,你可以点击安装按钮。

等待安装完成。
#### 第三步:开始安装 Dropbox
现在 Dropbox 安装程序已经安装完毕。按 `Windows` 键(也叫 `Super` 键),搜索 Dropbox 并点击它。

第一次启动时,它显示两个弹出窗口。一个是关于重启 Nautilus(Ubuntu 中的文件资源管理器),另一个是关于 Dropbox 的安装。

点击 “Restart Nautilus” -> “Close”(在 Nautilus 弹出窗口)或 “OK”(在安装弹出窗口),开始实际的 Dropbox 客户端下载和安装。如果 “Nautilus Restart” 在点击关闭按钮时没有关闭,请点击 “X” 按钮。
等待 Dropbox 的安装完成。

哦!需要重新启动 Nautilus,因为 Dropbox 增加了一些额外的功能,如在文件资源管理器中显示同步状态。
当 Dropbox 安装完毕,它应该会自动带你到 Dropbox 的登录页面,或者你可以点击顶部的 Dropbox 图标并选择登录选项。

事实上,这就是你今后访问 Dropbox 设置的方式。
#### 第四步:开始在 Ubuntu 上使用 Dropbox

**注意**:在你成功登录之前,Dropbox 将不会工作。这里有一个问题。免费版的 Dropbox 限制了你可以链接到你的账户的设备数量。**如果你已经有 3 个链接的设备,你应该删除一些你不使用的旧设备。**
当你成功登录后,你应该看到在你的家目录中创建了一个 Dropbox 文件夹,你的云端文件开始出现在这里。

如果你想节省磁盘空间或带宽,你可以进入偏好设置并选择<ruby> 选择性同步 <rt> Selective Sync </rt></ruby>选项。该选项允许你只在本地系统上同步来自 Dropbox 云的选定文件夹。

Dropbox 会在每次启动时自动启动。我相信,这是你应该从任何云服务中期待的行为。
这就是你在 Ubuntu 上开始使用 Dropbox 所需要的一切。我希望这个教程对你有帮助。
---
via: <https://itsfoss.com/install-dropbox-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Dropbox is one of the [most popular cloud storage services available for Linux](https://itsfoss.com/cloud-services-linux/) and other operating systems.
In fact, Dropbox is one of the earliest services to provide a native Linux application. It still [supports 32-bit Linux systems](https://itsfoss.com/32-bit-linux-distributions/) that is also a commendable job.
In this beginner’s tutorial, I’ll show the steps for installing Dropbox on Ubuntu. The steps are really simple but some websites make it unnecessarily complicated.
## Install Dropbox on Ubuntu desktop
Let’s see the installation procedure, step by step.
### Step 1: Get Dropbox installer for Ubuntu
Dropbox offers DEB files for its installer. Go to the download section of its website:
And download the appropriate DEB file. Considering that you are using 64 bit Ubuntu, get the deb file for 64-bit version.
### Step 2: Install Dropbox installer
The deb file you downloaded is just an installer for Dropbox. Actual Dropbox installation starts later, similar to [installing Steam on Ubuntu](https://itsfoss.com/install-steam-ubuntu-linux/).
To [install the downloaded deb file](https://itsfoss.com/install-deb-files-ubuntu/), either double click on it or right click and select open with Software Install.
It will open the software center and you can click the install button.
Wait for the installation to finish.
### Step 3: Start Dropbox installation
Dropbox installer is now installed. Press the Windows key (also known as super key) and search for Dropbox and click on it.
On the first launch, it shows two popups. One about restarting Nautilus (the file explorer in Ubuntu) and the other about Dropbox installation.
Clicking either Restart Nautilus/Close (on the Nautilus popup) or OK (on the installation popup) starts the actual Dropbox client download and installation. If the ‘Nautilus Restart’ does not close on clicking Close button, click the x button.
Wait for the Dropbox installation to finish.
Oh! Nautilus restart is required because Dropbox adds some extra features like showing the synchronization status in the file explorer.
Once Dropbox is installed, it should either take you to the Dropbox login page automatically or you can hit the Dropbox icon at the top and select sign in option.
In fact, this is how you will be accessing Dropbox settings in the future.
[bug report here](https://bugs.launchpad.net/ubuntu/+source/nautilus-dropbox/+bug/2015620).
### Step 4: Start using Dropbox on Ubuntu
**Note**: Dropbox won’t work until you successfully sign in. Here’s a catch. The free version of Dropbox limits the number of devices you can link to your account. **If you already have 3 linked devices, you should remove some of the older ones that you do not use.**
Once you are successfully signed in, you should see a Dropbox folder created in your home directory and your files from the cloud starts appearing here.
If you want to save disk space or bandwidth, you can go to the Preferences and choose the Selective Sync option. The selective sync option allows you only sync selected folders from Dropbox cloud on your local system.
Dropbox automatically starts at each boot. This is the behavior you should expect from any cloud service, I believe.
It’s good to see a DEB file for Dropbox. You can do something similar to [install Mega cloud service on Ubuntu](https://itsfoss.com/install-mega-cloud-storage-linux/).
That’s all you need to get started with Dropbox on Ubuntu. I hope you find this tutorial helpful. |
13,776 | 谈谈 GNU/Linux 口水话 | https://itsfoss.com/gnu-linux-copypasta/ | 2021-09-12T10:34:00 | [
"Linux",
"GNU/Linux"
] | https://linux.cn/article-13776-1.html | 
*开源朗读者| 六开箱*
作为一个 Linux 用户,你可能遇到过以这样开头的一大段文字:“我想插一句话。你所说的 Linux,实际上是指 GNU/Linux。”
这让一些人对什么是 “Linux” 和什么是 “GNU/Linux” 感到困惑。对此,我在关于 [Linux 发行版的概念](https://itsfoss.com/what-is-linux-distribution/) 的文章中已经解释过。
基本上,[Linux 是一个内核](https://itsfoss.com/what-is-linux/),加上 [GNU 软件](https://www.gnu.org/),它就可以以操作系统的形式使用。
许多纯粹主义者和拥趸们不希望人们忘记 GNU 对基于 Linux 的操作系统的贡献。因此,他们经常在各种论坛和社区发布这篇长文(被称为 GNU Linux <ruby> 口水话 <rt> copypaste </rt></ruby>)。
我不清楚这些 GNU/Linux 口水话的起源,也不清楚它是从什么时候开始出现的。有些人把它归功于 Richard Stallman 的 [2011 年在 GNU 博客上的文章](https://www.gnu.org/gnu/linux-and-gnu.html)。我无法证实或否认这一点。
### 完整的 GNU/Linux 口水话
>
> 我只想插一句话。你所说的 Linux,实际上是 GNU/Linux,或者正如我最近所称,是 GNU + Linux。Linux 本身并不是一个操作系统,而是功能齐全的 GNU 系统的另一个自由组件,这个系统是由 GNU 核心库、shell 实用程序和重要的系统组件组成的、按 POSIX 定义构成的完整操作系统。
>
>
> 许多计算机用户每天都在运行着一个修改过的 GNU 系统,却没有意识到这一点。通过一个奇特的转折,这个今天被广泛使用的 GNU 版本通常被称为 Linux,而它的许多用户并不知道它基本上是由 GNU 项目开发的 GNU 系统。
>
>
> Linux 倒也真的是存在,这些人也在使用它,但它只是他们使用的系统的一部分罢了。Linux 是内核:在系统中该程序将机器的资源分配给你运行的其他程序。内核是操作系统的一个重要部分,但它本身是无用的;它只能在一个完整的操作系统的环境下发挥作用。Linux 通常与 GNU 操作系统结合使用:整个系统基本上是添加了 Linux 的 GNU,或者叫 GNU/Linux。所有所谓的 Linux 发行版实际上都是 GNU/Linux 的发行版!
>
>
>
### 到底什么是口水话?

你是否注意到,我使用了“Copypasta”(LCTT 译注:译者选择翻译为“口水话”,或许有更贴合中文的译法,请大家指正)这个术语。它与<ruby> 意大利面 <rt> pasta </rt></ruby>毫无关系。
[口水话](https://www.makeuseof.com/what-is-a-copypasta/) 是在互联网上复制和粘贴的文本块,通常是为了嘲弄或取笑别人。它是“<ruby> 复制-粘贴 <rt> copy-paste </rt></ruby>”一词的变种。
口水话也被认为是垃圾内容,因为它们被重复了一次又一次。以 GNU Linux 口水话为例。如果每次有人在讨论区中使用 Linux 这个词而不是 GNU/Linux 时,总会有几个人不断地粘贴这些大段的文本,那么就会惹恼其他成员。
### 你有没有贴过 GNU/Linux 口水话?
就个人而言,我从来没有这样做过。但是,说实话,当我还是一个新的 Linux 用户,在浏览一些 Linux 论坛时,我就是这样知道 GNU/Linux 这个术语的。
你呢?你有没有在 Linux 论坛上复制粘贴过“我想插一句话……”?你认为它是“嘲弄”工具,还是让人们了解 GNU 项目的必要之举?
---
via: <https://itsfoss.com/gnu-linux-copypasta/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

As a Linux user, you might have come across a long text that starts with “I’d like to interject for a moment. What you are referring to as Linux, is in fact, GNU/Linux”.
It makes some people confused about what is Linux and what is GNU/Linux. I have explained it in the article about the [concept of Linux distributions](https://itsfoss.com/what-is-linux-distribution/).
Basically, [Linux is a kernel](https://itsfoss.com/what-is-linux/) and with [GNU softwares](http://www.gnu.org/), it becomes usable in the form of an operating system.
Many purists and enthusiasts don’t want people to forget the contribution of GNU to the Linux-based operating systems. Hence, they often post this long text (known as GNU Linux copypasta) in various forums and communities.
I am not sure of the origin of the GNU/Linux copypasta and since when it came into existence. Some people attribute it to Richard Stallman’s [article on GNU blog in 2011](https://www.gnu.org/gnu/linux-and-gnu.html). I cannot confirm or deny that.
## Complete GNU/Linux Copypasta
I’d just like to interject for a moment. What you’re refering to as Linux, is in fact, GNU/Linux, or as I’ve recently taken to calling it, GNU plus Linux. Linux is not an operating system unto itself, but rather another free component of a fully functioning GNU system made useful by the GNU corelibs, shell utilities and vital system components comprising a full OS as defined by POSIX.
Many computer users run a modified version of the GNU system every day, without realizing it. Through a peculiar turn of events, the version of GNU which is widely used today is often called Linux, and many of its users are not aware that it is basically the GNU system, developed by the GNU Project.
There really is a Linux, and these people are using it, but it is just a part of the system they use. Linux is the kernel: the program in the system that allocates the machine’s resources to the other programs that you run. The kernel is an essential part of an operating system, but useless by itself; it can only function in the context of a complete operating system. Linux is normally used in combination with the GNU operating system: the whole system is basically GNU with Linux added, or GNU/Linux. All the so-called Linux distributions are really distributions of GNU/Linux!
## What is a Copypasta, again?

Did you notice that I used the term ‘copypasta’. It has nothing to do with Italian dish pasta.
[Copypasta](https://www.makeuseof.com/what-is-a-copypasta/) is a block of text which is copied and pasted across the internet, often to troll or poke fun at people. It is a degeneration of the term ‘copy-paste’.
Copypasta is also considered spam because they are repeated as it is a number of times. Take the example of GNU Linux copypasta. If a few people keep on pasting the huge text block every time someone uses Linux instead of GNU/Linux in a discussion forum, it would annoy other members.
## Have you ever used GNU/Linux Copypasta?
Personally, I have never done that. But, to be honest, that’s how I come to know about the term GNU/Linux when I was a new Linux users and was browsing through some Linux forum.
How about you? Have you ever copy-pasted the “I would like to interject for a moment” in a Linux forum? Do you think it’s a tool for ‘trolls’ or is it the necessary evil to make people aware of the GNU project? |
13,777 | 使用 Tangram 浏览器在 Linux 中运行 Web 应用 | https://itsfoss.com/tangram/ | 2021-09-12T11:03:26 | [
"Web应用"
] | https://linux.cn/article-13777-1.html |
>
> Tangram 是一个旨在帮助你在 Linux 中运行和管理 Web 应用的浏览器。一起来看看它是如何使用的吧。
>
>
>
对于一些工具来说,即使我们有许多 Linux 原生应用,但是许多人最终还是选择使用 Web 应用。
他们也许是使用 Electron 构建的应用,或是直接在浏览器中打开的网页,使用原生应用正在成为一种比较“传统”的做法。
当然,不管在什么平台运行 Web 应用都会占用更多的系统资源。而且,考虑到每一个服务都正在提供基于 Web 的方式,而不是原生体验,我们就需要一种有效管理 Web 应用的解决方案。
一款开源的 Linux 应用 Tangram 或许就是这个解决方案。
### Tangram:专为 Web 应用设计的浏览器

你可以选择其他 [优秀的浏览器](https://itsfoss.com/best-browsers-ubuntu-linux/) 来运行 Web 应用,但是如果你想完全专注于 Web 应用体验的浏览器,Tangram 是个不错的选择。
Tangram 的开发者从 GNOME Web、[Franz](https://itsfoss.com/franz-messaging-app/) 和 [Rambox](https://itsfoss.com/rambox/) 中获得了灵感。
没有其他花里胡哨的功能,只是能更改你的<ruby> 用户代理 <rt> User Agent </rt></ruby>和管理你所登录的 Web 应用。
它可以用于访问多个社交媒体,聊天工具,工作协同应用等等。
### Tangram 的特性

考虑到 Tangram 是一个基于 WebKitGTK 的精简化浏览器,它拥有的功能不算很多,下面是一些功能要点:
* 重新排列侧边栏的标签
* 方便地将任何一个 Web 服务添加为 Web 应用程序
* 调整用户代理(桌面端和移动端)
* 使用键盘快捷键
* 改变侧边栏(标签栏)的位置
你所需要做的就是加载一个 Web 服务,登录,然后点击“完成”,将其添加为 Web 应用程序。

### 在 Linux 中安装 Tangram
每个 Linux 发行版都可以通过 Flatpak 来安装 Tangram,你也可以在 [AUR](https://itsfoss.com/aur-arch-linux/) 中找到它。
如果你想通过终端来安装它,输入以下命令:
```
flatpak install flathub re.sonny.Tangram
```
如果你的系统没有启用 Flatpak,你可以参考我们的 [Flatpak 指南](https://itsfoss.com/flatpak-guide/)。
想要了解更多信息,请访问 [Tangram 的 Github 页面](https://github.com/sonnyp/Tangram)。
* [Tangram Browser](https://flathub.org/apps/details/re.sonny.Tangram)
你试过 Tangram 吗?你更喜欢 Web 应用还是原生应用?欢迎在下面的评论中分享你的想法。
---
via: <https://itsfoss.com/tangram/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[anine09](https://github.com/anine09) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | * Brief: Tangram is a browser that aims to help you run and manage web applications in Linux*.
*Let’s take a look at how it works.*
Even if we have native Linux applications available for several tools, many end up using web applications.
Maybe in the form of an electron app or directly through a web browser, native experiences are becoming an old-school thing.
Of course, running web applications, no matter the platform, needs more system resources. And, considering every service is going for a web-based approach instead of a native experience, we need solutions to manage the web apps efficiently.
An open-source Linux app, Tangram, could be the solution.
## Tangram: A Browser Tailored to Run Web Applications
You can choose to use some of the [best Linux web browsers](https://itsfoss.com/best-browsers-ubuntu-linux/) to run web applications. But, if you want something that entirely focuses on web application experience, Tangram is an exciting option.
The developer took inspiration from GNOME Web, [Franz](https://itsfoss.com/franz-messaging-app/), and [Rambox](https://itsfoss.com/rambox/).
You do not get any fancy features but just the ability to change the user agent and manage the web applications you have logged in to.
It can be used to access multiple social media platforms, chat messengers, work collaboration applications, and more.
## Features of Tangram
Considering it is a minimal browser based on WebKitGTK, not much you can do here. To list some of the essentials, here’s what you can do:
- Re-order tabs in the sidebar
- Easily add any web service as a web app
- Ability to tweak the user agent (Desktop/mobile)
- Keyboard shortcuts
- Change position of the sidebar (tab bar)
All you need to do is load up a web service, log in, and click on “**Done**” to add it as a web application.
## Installing Tangram in Linux
Tangram is available as a Flatpak for every Linux distribution, and you can also find it in [AUR](https://itsfoss.com/aur-arch-linux/).
If you want to install it via the terminal, type in the following command:
`flatpak install flathub re.sonny.Tangram`
You may refer to our [Flatpak guide](https://itsfoss.com/flatpak-guide/) if you do not have it enabled on your system.
To explore more about it, you can check out its [GitHub page](https://github.com/sonnyp/Tangram).
Have you tried this yet? Do you prefer web applications or native applications? Feel free to share your thoughts in the comments below. |
13,779 | 在 Linux 终端调整图像的大小 | https://opensource.com/article/21/9/resize-image-linux | 2021-09-12T23:50:00 | [
"图像",
"ImageMagick"
] | https://linux.cn/article-13779-1.html |
>
> 用 ImageMagick 的转换命令从你的终端缩放一张图像。
>
>
>

ImageMagick 是一个方便的多用途命令行工具,它能满足你所有的图像需求。ImageMagick 支持各种图像类型,包括 JPG 照片和 PNG 图形。
### 调整图像大小
我经常在我的 Web 服务器上使用 ImageMagick 来调整图像大小。例如,假设我想在我的个人网站上发一张我的猫的照片。我手机里的照片非常大,大约 4000x3000 像素,有 3.3MB。这对一个网页来说太大了。我使用 ImageMagick 转换工具来改变照片的大小,这样我就可以把它放在我的网页上。ImageMagick 是一套完整的工具,其中最常用的是 `convert` 命令。
ImageMagick 的 `convert` 命令使用这样的一般语法:
```
convert {input} {actions} {output}
```
要将一张名为 `PXL_20210413_015045733.jpg` 的照片调整到一个更容易管理的 500 像素宽度,请输入:
```
$ convert PXL_20210413_015045733.jpg -resize 500x sleeping-cats.jpg
```
现在新图片的大小只有 65KB。

你可以用 `-resize` 选项同时提供宽度和高度尺寸。但是,如果只提供宽度,ImageMagic 就会为你做计算,并通过调整输出图像的高度比例来自动保留长宽比。
### 在 Linux 上安装 ImageMagick
在 Linux 上,你可以使用你的包管理器安装 ImageMagick。例如,在 Fedora 或类似系统上:
```
$ sudo dnf install imagemagick
```
在 Debian 和类似系统上:
```
$ sudo apt install imagemagick
```
在 macOS 上,使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac)。
在 Windows 上,使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey) 即可。
---
via: <https://opensource.com/article/21/9/resize-image-linux>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ImageMagick is a handy multipurpose command-line tool for all your image needs. ImageMagick supports a variety of image types, including JPG photos and PNG graphics.
## Resizing images
I often use ImageMagick on my webserver to resize images. For example, let's say I want to include a photo of my cats on my personal website. The photo from my phone is very large, about 4000x3000 pixels, at 3.3MB. That's much too large for a web page. I use the ImageMagick convert tool to change the size of my photo so that I can include it on my web page. ImageMagick is a full suite of tools, one of the most common is the `convert`
command.
The ImageMagick `convert`
command uses this general syntax:
`convert {input} {actions} {output}`
To resize a photo called `PXL_20210413_015045733.jpg`
to a more manageable 500-pixel width, type this:
`$ convert PXL_20210413_015045733.jpg -resize 500x sleeping-cats.jpg`
The new image is now only 65KB in size.

Photograph by Jim Hall,
[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)
You can provide both width and height dimensions with the `-resize`
option. But, by providing only the width, ImageMagic does the math for you and automatically retains the aspect ratio by resizing the output image with a proportional height.
## Install ImageMagick on Linux
On Linux, you can install ImageMagick using your package manager. For instance, on Fedora or similar:
`$ sudo dnf install imagemagick`
On Debian and similar:
`$ sudo apt install imagemagick`
On macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac).
On Windows, use [Chocolatey](https://opensource.com/article/20/3/chocolatey).
## Comments are closed. |
13,780 | Firefox 在过去 12 年里损失了 5 亿用户及其 75% 份额的原因 | https://news.itsfoss.com/firefox-continuous-decline/ | 2021-09-13T12:41:45 | [
"Firefox"
] | https://linux.cn/article-13780-1.html |
>
> 一位有四十年编程经验的老程序员表达了他对 Firefox 浏览器为何逐渐衰退的看法。
>
>
>

最近有很多关于 Firefox 浏览器衰落的讨论,还有很多讨论 [它在过去两年里失去了 5000 万用户](https://news.itsfoss.com/firefox-decline/) 的文章。
但是 **实际上它的衰落已经有 12 年之久了,总共损失了 5 亿用户和它曾经拥有的市场份额的 75%**。
这一切都开始于 2009 年第三季度,其致命的决定是强迫……
### 顶部标签
自从 [做了这个决定](https://www.wired.com/2009/07/mozilla-considers-copying-chrome-for-firefox-4dot0/),Firefox 就开始丢失市场份额。PC 上的所有程序都使用针对活动窗口的标签。如微软 Office 和 Adobe 这样的专有软件,如 GIMP、3D 设计、视频编辑器、十六进制编辑器这样的 FOSS 软件,你能想的的种种软件都是这样的,这是标准的、合乎逻辑的设计。
然后,谷歌决定将标签放在其 Chrome 浏览器的顶部,该浏览器是为移动设备而非台式机设计的。在智能手机上,这可能是有意义的,因为没有空间来容纳一个完整的桌面风格的菜单布局。但在桌面上,它是反直觉的,并且会破坏与所有其他程序的工作流程。台式机的代码与手机不同,所以没有合理的理由试图将移动用户界面强加给台式机用户,而台式机是 Firefox 的主要用户群。在一个 400 万行的代码库中,由两行代码所制定的单一设置“太难维护”的论点,只是在侮辱用户的智商。代码不是草坪,如果你几周不管它,它也不会改变。
当用户对这一变化的投诉蜂拥而至时,我从一位不愿透露姓名的主要开发者那里得到的回应是:“我们有数亿用户。5000 人的抱怨并不代表大多数的用户。”这些投诉有一个共同的观点:“如果我想让我的浏览器看起来像 Chrome,我就会使用 Chrome。”于是他们就这么做了。
### 不断删除“没人使用”的功能
对 Firefox 所做的每项改动都是一样的做法。默认功能被改变了,但有一个菜单设置可以恢复它。然后菜单设置被删除,你只能通过`about:config` 来改变它。再然后,`about:config` 选项也被删除了。用户群的每一次抗议都得到了同样的回应:“你只是极少数人,大多数人喜欢这种改变。”
75% 并不是少数人。几乎每个人都讨厌这些变化,每一次变化都会把更多的用户赶走,而 Mozilla 工作人员傲慢的、居高临下的回应让用户们有苦难言,让他们再也不想回来了。仔细观察,你可以看到每次删除一些功能,用户数量都有明显的下降,只有在第三方组件或 CSS 恢复了这些变化时才会稳定下来。一次又一次,年复一年。他们没有学到任何教训。
光是移除设置还不够。Firefox 继续阉割附加组件和主题,强迫集中签名,并最终废除了 XUL,而没有足够的 Web 扩展 API 来替代失去的功能。在抱怨这一变化时,我再次与一位主要开发者(同一个人)交谈。他的回答是(原话)“人们并不是因为附加组件而使用 Firefox 的。我们的遥测显示 80% 的用户从未安装过任何附加组件。”也就是说,任何懂技术的人都会立即关闭遥测,因为他们不想让浏览器监视他们,对此我们也曾无数次抱怨过。
即使是他们在用户界面设计方面的一项重大举措,即可拖放定制的 Australis 界面,也因为可怕的默认布局和缺乏不需要 CSS 的选项而疏远了更多用户。难看的斜角标签(抄袭自 Chrome)是 Mozilla 唯一承认糟糕的用户界面变化,而且令人惊讶的是,他们只是在 Chrome 取消了斜角标签 **之后** 才这样做。
时至今日,Mozilla 仍然声称要听取用户的意见,但 12 年后,他们仍然无视我们,难看的默认 Proton 用户界面是最新强加给不情愿的用户群的愚蠢选择。(如果你认为我属于少数的话,可以在谷歌上输入 “Firefox Proton” 来查看最常搜索的建议。)幸运的是,它仍然可以用 `userChrome.css` 来大致修复,但即使是我,也已经厌倦了必须反复修补新的代码来跟上不断的弃用和格式变化。
### 糟糕的编码范式
Mozilla 的源代码是一场噩梦。例如,默认配置文件的位置被定义了 3 次,使用了 3 种不同的语言的不同的变量,其中之一是由位于不同文件中的多个变量组合生成的。我看到的另外一个例子是在 6 个不同的文件中定义的另一个全局变量。
在编译后,下载历史、访问过的网页、书签等等,都被一起塞进了乱七八糟的文件中。最终的结果是什么?试着从你的历史记录中删除 400 个条目,看看它需要多长时间。而从一个单独的文本文件中删除这么多行,只需要一瞬间。想改变一个图标的外观或为自定义搜索添加一个新的图标?它们大多只是 PNG,但它们被混淆并被封入 `omni.ja` 文件。本来可以用你选择的编辑器在几秒钟内改变,但你需要安装和学习 Eclipse 之类的程序,并在每次更改时重新编译文件。这样的例子不胜枚举。
难怪 Mozilla 的码农在寻找和修复错误方面这么困难。这导致了更糟糕的编码范式,为了修复错误而记录一切。它部分导致了...
### 糟糕的内存管理
如果一个程序坐在那里什么都不做,它的内存使用量不应该改变。看看我的内存管理器,我有 40 个进程在遵守这个原则。尽管什么都不做,却不断地读写磁盘的唯一程序是什么?Firefox。它正在运行 13 个进程,所有这些进程都在不断地做这两件事。我写了 40 年的代码,造了 30 年的电脑,所以我确实了解一点计算机如何工作的事情。这就是基础层面上的糟糕设计,在表面上做再多的修补也无济于事。
代码范式是 Mozilla 性能问题的根源,他们不会解决这个问题。我敢打赌,这也是 FirefoxOS 失败的原因,它是一个伟大的想法,但由于执行不力和编码实践问题,导致太多的错误无法修复而失败。
### 在告诉我们“我们重视你的隐私”的同时,侵犯了你的隐私
就是遥测。当你点击“禁用遥测”时,隐藏的遥测并没有被禁用。首次运行也要发出遥测信号。强制签署附加组件。无法关闭的自动更新,每 10 分钟发出一次信号。需要单独选择退出的“实验”。现在最新的问题是,只是为了制作一个自定义的主题,就强制使用基于 2FA 的应用以登录到 Firefox 插件帐户,如果不是强制签署附加组件,根本就不需要。
Mozilla 对用户隐私的尊重和对我们意见的尊重一样少。
### 总结
事情不一定是这样的。虽然还没有,但是不能承认自己的错误,也不考虑不同的意见的人,注定要停滞不前,走向衰败。Mozilla 的决策者似乎就是这样想的,所以我对未来不抱什么希望。希望你们中的一些人至少能从他们的错误中学习,在他们失败的地方取得成功。通过为用户提供他们想要的东西,而不是告诉他们应该想要什么来取得成功。通过提供市场上缺少的东西,而不是盲目地试图复制你的竞争对手。
*本文所表达的观点和意见仅代表作者本人,不一定反映本站和 It's FOSS 的官方政策或立场。*
>
> 作者信息:Dan 来自澳大利亚墨尔本,已经有大约 40 年的编码经验,做了 25 年的平面设计。他还从事基于 3D 打印机套件的开源机械设计。
>
>
>
---
via: <https://news.itsfoss.com/firefox-continuous-decline/>
作者:[Dan](https://news.itsfoss.com/author/team/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

There has been a lot of discussion lately about the decline of the Firefox browser and numerous articles about it [losing 50 Million users in the last two years](https://news.itsfoss.com/firefox-decline/).
But the ** real decline has been over 12 years with a total loss of half a Billion users** and 75% of the market share it once held.
It all started in 2009 Q3 with the fateful decision to force…
## Tabs-On-Top
As soon as [this decision was made](https://www.wired.com/2009/07/mozilla-considers-copying-chrome-for-firefox-4dot0/?ref=news.itsfoss.com), Firefox starting losing market share. Every other program on a PC uses tabs against the active window. Proprietary software like MS Office and Adobe, FOSS software like Notepad++ and GIMP, 3D design, video editors, hex editors, you name it: It is the standard, logical design.
Then Google decided to make the tabs on top standard for its Chrome browser, which was designed for mobile devices not desktops. On a smartphone it may make sense, as there isn’t room for a full desktop style menu layout. On a desktop it is counterintuitive and breaks workflow with all other programs. The code for desktops is different from phones so there was no rational reason to try and force a mobile UI onto desktop users who were Firefox’s primary userbase. The argument that it was “too hard to maintain” a single setting enacted by 2 lines of code in a 4 Million line codebase is just insulting to the intelligence of users. Code isn’t a lawn. It doesn’t change if you leave it alone for a few weeks.
When inundated with user complaints about the change, the response I received from a lead developer who shall remain nameless was “We have hundreds of millions of users. 5000 people complaining doesn’t represent the majority of users”. Those complaints had one common sentiment, “If I wanted my browser to look like Chrome I’d just use Chrome”. And so they did.
## Constant removal of features “that no-one uses”
Every change made to Firefox had the same pattern. The default feature was changed, but there was a menu setting to revert it. Then the menu setting was removed and you could only change it via about:config. Then the about:config option was removed. Every protest from the userbase met the same response “You’re just a tiny minority, most people like the change”.
75% is not a minority. Almost everyone hated the changes and each change pushed more users away, and the arrogant, condescending responses from Mozilla staff left a bitter taste in their mouth ensuring they would never return. Looking closely at the user numbers you could see a visible drop with every removal, only stabilising when a third party add-on or CSS would revert the change. Over and over, year after year. No lessons were learnt.
Removing settings wasn’t enough. Firefox went on to neuter add-ons and themes, forcing centralised signing and ultimately deprecating XUL without adequate webextension api’s to replace lost functionality. Complaining about this change I again spoke to one of the lead developers (same guy). His response was (exact quote) “People don’t use Firefox because of add-ons. Our telemetry shows 80% of users never install any add-ons” i.e. the telemetry that any tech savvy person immediately turns off because they don’t want their browser spying on them and about which we have also complained numerous times.
Even the one great move they made in UI design, the drag and drop customisable Australis interface, alienated more users because of the horrible default layout and lack of options that didn’t need CSS. The awful angled tabs (copied from chrome) is the only UI change Mozilla has admitted was terrible and they only did so, surprise surpise, AFTER chrome did away with them.
To this day, Mozilla still claims to want to hear from their users and after 12 years they still keep ignoring us, the awful default Proton UI being the latest foolish choice forced upon an unwilling userbase. (Type in “Firefox Proton” on Google to look at the most commonly searched suggestions if you think I’m in the minority). Fortunately it can still be mostly fixed with userChrome.css but even I’m getting sick of having to repeatedly patch together new code to keep up with constant deprecation and format changes.
## Bad coding paradigms
Mozilla’s source code is a nightmare. For example, default profile location is defined 3 times, using different variables, in 3 different languages, one of which is generated by combining multiple variables located in separate files. Another example I saw was another global variable being defined in 6 different files.
Post compiling, history for downloads, visited pages, bookmarks etc, are all shoved together into obfuscated files. The end result? Try deleting 400 entries from your history and watch how long it takes. Deleting that many lines from a separate text file would take a split second. Want to change the appearance of an icon or add a new one for a custom search? They’re mostly just PNGs, but they are obfuscated and sealed into the omni.ja file. Could otherwise be changed in seconds with your editor of choice, instead you need to install and learn a program like Eclipse and recompile the file with every change. The list goes on and on.
It is no wonder Mozilla’s coders have such trouble finding and fixing bugs. This led to an even worse coding paradigm, logging everything for the purpose of bugfixes. This is one of the culprits of…
## Poor memory management
If a program is sitting there doing nothing, its memory usage should not change. Looking at my memory manager I have 40 processes obeying this principle. What is the only program constantly reading and writing to disk despite doing nothing? Firefox. It is running 13 processes and all of them are constantly doing both. I’ve been coding for 40 years and building PC’s for 30 so I do know a thing or two about how computing works. This is just awful design at the base level and no amount of tinkering on the surface will fix that.
The code paradigm is the root of Mozilla’s performance issues and they won’t address it. I’ll wager that’s also the reason for the failure of FirefoxOS, which was a great idea but failed because of poor execution and coding practices resulting in too many bugs to fix.
## Invading your privacy at the same time as telling us “we value your privacy”
Telemetry. Hidden telemetry that isn’t disabled when you click “disable telemetry”. Firstrun pings. Forced signing of add-ons. Auto-updates you can’t switch off, pinging every 10 minutes. “Experiments” which require a separate opt out. Now the latest offence is enforcing app based 2FA to login to a Firefox Add-on account just to make a custom theme, which you wouldn’t need in the first place if not for forced add-on signing.
Mozilla has as little respect for their users privacy as they do for our opinions.
## Final thoughts
It didn’t have to be this way. It still doesn’t, but the mind that is incapable of admitting when it is wrong, or of considering differing opinions is doomed to stagnation and decay. The decision makers of Mozilla appear to have such minds so I do not hold out much hope for the future. Hopefully some of you out there can at least learn from their mistakes and succeed where they are failing. You succeed by giving users what they want, not telling them what they should want. By providing what is missing in the market, not blindly trying to copy your competitors.
*The views and opinions expressed are those of the authors and do not necessarily reflect the official policy or position of It’s FOSS.*
Author info: From Melbourne Australia, Dan has been coding for about 40 years and doing graphic design for 25 years. He also works on open source mechanical designs based on 3D printer kits.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,782 | Adobe 终止支持 Brackets,并建议使用 VS Code 替代 | https://news.itsfoss.com/adobe-kills-brackets-editor/ | 2021-09-14T09:25:33 | [
"Brackets",
"VSCode"
] | https://linux.cn/article-13782-1.html |
>
> Adobe 结束了对 Brackets 代码编辑器的支持,坚持让用户迁移到微软的 Visual Studio Code。不过,还好总还算是留下了一个复刻。
>
>
>

Brackets 是一个令人印象深刻的现代开源代码编辑器,可用于 Windows、macOS 和 Linux。
Adobe 以一个社区引导的项目的形式创建了它,来帮助 Web 开发者。我们之前把它列为 [可供编程人员使用的最佳现代文本编辑器](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) 之一。
不幸的是,Adobe 在 2021 年 9 月 1 日结束了对 Brackets 的支持。
### 为什么 Adobe 停用了 Brackets?

看起来可能是 Adobe 与微软的合作关系促使他们拔掉了这个社区项目的插头。
因此,他们建议用户迁移到微软的 Visual Studio Code 编辑器。

这是 Brackets 项目中止后 GitHub 的原始页面上的内容。
### Visual Studio Code 作为 Brackets 的替代品
当然,微软的 Visual Studio Code 是一个很好的替代品,而且建立在开源的基础上。然而,当你从他们的网站上下载 Visual Studio Code 时,它并不在一个促进自由和开源软件的许可证之下。
因此,你可能不得不从源代码构建,或者尝试 [VSCodium](https://vscodium.com),这是一个没有遥测/跟踪功能的 Visual Studio Code 的自由许可版本。
另外,有一个 [关于从 Brackets 迁移的官方指南](https://code.visualstudio.com/migrate-from-brackets),如果你感兴趣,可以去看看。
### Brackets 将继续以没有 Adobe 的复刻出现

尽管 Adobe 已经停止了这个项目,但 [原网站](https://brackets.io) 仍然存在,以维持这个项目的复刻。
该项目名称可能会改变,但从目前来看,它叫 “Brackets Continued”,以帮助用户识别该复刻。
请注意,这个复刻项目还没有发布,我们也不知道它是否会作为一个独立的项目继续下去。
所以,如果你想帮助 Brackets 复刻,并以某种方式帮助维护它,请前往其 GitHub 页面了解更多细节。
* [Brackets Continued(复刻)](https://github.com/brackets-cont/brackets)
你喜欢用什么作为你的代码编辑器?你喜欢用 Brackets 代码编辑器进行 Web 开发工作吗?欢迎在评论中分享你的想法。
---
via: <https://news.itsfoss.com/adobe-kills-brackets-editor/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Brackets was an impressive open-source modern code editor available for Windows, macOS, and Linux.
Adobe created it as a community-guided project to help web developers. We previously listed it as one of the [best modern text editors available for coders](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/?ref=news.itsfoss.com).
Unfortunately, Adobe ended its support for Brackets on September 1, 2021.
## Why Did Adobe Discontinue Brackets?
It looks like Adobe’s partnership with Microsoft may have encouraged them to pull the plug off the community project.
Hence, they recommend users migrate to Microsoft’s Visual Studio Code editor.

This is what Brackets’ original GitHub page says after the discontinuation of the project.
## Visual Studio Code as a Replacement to Brackets
Of course, Microsoft’s Visual Studio Code is a fantastic alternative and built on open-source. However, when you download the Visual Studio Code from their website, it does not come under a license that promotes free and open-source software.
So, you may have to build from source or try [VSCodium](https://vscodium.com/?ref=news.itsfoss.com), a freely licensed edition of Visual Studio Code minus the telemetry/tracking.
Also, there is an [official guide on migrating from Brackets](https://code.visualstudio.com/migrate-from-brackets?ref=news.itsfoss.com) that you can explore if interested.
## Brackets Will Continue as a Fork Without Adobe
Even though Adobe has discontinued the project, the [original website](https://brackets.io/?ref=news.itsfoss.com) still exists to maintain a fork of the project.
The project’s name is subject to change, but as of now, it’s “**Brackets Continued**” to help users identify the fork.
Do note that the fork does not yet have a release, and we have no idea if it will continue as an independent project.
So, if you want to help Brackets fork and help maintain it somehow, head to its GitHub page for more details.
*What do you prefer to use as your code editor? Did you like Brackets code editor for web development work? Feel free to share your thoughts on this in the comments.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,783 | 如何在 Linux 终端中退出一个程序 | https://itsfoss.com/stop-program-linux-terminal/ | 2021-09-14T11:24:00 | [
"退出"
] | https://linux.cn/article-13783-1.html | 
有趣的是,当你刚接触一些东西时,最简单的事情也会变得复杂。
有一天,我发现我的朋友搞不清楚如何退出 `top` 命令。他没有中止这个命令,而是关闭了整个终端程序。
这不仅是不必要的,而且是一件不好的事情。
### 在 Linux 里中止程序
在 Linux 中,你可以使用 `Ctrl+C` 键来中止终端中的运行程序。这对 Ubuntu 和其他 Linux 发行版都适用。
以 `ping` 命令为例。如果你不中止它,它将持续显示结果。
按住 `Ctrl` 键并同时按下 `C` 键。它向正在运行的程序发送 [SIGINT 信号](https://linuxhandbook.com/sigterm-vs-sigkill/#what-is-sigkill)以强制退出该命令。

你看到 `^C` 了吗?这个插入符号(`^`)代表 `Ctrl`。所以基本上,终端将 `Ctrl+C` 的按键显示为 `^C`。
`Ctrl+C` 对于那些被设计为持续运行直到被打断的命令非常有效。你觉得你需要取消命令,就用 `Ctrl+C`。
在一个更复杂的方法中,你可以 [找到进程 ID 并杀死一个正在运行的进程](https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/)。这是更高级的东西,只有进程在后台或由其他用户运行或在另一个终端窗口运行时使用。
除此以外,还有一些其他的命令和命令行工具也有自己的退出命令。让我在这里简单地提一下其中的一些。
#### 如何退出 Vim 编辑器
[退出 Vim 编辑器](https://itsfoss.com/how-to-exit-vim/) 在 Linux 世界里闹出了很多笑话。当你刚接触这个强大的基于命令行的文本编辑器时,是很难搞清楚的。在几种退出 `vim` 的方法中,最常见的是按 `Esc` 键,然后输入冒号(`:`),再输入 `q!` 表示不保存而强制退出,或者 `wq` 表示保存并退出。

#### 如何退出 Nano 编辑器
退出 [Nano 编辑器](https://itsfoss.com/nano-editor-guide/)比退出 Vim 要简单一些。为什么?因为 Nano 在底部有快捷方式。如果你是新手,你可能不明白,但至少你下次就能搞清楚了。
要退出 Nano,按 `Ctrl+X`。它将询问你是否要保存对文件所做的修改。你可以输入你的选择。

#### 如何退出 less 命令
`less` 是一个奇妙的命令,它可以让你在不像 `cat` 命令那样杂乱的终端屏幕上进行查看。如果你在 `less` 命令的视图内,使用 `q` 键来退出 `less`。
#### 如何退出终端
要退出终端本身,不是关闭终端,而是使用 `Ctrl+D` 键盘快捷键或输入退出命令:
```
exit
```
这实际上是让你从当前的 shell 中退出。当你[在 Ubuntu 或其他发行版中打开一个终端](https://itsfoss.com/open-terminal-ubuntu/),它会运行默认的 shell。当你从这个 shell 退出时,终端也会结束。`Ctrl+D` 是做同样事情的快捷方式,并退出终端。
我希望你觉得这个快速教程对你有帮助。我强烈建议你学习这些 [Linux 命令技巧](https://itsfoss.com/linux-command-tricks/)。
有问题或建议?请在下面留下评论。
---
via: <https://itsfoss.com/stop-program-linux-terminal/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It’s amusing how the simplest of things could be complicated when you are new to something.
The other day, I found my friend could not figure out how to exit the top command. Instead of stopping the command, he closed the entire terminal application.
That’s not only unnecessary, but it is also a not good thing to do.
## Stopping programs in Linux
In Linux, you can use the Ctrl+C keys to stop a running program in the terminal. This works for Ubuntu as well as any other Linux distribution.
Take the [ping command for example](https://itsfoss.com/ping-command/). If you do not stop it, it will keep on displaying the result.
Hold the Ctrl button and press the C key at the same time. It sends the [SIGKILL signal](https://linuxhandbook.com/sigterm-vs-sigkill/#what-is-sigkill) to the running program to force quit the command.
Do you see the ^C? The caret (^) means Ctrl. So basically, the terminal shows the Ctrl+C keystrokes as ^C.
The Ctrl+C works very well for the commands designed to keep running until interrupted. You feel like you have to cancel the command, use Ctrl+C.
You can [find the process ID and kill a running process](https://itsfoss.com/how-to-find-the-process-id-of-a-program-and-kill-it-quick-tip/) in a more complicated method. That’s more advanced stuff and used only when the process is running in the background or by another user or in another terminal window.
Apart from that, some other commands and command line tools have their own exit commands. Let me briefly mention some of them here.
### How to exit Vim editor
[Existing Vim editor](https://itsfoss.com/how-to-exit-vim/) has made so many jokes in the Linux world. It is difficult to figure out when you are new to this powerful command line based text editor. Among several ways of quitting vim, the most common is to press the Esc key and then type a colon (:) and then type `q!`
for force quit without save or `wq`
for save and quit.
### How to exit Nano editor
Quitting the [Nano editor](https://itsfoss.com/nano-editor-guide/) is a bit simpler than exiting Vim. Why? Because Nano mentions the shortcut at the bottom. You may not understand it if you are new to it but at least you’ll be able to figure it out the next time.
To exit Nano, press Ctrl+X. It will ask if you want to save the changes made to the file or not. You can enter your choice.
### How to exit less command
The less is an excellent command that lets you view without cluttering your terminal screen like the cat command. If you are inside the less command view, use the key `q`
to exit less.
### How to exit the terminal
To exit the terminal itself, instead of closing the terminal, either use Ctrl+D keyboard shortcut or type the exit command:
`exit`
This actually exists you from the current shell. When you [open a terminal in Ubuntu](https://itsfoss.com/open-terminal-ubuntu/) or any other Linux distribution, it runs the default shell. When you exit from this shell, terminal ends as well. Ctrl+D is the shortcut to do the same and quit the terminal.
I hope you find this quick tutorial helpful. I highly recommend learning these [Linux command tips](https://itsfoss.com/linux-command-tricks/). |
13,785 | 恢复 GNOME 顶栏的托盘图标 | https://itsfoss.com/enable-applet-indicator-gnome/ | 2021-09-15T09:18:00 | [
"GNOME"
] | https://linux.cn/article-13785-1.html | GNOME 是一款流行的 Linux 桌面环境,致力于为 Linux 用户提供现代化的桌面体验。
虽然这款桌面绝大部分功能都不错,但 GNOME 团队的某些决定确实也让许多用户恼火、质疑。
前脚不能在桌面摆放图标和文件,后脚将右键菜单中的 [新建文档选项移除](https://itsfoss.com/add-new-document-option/),现在,除此之外,GNOME 同样也移除了托盘图标栏功能。
怎么说,你总得知道托盘图标栏是什么吧?这些小图标允许你使用相应应用程序的附加功能。我自己的 Ubuntu 系统里就有许多托盘图标。

这一砍就砍出了大问题,尤其是针对那些完全依赖托盘图标的软件的致命打击。就拿 [Dropbox](https://www.dropbox.com) 举例子吧,你只能通过 Dropbox 的托盘图标菜单来访问 Dropbox 的设置页面,很不幸,你在 GNOME 中就完全找不到这个图标。
这确实是个大问题,好在,我们还是有解决办法的。
### 借助插件来重新启用 GNOME 的托盘图标栏
如果你在用 GNOME,想必你已经知道 GNOME 插件是什么了。这些小插件基本上是由热心的独立开发者开发的。
如果你没有准备好,那么就去 [启用 GNOME 插件](https://itsfoss.com/gnome-shell-extensions/) 吧。这一步其实非常简单,使用 Chrome 或 Firefox 打开任意一个插件的页面,然后页面会提示你安装浏览器扩展。安装这个扩展,然后就可以启程了。

现在,有一些可以向顶栏增加托盘图标的 GNOME 插件。在撰写本篇教程的时候,[AppIndicator and KStatusNotifierItem Support](https://extensions.gnome.org/extension/615/appindicator-support/) 这款插件在 GNOME 的较新版本中已经有良好的开发优化与支持。
前往插件的页面:
* [AppIndicator 插件](https://extensions.gnome.org/extension/615/appindicator-support/)
在这个页面中,你应该能看到一个开关按钮。点击这个按钮即可安装该插件。

接下来会有一个弹窗,弹出后请点击“安装”。

也许安装插件后,插件不会立即生效。此时,你必须重启 GNOME。在 Xorg 会话中,你只需要按下 `Alt + F2` 并输入 `r` 即可重启 GNOME,但这个操作不支持 Wayland 会话。
注销当前会话,并且重新登录,此后托盘图标应该就能成功启用了。如果你安装了任何一款带托盘图标的软件,那么你应该可以在顶栏上看见这些图标的身影了。
于我而言,我已经安装了 Dropbox,因此托盘图标就直接出现在顶栏上了。

希望这个小技巧能帮助你恢复 GNOME 顶栏中的托盘图标。
我完全不理解,为什么 GNOME 的开发者会认为把这种实用性极强的功能删除会是个好主意。不过,上帝关上了一扇门,却(通常)会再打开一扇窗。好好享受按你的偏好运作的 GNOME 吧。
---
via: <https://itsfoss.com/enable-applet-indicator-gnome/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

GNOME is the popular desktop environment that thrives to give Linux a modern desktop experience.
While it works for the most part, some of their decisions has left the user fuming and questioning.
You cannot have icons and files on the desktop, [new document option has been removed](https://itsfoss.com/add-new-document-option/) from the right click context menu. In addition to that, GNOME has also removed the applet indicator functionality.
You know what indicator applets are, don’t you? Those little icons that let you access additional features of the given application. I have plenty of them in my Ubuntu system.
And this creates a problem, specially for applications that rely completely on these applet indicators to function. Take [Dropbox](https://www.dropbox.com/?ref=itsfoss.com) for example. The only way to access Dropbox settings is through the app-indicator and you won’t find it in GNOME.
That’s a problem, but thankfully, there is a workaround for that.
## Enabling applet indicator in GNOME via extensions
If you are using GNOME, you probably already know what GNOME Extensions are. These are basically small add-ons developed by enthusiastic, independent developers.
If not done already, [enable GNOME extensions](https://itsfoss.com/gnome-shell-extensions/). It’s actually quite simple. Go to any GNOME extension’s page using Firefox or Chrome and it will suggest downloading a browser extension. Install it and you are good to go.
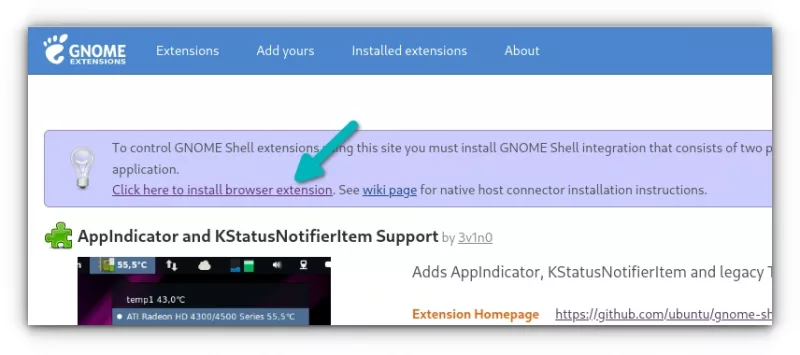
Now, there are several GNOME extensions available that allow adding applet indicators in the top panel. At the time of writing this tutorial, [AppIndicator and KStatusNotifierItem Support](https://extensions.gnome.org/extension/615/appindicator-support/?ref=itsfoss.com) extension is well developed and supported for the recent GNOME versions.
Go to its webpage:
On the page, you should see a toggle button. Click it to install it.
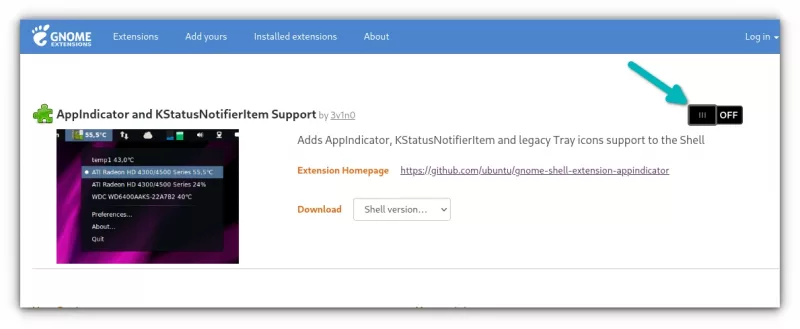
There will be a pop-up. Hit install when you see it.
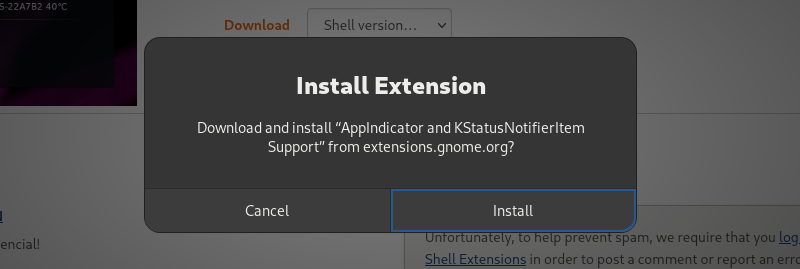
The results may be seen immediately. If you have any applications installed that provides an indicator applet, you should see it on the top panel.
If that's not the case, you’ll have to restart GNOME. On Xorg, you could just use Alt+F2 and enter r but that does not work in Wayland.
Log out of the system and log back in. Applet indicator should be activated now.
In my case, I had Dropbox already installed and hence it started showing the icon in the top panel.
I hope this little tip help you gain access to the app indicators in the top panel of GNOME again.
## More on GNOME tweaking
There is another extension that provides similar features. You may try that as well if you want.
[Tray Icons: Reloaded - GNOME Shell Extensions](https://extensions.gnome.org/extension/2890/tray-icons-reloaded/)
If you want some more GNOME customization, try this:
[Customizing GNOME with Just Perfection ExtensionAdd new customization aspects to your Linux desktop with Just Perfection GNOME Extension.](https://itsfoss.com/just-perfection-gnome-extension/)

I do not know why the GNOME developers though that dropping this essential feature was a good idea. Anyway, if one door closes, another opens (usually). Enjoy GNOME to your liking. |
13,786 | 浅谈慢速的二次算法与快速的 hashmap | https://jvns.ca/blog/2021/09/10/hashmaps-make-things-fast/ | 2021-09-15T09:45:31 | [
"hashmap"
] | https://linux.cn/article-13786-1.html | 
大家好!昨天我与一位朋友聊天,他正在准备编程面试,并试图学习一些算法基础知识。
我们聊到了<ruby> 二次时间 <rt> quadratic-time </rt></ruby>与<ruby> 线性时间 <rt> linear-time </rt></ruby>算法的话题,我认为在这里写这篇文章会很有趣,因为避免二次时间算法不仅在面试中很重要——有时在现实生活中了解一下也是很好的!后面我会快速解释一下什么是“二次时间算法” :)
以下是我们将要讨论的 3 件事:
1. 二次时间函数比线性时间函数慢得非常非常多
2. 有时可以通过使用 hashmap 把二次算法变成线性算法
3. 这是因为 hashmap 查找非常快(即时查询!)
我会尽量避免使用数学术语,重点关注真实的代码示例以及它们到底有多快/多慢。
### 目标问题:取两个列表的交集
我们来讨论一个简单的面试式问题:获取 2 个数字列表的交集。 例如,`intersect([1,2,3], [2,4,5])` 应该返回 `[2]`。
这个问题也是有些现实应用的——你可以假设有一个真实程序,其需求正是取两个 ID 列表的交集。
### “显而易见”的解决方案:
我们来写一些获取 2 个列表交集的代码。下面是一个实现此需求的程序,命名为 `quadratic.py`。
```
import sys
# 实际运行的代码
def intersection(list1, list2):
result = []
for x in list1:
for y in list2:
if x == y:
result.append(y)
return result
# 一些样板,便于我们从命令行运行程序,处理不同大小的列表
def run(n):
# 定义两个有 n+1 个元素的列表
list1 = list(range(3, n)) + [2]
list2 = list(range(n+1, 2*n)) + [2]
# 取其交集并输出结果
print(list(intersection(list1, list2)))
# 使用第一个命令行参数作为输入,运行程序
run(int(sys.argv[1]))
```
程序名为 `quadratic.py`(LCTT 译注:“quadratic”意为“二次方的”)的原因是:如果 `list1` 和 `list2` 的大小为 `n`,那么内层循环(`if x == y`)会运行 `n^2` 次。在数学中,像 `x^2` 这样的函数就称为“二次”函数。
### `quadratic.py` 有多慢?
用一些不同长度的列表来运行这个程序,两个列表的交集总是相同的:`[2]`。
```
$ time python3 quadratic.py 10
[2]
real 0m0.037s
$ time python3 quadratic.py 100
[2]
real 0m0.053s
$ time python3 quadratic.py 1000
[2]
real 0m0.051s
$ time python3 quadratic.py 10000 # 10,000
[2]
real 0m1.661s
```
到目前为止,一切都还不错——程序仍然只花费不到 2 秒的时间。
然后运行该程序处理两个包含 100,000 个元素的列表,我不得不等待了很长时间。结果如下:
```
$ time python3 quadratic.py 100000 # 100,000
[2]
real 2m41.059s
```
这可以说相当慢了!总共花费了 160 秒,几乎是在 10,000 个元素上运行时(1.6 秒)的 100 倍。所以我们可以看到,在某个点之后,每次我们将列表扩大 10 倍,程序运行的时间就会增加大约 100 倍。
我没有尝试在 1,000,000 个元素上运行这个程序,因为我知道它会花费又 100 倍的时间——可能大约需要 3 个小时。我没时间这样做!
你现在大概明白了为什么二次时间算法会成为一个问题——即使是这个非常简单的程序也会很快变得非常缓慢。
### 快速版:`linear.py`
好,接下来我们编写一个快速版的程序。我先给你看看程序的样子,然后再分析。
```
import sys
# 实际执行的算法
def intersection(list1, list2):
set1 = set(list1) # this is a hash set
result = []
for y in list2:
if y in set1:
result.append(y)
return result
# 一些样板,便于我们从命令行运行程序,处理不同大小的列表
def run(n):
# 定义两个有 n+1 个元素的列表
list1 = range(3, n) + [2]
list2 = range(n+1, 2*n) + [2]
# 输出交集结果
print(intersection(list1, list2))
run(int(sys.argv[1]))
```
(这不是最惯用的 Python 使用方式,但我想在尽量避免使用太多 Python 思想的前提下编写代码,以便不了解 Python 的人能够更容易理解)
这里我们做了两件与慢速版程序不同的事:
1. 将 `list1` 转换成名为 `set1` 的 set 集合
2. 只使用一个 for 循环而不是两个
### 看看 `linear.py` 程序有多快
在讨论 *为什么* 这个程序快之前,我们先在一些大型列表上运行该程序,以此证明它确实是很快的。此处演示该程序依次在大小为 10 到 10,000,000 的列表上运行的过程。(请记住,我们上一个的程序在 100,000 个元素上运行时开始变得非常非常慢)
```
$ time python3 linear.py 100
[2]
real 0m0.056s
$ time python3 linear.py 1000
[2]
real 0m0.036s
$ time python3 linear.py 10000 # 10,000
[2]
real 0m0.028s
$ time python3 linear.py 100000 # 100,000
[2]
real 0m0.048s <-- quadratic.py took 2 minutes in this case! we're doing it in 0.04 seconds now!!! so fast!
$ time python3 linear.py 1000000 # 1,000,000
[2]
real 0m0.178s
$ time python3 linear.py 10000000 # 10,000,000
[2]
real 0m1.560s
```
### 在极大型列表上运行 `linear.py`
如果我们试着在一个非常非常大的列表(100 亿 / 10,000,000,000 个元素)上运行它,那么实际上会遇到另一个问题:它足够 *快* 了(该列表仅比花费 4.2 秒的列表大 100 倍,因此我们大概应该能在不超过 420 秒的时间内完成),但我的计算机没有足够的内存来存储列表的所有元素,因此程序在运行结束之前崩溃了。
```
$ time python3 linear.py 10000000000
Traceback (most recent call last):
File "/home/bork/work/homepage/linear.py", line 18, in <module>
run(int(sys.argv[1]))
File "/home/bork/work/homepage/linear.py", line 13, in run
list1 = [1] * n + [2]
MemoryError
real 0m0.090s
user 0m0.034s
sys 0m0.018s
```
不过本文不讨论内存使用,所以我们可以忽略这个问题。
### 那么,为什么 `linear.py` 很快呢?
现在我将试着解释为什么 `linear.py` 很快。
再看一下我们的代码:
```
def intersection(list1, list2):
set1 = set(list1) # this is a hash set
result = []
for y in list2:
if y in set1:
result.append(y)
return result
```
假设 `list1` 和 `list2` 都是大约 10,000,000 个不同元素的列表,这样的元素数量可以说是很大了!
那么为什么它还能够运行得如此之快呢?因为 hashmap!!!
### hashmap 查找是即时的(“常数级时间”)
我们看一下快速版程序中的 `if` 语句:
```
if y in set1:
result.append(y)
```
你可能会认为如果 `set1` 包含 1000 万个元素,那么这个查找——`if y in set1` 会比 `set1` 包含 1000 个元素时慢。但事实并非如此!无论 `set1` 有多大,所需时间基本是相同的(超级快)。
这是因为 `set1` 是一个哈希集合,它是一种只有键没有值的 hashmap(hashtable)结构。
我不准备在本文中解释 *为什么* hashmap 查找是即时的,但是神奇的 Vaidehi Joshi 的 [basecs](https://medium.com/basecs) 系列中有关于 [hash table](https://medium.com/basecs/taking-hash-tables-off-the-shelf-139cbf4752f0) 和 [hash 函数](https://medium.com/basecs/hashing-out-hash-functions-ea5dd8beb4dd) 的解释,其中讨论了 hashmap 即时查找的原因。
### 不经意的二次方:现实中的二次算法!
二次时间算法真的很慢,我们看到的的这个问题实际上在现实中也会遇到——Nelson Elhage 有一个很棒的博客,名为 [不经意的二次方](https://accidentallyquadratic.tumblr.com/),其中有关于不经意以二次时间算法运行代码导致性能问题的故事。
### 二次时间算法可能会“偷袭”你
关于二次时间算法的奇怪之处在于,当你在少量元素(如 1000)上运行它们时,它看起来并没有那么糟糕!没那么慢!但是如果你给它 1,000,000 个元素,它真的会花费几个小时去运行。
所以我认为它还是值得深入了解的,这样你就可以避免无意中使用二次时间算法,特别是当有一种简单的方法来编写线性时间算法(例如使用 hashmap)时。
### 总是让我感到一丝神奇的 hashmap
hashmap 当然不是魔法(你可以学习一下为什么 hashmap 查找是即时的!真的很酷!),但它总是让人 *感觉* 有点神奇,每次我在程序中使用 hashmap 来加速,都会使我感到开心 :)
---
via: <https://jvns.ca/blog/2021/09/10/hashmaps-make-things-fast/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello! I was talking to a friend yesterday who was studying for a programming interview and trying to learn some algorithms basics.
The topic of quadratic-time vs linear-time algorithms came up, I thought this would be fun to write about here because avoiding quadratic-time algorithms isn’t just important in interviews – it’s sometimes good to know about in real life too! I’ll explain what a “quadratic-time algorithm is” in a minute :)
here are the 3 things we’ll talk about:
- quadratic time functions are WAY WAY WAY slower than linear time functions
- sometimes you can make a quadratic algorithm into a linear algorithm by using a hashmap
- this is because hashmaps lookups are very fast (instant!)
I’m going to try to keep the math jargon to a minimum and focus on real code examples and how fast/slow they are.
### our problem: intersect two lists
Let’s talk about a simple interview-style problem: getting the intersection of
2 lists of numbers. For example, `intersect([1,2,3], [2,4,5])`
should return
`[2]`
.
This problem is also somewhat realistic – you could imagine having a real program where you need to take the intersection of 2 lists of IDs.
### the “obvious” solution:
Let’s write some code to take the intersection of 2 lists. Here’s a program that does it, called `quadratic.py`
.
```
import sys
# the actual code
def intersection(list1, list2):
result = []
for x in list1:
for y in list2:
if x == y:
result.append(y)
return result
# some boilerplate so that we can run it from the command line on lists of
# different sizes
def run(n):
# make 2 lists of n+1 elements
list1 = list(range(3, n)) + [2]
list2 = list(range(n+1, 2*n)) + [2]
# intersect them and print out the result
print(list(intersection(list1, list2)))
# Run with the program's first command line argument
run(int(sys.argv[1]))
```
The reason it’s called `quadratic.py`
is that if `list1`
and `list2`
have size
`n`
, then the inner loop (`if x == y`
) will run `n^2`
times. And in math,
functions like `x^2`
are called “quadratic” functions.
### how slow is `quadratic.py`
?
Let’s run this program with a bunch of lists of different lengths. The
intersection of the two lists is always the same: `[2]`
.
```
$ time python3 quadratic.py 10
[2]
real 0m0.037s
$ time python3 quadratic.py 100
[2]
real 0m0.053s
$ time python3 quadratic.py 1000
[2]
real 0m0.051s
$ time python3 quadratic.py 10000 # 10,000
[2]
real 0m1.661s
```
So far none of this is too bad – it’s still taking less than 2 seconds.
Then I ran it on two lists with 100,000 elements, and I had to wait a LONG time. Here’s the result:
```
$ time python3 quadratic.py 100000 # 100,000
[2]
real 2m41.059s
```
This is very slow! It’s 160 seconds, which is almost exactly 100x longer than it did to run on 10,000 elements (which was 1.6 seconds). So we can see that after a certain point, every time we make the list 10x bigger, the program takes about 100x longer to run.
I didn’t try to run this program on 1,000,000 elements, because I knew it would take 100x longer again – probably about 3 hours. I don’t have time for that!
You can probably see now why quadratic time algorithms can be a problem – even this very simple program starts getting very slow pretty quickly.
### let’s write a fast version: `linear.py`
Okay, so let’s write a fast version of the program. First I’ll show you the program, then I’ll explain it.
```
import sys
# the actual algorithm
def intersection(list1, list2):
set1 = set(list1) # this is a hash set
result = []
for y in list2:
if y in set1:
result.append(y)
return result
# some boilerplate so that we can run it from the command line on lists of
# different sizes
def run(n):
# make 2 lists of n+1 elements
list1 = range(3, n) + [2]
list2 = range(n+1, 2*n) + [2]
# print out the intersection
print(intersection(list1, list2))
run(int(sys.argv[1]))
```
(this isn’t the most idiomatic Python, but I wanted to write it without using too many python-isms so that people who don’t know Python could understand it more easily)
We’ve done 2 things differently here than our slow program:
- convert
`list1`
into a set called`set1`
- only use one for loop instead of two for loops
### let’s see how fast this `linear.py`
program is
Before we talk about *why* this program is fast, let’s first prove that it’s
fast by running it on some big lists. Here it is running on lists of size 10 to
10,000,000. (remember that our original program started getting SUPER slow when
run on 100,000 elements)
```
$ time python3 linear.py 100
[2]
real 0m0.056s
$ time python3 linear.py 1000
[2]
real 0m0.036s
$ time python3 linear.py 10000 # 10,000
[2]
real 0m0.028s
$ time python3 linear.py 100000 # 100,000
[2]
real 0m0.048s <-- quadratic.py took 2 minutes in this case! we're doing it in 0.04 seconds now!!! so fast!
$ time python3 linear.py 1000000 # 1,000,000
[2]
real 0m0.178s
$ time python3 linear.py 10000000 # 10,000,000
[2]
real 0m1.560s
```
### running `linear.py`
on an extremely big list
If we try to run it on a very very big list (10 billion / 10,000,000,000
elements), then actually we run into a different problem: it’s *fast* enough
(that list is only 100x bigger than the list that took 4.2 seconds, so we could
probably do it in 420 seconds), but my computer doesn’t have enough memory to
store all of the elements of the list and so the program crashes before it gets
there.
```
$ time python3 linear.py 10000000000
Traceback (most recent call last):
File "/home/bork/work/homepage/linear.py", line 18, in <module>
run(int(sys.argv[1]))
File "/home/bork/work/homepage/linear.py", line 13, in run
list1 = [1] * n + [2]
MemoryError
real 0m0.090s
user 0m0.034s
sys 0m0.018s
```
We’re not talking about memory usage in this blog post though, so let’s ignore that.
### okay, why is `linear.py`
fast?
Now I’ll try to explain why `linear.py`
is fast.
Here’s the code again:
```
def intersection(list1, list2):
set1 = set(list1) # this is a hash set
result = []
for y in list2:
if y in set1:
result.append(y)
return result
```
Let’s say that `list1`
and `list2`
are both lists of about 10,000,000
different elements. That’s kind of a lot of elements!
So why is this able to run so fast? HASHMAPS!!!
### hashmap lookups are instant (“constant time”)
Let’s look at this if statement from our fast program:
```
if y in set1:
result.append(y)
```
You might think that this check – `if y in set1`
– would be slower if the `set1`
contains 10 million elements than it is if `set1`
contains 1000 elements. But
it’s not! It always takes basically the same amount of time (SUPER FAST), no
matter how big `set1`
gets.
This is because `set1`
is a hash set, which is a type of hashmap/hashtable which only has keys and no values.
I’m not going to explain *why* hashmap lookups are instant in this post, but the amazing
Vaidehi Joshi’s [basecs](https://medium.com/basecs) series has explanations of [hash tables](https://medium.com/basecs/taking-hash-tables-off-the-shelf-139cbf4752f0)
and [hash functions](https://medium.com/basecs/hashing-out-hash-functions-ea5dd8beb4dd) which talk about it.
### accidentally quadratic: real life quadratic algorithms!
This issue that we saw where quadratic time algorithms are really slow is
actually a problem that shows up in real life – Nelson Elhage has a great blog
called [accidentally quadratic](https://accidentallyquadratic.tumblr.com/) with
stories about performance problems caused by code that accidentally ran in
quadratic time.
### quadratic time algorithms can kind of sneak up on you
The weird thing about quadratic time algorithms is that when you run them on a small number of elements (like 1000), it doesn’t seem so bad! It’s not that slow! But then if you throw 1,000,000 elements at it, it can really take hours to run.
So I think it’s worth being broadly aware of them, so you can avoid writing them by accident. Especially if there’s an easy way to write a linear-time algorithm instead (like using a hashmap).
### sometimes the “slow” algorithm is actually faster
If you’re doing serious performance work, for example on an embedded system, it’s also important to realize that a “faster” algorithm like this example of using a hashmap will often actually be slower on a small number of elements. (I’ve never run into this myself, but friends have told me that it comes up)
For example, this great blog post [Linear vs Binary Search](https://schani.wordpress.com/2010/04/30/linear-vs-binary-search/) has
some benchmarks showing that linear search is faster than binary search for
small arrays (up to 100 elements!)
### hashmaps always feel a little magical to me
Hashmaps aren’t magic of course (you can learn the math behind why hashmap
lookups are instant! it’s cool!), but it always *feels* a little magical to me,
and every time I use hashmaps in a program to speed things up it makes me happy
:) |
13,787 | 怎样在 Linux 终端下使用 dd 命令创建一个临场 USB 驱动器 | https://itsfoss.com/live-usb-with-dd-command/ | 2021-09-15T10:49:48 | [
"dd",
"USB"
] | https://linux.cn/article-13787-1.html | 
有很多的图形化工具可以用来创建<ruby> 临场 <rt> live </rt></ruby> USB 驱动器。Linux 上的 [Etcher](https://itsfoss.com/install-etcher-linux/) 可能是最受欢迎的。为此,Ubuntu 也开发了自己的启动盘创建工具。
但是,资深 Linux 用户可能更喜欢使用 `dd` 命令在 Linux 终端中创建临场 USB,这会更快速便捷。
`dd` 命令是一个 [命令行](https://itsfoss.com/gui-cli-tui/) 工具,它提供了用来复制和转换文件的强大功能。
一个常见的使用示例是,用户使用 `dd` 命令将 ISO 文件写入到他们的外部存储设备(例如 USB 驱动盘),以用来给他们的电脑或者笔记本安装一个新的 Linux 发行版。
这就是我将在本教程中展示的内容。我将带你认识需要的命令,从终端找到我们的 USB 驱动器,然后对 ISO 文件进行实际刷写。
### 使用 dd 命令从 ISO 镜像创建临场 USB
在我向你展示步骤前,让我带你快速过一下你将要使用到的命令并解释它的作用。
这是一个使用命令刷写 ISO 的例子:
```
dd if="./filename.iso" of="/dev/sdb" status="progress" conv="fsync"
```
让我们来看看 [dd 命令](https://linuxhandbook.com/dd-command/) 实际都做了些什么。
#### 理解 dd 命令

首先,你输入 `dd`。没错,这就是你要运行的程序的名称。
接下来,你指定 `if="./filename.iso"`。`if` 代表<ruby> 输入文件 <rt> input file </rt></ruby>,告诉 `dd` 命令你将要向外部存储设备写入哪个文件。
之后,你输入 `of="/dev/sdb"`。和 `if` 一样,`of` 代表的是<ruby> 输出文件 <rt> output file </rt></ruby>。
要记住的是,输出文件在技术上不必是系统上的文件。你还可以指定诸如外部设备路径之类的内容(如示例所示),它看起来像系统上的普通文件,但实际上指向连接到你机器的设备。
`status` 可以设定为 3 个选项:`none`、`noxfer` 和 `progress`。
* 你设置的 `progress` 选项将使 `dd` 任务显示有关已将多少 ISO 文件传输到存储驱动器的定期统计信息,以及对 `dd` 任务完成前需要多长时间的估计。
* 如果你改为设置 `none` 选项,`dd` 任务在写入 ISO 文件期间只会打印错误消息,并且删除进度条之类的内容。
* `noxfer` 选项隐藏了传输完成后打印的一些信息,例如从开始到完成所用的时间。
最后,你将 `conv` 选项设置为 `fsync`。这会导致 `dd` 任务在整个 ISO 文件写入 USB 驱动器之前不会报告成功写入。
如果你省略这个选项,`dd` 任务会工作的很好(并且实际上可能看起来运行得更快),但你可能会发现你的系统需要很长时间才能告诉你移除 USB 驱动器是安全的,因为它会在后台完成 ISO 的内容写入,从而允许你在此期间做其它事情。
**现在你明白了你必须做什么,让我们看看如何去做。**
>
> **注意事项**
>
>
> 命令行是把双刃剑。当你在命令行使用类似于 `dd` 命令时必须十分小心。你必须确保你目标输出文件是正确的设备。一个错误的步骤就可能会格式化你的系统硬盘,你的操作系统也会因此而损坏。
>
>
>
#### 第 0 步: 下载所需的 ISO 镜像
不用说,你需要有一个 ISO 镜像文件才能将其刷写到 USB 上。
我将使用 Ubuntu 20.04 ISO(可在此处[下载](https://ubuntu.com/download/desktop/thank-you?version=20.04.2.0&architecture=amd64))来测试我之前介绍的 `dd` 命令。
#### 第 1 步: 获取 USB 盘符
插入你的 USB 驱动器。
我为 `of` 参数输入的具体路径是 `/dev/sdb`。USB 磁盘通常会标记为 `/dev/sdb`,但这不是硬性规定。
此路径可能因你的系统而异,你可以使用 `lsblk` 命令确认 USB 磁盘的路径。只需从列表中查找一个看起来像你的 USB 磁盘大小的驱动器,就可以了。

如果你更熟悉 GUI 程序,还可以使用 GNOME Disks 等工具找到驱动器的路径。

现在你已经确认了外部驱动器的路径,让我们开始创建临场 USB。
#### 第 2 步:将 ISO 文件写入 USB 磁盘
在下载 ISO 文件的目录打开一个终端,然后运行以下命令(如果 `/dev/sdb` 与你的存储设备名称不同,请记住将其替换):
```
sudo dd if="./ubuntu-20.04.2.0-desktop-amd64.iso" of="/dev/sdb" status="progress" conv="fsync"
```
之后,让 `dd` 去做剩下的事情,它会在完成后打印一条完成消息:

就像这样,你已经在 Linux 终端中使用 `dd` 命令刷写了 ISO 文件!
### 总结
现在,你可以通过终端做更多的事情,让你的工作效率大大提高。
对 `dd` 命令有任何没解决的问题,或者无法正常工作?请随时在下面的评论部分中留下你的问题。
---
via: <https://itsfoss.com/live-usb-with-dd-command/>
作者:[Hunter Wittenborn](https://itsfoss.com/author/hunter/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are several graphical tools available for creating live USB. [Etcher on Linux](https://itsfoss.com/install-etcher-linux/) is probably the most popular. Ubuntu has its own Startup Disk Creator tool for this purpose.
However, advanced Linux users swear by the comfort and swiftness of creating live USBs in Linux terminal using the dd command.
The dd command is a [CLI tool](https://itsfoss.com/gui-cli-tui/) that gives you powerful features for copying and converting files.
A common use case that people use dd for is to write ISO files to an external storage device such as a USB drive, which can be used to do things like install a new Linux distribution onto a computer or laptop.
That’s what I am going to show in this tutorial. I’ll go over the commands you will need to run, finding our USB drive from the terminal, and then finally doing the actual flashing of the ISO file.
## Creating live USB from ISO with dd command
Before I show you the steps, let me quickly go over the command which you’ll be using and explain what it does.
Here’s the example command for flashing of the ISO:
`dd if="./filename.iso" of="/dev/sdb" status="progress" conv="fsync"`
Let’s go over what exactly that [dd command](https://linuxhandbook.com/dd-command/) is doing.
### Understanding the above dd command
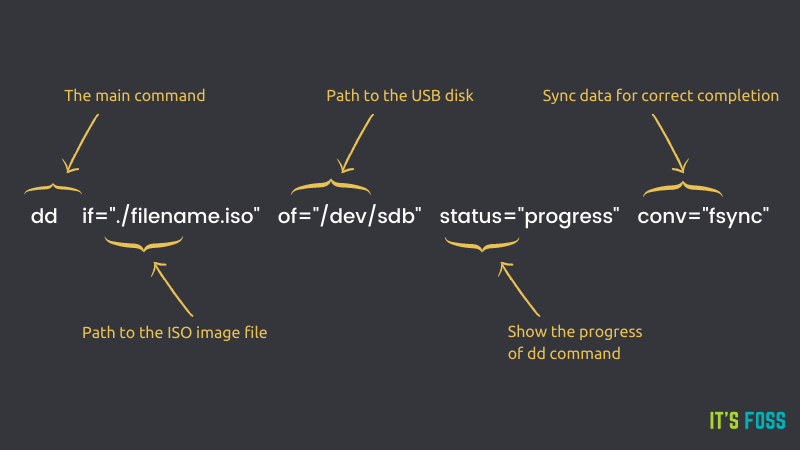
First, you enter `dd`
. As expected, this is just the name of the program you are going to run.
Next, you specify `if="./filename.iso"`
. `if`
stands for input file, which tells `dd`
what file you are going to be writing to the external storage drive.
After that, you enter `of="/dev/sdb"`
. As was with `if`
, `of`
simply stands for output file.
The thing to remember is that the output file doesn’t technically have to be a file on your system. You can also specify things like the path to an external device (as shown in the example), which just **looks** like a normal file on your system, but actually points to a device connected to your machine.
`status`
can be set to three options: `none`
, `noxfer`
and `progress.`
The `progress`
option that you set will cause dd to show periodic statistics on how much of the ISO has been transferred to the storage drive, as well as an estimation on how much longer it will be until dd is finished.
If you were to have set the `none`
option instead, dd would only print error messages during the writing of the ISO, thus removing things like the progress bar.
The `noxfer`
option hides some information that’s printed after a transfer is complete, such as how long it took from start to finish.
Lastly, you set the `conv`
option to `fsync`
. This causes dd to not report a successful write until the entire ISO has been written to the USB drive.
If you omit this option, dd will still write just fine (and might actually appear to run quicker), but you might find your system taking quite a while before it tells you it’s safe to remove the USB drive as it will finish writing the ISO’s content in the background, thus allowing you to do other things in the meantime.
*Now that you understand what you have to do, let’s see how to do it.*
Warning
The command line is a double-edged sword. Be extra careful when you are running a command like dd. You must make sure that you are using the correct device for the output file destination. One wrong step and you may format your main system disk and lose your operating system.
### Step 0: Download the desired ISO
This goes without saying that you need to have an ISO image file in order to flash it on a USB.
I am going to use Ubuntu 20.04 ISO (downloadable [here](https://ubuntu.com/download/desktop/thank-you?version=20.04.2.0&architecture=amd64)) to test the dd command I showed earlier.
### Step 1: Get the USB disk label
Plug in your USB disk.
The specific path I entered for `of`
was `/dev/sdb`
. The USB disks are usually labelled /dev/sdb but that’s not a hard and fast rule.
This path may differ on your system, but you can confirm the path of the drive with the `lsblk`
command. Just look for a listing that looks like the size of your USB drive, and that’ll be it.
If you are more comfortable with GUI programs, you can also find the drive’s path with tools like GNOME Disks.
Now that you have established the path to our external drive, let’s create the live USB.
### Step 2: Writing the ISO file to the USB disk
Open up a terminal at the directory where the ISO file is downloaded, and run the following (remember to replace `/dev/sdb`
with the name of your storage device if it’s something different):
`sudo dd if="./ubuntu-20.04.2.0-desktop-amd64.iso" of="/dev/sdb" status="progress" conv="fsync"`
After that, just let dd do it’s thing, and it’ll print a completion message once it’s done:
And just like that, you’ve flashed an ISO with dd command in the Linux terminal!
## Wrapping Up
Now you’re on your way to doing even more things through the terminal, allowing you to do things faster and quicker than you might have been able to do before.
Got any remaining questions about the dd command, or something just not working right? Feel free to leave any of it in the comment section below. |
13,789 | 如何轻松安装 Debian Linux 系统 | https://itsfoss.com/install-debian-easily/ | 2021-09-16T12:37:00 | [
"Debian"
] | https://linux.cn/article-13789-1.html | 
安装 Debian 的轻松程度依赖于选择什么镜像。
如果你使用 Debain 官网的默认 ISO 镜像,安装 Debian 就比较费劲。你会卡在这种界面,让你从外部可移动介质上安装网络驱动。

当然你可以花时间去排除这个故障,但这让事情变得没有必要的复杂。
不用担心,让我来展示如何轻松地简单安装 Debian。
### 轻松安装 Debian 桌面系统的方法
在你查看这些步骤之前,请确认以下准备工作:
* 一个至少 4GB 大小的 USB 盘。
* 一个连接了互联网的系统(可以是要安装 Debian 的同一个机器)。
* 一个要安装的 Debian 的机器。它将会清理掉系统上所有数据,因此请复制重要数据到其他外部磁盘
你需要为 Debian 准备什么样配置的机器?这取决于你想用什么类型的 [桌面环境](https://itsfoss.com/what-is-desktop-environment/)。例如,GNOME 桌面系统可以在 4GB 内存上运行,但在 8GB 内存上更流畅一些。如果你只有 4GB 或更少的内存,还是建议尝试 KDE、Cinnamon 或 Xfce 桌面系统。
Debian 支持 [32 位和 64 位的指令架构](https://itsfoss.com/32-bit-64-bit-ubuntu/)。你需要根据你的 CPU 指令架构选择对应的 Debian ISO 镜像。
你的系统应该至少要有 25GB 可用的硬盘空间。越多越好。
>
> **警告!**
>
>
> 这个方法会移除磁盘上所有其他操作系统及其数据。
>
>
> 你可以保存你后面还需要用的个人信息、文档、照片等到外部 USB 盘或云存储中。
>
>
>
在这个教程中,我将展示安装带有 GNOME 桌面环境的 Debian 11 Bullseye 的步骤。即使你选择其他的桌面环境,步骤也应该是一样的。
这个教程是在 GPT 分区的 UEFI 系统上测试的。如果你的系统是 [MBR 而不是 GPT](https://itsfoss.com/check-mbr-or-gpt/),或是 [传统的 BIOS 而不是 UEFI](https://itsfoss.com/check-uefi-or-bios/),那么创建<ruby> 临场 <rt> Live </rt></ruby> USB 盘的步骤有一点不同。
#### 步骤 1:获取正确的 Debian ISO 镜像
在安装 Debian 过程中,选择正确的 ISO 镜像就已经成功一半了。令人惊讶的是,对于一个新的 Debian 用户来说,要浏览 Debian 的网站并找到最轻松好用的 ISO 真的很困难。
如果你点击 Debian 官网的下载按钮,它会下载一个最小化的网络安装文件,这对普通用户来说是非常复杂的。请 **不要** 使用这个。
反而,你应该用<ruby> 临场 <rt> Live </rt></ruby> ISO。但这里要注意,有一些单独的含有非自由软件(以包括网络硬件的驱动程序)的版本。
你应该下载这个非自由版的临场 ISO 镜像。不过另一个问题是,你不会在网站的显著位置注意到它,而且有各种架构的 BT 种子或直接下载的 URL。
让我把这些链接放在这里:
* [32 位和 64 位的主仓地址](https://cdimage.debian.org/images/unofficial/non-free/images-including-firmware/11.0.0-live+nonfree/)
* [Debian 11 官方下载](https://cdimage.debian.org/images/unofficial/non-free/images-including-firmware/11.0.0-live+nonfree/amd64/iso-hybrid/)
* [Debian 11 种子地址](https://cdimage.debian.org/images/unofficial/non-free/images-including-firmware/11.0.0-live+nonfree/amd64/bt-hybrid/)
你会看到几个文件,文件名中提到了桌面环境。选择一种你要的桌面环境。直接下载的话,直接点击 .iso 结尾的链接即可。

一旦你有了对应的 ISO 下载包,剩下就是和其他 Linux 发行版一样的标准安装流程了。
#### 步骤 2: 创建一个 Debian 的临场 USB 盘
将 USB 盘插入你的系统。在用之前最好格式化一下,反正它最终也会被格式化的。
你可以根据你的选择使用任何临场 USB 创建工具。如果你使用 Windows,可以使用 Rufus。我们在这里使用 Etcher,因为这个工具在 Windows 和 Linux 都可以用。
从它的官网下载 Etcher。
* [下载 Etcher](https://www.balena.io/etcher/)
我专门写过一篇 [在 Linux 下使用 Etcher 的教程](https://itsfoss.com/install-etcher-linux/),因此这里我就不深入介绍了。只要运行下载的可执行程序,浏览找到 Debian 的 ISO 镜像,确认选择正确的 USB 盘,然后点击 “Flash” 按钮即可。

不一会就创建好临场 USB 盘了。创建好之后,就可以开机引导了。
#### 步骤 3:从临场 USB 盘引导启动
重启你要安装 Debian 的机器。当显示制造商标识的时候,按下 `F2`、`F10` 或 `F12` 等键进入开机引导设置界面。你也可以从 Windows [进入到 UEFI 固件设置界面](https://itsfoss.com/access-uefi-settings-windows-10/)。
有些机器如果启用了<ruby> 安全启动 <rt> secure boot </rt></ruby>功能,就不允许从临场 USB 盘引导。如果是这种情况,请 [从 BIOS 设置里禁用安全启动](https://itsfoss.com/disable-secure-boot-windows/)
不同的的制造商在界面上会有一些差异。

你在 BIOS 里做了修改之后,按下 `F10` 保存并退出。你的系统将会重新启动。
再一次,当看到制造商的标识后按下 `F2`、`F10` 或 `F12` 查看引导配置。你应该可以看到从 USB 引导的选项,然后选中它。

一会儿就会看到如下图的显示界面,选择第一个选项。

#### 步骤 4: 开始安装 Debian
当你进入临场 Debian 会话,如果你使用 GNONE 桌面,它呈现一个欢迎界面,可以在此选择你的键盘和语言。当你看到这些界面时,只需要点击下一步。

欢迎界面之后,按下 `Windows` / `Super` 键进入活动区。你应该可以看到 Debian 的安装按钮。

它会打开一个友好的 [Calamares 图形安装器](https://calamares.io/)。从这里开始事情就比较简单了,

它会让你选择你的地理位置和时区。

下一个界面,会让你选择键盘类型。这儿请 **注意**。你的键盘会根据你所选的位置自动选择。例如,我的位置是印度,它会自动默认选择印度键盘和印地语。我需要将其改为印度英语。

下一个界面是关于磁盘分区和要安装 Debian 的地方。在本文中,把 Debian 作为你电脑上唯一的操作系统来安装。
最简单的方法是直接选择 “<ruby> 擦除磁盘 <rt> Erase Disk </rt></ruby>”。除了必须的 ESP 分区和交换分区外,Debian 会把其他所有东西都放在根挂载点(`/`)上。实际上,下面显示了你所选的安装方式后的磁盘布局。

如果你想把事情掌握在自己手中,你也可以选择手动分区,选择分配给 `/`、`/home`、`/boot` 或交换分区的大小。只有在你知道自己在做什么时,才可以这样做。
下一界面,你需要提供用户名和密码。但它不会设置 root 的密码,并将其保持为空。

这也意味着你可以用新创建的用户使用 `sudo` 。在“复杂的 Debian 安装”中,你也可以设置 root 密码,但这样你就必须手动将普通用户添加到 `sudoer` 列表。看看,这种安装过程是不是对新手来说很容易?
在继续实际安装之前,它会呈现你所做的选择的汇总信息。如果没有问题,就可以点击“<ruby> 安装 <rt> Install </rt></ruby>”按钮。

现在只需要等待安装完成。

几分钟后就会完成安装。当安装完成,它会提示重启。

重启系统后如果一切顺利,你应该可以看到 Debian 的 GRUB 界面。

### 疑难解答(如果系统没有启动到 Debian)
我遇到情况是,我的 Dell 系统不能识别任何要引导的操作系统。这很奇怪,我看见 Debian 经创建了一个 ESP 分区。
如果你也是同样的情况,进去 BIOS 配置里。检查<ruby> 启动顺序 <rt> Boot Sequence </rt></ruby>,如果你看不到任何东西,就点击“<ruby> 新增引导选项 <rt> Add Boot Option </rt></ruby>”。

它会提供一个增加 EFI 文件的选项。

由于在安装过程中 Debian 创建了 ESP 分区,因此一个包含必要文件的 `EFI` 目录已经创建好了。

它会显示一个 `Debian` 目录及其他目录。选择 `Debian` 目录。

在 `Debian` 目录,你将看到 `grubx64.efi`、`shimx64.efi` 等文件。请选择 `shimx64.efi`。

你需要给这个文件一个合适的名字。最后的界面应该如下:

现在你应该有了这个启动选项。因为我命名为 `Debian`,它显示了两个 `Debian` 引导选项(我猜其中一个是从 efi 文件来的)。按下 `F10` 保存退出 BIOS 的配置。

现在启动你的系统,你可以看到带有 Debian 启动选项的 GRUB 界面了。你现在可以体验 Debian 了。

### 你能安装 Debian 吗?
我写这篇文章的目的是让事情变得轻松点。并不是说你不能从默认的网络安装程序 ISO 来安装,只是它需要花更多的精力。
这个教程对你安装 Debian 有帮助吗?你如果还是有问题,请在下面留言给我,我会尽力提供帮助。
---
via: <https://itsfoss.com/install-debian-easily/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[巴龙](https://github.com/guevaraya) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Installing Debian could be easy or complicated depending upon the ISO you choose.
If you go with the default ISO provided by the Debian website, you’ll have a hard time installing Debian. You’ll be stuck at a screen that asks for network drivers to be installed from external removable media.

You may, of course, troubleshoot that, but it makes things unnecessarily complicated.
Don’t worry. Let me show the steps for installing Debian comfortably and easily.
## The easy way of installing Debian as a desktop
Before you see the steps, please have a look at the things you need.
- A USB key (pen drive) with at least 4 GB in size.
- A system with an active internet connection (could be the same system where it will be installed).
- A system where you’ll be installing Debian. It will wipe out everything on this system, so please copy your important data to some other external disk.
What kind of system specification you should have for Debian? It depends on the [desktop environment](https://itsfoss.com/what-is-desktop-environment/) you are going to use. For example, the GNOME desktop environment could work on 4 GB RAM but it will work a lot better on 8 GB RAM. If you have 4 GB or less, try using KDE, Cinnamon or Xfce desktops.
Debian also has both [32-bit and 64-bit architecture](https://itsfoss.com/32-bit-64-bit-ubuntu/) support. You’ll have to get the Debian ISO according to your processor architecture.
Your system should have at least 25 GB of disk space to function. The more, the merrier.
**This method removes all the other operating systems along with the data present on the disk. You may save your personal files, documents, pictures etc on an external USB disk or cloud storage if you want to use it later.**
**Warning!**In this tutorial, I am going to show the steps for installing Debian 11 Bullseye with GNOME desktop environment. The steps should be the same even if you choose some other desktop environment.
[MBR instead of GPT](https://itsfoss.com/check-mbr-or-gpt/)or
[legacy BIOS instead of UEFI](https://itsfoss.com/check-uefi-or-bios/), the live USB creation step will be different.
### Step 1: Getting the correct Debian ISO
Half of the battle in installing Debian is choosing the correct ISO. Surprisingly, it is really difficult to navigate through its website and find that ISO which is the easiest for a new Debian user.
If you click the Download button on the [homepage of Debian website](https://www.debian.org/?ref=itsfoss.com), it downloads a minimal net install file which will be super complicated for a regular user. Please DO NOT use this.
Instead, you should go for the live ISO. But here is a catch, there are separate live versions with non-free software (includes drivers for your networking hardware).
You should download this non-free live ISO. Another problem here is that you won’t get it mentioned prominently on the website and there are various URLs for torrents or direct downloads for various architecture.
Let me link them here.
[Main repo for 32 and 64 bit](https://cdimage.debian.org/images/unofficial/non-free/images-including-firmware/current-live/?ref=itsfoss.com)
[Debian 11 Direct](https://cdimage.debian.org/images/unofficial/non-free/images-including-firmware/current-live/amd64/iso-hybrid/?ref=itsfoss.com)
[Debian 11 Torrent](https://cdimage.debian.org/images/unofficial/non-free/images-including-firmware/current-live/amd64/bt-hybrid/?ref=itsfoss.com)
You’ll see several files with the of desktop environment mentioned in the filename. Choose the one with desktop environment of your choice. For direct downloads, click on the links that end with .iso.
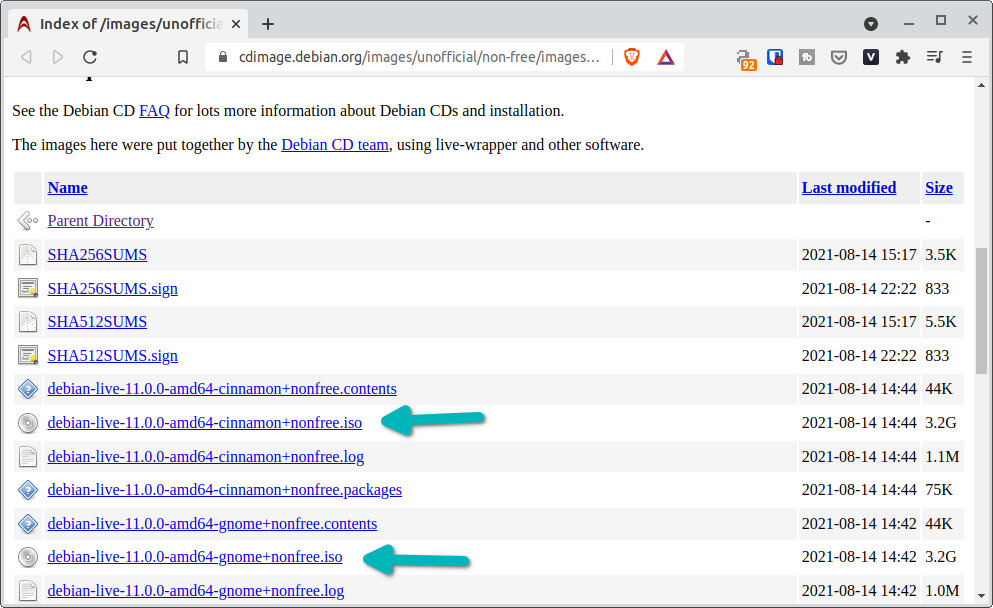
Once you have the appropriate ISO downloaded, the rest is standard procedure that you may have experienced with other Linux distributions.
### Step 2: Creating live USB of Debian
Plug in the USB into your system. It will be wise to format it just for the sake of it. It will be formatted anyway.
You can use any live USB creation tool of your choice. If you are using Windows, go with Rufus. I am going to use Etcher here because it is available for both Windows and Linux.
Download Etcher from its website.
I have a dedicated [tutorial on using Etcher in Linux](https://itsfoss.com/install-etcher-linux/) and thus I am not going to go in detail here. Just run the downloaded executable file, browse to the Debian ISO, make sure that the correct USB is selected and then hit the Flash button.
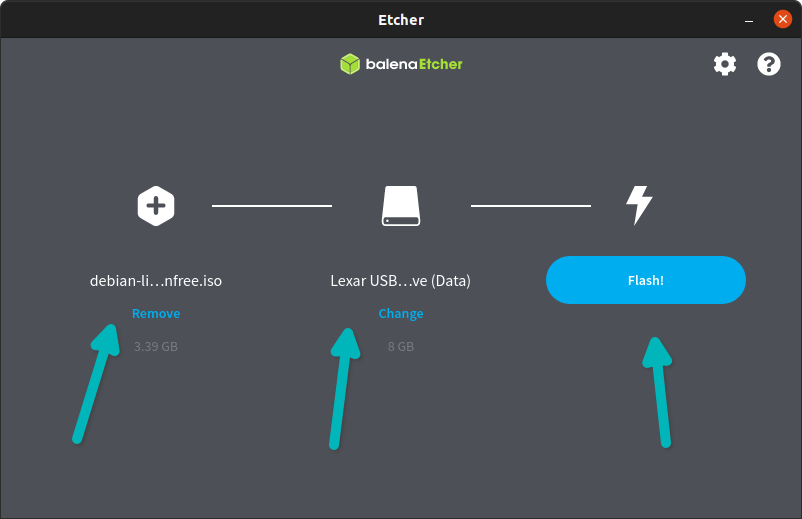
It may take a couple of minutes to create the live USB. Once that is ready, it is time to boot from it.
### Step 3: Boot from the live USB
Restart the system where you want to install Debian. When it is showing the manufacturer’s logo, press F2/F10 or F12 key to access the boot settings. You may also [access the UEFI firmware settings from Windows.](https://itsfoss.com/access-uefi-settings-windows-10/)
Some systems do not allow booting from live USB if secure boot is enabled. If that is the case, please [disable secure boot from the BIOS settings](https://itsfoss.com/disable-secure-boot-windows/).
The screen may look different for different manufacturers.
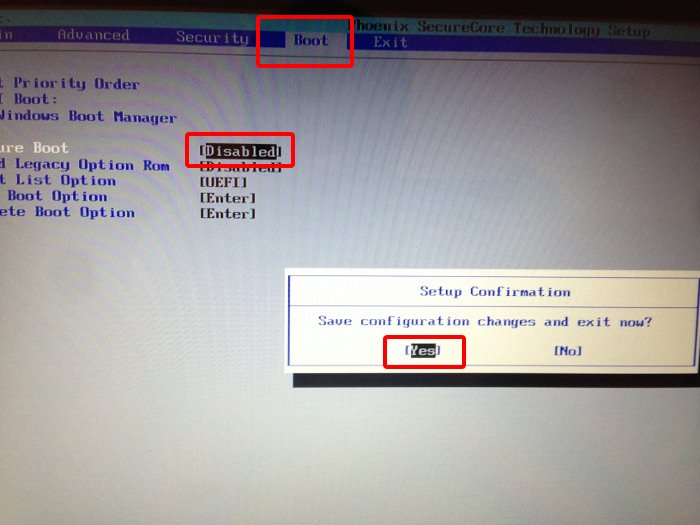
Once you make the change, press F10 to save and exit. Your system will boot once again.
Again, press F2/F10 or F12 to access the boot settings when it shows the manufacturer’s logo. You should see the option to boot from the USB. Select it.
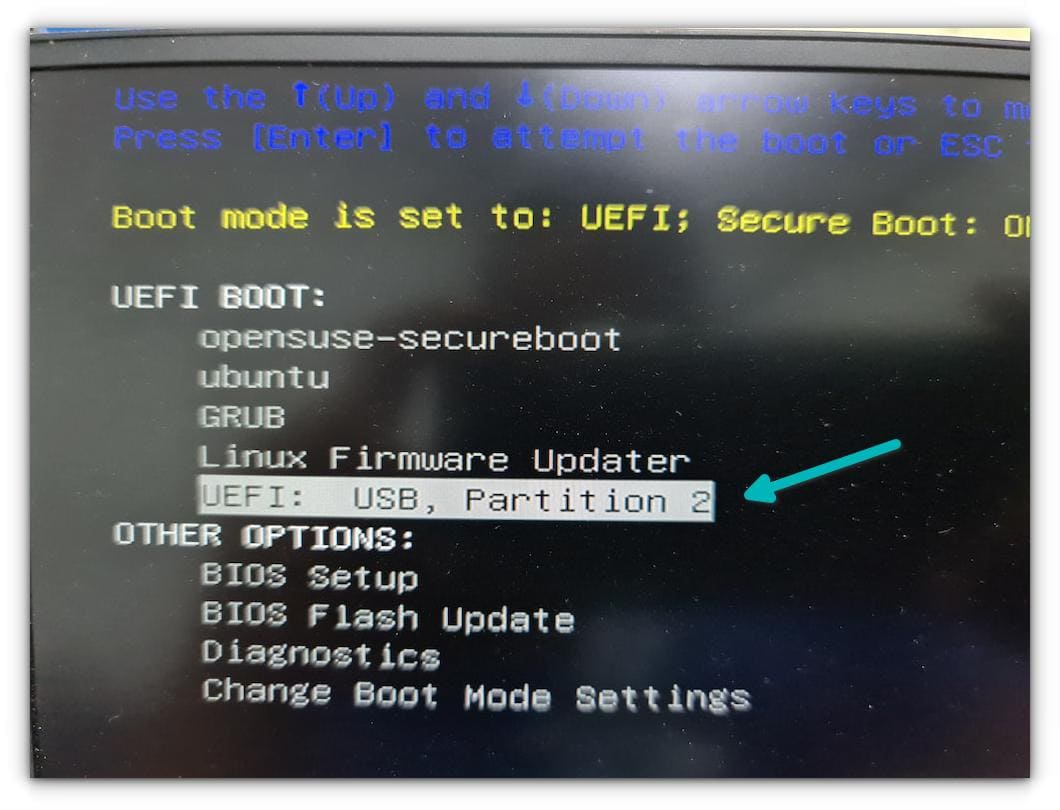
It takes a little bit of time and then you should see a screen like this. Go with the first option here.
### Step 4: Start Debian installation
When you enter the live Debian session, it may show some welcome screen with option to choose your keyboard and language if you are using GNOME desktop. Just hit next when you see those screens.
Once you are past the welcome screen, press the Windows/Super key to bring the activity area. You should see the Debian install button here.
It opens the friendly [Calamares graphical installer](https://calamares.io/?ref=itsfoss.com). Things are pretty straightforward from here.
It asks you to select your geographical location and time zone.
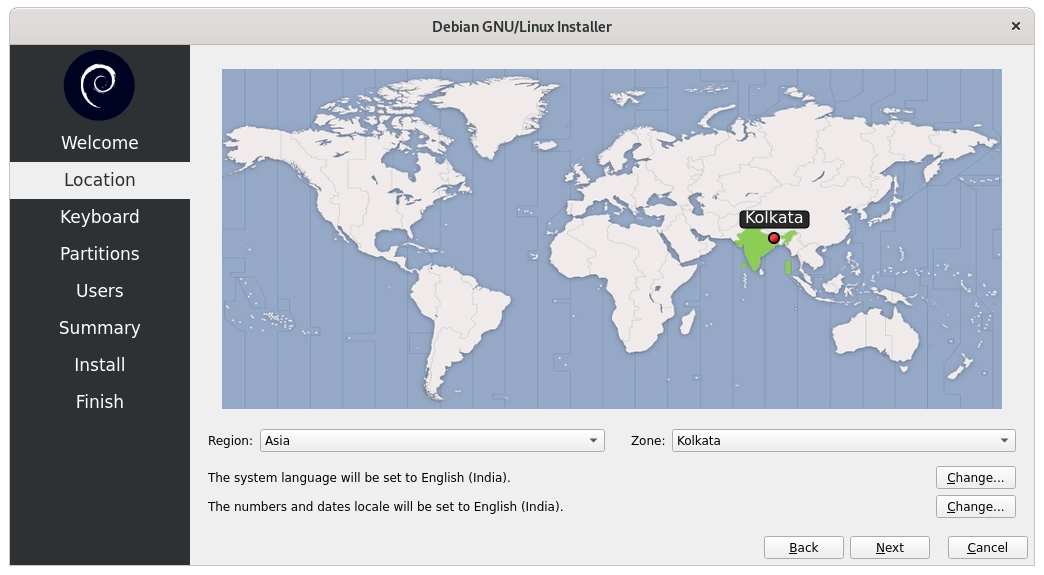
On the next screen, you’ll be asked to select the keyboard. Please **pay attention** here. Your keyboard is automatically selected based on your location. For example, I had used India as my location and it automatically set the default Indian keyboard with Hindi language. I had to change it to English India.
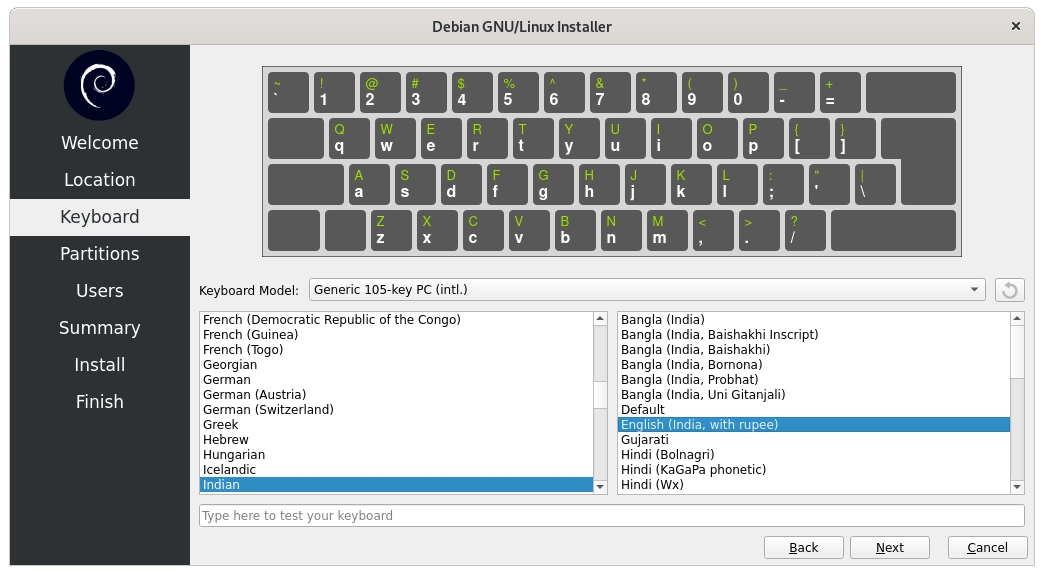
The next screen is about the disk partition and where you would like to install Debian. In this case, you are going to install Debian as the only operating system on your computer.
The easiest option would to go with ‘Erase disk’ option. Debian will put everything under root except the mandatory ESP partition and Swap space. In fact, it shows what your disk would like after your chosen installation method.
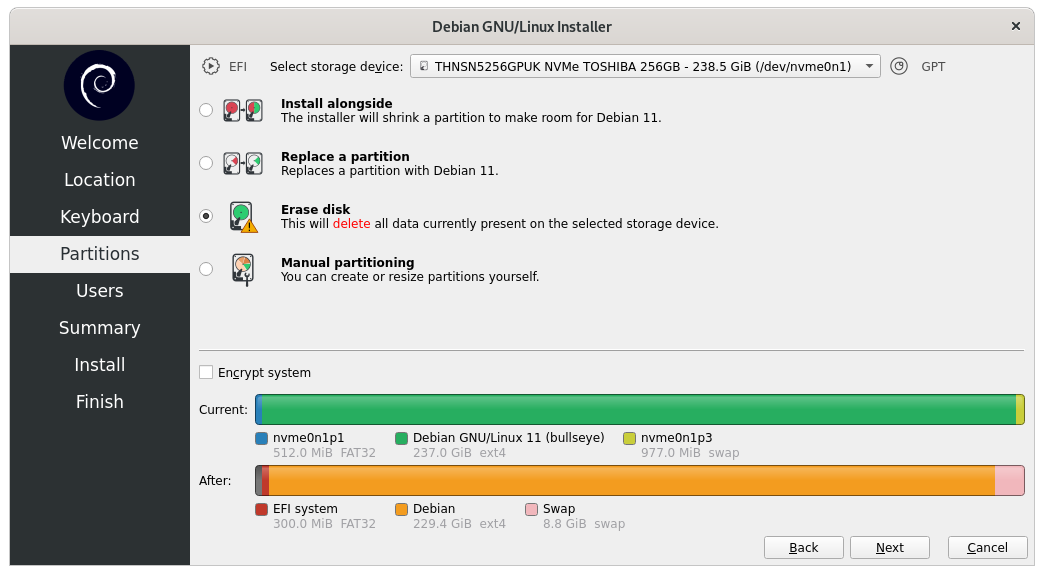
If you want to take matter in your hands, you may also opt for manual partitioning and choose how much you want to allot to root, home, boot or swap. Only do that when you know what you are doing.
On the next screen, you have to provide the username and password. It does not set root password and keeps it empty.
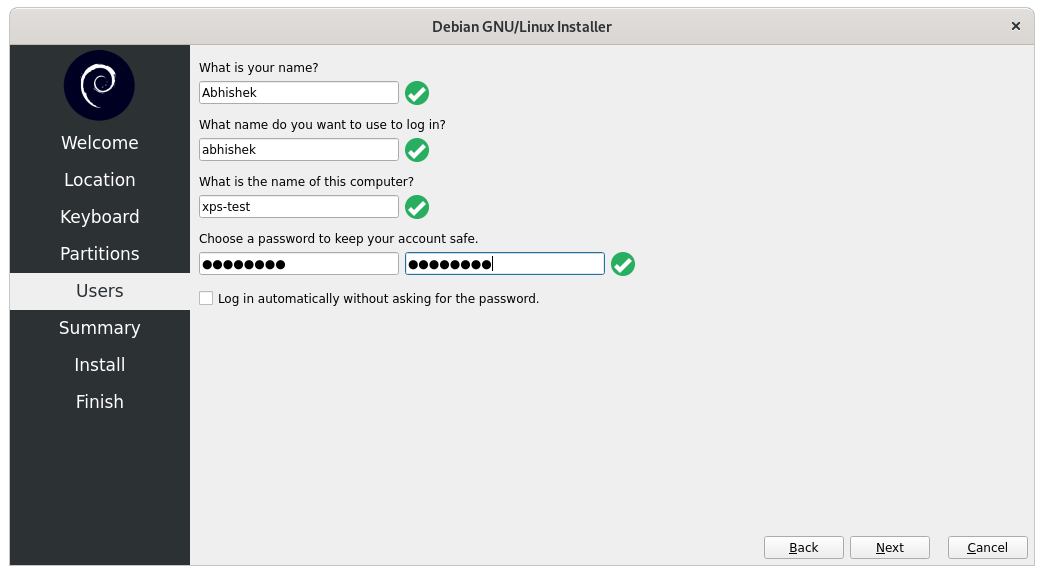
This also means that you can use sudo with the newly created user. In the ‘complicated Debian install’, you could also set root password but then you’ll have to add the normal user to sudoer list manually. See, this installation method is easier for beginners, right?
Before it goes on with the actual installation, it presents you with a summary of the choices you have made. If things look good, hit the install button.
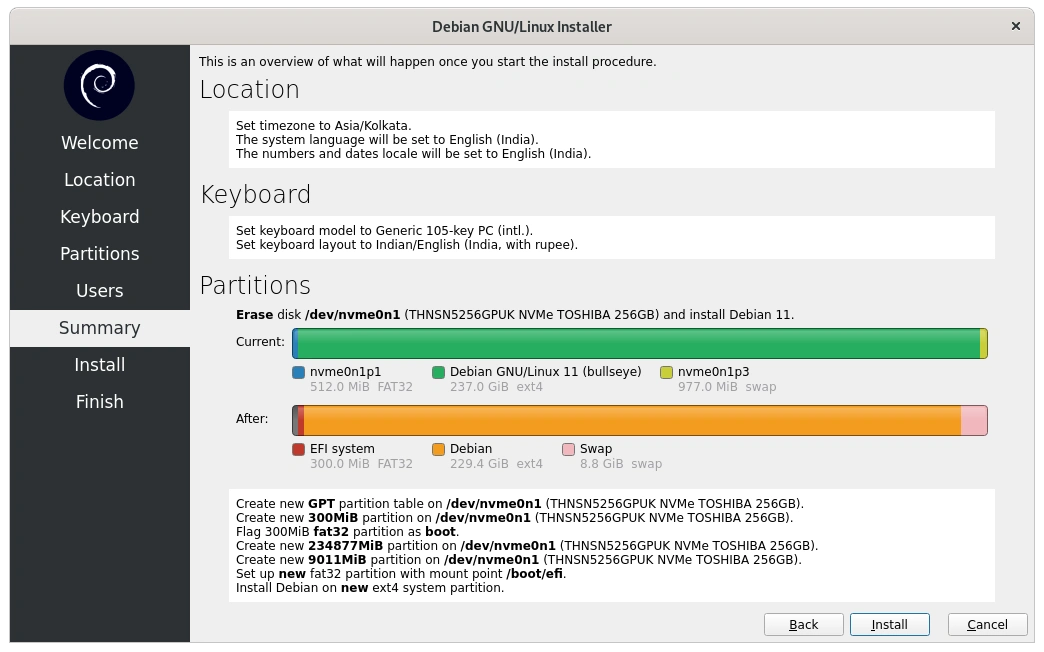
Now it is just a matter of waiting for the installation to finish.
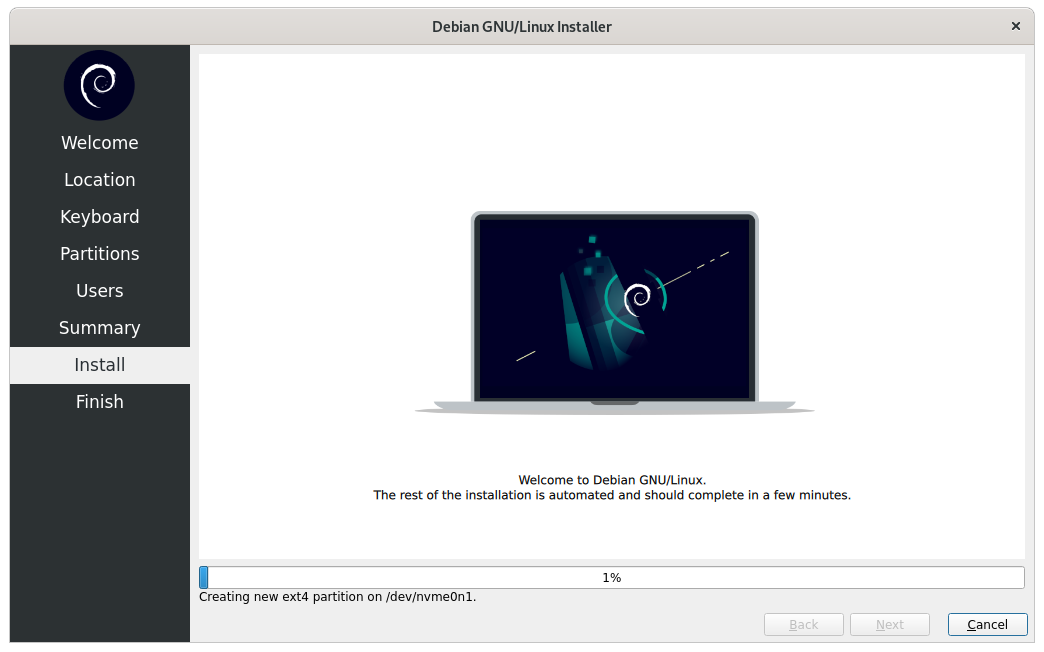
It takes a few minutes to complete the installation. When the installation finishes, it asks for a restart.
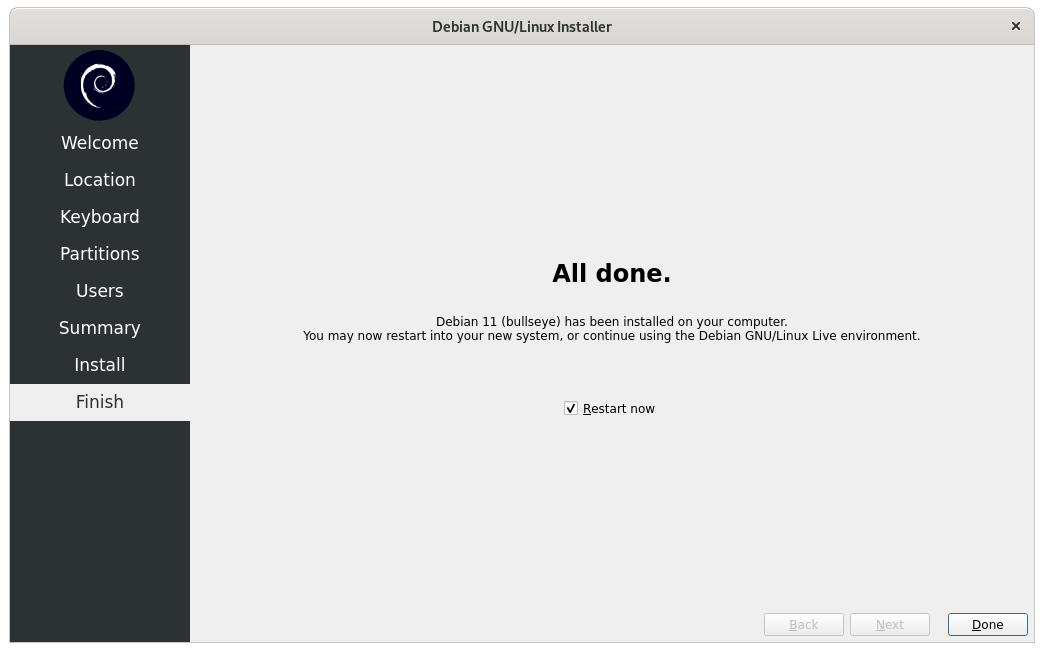
Restart your system and if everything goes well, you should see the grub screen with Debian.
## Troubleshooting tip (if your system does not boot into Debian)
In my case, my Dell system did not recognize any operating system to boot. This was weird because I had see Debian creating an ESP partition.
If it is the same case with you, go to BIOS settings. Check the boot sequence. If you do not see anything, click on the Add boot option.
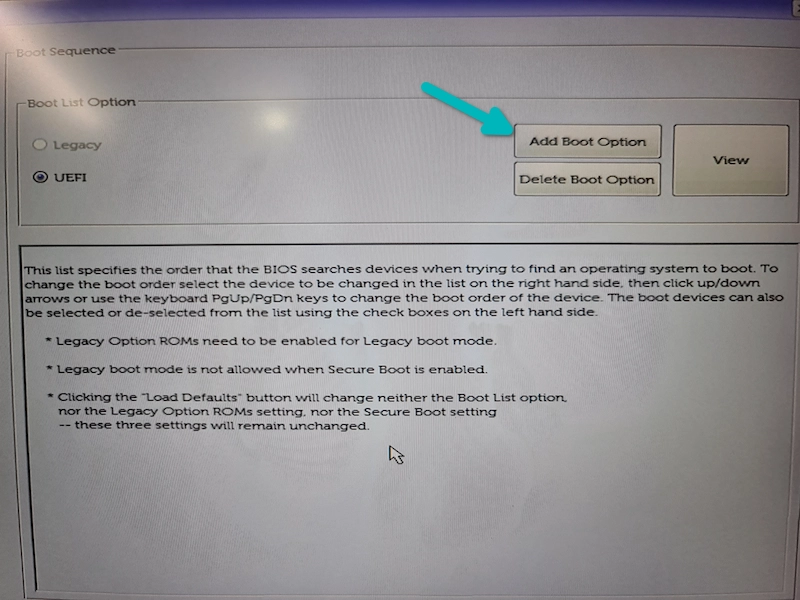
It should give you an option to add an EFI file.
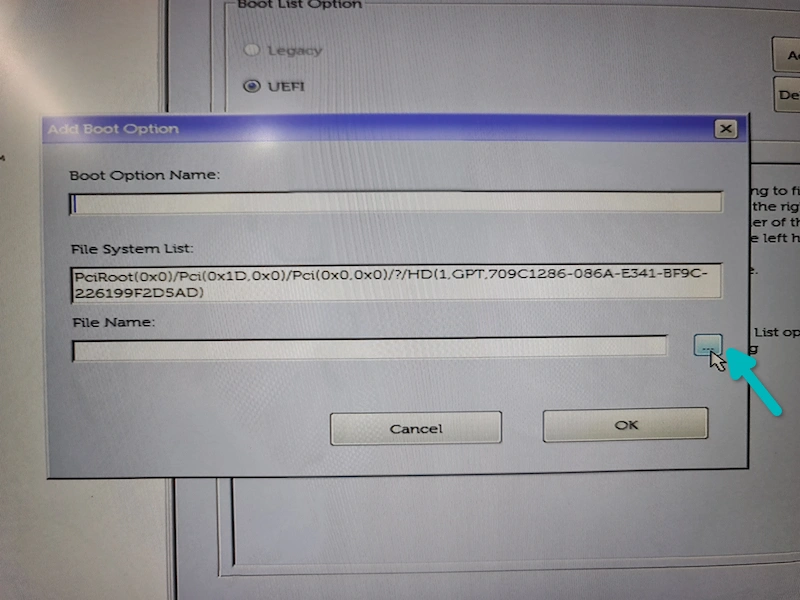
Since Debian created ESP partition during installation, there is an EFI directory created with necessary files.
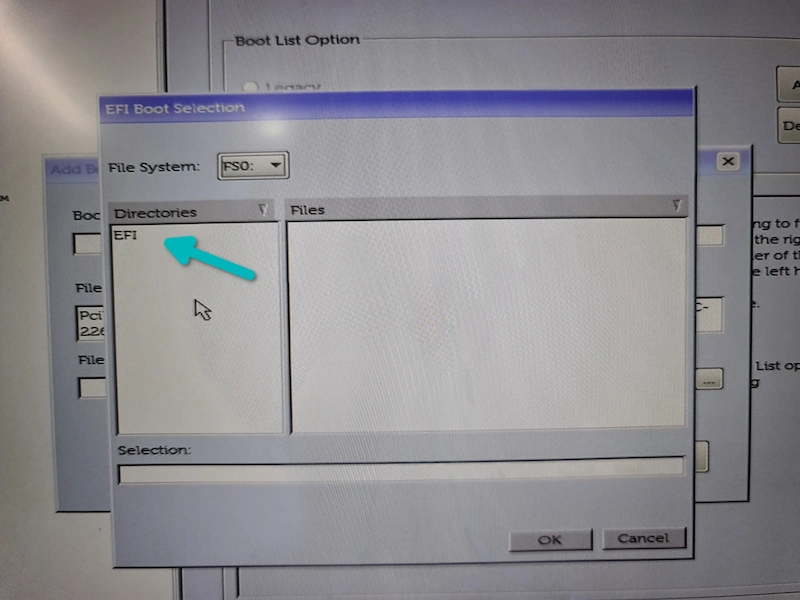
It should show a Debian folder along with some other folders. Select Debian folder.
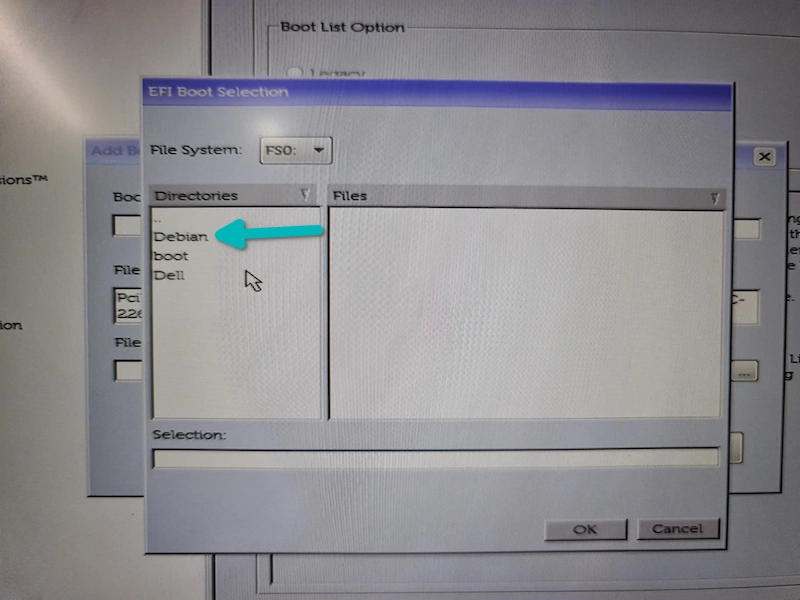
In this Debian folder, you’ll find files like grubx64.efi, shimx64.efi. Select shimx64.efi.
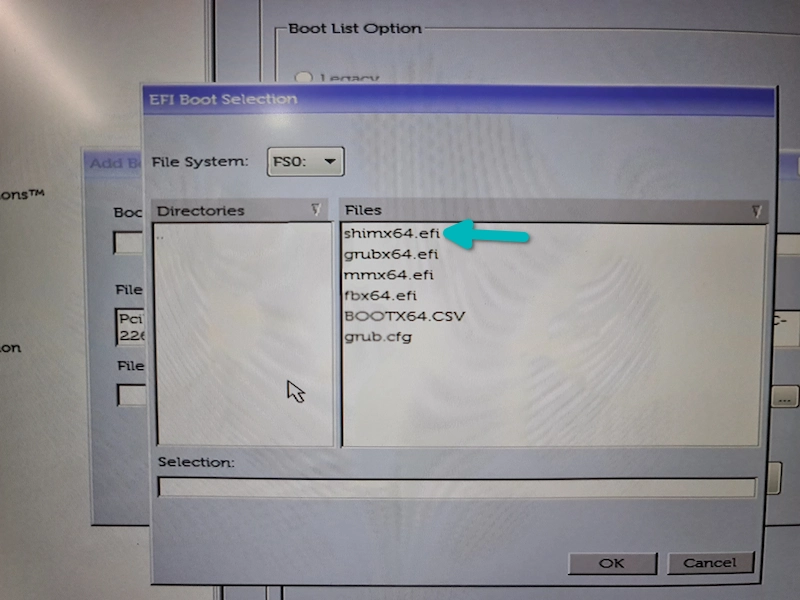
You may give this file an appropriate name. The final screen may look like this.
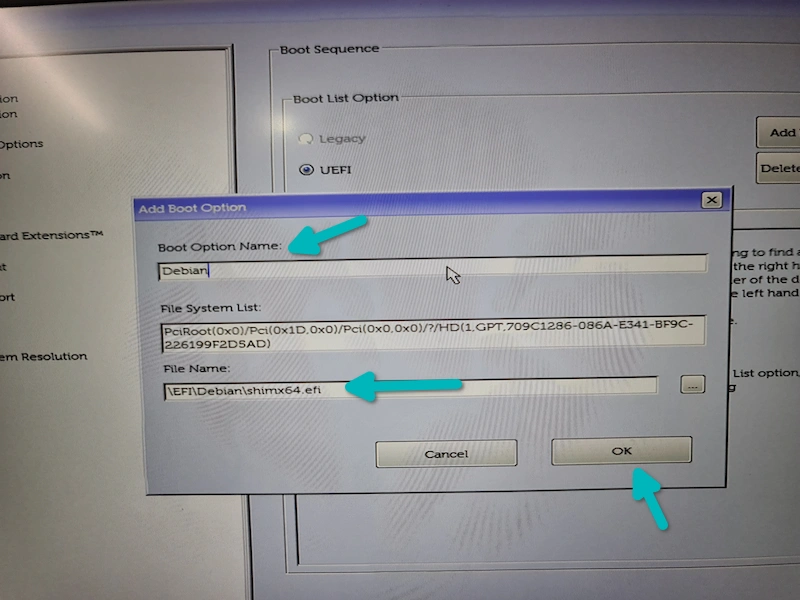
Now, you should have this boot option. Since I named it Debian, it shows two Debian boot options (one of them coming from the efi file I guess). Press F10 to save and exit the BIOS settings.
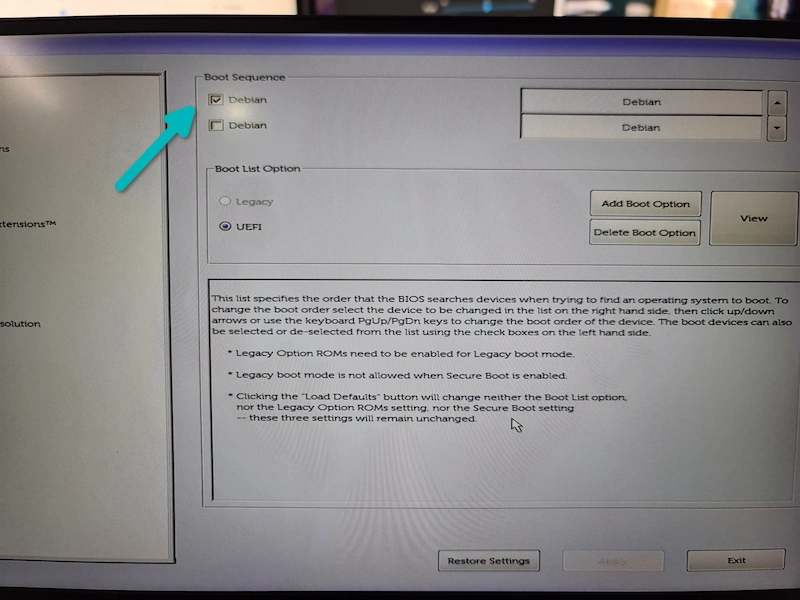
When your system boots now, you should see the grub screen with Debian boot option. You can start enjoying Debian now.

## Were you able to install Debian?
I hope I made things simpler here. It is not that you cannot install Debian from the default net installer ISO. It just takes (a lot) more effort.
Was this tutorial helpful for you in installing Debian? Are you still facing issues? Please let me know in the comment section and I’ll try to help you out. |
13,790 | 如何在 Ubuntu 中运行 Java 程序 | https://itsfoss.com/run-java-program-ubuntu/ | 2021-09-16T16:38:12 | [
"Java"
] | https://linux.cn/article-13790-1.html | 
听说,你已经开始学习 Java 编程了?很好。
你想在你的 Linux 系统上运行 Java 程序?那就更好了。
让我告诉你如何在 Ubuntu 和其他 Linux 发行版的终端中运行 Java。
### 在 Ubuntu 中运行 Java 程序
让我们在这里按正确的步骤进行。
#### 第一步:安装 Java 编译器
要运行一个 Java 程序,你需要先编译该程序。为此你需要 Java 编译器。
Java 编译器是 [JDK](https://jdk.java.net/)(<ruby> Java 开发工具包 <rt> Java Development Kit </rt></ruby>)的一部分。你需要安装 JDK,以便编译和运行 Java 程序。
首先,检查你的系统上是否已经安装了 Java 编译器:
```
javac --version
```
如果你看到类似 “Command ‘javac’ not found, but can be installed with” 的错误,这意味着你需要安装 Java 开发工具包。

在 Ubuntu 上安装 JDK 的最简单方法是使用 Ubuntu 的默认包:
```
sudo apt install default-jdk
```
你会被要求输入你的账户密码。当你输入密码时,屏幕上什么也看不到。这很正常。直接输入密码即可。当询问时,按回车键或 `Y` 键。

上述命令应该适用于其他基于 Debian 和 Ubuntu 的发行版,如 Linux Mint、Elementary OS 等。对于其他发行版,请使用你的发行版的包管理器。包的名称也可能不同。
安装完毕后,验证 `javac` 现在是否可用。

#### 第二步:在 Linux 中编译 Java 程序
要编译的话,你首先需要有一个 Java 程序文件。假设你创建了一个名为 `HelloWorld.java` 的新的 Java 程序文件,它的内容如下:
```
class HelloWorld{
public static void main(String args[]){
System.out.println("Hello World");
}
}
```
你可以 [使用终端下的 Nano 编辑器](https://itsfoss.com/nano-editor-guide/) 或 Gedit 图形化文本编辑器来编写你的 Java 程序。
```
javac HelloWorld.java
```
如果没有错误,上面的命令不会产生输出。
当你编译 Java 程序时,它会生成一个 .class 文件,文件名是你在程序中使用的类。你需要运行这个类文件。
#### 第三步:运行 Java 类文件
你不需要在这里指定类的扩展名。只需要类的名称。而这一次,你使用 `java` 命令,而不是 `javac`。
```
java HelloWorld
```
我的程序将在屏幕上打印 “Hello World”。

这就是你如何在 Linux 终端中运行一个 Java 程序。
这是最简单的一个例子。这个示例程序只有一个类。Java 编译器为你程序中的每个类都创建一个类文件。对于较大的程序和项目来说,事情会变得很复杂。
这就是为什么我建议 [在 Ubuntu 上安装 Eclipse](https://itsfoss.com/install-latest-eclipse-ubuntu/) 来进行 Java 编程。在 IDE 中编程更容易。
希望本教程对你有所帮助。有问题或建议吗?评论区都是你的。
---
via: <https://itsfoss.com/run-java-program-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | So, you have started learning Java programming? That’s good.
And you want to run the java programs on your Linux system? Even better.
Let me show how to run Java in terminal in Ubuntu and other Linux distributions.
## Running Java programs in Ubuntu
Let’s go in proper steps here.
### Step 1: Install Java compiler
To run a Java program, you need to compile the program first. You need Java compiler for this purpose.
The Java compiler is part of [JDK](https://jdk.java.net/) (Java Development Kit). You need to install JDK in order to compile and run Java programs.
First, check if you already have Java Compiler installed on your system:
`javac --version`
If you see an error like “Command ‘javac’ not found, but can be installed with”, this means you need to install Java Development Kit.
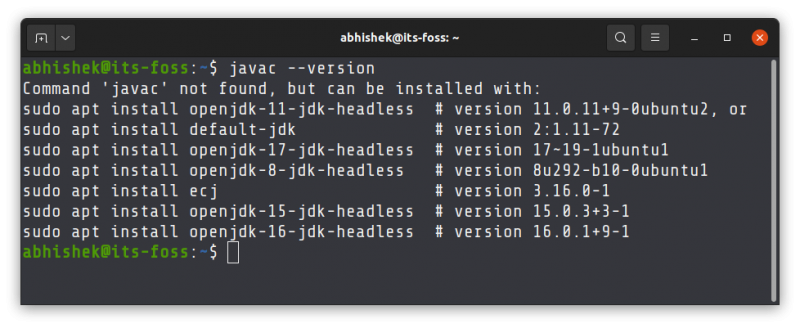
The simplest way to install JDK on Ubuntu is to go with the default offering from Ubuntu:
`sudo apt install default-jdk`
You’ll be asked to enter your account’s password. When you type the password, nothing is seen on the screen. That is normal. Just enter your password blindly. When asked, press the enter key or Y key.
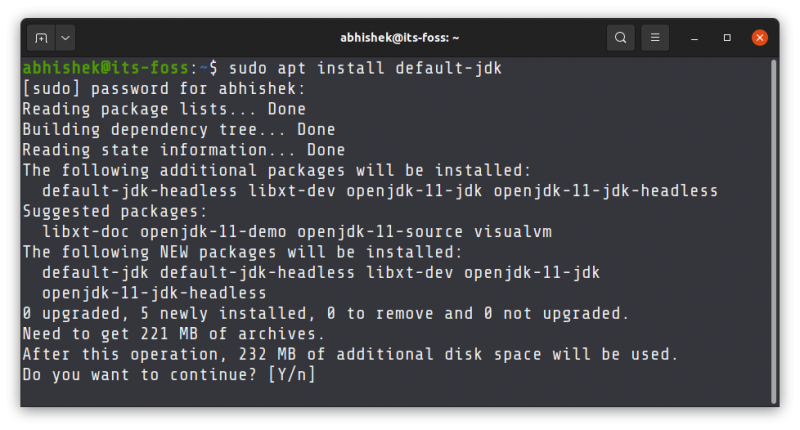
The above command should work for other Debian and Ubuntu based distributions like Linux Mint, elementary OS etc. For other distributions, use your distribution’s package manager. The package name could also be different.
Once installed, verify that javac is available now.
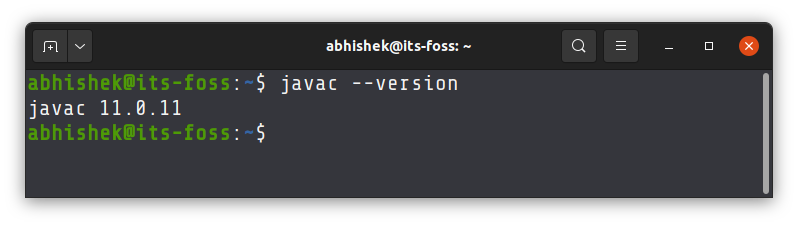
### Step 2: Compile Java program in Linux
You need to have a Java program file for this reason. Let’s say you create a new Java program file named **HelloWorld.java** and it has the following content:
```
class HelloWorld{
public static void main(String args[]){
System.out.println("Hello World");
}
}
```
You can [use Nano editor in terminal](https://itsfoss.com/nano-editor-guide/) or Gedit graphical text editor for writing your Java programs.
`javac HelloWorld.java`
If there is no error, the above command produces no output.
When you compile the Java program, it generates a .class file with the class name you used in your program. You have to run this class file.
### Step 3: Run the Java class file
You do not need to specify the class extension here. Just the name of the class. And this time, you use the command java, not javac.
`java HelloWorld`
This will print Hello World on the screen for my program.
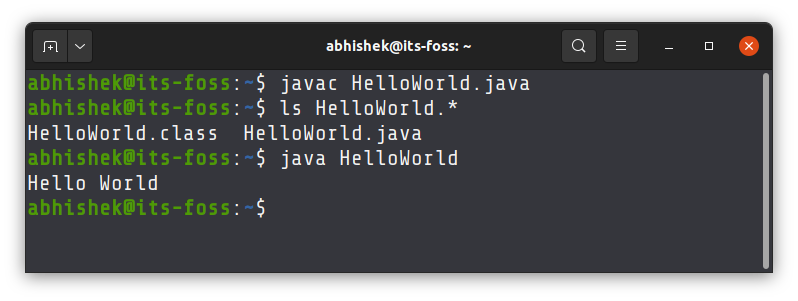
And that’s how you run a Java program in the Linux terminal.
This was the simplest of the example. The sample program had just one class. The Java compiler creates a class file for each class in your program. Things get complicated for bigger programs and projects.
This is why I advise [installing Eclipse on Ubuntu](https://itsfoss.com/install-latest-eclipse-ubuntu/) for proper Java programming. It is easier to program in an IDE.
I hope you find this tutorial helpful. Questions or suggestions? The comment section is all yours. |
13,792 | 容器的四大基础技术 | https://opensource.com/article/21/8/container-linux-technology | 2021-09-17T08:54:44 | [
"容器"
] | https://linux.cn/article-13792-1.html |
>
> 命名空间、控制组、seccomp 和 SELinux 构成了在系统上构建和运行一个容器进程的 Linux 技术基础。
>
>
>

在以前的文章中,我介绍过 [容器镜像](/article-13766-1.html) 及其 [运行时](/article-13772-1.html)。在本文中,我研究了容器是如何在一些特殊的 Linux 技术基础上实现的,这其中包括命名空间和控制组。

*图1:对容器有贡献的 Linux 技术(Nived Velayudhan, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
这些 Linux 技术构成了在系统上构建和运行容器进程的基础:
1. 命名空间
2. 控制组(cgroups)
3. Seccomp
4. SELinux
### 命名空间
<ruby> 命名空间 <rt> namespace </rt></ruby> 为容器提供了一个隔离层,给容器提供了一个看起来是独占的 Linux 文件系统的视图。这就限制了进程能访问的内容,从而限制了它所能获得的资源。
在创建容器时,Docker 或 Podman 和其他容器技术使用了 Linux 内核中的几个命名空间:
```
[nivedv@homelab ~]$ docker container run alpine ping 8.8.8.8
[nivedv@homelab ~]$ sudo lsns -p 29413
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 299 1 root /usr/lib/systemd/systemd --switched...
4026531837 user 278 1 root /usr/lib/systemd/systemd --switched...
4026533105 mnt 1 29413 root ping 8.8.8.8
4026533106 uts 1 29413 root ping 8.8.8.8
4026533107 ipc 1 29413 root ping 8.8.8.8
4026533108 pid 1 29413 root ping 8.8.8.8
4026533110 net 1 29413 root ping 8.8.8.8
```
#### 用户
用户(`user`)命名空间将用户和组隔离在一个容器内。这是通过分配给容器与宿主系统有不同的 UID 和 GID 范围来实现的。用户命名空间使软件能够以 root 用户的身份在容器内运行。如果入侵者攻击容器,然后逃逸到宿主机上,他们就只能以受限的非 root 身份运行了。
#### 挂载
挂载(`mnt`)命名空间允许容器有自己的文件系统层次结构视图。你可以在 Linux 系统中的 `/proc/<PID>/mounts` 位置找到每个容器进程的挂载点。
#### UTS
<ruby> Unix 分时系统 <rt> Unix Timeharing System </rt></ruby>(UTS)命名空间允许容器拥有一个唯一主机名和域名。当你运行一个容器时,即使使用 `- name` 标签,也会使用一个随机的 ID 作为主机名。你可以使用 [unshare 命令](https://opensource.com/article/19/10/namespaces-and-containers-linux) 来了解一下这个工作原理。
```
nivedv@homelab ~]$ docker container run -it --name nived alpine sh
/ # hostname
9c9a5edabdd6
/ #
nivedv@homelab ~]$ sudo unshare -u sh
sh-5.0# hostname isolated.hostname
sh-5.0# hostname
isolated.hostname
sh-5.0#
sh-5.0# exit
exit
[nivedv@homelab ~]$ hostname
homelab.redhat.com
```
#### IPC
<ruby> 进程间通信 <rt> Inter-Process Communication </rt></ruby>(IPC)命名空间允许不同的容器进程之间,通过访问共享内存或使用共享消息队列来进行通信。
```
[root@demo /]# ipcmk -M 10M
Shared memory id: 0
[root@demo /]# ipcmk -M 20M
Shared memory id: 1
[root@demo /]#
[root@demo /]# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0xd1df416a 0 root 644 10485760 0
0xbd487a9d 1 root 644 20971520 0
------ Semaphore Arrays --------
key semid owner perms nsems
```
#### PID
<ruby> 进程 ID <rt> Process ID </rt></ruby>(PID)命名空间确保运行在容器内的进程与外部隔离。当你在容器内运行 `ps` 命令时,由于这个命名空间隔离的存在,你只能看到在容器内运行的进程,而不是在宿主机上。
#### 网络
网络(`net`)命名空间允许容器有自己网络接口、IP 地址、路由表、端口号等视图。容器如何能够与外部通信?你创建的所有容器都会被附加到一个特殊的虚拟网络接口上进行通信。
```
[nivedv@homelab ~]$ docker container run --rm -it alpine sh
/ # ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: seq=0 ttl=119 time=21.643 ms
64 bytes from 8.8.8.8: seq=1 ttl=119 time=20.940 ms
^C
[root@homelab ~]# ip link show veth84ea6fc
veth84ea6fc@if22: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue
master docker0 state UP mode DEFAULT group default
```
### 控制组
控制组(`cgroup`)是组成一个容器的基本模块。控制组会分配和限制容器所使用的资源,如 CPU、内存、网络 I/O 等。容器引擎会自动创建每种类型的控制组文件系统,并在容器运行时为每个容器设置配额。
```
[root@homelab ~]# lscgroup | grep docker
cpuset:/docker
net_cls,net_prio:/docker
cpu,cpuacct:/docker
hugetlb:/docker
devices:/docker
freezer:/docker
memory:/docker
perf_event:/docker
blkio:/docker
pids:/docker
```
容器运行时为每个容器设置了控制组值,所有信息都存储在 `/sys/fs/cgroup/*/docker`。下面的命令将确保容器可以使用 50000 微秒的 CPU 时间片,并将内存的软、硬限制分别设置为 500M 和 1G。
```
[root@homelab ~]# docker container run -d --name test-cgroups --cpus 0.5 --memory 1G --memory-reservation 500M httpd
[root@homelab ~]# lscgroup cpu,cpuacct:/docker memory:/docker
cpu,cpuacct:/docker/
cpu,cpuacct:/docker/c3503ac704dafea3522d3bb82c77faff840018e857a2a7f669065f05c8b2cc84
memory:/docker/
memory:/docker/c3503ac704dafea3522d3bb82c77faff840018e857a2a7f669065f05c8b2cc84
[root@homelab c....c84]# cat cpu.cfs_period_us
100000
[root@homelab c....c84]# cat cpu.cfs_quota_us
50000
[root@homelab c....c84]# cat memory.soft_limit_in_bytes
524288000
[root@homelab c....c84]# cat memory.limit_in_bytes
1073741824
```
### SECCOMP
Seccomp 意思是“<ruby> 安全计算 <rt> secure computing </rt></ruby>”。它是一项 Linux 功能,用于限制应用程序进行的系统调用的集合。例如,Docker 的默认 seccomp 配置文件禁用了大约 44 个系统调用(总计超过 300 个)。
这里的思路是让容器只访问所必须的资源。例如,如果你不需要容器改变主机上的时钟时间,你可能不会使用 `clock_adjtime` 和 `clock_settime` 系统调用,屏蔽它们是合理的。同样地,你不希望容器改变内核模块,所以没有必要让它们使用 `create_module`、 `delete_module` 系统调用。
### SELinux
SELinux 是“<ruby> 安全增强的 Linux <rt> security-enhanced Linux </rt></ruby>”的缩写。如果你在你的宿主机上运行的是 Red Hat 发行版,那么 SELinux 是默认启用的。SELinux 可以让你限制一个应用程序只能访问它自己的文件,并阻止任何其他进程访问。因此,如果一个应用程序被破坏了,它将限制该应用程序可以影响或控制的文件数量。通过为文件和进程设置上下文环境以及定义策略来实现,这些策略将限制一个进程可以访问和更改的内容。
容器的 SELinux 策略是由 `container-selinux` 包定义的。默认情况下,容器以 `container_t` 标签运行,允许在 `/usr` 目录下读取(`r`)和执行(`x`),并从 `/etc` 目录下读取大部分内容。标签`container_var_lib_t` 是与容器有关的文件的通用标签。
### 总结
容器是当今 IT 基础设施的一个重要组成部分,也是一项相当有趣的技术。即使你的工作不直接涉及容器化,了解一些基本的容器概念和方法,也能让你体会到它们如何帮助你的组织。容器是建立在开源的 Linux 技术之上的,这使它们变得更加美好。
本文基于 [techbeatly](https://nivedv.medium.com/container-internals-deep-dive-5cc424957413) 的文章,并经授权改编。
---
via: <https://opensource.com/article/21/8/container-linux-technology>
作者:[Nived V](https://opensource.com/users/nivedv) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In previous articles, I have written about [container images](https://opensource.com/article/21/8/container-fundamentals-2) and [runtimes](https://opensource.com/article/21/8/deep-dive-container-runtimes). In this article, I look at how containers are made possible by a foundation of some special Linux technologies, including namespaces and control groups.
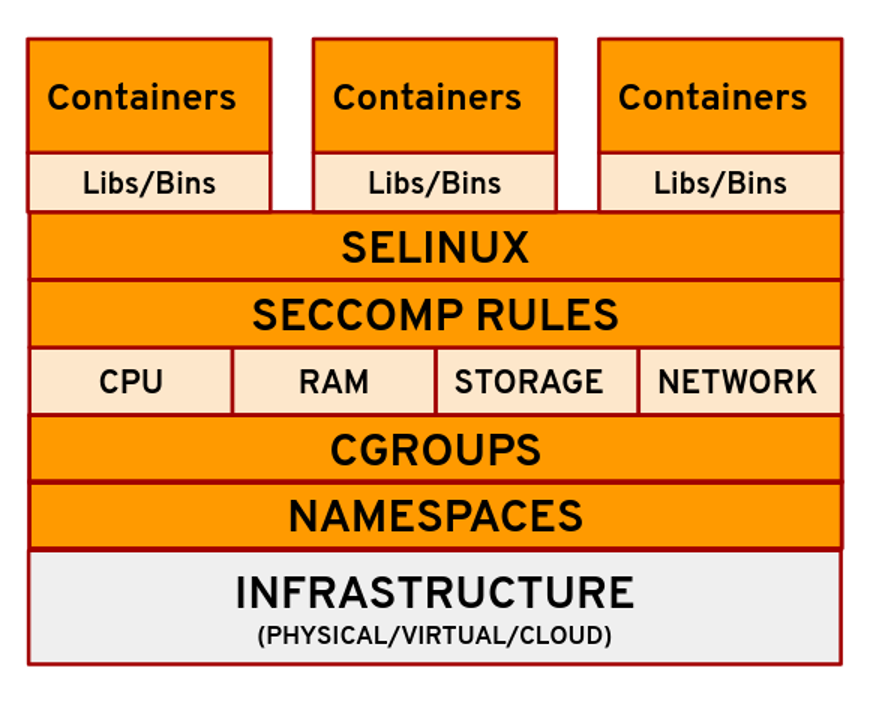
Figure 1: Linux technologies that contribute to containers
Linux technologies make up the foundations of building and running a container process on your system. Technologies include:
- Namespaces
- Control groups (cgroups)
- Seccomp
- SELinux
## Namespaces
*Namespaces* provide a layer of isolation for the containers by giving the container a view of what appears to be its own Linux filesystem. This limits what a process can see and therefore restricts the resources available to it.
There are several namespaces in the Linux kernel that are used by Docker or Podman and others while creating a container:
```
$ docker container run alpine ping 8.8.8.8
$ sudo lsns -p 29413
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 299 1 root /usr/lib/systemd/systemd --
switched...
4026533105 mnt 1 29413 root ping 8.8.8.8
4026533106 uts 1 29413 root ping 8.8.8.8
4026533105 ipc 1 29413 root ping 8.8.8.8
[...]
```
**User**
The user namespace isolates users and groups within a container. This is done by allowing containers to have a different view of UID and GID ranges compared to the host system. The user namespace enables the software to run inside the container as the root user. If an intruder attacks the container and then escapes to the host machine, they're confined to only a non-root identity.
**Mnt**
The mnt namespace allows the containers to have their own view of the system's file system hierarchy. You can find the mount points for each container process in the */proc/<PID>/mounts* location in your Linux system.
**UTS**
The Unix Timesharing System (UTS) namespace allows containers to have a unique hostname and domain name. When you run a container, a random ID is used as the hostname even when using the `— name`
tag. You can use the [ unshare command](https://opensource.com/article/19/10/namespaces-and-containers-linux) to get an idea of how this works.
```
$ docker container run -it --name nived alpine sh
/ # hostname
9c9a5edabdd6
/ #
$ sudo unshare -u sh
# hostname isolated.hostname
# hostname
# exit
$ hostname
homelab.redhat.com
```
**IPC**
The Inter-Process Communication (IPC) namespace allows different container processes to communicate by accessing a shared range of memory or using a shared message queue.
```
# ipcmk -M 10M
Shared memory id: 0
# ipcmk -M 20M
Shared memory id: 1
# ipcs
---- Message Queues ----
key msqid owner perms used-bytes messages
---- Shared Memory Segments
key shmid owner perms bytes nattch status
0xd1df416a 0 root 644 10485760 0
0xbd487a9d 1 root 644 20971520 0
[...]
```
**PID**
The Process ID (PID) namespace ensures that the processes running inside a container are isolated from the external world. When you run a `ps`
command inside a container, you only see the processes running inside the container and not on the host machine because of this namespace.
**Net**
The network namespace allows the container to have its own view of network interface, IP addresses, routing tables, port numbers, and so on. How does a container able to communicate to the external world? All containers you create get attached to a special virtual network interface for communication.
## Control groups (cgroups)
Cgroups are fundamental blocks of making a container. A cgroup allocates and limits resources such as CPU, memory, network I/O that are used by containers. The container engine automatically creates a cgroup filesystem of each type, and sets values for each container when the container is run.
## SECCOMP
Seccomp basically stands for *secure computing*. It is a Linux feature used to restrict the set of system calls that an application is allowed to make. The default seccomp profile for Docker, for example, disables around 44 syscalls (over 300 are available).
The idea here is to provide containers access to only those resources which the container might need. For example, if you don't need the container to change the clock time on your host machine, you probably have no use for the *clock_adjtime* and *clock_settime *syscalls, and it makes sense to block them out. Similarly, you don't want the containers to change the kernel modules, so there is no need for them to make* create_module, delete_module* syscalls.
## SELinux
SELinux stands for *security-enhanced Linux*. If you are running a Red Hat distribution on your hosts, then SELinux is enabled by default. SELinux lets you limit an application to have access only to its own files and prevent any other processes from accessing them. So, if an application is compromised, it would limit the number of files that it can affect or control. It does this by setting up contexts for files and processes and by defining policies that would enforce what a process can see and make changes to.
SELinux policies for containers are defined by the `container-selinux`
package. By default, containers are run with the **container_t** label and are allowed to read (r) and execute (x) under the */usr* directory and read most content from the */etc *directory. The label **container_var_lib_t** is common for files relating to containers.
## Wrap up
Containers are a critical part of today's IT infrastructure and a pretty interesting technology, too. Even if your role doesn't involve containerization directly, understanding a few fundamental container concepts and approaches gives you an appreciation for how they can help your organization. The fact that containers are built on open source Linux technologies makes them even better!
*This article is based on a techbeatly article and has been adapted with permission.*
## Comments are closed. |
13,793 | 在 Linux 上使用 lspci 命令查看硬件情况 | https://opensource.com/article/21/9/lspci-linux-hardware | 2021-09-17T09:14:35 | [
"lspci",
"硬件"
] | /article-13793-1.html |
>
> lspci 命令用于显示 Linux 系统上的设备和驱动程序。
>
>
>

当你在个人电脑或服务器上运行 Linux 时,有时需要识别该系统中的硬件。`lspci` 命令用于显示连接到 PCI 总线的所有设备,从而满足上述需求。该命令由 [pciutils](https://mj.ucw.cz/sw/pciutils/) 包提供,可用于各种基于 Linux 和 BSD 的操作系统。
### 基础用法
由于访问权限,普通用户运行 `lspci` 时显示的信息可能会受限,因此可以使用 `sudo` 运行命令,系统会给出完整的信息图。
直接运行 `lspci` 命令会列出 PCI 总线及其连接的设备,下图是在我的媒体中心 PC 上的演示样例。图中是一个基于 AMD Phenom CPU 的系统,所以它有一个 AMD 芯片组,以及 Atheros 无线适配器和 Nvidia 显卡。所有硬件设备都列出了详细信息,例如供应商、名称和型号等:
```
$ sudo lspci
00:00.0 Host bridge: Advanced Micro Devices, Inc. [AMD] RS880 Host Bridge
00:02.0 PCI bridge: Advanced Micro Devices, Inc. [AMD] RS780 PCI to PCI bridge (ext gfx port 0)
00:04.0 PCI bridge: Advanced Micro Devices, Inc. [AMD] RS780/RS880 PCI to PCI bridge (PCIE port 0)
00:05.0 PCI bridge: Advanced Micro Devices, Inc. [AMD] RS780/RS880 PCI to PCI bridge (PCIE port 1)
00:11.0 SATA controller: Advanced Micro Devices, Inc. [AMD/ATI] SB7x0/SB8x0/SB9x0 SATA Controller [AHCI mode]
00:12.0 USB controller: Advanced Micro Devices, Inc. [AMD/ATI] SB7x0/SB8x0/SB9x0 USB OHCI0 Controller
00:12.1 USB controller: Advanced Micro Devices, Inc. [AMD/ATI] SB7x0 USB OHCI1 Controller
00:12.2 USB controller: Advanced Micro Devices, Inc. [AMD/ATI] SB7x0/SB8x0/SB9x0 USB EHCI Controller
00:13.0 USB controller: Advanced Micro Devices, Inc. [AMD/ATI] SB7x0/SB8x0/SB9x0 USB OHCI0 Controller
00:13.1 USB controller: Advanced Micro Devices, Inc. [AMD/ATI] SB7x0 USB OHCI1 Controller
00:13.2 USB controller: Advanced Micro Devices, Inc. [AMD/ATI] SB7x0/SB8x0/SB9x0 USB EHCI Controller
00:14.0 SMBus: Advanced Micro Devices, Inc. [AMD/ATI] SBx00 SMBus Controller (rev 3c)
00:14.1 IDE interface: Advanced Micro Devices, Inc. [AMD/ATI] SB7x0/SB8x0/SB9x0 IDE Controller
00:14.3 ISA bridge: Advanced Micro Devices, Inc. [AMD/ATI] SB7x0/SB8x0/SB9x0 LPC host controller
00:14.4 PCI bridge: Advanced Micro Devices, Inc. [AMD/ATI] SBx00 PCI to PCI Bridge
00:14.5 USB controller: Advanced Micro Devices, Inc. [AMD/ATI] SB7x0/SB8x0/SB9x0 USB OHCI2 Controller
00:18.0 Host bridge: Advanced Micro Devices, Inc. [AMD] Family 10h Processor HyperTransport Configuration
00:18.1 Host bridge: Advanced Micro Devices, Inc. [AMD] Family 10h Processor Address Map
00:18.2 Host bridge: Advanced Micro Devices, Inc. [AMD] Family 10h Processor DRAM Controller
00:18.3 Host bridge: Advanced Micro Devices, Inc. [AMD] Family 10h Processor Miscellaneous Control
00:18.4 Host bridge: Advanced Micro Devices, Inc. [AMD] Family 10h Processor Link Control
01:00.0 VGA compatible controller: NVIDIA Corporation GK107 [GeForce GTX 650] (rev a1)
01:00.1 Audio device: NVIDIA Corporation GK107 HDMI Audio Controller (rev a1)
02:00.0 Network controller: Qualcomm Atheros AR9287 Wireless Network Adapter (PCI-Express) (rev 01)
```
### 详细输出
添加 `-v` 选项会显示每个设备的详细信息,你可以使用 `-vv` 或 `-vvv` 来获取更多的设备细节。在 `-v` 级别,`lspci` 会显示所有设备的各种子系统和内存地址、中断请求(IRQ)编号和一些其他功能信息。输出信息会非常长。在你的系统上试一试吧。
### 使用 grep 过滤搜索
你可能会需要缩小搜索范围。例如,RPM Fusion 网站有安装 Nvidia 图形驱动程序的说明,里面就首先使用了 `grep` 命令来定位显卡信息。下面是我在笔记本电脑上得到的输出:
```
$ sudo lspci | grep -e VGA
00:02.0 VGA compatible controller: Intel Corporation UHD Graphics 620 (rev 07)
$ sudo lspci | grep -e 3D
01:00.0 3D controller: NVIDIA Corporation GM108M [GeForce MX130] (rev a2)
```
下面(LCTT 译注:原文为 “above”,应为作者笔误)的 `grep` 命令在我的媒体中心 PC 上定位了一个 VGA 设备,但没有显示 3D 设备。
```
$ sudo lspci | grep -e VGA
01:00.0 VGA compatible controller: NVIDIA Corporation GK107 [GeForce GTX 650] (rev a1)
$ sudo lspci | grep -e 3D
$
```
### 按供应商 ID 搜索
还有另一种无需 `grep` 的方法可以使用。假设我想确认一下此计算机是否有其他的 Nvidia 设备,在此之前我们还需要一些额外信息,使用 `-nn` 选项显示的供应商和设备 ID 号。在我的媒体中心 PC 上,此选项会给出我的 VGA 卡、供应商 ID 和设备 ID:
```
$ sudo lspci -nn | grep -e VGA
01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GK107 [GeForce GTX 650] [10de:0fc6] (rev a1)
```
设备名称后的方括号内有用冒号分隔的数字,即供应商和设备 ID。输出表明 Nvidia Corporation 制造的设备的供应商 ID 为 `10de`。
`-d` 选项用于指定供应商、设备或类 ID 的所有设备。以下是我系统中的所有 Nvidia 设备(保留 `-nn` 以解析供应商 ID):
```
$ sudo lspci -nn -d 10de:
01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GK107 [GeForce GTX 650] [10de:0fc6] (rev a1)
01:00.1 Audio device [0403]: NVIDIA Corporation GK107 HDMI Audio Controller [10de:0e1b] (rev a1)
```
从输出中可以看到,除了显卡之外,我还有一个 Nvidia 音频设备。实际上它们都属于同一张 **Nvidia GeForce GTX 650** 卡,但这仍然是一个很好的示例。
### 内核模块
结合 PCI 硬件设备,`lspci` 可以使用 `-k` 选项显示内核加载了哪些驱动程序模块。我将此选项添加到我的 `lspci` 命令来查看有关我的 Nvidia 设备的信息。
```
$ sudo lspci -nn -k -d 10de:
01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GK107 [GeForce GTX 650] [10de:0fc6] (rev a1)
Subsystem: eVga.com. Corp. GK107 [GeForce GTX 650] [3842:2650]
Kernel driver in use: nvidia
Kernel modules: nvidiafb, nouveau, nvidia_drm, nvidia
01:00.1 Audio device [0403]: NVIDIA Corporation GK107 HDMI Audio Controller [10de:0e1b] (rev a1)
Subsystem: eVga.com. Corp. GK107 HDMI Audio Controller [3842:2650]
Kernel driver in use: snd_hda_intel
Kernel modules: snd_hda_intel
```
可以看到额外显示了两行:<ruby> 正在使用的内核驱动程序 <rt> Kernel driver in use </rt></ruby> 和 <ruby> 内核模块 <rt> Kernel modules </rt></ruby>,其中后者列出了可用于支持该设备的模块。
### 同步最新状态
新设备和供应商总是在不断迭代。如果看到显示为 `unknown` 的设备,说明你的 PCI 设备 ID 数据库可能已过时。有两种方法可以检查更新。`-Q` 选项会使用 DNS 查询中央数据库,当然,这需要联网。
```
$ sudo lspci -Q
```
你还可以通过运行命令 `update-pciids` 来更新本地 PCI ID 数据库。
```
$ sudo update-pciids
Downloaded daily snapshot dated 2021-08-22 03:15:01
```
### 了解有关你的硬件的更多信息
当然,`lspci` 只是 Linux 中用于查询系统硬件和软件的诸多命令之一。读者可以在阅读关于 USB 设备的文章,了解有关 Linux 硬件的更多信息:[使用此 USB ID 存储库识别 Linux 上的更多设备](https://opensource.com/article/20/8/usb-id-repository)。
---
via: <https://opensource.com/article/21/9/lspci-linux-hardware>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,795 | 从命令行使用 wget 调试网页错误 | https://opensource.com/article/21/9/wget-debug-web-server | 2021-09-17T22:50:23 | [
"wget",
"调试"
] | https://linux.cn/article-13795-1.html |
>
> 调试 Web 服务器的一种方法是使用 wget 命令行程序。
>
>
>

有时在管理一个网站时,事情会被搞得一团糟。你可能会删除一些陈旧的内容,用重定向到其他页面来代替。后来,在做了其他改动后,你发现一些网页变得完全无法访问了。你可能会在浏览器中看到一个错误:“该页面没有正确重定向”,并建议你检查你的 cookie。

调试这种情况的一个方法是使用 `wget` 命令行程序,使用 `-S` 选项来显示所有的服务器响应。当使用 `wget` 进行调试时,我也喜欢使用 `-O` 选项将输出保存到一些临时文件中,以备以后需要查看其内容。
```
$ wget -O /tmp/test.html -S http://10.0.0.11/announce/
--2021-08-24 17:09:49-- http://10.0.0.11/announce/
Connecting to 10.0.0.11:80... connected.
HTTP request sent, awaiting response...
HTTP/1.1 302 Found
Date: Tue, 24 Aug 2021 22:09:49 GMT
Server: Apache/2.4.48 (Fedora)
X-Powered-By: PHP/7.4.21
Location: http://10.0.0.11/assets/
Content-Length: 0
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
Content-Type: text/html; charset=UTF-8
Location: http://10.0.0.11/assets/ [following]
--2021-08-24 17:09:49-- http://10.0.0.11/assets/
Reusing existing connection to 10.0.0.11:80.
HTTP request sent, awaiting response...
HTTP/1.1 302 Found
Date: Tue, 24 Aug 2021 22:09:49 GMT
Server: Apache/2.4.48 (Fedora)
X-Powered-By: PHP/7.4.21
Location: http://10.0.0.11/announce/
Content-Length: 0
Keep-Alive: timeout=5, max=99
Connection: Keep-Alive
Content-Type: text/html; charset=UTF-8
Location: http://10.0.0.11/announce/ [following]
--2021-08-24 17:09:49-- http://10.0.0.11/announce/
Reusing existing connection to 10.0.0.11:80.
.
.
.
20 redirections exceeded.
```
我在这个输出中省略了很多重复的内容。通过阅读服务器的响应,你可以看到 `http://10.0.0.11/announce/` 立即重定向到 `http://10.0.0.11/assets/`,然后又重定向到 `http://10.0.0.11/announce/`。以此类推。这是一个无休止的循环,`wget` 将在 20 次重定向后退出。但有了这些调试信息,你可以修复重定向,避免循环。
---
via: <https://opensource.com/article/21/9/wget-debug-web-server>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sometimes when managing a website, things can get messed up. You might remove some stale content and replace it with a redirect to other pages. Later, after making other changes, you find some web pages become entirely inaccessible. You might see an error in your browser that "The page isn't redirecting properly" with a suggestion to check your cookies.
Screenshot by Jim Hall, CC-BY SA 4.0
One way to debug this situation is by using the `wget`
command-line program, with the `-S`
option to show all server responses. When using `wget`
for debugging, I also prefer to save the output to some temporary file, using the `-O`
option, in case I need to view its contents later.
```
$ wget -O /tmp/test.html -S http://10.0.0.11/announce/
--2021-08-24 17:09:49-- http://10.0.0.11/announce/
Connecting to 10.0.0.11:80... connected.
HTTP request sent, awaiting response...
HTTP/1.1 302 Found
Date: Tue, 24 Aug 2021 22:09:49 GMT
Server: Apache/2.4.48 (Fedora)
X-Powered-By: PHP/7.4.21
Location: http://10.0.0.11/assets/
Content-Length: 0
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
Content-Type: text/html; charset=UTF-8
Location: http://10.0.0.11/assets/ [following]
--2021-08-24 17:09:49-- http://10.0.0.11/assets/
Reusing existing connection to 10.0.0.11:80.
HTTP request sent, awaiting response...
HTTP/1.1 302 Found
Date: Tue, 24 Aug 2021 22:09:49 GMT
Server: Apache/2.4.48 (Fedora)
X-Powered-By: PHP/7.4.21
Location: http://10.0.0.11/announce/
Content-Length: 0
Keep-Alive: timeout=5, max=99
Connection: Keep-Alive
Content-Type: text/html; charset=UTF-8
Location: http://10.0.0.11/announce/ [following]
--2021-08-24 17:09:49-- http://10.0.0.11/announce/
Reusing existing connection to 10.0.0.11:80.
.
.
.
20 redirections exceeded.
```
I've omitted a lot of repetition in this output. By reading the server responses, you can see that `http ://10.0.0.11/announce/`
redirects immediately to `http ://10.0.0.11/assets/`
, which then redirects back to `http ://10.0.0.11/announce/`
. And so on. This is an endless loop and `wget`
will exit after 20 redirections. But armed with this debugging information, you can fix the redirects and avoid the loop.
## 1 Comment |
13,796 | 13 个最好的 React JavaScript 框架 | https://opensource.com/article/20/1/react-javascript-frameworks | 2021-09-18T09:57:56 | [
"React",
"JavaScript"
] | /article-13796-1.html |
>
> 如果你正在用 React.js 或 React Native 来开发用户界面的话,试试这些框架。
>
>
>

React.js 和 React Native 都是用来开发用户界面(UI)的很受欢迎的开源平台。在 StackOverflow 2019 年度开发者调查里,两个框架的可取性和使用情况都排名靠前。React.js 是 Facebook 在 2011 年开发的一个 JavaScript 库,来实现跨平台,动态以及高性能的 UI 设计需求;而 React Native 则是 Facebook 在 2015 年发布的框架,目的是使用 JavaScript 构建原生应用。
下面介绍 13 个最好的 React JavaScript 框架,都是开源项目。前 11 个(和 React 一样)都使用 MIT 许可证授权,后面两个使用 Apache 2.0 许可证。
### 1、Create React App
这个 Facebook 开发的命令行工具是 React Native 项目一定要用的。因为 [Create React App](https://github.com/facebook/create-react-app) 使用很简单,还可以避免你自己手动设定和配置应用,因此能节省大量的时间和精力。仅仅使用给一个简单的命令,就可以为你准备好创建 React 原生项目所需的一切。你可以用它来创建分类和文件,而且该框架还自带了工具用来构建,测试和启动应用。
```
# 安装软件包
$ npm install -g create-react-native-web-app
# 运行 create-react-native-web-app <项目目录>
$ create-react-native-web-app myApp
# 切换到创建的 <项目目录>
$ cd myApp
# 运行 Web/Ios/Android 调试
# Web
$ npm run web
# IOS(模拟)
$ npm run ios
# Android(实际连接的设备)
$ npm run android
```
#### 为什么选择 Create React App
1. 使用配置包、转码器,以及测试运行器进行开发的一流工具
2. 在应用架构里不需要配置以及没有额外文件
3. 确定的开发栈
4. 高效快速的开发工具
### 2、Material Kit React
[Material Kit React](https://github.com/creativetimofficial/material-kit-react) 是受谷歌的 Material Design 系统启发开发的,很适合用来创建 React UI 组件。这个库最大的优点是提供了大量的组件,可以互相搭配做出非常好的效果。有超过一千个完全编码的组件,每一个都有用文件夹组织起来的独立层。这样你就可以有上千个选项可以选择。它同时也包含一些示例页面,方便你从中寻找灵感,或者向别人分享你的点子或创意。
#### 安装 Material Kit
```
$ npm install @material-ui/core
```
#### 使用
```
import React from 'react';
import Button from '@material-ui/core/Button';
const App = () => (
<Button variant="contained" color="primary">
Hello World
</Button>
);
```
Material-UI 组件不需要其他额外设置,也不会干扰全局变量空间。
#### 优点
这个 React 组件支持简易快速的网页开发。你可以用它创建自己的设计系统,或者直接开始 Material Design。
### 3、Shards React
这个现代的 React UI 工具为了追求高效率,是从最底层开始构建的。它拥有现代的设计系统,可以让你按自己的想法任意定制。你甚至可以下载源文件,然后从代码级别定制。另外,它用来设计样式的 SCSS 语法提高了开发体验。
[Shards React](https://github.com/DesignRevision/shards-react) 基于 Shards,使用了 React Datepicker、React Popper(一个定位引擎)和 noUISlider。还带有非常优秀的 Material Design 图标。还有很多设计好的版本,可以帮你寻找灵感或上手。
#### 用 Yarn 或 NPM 安装 Shards
```
# Yarn
yarn add shards-react
# NPM
npm i shards-react
```
#### 优点
1. Shards 是一个轻量级的脚本,压缩后大概 13kb
2. Shards 默认支持响应式,图层可以适配任意大小屏幕
3. Shards 有完整的文档,可以快速开始构建漂亮的界面
### 4、Styled Components
这个高效的 CSS 工具可以用来为应用的可视界面创建小型可重用的组件。使用传统的 CSS,你可能会不小心覆盖掉网站其他位置的选择器,但 [Styled Components](https://github.com/styled-components/styled-components) 通过使用直接内嵌到组件里的 CSS 语法,可以完全避免这个问题。
#### 安装
```
npm install --save styled-components
```
#### 使用
```
const Button = styled.button`
background: background_type;
border-radius: radius_value;
border: abc;
color: name_of_color;
Margin: margin_value;
padding: value`;
```
#### 优点
1. 让组件有更好的可读性
2. 组件样式依赖 JavaScript
3. 创建定制 CSS 组件
4. 内嵌样式
5. 简单地调用 `styled()` 可以将组件甚至是自定义组件转换成样式组件
### 5、Redux
[Redux](https://github.com/reduxjs/redux) 是一个为 JavaScript 应用提供状态管理的方案。常用于 React.js,也可以用在其他类 React 框架里。
#### 安装
```
sudo npm install redux
sudo npm install react-redux
```
#### 使用
```
import { createStore } from "redux";
import rotateReducer from "reducers/rotateReducer";
function configureStore(state = { rotating: value}) {
return createStore(rotateReducer,state);
}
export default configureStore;
```
#### 优点
1. 可预计的状态更新有助于定义应用里的数据流
2. 逻辑上测试更简单,使用 reducer 函数进行时间旅行调试也更容易
3. 统一管理状态
### 6、React Virtualized
这个 React Native JavaScript 框架帮助渲染 large-list 和 tabular-data。使用 [React Virtualized](https://github.com/bvaughn/react-virtualized),你可以限制请求和文档对象模型(DOM)元素的数量,从而提高 React 应用的性能。
#### 安装
```
npm install react-virtualized
```
#### 使用
```
import 'react-virtualized/styles.css'
import { Column, Table } from 'react-virtualized'
import AutoSizer from 'react-virtualized/dist/commonjs/AutoSizer'
import List from 'react-virtualized/dist/commonjs/List'
{
alias: {
'react-virtualized/List': 'react-virtualized/dist/es/List',
},
...等等
}
```
#### 优点
1. 高效展示大量数据
2. 渲染超大数据集
3. 使用一系列组件实现虚拟渲染
### 7、React DnD
[React DnD](https://github.com/react-dnd/react-dnd/) 用来创建复杂的拖放界面。拖放控件库有很多,选用 React DnD 是因为它是基于 HTML5 的拖放 API 的,创建界面更简单。
#### 安装
```
npm install react-dnd-preview
```
#### 使用
```
import Preview from 'react-dnd-preview';
const generatePreview = ({itemType, item, style}) => {
return <div class="item-list" style={style}>{itemType}</div>;
};
class App extends React.Component {
...
render() {
return (
<DndProvider backend={MyBackend}>
<ItemList />
<Preview generator={generatePreview} />
// or
<Preview>{generatePreview}</Preview>
</DndProvider>
);
}
}
```
#### 优点
1. 漂亮自然的控件移动
2. 强大的键盘和屏幕阅读支持
3. 极限性能
4. 强大整洁的接口
5. 标准浏览器支持非常好
6. 中性样式
7. 没有额外创建 DOM 节点
### 8、React Bootstrap
这个 UI 库将 Bootstrap 的 JavaScript 替换成了 React,可以更好地控制每个组件的功能。每个组件都构建成能轻易访问,因此 [React Bootstrap](https://github.com/react-bootstrap/react-bootstrap) 有利于构建前端框架。有上千种 bootstrap 主题可以选择。
#### 安装
```
npm install react-bootstrap bootstrap
```
#### 使用
```
import 'bootstrap/dist/css/bootstrap.min.css';
import React from 'react';
import ReactDOM from 'react-dom';
import './index.css';
import App from './App';
import registerServiceWorker from './registerServiceWorker';
ReactDOM.render(<App />, document.getElementById('root'));
registerServiceWorker();
```
#### 优点
1. 可以简单导入所需的代码/组件
2. 通过压缩 Bootstrap 节省了输入和问题
3. 通过压缩 Bootstrap 减少了输入工作和冲突
4. 使用简单
5. 使用元素封装
### 9、React Suite
[React Suite](https://github.com/rsuite/rsuite) 是另一个高效的 React.js 框架,包含了大量组件库,方便开发企业级产品。支持所有主流浏览器和平台,适用于任何系统。还支持服务器端渲染。
#### 安装
```
npm i rsuite --save
```
#### 使用
```
import { Button } from 'rsuite';
import 'rsuite/styles/less/index.less';
ReactDOM.render(<Button>Button</Button>, mountNode);
```
#### 优点
1. 通过全局访问特性轻松管理应用
2. 使用 Redux 库集中管理系统状态
3. Redux 库有灵活的 UI 层,以及广泛的生态
4. Redux 库减少系统复杂度,并提供了全局访问特性
### 10、PrimeReact
[PrimeReact](https://github.com/primefaces/primereact) 最值得推荐的是它提供了几乎覆盖所有基本 UI 需求的组件,比如输入选项,菜单,数据展示,消息,等等。这个框架还优化了移动体验,帮助你设计触摸优化的元素。
#### 安装
```
npm install primereact --save
npm install primeicons --save
```
#### 使用
```
import {Dialog} from 'primereact/dialog';
import {Accordion,AccordionTab} from 'primereact/accordion';
dependencies: {
"react": "^16.0.0",
"react-dom": "^16.0.0",
"react-transition-group": "^2.2.1",
"classnames": "^2.2.5",
"primeicons": "^2.0.0"
}
```
#### 优点
1. 简单而高效
2. 容易使用
3. Spring 应用
4. 创建复杂用户界面
5. 好用而简单
### 11、React Router
[React Router](https://github.com/ReactTraining/react-router) 在 React Native 开发社区很受欢迎,因为它上手很容易。只需要你在电脑上安装 Git 和 npm 包管理工具,有 React 的基础知识,以及好学的意愿。没什么特别难的地方。
#### 安装
```
$ npm install --save react-router
```
#### 使用
```
import { Router, Route, Switch } from "react-router";
// 使用 CommonJS 模块
var Router = require("react-router").Router;
var Route = require("react-router").Route;
var Switch = require("react-router").Switch;
```
#### 优点
1. 动态路由匹配
2. 在导航时支持不同页面的 CSS 切换
3. 统一的应用结构和行为
### 12、Grommet
[Grommet](https://github.com/grommet/grommet) 常用于开发响应式、可访问的移动网页应用。这个用 Apache 2.0 许可证授权的 JavaScript 框架最大的优点是用很小的包提供了可访问性、模块化、响应式以及主题功能。这可能是它被一些公司广泛使用的主要原因,比如奈飞、通用电气、优步以及波音。
#### 安装 for yarn and npm
```
$ npm install grommet styled-components --save
```
#### 使用
```
"grommet-controls/chartjs": {
"transform": "grommet-controls/es6/chartjs/${member}",
"preventFullImport": true,
"skipDefaultConversion": true
```
#### 优点
1. 创建一个工具包来打包
2. 把开放政策发挥到极致
3. 重构有助于影响已成立的组织
### 13、Onsen UI
[Onsen UI](https://github.com/OnsenUI/OnsenUI) 另一个使用 HTML5 和 JavaScript 的手机应用开发框架,集成了 Angular、Vue 和 React,使用 Apache 2.0 许可证授权。
Onsen 提供了标签、侧边栏、堆栈导航以及其他组件。这个框架最好的地方是,它所有的组件都支持 iOS 和安卓 Material Design 自动适配,会根据不同的平台切换应用的外观。
#### 安装
```
npm install onsenui
```
#### 使用
```
(function() {
'use strict';
var module = angular.module('app', ['onsen']);
module.controller('AppController', function($scope) {
// more to come here
});
})();
```
#### 优点
1. Onsen UI 基于自由而开源代码
2. 不强制基于它开发的应用使用任何形式的 DRM
3. 内置了 JavaScript 和 HTML5 代码
4. 给最终用户带来原生体验
---
你最喜欢哪个 React JavaScript 框架?请在评论区分享。
---
via: <https://opensource.com/article/20/1/react-javascript-frameworks>
作者:[Amit Dua](https://opensource.com/users/amitdua) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zpl1025](https://github.com/zpl1025) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,798 | Kali Linux 2021.3 的新改进 | https://news.itsfoss.com/kali-linux-2021-3-release/ | 2021-09-18T22:21:00 | [
"Kali"
] | https://linux.cn/article-13798-1.html |
>
> Kali Linux 2021.3 带来了一些重要的功能改进以及一些新工具。此外还有一个惊喜,他们还宣布正在开发他们的第一个 NetHunter 智能手表。
>
>
>

Kali Linux 是 [用于渗透测试的最佳 Linux 发行版](https://itsfoss.com/linux-hacking-penetration-testing/) 之一。它是基于 Debian 的,但它可能不适合替代你的成熟的桌面操作系统。
最新的 2021.3 版本带来了一些重要的功能添加和改进。让我们来看看它们。
### 有何新变化?

#### OpenSSL 兼容性
重新配置了 [OpenSSL](https://www.openssl.org/),以扩大 Kali 可以连接的服务。因此,老式过期的协议,如 TLS 1.0 和 TLS 1.1 以及更旧的加密算法,在默认情况下是允许的。也就是说;它将让 Kali 可以连接到更多过时的服务器。然而,如果你不需要它,你可以改变这个选项。
#### 虚拟化的改进
众所周知,Kali 可以作为一个虚拟机完美地工作。首先,无论你的访客机是在 VirtualBox、VMware、Hyper-V 还是 QEMU+Spice 下运行,宿主机和访客机系统之间的拖放、复制和粘贴等操作都比以前更顺畅。
其次,使用 Kali-Tweaks 可以更容易为 Hyper-V 增强会话模式(一种虚拟化管理程序)配置 Kali。
简而言之,Kali Linux 2021.3 使得在设置虚拟环境时的体验更加完美。
#### Kali 工具
每一个 Kali 版本都包含新的工具,这是理所当然的。同样的,这个版本也不例外。Kali 加入的工具有:
* [Berate\_ap](https://pkg.kali.org/pkg/berate-ap) - 编组 MANA rogue Wi-Fi 接入点
* [CALDERA](https://pkg.kali.org/pkg/caldera) - 可扩展的自动对手模拟平台
* [EAPHammer](https://pkg.kali.org/pkg/eaphammer) - 针对 WPA2-Enterprise Wi-Fi 网络的 evil twin 攻击
* [HostHunter](https://pkg.kali.org/pkg/hosthunter) - 使用 OSINT 技术发现主机名的侦察工具
* [RouterKeygenPC](https://pkg.kali.org/pkg/routerkeygenpc) - 生成默认的 WPA/WEP 无线密钥
* [Subjack](https://pkg.kali.org/pkg/subjack) - 子域接管
* [WPA\_Sycophant](https://pkg.kali.org/pkg/wpa-sycophant) - EAP 中继攻击的邪恶客户端部分
#### Kali ARM 更新和 Kali-Tools
在 Kali 2021.3 中,对 ARM 设备的支持得到了更多的改进。我发现最吸引人的是:
* en\_US.UTF-8 是所有镜像的默认语言。
* 重新构建了 Kali ARM 构建脚本,以更好地支持一些设备。
* 树莓派镜像现在可以使用 `/boot` 分区上的 `wpa_supplicant.conf` 文件。
此外,Kali 刷新了其信息域 **Kali-Tools**,以提供简洁的工具概述、整洁的界面和快速的系统。
### 其他变化

Kali 还有其他一些不错的改进,包括:
* 改进了 Xfce 和 Gnome 版本的布局。Kali 并没有忘记 KDE,因为这是它最喜欢的桌面环境之一,已经内置了 KDE 5.21 是新的版本。
* 他们的文档网站中的一些重要页面进行了大幅更新。
* 与 Ampere 合作,让其 ARM 包构建机运行在 Ampere 的硬件上。因此,其大幅的提速使得 Kali 受益。
Kali 增强了针对安卓设备的移动渗透测试平台。换句话说,你现在可以在 Android 11 设备上安装 Kali NetHunter,而不需要完整的可工作的 [TWRP](http://twrp.me/)(Team Win Recovery Project)。最重要的是,由于其方便的安装程序,这一更新很有希望。
除了这个版本之外,他们还宣布了他们的第一个 NetHunter 智能手表,**TicHunter Pro**。但是,它仍然处于开发的最初阶段。
要了解更多关于这次升级的所有技术变化,请参考 [官方公告](https://www.kali.org/blog/kali-linux-2021-3-release/)。
### 总结
总的来说,这是一个重要的版本,提供了重要的改进和令人兴奋的新工具。从它的官方网站上下载它,就可以开始了。
* [下载 Kali Linux 2021.3](https://www.kali.org/get-kali/)
---
via: <https://news.itsfoss.com/kali-linux-2021-3-release/>
作者:[Omar Maarof](https://news.itsfoss.com/author/omar/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Kali Linux is one of the [best Linux distributions for penetration testing](https://itsfoss.com/linux-hacking-penetration-testing/?ref=news.itsfoss.com). It is based on Debian, but it may not be a suitable replacement for your full-fledged desktop operating system.
The latest 2021.3 release brings some significant feature additions and improvements onboard. Let us check them out.
## What’s New?
### OpenSSL Compatibility
[OpenSSL](https://www.openssl.org/?ref=news.itsfoss.com) has been **reconfigured to expand the services networked to Kali**. As a result, legacy protocols such as TLS 1.0 and TLS 1.1 and older ciphers are allowed by default. That is to say; it will grant Kali the capability of connecting to more out-of-date servers. However, you can alter this option if you do not need it.
### Virtualization Improvements
Kali is known to work flawlessly as a virtual machine. Firstly, actions like drag and drop, copy and paste between host and guest systems are smoother than ever, whether your guest machine is running under VirtualBox, VMware, Hyper-V, or QEMU+Spice.
Secondly, it is easier to configure Kali for Hyper-V Enhanced Session Mode, a virtualization hypervisor, using Kali-Tweaks.
In short, Kali Linux 2021.3 has made the experience even more seamless when setting up a virtual environment.
### Kali Tools
It is taken for granted that every release of Kali contains new tools. Likewise, this release is no exception. The tools that Kali added to its fleet are:
[Berate_ap](https://pkg.kali.org/pkg/berate-ap?ref=news.itsfoss.com)– Orchestrating MANA rogue Wi-Fi Access Points[CALDERA](https://pkg.kali.org/pkg/caldera?ref=news.itsfoss.com)– Scalable automated adversary emulation platform[EAPHammer](https://pkg.kali.org/pkg/eaphammer?ref=news.itsfoss.com)– Targeted evil twin attacks against WPA2-Enterprise Wi-Fi networks[HostHunter](https://pkg.kali.org/pkg/hosthunter?ref=news.itsfoss.com)– Recon tool for discovering hostnames using OSINT techniques[RouterKeygenPC](https://pkg.kali.org/pkg/routerkeygenpc?ref=news.itsfoss.com)– Generate default WPA/WEP Wi-Fi keys[Subjack](https://pkg.kali.org/pkg/subjack?ref=news.itsfoss.com)– Subdomain takeover[WPA_Sycophant](https://pkg.kali.org/pkg/wpa-sycophant?ref=news.itsfoss.com)– Evil client portion of EAP relay attack
#### Kali ARM Updates and Kali-Tools
With Kali 2021.3, ARM devices are getting more ameliorations. The ones I found eye-catching are:
- en_US.UTF-8 is the default locale on all images.
- The Kali ARM build scripts are rebuilt to better support some devices.
- Raspberry Pi images can now use a wpa_supplicant.conf file on the /boot partition.
Moreover, Kali has refreshed its information domain **Kali-Tools**, to provide a concise overview of tools, a neat and clean interface, and a fast system.
## Other Changes
Kali has seen other neat improvements as well that includes:
- Improvement to its layout for its Xfce and Gnome editions. Kali did not forget about KDE, as it is one of its favorite desktop environments. For instance, KDE 5.21 is the new version available baked in.
- Some of the important pages in their documentation site has received major updates.
- Partnered with Ampere to have its ARM package building machines running on Ampere’s hardware. As a consequence, Kali benefited from a burst in speed.
Kali’s mobile penetration testing platform for Android devices has seen an enhancement. In other words, you can now install Kali NetHunter on Android 11 devices without the need for a fully working [TWRP](http://twrp.me/?ref=news.itsfoss.com) (Team Win Recovery Project). Above all, this update is promising due to its convenient installation procedure.
In addition to this release, they also announced their first NetHunter smartwatch, **TicHunter Pro**. But, it is still in its very first stages of development.
To learn more about all the technical changes with this upgrade, refer to [the official announcement](https://www.kali.org/blog/kali-linux-2021-3-release/?ref=news.itsfoss.com).
## Summing Up
Overall, this is a significant release with valuable improvements and exciting new tools. Get started by downloading it from its official site.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,799 | 树莓派 Zero 与 Zero W 对比 | https://itsfoss.com/raspberry-pi-zero-vs-zero-w/ | 2021-09-19T09:14:35 | [
"树莓派"
] | https://linux.cn/article-13799-1.html | 树莓派十年前凭借 25 美元的迷你电脑掀起了一场革命。随着时间的推移,树莓派发布了许多变种。有些是对以前的型号进行升级,有些是为特定目的而制作的。
在所有的树莓派模块中,Pi Zero 和 Pi Zero W 是最便宜的型号,旨在用于小规模项目和 IoT 项目。这两种设备几乎是相同的,但是它们之间有一些微妙而重要的区别。
**那么,树莓派 Zero 和 Zero W 之间的区别是什么?Zero W 中的 W 代表的是<ruby> 无线 <rt> Wireless </rt></ruby>,它表示的是 Zero W 模块拥有无线功能。这是这两个相似模块之间的最大差异。**
让我们来详细了解一下。
### Pi Zero 与 Pi Zero W 之间的主要不同点

树莓派 Zero 是以在只有 A+ 板一半的大小上提供尽可能多的功能为目标。
而树莓派 Zero W 是为了支持无线在后来推出的,在不需要任何附加的组件和模块的情况下就可以使用蓝牙和 Wi-Fi。
这是两者之间的关键区别,其他的规格保持一致。
所以,如果你需要以下功能:
* 802.11 b/g/n 无线网口
* 蓝牙 4.1
* 低功耗蓝牙(BLE)
树莓派 Zero W 将是你的不二之选。
此外,树莓派 Zero W 还提供了一种带引脚的版本,叫做 “树莓派 Pi Zero WH”
### 树莓派 Zero 和 Zero W 的规格

[树莓派 Zero 和 Zero W 的规格](https://itsfoss.com/raspberry-pi-zero-w/) 几乎是一样的。
它们都具有 1 GHz 的单核 CPU 和 512 MB 的 RAM。至于接口方面,一个 mini HDMI 接口,支持 micro USB OTG、micro USB 供电和一个 CSI 摄像头接口(用于插入一个相机模块)。
这些板子会提供一种叫 [HAT](https://github.com/raspberrypi/hats)(<ruby> 顶部附加硬件 <rt> Hardware Attached on Top </rt></ruby>)兼容的 40 个引脚。但一般情况下,没有这些可以让你轻松插入接口的引脚。
你可以根据自己的功能需要选择使用 [各种树莓派兼容的系统](https://itsfoss.com/raspberry-pi-os/),但无论哪种情况,我还是推荐你使用树莓派 OS。
### 树莓派 Zero 系列值不值得买?

树莓派 Zero 是一种很受人们喜欢的单片机形式,即使你有很多树莓派 Zero 的替代品,树莓派 Zero 仍然是最推荐的选择。
当然,除非你有特殊需求。
除了板子的尺寸之外,定价、功率要求、运算能力也是这款 20 美元以下的板子的主要亮点。
因此,如果你正在寻找预算内满足基本功能的单片机,树莓派 Zero 就是专门为你打造的。
### 树莓派 Zero 系列价格怎么样?
树莓派 Zero 售价 **5 美元** ,Zero W 售价 **10 美元左右**,当然,根据其供应情况和地区,定价规则会不一样,如果你选择带引脚的版本树莓派 Zero WH ,售价大概是 **14 美元** 左右。
还有 [其他的设备可以代替树莓派 Zero](https://itsfoss.com/raspberry-pi-zero-alternatives/),它们价格也相差不大。
---
via: <https://itsfoss.com/raspberry-pi-zero-vs-zero-w/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[anine09](https://github.com/anine09) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Raspberry Pi created a revolution when it launched the $25 mini computer ten years ago. Over time, several variants of Raspberry Pi have been launched. Some upgrade a previous model and some are crafted for specific purposes.
Of all the Raspberry models, Pi Zero and Pi Zero W are the cheapest ones aimed at small-scale and IoT projects. Both devices are almost similar to each other but with a subtle and important difference.
**So, what is the difference between Raspberry Pi Zero and Zero W? The W in Zero W stands for Wireless and it depicts its wireless capability over the Pi Zero model. That’s the single biggest difference between the two similar models.**
Let’s take a look at it a bit more in detail.
## Key Difference Between Pi Zero and Pi Zero W

While Raspberry Pi Zero was built with the goal of providing more utility with half of the size of the A+ board.
And, Raspberry Pi Zero W was introduced later to include wireless connectivity built-in without needing a separate accessory/module to enable Bluetooth and Wi-Fi.
This is the key difference between the two, with the remaining specifications remaining identical.
So, if you want support for:
- 802.11 b/g/n wireless LAN
- Bluetooth 4.1
- Bluetooth Low Energy (BLE)
Raspberry Pi Zero W will be the definite choice to go with.
Also, Raspberry Pi Zero W offers a variant with header pins, which is “Raspberry Pi Zero WH”.
## Raspberry Pi Zero and Raspberry Pi Zero W Specifications

The [specifications for Raspberry Pi Zero W](https://itsfoss.com/raspberry-pi-zero-w/) and Zero are almost identical.
You get a 1 GHz single-core CPU coupled with 512 MB RAM. For connectivity, you get a mini HDMI port, micro USB OTG support, micro USB power, and a CSI Camera connector (to plug in a camera module).
These boards also feature a [HAT](https://github.com/raspberrypi/hats) (Hardware Attached on Top)-compatible 40 pin header, but generally, without the pins that let you easily plug the interfaces.
You can choose to explore the capabilities using [various Raspberry Pi OS](https://itsfoss.com/raspberry-pi-os/) available. In either case, just stick to the Raspberry Pi OS.
## Raspberry Pi Zero series: Is it worth It?

Raspberry Pi Zero is a single-board computer that is popular for its form factor. Even though you have plenty of [Raspberry Pi zero alternatives](https://itsfoss.com/raspberry-pi-zero-alternatives/), Raspberry Pi Zero is the recommended choice for all the good reasons.
Of course, unless you have specific requirements.
In addition to the size of the board, the pricing, power requirement, and processing power are some of the key highlights of this board under **$20**.
So, the Raspberry Zero series should work for you if you are looking for essential features under a budget.
[RasPad | Raspberry Pi Tablet For Your Creative ProjectsRasPad is a Raspberry Pi tablet that can help developers of every level. Experienced developers can use it for complicated IoT/AI projects and beginners can use it to build creative projects easily right away.](https://raspad.com/?ref=2zjdw82xs3)

## Is Raspberry Pi Zero series affordable?
Raspberry Pi Zero costs **$5** and the Raspberry Pi Zero W would cost you around **$10**.** **Of course, depending on its availability and region, the cost will differ. If you want the Raspberry Pi Zero W with header pins, it should cost you around **$14**.
[27 Super Cool Raspberry Pi Zero W Projects for DIY EnthusiastsThe small form factor of the Raspberry Pi Zero W enables a new range of projects. In fact, a lot of people use the Pi Zero in the final version of the project after prototyping on a different full-sized Pi board. And, that’s because it consumes much less power](https://itsfoss.com/raspberry-pi-zero-projects/)

There are other devices that can be used as an [alternative to Raspberry Pi Zero](https://itsfoss.com/raspberry-pi-zero-alternatives/) and they have a similar price tag. |
13,800 | 构建开源的社区健康分析平台 | https://opensource.com/article/21/9/openrit-mystic | 2021-09-19T10:08:00 | [
"社区"
] | /article-13800-1.html |
>
> 一个学术性的 OSPO 正在与 CHAOSS 软件合作,以建立一个社区健康分析平台。
>
>
>

<ruby> 罗切斯特理工学院 <rt> Rochester Institute of Technology </rt></ruby>(RIT)最近在增加其在开源世界的影响力方面取得了相当大的进展。RIT的自由和开源软件及自由文化辅修课程是学术界的第一个此类课程。例如,其开源项目办公室 Open@RIT 已经开始帮助 RIT 的教职员工和研究员为他们的开源项目建立和维护社区。
这些进展是由 RIT 的学生、教师和工作人员推动的。目前,大学里已经有越来越多的人在管理他们自己的开源项目。然而,运行一个完全的开源项目可能是很麻烦的。这主要来自于维护项目的社区和管理数据,如项目的代码、问题跟踪和仓库。
为了帮助他们,Open@RIT 正在创建一个名为 Mystic 的系统,这是一个社区健康分析平台,利用了 [GrimoireLab](https://chaoss.github.io/grimoirelab/),这是一个由 [CHAOSS](https://chaoss.community/) 软件开发的开源工具包,为开源项目提供了指标和分析。GrimoireLab 允许用户收集、丰富、过滤和可视化一个项目的数据,例如一个报告的问题被解决的时间、贡献者的关系等。
Mystic 将作为一个前端门户,任何人都可以提交他们的项目。在那里,项目将被直接发送到 GrimoireLab,它将在几分钟后为提交者计算并发布项目的指标。
>
> Open@RIT 的全栈开发者和 Mystic 的首席开发者 Emi Simpson 说:“我们希望 RIT 的任何管理、领导或参与开源项目的人都能将该项目提交给 Mystic,并获得他们需要的任何指标”。
>
>
>
这个过程很简单。登录 Mystic 后,上传项目的用户会打开一个弹出式窗口,输入项目的细节和数据源的链接,如 GitLab、RSS feed 和一个<ruby> 开放软件基金会 <rt> Open Software Foundation </rt></ruby>(OSF)项目名。一旦保存了细节和项目,Mystic 就会使用 GrimoireLab 从项目源中自动检索指标,并为每个源渲染图表。然后,该项目及其指标将显示在它自己的仪表板上。

这些仪表盘将并列显示在一个页面上,以供其他人查看,鼓励 RIT 内部的开源社区之间的合作开发和互动。Simpson 和 Open@RIT 希望这将增加 RIT 的开放工作的参与度,并进一步巩固该大学作为开放工作中心的地位。
>
> Simpson 说:“如果有人问 RIT 在为开源软件做什么,我希望人们能够指着 Mystic 和 GrimoireLab 说就是这些。通过建立‘这些是我们正在做的,这些是我们的贡献,这些是人们正在做的项目’的指标,我们可以在 RIT 建立一个以我们正在做的开源工作为中心的社区。”
>
>
>
目前,Mystic 仍在开发中,还没有准备好进入生产环境,但它对 RIT 和整个开源的潜力仍然是有目共睹的。未来的目标包括实现与大学报告工具的轻松整合,以及在项目层面和总体上的综合仪表盘。
你对 Mystic 的贡献感兴趣吗?[请与我们联系](https://opensource.ieee.org/rit/mystic) 开始吧。
---
via: <https://opensource.com/article/21/9/openrit-mystic>
作者:[Quinn Foster](https://opensource.com/users/quinn-foster) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,802 | 在 Linux 中使用 OBS 和 Wayland 进行屏幕录制 | https://itsfoss.com/screen-record-obs-wayland/ | 2021-09-20T16:37:09 | [
"屏幕录制"
] | https://linux.cn/article-13802-1.html | 有 [大量可用于 Linux 的屏幕录像机](https://itsfoss.com/best-linux-screen-recorders/)。但是当涉及到支持 [Wayland](https://wayland.freedesktop.org/) 时,几乎所有的都不能用。
这是个问题,因为许多新发布的版本都再次默认切换到 Wayland 显示管理器。而如果像屏幕录像机这样基本的东西不能工作,就会给人留下不好的体验。
[GNOME 的内置屏幕录像机](https://itsfoss.com/gnome-screen-recorder/) 可以工作,但它是隐藏的,没有 GUI,也没有办法配置和控制记录内容。此外,还有一个叫 [Kooha](https://itsfoss.com/kooha-screen-recorder/) 的工具,但它一直在屏幕上显示一个计时器。
只是为了录制屏幕而 [在 Xorg 和 Wayland 之间切换](https://itsfoss.com/switch-xorg-wayland/),这不是很方便。
这种情况下,我很高兴地得知,由于 Pipewire 的帮助,在 OBS Studio v27 中支持了 Wayland。但即使是这样,也不是很简单,因此我将向你展示使用 [OBS Studio](https://obsproject.com/) 在 Wayland 上录制屏幕的步骤。
### 使用 OBS 在 Wayland 上进行屏幕录制

让我们来看看它是如何完成的。
#### 第一步:安装 OBS Studio
你应该先安装 OBS Studio v27。它已经包含在 Ubuntu 21.10 中,我会在本教程中使用它。
要在 Ubuntu 18.04、20.04、Linux Mint 20 等系统上安装 OBS Studio 27,请使用 [官方的 OBS Studio PPA](https://launchpad.net/~obsproject/+archive/ubuntu/obs-studio)。
打开终端,逐一使用以下命令:
```
sudo add-apt-repository ppa:obsproject/obs-studio
sudo apt update
sudo apt install obs-studio
```
如果已经安装了 OBS Studio 的旧版本,它将被升级到较新的版本。
对于 Fedora、Arch 和其他发行版,请检查你的包管理器或非官方仓库以安装最新版本的 OBS Studio。
#### 第二步:检查 Wayland 捕获是否工作
请确认你正在使用 Wayland。现在启动 OBS Studio,查看它在第一次运行时显示的所有内容。我不打算展示这些。
主要步骤是添加 Pipewire 作为屏幕捕捉源。点击 “Sources” 列表下的 “+” 符号。

你有没有看到 “Screen Capture (PipeWire)” 的字样?

**如果没看到,请退出 OBS Studio**。这很正常。至少在 Ubuntu 下,OBS Studio 不会自动切换到使用 Wayland。对此有一个修复方法。
打开一个终端,使用以下命令:
```
export QT_QPA_PLATFORM=wayland
```
在同一个终端,运行以下命令,启动 OBS Studio:
```
obs
```
它将在终端上显示一些信息。不要理会它们。你的注意力应该放在 OBS Studio GUI 上。再次尝试添加屏幕捕捉。你现在应该看到 PipeWire 选项了。

你这次用 `QT_QPA_PLATFORM` 变量明确要求 OBS Studio 使用 Wayland。
选择 PipeWire 作为源,然后它要求你选择一个显示屏幕。选择它并点击分享按钮。

现在它应该无限次递归地显示你的屏幕。如果你看到了,你现在就可以开始在 Wayland 中录制屏幕了。

#### 第三步:让改变成为永久性的
这很好。你刚刚验证了你可以在 Wayland 上录制屏幕。但每次设置环境变量并从终端启动 OBS 并不方便。
你可以做的是**把这个变量导出到你的 `~/.bash_profile`(对你而言)或 `/etc/profile`(对系统中的所有用户而言)。**
```
export QT_QPA_PLATFORM=wayland
```
退出并重新登录。现在 OBS 会自动开始使用这个参数,你可以用它来录制 Wayland 的屏幕。
我希望这个快速技巧对你有帮助。如果你还有问题或建议,请在评论区告诉我。
---
via: <https://itsfoss.com/screen-record-obs-wayland/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are [tons of screen recorders available for Linux](https://itsfoss.com/best-linux-screen-recorders/). But when it comes to supporting [Wayland](https://wayland.freedesktop.org/), almost all of them do not work.
This is problematic because many new distribution releases are switching to Wayland display manager by default once again. And if something as basic as a screen recorder does not work, it leaves a bad experience.
[GNOME’s built-in screen recorder](https://itsfoss.com/gnome-screen-recorder/) works but it is hidden, has no GUI and no way to configure and control the recordings. There is another tool called [Kooha](https://itsfoss.com/kooha-screen-recorder/) but it keeps on displaying a timer on the screen.
[Switching between Xorg and Wayland](https://itsfoss.com/switch-xorg-wayland/) just for screen recording is not very convenient.
Amidst all this, I was happy to learn that Wayland support landed in OBS Studio with version 27 release thanks to Pipewire. But even there, it’s not straightforward and hence I am going to show you the steps for screen recording on Wayland using [OBS Studio](https://obsproject.com/).
## Using OBS to screen record on Wayland

Let’s see how it is done.
### Step 1: Install OBS Studio
You should install OBS Studio version 27 first. It is already included in Ubuntu 21.10 which I am using in this tutorial.
`sudo apt install obs-studio`
To install OBS Studio 27 on Ubuntu 18.04, 20.04, Linux Mint 20 etc, use the [official OBS Studio](https://launchpad.net/~obsproject/+archive/ubuntu/obs-studio)[ ](https://launchpad.net/~obsproject/+archive/ubuntu/obs-studio)[PPA](https://launchpad.net/~obsproject/+archive/ubuntu/obs-studio).
Open a terminal and use the following commands one by one:
```
sudo add-apt-repository ppa:obsproject/obs-studio
sudo apt update
sudo apt install obs-studio
```
If there is an older version of OBS Studio installed already, it will be upgraded to the newer version.
For Fedora, Arch and other distributions, please check your package manager or unofficial repositories for installing the latest version of OBS Studio.
### Step 2: Check if Wayland capture is working
Please make sure that you are using Wayland. Now start OBS Studio and go through all the stuff it shows on the first run. I am not going to show that.
The main step is to add Pipewire as a screen capture source. Click on the + symbol under the Sources list.
Do you see anything that reads Screen Capture (PipeWire)?
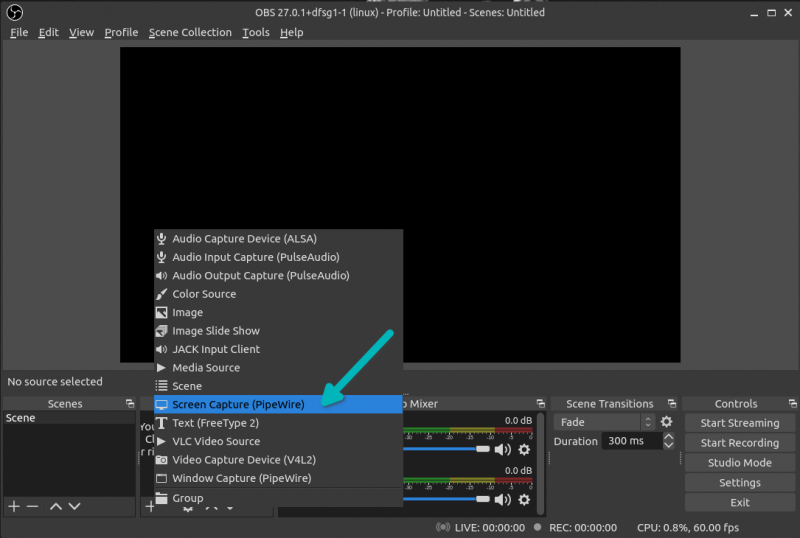
**If the answer is no, quit OBS Studio**. This is normal. OBS Studio does not switch to use Wayland automatically in Ubuntu at least. There is a fix for that.
Open a terminal and use the following command:
`export QT_QPA_PLATFORM=wayland`
In the same terminal, run the following command to start OBS Studio:
`obs`
It will show some message on the terminal. Ignore them. Your focus should be on the OBS Studio GUI. Try to add screen capture once again. You should see the PipeWire option now.

You explicitly asked OBS Studio to use Wayland this time with the QT_QPA_PLATFORM variable.
Select PipeWire as the source and then it asks you to choose a display screen. Select it and click on the Share button.
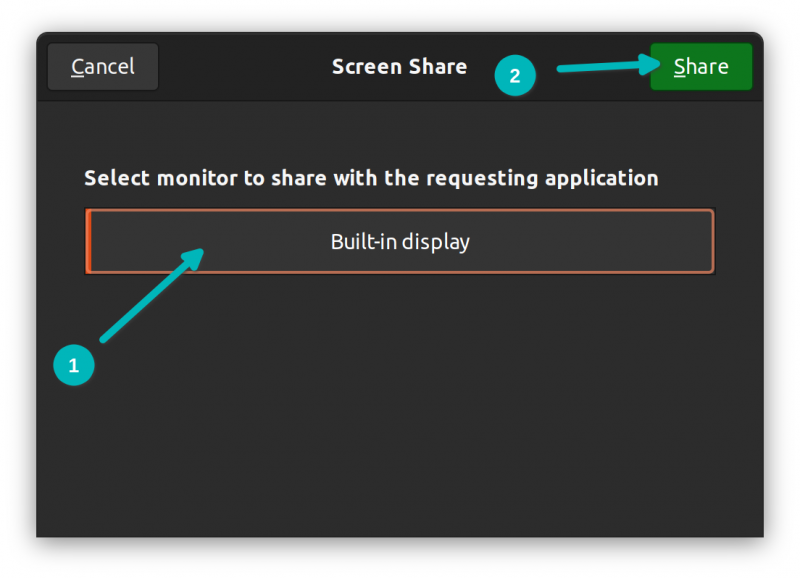
Now it should show your screen recursively infinite number of times. If you see that, you could start recording the screen in Wayland now.
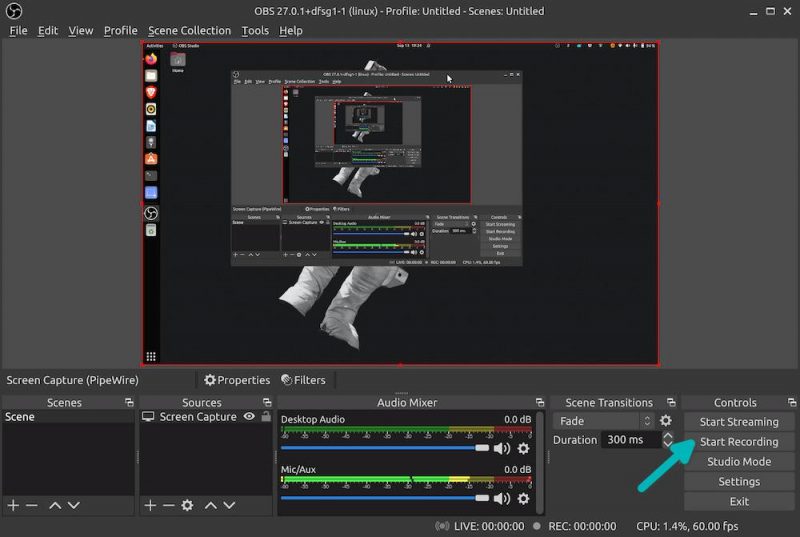
### Step 3: Make changes permanent
That was good. You just verified that you can record your screen on Wayland. But setting the environment variable and starting OBS from the terminal each time is not convenient.
What you can do is to **export the variable to your ~/.bash_profile (for you) or /etc/profile (for all users on the system).**
`export QT_QPA_PLATFORM=wayland`
Log out and log back in. Now OBS will automatically start using this parameter and you can use it to record your screen in Wayland.
**Note: I noticed that MEGA cloud service stopped working after this change. If you notice some applications stopped working after this change, revert it please.**
I hope you find this quick tip helpful. If you still have questions or suggestions, please let me know in the comment section. |
13,803 | 如何用 rpm-ostree 数据库检查更新信息和更新日志 | https://fedoramagazine.org/how-to-check-for-update-info-and-changelogs-with-rpm-ostree-db/ | 2021-09-20T16:54:49 | [
"Silverblue"
] | https://linux.cn/article-13803-1.html | 
这篇文章将教你如何使用 `rpm-ostree` 数据库及其子命令检查更新、检查更改的软件包和阅读更新日志。
这些命令将在 Fedora Silverblue 上进行演示,并且应该在任何使用 `rpm-ostree` 的操作系统上工作。
### 简介
假设你对不可更改的系统感兴趣。在基于容器技术构建用例时使用只读的基本系统听起来非常有吸引力,它会说服你选择使用 `rpm-ostree` 的发行版。
你现在发现自己在 [Fedora Silverblue](https://fedoramagazine.org/what-is-silverblue/)(或其他类似的发行版)上,你想检查更新。但你遇到了一个问题。虽然你可以通过 GNOME Software 找到 Fedora Silverblue 上的更新包,但你实际上无法阅读它们的更新日志。你也不能 [使用 dnf updateinfo 在命令行上读取它们](https://fedoramagazine.org/use-dnf-updateinfo-to-read-update-changelogs/),因为主机系统上没有 DNF。
那么,你应该怎么做呢?嗯,`rpm-ostree` 有一些子命令可以在这种情况下提供帮助。
### 检查更新
第一步是检查更新。只需运行:
```
$ rpm-ostree upgrade --check
...
AvailableUpdate:
Version: 34.20210905.0 (2021-09-05T20:59:47Z)
Commit: d8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4
GPGSignature: Valid signature by 8C5BA6990BDB26E19F2A1A801161AE6945719A39
SecAdvisories: 1 moderate
Diff: 4 upgraded
```
请注意,虽然它没有在输出中告诉更新的软件包,但它显示了更新的提交为 `d8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4`。这在后面会很有用。
接下来你需要做的是找到你正在运行的当前部署的提交。运行 `rpm-ostree status` 以获得当前部署的<ruby> 基提交 <rt> BaseCommit </rt></ruby>:
```
$ rpm-ostree status
State: idle
Deployments:
● fedora:fedora/34/x86_64/silverblue
Version: 34.20210904.0 (2021-09-04T19:16:37Z)
BaseCommit: e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1e
GPGSignature: Valid signature by 8C5BA6990BDB26E19F2A1A801161AE6945719A39
RemovedBasePackages: ...
LayeredPackages: ...
...
```
对于这个例子,基提交是`e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1e`。
现在你可以用 `rpm-ostree db diff [commit1] [commit2]` 找到这两个提交的差异。在这个命令中,`[commit1]` 将是当前部署的基提交,`[commit2]` 将是升级检查命令中的提交。
```
$ rpm-ostree db diff e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1e d8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4
ostree diff commit from: e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1e
ostree diff commit to: d8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4
Upgraded:
soundtouch 2.1.1-6.fc34 -> 2.1.2-1.fc34
```
`diff` 输出显示 `soundtouch` 被更新了,并指出了版本号。通过在前面的命令中加入 `-changelogs` 来查看更新日志:
```
$ rpm-ostree db diff e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1e d8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4 --changelogs
ostree diff commit from: e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1e
ostree diff commit to: d8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4
Upgraded:
soundtouch 2.1.1-6.fc34.x86_64 -> 2.1.2-1.fc34.x86_64
* dom ago 29 2021 Uwe Klotz <[email protected]> - 2.1.2-1
- Update to new upstream version 2.1.2
Bump version to 2.1.2 to correct incorrect version info in configure.ac
* sex jul 23 2021 Fedora Release Engineering <[email protected]> - 2.1.1-7
- Rebuilt for https://fedoraproject.org/wiki/Fedora_35_Mass_Rebuild
```
这个输出显示了提交说明以及版本号。
### 总结
使用 `rpm-ostree db`,你现在可以拥有相当于 `dnf check-update` 和 `dnf updateinfo` 的功能。
如果你想检查你所安装的更新的详细信息,这将非常有用。
---
via: <https://fedoramagazine.org/how-to-check-for-update-info-and-changelogs-with-rpm-ostree-db/>
作者:[Mateus Rodrigues Costa](https://fedoramagazine.org/author/mateusrodcosta/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article will teach you how to check for updates, check the changed packages, and read the changelogs with *rpm-ostree db* and its subcommands.
The commands will be demoed on a Fedora Silverblue installation and should work on any OS that uses *rpm-ostree*.
## Introduction
Let’s say you are interested in immutable systems. Using a base system that is read-only while you build your use cases on top of containers technology sounds very attractive and it persuades you to select a distro that uses *rpm-ostree*.
You now find yourself on [Fedora Silverblue](https://fedoramagazine.org/what-is-silverblue/) (or another similar distro) and you want to check for updates. But you hit a problem. While you can find the updated packages on Fedora Silverblue with GNOME Software, you can’t actually read their changelogs. You also can’t [use dnf updateinfo to read them on the command line](https://fedoramagazine.org/use-dnf-updateinfo-to-read-update-changelogs/), since there’s no DNF on the host system.
So, what should you do? Well, *rpm-ostree* has subcommands that can help in this situation.
## Checking for updates
The first step is to check for updates. Simply run *rpm-ostree upgrade –check*:
$rpm-ostree upgrade --check
...
AvailableUpdate:
Version: 34.20210905.0 (2021-09-05T20:59:47Z)
Commit: d8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4
GPGSignature: Valid signature by 8C5BA6990BDB26E19F2A1A801161AE6945719A39
SecAdvisories: 1 moderate
Diff: 4 upgraded
Notice that while it doesn’t tell the updated packages in the output, it does show the Commit for the update as *d8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4*. This will be useful later.
Next thing you need to do is find the Commit for the current deployment you are running. Run *rpm-ostree status* to get the BaseCommit of the current deployment:
$rpm-ostree statusState: idle Deployments: ● fedora:fedora/34/x86_64/silverblue Version: 34.20210904.0 (2021-09-04T19:16:37Z) BaseCommit: e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1e GPGSignature: Valid signature by 8C5BA6990BDB26E19F2A1A801161AE6945719A39 RemovedBasePackages: ... LayeredPackages: ... ...
For this example BaseCommit is *e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1e*.
Now you can find the diff of the two commits with *rpm-ostree db diff [commit1] [commit2]*. In this command *commit1* will be the BaseCommit from the current deployment and *commit2* will be the Commit from the upgrade checking command.
$rpm-ostree db diff e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1ed8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4ostree diff commit from: e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1e ostree diff commit to: d8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4 Upgraded: soundtouch 2.1.1-6.fc34 -> 2.1.2-1.fc34
The diff output shows that *soundtouch* was updated and indicates the version numbers. View the changelogs by adding *–changelogs* to the previous command:
$rpm-ostree db diff e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1ed8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4 --changelogsostree diff commit from: e279286dcd8b5e231cff15c4130a4b1f5a03b6735327b213ee474332b311dd1e ostree diff commit to: d8bab818f5abcfb58d2c038614965bf26426d55667e52018fcd295b9bfbc88b4 Upgraded: soundtouch 2.1.1-6.fc34.x86_64 -> 2.1.2-1.fc34.x86_64 * dom ago 29 2021 Uwe Klotz <[email protected]> - 2.1.2-1 - Update to new upstream version 2.1.2 Bump version to 2.1.2 to correct incorrect version info in configure.ac * sex jul 23 2021 Fedora Release Engineering <[email protected]> - 2.1.1-7 - Rebuilt for https://fedoraproject.org/wiki/Fedora_35_Mass_Rebuild
This output shows the commit notes as well as the version numbers.
## Conclusion
Using *rpm-ostree db * you are now able to have the functionality equivalent to *dnf check-update* and *dnf updateinfo*.
This will come in handy if you want to inspect detailed info about the updates you install.
## Naheem
Is there an easy way to check this for different endpoints, without rebasing?
An example would be to get an rpm diff between silverblue and kinoite, or between various silverblue branches.
## Felipe Henrique
You can also just use the following command:
rpm-ostree upgrade –preview
## Gilberto Garma
I installed today Fedora 34 gnome, my question is how can use Fedora Silver Blue and learn to use it, I read about it a couple of times and my curiosity for an immutable system is now bigger. Newbie, I think is not a problem when you have time and you have the wish to learn a little bit more about of Fedora Silverblue.
## Tino
What is the difference between rpm-ostree update and rpm-ostree upgrade ? |
13,805 | 如何在 VMware 中安装 Kali Linux | https://itsfoss.com/install-kali-linux-vmware/ | 2021-09-21T14:43:06 | [
"Kali"
] | https://linux.cn/article-13805-1.html | 
Kali Linux 是 [用于学习和练习黑客攻击和渗透测试的 Linux 发行版](https://itsfoss.com/linux-hacking-penetration-testing/) 的不二之选。
而且,如果你经常捣鼓 Linux 发行版,出于好奇心,你可能已经尝试过它。
>
> **警告!**
>
>
> 本文介绍的内容仅供学习 Kali Linux 的安装,请勿使用 Kali Linux 进行任何非授权的行为。Kali Linux 应该用于在授权的情况下,对授权的目标进行合理的渗透测试,以了解其脆弱性并加以防范。本文作译者和本站均不对非授权和非法的使用及其造成的后果负责。
>
>
>
然而,无论你用它做什么,它都不能替代正规成熟的桌面 Linux 操作系统。因此,(至少对于初学者来说)建议使用虚拟机程序(如 VMware)来安装 Kali Linux。
通过虚拟机,你可以把 Kali Linux 作为你的 Windows 或 Linux 系统中的一个常规应用程序来使用,就像在你的系统中运行 VLC 或 Skype 一样。
有一些免费的虚拟化工具可供使用。你可以 [在 Oracle VirtualBox 上安装 Kali Linux](https://itsfoss.com/install-kali-linux-virtualbox/) ,也可以使用 VMWare Workstation。
本教程重点介绍 VMWare。
### 在 Windows 和 Linux 的 VMware 上安装 Kali Linux
>
> **非 FOSS 警报!**
>
>
> VMWare 不是开源软件。
>
>
>
对于本教程,我假定你使用的是 Windows,是考虑到大多数 VMware 用户喜欢使用 Windows 10/11。
然而,除了在 Windows 上安装 VMWare 的部分,本 **教程对 Linux 也是有效的**。你可以 [轻松地在 Ubuntu 和其他 Linux 发行版上安装 VMWare](https://itsfoss.com/install-vmware-player-ubuntu-1310/)。
#### 步骤 1:安装 VMWare Workstation Player(在 Windows 上)
如果你的系统上已经安装了 VMware,你可以跳到安装 Kali Linux 的步骤。
前往 [VMWare 的 Workstation Player 官方网页](https://www.vmware.com/products/workstation-player.html),然后点击 “Download For Free” 按钮。

接下来,你可以选择版本(如果你想要特定的版本或遇到最新版本的 bug),然后点击 “Go to Downloads”。

然后你就会看到 Windows 和 Linux 版本的下载按钮。你需要点击 “Windows 64-bit” 的按钮,因为这就是我们在这里需要的。

顺便提一句,它不支持 32 位系统。
最后,当你得到下载的 .exe 文件时,启动它以开始安装过程。你需要点击 “Next” 来开始安装 VMware。

接下来,你需要同意这些政策和条件才能继续。

现在,你可以选择安装的路径。理想情况下,保持默认设置。但是,如果你在虚拟机中需要更好的键盘响应/屏幕上的键盘性能,你可能想启用 “<ruby> 增强型键盘驱动程序 <rt> Enhanced Keyboard Driver </rt></ruby>”。

进入下一步,你可以选择禁用每次启动程序时的更新检查(可能很烦人),并禁用向 VMware 发送数据,这是其用户体验改进计划的一部分。

如果你想使用桌面和开始菜单的快捷方式进行快速访问,你可以勾选这些设置,或像我一样将其取消。

现在,继续以开始安装。

这可能需要一些时间,完成后,你会看到另一个窗口,让你完成这个过程,并让你选择输入一个许可证密钥。如果你想获得商业许可,你需要 VMware Workstation 专业版,否则,该 Player 版本对个人使用是免费的。

>
> **注意!**
>
>
> 请确保你的系统已经启用了虚拟化功能。最近的 VMWare 的 Windows 版本要求你明确启用虚拟化以使用虚拟机。
>
>
>
#### 步骤 2:在 VMware 上安装 Kali Linux
开始时,你需要下载 Kali Linux 的镜像文件。而且,如果你打算在虚拟机上使用它,Kali Linux 会提供一个单独的 ISO 文件。

前往其 [官方下载页面](https://www.kali.org/get-kali/),下载可用的预构建的 VMware 镜像。

你可以直接下载 .7z 文件或利用 Torrent(一般来说速度更快)。在这两种情况下,你也可以用提供的 SHA256 值检查文件的完整性。
下载完成,你需要将文件解压到你选择的任何路径。

打开 VMware Workstation Player,然后点击 “<ruby> 打开一个虚拟机 <rt> Open a Virtual Machine </rt></ruby>”。现在,寻找你提取的文件夹。然后浏览它,直到你找到一个扩展名为 .vmx 的文件。
比如说,`Kali-Linux-2021.3-vmware-amd64.vmx`。

选择 .vmx 文件来打开该虚拟机。它应该直接出现在你的 VMware Player 中。
你可以选择以默认设置启动虚拟机。或者,如果你想调整分配给虚拟机的硬件,可以在启动前随意改变设置。

根据你的计算机硬件,你应该分配更多的内存和至少一半的处理器核心,以获得流畅的性能。
在这种情况下,我有 16GB 的内存和一个四核处理器。因此,为这个虚拟机分配近 7GB 的内存和两个内核是安全的。

虽然你可以分配更多的资源,但它可能会影响你的宿主机操作系统在工作时的性能。所以,建议在这两者之间保持平衡。
现在,保存设置并点击 “<ruby> 播放虚拟机 <rt> Play virtual machine </rt></ruby>” 来启动 Kali Linux on VMware。
当它开始加载时,你可能会看到一些提示,告诉你可以通过调整一些虚拟机设置来提高性能。
你不用必须这样做,但如果你注意到性能问题,你可以禁用<ruby> 侧通道缓解措施 <rt> side-channel mitigations </rt></ruby>(用于增强安全性)来提高虚拟机的性能。
另外,你可能会被提示下载并 [安装 VMware tools for Linux](https://itsfoss.com/install-vmware-tools-linux/);你需要这样做以获得良好的虚拟机体验。
完成之后,你就会看到 Kali Linux 的登录界面。

考虑到你启动了一个预先建立的 VMware 虚拟机,你需要输入默认的登录名和密码来继续。
* 用户名:`kali`
* 密码: `kali`

就是这样!你已经完成了在 VMware 上安装 Kali Linux。现在,你所要做的就是开始探索了!
### 接下来呢?
这里有一些你可以利用的提示:
* 如果剪贴板共享和文件共享不工作,请在访客系统(Kali Linux)上 [安装 VMWare tools](https://itsfoss.com/install-vmware-tools-linux/)。
* 如果你是新手,请查看这个 [Kali Linux 工具列表](https://itsfoss.com/best-kali-linux-tools/)。
如果你觉得这个教程有帮助,欢迎分享你的想法。你是否喜欢在不使用 VMware 镜像的情况下安装 Kali Linux?请在下面的评论中告诉我。
---
via: <https://itsfoss.com/install-kali-linux-vmware/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Kali Linux is the de facto standard of [Linux distributions used for learning and practicing hacking and penetration testing](https://itsfoss.com/linux-hacking-penetration-testing/).
And, if you’ve been tinkering around with Linux distros long enough, you might have tried it out just out of curiosity.
However, no matter what you use it for, it is not a replacement for a regular full-fledged desktop Linux operating system. Hence, it is recommended (at least for beginners) to install Kali Linux using a virtual machine program like VMware.
With a virtual machine, you can use Kali Linux as a regular application in your Windows or Linux system. It’s almost the same as running VLC or Skype in your system.
There are a few free virtualization tools available for you. You can [install Kali Linux on Oracle VirtualBox](https://itsfoss.com/install-kali-linux-virtualbox/) or use VMWare Workstation.
This tutorial focuses on VMWare.
## Installing Kali Linux on VMware on Windows and Linux
**Non-FOSS Warning!**VMWare is not open source software.
For this tutorial, I presume that you are using Windows, considering most VMware users prefer using Windows 10/11.
However, the **tutorial is also valid for Linux except the VMWare installation on Windows part**. You can
[easily install VMWare on Ubuntu](https://itsfoss.com/install-vmware-player-ubuntu-1310/)and other Linux distributions.
### Step 1: Install VMWare Workstation Player (on Windows)
If you already have VMware installed on your system, you can skip the steps to install Kali Linux.
Head to [VMWare’s official workstation player webpage](https://www.vmware.com/products/workstation-player.html?ref=itsfoss.com) and then click on the “**Download Free**” button.
Next, you get to choose the version (if you want something specific or encountering bugs in the latest version) and then click on “**Go to Downloads.**“
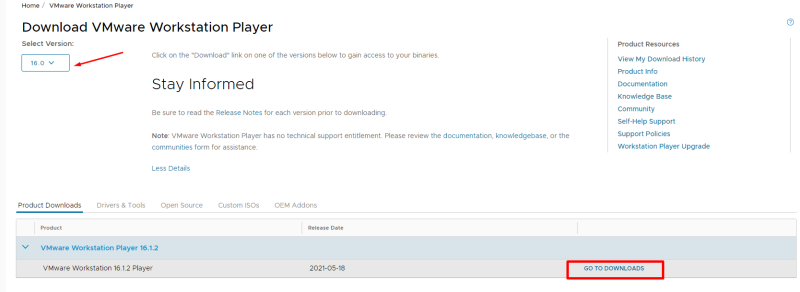
And then you get the download buttons for both Windows and Linux versions. You will have to click on the button for Windows 64-bit because that is what we need here.
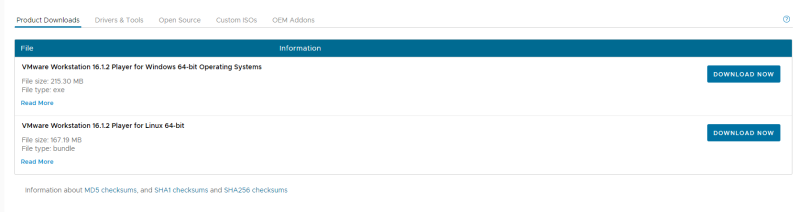
There is no support for 32-bit systems, in case you were wondering.
Finally, when you get the .exe file downloaded, launch it to start the installation process. You need to hit “Next” to get started installing VMware.
Next, you will have to agree to the policies and conditions to continue.
Now, you get to choose the path of your installation. Ideally, keep it at the default settings. But, if you need better keyboard response / in-screen keyboard performance in the virtual machine, you may want to enable the “**Enhanced Keyboard Driver**.”
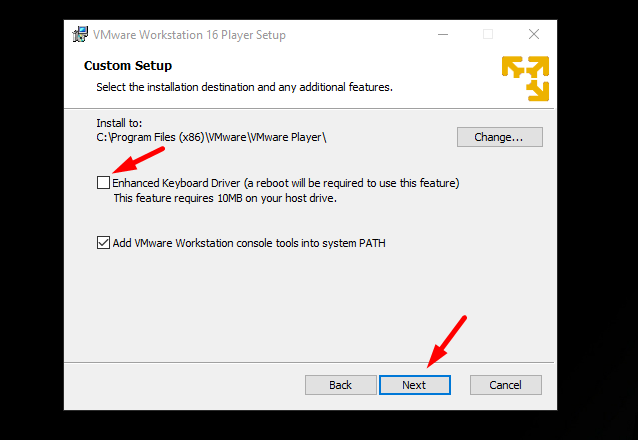
Proceeding to the next step, you can choose to disable checking for updates every time you start the program (can be annoying) and disable sending data to VMware as part of its user experience improvement program.
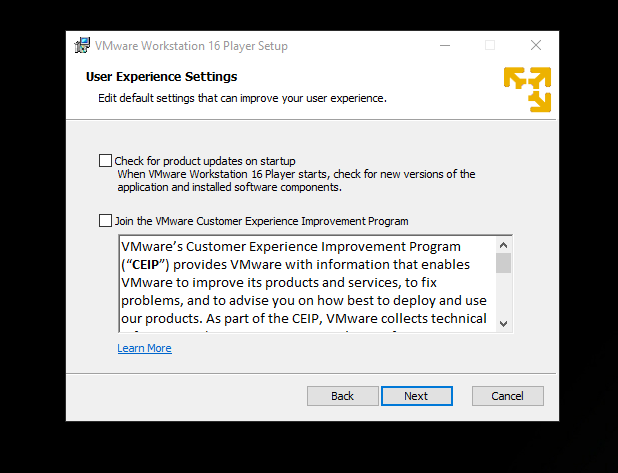
If you want quick access using desktop and start menu shortcuts, you can check those settings or toggle them off, which I prefer.
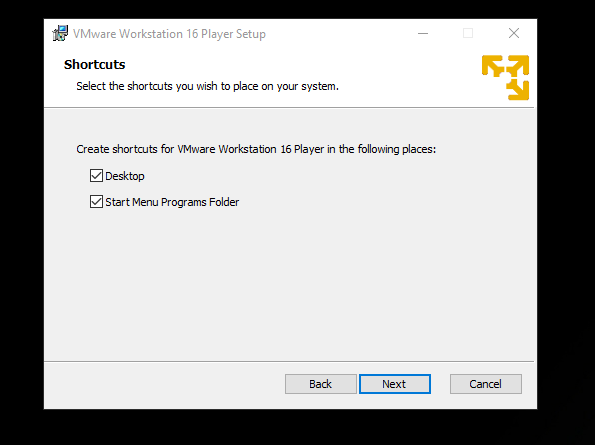
Now, you have to continue to start the installation.
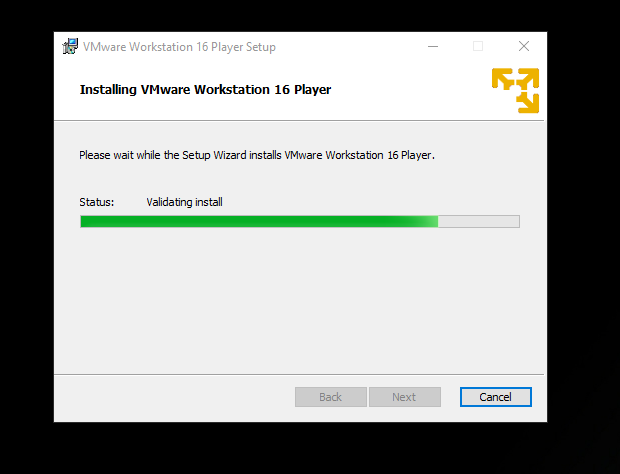
This may take a while, and when completed, you get greeted with another window that lets you finish the process and gives you the option to enter a license key. If you want to get the commercial license for your use-case, you need the VMware Workstation Pro edition, or else, the player is free for personal use.
### Step 2: Install Kali Linux on VMware
To get started, you need to download the image file of Kali Linux. And, when it comes to Kali Linux, they offer a separate ISO file if you plan to use it on a virtual machine.
Head to its [official download page](https://www.kali.org/get-kali/?ref=itsfoss.com) and download the prebuilt VMware image available.

You can download the** .7z** file directly or utilize Torrent (which is generally faster). In either case, you can also check the file integrity with the SHA256 value provided.
Once downloaded, you need to extract the file to any path of your choice.
Open VMware Workstation Player and then click on “**Open a Virtual Machine**.” Now, look for the folder you extracted. And navigate through it till you find a file with the “**.vmx**” extension.
For instance: **Kali-Linux-2021.3-vmware-amd64.vmx**
Select the .vmx file to open the virtual machine. And, it should appear right in your VMware player.
You can choose to launch the virtual machine with the default settings. Or, if you want to tweak the hardware allocated to the virtual machine, feel free to change the settings before you launch it.
Depending on your computer hardware, you should allocate more memory and at least half of your processor cores to get a smooth performance.
In this case, I have 16 Gigs of RAM and a quad-core processor. Hence, it is safe to allocate nearly 7 GB of RAM and two cores for this virtual machine.
While you can assign more resources, but it might affect the performance of your host operating system when working on a task. So, it is recommended to keep a balance between the two.
Now, save the settings and hit “**Play virtual machine**” to start Kali Linux on VMware.
When it starts loading up, you may be prompted with some tips to improve performance by tweaking some virtual machine settings.
You do not have to do that, but if you notice performance issues, you can disable side-channel mitigations (needed for enhanced security) to uplift the performance of the VM.
Also, you may be prompted to download and [install VMware tools for Linux](https://itsfoss.com/install-vmware-tools-linux/); you need to do this to get a good VM experience.
Once you do that, you will be greeted with Kali Linux’s login screen.
Considering that you launched a prebuilt VMware folder, you need to enter the default login and password to proceed.
**Username**: kali**Password:** kali
That’s it! You’re done installing Kali Linux on VMware. Now, all you have to do is start exploring!
## Where to go from here?
Here are a few tips you can utilize.
If clipboard sharing and file sharing are not working, [install VMWare tools](https://itsfoss.com/install-vmware-tools-linux/) on the guest system (Kali Linux).
If you are new to it, check out this [list of Kali Linux tools](https://itsfoss.com/best-kali-linux-tools/).
[21 Best Kali Linux Tools for Hacking and Penetration TestingHere’s our list of best Kali Linux tools that will allow you to assess the security of web-servers and help in performing hacking and pen-testing. If you read the Kali Linux review, you know why it is considered one of the best Linux distributions for hacking and pen-testing and](https://itsfoss.com/best-kali-linux-tools/)

In the mood for fun? Try the undercover mode.
[Pretend to be Using Windows with Kali Linux Undercover ModeThe latest Kali Linux release 2019.4 has introduced the undercover mode. Find out what is this undercover mode and how to use it. What is undercover mode in Kali Linux? Kali Linux 2019.4 release has introduced an interesting new feature called ‘undercover mode’. It’s basically a script](https://itsfoss.com/kali-linux-undercover-mode/)

Feel free to share your thoughts if you find this tutorial helpful. Do you prefer to install Kali Linux without using a VMware image ready to go? Let me know in the comments below. |
13,806 | 用 Linux sed 命令替换智能引号 | https://opensource.com/article/21/9/sed-replace-smart-quotes | 2021-09-21T15:14:14 | [
"引号",
"sed"
] | https://linux.cn/article-13806-1.html |
>
> 用你喜欢的 sed 版本去除“智能”引号。
>
>
>

在排版学中,一对引号传统上是朝向彼此的。它们看起来像这样:
“智能引号”
随着计算机在二十世纪中期的普及,这种朝向往往被放弃了。计算机的原始字符集没有太多的空间,所以在 ASCII 规范中,两个双引号和两个单引号被缩减为各一个是合理的。如今,通用的字符集是 Unicode,有足够的空间容纳许多花哨的引号和撇号,但许多人已经习惯了开头和结尾引号都只有一个字符的极简主义。此外,计算机实际上将不同种类的引号和撇号视为不同的字符。换句话说,对计算机来说,右双引号与左双引号或直引号是不同的。
### 用 sed 替换智能引号
计算机并不是打字机。当你按下键盘上的一个键时,你不是在按一个带有印章的控制杆。你只是按下一个按钮,向你的计算机发送一个信号,计算机将其解释为一个显示特定预定义字符的请求。这个请求取决于你的键盘映射。作为一个 Dvorak 打字员,我目睹了人们在发现我的键盘上的 “asdf” 在屏幕上产生 “aoeu” 时脸上的困惑。你也可能按了一些特殊的组合键来产生字符,如 ™ 或 ß 或 ≠,这甚至没有印在你的键盘上。
每个字母或字符,不管它是否印在你的键盘上,都有一个编码。字符编码可以用不同的方式表达,但对计算机来说,Unicode 序列 u2018 和 u2019 产生 `‘` 和 `’`,而代码 u201c 和 u201d 产生 `“` 和 `”` 字符。知道这些“秘密”代码意味着你可以使用 [sed](https://opensource.com/article/20/12/sed) 这样的命令以编程方式替换它们。任何版本的 sed 都可以,所以你可以使用 GNU sed 或 BSD sed,甚至是 [Busybox](https://opensource.com/article/21/8/what-busybox) sed。
下面是我使用的简单的 shell 脚本:
```
#!/bin/sh
# GNU All-Permissive License
SDQUO=$(echo -ne '\u2018\u2019')
RDQUO=$(echo -ne '\u201C\u201D')
$SED -i -e "s/[$SDQUO]/\'/g" -e "s/[$RDQUO]/\"/g" "${1}"
```
将此脚本保存为 `fixquotes.sh`,然后创建一个包含智能引号的单独测试文件:
```
‘Single quote’
“Double quote”
```
运行该脚本,然后使用 [cat](https://opensource.com/article/19/2/getting-started-cat-command) 命令查看结果:
```
$ sh ./fixquotes.sh test.txt
$ cat test.txt
'Single quote'
"Double quote"
```
### 安装 sed
如果你使用的是 Linux、BSD 或 macOS,那么你已经安装了 GNU 或 BSD 的 `sed`。这是原始 `sed` 命令的两个独特的重新实现,对于本文中的脚本来说,它们在功能上是一样的(不过并不是所有的脚本都是这样)。
在 Windows 上,你可以用 [Chocolatey](https://opensource.com/article/20/3/chocolatey) [安装 GNU sed](https://chocolatey.org/packages/sed)。
---
via: <https://opensource.com/article/21/9/sed-replace-smart-quotes>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In typography, a pair of quotation marks were traditionally oriented toward one another. They look like this:
“smart quotes”
As computers became popular in the mid-twentieth century, the orientation was often abandoned. The original character set of computers didn't have much room to spare, so it makes sense that two double-quotes and two single-quotes were reduced down to just one of each in the ASCII specification. These days the common character set is Unicode, with plenty of space for lots of fancy quotation marks and apostrophes, but many people have become used to the minimalism of just one character for both opening and closing quotes. Besides that, computers actually see the different kinds of quotation marks and apostrophes as distinct characters. In other words, to a copmuter the right double quote is different from the left double quote or a straight quote.
## Replacing smart quotes with sed
Computers aren't typewriters. When you press a key on your keyboard, you're not pressing a lever with an inkstamp attached to it. You're just pressing a button that sends a signal to your computer, which the computer interprets as a request to display a specific predefined character. The request depends on your keyboard map. As a Dvorak typist, I've witnessed the confusion on people's faces when they discover "asdf" on my keyboard produces "aoeu" on the screen. You may also have pressed special combinations of keys to produce characters, such as ™ or ß or ≠, that's not even printed on your keyboard.
Each letter or character, whether it's printed on your keyboard or not, has a code. Character encoding can be expressed in different ways, but to a computer the Unicode sequences u2018 and u2019 produce **‘** and **’**, while the codes u201c and u201d produce the **“** and **”** characters. Knowing these "secret" codes means you can replace them programmatically using a command like [sed](https://opensource.com/article/20/12/sed). Any version of sed will do, so you can use GNU sed or BSD sed or even [Busybox](https://opensource.com/article/21/8/what-busybox) sed.
Here's the simple shell script I use:
```
``````
#!/bin/sh
# GNU All-Permissive License
SED=$(which sed)
SDQUO=$(echo -ne '\u2018\u2019')
RDQUO=$(echo -ne '\u201C\u201D')
$SED -i -e "s/[$SDQUO]/\'/g" -e "s/[$RDQUO]/\"/g" "${1}"
```
Save this script as `fixquotes.sh`
and then create a separate test file containing smart quotes:
```
``````
‘Single quote’
“Double quote”
```
Run the script, and then use the [cat](https://opensource.com/article/19/2/getting-started-cat-command) command to see the results:
```
``````
$ sh ./fixquotes.sh test.txt
$ cat test.txt
'Single quote'
"Double quote"
```
## Install sed
If you’re using Linux, BSD, or macOS, then you already have GNU or BSD `sed`
installed. These are two unique reimplementations of the original `sed`
command, and for the script in this article they are functionally the same (that's not true for all scripts, though).
On Windows, you can [install GNU sed](https://chocolatey.org/packages/sed) with [Chocolatey](https://opensource.com/article/20/3/chocolatey).
## 3 Comments |
13,808 | 满足日常需求的应用(五):视频编辑器 | https://fedoramagazine.org/apps-for-daily-needs-part-5-video-editors/ | 2021-09-21T21:55:57 | [
"视频编辑器"
] | https://linux.cn/article-13808-1.html | 
视频编辑已经成为一种流行的活动。人们出于各种原因需要视频编辑,不管是工作、教育或仅仅是一种爱好。现在也有很多平台可以在互联网上分享视频,以及几乎所有的社交媒体和聊天工具都提供分享视频的功能。本文将介绍一些你可以在 Fedora Linux 上使用的开源视频编辑器。你可能需要安装提到的这些软件才能使用。如果你不熟悉如何在 Fedora Linux 中添加软件包,请参阅我之前的文章《[安装 Fedora 34 工作站后要做的事情](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/)》。这里列出了视频编辑器类别的一些日常需求的应用程序。
### Kdenlive
当有人问起 Linux 上的开源视频编辑器时,经常出现的答案是 Kdenlive。它是一个在开源用户群体中非常流行的视频编辑器。这是因为它的功能对于一般用途来说是足够的,而且对于非专业人士的人来说也很容易使用。
Kdenlive 支持多轨编辑,因此你可以将多个来源的音频、视频、图像和文本结合起来。这个应用程序还支持各种视频和音频格式,这样你就不必事先转换它们。此外,Kdenlive 提供了各种各样的效果和转场,以支持你的创造力来制作很酷的视频。Kdenlive 提供的一些功能有:用于创建 2D 字幕的字幕器、音频和视频范围、代理编辑、时间线预览、关键帧效果等等。

更多信息可在此链接中获得:<https://kdenlive.org/en/>
### Shotcut
Shotcut 与 Kdenlive 的功能大致相同。这个应用程序是一个通用的视频编辑器。它有一个相当简单的界面,但功能齐全,可以满足你视频编辑工作的各种需要。
Shotcut 拥有一套完整视频编辑功能,提供了从简单的编辑到高级的功能。它还支持各种视频、音频和图像格式。你不需要担心你的编辑历史,因为这个应用程序有无限的撤销和重做功能。Shotcut 还提供了各种视频和音频效果,因此你可以自由地创造性地制作你的视频作品。它提供的一些功能有:音频过滤器、音频混合、交叉淡化的音视频溶解过渡、音调发生器、速度变化、视频合成、3 路色轮、轨道合成/混合模式、视频过滤器等。

更多信息可在此链接中获得:<https://shotcut.org/>
### Pitivi
如果你想要一个具有直观和简洁用户界面的视频编辑器,Pitivi 将是正确的选择。你会对它的外观感到舒适,并且不难找到你需要的功能。这个应用程序被归类为非常容易学习,特别是如果你需要一个用于简单编辑需求的应用程序时。然而,Pitivi 仍然提供了种种功能,如修剪 & 切割、混音、关键帧音频效果、音频波形、音量关键帧曲线、视频过渡等。

更多信息可在此链接中获得:<https://www.pitivi.org/>
### Cinelerra
Cinelerra 是一个已经开发了很久的视频编辑器。它为你的视频工作提供了大量的功能,如内置帧渲染、各种视频效果、无限的层、8K 支持、多相机支持、视频音频同步、渲染农场、动态图形、实时预览等。这个应用程序可能不适合那些刚开始学习的人。我认为你需要一段时间来适应这个界面,特别是如果你已经熟悉了其他流行的视频编辑应用程序。但 Cinelerra 仍是一个有趣的选择,可以作为你的视频编辑器。

更多信息请见此链接:<http://cinelerra.org/>
### 总结
这篇文章介绍了四个在 Fedora Linux 上可用的视频编辑器应用,以满足你的日常需求。实际上,在 Fedora Linux 上还有很多其他的视频编辑器可以使用。你也可以使用 Olive(Fedora Linux 仓库)、 OpenShot(rpmfusion-free)、Flowblade(rpmfusion-free)等等。每个视频编辑器都有自己的优势。有些在纠正颜色方面比较好,而有些在各种转场和效果方面比较好。当涉及到如何轻松地添加文本时,有些则更好。请选择适合你需求的应用程序。希望这篇文章可以帮助你选择正确的视频编辑。如果你有使用这些应用程序的经验,请在评论中分享你的经验。
---
via: <https://fedoramagazine.org/apps-for-daily-needs-part-5-video-editors/>
作者:[Arman Arisman](https://fedoramagazine.org/author/armanwu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Video editing has become a popular activity. People need video editors for various reasons, such as work, education, or just a hobby. There are also now many platforms for sharing video on the internet. Almost all social media and chat messengers provide features for sharing videos. This article will introduce some of the open source video editors that you can use on Fedora Linux. You may need to install the software mentioned. If you are unfamiliar with how to add software packages in Fedora Linux, see my earlier article [Things to do after installing Fedora 34 Workstation](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/). Here is a list of a few apps for daily needs in the video editors category.
## Kdenlive
When anyone asks about an open source video editor on Linux, the answer that often comes up is Kdenlive. It is a very popular video editor among open source users. This is because its features are complete for general purposes and are easy to use by someone who is not a professional.
Kdenlive supports multi-track, so you can combine audio, video, images, and text from multiple sources. This application also supports various video and audio formats without having to convert them first. In addition, Kdenlive provides a wide variety of effects and transitions to support your creativity in producing cool videos. Some of the features that Kdenlive provides are titler for creating 2D titles, audio and video scopes, proxy editing, timeline preview, keyframeable effects, and many more.
More information is available at this link: [https://kdenlive.org/en/](https://kdenlive.org/en/)
## Shotcut
Shotcut has more or less the same features as Kdenlive. This application is a general purposes video editor. It has a fairly simple interface, but with complete features to meet the various needs of your video editing work.
Shotcut has a complete set of features for a video editor, ranging from simple editing to high-level capabilities. It also supports various video, audio, and image formats. You don’t need to worry about your work history, because this application has unlimited undo and redo. Shotcut also provides a variety of video and audio effects features, so you have freedom to be creative in producing your video works. Some of the features offered are audio filters, audio mixing, cross fade audio and video dissolve transition, tone generator, speed change, video compositing, 3 way color wheels, track compositing/blending mode, video filters, etc.
More information is available at this link: [https://shotcut.org/](https://shotcut.org/)
## Pitivi
Pitivi will be the right choice if you want a video editor that has an intuitive and clean user interface. You will feel comfortable with how it looks and will have no trouble finding the features you need. This application is classified as very easy to learn, especially if you need an application for simple editing needs. However, Pitivi still offers a variety of features, like trimming & cutting, sound mixing, keyframeable audio effects, audio waveforms, volume keyframe curves, video transitions, etc.
More information is available at this link: [https://www.pitivi.org/](https://www.pitivi.org/)
## Cinelerra
Cinelerra is a video editor that has been in development for a long time. There are tons of features for your video work such as built-in frame render, various video effects, unlimited layers, 8K support, multi camera support, video audio sync, render farm, motion graphics, live preview, etc. This application is maybe not suitable for those who are just learning. I think it will take you a while to get used to the interface, especially if you are already familiar with other popular video editor applications. But Cinelerra will still be an interesting choice as your video editor.
More information is available at this link: [http://cinelerra.org/](http://cinelerra.org/)
## Conclusion
This article presented four video editor apps for your daily needs that are available on Fedora Linux. Actually there are many other video editors that you can use in Fedora Linux. You can also use Olive (Fedora Linux repo), OpenShot (rpmfusion-free) , Flowblade (rpmfusion-free) and many more. Each video editor has its own advantages. Some are better at correcting color, while others are better at a variety of transitions and effects. Some are better when it comes to how easy it is to add text. Choose the application that suits your needs. Hopefully this article can help you to choose the right video editors. If you have experience in using these applications, please share your experience in the comments.
## Ralf Seidenschwang
Thanks Arman. Your series makes fun!
The only thing I have to do with video-editing is to find the right entry point and duration for small videos with I usually record with my mobile phone, for example short sport clips that I want to share with my friends. Sometimes I want to adjust the start (the first picture so to say and the preview picture) and the duration of the video.
Usually, I do not edit my videos, but for that purpose, I’m search a solution with a small footprint for cases I do not share directly from mobile to mobile.
Is there a favorite for that purpose available Arman?
## Franco
If we’re talking about software for Fedora, and not for mobile phones, I highly recommend Avidemux (avidemux-qt package in the rpmfusion-free repo). It has a very simple interface that lets you do exactly what you want. The best part is that if you’re simply adjusting the start and the duration of the video, you can export a new file without re-encoding, which means that the export process is super fast and there is no degradation in quality.
## Ralf Seidenschwang
That seems to be a fitting solution. Thank you very much. I will try this.
## John
Arman, you do a great job for deadly Linux users.
Thank you!
## AlexTheoto
Flowblade is very good video editor, with similar interface of Sony Vegas. It uses ffmpeg and it is available on flathub or rpmfusion-free
## Anon
Can you do one on PDF Editor and sponsorize Xournal++?
It allows to annotate PDF and will soon allow to select text from them too
## John Smith
I usually go for Kdenlive, which is very complete and regularly updated as well. I think Openshot should also have been mentioned, as it seems more recently updated than Pitivi, which last stable release was in September 2020. I don’t know much about Openshot or Pitivi, but when I look for software, I usually look when it was last updated. Not sure what to think of software which has not been updated for a while.
## Rich Alloway
I agree: OpenShot should have been included. It has its faults, but it has a combination of intuitiveness and power that I’ve found to be very unique and useful.
OpenShot gets used at least once a week to produce YouTube videos at my house!
If I can’t do something right in OpenShot, I can usually do it in at the command line with ffmpeg and import the result into OpenShot.
## AC2
Another vote for OpenShot.. Much better than Pitivi for sure!
Although with Fedora 34 Workstation now using ffmpeg v4.4, the audio output is borked…
## Huub
Another vote for OpenShot. Using it 3 times a week, no complaints. Even when it crashes (which rarely happens), it comes back with the last changes still applied.
## Franco
I believe Olive should have been more than a simple mention that it exists.
It is by far the most stable and fastest of the bunch.
It may not have all the features of Kdenlive, but it sure is MUCH more usable.
## MillironX
Agreed. As a long-time Adobe Premiere (Elements and Pro) user who transitioned to Linux, Olive was the only editor I tried that made the cut. The main reason it stood out was that it was the only editor that could handle native H.264 footage for real-time forward and reverse scrubbing on my Nvidia GTX 1060 Ti.
## Clive Wi
I tried several of the Linux Video editors, and found that Kdenlive was the best out of all of them, the most significant problem I had with all the others was not the features which their appeared to be plenty, it was I read the user manual and didn’t understand what I had to do to achieve the result that I wanted.
I would really recommend the creation of some videos because as they say “A picture is worth a 1000 words”
## Pedgerow
Thanks for writing this! I really wanted to learn video editing last year, because I wanted to make a music video for a song that’s very hard to find online. In the end, I used something called VSDC, but I didn’t really like it. I don’t know if it’s open-source. I will download one of the ones from this list and see if I like it more!
## Vincent B
Forgot Blender… Blender is also a very strong video editor, with a lot of functionalities , …
## NC
For some minor editing jobs, I’ve used Flowblade — it certainly has more capability than I’ve needed, so I’m not sure how it stacks up to, eg. Kdenlive, but it gets frequent updates and RPMs are available in rpmfusion.
http://jliljebl.github.io/flowblade/
## nuudul
mentioning davinci resolve would have been nice, but still a great article |
13,810 | 用 Linux 的 watch 命令观察命令和任务 | https://opensource.com/article/21/9/linux-watch-command | 2021-09-22T10:45:47 | [
"watch"
] | https://linux.cn/article-13810-1.html |
>
> 了解 watch 命令如何让你知道任务已完成或命令已执行。
>
>
>

有很多时候,你需要等待一些事情的完成,比如:
* 一个文件的下载。
* 创建或解压一个 [tar](https://opensource.com/article/17/7/how-unzip-targz-file) 文件。
* 一个 [Ansible](https://opensource.com/resources/what-ansible) 作业。
其中一些进程有进度指示,但有时进程是通过一层抽象运行的,衡量进度的唯一方法是通过其副作用。其中一些可能是:
* 一个正在下载的文件不断增长。
* 一个从 tarball 中提取的目录被文件填满了。
* Ansible 作业构建了一个[容器](https://opensource.com/resources/what-docker)。
你可以用这样的命令查询所有这些:
```
$ ls -l downloaded-file
$ find . | wc -l
$ podman ps
$ docker ps
```
但是反复运行这些命令,即使是利用 [Bash 历史](https://opensource.com/article/20/6/bash-history-control) 和**向上箭头**的便利,也是很乏味的。
另一种方法是写一个小的 Bash 脚本来为你自动执行这些命令:
```
while :
do
docker ps
sleep 2
done
```
但这样的脚本写起来也会很繁琐。你可以写一个小的通用脚本,并将其打包,这样它就可以一直被你使用。幸运的是,其他开源的开发者已经有了这样的经验和做法。
那就是 `watch` 这个命令。
### 安装 watch
`watch` 命令是 [procps-ng 包](https://opensource.com/article/21/8/linux-procps-ng)的一部分,所以如果你是在 Linux 上,你已经安装了它。
在 macOS 上,使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac) 安装 `watch`。在 Windows 上,使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey)。
### 使用 watch
`watch` 命令定期运行一个命令并显示其输出。它有一些文本终端的特性,所以只有最新的输出才会出现在屏幕上。
最简单的用法是:`watch <command>`。
例如,在 `docker ps` 命令前加上 `watch`,就可以这样操作:
```
$ watch docker ps
```
用 `watch` 命令,以及一些创造性的 Unix 命令行技巧,可以生成临时的仪表盘。例如,要计算审计事件:
```
$ watch 'grep audit: /var/log/kern.log |wc -l'
```
在最后一个例子中,如果有一个可视化的指示,表明审计事件的数量发生了变化,这可能是有用的。如果变化是预期的,但你想让一些东西看起来“不同”,`watch --differences` 就很好用。它可以高亮显示与上次运行的任何差异。如果你在多个文件中搜索,这一点尤其有效,所以你可以很容易地看到哪个文件发生了变化。
如果没有预期的变化,你可以使用 `watch --differences=permanent` 要求它们被“永久”高亮显示,以便知道哪些变化需要调查。这通常是更有用的。
### 控制频率
最后,有时该命令可能是资源密集型的,不应运行得太频繁。`-n` 参数控制频率。`watch` 默认使用 2 秒间隔,但是 `watch -n 10` 可能适合于资源密集型的情况,比如在子目录的任何文件中搜索一个模式:
```
$ watch -n 10 'find . -type f | xargs grep suspicious-pattern'
```
### 用 watch 观察一个命令
`watch` 命令对于许多临时性的系统管理任务非常有用,在这些任务中,你需要在没有进度条的情况下等待一些耗时的步骤,然后再进入下一个步骤。尽管这种情况并不理想,但 `watch` 可以使情况稍微好转。它让你有时间为工作做回顾性笔记!"。下载 [备忘录](https://opensource.com/downloads/watch-cheat-sheet),让有用的语法和选项触手可及。。
---
via: <https://opensource.com/article/21/9/linux-watch-command>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are many times when you need to wait for something to finish, such as:
Some of these processes have some sort of progress indication, but sometimes the process is run through a layer of abstraction, and the only way to measure the progress is through its side effects. Some of these might be:
- A file being downloaded keeps growing.
- A directory extracted from a tarball fills up with files.
- The Ansible job builds a
[container](https://opensource.com/resources/what-docker).
You can query all of these things with commands like these:
```
$ ls -l downloaded-file
$ find . | wc -l
$ podman ps
$ docker ps
```
But running these commands over and over, even if it is with the convenience of [Bash history](https://opensource.com/article/20/6/bash-history-control) and the **Up Arrow**, is tedious.
Another approach is to write a little Bash script to automate these commands for you:
```
while :
do
docker ps
sleep 2
done
```
But such scripts can also become tedious to write. You could write a little generic script and package it, so it's always available to you. Luckily, other open source developers have already been there and done that.
The result is the command `watch`
.
## Installing watch
The `watch`
command is part of the [ procps-ng package](https://opensource.com/article/21/8/linux-procps-ng), so if you're on Linux, you already have it installed.
On macOS, install `watch`
using [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac). On Windows, use [Chocolatey](https://opensource.com/article/20/3/chocolatey).
## Using watch
The `watch`
command periodically runs a command and shows its output. It has some text-terminal niceties, so only the latest output is on the screen.
The simplest usage is: `watch <command>`
.
For example, prefixing the
command with `docker ps``watch`
works like this:
`$ watch docker ps`
The `watch`
command, and a few creative Unix command-line tricks, can generate ad-hoc dashboards. For example, to count audit events:
`$ watch 'grep audit: /var/log/kern.log |wc -l'`
In the last example, it is probably useful if there's a visual indication that the number of audit events changed. If change is expected, but you want something to look "different," `watch --differences`
works well. It highlights any differences from the last run. This works especially well if you are grepping in multiple files, so you can easily see which one changed.
If changes are not expected, you can ask for them to be highlighted "permanently" to know which ones to investigate by using `watch --differences=permanent`
. This is often more useful.
## Controlling frequency
Finally, sometimes the command might be resource-intensive and should not be run too frequently. The `-n`
parameter controls the frequency. Watch uses two seconds by default, but `watch -n 10`
might be appropriate for something more resource-intensive, like grepping for a pattern in any file in a subdirectory:
`$ watch -n 10 'find . -type f | xargs grep suspicious-pattern'`
## Watch a command with watch
The `watch`
command is useful for many ad-hoc system administration tasks where you need to wait for some time-consuming step, without a progress bar, before moving on to the next one. Though this is not a great situation to be in, `watch`
can make it slightly better—and give you time to start working on those notes for the retrospective! Download the ** cheat sheet **to keep helpful syntax and options close at hand.
## Comments are closed. |
13,811 | YAML 使用入门 | https://opensource.com/article/21/9/intro-yaml | 2021-09-23T09:52:49 | [
"YAML"
] | /article-13811-1.html |
>
> 什么是 YAML,为什么我们现在应该开始使用它?
>
>
>

[YAML](https://yaml.org/)(<ruby> YAML 不是标记语言 <rt> YAML Ain't Markup Language </rt></ruby>)是一种适宜阅读理解的数据序列化语言。它的语法简单而易于阅读。它不包含引号、打开和关闭的标签或大括号。它不包含任何可能使人类难以解析嵌套规则的东西。你可以看一下你的 YAML 文档就知道它在什么。
### YAML 特性
YAML 有一些超级特性,使其优于其他序列化格式:
* 易于略读。
* 易于使用。
* 可在编程语言之间移植。
* 敏捷语言的原生数据结构。
* 支持通用工具的一致模型。
* 支持一次性处理。
* 表现力和可扩展性。
我将通过一些例子进一步向你展示 YAML 的强大。
你能弄清楚下面发生了什么吗?
```
-------
# My grocery list
groceries:
- Milk
- Eggs
- Bread
- Butter
...
```
上面的例子包含了一个简单的杂货购物清单,它是一个完全格式化的 YAML 文档。在 YAML 中,字符串不加引号,而列表需要简单的连字符和空格。一个 YAML 文档以 `---` 开始,以 `...` 结束,但它们是可选的。YAML中的注释以 `#` 开始。
缩进是 YAML 的关键。缩进必须包含空格,而不是制表符。虽然所需的空格数量是灵活的,但保持一致是个好主意。
### 基本元素
#### 集合
YAML 有两种类型的集合。列表(用于序列)和字典(用于映射)。列表是键值对,每个值都在一个新的行中,以连字符和空格开始。字典也是键值对,每个值都是一个映射,包含一个键、一个冒号和空格以及一个值。
例如:
```
# My List
groceries:
- Milk
- Eggs
- Bread
- Butter
# My dictionary
contact:
name: Ayush Sharma
email: [email protected]
```
列表和字典经常被结合起来,以提供更复杂的数据结构。列表可以包含字典,而字典可以包含列表。
#### 字符串
YAML 中的字符串不需要加引号。多行字符串可以用 `|` 或 `>` 来定义。前者保留了换行符,而后者则没有。
例如:
```
my_string: |
This is my string.
It can contain many lines.
Newlines are preserved.
```
```
my_string_2: >
This is my string.
This can also contain many lines.
Newlines aren't preserved and all lines are folded.
```
#### 锚点
YAML 可以通过节点锚点来获得可重复的数据块。`&` 字符定义了一个数据块,以后可以用 `*` 来引用。例如:
```
billing_address: &add1
house: B1
street: My Street
shipping_address: *add1
```
至止你对 YAML 的了解就足以让你开始工作了。你可以使用在线 YAML 解析器来测试。如果你每天都与 YAML 打交道,那么 [这个方便的备忘单](https://yaml.org/refcard.html) 会对你有所帮助。
*这篇文章最初发表在[作者的个人博客](https://notes.ayushsharma.in/2021/08/introduction-to-yaml)上,并经授权改编。*
---
via: <https://opensource.com/article/21/9/intro-yaml>
作者:[Ayush Sharma](https://opensource.com/users/ayushsharma) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,813 | Linux 黑话解释:什么是 sudo rm -rf?为什么如此危险? | https://itsfoss.com/sudo-rm-rf/ | 2021-09-23T15:35:00 | [
"sudo",
"rm"
] | https://linux.cn/article-13813-1.html | 
当你刚接触 Linux 时,你会经常遇到这样的建议:永远不要运行 `sudo rm -rf /`。在 Linux 世界里,更是围绕着 `sudo rm -rf` 有很多梗。

但似乎对于它也有一些混乱的认识。在 [清理 Ubuntu 以腾出空间](https://itsfoss.com/free-up-space-ubuntu-linux/) 的教程中,我建议运行一些涉及 `sudo` 和 `rm -rf` 的命令。一位读者问我,如果 `sudo rm -rf` 是一个不应该运行的危险的 Linux 命令,我为什么要建议这样做。
因此,我想到了写一篇 Linux 黑话解释,以消除误解。
### sudo rm -rf 在做什么?
让我们按步骤来学习。
`rm` 命令用于 [在 Linux 命令行中删除文件和目录](https://linuxhandbook.com/remove-files-directories/)。
```
$ rm agatha
$
```
但是因为有只读的 [文件权限](https://linuxhandbook.com/linux-file-permissions/),有些文件不会被立即删除。它们必须用选项 `-f` 强制删除。
```
$ rm books
rm: remove write-protected regular file 'books'? y
$ rm -f christie
$
```
另外,`rm` 命令不能被用来直接删除目录(文件夹)。你必须在 `rm` 命令中使用递归选项 `-r`。
```
$ rm new_dir
rm: cannot remove 'new_dir': Is a directory
```
因此最终,`rm -rf` 命令意味着递归地、强制删除指定的目录。
```
$ rm -r new_dir
rm: remove write-protected regular file 'new_dir/books'? ^C
$ rm -rf new_dir
$
```
下面是上述所有命令的截图。

如果你在 `rm -rf` 命令前加入 `sudo`,你就是在删除具有 root 权限的文件。这意味着你可以删除由 [root 用户](https://itsfoss.com/root-user-ubuntu/) 拥有的系统文件。
### 所以,sudo rm -rf 是一个危险的 Linux 命令?
嗯,任何删除东西的命令都可能是危险的,如果你不确定你正在删除什么。
把 `rm -rf` 命令看作一把刀。刀是一个危险的东西吗?有可能。如果你用刀切蔬菜,那是好事。如果你用刀切手指,那当然是不好的。
`rm -rf` 命令也是如此。它本身并不危险。它只是用来删除文件的。但是,如果你在不知情的情况下用它来删除重要文件,那就有问题了。
现在来看看 `sudo rm -rf /`。
你知道,使用 `sudo`,你是以 root 身份运行一个命令,这允许你对系统进行任何改变。
`/` 是根目录的符号。`/var` 表示根目录下的 `var` 目录。`/var/log/apt` 指的是根目录的 `log` 目录下的 `apt` 目录。

按照 [Linux 目录层次结构](https://linuxhandbook.com/linux-directory-structure/),Linux 文件系统中的一切都从根目录开始。如果你删除了根目录,你基本上就是删除了系统中的所有文件。
这就是为什么建议不要运行 `sudo rm -rf /` 命令,因为你会抹去你的整个 Linux 系统。
请注意,在某些情况下,你可能正在运行像 `sudo rm -rf /var/log/apt` 这样的命令,这可能是没问题的。同样,你必须注意你正在删除的东西,就像你必须注意你正在用刀切割的东西一样。
### 我在玩火:如果我运行 sudo rm -rf /,看看会发生什么呢?
大多数 Linux 发行版都提供了一个故障安全保护,防止意外删除根目录。
```
$ sudo rm -rf /
[sudo] password for abhishek:
rm: it is dangerous to operate recursively on '/'
rm: use --no-preserve-root to override this failsafe
```
我的意思是,人是会打错字的,如果你不小心打了 `/ var/log/apt`,而不是 `/var/log/apt`(`/` 和 `var` 之间的空格意味着你给出了 `/` 和 `var` 目录来删除),你将会删除根目录。(LCTT 译注:我真干过,键盘敲的飞起,结果多敲了一个空格,然后就丢了半个文件系统 —— 那时候 Linux 还没这种故障安全保护。)

别担心。你的 Linux 系统会照顾到这种意外。
现在,如果你一心想用 `sudo rm -rf /` 来破坏你的系统呢?你将必须使用它将要求你使用的 `-no-preserve-root` 选项与之配合。
不,请不要自己这样做。让我做给你看看。
所以,我在一个虚拟机中运行基本的操作系统。我运行 `sudo rm -rf / --no-preserve-root`,你可以在下面的视频中看到灯光熄灭(大约 1 分钟)。
### 清楚了么?
Linux 有一个活跃的社区,大多数人都会帮助新用户。 之所以说是大多数,是是因为有一些的邪恶坏人潜伏着捣乱新用户。他们经常会建议对初学者所面临的最简单的问题运行 `rm -rf /`。我认为这些白痴在这种邪恶行为中得到了某种至上主义的满足。我会立即将他们从我管理的论坛和群组中踢出去。
我希望这篇文章能让你更清楚地了解这些情况。你有可能仍然有一些困惑,特别是因为它涉及到根目录、文件权限和其他新用户可能不熟悉的东西。如果是这样的话,请在评论区告诉我你的疑惑,我会尽力去解决。
最后,请记住。<ruby> 不要喝酒胡搞 <rt> Don’t drink and root </rt></ruby>。在运行你的 Linux 系统时要安全驾驶。
---
via: <https://itsfoss.com/sudo-rm-rf/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you are new to Linux, you’ll often come across advice to never run `sudo rm -rf /`
. There are so many memes in the Linux world around `sudo rm -rf`
.

But it seems that there are some confusions around it. In the tutorial on [cleaning Ubuntu to make free space](https://itsfoss.com/free-up-space-ubuntu-linux/), I advised running some command that involved sudo and rm -rf. An It’s FOSS reader asked me why I am advising that if sudo rm -rf is a [dangerous Linux command](https://itsfoss.com/dangerous-linux-commands/) that should not be run.
And thus I thought of writing this chapter of Linux jargon buster and clear the misconceptions.
## sudo rm -rf: what does it do?
Let’s learn things in steps.
The rm command is used for [removing files and directories in Linux command line](https://linuxhandbook.com/remove-files-directories/).
```
abhishek@its-foss:$ rm agatha
abhishek@its-foss:$
```
But some files will not be removed immediate because of read only [file permissions](https://linuxhandbook.com/linux-file-permissions/). They have to be forced delete with the option `-f`
.
```
abhishek@its-foss:$ rm books
rm: remove write-protected regular file 'books'? y
abhishek@its-foss:$ rm -f christie
abhishek@its-foss:$
```
However, rm command cannot be used to delete directories (folders) directly. You have to use the recursive option `-r`
with the rm command.
```
abhishek@its-foss:$ rm new_dir
rm: cannot remove 'new_dir': Is a directory
```
And thus ultimately, rm -rf command means recursively force delete the given directory.
```
abhishek@its-foss:~$ rm -r new_dir
rm: remove write-protected regular file 'new_dir/books'? ^C
abhishek@its-foss:$ rm -rf new_dir
abhishek@its-foss:$
```
Here’s a screenshot of all the above commands:
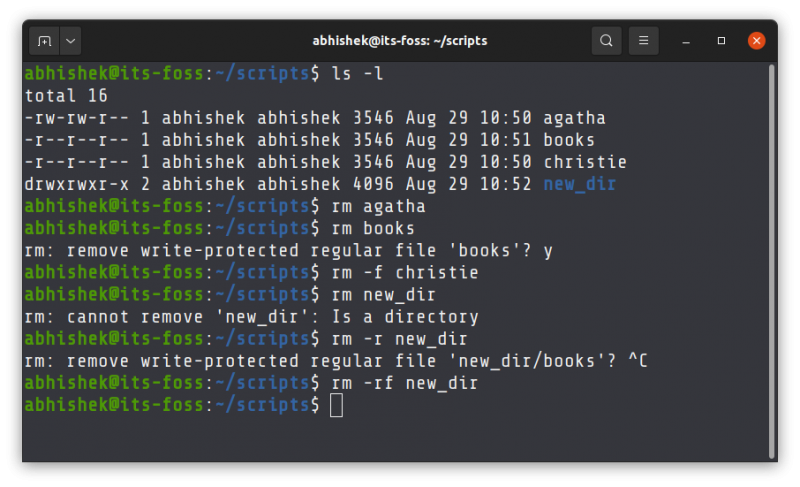
If you add sudo to the rm -rf command, you are deleting files with root power. That means you could delete system files owned by [root user](https://itsfoss.com/root-user-ubuntu/).
## So, sudo rm -rf is a dangerous Linux command?
Well, any command that deletes something could be dangerous if you are not sure of what you are deleting.
Consider **rm -rf command** as a knife. Is knife a dangerous thing? Possibly. If you cut vegetables with the knife, it’s good. If you cut your fingers with the knife, it is bad, of course.
The same goes for rm -rf command. It is not dangerous in itself. It is used for deleting files after all. But if you use it to delete important files unknowingly, then it is a problem.
Now coming to ‘sudo rm -rf /’.
You know that with sudo, you run a command as root, which allows you to make any changes to the system.
/ is the symbol for the root directory. /var means the var directory under root. /var/log/apt means apt directory under log, under root.
As per [Linux directory hierarchy](https://linuxhandbook.com/linux-directory-structure/), everything in a Linux file system starts at root. If you delete root, you are basically removing all the files of your system.
And this is why it is advised to not run `sudo rm -rf /`
command because you’ll wipe out your entire Linux system.
Please note that in some cases, you could be running a command like ‘sudo rm -rf /var/log/apt’ which could be fine. Again, you have to pay attention on what you are deleting, the same as you have to pay attention on what you are cutting with a knife.
## I play with danger: what if I run sudo rm -rf / to see what happens?
Most Linux distributions provide a failsafe protection against accidentally deleting the root directory.
```
abhishek@test-vm:~$ sudo rm -rf /
[sudo] password for abhishek:
rm: it is dangerous to operate recursively on '/'
rm: use --no-preserve-root to override this failsafe
```
I mean it is human to make typos and if you accidentally typed “/ var/log/apt” instead of “/var/log/apt” (a space between / and var meaning that you are providing / and var directories to for deletion), you’ll be deleting the root directory.
That’s quite good. Your Linux system takes care of such accidents.
Now, what if you are hell-bent on destroying your system with sudo rm -rf /? You’ll have to use It will ask you to use –no-preserve-root with it.
No, please do not do that on your own. Let me show it to you.
So, I have elementary OS running in a virtual machine. I run `sudo rm -rf / --no-preserve-root`
and you can see the lights going out literally in the video below (around 1 minute).
## Clear or still confused?
Linux has an active community where most people try to help new users. Most people because there are some evil trolls lurking to mess with the new users. They will often suggest running rm -rf / for the simplest of the problems faced by beginners. These idiots get some sort of supremacist satisfaction I think for such evil acts. I ban them immediately from the forums and groups I administer.
I also recommend going through some of the other potentially harmful Linux commands that are often used to trick new users.
[10 Destructive Linux Commands You Should Never RunWhat are the most dangerous Linux commands? I have been asked this question numerous times and I have avoided answering that because there is no definite list of dangerous Linux commands. You have the tools that enable you to control and modify every aspect of your operating system. I am](https://itsfoss.com/dangerous-linux-commands/)

I hope this article made things clearer for you. It’s possible that you still have some confusion, especially because it involves root, file permissions and other things new users might not be familiar with. If that’s the case, please let me know your doubts in the comment section and I’ll try to clear them.
In the end, remember. Don’t drink and root. Stay safe while running your Linux system :)
 |
13,816 | GNOME 41 发布:最受欢迎的 Linux 桌面环境的精细打磨 | https://news.itsfoss.com/gnome-41-release/ | 2021-09-24T13:08:02 | [
"GNOME"
] | https://linux.cn/article-13816-1.html |
>
> GNOME 41 是一次有价值的升级,它带来了新的应用程序、功能和细微的视觉改进。
>
>
>

现在 GNOME 41 稳定版终于发布了。
虽然 GNOME 40 带来了不少激进的改变,让许多用户不得不去适应新的工作流程,但 GNOME 41 似乎避免了这个问题。
在 GNOME 41 中没有明显的工作流程变化,但有增加了新的功能,做了全面的改进。
GNOME 41 的测试版已经发布了一段时间了。而且,为了发现它值得关注的地方,我们在发布前就使用 [GNOME OS](https://itsfoss.com/gnome-os/) 试用了它的稳定版。
### GNOME 41 有什么新功能?
GNOME 41 并没有给你带来任何新的视觉感受,但是一些有用的改进可以帮助你改善或控制工作流程。
此外,还升级了一些 GNOME 应用程序。
让我提一下 GNOME 41 的主要亮点。
#### GNOME 41 软件的上下文板块

每个版本中,用户都期待着对 GNOME “<ruby> 软件 <rt> Software </rt></ruby>”的改进。
虽然他们一直在朝着正确的方向改进它,但它需要一次视觉上的重新打造。而且,这一次,GNOME 41 带来了急需的 UI 更新。
软件商店的描述性更强了,看起来应该对新用户有吸引力。它使用表情符号/创意图标来对应用程序进行分类,使软件中心变得更时尚。
就像 [Apps for GNOME](https://news.itsfoss.com/apps-for-gnome-portal/) 门户网站一样,“软件”的应用程序屏幕包括了更多的细节,以尽可能地告知用户,而不需要参考项目页面或其网站。

换句话说,这些添加到应用程序页面的上下文板块,提供了有关设备支持、安全/许可、年龄等级、下载的大小、项目等信息。
你还可以为某些应用程序(如 GIMP)选择可用的附加组件,以便一次都安装上。这样你就可以节省寻找附加组件和单独安装它们的时间了。
事实证明,GNOME 41 “软件”比以前更有好用了。
#### 新的多任务选项

GNOME 41 打造了新的多任务设置以帮助你改善工作流程。
你可以通过切换热角来快速打开“<ruby> 活动概览 <rt> Activities Overview </rt></ruby>”。还添加了一个拖动窗口到边缘时调整其大小的能力。
根据你的需求,你可以设置一个固定的可用工作空间的数量,当然也可以保持动态数量。
除此以外,你还可以调整这些功能:
* 多显示器工作区
* 应用程序切换行为
当你有多个显示器时,你可以选择将工作空间限制在一个屏幕上,或在连接的显示器上连续显示。
而且,当你在切换应用程序并浏览它们时,你可以自定义只在同一工作区或在所有工作区预览应用程序。
#### 节电设置

在 GNOME 41 中,现在有一个有效节省电力的性能调整。这对于笔记本用户手动调整其性能,或者当一个应用程序要求切换模式以节省电力时,是非常有用的。

#### GNOME “日历”的改进
GNOME “<ruby> 日历 <rt> Calendar </rt></ruby>”现在可以打开 ICS 文件及导入活动。
#### 触摸板手势
无缝的工作流程的体验:可以利用三指垂直向上/向下滑动的动作来获得“活动概览”,以及利用三指水平向右/向左滑动的动作在工作空间之间导航。
很高兴看到他们重点放在改善使用触摸板的工作流程上,这类似于 [elementary OS 6 的功能](https://news.itsfoss.com/elementary-os-6-features/)。
#### GNOME 连接应用

添加了一个新的“<ruby> 连接 <rt> Connections </rt></ruby>”应用程序,可以连接到远程计算机,不管是什么平台。
我看到这个应用程序仍然是一个 alpha 版本,但也许随着接下来的几次更新,就会看到这个应用程序的完成版本。
我还没有试过它是否可以工作,但也许值得再写一篇简短的文章来告诉你如何使用它。
#### SIP/VoIP 支持
在 [GNOME 41 测试版](https://news.itsfoss.com/gnome-41-beta/) 中,我发现了对 SIP/VoIP 的支持。
如果你是一个商业用户或者经常打国际电话,你现在可以直接从 GNOME 41 的拨号盘上拨打 VoIP 电话了。
不幸的是,在使用带有 GNOME 41 稳定版的 GNOME OS 时,我无法找到包含的“<ruby> 通话 <rt> Calls </rt></ruby>”应用程序。所以,我无法截图给你看。
#### GNOME Web / Epiphany 的改进

GNOME Web(即 Epiphany 浏览器)最近进行了很多很棒的改进。
在 GNOME 41 中,Epiphany 浏览器现在利用 AdGuard 的脚本来阻止 YouTube 广告。别忘了,它还增加了对 Epiphany canary 构建版的支持。
#### 其他改进
在底层,有一些细微但重要的变化带来了更好、更快的用户体验。
例如,你可能会注意到,在应用程序/窗口的标题区域,图标更加醒目。这是为了提高清晰度和增强外观。
同样地,GNOME 应用程序和功能也有许多改进,你在使用它们时可能会发现:
* GNOME “<ruby> 地图 <rt> Map </rt></ruby>”现在以一种用户友好的方式显示平均海平面。
* Nautilus 文件管理器进行了改进,支持有密码保护的压缩文件,并能够让你切换启用/禁用自动清理垃圾的功能
* “<ruby> 音乐 <rt> Music </rt></ruby>”应用程序的用户界面进行了更新
* GNOME 文本编辑器有了更多功能
* GTK 更新至 4.4.0
* 增加 libawaita,以潜在地改善 GNOME 应用程序的用户体验
你可以参考 [官方更新日志和公告博文](https://help.gnome.org/misc/release-notes/41.0/) 来探索所有的技术变化。
### 总结
GNOME 41 可能不是一个突破性的升级,但它是一个带有许多有价值的补充的重要更新。
你可以期待在下个月发布 Fedora 35 中带有它。不幸的是,Ubuntu 21.10 将不包括它,但你可以在其他 Linux 发行版中等待它。
---
via: <https://news.itsfoss.com/gnome-41-release/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

GNOME 41 stable release is ultimately here.
While GNOME 40 was a radical change forcing many users to adapt to a new workflow, GNOME 41 seems to settle the dust.
With GNOME 41, there are no significant workflow changes but new **feature additions** and **improvements** across the board.
GNOME 41 beta has been out there for a while. And, we tried the stable release right before the release date using [GNOME OS](https://itsfoss.com/gnome-os/?ref=news.itsfoss.com) to highlight what you can expect with it.
## GNOME 41 Features: What’s New?
GNOME 41 does not give you any new visual treats but useful improvements to help you improve the workflow or take control of it.
There are some GNOME app upgrades that come along with it.
Let me mention the key highlights of GNOME 41.
### GNOME 41 Software Context Tiles
Every release, users look forward to the improvements made to the GNOME Software Center.
While they have been improving it in the right direction, it needed a visual overhaul. And, this time, GNOME 41 comes with a much-needed UI refresh.
The software store is more descriptive and should look appealing to new users. Using emojis/creative icons to categorize applications makes the software center pop.
Like the [Apps for GNOME](https://news.itsfoss.com/apps-for-gnome-portal/) portal, the application screens on the Software center include more details to inform the user as much as possible without needing to refer to the project page or the web.
In other words, these are the context tiles added to an app page that provides information about device support, safety/permissions, age rating, download size, the project, and more.
You also get to choose the available add-ons for a particular app like GIMP to install in one go. So, you save time from finding add-ons and installing them individually.
GNOME 41 Software should prove to be much more helpful than it ever was.
### New Multitasking Options
To help you improve the workflow, GNOME 41 comes baked in with new multitasking tweaks.
You get the toggle the hot corner to quickly open the Activities Overview. The ability to resize windows upon dragging them to the edges has also been added.
If you want, you can set a fixed number of workspaces available or keep it dynamic to adapt as you require.
In addition to these, you also get features to tweak:
- Multi-monitor workspaces
- Application switching behaviour
When you have multiple displays, you can choose to keep the workspaces restricted to a single screen or continue over connected displays.
And, when you head to switch applications and navigate through them, you can customize to preview the applications only in the same workspace or from all workspaces.
### Power Saving Settings
A helpful performance tweak to save power is now available in GNOME 41. This is incredibly useful for laptop users to tune their performance manually or if an app requests switching the mode to save power.
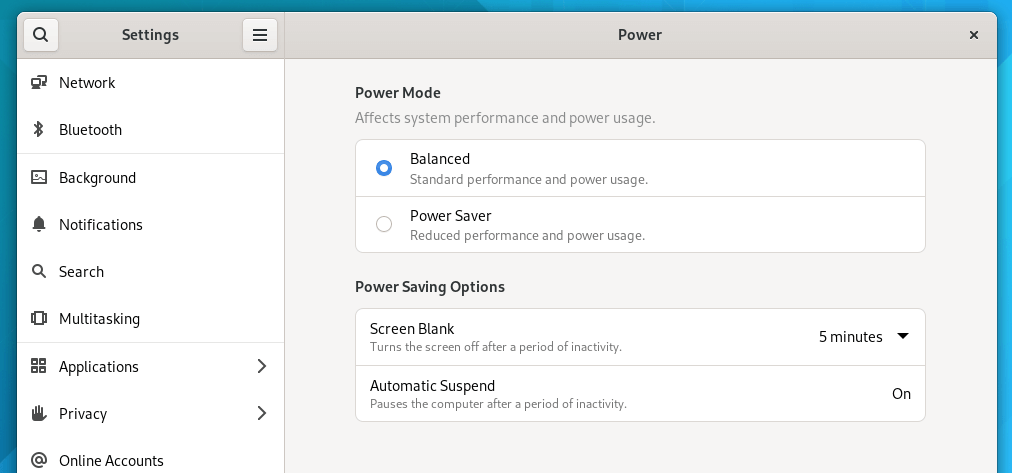
### GNOME Calendar Improvements
GNOME Calendar now can open ICS files along with the ability to import the events.
### Touchpad Gestures
The workflow experience should be seamless when you utilize three-finger vertical swipe up/down actions to get the activity overview, and three-finger horizontal swipe right/left actions to navigate between workspaces.
It is good to see the focus on improving the workflow using the touchpad, similar to [elementary OS 6 features](https://news.itsfoss.com/elementary-os-6-features/).
### GNOME Connections App
A new “Connections” app has been added to connect to remote computers no matter the platform.
I still see the application as an alpha build, but maybe with the following few updates, you should get the finished version of the application.
I haven’t tried if it works, but it might be worth another brief article to show you how to use it.
### SIP/VoIP Support
With [GNOME 41 beta release](https://news.itsfoss.com/gnome-41-beta/), we spotted the inclusion of SIP/VoIP support.
If you are a business user or prefer international calls, you can now make VoIP calls directly from the dialpad in GNOME 41.
Unfortunately, I couldn’t find the “Calls” app included when using GNOME OS with GNOME 41 stable release. So, I couldn’t grab a screenshot of how it looks.
### GNOME Web / Epiphany Improvements
GNOME Web or Epiphany browser has been receiving a lot of good improvements lately.
With GNOME 41, the epiphany browser now utilizes AdGuard’s script to block YouTube advertisements. Not to forget, the support for epiphany canary builds has been added as well.
### Other Improvements
Under the hood, several subtle but essential changes result in a better and faster user experience.
For instance, you may notice the icons more prominent in the header areas of application/windows. This is to improve clarity and enhance the look.
Similarly, there are numerous improvements to GNOME apps and functionalities that you might bump into when you use them:
- GNOME Map now shows the mean sea levels in a user-friendly way
- Improvements to Nautilus file manager to support password-protected zip files and the ability to toggle to let you enable/disable automatic trash cleaning
- Music app getting a UI refresh
- GNOME Text Editor gaining more features
- GTK updated to 4.4.0
- Addition of libawaita to potentially improve the user experience with GNOME apps
You can refer to the [official changelog and the announcement blog post](https://help.gnome.org/misc/release-notes/41.0/?ref=news.itsfoss.com) to explore all the technical changes.
## Wrapping Up
GNOME 41 may not be an experience-breaking upgrade, but it is a significant update with many valuable additions.
You can expect it with Fedora 35, which should release next month. Unfortunately, Ubuntu 21.10 will not include it, but you can wait it out for other Linux distributions.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,817 | 如何在树莓派 4 上安装 Ubuntu 桌面系统 | https://itsfoss.com/install-ubuntu-desktop-raspberry-pi/ | 2021-09-25T08:40:00 | [
"Ubuntu",
"树莓派"
] | https://linux.cn/article-13817-1.html |
>
> 本教程将详细告诉你在树莓派 4 设备上如何安装 Ubuntu 桌面。
>
>
>

革命性的<ruby> 树莓派 <rt> Raspberry Pi </rt></ruby>是最受欢迎的单板计算机。它拥有基于 Debian 的操作系统,叫做 <ruby> <a href="https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/"> 树莓派操作系统 </a> <rt> Raspberry Pi OS </rt></ruby>(原名 Raspbian)。
还有其他几个 [可用于树莓派的操作系统](https://itsfoss.com/raspberry-pi-os/),但几乎所有的都是轻量级的,适合于树莓派设备的小尺寸和低端硬件。
随着标榜 8GB 内存和支持 4K 显示的树莓派 4B 的推出,情况发生了变化。其目的是将树莓派作为常规桌面使用,并在更大程度上成功地做到了这一点。
在 4B 型号之前,你可以 [在树莓派上安装 Ubuntu 服务器](https://itsfoss.com/install-ubuntu-server-raspberry-pi/),但桌面版本却无法使用。然而,**Ubuntu 现在为树莓派 4 提供了官方的桌面镜像**。
在本教程中,我将展示在树莓派 4 上安装 Ubuntu 桌面的步骤。
首先,快速了解一下运行要求。
### 在树莓派 4 上运行 Ubuntu 的要求

以下是你需要的东西:
1. 一个能够联网的 Linux 或 Windows 系统。
2. [树莓派镜像工具](https://github.com/raspberrypi/rpi-imager) :树莓派的官方开源工具,可以在你的 SD 卡上写入发行版镜像。
3. Micro SD 卡:最低使用 16GB 的存储卡,推荐使用 32GB 的版本。
4. 一个基于 USB 的 Micro SD 卡读卡器(如果你的电脑没有读卡器)。
5. 树莓派 4 必备配件,如 HDMI 兼容显示器、[Micro HDMI 连接到标准 HDMI(A/M) 接口的电缆](https://www.raspberrypi.org/products/micro-hdmi-to-standard-hdmi-a-cable/)、[电源(建议使用官方适配器)](https://www.raspberrypi.org/products/type-c-power-supply/)、USB 的有线/无线键盘和鼠标/触摸板。
最好能够提前 [详细阅读树莓派的要求](https://itsfoss.com/things-you-need-to-get-your-raspberry-pi-working/) 。
现在,闲话少叙,让我快速带领你完成 SD 卡的镜像准备。
### 为树莓派准备 Ubuntu 桌面镜像
树莓派提供了一个 GUI 应用程序,用于将 ISO 镜像写入 SD 卡中。**这个工具还可以自动下载兼容的操作系统,如 Ubuntu、树莓派操作系统等**。

你可以从官方网站上下载这个工具的 Ubuntu、Windows 和 macOS 版本:
* [下载树莓派镜像工具](https://www.raspberrypi.org/software/)
在 Ubuntu 和其他 Linux 发行版上,你也可以使用 Snap 安装它:
```
sudo snap install rpi-imager
```
安装完毕后,运行该工具。当你看到下面的界面时,选择 “<ruby> 选择操作系统 <rt> CHOOSE OS </rt></ruby>”:

在“<ruby> 操作系统 <rt> Operating System </rt></ruby>”下,选择 “<ruby> 其它通用的操作系统 <rt> Other general purpose OS </rt></ruby>”:

现在,选择 “Ubuntu”:

接下来,选择 “Ubuntu Desktop 21.04(RPI 4/400)”,如下图所示。

>
> **注意:**
>
>
> 如果你没有一个稳定的网络连接,你可以 [从 Ubuntu 的网站上单独下载 Ubuntu 的树莓派镜像](https://ubuntu.com/download/raspberry-pi)。在镜像工具中,在选择操作系统时,从底部选择“<ruby> 使用自定义 <rt> Use custom </rt></ruby>”选项。你也可以使用 Etcher 将镜像写入到 SD 卡上。
>
>
>
将 Micro SD 卡插入读卡器中,等待它挂载。选择“<ruby> 存储设备 <rt> Storage </rt></ruby>”下的 “<ruby> 选择存储设备 <rt> CHOOSE STORAGE </rt></ruby>”:

你应该可以根据存储空间大小,识别你的 Micro SD 卡。这里,我使用的是 32GB 的卡:

现在点击“<ruby> 写入 <rt> WRITE </rt></ruby>”:

如果你已经备份了 SD 卡上的内容或是一张新卡,你可以直接进行:

由于这需要 [sudo](https://itsfoss.com/add-sudo-user-ubuntu/) 的权限,你必须输入密码。如果你从终端运行 `sudo rpi-imager`,就不会出现这种情况:

如果你的 SD 卡有点旧,这将需要一些时间。如果它是一个新的高速 SD 卡,就无需很长时间:

为确保镜像写入成功,我不建议跳过验证:

写入结束后,会有以下确认提示:

现在,从你的系统中安全移除 SD 卡。
### 在树莓派上使用装有 Ubuntu 的 MicroSD 卡
已经成功了一半了。与常规的 Ubuntu 安装不同,无需创建一个临场安装环境。Ubuntu 已经安装在 SD 卡上了,而且几乎可以直接使用了。让我们来看看这里还剩下什么。
#### 第 1 步:将 SD 卡插入树莓派中
对于第一次使用的用户来说,有时会有点困惑,不知道那个卡槽到底在哪里?不用担心。它位于电路板背面的左手边。下面是一个插入卡后的倒置视图。

按照这个方向将卡慢慢插入板子下面的卡槽,轻轻地插,直到它不再往前移动。你可能还会听到一点咔嚓声来确认。这意味着它已经完美地插入了。

当你把它插进去的时候,你可能会注意到在插槽中有两个小针脚调整了自己的位置(如上图所示),但这没关系。一旦插入,卡看起来会有一点突出。这就是它应该有的样子。

#### 第 2 步:设置树莓派
我无需在这里详细介绍。
保证电源线接头、微型 HDMI 线接头、键盘和鼠标接头(有线/无线)都牢固地连接到树莓派板的相关端口。
确保显示器和电源插头也已正确连接,然后再去打开电源插座。我不建议把适配器插到带电的插座上。参考 [电弧](https://www.electricianatlanta.net/what-is-electrical-arcing-and-why-is-it-dangerous/)。
确认了以上两个步骤后,你就可以 [打开树莓派设备的电源](https://itsfoss.com/turn-on-raspberry-pi/)。
#### 第 3 步:在树莓派上 Ubuntu 桌面的首次运行
当你打开树莓派的电源,你需要在初次运行时进行一些基本配置。你只需按照屏幕上的指示操作即可。
选择你的语言、键盘布局、连接到 WiFi 等:



你可以根据需求选择时区:

然后创建用户和密码:

之后的步骤将配置一些东西,这个过程需要一些时间:


系统会重新启动之前需要一些时间,最终,你将会来到 Ubuntu 的登录界面:

现在,你可以开始享受树莓派上的 Ubuntu 桌面了:

### 总结
我注意到**一个暂时的异常情况**。在进行安装时,我的显示器左侧有一个红色的闪烁边界。这种闪烁(也有不同的颜色)在屏幕的随机部分也能注意到。但在重启和第一次启动后,它就消失了。
很高兴能够看到它在树莓派上运行,我非常需要 Ubuntu 开始为树莓派等流行的 ARM 设备提供支持。
希望这个教程对你有所帮助。如果你有问题或建议,请在评论中告诉我。
---
via: <https://itsfoss.com/install-ubuntu-desktop-raspberry-pi/>
作者:[Avimanyu Bandyopadhyay](https://itsfoss.com/author/avimanyu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: This thorough tutorial shows you how to install Ubuntu Desktop on Raspberry Pi 4 device.*
The revolutionary Raspberry Pi is the most popular single board computer. It has its very own Debian based operating system called [Raspbian](https://itsfoss.com/tutorial-how-to-install-raspberry-pi-os-raspbian-wheezy/).
There are several other [operating systems available for Raspberry Pi](https://itsfoss.com/raspberry-pi-os/) but almost all of them are lightweight. This was appropriate for the small factor and low end hardware of the Pi devices.
This changes with the introduction of Raspberry Pi 4B that flaunts 8 GB RAM and supports 4K display. The aim is to use Raspberry Pi as a regular desktop and it succeeds in doing so to a larger extent.
Before the 4B model, you could [install the Ubuntu server on Raspberry Pi](https://itsfoss.com/install-ubuntu-server-raspberry-pi/) but the desktop version was not available. However, **Ubuntu now provides official desktop image for Pi 4 models**.
In this tutorial, I am going to show the steps for installing Ubuntu desktop on Raspberry Pi 4.
First, a quick look at the prerequisites.
## Prerequisites for running Ubuntu on Raspberry Pi 4

Here’s what you need:
- A Linux or Windows system with active internet connection.
[Raspberry Pi Imager](https://github.com/raspberrypi/rpi-imager): The official open source tool from Raspberry that gets you the distro image on your SD card.- Micro SD Card: Consider using at least a 16 GB storage for your card, albeit a 32 GB version is recommended.
- A USB based Micro SD Card Reader (if your computer does not have a card reader).
- Essential Raspberry Pi 4 accessories such as an HDMI compatible display,
[Micro HDMI to Standard HDMI (A/M) Cable](https://www.raspberrypi.org/products/micro-hdmi-to-standard-hdmi-a-cable/),[Power Supply (Official Adapter Recommended)](https://www.raspberrypi.org/products/type-c-power-supply/), USB Wired/Wireless Keyboard and Mouse/Touchpad.
It is good practice to [read in detail about the Pi requirements](https://itsfoss.com/things-you-need-to-get-your-raspberry-pi-working/) beforehand.
Now, without further delay, let me quickly walk you through the image preparation for the SD Card.
## Preparing the Ubuntu Desktop image for Raspberry Pi
Raspberry Pi provides a GUI application for writing the ISO image to the SD Card. **This tool can also download compatible operating systems like Ubuntu, Raspbian etc automatically**.

You can download this tool for Ubuntu, Windows and macOS from the official website:
On Ubuntu and other Linux distributions, you can also install it with Snap:
`sudo snap install rpi-imager`
Once installed, run the imager tool. When you see the screen below, select “CHOOSE OS”:

Under “Operating System”, select “Other general purpose OS”:
Now, select “Ubuntu”:
Next, select “Ubuntu Desktop 21.04 (RPI 4/400)” as shown below:
Note
If you do not have a good, consistent internet collection, you can [download the Ubuntu for Raspberry Pi image separately from Ubuntu’s website](https://ubuntu.com/download/raspberry-pi). In the Imager tool, while choosing the OS, go to the bottom and select “Use custom” option. You can also use Etcher for writing the image to the SD card.
Insert the micro SD card inside your Card reader and wait for it to mount. Select “CHOOSE STORAGE” under “Storage”:
You should be seeing only your micro SD card storage and you’d recognize it instantly based on the size. Here, I’ve used a 32 GB card:
Now click on “WRITE”:
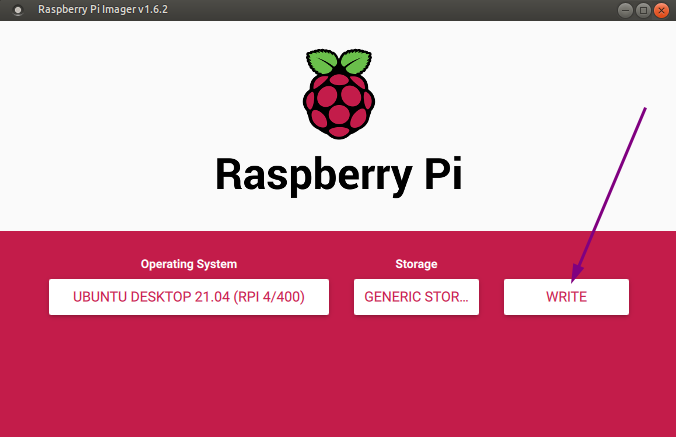
I’ll assume you have the contents of the SD card backed up. If it’s a new card, you can just proceed:
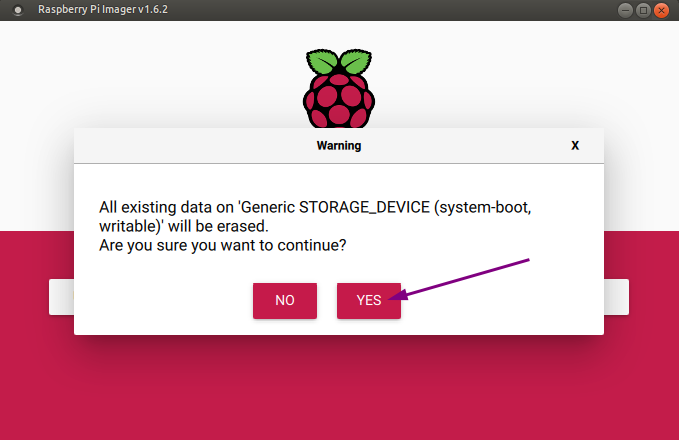
Since this is a [sudo](https://itsfoss.com/add-sudo-user-ubuntu/) privilege, you must enter your password. If you run `sudo rpi-imager`
from a terminal, this would not appear:
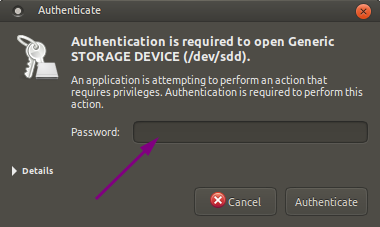
If your SD card is a bit old, it would take some time. But if it is a recent one with high speeds, it wouldn’t take long:

I also wouldn’t recommend skipping verification. Make sure the image write went successful:

Once it is over, you will get the following confirmation:
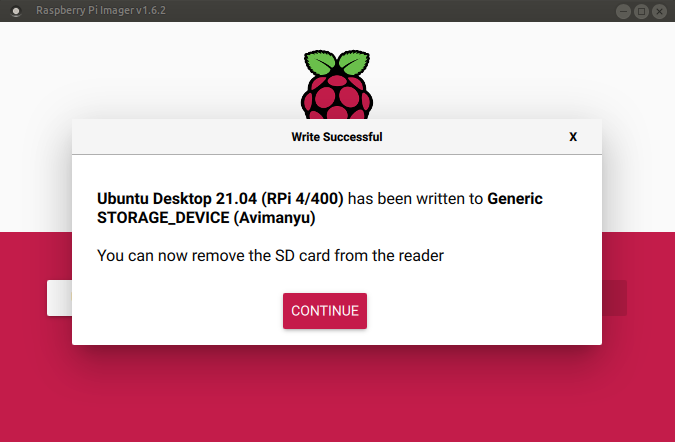
Now, safely-remove the SD card from your system.
## Using the micro SD card with Ubuntu on Raspberry Pi
Half of the battle is won. Unlike the regular Ubuntu install, you have not created a live environment. Ubuntu is already installed on the SD card and is almost read to use. Let’s see what remains here.
### Step 1: Insert the SD card into Pi
For first time users, it can take a bit confusing sometimes to figure out where on earth is that card slot! Not to worry. It is located below the board on the left-hand side. Here’s an inverted view with a card inserted:

Keep sliding the card in this orientation slowly into the slot below the board, gently until it no longer goes any further. This means it has just fit in perfectly. There won’t be any click sound.
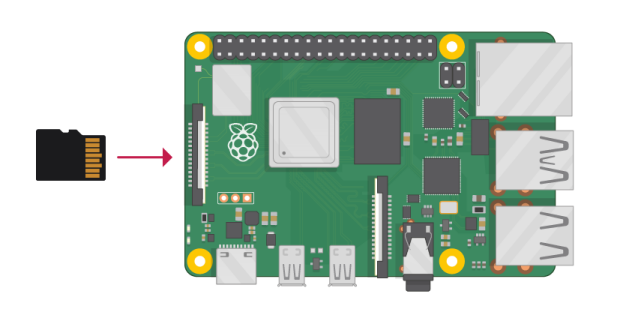
You might notice two little pins adjusting themselves in the slot (shown above) as you put it inside, but that’s ok. Once inserted, the card would look like a bit protruded. That’s how it is supposed to look like:
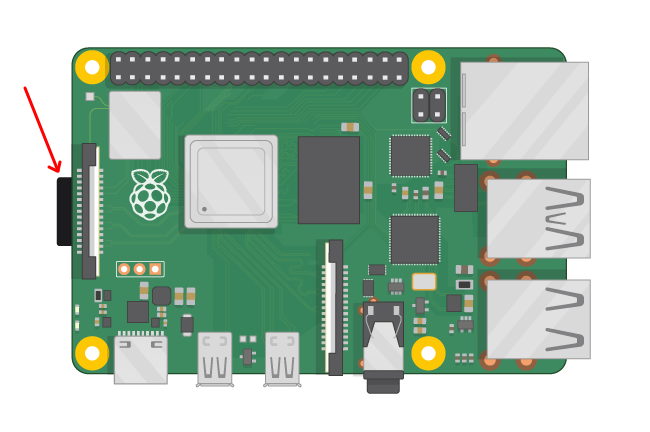
### Step 2: Setting Up the Raspberry Pi
I do not need to go in detail here, I presume.
Ensure that the power cable connector, micro HDMI cable connector, keyboard and mouse connectors (wired/non-wired) are securely connected to the Pi board in the relevant ports.
Make sure the display and power plug are properly connected as well, before you go ahead and turn on the power socket. I wouldn’t recommend plugging in the adapter to a live electrical socket. Look up [electrical arcing](https://www.electricianatlanta.net/what-is-electrical-arcing-and-why-is-it-dangerous/).
Once you’ve ensured the above two steps, you can [power on the Raspberry Pi device](https://itsfoss.com/turn-on-raspberry-pi/).
### Step 3: The first run of Ubuntu desktop on Raspberry Pi
Once you power on the Raspberry Pi, you’ll be asked to some basic configuration on your first run. You just have to follow the onscreen instructions.
Select your language, keyboard layout, connect to WiFi etc.
Select language Select keyboard layout Select WiFi
You’ll be asked to select the time zone:
And then create the user and password:
It will configure a couple of things and may take some time in doing so.
Finishing Ubuntu setup Finishing Ubuntu setup
It may take some time after this, your system will reboot and you’ll find yourself at the Ubuntu login screen:
You can start enjoying Ubuntu desktop on Raspberry Pi now.
## Conclusion
I noticed **a temporary anomaly**: A red flickering border on the left-hand side of my display while doing the installation. This flickering (also of different colors) was noticeable on random parts of the screen as well. But it went away after restarting and the first boot.
It was much needed that Ubuntu to start providing support for popular ARM devices like Raspberry Pi and I am happy to see it running on a Raspberry Pi.
I hope you find this tutorial helpful. If you have questions or suggestions, please let me know in the comments. |
13,821 | Linux 玩家终于可以玩《Apex Legends》、《Fortnite》等游戏了 | https://news.itsfoss.com/easy-anti-cheat-linux/ | 2021-09-25T16:45:56 | [
"游戏"
] | https://linux.cn/article-13821-1.html |
>
> 如果你是一个狂热的多人游戏玩家,你将能够玩到《Apex Legends》和《Fortnite》这样的热门游戏。但是,你可能需要等待一段时间。
>
>
>

Linux 玩家们,这可是个大新闻啊!
Epic Games 为其“简易反作弊”服务增加了完整的 Linux 支持,官方提供了兼容 [SteamPlay](https://itsfoss.com/steam-play/)(或 Proton)和 Wine 兼容性。
尽管我们预计这将在未来的某个时候发生,但 Steam Deck 的引入改变了 [在 Linux 上玩游戏](https://itsfoss.com/linux-gaming-guide/) 的场景。
你可能知道,Steam Deck 是由 Linux 驱动的,这就是为什么 Epic Games 有兴趣扩大对 Linux 平台的支持。
因此,可以说,如果不是 Valve 在 Steam Deck 上的努力,在 Linux 上获得“简易反作弊”支持的机会并不乐观。
### 多人游戏玩家可以考虑转到 Linux 上了
有了 [简易反作弊](https://www.easy.ac/en-us/) 的支持,许多流行的多人游戏,如《Apex Legends》、《Fortnite》、《Tom Clancy's Division 2》、《Rust》 和其他许多游戏应该可以在 Linux 上完美地运行了。
根据 Epic Games 的公告:
>
> 从最新的 SDK 版本开始,开发者只需在 Epic 在线服务开发者门户点击几下,就可以通过 Wine 或 Proton 激活对 Linux 的反作弊支持。
>
>
>
因此,开发人员可能需要一段时间来激活对各种游戏的反作弊支持。但是,对于大多数带有简易反作弊功能的游戏来说,这应该是一个绿色信号。
少了一个 [Windows 与 Linux 双启动](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/) 的理由。
《Apex Legends》 是我喜欢的多人游戏之一。而且,我不得不使用 Windows 来玩这个游戏。希望这种情况很快就会改变,在未来几周内,我可以在 Linux 上试一试!
同样,如果你几乎就要转到 Linux 了,但因为它与游戏的兼容性问题而迟疑,我想说问题已经解决了一半了!
当然,我们仍然需要对 BattleEye、其他反作弊服务和游戏客户端的官方支持。但是,这是个开端。
### Steam Deck 现在是一个令人信服的游戏选择
虽然许多人不确定 Steam Deck 是否支持所有的 AAA 级游戏,但这应该会有所改善!
[Steam Deck](https://www.steamdeck.com/en/) 现在应该是多人游戏玩家的一个简单选择。
### 总结
如果 Steam Deck 作为一个成功的掌上游戏机而成为了焦点,那么正如我们所知,在 Linux 上玩游戏也将发生改变。
而且,我认为 Epic Games 在其反作弊服务中加入 Linux 支持仅仅只是一个开始。
也许,我们永远都不用借助 [ProtonDB](https://www.protondb.com) 来在 Linux 上玩一个只有 Windows 支持的游戏;谁知道呢?但是,在这之后,Linux 游戏的未来似乎充满希望。
如果你是一个开发者,你可能想阅读 [该公告](https://dev.epicgames.com/en-US/news/epic-online-services-launches-anti-cheat-support-for-linux-mac-and-steam-deck) 来获得最新的 SDK。
你对 Epic Games 将简易反作弊引入 Linux 有何看法?欢迎在下面的评论中分享你的想法。
---
via: <https://news.itsfoss.com/easy-anti-cheat-linux/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux gamers, this is big news!
Epic Games adds complete Linux support for its Easy-Anti Cheat service, along with official [SteamPlay](https://itsfoss.com/steam-play/?ref=news.itsfoss.com) (or Proton) and Wine compatibility.
And, right after that, BattleEye also announced official support for Proton.
Even though we expected this to happen sometime in the future, the introduction of Steam Deck changed the scene for [gaming on Linux](https://itsfoss.com/linux-gaming-guide/?ref=news.itsfoss.com).
If you aren’t aware, Steam Deck is powered by Linux, which is why Epic Games was interested in expanding support to the Linux platform.
So, safe to say, if it wasn’t for Valve’s effort with Steam Deck, the chances of getting Easy Anti-Cheat support on Linux were not good.
## Multiplayer Gamers Can Consider Switching to Linux
With [Easy Anti-Cheat](https://www.easy.ac/en-us/?ref=news.itsfoss.com) support, many popular multiplayer titles like Apex Legends, Fortnite, Tom Clancy’s Division 2, Rust, and many other games could work flawlessly on Linux.
As per the announcement by Epic Games:
Starting with the latest SDK release, developers can activate anti-cheat support for Linux via Wine or Proton with just a few clicks in the Epic Online Services Developer Portal.
So, it may take a while for developers to activate the anti-cheat support for various games. But, it should be a green signal for most of the games with Easy Anti-Cheat.
And, the addition of BattleEye can make games like Rainbow Six Siege, Ghost Recon Breakpoint, and more, playable on Linux.
Apex Legends is one of the multiplayer titles I like. And, I had to use Windows to do that. Hopefully, that changes soon, and I get to try it on Linux in the coming weeks!
Similarly, if you were nearly making a switch to Linux but held back for its compatibility issues with games, I’d say that’s halfway resolved!
One less reason to [dual-boot Windows with Linux](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/?ref=news.itsfoss.com).
Sure, we still need the official support for other anti-cheat services and game clients. But, this is a start.
Now, all you have to do is wait for the game developers to enable the support for Steam Play to get most of the popular games working!
## Steam Deck is Now a Compelling Choice for Gaming
While many were unsure of Steam Deck’s support for all AAA games, this should improve things!
[Steam Deck](https://www.steamdeck.com/en/?ref=news.itsfoss.com) should now be an easy choice for multiplayer gamers.
## Wrapping Up
If Steam Deck steals the spotlight as a successful handheld gaming console, Linux gaming is going to change as we know it!
And, I think Epic Games adding Linux support to its anti-cheat service is just the beginning.
Maybe, we’ll never have to refer [ProtonDB](https://www.protondb.com/?ref=news.itsfoss.com) to play a Windows-only game on Linux; who knows
But, the future of Linux gaming seems promising this year!
If you are a developer, you might want to go through the [announcement](https://dev.epicgames.com/en-US/news/epic-online-services-launches-anti-cheat-support-for-linux-mac-and-steam-deck?ref=news.itsfoss.com) to get the latest SDK.
*What do you think about Epic Games bringing Easy Anti-Cheat to Linux? Feel free to share your thoughts in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,822 | 使用 Linux 命令行工具来了解你的 NVMe 驱动器 | https://opensource.com/article/21/9/nvme-cli | 2021-09-26T10:24:47 | [
"NVMe"
] | https://linux.cn/article-13822-1.html |
>
> nvme-cli 命令拥有诸多实用的选项,且它是控制和管理数据一种很好的方式。
>
>
>

NVMe 是指<ruby> 非易失性内存规范 <rt> Non-Volatile Memory Express </rt></ruby>,它规范了软件和存储通过 PCIe 和其他协议(包括 TCP)进行通信的方式。它是由非营利组织领导的 [开放规范](https://nvmexpress.org/),并定义了几种形式的固态存储。
我的笔记本电脑有一个 NVMe 驱动器,我的台式机也有。而且它们的速度很快。我喜欢我的电脑启动的速度,以及它们读写数据的速度。几乎没有延迟。
没过多久,我就对驱动这种超高速存储的技术产生了好奇,所以我做了一些调查。我了解到,NVMe 驱动器消耗的电力更少,而提供的数据访问速度甚至比 SATA 的 SSD 驱动器快得多。这很有趣,但我想知道更多关于我的特定 NVMe 驱动器的信息,我想知道它们与其他驱动器有何区别。我可以安全地擦除驱动器吗?我怎样才能检查它的完整性?
带着这些问题我在互联网上搜索,发现了一个开源项目,其中有一系列管理 NVMe 驱动器的工具。它被称为 [nvme-cli](https://github.com/linux-nvme/nvme-cli)。
### 安装 nvme-cli
你可以从你的发行版的包管理器中安装 `nvme-cli`。例如,在 Fedora、CentOS 或类似系统上:
```
$ sudo dnf install nvme-cli
```
在 Debian、Mint、Elementary 和类似系统上:
```
$ sudo apt install nvme-cli
```
### 探索 NVMe 驱动器
在安装 `nvme-cli` 后,我想探索我的驱动器。`nvme-cli` 没有手册页,但你可以通过输入 `nvme help` 获得很多帮助:
```
$ nvme help
nvme-1.14
usage: nvme <command> [<device>] [<args>]
The '<device>' may be either an NVMe character device (ex: /dev/nvme0) or an
nvme block device (ex: /dev/nvme0n1).
The following are all implemented sub-commands:
list List all NVMe devices and namespaces on machine
list-subsys List nvme subsystems
id-ctrl Send NVMe Identify Controller
id-ns Send NVMe Identify Namespace, display structure
id-ns-granularity Send NVMe Identify Namespace Granularity List, display structure
list-ns Send NVMe Identify List, display structure
list-ctrl Send NVMe Identify Controller List, display structure
nvm-id-ctrl Send NVMe Identify Controller NVM Command Set, display structure
primary-ctrl-caps Send NVMe Identify Primary Controller Capabilities
[...]
```
### 列出所有的 NVMe 驱动器
`sudo nvme list` 命令列出你机器上所有的 NVMe 设备和命名空间。我用它在 `/dev/nvme0n1` 找到了一个 NVMe 驱动器。下面是命令输出结果:
```
$ sudo nvme list
Node SN Model Namespace Usage Format FW Rev
--------------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- --------
/dev/nvme0n1 S42GMY9M141281 SAMSUNG MZVLB256HAHQ-000L7 1
214.68 GB / 256.06 GB 512 B + 0 B 0L2QEXD7
```
我有一个名为 `nvme0n1` 的驱动器。它列出了序列号、品牌、容量、固件版本等等。
通过使用 `id-ctrl` 子命令,你可以得到更多关于该硬盘和它所支持的特性的信息:
```
$ sudo nvme id-ctrl /dev/nvme0n1
NVME Identify Controller:
vid : 0x144d
ssvid : 0x144d
sn : S42GMY9M141281
mn : SAMSUNG MZVLB256HAHQ-000L7
fr : 0L2QEXD7
rab : 2
ieee : 002538
cmic : 0
mdts : 9
cntlid : 0x4
ver : 0x10200
rtd3r : 0x186a0
rtd3e : 0x7a1200
[...]
```
### 驱动器健康
你可以通过 `smart-log` 子命令来了解硬盘的整体健康状况:
```
$ sudo nvme smart-log /dev/nvme0n1
Smart Log for NVME device:nvme0n1 namespace-id:ffffffff
critical_warning : 0
temperature : 21 C
available_spare : 100%
available_spare_threshold : 10%
percentage_used : 2%
endurance group critical warning summary: 0
data_units_read : 5,749,452
data_units_written : 10,602,948
host_read_commands : 77,809,121
host_write_commands : 153,405,213
controller_busy_time : 756
power_cycles : 1,719
power_on_hours : 1,311
unsafe_shutdowns : 129
media_errors : 0
num_err_log_entries : 1,243
Warning Temperature Time : 0
Critical Composite Temperature Time : 0
Temperature Sensor 1 : 21 C
Temperature Sensor 2 : 22 C
Thermal Management T1 Trans Count : 0
Thermal Management T2 Trans Count : 0
Thermal Management T1 Total Time : 0
Thermal Management T2 Total Time : 0
```
这为你提供了硬盘的当前温度、到目前为止的使用时间、不安全的关机次数等等。
### 格式化一个 NVMe 驱动器
你可以用 `nvme-cli` 格式化一个 NVMe 驱动器,但要注意。这将删除驱动器上的所有数据!如果你的硬盘上有重要的数据,你必须在这样做之前将其备份,否则你**将会**丢失数据。子命令是 `format`:
```
$ sudo nvme format /dev/nvme0nX
```
(为了安全起见,我用 `X` 替换了驱动器的实际位置,以防止复制粘贴的错误。将 `X` 改为 `1` 或 `nvme list` 结果中列出的实际位置。)
### 安全地擦除 NVMe 驱动器
当你准备出售或处理你的 NVMe 电脑时,你可能想安全地擦除驱动器。这里的警告与格式化过程中的警告相同。首先要备份重要的数据,因为这个命令会删除这些数据!
```
$ sudo nvme sanitize /dev/nvme0nX
```
### 尝试 nvme-cli
`nvme-cli` 命令是在 [GPLv2](https://github.com/linux-nvme/nvme-cli/blob/master/LICENSE) 许可下发布的。它是一个强大的命令,有很多有用的选项,用来有效地控制和管理数据。
---
via: <https://opensource.com/article/21/9/nvme-cli>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | NVMe stands for *Non-Volatile Memory Express*, and it refers to how software and storage communicate across PCIe and other protocols, including TCP. It's an [open specification](https://nvmexpress.org/) led by a non-profit organization and defines several forms of solid-state storage.
My laptop has an NVMe drive, as does my desktop. And they're fast. I love how quickly my computers boot and how quickly they're able to read and write data. There's no perceptible delay.
It also didn't take long for me to get curious about the technology driving this ultra-fast storage, so I did a little investigation. I learned that NVMe drives consume less power while delivering much faster access to data compared to even SSD drives over SATA. That was interesting, but I wanted to know more about my particular NVMe drives, and I wanted to know how they compared with other drives. Could I securely erase the drive? How could I check its integrity?
Those questions led me to an Internet search that yielded an open source project with a collection of tools to manage NVMe drives. It's called [nvme-cli](https://github.com/linux-nvme/nvme-cli).
## Install nvme-cli
You can install `nvme-cli`
from your distribution's package manager. For instance, on Fedora, CentOS, or similar:
`$ sudo dnf install nvme-cli`
On Debian, Mint, Elementary, and similar:
`$ sudo apt install nvme-cli`
## Exploring an NVMe drive
After installing `nvme-cli`
for my distribution, I wanted to explore my drive. There's no man page for `nvme-cli`
, but you can get lots of help by entering `nvme help`
:
```
$ nvme help
nvme-1.14
usage: nvme <command> [<device>] [<args>]
The '<device>' may be either an NVMe character device (ex: /dev/nvme0) or an
nvme block device (ex: /dev/nvme0n1).
The following are all implemented sub-commands:
list List all NVMe devices and namespaces on machine
list-subsys List nvme subsystems
id-ctrl Send NVMe Identify Controller
id-ns Send NVMe Identify Namespace, display structure
id-ns-granularity Send NVMe Identify Namespace Granularity List, display structure
list-ns Send NVMe Identify List, display structure
list-ctrl Send NVMe Identify Controller List, display structure
nvm-id-ctrl Send NVMe Identify Controller NVM Command Set, display structure
primary-ctrl-caps Send NVMe Identify Primary Controller Capabilities
[...]
```
## List all NVMe drives
The `sudo nvme list`
command lists all NVMe devices and namespaces on your machine. I used it and found an NVMe drive at `/dev/nvme0n1`
. Here is the output:
```
$ sudo nvme list
Node SN Model Namespace Usage Format FW Rev
--------------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- --------
/dev/nvme0n1 S42GMY9M141281 SAMSUNG MZVLB256HAHQ-000L7 1
214.68 GB / 256.06 GB 512 B + 0 B 0L2QEXD7
```
I have a drive called `nvme0n1`
. It lists the serial number, brand, size, firmware revision, and so on.
You can get even more information about the drive and the features it supports by using the `id-ctrl`
subcommand:
```
$ sudo nvme id-ctrl /dev/nvme0n1
NVME Identify Controller:
vid : 0x144d
ssvid : 0x144d
sn : S42GMY9M141281
mn : SAMSUNG MZVLB256HAHQ-000L7
fr : 0L2QEXD7
rab : 2
ieee : 002538
cmic : 0
mdts : 9
cntlid : 0x4
ver : 0x10200
rtd3r : 0x186a0
rtd3e : 0x7a1200
[...]
```
## Drive health
You can read about the overall health of a drive with the `smart-log`
subcommand:
```
$ sudo nvme smart-log /dev/nvme0n1
Smart Log for NVME device:nvme0n1 namespace-id:ffffffff
critical_warning : 0
temperature : 21 C
available_spare : 100%
available_spare_threshold : 10%
percentage_used : 2%
endurance group critical warning summary: 0
data_units_read : 5,749,452
data_units_written : 10,602,948
host_read_commands : 77,809,121
host_write_commands : 153,405,213
controller_busy_time : 756
power_cycles : 1,719
power_on_hours : 1,311
unsafe_shutdowns : 129
media_errors : 0
num_err_log_entries : 1,243
Warning Temperature Time : 0
Critical Composite Temperature Time : 0
Temperature Sensor 1 : 21 C
Temperature Sensor 2 : 22 C
Thermal Management T1 Trans Count : 0
Thermal Management T2 Trans Count : 0
Thermal Management T1 Total Time : 0
Thermal Management T2 Total Time : 0
```
This provides you with the drive's current temperature, the hours of use it's had so far, how many times it was unsafely shut down, and so on.
## Formatting an NVMe drive
You can format an NVMe drive with `nvme-cli`
, but beware: This erases all of the data on the drive! If there's important data on your drive, you *must* back it up before doing this, or else you **will** lose data. The subcommand is `format`
:
`$ sudo nvme format /dev/nvme0nX`
(For safety, I've replaced the actual location of the drive with **X** to prevent copy-paste mishaps. Change the **X** to **1** or the appropriate location as listed in the results of `nvme list`
.)
## Securely erasing an NVMe drive
When you get ready to sell or dispose of your NVMe computer, you probably want to erase the drive securely. The same warnings apply here as with the format process: Back up important data first because this command erases it!
`$ sudo nvme sanitize /dev/nvme0nX`
## Try nvme-cli
The `nvme-cli`
command is released under a [GPLv2](https://github.com/linux-nvme/nvme-cli/blob/master/LICENSE) license. It's a robust command with lots of useful options, and it's a great way to take control of how you manage your data.
## 9 Comments |
13,824 | 用 Lima 在你的 Mac 上运行容器 | https://opensource.com/article/21/9/run-containers-mac-lima | 2021-09-27T09:15:14 | [
"容器",
"mac"
] | https://linux.cn/article-13824-1.html |
>
> Lima 可以帮助克服在 Mac 上运行容器的挑战。
>
>
>

在你的 Mac 上运行容器可能是一个挑战。毕竟,容器是基于 Linux 特有的技术,如控制组和命名空间。
幸运的是,macOS 拥有一个内置的<ruby> 虚拟机监控程序 <rt> hypervisor </rt></ruby>,允许在 Mac 上运行虚拟机(VM)。虚拟机监控程序是一个底层的内核功能,而不是一个面向用户的功能。
hyperkit 是一个可以使用 macOS 虚拟机监控程序运行虚拟机的 [开源项目](https://www.docker.com/blog/docker-unikernels-open-source/)。hyperkit 被设计成一个“极简化”的虚拟机运行器。与 VirtualBox 不同,它没有花哨的 UI 功能来管理虚拟机。
你可以获取 hyperkit,这是一个运行容器管理器的极简 Linux 发行版,并将所有部分组合在一起。但这将有很多变动组件,且听起来像有很多工作。特别是如果你想通过使用 `vpnkit` (一个开源项目,用于创建感觉更像是主机网络一部分的虚拟机网络)使网络连接更加无缝。
### Lima
当 [lima 项目](https://github.com/lima-vm/lima) 已经解决了这些细节问题时,就没有理由再去做这些努力了。让 `lima` 运行的最简单方法之一是使用 [Homebrew](https://brew.sh/)。你可以用这个命令安装 `lima`:
```
$ brew install lima
```
安装后,可能需要一些时间,就享受一些乐趣了。为了让 `lima` 知道你已经准备好了,你需要启动它。下面是命令:
```
$ limactl start
```
如果这是你第一次运行,你会被问到是否喜欢默认值,或者是否要改变其中的任何一项。默认值是非常安全的,但我喜欢生活在疯狂的一面。这就是为什么我跳进一个编辑器,从以下地方进行修改:
```
- location: "~"
# CAUTION: `writable` SHOULD be false for the home directory.
# Setting `writable` to true is possible but untested and dangerous.
writable: false
```
变成:
```
- location: "~"
# I *also* like to live dangerously -- Austin Powers
writable: true
```
正如评论中所说,这可能是危险的。可悲的是,许多现有的工作流程都依赖于挂载是可读写的。
默认情况下,`lima` 运行 `containerd` 来管理容器。`containerd` 管理器也是一个非常简洁的管理器。虽然使用一个包装的守护程序,如 `dockerd`,来增加这些漂亮的工效是很常见的,但也有另一种方法。
### nerdctl 工具
`nerdctl` 工具是 Docker 客户端的直接替换,它将这些功能放在客户端,而不是服务器上。`lima` 工具允许无需在本地安装就可以直接从虚拟机内部运行 `nerdctl`。
做完这些后,可以运行一个容器了!这个容器将运行一个 HTTP 服务器。你可以在你的 Mac 上创建这些文件:
```
$ ls
index.html
$ cat index.html
hello
```
现在,挂载并转发端口:
```
$ lima nerdctl run --rm -it -p 8000:8000 -v $(pwd):/html --entrypoint bash python
root@9486145449ab:/#
```
在容器内,运行一个简单的 Web 服务器:
```
$ lima nerdctl run --rm -it -p 8000:8000 -v $(pwd):/html --entrypoint bash python
root@9486145449ab:/# cd /html/
root@9486145449ab:/html# python -m http.server 8000
Serving HTTP on 0.0.0.0 port 8000 (<http://0.0.0.0:8000/>) ...
```
在另一个终端,你可以检查一切看起来都很好:
```
$ curl localhost:8000
hello
```
回到容器上,有一条记录 HTTP 客户端连接的日志信息:
```
10.4.0.1 - - [09/Sep/2021 14:59:08] "GET / HTTP/1.1" 200 -
```
一个文件是不够的,所以还要做些优化。 在服务器上执行 `CTRL-C`,并添加另一个文件:
```
^C
Keyboard interrupt received, exiting.
root@9486145449ab:/html# echo goodbye > foo.html
root@9486145449ab:/html# python -m http.server 8000
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
```
检查你是否能看到新的文件:
```
$ curl localhost:8000/foo.html
goodbye
```
### 总结
总结一下,安装 `lima` 需要一些时间,但完成后,你可以做以下事情:
* 运行容器。
* 将你的主目录中的任意子目录挂载到容器中。
* 编辑这些目录中的文件。
* 运行网络服务器,在 Mac 程序看来,它们是在 localhost 上运行的。
这些都是通过 `lima nerdctl` 实现的。
---
via: <https://opensource.com/article/21/9/run-containers-mac-lima>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Running containers on your Mac can be a challenge. After all, containers are based on Linux-specific technologies like cgroups and namespaces.
Luckily, macOS has a built-in hypervisor, allowing virtual machines (VMs) on the Mac. The hypervisor is a low-level kernel feature, not a user-facing one.
Enter `hyperkit`
, an [open source project](https://www.docker.com/blog/docker-unikernels-open-source/) that will run VMs using the macOS hypervisor. The `hyperkit`
tool is designed to be a "minimalist" VM runner. Unlike, say, VirtualBox, it does not come with fancy UI features to manage VMs.
You can grab `hyperkit`
, a minimalist Linux distribution running a container manager, and plumb all the pieces together. This would be a lot of moving parts, and sounds like a lot of work. Especially if you want to make the network connections a bit more seamless by using `vpnkit`
, an open source project to create a VM's network that feels more like part of the host's network.
## Lima
There is no reason to go to all that effort, when [the lima project](https://github.com/lima-vm/lima) has figured out the details. One of the easiest ways to get
`lima`
running is with [Homebrew](https://brew.sh/). You can install
`lima`
with this command:`$ brew install lima`
After installation, which might take a while, it is time to begin having some fun. In order to let `lima`
know you are ready for some fun, you need to start it. Here's the command:
`$ limactl start`
If this is your first time, you will be asked if you like the defaults or whether you want to change any of them. The defaults are pretty safe, but I like to live on the wild side. This is why I jump into an editor and make the following modifications from:
```
- location: "~"
# CAUTION: `writable` SHOULD be false for the home directory.
# Setting `writable` to true is possible but untested and dangerous.
writable: false
```
to:
```
- location: "~"
# I *also* like to live dangerously -- Austin Powers
writable: true
```
As it says in the comment, this can be dangerous. Many existing workflows, sadly, depend on this mounting to be read-write.
By default, `lima`
runs `containerd`
to manage containers. The `containerd`
manager is also a pretty frill-less one. While it is not uncommon to use a wrapper daemon, like `dockerd`
, to add those nice-to-have ergonomics, there is another way.
## The nerdctl tool
The `nerdctl`
tool is a drop-in replacement for the Docker client which puts those features in the client, not the server. The `lima`
tool allows running `nerdctl`
without installing it locally, directly from inside the VM.
Putting it all together, it is time to run a container! This container will run an HTTP server. You can create the files on your Mac:
```
$ ls
index.html
$ cat index.html
hello
```
Now, mount and forward the ports:
```
$ lima nerdctl run --rm -it -p 8000:8000 -v $(pwd):/html --entrypoint bash python
root@9486145449ab:/#
```
Inside the container, run a simple web server:
```
$ lima nerdctl run --rm -it -p 8000:8000 -v $(pwd):/html --entrypoint bash python
root@9486145449ab:/# cd /html/
root@9486145449ab:/html# python -m http.server 8000
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
```
From a different terminal, you can check that everything looks good:
```
$ curl localhost:8000
hello
```
Back on the container, there is a log message documenting the HTTP client's connection:
`10.4.0.1 - - [09/Sep/2021 14:59:08] "GET / HTTP/1.1" 200 -`
One file is not enough, so times to make some things better. **CTRL-C** the server, and add another file:
```
^C
Keyboard interrupt received, exiting.
root@9486145449ab:/html# echo goodbye > foo.html
root@9486145449ab:/html# python -m http.server 8000
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
```
Check that you can see the new file:
```
$ curl localhost:8000/foo.html
goodbye
```
## Wrap up
To recap, installing `lima`
takes a while, but after you are done, you can do the following:
- Run containers.
- Mount arbitrary sub-directories of your home directory into containers.
- Edit files in those directories.
- Run network servers that appear to Mac programs like they are running on localhost.
All with `lima nerdctl`
.
## 1 Comment |
13,826 | 2021 年了,我们能推荐使用 Linux 来玩游戏吗? | https://news.itsfoss.com/linux-for-gaming-opinion/ | 2021-09-27T12:14:23 | [
"Linux",
"游戏"
] | https://linux.cn/article-13826-1.html |
>
> 每天,Linux 都在进行不断进步,以支持具有适当图形支持的现代游戏。但是,我们能推荐 Linux 用于游戏吗?
>
>
>

你经常会听到 Linux 爱好者称赞 Linux 上改进的游戏功能。是的,考虑到在 Linux 桌面上支持现代游戏所取得的进步,Linux 已经在游戏方面获得了很大的提升。
甚至 Lutris 的创造者在我们的采访中也提到 [Linux 在游戏方面取得的进步简直令人难以置信](https://news.itsfoss.com/lutris-creator-interview/)。
但是,这有什么值得大肆宣传的吗?我们能向游戏玩家推荐 Linux 吗? Linux 适合玩游戏吗?
此文中,我想分享一些关于在 Linux 系统上玩游戏的的事情,并分享我对它的看法。
### 你可以在 Linux 上玩游戏吗?是的!
如果有人曾经告诉过你,不能在 Linux 上玩游戏,**那是不对的**。
你可以在 Linux 上玩各种游戏而不会出现任何大的障碍。而且,在大多数情况下,它是可玩的,并且会提供很好的游戏体验。
事实上,如果你不知道从哪里开始,我们有一份 [Linux 游戏终极指南](https://itsfoss.com/linux-gaming-guide/) 提供给你。
### 需要一个特定的 Linux 发行版才能玩游戏吗?
并非如此。这取决于你想获得多么方便的体验。
例如,如果你希望 Linux 发行版能够与你的图形驱动程序很好地配合,并获得最新的硬件支持,那么有一些发行版可以做到。同样,如果你只是想用集成的 GPU 玩原生的 Linux 独立游戏,任何发行版都可以。
因此,在你开启 Linux 游戏之旅的同时,会有一些因素影响你对发行版的选择。
不用担心,为了帮助你,我们提供了一份有用的 [最佳 Linux 游戏发行版列表](https://itsfoss.com/linux-gaming-distributions/)。
### Linux 上的虚拟现实游戏,唉……

我确信 VR 游戏还没有完全普及。但是,如果你想要在 VR 头盔上获得激动人心的体验,那么**选择 Linux 作为你的首选平台可能不是一个好主意**。
你没有在 Linux 上获得便利体验所需的驱动程序或应用程序。没有任何发行版可以帮助你解决此问题。
如果你想了解有关虚拟现实状态的详细信息,可以看看 [Boiling Steam](https://boilingsteam.com/the-state-of-virtual-reality-on-linux/) 上的博客文章和 [GamingOnLinux](https://www.gamingonlinux.com/2020/08/my-experiences-of-valves-vr-on-linux) 上的使用 Valve 的 VR 头盔的有趣体验。
我已经提供了这些博客文章的链接以供参考,但总而言之 —— 如果你想体验 VR 游戏,请避免使用 Linux(如果你实在太闲,请随意尝试)。
### 可以在 Linux 上玩 Windows 系统的游戏吗?
可以,也不可以。
你可以使用 [Steam Play 来玩 Windows 专属的游戏](https://itsfoss.com/steam-play/),但是它也存在一些问题,并不是每个游戏都可以运行。
例如,我最终还是使用 Windows 来玩《[地平线 4](https://forzamotorsport.net/en-US/games/fh4)》。如果你喜欢汽车模拟或赛车游戏,这是一款你可能不想错过的杰作。
或许我们在不久的将来可以看到它通过 Steam Play 完美的运行,谁知道呢?
因此,可以肯定的是,你会遇到许多类似的游戏,可能根本无法运行。这是残酷的事实。
而且,要知道该游戏是否可以在 Linux 上运行,请前往 [ProtonDB](https://www.protondb.com/) 并搜索该游戏,看看它是否至少具有 “**黄金**” 状态。
### 带有反作弊引擎的多人游戏可以吗?

许多游戏玩家更喜欢玩多人游戏,如《[Apex Legends](https://www.ea.com/games/apex-legends)》、《[彩虹六号:围攻](https://www.ubisoft.com/en-us/game/rainbow-six/siege)》和《[堡垒之夜](https://www.epicgames.com/fortnite/en-US/home)》。
然而,一些依赖于反作弊引擎的流行游戏还不能在 Linux 上运行。它仍然是一项进行中的工作,可能在未来的 Linux 内核版本中实现 —— 但目前还没有。
请注意,像 《[反恐精英:全球攻势](https://store.steampowered.com/app/730/CounterStrike_Global_Offensive/)》、《Dota 2》、《军团要塞 2》、《[英灵神殿](https://store.steampowered.com/app/892970/Valheim/)》等多人游戏提供原生 Linux 支持并且运行良好!
### 我会推荐使用 Linux 来玩游戏吗?

考虑到你可以玩很多 Windows 专属的游戏、原生的独立游戏,以及 Linux 原生支持的各种 AAA 游戏,我能推荐初次使用者尝试在 Linux 上玩游戏。
但是,需要**注意**的是 —— 我建议你列出你想玩的游戏列表,以确保它在 Linux 上运行没有任何问题。否则,你最终都可能浪费大量时间进行故障排除而没有结果。
不要忘记,我相信 Linux 上的 VR 游戏是一个很大的问题。
而且,如果你想探索所有最新最好的游戏,我建议你坚持使用 Windows 的游戏电脑。
**虽然我应该鼓励更多的用户采用 Linux 作为游戏平台,但我不会忽视为什么普通消费者仍然喜欢使用 Windows 机器来玩游戏的客观事实。**
你怎么认为呢?你同意我的想法吗?欢迎在下方的评论区分享你的想法!
---
via: <https://news.itsfoss.com/linux-for-gaming-opinion/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You will often hear Linux enthusiasts praise about the improved gaming capabilities on Linux. Yes, we have come a long way considering the advancements made to support modern games on Linux desktop.
Even Lutris’ creator mentions in our interview that the [progress Linux has made in terms of gaming is simply incredible](https://news.itsfoss.com/lutris-creator-interview/).
But, is it something to be hyped about? Can we recommend Linux to a gamer? Is Linux suitable for gaming?
In this article, I want to share a few things about gaming on a Linux system and share what I think about it.
## You Can Play Games on Linux: Yes!
If anyone’s ever told you that you cannot game on Linux, **that is not true**.
You can play a variety of games on Linux without any major hiccups. And, for the most part, it is playable and totally a good experience.
In fact, we have an ultimate guide for [Gaming on Linux](https://itsfoss.com/linux-gaming-guide/?ref=news.itsfoss.com) if you do not know where to start.
## Do I Need a Specific Linux Distro to Play Games?
Not really. It depends on how convenient you want the experience to be.
For instance, if you want a Linux distribution to work well with your graphics driver and get the latest hardware support, there’s something for that. Similarly, if you just want to play native Linux indie games with an integrated GPU, any Linux distro can work.
So, there are a few variables when choosing a Linux distribution for your gaming adventures.
Fret not, to help you out, we have a useful list of the [best Linux gaming distributions](https://itsfoss.com/linux-gaming-distributions/?ref=news.itsfoss.com).
## Virtual Reality Games on Linux: Uh-Oh!

I’m sure VR gaming is not something widely adopted yet. But, if you want the exciting experience on a VR headset, **choosing Linux as your preferred platform might be a bad idea**.
You do not have the necessary drivers or applications for a convenient experience on Linux. No distribution can help you solve this problem.
If you are curious, you can go through the details shed on the **state of virtual reality** in a blog post on [Boiling Steam](https://boilingsteam.com/the-state-of-virtual-reality-on-linux/?ref=news.itsfoss.com) and an interesting experience with Valve’s VR headset on [GamingOnLinux](https://www.gamingonlinux.com/2020/08/my-experiences-of-valves-vr-on-linux?ref=news.itsfoss.com).
I’ve linked those blog posts for reference but long story short — avoid Linux if you want to experience VR games (feel free to experiment if you have the time though).
## Can You Play Windows Exclusive Games on Linux?
Yes and No.
You can use [Steam Play to play Windows-only games](https://itsfoss.com/steam-play/?ref=news.itsfoss.com), **but it has its share of issues**. Not every game works.
For instance, I end up using Windows to play [Forza Horizon 4](https://forzamotorsport.net/en-US/games/fh4?ref=news.itsfoss.com). If you love car simulation or racing games, this is a masterpiece that you may not want to miss.
Maybe we will see it working through Steam Play without issues in the near future, who knows?
So, it is safe to assume that you will encounter many similar games that may not work at all. That’s the bitter truth.
And, to know if the game works on Linux, head to [ProtonDB](https://www.protondb.com/?ref=news.itsfoss.com) and search for the game to see if it has a “**Gold**” status at the very least.
## Multiplayer Gaming With Anti-Cheat Engines: Does It Work?

A huge chunk of gamers prefer playing multiplayer games like [Apex Legends](https://www.ea.com/games/apex-legends?ref=news.itsfoss.com), [Rainbow Six Siege](https://www.ubisoft.com/en-us/game/rainbow-six/siege?ref=news.itsfoss.com), and [Fortnite](https://www.epicgames.com/fortnite/en-US/home?ref=news.itsfoss.com).
However, some of those popular titles that rely on anti-cheat engines do not work on Linux yet. It is still something a work in progress and can be made possible in future Linux Kernel releases — just not yet.
Do note that multiplayer games like [CS:GO](https://store.steampowered.com/app/730/CounterStrike_Global_Offensive/?ref=news.itsfoss.com), Dota 2, Team Fortress 2, [Valheim](https://store.steampowered.com/app/892970/Valheim/?ref=news.itsfoss.com), and several more offer native Linux support and works great!
## Would I Recommend Linux for Gaming?

Considering that you can play a lot of Windows-specific games, native indie games, and a variety of AAA games with native Linux support, I can recommend a first-time user to try gaming on Linux.
But, that comes with a **caution** — I would suggest you to make a potential list of games that you want to play to make sure that it runs on Linux without any issues. In either case, you may end up wasting a lot of time troubleshooting with no results.
Not to forget, a big no to VR gaming on Linux, I believe.
And, if you want to explore all the latest and greatest titles, I will recommend you to stick to your Windows-powered gaming machine.
**While I should encourage more users to adopt Linux as a gaming platform, but I won’t be ignoring the practical side of why common consumers still prefer a Windows-powered machine to game on.**
*What do you think? Do you agree with my thoughts? Feel free to share what you feel in the comments below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,829 | 使用 Vagrant 在不同的操作系统上测试你的脚本 | https://opensource.com/article/21/9/test-vagrant | 2021-09-28T11:58:35 | [
"Vagrant",
"虚拟机"
] | https://linux.cn/article-13829-1.html |
>
> Vagrant 可以帮助你在你的电脑上运行其他操作系统,这意味着你可以构建、测试、疯狂折腾而不毁坏你的系统。
>
>
>

我使用 Vagrant 已经很长时间了。我使用几种 DevOps 工具,把它们全安装在一个系统上会搞得很乱。Vagrant 可以让你在不破坏系统的情况下随意折腾,因为你根本不需要在生产系统上做实验。
如果你熟悉 [VirtualBox](https://opensource.com/article/21/6/try-linux-virtualbox) 或 [GNOME Boxes](https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization),那么学习 Vagrant 很容易。Vagrant 有一个简单而干净的界面用于管理虚拟机。一个名为 `Vagrantfile` 的配置文件,允许你定制你的虚拟机(称为 “Vagrant <ruby> 盒子 <rt> box </rt></ruby>”)。一个简单的命令行界面让你启动、停止、暂停或销毁你的“盒子”。
考虑一下这个简单的例子。
假设你想写 Ansible 或 shell 脚本,在一个新的服务器上安装 Nginx。你不能在你自己的系统上这样做,因为你运行的可能不是你想测试的操作系统,或者没有所有的依赖项。启动新的云服务器进行测试可能会很费时和昂贵。这就是 Vagrant 派上用处的地方。你可以用它来启动一个虚拟机,用你的脚本来<ruby> 配备 <rt> provision </rt></ruby>它,并证明一切按预期工作。然后,你可以删除这个“盒子”,重新配备它,并重新运行你的脚本来验证它。你可以多次重复这个过程,直到你确信你的脚本在所有条件下都能工作。你可以将你的 Vagrantfile 提交给 Git,以确保你的团队正在测试完全相同的环境(因为他们将使用完全相同的测试机)。不会再有“但它在我的机器上运行良好!”这事了。
### 开始使用
首先,[在你的系统上安装 Vagrant](https://www.vagrantup.com/docs/installation),然后创建一个新的文件夹进行实验。在这个新文件夹中,创建一个名为 `Vagrantfile` 的新文件,内容如下:
```
Vagrant.configure("2") do |config|
config.vm.box = "ubuntu/hirsute64"
end
```
你也可以运行 `vagrant init ubuntu/hirsute64`,它将为你生成一个新的 Vagrant 文件。现在运行 `vagrant up`。这个命令将从 Vagrant 仓库中下载 `ubuntu/hirsuite64` 镜像。
```
Bringing machine 'default' up with 'virtualbox' provider...
==> default: Importing base box 'ubuntu/hirsute64'...
==> default: Matching MAC address for NAT networking...
==> default: Checking if box 'ubuntu/hirsute64' version '20210820.0.0' is up to date...
==> default: Setting the name of the VM: a_default_1630204214778_76885
==> default: Clearing any previously set network interfaces...
==> default: Preparing network interfaces based on configuration...
default: Adapter 1: nat
default: Adapter 2: hostonly
==> default: Forwarding ports...
default: 22 (guest) => 2222 (host) (adapter 1)
==> default: Running 'pre-boot' VM customizations...
==> default: Booting VM...
==> default: Waiting for machine to boot. This may take a few minutes...
default: SSH address: 127.0.0.1:2222
default: SSH username: vagrant
default: SSH auth method: private key
default: Warning: Remote connection disconnect. Retrying...
default: Warning: Connection reset. Retrying...
default:
default: Vagrant insecure key detected. Vagrant will automatically replace
default: this with a newly generated keypair for better security.
default:
default: Inserting generated public key within guest...
default: Removing insecure key from the guest if it's present...
default: Key inserted! Disconnecting and reconnecting using new SSH key...
==> default: Machine booted and ready!
```
此时,如果你打开你的 Vagrant 后端(如 VirtualBox 或 virt-manager),你会看到你的“盒子”已经有了。接下来,运行 `vagrant ssh` 登录到“盒子”。如果你能看到 Vagrant 的提示符,那么你就进入了!
```
~ vagrant ssh
Welcome to Ubuntu 21.04 (GNU/Linux 5.11.0-31-generic x86_64)
* Documentation: <https://help.ubuntu.com>
* Management: <https://landscape.canonical.com>
* Support: <https://ubuntu.com/advantage>
System information as of Sun Aug 29 02:33:51 UTC 2021
System load: 0.01 Processes: 110
Usage of /: 4.1% of 38.71GB Users logged in: 0
Memory usage: 17% IPv4 address for enp0s3: 10.0.2.15
Swap usage: 0% IPv4 address for enp0s8: 192.168.1.20
0 updates can be applied immediately.
vagrant@ubuntu-hirsute:~$
```
Vagrant 使用“基础盒子”来建立你的本地机器。在我们的例子中,Vagrant 从 [Hashicorp 的 Vagrant 目录](https://app.vagrantup.com/boxes/search)下载 `ubuntu/hirsuite64` 镜像,并插入 VirtualBox 来创建实际的“盒子”。
### 共享文件夹
Vagrant 将你的当前文件夹映射到 Vagrant “盒子”中的 `/vagrant`。这允许你在你的系统和“盒子”里保持文件同步。这很适合测试 Nginx 网站,通过将你的文件根目录指向 `/vagrant`。你可以使用 IDE 进行修改,“盒子”里的 Nginx 会提供这些修改。
### Vagrant 命令
有几个 Vagrant 命令,你可以用它们来控制你的“盒子”。
其中一些重要的命令是:
* `vagrant up`:启动一个“盒子”。
* `vagrant status`:显示当前“盒子”的状态。
* `vagrant suspend`:暂停当前的“盒子”。
* `vagrant resume`:恢复当前的“盒子”。
* `vagrant halt`:关闭当前的“盒子”。
* `vagrant destroy`:销毁当前的“盒子”。通过运行此命令,你将失去存储在“盒子”上的任何数据。
* `vagrant snapshot`:对当前的“盒子”进行快照。
### 试试 Vagrant
Vagrant 是一个使用 DevOps 原则进行虚拟机管理的工具,久经时间考验。配置你的测试机,与你的团队分享配置,并在一个可预测和可重复的环境中测试你的项目。如果你正在开发软件,那么通过使用 Vagrant 进行测试,你将为你的用户提供良好的服务。如果你不开发软件,但你喜欢尝试新版本的操作系统,那么没有比这更简单的方法了。今天就试试 Vagrant 吧!
这篇文章最初发表在 [作者的个人博客](https://notes.ayushsharma.in/2021/08/introduction-to-vagrant) 上,经许可后被改编。
---
via: <https://opensource.com/article/21/9/test-vagrant>
作者:[Ayush Sharma](https://opensource.com/users/ayushsharma) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I've been happy using Vagrant for quite a while now. I work with several DevOps tools, and installing them all on one system can get complicated. Vagrant lets you do cool things without breaking your system because you don't have to experiment on your production system at all.
If you're familiar with [VirtualBox](https://opensource.com/article/21/6/try-linux-virtualbox) or [GNOME Boxes](https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization), then learning Vagrant is easy. Vagrant is a simple and clean interface for working with virtual machines. A single config file, called `Vagrantfile`
, allows you to customize your virtual machines (called *Vagrant boxes*). A simple command-line interface lets you start, stop, suspend, or destroy your boxes.
Consider this simple example.
Let's say you want to write Ansible or shell scripts to install Nginx on a new server. You can't do it on your own system because you might not be running the operating system you want to test, or you may not have all of the dependencies for what you want to do. Launching new cloud servers for testing can be time-consuming and expensive. This is where Vagrant comes in. You can use it to bring up a virtual machine, provision it using your scripts, and prove that everything works as expected. You can then delete the box, re-provision it, and re-run your scripts to verify it. You can repeat this process as many times as you want until you're confident your scripts work under all conditions. And you can commit your Vagrantfile to Git to ensure your team is testing the exact same environment (because they'll be using the exact same test box). No more "…but it works fine on my machine!"
## Getting started
First, [install Vagrant on your system](https://www.vagrantup.com/docs/installation) and then create a new folder to experiment in. In this new folder, create a new file named `Vagrantfile`
with these contents:
```
Vagrant.configure("2") do |config|
config.vm.box = "ubuntu/hirsute64"
end
```
You can also run `vagrant init ubuntu/hirsute64`
, and it will generate a new Vagrantfile for you. Now run `vagrant up`
. This command will download the `ubuntu/hirsuite64`
image from the Vagrant registry.
```
Bringing machine 'default' up with 'virtualbox' provider...
==> default: Importing base box 'ubuntu/hirsute64'...
==> default: Matching MAC address for NAT networking...
==> default: Checking if box 'ubuntu/hirsute64' version '20210820.0.0' is up to date...
==> default: Setting the name of the VM: a_default_1630204214778_76885
==> default: Clearing any previously set network interfaces...
==> default: Preparing network interfaces based on configuration...
default: Adapter 1: nat
default: Adapter 2: hostonly
==> default: Forwarding ports...
default: 22 (guest) => 2222 (host) (adapter 1)
==> default: Running 'pre-boot' VM customizations...
==> default: Booting VM...
==> default: Waiting for machine to boot. This may take a few minutes...
default: SSH address: 127.0.0.1:2222
default: SSH username: vagrant
default: SSH auth method: private key
default: Warning: Remote connection disconnect. Retrying...
default: Warning: Connection reset. Retrying...
default:
default: Vagrant insecure key detected. Vagrant will automatically replace
default: this with a newly generated keypair for better security.
default:
default: Inserting generated public key within guest...
default: Removing insecure key from the guest if it's present...
default: Key inserted! Disconnecting and reconnecting using new SSH key...
==> default: Machine booted and ready!
```
At this point, if you open your Vagrant backend (such as VirtualBox or virt-manager), you'll see your box there. Next, run `vagrant ssh `
to log in to the box. If you can see the Vagrant prompt, then you’re in!
```
~ vagrant ssh
Welcome to Ubuntu 21.04 (GNU/Linux 5.11.0-31-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Sun Aug 29 02:33:51 UTC 2021
System load: 0.01 Processes: 110
Usage of /: 4.1% of 38.71GB Users logged in: 0
Memory usage: 17% IPv4 address for enp0s3: 10.0.2.15
Swap usage: 0% IPv4 address for enp0s8: 192.168.1.20
0 updates can be applied immediately.
vagrant@ubuntu-hirsute:~$
```
Vagrant uses "base boxes" to bring up your local machines. In our case, Vagrant downloads the `ubuntu/hirsuite64`
image from [Hashicorp’s Vagrant catalogue](https://app.vagrantup.com/boxes/search) and plugs into VirtualBox to create the actual box.
## Shared folders
Vagrant maps your current folder as `/vagrant`
within the Vagrant box. This allows you to keep your files in sync on your system and within the box. This is great for testing a Nginx website by pointing your document root to `/vagrant`
. You can use an IDE to make changes and Nginx within the box will serve them.
## Vagrant commands
There are several Vagrant commands which you can use to control your box.
Some of the important ones are:
`vagrant up`
: Bring a box online.`vagrant status`
: Show current box status.`vagrant suspend`
: Pause the current box.`vagrant resume`
: Resume the current box.`vagrant halt`
: Shutdown the current box.`vagrant destroy`
: Destroy the current box. By running this command, you will lose any data stored on the box.`vagrant snapshot`
: Take a snapshot of the current box.
## Try Vagrant
Vagrant is a time-tested tool for virtual machine management using DevOps principles. Configure your test machines, share the configs with your team, and test your projects in a predictable and reproducible environment. If you're developing software, then you'll do your users a great service by using Vagrant for testing. If you're not developing software but you love to try out new versions of an OS, then there's no easier way. Try Vagrant today!
*This article was originally published on the author's personal blog and has been adapted with permission.*
## Comments are closed. |
13,831 | 不是 Windows,也不是 Linux,Shrine 才是“神之操作系统” | https://itsfoss.com/shrine-os/ | 2021-09-28T15:48:45 | [
"Shrine",
"TempleOS"
] | https://linux.cn/article-13831-1.html | 
在生活中,我们都曾使用过多种操作系统。有些好,有些坏。但你能说你使用过由“神”设计的操作系统吗?今天,我想向你介绍 Shrine(圣殿)。
### 什么是 Shrine?

从介绍里,你可能想知道这到底是怎么回事。嗯,这一切都始于一个叫 Terry Davis 的人。在我们进一步介绍之前,我最好提醒你,Terry 在生前患有精神分裂症,而且经常不吃药。正因为如此,他在生活中说过或做过一些不被社会接受的事情。
总之,让我们回到故事的主线。在 21 世纪初,Terry 发布了一个简单的操作系统。多年来,它不停地换了几个名字,有 J Operating System、LoseThos 和 SparrowOS 等等。他最终确定了 [TempleOS](https://templeos.org/)(神庙系统)这个名字。他选择这个名字是因为这个操作系统将成为“神的圣殿”。因此,“神”给 Terry 的操作系统规定了以下 [规格](https://web.archive.org/web/20170508181026/http://www.templeos.org:80/Wb/Doc/Charter.html):
* 它将有 640×480 的 16 色图形显示
* 它将使用 “单声道 8 位带符号的类似 MIDI 的声音采样”
* 它将追随 Commodore 64,即“一个非网络化的简单机器,编程是目标,而不仅仅是达到目的的手段”
* 它将只支持一个文件系统(名为 “Red Sea”)
* 它将被限制在 10 万行代码内,以使它 “整体易于学习”
* “只支持 Ring-0 级,一切都在内核模式下运行,包括用户应用程序”
* 字体将被限制为 “一种 8×8 等宽字体”
* “对一切都可以完全访问。所有的内存、I/O 端口、指令和类似的东西都绝无限制。所有的函数、变量和类成员都是可访问的”
* 它将只支持一个平台,即 64 位 PC
Terry 用一种他称之为 HolyC(神圣 C 语言)的编程语言编写了这个操作系统。TechRepublic 称其为一种 “C++ 的修改版(‘比 C 多,比 C++ 少’)”。如果你有兴趣了解 HolyC,我推荐 [这篇文章](https://harrisontotty.github.io/p/a-lang-design-analysis-of-holyc) 和 [RosettaCode](https://rosettacode.org/wiki/Category:HolyC) 上的 HolyC 条目。
2013 年,Terry 在他的网站上宣布,TempleOS 已经完成。不幸的是,几年后的 2018 年 8 月,Terry 被火车撞死了。当时他无家可归。多年来,许多人通过他在该操作系统上的工作关注着他。大多数人对他在如此小的体积中编写操作系统的能力印象深刻。
现在,你可能想知道这些关于 TempleOS 的讨论与 Shrine 有什么关系。好吧,正如 Shrine 的 [GitHub 页面](https://github.com/minexew/Shrine) 所说,它是 “一个为异教徒设计的 TempleOS 发行版”。GitHub 用户 [minexew](https://github.com/minexew) 创建了 Shrine,为 TempleOS 添加 Terry 忽略的功能。这些功能包括:
* 与 TempleOS 程序 99% 的兼容性
* 带有 Lambda Shell,感觉有点像经典的 Unix 命令解释器
* TCP/IP 协议栈和开机即可上网
* 包括一个软件包下载器
minexew 正计划在未来增加更多的功能,但还没有宣布具体会包括什么。他有计划为 Linux 制作一个完整的 TempleOS 环境。
### 体验
让 Shrine 在虚拟机中运行是相当容易的。你所需要做的就是安装你选择的虚拟化软件。(我的是 VirtualBox)当你为 Shrine 创建一个虚拟机时,确保它是 64 位的,并且至少有 512MB 的内存。
一旦你启动到 Shrine,会询问你是否要安装到你的(虚拟)硬盘上。一旦安装完成(你也可以选择不安装),你会看到一个该操作系统的导览,你可以由此探索。
### 总结
TempleOS (和 Shrine)显然不是为了取代 Windows 或 Linux。即使 Terry 把它称为 “神之圣殿”,我相信在他比较清醒的时候,他也会承认这更像是一个业余的作业系统。考虑到这一点,已完成的产品相当 [令人印象深刻](http://www.codersnotes.com/notes/a-constructive-look-at-templeos/)。在 12 年的时间里,Terry 用他自己创造的语言创造了一个稍稍超过 10 万行代码的操作系统。他还编写了自己的编译器、图形库和几个游戏。所有这些都是在与他自己的个人心魔作斗争的时候进行的。
---
via: <https://itsfoss.com/shrine-os/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We’ve all used multiple operating systems in our lives. Some were good and some were bad. But can you say that you’ve ever used an operating system designed by God? Today, I’d like to introduce you to Shrine.
## What is Shrine?
From that introduction, you’re probably wondering what the heck is going on. Well, it all started with a guy named Terry Davis. Before we go any further, I’d better warn you that Terry suffered from schizophrenia during his life and often didn’t take his medication. Because of this, he said or did things during his life that were not quite socially acceptable.
Anyway, back to the story line. In the early 2000s, Terry released a simple operating system. Over the years, it went through several names, including J Operating System, LoseThos, and SparrowOS. He finally settled on the name [TempleOS](https://templeos.org/). He chose that name because this operating system would be God’s temple. As such. God gave Terry the following [specifications](https://web.archive.org/web/20170508181026/http://www.templeos.org:80/Wb/Doc/Charter.html) for the operating system:
- It would have 640×480 16 color graphics
- It would use “a single-voice 8-bit signed MIDI-like sample for sound”.
- It would follow the Commodore 64, i.e. “a non-networked, simple machine where programming was the goal, not just a means to an end”.
- It would only support one file system (named “Red Sea”).
- It would be limited to 100,000 lines of code to make it “easy to learn the whole thing”.
- “Ring-0-only. Everything runs in kernel mode, including user applications”
- The font would be limited to “one 8×8 fixed-width font”.
- The use would have “full access to everything. All memory, I/O ports, instructions, and similar things must never be off limits. All functions, variables and class members will be accessible.”
- It would only support one platform, 64-bit PCs.
Terry wrote this operating system using in a programming language that he called HolyC. TechRepublic called it a “modified version of C++ (“more than C, less than C++”)”. If you are interested in getting a flavor of HolyC, I would recommend, [this article](https://harrisontotty.github.io/p/a-lang-design-analysis-of-holyc) and the HolyC entry on [RosettaCode](https://rosettacode.org/wiki/Category:HolyC).
In 2013, Terry announced on his website that TempleOS was complete. Tragically, Terry died a few years later in August of 2018 when he was hit by a train. He was homeless at the time. Over the years, many people followed Terry through his work on the operating system. Most were impressed at his ability to write an operating system in such a small package.
Now, you are probably wondering what all this talk of TempleOS has to do with Shrine. Well, as the [GitHub page](https://github.com/minexew/Shrine) for Shrine states, it is “A TempleOS distro for heretics”. GitHub user [minexew](https://github.com/minexew) created Shrine to add features to TempleOS that Terry had neglected. These features include:
- 99% compatibility with TempleOS programs
- Ships with Lambda Shell, which feels a bit like a classic Unix command interpreter
- TCP/IP stack & internet access out of the box
- Includes a package downloader
minexew is planning to add more features in the future, but hasn’t announced what exactly will be included. He has plans to make a full TempleOS environment for Linux.
## Experience
It’s fairly easy to get Shrine virtualized. All you need to do is install your virtualizing software of choice. (Mine is VirtualBox.) When you create a virtual machine for Shrine, make sure that it is 64-bit and has at least 512 MB of RAM.
Once you boot into Shrine, you will be asked if you want to install to your (virtual) hard drive. Once that is finished (or not, if you choose), you will be offered a tour of the operating system. From there you can explore.
## Final Thoughts
Temple OS and (Shrine) is obviously not intended to be a replacement for Windows or Linux. Even though Terry referred to it as “God’s temple”, I’m sure in his more lucid moments, he would have acknowledged that it was more of a hobby operating system. With that in mind, the finished product is fairly [impressive](http://www.codersnotes.com/notes/a-constructive-look-at-templeos/). Over a twelve-year period, Terry created an operating system in a little over 100,000 lines of code, using a language that he had created himself. He also wrote his own compiler, graphics library and several games. All this while fighting his own personal demons. |
13,832 | 浅谈配置文件格式 | https://opensource.com/article/21/6/what-config-files | 2021-09-29T13:50:03 | [
"配置文件"
] | https://linux.cn/article-13832-1.html |
>
> 流行的配置文件格式有若干种,每种都有其自身优势。从中找到最适合你的格式吧!
>
>
>

计算机上有数以千计的配置文件。你可能永远不会直接与其中的大部分文件打交道,但它们确实散落在你的 `/etc` 以及 `~/.config`、`~/.local`、`/usr` 文件夹中。还有一些可能在 `/var`,甚至 `/opt` 文件夹中。如果无意中打开过或更改过它们,你就可能会有疑问:为什么有些配置文件看起来是某一种格式,而另一些则是看起来完全不同的格式?
存储配置是一项很灵活的任务,因为只要开发人员知道他们的代码是如何将数据存入文件的,他们就可以轻松编写代码来根据需要提取数据。然而,科技行业非常青睐有详细文档的标准化事物,因此多年来出现了几种比较普遍的格式用来简化配置任务。
### 为什么我们需要配置文件
配置文件对于现代计算来说很重要。它们使你能够自定义与应用程序交互的方式,或自定义应用程序与系统内其他程序的交互方式。有了配置文件,每当你启动某个应用程序时,它都会有“记忆”,记录了你喜欢如何去使用该程序。
配置文件的结构可以很简单,而且通常确实也很简单。例如,如果你要编写一个应用程序,程序唯一需要知道的是其用户的偏好名字,那么它的唯一配置文件就可以只包含一个词:用户名。就像下面这样:
```
Tux
```
但通常应用程序需要追踪的不仅仅是一条信息,因此配置文件通常会有一个键和一个值:
```
NAME='Tux'
SPECIES='Penguin'
```
即使没有编程经验,你也可以想象出代码如何解析这些数据。这里有两个简单的例子,一个使用 [awk 命令](https://opensource.com/article/20/9/awk-ebook),另一个使用 [grep 命令](https://opensource.com/downloads/grep-cheat-sheet)。两个例子都是只关注包含 `NAME` “键”的行,并返回出现在等号 (`=`) 之后的“值”:
```
$ awk -F'=' '/NAME/ { print $2; }' myconfig.ini
'Tux'
$ grep NAME fake.txt | cut -d'=' -f2
'Tux'
```
同样的原则适用于任何编程语言和任何配置文件。只要你有统一的数据结构,就可以在需要的时候编写简单的代码来提取和解析它。
### 选择格式
为了保证普遍有效性,配置文件最重要的一点是它们是一致的和可预测的。你绝对不会想做这样的事:以保存用户首选项的名义,将信息随意存储到文件中,然后花好几天时间逆向工程,来找到最终出现在文件中的随机信息。
流行的配置文件格式有若干种,每种格式都有自己的优势。
#### INI
INI 文件采用了键值对的格式:
```
[example]
name=Tux
style=widgety,fidgety
enabled=1
```
这种简单的配置风格很直观,只要你别选择使用糟糕的键名(比如用 `unampref` 这样的神秘键名来代替 `name`)就好。这些键值对很容易解析和编辑。
除了键和值之外,INI 格式还可以分 <ruby> 节 <rt> section </rt></ruby>。在下列示例代码中,`[example]` 和 `[demo]` 就是配置文件中的两个节:
```
[example]
name=Tux
style=widgety,fidgety
enabled=1
[demo]
name=Beastie
fullscreen=1
```
这几个配置语句解析起来有点复杂,因为有两个 `name` 键。想象一下,一个粗心的程序员在这个配置文件中查询 `name`,结果总是返回 `Beastie`,因为这是文件中对 `name` 的最后一个定义值。在解析这样的文件时,开发人员必须加倍小心地在各节中搜索键,这可能会很棘手,具体取决于用来解析该文件的语言。然而,它仍然是一种很流行的格式,大多数语言都会有一个现成的库来帮助程序员解析 INI 文件。
#### YAML
[YAML 文件](https://www.redhat.com/sysadmin/yaml-beginners) 是结构化列表,可以包含值或者键值对:
```
---
Example:
Name: 'Tux'
Style:
- 'widgety'
- 'fidgety'
Enabled: 1
```
YAML 格式很流行,部分原因是它看起来很整洁。数据要放置到相对其上层数据的特定位置,除此之外没有太多其他语法。然而,对于某些人来说的这种特色,在其他人眼中可能就是一个问题。许多开发人员不愿使用 YAML,正是因为它很看重本质上 *不存在* 的东西。如果你在 YAML 中缩进错误,YAML 解析器可能会将你的文件视为无效文件,即使不视为无效,返回的数据也可能是错误的。
大多数语言都有 YAML 解析器,并且有很好的开源 YAML linters(验证语法的应用程序)来帮你确保 YAML 文件的完整性。
#### JSON
JSON 文件在技术上来说是 YAML 的子集,因此其数据结构是相同的,尽管其语法完全不同:
```
{
"Example": {
"Name": [
"Tux"
],
"Style": [
"widgety",
"fidgety"
],
"Enabled": 1
}
}
```
JSON 在 JavaScript 程序员中很流行,这并不奇怪,因为 JSON 全称为<ruby> JavaScript 对象符号 <rt> JavaScript Object Notation </rt></ruby>。由于与 Web 开发密切相关,JSON 是 Web API 的常见输出格式。大多数编程语言都有解析 JSON 的库。
#### XML
XML 使用标签作为键,将配置值围绕起来:
```
<example>
<name>Tux</name>
<style priority="user">widgety</style>
<style priority="fallback">fidgety</style>
<enabled>1</enabled>
</example>
```
XML 经常被 Java 程序员使用,Java 有一套丰富的 XML 解析器。虽然 XML 以非常严格而著称,但同时也非常灵活。与有一系列特定标签的 HTML 不同,XML 中可以随意发明自己的标签。只要始终坚持相同的构建规则,并有一个良好的库来解析它,你就可以准确而轻松地提取数据。
有一些很好的开源 linter 可以帮你验证 XML 文件,并且大多数编程语言都提供用于解析 XML 的库。
#### 二进制格式
Linux 以纯文本配置为傲。这样做的优点是可以使用 [cat](https://opensource.com/article/19/2/getting-started-cat-command) 等基本工具查看配置数据,甚至可以使用你 [最喜欢的文本编辑器](https://opensource.com/article/21/2/open-source-text-editors) 来编辑配置。
但是,某些应用程序使用二进制格式配置,就意味着数据以某种非自然语言的格式进行编码。这些文件通常需要一个特殊的应用程序(通常是它们要配置的应用程序)来解释它们的数据。你无法查看这些文件,至少无法以任何有意义的方式查看,并且无法在其宿主应用程序之外编辑它们。选用二进制格式的一些原因如下:
* **速度:** 程序员可以使用自定义符号在二进制配置文件中的某些点注册特定的信息位。提取数据时不涉及搜索,因为所有内容都已标注了索引。
* **大小:** 文本文件可能会变大,如果选择压缩文本文件,实际上是在将其转换为二进制格式。二进制文件可以通过编码技巧变得更小(文本文件也是如此,但在某些时候,你的优化会使数据变得晦涩,以至于文件也成了二进制文件)。
* **晦涩:** 一些程序员甚至不希望人们查看他们的配置文件,因此将它们编码为二进制数据。这通常只会让用户感到沮丧,并不是使用二进制格式的好理由。
如果必须使用二进制格式进行配置,请使用已作为开放标准存在的格式,例如 [NetCDF](https://www.unidata.ucar.edu/software/netcdf/)。
### 找到有效的配置格式
配置格式帮助开发人员存储应用程序所需的数据,并帮助用户存储他们希望应用程序如何操作的偏好项。对于应该使用什么格式的问题,可能没有错误的答案,只要你觉得所使用的语言能很好地支持就可以。在开发应用程序时,查看可用格式,用一些样例数据建模,查看和评估你的编程语言提供的库和实用程序,然后选择你觉得最合适的一种格式吧。
---
via: <https://opensource.com/article/21/6/what-config-files>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are thousands of configuration files on your computer. You may never directly interact with the bulk of them, but they're scattered throughout your `/etc`
folder and in `~/.config`
and `~/.local`
and `/usr`
. There are probably some in `/var`
and possibly even in `/opt`
. If you've ever opened one by accident or to make a change, you may have wondered why some configuration files look one way while others look completely different.
Storing configurations is a flexible task because as long as developers know how their code puts data into a file, they can easily write code to extract that data as needed. However, the tech industry graciously favors well-documented standardization, so several well-known formats have evolved over the years to make configuration easy.
## Why we need configuration
Configuration files ("config files" for short) are important to modern computing. They allow you to customize how you interact with an application or how an application interacts with the rest of your system. It's thanks to config files that any time you launch an application, it has "memories" of how you like to use it.
Configuration files can be, and often are, very simple in structure. For instance, if you were to write an application, and the only thing it ever needed to know was its user's preferred name, then its one and only config file could contain exactly one word: the name of the user. For example:
`Tux`
Usually, though, an application needs to keep track of more than just one piece of information, so configuration often uses a key and a value:
```
NAME='Tux'
SPECIES='Penguin'
```
Even without programming experience, you can imagine how code parses that data. Here are two simple examples, one using the [ awk command](https://opensource.com/article/20/9/awk-ebook) and the other using the
[grep command](https://opensource.com/downloads/grep-cheat-sheet), focusing on just the line containing the "key" of
`NAME`
, and returning the "value" appearing after the equal sign (`=`
):```
$ awk -F'=' '/NAME/ { print $2; }' myconfig.ini
'Tux'
$ grep NAME fake.txt | cut -d'=' -f2
'Tux'
```
The same principle applies to any programming language and any configuration file. As long as you have a consistent data structure, you can write simple code to extract and parse it when necessary.
## Choose a format
To be broadly effective, the most important thing about configuration files is that they are consistent and predictable. The last thing you want to do is dump information into a file under the auspices of saving user preferences and then spend days writing code to reverse-engineer the random bits of information that have ended up in the file.
There are several popular formats for configuration files, each with its own strengths.
### INI
INI files take the format of key and value pairs:
```
[example]
name=Tux
style=widgety,fidgety
enabled=1
```
This simple style of configuration can be intuitive, with the only point of confusion being poor key names (for example, cryptic names like `unampref`
instead of `name`
). They're easy to parse and easy to edit.
The INI format features sections in addition to keys and values. In this sample code, `[example]`
and `[demo]`
are configuration sections:
```
[example]
name=Tux
style=widgety,fidgety
enabled=1
[demo]
name=Beastie
fullscreen=1
```
This is a little more complex to parse because there are *two* `name`
keys. You can imagine a careless programmer querying this config file for `name`
and always getting back `Beastie`
because that's the last name defined by the file. When parsing such a file, a developer must be careful to search within sections for keys, which can be tricky depending on the language used to parse the file. However, it's a popular enough format that most languages have an existing library to help programmers parse INI files.
### YAML
[YAML files](https://www.redhat.com/sysadmin/yaml-beginners) are structured lists that can contain values or key and value pairs:
```
---
Example:
Name: 'Tux'
Style:
- 'widgety'
- 'fidgety'
Enabled: 1
```
YAML is popular partly because it looks clean. It doesn't have much of a syntax aside from where you place the data in relation to previous data. What's a feature for some, though, is a bug for others, and many developers avoid YAML because of the significance it places on what is essentially *not there*. If you get indentation wrong in YAML, YAML parsers may see your file as invalid, and even if it's tolerated, it may return incorrect data.
Most languages have YAML parsers, and there are good open source YAML linters (applications to validate syntax) to help you ensure the integrity of a YAML file.
### JSON
JSON files are technically subsets of YAML, so its data structure is the same, although its syntax is completely different:
```
{
"Example": {
"Name": [
"Tux"
],
"Style": [
"widgety",
"fidgety"
],
"Enabled": 1
}
}
```
JSON is popular among JavaScript programmers, which isn't surprising, given that JSON stands for JavaScript Object Notation. As a result of being strongly associated with web development, JSON is a common output format for web APIs. Most programming languages have libraries to parse JSON.
### XML
XML uses tags as keys that surround a configuration value:
```
<example>
<name>Tux</name>
<style priority="user">widgety</style>
<style priority="fallback">fidgety</style>
<enabled>1</enabled>
</example>
```
XML is often used by Java programmers, and Java has a rich set of XML parsers. While it has a reputation of being quite strict, XML is simultaneously very flexible. Unlike HTML, which has a set of tags you're allowed to use, you can arbitrarily invent your own XML tags. As long as you structure it consistently and have a good library to parse it, you can extract your data with precision and ease.
There are some good open source linters to help you validate XML files, and most programming languages have a library to parse XML.
### Binary formats
Linux prides itself on plain-text configuration. The advantage is that you can see configuration data using basic tools like [cat](https://opensource.com/article/19/2/getting-started-cat-command), and you can even edit a configuration with your [favorite text editor](https://opensource.com/article/21/2/open-source-text-editors).
Some applications use binary formats, though, which means the data is encoded in some format that is not a natural language. These files usually require a special application (usually the application they're meant to configure) to interpret their data.
You can't view these files, at least not in a way that makes any sense, and you can't edit them outside of their host application. Some reasons for resorting to binary formats are:
**Speed:**A programmer can register specific bits of information at certain points within a binary's config file using custom notation. When the data is extracted, there's no searching involved because everything is already indexed.**Size:**Text files can get big, and should you choose to compress a text file, you're functionally turning it into a binary format. Binary files can be made smaller through tricks of encoding (the same is true of text files, but at some point, your optimizations make your data so obscure that it may as well be binary).**Obfuscation:**Some programmers don't want people even looking at their configuration files, so they encode them as binary data. This usually succeeds only in frustrating users. This is not a good reason to use binary formats.
If you must use a binary format for configuration, use one that already exists as an open standard, such as [NetCDF](https://www.unidata.ucar.edu/software/netcdf/).
## Find what works
Configuration formats help developers store the data their applications need and help users store preferences for how they want applications to act. There's probably no wrong answer to the question of what format you should use, as long as you feel well supported by the language you're using. When developing your application, look at the formats available, model some sample data, review and evaluate the libraries and utilities your programming language provides, and choose the one you feel the most confident about.
## Comments are closed. |
13,833 | 微软 Exchange 的一个开源替代方案 | https://opensource.com/article/21/9/open-source-groupware-grommunio | 2021-09-29T14:14:12 | [
"Exchange",
"群件"
] | https://linux.cn/article-13833-1.html |
>
> 开源用户现在有了一个强大的、功能齐全的群件选择。
>
>
>

多年来,微软 Exchange 作为一个平台牢牢统治着群件环境。然而,在 2020 年末,一个奥地利的开源软件开发商推出了 [grommunio](https://grommunio.com/en/),这是一个群件服务器和客户端,其外观和感觉让 Exchange 和 Outlook 用户感到很熟悉。
grmmunio 项目可以很好地替代 Exchange。开发者以与微软相同的方式将组件连接到平台上,它们支持 RPC (远程过程调用)与 HTTP 协议。据开发者介绍,grommunio 还包括许多常见的群件接口,如 IMAP、POP3、SMTP、EAS(Exchange ActiveSync)、EWS(Exchange Web Services)、CalDAV 和 CardDAV。有了这样广泛的支持,grommunio 可以顺利地整合到现有的基础设施中。
用户会注意到对 Outlook、Android 和 iOS 客户端来说几乎没有区别。当然,作为开源软件,它也支持其他客户端。由于集成了原生的 Exchange 协议,Outlook 和智能手机与 grommunio 的通信就像与微软 Exchange 服务器一样。日常的企业用户可以继续使用他们现有的客户端,而 grommunio 服务器则在后台安静地运行。
### 不仅仅是邮件
除了邮件功能外,grommunio 界面还提供了日历系统。可以直接在日历显示中或在一个新标签中点击创建约会。这很直观,正如你对现代工具的期望。用户可以创建、管理和分享日历以及地址簿。私人联系人或普通联系人都支持,而且你可以与同事分享一切。
任务管理在左边的下拉菜单中显示任务列表,它们可以有一个所有者和多个合作者。你可以为每个任务指定截止日期、类别、附件和其他属性。笔记可以以同样的方式被管理并与其他团队成员共享。
### 聊天、视频会议和文件同步
除了现代群件的所有标准功能外,grommunio 还提供聊天、视频会议和文件同步功能。它为企业实现了大规模的全面整合,具有极高的性能。对于开源的推动者来说,这是一个简单的选择,对于系统管理员来说,这是一个强大的选择。因为 grommunio 的目标是整合而不是重新发明,所以所有的组件都是标准的开源工具。

*用于高级视频会议的 Jitsi 集成(Markus Feilner, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
在 grommunio 会议功能的背后是 [Jitsi](https://opensource.com/article/20/5/open-source-video-conferencing),它以熟悉的用户界面顺利地集成到 grommunio 的用户界面中。完全集成和集中管理的聊天功能是基于 [Mattermost](https://opensource.com/education/16/3/mattermost-open-source-chat)。

*用于聊天的 Mattermost(Markus Feilner,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
[ownCloud](https://owncloud.com/) 承诺提供企业级的文件共享和同步,在点击“文件”按钮后开始。

*用于文件同步和交换的 ownCloud(Markus Feilner,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
grommunio 项目有一个强大的管理界面,包括角色、域和组织管理、预测性监测和自助服务门户。基于 shell 的向导指导管理员完成安装和从微软 Exchange 迁移数据。开发团队正在不断努力,以实现更好的整合和更集中的管理,并随之为管理员提供更好的工作流程。

*grommunio 的管理界面(Markus Feilner, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))*
### 探索 grommunio
grommunio 项目的目标很高,但它的开发者已经付出了努力,这一点很明显。一家专门从事税务咨询的德国托管服务机构最近宣布,他们的客户可以使用 grommunio,这是一个德国数据保护法特别严厉的行业。grommunio 项目做得很好:将现有的、成功的概念干净地结合在一起,实现了开放、安全和符合隐私的通信。
---
via: <https://opensource.com/article/21/9/open-source-groupware-grommunio>
作者:[Markus Feilner](https://opensource.com/users/mfeilner) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Microsoft Exchange has for many years been nearly unavoidable as a platform for groupware environments. Late in 2020, however, an Austrian open source software developer introduced [grommunio](https://grommunio.com/en/), a groupware server and client with a look and feel familiar to Exchange and Outlook users.
The grommunio project functions well as a drop-in replacement for Exchange. The developers connect components to the platform the same way Microsoft does, and they support RPC (Remote Procedure Call) with the HTTP protocol. According to the developers, grommunio also includes numerous interfaces of common groupware such as IMAP, POP3, SMTP, EAS (Exchange ActiveSync), EWS (Exchange Web Services), CalDAV, and CardDAV. With such broad support, grommunio integrates smoothly into existing infrastructures.
Users will notice little difference among Outlook, Android, and iOS clients. Of course, as open source software, it supports other clients, too. Outlook and smartphones communicate with grommunio just as they do with a Microsoft Exchange server, thanks to their integrated, native Exchange protocols. An everyday enterprise user can continue to use their existing clients with the grommunio server quietly running in the background.
## More than just mail
In addition to mail functions, a calendaring system is available in the grommunio interface. Appointments can be created by clicking directly in the calendar display or in a new tab. It's intuitive and just what you'd expect from a modern tool. Users can create, manage, and share calendars as well as address books. Private contacts or common contacts are possible, and you can share everything with colleagues.
Task management shows a list of tasks on the left in a drop-down menu, and they can have both one owner and multiple collaborators. You can assign deadlines, categories, attachments, and other attributes to each task. In the same way, notes can be managed and shared with other team members.
## Chat, video conferences, and file sync
In addition to all the standard features of modern groupware, grommunio also offers chat, video conferencing, and file synchronization. It does this with full integration on a large scale for the enterprise, with extraordinarily high performance. It's an easy choice for promoters of open source and a powerful option for sysadmins. Because grommunio aims to integrate rather than reinvent, all components are standard open source tools.
Jitsi integration for advanced video conferences (Markus Feilner, CC BY-SA 4.0)
Behind the meeting function in grommunio is [Jitsi](https://opensource.com/article/20/5/open-source-video-conferencing), smoothly integrated into the grommunio UI with a familiar user interface. The chat feature, fully integrated and centrally managed, is based on [Mattermost](https://opensource.com/education/16/3/mattermost-open-source-chat).
Mattermost for chat (Markus Feilner, CC BY-SA 4.0)
[ownCloud](https://owncloud.com/), which promises enterprise-level file sharing and synchronization, starts after a click on the Files button.
Owncloud for file synchronization and exchange (Markus Feilner, CC BY-SA 4.0)
The grommunio project has a powerful administrative interface, including roles, domain and organization management, predictive monitoring, and a self-service portal. Shell-based wizards guide admins through installation and migration of data from Microsoft Exchange. The development team is constantly working for better integration and more centralization for management, and with that comes a better workflow for admins.
grommunio's admin interface (Markus Feilner, CC BY-SA 4.0)
## Explore grommunio
The grommunio project has lofty goals, but its developers have put in the work, and it shows. A German hosting service specializing in tax consultants—a sector where German data protection laws are especially tough—recently announced that grommunio is available to their customers. The grommunio project gets a lot right: a clean combination of existing, successful concepts working together to enable open, secure, and privacy-compliant communication.
## Comments are closed. |
13,836 | 5 个可以替代 Zoom 的开源软件 | https://opensource.com/article/21/9/alternatives-zoom | 2021-09-30T11:44:19 | [
"视频会议"
] | https://linux.cn/article-13836-1.html |
>
> 试试这些开源视频会议服务之一。
>
>
>

我最近参加了 [实用开源信息(POSI)](https://opensource.org/posicfp) 会议,它是在一个自由开源的视频会议平台上举行的。当我参加了一系列关于开源软件的实际用途的精彩讲座时,我意识到视频会议在过去几年里已经变得非常普遍。
如果说开源做了什么,那就是提供了选择,现在越来越多的工人有了远程工作的自由,在你的连接方式上有一个选择是非常有意义的。
有时,你需要一个全功能的视频会议应用,其中包括审核、演示模式和分组讨论室,而其他时候,你想做的只是给朋友打一个快速电话,以便看到对方的脸。
### Jitsi
[Jitsi](http://jitsi.org) 是一个简单、随意、但强大的视频通话平台。你可以自己托管它,也可以在 [meet.jit.si](http://meet.jit.si) 的公共实例上使用它。它有可定制的 URL,可以很容易地与你想见面的朋友分享链接、通话中的聊天、管理控制,和通话录音。它的开发非常活跃,每年都会测试和发布一大批新功能。它是 [Opensource.com](http://Opensource.com) 用于我们每周会议的平台。
### Signal
[Signal](https://signal.org) 已经是一个流行的以安全为重点的聊天应用,最近它又增加了 [团体视频通话](https://support.signal.org/hc/en-us/articles/360052977792-Group-Calling-Voice-or-Video-with-Screen-Sharing) 的功能。视频通话非常适合简单的会议,而且因为你只能与你的 Signal 联系人列表中的其他人见面,所以不用担心你的视频通话会议上有不速之客。当你尝试定位你应该参与开会的虚拟房间时,也没有来回的“电话标签”。这一切都发生在 Signal 中,因此无需猜测。
Signal 本身是非常直观的,视频功能非常适合其现有惯例。简而言之,只要你的联系人在使用 Signal,这就是一个不费力的视频通话平台。这是我用于个人联系的应用,我经常使用其视频通话功能与朋友和家人联系。
### P2p.chat
[P2p.chat](https://p2p.chat/) 是这些中最简单的一个,无论是设计还是实现。通过 WebRTC 工作,p2p.chat 是一个 Web 应用,允许你直接连接到你正在呼叫的人,而不需要托管服务器。p2p.chat 的界面并不多,但这也是其吸引力的另一部分。没有管理控制或演示模式,因为 p2p.chat 在很大程度上是科幻片中承诺的“视频电话”:与远方的人进行轻松的人对人(或人们对人们)视频通话。
你可以使用自定义的 URL 来动态地创建一个会议空间,所以它们相对容易记忆(除了小的随机部分)和输入。我和不在 Signal 上的朋友使用 p2p.chat,它从未让我失望过。
### BigBlueButton
如果你需要严格的管理控制和极端的灵活性,[BigBlueButton](https://bigbluebutton.org/) 是你正在寻找的解决方案,它专为教室、会议和演讲而设计。有了 BigBlueButton,你可以让所有与会者静音,阻止和踢走一个与会者,创建分组讨论室,创建协作式白板,共享屏幕,进行演讲,以及记录会议。与会者可以“举起手”表示注意,并将他们的状态设定为非语言交流方式。它很容易使用,但它是一个严肃的平台,适用于重点和非常大的群体。我参加过一些使用 BigBlueButton 的技术会议,包括 [实用开源信息(POSI)](https://opensource.org/posicfp)会议。
### Wire
[Wire](https://wire.com/en/) 是寻找托管视频聊天和群件客户端的企业客户的绝佳选择。它是 [AGPL](https://opensource.org/licenses/AGPL-3.0) 许可,这个开源项目可用于桌面和服务器、安卓和 iOS。它具有视频通话、发信和文件共享的功能,因此,即使是远程会议,基本上也有亲自开会的所有便利。你可以在有限的时间内免费试用 Wire,然后为你的公司购买一份支持合同。另外,你也可以自己托管它。
### 开源视频聊天
没有理由满足于由你可能不完全信任的公司托管的专有视频通话。今天可用的开源选项对于与你的职业和个人生活中的所有人保持联系是非常好的。下次你想和朋友见面时,不妨试试这些解决方案之一。
---
via: <https://opensource.com/article/21/9/alternatives-zoom>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recently attended the [Practical Open Source Information POSI](https://opensource.org/posicfp) conference, which was held on a free and open source video conferencing platform. As I attended a series of excellent talks about practical uses of open source software, I realized how commonplace video conferencing had become over the past few years.
If open source does anything, it provides choice, and now that more and more workers have the freedom of working remotely, having an option in the way you connect makes a lot of sense.
Sometimes, you need a full-featured video conferencing application with moderation, a presentation mode, and breakout rooms, while other times, all you want to do is make a quick call to a friend so that you can see each other's faces.
Jitsi
[Jitsi](http://jitsi.org) is an easy, casual, but robust video calling platform. You can self host it or use it on the public instance at [meet.jit.si](http://meet.jit.si). It's got customizable URLs that make it easy to share links with friends you want to meet with, in-call chat, administrative controls, and call recording. It's very actively developed and has a whole collection of new features being tested and released each year. It's the platform Opensource.com uses for our weekly meetings.
Signal
[Signal](https://signal.org) is already a popular security-focused chat application, and it recently added [group video calls](https://support.signal.org/hc/en-us/articles/360052977792-Group-Calling-Voice-or-Video-with-Screen-Sharing) to its features. The video calls are great for simple meetings, and because you can only meet with other people in your Signal contact list, there's no concern over unwanted guests at your video call party. There's also no back and forth "phone tag" as you try to locate the virtual room you're supposed to be meeting in. It all happens in Signal, so there's no guesswork required.
Signal itself is pretty intuitive, and the video feature fits neatly into its existing conventions. In short, as long as your contacts are using Signal, this is a no-effort video calling platform. This is the application I use for personal contacts, and I regularly use its video calling feature to connect to friends and family.
P2p.chat
[P2p.chat](https://p2p.chat/) is the easiest of them all, in both design and implementation. Working through Web Real-Time Communication (WebRTC), p2p.chat is a web application that allows you to connect directly to the person you're calling, with no host server required. There's not much to the p2p.chat interface, but that's another part of its appeal. There's no administrative control or presentation mode because p2p.chat is very much the "vidphone" promised in sci-fi: A casual, no-effort person-to-person (or people-to-people) video call with somebody far away.
You use custom URLs to create a meeting space dynamically, so they're relatively easy to remember (aside from the small randomized part) and type. I use p2p.chat with friends who aren't on Signal, and it's never let me down.
BigBlueButton
Designed for classrooms, conferences, and presentations, [BigBlueButton](https://bigbluebutton.org/) is the solution you're looking for if you need strict admin controls and extreme flexibility. With BigBlueButton, you can mute all participants, block and kick a participant, create breakout rooms, create a collaborative whiteboard, share screens, give presentations, and record sessions. Participants can raise a digital hand for attention and set their status as a non-verbal method of communication. It's easy to use, but it's a serious platform for focused and very large groups. I've attended a few technical conferences using BigBlueButton, including the [Practical Open Source Information (POSI)](https://opensource.org/posicfp) conference.
Wire
[Wire](https://wire.com/en/) is an excellent choice for corporate customers looking for a hosted video chat and groupware client. Licensed under the [AGPL](https://opensource.org/licenses/AGPL-3.0), this open source project is available for desktop and server, Android, and iOS. It features video calling, messaging, and file sharing, so even a remote meeting essentially has all the conveniences of meeting in person. You can try Wire for free for a limited time and then purchase a support contract for your company. Alternately, you can host it yourself.
## Open source video chat
There's no reason to settle for proprietary video calling hosted by companies you may not fully trust. The open source options available today are great for keeping in touch with all the people in your professional and personal life. Try one of these solutions the next time you want to meet with friends.
## Comments are closed. |
13,837 | 用 Foreman 管理 CentOS Stream | https://opensource.com/article/21/9/centos-stream-foreman | 2021-09-30T13:35:50 | [
"Stream",
"CentOS"
] | https://linux.cn/article-13837-1.html |
>
> 这个例子让我们看到了在 Foreman 中管理和配置 CentOS Stream 内容的许多选项。
>
>
>

2021 年 12 月,CentOS 8 将达到生命终点,被 CentOS Stream 取代。CentOS Stream 和 CentOS 之前的迭代之间的主要变化之一是没有小版本。Centos Stream 采用了一个连续的发布周期。从今年年初开始,Foreman 社区的开发者开始看到 CentOS Stream 由于持续发布而提供的更早的错误检测和补丁的好处。我们不再需要等待下一个版本来利用最新的变化和错误修复。[一位资深的 Linux 社区爱好者](https://twitter.com/Det_Conan_Kudo/status/1337366036023218177?s=20) 指出,此举也使 RHEL 开发者比以往更接近 FOSS 社区。
然而,如果你是一个拥有数百或数千台服务器的管理员,你可能想控制新的软件包何时被添加到特定的服务器。如果你正在寻找一个免费的开源工具,帮助你确保生产服务器的稳定性,同时允许你安全地从 Centos Stream 中拉入最新的变化用于开发和测试,这就是 Foreman 可以帮助你的地方。有了 Foreman,你可以在生命周期环境的各个阶段管理你的 Centos Stream 内容。
### Foreman 介绍
Foreman 是一个完整的物理和虚拟服务器的生命周期管理工具。有了 Foreman,系统管理员有能力轻松实现重复性任务的自动化,快速部署应用程序,并主动管理内部或云中的服务器。Foreman 为<ruby> 配备 <rt> provisioning </rt></ruby>管理、配置管理和监控提供了企业级解决方案。由于其插件架构,Foreman 可以以无数种方式进行扩展。使用 Katello 插件,你可以把 Foreman 作为一个完整的<ruby> 内容管理 <rt> content management </rt></ruby>工具来管理 CentOS Stream,以及其他许多内容类型。
通过 Foreman 和 Katello,你可以准确地定义你希望每个环境包含哪些软件包。例如,生产环境可能使用已被验证为稳定的软件包,而开发环境可能需要最新、最先进的软件包版本。你还可以跨生命周期环境推广<ruby> 内容视图 <rt> content view </rt></ruby>。让我们来看看 Foreman 是如何完成这个任务的。
我们在这篇文章中使用了网页用户界面,但 Foreman 也有一个强大的 CLI 和 API。Katello 插件为 Pulp 项目提供了一个工作流和网页用户界面,你可以在 [这篇文章](https://opensource.com/article/20/8/manage-repositories-pulp) 中了解更多。我们在这里也提供了一个简单的工作流程,但是 Foreman 和 Katello 项目提供了许多不同的配置选项来满足你的具体需求。
本文假设 Foreman 和 Katello 已经安装完毕。关于如何安装的更多信息,请参阅 [Katello 安装手册](https://docs.theforeman.org/3.0/Installing_Server_on_Red_Hat/index-katello.html)。
### 创建一个产品
第一步是在 Foreman 中创建一个<ruby> 产品 <rt> product </rt></ruby>。该产品的功能是作为一个内部标签来存储 CentOS Stream 存储库。
1. 在 Foreman 网页用户界面,导航到“<ruby> 内容 <rt> Content </rt></ruby> > <ruby> 产品 <rt> Products </rt></ruby>”,并点击“<ruby> 创建产品 <rt> Create Product </rt></ruby>”。
2. 在“<ruby> 名称 <rt> Name </rt></ruby>”字段中,为产品输入一个名称。Foreman会根据你输入的“<ruby> 名称 <rt> Name </rt></ruby>”自动完成“<ruby> 标签 <rt> Label </rt></ruby>”字段,以后不能再更改。
### 将 CentOS Stream 存储库添加到产品中
现在你有了一个产品,你可以使用 AppStream 和 BaseOS 存储库的 URL,并将它们添加到你的新产品中。
1. 在 Foreman 网页用户界面中,导航到 “<ruby> 内容 <rt> Content </rt></ruby> > <ruby> 产品 <rt> Products </rt></ruby>”,选择你要使用的产品,然后点击 “<ruby> 新存储库 <rt> New Repository </rt></ruby>”。
2. 在“<ruby> 名称 <rt> Name </rt></ruby>”字段中,为存储库输入一个名称;例如,“Centos8StreamBaseOS”。Foreman 会根据你输入的“<ruby> 名称 <rt> Name </rt></ruby>”,自动完成“<ruby> 标签 <rt> Label </rt></ruby>”字段。
3. 从“<ruby> 类型 <rt> Type </rt></ruby>”列表中,选择存储库的类型,然后选择“Yum”。
4. 在 “URL” 字段中,输入 CentOS Stream Baseos 存储库的 URL,作为源: `http://mirror.centos.org/centos/8-stream/BaseOS/x86_64/os/`。
5. 选择“<ruby> 下载规则 <rt> Download Policy </rt></ruby>”列表。默认的是“<ruby> 按需 <rt> On Demand </rt></ruby>”,这意味着 Katello 将只下载元数据。如果你想下载所有的软件包,请改成“<ruby> 即时 <rt> Immediate </rt></ruby>”,它可以下载所有的软件包,可能会达到 20-30GB。
6. 确保“<ruby> 与镜像同步 <rt> Mirror on Sync </rt></ruby>”复选框被选中。这个选项确保在同步过程中,不再是上游存储库的一部分的内容被删除。
7. 点击“<ruby> 保存 <rt> Save </rt></ruby>”。
重复这些步骤,添加 AppStream 存储库及其 URL,例如,`http://mirror.centos.org/centos/8-stream/AppStream/x86_64/os/`。确保你使用最近的官方 CentOS 镜像来代替它。
要执行立即同步,在你的产品窗口,点击“<ruby> 立即同步 <rt> Sync Now </rt></ruby>”。最初的同步可能需要一些时间。你可以从“<ruby> 内容 <rt> Content </rt></ruby> > <ruby> 同步状态 <rt> Sync Status </rt></ruby>”查看同步状态。
同步完成后,你可以在“<ruby> 主机 <rt> Hosts </rt></ruby> > <ruby> 操作系统 <rt> Operating System </rt></ruby>”中查看新的 CentOS Stream 操作系统。请随意编辑名称和描述以满足你的要求。
如果你打算使用 Ansible 或 Puppet 等配置管理软件,Foreman 会自动创建一个操作系统报告。你可以在“<ruby> 管理 <rt> Administe </rt></ruby> > <ruby> 设置 <rt> Settings </rt></ruby> > <ruby> 忽略操作系统状况 <rt> Ignore facts for operating system </rt></ruby>”中关闭这个选项。重命名操作系统以匹配配置管理软件中的名称是一个好主意。例如,对于 Puppet,这将是“CentOS 8”。
### 定义你的基础设施的生命周期环境
应用程序生命周期是 Foreman 的内容管理功能的一个核心概念。应用程序的生命周期定义了一个特定的系统和它的软件在特定阶段的状况。例如,一个应用程序的生命周期可能很简单,你可能只有一个“开发”阶段和“生产”阶段。Foreman 提供了一些方法来以可控的方式定制每个应用生命周期阶段,以适应你的规范。
在这一点上,你必须创建你的生命周期环境路径。
1. 在 Foreman 网页用户界面中,导航到“<ruby> 内容 <rt> Content </rt></ruby> > <ruby> 生命周期环境 <rt> Lifecycle Environments </rt></ruby>”。
2. 点击“<ruby> 新环境路径 <rt> New Environment Path </rt></ruby>”,开始一个新的应用生命周期。
3. 在“<ruby> 名称 <rt> Name </rt></ruby>”字段中,为你的环境输入一个名称。
4. 在“<ruby> 描述 <rt> Description </rt></ruby>”字段中,为你的环境输入一个描述。
5. 点击“<ruby> 保存 <rt> Save </rt></ruby>”。
6. 根据你的需要添加尽可能多的环境路径。例如,你可以创建“dev”、“test”、“stage” 和 “production” 环境。要添加这些环境,点击“添加新环境”,完成“<ruby> 名称 <rt> Name </rt></ruby>”和“<ruby> 描述 <rt> Description </rt></ruby>”字段,并从“<ruby> 优先环境 <rt> Prior Environment* </rt></ruby>”列表中选择先前的环境,这样你就可以按照你预期使用的顺序将它们串联起来。
### 创建和发布一个内容视图
在 Foreman 中,“<ruby> 内容视图 <rt> Content View </rt></ruby>”是你的存储库在某个特定时间点的快照。内容视图提供了隔离软件包版本到你想保留的状态的机制。内容视图有很多可配置的功能,你可以用它来进一步细化。为了本教程的目的,让我们保持简单。
1. 在 Foreman 网页用户界面中,导航到“<ruby> 内容 <rt> Content </rt></ruby> > <ruby> 内容视图 <rt> Content View </rt></ruby>”,并点击“<ruby> 创建新视图 <rt> Create New View </rt></ruby>”。
2. 在“<ruby> 名称 <rt> Name </rt></ruby>”字段中,为视图输入一个名称。Foreman 会根据你输入的名称自动完成“<ruby> 标签 <rt> Label </rt></ruby>”字段。
3. 在“<ruby> 描述 <rt> Description </rt></ruby>”字段中,输入视图的描述。
4. 单击“<ruby> 保存 <rt> Save </rt></ruby>”以创建内容视图。
5. 在新的内容视图中,点击“<ruby> Yum 内容 <rt> Yum Contents </rt></ruby> > <ruby> 添加存储库 <rt> Add Repositories </rt></ruby>”,在“<ruby> 存储库选择 <rt> Repository Selection </rt></ruby>”区域,点击“<ruby> 添加 <rt> Add </rt></ruby>”。对于 BaseOS 和 Appstream 存储库,选择你想包括的软件包,然后点击“<ruby> 添加存储库 <rt> Add Repositories </rt></ruby>”。
6. 点击“<ruby> 发布新版本 <rt> Publish New Version </rt></ruby>”,在“<ruby> 描述 <rt> Description </rt></ruby>”区域,输入关于版本的信息以记录变化。
7. 单击“<ruby> 保存 <rt> Save </rt></ruby>”。
当你点击“<ruby> 发布新版本 <rt> Publish New Version </rt></ruby>”时,你创建了一个你已同步的所有内容的快照。这意味着你订阅此内容视图的每台服务器将只能访问与此生命周期环境相关的内容视图中的软件包版本。
每一个新的内容视图和后续版本都会首先发布到库环境,然后你可以在那里推广到其他环境。
### 跨生命周期环境推广内容
如果你已经测试了新的软件包,并且确信一切都很稳定,你可以把你的内容视图推广到另一个生命周期环境中。
1. 导航到“<ruby> 内容 <rt> Content </rt></ruby> > <ruby> 内容视图 <rt> Content Views </rt></ruby>”,选择你想推广的内容视图。
2. 点击内容视图的“<ruby> 版本 <rt> Versions </rt></ruby>”标签。
3. 选择你想推广的版本,并在“<ruby> 操作 <rt> Action </rt></ruby>”栏中,点击“<ruby> 推广 <rt> Promote </rt></ruby>”。
4. 选择你要推广内容视图的环境,并点击“<ruby> 推广版本 <rt> Promote Version </rt></ruby>”。
5. 再次点击“<ruby> 推广 <rt> Promote </rt></ruby>”按钮。这次选择生命周期环境,例如,“Test”,然后单击“<ruby> 推广版本 <rt> Promote Version </rt></ruby>”。
6. 最后,再次点击“<ruby> 推广 <rt> Promote </rt></ruby>”按钮。例如,选择“Production”环境并点击“<ruby> 推广版本 <rt> Promote Version </rt></ruby>”。
被分配到该特定环境的服务器现在可以从一套更新的软件包中提取。
### 创建一个激活密钥
为了将 CentOS Stream 服务器注册到你在特定生命周期中定义的内容,你必须创建一个激活密钥。激活密钥是一种与服务器共享凭证的安全方法。这使用了一个叫做“<ruby> 订阅管理器 <rt> subscription-manager </rt></ruby>的工具来订阅 CentOS Stream 服务器的内容。
当你创建了激活密钥后,将 CentOS Stream 订阅添加到激活密钥中。
1. 在 Foreman 网页用户界面中,导航到“<ruby> 内容 <rt> Content </rt></ruby> > <ruby> 激活密钥 <rt> Activation keys </rt></ruby>”,并点击“<ruby> 创建激活密钥 <rt> Create Activation Key </rt></ruby>”。
2. 在“<ruby> 名称 <rt> Name </rt></ruby>”栏中,输入激活密钥的名称。
3. 在“<ruby> 描述 <rt> Description </rt></ruby>”栏中,输入激活密钥的描述。
4. 从“<ruby> 环境 <rt> Environment </rt></ruby>”列表中,选择要使用的环境。
5. 从“<ruby> 内容视图 <rt> Content View </rt></ruby>”列表中,选择你刚才创建的内容视图。
6. 点击“<ruby> 保存 <rt> Save </rt></ruby>”。
### 从 Foreman 管理的内容中创建一个 CentOS Stream 主机
现在一切都准备好了。随着你创建的内容包含在内容视图中,并在整个生命周期中推广,你现在可以准确地用你想使用的内容来配置主机,并订阅你想让它们接收的更新。
要在 Foreman 中创建一个主机,请导航到“主机 > 创建主机”。
1. 在“<ruby> 名称 <rt> Name </rt></ruby>”字段中,为主机输入一个名称。
2. 单击“<ruby> 组织 <rt> Organization </rt></ruby>”和“<ruby> 位置 <rt> Location </rt></ruby>”选项卡,以确保配置环境自动设置为当前环境。
3. 从“<ruby> 部署在 <rt> Deploy On </rt></ruby>”列表中,选择“<ruby> 裸金属 <rt> Bare Metal </rt></ruby>”。
4. 单击“<ruby> 操作系统 <rt> Operating System </rt></ruby>”选项卡。
5. 从“<ruby> 架构 <rt> Architectures </rt></ruby>”列表中,选择“x86\_64”。
6. 从“<ruby> 操作系统 <rt> Operating System </rt></ruby>”列表中,选择“CentOS\_Stream 8”。
7. 勾选“<ruby> 构建模式 <rt> Build Mode </rt></ruby>”框。
8. 对于“<ruby> 媒体选择 <rt> Media Selection </rt></ruby>”,选择“<ruby> 同步的内容 <rt> Synced Content </rt></ruby>”来使用你之前同步的 CentOS Stream 内容。
9. 从“<ruby> 同步的内容 <rt> Synced Content </rt></ruby>”列表中,确保选择 “CentOS Stream”。
10. 从“<ruby> 分区表 <rt> Partition Table </rt></ruby>”列表中,对于这个演示,选择默认的 “Kickstart”,但有许多可用的选项。
11. 在“<ruby> Root 密码 <rt> Root Password </rt></ruby>”栏中,为你的新主机输入一个 root 密码。
12. 点击“<ruby> 接口 <rt> Interface </rt></ruby>”标签,并点击“<ruby> 编辑 <rt> Edit </rt></ruby>”,并添加一个 “<ruby> Mac 地址 <rt> Mac address </rt></ruby>”。
13. 点击“<ruby> 参数 <rt> Parameters </rt></ruby>”标签,并确保存在一个提供激活密钥的参数。如果没有,添加一个激活密钥。
14. 点击“<ruby> 提交 <rt> Submit </rt></ruby>”以保存主机条目。
现在,新的主机处于构建模式,这意味着当你打开它时,它将开始安装操作系统。
如果你导航到“<ruby> 主机 <rt> Hosts </rt></ruby> > <ruby> 内容主机 <rt> Content Hosts </rt></ruby>”,你可以看到你的主机所订阅的订阅、生命周期环境和内容视图的全部细节。
这个例子只是对你在 Foreman 中管理和配置 CentOS Stream 内容的众多选项的一个小窥视。如果你想了解更多关于如何管理 CentOS Stream 版本,控制你的服务器可以访问的内容,以及控制和保护你的基础设施的稳定性的详细信息,请查看 [Foreman 内容管理](https://docs.theforeman.org/master/Content_Management_Guide/index-foreman.html) 文档。当所有 CentOS Stream 内容在你的控制之下时,你可以创建和注册 Centos Stream,只使用你指定的内容。有关配备的更多详细信息,请参见 [Foreman 配备](https://docs.theforeman.org/master/Provisioning_Guide/index-foreman.html) 文档。如果你有任何问题、反馈或建议,你可以在 <https://community.theforeman.org/> 找到 Foreman 社区。
---
via: <https://opensource.com/article/21/9/centos-stream-foreman>
作者:[Melanie Corr](https://opensource.com/users/melanie-corr) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In December 2021, CentOS 8 will reach end of life and be replaced by CentOS Stream. One of the major changes between previous iterations of CentOS and CentOS Stream is the lack of minor versions. Centos Stream has adopted a continuous release cycle. From the beginning of this year, developers in the Foreman community started to see the benefits of earlier bug detection and patching that CentOS Stream offers as a result of the continuous releases. We no longer have to wait for the next release to take advantage of the latest changes and bugfixes. [A veteran Linux community enthusiast](https://twitter.com/Det_Conan_Kudo/status/1337366036023218177?s=20) noted that this move also brings RHEL developers closer than ever to the FOSS community.
However, if you are an administrator of hundreds or thousands of servers, you might want to exercise control over when new packages are added to particular servers. If you are looking for a free open source tool that helps you ensure stability of production servers, while at the same time allowing you to safely pull in the latest changes from Centos Stream for development and testing, this is where Foreman can help. With Foreman, you can manage your Centos Stream content at all stages of the lifecycle environment.
## What is Foreman?
Foreman is a complete lifecycle management tool for physical and virtual servers. With Foreman, system administrators have the power to easily automate repetitive tasks, quickly deploy applications, and proactively manage servers on-premise or in the cloud. Foreman provides enterprise-level solutions for provisioning management, configuration management, and monitoring. Thanks to its plugin architecture, Foreman can be extended in a myriad of ways. Using the Katello plugin, you can use Foreman as a complete content management tool to manage CentOS Stream, among many other content types.
With Foreman and Katello, you can define exactly which packages you want each environment to contain. For example, a Production environment might use packages that have been verified as stable, while a Developer environment might require the latest and greatest package versions available. You can also promote the content views across lifecycle environments. Let's take a look at how Foreman accomplishes this.
We reference the web UI in this article, but Foreman also has a robust CLI and API. The Katello plugin provides a workflow and web UI for the Pulp project, which you can read about more in [this article](https://opensource.com/article/20/8/manage-repositories-pulp). We also supply a simple workflow here, but Foreman and the Katello project offer many different configuration options to suit your specific needs.
This article assumes that Foreman and Katello are already installed. For more information about how to do that, see the [Katello installation manual](https://docs.theforeman.org/3.0/Installing_Server_on_Red_Hat/index-katello.html).
## Create a Product
The first step is to create a product in Foreman. The product functions as an internal label to store the CentOS Stream repositories.
- In the Foreman web UI, navigate to
**Content**>**Products**, and click**Create Product**. - In the
**Name**field, enter a name for the product. Foreman automatically completes the**Label**field based on what you have entered for**Name,**and this can't be changed later.
## Add the CentOS Stream repositories to the Product
Now that you have a product, you can use the URLs for the AppStream and BaseOS repositories and add them to your new product.
- In the Foreman web UI, navigate to
**Content**>**Products**, select the product you want to use, and then click**New Repository**. - In the
**Name**field, enter a name for the repository; for example,**Centos8StreamBaseOS**. Foreman automatically completes the**Label**field based on what you have entered for**Name**. - From the
**Type**list, select the type of repository, and then select**Yum**. - In the
**URL**field, enter the URL of the CentOS Stream Baseos repository to use as a source:[http://mirror.centos.org/centos/8-stream/BaseOS/x86_64/os/](http://mirror.centos.org/centos/8-stream/BaseOS/x86_64/os/) - Select the
**Download Policy**list. The default is**On Demand**- this means that Katello will only download metadata. If you want to download all the packages, change to**Immediate**, which downloads all the packages, which might run into 20-30 GB. - Ensure that the
**Mirror on Sync**check box is selected. This option ensures that content that is no longer part of the upstream repository is removed during synchronization. - Click
**Save**.
Repeat these steps to add the AppStream repositories with URLs, for example, [http://mirror.centos.org/centos/8-stream/AppStream/x86_64/os/](http://mirror.centos.org/centos/8-stream/AppStream/x86_64/os/). Ensure that you use the closest official CentOS mirror instead.
To perform an immediate synchronization, in your product window, click **Sync Now**. The initial synchronization can take some time. You can watch the synchronization status from **Content > Sync Status.**
After the synchronization completes, you can view the new CentOS Stream operating system in **Hosts > Operating System**. Feel free to edit the name and description to suit your requirements.
If you plan to use configuration management software like Ansible or Puppet, Foreman automatically creates an operating system report. You can turn this option off in **Administe > Settings > Ignore facts for operating system**. It is a good idea to rename the operating system to match the name in the configuration management software. For example, for Puppet, this would be *CentOS 8*.
## Define your infrastructure's Lifecycle Environment
The application life cycle is a concept central to Foreman's content management functions. The application life cycle defines how a particular system and its software look at a specific stage. For example, an application life cycle might be simple; you might only have a *development* stage and *production* stage. Foreman provides methods to customize each application life cycle stage in a controlled manner to suit your specifications.
At this point, you must create your lifecycle environment paths:
- In the Foreman web UI, navigate to
**Content**>**Lifecycle Environments**. - Click
**New Environment Path**to start a new application life cycle. - In the
**Name**field, enter a name for your environment. - In the
**Description**field, enter a description for your environment. - Click
**Save**. - Add as many environment paths as you need. For example, you can create
*dev*,*test,**stage,*and*production*environments. To add these environments, click**Add New Environment**, complete the**Name**and**Description**fields, and select the prior environment from the**Prior Environment**list so that you chain them together in the sequence you expect to use.
## Create and publish a Content View
In Foreman, a Content View is a snapshot of your repositories at a particular point in time. Content Views provide the mechanism for isolating package versions in a state that you want to preserve. Content Views have a lot of configurable features that you can use for further refinement. For the purposes of this tutorial, let's keep things simple.
- In the Foreman web UI, navigate to
**Content**>**Content Views**and click**Create New View**. - In the
**Name**field, enter a name for the view. Foreman automatically completes the**Label**field from the name you enter. - In the
**Description**field, enter a description of the view. - Click
**Save**to create the Content View. - In your new Content View, click
**Yum Content > Add Repositories**in the**Repository Selection**area, click**Add.**For both the BaseOS and Appstream repositories, select packages you want to include, then click**Add Repositories**. - Click
**Publish New Version**and in the**Description**field, enter information about the version to log changes. - Click
**Save**.
When you click **Publish New Version**, you create a snapshot of all the content that you have synchronized. This means that every server you subscribe to this Content View will have access only to the package versions in the Content View associated with this lifecycle environment.
Every new Content View and subsequent versions are published first to the Library environment, where you can then promote to additional environments.
## Promote content across lifecycle environments
If you have tested new packages and are satisfied that everything is stable, you can promote your Content View to another lifecycle environment.
- Navigate to
**Content**>**Content Views**and select the Content View that you want to promote. - Click the
**Versions**tab for the Content View. - Select the version you want to promote, and in the
**Actions**column, click**Promote**. - Select the environment where you want to promote the Content View and click
**Promote Version**. - Click the
**Promote**button again. This time select the lifecycle environment, for example,**Test**, and click**Promote Version**. - Finally, click on the
**Promote**button again. For example, select the**Production**environment and click**Promote Version**.
The servers that are assigned to that particular environment can now pull from an updated set of packages.
## Create an Activation Key
To register a CentOS Stream server to the content you have defined in a particular lifecycle, you must create an activation key. The activation key is a secure method of sharing credentials with a server. This uses a tool called **subscription-manager** to subscribe the CentOS Stream server to the content.
When you have created the activation key, add the CentOS Stream subscription to the activation key.
- In the Foreman web UI, navigate to
**Content > Activation keys**and click**Create Activation Key**. - In the
**Name**field, enter the name of the activation key. - In the
**Description**field, enter a description for the activation key. - From the
**Environment**list, select the environment to use. - From the
**Content View**list, select the Content View you created just now. - Click
**Save**.
## Create a CentOS Stream Host from Foreman managed content
Everything is now set up. With the content you have created contained in a content view, and promoted across lifecycles, you can now provision hosts with exactly the content you want to use and subscribe to the updates you want them to receive.
To create a host in Foreman, navigate to **Hosts > Create Host**.
- In the
**Name**field, enter a name for the host. - Click the
**Organization**and**Location**tabs to ensure that the provisioning context is automatically set to the current context. - From the
**Deploy On**list, select**Bare Metal**. - Click the
**Operating System**tab. - From the
**Architectures**list, select**x86_64**. - From the
**Operating System**list, select**CentOS_Stream 8.** - Check the
**Build Mode**box. - For
**Media Selection**, select**Synced Content**to use the CentOS Stream content you synced previously. - From the
**Synced****Content**list, ensure that CentOS Stream is selected. - From the
**Partition Table**list, for this demo, select**Kickstart**default, but there are many available options. - In the
**Root Password**field, enter a root password for your new host. - Click the
**Interface**tab, and click**Edit,**and add a**Mac address.** - Click the
**Parameters**tab, and ensure that a parameter exists that provides an activation key. If not, add an activation key. - Click
**Submit**to save the host entry.
Now the new host is in build mode, which means when you turn it on, it will begin installing the operating system.
If you navigate to **Hosts > Content Hosts,** you can see the full details of the subscriptions, lifecycle environment, and content view that your host is subscribed to.
This example is only a small glimpse into the many options you have to manage and provision CentOS Stream content in Foreman. If you want more detailed information about how you can manage CentOS Stream versions, control the content that your servers have access to, and control and protect the stability of your infrastructure, check out the [Foreman Content Management](https://docs.theforeman.org/master/Content_Management_Guide/index-foreman.html) documentation. With all CentOS Stream content under your control, you can create and register Centos Streams that consume only the content that you specify. For more detailed information on provisioning, see the [Foreman Provisioning](https://docs.theforeman.org/master/Provisioning_Guide/index-foreman.html) documentation. If you have any questions, feedback, or suggestions, you can find the Foreman community at [https://community.theforeman.org/](https://community.theforeman.org/)
## Comments are closed. |
13,839 | 在 Ubuntu Linux 上安装 AnyDesk | https://itsfoss.com/install-anydesk-ubuntu/ | 2021-10-01T16:58:03 | [
"AnyDesk"
] | https://linux.cn/article-13839-1.html |
>
> 这个初学者的教程讨论了在基于 Ubuntu 的 Linux 发行版上安装 AnyDesk 的 GUI 和终端方法。
>
>
>

[AnyDesk](https://anydesk.com/en) 是一个流行的远程桌面软件,可用于 Linux、Windows、BSD、macOS 和移动平台。
有了 AnyDesk,你可以用它远程访问其他电脑,或者让别人远程访问你的系统。不是每个人都可以访问它,因为需要两台设备都使用 AnyDesk。你必须接受传入的连接和/或提供一个安全连接的密码。
这对于向朋友、家人、同事甚至客户提供技术支持很有帮助。
在本教程中,我将向你展示在 Ubuntu 上安装 AnyDesk 的图形和命令行两种方法。你可以根据自己的喜好使用这两种方法。这两种方法都会在你的 Ubuntu 系统上安装相同的 AnyDesk 版本。
同样的方法应该适用于 Debian 和其他基于 Debian 和 Ubuntu 的发行版,如 Linux Mint,Linux Lite 等。
>
> **非 FOSS 警告!**
>
>
> AnyDesk 不是开源软件。这里涉及它是因为它在 Linux 上可用,而文章的重点是 Linux。
>
>
>
### 方法 1:使用终端在 Ubuntu 上安装 AnyDesk
在你的系统上 [打开终端程序](https://itsfoss.com/open-terminal-ubuntu/)。你需要一个像 `wget` 这样的工具来 [在终端下载文件](https://itsfoss.com/download-files-from-linux-terminal/),使用以下命令:
```
sudo apt update
sudo apt install wget
```
下一步是下载 AnyDesk 仓库的 GPG 密钥,并将其添加到你的系统的可信密钥中。这样,你的系统就会信任来自这个[外部仓库](https://itsfoss.com/adding-external-repositories-ubuntu/)的软件。
```
wget -qO - https://keys.anydesk.com/repos/DEB-GPG-KEY | sudo apt-key add -
```
你可以暂时忽略关于 `apt-key` 命令的废弃警告。下一步是将 AnyDesk 仓库添加到系统的仓库源中:
```
echo "deb http://deb.anydesk.com/ all main" | sudo tee /etc/apt/sources.list.d/anydesk-stable.list
```
更新包缓存,这样你的系统就能通过新添加的仓库了解到新应用的可用性。
```
sudo apt update
```
现在,你可以安装 AnyDesk 了:
```
sudo apt install anydesk
```
完成后,你可以从系统菜单或从终端本身启动 AnyDesk:
```
anydesk
```
你现在可以享受 AnyDesk 了。

### 方法 2:在 Ubuntu 上以图形方式安装 AnyDesk
如果你不习惯使用命令行,不用担心。你也可以不进入终端安装 AnyDesk。
你可以从 AnyDesk 官网下载 Ubuntu 上的 AnyDesk:
* [下载 Linux 上的 Anydesk](https://anydesk.com/en/downloads/linux)
你会看到一个“Download Now”的按钮。点击它。

当你点击下载按钮时,它会给你提供各种 Linux 发行版的选项。选择 Ubuntu 的那个:

它将下载 AnyDesk 的 DEB 文件。[安装 DEB 文件](https://itsfoss.com/install-deb-files-ubuntu/)很简单。要么双击它,要么右击并使用软件安装打开。

软件中心应用将被打开,你可以在那里安装它。

安装后,在系统菜单中搜索它并从那里开始。

这就好了。不是太难,是吗?
我不打算展示使用 AnyDesk 的步骤。我想你已经对这个问题有了一些了解。如果没有,请参考 [这篇文章](https://support.anydesk.com/Access)。
#### 故障排除提示
当我试图从系统菜单中运行 AnyDesk 时,它没有启动。于是,我从终端启动它,它显示了这个错误:
```
[email protected]:~$ anydesk
anydesk: error while loading shared libraries: libpangox-1.0.so.0: cannot open shared object file: No such file or directory
```
如果你看到 “[error while loading shared libraries](https://itsfoss.com/solve-open-shared-object-file-quick-tip/)” 信息,你要安装它所报错的软件包。在我的例子中,我是这样做的:
```
sudo apt install libpangox-1.0-0
```
这解决了我的问题,我希望它也能为你解决。
如果你有任何与此主题相关的问题,请在评论区告诉我。
---
via: <https://itsfoss.com/install-anydesk-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[AnyDesk](https://anydesk.com/en) is a popular remote desktop software for Linux, Windows, BSD, macOS, and mobile platforms.
With this tool, you can remotely access other computers using AnyDesk or let someone else remotely access your system. Not everyone can access it just because two devices use AnyDesk. You have to accept the incoming connection and provide a password for a secure connection.
This helps provide tech support to friends, family, colleagues, or even to customers.
In this tutorial, I’ll show graphical and command-line ways of installing AnyDesk on Ubuntu. You can use either method based on your preference. Both methods will install the same AnyDesk version on your Ubuntu system.
The same method should apply to Debian and other Debian and Ubuntu-based distributions such as Linux Mint, Linux Lite, etc.
**Non-FOSS Warning!**AnyDesk is not open source software. It is covered here because it is available on Linux and the article focuses on Linux.
## Method 1: Install AnyDesk on Ubuntu using terminal
[Open the terminal application](https://itsfoss.com/open-terminal-ubuntu/) on your system. You’ll need a tool like wget to [download files in the terminal. For th](https://itsfoss.com/download-files-from-linux-terminal/)at, use the following command:
```
sudo apt update
sudo apt install wget
```
The next step is to download the GPG key of the AnyDesk repository and add it to your system’s trusted keys. This way, your system will trust the software from this [external repository](https://itsfoss.com/adding-external-repositories-ubuntu/).
`wget -qO - https://keys.anydesk.com/repos/DEB-GPG-KEY | sudo apt-key add -`
You may ignore the [deprecated warning about the apt-key command](https://itsfoss.com/apt-key-deprecated/) for now. The next step is to add the AnyDesk repository to your system’s repository sources:
`echo "deb http://deb.anydesk.com/ all main" | sudo tee /etc/apt/sources.list.d/anydesk-stable.list`
Update the package cache so your system learns about the availability of new applications through the newly added repository.
`sudo apt update`
And now, you can install AnyDesk:
`sudo apt install anydesk`
Once that is done, you can start AnyDesk from the system menu or from the terminal itself:
`anydesk`
You can enjoy AnyDesk now.
## Method 2: Install AnyDesk on Ubuntu graphically
If you are not comfortable with the command line, no worries. You can also install AnyDesk without going into the terminal.
You can download AnyDesk for Ubuntu from the official AnyDesk website:
You’ll see a Download Now button. Click on it.

When you click on the download button, it gives you options for various Linux distributions. Select the one for Ubuntu:
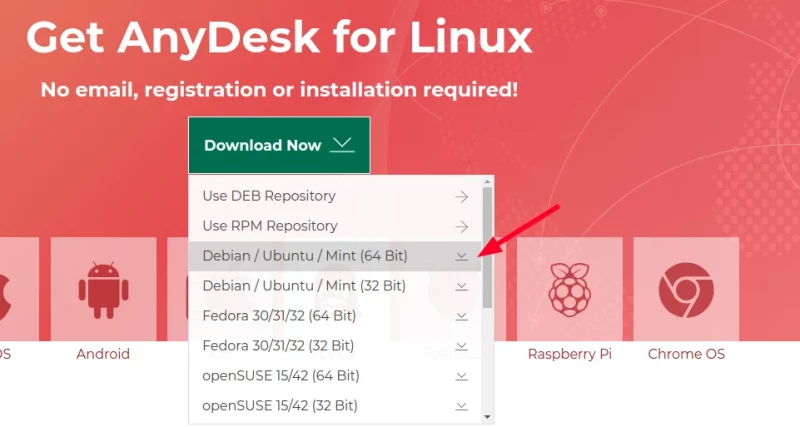
It will download the DEB file of the AnyDesk application. [Installing deb file](https://itsfoss.com/install-deb-files-ubuntu/) is easy. Either double-click on it or right-click and open it with Software Install.
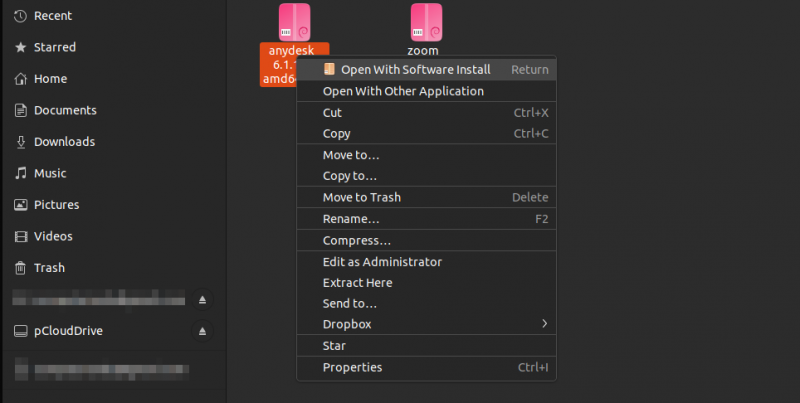
Software Center application will be opened and you can install it from there.
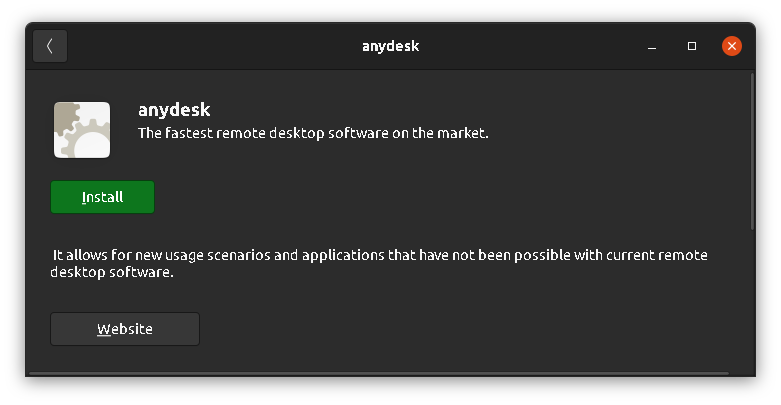
Once installed, search for it in the system menu and start from there.

That’s it. Not too hard, is it?
I am not going to show the steps for using AnyDesk. I think you already have some idea about that. If not, refer to [this article](https://support.anydesk.com/Access), please.
## Troubleshooting tip
When I tried to run AnyDesk from the system menu, it didn’t start. So, I started it from the terminal and it showed me this error:
```
abhishek@its-foss:~$ anydesk
anydesk: error while loading shared libraries: libpangox-1.0.so.0: cannot open shared object file: No such file or directory
```
If you see the [error while loading shared libraries](https://itsfoss.com/solve-open-shared-object-file-quick-tip/) message, you install the package it is complaining about. Here’s what I did in my case:
`sudo apt install libpangox-1.0-0`
That solved the issue for me and I hope it works for you also.
Please let me know in the comment section if you have any questions about this topic. |
13,840 | 如何在 Linux 上使用 BusyBox | https://opensource.com/article/21/8/what-busybox | 2021-10-01T18:52:00 | [
"BusyBox"
] | https://linux.cn/article-13840-1.html |
>
> BusyBox 是一个开源(GPL)项目,提供了近 400 个常用命令的简单实现。
>
>
>

我们很容易认为 Linux 的命令是理所当然的。当你安装 Linux 时,它们与系统捆绑在一起,而我们常常不问为什么它们会在那里。一些基本的命令,如 [cd](https://opensource.com/article/21/8/navigate-linux-directories)、[kill](https://opensource.com/article/18/5/how-kill-process-stop-program-linux) 和 echo,并不总是独立的应用程序,而是实际上内置于你的 shell 中。其他如 [ls](https://opensource.com/article/19/7/master-ls-command)、[mv](https://opensource.com/article/19/8/moving-files-linux-depth) 和 [cat](https://opensource.com/article/19/2/getting-started-cat-command) 是核心工具包(通常是 GNU `coreutils`)的一部分。但在开源的世界里,总是有一些替代品,其中最有趣的是 [BusyBox](https://www.busybox.net)。
### Linux 中的 BusyBox 简介
BusyBox 是一个开源(GPL)项目,提供近 400 个常用命令的简单实现,包括 `ls`、`mv`、`ln`、`mkdir`、`more`、`ps`、`gzip`、`bzip2`、`tar` 和 `grep`。它还包含了编程语言 `awk`、流编辑器 `sed`、文件系统检查工具 `fsck`、`rpm` 和 `dpkg` 软件包管理器,当然还有一个可以方便的访问所有这些命令的 shell(`sh`)。简而言之,它包含了所有 POSIX 系统需要的基本命令,以执行常见的系统维护任务以及许多用户和管理任务。
事实上,它甚至包含一个 `init` 命令,可以作为 PID 1 启动,以作为所有其它系统服务的父进程。换句话说,BusyBox 可以作为 [systemd](https://opensource.com/article/20/4/systemd)、OpenRC、sinit、init 和其他初始化系统的替代品。
BusyBox 非常小。作为一个可执行文件,它不到 1MB,所以它在 [嵌入式](https://opensource.com/article/21/3/rtos-embedded-development)、[边缘计算](https://opensource.com/article/17/9/what-edge-computing) 和 [物联网](https://opensource.com/article/21/3/iot-measure-raspberry-pi) 领域很受欢迎,因为这些场景的存储空间是很宝贵的。在容器和云计算的世界里,它作为精简的 Linux 容器镜像的基础镜像也很受欢迎。
### 极简主义
BusyBox 的部分魅力在于它的极简主义。它的所有命令都被编译到一个二进制文件里(`busybox`),它的手册只有 81 页(根据我对 `man` 送到 `pr` 管道的计算),但它涵盖了近 400 条命令。
作为一个例子的比较,这是 “原版” 的 `useradd —help` 的输出:
```
-b, --base-dir BASE_DIR base directory for home
-c, --comment COMMENT GECOS field of the new account
-d, --home-dir HOME_DIR home directory of the new account
-D, --defaults print or change the default config
-e, --expiredate EXPIRE_DATE expiration date of the new account
-f, --inactive INACTIVE password inactivity
-g, --gid GROUP name or ID of the primary group
-G, --groups GROUPS list of supplementary groups
-h, --help display this help message and exit
-k, --skel SKEL_DIR alternative skeleton dir
-K, --key KEY=VALUE override /etc/login.defs
-l, --no-log-init do not add the user to the lastlog
-m, --create-home create the user's home directory
-M, --no-create-home do not create the user's home directory
-N, --no-user-group do not create a group with the user's name
-o, --non-unique allow users with non-unique UIDs
-p, --password PASSWORD encrypted password of the new account
-r, --system create a system account
-R, --root CHROOT_DIR directory to chroot into
-s, --shell SHELL login shell of the new account
-u, --uid UID user ID of the new account
-U, --user-group create a group with the same name as a user
```
而这是是同一命令的 BusyBox 版本:
```
-h DIR Home directory
-g GECOS GECOS field
-s SHELL Login shell
-G GRP Group
-S Create a system user
-D Don't assign a password
-H Don't create home directory
-u UID User id
-k SKEL Skeleton directory (/etc/skel)
```
这种差异是一种特性还是一种限制,取决于你是喜欢你的命令拥有 20 个选项还是 10 个选项。对于一些用户和某些用例来说,BusyBox 的极简主义刚刚满足所需。对于其他人来说,它是一个很好的最小化环境,可以作为一个后备工具,或者作为安装更强大的工具的基础,比如 [Bash](https://opensource.com/article/20/4/bash-sysadmins-ebook)、[Zsh](https://opensource.com/article/19/9/getting-started-zsh)、GNU [Awk](https://opensource.com/article/20/9/awk-ebook) 等等。
### 安装 BusyBox
在 Linux 上,你可以使用你的软件包管理器安装 BusyBox。例如,在 Fedora 及类似发行版:
```
$ sudo dnf install busybox
```
在 Debian 及其衍生版:
```
$ sudo apt install busybox
```
在 MacOS 上,可以使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac)。在 Windows 上,可以使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey)。
你可以将 BusyBox 设置为你的 shell,使用 `chsh —shell` 命令,然后再加上 BusyBox `sh` 应用程序的路径。我把 BusyBox 放在 `/lib64` 中,但它的位置取决于你的发行版的安装位置。
```
$ which busybox
/lib64/busybox/busybox
$ chsh --shell /lib64/busybox/sh
```
用 BusyBox 全盘替换所有常见的命令要复杂一些,因为大多数发行版都是“硬接线”,会在特定的软件包寻找特定的命令。换句话说,虽然技术上可以用 BusyBox 的 `init` 替换系统的 `init`,但你的软件包管理器可能会拒绝让你删除包含 `init` 的软件包,以免你担心删除会导致系统无法启动。有一些发行版是建立在 BusyBox 之上的,所以从新环境开始可能是体验 BusyBox 系统的最简单方法。
### 试试 BusyBox
你不必为了尝试 BusyBox 而将你的 shell 永久改为 BusyBox。你可以从你当前的 shell 中启动一个 BusyBox shell。
```
$ busybox sh
~ $
```
不过你的系统仍然有安装的非 BusyBox 版本的命令,所以要体验 BusyBox 的工具,你必须把命令作为参数发给 `busybox` 可执行文件:
```
~ $ busybox echo $0
sh
~ $ busybox ls --help
BusyBox vX.YY.Z (2021-08-25 07:31:48 NZST) multi-call binary.
Usage: ls [-1AaCxdLHRFplinshrSXvctu] [-w WIDTH] [FILE]...
List directory contents
-1 One column output
-a Include entries that start with .
-A Like -a, but exclude . and ..
-x List by lines
[...]
```
为了获得“完整”的 BusyBox 体验,你可以为每个命令创建一个 `busybox` 的符号链接。这很容易,只要你使用 [for 循环](https://opensource.com/article/19/10/programming-bash-loops) 就行:
```
$ mkdir bbx
$ for i in $(bbx --list); do \
ln -s /path/to/busybox bbx/$i \
done
```
在你的 [路径](https://opensource.com/article/17/6/set-path-linux) 的 *开头* 添加这个符号链接目录,并启动 BusyBox:
```
$ PATH=$(pwd)/bbx:$PATH bbx/sh
```
### 用起来
BusyBox 是一个有趣的项目,也是一个可以实现 *极简* 计算的例子。无论你是把 BusyBox 作为 [你唤醒的](https://opensource.com/article/19/7/how-make-old-computer-useful-again) [古老的计算机](https://opensource.com/article/20/2/restore-old-computer-linux) 的轻量级环境,还是作为 [嵌入式设备](https://opensource.com/article/20/6/open-source-rtos) 的用户界面,抑或试用一个新的初始化系统,就算是为了好奇,让自己重新认识那些熟悉而又陌生的命令,都会很有意思。
---
via: <https://opensource.com/article/21/8/what-busybox>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It's easy to take Linux commands for granted. They come bundled with the system when you install Linux, and we often don't question why they're there. Some of the basic commands, such as [ cd](https://opensource.com/article/21/8/navigate-linux-directories),
[, and](https://opensource.com/article/18/5/how-kill-process-stop-program-linux)
`kill`
`echo`
aren't always independent applications but are actually built into your shell. Others, such as [,](https://opensource.com/article/19/7/master-ls-command)
`ls`
[, and](https://opensource.com/article/19/8/moving-files-linux-depth)
`mv`
[are part of a core utility package (often GNU](https://opensource.com/article/19/2/getting-started-cat-command)
`cat`
`coreutils`
specifically). But there are always alternatives in the world of open source, and one of the most interesting is [BusyBox](https://www.busybox.net).
## What is BusyBox in Linux?
BusyBox is an open source (GPL) project providing simple implementations of nearly 400 common commands, including `ls`
, `mv`
, `ln`
, `mkdir`
, `more`
, `ps`
, `gzip`
, `bzip2`
, `tar`
, and `grep`
. It also contains a version of the programming language `awk`
, the stream editor `sed`
, the filesystem checker `fsck`
, the `rpm`
and `dpkg`
package managers, and of course, a shell (`sh`
) that provides easy access to all of these commands. In short, it contains all the essential commands required for a POSIX system to perform common system maintenance tasks as well as many user and administrative tasks.
In fact, it even contains an `init`
command which can be launched as PID 1 to serve as the parent process for all other system services. In other words, BusyBox can be used as an alternative to [systemd](https://opensource.com/article/20/4/systemd), OpenRC, sinit, init, and other launch daemons.
BusyBox is very small. As an executable, it's under 1 MB, so it has gained much of its popularity in the [embedded](https://opensource.com/article/21/3/rtos-embedded-development), [Edge](https://opensource.com/article/17/9/what-edge-computing), and [IoT](https://opensource.com/article/21/3/iot-measure-raspberry-pi) space, where drive space is at a premium. In the world of containers and cloud computing, it's also popular as a foundation for minimal Linux container images.
## Minimalism
Part of the appeal of BusyBox is its minimalism. All of its commands are compiled into a single binary (`busybox`
), and its man page is a mere 81 pages (by my calculation of piping `man`
to `pr`
) but covers nearly 400 commands.
As an example comparison, here's the output of the `shadow`
version of `useradd --help`
:
```
-b, --base-dir BASE_DIR base directory for home
-c, --comment COMMENT GECOS field of the new account
-d, --home-dir HOME_DIR home directory of the new account
-D, --defaults print or change the default config
-e, --expiredate EXPIRE_DATE expiration date of the new account
-f, --inactive INACTIVE password inactivity
-g, --gid GROUP name or ID of the primary group
-G, --groups GROUPS list of supplementary groups
-h, --help display this help message and exit
-k, --skel SKEL_DIR alternative skeleton dir
-K, --key KEY=VALUE override /etc/login.defs
-l, --no-log-init do not add the user to the lastlog
-m, --create-home create the user's home directory
-M, --no-create-home do not create the user's home directory
-N, --no-user-group do not create a group with the user's name
-o, --non-unique allow users with non-unique UIDs
-p, --password PASSWORD encrypted password of the new account
-r, --system create a system account
-R, --root CHROOT_DIR directory to chroot into
-s, --shell SHELL login shell of the new account
-u, --uid UID user ID of the new account
-U, --user-group create a group with the same name as a user
```
And here's the BusyBox version of the same command:
```
-h DIR Home directory
-g GECOS GECOS field
-s SHELL Login shell
-G GRP Group
-S Create a system user
-D Don't assign a password
-H Don't create home directory
-u UID User id
-k SKEL Skeleton directory (/etc/skel)
```
Whether or not this difference is a feature or a limitation depends on whether you prefer to have 20 options or ten options in your commands. For some users and use-cases, BusyBox's minimalism provides just enough for what needs to be done. For others, it's a good minimal environment to have as a fallback or as a foundation for installing more robust tools like [Bash](https://opensource.com/article/20/4/bash-sysadmins-ebook), [Zsh](https://opensource.com/article/19/9/getting-started-zsh), GNU [Awk](https://opensource.com/article/20/9/awk-ebook), and so on.
## Installing BusyBox
On Linux, you can install BusyBox using your package manager. For example, on Fedora and similar:
`$ sudo dnf install busybox`
On Debian and derivatives:
`$ sudo apt install busybox`
On macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac). On Windows, use [Chocolatey](https://opensource.com/article/20/3/chocolatey).
You can set BusyBox as your shell using the `chsh --shell`
command, followed by the path to the BusyBox `sh`
application. I keep BusyBox in `/lib64`
, but its location depends on where your distribution installed it.
```
$ which busybox
/lib64/busybox/busybox
$ chsh --shell /lib64/busybox/sh
```
Replacing all common commands wholesale with BusyBox is a little more complex, because most distributions are "hard-wired" to look to specific packages for specific commands. In other words, while it's technically possible to replace `init`
with BusyBox's `init`
, your package manager may refuse to allow you to remove the package containing `init`
for fear of you causing your system to become non-bootable. There are some distributions built upon BusyBox, so starting fresh is probably the easiest way to experience a system built around BusyBox.
## Try BusyBox
You don't have to change your shell to BusyBox permanently just to try it. You can launch a BusyBox shell from your current shell:
```
$ busybox sh
~ $
```
Your system still has the non-BusyBox versions of commands installed, though, so to experience BusyBox's tools, you must issue commands as arguments to the `busybox`
executable:
```
~ $ busybox echo $0
sh
~ $ busybox ls --help
BusyBox vX.YY.Z (2021-08-25 07:31:48 NZST) multi-call binary.
Usage: ls [-1AaCxdLHRFplinshrSXvctu] [-w WIDTH] [FILE]...
List directory contents
-1 One column output
-a Include entries that start with .
-A Like -a, but exclude . and ..
-x List by lines
[...]
```
For the "full" BusyBox experience, you can create symlinks to `busybox`
for each command. This is easier than it sounds, as long as you use a [for-loop](https://opensource.com/article/19/10/programming-bash-loops):
```
$ mkdir bbx
$ for i in $(bbx --list); do \
ln -s /path/to/busybox bbx/$i \
done
```
Add your directory of symlinks at the *start* of your [path](https://opensource.com/article/17/6/set-path-linux), and launch BusyBox:
`$ PATH=$(pwd)/bbx:$PATH bbx/sh`
## Get busy
BusyBox is a fun project and an example of just how *minimal* computing can be. Whether you use BusyBox as a lightweight environment for an [ancient computer](https://opensource.com/article/20/2/restore-old-computer-linux) [you've rescued](https://opensource.com/article/19/7/how-make-old-computer-useful-again), as the userland for an [embedded device](https://opensource.com/article/20/6/open-source-rtos), to trial a new init system, or just as a curiosity, it can be fun reacquainting yourself with old familiar, yet somehow new, commands.
## Comments are closed. |
13,842 | 让 YAML 变得像它看起来一样简单 | https://opensource.com/article/21/9/yaml-cheat-sheet | 2021-10-02T10:18:31 | [
"YAML"
] | https://linux.cn/article-13842-1.html |
>
> YAML 看起来很简单,为什么它这么难写呢?了解成功使用 YAML 的两个秘诀。
>
>
>

如果你曾经尝试过写 YAML,你可能一开始会对它看起来很容易感到高兴。乍一看,经常用于配置文件、Ansible 剧本和普通文件数据库的 YAML 看起来就像购物清单一样直观。然而,YAML 的结构中有很多细微的差别,它隐藏着一个危险的秘密:YAML 实际上是一种高度精确、结构化和令人惊讶的严格语言。好消息是,你只需要了解两件事就可以知道 YAML 的工作原理。
关于 YAML 的真相是,YAML 中只有两种数据结构:<ruby> 序列 <rt> sequence </rt></ruby>和<ruby> 映射 <rt> mapping </rt></ruby>。这是两个花哨的名字,你会发现它代表了你非常熟悉的概念。这篇文章解释了这两种结构,更重要的是,介绍了它们是如何协同工作,使 YAML 成为表示你所关心的数据的强大方式。
### YAML 序列
YAML 序列是一个列表。在其最简单的形式中,每行有一个项目,每行以破折号和空格开始。
下面是一个例子:
```
---
- Linux
- BSD
- Illumos
```
不同的语言有不同的方式来表示这种数据。例如,在 Python 中,同一个列表可以写成 `['Linux', 'BSD', 'Illumos']`。当你在现实生活中写一个列表时,例如在你去买菜之前,你写的可能近似于 YAML 序列。
### YAML 映射
YAML 映射是一个关键术语与该术语的定义相结合。在其他语言中,映射被称为“键值对”或“词典”。
这里有一个例子:
```
---
Kernel: Linux
CPU: AMD
RAM: '16 GB'
```
不同的语言有不同的方式来表示这种数据。[在 Python 中](https://opensource.com/article/21/3/dictionary-values-python),例如,同样的数据可以写成 `{"Kernel": "Linux", "CPU": "AMD", "RAM": "16 GB"}`。在现实生活中,你可能会使用这种结构来计划,例如,与朋友的游戏之夜。一个朋友报名带零食,另一个报名带一副牌,另一个报名带一个棋盘游戏,等等。
### 组合序列和映射
你现在知道 YAML 的语法了。序列和映射是 YAML 中仅有的两种构件,你想在 YAML 中表示的任何东西都可以放在序列或映射中。
或者同时使用这二者!
是的,序列和映射可以被组合和嵌套,这就是 YAML 看起来很直观,但同时又感觉很复杂的原因之一。不过,只有四种可能的组合,一旦你学会如何看它们,YAML 就会觉得像它看起来一样简单。
### 序列的映射
当你想让一个键项有许多值时,你可以使用一个序列的映射。也就是说,你从一个映射(键)开始,但是给值一个列表:
```
---
Linux:
- Fedora
- Slackware
BSD:
- FreeBSD
- NetBSD
```
在这个示例代码中,`Linux` 是第一个键,它的值是一个序列,其中包含 `Fedora` 和 `Slackware`。第二个键是 `BSD`,它的值是一个序列,包含 `FreeBSD` 和 `NetBSD`。
### 映射的映射
当你想让一个键项的值中既有键又有值时,你可以使用映射的映射。也就是说,你从一个映射(键)开始,但是给值另一个映射。
这可能有点欺骗性,但它揭示了 YAML 中使用特定术语的原因:因为你只不过是创建了一个映射的列表,并不意味着你创建了一个序列。这里是一个映射的映射:
```
---
Desktop:
CPU: RISC-V
RAM: '32 GB'
Laptop:
CPU: AMD
RAM: '16 GB'
```
对大多数人来说,这看起来像一个列表。而且从技术上讲,它是一个列表。但重要的是要认识到,它不是 YAML 序列。它是一个映射,其中包含映射。作为半个 YAML 专家,你可以从明显缺少破折号的地方看出区别。
在 Ansible 剧本的所有结构中,我发现这个结构最容易欺骗人。作为人类,我们喜欢列表,当我们看到一个数据结构 *在字面上* 是列表时,大多数人会把它当成 YAML 序列。但是在 YAML 中,虽然序列是列表,但是列表并不总是序列。
### 序列的序列
就像你可以嵌套映射一样,你可以将一个序列嵌套到一个序列中:
```
---
- [Linux, FreeBSD, Illumos]
- [YAML, XML, JSON]
```
这可能是我在 YAML 的实际使用中遇到的最不常见的数据结构,但有时你需要一个列表的列表。
### 映射的序列
你也可以创建一个包含映射的序列。对于人类排序数据的方式来说,这并不太常见,但对于计算机来说,这可能是一个重要的结构。
这里有一个例子:
```
---
-
CPU: AMD
RAM: '16 GB'
-
CPU: Intel
RAM: '16 GB'
```
对于 YAML,这可能是最不直观的语法。我发现它在 Python 中呈现时更清晰:
```
[{"CPU": "AMD", "RAM": "16 GB"}, {"CPU": "Intel", "RAM": "16 GB"}]
```
方括号代表一个列表结构,这个列表包含两个字典。每个字典都包含键值对。
### 构建更好的 YAML
现在你知道了 YAML 的两个组成部分,以及它们如何被组合起来以表示复杂的数据结构。问题是:你要用 YAML 构建什么?
和很多人一样,我也使用 YAML 来编写 Ansible 剧本。我还用它作为一种简单的配置格式、作为 D&D 的角色表、表示项目组织所需的目录结构,等等。只要你能适应序列和映射的概念,你会发现 YAML 是一种很容易编写、阅读和(如果有合适的库)解析的格式。
如果你发现自己经常使用 YAML,请下载我们的 [YAML 速查表](https://opensource.com/downloads/yaml-cheat-sheet),以帮助你直观地了解基本数据结构及其组合,并帮助你记住一些额外的语法约定。通过一点点的练习,你会发现 YAML 真的和它看起来一样简单!
---
via: <https://opensource.com/article/21/9/yaml-cheat-sheet>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you've ever tried writing YAML, you may have been initially pleased with how apparently easy it looks. At first glance, the YAML that's often used for configuration files, Ansible playbooks, and flat-file databases looks more or less as intuitive as a shopping list. However, there's a lot of nuance in YAML's structure, and it conceals a dangerous secret: YAML is actually a highly precise, structured, and surprisingly strict language. The good news is that you only need to understand two things to know how YAML works.
The truth about YAML is that there are only two data structures in YAML: sequences and mappings. Those are two fancy names to represent what you'll discover are very familiar concepts. This article explains them both, and more importantly, how they work together to make YAML a powerful way to represent the data you care about.
## What's a YAML sequence?
A YAML sequence is a list. In its simplest form, there's one item per line, with each line beginning in a dash and a space.
Here's an example:
```
``````
---
- Linux
- BSD
- Illumos
```
Different languages have different ways of representing this kind of data. In Python, for example, the same list can be written as `['Linux', 'BSD', 'Illumos']`
. When you write a list in real life, for instance before you go shopping for groceries, you probably approximate a YAML sequence.
## What's a YAML mapping?
A YAML mapping is a key term combined with a definition for that term. A mapping in other languages is called a *key and value pair* or a *dictionary*.
Here's an example:
```
``````
---
Kernel: Linux
CPU: AMD
RAM: '16 GB'
```
Different languages have different ways of representing this kind of data. [In Python](https://opensource.com/article/21/3/dictionary-values-python), for example, the same data can be written as `{"Kernel": "Linux", "CPU": "AMD", "RAM": "16 GB"}`
. In real life, you might use this kind of structure to plan, for instance, a game night with friends. One friend signs up to bring snacks, another signs up to bring a deck of cards, another a board game, and so on.
## Combining sequences and mappings
You now know the syntax of YAML. Sequences and mappings are the only two kinds of building blocks available in YAML, and anything you want to represent in YAML can be placed into either a sequence or a mapping.
Or both!
Yes, sequences and mappings can be combined and nested, which is one reason YAML often looks intuitive and yet feels complex all at once. There are only four possible combinations, though, and once you learn to see them, YAML starts to feel as easy as it looks.
## Mapping sequences
When you want one key term to have many values, you use a mapping of sequences. That is, you start with a mapping (keys), but you insert a list for the values:
```
``````
---
Linux:
- Fedora
- Slackware
BSD:
- FreeBSD
- NetBSD
```
In this sample code, **Linux** is the first key, and its value is a sequence, which contains **Fedora** and **Slackware**. The second key is **BSD**, which has a value of a sequence containing **FreeBSD **and **NetBSD**.
## Mapping of mappings
When you want one key term to have values that themselves have both keys and values, you use a mapping of mappings. That is, you start with a mapping (keys), but you insert another mapping for the values.
This one can be deceptive, but it reveals why special terminology is used in YAML: just because you create a list of mappings doesn't mean you've created a *sequence*. Here's a mapping of mappings:
```
``````
---
Desktop:
CPU: RISC-V
RAM: '32 GB'
Laptop:
CPU: AMD
RAM: '16 GB'
```
To most people, that looks like a list. And technically, it is a list. But it's important to recognize that it is *not* a YAML sequence. It's a mapping, which contains mappings. Being a near-expert in YAML, you can spot the difference from the distinct lack of dashes.
Of all the constructs in Ansible playbooks, I find that this one tricks people the most. As humans, we like lists, and when we see a data structure that* is literally* a list, most people are compelled to translate that into a YAML sequence. But in YAML, although a sequence is a list, a list is not always a sequence.
## Sequence of sequences
Just as you can nest mappings, you can nest a sequence into a sequence:
```
``````
---
- [Linux, FreeBSD, Illumos]
- [YAML, XML, JSON]
```
This is probably the least common data structure I encounter in real-world uses of YAML, but sometimes you need a list of lists.
## Sequence of mappings
You can also create a sequence that contains mappings. This isn't terribly common for the way humans sort data, but for computers it can be an important construct.
Here's an example:
```
``````
---
-
CPU: AMD
RAM: '16 GB'
-
CPU: Intel
RAM: '16 GB'
```
As YAML, this is possibly the least intuitive syntax. I find it clearer when rendered in Python:
```
````[{"CPU": "AMD", "RAM": "16 GB"}, {"CPU": "Intel", "RAM": "16 GB"}]`
The square brackets represent a list structure, and the list contains two dictionaries. Each dictionary contains key and value pairs.
## Build better YAML
Now you know the two components of YAML, and how they can be combined to represent complex data structures. The question is: what will you build with YAML?
I use YAML, as many people do, for Ansible playbooks. I've also used it as an easy configuration format, as a character sheet for D&D, as a representation of a directory structure required for project organization, and much more. As long as you get comfortable with the concepts of sequences and mappings, you might find YAML an easy format to write, read, and (provided the right library) to parse.
If you're finding yourself working with YAML often, download our ** YAML cheat sheet** to help you visualize the basic data structures and their combinations and to help you remember some of the extra syntactical conventions available to you. With a little bit of practice, you'll find YAML really is as easy as it looks!
## Comments are closed. |
13,843 | Arch Linux 软件包制作入门 | https://itsfoss.com/create-pkgbuild/ | 2021-10-02T13:07:09 | [
"Arch",
"PKGBUILD"
] | https://linux.cn/article-13843-1.html | 
`PKGBUILD` 文件是为 Arch Linux 及其衍生版(如 Manjaro)构建和创建软件包的方式。
如果你曾经使用过 [AUR](https://itsfoss.com/aur-arch-linux/)(即 Arch Linux 的用户维护的 `PKGBUILD` 存储库),你甚至可能也遇到过它们。
但是,到底是如何从 `PKGBUILD` 到可安装软件包的呢?这两者之间到底发生了什么,如何把自己的软件制作成软件包呢?你将在这篇文章中了解这些。
### PKGBUILD 基础知识
对于那些熟悉 Bash 或其他 shell 的人来说,你可能知道,`PKGBUILD` 就是一个带有一些变量的 shell 脚本。
`PKGBUILD` 文件由变量和函数组成,所有这些都是用来定义软件包本身,以及如何构建它。
为了从 `PKGBUILD` 中创建一个软件包,需要使用 `makepkg` 命令行工具。在获得 `PKGBUILD` 文件后,你只需在包含 `PKGBUILD` 的目录中运行 `makepkg',就可以得到一个可安装的软件包了。

在本教程中,你将会看到我刚刚制作的软件包,它在运行时打印出 “Hello World!”。

### 准备
为了继续学习本教程,你需要创建几个文件。
首先,你需要创建一个名为 `PKGBUILD` 的文件,它将作为构建你的软件包的“配方”。
你需要做的另一个文件是一个叫 `hello-world.sh` 的文件。我稍后会解释它的用途。
你也可以用一个命令来创建这两个文件:
```
touch PKGBUILD hello-world.sh
```
你可以用 `ls` 命令检查这些文件是否被创建。

然后你就可以开始了!
### 设置你的 PKGBUILD 文件
我不会让你复制粘贴整个文件,而是和你一起键入每一行,这样你就能更好地理解每一行的目的。如果你不喜欢这种学习方式,我强烈推荐 [Arch 维基](https://wiki.archlinux.org/title/Creating_packages) 中为 Arch Linux 创建软件包的文章。
这篇文章也没有介绍 `PKGBUILD` 中可以设置的每一个选项,只是介绍了一些常用的选项,以便你能尽快上手。
说完了这些,打开你的文本编辑器,让我们直接进入正题吧。
#### pkgname
首先是 `pkgname` 变量。这是安装时定义软件包名称的东西,也是 [Arch Linux 的软件包管理器 pacman](https://itsfoss.com/pacman-command/) 跟踪软件包的方式。
这个变量(以及其他一些变量)的格式是 `variable=value`,变量名在左边,变量的值在右边,用等号隔开。
要设置包的名称,请在 `PKGBUILD` 中输入以下内容:
```
pkgname="hello-world"
```
* 要设置一个不同的软件包名称,用你的软件包的名称替换 `hello-world`。
* 这并不设置用于运行程序的命令,这将在下面的 `package()` 部分中处理。
#### pkgver
正如变量名称本身所述,它设置了你的软件包的版本(即 `1.0.0`)。这在用户更新他们的系统时很有用,因为设置更高的版本会提示用户升级。
要设置版本号,请在 `PKGBUILD` 中输入以下内容(在前一行之后):
```
pkgver="1.0.0"
```
#### pkgrel
这与 `pkgver` 变量有关,通常不需要知道。不过和 `pkgver` 变量一样,如果它被换到一个更高的数字,就将通知用户进行升级。
它适用于任何需要保持 `pkgver` 不变的情况下,例如 `PKGBUILD` 本身发生了变化。如果你为一个你使用的程序创建了一个 `PKGBUILD`(并希望保持软件包的版本相同),而你需要修复 `PKGBUILD` 本身的一个错误,这将是非常有用的。
要设置这个变量,请在 `PKGBUILD` 中输入以下内容:
```
pkgver="1"
```
这个变量应该 **总是** 从 `1` 开始,然后一次一次地向上移动。当 `pkgver` 本身向上移动时,这个变量可以(也应该)重置为 `1`,因为 `pkgver` 本身会通知用户升级。
#### pkgdesc
这将设置软件包的描述,用于帮助更好地识别该软件包。
要设置它,只需将描述放在引号内:
```
pkgdesc="Hello world in your terminal!"
```
#### arch
这个变量设置软件包所兼容的 [硬件架构](https://www.quora.com/What-is-CPU-architecture)。如果你不明白什么是架构,那也没关系,因为在大多数情况下,这个变量几乎是无用的。
无论如何,`makepkg` 仍然需要设置它,这样它就知道这个软件包与我们的系统是兼容的。
这个变量支持设置多个值,所以 `makepkg` 需要一个不同的语法,如下所示。
要设置它,请在 `PKGBUILD` 中输入以下内容:
```
arch=("x86_64")
```
如果你要设置多个值,需要用空格和引号分隔每个值,像这样。`arch=(“x86_x64" "arm")`。
#### depends
这列出了提供了我们的软件包所需功能的所有软件包。与 `arch` 一样,它也可以包含多个值,因此必须使用括号语法。
由于我们的软件包没有任何依赖关系,所以我们不需要在 `PKGBUILD` 中输入这个字段。然而,如果我们的软件包有依赖关系,我们就会使用与 `arch` 相同的语法。
#### optdepends
这里列出了那些并不是提供所需功能而是额外功能的软件包。
这与 `depends` 的语法相同。
#### conflicts
这告诉 `pacman` 哪些软件包会导致我们的软件包出现问题,或者以我们不希望的方式行事。
这里列出的任何软件包都会在我们的软件包被安装之前被卸载。
这与 `depends` 的语法相同。
#### license
这定义了你的程序所采用的 [软件许可证](https://en.wikipedia.org/wiki/Software_license)。如果你需要帮助你选择一个许可证,[Arch 维基](https://wiki.archlinux.org/title/PKGBUILD#license) 提供了一些信息。如果你不知道该怎么设置,将其设置为 `custom` 也可以。
这与 `arch` 和 `depends` 的语法相同:
```
license=("custom")
```
#### source
这就是 `makepkg` 如何知道要用什么文件来构建我们的软件包。它可以包含各种不同类型的源,包括本地文件和 URL。
在添加本地文件时,要输入相对于 `PKGBUILD` 文件的文件路径,比如以下目录布局:
```
PKGBUILD
file.txt
src/file.sh
```
如果你想在我们的 `PKGBUILD` 中包括 `file.sh`,你需要输入 `src/file.sh` 作为其名称。
当输入 URL 时,你只需输入完整的 URL,即 `https://mirrors.creativecommons.org/presskit/logos/cc.logo.large.png`。
你的这个软件包只需要 `hello-world.sh` 文件,由于它和 `PKGBUILD` 在同一个目录中,你只需输入它的名字作为 `source` 的值。
这个变量也使用与 `arch` 和 `depends` 相同的语法:
```
source=("hello-world.sh")
```
#### sha512sums
这是用来验证 `source` 中的文件没有被修改或下载错误。如何获得这个值的信息可以在 [Arch 维基关于 PKGBUILD 的文章](https://wiki.archlinux.org/title/PKGBUILD#Integrity) 中找到。
如果你宁愿不设置这个(或者你只是不需要,例如对于本地文件),你可以为 `source` 变量中的每个文件输入 `SKIP`:
```
sha512sums=("SKIP")
```
#### package()
这是最后一个,也是实际制作我们的包的最重要的部分。在处理这个问题时,知道两个变量很重要。
* `${srcdir}`:这是 `makepkg` 放置 `source` 变量中文件的地方。在这个目录中,你可以与这些文件进行交互,并对文件进行任何其他需要的修改。
* `${pkgdir}`:这是我们放置将被安装在系统中的文件的地方。 `${pkgdir}` 的文件夹结构是按照实际系统中的情况设置的(例如,使用 `pacman` 安装时,`${pkgdir}/usr/bin/hello-world` 会创建文件 `/usr/bin/hello-world`)。
`package()` 包含一个用于创建软件包的命令列表。
因此,如果(假设)你需要有个在 `/usr/share/motto.txt` 写着 “Linux is superior to Windows ”的文件,你会运行这样的东西:
```
package() {
mkdir -p "${pkgdir}/usr/share"
echo "Linux is superior to Windows" | tee "${pkgdir}/usr/share/motto.txt"
}
```
关于上述命令的一些说明:
* `${pkgdir}` 里面最初是 **不包含** 目录的。如果你跳过了 [mkdir 命令](https://linuxhandbook.com/mkdir-command/),`tee` 会输出一个错误,说这个目录不存在。
* 在指定目录时,**总是** 在它们前面加上 `${pkgdir}` 或 `${srcdir}` 变量。如果输入 `/usr/share/motto.txt`,就会按照字面意义指向你当前运行的系统中的 `/usr/share/motto.txt`。
对于你的 `PKGBUILD`,你将把 `hello-world.sh` 文件放在目标系统的 `/usr/bin/hello-world` 中。你还将使该文件在运行时说 “Hello to you!”。
要做到这一点,请在 `PKGBUILD` 中输入以下内容:
```
package() {
echo 'Hello to you!' > "${srcdir}/hello-world.sh"
mkdir -p "${pkgdir}/usr/bin"
cp "${srcdir}/hello-world.sh" "${pkgdir}/usr/bin/hello-world"
chmod +x "${pkgdir}/usr/bin/hello-world"
}
```
然后就完成了!用 `makepkg -si` 构建和安装软件包,然后在终端运行 `hello-world`,查看其输出。

### 总结
就这样,你已经制作了你的第一个 `PKGBUILD`!你走在了为自己甚至是为 AUR 制作实际的软件包的路上。
有什么问题,或者有什么地方不对吗?请随时在下面的评论区发表。
---
via: <https://itsfoss.com/create-pkgbuild/>
作者:[Hunter Wittenborn](https://itsfoss.com/author/hunter/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

PKGBUILD files are how packages are built and created for Arch Linux and its derivatives, such as Manjaro.
You may have even come across them a bit yourself if you’ve ever used the [AUR](https://itsfoss.com/aur-arch-linux/), Arch Linux’s user-curated repository of PKGBUILDs.
But how exactly do you go from a PKGBUILD to an installable package? What exactly is going on between the two, and how can you make them for your own packages? You’ll learn them in this article.
## PKGBUILD basics
For those who are familiar with Bash or other shells, you’ll be delighted to know, if you didn’t already, that a PKGBUILD is pretty much just a shell script with some variables.
PKGBUILD files consist of variables and functions, all of which are used to define the package itself, and how to build it.
To create a package from a PKGBUILD, the makepkg command line utility is used. After obtaining a PKGBUILD, you simply run `makepkg`
inside the directory containing the PKGBUILD, and voila, you have an installable package!
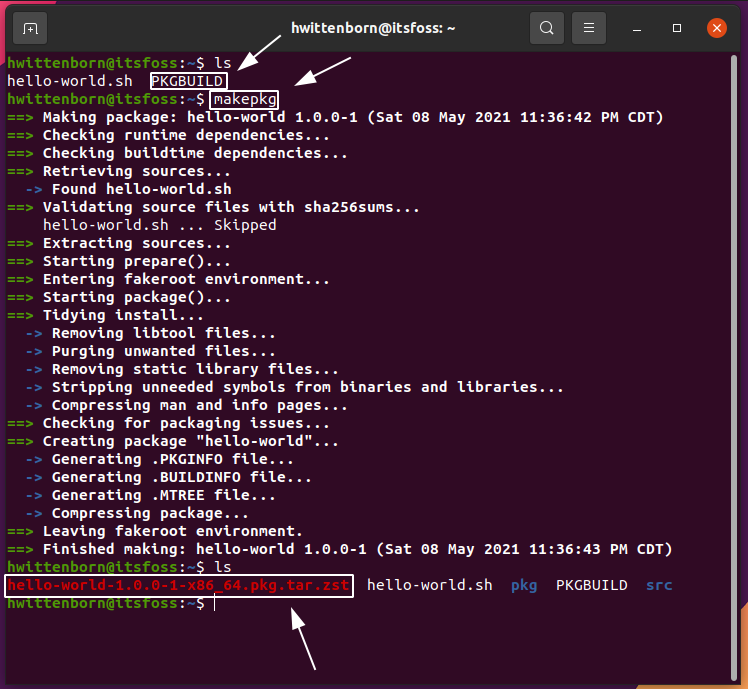
In this tutorial, you’ll be going over the package I just made, which prints “Hello World!” when run:
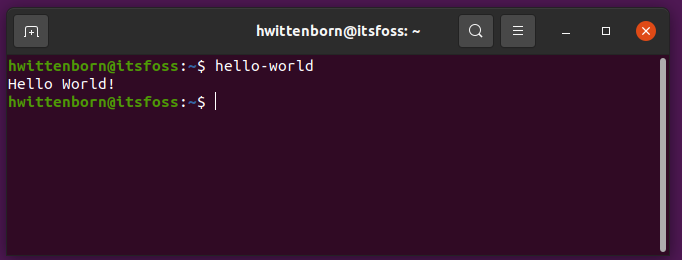
## Getting set up
To follow along with this tutorial, you need to create a couple of files.
First, you need to make a file called **PKGBUILD**. If it wasn’t already made clear, this will serve as the “recipe” for building your package.
The other file you’ll need to make is a file called **hello-world.sh**. I’ll explain its purpose a bit later.
You can create both of these files with a single command as well.
`touch PKGBUILD hello-world.sh`
You can check that the files were created with the ls command:
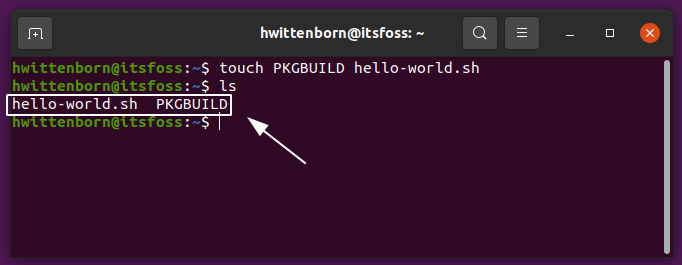
And you’re ready to go!
## Setting up your PKGBUILD file
**Instead of having you copy paste the whole file, I’ll be going over entering every line with you, so you can better understand the purpose of everything that’s happening. If you don’t prefer to learn this way, I’d highly recommend the **
[Arch Wiki article](https://wiki.archlinux.org/title/Creating_packages?ref=itsfoss.com)
*on creating packages for Arch Linux.*With that out of the way, open up your text editor, and let’s get straight into it!
### pkgname
First things first, the pkgname variable. This is what defines the name of your package when installing, and how [Arch Linux’s package manager pacman](https://itsfoss.com/pacman-command/) keeps track of the package.
The format of this variable (and some others) takes the form of variable=value, with the variable name on the left, the value of the variable on the right, separated by an equals sign.
To set the package name, enter the following into the PKGBUILD:
`pkgname="hello-world"`
- To set a different package name, replace
`hello-world`
with the name of the package. - This doesn’t set the command used to run the program. That’s handled a bit below in the
`package()`
section.
### pkgver
As is stated in the variable name itself, this sets the version of your package (i.e. 1.0.0). This is useful when a user updates their system, as setting a higher version will result in the user being prompted for an upgrade.
To set, enter the following into the PKGBUILD (after the previous line):
`pkgver="1.0.0"`
### pkgrel
This is related to the pkgver variable, and isn’t normally important to know about. Like the pkgver variable though, it will notify users for upgrades if it’s moved to a higher number.
It serves for any changes that require the pkgver to remain the same, such as any changes to the PKGBUILD itself. This would be useful if you’ve created a PKGBUILD for a program you use (and want to keep the version the same as the package’s), and you need to fix a bug in the PKGBUILD itself.
To set the variable, enter the following in the PKGBUILD:
`pkgver="1"`
This variable should **always** start at 1, and then move up one at a time. When the **pkgver** itself moves up, this can (and should) be reset to 1, as the pkgver itself will notify users that upgrades are available.
### pkgdesc
This will set the description of the package, which is used to help better identify the package.
To set it, just put the description inside of quotation marks:
`pkgdesc="Hello world in your terminal!"`
### arch
This variable sets the [architecture](https://www.quora.com/What-is-CPU-architecture?ref=itsfoss.com) the package is compatible with. It’s fine if you don’t understand what an architecture is, as it’s pretty much useless in most cases.
Regardless, makepkg still needs it to be set so it knows the package is compatible with our system.
This variable supports setting multiple values, so makepkg requires a different syntax as shown below.
To set it, enter the following in the PKGBUILD:
`arch=("x86_64")`
If you were to set multiple values for this, you would separate each value with a space and quotation marks like so: **arch=(“x86_x64” “arm”)**
### depends
This lists all of the packages that our package needs to function. Like **arch**, it can also contain multiple values, and thus must use the parenthesis syntax.
Since our package won’t have any dependencies, we don’t have to enter this field in the PKGBUILD. If our package did have dependencies however, we’d just use the same syntax as **arch**.
### optdepends
This lists packages that aren’t required to function, but that are needed for extra functionality.
This follows the same syntax as **depends**.
### conflicts
This tells pacman what packages would cause our package to act up or behave in a way we wouldn’t want.
Any package listed here would be uninstalled before ours is installed.
This follows the same syntax as **depends** as well.
### license
This defines the [software license](https://en.wikipedia.org/wiki/Software_license?ref=itsfoss.com) that your program is licensed under. The [Arch Wiki](https://wiki.archlinux.org/title/PKGBUILD?ref=itsfoss.com#license) has some info if you need help choosing a license. Setting this to `custom`
will work if you don’t know what to set this to.
This takes the same syntax as **arch** and **depends**:
`license=("custom")`
### source
This is how makepkg knows what files to use to build our package. This can contain a variety of different kinds of sources, including local files and URLs.
When adding local files, enter the file’s name relative to the PKGBUILD i.e. consider the following directory layout:
```
PKGBUILD
file.txt
src/file.sh
```
If you wanted to include **file.sh** in our PKGBUILD, you would enter **src/file.sh** as its name.
When entering URLs, you simply enter the full URL, i.e. https://mirrors.creativecommons.org/presskit/logos/cc.logo.large.png.
Your package only needs the hello-world.sh file, and since it’s in the same directory as the PKGBUILD, you just type its name as the value for **source**.
This variable also uses the same syntax as **arch** and **depends**:
`source=("hello-world.sh")`
### sha512sums
This is used to verify that the files in **source** haven’t been modified or downloaded incorrectly. Information on obtaining the values for this can be found in the [Arch Wiki article on PKGBUILDs](https://wiki.archlinux.org/title/PKGBUILD?ref=itsfoss.com#Integrity).
If you’d rather just not set this (or you just don’t need to, i.e. for local files), you can just enter SKIP for every file in the **source** variable:
`sha512sums=("SKIP")`
### package()
This is the last, and most important part to actually making our package. It’s important to know two variables when working with this:
**${srcdir}**: This is where makepkg puts the files in the**source**variable. This is the directory where you can interact with the files, and do any other needed modification to the files.- ${pkgdir}: This is where we place the files that will be installed on our system.
The folder structure for ${pkgdir} is set up as if it was on an actual system (i.e. ${pkgdir}/usr/bin/hello-world would create the file /usr/bin/hello-world when installing with pacman.
package() contains a list of commands used create a package.
So, if (hypothetically) you needed to have a file that reads Linux is superior to Windows at /usr/share/motto.txt, you would run something like this:
```
package() {
mkdir -p "${pkgdir}/usr/share"
echo "Linux is superior to Windows" | tee "${pkgdir}/usr/share/motto.txt"
}
```
A few notes on the above command:
- ${pkgdir} contains
**no**directories inside it at first. If you skipped the[mkdir command](https://linuxhandbook.com/mkdir-command/?ref=itsfoss.com), tee would output an error saying the directory doesn’t exist. - When specifying directories,
**always**prepend them with the**${pkgdir}**or**${srcdir}**variable. Entering something like /usr/share/motto.txt without such would point to the literal directory /usr/share/motto.txt on your currently running system.
For your PKGBUILD, you’re going to place the file hello-world.sh at /usr/bin/hello-world on your target system. You’ll also be making the file say “Hello to you!” when ran.
To do so, enter the following into your PKGBUILD:
```
package() {
echo 'Hello to you!' > "${srcdir}/hello-world.sh"
mkdir -p "${pkgdir}/usr/bin"
cp "${srcdir}/hello-world.sh" "${pkgdir}/usr/bin/hello-world"
chmod +x "${pkgdir}/usr/bin/hello-world"
}
```
And you’re done! Your resulting file should now look similar to this:
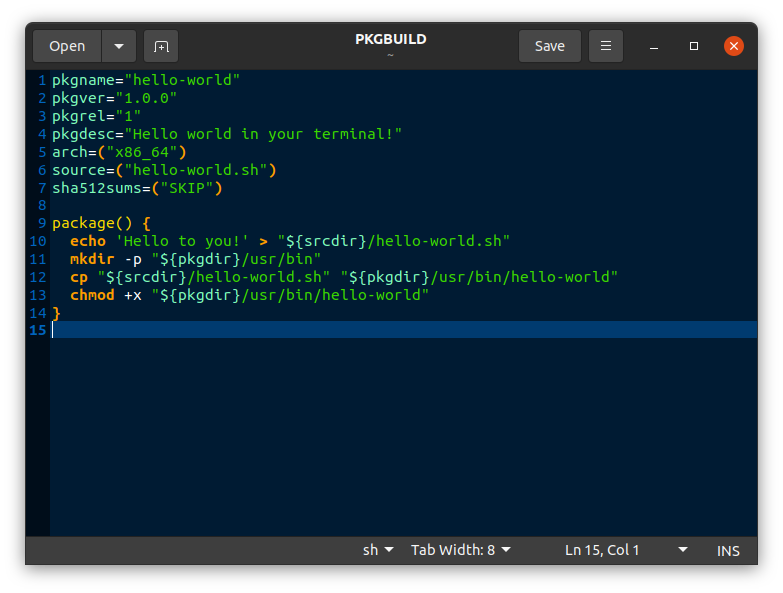
Now build and install the package with the `makepkg -si`
command, and then run `hello-world`
in your terminal to see its output.
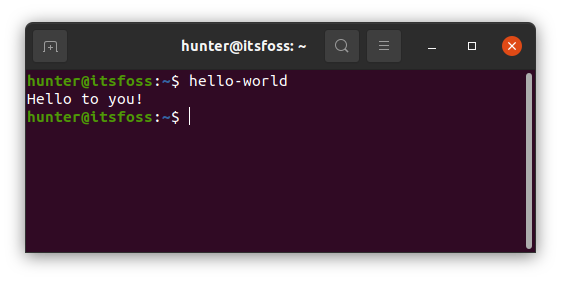
## Wrapping Up
And just like that, you have made your first PKGBUILD! You’re on your way to making actual packages for yourself, and maybe even the AUR.
Got any questions, or something just not working right? Feel free to post it in the comment section below. |
13,845 | 实例讲解代码之内存安全与效率 | https://opensource.com/article/21/8/memory-programming-c | 2021-10-03T10:12:45 | [
"内存",
"编程"
] | https://linux.cn/article-13845-1.html |
>
> 了解有关内存安全和效率的更多信息。
>
>
>

C 是一种高级语言,同时具有“<ruby> 接近金属 <rt> close-to-the-metal </rt></ruby>”(LCTT 译注:即“接近人类思维方式”的反义词)的特性,这使得它有时看起来更像是一种可移植的汇编语言,而不像 Java 或 Python 这样的兄弟语言。内存管理作为上述特性之一,涵盖了正在执行的程序对内存的安全和高效使用。本文通过 C 语言代码示例,以及现代 C 语言编译器生成的汇编语言代码段,详细介绍了内存安全性和效率。
尽管代码示例是用 C 语言编写的,但安全高效的内存管理指南对于 C++ 是同样适用的。这两种语言在很多细节上有所不同(例如,C++ 具有 C 所缺乏的面向对象特性和泛型),但在内存管理方面面临的挑战是一样的。
### 执行中程序的内存概述
对于正在执行的程序(又名 *<ruby> 进程 <rt> process </rt></ruby>*),内存被划分为三个区域:**<ruby> 栈 <rt> stack </rt></ruby>**、**<ruby> 堆 <rt> heap </rt></ruby>** 和 **<ruby> 静态区 <rt> static area </rt></ruby>**。下文会给出每个区域的概述,以及完整的代码示例。
作为通用 CPU 寄存器的替补,*栈* 为代码块(例如函数或循环体)中的局部变量提供暂存器存储。传递给函数的参数在此上下文中也视作局部变量。看一下下面这个简短的示例:
```
void some_func(int a, int b) {
int n;
...
}
```
通过 `a` 和 `b` 传递的参数以及局部变量 `n` 的存储会在栈中,除非编译器可以找到通用寄存器。编译器倾向于优先将通用寄存器用作暂存器,因为 CPU 对这些寄存器的访问速度很快(一个时钟周期)。然而,这些寄存器在台式机、笔记本电脑和手持机器的标准架构上很少(大约 16 个)。
在只有汇编语言程序员才能看到的实施层面,栈被组织为具有 `push`(插入)和 `pop`(删除)操作的 LIFO(后进先出)列表。 `top` 指针可以作为偏移的基地址;这样,除了 `top` 之外的栈位置也变得可访问了。例如,表达式 `top+16` 指向堆栈的 `top` 指针上方 16 个字节的位置,表达式 `top-16` 指向 `top` 指针下方 16 个字节的位置。因此,可以通过 `top` 指针访问实现了暂存器存储的栈的位置。在标准的 ARM 或 Intel 架构中,栈从高内存地址增长到低内存地址;因此,减小某进程的 `top` 就是增大其栈规模。
使用栈结构就意味着轻松高效地使用内存。编译器(而非程序员)会编写管理栈的代码,管理过程通过分配和释放所需的暂存器存储来实现;程序员声明函数参数和局部变量,将实现过程交给编译器。此外,完全相同的栈存储可以在连续的函数调用和代码块(如循环)中重复使用。精心设计的模块化代码会将栈存储作为暂存器的首选内存选项,同时优化编译器要尽可能使用通用寄存器而不是栈。
**堆** 提供的存储是通过程序员代码显式分配的,堆分配的语法因语言而异。在 C 中,成功调用库函数 `malloc`(或其变体 `calloc` 等)会分配指定数量的字节(在 C++ 和 Java 等语言中,`new` 运算符具有相同的用途)。编程语言在如何释放堆分配的存储方面有着巨大的差异:
* 在 Java、Go、Lisp 和 Python 等语言中,程序员不会显式释放动态分配的堆存储。
例如,下面这个 Java 语句为一个字符串分配了堆存储,并将这个堆存储的地址存储在变量 `greeting` 中:
```
String greeting = new String("Hello, world!");
```
Java 有一个垃圾回收器,它是一个运行时实用程序,如果进程无法再访问自己分配的堆存储,回收器可以使其自动释放。因此,Java 堆释放是通过垃圾收集器自动进行的。在上面的示例中,垃圾收集器将在变量 `greeting` 超出作用域后,释放字符串的堆存储。
* Rust 编译器会编写堆释放代码。这是 Rust 在不依赖垃圾回收器的情况下,使堆释放实现自动化的开创性努力,但这也会带来运行时复杂性和开销。向 Rust 的努力致敬!
* 在 C(和 C++)中,堆释放是程序员的任务。程序员调用 `malloc` 分配堆存储,然后负责相应地调用库函数 `free` 来释放该存储空间(在 C++ 中,`new` 运算符分配堆存储,而 `delete` 和 `delete[]` 运算符释放此类存储)。下面是一个 C 语言代码示例:
```
char* greeting = malloc(14); /* 14 heap bytes */
strcpy(greeting, "Hello, world!"); /* copy greeting into bytes */
puts(greeting); /* print greeting */
free(greeting); /* free malloced bytes */
```
C 语言避免了垃圾回收器的成本和复杂性,但也不过是让程序员承担了堆释放的任务。
内存的 **静态区** 为可执行代码(例如 C 语言函数)、字符串文字(例如“Hello, world!”)和全局变量提供存储空间:
```
int n; /* global variable */
int main() { /* function */
char* msg = "No comment"; /* string literal */
...
}
```
该区域是静态的,因为它的大小从进程执行开始到结束都固定不变。由于静态区相当于进程固定大小的内存占用,因此经验法则是通过避免使用全局数组等方法来使该区域尽可能小。
下文会结合代码示例对本节概述展开进一步讲解。
### 栈存储
想象一个有各种连续执行的任务的程序,任务包括了处理每隔几分钟通过网络下载并存储在本地文件中的数字数据。下面的 `stack` 程序简化了处理流程(仅是将奇数整数值转换为偶数),而将重点放在栈存储的好处上。
```
#include <stdio.h>
#include <stdlib.h>
#define Infile "incoming.dat"
#define Outfile "outgoing.dat"
#define IntCount 128000 /* 128,000 */
void other_task1() { /*...*/ }
void other_task2() { /*...*/ }
void process_data(const char* infile,
const char* outfile,
const unsigned n) {
int nums[n];
FILE* input = fopen(infile, "r");
if (NULL == infile) return;
FILE* output = fopen(outfile, "w");
if (NULL == output) {
fclose(input);
return;
}
fread(nums, n, sizeof(int), input); /* read input data */
unsigned i;
for (i = 0; i < n; i++) {
if (1 == (nums[i] & 0x1)) /* odd parity? */
nums[i]--; /* make even */
}
fclose(input); /* close input file */
fwrite(nums, n, sizeof(int), output);
fclose(output);
}
int main() {
process_data(Infile, Outfile, IntCount);
/** now perform other tasks **/
other_task1(); /* automatically released stack storage available */
other_task2(); /* ditto */
return 0;
}
```
底部的 `main` 函数首先调用 `process_data` 函数,该函数会创建一个基于栈的数组,其大小由参数 `n` 给定(当前示例中为 128,000)。因此,该数组占用 `128000 * sizeof(int)` 个字节,在标准设备上达到了 512,000 字节(`int` 在这些设备上是四个字节)。然后数据会被读入数组(使用库函数 `fread`),循环处理,并保存到本地文件 `outgoing.dat`(使用库函数 `fwrite`)。
当 `process_data` 函数返回到其调用者 `main` 函数时,`process_data` 函数的大约 500MB 栈暂存器可供 `stack` 程序中的其他函数用作暂存器。在此示例中,`main` 函数接下来调用存根函数 `other_task1` 和 `other_task2`。这三个函数在 `main` 中依次调用,这意味着所有三个函数都可以使用相同的堆栈存储作为暂存器。因为编写栈管理代码的是编译器而不是程序员,所以这种方法对程序员来说既高效又容易。
在 C 语言中,在块(例如函数或循环体)内定义的任何变量默认都有一个 `auto` 存储类,这意味着该变量是基于栈的。存储类 `register` 现在已经过时了,因为 C 编译器会主动尝试尽可能使用 CPU 寄存器。只有在块内定义的变量可能是 `register`,如果没有可用的 CPU 寄存器,编译器会将其更改为 `auto`。基于栈的编程可能是不错的首选方式,但这种风格确实有一些挑战性。下面的 `badStack` 程序说明了这点。
```
#include <stdio.h>;
const int* get_array(const unsigned n) {
int arr[n]; /* stack-based array */
unsigned i;
for (i = 0; i < n; i++) arr[i] = 1 + 1;
return arr; /** ERROR **/
}
int main() {
const unsigned n = 16;
const int* ptr = get_array(n);
unsigned i;
for (i = 0; i < n; i++) printf("%i ", ptr[i]);
puts("\n");
return 0;
}
```
`badStack` 程序中的控制流程很简单。`main` 函数使用 16(LCTT 译注:原文为 128,应为作者笔误)作为参数调用函数 `get_array`,然后被调用函数会使用传入参数来创建对应大小的本地数组。`get_array` 函数会初始化数组并返回给 `main` 中的数组标识符 `arr`。 `arr` 是一个指针常量,保存数组的第一个 `int` 元素的地址。
当然,本地数组 `arr` 可以在 `get_array` 函数中访问,但是一旦 `get_array` 返回,就不能合法访问该数组。尽管如此,`main` 函数会尝试使用函数 `get_array` 返回的堆栈地址 `arr` 来打印基于栈的数组。现代编译器会警告错误。例如,下面是来自 GNU 编译器的警告:
```
badStack.c: In function 'get_array':
badStack.c:9:10: warning: function returns address of local variable [-Wreturn-local-addr]
return arr; /** ERROR **/
```
一般规则是,如果使用栈存储实现局部变量,应该仅在该变量所在的代码块内,访问这块基于栈的存储(在本例中,数组指针 `arr` 和循环计数器 `i` 均为这样的局部变量)。因此,函数永远不应该返回指向基于栈存储的指针。
### 堆存储
接下来使用若干代码示例凸显在 C 语言中使用堆存储的优点。在第一个示例中,使用了最优方案分配、使用和释放堆存储。第二个示例(在下一节中)将堆存储嵌套在了其他堆存储中,这会使其释放操作变得复杂。
```
#include <stdio.h>
#include <stdlib.h>
int* get_heap_array(unsigned n) {
int* heap_nums = malloc(sizeof(int) * n);
unsigned i;
for (i = 0; i < n; i++)
heap_nums[i] = i + 1; /* initialize the array */
/* stack storage for variables heap_nums and i released
automatically when get_num_array returns */
return heap_nums; /* return (copy of) the pointer */
}
int main() {
unsigned n = 100, i;
int* heap_nums = get_heap_array(n); /* save returned address */
if (NULL == heap_nums) /* malloc failed */
fprintf(stderr, "%s\n", "malloc(...) failed...");
else {
for (i = 0; i < n; i++) printf("%i\n", heap_nums[i]);
free(heap_nums); /* free the heap storage */
}
return 0;
}
```
上面的 `heap` 程序有两个函数: `main` 函数使用参数(示例中为 100)调用 `get_heap_array` 函数,参数用来指定数组应该有多少个 `int` 元素。因为堆分配可能会失败,`main` 函数会检查 `get_heap_array` 是否返回了 `NULL`;如果是,则表示失败。如果分配成功,`main` 将打印数组中的 `int` 值,然后立即调用库函数 `free` 来对堆存储解除分配。这就是最优的方案。
`get_heap_array` 函数以下列语句开头,该语句值得仔细研究一下:
```
int* heap_nums = malloc(sizeof(int) * n); /* heap allocation */
```
`malloc` 库函数及其变体函数针对字节进行操作;因此,`malloc` 的参数是 `n` 个 `int` 类型元素所需的字节数(`sizeof(int)` 在标准现代设备上是四个字节)。`malloc` 函数返回所分配字节段的首地址,如果失败则返回 `NULL` .
如果成功调用 `malloc`,在现代台式机上其返回的地址大小为 64 位。在手持设备和早些时候的台式机上,该地址的大小可能是 32 位,或者甚至更小,具体取决于其年代。堆分配数组中的元素是 `int` 类型,这是一个四字节的有符号整数。这些堆分配的 `int` 的地址存储在基于栈的局部变量 `heap_nums` 中。可以参考下图:
```
heap-based
stack-based /
\ +----+----+ +----+
heap-nums--->|int1|int2|...|intN|
+----+----+ +----+
```
一旦 `get_heap_array` 函数返回,指针变量 `heap_nums` 的栈存储将自动回收——但动态 `int` 数组的堆存储仍然存在,这就是 `get_heap_array` 函数返回这个地址(的副本)给 `main` 函数的原因:它现在负责在打印数组的整数后,通过调用库函数 `free` 显式释放堆存储:
```
free(heap_nums); /* free the heap storage */
```
`malloc` 函数不会初始化堆分配的存储空间,因此里面是随机值。相比之下,其变体函数 `calloc` 会将分配的存储初始化为零。这两个函数都返回 `NULL` 来表示分配失败。
在 `heap` 示例中,`main` 函数在调用 `free` 后会立即返回,正在执行的程序会终止,这会让系统回收所有已分配的堆存储。尽管如此,程序员应该养成在不再需要时立即显式释放堆存储的习惯。
### 嵌套堆分配
下一个代码示例会更棘手一些。C 语言有很多返回指向堆存储的指针的库函数。下面是一个常见的使用情景:
1、C 程序调用一个库函数,该函数返回一个指向基于堆的存储的指针,而指向的存储通常是一个聚合体,如数组或结构体:
```
SomeStructure* ptr = lib_function(); /* returns pointer to heap storage */
```
2、 然后程序使用所分配的存储。
3、 对于清理而言,问题是对 `free` 的简单调用是否会清理库函数分配的所有堆分配存储。例如,`SomeStructure` 实例可能有指向堆分配存储的字段。一个特别麻烦的情况是动态分配的结构体数组,每个结构体有一个指向又一层动态分配的存储的字段。下面的代码示例说明了这个问题,并重点关注了如何设计一个可以安全地为客户端提供堆分配存储的库。
```
#include <stdio.h>
#include <stdlib.h>
typedef struct {
unsigned id;
unsigned len;
float* heap_nums;
} HeapStruct;
unsigned structId = 1;
HeapStruct* get_heap_struct(unsigned n) {
/* Try to allocate a HeapStruct. */
HeapStruct* heap_struct = malloc(sizeof(HeapStruct));
if (NULL == heap_struct) /* failure? */
return NULL; /* if so, return NULL */
/* Try to allocate floating-point aggregate within HeapStruct. */
heap_struct->heap_nums = malloc(sizeof(float) * n);
if (NULL == heap_struct->heap_nums) { /* failure? */
free(heap_struct); /* if so, first free the HeapStruct */
return NULL; /* then return NULL */
}
/* Success: set fields */
heap_struct->id = structId++;
heap_struct->len = n;
return heap_struct; /* return pointer to allocated HeapStruct */
}
void free_all(HeapStruct* heap_struct) {
if (NULL == heap_struct) /* NULL pointer? */
return; /* if so, do nothing */
free(heap_struct->heap_nums); /* first free encapsulated aggregate */
free(heap_struct); /* then free containing structure */
}
int main() {
const unsigned n = 100;
HeapStruct* hs = get_heap_struct(n); /* get structure with N floats */
/* Do some (meaningless) work for demo. */
unsigned i;
for (i = 0; i < n; i++) hs->heap_nums[i] = 3.14 + (float) i;
for (i = 0; i < n; i += 10) printf("%12f\n", hs->heap_nums[i]);
free_all(hs); /* free dynamically allocated storage */
return 0;
}
```
上面的 `nestedHeap` 程序示例以结构体 `HeapStruct` 为中心,结构体中又有名为 `heap_nums` 的指针字段:
```
typedef struct {
unsigned id;
unsigned len;
float* heap_nums; /** pointer **/
} HeapStruct;
```
函数 `get_heap_struct` 尝试为 `HeapStruct` 实例分配堆存储,这需要为字段 `heap_nums` 指向的若干个 `float` 变量分配堆存储。如果成功调用 `get_heap_struct` 函数,并将指向堆分配结构体的指针以 `hs` 命名,其结果可以描述如下:
```
hs-->HeapStruct instance
id
len
heap_nums-->N contiguous float elements
```
在 `get_heap_struct` 函数中,第一个堆分配过程很简单:
```
HeapStruct* heap_struct = malloc(sizeof(HeapStruct));
if (NULL == heap_struct) /* failure? */
return NULL; /* if so, return NULL */
```
`sizeof(HeapStruct)` 包括了 `heap_nums` 字段的字节数(32 位机器上为 4,64 位机器上为 8),`heap_nums` 字段则是指向动态分配数组中的 `float` 元素的指针。那么,问题关键在于 `malloc` 为这个结构体传送了字节空间还是表示失败的 `NULL`;如果是 `NULL`,`get_heap_struct` 函数就也返回 `NULL` 以通知调用者堆分配失败。
第二步尝试堆分配的过程更复杂,因为在这一步,`HeapStruct` 的堆存储已经分配好了:
```
heap_struct->heap_nums = malloc(sizeof(float) * n);
if (NULL == heap_struct->heap_nums) { /* failure? */
free(heap_struct); /* if so, first free the HeapStruct */
return NULL; /* and then return NULL */
}
```
传递给 `get_heap_struct` 函数的参数 `n` 指明动态分配的 `heap_nums` 数组中应该有多少个 `float` 元素。如果可以分配所需的若干个 `float` 元素,则该函数在返回 `HeapStruct` 的堆地址之前会设置结构的 `id` 和 `len` 字段。 但是,如果尝试分配失败,则需要两个步骤来实现最优方案:
1、 必须释放 `HeapStruct` 的存储以避免内存泄漏。对于调用 `get_heap_struct` 的客户端函数而言,没有动态 `heap_nums` 数组的 `HeapStruct` 可能就是没用的;因此,`HeapStruct` 实例的字节空间应该显式释放,以便系统可以回收这些空间用于未来的堆分配。
2、 返回 `NULL` 以标识失败。
如果成功调用 `get_heap_struct` 函数,那么释放堆存储也很棘手,因为它涉及要以正确顺序进行的两次 `free` 操作。因此,该程序设计了一个 `free_all` 函数,而不是要求程序员再去手动实现两步释放操作。回顾一下,`free_all` 函数是这样的:
```
void free_all(HeapStruct* heap_struct) {
if (NULL == heap_struct) /* NULL pointer? */
return; /* if so, do nothing */
free(heap_struct->heap_nums); /* first free encapsulated aggregate */
free(heap_struct); /* then free containing structure */
}
```
检查完参数 `heap_struct` 不是 `NULL` 值后,函数首先释放 `heap_nums` 数组,这步要求 `heap_struct` 指针此时仍然是有效的。先释放 `heap_struct` 的做法是错误的。一旦 `heap_nums` 被释放,`heap_struct` 就可以释放了。如果 `heap_struct` 被释放,但 `heap_nums` 没有被释放,那么数组中的 `float` 元素就会泄漏:仍然分配了字节空间,但无法被访问到——因此一定要记得释放 `heap_nums`。存储泄漏将一直持续,直到 `nestedHeap` 程序退出,系统回收泄漏的字节时为止。
关于 `free` 库函数的注意事项就是要有顺序。回想一下上面的调用示例:
```
free(heap_struct->heap_nums); /* first free encapsulated aggregate */
free(heap_struct); /* then free containing structure */
```
这些调用释放了分配的存储空间——但它们并 *不是* 将它们的操作参数设置为 `NULL`(`free` 函数会获取地址的副本作为参数;因此,将副本更改为 `NULL` 并不会改变原地址上的参数值)。例如,在成功调用 `free` 之后,指针 `heap_struct` 仍然持有一些堆分配字节的堆地址,但是现在使用这个地址将会产生错误,因为对 `free` 的调用使得系统有权回收然后重用这些分配过的字节。
使用 `NULL` 参数调用 `free` 没有意义,但也没有什么坏处。而在非 `NULL` 的地址上重复调用 `free` 会导致不确定结果的错误:
```
free(heap_struct); /* 1st call: ok */
free(heap_struct); /* 2nd call: ERROR */
```
### 内存泄漏和堆碎片化
“内存泄漏”是指动态分配的堆存储变得不再可访问。看一下相关的代码段:
```
float* nums = malloc(sizeof(float) * 10); /* 10 floats */
nums[0] = 3.14f; /* and so on */
nums = malloc(sizeof(float) * 25); /* 25 new floats */
```
假如第一个 `malloc` 成功,第二个 `malloc` 会再将 `nums` 指针重置为 `NULL`(分配失败情况下)或是新分配的 25 个 `float` 中第一个的地址。最初分配的 10 个 `float` 元素的堆存储仍然处于被分配状态,但此时已无法再对其访问,因为 `nums` 指针要么指向别处,要么是 `NULL`。结果就是造成了 40 个字节(`sizeof(float) * 10`)的泄漏。
在第二次调用 `malloc` 之前,应该释放最初分配的存储空间:
```
float* nums = malloc(sizeof(float) * 10); /* 10 floats */
nums[0] = 3.14f; /* and so on */
free(nums); /** good **/
nums = malloc(sizeof(float) * 25); /* no leakage */
```
即使没有泄漏,堆也会随着时间的推移而碎片化,需要对系统进行碎片整理。例如,假设两个最大的堆块当前的大小分别为 200MB 和 100MB。然而,这两个堆块并不连续,进程 `P` 此时又需要分配 250MB 的连续堆存储。在进行分配之前,系统可能要对堆进行 *碎片整理* 以给 `P` 提供 250MB 连续存储空间。碎片整理很复杂,因此也很耗时。
内存泄漏会创建处于已分配状态但不可访问的堆块,从而会加速碎片化。因此,释放不再需要的堆存储是程序员帮助减少碎片整理需求的一种方式。
### 诊断内存泄漏的工具
有很多工具可用于分析内存效率和安全性,其中我最喜欢的是 [valgrind](https://www.valgrind.org/)。为了说明该工具如何处理内存泄漏,这里给出 `leaky` 示例程序:
```
#include <stdio.h>
#include <stdlib.h>
int* get_ints(unsigned n) {
int* ptr = malloc(n * sizeof(int));
if (ptr != NULL) {
unsigned i;
for (i = 0; i < n; i++) ptr[i] = i + 1;
}
return ptr;
}
void print_ints(int* ptr, unsigned n) {
unsigned i;
for (i = 0; i < n; i++) printf("%3i\n", ptr[i]);
}
int main() {
const unsigned n = 32;
int* arr = get_ints(n);
if (arr != NULL) print_ints(arr, n);
/** heap storage not yet freed... **/
return 0;
}
```
`main` 函数调用了 `get_ints` 函数,后者会试着从堆中 `malloc` 32 个 4 字节的 `int`,然后初始化动态数组(如果 `malloc` 成功)。初始化成功后,`main` 函数会调用 `print_ints`函数。程序中并没有调用 `free` 来对应 `malloc` 操作;因此,内存泄漏了。
如果安装了 `valgrind` 工具箱,下面的命令会检查 `leaky` 程序是否存在内存泄漏(`%` 是命令行提示符):
```
% valgrind --leak-check=full ./leaky
```
绝大部分输出都在下面给出了。左边的数字 207683 是正在执行的 `leaky` 程序的进程标识符。这份报告给出了泄漏发生位置的详细信息,本例中位置是在 `main` 函数所调用的 `get_ints` 函数中对 `malloc` 的调用处。
```
==207683== HEAP SUMMARY:
==207683== in use at exit: 128 bytes in 1 blocks
==207683== total heap usage: 2 allocs, 1 frees, 1,152 bytes allocated
==207683==
==207683== 128 bytes in 1 blocks are definitely lost in loss record 1 of 1
==207683== at 0x483B7F3: malloc (in /usr/lib/x86_64-linux-gnu/valgrind/vgpreload_memcheck-amd64-linux.so)
==207683== by 0x109186: get_ints (in /home/marty/gc/leaky)
==207683== by 0x109236: main (in /home/marty/gc/leaky)
==207683==
==207683== LEAK SUMMARY:
==207683== definitely lost: 128 bytes in 1 blocks
==207683== indirectly lost: 0 bytes in 0 blocks
==207683== possibly lost: 0 bytes in 0 blocks
==207683== still reachable: 0 bytes in 0 blocks
==207683== suppressed: 0 bytes in 0 blocks
```
如果把 `main` 函数改成在对 `print_ints` 的调用之后,再加上一个对 `free` 的调用,`valgrind` 就会对 `leaky` 程序给出一个干净的内存健康清单:
```
==218462== All heap blocks were freed -- no leaks are possible
```
### 静态区存储
在正统的 C 语言中,函数必须在所有块之外定义。这是一些 C 编译器支持的特性,杜绝了在另一个函数体内定义一个函数的可能。我举的例子都是在所有块之外定义的函数。这样的函数要么是 `static` ,即静态的,要么是 `extern`,即外部的,其中 `extern` 是默认值。
C 语言中,以 `static` 或 `extern` 修饰的函数和变量驻留在内存中所谓的 **静态区** 中,因为在程序执行期间该区域大小是固定不变的。这两个存储类型的语法非常复杂,我们应该回顾一下。在回顾之后,会有一个完整的代码示例来生动展示语法细节。在所有块之外定义的函数或变量默认为 `extern`;因此,函数和变量要想存储类型为 `static` ,必须显式指定:
```
/** file1.c: outside all blocks, five definitions **/
int foo(int n) { return n * 2; } /* extern by default */
static int bar(int n) { return n; } /* static */
extern int baz(int n) { return -n; } /* explicitly extern */
int num1; /* extern */
static int num2; /* static */
```
`extern` 和 `static` 的区别在于作用域:`extern` 修饰的函数或变量可以实现跨文件可见(需要声明)。相比之下,`static` 修饰的函数仅在 *定义* 该函数的文件中可见,而 `static` 修饰的变量仅在 *定义* 该变量的文件(或文件中的块)中可见:
```
static int n1; /* scope is the file */
void func() {
static int n2; /* scope is func's body */
...
}
```
如果在所有块之外定义了 `static` 变量,例如上面的 `n1`,该变量的作用域就是定义变量的文件。无论在何处定义 `static` 变量,变量的存储都在内存的静态区中。
`extern` 函数或变量在给定文件中的所有块之外定义,但这样定义的函数或变量也可以在其他文件中声明。典型的做法是在头文件中 *声明* 这样的函数或变量,只要需要就可以包含进来。下面这些简短的例子阐述了这些棘手的问题。
假设 `extern` 函数 `foo` 在 `file1.c` 中 *定义*,有无关键字 `extern` 效果都一样:
```
/** file1.c **/
int foo(int n) { return n * 2; } /* definition has a body {...} */
```
必须在其他文件(或其中的块)中使用显式的 `extern` *声明* 此函数才能使其可见。以下是使 `extern` 函数 `foo` 在文件 `file2.c` 中可见的声明语句:
```
/** file2.c: make function foo visible here **/
extern int foo(int); /* declaration (no body) */
```
回想一下,函数声明没有用大括号括起来的主体,而函数定义会有这样的主体。
为了便于查看,函数和变量声明通常会放在头文件中。准备好需要声明的源代码文件,然后就可以 `#include` 相关的头文件。下一节中的 `staticProg` 程序演示了这种方法。
至于 `extern` 的变量,规则就变得更棘手了(很抱歉增加了难度!)。任何 `extern` 的对象——无论函数或变量——必须 *定义* 在所有块之外。此外,在所有块之外定义的变量默认为 `extern`:
```
/** outside all blocks **/
int n; /* defaults to extern */
```
但是,只有在变量的 *定义* 中显式初始化变量时,`extern` 才能在变量的 *定义* 中显式修饰(LCTT 译注:换言之,如果下列代码中的 `int n1;` 行前加上 `extern`,该行就由 *定义* 变成了 *声明*):
```
/** file1.c: outside all blocks **/
int n1; /* defaults to extern, initialized by compiler to zero */
extern int n2 = -1; /* ok, initialized explicitly */
int n3 = 9876; /* ok, extern by default and initialized explicitly */
```
要使在 `file1.c` 中定义为 `extern` 的变量在另一个文件(例如 `file2.c`)中可见,该变量必须在 `file2.c` 中显式 *声明* 为 `extern` 并且不能初始化(初始化会将声明转换为定义):
```
/** file2.c **/
extern int n1; /* declaration of n1 defined in file1.c */
```
为了避免与 `extern` 变量混淆,经验是在 *声明* 中显式使用 `extern`(必须),但不要在 *定义* 中使用(非必须且棘手)。对于函数,`extern` 在定义中是可选使用的,但在声明中是必须使用的。下一节中的 `staticProg` 示例会把这些点整合到一个完整的程序中。
### staticProg 示例
`staticProg` 程序由三个文件组成:两个 C 语言源文件(`static1.c` 和 `static2.c`)以及一个头文件(`static.h`),头文件中包含两个声明:
```
/** header file static.h **/
#define NumCount 100 /* macro */
extern int global_nums[NumCount]; /* array declaration */
extern void fill_array(); /* function declaration */
```
两个声明中的 `extern`,一个用于数组,另一个用于函数,强调对象在别处(“外部”)*定义*:数组 `global_nums` 在文件 `static1.c` 中定义(没有显式的 `extern`),函数 `fill_array` 在文件 `static2.c` 中定义(也没有显式的 `extern`)。每个源文件都包含了头文件 `static.h`。`static1.c` 文件定义了两个驻留在内存静态区域中的数组(`global_nums` 和 `more_nums`)。第二个数组有 `static` 修饰,这将其作用域限制为定义数组的文件 (`static1.c`)。如前所述, `extern` 修饰的 `global_nums` 则可以实现在多个文件中可见。
```
/** static1.c **/
#include <stdio.h>
#include <stdlib.h>
#include "static.h" /* declarations */
int global_nums[NumCount]; /* definition: extern (global) aggregate */
static int more_nums[NumCount]; /* definition: scope limited to this file */
int main() {
fill_array(); /** defined in file static2.c **/
unsigned i;
for (i = 0; i < NumCount; i++)
more_nums[i] = i * -1;
/* confirm initialization worked */
for (i = 0; i < NumCount; i += 10)
printf("%4i\t%4i\n", global_nums[i], more_nums[i]);
return 0;
}
```
下面的 `static2.c` 文件中定义了 `fill_array` 函数,该函数由 `main`(在 `static1.c` 文件中)调用;`fill_array` 函数会给名为 `global_nums` 的 `extern` 数组中的元素赋值,该数组在文件 `static1.c` 中定义。使用两个文件的唯一目的是凸显 `extern` 变量或函数能够跨文件可见。
```
/** static2.c **/
#include "static.h" /** declarations **/
void fill_array() { /** definition **/
unsigned i;
for (i = 0; i < NumCount; i++) global_nums[i] = i + 2;
}
```
`staticProg` 程序可以用如下编译:
```
% gcc -o staticProg static1.c static2.c
```
### 从汇编语言看更多细节
现代 C 编译器能够处理 C 和汇编语言的任意组合。编译 C 源文件时,编译器首先将 C 代码翻译成汇编语言。这是对从上文 `static1.c` 文件生成的汇编语言进行保存的命令:
```
% gcc -S static1.c
```
生成的文件就是 `static1.s`。这是文件顶部的一段代码,额外添加了行号以提高可读性:
```
.file "static1.c" ## line 1
.text ## line 2
.comm global_nums,400,32 ## line 3
.local more_nums ## line 4
.comm more_nums,400,32 ## line 5
.section .rodata ## line 6
.LC0: ## line 7
.string "%4i\t%4i\n" ## line 8
.text ## line 9
.globl main ## line 10
.type main, @function ## line 11
main: ## line 12
...
```
诸如 `.file`(第 1 行)之类的汇编语言指令以句点开头。顾名思义,指令会指导汇编程序将汇编语言翻译成机器代码。`.rodata` 指令(第 6 行)表示后面是只读对象,包括字符串常量 `"%4i\t%4i\n"`(第 8 行),`main` 函数(第 12 行)会使用此字符串常量来实现格式化输出。作为标签引入(通过末尾的冒号实现)的 `main` 函数(第 12 行),同样也是只读的。
在汇编语言中,标签就是地址。标签 `main:`(第 12 行)标记了 `main` 函数代码开始的地址,标签 `.LC0:`(第 7 行)标记了格式化字符串开头所在的地址。
`global_nums`(第 3 行)和 `more_nums`(第 4 行)数组的定义包含了两个数字:400 是每个数组中的总字节数,32 是每个数组(含 100 个 `int` 元素)中每个元素的比特数。(第 5 行中的 `.comm` 指令表示 `common name`,可以忽略。)
两个数组定义的不同之处在于 `more_nums` 被标记为 `.local`(第 4 行),这意味着其作用域仅限于其所在文件 `static1.s`。相比之下,`global_nums` 数组就能在多个文件中实现可见,包括由 `static1.c` 和 `static2.c` 文件翻译成的汇编文件。
最后,`.text` 指令在汇编代码段中出现了两次(第 2 行和第 9 行)。术语“text”表示“只读”,但也会涵盖一些读/写变量,例如两个数组中的元素。尽管本文展示的汇编语言是针对 Intel 架构的,但 Arm6 汇编也非常相似。对于这两种架构,`.text` 区域中的变量(本例中为两个数组中的元素)会自动初始化为零。
### 总结
C 语言中的内存高效和内存安全编程准则很容易说明,但可能会很难遵循,尤其是在调用设计不佳的库的时候。准则如下:
* 尽可能使用栈存储,进而鼓励编译器将通用寄存器用作暂存器,实现优化。栈存储代表了高效的内存使用并促进了代码的整洁和模块化。永远不要返回指向基于栈的存储的指针。
* 小心使用堆存储。C(和 C++)中的重难点是确保动态分配的存储尽快解除分配。良好的编程习惯和工具(如 `valgrind`)有助于攻关这些重难点。优先选用自身提供释放函数的库,例如 `nestedHeap` 代码示例中的 `free_all` 释放函数。
* 谨慎使用静态存储,因为这种存储会自始至终地影响进程的内存占用。特别是尽量避免使用 `extern` 和 `static` 数组。
本文 C 语言代码示例可在我的网站(<https://condor.depaul.edu/mkalin>)上找到。
---
via: <https://opensource.com/article/21/8/memory-programming-c>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | C is a high-level language with close-to-the-metal features that make it seem, at times, more like a portable assembly language than a sibling of Java or Python. Among these features is memory management, which covers an executing program's safe and efficient use of memory. This article goes into the details of memory safety and efficiency through code examples in C and a code segment from the assembly language that a modern C compiler generates.
Although the code examples are in C, the guidelines for safe and efficient memory management are the same for C++. The two languages differ in various details (e.g., C++ has object-oriented features and generics that C lacks), but these languages share the very same challenges with respect to memory management.
## Overview of memory for an executing program
For an executing program (aka *process*), memory is partitioned into three areas: The **stack**, the **heap**, and the **static area**. Here's an overview of each, with full code examples to follow.
As a backup for general-purpose CPU registers, the *stack* provides scratchpad storage for the local variables within a code block, such as a function or a loop body. Arguments passed to a function count as local variables in this context. Consider a short example:
```
void some_func(int a, int b) {
int n;
...
}
```
Storage for the arguments passed in parameters **a** and **b** and the local variable **n** would come from the stack unless the compiler could find general-purpose registers instead. The compiler favors such registers for scratchpad because CPU access to these registers is fast (one clock tick). However, these registers are few (roughly sixteen) on the standard architectures for desktop, laptop, and handheld machines.
At the implementation level, which only an assembly-language programmer would see, the stack is organized as a LIFO (Last In, First Out) list with **push** (insert) and **pop** (remove) operations. The **top** pointer can act as a base address for offsets; in this way, stack locations other than **top** become accessible. For example, the expression **top+16** points to a location sixteen bytes above the stack's **top**, and the expression **top-16** points to sixteen bytes below the **top**. Accordingly, stack locations that implement scratchpad storage are accessible through the **top** pointer. On a standard ARM or Intel architecture, the stack grows from high to low memory addresses; hence, to decrement **top** is to grow the stack for a process.
To use the stack is to use memory effortlessly and efficiently. The compiler, rather than the programmer, writes the code that manages the stack by allocating and deallocating the required scratchpad storage; the programmer declares function arguments and local variables, leaving the implementation to the compiler. Moreover, the very same stack storage can be reused across consecutive function calls and code blocks such as loops. Well-designed modular code makes stack storage the first memory option for scratchpad, with an optimizing compiler using, whenever possible, general-purpose registers instead of the stack.
The **heap** provides storage allocated explicitly through programmer code, although the syntax for heap allocation differs across languages. In C, a successful call to the library function **malloc** (or variants such as **calloc**) allocates a specified number of bytes. (In languages such as C++ and Java, the **new** operator serves the same purpose.) Programming languages differ dramatically on how heap-allocated storage is deallocated:
- In languages such as Java, Go, Lisp, and Python, the programmer does not explicitly deallocate dynamically allocated heap storage.
For example, this Java statement allocates heap storage for a string and stores the address of this heap storage in the variable **greeting**:
`String greeting = new String("Hello, world!");`
Java has a garbage collector, a runtime utility that automatically deallocates heap storage that is no longer accessible to the process that allocated the storage. Java heap deallocation is thus automatic through a garbage collector. In the example above, the garbage collector would deallocate the heap storage for the string after the variable **greeting** went out of scope.
- The Rust compiler writes the heap-deallocation code. This is Rust's pioneering effort to automate heap-deallocation without relying on a garbage collector, which entails runtime complexity and overhead. Hats off to the Rust effort!
- In C (and C++), heap deallocation is a programmer task. The programmer who allocates heap storage through a call to
**malloc**is then responsible for deallocating this same storage with a matching call to the library function**free**. (In C++, the**new**operator allocates heap storage, whereas the**delete**and**delete[]**operators free such storage.) Here's a C example:
```
char* greeting = malloc(14); /* 14 heap bytes */
strcpy(greeting, "Hello, world!"); /* copy greeting into bytes */
puts(greeting); /* print greeting */
free(greeting); /* free malloced bytes */
```
C avoids the cost and complexity of a garbage collector, but only by burdening the programmer with the task of heap deallocation.
The **static area** of memory provides storage for executable code such as C functions, string literals such as "Hello, world!", and global variables:
```
int n; /* global variable */
int main() { /* function */
char* msg = "No comment"; /* string literal */
...
}
```
This area is static in that its size remains fixed from the start until the end of process execution. Because the static area amounts to a fixed-sized memory footprint for a process, the rule of thumb is to keep this area as small as possible by avoiding, for example, global arrays.
Code examples in the following sections flesh out this overview.
## Stack storage
Imagine a program that has various tasks to perform consecutively, including processing numeric data downloaded every few minutes over a network and stored in a local file. The **stack** program below simplifies the processing (odd integer values are made even) to keep the focus on the benefits of stack storage.
```
#include <stdio.h>
#include <stdlib.h>
#define Infile "incoming.dat"
#define Outfile "outgoing.dat"
#define IntCount 128000 /* 128,000 */
void other_task1() { /*...*/ }
void other_task2() { /*...*/ }
void process_data(const char* infile,
const char* outfile,
const unsigned n) {
int nums[n];
FILE* input = fopen(infile, "r");
if (NULL == infile) return;
FILE* output = fopen(outfile, "w");
if (NULL == output) {
fclose(input);
return;
}
fread(nums, n, sizeof(int), input); /* read input data */
unsigned i;
for (i = 0; i < n; i++) {
if (1 == (nums[i] & 0x1)) /* odd parity? */
nums[i]--; /* make even */
}
fclose(input); /* close input file */
fwrite(nums, n, sizeof(int), output);
fclose(output);
}
int main() {
process_data(Infile, Outfile, IntCount);
/** now perform other tasks **/
other_task1(); /* automatically released stack storage available */
other_task2(); /* ditto */
return 0;
}
```
The **main** function at the bottom first calls the **process_data** function, which creates a stack-based array of a size given by argument **n** (128,000 in the current example). Accordingly, the array holds 128,000 x **sizeof(int)** bytes, which comes to 512,000 bytes on standard devices because an **int** is four bytes on these devices. Data then are read into the array (using library function **fread**), processed in a loop, and saved to the local file **outgoing.dat** (using library function **fwrite**).
When the **process_data** function returns to its caller **main**, the roughly 500MB of stack scratchpad for the **process_data **function become available for other functions in the **stack** program to use as scratchpad. In this example, **main** next calls the stub functions **other_task1** and **other_task2**. The three functions are called consecutively from **main**, which means that all three can use the same stack storage for scratchpad. Because the compiler rather than the programmer writes the stack-management code, this approach is both efficient and easy on the programmer.
In C, any variable defined inside a block (e.g., a function's or a loop's body) has an **auto** storage class by default, which means that the variable is stack-based. The storage class **register** is now outdated because C compilers are aggressive, on their own, in trying to use CPU registers whenever possible. Only a variable defined inside a block may be **register**, which the compiler changes to **auto** if no CPU register is available.Stack-based programming may be the preferred way to go, but this style does have its challenges. The **badStack** program below illustrates.
```
#include <stdio.h>
const int* get_array(const unsigned n) {
int arr[n]; /* stack-based array */
unsigned i;
for (i = 0; i < n; i++) arr[i] = 1 + 1;
return arr; /** ERROR **/
}
int main() {
const unsigned n = 16;
const int* ptr = get_array(n);
unsigned i;
for (i = 0; i < n; i++) printf("%i ", ptr[i]);
puts("\n");
return 0;
}
```
The flow of control in the **badStack** program is straightforward. Function **main** calls function **get_array** with an argument of 128, which the called function then uses to create a local array of this size. The **get_array** function initializes the array and returns to **main** the array's identifier **arr**, which is a pointer constant that holds the address of the array's first **int** element.
The local array **arr** is accessible within the **get_array** function, of course, but this array cannot be legitimately accessed once **get_array** returns. Nonetheless, function **main** tries to print the stack-based array by using the stack address **arr**, which function **get_array** returns. Modern compilers warn about the mistake. For example, here's the warning from the GNU compiler:
```
badStack.c: In function 'get_array':
badStack.c:9:10: warning: function returns address of local variable [-Wreturn-local-addr]
8 | return arr; /** ERROR **/
```
The general rule is that stack-based storage should be accessed only within the code block that contains the local variables implemented with stack storage (in this case, the array pointer **arr** and the loop counter** i**). Accordingly, a function should never return a pointer to stack-based storage.
## Heap storage
Several code examples highlight the fine points of using heap storage in C. In the first example, heap storage is allocated, used, and then freed in line with best practice. The second example nests heap storage inside other heap storage, which complicates the deallocation operation.
```
#include <stdio.h>
#include <stdlib.h>
int* get_heap_array(unsigned n) {
int* heap_nums = malloc(sizeof(int) * n);
unsigned i;
for (i = 0; i < n; i++)
heap_nums[i] = i + 1; /* initialize the array */
/* stack storage for variables heap_nums and i released
automatically when get_num_array returns */
return heap_nums; /* return (copy of) the pointer */
}
int main() {
unsigned n = 100, i;
int* heap_nums = get_heap_array(n); /* save returned address */
if (NULL == heap_nums) /* malloc failed */
fprintf(stderr, "%s\n", "malloc(...) failed...");
else {
for (i = 0; i < n; i++) printf("%i\n", heap_nums[i]);
free(heap_nums); /* free the heap storage */
}
return 0;
}
```
The **heap** program above has two functions: **main** calls **get_heap_array** with an argument (currently 100) that specifies how many **int** elements the array should have. Because the heap allocation could fail, **main** checks whether **get_heap_array** has returned **NULL**, which signals failure. If the allocation succeeds, **main** prints the **int **values in the array—and immediately thereafter deallocates, with a call to library function **free**, the heap-allocated storage. This is best practice.
The **get_heap_array** function opens with this statement, which merits a closer look:
`int* heap_nums = malloc(sizeof(int) * n); /* heap allocation */`
The **malloc** library function and its variants deal with bytes; hence, the argument to **malloc** is the number of bytes required for **n** elements of type **int**. (The **sizeof(int)** is four bytes on a standard modern device.) The **malloc** function returns either the address of the first among the allocated bytes or, in case of failure, **NULL**.
In a successful call to **malloc**, the returned address is 64-bits in size on a modern desktop machine. On handhelds and earlier desktop machines, the address might be 32-bits in size or, depending on age, even smaller. The elements in the heap-allocated array are of type **int**, a four-byte signed integer. The address of these heap-allocated **int**s is stored in the local variable **heap_nums**, which is stack-based. Here's a depiction:
```
heap-based
stack-based /
\ +----+----+ +----+
heap-nums--->|int1|int2|...|intN|
+----+----+ +----+
```
Once the **get_heap_array** function returns, stack storage for pointer variable **heap_nums** is reclaimed automatically—but the heap storage for the dynamic **int** array persists, which is why the **get_heap_array** function returns (a copy of) this address to **main**, which now is responsible, after printing the array's integers, for explicitly deallocating the heap storage with a call to the library function **free**:
`free(heap_nums); /* free the heap storage */`
The **malloc** function does not initialize heap-allocated storage, which therefore contains random values. By contrast, the **calloc **variant initializes the allocated storage to zeros. Both functions return **NULL** to signal failure.
In the **heap** example, **main** returns immediately after calling **free**, and the executing program terminates, which allows the system to reclaim any allocated heap storage. Nonetheless, the programmer should develop the habit of explicitly freeing heap storage as soon as it is no longer needed.
## Nested heap allocation
The next code example is trickier. C has various library functions that return a pointer to heap storage. Here's a familiar scenario:
1. The C program invokes a library function that returns a pointer to heap-based storage, typically an aggregate such as an array or a structure:
`SomeStructure* ptr = lib_function(); /* returns pointer to heap storage */`
2. The program then uses the allocated storage.
3. For cleanup, the issue is whether a simple call to **free** will clean up all of the heap-allocated storage that the library function allocates. For example, the **SomeStructure** instance may have fields that, in turn, point to heap-allocated storage. A particularly troublesome case would be a dynamically allocated array of structures, each of which has a field pointing to more dynamically allocated storage.The following code example illustrates the problem and focuses on designing a library that safely provides heap-allocated storage to clients.
```
#include <stdio.h>
#include <stdlib.h>
typedef struct {
unsigned id;
unsigned len;
float* heap_nums;
} HeapStruct;
unsigned structId = 1;
HeapStruct* get_heap_struct(unsigned n) {
/* Try to allocate a HeapStruct. */
HeapStruct* heap_struct = malloc(sizeof(HeapStruct));
if (NULL == heap_struct) /* failure? */
return NULL; /* if so, return NULL */
/* Try to allocate floating-point aggregate within HeapStruct. */
heap_struct->heap_nums = malloc(sizeof(float) * n);
if (NULL == heap_struct->heap_nums) { /* failure? */
free(heap_struct); /* if so, first free the HeapStruct */
return NULL; /* then return NULL */
}
/* Success: set fields */
heap_struct->id = structId++;
heap_struct->len = n;
return heap_struct; /* return pointer to allocated HeapStruct */
}
void free_all(HeapStruct* heap_struct) {
if (NULL == heap_struct) /* NULL pointer? */
return; /* if so, do nothing */
free(heap_struct->heap_nums); /* first free encapsulated aggregate */
free(heap_struct); /* then free containing structure */
}
int main() {
const unsigned n = 100;
HeapStruct* hs = get_heap_struct(n); /* get structure with N floats */
/* Do some (meaningless) work for demo. */
unsigned i;
for (i = 0; i < n; i++) hs->heap_nums[i] = 3.14 + (float) i;
for (i = 0; i < n; i += 10) printf("%12f\n", hs->heap_nums[i]);
free_all(hs); /* free dynamically allocated storage */
return 0;
}
```
The **nestedHeap** example above centers on a structure **HeapStruct** with a pointer field named **heap_nums**:
```
typedef struct {
unsigned id;
unsigned len;
float* heap_nums; /** pointer **/
} HeapStruct;
```
The function **get_heap_struct** tries to allocate heap storage for a **HeapStruct** instance, which entails allocating heap storage for a specified number of **float** variables to which the field **heap_nums** points. The result of a successful call to **get_heap_struct** can be depicted as follows, with **hs** as the pointer to the heap-allocated structure:
```
hs-->HeapStruct instance
id
len
heap_nums-->N contiguous float elements
```
In the **get_heap_struct** function, the first heap allocation is straightforward:
```
HeapStruct* heap_struct = malloc(sizeof(HeapStruct));
if (NULL == heap_struct) /* failure? */
return NULL; /* if so, return NULL */
```
The **sizeof(HeapStruct)** includes the bytes (four on a 32-bit machine, eight on a 64-bit machine) for the **heap_nums** field, which is a pointer to the **float** elements in a dynamically allocated array. At issue, then, is whether the **malloc** delivers the bytes for this structure or **NULL** to signal failure; if **NULL**, the **get_heap_struct** function returns **NULL** to notify the caller that the heap allocation failed.
The second attempted heap allocation is more complicated because, at this step, heap storage for the **HeapStruct** has been allocated:
```
heap_struct->heap_nums = malloc(sizeof(float) * n);
if (NULL == heap_struct->heap_nums) { /* failure? */
free(heap_struct); /* if so, first free the HeapStruct */
return NULL; /* and then return NULL */
}
```
The argument **n** sent to the **get_heap_struct** function indicates how many **float** elements should be in the dynamically allocated **heap_nums** array. If the required **float** elements can be allocated, then the function sets the structure's **id** and **len** fields before returning the heap address of the **HeapStruct**. If the attempted allocation fails, however, two steps are necessary to meet best practice:
1. The storage for the **HeapStruct** must be freed to avoid memory leakage. Without the dynamic **heap_nums** array, the **HeapStruct** is presumably of no use to the client function that calls **get_heap_struct**; hence, the bytes for the **HeapStruct** instance should be explicitly deallocated so that the system can reclaim these bytes for future heap allocations.
2. **NULL** is returned to signal failure.
If the call to the **get_heap_struct** function succeeds, then freeing the heap storage is also tricky because it involves two **free** operations in the proper order. Accordingly, the program includes a **free_all** function instead of requiring the programmer to figure out the appropriate two-step deallocation. For review, here's the **free_all** function:
```
void free_all(HeapStruct* heap_struct) {
if (NULL == heap_struct) /* NULL pointer? */
return; /* if so, do nothing */
free(heap_struct->heap_nums); /* first free encapsulated aggregate */
free(heap_struct); /* then free containing structure */
}
```
After checking that the argument **heap_struct** is not **NULL**, the function first frees the **heap_nums** array, which requires that the **heap_struct** pointer is still valid. It would be an error to release the **heap_struct** first. Once the **heap_nums** have been deallocated, the **heap_struct** can be freed as well. If **heap_struct** were freed, but **heap_nums** were not, then the **float** elements in the array would be leakage: still allocated bytes but with no possibility of access—hence, of deallocation. The leakage would persist until the **nestedHeap** program exited and the system reclaimed the leaked bytes.
A few cautionary notes on the **free** library function are in order. Recall the sample calls above:
```
free(heap_struct->heap_nums); /* first free encapsulated aggregate */
free(heap_struct); /* then free containing structure */
```
These calls free the allocated storage—but they do *not* set their arguments to **NULL**. (The **free** function gets a copy of an address as an argument; hence, changing the copy to **NULL** would leave the original unchanged.) For example, after a successful call to **free**, the pointer **heap_struct** still holds a heap address of some heap-allocated bytes, but using this address now would be an error because the call to **free** gives the system the right to reclaim and then reuse the allocated bytes.
Calling **free** with a **NULL** argument is pointless but harmless. Calling **free** repeatedly on a non-**NULL** address is an error with indeterminate results:
```
free(heap_struct); /* 1st call: ok */
free(heap_struct); /* 2nd call: ERROR */
```
## Memory leakage and heap fragmentation
The phrase "memory leakage" refers to dynamically allocated heap storage that is no longer accessible. Here's a code segment for review:
```
float* nums = malloc(sizeof(float) * 10); /* 10 floats */
nums[0] = 3.14f; /* and so on */
nums = malloc(sizeof(float) * 25); /* 25 new floats */
```
Assume that the first **malloc** succeeds. The second **malloc** resets the **nums** pointer, either to **NULL** (allocation failure) or to the address of the first **float** among newly allocated twenty-five. Heap storage for the initial ten **float** elements remains allocated but is now inaccessible because the **nums** pointer either points elsewhere or is **NULL**. The result is forty bytes (**sizeof(float) * 10**) of leakage.
Before the second call to **malloc**, the initially allocated storage should be freed:
```
float* nums = malloc(sizeof(float) * 10); /* 10 floats */
nums[0] = 3.14f; /* and so on */
free(nums); /** good **/
nums = malloc(sizeof(float) * 25); /* no leakage */
```
Even without leakage, the heap can fragment over time, which then requires system defragmentation. For example, suppose that the two biggest heap chunks are currently of sizes 200MB and 100MB. However, the two chunks are not contiguous, and process **P** needs to allocate 250MB of contiguous heap storage. Before the allocation can be made, the system must *defragment* the heap to provide 250MB contiguous bytes for **P**. Defragmentation is complicated and, therefore, time-consuming.
Memory leakage promotes fragmentation by creating allocated but inaccessible heap chunks. Freeing no-longer-needed heap storage is, therefore, one way that a programmer can help to reduce the need for defragmentation.
## Tools to diagnose memory leakage
Various tools are available for profiling memory efficiency and safety. My favorite is [valgrind](https://www.valgrind.org/). To illustrate how the tool works for memory leaks, here's the **leaky** program:
```
#include <stdio.h>
#include <stdlib.h>
int* get_ints(unsigned n) {
int* ptr = malloc(n * sizeof(int));
if (ptr != NULL) {
unsigned i;
for (i = 0; i < n; i++) ptr[i] = i + 1;
}
return ptr;
}
void print_ints(int* ptr, unsigned n) {
unsigned i;
for (i = 0; i < n; i++) printf("%3i\n", ptr[i]);
}
int main() {
const unsigned n = 32;
int* arr = get_ints(n);
if (arr != NULL) print_ints(arr, n);
/** heap storage not yet freed... **/
return 0;
}
```
The function **main** calls **get_ints**, which tries to **malloc** thirty-two 4-byte **int**s from the heap and then initializes the dynamic array if the **malloc** succeeds. On success, the **main** function then calls **print_ints**. There is no call to **free** to match the call to **malloc**; hence, memory leaks.
With the **valgrind** toolbox installed, the command below checks the **leaky** program for memory leaks (**%** is the command-line prompt):
`% valgrind --leak-check=full ./leaky`
Below is most of the output. The number on the left, 207683, is the process identifier of the executing **leaky** program. The report provides details of where the leak occurs, in this case, from the call to **malloc** within the **get_ints** function that **main** calls.
```
==207683== HEAP SUMMARY:
==207683== in use at exit: 128 bytes in 1 blocks
==207683== total heap usage: 2 allocs, 1 frees, 1,152 bytes allocated
==207683==
==207683== 128 bytes in 1 blocks are definitely lost in loss record 1 of 1
==207683== at 0x483B7F3: malloc (in /usr/lib/x86_64-linux-gnu/valgrind/vgpreload_memcheck-amd64-linux.so)
==207683== by 0x109186: get_ints (in /home/marty/gc/leaky)
==207683== by 0x109236: main (in /home/marty/gc/leaky)
==207683==
==207683== LEAK SUMMARY:
==207683== definitely lost: 128 bytes in 1 blocks
==207683== indirectly lost: 0 bytes in 0 blocks
==207683== possibly lost: 0 bytes in 0 blocks
==207683== still reachable: 0 bytes in 0 blocks
==207683== suppressed: 0 bytes in 0 blocks
```
If function **main** is revised to include a call to **free** right after the one to **print_ints**, then **valgrind** gives the **leaky** program a clean bill of health:
`==218462== All heap blocks were freed -- no leaks are possible`
## Static area storage
In orthodox C, a function must be defined outside all blocks. This rules out having one function defined inside the body of another, a feature that some C compilers support. My examples stick with functions defined outside all blocks. Such a function is either **static** or **extern**, with **extern** as the default.
C functions and variables with either **static** or **extern** as their storage class reside in what I've been calling the **static area** of memory because this area has a fixed size during program execution. The syntax for these two storage classes is complicated enough to merit a review. After the review, a full code example brings the syntactic details back to life. Functions or variables defined outside all blocks default to **extern**; hence, the storage class **static** must be explicit for both functions and variables:
```
/** file1.c: outside all blocks, five definitions **/
int foo(int n) { return n * 2; } /* extern by default */
static int bar(int n) { return n; } /* static */
extern int baz(int n) { return -n; } /* explicitly extern */
int num1; /* extern */
static int num2; /* static */
```
The difference between **extern** and **static** comes down to scope: an **extern** function or variable may be visible across files. By contrast, a **static** function is visible only in the file that contains the function's *definition*, and a **static** variable is visible only in the file (or a block therein) that has the variable's *definition*:
```
static int n1; /* scope is the file */
void func() {
static int n2; /* scope is func's body */
...
}
```
If a **static** variable such as **n1** above is defined outside all blocks, the variable's scope is the file in which the variable is defined. Wherever a **static** variable may be defined, storage for the variable is in the static area of memory.
An **extern** function or variable is defined outside all blocks in a given file, but the function or variable so defined then may be declared in some other file. The typical practice is to *declare* such a function or variable in a header file, which is included wherever needed. Some short examples clarify these tricky points.
Suppose that the **extern** function **foo** is *defined* in **file1.c**, with or without the keyword **extern**:
```
/** file1.c **/
int foo(int n) { return n * 2; } /* definition has a body {...} */
```
This function must be *declared* with an explicit **extern** in any other file (or block therein) for the function to be visible. Here's the declaration that makes the **extern** function **foo** visible in file **file2.c**:
```
/** file2.c: make function foo visible here **/
extern int foo(int); /* declaration (no body) */
```
Recall that a function declaration does not have a body enclosed in curly braces, whereas a function definition does have such a body.
For review, header files typically contain function and variable declarations. Source-code files that require the declarations then **#include** the relevant header file(s). The **staticProg** program in the next section illustrates this approach.
The rules get trickier (sorry!) with **extern** variables. Any **extern** object—function or variable—must be *defined* outside all blocks. Also, a variable defined outside all blocks defaults to **extern**:
```
/** outside all blocks **/
int n; /* defaults to extern */
```
However, the **extern** can be explicit in the variable's *definition* only if the variable is initialized explicitly there:
```
/** file1.c: outside all blocks **/
int n1; /* defaults to extern, initialized by compiler to zero */
extern int n2 = -1; /* ok, initialized explicitly */
int n3 = 9876; /* ok, extern by default and initialized explicitly */
```
For a variable defined as **extern** in **file1.c** to be visible in another file such as **file2.c**, the variable must be *declared* as explicitly **extern** in **file2.c** and not initialized, which would turn the declaration into a definition:
```
/** file2.c **/
extern int n1; /* declaration of n1 defined in file1.c */
```
To avoid confusion with **extern** variables, the rule of thumb is to use **extern** explicitly in a *declaration* (required) but not in a *definition* (optional and tricky). For functions, the **extern** is optional in a definition but needed for a declaration. The **staticProg** example in the next section brings these points together in a full program.
## The staticProg example
The **staticProg** program consists of three files: two C source files (**static1.c** and **static2.c**) together with a header file (**static.h**) that contains two declarations:
```
/** header file static.h **/
#define NumCount 100 /* macro */
extern int global_nums[NumCount]; /* array declaration */
extern void fill_array(); /* function declaration */
```
The **extern** in the two declarations, one for an array and the other for a function, underscores that the objects are *defined* elsewhere ("externally"): the array **global_nums** is defined in file **static1.c** (without an explicit **extern**) and the function **fill_array** is defined in file **static2.c** (also without an explicit **extern**). Each source file includes the header file **static.h**.The **static1.c** file defines the two arrays that reside in the static area of memory, **global_nums** and **more_nums**. The second array has a **static** storage class, which restricts its scope to the file (**static1.c**) in which the array is defined. As noted, **global_nums** as **extern** can be made visible in multiple files.
```
/** static1.c **/
#include <stdio.h>
#include <stdlib.h>
#include "static.h" /* declarations */
int global_nums[NumCount]; /* definition: extern (global) aggregate */
static int more_nums[NumCount]; /* definition: scope limited to this file */
int main() {
fill_array(); /** defined in file static2.c **/
unsigned i;
for (i = 0; i < NumCount; i++)
more_nums[i] = i * -1;
/* confirm initialization worked */
for (i = 0; i < NumCount; i += 10)
printf("%4i\t%4i\n", global_nums[i], more_nums[i]);
return 0;
}
```
The **static2.c** file below defines the **fill_array** function, which **main** (in the **static1.c** file) invokes; the **fill_array** function populates the **extern** array named **global_nums**, which is defined in file **static1.c**. The sole point of having two files is to underscore that an **extern** variable or function can be visible across files.
```
/** static2.c **/
#include "static.h" /** declarations **/
void fill_array() { /** definition **/
unsigned i;
for (i = 0; i < NumCount; i++) global_nums[i] = i + 2;
}
```
The **staticProg** program can be compiled as follows:
`% gcc -o staticProg static1.c static2.c`
## More details from assembly language
A modern C compiler can handle any mix of C and assembly language. When compiling a C source file, the compiler first translates the C code into assembly language. Here's the command to save the assembly language generated from the **static1.c** file above:
`% gcc -S static1.c`
The resulting file is **static1.s**. Here's a segment from the top, with added line numbers for readability:
```
.file "static1.c" ## line 1
.text ## line 2
.comm global_nums,400,32 ## line 3
.local more_nums ## line 4
.comm more_nums,400,32 ## line 5
.section .rodata ## line 6
.LC0: ## line 7
.string "%4i\t%4i\n" ## line 8
.text ## line 9
.globl main ## line 10
.type main, @function ## line 11
main: ## line 12
...
```
The assembly-language directives such as **.file** (line 1) begin with a period. As the name suggests, a directive guides the assembler as it translates assembly language into machine code. The **.rodata** directive (line 6) indicates that read-only objects follow, including the string constant **"%4i\t%4i\n"** (line 8), which function **main** (line 12) uses to format output. The function **main** (line 12), introduced as a label (the colon at the end makes it so), is likewise read-only.
In assembly language, labels are addresses. The label **main:** (line 12) marks the address at which the code for the **main** function begins, and the label **.LC0**: (line 7) marks the address at which the format string begins.
The definitions of the **global_nums** (line 3) and **more_nums** (line 4) arrays include two numbers: 400 is the total number of bytes in each array, and 32 is the number of bits in each of the 100 **int** elements per array. (The **.comm** directive in line 5 stands for **common name**, which can be ignored.)
The array definitions differ in that **more_nums** is marked as **.local** (line 4), which means that its scope is restricted to the containing file **static1.s**. By contrast, the **global_nums** array can be made visible across multiple files, including the translations of the **static1.c** and **static2.c** files.
Finally, the **.text** directive occurs twice (lines 2 and 9) in the assembly code segment. The term "text" suggests "read-only" but also covers read/write variables such as the elements in the two arrays. Although the assembly language shown is for an Intel architecture, Arm6 assembly would be quite similar. For both architectures, variables in the **.text** area (in this case, elements in the two arrays) are initialized automatically to zeros.
## Wrapping up
For memory-efficient and memory-safe programming in C, the guidelines are easy to state but may be hard to follow, especially when calls to poorly designed libraries are in play. The guidelines are:
- Use stack storage whenever possible, thereby encouraging the compiler to optimize with general-purpose registers for scratchpad. Stack storage represents efficient memory use and promotes clean, modular code. Never return a pointer to stack-based storage.
- Use heap storage carefully. The challenge in C (and C++) is to ensure that dynamically allocated storage is deallocated ASAP. Good programming habits and tools (such as
**valgrind**) help to meet the challenge. Favor libraries that provide their own deallocation function(s), such as the**free_all**function in the**nestedHeap**code example. - Use static storage judiciously, as this storage impacts the memory footprint of a process from start to finish. In particular, try to avoid
**extern**and**static**arrays.
The C code examples are available at my website ([https://condor.depaul.edu/mkalin](https://condor.depaul.edu/mkalin)).
## 3 Comments |
13,846 | 在 Fedora CoreOS 上运行 GitHub Actions | https://fedoramagazine.org/run-github-actions-on-fedora-coreos/ | 2021-10-03T11:03:12 | [
"CI",
"CD",
"GitHub"
] | https://linux.cn/article-13846-1.html | 
[GitHub Actions](https://docs.github.com/en/actions) 是一项为快速建立持续集成和交付(CI/CD)工作流程而提供的服务。这些工作流程在被称为“<ruby> 运行器 <rt> runner </rt></ruby>”的主机上运行。GitHub 提供的 [托管运行器](https://docs.github.com/en/actions/using-github-hosted-runners/about-github-hosted-runners) 的操作系统的选择是有限的(Windows Server、Ubuntu、MacOS)。
另一个选择是使用 [自托管](https://docs.github.com/en/actions/hosting-your-own-runners) 的运行器,这让仓库管理员对运行器有更多控制。自托管的运行程序是专门为某个存储库或组织服务的。下面的文章介绍了使用 Fedora CoreOS 配置自托管运行程序的步骤。
### 入门
Fedora CoreOS 是一个精简的操作系统,旨在便于大规模的部署和维护。该操作系统会自动更新,并默认提供运行容器所需的工具。由于这些原因,Fedora CoreOS 是运行 CI/CD 工作流程的一个极佳选择。
配置和配备 Fedora CoreOS 机器的第一步是生成一个 [Ignition](https://github.com/coreos/ignition) 文件。[Butane](https://github.com/coreos/butane) 允许你使用更友好的格式(YAML)生成 Ignition 文件。
#### 配置一个 Fedora CoreOS 运行器
要在 Fedora CoreOS 上执行 GitHub Actions,托管主机需要用于注册和运行该运行器的二进制文件和脚本。从 [Actions 运行器项目](https://github.com/actions/runner) 下载二进制文件和脚本,并部署在 `/usr/local/sbin/actions-runner` 下。
```
version: "1.3.0"
variant: fcos
storage:
directories:
- path: /usr/local/sbin/actions-runner
mode: 0755
user:
name: core
group:
name: core
files:
- path: /usr/local/sbin/actions-runner/actions-runner-linux.tar.gz
overwrite: true
contents:
source: https://github.com/actions/runner/releases/download/v2.278.0/actions-runner-linux-x64-2.278.0.tar.gz
mode: 0755
user:
name: core
group:
name: core
```
#### 注册和删除令牌
为一个项目配置运行器需要一个“<ruby> 令牌 <rt> token </rt></ruby>”。这可以防止在没有正确权限的情况下从项目中注册或删除自托管的运行器。GitHub 提供的令牌有一个小时的过期时间。如果运行器在这个时间之后重新启动,它将需要一个新的注册令牌。
该令牌可能出问题,特别是在 Fedora CoreOS 自动更新时。更新过程希望托管主机在收到新数据后至少每隔几周重启一次。
幸运的是,可以使用 GitHub REST API 来获取这些令牌,并在托管主机每次重启时自动配置运行器。下面的 `manage-runner.sh` 脚本使用 API 来获取令牌,删除任何已经配置好的运行器,并用新的令牌注册运行器。
```
#!/bin/bash
# Handles the Github Action runner configuration.
# Remove and Registration token expires after 1 hour, if we want our runner
# to work after a reboot (auto update) we need to refresh the tokens.
# First remove the runner with a fresh remove token
REMOVE_TOKEN=$(curl -u ${GITHUB_USER}:${GITHUB_TOKEN} -X POST -H "Accept: application/vnd.github.v3+json" https://api.github.com/repos/${GITHUB_USER}/${GITHUB_REPO}/actions/runners/remove-token | jq -r '.token')
/usr/local/sbin/actions-runner/config.sh remove --token ${REMOVE_TOKEN}
# Then register the runner with a fresh registration token
REGISTRATION_TOKEN=$(curl -u ${GITHUB_USER}:${GITHUB_TOKEN} -X POST -H "Accept: application/vnd.github.v3+json" https://api.github.com/repos/${GITHUB_USER}/${GITHUB_REPO}/actions/runners/registration-token | jq -r '.token')
/usr/local/sbin/actions-runner/config.sh --url https://github.com/cverna/fcos-actions-runner --token ${REGISTRATION_TOKEN} --labels fcos --unattended
```
上面的脚本使用了一些环境变量,包含 GitHub 用户名和用于验证 REST API 请求的 <ruby> <a href="https://docs.github.com/en/github/authenticating-to-github/creating-a-personal-access-token"> 个人访问令牌 </a> <rt> Personal Access Token </rt></ruby>。个人访问令牌需要存储库权限,以便成功检索运行器的注册和移除令牌。该令牌是安全敏感信息,所以最好将其存储在一个具有更严格权限的不同文件中。在这个例子中,这个文件是 `actions-runner`。
```
GITHUB_USER=<user>
GITHUB_REPO=<repo>
GITHUB_TOKEN=<personal_access_token>
```
以下是创建这两个文件 `manage-runner.sh` 和 `actions-runner` 的 Butane 片段。
```
- path: /usr/local/sbin/actions-runner/manage-runner.sh
contents:
local: manage-runner.sh
mode: 0755
user:
name: core
group:
name: core
- path: /etc/actions-runner
contents:
local: actions-runner
mode: 0700
user:
name: core
group:
name: core
```
### 在 Fedora CoreOS 上运行 Actions
最后,创建用于配置和启动运行器的 systemd 服务。在 Butane 配置文件中定义这些服务。
```
systemd:
units:
- name: github-runner-configure.service
enabled: true
contents: |
[Unit]
Description=Configure the github action runner for a repository
After=network-online.target boot-complete.target
Requires=boot-complete.target
[Service]
EnvironmentFile=/etc/actions-runner
Type=oneshot
RemainAfterExit=yes
User=core
WorkingDirectory=/usr/local/sbin/actions-runner
ExecStartPre=tar xvf actions-runner-linux.tar.gz --no-same-owner
ExecStart=/usr/local/sbin/actions-runner/manage-runner.sh
[Install]
WantedBy=multi-user.target
- name: github-runner.service
enabled: true
contents: |
[Unit]
Description=Run the github action runner
After=github-runner-configure.service
[Service]
WorkingDirectory=/usr/local/sbin/actions-runner
User=core
ExecStart=/usr/local/sbin/actions-runner/run.sh
[Install]
WantedBy=multi-user.target
```
这将创建两个服务:`github-runner-configure.service`(在主机启动完成后运行一次)和 `github-runner.service`(运行 Actions 运行器二进制文件并等待新的 CI/CD 作业)。
现在 Butane 配置已经完成,从中生成一个 Ignition 文件并配备一个 Fedora CoreOS Actions 运行器。
```
$ podman run -i --rm -v $PWD:/code:z --workdir /code quay.io/coreos/butane:release --pretty --strict --files-dir /code config.yaml -o config.ignition
```
一旦 Ignition 文件生成,它就可以用来在 [支持](https://docs.fedoraproject.org/en-US/fedora-coreos/bare-metal/) Fedora CoreOS 的平台上配备一个运行器。
### 配置一个 Action 来使用一个自托管的运行器
下面的测试 Action 工作流程将测试 FCOS 的自托管的运行器。在你的 git 存储库中创建以下文件 `.github/workflows/main.yml`。
```
# This is a basic workflow to help you get started with Actions
name: CI
# Controls when the action will run.
on:
# Triggers the workflow on push or pull request events but only for the main branch
push:
branches: [ main ]
pull_request:
branches: [ main ]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: fcos
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Runs a single command using the runners shell
- name: Run a one-line script
run: podman run --rm fedora-minimal:34 echo Hello World !
```
请注意,`runs-on` 的配置被设置为使用标签为 `fcos` 的运行器。
本文介绍的代码可以在 [这里](https://github.com/cverna/fcos-actions-runner) 中找到。
---
via: <https://fedoramagazine.org/run-github-actions-on-fedora-coreos/>
作者:[Clément Verna](https://fedoramagazine.org/author/cverna/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [GitHub Actions](https://docs.github.com/en/actions) is a service provided to quickly setup continuous integration and delivery (CI/CD) workflows . These workflows run on hosts called *runners*. GitHub provides [hosted runners](https://docs.github.com/en/actions/using-github-hosted-runners/about-github-hosted-runners) with a limited set of operating system choice (Windows Server, Ubuntu, MacOS).
Another option is to use [self-hosted](https://docs.github.com/en/actions/hosting-your-own-runners) runners which gives the repository administrator more control on the runners. Self-hosted runners are dedicated to a repository or organization. The following article goes through the steps of configuring self-hosted runners using Fedora CoreOS.
## Getting Started
Fedora CoreOS is a minimalist operating system designed to be easy to deploy and maintain at scale. The operating system will automaticaly update and provide, by default, the tools needed to run containers. For all of these reasons, Fedora CoreOS is a great choice to consider for running CI/CD workflows.
The first step to configure and provision a Fedora CoreOS machine is to generate an [Ignition](https://github.com/coreos/ignition) file. [Butane](https://github.com/coreos/butane) allows you to generate Ignition’s file using a friendlier format (YAML).
### Configure a Fedora CoreOS runner
To execute GitHub actions on Fedora CoreOS, the host needs the binaries and scripts used to register and run the runner. Download the binaries and scripts from the [actions runner project](https://github.com/actions/runner) and deploy under */usr/local/sbin/actions-runner*.
version: "1.3.0" variant: fcos storage: directories: - path: /usr/local/sbin/actions-runner mode: 0755 user: name: core group: name: core files: - path: /usr/local/sbin/actions-runner/actions-runner-linux.tar.gz overwrite: true contents: source: https://github.com/actions/runner/releases/download/v2.278.0/actions-runner-linux-x64-2.278.0.tar.gz mode: 0755 user: name: core group: name: core
### Registration and Removal token
Configuring runners for a project requires a “token”. This prevents registering or removing self-hosted runners from projects without the correct permissions. Tokens provided by Github have a one hour expiration time. If the runner restarts after this time it will require a new registration token.
The token can be problematic, in particular with Fedora CoreOS automatic updates. The update process expects that the host will restart at least once every couple weeks after receiving new data.
Luckily, it is possible to use GitHub REST API to obtain these tokens and automatically configure the runner every time the host restarts. The following *manage-runner.sh* script uses the APIs to retrieve a token, remove any runner already configured and register the runner with a new token.
#!/bin/bash # Handles the Github Action runner configuration. # Remove and Registration token expires after 1 hour, if we want our runner # to work after a reboot (auto update) we need to refresh the tokens. # First remove the runner with a fresh remove token REMOVE_TOKEN=$(curl -u ${GITHUB_USER}:${GITHUB_TOKEN} -X POST -H "Accept: application/vnd.github.v3+json" https://api.github.com/repos/${GITHUB_USER}/${GITHUB_REPO}/actions/runners/remove-token | jq -r '.token') /usr/local/sbin/actions-runner/config.sh remove --token ${REMOVE_TOKEN} # Then register the runner with a fresh registration token REGISTRATION_TOKEN=$(curl -u ${GITHUB_USER}:${GITHUB_TOKEN} -X POST -H "Accept: application/vnd.github.v3+json" https://api.github.com/repos/${GITHUB_USER}/${GITHUB_REPO}/actions/runners/registration-token | jq -r '.token') /usr/local/sbin/actions-runner/config.sh --url https://github.com/cverna/fcos-actions-runner --token ${REGISTRATION_TOKEN} --labels fcos --unattended
The script above uses a few environment variables that contain a GitHub username and a [Personal Access Token](https://docs.github.com/en/github/authenticating-to-github/creating-a-personal-access-token) used to authenticate the REST API requests. The Personal Access Token requires the repo permissions in order to successfully retrieve the runner registration and removal tokens. The token is security sensitive so it is better to store it in a different file with stricter permissions. In this example that file is *actions-runner*.
GITHUB_USER=<user> GITHUB_REPO=<repo> GITHUB_TOKEN=<personal_access_token>
Following is the Butane snippet that creates these two files – *manage-runner.sh* and *actions-runner*.
- path: /usr/local/sbin/actions-runner/manage-runner.sh contents: local: manage-runner.sh mode: 0755 user: name: core group: name: core - path: /etc/actions-runner contents: local: actions-runner mode: 0700 user: name: core group: name: core
## Running Actions on Fedora CoreOS
Finally, create the systemd services that will configure and start the runner. Define the services in the Butane configuration file.
systemd: units: - name: github-runner-configure.service enabled: true contents: | [Unit] Description=Configure the github action runner for a repository After=network-online.target boot-complete.target Requires=boot-complete.target [Service] EnvironmentFile=/etc/actions-runner Type=oneshot RemainAfterExit=yes User=core WorkingDirectory=/usr/local/sbin/actions-runner ExecStartPre=tar xvf actions-runner-linux.tar.gz --no-same-owner ExecStart=/usr/local/sbin/actions-runner/manage-runner.sh [Install] WantedBy=multi-user.target - name: github-runner.service enabled: true contents: | [Unit] Description=Run the github action runner After=github-runner-configure.service [Service] WorkingDirectory=/usr/local/sbin/actions-runner User=core ExecStart=/usr/local/sbin/actions-runner/run.sh [Install] WantedBy=multi-user.target
This creates two services, *github-runner-configure.service *(running once when the host has finished booting) and *github-runner.service *(running the Actions runner binaries and waiting for new CI/CD jobs).
Now that the Butane configuration is complete, generate an Ignition file out of it and provision a Fedora CoreOS Actions runner.
$ podman run -i --rm -v $PWD:/code:z --workdir /code quay.io/coreos/butane:release --pretty --strict --files-dir /code config.yaml -o config.ignition
Once the Ignition file is generated, it can be used to provision a runner on the platforms where Fedora CoreOS is [available](https://docs.fedoraproject.org/en-US/fedora-coreos/bare-metal/).
## Configure an Action to use a self-hosted runner
The following test Action workflow will test the FCOS self-hosted worker. Create the following file in your git repository *.github/workflows/main.yml*
# This is a basic workflow to help you get started with Actions name: CI # Controls when the action will run. on: # Triggers the workflow on push or pull request events but only for the main branch push: branches: [ main ] pull_request: branches: [ main ] # Allows you to run this workflow manually from the Actions tab workflow_dispatch: # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "build" build: # The type of runner that the job will run on runs-on: fcos # Steps represent a sequence of tasks that will be executed as part of the job steps: # Runs a single command using the runners shell - name: Run a one-line script run: podman run --rm fedora-minimal:34 echo Hello World !
Note that the *runs-on* configuration is set up to use a runner with the label *fcos*.
The code presented in this article is available [here](https://github.com/cverna/fcos-actions-runner).
## GitLabber
Very nice. One can also use docker images, though compute time limits and overhead still make a self configured runner useful.
## VladimirSlavik
Thank you, that’s a nice concise write-up.
## Ralf Seidenschwang
https://coreos.github.io/ignition/supported-platforms/
I‘m not pretty sure what this kernel parameter does? This seems to be for installation without any disks, so the kernel pulls the configuration from a link and configures the machine according to the config-files that was downloaded, and I assume disk partitioning is one of the tasks that can be found here. So the disks are not in use here and the pulled configuration via this Kernel parameter can be applied to the disks without the disks being touched upfront.
This sounds reasonable, but I would be very cautious with these automatic installation methods that are available for different products (like OpenShift), since they are pulling the same files from a internet source, ignoring my firewall settings completely.
Is that the way these installer scripts work?
## Sergey
Sorry to be off-topic, but I don’t think that’s what fcos is for. In my opinion, fkos is only supposed to ensure the launch of containers and no more.
And everything else should already be in them. For example the same ubi, etc.
## Elliott
I have to agree with Sergey; this really isn’t a use case for FCOS. FCOS is for having a clean, immutable environment for hosting containers. If you want to run your Github actions in a clean immutable image, then that is a great use case for running a container on FCOS.
The benefit of using a container on top of FCOS is that you can have multiple images with multiple runners. Maybe you’re compiling and packaging an application? Well with containers you can have a Fedora, RHEL, Debian, and an Ubuntu image so now you’re application gets compiled and packaged for all of them while only requiring a single FCOS host.
If you’re don’t have to use Github but want to pipeline your application, I’d recommend Gitlab instead. They have an RPM package for their runner. You can have the ignition file install the RPM and the podman-docker package, register the runner, and then set the executor to Docker. Then your pipelines can deploy images and containers on demand for running your jobs.
## Clément Verna
My interest in using FCOS in that case was to be able to very easily destroy and provision new runners. And also not having to care about updating the host since FCOS does that automatically for me.
With that configuration I can have a couple of long running runners, and quickly (a minute or so) burst new runners if needed.
Running GitLab CI runner on FCOS would be super interesting too, I believe that they provide a container image which could make it super easy.
Would you be interested do write a Fedora Magazine article about it ?
## Stephen Snow
Nice article Clement. Thanks for more useful tips, and another very suitable use for FCOS, as a Github Actions server.
## Ralf Seidenschwang
For people relatively new to the topic:
I’ve found that very helpful, the tutorial is half an hour long:
https://www.youtube.com/watch?v=R8_veQiYBjI
## Jiri Konecny
Hi, I just want to warn anyone using this guide. The guide is correct but GitHub self hosted runners are not recommended by GitHub because they are easy to attack.
Problem starts when external contributor will create a PR with a change to GitHub workflow. One problem is that external contributor could attach your self-hosted runner to any existing workflow with a pull_request trigger by just changing the workflow. The second problem is that the self-hosted runner immediately executing any code written to PR. So it’s pretty easy to use your host to access internal resources or use your runner for crypto currency mining.
To avoid such an issue you can do three things.
– Use private repository.
– Use only
and not
trigger. (beware, if you do it wrong, contributor has a write permissions and access to your secrets)
– Manually gate all external contributors to verify that they don’t changing your workflow. (See the third option here: https://github.blog/changelog/2021-07-01-github-actions-new-settings-for-maintainers/ )
## Aricjoshua
In that situation, my motivation for utilizing FCOS was to be able to quickly delete and provide new runners. Also, I don’t have to worry about upgrading the host because FCOS does it for me.
With that setup, I can have a few long-distance runners and rapidly (a minute or two) blast in fresh runners if needed. https://cookieclicker2.io/
Thank you! |
13,848 | Linux Mint 和 Fedora:应该使用哪一个? | https://itsfoss.com/linux-mint-vs-fedora/ | 2021-10-04T12:35:00 | [
"Fedora",
"Mint"
] | https://linux.cn/article-13848-1.html | 
Linux Mint 是一个 [为初学者定制的流行的 Linux 发行版](https://itsfoss.com/best-linux-beginners/),同时为用户提供了与 Windows 类似的体验。事实上,它有 [一些地方比 Ubuntu 做的更好](https://itsfoss.com/linux-mint-vs-ubuntu/),这使它成为每一类用户的合适选择。
它是基于 Ubuntu 的,完全由社区所支持。
另一方面,Fedora 是一个尝鲜发行版,它专注于纳入令人兴奋的变化,最终使其成为红帽企业 Linux(RHEL)的一部分。
与 Linux Mint 不同,Fedora 并不完全专注于个人(或非开发者)使用。即使他们提供了一个工作站版本,其目标也是开发者和有经验的 Linux 用户。
### Fedora 或 Mint,应该根据什么选择?
虽然我们知道 Fedora 并不是完全面向 Linux 新手的,但许多用户喜欢使用 Fedora 作为他们的日常系统。因此,在这篇文章中,我们将阐明两者之间的一些区别,以帮助你选择一个在你的台式机上使用的操作系统。
#### 系统要求 & 硬件兼容性

在选择任何 Linux 发行版之前,你都应该看一下它的系统要求,并检查硬件兼容性。
在这方面,Linux Mint 和 Fedora 都需要至少 2GB 的内存、20GB 的磁盘空间,以及 1024 x 768 分辨率的显示器来获得入门级的体验。
是的,官方文件可能提到 1GB 内存就可以起步,但要看实际使用情况。除非你有一台复古的电脑,想为一个特定的目的恢复它,否则它就不在考虑范围之内。

在技术上,两者都支持现代的和陈旧的硬件,你只有在安装时才会知道软件/驱动是否支持它。除非你有一个特殊的外围设备或具有特殊功能的硬件组件,否则硬件支持可能不是什么大问题。
Linux Mint 19 系列仍然提供了对 32 位系统的支持,你可以使用它到 2023 年 4 月。而 Fedora 已经不支持 32 位系统了。
#### 软件更新周期

Linux Mint 专注于长期发布版(LTS),支持时间为五年。它的维护方式与 Ubuntu 相同。但没有像 Ubuntu 那样提供付费的扩展支持。
Fedora 不提供 LTS 版本,而是每 6 个月推送一次新的更新,每个版本都会得到 13 个月的软件支持。如果你愿意,你可以跳过一个版本。
如果你只是想安装一个可以使用多年的 Linux 发行版,而不在乎是不是最新的技术/功能,那么 Linux Mint 是个不错的选择。
但是,如果你想要最新的和最伟大的 Linux 技术(在一些罕见的情况下,这也可能破坏你的计算体验),并接受适应 Fedora 推动的重大变化,Fedora 可以是一个选择。
#### 桌面环境的选择

Linux Mint 提供三种不同的 [桌面环境](https://itsfoss.com/best-linux-desktop-environments/):MATE、Cinnamon 和 Xfce。它们有相同的更新周期,并从发布之日起支持 5 年。
尽管 Fedora 不提供 LTS 版本,但你可以通过 Fedora spins 的形式选择各种桌面。你可以得到 KDE、LXQt、MATE、Cinnamon、LXDE,以及一个内置 i3 平铺窗口管理器的版本。

所以,如果你想有更多的选择,Fedora 可以是一个相当令人激动的选择。
#### 软件可用性

Linux Mint(或 Ubuntu)的默认软件库提供了大量可以安装的软件,而 Fedora 的默认软件库只坚持提供开源软件。
不仅仅限于此,Linux Mint 还配备了 [Synaptic 软件包管理器](https://itsfoss.com/synaptic-package-manager/),这是一个令人印象深刻的安装软件的轻量级工具。
尽管你可以 [在 Fedora 中启用第三方软件库](https://itsfoss.com/fedora-third-party-repos/),但这又是一个额外的步骤。而且,RPM Fusion 存储库可能没有 Ubuntu 的 universe 存储库那么庞大。

所以,对于 Linux Mint 来说,总的来说,你可以得到更多可安装的软件包和各种安装软件的方法,开箱即用。
#### 使用和安装的便利性
对于一个 Linux 的新嫩用户来说,Ubuntu 或任何基于 Ubuntu 的发行版通常都是一个很好的开端。
从 [Ubuntu 的安装体验](https://itsfoss.com/install-ubuntu/),到 [安装软件](https://itsfoss.com/remove-install-software-ubuntu/) 的简便性,同时还可以选择 LTS 版本,这让初学者觉得很方便。
而且,借助 Ubiquity 安装程序,Linux Mint 自然也有与 Ubuntu 相同的好处,因此,它的学习曲线最小,易于安装,易于使用。
虽然从表面上看 Fedora 并不复杂,但安装选项、软件包管理器以及默认存储库中缺乏的软件可能是一个耗时的因素。
如果你没有尝试过,我建议你试试我们的 [VirtualBox 版的 Fedora 安装指南](https://itsfoss.com/install-fedora-in-virtualbox/)。这是一个测试安装体验的好方法,然后再在你的任何生产系统上进行尝试。
#### 开箱即用的体验
最省事的体验通常是令人愉快的选择。嗯,对大多数人来说。
现在,你需要明白,根据硬件配置的不同,每个用户最终可能会有不同的“开箱即用”体验。
但是,作为参考,让我给你举个 Fedora 和 Linux Mint 的例子。
考虑到我的电脑上使用的是 NVIDIA GPU,我需要安装专有的驱动程序以获得最佳性能。

而且,当我启动 Linux Mint 时,使用“驱动程序管理器”应用程序,安装驱动程序相当容易。
但是,对于 Fedora,即使我按照我们的 [在 Fedora 中安装 Nvidia 驱动程序](https://itsfoss.com/install-nvidia-drivers-fedora/) 的指南,我在重启时还是出现了一个错误。

不仅如此,由于某些原因,我的有线网络似乎没有被激活,因此,我没有互联网连接。
是的,当你遇到问题时,你总是可以尝试着去排除故障,但是对于 Linux Mint,我不需要这么做。所以,根据我的经验,我会推荐 Linux Mint,它有更好的开箱体验。
#### 文档
如果你依赖于文档资源并想在这个过程中挑战自己,获得不错的学习经验,我推荐你去看看 [Fedora 的文档](https://docs.fedoraproject.org/en-US/docs/)。
你会发现最近和最新的 Fedora 版本的最新信息,这是件好事。
另一方面,[Linux Mint 的文档](https://linuxmint.com/documentation.php) 没有定期更新,但在你想深入挖掘时很有用。
#### 社区支持
你会得到一个良好的社区支持。[Linux Mint 的论坛](https://forums.linuxmint.com) 是一个很基础的平台,容易使用并能解决问题。
[Fedora 的论坛](https://ask.fedoraproject.org) 是由 Discourse 驱动的,它是最 [流行的现代开源论坛软件](https://itsfoss.com/open-source-forum-software/) 之一。
#### 企业与社区的角度
Fedora 得到了最大的开源公司 [红帽](https://www.redhat.com/en) 的支持 —— 因此你可以得到良好的持续创新和长期的支持。
然而,正因为 Fedora 并不是为日常电脑用户而建立的,每一个版本的选择都可能完全影响你的用户体验。
另一方面,Linux Mint 完全由一个充满激情的 Linux 社区所支持,专注于使 Linux 在日常使用中更加容易和可靠。当然,它依赖于 Ubuntu 作为基础,但如果社区不喜欢上游的东西,Linux Mint 也会做出大胆的改变。
例如,Linux Mint 与 Ubuntu 官方发行版不同,默认情况下禁用了 snap。所以,如果你想使用它们,你就必须 [在 Linux Mint 中启用 snap](https://itsfoss.com/enable-snap-support-linux-mint/)。
### 总结
如果你想为你的家用电脑选择一个没有问题的、易于使用的操作系统,我的建议是 Linux Mint。但是,如果你想体验最新的、最伟大的 Linux 操作系统,同时在你的 Linux 学习经历中进行一次小小的冒险,Fedora 可以是一个不错的选择。
虽然每个操作系统都需要某种形式的故障排除,没有什么能保证你的硬件完全不出问题,但我认为 Linux Mint 对大多数用户来说可能没有问题。
在任何情况下,你可以重新审视上面提到的比较点,看看什么对你的电脑最重要。
你怎么看?你会选择 Fedora 而不是 Mint 吗?还有,为什么?请在下面的评论中告诉我。
---
via: <https://itsfoss.com/linux-mint-vs-fedora/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux Mint is a [popular Linux distribution tailored for beginners](https://itsfoss.com/best-linux-beginners/) while providing a similar experience to former Windows users. In fact, it does a [few things better than Ubuntu](https://itsfoss.com/linux-mint-vs-ubuntu/), which makes it a suitable choice for every type of user.
It is completely community-powered, on top of Ubuntu as its base.
On the other hand, Fedora is a cutting-edge distribution that focuses on incorporating exciting changes that eventually makes it way to Red Hat Enterprise Linux (RHEL).
Unlike Linux Mint, Fedora does not exclusively focus on personal use (or non-developers). Even though they offer a workstation edition, they aim for developers and experienced Linux users.
## Fedora or Mint: What Should You Go For?
While we know that Fedora is not exactly geared towards Linux newbies, many users love using Fedora as their daily driver. So, in this article, we shall shed light on some differences between the two to help you pick one to use on your desktop machine.
### System Requirements & Hardware Compatibility

Before choosing any Linux distribution, you should always go through the system requirements and check the hardware compatibility.
Here, both Linux Mint and Fedora require at least 2 GB of RAM, 20 GB of disk space, and a 1024 x 768 resolution display to get an entry-level experience.
Yes, the official documentation may mention 1 GB of RAM to start with but let us be practical of your use-case. Unless you have a vintage computer that you want to revive for a specific purpose, it is out of the equation.
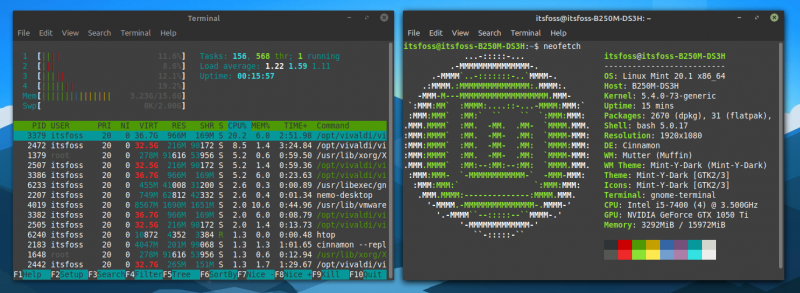
Technically, both support modern and old hardware. You will only know how it works along with the software/driver support when you get it installed. Unless you have a special peripheral or hardware component with specific features, hardware support may not be a big deal.
Linux Mint 19 series still provide support for 32-bit systems and you can use it till April 2023. Fedora doesn’t support 32-bit systems anymore.
### Software Update Cycle
Linux Mint focuses on Long-Term Releases (LTS) with a five-year support. It will be maintained same as Ubuntu. But there is no paid extension like Ubuntu offers.
Fedora does not offer an LTS release but pushes a new update every 6 months. Every version gets software support for 13 months. You get the ability to skip one version if you want.
If you just want to have a Linux distro installed for years without requiring the latest technology/features in an update, Linux Mint is the way to go.
But, if you want to the latest and greatest (which can also break your computing experience ins some rare cases) and accept to adapt with the major changes Fedora pushes, Fedora can be a choice.
### Desktop Environment Choices
Linux Mint provides three different [desktop environments](https://itsfoss.com/best-linux-desktop-environments/) — **MATE, Cinnamon, and Xfce**. All of them will have the same update cycle and will be supported for five years from their release.
Even though Fedora does not offer LTS releases, you get a variety of desktop choices in the form of Fedora spins. You get KDE, LXQt, MATE, Cinnamon, LXDE, and an edition with i3 tiling window manager baked in.
So, if you want more choices out of the box, Fedora can be a quite exciting choice.
### Software Availability
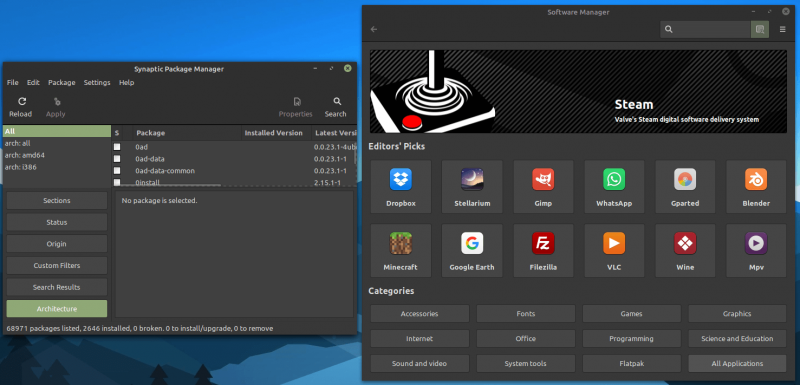
The default repositories of Linux Mint (or Ubuntu’s) offer a wide range of software to install. But Fedora’s default repository sticks only to open-source applications.
Not just limited to that, Linux Mint also comes packed with [Synaptic Package Manager](https://itsfoss.com/synaptic-package-manager/) which is an impressive lightweight tool to install software.
Even though you can [enable third-party repositories in Fedora](https://itsfoss.com/fedora-third-party-repos/), it is yet an additional step. Also, the RPM Fusion repository may not be as huge as Ubuntu’s universe repository.

So, with Linux Mint, overall, you get more packages available to install and more ways to install software, out of the box.
### Ease of Use & Installation
For an entirely new user, Ubuntu or any Ubuntu-based distribution generally fares well to start with.
Starting from the [installation experience in Ubuntu](https://itsfoss.com/install-ubuntu/) to the ease of [installing software](https://itsfoss.com/remove-install-software-ubuntu/) while having the option to opt for an LTS release is what a beginner finds handy.
And, Linux Mint naturally presents the same benefits of Ubuntu with Ubiquity installer – hence, it offers a minimal learning curve, easy to install and easy to use.
While Fedora is not complex by definition but the installation options, package manager, and lack of software in the default repositories may prove to be a time-consuming factor.
If you’ve never tried it, I suggest you to go through our [Fedora installation guide for VirtualBox](https://itsfoss.com/install-fedora-in-virtualbox/). It is a good way to test the installation experience before trying it out on your production system of any sort.
### Out of the Box Experience
The most hassle-free experience is usually the pleasant option. Well, for most people.
Now, you need to understand that depending on the hardware configuration, every user might end up having a different “out-of-the-box” experience.
But, for a reference, let me just give you my example for both Fedora and Linux Mint.
Considering I’m rocking an NVIDIA GPU on my PC, I need to install the proprietary drivers for the best performance.
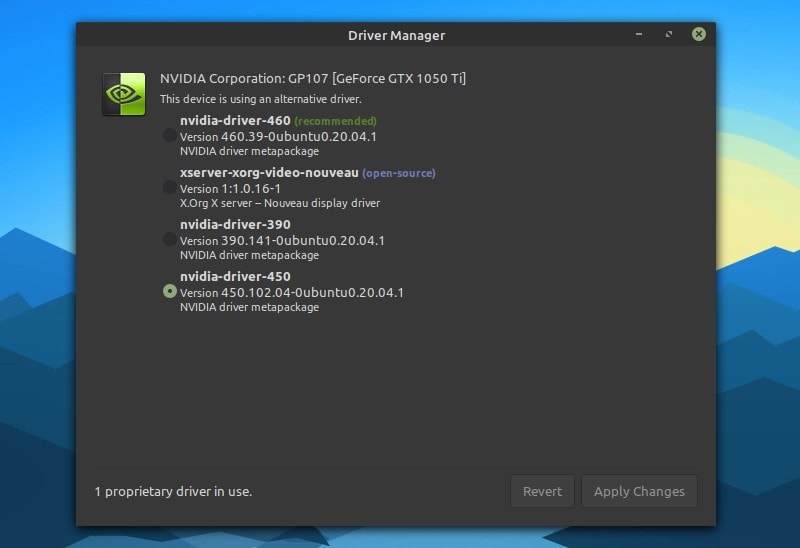
And, when I booted up Linux Mint, installing the drivers were pretty easy using the **Driver Manager** app.
But, with Fedora, even though I followed our guide on [installing Nvidia drivers in Fedora](https://itsfoss.com/install-nvidia-drivers-fedora/), I was presented with an error when I rebooted.
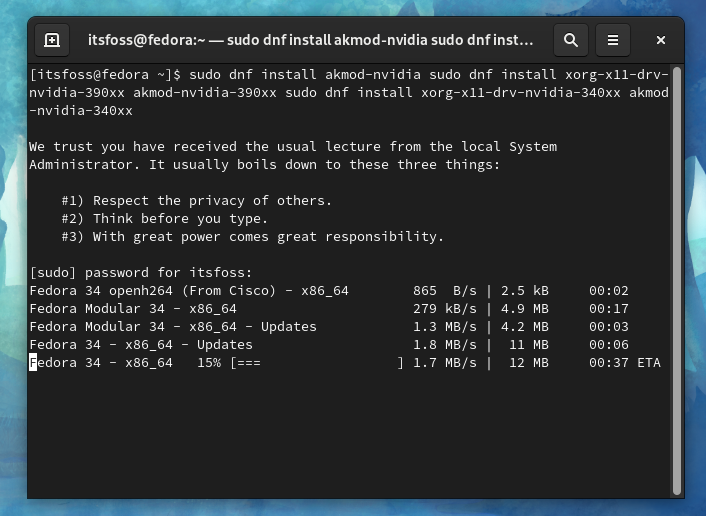
Not just that, for some reason, my wired network did not seem to be active – hence, I had no internet connectivity.
Yes, you should always try to troubleshoot when you run into issues, but I did not need to do that for Linux Mint. So, in my experience, I will recommend Linux Mint with a better out of the experience.
### Documentation
I would recommend going for [Fedora’s documentation](https://docs.fedoraproject.org/en-US/docs/) if you rely on resources and want to challenge yourself with a decent learning experience along the process.
You will find up-to-date information for recent and latest Fedora releases, which is a good thing.
On the other hand, [Linux Mint’s documentation](https://linuxmint.com/documentation.php) is not regularly updated but useful when you want to dig deeper.
### Community Support
You will get a good community support for both. The [Linux Mint forums](https://forums.linuxmint.com) is a basic platform which is easy to use and gets the job done.
[Fedora’s forum](https://ask.fedoraproject.org) is powered by Discourse, which happens to be one of the most [popular modern open-source forum software](https://itsfoss.com/open-source-forum-software/).
### Corporate vs Community Angle
Fedora is backed up by the biggest open-source company [Red Hat](https://www.redhat.com/en) – so you get a good level of constant innovation and support for the long run.
However, just because Fedora is not built for the daily computer users in mind, the choices made with every release may affect your user experience entirely.
On the other hand, Linux Mint is completely backed up by a passionate Linux community focusing on making Linux easier and reliable for everyday use. Of course, it depends on Ubuntu as the base but Linux Mint does make bold changes if the community does not like something from the upstream.
For instance, Linux Mint disabled snaps by default unlike official Ubuntu distro. So, you will have to [enable snaps in Linux Mint](https://itsfoss.com/enable-snap-support-linux-mint/) if you want to use them.
## Wrapping Up
If you want a no-nonsense and easy to use operating system for your home computer, Linux Mint would be my suggestion. But, if you want to experience the latest and greatest, while taking a little adventure in your Linux learning experience, Fedora can be a good pick.
While every operating system requires some form of troubleshooting and nothing can guarantee zero issues with your hardware, I think Linux Mint will have potentially no issues for the majority of the users.
In any case, you can re-visit the comparison points mentioned above to see what matters most for your computer.
What do you think? Would you pick Fedora over Mint? And, Why? Let me know in the comments below. |
13,849 | 通过写“猜数字”游戏学习 Fortran | https://opensource.com/article/21/1/fortran | 2021-10-04T12:53:17 | [
"Fortran",
"猜数字"
] | https://linux.cn/article-13849-1.html |
>
> Fortran 是在打孔卡时代编写的语言,因此它的语法非常有限。但你仍然可以用它编写有用和有趣的程序。
>
>
>

Fortran 77 是我学习的第一门编译型编程语言。一开始时,我自学了如何在 Apple II 上用 BASIC 编写程序,后来又学会在 DOS 上用 QBasic 编写程序。但是当我去大学攻读物理学时,我又学习了 [Fortran](https://en.wikipedia.org/wiki/Fortran)。
Fortran 曾经在科学计算中很常见。曾几何时,所有计算机系统都有一个 Fortran 编译器。Fortran 曾经像今天的 Python 一样无处不在。因此,如果你是像我这样的物理学专业学生,在 1990 年代工作,那你肯定学习了 Fortran。
我一直认为 Fortran 与 BASIC 有点相似,所以每当我需要编写一个简短程序,来分析实验室数据或执行其他一些数值分析时,我都会很快想到 Fortran。我在空闲时用 Fortran 编写了一个“猜数字”游戏,其中计算机会在 1 到 100 之间选择一个数字,并让我猜这个数字。程序会一直循环,直到我猜对了为止。
“猜数字”程序练习了编程语言中的几个概念:如何为变量赋值、如何编写语句以及如何执行条件判断和循环。这是学习新编程语言时一个很好的的实践案例。
### Fortran 编程基础
虽然 Fortran 这些年来一直在更新,但我最熟悉的还是 Fortran 77,这是我多年前学习的实现版本。Fortran 是程序员还在打孔卡上编程的年代创建的,因此“经典” Fortran 仅限于处理可以放在打孔卡上的数据。这意味着你只能编写符合以下限制条件的经典 Fortran 程序(LCTT 译注:后来的 Fortran 95 等版本已经对这些限制做了很大的改进,如有兴趣**建议直接学习新版**):
* 每张卡只允许一行源代码。
* 仅识别第 1-72 列(最后八列,73-80,保留给卡片分类器)。
* 行号(“标签”)位于第 1-5 列。
* 程序语句在第 7-72 列。
* 要表示跨行,请在第 6 列中输入一个连续字符(通常是 `+`)。
* 要创建注释行,请在第 1 列中输入 `C` 或 `*`。
* 只有字符 `A` 到`Z`(大写字母)、`0` 到`9`(数字)和特殊字符 `= + - * / ( ) , . $ ' :` 和空格能够使用。
虽然有这些限制,你仍然可以编写非常有用和有趣的程序。
### 在 Fortran 中猜数字
通过编写“猜数字”游戏来探索 Fortran。这是我的实现代码:
```
CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC
C PROGRAM TO GUESS A NUMBER 1-100
CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC
PROGRAM GUESSNUM
INTEGER SEED, NUMBER, GUESS
PRINT *, 'ENTER A RANDOM NUMBER SEED'
READ *, SEED
CALL SRAND(SEED)
NUMBER = INT( RAND(0) * 100 + 1 )
PRINT *, 'GUESS A NUMBER BETWEEN 1 AND 100'
10 READ *, GUESS
IF (GUESS.LT.NUMBER) THEN
PRINT *, 'TOO LOW'
ELSE IF (GUESS.GT.NUMBER) THEN
PRINT *, 'TOO HIGH'
ENDIF
IF (GUESS.NE.NUMBER) GOTO 10
PRINT *, 'THATS RIGHT!'
END
```
如果你熟悉其他编程语言,你大概可以通过阅读源代码来弄清楚这个程序在做什么。前三行是注释块,表示程序的功能。第四行 `PROGRAM GUESSNUM` 将其标识为一个 <ruby> 程序 <rt> program </rt></ruby>,并由最后一行的 `END` 语句关闭。
定义变量后,程序会提示用户输入随机数种子。Fortran 程序无法从操作系统初始化随机数生成器,因此你必须始终使用“种子”值和 `SRAND` <ruby> 子程序 <rt> subroutine </rt></ruby> 启动随机数生成器。
Fortran 使用 `RAND(0)` 函数生成 0 到 0.999…… 之间的随机数。参数 `0` 告诉 `RAND` 函数生成一个随机数。将此随机数乘以 100 以生成 0 到 99.999…… 之间的数字,然后加 1 得到 1 到 100.999…… 之间的值。`INT` 函数将结果截断为整数;因此,变量 `NUMBER` 就是一个介于 1 到 100 之间的随机数。
程序会给出提示,然后进入一个循环。Fortran 不支持更现代的编程语言中可用的 `while` 或 `do-while` 循环(LCTT 译注:Fortran 95 等新版支持,也因此在一定程度上减少了 `GOTO` 的使用)。相反,你必须使用标签(行号)和 `GOTO` 语句来构建自己的循环。这就是 `READ` 语句有一个行号的原因:你可以在循环末尾使用 `GOTO` 跳转到此标签。
穿孔卡片没有 `<`(小于)和 `>`(大于)符号,因此 Fortran 采用了另一种语法来进行值比较。要测试一个值是否小于另一个值,请使用 `.LT.`(小于)。要测试一个值是否大于另一个值,请使用 `.GT.`(大于)。等于和不等于分别是 `.EQ.` 和 `.NE.`。
在每次循环中,程序都会验证用户的猜测值。如果用户的猜测值小于随机数,程序打印 `TOO LOW`,如果猜测大于随机数,程序打印 `TOO HIGH`。循环会一直持续,直到用户的猜测值等于目标随机数为止。
当循环退出时,程序打印 `THATS RIGHT!` 并立即结束运行。
```
$ gfortran -Wall -o guess guess.f
$ ./guess
ENTER A RANDOM NUMBER SEED
93759
GUESS A NUMBER BETWEEN 1 AND 100
50
TOO LOW
80
TOO HIGH
60
TOO LOW
70
TOO LOW
75
TOO HIGH
73
TOO LOW
74
THATS RIGHT!
```
每次运行程序时,用户都需要输入不同的随机数种子。如果你总是输入相同的种子,程序给出的随机数也会一直不变。
### 在其他语言中尝试
在学习一门新的编程语言时,这个“猜数字”游戏是一个很好的入门程序,因为它以非常简单的方式练习了几个常见的编程概念。通过用不同的编程语言实现这个简单的游戏,你可以弄清一些核心概念以及比较每种语言的细节。
你有最喜欢的编程语言吗?如何用你最喜欢的语言来编写“猜数字”游戏?跟随本系列文章来查看你可能感兴趣的其他编程语言示例吧。
---
via: <https://opensource.com/article/21/1/fortran>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The first compiled programming language I learned was Fortran 77. While growing up, I taught myself how to write programs in BASIC on the Apple II and later in QBasic on DOS. But when I went to university to study physics, I learned [Fortran](https://en.wikipedia.org/wiki/Fortran).
Fortran used to be quite common in scientific computing. And once upon a time, all computer systems had a Fortran compiler. Fortran used to be as ubiquitous as Python is today. So if you were a physics student like me, working in the 1990s, you learned Fortran.
I always thought Fortran was somewhat similar to BASIC, so I quickly took to Fortran whenever I needed to write a quick program to analyze lab data or perform some other numerical analysis. And when I got bored, I wrote a "Guess the number" game in Fortran, where the computer picks a number between one and 100 and asks me to guess the number. The program loops until I guess correctly.
The "Guess the number" program exercises several concepts in programming languages: how to assign values to variables, how to write statements, and how to perform conditional evaluation and loops. It's a great practical experiment for learning a new programming language.
## The basics of Fortran programming
While Fortran has been updated over the years, I am most familiar with Fortran 77, the implementation I learned years ago. Fortran was created when programmers wrote programs on punched cards, so "classic" Fortran is limited to the data you could put on a punched card. That means you could only write classic Fortran programs with these limitations:
- Only one line of source code per card is allowed.
- Only columns 1–72 are recognized (the last eight columns, 73-80, are reserved for the card sorter).
- Line numbers ("labels") are in columns 1–5.
- Program statements go in columns 7–72.
- To continue a program line, enter a continuation character (usually
`+`
) in column 6. - To create a comment line, enter
`C`
or`*`
in column 1. - Only the characters
`A`
to`Z`
(uppercase),`0`
to`9`
(numbers), and the special characters`= + - * / ( ) , . $ ' :`
and space are used.
With these limitations, you can still write very useful and interesting programs.
## Guess the number in Fortran
Explore Fortran by writing the "Guess the number" game. This is my implementation:
```
CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC
C PROGRAM TO GUESS A NUMBER 1-100
CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC
PROGRAM GUESSNUM
INTEGER SEED, NUMBER, GUESS
PRINT *, 'ENTER A RANDOM NUMBER SEED'
READ *, SEED
CALL SRAND(SEED)
NUMBER = INT( RAND(0) * 100 + 1 )
PRINT *, 'GUESS A NUMBER BETWEEN 1 AND 100'
10 READ *, GUESS
IF (GUESS.LT.NUMBER) THEN
PRINT *, 'TOO LOW'
ELSE IF (GUESS.GT.NUMBER) THEN
PRINT *, 'TOO HIGH'
ENDIF
IF (GUESS.NE.NUMBER) GOTO 10
PRINT *, 'THATS RIGHT!'
END
```
If you are familiar with other programming languages, you can probably figure out what this program is doing by reading the source code. The first three lines are a comment block to indicate the program's function. The fourth line, `PROGRAM GUESSNUM`
, identifies this as a program, and it is closed by the `END`
statement on the last line.
After defining a few variables, the program prompts the user to enter a random number seed. A Fortran program cannot initialize the random number generator from the operating system, so you must always start the random number generator with a "seed" value and the `SRAND`
subroutine.
Fortran generates random numbers between 0 and 0.999... with the `RAND(0)`
function. The `0`
value tells the `RAND`
function to generate another random number. Multiply this random number by 100 to generate a number between 0 and 99.999…, and then add 1 to get a value between 1 and 100.999… The `INT`
function truncates this to an integer; thus, the variable `NUMBER`
is a random number between 1 and 100.
The program prompts the user, then enters a loop. Fortran doesn't support the `while`
or `do-while`
loops available in more modern programming languages. Instead, you must construct your own using labels (line numbers) and `GOTO`
statements. That's why the `READ`
statement has a line number; you can jump to this label with the `GOTO`
at the end of the loop.
Punched cards did not have the `<`
(less than) or `>`
(greater than) symbols, so Fortran adopted a different syntax to compare values. To test if one value is less than another, use the `.LT.`
(less than) comparison. To test if a value is greater than another, use `.GT.`
(greater than). Equal and not equal are `.EQ.`
and `.NE.`
, respectively.
In each iteration of the loop, the program tests the user's guess. If the user's guess is less than the random number, the program prints `TOO LOW`
, and if the guess is greater than the random number, the program prints `TOO HIGH`
. The loop continues until the user's guess is the same as the random number.
When the loop exits, the program prints `THATS RIGHT!`
and ends immediately.
```
$ gfortran -Wall -o guess guess.f
$ ./guess
ENTER A RANDOM NUMBER SEED
93759
GUESS A NUMBER BETWEEN 1 AND 100
50
TOO LOW
80
TOO HIGH
60
TOO LOW
70
TOO LOW
75
TOO HIGH
73
TOO LOW
74
THATS RIGHT!
```
Every time you run the program, the user needs to enter a different random number seed. If you always enter the same seed, the program will always pick the same random number.
## Try it in other languages
This "guess the number" game is a great introductory program when learning a new programming language because it exercises several common programming concepts in a pretty straightforward way. By implementing this simple game in different programming languages, you can demonstrate some core concepts and compare each language's details.
Do you have a favorite programming language? How would you write the "guess the number" game in it? Follow this article series to see examples of other programming languages that might interest you.
## 2 Comments |
13,851 | 官方的树莓派 4 外壳很烂!怎么样减少过热? | https://itsfoss.com/raspberry-pi-case-overheating/ | 2021-10-04T20:18:38 | [
"树莓派",
"散热"
] | https://linux.cn/article-13851-1.html | 
[树莓派 4](https://itsfoss.com/raspberry-pi-4/) 绝对是数百万人的最爱,特别是在极客社区里,我也不例外。但是你知道树莓派在没有适当冷却的情况下会限制性能吗?
在这里,我将介绍 [树莓派 4 官方外壳](https://www.raspberrypi.org/products/raspberry-pi-4-case/) 的一些严重缺点,同时也分享一些缓解这些缺点的方法。

在第一次启动后,我的安装在 [树莓派 4 官方外壳](https://www.raspberrypi.org/products/raspberry-pi-4-case/) 内的树莓派 4(8GB 内存版),在无人值守的升级启动时,会高达 80℃。我在 Ubuntu 上进行了所有的 [固件更新](https://www.einfochips.com/blog/understanding-firmware-updates-the-whats-whys-and-hows/),显然是为了 [解决发热问题](https://www.seeedstudio.com/blog/2019/11/29/raspberry-pi-4-firmware-update-pi-4-now-runs-cooler-than-ever/)。
就算在空闲时,这个烫手的香草和草莓蛋糕也绝不会低于 75℃。
我几乎无法使用它,直到我取下外壳顶部的白色盖子。它闲置时的温度降到只有 67℃ 左右 —— 你相信吗?即使是在我重新启动一段时间后再次检查也是这样。很明显,这仍然是不太可接受。如果我买了这个外壳并打算长期使用,我为什么要一直把盖子打开?
为什么会发生这样的事情?这都是因为官方的树莓派外壳的设计非常糟糕。
### 官方的树莓派 4 外壳是一个发热怪物!
简单地说,[热节流](https://www.pcmag.com/encyclopedia/term/thermal-throttling) 就是降低你的树莓派处理器(CPU)的性能,以使温度不超过极限高温(如 80℃)而 [导致损坏](https://www.pcgamer.com/cpu-temperature-overheat/)。
这个外壳是由塑料制成的,它是热的不良导体(简单的 [传统物理学](https://thermtest.com/stay-colder-for-longer-in-a-container-made-of-plastic-or-metal) 知识),因此无法将热量有效地散布到整个外壳和板子之外。因此,板上的处理器会发热,一旦温度达到惊人的程度,它的性能就会被降到一个极低的水平。我注意到,在第一次开机后,在**无人值守**的情况下进行升级时,CPU 的温度为 80℃,CPU 的使用率为 100%。
虽然这个官方的外壳看起来很美,但它对树莓派的性能造成了很大的影响。
如果你真的想让你的树莓派发挥最大的性能,你也必须负责它的冷却。这些发热问题不能被简单地忽视。
#### 热量被困在内部
一旦你把树莓派安装在这个外壳里,它甚至没有一个通风口可以让多余的热量排出。所以热量就一直在里面积累,直到达到那些疯狂的温度并触发了节流阀。
#### 没有风扇通风口(非常需要)
顶部的白色盖子上可以有一个圆形的通风口,至少可以把 [树莓派 4 的官方风扇](https://www.raspberrypi.org/products/raspberry-pi-4-case-fan/) 放在上面使用。
#### 没有被动冷却
如果外壳是金属的,它就可以作为散热器,有效地将树莓派板上的处理器的热量散发出去。
#### 除了发热问题之外,还有其他的缺点
树莓派 4 官方外壳还有一些缺点:
1. 不便于 SD 卡管理:将树莓派板子装入外壳内,并将 SD 卡端口放在正确的方向上,以便以后能够换卡,这不是很方便。
2. 没有螺丝钉系统:没有提供螺丝,也许是因为它可能会破坏机箱底座上的假支架,这些假支架看起来就像你可以用四颗螺丝把板子牢牢地固定在底座上。
### 你可以做什么来控制树莓派 4 的过热?
在做了一些紧张的研究之后,我找到了市场上一些最好的冷却解决方案 —— 这一切都要归功于我们了不起的改装社区。
#### 使用冰塔式冷却器
我首先发现了 [Jeff Geerling's](https://www.jeffgeerling.com/blog/2019/best-way-keep-your-cool-running-raspberry-pi-4) 对各种树莓派散热器的深入性能评估,他在网上被称为 [geerlingguy](https://www.jeffgeerling.com/about)。在看完温度统计后,我直接选择了冰塔式散热器,并组装了它:

它空闲和低载时的温度下降到 30℃,现在保持在 45℃ 左右。我还没有为它改装一个合适的外壳。我准备找个给冷却器提供了足够的空间的现成外壳。也许可以在亚马逊或其他网上商店找到这种外壳。
但我没有找到这种产品。
#### 使用铝制散热器进行被动散热
网上也有一个关于 [被动冷却](https://buildabroad.org/2016/11/05/passive-cooling/) 的出色视频,测评了一个用铝制散热片做的外壳。
它提供了一个热垫,它相当于台式机处理器上使用的散热膏。按照视频中显示的方式放置它,热量就会从树莓派板上的处理器散发到整个外壳内。这就是科学的神奇之处!
#### 改装官方的树莓派外壳
如果你仍然想买官方的外壳,建议你至少要做一个风扇的改装。
### 潜在的制造解决方案
这里有一些解决方案,通过应用 [DevOps](https://linuxhandbook.com/what-is-devops/) 启发的改进,可以使整个制造过程更容易。
* 想一想,从外壳顶部切下的那块圆形塑料可以回收,用来制造更多的树莓派 4 外壳,不是吗?这显然会是一个双赢的局面,同时也降低了成本!
* 铝是地球上最丰富的金属,但 [全球供应中断](https://www.reuters.com/article/global-metals-idUSL1N2Q90GA) 可能是一个挑战。即使如此,还有其他的 [导电性解决方案](https://news.mit.edu/2018/engineers-turn-plastic-insulator-heat-conductor-0330) 来探索用于设计案例的材料!
### 总结
希望这篇文章能帮助你从树莓派 4 中获得最大的收益。我很想知道你的想法、建议和经验,请在下面的评论中留言。请不要犹豫地分享。
---
via: <https://itsfoss.com/raspberry-pi-case-overheating/>
作者:[Avimanyu Bandyopadhyay](https://itsfoss.com/author/avimanyu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [Raspberry Pi 4](https://itsfoss.com/raspberry-pi-4/) is an absolute favorite among millions of people, especially in the nerd community, and I’m no exception. But did you know that the Pi throttles without proper cooling?
Here, I’m going to describe some serious drawbacks in the [Official Raspberry Pi 4 Case](https://www.raspberrypi.org/products/raspberry-pi-4-case/) and also share some ways to mitigate them.

After the first boot, my Raspberry Pi 4 (8 GB RAM version) mounted inside the [Official Raspberry Pi 4 case](https://www.raspberrypi.org/products/raspberry-pi-4-case/), would shoot to 80 °C when the unattended upgrades kicked in. I was on Ubuntu with all [firmware updates](https://www.einfochips.com/blog/understanding-firmware-updates-the-whats-whys-and-hows/) that are apparently supposed to [fix heating issues](https://www.seeedstudio.com/blog/2019/11/29/raspberry-pi-4-firmware-update-pi-4-now-runs-cooler-than-ever/).
On idle, this hot vanilla and strawberry cake would never go less than 75°C.
I could hardly use it until I removed the top white cover of the case. The temperature dropped to only around 67 °C on idle — Can you believe that? Even after I double-checked after a while with a reboot. This, obviously, still isn’t also quite acceptable. If I got the case and plan to use it for long-term purpose, why would I want to keep the case lid open all the time?
And why is something like this happening? It’s all because of a very poor design of the official Raspberry Pi case.
## The Official Raspberry Pi 4 Case is a Heat Monster!
[Thermal throttling](https://www.pcmag.com/encyclopedia/term/thermal-throttling) in simple terms, is a reduction in the performance of your Pi processor (CPU) so that the temperature does not exceed extremely high temperatures (such as 80 °C) and [cause damage](https://www.pcgamer.com/cpu-temperature-overheat/).
The case is built out of plastic — a poor conductor of heat (simple [old school physics](https://thermtest.com/stay-colder-for-longer-in-a-container-made-of-plastic-or-metal)), and hence is unable to dissipate it effectively throughout the case and out of the Pi board. Therefore, the processor on the Pi board heats up and gets throttled down to an extremely inferior level of performance, once it literally reaches a temperature of an alarming degree. I noticed a 100% CPU usage during * unattended upgrades* right after first boot with the CPU’s temperature at 80 °C.
Beautiful though it may look, the official case delivers a big blow to the Pi’s performance.
If you really want to get the most out of your Pi’s performance, you must take care of its cooling too. These heating issues cannot simply be ignored:
### Heat gets trapped
Once you set up the Pi inside this case there is not even a single vent for that excess heat to escape. So it keeps getting accumulated inside until it reaches those crazy temps and triggers the throttle.
### No fan outlet (badly needed)
The top white cover could have had a circular vent on top of the case for at least the [Official Raspberry Pi 4 Fan](https://www.raspberrypi.org/products/raspberry-pi-4-case-fan/).
### No passive cooling
If the case had been of metal, it could have doubled up as heat-sink and dissipate the heat efficiently out of the processor residing on the Pi board.
### Other drawbacks apart from heating issues
The official Pi 4 case has a few more drawbacks:
- Inconvenient SD Card Management: It is not very convenient to assemble the Pi board inside the case and get the SD card port in the correct orientation to be able to switch cards later on.
- No Screwing System: No screws are provided, maybe because it could break the dummy holders on the base of the case that almost look like you could use four screws to fix the board securely onto the base.
## What can you do to control the overheating in Raspberry Pi 4?
After doing some intense research, I found some of the best cooling solutions available in the market – all thanks to our amazing modding community!
### Use an ice tower cooler
I first found [an in-depth performance review of various Pi coolers at Jeff Geerling’s](https://www.jeffgeerling.com/blog/2019/best-way-keep-your-cool-running-raspberry-pi-4), who is known online as ** geerlingguy**. I straightaway went for the ICE tower cooler after going through the temperature stats and assembled it:

[lasso box=”B07V35SXMC” link_id=”21354″ ref=”geeekpi-raspberry-pi-cooling-fan-raspberry-pi-ice-tower-cooler-rgb-cooling-fan-with-raspberry-pi-heatsink-for-raspberry-pi-4-model-b-raspberry-pi-3b-raspberry-pi-3-model-b” id=”101740″]
Temperatures dropped to 30 °C on idle and under load, it now stays at around 45 °C. I’m yet to mod a proper case for it. There are ready to purchase cases with enough space for the cooler. You may find such cases on Amazon or other online stores.
Preview | Product | Price | |
---|---|---|---|
![]() |
[KVM Switch HDMI 2 Port Box,ABLEWE USB and HDMI Switch for 2 Computers Share Keyboard Mouse Printer...](https://www.amazon.com/dp/B08NVKHRRT?tag=chmod7mediate-20&linkCode=ogi&th=1&psc=1)[Buy on Amazon](https://www.amazon.com/dp/B08NVKHRRT?tag=chmod7mediate-20&linkCode=ogi&th=1&psc=1)### Use an aluminum heat sink for passive cooling
There is also a remarkable video online on [passive cooling](https://buildabroad.org/2016/11/05/passive-cooling/), reviewing an aluminum heat-sink-as-a-case.
A thermal pad is provided, which is equivalent to the thermal paste used on Desktop processors. On placing it in the manner shown in the video, the heat is dissipated out of the processor on the Pi board throughout the whole case. A wonderful magic of science!
Preview | Product | Price | |
---|---|---|---|
![]() |
[KVM Switch HDMI 2 Port Box,ABLEWE USB and HDMI Switch for 2 Computers Share Keyboard Mouse Printer...](https://www.amazon.com/dp/B08NVKHRRT?tag=chmod7mediate-20&linkCode=ogi&th=1&psc=1)[Buy on Amazon](https://www.amazon.com/dp/B08NVKHRRT?tag=chmod7mediate-20&linkCode=ogi&th=1&psc=1)### Modding the official Pi case
If you still want to get the official case, it is advisable to at-least go for a fan mod:
## Potential Manufacturing Solutions
Here are some solutions that can make the whole process of manufacturing easier, by applying [DevOps](https://linuxhandbook.com/what-is-devops/) inspired improvements:
- Think about it, that circular piece of plastic cut out from the top of the cover could be recycled to manufacture so many more Pi 4 cases in production. Isn’t it? It would clearly be a win-win scenario and also lowers costs as well!
- Aluminium is the most abundant metal on earth, but
[global supply disruptions](https://www.reuters.com/article/global-metals-idUSL1N2Q90GA)can be challenging. Even then, there are other[conductivity solutions](https://news.mit.edu/2018/engineers-turn-plastic-insulator-heat-conductor-0330)to explore materials used for the designing the case.
**Personal Notes**
Hope this write-up helps you in getting the most out of your Raspberry Pi 4. It’s been a quite a while since I used to write here on ** It’s FOSS**. Feels good to be back. I’d love to know your thoughts, suggestions, and experiences down in the comments below. Please do not hesitate to share. |
13,852 | 使用 trace-cmd 追踪内核 | https://opensource.com/article/21/7/linux-kernel-trace-cmd | 2021-10-05T14:58:24 | [
"追踪",
"内核"
] | https://linux.cn/article-13852-1.html |
>
> trace-cmd 是一个易于使用,且特性众多、可用来追踪内核函数的命令。
>
>
>

在 [之前的文章](/article-13752-1.html) 里,我介绍了如何利用 `ftrace` 来追踪内核函数。通过写入和读出文件来使用 `ftrace` 会变得很枯燥,所以我对它做了一个封装来运行带有选项的命令,以启用和禁用追踪、设置过滤器、查看输出、清除输出等等。
[trace-cmd](https://lwn.net/Articles/410200/) 命令是一个可以帮助你做到这一点的工具。在这篇文章中,我使用 `trace-cmd` 来执行我在 `ftrace` 文章中所做的相同任务。由于会经常参考那篇文章,建议在阅读这篇文章之前先阅读它。
### 安装 trace-cmd
本文中所有的命令都运行在 root 用户下。
因为 `ftrace` 机制被内置于内核中,因此你可以使用下面的命令进行验证它是否启用:
```
# mount | grep tracefs
none on /sys/kernel/tracing type tracefs (rw,relatime,seclabel)
```
不过,你需要手动尝试安装 `trace-cmd` 命令:
```
# dnf install trace-cmd -y
```
### 列出可用的追踪器
当使用 `ftrace` 时,你必须查看文件的内容以了解有哪些追踪器可用。但使用 `trace-cmd`,你可以通过以下方式获得这些信息:
```
# trace-cmd list -t
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
```
### 启用函数追踪器
在我 [之前的文章](/article-13752-1.html) 中,我使用了两个追踪器,在这里我也会这么做。用 `function` 启用你的第一个追踪器:
```
$ trace-cmd start -p function
plugin 'function'
```
### 查看追踪输出
一旦追踪器被启用,你可以通过使用 `show` 参数来查看输出。这只显示了前 20 行以保持例子的简短(见我之前的文章对输出的解释):
```
# trace-cmd show | head -20
## tracer: function
#
# entries-in-buffer/entries-written: 410142/3380032 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
gdbus-2606 [004] ..s. 10520.538759: __msecs_to_jiffies <-rebalance_domains
gdbus-2606 [004] ..s. 10520.538760: load_balance <-rebalance_domains
gdbus-2606 [004] ..s. 10520.538761: idle_cpu <-load_balance
gdbus-2606 [004] ..s. 10520.538762: group_balance_cpu <-load_balance
gdbus-2606 [004] ..s. 10520.538762: find_busiest_group <-load_balance
gdbus-2606 [004] ..s. 10520.538763: update_group_capacity <-update_sd_lb_stats.constprop.0
gdbus-2606 [004] ..s. 10520.538763: __msecs_to_jiffies <-update_group_capacity
gdbus-2606 [004] ..s. 10520.538765: idle_cpu <-update_sd_lb_stats.constprop.0
gdbus-2606 [004] ..s. 10520.538766: __msecs_to_jiffies <-rebalance_domains
```
### 停止追踪并清除缓冲区
追踪将会在后台继续运行,你可以继续用 `show` 查看输出。
要停止追踪,请运行带有 `stop` 参数的 `trace-cmd` 命令:
```
# trace-cmd stop
```
要清除缓冲区,用 `clear` 参数运行它:
```
# trace-cmd clear
```
### 启用函数调用图追踪器
运行第二个追踪器,通过 `function_graph` 参数来启用它。
```
# trace-cmd start -p function_graph
Plugin 'function_graph'
```
再次使用 `show` 参数查看输出。正如预期的那样,输出与第一次追踪输出略有不同。这一次,它包括一个**函数调用**链:
```
# trace-cmd show | head -20
## tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
4) 0.079 us | } /* rcu_all_qs */
4) 0.327 us | } /* __cond_resched */
4) 0.081 us | rcu_read_unlock_strict();
4) | __cond_resched() {
4) 0.078 us | rcu_all_qs();
4) 0.243 us | }
4) 0.080 us | rcu_read_unlock_strict();
4) | __cond_resched() {
4) 0.078 us | rcu_all_qs();
4) 0.241 us | }
4) 0.080 us | rcu_read_unlock_strict();
4) | __cond_resched() {
4) 0.079 us | rcu_all_qs();
4) 0.235 us | }
4) 0.095 us | rcu_read_unlock_strict();
4) | __cond_resched() {
```
使用 `stop` 和 `clear` 命令来停止追踪和清除缓存区:
```
# trace-cmd stop
# trace-cmd clear
```
### 调整追踪以增加深度
如果你想在函数调用中看到更多的深度,你可以对追踪器进行调整:
```
# trace-cmd start -p function_graph --max-graph-depth 5
plugin 'function_graph'
```
现在,当你将这个输出与你之前看到的进行比较时,你应该看到更多的嵌套函数调用:
```
# trace-cmd show | head -20
## tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
6) | __fget_light() {
6) 0.804 us | __fget_files();
6) 2.708 us | }
6) 3.650 us | } /* __fdget */
6) 0.547 us | eventfd_poll();
6) 0.535 us | fput();
6) | __fdget() {
6) | __fget_light() {
6) 0.946 us | __fget_files();
6) 1.895 us | }
6) 2.849 us | }
6) | sock_poll() {
6) 0.651 us | unix_poll();
6) 1.905 us | }
6) 0.475 us | fput();
6) | __fdget() {
```
### 了解可被追踪的函数
如果你想只追踪某些函数而忽略其他的,你需要知道确切的函数名称。你可以用 `list -f` 参数来得到它们。例如搜索常见的内核函数 `kmalloc`,它被用来在内核中分配内存:
```
# trace-cmd list -f | grep kmalloc
bpf_map_kmalloc_node
mempool_kmalloc
__traceiter_kmalloc
__traceiter_kmalloc_node
kmalloc_slab
kmalloc_order
kmalloc_order_trace
kmalloc_large_node
__kmalloc
__kmalloc_track_caller
__kmalloc_node
__kmalloc_node_track_caller
[...]
```
下面是我的测试系统中可被追踪的函数总数:
```
# trace-cmd list -f | wc -l
63165
```
### 追踪内核模块相关的函数
你也可以追踪与特定内核模块相关的函数。假设你想追踪 `kvm` 内核模块相关的功能,你可以通过以下方式来实现。请确保该模块已经加载:
```
# lsmod | grep kvm_intel
kvm_intel 335872 0
kvm 987136 1 kvm_intel
```
再次运行 `trace-cmd`,使用 `list` 参数,并从输出结果中,`grep` 查找以 `]` 结尾的行。这将过滤掉内核模块。然后 `grep` 内核模块 `kvm_intel` ,你应该看到所有与该内核模块有关的函数。
```
# trace-cmd list -f | grep ]$ | grep kvm_intel
vmx_can_emulate_instruction [kvm_intel]
vmx_update_emulated_instruction [kvm_intel]
vmx_setup_uret_msr [kvm_intel]
vmx_set_identity_map_addr [kvm_intel]
handle_machine_check [kvm_intel]
handle_triple_fault [kvm_intel]
vmx_patch_hypercall [kvm_intel]
[...]
vmx_dump_dtsel [kvm_intel]
vmx_dump_sel [kvm_intel]
```
### 追踪特定函数
现在你知道了如何找到感兴趣的函数,请用一个例子把这些内容用于时间。就像前面的文章一样,试着追踪与文件系统相关的函数。我的测试系统上的文件系统是 `ext4`。
这个过程略有不同;你在运行命令时,不使用 `start` 参数,而是在 `record` 参数后面加上你想追踪的函数的“模式”。你还需要指定你想要的追踪器;在这种情况下,就是 `function_graph`。该命令会继续记录追踪,直到你用 `Ctrl+C` 停止它。所以几秒钟后,按 `Ctrl+C` 停止追踪:
```
# trace-cmd list -f | grep ^ext4_
# trace-cmd record -l ext4_* -p function_graph
plugin 'function_graph'
Hit Ctrl^C to stop recording
^C
CPU0 data recorded at offset=0x856000
8192 bytes in size
[...]
```
### 查看追踪记录
要查看你之前的追踪记录,运行带有 `report` 参数的命令。从输出结果来看,很明显过滤器起作用了,你只看到 `ext4` 相关的函数追踪:
```
# trace-cmd report | head -20
[...]
cpus=8
trace-cmd-12697 [000] 11303.928103: funcgraph_entry: | ext4_show_options() {
trace-cmd-12697 [000] 11303.928104: funcgraph_entry: 0.187 us | ext4_get_dummy_policy();
trace-cmd-12697 [000] 11303.928105: funcgraph_exit: 1.583 us | }
trace-cmd-12697 [000] 11303.928122: funcgraph_entry: | ext4_create() {
trace-cmd-12697 [000] 11303.928122: funcgraph_entry: | ext4_alloc_inode() {
trace-cmd-12697 [000] 11303.928123: funcgraph_entry: 0.101 us | ext4_es_init_tree();
trace-cmd-12697 [000] 11303.928123: funcgraph_entry: 0.083 us | ext4_init_pending_tree();
trace-cmd-12697 [000] 11303.928123: funcgraph_entry: 0.141 us | ext4_fc_init_inode();
trace-cmd-12697 [000] 11303.928123: funcgraph_exit: 0.931 us | }
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.081 us | ext4_get_dummy_policy();
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.133 us | ext4_get_group_desc();
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.115 us | ext4_free_inodes_count();
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.114 us | ext4_get_group_desc();
```
### 追踪一个特定的 PID
假设你想追踪与一个进程(PID)有关的函数。打开另一个终端,注意运行中的 shell 的PID:
```
# echo $$
10885
```
再次运行 `record` 命令,用 `-P` 选项传递PID。这一次,让终端运行(也就是说,先不要按 `Ctrl+C` ):
```
# trace-cmd record -P 10885 -p function_graph
Plugin 'function_graph'
Hit Ctrl^C to stop recording
```
### 在 shell 上运行一些命令
移动到另一个终端,在那里你有一个以特定 PID 运行的 shell,并运行任何命令,例如,`ls` 命令用来列出文件:
```
# ls
Temp-9b61f280-fdc1-4512-9211-5c60f764d702
tracker-extract-3-files.1000
v8-compile-cache-1000
[...]
```
移动到你启用追踪的终端,按 `Ctrl+C` 停止追踪:
```
# trace-cmd record -P 10885 -p function_graph
plugin 'function_graph'
Hit Ctrl^C to stop recording
^C
CPU1 data recorded at offset=0x856000
618496 bytes in size
[...]
```
在追踪的输出中,你可以看到左边是 PID 和 Bash shell,右边是与之相关的函数调用。这对于缩小你的追踪范围是非常方便的:
```
# trace-cmd report | head -20
cpus=8
<idle>-0 [001] 11555.380581: funcgraph_entry: | switch_mm_irqs_off() {
<idle>-0 [001] 11555.380583: funcgraph_entry: 1.703 us | load_new_mm_cr3();
<idle>-0 [001] 11555.380586: funcgraph_entry: 0.493 us | switch_ldt();
<idle>-0 [001] 11555.380587: funcgraph_exit: 7.235 us | }
bash-10885 [001] 11555.380589: funcgraph_entry: 1.046 us | finish_task_switch.isra.0();
bash-10885 [001] 11555.380591: funcgraph_entry: | __fdget() {
bash-10885 [001] 11555.380592: funcgraph_entry: 2.036 us | __fget_light();
bash-10885 [001] 11555.380594: funcgraph_exit: 3.256 us | }
bash-10885 [001] 11555.380595: funcgraph_entry: | tty_poll() {
bash-10885 [001] 11555.380597: funcgraph_entry: | tty_ldisc_ref_wait() {
bash-10885 [001] 11555.380598: funcgraph_entry: | ldsem_down_read() {
bash-10885 [001] 11555.380598: funcgraph_entry: | __cond_resched() {
```
### 试一试
这些简短的例子显示了使用 `trace-cmd` 命令而不是底层的 `ftrace` 机制,是如何实现既容易使用又拥有丰富的功能,许多内容本文并没有涉及。要想了解更多信息并更好地使用它,请查阅它的手册,并尝试使用其他有用的命令。
---
via: <https://opensource.com/article/21/7/linux-kernel-trace-cmd>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my [previous article](https://opensource.com/article/21/7/analyze-linux-kernel-ftrace), I explained how to use `ftrace`
to trace kernel functions. Using `ftrace`
by writing and reading from files can get tedious, so I used a wrapper around it to run commands with options to enable and disable tracing, set filters, view output, clear output, and more.
The [trace-cmd](https://lwn.net/Articles/410200/) command is a utility that helps you do just this. In this article, I use `trace-cmd`
to perform the same tasks I did in my `ftrace`
article. Since I refer back to that article frequently, I recommend you read it before you read this one.
## Install trace-cmd
I run the commands in this article as the root user.
The `ftrace`
mechanism is built into the kernel, and you can verify it is enabled with:
```
# mount | grep tracefs
none on /sys/kernel/tracing type tracefs (rw,relatime,seclabel)
```
However, you need to install the `trace-cmd`
utility manually.
`# dnf install trace-cmd -y`
## List available tracers
When using `ftrace`
, you must view a file's contents to see what tracers are available. But with `trace-cmd`
, you can get this information with:
```
# trace-cmd list -t
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
```
## Enable the function tracer
In my [earlier article](https://opensource.com/article/21/7/analyze-linux-kernel-ftrace), I used two tracers, and I'll do the same here. Enable your first tracer, `function`
, with:
```
$ trace-cmd start -p function
plugin 'function'
```
## View the trace output
Once the tracer is enabled, you can view the output by using the `show`
arguments. This shows only the first 20 lines to keep the example short (see my earlier article for an explanation of the output):
```
# trace-cmd show | head -20
## tracer: function
#
# entries-in-buffer/entries-written: 410142/3380032 #P:8
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
gdbus-2606 [004] ..s. 10520.538759: __msecs_to_jiffies <-rebalance_domains
gdbus-2606 [004] ..s. 10520.538760: load_balance <-rebalance_domains
gdbus-2606 [004] ..s. 10520.538761: idle_cpu <-load_balance
gdbus-2606 [004] ..s. 10520.538762: group_balance_cpu <-load_balance
gdbus-2606 [004] ..s. 10520.538762: find_busiest_group <-load_balance
gdbus-2606 [004] ..s. 10520.538763: update_group_capacity <-update_sd_lb_stats.constprop.0
gdbus-2606 [004] ..s. 10520.538763: __msecs_to_jiffies <-update_group_capacity
gdbus-2606 [004] ..s. 10520.538765: idle_cpu <-update_sd_lb_stats.constprop.0
gdbus-2606 [004] ..s. 10520.538766: __msecs_to_jiffies <-rebalance_domains
```
## Stop tracing and clear the buffer
Tracing continues to run in the background, and you can keep viewing the output using `show`
.
To stop tracing, run `trace-cmd`
with the `stop`
argument:
`# trace-cmd stop`
To clear the buffer, run it with the `clear`
argument:
`# trace-cmd clear`
## Enable the function_graph tracer
Enable the second tracer, `function_graph`
, by running:
```
# trace-cmd start -p function_graph
plugin 'function_graph'
```
Once again, view the output using the `show`
argument. As expected, the output is slightly different from the first trace output. This time it includes a `function calls`
chain:
```
# trace-cmd show | head -20
## tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
4) 0.079 us | } /* rcu_all_qs */
4) 0.327 us | } /* __cond_resched */
4) 0.081 us | rcu_read_unlock_strict();
4) | __cond_resched() {
4) 0.078 us | rcu_all_qs();
4) 0.243 us | }
4) 0.080 us | rcu_read_unlock_strict();
4) | __cond_resched() {
4) 0.078 us | rcu_all_qs();
4) 0.241 us | }
4) 0.080 us | rcu_read_unlock_strict();
4) | __cond_resched() {
4) 0.079 us | rcu_all_qs();
4) 0.235 us | }
4) 0.095 us | rcu_read_unlock_strict();
4) | __cond_resched() {
```
Use the `stop`
and `clear`
commands to stop tracing and clear the buffer:
```
# trace-cmd stop
# trace-cmd clear
```
## Tweak tracing to increase depth
If you want to see more depth in the function calls, you can tweak the tracer:
```
# trace-cmd start -p function_graph --max-graph-depth 5
plugin 'function_graph'
```
Now when you compare this output with what you saw before, you should see more nested function calls:
```
# trace-cmd show | head -20
## tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
6) | __fget_light() {
6) 0.804 us | __fget_files();
6) 2.708 us | }
6) 3.650 us | } /* __fdget */
6) 0.547 us | eventfd_poll();
6) 0.535 us | fput();
6) | __fdget() {
6) | __fget_light() {
6) 0.946 us | __fget_files();
6) 1.895 us | }
6) 2.849 us | }
6) | sock_poll() {
6) 0.651 us | unix_poll();
6) 1.905 us | }
6) 0.475 us | fput();
6) | __fdget() {
```
## Learn available functions to trace
If you want to trace only certain functions and ignore the rest, you need to know the exact function names. You can get them with the `list`
argument followed by `-f`
. This example searches for the common kernel function `kmalloc`
, which is used to allocate memory in the kernel:
```
# trace-cmd list -f | grep kmalloc
bpf_map_kmalloc_node
mempool_kmalloc
__traceiter_kmalloc
__traceiter_kmalloc_node
kmalloc_slab
kmalloc_order
kmalloc_order_trace
kmalloc_large_node
__kmalloc
__kmalloc_track_caller
__kmalloc_node
__kmalloc_node_track_caller
[...]
```
Here's the total count of functions available on my test system:
```
# trace-cmd list -f | wc -l
63165
```
## Trace kernel module-related functions
You can also trace functions related to a specific kernel module. Imagine you want to trace `kvm`
kernel module-related functions. Ensure the module is loaded:
```
# lsmod | grep kvm_intel
kvm_intel 335872 0
kvm 987136 1 kvm_intel
```
Run `trace-cmd`
again with the `list`
argument, and from the output, `grep`
for lines that end in `]`
. This will filter out the kernel modules. Then `grep`
the kernel module `kvm_intel`
, and you should see all the functions related to that kernel module:
```
# trace-cmd list -f | grep ]$ | grep kvm_intel
vmx_can_emulate_instruction [kvm_intel]
vmx_update_emulated_instruction [kvm_intel]
vmx_setup_uret_msr [kvm_intel]
vmx_set_identity_map_addr [kvm_intel]
handle_machine_check [kvm_intel]
handle_triple_fault [kvm_intel]
vmx_patch_hypercall [kvm_intel]
[...]
vmx_dump_dtsel [kvm_intel]
vmx_dump_sel [kvm_intel]
```
## Trace specific functions
Now that you know how to find functions of interest, put that knowledge to work with an example. As in the earlier article, try to trace filesystem-related functions. The filesystem I had on my test system was `ext4`
.
This procedure is slightly different; instead of `start`
, you run the command with the `record`
argument followed by the "pattern" of the functions you want to trace. You also need to specify the tracer you want; in this case, that's `function_graph`
. The command continues recording the trace until you stop it with **Ctrl+C**. So after a few seconds, hit **Ctrl+C** to stop tracing:
```
# trace-cmd list -f | grep ^ext4_
# trace-cmd record -l ext4_* -p function_graph
plugin 'function_graph'
Hit Ctrl^C to stop recording
^C
CPU0 data recorded at offset=0x856000
8192 bytes in size
[...]
```
## View the recorded trace
To view the trace you recorded earlier, run the command with the `report`
argument. From the output, it's clear that the filter worked, and you see only the ext4-related function trace:
```
# trace-cmd report | head -20
[...]
cpus=8
trace-cmd-12697 [000] 11303.928103: funcgraph_entry: | ext4_show_options() {
trace-cmd-12697 [000] 11303.928104: funcgraph_entry: 0.187 us | ext4_get_dummy_policy();
trace-cmd-12697 [000] 11303.928105: funcgraph_exit: 1.583 us | }
trace-cmd-12697 [000] 11303.928122: funcgraph_entry: | ext4_create() {
trace-cmd-12697 [000] 11303.928122: funcgraph_entry: | ext4_alloc_inode() {
trace-cmd-12697 [000] 11303.928123: funcgraph_entry: 0.101 us | ext4_es_init_tree();
trace-cmd-12697 [000] 11303.928123: funcgraph_entry: 0.083 us | ext4_init_pending_tree();
trace-cmd-12697 [000] 11303.928123: funcgraph_entry: 0.141 us | ext4_fc_init_inode();
trace-cmd-12697 [000] 11303.928123: funcgraph_exit: 0.931 us | }
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.081 us | ext4_get_dummy_policy();
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.133 us | ext4_get_group_desc();
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.115 us | ext4_free_inodes_count();
trace-cmd-12697 [000] 11303.928124: funcgraph_entry: 0.114 us | ext4_get_group_desc();
```
## Trace a specific PID
Say you want to trace functions related to a specific persistent identifier (PID). Open another terminal and note the PID of the running shell:
```
# echo $$
10885
```
Run the `record`
command again and pass the PID using the `-P`
option. This time, let the terminal run (i.e., do not press **Ctrl+C** yet):
```
# trace-cmd record -P 10885 -p function_graph
plugin 'function_graph'
Hit Ctrl^C to stop recording
```
## Run some activity on the shell
Move back to the other terminal where you had a shell running with a specific PID and run any command, e.g., `ls`
to list files:
```
# ls
Temp-9b61f280-fdc1-4512-9211-5c60f764d702
tracker-extract-3-files.1000
v8-compile-cache-1000
[...]
```
Move back to the terminal where you enabled tracing and hit **Ctrl+C** to stop tracing:
```
# trace-cmd record -P 10885 -p function_graph
plugin 'function_graph'
Hit Ctrl^C to stop recording
^C
CPU1 data recorded at offset=0x856000
618496 bytes in size
[...]
```
In the trace's output, you can see the PID and the Bash shell on the left and the function calls related to it on the right. This can be pretty handy to narrow down your tracing:
```
# trace-cmd report | head -20
cpus=8
<idle>-0 [001] 11555.380581: funcgraph_entry: | switch_mm_irqs_off() {
<idle>-0 [001] 11555.380583: funcgraph_entry: 1.703 us | load_new_mm_cr3();
<idle>-0 [001] 11555.380586: funcgraph_entry: 0.493 us | switch_ldt();
<idle>-0 [001] 11555.380587: funcgraph_exit: 7.235 us | }
bash-10885 [001] 11555.380589: funcgraph_entry: 1.046 us | finish_task_switch.isra.0();
bash-10885 [001] 11555.380591: funcgraph_entry: | __fdget() {
bash-10885 [001] 11555.380592: funcgraph_entry: 2.036 us | __fget_light();
bash-10885 [001] 11555.380594: funcgraph_exit: 3.256 us | }
bash-10885 [001] 11555.380595: funcgraph_entry: | tty_poll() {
bash-10885 [001] 11555.380597: funcgraph_entry: | tty_ldisc_ref_wait() {
bash-10885 [001] 11555.380598: funcgraph_entry: | ldsem_down_read() {
bash-10885 [001] 11555.380598: funcgraph_entry: | __cond_resched() {
```
## Give it a try
These brief examples show how using `trace-cmd`
instead of the underlying `ftrace`
mechanism is both easy to use and rich in features, including many I didn't cover here. To learn more and get better at it, consult its man page and try out its other useful commands.
## Comments are closed. |
13,854 | Below:一个时间旅行的资源监控器 | https://fedoramagazine.org/below-a-time-traveling-resource-monitor/ | 2021-10-06T09:31:00 | [
"监控",
"below"
] | https://linux.cn/article-13854-1.html | 
在这篇文章中,我们将介绍 `below`:一个用于现代 Linux 系统的 Apache 2.0 许可的资源监视器。`below` 可以让你重放以前记录的数据。

### 背景
内核的主要职责之一是调度对资源的访问。有时这可能意味着分配物理内存,使多个进程可以共享同一主机。其他时候,它可能意味着确保 CPU 时间的公平分配。在这些场景里,内核提供了机制,而将策略留给了“别人”。近来,这个“别人”通常是 systemd 或 dockerd 这样的运行时。运行时接受来自调度器或最终用户的输入(类似于运行什么和如何运行)并在内核上转动正确的旋钮和拉动正确的杠杆,从而使工作负载能够*好好*工作。
在一个完美的世界里,故事就到此结束了。然而,现实情况是,资源管理是一个复杂的、相当不透明的技术混合体,在几十年里计算技术不断发展。尽管其中一些技术有各种缺陷和死角,但最终的结果是,容器运作得比较好。虽然用户通常不需要关心这些细节,但对于基础设施运营商来说,对他们的技术架构拥有可见性是至关重要的。可见性和可调试性对于检测和调查错误的配置、问题和系统性故障至关重要。
让事情变得更加复杂的是,资源中断往往难以重现。经常需要花费数周时间等待一个问题重新出现,以便调查其根本原因。规模的扩大进一步加剧了这个问题:我们不能在*每台*主机上运行一个自定义脚本,希望在错误再次发生时记录下关键状态的片段。因此,需要更复杂的工具。这就出现了 `below`。
### 动机
历史上,Facebook 一直是 [atop](https://www.atoptool.nl/) 的忠实用户。`atop` 是一个用于 Linux 的性能监视器,能够报告所有进程的活动以及各种系统级活动。与 `htop` 等工具相比,`atop` 最引人注目的功能之一是能够作为一个守护程序记录历史数据。这听起来是一个简单的功能,但在实践中,这使得调试无数的生产问题成为可能。有了足够长的数据保留,就有可能在时间上回溯,查看在问题或故障发生之前、期间和之后的主机状态。
不幸的是,随着时间的推移,人们发现`atop` 有某些不足之处。首先,<ruby> <a href="https://en.wikipedia.org/wiki/Cgroups"> 控制组 </a> <rt> cgroup </rt></ruby> 已经成为控制和监视 Linux 机器上资源的实际方式。`atop` 仍然缺乏对这一基本构建模块的支持。第二,`atop` 用自定义的 delta 压缩方法在磁盘上存储数据。这在正常情况下运行良好,但在沉重的资源压力下,主机很可能会丢失数据点。由于使用了 delta 压缩,在数据最重要的时间段内,数据可能会大面积丢失。第三,用户体验有一个陡峭的学习曲线。我们经常听到 `atop` 的资深用户说,他们喜欢密集的布局和众多的键盘绑定。然而,这也是一把双刃剑。当一个刚进入这个领域的人想要调试一个生产问题时,他们现在要同时解决两个问题:手头的问题和如何使用 `atop`。
`below` 是由 Facebook 的资源控制团队为其设计和开发的,并得到了 `atop` 生产环境用户的支持。顾名思义,资源控制团队负责的是规模化的资源管理。该团队由内核开发人员、容器运行时开发人员和硬件人员组成。认识到下一代系统监控器的机会,我们在设计 `below` 时考虑到以下几点:
* 易用性:`below` 必须既能为新用户提供直观的体验,又能为日常用户提供强大的功能。 \*有意义的统计数据:`below` 显示准确和有用的统计数据。即便可以,但我们尽量避免收集和倾倒统计数字。
* 灵活性:当默认设置不合适时,我们允许用户自定义他们的体验。例如包括可配置的键绑定、可配置的默认视图,以及脚本界面(默认为终端用户接口)。
### 安装
安装该软件包:
```
# dnf install -y below
```
打开记录守护进程:
```
# systemctl enable --now below
```
### 快速介绍
`below` 最常用的模式是重放模式。顾名思义,重放模式是重放以前记录的数据。假设你已经启动了记录守护程序,那么通过运行以下程序启动一个会话:
```
$ below replay --time "5 minutes ago"
```
然后你会看到控制组视图:

如果你不知道该怎么操作,或者忘记了一个键位,按 `?` 可以进入帮助菜单。
屏幕的最上方是状态栏。状态栏显示关于当前样本的信息。你可以通过按 `t` 和 `T` 分别向前和向后移动样本。中间的部分是系统概览。系统概览包含了关于整个系统的统计数据,一般来说,这些数据总是很有用的。第三部分也是最下面的部分是多用途视图。上面的图片显示了控制组视图。此外,还有进程和系统视图,分别通过按 `p` 和`s` 来访问。
按 `↑` 和 `↓` 来移动列表选择。按回车键来折叠和展开控制组。假设你发现了一个感兴趣的控制组,你想看看它里面有哪些进程在运行。要放大进程视图,选择控制组并按 `z`:

再按 `z` 返回到控制组视图。这个视图有时会有点长。如果你对你要找的东西有一个模糊的概念,你可以通过按 `/` 并输入一个过滤器来过滤控制组名称。

在这一点上,你可能已经注意到了一个我们还没有探索过的标签系统。要在标签中向前和向后循环,可以分别按 `Tab` 和 `Shift` + `Tab`。我们把这个问题留给读者去做练习。
### 其他功能
在底层,`below` 有一个强大的设计和架构。Facebook 正在不断升级到更新的内核,所以我们从不假设数据源是可用的。这种默契的假设使得内核和 `below`版本之间能够完全向前和向后兼容。此外,每个数据点都用 zstd 压缩并完整地存储。这解决了我们看到的 `atop` 在大规模时的 delta 压缩问题。根据我们的测试,我们的每个样本压缩可以达到平均 5 倍的压缩率。
`below` 也使用 [eBPF][8] 来收集关于短暂进程(生存时间短于数据收集间隔的进程)的信息。相比之下,`atop` 使用 BSD 进程核算来实现这一功能,这是一个已知缓慢且容易发生优先级转换的内核接口。
对于用户来说,`below` 还支持实时模式和一个转储接口。实时模式将记录守护程序和 TUI 会话合并到一个进程中。这对于浏览系统状态是很方便的,不需要为数据存储投入长期运行的守护程序或磁盘空间。转储接口是一个可编写脚本的接口,用于所有的 `below` 数据存储。转储既强大又灵活,详细的数据以 CSV、JSON 和人类可读格式提供。
### 总结
`below` 是一个 Apache 2.0 许可的开源项目,我们(`below` 的开发者)认为它比资源监控领域的现有工具具有引人注目的优势。我们已经花了大量的精力来准备 `below`,以提供开源使用,所以我们希望读者和社区有机会尝试 `below`,并报告错误和功能要求。
---
via: <https://fedoramagazine.org/below-a-time-traveling-resource-monitor/>
作者:[Daniel Xu](https://fedoramagazine.org/author/dxuu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this article, we introduce *below*: an Apache 2.0 licensed resource monitor for modern Linux systems. *below* allows you to replay previously recorded data.
## Background
One of the kernel’s primary responsibilities is mediating access to resources. Sometimes this might mean parceling out physical memory such that multiple processes can share the same host. Other times it might mean ensuring equitable distribution of CPU time. In all these contexts, the kernel provides the mechanism and leaves the policy to “someone else”. In more recent times, this “someone else” is usually a runtime like systemd or dockerd. The runtime takes input from a scheduler or end user — something along the lines of what to run and how to run it — and turns the right knobs and pulls the right levers on the kernel such that the workload can —well — get to work.
In a perfect world this would be the end of the story. However, the reality is that resource management is a complex and rather opaque amalgam of technologies that has evolved over decades of computing. Despite some of this technology having various warts and dead ends, the end result — a container — works relatively well. While the user does not usually need to concern themselves with the details, it is crucial for infrastructure operators to have visibility into their stack. Visibility and debuggability are essential for detecting and investigating misconfigurations, bugs, and systemic issues.
To make matters more complicated, resource outages are often difficult to reproduce. It is not unusual to spend weeks waiting for an issue to reoccur so that the root cause can be investigated. Scale further compounds this issue: one cannot run a custom script on *every* host in the hopes of logging bits of crucial state if the bug happens again. Therefore, more sophisticated tooling is required. Enter *below*.
## Motivation
Historically Facebook has been a heavy user of *atop* [0]. *atop* is a performance monitor for Linux that is capable of reporting the activity of all processes as well as various pieces of system level activity. One of the most compelling features *atop* has over tools like *htop* is the ability to record historical data as a daemon. This sounds like a simple feature, but in practice this has enabled debugging countless production issues. With long enough data retention, it is possible to go backwards in time and look at the host state before, during, and after the issue or outage.
Unfortunately, it became clear over the years that *atop* had certain deficiencies. First, cgroups [1] have emerged as the defacto way to control and monitor resources on a Linux machine. *atop* still lacks support for this fundamental building block. Second, *atop* stores data on disk with custom delta compression. This works fine under normal circumstances, but under heavy resource pressure the host is likely to lose data points. Since delta compression is in use, huge swaths of data can be lost for periods of time where the data is most important. Third, the user experience has a steep learning curve. We frequently heard from *atop* power users that they love the dense layout and numerous keybindings. However, this is a double edged sword. When someone new to the space wants to debug a production issue, they’re solving two problems at once now: the issue at hand and how to use *atop*.
*below* was designed and developed by and for the resource control team at Facebook with input from production *atop* users. The resource control team is responsible for, as the name suggests, resource management at scale. The team is comprised of kernel developers, container runtime developers, and hardware folks. Recognizing the opportunity for a next-generation system monitor, we designed *below* with the following in mind:
- Ease of use:
*below*must be both intuitive for new users as well as powerful for daily users - Opinionated statistics:
*below*displays accurate and useful statistics. We try to avoid collecting and dumping stats just because we can. - Flexibility: when the default settings are not enough, we allow the user to customize their experience. Examples include configurable keybindings, configurable default view, and a scripting interface (the default being a terminal user interface).
## Install
To install the package:
# dnf install -y below
To turn on the recording daemon:
# systemctl enable --now below
## Quick tour
*below*’s most commonly used mode is replay mode. As the name implies, replay mode replays previously recorded data. Assuming you’ve already started the recording daemon, start a session by running:
$ below replay --time "5 minutes ago"
You will then see the cgroup view:
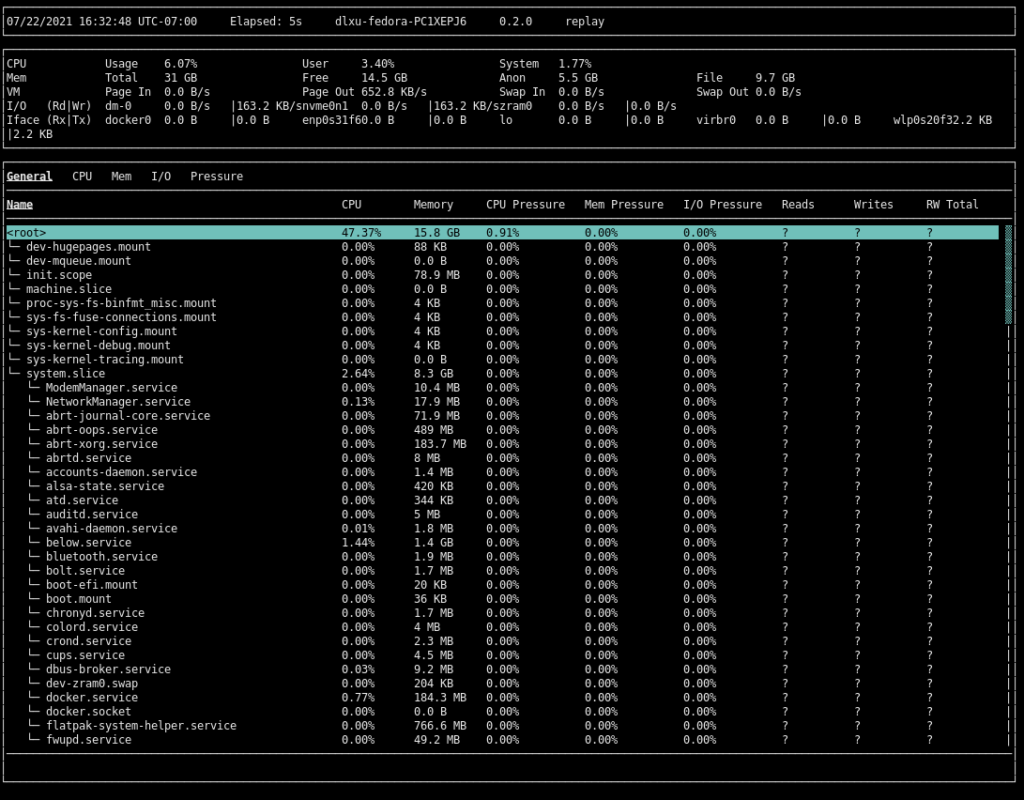
If you get stuck or forget a keybinding, press **?** to access the help menu.
The very top of the screen is the status bar. The status bar displays information about the current sample. You can move forwards and backwards through samples by pressing **t** and **T**, respectively. The middle section is the system overview. The system overview contains statistics about the system as a whole that are generally always useful to see. The third and lowest section is the multipurpose view. The image above shows the cgroup view. Additionally, there are process and system views, accessible by pressing **p** and **s**, respectively.
Press **↑** and **↓** to move the list selection. Press **<Enter>** to collapse and expand cgroups. Suppose you’ve found an interesting cgroup and you want to see what processes are running inside it. To zoom into the process view, select the cgroup and press **z**:
Press **z** again to return to the cgroup view. The cgroup view can be somewhat long at times. If you have a vague idea of what you’re looking for, you can filter by cgroup name by pressing **/** and entering a filter:
At this point, you may have noticed a tab system we haven’t explored yet. To cycle forwards and backwards through tabs, press **<Tab>** and **<Shift> + <Tab>** respectively. We’ll leave this as an exercise to the reader.
## Other features
Under the hood, *below* has a powerful design and architecture. Facebook is constantly upgrading to newer kernels, so we never assume a data source is available. This tacit assumption enables total backwards and forwards compatibility between kernels and *below* versions. Furthermore, each data point is zstd compressed and stored in full. This solves the issues with delta compression we’ve seen *atop* have at scale. Based on our tests, our per-sample compression can achieve on average a 5x compression ratio.
*below* also uses eBPF [2] to collect information about short-lived processes (processes that live for shorter than the data collection interval). In contrast, *atop* implements this feature with BSD process accounting, a known slow and priority-inversion-prone kernel interface.
For the user, *below* also supports live-mode and a dump interface. Live mode combines the recording daemon and the TUI session into one process. This is convenient for browsing system state without committing to a long running daemon or disk space for data storage. The dump interface is a scriptable interface to all the data *below* stores. Dump is both powerful and flexible — detailed data is available in CSV, JSON, and human readable format.
## Conclusion
*below* is an Apache 2.0 licensed open source project that we (the *below* developers) think offers compelling advantages over existing tools in the resource monitoring space. We’ve spent a great deal of effort preparing *below* for open source use so we hope that readers and the community get a chance to try *below* out and report back with bugs and feature requests.
[0]: [https://www.atoptool.nl/](https://www.atoptool.nl/)
[1]: [https://en.wikipedia.org/wiki/Cgroups](https://en.wikipedia.org/wiki/Cgroups)
[2]: [https://ebpf.io/](https://ebpf.io/)
## Timothée Ravier
Link to the project: https://github.com/facebookincubator/below
## Nathan Scott
Interesting stuff – it’s a fascinating area. ‘below’ sounds like a project that is just starting to tackle some of the hard problems that have been solved by the Performance Co-Pilot toolkit too. PCP has been in use and solving production problems for over 20 years – it’d be interesting to read a comparison to PCP instead of atop.
https://pcp.io/
https://pcp.readthedocs.io/
https://github.com/performancecopilot/pcp/
Let me know if I can help with that? Also happy to discuss design choices made in PCP over the years that may be of assistance as you start to develop ‘below’ – shoot me an email if interested.
cheers!
## Daniel Xu
Hey Nathan,
I haven’t looked very closely at PCP before, but based on what I learned in the last 20 minutes, PCP looks quite powerful and has a lot of front-end options. I’d say the main distinction w/ below is that below is more opinionated and targeted towards troubleshooting resource issues.
One thing that could be interesting is using below’s front-end w/ PCP’s backend. below’s code is structured to support different backends already (used internally for our remote view capability).
## Nathan Scott
Hi Daniel,
Great idea – it sounds like the code is quite similarly structured to https://htop.dev where we’ve recently merged the first version of a PCP backend in similar fashion:
https://github.com/htop-dev/htop/pull/536
We then also introduced the ability to extend the UI with any metric, which may be an interesting possibility for ‘below’ to look into as well:
https://github.com/htop-dev/htop/pull/669
https://github.com/htop-dev/htop/pull/707
I’ll send you an email to continue the discussion and explore these ideas further.
## Ben
Hi,
Thanks for the informative article. However, it seems (for me) that it’s not yet available (I’m on Fedora 33, can’t upgrade yet).
Dnf is unable to find it (either via search or install), seems it’s only available as an rpm for F34
However, “cargo install below” works perfectly (for me)
Thanks,
Ben
## Anthropy
If you enjoy performance monitoring especially on production systems, you could also look at things like Netdata (simple webgui, basically zero config) or things like Prometheus (can work together with netdata) or Sensu or Nagios or Zabbix, to get an insight into historical usage of basically every resource, also for entire clusters and such. It’ll also allow you to set up alerting based on resource usage so you can act before it crashes instead of debugging it after the fact.
And it may sound overkill, but Netdata is really lightweight and can also be used over SSH tunnels and such, so there’s no need to set up extra ports or anything like that, and it does so much more than stuff like atop/below from my experience.
Not to say atop/below and other tools like PCP (which also works with Cockpit btw, if you prefer that web gui instead) don’t have their value, everyone has their own preferences, but for production systems and larger scale deployments, stuff like netdata + prometheus or something else like that can be really beneficial so I thought I’d mention it at least. |
13,855 | 学习 Core Java 的 8 个原因 | https://opensource.com/article/21/10/why-i-learned-core-java | 2021-10-06T09:48:21 | [
"Java"
] | https://linux.cn/article-13855-1.html |
>
> 在学习建立在 Java 之上的所有相关工具时,了解 Core Java 会给你带来很大的优势。
>
>
>

计算机编程(也被称为 *编码*)的重点不是使用哪种编程语言,而是发展编程逻辑和学习像程序员一样思考。你一开始使用的编程语言应该是在这一努力过程中对你帮助最大的语言。因此,你必须问自己一个问题,“作为一个程序员,你想开发什么?”
例如,如果你想从事安卓应用开发、视频游戏开发、桌面 GUI 应用,或者只是一般的软件开发,我认为学习 Java 是一个很好的选择。我选择的语言是 Java,它为我提供了一个完整的编程世界。在我居住的印度,Java 程序员的平均工资约为每年 59 万印度卢比(LPA)(根据你的经验,可以高达 100 LPA)。
不过,Java 是一种庞大的语言,有很多框架和变体可供选择。Core Java 是科技行业发展出来的术语,指的是 Java 语言的中心组件,人们用它来编写框架,并围绕 Java 发展了丰富的产业。我认为,Core Java 是你能获得的最强大的技能之一,因为在学习建立在它之上的所有相关工具时,了解 Java 的基础知识会给你带来巨大的优势。
以下是我选择 Core Java 的八大理由,我想你也会认可:
### 1、Java 是一种不断发展的编程语言
Java 有重要的企业支持,但 Java 开发中最重要的组成部分是 [OpenJDK](https://developer.ibm.com/components/open-jdk/),这是个开源的 Java 开发工具包。OpenJDK 社区以促进和维护开发源码、开放创新和开放标准为使命,致力于改进和维护 Java 及其工具链的开源实现。
它的每一个版本都会增加创新和便利,使 Java 对开发者和用户都更容易。例如,就在 Java 11 中,他们增加了运行 .java 文件的能力。现在,运行一个单文件的 Java 应用程序所需要的只是 `java` 命令,不需要进行编译:
```
$ java ./hello.java
Hello world
```
你可以使用 Java 做 Web、移动或桌面的应用程序编程。它是一种高度通用的语言。它有许多有趣的特点,如动态编码、多种安全功能、平台无关的特点和以网络为中心的设计。
### 2、Java 锚定了安卓应用开发
你可以使用 Java 来创建安卓用程序。安卓市场巨大,对移动程序员的需求只会越来越大。即使你对成为一个专业的应用程序开发人员不感兴趣,定制你的移动体验的能力也是很强大的,而 Java 使之成为可能。
而且,这比你想象的要容易得多!学习 Core Java 可以让你轻松地掌握安卓开发工具包或可以输出到移动平台的框架,如 [Processing](http://processing.org/)。
### 3、丰富的 API 使得 Java 易于使用
Java 的 API(<ruby> 应用编程接口 <rt> Application Programming Interface </rt></ruby>)包括类、包、接口等。Java 主要有三种类型的 API:
* 官方的 Java Core API
* 最佳的官方 Java API
* 非官方的 API
API 使编程更容易,因为你可以在不知道其内部实现的情况下构建应用程序。根据我的经验,许多公司喜欢用 Java 而不是其他选择,就是因为 Java API 的力量。
### 4、开源库
几乎有无穷无尽的 Java 开源库,包括 Maven、Guava、Apache Commons、Jhipster,等等。你可以复制、学习和分享这些库的资源。它们使编程更容易获得、更快、更便宜,也更有教育意义。
### 5、Java 有可靠的开发工具
Java 有一些我最喜欢的 IDE(<ruby> 集成开发环境 <rt> Integrated Development Environments </rt></ruby>),包括 [Eclipse](https://opensource.com/article/20/12/eclipse)、[NetBeans](https://opensource.com/article/20/12/netbeans)、[BlueJ](https://opensource.com/article/20/7/ide-java#bluej) 和 IntelliJ IDEA。它们提供了调试、语法高亮、代码补完、语言支持、自动重构等功能。简而言之,IDE 在 Java 的成功和你在 Java 学习中起着至关重要的作用!
### 6、印度对 Java 开发人员的需求
谷歌、Netflix 和 Instagram 等巨头都使用 Java 进行后台开发。印度公司正在积极寻找雇用 Java 程序员来开发安卓应用程序、新的 API 和云上的微服务。这种需求转化为更多的工作机会。
### 7、Java 有庞大的编程社区
Java 程序员的社区庞大,囊括了从初学者到专家的所有人。我发现这个社区很热情待人,当你寻求支持的时候,他们会给予帮助。最重要的是,通过参与在线讨论,我学到了大量的新技巧。作为社区的一分子,这是我了解最新趋势、学习更多语言和跟上发展的重要途径。
### 8、Java 是独立于平台
Java 是平台无关的,这一点使它具有很高的价值。Java 源代码被编译成字节码,在 Java 虚拟机(JVM)上运行。任何运行 JVM 的平台(支持所有主要平台)都可以运行你的 Java 应用程序。你只需写一次,就可以在任何地方运行!这并不只是理论上的,Java 实际上已经实现了这一点。你可以在你开发的任何平台上编写 Java,并将其交付给你的所有目标平台。
网上有很多学习 Java 的资源,包括 [Opensource.com](http://Opensource.com) 上有一个 [速查表](https://opensource.com/downloads/java-cheat-sheet)。还有一个很好的 [在线 Java 课程](https://www.learnvern.com/course/core-java-programming-tutorial),可以用印地语免费学习。
---
via: <https://opensource.com/article/21/10/why-i-learned-core-java>
作者:[Shantam Sahai](https://opensource.com/users/shantam-sahai) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Computer programming, also known as *coding *for short, is not about which language you use. It's about developing programming logic and learning to think like a programmer. The language you start with should be the one that helps you the most in this endeavor. So you have to ask yourself the question: "What do you want to do as a programmer?"
For example, if you want to work on Android app development, video game development, desktop GUI applications, or just general software development, I think learning Java is an excellent option. It's the language I chose, and it has made a whole world of programming available to me. In India, where I live, the average salary of a Java programmer is around 5.9 Lakhs per Annum (LPA) (it can be as high as 10 LPA, depending on your experience.)
Java is a vast language, though, with lots of frameworks and variants to choose from. *Core Java* is the term the tech industry has developed to refer to the central components of the Java language—the thing that people use to write the frameworks and has developed the cottage industry around Java. I believe that Core Java is one of the most powerful skills you can acquire because understanding the basics of Java gives you a significant advantage when learning all of the related tools built on top of it.
Here are the top eight reasons I chose Core Java, and I think you should too:
## 1. Java is an evolving programming language
Java has significant corporate backing, but the most important component in Java development is [OpenJDK](https://developer.ibm.com/components/open-jdk/)—the open source Java Development Kit. With a mission statement to promote and maintain open source, open innovation, and open standards, the OpenJDK community is committed to improving and maintaining an open source implementation of Java and its toolchain.
Innovations and conveniences get added with every release, making Java easier for developers and users alike. For instance, it was just in Java 11 that they added the ability to run .java files. Now, all it takes to run a single-file Java application is the `java`
command, no compilation required:
```
$ java ./hello.java
Hello world
```
You can use Java to program applications for the web, mobile, or desktop. It's a highly versatile language. It has many interesting features such as dynamic coding, multiple security features, platform-independent characteristics, and network-centric design.
## 2. Java anchors android app development
You can use Java to create Android apps. The Android market is enormous, and the demand for mobile programmers is only growing. Even if you're not interested in becoming a professional app developer, the ability to customize your mobile experience is a powerful one, and Java makes it possible.
And it's easier than you might think! Learning Core Java makes it easy for you to pick up Android development kits or frameworks that export to mobile platforms, like [Processing](http://processing.org/).
## 3. Rich APIs make Java easy to use
Java's API (Application Programming Interface) includes classes, packages, interfaces, and more. Java has mainly three types of APIs:
- Official Java Core APIs
- Optimal official Java APIs
- Unofficial APIs
An API makes programming easier because you can construct applications without knowing their inside implementations. In my experience, many companies prefer Java over other options because of the strength of the Java API.
## 4. Open source libraries
There are nearly endless open source libraries for Java, including Maven, Guava, Apache Commons, Jhipster, and much more. You can copy, study, and share resources from these libraries. They make programming more accessible, faster, cheaper, and more educational.
## 5. Java has reliable development tools
Java has some of my favorite IDEs (Integrated Development Environments), including [Eclipse](https://opensource.com/article/20/12/eclipse), [NetBeans](https://opensource.com/article/20/12/netbeans), [BlueJ](https://opensource.com/article/20/7/ide-java#bluej), and IntelliJ IDEA. They provide debugging, syntax highlighting, code completion, language support, automated refactoring, and more. In short, IDEs play an essential role in Java's success and in your success as you learn it!
## 6. Demand for Java developers in India
Giants like Google, Netflix, and Instagram use Java for backend development. Indian companies are actively looking to hire Java programmers to develop Android apps, new APIs, and microservices on the cloud. This demand translates to more job opportunities.
## 7. The Java programming community is huge
The community of Java programmers is vast. It ranges from groups of beginners to experts. I have found the community to be welcoming and helpful when you ask for support. Most importantly, I've learned tons of new tricks by involving myself in online discussions. Being a part of the community has been a vital way for me to keep up with the latest trends, learn more about the language, and keep up with development.
## 8. Java is platform-independent
The fact that Java is platform-independent makes it highly valuable. Java source code is compiled down to bitcode, which runs on the Java Virtual Machine (JVM). Any platform running a JVM (and all the major platforms do) can run your Java application. You write once and run everywhere! And this isn't just a theoretical position: Java has actually achieved this. You can write Java on whatever platform you develop on and deliver it to all your target platforms.
There are many resources online to learn Java, including a [cheat sheet](https://opensource.com/downloads/java-cheat-sheet) here on Opensource.com. There's also a great [online Java course](https://www.learnvern.com/course/core-java-programming-tutorial) available in Hindi for free.
## Comments are closed. |
13,857 | 由 Facebook 事故引发的 BGP 工具探索 | https://jvns.ca/blog/2021/10/05/tools-to-look-at-bgp-routes/ | 2021-10-07T09:37:00 | [
"BGP"
] | https://linux.cn/article-13857-1.html | 
昨天,Facebook 发生了由 BGP 引起的离线事故。我对学习更多关于 BGP 的知识已经隐约感兴趣了很长时间,所以我阅读了一些文章。
我感到很沮丧,因为没有一篇文章告诉我如何在我的电脑上实际查找与 BGP 有关的信息,因此我 [写了一条询问有关工具的推特](https://twitter.com/b0rk/status/1445199475195236356)。
我一如既往地得到了一堆有用的回复,所以这篇博文展示了一些你可以用来查询 BGP 信息的工具。这篇文章中可能会有较多的错误,因为我对 BGP 不是很了解。
### 我不能发布 BGP 路由
我从来没有了解过 BGP 的原因之一是,据我所知,我没有在互联网上发布 BGP 路由的权限。
对于大多数网络协议,如果需要,你可以非常轻松地自己实现该协议。例如,你可以:
* 发行你自己的 TLS 证书
* 编写你自己的 HTTP 服务器
* 编写你自己的 TCP 实现
* 为你的域名编写你自己的权威 DNS 服务器(我现在正在为一个小项目尝试这样做)
* 建立你自己的证书机构(CA)
但是对于 BGP,我认为除非你拥有自己的 ASN,否则你不能自己发布路由(你*可以*在你的家庭网络上实现 BGP,但这对我来说有点无聊,当我做实验的时候,我希望它们真的在真正的互联网上)。
无论如何,尽管我不能用它做实验,但我仍然认为它超级有趣,因为我喜欢网络,所以我将向你展示我找到的一些用来学习 BGP 的工具。
首先我们来谈谈 BGP 的一些术语。我打算很快掠过,因为我对工具更感兴趣,而且网上有很多关于 BGP 的高水平解释(比如这篇 [cloudflare 的文章](https://blog.cloudflare.com/october-2021-facebook-outage/))。
### AS 是什么?
我们首先需要了解的是 AS(“<ruby> 自治系统 <rt> autonomous system </rt></ruby>”)。每个 AS:
1. 由一个组织拥有(通常是一个大型组织,如你的 ISP、政府、大学、Facebook 等)。
2. 控制一组特定的 IP 地址(例如,我的 ISP 的 AS 包括 247,808 个 IP 地址)。
3. 有一个编号 ASN(如 1403)。
下面是我通过做一些实验对 AS 的一些观察:
* 一些相当大的科技公司并没有自己的 AS。例如,我在 BGPView 上查看了 Patreon,就我所知,他们没有自己的 AS,他们的主要网站(`patreon.com`,[104.16.6.49](https://bgpview.io/ip/104.16.6.49))在 Cloudflare 的 AS 中。
* 一个 AS 可以包括许多国家的 IP。Facebook 的 AS([AS32934](https://bgpview.io/asn/32934#prefixes-v4))肯定有新加坡、加拿大、尼日利亚、肯尼亚、美国和其他国家的 IP 地址。
* 似乎 IP 地址可以在一个以上的 AS 中。例如,如果我查找 [209.216.230.240](https://bgpview.io/ip/209.216.230.240),它有 2 个 ASN 与之相关:`AS6130` 和 `AS21581`。显然,当这种情况发生时,更具体的路线会被优先考虑 —— 所以到该 IP 的数据包会被路由到 `AS21581`。
### 什么是 BGP 路由?
互联网上有很多的路由器。例如,我的 ISP 就有路由器。
当我给我的 ISP 发送一个数据包时(例如通过运行 `ping 129.134.30.0`),我的 ISP 的路由器需要弄清楚如何将我的数据包实际送到 IP 地址 `129.134.30.0`。
路由器计算的方法是,它有一个**路由表**:这是个有一堆 IP 地址范围的列表(比如 `129.134.30.0/23`),以及它知道的到达该子网的路由。
下面是一个 `129.134.30.0/23` (Facebook 的一个子网)的真实路由的例子。这不是来自我的 ISP。
```
11670 32934
206.108.35.2 from 206.108.35.254 (206.108.35.254)
Origin IGP, metric 0, valid, external
Community: 3856:55000
Last update: Mon Oct 4 21:17:33 2021
```
我认为这是在说通往 `129.134.30.0` 的一条路径是通过机器 `206.108.35.2`,这是在它的本地网络上。所以路由器接下来可能会把我的 ping 包发送到 `206.108.35.2`,然后 `206.108.35.2` 会知道如何把它送到 Facebook。开头的两个数字(`11670 32934`)是 ASN。
### BGP 是什么?
我对 BGP 的理解非常浅薄,它是一个公司用来公布 BGP 路由的协议。
昨天发生在 Facebook 身上的事情基本上是他们发布了一个 BGP 公告,撤销了他们所有的 BGP 路由,所以世界上的每个路由器都删除了所有与 Facebook 有关的路由,没有流量可以到达那里。
好了,现在我们已经涵盖了一些基本的术语,让我们来谈谈你可以用来查看 AS 和 BGP 的工具吧!
### 工具 1:用 BGPView 查看你的 ISP 的 AS
为了使 AS 这个东西不那么抽象,让我们用一个叫做 [BGPView](https://bgpview.io)的 工具来看看一个真实的 AS。
我的 ISP(EBOX)拥有 [AS 1403](https://bgpview.io/asn/1403)。这是 [我的 ISP 拥有的 IP 地址](https://bgpview.io/asn/1403#prefixes-v4)。如果我查找我的计算机的公共 IPv4 地址,我可以看到它是我的 ISP 拥有的IP地址之一:它在 `104.163.128.0/17` 块中。
BGPView 也有这个图,显示了我的 ISP 与其他 AS 的连接情况。

### 工具 2:traceroute -A 和 mtr -z
好了,我们感兴趣的是 AS 。让我们看看我从哪些 AS 中穿过。
`traceroute` 和 `mtr` 都有选项可以告诉你每个 IP 的 ASN。其选项分别是 `traceroute -A` 和 `mtr -z`。
让我们看看我用 `mtr` 在去 `facebook.com` 的路上经过了哪些 AS!
```
$ mtr -z facebook.com
1. AS??? LEDE.lan
2. AS1403 104-163-190-1.qc.cable.ebox.net
3. AS??? 10.170.192.58
4. AS1403 0.et-5-2-0.er1.mtl7.yul.ebox.ca
5. AS1403 0.ae17.er2.mtl3.yul.ebox.ca
6. AS1403 0.ae0.er1.151fw.yyz.ebox.ca
7. AS??? facebook-a.ip4.torontointernetxchange.net
8. AS32934 po103.psw01.yyz1.tfbnw.net
9. AS32934 157.240.38.75
10. AS32934 edge-star-mini-shv-01-yyz1.facebook.com
```
这很有意思,看起来我们直接从我的 ISP 的 AS(`1403`)到 Facebook 的 AS(`32934`),中间有一个“互联网交换”。
>
> 我不确定 <ruby> <a href="https://en.wikipedia.org/wiki/Internet_exchange_point"> 互联网交换 </a> <rt> internet exchange </rt></ruby>(IX)是什么,但我知道它是互联网的一个极其重要的部分。不过这将是以后的事了。我猜是,它是互联网中实现“对等”的部分,就假设它是一个有巨大的交换机的机房,里面有无限的带宽,一堆不同的公司把他们的电脑放在里面,这样他们就可以互相发送数据包。
>
>
>
#### mtr 用 DNS 查找 ASN
我对 `mtr` 如何查找 ASN 感到好奇,所以我使用了 `strace`。我看到它看起来像是在使用 DNS,所以我运行了 [dnspeep](https://github.com/jvns/dnspeep/),然后就看到了!
```
$ sudo dnspeep
...
TXT 1.190.163.104.origin.asn.cymru.com 192.168.1.1 TXT: 1403 | 104.163.176.0/20 | CA | arin | 2014-08-14, TXT: 1403 | 104.163.160.0/19 | CA | arin | 2014-08-14, TXT: 1403 | 104.163.128.0/17 | CA | arin | 2014-08-14
...
```
所以,看起来我们可以通过查找 `1.190.163.104.origin.asn.cymru.com` 上的 `txt` 记录找到 `104.163.190.1` 的 ASN,像这样:
```
$ dig txt 1.190.163.104.origin.asn.cymru.com
1.190.163.104.origin.asn.cymru.com. 13911 IN TXT "1403 | 104.163.160.0/19 | CA | arin | 2014-08-14"
1.190.163.104.origin.asn.cymru.com. 13911 IN TXT "1403 | 104.163.128.0/17 | CA | arin | 2014-08-14"
1.190.163.104.origin.asn.cymru.com. 13911 IN TXT "1403 | 104.163.176.0/20 | CA | arin | 2014-08-14"
```
这很好!让我们继续前进吧。
### 工具 3:数据包交换所的观察镜
PCH(“<ruby> 数据包交换所 <rt> packet clearing house </rt></ruby>”)是运行大量互联网交换点的组织。“<ruby> 观察镜 <rt> looking glass </rt></ruby>”似乎是一个通用术语,指的是让你从另一个人的计算机上运行网络命令的 Web 表单。有一些观察镜不支持 BGP,但我只对那些能显示 BGP 路由信息的观察镜感兴趣。
这里是 PCH 的观察镜: <https://www.pch.net/tools/looking_glass/> 。
在该网站的 Web 表单中,我选择了多伦多 IX(“TORIX”),因为 `mtr` 说我是用它来访问 `facebook.com` 的。
#### 操作 1:显示 ip bgp 摘要
下面是输出结果。我修改了其中的一些内容:
```
IPv4 Unicast Summary:
BGP router identifier 74.80.118.4, local AS number 3856 vrf-id 0
BGP table version 33061919
RIB entries 513241, using 90 MiB of memory
Peers 147, using 3003 KiB of memory
Peer groups 8, using 512 bytes of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
...
206.108.34.248 4 1403 484672 466938 0 0 0 05w3d03h 50
...
206.108.35.2 4 32934 482088 466714 0 0 0 01w6d07h 38
206.108.35.3 4 32934 482019 466475 0 0 0 01w0d06h 38
...
Total number of neighbors 147
```
我的理解是,多伦多 IX(“TORIX”)直接连接到我的 ISP (EBOX,AS 1403)和 Facebook(AS 32934)。
#### 操作 2:显示 ip bgp 129.134.30.0
这是筛选自 `show ip bgp` 对 `129.134.30.0`(Facebook 的一个 IP 地址)的输出:
```
BGP routing table entry for 129.134.30.0/23
Paths: (4 available, best #4, table default)
Advertised to non peer-group peers:
206.220.231.55
11670 32934
206.108.35.2 from 206.108.35.254 (206.108.35.254)
Origin IGP, metric 0, valid, external
Community: 3856:55000
Last update: Mon Oct 4 21:17:33 2021
11670 32934
206.108.35.2 from 206.108.35.253 (206.108.35.253)
Origin IGP, metric 0, valid, external
Community: 3856:55000
Last update: Mon Oct 4 21:17:31 2021
32934
206.108.35.3 from 206.108.35.3 (157.240.58.225)
Origin IGP, metric 0, valid, external, multipath
Community: 3856:55000
Last update: Mon Oct 4 21:17:27 2021
32934
206.108.35.2 from 206.108.35.2 (157.240.58.182)
Origin IGP, metric 0, valid, external, multipath, best (Older Path)
Community: 3856:55000
Last update: Mon Oct 4 21:17:27 2021
```
这似乎是在说,从该 IX 到 Facebook 有 4 条路线。
**魁北克 IX 似乎对 Facebook 一无所知**。
我也试过从魁北克 IX(“QIX”,它可能离我更近,因为我住在蒙特利尔而不是多伦多)做同样的事情。但 QIX 似乎对 Facebook 一无所知:当我输入`129.134.30.0` 时,它只是说 “% 网络不在表中”。
所以我想这就是为什么我被送到多伦多 IX 而不是魁北克的 IX。
#### 更多的 BGP 观察镜
这里还有一些带观察镜的网站,可以从其他角度给你类似的信息。它们似乎都支持相同的 `show ip bgp` 语法,也许是因为他们运行的是同一个软件?我不太确定。
* <http://www.routeviews.org/routeviews/index.php/collectors/>
* <http://www.routeservers.org/>
* <https://lg.he.net/>
似乎有很多这样的观察镜服务,远不止这 3 个列表。
这里有一个与这个列表上的一个服务器进行会话的例子:`route-views.routeviews.org`。这次我是通过 telnet 连接的,而不是通过 Web 表单,但输出的格式看起来是一样的。
```
$ telnet route-views.routeviews.org
route-views>show ip bgp 31.13.80.36
BGP routing table entry for 31.13.80.0/24, version 1053404087
Paths: (23 available, best #2, table default)
Not advertised to any peer
Refresh Epoch 1
3267 1299 32934
194.85.40.15 from 194.85.40.15 (185.141.126.1)
Origin IGP, metric 0, localpref 100, valid, external
path 7FE0C3340190 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
6939 32934
64.71.137.241 from 64.71.137.241 (216.218.252.164)
Origin IGP, localpref 100, valid, external, best
path 7FE135DB6500 RPKI State valid
rx pathid: 0, tx pathid: 0x0
Refresh Epoch 1
701 174 32934
137.39.3.55 from 137.39.3.55 (137.39.3.55)
Origin IGP, localpref 100, valid, external
path 7FE1604D3AF0 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
20912 3257 1299 32934
212.66.96.126 from 212.66.96.126 (212.66.96.126)
Origin IGP, localpref 100, valid, external
Community: 3257:8095 3257:30622 3257:50001 3257:53900 3257:53904 20912:65004
path 7FE1195AF140 RPKI State valid
rx pathid: 0, tx pathid: 0
Refresh Epoch 1
7660 2516 1299 32934
203.181.248.168 from 203.181.248.168 (203.181.248.168)
Origin IGP, localpref 100, valid, external
Community: 2516:1030 7660:9001
path 7FE0D195E7D0 RPKI State valid
rx pathid: 0, tx pathid: 0
```
这里有几个路由的选择:
* `3267 1299 32934`
* `6939 32934`
* `701 174 32934`
* `20912 3257 1299 32934`
* `7660 2516 1299 32934`
我想这些都有不止一个 AS 的原因是,`31.13.80.36` 是 Facebook 在多伦多的 IP 地址,所以这个服务器(可能在美国西海岸,我不确定)不能直接连接到它,它需要先到另一个 AS。所以所有的路由都有一个或多个 ASN。
最短的是 `6939`(“Hurricane Electric”),它是一个 “全球互联网骨干”。他们也有自己的 [Hurricane Electric 观察镜](https://lg.he.net/) 页面。
### 工具 4:BGPlay
到目前为止,所有其他的工具都只是向我们展示了 Facebook 路由的当前状态,其中一切正常,但这第四个工具让我们看到了这个 Facebook BGP 互联网灾难的历史。这是一个 GUI 工具,所以我将包括一堆屏幕截图。
该工具在 <https://stat.ripe.net/special/bgplay>。我输入了 IP 地址 `129.134.30.12`(Facebook 的一个 IP),如果你想一起试试。
首先,让我们看看一切出错之前的状态。我点击了在 10 月 4 日 13:11:28 的时间线,得到了这个结果:

我最初发现这很让人不知所措。发生了什么事?但后来有人在推特上指出,下一个要看的地方是点击 Facebook 灾难发生后的时间线(10 月 4 日 18 点 38 分)。

很明显,这张图有问题:所有的 BGP 路线都不见了!哦,不要!
顶部的文字显示了最后一条 Facebook BGP 路由的消失:
```
Type: W > withdrawal Involving: 129.134.30.0/24
Short description: The route 50869, 25091, 32934 has been withdrawn.
Date and time: 2021-10-04 16:02:33 Collected by: 20-91.206.53.12
```
如果我再点击“<ruby> 快进 <rt> fast forward </rt></ruby>”按钮,我们看到 BGP 路由开始回来了。

第一个宣告的是 `137409 32934`。但我不认为这实际上是第一个宣布的,在同一秒内有很多路由宣告(在 2021-10-04 21:00:40),我认为 BGPlay 内部的排序是任意的。
如果我再次点击“<ruby> 快进 <rt> fast forward </rt></ruby>”按钮,越来越多的路由开始回来,路由开始恢复正常。
我发现在 BGPlay 里看这个故障真的很有趣,尽管一开始界面很混乱。
### 也许了解一下 BGP 是很重要的?
我在这篇文章的开头说,你不能改变 BGP 路由,但后来我想起在 2016 年或 2017 年,有一个 [Telia 路由问题](https://news.ycombinator.com/item?id=14246888),给我们的工作造成了一些小的网络问题。而当这种情况发生时,了解为什么你的客户无法到达你的网站其实是很有用的,即使它完全不受你控制。当时我不知道这些工具,但我希望能知道!
我认为对于大多数公司来说,应对由其他人的错误 BGP 路由造成的中断,你所能做的就是“什么都不做,等待它得到修复”,但能够\_自信地\_什么都不做是很好的。
### 一些发布 BGP 路由的方法
如果你想(作为一个业余爱好者)真正发布 BGP 路由,这里有一些评论中的链接:
* [获取你自己的 ASN 的指南](https://labs.ripe.net/author/samir_jafferali/build-your-own-anycast-network-in-nine-steps/)
* [dn42](https://dn42.eu/Home) 似乎有一个 BGP 的实验场(它不在公共互联网上,但确实有其他人在上面,这似乎比自己在家里做 BGP 实验更有趣)
### 目前就这些了
我想还有很多 BGP 工具(比如 PCH 有一堆 [路由数据的每日快照](https://www.pch.net/resources/Routing_Data/IPv4_daily_snapshots/),看起来很有趣),但这篇文章已经很长了,而且我今天还有其他事情要做。
我对我作为一个普通人可以得到这么多关于 BGP 的信息感到惊讶,我一直认为它是一个“秘密的网络巫师”这样的东西,但显然有各种公共机器,任何人都可以直接 telnet 到它并用来查看路由表!没想到!
---
via: <https://jvns.ca/blog/2021/10/05/tools-to-look-at-bgp-routes/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
13,858 | Linux 上 5 个基于 Chromium 的浏览器 | https://news.itsfoss.com/chrome-like-browsers-2021/ | 2021-10-07T13:16:03 | [
"浏览器",
"Chrome"
] | https://linux.cn/article-13858-1.html |
>
> 谷歌浏览器可能不是 Linux 用户的最佳浏览器。在这里,我们探讨了 Linux 平台的其他潜在选择。
>
>
>

想摆脱谷歌?想为你的 Linux 系统寻找可能比谷歌浏览器(和类似的)更好的浏览器?
幸运的是,有多个谷歌浏览器的替代品,你可以试试。
它们中的每一个都带来了一些有趣的东西,同时也保持了 Chrome 所特有的奇妙兼容性。请继续阅读,了解这些浏览器的更多信息。
### 比谷歌浏览器更好的选择
>
> 注:虽然 [自由和开源软件在取代科技巨头方面扮演着关键角色](https://news.itsfoss.com/save-privacy-with-foss/),但除了谷歌浏览器之外,Linux 上的任何选择都是一个好的开始。因此,你也会发现一些非 FOSS 的选择。
>
>
>
在我看来,Chrome 的最佳替代品是基于 Chromium 的浏览器,这意味着它们与 Chrome 共享相同的基因。这样做的好处是,它们已经拥有与 Chrome 相同的功能,同时有更多时间来增加自己的功能。
另外,如果你愿意,你可以了解一下不基于 Chromium 的 [Chrome 开源替代品](https://itsfoss.com/open-source-browsers-linux/)。
无论如何,即使谷歌浏览器的替代品对你来说并不优越,也值得尝试远离科技巨头。
我们收集了一些在各方面与 Chrome 相当或更好的浏览器。闲话少说,以下是我挑选的五款比 Chrome 本身更好的类似 Chrome 的浏览器:
* UnGoogled Chromium
* Brave
* Edge
* Vivaldi
* Opera
这份名单没有排名顺序。
### 1、UnGoogled Chromium

特点:
* 移除针对谷歌域名的功能
* 在运行时阻止对 Google 的内部请求
* 从源代码中剥离谷歌的二进制文件
* 许多新的命令行开关和 `chrome://flags` 条目
* 强制所有弹出式窗口为标签
对于那些隐私爱好者来说,[UnGoogled Chromium](https://github.com/Eloston/ungoogled-chromium) 浏览器将是一个天赐良机。虽然它可能看起来与 Chrome 相同,但它有许多隐私方面的调整。
顾名思义,对于 Chrome 浏览器的用户来说,最大的倒退将是没有谷歌的服务集成。但这也意味着不再有对谷歌的内部请求、谷歌网址跟踪等等。
它没有吹嘘任何非凡的东西来保护你的隐私,但它应该比谷歌浏览器更好。
你也可以选择通过 `chrome://flags` 设置来探索和切换隐私设置。
总而言之,UnGoogled Chromium 提供了一种熟悉的浏览体验,同时还加入了一套隐私功能。它是可靠的,而且还与 Chrome 扩展程序庞大的生态系统兼容。
### 2、Brave

特点:
* 内置广告拦截器
* 更快的页面加载时间
* Brave 奖励计划
* 能够在设备之间进行同步
* 支持 Chrome Web 商店
当 [Brave](https://brave.com) 在 2016 年首次登上舞台时,世界各地的人们都震惊于它的隐私和性能特点。在发布时,这包括了一个内置的广告屏蔽器和一个新的用户界面。
从那时起,该浏览器有了更多的功能,包括奖励计划和 [Tor](https://itsfoss.com/tor-guide/) 整合。这使得它成为增长最快的浏览器之一。
### 3、Edge

特点:
* 支持 Chrome Web 商店
* 儿童浏览模式(额外的保护和更简单的用户界面)
* 良好的 PDF 编辑工具
* 内置优惠券搜索器
* 阅读模式
* 内置密码生成器
当微软 [Edge](https://www.microsoftedgeinsider.com/en-us/download) 在 2015 年首次与 Windows 10 一起发布时,它因缓慢和有缺陷而被广泛批评。然而,在 2020 年初,它使用 Chromium Web 引擎完全重新制作了。
这也是 Chrome 浏览器所基于的引擎,这提供了现代和快速的浏览体验。这种转变的一个好处是 Web 浏览器能够在许多不同的平台上运行,从 Windows 7 和 macOS 到 Ubuntu 和其他基于 Linux 的发行版。
我知道,如果你因为某些原因讨厌微软,这可能不会吸引你 —— 但 Linux 版的微软 Edge 是谷歌 Chrome 浏览器的一个重要替代品。
### 4、Vivaldi

特点:
* 内置翻译器
* Vivaldi Email(Beta)
* Feed 阅读器(Beta)
* Vivaldi 日历(Beta)
* 可高度定制的用户界面
* 内置广告拦截器
* 支持 Chrome Web 商店
* 标签分组
* 分屏标签
[Vivaldi](https://vivaldi.com) 于 2016 年首次发布,它在浏览器大战中迅速崛起。它最初是为对 [Presto](https://en.wikipedia.org/wiki/Presto_(browser_engine)) [布局引擎](https://en.wikipedia.org/wiki/Browser_engine) 过渡不满的 Opera 用户设计的,它已经成功地重新实现了 Opera 过渡到 Chromium 期间失去的许多功能。
令人惊讶的是,它在基于 Chromium 的情况下还能做到这一点(正是 Opera 放弃这些功能的原因)。
最新的 [Vivaldi 4.0 版本](https://news.itsfoss.com/vivaldi-4-0-release/) 也为高级用户提供了一些功能。
虽然它不是 100% 的自由软件,但其 93% 的源代码是可用的,只有用户界面是专有的。考虑到 Vivaldi 的开发团队积极关注着 Linux 用户的改进,Vivaldi 提供了大量的功能,这可能是一个值得权衡的结果。
### 5、Opera

特点:
* 内置虚拟专用网络
* 轻松访问社交媒体
* 内置加密货币钱包
* 欺诈和恶意软件保护
* 高度可见的网站安全徽章
虽然 [Opera](https://www.opera.com) 从未成为 Web 浏览器之王,但它一直存在于关于使用何种浏览器的争论中。它最初是基于其内部的 Presto 布局引擎的,在 2013 年切换到 Chromium。
不幸的是,这一转换意味着 Opera 团队被迫放弃了其最知名的一些功能,为 Vivaldi 和 Firefox 等替代品填补 Opera 留下的空间铺平道路。
这并不是说 Opera 缺乏功能,它包含了许多功能。
### 总结
在这里,我们列出了为 Linux 桌面平台上用户量身定做的浏览器。
无论你是想要更多的功能、更好的用户界面,还是想要帮助你摆脱谷歌的束缚,都有一个选择适合你。
由于所有这些浏览器都是基于 Chromium 的,它们都能像 Chrome 一样提供良好的兼容性和用户体验。因此,请切换到这些类似 Chrome 的浏览器中,享受它们各自赋予的自由吧。
2021 年,你最喜欢的 Linux 上谷歌浏览器的替代品是什么?请在下面的评论中告诉我。
---
via: <https://news.itsfoss.com/chrome-like-browsers-2021/>
作者:[Jacob Crume](https://news.itsfoss.com/author/jacob/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Want to switch away from Google? But, looking for something potentially better than Google Chrome (and similar) for your Linux system?
Fortunately, there are multiple Google Chrome alternatives that you can try.
Each of them brings something interesting to the table, while also keeping the fantastic compatibility Chrome is known for. Read on to find out more about these browsers.
## Options That Are Better Than Google Chrome
**Note:** *While free and open-source software plays a crucial role in replacing big tech, any choice available on Linux other than Google Chrome should be a good start. Hence, you will find some non-FOSS options as well.*
In my opinion, the best alternatives to Chrome are Chromium-based, meaning that they share the same DNA with Chrome. The advantage of this is that they already have feature parity with Chrome, while having more time to add their own.
Also, if you want, you can explore [open source alternatives to Chrome](https://itsfoss.com/open-source-browsers-linux/?ref=news.itsfoss.com) that are not based on Chromium.
In any case, even if the alternatives to Google Chrome do not seem superior to you, it is worth a try to move away from Big Tech.
The result of this is a collection of Linux web browsers that are equal or better than Chrome in various aspects. Without further ado, here are my top five picks for Chrome-like browsers that are better than Chrome itself:
**UnGoogled Chromium****Brave****Microsoft Edge****Vivaldi****Opera**
This list is in no order of ranking.
## 1. UnGoogled Chromium
**Features:**
- Removal of functionality specific to Google domains.
- Blocking of internal requests to Google at runtime.
- Stripping Google binaries from the source code.
- Many new command-line switches and
`chrome://flags`
entries. - Forces all pop-ups into tabs.
For the privacy fans out there, this browser will be a godsend. While it may look identical to Chrome, it has many privacy tweaks under-the-hood.
As the name suggests, the biggest setback for Chrome users will be the absence of Google’s service integrations. This also means no more internal requests to Google, Google URL tracking, and much more.
It does not boast anything extraordinary to protect your privacy, but it should be better than Google Chrome.
You can choose to explore and toggle privacy settings at will through the Chrome flags settings as well.
All-in-all, UnGoogled Chromium provides a familiar browsing experience, with a suite of privacy features added in as well. It is reliable and is also compatible with the large ecosystem of Chrome extensions.
## 2. Brave
**Features:**
- Built-in ad blocker.
- Faster page loading times.
- Brave rewards program.
- Ability to synchronise between devices.
- Chrome web store support.
When Brave first marched onto the stage in 2016, people around the world were gawking at its privacy and performance features. At launch, these included a built-in ad-blocker and a new UI.
Since then, the browser has gained many more features, including a rewards program and [Tor ](https://itsfoss.com/tor-guide/?ref=news.itsfoss.com)integration. This has led it to become one of the fastest-growing browsers.
## 3. Microsoft Edge
**Features:**
- Chrome Web Store support
- Child browsing mode (additional protection and simpler UI)
- Good PDF editing tools
- Built-in coupon finder
- Reader Mode
- Built-in password generator
When Microsoft Edge first released alongside Windows 10 in 2015, it was widely criticized for being slow and buggy. However, in early 2020 it was completely remade using the Chromium web engine.
This is the same engine Chrome is based on. The result of this is a modern and fast browsing experience. One perk of this transition is the web browser’s ability to run on many different platforms, from Windows 7 and macOS to Ubuntu and other Linux-based distros.
I know, if you hate Microsoft for some reason, this may not entice you – but Microsoft Edge for Linux is a serious alternative to Google Chrome.
## 4. Vivaldi

**Features:**
- Built-in translator
- Vivaldi Email (Beta)
- Feed Reader (Beta)
- Vivaldi Calendar (Beta)
- Highly customizable UI
- Built-in Ad Blocker
- Chrome Web Store support
- Tab grouping
- Split-screen tabs
First released in 2016, Vivaldi has quickly risen the ranks in browser wars. Originally designed for Opera users disgruntled by its transition from the [Presto](https://en.wikipedia.org/wiki/Presto_(browser_engine)?ref=news.itsfoss.com) [layout engine](https://en.wikipedia.org/wiki/Browser_engine?ref=news.itsfoss.com), it has managed to re-implement many of the features lost during Opera’s transition to Chromium.
Amazingly, it has managed to do this all while being based on Chromium (the very reason Opera dropped these features).
The latest [Vivaldi 4.0 release](https://news.itsfoss.com/vivaldi-4-0-release/) also turned the tables with several features for power users.
While it isn’t 100% FOSS, 93% of its source code is available, with only the UI being proprietary. Considering Vivaldi’s development team actively focus on Linux users for improvement, this could be a worthy tradeoff due to the sheer number of features Vivaldi offers.
## 5. Opera

**Features:**
- Built-in VPN
- Easy access to social media
- Built-in cryptocurrency wallet
- Fraud and malware protection
- Highly visible website security badge
While it has never been the king of web browsers, Opera has always been present in the debate over which browser to use. Originally based on its in-house Presto Layout Engine, it switched over to Chromium in 2013.
Unfortunately, this switch meant that the Opera team was forced to drop some of its most well-known features, paving the way for alternatives such as Vivaldi and Firefox to fill the space Opera had left.
That isn’t to say that Opera is without features. It contains many, some of which are listed below.
## Wrapping Up
Here we have listed a wide variety of browsers tailored to all kinds of users on any desktop platform.
No matter whether you want more features, a better user interface, or something that helps you get away from Google, there is an option for you.
Since all these browsers are based on Chromium, they all offer a good compatibility and user experience like Chrome. So, switch to one of these Chrome-like browsers and enjoy the freedom that each of them grants!
*What’s your favorite alternative to Google Chrome on Linux in 2021? Let me know in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,860 | 用 jconsole 在 Linux 上监控你的 Java | https://opensource.com/article/21/10/monitor-java-linux-jconsole | 2021-10-08T13:11:34 | [
"Java"
] | https://linux.cn/article-13860-1.html |
>
> 如何使用 Java 开发工具包中的 Java 监控和管理控制台。
>
>
>

Java 开发工具包(JDK)提供了开发 Java 应用程序的二进制文件、工具和编译器。其中一个有用的工具是 `jconsole`。
为了演示,我将使用 WildFly J2EE 应用服务器,它是 JBOSS 开源应用服务器项目的一部分。首先,我启动了一个独立的实例。
```
~/wildfly/24.0.1/bin$ ./standalone.sh
=========================================================================
JBoss Bootstrap Environment
JBOSS_HOME: /home/alan/wildfly/24.0.1
JAVA: /usr/lib/jvm/java-11-openjdk-11.0.11.0.9-5.fc34.x86_64/bin/java
```
现在,在另一个终端,输入 `jconsole`。
```
$ jconsole
```
启动后,jconsole 会列出本地实例。选择“<ruby> 本地进程 <rt> Local Process </rt></ruby>”,然后选择进程的名称并点击“<ruby> 连接 <rt> Connect </rt></ruby>”。这就是连接并开始使用运行中的 Java 虚拟机(JVM)的 jconsole 的全部过程。

### 概述
这个 Java 监控和管理控制台在仪表板的顶部显示进程标识符(PID)。“<ruby> 概述 <rt> Overview </rt></ruby>”标签有四个图表,显示“<ruby> 堆内存使用情况 <rt> Heap Memory Usage </rt></ruby>”、“<ruby> 线程 <rt> Threads </rt></ruby>”、“<ruby> 类 <rt> Classes </rt></ruby>”和“<ruby> CPU 使用情况 <rt> CPU Usage </rt></ruby>”的重要信息。

沿着顶部的标签提供每个区域的更详细的视图。
### 内存
“<ruby> 内存 <rt> Memory </rt></ruby>”标签显示 JVM 所使用的内存的各个方面的图表。分配给 JVM 的服务器系统内存量被称为“<ruby> 堆 <rt> Heap </rt></ruby>”。这个屏幕还提供了关于堆的内部组件使用情况的详细信息,例如 “<ruby> 伊甸园 <rt> Eden Space </rt></ruby>”、“<ruby> 老年代 <rt> Old Gen </rt></ruby>” 和 “<ruby> 幸存者区 <rt> Survivor Space </rt></ruby>”。你也可以手动请求一个垃圾收集动作。

### 线程
“<ruby> 线程 <rt> Threads </rt></ruby>”标签显示有多少线程在运行。你也可以手动检查是否存在死锁。

### 类
“<ruby> 类 <rt> Classes </rt></ruby>”标签告诉你有多少类被加载,有多少被卸载。

### 虚拟机摘要
“<ruby> 虚拟机摘要 <rt> VM Summary </rt></ruby>”标签提供了许多关于应用程序和主机系统的细节。你可以了解你所处的操作系统和架构、系统内存总量、CPU 数量,甚至交换空间。

摘要中显示的关于 JVM 的进一步细节,包括当前和最大的堆大小以及正在使用的垃圾收集器的信息。底部的窗格列出了传递给 JVM 的所有参数。
### MBeans
最后一个标签,MBeans,让你通过所有的 MBeans 向下钻取,以查看每个 MBeans 的属性和值。

### 总结
Java 已经存在了很长时间,它将继续为全球数百万的系统提供动力。有很多开发环境和监控系统可以使用,但像 `jconsole` 这样的包含在基本工具包中的工具非常有价值。
---
via: <https://opensource.com/article/21/10/monitor-java-linux-jconsole>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Java Development Kit (JDK) provides binaries, tools, and compilers for the development of Java applications. One helpful tool included is jconsole.
To demonstrate, I will use the WildFly J2EE application server, which is part of the JBOSS open source application server project. First, I start up a standalone instance.
```
~/wildfly/24.0.1/bin$ ./standalone.sh
=========================================================================
JBoss Bootstrap Environment
JBOSS_HOME: /home/alan/wildfly/24.0.1
JAVA: /usr/lib/jvm/java-11-openjdk-11.0.11.0.9-5.fc34.x86_64/bin/java
```
Now, in another terminal, I type `jconsole`
.
$ jconsole
Upon launching, jconsole lists local instances. Select Local Process, then select the name of the process and click Connect. That is all it takes to connect and begin using jconsole with a running Java Virtual Machine (JVM).
(Alan Formy-Duvall, CC BY-SA 4.0)
## Overview
The Java Monitoring and Management Console shows the process identifier (PID) at the top of the dashboard. The Overview tab has four graphs to show the vitals for Heap Memory Usage, Threads, Classes, and CPU Usage.
(Alan Formy-Duvall, CC BY-SA 4.0)
The tabs along the top provide more detailed views of each area.
## Memory
The Memory tab displays graphs of various aspects of the memory being used by the JVM. The amount of the server system memory allocated to the JVM is called the heap. This screen also provides details about usage by the internal components of the heap, such as the Eden Space, Old Gen, and the Survivor Space. You can manually request a garbage collection action as well.
(Alan Formy-Duvall, CC BY-SA 4.0)
## Threads
The Threads tab shows how many threads are running. You can also manually check for deadlocks.
(Alan Formy-Duvall, CC BY-SA 4.0)
## Classes
The classes tab tells you how many classes are loaded and how many have been unloaded.
(Alan Formy-Duvall, CC BY-SA 4.0)
## VM Summary
The VM Summary tab provides many details about the application and the host system. You can learn which operating system and architecture you are on, the total amount of system memory, the number of CPUs, and even swap space.
(Alan Formy-Duvall, CC BY-SA 4.0)
Further details about the JVM shown in the summary include current and maximum heap size and information about the garbage collectors in use. The bottom pane lists all of the arguments passed to the JVM.
## MBeans
The last tab, MBeans, lets you drill down through all of the MBeans to view attributes and values for each.
(Alan Formy-Duvall, CC BY-SA 4.0)
## Conclusion
Java has been around a long time, and it continues to power millions of systems worldwide. Plenty of development environments and monitoring systems are available, but having a tool like jconsole included in the base kit can be highly valuable.
## Comments are closed. |
13,861 | NMState:一个声明式网络配置工具 | https://fedoramagazine.org/nmstate-a-declarative-networking-config-tool/ | 2021-10-08T14:58:26 | [
"网络",
"申明式"
] | https://linux.cn/article-13861-1.html | 
这篇文章描述并演示了 NMState,这是一个使用声明式方法配置主机的网络管理器。这意味着你可以通过 API 定义所需的配置状态,而工具则通过<ruby> 提供者 <rt> provider </rt></ruby>来应用配置。
### 配置方法:命令式与声明式
网络管理有时候是一项非常复杂的任务,这取决于环境的规模和多样性。在 IT 的早期,网络管理依赖于网络管理员在网络设备上手动执行命令。如今,<ruby> 基础设施即代码 <rt> Infrastructure as Code </rt></ruby>(IaC)允许以不同的方式将这些任务自动化。z这基本上有两种方法:命令式或声明式。
在命令式方法中,你会定义“如何”达到所需的配置状态。而在声明式范式里则定义了“什么”是所需的配置状态,所以它不确定哪些步骤是必需的,也不确定它们必须以何种顺序执行。这种方法目前正在聚集更多的人员参与,你可以在目前使用的大多数管理和编排工具上找到它。
### NMState:一个声明式的工具
NMState 是一个网络管理器,允许你按照声明式方法配置主机。这意味着你通过一个北向的声明式 API 定义所需的配置状态,这个工具通过南向的<ruby> 提供者 <rt> provider </rt></ruby>应用配置。
目前 NMState 支持的唯一的提供者是 NetworkManager,它是为 Fedora Linux 提供网络功能的主要服务。不过,NMState 的开发计划中将逐渐增加其他提供者。
关于 NMState 的进一步信息,请访问其项目 [站点](https://nmstate.io/) 或 GitHub [仓库](https://github.com/nmstate/nmstate)。
### 安装
NMState 在 Fedora Linux 29+ 上可用,需要在系统上安装并运行 NetworkManager 1.26 或更高版本。下面是在 Fedora Linux 34 上的安装情况:
```
$ sudo dnf -y install nmstate
...
输出节略
...
Installed:
NetworkManager-config-server-1:1.30.4-1.fc34.noarch gobject-introspection-1.68.0-3.fc34.x86_64 nispor-1.0.1-2.fc34.x86_64 nmstate-1.0.3-2.fc34.noarch
python3-gobject-base-3.40.1-1.fc34.x86_64 python3-libnmstate-1.0.3-2.fc34.noarch python3-nispor-1.0.1-2.fc34.noarch python3-varlink-30.3.1-2.fc34.noarch
Complete!
```
这样,你可以使用 `nmstatectl` 作为 NMState 的命令行工具。请参考 `nmstatectl -help` 或 `man nmstatectl` 以了解关于这个工具的进一步信息。
### 使用 NMstate
首先要检查系统中安装的 NMState 版本:
```
$ nmstatectl version
1.0.3
```
检查一个网络接口的当前配置,例如 `eth0` 的配置:
```
$ nmstatectl show eth0
2021-06-29 10:28:21,530 root DEBUG NetworkManager version 1.30.4
2021-06-29 10:28:21,531 root DEBUG Async action: Retrieve applied config: ethernet eth0 started
2021-06-29 10:28:21,531 root DEBUG Async action: Retrieve applied config: ethernet eth1 started
2021-06-29 10:28:21,532 root DEBUG Async action: Retrieve applied config: ethernet eth0 finished
2021-06-29 10:28:21,533 root DEBUG Async action: Retrieve applied config: ethernet eth1 finished
---
dns-resolver:
config: {}
running:
search: []
server:
- 192.168.122.1
route-rules:
config: []
routes:
config: []
running:
- destination: fe80::/64
metric: 100
next-hop-address: ''
next-hop-interface: eth0
table-id: 254
- destination: 0.0.0.0/0
metric: 100
next-hop-address: 192.168.122.1
next-hop-interface: eth0
table-id: 254
- destination: 192.168.122.0/24
metric: 100
next-hop-address: ''
next-hop-interface: eth0
table-id: 254
interfaces:
- name: eth0
type: ethernet
state: up
ipv4:
enabled: true
address:
- ip: 192.168.122.238
prefix-length: 24
auto-dns: true
auto-gateway: true
auto-route-table-id: 0
auto-routes: true
dhcp: true
ipv6:
enabled: true
address:
- ip: fe80::c3c9:c4f9:75b1:a570
prefix-length: 64
auto-dns: true
auto-gateway: true
auto-route-table-id: 0
auto-routes: true
autoconf: true
dhcp: true
lldp:
enabled: false
mac-address: 52:54:00:91:E4:4E
mtu: 1500
```
正如你在上面看到的,这个网络配置显示了四个主要部分:
* `dns-resolver`:这部分是这个接口的名字服务器配置。
* `route-rules`:它说明了路由规则。
* `routes`:它包括动态和静态路由。
* `interfaces`:这部分描述了 ipv4 和 ipv6 设置。
### 修改配置
你可以在两种模式下修改所需的配置状态:
* 交互式:通过 `nmstatectl edit` 编辑接口配置。这个命令调用环境变量 `EDITOR` 定义的文本编辑器,因此可以用 yaml 格式编辑网络状态。完成编辑后,NMState 将应用新的网络配置,除非有语法错误。
* 基于文件的:使用 `nmstatectl apply` 应用接口配置,它从先前创建的 yaml 或 json 文件中导入一个所需的配置状态。
下面几节告诉你如何使用 NMState 来改变网络配置。这些改变可能会对系统造成破坏,所以建议在测试系统或客户虚拟机上执行这些任务,直到你对 NMState 有更好的理解。
这里使用的测试系统有两个以太网接口,`eth0` 和 `eth1`:
```
$ ip -br -4 a
lo UNKNOWN 127.0.0.1/8
eth0 UP 192.168.122.238/24
eth1 UP 192.168.122.108/24
```
#### 互动配置模式的例子
使用 `nmstatectl edit` 命令将 `eth0` 接口的 MTU 改为 9000 字节,如下所示:
```
$ sudo nmstatectl edit eth0
---
dns-resolver:
config: {}
running:
search: []
server:
- 192.168.122.1
route-rules:
config: []
routes:
config: []
running:
- destination: fe80::/64
metric: 100
next-hop-address: ''
next-hop-interface: eth0
table-id: 254
- destination: 0.0.0.0/0
metric: 100
next-hop-address: 192.168.122.1
next-hop-interface: eth0
table-id: 254
- destination: 192.168.122.0/24
metric: 100
next-hop-address: ''
next-hop-interface: eth0
table-id: 254
interfaces:
- name: eth0
type: ethernet
state: up
ipv4:
enabled: true
address:
- ip: 192.168.122.123
prefix-length: 24
auto-dns: true
auto-gateway: true
auto-route-table-id: 0
auto-routes: true
dhcp: true
ipv6:
enabled: true
address:
- ip: fe80::c3c9:c4f9:75b1:a570
prefix-length: 64
auto-dns: true
auto-gateway: true
auto-route-table-id: 0
auto-routes: true
autoconf: true
dhcp: true
lldp:
enabled: false
mac-address: 52:54:00:91:E4:4E
mtu: 9000
```
在保存并退出编辑器后,NMState 应用新的网络期望状态:
```
2021-06-29 11:29:05,726 root DEBUG Nmstate version: 1.0.3
2021-06-29 11:29:05,726 root DEBUG Applying desire state: {'dns-resolver': {'config': {}, 'running': {'search': [], 'server': ['192.168.122.1']}}, 'route-rules': {'config': []}, 'routes': {'config': [], 'running': [{'destination': 'fe80::/64', 'metric': 102, 'next-hop-address': '', 'next-hop-interface': 'eth0', 'table-id': 254}, {'destination': '0.0.0.0/0', 'metric': 102, 'next-hop-address': '192.168.122.1', 'next-hop-interface': 'eth0', 'table-id': 254}, {'destination': '192.168.122.0/24', 'metric': 102, 'next-hop-address': '', 'next-hop-interface': 'eth0', 'table-id': 254}]}, 'interfaces': [{'name': 'eth0', 'type': 'ethernet', 'state': 'up', 'ipv4': {'enabled': True, 'address': [{'ip': '192.168.122.238', 'prefix-length': 24}], 'auto-dns': True, 'auto-gateway': True, 'auto-route-table-id': 0, 'auto-routes': True, 'dhcp': True}, 'ipv6': {'enabled': True, 'address': [{'ip': 'fe80::5054:ff:fe91:e44e', 'prefix-length': 64}], 'auto-dns': True, 'auto-gateway': True, 'auto-route-table-id': 0, 'auto-routes': True, 'autoconf': True, 'dhcp': True}, 'lldp': {'enabled': False}, 'mac-address': '52:54:00:91:E4:4E', 'mtu': 9000}]}
--- output omitted ---
2021-06-29 11:29:05,760 root DEBUG Async action: Update profile uuid:2bdee700-f62b-365a-bd1d-69d9c31a9f0c iface:eth0 type:ethernet started
2021-06-29 11:29:05,792 root DEBUG Async action: Update profile uuid:2bdee700-f62b-365a-bd1d-69d9c31a9f0c iface:eth0 type:ethernet finished
```
现在,使用 `ip` 命令和 `eth0` 的配置文件来检查 `eth0` 的 `MTU` 是不是 9000 字节。
```
$ ip link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:91:e4:4e brd ff:ff:ff:ff:ff:ff
altname enp1s0
$ sudo cat /etc/NetworkManager/system-connections/eth0.nmconnection
[sudo] password for admin:
[connection]
id=eth0
uuid=2bdee700-f62b-365a-bd1d-69d9c31a9f0c
type=ethernet
interface-name=eth0
lldp=0
permissions=
[ethernet]
cloned-mac-address=52:54:00:91:E4:4E
mac-address-blacklist=
mtu=9000
[ipv4]
dhcp-client-id=mac
dhcp-timeout=2147483647
dns-search=
method=auto
[ipv6]
addr-gen-mode=eui64
dhcp-duid=ll
dhcp-iaid=mac
dhcp-timeout=2147483647
dns-search=
method=auto
ra-timeout=2147483647
[proxy]
```
#### 基于文件的配置模式的例子
让我们使用基于文件的方法来设置一个新的配置状态。这里我们禁用 `eth1` 接口的 IPv6 配置。
首先,创建一个 yaml 文件来定义 `eth1` 接口的期望状态。使用 `nmstatectl show` 来保存当前设置,然后使用 `nmstatectl edit` 来禁用 IPv6。
```
$ nmstatectl show eth1 > eth1.yaml
$ vi eth1.yaml
---
dns-resolver:
config: {}
running:
search: []
server:
- 192.168.122.1
route-rules:
config: []
routes:
config: []
running:
- destination: fe80::/64
metric: 101
next-hop-address: ''
next-hop-interface: eth1
table-id: 254
- destination: 0.0.0.0/0
metric: 101
next-hop-address: 192.168.122.1
next-hop-interface: eth1
table-id: 254
- destination: 192.168.122.0/24
metric: 101
next-hop-address: ''
next-hop-interface: eth1
table-id: 254
interfaces:
- name: eth1
type: ethernet
state: up
ipv4:
enabled: true
address:
- ip: 192.168.122.108
prefix-length: 24
auto-dns: true
auto-gateway: true
auto-route-table-id: 0
auto-routes: true
dhcp: true
ipv6:
enabled: false
address:
- ip: fe80::5054:ff:fe3c:9b04
prefix-length: 64
auto-dns: true
auto-gateway: true
auto-route-table-id: 0
auto-routes: true
autoconf: true
dhcp: true
lldp:
enabled: false
mac-address: 52:54:00:3C:9B:04
mtu: 1500
```
保存新的配置后,用它来应用新的状态:
```
$ sudo nmstatectl apply eth1.yaml
2021-06-29 12:17:21,531 root DEBUG Nmstate version: 1.0.3
2021-06-29 12:17:21,531 root DEBUG Applying desire state: {'dns-resolver': {'config': {}, 'running': {'search': [], 'server': ['192.168.122.1']}}, 'route-rules': {'config': []}, 'routes': {'config': [], 'running': [{'destination': 'fe80::/64', 'metric': 101, 'next-hop-address': '', 'next-hop-interface': 'eth1', 'table-id': 254}, {'destination': '0.0.0.0/0', 'metric': 101, 'next-hop-address': '192.168.122.1', 'next-hop-interface': 'eth1', 'table-id': 254}, {'destination': '192.168.122.0/24', 'metric': 101, 'next-hop-address': '', 'next-hop-interface': 'eth1', 'table-id': 254}]}, 'interfaces': [{'name': 'eth1', 'type': 'ethernet', 'state': 'up', 'ipv4': {'enabled': True, 'address': [{'ip': '192.168.122.108', 'prefix-length': 24}], 'auto-dns': True, 'auto-gateway': True, 'auto-route-table-id': 0, 'auto-routes': True, 'dhcp': True}, 'ipv6': {'enabled': False}, 'lldp': {'enabled': False}, 'mac-address': '52:54:00:3C:9B:04', 'mtu': 1500}]}
--- output omitted ---
2021-06-29 12:17:21,582 root DEBUG Async action: Update profile uuid:5d7244cb-673d-3b88-a675-32e31fad4347 iface:eth1 type:ethernet started
2021-06-29 12:17:21,587 root DEBUG Async action: Update profile uuid:5d7244cb-673d-3b88-a675-32e31fad4347 iface:eth1 type:ethernet finished
--- output omitted ---
Desired state applied:
---
dns-resolver:
config: {}
running:
search: []
server:
- 192.168.122.1
route-rules:
config: []
routes:
config: []
running:
- destination: fe80::/64
metric: 101
next-hop-address: ''
next-hop-interface: eth1
table-id: 254
- destination: 0.0.0.0/0
metric: 101
next-hop-address: 192.168.122.1
next-hop-interface: eth1
table-id: 254
- destination: 192.168.122.0/24
metric: 101
next-hop-address: ''
next-hop-interface: eth1
table-id: 254
interfaces:
- name: eth1
type: ethernet
state: up
ipv4:
enabled: true
address:
- ip: 192.168.122.108
prefix-length: 24
auto-dns: true
auto-gateway: true
auto-route-table-id: 0
auto-routes: true
dhcp: true
ipv6:
enabled: false
lldp:
enabled: false
mac-address: 52:54:00:3C:9B:04
mtu: 1500
```
你可以检查看到 `eth1` 接口没有配置任何 IPv6:
```
$ ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.238/24 fe80::5054:ff:fe91:e44e/64
eth1 UP 192.168.122.108/24
$ sudo cat /etc/NetworkManager/system-connections/eth1.nmconnection
[connection]
id=eth1
uuid=5d7244cb-673d-3b88-a675-32e31fad4347
type=ethernet
interface-name=eth1
lldp=0
permissions=
[ethernet]
cloned-mac-address=52:54:00:3C:9B:04
mac-address-blacklist=
mtu=1500
[ipv4]
dhcp-client-id=mac
dhcp-timeout=2147483647
dns-search=
method=auto
[ipv6]
addr-gen-mode=eui64
dhcp-duid=ll
dhcp-iaid=mac
dns-search=
method=disabled
[proxy]
```
#### 临时应用改变
NMState 的一个有趣的功能允许你临时配置一个期望的网络状态。如果你对这个配置感到满意,你可以事后提交。否则,当超时(默认为 60 秒)过后,它将回滚。
修改前面例子中的 `eth1` 配置,使它有一个 IPv4 静态地址,而不是通过 DHCP 动态获得。
```
$ vi eth1.yaml
---
dns-resolver:
config: {}
running:
search: []
server:
- 192.168.122.1
route-rules:
config: []
routes:
config: []
running:
- destination: fe80::/64
metric: 101
next-hop-address: ''
next-hop-interface: eth1
table-id: 254
- destination: 0.0.0.0/0
metric: 101
next-hop-address: 192.168.122.1
next-hop-interface: eth1
table-id: 254
- destination: 192.168.122.0/24
metric: 101
next-hop-address: ''
next-hop-interface: eth1
table-id: 254
interfaces:
- name: eth1
type: ethernet
state: up
ipv4:
enabled: true
address:
- ip: 192.168.122.110
prefix-length: 24
auto-dns: true
auto-gateway: true
auto-route-table-id: 0
auto-routes: true
dhcp: false
ipv6:
enabled: false
lldp:
enabled: false
mac-address: 52:54:00:3C:9B:04
mtu: 1500
```
现在,使用选项 `no-commit` 临时应用这个配置,让它只在 30 秒内有效。这可以通过添加选项 `timeout` 来完成。同时,我们将运行 `ip -br a` 命令三次,看看配置在 `eth1` 接口的 IPv4 地址是如何变化的,然后配置就会回滚。
```
$ ip -br a && sudo nmstatectl apply --no-commit --timeout 30 eth1.yaml && sleep 10 && ip -br a && sleep 25 && ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.238/24 fe80::5054:ff:fe91:e44e/64
eth1 UP 192.168.122.108/24
2021-06-29 17:29:18,266 root DEBUG Nmstate version: 1.0.3
2021-06-29 17:29:18,267 root DEBUG Applying desire state: {'dns-resolver': {'config': {}, 'running': {'search': [], 'server': ['192.168.122.1']}}, 'route-rules': {'config': []}, 'routes': {'config': [], 'running': [{'destination': 'fe80::/64', 'metric': 101, 'next-hop-address': '', 'next-hop-interface': 'eth1', 'table-id': 254}, {'destination': '0.0.0.0/0', 'metric': 101, 'next-hop-address': '192.168.122.1', 'next-hop-interface': 'eth1', 'table-id': 254}, {'destination': '192.168.122.0/24', 'metric': 101, 'next-hop-address': '', 'next-hop-interface': 'eth1', 'table-id': 254}]}, 'interfaces': [{'name': 'eth1', 'type': 'ethernet', 'state': 'up', 'ipv4': {'enabled': True, 'address': [{'ip': '192.168.122.110', 'prefix-length': 24}], 'dhcp': False}, 'ipv6': {'enabled': False}, 'lldp': {'enabled': False}, 'mac-address': '52:54:00:3C:9B:04', 'mtu': 1500}]}
--- output omitted ---
Desired state applied:
---
dns-resolver:
config: {}
running:
search: []
server:
- 192.168.122.1
route-rules:
config: []
routes:
config: []
running:
- destination: fe80::/64
metric: 101
next-hop-address: ''
next-hop-interface: eth1
table-id: 254
- destination: 0.0.0.0/0
metric: 101
next-hop-address: 192.168.122.1
next-hop-interface: eth1
table-id: 254
- destination: 192.168.122.0/24
metric: 101
next-hop-address: ''
next-hop-interface: eth1
table-id: 254
interfaces:
- name: eth1
type: ethernet
state: up
ipv4:
enabled: true
address:
- ip: 192.168.122.110
prefix-length: 24
dhcp: false
ipv6:
enabled: false
lldp:
enabled: false
mac-address: 52:54:00:3C:9B:04
mtu: 1500
Checkpoint: NetworkManager|/org/freedesktop/NetworkManager/Checkpoint/7
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.238/24 fe80::5054:ff:fe91:e44e/64
eth1 UP 192.168.122.110/24
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.238/24 fe80::5054:ff:fe91:e44e/64
eth1 UP 192.168.122.108/24
```
从上面可以看到,`eth1` 的 IP 地址从 `192.168.122.108` 暂时变成了 `192.168.122.110`,然后在超时结束后又回到了 `192.168.122.108`。
### 总结
NMState 是一个声明式的网络配置工具,目前可以通过 NetworkManager API 在主机中应用所需的网络配置状态。这种状态既可以用文本编辑器交互式地定义,也可以用基于文件的方法创建一个 yaml 或 json 文件。
这种工具提供了“基础设施即代码”,它可以自动化网络任务,也减少了使用传统配置方法可能出现的潜在错误配置或不稳定的网络情况。
---
via: <https://fedoramagazine.org/nmstate-a-declarative-networking-config-tool/>
作者:[Maurizio Garcia](https://fedoramagazine.org/author/malgnuz/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This article describes and demonstrates NMState, a network manager that uses a declarative approach to configure hosts. This means you define the desired configuration state through an API and the tool applies the configuration through a provider.
## Configuration approaches: imperative vs declarative
Networking management can be a very complex task depending on the size and diversity of the environment. In the early days of IT, networking management relied on manual procedures performed by network administrators over networking devices. Nowadays, Infrastructure as Code (IaC) allows automation of those tasks in a different way. There are, essentially two approaches: imperative or declarative.
In an imperative approach you define “how” you will arrive at a desired configuration state. The declarative paradigm defines “what” is the desired configuration state, so it does not shape which steps are required nor in which order they must be performed. This approach is currently gathering more adepts and you can find it on most of the management and orchestration tools currently used.
## NMState: a declarative tool
NMState is a network manager that allows you to configure hosts following a declarative approach. It means you define the desired configuration state through a northbound declarative API and this tool applies the configuration through a southbound provider.
Currently the only provider supported by NMState is NetworkManager, which is the main service to address networking capabilities on Fedora Linux. However, the development life cycle of NMState will add other providers gradually.
For further information regarding NMState please visit either its project [site](https://nmstate.io/) or github [repository](https://github.com/nmstate/nmstate).
## Installation
NMState is available on Fedora Linux 29+ and requires NetworkManager 1.26 or later installed and running on the system. The following shows the installation on Fedora Linux 34:
$sudo dnf -y install nmstate…output omitted… Installed: NetworkManager-config-server-1:1.30.4-1.fc34.noarch gobject-introspection-1.68.0-3.fc34.x86_64 nispor-1.0.1-2.fc34.x86_64 nmstate-1.0.3-2.fc34.noarch python3-gobject-base-3.40.1-1.fc34.x86_64 python3-libnmstate-1.0.3-2.fc34.noarch python3-nispor-1.0.1-2.fc34.noarch python3-varlink-30.3.1-2.fc34.noarch Complete!
At this point you can use *nmstatectl* as a command line tool for NMState. Please refer to either *nmstatectl –help* or *man nmstatectl* for further information about this tool.
## Using NMstate
Start by checking the NMState version installed in the system:
$nmstatectl version1.0.3
Check the current configuration of a networking interface, e.g. the *eth0* configuration:
$nmstatectl show eth02021-06-29 10:28:21,530 root DEBUG NetworkManager version 1.30.4 2021-06-29 10:28:21,531 root DEBUG Async action: Retrieve applied config: ethernet eth0 started 2021-06-29 10:28:21,531 root DEBUG Async action: Retrieve applied config: ethernet eth1 started 2021-06-29 10:28:21,532 root DEBUG Async action: Retrieve applied config: ethernet eth0 finished 2021-06-29 10:28:21,533 root DEBUG Async action: Retrieve applied config: ethernet eth1 finished --- dns-resolver: config: {} running: search: [] server: - 192.168.122.1 route-rules: config: [] routes: config: [] running: - destination: fe80::/64 metric: 100 next-hop-address: '' next-hop-interface: eth0 table-id: 254 - destination: 0.0.0.0/0 metric: 100 next-hop-address: 192.168.122.1 next-hop-interface: eth0 table-id: 254 - destination: 192.168.122.0/24 metric: 100 next-hop-address: '' next-hop-interface: eth0 table-id: 254 interfaces: - name: eth0 type: ethernet state: up ipv4: enabled: true address: - ip: 192.168.122.238 prefix-length: 24 auto-dns: true auto-gateway: true auto-route-table-id: 0 auto-routes: true dhcp: true ipv6: enabled: true address: - ip: fe80::c3c9:c4f9:75b1:a570 prefix-length: 64 auto-dns: true auto-gateway: true auto-route-table-id: 0 auto-routes: true autoconf: true dhcp: true lldp: enabled: false mac-address: 52:54:00:91:E4:4E mtu: 1500
As you can see above the networking configuration shows four main sections:
**dns-resolver**: this section has the nameserver configuration for this interface.**route-rules**: it states the routing rules.**routes**: it includes both dynamic and static routes.**Interfaces**: this section describes both ipv4 and ipv6 settings.
## Modify the configuration
You can modify the desired configuration state in two modes:
**Interactive**: editing the interface configuration through*nmstatectl edit*. This command invokes the text editor defined by the environment variable EDITOR so the network state can be edited in yaml format. After finishing the edition NMState will apply the new network configuration unless there are syntax errors.
**File-based**: applying the interface configuration using*nmstatectl apply*which imports a desired configuration state from a yaml or json file earlier created.
The following sections show you how to change the networking configuration using NMState. These changes can be disruptive to the system so the recommendation is to perform these tasks on a test system or guest VM till you get a better understanding of NMState.
The test system in use herehas two Ethernet interfaces: *eth0* and *eth1*:
$ip -br -4 alo UNKNOWN 127.0.0.1/8 eth0 UP 192.168.122.238/24 eth1 UP 192.168.122.108/24
### Example of interactive configuration mode:
Change theMTUofeth0interface to 9000 bytes using thenmstatectl editcommand as follows (all changes are in bold):
$sudo nmstatectl edit eth0--- dns-resolver: config: {} running: search: [] server: - 192.168.122.1 route-rules: config: [] routes: config: [] running: - destination: fe80::/64 metric: 100 next-hop-address: '' next-hop-interface: eth0 table-id: 254 - destination: 0.0.0.0/0 metric: 100 next-hop-address: 192.168.122.1 next-hop-interface: eth0 table-id: 254 - destination: 192.168.122.0/24 metric: 100 next-hop-address: '' next-hop-interface: eth0 table-id: 254 interfaces: - name: eth0 type: ethernet state: up ipv4: enabled: true address: - ip: 192.168.122.123 prefix-length: 24 auto-dns: true auto-gateway: true auto-route-table-id: 0 auto-routes: true dhcp: true ipv6: enabled: true address: - ip: fe80::c3c9:c4f9:75b1:a570 prefix-length: 64 auto-dns: true auto-gateway: true auto-route-table-id: 0 auto-routes: true autoconf: true dhcp: true lldp: enabled: false mac-address: 52:54:00:91:E4:4Emtu: 9000
After saving and exiting the edito, NMState applies the new network desired state:
2021-06-29 11:29:05,726 root DEBUG Nmstate version: 1.0.3 2021-06-29 11:29:05,726 root DEBUG Applying desire state: {'dns-resolver': {'config': {}, 'running': {'search': [], 'server': ['192.168.122.1']}}, 'route-rules': {'config': []}, 'routes': {'config': [], 'running': [{'destination': 'fe80::/64', 'metric': 102, 'next-hop-address': '', 'next-hop-interface': 'eth0', 'table-id': 254}, {'destination': '0.0.0.0/0', 'metric': 102, 'next-hop-address': '192.168.122.1', 'next-hop-interface': 'eth0', 'table-id': 254}, {'destination': '192.168.122.0/24', 'metric': 102, 'next-hop-address': '', 'next-hop-interface': 'eth0', 'table-id': 254}]}, 'interfaces': [{'name': 'eth0', 'type': 'ethernet', 'state': 'up', 'ipv4': {'enabled': True, 'address': [{'ip': '192.168.122.238', 'prefix-length': 24}], 'auto-dns': True, 'auto-gateway': True, 'auto-route-table-id': 0, 'auto-routes': True, 'dhcp': True}, 'ipv6': {'enabled': True, 'address': [{'ip': 'fe80::5054:ff:fe91:e44e', 'prefix-length': 64}], 'auto-dns': True, 'auto-gateway': True, 'auto-route-table-id': 0, 'auto-routes': True, 'autoconf': True, 'dhcp': True}, 'lldp': {'enabled': False}, 'mac-address': '52:54:00:91:E4:4E', 'mtu': 9000}]} --- output omitted --- 2021-06-29 11:29:05,760 root DEBUG Async action: Update profile uuid:2bdee700-f62b-365a-bd1d-69d9c31a9f0c iface:eth0 type:ethernet started 2021-06-29 11:29:05,792 root DEBUG Async action: Update profile uuid:2bdee700-f62b-365a-bd1d-69d9c31a9f0c iface:eth0 type:ethernet finished
Now, use both the *ip* command and also the *eth0* configuration file to check that the *MTU* of *eth0* is 9000 bytes.
$ip link show eth02: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9000 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:91:e4:4e brd ff:ff:ff:ff:ff:ff altname enp1s0 $sudo cat /etc/NetworkManager/system-connections/eth0.nmconnection[sudo] password for admin: [connection] id=eth0 uuid=2bdee700-f62b-365a-bd1d-69d9c31a9f0c type=ethernet interface-name=eth0 lldp=0 permissions= [ethernet] cloned-mac-address=52:54:00:91:E4:4E mac-address-blacklist= mtu=9000 [ipv4] dhcp-client-id=mac dhcp-timeout=2147483647 dns-search= method=auto [ipv6] addr-gen-mode=eui64 dhcp-duid=ll dhcp-iaid=mac dhcp-timeout=2147483647 dns-search= method=auto ra-timeout=2147483647 [proxy]
### Example of file-based configuration mode:
Let’s use the file-based approach to set a new config state. In this case disable the IPv6 configuration in *eth1* interface.
First, create a yaml file to define the desired state of the *eth1 *interface. Use *nmstatectl show* to save the current settings then *nmstatectl edit* to disable IPv6. Again, all changes are in bold and deletions are shown with strike-through:
$nmstatectl show eth1 > eth1.yaml$vi eth1.yaml--- dns-resolver: config: {} running: search: [] server: - 192.168.122.1 route-rules: config: [] routes: config: [] running: - destination: fe80::/64 metric: 101 next-hop-address: '' next-hop-interface: eth1 table-id: 254 - destination: 0.0.0.0/0 metric: 101 next-hop-address: 192.168.122.1 next-hop-interface: eth1 table-id: 254 - destination: 192.168.122.0/24 metric: 101 next-hop-address: '' next-hop-interface: eth1 table-id: 254 interfaces: - name: eth1 type: ethernet state: up ipv4: enabled: true address: - ip: 192.168.122.108 prefix-length: 24 auto-dns: true auto-gateway: true auto-route-table-id: 0 auto-routes: true dhcp: true ipv6:enabled: false~~address:~~~~- ip: fe80::5054:ff:fe3c:9b04~~~~prefix-length: 64~~~~auto-dns: true~~~~auto-gateway: true~~~~auto-route-table-id: 0~~~~auto-routes: true~~~~autoconf: true~~lldp: enabled: false mac-address: 52:54:00:3C:9B:04 mtu: 1500~~dhcp: true~~
After saving the new configuration, use it to apply the new state:
$sudo nmstatectl apply eth1.yaml2021-06-29 12:17:21,531 root DEBUG Nmstate version: 1.0.3 2021-06-29 12:17:21,531 root DEBUG Applying desire state: {'dns-resolver': {'config': {}, 'running': {'search': [], 'server': ['192.168.122.1']}}, 'route-rules': {'config': []}, 'routes': {'config': [], 'running': [{'destination': 'fe80::/64', 'metric': 101, 'next-hop-address': '', 'next-hop-interface': 'eth1', 'table-id': 254}, {'destination': '0.0.0.0/0', 'metric': 101, 'next-hop-address': '192.168.122.1', 'next-hop-interface': 'eth1', 'table-id': 254}, {'destination': '192.168.122.0/24', 'metric': 101, 'next-hop-address': '', 'next-hop-interface': 'eth1', 'table-id': 254}]}, 'interfaces': [{'name': 'eth1', 'type': 'ethernet', 'state': 'up', 'ipv4': {'enabled': True, 'address': [{'ip': '192.168.122.108', 'prefix-length': 24}], 'auto-dns': True, 'auto-gateway': True, 'auto-route-table-id': 0, 'auto-routes': True, 'dhcp': True}, 'ipv6': {'enabled': False}, 'lldp': {'enabled': False}, 'mac-address': '52:54:00:3C:9B:04', 'mtu': 1500}]} --- output omitted --- 2021-06-29 12:17:21,582 root DEBUG Async action: Update profile uuid:5d7244cb-673d-3b88-a675-32e31fad4347 iface:eth1 type:ethernet started 2021-06-29 12:17:21,587 root DEBUG Async action: Update profile uuid:5d7244cb-673d-3b88-a675-32e31fad4347 iface:eth1 type:ethernet finished --- output omitted --- Desired state applied: --- dns-resolver: config: {} running: search: [] server: - 192.168.122.1 route-rules: config: [] routes: config: [] running: - destination: fe80::/64 metric: 101 next-hop-address: '' next-hop-interface: eth1 table-id: 254 - destination: 0.0.0.0/0 metric: 101 next-hop-address: 192.168.122.1 next-hop-interface: eth1 table-id: 254 - destination: 192.168.122.0/24 metric: 101 next-hop-address: '' next-hop-interface: eth1 table-id: 254 interfaces: - name: eth1 type: ethernet state: up ipv4: enabled: true address: - ip: 192.168.122.108 prefix-length: 24 auto-dns: true auto-gateway: true auto-route-table-id: 0 auto-routes: true dhcp: true ipv6: enabled: false lldp: enabled: false mac-address: 52:54:00:3C:9B:04 mtu: 1500
You can check that the *eth1* interface does not have any IPv6 configured:
$ip -br alo UNKNOWN 127.0.0.1/8 ::1/128 eth0 UP 192.168.122.238/24 fe80::5054:ff:fe91:e44e/64 eth1 UP 192.168.122.108/24 $sudo cat /etc/NetworkManager/system-connections/eth1.nmconnection[connection] id=eth1 uuid=5d7244cb-673d-3b88-a675-32e31fad4347 type=ethernet interface-name=eth1 lldp=0 permissions= [ethernet] cloned-mac-address=52:54:00:3C:9B:04 mac-address-blacklist= mtu=1500 [ipv4] dhcp-client-id=mac dhcp-timeout=2147483647 dns-search= method=auto [ipv6] addr-gen-mode=eui64 dhcp-duid=ll dhcp-iaid=mac dns-search= method=disabled [proxy]
### Applying changes temporarily
An interesting feature of NMState allows you to configure a desired networking state temporarily. In case you are satisfied with the configuration you can commit it afterwards. Otherwise it will rollback when the timeout expires (default is 60 sec).
Modify the *eth1* configuration from the previous example so it has an IPv4 static address instead of getting it dynamically by DHCP.
$vi eth1.yaml--- dns-resolver: config: {} running: search: [] server: - 192.168.122.1 route-rules: config: [] routes: config: [] running: - destination: fe80::/64 metric: 101 next-hop-address: '' next-hop-interface: eth1 table-id: 254 - destination: 0.0.0.0/0 metric: 101 next-hop-address: 192.168.122.1 next-hop-interface: eth1 table-id: 254 - destination: 192.168.122.0/24 metric: 101 next-hop-address: '' next-hop-interface: eth1 table-id: 254 interfaces: - name: eth1 type: ethernet state: up ipv4: enabled: true address:- ip: 192.168.122.110prefix-length: 24~~auto-dns: true~~~~auto-gateway: true~~~~auto-route-table-id: 0~~~~auto-routes: true~~dhcp: falseipv6: enabled: false lldp: enabled: false mac-address: 52:54:00:3C:9B:04 mtu: 1500
Now, apply this config temporarily using the option *no-commit* so it will be valid only for 30 seconds. This can be done adding the option *–timeout*. Meanwhile, we will run the *ip -br a* command three times to see how the IPv4 address configured in *eth1* interface changes and then the configuration rolls back.
$ip -br a && sudo nmstatectl apply --no-commit --timeout 30 eth1.yaml && sleep 10 && ip -br a && sleep 25 && ip -br alo UNKNOWN 127.0.0.1/8 ::1/128 eth0 UP 192.168.122.238/24 fe80::5054:ff:fe91:e44e/64 eth1 UP 192.168.122.108/24 2021-06-29 17:29:18,266 root DEBUG Nmstate version: 1.0.3 2021-06-29 17:29:18,267 root DEBUG Applying desire state: {'dns-resolver': {'config': {}, 'running': {'search': [], 'server': ['192.168.122.1']}}, 'route-rules': {'config': []}, 'routes': {'config': [], 'running': [{'destination': 'fe80::/64', 'metric': 101, 'next-hop-address': '', 'next-hop-interface': 'eth1', 'table-id': 254}, {'destination': '0.0.0.0/0', 'metric': 101, 'next-hop-address': '192.168.122.1', 'next-hop-interface': 'eth1', 'table-id': 254}, {'destination': '192.168.122.0/24', 'metric': 101, 'next-hop-address': '', 'next-hop-interface': 'eth1', 'table-id': 254}]}, 'interfaces': [{'name': 'eth1', 'type': 'ethernet', 'state': 'up', 'ipv4': {'enabled': True, 'address': [{'ip': '192.168.122.110', 'prefix-length': 24}], 'dhcp': False}, 'ipv6': {'enabled': False}, 'lldp': {'enabled': False}, 'mac-address': '52:54:00:3C:9B:04', 'mtu': 1500}]} --- output omitted --- Desired state applied: --- dns-resolver: config: {} running: search: [] server: - 192.168.122.1 route-rules: config: [] routes: config: [] running: - destination: fe80::/64 metric: 101 next-hop-address: '' next-hop-interface: eth1 table-id: 254 - destination: 0.0.0.0/0 metric: 101 next-hop-address: 192.168.122.1 next-hop-interface: eth1 table-id: 254 - destination: 192.168.122.0/24 metric: 101 next-hop-address: '' next-hop-interface: eth1 table-id: 254 interfaces: - name: eth1 type: ethernet state: up ipv4: enabled: true address: - ip: 192.168.122.110 prefix-length: 24 dhcp: false ipv6: enabled: false lldp: enabled: false mac-address: 52:54:00:3C:9B:04 mtu: 1500 Checkpoint: NetworkManager|/org/freedesktop/NetworkManager/Checkpoint/7 lo UNKNOWN 127.0.0.1/8 ::1/128 eth0 UP 192.168.122.238/24 fe80::5054:ff:fe91:e44e/64 eth1 UP 192.168.122.110/24 lo UNKNOWN 127.0.0.1/8 ::1/128 eth0 UP 192.168.122.238/24 fe80::5054:ff:fe91:e44e/64 eth1 UP 192.168.122.108/24
As you can see from above, the *eth1* IP address changed temporarily from 192.168.122.108 to 192.168.122.110 and then it returned to 192.168.122.108 after the timeout expired.
## Conclusion
NMState is a declarative networking configuration tool that currently applies the desired networking configuration state in a host through the NetworkManager API. This state can be defined either interactively using a text editor or with a file-based approach creating a yaml or json file.
This kind of tool provides Infrastructure as Code, it allows the automation of networking tasks and also reduces potential misconfigurations or unstable networking scenarios that could arise using legacy configuration methods.
## Osqui
So it’s like Ubuntu’s Netplan, right?
## Maurizio Garcia
Thanks for reading this article and bringing up this comparison.
I think that NMState has a much wider scope than Netplan.
NMState provides an API that can be consumed by graphical configuration interfaces like Cockpit, configuration managers like Ansible or even platforms like Kubernetes to establish the network configuration of their managed systems.
On the other hand, Netplan can abstract you from the configuration of the renderer used: NetworkManager or Systemd-networkd. However, it does not provide an API that can be consumed by other applications or platforms and it requires the presence of configuration files located at /[lib,etc,runisha/netplan/*.yaml in the system that is going to be managed.
You can find further information regarding NMState at https://nmstate.io/.
## Osqui
Thanks a lot for your so nice clarification!
## RW
Thanks for the write up on this tool! I found the article interesting and informative, I will be looking further into this tool as a result and looking for similar tools – now that I know this exists.
## Maurizio Garcia
Thanks for reading this article.
## Brad Smith
Nicely done! Very informative. This will be useful.
## Maurizio Garcia
Hi Brad,
Thanks for reading this article.
## Renier Collazo
Yeah, another tool that uses declarative syntax, IaC and Yaml files, cool..
## Maurizio Garcia
Hi Renier,
Thanks for reading this article |
13,864 | 如何从 Linux 发行版的仓库中安装 Java | https://opensource.com/article/21/9/install-java-linux-repositories | 2021-10-09T09:27:00 | [
"Java"
] | https://linux.cn/article-13864-1.html |
>
> 无论你喜欢哪个发行版和包管理器,都可以都很容易地在你的 Linux 系统上安装 Java。
>
>
>

把 Java 安装到你的 Linux 桌面上有多种方法。一个明显的方式是使用你的 Linux 发行版中提供的软件包。请注意,这并不适合所有人。例如,有些用户可能需要一个非常具体的 Java 版本。
在你开始之前,你必须确定你需要“哪种 Java”。你是否只需要运行一些 `.class` 文件或 `.jar` 文件?还是你正在编写一些需要编译的代码?
就我而言,我运行的大部分 Java 都是我自己(至少部分)编写的 Java,所以安装完整的 Java 开发工具包(或称 JDK)总是有意义的,它包含了 Java 编译器、库和一些非常有用的工具。当然,在这里,我们更倾向于使用开源的 JDK,称为 [OpenJDK](https://openjdk.java.net/)。
由于我主要在 Ubuntu Linux 发行版上工作,我的软件包管理器是 `apt`。我可以用 `apt` 来查找哪些 OpenJDK 包是可用的:
```
apt list OpenJDK\*
```
这个命令的输出看起来像这样:
```
Listing... Done
openjdk-11-dbg/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-dbg/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-demo/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-demo/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-doc/hirsute-updates,hirsute-updates,hirsute-security,hirsute-security 11.0.11+9-0ubuntu2 all
openjdk-11-jdk-headless/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-jdk-headless/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-jdk/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-jdk/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-jre-dcevm/hirsute 11.0.10+1-1 amd64
openjdk-11-jre-headless/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-jre-headless/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-jre-zero/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-jre-zero/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-jre/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-jre/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-source/hirsute-updates,hirsute-updates,hirsute-security,hirsute-security 11.0.11+9-0ubuntu2 all
openjdk-15-dbg/hirsute 15.0.3+3-1 amd64
openjdk-15-dbg/hirsute 15.0.3+3-1 i386
openjdk-15-demo/hirsute 15.0.3+3-1 amd64
...
openjdk-8-jre/hirsute-updates,hirsute-security 8u292-b10-0ubuntu1 i386
openjdk-8-source/hirsute-updates,hirsute-updates,hirsute-security,hirsute-security 8u292-b10-0ubuntu1 all
```
我在上面用 `...` 省略了不少行。
事实证明,即使限制在 OpenJDK 中,我仍然有很多选择:
* 不同的架构(在我的例子中,i386 还是 amd64)。
* 不同的 Java 版本(就我而言,有 8、11、15、16、17 等)。
* 纯粹的 OpenJDK 或无头版本。
* Java 运行时环境(JRE)。
* 用于调试、演示,以及是否包含源代码等。
同样,在我的情况中,我主要对纯粹的普通 OpenJDK 感兴趣。
假设我想为我的 amd64 架构安装 Java 11 版本的普通 OpenJDK,我可以输入:
```
sudo apt install -a=amd64 openjdk-11-jdk
```
几分钟后,我就可以编译、运行、调试和打包我的 Java 代码了。
注意,很有可能需要同时安装多个版本的 Java,有时甚至是必要的。在 Ubuntu 中,有一个有用的工具,叫做 `update-java-alternatives`,它可以 [显示并配置在使用哪个 Java 环境](http://manpages.ubuntu.com/manpages/hirsute/man8/update-java-alternatives.8.html)。
那些使用不同 Linux 发行版的人,一般来说,可以采取类似的方法。其他的几个发行版(如 Debian 和 Mint)也使用 `apt` ,尽管可用的软件包可能不同。发行版可能使用不同的软件包管理器。例如, [Fedora 安装 Java 的文档页面](https://docs.fedoraproject.org/en-US/quick-docs/installing-java/) 显示了如何使用 Fedora `dnf` 包管理器来处理安装。首先,为了显示可用的版本,输入:
```
dnf search openjdk
```
接下来,要安装完整的开发 x86\_64 架构版本,请输入:
```
sudo dnf install java-11-openjdk-devel.x86_64
```
同样地,Fedora 提供了 `alternatives` 工具来 [显示和配置 Java 环境](https://tecadmin.net/install-java-on-fedora/)。
再比如,[很棒的 Arch Linux 维基](https://wiki.archlinux.org/title/java#OpenJDK) 显示对应的软件包是 `jdk11-openjdk`。该维基还解释了许多在 Arch 中使用 Java 的其他重要细节,比如使用 `archlinux-java` 工具来显示安装了哪些 Java 环境或选择一个不同的默认环境。Arch 使用一个叫 `pacman` 的包管理器,它也有文档 [在 Arch Linux 维基上](https://wiki.archlinux.org/title/pacman#Querying_package_databases)。
不管你喜欢哪个发行版和软件包管理器,在你的 Linux 系统上获得 Java 是很容易的。当然,在安装之前,要考虑版本和功能。还要记住,在同一台电脑上有管理两个或多个 Java 版本的方法。我的大多数例子都使用了 `apt`,但也要记得可以选择使用 `dnf`。
---
via: <https://opensource.com/article/21/9/install-java-linux-repositories>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are a number of different ways to install Java on your Linux desktop. An obvious route is to use the packages provided in your Linux distribution. Note that this doesn’t work for everyone; for example, some users may need a very specific version of Java.
Before you can start, you must determine “which Java” you need. Do you just need to run some `.class`
files or a `.jar`
file? Or are you writing some code that you need to compile?
In my case, most of the Java I run is Java that I have (at least partly) written myself, so it always makes sense to install the full Java Development Kit, or JDK, which comes with a Java compiler, libraries, and some really useful utilities. And of course, hereabouts, we give preference to the open source JDK, called [OpenJDK](https://openjdk.java.net/).
Since I primarily work on the Ubuntu Linux distribution, my package manager is `apt`
. I can use `apt`
to find out which OpenJDK packages are available:
`apt list OpenJDK\*`
The output of this command looks like:
```
Listing... Done
openjdk-11-dbg/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-dbg/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-demo/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-demo/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-doc/hirsute-updates,hirsute-updates,hirsute-security,hirsute-security 11.0.11+9-0ubuntu2 all
openjdk-11-jdk-headless/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-jdk-headless/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-jdk/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-jdk/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-jre-dcevm/hirsute 11.0.10+1-1 amd64
openjdk-11-jre-headless/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-jre-headless/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-jre-zero/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-jre-zero/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-jre/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 amd64
openjdk-11-jre/hirsute-updates,hirsute-security 11.0.11+9-0ubuntu2 i386
openjdk-11-source/hirsute-updates,hirsute-updates,hirsute-security,hirsute-security 11.0.11+9-0ubuntu2 all
openjdk-15-dbg/hirsute 15.0.3+3-1 amd64
openjdk-15-dbg/hirsute 15.0.3+3-1 i386
openjdk-15-demo/hirsute 15.0.3+3-1 amd64
...
openjdk-8-jre/hirsute-updates,hirsute-security 8u292-b10-0ubuntu1 i386
openjdk-8-source/hirsute-updates,hirsute-updates,hirsute-security,hirsute-security 8u292-b10-0ubuntu1 all
```
I have elided quite a few lines above with `...`
.
It turns out that, even though I’m limiting myself to the OpenJDK, I still have plenty of options for:
- The architecture (in my case, whether i386 or amd64).
- The version of Java (in my case, whether 8, 11, 15, 16, 17).
- The pure OpenJDK or the headless version.
- The Java Runtime Environment or JRE.
- Options for debugging, demo, source code, etc.
Again, in my case, primarily, I’m just interested in the pure vanilla OpenJDK.
Supposing then I want to install the Java 11 version of the plain vanilla OpenJDK for my amd64 architecture, I can type:
`sudo apt install -a=amd64 openjdk-11-jdk`
A few minutes later, I’ll be able to compile, run, debug, and package my Java code.
Note that it’s quite possible, and sometimes even desirable, to have multiple versions of Java installed simultaneously. In the case of Ubuntu, there is a useful utility called `update-java-alternatives`
that [displays and configures which java environment](http://manpages.ubuntu.com/manpages/hirsute/man8/update-java-alternatives.8.html) to use at any point in time.
Those of you using a different Linux distro can, in general, take a similar approach. Several other distros (such as Debian and Mint) also use `apt`
, though the available packages may differ. Other distros use different package managers. For example, [the Fedora documentation page for Installing Java](https://docs.fedoraproject.org/en-US/quick-docs/installing-java/) shows how to use the Fedora `dnf`
package manager to handle the installation. First, to show the available version, type:
`dnf search openjdk`
Next, to install the full development x86_64 architecture version, type:
`sudo dnf install java-11-openjdk-devel.x86_64`
Similarly, Fedora provides the `alternatives`
utility to [display and configure the Java environment](https://tecadmin.net/install-java-on-fedora/).
For another example, the [wonderful Arch Linux wiki](https://wiki.archlinux.org/title/java#OpenJDK) shows the corresponding package is `jdk11-openjdk`
**. **The wiki also explains many other important details related to using Java in Arch, such as using the `archlinux-java`
utility to show what Java environments are installed or select a different default environment. Arch uses a package manager called `pacman`
, which is also documented [here on the Arch Linux wiki](https://wiki.archlinux.org/title/pacman#Querying_package_databases).
Regardless of which distribution and package manager you prefer, it is easy to get Java on your Linux system. Consider version and function, of course, before installing. Also keep in mind that there are options for managing two or more Java versions on the same computer. Most of my examples used `apt`
, but keep in mind the `dnf`
options, too.
## Comments are closed. |
13,865 | 《赛博朋克 2077》等 DirectX 11/12 游戏可在 Linux 上体验 DLSS 了 | https://news.itsfoss.com/nvidia-dlss-dx-11-12-proton/ | 2021-10-09T10:34:00 | [
"游戏"
] | https://linux.cn/article-13865-1.html |
>
> 通过 Steam Proton 的实验版本,期待已久的 Nvidia DLSS 支持在 Linux 上的 DirectX 11/12 大作中出现。
>
>
>

6 月,英伟达 [宣布](https://www.nvidia.com/en-us/geforce/news/june-2021-rtx-dlss-game-update/) 通过 Steam Proton 支持 Linux 中的 DLSS,并为基于 Vulkan 的游戏提供了测试版驱动程序。
DLSS 是指<ruby> 深度学习超级采样 <rt> Deep Learning Super Sampling </rt></ruby>。它利用由 RTX GPU 中的 Tensor 核心提供支持的深度学习算法来提升游戏中的图像。这将使图像更清晰、更锐利,并提高帧率。

这种 [升级技术](https://news.itsfoss.com/intel-xess-open-source/) 类似于 AMD 的 Fidelity FX,甚至更接近于英特尔即将推出的 XeSS,与 DLSS 不同的是这两者都是开源的。玩家已经可以通过 [GloriousEggroll](https://github.com/GloriousEggroll/proton-ge-custom) 的定制 Proton GE 版本体验到 Fidelity FX。
此外,英伟达还计划在今年秋天之前将支持范围扩大到 DirectX 游戏。
而且,随着最新的 Proton 实验性支持,这一切终于实现了。使用英伟达 GPU 的 Linux 游戏玩家现在可以用 DLSS 玩他们最喜欢的基于 DX11/12 的游戏。
考虑到我们很快就能在 Linux 上玩各种多人游戏,并且 [Proton 中添加了对 BattleEye & Easy-Anti Cheat 的支持](https://news.itsfoss.com/easy-anti-cheat-linux/),这是进行这项添加的最好时机。
### Steam Porton 的重大更新
几天前,伴随着 Proton 6.3-7 的一波改进,Valve 终于设法将 DLSS 支持添加到 Proton 的 DirectX 11/12 游戏实验分支中。
在此之前,需要一个测试版驱动程序才能将 DLSS 用于基于 Vulkan 的游戏,例如 DOOM Eternal。
但是,现在不再如此 —— 尽管推荐使用最新的驱动程序。
作为补充,DXVK 和 Steamworks SDK 也已经更新到最新的开发版本。此外,还修复了特定游戏的性能问题和其他错误。
你可以查看 Proton 的 [官方 GitHub 更新日志](https://github.com/ValveSoftware/Proton/wiki/Changelog) 来了解到目前为止支持的所有游戏的改进列表。
### 为 DX11/12 游戏启用 DLSS
启用 DLSS 是一个简单明了的过程。
首先,你必须确保你的 Windows 游戏可以在 Proton Experimental 上运行。
这可以通过右键点击游戏并选择“<ruby> 属性 <rt> Properties </rt></ruby>”来完成。然后在“<ruby> 兼容性 <rt> Compatibility </rt></ruby>”下,你需要勾选“<ruby> 强制使用特定的 Steam Play 兼容工具 <rt> Force the use of a specific Steam Play compatibility tool </rt></ruby>”复选框。接下来,从下拉菜单中选择 “Proton Experimental”。

最后,你需要在“<ruby> 启动选项 <rt> Launch Options </rt></ruby>”中插入命令:`PROTON_HIDE_NVIDIA_GPU=0 PROTON_ENABLE_NVAPI=1 %command%` 。

这就行了。你就可以用 DLSS 玩你的游戏了!
### 总结
英伟达 DLSS 对于许多游戏来说是一个非常需要的功能,因为它的作用很大。
Linux 从一开始就没有对 DLSS 的全面支持。但是,看起来它很快就会在未来的 Proton 稳定版本中提供,并进行必要的改进。
Linux 玩家终于可以用基于 RTX 的 GPU 在许多游戏中体验到更好的帧率和视觉质量。
虽然我在 AMD 显卡上使用 Fidelity FX,但我仍然渴望在 RTX GPU 上尝试 DLSS!
你对英伟达 DLSS 的到来有什么感觉?你会很快尝试它吗?欢迎在下面分享你的评论。
转自:[GamingOnLinux](https://www.gamingonlinux.com/2021/10/proton-experimental-expands-nvidia-dlss-support-on-linux-to-directx-11-titles)。
---
via: <https://news.itsfoss.com/nvidia-dlss-dx-11-12-proton/>
作者:[Rishabh Moharir](https://news.itsfoss.com/author/rishabh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

In June, Nvidia [announced](https://www.nvidia.com/en-us/geforce/news/june-2021-rtx-dlss-game-update/?ref=news.itsfoss.com) the support for** DLSS** in Linux via Steam Proton and a beta driver for Vulkan-based games.
DLSS stands for Deep Learning Super Sampling. It utilizes deep learning algorithms powered by Tensor cores found in RTX GPUs to upscale images inside games. This results in clearer and sharper images along with higher framerates.

This [upscaling technology is similar](https://news.itsfoss.com/intel-xess-open-source/) to AMD’s Fidelity FX and even closer to Intel’s upcoming XeSS, both open-source, unlike DLSS. Gamers already have the benefit of making use of Fidelity FX through [GloriousEggroll’s](https://github.com/GloriousEggroll/proton-ge-custom?ref=news.itsfoss.com) custom Proton GE versions.
Moreover, NVIDIA also planned to expand support to DirectX games by this fall.
And, finally, with the latest Proton Experiment support, that’s happening. Linux gamers using Nvidia GPUs can now play their favorite DX11/12 based games with DLSS.
There couldn’t be a better time for this addition, considering we will be able to play various multiplayer games soon on Linux with the [support for BattleEye & Easy-Anti Cheat added to Proton](https://news.itsfoss.com/easy-anti-cheat-linux/).
## Major Updates to Steam Play Proton
Along with a wave of improvements in Proton 6.3-7, Valve has finally managed to add DLSS support into Proton’s Experimental branch for DirectX 11/12 games a few days ago.
Previously, a beta driver was required to use DLSS for Vulkan-based games like DOOM Eternal.
But, that isn’t the case anymore—although the latest drivers are recommended.
To complement this, DXVK and the Steamworks SDK have also been updated to the latest development versions. Additionally, performance issues for specific games and other bugs have also been fixed.
You can check Proton’s[ official GitHub changelog](https://github.com/ValveSoftware/Proton/wiki/Changelog?ref=news.itsfoss.com) to explore the list of improvements for all the games supported so far.
## Enabling DLSS for DX11/12 Games
Enabling DLSS is a straightforward process.
First, you have to make sure that your Windows game runs on Proton Experimental.
This can be done by right-clicking on the game and selecting Properties. Then under Compatibility, you need to tick the “Force the use of a specific Steam Play compatibility tool” checkbox. Next, choose Proton Experimental from the drop-down menu.
Finally, you need to insert the command `PROTON_HIDE_NVIDIA_GPU=0 PROTON_ENABLE_NVAPI=1 %command%`
in **Launch Options**.
That’s it! You’re all set to play your games with DLSS!
## Summing Up
Nvidia DLSS is a much-needed feature for many games, given the difference it makes.
Linux did not have full-fledged support for DLSS from the get-go. But, it looks like it will soon be available in a future stable Proton version along with necessary improvements.
Linux gamers can finally experience better frame rates and visual quality for many games with their RTX-based GPUs.
Although I use Fidelity FX on my AMD graphics card, I still crave to try out DLSS on an RTX GPU!
*How do you feel about the arrival of Nvidia’s DLSS? Will you be trying it out soon? Feel free to share your comments below.*
**Via:** [GamingOnLinux](https://www.gamingonlinux.com/2021/10/proton-experimental-expands-nvidia-dlss-support-on-linux-to-directx-11-titles?ref=news.itsfoss.com)
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,868 | Dialect:Linux 下的开源翻译应用 | https://itsfoss.com/dialect/ | 2021-10-10T11:57:31 | [
"翻译"
] | https://linux.cn/article-13868-1.html |
>
> Dialect 是一个简单明了的应用,可以让你使用 Web 服务进行语言间的翻译。想要了解更多的话,让我们来一窥究竟。
>
>
>

虽然你可以启动 Web 浏览器并直接使用任何翻译服务来完成工作,但桌面应用有时会派上用场。
Dialect 是一个简单的翻译应用,可以利用 Web 服务进行翻译,同时给你一些额外的能力。
### 使用谷歌翻译和 LibreTranslate 的开源翻译应用

Dialect 是一个主要为 GNOME 桌面定制的应用,但它在其他桌面环境下也应该能正常工作。
它可以让你快速翻译语言,同时还有一些额外的选项。
在其核心部分,你可以选择谷歌翻译或 LibreTranslate 翻译服务。
尽管 LibreTranslate 达不到谷歌翻译的准确性,但把它作为一个选项来切换是一个很好的补充。至少,对于一些基本的用法,如果用户不想利用谷歌的服务,你的桌面上就有一个备选方案。
### Dialect 的特点

除了切换翻译服务外,你还能得到如下个功能:
* 发音
* 文本到语音(TTS)功能(谷歌)
* 黑暗模式
* 翻译快捷方式
* 实时翻译
* 剪贴板按钮可快速复制/粘贴
* 翻译历史(撤销/重做)
正如你在截图中所注意到的,实时翻译功能可能会因为滥用 API 而使你的 IP 地址被禁止使用服务。

我试着使用 LibreTranslate(如上图所示)和谷歌翻译,并启用实时翻译功能,它工作得很好。
也许,如果你经常依赖翻译,你可能想避免这个实时翻译。但是,对于我的临时使用,在相当多的测试中,该服务并没有导致 IP 地址被禁止。
重要的是要注意,如果你想,你可以指定一个自定义的 LibreTranslate 实例。默认情况下,它使用 “[translate.astian.org](http://translate.astian.org)” 作为实例。
你可能找不到一个单独显示的翻译历史区域,但窗口左上角的箭头按钮会让你看到你以前的翻译,以及翻译设置。
所以,它也可以作为一个重做/撤销的功能。
### 在 Linux 中安装 Dialect
[Dialect](https://flathub.org/apps/details/com.github.gi_lom.dialect) 是以 [Flatpak](https://itsfoss.com/what-is-flatpak/) 的形式提供的。所以,你应该能够在你选择的任何 Linux 发行版上安装它。如果你是新手,你可能想看看我们的 [Flatpak 指南](https://itsfoss.com/flatpak-guide/) 以获得帮助。
首先,添加 Flathub 仓库:
```
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
然后安装应用:
```
flatpak install flathub com.github.gi_lom.dialect
```
安装后,在系统菜单中寻找它,并从那里启动它。
你也可以浏览它的 [GitHub 页面](https://github.com/dialect-app/dialect/) 了解更多信息。
---
via: <https://itsfoss.com/dialect/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief:** Dialect is a straightforward app that lets you translate between languages using web services. To explore more, let us take a closer look.
While you can launch the web browser and directly use any translation service to get the job done, a desktop app can sometimes come in handy.
Dialect is a simple translation app that utilizes web services to translate while giving you some extra abilities.
## Open-Source Translation App with Google Translate & LibreTranslate
Dialect is primarily an app tailored for GNOME desktops, but it should work fine with other desktop environments.
It lets you quickly translate languages along with a few extra options.
At its core, it lets you choose between Google Translate or LibreTranslate as the translation service.
Even though LibreTranslate cannot come close to Google Translate’s accuracy, featuring it as an option to switch is an excellent addition. At least, for some basic usage, if a user does not want to utilize Google’s services, you have an alternative ready on your desktop.
## Features of Dialect
Along with the ability to switch translation services, you get a few more tweaks:
- Pronunciation
- Text to Speech functionality (Google)
- Dark mode
- Translation shortcut
- Live Translation
- Clipboard buttons to quickly copy/paste
- Translation history (undo/redo)
As you can notice in the screenshot, the live translation feature may get your IP addressed banned from using the service because of API abuse.
I tried using LibreTranslate (as shown in the image above) and Google Translate with the live translation feature enabled, and it worked fine.
Maybe if you rely on translations quite often, you may want to avoid the feature. But, for my quick usage, the services didn’t ban by IP address for quite a few test runs.
It is important to note that you can specify a custom LibreTranslate instance if you want. By default, it uses “translate.astian.org” as the instance.
You may not find a separate translation history section, but the arrow buttons in the top-left corner of the window will let you see your previous translations and the translation settings as well.
So, it works as a redo/undo feature as well.
## Installing Dialect in Linux
Dialect is available as a [Flatpak](https://itsfoss.com/what-is-flatpak/). So, you should be able to install it on any Linux distro of your choice. If you are new to this, you might want to check out our [Flatpak guide](https://itsfoss.com/flatpak-guide/) for help.
First, add Flathub repo:
`flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo`
And then install the application:
`flatpak install flathub com.github.gi_lom.dialect`
Once installed, look for it in the system menu and start it from there.
You can also explore its [GitHub page](https://github.com/dialect-app/dialect/) for more information. |
13,869 | 如何在 Linux 上手动安装 Java | https://opensource.com/article/21/9/install-java-manually-linux | 2021-10-10T14:38:51 | [
"Java"
] | https://linux.cn/article-13869-1.html |
>
> 手动安装可以让用户更好的控制 Java 运行时环境。
>
>
>

[使用 Linux 发行版的软件包管理工具来安装 Java 软件包](/article-13864-1.html) 是很容易的。然而,有时你需要手动安装 Java。这对基于 Java 的应用服务器(如 Tomcat 或 JBoss)的管理员特别重要。许多开源和专有软件产品都依赖于这些服务。
### 开发者或运行时套件?
<ruby> Java 虚拟机 <rt> Java Virtual Machine </rt></ruby>(JVM)以两种不同的形式提供:<ruby> Java 开发工具包 <rt> Java Development Kit </rt></ruby>(JDK)或 <ruby> Java 运行时环境 <rt> Java Runtime Environment </rt></ruby>(JRE)。
软件开发人员通常需要 JDK。它包含编译、运行和测试源代码所需的二进制文件。部署一个预先建立的 Java 应用程序通常只需要 JRE。它不包括编译器和其他开发工具。由于安全性的提高和空间的限制,通常在生产环境中安装 JRE。
### 获取 Java
你可以从网上下载开源的 Java 软件。你可以在 [Red Hat Developer](https://developers.redhat.com/products/openjdk/download)、[Adoptium.net](https://adoptium.net/) 下载 OpenJDK 打包文件,或从 Azul 下载 [Zulu 社区版](https://www.azul.com/downloads/zulu-community) 。
### 安装 Java
设置一个目录来存放 Java 文件。我喜欢创建一个简单的名为 `java` 的目录,这样我就可以在一个专门的目录中下载并解压打包文件:
```
$ mkdir -p java/jdk
```
让我们在这个例子中使用 JDK。将下载的文件保存到 `jdk` 目录下。然后换到该目录:
```
$ cd java/jdk
$ ls
OpenJDK11U-jdk_x64_linux_hotspot_11.0.12_7.tar.gz
```
提取该打包文件。注意,`tar` 会创建一个新的目录:
```
$ tar xvzf OpenJDK11U-jdk_x64_linux_hotspot_11.0.12_7.tar.gz
$ ls
jdk-11.0.12+7 OpenJDK11U-jdk_x64_linux_hotspot_11.0.12_7.tar.gz
```
使用 `-version` 选项确认新 JVM 的版本。
```
$ cd jdk-11.0.12+7/bin
$ ./java -version
```
JVM 的版本输出看起来类似这样:
```
openjdk version "11.0.12" 2021-07-20
OpenJDK Runtime Environment Temurin-11.0.12+7 (build 11.0.12+7)
OpenJDK 64-Bit Server VM Temurin-11.0.12+7 (build 11.0.12+7, mixed mode)
```
#### 环境变量
为了确保一个特定的应用程序能够正常工作,它需要确切地知道如何定位 JVM。有两个主要的变量需要设置:`JAVA_HOME` 和 `PATH`。
```
$ echo $JAVA_HOME
$ echo $PATH
```
这些可以在用户的 `.bashrc` 文件中设置。确保这些变量出现在 [任何设置 PATH 的现有代码](https://opensource.com/article/17/6/set-path-linux) 之后:
```
#Set the JAVA_HOME
export JAVA_HOME=~/java/jdk/jdk-11.0.12+7
#Add the JAVA_HOME to the PATH
export PATH="$JAVA_HOME/bin:$PATH"
```
### 手动安装的情况
有几种情况需要手动安装 Java。请考虑以下三种情况:
一种情况可能是要求使用不同的,也许是较早的,在你的 Linux 发行版的软件库中已经没有的 Java 版本。
另一个例子可能是由安全推动的决定,即 Java 不会被默认安装在操作系统上或在“根级别”上。
第三种情况是可能需要几个不同版本的 Java,通常是因为 J2EE Web 应用程序的多个实例在同一台服务器上运行。由于越来越多地使用虚拟机和容器来隔离进程,这种操作系统共享在今天已经不太常见了。然而,由于需要维护不同的容器镜像,对手动安装的理解仍然至关重要。
### 总结
我演示了我手动安装 Java 运行时环境的方式,但你可以制定一个最适合你需求的惯例。最终,手动安装让用户可以更好的控制 Java 运行时环境。
---
via: <https://opensource.com/article/21/9/install-java-manually-linux>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It is easy to use your Linux distribution's package management tool to install the Java software packages. However, sometimes you need to do a manual installation of Java. This is of particular importance to administrators of Java-based application servers such as Tomcat or JBoss. Many open source and proprietary software products rely on these services.
## Developer or Runtime kit?
The Java Virtual Machine (JVM) is provided in two different forms: The Java Development Kit (JDK) or the Java Runtime Environment (JRE).
Software developers usually need the JDK. It contains the binaries necessary for compiling, running, and testing the source code. To deploy a pre-built Java application generally only requires the JRE. It doesn't include the compilers and other development tools. The JRE is typically installed in production environments due to increased security and space limitations.
## Get Java
You can download open source Java software from the internet. You can find downloads of OpenJDK tarballs at [Red Hat Developer](https://developers.redhat.com/products/openjdk/download), [Adoptium.net](https://adoptium.net/ "https://Adoptium.net"), or the [Zulu Community edition](https://www.azul.com/downloads/zulu-community "https://www.azul.com/downloads/zulu-community") from Azul.
## Install Java
Set up a directory to hold the Java files. I like to create one simply called `java`
so I can download and extract the tarball in a dedicated directory.
`$ mkdir -p java/jdk`
Let's use the JDK in this example. Save the downloaded file to the `jdk`
directory. Then change into that directory:
```
$ cd java/jdk
$ ls
OpenJDK11U-jdk_x64_linux_hotspot_11.0.12_7.tar.gz
```
Extract the tarball. Note that `tar`
will create a new directory:
```
$ tar xvzf OpenJDK11U-jdk_x64_linux_hotspot_11.0.12_7.tar.gz
$ ls
jdk-11.0.12+7 OpenJDK11U-jdk_x64_linux_hotspot_11.0.12_7.tar.gz
```
Confirm the version of the new JVM using the `-version`
option:
```
$ cd jdk-11.0.12+7/bin
$ ./java -version
```
The version output of the JVM looks similar to this:
```
openjdk version "11.0.12" 2021-07-20
OpenJDK Runtime Environment Temurin-11.0.12+7 (build 11.0.12+7)
OpenJDK 64-Bit Server VM Temurin-11.0.12+7 (build 11.0.12+7, mixed mode)
```
### Environment variables
To ensure that a given application works correctly, it needs to know exactly how to locate the JVM. Two main variables should be set: **JAVA_HOME** and **PATH**:
```
$ echo $JAVA_HOME
$ echo $PATH
```
These can be set in the user's `.bashrc`
file. Make sure that the variables come after [any existing code that sets PATH](https://opensource.com/article/17/6/set-path-linux):
```
#Set the JAVA_HOME
export JAVA_HOME=~/java/jdk/jdk-11.0.12+7
#Add the JAVA_HOME to the PATH
export PATH="$JAVA_HOME/bin:$PATH"
```
## Manual install situations
Different situations require a manual installation of Java. Consider the following three scenarios.
One situation could be a requirement for a different, perhaps older, version of Java that is not available in your Linux distribution's software repositories.
Another example could be a security-driven decision that Java will not be installed on an operating system by default or at the "root level."
A third situation could be the need for several different versions of Java, usually because multiple instances of a J2EE web application are running on the same server. This OS sharing is less common today due to the increased usage of virtual machines and containers to isolate processes. However, the need to maintain varying container images continues to make the understanding of manual installation vital.
## Wrap up
I demonstrated how I like to install the Java runtime environment but feel free to make up a convention that works best for your needs. Ultimately, manual installation provides the user with the highest level of control over the Java runtime environment.
## 1 Comment |
13,871 | 在 Linux 上使用 jps 命令检查 Java 进程 | https://opensource.com/article/21/10/check-java-jps | 2021-10-11T10:28:12 | [
"Java"
] | https://linux.cn/article-13871-1.html |
>
> 系统上运行着诸多进程,通过 `jps` 命令能够快速有效识别 Java 进程。
>
>
>

在 Linux 中,有一些用于查看系统上运行进程的命令。进程是指由内核管理的正在进行的事件。每启动一个应用程序时,就会产生一个进程,但也有许多在计算机后台运行的进程,如保持系统时间准确的进程、监听新文件系统的进程、索引化文件的进程等。有一些可以用来监测这些进程的实用程序,比如包含在 [procps-ng 包](https://opensource.com/article/21/8/linux-procps-ng) 中的程序,但它们往往都是对各种进程通用的。它们会查看计算机上的所有进程,你可以根据需要过滤结果列表。
在 Linux 中,可以通过 `ps` 命令查看进程。这是查看当前系统上运行进程最简单的方法。
```
$ ps
PID TTY TIME CMD
4486 pts/0 00:00:00 bash
66930 pts/0 00:00:00 ps
```
你也可以通过 `ps` 命令,并配合结果输出管道符进行 `grep`,从而查看系统上运行的 Java 进程,。
```
$ ps ax |grep java
67604 pts/1 Sl+ 0:18 /usr/lib/jvm/java-11-openjdk-11.0.12.0.7-4.fc34.x86_64/bin/java -D[Standalone] -server -Xms64m -Xmx512m -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m -Djava.net.preferIPv4Stack=true -Djboss.modules.system.pkgs=org.jboss.byteman -Djava.awt.headless=true --add-exports=java.desktop/sun.awt=ALL-UNNAMED --add-exports=java.naming/com.sun.jndi.ldap=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.lang.invoke=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.security=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.management/javax.management=ALL-UNNAMED --add-opens=java.naming/javax.naming=ALL-UNNAMED -Dorg.jboss.boot.log.file=/home/alan/wildfly/24.0.1/standalone/log/server.log -Dlogging.configuration=file:/home/alan/wildfly/24.0.1/standalone/configuration/logging.properties -jar /home/alan/wildfly/24.0.1/jboss-modules.jar -mp /home/alan/wildfly/24.0.1/modules org.jboss.as.standalone -Djboss.home.dir=/home/alan/wildfly/24.0.1 -Djboss.server.base.dir=/home/alan/wildfly/24.0.1/standalone
```
然而,OpenJDK 有自己专属的进程监视器。<ruby> Java 虚拟机进程状态 <rt> Java Virtual Machine Process Status </rt></ruby>(jps)工具可以帮你扫描系统上所有运行的 Java 虚拟机(JVM)实例。
要想实现与 `ps` 命令类似的输出,可以使用 `-v` 选项。这很实用,这与 `ps` 相比,可以减少你的输入。
```
$ jps -v
67604 jboss-modules.jar -D[Standalone] -Xms64m -Xmx512m -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m -Djava.net.preferIPv4Stack=true -Djboss.modules.system.pkgs=org.jboss.byteman -Djava.awt.headless=true --add-exports=java.desktop/sun.awt=ALL-UNNAMED --add-exports=java.naming/com.sun.jndi.ldap=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.lang.invoke=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.security=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.management/javax.management=ALL-UNNAMED --add-opens=java.naming/javax.naming=ALL-UNNAMED -Dorg.jboss.boot.log.file=/home/alan/wildfly/24.0.1/standalone/log/server.log -Dlogging.configuration=file:/home/alan/wildfly/24.0.1/standalone/configuration/logging.properties
```
`jps` 命令的默认输出包含进程标识符,类名或 Jar 文件名。
```
$ jps
67604 jboss-modules.jar
69430 Jps
```
**注意:** `jps` 的手册页指出此命令是试验性且不受支持的。尽管如此,它仍然是一个不错的选择,因为一个系统通常运行着许多进程,这种只识别 Java 进程的快速方法是很有用的。
当下的 Java 仍然是一种流行的语言,所以熟悉 Java 开发工具包和运行时环境仍然很重要。它们包含着许多适用于 Java 应用程序开发和维护的工具。
---
via: <https://opensource.com/article/21/10/check-java-jps>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | On Linux, there are commands to view processes running on your system. A process is any ongoing event being managed by the kernel. A process is spawned when you launch an application, but there are also many other processes running in the background of your computer, including programs to keep your system time accurate, to monitor for new filesystems, to index files, and more. The utilities, such as those included in the [procps-ng package](https://opensource.com/article/21/8/linux-procps-ng), that monitor these processes tend to be intentionally generic. They look at all processes on your computer so you can filter the list based on what you need to know.
On Linux, you can view processes with the `ps`
command. It is the simplest way to view the running processes on your system.
```
$ ps
PID TTY TIME CMD
4486 pts/0 00:00:00 bash
66930 pts/0 00:00:00 ps
```
You can use the `ps`
command to view running Java processes on a system also by piping output to `grep`
.
```
$ ps ax |grep java
67604 pts/1 Sl+ 0:18 /usr/lib/jvm/java-11-openjdk-11.0.12.0.7-4.fc34.x86_64/bin/java -D[Standalone] -server -Xms64m -Xmx512m -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m -Djava.net.preferIPv4Stack=true -Djboss.modules.system.pkgs=org.jboss.byteman -Djava.awt.headless=true --add-exports=java.desktop/sun.awt=ALL-UNNAMED --add-exports=java.naming/com.sun.jndi.ldap=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.lang.invoke=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.security=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.management/javax.management=ALL-UNNAMED --add-opens=java.naming/javax.naming=ALL-UNNAMED -Dorg.jboss.boot.log.file=/home/alan/wildfly/24.0.1/standalone/log/server.log -Dlogging.configuration=file:/home/alan/wildfly/24.0.1/standalone/configuration/logging.properties -jar /home/alan/wildfly/24.0.1/jboss-modules.jar -mp /home/alan/wildfly/24.0.1/modules org.jboss.as.standalone -Djboss.home.dir=/home/alan/wildfly/24.0.1 -Djboss.server.base.dir=/home/alan/wildfly/24.0.1/standalone
```
OpenJDK, however, has its very own specific process monitor. The Java Virtual Machine Process Status (jps) tool allows you to scan for each running instance of the Java Virtual Machine (JVM) on your system.
To view a similar output as seen in the `ps`
command, use the `-v`
option. This is useful, partly because it requires less typing.
```
$ jps -v
67604 jboss-modules.jar -D[Standalone] -Xms64m -Xmx512m -XX:MetaspaceSize=96M -XX:MaxMetaspaceSize=256m -Djava.net.preferIPv4Stack=true -Djboss.modules.system.pkgs=org.jboss.byteman -Djava.awt.headless=true --add-exports=java.desktop/sun.awt=ALL-UNNAMED --add-exports=java.naming/com.sun.jndi.ldap=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.lang.invoke=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.security=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.management/javax.management=ALL-UNNAMED --add-opens=java.naming/javax.naming=ALL-UNNAMED -Dorg.jboss.boot.log.file=/home/alan/wildfly/24.0.1/standalone/log/server.log -Dlogging.configuration=file:/home/alan/wildfly/24.0.1/standalone/configuration/logging.properties
```
The default `jps`
output provides the process identifier and the class name or Jar file name of each detected instance.
```
$ jps
67604 jboss-modules.jar
69430 Jps
```
**Note:** The man page for `jps`
states that it is experimental and unsupported. Still, it's a nice-to-have option because often many processes are running on a system, and having a quick way to identify only Java is useful.
Because Java is still a popular language today, being familiar with the Java Development Kit and Runtime Environment remains important. They contain many tools applicable to the development and maintenance of Java applications.
## 1 Comment |
13,872 | 基于 KDE 的最佳 Linux 发行版 | https://itsfoss.com/best-kde-distributions/ | 2021-10-11T11:54:59 | [
"KDE",
"发行版"
] | https://linux.cn/article-13872-1.html | 
KDE 是目前最具定制性和最快速的桌面环境之一。虽然你可以随时安装 KDE,但最好选择一个 KDE 开箱即用的 Linux 发行版。
在这里,让我列出一些最好的基于 KDE 的 Linux 发行版。
无论你选择什么作为你的首选发行版,你都可以参考我们的 [KDE 定制指南](https://itsfoss.com/kde-customization) 来调整你的体验。
注意:该列表没有特定的排名顺序。
### 1、KDE Neon

主要亮点:
* 官方 KDE 发行版
* 最新的 KDE Plasma 稳定版
* 专注于最新的 KDE 软件
* 不是桌面发行版的完美替代品
如果你想获得 KDE Plasma 的最新体验,[KDE Neon](https://neon.kde.org/index) 是最佳选择之一。
即使它是建立在稳定版的 Ubuntu LTS 基础之上,你也总是能在最新的 KDE 版本发布后立即得到交付。
与其他发行版不同,它不注重完整的桌面用户体验,而是重点关注在 KDE 软件包上。所以,它可能不是每个人的完美桌面替代品。然而,如果你希望使用最新的 KDE 软件,KDE Neon 是一个不错的选择。
其“用户版”应该是你需要的,但如果你愿意尝试预先发布的功能,你也可以选择尝试“测试版”或“不稳定版”。
如果你想知道它与 Kubuntu 有什么不同,你应该查看 [KDE Neon vs Kubuntu](https://itsfoss.com/kde-neon-vs-kubuntu/) 的比较来探索它。
### 2、Kubuntu

主要亮点:
* 基于 Ubuntu 的以桌面为重点的 Linux 发行版
* 提供 LTS 和非 LTS 版本
* 良好的硬件兼容性
如果 KDE 软件套件不是你关注的重点,那么 Kubuntu 应该是你可以作为 Linux 桌面使用的一个优秀发行版。
Kubuntu 是 Ubuntu 的一个官方版本,它为其 LTS 版本提供了三年的更新支持。与 KDE Neon 不同的是,你可以得到对各种应用程序更好的支持,而不仅仅是局限于 KDE 软件。
你可以选择 LTS 版或非 LTS 版来获得最新的 Ubuntu 功能。
与其他一些基于 KDE 的发行版相比,Kubuntu 具有更好的硬件兼容性。考虑到它可以为各种笔记本电脑提供动力,如 Kubuntu Focus、Slimbook 等,其硬件兼容性是你可以信赖的。
### 3、Manjaro KDE

主要亮点:
* 基于 Arch 的 Linux 发行版
* 滚动式发布更新
* 对于新的 Linux 用户来说学习难度不大
Manjaro 是一个基于 Arch Linux 的发行版,它使得使用 Arch 作为桌面 Linux 平台变得容易。
它按照滚动发布的时间表进行发布,这应该有助于你快速获得最新的软件包,而不必担心软件更新时间。
如果你是一个新的 Linux 用户,你可以考虑一直使用 Flatpak 或 Snaps 来安装各种应用程序。虽然 Manjaro 让你很容易使用 Arch,但它对新用户来说多多少少还是有一点学习曲线。所以,你可能需要查看 [Arch 维基](https://wiki.archlinux.org) 来了解更多信息。
### 4、Fedora KDE Spin
主要亮点:
* 一个独特的基于 KDE 的 Linux 发行版(如果你不喜欢主流的 Ubuntu/Arch 发行版)
* 为工作站和服务器量身定做
* 对于新的 Linux 用户来说可能需要适应
* 硬件兼容性可能是个问题
Fedora 是一个独立的发行版(不基于 Ubuntu/Arch),作为 Red Hat Enterprise Linux 的上游。
而 Fedora Spin 版为用户提供了各种备用的桌面。如果你想要 KDE,你需要下载 Fedora 的 KDE Spin。
像 KDE Neon 一样,Fedora 并不专注于提供一个最佳的桌面体验,而是旨在实验对工作站或服务器有用的最新技术。
因此,如果你有信心解决 Linux 发行版上较新技术实现所带来的任何问题/挑战,[Fedora KDE Spin](https://spins.fedoraproject.org/en/kde/) 是一个不错的选择。
### 5、openSUSE

主要亮点:
* 适用于需要使用多种工具的系统管理员和开发人员
* 有两个不同的版本,包括稳定版和滚动版
[openSUSE](https://www.opensuse.org) 是另一个独立的 Linux 发行版,默认采用 KDE 桌面。虽然它把自己定位为桌面用户的选择之一,但我在过去曾遇到过硬件兼容性问题。
然而,对于想在桌面上使用 YaST、Open Build Service、Kiwi 等工具的系统管理员或开发者来说,它是一个很好的选择,开箱即用。
它提供了一个稳定版和一个滚动发布版。根据你的要求选择最适合你的。
### 6、Garuda Linux

主要亮点:
* 滚动发布的发行版
* BTRFS 作为默认文件系统
* 预装了基本的 GUI 工具,使 Arch Linux 的使用变得简单
[Garuda Linux](https://garudalinux.org) 是一个基于 Arch 的现代发行版,专注于开箱即用的定制体验。
KDE 版本(或 Dr460nized 版本)提供了漂亮的体验,同时可使用类似 macOS 的工作流程进行调整。
当然,如果你是一个有经验的 Linux 用户,你可以定制你现有的发行版来模仿同样的体验。
锦上添花的是,Garuda Linux 还提供了其 KDE 版本的不同变体,一个预装了游戏工具,一个用于渗透测试,另一个作为基本的 Linux 桌面系统。
### 7、Nitrux OS

主要亮点:
* 基于 Debian 的发行版,不同的风格
* 独特的桌面体验
一个基于 Debian 的 Linux 发行版,具有开箱即用的 KDE。与 Kubuntu 不同,Nitrux 最终可能提供的是一个更快的 KDE Plasma 更新和较新的 Linux 内核升级。
[Nitrux OS](https://nxos.org) 在以其 NX 桌面为特色的同时,提供了一个美丽而独特的体验。
如果你想尝试一些不同的 KDE 搭载,Nitrux OS 将是一个不错的选择。
### 8、MX Linux KDE

主要亮点:
* 基于 Debian 的发行版
* 轻量级
* 预装了有用的 MX 工具
不在意外观,但想要一个简单的、可定制的、基于 Debian 的 KDE 桌面?[MX Linux KDE 版](https://mxlinux.org) 应该是一个很好的选择,因为它以迅捷的性能和预装的基本工具而闻名。
如果你想调整默认的用户体验,你还可以得到几个 KDE 主题。
### 总结
在这个列表之外,其他几个 Linux 发行版也将 KDE 桌面作为他们的首选。
总体来说,Nitrux OS 应该是一个独特的选择,如果你想远离基于 Ubuntu 的发行版,还有像 Garuda Linux 和 Manjaro 这样基于 Arch 的可靠发行版可以尝试。
你最喜欢的基于 KDE 的 Linux 发行版是什么?你是专注于开箱即用的定制,还是喜欢自己定制 KDE 体验?
---
via: <https://itsfoss.com/best-kde-distributions/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

KDE is one of the most customizable and fastest desktop environments out there. While you can always install KDE if you know-how, it is best to choose a Linux distribution that comes with KDE out-of-the-box.
Here, let me list some of the best KDE-based Linux distros.
No matter what you choose as your preferred distro, you can refer to our [KDE customization guide](https://itsfoss.com/kde-customization) to tweak your experience.
## 1. KDE Neon
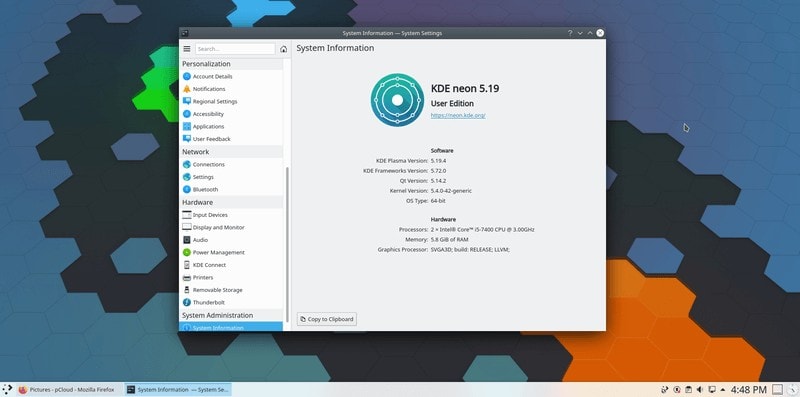
Key Highlights:
- Official KDE distribution
- Latest stable KDE Plasma version
- Focuses on the latest KDE software
- Not a perfect replacement as a desktop distro
KDE Neon is one of the exciting choices if you want to get your hands on the latest KDE Plasma experience.
Even if it utilizes a stable Ubuntu LTS base, you always get the newest KDE version delivered as soon as it is released.
Unlike any other distros, it does not focus on a complete desktop user experience but the KDE software packages. So, it may not be the perfect desktop replacement for everyone. However, if you focus on using the latest KDE software, KDE Neon is a decent choice.
The User Edition is what you need to opt for, but you also have the choice to try “Testing” or “Unstable” editions if you are willing to try pre-released features.
## 2. Kubuntu
Key Highlights:
- An Ubuntu-based desktop-focused Linux distro
- Offers both LTS and non-LTS versions
- Good hardware compatibility
Kubuntu should be an excellent distro for your Linux desktop if the KDE software suite is not your focus.
Kubuntu is an official flavor of Ubuntu, which provides three years of updates for its LTS editions. Unlike KDE Neon, you get better support for various applications and are not just limited to KDE software.
You get the option to opt for an LTS edition or a non-LTS version to get the latest Ubuntu features.
Kubuntu has improved hardware compatibility when compared to some other KDE-based distros. Considering, it powers a variety of laptops that include Kubuntu Focus, Slimbook, and more, the hardware compatibility is something that you can rely on.
[KDE Neon vs Kubuntu: What’s the Difference Between the Two KDE Distribution?When you find two Linux distributions based on Ubuntu and powered up by KDE, which one do you choose? * Kubuntu is the official KDE flavor from Ubuntu. * KDE Neon is the Ubuntu-based distribution by KDE itself. I know it is often confusing especially if you have never used either of](https://itsfoss.com/kde-neon-vs-kubuntu/)

## 3. Manjaro KDE
Key Highlights:
- Arch-based Linux distro
- Rolling-release updates
- Presents a slight learning curve to new Linux users
Manjaro is an Arch-Linux-based distribution that makes it easy to use Arch as a desktop Linux platform.
It follows a rolling-release schedule, which should help you get the latest packages quickly without worrying about the software update period.
If you are a new Linux user, you may want to stick to Flatpak or Snaps to install any application. While Manjaro makes it easy to use Arch, it does present a slight learning curve to new users. So, you might want to check the [Arch wiki](https://wiki.archlinux.org/?ref=itsfoss.com) to explore more.
## 4. Fedora KDE Spin
Key Highlights:
- A unique KDE-based Linux distribution (if you don’t prefer mainstream Ubuntu/Arch distros)
- Tailored for workstations and servers
- May not be convenient for new Linux users
- Hardware compatibility can be an issue
Fedora is an independent distribution (not based on Ubuntu/Arch) that acts as an upstream for Red Hat Enterprise Linux.
And, Fedora spin editions feature alternate desktops for users. If you want KDE, you need to download Fedora’s KDE spin.
Like KDE Neon, Fedora does not focus on providing a great desktop experience but aims to implement the latest technology useful for a workstation or server.
So, if you are confident to tackle any issues/challenges that come with newer technology implementations on a Linux distro, Fedora KDE spin can be a good choice.
## 5. openSUSE
Key Highlights:
- Suitable for system administrators and developers requiring access to several tools
- Two different editions available including a stable and a rolling-release
openSUSE is yet another independent Linux distribution featuring the KDE desktop by default. While it pitches itself as one of the choices for desktop users, I have had hardware compatibility issues in the past.
However, it can be a good choice for system administrators or developers who want to access tools like YaST, Open Build Service, Kiwi, and more on their desktop, out-of-the-box.
It offers a stable edition and a rolling-release version. As per your requirements, choose what’s best for you.
## 6. Garuda Linux

Key Highlights:
- Rolling-release distro
- BTRFS as the default filesystem
- Comes with essential pre-installed GUI tools to make the Arch Linux experience easy
Garuda Linux is a modern Arch-based distribution that focuses on a customized experience out-of-the-box.
The KDE version (or the Dr460nized edition) offers a beautiful experience while tweaking it with a macOS-like workflow.
Of course, if you are an experienced Linux user, you may customize your existing distribution to mimic the same experience.
As a cherry on top, Garuda Linux also provides different variants of its KDE editions, one with pre-installing gaming tools, one for penetration testing, and another as an essential Linux desktop system.
## 7. Nitrux OS
Key Highlights:
- Debian-based distribution for a change
- Unique desktop experience
A Debian-based Linux distribution that features KDE out-of-the-box. Unlike Kubuntu, Nitrux may end up offering faster KDE plasma updates and newer Linux Kernel upgrades.
Nitrux OS offers a beautiful and unique experience while featuring its NX Desktop.
If you want to try something different with KDE onboard, Nitrux OS would be a great pick.
## 8. MX Linux KDE
Key Highlights:
- Debian-based distro
- Lightweight
- Useful MX Tools pre-installed
Don’t need the looks but want a simple and customizable KDE desktop with a Debian base? MX Linux KDE edition should be a fantastic choice as it is known for its snappy performance and pre-installed essential tools baked in.
You also get several KDE themes if you want to tweak the default user experience.
## Wrapping Up
In addition to this list, several other Linux distributions feature KDE desktop as their preferred choice.
Nitrux OS should be a unique pick overall, and if you want to move away from Ubuntu-based distributions, there are solid arch-based distros like Garuda Linux and Manjaro to try.
What is your favorite KDE-based Linux distribution? Do you focus on out-of-the-box customization or prefer to customize the KDE experience yourself? |
13,874 | /e/ 云:一个去谷歌化的 Google Drive 替代方案 | https://news.itsfoss.com/e-cloud/ | 2021-10-12T12:29:00 | [
"Nextcloud",
"/e/"
] | https://linux.cn/article-13874-1.html | 
>
> /e/ 云是 e.foundation 使用 Nextcloud 等开源工具创立的,以作为 Google Drive 和 Gmail 的替代品。
>
>
>

Google Drive 是一种流行的云存储服务,在大多数情况下效果很好。
然而,它可能不是最关注隐私的选择。因此,要完全控制你的数据,最好的办法是启动一个 [Nextcloud](https://itsfoss.com/nextcloud/) 实例,存储你的基本数据,并可以访问其他协作工具。
虽然这听起来不错,但不是每个人都能投入精力来创建和维护他们的实例。这就是 /e/ 云上场的时候了,它是由 [去谷歌化的安卓操作系统 /e/ 操作系统](https://itsfoss.com/e-os-review/) 背后的同一个团队建立的。
/e/ 云主要将自己定位为一个新的 Google Drive 私人替代品,并提供一个取代 Gmail 的邮箱。
### /e/ 云:带有邮箱的 Nextcloud 及 OnlyOffice

当你创建一个 /e/ 账户时,它会给你一个私人电子邮件地址 [[email protected]](mailto:[email protected])。
而且,同邮箱地址一起,你会得到 1GB 的免费 /e/ 云存储空间和一个由 Nextcloud 和 OnlyOffice 为核心的协作平台。
因此,如果你想利用 Nextcloud 和 OnlyOffice 来取代谷歌的工具套件,而不需要自己全部设置,/e/ 云可以成为一个引人注目的以隐私为中心的选择。

除了 OnlyOffice 的文件存储和文档支持外,你还可以使用日历,存储笔记,并添加任务。
因此,它也可以成为一个正式的以隐私为中心的协作平台,你可以免费使用。
如果你想要更多的存储空间,你可以将你的订阅升级到付费计划,你可以根据需要选择 20 到 1TB 的存储空间,并按月/年计费。定价计划起价低至 3 美元/月。
毫无疑问,如果你在手机上使用 /e/ 操作系统或使用一个 /e/ 智能电话,这应该是一种无缝体验。
但是,你也可以使用第三方邮件客户端和 Nextcloud 移动应用在任何设备上使用它。
* [注册 /e/ 云](https://e.foundation/e-email-invite/)
### 总结
考虑到它相对较新,正计划增加几个功能,包括端到端加密,从 Google Drive 迁移等。
你可以注册一个帐户并免费试用。
对于像 /e/ 云这样以 Nextcloud 为核心的主流解决方案,除了电子邮件和协作服务外,还能帮助你安全地管理/存储文件,你觉得怎么样?
---
via: <https://news.itsfoss.com/e-cloud/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Google Drive is a popular cloud storage service that works great for the most part.
However, it may not be the most private option out there. So, to take total control of your data, the best way is to spin up a [Nextcloud](https://itsfoss.com/nextcloud/?ref=news.itsfoss.com) instance and store your essential data while getting access to other collaboration tools.
While that sounds good to hear, not everyone can put the effort to create and maintain their instance. This is where ecloud comes in—built by the same team behind [ /e/ OS, the de-googled Android operating system](https://itsfoss.com/e-os-review/?ref=news.itsfoss.com).
ecloud pitches itself primarily as a new private alternative to Google Drive and offers a mailbox to replace Gmail.
## /e/ cloud: Nextcloud & OnlyOffice With Mailbox
When you create an /e/ account, it gives you a private email address [[email protected]](/cdn-cgi/l/email-protection)
And, along with the email address, you get **1 GB** free ecloud storage space and a collaboration platform powered by Nextcloud and OnlyOffice at its core.
So, if you want to utilize Nextcloud and OnlyOffice to replace Google’s suite of tools without setting it up all yourself, /e/ cloud can be a compelling privacy-centric choice.
In addition to the file storage and document support with OnlyOffice, you can also use a calendar, store notes, and add tasks.
Hence, it can also be a decent privacy-focused collaboration platform that you can use for free.
If you want more storage, you can upgrade your subscription to a paid plan where you opt for 20 to 1 TB of storage as required with monthly/yearly billing options. The pricing plans start as low as **$3/month**.
Undoubtedly, it should be a seamless experience if you are using /e/ OS on your phone or a /e/ smartphone.
But, you can also use it on any device using third-party mail clients and the Nextcloud mobile app.
## Wrapping Up
Considering it is relatively new, several features are planned to be added that include end-to-end encryption, migration from Google Drive, and more.
You can sign up for an account and try it out free.
*What do you think about a mainstream solution like /e/ cloud that uses Nextcloud at its core to help you manage/store files securely in addition to email and collaboration services?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,875 | 使用 Jekyll 构建你的网站 | https://opensource.com/article/21/9/build-website-jekyll | 2021-10-12T14:53:58 | [
"Jekyll",
"HTML"
] | https://linux.cn/article-13875-1.html |
>
> Jekyll 是一个开源的静态网站生成器。你可以使用 Markdown 编写内容,使用 HTML/CSS 来构建和展示,Jekyll 会将其编译为静态的 HTML。
>
>
>

近年来开始流行静态网站生成器和 JAMStack,而且理由很充分,它们不需要复杂的后端,只需要静态的 HTML、CSS 和 Javascript。没有后端意味着更好的安全性、更低的运营开销和更便宜的托管。双赢!
在本文中,我将讨论 Jekyll。在撰写本文时,[我的个人网站使用的是 Jekyll](https://gitlab.com/ayush-sharma/ayushsharma-in)。Jekyll 使用 Ruby 引擎将用 Markdown 编写的文章转换成 HTML。[Sass](https://sass-lang.com/) 可以将复杂的 CSS 规则应用到普通文本文件中。[Liquid](https://shopify.github.io/liquid/) 允许对静态内容进行编程控制。
### 安装 Jekyll
[Jekyll 网站](https://jekyllrb.com/docs/installation/) 提供了 Linux、MacOS 和 Windows 安装说明。安装完成之后,[快速引导](https://jekyllrb.com/docs/) 将会安装一个基础的 Hello-World 项目。
现在在你的浏览器访问 `http://localhost:4000`,你可以看到你的默认“真棒”博客。

### 目录结构
这个默认站点包含以下的文件和文件夹:
* `_posts`: 你的博客文章。
* `_site`: 最终编译成的静态网站文件。
* `about.markdown`: “关于页”的内容。
* `index.markdown`: “主页”的内容。
* `404.html`: “404 页”的内容。
* `_config.yml`: Jekyll 的全站配置文件。
### 创建新的博客帖子
创建帖子很简单。你需要做的就是在 `_post` 目录下使用正确的格式和扩展名创建一个新文件,这样就完成了。
有效的文件名像 `2021-08-29-welcome-to-jekyll.markdown` 这样。一个博客文件必须包含 Jekyll 所谓的 YAML <ruby> 卷首块 <rt> Front Matter </rt></ruby>。它是文件开头的一个包含元数据的特殊部分。如果你查看默认的帖子,你可以看到以下内容:
```
---
layout: post
title: "Welcome to Jekyll!"
date: 2021-08-29 11:28:12 +0530
categories: jekyll update
---
```
Jekyll 会使用上面的元数据,你也可以自定义 `key: value` 键值对。如果你需要一些提示,[请查看我的网站的卷首](https://gitlab.com/ayush-sharma/ayushsharma-in/-/blob/2.0/_posts/2021-07-15-the-evolution-of-ayushsharma-in.md)。除了前面的问题,你还可以 [使用内置的 Jekyll 变量](https://jekyllrb.com/docs/variables/) 来自定义你的网站。
让我们创建一个新的帖子。在 `_posts` 文件夹下创建 `2021-08-29-ayushsharma.markdown`。内容如下:
```
---
layout: post
title: "Check out ayushsharma.in!"
date: 2021-08-29 12:00:00 +0530
categories: mycategory
---
This is my first post.
# This is a heading.
## This is another heading.
This is a [link](<http://notes.ayushsharma.in>)
This is my category:
```
如果 `jekyll serve` 命令仍在运行,刷新页面,你将看到下面的新帖子。

恭喜你创建了你的第一篇帖子!这个过程看起来很简单,但是你可以通过 Jekyll 做很多事情。使用简单的 Markdown,你可以归档博客、高亮显示代码片段以及分类管理帖子。
### 草稿
如果你还没准备好发布你的内容,你可以创建一个 `_drafts` 文件夹。此文件夹中的 Markdown 文件仅通过传递 `--drafts--` 参数来呈现。
### 布局和包含
请注意 `_post` 文件夹中两篇文章的卷首块,你将在其中看到 `layout: post`。`_layout` 文件夹中包含所有布局。你不会在源代码中找到它们,因为 Jekyll 默认加载它们。Jekyll 使用的默认源代码在 [这里](https://github.com/jekyll/minima/blob/master/_layouts/post.html)。如果你点击该链接,你可以看到 `post` 的布局使用了默认(`default`)布局。默认布局包含的代码 `{{ content }}` 是注入内容的地方。布局文件还将包含 `include` 指令。它们从 [`include` 文件夹](https://github.com/jekyll/minima/tree/master/_includes) 加载文件,并使用不同的组件组成页面。
总的来说,这就是布局的工作方式:你在卷首块定义它们并将你的内容注入其中。而包含则提供了页面的其它部分以组成整个页面。这是一种标准的网页设计技术:定义页眉、页脚、旁白和内容元素,然后在其中注入内容。这就是静态站点生成器的真正威力,完全以编程的方式控制,将你的网站组装起来并最终编译成静态的 HTML。
### 页面
你网站上的所有内容并不都是文章或博客。你需要“关于”页面、“联系”页面、“项目”页面或“作品”页面。这就是“页面”的用武之地。它们的工作方式与“帖子”完全一样,这意味着它们是带有卷首块的 Markdown 文件。但它们不会放到 `_posts` 目录。它们要么保留在你的项目根目录中,要么保留在它们自己的文件夹中。对于布局和包含,你可以使用与帖子相同的布局或创建新帖子。 Jekyll 非常灵活,你可以随心所欲地发挥你的创意!你的默认博客已经有 `index.markdown` 和 `about.markdown`。请随意自定义它们。
### 数据文件
数据文件位于 `_data` 目录中,可以是 `.yml`、`.json`、`.csv` 等格式的文件。例如,一个 `_data/members.yml` 文件可能包含:
```
- name: A
github: a@a
- name: B
github: b@b
- name: C
github: c@c
```
Jekyll 在网站生成的时候读取这些内容。你可以通过 `site.data.members` 访问它们。
```
<ul>
{ % for member in site.data.members % }
<li>
<a href="https://github.com">
{ { member.name } }
</a>
</li>
{ % endfor %}
</ul>
```
### 永久链接
你的 `_config.yml` 文件定义了永久链接的格式。你可以使用各种默认变量来组合你自己的自定义永久链接。
### 构建你最终的网站
命令 `jekyll serve` 非常适合本地测试。但是一旦你完成了本地测试,你将需要构建要发布的最终工作。命令 `jekyll build --source source_dir --destination destination_dir` 将你的网站构建到 `_site` 文件夹中。请注意,此文件夹在每次构建之前都会被清理,所以不要将重要的东西放在那里。生成内容后,你可以将其托管在你的静态托管服务上。
你现在应该对 Jekyll 的功能以及主要部分的功能有一个全面的了解。如果你正在寻找灵感,官方 [JAMStack 网站上有一些很棒的例子](https://jamstack.org/examples/)。

编码快乐。
本文首发于[作者个人博客](https://notes.ayushsharma.in/2021/08/introduction-to-jekyll),经授权改编。
---
via: <https://opensource.com/article/21/9/build-website-jekyll>
作者:[Ayush Sharma](https://opensource.com/users/ayushsharma) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Static website generators and JAMStack have taken off in recent years. And with good reason. There is no need for complex backends with only static HTML, CSS, and Javascript to serve. Not having backends means better security, lower operational overhead, and cheaper hosting. A win-win-win!
In this article, I'm going to talk about Jekyll. As of this writing, [my personal website uses Jekyll](https://gitlab.com/ayush-sharma/ayushsharma-in). Jekyll uses a Ruby engine to convert articles written in Markdown to generate HTML. [Sass](https://sass-lang.com/) allows merging complex CSS rules into flat files. [Liquid](https://shopify.github.io/liquid/) allows some programmatic control over otherwise static content.
## Install Jekyll
The [Jekyll website](https://jekyllrb.com/docs/installation/) has installation instructions for Linux, MacOS, and Windows. After installation, the [Quickstart guide](https://jekyllrb.com/docs/) will set up a basic Hello-World project.
Now visit `http://localhost:4000`
in your browser. You should see your default "awesome" blog.
Screenshot by Ayush Sharma, CC BY-SA 4.0
## Directory structure
The default site contains the following files and folders:
`_posts`
: Your blog entries.`_site`
: The final compiled static website.`about.markdown`
: Content for the about page.`index.markdown`
: Content for the home page.`404.html`
: Content for the 404 page.`_config.yml`
: Site-wide configuration for Jekyll.
## Creating new blog entries
Creating posts is simple. All you need to do is create a new file under `_posts`
with the proper format and extension, and you’re all set.
A valid file name is `2021-08-29-welcome-to-jekyll.markdown`
. A post file must contain what Jekyll calls the YAML Front Matter. It’s a special section at the beginning of the file with the metadata. If you see the default post, you’ll see the following:
```
---
layout: post
title: "Welcome to Jekyll!"
date: 2021-08-29 11:28:12 +0530
categories: jekyll update
---
```
Jekyll uses the above metadata, and you can also define custom `key: value`
pairs. If you need some inspiration, [have a look at my website's front matter](https://gitlab.com/ayush-sharma/ayushsharma-in/-/blob/2.0/_posts/2021-07-15-the-evolution-of-ayushsharma-in.md). Aside from the front matter, you can [use in-built Jekyll variables](https://jekyllrb.com/docs/variables/) to customize your website.
Let’s create a new post. Create `2021-08-29-ayushsharma.markdown`
in the `_posts`
folder. Add the following content:
```
---
layout: post
title: "Check out ayushsharma.in!"
date: 2021-08-29 12:00:00 +0530
categories: mycategory
---
This is my first post.
# This is a heading.
## This is another heading.
This is a [link](http://notes.ayushsharma.in)
This is my category:
```
If the `jekyll serve`
command is still running, refresh the page, and you'll see the new entry below.
Screenshot by Ayush Sharma, CC BY-SA 4.0
Congrats on creating your first article! The process may seem simple, but there's a lot you can do with Jekyll. Using simple markdown, you can generate an archive of posts, syntax highlighting for code snippets, and separate pages for posts in one category.
## Drafts
If you're not ready to publish your content yet, you can create a new `_drafts`
folder. Markdown files in this folder are only rendered by passing the `--drafts`
argument.
## Layouts and Includes
Note the front matter of the two articles in our `_posts`
folder, and you'll see `layout: post`
in the Front Matter. The `_layout`
folder contains all the layouts. You won't find them in your source code because Jekyll loads them by default. The default source code used by Jekyll is [here](https://github.com/jekyll/minima/blob/master/_layouts/post.html). If you follow the link, you'll see that the `post`
layout uses the [ default layout](https://github.com/jekyll/minima/blob/master/_layouts/default.html#L12). The default layout contains the code
`{{ content }}`
which is where content is injected. The layout files will also contain `include`
directives. These load files from the [and allow composing a page using different components.](https://github.com/jekyll/minima/tree/master/_includes)
`includes`
folderOverall, this is how layouts work—you define them in the front matter and inject your content within them. Includes provide other sections of the page to compose a whole page. This is a standard web-design technique—defining header, footer, aside, and content elements and then injecting content within them. This is the real power of static site generators—full programmatic control over assembling your website with final compilation into static HTML.
## Pages
Not all content on your website will be an article or a blog post. You'll need about pages, contact pages, project pages, or portfolio pages. This is where Pages come in. They work exactly like Posts do, meaning they're markdown files with front matter. But they don't go in the `_posts`
directory. They either stay in your project root or in folders of their own. For Layouts and Includes, you can use the same ones as you do for your Posts or create new ones. Jekyll is very flexible and you can be as creative as you want! Your default blog already has `index.markdown`
and `about.markdown`
. Feel free to customize them as you wish.
## Data files
Data files live in the `_data`
directory, and can be `.yml`
, `.json`
, or `.csv`
. For example, a `_data/members.yml`
file may contain:
```
- name: A
github: a@a
- name: B
github: b@b
- name: C
github: c@c
```
Jekyll reads these during site generation. You can access them using `site.data.members`
.
```
<ul>
{ % for member in site.data.members %}
<li>
<a href="https://github.com/">
{ { member.name }}
</a>
</li>
{ % endfor %}
</ul>
```
## Permalinks
Your `_config.yml`
file defines the format of your permalinks. You can [use a variety of default variables](https://jekyllrb.com/docs/permalinks/) to assemble your own custom permalink.
## Building your final website
The command `jekyll serve `
is great for local testing. But once you're done with local testing, you'll want to build the final artifact to publish. The command `jekyll build --source source_dir --destination destination_dir`
builds your website into the `_site`
folder. Note that this folder is cleaned up before every build, so don't place important things in there. Once you have the content, you can host it on a static hosting service of your choosing.
You should now have a decent overall grasp of what Jekyll is capable of and what the main bits and pieces do. If you’re looking for inspiration, the official [JAMStack website has some amazing examples](https://jamstack.org/examples/).
Screenshot by Ayush Sharma, CC BY-SA 4.0
Happy coding :)
*This article was originally published on the author's personal blog and has been adapted with permission.*
## Comments are closed. |
13,877 | [初级] 如何在 Ubuntu 中安装 Vivaldi 浏览器 | https://itsfoss.com/install-vivaldi-ubuntu-linux/ | 2021-10-13T14:25:55 | [
"Vivaldi",
"浏览器"
] | https://linux.cn/article-13877-1.html | 
>
> 你将在本篇新手教程中学习如何在 Ubuntu、Debian 及其他 Linux 发行版中安装 Vivaldi 网页浏览器,同时本教程也将介绍如何更新和卸载该软件。
>
>
>
[Vivaldi](https://vivaldi.com/) 是一款日益流行的网页浏览器。它基于 Chromium 内核,因此它拥有和 Chrome 类似的功能,但它也新增了一些其他特色功能,让这款浏览器与众不同、更为直观。
它内置了标签组、广告拦截、鼠标手势、笔记管理,甚至还有命令连锁。你甚至可以借助切分视图来一次性浏览多个页面。当然,相比于 Chrome,Vivaldi 更加尊重你的隐私。

[Manjaro Linux 近期使用 Vivaldi 取代 Firefox 作为其部分变体的默认浏览器](https://news.itsfoss.com/vivaldi-replaces-firefox-manjaro/),你可以从这件事来了解 Vivaldi 浏览器的受欢迎程度。
如果你想尝试一下这款浏览器的话,接下来让我告诉你,如何在 Linux 上安装 Vivaldi。你将了解到:
* 安装 Vivaldi 的 GUI 和命令行方式
* 将 Vivaldi 更新到最新版本的技巧
* 在 Ubuntu 中卸载 Vivaldi 的方式
>
> **非自由软件警告!**
>
>
> Vivaldi 并非完全的开源软件。它的 UI 界面是闭源的。之所以在这里介绍这款浏览器,是因为 Vivaldi 团队正努力让该软件在 Linux 平台上可用。
>
>
>
### 方式 1:在 Ubuntu 中安装 Vivaldi [GUI 方式]
好消息是,Vivaldi 提供了预先构建好的安装包,包括 Ubuntu/Debian 的 DEB 文件,以及 Fedora、Red Hat、SUSE 的 RPM 文件。
它支持 32 位和 64 位平台,也支持 [像树莓派之类的 ARM 设备](https://itsfoss.com/raspberry-pi-alternatives/)。

安装过程非常简单。你只需要前往 Vivaldi 的官网下载正确的安装包文件,双击打开,然后安装,大功告成。
我将详细介绍在 Ubuntu/Debian 下的安装过程。对于其他类型的发行版,你可以使用类似的步骤。
#### 第 1 步:下载 Vivaldi
前往 Vivaldi 的下载页面,下载支持 Ubuntu 的 DEB 格式安装包。
* [下载 Vivaldi](https://vivaldi.com/download/)

#### 第 2 步:安装刚刚下载的 DEB 文件
前往你刚刚下载 DEB 文件的下载文件夹。[安装 DEB 文件](https://itsfoss.com/install-deb-files-ubuntu/) 非常简单,只需要双击打开,或者右键后使用软件中心打开即可。

这将打开软件中心,在这里可以看到安装 Vivaldi 的选项。点击安装按钮即可。

你将需要输入系统账户的密码,输入密码授权后,Vivaldi 很快就能完成安装,随后安装按钮也变成了移除按钮。这表明 Vivaldi 已经安装完成了。
#### 第 3 步:使用 Vivaldi
按下 `Super`(`Windows`)键打开系统菜单,搜索 Vivaldi,然后单击 Vivaldi 的图标。

首次启动时,你将看到如下界面。

既然你已经知道了这个方法,那我接下来将展示在 Ubuntu/Debian 使用终端安装 Vivaldi 的方法。
### 方式 2:借助终端,在 Ubuntu/Debian 上安装 Vivaldi
打开终端,确认你已经安装了用于 [在命令行下下载文件](https://itsfoss.com/download-files-from-linux-terminal/) 的 `wget`。
```
sudo apt install wget
```
接下来,获取 Vivaldi 仓库的公钥并添加到系统,以让系统信任该来源的软件包。如果你感兴趣的话,你可以阅读 [关于在 Ubuntu 添加第三方软件仓库的文章](https://itsfoss.com/adding-external-repositories-ubuntu/)。
```
wget -qO- https://repo.vivaldi.com/archive/linux_signing_key.pub | sudo apt-key add -
```
添加完该密钥后,再添加 Vivaldi 的仓库:
```
sudo add-apt-repository 'deb https://repo.vivaldi.com/archive/deb/ stable main'
```
现在距离完成也只有一步之遥了。更新软件仓库缓存并安装 Vivaldi。
```
sudo apt update && sudo apt install vivaldi-stable
```
大功告成。现在,前往系统菜单搜索并启动 Vivaldi 吧。
### 在 Ubuntu 中更新 Vivaldi
GUI 和命令行这两种方式都会在系统里添加 Vivaldi 的仓库。这意味着,只要 Vivaldi 发布了新版本,你就可以在系统更新中一并获取 Vivaldi 的更新。

一般情况下,你更新 Ubuntu 系统时,如果 Vivaldi 发布了新版本,那么 Vivaldi 也同时会被更新。

### 在 Ubuntu 中卸载 Vivaldi
如果你不喜欢 Vivaldi 或者不再使用,你可以直接卸载。现在,如果你想 [在 Ubuntu 中卸载软件](https://itsfoss.com/uninstall-programs-ubuntu/),你可能会想到软件中心,但软件中心不会查找到外部和第三方的软件包。
目前你必须使用终端卸载 Vivaldi,即便你是使用 GUI 方式安装的。其实这也很简单,打开终端,输入以下命令:
```
sudo apt remove vivaldi-stable
```
`sudo` 会 [在 Ubuntu 中给予你 root 权限](https://itsfoss.com/root-user-ubuntu/)。你需要输入当前账户的密码。输入密码时,你可能不会在屏幕上看见输入密码的痕迹。这是正常现象,直接输入密码即可,随后 Vivaldi 将被卸载。
希望这篇关于如何在 Linux 安装 Vivaldi 的教程对你有用。
---
via: <https://itsfoss.com/install-vivaldi-ubuntu-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Vivaldi](https://vivaldi.com/?ref=itsfoss.com) is an increasingly popular web browser. It is based on Chromium, so you have Chrome-like features, but it adds several other features to give a different, intuitive interface.
It comes with tab grouping, ad blocker, mouse gestures, and notes manager, and even allows adding macros. You could even use split viewing to view multiple pages at once. It also respects your privacy, unlike Chrome.
You can understand the popularity of this browser from the fact that [Manjaro Linux replaced Firefox with Vivaldi as the default browser](https://news.itsfoss.com/vivaldi-replaces-firefox-manjaro/?ref=itsfoss.com) in some of its variants.
Let me show you how to install Vivaldi on Linux if you want to try it.
In this tutorial, you’ll learn:
- GUI and command line methods for installing Vivaldi
- Tips on updating Vivaldi to the newest version
- Steps for removing Vivaldi from Ubuntu
- Suggestions on improving your Vivaldi experience
**Non-FOSS Warning!**Vivaldi is not completely open-source software. Its UI is closed source. It’s been covered here because the Vivaldi team made an effort to make its software available on Linux.
## Installing Vivaldi on Ubuntu [GUI Method]
The good thing is that Vivaldi provides pre-built binaries in DEB form for Ubuntu/Debian based distros and in RPM form for Fedora, Red Hat, and SUSE.
It is available for both 32 bit and 64-bit platforms and [ARM devices like Raspberry Pi](https://itsfoss.com/raspberry-pi-alternatives/).
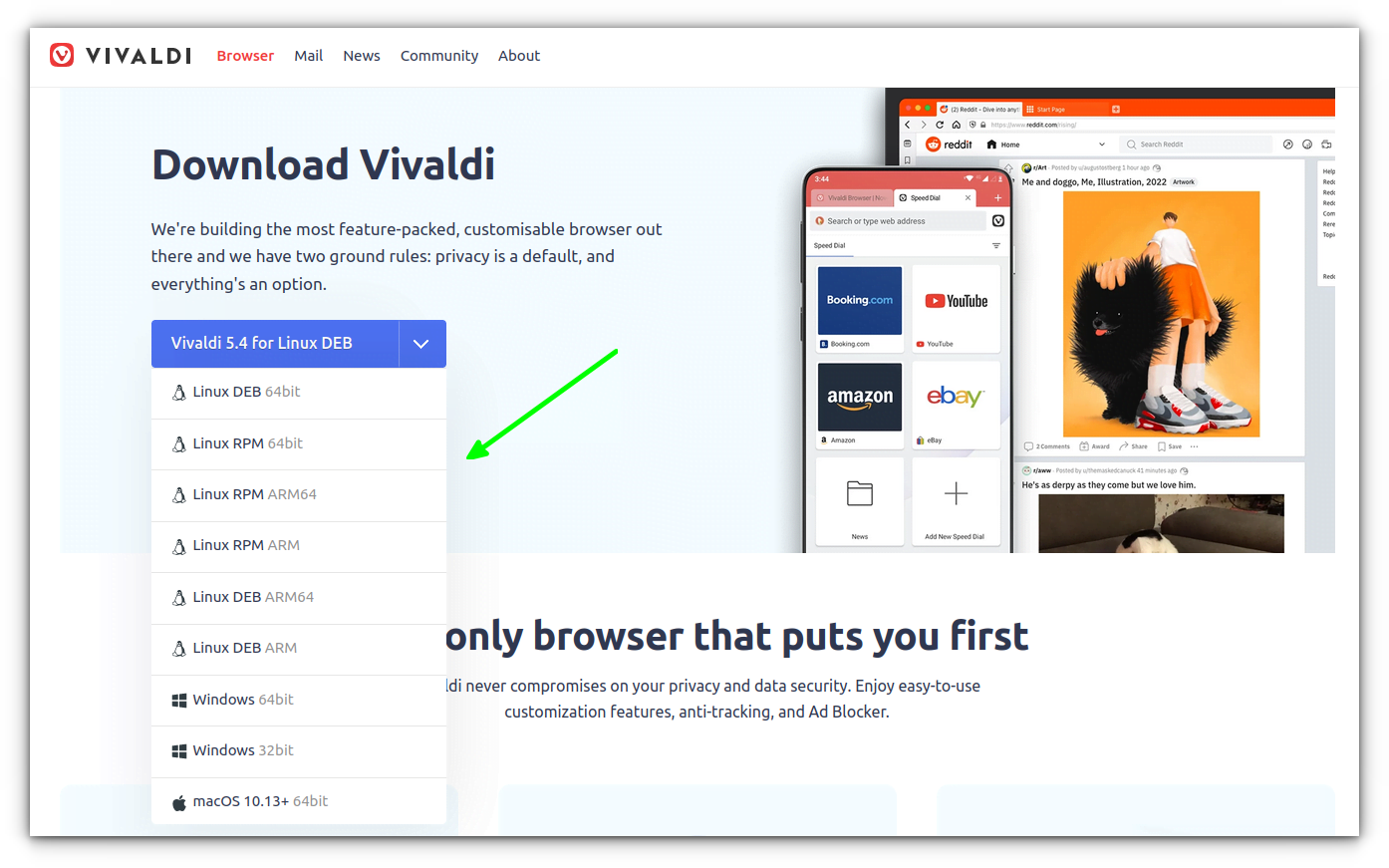
The installation process is really simple. You go to the Vivaldi web page and download the appropriate installer file and then double-click on it to install it. That’s it.
I’ll show the steps in detail for Ubuntu/Debian. You can use similar steps for other distributions.
### Step 1: Download Vivaldi
Go to Vivaldi’s download page and download the DEB file for Ubuntu.
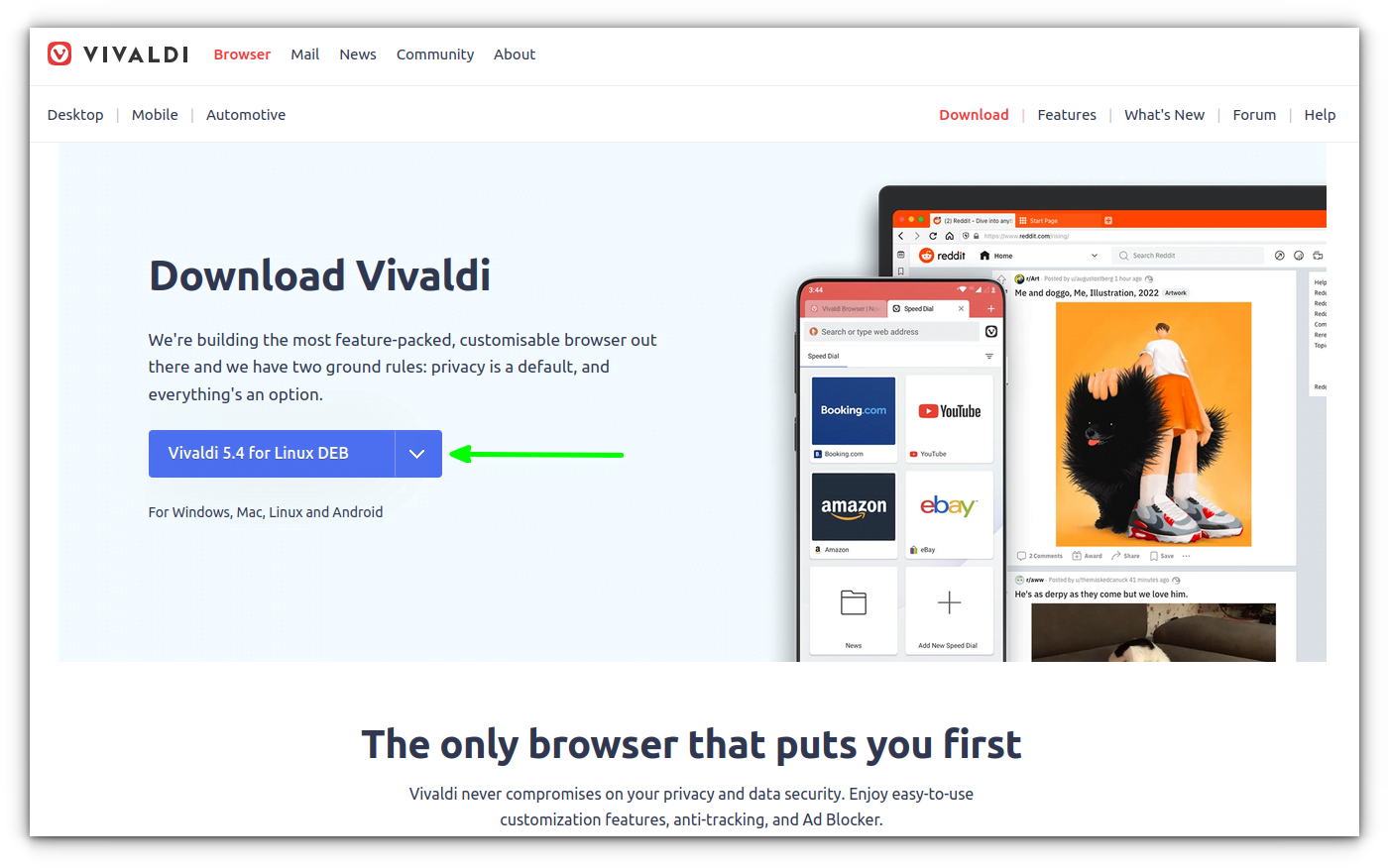
### Step 2: Install the downloaded DEB file
Go to the Downloads folder where you have the deb file downloaded. [Installing deb file](https://itsfoss.com/install-deb-files-ubuntu/) is easy. Either just double-click on it or right-click to open it with the software center. If it opens in archive manager, you can easily fix that [deb file issue in Ubuntu 22.04 or 20.04](https://itsfoss.com/cant-install-deb-file-ubuntu/).
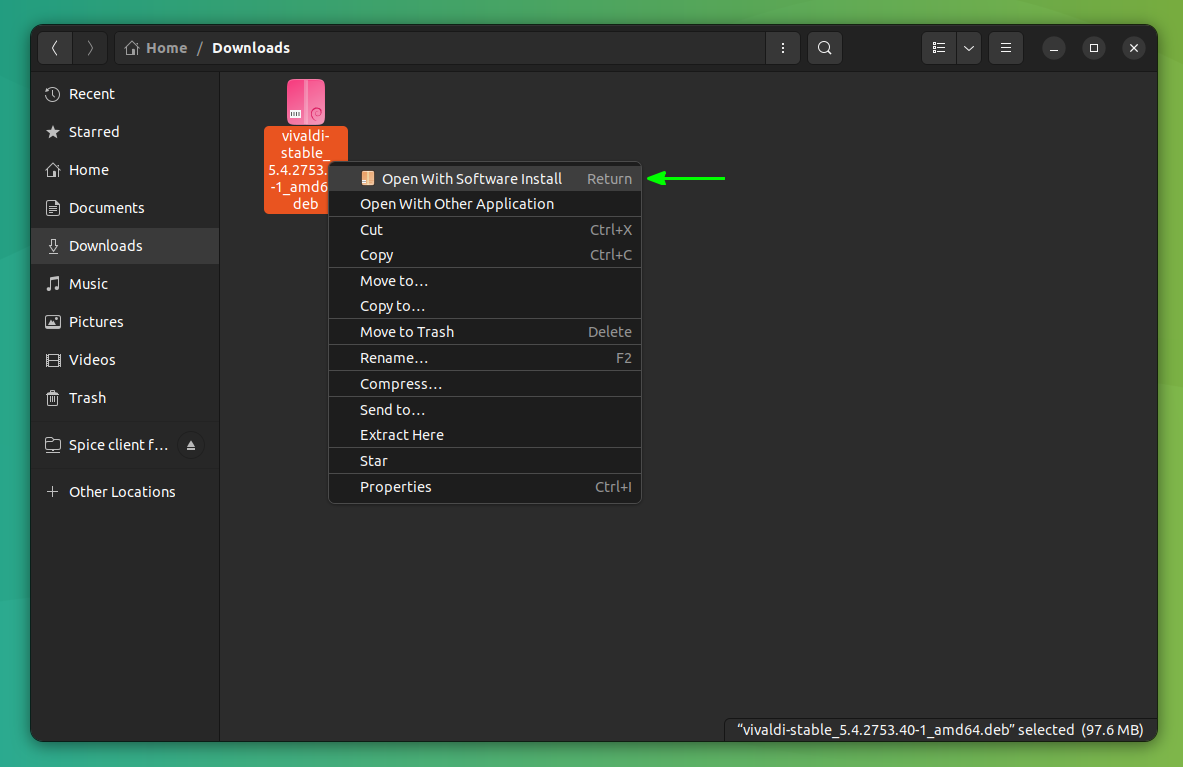
It will open the software center application and here, you can see the option to install Vivaldi. Just hit the Install button.
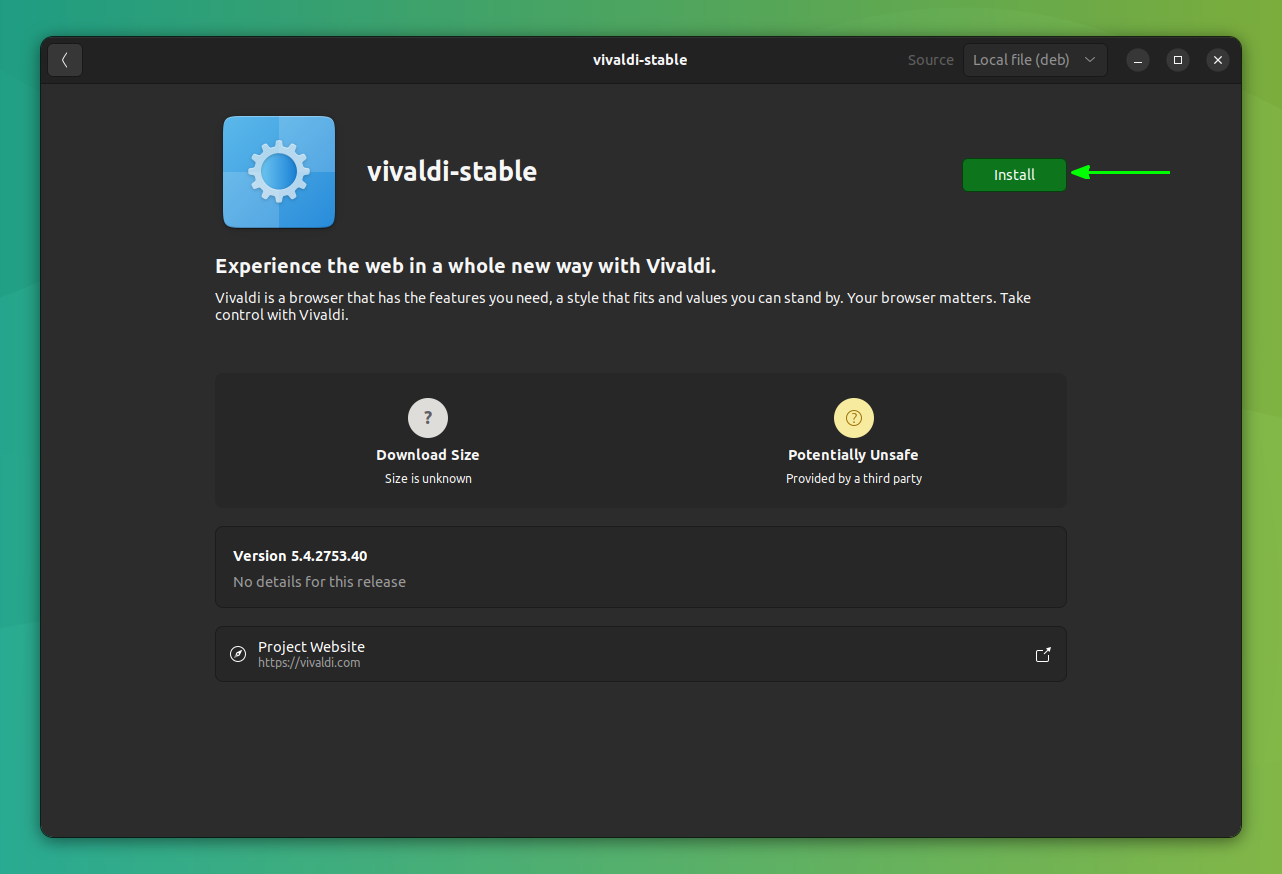
You’ll be asked to enter your system’s account password. Enter that and you should have it installed in a few seconds. You’ll see that the Install option changes to remove. This is an indication that Vivaldi is now installed.
### Step 3: Using Vivaldi
Open the system menu by pressing the super (Windows) key and searching for Vivaldi. Click on the Vivaldi icon.

You’ll see a screen like this on the first run.
Now that you know this method let me quickly show you how to install Vivaldi on Ubuntu and Debian from the terminal
## Installing Vivaldi on Ubuntu and Debian from the command line
Open a terminal and make sure that you have wget installed for [downloading files in the command line.](https://itsfoss.com/download-files-from-linux-terminal/)
`sudo apt install wget`
Next, get the public key of the Vivaldi repository and add it to your system so that your system trusts the packages coming from it. If interested, read [this article about adding external repository in Ubuntu](https://itsfoss.com/adding-external-repositories-ubuntu/).
`wget -qO- https://repo.vivaldi.com/archive/linux_signing_key.pub | gpg --dearmor | sudo dd of=/usr/share/keyrings/vivaldi-browser.gpg`
Once the key has been added, add the Vivaldi repository as well:
`echo "deb [signed-by=/usr/share/keyrings/vivaldi-browser.gpg arch=$(dpkg --print-architecture)] https://repo.vivaldi.com/archive/deb/ stable main" | sudo dd of=/etc/apt/sources.list.d/vivaldi-archive.list`
Now you are almost set. Update the package cache and install it.
`sudo apt update && sudo apt install vivaldi-stable`
And that’s it. Search for it in the menu and start it from there.
## Updating Vivaldi on Ubuntu
Both GUI and command-line methods add the Vivaldi repository to your system. This means that whenever there is a new Vivaldi release, you get it along with the system updates.
Basically, you update the Ubuntu system and it updates the Vivaldi browser if there is a new version available.
## Removing Vivaldi from Ubuntu
If you do not like Vivaldi or no longer want to use it, you can surely remove it. Now, to [uninstall applications from Ubuntu](https://itsfoss.com/uninstall-programs-ubuntu/), you may use Software Center but it may not always find the external, third-party installed software.
You’ll have to use the terminal now even though you used GUI method to install it. That’s really easy. Open a terminal and use the command below:
`sudo apt remove vivaldi-stable`
Sudo gives you [root access in Ubuntu](https://itsfoss.com/root-user-ubuntu/). You’ll have to enter your account’s password. While entering the password, nothing is seen on the screen. That’s normal. Enter the password blindly and it will be removed.
**Intermediate to advance Linux users** may also want to remove the browsing and application specific data using the command line:
```
rm -rf ~/.config/vivaldi
rm -rf ~/.cache/vivaldi
```
## Troubleshooting common issues with Vivaldi Browser
Although Vivaldi is one of the best chromium web browsers, offering huge customization, you may encounter some issues.
One of the issues is glitches in fonts on some systems. The **fonts seem overlapping**.
This issue was faced on my Fedora install of Vivaldi. This issue can sometimes be rectified by **disabling Hardware Acceleration** in Vivaldi Settings.
Now, restart the browser to take full effect.
Another issue is the **fonts and tabs may look too small on some devices**. It’s just the UI elements, the web pages are displayed normally.
If you experience this issue, you can change the “Interface zoom” settings.
## What else?
[Brave and Vivaldi](https://itsfoss.com/brave-vs-vivaldi/) are two Chrome like browsers that give you a good browsing experience.
So, you learned to install Vivaldi on Ubuntu and Debian-based distributions. You also learned about updating and removing it. And I do hope the tip about changing the hardware acceleration settings helped you to have a better Vivaldi experience.
Let me know if you have any questions or suggestions. |
13,879 | 我如何使用 Ansible 和 anacron 实现自动化 | https://opensource.com/article/21/9/ansible-anacron-automation | 2021-10-14T10:44:00 | [
"Ansible",
"自动化",
"anacron"
] | https://linux.cn/article-13879-1.html |
>
> 有了 anacron,我可以把脚本和 Ansible 剧本放到合适的地方,以完成各种琐碎的任务。
>
>
>

自动化是伟大的 IT 和 DevOps 理想,但根据我的经验,可能根本不存在什么不方便的东西。有很多次,我为某些任务想出了一个很好的解决方案,我甚至会编写脚本,但我没有让它真正实现自动化,因为在我工作的机器上不存在易于自动化的基础设施。
我最喜欢的简易自动化工具曾经是 cron 系统,它古老、可靠、面向用户,而且简单(除了一个我永远无法记住的调度语法之外)。然而,cron 的问题是,它假定一台电脑每天 24 小时都在工作。在错过了太多预定的备份之后,我发现了 [anacron](https://opensource.com/article/21/2/linux-automation),一个基于时间戳而非预定时间的 cron 系统。如果你的电脑在通常情况下运行时处于关闭状态,anacron 会确保它在电脑重新开启时运行。创建一个作业只需要简单地把一个 shell 脚本放到三个目录中:`cron.day`、`cron.weekly` 或者 `cron.monthly` (如果你想的话,你可以定义更多)。有了 anacron,我发现自己把脚本和 Ansible 剧本用在了各种琐碎的任务中,包括弹出到期和事件提醒。
这是一个现代问题的简单而明显的解决方案,但如果 anacron 没有安装在电脑上,那它对我就没有用。
### 用 Ansible 进行软件设置
任何时候我设置一台新的计算机,无论是笔记本电脑、工作站还是服务器,我都会安装 anacron。这很简单,但是 anacron 的安装只提供了 `anacron` 命令。它并没有设置 anacron 的用户环境。所以我创建了一个 Ansible 剧本来设置用户需要什么来使用 anacron 并安装 `anacron` 命令。
首先,标准的 Ansible 模板:
```
---
- hosts: localhost
tasks:
```
### 用 Ansible 创建目录
接下来,我创建了用于 Anacron 的目录树。你可以把它看成是一种透明的 crontab。
```
- name: create directory tree
ansible.builtin.file:
path: "{{ item }}"
state: directory
with_items:
- '~/.local/etc/cron.daily'
- '~/.local/etc/cron.weekly'
- '~/.local/etc/cron.monthly'
- '~/.var/spool/anacron'
```
这个语法可能看起来有点奇怪,但它实际上是一个循环。`with_items:` 指令定义了四个要创建的目录,Ansible 在 `ansible.buildin.file:` 指令中为每个目录迭代一次(目录名填充了 `{{ item }}` 变量)。与 Ansible 中的一切一样,如果目录已经存在,不会有错误或冲突。
### 用 Ansible 复制文件
`ansible.buildin.copy` 模块将文件从一个地方复制到另一个地方。为了让它工作,我需要创建一个叫做 `anacrontab` 的文件。它不是 Ansible 剧本,所以我把它放在我的 `~/Ansible/data` 目录下,那里是我的剧本的支持文件。
```
- name: copy anacrontab into place
ansible.builtin.copy:
src: ~/Ansible/data/anacrontab
dest: ~/.local/etc/anacrontab
mode: '0755'
```
我的 `anacrontab` 文件很简单,模仿了一些发行版默认安装在 `/etc/anacron` 中的文件:
```
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
1 0 cron.day run-parts $HOME/.local/etc/cron.daily/
7 0 cron.wek run-parts $HOME/.local/etc/cron.weekly/
30 0 cron.mon run-parts $HOME/.local/etc/cron.monthly/
```
### 登录时运行 anacron
大多数 Linux 发行版将 anacron 配置为从 `/etc/anacron` 读取作业。我主要是作为一个普通用户使用 anacron,所以我从我的登录账号 `~/.profile` 启动 anacron。我不想让自己记住这些配置,所以我让 Ansible 来做。我使用 `ansible.buildin.lineinfile` 模块,它会在 `~/.profile` 不存在时创建它,并插入 anacron 的启动行。
```
- name: add local anacrontab to .profile
ansible.builtin.lineinfile:
path: ~/.profile
regexp: '^/usr/sbin/anacron'
line: '/usr/sbin/anacron -t ~/.local/etc/anacrontab'
create: true
```
### 用 Ansible 安装 anacron
对于我的大多数系统来说,`dnf` 模块可以用来安装软件包,但我的工作站运行的是 Slackware(使用 `slackpkg`),有时不同的 Linux 发行版也会进入我的收藏。`ansible.buildin.package` 模块提供了一个安装软件包的通用接口,所以我把它用在这个剧本上。幸运的是,我还没有遇到一个名为 `anacron` 的仓库不是 `anacron`,所以现在,我不必考虑软件包名称的潜在差异。
这实际上是一个单独的剧本,因为软件包的安装需要权限升级,它由 `becomes: true` 指令提供。
```
- hosts: localhost
become: true
tasks:
- name: install anacron
ansible.builtin.package:
name: anacron
state: present
```
### 使用 anacron 和 Ansible 实现轻松自动化
为了用 Ansible 安装 anacron,我运行该剧本:
```
$ ansible-playbook ~/Ansible/setup-anacron.yaml
```
从此,我就可以编写 shell 脚本来执行一些琐碎但重复的任务,然后把它复制到 `~/.local/etc/cron.daily`,让它每天自动运行一次(或者大约如此)。我还为诸如 [清理下载文件夹](https://opensource.com/article/21/9/keep-folders-tidy-ansible) 之类的任务编写了 Ansible 剧本。我把我的剧本放在 `~/Ansible` 里,这是我保存 Ansible 剧本的地方,然后在 `~/.local/etc/cron.daily` 里创建一个 shell 脚本来执行这个剧本。这很简单,不费吹灰之力,而且很快成为习惯。
---
via: <https://opensource.com/article/21/9/ansible-anacron-automation>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Automation is the great IT and DevOps ideal, but in my experience, anything that's not immediately convenient may as well not exist at all. There have been many times when I've come up with a pretty good solution for some task, and I'll even script it, but I stop short of making it literally automated because the infrastructure for easy automation doesn't exist on the machine I'm working on.
My favorite easy automation tool used to be the cron system—old, reliable, user-facing, and (aside from a scheduling syntax I can never commit to memory) simple. However, the problem with cron is that it assumes a computer is on 24 hours a day, every day. After missing one too many scheduled backups, I discovered [anacron](https://opensource.com/article/21/2/linux-automation), the cron system based on timestamps rather than scheduled times. If your computer is off when a job would typically have run, anacron ensures that it's run when the computer is back on. Creating a job is as easy as dropping a shell script into one of three directories: `cron.daily`
, `cron.weekly`
, or `cron.monthly`
(you can define more if you want). With anacron, I find myself dropping scripts and Ansible playbooks into place for all manner of trivial tasks, including pop-up reminders of upcoming due dates or events.
It's a simple and obvious solution to a modern problem, but it does me no good if anacron isn't installed on the computer.
## Software setup with Ansible
Any time I set up a new computer, whether it's a laptop, workstation, or server, I install anacron. That's easy, but an anacron install only provides the anacron command. It doesn't set up the anacron user environment. So I created an Ansible playbook to set up what the user needs to use anacron and install the anacron command.
First, the standard Ansible boilerplate:
```
---
- hosts: localhost
tasks:
```
## Creating directories with Ansible
Next, I create the directory tree I use for anacron. You can think of this as a sort of transparent crontab.
```
- name: create directory tree
ansible.builtin.file:
path: "{{ item }}"
state: directory
with_items:
- '~/.local/etc/cron.daily'
- '~/.local/etc/cron.weekly'
- '~/.local/etc/cron.monthly'
- '~/.var/spool/anacron'
```
The syntax of this might seem a little strange, but it's actually a loop. The `with_items:`
directive defines four directories to create, and Ansible iterates over the `ansible.builtin.file:`
directive once for each directory (the directory name populates the `{{ item }}`
variable). As with everything in Ansible, there's no error or conflict if the directory already exists.
## Copying files with Ansible
The `ansible.builtin.copy`
module copies files from one location to another. For this to work, I needed to create a file called `anacrontab`
. It's not an Ansible playbook, so I keep it in my `~/Ansible/data`
directory, where I keep support files for my playbooks.
```
- name: copy anacrontab into place
ansible.builtin.copy:
src: ~/Ansible/data/anacrontab
dest: ~/.local/etc/anacrontab
mode: '0755'
```
My `anacrontab`
file is simple and mimics the one some distributions install by default into `/etc/anacron`
:
```
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
1 0 cron.day run-parts $HOME/.local/etc/cron.daily/
7 0 cron.wek run-parts $HOME/.local/etc/cron.weekly/
30 0 cron.mon run-parts $HOME/.local/etc/cron.monthly/
```
## Running anacron on login
Most Linux distributions configure anacron to read jobs from `/etc/anacron`
. I mostly use anacron as a regular user, so I launch anacron from my login `~/.profile`
. I don't want to have to remember to configure that myself, so I have Ansible do it. I use the `ansible.builtin.lineinfile`
module, which creates `~/.profile`
if it doesn't already exist and inserts the anacron launch line.
```
- name: add local anacrontab to .profile
ansible.builtin.lineinfile:
path: ~/.profile
regexp: '^/usr/sbin/anacron'
line: '/usr/sbin/anacron -t ~/.local/etc/anacrontab'
create: true
```
## Installing anacron with Ansible
For most of my systems, the `dnf`
module would work for package installation, but my workstation runs Slackware (which uses `slackpkg`
), and sometimes a different Linux distro makes its way into my collection. The `ansible.builtin.package`
module provides a generic interface to package installation, so I use it for this playbook. Luckily, I haven't come across a repo that names `anacron`
anything but `anacron`
, so for now, I don't have to account for potential differences in package names.
This is actually a separate play because package installation requires privilege escalation, provided by the `becomes: true`
directive.
```
- hosts: localhost
become: true
tasks:
- name: install anacron
ansible.builtin.package:
name: anacron
state: present
```
## Using anacron and Ansible for easy automation
To install anacron with Ansible, I run the playbook:
`$ ansible-playbook ~/Ansible/setup-anacron.yaml`
From then on, I can write shell scripts to perform some trivial but repetitive task and copy it into `~/.local/etc/cron.daily`
to have it automatically run once a day (or thereabouts). I also write Ansible playbooks for tasks such as [cleaning out my downloads folder](https://opensource.com/article/21/9/keep-folders-tidy-ansible). I place my playbooks in `~/Ansible`
, which is where I keep my Ansible plays, and then create a shell script in `~/.local/etc/cron.daily`
to execute the play. It's easy, painless, and quickly becomes second nature.
## Comments are closed. |
13,881 | 在 systemd 中使用控制组管理资源 | https://opensource.com/article/20/10/cgroups | 2021-10-14T11:46:31 | [
"控制组",
"systemd",
"cgroup"
] | https://linux.cn/article-13881-1.html |
>
> 控制组可以按照应用管理资源,而不是按照组成应用的单个进程。
>
>
>

作为一个系统管理员,没有事情比意外地耗尽计算资源让我更觉得沮丧。我曾不止一次填满了一个分区的所有可用磁盘空间、耗尽内存、以及没有足够的 CPU 时间在合理的时间内处理我的任务。资源管理是系统管理员最重要的工作之一。
资源管理的关键是保证所有的进程能够相对公平的访问需要的系统资源。资源管理还包括确保在需要时添加内存、硬盘驱动器空间、还有 CPU 处理能力;或者在无法添加时限制资源的使用。此外,应该阻止独占系统资源的用户,无论其是否有意。
系统管理员可以通过一些工具监控和管理不同的系统资源。例如,[top](https://en.wikipedia.org/wiki/Top_(software)) 和类似的工具允许你监控内存、I/O、存储(磁盘、SSD 等)、网络、交换空间、CPU 的用量等。这些工具,尤其是那些以 CPU 为中心的工具,大部分基于以运行的进程为基本单位进行控制的模型。它们最多只是提供了一种方式来调整 `nice` 数字,从而修改优先级,或者杀死一个运行的进程。(要了解 `nice` 数字的信息,查看 [使用 Glances 监控 Linux 和 Windows 主机](https://opensource.com/article/19/11/monitoring-linux-glances))。
SystemV 环境中基于传统的资源管理的其他工具,由 `/etc/security/limits.conf` 文件和 `/etc/security/limits.d` 中的本地配置文件控制。资源可以按照用户或组以一种相对粗糙但实用的方式限制。可以管理的资源包括内存的各个方面、每日的总 CPU 时间、数据总量、优先级、`nice` 数字、并发登录的数量、进程数、文件大小的最大值等。
### 使用控制组管理进程
[systemd 和 SystemV](https://opensource.com/article/20/4/systemd) 之间的一个主要差异是管理进程的方式。SystemV 将每个进程视作一个独立的实体。systemd 将相关的进程集中到一个控制组,简写做 [cgroup](https://en.wikipedia.org/wiki/Cgroups),并将控制组作为一个整体管理系统资源。这意味着资源能够基于应用管理,而不是由组成应用的各个进程来管理。
控制组的控制单元称作<ruby> 切片单元 <rt> slice unit </rt></ruby>。切片是允许 systemd 以树状格式控制程序次序,从而简化管理的概念化。
### 查看控制组
我将从一些允许你查看不同类型控制组信息的命令开始。 `systemctl status <service>` 命令显示一个特定服务的切片信息,包括服务的切片。这个例子展示了 `at` 守护进程:
```
[root@testvm1 ~]# systemctl status atd.service
● atd.service - Deferred execution scheduler
Loaded: loaded (/usr/lib/systemd/system/atd.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2020-09-23 12:18:24 EDT; 1 day 3h ago
Docs: man:atd(8)
Main PID: 1010 (atd)
Tasks: 1 (limit: 14760)
Memory: 440.0K
CPU: 5ms
CGroup: /system.slice/atd.service
└─1010 /usr/sbin/atd -f
Sep 23 12:18:24 testvm1.both.org systemd[1]: Started Deferred execution scheduler.
[root@testvm1 ~]#
```
这是一个我感到 systemd 比 SystemV 和旧的初始化程序更好用的原因的绝佳示例。这里的信息远比 SystemV 能够提供的丰富。`CGroup` 项包括的层级结构中,`system.slice` 是 systemd(PID 1),`atd.service` 在下一层,是 `system.slice` 的一部分。`CGroup` 项的第二行还显示了进程 ID(PID)和启动守护进程使用的命令。
`systemctl` 命令可以列出多个控制组项,`--all` 参数列出所有的切片,包括当前没有激活的切片:
```
[root@testvm1 ~]# systemctl -t slice --all
UNIT LOAD ACTIVE SUB DESCRIPTION
-.slice loaded active active Root Slice
system-getty.slice loaded active active system-getty.slice
system-lvm2\x2dpvscan.slice loaded active active system-lvm2\x2dpvscan.slice
system-modprobe.slice loaded active active system-modprobe.slice
system-sshd\x2dkeygen.slice loaded active active system-sshd\x2dkeygen.slice
system-systemd\x2dcoredump.slice loaded inactive dead system-systemd\x2dcoredump.slice
system-systemd\x2dfsck.slice loaded active active system-systemd\x2dfsck.slice
system.slice loaded active active System Slice
user-0.slice loaded active active User Slice of UID 0
user-1000.slice loaded active active User Slice of UID 1000
user.slice loaded active active User and Session Slice
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
11 loaded units listed.
To show all installed unit files use 'systemctl list-unit-files'.
[root@testvm1 ~]#
```
关于这个数据,第一个需要注意的是数据显示了 UID 0(root)和 UID 1000 的用户切片,UID 1000 是我登录的用户。这里列出了组成每个切片的切片部分,而不是服务。还说明了每个用户登录时都会为其创建一个切片,这为将一个用户的所有任务作为单个控制组项进行管理提供了一种方式。
### 探索控制组的层次结构
目前为止一切顺利,但是控制组是分层的,所有的服务单元作为其中一个控制组的成员运行。要查看这个层次结构很简单,使用一个旧命令和 systemd 的一个新命令即可。
`ps` 命令可以用于映射进程的和其所处的控制组层次。注意使用 `ps` 命令时需要指明想要的数据列。我大幅削减了下面命令的输出数量,但是试图保留足够的数据,以便你能够对自己系统上的输出有所感受:
```
[root@testvm1 ~]# ps xawf -eo pid,user,cgroup,args
PID USER CGROUP COMMAND
2 root - [kthreadd]
3 root - \_ [rcu_gp]
4 root - \_ [rcu_par_gp]
6 root - \_ [kworker/0:0H-kblockd]
9 root - \_ [mm_percpu_wq]
10 root - \_ [ksoftirqd/0]
11 root - \_ [rcu_sched]
12 root - \_ [migration/0]
13 root - \_ [cpuhp/0]
14 root - \_ [cpuhp/1]
<删节>
625406 root - \_ [kworker/3:0-ata_sff]
625409 root - \_ [kworker/u8:0-events_unbound]
1 root 0::/init.scope /usr/lib/systemd/systemd --switched-root --system --deserialize 30
588 root 0::/system.slice/systemd-jo /usr/lib/systemd/systemd-journald
599 root 0::/system.slice/systemd-ud /usr/lib/systemd/systemd-udevd
741 root 0::/system.slice/auditd.ser /sbin/auditd
743 root 0::/system.slice/auditd.ser \_ /usr/sbin/sedispatch
764 root 0::/system.slice/ModemManag /usr/sbin/ModemManager
765 root 0::/system.slice/NetworkMan /usr/sbin/NetworkManager --no-daemon
767 root 0::/system.slice/irqbalance /usr/sbin/irqbalance --foreground
779 root 0::/system.slice/mcelog.ser /usr/sbin/mcelog --ignorenodev --daemon --foreground
781 root 0::/system.slice/rngd.servi /sbin/rngd -f
782 root 0::/system.slice/rsyslog.se /usr/sbin/rsyslogd -n
<删节>
893 root 0::/system.slice/sshd.servi sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups
1130 root 0::/user.slice/user-0.slice \_ sshd: root [priv]
1147 root 0::/user.slice/user-0.slice | \_ sshd: root@pts/0
1148 root 0::/user.slice/user-0.slice | \_ -bash
1321 root 0::/user.slice/user-0.slice | \_ screen
1322 root 0::/user.slice/user-0.slice | \_ SCREEN
1323 root 0::/user.slice/user-0.slice | \_ /bin/bash
498801 root 0::/user.slice/user-0.slice | | \_ man systemd.resource-control
498813 root 0::/user.slice/user-0.slice | | \_ less
1351 root 0::/user.slice/user-0.slice | \_ /bin/bash
123293 root 0::/user.slice/user-0.slice | | \_ man systemd.slice
123305 root 0::/user.slice/user-0.slice | | \_ less
1380 root 0::/user.slice/user-0.slice | \_ /bin/bash
625412 root 0::/user.slice/user-0.slice | | \_ ps xawf -eo pid,user,cgroup,args
625413 root 0::/user.slice/user-0.slice | | \_ less
246795 root 0::/user.slice/user-0.slice | \_ /bin/bash
625338 root 0::/user.slice/user-0.slice | \_ /usr/bin/mc -P /var/tmp/mc-root/mc.pwd.246795
625340 root 0::/user.slice/user-0.slice | \_ bash -rcfile .bashrc
1218 root 0::/user.slice/user-1000.sl \_ sshd: dboth [priv]
1233 dboth 0::/user.slice/user-1000.sl \_ sshd: dboth@pts/1
1235 dboth 0::/user.slice/user-1000.sl \_ -bash
<删节>
1010 root 0::/system.slice/atd.servic /usr/sbin/atd -f
1011 root 0::/system.slice/crond.serv /usr/sbin/crond -n
1098 root 0::/system.slice/lxdm.servi /usr/sbin/lxdm-binary
1106 root 0::/system.slice/lxdm.servi \_ /usr/libexec/Xorg -background none :0 vt01 -nolisten tcp -novtswitch -auth /var/run/lxdm/lxdm-:0.auth
370621 root 0::/user.slice/user-1000.sl \_ /usr/libexec/lxdm-session
370631 dboth 0::/user.slice/user-1000.sl \_ xfce4-session
370841 dboth 0::/user.slice/user-1000.sl \_ /usr/bin/ssh-agent /bin/sh -c exec -l bash -c "/usr/bin/startxfce4"
370911 dboth 0::/user.slice/user-1000.sl \_ xfwm4 --display :0.0 --sm-client-id 2dead44ab-0b4d-4101-bca4-e6771f4a8ac2
370930 dboth 0::/user.slice/user-1000.sl \_ xfce4-panel --display :0.0 --sm-client-id 2ce38b8ef-86fd-4189-ace5-deec1d0e0952
370942 dboth 0::/user.slice/user-1000.sl | \_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libsystray.so 6 23068680 systr
ay Notification Area Area where notification icons appear
370943 dboth 0::/user.slice/user-1000.sl | \_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libpulseaudio-plugin.so 8 2306
8681 pulseaudio PulseAudio Plugin Adjust the audio volume of the PulseAudio sound system
370944 dboth 0::/user.slice/user-1000.sl | \_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libxfce4powermanager.so 9 2306
8682 power-manager-plugin Power Manager Plugin Display the battery levels of your devices and control the brightness of your display
370945 dboth 0::/user.slice/user-1000.sl | \_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libnotification-plugin.so 10 2
3068683 notification-plugin Notification Plugin Notification plugin for the Xfce panel
370948 dboth 0::/user.slice/user-1000.sl | \_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libactions.so 14 23068684 acti
ons Action Buttons Log out, lock or other system actions
370934 dboth 0::/user.slice/user-1000.sl \_ Thunar --sm-client-id 2cfc809d8-4e1d-497a-a5c5-6e4fa509c3fb --daemon
370939 dboth 0::/user.slice/user-1000.sl \_ xfdesktop --display :0.0 --sm-client-id 299be0608-4dca-4055-b4d6-55ec6e73a324
370962 dboth 0::/user.slice/user-1000.sl \_ nm-applet
<删节>
```
你可以使用 `systemd-cgls` 命令查看整个层次结构,这个命令不需要任何的复杂参数,更加简单。
我也大幅缩短了这个树状结构,但是保留了足够多的输出,以便你能够了解在自己的系统上执行这个命令时应该看到的数据总量和条目类型。我在我的一个虚拟机上执行了这个命令,输出大概有 200 行;我的主要工作站的输出大概有 250 行。
```
[root@testvm1 ~]# systemd-cgls
Control group /:
-.slice
├─user.slice
│ ├─user-0.slice
│ │ ├─session-1.scope
│ │ │ ├─ 1130 sshd: root [priv]
│ │ │ ├─ 1147 sshd: root@pts/0
│ │ │ ├─ 1148 -bash
│ │ │ ├─ 1321 screen
│ │ │ ├─ 1322 SCREEN
│ │ │ ├─ 1323 /bin/bash
│ │ │ ├─ 1351 /bin/bash
│ │ │ ├─ 1380 /bin/bash
│ │ │ ├─123293 man systemd.slice
│ │ │ ├─123305 less
│ │ │ ├─246795 /bin/bash
│ │ │ ├─371371 man systemd-cgls
│ │ │ ├─371383 less
│ │ │ ├─371469 systemd-cgls
│ │ │ └─371470 less
│ │ └─[email protected] …
│ │ ├─dbus-broker.service
│ │ │ ├─1170 /usr/bin/dbus-broker-launch --scope user
│ │ │ └─1171 dbus-broker --log 4 --controller 12 --machine-id 3bccd1140fca488187f8a1439c832f07 --max-bytes 100000000000000 --max-fds 25000000000000 --max->
│ │ ├─gvfs-daemon.service
│ │ │ └─1173 /usr/libexec/gvfsd
│ │ └─init.scope
│ │ ├─1137 /usr/lib/systemd/systemd --user
│ │ └─1138 (sd-pam)
│ └─user-1000.slice
│ ├─[email protected] …
│ │ ├─dbus\x2d:1.2\x2dorg.xfce.Xfconf.slice
│ │ │ └─dbus-:[email protected]
│ │ │ └─370748 /usr/lib64/xfce4/xfconf/xfconfd
│ │ ├─dbus\x2d:1.2\x2dca.desrt.dconf.slice
│ │ │ └─dbus-:[email protected]
│ │ │ └─371262 /usr/libexec/dconf-service
│ │ ├─dbus-broker.service
│ │ │ ├─1260 /usr/bin/dbus-broker-launch --scope user
│ │ │ └─1261 dbus-broker --log 4 --controller 11 --machine-id
<删节>
│ │ └─gvfs-mtp-volume-monitor.service
│ │ └─370987 /usr/libexec/gvfs-mtp-volume-monitor
│ ├─session-3.scope
│ │ ├─1218 sshd: dboth [priv]
│ │ ├─1233 sshd: dboth@pts/1
│ │ └─1235 -bash
│ └─session-7.scope
│ ├─370621 /usr/libexec/lxdm-session
│ ├─370631 xfce4-session
│ ├─370805 /usr/bin/VBoxClient --clipboard
│ ├─370806 /usr/bin/VBoxClient --clipboard
│ ├─370817 /usr/bin/VBoxClient --seamless
│ ├─370818 /usr/bin/VBoxClient --seamless
│ ├─370824 /usr/bin/VBoxClient --draganddrop
│ ├─370825 /usr/bin/VBoxClient --draganddrop
│ ├─370841 /usr/bin/ssh-agent /bin/sh -c exec -l bash -c "/usr/bin/startxfce4"
│ ├─370910 /bin/gpg-agent --sh --daemon --write-env-file /home/dboth/.cache/gpg-agent-info
│ ├─370911 xfwm4 --display :0.0 --sm-client-id 2dead44ab-0b4d-4101-bca4-e6771f4a8ac2
│ ├─370923 xfsettingsd --display :0.0 --sm-client-id 261b4a437-3029-461c-9551-68c2c42f4fef
│ ├─370930 xfce4-panel --display :0.0 --sm-client-id 2ce38b8ef-86fd-4189-ace5-deec1d0e0952
│ ├─370934 Thunar --sm-client-id 2cfc809d8-4e1d-497a-a5c5-6e4fa509c3fb --daemon
│ ├─370939 xfdesktop --display :0.0 --sm-client-id 299be0608-4dca-4055-b4d6-55ec6e73a324
<删节>
└─system.slice
├─rngd.service
│ └─1650 /sbin/rngd -f
├─irqbalance.service
│ └─1631 /usr/sbin/irqbalance --foreground
├─fprintd.service
│ └─303383 /usr/libexec/fprintd
├─systemd-udevd.service
│ └─956 /usr/lib/systemd/systemd-udevd
<删节>
├─systemd-journald.service
│ └─588 /usr/lib/systemd/systemd-journald
├─atd.service
│ └─1010 /usr/sbin/atd -f
├─system-dbus\x2d:1.10\x2dorg.freedesktop.problems.slice
│ └─dbus-:[email protected]
│ └─371197 /usr/sbin/abrt-dbus -t133
├─sshd.service
│ └─893 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups
├─vboxservice.service
│ └─802 /usr/sbin/VBoxService -f
├─crond.service
│ └─1011 /usr/sbin/crond -n
├─NetworkManager.service
│ └─765 /usr/sbin/NetworkManager --no-daemon
├─switcheroo-control.service
│ └─787 /usr/libexec/switcheroo-control
<删节>
```
这个树状视图显示了所有的用户和系统切片,以及每个控制组内正在运行的服务和程序。注意叫作 `scope`(范围)的单元,它将相关的程序组成一个管理单元,在上面列出的结果中就是 `user-1000.slice`。`user-1000.slice/session-7.scope` 控制组包含了 GUI 桌面程序层次结构,以 LXDM 显示管理器会话和其所有的子任务开始,包括像 Bash 命令行解释器和 Thunar GUI 文件管理器之类的程序。
配置文件中不定义范围单元,而是作为启动相关程序组的结果程序化生成的。范围单元不创建或启动作为控制组的组成部分运行的进程。范围内的所有进程都是平等的,没有内部的层次结构。一个范围的生命周期在第一个进程创建时开始,在最后一个进程销毁时结束。
在你的桌面打开多个窗口,比如终端模拟器、LibreOffice、或者任何你想打开的,然后切换到一个可用的虚拟控制台,启动类似 `top` 或 [Midnight Commander](https://midnight-commander.org/) 的程序。在主机运行 `systemd-cgls` 命令,留意整体的层次结构和范围单元。
`systemd-cgls` 命令提供的控制组层次结构表示(以及组成控制组单元的细节),比我见过的其他任何指令都要完整。和 `ps` 命令提供的输出相比,我喜欢 `systemd-cgls` 命令更简洁的树形表示。
### 来自朋友们的一点帮助
介绍完这些基础知识后,我曾计划过深入研究控制组的更多细节,以及如何使用,但是我在 [Opensource.com](http://Opensource.com) 的姐妹网站 [Enable Sysadmin](https://www.redhat.com/sysadmin/) 上发现了一系列四篇优秀文章,由 Red Hat 公司的 [Steve Ovens](https://www.redhat.com/sysadmin/users/steve-ovens) 所作。与其从头重写 Steve 的文章,我觉得倒不如通过链接到这些文章,利用他的控制组专业知识:
1. [一个 Linux 系统管理员对控制组的介绍](https://www.redhat.com/sysadmin/cgroups-part-one)
2. [如何用 CPUShares 管理控制组](https://www.redhat.com/sysadmin/cgroups-part-two)
3. [用更难的方式,手动管理控制组](https://www.redhat.com/sysadmin/cgroups-part-three)
4. [用 systemd 管理控制组](https://www.redhat.com/sysadmin/cgroups-part-four)
像我一样享受这些文章并从中汲取知识吧。
### 其他资源
互联网上充斥着大量关于 systemd 的信息,但大部分都简短生硬、愚钝、甚至令人误解。除了本文提到的资源,下面的网页提供了关于 systemd 启动更详细可靠的信息。自从我开始这一系列的文章来反映我所做的研究以来,这个的列表已经变长了。
* Fedora 项目有一个优质实用的 [systemd 指南](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html),几乎有你使用 systemd 配置、管理、维护一个 Fedora 计算机需要知道的一切。
* Fedora 项目还有一个好用的 [速查表](https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet),交叉引用了古老的 SystemV 命令和对应的 systemd 命令。
* [systemd.unit(5) 手册页](https://man7.org/linux/man-pages/man5/systemd.unit.5.html) 包含了一个不错的单元文件中各个节的列表,以及这些节的配置选项和简洁的描述。
* Red Hat 文档包含了一个 [单元文件结构](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/configuring_basic_system_settings/managing-services-with-systemd_configuring-basic-system-settings#Managing_Services_with_systemd-Unit_File_Structure) 的有用描述,还有一些其他的重要信息。
* 要获取 systemd 的详细技术信息和创立的原因,查看 [Freedesktop.org](http://Freedesktop.org) 的 [systemd 描 述](https://www.freedesktop.org/wiki/Software/systemd/)。这个使我发现过的最棒页面之一,因为其中包含了许多指向其他重要准确文档的链接。
* [Linux.com](http://Linux.com) 上 “systemd 的更多乐趣” 提供了更高级的 systemd [信息和提示](https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/)。
* 查看 [systemd.resource-control(5)](https://man7.org/linux/man-pages/man5/systemd.resource-control.5.html) 的手册页
* 查看 [*Linux 内核用户和管理员指南*](https://www.kernel.org/doc/html/latest/admin-guide/index.html) 中的 [控制组 v2 条目](https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html)。
还有一系列针对系统管理员的深度技术文章,由 systemd 的设计者和主要开发者 Lennart Poettering 所作。这些文章写于 2010 年 4 月到 2011 年 9 月之间,但在当下仍然像当时一样有 价值。关于 systemd 及其生态的许多其他优秀的作品都是基于这些文章的。
* [Rethinking PID 1](http://0pointer.de/blog/projects/systemd.html)
* [systemd for Administrators, Part I](http://0pointer.de/blog/projects/systemd-for-admins-1.html)
* [systemd for Administrators, Part II](http://0pointer.de/blog/projects/systemd-for-admins-2.html)
* [systemd for Administrators, Part III](http://0pointer.de/blog/projects/systemd-for-admins-3.html)
* [systemd for Administrators, Part IV](http://0pointer.de/blog/projects/systemd-for-admins-4.html)
* [systemd for Administrators, Part V](http://0pointer.de/blog/projects/three-levels-of-off.html)
* [systemd for Administrators, Part VI](http://0pointer.de/blog/projects/changing-roots)
* [systemd for Administrators, Part VII](http://0pointer.de/blog/projects/blame-game.html)
* [systemd for Administrators, Part VIII](http://0pointer.de/blog/projects/the-new-configuration-files.html)
* [systemd for Administrators, Part IX](http://0pointer.de/blog/projects/on-etc-sysinit.html)
* [systemd for Administrators, Part X](http://0pointer.de/blog/projects/instances.html)
* [systemd for Administrators, Part XI](http://0pointer.de/blog/projects/inetd.html)
---
via: <https://opensource.com/article/20/10/cgroups>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[YungeG](https://github.com/YungeG) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There is little more frustrating to me as a sysadmin than unexpectedly running out of a computing resource. On more than one occasion, I have filled all available disk space in a partition, run out of RAM, and not had enough CPU time to perform my tasks in a reasonable amount of time. Resource management is one of the most important tasks that sysadmins do.
The point of resource management is to ensure that all processes have relatively equal access to the system resources they need. Resource management also involves ensuring that RAM, hard drive space, and CPU capacity are added when necessary or rationed when that is not possible. In addition, users who hog system resources, whether intentionally or accidentally, should be prevented from doing so.
There are tools that enable sysadmins to monitor and manage various system resources. For example, [top](https://en.wikipedia.org/wiki/Top_(software)) and similar tools allow you to monitor the use of memory, I/O, storage (disk, SSD, etc.), network, swap space, CPU usage, and more. These tools, particularly those that are CPU-centric, are mostly based on the paradigm that the running process is the unit of control. At best, they provide a way to adjust the nice number–and through that, the priority—or to kill a running process. (For information about nice numbers, see [ Monitoring Linux and Windows hosts with Glances](https://opensource.com/article/19/11/monitoring-linux-glances).)
Other tools based on traditional resource management in a SystemV environment are managed by the `/etc/security/limits.conf`
file and the local configuration files located in the `/etc/security/limits.d`
directory. Resources can be limited in a fairly crude but useful manner by user or group. Resources that can be managed include various aspects of RAM, total CPU time per day, total amount of data, priority, nice number, number of concurrent logins, number of processes, maximum file size, and more.
## Using cgroups for process management
One major difference between [systemd and SystemV](https://opensource.com/article/20/4/systemd) is how they handle processes. SystemV treats each process as an entity unto itself. systemd collects related processes into control groups, called [cgroups](https://en.wikipedia.org/wiki/Cgroups) (short for control groups), and manages system resources for the cgroup as a whole. This means resources can be managed per application rather than by the individual processes that make up an application.
The control units for cgroups are called slice units. Slices are a conceptualization that allows systemd to order processes in a tree format for ease of management.
## Viewing cgroups
I'll start with some commands that allow you to view various types of information about cgroups. The `systemctl status <service>`
command displays slice information about a specified service, including its slice. This example shows the `at`
daemon:
```
[root@testvm1 ~]# systemctl status atd.service
● atd.service - Deferred execution scheduler
Loaded: loaded (/usr/lib/systemd/system/atd.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2020-09-23 12:18:24 EDT; 1 day 3h ago
Docs: man:atd(8)
Main PID: 1010 (atd)
Tasks: 1 (limit: 14760)
Memory: 440.0K
CPU: 5ms
CGroup: /system.slice/atd.service
└─1010 /usr/sbin/atd -f
Sep 23 12:18:24 testvm1.both.org systemd[1]: Started Deferred execution scheduler.
[root@testvm1 ~]#
```
This is an excellent example of one reason that I find systemd more usable than SystemV and the old init program. There is so much more information here than SystemV could provide. The cgroup entry includes the hierarchical structure where the `system.slice`
is systemd (PID 1), and the `atd.service`
is one level below and part of the `system.slice`
. The second line of the cgroup entry also shows the process ID (PID) and the command used to start the daemon.
The `systemctl`
command shows multiple cgroup entries. The `--all`
option shows all slices, including those that are not currently active:
```
[root@testvm1 ~]# systemctl -t slice --all
UNIT LOAD ACTIVE SUB DESCRIPTION
-.slice loaded active active Root Slice
system-getty.slice loaded active active system-getty.slice
system-lvm2\x2dpvscan.slice loaded active active system-lvm2\x2dpvscan.slice
system-modprobe.slice loaded active active system-modprobe.slice
system-sshd\x2dkeygen.slice loaded active active system-sshd\x2dkeygen.slice
system-systemd\x2dcoredump.slice loaded inactive dead system-systemd\x2dcoredump.slice
system-systemd\x2dfsck.slice loaded active active system-systemd\x2dfsck.slice
system.slice loaded active active System Slice
user-0.slice loaded active active User Slice of UID 0
user-1000.slice loaded active active User Slice of UID 1000
user.slice loaded active active User and Session Slice
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
11 loaded units listed.
To show all installed unit files use 'systemctl list-unit-files'.
[root@testvm1 ~]#
```
The first thing to notice about this data is that it shows user slices for UIDs 0 (root) and 1000, which is my user login. This shows only the slices and not the services that are part of each slice. This data shows that a slice is created for each user at the time they log in. This can provide a way to manage all of a user's tasks as a single cgroup entity.
## Explore the cgroup hierarchy
All is well and good so far, but cgroups are hierarchical, and all of the service units run as members of one of the cgroups. Viewing that hierarchy is easy and uses one old command and one new one that is part of systemd.
The `ps`
command can be used to map the processes and their locations in the cgroup hierarchy. Note that it is necessary to specify the desired data columns when using the `ps`
command. I significantly reduced the volume of output from this command below, but I tried to leave enough so you can get a feel for what you might find on your systems:
```
[root@testvm1 ~]# ps xawf -eo pid,user,cgroup,args
PID USER CGROUP COMMAND
2 root - [kthreadd]
3 root - \_ [rcu_gp]
4 root - \_ [rcu_par_gp]
6 root - \_ [kworker/0:0H-kblockd]
9 root - \_ [mm_percpu_wq]
10 root - \_ [ksoftirqd/0]
11 root - \_ [rcu_sched]
12 root - \_ [migration/0]
13 root - \_ [cpuhp/0]
14 root - \_ [cpuhp/1]
<SNIP>
625406 root - \_ [kworker/3:0-ata_sff]
625409 root - \_ [kworker/u8:0-events_unbound]
1 root 0::/init.scope /usr/lib/systemd/systemd --switched-root --system --deserialize 30
588 root 0::/system.slice/systemd-jo /usr/lib/systemd/systemd-journald
599 root 0::/system.slice/systemd-ud /usr/lib/systemd/systemd-udevd
741 root 0::/system.slice/auditd.ser /sbin/auditd
743 root 0::/system.slice/auditd.ser \_ /usr/sbin/sedispatch
764 root 0::/system.slice/ModemManag /usr/sbin/ModemManager
765 root 0::/system.slice/NetworkMan /usr/sbin/NetworkManager --no-daemon
767 root 0::/system.slice/irqbalance /usr/sbin/irqbalance --foreground
779 root 0::/system.slice/mcelog.ser /usr/sbin/mcelog --ignorenodev --daemon --foreground
781 root 0::/system.slice/rngd.servi /sbin/rngd -f
782 root 0::/system.slice/rsyslog.se /usr/sbin/rsyslogd -n
<SNIP>
893 root 0::/system.slice/sshd.servi sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups
1130 root 0::/user.slice/user-0.slice \_ sshd: root [priv]
1147 root 0::/user.slice/user-0.slice | \_ sshd: root@pts/0
1148 root 0::/user.slice/user-0.slice | \_ -bash
1321 root 0::/user.slice/user-0.slice | \_ screen
1322 root 0::/user.slice/user-0.slice | \_ SCREEN
1323 root 0::/user.slice/user-0.slice | \_ /bin/bash
498801 root 0::/user.slice/user-0.slice | | \_ man systemd.resource-control
498813 root 0::/user.slice/user-0.slice | | \_ less
1351 root 0::/user.slice/user-0.slice | \_ /bin/bash
123293 root 0::/user.slice/user-0.slice | | \_ man systemd.slice
123305 root 0::/user.slice/user-0.slice | | \_ less
1380 root 0::/user.slice/user-0.slice | \_ /bin/bash
625412 root 0::/user.slice/user-0.slice | | \_ ps xawf -eo pid,user,cgroup,args
625413 root 0::/user.slice/user-0.slice | | \_ less
246795 root 0::/user.slice/user-0.slice | \_ /bin/bash
625338 root 0::/user.slice/user-0.slice | \_ /usr/bin/mc -P /var/tmp/mc-root/mc.pwd.246795
625340 root 0::/user.slice/user-0.slice | \_ bash -rcfile .bashrc
1218 root 0::/user.slice/user-1000.sl \_ sshd: dboth [priv]
1233 dboth 0::/user.slice/user-1000.sl \_ sshd: dboth@pts/1
1235 dboth 0::/user.slice/user-1000.sl \_ -bash
<SNIP>
1010 root 0::/system.slice/atd.servic /usr/sbin/atd -f
1011 root 0::/system.slice/crond.serv /usr/sbin/crond -n
1098 root 0::/system.slice/lxdm.servi /usr/sbin/lxdm-binary
1106 root 0::/system.slice/lxdm.servi \_ /usr/libexec/Xorg -background none :0 vt01 -nolisten tcp -novtswitch -auth /var/run/lxdm/lxdm-:0.auth
370621 root 0::/user.slice/user-1000.sl \_ /usr/libexec/lxdm-session
370631 dboth 0::/user.slice/user-1000.sl \_ xfce4-session
370841 dboth 0::/user.slice/user-1000.sl \_ /usr/bin/ssh-agent /bin/sh -c exec -l bash -c "/usr/bin/startxfce4"
370911 dboth 0::/user.slice/user-1000.sl \_ xfwm4 --display :0.0 --sm-client-id 2dead44ab-0b4d-4101-bca4-e6771f4a8ac2
370930 dboth 0::/user.slice/user-1000.sl \_ xfce4-panel --display :0.0 --sm-client-id 2ce38b8ef-86fd-4189-ace5-deec1d0e0952
370942 dboth 0::/user.slice/user-1000.sl | \_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libsystray.so 6 23068680 systr
ay Notification Area Area where notification icons appear
370943 dboth 0::/user.slice/user-1000.sl | \_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libpulseaudio-plugin.so 8 2306
8681 pulseaudio PulseAudio Plugin Adjust the audio volume of the PulseAudio sound system
370944 dboth 0::/user.slice/user-1000.sl | \_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libxfce4powermanager.so 9 2306
8682 power-manager-plugin Power Manager Plugin Display the battery levels of your devices and control the brightness of your display
370945 dboth 0::/user.slice/user-1000.sl | \_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libnotification-plugin.so 10 2
3068683 notification-plugin Notification Plugin Notification plugin for the Xfce panel
370948 dboth 0::/user.slice/user-1000.sl | \_ /usr/lib64/xfce4/panel/wrapper-2.0 /usr/lib64/xfce4/panel/plugins/libactions.so 14 23068684 acti
ons Action Buttons Log out, lock or other system actions
370934 dboth 0::/user.slice/user-1000.sl \_ Thunar --sm-client-id 2cfc809d8-4e1d-497a-a5c5-6e4fa509c3fb --daemon
370939 dboth 0::/user.slice/user-1000.sl \_ xfdesktop --display :0.0 --sm-client-id 299be0608-4dca-4055-b4d6-55ec6e73a324
370962 dboth 0::/user.slice/user-1000.sl \_ nm-applet
<SNIP>
```
You can view the entire hierarchy with the `systemd-cgls`
command, which is a bit simpler because it does not require any complex options.
I have shortened this tree view considerably. as well, but I left enough to give you some idea of the amount of data as well as the types of entries you should see when you do this on your system. I did this on one of my virtual machines, and it is about 200 lines long; the amount of data from my primary workstation is about 250 lines:
```
[root@testvm1 ~]# systemd-cgls
Control group /:
-.slice
├─user.slice
│ ├─user-0.slice
│ │ ├─session-1.scope
│ │ │ ├─ 1130 sshd: root [priv]
│ │ │ ├─ 1147 sshd: root@pts/0
│ │ │ ├─ 1148 -bash
│ │ │ ├─ 1321 screen
│ │ │ ├─ 1322 SCREEN
│ │ │ ├─ 1323 /bin/bash
│ │ │ ├─ 1351 /bin/bash
│ │ │ ├─ 1380 /bin/bash
│ │ │ ├─123293 man systemd.slice
│ │ │ ├─123305 less
│ │ │ ├─246795 /bin/bash
│ │ │ ├─371371 man systemd-cgls
│ │ │ ├─371383 less
│ │ │ ├─371469 systemd-cgls
│ │ │ └─371470 less
│ │ └─[email protected] …
│ │ ├─dbus-broker.service
│ │ │ ├─1170 /usr/bin/dbus-broker-launch --scope user
│ │ │ └─1171 dbus-broker --log 4 --controller 12 --machine-id 3bccd1140fca488187f8a1439c832f07 --max-bytes 100000000000000 --max-fds 25000000000000 --max->
│ │ ├─gvfs-daemon.service
│ │ │ └─1173 /usr/libexec/gvfsd
│ │ └─init.scope
│ │ ├─1137 /usr/lib/systemd/systemd --user
│ │ └─1138 (sd-pam)
│ └─user-1000.slice
│ ├─[email protected] …
│ │ ├─dbus\x2d:1.2\x2dorg.xfce.Xfconf.slice
│ │ │ └─dbus-:[email protected]
│ │ │ └─370748 /usr/lib64/xfce4/xfconf/xfconfd
│ │ ├─dbus\x2d:1.2\x2dca.desrt.dconf.slice
│ │ │ └─dbus-:[email protected]
│ │ │ └─371262 /usr/libexec/dconf-service
│ │ ├─dbus-broker.service
│ │ │ ├─1260 /usr/bin/dbus-broker-launch --scope user
│ │ │ └─1261 dbus-broker --log 4 --controller 11 --machine-id
<SNIP>
│ │ └─gvfs-mtp-volume-monitor.service
│ │ └─370987 /usr/libexec/gvfs-mtp-volume-monitor
│ ├─session-3.scope
│ │ ├─1218 sshd: dboth [priv]
│ │ ├─1233 sshd: dboth@pts/1
│ │ └─1235 -bash
│ └─session-7.scope
│ ├─370621 /usr/libexec/lxdm-session
│ ├─370631 xfce4-session
│ ├─370805 /usr/bin/VBoxClient --clipboard
│ ├─370806 /usr/bin/VBoxClient --clipboard
│ ├─370817 /usr/bin/VBoxClient --seamless
│ ├─370818 /usr/bin/VBoxClient --seamless
│ ├─370824 /usr/bin/VBoxClient --draganddrop
│ ├─370825 /usr/bin/VBoxClient --draganddrop
│ ├─370841 /usr/bin/ssh-agent /bin/sh -c exec -l bash -c "/usr/bin/startxfce4"
│ ├─370910 /bin/gpg-agent --sh --daemon --write-env-file /home/dboth/.cache/gpg-agent-info
│ ├─370911 xfwm4 --display :0.0 --sm-client-id 2dead44ab-0b4d-4101-bca4-e6771f4a8ac2
│ ├─370923 xfsettingsd --display :0.0 --sm-client-id 261b4a437-3029-461c-9551-68c2c42f4fef
│ ├─370930 xfce4-panel --display :0.0 --sm-client-id 2ce38b8ef-86fd-4189-ace5-deec1d0e0952
│ ├─370934 Thunar --sm-client-id 2cfc809d8-4e1d-497a-a5c5-6e4fa509c3fb --daemon
│ ├─370939 xfdesktop --display :0.0 --sm-client-id 299be0608-4dca-4055-b4d6-55ec6e73a324
<SNIP>
└─system.slice
├─rngd.service
│ └─1650 /sbin/rngd -f
├─irqbalance.service
│ └─1631 /usr/sbin/irqbalance --foreground
├─fprintd.service
│ └─303383 /usr/libexec/fprintd
├─systemd-udevd.service
│ └─956 /usr/lib/systemd/systemd-udevd
<SNIP>
├─systemd-journald.service
│ └─588 /usr/lib/systemd/systemd-journald
├─atd.service
│ └─1010 /usr/sbin/atd -f
├─system-dbus\x2d:1.10\x2dorg.freedesktop.problems.slice
│ └─dbus-:[email protected]
│ └─371197 /usr/sbin/abrt-dbus -t133
├─sshd.service
│ └─893 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups
├─vboxservice.service
│ └─802 /usr/sbin/VBoxService -f
├─crond.service
│ └─1011 /usr/sbin/crond -n
├─NetworkManager.service
│ └─765 /usr/sbin/NetworkManager --no-daemon
├─switcheroo-control.service
│ └─787 /usr/libexec/switcheroo-control
<SNIP>
```
This tree view shows all of the user and system slices and the services and programs running in each cgroup. Notice the units called "scopes," which group related programs into a management unit, within the `user-1000.slice`
in the listing above. The `user-1000.slice/session-7.scope`
cgroup contains the GUI desktop program hierarchy, starting with the LXDM display manager session and all of its subtasks, including things like the Bash shell and the Thunar GUI file manager.
Scope units are not defined in configuration files but are generated programmatically as the result of starting groups of related programs. Scope units do not create or start the processes running as part of that cgroup. All processes within the scope are equal, and there is no internal hierarchy. The life of a scope begins when the first process is created and ends when the last process is destroyed.
Open several windows on your desktop, such as terminal emulators, LibreOffice, or whatever you want, then switch to an available virtual console and start something like `top`
or [Midnight Commander](https://midnight-commander.org/). Run the `systemd-cgls`
command on your host, and take note of the overall hierarchy and the scope units.
The `systemd-cgls`
command provides a more complete representation of the cgroup hierarchy (and details of the units that make it up) than any other command I have found. I prefer its cleaner representation of the tree than what the `ps`
command provides.
## With a little help from my friends
After covering these basics, I had planned to go into more detail about cgroups and how to use them, but I discovered a series of four excellent articles by Red Hat's [Steve Ovens](https://www.redhat.com/sysadmin/users/steve-ovens) on Opensource.com's sister site [Enable Sysadmin](https://www.redhat.com/sysadmin/). Rather then basically rewriting Steve's articles, I decided it would be much better to take advantage of his cgroup expertise by linking to them:
[A Linux sysadmin's introduction to cgroups](https://www.redhat.com/sysadmin/cgroups-part-one)[How to manage cgroups with CPUShares](https://www.redhat.com/sysadmin/cgroups-part-two)[Managing cgroups the hard way—manually](https://www.redhat.com/sysadmin/cgroups-part-three)[Managing cgroups with systemd](https://www.redhat.com/sysadmin/cgroups-part-four)
Enjoy and learn from them, as I did.
## Other resources
There is a great deal of information about systemd available on the internet, but much is terse, obtuse, or even misleading. In addition to the resources mentioned in this article, the following webpages offer more detailed and reliable information about systemd startup. This list has grown since I started this series of articles to reflect the research I have done.
- The Fedora Project has a good, practical
[guide](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html)[to systemd](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html). It has pretty much everything you need to know in order to configure, manage, and maintain a Fedora computer using systemd. - The Fedora Project also has a good
[cheat sheet](https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet)that cross-references the old SystemV commands to comparable systemd ones. - The
[systemd.unit(5) manual page](https://man7.org/linux/man-pages/man5/systemd.unit.5.html)contains a nice list of unit file sections and their configuration options along with concise descriptions of each. - Red Hat documentation contains a good description of the
[Unit file structure](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/configuring_basic_system_settings/managing-services-with-systemd_configuring-basic-system-settings#Managing_Services_with_systemd-Unit_File_Structure)as well as other important information. - For detailed technical information about systemd and the reasons for creating it, check out Freedesktop.org's
[description of systemd](https://www.freedesktop.org/wiki/Software/systemd/). This page is one of the best I have found because it contains many links to other important and accurate documentation. - Linux.com's "More systemd fun" offers more advanced systemd
[information and tips](https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/). - See the man page for
[systemd.resource-control(5)](https://man7.org/linux/man-pages/man5/systemd.resource-control.5.html). - In
, see the*The Linux kernel user's and administrator's guide*[Control Group v2](https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html)entry.
There is also a series of deeply technical articles for Linux sysadmins by Lennart Poettering, the designer and primary developer of systemd. These articles were written between April 2010 and September 2011, but they are just as relevant now as they were then. Much of everything else good that has been written about systemd and its ecosystem is based on these papers.
[Rethinking PID 1](http://0pointer.de/blog/projects/systemd.html)[systemd for Administrators, Part I](http://0pointer.de/blog/projects/systemd-for-admins-1.html)[systemd for Administrators, Part II](http://0pointer.de/blog/projects/systemd-for-admins-2.html)[systemd for Administrators, Part III](http://0pointer.de/blog/projects/systemd-for-admins-3.html)[systemd for Administrators, Part IV](http://0pointer.de/blog/projects/systemd-for-admins-4.html)[systemd for Administrators, Part V](http://0pointer.de/blog/projects/three-levels-of-off.html)[systemd for Administrators, Part VI](http://0pointer.de/blog/projects/changing-roots)[systemd for Administrators, Part VII](http://0pointer.de/blog/projects/blame-game.html)[systemd for Administrators, Part VIII](http://0pointer.de/blog/projects/the-new-configuration-files.html)[systemd for Administrators, Part IX](http://0pointer.de/blog/projects/on-etc-sysinit.html)[systemd for Administrators, Part X](http://0pointer.de/blog/projects/instances.html)[systemd for Administrators, Part XI](http://0pointer.de/blog/projects/inetd.html)
## Comments are closed. |
13,884 | Seahorse:在 Linux 中管理你的密码和加密密钥 | https://itsfoss.com/seahorse/ | 2021-10-15T12:04:15 | [
"Seahorse",
"密码"
] | https://linux.cn/article-13884-1.html |
>
> Seahorse 是一个简洁的开源密码和加密密钥管理器,让我们来探讨一下它的功能和如何安装它。
>
>
>

我们经常倾向于忽视许多默认/预装的应用,尤其是在内置了大量工具和实用程序时。
你可以在各种 Linux 发行版上使用的这样一个有用的工具是 **GNOME 的 Seahorse**。
### Seahorse:GNOME 的密码及加密密钥管理器

主要来说,Seahorse 是一个预装在 GNOME 桌面的应用,并为其量身定做。
然而,你可以在你选择的任何 Linux 发行版上使用它。它是一个简单而有效的工具,可以在本地管理你的密码和加密密钥/钥匙环。
如果你是第一次使用,你可能想读一下 [Linux 中钥匙环的概念](https://itsfoss.com/ubuntu-keyring/)。
如果你不喜欢基于云的密码管理器,Seahorse 可以很好地解决你的要求。尽管它看起来很简单,但有几个基本功能你可能会觉得很有用。
当然,如果你的不太涉及管理加密密钥(或本地存储),你也应该探索一些 [可用于 Linux 的最佳密码管理器](https://itsfoss.com/password-managers-linux/) 。
### Seahorse 的特点
虽然你可以很容易地把它作为一个本地(离线)密码管理器,但在处理加密密钥时,你也可以用 Seahorse 做一些事情来加强你的安全管理。

一些关键的亮点是:
* 能够存储 SSH 密钥(用于访问远程计算机/服务器)
* 存储用于保护电子邮件和文件的 GPG 密钥
* 支持为应用和网络添加密码钥匙环
* 安全地存储证书的私钥
* 存储一个密码/密语
* 能够导入文件并快速存储它们
* 查找远程密钥
* 同步和发布密钥
* 能够查找/复制 VPN 密码

### 在 Linux 中安装 Seahorse
如果你使用的是基于 GNOME 的发行版,你应该已经安装了它。你可以搜索 “Seahorse” 或者 “Passwords” 来找到它。
在其他情况下,你可以在软件中心搜索到它。根据我的快速测试,它在 KDE、LXQt 和不同的桌面环境下应该可以正常工作。

此外,你可以找到它的 [Flatpak 包](https://www.flathub.org/apps/details/org.gnome.seahorse.Application)。所以,无论你使用的是哪种 Linux 发行版,都可以安装 Seahorse。
如果你使用的是 Arch Linux,你也应该在 [AUR](https://itsfoss.com/aur-arch-linux/) 中找到它。
* [Seahorse](https://wiki.gnome.org/Apps/Seahorse/)
你对使用 Seahorse 来取代其他密码管理器有何看法?你是否已经用它来管理加密密钥?请在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/seahorse/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief:**A simple open-source password and encryption key manager app, let’s explore what it has to offer and how you can get it installed.*
We often tend to ignore many default/pre-installed applications, especially when numerous tools and utilities are baked in.
One such helpful tool that you can use on various Linux distributions is **GNOME’s Seahorse**.
## Seahorse: GNOME’s Password & Encryption Key Manager
Primarily, Seahorse is an application that comes pre-installed with GNOME desktop and tailored for the same.
However, you can use it on just about any Linux distribution of your choice. It is a simple and effective utility to manage your passwords and encryption keys / keyring locally.
You might want to read about the [concept of keyring in Linux](https://itsfoss.com/ubuntu-keyring/) if it’s a first for you.
If you are not a fan of cloud-based password managers, Seahorse can be a great solution to your requirements. Even though it looks straightforward, there are a few essential features that you may find useful.
Of course, you should also explore some of the [best password managers available for Linux](https://itsfoss.com/password-managers-linux/) if your priority doesn’t involve managing encryption keys (or local storage).
## Features of Seahorse
While you can easily use it as a local (offline) password manager, there are a couple of things that you can do with Seahorse to step up your security management when dealing with encryption keys as well.
Some key highlights are:
- Ability to store Secure Shell key (used to access remote computers/servers)
- Store GPG keys used to secure emails and files
- Supports adding password keyring for application and networks
- Securely store private key of a certificate
- Store a password / secret phrase
- Ability to import files and quickly store them
- Find remote keys
- Sync and publish keys
- Ability to find/copy VPN password
## Installing Seahorse in Linux
If you are using a GNOME-based distribution, you should already have it installed. You need to look for “Seahorse” or “Passwords” to find it.
In other cases, you can search for it in the software center. It should work fine with KDE, LXQt, and different desktop environments as per my quick tests.
Moreover, you can find its [Flatpak package](https://www.flathub.org/apps/details/org.gnome.seahorse.Application) available. So, no matter the Linux distribution you are using, Seahorse can be installed.
If you are using Arch Linux, you should also find it in [AUR](https://itsfoss.com/aur-arch-linux/).
What do you think about using Seahorse to replace other password managers? Were you already using it to manage encryption keys? Let me know your thoughts in the comments below. |
13,885 | 纪念 25 周年:KDE Plasma 5.23 发布 | https://news.itsfoss.com/kde-plasma-5-23-release/ | 2021-10-15T13:40:00 | [
"KDE"
] | https://linux.cn/article-13885-1.html | 
多年来,KDE Plasma 一直是最常用的桌面环境之一。这是因为它似乎有无穷无尽的定制选项、华丽的外观和有料的更新。
随着 KDE Plasma 5.23 的发布,这个桌面环境已经工作了 25 年。因此,这个版本也被称为 “Plasma 25 周年版”。
让我们回想一下,1996 年 10 月 14 日,KDE 的创始人 Matthias Ettrich [向一个新闻组](https://groups.google.com/g/de.comp.os.linux.misc/c/SDbiV3Iat_s/m/zv_D_2ctS8sJ?pli=1) 发出了呼唤,为他的 “<ruby> Kool 桌面环境 <rt> Kool Desktop Environment </rt></ruby>(KDE)” 项目寻求其他程序员的帮助。
而你看,KDE 现在呢?
在这次更新中,我们可以看到包括 Plasma 内部和第三方应用程序在内的一些重大 UI 改进。
### KDE Plasma 5.23: 有什么新东西?
这次更新带来了许多改进,包括:
* 桌面重点颜色
* 新的 Breeze 主题
* 新的电源管理快速控制
* 应用程序启动器有更多的自定义选项
* 数以百计的错误修复
在这里,我们将看到所有这些新的改进:
#### 桌面重点颜色

在系统设置中,你会发现有一个可以改变你的桌面重点颜色的选项,你可以选择一个你喜欢的自定义颜色或与默认应用的主题相融合的颜色。
#### 新的 Breeze 主题

这次更新带来了全新的 Breeze 主题:Breeze - Blue Ocean。默认主题经过多年的改进,这一次,它侧重于使视觉效果更加清晰和易于识别。
总的来说,新的主题提供了顺滑的外观。除了主题之外,图标也变得更加突出;增加了一个加载齿轮图标。而且,许许多多这样的细微变化已经进入了 KDE Plasma 5.23,以增强桌面的外观和感觉。
正如开发者 Nate Graham 在测试版发布时所说:
>
> 还有很多时间可以根据需要调整最终的外观,但总的来说,我认为它真的很棒了,我希望你和我一样喜欢它。
>
>
>
#### 系统设置中增强的搜索功能
为了更容易找到你要找的东西,KDE Plasma 5.23 增加了更多的关键词组合,以使你使用搜索栏寻找时可以快速提示你相关设置。
#### 系统托盘的改进

虽然系统托盘已经提供了许多控制,但现在监控你连接的网络以及访问剪贴板有了更精细的选项。
系统托盘也改进了显示正在播放的活动媒体时的整体外观。
#### 新的电源管理快速控制
随着 Linux 5.12 的发布,增加了一个电源管理功能。现在,KDE 引入了一种简单的调整方式,它出现在新的快速控制中。
它有三个选项:节电、平衡和性能。只需要一次点击就可以节省电池电力并根据需要调整性能。
#### 应用程序启动器的改进

在 Plasma 5.21 中,KDE 引入了一个新的应用程序启动器,叫做 Kickoff。虽然它受到了普遍欢迎,但一些用户也抱怨与旧的启动器相比,自定义选项较少。
好在 Plasma 5.23 解决了这个问题,为 Kickoff 引入了一些全新的自定义选项。这些选项包括以下能力:
* 图标化电源和用户控件
* 所有项目都采用选择列表或网格视图,而不仅仅是收藏夹菜单
* 新的键盘快捷键 `CTRL+F` 可以快速聚焦到搜索栏
* 在右上角添加了一个新的按针状按钮,以保持应用程序启动器处于活动状态
总的来说,我预计用户会相当受欢迎这些新选项,特别是那些因为它有如此之多的定制选项而使用 KDE 的用户。
### 其他改进措施
其他的常规改进包括:
* 优化了 Wayland 会话
* 通过“反馈”程序提高了数据透明度
* 改进了 KDE 的 Discover(应用中心)的性能
要探索更多关于该版本的信息,你可以查看 [官方公告](https://kde.org/announcements/plasma/5/5.23.0/) 及其 [更新日志](https://kde.org/announcements/changelogs/plasma/5/5.22.5-5.23.0/)。
### 总结
虽然不是有史以来最大的版本,但这是一个重要的版本,具有纪念其 25 周年的宝贵补充。像往常一样,你应该在未来几个月内的某个时候收到更新,这取决于你的发行版。
你对 KDE Plasma 5.23 的改进有什么看法?请在下面的评论中告诉我。
---
via: <https://news.itsfoss.com/kde-plasma-5-23-release/>
作者:[Jacob Crume](https://news.itsfoss.com/author/jacob/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

For years, KDE Plasma has been among the most-used desktop environments. This is due to its seemingly endless customization options, flashy looks, and feature-filled updates.
With KDE Plasma 5.23, the desktop environment marks 25 years of work. Hence, this release is also known as Plasma 25th Anniversary Edition.
It’s just wild to imagine that Matthias Ettrich (founder of KDE) [reached out to a newsgroup](https://groups.google.com/g/de.comp.os.linux.misc/c/SDbiV3Iat_s/m/zv_D_2ctS8sJ?pli=1&ref=news.itsfoss.com) back on **October 14, 1996**, to get help from fellow programmers for his “Kool Desktop Environment” project.
And, look, where we are now…
In this update, we get to see some significant UI improvements, both within Plasma and third-party apps.
## KDE Plasma 5.23: What’s New?
This update brings many improvements, including:
- Desktop accent colors
- New breeze theme
- New power management quick control
- More customization options for the app launcher
- Hundreds of bugfixes
Here, we will be looking at all these new improvements.
### Desktop Accent Colors
In System Settings, you will find an option to change the accent color of your desktop. You can choose a custom color of your choice or blend in with the theme applied by default.
### New Breeze Theme
This update brings a brand-new Breeze theme: Breeze – Blue Ocean. The default theme has improved over the years, and this time, it focuses on making the visuals clearer and accessible.
Overall, the new theme provides a glossy look. In addition to the theme, the icons have been made more prominent; a loading gear icon has been added. And, many such subtle differences have made their way to KDE Plasma 5.23 to enhance the look and feel of the desktop.
As developer Nate Graham said during the beta releases:
There is a lot of time left to tweak the final appearance as needed, but overall I think it’s really nice, and I hope you’re as excited about it as I am
### Enhanced Search Functionality in System Settings
To make it easier to find what you’re looking for, KDE Plasma 5.23 has added more combinations of keywords that quickly suggests the related settings you look for using the search bar.
### System Tray Improvements
While the system tray already offers many controls, you get finer options to monitor your connected networks and access the clipboard.
The system tray has also improved the overall look when displaying the active media being played.
### New Power Management Quick Control
With the release of Linux 5.12, a power management feature was added. Now, KDE has introduced an easy way of adjusting this, which comes in new quick control.
It has three options: Power Saver, Balanced, and Performance. All it takes is a single click to save the battery and tweak the performance as needed.
### Improvements to Application Launcher
With Plasma 5.21, KDE introduced a new app launcher called Kickoff. While it was generally well-received, some users did complain about the fewer customization options compared to the older launcher.
Fortunately, Plasma 5.23 fixes this, introducing some brand-new customization options for Kickoff. These include the ability to:
- Iconify the Power and User controls
- Choose list or grid view for all items, not just the favourites menu
- New keyboard shortcut to quickly focus on the search bar (CTRL+F)
- A new pin button added to the top-right corner to keep the application launcher active
Overall, I expect these new options to be quite popular among users, especially those using KDE, because of its incredible customization options.
## Other Improvements
Other usual improvements include:
- Making Wayland sessions better
- Improved data transparency through the Feedback applicatino
- Performance improvements to KDE’s Discover (app center)
To explore more about the release, you can check out the [official announcement post](https://kde.org/announcements/plasma/5/5.23.0/?ref=news.itsfoss.com) and its [changelog](https://kde.org/announcements/changelogs/plasma/5/5.22.5-5.23.0/?ref=news.itsfoss.com).
## Wrapping Up
While not the biggest release ever, this is a significant release with valuable additions marking its 25th anniversary. As always, you should receive the updates sometime within the next few months, depending on your distribution.
*What do you think about the improvements with KDE Plasma 5.23? Let me know in the comments down below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,887 | Ubuntu 21.10 版现已发布!终于带来了 Ubuntu 特色的 GNOME 40 | https://news.itsfoss.com/ubuntu-21-10-release/ | 2021-10-16T10:02:16 | [
"Ubuntu"
] | https://linux.cn/article-13887-1.html | 
>
> Ubuntu 21.10 是一个激动人心的版本,包含了 GNOME 40 和几个显著的变化。准备已经驶向了 Ubuntu 22.04 LTS 吗?
>
>
>
Ubuntu 21.10 是下一个大型 LTS 更新之前的最后一个非 LTS 版本。代号为 Impish Indri 的 Ubuntu 21.10 将被支持**九个月,直到 2022 年 7 月**。
除非你想尝试最新和最棒的功能,否则你应该坚持使用 Ubuntu 20.04 LTS 并等待 Ubuntu 22.04 LTS。
现在你可以下载 Ubuntu 21.10 并在你的系统上安装,让我重点介绍一下这次更新的几个亮点。
### Ubuntu 21.10 “Impish Indri” 有何新变化?

Ubuntu 21.10 出炉时有几个重大变化。一些最有影响的改进包括:
* 新的安装程序
* 增加了 GNOME 40
* 抛弃了混合主题,选择了浅色/深色主题
* 包括 Linux 内核 5.13
* 加入了支持蓝牙 LDAC 的 PulseAudio 15
* 带有 Nvidia 专有驱动程序的 Wayland 会话
GNOME 40 可以说是 Ubuntu 中令人耳目一新的变化,但你只有在体验之后才能知道。为了让你快速感受一下,下面是这个版本中你可以期待的所有变化。
#### 粉饰一新的安装程序

虽然 Ubuntu 的安装程序很容易使用,对新手也很友好,但 Canonical 希望通过对安装程序进行视觉和技术上的改造,使其更上一层楼。
开发团队利用 Flutter 使安装程序在所有其他 Ubuntu 口味和系统配置中保持一致。

#### GNOME 40

Ubuntu 的桌面体验与 GNOME 40 融为一体,没有提供任何混乱的布局。停靠区依然存在,水平活动概览也与之无缝衔接。
当然,[GNOME 40](https://news.itsfoss.com/gnome-40-release/) 中的所有改进,如核心应用程序的更新、工作区的改变等等,都会延续到 Ubuntu 21.10 中,只是 Canonical 做了一些改动。
就我个人而言,我并不喜欢 GNOME 40 的工作流程,但你可能会想体验一下。
#### 主题的变化

我喜欢改进后的颜色方案,其目的是为了更好地与 Canonical 的 Ubuntu 品牌相融合。
然而,当涉及到与应用程序和整体主题选择的一致性时,混合(标准)主题是有点问题的。
在 Ubuntu 21.10 中,你会看到深色和浅色主题,而浅色是开箱即用的默认选择。如果你想进一步了解,你可以阅读我们的 [过去的报道以更多了解这一变化](https://news.itsfoss.com/ubuntu-21-10-theme-change/)。
#### Linux 内核 5.13
Linux 内核 5.13 的加入增加了对未来的英特尔和 AMD 芯片的支持,以及对苹果 M1 的初步支持。
你可以就一步了解 [Linux 内核 5.13](https://news.itsfoss.com/linux-kernel-5-13-release/) 的信息,但总的来说,它应该给你更好的硬件兼容性。
#### PulseAudio 15 支持蓝牙 LDAC
考虑到现在有更多的蓝牙耳机支持 LDAC,当你在桌面上使用 Ubuntu 21.10 时,你可以利用这一功能。
别担心,如果你不想尝试非 LTS 版本,Ubuntu 22.04 LTS 将包括同样的改进。所以,你必须耐心等待,直到明年才能利用这一点。
除此之外,PulseAudio 15 还带来了一系列的改进,你可以参考它的 [官方更新日志以了解更多信息](https://www.freedesktop.org/wiki/Software/PulseAudio/Notes/15.0/) 。
#### Wayland 会话与 NVIDIA 专有驱动程序
现在,即使你使用 NVIDIA 专有的驱动程序,如果你需要也可以切换到 Wayland 会话。
#### Ubuntu 21.10 中的其他变化

Ubuntu 21.10 版本为其云镜像、树莓派支持和安全性带来了一系列高质量的变化。
其中一些值得注意的变化包括:
* [Firefox 默认采用 Snap](https://news.itsfoss.com/ubuntu-firefox-snap-default/)
* LibreOffice、Thunderbird 更新
* Ubuntu Sever 的改进
* 新的 PHP 默认为 8.0.8
如果你想探索所有的技术细节,你可能想参考一下 [官方发布说明](https://discourse.ubuntu.com/t/impish-indri-release-notes/21951)。
### 下载并升级到 Ubuntu 21.10
你可以选择全新安装或使用软件升级器 [从 Ubuntu 21.04 升级](https://itsfoss.com/upgrade-ubuntu-to-newer-version/) 到 Ubuntu 21.10。
请注意,如果你正在使用 Ubuntu 20.04 LTS,建议等待下一个 LTS 版本,除非你知道自己在做什么。
* [下载Ubuntu 21.10](https://releases.ubuntu.com/21.10/)
---
via: <https://news.itsfoss.com/ubuntu-21-10-release/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Ubuntu 21.10 is the last non-LTS release before the next big LTS update. Codenamed, Impish Indri, Ubuntu 21.10 will be supported for **nine months until July 2022**.
Unless you want to try the latest and greatest features, you should stick to Ubuntu 20.04 LTS and wait for Ubuntu 22.04 LTS.
Now that you can download and install Ubuntu 21.10 on your systems, let me highlight a few things about this update.
## Ubuntu 21.10 “Impish Indri”: What’s New?
Ubuntu 21.10 comes baked with several significant changes. Some of the most impactful improvements include:
- New installer
- Addition of GNOME 40
- Ditching the mixed theme and opting for light/dark theming
- Including Linux Kernel 5.13
- Inclusion of PulseAudio 15 with Bluetooth LDAC support
- Wayland session with Nvidia proprietary driver
GNOME 40 can be a refreshing change with Ubuntu but you can only tell that after you experience it. To give you a quick idea, here’s what you can expect with all the changes included in this release.
## Refreshed Installer
While Ubuntu’s installer was easy to use and newbie-friendly, Canonical wants to take it up a notch by giving the installer a visual and technical overhaul.
The dev team utilizes Flutter to make the installer consistent across all other Ubuntu flavors and system configurations.
## GNOME 40
Ubuntu’s desktop experience blends in with GNOME 40 without offering any confusing layouts. The dock remains and the horizontal activity overview works seamlessly with that.
Of course, all the improvements in [GNOME 40](https://news.itsfoss.com/gnome-40-release/) like core app updates, workspace changes, and more carry over to Ubuntu 21.10 with a few teaks from Canonical.
Personally, I didn’t like the workflow with GNOME 40, but you may want to take it up for a spin.
## Changes in Theme
I like the improved color scheme that aims to blend in better with Canonical’s branding for Ubuntu.
However, the mixed (Standard) theme was a bit problematic when it came to being consistent with applications and overall theme selection.
Going forward with Ubuntu 21.10, you will only notice a dark and light theme while the light being the default choice out-of-the-box. If you’re curious, you can read our [past coverage to know more about this change](https://news.itsfoss.com/ubuntu-21-10-theme-change/).
## Linux Kernel 5.13
The addition of Linux Kernel 5.13 adds support for future Intel and AMD chips along with initial Apple M1 support.
You can explore more about [Linux Kernel 5.13](https://news.itsfoss.com/linux-kernel-5-13-release/) but overall, it should give you way better hardware compatibility.
## PulseAudio 15 With Bluetooth LDAC Support
Considering that more Bluetooth headphones now support LDAC, you get to utilize the capability when using Ubuntu 21.10 on your desktop.
Fret not, if you do not want to try a non-LTS release, Ubuntu 22.04 LTS will include the same improvement. So, you will have to be patient till next year to make use of that.
In addition to that, PulseAudio 15 brings in a range of improvements, you can refer to its [official changelog to know more about that.](https://www.freedesktop.org/wiki/Software/PulseAudio/Notes/15.0/?ref=news.itsfoss.com)
## Wayland Session with NVIDIA Proprietary Driver
Now, even if you use the proprietary NVIDIA drivers, you will be able to switch to a Wayland session if you need it.
## Other Changes in Ubuntu 21.10
Ubuntu 21.10 release brings in a host of quality changes to its cloud images, Raspberry Pi support, and security as well.
Some of those notable changes include:
[Including Firefox as a Snap by default](https://news.itsfoss.com/ubuntu-firefox-snap-default/)- Package updates to LibreOffice, Thunderbird
- Ubuntu server improvements
- New PHP default to 8.0.8
If you want to explore all the technical details, you might want to refer to the [official release notes](https://discourse.ubuntu.com/t/impish-indri-release-notes/21951?ref=news.itsfoss.com).
## Download and Upgrade to Ubuntu 21.10
You can opt for a fresh installation or [upgrade from Ubuntu ](https://itsfoss.com/upgrade-ubuntu-to-newer-version/?ref=news.itsfoss.com)21.04 to Ubuntu 21.10 using the software updater.
Do note that if you are using Ubuntu 20.04 LTS, it is recommended to wait for the next LTS release, unless you know what you are doing.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,888 | 最新 OpenPGP.js 版本的 3 个新功能 | https://opensource.com/article/21/10/openpgpjs | 2021-10-16T11:57:31 | [
"OpenPGP",
"邮件"
] | https://linux.cn/article-13888-1.html |
>
> OpenPGP.js 是一个实现了 OpenPGP 标准的密码学库,最常用于电子邮件加密。
>
>
>

[OpenPGP.js](https://github.com/openpgpjs/openpgpjs) 是一个实现了 [OpenPGP 标准](https://tools.ietf.org/html/rfc4880) 的密码学库,最常用于电子邮件加密。ProtonMail、Mailvelope 和 FlowCrypt 都使用 OpenPGP.js,这还仅仅是其中一些。也就是说 OpenPGP.js 库对数百万用户的信息进行了加密。
OpenPGP 标准首次发布于 20 世纪 90 年代,像几乎任何东西一样,需要维护和更新,以保证安全和可用性。该标准的“加密刷新” [正在进行中](https://datatracker.ietf.org/doc/charter-ietf-openpgp/),它增加了现代的加密算法并废除了过时的算法。为了提高可用性,各种电子邮件应用程序现在允许用户无缝加密他们的通信,用户无需管理他们的密钥或他们的联系人的密钥。
OpenPGP.js 于 2014 年首次发布,开始基于一个名为 GPG4Browsers 的早期原型,该原型基于 Herbert Hanewinkel(以及其他贡献者)的几个脚本。OpenPGP.js 的第二个版本于 2016 年发布,完全重新设计,使用 Uint8Arrays 而不是字符串(这大大增加了其性能),并在内部使用现代 ES6 模块而不是 CommonJS 模块。第 3 和第 4 版都是在 2018 年发布的,分别增加了对椭圆曲线加密法(ECC)和流的支持。
我和我的团队继续在 OpenPGP.js 上工作,以确保其发展为一个易于使用的强加密库。
### 1、默认的椭圆曲线加密
在 OpenPGP.js 第 4 版中,生成新密钥时默认使用 RSA。虽然 ECC 更快、更安全,但 Curve25519 还没有在 OpenPGP 规范中得到标准化。加密刷新草案包括了 Curve25519,并且预计它将“按原样”包含在下一版本的 OpenPGP 规范中,因此 OpenPGP.js 第 5 版现在默认使用 ECC 生成密钥。
### 2、只导入你需要的模块
同样,虽然 OpenPGP.js 内部使用 ES6 模块多年,但第 4 版仍然没有发布一个合适的 ES6 模块。相反,它只发布了一个<ruby> 通用模块定义 <rt> Univeral Module Definition </rt></ruby>(UMD)模块,可以在浏览器和 Node.js 上运行。在第 5 版中,这种情况有所改变,为浏览器和 Node.js 发布了单独的模块(包括 ES6 和非 ES6),使库用户更容易在所有平台上导入 OpenPGP.js ,且(当使用 ES6 模块时)只导入他们需要的部分。这在很大程度上是通过将构建系统切换到 [rollup](https://rollupjs.org/) 来实现的。
### 3、拒绝弱加密技术
还有许多其他的安全改进。例如,1024 位 RSA 密钥、ElGamal 和 DSA 密钥被认为是不安全的,并被默认拒绝。此外,第 4 版已经默认使用 AES 加密,第 5 版现在完全默认拒绝使用较弱的算法进行加密,即使公钥声称只支持较弱的算法。相反,它假定所有的 OpenPGP 实现都支持 AES(这种情况已经存在很长时间了)。
### OpenPGP.js 的下一步是什么?
展望未来,有一些安全方面的改进要做。用于识别公钥的密钥指纹仍然使用 SHA-1,尽管在加密技术更新中计划对此进行修复。同时,建议使用不同的方法来确定用于加密的任何公钥的真实性,例如使用提议的 <ruby> <a href="https://datatracker.ietf.org/doc/html/draft-koch-openpgp-webkey-service"> 网络密钥目录 </a> <rt> Web Key Directory </rt></ruby>(WKD)标准直接从收件人的域中获取整个密钥,这已经由各种 [电子邮件提供商](https://wiki.gnupg.org/WKD#Mail_Service_Providers_offering_WKD) 实现。WKD 支持内置于 OpenPGP.js 第 4 版,但在第 5 版中是一个单独的模块,以保持主库的精简。
同样,当用密码而不是公钥加密信息或文件时(例如:在使用 OpenPGP 进行电子邮件加密时不常见,但在用于加密备份时更常见),密码会使用相对较弱的<ruby> 密钥衍生函数 <rt> Key Derivation Function </rt></ruby>(KDF)转换为对称密钥。因此,建议应用在将用户的密码传递给 OpenPGP.js 之前,先通过一个强大的 KDF,如 [Argon2](https://en.wikipedia.org/wiki/Argon2) 或 [scrypt](https://en.wikipedia.org/wiki/Scrypt)。希望加密刷新草案会包括这些算法中的一种,以便在未来的 OpenPGP.js 版本中实现。
### 如何使用 OpenPGP.js 第 5 版
不过现在,OpenPGP.js 第 5 版已经 [发布](https://www.npmjs.com/package/openpgp) 到 npm 仓库。如果你喜欢,可以随时试用!欢迎在 GitHub 的 [讨论版](https://github.com/openpgpjs/openpgpjs/discussions) 中进行反馈。然而,请注意,虽然 OpenPGP.js 是一个通用的加密库,但它的主要使用情况是在需要与 OpenPGP 规范兼容的情况下(例如,在发送或接收 PGP 加密的电子邮件时)。对于其他的使用情况,不同的库可能是一个更合适或性能更好的选择。当然,总的来说,在尝试使用任何加密技术时都要小心。
感谢阅读,这里是保护电子邮件的未来!
---
via: <https://opensource.com/article/21/10/openpgpjs>
作者:[Daniel Huigens](https://opensource.com/users/twiss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [OpenPGP.js](https://github.com/openpgpjs/openpgpjs) is a cryptography library that implements the [OpenPGP standard](https://tools.ietf.org/html/rfc4880), most commonly used for email encryption. ProtonMail, Mailvelope, and FlowCrypt all use OpenPGP.js, to name a few. That means the OpenPGP.js library encrypts millions of users' messages.
The OpenPGP standard, first published in the 1990s, like almost anything, requires maintenance and updating for both security and usability. A "crypto refresh" of the standard [is in the works](https://datatracker.ietf.org/doc/charter-ietf-openpgp/), which adds modern encryption algorithms and deprecates outdated ones. To improve usability, various email applications now allow users to seamlessly encrypt their communication—without managing their keys or those of their contacts.
First released in 2014, OpenPGP.js began based on an early prototype called GPG4Browsers, which is based on several scripts by Herbert Hanewinkel (among other contributors). The second version of OpenPGP.js, released in 2016, was completely reworked to use Uint8Arrays instead of strings (which significantly increased its performance) and modern ES6 modules rather than CommonJS modules internally. Versions 3 and 4, both released in 2018, added support for Elliptic-curve cryptography (ECC) and streaming, respectively.
My team and I continue working on OpenPGP.js to ensure its evolution as an easy-to-use library for strong encryption.
## 1. Elliptic-curve cryptography by default
In OpenPGP.js version 4, RSA was used when generating new keys by default. Although ECC is faster and more secure, Curve25519 had not been standardized in the OpenPGP specification yet. The crypto refresh draft does include Curve25519, and it is expected to be included "as is" in the next version of the OpenPGP specification, so OpenPGP.js version 5 now generates keys using ECC by default.
## 2. Import only the modules you need
Similarly, while OpenPGP.js used ES6 modules internally for years, version 4 still didn't publish a proper ES6 module. Instead, it published only a Univeral Module Definition (UMD) module that could run both in the browser and on Node.js. In version 5, this changes by publishing separate modules for the browser and Node.js (both ES6 and non-ES6), making it easier for library users to import OpenPGP.js on all platforms and (when using the ES6 module) only import the parts they need. This is enabled in large part by switching the build system to [rollup](https://rollupjs.org/).
## 3. Reject weak cryptography
There are also many other security improvements. For example, 1024-bit RSA keys, ElGamal, and DSA keys are considered insecure and are rejected by default. Additionally, where version 4 already defaulted to AES-encryption, version 5 now refuses to encrypt using weaker algorithms entirely by default, even if the public key claims to only support a weaker algorithm. It instead assumes that all OpenPGP implementations support AES (which has been the case for a very long time).
## What's next for OpenPGP.js
Looking ahead, there are some security improvements to make. Key fingerprints, used to identify public keys, still use SHA-1, though a fix for this is planned in the crypto refresh. In the meantime, it is recommended to use different means to ascertain the authenticity of any public key used for encryption, such as by fetching the entire key directly from the recipient's domain using the proposed [Web Key Directory (WKD)](https://datatracker.ietf.org/doc/html/draft-koch-openpgp-webkey-service) standard—already implemented by various [email providers](https://wiki.gnupg.org/WKD#Mail_Service_Providers_offering_WKD). WKD support was built into OpenPGP.js version 4 but is a separate module in version 5 to keep the main library lean.
Similarly, when encrypting messages or files with a password rather than a public key (uncommon when using OpenPGP for email encryption, but more so when used for encrypted backups, for example), the password is converted to a symmetric key using a relatively weak key derivation function (KDF). It is thus advisable for applications to pass the user's password through a strong KDF, such as [Argon2](https://en.wikipedia.org/wiki/Argon2) or [scrypt](https://en.wikipedia.org/wiki/Scrypt), before passing it to OpenPGP.js. Hopefully, the crypto refresh will include one of these algorithms to implement in a future version of OpenPGP.js.
## How to use OpenPGP.js version 5
For now, though, OpenPGP.js version 5 has been [published](https://www.npmjs.com/package/openpgp) to the npm package registry. If you like, feel free to try it out! Feedback is welcome in the [discussions tab](https://github.com/openpgpjs/openpgpjs/discussions) on GitHub. Please note, however, that while OpenPGP.js is a general-purpose encryption library, its primary use case is in situations where compatibility with the OpenPGP specification is required (for example, when sending or receiving PGP-encrypted email). For other use cases, a different library may be a more appropriate or performant choice. In general, of course, be careful when rolling any crypto.
Thanks for reading, and here's to securing the future of email!
## Comments are closed. |
13,890 | Linus Torvalds :开源改变了 Linux, 否则它就完了 | https://news.itsfoss.com/open-source-changed-linux-torvalds/ | 2021-10-17T10:09:48 | [
"Linux"
] | https://linux.cn/article-13890-1.html |
>
> Linux 本来会像其他业余项目一样被抛在后面,但开源改变了这一点。
>
>
>

你可能已经知道这个故事,30 年前,芬兰学生 Linus Torvalds 开发了一个业余项目,创建了一个类 UNIX 操作系统。
你不知道的是,Torvalds 认为这个业余项目已经完成了,他本想把它抛在脑后,做一些新的、有趣的项目。
那么,是什么让他在这个“业余项目”上工作了 30 年呢?答案是开源。
### 开源改变了 Linux
在最近结束的 [北美开源峰会](https://events.linuxfoundation.org/open-source-summit-north-america/) 上,Linus Torvalds 分享了一些关于 Linux 项目过去、现在和未来的见解。
当回忆起这个项目的最初情况时,[Torvalds 说](https://thenewstack.io/linus-torvalds-on-community-rust-and-linuxs-longevity/) 他本以为会以“已完成的状态”抛下 Linux 这个项目,而去做些新的、有趣的事情。
>
> 显然是开源改变了这一切。这个项目,如果是由我来决定,我可能会把它抛在一边,但是突然间,我开始收到各种问题,最后还有人们提交的补丁,这使得我的动力不断持续。现在 30 年过去了,这仍然是动力所在。
>
>
>
Torvalds 还补充说,就他而言,Linux 在过去 29 年里已经完成了。以后添加的每一个其他的功能,都是其他人需要、想要或感兴趣的。
许多开发人员都会遇到这种情况。你在一个项目上工作,认为它已经达到“完成”的状态了,如果这个项目没有足够的吸引力,你就会对它失去兴趣,转而去做一些“新的、有趣的”事情。实际上继续这个项目的真正动力来自用户和认可。
当被问及 Linux 50 周年要做些什么时,Torvalds 说,他不认为自己在 70 岁的时候还能继续做内核编程。然后他还补充说,他也没想过自己在 50 岁还在做内核编程,但他现在却在做这个事情。
>
> “不知何故,我不认为我 70 岁还能做内核编程。但是另一方面,几年前,我也没想到自己 50 岁还在做内核编程,所以……我们拭目以待。”
>
>
>
我们总是愿意听 Torvalds 谈论 Linux,作为一个热心的 Linux 用户,我们还有如此多需要学习和交流的东西!
来源:[The News Stack](https://thenewstack.io/linus-torvalds-on-community-rust-and-linuxs-longevity/)
---
via: <https://news.itsfoss.com/open-source-changed-linux-torvalds/>
作者:[Abhishek](https://news.itsfoss.com/author/root/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zd200572](https://github.com/zd200572) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You probably already know the story. 30 years ago, Finnish student Linus Torvalds created a UNIX-like operating system as a hobby project.
What you do not know is that Torvalds thought that the hobby project was done, and he would have left it behind to work on some new and interesting project.
So, what made his work on this ‘hobby project’ for 30 years? The answer is open source.
## Open source changed Linux
At the recently concluded [Open Source Summit North America event](https://events.linuxfoundation.org/open-source-summit-north-america/?ref=news.itsfoss.com), Linus Torvalds shared some insights into the past, present and future of the Linux project.
While remembering the beginning of the project, [Torvalds said](https://thenewstack.io/linus-torvalds-on-community-rust-and-linuxs-longevity/?ref=news.itsfoss.com) that he’d expected to leave behind Linux in a ‘done state’ to work for something new and interesting.
That was clearly then what open source changed. Because suddenly this project — that I probably would’ve left behind, if it was only up to me — I started getting questions about, and eventually patches — that just kept the motivation going. And here we are 30 years later, and it’s still what keeps the motivation going.
Torvalds also added that as far as he is concerned, Linux is done for the past 29 years. Every other feature that has been added later is about what other people needed, wanted or were interested in.
Many developers would relate to this. You work on a project and think that it has reached a ‘done’ state. If the project does not get enough traction, you lose interest to work on it and move to something ‘new and exciting’. The real motivation to continue the project comes from the users and the recognition.
When asked about what they should be doing for the 50th anniversary of Linux, Torvalds said that he doesn’t see himself doing kernel programming at the age of 70. Then he also chipped in that he didn’t imagine himself doing kernel programming at the age of 50 as well and yet he is doing that at present.
“Somehow I don’t see myself doing kernel programming when I’m 70. But on the other hand, I didn’t see myself doing kernel programming when I was 50 either, a few years back. So… we’ll see.”
It is always endearing to listen to Torvalds talking about Linux. So much to learn and to relate as an ardent Linux user, right?
*Source: The News Stack*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,891 | 如何使用 Apache 软件处理实时数据 | https://opensource.com/article/20/2/real-time-data-processing | 2021-10-17T10:56:45 | [
"数据",
"Apache"
] | https://linux.cn/article-13891-1.html |
>
> 开源以丰富的项目画布引领着处理实时事件的方向。
>
>
>

在“永不下线”的未来,入网设备规模可能会达到数十亿。存储原始数据,日后再进行分析的方案将不再能满足需求,因为用户需要实时且准确的响应。要对故障等对环境敏感的状况进行预测,实时处理数据也必不可少 —— 数据到达数据库后再处理肯定是来不及的。
有人可能会说,“云可扩展性”能够满足实时处理流数据的需求,但一些简单的例子就能表明它永远无法满足对无界数据流进行实时响应的需求。从移动设备到物联网,都需要一种新的范式来满足需求。尽管云计算依赖于对大数据“先存储后分析”的方案,但也迫切需要一种能够处理持续、杂乱和海量数据流的软件框架,并在数据流到达时立即对其进行处理,以保证实时的响应、预测和对数据的洞悉。
例如,在加利福尼亚州的帕洛阿尔托市,每天从基础交通设施产生的流数据比 Twitter Firehose 还要多。这是很大的数据量。为 Uber、Lyft 和 FedEx 等消费者预测城市交通需要实时的分析、学习和预测。云处理不可避免地导致每个事件大约会有半秒的延迟。
我们需要一个简单而强大的编程范式,让应用程序在类似下面的情况时能够动态处理无界数据流:
* 数据量巨大,或原始数据的移动成本很高。
* 数据由广泛分布的资产(例如移动设备)生成。
* 数据具有转瞬即逝的价值,即时分析迫在眉睫。
* 需要始终洞悉最新数据情况,外推法行不通。
### 发布和订阅
事件驱动系统领域中有一个关键架构模式:<ruby> 发布/订阅 <rt> publish/subscribe </rt></ruby> 消息传递模式。这是一种异步通信方法,其中消息会从 *发布者*(数据产生方)传递到 *订阅者*(处理数据的应用程序)。发布/订阅模式可以将消息发送者与消费者分离开来。
在发布/订阅模式中,消息源会 *发布* 针对某个 <ruby> 主题 <rt> topic </rt></ruby> 的 <ruby> 事件 <rt> event </rt></ruby> 至 <ruby> 服务端 <rt> broker </rt></ruby>,后者按接收顺序存储它们。应用程序可以 *订阅* 一个或多个 *主题*,然后 *服务端* 会转发匹配的事件。 Apache Kafka 和 Pulsar 以及 CNCF NATS 是发布/订阅系统。 发布/订阅的云服务包括 Google Pub/Sub、AWS Kinesis、Azure Service Bus、Confluent Cloud 等。(LCTT 译注:本段部分术语英文名称更为泛用,针对这些术语,采用了中英文标注。)
发布/订阅系统不会 *运行* 订阅者应用程序,它们只是 *传递* 数据给相应主题的订阅者。
流数据通常包含应用程序或基础架构状态更新的事件。在选择架构来处理数据时,发布/订阅框架等数据分发系统的作用是有限的。消费者应用程序的“处理方式”超出了发布/订阅系统的范围。这让开发人员的管理变得极具复杂性。所谓的流处理器是一种特殊的订阅者,可以动态分析数据并将结果返回给同一个服务端。
### Apache Spark
[Apache Spark](https://spark.apache.org/) 是用于大规模数据处理的统一分析引擎。通常将 Apache Spark Streaming 用作流处理器,例如给机器学习模型提供新数据。Spark Streaming 将数据分成小批量,每个小批量都由 Spark 模型或其他系统独立分析。事件流可以被分组成小批量以进行分析,但流处理器本身必须具有弹性:
* 流处理器必须能够根据数据速率进行扩展,甚至要能够跨越服务器和云,并且还可以跨实例实现负载均衡,以确保弹性和其他应用层的需求。
* 它必须能够分析来自不同来源的数据,这些数据源的报告速率可能相差很大。这意味着它必须是有状态的,或者将状态存储在数据库中。当使用 Spark Streaming 作为流处理器时,通常会使用后一种方法,这种方法在需要超低延迟响应时可能会存在性能问题。
相关项目 [Apache Samza](https://samza.apache.org/) 也提供了一种处理实时事件流的方法,并使用 [Hadoop Yarn](https://hadoop.apache.org/) 或 [Apache Mesos](http://mesos.apache.org/) 来管理计算资源,以便进行弹性扩展。
### 解决数据扩展问题
需要注意的是,即使是 Samza 也不能完全减轻开发人员的数据处理需求。扩展数据规模意味着处理事件的任务需要跨多个实例进行负载均衡,而使用数据库是实例间共享结果应用层状态的唯一方法。然而,当应用程序任务之间的状态协调转移到数据库时,对性能会产生不可避免的连锁反应。此外,数据库的选择也至关重要。随着系统的扩展,数据库的集群管理会成为下一个潜在的瓶颈。
这个问题可以通过有状态、有弹性的替代方案来解决,并且这样的解决方案可以用来代替流处理器。在应用程序级别(容器或实例内),这些解决方案依据流的更新,动态构建并发、互连的“web 代理”的有状态模型。代理是并发的“微服务”,它们消费单一来源的原始数据并维护它们的状态。基于数据中发现的源之间的真实关系(如包含和临近),代理实现互连以共享状态。代理也因此形成了一个并发服务图,可以分析它们自己的状态和链接到的代理的状态。数据源将原始数据转换为状态,并根据自身及其链接子图的变化进行分析、学习和预测,每个代理都为单个这样的数据源提供微服务。
这些解决方案允许大量的代理(真实数据源的数字类比)分布,甚至还有在应用层使代理互连的分布式图,从而简化了应用架构。这是因为代理之间互连的本质,是映射到解决方案的当前运行时执行实例和代理本身的 URL。通过这种方式,应用程序可以跨实例无缝扩展,而无需担心 DevOps 问题。代理消费数据并维护状态,还会计算自己和其他代理的状态。由于代理是有状态的,因此不需要数据库,并且数据洞察是以内存速度计算的。
### 使用开源阅读数据世界
我们查看数据的方式正在发生翻天覆地的变化:不再将数据库用作记录系统,取而代之的是现实世界,现实世界事物的数字类比可以不断地传输它们的状态。幸运的是,开源社区在处理实时事件的项目丰富度方面处于领先地位。从发布/订阅模式(其中最活跃的社区是 Apache Kafka、Pulsar 和 CNCF NATS)到持续处理流数据的分析框架,包括 Apache Spark、[Flink](https://flink.apache.org/)、[Beam](https://beam.apache.org)、Samza,以及 Apache 许可的 [SwimOS](https://github.com/swimos/swim) 和 [Hazelcast](https://hazelcast.com/),对开发人员来说,可选择项目非常之多。可以说,没有什么地方比开源社区的专有软件框架更多了。试看软件的未来,必是开源的天下。
---
via: <https://opensource.com/article/20/2/real-time-data-processing>
作者:[Simon Crosby](https://opensource.com/users/simon-crosby) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the "always-on" future with billions of connected devices, storing raw data for analysis later will not be an option because users want accurate responses in real time. Prediction of failures and other context-sensitive conditions require data to be processed in real time—certainly before it hits a database.
It's tempting to simply say "the cloud will scale" to meet demands to process streaming data in real time, but some simple examples show that it can never meet the need for real-time responsiveness to boundless data streams. In these situations—from mobile devices to IoT—a new paradigm is needed. Whereas cloud computing relies on a "store then analyze" big data approach, there is a critical need for software frameworks that are comfortable instantly processing endless, noisy, and voluminous streams of data as they arrive to permit a real-time response, prediction, or insight.
For example, the city of Palo Alto, Calif. produces more streaming data from its traffic infrastructure per day than the Twitter Firehose. That's a lot of data. Predicting city traffic for consumers like Uber, Lyft, and FedEx requires real-time analysis, learning, and prediction. Event processing in the cloud leads to an inescapable latency of about half a second per event.
We need a simple yet powerful programming paradigm that lets applications process boundless data streams on the fly in these and similar situations:
- Data volumes are huge, or moving raw data is expensive.
- Data is generated by widely distributed assets (such as mobile devices).
- Data is of ephemeral value, and analysis can't wait.
- It is critical to always have the latest insight, and extrapolation won't do.
## Publish and subscribe
A key architectural pattern in the domain of event-driven systems is the concept of pub/sub or publish/subscribe messaging. This is an asynchronous communication method in which messages are delivered from *publishers* (anything producing data) to *subscribers (*applications that process data). Pub/sub decouples arbitrary numbers of senders from an unknown set of consumers.
In pub/sub, sources *publish* events for a *topic* to a *broker* that stores them in the order in which they are received. An application *subscribes* to one or more *topics*, and the *broker* forwards matching events. Apache Kafka and Pulsar and CNCF NATS are pub/sub systems. Cloud services for pub/sub include Google Pub/Sub, AWS Kinesis, Azure Service Bus, Confluent Cloud, and others.
Pub/sub systems do not *run* subscriber applications—they simply *deliver* data to topic subscribers.
Streaming data often contains events that are updates to the state of applications or infrastructure. When choosing an architecture to process data, the role of a data-distribution system such as a pub/sub framework is limited. The "how" of the consumer application lies beyond the scope of the pub/sub system. This leaves an enormous amount of complexity for the developer to manage. So-called stream processors are a special kind of subscriber that analyzes data on the fly and delivers results back to the same broker.
## Apache Spark
[Apache Spark](https://spark.apache.org/) is a unified analytics engine for large-scale data processing. Often, Apache Spark Streaming is used as a stream processor, for example, to feed machine learning models with new data. Spark Streaming breaks data into mini-batches that are each independently analyzed by a Spark model or some other system. The stream of events is grouped into mini-batches for analysis, but the stream processor itself must be elastic:
- The stream processor must be capable of scaling with the data rate, even across servers and clouds, and also balance load across instances, ensuring resilience and other application-layer needs.
- It must be able to analyze data from sources that report at widely different rates, meaning it must be stateful—or store state in a database. This latter approach is often used when Spark Streaming is used as the stream processor and can cause performance problems when ultra-low latency responses are needed.
A related project, [Apache Samza](https://samza.apache.org/), offers a way to process real-time event streams, and to scale elastically using [Hadoop Yarn](https://hadoop.apache.org/) or [Apache Mesos](http://mesos.apache.org/) to manage compute resources.
## Solving the problem of scaling data
It's important to note that even Samza cannot entirely alleviate data processing demands for the application developer. Scaling data rates mean that tasks to process events need to be load-balanced across many instances, and the only way to share the resulting application-layer state between instances is to use a database. However, the moment state coordination between tasks of an application devolves to a database, there is an inevitable knock-on effect upon performance. Moreover, the choice of database is crucial. As the system scales, cluster management for the database becomes the next potential bottleneck.
This can be solved with alternative solutions that are stateful, elastic, and can be used in place of a stream processor. At the application level (within each container or instance), these solutions build a stateful model of concurrent, interlinked "web agents" on the fly from streaming updates. Agents are concurrent "nano-services" that consume raw data for a single source and maintain their state. Agents interlink to share state based on real-world relationships between sources found in the data, such as containment and proximity. Agents thus form a graph of concurrent services that can analyze their own state and the states of agents to which they are linked. Each agent provides a nano-service for a single data source that converts from raw data to state and analyzes, learns, and predicts from its own changes and those of its linked subgraph.
These solutions simplify application architecture by allowing agents—digital twins of real-world sources—to be widely distributed, even while maintaining the distributed graph that interlinks them at the application layer. This is because the links are URLs that map to the current runtime execution instance of the solution and the agent itself. In this way, the application seamlessly scales across instances without DevOps concerns. Agents consume data and maintain state. They also compute over their own state and that of other agents. Because agents are stateful, there is no need for a database, and insights are computed at memory speed.
## Reading world data with open source
There is a sea change afoot in the way we view data: Instead of the database being the system of record, the real world is, and digital twins of real-world things can continuously stream their state. Fortunately, the open source community is leading the way with a rich canvas of projects for processing real-time events. From pub/sub, where the most active communities are Apache Kafka, Pulsar, and CNCF NATS, to the analytical frameworks that continually process streamed data, including Apache Spark, [Flink](https://flink.apache.org/), [Beam](https://beam.apache.org), Samza, and Apache-licensed [SwimOS](https://github.com/swimos/swim) and [Hazelcast](https://hazelcast.com/), developers have the widest choices of software systems. Specifically, there is no richer set of proprietary software frameworks available. Developers have spoken, and the future of software is open source.
## Comments are closed. |
13,894 | C 语言编程中的 5 个常见错误及对应解决方案 | https://opensource.com/article/21/10/programming-bugs | 2021-10-18T17:41:00 | [
"C语言"
] | https://linux.cn/article-13894-1.html |
>
> 增强 C 语言程序的弹性和可靠性的五种方法。
>
>
>

即使是最好的程序员也无法完全避免错误。这些错误可能会引入安全漏洞、导致程序崩溃或产生意外操作,具体影响要取决于程序的运行逻辑。
C 语言有时名声不太好,因为它不像近期的编程语言(比如 Rust)那样具有内存安全性。但是通过额外的代码,一些最常见和严重的 C 语言错误是可以避免的。下文讲解了可能影响应用程序的五个错误以及避免它们的方法:
### 1、未初始化的变量
程序启动时,系统会为其分配一块内存以供存储数据。这意味着程序启动时,变量将获得内存中的一个随机值。
有些编程环境会在程序启动时特意将内存“清零”,因此每个变量都得以有初始的零值。程序中的变量都以零值作为初始值,听上去是很不错的。但是在 C 编程规范中,系统并不会初始化变量。
看一下这个使用了若干变量和两个数组的示例程序:
```
#include <stdio.h>
#include <stdlib.h>
int
main()
{
int i, j, k;
int numbers[5];
int *array;
puts("These variables are not initialized:");
printf(" i = %d\n", i);
printf(" j = %d\n", j);
printf(" k = %d\n", k);
puts("This array is not initialized:");
for (i = 0; i < 5; i++) {
printf(" numbers[%d] = %d\n", i, numbers[i]);
}
puts("malloc an array ...");
array = malloc(sizeof(int) * 5);
if (array) {
puts("This malloc'ed array is not initialized:");
for (i = 0; i < 5; i++) {
printf(" array[%d] = %d\n", i, array[i]);
}
free(array);
}
/* done */
puts("Ok");
return 0;
}
```
这个程序不会初始化变量,所以变量以系统内存中的随机值作为初始值。在我的 Linux 系统上编译和运行这个程序,会看到一些变量恰巧有“零”值,但其他变量并没有:
```
These variables are not initialized:
i = 0
j = 0
k = 32766
This array is not initialized:
numbers[0] = 0
numbers[1] = 0
numbers[2] = 4199024
numbers[3] = 0
numbers[4] = 0
malloc an array ...
This malloc'ed array is not initialized:
array[0] = 0
array[1] = 0
array[2] = 0
array[3] = 0
array[4] = 0
Ok
```
很幸运,`i` 和 `j` 变量是从零值开始的,但 `k` 的起始值为 32766。在 `numbers` 数组中,大多数元素也恰好从零值开始,只有第三个元素的初始值为 4199024。
在不同的系统上编译相同的程序,可以进一步显示未初始化变量的危险性。不要误以为“全世界都在运行 Linux”,你的程序很可能某天在其他平台上运行。例如,下面是在 FreeDOS 上运行相同程序的结果:
```
These variables are not initialized:
i = 0
j = 1074
k = 3120
This array is not initialized:
numbers[0] = 3106
numbers[1] = 1224
numbers[2] = 784
numbers[3] = 2926
numbers[4] = 1224
malloc an array ...
This malloc'ed array is not initialized:
array[0] = 3136
array[1] = 3136
array[2] = 14499
array[3] = -5886
array[4] = 219
Ok
```
永远都要记得初始化程序的变量。如果你想让变量将以零值作为初始值,请额外添加代码将零分配给该变量。预先编好这些额外的代码,这会有助于减少日后让人头疼的调试过程。
### 2、数组越界
C 语言中,数组索引从零开始。这意味着对于长度为 10 的数组,索引是从 0 到 9;长度为 1000 的数组,索引则是从 0 到 999。
程序员有时会忘记这一点,他们从索引 1 开始引用数组,产生了<ruby> “大小差一” <rt> off by one </rt></ruby>错误。在长度为 5 的数组中,程序员在索引“5”处使用的值,实际上并不是数组的第 5 个元素。相反,它是内存中的一些其他值,根本与此数组无关。
这是一个数组越界的示例程序。该程序使用了一个只含有 5 个元素的数组,但却引用了该范围之外的数组元素:
```
#include <stdio.h>
#include <stdlib.h>
int
main()
{
int i;
int numbers[5];
int *array;
/* test 1 */
puts("This array has five elements (0 to 4)");
/* initalize the array */
for (i = 0; i < 5; i++) {
numbers[i] = i;
}
/* oops, this goes beyond the array bounds: */
for (i = 0; i < 10; i++) {
printf(" numbers[%d] = %d\n", i, numbers[i]);
}
/* test 2 */
puts("malloc an array ...");
array = malloc(sizeof(int) * 5);
if (array) {
puts("This malloc'ed array also has five elements (0 to 4)");
/* initalize the array */
for (i = 0; i < 5; i++) {
array[i] = i;
}
/* oops, this goes beyond the array bounds: */
for (i = 0; i < 10; i++) {
printf(" array[%d] = %d\n", i, array[i]);
}
free(array);
}
/* done */
puts("Ok");
return 0;
}
```
可以看到,程序初始化了数组的所有值(从索引 0 到 4),然后从索引 0 开始读取,结尾是索引 9 而不是索引 4。前五个值是正确的,再后面的值会让你不知所以:
```
This array has five elements (0 to 4)
numbers[0] = 0
numbers[1] = 1
numbers[2] = 2
numbers[3] = 3
numbers[4] = 4
numbers[5] = 0
numbers[6] = 4198512
numbers[7] = 0
numbers[8] = 1326609712
numbers[9] = 32764
malloc an array ...
This malloc'ed array also has five elements (0 to 4)
array[0] = 0
array[1] = 1
array[2] = 2
array[3] = 3
array[4] = 4
array[5] = 0
array[6] = 133441
array[7] = 0
array[8] = 0
array[9] = 0
Ok
```
引用数组时,始终要记得追踪数组大小。将数组大小存储在变量中;不要对数组大小进行<ruby> 硬编码 <rt> hard-code </rt></ruby>。否则,如果后期该标识符指向另一个不同大小的数组,却忘记更改硬编码的数组长度时,程序就可能会发生数组越界。
### 3、字符串溢出
字符串只是特定类型的数组。在 C 语言中,字符串是一个由 `char` 类型值组成的数组,其中用一个零字符表示字符串的结尾。
因此,与数组一样,要注意避免超出字符串的范围。有时也称之为 *字符串溢出*。
使用 `gets` 函数读取数据是一种很容易发生字符串溢出的行为方式。`gets` 函数非常危险,因为它不知道在一个字符串中可以存储多少数据,只会机械地从用户那里读取数据。如果用户输入像 `foo` 这样的短字符串,不会发生意外;但是当用户输入的值超过字符串长度时,后果可能是灾难性的。
下面是一个使用 `gets` 函数读取城市名称的示例程序。在这个程序中,我还添加了一些未使用的变量,来展示字符串溢出对其他数据的影响:
```
#include <stdio.h>
#include <string.h>
int
main()
{
char name[10]; /* Such as "Chicago" */
int var1 = 1, var2 = 2;
/* show initial values */
printf("var1 = %d; var2 = %d\n", var1, var2);
/* this is bad .. please don't use gets */
puts("Where do you live?");
gets(name);
/* show ending values */
printf("<%s> is length %d\n", name, strlen(name));
printf("var1 = %d; var2 = %d\n", var1, var2);
/* done */
puts("Ok");
return 0;
}
```
当你测试类似的短城市名称时,该程序运行良好,例如伊利诺伊州的 `Chicago` 或北卡罗来纳州的`Raleigh`:
```
var1 = 1; var2 = 2
Where do you live?
Raleigh
<Raleigh> is length 7
var1 = 1; var2 = 2
Ok
```
威尔士的小镇 `Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch` 有着世界上最长的名字之一。这个字符串有 58 个字符,远远超出了 `name` 变量中保留的 10 个字符。结果,程序将值存储在内存的其他区域,覆盖了 `var1` 和 `var2` 的值:
```
var1 = 1; var2 = 2
Where do you live?
Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch
<Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch> is length 58
var1 = 2036821625; var2 = 2003266668
Ok
Segmentation fault (core dumped)
```
在运行结束之前,程序会用长字符串覆盖内存的其他部分区域。注意,`var1` 和 `var2` 的值不再是起始的 `1` 和 `2`。
避免使用 `gets` 函数,改用更安全的方法来读取用户数据。例如,`getline` 函数会分配足够的内存来存储用户输入,因此不会因输入长值而发生意外的字符串溢出。
### 4、重复释放内存
“分配的内存要手动释放”是良好的 C 语言编程原则之一。程序可以使用 `malloc` 函数为数组和字符串分配内存,该函数会开辟一块内存,并返回一个指向内存中起始地址的指针。之后,程序可以使用 `free` 函数释放内存,该函数会使用指针将内存标记为未使用。
但是,你应该只使用一次 `free` 函数。第二次调用 `free` 会导致意外的后果,可能会毁掉你的程序。下面是一个针对此点的简短示例程序。程序分配了内存,然后立即释放了它。但为了模仿一个健忘但有条理的程序员,我在程序结束时又一次释放了内存,导致两次释放了相同的内存:
```
#include <stdio.h>
#include <stdlib.h>
int
main()
{
int *array;
puts("malloc an array ...");
array = malloc(sizeof(int) * 5);
if (array) {
puts("malloc succeeded");
puts("Free the array...");
free(array);
}
puts("Free the array...");
free(array);
puts("Ok");
}
```
运行这个程序会导致第二次使用 `free` 函数时出现戏剧性的失败:
```
malloc an array ...
malloc succeeded
Free the array...
Free the array...
free(): double free detected in tcache 2
Aborted (core dumped)
```
要记得避免在数组或字符串上多次调用 `free`。将 `malloc` 和 `free` 函数定位在同一个函数中,这是避免重复释放内存的一种方法。
例如,一个纸牌游戏程序可能会在主函数中为一副牌分配内存,然后在其他函数中使用这副牌来玩游戏。记得在主函数,而不是其他函数中释放内存。将 `malloc` 和 `free` 语句放在一起有助于避免多次释放内存。
### 5、使用无效的文件指针
文件是一种便捷的数据存储方式。例如,你可以将程序的配置数据存储在 `config.dat` 文件中。Bash shell 会从用户家目录中的 `.bash_profile` 读取初始化脚本。GNU Emacs 编辑器会寻找文件 `.emacs` 以从中确定起始值。而 Zoom 会议客户端使用 `zoomus.conf` 文件读取其程序配置。
所以,从文件中读取数据的能力几乎对所有程序都很重要。但是假如要读取的文件不存在,会发生什么呢?
在 C 语言中读取文件,首先要用 `fopen` 函数打开文件,该函数会返回指向文件的流指针。你可以结合其他函数,使用这个指针来读取数据,例如 `fgetc` 会逐个字符地读取文件。
如果要读取的文件不存在或程序没有读取权限,`fopen` 函数会返回 `NULL` 作为文件指针,这表示文件指针无效。但是这里有一个示例程序,它机械地直接去读取文件,不检查 `fopen` 是否返回了 `NULL`:
```
#include <stdio.h>
int
main()
{
FILE *pfile;
int ch;
puts("Open the FILE.TXT file ...");
pfile = fopen("FILE.TXT", "r");
/* you should check if the file pointer is valid, but we skipped that */
puts("Now display the contents of FILE.TXT ...");
while ((ch = fgetc(pfile)) != EOF) {
printf("<%c>", ch);
}
fclose(pfile);
/* done */
puts("Ok");
return 0;
}
```
当你运行这个程序时,第一次调用 `fgetc` 会失败,程序会立即中止:
```
Open the FILE.TXT file ...
Now display the contents of FILE.TXT ...
Segmentation fault (core dumped)
```
始终检查文件指针以确保其有效。例如,在调用 `fopen` 打开一个文件后,用类似 `if (pfile != NULL)` 的语句检查指针,以确保指针是可以使用的。
人都会犯错,最优秀的程序员也会产生编程错误。但是,遵循上面这些准则,添加一些额外的代码来检查这五种类型的错误,就可以避免最严重的 C 语言编程错误。提前编写几行代码来捕获这些错误,可能会帮你节省数小时的调试时间。
---
via: <https://opensource.com/article/21/10/programming-bugs>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Even the best programmers can create programming bugs. Depending on what your program does, these bugs could introduce security vulnerabilities, cause the program to crash, or create unexpected behavior.
The C programming language sometimes gets a bad reputation because it is not memory safe like more recent programming languages, including Rust. But with a little extra code, you can avoid the most common and most serious C programming bugs. Here are five bugs that can break your application and how you can avoid them:
## 1. Uninitialized variables
When the program starts up, the system will assign it a block of memory that the program uses to store data. That means your variables will get whatever random value was in memory when the program started.
Some environments will intentionally "zero out" the memory as the program starts up, so every variable starts with a zero value. And it can be tempting to assume in your programs that all variables will begin at zero. However, the C programming specification says that the system does not initialize variables.
Consider a sample program that uses a few variables and two arrays:
```
#include <stdio.h>
#include <stdlib.h>
int
main()
{
int i, j, k;
int numbers[5];
int *array;
puts("These variables are not initialized:");
printf(" i = %d\n", i);
printf(" j = %d\n", j);
printf(" k = %d\n", k);
puts("This array is not initialized:");
for (i = 0; i < 5; i++) {
printf(" numbers[%d] = %d\n", i, numbers[i]);
}
puts("malloc an array ...");
array = malloc(sizeof(int) * 5);
if (array) {
puts("This malloc'ed array is not initialized:");
for (i = 0; i < 5; i++) {
printf(" array[%d] = %d\n", i, array[i]);
}
free(array);
}
/* done */
puts("Ok");
return 0;
}
```
The program does not initialize the variables, so they start with whatever values the system had in memory at the time. Compiling and running this program on my Linux system, you'll see that some variables happen to have "zero" values, but others do not:
```
These variables are not initialized:
i = 0
j = 0
k = 32766
This array is not initialized:
numbers[0] = 0
numbers[1] = 0
numbers[2] = 4199024
numbers[3] = 0
numbers[4] = 0
malloc an array ...
This malloc'ed array is not initialized:
array[0] = 0
array[1] = 0
array[2] = 0
array[3] = 0
array[4] = 0
Ok
```
Fortunately, the `i`
and `j`
variables start at zero, but `k`
has a starting value of 32766. In the numbers array, most elements also happen to start with zero, except the third element, which gets an initial value of 4199024.
Compiling the same program on a different system further shows the danger in uninitialized variables. Don't assume "all the world runs Linux" because one day, your program might run on a different platform. For example, here's the same program running on FreeDOS:
```
These variables are not initialized:
i = 0
j = 1074
k = 3120
This array is not initialized:
numbers[0] = 3106
numbers[1] = 1224
numbers[2] = 784
numbers[3] = 2926
numbers[4] = 1224
malloc an array ...
This malloc'ed array is not initialized:
array[0] = 3136
array[1] = 3136
array[2] = 14499
array[3] = -5886
array[4] = 219
Ok
```
Always initialize your program's variables. If you assume a variable will start with a zero value, add the extra code to assign zero to the variable. This extra bit of typing upfront will save you headaches and debugging later on.
## 2. Going outside of array bounds
In C, arrays start at array index zero. That means an array that is ten elements long goes from 0 to 9, or an array that is a thousand elements long goes from 0 to 999.
Some programmers sometimes forget this and introduce "off by one" bugs where they reference the array starting at one. In an array that is five elements long, the value the programmer intended to find at array element "5" is not actually the fifth element of the array. Instead, it is some other value in memory, not associated with the array at all.
Here's an example that goes well outside the array bounds. The program starts with an array that's only five elements long but references array elements from outside that range:
```
#include <stdio.h>
#include <stdlib.h>
int
main()
{
int i;
int numbers[5];
int *array;
/* test 1 */
puts("This array has five elements (0 to 4)");
/* initalize the array */
for (i = 0; i < 5; i++) {
numbers[i] = i;
}
/* oops, this goes beyond the array bounds: */
for (i = 0; i < 10; i++) {
printf(" numbers[%d] = %d\n", i, numbers[i]);
}
/* test 2 */
puts("malloc an array ...");
array = malloc(sizeof(int) * 5);
if (array) {
puts("This malloc'ed array also has five elements (0 to 4)");
/* initalize the array */
for (i = 0; i < 5; i++) {
array[i] = i;
}
/* oops, this goes beyond the array bounds: */
for (i = 0; i < 10; i++) {
printf(" array[%d] = %d\n", i, array[i]);
}
free(array);
}
/* done */
puts("Ok");
return 0;
}
```
Note that the program initializes all the values of the array, from 0 to 4, but then tries to read 0 to 9 instead of 0 to 4. The first five values are correct, but after that you don’t know what the values will be:
```
This array has five elements (0 to 4)
numbers[0] = 0
numbers[1] = 1
numbers[2] = 2
numbers[3] = 3
numbers[4] = 4
numbers[5] = 0
numbers[6] = 4198512
numbers[7] = 0
numbers[8] = 1326609712
numbers[9] = 32764
malloc an array ...
This malloc'ed array also has five elements (0 to 4)
array[0] = 0
array[1] = 1
array[2] = 2
array[3] = 3
array[4] = 4
array[5] = 0
array[6] = 133441
array[7] = 0
array[8] = 0
array[9] = 0
Ok
```
When referencing arrays, always keep track of its size. Store that in a variable; don't hard-code an array size. Otherwise, your program might stray outside the array bounds when you later update it to use a different array size, but you forget to change the hard-coded array length.
## 3. Overflowing a string
Strings are just arrays of a different kind. In the C programming language, a string is an array of `char`
values, with a zero character to indicate the end of the string.
And so, like arrays, you need to avoid going outside the range of the string. This is sometimes called *overflowing a string*.
One easy way to overflow a string is to read data with the `gets`
function. The `gets`
function is very dangerous because it doesn't know how much data it can store in a string, and it naively reads data from the user. This is fine if your user enters short strings like `foo`
but can be disastrous when the user enters a value that is too long for your string value.
Here's a sample program that reads a city name using the `gets`
function. In this program, I've also added a few unused variables to show how string overflow can affect other data:
```
#include <stdio.h>
#include <string.h>
int
main()
{
char name[10]; /* Such as "Chicago" */
int var1 = 1, var2 = 2;
/* show initial values */
printf("var1 = %d; var2 = %d\n", var1, var2);
/* this is bad .. please don't use gets */
puts("Where do you live?");
gets(name);
/* show ending values */
printf("<%s> is length %d\n", name, strlen(name));
printf("var1 = %d; var2 = %d\n", var1, var2);
/* done */
puts("Ok");
return 0;
}
```
That program works fine when you test for similarly short city names, like `Chicago`
in Illinois or `Raleigh`
in North Carolina:
```
var1 = 1; var2 = 2
Where do you live?
Raleigh
<Raleigh> is length 7
var1 = 1; var2 = 2
Ok
```
The Welsh town of `Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch`
has one of the longest names in the world. At 58 characters, this string goes well beyond the 10 characters reserved in the `name`
variable. As a result, the program stores values in other areas of memory, including the values of `var1`
and `var2`
:
```
var1 = 1; var2 = 2
Where do you live?
Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch
<Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch> is length 58
var1 = 2036821625; var2 = 2003266668
Ok
Segmentation fault (core dumped)
```
Before aborting, the program used the long string to overwrite other parts of memory. Note that `var1`
and `var2`
no longer have their starting values of `1`
and `2`
.
Avoid `gets`
, and use safer methods to read user data. For example, the `getline`
function will allocate enough memory to store user input, so the user cannot accidentally overflow the string by entering a long value.
## 4. Freeing memory twice
One of the rules of good C programming is, "if you allocate memory, you should free it." Programs can allocate memory for arrays and strings using the `malloc`
function, which reserves a block of memory and returns a pointer to the starting address in memory. Later, the program can release the memory using the `free`
function, which uses the pointer to mark the memory as unused.
However, you should only use the `free`
function once. Calling `free`
a second time will result in unexpected behavior that will probably break your program. Here's a short example program to show that. It allocates memory, then immediately releases it. But like a forgetful-but-methodical programmer, I also freed the memory at the end of the program, resulting in freeing the same memory twice:
```
#include <stdio.h>
#include <stdlib.h>
int
main()
{
int *array;
puts("malloc an array ...");
array = malloc(sizeof(int) * 5);
if (array) {
puts("malloc succeeded");
puts("Free the array...");
free(array);
}
puts("Free the array...");
free(array);
puts("Ok");
}
```
Running this program causes a dramatic failure on the second use of the `free`
function:
```
malloc an array ...
malloc succeeded
Free the array...
Free the array...
free(): double free detected in tcache 2
Aborted (core dumped)
```
Avoid calling `free`
more than once on an array or string. One way to avoid freeing memory twice is to locate the `malloc`
and `free`
functions in the same function.
For example, a solitaire program might allocate memory for a deck of cards in the main function, then use that deck in other functions to play the game. Free the memory in the main function, rather than some other function. Keeping the `malloc`
and `free`
statements together helps to avoid freeing memory more than once.
## 5. Using invalid file pointers
Files are a handy way to store data. For example, you might store configuration data for your program in a file called `config.dat`
. The Bash shell reads its initial script from `.bash_profile`
in the user's home directory. The GNU Emacs editor looks for the file `.emacs`
for its starting values. And the Zoom meeting client uses the `zoomus.conf`
file to read its program configuration.
So the ability to read data from a file is important for pretty much all programs. But what if the file you want to read isn't there?
To read a file in C, you first open the file using the `fopen`
function, which returns a stream pointer to the file. You can use this pointer with other functions to read data, such as `fgetc`
to read the file one character at a time.
If the file you want to read isn't there or isn't readable by your program, then the `fopen`
function will return `NULL`
as the file pointer, which is an indication the file pointer is invalid. But here's a sample program that innocently does not check if `fopen`
returned `NULL`
and tries to read the file regardless:
```
#include <stdio.h>
int
main()
{
FILE *pfile;
int ch;
puts("Open the FILE.TXT file ...");
pfile = fopen("FILE.TXT", "r");
/* you should check if the file pointer is valid, but we skipped that */
puts("Now display the contents of FILE.TXT ...");
while ((ch = fgetc(pfile)) != EOF) {
printf("<%c>", ch);
}
fclose(pfile);
/* done */
puts("Ok");
return 0;
}
```
When you run this program, the first call to `fgetc`
results in a spectacular failure, and the program immediately aborts:
```
Open the FILE.TXT file ...
Now display the contents of FILE.TXT ...
Segmentation fault (core dumped)
```
Always check the file pointer to ensure it's valid. For example, after calling `fopen`
to open a file, check the pointer's value with something like `if (pfile != NULL)`
to ensure that the pointer is something you can use.
We all make mistakes, and programming bugs happen to the best of programmers. But if you follow these guidelines and add a little extra code to check for these five types of bugs, you can avoid the most serious C programming mistakes. A few lines of code up front to catch these errors may save you hours of debugging later.
## 2 Comments |
13,895 | 如何在 Debian 和 Kali Linux 上安装 Chrome 浏览器 | https://itsfoss.com/install-chrome-debian-kali-linux/ | 2021-10-18T17:57:24 | [
"Chrome"
] | https://linux.cn/article-13895-1.html |
>
> Debian 和基于 Debian 的 Kali Linux 将 Firefox 作为默认的网页浏览器。但这并不意味着你不能在其中安装其他网页浏览器。
>
>
>

Chrome 浏览器非常流行,你可能已经在其他系统上使用它了。如果你想在 Debian 上安装 Chrome,你肯定可以这样做。
你在 Debian 的软件库中找不到 Chrome,因为它不是开源软件,但你可以从 Chrome 网站下载并安装它。
在本教程中,我将向你展示在 Debian 上安装 Chrome 的两种方法:
* GUI 方法
* 命令行方法
让我们先从 GUI 方法开始。
>
> 注意:我在这里的例子中使用的是 Debian,但由于 Kali Linux 是基于 Debian 的,所以同样的方法也适用于 Kali Linux。
>
>
>
### 方法 1: 在 Debian 上以图形方式安装 Chrome 浏览器
这是一个不费吹灰之力的方法。你去 Chrome 网站,下载 deb 文件,然后双击它来安装它。我将详细地展示这些步骤,这样你就能很容易地掌握了。
前往 Chrome 的网站。
[Get Google Chrome](https://www.google.com/chrome/)
你会看到下载 Chrome 的选项。

当你点击下载按钮时,它会给你两个下载安装文件的选项。选择写着 Debian/Ubuntu 的那个。

**请注意,Chrome 浏览器不适用于 32 位系统。**
接下来,你应该选择将文件保存到电脑中,而不是在软件中心打开进行安装。这样一来,下载的文件将被保存在下载文件夹中,而不是临时目录中。

进入下载文件夹,右击下载的 DEB 文件,选择用 “Software Install” 打开它。

它将打开软件中心,你应该看到现在安装 Chrome 浏览器的选项。点击安装按钮。

你会被要求输入账户的密码。这是你用来登录系统的同一密码。

在不到一分钟的时间里,Chrome 就会安装完毕。你现在应该看到一个删除选项,这表明软件已经安装完毕。

当 Chrome 在 Debian 上安装完毕,在系统菜单中搜索它并启动它。

它将要求成为你的默认浏览器,并将崩溃报告发送给谷歌。你可以取消勾选这两个选项。然后你就可以看到谷歌浏览器的窗口。

如果你登录了你的谷歌账户,你应该可以在这里同步你的密码、书签和其他浏览数据。好好体验吧!
还有一点,安装完 Chrome 后,你可以从系统中删除下载的 DEB 文件。不再需要它了,甚至在卸载 Chrome 时也不需要。
### 方法 2:在 Debian 上从终端安装 Chrome
你刚才看到的内容可以在终端中轻松实现。
首先,确保你的软件包缓存已经刷新,并且你已经安装了 `wget`,用于 [在终端中从网上下载文件](https://itsfoss.com/download-files-from-linux-terminal/)。
```
sudo apt update && sudo apt install wget
```
接下来是下载 Chrome 的 .deb 文件。
```
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
```
下载后,你可以用 `apt` 命令 [在终端安装 deb 文件](https://itsfoss.com/install-deb-files-ubuntu/),像这样:
```
sudo apt install ./google-chrome-stable_current_amd64.deb
```
安装完成后,你就可以开始使用 Chrome 了。
### 额外提示:更新 Chrome
这两种方法都会将谷歌的软件库添加到你的系统中。你可以在你的 `sources.list.d` 目录中看到它:
```
cat /etc/apt/sources.list.d/google-chrome.list
```
这意味着 Chrome 将与 Debian 和 Kali Linux 中的其他系统更新一起被更新。你知道 [如何在命令行中更新你的 Kali Linux](https://linuxhandbook.com/update-kali-linux/) 或 Debian 系统么?只要使用这个命令:
```
sudo apt update && sudo apt upgrade -y
```
### 从你的系统中卸载 Chrome
即使你选择用 GUI 方法在 Debian 上安装 Chrome,你也必须使用终端来删除它。
不要担心。这其实只是一个命令:
```
sudo apt purge google-chrome-stable
```
根据要求输入你的账户密码。当你输入密码时,屏幕上没有任何显示。这没关系。输入它并按回车键,确认删除。

好了,就这些了。我希望你觉得这个教程有帮助。
---
via: <https://itsfoss.com/install-chrome-debian-kali-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Debian and Debian-based Kali Linux come with Firefox as the default web browser. But this does not mean that you cannot install other web browsers in it.
Google Chrome is hugely popular and you probably already use it on other systems. If you want to install Chrome on Debian, you can surely do so.
You won’t find Google Chrome in the repositories of Debian because it is not open source software but you can download and install it from Chrome website.
In this tutorial, I’ll show you two methods of installing Chrome on Debian:
- GUI method
- Command line method
Let’s start with the GUI method first.
*Note: I am using Debian in the examples here but since Kali Linux is based on Debian, the same methods are also applicable to Kali Linux.*
## Method 1: Installing Chrome on Debian Graphically
This is a no-brainer. You go to the Google Chrome website, download the deb file and double lick on it to install it. I am going to show the steps in detail so that it is easy for you to follow it.
Go to Google Chrome’s website.
You’ll see the option to download Google Chrome.
When you click on the download button, it gives you two options for downloading the installer file. Go with the one that says Debian/Ubuntu.
**Please note that Google Chrome is NOT available for 32-bit systems.**
In the next screen, you should opt for saving the file to the computer instead of opening it in software center for installation. This way, the downloaded file will be saved in the Downloads folder instead of the temp directory.
Go to the Download folders and right click on the downloaded deb file and choose to open it with Software Install.
It will then open the software center and you should see the option to install Chrome now. Click on the install button.
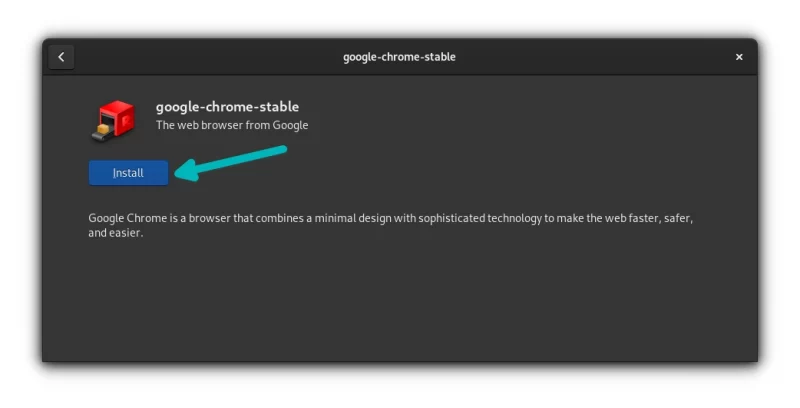
You’ll be asked to enter your account’s password. This is the same password you use to log into your system.
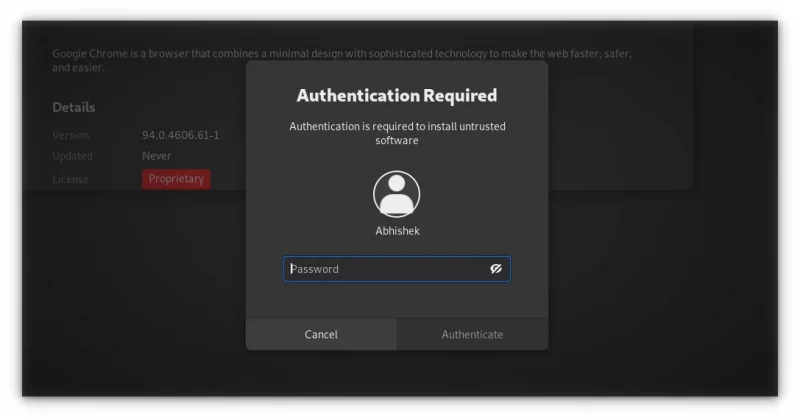
In less than a minute, Google Chrome will be installed. You should see a remove option now which indicates that the software is installed.
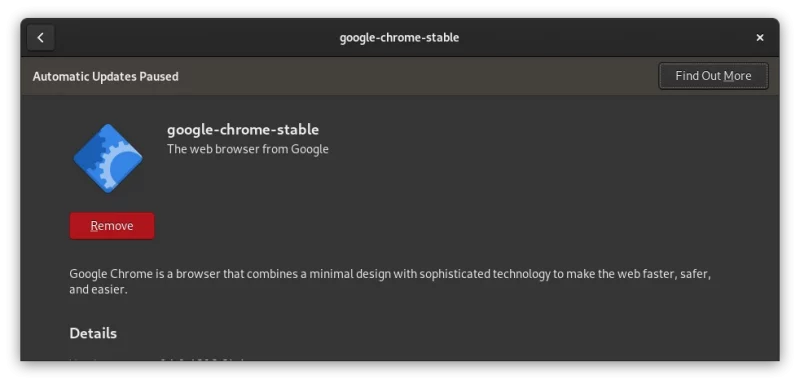
Once Chrome is installed on Debian, search for it in the system menu and start it.

It will ask to be your default browser and send the crash reports to Google. You can uncheck either or both options. And then you can see Google Chrome browser window.
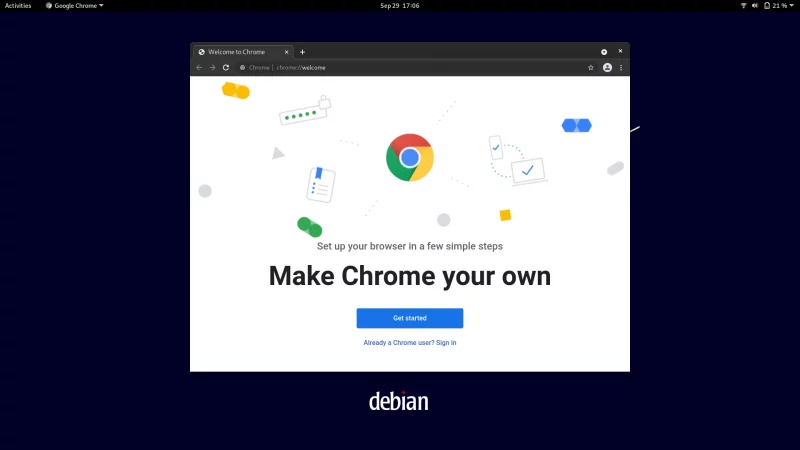
If you log into your Google account, you should be able to sync your passwords, bookmarks and other browsing data here. Enjoy it!
Another thing, after installing Chrome, you can delete the downloaded DEB file from your system. It is not needed anymore, not even for uninstalling Chrome.
## Method 2: Install Google Chrome on Debian from the terminal
What you just saw above can be easily achieved in the terminal.
First, make sure that your package cache is refreshed and you have wget installed for [downloading files from the web in the terminal](https://itsfoss.com/download-files-from-linux-terminal/).
`sudo apt update && sudo apt install wget`
The next option is to download the .deb file of Google Chrome:
`wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb`
Once downloaded, you can [install the deb file in the terminal](https://itsfoss.com/install-deb-files-ubuntu/) with apt command like this:
`sudo apt install ./google-chrome-stable_current_amd64.deb`
Once the installation completes, you can start using Chrome.
## Bonus tip: Updating Google Chrome
Both methods add Google’s repository to your system. You can see it in your sources.lis.d directory:
`cat /etc/apt/sources.list.d/google-chrome.list `
This means that Google Chrome will be updated with other system updates in Debian and Kali Linux. You know [how to update your Kali Linux](https://linuxhandbook.com/update-kali-linux/?ref=itsfoss.com) or Debian system in command line? Just use this command:
`sudo apt update && sudo apt upgrade -y`
## Uninstall Google Chrome from your system
Even if you chose to install Chrome on Debian using the GUI method, you’ll have to use the terminal to remove it.
Don’t worry. It’s really just one command:
`sudo apt purge google-chrome-stable`
Enter your account password when asked. Nothing is displayed on the screen when you type the password. That’s okay. Type it and press enter and confirm the deletion.
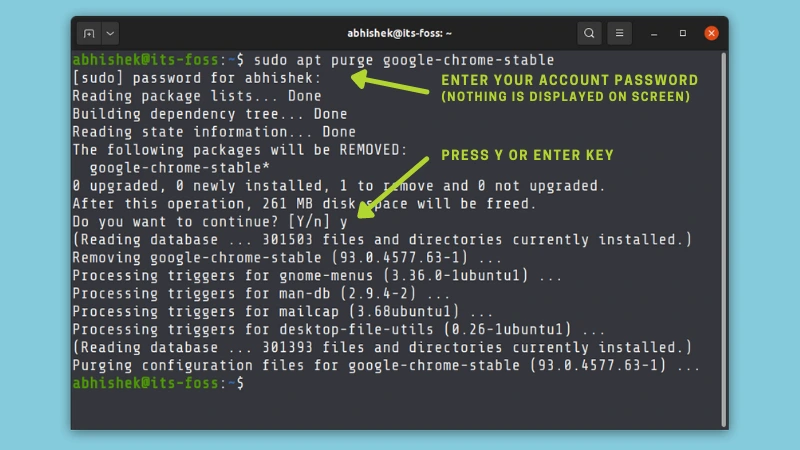
Well, that’s about it. I hope you find this tutorial helpful. |
13,897 | 浅谈主机名 | https://opensource.com/article/21/10/what-hostname | 2021-10-19T13:43:34 | [
"主机名",
"hostname"
] | https://linux.cn/article-13897-1.html |
>
> 主机名是人类用来指代特定计算机的标签。
>
>
>

计算机有网络地址,但人类通常很难记住它们。主机名是帮助人类参考特定计算机的标签。例如,你可能不会导航到 `192.168.1.4`,而是导航到 `linuxlaptop` 或 `linuxlaptop.local`。
### 地址和名称
所有联网的计算机(也被称为<ruby> 主机 <rt> host </rt></ruby>)都需要一个地址:一个与之相关的唯一数字,以使数据报文能够在它们之间进行正确的数据通信。这就是所谓的<ruby> 互联网协议 <rt> Internet Protocol </rt></ruby>(IP)地址。数字 `54.204.39.132` 是一个<ruby> 互联网协议第四版 <rt> Internet Protocol version 4 </rt></ruby>(IPv4)地址。较新的 IPv6 地址要长得多,像这样:`2001:0db6:3c4d:0017:0000:0000:2a2f:1a2b`。 哇!这将是很难记住的!
```
$ ip addr show
```
计算机也可以被赋予标签。被称为<ruby> 主机名 <rt> hostname </rt></ruby>,这些是友好的名称,便于参考。我可以把我的计算机的主机名设置为 `copperhead`。只要这个名字在网络上是唯一的,所有其他用户和计算机都可以把 `copperhead` 作为地址,而不是 IP 地址。
```
$ hostname -s
```
你可以更新你的计算机的主机名。
阅读 Seth Kenlon 的文章 [如何在 Linux 上更改主机名](https://opensource.com/article/21/10/how-change-hostname-linux),了解如何在 Linux 上这样做。
#### 完全限定域名
从技术上讲,主机名包括一个域名。如果我的域名是 `mycompany.com`,那么我的计算机的主机名是 `copperhead.mycompany.com`,以句点分隔。这就形成了一个<ruby> 完全限定域名 <rt> fully qualified domain name </rt></ruby>(FQDN)。这很重要,因为 IP 地址可以解析为 FQDN。
```
host.domain.topleveldomain
```
例如:`www.example.com` 是一个完全限定域名。
你的域名一般已经确定了,所以你只负责提供主机部分。本文的重点是主机。
#### 名称解析
将 IP 地址转换为相应的主机名的过程被称为名称解析。这个过程首先发生在本地主机表中。Linux 使用文件 `/etc/hosts` 来存储这个表。
```
cat /etc/hosts
```
还有一个分层的、去中心化的基于网络的系统提供解析,称为<ruby> 域名系统 <rt> Domain Name System </rt></ruby>(DNS)。这时 FQDN 变得非常重要。
```
$ dig www.opensource.com
```
### 名称的乐趣
为我们的计算机起名字可能很有趣。如果你有很多,你可以使用一个主题。我曾经为一家公司工作,该公司将所有的服务器都以蛇命名。
后来我工作的一家公司,我是一个数据中心经理,使用啤酒品牌。当我们收到一个新的服务器时,这很令人兴奋,因为我会给开发团队发邮件征求建议。我们大约有 100 台服务器。这些提供了一个有趣的清单,反映了公司的多样性。我们有从库尔斯和百威到阿姆斯特尔和浅粉象的一切。我们有虎牌啤酒、胜狮啤酒和札幌啤酒等等!
我们认为这很酷!然后,想象一下,当你试图记住卢云堡是拥有最多内存的虚拟化服务器,佩罗尼是 SQL 数据库服务器,喜力是新的域控制器时,会发生什么,特别是对于一个快速发展的公司的新员工。
### 惯例
当然,主机名是所有者的选择,所以请尽情发挥。然而,根据环境的不同,使用容易记忆的名字或基于命名惯例的名字可能更有意义,因为这些名字有利于描述主机。
#### 有用的名字
如果你想放弃有趣的东西,并对你的系统进行有益的命名,也许可以考虑它们的功能。数据库服务器可以被命名为 `database1`、`database2`、`database3` 等等。Web 服务器可以命名为 `webserver1`、`webserver2` 等等。
#### 位置名称
我在许多客户那里使用了一种技术,用一组字符的位置来命名服务器主机,这些字符描述了该系统的一个方面,有助于识别。例如,如果我正在为内政部(DOI)开发一个业务流程管理(BPM)系统,我就会在命名规则中加入他们的缩写词。
此外,就像许多大型企业、金融机构和政府一样,他们可能有不同的数据中心,位于不同的地理位置,以达到性能或灾难恢复的目的。因此,比如说,位于北美大陆东海岸的数据中心被称为 ED(East Data center),而位于西海岸的数据中心则是 WD(West Data center)。
所有这些信息将汇集到一个名称中,如 `doibpm1ed` 或 `doibpm1wd`。因此,虽然这些名字看起来不长,但在这个项目上工作的人可以很容易地识别它们的目的和位置,而且这个名字甚至可以对潜在的恶意者混淆它们的用途。换句话说,业主可以选择只对内部人员有意义的命名方式
### 互联网标准
有几个标准管理着主机名。你可以在<ruby> 互联网工程任务组 <rt> Internet Engineering Task Force </rt></ruby>(IETF)维护的<ruby> 意见征求 <rt> Requests for Comment </rt></ruby>(RFC)中找到这些标准。由此,请遵守以下规定:
* 主机名的长度应该在 1 到 63 个 ASCII 字符之间
* 一个 FQDN 的最大长度为 253 个 ASCII 字符
* 不区分大小写
* 允许的字符:`a` 到 `z`,`0` 到 `9`,`-`(连字符),和 `_`(下划线)。
我希望这篇文章能帮助你澄清主机名。玩得开心,发挥创意。
---
via: <https://opensource.com/article/21/10/what-hostname>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Computers have network addresses, but they're usually difficult for humans to remember. Hostnames are labels intended to help humans refer to a specific computer. Instead of navigating to 192..168.1.4, for instance, you might navigate to `linuxlaptop `
or `linuxlaptop.local`
.
## Addresses and Names
All networked computers (also referred to as hosts) need an address—a unique number associated with it that allows for datagrams to route among them for correct data communications. This is known as the Internet Protocol (IP) address. The number 54.204.39.132 is an Internet Protocol version 4 (IPv4) address. The newer IPv6 addresses are much longer, like this: 2001:0db6:3c4d:0017:0000:0000:2a2f:1a2b. WHOA! That is going to be hard to memorize!
`$ ip addr show`
Computers can also be given labels. Known as the hostname, these are friendly names for easier reference. I could set my computer's hostname to be *copperhead*. As long as that name is unique on the network, all other users and computers can refer to it as copperhead instead of the IP address number.
`$ hostname -s`
You can update your computer's hostname.
Read Seth Kenlon's article [How to change a hostname on Linux](https://opensource.com/article/21/10/how-change-hostname-linux) to learn how to do that on Linux.
### Fully qualified domain name
Technically, the hostname includes a domain name. If my domain name is mycompany.com, then together—delimited by periods, my computer's hostname is copperhead.mycompany.com. This forms a fully qualified domain name (FQDN). This is important because the IP address resolves to the FQDN.
`host.domain.topleveldomain`
For example: `www.example.com`
is a fully qualified domain name.
Your domain name is generally determined already, so you're only responsible for providing the host portion. This article focuses on the host.
### Name resolution
The process of translating the IP address to the corresponding hostname is known as name resolution. The first place that this occurs is in a local hosts table. Linux uses the file `/etc/hosts`
to store this table.
`cat /etc/hosts`
There is also a hierarchical and decentralized network-based system that provides resolution called the Domain Name System (DNS). This is when the FQDN becomes really important.
`$ dig www.opensource.com`
## Fun with names
It can be fun to think up names for our computers. If you have many, you could use a theme. I once worked for a company that named all of its servers after snakes.
A later company I worked for, where I was a data center manager, used beer brands. It was exciting when we received a new server because I would email the development team for suggestions. We had roughly 100 servers. These provided an interesting list that reflected the diversity of the company. We had everything from coors and bud to amstel and deleriumtremens. We had tiger and singha and sapporo and many others too!
We thought it was cool! Then again, imagine what happens when you try to remember that lowenbrau is the virtualization server with the most RAM and peroni is the SQL database server and heineken is the new domain controller, particularly for new employees in a rapidly growing company.
## Conventions
Hostnames are the choice of the owner, of course, so have fun with it. However, depending on the environment, it might make more sense to use names that are easy to remember or based on a naming convention that lends to being descriptive to the host.
### Useful names
If you want to forego the fun and helpfully name your systems, perhaps consider their function. Database servers might be named database1, database2, database3, and so on. Web servers might be webserver1, webserver2, and so on.
### Positional names
I have used a technique with many clients to name server hosts with sets of characters in positions that describe an aspect of that system that helps identification. For example, if I were working on a Business Process Management (BPM) system for the Department of the Interior (DOI), I would incorporate their acronyms in the naming convention.
Furthermore, just as with many large corporations, financial institutions, and governments, they might have various data centers located in disparate geographical locations for purposes of performance or disaster recovery. So, say, a data center on the East coast of the North American continent is referred to as ED, and those on the West coast are WD. East Data center and West Data center.
All of this information would come together in a name such as doibpm1ed or doibpm1wd. So, while these names don't look like much, someone working on this project would readily be able to identify each as to their purpose and location, and the name may even help to obfuscate their usage to would-be mal-actors. In other words, the owner could choose naming that would only make sense to insiders.
## Internet standards
Several standards govern hostnames. You can find these in Requests for Comment (RFC) maintained by The Internet Engineering Task Force (IETF). As of now, adhere to the following:
- A hostname should be between 1 and 63 ASCII characters in length
- A FQDN has a maximum length of 253 ASCII characters
- Case-insensitive
- Allowed characters: a to z, 0 to 9, - (hyphen), and _ (underscore)
I hope this article helps to clarify hostnames. Have some fun and be creative.
## Comments are closed. |
13,900 | 《代码英雄》第四季(8):史蒂夫·沃兹尼亚克轶事 | https://www.redhat.com/en/command-line-heroes/season-4/steve-wozniak | 2021-10-19T17:27:00 | [
"代码英雄"
] | https://linux.cn/article-13900-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》第四季(8):史蒂夫·沃兹尼亚克轶事](https://www.redhat.com/en/command-line-heroes/season-4/steve-wozniak)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/64943244-8a71-440e-ad39-d6165ebeac29/clh-s4-ep-woz-vfinal_tc.mp3)脚本。
>
> 导语:<ruby> 史蒂夫·沃兹尼亚克 <rt> Steve Wozniak </rt></ruby>(即<ruby> 沃兹 <rt> Woz </rt></ruby>)对硬件世界产生了巨大的影响。第四季介绍了许多他设计、制造、参与,以及受到他的启发的设备。但对沃兹来说,最重要的往往并不是他所创造的设备,而是他如何建造它们。
>
>
> 沃兹讲述了他早期的<ruby> 黑客改造 <rt> tinkering </rt></ruby>工作如何引发了他对工程的终生热情。他在高中时就开始在 GE 225 上学习计算机知识。很快,他就开始设计改进他想买的电脑,并最终确定了他的口号,即“简洁设计”。这种理念使得他在自制计算机俱乐部看到 Altair 8800 后完成了 Apple I,并为 Apple II 设计了软盘驱动器。但那时他最自豪的是他的工程成就得到了认可,并与世界分享了这些成就。
>
>
>
**00:00:01 - Saron Yitbarek**:
大家好,我是红帽原创播客《代码英雄》的主持人 Saron Yitbarek。如果你在数的话,本季是我们节目的第四季。在这一季中我们带你踏上了一段具有历史性的旅程,走进硬件世界以及那些敢于改变硬件制造传统的团队。从 Eagle 小型机到 GE-225 大型机,从 Altair 8800 到软盘,从 Palm 的掌上电脑到世嘉的电视游戏机,虽然这些机器现在已经过时,被大家所遗忘,但它们为今天的硬件演变和开发者们的发展铺平了道路。
**00:00:44**:
在此过程中,这些机器激发了个人计算机革命、开源软件运动和开源硬件运动,改变了计算机的历史进程。但在我们第四季结束之前,还有一件事要说。
**00:01:03 - <ruby> 史蒂夫·沃兹尼亚克 <rt> Steve Wozniak </rt></ruby>**:
我是<ruby> 史蒂夫·沃兹尼亚克 <rt> Steve Wozniak </rt></ruby>,苹果电脑公司的联合创始人。很高兴与您交谈。

>
> 三十多年来,史蒂夫·沃兹尼亚克一直在帮助塑造计算机行业。他的早期贡献包括设计苹果公司的第一条产品线:Apple I 和 Apple II。他帮助创建了<ruby> 电子前沿基金会 <rt> Electronic Frontier Foundation </rt></ruby>(EFF),并且是<ruby> 科技博物馆 <rt> Tech Museum </rt></ruby>、<ruby> 硅谷芭蕾舞团 <rt> Silicon Valley Ballet </rt></ruby>和<ruby> 圣何塞儿童探索博物馆 <rt> Children’s Discovery Museum of San Jose </rt></ruby>的创始赞助商。2017 年,他共同创办了<ruby> 沃兹大学 <rt> Woz U </rt></ruby>。
>
>
>
**00:01:08 - Saron Yitbarek**:
如果你回想一下本季的前面几集,就会发现史蒂夫·沃兹尼亚克的名字不止出现过一次、两次,而是很多次。这是因为沃兹(这是人们对他的亲切称呼),他不仅经历了那段历史,而且在其中发挥了重要作用。这个非常特别的代码英雄现在坐在这里,和我们谈论他在硬件历史上的亲身经历。让我们先从询问他钟爱的第一件硬件开始。
**00:01:42 - 史蒂夫·沃兹尼亚克**:
在我很小很小的时候,大概是 10 岁,我爱上了一台晶体管收音机,很多年以来,我睡觉的时候都会把它放在枕边播放音乐。这算是第一个,在那之后还经历了许多,在我做过的科学展览中就有几百个不可思议的部件。现在,谈到计算机方面的东西、命令行的东西,在我 10 岁那年,不知何故发现了一本叫做《数字逻辑》的小册子,我用它在纸上涂鸦。在那时我就说,“计算机将会是我一生的挚爱”。
**00:02:19 - Saron Yitbarek**:
20 世纪 60 年代,当史蒂夫·沃兹尼亚克还在上高中的时候,他有机会在通用电气公司(GE)放到他学校的一款电传终端机上试用分时系统,也就是我们在第二集中介绍 GE-225 大型机时讨论过的系统。
**00:02:37 - 史蒂夫·沃兹尼亚克**:
当时既没有书,也没有杂志告诉你“计算机是什么?”。在高中时我得到了……我记得是得到许可……去参与一次测试,测试我们几天前才有的一个小装置。它是一种和分时系统相连的<ruby> 电传打字机 <rt> teletype </rt></ruby>,在这上面可以运行一些用 BASIC 语言编写的程序。我在上面做了一些实验并且感叹道:“嗯,这个 BASIC 有点简洁。”
**00:02:58 - Saron Yitbarek**:
在他高中的最后一年,沃兹尼亚克的电子老师安排他去加州森尼维尔的一家当地公司 Sylvania 学习如何为他们的计算机编程。
**00:03:10 - 史蒂夫·沃兹尼亚克**:
我的电子老师让我去一家公司,每周用 Fortran 语言在一台 IBM 1170 上编程一次,我想 1170 大概是这台计算机的编号。我当时还没有看到它的架构。但是当有一天我去那里的时候,在一个工程师的桌子上看到有一本叫做《小型计算机手册》的书,描述了 PDP-8 <ruby> 小型计算机 <rt> minicomputer </rt></ruby>。
**00:03:33 - Saron Yitbarek**:
在第 1 集中,我们介绍了《<ruby> 新机器的灵魂 <rt> The Soul of a New Machine </rt></ruby>》这本书中讲述的故事,该故事讲述了<ruby> 通用数据公司 <rt> Data General </rt></ruby>的小型计算机 Eagle 是如何对抗<ruby> 数字设备公司 <rt> Digital Equipment Corporation </rt></ruby>的小型计算机 VAX 的。PDP-8 是 VAX 的前身,并且也是数字设备公司第一款成功商用的小型计算机。
**00:03:53 - 史蒂夫·沃兹尼亚克**:
他们让我那种那本手册,把它给了我。我把它带回家研究。我的天,这本手册上记录了所有的小寄存器中不同的 1 和 0 代表什么意思,它们意味着什么指令,以及数据是如何存储在内存中的。天哪。于是我开始坐着在纸上写到:“我想知道我是否可以设计一台电脑。”这对我来说是一个重要的开始。我得到了这本小册子,我可以订购手册来获得零件。此时的问题是怎么能找到一家电脑公司,并且得到这家公司的地址呢?
**00:04:19**:
斯坦福直线加速器中心,我开车就能去,世界上最聪明的人都不锁门(所以那里会开着门)。我会在周日去,在他们的主楼里走走。我在那里的二楼找到了图书馆,坐了下来,那里有计算机方面的期刊和杂志,你也可以在图书馆中的小卡片上订购手册。我订购了一本通用数据公司的手册,它显示了总裁、运营主管、软件与工程主管的鼎鼎大名。但你知道那不是我想要的。
**00:04:51**:
我想要知道 1 和 0 的含义。在最后一页,它展示了一条指令,那是一条算术指令。我习惯于每台电脑都有 56 条指令。每个指令,每一个小比特,都有各自小的含义。一个比特可能代表在加法之前设置进位。另外三位比特可能意味着你要做加法、减法、异或运算,以及其他一些操作。那么其他的比特就会问:等一下,你是要补码运算的结果还是移位运算的结果?移位运算有进位吗?每一个比特都有各自的含义。
**00:05:21**:
我坐了下来,每个周末都在设计计算机,而那时小型计算机问世了。我坐下来设计它,每一个具有含义的比特,其实就是一根连接到芯片上的线,用来实现具体的功能,它的芯片数是我设计的其他小型计算机的一半,而且工作得一样好。我的墙上贴着那张他们和宣传册一起寄来的海报,就像普通的计算机设备一样,它是放在机架中的,因为它是前置面板,开关代表着 0 和 1,灯也代表着 0 和 1,全是些古怪的东西。
**00:05:54**:
而他们还有另一张图片,就像那种放在桌面上的台式机那样。这引起了我的兴趣,你怎么能想象出电脑居然可以放在桌面上呢?我告诉我的父亲我爱上了它,肯定地对我父亲说:“总有一天我会拥有一台 4K 大小的通用数据公司的 Nova 牌电脑。”为什么大小是 4K ?因为需要 4K 的空间才能运行像我编程所使用的 Fortran,或是 ALGOL、PL/I 这样的语言、任何需要 4K 的编程语言。我之前从来没有用 BASIC 编程过,我把这个告诉我父亲的时候,他说这个电脑和房子一样贵,我回答道,“那我就住在公寓里。”当时我就决定:我要有一台可以真正使用的电脑,尽管要整天切换 1 和 0,用按钮来把它存入内存,但这就是我想要的,它甚至比房子更加重要。
**00:06:42 - Saron Yitbarek**:
通用数据公司的 16 位 Nova 牌小型计算机是 32 位计算机 Eclipse 的前身,就是第 1 集中代号为 Eagle 的那个。实际上,正是 Nova 小型计算机启发了沃兹的工程设计理念。
**00:06:59 - 史蒂夫·沃兹尼亚克**:
这台计算机教会了我,应该始终用现有的部件来设计东西,以使用最少的结构和零件。那是我非常擅长的事情,我一直在从事设计工作,总是试图使用芯片更少的架构。如果围绕已有的芯片进行设计,那么从某种意义上讲,可以理解为用更少的部件、更干净、更少的工作量。后来这也成为我设计的口头禅,始终寻求简单、直接、易懂,不要构建出这样复杂化的东西:来让一项工作在 20 个芯片上运行,实现正确的功能、得到正确的信号,而是寻找简单、直接的方法。
**00:07:39 - Saron Yitbarek**:
沃兹的设计理念让我想起我们在第 5 集中提到的 Palm 公司用来开发应用程序的 Palm 之禅:让它简单。
**00:07:51**:
还记得第 3 集中我们谈到的 Altair 8800 和个人计算机的诞生吗?史蒂夫·沃兹尼亚克参加了自制计算机俱乐部具有决定性的第一次会议,当时他一直制作自己的版本的计算机。
**00:08:07 - 史蒂夫·沃兹尼亚克**:
在那里,我展示了各种电子游戏的设计,比如 Altair 游戏,我甚至为 Altair 设计出了“越狱”。我还看到了当今互联网的前身:ARPANET,它开始时全国大概只有五六台计算机。我看到有人在那上面,在那时我已经知道如何设计点东西了。可以使用我的电视作为输出,我曾为电子游戏做过。所以我做了一个带键盘的小终端,花了 60 美元。在当时,这是这些东西中最昂贵的部分。我有了一个键盘和一个视频显示器,我可以通过电话线与 ARPANET 联系,在那些日子里,通过非常慢的电话线调制解调器发送文本非常缓慢,我可以在波士顿的一台电脑上打字,可以打字回给我。我还可以切换到加州大学洛杉矶分校的电脑上,在上面读取文件、运行程序。这太不可思议了!
**00:08:57**:
我听说有一家俱乐部要成立了,还没有取名,只是一群技术爱好者。我想,“哦,天哪!我要炫耀一下,我有个小设计,没人知道其实可以使用自己的电视来进行显示。我要去炫耀我的设计,把它传播出去,我将成为一个英雄。”我到了俱乐部后,那里的每个人都在谈论这个叫做 Altair 的东西。它曾出现在《<ruby> 大众电子 <rt> Popular Electronics </rt></ruby>》杂志的封面上,但我对此一无所知。有一些在这个俱乐部里的人去那个公司参观过,他们都在谈论现在你可以花 400 美元购买一台计算机。这是一台只有 256 字节内存的机器,它使用了静态内存。用的是英特尔的数据手册、英特尔的微处理器,英特尔展示了用这种方式具体连接到这些开关和灯,然后你可以有一个小系统来输入 1 和 0。
**00:09:39**:
在那之前,我用自己五年前买的芯片设计制造了自己的计算机。我曾经做过这些事,所以很清楚这些人在看什么,400 美元对一个人来说是负担得起的。设计师必须围绕静态存储器进行设计,这是计算机中最昂贵的部件,这也是为什么它只有 256 字节内存的原因。但如果你必须拥有 4K 的内存才能使用一种编程语言,那这些静态内存的成本就太高了,超出了任何正常人的能力范围,所以我们甚至不会认为它是一台能做有用事情的电脑。什么是有用的事情?遇到问题,输入程序,解决问题。
**00:10:14**:
现在,我坐在那里思考。我在惠普公司工作,研究能让人使用的计算器,而我有可以与 ARPANET 上的计算机进行通讯的小机器。我说,“等一下。”我发现微处理器的价格终于降下来了。英特尔的那款单个微处理器是 400 美元,我负担不起,Altair 就是基于它的。作为一名惠普的员工,我可以花 40 美元买到一个摩托罗拉 6800。因此,我设计出了具有微处理器和内存的计算机,不是那种买不起的昂贵的、价值 32 个芯片的静态内存。它只需要 8 块动态内存芯片,然后还有 5 块其他芯片帮助它循环,使它不致于丢失数据,这就是所谓的刷新。
**00:10:56**:
我围绕着摩托罗拉公司的 6800 设计计算机,之后一家公司在旧金山的一次展览上推出了 6502 微处理器。我买了那个微处理器,你知道的,整个设计计算机的公式都在我的脑海里,我很快就会拥有自己的计算机,而且我确实做到了。
**00:11:17 - Saron Yitbarek**:
沃兹并不是 BASIC 语言的忠实粉丝。但是,随着微软软件业务的起步:Altair BASIC 的推出,他意识到比尔·盖茨和保罗·艾伦的 BASIC 版本将会广泛使用。
**00:11:31 - 史蒂夫·沃兹尼亚克**:
Altair 一出现在我们俱乐部,我们就得到了这个消息。比尔·盖茨和保罗·艾伦已经为它开发了 BASIC。我的嗅觉告诉我,家用计算机的关键作用不再是传统意义上的计算机那样,也不再是库存量、销售数据、就业率,这些所有大公司用大型机在做的事情。不,它将会是游戏。它的关键是游戏、是 BASIC。我使用 Fortran、ALGOL 和 PL/I 以及一些汇编语言和科学计算的语言进行编程。除了高中的那三天之外,我一生中从未接触过 BASIC 语言,因为我觉得这是一种孩子的语言。
**00:12:08**:
这不是我们科学家真正使用的语言,我说:“这台机器上必须装有 BASIC 环境。”问题是没有其他人协助我的工作,这意味着,我不仅要开发硬件,还必须编写 BASIC 语言。我从来没有上过编写语言的课程,所以我写了自己的 BASIC 语言。我晚上去了我工作的惠普公司,打开 BASIC 手册,在纸上记录下 BASIC 的所有指令。我没有意识到此 BASIC 非彼 BASIC,和在所有的书中提起过的<ruby> 数字设备公司 <rt> Digital Equipment Corporation </rt></ruby>(DEC)所使用的那种 BASIC 语言、比尔盖茨也编写过的那种,在处理字符串和字的方式上完全是一种不同的语言。
**00:12:45**:
它们处理字的方法和惠普公司完全不同。那时候我认为,你编写了一个 BASIC 语言,你用你的计算机来运行 BASIC,这在哪儿都是一样的。但事实并不是这样。所以这是一个关键,Altair 意识到现在必须要有一种自己的语言,这种语言必须是 BASIC 语言,否则人们不会把它放在家里。
**00:13:03 - Saron Yitbarek**:
在第 4 集中,我们了解到软盘是如何产生的,但是这种便携式存储方式是随着 Apple II 的磁盘驱动器的发明才变得无处不在。史蒂夫·沃兹尼亚克在巨大的压力下,用两周的时间创造出这个漂亮的硬件。这是他的故事。
**00:13:25 - 史蒂夫·沃兹尼亚克**:
实际上,苹果公司遇到了一个问题。我们的 Apple II 计算机最初使用的是盒式磁带。这意味着你要进行手动操作,如果需要某个特定程序,要在盒式磁带中搜索,在磁带中找到这个程序,将其放入磁带播放器中,然后再把它读入计算机。这不像你可以输入 “run checkbook” 命令来运行一个支票薄程序那样。我希望有一天能够达到那个水平,我们召开了一次员工会议。他们允许苹果公司……刚成立还不到一年的苹果公司,和 Commodore 和 Radio Shack 这三家个人计算机公司参加内华达州拉斯维加斯的 CES 展览。
**00:14:00**:
哇哦!除了在电影里,我从来没有见过拉斯维加斯。我想去那里,在我们的员工会议上,“嗯,我们只打算派三个营销人员去。”Mike Markkula 说,他负责市场营销,是我们的投资人,与我和<ruby> 史蒂夫·乔布斯 <rt> Steve Jobs </rt></ruby>拥有同等的股份。史蒂夫·乔布斯会去,我们的销售人员 Gene Carter 也会去。我当时在想怎么去,只是不好意思说 “嘿!我是创始人之一,让我去看看拉斯维加斯!付钱让我去吧。”所以我举起了我的手,我也不知道那时为什么这么做。这场展览在两周以后开始。举手后我试图找个话题:“如果我们有了软盘,可以在展览上面展示它吗?”Mike Markkula 回答道:“当然可以!”他是我们公司中可以做主的人。这下球又踢到我这边了。
**00:14:38**:
如果对磁盘,它的软件和硬件一无所知的我能开发出一张软盘,在这张软盘上实现 “run checkbook”,在两周内做到这一点,他们就得带我去维加斯。如果他们要在展览会上介绍软盘,就得带上我。为此我每一天都在工作,不分昼夜、元旦、圣诞节,每一天都在工作。
**00:14:59**:
最开始我把视线聚焦在 Shugart 公司的五英寸软盘上,我注视着它,在脑海中对它进行逆向工程,把所有的东西都拆开,并且说道:“它需要的是大块数据,0 和 1,每个 4 微秒,我可以使用一根线来从我的计算机上提供这些数据。”所以我取出了所有的 Shugart 数字芯片,所有步进轨道的芯片,轨道之间切换使用所谓的步进电机,有 A、B、C、D 相位,每个相隔一个相位。A 是第一轨道,然后是 B-C,现在是第二轨道,再之后是 D-A,第三轨道。我一开始就去掉了他们的 20 块芯片,对自己说,“我只需要使用尽可能少的电路。”
**00:15:36**:
最后,我想到使用 7 块 1 美元的小芯片,可以在 4 微秒内一次写入这些数据位,以满足软盘的规格。我的计算机可以通过软件以不同的数据编码形式来计算出我需要发送的 0 和 1 。但更困难的是,当我把它放到我可以写入它的地方时,我可以用示波器看到信号高高低低变化,但我不知道它在哪里开始和停止。现在我必须要读取它。
**00:16:04**:
为了读取它,有一个比特进来,然后你需要做的就是等待...它将会在 4 或 8 微秒内切换,所以时间大约在 6 微秒内,你可以内置计时器然后说道:“在那段时间内信号从高到低还是从低到高?”我需要很多的芯片,可能是 10 到 20 个,这谁又知道呢?这里面的计时器会确定什么时候真正做出信号翻转的决定。然后我说:“我有一个 7 MHz 的时钟,我做一个所谓的状态机。”我在大学三年级的时候就上过一门状态机课程,状态机一般会有一个地址,来标识着现在所在的位置,或者是一个状态号。我只是想到了进入一个小 ROM 芯片的地址,我现在手里有这个 256 \* 8 的 ROM 芯片。
**00:16:48**:
我会把地址放在那个状态,这就决定了它现在的位置,然后放入软盘读取头的读到的比特。我把那个读取到的比特放进去,ROM 决定我的下一个状态,然后下一个状态就出现了这些比特。我可以在 7 MHz 的条件下翻转 28 个周期,这相当于是 4 微秒的时间,可以让它进入阶段 1、阶段 2、阶段 3 ... 阶段 28,最后在阶段 40 左右,它将做出决定:我有没有得到脉冲?我是要把一个 0 还是一个 1 移到寄存器中放入计算机中。
**00:17:23**:
整个过程只需要两块芯片就可以读取所有的数据。回首往事,我不知道当年脑海中奇妙的想法是如何涌出的。我只是在观察问题出在哪里,做这项工作的最小零件数量是多少,而不是它曾经 …… 因为我以前不知道这是怎么做的。我有一个名叫 Randy Wigginton 的高中生程序员,那些日子一直在协助我工作。当我完成了全部的工作以后,不禁说道:“为什么他们卖给 Altair 和 S-100 这些计算机的电路板体型都这么大?”
**00:17:51**:
我拿出来一样东西,我想那是 North Star 的 8 英寸软盘什么的。我看了看他们的电路板,上面有 50 个芯片。而我的只有 8 个,我可以控制两个软盘驱动器,并且正常工作。我们在展会上介绍了它。我去了拉斯维加斯,我要教我的高中朋友 Randy 玩骰子,他还赢了我 35 美元。这是一个很大而且重要的区别,因为对于用户而言,能够运行程序是一个巨大的进步。
**00:18:21 - Saron Yitbarek**:
在第 6 集中,我们了解了新一代的创客,即开源硬件运动背后的人们。这一运动被比作“自制计算机俱乐部”以及当时进行的所有合作与创新。我们问沃兹,他对硬件领域再次产生的创造力和开放性有何看法。
**00:18:44 - 史蒂夫·沃兹尼亚克**:
是的,我也是这样认为。你应该总是制作一些东西,并且分享你所拥有的东西,让别人能够运用他们自己的技能和经验对它加以拓展,做出比你原先想象的更新颖的事情,并将其应用到世界上不同的领域中,而不仅仅是一个你所理解那个小小的应用。我完全赞成。现在很多嵌入式处理器,有人做了这样的微处理器,实际上更像是制造了一张名片,它的厚度薄到像是上面只有一块扁平芯片的名片。你应该不知道,它还可以插入 USB 接口中。他花 2 美元建造了一台完整的 Linux 计算机。
**00:19:17**:
这些太令人兴奋了。我做了一个小的 PDP-8 套件,他们称之为 PiDP-8。树莓派是计算机,而这个套件有旧式 PDP-8 小型计算机所有的灯和开关,它还可以运行当时的一些 PDP-8 程序。PDP-8 最大内存只有 4K,这就是你如何让它与其他东西连接的方式。现在的处理器是树莓派里面的软件。你现在可以把树莓派与传感器和输出设备连接起来,人们就会想要进行实验和探索。
**00:19:52**:
回到构建某些复古计算机的过程中,肯定会教你如何将硬件连接到硬件,如何将其连接,以及如何使用它来做更多的事情。我能做什么还没做的事情?可能有点不同。这就是我喜欢的。独立的人,往往是学生。我想要学习,想尝试一些对生活没有任何价值的东西。我回顾这一系列的项目,可能有 10 或 15 个项目,没有任何价值。它们当时只是我觉得有趣的事情:“也许我可以做这个,我会尝试把这个放在一起,我会把这个构建起来。”如果你知道芯片的内部的构造方式,就可以弄清整个电路是如何工作的。
**00:20:28 - Saron Yitbarek**:
作为苹果公司的创始人之一,史蒂夫·沃兹尼亚克是现代科技的象征。但是对他来说,成功与名气无关。最重要的是让他的工作被看到,而工作始于命令行。
**00:20:45 - 史蒂夫·沃兹尼亚克**:
在我的一生中,甚至在苹果公司之前,我为公司做了很多项目,比如有史以来第一个酒店电影系统,电视台的使用一英寸磁带卷的时间码。我在做各种电路,一直以我的工程为荣。我希望其他工程师也能看到我的作品,因为一个工程师能看到普通人看不到的东西。不是它做什么,它是如何构造的。我想让他们看到它,为我的工程技能而发出惊叹。
**00:21:14**:
最近,我获得了 IEEE 奖金。这是你一生中能得到的其他工程师对电子工程的最高认可。我的意思是,它几乎让我热泪盈眶。这就是我想要的。不是创办一家公司,不是开创一个行业,而是想以一个伟大的工程师而闻名。现在工程师们可以看到我做了什么,他们看到了它的效果,但他们不能看着我的原理图和代码说,“你是怎么写这些代码的?”
**00:21:41**:
这是我一生中获得的最有意义的奖项之一。因为那是我一直想要的,没有人知道。每个人都认为,“哦,我的第一台电脑是 Apple II ,我在上面做这个做那个,在学校里运行这些程序,哇,是你设计了它!”那很酷。但他们不是从工程的角度来看的。
**00:21:58 - Saron Yitbarek**:
谢谢你,史蒂夫·沃兹尼亚克,感谢你参加我们的《代码英雄》访谈。在这一季结束之前,我想请一位特别嘉宾来告诉大家第五季的情况。
**00:22:10 - Clive Thompson**:
我是<ruby> 克莱夫·汤普森 <rt> Clive Thompson </rt></ruby>,《<ruby> 程序员 <rt> Coders </rt></ruby>》一书的作者。在第五季中,我将会是 Saron 旁边的嘉宾,讲述开发者的职业生涯。不要错过它。
**00:22:21 - Saron Yitbarek**:
《代码英雄》是红帽的原创播客。请访问 [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes "redhat.com/commandlineheroes") 来看看我们对你在上一季听到的硬件的所有出色研究。我是 Saron Yitbarek,
**00:22:34 - 史蒂夫·沃兹尼亚克**:
我是史蒂夫·沃兹尼亚克。生命不息,编码不止。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-4/steve-wozniak>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[xiao-song-123](https://github.com/xiao-song-123) 校对:[pityonline](https://github.com/pityonline), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Steve Wozniak (aka Woz) has had a tremendous effect on the world of hardware. Season 4 features many of the devices he’s designed, built, worked on, and been inspired by. But for Woz, what’s most important isn’t necessarily the devices he’s created—it’s how he built them.
Woz recounts how his early tinkering led to a lifelong passion for engineering. He started learning about computers on a GE 225 in high school. Soon enough, he was designing improvements to computers he wanted to buy—eventually defining his mantra for simplicity in design. That philosophy helped him finish the Apple I after seeing the Altair 8800 at the Homebrew Computer Club, and to create the floppy drive for the Apple II. But what he’s proudest of these days is the recognition for his engineering accomplishments—and sharing them with the world.

**00:01** - *Saron Yitbarek*
Hello, I'm Saron Yitbarek, host of Command Line Heroes, an original podcast from Red Hat. This season, our fourth season, if you're counting, we took you on a historical journey into the world of hardware and the teams who dare to change the rules to make them. From the Eagle minicomputer to the GE-225 mainframe, the Altair 8800 to the floppy disk, the PalmPilot to the Sega Dreamcast, machines that are now obsolete and largely forgotten, but they all paved the way to the hardware of today and how we've evolved as developers.
**00:44** - *Saron Yitbarek*
Along the way, these machines changed the course of computing history by inspiring the personal computer revolution, the open source software movement, and the open source hardware movement. But before we close the doors on Season 4, there's one more thing.
**01:03** - *Steve Wozniak*
I'm Steve Wozniak, co-founder of Apple Computer. Glad to talk to you.
**01:08** - *Saron Yitbarek*
If you recall from many of our episodes this season, Steve Wozniak's name came up not once, not twice, but on several occasions. That's because the Woz, as he's affectionately known, not only lived that history, but he was instrumental in it. This very special command line hero sat down with us to talk about his lived experience in the annals of hardware. We started by asking him about the first piece of hardware he ever fell in love with.
**01:42** - *Steve Wozniak*
When I was very, very young, maybe 10 years old, I fell in love with a transistor radio, and for years I would sleep with it playing music by the side of my head then. So that was kind of a first one, but there were a lot of other steps in there. There were science fair projects that I did that were just hundreds of .incredible parts. Now, when if you get down to computerish stuff, command line stuff, I somehow discovered when I was 10 years old, a manual that talked about logic, digital logic, and I would play games on paper with it. And I said, "Computers are going to be the love of my life."
**02:19** - *Saron Yitbarek*
In the 1960s, when he was still in high school, Steve Wozniak had an opportunity to try out a time-sharing system via a teletype terminal that GE brought into his school. It was the same system we talked about in episode 2 when we featured the GE-225 mainframe.
**02:37** - *Steve Wozniak*
There were no books, no magazines. You couldn't find out “What is a computer?” And in high school, I got permission to go ... I guess I did, a gadget we had for just a few days, it was a test. It was a teletype connected to a time-sharing system to run some programs in BASIC. And so I did a few things and I said, "Well, this BASIC is kind of neat."
**02:58** - *Saron Yitbarek*
In his last high school year, Wozniak's electronics teacher arranged for him to go to Sylvania, a local company in Sunnyvale, California, to learn how to program their computer.
**03:10** - *Steve Wozniak*
My electronics teacher got me to go down to a company and program once a week in Fortran on an IBM 1170, I think was the computer number. And I didn't see its architecture yet. But while I was down there one day, I saw a book on a desk, an engineer's desk, called The Small Computer Handbook, describing the PDP-8 minicomputer.
**03:33** - *Saron Yitbarek*
In episode 1, we featured the story told in the book, The Soul of a New Machine, about how Data General's minicomputer, the Eagle, went up against Digital Equipment Corporation's VAX minicomputer. The PDP-8 was a precursor to the VAX and DEC's first commercially successful minicomputer.
**03:53** - *Steve Wozniak*
They let me have the manual. They gave it to me. I took it home and I studied it. My gosh, it had all the little registers at what different ones and zeroes mean, what instructions they mean, how the data is stored in memory. Oh, my gosh. So I started sitting down on paper saying, "I wonder if I could design a computer." And that was a big start for me. And I got this brochure. I would order brochures to get the parts. How could you ever get a hold of a computer company? How could you get their address?
**04:19** - *Steve Wozniak*
Stanford Linear Accelerator Center, I would drive down, and the smartest people in the world don't lock doors. I'd go on a Sunday, I'd go into their main building and just walk around. And I found the library on the second floor, and I'd sit down, and there were computer journals and magazines, and they had little cards you could order manuals from. So I ordered the Data General manual, and it came kind of showing the big, established names of the president and the head of operations and the head of software and engineering. Wow. And you know, but it wasn't what I want.
**04:51** - *Steve Wozniak*
I want the guts of ones and zeroes. On the last page, it showed that they had one instruction, one arithmetic instruction. I was used to like—every computer came out with 56 instructions. One instruction, and little bits had individual, small meanings. One bit might mean set the carry before the addition. Another bit, three bits might mean do you add, subtract, or exclusive or, and some other operations. And then another bit said, do you complement the result and do you shift the result? And do you shift the carry in? Wait a minute. Each bit had an individual meaning.
**05:21** - *Steve Wozniak*
When I finally sat down to design that computer, I was designing computers every weekend, minicomputers as they came out. I sat down to design it, and every time they had one bit with one meaning, that bit was a wire that ran to the chip that did exactly that thing, and it wound up with about half as many chips as all my other minicomputer designs, and it was just as good. I had posters of that computer on my wall that they shipped with their brochure. One was of it in a rack, like normal computerish stuff, you know, because it was front panel, switches for ones and zeroes, lights for ones and zeroes, all that geeky stuff.
**05:54** - *Steve Wozniak*
But they had another picture that was like a desktop version sitting on a tabletop. How could you ever imagine a computer on a tabletop? Caught my attention. And I decided, I also told my dad, I fell in love with it so much. I told my father, "Someday I'm going to own a 4K Data General Nova computer." Why 4K? You need 4K to run a language like Fortran, which I'd programmed in, or ALGOL or PL/I, any programming language needed 4K. I had never programmed in BASIC, so I told my dad that, and he said it costs as much as a house, and I said, "I'll live in an apartment." I had made up my mind then and there. I was going to have a computer that I could actually use. Even though I'm going to toggle in ones and zeroes all day and push a button to get it into memory, that's what I wanted in my life more than even a home.
**06:42** - *Saron Yitbarek*
Data General's 16-bit Nova minicomputer was a precursor to the 32-bit Eclipse, code-named Eagle from episode 1. In fact, the Nova minicomputer inspired Woz's engineering design philosophy.
**06:59** - *Steve Wozniak*
This computer taught me, you should always architect things to use the parts that are available to have the least structure and the fewest parts. That was something I became very good at. I'd been working and working at designs, always trying to get fewer and fewer chips, and if you design it around chips that already exist, you can use much fewer parts and much cleaner, much less work, in a sense, to understand it. And that became my mantra for design. Always seek simple, straightforward, easily understood, and don't complicate it by coming up with something you want to build and then wind up putting 20 chips together to kind of do the right functions and get the right signals on wires. No, look for the simple, direct approach.
**07:39** - *Saron Yitbarek*
Woz's design philosophy reminds me of the Zen of Palm, Palm's approach to building apps, which we talked about on episode 5: Make it simple.
**07:51** - *Saron Yitbarek*
Remember in episode 3 when we talked about the Altair 8800 and the birth of the personal computer? Steve Wozniak had been working on his own version during that time when he went to that fateful first meeting of the Homebrew Computer Club.
**08:07** - *Steve Wozniak*
I was showing all these designs of video games like Atari games, and I even designed Breakout for Atari, and I saw the ARPANET. That's the forerunner of today's internet, but it started out with like five or six computers spread all across the country. I saw somebody on that, and I knew how to design anything by then. And to use my TV as output, I had done that for video games. So I sat down and built a little terminal with a keyboard that costs 60 bucks. Way back then, that was the most expensive part of any of these things. I had a keyboard and a video display, and I could, over the phone line, contact the ARPANET and go on with very slow texting for very slow over phone line modems in those days, and I could type to a computer in Boston that could type back to me. And I could switch over to a computer at UCLA, and then I could read files and I could run programs. This was so incredible.
**08:57** - *Steve Wozniak*
I heard a club was starting. It did not have a name—it was just tech enthusiasts—and I thought, "Oh, my gosh. I'll show off. I have this little design. Nobody knows you can use your own TV that you own. I'll go and show off my design and give it away, and I'll be a hero." I went down to the club, and everybody was talking about this thing called the Altair. It had been on the front of Popular Electronics. I didn't know about it. There were people that had gone and visited the company at the club. They were all talking about now you can buy a computer for $400. It was a machine with only 256 bytes of RAM for that price, and it used static RAM. All it was, was an Intel datasheet, Intel microprocessor, with Intel showing you exactly connected this way to these switches and these lights, and then you could have a little system to punch in ones and zeroes.
**09:39** - *Steve Wozniak*
I had designed and built my own computer out of chips I got five years before that. I'd been there and done that. I knew exactly what these people were looking at, and 400 bucks was affordable by a human. They had to design it around static memories, the most expensive part of any computer. That's why it only had 256 bytes of memory. But if you had to put up like 4K of memory to have a programming language, those static memories cost so much. It was just out of the range of any normal human, so we wouldn't have even considered it was a computer that could do useful things. What's a useful thing? Have a problem, type in a program, solve the problem.
**10:14** - *Steve Wozniak*
And now, I'm sitting there thinking. I'm working at Hewlett-Packard on calculators that work with humans, and I have my little machine that can talk to a computer far away on the ARPANET. I said, "Wait a minute." I discovered the price of microprocessors had finally come down. The Intel one was $400. I could not afford that. For a single microprocessor, that's what the Altair was based on: Intel. And then as an HP employee, I could buy a Motorola 6800 for $40. Whoa. So I designed my computer to put a microprocessor and memory. Not expensive static memory that you can't afford, 32 chips worth. Just eight chips of dynamic memory and then five other chips to help cycle it and make it not forget its data. It's called refreshing.
**10:56** - *Steve Wozniak*
So I designed that computer around the 6800 from Motorola, and then a company introduced the 6502 microprocessor at a show in San Francisco and, oh, I bought that microprocessor, you know, and I knew—the whole formula was in my head. I'd have my own computer very soon. And I did.
**11:17** - *Saron Yitbarek*
Woz wasn't a big fan of the BASIC language. But with the introduction of Altair BASIC, the start of Microsoft software business, he realized Bill Gates and Paul Allen's version of BASIC would become widespread.
**11:31** - *Steve Wozniak*
Now the Altair, once it was out in our club, we knew very well. Bill Gates and Paul Allen had developed a BASIC for it. And I sniffed the wind. The key to computers in the home was going to not be what computers were used for traditionally, which was inventory levels, sales figures, employment, all the stuff big companies did with mainframes. No, it was going to be games. The key to it was games. And the key was BASIC. I had programmed in Fortran, ALGOL, and PL/I, and some assembly languages, the scientific languages. I had never touched BASIC in my life except for those three days in high school because it was a kid's language kind of.
**12:08** - *Steve Wozniak*
It wasn't really the language we scientists use, and I said, "Gotta have BASIC on this machine." And the trouble is I had no one else working with me. I mean, I not only developed the hardware, I had to write the BASIC language. I'd never taken a course in writing languages, so I wrote my own BASIC. I went into Hewlett-Packard at night where I worked, and I opened up the BASIC manual, and I started making notes on paper what all the commands were in BASIC. I didn't realize that BASIC was not BASIC—that the BASIC that digital equipment used that was in all the books and Bill Gates had programmed was totally a different language in how they handled strings of characters, words.
**12:45** - *Steve Wozniak*
They handled words totally different than Hewlett-Packard. I just thought if you write a BASIC, you make your own computer running BASIC, it's the same everywhere. No, it wasn't. So that was a key of the Altair was realizing that now you have to have a language, and the language is BASIC or people won't want it in their homes.
**13:03** - *Saron Yitbarek*
In episode 4, we learned how the floppy disk came to be, but this portable storage method only became ubiquitous with the invention of the Apple II's disk drive. Steve Wozniak created this beautiful piece of hardware in a high pressure, two-week time frame. Here's his story.
**13:25** - *Steve Wozniak*
An issue came up at Apple actually. What we started out with was an Apple II computer with cassette tapes. That means you manually, if you wanted a certain program, you search through the cassette tape, found that program, put it in a tape player and read it into your computer. It wasn't like you could type “run checkbook” to run a checkbook program. I wanted to get to that level someday, and we had a staff meeting, and they were going to allow ... Apple, since we were less than a year old ... Apple, Commodore, and Radio Shack, three personal computer companies, into the CES show in Las Vegas, Nevada.
**14:00** - *Steve Wozniak*
Wow. I had never seen Las Vegas except in movies. I wanted to go there, and in our staff meeting it was said, "Well, we're only going to send three marketing people." Mike Markkula, who ran marketing and was our investor, equal stock owner to me and Steve Jobs. Steve Jobs would go, and our sales guy, Gene Carter, would go. And I was thinking, I'm just too shy to say, "Hey, I'm a founder. Let me go see Las Vegas. Pay for me to go." So I raised my hand. I don't know why I did this. The show was in two weeks. I said, "If we have a floppy disk, can we show it?" Mike Markkula said, "Yes," and my wheels are spinning. He was the adult in the company. My wheels are spinning in the back of my head.
**14:38** - *Steve Wozniak*
If I can develop a floppy disk, not knowing a thing about disks, hardware or software, if I can do it in two weeks to where you can say “run checkbook,” they'll have to take me to Vegas. If they're going to show the floppy disk, they'll have to take me. I worked every single day, day and night, New Year's Day, Christmas Day, every day I worked on it.
**14:59** - *Steve Wozniak*
I first looked at the Shugart five-inch floppy disk. I looked at it, and I sort of reverse engineered it in my head, and I took everything apart and I said, "All it needs is chunks of data, zeroes and ones, four microseconds each. I can supply that from my computer with one wire." So I took out all the Shugart digital chips, all the ones that would step tracks, track to track to track with what's called stepping motor, had phases, A, B, C, D, and every other phase. A would be a track one, and then you go B-C, and now you're on track two. And you go D-A again, you're on track three. I stripped out 20 of their chips to begin with, and then I said, "I'm just going to have the minimum circuits I can."
**15:36** - *Steve Wozniak*
I came up with, in the end, seven little $1 chips, and I could write those data bits out four microseconds at a time to meet the specs of the floppy disk. And my computer could do the software to figure out what ones and zeroes I had to send that equaled ones and zeroes in a different coded data form. But the more difficult thing was, then I got it to where I could write it, and I could look with an oscilloscope and see the data going up and down, but I don't know where any of it starts and stops. Now I have to read it.
**16:04** - *Steve Wozniak*
To read it, you have one bit coming in, and what you can do is you can wait ... it's going to switch in either four or eight microseconds, so around six microseconds, you could build in little timers and say, "Did the signal go from up to down or down to up in those periods?" It would have taken me so many chips, 10 to 20 chips, who knows, with timers in there to determine when is it really making the decision to flip. And then I said, "I've got a little seven megahertz clock, and I'll make what's called a state machine." I'd had a state machine course in my third year of college, and a state machine basically has an address that says where I am now, or a state number, and I just think of addresses into a little ROM chip, a little 256 by 8 ROM chip that was available now.
**16:48** - *Steve Wozniak*
I'll put an address in that's at state. That's where it is now in deciding things, and in comes this one bit that's coming from the read head of the floppy. I'll put that one read bit in, and then the ROM decides here's what my next state will be, and then here comes the bits the next day. And I could flip it—28 of those cycles at seven megahertz equals a four-microsecond stretch, and I could just have it go to stage one, stage two, stage three, stage 28, and then eventually around stage 40 or something, it makes a decision. Did I get a pulse or not? I'll shift a zero or I'll shift a one into the register that goes to the computer.
**17:23** - *Steve Wozniak*
This whole thing was two chips just to read all that data. I look back, I do not know where the magic was pouring out of my head in those days. I just looked at what's the problem, what is the absolute minimum number of parts to do that job and not how it's ever ... because I'd never known how it was done before. I had a high school programmer, Randy Wigginton, working on this with me all those days too. When I got all done, I said, "Why are the other boards so big that they sell for Altair and the S-100 computers?"
**17:51** - *Steve Wozniak*
And I pulled out, I think it was a North Star eight-inch floppy disk or something. I looked at their board, and it had like 50 chips on it. I only had eight on mine, and I could handle two floppy drives. And it worked. We introduced it at the show. I got to see Las Vegas, I got to teach my high school friend Randy how to play craps, and he won 35 bucks, and that was a big, important difference. To be able to run a program is a huge step for a user.
**18:21** - *Saron Yitbarek*
In episode 6, we learned about a whole new generation of makers, the people behind the open source hardware movement. This movement has been compared to the Homebrew Computer Club and all the collaboration and innovation that was going on then. We asked Woz what he thinks of the creativity and openness being generated in hardware again.
**18:44** - *Steve Wozniak*
Well, I believe in it. And you should always make things and share what you have and make it possible for others to use their own skills and experience and expand on it and do something new and more than you had even thought of originally and apply it to a lot of different applications in the world. Not just one tiny one that you understand. No, I'm totally for that. And a lot of the embedded processors now, these tiny little processors, here's a guy who actually built a business card, as thin as a business card with a little flat chip on it, you know barely, and it plugs into USB. For $2 he builds it, and it's a full Linux computer.
**19:17** - *Steve Wozniak*
These things are just so exciting. I built a little a PDP-8 kit, PiDP-8 they call it. The Raspberry Pi is the computer, and the kit is just all the lights and switches for the old PDP-8 minicomputer, and it can run some PDP-8 programs from back then. Only has 4K of memory maximum, and it's how do you connect it to something. The processor is now software inside of a Raspberry Pi. And now you can connect Raspberry Pi to sensors and output devices, and people will want to experiment and explore.
**19:52** - *Steve Wozniak*
Going back to building some of the retro computers sure teaches you how hardware connects to hardware and how to hook it up and how to do more things with it. What can I do that hasn't been done yet? A little bit differently maybe. That's what I love. The independent person, usually a student. I want to learn, I want to try something. It doesn't have any value in life. I look back to a series of projects, maybe 10 or 15 projects where they didn't have any value. They were just fun things I thought of at the time: "Maybe I can do this. I'll try putting this together. I'll build this up." If you know how a chip is constructed inside, you could figure out how the whole circuit is going to work.
**20:28** - *Saron Yitbarek*
As one of the founders of Apple, Steve Wozniak is an icon of modern technology. But for him, success isn't about fame. What's most important is being seen for his work, and that work starts at the command line.
**20:45** - *Steve Wozniak*
All my life, even before Apple, I was doing a lot of projects on the side for companies, electronic projects like the first hotel movie system ever, timecodes for the one-inch tape reels that television stations used. I was doing all the circuits, and I was always proud of my engineering. I wanted other engineers to look at my work, as an engineer could see things that a normal person can't. Not what it does, how it's built. And I wanted them to look at it and “Whoa” and be amazed at my engineering skills.
**21:14** - *Steve Wozniak*
Recently, I got an IEEE fellowship. That's the highest electrical engineering kind of acknowledgement by other engineers you can get in your life. I mean, it just almost brings tears to me. That's what I wanted. Not to start a company, not to start an industry as much as I wanted to be known as a great engineer. Now engineers can see what I did. They see the effects of it, but they can't look at my schematics and my code and say, "How did you do that code?"
**21:41** - *Steve Wozniak*
It is one of the most meaningful awards I've ever gotten in my life. Because that's what I always wanted. And nobody knows that. Everybody thinks, "Oh, my first computer was an Apple II, and I did this and that on it and ran these programs at school and wow, and you designed it." That's cool. But they aren't looking from the engineering point of view.
**21:58** - *Saron Yitbarek*
Thank you, Steve Wozniak, for joining us on Command Line Heroes. Before I close out the season, I'd like to bring on another special guest to tell you about season 5.
**22:10** - *Clive Thompson*
I'm Clive Thompson, author of the book, Coders. I'll be Saron's fireside guests during season 5, all about the career life of developers. Don't miss it.
**22:21** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Go to [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) to check out all our great research on the hardware you heard about this past season. I'm Saron Yitbarek and ...
**22:34** - *Steve Wozniak*
I'm Steve Wozniak. Keep on coding.
### Steve Wozniak
For more than thirty years, Steve Wozniak has helped shape the computing industry. His early contributions include designing Apple’s first line of products: the Apple I and II. He helped found the Electronic Frontier Foundation, and was a founding sponsor of the Tech Museum, the Silicon Valley Ballet, and the Children’s Discovery Museum of San Jose. In 2017, he co-founded Woz U. |
13,901 | PinePhone Pro:一款价位适中的 Linux 旗舰智能手机 | https://news.itsfoss.com/pinephone-pro-introduced/ | 2021-10-20T10:04:44 | [
"PinePhone",
"手机"
] | https://linux.cn/article-13901-1.html |
>
> 售价 399 美元的 PinePhone Pro 是一款 Linux 智能手机,或许有潜力取代一些预算相当的 Android 设备。但作为消费者,还需要等待几个月。
>
>
>

早在 2019 年,当 Pine64 宣布推出 PinePhone 时,没有人想到它会变得如此受欢迎。在短短两年间,Pine64 已经成功建立了一个由数万名开发者和用户组成的社区,大家一起努力使 Linux 完美地跑在了手机上。
现在,随着 PinePhone Pro 的宣布,Pine64 正在扩大 Linux 手机的受众范围。这个设备有许多令人难以置信的新功能,所有这些都使它可以与许多中档 Android 手机相提并论。
### PinePhone Pro 功能

与原来的 PinePhone 相比,PinePhone Pro 带来了巨大的升级。这些升级中最值得注意的是使用了 Rockchip 的六核 RK3399S SoC 芯片,这应该能显著地提升性能。其他一些值得注意的功能和升级还有:
* 4GB LPDDR4 内存
* 128GB 存储 + microSD 卡插槽
* 6 英寸 IPS 显示屏,采用 **大猩猩 4 号玻璃**。
* 1300 万像素(后置)+ 500 万像素(前置)的摄像头
让我们来探讨一下这方面的更多细节。
#### 性能更好

到目前为止,最重要的升级是 RK3399S SoC 的加入,它是 Pine64 和 Rockchip 合作的结果。这个令人印象深刻的强大 SoC 包含 6 个 CPU 核心,以及一个四核 Mali T860 GPU。
这一组合带来了显著的性能提升,使得 PinePhone Pro 的性能与大多数中档安卓手机相当。这带来了一个更快的系统,能够运行许多桌面级应用程序,如用于照片编辑的 GIMP 和用于仿真游戏的 RetroArch。
总的来说,这次升级将大大改善开发者和消费者的用户体验。
#### 内存更多
考虑到智能手机已经开始提供 6GB 内存作为基本变体时,Linux 智能手机也应该使用更多的内存来保持流畅。虽然在优化方面已经做了很多工作,但更多的内存总是有益的。
PinePhone Pro 提供了 4GB 的内存,当放在基座上时可以有更大的通用性,当作为手机使用时可以多打开几个应用程序。我对此感到非常兴奋,因为它应该能够模拟更多的游戏,增加 PinePhone Pro 作为娱乐设备的吸引力。
#### 存储空间升级
我的原版的 PinePhone 面临的最大挑战之一是存储空间不足。从看电影到玩仿真游戏,我不得不不断地删除文件以获得足够的存储空间。
然而,在 PinePhone Pro 上,Pine64 已经解决了这个问题,它提供了 128GB 的闪存,这对任何人来说都足够了。
#### 显示屏改进

虽然这并不是原版 PinePhone 的痛点,但 PinePhone Pro 的显示屏已经升级,变得更大,采用了大猩猩 4 号玻璃。这是非常值得欢迎的,这款手机现在应该可以提供明显改善的防刮伤性能和更多可用的屏幕空间。
虽然 AMOLED 面板会很好,但这在一定程度上会提高价格,可能会降低设备的吸引力。总的来说,我对这次升级很满意,我相信许多用户也是这样。
#### 相机升级
至少对我来说,原版的 PinePhone 的摄像头是一个相当大的痛点。主摄像头只有 500 万像素,还有一个小小的 200 万像素的前置摄像头,这两个摄像头都不能拍出非常高质量的图像。
原版的 PinePhone 的主摄像头已被移到 PinePhone Pro 的前面。它与一个 1300 万像素的索尼摄像头传感器相配,能够录制 4K 视频和提供更高的图像质量。
用户终于可以用他们的 Linux 智能手机来拍摄照片,在社交媒体平台上分享了。
### 你可以升级你的原版 PinePhone 吗?
这是我看到该公告时问的第一个问题。不幸的是,将你的 PinePhone 升级到 PinePhone Pro 主板是不可行的。我认为 Pine64 解释得很好:
>
> 虽然 PinePhone Pro 的主板尺寸适合 PinePhone,但机框、IPS 显示面板、摄像头、子板和散热系统都不同。例如,PinePhone Pro 的摄像头就不适合 PinePhone 的机框,而且与 PinePhone Pro 的主板在电气上不兼容。散热是另一个重要的考虑因素,因为在原来的 PinePhone 的机框中,较高的热量输出可能不能简单地忽略,这需要克服解决。
>
>
>
虽然 Pine64 不建议升级你原来的 PinePhone 的主板,但我认为尝试一下还是很有意思的。虽然令人失望,但也应该注意到,Pine64 并不打算停止原来的 PinePhone 开发,因为它对于想要一个便宜的 Linux 手机作为基本用途的人来说是完美的。
### 总结
总的来说,我非常兴奋地看到又一个设备进入 Linux 手机市场,尤其是像 PinePhone Pro 这样将得到良好支持(希望是这样)的设备。尽管其价格是 399 美元,但我认为很多人都会蜂拥而至购买这款手机。
如果你认为你可能是这些人中的一员,但你得等待几个月后的正式发布。
然而,想要获得早期设备的开发者现在可以点击下面的按钮来预购 PinePhone Pro。
* [预购PinePhone Pro](https://preorder.pine64.org/)
关于 PinePhone Pro 的可用性和规格的更多细节,你应该去他们的 [官方网站](https://www.pine64.org/pinephonepro/) 看看。
你要买 PinePhone Pro 吗?请在下面的评论中告诉我!
---
via: <https://news.itsfoss.com/pinephone-pro-introduced/>
作者:[Jacob Crume](https://news.itsfoss.com/author/jacob/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Back in 2019, when Pine64 announced the PinePhone, no one expected it to become as popular. Within just two years, Pine64 has managed to build a community of tens of thousands of developers and users, all working together to make Linux usable on a mobile phone.
Now, Pine64 is widening the audience for Linux phones with the announcement of the PinePhone Pro. This device has many incredible new features, all of which put it on par with many mid-range Android phones.
## PinePhone Pro Features

Compared to the original PinePhone, the PinePhone Pro is a massive upgrade. The most notable of these upgrades is the usage of the Rockchip Hexa-core RK3399S SoC, which should provide a significant performance boost. Some other notable features and upgrades include:
- 4GB LPDDR4 RAM
- 128GB storage + microSD card slot
- 6″ IPS display with
- 13 MP (rear) + 5 MP (front) cameras
Let us explore more details on that.
### Better Performance

By far the most significant upgrade, the inclusion of the RK3399S SoC is the result of a collaborative effort by Pine64 and Rockchip. This impressively powerful SoC packs 6 CPU cores, as well as a quad-core Mali T860 GPU.
This combination delivers significant performance gains, putting the PinePhone Pro in a similar performance bracket to most mid-range Android phones. The result is a much faster system capable of running many desktop-class applications such as GIMP for photo editing and RetroArch for emulation.
Overall, this upgrade will significantly improve the user experience for both developers and consumers.
### More Memory (RAM)
Considering when smartphones have started to offer 6 GB RAM as the base variants, a Linux smartphone should also use extra memory to keep things smooth. Although a lot of work has gone into optimizing this, more RAM is always beneficial.
The PinePhone Pro offers 4 GB of RAM, allowing greater versatility when docked and a few more open applications when used as a phone. I’m pretty excited about this, as it should enable more games to be emulated, increasing the PinePhone Pro’s appeal as an entertainment device.
### Upgraded Storage
One of the biggest challenges I faced with my original PinePhone was the lack of storage. From watching movies to playing emulated games, I constantly had to delete files to have enough storage.
With the PinePhone Pro, however, Pine64 has fixed this, offering it with 128 GB of flash storage, which should be enough for anyone.
### Improved Display

While not precisely a sore point of the original PinePhone, the display has been upgraded with the PinePhone Pro to be larger and have Gorilla Glass 4. This is highly welcome, as the phone should now offer significantly improved scratch resistance and more usable screen real estate.
While it would have been nice to see an AMOLED panel, this would have increased the price somewhat, possibly reducing the device’s appeal. Overall, I am happy with this upgrade, and I’m sure many users will be too.
### Essential Camera Upgrades
For me, at least, the original PinePhone’s cameras were a pretty big sore point. The primary shooter, which was just 5 MP, was accompanied by a tiny 2 MP front camera, neither of which produced very high-quality images.
The main shooter from the original PinePhone has been moved to the front of the PinePhone Pro. This is paired with a 13 MP Sony sensor capable of 4K video recording and much higher quality images.
Users can finally utilize their Linux smartphones to take photos to share across social media platforms.
## Can You Upgrade Your Original PinePhone?
This was one of the first questions I asked when I saw the announcement. Unfortunately, it is not feasible to upgrade your PinePhone to a PinePhone Pro mainboard. I think Pine64 explains it pretty well:
While the PinePhone Pro’s mainboard will fit the PinePhone, the chassis, IPS display panel, cameras, the daughterboard, and thermal dissipation systems are all different. For instance, the PinePhone Pro’s cameras will not fit into the PinePhone chassis and are electrically incompatible with PinePhone Pro’s mainboard. Thermal dissipation is another important consideration, as the higher heat output may not be trivial to overcome in the original PinePhone’s chassis.
Although Pine64 doesn’t recommend upgrading your original PinePhone’s mainboard, I think it would still be interesting to see what could be achieved by trying. While disappointing, it should also be noted that Pine64 has no intention of stopping the development of the original PinePhone, as it is perfect for people wanting a cheap Linux phone for fundamental usage.
## Wrapping Up
Overall, I am incredibly excited to see yet another device enter the Linux phone market, especially one as well-supported as the PinePhone Pro will (hopefully) be. Despite the **$399** price tag, I think that many people will flock to buy this phone.
If you think you might be one of those people, you will have to wait a few months for the official release.
However, developers wanting to receive an early unit can now click the button below to preorder the PinePhone Pro.
For more details on the availability and specifications of PinePhone Pro, you should head to their [official website](https://www.pine64.org/pinephonepro/?ref=news.itsfoss.com).
*Are you going to get a PinePhone Pro?* *Let me know in the comments below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,902 | 如何现在就升级到 Ubuntu 21.10 | https://itsfoss.com/upgrade-ubuntu-to-newer-version/ | 2021-10-20T10:51:06 | [
"Ubuntu"
] | https://linux.cn/article-13902-1.html | [Ubuntu 21.10 “Impish Indri” 刚刚发布](/article-13887-1.html)。如果你正在使用 Ubuntu 21.04,你应该有升级到 Ubuntu 21.10 的选项。

然而,这种推出将是逐步的。这意味着不是每个人都会立即得到新版本可用的通知。在你看到升级选项之前,可能需要几周的时间。
但是,如果你迫不及待地想获得带有 GNOME 40 和其他新功能的 Ubuntu 21.10 呢?你真的需要等待吗?不用。
### 现在就从 Ubuntu 21.04 升级到 Ubuntu 21.10
以下是你要做的。打开“<ruby> 软件和更新 <rt> Software & Updates </rt></ruby>”应用:

并确保你在“<ruby> 更新 <rt> Updates </rt></ruby>”标签下将“<ruby> 通知我新的 Ubuntu 版本 <rt> Notify me of a new Ubuntu version </rt></ruby>”设置为“<ruby> 任何新版本 <rt> For any new version </rt></ruby>”。

现在打开终端,输入以下命令,以确保你的系统已经更新:
```
sudo apt update && sudo apt upgrade
```
当你的 Ubuntu 21.04 系统安装了所有的更新,运行更新管理器来寻找开发版本(本例中为 Ubuntu 21.10)。
```
update-manager -d
```
它将打开寻找更新的“<ruby> 更新管理器 <rt> Update Manager </rt></ruby>”。由于你已经更新了系统,它不会找到新的更新来安装。然而,它将看到 Ubuntu 21.10 现在已经可用。

你可以点击“<ruby> 升级 <rt> Upgrade </rt></ruby>”按钮,按照屏幕上的选项开始升级程序。你需要有良好的网络速度来下载 2GB 的更新。确保你的系统在升级过程中保持与电源的连接。
享受 Ubuntu 21.10!
(题图:[discourse.ubuntu.com](https://discourse.ubuntu.com/t/wallpaper-competition-for-impish-indri-ubuntu-21-10/22852))
---
via: <https://itsfoss.com/upgrade-ubuntu-to-newer-version/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Ubuntu 24.04 LTS is here. If you are using Ubuntu 22.04 Long-term support release, you will not be immediately notified of this release. It might take a bit of time.
However, you can choose to upgrade your system to Ubuntu 24.04 LTS right now.
In either case, if you are using Ubuntu 23.10, you can upgrade to the latest LTS release as well.
No matter what you have now, if you want to get your hands on Ubuntu 24.04 LTS that [comes with GNOME 46](https://news.itsfoss.com/gnome-46-release/) and other new features, you no longer have to wait.
You can easily upgrade your system to Ubuntu 24.04 LTS right now.
Once you upgrade, you cannot go back to the previous version. You’ll have to freshly install it.
## Upgrading to Ubuntu 24.04 LTS from Ubuntu 23.10 Right Now
[make a backup of your data](https://itsfoss.com/backup-restore-linux-timeshift/)on an external disk. Having a
[live Ubuntu USB](https://itsfoss.com/intsall-ubuntu-on-usb/)helps you reinstall in some rare unfortunate incidents when the upgrade doesn’t go as planned.
Here, I assume that you are using Ubuntu 23.04 and want to upgrade. You can check what Ubuntu version you have using the following command in the terminal:
`lsb_release -a`
Here's the output you will see:
```
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 23.10
Release: 23.10
Codename: mantic
```
Here’s what you do. Open the Software & Updates application:

And make sure that you have set “Notify me of a new Ubuntu version” to “For any new version” under the Updates tab. This should be the case if you are using Ubuntu 23.10 in the first place.
Now open a terminal and enter the following command to make sure that your system is updated:
`sudo apt update && sudo apt upgrade`
Now run the Software Updater, and it should show you the option to upgrade to Ubuntu 24.04 LTS.
## Still don’t see the upgrade?
If you do not see the upgrade notification, you can still force it to find it for you.
You can make the update manager to look for development releases (Ubuntu 23.10 in this case) with this command:
`update-manager -d`
It will open the Update Manager tool that looks for updates. Since you have already updated the system, it won’t find new updates to install. However, it will see that Ubuntu 24.04 LTS is now available.
You can hit the upgrade button and follow the on-screen option to start the upgrade procedure.
Ensure these two things:
**You should have a good internet speed to download the update (~2 GB or more).****Your system should stay connected to a power source during the upgrade.**
The upgrade starts like this:
The next step shows you that the third-party PPAs will be disabled (so you will have to **manually enable them after the upgrade if needed**)

It will then prompt you to show the number of new packages to be installed and the ones that are no longer needed:
Hit “**Start Upgrade**” to continue with the upgrade process. The system will disable the lock screen during the upgrade process, and you will be notified of the same. Click Close.
Now it will download the packages, refresh/update packages, and install all the essentials.
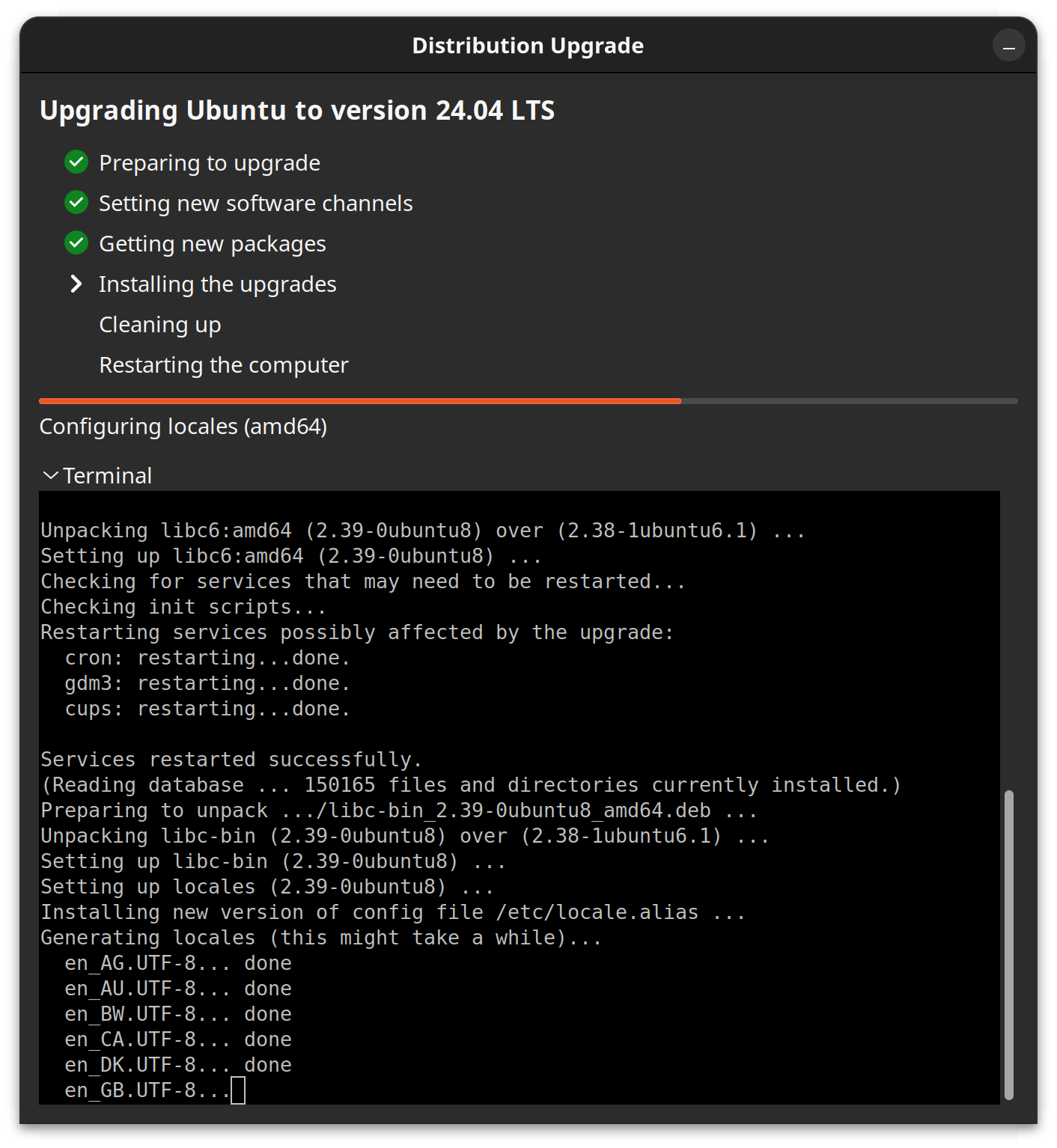
Next, you will be shown a prompt to remove obsolete packages. You can choose to keep any of them, but for the most part, you should be good.
You can continue the upgrade process and when it is done, it will ask you to restart the system to apply the upgrade.
And, done! **You have Ubuntu 23.10 installed on your system now:**
In case you are still using Ubuntu 22.04 LTS, and deciding if you want to upgrade to Ubuntu 24.04 LTS, you can decide by checking the changes between the two LTS editions:
[Ubuntu 22.04 vs 24.04: What Has Changed?What are the differences between Ubuntu 22.04 and Ubuntu 24.04? Should you upgrade to Ubuntu 24.04? Find out more here.](https://itsfoss.com/ubuntu-24-04-vs-22-04/)
 |
13,904 | 我推荐尝试的 5 个 Markdown 编辑器 | https://opensource.com/article/21/10/markdown-editors | 2021-10-21T09:58:45 | [
"Markdown"
] | https://linux.cn/article-13904-1.html |
>
> 每个人都有自己喜欢的 Markdown 编辑器。这里有几个我已经试过的。
>
>
>

你可以用 Markdown 做任何事情:给网站排版、编写书籍和撰写技术文档只是它的一些用途。我喜欢它创建富文本文档可以如此简单。每个人都有自己喜欢的 Markdown 编辑器。在我的 Markdown 之旅中,我使用了好几个。下面是我考虑过的五个 Markdown 编辑器。
### Abricotine
[Abricotine](https://abricotine.brrd.fr/) 是一个在 [GPLv](https://github.com/brrd/abricotine/blob/develop/LICENSE) 下发布的开源编辑器。你可以手动输入格式,或者使用菜单插入 [GitHub 风格的 Markdown](https://guides.github.com/features/mastering-markdown/)。Abricotine 允许你在输入时预览文本元素,如标题、图片、数学、嵌入式视频和待办事项。该编辑器只能将文件导出为 HTML。你可以在 Linux、macOS 和 Windows 上使用 Abricotine。

### MarkText
[MarkText](https://marktext.app/) 是一个简单的 Markdown 编辑器。它有很多功能,而且在处理 Markdown 格式的文件方面做得很好。MarkText 也支持 GitHub 风格的 Markdown,它允许你添加表格和带有语法高亮的代码块。它支持实时预览,并且有一个简单的界面。MarkText 是在 [MIT](https://github.com/marktext/marktext/blob/develop/LICENSE) 下授权的。它支持 HTML 和 PDF 格式的输出。MarkText 可以在 Linux、macOS 和 Windows 上使用。

### Ghostwriter
[Ghostwriter](https://wereturtle.github.io/ghostwriter/) 是一个用于 Linux 和 Windows 的 Markdown 编辑器。根据其网站用户的说法。“享受无干扰的写作体验,包括全屏模式和简洁的界面。有了 Markdown,你可以现在写,以后再格式化”。它有内置的默认的浅色和深色主题,或者你可以自己编写。你可以将文件实时按 HTML 预览,你可以直接复制和粘贴到博客中,或导出为其他格式。Ghostwriter 是在 [GPLv3](https://github.com/wereturtle/ghostwriter/blob/master/COPYING) 下发布的。

### Atom
[Atom](https://atom.io/) 被称为 21 世纪的可自定义文本编辑器。它也可以作为一个 Markdown 编辑器使用。它可以在 Linux、Windows 和 macOS上运行,并以 [MIT](https://github.com/atom/atom/blob/master/LICENSE.md) 许可证发布。它支持 GitHub 风格的 Markdown,并且按下 `Ctrl+Shift+M` 可以打开一个预览面板,这样你就可以轻松地看到 HTML 预览。你可以通过创建一个文件并以 `.md` 文件扩展名保存来轻松入门。这告诉 Atom 它是一个 Markdown 文件。Atom 会自动应用正确的包和语法高亮。

### VSCodium
[VSCodium](https://vscodium.com/) 是微软的 VSCode 编辑器的自由开源版本,没有内置在微软产品中的遥测技术。它以 [MIT](https://github.com/VSCodium/vscodium/blob/master/LICENSE) 许可证发布,并提供了 VSCode 的所有功能,而没有专有特性。除了其他功能外,VSCodium 还可以作为一个 Markdown 编辑器。创建一个新文件,点击 “选择一个语言”,选择 “Markdown”,然后开始写你的代码。通过按 `Ctrl-Shift+V` 轻松预览文本,然后再切换回编辑器。你也可以通过添加一个扩展来轻松地扩展 Markdown 编辑器。我最喜欢的插件是 [Markdown editor](https://github.com/zaaack/vscode-markdown-editor),它是 [MIT](https://github.com/zaaack/vscode-markdown-editor/blob/master/LICENSE) 许可证。

你最喜欢的 Markdown 编辑器是什么? 让我们在评论中知道。
---
via: <https://opensource.com/article/21/10/markdown-editors>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You can use markdown for anything—formatting websites, authoring books, and writing technical documentation are just some of its uses. I love how easy it is to create rich documents. Everyone has their favorite markdown editor. I have used several on my markdown journey. Here are five markdown editors I have considered.
[Abricotine](https://abricotine.brrd.fr/)is an open source editor released under the[GPL v.3.0](https://github.com/brrd/abricotine/blob/develop/LICENSE). You can enter formatting by hand or use the menu to insert[Github flavored Markdown](https://guides.github.com/features/mastering-markdown/). Abricotine allows you to preview text elements like headers, images, math, embedded videos, and to-do lists as you type. The editor is limited to exporting documents as HTML. You can use Abricotine on Linux, macOS, and Windows.
(Seth Kenlon,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))[MarkText](https://marktext.app/)is a simple markdown editor. It has many features, and it does a good job of handling documents formatted in markdown. MarkText also supports Github flavored Markdown, which allows you to add tables and blocks of code with syntax highlighting. It supports real-time preview and has a simple interface. MarkText is licensed under[MIT](https://github.com/marktext/marktext/blob/develop/LICENSE). It supports output in HTML and PDF. MarkText is available on Linux, macOS, and Windows.
(Seth Kenlon,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))[Ghostwriter](https://wereturtle.github.io/ghostwriter/)Is a markdown editor for Linux and Windows. According to users of its website: "Enjoy a distraction-free writing experience, including a full-screen mode and a clean interface. With markdown, you can write now and format later." It has built-in light and dark themes that come by default, or you can write your own. You can preview documents as live HTML that you can copy and paste directly into a blog or export into another format. Ghostwriter is released under the[GPL v.3.0](https://github.com/wereturtle/ghostwriter/blob/master/COPYING).
(Seth Kenlon,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))[Atom](https://atom.io/)is billed as a hackable text editor for the twenty-first century. It can function as a markdown editor too. It runs on Linux, Windows, and macOS and is released with an[MIT](https://github.com/atom/atom/blob/master/LICENSE.md)license. It supports Github flavored Markdown, and**Ctrl**+**Shift**+**M**opens a preview panel so you can easily see the HTML preview. You can get started easily by creating a file and saving it with the`.md`
file extension. This tells Atom that it is a markdown file. Atom automatically applies the right packages and syntax highlighting.
(Seth Kenlon,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))[VSCodium](https://vscodium.com/)is the free open source code release of Microsoft's VSCode editor without the telemetry built into the stock Microsoft product. It is released with an[MIT](https://github.com/VSCodium/vscodium/blob/master/LICENSE)license and provides all the functionality of VSCode without the proprietary features. In addition to its other features, VSCodium can function as a markdown editor. Create a new file, click**Select a Language**, choose*Markdown*and begin writing your code. Easily preview the text by pressing**Ctrl**-**Shift**+**V**and then toggle back to the editor. You can also easily extend the markdown editor by adding an extension. This is my favorite is[markdown editor](https://github.com/zaaack/vscode-markdown-editor)and it has an[MIT](https://github.com/zaaack/vscode-markdown-editor/blob/master/LICENSE)license.
(Seth Kenlon,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
What's your favorite markdown editor? Let us know in the comments.
## 11 Comments |
13,905 | Dash to Dock 终于可以在 GNOME 40 上使用了 | https://news.itsfoss.com/dash-to-dock-gnome-40/ | 2021-10-21T11:02:39 | [
"GNOME"
] | https://linux.cn/article-13905-1.html |
>
> Dash to Dock v70 增加了对 GNOME 40 的支持,并放弃了对较旧版本的 GNOME Shell 的支持。但是,你可以继续使用旧版本。
>
>
>

Dash to Dock 是多年来最 [有用的 GNOME 扩展](https://itsfoss.com/best-gnome-extensions/) 之一。随着 [GNOME 40](https://news.itsfoss.com/gnome-40-release/) 的引入,很多人都没能让这个扩展在它上面工作起来。
当然,作为一个流行的扩展,对 GNOME 40 的支持预计很快就会被加入。终于,它来了!
如果你不知道,GNOME 40 包括一个水平工作区视图,这影响了一些人的工作流程,但 Ubuntu 即使在 GNOME 40 中也没有移动 Dock 的打算。
所以,你仍然可以使用 Dash to Dock 来从概览区得到一个水平的 Dock。
### Dash to Dock v70 放弃了对旧的 GNOME Shell 的支持

Dash to Dock v70,对 GNOME 40 和特定的 3.34 版的 GNOME Shell 提供了支持。
然而,为了支持 GNOME 40 而对扩展所做的技术修改也意味着新版本的扩展不能再与旧版本的 GNOME Shell 一起工作。
如果你没有运行 GNOME 40,你仍然可以使用旧的 v69,它应该可以很好地工作。而且,除了增加了对 GNOME 40 的支持,在功能上也没有什么不同。
该扩展的未来发展可能很有趣,他们是否会考虑为不同的 GNOME Shell 版本而增加不同的扩展软件包,并提供新的功能?让我们拭目以待。
### 安装 Dash to Dock 的方法

你可以从 [GNOME 扩展网站](https://extensions.gnome.org/extension/307/dash-to-dock/) 中通过简单的切换按钮来安装这个扩展。如果你是新手,我建议通过我们的 [GNOME 扩展安装指南](https://itsfoss.com/gnome-shell-extensions/) 来开始。
* [Dash to Dock GNOME 扩展](https://extensions.gnome.org/extension/307/dash-to-dock/)
值得注意的是,你需要使用一个兼容的网页浏览器来安装这个扩展。虽然它应该可以在大多数浏览器上使用([基于 Chromium 的浏览器](https://news.itsfoss.com/chrome-like-browsers-2021/) 应该可以),但正如 [OMG! Ubuntu](https://www.omgubuntu.co.uk/2021/10/dash-to-dock-official-gnome-40-support?) 最初报道的那样,Ubuntu 21.10 中 Snap 打包的 Firefox 浏览器可能无法使用。
你试过这个扩展了吗?欢迎在下面的评论中告诉我你的想法。
---
via: <https://news.itsfoss.com/dash-to-dock-gnome-40/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Dash to Dock is one of the most [useful GNOME extensions](https://itsfoss.com/best-gnome-extensions/?ref=news.itsfoss.com) for years now. With the introduction of [GNOME 40](https://news.itsfoss.com/gnome-40-release/), many failed to make the extension work with it.
Of course, being a popular option, the support for GNOME 40 was expected to be added soon enough. And, finally, it is here!
If you did not know, GNOME 40 includes a horizontal workspace view, which affected the workflow for some, but Ubuntu did not move the dock even with GNOME 40.
So, you can still use Dash to Dock to get a horizontal dock from the overview area.
## Dash to Dock v70 Drops Support for Older GNOME Shells
With Dash to Dock v70, you get the necessary support for GNOME 40 and accurately GNOME shell 3.34.
However, the technical changes made to the extension to support GNOME 40 also meant that the new version could no longer work with older versions.
If you are not running GNOME 40, you can still use the older v69, which should work well. And, except GNOME 40 support addition, there’s nothing different feature-wise.
It will be interesting to see future releases for the extension from now on. Will they consider adding two different packages with new features for various Gnome shells? Let us wait for that.
## Here’s How To Install Dash to Dock
You can install the extension right from the [GNOME extension website](https://extensions.gnome.org/extension/307/dash-to-dock/?ref=news.itsfoss.com) with a simple toggle. In case you are new to this, I recommend going through our [guide on installing GNOME extensions](https://itsfoss.com/gnome-shell-extensions/?ref=news.itsfoss.com) to get started.
It is worth noting that you need to use a compatible web browser to install the extension. While it should work with most browsers ([Chromium-based browsers](https://news.itsfoss.com/chrome-like-browsers-2021/) should work), Firefox’s snap-packaged browser in Ubuntu 21.10 may not work, as reported initially by [OMG!Ubuntu](https://www.omgubuntu.co.uk/2021/10/dash-to-dock-official-gnome-40-support?ref=news.itsfoss.com).
Have you tried the extension yet? Feel free to let me know your thoughts in the comments below.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,908 | 在 Apache Cassandra 中定义和优化数据分区 | https://opensource.com/article/20/5/apache-cassandra | 2021-10-22T10:36:59 | [
"Cassandra"
] | https://linux.cn/article-13908-1.html |
>
> 速度和可扩展性是 Apache Cassandra 不变的追求;来学习一下如何充分发挥它的专长吧。
>
>
>

Apache Cassandra 是一个数据库,但又不是一个简单的数据库;它是一个复制数据库,专为可扩展性、高可用性、低延迟和良好性能而设计调整。Cassandra 可以帮你的数据在区域性中断、硬件故障时,以及很多管理员认为数据量过多的情况下幸免于难。
全面掌握数据分区知识,你就能让 Cassandra 集群实现良好的设计、极高的性能和可扩展性。在本文中,我将探究如何定义分区,Cassandra 如何使用这些分区,以及一些你应该了解的最佳实践方案和已知问题。
基本概念是这样的: 供数据库关键函数(如数据分发、复制和索引化)使用的原子单元,单个这样的数据块就是一个分区。分布式数据系统通常会把传入的数据分配到这些分区中,使用简单的数学函数(例如 identity 或 hashing 函数)执行分区过程,并用得到的 “分区键” 对数据分组,进一步再形成分区。例如,假设传入数据是服务器日志,使用 “identity” 分区函数和每个日志的时间戳(四舍五入到小时值)作为分区键,我们可以对这些数据进行分区,实现每个分区各保存一小时的日志的目的。
### Cassandra 中的数据分区
Cassandra 作为分布式系统运行,并且符合前述数据分区原则。使用 Cassandra,数据分区依赖于在集群级别配置的算法和在表级别配置的分区键。

Cassandra 查询语言(CQL)使用大家很熟悉的 SQL 表、行、列等术语。在上面的示例图中,表配置的主键中包含了分区键,具体格式为:<ruby> 主键 <rt> Primary Key </rt></ruby> = <ruby> 分区键 <rt> Partition Key </rt></ruby> + [<ruby> 聚簇列 <rt> Clustering Columns </rt></ruby>] 。
Cassandra 中的主键既定义了唯一的数据分区,也包含着分区内的数据排列依据信息。数据排列信息取决于聚簇列(非必需项)。每个唯一的分区键代表着服务器(包括其副本所在的服务器)中管理的若干行。
### 在 CQL 中定义主键
接下来的四个示例演示了如何使用 CQL 语法表示主键。定义主键会让数据行分到不同的集合里,通常这些集合就是分区。
#### 定义方式 1(分区键:log\_hour,聚簇列:无)
```
CREATE TABLE server_logs(
log_hour TIMESTAMP PRIMARYKEY,
log_level text,
message text,
server text
)
```
这里,有相同 `log_hour` 的所有行都会进入同一个分区。
#### 定义方式 2(分区键:log\_hour,聚簇列:log\_level)
```
CREATE TABLE server_logs(
log_hour TIMESTAMP,
log_level text,
message text,
server text,
PRIMARY KEY (log_hour, log_level)
)
```
此定义方式与方式 1 使用了相同的分区键,但此方式中,每个分区的所有行都会按 `log_level` 升序排列。
#### 定义方式 3(分区键:log\_hour,server,聚簇列:无)
```
CREATE TABLE server_logs(
log_hour TIMESTAMP,
log_level text,
message text,
server text,
PRIMARY KEY ((log_hour, server))
)
```
在此定义中,`server` 和 `log_hour` 字段都相同的行才会进入同一个分区。
#### 定义方式 4(分区键:log\_hour,server,聚簇列:log\_level)
```
CREATE TABLE server_logs(
log_hour TIMESTAMP,
log_level text,
message text,
server text,
PRIMARY KEY ((log_hour, server),log_level)
)WITH CLUSTERING ORDER BY (column3 DESC);
```
此定义方式与方式 3 分区相同,但分区内的行会依照 `log_level` 降序排列。
### Cassandra 如何使用分区键
Cassandra 依靠分区键来确定在哪个节点上存储数据,以及在需要时定位数据。Cassandra 通过查看表中的分区键来执行这些读取和写入操作,并使用<ruby> 令牌 <rt> tokens </rt></ruby>(一个 -2^{63}−263 到 +2^{63}-1+263−1 范围内的 long 类型值)来进行数据分布和索引。这些令牌通过分区器映射到分区键,分区器使用了将分区键转换为令牌的分区函数。通过这种令牌机制,Cassandra 集群的每个节点都拥有一组数据分区。然后分区键在每个节点上启用数据索引。

图中显示了一个三节点的 Cassandra 集群以及相应的令牌范围分配。这只是一个简单的示意图:具体实现过程使用了 [Vnodes](https://www.instaclustr.com/cassandra-vnodes-how-many-should-i-use/)。
### 数据分区对 Cassandra 集群的影响
用心的分区键设计对于实现用例的理想分区大小至关重要。合理的分区可以实现均匀的数据分布和强大的 I/O 性能。分区大小对 Cassandra 集群有若干需要注意的影响:
* 读取性能 —— 为了在磁盘上的 SSTables 文件中找到分区,Cassandra 使用缓存、索引和索引摘要等数据结构。过大的分区会降低这些数据结构的维护效率,从而对性能产生负面影响。Cassandra 新版本在这方面取得了长足的进步:特别是 3.6 及其以上版本的 Cassandra 引擎引入了存储改进,针对大型分区,可以提供更好的性能,以及更强的应对内存问题和崩溃的弹性。
* 内存使用 —— 大分区会对 JVM 堆产生更大的压力,同时分区的增大也降低了垃圾收集机制的效率。
* Cassandra 修复 —— 大分区使 Cassandra 执行修复维护操作(通过跨副本比较数据来保持数据一致)时更加困难。
* “墓碑”删除 —— 听起来可能有点骇人,Cassandra 使用称为“<ruby> 墓碑 <rt> tombstones </rt></ruby>”的独特标记来记录要删除的数据。如果没有合适的数据删除模式和压缩策略,大分区会使删除过程变得更加困难。
虽然这些影响可能会让人更倾向于简单地设计能产生小分区的分区键,但数据访问模式对理想的分区大小也有很大影响(有关更多信息,请阅读关于 [Cassandra 数据建模](https://www.instaclustr.com/resource/6-step-guide-to-apache-cassandra-data-modelling-white-paper/) 的深入讲解)。数据访问模式可以定义为表的查询方式,包括表的所有 `select` 查询。 理想情况下,CQL 选择查询应该在 `where` 子句中只使用一个分区键。也就是说,当查询可以从单个分区,而不是许多较小的分区获取所需数据时,Cassandra 是最有效率的。
### 分区键设计的最佳实践
遵循分区键设计的最佳实践原则,这会帮你得到理想的分区大小。根据经验,Cassandra 中的最大分区应保持在 100MB 以下。理想情况下,它应该小于 10MB。虽然 Cassandra 3.6 及其以上版本能更好地支持大分区,但也必须对每个工作负载进行仔细的测试和基准测试,以确保分区键设计能够支持所需的集群性能。
具体来说,这些最佳实践原则适用于任何分区键设计:
* 分区键的目标必须是将理想数量的数据放入每个分区,以支持其访问模式的需求。
* 分区键应禁止无界分区:那些大小可能随着时间无限增长的分区。例如,在上面的 `server_logs` 示例中,随着服务器日志数量的不断增加,使用服务器列作为分区键就会产生无界分区。相比之下,使用 `log_hour` 将每个分区限制为一个小时数据的方案会更好。
* 分区键还应避免产生分区倾斜,即分区增长不均匀,有些分区可能随着时间的推移而不受限制地增长。在 `server_logs` 示例中,在一台服务器生成的日志远多于其他服务器的情况下使用服务器列会产生分区倾斜。为了避免这种情况,可以从表中引入另一个属性来强制均匀分布,即使要创建一个虚拟列来这样做,也是值得的。
* 使用时间元素和其他属性的组合分区键,这对时间序列数据分区很有帮助。这种方式可以防止无界分区,使访问模式能够在查询特定数据时使用时间属性,而且能够对特定时间段内的数据进行删除。上面的每个示例都使用了 `log_hour` 时间属性来演示这一点。
还有一些工具可用于帮助测试、分析和监控 Cassandra 分区,以检查所选模式是否高效。通过仔细设计分区键,使解决方案的数据和需求保持一致,并遵循最佳实践原则来优化分区大小,你就可以充分利用数据分区,更好地发挥 Cassandra 的可扩展性和性能潜力。
---
via: <https://opensource.com/article/20/5/apache-cassandra>
作者:[Anil Inamdar](https://opensource.com/users/anil-inamdar) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Apache Cassandra is a database. But it's not just any database; it's a replicating database designed and tuned for scalability, high availability, low-latency, and performance. Cassandra can help your data survive regional outages, hardware failure, and what many admins would consider excessive amounts of data.
Having a thorough command of data partitions enables you to achieve superior Cassandra cluster design, performance, and scalability. In this article, I'll examine how to define partitions and how Cassandra uses them, as well as the most critical best practices and known issues you ought to be aware of.
To set the scene: partitions are chunks of data that serve as the atomic unit for key database-related functions like data distribution, replication, and indexing. Distributed data systems commonly distribute incoming data into these partitions, performing the partitioning with simple mathematical functions such as identity or hashing, and using a "partition key" to group data by partition. For example, consider a case where server logs arrive as incoming data. Using the "identity" partitioning function and the timestamps of each log (rounded to the hour value) for the partition key, we can partition this data such that each partition holds one hour of the logs.
## Data partitions in Cassandra
Cassandra operates as a distributed system and adheres to the data partitioning principles described above. With Cassandra, data partitioning relies on an algorithm configured at the cluster level, and a partition key configured at the table level.
Cassandra Query Language (CQL) uses the familiar SQL table, row, and column terminologies. In the example diagram above, the table configuration includes the partition key within its primary key, with the format: Primary Key = Partition Key + [Clustering Columns].
A primary key in Cassandra represents both a unique data partition and a data arrangement inside a partition. Data arrangement information is provided by optional clustering columns. Each unique partition key represents a set of table rows managed in a server, as well as all servers that manage its replicas.
## Defining primary keys in CQL
The following four examples demonstrate how a primary key can be represented in CQL syntax. The sets of rows produced by these definitions are generally considered a partition.
### Definition 1 (partition key: log_hour, clustering columns: none)
```
CREATE TABLE server_logs(
log_hour timestamp PRIMARYKEY,
log_level text,
message text,
server text
)
```
Here, all rows that share a **log_hour** go into the same partition.
### Definition 2 (partition key: log_hour, clustering columns: log_level)
```
CREATE TABLE server_logs(
log_hour timestamp,
log_level text,
message text,
server text,
PRIMARY KEY (log_hour, log_level)
)
```
This definition uses the same partition key as Definition 1, but here all rows in each partition are arranged in ascending order by **log_level**.
### Definition 3 (partition key: log_hour, server, clustering columns: none)
```
CREATE TABLE server_logs(
log_hour timestamp,
log_level text,
message text,
server text,
PRIMARY KEY ((log_hour, server))
)
```
In this definition, all rows share a **log_hour** for each distinct **server** as a single partition.
### Definition 4 (partition key: log_hour, server, clustering columns: log_level)
```
CREATE TABLE server_logs(
log_hour timestamp,
log_level text,
message text,
server text,
PRIMARY KEY ((log_hour, server),log_level)
)WITH CLUSTERING ORDER BY (column3 DESC);
```
This definition uses the same partition as Definition 3 but arranges the rows within a partition in descending order by **log_level**.
## How Cassandra uses the partition key
Cassandra relies on the partition key to determine which node to store data on and where to locate data when it's needed. Cassandra performs these read and write operations by looking at a partition key in a table, and using tokens (a long value out of range -2^63 to +2^63-1) for data distribution and indexing. These tokens are mapped to partition keys by using a partitioner, which applies a partitioning function that converts any partition key to a token. Through this token mechanism, every node of a Cassandra cluster owns a set of data partitions. The partition key then enables data indexing on each node.
A Cassandra cluster with three nodes and token-based ownership. This is a simplistic representation: the actual implementation uses Vnodes.
## Data partition impacts on Cassandra clusters
Careful partition key design is crucial to achieving the ideal partition size for the use case. Getting it right allows for even data distribution and strong I/O performance. Partition size has several impacts on Cassandra clusters you need to be aware of:
- Read performance—In order to find partitions in SSTables files on disk, Cassandra uses data structures that include caches, indexes, and index summaries. Partitions that are too large reduce the efficiency of maintaining these data structures – and will negatively impact performance as a result. Cassandra releases have made strides in this area: in particular, version 3.6 and above of the Cassandra engine introduce storage improvements that deliver better performance for large partitions and resilience against memory issues and crashes.
- Memory usage— Large partitions place greater pressure on the JVM heap, increasing its size while also making the garbage collection mechanism less efficient.
- Cassandra repairs—Large partitions make it more difficult for Cassandra to perform its repair maintenance operations, which keep data consistent by comparing data across replicas.
- Tombstone eviction—Not as mean as it sounds, Cassandra uses unique markers known as "tombstones" to mark data for deletion. Large partitions can make that deletion process more difficult if there isn't an appropriate data deletion pattern and compaction strategy in place.
While these impacts may make it tempting to simply design partition keys that yield especially small partitions, the data access pattern is also highly influential on ideal partition size (for more information, read this in-depth guide to [Cassandra data modeling](https://www.instaclustr.com/resource/6-step-guide-to-apache-cassandra-data-modelling-white-paper/)). The data access pattern can be defined as how a table is queried, including all of the table's **select** queries. Ideally, CQL select queries should have just one partition key in the **where** clause—that is to say, Cassandra is most efficient when queries can get needed data from a single partition, instead of many smaller ones.
## Best practices for partition key design
Following best practices for partition key design helps you get to an ideal partition size. As a rule of thumb, the maximum partition size in Cassandra should stay under 100MB. Ideally, it should be under 10MB. While Cassandra versions 3.6 and newer make larger partition sizes more viable, careful testing and benchmarking must be performed for each workload to ensure a partition key design supports desired cluster performance.
Specifically, these best practices should be considered as part of any partition key design:
- The goal for a partition key must be to fit an ideal amount of data into each partition for supporting the needs of its access pattern.
- A partition key should disallow unbounded partitions: those that may grow indefinitely in size over time. For instance, in the
**server_logs**examples above, using the server column as a partition key would create unbounded partitions as the number of server logs continues to increase. In contrast, using**log_hour**limits each partition to an hour of data. - A partition key should also avoid creating a partition skew, in which partitions grow unevenly, and some are able to grow without limit over time. In the
**server_logs**examples, using the server column in a scenario where one server generates considerably more logs than others would produce a partition skew. To avoid this, a useful technique is to introduce another attribute from the table to force an even distribution, even if it's necessary to create a dummy column to do so. - It's helpful to partition time-series data with a partition key that uses a time element as well as other attributes. This protects against unbounded partitions, enables access patterns to use the time attribute in querying specific data, and allows for time-bound data deletion. The examples above each demonstrate this by using the
**log_hour**time attribute.
Several tools are available to help test, analyze, and monitor Cassandra partitions to check that a chosen schema is efficient and effective. By carefully designing partition keys to align well with the data and needs of the solution at hand, and following best practices to optimize partition size, you can utilize data partitions that more fully deliver on the scalability and performance potential of a Cassandra deployment.
## 1 Comment |
13,909 | 使用 logrotate 命令轮转和归档日志 | https://opensource.com/article/21/10/linux-logrotate | 2021-10-22T11:38:44 | [
"日志"
] | https://linux.cn/article-13909-1.html |
>
> 使用此 Linux 命令保持日志文件更新。
>
>
>

日志非常适合找出应用程序在做什么或对可能的问题进行故障排除。几乎我们处理的每个应用程序都会生成日志,我们希望我们自己开发的应用程序也生成日志。日志越详细,我们拥有的信息就越多。但放任不管,日志可能会增长到无法管理的大小,反过来,它们可能会成为它们自己的问题。因此,最好将它们进行裁剪,保留我们需要的那些,并将其余的归档。
### 基本功能
`logrotate` 实用程序在管理日志方面非常出色。它可以轮转日志、压缩日志、通过电子邮件发送日志、删除日志、归档日志,并在你需要时开始记录最新的。
运行 `logrotate` 非常简单——只需要运行 `logrotate -vs state-file config-file`。在上面的命令中,`v` 选项开启详细模式,`s` 指定一个状态文件,最后的 `config-file` 是配置文件,你可以指定需要做什么。
### 实战演练
让我们看看在我们的系统上静默运行的 `logrotate` 配置,它管理我们在 `/var/log` 目录中找到的大量日志。查看该目录中的当前文件。你是否看到很多 `*.[number].gz` 文件?这就是 `logrotate` 正在做的。你可以在 `/etc/logrotate.d/rsyslog` 下找到此配置文件。我的配置文件如下:
```
/var/log/syslog
{
rotate 7
daily
missingok
notifempty
delaycompress
compress
postrotate
reload rsyslog > /dev/null 2>&1 || true
endscript
}
/var/log/mail.info
/var/log/mail.warn
/var/log/mail.err
/var/log/mail.log
/var/log/daemon.log
/var/log/kern.log
/var/log/auth.log
/var/log/user.log
/var/log/lpr.log
/var/log/cron.log
/var/log/debug
/var/log/messages
{
rotate 4
weekly
missingok
notifempty
compress
delaycompress
sharedscripts
postrotate
reload rsyslog > /dev/null 2>&1 || true
endscript
}
```
该文件首先定义了轮转 `/var/log/syslog` 文件的说明,这些说明包含在后面的花括号中。以下是它们的含义:
* `rotate 7`: 保留最近 7 次轮转的日志。然后开始删除超出的。
* `daily`: 每天轮转日志,与 `rotate 7` 一起使用,这意味着日志将保留过去 7 天。其它选项是每周、每月、每年。还有一个大小参数,如果日志文件的大小增加超过指定的限制(例如,大小 10k、大小 10M、大小 10G 等),则将轮转日志文件。如果未指定任何内容,日志将在运行 `logrotate` 时轮转。你甚至可以在 cron 中运行 `logrotate` 以便在更具体的时间间隔内使用它。
* `missingok`: 如果日志文件缺失也没关系。不要惊慌。
* `notifempty`: 日志文件为空时不轮转。
* `compress`: 开启压缩,使用 `nocompress` 关闭它。
* `delaycompress`: 如果压缩已打开,则将压缩延迟到下一次轮转。这允许至少存在一个轮转但未压缩的文件。如果你希望昨天的日志保持未压缩以便进行故障排除,那么此配置会很有用。如果某些程序在重新启动/重新加载之前可能仍然写入旧文件,这也很有帮助,例如 Apache。
* `postrotate/endscript`: 轮转后运行此部分中的脚本。有助于做清理工作。还有一个 `prerotate/endscript` 用于在轮转开始之前执行操作。
你能弄清楚下一节对上面配置中提到的所有文件做了什么吗?第二节中唯一多出的参数是 `sharedscripts`,它告诉 `logrotate` 在所有日志轮转完成之前不要运行 `postrotate/endscript` 中的部分。它可以防止脚本在每一次轮转时执行,只在最后一次轮转完成时执行。
### 看点新的东西
我使用下面的配置来处理我系统上的 `Nginx` 的访问和错误日志。
```
/var/log/nginx/access.log
/var/log/nginx/error.log {
size 1
missingok
notifempty
create 544 www-data adm
rotate 30
compress
delaycompress
dateext
dateformat -%Y-%m-%d-%s
sharedscripts
extension .log
postrotate
service nginx reload
endscript
}
```
上面的脚本可以使用如下命令运行:
```
logrotate -vs state-file /tmp/logrotate
```
第一次运行该命令会给出以下输出:
```
reading config file /tmp/logrotate
extension is now .log
Handling 1 logs
rotating pattern: /var/log/nginx/access.log
/var/log/nginx/error.log 1 bytes (30 rotations)
empty log files are not rotated, old logs are removed
considering log /var/log/nginx/access.log
log needs rotating
considering log /var/log/nginx/error.log
log does not need rotating
rotating log /var/log/nginx/access.log, log->rotateCount is 30
Converted ' -%Y-%m-%d-%s' -> '-%Y-%m-%d-%s'
dateext suffix '-2021-08-27-1485508250'
glob pattern '-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]'
glob finding logs to compress failed
glob finding old rotated logs failed
renaming /var/log/nginx/access.log to /var/log/nginx/access-2021-08-27-1485508250.log
creating new /var/log/nginx/access.log mode = 0544 uid = 33 gid = 4
running postrotate script
* Reloading nginx configuration nginx
```
第二次运行它:
```
reading config file /tmp/logrotate
extension is now .log
Handling 1 logs
rotating pattern: /var/log/nginx/access.log
/var/log/nginx/error.log 1 bytes (30 rotations)
empty log files are not rotated, old logs are removed
considering log /var/log/nginx/access.log
log needs rotating
considering log /var/log/nginx/error.log
log does not need rotating
rotating log /var/log/nginx/access.log, log->rotateCount is 30
Converted ' -%Y-%m-%d-%s' -> '-%Y-%m-%d-%s'
dateext suffix '-2021-08-27-1485508280'
glob pattern '-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]'
compressing log with: /bin/gzip
renaming /var/log/nginx/access.log to /var/log/nginx/access-2021-08-27-1485508280.log
creating new /var/log/nginx/access.log mode = 0544 uid = 33 gid = 4
running postrotate script
* Reloading nginx configuration nginx
```
第三次运行它:
```
reading config file /tmp/logrotate
extension is now .log
Handling 1 logs
rotating pattern: /var/log/nginx/access.log
/var/log/nginx/error.log 1 bytes (30 rotations)
empty log files are not rotated, old logs are removed
considering log /var/log/nginx/access.log
log needs rotating
considering log /var/log/nginx/error.log
log does not need rotating
rotating log /var/log/nginx/access.log, log->rotateCount is 30
Converted ' -%Y-%m-%d-%s' -> '-%Y-%m-%d-%s'
dateext suffix '-2021-08-27-1485508316'
glob pattern '-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]'
compressing log with: /bin/gzip
renaming /var/log/nginx/access.log to /var/log/nginx/access-2021-08-27-1485508316.log
creating new /var/log/nginx/access.log mode = 0544 uid = 33 gid = 4
running postrotate script
* Reloading nginx configuration nginx
```
状态文件的内容如下所示:
```
logrotate state -- version 2
"/var/log/nginx/error.log" 2021-08-27-9:0:0
"/var/log/nginx/access.log" 2021-08-27-9:11:56
```
* [下载 Linux logrotate 备忘单](https://opensource.com/downloads/logrotate-cheat-sheet)
本文首发于[作者个人博客](https://notes.ayushsharma.in/2017/01/fiddling-with-logrotate),经授权改编。
---
via: <https://opensource.com/article/21/10/linux-logrotate>
作者:[Ayush Sharma](https://opensource.com/users/ayushsharma) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Logs are great for finding out what an application is doing or troubleshooting a possible problem. Almost every application we deal with generates logs, and we want the applications we develop ourselves to generate them too. The more verbose the logs, the more information we have. But left to themselves, logs can grow to an unmanageable size, and they can, in turn, become a problem of their own. So it's a good idea to keep them trimmed down, keep the ones we're going to need, and archive the rest.
## Basics
The `logrotate`
utility is excellent at managing logs. It can rotate them, compress them, email them, delete them, archive them, and start fresh ones when you need them.
Running `logrotate`
is pretty simple—just run `logrotate -vs state-file config-file`
. In the above command, the `v`
option enables verbose mode, `s`
specifies a state file, and the final `config-file`
mentions the configuration file, where you specify what you need done.
## Hands-on
Let's check out a `logrotate`
configuration that is running silently on our system, managing the wealth of logs we find in the `/var/log`
directory. Check out the current files in that directory. Do you see a lot of `*.[number].gz`
files? That’s what `logrotate`
is doing. You can find the configuration file for this under `/etc/logrotate.d/rsyslog`
. Mine looks like this:
```
/var/log/syslog
{
rotate 7
daily
missingok
notifempty
delaycompress
compress
postrotate
reload rsyslog >/dev/null 2>&1 || true
endscript
}
/var/log/mail.info
/var/log/mail.warn
/var/log/mail.err
/var/log/mail.log
/var/log/daemon.log
/var/log/kern.log
/var/log/auth.log
/var/log/user.log
/var/log/lpr.log
/var/log/cron.log
/var/log/debug
/var/log/messages
{
rotate 4
weekly
missingok
notifempty
compress
delaycompress
sharedscripts
postrotate
reload rsyslog >/dev/null 2>&1 || true
endscript
}
```
The file starts with defining the instructions for rotating the `/var/log/syslog`
file and the instructions are contained within the curly braces that follow. Here’s what they mean:
`rotate 7`
: Keep logs from the last seven rotations. Then start deleting them.`daily`
: Rotate the log daily. Along with`rotate 7`
, this would mean that logs would be kept for the last seven days. Other options are`weekly`
,`monthly`
,`yearly`
. There is also a`size`
parameter that will rotate log files if their size increases beyond a specified limit—for example,`size 10k`
,`size 10M`
,`size 10G`
, etc. If nothing is specified, logs will be rotated whenever`logrotate`
runs. You can even run`logrotate`
in a`cron`
to use it at more specific time intervals.`missingok`
: It’s okay if the log file is missing. Don’t Panic.`notifempty`
: Don’t rotate if the log file is empty.`delaycompress`
: If compression is on, delay compression until the next rotation. This allows at least one rotated but uncompressed file to be present. Useful if you want yesterday’s logs to stay uncompressed for troubleshooting. It is also helpful if some program might still write to the old file until it is restarted/reloaded, like Apache.`compress`
: Compression is on. Use`nocompress`
to turn it off.`postrotate/endscript`
: Run the script within this section after rotation. Helpful in doing cleanup stuff. There is also a`prerotate/endscript`
for doing things before rotation begins.
Can you figure out what the next section does for all those files mentioned in the configuration above? The only additional parameter in the second section is `sharedscripts`
, which tells `logrotate`
to not run the section within `postrotate/endscript`
until all log rotation is complete. It prevents the script from being executed for every log rotated and runs once at the end.
## Something New
I’m using the following configuration for dealing with Nginx access and error logs on my system.
```
/var/log/nginx/access.log
/var/log/nginx/error.log {
size 1
missingok
notifempty
create 544 www-data adm
rotate 30
compress
delaycompress
dateext
dateformat -%Y-%m-%d-%s
sharedscripts
extension .log
postrotate
service nginx reload
endscript
}
```
The above script can be run using:
```
logrotate -vs state-file /tmp/logrotate
```
Running the command for the first time gives this output:
```
reading config file /tmp/logrotate
extension is now .log
Handling 1 logs
rotating pattern: /var/log/nginx/access.log
/var/log/nginx/error.log 1 bytes (30 rotations)
empty log files are not rotated, old logs are removed
considering log /var/log/nginx/access.log
log needs rotating
considering log /var/log/nginx/error.log
log does not need rotating
rotating log /var/log/nginx/access.log, log->rotateCount is 30
Converted ' -%Y-%m-%d-%s' -> '-%Y-%m-%d-%s'
dateext suffix '-2021-08-27-1485508250'
glob pattern '-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]'
glob finding logs to compress failed
glob finding old rotated logs failed
renaming /var/log/nginx/access.log to /var/log/nginx/access-2021-08-27-1485508250.log
creating new /var/log/nginx/access.log mode = 0544 uid = 33 gid = 4
running postrotate script
* Reloading nginx configuration nginx
```
And running it a second time:
```
reading config file /tmp/logrotate
extension is now .log
Handling 1 logs
rotating pattern: /var/log/nginx/access.log
/var/log/nginx/error.log 1 bytes (30 rotations)
empty log files are not rotated, old logs are removed
considering log /var/log/nginx/access.log
log needs rotating
considering log /var/log/nginx/error.log
log does not need rotating
rotating log /var/log/nginx/access.log, log->rotateCount is 30
Converted ' -%Y-%m-%d-%s' -> '-%Y-%m-%d-%s'
dateext suffix '-2021-08-27-1485508280'
glob pattern '-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]'
compressing log with: /bin/gzip
renaming /var/log/nginx/access.log to /var/log/nginx/access-2021-08-27-1485508280.log
creating new /var/log/nginx/access.log mode = 0544 uid = 33 gid = 4
running postrotate script
* Reloading nginx configuration nginx
```
And running it a third time:
```
reading config file /tmp/logrotate
extension is now .log
Handling 1 logs
rotating pattern: /var/log/nginx/access.log
/var/log/nginx/error.log 1 bytes (30 rotations)
empty log files are not rotated, old logs are removed
considering log /var/log/nginx/access.log
log needs rotating
considering log /var/log/nginx/error.log
log does not need rotating
rotating log /var/log/nginx/access.log, log->rotateCount is 30
Converted ' -%Y-%m-%d-%s' -> '-%Y-%m-%d-%s'
dateext suffix '-2021-08-27-1485508316'
glob pattern '-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]'
compressing log with: /bin/gzip
renaming /var/log/nginx/access.log to /var/log/nginx/access-2021-08-27-1485508316.log
creating new /var/log/nginx/access.log mode = 0544 uid = 33 gid = 4
running postrotate script
* Reloading nginx configuration nginx
```
The contents of the state file look like this:
```
logrotate state -- version 2
"/var/log/nginx/error.log" 2021-08-27-9:0:0
"/var/log/nginx/access.log" 2021-08-27-9:11:56
```
**Download the Linux logrotate cheat sheet.**
*This article was originally published on the author's personal blog and has been adapted with permission.*
## Comments are closed. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.