
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
14,080 | 使用 LVM 添加存储 | https://opensource.com/article/21/9/add-storage-lvm | 2021-12-13T23:51:31 | [
"LVM"
] | https://linux.cn/article-14080-1.html |
>
> LVM 为你配置存储的方式提供了极大的灵活性。
>
>
>

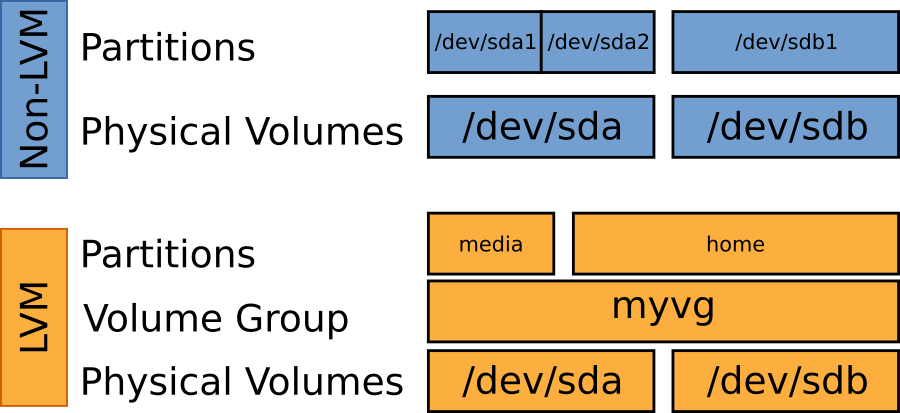
<ruby> 逻辑卷管理器 <rt> Logical Volume Manager </rt></ruby>(LVM)允许在操作系统和硬件之间建立一个抽象层。通常,你的操作系统会查找磁盘(`/dev/sda`、`/dev/sdb` 等)和这些磁盘中的分区(`/dev/sda1`、`/dev/sdb1` 等)。
LVM 在操作系统和磁盘之间创建了一个虚拟层。LVM 不是一个驱动器持有一定数量的分区,而是创建一个统一的存储池(称为<ruby> 卷组 <rt> Volume Group </rt></ruby>),跨越任意数量的物理驱动器(称为<ruby> 物理卷 <rt> Physical Volume </rt></ruby>)。使用卷组中可用的存储,LVM 可以为你的操作系统提供类似磁盘和分区的功能。
操作系统完全没有意识到它被“欺骗”了。

由于 LVM 虚拟地创建卷组和逻辑卷,因此即使在系统运行时,也可以轻松调整它们的大小或移动它们,或者创建新卷。此外,LVM 提供了其它情况下不存在的特性,比如创建逻辑卷的活动快照时无需首先卸载磁盘。
LVM 中的卷组是一个命名的虚拟容器,将底层物理磁盘组合在一起。它充当一个池,可以从中创建不同大小的<ruby> 逻辑卷 <rt> Logical Volume </rt></ruby>。逻辑卷包含实际的文件系统并且可以跨越多个磁盘,并且不需要物理上连续。
### 特性
* 分区名称通常具有系统名称,例如 `/dev/sda1`。LVM 具有便于人们理解的名称,例如 `home` 或者 `media`。
* 分区的总大小受底层物理磁盘大小的限制。在 LVM 中,卷可以跨越多个磁盘,并且仅受 LVM 中所有物理磁盘总大小的限制。
* 分区通常只有在磁盘未使用且已卸载时才能调整大小、移动或删除。LVM 卷可以在系统运行时进行操作。
* 只能通过分配与分区相邻的可用空间来扩展分区。LVM 卷可以从任何地方占用可用空间。
* 扩展分区涉及移动数据以腾出可用空间,这非常耗时,并且可能会在断电期间导致数据丢失。LVM 卷可以从卷组中的任何地方占用可用空间,甚至可以在另一块磁盘上。
* 因为在 LVM 中创建卷非常容易,所以它鼓励创建不同的卷,例如创建单独的卷来测试功能或尝试不同的操作系统。对于分区,此过程将非常耗时并且容易出错。
* 快照只能在 LVM 中创建。它允许你创建当前逻辑卷的时间点镜像,即使在系统运行时也可以。这非常适合备份。
### 测试设置
作为演示,假设你的系统具有以下驱动器配置:
```
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
`-xvda1 202:1 0 8G 0 part /
xvdb 202:16 0 1G 0 disk
xvdc 202:32 0 1G 0 disk
xvdd 202:48 0 2G 0 disk
xvde 202:64 0 5G 0 disk
xvdf 202:80 0 8G 0 disk
```
#### 步骤 1. 初始化磁盘以用于 LVM
运行 `pvcreate /dev/xvdb /dev/xvdc /dev/xvdd /dev/xvde /dev/xvdf`。输出应如下:
```
Physical volume "/dev/xvdb" successfully created
Physical volume "/dev/xvdc" successfully created
Physical volume "/dev/xvdd" successfully created
Physical volume "/dev/xvde" successfully created
Physical volume "/dev/xvdf" successfully created
```
使用 `pvs` 或者 `pvdisplay` 查看结果:
```
"/dev/xvde" is a new physical volume of "5.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvde
VG Name
PV Size 5.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID 728JtI-ffZD-h2dZ-JKnV-8IOf-YKdS-8srJtn
"/dev/xvdb" is a new physical volume of "1.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvdb
VG Name
PV Size 1.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID zk1phS-7uXc-PjBP-5Pv9-dtAV-zKe6-8OCRkZ
"/dev/xvdd" is a new physical volume of "2.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvdd
VG Name
PV Size 2.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID R0I139-Ipca-KFra-2IZX-o9xJ-IW49-T22fPc
"/dev/xvdc" is a new physical volume of "1.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvdc
VG Name
PV Size 1.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID FDzcVS-sq22-2b13-cYRj-dXHf-QLjS-22Meae
"/dev/xvdf" is a new physical volume of "8.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvdf
VG Name
PV Size 8.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID TRVSH9-Bo5D-JHHb-g0NX-8IoS-GG6T-YV4d0p
```
#### 步骤 2. 创建卷组
运行 `vgcreate myvg /dev/xvdb /dev/xvdc /dev/xvdd /dev/xvde /dev/xvdf`。通过 `vgs` 或者 `vgdisplay` 查看结果:
```
--- Volume group ---
VG Name myvg
System ID
Format lvm2
Metadata Areas 5
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 5
Act PV 5
VG Size 16.98 GiB
PE Size 4.00 MiB
Total PE 4347
Alloc PE / Size 0 / 0
Free PE / Size 4347 / 16.98 GiB
VG UUID ewrrWp-Tonj-LeFa-4Ogi-BIJJ-vztN-yrepkh
```
#### 步骤 3: 创建逻辑卷
运行以下命令:
```
lvcreate myvg --name media --size 4G
lvcreate myvg --name home --size 4G
```
使用 `lvs` 或者 `lvdisplay` 验证结果:
```
--- Logical volume ---
LV Path /dev/myvg/media
LV Name media
VG Name myvg
LV UUID LOBga3-pUNX-ZnxM-GliZ-mABH-xsdF-3VBXFT
LV Write Access read/write
LV Creation host, time ip-10-0-5-236, 2017-02-03 05:29:15 +0000
LV Status available
# open 0
LV Size 4.00 GiB
Current LE 1024
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:0
--- Logical volume ---
LV Path /dev/myvg/home
LV Name home
VG Name myvg
LV UUID Hc06sl-vtss-DuS0-jfqj-oNce-qKf6-e5qHhK
LV Write Access read/write
LV Creation host, time ip-10-0-5-236, 2017-02-03 05:29:40 +0000
LV Status available
# open 0
LV Size 4.00 GiB
Current LE 1024
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:1
```
#### 步骤 4: 创建文件系统
使用以下命令创建文件系统:
```
vgcreate myvg /dev/xvdb /dev/xvdc /dev/xvdd /dev/xvde /dev/xvdf
mkfs.ext3 /dev/myvg/media
mkfs.ext3 /dev/myvg/home
```
挂载它:
```
mount /dev/myvg/media /media
mount /dev/myvg/home /home
```
使用 `lsblk` 命令查看完整配置:
```
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
`-xvda1 202:1 0 8G 0 part /
xvdb 202:16 0 1G 0 disk
xvdc 202:32 0 1G 0 disk
xvdd 202:48 0 2G 0 disk
xvde 202:64 0 5G 0 disk
`-myvg-media 252:0 0 4G 0 lvm /media
xvdf 202:80 0 8G 0 disk
`-myvg-home 252:1 0 4G 0 lvm /home
```
#### 步骤 5: 扩展 LVM
添加一块新的 `/dev/xvdg` 磁盘。要扩展 `home` 卷,运行以下命令:
```
pvcreate /dev/xvdg
vgextend myvg /dev/xvdg
lvextend -l 100%FREE /dev/myvg/home
resize2fs /dev/myvg/home
```
运行 `df -h`,你应该可以看到新的磁盘大小。
就是这样!
LVM 为你配置存储的方式提供了极大的灵活性。尝试一下,并享受 LVM 的乐趣!
本文首发于 [作者个人博客](https://notes.ayushsharma.in/2017/02/working-with-logical-volume-manager-lvm),经授权改编。
---
via: <https://opensource.com/article/21/9/add-storage-lvm>
作者:[Ayush Sharma](https://opensource.com/users/ayushsharma) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Logical Volume Manager (LVM) allows for a layer of abstraction between the operating system and the hardware. Normally, your OS looks for disks (`/dev/sda`
, `/dev/sdb`
, and so on) and partitions within those disks (`/dev/sda1`
, `/dev/sdb1`
, and so on).
In LVM, a virtual layer is created between the operating system and the disks. Instead of one drive holding some number of partitions, LVM creates a unified storage pool (called a *Volume Group*) that spans any number of physical drives (called *Physical Volumes*). Using the storage available in a Volume Group, LVM provides what appear to be disks and partitions to your OS.
And the operating system is completely unaware that it's being "tricked."
Opensource.com, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)
Because the LVM creates volume groups and logical volumes virtually, it makes it easy to resize or move them, or create new volumes, even while the system is running. Additionally, LVM provides features that are not present otherwise, like creating live snapshots of logical volumes, without unmounting the disk first.
A volume group in an LVM is a named virtual container that groups together the underlying physical disks. It acts as a pool from which logical volumes of different sizes can be created. Logical volumes contain the actual file system and can span multiple disks, and don't need to be physically contiguous.
## Features
- Partition names normally have system designations like
`/dev/sda1`
. LVM volumes have normal human-understandable names, like`home`
or`media`
. - The total size of partitions is limited by the size of the underlying physical disk. In LVM, volumes can span multiple disks, and are only limited by the total size of all physical disks in the LVM.
- Partitions can normally only be resized, moved, or deleted when the disk is not in use and is unmounted. LVM volumes can be manipulated while the system is running.
- Partitions can only be expanded by allocating them free space adjacent to the partition. LVM volumes can take free space from anywhere.
- Expanding a partition involves moving the data around to make free space, which is time-consuming and could lead to data loss during a power outage. LVM volumes can take free space from anywhere in the volume group, even on another disk.
- Because it’s so easy to create volumes in an LVM, it encourages creating different volumes, like creating separate volumes to test features or to try different operating systems. With partitions, this process would be time-consuming and error-prone.
- Snapshots can only be created in an LVM. It allows you to create a point-in-time image of the current logical volume, even while the system is running. This is great for backups.
## Test setup
As a demonstration, assume your system has the following drive configuration:
```
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
`-xvda1 202:1 0 8G 0 part /
xvdb 202:16 0 1G 0 disk
xvdc 202:32 0 1G 0 disk
xvdd 202:48 0 2G 0 disk
xvde 202:64 0 5G 0 disk
xvdf 202:80 0 8G 0 disk
```
### Step 1. Initialize disks to use with LVM
Run `pvcreate /dev/xvdb /dev/xvdc /dev/xvdd /dev/xvde /dev/xvdf`
. The output should be:
```
Physical volume "/dev/xvdb" successfully created
Physical volume "/dev/xvdc" successfully created
Physical volume "/dev/xvdd" successfully created
Physical volume "/dev/xvde" successfully created
Physical volume "/dev/xvdf" successfully created
```
See the result using `pvs`
or `pvdisplay`
:
```
"/dev/xvde" is a new physical volume of "5.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvde
VG Name
PV Size 5.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID 728JtI-ffZD-h2dZ-JKnV-8IOf-YKdS-8srJtn
"/dev/xvdb" is a new physical volume of "1.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvdb
VG Name
PV Size 1.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID zk1phS-7uXc-PjBP-5Pv9-dtAV-zKe6-8OCRkZ
"/dev/xvdd" is a new physical volume of "2.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvdd
VG Name
PV Size 2.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID R0I139-Ipca-KFra-2IZX-o9xJ-IW49-T22fPc
"/dev/xvdc" is a new physical volume of "1.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvdc
VG Name
PV Size 1.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID FDzcVS-sq22-2b13-cYRj-dXHf-QLjS-22Meae
"/dev/xvdf" is a new physical volume of "8.00 GiB"
--- NEW Physical volume ---
PV Name /dev/xvdf
VG Name
PV Size 8.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID TRVSH9-Bo5D-JHHb-g0NX-8IoS-GG6T-YV4d0p
```
### Step 2. Create the volume group
Run `vgcreate myvg /dev/xvdb /dev/xvdc /dev/xvdd /dev/xvde /dev/xvdf`
. See the results with `vgs`
or `vgdisplay`
:
```
--- Volume group ---
VG Name myvg
System ID
Format lvm2
Metadata Areas 5
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 5
Act PV 5
VG Size 16.98 GiB
PE Size 4.00 MiB
Total PE 4347
Alloc PE / Size 0 / 0
Free PE / Size 4347 / 16.98 GiB
VG UUID ewrrWp-Tonj-LeFa-4Ogi-BIJJ-vztN-yrepkh
```
### Step 3: Create logical volumes
Run the following commands:
```
lvcreate myvg --name media --size 4G
lvcreate myvg --name home --size 4G
```
Verify the results using `lvs`
or `lvdisplay`
:
```
--- Logical volume ---
LV Path /dev/myvg/media
LV Name media
VG Name myvg
LV UUID LOBga3-pUNX-ZnxM-GliZ-mABH-xsdF-3VBXFT
LV Write Access read/write
LV Creation host, time ip-10-0-5-236, 2017-02-03 05:29:15 +0000
LV Status available
# open 0
LV Size 4.00 GiB
Current LE 1024
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:0
--- Logical volume ---
LV Path /dev/myvg/home
LV Name home
VG Name myvg
LV UUID Hc06sl-vtss-DuS0-jfqj-oNce-qKf6-e5qHhK
LV Write Access read/write
LV Creation host, time ip-10-0-5-236, 2017-02-03 05:29:40 +0000
LV Status available
# open 0
LV Size 4.00 GiB
Current LE 1024
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 252:1
```
### Step 4: Create the file system
Create the file system using:
```
mkfs.ext3 /dev/myvg/media
mkfs.ext3 /dev/myvg/home
```
Mount it:
```
mount /dev/myvg/media /media
mount /dev/myvg/home /home
```
See your full setup using `lsblk`
:
```
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
`-xvda1 202:1 0 8G 0 part /
xvdb 202:16 0 1G 0 disk
xvdc 202:32 0 1G 0 disk
xvdd 202:48 0 2G 0 disk
xvde 202:64 0 5G 0 disk
`-myvg-media 252:0 0 4G 0 lvm /media
xvdf 202:80 0 8G 0 disk
`-myvg-home 252:1 0 4G 0 lvm /home
```
### Step 5: Extending the LVM
Add a new disk at `/dev/xvdg`
. To extend the `home`
volume, run the following commands:
```
pvcreate /dev/xvdg
vgextend myvg /dev/xvdg
lvextend -l 100%FREE /dev/myvg/home
resize2fs /dev/myvg/home
```
Run `df -h`
and you should see your new size reflected.
And that's it!
LVM enables extreme flexibility in how you configure your storage. Try it out, and have fun with LVM!
*This article was originally published on the author's personal blog and has been adapted with permission.*
## 1 Comment |
14,082 | 手把手指导:在 Linux 上使用 GPG 加解密文件 | https://itsfoss.com/gpg-encrypt-files-basic/ | 2021-12-15T13:36:45 | [
"GPG",
"加密"
] | https://linux.cn/article-14082-1.html | 
[GnuPG](https://gnupg.org/),俗称 GPG,是一个非常通用的工具,被广泛用作电子邮件、信息、文件或任何你需要安全地发送给别人的东西的加密行业标准。
学习使用 GPG 很容易,你可以在几分钟内就学会使用它。
在本教程中,我将告诉你如何用 GPG 加密和解密文件。这是一个简单的教程,你可以在你的 Linux 系统上尝试所有的练习。这将帮助你练习 GPG 命令,并在你完全陌生的情况下理解它。
请先阅读整个教程,然后开始自己做。
### GPG 是如何进行加密的?

要使用 GPG,你首先需要有一个 GPG 密钥。
GPG 密钥是你在后面的教程中用来加密(或解密)文件的东西。它也是用来识别你的身份的,你的名字和电子邮件也会与密钥绑定。
GPG 密钥的工作原理是使用两个文件,一个私钥和一个公钥。这两个密钥是相互联系的,并且 GPG 的所有功能都需要使用它们,特别是对文件加密和解密。
当你用 GPG 加密一个文件时,它使用的是私钥。然后,这个新的加密文件**只能**用配对的公钥进行解密。
私钥,顾名思义,是以私下的、不给任何人看的方式来存储的密钥。
另一方面,公钥是用来给其他人的,或者你希望能够解密你的文件的任何人。
这就是 GPG 的加密方法的主要作用。它允许你对文件进行本地加密,然后允许其他人确保他们收到的文件实际上是由你发送的。因为他们能够解密文件的唯一方法是使用你的公钥,而这只有在文件首先使用你的私钥加密的情况下才有效。
**反之**,其他人可以用你的公钥对文件进行加密,而唯一能够解密的方法是用你的私钥。因此,允许其他人公开发布文件,而不用担心除了你以外的人能够阅读它们。(LCTT 译注:另外一个常见的用例是你用你的私钥对公开发布的文件进行签名,别人使用你的公钥通过验证你的签名而确信文件是你发布的、并没有被篡改。但本文没有涉及这个用例。)
换句话说,如果一个文件是用私钥加密的,它只能用相应的公钥解密。而如果一个文件是用公钥加密的,它只能用相应的私钥解密。
#### 你已经在使用 GPG 而没有意识到
一个最常见的使用 GPG 的例子是在 Linux 软件包管理器中,特别是 [外部仓库](https://itsfoss.com/adding-external-repositories-ubuntu/)。你把开发者的公钥添加到你系统的可信密钥中。开发者用他/她的私钥签署软件包(生成签名)。由于你的 Linux 系统拥有该公钥文件,它就能理解该软件包实际上是来自受信任的开发者。
许多加密服务在你没有意识到的情况下使用了某种 GPG 的实现。但现在最好不要去研究这些细节。
现在你对这个概念有点熟悉了,让我们看看如何使用 GPG 来加密一个文件,然后用它来解密。
### 用 GPG 对文件进行加密和解密

这是一个非常简单的场景。我假定你只有一个系统,你想看看 GPG 是如何工作的。你并没有把文件发送到其他系统。你对文件进行加密,然后在同一个系统上解密。
当然,这不是一个实际的用例,但这也不是本教程的目的。我的目的是让你熟悉 GPG 命令和功能。之后,你可以在现实世界中使用这些知识(如果需要的话)。为此,我将告诉你如何与他人分享你的公钥。
#### 第一步:安装 GPG
GPG 可以在大多数发行版的软件库中找到,开箱即用。
在基于 Debian 和 Ubuntu 的系统中,安装 `gpg` 包:
```
sudo apt install gpg
```
如果你使用 [基于 Arch 的发行版](https://itsfoss.com/arch-based-linux-distros/),用 [pacman 命令](https://itsfoss.com/pacman-command/) 安装 `gnupg` 软件包:
```
sudo pacman -S gnupg
```
#### 第二步:生成一个 GPG 密钥
在你的系统上生成一个 GPG 密钥只需要一条简单的命令。
只要运行下面的命令,就会生成你的密钥(你可以对大多数问题使用默认值,如下面的下划线部分所示)。
```
gpg --full-generate-key
```

**检查 GPG 密钥**
然后你可以通过使用 `--list-secret-keys` 和 `--list-public-keys` 参数,分别看到私钥和公钥都是通过 `pub` 下显示的那个 ID 相互绑定的。

#### 第三步:用 GPG 加密一个文件
现在你已经设置了 GPG 密钥,你可以开始对我们的文件进行加密了。
使用下面的命令来加密文件:
```
gpg --encrypt --output file.gpg --recipient [email protected] file
```
让我们快速浏览一下该命令的内容:
首先,你指定了 `—encrypt` 选项。这告诉 GPG,我们将对一个文件进行加密。
接下来,你指定了 `--output file.gpg`。这可以是任何名字,不过惯例是给你要加密的文件的名称加上 `.gpg` 扩展名(所以 `message.txt` 会变成 `message.txt.gpg`)。
接下来,你输入 `—recipient [email protected]`。这指定了一个相应的 GPG 密钥的电子邮件,这个密钥实际上在这个系统上还不存在。
有点迷惑?
工作原理是,你在这里指定的电子邮件必须与你本地系统中的公钥相联系。
通常情况下,这将是来自另外一个人的 GPG 公钥,你要用它来加密你的文件。之后,该文件将只能用该用户的私钥进行解密。
在这个例子中,我将使用我以前的与 `[email protected]` 关联的 GPG 密钥。因此,其逻辑是,我用 `[email protected]` 的 *公钥* 对文件进行加密,然后只能用 `[email protected]` 的 *私钥* 进行解密。
如果你是为别人加密文件,你只有该公钥,但由于你是为自己加密文件,你的系统上有这两个密钥。
最后,你只需指定你要加密的文件。在这个例子中,让我们使用一个名为 `message.txt` 的文件,内容如下:
```
We're encrypting with GPG!
```

同样地,如果电子邮件是 `[email protected]`,新的 GPG 命令将如下所示:
```
gpg --encrypt --output message.txt.gpg --recipient [email protected] message.txt
```

如果你尝试阅读该文件,你会看到它看起来像乱码。这是预料之中的,因为该文件现在已经被加密了。

现在让我们删除未加密的 `message.txt` 文件,这样你就可以看到 `message.txt.gpg` 文件实际上在没有原始文件的情况下也能正常解密。

#### 第四步:用 GPG 解密加密的文件
最后,让我们来实际解密加密的信息。你可以用下面的命令来做。
```
gpg --decrypt --output file file.gpg
```
通过这里的参数,我们首先指定 `—decrypt`,它告诉 GPG 你将会解密一个文件。
接下来,你输入 `—output` 文件,这只是告诉 GPG,在你解密后,你将把我们文件的解密形式保存到哪个文件。
最后,你输入 `file.gpg`,这是你的加密文件的路径。
按照这个例子,我使用的命令是这样的。
```
gpg --decrypt --output message.txt message.txt.gpg
```

然后就完成了!当你想用 GPG 加密和解密文件时,这就是全部内容了。
剩下你可能想知道的是如何与他人分享你的公钥,以便他们在将文件发送给你之前对其进行加密。
### 发送和接收 GPG 密钥
要给别人发送一个 GPG 密钥,你首先需要从你的**钥匙链**中导出它,它包含了你所有的公钥和私钥。
要导出一个密钥,只需在你的钥匙链中找到密钥的 ID,然后运行以下命令,用密钥的 ID 替换 `id`,用你想保存的文件名替换 `key.gpg`。
```
gpg --output key.gpg --export id
```

要导入一个密钥,只需把输出文件(来自前面的命令)给其他用户,然后让他们运行下面的命令。
```
gpg --import key.gpg
```

但要正常使用该密钥,你需要验证该密钥,以便 GPG 正确地信任它。
这可以通过在其他用户的系统上使用 `--edit-key` 参数来完成,然后对密钥进行签名。
首先运行 `gpg --edit-key id`:

接下来,使用 `—fpr` 参数,它将显示密钥的指纹。这个命令的输出应该与你自己机器上的输出进行验证,这可以通过在你的系统上运行同样的 `--edit-key` 参数来找到。

如果一切吻合,只需使用 `—sign` 参数,一切就可以开始了。

就是这样!其他用户现在可以开始用你的公钥加密文件了,就像你之前做的那样,这可以确保它们只有在你用你的私钥解密时才能被你读取。
这就是使用 GPG 的所有基础知识!
### 总结
现在你已经了解了开始使用 GPG 所需要的一切,包括为自己和他人加密文件。正如我前面提到的,这只是为了了解 GPG 的加密和解密过程是如何工作的。你刚刚获得的基本 GPG 知识在应用于真实世界的场景中时可以更上一层楼。
还需要一些帮助来弄清楚一些东西,或者有一些不工作的东西?欢迎在下面的评论中留下任何内容。
---
via: <https://itsfoss.com/gpg-encrypt-files-basic/>
作者:[Hunter Wittenborn](https://itsfoss.com/author/hunter/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[GnuPG](https://gnupg.org/?ref=itsfoss.com), popularly known as GPG, is an extremely versatile tool, being widely used as the industry standard for encryption of things like emails, messages, files, or just anything you need to send to someone securely.
It’s easy to get started with GPG, and you can be on your way with using it in a matter of minutes.
In this tutorial, I’ll show you how to encrypt and decrypt files with GPG.
*This is a simple tutorial, and you may try all of it to practice on your Linux system as well. This will help you practice the GPG commands and understand it when you are absolutely new to it.*Read the entire tutorial first and then start doing it on your own.
## What are GPG Keys?
To start using GPG, you’ll first need to have a GPG key.
A GPG key is what you’ll use to encrypt (or decrypt) files later in the tutorial. It’s also what is used to identity you, with things like your name and email being tied to the key as well.
GPG keys work by using two files, a private key and a public key. These two keys are tied to each other, and are both needed to use all of GPG’s functionality, notably encrypting and decrypting files.
The private key is meant to be stored in a fashion stated directly in its name – privately, and not given out to anyone.
The public key, on the other hand, is meant to be given to others, or anyone you want to be able to communicate with.
### How GPG Encryption Work?
As said above, GPG encryption utilizes both the public and private keys, an asymmetric encryption technique. It allows you to encrypt files locally and then allows others to be ensured that the files they received were actually sent from you.
When you intend to encrypt a file using GPG, you will use the **Public key** of the person to whom you intend to send the file. Then, the receiver can decrypt that file using his private key. Let us go in a bit of detail.
You now know that GPG works with the public-private key pair. While you create a key on your system, it generates the public and private key. When a file is encrypted using your public key, only your associated private key can decrypt it. Not even your Public key, the one used to encrypt that file, can decrypt it.
So, let’s say a person called *Sender *wants to encrypt a file and send it to another person called *Receiver*.
*Sender*will ask the*Receiver*to send his public key to him.- Receiver will send his public key to the Sender. This can be either by email or through any public key server like
[https://keyserver.ubuntu.com/](https://keyserver.ubuntu.com/) - When
*Sender*gets the public key of the*Receiver*, he/she encrypts the file that needs to be transmitted with the Receiver’s public key. - The file is now transmitted to the Receiver.
- Once
*Receiver*gets the encrypted file, he/she will decrypt the file using his/her Private Key. This is possible because the file was encrypted using the*Receiver’s*public key. - Thus, the communication is completed securely, without any other person decrypting the message.
Here's an illustration to describe the process:
Encrypt and Decrypt Files using GPG Keys
### Why You Should Never Encrypt Files with your Private Key?
You should NEVER encrypt a file using your private key. This is because, if you encrypt the file using your private key, then the only key that can decrypt that file is your public key. As the name suggests, a Public key is meant to be shared with others or added to public key servers. Thus, in essence, anybody, who has access to your public key, can decrypt your data.
This is not acceptable, since you encrypt a file only to be decrypted by the receiver, and that’s the point of encryption in the first place.
### You are already using GPG without realizing
One of the most common examples of using GPG is in the Linux package manager, specially the [external repositories](https://itsfoss.com/adding-external-repositories-ubuntu/). You add the public key of the developer into your system’s trusted keys. The developer signs the packages (generates a signature) with his/her private key. Since your Linux system has the public file, it understands that the package is actually coming from the trusted developer.
A number of encrypted services use some sort of GPG implementation underneath without you realizing it. But it’s better to not go into those details right now.
Now that you are a bit familiar with the concept, let’s see how you can use GPG for encrypting a file and then use it to decrypt.
## Encrypting and decrypting files with GPG

This is a very simplistic scenario. Here, we presume that, you have two systems, with public-private key pairs. You want to encrypt a file and then decrypt on the other system.
### Step 1: Installing GPG
Firstly, you need to install GPG on both systems. GPG can be found in most distribution’s repositories out of the box.
On Debian and Ubuntu-based systems, install the gpg package:
`sudo apt install gpg`
If you use [Arch-based distributions](https://itsfoss.com/arch-based-linux-distros/), install the gnupg package with the [pacman command](https://itsfoss.com/pacman-command/):
`sudo pacman -S gnupg`
### Step 2: Generating a GPG key
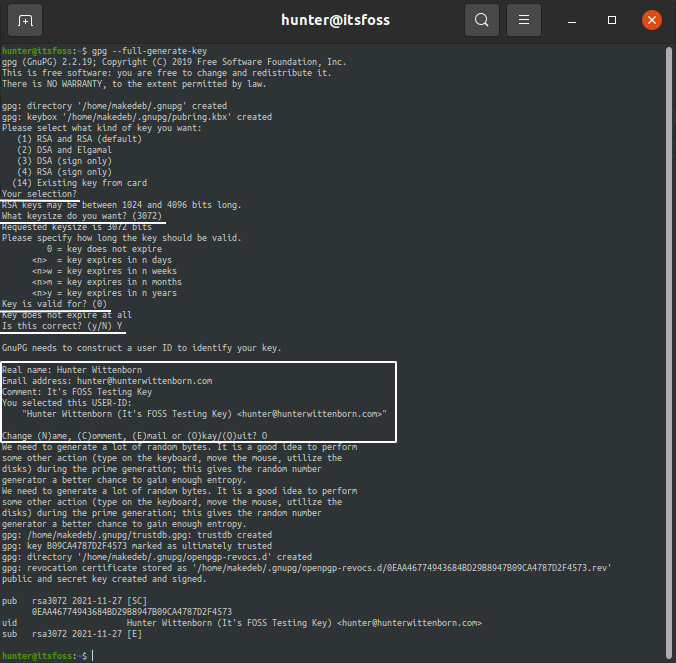
Generating a GPG key on your system is a simple one-command procedure.
Just run the following command, and your key will be generated. You can use the defaults for most questions as shown below.
`gpg --full-generate-key`
**Checking the GPG Key**
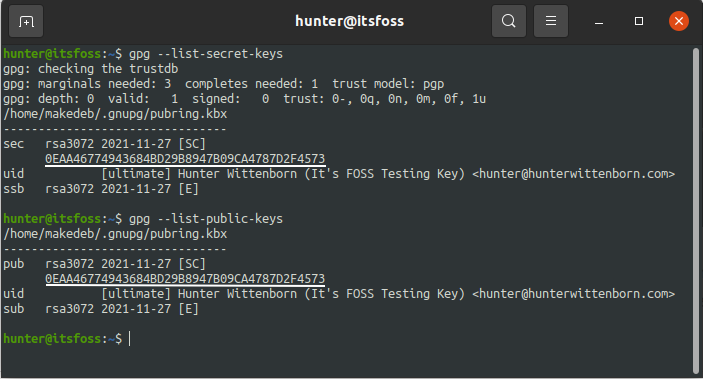
You can then see that the private key and public key are both tied to each other by that ID shown under **pub** by using the **–list-secret-keys** and **–list-public-keys** commands respectively:
You should do this on both the systems you want to communicate with.
### Step 3: Receiving the Public Key of the Receiver
To encrypt the file, you need the Public key of the receiver. So, for simplicity, the receiver can send his public key as a text file to you.
For this, the receiver should export his public key to an ASCII armored format. You can use the command below.
`gpg --output sample.gpg --export --armor `[[email protected]](/cdn-cgi/l/email-protection)
Here,
is the email address used for the key pair of the receiver.[[email protected]](/cdn-cgi/l/email-protection)
It will create an ASCII armored file called *sample.gpg* (with the `--armor`
option)*,* which is easier to send to other people.
Now, the receiver can send the file to the sender using email, or other means.
### Step 4: Import the Public key of the Receiver
Once you receive the public key of the receiver, you should import it to your system. This is to make sure that, the key is accessible, and you can encrypt data using that key.
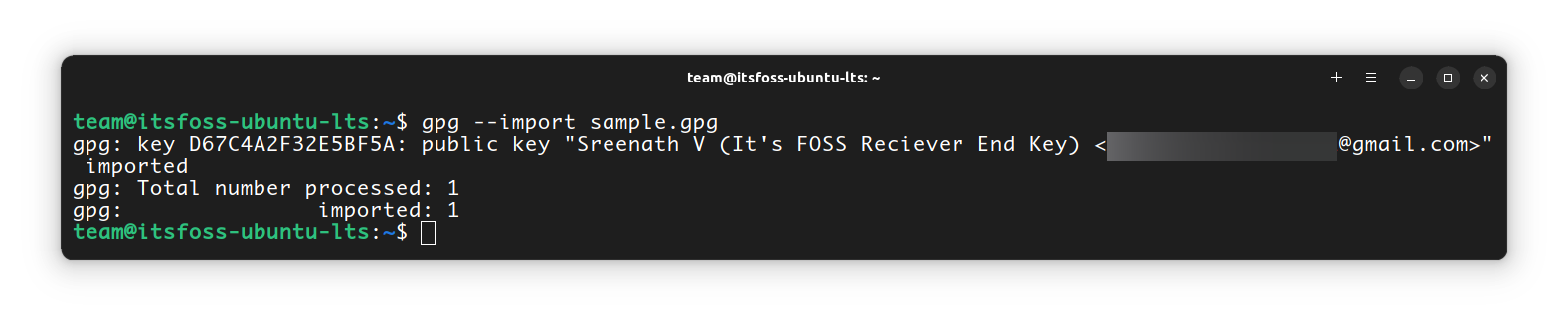
To import the key, go to the directory where you downloaded the file and just run:
`gpg --import sample.gpg`
### Step 4: Verify the Fingerprint of the Key
Are you sure the key you got is from the right person you want to communicate with? What if it was a wrong key so that you encrypted the data, only to be decrypted by an unexpected person? To avoid this, you should make sure that the key you got is from the person that you aim to communicate with.
GPG Fingerprint is used to verify the authenticity of the key. Once you receive the key, first, list the keys:
`gpg --list-keys`
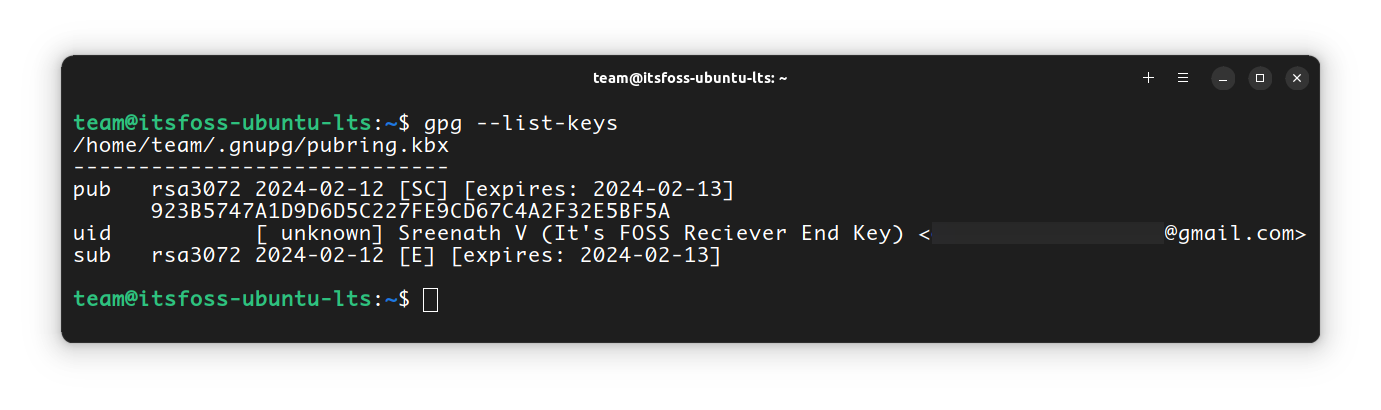
Now, from the list of public keys, note the one that is from the receiver. To start to verify the key, run the gpg command with the `--edit-key`
option on the sender’s system.
`gpg --edit-key `[[email protected]](/cdn-cgi/l/email-protection)
This will enter you into a `command>`
prompt. Here, run the `fpr`
command, which will show the fingerprint for the key.
`fpr`
It will print a fingerprint of the key. This should be validated against the output on the other machine (sender and receiver), which can be found by running the same ** --edit-key** command on that system.
You can verify it by calling the sender or by some other authentic means to verify the identity of the receiver.
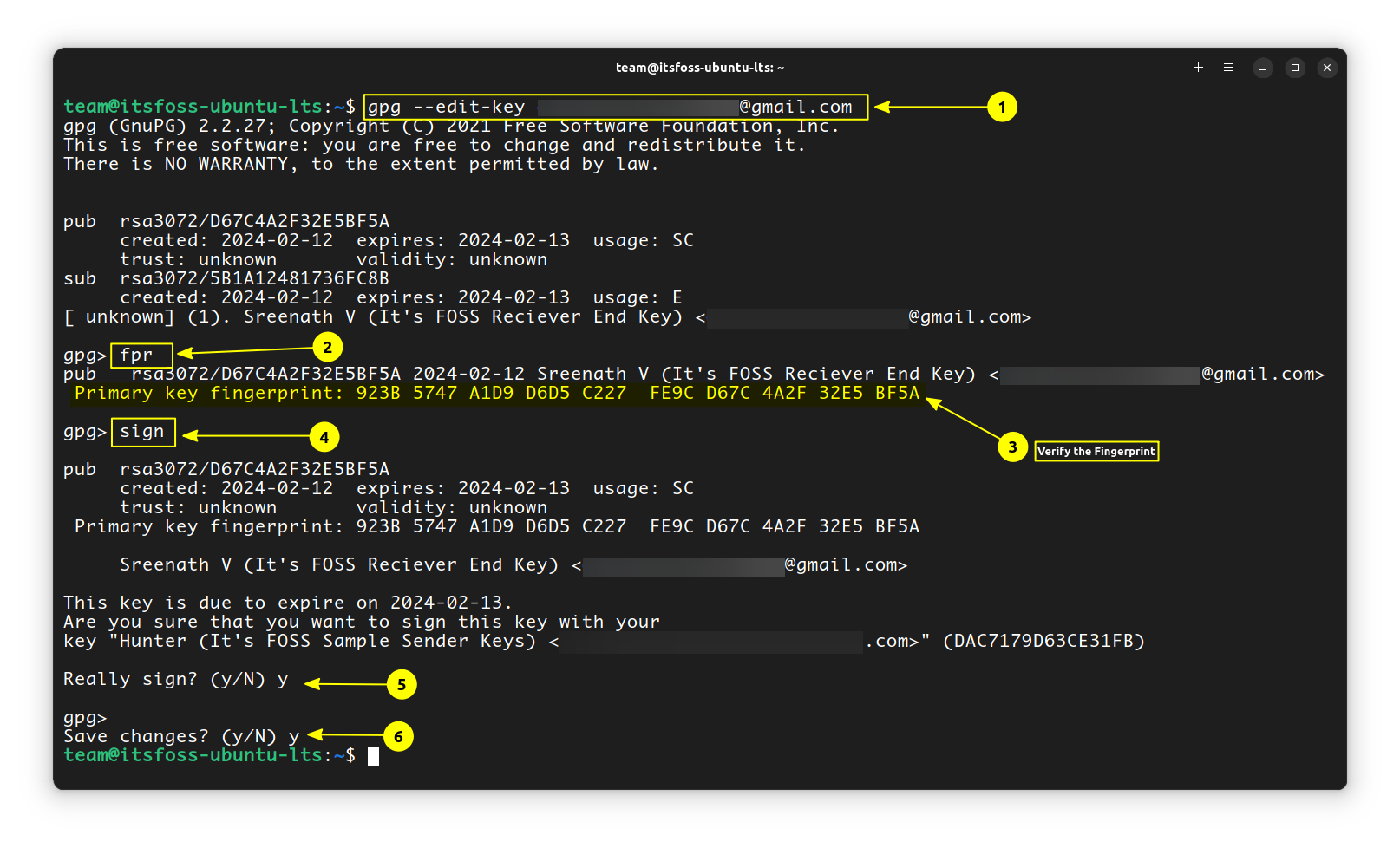
Once you found the fingerprint are matching, on the same command prompt, enter:
`sign`
It will ask you to confirm with a passphrase. Do it and you are ok to go. You can exit the prompt using CTRL+D. Press `y`
to save changes and exit.
### Step 5: Encrypt the File
Now that you’ve set up the GPG keys, you can start encrypting our files! Let’s say `document.txt`
is the name of or file, that needs to be encrypted.
Use the following command to encrypt files:
`gpg --output document.txt.gpg --encrypt --recipient `[[email protected]](/cdn-cgi/l/email-protection) document.txt
Let’s go over what that command does very quick:
First, you specified ** --output file.gpg**. This can be anything, though it’s typically the name of the file you’re encrypting plus a
**.gpg**extension (so
**document.txt**would become
**document.txt.gpg**).
Then, you specified the ** --encrypt** option. This tells GPG that we’ll be encrypting a file.
Next, you type ** --recipient **. This specifies the email for a corresponding GPG key of the receiver, that you have received and imported earlier.
[[email protected]](/cdn-cgi/l/email-protection)

When you try to view the content of this encrypted file, it will be some gibberish.
### Step 6: Send the Encrypted File
You can now send this file to the recipient through any means. Only the receiver, with his Private key can now decrypt this message.
### Step 7: Decrypt the Message
On the receiver’s end, you have `document.txt.gpg`
file, which is the encrypted file. To decrypt that file, you will run:
`gpg --output document.txt --decrypt document.txt.gpg`
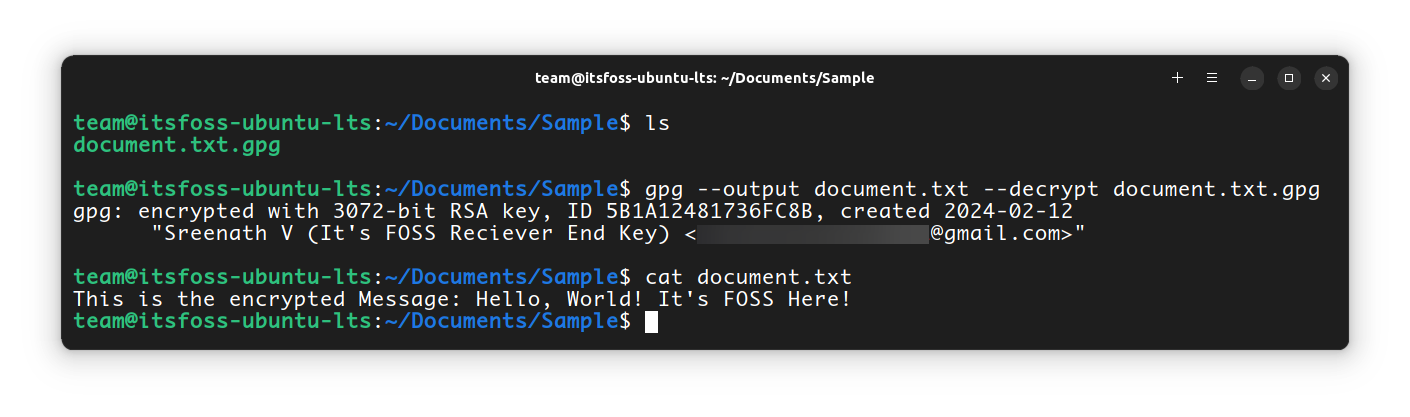
Going through the argument here, we first enter ** --output** file, which tells GPG what file you’ll be saving the encrypted form of our file to after you decrypt it.
Then, we specify the option ** --decrypt**, which tells GPG that you’re going to be decrypting a file.
Lastly, you enter ** file.gpg**, which is just the path to your encrypted file.
What this means is, you are decrypting the ** document.txt.gpg** file to the original
`document.txt`
**. It will ask for the password, that the receiver has set. Give it and you are done!**
*using the private key of the receiver*If you try to decrypt the document on the sender’s end itself, then you will get an error:
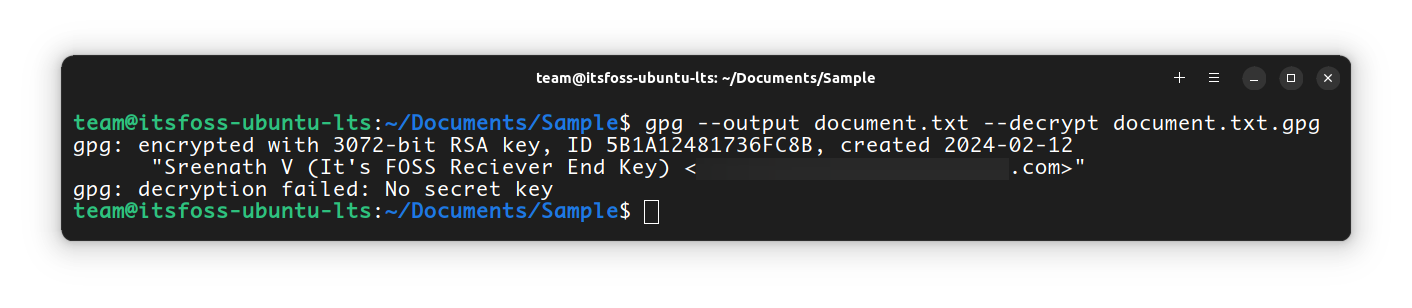
This is because the file was encrypted using the Receiver’s public key. So the only key, that can decrypt this data is the Receiver’s private key.
### Encrypting and Decrypting for Self
If you want to encrypt and decrypt for yourself, you can do that as well. First, encrypt a file using:
`gpg --output document.txt.gpg --encrypt --recipient `[[email protected]](/cdn-cgi/l/email-protection) document.txt
Here, the
is the email address corresponding to the gpg key of your system. Now, to decrypt the same, you can use:[[email protected]](/cdn-cgi/l/email-protection)
`gpg --output document.txt --decrypt document.txt.gpg`
This will ask for the passphrase. Give it and you are done.
## Wrapping Up
You’ve now gone over everything you need to start using GPG. As I mentioned earlier, this is just for understanding how the GPG encryption and decryption process works. The basic GPG knowledge you just acquired can be taken to the next level when applied in real-world scenarios.
*Need some help figuring out something still, or something just not working right? You are welcome to leave any of it in the comments below.* |
14,083 | Pop!_OS 21.10 发布! | https://news.itsfoss.com/pop-os-21-10/ | 2021-12-15T16:36:00 | [] | https://linux.cn/article-14083-1.html |
>
> Pop!\_OS 21.10 包含了新的 Linux 内核、新的应用程序库以及 System76 为帮助 Pop!\_OS 发展而引入的一些重要变化。
>
>
>

Pop!\_OS 无疑是 [最好的 Linux 发行版](https://itsfoss.com/best-linux-distributions/) 之一,也是目前面向 Linux 新手(和游戏玩家)推荐的热门选择之一。
如果你不喜欢非 LTS 版本,你应该坚持使用 [Pop!\_OS 20.04 LTS](https://itsfoss.com/pop-os-20-04-review/)。但是,如果你想看看最新和最棒的更新,那么,Pop!\_OS 21.10 终于就绪,可以下载了!
别忘了,Pop!\_OS 21.10 的发布是为明年 4 月的 Pop!\_OS 22.04 LTS 的潜在功能清单打的前站,你可以期待一下。
### Pop!\_OS 21.10 有什么新功能?
请注意,即使 Pop!\_OS 21.10 将 GNOME 40 作为最重要的变化之一,也应该会有类似于 Pop!\_OS 21.04 的 [COSMIC 桌面体验](https://news.itsfoss.com/pop-os-21-04-beta-release/)。
也就是说,在 Pop!\_OS 21.10 中有一些关键的变化,应该会增强你的 Linux 桌面体验,并使你更轻松。
#### 新的应用程序库
在 Pop!\_OS 21.10 中,全屏应用程序菜单已被一个单独的可搜索窗口取代。这应该不那么碍事,而且很方便。

这不仅仅是 System76 对 GNOME 40 的独特调整,在功能上它应该比传统的全屏应用菜单提供更多的好处。
例如,新的应用程序库应该可以增强多显示器的体验,让你在你关注的屏幕中快速搜索一个应用程序,而不是占用整个屏幕。
它还可以让你快速搜索应用程序(或根据你的搜索查询过滤它们)。不仅仅限于已安装的应用程序,它还会显示可以使用 Pop!\_Shop 安装的应用程序。

你可以使用工作区右侧的 “<ruby> 应用程序 <rt> Applications </rt></ruby>” 按钮访问应用程序库,或执行四指向右滑动,按 `Super+A` 也行。
#### System76 用自己的存储库取代 Launchpad
如果你一直在关注我们,你可能已经知道了 [System76 将 PPA 软件库转移到其系统之中](https://news.itsfoss.com/pop-os-ppa-repo-move/)。

总的来说,这应该有助于他们控制软件包,并比 Ubuntu/Canonical 的默认仓库更快地推送更新。
#### GNOME 更新
从 GNOME 3.38.4 跳到 40 应该会引入几个 [GNOME 40 改进](https://news.itsfoss.com/gnome-40-release/),至少对核心应用程序是这样。
一些值得注意的改进包括设置中的 Wi-Fi 排序,这意味着,可用的网络将按照活动连接、先前连接和信号强度的顺序显示,以按有用顺序呈现可用 Wi-Fi 网络。
你还可以注意到在你搜索某些东西后,文件中的自动补全功能。
#### 最新的 Linux 内核及 NVIDIA 驱动程序

众所周知,Pop!\_OS 比许多其他发行版更快地推送最新的 Linux 内核。Pop!\_OS 21.04 已经在运行 [Linux 内核 5.15](https://news.itsfoss.com/linux-kernel-5-15-release/),而 Pop!\_OS 21.10 继续使用它。
在这里,Pop!\_OS 21.10 带来了 Linux 内核 5.15.5,并且还打包了最新的可用 NVIDIA 驱动程序,以便与较新的硬件保持最佳的兼容性。
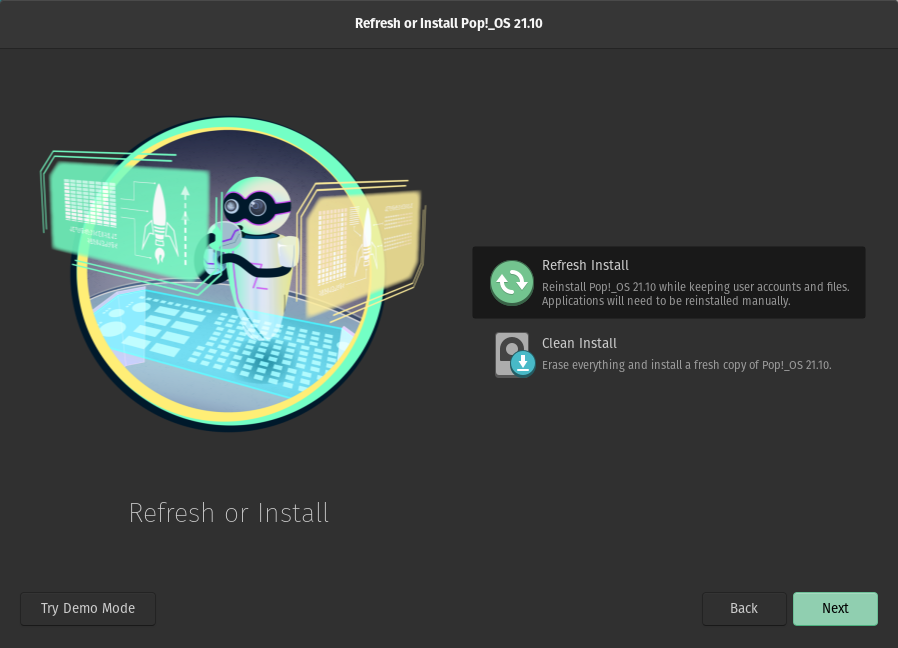
#### 全新安装

每当 Pop!\_OS 从恢复分区安装时,它让你选择“<ruby> 全新安装 <rt> Refresh Install </rt></ruby>”。
通过这种方式,你可以重新安装 Pop!\_OS,而不会丢失主目录中的文件。如果有什么东西不能工作,而你又不能排除故障,重新安装应该会使事情恢复到默认状态,这时它就会派上用场。
#### 对 Pop!\_OS 升级的改进

通过 Pop!\_OS 21.10,你还会有更好的升级体验。
为了方便起见,Pop!\_OS 在升级发行版时对其行为做了一些改变。其中一些是:
* 自动禁用用户添加的 PPA 以避免升级冲突。
* 现在在升级发行版之前会更新恢复分区,如果使用恢复分区第一次没有成功,之一可以给你一个可以轻松地重新安装发行版的媒介。
#### 用于树莓派 4 的技术预览版
截至目前,这还是针对树莓派 4 的实验,但你可以下载 ARM 平台的技术预览版。
他们计划在未来的 Pop!\_OS 版本中引入 Pop!\_Pi。
### 关于 Pop!\_OS 21.10 的想法
Pop!\_OS 一直在努力使桌面 Linux 的体验尽可能可靠,同时拥有一些最新的软件包。
通过 Pop!\_OS 21.10,更新的桌面环境、Linux 内核和可用性改进使这次升级变得有用。
如果你正在使用一个非 LTS 版本,你肯定应该考虑尽快升级。请注意,在你进行升级之前,你应该备份你的数据。
### 下载 Pop!\_OS 21.10
你可以找到两种用于 Pop!\_OS 21.10 的不同 ISO ,一种用于 NVIDIA,另一种用于 Intel/AMD。
请前往 [官方下载](https://pop.system76.com) 页面,下载你需要的 ISO。
如果你已经安装了 Pop!\_OS 21.04,在他们的官方公告之后,你应该很快收到升级通知,或者前往系统设置并应用升级。
如果你使用的是终端,输入以下命令:
```
sudo apt update
sudo apt full-upgrade
pop-upgrade release upgrade
```
你也可以阅读他们 [官方公告帖子](https://blog.system76.com/post/670564272872488960/popos-2110-has-landed) 中提到的细节。
你对 Pop!\_OS 21.10 有什么看法?请在下面的评论中告诉我你的想法。
---
via: <https://news.itsfoss.com/pop-os-21-10/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Pop!_OS is undoubtedly one of the [best Linux distributions](https://itsfoss.com/best-linux-distributions/?ref=news.itsfoss.com), also happens to be a popular recommendation currently for Linux newbies (and gamers).
If you do not prefer non-LTS releases, you should stick to [Pop!_OS 20.04 LTS](https://itsfoss.com/pop-os-20-04-review/?ref=news.itsfoss.com). But, if you are looking for the latest and greatest update, Pop!_OS 21.10 is finally here for you to download!
Not to forget, the Pop!_OS 21.10 release sets things in motion for a potential list of features that you can expect with Pop!_OS 22.04 LTS, April next year.
## Pop!_OS 21.10: What’s New?
Note that even if Pop!_OS 21.10 features GNOME 40 as one of the most considerable changes, you should expect a similar [COSMIC desktop experience](https://news.itsfoss.com/pop-os-21-04-beta-release/) as you did with Pop!_OS 21.04.
That being said, there are some key changes in Pop!_OS 21.10 that should enhance your Linux desktop experience, and make things easier.
### New Application Library
With Pop!_OS 21.10, the full-screen application menu has been replaced by a separate searchable window. This should be less obstructive and come in handy.
It is not just a unique tweak to GNOME 40 by System76, but it should functionally provide more benefits than the traditional full-screen app drawer.
For instance, the new application library should enhance the multi-monitor experience by letting you quickly search for an application in the screen you focus, instead of taking up the full screen.
It also lets you quickly search for an application (or filter them as per your search query). Not just limited to the applications installed, but it will also display the applications that can be installed using the Pop!_Shop.
You can access the application library using the “**Applications**” button right to the Workspaces, or perform a four-finger swipe right, or press **Super + A**.
### System76’s Repositories Replacing Launchpad
If you have been following us, you might have already read about [System76 moving PPA repositories to its system](https://news.itsfoss.com/pop-os-ppa-repo-move/).
Overall, this should help them take control of packages and push updates faster than Ubuntu/Canonical’s default repositories.
### GNOME Updates
The jump from GNOME 3.38.4 to 40 should introduce several [GNOME 40 improvements](https://news.itsfoss.com/gnome-40-release/), at least to the core applications.
Some notable improvements include Wi-Fi sorting in the Settings, meaning, the available networks will show up in the order of active connection, previous connections, and strength of the signal, to present a useful order of available Wi-Fi networks.
You can also notice auto-completion in Files after you search for something.
### Latest Linux Kernel & NVIDIA Driver
Pop!_OS is known to push the latest Linux Kernel faster than many other distributions. Pop!_OS 21.04 was already running [Linux Kernel 5.15](https://news.itsfoss.com/linux-kernel-5-15-release/), and Pop!_OS 21.10 continues with it.
Here, Pop!_OS 21.10 brings in Linux Kernel 5.15.5 and also packs in the latest available NVIDIA driver for best compatibility with newer hardware.
### Refresh Install Option
Whenever Pop!_OS is installed from the recovery partition, it lets you choose to opt for “Refresh Install”.
In this way, you get to re-install Pop!_OS without losing your files in the Home directory. It should come in handy if something fails to work, and you cannot troubleshoot it, a re-installation should bring back things to their default state.
### Improvements to Pop!_OS Upgrade
With Pop!_OS 21.10, you can also expect a better upgrade experience.
To make things convenient, Pop!_OS made some changes to its behavior when the distribution is upgraded. Some of them are:
- Disabling the user-added PPAs automatically to avoid upgrade conflicts.
- The recovery partition is now updated before upgrading the distribution to give you a medium to easily re-install the distro if the installation using the restore partition does not succeed the first time.
### Tech-Preview for Raspberry Pi 4
As of now, it is entirely an experiment for Raspberry Pi 4 but you can download a tech preview release for the ARM platform.
They plan to introduce Pop!_Pi with future Pop!_OS releases.
## Thoughts on Pop!_OS 21.10
Pop!_OS is constantly making efforts to make the desktop Linux experience as reliable as possible while having some of the latest packages at the same time.
With Pop!_OS 21.10, an updated desktop environment, Linux Kernel, and usability improvements make up for a useful upgrade.
If you are using a non-LTS release, you should definitely consider upgrading as soon as possible. Note that you should always backup your data before you proceed to upgrade.
## Download Pop!_OS 21.10
You can find two different ISOs available for Pop!_OS 21.10, one for NVIDIA, and the other for Intel/AMD.
Head to the official download page and download the ISO you require.
If you already had Pop!_OS 21.04 installed, you should get an upgrade notification soon following their official announcement or head to the system settings and apply the upgrade.
If you are using the terminal, type in the following commands:
```
sudo apt update
sudo apt full-upgrade
pop-upgrade release upgrade
```
You can also read the details mentioned in their [official announcement post](https://blog.system76.com/post/670564272872488960/popos-2110-has-landed?ref=news.itsfoss.com).
*What do you think about Pop!_OS 21.10? Let me know your thoughts in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,085 | Linux 黑话解释:什么是定时任务 | https://itsfoss.com/cron-job/ | 2021-12-16T11:27:01 | [
"cron"
] | https://linux.cn/article-14085-1.html | 
在本期的《Linux 黑话解释》系列文章中,你将了解到 Linux 中的<ruby> 定时任务 <rt> cron job </rt></ruby>功能。你将通过学习编辑 `crontab` 文件来创建定时任务。
### 何为定时任务
`cron` 是一个用于按计划运行短小且快速的命令的实用命令行工具。该工具是一个方便、经典的系统管理工具,通过和其他工具结合使用可以自动运行各式各样的任务。比如,有些人通过把 `rsync` 和 `cron` 结合使用,在特定的时间自动创建每日备份和每周备份。也有些人使用 `cron` 来分析服务器日志,并且结合邮件系统功能,在日志检测到错误时自动发送告警邮件。
`cron` 就如同“瑞士军刀”一样,可以多场景多样化使用。尽可能发挥你的想象,去挖掘它的功能。
其实 `cron` 的使用很容易上手,只需要几秒钟。不过在我们开始上手之前,先来讨论下几个经常容易混淆的概念。
### cron、定时任务、crontab
有三个术语比较容易混淆:`cron`、定时任务和 `crontab`,让我们来看看它们的含义:
| 术语 | 含义 |
| --- | --- |
| `cron` | 这是安装在系统上的实际执行定时任务的 [守护进程](https://itsfoss.com/linux-daemons/)。 |
| 定时任务 | “任务”是指一段启动并运行的程序。`cron` 可以按照约定的时间计划运行各种任务,这样的任务通常叫做“定时任务”。 |
| [crontab](https://linuxhandbook.com/crontab/) | 这是一个文件,用于定义定时任务。一个 `crontab` 文件可以通过表格形式(每一行就是一个定时任务)定义多个定时任务。 |
来看一个简单例子:创建一个定时任务,每小时向 `crontabl_log.txt` 文件打印 `Linux is cool!`。
```
0 * * * * echo "Linux is Cool!" >> ~/crontab_log.txt
```
是不是这么个简单定时任务的例子都让你感到惊恐,这是因为你需要懂得如何去读懂一个定时任务的属性。
我将在后文中讲述这个基础理论知识。
### 上手 cron
我们通过另一个例子来看看 `cron` 如何工作。
为了创建定时任务(或者说 `cron` 将要执行的命令任务),你只需要运行:
```
crontab -e
```
这将会打开一个文件,用于编辑定时任务:

其中,所有以 `#` 开头的行都是注释,用于指导你如何使用 `cron`,如果觉得没用可以删除它们。
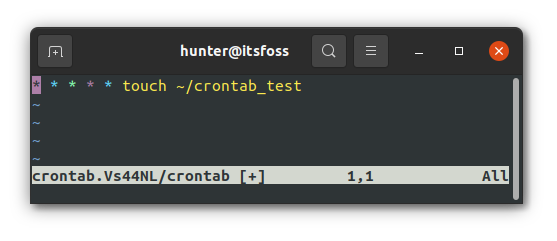
我们将创建如下任务,作为我们的第一个定时任务:
```
* * * * * touch ~/crontab_test
```
让我快速看看该任务将会做什么:
定时任务都是以 “分钟 小时 天 月 周 命令” 形式呈现:
* 分钟:指该任务在哪一分钟会被执行。所以,该值为 `0` 则代表在每个小时开始时运行,`5` 则代表在每个小时的第 5 分钟会运行。
* 小时:指该任务在一天中的哪个小时会被执行,取值范围为 `0-23`。没有 `24` 的原因是 `23` 时的末尾是半夜 `11:59`,然后就是每天的开始 `0` 时。分钟的取值范围定义逻辑与之类似。
* 天:指一个月中的哪一天执行该任务,取值范围是 `1-31`(不同于前面的分钟和小时从 `0` 开始取值)。
* 月:指该任务在哪个月被执行,取值范围是 `1-12`。
* 周:指该任务在星期几被执行,从周日开始算起,取值范围是 `0-6`(分别对应周日、周一到周六)。
* 命令:是你想要运行的命令任务。

如果想对 “分钟 小时 天 月 周” 部分有更详细的理解,可以参考 [Crontab guru 网站](https://crontab.guru/),该网站可以帮助你理解正在执行什么。
接着之前的例子 `* * * * * touch ~/crontab_test`,表示每分钟创建一次 `~/crontab_test` 文件。
让我们将该任务编辑进 `crontab` 然后看看执行结果:

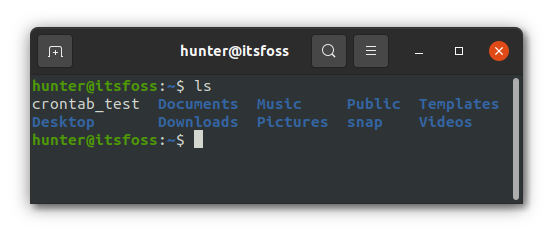
等到下一分钟,你就会发现你的家目录下多了文件 `crontab_test`:

这便是 `cron` 的基础应用示例。
### 一个实用的定时任务示例
假设你想创建一个脚本,用于拷贝多个目录内容到一个路径并打包作为备份,该如何实现?
通过 `cron` 定时任务就可以很容易实现该功能。
请看如下脚本:
```
#!/usr/bin/bash
echo "Backing up..."
mkdir -p ~/.local/tmp/
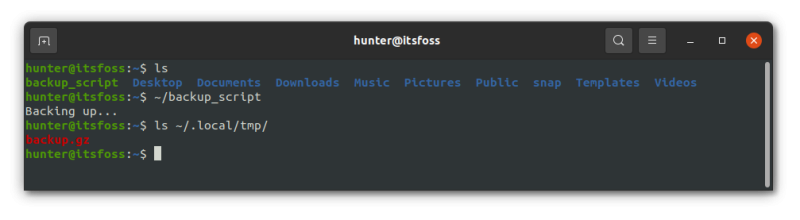
tar -Pc ~/Documents/ -f ~/.local/tmp/backup.gz
```
该脚本做了如下事情:
1. 确保备份路径目录 `~/.local/tmp/` 存在。
2. 将目录 `~/Documents/` 下的所有内容打包至文件 `~/.local/tmp/backup.gz`。
我们先来手动运行该脚本,看看它到底如何工作。
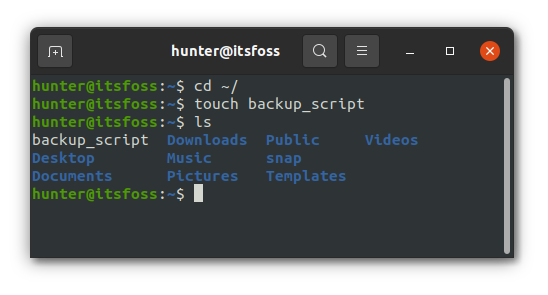
首先,我们在家目录(`~`)下创建该脚本,命令为 `backup_script`,如下图所示:

然后编辑 `backup_script` 脚本,写入上面那个脚本代码。
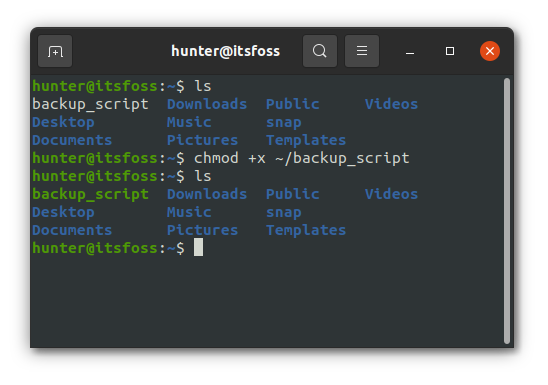
接着,赋予 `backup_script` 可执行权限:

最后运行脚本 `~/backup_script`,进行功能验证:

你可以通过运行命令 `tar -xf ~/.local/tmp/backup.gz -C <output_dir>` 来进行备份恢复,这里 `<output_dir>` 是指文件要恢复到的路径目录。
接下来,就可以用 `cron` 工具来进行定时任务运行该脚本了。
举个例子,假设需要每天的凌晨 3 点运行该备份脚本,你可以在 `crontab` 中输入如下命令:
```
* 3 * * * ~/backup_script
```
这样你就可以每天自动进行备份操作了。
### 后记
本文简单介绍了定时任务功能。尽管我不确定 Linux 桌面用户使用该功能多不多,但我知道定时任务功能被许多系统管理员广泛应用。如果你有什么想法,欢迎在评论区留言。
---
via: <https://itsfoss.com/cron-job/>
作者:[Hunter Wittenborn](https://itsfoss.com/author/hunter/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jrglinux](https://github.com/jrglinux) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

In this part of our Linux Jargon Buster series, you’ll learn about cron in Linux. You’ll also learn the basics of creating cron jobs by editing crontab.
## What is a cron job in Linux?
Cron is a command line utility to run small and quick commands on a scheduled basis. This is a handy, classic sysadmin tool for automating various tasks by combining it with othe tools. For example, some people combine rsync and cron to automatically create a daily or weekly backup at a certain time. Some people use it to analyze server logs and combine it with mail function to send an email if there is certain kind of error detected in the logs.
Cron is like the Swiss army knife. It can be used for a variety of use cases. It’s really up to your imagination on what to use it for.
Getting started with cron is super easy, and only takes a matter of seconds to get started. But before I show you that, I’ll discuss something else that often confuses Linux users.
## Cron vs cron job vs crontab
You are likely to come across three terms that sound similar to each other: cron, cron job and crontab. Let me quickly tell you what are those:
cron: This is the actual program you install on your system and run as a [daemon](https://itsfoss.com/linux-daemons/).
cron job: A job in Linux is a program that is up and running. Cron can handle multiple tasks and run them at their scheduled time. Each of these tasks are referred to as ‘cron jobs’.
[crontab](https://linuxhandbook.com/crontab/): This is the file (and command) where you define what task to run and how often to run it. A crontab can have multiple cron jobs in it in a tabular form where each row is a cron job.
Let me share a sample cron job example that runs every hour and prints “Linux is cool!” to a file name crontab_log.txt.
`0 * * * * echo "Linux is Cool!" >> ~/crontab_log.txt`
Even the simplest of the cron job may look scary and intimidating. This is because you need to know how to read a cron job properly.
I’ll take this theoretical knowledge of cron to the next level in the next section.
## Getting started with Cron
Let’s start with (another) simple example of how Cron works.
To create Cron jobs, or the commands that cron will execute, you simply run:
`crontab -e`
It will pull up a file to edit cron jobs with:
All the lines that start with `#`
(that being all the lines) only serve to help guide you on how to use cron, and can be removed if you don’t need them.
We’ll be using the following as our first Cron job though:
`* * * * * touch ~/crontab_test`
Let’s go through what that will do real quick:
Cron jobs come in the form `minute hour day month week command`
.
**minute**in this context simply means what minutes of an hour the job will run. So specifying`0`
would run at the very beginning of an hour, and specifying`5`
would run on the fifth minute of an hour.- Next, the
**hour**declaration specified what hours of a day a job can run, ranging from values 0-23. The reason there isn’t a 24th hour option here is that`23`
goes to the very end of what would be 11:59, at which point your at midnight, or hour`0`
of the next day. This same logic applies to the`minute`
declaration mentioned previously. **day**specifies what day of a month a job can run on, that being 1-31 (unlike the previous examples which started on`0`
).**month**specifies which months of the year a job can run on, and takes values ranging from 1-12.- Lastly,
**week**specifies which days of the week a job runs on, starting on Sunday, with values from 0-6, unlike the last two.
You then specify **command** which is just the command you want to run.
If you want more help understanding the minute hour day month week part, I’d highly recommend the [Crontab guru](https://crontab.guru/) website, which can greatly help break down what exactly is going on:
Following the previous example of *** * * * * touch ~/crontab_test** though, you’ll simply be running touch ~/crontab_test every minute.
Let’s put that into the crontab and then see it in action:
If you then wait until the next minute, you’ll see the crontab_test file located in your home directory:
And that’s the basics to using cron!
## A useful example of cron job
That was far too simple (and useless probably).
Say you want to do something a bit more complex, say a backup script that needs to copy files from multiple directories on your system into a single folder, and then archives that backup into a single file.
This can be easily done by simply putting our commands into a script, which can then in turn be called by cron.
Let’s use the following script as an example:
```
#!/usr/bin/bash
echo "Backing up..."
mkdir -p ~/.local/tmp/
tar -Pc ~/Documents/ -f ~/.local/tmp/backup.gz
```
This script does the following things:
- Makes sure the ~/.local/tmp/backup_dir directory exists on the system.
- Puts everything from ~/Documents/ into an archive located at ~/.local/tmp/backup.gz.
Let’s run the script manually first so we can see that it actually works.
First, let’s put the script at ~/backup_script like so:
Then just copy the script contents that were shown above into the file.
You then need to tell the system that our script is allowed to be executed by simply running chmod +x ~/backup_script:
You can then test run our script by running ~/backup_script.sh, which simply tells our system the path to our script:
You could then restore this backup by just running tar -xf ~/.local/tmp/backup.gz -C output_dir, where output_dir is the directory to save the files to.
This script can now run on a scheduled basis by using Cron!
For example, if you wanted the script to run daily at 3 a.m., you could use the following syntax in cron:
`0 3 * * * ~/backup_script`
And then you’d have backups being created on a daily basis.
## Wrapping Up
And that’s just the introduction to cron jobs. It is widely used by the sysadmins though I am not sure of many usecases for desktop Linux users. If you do, please suggest some in the comment section. |
14,086 | Python Beautiful Soup 刮取简易指南 | https://opensource.com/article/21/9/web-scraping-python-beautiful-soup | 2021-12-16T14:21:29 | [
"爬虫",
"爬取",
"刮取",
"Python"
] | https://linux.cn/article-14086-1.html |
>
> Python 中的 Beautiful Soup 库可以很方便的从网页中提取 HTML 内容。
>
>
>

今天我们将讨论如何使用 Beautiful Soup 库从 HTML 页面中提取内容,之后,我们将使用它将其转换为 Python 列表或字典。
### 什么是 Web 刮取,为什么我需要它?
答案很简单:并非每个网站都有获取内容的 API。你可能想从你最喜欢的烹饪网站上获取食谱,或者从旅游博客上获取照片。如果没有 API,提取 HTML(或者说 <ruby> 刮取 <rt> scraping </rt></ruby> 可能是获取内容的唯一方法。我将向你展示如何使用 Python 来获取。
**并非所以网站都喜欢被刮取,有些网站可能会明确禁止。请于网站所有者确认是否同意刮取。**
### Python 如何刮取网站?
使用 Python 进行刮取,我们将执行三个基本步骤:
1. 使用 `requests` 库获取 HTML 内容
2. 分析 HTML 结构并识别包含我们需要内容的标签
3. 使用 Beautiful Soup 提取标签并将数据放入 Python 列表中
### 安装库
首先安装我们需要的库。`requests` 库从网站获取 HTML 内容,Beautiful Soup 解析 HTML 并将其转换为 Python 对象。在 Python3 中安装它们,运行:
```
pip3 install requests beautifulsoup4
```
### 提取 HTML
在本例中,我将选择刮取网站的 [Techhology](https://notes.ayushsharma.in/technology) 部分。如果你跳转到此页面,你会看到带有标题、摘录和发布日期的文章列表。我们的目标是创建一个包含这些信息的文章列表。
网站页面的完整 URL 是:
```
https://notes.ayushsharma.in/technology
```
我们可以使用 `requests` 从这个页面获取 HTML 内容:
```
#!/usr/bin/python3
import requests
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
print(data.text)
```
变量 `data` 将包含页面的 HTML 源代码。
### 从 HTML 中提取内容
为了从 `data` 中提取数据,我们需要确定哪些标签具有我们需要的内容。
如果你浏览 HTML,你会发现靠近顶部的这一段:
```
<div class="col">
<a href="/2021/08/using-variables-in-jekyll-to-define-custom-content" class="post-card">
<div class="card">
<div class="card-body">
<h5 class="card-title">Using variables in Jekyll to define custom content</h5>
<small class="card-text text-muted">I recently discovered that Jekyll's config.yml can be used to define custom
variables for reusing content. I feel like I've been living under a rock all this time. But to err over and
over again is human.</small>
</div>
<div class="card-footer text-end">
<small class="text-muted">Aug 2021</small>
</div>
</div>
</a>
</div>
```
这是每篇文章在整个页面中重复的部分。我们可以看到 `.card-title` 包含文章标题,`.card-text` 包含摘录,`.card-footer > small` 包含发布日期。
让我们使用 Beautiful Soup 提取这些内容。
```
#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup
from pprint import pprint
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
my_data = []
html = BeautifulSoup(data.text, 'html.parser')
articles = html.select('a.post-card')
for article in articles:
title = article.select('.card-title')[0].get_text()
excerpt = article.select('.card-text')[0].get_text()
pub_date = article.select('.card-footer small')[0].get_text()
my_data.append({"title": title, "excerpt": excerpt, "pub_date": pub_date})
pprint(my_data)
```
以上代码提取文章信息并将它们放入 `my_data` 变量中。我使用了 `pprint` 来美化输出,但你可以在代码中忽略它。将上面的代码保存在一个名为 `fetch.py` 的文件中,然后运行它:
```
python3 fetch.py
```
如果一切顺利,你应该会看到:
```
[{'excerpt': "I recently discovered that Jekyll's config.yml can be used to"
"define custom variables for reusing content. I feel like I've"
'been living under a rock all this time. But to err over and over'
'again is human.',
'pub_date': 'Aug 2021',
'title': 'Using variables in Jekyll to define custom content'},
{'excerpt': "In this article, I'll highlight some ideas for Jekyll"
'collections, blog category pages, responsive web-design, and'
'netlify.toml to make static website maintenance a breeze.',
'pub_date': 'Jul 2021',
'title': 'The evolution of ayushsharma.in: Jekyll, Bootstrap, Netlify,'
'static websites, and responsive design.'},
{'excerpt': "These are the top 5 lessons I've learned after 5 years of"
'Terraform-ing.',
'pub_date': 'Jul 2021',
'title': '5 key best practices for sane and usable Terraform setups'},
... (truncated)
```
以上是全部内容!在这 22 行代码中,我们用 Python 构建了一个网络刮取器,你可以在 [我的示例仓库中找到源代码](https://gitlab.com/ayush-sharma/example-assets/-/blob/fd7d2dfbfa3ca34103402993b35a61cbe943bcf3/programming/beautiful-soup/fetch.py)。
### 总结
对于 Python 列表中的网站内容,我们现在可以用它做一些很酷的事情。我们可以将它作为 JSON 返回给另一个应用程序,或者使用自定义样式将其转换为 HTML。随意复制粘贴以上代码并在你最喜欢的网站上进行试验。
玩的开心,继续编码吧。
*本文最初发表在[作者个人博客](https://notes.ayushsharma.in/2021/08/a-guide-to-web-scraping-in-python-using-beautifulsoup)上,经授权改编。*
---
via: <https://opensource.com/article/21/9/web-scraping-python-beautiful-soup>
作者:[Ayush Sharma](https://opensource.com/users/ayushsharma) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today we'll discuss how to use the Beautiful Soup library to extract content from an HTML page. After extraction, we'll convert it to a Python list or dictionary using Beautiful Soup.
## What is web scraping, and why do I need it?
The simple answer is this: Not every website has an API to fetch content. You might want to get recipes from your favorite cooking website or photos from a travel blog. Without an API, extracting the HTML, or *scraping*, might be the only way to get that content. I'm going to show you how to do this in Python.
**Not all websites take kindly to scraping, and some may prohibit it explicitly. Check with the website owners if they're okay with scraping.**
## How do I scrape a website in Python?
For web scraping to work in Python, we're going to perform three basic steps:
- Extract the HTML content using the
`requests`
library. - Analyze the HTML structure and identify the tags which have our content.
- Extract the tags using Beautiful Soup and put the data in a Python list.
## Installing the libraries
Let's first install the libraries we'll need. The `requests`
library fetches the HTML content from a website. Beautiful Soup parses HTML and converts it to Python objects. To install these for Python 3, run:
`pip3 install requests beautifulsoup4`
## Extracting the HTML
For this example, I'll choose to scrape the [Technology](https://notes.ayushsharma.in/technology) section of this website. If you go to that page, you'll see a list of articles with title, excerpt, and publishing date. Our goal is to create a list of articles with that information.
The full URL for the Technology page is:
`https://notes.ayushsharma.in/technology`
We can get the HTML content from this page using `requests`
:
```
#!/usr/bin/python3
import requests
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
print(data.text)
```
The variable `data`
will contain the HTML source code of the page.
## Extracting content from the HTML
To extract our data from the HTML received in `data`
, we'll need to identify which tags have what we need.
If you skim through the HTML, you’ll find this section near the top:
```
<div class="col">
<a href="https://opensource.com/2021/08/using-variables-in-jekyll-to-define-custom-content" class="post-card">
<div class="card">
<div class="card-body">
<h5 class="card-title">Using variables in Jekyll to define custom content</h5>
<small class="card-text text-muted">I recently discovered that Jekyll's config.yml can be used to define custom
variables for reusing content. I feel like I've been living under a rock all this time. But to err over and
over again is human.</small>
</div>
<div class="card-footer text-end">
<small class="text-muted">Aug 2021</small>
</div>
</div>
</a>
</div>
```
This is the section that repeats throughout the page for every article. We can see that `.card-title`
has the article title, `.card-text`
has the excerpt, and `.card-footer > small`
has the publishing date.
Let's extract these using Beautiful Soup.
```
#!/usr/bin/python3
import requests
from bs4 import BeautifulSoup
from pprint import pprint
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
my_data = []
html = BeautifulSoup(data.text, 'html.parser')
articles = html.select('a.post-card')
for article in articles:
title = article.select('.card-title')[0].get_text()
excerpt = article.select('.card-text')[0].get_text()
pub_date = article.select('.card-footer small')[0].get_text()
my_data.append({"title": title, "excerpt": excerpt, "pub_date": pub_date})
pprint(my_data)
```
The above code extracts the articles and puts them in the `my_data`
variable. I'm using `pprint`
to pretty-print the output, but you can skip it in your code. Save the code above in a file called `fetch.py`
, and then run it using:
`python3 fetch.py`
If everything went fine, you should see this:
```
[{'excerpt': "I recently discovered that Jekyll's config.yml can be used to"
"define custom variables for reusing content. I feel like I've"
'been living under a rock all this time. But to err over and over'
'again is human.',
'pub_date': 'Aug 2021',
'title': 'Using variables in Jekyll to define custom content'},
{'excerpt': "In this article, I'll highlight some ideas for Jekyll"
'collections, blog category pages, responsive web-design, and'
'netlify.toml to make static website maintenance a breeze.',
'pub_date': 'Jul 2021',
'title': 'The evolution of ayushsharma.in: Jekyll, Bootstrap, Netlify,'
'static websites, and responsive design.'},
{'excerpt': "These are the top 5 lessons I've learned after 5 years of"
'Terraform-ing.',
'pub_date': 'Jul 2021',
'title': '5 key best practices for sane and usable Terraform setups'},
... (truncated)
```
And that's all it takes! In 22 lines of code, we've built a web scraper in Python. You can find the [source code in my example repo](https://gitlab.com/ayush-sharma/example-assets/-/blob/fd7d2dfbfa3ca34103402993b35a61cbe943bcf3/programming/beautiful-soup/fetch.py).
## Conclusion
With the website content in a Python list, we can now do cool stuff with it. We could return it as JSON for another application or convert it to HTML with custom styling. Feel free to copy-paste the above code and experiment with your favorite website.
Have fun, and keep coding.
*This article was originally published on the author's personal blog and has been adapted with permission.*
## Comments are closed. |
14,088 | 用开源的 Darktable 进行照片处理 | https://opensource.com/article/21/12/open-source-photo-processing-darktable | 2021-12-17T11:01:00 | [
"Darktable",
"照片"
] | /article-14088-1.html |
>
> 如果你拍摄的照片值得处理,那么你可以看看 Darktable 为你提供了什么。
>
>
>

很难说好照片是如何产生的。你必须在正确的时间出现在正确的地点。你必须准备好相机和构图的观察力。而这只是发生在相机里的部分。好的摄影还有另一个阶段,许多人都没有想到这一点。它曾经需要在 *暗房* 中的灯光和化学品,但在今天的数字工具中,后期制作发生在暗房软件中。最好的照片处理器之一是 [Darktable](https://www.darktable.org/),我在 2016 年写了一篇 [介绍 Darktable](https://opensource.com/life/16/4/how-use-darktable-digital-darkroom) 的文章。那篇文章已经过去五年了,所以我想我应该重新审视一下这个应用,写一写它的一个高级功能:蒙版。
自从我最初写下这篇文章以来,Darktable 并没有什么变化,在我看来,这是一个真正好的应用的标志之一。一个稳定的界面和持续的优秀性能是人们对软件的所有要求,而 Darktable 依旧熟悉而强大。如果你是 Darktable 的新手,请阅读我的 [介绍性文章](https://opensource.com/life/16/4/how-use-darktable-digital-darkroom),了解基础知识。
### 什么是蒙版?
在照片处理中,蒙版被用来限制你对图像的调整,使其只限于图像的一个区域。
直观地说,<ruby> 蒙版 <rt> mask </rt></ruby> 是视觉艺术中的一种技术,用一种材料来遮挡另一种材料。如果你曾经在你的公寓或房子里画过一面墙,你可能使用过 *遮蔽胶带*(也叫油漆工胶带)来保护相邻的墙壁或造型不受杂乱笔触的影响。完成后,你剥去遮蔽胶带,你就有了漂亮的油漆直线。
<ruby> 模板 <rt> stencil </rt></ruby>也是遮蔽的一种形式。

(Seth Kenlon, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
这是一种在摄影中使用了一个世纪的技术,因此,数字摄影工具有一个类似的技术也是合理的。
### 在 Darktable 中使用蒙版
在这个例子中,我使用了 Flickr 用户 **bcnewdemocrats** 的创作共用照片。这是一张很好的照片,因为它有迷人的主题(两个孩子在他们非常耐心的父亲脸上涂抹 Holi 粉)。因为它是关于印度的五彩节,所以它在整个过程中都有色彩飞溅。

(bcnewdemocrats, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
这是一张不需要改进的照片,但并不是所有的调整都需要剧烈变化才能产生显著效果。
色彩校正滤镜提供了一个特别明显的调整。在彩色摄影中,尤其是人物摄影中,一个常见的修正是添加 *琥珀色*(一种偏红的橙色)。人类肤色受益于琥珀色,因为我们把这种颜色与温暖和生命联系起来。
点击 “<ruby> 开启 <rt> On </rt></ruby>” 按钮,激活 Darktable 窗口右侧的色彩校正调整面板。将中心点向上和向右拖动,给照片增加琥珀色。

(Seth Kenlon, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
这样做之后,整张照片就会浸透在琥珀色里。

(Seth Kenlon, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
在色彩校正面板的底部,点击 “<ruby> drawn & parametric mask <rt> 绘制和参数化蒙版 </rt></ruby>” 按钮。

(Seth Kenlon, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
在显示出来的工具栏中,你有几种蒙版形状可以选择。有圆、椭圆、路径、画笔、梯度,还有一个编辑现有蒙版的选项。为了简单起见,选择圆形,然后点击你的对象的脸。

(Seth Kenlon, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
你的色彩校正滤镜立即被限制在你的圆形蒙版的区域内,给你的主要对象一个令人愉快的琥珀色调,同时避开背景。

(Seth Kenlon, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
你可以通过切换色彩校正滤镜的关闭和开启来看到区别。
### 复用蒙版
如果你想只对被摄者的脸部应用另一个滤镜,你不必为那个新的滤镜再创建一个蒙版。当你创建一个蒙版时,它会被添加到位于 Darktable 界面左边的 “<ruby> 蒙版管理器 <rt> mask manager </rt></ruby>” 面板上。默认的名字是非常通用的,但你可以双击每个蒙版的名字来重命名它。

(Seth Kenlon, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
当你应用一个新的滤镜时,不是选择一个新的蒙版形状来创建,而是点击 “<ruby> 不使用蒙版 <rt> no mask used </rt></ruby>” 下拉菜单来查看现有的蒙版列表,以及之前在同一个滤镜上一起使用过的自动分组的蒙版。选择你想用于新滤镜的蒙版或蒙版组。

(Seth Kenlon, [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
### 更多蒙版
在 Darktable 中还有很多其他类型的蒙版和蒙版功能可以探索。你可以用路径和画笔工具创建复杂的形状。你也可以完全放弃使用形状,并根据色度和亮度值将过滤器限制在图像的某个区域。你可以调整蒙版的模糊度和扩散度等。在 Darktable 中进行的所有调整中,最好的一点是它们都是动态的、非破坏性的。如果你改变主意,你可以随时关闭它们,而且你实际上从未影响过图像数据本身。这并不奇怪,因为 Darktable 确实是一个强大的摄影工具,如果你拍摄的照片值得处理,你就应该看看 Darktable 为你提供了什么。
---
via: <https://opensource.com/article/21/12/open-source-photo-processing-darktable>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
14,089 | 在 Linux 终端使用 inxi 命令获取各种系统信息 | https://itsfoss.com/inxi-system-info-linux/ | 2021-12-17T13:49:38 | [
"inxi"
] | https://linux.cn/article-14089-1.html | 
`inix` 是一个用于获取 Linux 系统信息的终端命令。能够获取软件和硬件的详细信息,比如计算机型号、内核版本、发行版号以及桌面环境等信息,甚至可以读取主存模块占用主板的哪块 RAM 卡槽等详细信息。
`inxi` 还可以用于监控系统中正在消耗 CPU 或者内存资源的进程。
在本文中,我将展示使用 `inxi` 命令获取系统信息的常用操作。
首先,我将展示下如何安装 `inxi` 命令。
### 在 Linux 上安装 inxi
`inxi` 是一个非常流行的工具,所以在大多数 Linux 发行版仓库中都可以轻松获取到该工具。不过还没有流行到各大 Linux 发行版默认就安装了该软件,所以需要我们自己安装一下。
在 Ubuntu/Debian 发行版系统中,安装命令:
```
sudo apt install inxi
```
在 Fedora/RHEL8-based 等发行版中,安装命令:
```
sudo dnf install -y epel-release
sudo dnf install -y inxi
```
在 `Arch Linux` 以及它的派生分支版本中,安装命令:
```
sudo pacman -S inxi
```
### 使用 inxi 获取系统信息
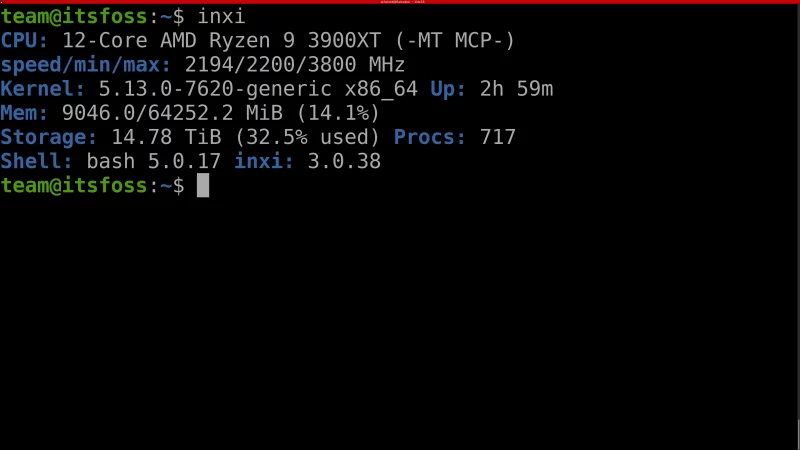
你可以在终端运行 `inxi` 命令来总体浏览下系统信息。
```
inxi
```
如下图所示,运行 `inxi` 命令可以简要浏览 CPU、时钟频率(`speed/min/max`)、内核(`Kernel`)、内存(`Mem`)、磁盘存储空间(`Storage`)、运行进程数量(`Procs`)以及 Shell 等信息。

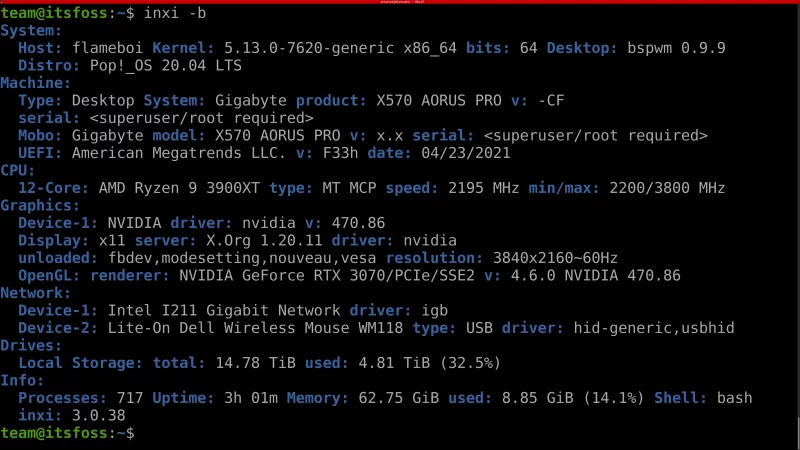
使用 `-b` 参数可以获取更为详细的系统信息。`-b` 参数会读取更多有关 CPU、驱动器、当前运行进程、主板 UEFI 版本、GPU、显示分辨率以及网络设备等详细信息。
```
inxi -b
```

类似 `-b` 参数使用方法,`inxi` 还有许多其他的参数可供使用。你可以综合使用这些参数来获取你关心的信息。
让我们看几个实例。
### 获取音频设备信息
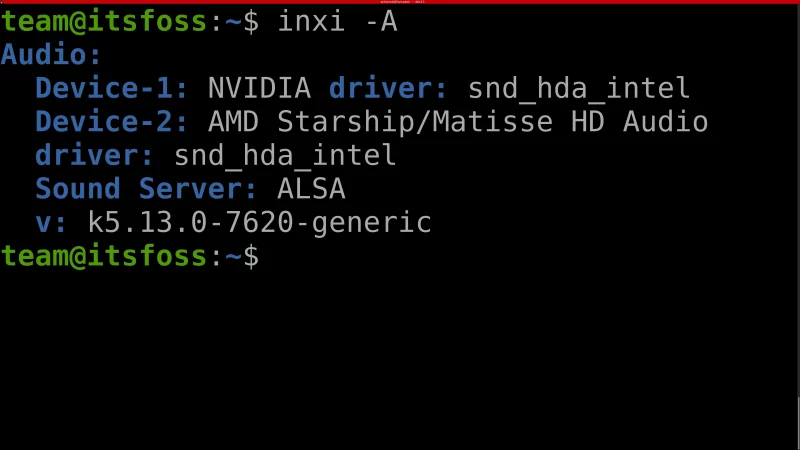
使用 `-A` 参数可以获取有关音频(输出)设备信息,包括物理音频(输出)设备、声音服务器以及音频驱动等详细信息。
```
inxi -A
```

### 获取电池信息
使用 `-B` 参数,可以获取有关电池的信息(如果安装了电池)。你将读取到例如以 `Wh`(瓦特小时)为单位的当前电池电量和状况。
因为我使用的是台式机,所以这里仅仅作为一个示例,让我们看看使用 `inxi -B` 会输出什么。
```
Battery: ID-1: BAT0 charge: 50.0 Wh (100.0%) condition: 50.0/50.0
```
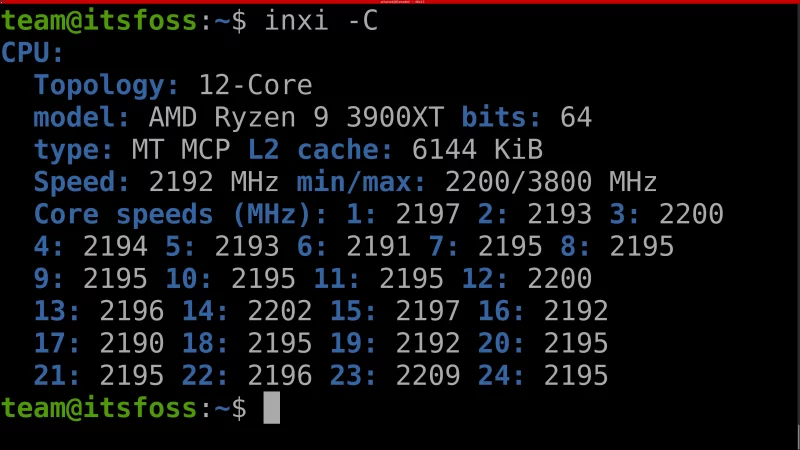
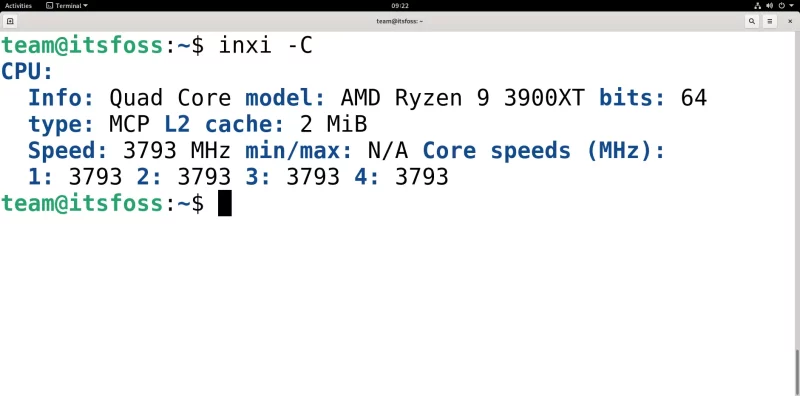
### 获取 CPU 信息
`-C` 参数用于获取有关 CPU 的详细信息。比如包括 CPU 缓存大小、频率(单位 `MHz`,如果有多核,会显示每个核心的频率)、核心数、CPU 型号以及 CPU 是 32 位还是 64 位。
```
inxi -C
```

注意,如果是在虚拟机中使用 `inix -C`,`inxi` 读取到的 `CPU` 的最大和最小频率可能异常。下面是一个在四核 Debian 11 虚拟机中使用 `-C` 参数的示例输出。

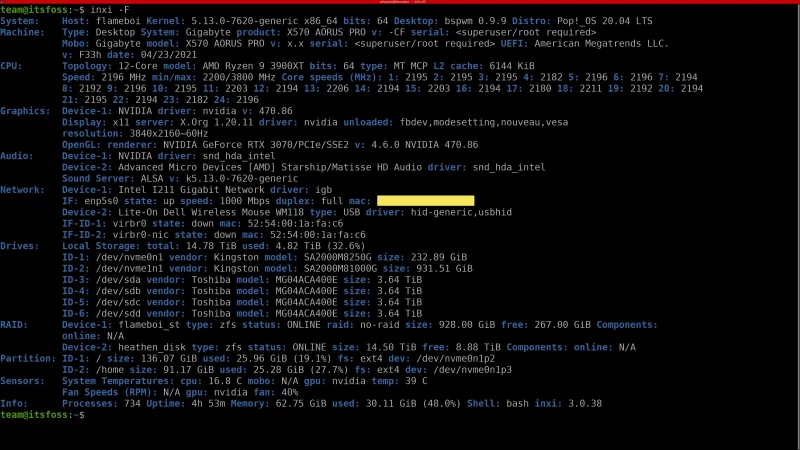
### 获取更多的系统信息
使用 `-F` 参数可以获取更详细的系统信息(类似 `-b` 参数,但会更为详细)。几乎囊括了所有层次的系统信息。
```
inxi -F
```

### 获取图形显示相关信息
`-G` 参数可以获取和图形相关的信息。
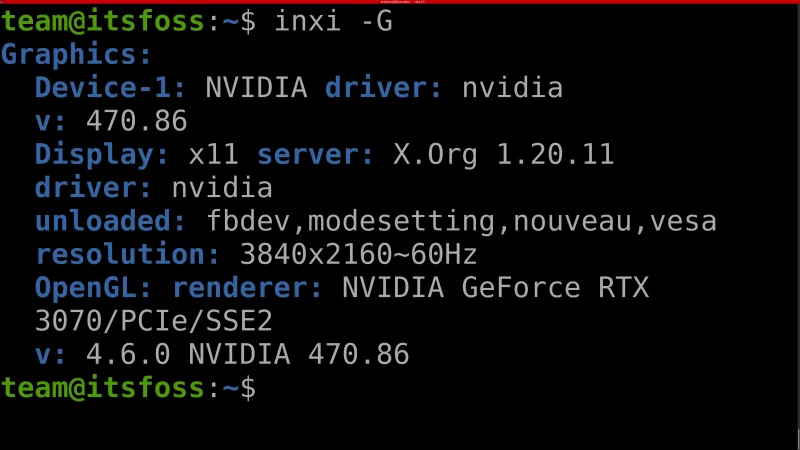
它会显示所有的图形设备(GPU)、正在使用的 GPU 驱动(有助于检查是否使用 Nvidia 驱动还是 nouveau 驱动)、显示输出分辨率和驱动程序版本。
```
inxi -G
```

### 获取运行进程信息
`-I` 参数(大写字母 `i`)显示正在运行的进程、当前 shell 、内存(内存使用情况)以及 `inxi` 版本号等信息。

### 获取内存信息
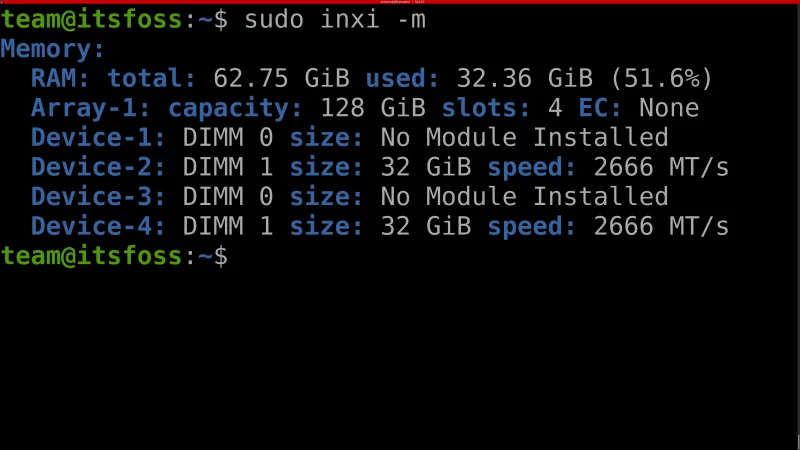
可能你已经猜到了,`-m` 参数可以获取与内存相关的信息。
它读取了如总可用内存、最大内存容量(硬件或 CPU 支持的)、主板物理内存插槽数、是否存在 ECC、插入的内存插槽,以及枚举每个插槽中运行的内存模块的大小和运行速度等信息。
```
inxi -m
```
要使用 `-m` 参数获取更详细的信息,例如最大容量、每个插槽的内存模块信息等,需要超级用户权限。
```
sudo inxi -m
```

如果只是希望简短的输出内存信息,可以使用 `-memory-short` 参数。
使用 `-memroy-short` 参数将会只显示总内存以及当前已使用的内存量。
### 查看正在使用的包存储库
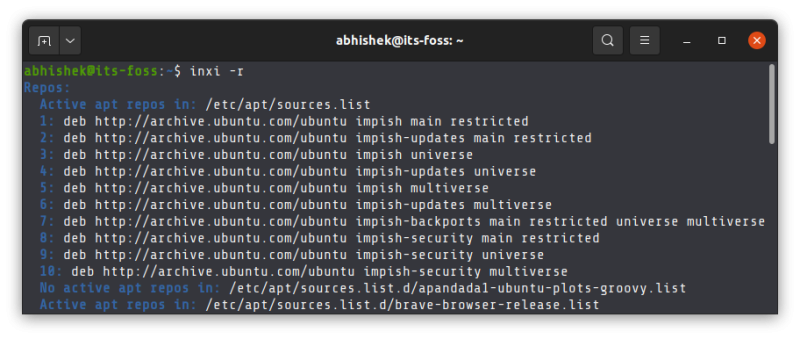
当使用 `-r` 参数时,会列举当前正在使用的包管理仓库或者更新本地仓库缓存中的所有存储库列表。

### 获取 RAID 设备信息
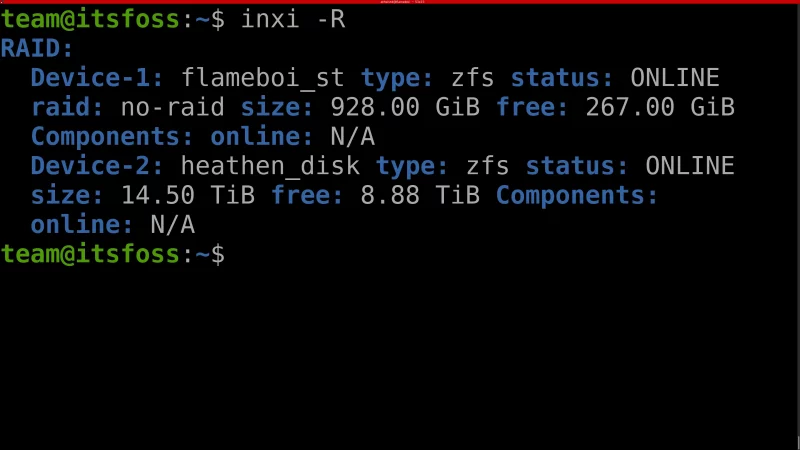
`-R` 参数用于获取所有 RAID 设备相关信息。
令人惊喜的是,它甚至显示了有关 ZFS RAID(默认情况下,多数 Linux 系统不包含该文件系统)的信息。它显示了 RAID 设备上文件系统的详细信息、状态(包含离线状态、总大小和可用大小等)。
```
inxi -R
```

### 在 Linux 终端中查询天气(对,这是可以的)
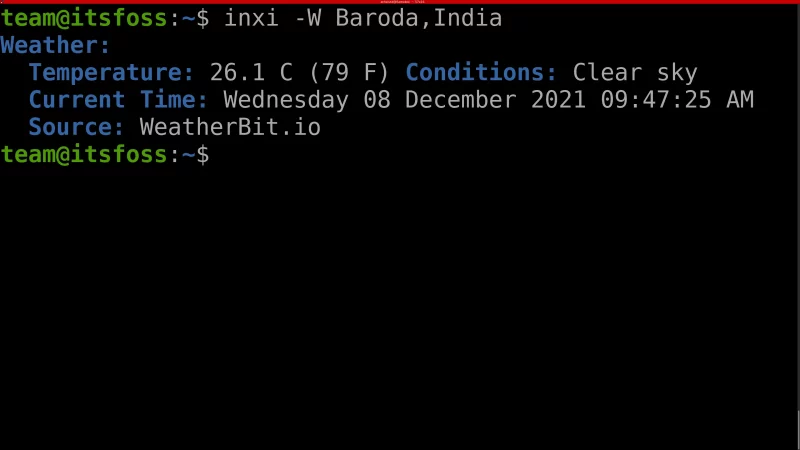
利用 `-W` 参数,你可以查询地球上任何地方的天气情况。
`-W` 参数后面,需要携带以下中的任一一个体现位置的信息
* 邮政编码
* 纬度
* 城市(及州)、国家(不能含有空格,使用 “+” 替换空格)
```
inxi -W Baroda,India
```

### 监控系统资源使用情况
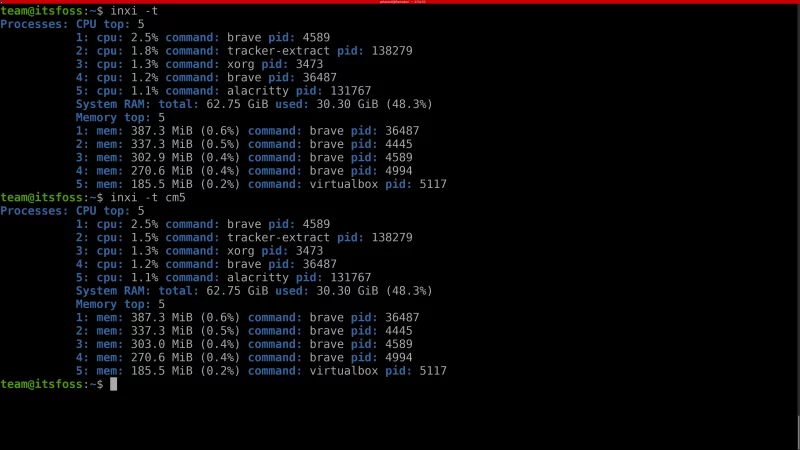
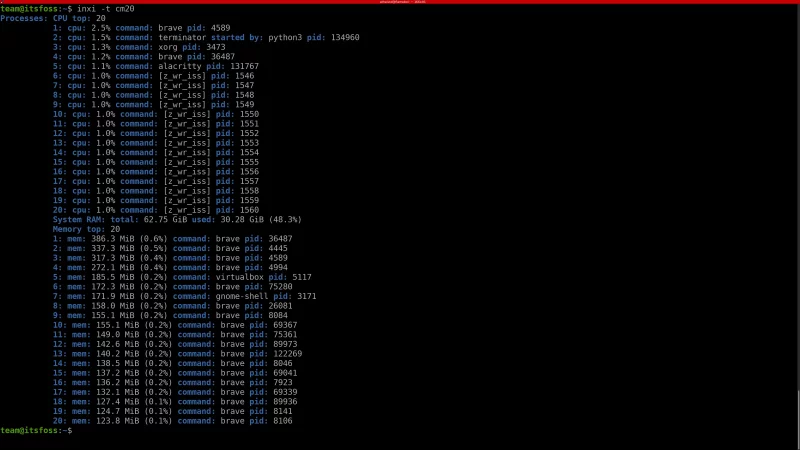
`inxi` 除了提供有关已安装的硬件和驱动的信息外,还可以用于资源监控。
使用 `-t` 参数可以显示进程信息。你还可以可选项 `-c` (用于 CPU)和 `-m`(用于内存)。这些选项结合使用可以按指定数量列出进程信息。
下面是一些使用 `-t` 参数监控资源信息的示例。
```
inxi -t
```
命令 `inxi -t` 默认效果等同于 `inxi -t cm5` 的效果。

```
inxi -t cm10
```

偶尔需要监控资源使用情况时,该工具挺管用。如果需要更多的资源监控功能,则推荐使用 [专用系统资源监控工具](https://itsfoss.com/linux-system-monitoring-tools/)。
### 总结
对于需要诊断计算机问题以及获取那些并不熟悉的软硬件信息的人来说,`inxi` 工具是十分便利且有用的。它能识别那些消耗 CPU、内存的进程;可以检查是否安装了合适的图形驱动程序、主板 UEFI/BIOS 是否需要更新等等。
事实上,在 `inxi` 开源社区论坛上,我们要求那些寻求帮助的成员提供 `inxi` 命令输出内容以便判断他们当前正在使用什么样的系统环境。
我知道也有其他的工具可以读取 Linux 上的硬件信息,不过 `inxi` 同时能读取硬件和软件信息,这也是我喜欢它的地方所在。
你使用 `inxi` 或者其他工具么?欢迎在评论区留言分享交流。
---
via: <https://itsfoss.com/inxi-system-info-linux/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jrglinux](https://github.com/jrglinux) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

inxi is a CLI tool that lists information about your Linux system. This includes both hardware and software details. You get simple details like which computer model you have, which kernel, distribution and desktop environment you are using etc. You also get details like which RAM slot of your motherboard is occupied by memory modules etc.
It can also be used to monitor processes that are running on your computer that are either consuming CPU resources or memory resources, or both.
In this tutorial, I’ll show some of the popular use cases of inxi to get information for your Linux system.
But first, let me quickly show you how to install inxi.
## Install inxi on your Linux distribution
[Inxi](https://github.com/smxi/inxi?ref=itsfoss.com) is a popular software that is available in the repository of most Linux distributions. Not popular enough to have it installed by default.
To install inxi on Ubuntu and Debian based distributions, use this command:
`sudo apt install inxi`
To install inxi on Fedora and RHEL8-based distributions, use:
```
sudo dnf install -y epel-release
sudo dnf install -y inxi
```
To install inxi on Arch Linux and it’s derivatives, look for it in the AUR:
## Using inxi to get Linux system details
You can get an overview of your system information by simply running the inxi command in your terminal.
`inxi`
As you can see in the image below, it gives a brief overview of CPU information, clockspeed, Kernel, RAM (displayed with Mem) and storage information along with number of running processes and shell version details.
You can also use the “-b” flag to show a more detailed overview of your system information. It will show more information regarding your CPU, drives, currently running processes, motherboard UEFI version, GPU, display resolution, network devices etc
`inxi -b`
As you might have noticed by the use of the “-b” flag, inxi, just like any command line utility, it has a lot of flags that influence the output of inxi once executed. You can use these flags or combine them to get only certain detailed information.
Let me show a few example.
### Get details of audio devices
Using the “-A” flag will present you with information about your audio [output] devices. That will display the physical audio [output] devices, sound server and the audio driver details.
`inxi -A`
### Get battery information
The “-B” flag will show details about your battery (if there is a battery present). You will get details like the current battery charge in Wh (Watt hours) and the condition.
Since I use a desktop, here is a sample output of what the output would look like if the “-B” flag was used with inxi with a battery attached
`Battery: ID-1: BAT0 charge: 50.0 Wh (100.0%) condition: 50.0/50.0`
### Get detailed CPU information
The -C flag shows detailed CPU information. That includes your CPU cache size, speed in MHz (of each core, if there are multiple cores), number of cores, CPU model and also if [your CPU is 32-bit or 64-bit](https://itsfoss.com/32-bit-64-bit-ubuntu/).
`inxi -C`
Make note, if you run inxi -C in a virtual machine, detecting your CPU’s minimum and maximum CPU frequency can be quite tricky for inxi. Below is a sample output of using the “-C” flag with inxi in a quad core Debian 11 Virtual Machine.
### Get even more detailed system information
The “-F” flag will show detailed system information (like the “-b” flag, but even more in depth). It includes almost everything to get a high level overview of the system that you are dealing with.
`inxi -F`
### Get graphics related information
The “-G” flag displays the data about everything related to Graphics.
It shows you all your Graphics Devices (GPUs), the [GPU] driver that is being used (helpful to check if you are using the Nvidia driver or the nouveau driver), display output resolution and driver version.
`inxi -G`
### Get running process info
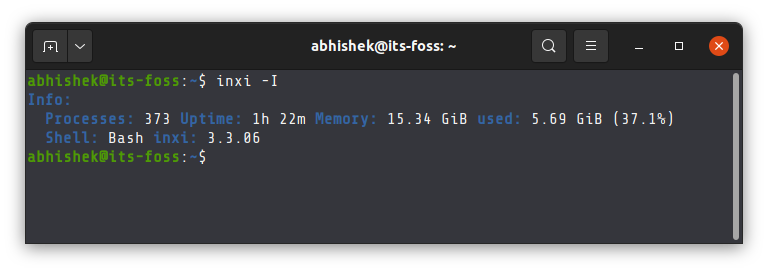
The “-I” (upper case i) shows detailed information about running processes, your current shell, memory (and memory usage) and inxi version.
### Get RAM information
As you might have guessed, the -m flag shows you memory (RAM) related information.
It provides information such as total available memory, maximum capacity of memory supported [by your hardware platform or by your CPU manufacturer], number of physical memory slots available on the motherboard, if ECC is present or not, the memory slots that are populated and also what is the size of each module along with the speed that said module is running at, per enumerated slot(s).
`inxi -m`
To take advantage of the in-depth details provided by the “-m” flag, like the maximum capacity, RAM module details that is at each slot, you need super-user privileges.
`sudo inxi -m`
If you just want the output to be short and not in this in-depth, you can use the “–memory-short” flag with inxi.
Using the “–memory-short” flag will only show total memory that is available and how much of it is currently in use.
### See which package repository is in use
When you use the “-r” flag with inxi, it will present you with a list of all the repositories that your package manager is currently using or updating local repository cache with.
### Get RAID devices details
The “-R” flag shows you information about all the RAID devices.
Surprisingly, it even shows information about ZFS RAID (because this file system is not included in many Linux distributions by default). It shows details about the file system on the RAID device, status – if it is online or offline, total size and available size.
`inxi -R`
### Check weather information in Linux terminal (yes, that’s possible too)
And, as a bonus, you can even check the weather of any place on Earth with the “-W” flag.
The “-W” flag needs to be followed by either one of the following location descriptors
- Postal code or zip code
- Latitude,longitude
- City[,state],country (must not contain spaces; replace spaces with the “+” sign)
`inxi -W Baroda,India`
## Monitoring the usage of system resource(s) with inxi
Along with all the verbose information that inxi provides about your installed hardware and the software that drives it, it can also be used for resource monitoring purposes.
Use the “-t” flag to show processes. You can also use the non-mandatory options “c” (for CPU) and “m” (for RAM). These options can also be combined with a numerical value that lists desired amount of processes.
Below are a few examples of using the “-t” flag to monitor system resources.
`inxi -t`
If you run inxi with “-t” flag but without the non-mandatory options, it will output assuming that you typed added the “cm5” options.
`inxi -t cm10`
That’s fine for rare use but there are [dedicated system resource monitoring tools](https://itsfoss.com/linux-system-monitoring-tools/) that are easier to use and have more functionalities.
## In the end…
For the individuals who have to diagnose issues with computers and it’s system information that they are not aware about, inxi can be incredibly helpful. It shows the processes that are consuming CPU, memory; you can check if the correct graphics drivers are being used, if the motherboard UEFI/BIOS is up to date, and much more.
In fact, on [It’s FOSS Community forum](https://itsfoss.community/?ref=itsfoss.com), we ask members to share the output of inxi command while seeking help so that it is easier to see what kind of system is in use.
I know there are other tools that provide [hardware info on Linux](https://itsfoss.com/hardinfo/) but inxi combines both hardware and software details and that’s why I like it.
Do you use inxi or some other tool? Share your experience in the comments please. |
14,091 | 用 Jekyll 和 Git 展示你的源码 | https://opensource.com/article/21/12/reveal-source-code-jinja2-git | 2021-12-18T09:33:00 | [
"Jekyll"
] | https://linux.cn/article-14091-1.html |
>
> 我是如何通过链接每个页面回到其原始源代码来保持我的网站开放的。
>
>
>

我是一个开源的超级粉丝。
我支持这项事业的一个小方法是从一开始就保持我的个人博客网站开放。我这样做的部分原因是让人们看到每个页面背后的变化历史。还因为当我开始使用 [Jekyll](https://opensource.com/article/21/9/build-website-jekyll) 时,我没有找到很多开源的 Jekyll 博客可以学习。我希望保持我的网站开放并公开我的尝试和错误,可以为其他人节省很多时间。
### Jekyll 的 page.path 变量
我实现这一目标的方法之一是将我发布的每一个条目链接到其原始的 [Markdown](https://opensource.com/article/19/9/introduction-markdown)。[Jekyll 的变量](https://jekyllrb.com/docs/variables/#page-variables) 中正好有一个需要的工具:`page.path`。这个变量包含每个页面的原始文件系统路径。官方的描述甚至强调了它的作用是链接回源!
在一篇文章的 Markdown 文件中打印 `{{page.path }}`,可以得到类似这样的结果:
```
_posts/2021-10-10-example.md
```
假设该文章的源代码存在于这个路径:
```
https://example.com/ayushsharma-in/-/blob/master/_posts/2021-10-10-example.md
```
如果你在任何文章的 `page.path` 前加上 `https://example.com/ayushsharma-in/-/blob/master/`,它就会生成一个返回其源码的链接。
在 Jekyll 中,生成这个完整的链接看起来像这样:
```
<a href="{{ page.path | prepend: site.content.blog_source_prefix }}" target="_blank">View source</a>
```
就是这么简单。
### Jekyll 和开放 Web
现代 Web 是一种错综复杂的多层次技术,但这并不意味着它必须让人摸不清。有了 Jekyll 的变量,你可以确保你的用户可以,了解更多关于你是如何建立你的网站的,如果他们愿意的话。
你可以在我的[个人博客](https://www.ayushsharma.in)上看到真实的例子:滚动到底部的查看源码链接。
本文改编自 [ayush sharma 的笔记](https://www.ayushsharma.in/2021/11/linking-jekyll-pages-back-to-their-git-source-code),并经许可转载。
---
via: <https://opensource.com/article/21/12/reveal-source-code-jinja2-git>
作者:[Ayush Sharma](https://opensource.com/users/ayushsharma) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I'm a huge fan of open source.
One of the little ways I've supported the cause is by keeping my personal blog site open from the very beginning. I do this partly to let people see the history of changes behind each page. But I also do it because, when I started using [Jekyll](https://opensource.com/article/21/9/build-website-jekyll), I didn't find many open source Jekyll blogs to learn from. My hope is that keeping my website open and exposing my trials and errors will save someone else a lot of time.
## The Jekyll page.path variable
One way I achieve that is by linking every entry I post back to its original [Markdown](https://opensource.com/article/19/9/introduction-markdown). [Jekyll's helpful variables](https://jekyllrb.com/docs/variables/#page-variables) have exactly the tool that's needed: the `page.path`
. This variable contains the raw filesystem path of each page. The official description even highlights its usefulness for linking back to the source!
Printing `{{ page.path }}`
within an article's Markdown file outputs something similar to this:
`_posts/2021-10-10-example.md`
Assume that the article's source code existed at this path:
`https://example.com/ayushsharma-in/-/blob/master/_posts/2021-10-10-example.md`
If you prepend `https://example.com/ayushsharma-in/-/blob/master/`
to any article's `page.path`
, it generates a link back to its source code.
In Jekyll, generating this full link looks like this:
`<a href="{{ page.path | prepend: site.content.blog_source_prefix }}" target="_blank">View source</a>`
It's that easy.
## Jekyll and the open web
The modern web is an intricate and multilayered technology, but that doesn't mean it has to obfuscate. With Jekyll's variables, you ensure that your users can, if they wish, learn more about how you built your site.
You can see real-world examples on my [personal blog](https://www.ayushsharma.in): scroll to the bottom for the View Source link.
This article is adapted from [ayush sharma's notes](https://www.ayushsharma.in/2021/11/linking-jekyll-pages-back-to-their-git-source-code) and is republished with permission.
## Comments are closed. |
14,092 | 为 Linux 用户准备的 FreeDOS 命令 | https://opensource.com/article/21/6/freedos-linux-users | 2021-12-18T10:23:38 | [
"FreeDOS"
] | https://linux.cn/article-14092-1.html |
>
> 如果你已经熟悉了 Linux 命令行,尝试这些命令有助于轻松地进入 FreeDOS 。
>
>
>

如果你已经尝试过 FreeDOS ,你可能已经被命令行所吓倒。DOS 命令可能稍微不同于你所使用的 Linux 命令行,因此,使用它的命令行上需要学习一些新的命令。
但是对于 Linux 用户来说,它不是一种 “全新的” 体验。在 FreeDOS 中,除了 DOS 命令之外,我们还包含一些已经熟悉的标准的 Unix 命令。因此,如果你已经熟悉了 Linux 命令行,尝试这些命令有助于轻松地进入 FreeDOS :
### 在四周走走
在 FreeDOS 文件系统中使用 `cd` 命令来 *更改目录* 。在 FreeDOS 上的用法在 Linux 上的用法基本相同。要更改到一个名称为 `apps` 的子目录,输入 `cd apps` 。要回到先前的目录,输入 `cd ..` 。
在 FreeDOS 上导航浏览目录和路径是仅有的不同点,目录分隔符是 `\`(“反斜杠”)而不是你在 Linux 上使用的 `/` (“正斜杠”)。例如,让我们假设你在 `\devel` 目录之中,你想移动到 `\fdos` 目录。这两个目录相对于 *根* 目录而言是处于相同的 “层次” 之中的。因此,你可以输入 `cd ..\fdos` 来 “向后返回” 一个目录层次(使用 `..`) ,然后再 “转到” `fdos` 目录。
要更改到一个新的目录,你可以使用先前提到的反斜杠来替换需要给出的完整的路径。如果你已经深入了另外一个路径之中,并且只是像立即切换到新的位置,那么这会是非常方便的。例如,要更改到 `\temp` 目录,你可以输入 `cd \temp` 。
```
C:\>cd apps
C:\APPS>cd ..
C:\>cd devel
C:\DEVEL>cd ..\fdos
C:\FDOS>cd \temp
C:\TEMP>_
```
在 FreeDOS 中,像大多数的 DOS 系统一样,你可以在DOS 提示符中看到你的当前路径。在 Linux 上,你的提示符可能类似于 `$` 。在 FreeDOS 上,提示符会列出当前的驱动器及其当前的路径,接下来使用 `>` 作为提示符(看做 Linux 上的 `$`)。
### 列出和显示文件
在 Linux 上,列出当前目录中文件的标准命令是 `ls` 命令。在 FreeDOS ,它是一个不同的命令: `dir` 。但是你可以创建一个 *别名* 来获取一种与 `ls` 类似的行为。
要为另外一个命令创建一个别名,使用内置的 `alias` 命令。例如,使用此命令来为 `ls` 定义一个别名,这个别名将显示一个目录列表,与在 Linux 上使用 `ls` 类似:
```
C:\>alias ls=dir /one /w /b /l
C:\>ls
[apps] command.com [devel] fdauto.bat fdconfig.sys
[fdos] kernel.sys [src] [temp]
C:\>
```
在 FreeDOS 上的命令选项格式与 Linux 稍微不同。在 Linux 上, 你使用一个连字符号(`-`)表示选项。但是在 FreeDOS 上,你使用一个正斜杠来表示选项。上面的 `alias` 命令使用斜杆杠字符 — 它们是 `dir` 的选项。`/one` 可选择项告诉 `dir` 以某种方式排序(`o`):先按名称(`n`)再按扩展名(`e`)来排序一些文件和目录。`/w` 使用一个 “宽” 目录列表,`/b` 使用一种不带有 `dir` 通常提供的其它信息的 “裸” 显示,`/l` 指示 `dir` 以小写字母的形式显示文件和目录。
注意,针对于 FreeDOS 的 `dir` 命令的命令行选项与针对于 Linux 的 `ls` 命令的命令行选项截然不同,因此,你不能像你在 Linux 上一样精确地使用这个 `ls` 别名。例如,在 FreeDOS 上使用此别名输入 `ls -l` 将产生一条 “文件未找到” 的错误,因为底层的 FreeDOS 的 `dir` 命令不能找到一个名称为 `-l` 的文件。不过,对于基本的 “查看在我的系统上有哪些文件” 来说,这个 `ls` 别名已经足够帮助 Linux 用户开始使用 FreeDOS 了。
类似地,你可以为 FreeDOS 的 `type` 命令创建一个别名,来像 Linux 的 `cat` 命令一样工作。两个重新都会显示一个文本文件的内容。虽然 `type` 不支持你可能在 Linux 下使用的命令行选项,但是显示一单个文件的基本用法是相同的。
```
C:\FDOS>alias cat=type
C:\FDOS>cat version.fdi
PLATFORM=FreeDOS
VERSION=1.3-RC4
RELEASE=2021-04-30
C:\FDOS>
```
### 其它的类 Unix 命令
FreeDOS 包含一些精选的其它常见的类 Unix 命令,因此 Linux 用户将不会感觉到拘束。为在 FreeDOS 上使用这些 Linux 命令,你可能需要从 “FreeDOS Installer” - “My Package List Editor Software (FDIMPLES)” 软件包管理器来安装 “Unix Like Tools” 软件包。

(Jim Hall, CC-BY SA 4.0)
并不是所有的类 Unix 实用程序都能像在 Linux 上对应的实用程序一样 *一致地* 工作。这就是我们称其为 *类 Unix* 的原因。如果你将要使用一些深层次的命令行选项,你可能需要检查其兼容性,不过,对于典型的用法是没有问题的。开始在 FreeDOS 上使用这些类 Unix 命令:
`cal` 命令是标准的 Unix 的日历程序。例如,为显示当前月份的日历,只需要输入 `cal` 。为查看一个具体指定的月份,将月份和年份作为参数予以给定:
```
C:\>cal 6 1994
June 1994
Su Mo Tu We Th Fr Sa
1 2 3 4
5 6 7 8 9 10 11
12 13 14 15 16 17 18
19 20 21 22 23 24 25
26 27 28 29 30
```
使用 `du` 命令来查看你的磁盘使用情况。这是 Linux 的 `du` 命令的简单版本,并且不支持路径以外的任何命令行选项。
```
C:\>du -s apps
usage: du (start path)
C:\>du apps
158784 C:\APPS\FED
0 C:\APPS
Total from C:\APPS is 158784
C:\>
```
`head` 命令显示一个文件的前几行。例如,这是一种确定一个文件是否包含正确数据的简单方法。
```
C:>head fdauto.bat
@ECHO OFF
set DOSDIR=C"\FDOS
set LANG=EN
set TZ=UTC
set PATH=%dosdir%\BIN
if exist %dosdir%\LINKS\NUL set PATH=%path%;%dosdir%\LINKS
set NLSPATH=%dosdir%\NLS
set HELPPATH=%dosdir%\HELP
set TEMP=%dosdir%\TEMP
set TMP=%TEMP%
C:\>
```
要查看一个完整的文件,使用 `more` 命令,在 FreeDOS 上的默认文件查看器。这将一次显示一屏的文件,然后在显示下一屏的信息前,打印一个按下一次按键的提示。`more` 命令是一个非常简单的文件查看器;在 Linux 上你可能已经使用过一个功能更全面的查看器,可以尝试一下 `less` 命令。`less` 命令提供 “向后” 滚动一个文件的能力,以防你错过一些东西。你还可以搜索具体指定的文本。
```
C:\>less fdauto.bat
@ECHO OFF
set DOSDIR=C"\FDOS
set LANG=EN
set TZ=UTC
set PATH=%dosdir%\BIN
if exist %dosdir%\LINKS\NUL set PATH=%path%;%dosdir%\LINKS
set NLSPATH=%dosdir%\NLS
set HELPPATH=%dosdir%\HELP
set TEMP=%dosdir%\TEMP
set TMP=%TEMP%
[...]
```
如果在你的程序路径变量(`PATH`)中有很多的目录,并且不确定某个程序是从哪里运行的,你可以使用 `which` 命令。这个命令将扫描程序路径变量,并且将打印出你正在查找的程序的完整的位置。
```
C:\>which less
less C:\>FDOS\BIN\LESS.EXE
C:\>_
```
FreeDOS 1.3 RC4 包含其它的类 Unix 命令,你可能会在其它更特殊的情况下使用。这些命令包括:
* `bc`:任意精度数字处理语言
* `sed`:流编辑器
* `grep` 和 `xgrep`:使用正则表达式搜索一个文本文件
* `md5sum`:生成一个文件的一个 MD5 签名
* `nro`:简单排版,使用 nroff 宏
* `sleep`:暂停系统几秒钟
* `tee`:保存一个命令行流的副本
* `touch`:修改一个文件的时间戳
* `trch`:转换单个字符(像 Linux 的 `tr` 一样)
* `uptime`:报告你 FreeDOS 系统已经运行多长的时间
### 在你控制下的 FreeDOS
FreeDOS ,像 Linux 和 BSD 一样,是开源的。不管你是想通过学习一种新的命令行交互方式来挑战你自己,还是想再去熟悉令人舒适的类 Unix 工具,FreeDOS 都是一款有趣的值得尝鲜的操作系统。尝试一下!
---
via: <https://opensource.com/article/21/6/freedos-linux-users>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean](https://github.com/robsean) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you've tried FreeDOS, you might have been stymied by the command line. The DOS commands are slightly different from how you might use the Linux command line, so getting around on the command line requires learning a few new commands.
But it doesn't have to be an "all new" experience for Linux users. We've always included some standard Unix commands in FreeDOS, in addition to the DOS commands that are already similar to Linux. So if you're already familiar with the Linux command line, try these commands to help ease into FreeDOS:
## Getting Around
Use the `cd`
command to *change directory* in the FreeDOS filesystem. The usage is basically the same on FreeDOS as it is on Linux. To change into a subdirectory called `apps`
, type `cd apps`
. To go back to the previous directory, type `cd ..`
.
The only difference when navigating through directories and paths is that on FreeDOS, the directory separator is `\`
("backslash") instead of `/`
("forward slash") that you use on Linux. For example, let's say you were in the `\devel`
directory and you wanted to move to the `\fdos`
directory. Both of those are at the same "level" relative to the *root* directory. So you could type `cd ..\fdos`
to "back up" one directory level (with `..`
) and then "go into" the `fdos`
directory.
To change to a new directory, you could instead give the full path with the leading backslash. This is handy if you are already deep into another path, and just want to switch immediately to the new location. For example, to change to the `\temp`
directory, you can type `cd \temp`
.
```
C:\>cd apps
C:\APPS>cd ..
C:\>cd devel
C:\DEVEL>cd ..\fdos
C:\FDOS>cd \temp
C:\TEMP>_
```
In FreeDOS, like most DOS systems, you can see your current path as part of the DOS prompt. On Linux, your prompt is probably something like `$`
. On FreeDOS, the prompt lists the current drive, the current path within that drive, then `>`
as the prompt (taking the place of `$`
on Linux).
## Listing and Displaying Files
On Linux, the standard command to list files in the current directory is the `ls`
command. On FreeDOS, it's a different command: `dir`
. But you can get a similar behavior as `ls`
by creating an *alias*.
To create an alias to another command, use the built-in `alias`
command. For example, use this command to define an alias for `ls`
that will display a directory listing in a similar way to using `ls`
on Linux:
```
C:\>alias ls=dir /one /w /b /l
C:\>ls
[apps] command.com [devel] fdauto.bat fdconfig.sys
[fdos] kernel.sys [src] [temp]
C:\>
```
The command option format is slightly different on FreeDOS than on Linux. On Linux, you start options with a hyphen character (`-`
). But on FreeDOS, options start with a forward slash. The `alias`
command above uses the slash character—those are options to `dir`
. The `/one`
option tells `dir`
to order (o) in a certain way: sort any files and directories by name (n) and then by extension (e). Using `/w`
says to use a "wide" directory listing, `/b`
uses a "bare" display without the other information `dir`
usually provides, and `/l`
instructs `dir`
to display files and directories in lowercase.
Note that the command-line options for the FreeDOS `dir`
command are quite different from the options to Linux `ls`
, so you can't use this `ls`
alias exactly like you would on Linux. For example, typing `ls -l`
with this alias on FreeDOS will result in a "File not found" error, because the underlying FreeDOS `dir`
command will be unable to find a file called `-l`
. But for basic "see what files I have on my system," this `ls`
alias is good enough to help Linux users get started with FreeDOS.
Similarly, you can create an alias for the FreeDOS `type`
command, to act like the Linux `cat`
command. Both programs display the contents of a text file. While `type`
doesn't support the command-line options you might use under Linux, the basic usage to display a single file will be the same.
```
C:\FDOS>alias cat=type
C:\FDOS>cat version.fdi
PLATFORM=FreeDOS
VERSION=1.3-RC4
RELEASE=2021-04-30
C:\FDOS>
```
## Other Unix-like Commands
FreeDOS includes a selection of other common Unix-like commands, so Linux users will feel more at home. To use these Linux commands on FreeDOS, you may need to install the **Unix Like Tools** package from the **FreeDOS Installer - My Package List Editor Software** (FDIMPLES) package manager.
Image by Jim Hall, CC-BY SA 4.0
Not all of the Unix-like utilities work *exactly* like their Linux counterparts. That's why we call them *Unix-like*. You might want to check the compatibility if you're using some esoteric command-line options, but typical usage should be fine. Start with these common Unix-like commands on FreeDOS:
The `cal`
command is the standard Unix calendar program. For example, to display the calendar for the current month, just type `cal`
. To view a specific month, give the month and year as arguments:
```
C:\>cal 6 1994
June 1994
Su Mo Tu We Th Fr Sa
1 2 3 4
5 6 7 8 9 10 11
12 13 14 15 16 17 18
19 20 21 22 23 24 25
26 27 28 29 30
```
View your disk usage with the `du`
command. This is a simple version of the Linux *disk usage* command and doesn't support any command-line options other than a path.
```
C:\>du -s apps
usage: du (start path)
C:\>du apps
158784 C:\APPS\FED
0 C:\APPS
Total from C:\APPS is 158784
C:\>
```
The `head`
command displays the first few lines of a file. For example, this is a handy way to determine if a file contains the correct data.
```
C:\>head fdauto.bat
@ECHO OFF
set DOSDIR=C"\FDOS
set LANG=EN
set TZ=UTC
set PATH=%dosdir%\BIN
if exist %dosdir%\LINKS\NUL set PATH=%path%;%dosdir%\LINKS
set NLSPATH=%dosdir%\NLS
set HELPPATH=%dosdir%\HELP
set TEMP=%dosdir%\TEMP
set TMP=%TEMP%
C:\>
```
To view an entire file, use the `more`
command, the default file viewer on FreeDOS. This displays a file one screenful at a time, then prints a prompt to press a key before displaying the next screenful of information. The `more`
command is a very simple file viewer; for a more full-featured viewer like you might use on Linux, try the `less`
command. The `less`
command provides the ability to scroll "backwards" through a file, in case you missed something. You can also search for specific text.
```
C:\>less fdauto.bat
@ECHO OFF
set DOSDIR=C"\FDOS
set LANG=EN
set TZ=UTC
set PATH=%dosdir%\BIN
if exist %dosdir%\LINKS\NUL set PATH=%path%;%dosdir%\LINKS
set NLSPATH=%dosdir%\NLS
set HELPPATH=%dosdir%\HELP
set TEMP=%dosdir%\TEMP
set TMP=%TEMP%
[...]
```
If you have a lot of directories in your program path variable (`PATH`
) and aren't sure where a certain program is running from, you can use the `which`
command. This scans the program path variable, and prints the full location of the program you are looking for.
```
C:\>which less
less C:\>FDOS\BIN\LESS.EXE
C:\>_
```
FreeDOS 1.3 RC4 includes other Unix-like commands that you might use in other, more specific situations. These include:
**bc**: Arbitrary precision numeric processing language**sed**: Stream editor**grep**and**xgrep**: Search a text file using regular expression**md5sum**: Generate an MD5 signature of a file**nro**: Simple typesetting using nroff macros**sleep**: Pause the system for a few seconds**tee**: Save a copy of a command-line stream**touch**: Modify a file's timestamp**trch**: Translate single characters (like Linux tr)**uptime**: Report how long your FreeDOS system has been running
## FreeDOS at your command
FreeDOS, like Linux and BSD, is open source. Whether you want to challenge yourself by learning a new style of command-line interaction, or you want to fall back on the comfort of familiar Unix-like tools, FreeDOS is a fun and fresh operating system to explore. Give it a try!
## Comments are closed. |
14,093 | Linux 黑话解释:TTY 是什么? | https://itsfoss.com/what-is-tty-in-linux/ | 2021-12-18T15:51:50 | [
"TTY",
"终端"
] | https://linux.cn/article-14093-1.html | 
谈到 Linux 和 UNIX 时,你一定听说过 “TTY” 这个术语,但是,这玩意是什么?
作为一个桌面用户,它对你有用吗?你需要它吗?你能用它做什么?
在本文中,让我向你介绍这些,帮助你熟悉 Linux 中的 TTY。
注意:这个问题没有明确的答案,但它与过去的输入/输出设备的交互方式有关。因此,你必须了解一些历史,才能清楚地了解情况。
### “TTY” 背后的历史
一切始于 19 世纪 30 年代的<ruby> 电传打印机 <rt> Teleprinter </rt></ruby>。
电传打印机可以让你通过电线发送或接受消息,它取代了摩尔斯电码通信,那是一种需要两个操作员才能有效地相互通信的方式。
一台电传打印机只需要一个操作员就可以轻松地传递消息。虽然它没有现代布局的键盘,但它的系统后来由 Donald Murray 在 1901 年进行了改良,包括了一个类似打字机的键盘。
Murray 电码减少了操作员发送消息的工作量。这才使得电传打印机在 1908 年有了发展成为商业<ruby> 电传打字机 <rt> Teletypewriter </rt></ruby>的可能。TTY 即是电传打字机的缩写。

电传打字机和普通<ruby> 打字机 <rt> typewriter </rt></ruby>的区别在于,电传打字机连接到通信设备,直接发送输入的消息。
[电传打字机使人类在没有计算机的情况下通过电线进行更快的通信成为可能](https://en.wikipedia.org/wiki/Teletype_Corporation#/media/File:What-is-teletype.jpg)。
从这时起,“TTY” 一词就存在了。
### (相对)现代的概念
现在,你一定想知道,它是如何进入现代计算机和 Linux 的?
最初是当电传打字机进入了市场,几年后半导体晶体管发展起来,然后演变成微处理器,为计算机的出现做好了准备。
最初的计算机没有键盘的概念,<ruby> 打孔卡 <rt> Punch card </rt></ruby>就是输入的方法。

随着计算机的发展,批量输入的打孔卡最终被电传打字机取代,成为一种方便的输入/输出设备。

随着技术的进步,电传打字机被电子技术“虚拟化”了。因此,你不需要一个物理的、机械的 TTY,而是一个虚拟的电子 TTY。
早期的计算机甚至没有视频屏幕。字符被打印在纸上而不是显示在屏幕上。因此,你会看到“<ruby> 打印 <rt> print </rt></ruby>”这个术语而不是“<ruby> 显示 <rt> display </rt></ruby>”。随着技术的进步,视频显示后来被添加到终端中。
换句话说,你可能听说过把它们称为“视频终端”。或者,你可以称它们为“物理”终端。
后来,它们演变成具有更强的能力和功能的软件仿真的终端。
这就是所谓的“<ruby> 终端仿真器 <rt> terminal emulator </rt></ruby>”,如 GNOME 终端或 Konsole,或者其他 [你在 Linux 上找到的各种终端仿真器](https://itsfoss.com/linux-terminal-emulators/)。
### 所以,Linux 中的 TTY 到底是什么?
在 Linux 或 UNIX 中,TTY 变为了一个抽象设备。有时它指的是一个物理输入设备,例如串口,有时它指的是一个允许用户和系统交互的虚拟 TTY([参考此处](https://unix.stackexchange.com/questions/4126/what-is-the-exact-difference-between-a-terminal-a-shell-a-tty-and-a-con))。
TTY 是 Linux 或 UNIX 的一个子系统,它通过 TTY 驱动程序在内核级别实现进程管理、行编辑和会话管理。
在编程的场景下,你还需要深入研究。但是考虑到本文的范围,这可能是一个容易理解的定义。
如果你好奇的话,你可以查看一个有点旧的资源([TTY 揭秘](https://www.linusakesson.net/programming/tty/index.php)),它尽可能的澄清了 Linux 和 UNIX 系统中的 TTY 的各种技术细节。
事实上,每当你在系统中启动一个终端仿真器或使用任何类型的 shell 时,它都会与虚拟 TTY(也被称为<ruby> 伪 TTY <rt> pseudo-TTY </rt></ruby>,即 PTY)进行交互。
你可以在终端仿真器中输入 `tty` 来找到相关联的 PTY。
### 如何在 Linux 中访问 TTY?

在 Linux 中很容易访问 TTY。事实上,当我不知道它是什么时,我不小心打开了它,于是对要做什么、如何摆脱它感到恐慌。
在大多数 *发行版* 中,你可以使用以下键盘快捷键来得到 TTY 屏幕:
* `CTRL + ALT + F1` – 锁屏
* `CTRL + ALT + F2` – 桌面环境
* `CTRL + ALT + F3` – TTY3
* `CTRL + ALT + F4` – TTY4
* `CTRL + ALT + F5` – TTY5
* `CTRL + ALT + F6` – TTY6
你最多可以访问六个 TTY。但是,前两个快捷方式指向发行版的锁定屏幕和桌面环境。

而其他快捷方式将会让你进入一个命令行界面。
### 什么时候应该使用 TTY?
TTY 不仅是一个技术宝藏,即使像我这样不是开发人员的用户,它也很有用。
在图形桌面环境冻结的情况下,它应该可以派上用场。在某些情况下,从 TTY 重建桌面环境能帮助解决程序问题。
或者,你也可以选择在 TTY 中执行任务,例如更新 Linux 系统等。在这些情况下,你不希望显示问题中断你的进程。
最坏的情况是,如果图形用户界面失去响应,你可以进入 TTY 并重新启动计算机。
有些用户还喜欢在 TTY 的帮助下传输大文件(我不是其中之一)。
### Linux 中的 TTY 命令

当你在终端模拟器中输入 `tty` 时,它将打印连接到标准输入的终端文件名,就像手册页描述的一样。
换句话说,要知道你连接的 TTY 编号,只需输入 `tty`。并且,如果有多个用户远程连接到 Linux 机器,你可以使用 `who` 命令来检查其他用户连接到的是哪个 TTY。
---
via: <https://itsfoss.com/what-is-tty-in-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You must have heard about the term “TTY” when it comes to Linux and UNIX. But, what is it?
Is it useful to you as a desktop user? Do you need it? And, what can you do with it?
In this article, let me mention everything essential to get you familiar with the term TTY in Linux.
Do note that there’s no definitive answer to this, but it relates to how input/output devices interacted in the past. So, you will have to know a bit of history to get a clear picture.
## History Behind the Term ‘TTY’
It all starts with a Teleprinter in the 1830s.
Teleprinters let you send/receive text messages over the wire. It was a replacement to Morse code communication, where two operators were needed to effectively communicate with one another.
And, a Teleprinter just needed a single operator to easily convey a message. While it did not have a modern-layout keyboard, its system was later evolved by Donald Murray in 1901 to include a typewriter-like keyboard.
The Murray code reduced the effort for operators to send a message. And, this made it possible for a Teleprinter to evolve as a commercial Teletypewriter in 1908. TTY is shorthand for Teletypewriter.

[Wikimedia](https://commons.wikimedia.org/wiki/File:WACsOperateTeletype.jpg?ref=itsfoss.com)
The difference between the Teletypewriter and a regular typewriter was that a Teletypewriter was attached to a communication device to send the typed message.
[Teletypewriter made it possible for humans to communicate faster](https://en.wikipedia.org/wiki/Teletype_Corporation?ref=itsfoss.com#/media/File:What-is-teletype.jpg) over a wire without any computers until now.
And, this is where “**TTY**” came into existence.
## The (relatively) Modern Concept
Now, you must be wondering, how did it land into modern computing and in Linux?
Well, for starters, when Teletypewriter hit the market, some years later semiconductor transistors were developed which then evolved into microprocessors making a computer possible.
Initial computers didn’t have the concept of a keyboard. Punch cards were the input method.

[Image credit](https://www.computerhistory.org/revolution/punched-cards/2/intro/12?ref=itsfoss.com)
While computers were evolving, batch input cards were eventually replaced by Teletypewriters as a convenient input/output device.

With technological advancements, the Teletypewriters were ‘virtualized’ using electronics. So, you wouldn’t need a physical, mechanical TTY, but a virtual, electronic TTY.
Earlier computers didn’t even have video screens. Things were printed on paper instead of displaying on a screen (which didn’t exist). And hence you see the use of the term ‘print’, not ‘display’. Videos were added to terminals later as technology advanced.
In other words, you might have heard of them as video terminals. Or, you could call them “physical” terminals.
And, then these evolved into software emulated terminals which came with enhanced abilities and features.
This is what you call a “terminal emulator”. For instance, GNOME Terminal, or Konsole, are some of the [best terminal emulators that you will find for Linux](https://itsfoss.com/linux-terminal-emulators/).
## So, What is TTY in Linux?
When it comes to Linux, TTY is an abstract device in UNIX and Linux. Sometimes it refers to a physical input device such as a serial port, and sometimes it refers to a virtual TTY where it allows users to interact with the system ([reference](https://unix.stackexchange.com/questions/4126/what-is-the-exact-difference-between-a-terminal-a-shell-a-tty-and-a-con?ref=itsfoss.com)).
TTY is a subsystem in Linux and Unix that makes process management, line editing, and session management possible at the kernel level through TTY drivers.
In terms of programming, you need to dive in deep. But, considering the scope of this article, this could be an easy definition to digest.
If you are curious, you can explore an old resource ([TTY Demystified](https://www.linusakesson.net/programming/tty/index.php?ref=itsfoss.com)) that tries to clear up TTY in Linux and Unix systems with all the technical details you need.
In fact, whenever you launch a terminal emulator or use any kind of shell in your system, it interacts with virtual TTYs that are known as pseudo-TTYs or PTY.
You can just type in TTY in your terminal emulator to find the associated PTY.
## How to Access TTY in Linux?
It is easy to access TTY in Linux. In fact, when I did not have a clue what it was, I accidentally accessed it and panicked about what to do (how to get out from it).
You can get the TTY screen by using the following keyboard shortcuts on * most distributions*:
**CTRL + ALT + F1** – Lockscreen**CTRL + ALT + F2** – Desktop Environment**CTRL + ALT + F3** – TTY3**CTRL + ALT + F4** – TTY4**CTRL + ALT + F5** – TT5**CTRL + ALT + F6** – TTY6
You can access up to six TTYs in total. However, the first two shortcuts point to the distribution’s lock screen and the desktop environment.
So, you get a command-line interface with the rest of the shortcuts.
## When Would You Use TTY in Linux?
TTY is not just a technical treasure. It is useful even for users like me who aren’t developers.
It should come in handy in case the graphical desktop environment freezes. In some cases, reinstalling the desktop environment from the TTY helps resolve the program.
Or, you can also choose to carry out tasks in TTY like updating the Linux system and similar, where you do not want visual issues to interrupt your process.
Worst-case scenario, you can go to the TTY and reboot the computer if your graphical user interface is unresponsive.
Some users also prefer to perform large file transfers with the help of TTY (I am not one of them).
## TTY as a Command in Linux
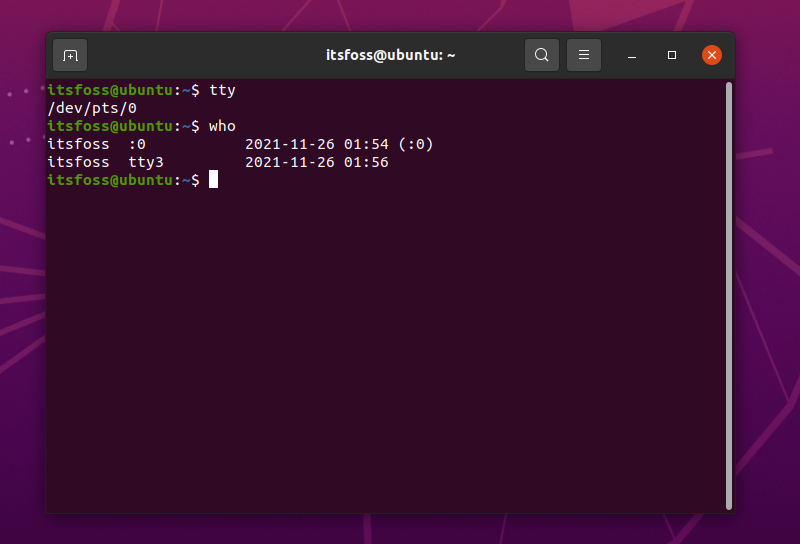
When you type in TTY in your terminal emulator, it will print the file name of the terminal connected to the standard input, as described by the man page.
In other words, to know the TTY number you are connected to, just type in TTY. And, if there are multiple users connected to the Linux machine remotely, you can use the **who** command to check what other users are connected to. |
14,095 | ShardingSphere 分布式数据库简介 | https://opensource.com/article/21/12/apache-shardingsphere | 2021-12-19T09:34:15 | [
"数据库"
] | https://linux.cn/article-14095-1.html |
>
> Apache ShardingSphere 是一个开源的分布式数据库,它还有一个用户和开发人员需要的生态系统,为之提供了定制和云原生的体验。
>
>
>

Apache ShardingSphere 是一个开源的分布式数据库,它还有一个用户和开发人员需要的生态系统,为之提供了定制和云原生的体验。在加入 Apache 基金会的三年里,ShardingSphere 核心团队与社区一起努力工作,创建了一个开源的、强大的、分布式的数据库和一个支持性生态系统。
ShardingSphere 并不完全符合业界通常的简单分布式数据库中间件解决方案的模式。ShardingSphere 重新创建了分布式可插拔系统,使实际的用户实施方案得以蓬勃发展,并为社区和数据库行业贡献有价值的解决方案。
ShardingSphere 的目标是 *Database Plus* 概念。
### Database Plus
Database Plus 的出发点是在零散的数据库基本服务之上建立一个标准层和生态系统层。统一的、标准化的数据库使用规范为上层应用提供了保障,尽可能的减少了企业因底层数据库碎片化而面临的挑战。为了连接数据库和应用,它使用了流量和数据的渲染和解析。它为用户提供了增强的核心功能,如分布式数据库、数据安全、数据库网关和压力测试。
ShardingSphere 为 Database Plus 使用了可插拔的内核架构。这意味着模块化,这为用户提供了灵活性。它有几个不同的层:
* **基础层:** 提供各种访问终端和访问形式,满足用户在不同场景下的需求。
* **插件层:** 通过实现可扩展性提供基础设施支持。
* **功能层:** 提供各种满足用户需求的功能插件,使用户在选择和组合插件时具有高度的灵活性。
* **产品层:** 这是终端用户看到的层。这为他们提供了面向行业和特定场景的产品。换句话说,它为用户提供了适合他们所做的任何工作的工具。

(Trista Pan, [CC BY-SA 4.0](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tps:/creativecommons.org/licenses/by-sa/4.0))
### 用 DistSQL 进行标准化的集群管理
Apache ShardingSphere 采用独特的 SQL 方言 DistSQL(分布式 SQL)来连接 ShardingSphere 生态系统的所有元素。作为 ShardingSphere 分布式数据库生态系统的标准交互语言,DistSQL 允许用户使用一个 SQL 命令来创建、修改或删除分布式数据库表或对其进行加密或解密。DistSQL 还支持分布式调度管理。

(Trista Pan, [CC BY-SA 4.0](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tps:/creativecommons.org/licenses/by-sa/4.0))
### 多访问终端
ShardingSphere JDBC 和 ShardingSphere Proxy 经过两年的打磨和测试,目前已经可以投入生产。许多社区用户提供了相关的生产社区案例。
多亏共享核心架构,以及不同的 ShardingSphere 适配器,如果用户的生产环境需要,可以选择混合适配器部署(如下图所示)。

(Trista Pan, [CC BY-SA 4.0](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tps:/creativecommons.org/licenses/by-sa/4.0))
### 分布式治理
在 ShardingSphere 生态系统中,计算和存储是分开的,因此具备对数据库进行分布式治理的能力,所以你可以维护许多存储节点、计算节点,实施断路器,并确保高可用性。

(Trista Pan, [CC BY-SA 4.0](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tps:/creativecommons.org/licenses/by-sa/4.0))
### 使用 Grafana 监控
ShardingSphere 也有状态指标来监控你的基础设施。代理动态加载机制为你提供了指标和跟踪指标,方便您将 APM 系统与 Grafana 仪表板集成。

(Trista Pan, [CC BY-SA 4.0](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tps:/creativecommons.org/licenses/by-sa/4.0))
### 分布式社区的分布式数据库
社区正在继续优化 ShardingSphere,并整合新的想法和行业场景。社区构建了它,而开发的主要动力之一是用户反馈。这是开源的一个特点,但也是这个团队的实践方法。ShardingSphere 社区的核心团队成员很乐意指导任何对开源感兴趣的人,并为有兴趣帮助开发的学生提供实践问题。团队也希望有新的朋友或贡献者加入社区,促进思想的开放交流,创造一个真正的全球开发者社区。
---
via: <https://opensource.com/article/21/12/apache-shardingsphere>
作者:[Trista Pan](https://opensource.com/users/trista-pan) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Apache ShardingSphere is an open source distributed database, plus an ecosystem users and developers need for their database to provide a customized and cloud-native experience. In the three years since it joined the Apache Foundation, the ShardingSphere core team has worked hard with the community to create an open source, robust, and distributed database and a supporting ecosystem.
ShardingSphere doesn't quite fit into the usual industry mold of a simple distributed database middleware solution. ShardingSphere recreates the distributed pluggable system, enabling actual user implementation scenarios to thrive and contributing valuable solutions to the community and the database industry.
The aim of ShardingSphere is the *Database Plus* concept.
## Database Plus
Database Plus sets out to build a standard layer and an ecosystem layer above the fragmented database's basic services. A unified and standardized database usage specification provides for upper-level applications, and the challenges faced by businesses due to underlying databases fragmentation get minimized as much as possible. To link databases and applications, it uses traffic and data rendering and parsing. It provides users with enhanced core features, such as a distributed database, data security, database gateway, and stress testing.
ShardingSphere uses a pluggable kernel architecture for Database Plus. That means there's modularity, which provides flexibility for the user. There are a few different layers:
**Foundation layer:**Provides a variety of access terminals and access forms to meet users' needs in different scenarios.**Plugin layer:**Provides infrastructure support by enabling extensibility.**Function layer:**Provides a variety of functional plugins that meet users' needs, allowing users a high degree of flexibility in plugin choice and combination.**Product layer:**This is the layer end users see. This provides them with industry-oriented and specific scenario-oriented products. In other words, it gives the users the right tools for whatever job they're doing.
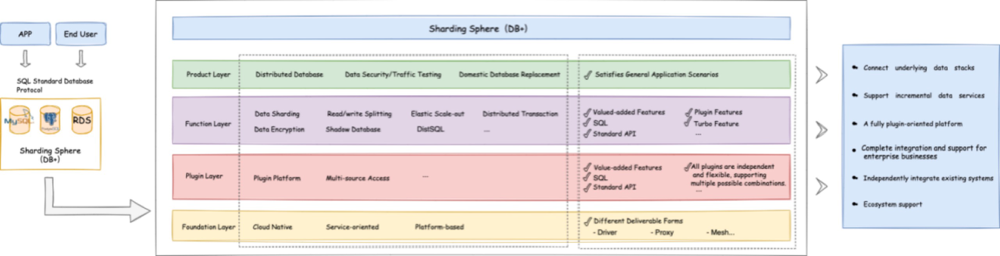
(Vernoica Xu, CC BY-SA 4.0)
## Standardized cluster management with DistSQL
Apache ShardingSphere features the unique SQL dialect of DistSQL (distributed SQL) to connect all elements of the ShardingSphere ecosystem. As the standard interaction language of the ShardingSphere distributed database ecosystem, DistSQL allows users to use one SQL command to create, modify, or delete a distributed database table or encrypt or decrypt it. DistSQL also supports distributed scheduling management.
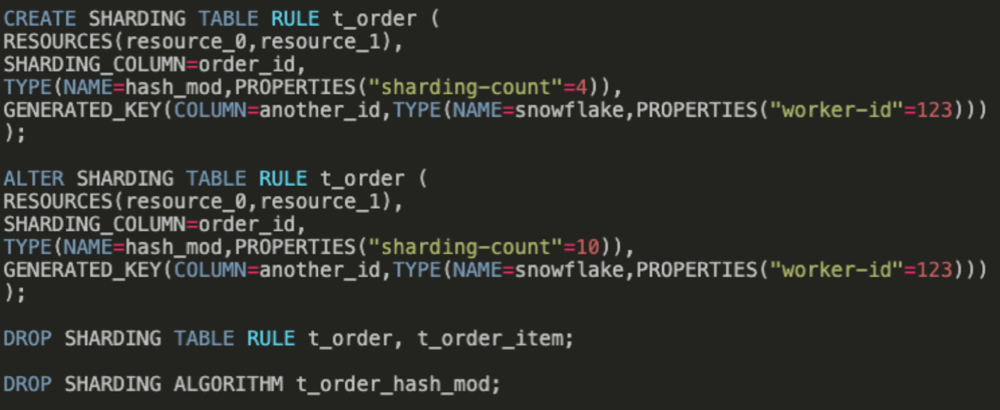
(Vernoica Xu, CC BY-SA 4.0)
## Multi-access terminal
ShardingSphere JDBC and ShardingSphere Proxy have been polished and tested for two years and are now available in production. Many community users provided relevant production community cases.
Thanks to the shared core architecture, and different ShardingSphere adapters, users can choose hybrid adapter deployments if their production environment requires them to do so (shown in the figure below).
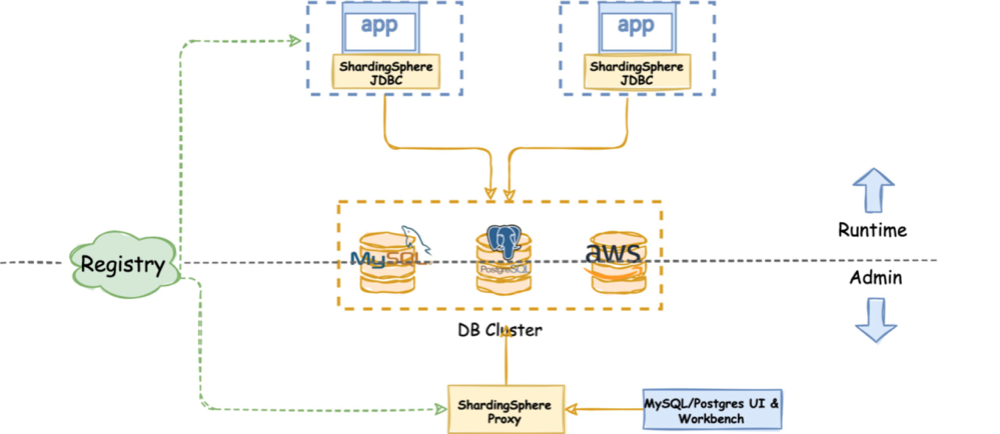
(Vernoica Xu, CC BY-SA 4.0)
## Distributed governance
In the ShardingSphere ecosystem, where computing and storage are separated, there's the ability for distributed governance of databases so you can maintain many storage nodes, computing nodes, implement circuit breakers, and ensure high availability.
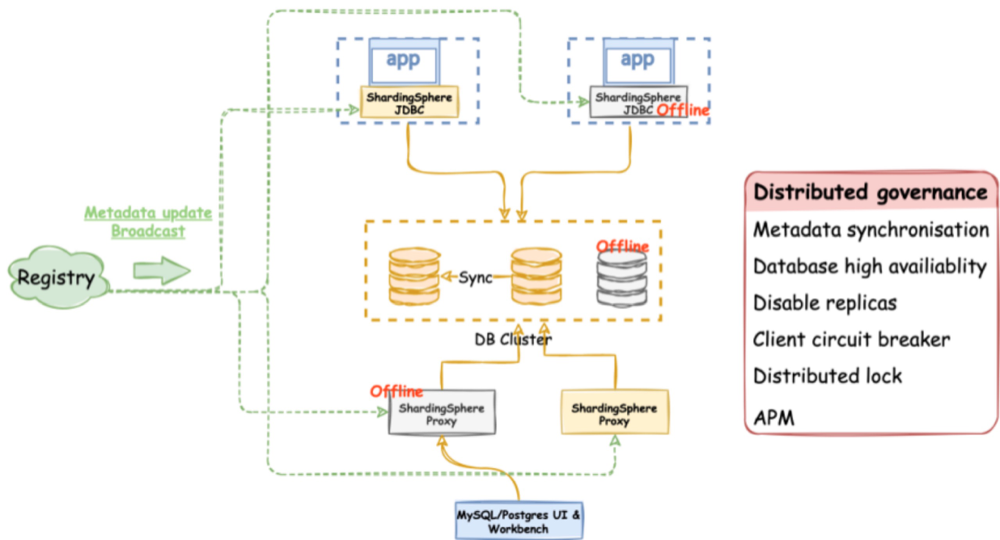
(Vernoica Xu, CC BY-SA 4.0)
## Monitoring with Grafana
ShardingSphere also has status indicators to monitor your infrastructure. The agent dynamic loading mechanism provides you with metrics and tracing indicators, making it convenient to integrate the APM system with a Grafana dashboard.
(Vernoica Xu, CC BY-SA 4.0)
## Distributed database for a distributed community
The community is continuing to optimize ShardingSphere and to integrate new ideas and industry scenarios. The community built it, and one of the main driving forces of development is user feedback. That's a feature of open source, but it's also a method of practice for this team. The core team members of the ShardingSphere community are happy to mentor anyone interested in open source and provide practice issues for students interested in helping in development. The team also hopes that new friends or contributors will join the community, promote the open exchange of ideas, and create a truly global developer community.
## Comments are closed. |
14,096 | 用 Linux 命令优化网页图片 | https://opensource.com/article/21/12/optimize-web-images-linux | 2021-12-19T10:04:39 | [
"图片"
] | https://linux.cn/article-14096-1.html |
>
> 为网页上的缩略图和横幅图片生成经过调整和优化的图片。
>
>
>

以前我在处理网页工作时,我对图像敬而远之。处理和优化图像既不精确又费时。
后来我发现了一些命令,改变了我的想法。为了创建网页,我使用 Jekyll,所以我在说明中包括了它。然而,这些命令也可以用于其他静态网站生成器。
### Linux 上的图像命令
对我来说有用的命令是 `optipng`、`jpegoptim`,当然还有古老的 `imagemagick`。它们一起使处理图像变得容易管理,甚至可以自动化。
下面是我如何使用这些命令实现我的解决方案的概述。我把文章图片放在我的 `static/images` 文件夹中。在那里,我生成了所有 PNG 和 JPG 图片的两个副本:
1. 一个裁剪过的缩略图版本,尺寸为 422×316
2. 一个更大的横幅版本,尺寸为 1024×768
然后,我把每个副本(缩略图和横幅)放入自己的文件夹,并利用 Jekyll 的自定义变量来确定文件夹路径。下面我将更详细地介绍这些步骤中的每一步。
#### 安装
要跟上我的解决方案,请确保你已经安装了所有的命令。在 Linux 上,你可以使用软件包管理器安装 `optipng`、`jpegoptim` 和 `imagemagick`。
在 Fedora、CentOS、Mageia 和类似系统上:
```
$ sudo dnf install optipng jpegoptim imagemagick
```
在 Debian、Elementary、Mint 和类似系统上:
```
$ sudo apt install optipng jpegoptim imagemagick
```
在 macOS 上,使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac):
```
brew install optipng jpegoptim imagemagick
```
在 Windows 上,使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey)。
### 为缩略图和横幅创建文件夹
安装完这些命令后,我在 `static/images` 下创建了新的文件夹。生成的缩略图放在 `img-thumbs`,横幅放在 `img-normal`。
```
$ cd static/images
$ mkdir -p img-thumbs img-normal
```
创建了文件夹后,我把所有的 GIF、SVG、JPG 和 PNG 文件复制到这两个文件夹。我把 GIF 和 SVG 原封不动地用于缩略图和横幅图片。
```
$ cp content/*.gif img-thumbs/; cp content/*.gif img-normal/
$ cp content/*.svg img-thumbs/; cp content/*.svg img-normal/
$ cp content/*.jpg img-thumbs/; cp content/*.jpg img-normal/
$ cp content/*.png img-thumbs/; cp content/*.png img-normal/
```
### 处理缩略图
为了调整和优化缩略图的大小,我使用了三个命令。
我使用 `ImageMagick` 的 `mogrify` 命令来调整 JPG 和 PNG 的大小。因为我希望缩略图是 422×316,所以命令看起来像这样:
```
$ cd img-thumbs
$ mogrify -resize 422x316 *.png
$ mogrify -format jpg -resize 422x316 *.jpg
```
现在我用 `optipng` 优化 PNG,用 `jpegoptim` 优化 JPG:
```
$ for i in *.png; do optipng -o5 -quiet "$i"; done
$ jpegoptim -sq *.jpg
```
在上述命令中:
* 对于 `optipng`,`-o5` 开关设置了优化的级别,0 是最低的。
* 对于`jpegoptim`,`-s` 剥离所有图像元数据,`-q` 设置安静模式。
### 处理横幅
我处理横幅图片的方法与处理缩略图的方法基本相同,除了尺寸外,横幅图片的尺寸为 1024×768。
```
$ cd ..
$ cd img-normal
$ mogrify -resize 1024x768 *.png
$ mogrify -format jpg -resize 1024x768 *.jpg
$ for i in *.png; do optipng -o5 -quiet "$i"; done
$ jpegoptim -sq *.jpg
```
### 配置 Jekyll 中的路径
`img-thumbs` 目录现在包含我的缩略图,`img-normal` 包含横幅。为了更轻松一些,我在Jekyll的 `_config.yml` 中把它们都设置为自定义变量。
```
content-images-path: /static/images/img-normal/
content-thumbs-images-path: /static/images/img-thumbs/
```
使用这些变量很简单。当我想显示缩略图时,我把 `content-thumbs-images-path` 加到图片上。当我想显示完整的横幅时,我在前面添加 `content-images-path`。
```
{% if page.banner_img %}
<img src="{{ page.banner_img | prepend: site.content-images-path | \
prepend: site.baseurl | prepend: site.url }}" alt="Banner image for \
{{ page.title }}" />
{% endif %}
```
### 总结
我可以对我的优化命令做几个改进。
使用 `rsync` 只复制改变过的文件到 `img-thumbs` 和 `img-normal` 是一个明显的改进。这样一来,我就不会一次又一次地重新处理文件。将这些命令添加到 [Git 提交前钩子](https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6) 或 CI 流水线中是另一个有用的步骤。
调整和优化图像以减少其大小,对用户和整个网页来说都是一种胜利。也许我减少图片尺寸的下一步将是 [webp](https://opensource.com/article/20/4/webp-image-compression)。
更少的字节通过电线传输意味着更低的碳足迹,但这是另一篇文章。目前,用户体验的胜利已经足够好了。
本文原载于[作者的博客](https://www.ayushsharma.in/2021/11/optimising-jpg-and-png-images-for-a-jekyll-blog),已获授权转载。
---
via: <https://opensource.com/article/21/12/optimize-web-images-linux>
作者:[Ayush Sharma](https://opensource.com/users/ayushsharma) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I used to stay away from images when working online. Handling and optimizing images can be both imprecise and time-consuming.
Then I found some commands that changed my mind. To create web pages, I use Jekyll, so I've included that in the directions. However, these commands will also work with other static site generators.
## Image commands on Linux
The commands that made all the difference for me are `optipng`
, `jpegoptim`
, and, of course, the venerable `imagemagick`
. Together, they make handling images easy to manage or even automate.
Here’s an overview of how I implemented my solution using these commands. I placed article images in my `static/images`
folder. From there, I generated two copies of all PNG and JPG images:
- A cropped thumbnail version measuring 422 by 316
- A larger banner version, measuring 1024 by 768
Then I placed each copy (the thumbnail and the banner) into its own folder, and I leveraged Jekyll's custom variables for the folder paths. I outline each of these steps in greater detail below.
### Installation
To follow along with my solution, be sure you have all the commands installed. On Linux, you can install `optipng`
, `jpegoptim`
, and `imagemagick`
using your package manager.
On Fedora, CentOS, Mageia, and similar:
$ sudo dnf install optipng jpegoptim imagemagick
On Debian, Elementary, Mint, and similar:
$ sudo apt install optipng jpegoptim imagemagick
On macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac).
brew install optipng jpegoptim imagemagick
On Windows, use [Chocolatey](https://opensource.com/article/20/3/chocolatey).
## Creating folders for thumbnails and banners
After installing the commands, I created new folders under `static/images`
. Generated thumbnails get placed into `img-thumbs`
, and banners go in `img-normal`
.
```
$ cd static/images
$ mkdir -p img-thumbs img-normal
```
With the folders created, I copied all GIF, SVG, JPG, and PNG files to both folders. I use the GIFs and SVGs as-is for thumbnails and banner images.
```
$ cp content/*.gif img-thumbs/; cp content/*.gif img-normal/
$ cp content/*.svg img-thumbs/; cp content/*.svg img-normal/
$ cp content/*.jpg img-thumbs/; cp content/*.jpg img-normal/
$ cp content/*.png img-thumbs/; cp content/*.png img-normal/
```
## Processing thumbnails
To resize and optimize the thumbnails, I use my three commands.
I use the `mogrify`
command from `ImageMagick`
to resize the JPGs and PNGs. Since I want the thumbnails to be 422 by 316, the command looks like this:
```
$ cd img-thumbs
$ mogrify -resize 422x316 *.png
$ mogrify -format jpg -resize 422x316 *.jpg
```
Now I optimize the PNGs using `optipng`
and the JPGs using `jpegoptim`
:
```
$ for i in *.png; do optipng -o5 -quiet "$i"; done
$ jpegoptim -sq *.jpg
```
In the above command:
- For
`optipng`
,`-o5`
switch sets the level of optimization, with 0 being the lowest. - For
`jpegoptim`
,`-s`
strips all image metadata, and`-q`
sets quiet mode.
## Processing banners
I process the banner images in essentially the same way I process the thumbnails, aside from the dimensions, which are 1024 by 768 for banners.
```
$ cd ..
$ cd img-normal
$ mogrify -resize 1024x768 *.png
$ mogrify -format jpg -resize 1024x768 *.jpg
$ for i in *.png; do optipng -o5 -quiet "$i"; done
$ jpegoptim -sq *.jpg
```
## Configuring the paths in Jekyll
The `img-thumbs`
directory now contains my thumbnails. and `img-normal`
contains the banners. To make my life easier, I set both of them to custom variables in my Jekyll `_config.yml`
.
```
content-images-path: /static/images/img-normal/
content-thumbs-images-path: /static/images/img-thumbs/
```
Using the variables is simple. When I want to display the thumbnail, I prepend `content-thumbs-images-path`
to the image. When I want to display the full banner, I prepend `content-images-path`
.
```
{% if page.banner_img %}
<img src="{{ page.banner_img | prepend: site.content-images-path | \
prepend: site.baseurl | prepend: site.url }}" alt="Banner image for \
{{ page.title }}" />
{% endif %}
```
## Conclusion
There are several improvements I could make to my optimization commands.
Using `rsync`
to copy only changed files to `img-thumbs`
and `img-normal`
is one obvious improvement. That way, I'm not reprocessing files over and over again. Adding those commands to [Git pre-commit hooks](https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6) or a CI pipeline is another useful step.
Resizing and optimizing images to reduce their size is a win for the user and the web as a whole. Maybe my next step for reducing image sizes will be [webp](https://opensource.com/article/20/4/webp-image-compression).
Fewer bytes transmitted over the wire means a lower carbon footprint, but that's another article. The UX victory is good enough for now.
*This article was originally posted on the author's blog and has been republished with permission.*
## 1 Comment |
14,098 | 使用 Goxel 制作开源 3D 像素艺术 | https://opensource.com/article/21/12/3d-pixel-art-goxel | 2021-12-20T12:54:22 | [
"3D",
"像素艺术"
] | https://linux.cn/article-14098-1.html |
>
> 使用 Goxel 构建模型很有趣,就像没有锋利边缘的乐高、没有“爬行者”的 Minecraft 一样。
>
>
>

我喜欢乐高,这不是什么秘密,但我的乐高收藏现在离我很远,而且把满满一柜子的经典乐高套装在世界各地搬来搬去看起来也不太可行。为了解决这个问题,从 [在乐高 CAD 中建立模型](https://opensource.com/article/20/6/open-source-virtual-lego) 到 [在 Blender 中用乐高纹理对模型进行造型](https://opensource.com/article/20/7/lego-blender-bricker),我做了很多虚拟化的工作。最近我发现了 [Goxel](https://goxel.xyz/)。这个简单得令人震惊的 3D 建模应用并没有自称是基于乐高的,也没提和乐高有什么关系。然而,用 3D 像素建立模型的感觉与用乐高积木建立模型的满足感惊人地相似。你可以把 Goxel 看作是一个像素绘画程序,但却是 3D 的。
Goxel 采取了一种独特的 3D 建模方法,它专门针对 <ruby> 低模 <rt> low polygon </rt></ruby> 建模。如果你想雕刻出栩栩如生的模型,就不应该使用这个程序。但是,如果你喜欢 Minecraft 和其他低模艺术的美感,那么你应该试试 Goxel。
### 在 Linux 上安装 Goxel
你可以从 [Flathub](https://flathub.org/apps/details/io.github.guillaumechereau.Goxel) 将 Goxel 作为 [Flatpak](https://opensource.com/article/21/11/install-flatpak-linux) 安装在 Linux 上。
对于 Android、Windows macOS 和 iOS,请到 [Goxel 网站](https://goxel.xyz/) 下载安装程序。
Goxel 是开源的,在 GPLv3 许可下发布。
### 使用体素绘画
当你第一次启动 Goxel 时,在 Goxel 窗口的中间会有一个空的“空间”或容器。这就是你的画布。

正是在这个容器中,且只有在这个容器中,你才能建立你的模型。在大多数三维建模应用中,<ruby> 深度感知 <rt> depth perception </rt></ruby>是一种努力才能得到的技能,所以 Goxel 限制了你工作的空间,以防止你最终出现模型和模型部件彼此相距甚远的情况。Goxel 还限制你在一个严格的网格中移动。你可以沿 Y 轴上下移动,沿 X 轴左右移动,沿 Z 轴前后移动,但只能在一个三维像素(或称为 <ruby> 体素 <rt> voxel </rt></ruby>)的片段中移动。不管用于什么意图和目的,Goxel 的体素就是用来建立模型的虚拟乐高砖块。
Goxel 中没有太多工具,这对一个三维建模应用来说是一个真正的特点。默认情况下,你已经激活了铅笔工具,所以你可以通过点击鼠标在体素容器内的任何地方立即开始建造。

试着点击容器周围,以查看添加体素的位置。Goxel 让你比较容易地看到你的铅笔即将添加体素的地方,可以把体素当作砖块,它假设当你靠近一个现有的体素时是准备把你的下一个体素连接到它。即便如此,在二维屏幕上实现三维也很困难。有时,体素会被添加到一个你没有意识到的地方。确保你的体素被添加到你想添加的地方的最好方法是经常旋转容器。你可以用键盘上的方向键来旋转容器,或者你可以点击并拖动鼠标中键。右击并拖动容器可在 Goxel 工作区中移动,而鼠标的滚轮可以放大和缩小。
### 平面标记
Goxel 还提供了另一个对齐体素的技巧,那就是以半透明和临时平面的形式提供指导。当你在你的容器中添加一个平面时,它会创建一种力场,使你的铅笔无法通过。

其结果是,你只能沿着两个轴线安全地作画,而不能沿着第三个轴线作画。你可以沿着网格轻推平面,这样你就可以分片添加体素,就像 3D 打印机向物理模型添加一样。
禁用平面控制中的 “<ruby> 可见 <rt> Visible </rt></ruby>” 选项可以移除平面。

### Goxel 工具栏
顶部的工具栏包含七个按钮。从左到右:
* <ruby> 撤销 <rt> Undo </rt></ruby>
* <ruby> 重做 <rt> Redo </rt></ruby>
* <ruby> 删除所有的东西,且无需确认 <rt> Delete everything without confirmation </rt></ruby>
* <ruby> 添加一个体素 <rt> Add a voxel </rt></ruby>
* <ruby> 减去(删除)一个体素 <rt> Subtract (remove) a voxel </rt></ruby>
* <ruby> 画一个体素 <rt> Paint a voxel </rt></ruby>
* <ruby> 设置油漆颜色 <rt> Set the paint color </rt></ruby>
你可以在单个体素上作画,也可以使用铅笔左边的形状工具,一次性添加体素区域。
除了用铅笔删除体素外,你还可以使用激光工具在体素出现在作为计算机显示器的 2D 屏幕上时对其进行调整。在形状工具的右边,把你的光标变成一个十字准线。把它指向你看到的体素,然后点击它来擦除。
### 极简主义的宁静
Goxel 追求简单,不仅在于它生产的内容,还在于它的生产方式。我在本文中只讨论了 Goxel 的绘图工具。虽然还有其他功能,例如控制光线的俯仰角和偏航角的能力、阴影的强度以及虚拟摄像机的位置,但该应用力求以最佳方式使事情变得简单自然。使用 Goxel 构建模型非常有趣,就像没有锋利边缘的乐高玩具,或者没有“爬行者”的 Minecraft。去使用 Goxel,并构建一些模型吧!
---
via: <https://opensource.com/article/21/12/3d-pixel-art-goxel>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I make it no secret that I love Lego, but I've moved far away from my Lego collection, and shipping a closet full of classic Lego sets all the way around the world is currently a problematic proposal. I've done a lot of virtualization to solve this problem, from [building models in Lego CAD](https://opensource.com/article/20/6/open-source-virtual-lego) to [styling models with a Lego texture in Blender](https://opensource.com/article/20/7/lego-blender-bricker). Recently I discovered [Goxel](https://goxel.xyz/). This shockingly easy 3D modeling application makes no conceit of being Lego-based or even Lego-adjacent. Yet, the sensation of building models with 3D pixels is surprisingly similar to the satisfaction of building with Lego bricks. You can think of Goxel as a pixel paint program, but in 3D.
Goxel takes a unique approach to 3D modeling, and it's geared specifically to *low polygon* modeling. This isn't the application to use if you're looking to sculpt life-like models. But if you like the aesthetic of Minecraft and other low poly art, then you need to try Goxel.
## Install Goxel on Linux
You can install Goxel as a [Flatpak](https://opensource.com/article/21/11/install-flatpak-linux) on Linux from [Flathub](https://flathub.org/apps/details/io.github.guillaumechereau.Goxel).
For Android, Windows macOS, and iOS, go to the [Goxel website](https://goxel.xyz/) to download an installer.
Goxel is open source, released under the GPLv3 license.
## Painting with voxels
When you first launch Goxel, you get an empty "room" or container in the middle of the Goxel window. This is your canvas.
(Seth Kenlon, CC BY-SA 4.0)
It's in this container and only within it that you'll build your models. In most 3D modeling applications, depth perception is an acquired skill, so Goxel constrains the space you have to work in to prevent you from ending up with models and model parts miles away from each other. Goxel also restricts your movements in a strict grid. You can move up and down along a Y-axis, right and left along an X-axis, and "near" and "far" along a Z-axis, but only in segments of one 3D pixel (or *voxel*, as they're called). For all intents and purposes, the voxels of Goxel are the virtual Lego bricks you use to build your model.
There aren't many tools in Goxel, and that's a real feature for a 3D modeling application. By default, you've already got the pencil tool active, so you can start building right away by clicking your mouse any place within the voxel container.
(Seth Kenlon, CC BY-SA 4.0)
Try clicking around the container to see where a voxel gets added. Goxel makes it relatively easy to see where your pencil is about to add a voxel, and it treats voxels like bricks by assuming that when you're near an existing voxel, you want to connect your next voxel to it. Even so, 3D on a 2D screen is difficult. Sometimes voxels get added in a spot you didn't realize you were pointing at. The best way to ensure your voxels get added where you mean for them to get added is to rotate the container often. You can rotate the container using the arrow keys on your keyboard, or you can click and drag the middle-mouse button. A right-click and drag moves the container within the Goxel workspace, and the scroll-wheel of your mouse zooms in and out.
## Planar markers
There's another trick to aligning voxels that Goxel provides, and that's a guide in the form of a translucent and temporary plane. When you add a plane to your container, it creates a kind of force field through which your pencil cannot pass.
(Seth Kenlon, CC BY-SA 4.0)
The result is that you can safely paint along only two axes but not along the third. You can nudge the plane along the grid so that you're adding voxels in slices, much as a 3D printer adds to a physical model.
Disable the **Visible** option in the plane controls to remove a plane.
(Seth Kenlon, CC BY-SA 4.0)
## Goxel toolbar
The top toolbar contains seven buttons. From left to right:
- Undo
- Redo
- Delete
*everything without confirmation* - Add a voxel
- Subtract (remove) a voxel
- Paint a voxel
- Set the paint color
You can paint in single voxels or use the shape tool to the left of the pencil to add regions of voxels all at once.
In addition to removing voxels with the pencil, you can also use the laser tool to zap voxels as they appear on the 2D screen that is your computer monitor. The Laser tool, to the right of the shape tool, turns your cursor into a crosshair. Point it at a voxel you see and click on it to erase.
## The tranquility of minimalism
Goxel is intentionally simple, not just in what it produces but also in how it produces. I've only discussed the drawing tools of Goxel in this article. While there are other features, like the ability to control the pitch and yaw of the sun, the intensity of shadows, and the position of virtual cameras, the application strives to keep things simple and underwhelming in the best of ways. Building models with Goxel is a lot of fun, like the best part of Lego without the sharp edges and like Minecraft without the Creepers. Go get Goxel, and build some models!
## Comments are closed. |
14,099 | 从 Linux 终端打印文件 | https://opensource.com/article/21/9/print-files-linux | 2021-12-20T13:58:28 | [
"lpr",
"打印"
] | https://linux.cn/article-14099-1.html |
>
> 使用 lpr 命令在终端中打印文件。
>
>
>

[在 Linux 上打印很容易](https://opensource.com/article/21/8/setup-your-printer-linux),但有时感觉要做很多工作,比如启动应用程序、打开文件、在菜单中找到打印选项,单击确认按钮等等。当你是一个终端用户时,通常希望使用简单的触发器执行复杂的操作。打印很复杂,但没有什么比 `lpr` 命令更简单了。
### 使用 lpr 命令打印
使用 `lpr` 命令在终端打印文件:
```
$ lpr myfile.odt
```
如果失败的话,你需要设置默认打印机或手动指定打印机。
### 设置默认打印机
根据我在 1984 年印刷的 Berkeley 4.2 手册的旧版本中找到的资料,`lpr` 命令会分页并将文件发送到打印机池,后者将数据传输到称为 <ruby> 行式打印机 <rt> line printer </rt></ruby> 的东西。

现在,最初的 `lpr` 命令已经无法满足,因为现代计算机可以访问多台打印机,而且是那些比点阵行式打印机复杂得多的打印机。现在有一个称为<ruby> 通用 Unix 打印系统 <rt> Common Unix Printing System </rt></ruby>(CUPS)子系统,可以跟踪你的计算机可以访问的所有打印机,计算机应该使用哪个驱动程序与每台打印机通信,默认使用哪台打印机等等。 CUPS 捆绑提供的 `lpr.cups` 或 `lpr-cups` 命令通常以符号链接到 `lpr`,允许你首先借助 CUPS 配置从终端打印。
使用 `lpr` 打印文件,你应该首先设置默认打印机。你可以在系统的打印机设置中设置:

或者,你也可以使用 `lpadmin` 命令设置:
```
$ sudo lpadmin -d HP_LaserJet_P2015_Series
$ lpstat -v
device for HP_LaserJet_P2015_Series: ipp://10.0.1.222:631/printers/HP_LaserJet_P2015_Series
```
### 使用环境变量设置
你不能在没有管理员账户的系统上设置默认打印机,因为更改打印机默认设置是一项特权任务。在 `lpr` 借助 CUPS 找到目标打印机前,它会在系统中查询 `PRINTER` [环境变量](https://opensource.com/article/19/8/what-are-environment-variables)。
在本例中,`HP_LaserJet_P2015_Series` 是打印机的名称。将 `PRINTER` 设置为该值:
```
$ PRINTER=HP_LaserJet_P2015_Series
$ export PRINTER
```
一旦设置了 `PRINTER` 变量,你就可以打印了:
```
$ lpr myfile.pdf
```
### 获取连接的打印机列表
你可以使用 `lpstat` 命令查看所有连接到系统接受打印任务的打印机:
```
$ lpstat -a
HP_LaserJet_P2015_Series accepting requests since Sun 1 Aug 2021 10:11:02 PM NZST
r1060 accepting requests since Wed 18 Aug 2021 04:43:57 PM NZST
```
### 打印到任意一台打印机
将打印机添加到系统后,并且现在你知道如何识别它们了,你可以打印到其中任何一台,无论你是否设置了默认打印机:
```
$ lpr -P HP_LaserJet_P2015_Series myfile.txt
```
### 如何定义打印机
CUPS 有一个友好的前端页面,可通过 Web 浏览器如 Firefox 访问。虽然它使用 Web 浏览器作为用户界面,但它实际上是在本机(一个称为 `localhost` 的位置)的 631 端口上提供服务。CUPS 管理连接到计算机的打印机,并将其配置存储在 `/etc/cups/priters.conf` 中。
`printers.conf` 文件包含详细描述计算机可以访问的打印设备的定义。不要直接编辑它,但如果你想这样做,你必须先停止 `cupsd` 守护进程。
一个典型的文件定义如下所示:
```
<Printer r1060>
Info Ricoh 1060
Location Downstairs
MakeModel Ricoh Aficio 1060 - CUPS+Gutenprint v5.2.6
DeviceURI lpd://192.168.4.8
State Idle
StateTime 1316011347
Type 12308
Filter application/vnd.cups-raw 0 -
Filter application/vnd.cups-raster 100 rastertogutenprint.5.2
Accepting Yes
Shared No
JobSheets none none
QuotaPeriod 0
PageLimit 0
KLimit 0
OpPolicy default
ErrorPolicy stop-printer
</Printer>
```
在本例中,打印机的名称是 `r1060`,即 “Ricoh Aficio 1060”。
`MakeModel` 属性是从 `lpinfo` 命令中提取的,该命令列出了系统上所有可用的打印机驱动程序。假设你知道要打印到 Ricoh Aficio 1060,那么你会发出以下命令:
```
$ lpinfo -m | grep 1060
gutenprint.5.2://brother-hl-1060/expert Brother HL-1060 - CUPS+Gutenprint v5.2.11
gutenprint.5.2://ricoh-afc_1060/expert Ricoh Aficio 1060 - CUPS+Gutenprint v5.2.11
```
它会列出已安装的相关驱动程序。
`MakeModel` 属性是结果的后半部分。在本例中为 `Ricoh Aficio 1060 - CUPS+Gutenprint v5.2.11`。
`DeviceURI` 属性标识打印机在网络上的位置(或物理位置,例如 USB 端口)。在本例中,它是 `lpd://192.168.4.8`,因为我使用 `lpd` 协议将数据发送到一台网络打印机。在我的另一个系统上,我有一个通过 USB 连接的 HP LaserJect 打印机,因此 `DeviceURI` 是 `hp:/usb/HP_LaserJet_P2015_Series?serial=00CNCJM26429`。
### 在终端中打印
将作业发送到打印机是一个简单的过程,只要你了解连接到系统的设备以及如何识别它们。在终端打印非常快速、高效,并且易于编写脚本或作为批处理作业完成。试试看!
---
via: <https://opensource.com/article/21/9/print-files-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Printing on Linux is easy](https://opensource.com/article/21/8/setup-your-printer-linux), but sometimes it feels like a lot of work to launch an application, open a file, find the **Print** selection in the menu, click a confirmation button, and so on. When you're a Linux terminal user, you often want to perform complex actions with simple triggers. Printing is complex, and there's little as simple as the `lpr`
command.
## Print using the lpr command
To print a file from your terminal, use the `lpr`
command:
`$ lpr myfile.odt`
Should that fail, you need to set a default printer or specify a printer manually.
## Setting a default printer
According to my well-worn copy of a Berkeley 4.2 manual printed in 1984, the `lpr`
command paginated and sent a file to a printer spool, which streamed data to something called a *line printer*.
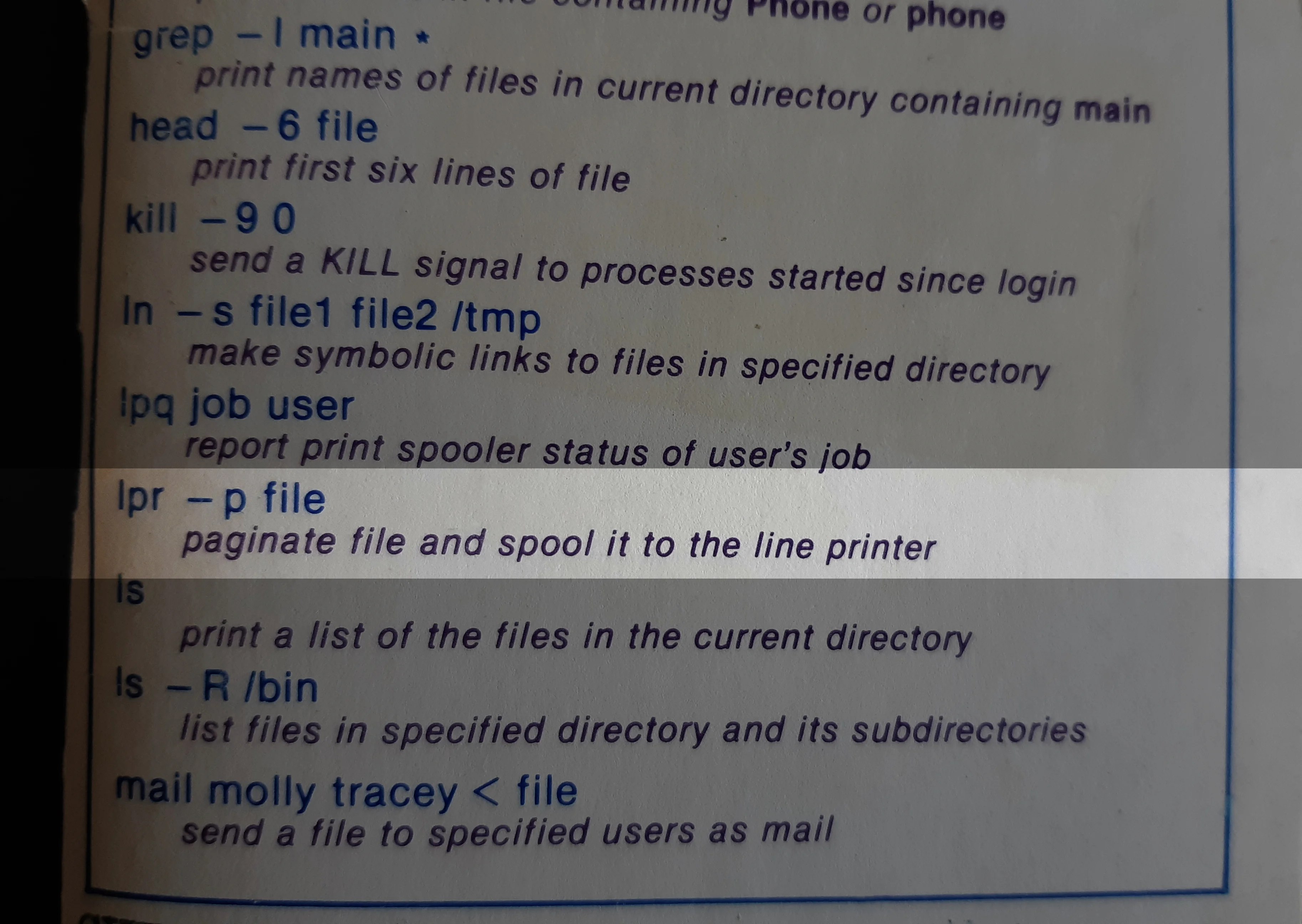
Figure 1: The lpr command.
These days, the actual `lpr`
command is insufficient because modern computers are likely to have access to several printers, and certainly to printers a lot more complex than a dot-matrix line printer. Now there's a subsystem, called the Common Unix Printing System (CUPS), to keep track of all the printers that you want your computer to access, which driver your computer should use to communicate with each printer, which printer to use by default, and so on. The `lpr.cups`
or `lpr-cups`
commands, bundled with CUPS and usually symlinked to `lpr`
, allow you to print from a terminal by referencing your Common Unix Printing System (CUPS) configuration first.
To print a file with `lpr`
, you should first set a default printer. You can set a default printer in your system's printer settings:
Figure 2: Set a default printer.
Alternately, you can mark a printer as the default with the `lpadmin`
command:
```
$ sudo lpadmin -d HP_LaserJet_P2015_Series
$ lpstat -v
device for HP_LaserJet_P2015_Series: ipp://10.0.1.222:631/printers/HP_LaserJet_P2015_Series
```
## Setting a default destination with environment variables
You aren't permitted to set your own default printer on systems you don't have an admin account on because changing print destinations is considered a privileged task. Before `lpr`
references CUPS for a destination, it queries your system for the **PRINTER** [environment variable](https://opensource.com/article/19/8/what-are-environment-variables).
In this example, `HP_LaserJet_P2015_Series`
is the human-readable name given to the printer. Set **PRINTER** to that value:
```
$ PRINTER=HP_LaserJet_P2015_Series
$ export PRINTER
```
Once the **PRINTER** variable has been set, you can print:
`$ lpr myfile.pdf`
## Get a list of attached printers
You can see all the printers that are accepting print jobs and that are attached to your system with the `lpstat`
command:
```
$ lpstat -a
HP_LaserJet_P2015_Series accepting requests since Sun 1 Aug 2021 10:11:02 PM NZST
r1060 accepting requests since Wed 18 Aug 2021 04:43:57 PM NZST
```
## Printing to an arbitrary printer
Once you have added printers to your system, and now that you know how to identify them, you can print to any one of them, whether you have a default destination set or not:
`$ lpr -P HP_LaserJet_P2015_Series myfile.txt`
## How printers are defined
CUPS has a user-friendly front-end accessible through a web browser such as Firefox. Even though it uses a web browser as its user interface, it's actually a service running locally on your computer (a location called **localhost**) on port 631. CUPS manages printers attached to your computer, and it stores its configuration in `/etc/cups/printers.conf`
.
The `printers.conf`
file consists of definitions detailing the printing devices your computer can access. You're not meant to edit it directly, but if you do, then you must stop the `cupsd`
daemon first.
A typical entry looks something like this:
```
<Printer r1060>
Info Ricoh 1060
Location Downstairs
MakeModel Ricoh Aficio 1060 - CUPS+Gutenprint v5.2.6
DeviceURI lpd://192.168.4.8
State Idle
StateTime 1316011347
Type 12308
Filter application/vnd.cups-raw 0 -
Filter application/vnd.cups-raster 100 rastertogutenprint.5.2
Accepting Yes
Shared No
JobSheets none none
QuotaPeriod 0
PageLimit 0
KLimit 0
OpPolicy default
ErrorPolicy stop-printer
</Printer>
```
In this example, the printer's name is `r1060`
, a human-readable identifier for a Ricoh Aficio 1060.
The *MakeModel* attribute is pulled from the `lpinfo`
command, which lists all available printer drivers on your system. Assuming you know that you have a Ricoh Aficio 1060 that you want to print to, then you would issue this command:
```
$ lpinfo -m | grep 1060
gutenprint.5.2://brother-hl-1060/expert Brother HL-1060 - CUPS+Gutenprint v5.2.11
gutenprint.5.2://ricoh-afc_1060/expert Ricoh Aficio 1060 - CUPS+Gutenprint v5.2.11
```
This command lists the relevant drivers you have installed.
The *MakeModel* is the last half of the result. In this example, that's `Ricoh Aficio 1060 - CUPS+Gutenprint v5.2.11`
.
The *DeviceURI* attribute identifies where the printer is found on the network (or physical location, such as the USB port). In this example, the *DeviceURI* is `lpd://192.168.4.8`
because I'm using the `lpd`
(line printer daemon) protocol to send data to a networked printer. On a different system, I have an HP LaserJet attached by a USB cable, so the *DeviceURI* is DeviceURI `hp:/usb/HP_LaserJet_P2015_Series?serial=00CNCJM26429`
.
## Printing from the terminal
Sending a job to a printer is an easy process, as long as you understand the devices attached to your system and how to identify them. Printing from the terminal is fast, efficient, and easily scripted or done as a batch job. Try it out!
## Comments are closed. |
14,102 | 使用 Ansible 在树莓派上部署 Mycroft AI 语音助手 | https://opensource.com/article/21/12/mycroft-raspberry-pi-ansible | 2021-12-21T13:57:58 | [
"Ansible"
] | https://linux.cn/article-14102-1.html |
>
> 使用本文中的这些 Ansible 剧本可以帮你获得更优的 Mycroft AI 体验。
>
>
>

Mycroft AI 是一款虚拟助手应用程序,可以响应语音请求并完成相应的任务,比如在互联网上搜索你需要的某些信息,或者下载你喜欢的博客等等。这是一款优秀的开源软件,不同于那些收集个人数据业务的公司的同款软件,Mycroft AI 注重于保护隐私以及提供平台灵活性。
Mycroft AI 使用 python 开发,可以安装于不同的硬件平台上。家喻户晓的树莓派便是一个非常热门的运行语音助手的硬件方案(不过不是唯一的方案)。方便的是,Mycroft 为树莓派提供了 [Picroft](https://mycroft-ai.gitbook.io/docs/using-mycroft-ai/get-mycroft/picroft) 镜像,虽然目前 Picroft 还有一些限制,比如不支持 64 位系统,不过不能阻止它成为一种优秀的解决方案。
### 树莓派 4,我选择的目标平台
树莓派在 Mycroft 社区中非常受欢迎,因为其性价比高,在教育行业中有着巨大的优势,并且由于 Mycroft 提供的便捷功能以及树莓派本身易于访问的输入/输出(GPIO)引脚等,为树莓派提供了有趣的扩展可能(比如,提供 [唤醒词 LED GPIO](https://github.com/smartgic/mycroft-wakeword-led-gpio-skill) 能力)。
树莓派 4B 具有足够的 CPU 算力以及内存来平稳运行 Mycroft。我使用的是 8G 内存的树莓派4B,运行 Raspberry Pi OS Bullseye 64-bit 系统,你可以从 [RaspberryPi.org](https://downloads.raspberrypi.org/raspios_lite_arm64/images/raspios_lite_arm64-2021-11-08/2021-10-30-raspios-bullseye-arm64-lite.zip) 网站下载该系统镜像文件。
### 自动化这件事
构建你自己的 Mycroft AI 系统,必须要注意一些细节问题。根据我(一年以来)的初步经验,以下罗列了一些重要的技术细节点:
* 音频输出(扬声器配置)
* 音频输入(麦克风配置)
* 麦克风质量(以购买的实际硬件为准)
* 唤醒词响应(比如打招呼 “嘿,Mycroft”)
* 响应延迟(比如提问 “天气怎么样”)
这些并不是 Mycroft AI 的问题(LCTT 译注:难道软件平台就没有处理延时问题?),它们只能是你在选择硬件和配置操作时必须牢记关心的事情。树莓派本身能够运行 Mycroft AI,但有一些配置需要额外的注意下:
* CPU 调度器
* SD 卡性能
* PulseAudio 配置
* 网络延迟
我做了大量的研究和实践来解决上面列出这些令人头疼的注意点,最终我实现了我的“终极”目标 —— 最流畅的体验!
### Ansible 雪中送炭
我已经摸索出了最流畅的体验配置,但是如何确保在任何树莓派 4 板子上都能不遗漏每一个设置细节,然后达到重新部署这种流畅性体验的目标呢?
[Ansible](https://github.com/ansible/ansible) 能帮助你实现。Ansible 在设计上是幂等设计,这意味着它仅在需要时响应更改的请求。如果一切配置正确,Ansible 不会改变任何事情。这便是幂等设计的优美之处。
为了达到这一目的,我使用了两种 Ansible 场景角色工具:
* 一个用于配置和调整树莓派
* 一个用于安装和配置 Mycroft AI
### Ansible prepi 角色
[Ansible prepi role](https://github.com/smartgic/ansible-role-prepi) 应用了一些配置,以便让树莓派 4B 发挥更佳的性能以及为安装 Mycroft 做前提准备。
* 更新 Raspberry Pi OS 至最新版本
* 添加 Debian backports 仓库
* 使用 next 分支更新固件,该分支支持 5.15 版本内核以及边缘固件
* 使用测试版本更新 EEPROM,该版本支持边缘功能
* 设置 `initial_turbo` 用来加速启动过程
* 将树莓派超频至 2GHz
* 在 RAMDisck 上挂载 `/tmp`
* 优化 `/` 分区挂载选项,提升 SD 卡读/写性能
* 管理 I2C、SPI、UART 接口
* 设置 CPU 控制器至避免在空间内核函数之间发生上下文切换的模式,以便提升性能
* 安装和配置 PulseAduio(非系统范围)
* 新固件或者 EEPROM 安装后重启树莓派
### Ansible mycroft 角色
[Ansible mycroft role](https://github.com/smartgic/ansible-role-mycroft) 基于脚本 `dev_setup.sh` 从 Github 仓库获取并安装和配置 Mycroft AI,该脚本是 Mycroft 核心团队提供。
* 需要准备 Python3 环境
* 系统集成环境
* 额外的安装技能
* 安装 Boto3、py\_mplayer、pyopenssl 库
* 支持 IPC 的 RAMDisck
* 支持文件配置
* PulseAudio 优化
* 安全的 Mycroft 消息总线 websocket
我利用 [Ansible 剧本](https://github.com/smartgic/ansible-playbooks-mycroft) 来协调上面两个角色的使用。
### 个人配置需求
下面列举了一些个人配置的需求:
* 能上网的树莓派 4B 板子(或者更新的板子)
* [Raspberry Pi OS 64-bit](https://downloads.raspberrypi.org/raspios_arm64/images)
* Ansible 2.9(或者更新版本)
* 可正常工作的 SSH
推荐使用 [Etcher](https://opensource.com/article/18/7/getting-started-etcherio) 来烧录 Raspberry Pi OS 镜像至 SD 卡,你也可以使用你选择的镜像烧录工具。
我将树莓派超频来提升性能,不过这可能对你的硬件是一种潜在危险。在使用我的 Ansible 剧本配置之前,请先仔细阅读。你需要为你的每个配置选择负责。你将决定使用哪个固件、哪个 EEPROM。超频的话需要记得提供相应的冷却系统。
### 执行 Ansible 剧本
第一步,使用命令从 Github 获取 Ansible 剧本:
```
$ git clone https://github.com/smartgic/ansible-playbooks-mycroft.git
```
源码中,`requirements.yml` 文件中提供了该剧本的依赖角色列表,必须从 Ansible Galaxy 中检索这些依赖。
```
$ cd ansible-playbooks-mycroft
$ ansible-galaxy install -r requirements.yml
Starting galaxy role install process
- downloading role 'mycroft', owned by smartgic
- downloading role from https://github.com/smartgic/ansible-role-mycroft/archive/main.tar.gz
- extracting smartgic.mycroft to /home/goldyfruit/.ansible/roles/smartgic.mycroft
- smartgic.mycroft (main) was installed successfully
- downloading role 'prepi', owned by smartgic
- downloading role from https://github.com/smartgic/ansible-role-prepi/archive/main.tar.gz
- extracting smartgic.prepi to /home/goldyfruit/.ansible/roles/smartgic.prepi
- smartgic.prepi (main) was installed successfully
```
第二步,编辑仓库中的 Ansible 清单,设置需要管理的主机。
```
[rpi]
rpi4b01 ansible_host=192.168.1.97 ansible_user=pi
```
`[rpi]` 代表组,无需更改。该组有一个主机 `rpi4b01`,其 IP 地址为 `192.168.1.97`, 并创建 `pi` 作为 Linux(Raspberry Pi OS)上的默认用户。
现在比较棘手的部分到了:你希望每个选项怎么配置?这取决于你自己,下面是我的首选配置,供你参考:
```
# file: install-custom.yml
- hosts: rpi
gather_facts: yes
become: yes
pre_tasks:
- name: Install Python 3.x Ansible requirement
raw: apt-get install -y python3
changed_when: no
tags:
- always
vars:
# PREPI
prepi_pi_user: pi
prepi_hostname: mylovelypi
prepi_firmware_update: yes
prepi_overclock: yes
prepi_force_turbo: yes
prepi_cpu_freq: 2000
prepi_pulseaudio_daemon: yes
# MYCROFT
mycroft_branch: dev
mycroft_user: "{{ prepi_pi_user }}"
mycroft_skills_update_interval: 2.0
mycroft_recording_timeout_with_silence: 3.0
mycroft_enclosure_name: picroft
mycroft_extra_skills:
- https://github.com/smartgic/mycroft-finished-booting-skill.git
tasks:
- import_role:
name: smartgic.prepi
- import_role:
name: smartgic.mycroft
```
上面的配置内容需要保存在文件里(比如,`install-custom.yml`)。
现在关键步骤:运行你新创建的剧本。
```
$ ansible-playbook -i inventory install-custom.yml -k
```
`-k` 选项只有在不需要 SSH 密钥的时候才使用。在命令执行期间,树莓派可能会重启若干次。Ansible 剧本会自动处理这个问题,不必担心。
Ansible 配置完成后,你可以看到一条祝贺消息,提示你下一步需要做什么。

### Ansible 让定制 Mycroft 变得更容易
这些 Ansible 剧本是我开始使用 Mycroft AI 后学到的经验教训。它们帮助我在任何一个地方都能构建、重构、定制、拷贝我的安装,并保持一致,这让我很省心!
读完此文,你有何意见、问题或疑虑?欢迎在 Twitter上 [@goldyfruit](https://twitter.com/goldyfruit)上和我交流,或者访问 [Mycroft 频道](https://chat.mycroft.ai/community/channels/general) 搜寻答案。
---
via: <https://opensource.com/article/21/12/mycroft-raspberry-pi-ansible>
作者:[Gaëtan Trellu](https://opensource.com/users/goldyfruit) 选题:[lujun9972](https://github.com/lujun9972) 译者:[jrglinux](https://github.com/jrglinux) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Mycroft AI is a virtual assistant application that can respond to verbal requests and complete tasks such as searching the Internet for some information you need, or downloading your favorite podcast, and so on. It's a fine piece of open source software that, unlike similar software from companies in the business of harvesting personal data, provides privacy and platform flexibility.
Mycroft AI, written in Python, can install on many different hardware platforms. The famous Raspberry Pi board is a popular choice *(but not the only one)* to run the voice assistant. Conveniently, Mycroft provides an image for Raspberry Pi, which is called [Picroft](https://mycroft-ai.gitbook.io/docs/using-mycroft-ai/get-mycroft/picroft). Picroft is an excellent solution, but it does have some limitations, such as the lack of 64-bit support.
## Raspberry Pi 4, the platform of choice and my target
The Raspberry Pi board is popular within the Mycroft community because it's inexpensive, has a lot of educational potential, and provides the possibility of interesting expansions thanks to Mycroft's skills and the Pi's easy access to General-Purpose Input/Output (GPIO) pins (for example, the [wake word LED GPIO skill](https://github.com/smartgic/mycroft-wakeword-led-gpio-skill)).
The model 4B has enough CPU power and memory to run Mycroft smoothly. I use the model 4B with 8GB of RAM, running Raspberry Pi OS Bullseye 64-bit Lite, which you can download from [RaspberryPi.org](https://downloads.raspberrypi.org/raspios_lite_arm64/images/raspios_lite_arm64-2021-11-08/2021-10-30-raspios-bullseye-arm64-lite.zip).
## Another automation story
Building your own Mycroft AI system does mean that you must pay attention to some details. According to my initial experience (from a year ago), here is a list of important technical details you must keep in mind:
- Audio output
*(speaker configuration)* - Audio input
*(microphone configuration)* - Microphone quality (
*the actual hardware you buy*) - Wake word response
*("Hey Mycroft!")* - Latency of response
*("What's the weather like?")*
These aren't issues of Mycroft AI, they're just the things you must keep in mind while choosing your hardware and configuring your operating system. The Pi itself is capable of running Mycroft AI, but there are adjustments that require special configuration. Specifically, these are:
- CPU scheduler
- SD card performances
- PulseAudio configuration
- Network latency
I had to do a lot of research and manual actions to solve the headaches from the list above, but I did achieve the "ultimate" goal—the smoothest experience!
## Ansible to the rescue!
So now that I've created *the smoothest experience*, how do I ensure that every action done to achieve this goal gets captured and gets re-applied only if required on any Raspberry Pi 4 board?
[Ansible](https://github.com/ansible/ansible) to the rescue! Ansible is idempotent by design, which means that it applies the requested changes only if required. If everything is configured correctly, Ansible does not change a thing. This is the beauty of idempotency!
To achieve this ultimate goal, I use two Ansible roles:
- One to configure and tweak the Raspberry Pi
- One to install and configure Mycroft AI
### Ansible prepi role
The [Ansible prepi role](https://github.com/smartgic/ansible-role-prepi) applies some configurations to obtain better performances from a Raspberry Pi 4B board and prepare the path to Mycroft.
- Update Raspberry Pi OS to the latest version
- Add Debian backports repository
- Update firmware using the next branch, which provides kernel 5.15 and edge firmware
- Update EEPROM using the beta version, which provides edge features
- Setup initial_turbo to speed up the boot process
- Overclock the Raspberry Pi to 2Ghz
- Mount /tmp on a RAMDisk
- Optimize / partition mount options to improve SDcard read/write
- Manage I2C, SPI & UART interfaces
- Set CPU governor to performance to avoid context switching between the idle* kernel functions
- Install and configure PulseAudio
*(non-system wide)* - Reboot the Raspberry Pi when new firmware or EEPROM gets installed
### Ansible mycroft role
This [Ansible mycroft role](https://github.com/smartgic/ansible-role-mycroft) installs and configures Mycroft AI Core from the GitHub repository based on the `dev_setup.sh`
Bash script provided by the Mycroft core team.
- Python 3 virtual environment
- Systemd integration
- Extra skills installation
- Boto3, py_mplayer, and pyopenssl libraries install
- RAMDisk support for IPC
- File configuration support
- PulseAudio optimizations
- Secure Mycroft message bus websocket
I'll need an [Ansible playbook](https://github.com/smartgic/ansible-playbooks-mycroft) to orchestrate the two roles.
## Personal requirements
Here is a list of requirements for this project:
- Raspberry Pi 4B board (or later) connected to your network
[Raspberry Pi OS 64-bit](https://downloads.raspberrypi.org/raspios_arm64/images)- Ansible 2.9 (or later)
- SSH, up and running
To burn the Raspberry Pi OS image to the SD card, you can use [Etcher](https://opensource.com/article/18/7/getting-started-etcherio) or the imaging tool of your choice.
I overclock my Pi to get a boost in performance, but this can be dangerous to your hardware. Before using my Ansible playbooks, read them carefully! *You are responsible for the choices made with this role.* You decide which firmware, which EEPROM you want to use. The same rule applies to the overclocking feature. **Remember that overclocking requires a proper cooling system.**
## Execute the Ansible playbook
The first step is to retrieve the Ansible playbooks from GitHub. Use the following `git`
command:
`$ git clone https://github.com/smartgic/ansible-playbooks-mycroft.git`
This repository contains an Ansible `requirements.yml`
file which provides a list of Ansible roles required by this playbook, the roles must be retrieved from Ansible Galaxy.
```
$ cd ansible-playbooks-mycroft
$ ansible-galaxy install -r requirements.yml
Starting galaxy role install process
- downloading role 'mycroft', owned by smartgic
- downloading role from https://github.com/smartgic/ansible-role-mycroft/archive/main.tar.gz
- extracting smartgic.mycroft to /home/goldyfruit/.ansible/roles/smartgic.mycroft
- smartgic.mycroft (main) was installed successfully
- downloading role 'prepi', owned by smartgic
- downloading role from https://github.com/smartgic/ansible-role-prepi/archive/main.tar.gz
- extracting smartgic.prepi to /home/goldyfruit/.ansible/roles/smartgic.prepi
- smartgic.prepi (main) was installed successfully
```
The second step is to edit the Ansible inventory provided in the repository to reference the hosts I need to be managed by Ansible.
```
[rpi]
rpi4b01 ansible_host=192.168.1.97 ansible_user=pi
```
`[rpi]`
is the group and should not be changed. This group has one host named `rpi4b01`
, which has IP `192.168.1.97`
and provides `pi`
as Linux (default on Raspberry Pi OS) user for Ansible to connect with.
Now the tricky part: what value do you want for each option? It's up to you, but here's my go-to configuration:
```
# file: install-custom.yml
- hosts: rpi
gather_facts: yes
become: yes
pre_tasks:
- name: Install Python 3.x Ansible requirement
raw: apt-get install -y python3
changed_when: no
tags:
- always
vars:
# PREPI
prepi_pi_user: pi
prepi_hostname: mylovelypi
prepi_firmware_update: yes
prepi_overclock: yes
prepi_force_turbo: yes
prepi_cpu_freq: 2000
prepi_pulseaudio_daemon: yes
# MYCROFT
mycroft_branch: dev
mycroft_user: "{{ prepi_pi_user }}"
mycroft_skills_update_interval: 2.0
mycroft_recording_timeout_with_silence: 3.0
mycroft_enclosure_name: picroft
mycroft_extra_skills:
- https://github.com/smartgic/mycroft-finished-booting-skill.git
tasks:
- import_role:
name: smartgic.prepi
- import_role:
name: smartgic.mycroft
```
The content needs to be saved in a file (for example, `install-custom.yml`
).
And now the moment of truth: run your freshly created playbook.
`$ ansible-playbook -i inventory install-custom.yml -k`
The `-k`
option from `ansible-playbook`
command is only required if not using the SSH key. During the playbook execution, the Raspberry Pi could reboot a couple of times. The playbook is smart enough to handle this.
Once Ansible is done, you see a congratulatory message, which prompts you for the next steps you need to take.
(Gaëtan Trellu, CC BY-SA 4.0)
## Ansible makes custom Mycroft easy
These playbooks are the lessons I learned since starting my journey with Mycroft AI. It allows me to build, re-build, customize, and replicate my install with the peace of mind of having consistency everywhere!
Do you have any comments, questions, or concerns? Leave a comment, visit me on Twitter [@goldyfruit](https://twitter.com/goldyfruit), or stop by [Mycroft channels](https://chat.mycroft.ai/community/channels/general).
## Comments are closed. |
14,103 | 2021 年的 12 件 Linux 大事 | https://news.itsfoss.com/biggest-linux-stories-2021/ | 2021-12-21T18:01:37 | [
"Linux"
] | https://linux.cn/article-14103-1.html |
>
> 现在,是时候回顾一下今年影响 Linux 和 Linux 用户的一些大事了。
>
>
>

2021 年即将结束。Linux 今年屡有大事,虽然并不全是好消息。
让我来分享一些来自 Linux 世界的大事,这些事件对普通的 Linux 用户,特别是桌面 Linux 用户有一定的影响。
### 1、RMS 重返自由软件基金会
<ruby> 自由软件基金会 <rt> Free Software Foundation </rt></ruby>(FSF)的创始主席 [Richard Stallman(RMS)在 2019 年因媒体的抨击而被迫辞职](https://itsfoss.com/richard-stallman-controversy/)。然而,这位标志性的嬉皮士技术人在今年 3 月份的 LibrePlanet 活动中出人意料地 [宣布复出](https://news.itsfoss.com/richard-stallman-is-back-at-fsf/)。
虽然自由软件运动是 Stallman 在 80 年代发起的,并创立了自由软件基金会(FSF),但这次他是以董事会成员之一的身份回归的,而不是以主席的身份。
这段插曲使开源世界再次分裂。许多组织和开发者反对他的回归。但与此同时,Stallman 也得到了 [来自非美国开发者的压倒性支持](https://news.itsfoss.com/stallman-supporters-not-giving-up/)。
尽管 [Stallman 已经道歉](https://news.itsfoss.com/stallman-apologizes/),但许多来自 GNOME 和<ruby> 开源推进计划 <rt> Open Source Initiative </rt></ruby>的人 [主张撤换整个 FSF 董事会](https://news.itsfoss.com/stallman-return-revolt/)。
许多主要的赞助商因此断绝了与 FSF 的关系,但 FSF 在财政困难的情况下仍在坚持。2021 年即将结束,Stallman 仍然活跃在他 30 多年前创立的组织的董事会中。
### 2、Arch Linux 引入了一个安装程序
不过不是图形化的。
你可能已经知道,安装 Arch Linux 并不像安装 Ubuntu 或 Fedora 那样简单。没有图形化的安装程序。一切都必须通过命令行来完成,但即使是这样,你也必须参考一些文档。
Arch Linux 试图通过提供一个用来指导你的安装脚本来改善这种情况。

当然,它不像图形化的安装那么舒服,但至少有指导的 Arch Linux 安装总比没有好。
这个 [archinstall 脚本可以在较新的 Arch Linux ISO 中找到](https://news.itsfoss.com/arch-linux-easy-install/),你可以在安装 Arch Linux 时在 TTY 中输入 `archinstall` 来使用它。
### 3、微软 Edge 浏览器登陆 Linux

它已经测试一年多了,但在 2021 年我们终于看到了 [微软基于 Chromium 的 Linux 版 Edge 浏览器的最终稳定版](https://news.itsfoss.com/microsoft-edge-stable-release/)。
我知道一些 Linux 用户彻底反对接触任何微软的东西,这当然很好。它只是为 Linux 上长长的可用网页浏览器列表增加了一个选择。在 Windows 系统上使用 Edge 的人现在有能力在 Linux 上使用和同步他们的浏览器活动。
一些 [在 Linux 上安装了 Edge 浏览器](https://itsfoss.com/microsoft-edge-linux/) 的用户发现它出乎意料地好。就个人而言,比起其他浏览器,我还是更喜欢 Firefox,但如果 Edge 能把超高清或全高清的 Netflix 流媒体带到 Linux 上,它可能会成为我的辅助浏览器。
### 4、CentOS 替代品的崛起
红帽公司去年震惊了 Linux 世界,它决定 [干掉稳定的 CentOS,转而支持滚动发布的 CentOS Stream](https://itsfoss.com/centos-stream-fiasco/)。
这催生了 [几个 CentOS 替代发行版](https://itsfoss.com/rhel-based-server-distributions/)。其中获得了最多人气和 CentOS 市场份额的两个发行版是 Rocky Linux 和 Alma Linux。
[Rocky Linux 是由 Gregory M. Kurtzer 创建的](https://news.itsfoss.com/rocky-linux-announcement/),他是 CentOS 的最初的创建者。
[Alma Linux](https://almalinux.org/) 是由 CloudLinux 创建的,它是一家提供了基于 CentOS 的服务器和内核补丁服务的企业。
这两个发行版已经占领了 CentOS 留下的市场。[红帽公司向小型企业免费提供 RHEL 许可证的计划](https://news.itsfoss.com/rhel-no-cost-option/) 并没有那么成功。
### 5、Steam Deck
Valve 发布了一款名为 Steam Deck 的掌上游戏设备。它产生了相当大的反响,预购即售罄。
它与 Linux 有什么关系?有两个:
首先,Steam Deck 运行在基于 Arch Linux 的定制 Steam OS 上。考虑到这些游戏将在基于 Linux 的操作系统上运行,这给桌面 Linux 上的游戏也带来了希望。
第二,Steam 声称所有的游戏(无论它们是否只在 Windows 上运行)都将可以在 Steam Deck 上运行。这个口号太大了,但是 [Steam 已经开始验证能在 Deck 上运行的游戏](https://news.itsfoss.com/steamdeck-verified/)。这可能意味着经过 Deck 验证的游戏在桌面 Linux 上应该也能正常运行。

### 6、反作弊引擎正式支持 Linux
对 Linux 玩家来说这是又一个 2021 年的大新闻。[Epic Games 为其 Easy-Anti Cheat 服务增加了完整的 Linux 支持,以及官方 SteamPlay(或 Proton)和 Wine 兼容性](https://news.itsfoss.com/easy-anti-cheat-linux/)。
Easy-Anti-Cheat 是 Epic 提供的业界领先的反作弊服务,可以防止多人 PC 游戏中的黑客攻击和作弊。
这是一个重大举措,因为 Linux 游戏玩家经常被禁止参与许多流行的多人游戏,如《堡垒之夜》、《战地》。随着反作弊支持的加入,在 Linux 上玩主流多人游戏变得更加容易。
### 7、GNOME 40

[GNOME 40 是一个激进的版本](https://news.itsfoss.com/gnome-40-release/)。几乎和 GNOME 3 一样激进。
不,将版本号从 3.38 跳到 40 并不是关键因素。
GNOME 40 换成了三指轻扫的水平布局。这种水平方式使得第 40 版在用户界面和用户体验上与之前的版本有很大不同。
### 8、内核 5.15 中支持 NTFS
这可能看起来没什么,但 Linux 内核中对 NTFS 文件系统的适当驱动支持对许多人来说是件大事,特别是对于共享分区来说。
之前,NTFS 文件系统是在用户空间(FUSE)中借助 ntfs-3g 软件包使用的。这意味着数据的读取和写入速度很慢。
原生的驱动程序改善了 Linux 中 NTFS 文件系统的性能。
### 9、Linux 已经 30 岁了

Linux 内核比许多 Linux 用户都要老。它诞生于 1991 年 9 月,当时芬兰计算机科学专业的学生 Linus Torvalds 宣布了这个 “爱好项目”,它本应不是 “大而专业” 的。
Torvalds 以 Linux 项目作为他的毕业论文取得了他的硕士学位。Torvalds 不可能知道他的 “爱好” 将成为今天 IT 世界的支柱和一个成功的开源项目的代表。
### 10、Linus Tech Tips 对 Linux 桌面的实验
这是另一位将 Linux 推上风口浪尖的 Linus。
Linus Sebastian 是顶级的技术 YouTuber 之一,他开始挑战日常使用 Linux 30 天的目标。
一个拥有数百万订阅者的流行 YouTuber 使用了 Linux。这是一个前所未有的机会,是桌面 Linux 被数百万 Windows 用户看到的一次大公关。
但是它出了问题。实际上,是可怕的错误。
Linus Sebastian 在 Linux 上遇到了困难。他遇到了各种困难,[最后在试图安装 Steam 的时候毁掉了他的 Pop!\_OS 系统](https://news.itsfoss.com/more-linux-distros-become-linus-proof/)。

我不知道 Torvalds 是否看到了那些视频,这个与他同名的人在他的造物中苦苦挣扎。
### 11、苹果的 M1 Mac 上的 Linux
一个苹果让世界认识了重力(尽管它已经存在)。一个苹果让世界认识了 ARM 处理器(尽管它也已经存在)。
苹果公司基于 ARM 的 M1 系列因其性能提升而在用户中大受欢迎。有一个专门的项目 [Asahi](https://asahilinux.org/) 正在努力使 Linux 可以在苹果 M1 设备上运行。
2021 年,Asahi Linux 取得了一些良好的进展。他们的工作也将使其他发行版受益。

### 12、Windows 11 发布
为什么 Windows 11 的发布与 Linux 有关呢?因为不是所有的现有系统都有资格运行 Windows 11。这意味着当 Windows 10 支持结束时,将有一大批设备运行一个过时的操作系统。他们中的一些人会转移到 Linux。
不要认为我过于乐观。当 Windows XP 支持结束时,我已经看到了这种流亡。一些 Linux Mint 和 Zorin OS 用户曾经是 Windows XP 的移民。

### 让我们希望 2022 年对我们所有人都好一些
2020 年开始的 COVID-19 流行病在今年继续困扰着世界。看看 Omicron 变种的传播情况,2022 年的情况看起来也不太乐观。
但是,让我们不要太悲观,庆祝新的一年,希望明年对桌面 Linux 用户和其他所有人会更好。
---
via: <https://news.itsfoss.com/biggest-linux-stories-2021/>
作者:[Abhishek](https://news.itsfoss.com/author/root/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The year 2021 is coming to an end. Linux has been making headlines this year as well, and not always in a good way.
Let me share some of the biggest stories from the world of Linux that impacts the users of Linux in general and desktop Linux in particular.
## 1. Stallman comes back
Free Software Foundation’s founding President [Richard Stallman was forced to resign](https://itsfoss.com/richard-stallman-controversy/?ref=news.itsfoss.com) after a media outrage in 2019. The iconic hippie techie made a surprise [comeback announcement](https://news.itsfoss.com/richard-stallman-is-back-at-fsf/) during LibrePlanet event in March.
Though Stallman started the Free Software movement and founded the Free Software Foundation (FSF) in the 80s, he returned as one of the board directors, not as its President.
The episode divided the open source world once again. Many organizations and developers opposed his return. At the same time, Stallman also got [overwhelming support from non-USA developers](https://news.itsfoss.com/stallman-supporters-not-giving-up/).
Though [Stallman apologized](https://news.itsfoss.com/stallman-apologizes/), many people from GNOME and Open Source Initiative [advocated to remove entire FSF board.](https://news.itsfoss.com/stallman-return-revolt/)
Many major sponsors severed their ties with FSF but remained adamant among the financial difficulties. 2021 is coming to an end and Stallman remains on the board of the organization he founded more than 30 years ago.
## 2. Arch Linux introduces an installer
Not a graphical one though.
You probably already know that installing Arch Linux is not as easy as installing Ubuntu or Fedora. There is no graphical installer. Everything has to be done via the command line but even for that you have to refer to some documentation.
Arch Linux tries to improve the situation by providing a helpful script that could guide you for the installation.
Of course, it is not as comfortable as a graphical one but at least the guided Arch Linux install is better than none.
This [archinstall script is available in the newer Arch Linux ISO](https://news.itsfoss.com/arch-linux-easy-install/) can can be accessed by typing archinstall in the TTY while installing Arch Linux.
## 3. Microsoft Edge browser comes to Linux
It was already in beta for over a year, but 2021 sees the[ final stable release of Microsoft’s Chromium-based Edge browser for Linux](https://news.itsfoss.com/microsoft-edge-stable-release/).
I know some Linux users are completely against touching anything Microsoft and that’s fine. It just adds one more option to the long list of available web browsers on Linux. People who use Edge on Windows systems now have the ability to use and sync their browser activity on Linux.
Several users who [installed Edge browser on Linux](https://itsfoss.com/microsoft-edge-linux/?ref=news.itsfoss.com) found it surprisingly good. Personally, I still prefer Firefox over any other browser but if Edge could bring Ultra HD or Full HD Netflix streaming to Linux, it could become my secondary browser.
## 4. Rise of CentOS replacements
Red Hat shocked the Linux world last years when it decided to [kill the stable CentOS in favor of the rolling release version CentOS Stream](https://itsfoss.com/centos-stream-fiasco/?ref=news.itsfoss.com).
This gave birth to [several CentOS replacement distributions](https://itsfoss.com/rhel-based-server-distributions/?ref=news.itsfoss.com). Two distros that got the most of the popularity and CentOS’ market share are Rocky Linux and Alma Linux.
[Rocky Linux is created by Gregory M. Kurtzer](https://news.itsfoss.com/rocky-linux-announcement/), the original creator of CentOS.
[Alma Linux](https://almalinux.org/?ref=news.itsfoss.com) is created by CloudLinux, an enterprise which was already providing CentOS based servers and kernel patching service.
These two distros have captured the market left open by CentOS. [Red Hat’s plan of giving free RHEL licenses to small businesses](https://news.itsfoss.com/rhel-no-cost-option/) was not as successful.
## 5. Steam Deck
Valve announced a handheld gaming device called Steam Deck. It generated quite a buzz and sold out on pre-orders.
How does it relate to Linux? For two reasons.
First, Steam Deck runs a custom Steam OS based on Arch Linux. Considering that the games will be running on a Linux-based OS, this gives hope for gaming on desktop Linux as well.
Second, Steam claimed that all games (whether they are Windows-only) will run on Steam Deck. That’s too big a claim but [Steam has started verifying games that work with Deck](https://news.itsfoss.com/steamdeck-verified/). This could mean the Deck verified games should work well on desktop Linux as well.

## 6. Anti-Cheat Engines officially supporting Linux
Another big news for Linux gamers in 2021. [Epic Games added complete Linux support for its Easy-Anti Cheat service, along with official SteamPlay (or Proton) and W](https://news.itsfoss.com/easy-anti-cheat-linux/)ine compatibility.
The Easy-Anti-Cheat is industry-leading anti-cheating service from Epic that prevents hacking and cheating in multiplayer PC games.
This is a big move because Linux gamers were often banned from many popular multiplayer games like Fortnite, Battlefield. With the anti-cheat support added, playing mainstream multiplayer games becomes easier on Linux.
## 7. GNOME 40

[GNOME 40 was a radical release](https://news.itsfoss.com/gnome-40-release/). Almost as radical as GNOME 3.
No, jumping the versioning number from 3.38 to 40 is not the crucial factor here.
GNOME 40 switched to a horizontal layout with three finger swiping. This horizontal approach made the version 40 a lot different in UI and UX from its predecessors.
## 8. NTFS Support in Kernel 5.15
This may not look like a lot but proper driver support for NTFS file system in Linux Kernel is a big deal for many, specially for shared partitions.
Until now, NTFS file system was used in the userspace (FUSE) with the help of ntfs-3g packages. This meant slow read and write of data.
The native driver improves the performance of NTFS filesystem in Linux.
## 9. Linux is 30 years old

Linux kernel is older than many Linux users. It was started in September 1991 when Finnish computer science student Linus Torvalds announced this ‘hobby project’ which was not supposed be ‘big and professional’.
Torvalds completed his Master’s degree with the Linux project as his final thesis. Little did Torvalds knew that his ‘hobby’ will become the backbone of today’s IT world and the face of a successful open source project.
## 10. Linus Tech Tips’s experiments with Linux desktop
Another Linus that put Linux in the limelight.
One of the top tech YouTuber, Linus Sebastian, began a challenge to use Linux as his daily driver for 30 days.
A popular YouTube with millions of subscribers covering Linux. This was a huge opportunity, a big PR for the desktop Linux to be seen by millions of Windows users.
But it went wrong. Horribly wrong, actually.
Linus Sebastian had a difficult time with Linux. He struggled at most points and [ended up destroying his Pop!_OS install while trying to install Steam.](https://news.itsfoss.com/more-linux-distros-become-linus-proof/)

I wonder if Torvalds saw any of those videos where his namesake struggled so much with his creation.
## 11. Linux on Apple’s M1 Macs
An apple made the world aware of gravity (though it already existed). An Apple made the world aware of ARM processors (though it already existed).
Apple’s ARM based M1 series is a huge hit among the users for its performance boost. There is a dedicated project [Asahi](https://asahilinux.org/?ref=news.itsfoss.com) that is working to make Linux work on the Apple M1 devices.
The year 2021 saw some good progress by Asahi Linux. Their work is going to benefit other distributions as well.
[Image Credit](https://twitter.com/marcan42/status/1458473546225577987/photo/1?ref=news.itsfoss.com)
## 12. Windows 11 release
How come Windows 11 release relates to Linux? Because not all existing systems are eligible to run Windows 11. This means when Windows 10 support ends, there will be a good bunch of devices running an obsolete operating system. Some of them would move to Linux.
Don’t think I am over optimistic. I have seen this when exodus when Windows XP support ended. A number of Linux Mint and Zorin OS users are Windows XP migrants.

## Let’s hope 2022 is better for all of us
The COVID-19 epidemic that started in 2020 continued to trouble the world this year as well. Looking at how Omicron variant is spreading, things do not look too bright for 2022 as well.
But let’s not be too pessimistic and celebrate this festive season with hope that the next year will be better for desktop Linux users and everyone else.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,105 | 好消息!80% 的 Steam 前 100 名游戏可以在 Linux 上运行了 | https://news.itsfoss.com/linux-game-rise-prtondb-dec-21/ | 2021-12-22T10:10:40 | [
"Steam",
"游戏"
] | https://linux.cn/article-14105-1.html |
>
> 多亏了 Proton 和 Steam Play,可以在 Linux 上更好地玩游戏了。
>
>
>

自从 [Steam 宣布 Proton 计划](https://itsfoss.com/steam-play-proton/) 以来,我有一种感觉,Linux 上的游戏将迎来好时光。我很高兴我没有看错。
根据 [ProtonDB 网站](https://www.protondb.com/),在 Steam 上排名前 100 的游戏中,80% 都得到了黄金或更好的评价。这实际上意味着,这些游戏在 Linux 桌面上会运行得很好。

如果你对各种评级感到困惑,下面是它的含义:
* 原生:游戏可以在 Linux 上原生运行
* 白金:开箱就能完美运行
* 黄金:调整后可完美运行
* 白银:运行时有小问题,但一般来说是可玩的
* 青铜:可以运行,但经常崩溃或有问题,不能舒适地玩
* 残缺:要么无法启动,要么根本无法玩
简单来说,如果一个纯 Windows 的游戏至少达到黄金级评分,你应该能够通过 Steam Play 在 Linux 上玩这个游戏。
如果你看一下统计数字,在 Steam 上排名前 1000 的游戏中,有超过 750 个现在可以在 Linux 上玩。然而,在写这篇文章的时候,Steam 前 10 名游戏中只有 4 个在 Linux 上运行良好。

### ProtonDB 评级的可靠性如何?
请注意,这些评级不是来自 Steam 本身。这些评级是基于游戏玩家在 Linux 上用 Proton 测试游戏时的报告。它提供了游戏表现的综合分数。
你可能想知道这些非官方的评级是否可靠?好吧,可能有很多因素,比如你的系统的 CPU、图形驱动等等。但是 ProtonDB 的评分可以帮助你确定你是否可以通过 Steam 在 Linux 上 [尝试一个纯 Windows 的游戏](https://itsfoss.com/steam-play/)。
### 到底什么是 Steam Play 和 Proton?
如果你是新手,让我快速回顾一下,以帮助你更好地理解本文。
Steam 是一个可以让你安装和启动游戏的平台和客户端。它可以在 Windows、Linux 和 macOS 上运行。而游戏也会正确地标记为它们所能使用的平台。
几年前,Steam 推出了一个新的开源工具,名为 Proton 。它底层使用了 WINE 和许多其他工具,以改善 Linux 上纯 Windows 游戏的兼容性。
这项功能在 Steam 平台上提供在 Steam Play 测试版中,你必须从设置中明确启用它。
自此之后,志愿者和 Linux 游戏社区一起创建了一个可以在 Linux 上玩的游戏数据库。它最终演变成一个基于玩家反馈的评级系统。
Steam 也有自己的 [手持设备 Steam Deck 的评级系统](https://news.itsfoss.com/steamdeck-verified/)。
就个人而言,我更喜欢在 PS4 上玩有完整故事情节的单人游戏(因为我至今没有 PS5)。但我正在考虑搭建一个小型的游戏设备,使用 Steam 在 Linux 上玩游戏,特别是在过去几年里,Linux 游戏有了很大的改进。
你如何看待 Steam 和 Linux 游戏的发展?
---
via: <https://news.itsfoss.com/linux-game-rise-prtondb-dec-21/>
作者:[Abhishek](https://news.itsfoss.com/author/root/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Ever since [Steam announced the Proton project](https://itsfoss.com/steam-play-proton/?ref=news.itsfoss.com), I had a feeling that gaming on Linux is going to see some sunny days. I am glad I was not wrong.
According to [ProtonDB website](https://www.protondb.com/?ref=news.itsfoss.com), 80% of the top 100 games on Steam now have gold or better ratings. Which actually means, that these games will work quite well on Linux desktop.

If you are confused about the various ratings, here’s what it means:
- Native: Game is available on Linux natively
- Platinum: Runs perfectly out of the box
- Gold: Runs perfectly after tweaks
- Silver: Runs with minor issues, but generally is playable
- Bronze: Runs, but often crashes or has issues preventing from playing comfortably
- Borked: Either won’t start or is crucially unplayable
Basically, you should be able to enjoy a Windows-only game on Linux via Steam Play if it has at least Gold status.
If you look at the stats, more than 750 of the top thousand games on Steam are now playable on Linux. Now that is something, however, only 4 out of top 10 Steam games run fine on Linux at the time of writing this article.
## How reliable are the ProtonDB ratings?
Please note that these ratings are not from Steam itself. These ratings are based on reports from gamers as they test games with Proton on Linux. It provides aggregate scores of how well games perform.
You may wonder if these unofficial ratings can be taken for granted. Well, there could be lots of factors like your system’s CPU, graphics drivers etc. But the ProtonDB ratings help you in determining if you could try a Windows-only game on Linux via Steam. You need to [enable Steam Play](https://itsfoss.com/steam-play/?ref=news.itsfoss.com) here.
## What is Steam Play and Proton, again?
If you are new to it, let me quickly recall a few things to help you understand better.
Steam is a platform and client that allows you to install and launch games. It works on Windows, Linux and macOS. Games are properly marked for the platforms they are available on.
A few years back, Steam introduced a new open source tool called Proton. It uses WINE and many other tool underneath to improve the compatibility of Windows-only games on Linux.
This feature is available on Steam platform through the Steam Play feature in beta. You have to explicitly enable it from the settings.
Since its inception, volunteers and Linux gaming community came together to create a database of games that could be played on Linux. It eventually evolved into a ratings system based on the feedback by gamers.
Steam also has its own [rating system for its handheld gami](https://news.itsfoss.com/steamdeck-verified/)ng device Steam Deck.
Personally, I prefer to play single player games with good story line on PS4 (because I could not get a PS5 so far). But I am considering a small gaming set up and play games on Linux using Steam specially when Linux gaming has improved a lot in the last few years.
How do you see the progress of Steam and Linux gaming?
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,107 | 着色器入门:符号距离函数! | https://jvns.ca/blog/2020/03/15/writing-shaders-with-signed-distance-functions/ | 2021-12-22T16:27:53 | [
"着色器"
] | https://linux.cn/article-14107-1.html | 
大家好!不久前我学会了如何使用着色器制作有趣的闪亮旋转八面体:

我的着色器能力仍然非常基础,但事实证明制作这个有趣的旋转八面体比我想象中要容易得多(从其他人那里复制了很多代码片段!)。
我在做这件事时, 从一个非常有趣的叫做 [符号距离函数教程:盒子和气球](https://www.shadertoy.com/view/Xl2XWt) 的教程中学到了“符号距离函数”的重要思路。
在本文中,我将介绍我用来学习编写简单着色器的步骤,并努力让你们相信着色器并不难入门!
### 更高级着色器的示例
如果你还没有看过用着色器做的真正有趣的事情,这里有几个例子:
1. 这个非常复杂的着色器就像一条河流的真实视频:<https://www.shadertoy.com/view/Xl2XRW>
2. 一个更抽象(更短!)有趣的着色器,它有很多发光的圆圈:<https://www.shadertoy.com/view/lstSzj>
### 步骤一:我的第一个着色器
我知道你可以在 shadertoy 上制作着色器,所以我去了 <https://www.shadertoy.com/new>。它们提供了一个默认着色器,如下图所示:

代码如下:
```
void mainImage( out vec4 fragColor, in vec2 fragCoord )
{
// 规范像素坐标 (从 0 到 1)
vec2 uv = fragCoord / iResolution.xy;
// 随时间改变像素颜色
vec3 col = 0.5 + 0.5 * cos(iTime + uv.xyx + vec3(0, 2, 4));
// 输出到屏幕
fragColor = vec4(col, 1.0);
}
```
虽然还没有做什么令人兴奋的事情,但它已经教会了我着色器程序的基本结构!
### 思路:将一对坐标(和时间)映射到一个颜色
这里的思路是获得一对坐标作为输入(`fragCoord`),你需要输出一个 RGBA 向量作为此坐标的颜色。该函数也可以使用当前时间(`iTime`),图像从而可以随时间变化。
这种编程模型(将一对坐标和时间映射到其中)的巧妙之处在于,它非常容易并行化。我对 GPU 了解不多,但我的理解是,这种任务(一次执行 10000 个微不足道的可并行计算)正是 GPU 擅长的事情。
### 步骤二:使用 `shadertoy-render` 加快开发迭代
玩了一段时间的 shadertoy 之后,我厌倦了每次保存我的着色器时都必须在 shadertoy 网站上单击“重新编译”。
我找到了一个名为 [shadertoy-render](https://github.com/alexjc/shadertoy-render) 命令行工具,它会在每次保存时实时查看文件并更新动画。现在我可以运行:
```
shadertoy-render.py circle.glsl
```
并更快地开发迭代!
### 步骤三:画一个圆圈
接下来我想 —— 我擅长数学!我可以用一些基本的三角学来画一个会弹跳的彩虹圈!
我知道圆的方程为(`x^2 + y^2 = 任意正数`!),所以我写了一些代码来实现它:

代码如下:(你也可以 [在 shadertoy 上查看](https://www.shadertoy.com/view/tsscR4))
```
void mainImage( out vec4 fragColor, in vec2 fragCoord )
{
// 规范像素坐标 (从 0 到 1)
vec2 uv = fragCoord / iResolution.xy;
// 绘制一个中心位置依赖于时间的圆
vec2 shifted = uv - vec2((sin(iGlobalTime) + 1) / 2, (1 + cos(iGlobalTime)) / 2);
if (dot(shifted, shifted) < 0.03) {
// 改变像素颜色
vec3 col = 0.5 + 0.5 * cos(iGlobalTime + uv.xyx + vec3(0, 2, 4));
fragColor = vec4(col, 1.0);
} else {
// 使圆之外的其他像素都是黑色
fragColor = vec4(0,0, 0, 1.0);
}
}
```
代码将坐标向量 `fragCoord` 与自身点积,这与计算 `x^2 + y^2` 相同。我还在这个圆圈的中心玩了一点花活 – 圆心为 `vec2((sin(iGlobalTime) + 1)/ 2,(1 + cos(faster)) / 2`,这意味着圆心也随着时间沿另一个圆移动。
### 着色器是一种学习数学的有趣方式!
我觉得有意思的(即使我们没有做任何超级高级的事情!)是这些着色器为我们提供了一种有趣的可视化方式学习数学 - 我用 `sin` 和 `cos` 来使某些东西沿着圆移动,如果你想更直观地了解三角函数的工作方式, 也许编写着色器会是一种有趣的方法!
我喜欢的是,可以获得有关数学代码的即时视觉反馈 - 如果你把一些东西乘以 2,图像里的东西会变得更大!或更小!或更快!或更慢!或更红!
### 但是我们如何做一些真正有趣的事情呢?
这个会弹跳的圆圈很好,但它与我见过的其他人使用着色器所做的非常奇特的事情相去甚远。那么下一步要做什么呢?
### 思路:不要使用 if 语句,而是使用符号距离函数!
在我上面的圆圈代码中,我基本上是这样写的:
```
if (dot(uv, uv) < 0.03) {
// 圆里的代码
} else {
// 圆外的代码
}
```
但问题(也是我感到卡住的原因)是不清楚如何将它推广到更复杂的形状!编写大量的 `if` 语句似乎不太好用。那人们要如何渲染这些 3d 形状呢?
所以!<ruby> 符号距离函数 <rt> Signed distance function </rt></ruby> 是定义形状的另一种方式。不是使用硬编码的 `if` 语句,而是定义一个 **函数**,该函数告诉你,对于世界上的任何一个点,该点与你的形状有多远。比如,下面是球体的符号距离函数。
```
float sdSphere( vec3 p, float center )
{
return length(p) - center;
}
```
符号距离函数非常棒,因为它们:
* 易于定义!
* 易于组合!如果你想要一个被切去一块的球体, 你可以用一些简单的数学来计算并集/交集/差集。
* 易于旋转/拉伸/弯曲!
### 制作旋转陀螺的步骤
当我开始时,我不明白需要编写什么代码来制作一个闪亮的旋转东西。结果表明如下是基本步骤:
1. 为想要的形状创建一个符号距离函数(在我的例子里是八面体)
2. 光线追踪符号距离函数,以便可以在 2D 图片中显示它(或沿光线行进?我使用的教程称之为光线追踪,我还不明白光线追踪和光线行进之间的区别)
3. 编写代码处理形状的表面纹理并使其发光
我不打算在本文中详细解释符号距离函数或光线追踪,因为我发现这个 [关于符号距离函数的神奇教程](https://www.shadertoy.com/view/Xl2XWt) 非常友好,老实说,它比我做的更好,它解释了如何执行上述 3 个步骤,并且代码有大量的注释,非常棒。
* 该教程名为“符号距离函数教程:盒子和气球”,它在这里:<https://www.shadertoy.com/view/Xl2XWt>
* 这里有大量符号距离函数,你可以将其复制粘贴到代码中(以及组合它们以制作其他形状的方法):<http://www.iquilezles.org/www/articles/distfunctions/distfunctions.htm>
### 步骤四:复制教程代码并开始更改内容
我在这里使用了久负盛名的编程实践,即“复制代码并以混乱的方式更改内容,直到得到我想要的结果”。
最后一堆闪亮的旋转八面体着色器在这里:<https://www.shadertoy.com/view/wdlcR4>
动画出来的样子是这样的:

为了做到这一点,我基本上只是复制了关于符号距离函数的教程,该函数根据符号距离函数呈现形状,并且:
* 将 `sdfBalloon` 更改为 `sdfOctahedron`,并使八面体旋转而不是在我的符号距离函数中静止不动
* 修改 `doBalloonColor` 着色功能,使其有光泽
* 有很多八面体而不是一个
### 使八面体旋转!
下面是我用来使八面体旋转的代码!事实证明这真的很简单:首先从 [这个页面](http://www.iquilezles.org/www/articles/distfunctions/distfunctions.htm) 复制一个八面体符号距离函数,然后添加一个 `rotate` 使其根据时间旋转,然后它就可以旋转了!
```
vec2 sdfOctahedron( vec3 currentRayPosition, vec3 offset ){
vec3 p = rotate((currentRayPosition), offset.xy, iTime * 3.0) - offset;
float s = 0.1; // s 是啥?
p = abs(p);
float distance = (p.x + p.y + p.z - s) * 0.57735027;
float id = 1.0;
return vec2( distance, id );
}
```
### 用一些噪音让它发光
我想做的另一件事是让我的形状看起来闪闪发光/有光泽。我使用了在 [这个 GitHub gist](https://gist.github.com/patriciogonzalezvivo/670c22f3966e662d2f83) 中找到的噪声函数使表面看起来有纹理。
以下是我如何使用噪声函数的代码。基本上,我只是随机地将参数更改为噪声函数(乘以 2?3?1800?随你!),直到得到喜欢的效果。
```
float x = noise(rotate(positionOfHit, vec2(0, 0), iGlobalTime * 3.0).xy * 1800.0);
float x2 = noise(lightDirection.xy * 400.0);
float y = min(max(x, 0.0), 1.0);
float y2 = min(max(x2, 0.0), 1.0);
vec3 balloonColor = vec3(y, y + y2, y + y2);
```
编写着色器很有趣!
---------
上面就是全部的步骤了!让这个八面体旋转并闪闪发光使我很开心。如果你也想用着色器制作有趣的动画,希望本文能帮助你制作出很酷的东西!
通常对于不太了解的主题,我可能在文章中说了至少一件关于着色器的错误事情,请让我知道错误是什么!
再说一遍,如下是我用到的两个资源:
1. “符号距离函数教程:盒子和气球”:<https://www.shadertoy.com/view/Xl2XWt>(修改和玩起来真的很有趣)
2. 可以将大量符号距离函数复制并粘贴到你的代码中:<http://www.iquilezles.org/www/articles/distfunctions/distfunctions.htm>
---
via: <https://jvns.ca/blog/2020/03/15/writing-shaders-with-signed-distance-functions/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Starryi](https://github.com/Starryi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
14,108 | 马上改用 Firefox 的 5 个理由 | https://opensource.com/article/21/9/switch-to-firefox | 2021-12-23T16:37:00 | [
"Firefox"
] | https://linux.cn/article-14108-1.html |
>
> 19 年前,Mozilla Firefox 发布了 0.1 版。
>
>
>

*开源朗读者 | 淮晋阳*
Mozilla Firefox 是一个让我对开源大开眼界应用程序。这肯定不是转折点,而是几个开源应用程序逐渐吸引我注意力,这是累积效应的的一小部分。并且这最终导致我转向 Linux,并且从未回头。自从切换到 Firefox(这发生在我有意识地转向开源之前)以来,我一直是一个狂热的 Firefox 用户。我的手机一直是 Firefox OS 的手机,直到这个项目被放弃。不过,有趣的是,我并不特别地认为自己是 Firefox 的 *粉丝* 。我从那时到现在一直在使用 Firefox,是因为从许多方面来说它都是最佳的浏览器。接下来是我认为应该马上 [改用 Firefox](http://getfirefox.org) 的五个原因。
### 1、Firefox 专注隐私
Firefox 的维护者是 [Mozilla 基金会](https://foundation.mozilla.org/en/),这是一个完全不以你的个人数据为动机的非营利组织。Mozilla 不关心你搜索的内容、访问的网站或你网站上使用的时间。这不是 Mozilla 的商业模式,但它显然是许多其他流行浏览器的商业模式。
即使你不反对浏览器以隐私为由跟踪你的活动,你可能也曾有过这样的经历:只是一次性购买过某件不寻常的礼物,就导致你访问的每个网站都试图向你出售该物品。互联网很大,所以有时根据用户的兴趣来重组它似乎是一个好主意。我承认,如果我所有的搜索都可以“开源”给它们,可能会提供更相关的结果。但话又说回来,我宁愿主动选择这种优化,而不是让它以及许多其他未知因素一起,在我的控制之外为我做出决定。

Mozilla 的数据政策是这样的: [尽量少拿、保持安全、毫无隐藏。](https://blog.mozilla.org/en/products/firefox/firefox-data-privacy-promise/)
不止如此,Firefox 还提供了帐户 [监控](https://monitor.firefox.com),这是 Mozilla 的一项可选服务,如果你的任何在线帐户因大规模数据泄露而受到损害,它就会提醒你。另外,Mozilla 使用开源的 Wireguard 提供付费 VPN 服务,因此无论何时何地你都可以安全浏览。
### 2、Firefox 可以使用容器
很难相信的是,曾经有一段时间,当时领先的网页浏览器没有标签页功能。在上世纪 90 年代末和本世纪 00 年代初,当你想同时访问两个网页时,你必须打开两个单独的浏览器窗口。Firefox(以及之前的 Mozilla 浏览器)是标签页界面的早期使用者。
标签页是现在浏览器的标配,但是通过 Firefox 的扩展,标签页界面的功能有了有趣的新变化。由 Mozilla 自己开发的 [Firefox 多帐户容器插件](https://github.com/mozilla/multi-account-containers#readme) 可以将每个标签页变成浏览器中的一个隔离的“容器”。

例如,假设你的雇主使用谷歌应用,但你信不过谷歌接触你的个人信息。你可以使用多账户容器插件来隔离你的工作活动,以便谷歌仅触及你的职业生活,而无法访问你日常生活的任何部分。
你甚至可以使用两个不同的帐户打开同一个网站,此外由于标签页是用颜色标识的,因此无论你是要隔离网站还是只是在浏览器中添加新的视觉提示,这都很有帮助。
### 3、Firefox 的用户界面设计
尽管我们人类可能对新事物更感兴趣,但在熟悉又可靠的东西中我们能找到更多的舒适感。多年以来,Firefox 不断更新其界面,并且拥有了相当多的创新,而这些创新现在已经成为非官方的行业标准。但就总体来说,它一直保持不变。Firefox 的用户界面保留了你认为理所当然的所有标准惯例。
当你下载文件时,系统会提示你选择让 Firefox 如何处理该文件。根据你的选择,你可以在适当的应用程序中打开文件或将其保存到硬盘驱动器。你可以选择让 Firefox 记住你的选择并作为你将来的选择,或者让它继续提示你。

当你需要应用程序菜单时,可以在现代的“汉堡包式”的菜单中找到它,或者你可以按 `Alt` 键在 Firefox 的窗口顶部显示传统菜单。
无论你是否是 Firefox 的长期用户,Firefox 中的一切都看起来很熟悉,因为它建立在多年的用户界面设计经验之上。在它可以创新的地方,它就会去创新,但是如果这些创新会违反直觉,它就会废弃这种创新。
### 4、Firefox 的开发者工具
回溯万维网的早期,你可以浏览到任何网站并查看其源代码。仅仅这样做几次就很有可能学习到 HTML 的知识。一切都是公开的、透明的、显而易见的,而且相对简单的。
互联网已经逐渐演变成为一个强大的 [基于云的超级计算机](https://www.redhat.com/en/products/open-hybrid-cloud),现在从网站中提取有意义的上下文有时需要的不仅仅是其底层标记的文本转储。为了确保每个人都可以对网站的功能进行逆向工程(和正向工程),Firefox 在浏览器中集成了一套功能强大的开发工具。

虽然这最初是基于 Firefox 的创新(在 2006 年推出的 [Firebug](https://getfirebug.com/)),但现在许多浏览器都有开发者工具功能。然而,并非所有的开发者工具都一样,正是 Firefox 的开发者面板使 Firefox 成为我进行网页设计和用户体验测试的首选浏览器。
### 5、Firefox 是开源的
最为重要的是,Firefox 是完全开源的。这是一个优秀的浏览器,并且对你毫无隐藏。除了保持互联网开放,教育人们了解互联网,并推广日常工作的开源解决方案之外,它没有别有用心的动机。

你可以为 Firefox 做出贡献。你可以对你不喜欢的部分提交报告。你可以看到与互联网交互时运行的代码。几十年来,Firefox 一直在支持开放互联网。它忠于其自身的原则,并且可以说已经迫使几个竞争对手走向开源。如果 Firefox 没有抬高公众的期望,它们可能不会选择开源。
Firefox 是现代互联网上的具有影响力的力量,它是一款优秀的浏览器。Firefox 可以在你的桌面和移动设备上运行,因此想让自己轻松一点,[就安装个 Firefox 吧](http://getfirefox.com)。
---
via: <https://opensource.com/article/21/9/switch-to-firefox>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[leo314159](https://github.com/leo314159) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Mozilla Firefox was one of the applications that opened my eyes to open source. It wasn't by any means the tipping point, but it was part of a larger cumulative effect of several open source applications grabbing my attention, which ultimately resulted in me switching to Linux, and never looking back. Since switching to Firefox, which occurred well before I consciously changed to open source, I've been an avid Firefox user. My mobile phone was a Firefox OS mobile phone, and it was until the project was abandoned. Interestingly, though, I didn't necessarily consider myself a Firefox *fan*. I used it then and continue to use it today because it continues to be the best browser available in many different ways. Here are five reasons you should [switch to Firefox](http://getfirefox.org) right now.
## 1. Firefox is focused on privacy
The maintainer of Firefox is the [Mozilla foundation](https://foundation.mozilla.org/en/), a non-profit organization not motivated at all by your personal data. Mozilla doesn't care about what you search for, what websites you visit, or how much time you spend on the web. That's just not Mozilla's business model, but it is expressly the business model of many other popular browsers.
Even if you don't object to a browser tracking your activities for privacy reasons, you may have had the experience of making that one-time purchase of an unusual gift, only to have every site you visit try to sell you that item for the rest of your life. The Internet is big, so it sometimes seems like a good idea to restructure it based on users' interests. I admit that if all of my searches could have "open source" appended to them, it would probably provide more relevant results. But then again, I'd rather opt in to that kind of optimization rather than have it, along with many other unknowns, being decided for me, outside my control.
Privacy in Firefox (Seth Kenlon, CC BY-SA 4.0)
Mozilla has this policy: [Take less. Keep it safe. No secrets.](https://blog.mozilla.org/en/products/firefox/firefox-data-privacy-promise/)
Never one to stop short, Firefox also offers account [monitoring](https://monitor.firefox.com), an optional service from Mozilla that alerts you if any of your online accounts become compromised through a large-scale data breach. Additionally, Mozilla offers a paid VPN service using open source Wireguard software so you can browse safely from anywhere.
## 2. Firefox can use containers
It may be hard to believe, but there was a time when leading web browsers did not feature tabs. In the late 90s and early 00s, when you wanted to visit two web pages simultaneously, you had to open two separate browser windows. Firefox (and the Mozilla browser before it) was an early adopter of the tabbed interface.
Tabs are expected in browsers now, but through Firefox's extensions, there's been an interesting new twist on the power of the tabbed interface. Developed by Mozilla itself, the [Firefox Multi-Account Containers plugin](https://github.com/mozilla/multi-account-containers#readme) can turn each tab into an isolated "container" within your browser.

Containerized tabs in Firefox (Seth Kenlon, CC BY-SA 4.0)
For instance, say your employer uses Google Apps, but you don't trust Google with your personal information. You can use the Multi-Account Containers plugin to isolate your work activities so that Google touches only your professional life and has no access to any other part of your life.
You can even open the same site with two different accounts, and as a bonus, the tabs are color-coded, so it's useful whether you're looking to isolate sites or just add new visual cues to your browser.
## 3. Firefox user interface design
As much as we humans tend to get excited about new things, there's just as much comfort to be found in something familiar and reliable. Firefox has updated its interface over the years, and it's had its fair share of innovations that are now unofficial industry standards, but overall it has remained very much the same. Its user interface retains all the standard conventions you already take for granted.
When you download a file, you're prompted for how you want Firefox to handle the file. At your option, you can open the file in an appropriate application or save it to your hard drive. You can prompt Firefox to remember your choices for the future or have it continue to prompt you.

Firefox user interface (Seth Kenlon, CC BY-SA 4.0)
When you need an application menu, you can find it in a modern-style "hamburger" menu, or else you can press the **Alt** key to show a traditional menu along the top of the Firefox window.
Everything in Firefox is familiar, whether you're a long-time user of Firefox or not because it builds on years of user interface design. Where it can innovate, it does, but where it's counter-productive to change something intuitive, it refrains.
## 4. Developer tools in Firefox
Back in the early days of the world wide web, you could navigate to any website and view the source code. There was a high chance of learning HTML just from doing this a few times. Everything was open, transparent, obvious, and relatively straightforward.
The Internet has evolved into a powerful [cloud-based supercomputer](https://www.redhat.com/en/products/open-hybrid-cloud), and extracting meaningful context from a website now sometimes requires more than just a text dump of its underlying markup. To ensure everyone can reverse engineer (and engineer) how a website functions, Firefox incorporates a set of powerful development tools into the browser.
Developer tools (Seth Kenlon, CC BY-SA 4.0)
Although this was a Firefox-based innovation originally (by [Firebug](https://getfirebug.com/) back in 2006), many browsers have a devtools feature now. Not all devtools are equal, though, and it's Firefox's developer panels that make Firefox my go-to browser for web design and UX testing.
## 5. Firefox is open source
Most importantly, Firefox is fully open source. It's an excellent browser with nothing to hide. It's got no ulterior motive aside from keeping the web open, educating people about the Internet, and promoting open source solutions to everyday tasks.

Firefox is open source (Seth Kenlon, CC BY-SA 4.0)
You can contribute to Firefox. You can file bugs about things that you don't like. You can see the code you run when you interface with the Internet. Firefox has taken a stand for the open web for decades. It's stayed true to its principles and arguably has forced the hand of several competitors who probably wouldn't have chosen to go open source if Firefox hadn't set the public's expectations.
Firefox is a powerful force on the modern Internet, and it's a great browser. Firefox runs on your desktop and mobile devices, so do yourself a favor and [get Firefox](http://getfirefox.com).
## 6 Comments |
14,109 | Fly-Pie:一个为鼠标操作为主的用户提供的有趣菜单启动器 | https://itsfoss.com/fly-pie/ | 2021-12-23T17:30:00 | [
"启动器",
"Fly-Pie"
] | https://linux.cn/article-14109-1.html |
>
> Fly-Pie 是一个用于 GNOME 的独特的菜单启动器,以操作鼠标为主的用户可以用它进行一些操作。
>
>
>
应用启动器可以方便地快速切换到一个活动窗口,启动新的应用,等等。
[Ulauncher](https://itsfoss.com/ulauncher/) 就是这样一个应用启动器,如果你的 Linux 发行版没有提供一个开箱即用的,那么你可以使用它。
如果这已经激起了你的兴趣,你会发现 Fly-Pie 更有趣!以操作鼠标为主的用户总是把一只手放在鼠标上而不是依赖键盘进行导航,Fly-Pie 就是为他们量身定做的应用启动器。

### Fly-Pie:可定制的菜单,作为 GNOME shell 扩展使用
是的,不幸的是,Fly-Pie 只针对 GNOME 用户。我不确定是否有类似的东西适用于 KDE 或其他桌面环境。如果你知道的话,请在评论区提出你的建议。
Fly-Pie 主要为快捷方式、应用、媒体控制、最大化/最小化窗口、工作区导航提供了视觉上的互动图标,并且,比传统应用启动器更多的选项。

你可以进一步展开子菜单和下下级菜单。所以,你可以有很多的用例,它应该能发挥鼠标或触摸板的强大导航功能。

最重要的是它是高度可定制的。你可以选择背景图片、颜色、自定义图标、分支菜单等。
让我来重点介绍它的一些功能。
### Fly-Pie 的特点

如果你是一个以鼠标或触摸板操作为主的用户,Fly-Pie 为你提供了令人兴奋的导航能力。显而易见,如果你是一个有经验的键盘用户,这并不适合你(但你应该试一下!)。
以下是你可以期待的 Fly-Pie 的一些主要功能:
* 使用键盘快捷键启动 Fly-Pie 菜单
* 能够在菜单上添加媒体控制和工作区导航
* 添加自定义图标,为你的桌面定制个性化的菜单
* 添加喜爱的应用,以便快速访问
* 关闭一个应用程序窗口
* 一目了然地检查正在运行的应用,并导航到该窗口
* 自定义菜单的出现和消失的动画
* 如果你想让它一直作为覆盖层留在你的屏幕上,能够调整不透明度
* 调整连接子菜单的跟踪线
* 你可以根据你的鼠标和触摸板的敏感度,设置一个阈值或笔触角度来定制用户体验
* 细致的控制来改变颜色,定制图标等
* 能够定制子菜单和下下级菜单
* 检查实时预览,以便在使用前轻松定制和测试菜单
* 通过绘画手势选择项目

除了这些功能外,它还增加了一个成就功能,以鼓励用户探索菜单工具的各种使用情况。
下面是开发者在 YouTube 上播放的一段官方视频,展示了它的操作:
### 在 Linux 中安装 Fly-Pie
考虑到它是一个 GNOME 扩展,你必须得首先 [进行设置,以便能够在你的 Linux 发行版上使用 GNOME 扩展](https://itsfoss.com/gnome-shell-extensions/)。
设置完成后,你就可以前往 [Fly-Pie 的 GNOME 扩展页面](https://extensions.gnome.org/extension/3433/fly-pie/) 并轻松地安装该扩展。
你应该能够在该页面卸载它并访问设置。如果你感兴趣,可以探索它的 [GitHub 页面](https://github.com/Schneegans/Fly-Pie),了解更多信息。
它的 GitHub 页面还包括了帮助你探索其所有功能的文档。
### 关于使用 Fly-Pie 菜单启动器的想法
Fly-Pie 菜单并不完全是为了取代应用启动器。然而,根据你的使用情况,它可以作为一个基于覆盖层的菜单或一个以鼠标操作为主的启动器来访问选项/应用,非常方便。
尽管它是可定制的,但原版看起来是最好的,可以很容易地与你在 Linux 桌面上的任何类型的主题融合在一起。
令人印象深刻的是,它可以找到细微的调整来定制图标、缩放、颜色、透明度等等。如果你愿意,你可以试试。
考虑到我不是一个使用键盘导航的人,Fly-Pie 看起来是一个有用的 GNOME 扩展,可以节省时间,并为桌面体验增加一个独特的点。
即使你认为这不适合你,我也会建议你试一试,看看它是如何工作的,它确实很有趣。
你对 Fly-Pie 有什么看法?欢迎在下面的评论中分享你的想法。
---
via: <https://itsfoss.com/fly-pie/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief:** Fly-Pie is a unique menu launcher for GNOME that makes several actions accessible for a mouse-centric user.
An application launcher makes things convenient to quickly navigate to an active window, launch a new app, and so on.
[Ulauncher](https://itsfoss.com/ulauncher/) is one such application launcher to use if your Linux distribution does not offer any out-of-the-box.
If that spikes your interest already, you will find Fly-Pie interesting! An application launcher tailored for users who primarily use a mouse and always place one hand to navigate using the mouse instead of the keyboard.

## Fly-Pie: Customizable Menu That Works as a GNOME Shell Extension
Yes, unfortunately, Fly-Pie is for GNOME users only. I’m not sure if there is something similar for KDE or other desktop environments; drop your suggestions in the comments box if you know.
Fly-Pie focuses on providing visually interactive icons for shortcuts, applications, media controls, maximize/minimize window, workspace navigation, and more options than a traditional application launcher.

It branches out to children sub-menus and grand-children menu as you expand further. So, you can have a lot of use-cases, and it should facilitate powerful navigation capabilities using the mouse or touchpad.
The best thing is- it is highly customizable. You can choose a background image, color, customize the icons, branch menus, and more.
Let me highlight some of its capabilities while mentioning the features available.
## Features of Fly-Pie
Fly-Pie gives you an exciting navigation capability if you are a mouse-centric or touchpad user. For obvious reasons, if you are a power keyboard user, this isn’t for you (but you should give it a try!).
Here are some of the key features that you can expect with Fly-Pie:
- Use a keyboard shortcut to launch the Fly-Pie menu
- Ability to add media controls and workspace navigation to the menu
- Add custom icons to personalize the menu for your desktop
- Add favorite apps for quick access
- Close an app window
- Check for running apps at a glance and navigate to the window
- Customize the animation for the menu to appear and disappear
- Ability to adjust opacity if you want it to stay on your screen as an overlay all the time
- Adjust the trace line connecting the sub-menus
- You can set a threshold or stroke angle to customize the user experience as per your mouse and touchpad sensitivity
- Fine grain controls to change the color, customize the icon, and more
- Ability to customize the sub-menu and the grandchildren menu
- Check livepreview to easily customize and test the menu before using it
- Select items by drawing gestures
In addition to the features, it also adds an achievement functionality to encourage the user to explore a variety of use-cases with the menu tool.
Here is an official YouTube video by the developer that shows it in action:
## Installing Fly-Pie in Linux
Considering it as a GNOME extension, you will have to first [set things to be able to use GNOME extensions on your Linux distribution](https://itsfoss.com/gnome-shell-extensions/).
Once you are done with the setup, you can head to [Fly-Pie’s GNOME extension page](https://extensions.gnome.org/extension/3433/fly-pie/) and easily install the extension.
You should be able to uninstall it from there and access the settings. If you are curious, you can explore its [GitHub page](https://github.com/Schneegans/Fly-Pie) for more information.
The GitHub page also includes documentation to help you explore all of its capabilities.
## Thoughts on Using Fly-Pie Menu Launcher
The Fly-Pie menu is not exactly meant to replace the application launcher. However, depending on your use-case, it could come in extremely handy as an overlay-based menu or a mouse-centric launcher to access options/applications.
Even though it is customizable, the stock looks the best and blends in easily with any type of theme you have going on in your Linux desktop.
It is impressive to find fine-grained tweaks to customize the icons, scaling, color, transparency, and more. You can play around with it if you prefer.
Considering I am not someone who navigates using the keyboard, Fly-Pie looks like a useful GNOME extension to have that saves time, and adds a unique point to the desktop experience.
Even if you think this is not for you, I would suggest trying it out just to explore how it works, it is interesting indeed!
What do you think about Fly-Pie? Feel free to share your thoughts in the comments down below. |
14,111 | 在 FreeDOS 中使用批处理文件 | https://opensource.com/article/21/3/batch-files-freedos | 2021-12-24T10:28:01 | [
"FreeDOS",
"批处理"
] | https://linux.cn/article-14111-1.html |
>
> 编写你自己的简单程序来自动执行通常需要大量输入的任务的批处理文件,是一种极好的方法。
>
>
>

在 Linux 上,创建 *shell 脚本* 来自动执行重复的任务是很常见的。类似地,在开源版的旧式 DOS 操作系统 [FreeDOS](https://www.freedos.org/) 上,你可以创建一个包含数个 FreeDOS 命令的 *批处理文件* 。然后,你就可以运行你的批处理文件来按顺序执行每个命令。
你可以使用一个 ASCII 文本编辑器来创建批处理文件,诸如 FeeDOS 的 Edit 应用程序。在你创建一个批处理文件后,你可以使用一个文件名称加上扩展名 `.bat` 来保存它。文件名称应该是唯一的。如果你使用 FreeDOS 的一个命令的名称作为你自己的文件名称,那么可能将会执行 FreeDOS 的命令,而不会是你的批处理文件。
实际上,所有的内部的和外部的 FreeDOS 命令都可以在一个批处理文件中使用。在你创建一个批处理文件时,你其实就是在编写一个程序。FreeDOS 批处理文件可能没有结构化编程语言的功能,但是对于耗时短暂却重复乏味的任务来说,它是非常方便的。
### 注释你的代码
对于任何程序员来说,学习的第一个好习惯都应该是:在一个程序中放置注释来解释该代码正在做什么。这是一件非常容易完成的事情,但是你需要仔细,不要傻傻地让操作系统来执行你的注释。避免出现这种情况的方法是在一个注释行的开头处放置 `REM`(“remark” 的缩写) 。
FreeDOS 忽略以 `REM` 开头的代码行。但是任何查看源文件代码(即你在你的批处理文件中所编写的文本)的人都可以读取你的注释并理解它在做什么。这也是一种临时性禁用一个命令而不需要删除它的一种方法。只需要打开你的批处理文件来进行编辑,在你想要禁用行的开头处放置 `REM` ,并保存它。在你想要重新启用这个命令时,只需要打开文件来进行编辑和移除 `REM` 。这种技巧有时被称为 “注释掉” 一个命令。
### 开始设置
在你开始编写你自己的批处理文件前,我建议在 FreeDOS 中创建一个临时目录。这将会为你提供一个处理批处理文件的安全空间,不会意外地删除、移动,或重命名重要的系统文件或目录。在 FreeDOS 上,你可以使用 `MD` 命令来 [创建一个目录](https://opensource.com/article/21/2/freedos-commands-you-need-know) :
```
C:\>MD TEMP
C:\>CD TEMP
C:\TEMP>
```
FreeDOS 的 `ECHO` 命令会控制当你运行一个批处理文件时在屏幕上显示的东西。例如,这里是一个简单是单行批处理文件:
```
ECHO Hello world
```
如果你创建这个文件并运行它,你将看到在屏幕上显示的句子。从命令行中完成这项操作的最快的方法是:使用 `COPY` 命令来从你的键盘中(`CON`)获取输入,并将其放置到文件 `TEST1.BAT` 之中。接下来,按下组合键 `Ctrl+Z` 来停止复制过程,按下你键盘上的 `Return` 或 `Enter` 按键来返回一个提示。
在你的临时目录中尝试创建这个文件为 `TEST1.BAT` ,接下来运行它:
```
C:\TEMP>COPY CON TEST1.BAT
CON => TEST1.BAT
ECHO Hello world
^Z
C:\TEMP>TEST1
Hello world
```
当你想要显示一段文本时,这可能很有用。例如,在一个程序完成它的任务时,你可能会在你的屏幕上看到一条告诉你需要等待的消息,或者在一个网络环境中时,你可能会看到一条登录消息。
如果你想要显示一个空行怎么办?你可能会认为 `ECHO` 命令本身就可以达到目的,但是单独一个 `ECHO` 命令只会询问 FreeDOS 来响应 `ECHO` 是打开还是关闭:
```
C:\TEMP>ECHO
ECHO is on
```
获取一个空白行的方法是在 `ECHO`后紧接着使用一个 `+`符号:
```
C:\TEMP>ECHO+
C:\TEMP>
```
### 批处理文件变量
变量是一个存储你需要你的批处理文件临时记住的信息的位置。这是编程的一个重要的功能,因为你不能总是知道你的批处理文件需要使用什么样的数据。这里有一个用于演示的简单示例。
创建 `TEST3.BAT` :
```
@MD BACKUPS
COPY %1 BACKUPS\%1
```
变量是使用百分比符号和随后的数字表示的,因此,这个批处理文件将在你的当前目录中创建一个 `BACKUPS` 子目录,然后将复制变量 `%1` 到 `BACKUPS` 文件夹之中。这个变量是什么?当你运行批处理文件时,变量由你决定:
```
C:\TEMP>TEST3 TEMP1.BAT
TEST1.BAT => BACKUPS\TEST1.BAT
```
你的批处理文件已经复制 `TEST1.BAT` 到一个名称为 `BACKUPS` 的子目录,因为在你运行批处理文件时,你标识这个文件为一个参数。你的批处理文件将把 `%1` 替换为 `TEST1.BAT` 。
变量是按位置的。变量 `%1` 是你提供给命令的第一个参数,变量 `%2` 是第二个参数,以此类推。假设你创建一个批处理文件来列出一个目录的内容:
```
DIR %1
```
尝试运行它:
```
C:\TEMP>TEST4.BAT C:\HOME
ARTICLES
BIN
CHEATSHEETS
GAMES
DND
```
这像预期一样的工作。但是下面这个却失败了:
```
C:\TEMP>TEST4.BAT C:\HOME C:\DOCS
ARTICLES
BIN
CHEATSHEETS
GAMES
DND
```
如果你尝试它,你将得到第一个参数(`C:\HOME`)的列表,而得不到第二个参数(`C:\DOCS`)的列表。这是因为你的批处理文件仅查找一个变量(`%1`),此外,`DIR` 命令也仅能获取一个目录。
此外,当你运行一个批处理文件时,你也不需要为其具体指定扩展名 —— 除非你运气相当不好地为批处理文件选取了一个与 FreeDOS 外部命令或类似命令相同的名称。当 FreeDOS 执行命令时,它按下面的顺序执行:
1. 内部命令
2. 带有 \*.COM 扩展名的外部命令
3. 带有 \*.EXE 扩展名的外部命令
4. 批处理文件
### 多个参数
好的,选择重新编写 `TEST4.BAT` 文件来使一个命令可以获取两个参数,以便你可以看到这是如何工作的。首先,使用 `EDIT` 应用程序来创建一个简单的名称为 `FILE1.TXT` 的文本文件。在其中放置一段某种类型(例如,“Hello world”)的语句,并在你的 `TEMP` 工作目录中保存文件。
接下来,使用 `EDIT` 来更改你的 `TEST4.BAT` 文件:
```
COPY %1 %2
DIR
```
保存它,然后执行命令:
```
C:\TEMP\>TEST4 FILE1.TXT FILE2.TXT
```
在运行你的批处理文件时,你会看一个你的 `TEMP` 目录的目录列表。在列出的文件之中,你有 `FILE1.TXT` 和 `FILE2.TXT` ,它们是由你的批处理文件所创建的。
### 嵌套批处理文件
批处理文件的另一个功能是能够 “嵌套” ,这意味着一个批处理文件可以在另外一个批处理文件中被调用和运行。为查看这是如何工作的,从一对简单的批处理文件开始:
第一个文件被称为 `NBATCH1.BAT` :
```
@ECHO OFF
ECHO Hello
CALL NBATCH2.BAT
ECHO world
```
第一行 (`@ECHO OFF`) 轻轻地告诉批处理文件在你运行它时仅显示命令 (而不是命令本身) 的输出。你可能会在前面的示例中注意到这里有很多关于批处理文件正在做什么的反馈;在这种情况下,你正在允许你的批处理文件仅显示结果。
第二个批处理被称为 NBATCH2.BAT :
```
echo from FreeDOS
```
使用 `EDIT` 来创建这两个文件,并在你的 TEMP 子目录中保存它们。运行 `NBATCH1.BAT` 来查看会发生什么:
```
C:\TEMP\>NBATCH1.BAT
Hello
from FreeDOS
world
```
你的第二个批处理文件将在第一个批处理文件之中通过 `CALL` 命令来执行,它将提供在你 “Hello world” 信息中间的字符串 “from FreeDOS” 。
### FreeDOS 脚本
编写你自己的简单程序来自动执行通常需要大量输入的任务的批处理文件,是一种极好的方法。你使用的 FreeDOS 越多, 你将越熟悉它的命令,在你熟知命令后,在一个批处理文件中列出它们仅是一件使你的 FreeDOS 系统让你生活轻松的事情。尝试一下!
---
via: <https://opensource.com/article/21/3/batch-files-freedos>
作者:[Kevin O'Brien](https://opensource.com/users/ahuka) 选题:[lujun9972](https://github.com/lujun9972) 译者:[robsean]](<https://github.com/robsean>) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | On Linux, it's common to create *shell scripts* to automate repetitive tasks. Similarly, on [FreeDOS](https://www.freedos.org/), the open source implementation of old DOS operating systems, you can create a *batch file* containing several FreeDOS commands. Then you can run your batch file to execute each command in order.
You create a batch file by using an ASCII text editor, such as the FreeDOS Edit application. Once you create a batch file, you save it with a file name and the extension `.bat`
. The file name should be unique. If you use a FreeDOS command name as your own file name, the FreeDOS command probably will execute instead of your batch file.
Virtually all internal and external FreeDOS commands can be used in a batch file. When you create a batch file, you are essentially writing a program. FreeDOS batch files may not have the power of a structured programming language, but they can be very handy for quick but repetitive tasks.
## Commenting your code
The No. 1 good habit for any programmer to learn is to put comments in a program to explain what the code is doing. This is a very good thing to do, but you need to be careful not to fool the operating system into executing your comments. The way to avoid this is to place `REM`
(short for "remark") at the beginning of a comment line.
FreeDOS ignores lines starting with `REM`
. But anyone who looks at the source code (the text you've written in your batch file) can read your comments and understand what it's doing. This is also a way to temporarily disable a command without deleting it. Just open your batch file for editing, place `REM`
at the beginning of the line you want to disable, and save it. When you want to re-enable that command, just open the file for editing and remove `REM`
. This technique is sometimes referred to as "commenting out" a command.
## Get set up
Before you start writing your own batch files, I suggest creating a temporary directory in FreeDOS. This can be a safe space for you to play around with batch files without accidentally deleting, moving, or renaming important system files or directories. On FreeDOS, you [create a directory](https://opensource.com/article/21/2/freedos-commands-you-need-know) with the `MD`
command:
```
C:\>MD TEMP
C:\>CD TEMP
C:\TEMP>
```
The `ECHO`
FreeDOS command controls what is shown on the screen when you run a batch file. For instance, here is a simple one-line batch file:
`ECHO Hello world`
If you create this file and run it, you will see the sentence displayed on the screen. The quickest way to do this is from the command line: Use the `COPY`
command to take the input from your keyboard (`CON`
) and place it into the file `TEST1.BAT`
. Then press **Ctrl**+**Z** to stop the copy process, and press Return or Enter on your keyboard to return to a prompt.
Try creating this file as `TEST1.BAT`
in your temporary directory, and then run it:
```
C:\TEMP>COPY CON TEST1.BAT
CON => TEST1.BAT
ECHO Hello world
^Z
C:\TEMP>TEST1
Hello world
```
This can be useful when you want to display a piece of text. For instance, you might see a message on your screen telling you to wait while a program finishes its task, or in a networked environment, you might see a login message.
What if you want to display a blank line? You might think that the `ECHO`
command all by itself would do the trick, but the `ECHO`
command alone asks FreeDOS to respond whether `ECHO`
is on or off:
```
C:\TEMP>ECHO
ECHO is on
```
The way to get a blank line is to use a `+`
sign immediately after `ECHO`
:
```
C:\TEMP>ECHO+
C:\TEMP>
```
## Batch file variables
A variable is a holding place for information you need your batch file to remember temporarily. This is a vital function of programming because you don't always know what data you want your batch file to use. Here's a simple example to demonstrate.
Create `TEST3.BAT`
:
```
@MD BACKUPS
COPY %1 BACKUPS\%1
```
Variables are signified by the use of the percentage symbol followed by a number, so this batch file creates a `BACKUPS`
subdirectory in your current directory and then copies a variable `%1`
into a `BACKUPS`
folder. What is this variable? That's up to you to decide when you run the batch file:
```
C:\TEMP>TEST3 TEMP1.BAT
TEST1.BAT => BACKUPS\TEST1.BAT
```
Your batch file has copied `TEST1.BAT`
into a subdirectory called `BACKUPS`
because you identified that file as an argument when running your batch file. Your batch file substituted `TEST1.BAT`
for `%1`
.
Variables are positional. The variable `%1`
is the first argument you provide to your command, while `%2`
is the second, and so on. Suppose you create a batch file to list the contents of a directory:
`DIR %1`
Try running it:
```
C:\TEMP>TEST4.BAT C:\HOME
ARTICLES
BIN
CHEATSHEETS
GAMES
DND
```
That works as expected. But this fails:
```
C:\TEMP>TEST4.BAT C:\HOME C:\DOCS
ARTICLES
BIN
CHEATSHEETS
GAMES
DND
```
If you try that, you get the listing of the first argument (`C:\HOME`
) but not of the second (`C:\DOCS`
). This is because your batch file is only looking for one variable (`%1`
), and besides, the `DIR`
command can take only one directory.
Also, you don't really need to specify a batch file's extension when you run it—unless you are unlucky enough to pick a name for the batch file that matches one of the FreeDOS external commands or something similar. When FreeDOS executes commands, it goes in the following order:
- Internal commands
- External commands with the *.COM extension
- External commands with the *.EXE extension
- Batch files
## Multiple arguments
OK, now rewrite the `TEST4.BAT`
file to use a command that takes two arguments so that you can see how this works. First, create a simple text file called `FILE1.TXT`
using the `EDIT`
application. Put a sentence of some kind inside (e.g., "Hello world"), and save the file in your `TEMP`
working directory.
Next, use `EDIT`
to change your `TEST4.BAT`
file:
```
COPY %1 %2
DIR
```
Save it, then execute the command:
`C:\TEMP\>TEST4 FILE1.TXT FILE2.TXT`
Upon running your batch file, you see a directory listing of your `TEMP`
directory. Among the files listed, you have `FILE1.TXT`
and `FILE2.TXT`
, which were created by your batch file.
## Nested batch files
Another feature of batch files is that they can be "nested," meaning that one batch file can be called and run inside another batch file. To see how this works, start with a simple pair of batch files.
The first file is called `NBATCH1.BAT`
:
```
@ECHO OFF
ECHO Hello
CALL NBATCH2.BAT
ECHO world
```
The first line (`@ECHO OFF`
) quietly tells the batch file to show only the output of the commands (not the commands themselves) when you run it. You probably noticed in previous examples that there was a lot of feedback about what the batch file was doing; in this case, you're permitting your batch file to display only the results.
The second batch file is called NBATCH2.BAT:
`echo from FreeDOS`
Create both of these files using `EDIT`
, and save them in your TEMP subdirectory. Run `NBATCH1.BAT`
to see what happens:
```
C:\TEMP\>NBATCH1.BAT
Hello
from FreeDOS
world
```
Your second batch file was executed from within the first by the `CALL`
command, which provided the string "from FreeDOS" in the middle of your "Hello world" message.
## FreeDOS scripting
Batch files are a great way to write your own simple programs and automate tasks that normally require lots of typing. The more you use FreeDOS, the more familiar you'll become with its commands, and once you know the commands, it's just a matter of listing them in a batch file to make your FreeDOS system make your life easier. Give it a try!
*Some of the information in this article was previously published in DOS lesson 15: Introduction to batch files and DOS lesson 17: Batch file variables; nested batch files (both CC BY-SA 4.0).*
## Comments are closed. |
14,112 | 7 个最好的 Linux 滚动发行版 | https://itsfoss.com/best-rolling-release-distros/ | 2021-12-24T12:11:04 | [
"发行版",
"滚动发行版"
] | https://linux.cn/article-14112-1.html | 
林林总总的 Linux 发行版可以根据它们的特点、功能、预期用户群等分为不同的类别。在这篇文章中,我将列出一些最好的滚动发布的 Linux 发行版。
你知道什么是 [滚动发布的发行版](https://itsfoss.com/rolling-release/) 吗?这些发行版不会等待 6 个月或更长时间才发布一个新的版本,提供给你更新的 Linux 内核、桌面环境和其他主要软件组件。它们会在这些组件发布后很快就进行更新。你不必将你的发行版从一个主要版本升级到下一个版本,因为你的发行版会定期得到升级。
现在你已经知道了,让我们来看看一些最好的滚动发布的 Linux 发行版。
### 你可以在桌面上使用的最佳滚动发行版
是的,这个列表主要是针对桌面用户。这里列出的一些发行版可能有服务器版本,但这不是这里的重点。
请注意,这并不是一个排名表。
#### 1、openSUSE Tumbleweed

老派的 openSUSE 多年来一直按部就班地顺着版本号发布他们的系统。但在几年前,他们决定改变他们的产品,创建了 [openSUSE Leap 和 Tumbleweed](https://itsfoss.com/opensuse-leap-vs-tumbleweed/)。
openSUSE Leap 采用的是版本式发布,每隔几年就会有一个新的版本,而 Tumbleweed 则是滚动式发布,新的软件在发布后不久就会出现在这个系统中。
[openSUSE Tumbleweed](https://get.opensuse.org/tumbleweed/) 对于那些想留在红帽 RPM 阵营的人来说是一个很好的选择。openSUSE 有多样化的生态系统,它有一个巨大的软件库,Zypper 和 YaST 为你的软件包管理提供了很多选择。
#### 2、Arch Linux

毋庸置疑,[Arch Linux](https://archlinux.org/) 是最流行的滚动发布版本。它几乎就是滚动发布的同义词。
[Arch Linux](https://itsfoss.com/why-arch-linux/) 在 Linux 用户中具有崇高地位的原因有很多。我认为这更多是与 [安装 Arch Linux](https://itsfoss.com/install-arch-linux/) 后的成就感有关,因为即使是安装程序,它都很别人不一样。
Arch 在其软件库中正式提供了一大批软件。而 [AUR 则通过社区的努力,几乎使所有其他的 Linux 软件都可以使用](https://itsfoss.com/aur-arch-linux/)。
如果你对 Linux 有一定的经验,想挑战自己的水平,这是一个不错的选择。
#### 3、Manjaro Linux

[Manjaro](https://manjaro.org/) 基本上是免除了所有麻烦的 Arch Linux。
它是基于 Arch Linux 的,所以它具有 Arch Linux 的大部分优点。你可以得到 Pacman 和 AUR 的滚动发布模式。同时,Manjaro 有图形化的安装程序、基于 GUI 的软件包管理器和其他图形化工具来改善你的桌面体验。
Manjaro 更容易安装,也更容易使用。对于那些想舒适地呆在 Arch 领域的人来说是个不错的选择。
注意: 还有 [许多其他基于 Arch Linux 的优秀发行版](https://itsfoss.com/arch-based-linux-distros/),但我无法将其列入此列表中。如果你愿意,你可以试试 Garuda Linux、[EndeavourOS](https://endeavouros.com/) 和其他许多基于 Arch 的发行版。
#### 4、Solus Linux

和 Manjaro 一样,[Solus](https://getsol.us/home/) 也是一个 “谨慎” 的滚动发行版。与 Manjaro 不同的是,它不是基于 Arch 的。它是从头开始创建的,使用的是 [eopkg 软件包管理器](https://itsfoss.com/eopkg-commands/)。Solus 因创造了现代而直观的 Budgie 桌面环境备受赞誉。
像其他滚动发布的发行版一样,一旦你安装了 Solus,你就不需要升级到下一个版本的发行版(也可以像 ISO 刷新一样进行全新安装,带有更新的软件包)。
万一有欠缺的软件包也可以用 Snap 应用程序来补足。
如果你想要一些不同的东西,但又不至于复杂到让你感到不舒服,那么 Solus 是一个不错的选择。
#### 5、Debian Testing

你没有想到吧?Debian 以其对稳定性的关注而闻名,以至于其稳定的有时就像是陈旧,因为它提供的软件版本已经相当老旧。
但那是针对稳定分支的。Debian 有几个分支,其中一个叫做 Testing 分支。
看起来 Testing 是某种测试版、不稳定的版本,但这并不完全正确。[Debian Testing](https://wiki.debian.org/DebianTesting) 其实是下一个 Debian 稳定版本。实际的开发分支是 Debian Unstable(即 Sid)。Debian Testing 介于不稳定版和稳定版分支之间,它会在稳定版之前添加新的功能。
有些人在配置 Debian 时,在源列表中加入 `testing`。这使得他们的 Debian 系统永远停留在测试阶段。这是一种滚动发布的模式,Debian 用户可以不必离开舒适的 APT 和 deb 软件包管理系统。
#### 6、Void Linux

这是一个不寻常的、不太出名的发行版。[Void](https://voidlinux.org/) 也是从头开始创建的,也就是说,它不是基于 Arch、Red Hat 或 Debian。
它是滚动发布的,但不像 Arch 那样激进。它优先考虑的是稳定性。这意味着当新的版本发布时,你不需要升级版本,但你也不会在最新的桌面环境版本一发布就得到它。
与其他发行版不同的另一点是,它使用 [runit](http://smarden.org/runit/) 作为初始化系统。
总的来说,如果你是一个有经验的 Linux 用户,Void 是一个不错的选择。
#### 7、Gentoo Linux

另一个是你的同行们警告过的 [专家级 Linux 发行版](https://itsfoss.com/advanced-linux-distros/) 之一。
[Gentoo](https://www.gentoo.org/) 不是每个人都能享用的茶或咖啡(无论你喜欢哪一种)。从安装到配置再到软件包管理都需要一定的专业知识和时间。
但是它有一个小众的专家用户群,他们会在编译一切需要的组件时废寝忘食。
如果你觉得其他发行版都不够有挑战性,Gentoo 可能是你的选择。
### 你对滚动发布的发行版有什么建议?
正如我之前提到的,我在这里特意将其他基于 Arch 的发行版排除在外,否则列表中就只有 Arch 的衍生产品了。
但你可以自由地投出你的推荐,即使它是基于 Arch 的。评论区都是你的。
---
via: <https://itsfoss.com/best-rolling-release-distros/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

There are so many Linux distributions that can be divided into different categories based on their characteristics, update schedule, features, intended user base and more.
In this article, I will list some of the best rolling release Linux distributions. If you are curious, these distros are special because of their update cycle.
[rolling release distro](https://itsfoss.com/rolling-release/)?
These distros do not wait for six months or more to release a new version with newer versions of the Linux kernel, desktop environment and other major software components.
They update these components soon after they are released. You do not have to upgrade your distribution from one major version to the next because your distribution keeps getting the upgrades regularly.
Now that you have an idea of what I am going to list, let’s take a look at some of the best rolling release distros that you can use on the desktop.
**Suggested Read 📖**
[What is a Rolling Release Distribution?What is rolling release? What is a rolling release distribution? How is it different from the point release distributions? All your questions answered.](https://itsfoss.com/rolling-release/)

*In addition, note that this is not a ranking list.*## 1. openSUSE Tumbleweed

The good old openSUSE focused on stability for years with their point release system. A few years ago, they decided to change their offering by creating [openSUSE Leap and Tumbleweed](https://itsfoss.com/opensuse-leap-vs-tumbleweed/).
While openSUSE Leap follows a point release with a new version coming after every few years, Tumbleweed is rolling release with new software landing in soon after their release.
[openSUSE Tumbleweed](https://get.opensuse.org/tumbleweed/?ref=itsfoss.com) makes a great choice for those who want to stay on the RPM side (Red Hat side). openSUSE ecosystem is a lot more diverse with a huge repository of software and Zypper and YaST gives you plenty of options for package management.
## 2. Rhino Linux
Rhino Linux is an Ubuntu-based rolling release offering that features the XFCE desktop environment.
It utilizes [Pacstall](https://github.com/pacstall/pacstall) at its core to let you easily manage/install packages. You can also choose to enable Flatpak and extras like [Nala](https://itsfoss.com/nala/) for package management from its welcome screen.
**Suggested Read 📖**
[Apt++? Nala is Like Apt in Ubuntu but BetterNala is a Python-based frontend for apt package management. Inspired by the DNF package manager, Nala seems like a promising tool for Ubuntu and Debian users.](https://itsfoss.com/nala/)

## 3. Arch Linux

BTW, [Arch Linux](https://archlinux.org/?ref=itsfoss.com) is the most popular rolling release distribution. It’s almost a synonym with rolling release.
There are plenty of [reasons why Arch Linux has ](https://itsfoss.com/why-arch-linux/)a cult status among Linux users. I think it’s more to do with the sense of achievement one feels after [installing Arch Linux](https://itsfoss.com/install-arch-linux/) because even the installation procedure is not like other distros.
Arch has a good bunch of software available officially in its repositories. And then [Arch User Repository (AUR)](https://itsfoss.com/aur-arch-linux/) makes almost any other Linux software available through the community effort.
This is a good choice if you are a bit experienced with Linux and want to challenge yourself to the next level.
**Suggested Read 📖**
[6 Reasons Why People Love to Use Arch LinuxArch Linux has a cult status among desktop Linux users. What makes Arch Linux so popular? Why people use Arch Linux? This article answers these questions.](https://itsfoss.com/why-arch-linux/)

## 4. Manjaro Linux

[Manjaro](https://manjaro.org/?ref=itsfoss.com) is basically Arch, minus all the hassle that comes with Arch Linux.
It is based on Arch Linux, so it gets most of the positives of Arch Linux. You get Pacman and AUR with a rolling release model. And at the same time, Manjaro has a graphical installer, a GUI-based package manager and other graphical tools to improve your desktop experience.
Manjaro is easier to install, easier to use. A good choice for those who want to stay in the Arch domain comfortably.
**Suggested Read 📖**
[What is Arch User Repository (AUR)? How to Use AUR on Arch and Manjaro Linux?What is AUR in Arch Linux? How do I use AUR? Is it safe to use? This article explains it all.](https://itsfoss.com/aur-arch-linux/)

## 5. Solus Linux

Like Manjaro, [Solus](https://getsol.us/home/?ref=itsfoss.com) is also a ‘careful’ rolling release distro. Unlike Manjaro, it is not based on Arch. It’s created from scratch and uses an [eopkg package manager](https://itsfoss.com/eopkg-commands/). Solus is credited for the creation of the modern and intuitive Budgie desktop environment.
Like other rolling release distros, once you have installed Solus, you don’t need to upgrade to the next version release (which is like ISO refresh to have newer updates for fresh installation).
The slight lack of packages can be compensated with Snap applications.
Solus is a good choice if you want something different but not complicated enough to make you uncomfortable.
## 6. Debian Testing

You did not expect this, did you? Debian is known for its focus on stability, so much that stability sometimes equals stale, as the software versions it provides are old.
But that’s for the stable branch. Debian has several branches and one of them is called Testing.
It may seem like Testing is some sort of beta, unstable version, but that’s not entirely true. [Debian Testing](https://wiki.debian.org/DebianTesting?ref=itsfoss.com) is the next Debian stable version. The actual development branch is the Debian Unstable (also known as Sid). Debian Testing lies somewhere in between the unstable and stable branch, where it gets the new features before the stable release.
Some people configure Debian with ‘testing’ in the sources list. That makes their Debian system stay on testing forever. This is a sort of rolling release model that Debian user can enjoy without having to leave the comfort of APT and the deb package management system.
## 7. Void Linux

An unusual and not-so-known distribution. [Void](https://voidlinux.org/?ref=itsfoss.com) is also one of the [distros created from scratch](https://itsfoss.com/independent-linux-distros/), i.e., it’s not based on Arch, Red Hat or Debian.
It is rolling release but not bleeding edge like Arch. It gives preference to stability. This means that you don’t need to upgrade versions when a new one releases, but you don’t get the latest desktop environment version as soon as it is released.
Another thing that separates it from other distributions is the use of [runit](http://smarden.org/runit/?ref=itsfoss.com) as init system.
Altogether, Void is a good choice if you are an experienced Linux user.
**Suggested Read 📖**
[13 Independent Linux Distros That are Built From ScratchUnique and independent Linux distributions that are totally built from scratch. Sounds interesting? Check out the list here.](https://itsfoss.com/independent-linux-distros/)

## 8. Gentoo Linux

Another one of those [expert Linux distributions](https://itsfoss.com/advanced-linux-distros/) your peers warned about.
[Gentoo](https://www.gentoo.org/?ref=itsfoss.com) is not everyone’s cup of tea or coffee (whichever you prefer). Everything from the installation to configuration to package management requires some sort of expertise and time.
But it has a niche user base of experts whose neck beard touch their toes while they compile everything under the sun (*no discrimination, just traditionally picturing an expert!*)
Gentoo could be the distro of your choice if you feel like every other distro is not challenging enough.
[many other good distributions based on Arch Linux](https://itsfoss.com/arch-based-linux-distros/)that I could not include in this list, like EndeavourOS. If you'd like, you may explore more options from the list below.
**Suggested Read 📖**
[Top 10 User-friendly Arch-Based Linux Distributions [2023]Want to experience Arch Linux without the hassle of the complicated installation and setup? Here are a few user-friendly Arch-based Linux distributions.](https://itsfoss.com/arch-based-linux-distros/)

## What’s your recommendation for rolling release distro?
As I mentioned earlier, I have deliberately left out other Arch-based distributions here; otherwise the list would have been filled with Arch derivatives only.
But you are free to pitch in your recommendation, even if it is based on Arch. The comment section is all yours. |
14,114 | 在 Linux 上用 Markdown 编写你的电影剧本 | https://opensource.com/article/21/12/linux-fountain | 2021-12-25T10:26:40 | [
"剧本",
"markdown"
] | https://linux.cn/article-14114-1.html |
>
> Fountain markdown 技术只需要一个纯文本编辑器,如 Atom、Kate、Gedit 或类似的编辑器,它可以导出一个正确格式的 HTML 或 PDF 剧本。
>
>
>

剧本是一部电影的蓝图,过去它是在打字机上撰写的。你买台打字机就可以写剧本,可以写好多好多剧本。而现在没人用打字机写剧本了,因为打字机不再流行。
不过,令人费解的是,随着写作技术变得 “越好”,写剧本就越难。在剧本领域有严格的格式化规则,以帮助电影拍摄中的助理导演(AD)估计每个场景需要拍摄多长时间。你可能认为电脑会比在打字机上的完全手工过程更容易做到。然而,流行的计算机却用昂贵的软件来限制作家,这些软件已经嵌入了好莱坞文化。如果你没有合适的软件,你就会被告知,你永远不可能成为一个正式的编剧。
不过,所有这些都随着开源软件的出现而改变,写剧本的最简单方法之一就是根本不使用特殊的软件。[Fountain](http://fountain.io) markdown 技术只需要一个纯文本编辑器,如 [Atom](https://opensource.com/article/20/12/atom)、[Kate](https://opensource.com/article/20/12/kate-text-editor)、[Gedit](https://opensource.com/article/20/12/gedit),或类似的,它可以导出一个正确格式的 HTML 或 PDF 剧本。
### 安装 Fountain
Fountain 不需要安装,因为它不是软件;它是一套你在写作时使用的规则。你在写作时已经遵循了一些规则,比如你把句子的第一个字母大写,用句号来结束每句话,等等。当你用 Fountain 写作时,只需要添加一些专门针对剧本的新规则。
### 片段
在剧本中,每个场景都由一行大写字母划定,以 `INT.` 或 `EXT.` 开头,然后是一个地点、一个破折号,以及一天中的时间。这些说明被称为 “片段”。方便的是,这也是 Fountain 的规则,所以不用记住什么新的东西就可以创建一个片段。
```
EXT. CASTLE COURTYARD - DAY
```
### 动作
当演员被要求执行一个特定的动作时,剧本中就会包含动作文本。这是正常的普通文本,完全按照你在书中写的文字来写。所有正常的规则都适用,所以对动作文本不用特别记什么规则。
```
A wizard wanders out of a great stone door. She approaches the center of the courtyard and pauses. Something's caught her eye.
It's a book. She leans down and picks it up.
```
### 对话
剧本中的对话格式是从左右边距缩进的。对于普通观众来说,它可能看起来是居中的,但实际上它是左对齐的。采用这种格式是为了帮助演员定位他们的台词,并使得剧本给口语对话留出更多的空间,因为在电影中,口语对话往往占据了大部分的时间。
在 Fountain 中,对话的规则是用大写字母写出说话的角色的名字。然后在下一行,正常写出对话内容。
```
WIZARD
I can sense your power. Grep? Sed? What strange terms!
```
当你导出你的剧本时,对话会被调整为适当的格式。
### 转场
现在这种做法已经不流行了,但传统上,在剧本中会有一些特殊的转场迹象,因为在很久以前,一些转场是要花很多钱的。今天,你仍然可以在剧本中看到转场,但它往往更多的是作为一组场景(或者,经典的整个电影<ruby> 淡出 <rt> FADE OUT. </rt></ruby>)的一种标点符号,而不是对编辑的实际指示。
要在 Fountain 中创建一个过渡,在你的文本前加上大于号(`>`)。
```
>ANGLE ON:
The book's title page. It reads "Introduction to Linux."
>FADE OUT.
```
### 更多的规则
你可以在你的剧本中使用许多其他的 Markdown 约定,比如用星号来斜体、加粗和给文字加下划线。在 Fountain 中还有更多的规则来处理边缘情况和风格上的例外,但这四条规则在大多数情况下是你所需要的。
不过,Fountain 的简单性表明,一百年前的剧本格式设计得多么好。它有一个标准的结构,使人的眼睛很容易解析,这种可预测性也能很好地转化为计算机的解析。
### 输出和渲染
一旦你写完了,你就可以使用渲染程序将你的剧本导出为适当的格式。有 [几个渲染器可用](https://fountain.io/apps),但我最喜欢的是 Atom 编辑器。要配置 Atom 以适当的格式显示 Fountain 预览文件,并在完成后将其导出为 PDF,请进入“编辑” 菜单,选择 “偏好”,并点击左侧面板中的 “安装” 链接。在搜索栏中,输入 “fountain” 来安装由开发者 *superlou* 发布的 Fountain 插件。

在安装时,你会被提示同意安装它的一些依赖项。一旦安装完毕,你可以进入 “软件包” 菜单,选择 “Fountain”,然后查看你的剧本预览或导出 PDF 版本。
Emacs 也有一个 Fountain 模式 ,它还可以在你输入时执行一些基本的格式化。

无论你使用什么文本编辑器,你总是可以使用专门的应用程序来渲染你的剧本。有一个叫 `Screenplain` 的 Python 模块我觉得很好用。要安装它,请在终端键入以下内容:
```
$ python3 -m pip install 'screenplain[PDF]' --user
```
这样将一个剧本渲染成 PDF:
```
$ screenplain --format pdf myscreenplay.fountain > script.pdf
```

### 开源的电影剧本
Fountain 是方便的。你可以撰写你的剧本,而不需要特别复杂的应用程序。
Fountain 是省钱的。你可以撰写你的剧本而不需要昂贵的软件。
Fountain 是灵活的。你可以在你用来写作的应用程序中进行创作。
Fountain 是适宜保存的。你不会因为一个应用程序过时了,或者没有商业支持了,或者因为你买不起而不能访问你的作品。
使用 Fountain 有很多很好的理由,但最重要的一点是它能帮助你专注于创作。如果你心中酝酿了一部电影,就用 Fountain 来写。这是通向可能是一个非常令人兴奋的旅程的第一步。
---
via: <https://opensource.com/article/21/12/linux-fountain>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A screenplay is the blueprint for a movie, and it used to be written on a typewriter. You bought the typewriter, and you could write a screenplay. And not just one screenplay, but lots of them. You could write screenplays until typewriters fell out of fashion.
The puzzling thing is, though, that as technology for writing became "better," the harder it got to write screenplays. There are strict formatting rules in the screenplay world implemented to help the Assistant Director (AD) on a film shoot estimate how long each scene would take to shoot. You'd think that a computer would make this easier than the exclusively manual process required on a typewriter. Yet, popular computers managed to restrict writers with expensive software that became embedded in Hollywood culture. If you didn't have the right software, you were told that you could never be a serious screenwriter.
All that changed with open source software, though, and one of the simplest methods of writing screenplays is not to use special software at all. The [Fountain](http://fountain.io) markdown technique requires just a plain text editor, like [Atom](https://opensource.com/article/20/12/atom), [Kate](https://opensource.com/article/20/12/kate-text-editor), [Gedit](https://opensource.com/article/20/12/gedit), or similar, and it exports to a properly formatted HTML or PDF screenplay.
## Install Fountain
Fountain doesn't require installation because it's not software; it's a set of rules you use as you write. You already follow rules when writing: you capitalize the first letter of a sentence, end each sentence with a full-stop, and so on. When you write in Fountain, you add a few new rules specific to screenplays.
## Slugs
In a screenplay, each scene is delimited by a line written in capital letters, starting with either INT. or EXT., a location, a dash, and the time of day. These instructions are referred to as *slugs*. Conveniently, that's also the rule in Fountain, so there's nothing new to remember to create a slug.
`EXT. CASTLE COURTYARD - DAY`
## Action
When an actor is required to perform a specific action, a screenplay contains action text. This is normal prose, written exactly as you'd write text in a book. All normal rules apply, so nothing new to remember for action text.
```
A wizard wanders out of a great stone door. She approaches the center of the courtyard and pauses. Something's caught her eye.
It's a book. She leans down and picks it up.
```
## Dialog
Screenplays format dialog indented from both left and right margins. To a casual viewer, it might appear centered, but it's actually left-justified. It's formatted this way to help actors locate their lines and to force the screenplay to take up more space for spoken dialog because, in movies, that's often what occupies much of the running time.
In Fountain, the rule for dialog is to write the name of the character who's speaking in capital letters. On the next line, write the dialog normally.
```
WIZARD
I can sense your power. Grep? Sed? What strange terms!
```
When you export your screenplay, the dialog gets adjusted with the appropriate formatting.
## Transitions
It's somewhat fallen out of favor now, but traditionally, there were indications of special transitions in screenplays because, long ago, some transitions cost a lot of money. You still see transitions in screenplays today, but it's often meant more as a sort of punctuation mark for a group of scenes (or, in the case of the classic FADE OUT., the whole movie) rather than an actual instruction for the editor.
To create a transition in Fountain, prefix your text with the greater-than symbol (>).
```
>ANGLE ON:
The book's title page. It reads "Introduction to Linux."
>FADE OUT.
```
## More rules
You can use many other markdown conventions in your screenplays, such as asterisks to italicize, embolden, and underline text. And there are yet more rules in Fountain for edge cases and stylistic exceptions, but these four rules are all you need most of the time.
The simplicity of Fountain, though, demonstrates how well designed the screenplay format was a hundred years ago. It had a standard structure that made it easy for human eyes to parse, and such predictability translates well for computer parsing, as well.
## Exporting and rendering
Once you're done writing, you can export your screenplay to its proper format using a rendering application. There are [several renderers available](https://fountain.io/apps), but one of my favorites is the Atom editor. To configure Atom to display Fountain previews files in the appropriate format, and to export them to PDF when you're done, go to the **Edit** menu, select **Preferences**, and click the **Install** link in the left panel. In the search field, type **fountain** and install the Fountain plugin released by developer *superlou*.
(Seth Kenlon, CC BY-SA 4.0)
You're prompted to agree to install some of its dependencies as it installs. Once everything's installed, you can go to the **Packages** menu, select **Fountain**, and either view a preview of your screenplay or export a PDF version.
There's a **fountain-mode** for Emacs, too, which has the added convenience of performing some basic formatting as you type.

(Seth Kenlon, CC BY-SA 4.0)
Regardless of what text editor you use, you can always render your screenplay using dedicated applications. There's a Python module called Screenplain that works well for me. To install it, type this into a terminal:
`$ python3 -m pip install 'screenplain[PDF]' --user`
To render a screenplay to PDF:
`$ screenplain --format pdf myscreenplay.fountain > script.pdf`

(Seth Kenlon, CC BY-SA 4.0)
## Screenplays with open source
Fountain is about convenience. You can write your screenplay without the complexity of a special application.
Fountain is about budget. You can write your screenplay without costly software.
Fountain is about flexibility. You can create in the application you already use for writing.
And Fountain is about preservation. You won't lose access to your work because an application goes out of style, or out of business, or because you can't afford it.
There are many great reasons to use Fountain, but the most important one is that it helps you focus on creativity. If you've got a movie in mind, write it in Fountain. It's the first step to what could be a very exciting journey.
## 2 Comments |
14,115 | GNOME 搜索功能的一些小技巧 | https://itsfoss.com/control-gnome-file-search/ | 2021-12-25T11:59:07 | [
"GNOME",
"搜索"
] | https://linux.cn/article-14115-1.html | 
你可能已经注意到,当你在 GNOME 菜单/活动区搜索某样东西时,它也会显示名称与搜索词相匹配的文件,以及已安装的应用。

这是个很方便的功能。如果你记得文件名,甚至是它的一部分,你可以很容易地搜索到它,只需按下 `Super` 键(`Windows` 键)并输入文件名就可以打开它。
但是,围绕这个搜索功能,有一些你可能不知道或从未关心过的小问题。
在这篇文章中,我将分享你如何控制 GNOME 搜索功能,从搜索选项中添加或隐藏文件夹,以及完全禁用它。
注意:这专门针对使用 GNOME 的发行版。请 [确认你使用的是哪种桌面环境](https://itsfoss.com/find-desktop-environment/),确保是 GNOME。
### 文件搜索的默认位置
GNOME 的搜索功能使用了一个叫做 [Tracker Miner FS](https://wiki.gnome.org/Projects/Tracker/Documentation/GettingStarted) 的工具。请不要被 “tracker” 和 “miner” 这样的术语吓到。它不是在监视你,也不是在你的系统上挖掘加密货币。它的基本功能是作为一个搜索引擎和数据库,为你提供即时搜索结果。
默认情况下,文件索引发生在元文件夹,如文档、音乐、图片和视频目录及其子目录。主页和下载文件夹中的文件也会被索引,但不包括其子目录中的文件。

如果你在你的主文件夹中创建了一些新的目录,这些文件将不会被索引。
然而,最近访问的文件也会被自动编入索引。如果你最近打开了一个文件,它将被添加到 “最近的文件” 中,并将出现在搜索结果中,而不管它在什么地方。
如果你还不知道的话,你可以在文件管理器中看到你最近访问的文件:

### 在搜索结果中添加一个文件夹的内容
假设你在你的主目录中为编码项目创建了一个文件夹。这些文件不会被索引,也不会出现在搜索结果中(除非你通过双击打开了一个文件,并且它被添加到最近的文件中)。
要在搜索结果中添加自定义文件夹中的文件,你可以将该文件夹添加到搜索位置。
通过在菜单/活动区搜索打开 “设置” 应用。

从左侧边栏进入 “搜索” 选项,点击顶部的“搜索位置”选项。在弹出的窗口中,进入 “其他” 标签,点击 “+” 符号。它将打开文件浏览器,你可以添加你想要的文件夹。

如果你在刚刚添加的文件夹中搜索一个文件名进行测试,你现在应该在搜索结果中看到它。它应该是即时的,但如果不是,请尝试注销或重启系统。
### 从搜索结果中隐藏一个文件夹
如果你不希望某个特定文件夹的文件出现在搜索结果中,你可以隐藏它。
如果你不希望在搜索中出现图片、文档、视频等元文件夹的内容,你可以从搜索位置设置中禁用它。

如果你只想让文档下的某个文件夹的内容不出现在搜索结果中,你只需要在该文件夹中创建一个名为 `.nomedia` 的新文件。你也可以将该文件命名为 `.git`、`.trackerignore` 或 `.hg`。

如果你在鼠标右键中没有看到创建新文件的选项,你必须做一些调整来增加 [在右键上下文菜单中创建新文件选项](https://itsfoss.com/add-new-document-option/)。还要注意的是,任何名称中以 `.` 开头的文件都会被隐藏起来,不能被正常查看。要 [切换显示隐藏文件](https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/),按 `Ctrl+H` 键。
这种隐藏可能不会立即生效,因为该文件可能已经被索引了。你可能必须注销或重启才能看到效果。
如果你手动访问一个文件,它将被添加到最近的文件中,并且会出现在搜索结果中,尽管文件夹中的文件被忽略了。
你可以从 “设置 -> 隐私 -> 文件历史 & 垃圾箱” 删除最近的文件历史或完全禁用它(如果你想的话)。不过我认为没有必要,所以在这里你自己决定吧。

### 禁用所有文件的搜索结果
如果你不希望任何文件出现在搜索结果中,你可以在搜索设置中完全禁用对文件的搜索。

你应该通过点击顶部的搜索切换按钮完全禁用搜索功能,它可能会干扰 GNOME 桌面环境的正常功能。
关于它的更多细节可以在 [项目主页] 中找到。
### 总结
这里的 *讨论的是文件搜索*。GNOME 桌面也可以在日历、字符映射和其他一些程序中进行搜索。你可以禁用或启用可用的搜索选项,但我们这篇不针对这些。
我希望你觉得这个快速提示对 [定制你的 GNOME 体验](https://itsfoss.com/gnome-tricks-ubuntu/) 有帮助。如果你知道其他一些你想让别人知道的技巧,请在评论中与我们分享。
---
via: <https://itsfoss.com/control-gnome-file-search/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You might have already noticed that when you search for something in the GNOME menu/activities area, it also shows the files with names matching the searched term along with installed applications.
That’s a handy feature. If you remember the file name or even part of it, you can easily search for it and open it just by pressing the Super key (Windows key) and typing the name.
But there are a few nit bits around this search feature that you might not know about or never cared for.
In this article, I’ll share how you can control the GNOME search feature, add or hide folders from the search option and disable it completely.
*Note: This is exclusively for distributions using GNOME. Please verify which desktop environment you are using and ensure it is GNOME.*
## Default locations for file search
The GNOME search feature utilizes a utility called [Tracker Miner FS](https://wiki.gnome.org/Projects/Tracker/Documentation/GettingStarted). Please do not get alarmed by the terms like *tracker* and *miner*. It’s not spying on you or mining crypto on your system. It basically functions as a search engine and a database to provide you instant search results.
By default, the file indexing takes place in the meta folders like Documents, Music, Pictures and Videos directories and their sub-directories. Files in the Home and Downloads folders are also indexed but not the ones in their sub-directories.
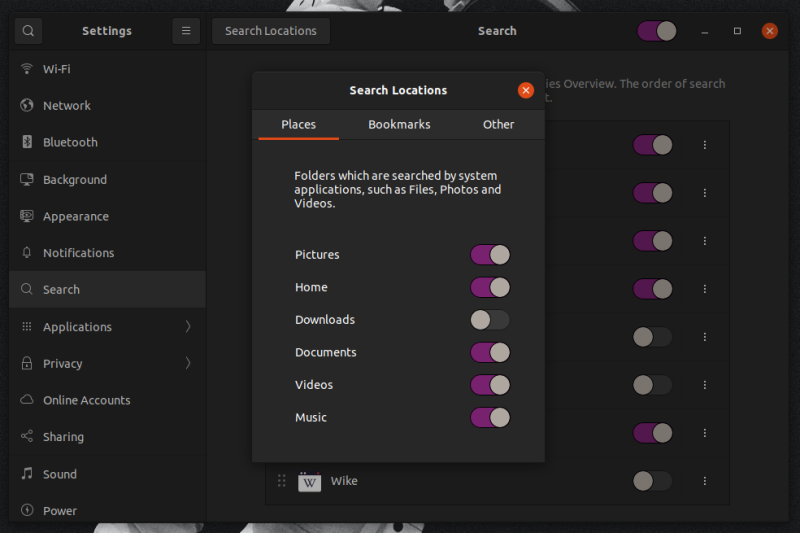
If you have created some new directories in your home folder, those files will not be indexed.
However, the recently accessed files are also indexed automatically. If you have opened a file recently, it is added to the ‘recent files’ and will appear in the search results irrespective of its location.
In case you didn’t know already, you can see your recently accessed files in the file manager:
## Adding a folder content to search results
Suppose you have created a folder for coding projects in your home directory. These files won’t be indexed and won’t appear in search results (unless you have opened a file by double clicking and it is added to the recent files).
To add the files from a custom folder in the search result, you can add the folder to the search locations.
Open the Settings application by searching for it in the menu/activity area:
Go to the **Search** option from the left sidebar and click on the **Search Locations** option at the top. In the pop-up window, go to the **Other** tab and click on the **+ symbol**. It will add the file browser and you can add your desired folder.
If you test by searching a filename in the just added folder, you should see it in the search results now. It should be instant but if it is not, try logging out or rebooting the system.
## Hide a folder from search results
If you don’t want files from a specific folder to appear in the search result, you can hide it.
If you don’t want the content of the meta folders like Pictures, Documents, Videos in search, you disable it from the Search Location settings.
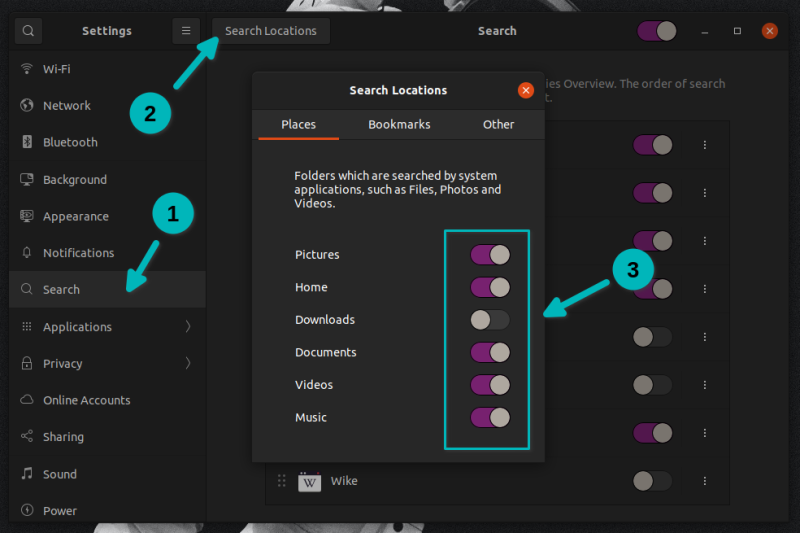
If you want the contents of only a certain folder under Documents to NOT appear in the search result, you just have to create a new file named **.nomedia** in that folder. You may also name the file .git, .trackerignore or .hg.
If you don’t see the option to create new file in right mouse lick, you’ll have to do some tweaking to add the [create new document option in the right click context menu](https://itsfoss.com/add-new-document-option/). Also note that any files starting with a . in its name is hidden from normal view. To [toggle hidden files](https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/), press Ctrl+H keys.
This hiding might not work immediately because the file is probably already indexed. You may have to log out or reboot to see the effect.
If you access a file manually, it will be added to the recent files and will appear in the search result despite the ignore file in the folder.
You can delete the recent files history or disable it altogether (if you want) from **Settings-> Privacy-> File History & Trash**. I don’t see the need of it, though, so make your own decision here.
## Disable search results for all files
If you do not want any files to appear in the search results, you can disable search for Files altogether from the search settings.
You should disable the search functionality altogether by clicking the Search toggle button at the top as it may interfere with the normal functionality of the GNOME desktop environment.
More details on it can be found on the [project’s homepage](https://gnome.pages.gitlab.gnome.org/tracker/).
## Conclusion
The ** discussion here is about file search**. GNOME desktop also searches in Calendar, Characters and some other utilities. You can disable or enable the available search options but let’s not focus on that.
I hope you find this quick tip helpful in [customizing your GNOME experience](https://itsfoss.com/gnome-tricks-ubuntu/). If you know some other neat trick that you want others to know, please share it with us in the comments. |
14,117 | 为开放实践图书馆做出贡献的 7 种方式 | https://opensource.com/article/21/10/open-practice-library | 2021-12-26T09:44:27 | [
"开放实践"
] | /article-14117-1.html |
>
> 向开放实践图书馆做出贡献是参与全球实践者社区的一种有趣方式,这些实践者都愿意分享他们的知识并改进他们自己的工作方式。
>
>
>

[开放实践图书馆](https://openpracticelibrary.com/learn) 是一个社区驱动的实践集合,以支持团队的协作。“实践” 是一种行为或一个 “技巧”,是团队用来改善他们实现目标的方式。有时这些目标是技术性的,如编程和 IT,但所有的团队都可以用来帮助定义他们的实践。无论你是教师、活动策划者、销售人员还是艺术家,这个过程都很重要。对于一个团队,站在同一起跑线上是至关重要的,而这正是开放实践图书馆可以帮助你做到的。
该图书馆借鉴了来自不同背景的从业者的经验。如果你是一个敏捷开发从业者或用户体验研究员,你可能会对该图书馆中的一些实践感到熟悉。作为一个系统管理员、网站可靠性工程师或软件开发人员,你也可能认出一些你自己的工具包中的实践。
为了支持跨职能的团队共同建立他们的协作技能,开放实践图书馆向所有人开放,让他们使用、学习、分享,甚至贡献,无论他们的角色或工作职能如何。许多人在使用这个图书馆的时候,惊讶地发现他们可以为其做出贡献!因此,下面我将介绍一下你可以为开放实践图书馆做出贡献的七种不同方式,然后探讨一下你可能为之贡献的三个原因。
### 1、添加评论
分享你使用该实践的经验。它对你有用吗?你会改变什么吗?对其他使用该实践的人有什么建议吗?请登录评论系统,与社区展开讨论。
**方法:** 在每个实践页面的底部都有一个评论区。

要加入评论对话,你必须在 [Hyvor Talk](https://talk.hyvor.com) 上注册一个账户。
### 2、传播消息
向其他人介绍开放实践图书馆并邀请他们也来贡献力量,以帮助开放实践图书馆社区的发展。可以在 [Twitter](https://twitter.com/practicelibrary)、[Instagram](https://www.instagram.com/openpracticelibrary) 上找到实践图书馆,并收听 [该播客](https://podcasts.apple.com/us/podcast/open-practice-podcast/id1501715186)。
### 3、添加你最喜欢的实践
你是一个拥有久经考验的方法的实践者,而图书馆里还没有涉及这个方法吗?如果能与大家分享,那就太好了。请注意,这些内容是在创意共享许可下授权的,以确保其开放给所有人使用并与他人分享。请查看该图书馆的 [编辑风格指南](https://openpracticelibrary.com/page/editorial/),了解更多关于如何为其撰写一篇实践。
OK,准备好了吗?
从菜单中选择 <ruby> 添加一个实践 <rt> Add a Practice </rt></ruby>。

这将使你进入内容管理系统(CMS)的登录页面。该图书馆使用开源的 Netlify CMS 来管理投稿。
选择 <ruby> 用 Netlify 身份登录 <rt> Login with Netlify Identity </rt></ruby>。

然后点击 <ruby> 使用 GitHub 继续 <rt> Continue with GitHub </rt></ruby>。

接下来,用你的 GitHub 信息登录,或者(免费)创建一个账户。

登录后,选择 <ruby> 新的实践 <rt> New Practice </rt></ruby>,这将使你进入一个表格,可以将实践添加到集合中。

一旦你起草了新的实践,你还需要把你的名字和 GitHub 用户名添加到 CMS 中,以便在 <ruby> 实践 <rt> Practice </rt></ruby> 页面上显示。从 <ruby> 快速添加 <rt> Quick add </rt></ruby> 菜单中选择 <ruby> 作者 <rt> Author </rt></ruby>,或者从 <ruby> 集合 <rt> Collections </rt></ruby> 菜单中选择 <ruby> 作者 <rt> Author </rt></ruby>,然后选择 <ruby> 新作者 <rt> New Author </rt></ruby>。

### 4、添加一个有用的资源或链接
点击 <ruby> 改进此实践 <rt> Improve this Practice </rt></ruby> 按钮,找到 <ruby> 我们喜欢的链接 <rt> links we love </rt></ruby>部分。发布网址、添加描述、并选择类别(例如,视频、博客)。

你可以搜索你想改进的实践,例如,“Affinity Mapping”。

然后点击实践名称,打开编辑页面。
### 5、看到一个错别字?
点击 <ruby> 改进此实践 <rt> Improve this Practice </rt></ruby> 按钮,直接去修改它吧
### 6、在 GitHub 上添加一个议题
看到有什么不对的地方吗?对某个功能有建议?请让社区知道。
**如何做:** 到 [议题页面](https://github.com/openpracticelibrary/openpracticelibrary/issues/new) 并登录 GitHub 来添加一个新议题。
### 7、帮助处理网站的代码
在 GitHub 上有一个累积的议题,列出了网站上需要帮助的地方。如果你想卷起袖子,[帮助修复错误](https://github.com/openpracticelibrary/openpracticelibrary/issues?q=is%3Aissue+is%3Aopen+label%3ABug) 或开发新功能 —— 你甚至还可以贡献代码。
### 总结
为什么要贡献?这里有三个原因供你考虑。
1. “寓学于教”是一句古老的罗马谚语。
通过写下来并与他人分享,你会加深自己对所使用的实践的理解。对该实践的来源背景做一些研究,帮助注明原始来源,并找到其使用的例子。
2. 提高你的写作技巧。
通过遵循编辑风格指南,你正在学习调整你的自然写作风格以适应特定的标准。这是一项有价值的基本沟通技巧,你可以在一系列的环境中应用。
3. 展示领导力。
通过与一个开放的全球社区分享你的知识和专长,你可以帮助他人成长并从你的深度经验中学习。
[向开放实践图书馆贡献](https://openpracticelibrary.com/page/contribution-guide) 是参与全球开放的实践者社区的一种有趣而简单的方式,这些实践者都愿意分享他们的知识,并试图改善他们自己的工作方式。
---
via: <https://opensource.com/article/21/10/open-practice-library>
作者:[Donna Benjamin](https://opensource.com/users/kattekrab) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
14,118 | 我把 Pop!_OS Linux 作为主要系统的 7 个原因 | https://itsfoss.com/why-use-pop-os/ | 2021-12-26T11:57:00 | [] | https://linux.cn/article-14118-1.html | 
Pop!\_OS 是向 Linux 初学者和游戏玩家的热门推荐。但是,Pop!\_OS 从其他基于 Ubuntu 的发行版中脱颖而出的原因有哪些?为什么你应该考虑把它作为你电脑日常使用的系统?
三年前,我从 Ubuntu 转到了 [Pop!\_OS](https://itsfoss.com/pop-os-vs-ubuntu/),从那时起它就成了我的日常系统。
让我为你指出选择它作为你的日常操作系统的好处。
### 选择 Pop!\_OS 而不是其他 Linux 发行版的原因
请注意,这里列出的一些原因可能是主观的,完全取决于你想要什么,以及你期望的桌面体验。
考虑到这一点,让我强调一下为什么我选择 [Pop!\_OS](https://pop.system76.com/) 作为我的主要操作系统,而不是其他 Linux 发行版。
#### 1、单独的 NVIDIA/AMD ISO

如果你有一个装有 Nvidia GPU 的机器,使用 [Nouveau](https://nouveau.freedesktop.org)(Nvidia 显卡的开源驱动程序)来使其工作是不可行的。
好吧,你的显示器可以工作,但你不能发挥你的显卡的优势。
例如,你会在几乎所有需要利用 GPU 的任务中遇到卡顿和性能问题。
因此,专有的 Nvidia 驱动程序是解决这些问题的唯一解决方案。
而且,为了让添加专有驱动程序能够开箱即用,发行版需要将其包含在 ISO 中,或者提供一个单独的 ISO,其中包含 Nvidia 最新可用的专有驱动程序。
虽然你肯定可以手动安装专有驱动程序,但这并不是完美的体验。
顺便说一句,对于大多数流行的 Linux 发行版,这个过程应该与 [在 Linux Mint 中安装 Nvidia 驱动程序](https://itsfoss.com/nvidia-linux-mint/) 类似。

请注意,有时你需要排除故障或重新安装正确的(或较早的驱动版本)才能正确使用 Nvidia 显卡。
但是,如果你有单独的 ISO 来支持 Nvidia 的系统或 Nvidia 图形安装模式(如 Zorin OS),那就可以消除手动安装 Nvidia 驱动程序的麻烦。
这不仅仅是为了方便使用,而是 Pop!\_OS 通过提供帮助性的 Nvidia ISO 做到了开箱即用。
当我试图手动安装专有驱动程序时,我曾在 Linux Mint、Ubuntu 和其他一些发行版上遇到过问题。因此,Pop!\_OS 对于我带有 Nvidia 显卡的系统来说,设置起来非常容易。
#### 2、自动平铺管理器

如果没有平铺管理器,你需要不断地拖放(和移动)你的活动窗口来组织它们以便快速访问。
因此,一个窗口平铺管理器可以方便地自动组织你启动的应用程序的活动窗口。
当然,使用平铺管理器的体验会因你的屏幕尺寸而不同,但即使你有一个尺寸不大的 27 英寸显示屏,它也应该会有明显的体验改善。
我自己一直在使用它,即使没有大显示器(或双显示器设置)。
我从来没有在笔记本电脑上使用过它,但整天工作时,拥有一个自动窗口平铺管理器(你可以启用/禁用)听起来是一个有用的功能。
它有助于提高你的多任务处理能力,而不一定要移动到不同的工作空间。
#### 3、使用的便利性
为什么你认为 Ubuntu 是 [最好的 Linux 发行版](https://itsfoss.com/best-linux-distributions/) 之一?
多年来,它一直设法提供易于使用的现代桌面体验。
令人印象深刻的是,System76 已经设法将 Pop!\_OS 的用户体验在 Ubuntu 的基础上提升了一个档次。
因此,Pop!\_OS 不仅仅是另一个 Ubuntu 发行版,它的应用启动器、应用库、坞站、工作区定制以及其他各种优化都带来了独特的桌面体验。
对于我的使用情况而言,它感觉比 Ubuntu 更好。别忘了,它还包括一些工具,比如 [Popsicle](https://github.com/pop-os/popsicle),这些工具在以后的工作中会很方便。
#### 4、较新的 Linux 内核

Ubuntu 可能不具有最新和最棒的 Linux 内核,特别是它的 LTS 版本时。
然而,Pop!\_OS 尽力提供最新的 Linux 内核版本,即使是在 LTS 版本中。例如,Ubuntu 20.04.3 LTS 包含了 Linux 内核 5.11,但 Pop!\_OS 20.04 LTS 具有 Linux 内核 5.13。
对于大多数用户来说,这可能不是什么大问题,但是 Pop!\_OS 比其他大多数 Linux 发行版更快地推送了更新的 Linux 内核。
如果你想让你的最新和最棒的硬件与 Linux 发行版很好地配合工作,Pop!\_OS 是一个绝妙的选择。
#### 5、应用程序启动器

应用程序启动器在快速启动应用程序或在活动窗口之间进行导航时非常方便。
使用快捷方式(也可能是链接到它的宏,就像我使用的那样)调用启动器的能力,使它成为启动应用程序和在它们之间进行导航的最快捷的方式之一。
当然,你可以安装像 [Ulauncher](https://itsfoss.com/ulauncher/) 这样的工具来实现同样的目的。不过,它是预先配置、开箱即用的,不需要任何故障排除,这很方便。
#### 6、快速升级过程
尽管升级 Linux 发行版通常是无忧无虑的,但 Pop!\_OS 在每次更新时都尽力完善和改进这个过程。
例如,在 Pop!\_OS 21.10 中,他们引入了一些改进措施,以防止升级过程中的冲突,并使其成为一个顺畅的过程。
事实上,我从 Pop!\_OS 21.04 升级到 21.10 只需点击几下,没有遇到任何问题。
#### 7、努力改善现代桌面体验
Pop!\_OS 可能不是一个 [轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/),但它专注于为现代桌面用户提供一流的体验。
虽然有很多适合老式电脑的 Linux 发行版,但以新一代硬件为目标同样重要。
System76 也在他们的最新笔记本硬件配置上测试过该发行版,Pop!\_OS 在这方面表现得非常好。
此外,Pop!\_OS 还提供了开箱即用的调整功能,使用户在操作系统方面的体验变得简单。虽然 Linux 就是不断调整和控制你的系统,但 Pop!\_OS 似乎成功地使它成为一个主流选择和一个可行的 Ubuntu 替代品,这可能对一些人来说更好。
#### 补充:软件包更新
System76 最近在 [Pop!\_OS 21.10 版本](https://news.itsfoss.com/pop-os-21-10/) 中从 Launchpad 转向了自己的软件库。
这应该能让他们更快地推送更新,并控制软件包以确保用户的最佳体验。
这也应该使 Pop!\_Shop 更加有用。因此,这是又一个在我的机器上继续使用 Pop!\_OS 的理由。
### 总结
Pop!\_OS 在很多地方做的很好。
如果你对选择一个易于使用、与最新硬件兼容、适合各种使用情况的 Linux 发行版感到困惑,我会推荐 Pop!\_OS。
上述原因是我坚持使用它的原因,即使在我曾经尝试切换到 Zorin OS 和 Linux Mint 几个月。
---
via: <https://itsfoss.com/why-use-pop-os/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Pop!_OS is a popular recommendation for Linux beginners and gamers alike. But, what are some of the reasons that Pop!_OS stands out from other Ubuntu-based distros available? Why should you consider it as a daily driver for your computer?
I switched to [Pop OS from Ubuntu](https://itsfoss.com/pop-os-vs-ubuntu/) three years ago and it has been my daily driver since then.
Let me point out the benefits of choosing it as the operating system of your choice.
## Reasons to Pick Pop!_OS Over Other Linux Distributions
Note that some of the reasons listed could be entirely subjective to what you want, and how you expect your desktop experience to be.
With that in mind, let me highlight why I chose [Pop!_OS](https://pop.system76.com/) as my main OS over other Linux distributions:
### 1. Separate NVIDIA/AMD ISO

In case you have a system with Nvidia GPU, it is not feasible to make it work using [Nouveau](https://nouveau.freedesktop.org) (an open-source driver for Nvidia cards).
Well, you get a working display, but you cannot utilize the benefits of your graphics card.
For instance, you will encounter stuttering and performance issues with almost every task that needs to utilize the GPU.
Hence, the proprietary Nvidia drivers are the only solution to make things right.
And, to conveniently add the proprietary driver out of the box, the distro needs to include it in the ISO itself or offer a separate ISO with Nvidia’s latest available proprietary driver.
While you can always manually install the proprietary drivers, it is not always a flawless experience.
The procedure should be similar to that of [installing Nvidia drivers in Linux Mint](https://itsfoss.com/nvidia-linux-mint/) for most of the popular Linux distros if you are curious.

Note that, at times, you will need to troubleshoot or re-install the correct (or an older driver version of the driver) to use Nvidia graphics properly.
But, if you get a separate ISO for Nvidia-powered systems, or an Nvidia graphics installation mode (like Zorin OS), it eliminates the hassle of installing Nvidia drivers manually.
This is not just about the ease of use, but Pop!_OS always works out of the box with the help Nvidia ISOs offered.
I have had issues with Linux Mint, Ubuntu, and a few other distributions when I tried to manually install the proprietary drivers. So, Pop!_OS is a breeze to set up for my system with Nvidia graphics.
### 2. Automatic Tiling Manager

Without a tiling manager, you need to constantly drag and drop (and move) your active windows to organize them for quick access.
So, a window tiling manager makes it convenient to automatically organize the active windows of any application that you launch.
Of course, the experience with a tiling manager will differ as per your screen size, but even if you have a modest 27-inch size display, it should be a noticeable experience.
I find myself using it all the time, even without a big monitor (or a dual-monitor setup).
I have never used it on a laptop, but at the end of the day, having an automatic window tiling manager (that you can enable/disable) sounds like a useful feature.
It helps with enhancing your multi-tasking capabilities without necessarily moving to different workspaces.
### 3. Ease of Use
Why do you think Ubuntu is one of the [best Linux distributions](https://itsfoss.com/best-linux-distributions/)?
It manages to offer an easy-to-use modern desktop experience for years now.
Impressively, System76 has managed to polish the user experience in Pop!_OS up a notch on top of Ubuntu.
Hence, Pop!_OS is not just another Ubuntu distro, but the presence of an application launcher, application library, dock, workspace customizations, and various other optimizations lead to a unique desktop experience.
For my use-case, it feels better than Ubuntu. Not to forget, it also includes some of its tools like [Popsicle](https://github.com/pop-os/popsicle) that comes in handy later down the road.
### 4. Newer Linux Kernel

Ubuntu may not feature the latest and greatest Linux Kernel, especially when it comes to LTS releases.
However, Pop!_OS tries its best to offer the latest Linux Kernel releases even for the LTS releases. For instance, Ubuntu 20.04.3 LTS packs in Linux Kernel 5.11, but Pop!_OS 20.04 LTS features Linux Kernel 5.13.
For most users, this may not be a big deal, but Pop!_OS pushes newer Linux Kernel faster than most other Linux distributions.
If you want your latest and greatest hardware to work well with Linux distros, Pop!_OS is a fantastic bet.
### 5. Application Launcher

Application launcher comes in incredibly handy to quickly launch an app or navigate between active windows.
The ability to invoke the launcher using a shortcut (or maybe a macro linked to it, as I use it) makes it one of the quickest ways to launch applications and navigate between them.
Of course, you can install tools like [Ulauncher](https://itsfoss.com/ulauncher/) to achieve the same. However, having it pre-configured and working out of the box without any troubleshooting is convenient.
### 6. Fast Upgrade Process
Even though upgrading Linux distributions is usually hassle-free, Pop!_OS tries its best to refine and improve the upgrade process with every update.
For instance, with Pop!_OS 21.10, they introduced improvements that would prevent conflicts in the upgrade process and make it a seamless process.
In fact, I upgraded from Pop!_OS 21.04 to 21.10 in a few clicks without any issues.
### 7. Thrives to Improve the Modern Desktop Experience
Pop!_OS may not be a [lightweight Linux distro](https://itsfoss.com/lightweight-linux-beginners/), but it focuses on providing a top-notch experience for modern desktop users.
While there are plenty of good Linux distributions for older computers, it is equally important to aim for newer-gen hardware.
Pop!_OS does that incredibly well considering System76 also tests the distribution on latest hardware configurations with their laptops.
In addition, Pop!_OS also offers out-of-the-box tweaks that makes things easy for a user in terms of OS experience. While Linux is all about tweaking and taking control of your system, Pop!_OS seems to be succeeding in making it a mainstream option and a viable alternative to Ubuntu that could prove to be better for some.
### Bonus: Package Updates
System76 has recently switched away from Launchpad to its own repositories with the [Pop!_OS 21.10 release](https://news.itsfoss.com/pop-os-21-10/).
It should let them push updates faster, and take control of packages to ensure the best experience for users.
This should also make the Pop!_Shop more useful. So, yet another reason to keep using Pop!_OS on my machine.
## Wrapping Up
Pop!_OS does a lot of good things.
And, if you are confused with choosing a Linux distro that is easy to use, compatible with latest hardware, and fits various use-cases, I would recommend Pop!_OS.
The above-mentioned reasons are why I stick to it even after I tried switching away to Zorin OS and Linux Mint for a few months. |
14,120 | elementary OS 6 应该改进体验的 5 个地方 | https://news.itsfoss.com/elementary-os-6-things-to-improve/ | 2021-12-27T11:47:02 | [
"elementaryOS"
] | https://linux.cn/article-14120-1.html |
>
> elementary OS 是一个漂亮的 Linux 发行版,但它适合所有人吗?它们是否有可以做得更好的地方?下面是我的想法。
>
>
>

[elementary OS 的 6.1 是最新的版本](https://news.itsfoss.com/elementary-os-6-1-release/),它做了许多基本的改进,带来了一些新功能。
当然,为你的系统选择的 Linux 发行版在很多方面都是不同的。然而,我认为在 elementary OS 中,有一些事情可以做得更好。
在这里,我列出了 elementary OS 中可以做的一些改进。
不过,这仅代表我个人观点,请诸位轻喷。
### elementary OS 中可以改进的东西
如果你想看的话,我也打算指出其他发行版的我不喜欢东西(从这篇开始)。
发行版通常仅展示其好的一面,除非有人指出一个发行版中潜在的细微差别,否则你无法真正确定这个发行版是否适合你。
#### 1、没有内置的 Debian 软件包安装程序

它是一个基于 Ubuntu 的发行版,但下载一个 deb 文件后才发现无法安装,还得让你寻找解决方案。
这当然是有原因的,因为 elementary OS 在 [elementary OS 6 发布](https://news.itsfoss.com/elementary-os-6-release/) 时切换到了只使用 Flatpak 的模式,即使是对于第一方的应用程序也是如此。
然而,新用户很可能不知道像 Eddy 这样的解决方案,它是一个 Debian 软件包安装程序,可以在 AppCenter 中找到。
当你尝试安装 deb 包时,指向该工具的通知/提示应该说明清楚。或者,预下安装 Eddy 应该会让事情变得更方便。
#### 2、Flathub 支持开箱即用

Flatpak 优先的方法使安装软件更加安全和方便。然而,你不能通过 Flathub 安装 Flatpak 应用程序,除非你(使用终端)手动添加了第三方 Flatpak 仓库。
即使 AppCenter 提供了 Flatpak 应用程序,但它可能不足以满足所有用户的需要。相比之下,Flathub 提供了大量的 Flatpak 应用程序。
虽然提供第一方的体验,并且让用户能够在需要时启用第三方(Flathub)是件好事,但是否可以做些什么来轻松启用 Flathub 的支持,而无需去终端?(忽略 flatpak 的参考文件)

好吧,我认为用一个快速切换开关来启用/禁用开箱即用的 Flathub 支持可以使事情变得更好。
或者,像你在上面的截图中注意到的那样,在建议启用 Flathub 的同时提到该命令。
#### 3、最小化按钮

考虑到 elementary OS 没有像 Pop!\_OS 那样的自动平铺窗口功能,许多应用程序上缺少最小化按钮可能会让人觉得令人不适。
是的,你可以利用键盘上的快捷键 `Super+H` 来隐藏/最小化窗口。然而,对于以鼠标操作为主的用户来说,没有最小化按钮的感觉并不舒服。
#### 4、没有系统托盘支持

根据他们的设计选择,elementary OS 团队认为最好不要有系统托盘的支持(或者是我从 Reddit 的一些帖子中了解到的情况)。
不幸的是,系统托盘的图标对于快速访问和关注某事物的状态非常有用。
例如,我可以从应用指示器图标中快速访问 Flameshot 截图工具,在使用 Insync 等工具时检查同步状态,当 Slack 中有我的信息时也会得到通知。
而如果没有系统托盘图标的整合支持,我就不能做这些事情,这是一个缺陷。
#### 5、一个单独的 NVIDIA ISO

单独的 NVIDIA ISO(或 Nvidia 显卡安装模式)比通过软件中心安装专有的 Nvidia 驱动程序要方便得多。
当然,我在使用 AppCenter 安装 Nvidia 驱动时没有任何问题。但是,有了单独的 ISO,你就省去了安装后的额外步骤。
### 总结
每个操作系统都有缺陷,Linux 发行版也不例外。
有时这些细微的差别是根据其目标用户设计出来的。你可能喜欢也可能不喜欢一个发行版所做的一切,这就是为什么要知道它们能否做得更好(或是否适合你)。
elementary OS 无疑是 [最漂亮的 Linux 发行版之一](https://itsfoss.com/beautiful-linux-distributions/)。但是,它适合你吗?
好吧,如果我提到的一些观点是你不在意的,那它对你来说应该是很好的体验。
---
via: <https://news.itsfoss.com/elementary-os-6-things-to-improve/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[elementary OS 6.1 is the latest release](https://news.itsfoss.com/elementary-os-6-1-release/) with many essential improvements and new features.
Of course, the choice of a Linux distro for your system varies on many levels. However, I think there are a few things in elementary OS that could have been done differently.
Here, I list some of the aspects that could use some improvements in elementary OS.
*Note that this is entirely my opinion, so take it with a pinch of salt.*
## Things That Can Be Improved in elementary OS
If you are curious, I plan to point out things I don’t like for other distributions as well (starting with this).
It is usual to feature the good stuff but unless someone points out the potential nuances in a distro, you cannot really decide whether the distro is for you or not.
### 1. No Built-in Debian Package Installer
Considering it as an Ubuntu-based distribution, downloading a deb file to only find that you cannot install, makes you look for solutions.
This makes sense because elementary OS switched to a Flatpak-only model with [elementary OS 6 release](https://news.itsfoss.com/elementary-os-6-release/), even for the first-party applications.
However, new users are likely to be unaware of solutions like “**Eddy**” which is a Debian package installer and available in the AppCenter.
A notice/tip that points to you to the tool when you try installing a deb package should make it clear. Or, having Eddy pre-installed should make things convenient.
### 2. Flathub Support out of the box
The Flatpak-first approach makes things more secure and convenient. However, you cannot install Flatpak applications via Flathub unless you manually add the third-party Flatpak repo (using the terminal).
Even though AppCenter features Flatpak applications, it may not be enough for all users. In contrast, Flathub offers a massive collection of Flatpaks.
While it is good to offer a first-party experience and give the ability to the user to enable third-party (Flathub) if required, but can something be done to easily enable the Flathub support without heading to the terminal? (ignoring the flatpak ref files)
Well, I think a quick toggle switch to enable/disable out-of-the-box support for Flathub could make things better.
Or, mention the command along with the suggestion to enable Flathub as you noticed in the screenshots above.
### 3. Minimize button
Considering elementary OS does not feature any auto-tiling window feature like Pop!_OS, the lack of minimize button on many applications could prove to be annoying.
Yes, you can utilize the keyboard shortcut **Super + H** to hide/minimize the window. However, for mouse-oriented users, it does not feel comfortable to not have a minimize button.
### 4. No System Tray Support

As per their design choices, the elementary OS team thinks that its best to not have system tray support (or so I read as per some Reddit posts).
Unfortunately, the system tray icons are incredibly useful for quick access, and to keep an eye on the status of something.
For instance, I can quickly access the Flameshot screenshot tool from the app indicator icon, check sync status when using a tool like Insync, and also get informed when there is a message for me in Slack.
And, without the system tray icon integration support, I cannot do any of this, which is a deal-breaker.
### 5. A Separate NVIDIA ISO
A separate NVIDIA ISO (or Nvidia graphics installation mode) is much more convenient than installing a proprietary Nvidia driver through the software center.
Sure, I did not have any issues installing Nvidia drivers using the AppCenter. But, with a separate ISO, you eliminate the additional step after installation.
## Wrapping Up
There are flaws in every operating system, a Linux distribution is not an exception.
Sometimes these nuances are there by design, as per their targeted users. You may or may not like everything that a distro does, which is why it is important to know what can they do better (or if it is suitable for you).
elementary OS is undoubtedly [one of the most beautiful Linux distributions](https://itsfoss.com/beautiful-linux-distributions/?ref=news.itsfoss.com) out there. But, is it the one for you?
Well, if some of the points that I mention do not bother you, it should be a great experience for you.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,121 | 用 pdftk-java 命令编辑 PDF 的 4 种方法 | https://opensource.com/article/21/12/edit-pdf-linux-pdftk | 2021-12-27T13:07:25 | [
"PDF"
] | /article-14121-1.html |
>
> 用这个方便的 Linux 命令合并 PDF、删除页面、分割 PDF 和填写表格。
>
>
>

技术白皮书、手稿和 RPG 手册,我每天都要处理大量的 PDF 文件。PDF 格式之所以受欢迎,是因为它包含经过处理的 PostScript 代码。PostScript 是现代打印机的原生语言,所以出版商经常将一本书的数字版本发布为 PDF,因为他们已经投入了时间和精力来制作印刷用的文件。但是,PDF 并不是一种可编辑的格式,虽然可以进行一些逆向处理,但它是数字数据发送到打印机之前的最后一站。即便如此,有时你还是需要对 PDF 进行调整,而我最喜欢的工具之一就是 [pdftk-java](https://gitlab.com/pdftk-java/pdftk) 命令。
### 在 Linux 上安装 pdftk-java
顾名思义,`pdftk-java` 是用 Java 编写的,所以只要你安装了 Java,它就能在所有主流的操作系统上工作。
Linux 和 macOS 用户可以从 [AdoptOpenJDK.net](https://adoptopenjdk.net/releases.html) 安装 Java。Windows 用户可以安装 [Red Hat 的 OpenJDK 的 Windows版本](https://developers.redhat.com/products/openjdk/download)。
要安装 `pdftk-java`:
1、从 Gitlab 仓库下载 [pdftk-all.jar 程序](https://gitlab.com/pdftk-java/pdftk/-/jobs/1527259628/artifacts/raw/build/libs/pdftk-all.jar),并将其保存到 `~/.local/bin/` 或[你 path 变量中的其他位置](https://opensource.com/article/17/6/set-path-linux)。
2、在你喜欢的文本编辑器中打开 `~/.bashrc` 并添加这一行:
```
alias pdftk='java -jar $HOME/.local/bin/pdftk-all.jar'
```
3、加载你的新 Bash 设置:
```
$ source ~/.bashrc
```
### 命令语法
一个有效的 `pdftk-java` 命令的结构遵循一个模式,但在模式中的内容有很大的灵活性。语法有点不寻常,因为它没有使用传统风格的 [终端选项](https://opensource.com/article/21/8/linux-terminal),但经过实践,它并不难记。
* `pdftk`:调用该命令的别名
* 输入文件:你想修改的 PDF 文件
* 动作:你想对输入文件做什么
* 输出:你想在哪里保存你修改过的 PDF 文件
最复杂的是动作部分,所以我将从简单的任务开始。
### 将两个 PDF 文件合并成一个
一本书的封面通常在一个单独的应用中创建,如 Inkscape 或 GIMP,而书的其他部分通常在 Scribus 等排版程序或 LibreOffice 等办公套件中完成,这种情况并不罕见。你可以在你的排版应用中把这两者结合起来。像 Scribus 这样的出版软件可以很容易地引用一张图片,这样当封面改变时,它就会在版面中自动更新。然而,也可以用 `pdftk-java` 将封面预置到 PDF 中:
```
$ pdftk cover.pdf body.pdf \
cat \
output book.pdf
```
在这个例子中,动作是 `cat` 即 <ruby> 连接 <rt> concatenate </rt></ruby> 的缩写,和 Linux 的 [cat 命令](https://opensource.com/article/19/2/getting-started-cat-command) 一样,它将一个或多个 PDF 文件串联成一个数据流,数据流被引导到“<ruby> 输出 <rt> output </rt></ruby>”参数指定的任何文件中。
### 从一个 PDF 中删除页面
你不能确切地从一个 PDF 中删除一页,但你可以创建一个新的 PDF,只包含你想保留的页面。
```
$ pdftk book.pdf \
cat 1 3-end \
output shorter-book.pdf
```
在这个例子中,我的书的文件的第 1 页,以及从 3 到结尾的所有页面,都被保存到一个新文件中。因此,我删除的那一页是第 2 页。
### 将一个 PDF 分割成不同的文件
将一个 PDF 文件分割成许多不同的文件也使用 `cat` 动作,它的原理与删除页面相似。你可以通过将你想要的页面发送到一个新文件来分割一个 PDF:
```
$ pdftk book.pdf \
cat 1-15 \
output part-1.pdf
$ pdftk book.pdf \
cat 16-42 \
output part-2.pdf
```
如果你需要将一个 PDF 分割成单页文件,有一个特殊的动作,叫做 `burst`:
```
$ pdftk book.pdf burst
$ ls
book.pdf pg_0001.pdf pg_0002.pdf
pg_0003.pdf pg_0004.pdf pg_0005.pdf
[...]
```
### 填写表格
很少有人能否认多年来 PDF 格式变得越来越臃肿,而你有时在 PDF 文件中发现的一个功能是可填写的表格。你会在美国税务文件、RPG 角色表、线上学校作业本和其他旨在互动的 PDF 文件中看到这种情况。虽然大多数现代的 PDF 浏览器,比如 GNOME 的 Evince 和 KDE 的 Okular,都可以填写 PDF 表格,但你也可以在 `pdftk-java` 的帮助下填写 PDF 表格。
首先,你必须使用 `generate_fdf` 动作提取表单数据。这将提取表单元素的 ID,并将它们放入一个文本文件。
```
$ pdftk character-sheet.pdf \
generate_fdf \
output chsheet-form.txt
```
你的目标文件(在这个例子中是 `chsheet-form.txt`)包含 PDF 中的表格数据,但只是文本部分。你可以在任何标准的文本编辑器中编辑它,如 [Atom](https://opensource.com/article/20/12/atom) 或 [Gedit](https://opensource.com/article/20/12/gedit)。
在对生成 PDF 的组织的工作流程的有时令人钦佩和有时尴尬的一瞥中,你会发现一些表格有明确的标签,而其他表格有默认的名字,如 “Checkbox\_001” 和 “Textfield-021”,所以你可能要把你的文本文件和你的 PDF 对照一下,但如果你要写一个脚本来自动填写表格,这可能是值得的。每个标签都被标记为 `/T` 项,在接下来的一行中,有空间(标记为 `/V`)提供给文本输入。下面是一个片段,它的标签有上下文,并填入了一些数据:
```
/T (CharacterName 2)
/V (Abaddon)
>>
<<
/T (SlotsTotal 24)
/V ()
>>
<<
/T (Hair)
/V (Brown)
>>
<<
/T (AC)
/V (15)
>>
<<
/T (Background)
/V ()
>>
<<
/T (DEXmod )
/V ()
```
当你输入了表单数据,你就可以用 `fill_form` 动作将你的文本输入与 PDF 结构结合起来:
```
$ pdftk character-sheet.pdf \
fill_form chsheet-form.txt \
output completed.pdf
```
下面是一个结果示例。

### PDF 修改变得简单
当你处理大量的 PDF 文件或通过 shell 脚本处理 PDF 文件时,像 `pdftk-java` 这样的工具是非常有价值的,因为它使你不必手动做所有的事情。当我从 [Docbook](https://opensource.com/article/17/9/docbook) 的输出建立一个 PDF 时,它是一个 Makefile,调用 `pdftk-java` 完成任何数量的任务,所以我没有机会忘记某个步骤或打错命令,也没有必要把时间花在这上面。在你自己的工作流程中,还有很多其他的原因你可能会使用 `pdftk-java`,它还可以做很多其他的事情,包括 `shuffle`、`rotate`、`dump_data`、`update_info` 和 `attach_files` 等动作。如果你发现自己经常与 PDF 文件打交道,可以试试 `pdftk-java`。
---
via: <https://opensource.com/article/21/12/edit-pdf-linux-pdftk>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
14,123 | 曾经遗失的 Linus Torvalds 首次在大型会议上的演讲 | 2021-12-28T00:17:00 | [
"Linus"
] | /article-14123-1.html | 
这是承诺已久的、送给所有热爱 GNU/Linux 的好男孩、好女孩们的圣诞礼物。
那是 1993 年 11 月,我收到了我的第一张 CD,它上面标有 “**一个完整的、带源代码的 Unix 系统,售价 99 美元**”。 虽然我对这一说法持怀疑态度(因为当时 USL 与 BSDi 的诉讼正激烈地进行着),但抱着试试看的态度,我寄出了 99 美元,就为了在邮件中收到一本薄薄的小册子和一张 CD-ROM。
由于我没有能运行它的英特尔的 “个人电脑” ,我所能做的就是把这张光盘挂载在我的 MIPS/Ultrix 工作站上,然后阅读它的手册(`man 1`)。
虽然我对它很感兴趣,但却将其束之高阁,而没实际运行它。
大约在 1994 年 2 月,DECUS 的 UNISIG 主席 Kurt Reisler 发送了电子邮件(出于某种原因抄送给我),说想把这位我从未在芬兰任何地方听说过的人带到 1994 年 5 月在新奥尔良举行的 DECUS 会议上,让他去讲讲一个甚至不能在 Ultrix 或 DEC/OSF1 上运行的项目。
在 Kurt 发送了许多电子邮件,但没有为这次旅行筹集到钱之后,我发了个善心,让我的管理层资助了这次旅行。这里面其实还有很多故事,需要我也资助一台又臭、又弱、又可怜的英特尔电脑来运行这个项目,但这些事情已经在其他地方讲过了,不再赘述。
等我到了 DECUS,我发现 Kurt 试图在这台又臭、又弱、又可怜的英特尔电脑上安装这个 “项目”,但看起来运气不佳。这时,一个留着棕褐色头发、戴着金属框眼镜、穿着羊毛袜和凉鞋的帅气年轻人出现了。他操着一口轻快的欧洲口音的流利英语,说:“May I help you?”
10 分钟后,GNU/Linux 就在那台又臭又弱又可怜的英特尔电脑上运行起来了。
我坐下来使用它,感到很惊讶。它很好,非常、非常好。
我发现那天晚些时候,Linus(当然是 Linus Torvalds)要发表两个演讲:一个是《Linux 简介》,另一个是 《Linux 的实现问题》。
Linus 对发表这些演讲感到非常紧张。这是他第一次在一个重要的会议(有大约 19000 人参加了那个 DECUS)上用英语给英语听众们做演讲。他一直觉得自己好像要呕吐了。我告诉他,会没事的。他发表了演讲。虽然每场讲座只有四十多人到场,但掌声不断。
关于蒸汽驱动的内河船只、名为 “飓风” 的烈性酒精饮料、大量的设备和资金,以及只是基于善意和握手的工程资源的其余故事,以前在其他地方也讲过,这里也不说了。
不幸的是,Linus 所做的演讲已经丢失。
直到现在。
在我打扫办公室的时候,我发现了一些 Linus 谈话的录音带,这是我用自己的钱买的。现在,为了给你们制作这份礼物,我又得买一台好的录音带播放机,用 Audacity 捕获了音频,然后制作出这些录音带的数字拷贝,并放在 [这里](https://archive.org/details/199405-decusnew-orleans/199405DECUSNewOrleansLinusAnIntroductionToLinux.ogg)。不幸的是,我没有幻灯片的副本,我也不确定 Linus 的演讲有多少张幻灯片,我也不觉得你会需要它们。(LCTT 译注:有评论给出了 [幻灯片](http://blu.org/meetings/1994/08/)。)
这就是给你的圣诞礼物,来自将近三十年前。 祝大家 “Linuxing” 快乐,无论你的宗教或信仰如何。
### 资源
#### 《Linux 简介》
幻灯片:
<https://img.linux.net.cn/static/pdf/DECUS-Linux-Intro.pdf>
音频:
#### 《Linux 的实现问题》
幻灯片:
<https://img.linux.net.cn/static/pdf/DECUS-Linux-Kernel.pdf>
音频:
---
via: <https://archive.org/details/199405-decusnew-orleans/199405DECUSNewOrleansLinusAnIntroductionToLinux.ogg>
作者:[John Hall](https://archive.org/search.php?query=creator%3A%22John+Hall%22) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-14121-1.html) 荣誉推出
| null | HTTPSConnectionPool(host='archive.org', port=443): Max retries exceeded with url: /details/199405-decusnew-orleans/199405DECUSNewOrleansLinusAnIntroductionToLinux.ogg (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7b83275cba60>, 'Connection to archive.org timed out. (connect timeout=10)')) | null |
|
14,124 | AppImage Pool:一个帮助你寻找和管理 AppImage 的应用商店 | https://itsfoss.com/appimagepool/ | 2021-12-28T10:54:27 | [
"AppImage"
] | https://linux.cn/article-14124-1.html |
>
> 这是一个管理和寻找 AppImage 应用的有趣的 GUI 前端。让我们来了解一下它!
>
>
>
我们有很多关于 [AppImage 的历史和制作它](https://itsfoss.com/appimage-interview/) 的信息。如果你是 Linux 的新手,你也应该看看我们的 [AppImage 使用指南](https://itsfoss.com/use-appimage-linux/)。
AppImage 使应用可以很容易地在不同的发行版上运行,而不需要安装依赖关系或任何东西。
然而,与 [Flatpak](https://itsfoss.com/what-is-flatpak/) 的 Flathub 不同,你可能找不到一个浏览 AppImage 应用的门户。
[Nitrux OS](https://nxos.org) 中的 NX 软件中心做了类似的工作,但它不能轻易安装在其他发行版上。因此,AppImage Pool 作为 AppImage 应用的应用商店上场了,你可以安装在任何 Linux 发行版上。
### AppImage Pool:一个管理和寻找 AppImage 应用的 GUI 前端

AppImage Pool 是一个使用 Flutter 构建的 GUI 前端,它从 [AppImageHub](https://www.appimagehub.com) 获取应用数据,并让你快速搜索、下载和管理 AppImage 应用。
它并不托管任何 AppImage 文件,但它可以让你从项目的 GitHub 页面下载可用的 AppImage 文件。
当你试图下载一个 AppImage 文件时,它会从应用的 GitHub 发布页列出所有下载方式。
我不确定它是否仅限于来自 GitHub 的项目,但你可以在 [AppImageHub 门户](https://www.appimagehub.com) 中找到各种不同方式。
### AppImage Pool 的特点

AppImage 是一个简单直白的应用商店,可以让你搜索、下载和管理 AppImage 文件。
其中一些功能包括:
* 能够下载特定版本的 AppImage 文件
* 按类别过滤应用
* 下载进度图标
* 管理所有已安装的 AppImages
* 查看下载历史
考虑到该应用是使用 Flutter 构建的,它给人带来了快捷的用户体验。
如果你是一个开发者,这鼓励了你使用它制作一个应用的话,你也可以 [在 Linux 中安装 Flutter](https://itsfoss.com/install-flutter-linux/)。

### 在 Linux 中安装 AppImage Pool
由于明显的原因,开发者提供了一个可供下载的 AppImage 文件。
你也可以选择从 [Flathub](https://flathub.org/apps/details/io.github.prateekmedia.appimagepool) 中 [安装它的 Flatpak 包](https://itsfoss.com/flatpak-guide/)。如果你想测试它即将发布的任何版本,也有一个每夜构建的 AppImage 版本。
在其 [GitHub 页面](https://github.com/prateekmedia/appimagepool) 上可以了解关于它的更多信息。
* [AppImage Pool 下载](https://github.com/prateekmedia/appimagepool/releases)
### 使用 AppImage Pool 的感受

该应用可以如预期的工作。然而,我注意到,列出的一些应用没有下载链接或任何相关信息。
毕竟,这些数据是来自于 AppImageHub 的。
另外,你可能会觉得奇怪,有些应用只列出了预发布的 AppImage 文件,比如 Blender。

虽然这也是可以选择项目发布分支的一个优势,但我认为我不会下载预发布包。
总的来说,找到一个能让人轻松下载和管理 AppImages 的东西是件好事。
我建议你试一试,并在下面的评论区告诉我你的想法。
---
via: <https://itsfoss.com/appimagepool/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief: **An interesting GUI front-end to manage and find AppImage applications; let us find out more about it!
We have plenty of information on [the history of AppImage and its making](https://itsfoss.com/appimage-interview/). If you are new to Linux, you should also check out our [guide on using AppImage](https://itsfoss.com/use-appimage-linux/).
AppImage makes it easy for applications to work across various distributions without needing to install dependencies or anything.
However, unlike Flathub for [Flatpaks](https://itsfoss.com/what-is-flatpak/), you may not find a lot of portals like [NX Software Center](https://github.com/Nitrux/nx-software-center/releases) in [Nitrux OS](https://nxos.org) to browse applications available as AppImages.
AppImage Pool comes to the rescue as another app store for AppImage applications that you can install in any Linux distribution.
## AppImage Pool: A GUI Front-End to Manage and Find AppImage Applications
AppImage Pool is a GUI front-end built using Flutter that fetches application data from [AppImageHub](https://www.appimagehub.com) and lets you quickly search, download, and manage AppImage applications.
It does not host any AppImage files, but it lets you download available AppImage files from the project’s GitHub page.
When you attempt to download an AppImage file, it lists all the available options for an app from its GitHub releases section.
I’m not sure whether it is limited to projects from GitHub, but you get all the curated options featured in the [AppImageHub portal](https://www.appimagehub.com).
## Features of AppImage Pool
AppImage is a straightforward app store that lets you search, download, and manage AppImage files.
Some of the features include:
- Ability to download a specific version of AppImage file
- Filter applications by categories
- Download progress icon
- Manage all installed AppImages
- View download history
Considering the app is built using Flutter, it offers a snappy experience.
If you are a developer, you can [install Flutter in Linux](https://itsfoss.com/install-flutter-linux/), too, if this encourages you to make an app using it.
## Installing AppImage Pool in Linux
For obvious reasons, the developer offers an AppImage file available to download.
You can also choose to [install the Flatpak package](https://itsfoss.com/flatpak-guide/) from [Flathub](https://flathub.org/apps/details/io.github.prateekmedia.appimagepool). There’s also a nightly AppImage release if you want to test out any of its upcoming releases.
Explore more about it on its [GitHub page](https://github.com/prateekmedia/appimagepool).
## Thoughts on Using AppImage Pool
The application works as expected. However, I noticed that some of the applications listed did not have a download link or any information associated.
After all, the data is being sourced from AppImageHub.
Also, you might find it weird that some applications list only pre-release AppImage files, such as Blender.
While this can also be an advantage in selecting the release branch of a project, I don’t think I would download pre-release packages.
Overall, it is good to find something that makes it easy to download and manage AppImages.
I suggest you give it a try and let me know your thoughts in the comments section below. |
14,126 | 真的,你的笔记本电脑赛过千万亿台 60 年前的大型机 | https://spectrum.ieee.org/ibm-mainframe | 2021-12-29T00:05:00 | [
"大型机"
] | https://linux.cn/article-14126-1.html | 
每当我听到有人大谈特谈我们现在的计算机要比上世纪 60 年代阿波罗登月时期的计算机强大得多时,我都会感到震惊。这些比较通常严重低估了差异。
1961 年,世界上的一些大学已经购买了 IBM 7090 大型机。7090 系列是第一个全晶体管计算机系列,以今天的货币计算,它的成本为 2000 万美元,相当于今天的顶级笔记本电脑的 6000 倍。它的早期买家通常将计算机作为整个校园的共享资源来部署。很少有用户能幸运地每周获得一小时的计算机时间。
7090 的时钟周期为 2.18 微秒,因此其工作频率略低于 500 KHz。但在那个年代,计算机指令没有流水线执行,所以大多数指令需要一个以上的时钟周期来执行。一些整数运算需要 14 个时钟周期,而一个浮点运算可能需要 15 个时钟周期。因此,通常估计 7090 每秒钟可以执行约 10 万条指令。而大多数现代计算机的 CPU 核心能够以每秒 30 亿条指令的速度持续运行,甚至其峰值速度要快得多。这就是 3 万倍的差距,所以一个有四核或八核的现代芯片很容易达到比 7090 快 10 万倍的运算速度。
与 1961 年那个得到一小时计算机时间的幸运儿不同,你可以一直运行你的笔记本电脑,每周你可以累计得到超过 1900 年的 7090 计算机时间。(我不想问其中有多少时间是花在“我的世界”游戏上的)。
继续这个比较,考虑一下训练流行的自然语言人工智能模型 GPT-3 所需的指令数量。在云服务器上执行这些指令相当于 355 年的笔记本电脑时间,这在 7090 上就是超过 3600 万年。当你等待这项工作完成时,你会需要大量的咖啡。
但是,说真的,这种比较对今天的电脑还是不公平的。你的笔记本电脑可能有 16 GB 的主内存。而 7090 的最大内存为 144 KB。要运行同样的程序,需要将大量的数据从 7090 中换入换出,而且必须使用磁带来完成。当时最好的磁带机的最大数据传输率为每秒 60KB。虽然一台 7090 计算机上可以连接 12 个磁带设备,但这个速率是在它们之间共享的。而且,这种共享需要一组人类操作员来交换驱动器上的磁带;以这种方式读取(或写入)16GB 的数据将需要三天时间。因此,与今天的速度相比,数据传输也慢了大约 10 万倍。
所以现在 7090 看起来运行速度是你 2021 年的笔记本电脑的千万亿分之一(10<sup> -15</sup>)。在现代的笔记本电脑上运行一周的计算任务,就算是 7090 从宇宙诞生就开始运行也做不完。
但等等,不止如此。笔记本电脑中的每个核心都有内置的 SIMD(单指令、多数据)扩展,在用于向量运算时可以大幅提升浮点运算速度。而在 7090 上甚至没有这些东西的影子。然后是 GPU,最初用于图形加速,但现在用于大部分的人工智能学习,如训练 GPT-3。最新的 iPhone 芯片 A15 Bionic 上就不止一个 GPU,而是有五个 GPU,以及一个额外的神经引擎,在我们所做的所有其他比较的基础上,它可以每秒运行 15 万亿次算术运算。
短短 60 年的差异让人难以置信。但我想知道,我们是否有效地利用了所有这些计算能力,可以像我们的祖先从纸笔到 7090 的飞跃那样做出改变?
这篇文章将以《摩尔如此之多》为题发表在 2022 年 1 月的印刷版上。
---
via: <https://spectrum.ieee.org/ibm-mainframe>
作者:[Rodney Brooks](https://spectrum.ieee.org/u/rodney-brooks) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-14123-1.html) 荣誉推出
| 200 | OK | **Whenever I hear someone rhapsodize **about how much more computer power we have now compared with what was available in the 1960s during the Apollo era, I cringe. Those comparisons usually grossly *underestimate* the difference.
By 1961, a few universities around the world had bought [IBM 7090 mainframes](https://www.ibm.com/ibm/history/exhibits/mainframe/mainframe_PP7090.html). The 7090 was the first line of all-transistor computers, and it cost US $20 million in today's money, or about 6,000 times as much as a top-of-the-line laptop today. Its early buyers typically deployed the computers as a shared resource for an entire campus. Very few users were fortunate enough to get as much as an hour of computer time per week.
The 7090 had a clock cycle of 2.18 microseconds, so the operating frequency was just under 500 kilohertz. But in those days, instructions were not [pipelined](https://cs.stanford.edu/people/eroberts/courses/soco/projects/risc/pipelining/index.html), so most took more than one cycle to execute. Some integer arithmetic took up to 14 cycles, and a floating-point operation could hog up to 15. So the 7090 is generally estimated to have executed about 100,000 instructions per second. Most modern computer cores can operate at a sustained rate of 3 billion instructions per second, with much faster peak speeds. That is 30,000 times as fast, so a modern chip with four or eight cores is easily 100,000 times as fast.
Unlike the lucky person in 1961 who got an hour of computer time, you can run your laptop all the time, racking up more than 1,900 years of 7090 computer time every week. (Far be it from me to ask how many of those hours are spent on *Minecraft*.)
Continuing with this comparison, consider the number of instructions needed to train the popular natural-language AI model, [GPT-3](https://spectrum.ieee.org/open-ais-powerful-text-generating-tool-is-ready-for-business). Executing them on cloud servers took the equivalent of 355 years of laptop time, which translates to more than 36 million years on the 7090. You’d need a *lot* of coffee as you waited for that job to finish.
A week of computing time on a modern laptop would take *longer than the age of the universe* on the 7090.
But, really, this comparison is unfair to today’s computers. Your laptop probably has 16 gigabytes of main memory. The 7090 maxed out at 144 kilobytes. To run the same program would require an awful lot of shuffling of data into and out of the 7090—and it would have to be done using [magnetic tapes](https://spectrum.ieee.org/tape-is-back-and-better-than-ever). The best tape drives in those days had maximum data-transfer rates of 60 KB per second. Although 12 tape units could be attached to a single 7090 computer, that rate needed to be shared among them. But such sharing would require that a group of human operators swap tapes on the drives; to read (or write) 16 GB of data this way would take three days. So data transfer, too, was slower by a factor of about 100,000 compared with today’s rate.
So now the 7090 looks to have run at about a quadrillionth (10-15) the speed of your 2021 laptop. A week of computing time on a modern laptop would take *longer than the age of the universe* on the 7090.
But wait, there’s more! Each core in your laptop has built-in [SIMD](https://www.sciencedirect.com/topics/computer-science/single-instruction-multiple-data) (single instruction, multiple data) extensions that turbocharge floating-point arithmetic, used for vector operations. Not even a whiff of those on the 7090. And then there’s the GPU, originally used for graphics speedup, but now used for the bulk of AI learning such as in training [GPT-3](https://spectrum.ieee.org/tag/gpt-3). And the latest iPhone chip, the A15 Bionic, has not one, but five GPUs, as well as a bonus neural engine that runs 15 trillion arithmetic operations per second on top of all the other comparisons we have made.
The difference in just 60 years is mind boggling. But I wonder, are we using all that computation effectively to make as much difference as our forebears did after the leap from pencil and paper to the 7090?
*This article appears in the January 2022 print issue as “So Much Moore.”*
[Rodney Brooks](https://spectrum.ieee.org/u/rodney-brooks)
[Rodney Brooks](https://rodneybrooks.com/) is the [Panasonic Professor of Robotics (emeritus) at MIT](https://people.csail.mit.edu/brooks/), where he was director of the AI Lab and then [CSAIL](https://www.csail.mit.edu/). He has been cofounder of [iRobot](https://www.irobot.com/), [Rethink Robotics](https://spectrum.ieee.org/robotics/industrial-robots/rethink-robotics-baxter-robot-factory-worker), and [Robust AI](https://www.robust.ai/), where he is currently CTO. |
14,127 | 我在大型机上玩俄罗斯方块 | https://opensource.com/article/21/12/mainframe-tetris | 2021-12-29T10:23:52 | [
"大型机",
"俄罗斯方块"
] | /article-14127-1.html |
>
> 下面是我如何通过访问虚拟 Linux 服务器,在大型机上编译和玩我最喜欢的游戏。
>
>
>

可以 [在现代大型机上运行 Linux](https://opensource.com/article/19/9/linux-mainframes-part-1) 的能力为在该平台上做各种事情打开了大门。一个 Apache HTTP 服务器?很简单!一个数据库?你想用 SQL 还是 NoSQL?Kubernetes?当然没问题!正如我在 [大型机上的 Linux:过去和现在](https://opensource.com/article/19/9/linux-mainframes-part-2) 中总结的那样,今天所有最流行的服务器 Linux 发行版都有大型机的版本。
这对那些在大型机上运行关键任务基础设施的公司来说是个好消息,但如果你只是想玩玩大型机呢?我第一次在 IBM LinuxONE 上使用 bash shell 时,安装了 irssi 聊天客户端,向 IRC 上的所有朋友展示了 `/proc/cpuinfo` 的输出,以炫耀这是一个 s390x 架构的系统。
一开始,我对下一步该做什么感到茫然。然后我想,用这台巨大的计算机来玩游戏会很有趣。我首先想到的是 [NetHack](https://www.nethack.org/),但事实证明,我可以用简单的 `apt install nethack-console` 来安装它。不,我应该编译一些东西才好玩!对于每一种计算机架构,你都需要为其编写的编译器和解释器。Linux 在大型机上已有 20 多年的历史,你通常期望的大多数编译器和解释器都已经被移植了。
在我的成长过程中,我最喜欢的游戏之一是俄罗斯方块,所以它是我进行实验的合理选择。我找到了一个用 C 语言编写的开源俄罗斯方块游戏,叫做 [vitetris](http://victornils.net/tetris/),并试了试。这就像在任何其他 Linux 服务器上编译一个 C 语言程序一样。
首先,我需要安装一些依赖项。这台主机运行的是 Linux,所以我可以用我的包管理器来 [安装构建需求](https://opensource.com/article/21/11/compiling-code),然后我就顺利完成了。
接下来,就是获取代码和构建的问题了:
```
curl -LO https://github.com/vicgeralds/vitetris/archive/v0.58.0.tar.gz
tar xvf v0.58.0.tar.gz
cd vitetris-0.58.0/
./configure
make
```
不一会儿,我就开始玩我最喜欢的游戏了!
```
./tetris
```

正如我所说,这与在 Linux 服务器上构建其他 C 程序完全一样,但你是在大型机上做的。
不幸的是,我的车库里还没有一台大型机。相反,我是在马里斯特学院通过 [IBM LinuxONE 社区云](https://developer.ibm.com/gettingstarted/ibm-linuxone/) 计划托管的虚拟服务器上完成了这一切。它让你免费访问一个 s390x 架构的 Linux 服务器,你可以选择最流行的发行版。通过这个虚拟服务器,你可以在 120 天内进行实验。
如果你是一个开源项目的代表,正在考虑在 s390x 上为 Linux 构建你的应用,也有一个项目适合你。当我不玩俄罗斯方块的时候,我在 IBM 的实际工作就是与开源社区合作来做这件事。你可以请求一个永久的 Linux 虚拟服务器供你的社区用于开发,无论是进行手动测试以查看你的应用是否会构建,或正式将其添加到项目的持续集成系统中都行。我建议从社区云开始做一些实验,然后你可以填写 [这个表格](https://www.ibm.com/community/z/open-source/virtual-machines-request/) 来启动获得永久虚拟服务器的流程。
---
via: <https://opensource.com/article/21/12/mainframe-tetris>
作者:[Elizabeth K. Joseph](https://opensource.com/users/pleia2) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
14,130 | 一个小时内创建一个 CentOS 家庭实验室 | https://opensource.com/article/19/6/create-centos-homelab-hour | 2021-12-30T09:37:46 | [
"家庭实验室"
] | https://linux.cn/article-14130-1.html |
>
> 用一个带有虚拟化软件的系统(CentOS ISO),花费一个小时左右来设置一套自给自足的基本 Linux 服务器。
>
>
>

当学习新的 Linux 技能时(或像我一样学习 Linux 认证),在笔记本电脑上有一些可用的虚拟机(VM)是很有帮助的,这样你就可以在上面学习。
但是,如果在没有良好互联网连接的地方,你却想在一个 Web 服务器上工作,该怎么办? 想要使用没有安装过的其他软件,该怎么办? 如果需要从发行版的存储库中下载它,那么你可能会碰壁。只要做一点准备,你就可以设置一个 [家庭实验室](https://opensource.com/article/19/3/home-lab),你就在任何地方安装所需的任何东西,无论是否有网络连接。
要求如下:
* 一个你打算使用的已下载的 Linux 发行版(例如,CentOS、Red Hat 等)ISO 文件
* 一台具有虚拟化功能的主机。这里使用带有 [KVM](https://en.wikipedia.org/wiki/Kernel-based_Virtual_Machine) 和 [virt-manager](https://virt-manager.org/) 的 [Fedora](https://getfedora.org/),但其它 Linux 也可以类似工作。你甚至可以使用 Windows 或 Mac 进行虚拟化,但在实现方面存在一些差异
* 大约一个小时
### 1、为存储主机创建一个虚拟机
使用 `virt-manager` 创建一个中等规格的虚拟机:1GB RAM、一个 CPU 和 16GB 磁盘空间就足够。
在虚拟机上安装 [CentOS 7](https://www.centos.org/download/)。

选择你的语言并继续。
单击 “<ruby> 安装位置 <rt> Installation Destination </rt></ruby>”,选择本地磁盘,勾选 “<ruby> 自动配置分区 <rt> Automatically Configure Partitioning </rt></ruby>” 复选框,然后单击左上角的 “<ruby> 完成 <rt> Done </rt></ruby>”。
在 “<ruby> 软件选择 <rt> Software Selection </rt></ruby>” 下,选中 “<ruby> 基础设施服务器 <rt> Infrastructure Server </rt></ruby>” ,选中 “<ruby> FTP 服务器 <rt> FTP Server </rt></ruby>” 复选框,然后单击 “<ruby> 完成 <rt> Done </rt></ruby>”。

选择 “<ruby> 网络和主机名 <rt> Network and Host Name </rt></ruby>”,启用右上方的 “<ruby> 以太网 <rt> Ethernet </rt></ruby>” ,然后单击左上角的 “<ruby> 完成 <rt> Done </rt></ruby>”。
单击 “<ruby> 开始安装 <rt> Begin Installation </rt></ruby>” 开始安装操作系统。
在安装时务必设置一个 root 密码,就可以创建一个带有密码的用户。
### 2、启动 FTP 服务
下一步是启动并设置 FTP 服务以运行并允许它通过防火墙。
用 root 密码登录,然后启动 FTP 服务器:
```
systemctl start vsftpd
```
允许它在每次启动时都能工作:
```
systemctl enable vsftpd
```
设置防火墙允许通过的端口:
```
firewall-cmd --add-service=ftp --perm
```
立即启用此更改:
```
firewall-cmd --reload
```
获取你的 IP 地址:
```
ip a
```
(可能是 `eth0`),在之后会用到。
### 3、复制本地存储库中的文件
通过虚拟化软件将安装 CD 挂载到虚拟机。
创建待挂载光盘的临时目录:
```
mkdir /root/temp
```
挂载安装 CD:
```
mount /dev/cdrom /root/temp
```
将所有文件复制到 FTP 服务器目录下:
```
rsync -avhP /root/temp/ /var/ftp/pub/
```
### 4、将服务器指向本地存储库
基于 Red hat 的系统使用以 `repo` 结尾的文件来确定从哪里获得软件更新和新的软件。这些文件在以下路径
```
cd /etc/yum.repos.d
```
你需要摆脱那些使你的服务器在互联网上寻找 CentOS 存储库的存储库文件。可以把它们复制到根目录下保存起来:
```
mv * ~
```
然后创建一个新的存储库文件来指向你的服务器。使用常用的文本编辑器创建一个名为 `network.repo` 文件,输入以下内容(将 `<your IP>` 替换为在步骤 2 中获得的 IP 地址),然后保存:
```
[network]
name=network
baseurl=ftp://192.168.122.<your ip>/pub
gpgcheck=0
```
完成后,可以用下面的命令来测试:
```
yum clean all; yum install ftp
```
如果 FTP 客户端按照预期从 “network” 存储库安装,那么本地仓库就已经设置好了!

### 5、使用你设置的存储库安装一个新的虚拟机
回到虚拟机管理器,并创建另一个虚拟机。但这一次,选择 “<ruby> 网络安装 <rt> Network Install </rt></ruby>”, URL 为:
```
ftp://192.168.122.<your IP>/pub
```
如果你使用的是不同的宿主机操作系统或虚拟管理器,像前面一样安装虚拟机,并进行下一步。
### 6、将新的虚拟机设置为使用现有的“network”存储库
你可以从现有服务器复制存储库文件到这里使用。
和第一个服务器示例一样,输入:
```
cd /etc/yum.repos.d
mv * ~
```
然后:
```
scp [email protected].<your IP>:/etc/yum.repos.d/network.repo /etc/yum.repos.d
```
现在可以使用新的虚拟机并从本地存储库获取所有软件了。
再测试一遍:
```
yum clean all; yum install screen
```
这将从本地存储服务器安装软件。
这种设置,让你能够脱离网络安装软件,创建一个更可靠的环境,扩展你的技能。
---
via: <https://opensource.com/article/19/6/create-centos-homelab-hour>
作者:[Bob Murphy](https://opensource.com/users/murph) 选题:[lujun9972](https://github.com/lujun9972) 译者:[JaphiaChen](https://github.com/JaphiaChen) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When working on new Linux skills (or, as I was, studying for a Linux certification), it is helpful to have a few virtual machines (VMs) available on your laptop so you can do some learning on the go.
But what happens if you are working somewhere without a good internet connection and you want to work on a web server? What about using other software that you don't already have installed? If you were depending on downloading it from the distribution's repositories, you may be out of luck. With a bit of preparation, you can set up a [homelab](https://opensource.com/article/19/3/home-lab) that will allow you to install anything you need wherever you are, with or without a network connection.
The requirements are:
- A downloaded ISO file of the Linux distribution you intend to use (for example, CentOS, Red Hat, etc.)
- A host computer with virtualization. I use
[Fedora](https://getfedora.org/)with[KVM](https://en.wikipedia.org/wiki/Kernel-based_Virtual_Machine)and[virt-manager](https://virt-manager.org/), but any Linux will work similarly. You could even use Windows or Mac with virtualization, with some difference in implementation - About an hour of time
## 1. Create a VM for your repo host
Use virt-manager to create a VM with modest specs; 1GB RAM, one CPU, and 16GB of disk space are plenty.
Install [CentOS 7](https://www.centos.org/download/) on the VM.
Select your language and continue.
Click *Installation Destination*, select your local disk, mark the *Automatically Configure Partitioning* checkbox, and click *Done *in the upper-left corner.
Under *Software Selection*, select *Infrastructure Server*, mark the *FTP Server* checkbox, and click *Done*.
Select *Network and Host Name*, enable Ethernet in the upper-right, then click *Done* in the upper-left corner.
Click *Begin Installation* to start installing the OS.
You must create a root password, then you can create a user with a password as it installs.
## 2. Start the FTP service
The next step is to start and set the FTP service to run and allow it through the firewall.
Log in with your root password, then start the FTP server:
`systemctl start vsftpd`
Enable it to work on every start:
`systemctl enable vsftpd`
Set the port as allowed through the firewall:
`firewall-cmd --add-service=ftp --perm`
Enable this change immediately:
`firewall-cmd --reload`
Get your IP address:
`ip a`
(it's probably **eth0**). You'll need it in a minute.
## 3. Copy the files for your local repository
Mount the CD you installed from to your VM through your virtualization software.
Create a directory for the CD to be mounted to temporarily:
`mkdir /root/temp`
Mount the install CD:
`mount /dev/cdrom /root/temp`
Copy all the files to the FTP server directory:
`rsync -avhP /root/temp/ /var/ftp/pub/`
## 4. Point the server to the local repository
Red Hat-based systems use files that end in **.repo** to identify where to get updates and new software. Those files can be found at
`cd /etc/yum.repos.d`
You need to get rid of the repo files that point your server to look to the CentOS repositories on the internet. I prefer to copy them to root's home directory to get them out of the way:
`mv * ~`
Then create a new repo file to point to your server. Use your favorite text editor to create a file named **network.repo** with the following lines (substituting the IP address you got in step 2 for *<your IP>*), then save it:
```
[network]
name=network
baseurl=ftp://192.168.122.<your ip>/pub
gpgcheck=0
```
When that's done, we can test it out with the following:
`yum clean all; yum install ftp`
If your FTP client installs as expected from the "network" repository, your local repo is set up!
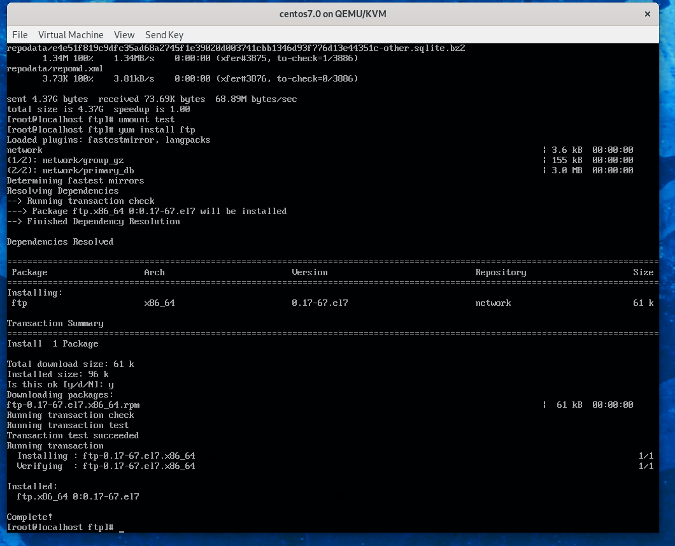
## 5. Install a new VM with the repository you set up
Go back to the virtual machine manager, and create another VM—but this time, select *Network Install* with a URL of:
`ftp://192.168.122.<your IP>/pub`
If you're using a different host OS or virtualization manager, install your VM similarly as before, and skip to the next section.
## 6. Set the new VM to use your existing network repository
You can copy the repo file from your existing server to use here.
As in the first server example, enter:
```
cd /etc/yum.repos.d
mv * ~
```
Then:
`scp [email protected].<your IP>:/etc/yum.repos.d/network.repo /etc/yum.repos.d`
Now you should be ready to work with your new VM and get all your software from your local repository.
Test this again:
`yum clean all; yum install screen`
This will install your software from your local repo server.
This setup, which gives you independence from the network with the ability to install software, can create a much more dependable environment for expanding your skills on the road.
*Bob Murphy will present this topic as well as an introduction to GNU Screen at Southeast Linux Fest, June 15-16 in Charlotte, N.C.*
## 2 Comments |
14,131 | Bash Shell 脚本新手指南(一) | https://fedoramagazine.org/bash-shell-scripting-for-beginners-part-1/ | 2021-12-30T10:14:39 | [
"Bash",
"脚本"
] | https://linux.cn/article-14131-1.html | 
如标题所示,本文将涵盖面向初学者的 Bash Shell 脚本知识。虽然本文没有回顾 Bash 的历史,但是有很多资源能够便于读者了解相关内容,读者也可以直接访问 <https://www.gnu.org/software/bash/> 上的 GNU 项目。我们会从了解一些非常基本的概念开始,然后再将相关知识综合起来。
### 创建脚本文件
首先来创建一个脚本文件。我们要确保当前目录为家目录。
```
cd ~
```
在主目录中创建示例文件。文件名可以是任意名称,本文使用 `learnToScript.sh` 作为文件名。
```
touch learnToScript.sh
```
此时家目录中就生成了一个名为 `learnToScript.sh` 的文件。输入以下命令以检验该文件是否存在,还可以注意到其权限是 `-rw-rw-r–`。
```
[zexcon@trinity ~]$ ls -l
total 7
drwxr-xr-x. 1 zexcon zexcon 90 Aug 30 13:08 Desktop
drwxr-xr-x. 1 zexcon zexcon 80 Sep 16 08:53 Documents
drwxr-xr-x. 1 zexcon zexcon 1222 Sep 16 08:53 Downloads
-rw-rw-r--. 1 zexcon zexcon 70 Sep 17 10:10 learnToScript.sh
drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Music
drwxr-xr-x. 1 zexcon zexcon 318 Sep 15 13:53 Pictures
drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Public
drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Videos
[zexcon@trinity ~]$
```
正式开始之前还有一件事要做。可以试一下在没有写入任何内容的情况下执行脚本,命令行输入以下内容:
```
./learnToScript.sh
```
```
[zexcon ~]$ ./learnToScript.sh
bash: ./learnToScript.sh: Permission denied
```
提示权限被拒绝,因为该文件没有执行权限。所以你需要更改文件的权限才能执行脚本。如果你不熟悉权限相关知识,建议阅读 [Paul W. Frields](http://pfrields.id.fedoraproject.org/) 写的 Fedora 杂志文章。
* [命令行小知识:权限](https://fedoramagazine.org/command-line-quick-tips-permissions/)
* [命令行小知识:深入权限](https://fedoramagazine.org/command-line-quick-tips-more-about-permissions/)
假定我们已经了解了权限相关知识,回到终端更改 `learnToScript.sh` 文件,增加执行权限。输入以下内容:
```
chmod 755 learnToScript.sh
```
```
[zexcon@trinity ~]$ ls -l
total 7
drwxr-xr-x. 1 zexcon zexcon 90 Aug 30 13:08 Desktop
drwxr-xr-x. 1 zexcon zexcon 80 Sep 16 08:53 Documents
drwxr-xr-x. 1 zexcon zexcon 1222 Sep 16 08:53 Downloads
-rwxr-xr-x. 1 zexcon zexcon 70 Sep 17 10:10 learnToScript.sh
drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Music
drwxr-xr-x. 1 zexcon zexcon 318 Sep 15 13:53 Pictures
drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Public
drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Videos
[zexcon@trinity ~]$
```
好的,现在一切准备就绪,你已经获得了 `learnToScript.sh` 命令的读取、写入和执行权限 (`-rwxr-xr-x`)。
### 编辑脚本文件
下面的内容需要你熟悉 `vim` 或其他类似的文本编辑器,本文选用 `vim`。在命令提示符下输入以下内容:
```
vim learnToScript.sh
```
这会打开一个空的文本文件,里面有一堆波浪号。键盘输入 `i` 将进入插入模式。通过查看终端窗口的左下角,你可以确认它处于该模式。(友情推荐,[nano](https://fedoramagazine.org/gnu-nano-minimalist-console-editor/) 编辑器也很不错。)
接下来我们要确保文件被正确的解释器识别。因此,输入 `#!` 和 bash 的目录 `/bin/bash`:
```
#!/bin/bash
```
本文教程步骤的最后一件事是保存文档。按 `Esc` 退出输入模式,然后按 `Shift+:`。在冒号处输入 `wq`,按下回车键,就会写入(`w`)文件并退出(`q`)`vim` 编辑器。
>
> 使用 `vim` 时要记住,要想写入文档,就需要输入 `i`,此时你会在底部看到 `–INSERT–`。要保存文档,就需要按 `Esc` 退出输入模式,然后按 `Shift+:`,输入 `w` 写入文件;或者按 `Esc`,然后 `Shift+:` 输入 `q`,实现退出而不保存;或者将 `wq` 连在一起,可以实现写入并关闭文件。`Esc` 本身就只是退出插入模式。你可以在其 [官方网站](https://www.vim.org/docs.php) 或 [教程网站](https://linuxhandbook.com/basic-vim-commands/) 上找到更多关于 `vim` 的信息。
>
>
>
### 开始正式写脚本
#### echo 命令
`echo` 命令用于向终端返回一些信息,可以使用单引号、双引号或不使用引号。那么让我们用一个传统的 Hello World 来试试它!
```
#!/bin/bash
echo Hello World!
echo 'Hello World!'
echo "Hello World!"
```
```
[zexcon ~]$ ./learnToScript.sh
Hello World!
Hello World!
Hello World!
[zexcon ~]$
```
注意,上述三行得到了相同的结果。使用单引号、双引号或不使用引号的结果不是一定相同的,但在这个基本脚本中确实得到了同样的结果。在某些情况下,引号的类型不同会导致结果差异。至此恭喜你编写了第一个 Bash 脚本。当你继续创建更多脚本并放飞你的想法时,可能会需要了解以下更多的知识。
#### 命令替换 $( ) 和 ` `
命令替换可以实现以下效果:获取在命令行执行命令的结果,并将该结果写入变量。例如,如果在命令提示符下输入 `ls`,可以获得当前工作目录的列表。我们用这个命令来实践一下。命令替换选项有两个,请注意:第一个选项使用键盘左侧 `Tab` 键上方的反引号。它与波浪号 `~` 在一个键位上。第二个选项使用 shell 变量。
```
#!/bin/bash
command1=`ls`
echo $command1
command2=$(ls)
echo $command2
```
```
[zexcon ~]$ ./learnToScript.sh
Desktop Documents Downloads learnToScript.sh Music Pictures Public snap Videos
Desktop Documents Downloads learnToScript.sh Music Pictures Public snap Videos
[zexcon ~]$
```
注意变量、等号和命令开头之间不要有空格。使用这两个选项得到的结果是完全相同的。请注意,变量需要以美元符号开头。如果你忘记了,并且回显了不带美元符号的命令变量,会只输出命令的名称,如下所示:
```
#!/bin/bash
command1=`ls`
echo command1
command2=$(ls)
echo command2
```
```
[zexcon ~]$ ./learnToScript.sh
command1
command2
[zexcon ~]$
```
#### 双括号 (())
那么双括号有什么用呢? 很简单,双括号用于数学方程式。
```
#!/bin/bash
echo $((5+3))
echo $((5-3))
echo $((5*3))
echo $((5/3))
```
```
[zexcon ~]$ ./learnToScript.sh
8
2
15
1
[zexcon ~]$
```
### 结语
至此,我们已经创建了第一个脚本。我们知道了如何执行多个命令:将它们放在一个脚本中并运行,就可以获得结果。下一篇文章会继续讨论,了解输入和输出的重定向、管道命令、使用双括号或者添加注释等知识。
---
via: <https://fedoramagazine.org/bash-shell-scripting-for-beginners-part-1/>
作者:[zexcon](https://fedoramagazine.org/author/zexcon/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As the title implies this article will be covering Bash Shell Scripting at a beginner level. I’m not going to review the history of Bash but there are many resources to fill you in or you can visit the GNU project at [https://www.gnu.org/software/bash/](https://www.gnu.org/software/bash/). We will start out with understanding some very basic concepts and then start to put things together.
### Creating a script file
The first thing to do is create a script file. First make sure the home directory is the current directory.
cd ~
In the home directory, create the example file. This can be named anything but *learnToScript.sh* will be used in this article.
touch learnToScript.sh
From this point there will be a file called *learnToScript.sh* in your home directory. Verify it exists and also notice the privileges for that file are -rw-rw-r– by typing the following.
ls -l
[zexcon@trinity ~]$ ls -l total 7 drwxr-xr-x. 1 zexcon zexcon 90 Aug 30 13:08 Desktop drwxr-xr-x. 1 zexcon zexcon 80 Sep 16 08:53 Documents drwxr-xr-x. 1 zexcon zexcon 1222 Sep 16 08:53 Downloads -rw-rw-r--. 1 zexcon zexcon 70 Sep 17 10:10 learnToScript.sh drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Music drwxr-xr-x. 1 zexcon zexcon 318 Sep 15 13:53 Pictures drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Public drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Videos [zexcon@trinity ~]$
There is one more thing that needs to be done to get started. Let’s try and execute the script with nothing written in it. Type the following:
./learnToScript.sh
[zexcon ~]$ ./learnToScript.sh bash: ./learnToScript.sh: Permission denied
You get permission denied because there are no execute permissions on the file. You need to change the permissions of the file to be able to execute the script. If you are not familiar with permissions I would recommend reading the Fedora Magazine articles written by Paul W. Frields:
[Command line quick tips: Permissions]
[Command line quick tips: More about permissions]
At this point you’ve brushed up on permissions, so back to the terminal and let’s change the *learnToScript.sh* file so it will execute. Type in the following to allow execution of the file.
chmod 755 learnToScript.sh
[zexcon@trinity ~]$ ls -l total 7 drwxr-xr-x. 1 zexcon zexcon 90 Aug 30 13:08 Desktop drwxr-xr-x. 1 zexcon zexcon 80 Sep 16 08:53 Documents drwxr-xr-x. 1 zexcon zexcon 1222 Sep 16 08:53 Downloads -rwxr-xr-x. 1 zexcon zexcon 70 Sep 17 10:10 learnToScript.sh drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Music drwxr-xr-x. 1 zexcon zexcon 318 Sep 15 13:53 Pictures drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Public drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Videos [zexcon@trinity ~]$
Okay now you’re ready, you have read, write and execute permissions (-rwxr-x r-x) to the *learnToScript.sh* command.
### Editing a script file
Take a moment and make certain you are familiar with *vim* or any text editor. Throughout this article I will be utilizing *vim*. At the command prompt type the following:
vim learnToScript.sh
This will bring you to an empty text file with a bunch of tildes in it. Type *i* on your keyboard and this will move you into — INSERT — mode. You can see it’s in this mode by looking at the bottom left of the terminal window. (Note that an alternative editor is the [ nano editor](https://fedoramagazine.org/gnu-nano-minimalist-console-editor/).)
From here you need to make sure that the file is recognized by the correct interpreter. So enter the shebang ( #! ) and the directory to your bash, /bin/bash:
#!/bin/bash
One last thing that you will use throughout the article is saving the document. Hit *Esc* to leave input mode, then Shift + Colon. At the colon you will enter *wq*. This will write(*w*) the file and quit(*q*) *vim* once you hit enter.
A few things to remember while using *vi*m, anytime you want to write into a document you need to enter *i* and you will see –INSERT– at the bottom. Anytime you want to save, you will need to hit *Esc* to leave input mode, and then *Shift+:* to enter *w* to write the file or *Esc* then *Shift+: *to enter *q* to quit and not save. Or add both *wq* together and it will write and close. *Esc* by itself will exit INSERT mode. You can find much more about *vim* at it’s [website](https://www.vim.org/docs.php) or this [get started](https://linuxhandbook.com/basic-vim-commands/) site.
## Lets start scripting…
### echo
The *echo* command is used to return something to the terminal. You will notice that you can use single quotes, double quotes or no quotes. So let’s take a look at it with a traditional Hello World!
#!/bin/bash echo Hello World! echo 'Hello World!' echo "Hello World!"
[zexcon ~]$ ./learnToScript.sh Hello World! Hello World! Hello World! [zexcon ~]$
Notice that you get the same result with all three options. This is not always the case but in this basic script it is. In some circumstances the type of quotes will make a difference. By the way, congratulations you have written your first Bash script. Let’s look at a few things that you will want to know as you continue to create more scripts and let your mind run wild.
### Command Substitution $( ) or ` `
Command substitution allows you to get the results of a command you might execute at the command line and write that result to a variable. For example if you type* ls* at the command prompt you will get a list of the current working directory. So let’s put this into practice. You have two options for command substitution. Note that the first option uses a back tick found above the Tab key on the left side of the keyboard. It is paired with the tilde ~ key. The second option uses a shell variable.
#!/bin/bash command1=`ls` echo $command1 command2=$(ls) echo $command2
[zexcon ~]$ ./learnToScript.sh Desktop Documents Downloads learnToScript.sh Music Pictures Public snap Videos Desktop Documents Downloads learnToScript.sh Music Pictures Public snap Videos [zexcon ~]$
Notice no space between the variable, equal sign, and the start of the command. You get the exact same result with both options. Note that variables need to be led by a dollar sign. If you forget and you echo out the command variable without the dollar sign you will just see the name of the command as shown in the next example.
#!/bin/bash command1=`ls` echo command1 command2=$(ls) echo command2
[zexcon ~]$ ./learnToScript.sh command1 command2 [zexcon ~]$
### Double Parentheses (())
So what are double parentheses for? Double parentheses are simple, they are for mathematical equations.
#!/bin/bash echo $((5+3)) echo $((5-3)) echo $((5*3)) echo $((5/3))
[zexcon ~]$ ./learnToScript.sh 8 2 15 1 [zexcon ~]$
## Conclusion
At this point we have created our first script. We have an idea how to take several commands, place them in a script and run it to get the results. We will continue this discussion in the next article and look at redirection of input and output, the pipe command, using double brackets or maybe just adding some comments.
## Athan
The chmod command is inconsistent with what the targeted outcome is.
## Stephen Snow
Hello, good catch,
~~I changed it to “chmod 755~~ to be consistent with the results displayed . Oops, it was correct originally so I retracted my change.## Donald Sebastian Leung
Wouldn’t it be better to change both (1) the command to
and (2) the output of
to match the command?
permissions is weird (and insecure) because anyone can edit your script, even if you are the only one that can execute it.
Or just
and you don’t have to worry about accidentally making your script world-writable.
## Richard England
That was missed in editing. It has been corrected.
## Bthan
It’s still wrong. The listing says “-rwxrw-rw-” but below the listing you say “execute permissions (-rwxr-xr-x)”.
Chmod 766 is wrong. 6 is read and WRITE, so a security issue that others can alter your script on the fly. Use 755 instead.
Why don’t you use “chmod +x” to give execute permissions?
Oh, and BTW. the link to Paul W. Fields is broken too.
## Richard England
Corrections were made for the permissions. But the links to the other articles appear to be correct. What are you seeing when attempting to view them?
## Bthan
Actually, the link is not broken, but it’s an empty page.
The link to Paul’s profile:
“… recommend reading the Fedora Magazine articles written by Paul W. Frields.”
The page says:
This page is primarily used internally
## Richard England
The link to Paul W. Frields should not have been a link. The two images (that are links to the two articles) are the important part. The OpenID link has been removed.
## Scott Auge
LOL I read it because there is “always a sentence of interest reading” and that’s the truth, because $(()) was new to me and I had read two bash manuals!
## Daniel
Good.
## Breno
I would recommend
instead of
at a beginner level. Also,
sounds more intuitive for a beginner to me.
## Thuur
You can also check this permission site :
http://permissions-calculator.org/
## Anil F Duggirala
Thanks so much for this. Always been curious about these scripts. Thanks for allowing me to get into it so smoothly.
I already know vim, I hope your other readers don’t get lost or discouraged by getting stuck with vim. Also, keep in mind that there are various different keyboard layouts, not just US English.
thanks so much,
## zexcon
Thank you I’ve added the specification into the next article for clarification on the keyboard.
## person
Why do i have to be at ~
## Joao Rodrigues
You don’t
haveto be at ~. You can place your script anywhere you have write permission.You could, for example, place it in ~/.local/bin or ~/bin. These directories are ususally in your $PATH, so you could call your script from any directory by just typing “learnToScript.sh” instead of “~/learnToScript.sh”
## zexcon
You don’t have to be in your home directory. This is only for simplicity of the article. You can place your script any place you just need to specify the path or be in the location to run the script.
## Smackeyacky
The file listing of the directory containing your script shows the right permissions for chmod 766, but the text underneath says you wanted rwxr-xr-x which is 755. Change the command to 755 and fix the listing of files and it will be consistent.
## Darvond
While I’d
suggest vim for a beginner, I do understand it is the defacto. (For some reason; though it and emacs have been outmoded for years in terms of sheer sanity by others.)neverBut! Fedora’s default editor is nano; should that not be the editor invoked accordingly?
Instead of the one that requires complex
bespoke keystrokesjust to enter insertion mode?## Richard England
For some (perhaps many) vi/vim is what they know and it was the standard editor for some time. A note has been added pointing out that nano is an alternative. The point of the article was not the editor to use rather the script that was being created.
But thank you for your input.
## Brian
I never had any trouble using vim or vi when I was teaching myself to program from the command line. What is the point in trying to discourage beginners from learning something that is NOT THAT DIFFICULT in the first place? Entering insertion mode in vi or vim requires — i . Leaving insertion mode requires the– Esc — the escape key. This is difficult ? Saving a file requires– :wq and the name of the file if it’s a new file — :wq ./Boogers
Quiting without saving requires– :q! How hard is that? Personally, I don’t like nano at all.
Aside from that, I’ve had Fedora on my box for 20 years, and I never had nano installed at all until last year.
## Darvond
Beg pardon from someone born after the German Reunification and ergo; the Emacs/Vim Holy Wars.
The way my opinion flows is this: When people open an editor, they want to
edit. Drop in, start typing.But it may also be worth noticing that no graphical editor really goes out of their way to emulate vi because you just focus the window
and type.Even ancient tools from the other side of the force like QBASIC’s Editor didn’t require anything weird to get going.
## Richard England
…and the wars continue. 🙂
## Inci
Great intro! Looking forward for part 2.
## edier88
Great!
This is really important for sysadmins and developers.
Looking forward for the next parts!
## Stathis
You might want to consider changing the shebang line of the script to
This seems to be preferred nowadays.
As it does not assume “bash” to be present in a specific directory it helps promote portability.
## Joao Rodrigues
Well, that just assumes “env” is present in /usr/bin
You have to put an absolute path in the hashbang. You have to start assuming something at some point. If for some reason bash is not in /bin, a more sensible approach would be just to symlink bash in /bin.
## Bryan
Very nice article sir
## Putin
Unrelated to the above topic at hand, I wish to say that I now love Fedora. Been using Ubuntu and its derivatives for the past 20 years until a couple of weeks ago where I just happened to stumble upon the Distrowatch website. Yes, I never knew it existed. Wanted a change of scene and somehow Fedora looked very enticing. Got it installed on main machine without a second thought. Loving it. The community is fantastic. Keep it up folks.
## Pedgerow
Thanks for this! Please explain how to take input in a future article. I have never been sure about how to do this, but I assume it’s very basic. By this I mean, how can I pass an argument to a Bash script? Like if I wanted to write a script that did the same as “echo”, and it only contained one command and that was “echo $input”, what else would I need to put in the script to make it work?
Also, does it have to start with #!/bin/bash, or can it start with something else? What if I put the script file (echov2.sh or whatever) in a different path? It would be very cool if you could answer these questions in a future article.
## Gregory Bartholomew
The words (parameters) passed to the script on the command line are available in the numbered variables $1, $2, $3, etc. If you want them all at once, you can use $*. So in your script, you would put “echo $*”. There is also a $@ that you may see used from time to time. It is similar to $* but it “tokenizes” the parameters a little differently. But that is a more advanced topic. 🙂
## Dietmar
If you ever consider to look into
bash, shellscriptingor just the bestLinuxCLI tutorials of all times – ask your search engine forMachtelt Garrels, Bash Guide for Beginners
and
Mendel Cooper, Advanced Bash-Scripting Guide
to be found here:
https://tldp.org/guides.html
For me this is the greatest IT – literature of all times.
A reference and a tutorial and an introduction and a specialists treasure trove in one.
Second to none.
Give it a try! Fell in love with bash scripting … |
14,133 | 《代码英雄》第五季(1):成为一个码农 | https://www.redhat.com/en/command-line-heroes/season-5/becoming-a-coder | 2021-12-31T10:17:00 | [
"码农",
"代码英雄"
] | https://linux.cn/article-14133-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》第五季(1):成为一个码农](https://www.redhat.com/en/command-line-heroes/season-5/becoming-a-coder)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/437f21ae-f25f-4ef8-a5bd-6b0dbec1c869/clh-s5ep1-becoming-a-coder-vfinal_tc.mp3)脚本。
>
> 导语:代码英雄们是软件工程师、开发人员、程序员、系统管理员,他们俗称码农。他们的职业的多样性几乎和他们找到工作的途径一样多。
>
>
> Saron Yitbarek 和 Clive Thompson 在本季开篇探讨了编程人员开始其技术职业的一些方式 —— 有些是常见的,有些是意想不到的。许多人选择从拿到计算机科学学位开始。但是,不要低估成熟的培训班路线、中后期的职业转换者,以及来自与技术绝缘的地方的编程人员。你可能会惊讶于是谁响应了编码的号召,他们来自哪里,已经取得了多少成就。
>
>
>
**00:00:01 - Saron Yitbarek**:
想象一下,你被困在一个荒岛上。你发现了一架损坏的螺旋桨飞机,有一些工具,还有一本便携手册。你之前从来没有修理过飞机,但你非常想离开这座岛,所以着手修理这架飞机。你离开荒岛的决心可能使那架飞机再次飞行起来。当然,这是一个非常极端的例子,但是,当你试图弄清楚如何将某些东西放在一起时,比如飞机这种结构性的东西摆在你的面前,你都会在心里去想怎么处理,而且有手册可以帮助你。但是如果是软件呢,如果我们不在那个计算机的世界里,很难弄清楚怎么去处理这些 0 和 1。甚至即使你身处其中,也很难想象你正在组合起来的东西。这就是人们发现自己所处的境地。
**00:00:49 - Clive Thompson**:
在写了 25 年有关软件及其对日常生活的影响的文章之后,我意识到大多数人都不知道软件是如何制造的、是谁制造的、为什么要制造它。他们不理解,所有这些软件工程师代表他们做出的决定是什么。这就是一个巨大的谜团。因此,我决定写一本书,揭开这个谜团,向人们展示代码是如何编写的,以及谁编写的。
**00:01:21 - Saron Yitbarek**:
那本书叫做《<ruby> 码农:新部落的建立和世界的重塑 <rt> Coders: The Making of a New Tribe and the Remaking of the World </rt></ruby>》。作者是科技记者 Clive Thompson。在过去的四季节目中,我们精选了许多史诗般的故事,讲述了代码英雄们如何塑造我们周围的环境。但是,我们没有谈及的是编程这件工作本身,它是如何完成的,它是如何随着时间推移而变化的,它会如何发展,以及我们如何才能获得一份编程人员的工作,尤其是第一份。我们整理了一个 3 集的小型剧集,专门致力于讲述一个编程人员的工作。
**00:02:01**:
欢迎来到《代码英雄》的全新一季,这是红帽的原创播客。我是主持人 Saron Yitbarek,《码农》一书的作者,也是本播客的朋友 Clive Thompson 将与我们一起参加这一季所有 3 集的节目。欢迎你,Clive。
**00:02:19 - Clive Thompson**:
很高兴来到这儿,Saron。
**00:02:20 - Saron Yitbarek**:
Clive,最近几年你完全投身于编程人员的世界当中。为了你的书,已经采访了 200 多位开发者、系统管理员、架构师、工程师和程序员吧。
**00:02:31 - Clive Thompson**:
是的。我与整个软件生态系统中的很多软件开发者都交流过。
**00:02:37 - Saron Yitbarek**:
太好了。你是完美的领路人。很高兴你能加入我的节目。
**00:02:40 - Clive Thompson**:
我也很高兴能加入。
**00:02:41 - Saron Yitbarek**:
让我们从成为一个编程人员最传统的途径开始:上大学取得计算机科学学位。
**00:02:48 - Vinamrata Singal**:
我认为,作为一个产品经理拥有这种技术基础很重要。我很高兴自己通过计算机科学课程做到了这一点,因为我觉得自己不仅了解了如何编写程序来执行此操作,而且还了解了幕后的情况。
**00:03:06 - Saron Yitbarek**:
这位是 Vinamrata Singal。她于 2016 年毕业于斯坦福大学,并获得了计算机科学(CS)学位。她说,她的教育经历让她获得了 Facebook、Google 以及其他公司的产品经理职位。Clive,大多数的编程人员都有计算机科学学位吗?
**00:03:24 - Clive Thompson**:
如果你看一下 Stack Overflow(一个大型的开发者网站)的调查,他们每年会对成千上万的用户进行调查。他们的数据表明,在 Stack Overflow,60% 的编程人员都是专业人员,其中一些人接受过某种形式的正规计算机科学的教育,或者类似于电气工程之类的教育。可能比这个比例更高一点,就比如说是 2/3 吧。要成为一名编程人员,获得计算机科学或者与其相关的学位仍然是最普遍的途径。
**00:04:01 - Saron Yitbarek**:
这是因为计算机科学学位更值钱么?
**00:04:04 - Clive Thompson**:
是的,这就是经济学家所说的高成本信号。它们表明,我愿意花大量的时间来学习这些知识,所以我是一个好的雇佣对象。如果你是一个开发者,你必须不断学习。新的框架、新的语言、新的环境等等。一些雇主告诉我,他们喜欢使用获得计算机学位人选的原因是,这些人花了 4 年时间专注学习,而且他们会继续学习下去。
**00:04:37 - Vinamrata Singal**:
当你拿到本科学位的时候,除了学习这些计算机知识,你也学习了理论数学,也学习了算法、学习了网络和计算机系统。我认为所有的这些,给了你一个非常坚实的基础,所以不管你要转换还是不转换行业,那都很容易。
**00:04:56 - Vinamrata Singal**:
斯坦福大学的学位会让他们被认真对待。老实说,这就是信心。这也有很大的作用,让你不会感觉到自己滥竽充数。然后,就像你在申请工作后,雇主们都愿意和你谈谈,只是因为你身处这个庞大的网络就简单得多。
**00:05:12 - Saron Yitbarek**:
计算机科学学位是否使他们比非计算机专业的员工表现的更好?
**00:05:21 - Clive Thompson**:
这是一个非常好的问题。这个问题很难回答,因为我从不同的雇主那儿获得了完全不同的答案。一些人告诉我,“是的,学计算机的人相比自学成才或者来自培训机构的人更自信、更有底气而且遇到情况时能采取迅速有力的行动”。然而,我也听到过完全相反的观点,例如,David Kalt,他运营着 Reverb,该公司是一家主要销售音乐设备、出人意料的成长并且盈利的电子商务网站。他说,我曾经说过我只想要学计算机的毕业生,但是他们不具备想要成为高效率团队成员的所有技能。因此他开始越来越多的雇用培训班出身的人员、自我成才的人员,或者之前业余学过这方面的音乐人。
**00:06:11**:
你也会听到对非计算机科学出身的人的赞扬。我想是来自于某一类投资人或者是老派编程人员。他们有五六十岁,自学成才,在上世纪 80 年代就使用过 Commodore 64。当他们看到有人走过来说,“是的,我只是不喜欢在酒店的工作,所以在 YouTube 和 Code Academy 上学了很多东西。” 他们会说,“是的,我想要那个人”。我们应该说这是完全不同的两类选择。有一类雇主非常严格,只雇佣有计算机科学学位的人员。还有一类雇主有时觉得自学成才或为了改变职业而去参加培训班的人才真正值得自豪。
**00:06:55 - Ali Spittel**:
我的故事很独特。我在一个偏僻的地方长大,我的高中学校的经费肯定不高,所以直到我进了大学我才知道什么是编程。
**00:07:10 - Saron Yitbarek**:
Ali Spittel 是一名软件工程师,也是开发培训班 General Assembly 的一名杰出教职员。她从大学开始学计算机科学,然后发现自己走上了一条完全不同的道路,走向了编码生涯。
**00:07:24 - Ali Spittel**:
我学习了 Python,完全爱上了它。我觉得非常神奇的是,你将某些内容输入计算机,然后它就可以输出一些东西。然后我很快就决定主攻计算机科学双学位。但是当下学期我学习了 C++ 的自由开源软件的数据结构和算法,我确实通过了那门课程,但是我是点灯熬油,付出十分努力才通过的。然后我就觉得编程真的不适合我,就退学了,继续我原来的专业,也就是政治学。大约一个学期后,我在做一份实习,主要是政治工作的数据分析。我意识到我可以用编程来使很多工作自动化。他们发现了这一点,并推荐我担任软件工程师的职位。
**00:08:17 - Saron Yitbarek**:
我采访过数百人,我几乎总是会问这样一个问题: “计算机科学学位真的有价值吗?你真的需要它吗?你可以自学成才吗?” 我只是想了解一下这方面的情况。我猜,计算机科学学位会非常有价值,因为你要花 4 年的时间来学习这些精心挑选的信息。但是,在这些采访中,我会得到各种类型的答案。有人对我说,“实际上,它真的不太实用。” 也有人对我说:“那些理论知识太有价值了。”
**00:08:47 - Clive Thompson**:
是的,我也听到了各种反馈。我从一些人那里听到了一些说法,他们强调说,我们需要有计算机科学学位的人,我们不太想要那些没有这些学位的人。但还有另一群人,我想你听到过他们完全相反的意见。他们说,不不不,我们想要的是那些有实际经验的、能够团队合作的人,我们喜欢能跳出思维定式的人。如果一个人是自学的,他们会比上大学的人有更好的成长心态,因为也许上大学的人习惯了别人给他们东西。课程就在那里,他们按部就班地学习就行。而那些只是自学了一些 HTML、CSS、JavaScript 和 Node 的人,把自己变成了一个全栈工程师。毋庸置疑,在团队中就是想要这样一个放那儿就能干活的人。
**00:09:38 - Ali Spittel**:
不同的学习方法各有适合的人。计算机科学是不可思议的,因为你学到的所有这些理论基础可以为你的日常工作奠定基础。自学是另一个很好的途径。这是我的主要起步方式,它将使你在工作中拥有学习这些东西的基础,这是你无论如何都要需要的。最后是培训班。如果可以回头再来的话,我会去参加一个培训班,因为可以让一位指导老师来监督以及鼓励你的学习,有一个可以遵循的课程,而且在老师指导的课堂上,你仍然可以自学。但话虽如此,我认为每条路都有你选择它的合理性,它们都应该存在,不同的道理适合不同的人。
**00:10:44 - Kush Patel**:
8 年来,我们毕业了大约 3000 名学生,并且能将其中 95% 的学生安置到软件工程职位上,他们在旧金山校区的工资中位数约为 10 万美元,在纽约校区的工资中位数约为 9 万美元,并且这些学生是在顶尖的高科技公司里。
**00:11:00 - Saron Yitbarek**:
Kush Patel 是 App Academy 培训班的 CEO。他的培训班有一个学费模式,可让毕业生找到工作之后再付款。这使得更多的学生有机会学习编程。这些毕业生被 Google 之类的公司雇用,可以赚到可观的薪水。
**00:11:18 - Kush Patel**:
这些年来,我们有大约 100 名学生进入了 Google。基本上,这比那些顶尖的计算机科学教育都有优势,这是一种非常便捷的方式,可以让学生获得技术领域最热门的工作之一。
**00:11:32 - Saron Yitbarek**:
所以,Clive,App Academy 是编程培训班的典范么?
**00:11:36 - Clive Thompson**:
我想说的是,他们是优秀的编程培训班的典型代表,但是培训班本来就是良莠不齐的。有出色的、管理良好的、可以教人们很多东西的地方;也有一些非常不可靠,从来没让人找到过工作的机构。
**00:11:57 - Saron Yitbarek**:
我是在大约 6 年前从一个编程培训班毕业的,那时培训班感觉像雨后春笋般冒出来。它在成长,是一个萌芽中的产业。从那以后,我觉得培训班已经有了很大的发展。你觉得呢?
**00:12:12 - Clive Thompson**:
是的,是这样的。可能需要对最好的编程培训班稍微降低一些期望。我认为他们从一开始就承诺每个人都将得到这些好工作,但这并不总是可能的。他们设定的期望过高。他们也意识到他们必须在找工作这方面真的下很大功夫。因为他们可以给人这些技能,但让他们从事初级开发工作是非常重要的,在那里他们可以学到更多。
**00:12:43 - Saron Yitbarek**:
我认为,这些年来,为培训班支付费用的方式已经发生了改变。这真的很吸引人。甚至在接受培训后再付款的做法也更正式了,有了 ISA,有了收入分成协议,我想,这也是一种更有约束力的做法。这种做法有利有弊。有一种这样的风险,就是当你实际上没有得到任何收入的时候,你却不得不还钱。
**00:13:06 - Clive Thompson**:
我同意。因为培训班增长太快了,而且它们显然是在填补一个空缺。计算机科学学位的增长速度不足以满足公司的需求。它们需要其他的途径。培训班填补了这一空白。但这意味着它们以一种奇怪的方式向着社区学院的方式发展,从理论上讲,你希望它们这样发展。社区学院是受到监管的。实际上我认为,各级政府可能会给培训班制定一些标准,这肯定很好,因为如果他们能够制定出非常、非常好的标准,并且可能获得真正的认可,那么它会鼓励最好的培训班达到这些标准。其他不满足这些法规要求的培训班,要么被淘汰,要么被关闭。
**00:14:02 - Saron Yitbarek**:
让我们和一家大型科技公司的人谈谈关于非传统招聘的事情。作为 LinkedIn 的高级工程经理,Will White 多年来雇佣了很多程序员。他们中的大多数都是计算机科学专业的毕业生,但他意识到他们的数量不足以填补空缺的职位。三年前,该公司启动了一个名为 “Reach” 的学徒计划。
**00:14:25 - Will White**:
Reach 项目是一个多年的计划,我们引进学徒,通过将他们与不同的导师和经理配对,帮助他们培训工程技能。我们相信,顶尖的人才可以来自任何地方,而 Reach 是我们寻找人才的途径之一,尤其是在计算机专业之外的学生。一般来说,我们寻找的是对工程有激情的人,这种激情可以表现在很多方面,无论是花时间去培训班的人,还是花了很多时间在自学上的人,比如业余参与一个项目,或者编写代码,并试图提交一个拉取请求让开源项目接受它。
**00:15:16 - Saron Yitbarek**:
Clive,刚才 Will 和 Ali 都在谈论自学成才,在你的研究中,你也遇到了一些自学成才的编程人员吧。
**00:15:25 - Clive Thompson**:
有很多自学成才的编程人员。与我们之前提到的对应的是,Stack Overflow 调查中约有三分之一的人完全或至少基本上是自学成才的。Sarah Drasner 是一位出色的全栈工程师。最初因在 SVG 图形方面的开创性工作而闻名。而且,她真的是自学成才的,她原来是博物馆的插画师,但后来这份工作搁浅了,因为他们有了一台相机,拍照比她画的更好。她的雇主说:“要不你来为我们做网站吧?” 那时候网站还处于早期。然后她说,“当然可以。” 她回到家就开始看书,试着学习怎么去做个网站。她走了那条路,并在接下来的几年内成为了一名杰出的开发者,在她的领域大名鼎鼎。而这这种故事并不罕见。
**00:16:26**:
Mike Krieger 是 Instagram 的两位幕后开发者之一,他承担了很多繁重的工作。他最初还是个孩子的时候就开始自学做网站。最初是一些超小的开源项目,帮助创建过 Thunderbird 插件等等,这就是他起步的地方。这确实使他取得了很大的进步。对我来说,实际上我认为自学成才的机制真的很有趣,而且它变得比以往任何时候都容易,因为有很多资源都唾手可得,比如 FreeCodeCamp。实际上,我就是这样学习 HTML、CSS 和 JavaScript 的。然后还有无数的 YouTube 视频、开源项目和黑客马拉松。自学是一个令人惊讶的上升通道。
**00:17:24 - Rusty Justice**:
我是你所见过的最不可能从事技术工作的人之一。我是一名采矿工程师,学的是土木工程。我自学的动机是出于需要。我们的煤炭产业是这个地区占主导地位的行业,但这个行业崩溃了,因此出现了很多失业人员。
**00:17:43 - Saron Yitbarek**:
在这个片段里有我一直以来最喜欢的名字之一,Rustry Justice。他来自<ruby> 阿巴拉契亚 <rt> Appalachia </rt></ruby>中部<ruby> 肯塔基州 <rt> Kentucky </rt></ruby>的<ruby> 皮克维尔 <rt> Pikeville </rt></ruby>,那里的主要产业一直是煤炭开采。Rusty 在采矿业经营业务已有多年,直到 5 年前该行业崩溃为止,然后他和他的商业伙伴决定采取行动。他们创立了数字服务公司 Bit Source。Clive,你在书中写过关于 Rsuty 的文章。他是越来越多的在职业生涯中期进入编程行业的一个例子。你使用了一个称为“<ruby> 码农 <rt> blue collar coder </rt></ruby>”的术语。那是什么意思?
**00:18:22 - Clive Thompson**:
好吧,这主要是指以一种可能与我们在过去 15 到 20 年里谈论编程人员的方式有点不同的方式来进行这项工作的编程人员。长期以来,对编程人员的印象是穿着连帽衫的小伙子,他们搬家到硅谷,他们可以创办一家初创公司,并获得数百万美元的投资,也许成为了亿万富翁。码农的意思是,他更像是从事 20 世纪的蓝领工作的人,就像那些在克莱斯勒生产线上从事熟练技术工作、制造汽车的人一样。他们具有丰富的技术技能,但被认为是从事一种稳定的中产阶级工作,码农更像是这种。码农这种工作正在接近蓝领工作,因为我们做这项工作,不是为了成为赚取数百万美元的连帽衫小子,而是为了拥有一份稳定的 21 世纪的中产阶级工作。
**00:19:19**:
事实上,只有 8% 的编程工作在硅谷,在那种众所周知的消费软件领域。在美国的其他地方,都有从事编程工作的人。他们无处不在,他们在田纳西州、在俄亥俄州、在纽约州北部。他们不在 Facebook 和 Google,他们在银行、在保险公司、餐馆或工业公司工作。这些行业都需要软件开发人员。当人们把目光放在传统领域之外时,就会用一种不同的思考方式来思考职业轨迹。这就是我们看到的码农的来源。
**00:19:59 - Saron Yitbarek**:
你在书中提到了另外一个码农,另一个有着神奇名字的人,Garland Couch。他曾在一家大型矿业公司做了 15 年的维修计划员,后来被解雇了。后来他加入了 Rusty 的公司,进入了科技行业。下面是他刚开始在 Bit Source 工作时的情况。
**00:20:21 - Garland Couch**:
我过去开玩笑说,这是一个半严肃的笑话,工作了 22 周之后我们都不知道彼此的姓氏,因为每个人都是进来、坐下来、戴上耳机,然后开始工作。没有人说话、没有笑声、没有玩笑、也没有争吵。你要明白,这是 10 个失业的人试图找到一份工作。那是非常艰难的 22 周,我们 10 个人都非常专注于学习需要学习的东西。
**00:20:57 - Saron Yitbarek**:
Clive,你采访过很多转型做技术的蓝领工人,比如 Garland 和 Rusty,这些转型大部分情况下成功了吗?
**00:21:06 - Clive Thompson**:
是的。所有我采访过的人在很大程度上都取得了相当不错的成功。我认为有些事情对他们是有所帮助的,因为他们年纪稍大,在事业上小有建树。他们有严肃的目的,这可能是你年轻时没有的。他们知道如何学习,知道如何自学。他们知道自己付出的是什么,因为他们想要一个新的事业。也许他们以前的事业正在消失,就 Garland 来说。他们绝不缺乏热情和坚持不懈的精神,而这些正是我认为做好编程所需要的,而且他们对当地市场的需求也经常有所了解。
**00:21:46**:
在 Garland 的案例中,他有一个当地市场,那就是在肯塔基州成立了一家新的高科技公司。另一个优势是,一些我采访过的真正成功的人,他们对软件用在什么地方有更开阔的看法。如果你和一个普通的 19 岁学生交谈,他们会认为软件就是 Instagram,仅此而已。但是如果你和一个 31 岁在酒店业工作过的人交谈,他们知道酒店使用了大量的软件,他们会说,我要去那里工作,那些领域急需人才。
**00:22:22 - Rusty Justice**:
就我个人而言,最大的教训是,在被告知有这些编程工作时得到了太多的错误信息,我真的是太天真了。我们被告知缺少某某数量的开发者,所以从事它们就有赚钱的可能。而这种收入水平和我们在这些采矿工作中失去工作的收入水平是相当的。所以我们想,如果我们学会了编程,那么世界就会为我们打开大门,我们就会有工作。但是没有人会雇佣我们,因为你们为什么要雇佣我们呢?我们是一群从来没有做过这种工作的人。我们必须向市场证明我们提供了价值。
**00:23:03 - Garland Couch**:
我认为,现实世界的经验,在其他行业、其他环境和大公司工作过,干过我们之前干过的工作,对我们现在所做的事情肯定有帮助。我给你举个例子:有一个公司希望我们为公路卡车司机开发一个应用程序。我们这里的工作人员有 CDL 执照。大家马上就会想,等等,你们有真正开过卡车的开发人员吗?是的,我们有。
**00:23:41 - Saron Yitbarek**:
像阿巴拉契亚这样的地区有很多负面的刻板印象,但是 Rusty 和 Garland 以及他们社区的其他人正在做的是创造积极改变的模式,他们为此感到非常自豪。Garland 总结说,
**00:23:56 - Garland Couch**:
对我来说,蓝领意味着一个努力工作的人愿意投入工作,愿意苦干和解决问题。对我来说,码农这个词是一种赞美。
**00:24:17 - Gillian**:
在我参加培训班的一个月后,我想,“我到底在做什么?” 但随着时间推移。课程真的很紧张。尽管很困难,但我发现我自己并不是很累,只是很兴奋地想看到我第二天能做些什么,我如何能变得更强。在那个时候,我知道自己真的很喜欢所做的事情。
**00:24:42 - Saron Yitbarek**:
这位是 Gillian。她曾是一名 20 多年的物理学家,由于她的工作被裁员了,她决定试一试编写代码。她在 50 多岁时参加了一个 Java™ 培训班。从培训班毕业两周后,她在金融服务业找到了一份工作。现在,她的事业蒸蒸日上,但她知道她的剩下的职业生涯可能会一直处于初级阶段,因为她从业比较晚,但这对她来说没什么问题。她很开心,她为自己的团队做出了贡献。
**00:25:11 - Gillian**:
我可能没有他们做 Java 开发那么熟练,也没有他们那么丰富的经验,但是我可以思考,我可以分析,我可以发现问题,提出明智的疑问。我可能不知道答案,但至少我知道该问什么问题,因为我有很多解决问题的经验。
**00:25:33 - Saron Yitbarek**:
所以,Clive,让我们来谈谈这个行业的老年工作者。Gillian 提到她是一名初级程序员,可能在职业生涯的余下时间里她继续是一名初级程序员,她非常乐意这样做。我想知道,如果你在中年时才开始从事编程,什么样才算成功?
**00:25:49 - Clive Thompson**:
我采访过的很多人年纪都比较大,他们进入这个行业是因为他们对现有的行业不再感兴趣了,他们渴望创造东西,渴望成为一名工程师,或者可能他们现有的行业正在分崩离析。他们想,我需要一个真正成长的地方,所以他们并不一定一心要成为编程金字塔的顶尖人物。他们想要有回报的、稳定的工作。毫无疑问,他们会找到一份这样的编程工作,如果他们能找到第一份工作,踏踏实实地进入工作岗位,证明了自己的价值,那就够了。他们更倾向于码农。
**00:26:33 - Elisabeth Greenbaum Kasson**:
一般来说是这样的,但也有一种观念认为,如果你年纪大了,你就不再具有接受教育的能力,你不再灵活了,你觉得自己什么都知道了。这真的很可惜,因为招聘经理错过的是那些拥有丰富经验的人,他们知道如何在某个特定时间发生的事情上作出调整。
**00:26:57 - Saron Yitbarek**:
这位是技术及商业记者 Elisabeth Greenbaum Kasson。她说,“在技术行业,年龄歧视是非常现实的。许多程序员一生都在编程。随着年龄的增长,获得一个新的编程工作开始变得越来越难。很多年长的程序员在求职时都被忽视了。”
**00:27:18**:
那么 Clive,你采访过很多程序员。他们中有多少人经历过年龄歧视?他们有哪些故事?
**00:27:24 - Clive Thompson**:
如果他们没有成功跃入高层管理岗位,很多人就会遭遇年龄歧视。老年开发人员有两种类型:有些人成功地升到了管理层。他们管理着一个完整的团队,然后可能会成为副总裁、CTO,或者创办自己的公司成为 CEO。他们是快乐的,他们在发号施令。他们利用自己的经验来指挥和管理由年轻、求知若渴的开发人员组成的大型团队。但是还有另外一群程序员不想成为管理人员。他们喜欢创造东西。他们喜欢成为解决问题的工程师。他们面临的问题是,科技行业的环境不能让这些人一直这样做到四十岁、五十岁,乃至六十岁。
**00:28:19**:
这个行业想要年轻人,可以 996 而没有抱怨,没有孩子、没有任何责任、不要更多的钱。你会想,哇,软件开发人员的工资很高,确实如此。但如果你有几个孩子和一所房子,你可能想要更多的钱,你想要稳定,你不想工作那么长时间。也许你并不需要这些,因为你现在觉得这样挺好。但是雇主们错误的认为,如果你没有疯狂地每周工作 100 个小时,你就没有产出。所有这些打击都会针对那些只想成为高效率的开发者,他们开始被排挤出去。
**00:28:59 - Elisabeth Greenbaum Kasson**:
他们可以做的事情就是让自己变得更容易被雇用,出现在他们认为自己不可能出现的地方。例如,我认为很多 50 多岁的人应该多用用 GitHub,去参加可能都是年轻的人的聚会,去参加一些针对特定编程小组的聚会,在那儿他们可以结交一下人脉了解当前正在发生的事情。
**00:29:26 - Saron Yitbarek**:
Clive,你对程序员在职业生涯后期还有什么忠告吗?
**00:29:32 - Clive Thompson**:
当然,我实际上问过那些还在编程并且很乐意编程的老开发者,他们的秘密是什么。一般来说,他们告诉我的是,不断地学习、学习、学习,用新框架和新语言来构建些东西,这是至关重要的,这样他们就能有一个代码库来证明他们能做到这些事情。这是我展示的,使用新的工具集、使用新的语言、新的框架。这真的很重要。我认为 Elisabeth 说得很对。这些老开发者们还谈到了保持外向和现实联络的价值,以及从黑客马拉松到聚会的所有这些事情。
**00:30:15**:
我在旧金山遇到的这位典型的灰胡子,字面意义上的灰胡子。这位程序员说,他突破了,因为他参加了一个物联网黑客马拉松,都是嵌入式设备和非常小的处理器,比如 Arduinos,有非常严格的内存限制。他说就像是,“这把我带回了上世纪 70 年代,当时我刚进入这个领域,那时台式电脑的内存非常有限。” 这些都是他找到的让自己走出去并融入社区的方法。最后他意识到,哇,实际上有很多我可以做的物联网工作。让自己保持与时俱进,似乎真的能帮助许多较老的开发人员摆脱困境。
**00:31:01 - Saron Yitbarek**:
Clive,最后一个问题。无论一个程序员在职业生涯中处于什么位置,无论他们通过什么途径成为一名程序员,你采访过的程序员都有哪些共同之处?成功的关键指标是什么?
**00:31:15 - Clive Thompson**:
真正重要的是对学习和成长的持续渴望。我遇到的每一个成功的程序员都是如此。他们都有永不满足的好奇心。一旦他们发现某些东西存在可能性,比如一种发展起来的语言,出现了一个新框架,出现了一个新技术栈,他们就想了解它,想要探索它,摆弄它。他们会在业余时间创造一些东西,只是想看看到底有什么可能。
**00:31:42**:
如果有人听完这段话会想,嘿,也许我也想成为一名程序员。成功实现转型的人都有那种熊熊燃烧的好奇心,他们喜欢这份工作,会发现它的乐趣,会在业余时间为快乐而去做它。事实上,他们喜欢它,是因为它给了他们一种成就感和解决问题的感觉,这是他们在以前的工作中没有的。所以,如果让我说,每一个成功的人,包括那些成功转型的人,都有一种令人惊叹的好奇心和对琢磨这些新事物的渴望,这让他们不断进步。
**00:32:21 - Saron Yitbarek**:
Clive,非常感谢你和我一起来谈论程序员的职业道路。
**00:32:26 - Clive Thompson**:
我也很高兴。
**00:32:27 - Saron Yitbarek**:
现在我们了解了我们来自哪里,在我们的职业生涯中走过了什么道路,让我们看看如何以及在哪里做最好的工作。下一集,Clive,你会回来加入我,对吗?
**00:32:41 - Clive Thompson**:
肯定的。
**00:32:44 - Saron Yitbarek**:
《代码英雄》是红帽的原创播客。我们另外还有一些关于程序员职业道路的采访和研究。登录 [redhat.com/commandlineheroes](http://redhat.com/commandlineheroes) 了解更多信息。我是 Saron Yitbarek。
**00:32:58 - Clive Thompson**:
我是 Clive Thompson。
**00:32:58 - Saron Yitbarek**:
坚持编程。
**00:32:59 - Clive Thompson**:
坚持编程。
**00:33:01 - Saron Yitbarek**:
再来一遍。1,2,3 我们会坚持编程。1,2,3,坚持编程。
**00:33:10 - Clive Thompson**:
坚持编程。
**00:33:17 - Saron Yitbarek**:
坚持编程。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-5/becoming-a-coder>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[mrpingan](https://github.com/mrpingan) 校对:[acyanbird](https://github.com/acyanbird), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Command line heroes are software engineers, developers, programmers, systems administrators—coders. That variety in coding careers is almost as varied as the paths coders take to land their jobs.
Saron Yitbarek and Clive Thompson start the season by exploring some ways coders start their tech careers—some common, many unexpected. Many choose to start with a degree in computer science. But don’t underestimate the maturing bootcamp tracks, the mid-to-late-career switchers, and coders from outside the insulated tech hubs. You might be surprised who answers the call to code, where they come from—and how much they’ve already accomplished.
**00:01** - *Saron Yitbarek*
You're stuck on a desert island. You discover a broken down prop plane, some tools, and a handy-dandy manual. You've never fixed a plane before, but you're desperate to get off the island, so you get to work. Your determination might be enough to get that plane flying again. Now this is an extreme example, but when you're trying to figure out how something is put together, especially something that's physically in front of you like a plane, you've got a mental image of what you're working with and a manual to help you along. But what about software? If you're outside that world, it's pretty hard to figure out what to do with all those ones and zeros. And even when you're in it, it can be hard to visualize what you're putting together. That's the situation one person found themself in.
**00:49** - *Clive Thompson*
After 25 years of writing about software and its impact on everyday life, I realized that most people had no idea how software was made, or who made it, or why they wanted to make it. They didn't understand, you know, what were the decisions being made on their behalf by all these software engineers. It's just this huge mystery. I decided I wanted to write a book that would unlock that mystery, and show people how code gets made and who makes it.
**01:21** - *Saron Yitbarek*
That book is called, Coders: The Making of a New Tribe and the Remaking of the World. And the author is science and technology journalist, Clive Thompson. For the last 4 seasons, we featured so many epic stories of how coders have shaped the landscape around us. But what we haven't talked much about is the job itself, how it's done, how it's changed over time, how it might be evolving, and how we go about getting a job as a coder, especially for the first time. We've put together a mini-season of 3 episodes devoted to the job of being a coder.
**02:01** - *Saron Yitbarek*
Welcome to an all-new season of Command Line Heroes, an original podcast from Red Hat. I'm your host, Saron Yitbarek, and joining us for all 3 episodes this season is author of Coders and friend of the pod, Clive Thompson. Welcome, Clive.
**02:19** - *Clive Thompson*
Happy to be here, Saron.
**02:20** - *Saron Yitbarek*
Clive, you spent the last few years fully immersed in the world of coders. You've interviewed over 200 developers, sys admins, architects, engineers, and programmers for your book.
**02:31** - *Clive Thompson*
Yeah. I spoke to, boy, an awful lot of software developers all over the ecosystem.
**02:37** - *Saron Yitbarek*
Great. You're the perfect co-pilot. So glad you could join me.
**02:40** - *Clive Thompson*
Good to be here.
**02:41** - *Saron Yitbarek*
Let's start with the most traditional path to becoming a coder, going to college to get a computer science degree.
**02:48** - *Vinamrata Singal*
I think for what I do as a product manager, it's important to have that technical foundation. I'm glad I did it through a computer science program, because I feel like I don't only understand how I program something to do this, but I also understand what goes on under the hood.
**3:06** - *Saron Yitbarek*
That was Vinamrata Singal. She graduated from Stanford University in 2016 with a computer science (CS) degree. She says her education set her up for product managing positions at Facebook, Google, and other companies. Clive, do most coders out there, get CS degrees?
**03:24** - *Clive Thompson*
If you look at the Stack Overflow survey—that's the big coding site, and that they do a fantastic survey of 10s of 1000s of their users every year—their data suggests that about 60% of the coders that are on Stack Overflow that are professional, they have some sort of formal computer science training, or something close to it like electrical engineering. And the numbers may be a little higher than that, but let's just say two-thirds. It is still the most common route, far and away, for becoming a coder, is to go and get a computer science degree or something related to it.
**04:01** - *Saron Yitbarek*
Is that because CS degrees are lucrative?
**04:04** - *Clive Thompson*
Yeah, they are what an economist would call a costly signal. They indicate that, hey, I'm someone who's willing to spend a lot of time learning the stuff, so I'd be a good person to hire. If you're a developer, you're having to constantly learn all the time. New frameworks, new languages, new environments. Some of the reasons employers would tell me that they like getting people from computer science degrees is because those people just spent 4 years doing nothing but learning. And they're going to need to keep on learning.
**04:37** - *Vinamrata Singal*
When you get an undergraduate degree, you're learning that, but you're also learning the theoretical math. You're also learning about algorithms, and you're learning about networking and computer systems. And I think all of those just give you a very solid foundation so that if you were to switch industries or what not, like it would just be a lot easier.
**04:56** - *Vinamrata Singal*
The Stanford degree helped with being taken seriously. Honestly, just confidence. That's a big part of it, too. Dealing with imposter syndrome. And then also like people want to talk to you even applying to jobs after, you just, it's just a lot easier because of this big network you have.
**05:12** - *Saron Yitbarek*
Do CS degrees make them better performers than those who come into the industry non-traditionally?
**05:21** - *Clive Thompson*
That's a really great question. That's a hard one to answer because I got completely different answers from different employers. I had some people tell me that, "Yeah, CS people are just more confident and more self-assured and can hit the ground running, than self-trained people or bootcamp people." And then I heard exactly the opposite. I heard for example, David Kalt, he runs Reverb, which has become the dominant eCommerce site for selling musical equipment. Fantastically, growing, profitable firm. And he's like, I used to say, I only wanted CS grads, but they just didn't have all the sort of life skills that you want to be a productive team member. And more and more, he started hiring bootcamp people, self-trained people, people who are musicians who learned it on the side.
**06:11** - *Clive Thompson*
You also hear praise for the non-computer science people. I think from a certain class of investor or even old school coder. They're in their 50s or 60s and they taught themselves, using a Commodore 64 back in the 80s. When they see someone who came along and said, "Yeah, I just, I had some job in hospitality, and I hated it, and I learned a ton of stuff on YouTube and Code Academy." They're like, "Yeah, I want that person." It is very bimodal, shall we say. There is a class of employers that is really rigorous about only hiring CS. And there's a whole other class that actually sometimes regards as a real mark of pride to be self-taught or a scrappy person who changed their career and went to a bootcamp.
**06:55** - *Ali Spittel*
My story is very unique. I grew up in the middle of nowhere and my high school definitely was not highly funded. And so I did not know what programming was until I got into college.
**07:10** - *Saron Yitbarek*
Ali Spittel is a software engineer and a distinguished faculty member at General Assembly, a coding bootcamp. She started off taking computer science in college, but found herself going on a completely different path towards a coding career.
**07:24** - *Ali Spittel*
I learned Python. I fell absolutely in love with it. I thought it was magical how you could type something into the computer and something else would come out. And I quickly decided that I was going to double major in computer science, but then the next semester I took data structures and algorithms in C++ FLOSS, and I did make it through, but I was pulling all-nighters and was working so hard just to even make it through the class. And then I decided that programming really wasn't for me, dropped out, and just went along with my original major, which was political science. About a semester later, I was doing an internship that was mostly data analysis for political work. And I realized that I could automate a lot of my own job with programming. They found out about that and recommended me for a software engineering role.
**08:17** - *Saron Yitbarek*
I've interviewed hundreds of people, myself, and I almost always ask the question, “Is a CS degree actually valuable? Do you need it? Are you okay kind of being self-taught?” Just trying to get a feel for that. And I would guess that a CS degree would be super valuable because you're spending 4 years learning this very highly curated set of information. But then when I have these conversations, I get all types of answers. I get people who've said, "Actually, it really wasn't that practical." And I've had people who say, "Oh, that theoretical knowledge is so valuable."
**08:47** - *Clive Thompson*
Yeah. And I've also heard a mix. I've heard a strong signal from the people who are like, okay, we need computer science degrees. We don't really take seriously people that haven't done that. But there is also this whole other group that I think you've heard from that is completely the opposite. They're like, no, no, no. We want people who have real-world experience who can work in teams. We like people who can think outside of the box. And if someone's taught themselves, they have an even better growth mindset than someone that went to college, because maybe the person at college was accustomed to having stuff handed to them. The curriculum was there, they were marching through it. Whereas the person who just taught themselves some HTML, then some CSS, and then some JavaScript and Node and turned themselves into a full stack engineer. My God, that's someone with enormous get-up-and-go who you want on their team.
**09:38** - *Ali Spittel*
A different learning path is good for everybody. Computer science is incredible because you can learn all these theoretical bases for what you're going to be doing on a day-to-day basis. Self-teaching is another great path. That's mostly how I got my start, and it's going to make it so that you have this basis in learning these things on the job, which is what you're going to have to do anyways. And then the last part is bootcamps. If I were to go back and do it over again, I would do a bootcamp because of the ability to have an instructor that is looking over your work, but also the encouragement of having a curriculum to follow and the direction to still teach yourself while you are in an instructor-led classroom. But that being said, I think that every single path has valid reasons why you should choose it, and they should all be around and have different benefits for different people.
**10:44** - *Kush Patel*
Over 8 years, we have graduated about 3,000 students and been able to place about 95% of those students into software engineering roles with a median salary of about US$100,000 in our San Francisco campus and about US$90,000 from our New York campus, and have placed those students at top tech companies.
**11:00** - *Saron Yitbarek*
Kush Patel is the CEO of App Academy bootcamp. His bootcamp has a tuition model that allows graduates to pay after getting a job. This gives a lot more students a chance to learn to code. Graduates have been hired by companies like Google and can earn a decent salary.
**11:18** - *Kush Patel*
Over those years, we have placed about a 100 students at Google, which compares very favorably to basically every top computer science program. A very expedient way to land in one of the hottest jobs in technology.
**11:32** - *Saron Yitbarek*
So Clive, is App Academy bootcamp typical of coding bootcamps?
**11:36** - *Clive Thompson*
I would say they're typical of good coding bootcamps, but the bootcamp world itself is really diverse, ranging from fantastic, well-run places that I think teach people a lot, to some very sketchy fly-by-night organizations that have never got anyone a job.
**11:57** - *Saron Yitbarek*
So I graduated from a coding bootcamp about 6 years ago now, I think, and back then it felt like bootcamps were popping up. It was growing, it was a budding industry. And since then, I feel like bootcamps have evolved over the years. Is that something that you've seen?
**12:12** - *Clive Thompson*
Yeah, definitely. The best ones have maybe moderated a little bit their expectations. I think they came out of the gate basically promising that everyone was going to get these really great jobs, then that wasn't always possible. They sort of worked harder on setting expectations. They also realized they had to work really hard on the sort of job hunt part. Because they could give someone those skills, but it was really important to get them into a junior development job where they're going to learn a lot more.
**12:43** - *Saron Yitbarek*
I think the way that you pay for a bootcamp has changed over the years. And that's been really fascinating. Even the idea of paying after you get that training has become a little bit more official with ISAs, with income share agreements, kind of making that a little bit more binding, I guess. And there's some pros and cons to that. There's the danger of having to pay back when you didn't actually get anything in return.
**13:06** - *Clive Thompson*
I agree. Because bootcamps have grown so dramatically, and because they're clearly filling a hole. There aren't enough computer science programs. They can't expand fast enough to create all the CS degrees that these companies need. They need some other route. Bootcamps are sort of filling this gap. But that means in a weird way that they're sort of moving in the direction that community colleges, theoretically, you'd like to see them move in. Community colleges are regulated. I actually think that the government, local governments, state governments, federal governments could probably work on some standards for bootcamps that would be great because if they could make really, really good ones, and there could be a real stamp of approval, then it would encourage the best bootcamps to rise to those standards. And the other ones would either get flushed out or even shut down if they can't meet those regulatory requirements.
**14:02** - *Saron Yitbarek*
Let's talk to someone from a larger tech company about hiring non-traditionally. Will White has hired a lot of coders over the years, as a senior engineering manager at LinkedIn. The majority of them are CS grads, but he's realized there aren't enough of them to fill available positions. Three years ago, the company started an apprenticeship program called Reach.
**14:25** - *Will White*
The Reach program is a multi-year initiative where we bring in apprentices and help them train their engineering skills by pairing them with different mentors and managers. We believe that top talent can come from anywhere and Reach is one of the avenues that we use to find that talent. Particularly outside of the pool of CS candidates. Generally speaking, we're looking for folks with a passion for engineering and that can manifest in a lot of different ways, whether it's folks that have taken time to go to a bootcamp or have spent a lot of time pursuing self-learning on their own time. Things like tackling a project on the side, or writing code and trying to get a pull request received and accepted by an open source project that you've been working with.
**15:16** - *Saron Yitbarek*
Clive, both Will and Ali from earlier, talk about self-learning and you encountered a few self-taught coders yourself when you were doing your research.
**15:25** - *Clive Thompson*
There are an awful lot of self-taught coders. We're talking about, around one-third of the people in the Stack Overflow surveys are entirely, or at least substantially, self-taught. Sarah Drasner is a fantastic full-stack engineer. Became originally well known for her pioneering work in SVG graphics. And, she literally taught herself because her original job being an illustrator at a museum was sort of mothballed, because they essentially got a camera that was better at taking pictures than she was at drawing them. Her employer said, "Well, do you want to make websites for us?" And this is early on in the web. And she said, "Yeah, sure." And went home and literally just started reading books and trying to learn how to do it. She took that route and over the next number of years became an absolutely fantastic developer, top in her field. And those stories are not that unusual.
**16:26** - *Clive Thompson*
Mike Krieger, the coder behind Instagram, one of the two developers, but he did a lot of the heavy lifting. He originally taught himself as a kid, making websites. Started working on crazy little open source projects, helping to create plug-ins for Thunderbird. And that's where he started in it. It really raised him upwards heavily. To me, I actually think the self-taught mechanism is really interesting, and it's gotten easier than ever because there are resources that are set up for it, like FreeCodeCamp, which is how I learned HTML and CSS and JavaScript actually. And then there's just a million YouTube videos and open source projects and hackathons. Self-taught is a surprisingly viable on-ramp.
**17:24** - *Rusty Justice*
I'm the least likely person you'll ever meet to be in tech. I'm a mining engineer and a civil engineer by education. Necessity was what prompted us. We just had our coal industry here, which is the predominant industry in the region, collapsed. And so there was a huge unemployment problem.
**17:43** - *Saron Yitbarek*
That's a clip from a man with one of my favorite names ever, Rusty Justice. He's from Pikeville, Kentucky in central Appalachia, where the main industry has always been coal mining. Rusty ran businesses in the mining industry for years until the industry collapsed 5 years ago, then he and his business partner decided to pivot. They started Bit Source, a digital services company. Clive, you wrote about Rusty in your book. He's an example of a growing group of coders who've come into the industry mid-career. You used a term you called “blue collar coders.” What does that mean?
**18:22** - *Clive Thompson*
Well, it basically means a coder who is approaching the job in a way that's maybe a little different from how we've talked about coders in the last 15 or 20 years. For a long time, the idea of the coder was this young guy in a hoodie who's moving to Silicon Valley so they can do a startup and get millions of dollars in investment and maybe become a billionaire. And what blue collar coding means is someone who's approaching it more like the blue collar jobs of the 20th century, like the people who went to work doing skilled technical work on a Chrysler line, building cars. They had enormous technical skills, but it was considered to be sort of this stable middle class job. And that's kind of more what the idea of blue collar coding is. It's approaching the job as, we're not here to be this kid in a hoodie making millions, we're here to have a stable middle class job of the 21st century.
**19:19** - *Clive Thompson*
The truth is, only 8% of all coding jobs are in Silicon Valley, in that sort of, well-known area of consumer software. Everywhere else in the US, there's coding jobs. They're everywhere. They're in Tennessee, they're in Ohio, they're in upstate New York and they're not at Facebook and Google. They are at banks. They are at insurance companies, restaurants, or industrial companies. They all need software developers. And there's this kind of different way of thinking about what the career arc is when people are aiming outside that traditional area. And that's kind of where we're seeing blue collar coding coming from.
**19:59** - *Saron Yitbarek*
You featured another blue collar coder in your book, another person with an amazing name, Garland Couch. He used to work as a maintenance planner for a major mining company for 15 years before he got laid off. Then he joined Rusty's company and moved into the tech industry. Here's what it was like when he first started at Bit Source.
**20:21** - *Garland Couch*
I've joked in the past, and it's a semi-serious joke, that we really didn't know each other's last names for 22 weeks because everybody came in, sat down, and put their headphones on and went to work. And there was no talking, there was no laughing and joking and cutting up. You have to understand these are 10 people who were out of work trying to get a job. It was a very serious 22 weeks and all 10 of us were really, really focused on learning what needed to be learned.
**20:57** - *Saron Yitbarek*
Clive, you talked to a lot of blue collar workers who transitioned into tech, like Garland and Rusty, have these transitions been successful for the most part?
**21:06** - *Clive Thompson*
Yeah. All the people I talked to had enjoyed pretty good success for the most part. I think some of the things that helped out was because they were a little older, and a little on in their careers; they had a seriousness of purpose that maybe you don't have when you're a lot younger. They know how to learn. They know how to teach themselves. They have a sense that the stakes are important because they want a new career. Maybe their old career was vanishing, in the case of Garland. They definitely were not at all lacking in the passion and stick-to-it-ness that I think you really need to do well in coding, but also they often had sort of a sense of what their local market needed.
**21:46** - *Clive Thompson*
And in Garland's case, he had a local market that was starting this new high tech firm out in Kentucky. The other advantage that I think some of the people I spoke to who were really successful was that they had this broader view of where software exists. If you talk to the average 19-year-old student going into computer science, they think of software as Instagram and that's it. But if you talk to someone who has been working in the hospitality industry and they're 31, they know that hotels use a huge amount of software and they're like, I'm going to go work there. And those areas are hungry for talent.
**22:22** - *Rusty Justice*
The biggest learning lesson, personally, is all the misinformation we received when we were told about all these coding jobs and really it was a naivete on my part. I think more than anything, we were told there was a shortage of x number of developers so they had this earning potential. And the earning potential was equivalent to the earning potential we'd lost in these mining jobs. And so we thought if we just learned to code, then the world will beat a path to our door, and we'll have jobs. But nobody beat a path to our door to hire us because really why would you? You're a bunch of people that have never done it before. We've had to prove to the marketplace that we provide value.
**23:03** - *Garland Couch*
do think that real world experience—working in other industries and in other environments and in major corporations and dealing with those things that we dealt with—definitely helps with what we do now. I'll give you an example: we had a company that wanted us to build a bubble application for over-the-road truckers. And we had actually people that work here that have CDL licenses. Immediately it was like, wait a minute, you've got developers that actually have driven trucks? Yeah, we do.
**23:41** - *Saron Yitbarek*
Areas like Appalachia carry a lot of negative stereotypes, but what Rusty and Garland and others in their community are doing is creating models of positive disruption. And they're really proud of that. A final word from Garland.
**23:56** - *Garland Couch*
For me, blue collar means, that's a hard working individual who is willing to put in the work and willing to grind through things and solve problems. For me, the term blue collar coder, is a compliment.
**24:17** - *Gillian*
When I started the bootcamp, one month in, I'm like, “What on earth am I doing?” But the hours were long. It was really intense. But even though it was difficult, I really found that I wasn't really very tired and I just was excited to see what I could do the next day, how I could actually get better. At that point I knew I really enjoyed what I was doing.
**24:42** - *Saron Yitbarek*
That's Gillian. She was a physicist for over 20 years. When her job became redundant, she decided to give coding a go. She joined a Java™ bootcamp in her fifties. Two weeks after graduating from bootcamp, she got a job in the financial services industry. Now she's thriving, but understands that she'll likely be a junior, the rest of her career because she joined later in life, but that's okay with her. She's happy. And she contributes to her team.
**25:11** - *Gillian*
I might not be as skillful as they are doing Java development or have as much experience, but I can think. I can be analytical and I can look at the problem and ask intelligent questions. I might not know the answer, but at least I know the right questions to ask because I have experience doing a lot of problem solving.
**25:33** - *Saron Yitbarek*
So Clive, let's talk about being in the industry as an older worker. Gillian mentioned that she is a junior coder, and she's probably going to stay a junior coder for the rest of her career, which she's perfectly happy doing. I'm wondering if you start coding midlife, what does success look like?
**25:49** - *Clive Thompson*
A lot of the people I spoke to who were older, were getting into it because their existing industry wasn't interesting to them anymore. They hungered to make things, to be an engineer, or maybe their existing industry was falling apart. And they were like, I need someplace that's actually growing. And so they're not necessarily focused on becoming the top dog in the coding pyramid. They want rewarding, stable work. And definitely they're going to find that in coding, if they can get their first job and get their toe in the door and prove their worth, that's going to be there. Their motivations are much more along that blue color coding idea.
**26:33** - *Elisabeth Greenbaum Kasson*
It is partially society in general, but it's also the notion that if you're older, you're no longer teachable. You’re no longer flexible. That you feel that you know everything already, which is really crap, because what hiring managers are missing out on is people with a wealth of experience who really know how to ride up and down on whatever's happening at any given time.
**26:57** - *Saron Yitbarek*
That's Elisabeth Greenbaum Kasson, a technology and business journalist. And she says, "Ageism in the tech industry is very real. Many coders have been programming their whole lives. And as they age, getting a new programming gig starts to get harder. A lot of older coders get overlooked for jobs."
**27:18** - *Saron Yitbarek*
So Clive, you've interviewed tons of programmers. How many of them had experienced ageism and what are some of their stories?
**27:24** - *Clive Thompson*
Quite a few had experienced ageism if they had not managed to vault themselves up into the high levels of management. There's kind of 2 types of older developers. There are the ones who succeed in sort of jumping upwards to management. They're managing a whole team, and then maybe becoming vice president, CTO, or maybe becoming CEO and starting their own company. And they're happy. They're calling the shots. They're using their experience to sort of command and manage large teams of young, hungry developers. But there's this whole other cohort of coders who don't want to become management. They like making things. They like being the engineer that works to solve the problem. The problem they face is that the tech industry is not set up to let those people keep on doing that into their forties and fifties and sixties.
**28:19** - *Clive Thompson*
It wants people that are young and can work 100 hours a week without complaining, don't have any children or any responsibilities, and don't ask for more money. You think that, wow, software developers are paid a lot and they are, but if you've got a couple of kids and a house, you want even more money, you want stability and you don't want to work all those crazy hours. Maybe you don't need to because you're really good right now. But the employers assume falsely that if you're not doing the 100 crazy hours a week, you're not producing. There's all these strikes that start coming up against developers who just want to be a productive developer, and they start getting pushed out.
**28:59** - *Elisabeth Greenbaum Kasson*
The thing they can do just in terms of making themselves hireable is being visible in places where they wouldn't think to be visible. I think a lot of people in their fifties may underestimate GitHub for instance, or going to meetups where everybody might be significantly younger. Meetups for particular programming group-specific organizations, things like that, where they can go out and network a little bit and find out what's going on to remain current.
**29:26** - *Saron Yitbarek*
Clive, do you have any other words of wisdom for coders at a later stage in their career?
**29:32** - *Clive Thompson*
Sure. I actually asked older developers who were still doing it and still happy doing it, what their secrets were. And generally what they told me was that it was crucial to keep on learning, learning, learning, and building things in new frameworks and new languages that were sort of in demand so that they could have a repo that shows that they can do this stuff. Here's me showing, working with this new tool set in this new language, this new framework. That's a really big thing. And I think actually Elisabeth is exactly right. They also talked about the value of remaining outgoing and physically networking and all these things ranging from hackathons to meetups.
**30:15** - *Clive Thompson*
This classic gray beard, literally gray beard, coder that I met out in San Francisco said that he cracked up because he went to a IoT hackathon that was all embedded devices and really small processors, like Arduinos that have really strict memory limitations. And he was sort of saying, "This takes me back to the 1970s when I got into this, because, back then a desktop computer had enormously tight memory limitations." And so these were ways that he found to get himself out there and connected into the community. And he ended up realizing, wow, there's actually a lot of IoT work I can do. Keeping yourself out there and keeping yourself current really seemed to help a lot of the older developers out.
**31:01** - *Saron Yitbarek*
Clive, one final question to wrap. No matter what point a coder is in their career, whatever path they took to become a coder, what are some things all coders you spoke to had in common? What are some of the key indicators of success?
**31:15** - *Clive Thompson*
A really big one is a constant hunger to learn and to grow. That is true of every successful coder I met. They were insatiably curious. The instant that they discovered something was possible, a language had grown, a framework emerged, a tech stack had emerged, they wanted to know it. They wanted to explore it. They wanted to poke around with it. They wanted to build something in their spare time just to see what the heck was possible.
**31:42** - *Clive Thompson*
If anyone's listening to this and thinking, hey, maybe I want to sort of become a coder. The people that successfully made that switch have that deep burning curiosity, they enjoy the work. They would find it fun, and they will do it for pleasure in their spare time. In fact, they often like it because it gives them a sense of accomplishment and a sense of problem solving that they didn't have in their old jobs. And so, if I were to say the one thing that everyone who is successful had, including the people that made this transition, they had that incredible curiosity and hunger to tinker with these new things that kept them moving forward.
**32:21** - *Saron Yitbarek*
Thank you so much for joining me to talk about coder career paths, Clive.
**32:26** - *Clive Thompson*
I had a lot of fun.
**32:27** - *Saron Yitbarek*
Now that we know more about where we came from, what paths we took to get here in our careers, let's examine how and where we do our best work. In our next episode, Clive, you'll be back to join me, won't you?
**32:41** - *Clive Thompson*
Absolutely.
**32:44** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. We've got some extra interviews and research about the career paths of coders. Go to redhat.com/commandlineheroes for more. I'm Saron Yitbarek.
**32:58** - *Clive Thompson*
And I'm Clive Thompson.
**32:58** - *Saron Yitbarek*
Keep on coding.
**32:59** - *Clive Thompson*
Keep on coding.
**33:01** - *Saron Yitbarek*
Try that again. Let's count. I'll do one, two, three, and then we'll do keep on coding. Okay. One, two, three, keep on coding.
**33:10** - *Clive Thompson*
Keep on coding.
**33:17** - *Saron Yitbarek*
Keep on coding.
### Further reading
[ From Coal To Code: A New Path For Laid-Off Miners In Kentucky](//www.npr.org/sections/alltechconsidered/2016/05/06/477033781/from-coal-to-code-a-new-path-for-laid-off-miners-in-kentucky) by Erica Peterson
[ Stories from 300 developers who got their first tech job in their 30s, 40s, and 50s](//www.freecodecamp.org/news/stories-from-300-developers-who-got-their-first-tech-job-in-their-30s-40s-and-50s-64306eb6bb27/) by Jessie Frazelle
[ Getting a Programming Job When You’re Over 50](//insights.dice.com/2016/06/07/getting-a-programming-job-when-youre-over-50/) by Elisabeth Greenbaum Kasson
[ Being a Junior Developer at 30](//hackernoon.com/being-a-junior-developer-at-30-38309f1daee8) by Eva Lettner
[ The Career Advice I Wish I Had](//welearncode.com/career-advice/) by Ali Spittel
### Clive Thompson
Tech journalist and friend of the podcast, Clive Thomspon joins us for this 3-episode mini-season on decoding coders. Clive shares insights from his many years as a tech journalist and the over 200 interviews he’s conducted with coders for his latest book: "Coders: The Making of a New Tribe and the Remaking of the World." |
14,134 | 2021 总结:5 个开源安全资源 | https://opensource.com/article/21/12/open-source-security | 2021-12-31T11:22:15 | [
"安全"
] | https://linux.cn/article-14134-1.html |
>
> 你现在需要读的 2021 安全总结文章。
>
>
>

2021 年我们最常见的讨论之一是你自己数据的安全和隐私。显然,你的数据是你的,密码是安全的关键。今年的安全类的作者们提供了有用的知识和开源工具来保持你的数据和硬件安全。
以下是我对今年安全之旅选出的前五篇文章。
### 《6 个开源工具和初学者保护 Linux 服务器的技巧》
[Sahana Sreeram](https://opensource.com/users/sahanasreeram01gmailcom) 提供了从更新到恶意软件扫描的 [六个基本的服务器安全小知识](https://opensource.com/article/21/4/securing-linux-servers)。这篇文章为你在家里或工作中的 Linux 服务器提供了一个起点。要特别注意密码强度部分和为你的服务器创建降低风险的密码策略要求的工具,因为这是你所使用的任何操作系统上最关键的做法。这篇文章是一篇实用指南,指导你在 Linux 服务器的日常工作中进行安全工作。正如 Sahana 所指出的,安全领域无疑正在扩大,这篇文章给了每个人着手预防的机会。
### 《用开源软件保护你的文件的 5 种方法》
接下来的 [这篇文章](https://opensource.com/article/21/4/secure-documents-open-source) 对于像我这样写了大量的文档(从文章到个人研究笔记都有)的人来说是非常有用的。作者 [Ksenia Fedoruk](https://opensource.com/users/ksenia-fedoruk) 首先列出了保存文档的开源云存储服务。接下来,她介绍了加密的重要性以及在我们的文档中使用加密的方法。她还清楚地介绍了文件的数字签名和水印以及使用哪些开源工具。最后,文章涵盖了对我们制作和使用的文档进行密码保护的情况。结尾处的提醒遵循了今年安全领域的一个共同主题:你的数据是你的。
### 《4 个清除你的数据的 Linux 工具》
在 [这篇文章](https://opensource.com/article/21/10/linux-tools-erase-data) 中,[Don Watkins](https://opensource.com/users/don-watkins) 涵盖了硬件的用途和维护。它以一系列擦除硬盘的工具作为引子,这样你的数据就不能被下一个使用设备的人拿走。在几个小的演练中,Don 涵盖了使用 GNU shred、ShredOS、`dd` 命令,以及最后的 `nvme-cli`。每一个都可以从你的硬件中删除所有的数据,并对你正在使用的、不再需要的硬盘进行删除。Don 的结论提供了一个温和的提醒:如果你要卖掉你的硬件,这并不意味着下一个人应该拥有你的数据。你的数据是你的。
### 《在 Linux 命令行上生成密码》
正如我在本期中早先时候指出的那样,密码对于今年的安全总结至关重要。在 [这篇文章](https://opensource.com/article/21/7/generate-passwords-pwgen) 中,我们的作者 [Sumantro Mukherjee](https://opensource.com/users/sumantro) 首先介绍了许多网站在涉及到密码时可以有(也应该有)一个严格的规定。这篇文章循序渐进地介绍了如何使用 `pwgen`,首先是安装它,然后是生成密码。这是一个有用的工具,Sumantro 详细介绍了如何使用一些标志来生成符合任何网站或应用的要求和策略的密码。在这篇读物的最后,最后的总结包含了链接到一个方便的开源密码管理器列表,这个列表是我们的另一位作者 [Jason Baker](https://opensource.com/users/jason-baker) 在今年早些时候写的。这是一个重要的读物,可以让你为你在网站上的日常使用制定更好的密码,以防止黑客攻击或丢失你的账户中的数据。
### 《用这个开源软件加密你的文件》
今年的安全总结的最后,是一篇关于加密和加密文件的 [文章](https://opensource.com/article/21/4/open-source-encryption)。[Seth Kenlon](https://opensource.com/users/seth) 介绍了一个名为 VeraCrypt 的开源跨平台加密工具。Seth 的演练深入解释了如何安装和使用 VeraCrypt,并展示了这个很酷的软件的易用性。但在此之前,他还简要介绍了 VeraCrypt 的前身 TrueCrypt 的历史,以及 VeraCrypt 是如何向后兼容以前用 TrueCrypt 的加密卷的。通过这个易于使用的开源加密软件,Seth 已经证明,你可以在本地拥有你的数据,并以你想要的方式进行加密。
### 荣誉提名
虽然这五篇是我今年的最爱,但这里还有两篇同样值得一读的提名文章。
* [Seth Kenlon](https://opensource.com/users/seth) 的《[了解开源安全的 Linus 法则](http://opensource.com/article/21/2/open-source-security)》。
* [Mike Calizo](https://opensource.com/users/mcalizo) 的《[如何成功执行 DevSecOps](http://opensource.com/article/21/2/devsecops)》。
每篇文章都对安全策略和采用情况进行了结构化解读。
### 关于安全的总结
我强烈建议在今年阅读这些文章和 [其他几篇](https://opensource.com/tags/security)。这些将使你为 2022 年安全世界的发展做好准备。你可以成为新一年的安全冠军。
你有一些想要推荐的工具吗?请留下评论或 [提出你的文章构思](https://opensource.com/how-submit-article)。
---
via: <https://opensource.com/article/21/12/open-source-security>
作者:[Jessica Cherry](https://opensource.com/users/cherrybomb) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the most prevalent discussions on Opensource.com in 2021 was about the security and privacy of your own data. A noticeable theme was that your data is yours and that passwords were key to security. This year's security authors provided helpful tips and open source tools for keeping your data and hardware secure.
Here is my top-five countdown of this year's security journey.
[6 open source tools and tips to securing a Linux server for beginners](https://opensource.com/article/21/4/securing-linux-servers)
[Sahana Sreeram](https://opensource.com/users/sahanasreeram01gmailcom) provides six fundamental server security tips, starting with updates and ending with malware scanning. This article provides a head start with your Linux servers either at home or work. Pay extra attention to the password strength section and the tools to create risk-reducing requirements on password policies for your server, as this is the most critical practice on any operating system you are using. This article is a practical guide to working on security in your day-to-day work on Linux servers. As Sahana points out, the security landscape is undoubtedly expanding, and this article gives everyone the chance to start working on prevention.
[5 ways to protect your documents with open source software](https://opensource.com/article/21/4/secure-documents-open-source)
This next article is excellent for people like myself who write a ton of documentation on everything from articles to personal research notes. Author [Ksenia Fedoruk](https://opensource.com/users/ksenia-fedoruk) starts with a list of open source cloud storage services to save your documents. Next, she covers the importance of encryption and the ways to use encryption with our docs. She also covers digital signature and watermarking of documents in clear detail and what open source tools to use. Finally, the article covers the use of password protection of the docs we've made and worked with. The reminder in the ending follows a common theme this year in security: Your data is yours.
[4 Linux tools to erase your data](https://opensource.com/article/21/10/linux-tools-erase-data)
In this article, [Don Watkins](https://opensource.com/users/don-watkins) covers the responsibility and caretaking of hardware. It leads off with a series of tools to wipe hard drives so that your data can't be taken from the next person to use the equipment. In several small walk-throughs, Don covers using GNU shred, ShredOS, the `dd`
command, and finally `nvme-cli`
. Each of these can remove all the data from your hardware and sanitize the hard drives you were working on and no longer need. Don's concluding thoughts provide a gentle reminder that if you are selling your hardware, that doesn't mean the next person should have your data. Your data is yours.
[Generate passwords on the Linux command line](https://opensource.com/article/21/7/generate-passwords-pwgen)
As I pointed out earlier in this countdown, passwords are essential to this year's security round-up. In this article, our writer [Sumantro Mukherjee](https://opensource.com/users/sumantro) starts by covering how many websites can have (and should have) strict rules when it comes to passwords. This step-by-step article covers how to use `pwgen`
, starting by installing it and then generating passwords. This was a useful tool to cover, and Sumantro details how to use some flags to generate a password tailored to any website's or application's requirements and policies. At the end of this read, the final thoughts include a link to a handy list of open source password managers written earlier this year by another of our authors, [Jason Baker](https://opensource.com/users/jason-baker). This is an important read to start making better passwords for your everyday use on websites to prevent hacking or any data loss in your accounts.
[Encrypt your files with this open source software](https://opensource.com/article/21/4/open-source-encryption)
Finally, in this year's security countdown, is an article about encryption and encrypting your files. [Seth Kenlon](https://opensource.com/users/seth) covers an open source cross-platform encryption tool called VeraCrypt. Seth's walk-through explains in-depth how to install and use VeraCrypt and shows the ease of use of this cool bit of software. But not before giving a brief history on VeraCrypts predecessor, TrueCrypt, and how VeraCrypt is backward compatible with previously encrypted volumes by TrueCrypt. With this easy-to-use open source software encryption, Seth has proven that you can own your data locally and encrypt it the way you want.
## Honorable mentions
While these five were my favorite this year, here are two additional honorable mentions that are also worth the read.
- Seth Kenlon's
[Understanding Linus's Law for open source security](http://opensource.com/article/21/2/open-source-security) [Mike Calizo's](https://opensource.com/users/mcalizo)[How to adopt DevSecOps successfully](http://opensource.com/article/21/2/devsecops)
Each of these gives a structured read on security policies and adoption.
## Final thoughts on security
I highly recommend reading each of these articles and [several others](https://opensource.com/tags/security) this year. These will prepare you for what's to come in the world of security in 2022. You could be the new year's security champion.
Have some tools you want to suggest? Leave a comment or [pitch your article idea](https://opensource.com/how-submit-article).
## 1 Comment |
14,136 | Maui Shell 来了,开启 Linux 桌面新时代 | https://news.itsfoss.com/maui-shell-unveiled/ | 2022-01-01T10:51:29 | [
"DE",
"桌面",
"Maui"
] | https://linux.cn/article-14136-1.html |
>
> 除了 System76 宣布了基于 RUST 的新桌面环境之外,还有别的团队也给桌面 Linux 用户带来了一些新东西。
>
>
>

过去的几年里,我们很欣慰地看到 [Nitrux Linux](https://nxos.org/) 背后的团队正在扩大他们对 Linux 社区的影响。如今,伴随着全新 Maui Shell 的发布,他们的影响也已经得到了进一步扩大。
让我们一起来看看吧!
### 关于 Maui 项目的一些背景介绍

作为由 Nitrux Linux 团队原班人马创建、开发、维护的项目,Maui 项目已经开发了许多基础应用。实际上,他们的文件管理器 [Index](http://mauikit.org/apps/index) 甚至成功进入了我们的 [2021 年五大应用列表](https://news.itsfoss.com/linux-apps-discovered-2021/) 之中!
他们的所有应用均使用 MauiKit 这款定制框架开发。基于 Kirigami 的 MauiKit 专注于跨终端融合性,因此开发出来的应用可以在电脑和手机端拥有一致的体验。此外,它为开发者提供了更多的预置组件,因此创建应用可以更加便捷。
目前 Maui 项目开发的部分应用包括:
* Index(文件管理器)
* Nota(文本编辑器)
* VVave(音乐播放器)
* Clip(视频播放器)
* Pix(图片查看器)
虽然这些自制应用本身质量不错,但它们在 Nitrux Linux 的默认桌面环境 KDE Plasma 里总显得不合群。因此,Maui Shell 应运而生。
### Maui Shell 介绍

借助与 Maui 应用相同的 MauiKit 和 Qt 技术底层,Maui Shell 是 Nitrux 在桌面环境领域的一个新尝试。从上面的截图可以看出,它在很大程度上受到了 GNOME Shell 的启发,这在使用过程中也确实有所体现。
但,这并不意味着 Maui Shell 没有原创的地方。从底部上滑可打开类似于 GNOME “活动”的概览界面。与此相邻的是一个小 Dock,可以通过相当美观的启动器来启动应用。右上角有一个与 macOS 相似的控制中心,内有精心设计的菜单和许多控制功能。
在我使用它的过程中,一切都是如此精致、自然。我感觉这与它极致现代、扁平的设计美学有关,我甚至认为 Maui Shell 已经超越了 GNOME 和 KDE Plasma 等同类软件。说到 Plasma,与 Nitrux 的默认 Plasma 版本相比,Maui Shell 在低端设备(和虚拟机)上的反应更加灵敏。
总的来说,我预测 Maui Shell 将依靠其实用性成为 “Linux 桌面环境之王”。然而,我还没谈到 Maui Shell 最核心的特性:<ruby> 跨终端自适应性 <rt> Convergence </rt></ruby>。
### 主流之中的融合
许多人可能还记得 2010 年 Canonical 开发了一款类似的跨终端桌面环境 Unity,它最终以失败落幕,到 2018 年则被完全淘汰了。但是,Unity 和 Maui Shell 有一个共同特性 —— 那就是跨终端融合性。
随着 Linux 在移动端的开发力度逐渐加大,跨终端支持变得尤为重要。由此来看,一个新的桌面环境竟能同时支持桌面端和移动端,的确不可思议。
这一点必须依靠大量的跨终端应用实现,而 Maui 已经处在了完美的衔接点上。这仅仅是我相信 Maui Shell 能成为 Linux 桌面未来的原因之一。
### 立即试用 Maui Shell
与其他新发布的软件不同,Maui Shell 已经预装于新发布的 Nitrux 1.8。如果你想亲自尝试一下,那请随时从下方链接中获取 ISO 镜像。但是,在尝试之前,请务必知晓:Maui Shell 仍处于早期开发阶段。
尽管 Maui Shell 拥有许多特色功能,但部分功能可能存在问题、尚未实现,要么就是缺失了,其中包括:
* 蓝牙支持
* PulseAudio 支持
* 网络开关
* 媒体控制(MPRIs)
* 拖放支持
* 多显示器支持
* 设置应用
* XWayland Shell 插件
因此,我暂时不能建议你使用 Maui Shell 作为主力桌面环境。为此,你可能需要等待 2022 年秋季发布的正式版本。
在此之前,我仍将持续关注 Maui Shell。对于这款桌面环境,你的评价如何?欢迎在评论区说出你的想法!
---
via: <https://news.itsfoss.com/maui-shell-unveiled/>
作者:[Jacob Crume](https://news.itsfoss.com/author/jacob/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Over the past few years, it has been extremely exciting to see the team behind [Nitrux Linux](https://nxos.org/?ref=news.itsfoss.com) expand their influence on the Linux community. Now, this influence is set to expand even further with their brand-new Maui Shell.
Let’s take a look at it!
## A Little Bit Of Background on The Maui Project
Created, developed, and maintained by the same team behind Nitrux Linux, the Maui project has produced a wide variety of essential apps. In fact, their file manager, [Index](http://mauikit.org/apps/index?ref=news.itsfoss.com), even managed to make it onto our list of [my top 5 apps of 2021](https://news.itsfoss.com/linux-apps-discovered-2021/)!
All their apps use a custom framework called MauiKit. Based on Kirigami, MauiKit is designed to be convergent, meaning that apps run equally well on desktops and phones. Additionally, it gives developers a greater set of pre-made widgets to make creating apps faster.
Some of the apps they have produced so far include:
- Index (File manager)
- Nota (Note-taking app)
- VVave (Music player)
- Clip (Video player)
- Pix (Image viewer)
While these are all great apps on their own, they have always looked a bit out-of-place on Nitrux Linux’s default KDE Plasma desktop environment. That’s where Maui Shell comes in.
## The Maui Shell
Built using the same MauiKit and Qt technologies as the Maui apps, Maui Shell is a new venture into the desktop environment space for Nitrux. From the above screenshot, it can be seen that it is heavily inspired by Gnome Shell, and this really shows during use.
However, that doesn’t mean that it isn’t original. Swiping up from the bottom opens up a Gnome activites-like overview. Accompanied by this is a small dock that allows for launching apps through the rather beautiful launcher. Up at the top right, a very macOS-like control center can be seen, with a huge number of controls available in a number of very well-thought-out menus.
During my use of it, everything felt extremely well-designed and natural. I suspect this has something to do with the very modern and flat aesthetic of it, in my opinion even beating alternatives like Gnome and KDE Plasma. Speaking of Plasma, Maui shell feels much more responsive on low-end systems (and virtual machines) compared to the default Plasma version on Nitrux.
Overall, from a usability standpoint, I expect that Maui shell will soon reign king. However, I have yet to touch on what is arguably Maui Shell’s greatest feature: Convergence.
## Convegence In The Mainstream
Many of you will remember Canonical’s attempts back in 2010 to create a similar environment called Unity. In the end, it ended up being a huge failure, with it being completely phased out by 2018. However, it had one key feature it shares with Maui Shell: Convergence.
As Linux on mobile devices gains development effort, convergence support is becoming ever more important. As such, it is incredible to see a new desktop environment have equal support for desktop and mobile form-factors.
This can really only be achieved when there are a variety of pre-existing convergent apps, and Maui is in a unique position where this exists. This is just one reason why I believe that Maui Shell may just be the future of desktop Linux.
## Trying Out Maui Shell For Yourself
Unlike many other newly-released pieces of software, Maui Shell is available out-of-the-box on the newly-released Nitrux 1.8. If you want to try it out for yourself, feel free to grab the ISO from the link below. However, before you do, it should be noted that Maui Shell is still in early development.
Despite the long list of innovative features, some elements are either broken, not implemented yet, or just missing. Some of these include:
- Bluetooth support
- PulseAudio support
- Network toggles
- MPRIs control
- Drag and drop support
- Multi-screen support
- A settings app
- XWayland shell extension.
Because of this, I can’t recommend that you use Maui Shell as your daily driver. For that, you will probably have to wait for the final release in fall 2022.
Until then, I will definitely be keeping my eye on Maui shell. What are your thoughts on it? Let us know in the comments below!
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,137 | 为什么在 Linux 中“文件夹”被称为“目录”? | https://itsfoss.com/folder-directory-linux/ | 2022-01-01T11:53:19 | [
"目录",
"文件夹"
] | https://linux.cn/article-14137-1.html | 如果你最开始使用的是 Windows 电脑,你很可能会使用“<ruby> 文件夹 <rt> folder </rt></ruby>”这个术语。
但当你换到 Linux 时,你会发现文件夹通常被称为“<ruby> 目录 <rt> directory </rt></ruby>”。
这可能使一些新的 Linux 用户感到困惑。你应该叫它文件夹还是目录?它们有区别吗?
事情是这样的。如果你愿意,你可以叫它文件夹,如果你喜欢,也可以叫它目录。这没有什么区别。
但是,如果你想知道为什么文件夹在 Linux 中被称为目录,这里有一些解释。
### 为什么在 Linux 中文件夹被称为目录?
在我解释之前,让我们回顾一下文件夹和目录在现实世界中的用途。
在现实中,文件夹(封套)可以用来保存几个文件(或其他项目)。而目录则可以用来维护项目的索引,这样你就可以找到哪个项目位于哪里。

现在,让我们回到目录。这个词甚至在 Linux 存在之前就已经存在了。它来自 UNIX 时代。Linux 继承了 UNIX 的很多东西,这只是其中的一个。
现在让我告诉你一些可能让你吃惊的事情。目录并不是真的把文件放在里面。目录是一个“特殊的文件”,它知道文件在存储中的位置(通过 [inode](https://linuxhandbook.com/inode-linux/))。
这就说明了为什么它被称为目录。目录用来保存项目的索引,而不用保存项目本身。Linux 和 UNIX 中的目录并不保存它里面的文件。它们只是记录文件位置的信息。
如果你想了解更多关于它的信息,我这篇关于 [硬链接](https://linuxhandbook.com/hard-link/) 的文章应该可以帮助你。
那么,为什么它被称为文件夹呢?依我看,这是视角的原因。当你在一个图形环境中时,你会将事物可视化。在这里,文件可以像页面一样被可视化,这些文件页面被存储在一个封套(文件夹)中。
当操作系统开始使用图形元素时,我认为一些术语也相应地发生了变化,目录 -> 文件夹就是其中之一。
### 你应该叫它文件夹还是目录?
这完全取决于你。你可以按你的习惯使用这两个术语。
然而,如果你正在学习 Linux 命令行或经常使用它,使用目录这个术语可能会有一点帮助。
有一些 Linux 命令,如 `mkdir`、`rmdir` 等,术语 “dir” 给出了一个提示,即这些命令与目录有关。
同样,许多 Linux 命令和 bash 脚本会使用选项 `-d` 表示目录,`-f` 表示文件。
甚至终端中的文件属性也会通过在目录前面加上字母 “d” 来区分文件和文件夹(目录)。
拿这个例子来说,我有一个名为 `some` 的文件和一个名为 `something` 的文件夹/目录。请注意各种 Linux 命令是如何用 “dir” 或 “d” 来区分文件和目录的。

所有这些让我觉得,在使用 Linux 命令时,使用 “目录” 这个术语会有好处。你的潜意识会更容易将 “dir” 和 “d” 与目录联系起来。
再说一次,你想叫它文件夹或目录这完全取决于你。人们会明白你指的是什么。
我刚刚对目录一词的历史渊源做了一些分析,这应该会给你一些提示,为什么人们说 “在 Linux/UNIX 中,所有东西都是一个文件”。
现在我结束了我的胡言乱语,我请你对它进行评论。如果你发现任何技术上的不准确之处,请告诉我。
---
via: <https://itsfoss.com/folder-directory-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you start using computers with Windows, you are likely to use the term folder.
But when you switch to Linux, you’ll find that folders are often termed as directories.
This may confuse some new Linux users. Should you call it a folder or a directory? Is there even a difference?
Here’s the thing. You can call it a folder if you want or a directory if you like. It won’t make a difference.
But if you wonder why a folder is called a directory in Linux, here is some explanation.
## Why is a folder called a directory in Linux?
Before I explain that, let’s recall what a folder and directory are used for in the real world.
A folder (envelope) can be used to keep several files (or other items) in it. A directory can be used to maintain an index of items so that you can find which items is located where.

Now, let’s go back to directory. The term existed even before the existence of Linux. It is coming from the UNIX era. Linux inherits a lot of things from UNIX and this is just one of those many things.
Now let me tell you something that may surprise you. A directory does NOT really keep files inside it.* Directory is a ‘special file’ that knows where (the content of) a file is stored in the memory (through inode).*
This makes sense why it is called directory. A directory keeps the index of items, not necessarily the items themselves. The directories in Linux and UNIX don’t keep the files inside them. They just have the information about the location of files.
If you want to learn more about it, my article on [hard links](https://linuxhandbook.com/hard-link/) should help you.
[Hard Link in Linux: Everything Important You Need to KnowLearn the concept of hard links in Linux and its association with inodes in this tutorial.](https://linuxhandbook.com/hard-link/)

So, why is it called a folder then? To me, it comes from the perspective. When you are in a graphical environment, you visualize things. Here, files can be visualized like pages and those file pages are stored in an envelope (folder).
When the operating systems started using graphical elements, I think some terms were changed accordingly and directory-folder was one of them.
## Should you call it folder or directory?
That’s entirely up to you. You can use either term at your convenience.
However, if you are learning Linux command line or use it often, using the term directory could be a tad bit more helpful.
There are Linux commands like mkdir, rmdir etc. The term ‘dir’ gives a hint that these commands have something to do with directories.
Similarly, many Linux commands and bash scripts will use option `-d`
for directories and `-f`
for files.
Even the file properties in the terminal distinguish between files and folders (directories) by putting the letter `d`
in front of the directories.
Take this example where I have a file names ‘some’ and a folder/directory named ‘something’. Notice how various Linux commands distinguish between file and directory with ‘dir’ or ‘d’.
All this makes me think that using the term ‘directory’ will be beneficial while using Linux commands. It would be easier for your subconscious mind to relate the terms ‘dir’ and ‘d’ with directory.
Once again, it’s entirely up to you if you want to call it a folder or directory. People would understand what you are referring to.
I just gave some insight into the historical origin of the term directory and this should give you some hint on why people say ‘everything is a file in Linux/UNIX’.
Now that I end my ramblings, I invite your comment on it. If you find any technical inaccuracies, let me know, please. |
14,139 | Kubernetes 集群日志基础 | https://opensource.com/article/21/11/cluster-logging-kubernetes | 2022-01-02T10:58:21 | [
"Kubernetes",
"日志"
] | /article-14139-1.html |
>
> 探索 Kubernetes 中不同容器日志记录模式的工作原理。
>
>
>

服务器和应用程序日志记录是开发人员、运维人员和安全团队了解应用程序在其生产环境中运行状态的重要工具。
日志记录使运维人员能够确定应用程序和所需组件是否运行平稳,并检测是否发生了异常情况,以便他们能够对这种情况做出反应。
对于开发人员,日志记录提供了在开发期间和之后对代码进行故障排除的可见性。在生产环境中,开发人员通常依赖于没有调试工具的日志记录工具。在加上系统的日志记录,开发人员可以与运维人员携手合作,有效地解决问题。
日志记录工具最重要的受益者是安全团队,尤其是在云原生的环境中。能够从应用程序和系统日志中收集信息使得安全团队能够分析来自身份验证、应用程序访问恶意软件活动的数据,并在需要时进行响应。
Kubernetes 是领先的容器平台,越来越多的应用程序通过 Kubernetes 部署到生产环境。我相信了解 Kubernetes 的日志架构是一项非常重要的工作,每个开发、运维和安全团队都需要认真对待。
在本文中,我将讨论 Kubernetes 中不同容器日志记录模式的工作原理。
### 系统日志记录和应用日志记录
在深入研究 Kubernetes 日志记录架构之前,我想探索不同的日志记录方法以及这两种功能如何成为 Kubernetes 日志记录的关键特性。
有两种类型的系统组件:在容器中运行的组件和不在容器中运行的组件。例如:
* Kubernetes 调度者和 `kube-proxy` 运行在容器中。
* `kubelet` 和容器运行时不在容器中运行。
与容器日志类似,系统容器日志存储在 `/var/log` 目录中,你应该定期轮换它们。
在这里,我研究的是容器日志记录。首先,我看一下集群级别的日志记录以及为什么它对集群运维人员很重要。集群日志提供有关集群如何执行的信息。诸如为什么 <ruby> 吊舱 <rt> Pod </rt></ruby> 被下线或节点死亡之类的信息。集群日志记录还可以捕获诸如集群和应用程序访问以及应用程序如何利用计算资源等信息。总体而言,集群日志记录工具为集群运维人员提供操作集群和安全有用的信息。
捕获容器日志的另一种方法是通过应用程序的本机日志记录工具。现代应用程序设计很可能具有日志记录机制,可帮助开发人员通过标准输出 (`stdout`) 和错误流 (`stderr`) 解决应用程序性能问题。
为了拥有有效的日志记录工具,Kubernetes 实现需要应用程序和系统日志记录组件。
### Kubernetes 容器日志的 3 种类型
如今,在大多数的 Kubernetes 实现中,你可以看到三种主要的集群级日志记录方法。
1. 节点级日志代理
2. 用于日志记录的<ruby> 挎斗 <rt> Sidecar </rt></ruby>容器应用程序
3. 将应用程序日志直接暴露给日志后端
#### 节点级日志代理
我想考虑节点级日志代理。你通常使用 DaemonSet 作为部署策略来实现这些,以便在所有 Kubernetes 节点中部署一个吊舱(充当日志代理)。然后,该日志代理被配置为从所有 Kubernetes 节点读取日志。你通常将代理配置为读取节点 `/var/logs` 目录捕获 `stdout`/`stderr` 流并将其发送到日志记录后端存储。
下图显示了在所有节点中作为代理运行的节点级日志记录。

以使用 `fluentd` 方法为例设置节点级日志记录,你需要执行以下操作:
1、首先,你需要创建一个名为 fluentdd 的服务账户。Fluentd 吊舱使用此服务账户来访问 Kubernetes API,你需要在日志命名空间中使用标签 `app: fluentd` 创建它们:
```
#fluentd-SA.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd
```
你可以在此 [仓库](https://github.com/mikecali/kubernetes-logging-example-article) 中查看完整示例。
2、接着,你需要创建一个名称为 `fluentd-configmap` 的 ConfigMap。这为 `fluentd daemonset` 提供了一个配置文件,其中包含所有必需的属性。
```
#fluentd-daemonset.yaml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
app: fluentd
kubernetes.io/cluster-service: "true"
template:
metadata:
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
spec:
serviceAccount: fluentd
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.7.3-debian-elasticsearch7-1.0
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENT_ELASTICSEARCH_USER
value: "elastic"
- name: FLUENT_ELASTICSEARCH_PASSWORD
valueFrom:
secretKeyRef:
name: efk-pw-elastic
key: password
- name: FLUENT_ELASTICSEARCH_SED_DISABLE
value: "true"
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: fluentconfig
mountPath: /fluentd/etc/fluent.conf
subPath: fluent.conf
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: fluentconfig
configMap:
name: fluentdconf
```
你可以在此 [仓库](https://github.com/mikecali/kubernetes-logging-example-article) 中查看完整示例。
现在,我们来看看如何将 `fluentd daemonset` 部署为日志代理的代码。
```
#fluentd-daemonset.yaml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
app: fluentd
kubernetes.io/cluster-service: "true"
template:
metadata:
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
spec:
serviceAccount: fluentd
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.7.3-debian-elasticsearch7-1.0
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENT_ELASTICSEARCH_USER
value: "elastic"
- name: FLUENT_ELASTICSEARCH_PASSWORD
valueFrom:
secretKeyRef:
name: efk-pw-elastic
key: password
- name: FLUENT_ELASTICSEARCH_SED_DISABLE
value: "true"
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: fluentconfig
mountPath: /fluentd/etc/fluent.conf
subPath: fluent.conf
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: fluentconfig
configMap:
name: fluentdconf
```
将这些放在一起执行:
```
kubectl apply -f fluentd-SA.yaml \
-f fluentd-configmap.yaml \
-f fluentd-daemonset.yaml
```
#### 用于日志记录的挎斗容器应用程序
另一种方法是使用带有日志代理的专用挎斗容器。容器最常见的实现是使用 [Fluentd](https://www.fluentd.org/) 作为日志收集器。在企业部署中(你无需担心一点计算资源开销),使用 `fluentd`(或[类似](https://www.g2.com/products/fluentd/competitors/alternatives))实现的挎斗容器提供了集群级日志记录的灵活性。这是因为你可以根据需要捕获的日志类型、频率和其它可能的调整来调整和配置收集器代理。
下图展示了作为日志代理的挎斗容器。

例如,一个吊舱运行单个容器,容器使用两种不同的格式写入两个不同的日志文件。吊舱的配置文件如下:
```
#log-sidecar.yaml
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
```
把它们放在一起,你可以运行这个吊舱:
```
$ kubectl apply -f log-sidecar.yaml
```
要验证挎斗容器是否用作日志代理,你可以执行以下操作:
```
$ kubectl logs counter count-log
```
预期的输出如下所示:
```
$ kubectl logs counter count-log-1
Thu 04 Nov 2021 09:23:21 NZDT
Thu 04 Nov 2021 09:23:22 NZDT
Thu 04 Nov 2021 09:23:23 NZDT
Thu 04 Nov 2021 09:23:24 NZDT
```
#### 将应用程序日志直接暴露给日志后端
第三种方法(在我看来)是 Kubernetes 容器和应用程序日志最灵活的日志记录解决方案,是将日志直接推送到日志记录后端解决方案。尽管此模式不依赖于原生 Kubernetes 功能,但它提供了大多数企业需要的灵活性,例如:
1. 扩展对网络协议和输出格式的更广泛支持。
2. 提供负载均衡能力并提高性能。
3. 可配置为通过上游聚合接受复杂的日志记录要求。
因为这第三种方法通过直接从每个应用程序推送日志来依赖非 Kubernetes 功能,所以它超出了 Kubernetes 的范围。
### 结论
Kubernetes 日志记录工具是企业部署 Kubernetes 集群的一个非常重要的组件。我讨论了三种可能的可用模式。你需要找到适合你需求的模式。
如上所述,使用 `daemonset` 的节点级日志记录是最容易使用的部署模式,但它也有一些限制,可能不适合你的组织的需要。另一方面,挎斗 模式提供了灵活性和自定义,允许你自定义要捕获的日志类型,但是会提高计算机的资源开销。最后,将应用程序日志直接暴露给后端日志工具是另一种允许进一步定制的诱人方法。
选择在你,你只需要找到适合你组织要求的方法。
---
via: <https://opensource.com/article/21/11/cluster-logging-kubernetes>
作者:[Mike Calizo](https://opensource.com/users/mcalizo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
14,140 | 2021 年我最喜欢的五个 Linux 应用程序 | https://news.itsfoss.com/linux-apps-discovered-2021/ | 2022-01-02T16:58:44 | [
"应用"
] | https://linux.cn/article-14140-1.html |
>
> 这些应用程序可能不是绝对的必需品,但我很高兴在 2021 年发现了它们。
>
>
>

在这个 2021 年,我目睹了数百个有趣的 Linux 应用程序的开发取得了进展,并因此获得了更多用户。虽然其中一些已经止步,但其它的应用还在继续发展,不断地获得更多的关注和新功能。
虽然我希望我可以对所有这些应用都有所了解,但显然这是不可能的。不过,我已经挑选了 5 个我最喜欢的应用,并在这里与你分享它们。它们可能不会被列入 [必需的 Linux 应用程序名单](https://itsfoss.com/essential-linux-applications/),但我却十分青睐它们。
在开始之前,应该注意的是,所有这些应用程序,除了 EverSticky 之外,都是融合性的,这意味着它们同样适用于桌面和移动 Linux 设备。随着 PinePhone 和 Librem 5 等设备变得越来越流行,我认为融合性应用是相当重要的,看到这么多的此类应用正在开发中,真是太好了。
言归正传,让我们来看看第一个应用程序。
### Index

早在 2016 年,当 KDE 发布 Kirigami 时,很明显,它是 KDE 的应用程序的未来。不幸的是,将成千上万的应用程序转换到一个新的 UI 工具包是相当困难的,这导致了 KDE 应用程序之间严重的不一致。
五年后的今天,作为桌面级应用的 UI 工具包,我们终于看到 Kirigami 被真正重视起来,这在文件管理器 Index 中得到了完美的体现。这个漂亮的应用程序能成为 Plasma Mobile 和 Nitrix Linux 的默认文件管理器,自然有原因的。
虽然不像 KDE 的默认文件管理器 Dolphin 那样功能丰富,但它有集成终端、文件预览、标签和分割视图模式等功能。这使得它可以和 Gnome 的 Nautilus 相提并论,同时它还有融合性和基于 Kirigami 的明显优势。
自从发现了它,我就只用它了,甚至没有想过要换回 Dolphin 或 Nautilus。我强烈推荐给任何想尝试新文件管理器的人。
* [获取 Index](https://mauikit.org/apps/index/)
### Vakzination
我相信大家都会这样认为,过去的两年是艰难的,但是在隧道的尽头有一道光。随着疫苗的推出,我们似乎终于接近了这场大流行病的终点。
不幸的是,这也意味着许多人不得不习惯于疫苗证书的概念,其中许多现在是数字证书。这对 Linux 用户来说可能是个问题,因为卫生部门很少有资源为 Linux 开发疫苗接种证书应用程序。
然而,这并没有阻止一些社区成员致力于开发一个自由开源的替代方案,从而产生了 Vakzination。作为一个 KDE 应用程序,它使用 Kirigami 和 Qt Quick 创建了一个快速、现代和用户友好的疫苗接种证书应用程序,使用起来非常方便和快捷。
它目前支持以下证书格式:
* [印度疫苗接种证书](https://en.wikipedia.org/wiki/Verifiable_credentials)
* [欧盟 “数字绿色证书”(DCG)疫苗接种、测试和康复证书](https://github.com/eu-digital-green-certificates)
老实说,我觉得社区在这个应用程序上取得的成就相当不可思议,在此希望他们能尽快增加更多的格式支持。
* [获取 Vakzination](https://invent.kde.org/plasma-mobile/vakzination)
### Elisa

Elisa 是另一个基于 Kirigami 的应用程序,是一个来自 KDE 的快速而漂亮的音乐播放器。它支持所有主要的音频格式,并集成到 Baloo 文件索引器中,以确保你所有的音乐都被收录。
>
> Elisa 是一个由 KDE 社区开发的音乐播放器,努力做到简单和好用。我们也认识到,我们需要一个灵活的产品来考虑用户的不同工作流程和使用情况。我们专注于与 KDE 社区的 Plasma 桌面进行良好整合,而不影响对其他平台(其他 Linux 桌面环境、Windows 和 Android)的支持。
>
>
> 据 [Elisa 网站](https://elisa.kde.org/)
>
>
>
总的来说,对于任何平台来说,它都是一个伟大的音乐播放器,对于 KDE Plasma 和 Plasma Mobile 用户来说更是如此。
* [获取 Elisa](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/news/tmp.C4FwOdq3pZ)
### Fractal

继续看看 Gnome 应用程序,Fractal 已经迅速成为我最喜欢的信息应用。它使用了成熟的 Matrix 通信协议,并支持用户可能期望的现代消息应用程序的所有功能。
它有些值得注意的功能,如图像和视频预览,以及对所有 Matrix 功能的支持。此外,它使用 LibHandy 库,这意味着它可以在移动设备上完美地工作,如 PinePhone 和 Librem 5。
总的来说,我对这个应用程序非常满意,因为它几乎适合任何希望与朋友或家人交流的人。
* [获取 Fractal](https://wiki.gnome.org/Apps/Fractal)
### EverSticky

到目前为止,EverSticky 是这个名单上最小的项目,它是一个类似于 Windows 11 的<ruby> 便签应用 <rt> Sticky Notes </rt></ruby> 的小型记事应用。与许多其他可用于 Linux 的便签应用不同,EverSticky 有一个关键优势,它能够同步到印象笔记。
这意味着所有在 EverSticky 上做的笔记也会出现在任何其他登录到印象笔记的设备上。为了帮助尽量减少用户界面混乱(用 Qt 构建),它利用了一个托盘图标,类似于所有最近版本的 Windows 中的图标。
从我的使用经验来看,它工作得非常好,我的所有笔记都能在我的所有设备之间无缝同步。我强烈建议你自己尝试一下。
* [获取 EverSticky](https://github.com/itsmejoeeey/eversticky)
总的来说,我对 Linux 上的应用程序的未来感到兴奋。随着越来越多的人开始关注对开源项目的贡献,我希望我们能得到更多像这样不可思议的应用程序。
你今年还发现了其他一些有趣的新应用吗?请在下面的评论中分享它们。
---
via: <https://news.itsfoss.com/linux-apps-discovered-2021/>
作者:[Jacob Crume](https://news.itsfoss.com/author/jacob/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Over the course of 2021, I have watched hundreds of interesting Linux apps gain development effort and users. While some of these have been discontinued, others live on, and all the time gaining popularity and new features.
While I wish that I could shed some light on all of these, this is unfortunately not possible. However, I have picked my top 5 favorites and shall share them with you here. They may not make the [list of essential Linux applications but I absolutely love them.](https://itsfoss.com/essential-linux-applications/?ref=news.itsfoss.com)
Before we get started, it should be noted that all these apps—with the exception of EverSticky—are convergent, meaning they work equally well on desktop and mobile Linux devices. As devices such as the PinePhone and Librem 5 become more popular, I think it is quite important that convergent apps are supported, and it is great to see so many in development.
With that out of the way, let’s get onto our first app.
## Index
[MauiKit](https://mauikit.org/apps/index/?ref=news.itsfoss.com)
Back in 2016, when KDE released Kirigami, it was evident that it was the future of apps for KDE. Unfortunately, converting thousands of apps to a new UI toolkit is quite difficult, resulting in severe inconsistency between KDE applications.
Now, five years later, we are finally seeing Kirigami really being taken seriously as a UI toolkit for desktop-class apps, demonstrated perfectly in the file manager Index. This beautiful app is the default file manager of Plasma Mobile and Nitrix Linux, and for good reason.
While not as feature-rich as Dolphin, KDE’s default file manager, it does have an integrated terminal, file previews, tabs, and a split-view mode. This puts it on-par with Gnome’s Nautilus, with the obvious advantages of being convergent and Kirigami-based.
Since discovering it, I have used it exclusively, without even a thought of switching back to Dolphin or Nautilus. I would highly recommend it to anyone looking to experiment with their file manager.
## Vakzination
I’m sure we can all agree that the past two years have been tough, but there is a light at the end of the tunnel. As vaccines roll out, it seems that we are finally nearing the end of this pandemic.
Unfortunately, this also means many people are having to get used to the idea of vaccine certificates, many of which are now digital. This can be problematic for Linux users, as health authorities rarely have the resources to develop vaccination certificate apps for Linux.
However, this hasn’t stopped some community members from working on a FOSS alternative, resulting in the creation of Vakzination. As a KDE app, it uses Kirigami and Qt Quick to create a fast, modern, and user-friendly vaccination certificate app that is easy and quick to use.
It currently supports the following certificate formats:
[Indian vaccination certificates](https://en.wikipedia.org/wiki/Verifiable_credentials?ref=news.itsfoss.com)[EU “Digitial Green Certificate” (DCG) vaccination, test and recovery certificates](https://github.com/eu-digital-green-certificates?ref=news.itsfoss.com)
I honestly find it quite incredible what the community has managed to achieve with this app, and here’s hoping that they can add more format support soon.
## Elisa
Yet another Kirigami-based app, Elisa is a fast and beautiful music player from KDE. It supports all major audio formats, and is integrated into the Baloo file indexer to ensure that all your music is picked up.
Elisa is a music player developed by the KDE community that strives to be simple and nice to use. We also recognize that we need a flexible product to account for the different workflows and use-cases of our users. We focus on a very good integration with the Plasma desktop of the KDE community without compromising support for other platforms (other Linux desktop environments, Windows, and Android).
[Elisa website]
Overall, it is a great music player for any platform, and even more so for KDE Plasma and Plasma Mobile users.
## Fractal
[Gnome Wiki](https://wiki.gnome.org/Apps/Fractal?ref=news.itsfoss.com)
Moving on to a Gnome application, Fractal has quickly become my favorite messaging app of all time. It makes use of the well-established Matrix communication protocol and supports all the features that a user might expect of a modern messaging app.
Among its more notable features are image and video previews, and support for all Matrix features. Additionally, it uses the LibHandy library, meaning that it works flawlessly on mobile devices such as the PinePhone and Librem 5.
Overall, I am extremely pleased with this app, as it suits the needs of almost anyone looking to communicate with friends or family.
## EverSticky
By far the smallest project on this list, EverSticky is a small note-taking app similar to Windows 11’s Sticky Notes app. Unlike many of the other sticky-note apps available for Linux, EverSticky has one key advantage: The ability to sync to EverNote.
This means that all notes that are taken on EverSticky will also appear on any other devices signed in to EverNote. To help minimize clutter within the UI (built with Qt), it makes use of a tray icon, similar to those found in all recent versions of Windows.
From my experience with it, it works really well, with all my notes syncing seamlessly between all my devices. I’d highly recommend you try it out for yourself.
Overall, I am really quite excited about the future of apps on Linux. As more and more people start looking towards contributing to open-source projects, I can only hope that we get more incredible apps like these.
Do you have some other interesting new apps that you discovered this year? Share them down in the comments below!
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,142 | 2021 总结:10 个创意树莓派项目 | https://opensource.com/article/21/12/raspberry-pi-projects | 2022-01-03T09:44:29 | [
"树莓派"
] | /article-14142-1.html |
>
> 你的下一个最流行的树莓派项目。
>
>
>

树莓派是最受欢迎的单板计算机品牌之一。它流行的部分原因是人们用树莓派制造了大量独特而有趣的项目。人们在各种项目中使用了树莓派,并提供了说明,以便其他人可以重新创建他们的项目。以下是在 2021 年发表的十篇最受欢迎的树莓派文章。我希望在你摆弄自己树莓派时,它们能给你带来启发。
### 《用树莓派建立一个家庭恒温器》
Joe Truncale 在 2020 年 10 月搬进了新家。家里的老式供暖系统需要改进。他的文章提供了关于他如何 [使用树莓派和 ThermOS](https://opensource.com/article/21/3/thermostat-raspberry-pi) 来替换家中的恒温器的详细说明。
### 《在树莓派上建立一个精简服务器》
树莓派可以作为一个很好的服务器。Alan Formy-Duval 展示了如何 [建立一个精简服务器](https://opensource.com/article/21/1/minimal-server-raspberry-pi) 以节约系统资源。他的说明提供了许多关于如何最大限度地利用树莓派的有用提示。
### 《我是如何在公共图书馆的树莓派 400 上教授 Python 的》
树莓派是一个很好的教学工具。在这篇文章中,Don Watkins 讲述了他如何在一个公共图书馆 [使用树莓派 400 教授 Python](https://opensource.com/article/21/6/teach-python-raspberry-pi)。他描述了他是如何设置树莓派 400 以及如何教授课程的。
### 《用 Cockpit 管理你的树莓派》
Alan Formy-Duval 解释了如何 [使用 Cockpit 来管理你的树莓派](/article-13487-1.html)。他详细介绍了如何在树莓派操作系统上安装和使用 Cockpit,并对 Cockpit 的功能做了大致的介绍。正如他在文章中指出的那样,“就像在其他 Linux 系统上一样,Cockpit 可以在树莓派上发挥功用”,这使得这篇文章也可以用于有兴趣在其他系统上使用 Cockpit 的用户。
### 《使用树莓派建立一个具有移动连接功能的路由器》
你可以用树莓派轻松地制作你自己的路由器。在这个教程中,Lukas Janėnas 解释了如何 [建立一个具有移动连接的路由器](https://opensource.com/article/21/3/router-raspberry-pi)。他提供了关于如何在树莓派上安装和配置 OpenWRT 的详细说明。
### 《用树莓派和一个低功耗显示器追踪你的家庭日历》
Javier Pena 使用树莓派和一个墨水屏显示器 [建立了一个家庭日历](/article-13222-1.html)。这篇文章提供了关于该项目中使用的硬件和软件的信息。使用所提供的说明,你可以轻松地为自己的家庭创建一个数字日历。
### 《用树莓派投射你的安卓设备》
在 Sudeshna Sur 的这篇文章中,可以了解到如何 [用树莓派投射你的安卓设备](https://opensource.com/article/21/3/android-raspberry-pi)。Sudeshna 使用 Scrcpy 来完成这个任务。她提供了关于如何设置 Scrcpy 和配置你的手机的说明,以便它们一起工作。
### 《对树莓派 400 的测评》
Don Watkins [测评了树莓派 400](https://opensource.com/article/21/3/raspberry-pi-400-review),提供了多张他的树莓派 400 开箱图片,并提供了对该设备和捆绑配件的出色书面评论。关于这个 100 美元的大礼包,他有很多好话要说。
### 《用树莓派和 Prometheus 监控你家里的温度和湿度》
在 Chris Collins 的教程中,学习如何 [监测你家里的温度和湿度](https://opensource.com/article/21/7/home-temperature-raspberry-pi-prometheus)。Chris 解释了如何使用 Prometheus 和树莓派来收集和存储数据。他提供了关于安装 Prometheus 的说明,设置 Prometheus 来跟踪数据,创建一个 systemd 单元和日志记录等等,最后还说明了如何把所有的步骤结合起来创建完成的项目。
### 《在树莓派集群中部署 Ceph》
AJ Canlas 教授了如何 [在树莓派集群中部署 Ceph](/article-13020-1.html)。这篇文章提供了使用 `ceph-ansible` Ansible 剧本部署 Ceph 的说明。需要的硬件是四个树莓派 4B 4GB 型号,四个 32GB 的 microSD 卡用于启动操作系统,四个带风扇和散热器的外壳,四个树莓派电源,以及六个 32GB 的 USB 闪存用于 Ceph OSD 节点。这是一套很大的设备,但如果你手上有这样的硬件,这是一个迷人的项目,可以尝试一下。
---
via: <https://opensource.com/article/21/12/raspberry-pi-projects>
作者:[Joshua Allen Holm](https://opensource.com/users/holmja) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
14,143 | 2022 年值得期待的 7 款 Linux 发行版 | https://news.itsfoss.com/linux-distro-releases-2022/ | 2022-01-03T10:59:18 | [
"发行版"
] | https://linux.cn/article-14143-1.html |
>
> 2022 年已至,是时候期待一些激动人心的发行版更新了!这里我们挑选了一些值得关注的发行版选择。
>
>
>

是时候和 2021 年说再见了。
如果你错过了 [2021 年的 Linux 大事件](/article-14103-1.html),现在你也可以去回顾一下。
不过,考虑到 2021 年已有许多令人印象深刻的发行版推出,2022 年,对于较新的 Linux 发行版以及现有版本的更新,人们的期待值已经直达顶峰。
与十年前相比,Linux 发行版如今更加注重用户体验。这不仅仅关乎资源占用,更关系到发行版的外观及对现代桌面硬件的兼容性。
先来简单回顾一下 —— [elementary OS 6.1](https://news.itsfoss.com/elementary-os-6-1-release/)、[Zorin OS 16](https://news.itsfoss.com/zorin-os-16-release/)、[Pop!\_OS 21.10](/article-14083-1.html) 和 Linux Mint 20.3 都是于 2021 年推出的大型 Linux 发行版的更新版。这些发行版都专注于改善用户体验、改进视觉、优化生产力。
毫无疑问,你可以选择上述发行版并感受前所未有的桌面体验,也可以获取 [最佳 Linux 发行版](https://itsfoss.com/best-linux-distributions/) 的最新更新。
所以,到了 2022 年,你又应该期待什么?是否会有一个能让用户体验更上一层楼的发行版呢?
答案是肯定的,这里就有一些你值得关注的发行版。在此我列出了清单,重点强调 2022 年这些发行版的计划更新内容。
### 2022 年最值得期待的发行版
请注意:这里列出的大部分发行版的官方信息暂时缺失,不过本文章将定期更新以补充最新消息。
#### 1、Slackware 15

Slackware 是至今为止 [最长寿的活跃发行版](https://news.itsfoss.com/slackware-15-beta-release/)。Slackware 15 Beta 版已在去年发布,稳定版将于 2022 年初发布。
对于新手级桌面用户来说,这并不那么吸引人,不过如果你想要一款支持旧硬件,或者能够有效利用资源的发行版,Slackware 可以成为你的候选方案。
再次强调一下,Slackware 15 将是时隔六年后的一个大版本更新,所以这是一件大事。
不过,这款发行版会更适合有经验的 Linux 用户。
因此,如果你对此不感兴趣的话,你可以去看看 [最轻量级的 Linux 发行版列表](https://itsfoss.com/lightweight-linux-beginners/)。
#### 2、Ubuntu 22.04 LTS

Ubuntu 的下一个 LTS 版本 22.04(代号 Jammy Jellyfish)将于 2022 年 4 月 21 日发布。
在 Ubuntu 22.04 LTS 中,你将可以体验到 GNOME 42 桌面环境、全新的安装器,以及默认使用 Wayland 的桌面会话。
[Ubuntu 21.10](/article-13887-1.html) 的一系列改进也将在 Ubuntu 22.04 LTS 中一并出现。
#### 3、Zorin OS 17

[Zorin OS 16](https://news.itsfoss.com/zorin-os-16-features/) 凭借其新增的许多功能及用户体验改进,让我们留下了极其深刻的印象。
我认为 Zorin OS 16 是一次极大地增强了桌面体验的更新。
考虑到 Zorin OS 16 中已经有了大幅改进,我们应该转投于下一个大版本更新 —— 将于 2022 年发布的 Zorin OS 17。当然,它应该会基于 Ubuntu 22.04 LTS,不过你更应该期待一下视觉方面的改进。
#### 4、Pop!\_OS 22.04

[Pop!\_OS](https://pop.system76.com) 是一款开箱即用的稳定发行版。与其他发行版不同, Pop!\_OS 并不意在于“更棒的视觉体验”,而是专注于增强工作流环境,同时提供独特的桌面体验。
System76 [将仓库从 Launchpad 转移出去](https://news.itsfoss.com/pop-os-ppa-repo-move/) 和计划 [使用 Rust 从头构建桌面环境](https://news.itsfoss.com/pop-os-cosmic-rust/) 这几件激动人心的举措,使我更有意愿去关注他们的发展动态。
毫无疑问,[Pop!\_OS 能够成为我的主力系统](/article-14118-1.html)。
此外,Pop!\_OS 22.04 将会是 System76 对其操作系统后续规划的有力支撑,所以,拭目以待吧。
#### 5、Linux Mint 21

[Linux Mint](https://linuxmint.com) 团队可能不会推出很多变化,但从 Linux Mint 20.3 开始,他们开始专注于改善视觉了。
我并不希望有任何破坏性变更。不过,Linux Mint 21 仍旧有值得期待的重大视觉优化,毕竟他们确实需要向更现代的桌面环境发展了。
#### 6、CutefishOS

[CutefishOS](https://cn.cutefishos.com) 目前仍处于早期开发阶段(虽然已经到了 Beta 测试阶段),尚未进入稳定阶段。
根据我对其 Beta 测试版本的体验,CutefishOS 在用户体验上 [可以与深度操作系统相媲美](/article-14058-1.html)。当然我仍旧持谨慎态度,毕竟它还没到达稳定阶段。
不过,CutefishOS 确实是款值得关注的项目,毕竟,更多的发行版将开始意识到改进用户体验的重要性,并试图与现有的 [最美 Linux 发行版](https://itsfoss.com/beautiful-linux-distributions/) 一决高下,这么“卷”起来总归是好事。
#### 7、Fedora 36

[Fedora](https://getfedora.org) 团队已经从 [Linus Tech Tip 的 Linux 日用挑战系列视频](/article-14053-1.html) 中认真地听取了用户反馈。
事实上,[红帽公司已经捐赠了 1 万美元](https://www.gamingonlinux.com/2021/12/red-hat-donates-10k-to-obs-studio-flatpak-to-be-official-for-linux/) 来帮助 OBS 构建 Flatpak 官方包。
即便 Fedora 并非 Linux 游戏玩家的理想发行版,Fedora 团队也在努力使 Workstation 版本兼顾稳定性和最新功能。
[Fedora 35](/article-13949-1.html) 正是一个优秀案例,它带来了 GNOME 41 和全新的 KDE 变体版本。
我并不敢保证 Fedora 36 能更适合游戏玩家,但有一些预期的变化,比如 Wayland 默认使用 NVIDIA 专有驱动,以及新的 GNOME 42 桌面环境。如果你想关注开发动态,你可以查阅 [官方的更新内容列表](https://www.fedoraproject.org/wiki/Releases/36/ChangeSet)。
#### 额外:Nitrux Linux
我本来没有计划在这里介绍 Nitrux 的,但 Nitrux 几天前突然 [推出了 Maui Shell 项目](https://nxos.org/news/introducing-maui-shell/)。
Maui Shell 是一款跨终端的桌面环境,支持电脑、平板、手机。听起来是不是有点像当年 Ubuntu 的 Unity 呢?Nitrux 项目在设计方面一直很出色,所以我对这款新的桌面环境的期待值已经拉满了。

Maui Shell 项目仍在大力开发中。它将在接下来的几个月里添加新功能,以确保其基本可用。我们可以期待 2022 年它会变成什么样子。
### 结束语
即便我们列出了这么多发行版,谁知道哪个发行版又会突然出现,并拿下头条呢?
也许是 [EndeavourOS](https://endeavouros.com)、[Garuda Linux](https://garudalinux.org) 的重量级更新,又或者是别的?
2022 年,你又会期待哪款发行版呢?不要介意,欢迎在评论区分享你的想法。
---
via: <https://news.itsfoss.com/linux-distro-releases-2022/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It is time to bid farewell to 2021.
You might want to go through some of the [biggest Linux stories of 2021](https://news.itsfoss.com/biggest-linux-stories-2021/) if you missed them.
However, considering some of the impressive distro releases in 2021, excitement for newer Linux distributions and upgrades for 2022 is at its peak.
Compared to the last decade, Linux distributions are now focusing more on the user experience aspect. It is no longer just about the resource usage but how a distribution looks and works with modern desktop hardware.
To give you a quick recap—[elementary OS 6.1](https://news.itsfoss.com/elementary-os-6-1-release/), [Zorin OS 16](https://news.itsfoss.com/zorin-os-16-release/), [Pop!_OS 21.10](https://news.itsfoss.com/pop-os-21-10/), and Linux Mint 20.3 were some of the biggest Linux distribution releases. The distributions concentrated on improving the user experience for a better look/feel or enhancing the productivity use-cases.
Undoubtedly, you can choose to get an unrivaled desktop experience from some of these or the latest updates for the [best Linux distributions](https://itsfoss.com/best-linux-distributions/?ref=news.itsfoss.com).
So, what should you expect for 2022? Are there any expected distro releases that plan to take things up a notch?
Yes, there are several distros you should keep an eye for. Here, I shall highlight a list of distros and their potential stated for release next year.
## Most Anticipated Distro Releases for 2022
Note that official information for most distributions is not available yet. However, this article will be regularly updated to reflect the latest information.
### 1. Slackware 15

Slackware is the [oldest active distribution](https://news.itsfoss.com/slackware-15-beta-release/) as of now. Slackware 15 beta was released last year and the stable version should be available in early 2022.
While this may not be an exciting release for new desktop users, if you want a distro for older hardware or something that makes efficient use of resources, this can be a candidate.
Not to forget, Slackware 15 will be a major release after six years, so it is a big deal.
However, it is mostly suitable for experienced Linux users.
Hence, if this does not interest you, you might want to look for some of the [most lightweight Linux distributions](https://itsfoss.com/lightweight-linux-beginners/?ref=news.itsfoss.com).
### 2. Ubuntu 22.04 LTS

The schedule for Ubuntu’s next LTS release, codenamed Jammy Jellyfish, is already official for April 21, 2022.
With Ubuntu 22.04 LTS, you can expect GNOME 42 as the desktop environment, a new installer, and Wayland as the default desktop session.
The improvements to [Ubuntu 21.10](https://news.itsfoss.com/ubuntu-21-10-release/) should also carry over to Ubuntu 22.04 LTS.
### 3. Zorin OS 17
[Zorin OS 16](https://news.itsfoss.com/zorin-os-16-features/) was an impressive release with numerous feature additions and UX improvements.
I think Zorin OS 16 was one of the most extensive upgrades in terms of quality changes for an enhanced desktop experience.
Considering they have improved a lot with Zorin OS 16, it is only fair to be excited about what’s coming to its next major release, Zorin OS 17 in 2022. Of course, you should expect it to be based on Ubuntu 22.04 LTS, but it should be a surprise to expect visual changes/improvements.
### 4. Pop!_OS 22.04
[Pop!_OS](https://pop.system76.com/?ref=news.itsfoss.com) is a solid distribution out of the box. Unlike some others, it does not primarily aim to “look better”, but focuses on enhancing the workflow while providing a unique desktop experience.
System76’s [decision to switch away from Launchpad](https://news.itsfoss.com/pop-os-ppa-repo-move/) and plans to [build a Rust-based desktop environment from scratch](https://news.itsfoss.com/pop-os-cosmic-rust/) are some of the exciting developments that make me want to keep an eye on them.
No wonder [Pop!_OS is my daily driver](https://itsfoss.com/why-use-pop-os/?ref=news.itsfoss.com).
And, Pop!_OS 22.04 can be the pillars of System76’s ambitious plans for the future of its operating system. So, looking forward to it makes sense to see what they plan to do next.
### 5. Linux Mint 21

The [Linux Mint](https://linuxmint.com/?ref=news.itsfoss.com) team may not introduce massive changes, but they have started to focus on improving the look/feel of the distro starting with Linux Mint 20.3.
I wouldn’t want anything different about them. Still, Linux Mint 21 could be a release where you could expect some significant visual overhaul, considering they need to improve the user experience for the modern desktop.
### 6. CutefishOS

[CutefishOS](https://en.cutefishos.com/?ref=news.itsfoss.com) is in its early stage of development (beta phase) and hasn’t reached a stable release yet.
As per my experience with its beta release, it could [rival the likes of Deepin Linux](https://news.itsfoss.com/cutefishos-intro/) in terms of user experience. Of course, I would be cautious about it, considering it does not have a stable release yet.
However, CutefishOS should be an exciting project to keep an eye on. After all, it is good to more distributions compete to provide a pleasing user experience to compete with some of the [most beautiful Linux distributions](https://itsfoss.com/beautiful-linux-distributions/?ref=news.itsfoss.com) available.
### 7. Fedora 36
Team [Fed](https://getfedora.org/?ref=news.itsfoss.com)[o](https://getfedora.org/?ref=news.itsfoss.com)[ra](https://getfedora.org/?ref=news.itsfoss.com) has been taking the feedback from [Linus Tech Tip’s Linux challenge series results](https://news.itsfoss.com/more-linux-distros-become-linus-proof/) seriously.
In fact, [Red Hat contributed $10,000](https://www.gamingonlinux.com/2021/12/red-hat-donates-10k-to-obs-studio-flatpak-to-be-official-for-linux/?ref=news.itsfoss.com) to help make the OBS Flatpak official for Linux.
While Fedora isn’t considered an ideal distribution for Linux gamers, they have been making efforts to their Workstation edition to feature the latest and greatest without compromising the system’s stability.
[Fedora 35](https://news.itsfoss.com/fedora-35-release/) release was an impressive example of that, to debut GNOME 41 and introduce a new KDE variant.
I can’t say if Fedora 36 will be more suitable for gamers, but some expected changes include Wayland by default with Nvidia proprietary drivers and GNOME 42. An [official list of expected changes](https://www.fedoraproject.org/wiki/Releases/36/ChangeSet?ref=news.itsfoss.com) is available if you want to keep an eye on it.
### Bonus: Nitrux Linux
I didn’t plan to include Nitrux in this list initially but then [Nitrux introdu](https://nxos.org/news/introducing-maui-shell/?ref=news.itsfoss.com)ced the Maui shell a couple of days ago.
Maui Shell is a convergent shell for desktops, tablets, and phones. Sounds like what Ubuntu wanted to with Unity, right? The Nitrux project has always been good with design part so I am excited for this new shell.

The project is still under heavy development. It plans to add a number of features to make it usable in the coming months. We should see how it comes around in 2022.
## Wrapping Up
Even with the list here, there should be some surprise releases that could steal the headlines, who knows?
Maybe an exciting update to [EndeavourOS](https://endeavouros.com/?ref=news.itsfoss.com), [Garuda Linux](https://garudalinux.org/?ref=news.itsfoss.com), or something else?
What distribution are you looking forward to in 2022? Please don’t hesitate to share your thoughts in the comments down below.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,145 | 用 Samba 跨平台共享文件 | https://opensource.com/article/21/12/file-sharing-linux-samba | 2022-01-04T09:27:17 | [
"Samba"
] | https://linux.cn/article-14145-1.html |
>
> Samba 是一种灵活的文件共享工具,它将你可能在组织中运行的所有不同平台结合在一起。
>
>
>

在我接触 Linux 的早期,我是纽约州一个小型学前教育学区的技术总监。我们的技术预算总是捉襟见肘。我们是一个 Windows 2000 活动目录域,但我们的中央服务器磁盘空间有限,而且没有教师的主目录。此外,我们经历过十几次员工电脑硬盘故障。
我正在寻找一种方法,以最小的成本保存员工的工作。这时我发现了 Samba。在那之前,我一直将 Linux 用于内容过滤,不知道我们的 Windows 工作站可以连接到服务器并保存文件备份。
[Samba 项目](https://www.samba.org/) 自 1992 年以来一直存在。当我开始试验这个项目的时候,这个项目已经有 10 年历史了,我对如何配置它一无所知。我买了一本书并阅读了如何实现它,然后我从我们的电脑柜中取出一台旧电脑,购买了一个 300G 的希捷 IDE 驱动器,安装了 Linux,并配置了 Samba。我使用了一个简单的配置,并且它成功了。在向我们的一个 IT 助理展示后,我们部署了这个解决方案。硬盘故障的问题继续存在,但我们的员工不再需要担心失去他们所有的辛苦工作。
Samba 采用 [GPL](https://www.samba.org/samba/docs/GPL.html) 许可证,并在大多数 Linux 发行版上广泛使用。Samba 有很好的 [文档](https://www.samba.org/samba/docs/),Fedora 用户可以查阅这份在 [Fedora 上配置 Samba](https://docs.fedoraproject.org/en-US/quick-docs/samba/) 的文档。
### 在 Linux 上安装 Samba
你可以使用你的发行版的包管理器来安装 Samba。
在 Fedora、CentOS、RHEL、Mageia 和类似的系统上:
```
$ sudo dnf install samba
```
在 Debian, Linux Mint 和类似系统上:
```
$ sudo apt install samba
```
### 用 Samba 创建一个共享文件夹
创建一个简单的共享文件夹只需要五个步骤。
1、在你的 Linux 服务器上创建一个你希望用户能够保存共享文件的目录。这个目录可以是服务器上的任何地方:在 `/home` 或 `/opt` 或任何最适合你的地方。我使用我的主目录,我把共享目录称为 `sambashare`。
```
$ mkdir /home/don/sambashare
```
在 Fedora 和其他运行 SELinux 的发行版上,你必须对这个共享目录给予安全许可:
```
$ sudo semanage fcontext --add --type "samba_share_t" ~/sambashare
$ sudo restorecon -R ~/sambashare
```
2、用 Nano 或你选择的文本编辑器编辑 Samba 配置文件。
```
$ sudo nano /etc/samba/smb.conf
```
在 `smb.conf` 文件的底部添加以下内容,用你自己的共享目录的位置替换我例子中的 `/home/don/sambashare` 路径:
```
[sambashare]
comment = Samba on Linux
path = /home/don/sambashare
read only = no
browsable = yes
```
如果你使用 Nano,按 `Ctrl-O`,然后按**回车**来保存,按 `Ctrl-X` 退出。
3、启动或重启 Samba 服务,这取决于你的发行版。
在 Fedora 和类似的系统中,没有明确的许可,服务是不会启动的,所以现在就可以启动 Samba,并在启动时启动:
```
$ sudo systemctl enable –now smb.conf
```
在 Debian 和类似系统中,Samba 默认在安装后启动,所以你必须现在就重启它:
```
$ sudo service smbd restart
```
4、更新你的防火墙规则,允许访问你的 Samba 共享。该如何做取决于你的系统使用什么防火墙。
如果你正在运行 firewalld:
```
$ sudo firewall-cmd --permanent --add-service=samba
$ sudo firewall-cmd --reload
```
如果你正在运行 UFW:
```
$ sudo ufw allow samba
```
5、现在你需要设置一个密码来访问你的 Samba 共享。这个用户名(在我的例子中是 don)必须属于你系统中的一个账户。
```
$ sudo smbpasswd -a don
```
我在每个 Samba 共享中都放置了一个简单的 `README` 文件,这样用户就会明白这个目录位于服务器上,他们必须在 VPN 上才能从家里访问它等等。
### 从 Windows 和 Mac 访问 Samba
在 Windows 电脑上,打开文件管理器(Windows Explorer),访问路径 `ip-address-of-the-Linux-computer/sambashare`。系统会提示你输入 Samba 共享密码,然后 `sambashare` 目录中的文件会出现在你的文件管理器窗口中,就像它们存在于你的桌面上一样。你可以开始在网络上的这个新共享目录中存储你的文件。
在 macOS 电脑上,进入 Finder 菜单,选择 Go。在出现的对话框中,输入 `smb://ip-address/sambashare`,并按照提示输入 Samba 密码。
### Samba 意味着共享
Samba 使共享文件变得容易。你可以在 Samba 中使用许多其他方案来创建共享位置,包括用户组的公共文件夹,只接受传入文件的收件箱,以及其他你可能需要的东西。它是开源的、灵活的,而且它把你可能在你的办公室里运行的所有不同的平台联合起来。
---
via: <https://opensource.com/article/21/12/file-sharing-linux-samba>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the early days of my Linux experience, I was the technology director of a small PreK-12 school district in the state of New York. Our technology budget was always stretched to the limit. We were a Windows 2000 Active Directory Domain, but we had limited central server disk space and no teacher home directories. In addition, we experienced a dozen or so hard disk failures for staff computers.
I was looking for a way to preserve staff work at a minimal cost. That's when I discovered Samba. I used Linux up to that point for content filtering, having no idea that our Windows workstations could connect to a server and keep their files backed up.
The [Samba project](https://www.samba.org/) has been around since 1992. The project was 10 years old when I started experimenting with it and knew nothing about how to configure it. I bought a book and read about how to implement it, then I took one of the older computers from our computer closet, purchased a 300-gigabyte Seagate IDE drive, installed Linux, and configured Samba. I used a simple configuration, and it worked. After showing it to one of our IT assistants, we deployed the solution. The hard drive failure problem continued, but our staff no longer had to worry about losing all their hard work.
Samba is licensed with [GPL](https://www.samba.org/samba/docs/GPL.html) and is widely available on most Linux distributions. Samba has excellent [documentation](https://www.samba.org/samba/docs/), and Fedora users can consult documentation about [Samba on Fedora](https://docs.fedoraproject.org/en-US/quick-docs/samba/).
## Install Samba on Linux
You can install Samba using your distribution's package manager.
On Fedora, CentOS, RHEL, Mageia, and similar:
`$ sudo dnf install samba`
On Debian, Linux Mint, and similar:
`$ sudo apt install samba`
## Create a shared folder with Samba
Creating a simple shared folder only takes five steps.
1. Create a directory on your Linux server where you want users to be able to save shared files. This directory can be anywhere on the server: in `/home`
or `/opt`
or whatever works best for you. I use my home directory, and I call the shared directory `sambashare`
.
`$ mkdir /home/don/sambashare`
On Fedora and other distributions running SELinux, you must give security clearance to this shared directory:
```
$ sudo semanage fcontext --add --type "samba_share_t" ~/sambashare
$ sudo restorecon -R ~/sambashare
```
2. Edit the Samba configuration file with Nano or the text editor of your choice.
`$ sudo nano /etc/samba/smb.conf`
Add this to the bottom of the `smb.conf`
file, replacing my example path of `/home/don/sambashare`
with the location of your own shared directory:
```
[sambashare]
comment = Samba on Linux
path = /home/don/sambashare
read only = no
browsable = yes
```
If you're using Nano, press **Ctrl-O** and then **Return** to save and **Ctrl-X** to exit.
3. Start or restart the Samba service, depending on your distribution.
On Fedora and similar, services don't start without your explicit permission, so enable Samba to start now, and on boot:
`$ sudo systemctl enable –now smb.conf`
On Debian and similar, Samba starts after installation by default, so you must restart it now:
`$ sudo service smbd restart`
4. Update your firewall rules to allow access to your Samba share. How you do this depends on what firewall your system uses.
If you're running firewalld:
```
$ sudo firewall-cmd --permanent --add-service=samba
$ sudo firewall-cmd --reload
```
If you're running UFW:
`$ sudo ufw allow samba`
5. Now you need to set up a password to access your Samba share. The username (don, in my example) must belong to an account on your system.
`$ sudo smbpasswd -a don`
I place a simple `README`
file in each Samba share so users understand that the directory is located on the server, that they must be on the VPN to access it from home, and so on.
## Accessing Samba from Windows and Mac
On a Windows computer, open the file manager (Windows Explorer) and edit the file path to `\ip-address-of-the-Linux-computer\sambashare`
. You're prompted for the Samba share password, and then the files in the `sambashare`
directory appear in your file manager window, just as if they existed locally on your desktop. You can begin storing your files on this new shared directory on your network.
On a macOS computer, go to the Finder menu and select Go. In the dialogue box that appears, type in `smb://ip-address/sambashare`
and follow the prompts to enter your Samba password.
## Samba means sharing
Samba makes sharing files easy. You can use many other schemes within Samba to create shared locations, including common folders for groups of users, inboxes that accept incoming files only, and whatever else you might need. It's open source, flexible, and it unites all the different platforms you might have running in your organization.
## Comments are closed. |
14,146 | Ubuntu 服务器版与桌面版有什么区别? | https://itsfoss.com/ubuntu-server-vs-desktop/ | 2022-01-04T12:21:00 | [
"服务器",
"Ubuntu",
"桌面"
] | https://linux.cn/article-14146-1.html | 
当你点击 [Ubuntu 网站](https://ubuntu.com/) 上的下载按钮时,它会给你几个选项。其中两个分别是 Ubuntu 桌面版和 Ubuntu 服务器版。
这可能会让新用户感到困惑。为什么会有两个(实际上是四个)?应该下载哪一个?Ubuntu 桌面版还是服务器版?它们是一样的吗?有什么区别?

我将解释 Ubuntu 的桌面版和服务器版的区别。我还会解释你应该使用哪个变体。
### Ubuntu 桌面版与 Ubuntu 服务器版

要了解 Ubuntu 桌面版和服务器版的区别,你应该了解桌面操作系统和服务器操作系统的区别。
#### 桌面操作系统
<ruby> 桌面电脑 <rt> Desktop </rt></ruby>是指个人电脑(PC)。桌面电脑操作系统带有一个图形用户界面,以便用户可以使用鼠标和键盘操作。桌面电脑的主要目的是给你一个系统,可以用来浏览网页、编辑文档、查看/编辑图片和视频、编码和游戏。基本上,就是为个人、终端用户或家庭成员提供了一个通用的计算机。
我在这里使用桌面电脑这个术语,但这并不意味着它不能用于笔记本电脑。桌面电脑是个人电脑的通用术语。
#### 服务器操作系统
另一方面,服务器操作系统是专门为托管网站、应用程序、媒体服务器、数据库等网络服务而打造的。
通常情况下,服务器操作系统不带有图形界面。如果是基于 Linux 的操作系统,你就得通过终端的命令来使用该系统。
这里的好处是,服务器操作系统不需要(浪费)大量的内存和计算能力,因为它们不使用 [图形化桌面环境](https://itsfoss.com/what-is-desktop-environment/)。除此以外,服务器操作系统的软件包配置也不同。
现在你对服务器和桌面的区别有了一些了解,让我们看看 Ubuntu 服务器版和桌面版的区别。
#### 用户界面
Ubuntu 服务器版和桌面版之间最明显的区别是用户界面。
Ubuntu 桌面版的特点是采用 GNOME 桌面环境的图形化用户界面。这使得它在鼠标点击的帮助下更容易使用。

Ubuntu 服务器版采用<ruby> 无头方式 <rt> headless </rt></ruby>运行。你只有在登录后才会看到一个终端界面。你经常会从其他电脑上通过 SSH 来远程管理它。

#### 安装
[由于有了图形化的安装程序,将 Ubuntu 作为桌面电脑是很容易的](https://itsfoss.com/install-ubuntu/)。你可以创建一个<ruby> 临场 USB <rt> Live USB </rt></ruby>,无需安装即可体验桌面版。如果你喜欢,你可以按照屏幕上的指示在几分钟内安装它。

将 Ubuntu 作为服务器安装并不像桌面版那样简单。你只能使用终端界面。如果你不熟悉这个流程,即使是最简单的任务,如连接到 Wi-Fi,也可能是一个困难的任务。

#### 应用程序
在 Ubuntu 桌面版中,默认的应用程序集主要针对普通计算机用户。因此,你会发现网页浏览器、办公套件、媒体播放器、游戏等。

Ubuntu 服务器版的应用程序更多的是为运行网络服务而定制的。而这还不是全部。有些应用程序的配置也是不同的。以 SSH 为例。Ubuntu 服务器预设了 SSH,这样你就可以轻松地从远程系统连接到它。而在 Ubuntu 桌面版上,你必须明确启用 SSH 才行。
#### 硬件要求
由于桌面版具有图形用户界面,你需要至少 4GB 的内存来运行 Ubuntu 桌面版。磁盘空间至少要有 20GB。
这就是 Ubuntu 服务器的有趣之处。它没有图形化的界面。命令行界面不会消耗大量的系统资源。因此,你可以在 512MB 和 5GB 磁盘空间的机器上轻松运行 Ubuntu 服务器。(LCTT 译注:当然,对于服务器环境来说,内存和磁盘空间是多多益善。)
服务器上的内存和磁盘空间受制于你所运行的网络服务。如果一个网络应用需要至少 2GB 的内存,你就应该有这么多的内存。但在最简单的情况下,即使是 512MB 或 1GB 的内存也可以工作。
#### 用途
这是 Ubuntu 桌面版和服务器版之间的主要区别。问问自己,你想把 Ubuntu 用于什么目的?
如果是专门用于部署网络服务,那就选择 Ubuntu 服务器。请记住,你需要有基本的 Linux 命令行知识来使用终端。
如果你想把 Ubuntu 作为像 Windows 一样的普通电脑使用,那就选择 Ubuntu 桌面版。如果你想用它来学习 Linux 命令,或用于学习的 Docker 或者甚至是简单的(但是本地的)LAMP 服务器环境,请继续使用 Ubuntu 桌面。
对于服务器来说,Ubuntu 服务器版要比 Ubuntu 桌面版好。对于常规的计算机使用,Ubuntu 桌面版是更好的选择。
#### 你应该在服务器上使用 Ubuntu 桌面版还是在服务器上安装图形界面?
是这样的,Ubuntu 桌面版和服务器版都是 Linux,你可以用 Ubuntu 桌面版作为服务器来托管网页服务。这没问题。
同样地,[你可以在 Ubuntu 服务器上安装图形界面](https://itsfoss.com/install-gui-ubuntu-server/),并以图形方式使用它。这也是可行的。

但仅仅因为它可行,并不意味着你应该这么做。它违背了为服务器和桌面电脑创建不同版本的全部目的。
你必须付出额外的努力来将服务器版转换为桌面版,反之亦然。为什么要承受这种痛苦呢?
如果你使用 Ubuntu 的目的很明确,那就下载并安装合适的 Ubuntu 版本。
我希望这能使围绕 Ubuntu 桌面版和服务器版的选择现在更清楚一些。如果你有问题或建议,请利用评论区。
---
via: <https://itsfoss.com/ubuntu-server-vs-desktop/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you click on the download button on the [Ubuntu website](https://ubuntu.com/?ref=itsfoss.com), it gives you a few options. Two of them are Ubuntu Desktop and Ubuntu Server.
This could confuse new users. Why are there two (actually 4 of them)? Which one should be downloaded? Ubuntu desktop or server? Are they the same? What is the difference?
I am going to explain the difference between the desktop and server editions of Ubuntu. I’ll also explain which variant you should be using.
## Ubuntu desktop vs Ubuntu server

To understand the difference between Ubuntu desktop and server, you should understand the difference between a desktop and a server operating system.
### Desktop
A desktop is referred to a personal computer. A desktop operating system comes with a graphical user interface so that the users can use their mouse and keyboard. The primary purpose of a desktop is to give you a system that can be used for web browsing, document editing, viewing/editing pictures and videos, coding and gaming. Basically, a general purpose computer for individuals, end users, or family members.
I am using the term desktop here, but this does not mean that it cannot be used on a laptop. Desktop is the generic term for a personal computer.
### Server
On the other hand, a server operating system is specifically created for hosting web services like websites, apps, media servers, databases etc.
Usually, a server operating system does not come with a graphical interface. If it is Linux based operating system, you’ll have to use the system entirely via commands in terminal.
The advantage here is that the server OS do not need a lot of RAM and computational power because they do not use [graphical desktop environment](https://itsfoss.com/what-is-desktop-environment/). Apart from that, the server operating system has packages configured differently as well.
Now that you understand the difference between server and desktop a little, let’s see the difference between Ubuntu server and desktop.
### The user interface
The most visible difference between Ubuntu server and desktop is the user interface.
Ubuntu desktop features a graphical user interface with GNOME desktop environment. This makes it easier to use with the help of mouse clicks.
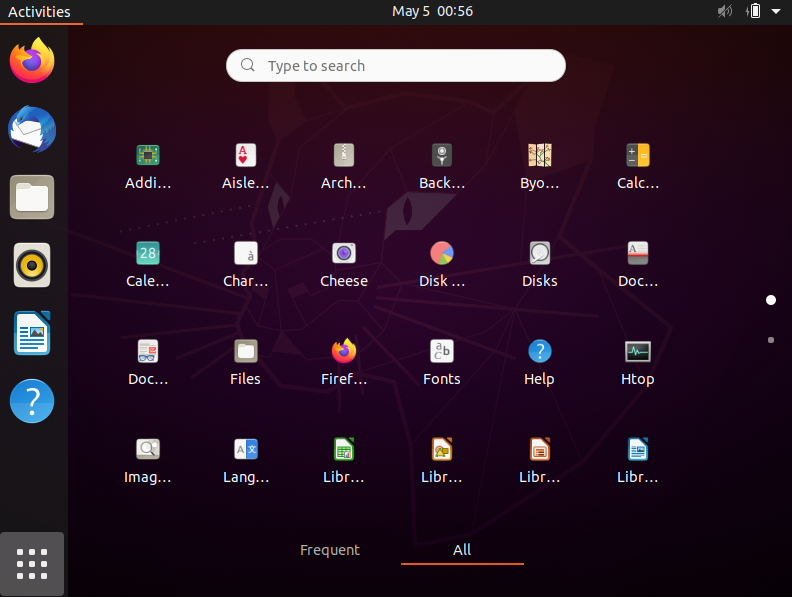
Ubuntu server edition runs headless. You will only see a terminal interface when you are logged in to it. You’ll often manage it remotely from other computers overs SSH.
### Installation
[Installing Ubuntu as a desktop is easy](https://itsfoss.com/install-ubuntu/) thanks to the graphical installer. You can create a live USB and experience the desktop version without installing. If you like it, you can install it in minutes following the on-screen instructions.
Installing Ubuntu as a server is not as easy as the desktop edition. You are stuck with terminal interface. Even the simplest tasks like connecting to Wi-Fi could be a difficult task if you are not familiar with the procedure.
### Applications
The default set of applications in Ubuntu desktop is focused on regular computer users. So, you’ll find web browsers, office suite, media players, games etc.
Ubuntu server has applications that are more tailored for running web services. And that’s not it. Some applications are also configured differently. Take SSH for example. Ubuntu server has SSH preconfigured so that you can easily connect to it from remote systems. You have to explicitly enable SSH on Ubuntu desktop.
### Hardware requirement
Since the desktop edition features a graphical user interface, you need at least 4 GB of RAM to run Ubuntu desktop. Disk space should be 20 GB at least.
This is where it gets interesting for Ubuntu server. It does not have a graphical interface. The command line interface does not consume a lot of system resources. As a result, you can easily run Ubuntu server on a machine with 512 MB and 5 GB of disk space.
The RAM and disk space on the server is subjected to the web service you run. If a web application requires at least 2 GB of RAM, you should have that much of RAM. But in the simplest of scenario, even 512 MB or 1 GB of RAM could work.
### Usage
This is the main differentiator between Ubuntu desktop and server. Ask yourself, for what purpose you want to use Ubuntu?
If it is specifically for deploying web services, go for Ubuntu server. Keep in mind that you need to have basic Linux command line knowledge to navigate through the terminal.
If you want to use Ubuntu as a regular computer like Windows, go with Ubuntu desktop. If you want to use it for learning Linux commands, Docker or even simple (but local) LAMP server installation for learning, stay with Ubuntu desktop.
For a server, Ubuntu server is better than Ubuntu desktop. For regular computing usage, Ubuntu desktop is the better choice.
### Should you use Ubuntu desktop for server or install GUI on server?
Here’s the thing. Both Ubuntu desktop and server are Linux. You can use Ubuntu desktop as server for hosting web services. That works.
Similarly, [you can install GUI on Ubuntu server](https://itsfoss.com/install-gui-ubuntu-server/) and use it graphically. That also works.
But just because it works, doesn’t mean you should do it. It defies the entire purpose of creating different editions for server and desktop.
You have to put extra effort in converting a server to desktop and vice versa. Why take that pain?
If your purpose of using Ubuntu is clear, download and install the appropriate Ubuntu edition.
*I hope this makes things around Ubuntu desktop and server editions a bit more clear now. If you have questions or suggestions, please utilize the comment section.* |
14,148 | 2021 总结:值得尝试的 9 个开源替代品 | https://opensource.com/article/21/12/open-source-alternatives | 2022-01-05T10:21:23 | [
"替代品"
] | https://linux.cn/article-14148-1.html |
>
> 无论你在寻找什么工具,都有大量的开源软件的替代品供你选择。
>
>
>

2021 年又是一个主要在网上度过的年份,但这对开源世界来说并不新鲜。在任何地方工作的能力是我们的 DNA,在大流行之前,远程工作就已经进入了主流。
然而,今年在屏幕前的所有时间使我们的社区考虑开源的替代方案。无论你需要什么样的工具,许多流行的供应商都不是你唯一的选择。
如果你对 Zoom 感到厌倦,想要一个非 Salesforce 家的 CRM,或者想要一个非谷歌的分析工具,请继续阅读。我们有推荐了 2021 年最受读者喜爱的开源替代品的文章。
### 我最喜欢的开源项目管理工具
如果你在管理一个项目,可能看起来你有无穷无尽的工具可以选择。随着甘特图跨入敏捷领域,现在更常见的是看到它们被部署在大型项目的服务中。
如果你认为微软 Project 是你唯一的选择,别担心,Frank Bergmann 分享了几个 [开源替代品](https://opensource.com/article/21/3/open-source-project-management),供单个用户计划和跟踪大型单一项目。Redmine、ProjectLibre 和 TaskJuggler 都是这个列表中涉及的开源替代品。
### 微软 Exchange 的一个开源替代品
微软 Exchange 在群件中的主导地位可能即将结束。2020年,一位奥地利的开源开发者建立了 grommunio,作为 Exchange 的开源替代品。
在 Markus Feilner 的 [对 grommunio 的评论](https://opensource.com/article/21/9/open-source-groupware-grommunio)中,他分享了该工具提供的大量功能清单。集成的原生 exchange 协议使 Outlook 和智能手机能够像连接到 Exchange 一样连接到 grommunio。在这个强大的列表中,日历管理、视频会议和会议功能是由 [Jitsi](https://opensource.com/article/20/5/open-source-video-conferencing) 提供的。
### 用这个开源的财务工具在 Linux 上管理你的预算
当涉及到资金管理时,Linux 可能不是你想到的第一个工具平台。然而,事实证明,有许多建立在 Linux 上的应用可以帮助保持你的个人财务状况良好。
像 HomeBank 和 KMyMoney 这样的产品可以让你从银行导入数据,并根据你的预算审查支出。[本文作者](https://opensource.com/article/21/2/linux-skrooge) Seth Kenlon 更喜欢 Skrooge,并分享了他如何使用它。如果你正在寻找一个追踪支出的开源工具,这可能是一个。
### 5 个替代 Zoom 的开源工具
在大流行的近两年时间里,可以说我们中的大多数人都被 Zoom 困住了。对我们中的许多人来说,大多数工作和社会活动都完全在网上进行。但正如 Seth Kenlon 敏锐地指出的那样,开源最大的好处之一就是可以远程工作。因此,如果你对 Zoom 感到厌烦,[开源爱好者有几个选择](https://opensource.com/article/21/9/alternatives-zoom)。
像 Jitsi 这样受欢迎的名字也在这个名单上,还有一些令人惊讶的名字。例如,你知道 Signal 在其功能列表中增加了小组视频通话吗?P2p.chart、BigBlueButton 和 Wire 也进入了这个从小型团体电话到公司会议的各种视频需求的工具列表。
### 用 Doodle 的开源替代品来安排约会
像 Doodle 这样的约会安排应用省去了很多挑选互不冲突日期的麻烦。对于像 Kevin Sonney 这样主持播客的人来说,这些工具可以帮助他和每个客人轻松找到适合他们双方的日期。
虽然 Doodle 赢得了大众投票,但 Sonney [在这篇文章](https://opensource.com/article/21/1/open-source-scheduler) 分享了他使用 Easy!Appointments 的经验。它旨在帮助服务机构,Easy!Appointments 有一个 WordPress 插件,让用户把请求表格放在页面或帖子上。该应用还与谷歌日历同步,并有添加与其他后端同步的支持。
### 为什么选择 Plausible 作为谷歌分析的开源替代品
如果你需要使用网络分析,似乎谷歌分析是你唯一的选择。Uku Taht 和 Marko Saric 在建立 [Plausible.io](http://Plausible.io) 时,就着手改变这种情况,以提供一个开源的分析工具,可以管理大量的数据而不会出现性能下降。发布两年后,Plausible 每月可以抓取超过 8000 万条记录。
在这篇文章中,Ben Rometsch 分享了 [Plausible 的历程](https://opensource.com/article/21/2/plausible),从带有敏感代码的软件到 AGPL 下的开源选择。如果你想知道这个小小的分析引擎是如何在 GitHub 上从 500 颗星发展到 4300 颗星的,那么这篇文章很值得一读。
### 试试 Chatwoot,一个开源的客户关系平台
想找一个涵盖客服管理/支持的开源端到端平台?如果你想要 Salesforce 或 Zendesk 以外的东西,用 Ruby 和 Vue.js 构建的 Chatwoot 可能是一个可行的选择。
Nitish Tiwari 在 [这篇文章](https://opensource.com/article/21/6/chatwoot) 中分享了 Chatwoot 的架构、安装和主要功能。它可以在几个平台上使用,包括 Linux 和 Docker。这篇文章分享了使用 Docker 的安装过程,以及渠道和集成等功能。
### 开始使用开源的客户数据平台
如果你正在管理大规模数据,你很可能使用或正在寻找一个数据仓库。那些寻找开源仓库的人可以考虑 RudderStack,它在数据仓库上建立客户数据湖之前收集和路由事件流数据。
Amey Varangaonkar [分享了如何获得 RudderStack 的工作空间令牌](https://opensource.com/article/21/3/rudderstack-customer-data-platform),然后在 Docker 或 Kubernetes 上安装和部署。该工具的 rudder-server 仓库和目标集成是开源的,让用户看到该工具如何完成复杂的任务。在一个充满风险的黑盒子时代,拥有这种透明度是一个很大的好处。
### 试试 Dolibarr,一个开源的客户关系管理平台
你没有看错:这是另一篇关于客户关系管理的开源替代品的文章。[Pradeep Vijayakumar 的这篇文章](https://opensource.com/article/21/7/open-source-dolibarr) 涵盖了 Dolibarr,它在拥有 CRM 功能的同时还拥有强大的 ERP 功能。
Vijayakumar 就在做 Dolibarr 开发工作,所以他对安装它的 CRM、添加客户数据和设置活动的知识是非常丰富的。截图显示了每个过程的细节,并提供了优化工具的有用提示。
---
via: <https://opensource.com/article/21/12/open-source-alternatives>
作者:[Lauren Maffeo](https://opensource.com/users/lmaffeo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 2021 was another year spent largely online, but that's nothing new for the open source world. The ability to work from anywhere is in our DNA, preceding the pandemic that ushered remote work into the mainstream.
Still, all that time in front of screens this year made our community consider open source alternatives. Regardless of the tool type you need, many of the most popular vendors are not your only option.
If you're burned out on Zoom, want a CRM that's not Salesforce, or would like an analytics tool that Google doesn't own, read on. We've got the most popular articles on open source alternatives that readers loved in 2021.
## My favorite open source project management tools
If you're managing a project, it might seem like you have an endless amount of tools to choose from. With Gantt charts crossing into Agile territory, it's now more common to see them deployed in service of large projects.
If you think Microsoft Project is your only option, fear not. Frank Bergmann shares several [open source alternatives](https://opensource.com/article/21/3/open-source-project-management) for single users to plan and track large, single projects. Redmine, ProjectLibre, and TaskJuggler are among the open source alternatives covered in this list.
## An open source alternative to Microsoft Exchange
Microsoft Exchange's dominance in groupware might be coming to an end. In 2020, an Austrian open source developer built grommunio to serve as an open source alternative to Exchange.
In his [review of grommunio](https://opensource.com/article/21/9/open-source-groupware-grommunio), Markus Feilner shares the vast list of features that the tool offers. Integrated, native exchange protocols let Outlook and smartphones connect to grommunio the same way they'd connect to Exchange. Calendar management, video conferencing, and meeting capabilities courtesy of [Jitsi](https://opensource.com/article/20/5/open-source-video-conferencing) are among this robust list.
## Manage your budget on Linux with this open source finance tool
When it comes to money management, Linux likely isn't the first tool platform you think of. However, it turns out that there are many apps built on Linux to help keep your personal finances on track.
Options like HomeBank and KMyMoney let you import data from your bank and review expenses against your budget. Seth Kenlon, [this article's author](https://opensource.com/article/21/2/linux-skrooge), prefers Skrooge and shares how he uses it. If you're looking for an open source tool to track expenditures, this could be the one.
## 5 open source alternatives to Zoom
Almost two years into the pandemic, it's safe to say most of us are all Zoom-ed out. For many of us, most work and social events are exclusively online. But as Seth Kenlon astutely points out, one of open source's biggest benefits is the ability to work remotely. Accordingly, [open source enthusiasts have several choices](https://opensource.com/article/21/9/alternatives-zoom) if you're sick of Zoom.
Popular names like Jitsi make this list, along with some surprises. For instance, did you know that Signal added group video calls to its features list? P2p.chart, BigBlueButton, and Wire also make this list of tools based on various video needs, from small group calls to corporate meetings.
## Schedule appointments with an open source alternative to Doodle
Appointment scheduling apps like Doodle save the song and dance of picking mutually available dates. For folks like Kevin Sonney, who hosts a podcast, these tools help him and each guest easily find dates that suit them both.
While Doodle wins the popular vote, Sonney shares his experience with Easy!Appointments [in this article](https://opensource.com/article/21/1/open-source-scheduler). Aimed at helping service organizations, Easy!Appointments has a WordPress plug-in that lets users put request forms on pages or posts. The app also syncs with Google Calendar, and there's talk of adding support to sync with additional backends.
## Why choose Plausible for an open source alternative to Google Analytics
If you need to use web analytics, it might seem like Google Analytics is your only option. Uku Taht and Marko Saric set out to change that when they built Plausible.io to provide an open source analytics tool that could manage large amounts of data without a performance decline. Two years post-release, Plausible can ingest over 80 million records per month.
In this article, Ben Rometsch shares [Plausible's journey](https://opensource.com/article/21/2/plausible) from software with sensitive code to an open source option under AGPL. It's well worth the read if you're curious how this little analytics engine that could grew from 500 to 4300 stars on GitHub.
## Try Chatwoot, an open source customer relationship platform
Looking for an open source end-to-end platform that covers ticket management/support? Built with Ruby and Vue.js, Chatwoot might be a viable choice if you want something other than Salesforce or Zendesk.
Nitish Tiwari shares Chatwoot's architecture, installation, and key features in [this piece](https://opensource.com/article/21/6/chatwoot). It's available on several platforms, including Linux and Docker. This article shares the installation process for Docker, along with features like channels and integrations.
## Get started with an open source customer data platform
If you're managing data at scale, you likely use or are searching for a data warehouse. Those searching for an open source warehouse can consider RudderStack, which collects and routes event stream data before building customer data lakes on data warehouses.
Amey Varangaonkar [shares how to get RudderStack's workspace token](https://opensource.com/article/21/3/rudderstack-customer-data-platform), then install and deploy on Docker or Kubernetes. The tool's rudder-server repository and destination integrations are open source, letting users see how the utility completes complicated tasks. In an era of risky black boxes, having this transparency is a big benefit.
## Try Dolibarr, an open source customer relationship management platform
You're not seeing things: This is another article on open source alternatives to customer relationship management. [This piece](https://opensource.com/article/21/7/open-source-dolibarr) by Pradeep Vijayakumar covers Dolibarr, which has robust ERP features along with its CRM status.
Vijayakumar works directly on Dolibarr, so his knowledge of installing its CRM, adding customer data, and setting up campaigns is unparalleled. Screenshots show each process in detail, with helpful hints to optimize the tool.
## 1 Comment |
14,149 | 想在 Ubuntu 上使用深度桌面?UbuntuDDE Remix 21.10 来了! | https://news.itsfoss.com/ubuntudde-remix-21-10/ | 2022-01-05T11:00:14 | [
"深度"
] | https://linux.cn/article-14149-1.html |
>
> 想在不安装深度操作系统的情况下获得最新的深度桌面体验吗?UbuntuDDE Remix 21.10 终于登场了!
>
>
>

[深度 20.3](https://news.itsfoss.com/deepin-20-3-release/) 已经发布了一段时间,做了一些基本的改进和细微的视觉变化。
但是,如果你想在 Ubuntu 上面获得最新的深度桌面体验?UbuntuDDE Remix 21.10 “Impirish Indri” 终于登场了。
这可能是新年伊始第一周中令人兴奋的发布之一吧?
### UbuntuDDE Remix 21.10:有什么新内容?
该版本的关键亮点是增加了最新的深度桌面。你应该还会发现一个更新的 Linux 内核、Calamares 安装程序、更新的应用程序、新的壁纸,以及其他改进。
下面让我介绍一下这些基本的变化。
#### Ubuntu 21.10 & Linux 内核 5.13

[Linux 内核 5.13](https://news.itsfoss.com/linux-kernel-5-13-release/) 是一个必不可少的升级,它包括了一些硬件改进和安全增强。
具体来说,UbuntuDDE Remix 21.10 采用了 Linux 内核 5.13.0-22。
而且,这是建立在 [Ubuntu 21.10](https://news.itsfoss.com/ubuntu-21-10-release/) 的基础上的。因此,在这里你也可以得到 Ubuntu 21.10 的改进和功能。
#### 最新的深度桌面环境
有了最新的深度桌面,你也可以期待最新的软件包,包括更新的深度商店等等。

新的壁纸应该可以让你使桌面看起来很有美感。

#### 更新的软件包
Firefox 95.0 是默认的网页浏览器。LibreOffice 7.2.3.2 是默认的办公应用程序。
此外,你会发现其他几个与深度操作系统相关的软件包已经更新到最新版本。
#### 其他改进措施
不仅仅限于新增加的内容,你还会发现针对 UbuntuDDE 和上游深度桌面体验的错误修复。
你可以通过 [官方公告博文](https://ubuntudde.com/blog/ubuntudde-remix-21-10-impish-release-note) 了解更多关于该版本的信息。
### 下载 UbuntuDDE Remix 21.10
你可以从其官方网站上抓取 ISO 文件并安装。如果你想了解任何已知的问题,或获得帮助,你可以看看他们的 [论坛或群组](https://ubuntudde.com/support/)。
* [UbuntuDDE Remix 21.10](https://ubuntudde.com)
---
via: <https://news.itsfoss.com/ubuntudde-remix-21-10/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Deepin 20.3](https://news.itsfoss.com/deepin-20-3-release/) has been around for a while now with some essential improvements and subtle visual changes.
But, if you were looking to get your hands on the latest Deepin desktop experience on top of Ubuntu? UbuntuDDE Remix 21.10 “Impirish Indri” has finally arrived.
Probably one of the exciting releases to start the new year week, eh?
## UbuntuDDE Remix 21.10: What’s New?
The key highlight of the release is the addition of the latest Deepin desktop. You should also find a newer Linux Kernel, the Calamares installer, updated applications, new wallpapers, and other improvements.
Let me mention the essential changes below.
### Ubuntu 21.10 & Linux Kernel 5.13
[Linux Kernel 5.13](https://news.itsfoss.com/linux-kernel-5-13-release/) is an essential upgrade that includes several hardware improvements and security enhancements.
UbuntuDDE Remix 21.10 features Linux Kernel 5.13.0-22, to be specific.
And, this is on top of [Ubuntu 21.10](https://news.itsfoss.com/ubuntu-21-10-release/) as its base. So, if you want to access the perks and features of Ubuntu 21.10, you should be able to do that here.
### Latest Deepin Desktop Environment
With the latest Deepin Desktop on board, you can also expect the newest software packages, including an updated DDE Store and more.

The presence of new wallpapers should help you make the desktop look aesthetically pleasing.
### Updated Software Packages
Firefox 95.0 is the default web browser baked in. And, you get LibreOffice 7.2.3.2 as the default office application.
In addition, you will find several other software packages associated with Deepin updated to the latest version available.
### Other Improvements
Not just limited to new additions, but you will also find bug fixes addressing UbuntuDDE and the upstream Deepin Desktop experience.
You can learn more about the release via the [official announcement blog post](https://ubuntudde.com/blog/ubuntudde-remix-21-10-impish-release-note?ref=news.itsfoss.com).
## Download UbuntuDDE Remix 21.10
You can grab the ISO file from its official website and install it. If you are curious to learn more about any known issues or get help with your experience on the distro, you can take a look at their [forum or groups](https://ubuntudde.com/support/?ref=news.itsfoss.com).
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,150 | Pinta 2.0 发布,移植到 GTK 3,改进了 HiDPI 支持 | https://news.itsfoss.com/pinta-2-0-release/ | 2022-01-05T12:24:24 | [
"Pinta"
] | https://linux.cn/article-14150-1.html |
>
> 随着最新版本的发布,Pinta 终于带来了视觉上的更新和改进、移植到了 GTK 3 和 .NET 6。
>
>
>

新的一年的一周,你是否正在期待一些最新的开源应用发布。
你很幸运,Pinta 在新年前就宣布了他们的重大升级版本。
Pinta 是一个轻量级的绘画应用,可以作为一个简单的图像编辑工具。作为 [顶级开源绘画应用](https://itsfoss.com/open-source-paint-apps/) 之一,Pinta 的新版本将其基础转移到 GTK3 和 .NET 6,并带来了一些新的功能和用户界面改进。
它是一个跨平台的开源应用程序,可用于 Linux、Windows 和 MacOS。
让我们来看看 Pinta 2.0 提供了什么。
### 有什么新变化?

#### GTK3 移植
如上所述,Pinta 现在已经被移植到了 GTK3,应该可以支持 GTK3 主题。虽然这可能不会带来巨大的变化,但作为一个 Linux 的原生应用程序,肯定会对体验有所改善。
GTK 对话框和小工具也得到了相应的调整。这包括增加了 GTK 字体选择器,取代了旧的文本工具,并使用了平台原生的文件对话框。
#### 用户界面的改进
在用户界面方面,有许多变化和改进。其中一些包括:
* 使用 HiDPI 显示器的用户或许遇到的问题更少
* 一些工具现在使用旋转按钮而不是组合框
* 可以在状态栏上查看位置、缩放和调色板等信息
* 调色板现在显示最近使用的颜色
* 使用鼠标中键,你可以轻松地缩放和平移画布
* 取消了 “插件” 和 “最近打开” 菜单项
如果你使用 macOS,你可以注意到它使用了全局菜单而不是应用程序菜单,使其看起来更干净。
#### 其他改进措施
这个版本还改进了油漆桶、选择工具和魔杖工具的性能,也修复了大量的错误。
Windows 和 macOS 版本也得到了改进和更新。
你可以参考 [官方发布说明](https://www.pinta-project.com/releases/2-0) 了解更多技术细节。
### 下载 Pinta 2.0
我觉得将 Pinta 移植到 GTK3 的决定会受到用户的欢迎,但由于 [GTK 4.0](https://news.itsfoss.com/gtk-4-release/) 已经崭露头角,是否有点太晚了?让我们拭目以待。
总的来说,这个版本为用户的桌面外观提供了统一性。Pinta 2.0 看起来是一个做了有益改进的可靠版本。
你可以以 Flatpak、Snap、Tarball 等以及其它用于 Linux 的软件包格式下载 Pinta 2.0。
Windows 和 macOS 用户可以使用各自的安装程序,现在它捆绑了所有必要的依赖,如 GTK 和 .NET / Mono。
* [下载 Pinta 2.0](https://www.pinta-project.com/releases/)
---
via: <https://news.itsfoss.com/pinta-2-0-release/>
作者:[Rishabh Moharir](https://news.itsfoss.com/author/rishabh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Were you looking for some latest open-source app releases to start the new year week?
You’re lucky; Pinta announced their major upgrade right before the new year.
Pinta is a lightweight drawing app that serves as a simple image editing tool. One of the [top open-source drawing and painting apps](https://itsfoss.com/open-source-paint-apps/?ref=news.itsfoss.com) out there, Pinta’s new release shifts its base to GTK3 and .NET 6 and brings some new features and UI improvements.
It is a cross-platform open-source application available for Linux, Windows, and macOS.
Let’s take a look at what Pinta 2.0 has to offer.
## What’s New?
### GTK3 Port
As mentioned above, Pinta has now been ported to GTK3 and should support GTK3 themes. Having said this, the look and feel of the app now match that of the desktop using GTK 3. While this may not make a huge difference, it should surely improve the experience as a native app for Linux.
The GTK dialogs and widgets have also been tweaked accordingly. This includes the addition of the GTK font chooser that replaces the old text tool and the use of platform-native file dialogs.
### UI Improvements
There have been numerous changes and improvements to the UI. Some of them include:
- Users working with HiDPI displays can expect fewer issues
- Some tools now use spin-buttons instead of combo boxes
- Info like the position, zoom and color palette can be viewed on the status bar
- The color palette now displays recently used colors
- Using the middle mouse button, you can easily zoom and pan the canvas
- “Add-ins” and the “Open Recent” menu item have been taken away
If you use macOS, you can notice the global menu instead of an application menu, giving it a cleaner look.
### Other Improvements
This release also brings performance improvements for the paint bucket, selection tools, and magic wand tools. Numerous bug fixes have also been addressed.
The Windows and macOS versions have also received improvements and updates.
You can refer to the [official release notes](https://www.pinta-project.com/releases/2-0?ref=news.itsfoss.com) for more technical details.
## Download Pinta 2.0
I feel the decision to port Pinta to GTK3 will be well received by the users but is it too late with [GTK 4.0](https://news.itsfoss.com/gtk-4-release/) already in the wild? Let’s see.
Overall, the release should provide uniformity to the user’s desktop appearance. Pinta 2.0 looks like a solid release with valuable improvements.
You can download Pinta 2.0 as a Flatpak, Snap, Tarball, and more for Linux.
Windows and macOS users can use the respective installers that now bundle all the necessary dependencies like GTK and .NET / Mono.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,152 | 2021 总结:开源软件改变商业的 5 种方式 | https://opensource.com/article/21/12/open-source-software-business | 2022-01-06T10:07:00 | [
"商业"
] | https://linux.cn/article-14152-1.html |
>
> 这组文章展示了企业如何与开源软件连接。
>
>
>

开源软件不仅仅创造了专有软件的替代品。在商业方面,开源已经成为一个“力量的倍增器”来改变组织的经营方式。同时,越来越多的公司开始采用更多的开源方法,甚至在管理团队和流程方面。
在过去的一年里,我们发表了许多优秀的文章,展示了企业如何与开源软件相联系。以下是一些阅读量最大的文章:
### 《开源给你带来竞争优势的 4 种方式》
为了在当今快节奏的世界中取得成功,企业必须对数字解决方案进行明智的投资,使他们能够更快地行动并提高运营的灵活性。这正是越来越多的各种规模和各种行业的组织拥抱开源解决方案的原因。根据麦肯锡的一份报告,开源的采用是表现优异的组织的最大差异化因素。[Jason Blais](https://opensource.com/users/jasonblais) 写了采用开源技术可以帮助组织推动竞争优势和体验更好的业务成果的 [四个原因](https://opensource.com/article/21/4/open-source-competitive-advantage)。
### 《为什么 Crate.io 回归其纯粹的开源根源》
开源技术提供企业级的可扩展性、性能、安全性和可靠性。信任就在那里,而且是当之无愧的。但除了顽固的开源信徒之外,较少被人称道的是日常社区贡献的内部运作,在原子级别建立了这些宏观利益。对于那些提供开源技术的人来说,社区不断的用户驱动的测试和加固将这些技术锻造成强大和成熟的解决方案。Crate.io 的联合创始人 [Bernd Dorn](https://opensource.com/users/bernd-dorn) 写道,该组织从“开放核心” [转变](https://opensource.com/article/21/4/crate-open-source) 为采用 Apache 2.0 许可的纯开源。
### 《为什么非营利组织选择开源软件》
随着科技和数据安全意识的提高,开源软件比以往任何时候都更成为各阶层组织的首选。非营利组织在财务方面尤其脆弱,同时又要处理重要的社会和环境问题。[Michael Korotaev](https://opensource.com/users/michaelk) 以 Nextcloud 和 ONLYOFFICE为 例,写了关于在非营利组织中 [采用开源协作技术](https://opensource.com/article/21/9/nonprofit-open-source) 的文章。
### 《管理开源产品路线图》
客户,以及与他们交谈的销售和营销团队,都喜欢一个路线图。它让他们了解什么是现实的,什么是不现实的。路线图也是一个产品的核心。[Scott McCarty](https://opensource.com/users/fatherlinux) 写了关于 [管理开源产品路线图](https://opensource.com/article/21/9/open-source-product-roadmap) 的文章,以及为什么专有产品的路线图与建立在开源供应链上的产品没有什么不同。产品经理与客户交谈,对他们的需求进行排序,制定路线图,然后找出如何通过建设、购买和合作来提供能力。
### 《将开源产品推向市场》
产品营销和计划中的信息传递的作用对于一个成功的发布至关重要。Scott McCarty 继续他关于开源供应链中的产品管理的系列文章,讨论了 [开源和产品营销的交叉点](https://opensource.com/article/21/10/open-source-product-market)。
---
via: <https://opensource.com/article/21/12/open-source-software-business>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Open source software isn't just about creating alternatives to proprietary software. On the business side, open source has become a "force multiplier" to transform how organizations do business. At the same time, more companies have started to adopt more open source methodologies, even in managing teams and processes.
In the last year, we ran many great articles that show how businesses connect with open source software. Here are some of the most-read articles:
[4 ways open source gives you a competitive edge](https://opensource.com/article/21/4/open-source-competitive-advantage)
To succeed in today's fast-paced world, organizations must make smart investments in digital solutions that enable them to move faster and increase operational agility. This is precisely why more and more organizations of all sizes and across all industries are embracing open source solutions. According to a McKinsey report, open source adoption is the biggest differentiator for top-performing organizations. [Jason Blais](https://opensource.com/users/jasonblais) wrote about four reasons why adopting open source technology can help organizations drive competitive advantage and experience better business outcomes.
[Why Crate.io has returned to its pure open source roots](https://opensource.com/article/21/4/crate-open-source)
Open source technologies provide enterprise-level scalability, performance, security, and reliability. Trust is there, and it's deserved. But what's less celebrated, other than by die-hard open source adherents, are the inner workings of the everyday community contributions building those macro benefits at the atomic level. For those offering open source technologies, the community's constant user-driven testing and hardening forges those technologies into robust and proven solutions. Crate.io co-founder [Bernd Dorn](https://opensource.com/users/bernd-dorn) wrote about shifting the organization away from "open core" to pure open source with the Apache License 2.0.
[Why nonprofit organizations choose open source software](https://opensource.com/article/21/9/nonprofit-open-source)
With tech and data safety awareness rising, open source software is becoming a go-to option for organizations of all classes more than ever. Nonprofit organizations are particularly vulnerable on the financial side while at the same time dealing with vital social and environmental issues. [Michael Korotaev](https://opensource.com/users/michaelk) wrote about adopting open source collaboration technologies in nonprofit organizations, using Nextcloud and ONLYOFFICE as examples.
[Managing the open source product roadmap](https://opensource.com/article/21/9/open-source-product-roadmap)
Customers, as well as the sales and marketing teams who talk to them, love a roadmap. It gives them a sense of what is realistic and what is not. The roadmap is also at the heart of a product. [Scott McCarty](https://opensource.com/users/fatherlinux) wrote about managing the open source product roadmap and why the roadmap of a proprietary product isn't that different from one that's built on an open source supply chain. Product managers talk to customers, rank their needs, lay out a roadmap, and then figure out how to deliver capabilities by building, buying, and partnering.
[Going to market with an open source product](https://opensource.com/article/21/10/open-source-product-market)
The role of product marketing and planned messaging is critical to a successful release. Scott McCarty continues his series of articles on product management in an open source supply chain by discussing the intersection of open source and product marketing.
## Comments are closed. |
14,153 | 英特尔正准备为 Linux 提供 Windows 用户所没有的 “超能力” | https://news.itsfoss.com/intel-linux-kernel/ | 2022-01-06T14:02:43 | [
"固件"
] | https://linux.cn/article-14153-1.html |
>
> 英特尔计划在 Linux 内核 5.17 中引入一个特殊的变化,可以在不重启系统的情况下更新系统固件。
>
>
>

去年发现的几个安全漏洞,使得系统管理员很难在不停机的情况下迅速修补系统。
如果能做出一些改进,在不重启系统的情况下更新一些关键组件以提高安全/性能呢?
英特尔旨在通过其新的 PFRUT(<ruby> 平台固件运行时更新和遥测 <rt> Platform Firmware Runtime Update and Telemetry </rt></ruby>)驱动程序来实现这一目标。
### 英特尔计划在 Linux 内核 5.17 中提供 PFRUT
虽然 Linux 内核 5.16 将在本周晚些时候发布,不过英特尔的目标是将这一新的功能合并到即将发布的 Linux 内核 5.17 稳定版。
但是,它究竟是什么?
有了 PFRUT 驱动,特定组件(或系统固件)可以在系统运行时进行更新,而不需要重新启动。
最初,英特尔倾向于将其称为“无缝更新”解决方案。然而,随着最近被添加到 Linux 电源管理的 linux-next 分支中的 Linux 内核提交,他们可能会继续使用一个厂商中立的名字,即 `pfrut_driver`。
顺便说一句,linux-next 分支代表着这些变化将进入下一个 Linux 内核稳定版(5.17)。
在技术上,这个 [提交](https://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git/commit/?h=linux-next&id=0db89fa243e5edc5de38c88b369e4c3755c5fb74) 对该变化的解释如下:
>
> 用户应该提供 EFI 封包,并通过将该封包写入设备的特殊文件以将其传递给驱动程序。驱动程序在特定的 <ruby> ACPI 平台固件运行时更新 <rt> ACPI Platform Firmware Runtime Update </rt></ruby>设备(INTC1080)的 ACPI \_DSM 方法的帮助下,将封包传输到平台固件,而实际的固件更新是由平台固件中的低级管理模式代码进行的。
>
>
>
就像人们通常期望的那样,这应该可以消除停机时间,可以对解决任何安全和性能改进的固件进行基本更新。而且,系统固件更新可以很容易地直接通过操作系统(这里是 Linux)进行。
正如其中一个 [详细说明其工作原理的 PDF 文件](https://uefi.org/sites/default/files/resources/Intel_MM_OS_Interface_Spec_Rev100.pdf) 中强调的那样,驱动程序的遥测部分是为了 “从 MM 中检索日志信息,以进行监控并找出问题的根本原因”。
请注意,这只有在 Linux 系统和英特尔芯片上才能实现。
考虑到当你需要修补系统固件以抵御安全问题时,等待系统上的任务完成不是一种理想状况,这种能力的增加应该是非常方便的。
### 这是为 Linux 桌面或服务器准备的吗?
该改进主要是为服务器专用硬件量身定做的。
英特尔的官方文件指出,这是为具有高服务水平协议(SLA)的系统准备的,这种 SLA 需要尽量减少重启。
然而,这对拥有企业级系统的特定桌面用户群应该也是有用的。
虽然这可能不是桌面 Linux 发行版必不可少的东西,但它可能是改善用户体验的一个令人兴奋的开始。特别是对于热衷于保持系统固件更新而不严重干扰其工作的用户。
这也应该可以引入更多类型的更新的可能性,当涉及到 BIOS 或 UEFI 时,可以由操作系统而不是主板处理。
这不仅限于为你的桌面配置服务器级别的硬件的 Linux 桌面用户。
虽然目前只限于 Linux 系统,但这也应该很快可以用于 Windows 和其他操作系统。
你对英特尔推出的这一变化有何看法?你认为这是对系统固件更新处理方式的一个重大改进吗?
欢迎在下面的评论中分享你的想法。
---
via: <https://news.itsfoss.com/intel-linux-kernel/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Last year, several security vulnerabilities were discovered, making it difficult for system administrators to patch the systems without downtime quickly.
What if some improvements can be made to update some critical components for security/performance improvements without rebooting a system?
Intel aims to achieve that with its new PFRUT (Platform Firmware Runtime Update and Telemetry) driver.
## Intel Plans to Make PFRUT Available With Linux Kernel 5.17
While Linux Kernel 5.16 is due later this weekend, Intel aims to merge this new addition with the upcoming Linux Kernel 5.17 stable release.
But, what exactly is it?
With PFRUT driver, specific components (or the system firmware) can be updated while the system is running without needing to reboot.
Initially, Intel preferred to call it a “Seamless Update” solution. However, with the recent commit for Linux Kernel added to the Linux power management’s “linux-next” branch, they might be sticking to a vendor-neutral name, **pfrut_driver**.
If you are curious, the “linux-next” branch means that those changes will make their way to the next Linux Kernel 5.17 stable release.
In technical terms, the [commit](https://git.kernel.org/pub/scm/linux/kernel/git/rafael/linux-pm.git/commit/?h=linux-next&id=0db89fa243e5edc5de38c88b369e4c3755c5fb74&ref=news.itsfoss.com) explains the change as follows:
The user is expected to provide the EFI capsule, and pass it to the driver by writing the capsule to a device special file. The capsule is transferred by the driver to the platform firmware with the help of an ACPI _DSM method under the special ACPI Platform Firmware Runtime Update device (INTC1080), and the actual firmware update is carried out by the low-level Management Mode code in the platform firmware
This should eliminate any downtime, as one would typically expect with an essential update to firmware addressing any security and performance improvements. And, system firmware updates can be easily applied directly through the operating system (Linux, here).
The telemetry part of the driver exists to “*retrieve log messages from MM for monitoringand the root cause of issues*,” as highlighted in one of the
[PDFs detailing how this works](https://uefi.org/sites/default/files/resources/Intel_MM_OS_Interface_Spec_Rev100.pdf?ref=news.itsfoss.com).
Note that this is only possible with a Linux system and an Intel chip on board.
The addition of this ability should come in incredibly handy, considering it is not ideal to wait for a task to complete when you need to patch the system firmware to defend against a security issue.
## Is This for Linux Desktop or Server?
Primarily, the improvement is tailored to benefit server-specific hardware.
The official Intel documentation states it is meant for systems with high service level agreements (SLAs) requiring a minimal number of reboots.
However, this should be useful for a specific group of desktop users with enterprise-grade systems.
While this may not be something essential for desktop Linux distros, it could be an exciting start to something that improves the user experience. Specifically for users keen to keep their system firmware updated without severe interruptions to their active work.
This should also introduce the possibility of more types of updates that can be handled by the operating system instead of the motherboard when it comes to BIOS or UEFI.
Not just limited to the support for Linux desktop users, one would need to have server-grade hardware configured for your desktop.
This is limited to Linux systems, but this should also be possible for Windows and other operating systems soon.
*What do you think about this change introduced by Intel? Do you think it is a significant improvement to how system firmware updates are being handled?*
Feel free to share your thoughts in the comments below.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,155 | Linux Mint 20.3 “Una” 发布 | https://news.itsfoss.com/linux-mint-20-3-una-release/ | 2022-01-07T10:59:04 | [
"Mint"
] | https://linux.cn/article-14155-1.html |
>
> Linux Mint 20.3 “Una” 有一些细微的视觉变化,弥补了现代外观,以及新的应用改进。
>
>
>

代号为 “Una” 的 Linux Mint 20.3 终于来了。官方公告应该很快就会跟进,但它现在已经可以下载了!
虽然 [Linux Mint 20.2](https://news.itsfoss.com/linux-mint-20-2-release/) 有一些令人印象深刻的改进,但 Linux Mint 20.3 看起来也是一个不错的版本。
在这里,我会重点指出 Linux Mint 20.3 的关键变化。
### Linux Mint 20.3 的新变化

在这个版本中,Linux Mint 20.3 包含了最新的 Cinnamon 5.2,一些细微的视觉变化,以及其他各种改进。
请注意,在 Xfce 和 MATE 版中的变化是一样的(不包括桌面环境的具体改进)。
#### Cinnamon 5.2 桌面环境
在 Cinnamon 5 中,增加了一些调整和管理桌面环境所消耗资源的功能。
这一次,升级的重点是几个新功能。日历小程序增强了功能,当你点击系统时间/日期图标时,可以直接从系统托盘上显示事件。
如果你使用 GNOME 日历或在线账户(如 Google 日历),这些事件应该是同步的。

除此以外,你还会发现 Nemo 文件管理器的改进和窗口动画的细微变化。
还有一些必要的错误修复和总体上的小改进。
#### 新的背景
新的版本、新的壁纸,总是令人耳目一新。而且,Mint 20.3 也不会让你失望。

你会得到一个精心策划的美妙的壁纸集,你可以选择使用。
#### 视觉主题刷新及深色模式

在 Linux Mint 20.3 中,主题已经进行了改造,对重点颜色轻微进行了重新处理(使其更时尚一些),并从一些小部件中删除了它。
与窗口的圆角一起,这构成了一个更干净和现代的外观。
总的来说,包括新的图标,Linux Mint 20.3 带来了一个新的主题包。
如果你想要同样的外观,同时保持其他的优点,你可以简单地从仓库安装传统主题包并应用它。

一旦你安装了传统主题包,就可以在选择中找到它了。

不仅如此,你可以注意到,我更喜欢用深色模式的截图来写文章,因为 Linux Mint 20.3 终于把更多的注意力放在深色模式上!
一些默认的应用程序,如 Hypnotix、Gnome 终端、Celluloid,都是在启用深色模式的情况下启动的。如果你愿意,你可以永久地禁用它们。
### 新的 Thingy 应用程序
当 Clem(Linux Mint 的首席开发者)暗示会有一个新的惊喜应用时,我们 [很快就在 Linux Mint 20.3 里发现了它](https://news.itsfoss.com/linux-mint-20-3-release-thingy/)。
在稳定版更新之前,测试版就已经确认了它。

新的 Thingy 应用程序也被称为 “Library”,它实际上是 Linux Mint 默认的文档管理器。你可以下载电子书和其他 PDF 文件,Library 应用应该会自动从下载目录中检测到它。
#### 应用程序的改进

一些默认的应用程序,如 Hypnotix IPTV 播放器和便签现在可以分别让你搜索频道或便签。
### 其他改进
其他一些改进有助于提高性能,更好地节省电力,以及更多。
考虑到它是基于 Ubuntu 20.04.3 的,带有 Linux 内核 5.4 LTS。

你可以在官方公告帖子中找到更多关于这些变化的信息。
### 下载 Linux Mint 20.3
你可以从官方主页上下载 ISO。他们还没有更新下载页面,但你可以从他们的 [Torrent 下载页面](https://linuxmint.com/torrents/) 找到最新的 ISO。
如果你想要直接的下载链接,你可以看一下 [全球镜像](https://mirrors.edge.kernel.org/linuxmint/stable/20.3/) 来获得所有的 Linux Mint 版本。
* [Linux Mint 20.3](https://linuxmint.com/download.php)
---
via: <https://news.itsfoss.com/linux-mint-20-3-una-release/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux Mint 20.3, codenamed “Una” has finally arrived. The official announcement should follow up soon, but it’s now available for download!
While [Linux Mint 20.2](https://news.itsfoss.com/linux-mint-20-2-release/) included some impressive improvements, Linux Mint 20.3 looks like an exciting release as well.
Here, I highlight the key changes in Linux Mint 20.3.
## Linux Mint 20.3: What’s New?

With this release, Linux Mint 20.3 packs in the latest Cinnamon 5.2, some minor visual changes, and various other improvements.
Note that the changes remain the same for Xfce and MATE editions (excluding the desktop environment-specific improvements).
We also had a video to emphasize the changes; check it out here:
### Cinnamon 5.2 Desktop Environment
With Cinnamon 5, there were a few additions to tweak and manage the resources consumed by the desktop environment.
This time, the upgrade focuses on a couple of new features. The calendar applet is more functional and can display events right from the system tray when you click on the system time/date icon.
The events should sync if you use GNOME calendar or an online account (like Google Calendar).
In addition to this, you will also find improvements to the Nemo file manager and subtle changes to window animations.
There are also some necessary bug fixes and minor improvements overall.
### New Backgrounds
It is always refreshing to find new wallpapers for the latest release. And, Mint 20.3 will not disappoint you.
You get a fantastic curated collection of wallpapers that you can choose to use.
### Visual Theme Refresh & Dark Mode Improvements
With Linux Mint 20.3, the theme has been revamped with a slight re-touch to the accent color (making it pop) and removing it from a few widgets.
This, along with rounded corners for windows, makes up for a cleaner and modern look.
Overall, including the new icons, Linux Mint 20.3 packs in a new theme package.
If you want the same look while keeping other benefits intact, you can simply install the legacy theme package from the repository and apply it.
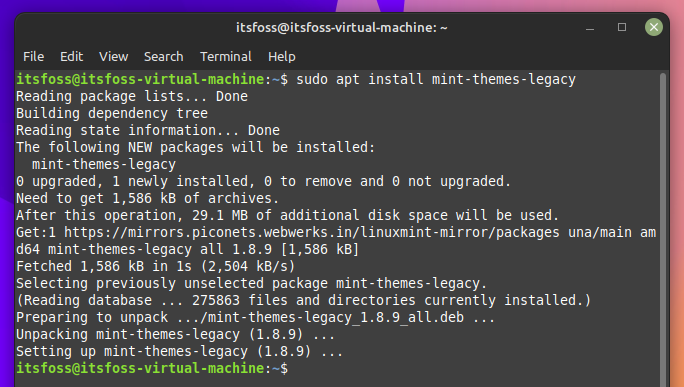
Once you install the legacy package, you should find it available for selection:
Not just limited to that, as you can notice, I preferred dark-mode screenshots for the article because Linux Mint 20.3 puts more focus on dark mode, finally!
Some of the default apps like Hypnotix, Gnome terminal, Celluloid launch with the dark-mode enabled. You can permanently disable them if you prefer.
## New “Thingy” App
When Clem (Linux Mint’s Lead Developer) hinted at a new surprise app, we [quickly discovered what’s coming to Linux Mint 20.3](https://news.itsfoss.com/linux-mint-20-3-release-thingy/).
And, the beta release confirmed it before the stable update.

The new “Thingy” app is also known as “**Library**” which is essentially a document manager for Linux Mint by default. You can download ebooks and other PDF files, and the Library app should automatically detect it from the Downloads directory.
### App Improvements
Some of the default applications like Hypnotix IPTV player, and sticky notes now have the ability to let you search for a channel or a note, respectively.
## Other Improvements
Several other improvements contribute to better performance, better power saving, and more.
Considering it is based on Ubuntu 20.04.3, it features Linux Kernel 5.4 LTS.
You can find more information about the changes in the official announcement post.
## Download Linux Mint 20.3
You can download the ISO from the official homepage. They haven’t updated the download page, but you can find the latest ISOs from their [torrents download page](https://linuxmint.com/torrents/?ref=news.itsfoss.com).
If you want direct download links, you can look at the [global mirror](https://mirrors.edge.kernel.org/linuxmint/stable/20.3/?ref=news.itsfoss.com) to get all the Linux Mint editions.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,156 | 2021 总结:经营小型企业的开源工具 | https://opensource.com/article/21/12/open-source-business-tools | 2022-01-07T12:23:46 | [
"商业",
"开源"
] | https://linux.cn/article-14156-1.html |
>
> 这些文章显示了开源作为工具、平台或集成点在商业中的力量。
>
>
>

今年,我们刊登了几篇关注商业中的开源的好文章。这些文章展示了开源作为工具、平台或集成点在商业中的力量。让我们回顾一下 2021 年的一些顶级开源商业故事。
### 《我最喜欢的开源项目管理工具》
如果你在办公环境中管理过项目,你很可能使用微软 Project 来跟踪任务和分配。然而,开源社区已经创造了许多跟踪项目的选项。对于你的 [项目管理需求](https://opensource.com/article/21/3/open-source-project-management),[Frank Bergmann](http://fraber) 写了关于使用 Redmine、project-open、ProjectLibre、GanttProject、TaskJuggler 和 ProjeQtOr。
### 《使用 Apache Superset 进行开源商业智能报告》
通过商业智能,你可以通过对数据进行分类、安排结果和显示上下文信息来更好地了解你的信息。对于任何想要做出“数据驱动”决策的组织来说,商业智能(BI)是一项关键技术。[Maxime Beauchemin](https://opensource.com/users/mistercrunch) 的文章讨论了 [Apache Superset](https://opensource.com/article/21/4/business-intelligence-open-source),以及它如何成熟地成为一个领先的开源 BI 解决方案。
### 《6 个用于餐馆和零售商的 WordPress 插件》
这场大流行病可能永久性地改变了许多人喜欢做生意的方式。餐馆和其他当地的零售机构不能再像以前那样依赖上门交易了。网上订购食品和其他物品已经成为一种常态和期望。当大流行结束后,消费者不太可能背弃电子商务的便利。[Don Watkins](https://opensource.com/users/don-watkins) 写了 [六个开源插件](https://opensource.com/article/21/3/wordpress-plugins-retail),帮助你创建一个 WordPress 网站,满足你的客户对网上购物、路边取货和送货的偏好。它还可以建立你的品牌和你的客户群。
### 《试试 Chatwoot,一个开源的客户关系平台》
在任何有面向客户的业务中,保持与客户的互动是至关重要的。我们最后一次接触这个客户是什么时候,或者他们最后一次接触我们是什么时候?我们的组织中谁做了回应?什么服务水平协议制约着这种关系?这些和其他问题最好在客户关系管理系统(CRM)中进行管理。[Nitish Tiwari](https://opensource.com/users/tiwarinitish86) 介绍了 [Chatwoot](https://opensource.com/article/21/6/chatwoot),一个用 Ruby 和 Vue.js 构建的开源客户关系平台。Chatwoot 是从零开始写的,目的是让客户关系团队建立端到端的票据管理和支持平台。本文将介绍 Chatwoot 的架构、安装和主要功能。
### 《试试 Dolibarr,一个开源的客户关系管理平台》
无论你是经营零售店、餐厅、酒吧、超市、健身房还是其他业务,你都需要一个可靠的方式来与你的客户保持联系。毕竟,他们是客户,因为他们喜欢你做的事情,如果他们与你分享了他们的联系信息,他们想听到更多关于你所提供的东西。[Pradeep Vijayakumar](https://opensource.com/users/deepschennai) 介绍了 [Dolibarr](https://opensource.com/article/21/7/open-source-dolibarr) 项目,一个开源的企业资源规划(ERP)和客户关系管理(CRM)软件。Dolibarr 提供了一整套 ERP 功能,包括销售点(POS)、发票、存货和库存管理、销售订单、采购订单和人力资源管理。
### 《微软 Exchange 的一个开源替代品》
多年来,微软 Exchange 作为群件环境的必然选择。然而,在 2020 年末,一个奥地利的开源软件开发商推出了 [grommunio](https://opensource.com/article/21/9/open-source-groupware-grommunio),它是一个群件服务器和客户端,其外观和感觉为 Exchange 和 Outlook 用户所熟悉。[Markus Feilner](https://opensource.com/users/mfeilner) 写了关于 grommunio 如何在企业中取代 Exchange,成为群件的一个强大而功能齐全的选择。
### 《用这个开源工具简化发票的指南》
许多 IT 项目在开发过程中会延迟、超出预算,并出现巨大的变化。这些问题使开具发票成为 IT 领域最费力的活动之一。Frank Bergmann 写了一篇关于开源项目如何 [简化开票过程](https://opensource.com/article/21/7/open-source-invoicing-po) 的文章。如果你决定成为自雇人士或成立一个创业公司,Frank 的文章也可以作为处理财务工作的指南。
### 开源是好生意
开源软件不仅仅是为开发者服务的。企业也可以利用开源软件的力量。事实上,开源是许多商业领域的一个主要驱动力。你今天使用的工具可能本身就是开源软件,或者使用开源作为堆栈的一部分。
---
via: <https://opensource.com/article/21/12/open-source-business-tools>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This year, Opensource.com ran several great articles focusing on open source in business. These articles show the power of open source in business as tools, platforms, or integration points. Let's review some of the top open source business stories from 2021:
[My favorite open source project management tools](https://opensource.com/article/21/3/open-source-project-management)
If you've managed projects in an office environment, the odds are you've probably used Microsoft Project to track tasks and assignments. However, the open source community has created many options for tracking projects. For your project management needs, [Frank Bergmann](http://fraber) wrote about using Redmine, ]project-open[, ProjectLibre, GanttProject, TaskJuggler, and ProjeQtOr.
[Use Apache Superset for open source business intelligence reporting](https://opensource.com/article/21/4/business-intelligence-open-source)
With business intelligence, you can get a better view of your information by sorting data, arranging results, and displaying contextual information. Business Intelligence (BI) is a key technology for any organization that wants to make "data-driven" decisions. [Maxime Beauchemin](https://opensource.com/users/mistercrunch) article discusses Apache Superset and how it has matured into a leading open source BI solution.
[6 WordPress plugins for restaurants and retailers](https://opensource.com/article/21/3/wordpress-plugins-retail)
The pandemic changed how many people prefer to do business—probably permanently. Restaurants and other local retail establishments can no longer rely on walk-in trade, as they once had. Online ordering of food and other items has become the norm and the expectation. It is unlikely consumers will turn their backs on the convenience of e-commerce once the pandemic is over. [Don Watkins](https://opensource.com/users/don-watkins) wrote about six open source plugins to help you create a WordPress site that meets your customers' preferences for online shopping, curbside pickup, and delivery. It also builds your brand and your customer base.
[Try Chatwoot, an open source customer relationship platform](https://opensource.com/article/21/6/chatwoot)
In any business with a customer-facing component, it's critical to keep on top of customer interaction. When did we last contact this customer, or when did they last contact us? Who responded from our organization? What service level agreements govern the relationship? These and other questions are best managed in a customer relationship management system (CRM). [Nitish Tiwari](https://opensource.com/users/tiwarinitish86) wrote about Chatwoot, an open source customer relationship platform built with Ruby and Vue.js. Chatwoot was written from scratch to allow customer-relations teams to build end-to-end ticket management and support platforms. This article looks at Chatwoot's architecture, installation, and key features.
[Try Dolibarr, an open source customer relationship management platform](https://opensource.com/article/21/7/open-source-dolibarr)
Whether you run a retail store, restaurant, pub, supermarket, gym, or any other business, you need a reliable way to keep in touch with your customers. After all, they're customers because they like what you do, and if they've shared their contact information with you, they want to hear more about what you have to offer. [Pradeep Vijayakumar](https://opensource.com/users/deepschennai) wrote about the Dolibarr project, an open source enterprise resource planning (ERP) and customer relationship management (CRM) software. Dolibarr provides a whole range of ERP features, including point-of-sale (POS), invoicing, stock and inventory management, sales orders, purchase orders, and human resources management.
[An open source alternative to Microsoft Exchange](https://opensource.com/article/21/9/open-source-groupware-grommunio)
Microsoft Exchange has for many years been nearly unavoidable as a platform for groupware environments. Late in 2020, however, an Austrian open source software developer introduced grommunio, a groupware server and client with a look and feel familiar to Exchange and Outlook users. [Markus Feilner](https://opensource.com/users/mfeilner) wrote about how grommunio can replace Exchange in the enterprise as a robust and fully functional choice for groupware.
[A guide to simplifying invoicing with this open source tool](https://opensource.com/article/21/7/open-source-invoicing-po)
Many IT projects are late, over budget, and subject to dramatic changes during development. These issues make invoicing one of the most taxing activities in IT. Frank Bergmann wrote about how ]project-open[ simplifies the process of invoicing. Frank's article can also serve as a guide to handling financial tasks if you decide to become self-employed or set up a startup.
## Open source is good business
Open source software isn't just for developers. Businesses can leverage the power of open source software, as well. In fact, open source is a major driver in many business areas. The tool you're using today might itself be open source software or using open source as part of the stack.
## Comments are closed. |
14,159 | 使用 OBS 搭建视频流媒体服务器 | https://opensource.com/article/19/1/basic-live-video-streaming-server | 2022-01-08T10:29:44 | [
"流媒体",
"OBS"
] | https://linux.cn/article-14159-1.html |
>
> 在 Linux 或 BSD 操作系统上设置基本的实时流媒体服务器。
>
>
>

实时视频流越来越流行。亚马逊的 Twitch 和谷歌的 YouTube 等平台拥有数百万用户,这些用户消磨了无数小时的来观看直播和录制视频。这些视频服务通常可以免费使用,但需要你拥有一个帐户,并且一般会将你的视频内容隐藏在广告中。有些人不希望他们的视频提供给大众观看,或者想更多地控制自己的视频内容。幸运的是,借助强大的开源软件,任何人都可以设置直播服务器。
### 入门
在本教程中,我将说明如何使用 Linux 或 BSD 操作系统设置基本的实时流媒体服务器。
搭建实时流媒体服务器不可避免地提到系统需求问题。这些需求多种多样,因为实时流媒体涉及许多因素,例如:
* **流媒体质量:** 你想以高清流媒体播放还是标清视频就可以满足你的需求?
* **收视率:** 你的视频预计有多少观众?
* **存储:** 你是否打算保留已保存的视频流副本?
* **访问:** 你的视频流是私有的还是向全世界开放的?
在硬件要求方面没有固定规则,因此我建议你进行测试,以便找到最适合你需求的配置。本项目中,我将服务器安装在配有 4GB 内存、20GB 硬盘空间和单个 Intel i7 处理器内核的虚拟机上。
本项目使用<ruby> 实时消息传递协议 <rt> Real-Time Messaging Protocol </rt></ruby>(RTMP)来处理音频和视频流。当然还有其他协议可用,但我选择 RTMP 是因为它具有广泛的支持。鉴于像 WebRTC 这样的开放标准变得更加兼容,我比较推荐这条路线。
同样重要的是,要明白“实时”并不总是意味着即时。视频流必须经过编码、传输、缓冲和显示,这通常会增大延迟。延迟可以被缩短或延长,具体取决于你创建的流类型及其属性。
### 设置 Linux 服务器
你可以使用许多不同的 Linux 发行版,但我更喜欢 Ubuntu,因此我下载了 [Ubuntu 服务器版](https://www.ubuntu.com/download/server) 作为我的操作系统。如果你希望你的服务器具有图形用户界面(GUI),请随意使用 [Ubuntu 桌面版](https://www.ubuntu.com/download/desktop) 或其多种风味版本之一。然后,我在我的计算机或虚拟机上启动了 Ubuntu 安装程序,并选择了最适合我的环境的设置。以下是我采取的步骤。
注意:因为这是一个服务器,你可能需要设置静态网络。

安装程序完成并重新启动系统后,你会看到一个可爱的新 Ubuntu 系统。 与任何新安装的操作系统一样,安装任何可用的更新:
```
sudo apt update
sudo apt upgrade
```
这个流媒体服务器将使用非常强大通用的 Nginx 网络服务器,所以你需要安装它:
```
sudo apt install nginx
```
然后你需要获取 RTMP 模块,以便 Nginx 可以处理你的媒体流:
```
sudo add-apt-repository universe
sudo apt install libnginx-mod-rtmp
```
修改你的网页服务器配置,使其能够接受和传送你的媒体流。
```
sudo nano /etc/nginx/nginx.conf
```
滚动到配置文件的底部并添加以下代码:
```
rtmp {
server {
listen 1935;
chunk_size 4096;
application live {
live on;
record off;
}
}
}
```

保存配置。我是使用 [Nano](https://www.nano-editor.org/) 来编辑配置文件的异端。在 Nano 中,你可以通过快捷键 `Ctrl+X`、`Y` 并按下回车来保存你的配置。
这么一个非常小的配置就可以创建一个可工作的流服务器。稍后你将添加更多内容到此配置中,但这是一个很好的起点。
在开始第一个流之前,你需要使用新配置重新启动 Nginx:
```
sudo systemctl restart nginx
```
### 设置 BSD 服务器
如果是“小恶魔”(LCTT 译者注:FreeBSD 的标志是一个拿着叉子的红色小恶魔)的信徒,那么建立并运行一个流媒体服务器也非常容易。
前往 [FreeBSD](https://www.freebsd.org/) 网站并下载最新版本。在你的计算机或虚拟机上启动 FreeBSD 安装程序,然后执行初始步骤并选择最适合你环境的设置。由于这是一个服务器,你可能需要设置静态网络。
在安装程序完成并重新启动系统后,你应该就拥有了一个闪亮的新 FreeBSD 系统。像任何其他新安装的系统一样,你可能希望更新所有内容(从这一步开始,请确保你以 root 身份登录):
```
pkg update
pkg upgrade
```
安装 [Nano](https://www.nano-editor.org/) 来编辑配置文件:
```
pkg install nano
```
这个流媒体服务器将使用非常强大通用的 Nginx 网络服务器。 你可以使用 FreeBSD 所拥有的优秀 ports 系统来构建 Nginx。
首先,更新你的 ports 树:
```
portsnap fetch
portsnap extract
```
进入 Nginx ports 目录:
```
cd /usr/ports/www/nginx
```
运行如下命令开始构建 Nginx:
```
make install
```
你将看到一个屏幕,询问你的 Nginx 构建中要包含哪些模块。对于这个项目,你需要添加 RTMP 模块。向下滚动直到选中 RTMP 模块,并按下空格键。然后按回车键继续剩下的构建和安装。
Nginx 安装完成后,就该为它配置流式传输了。
首先,在 `/etc/rc.conf` 中添加一个条目以确保 Nginx 服务器在系统启动时启动:
```
nano /etc/rc.conf
```
将此文本添加到文件中:
```
nginx_enable="YES"
```

接下来,创建一个网站根目录,Nginx 将从中提供其内容。我自己的目录叫 `stream`:
```
cd /usr/local/www/
mkdir stream
chmod -R 755 stream/
```
现在你已经创建了你的流目录,通过编辑配置文件来配置 Nginx:
```
nano /usr/local/etc/nginx/nginx.conf
```
在文件顶部加载你的流媒体模块:
```
load_module /usr/local/libexec/nginx/ngx_stream_module.so;
load_module /usr/local/libexec/nginx/ngx_rtmp_module.so;
```

在 `Server` 部分下,更改 `root` 位置以匹配你之前创建的目录位置:
```
Location / {
root /usr/local/www/stream
}
```

最后,添加你的 RTMP 设置,以便 Nginx 知道如何处理你的媒体流:
```
rtmp {
server {
listen 1935;
chunk_size 4096;
application live {
live on;
record off;
}
}
}
```
保存配置。在 Nano 中,你可以通过快捷键 `Ctrl+X`、`Y`,然后按回车键来执行此操作。
如你所见,这么一个非常小的配置将创建一个工作的流服务器。稍后,你将添加更多内容到此配置中,但这将为你提供一个很好的起点。
但是,在开始第一个流之前,你需要使用新配置重新启动 Nginx:
```
service nginx restart
```
### 设置你的流媒体软件
#### 使用 OBS 进行广播
现在你的服务器已准备好接受你的视频流,是时候设置你的流媒体软件了。本教程使用功能强大的开源的 Open Broadcast Studio(OBS)。
前往 [OBS 网站](https://obsproject.com/),找到适用于你的操作系统的版本并安装它。OBS 启动后,你应该会看到一个首次运行向导,该向导将帮助你使用最适合你的硬件的设置来配置 OBS。

OBS 没有捕获任何内容,因为你没有为其提供源。在本教程中,你只需为流捕获桌面。单击“<ruby> 来源 <rt> Source </rt></ruby>”下的 “+” 按钮,选择“<ruby> 显示捕获 <rt> Screen Capture </rt></ruby>”,然后选择要捕获的桌面。
单击“<ruby> 确定 <rt> OK </rt></ruby>”,你应该会看到 OBS 镜像了你的桌面。
现在可以将你新配置的视频流发送到你的服务器了。在 OBS 中,单击“<ruby> 文件 > 设置 <rt> File > Settings </rt></ruby>”。 单击“<ruby> 流 <rt> Stream </rt></ruby>”部分,并将“<ruby> 串流类型 <rt> Stream Type </rt></ruby>” 设置为“<ruby> 自定义流媒体服务器 <rt> Custom Streaming Server </rt></ruby>”。
在 URL 框中,输入前缀 `rtmp://` 后跟流媒体服务器的 IP 地址,后跟 `/live`。例如,`rtmp://IP-ADDRESS/live`。
接下来,你可能需要输入“<ruby> 串流密钥 <rt> Stream key </rt></ruby>”,这是观看你的流所需的特殊标识符。 在“<ruby> 串流密钥 <rt> Stream key </rt></ruby>”框中输入你想要(并且可以记住)的任何关键词。

单击“<ruby> 应用 <rt> Apply </rt></ruby>”,然后单击“<ruby> 确定 <rt> OK </rt></ruby>”。
现在 OBS 已配置为将你的流发送到你的服务器,你可以开始你的第一个视频流。 单击“<ruby> 开始推流 <rt> Start Streaming </rt></ruby>”。
如果一切正常,你应该会看到按钮更改为“<ruby> 停止推流 <rt> Stop Streaming </rt></ruby>”,并且在 OBS 的底部将出现一些带宽指标。

如果你收到错误消息,请仔细检查 OBS 中的流设置是否有拼写错误。如果一切看起来都不错,则可能是另一个问题阻止了它的工作。
### 观看你的视频流
如果没有人观看,就说明直播视频不是很好,所以请成为你的第一个观众!
有许多支持 RTMP 的开源媒体播放器,但最著名的可能是 [VLC 媒体播放器](https://www.videolan.org/vlc/index.html)。
安装并启动 VLC 后,通过单击“<ruby> 媒体 > 打开网络串流 <rt> Media > Open Network Stream </rt></ruby>” 打开你的流。输入你的流的路径,添加你在 OBS 中设置的串流密钥,然后单击“<ruby> 播放 <rt> Play </rt></ruby>”。 例如,`rtmp://IP-ADDRESS/live/SECRET-KEY`。
你现在应该可以看到自己的实时视频流了!

### 接下来要做什么?
本项目是一个非常简单的设置,可以让你开始工作。 以下是你可能想要使用的另外两个功能。
* **限制访问:** 你可能想要做的下一件事情是限制对你服务器的访问,因为默认设置允许任何人与服务器之间进行流传输。有多种设置方法,例如操作系统防火墙、[.htaccess 文件](https://httpd.apache.org/docs/current/howto/htaccess.html),甚至使用 [STMP 模块中的内置访问控制](https://github.com/arut/nginx-rtmp-module/wiki/Directives#access)。
* **录制流:** 这个简单的 Nginx 配置只会流传输而不会保存你的视频,但这很容易修改。在 Nginx 配置文件中的 RTMP 部分下,设置录制选项和要保存视频的位置。确保你设置的路径存在并且 Nginx 能够写入它。
```
application live {
live on;
record all;
record_path /var/www/html/recordings;
record_unique on;
}
```
实时流媒体的世界在不断发展,如果你对更高级的用途感兴趣,可以在互联网上找到许多其他很棒的资源。祝你好运,直播快乐!
---
via: <https://opensource.com/article/19/1/basic-live-video-streaming-server>
作者:[Aaron J.Prisk](https://opensource.com/users/ricepriskytreat) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Starryi](https://github.com/Starryi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Live video streaming is incredibly popular—and it's still growing. Platforms like Amazon's Twitch and Google's YouTube boast millions of users that stream and consume countless hours of live and recorded media. These services are often free to use but require you to have an account and generally hold your content behind advertisements. Some people don't need their videos to be available to the masses or just want more control over their content. Thankfully, with the power of open source software, anyone can set up a live streaming server.
## Getting started
In this tutorial, I'll explain how to set up a basic live streaming server with a Linux or BSD operating system.
This leads to the inevitable question of system requirements. These can vary, as there are a lot of variables involved with live streaming, such as:
**Stream quality:**Do you want to stream in high definition or will standard definition fit your needs?**Viewership:**How many viewers are you expecting for your videos?**Storage:**Do you plan on keeping saved copies of your video stream?**Access:**Will your stream be private or open to the world?
There are no set rules when it comes to system requirements, so I recommend you experiment and find what works best for your needs. I installed my server on a virtual machine with 4GB RAM, a 20GB hard drive, and a single Intel i7 processor core.
This project uses the Real-Time Messaging Protocol (RTMP) to handle audio and video streaming. There are other protocols available, but I chose RTMP because it has broad support. As open standards like WebRTC become more compatible, I would recommend that route.
It's also very important to know that "live" doesn't always mean instant. A video stream must be encoded, transferred, buffered, and displayed, which often adds delays. The delay can be shortened or lengthened depending on the type of stream you're creating and its attributes.
## Setting up a Linux server
You can use many different distributions of Linux, but I prefer Ubuntu, so I downloaded the [Ubuntu Server](https://www.ubuntu.com/download/server) edition for my operating system. If you prefer your server to have a graphical user interface (GUI), feel free to use [Ubuntu Desktop](https://www.ubuntu.com/download/desktop) or one of its many flavors. Then, I fired up the Ubuntu installer on my computer or virtual machine and chose the settings that best matched my environment. Below are the steps I took.
Note: Because this is a server, you'll probably want to set some static network settings.
After the installer finishes and your system reboots, you'll be greeted with a lovely new Ubuntu system. As with any newly installed operating system, install any updates that are available:
```
sudo apt update
sudo apt upgrade
```
This streaming server will use the very powerful and versatile Nginx web server, so you'll need to install it:
`sudo apt install nginx`
Then you'll need to get the RTMP module so Nginx can handle your media stream:
```
sudo add-apt-repository universe
sudo apt install libnginx-mod-rtmp
```
Adjust your web server's configuration so it can accept and deliver your media stream.
`sudo nano /etc/nginx/nginx.conf`
Scroll to the bottom of the configuration file and add the following code:
```
rtmp {
server {
listen 1935;
chunk_size 4096;
application live {
live on;
record off;
}
}
}
```
Save the config. Because I'm a heretic, I use [Nano](https://www.nano-editor.org/) for editing configuration files. In Nano, you can save your config by pressing **Ctrl+X**, **Y**, and then **Enter.**
This is a very minimal config that will create a working streaming server. You'll add to this config later, but this is a great starting point.
However, before you can begin your first stream, you'll need to restart Nginx with its new configuration:
`sudo systemctl restart nginx`
## Setting up a BSD server
If you're of the "beastie" persuasion, getting a streaming server up and running is also devilishly easy.
Head on over to the [FreeBSD](https://www.freebsd.org/) website and download the latest release. Fire up the FreeBSD installer on your computer or virtual machine and go through the initial steps and choose settings that best match your environment. Since this is a server, you'll likely want to set some static network settings.
After the installer finishes and your system reboots, you should have a shiny new FreeBSD system. Like any other freshly installed system, you'll likely want to get everything updated (from this step forward, make sure you're logged in as root):
```
pkg update
pkg upgrade
```
I install [Nano](https://www.nano-editor.org/) for editing configuration files:
`pkg install nano`
This streaming server will use the very powerful and versatile Nginx web server. You can build Nginx using the excellent *ports* system that FreeBSD boasts.
First, update your ports tree:
```
portsnap fetch
portsnap extract
```
Browse to the Nginx ports directory:
`cd /usr/ports/www/nginx`
And begin building Nginx by running:
`make install`
You'll see a screen asking what modules to include in your Nginx build. For this project, you'll need to add the RTMP module. Scroll down until the RTMP module is selected and press **Space**. Then Press **Enter** to proceed with the rest of the build and installation.
Once Nginx has finished installing, it's time to configure it for streaming purposes.
First, add an entry into **/etc/rc.conf** to ensure the Nginx server starts when your system boots:
`nano /etc/rc.conf`
Add this text to the file:
`nginx_enable="YES"`
Next, create a webroot directory from where Nginx will serve its content. I call mine **stream**:
```
cd /usr/local/www/
mkdir stream
chmod -R 755 stream/
```
Now that you have created your stream directory, configure Nginx by editing its configuration file:
`nano /usr/local/etc/nginx/nginx.conf`
Load your streaming modules at the top of the file:
```
load_module /usr/local/libexec/nginx/ngx_stream_module.so;
load_module /usr/local/libexec/nginx/ngx_rtmp_module.so;
```
Under the **Server **section, change the webroot location to match the one you created earlier:
```
Location / {
root /usr/local/www/stream
}
```
And finally, add your RTMP settings so Nginx will know how to handle your media streams:
```
rtmp {
server {
listen 1935;
chunk_size 4096;
application live {
live on;
record off;
}
}
}
```
Save the config. In Nano, you can do this by pressing **Ctrl+X**, **Y**, and then **Enter.**
As you can see, this is a very minimal config that will create a working streaming server. Later, you'll add to this config, but this will provide you with a great starting point.
However, before you can begin your first stream, you'll need to restart Nginx with its new config:
`service nginx restart`
## Set up your streaming software
### Broadcasting with OBS
Now that your server is ready to accept your video streams, it's time to set up your streaming software. This tutorial uses the powerful and open source Open Broadcast Studio (OBS).
Head over to the [OBS website](https://obsproject.com/) and find the build for your operating system and install it. Once OBS launches, you should see a first-time-run wizard that will help you configure OBS with the settings that best fit your hardware.
OBS isn't capturing anything because you haven't supplied it with a source. For this tutorial, you'll just capture your desktop for the stream. Simply click the **+** button under **Source**, choose **Screen Capture**, and select which desktop you want to capture.
Click OK, and you should see OBS mirroring your desktop.
Now it's time to send your newly configured video stream to your server. In OBS, click **File** > **Settings**. Click on the **Stream** section, and set **Stream Type** to **Custom Streaming Server**.
In the URL box, enter the prefix **rtmp://** followed the IP address of your streaming server followed by **/live**. For example, **rtmp://IP-ADDRESS/live**.
Next, you'll probably want to enter a Stream key—a special identifier required to view your stream. Enter whatever key you want (and can remember) in the **Stream key** box.
Click **Apply** and then **OK**.
Now that OBS is configured to send your stream to your server, you can start your first stream. Click **Start Streaming**.
If everything worked, you should see the button change to **Stop Streaming** and some bandwidth metrics will appear at the bottom of OBS.

If you receive an error, double-check Stream Settings in OBS for misspellings. If everything looks good, there could be another issue preventing it from working.
## Viewing your stream
A live video isn't much good if no one is watching it, so be your first viewer!
There are a multitude of open source media players that support RTMP, but the most well-known is probably [VLC media player](https://www.videolan.org/vlc/index.html).
After you install and launch VLC, open your stream by clicking on **Media** > **Open Network Stream**. Enter the path to your stream, adding the Stream Key you set up in OBS, then click **Play**. For example, **rtmp://IP-ADDRESS/live/SECRET-KEY**.
You should now be viewing your very own live video stream!
## Where to go next?
This is a very simple setup that will get you off the ground. Here are two other features you likely will want to use.
-
**Limit access:**The next step you might want to take is to limit access to your server, as the default setup allows anyone to stream to and from the server. There are a variety of ways to set this up, such as an operating system firewall,[.htaccess file](https://httpd.apache.org/docs/current/howto/htaccess.html), or even using the[built-in access controls in the RTMP module](https://github.com/arut/nginx-rtmp-module/wiki/Directives#access). -
**Record streams:**This simple Nginx configuration will only stream and won't save your videos, but this is easy to add. In the Nginx config, under the RTMP section, set up the recording options and the location where you want to save your videos. Make sure the path you set exists and Nginx is able to write to it.
```
application live {
live on;
record all;
record_path /var/www/html/recordings;
record_unique on;
}
```
The world of live streaming is constantly evolving, and if you're interested in more advanced uses, there are lots of other great resources you can find floating around the internet. Good luck and happy streaming!
## 17 Comments |
14,160 | 用 NumPy 在 Python 中处理数字 | https://opensource.com/article/21/9/python-numpy | 2022-01-08T17:46:44 | [
"NumPy"
] | /article-14160-1.html |
>
> 这篇文章讨论了安装 NumPy,然后创建、读取和排序 NumPy 数组。
>
>
>

NumPy(即 **Num**erical **Py**thon)是一个库,它使得在 Python 中对线性数列和矩阵进行统计和集合操作变得容易。[我在 Python 数据类型的笔记中介绍过](https://notes.ayushsharma.in/2018/09/data-types-in-python),它比 Python 的列表快几个数量级。NumPy 在数据分析和科学计算中使用得相当频繁。
我将介绍安装 NumPy,然后创建、读取和排序 NumPy 数组。NumPy 数组也被称为 ndarray,即 N 维数组的缩写。
### 安装 NumPy
使用 `pip` 安装 NumPy 包非常简单,可以像安装其他软件包一样进行安装:
```
pip install numpy
```
安装了 NumPy 包后,只需将其导入你的 Python 文件中:
```
import numpy as np
```
将 `numpy` 以 `np` 之名导入是一个标准的惯例,但你可以不使用 `np`,而是使用你想要的任何其他别名。
### 为什么使用 NumPy? 因为它比 Python 列表要快好几个数量级
当涉及到处理大量的数值时,NumPy 比普通的 Python 列表快几个数量级。为了看看它到底有多快,我首先测量在普通 Python 列表上进行 `min()` 和 `max()` 操作的时间。
我将首先创建一个具有 999,999,999 项的 Python 列表:
```
>>> my_list = range(1, 1000000000)
>>> len(my_list)
999999999
```
现在我将测量在这个列表中找到最小值的时间:
```
>>> start = time.time()
>>> min(my_list)
1
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
Time elapsed in milliseconds: 27007.00879096985
```
这花了大约 27,007 毫秒,也就是大约 **27 秒**。这是个很长的时间。现在我试着找出寻找最大值的时间:
```
>>> start = time.time()
>>> max(my_list)
999999999
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
Time elapsed in milliseconds: 28111.071348190308
```
这花了大约 28,111 毫秒,也就是大约 **28 秒**。
现在我试试用 NumPy 找到最小值和最大值的时间:
```
>>> my_list = np.arange(1, 1000000000)
>>> len(my_list)
999999999
>>> start = time.time()
>>> my_list.min()
1
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
Time elapsed in milliseconds: 1151.1778831481934
>>>
>>> start = time.time()
>>> my_list.max()
999999999
>>> print('Time elapsed in milliseconds: ' + str((time.time() - start) * 1000))
Time elapsed in milliseconds: 1114.8970127105713
```
找到最小值花了大约 1151 毫秒,找到最大值 1114 毫秒。这大约是 **1 秒**。
正如你所看到的,使用 NumPy 可以将寻找一个大约有 10 亿个值的列表的最小值和最大值的时间 **从大约 28 秒减少到 1 秒**。这就是 NumPy 的强大之处。
### 使用 Python 列表创建 ndarray
有几种方法可以在 NumPy 中创建 ndarray。
你可以通过使用元素列表来创建一个 ndarray:
```
>>> my_ndarray = np.array([1, 2, 3, 4, 5])
>>> print(my_ndarray)
[1 2 3 4 5]
```
有了上面的 ndarray 定义,我将检查几件事。首先,上面定义的变量的类型是 `numpy.ndarray`。这是所有 NumPy ndarray 的类型:
```
>>> type(my_ndarray)
<class 'numpy.ndarray'>
```
这里要注意的另一件事是 “<ruby> 形状 <rt> shape </rt></ruby>”。ndarray 的形状是 ndarray 的每个维度的长度。你可以看到,`my_ndarray` 的形状是 `(5,)`。这意味着 `my_ndarray` 包含一个有 5 个元素的维度(轴)。
```
>>> np.shape(my_ndarray)
(5,)
```
数组中的维数被称为它的 “<ruby> 秩 <rt> rank </rt></ruby>”。所以上面的 ndarray 的秩是 1。
我将定义另一个 ndarray `my_ndarray2` 作为一个多维 ndarray。那么它的形状会是什么呢?请看下面:
```
>>> my_ndarray2 = np.array([(1, 2, 3), (4, 5, 6)])
>>> np.shape(my_ndarray2)
(2, 3)
```
这是一个秩为 2 的 ndarray。另一个要检查的属性是 `dtype`,也就是数据类型。检查我们的 ndarray 的 `dtype` 可以得到以下结果:
```
>>> my_ndarray.dtype
dtype('int64')
```
`int64` 意味着我们的 ndarray 是由 64 位整数组成的。NumPy 不能创建混合类型的 ndarray,必须只包含一种类型的元素。如果你定义了一个包含混合元素类型的 ndarray,NumPy 会自动将所有的元素类型转换为可以包含所有元素的最高元素类型。
例如,创建一个 `int` 和 `float` 的混合序列将创建一个 `float64` 的 ndarray:
```
>>> my_ndarray2 = np.array([1, 2.0, 3])
>>> print(my_ndarray2)
[1. 2. 3.]
>>> my_ndarray2.dtype
dtype('float64')
```
另外,将其中一个元素设置为 `string` 将创建 `dtype` 等于 `<U21` 的字符串 ndarray,意味着我们的 ndarray 包含 unicode 字符串:
```
>>> my_ndarray2 = np.array([1, '2', 3])
>>> print(my_ndarray2)
['1' '2' '3']
>>> my_ndarray2.dtype
dtype('<U21')
```
`size` 属性将显示我们的 ndarray 中存在的元素总数:
```
>>> my_ndarray = np.array([1, 2, 3, 4, 5])
>>> my_ndarray.size
5
```
### 使用 NumPy 方法创建 ndarray
如果你不想直接使用列表来创建 ndarray,还有几种可以用来创建它的 NumPy 方法。
你可以使用 `np.zeros()` 来创建一个填满 0 的 ndarray。它需要一个“形状”作为参数,这是一个包含行数和列数的列表。它还可以接受一个可选的 `dtype` 参数,这是 ndarray 的数据类型:
```
>>> my_ndarray = np.zeros([2,3], dtype=int)
>>> print(my_ndarray)
[[0 0 0]
[0 0 0]]
```
你可以使用 `np. ones()` 来创建一个填满 `1` 的 ndarray:
```
>>> my_ndarray = np.ones([2,3], dtype=int)
>>> print(my_ndarray)
[[1 1 1]
[1 1 1]]
```
你可以使用 `np.full()` 来给 ndarray 填充一个特定的值:
```
>>> my_ndarray = np.full([2,3], 10, dtype=int)
>>> print(my_ndarray)
[[10 10 10]
[10 10 10]]
```
你可以使用 `np.eye()` 来创建一个单位矩阵 / ndarray,这是一个沿主对角线都是 `1` 的正方形矩阵。正方形矩阵是一个行数和列数相同的矩阵:
```
>>> my_ndarray = np.eye(3, dtype=int)
>>> print(my_ndarray)
[[1 0 0]
[0 1 0]
[0 0 1]]
```
你可以使用 `np.diag()` 来创建一个沿对角线有指定数值的矩阵,而在矩阵的其他部分为 `0`:
```
>>> my_ndarray = np.diag([10, 20, 30, 40, 50])
>>> print(my_ndarray)
[[10 0 0 0 0]
[ 0 20 0 0 0]
[ 0 0 30 0 0]
[ 0 0 0 40 0]
[ 0 0 0 0 50]]
```
你可以使用 `np.range()` 来创建一个具有特定数值范围的 ndarray。它是通过指定一个整数的开始和结束(不包括)范围以及一个步长来创建的:
```
>>> my_ndarray = np.arange(1, 20, 3)
>>> print(my_ndarray)
[ 1 4 7 10 13 16 19]
```
### 读取 ndarray
ndarray 的值可以使用索引、分片或布尔索引来读取。
#### 使用索引读取 ndarray 的值
在索引中,你可以使用 ndarray 的元素的整数索引来读取数值,就像你读取 Python 列表一样。就像 Python 列表一样,索引从 `0` 开始。
例如,在定义如下的 ndarray 中:
```
>>> my_ndarray = np.arange(1, 20, 3)
```
第四个值将是 `my_ndarray[3]`,即 `10`。最后一个值是 `my_ndarray[-1]`,即 `19`:
```
>>> my_ndarray = np.arange(1, 20, 3)
>>> print(my_ndarray[0])
1
>>> print(my_ndarray[3])
10
>>> print(my_ndarray[-1])
19
>>> print(my_ndarray[5])
16
>>> print(my_ndarray[6])
19
```
#### 使用分片读取 ndarray
你也可以使用分片来读取 ndarray 的块。分片的工作方式是用冒号(`:`)操作符指定一个开始索引和一个结束索引。然后,Python 将获取该开始和结束索引之间的 ndarray 片断:
```
>>> print(my_ndarray[:])
[ 1 4 7 10 13 16 19]
>>> print(my_ndarray[2:4])
[ 7 10]
>>> print(my_ndarray[5:6])
[16]
>>> print(my_ndarray[6:7])
[19]
>>> print(my_ndarray[:-1])
[ 1 4 7 10 13 16]
>>> print(my_ndarray[-1:])
[19]
```
分片创建了一个 ndarray 的引用(或视图)。这意味着,修改分片中的值也会改变原始 ndarray 的值。
比如说:
```
>>> my_ndarray[-1:] = 100
>>> print(my_ndarray)
[ 1 4 7 10 13 16 100]
```
对于秩超过 1 的 ndarray 的分片,可以使用 `[行开始索引:行结束索引, 列开始索引:列结束索引]` 语法:
```
>>> my_ndarray2 = np.array([(1, 2, 3), (4, 5, 6)])
>>> print(my_ndarray2)
[[1 2 3]
[4 5 6]]
>>> print(my_ndarray2[0:2,1:3])
[[2 3]
[5 6]]
```
#### 使用布尔索引读取 ndarray 的方法
读取 ndarray 的另一种方法是使用布尔索引。在这种方法中,你在方括号内指定一个过滤条件,然后返回符合该条件的 ndarray 的一个部分。
例如,为了获得一个 ndarray 中所有大于 5 的值,你可以指定布尔索引操作 `my_ndarray[my_ndarray > 5]`。这个操作将返回一个包含所有大于 5 的值的 ndarray:
```
>>> my_ndarray = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
>>> my_ndarray2 = my_ndarray[my_ndarray > 5]
>>> print(my_ndarray2)
[ 6 7 8 9 10]
```
例如,为了获得一个 ndarray 中的所有偶数值,你可以使用如下的布尔索引操作:
```
>>> my_ndarray2 = my_ndarray[my_ndarray % 2 == 0]
>>> print(my_ndarray2)
[ 2 4 6 8 10]
```
而要得到所有的奇数值,你可以用这个方法:
```
>>> my_ndarray2 = my_ndarray[my_ndarray % 2 == 1]
>>> print(my_ndarray2)
[1 3 5 7 9]
```
### ndarray 的矢量和标量算术
NumPy 的 ndarray 允许进行矢量和标量算术操作。在矢量算术中,在两个 ndarray 之间进行一个元素的算术操作。在标量算术中,算术运算是在一个 ndarray 和一个常数标量值之间进行的。
如下的两个 ndarray:
```
>>> my_ndarray = np.array([1, 2, 3, 4, 5])
>>> my_ndarray2 = np.array([6, 7, 8, 9, 10])
```
如果你将上述两个 ndarray 相加,就会产生一个两个 ndarray 的元素相加的新的 ndarray。例如,产生的 ndarray 的第一个元素将是原始 ndarray 的第一个元素相加的结果,以此类推:
```
>>> print(my_ndarray2 + my_ndarray)
[ 7 9 11 13 15]
```
这里,`7` 是 `1` 和 `6` 的和,这是我相加的 ndarray 中的前两个元素。同样,`15` 是 `5` 和`10` 之和,是最后一个元素。
请看以下算术运算:
```
>>> print(my_ndarray2 - my_ndarray)
[5 5 5 5 5]
>>>
>>> print(my_ndarray2 * my_ndarray)
[ 6 14 24 36 50]
>>>
>>> print(my_ndarray2 / my_ndarray)
[6. 3.5 2.66666667 2.25 2. ]
```
在 ndarray 中加一个标量值也有类似的效果,标量值被添加到 ndarray 的所有元素中。这被称为“<ruby> 广播 <rt> broadcasting </rt></ruby>”:
```
>>> print(my_ndarray + 10)
[11 12 13 14 15]
>>>
>>> print(my_ndarray - 10)
[-9 -8 -7 -6 -5]
>>>
>>> print(my_ndarray * 10)
[10 20 30 40 50]
>>>
>>> print(my_ndarray / 10)
[0.1 0.2 0.3 0.4 0.5]
```
### ndarray 的排序
有两种方法可以对 ndarray 进行原地或非原地排序。原地排序会对原始 ndarray 进行排序和修改,而非原地排序会返回排序后的 ndarray,但不会修改原始 ndarray。我将尝试这两个例子:
```
>>> my_ndarray = np.array([3, 1, 2, 5, 4])
>>> my_ndarray.sort()
>>> print(my_ndarray)
[1 2 3 4 5]
```
正如你所看到的,`sort()` 方法对 ndarray 进行原地排序,并修改了原数组。
还有一个方法叫 `np.sort()`,它对数组进行非原地排序:
```
>>> my_ndarray = np.array([3, 1, 2, 5, 4])
>>> print(np.sort(my_ndarray))
[1 2 3 4 5]
>>> print(my_ndarray)
[3 1 2 5 4]
```
正如你所看到的,`np.sort()` 方法返回一个已排序的 ndarray,但没有修改它。
### 总结
我已经介绍了很多关于 NumPy 和 ndarray 的内容。我谈到了创建 ndarray,读取它们的不同方法,基本的向量和标量算术,以及排序。NumPy 还有很多东西可以探索,包括像 `union()` 和 `intersection()`这样的集合操作,像 `min()` 和 `max()` 这样的统计操作,等等。
我希望我上面演示的例子是有用的。祝你在探索 NumPy 时愉快。
本文最初发表于 [作者的个人博客](https://notes.ayushsharma.in/2018/10/working-with-numpy-in-python),经授权后改编。
---
via: <https://opensource.com/article/21/9/python-numpy>
作者:[Ayush Sharma](https://opensource.com/users/ayushsharma) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
14,162 | 物联网提供了一种通过联网温度计跟踪 COVID-19 的方法 | https://www.networkworld.com/article/3539058/iot-offers-a-way-to-track-covid-19-via-connected-thermometers.html | 2022-01-09T08:59:00 | [
"温度计"
] | https://linux.cn/article-14162-1.html |
>
> COVID-19 大流行使一家联网温度计制造商 Kinsa 成为全国知名企业,因为它提供了一个可能了解疾病传播的窗口。
>
>
>

一家名为 Kinsa 的公司正在利用 [物联网](https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html) 技术来创建一个连接温度计的网络,收集大量的匿名健康数据,这些数据可以为了解当前和未来的流行病提供帮助。
该公司创始人兼首席执行官 Inder Singh 表示,能够近乎实时地跟踪美国各地的发烧水平,对于广大公众以及医疗保健部门和政府的决策者来说,都可能是一条至关重要的信息。
该系统的联网技术相对简单 —— 温度计通过蓝牙连接到用户手机上的一个应用程序,该应用程序通过互联网将匿名数据报告给 Kinsa 的云。Singh 强调说,该公司只整理到县一级的数据,并声称通过 Kinsa 的数据识别个人几乎是不可能的。
“我们不提供个人身份信息,我们不提供识别数据,”他说。“这款应用程序只会引导你找到你需要的护理和服务。”
有了体温读数和一些关于体温测量者的基本人口统计信息以及他们的其他症状,这款应用程序可以提供基本的指导,比如是否需要去看医生,以及用户所在的区域是否出现了异常的发烧程度。
然而,真正的价值在于 Kinsa 在其 [美国健康天气地图](https://images.idgesg.net/images/article/2020/04/kinsa_influenza_map_2020-04-21_by_kinsa_leaflet_openstreetmap_carto_2400x1600-100839260-large.jpg?auto=webp&quality=85,70) 上分析和细分的聚合数据,这些数据是从该公司生态系统中的 100 多万个温度计收集而来的。根据 Singh 的说法,这个想法是为了给公众提供一种方式,让他们对自己的健康做出更明智的决定。
“这是一个参与性很强的活动,”他说。“每个人都能得到数据,每个人都能做出反应。”
Kinsa 仍然直接向消费者销售温度计,但该公司正计划与地方政府、卫生部门甚至学区进行更密切的合作——辛格说,Kinsa 已经与美国两个州(他拒绝透露其名称)以及包括佛罗里达州的圣奥古斯丁在内的多个市政府合作。
他说:“我们的希望是,我们能够找出如何建立一个可扩展的模型 —— 我们永远不会只靠卖 20 美元的温度计就可以在全球范围内扩展。”。我们的目标是使该产品能够广泛应用,从而成为医疗保健部门有意义的早期预警系统。
---
via: <https://www.networkworld.com/article/3539058/iot-offers-a-way-to-track-covid-19-via-connected-thermometers.html>
作者:[Jon Gold](https://www.networkworld.com/author/Jon-Gold/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[CN-QUAN](https://github.com/CN-QUAN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
14,163 | 在 Linux 上用 Audacity 编辑音频 | https://opensource.com/article/21/12/audacity-linux-creative-app | 2022-01-09T13:02:54 | [
"Audacity",
"音频"
] | https://linux.cn/article-14163-1.html |
>
> Audacity 是开源软件世界中的一个经典的强大工具,可以用于录音、编辑等对声音进行操作。
>
>
>

Audacity 声音编辑器是填补了一个似乎没有人意识到的空白的开源应用程序。它最初是在卡内基梅隆大学开发的,当时很多人还认为电脑只是用来办公和学习的,要进行严肃的多媒体工作需要特殊的 DSP 外围设备。Audacity 认识到,普通计算机用户偶尔也需要编辑音频。在此后的 20 年里,Audacity 团队一直为录音和清理声音打造这个开源的应用程序。
我经常使用 Audacity,作为一个受过培训的编辑,我已经习惯了在我的应用程序中使用重要的、通常是单键的键盘快捷键。通过围绕单个字母建立快捷键,你可以一只手放在鼠标上,一只手放在键盘上,所以选择一个工具或一个重要功能和点击鼠标之间的延迟仅仅是几毫秒而已。在本文中,我将专门给出我在 Audacity 中使用的键盘快捷方式,如果你想优化自己的设置可以参考。
### 在 Linux 上安装 Audacity
在大多数 Linux 发行版上,Audacity 都可以从你的软件包管理器中获得。在 Fedora、Mageia 和类似的发行版上:
```
$ sudo dnf install audacity
```
在 Elementary、Mint 和其他基于 Debian 的发行版上:
```
$ sudo apt install audacity
```
然而,我是以 [Flatpak](https://opensource.com/article/21/11/how-install-flatpak-linux) 方式来使用 Audacity 的。
在 Windows 或 macOS 上,可以从 [Audacity 网站](https://www.audacityteam.org/) 下载一个 Audacity 安装程序。
它最近有一个叫做 [Tenacity](https://github.com/tenacityteam/tenacity) 的复刻版本,是另外的开发者团队准备延续 Audacity 的传统而开发的。在写这篇文章的时候,两者基本上是相同的应用程序,所以这篇文章同样适用于两者。以后是否在功能上有分歧,还有待观察。
安装后,从你的应用程序或活动菜单中启动该应用程序。
### 在 Audacity 中设置输入
首先,你必须设置你的音频 *输入*,以便 Audacity 接收你使用的麦克风或音频接口的信号。你选择什么输入取决于你的设置和你拥有的音频外围设备。USB 麦克风通常被标为 <ruby> 麦克风 <rt> Microphone </rt></ruby>,但带有 1/8" 输入插孔的麦克风可能被标为 <ruby> 线路输入 <rt> Line in </rt></ruby>。你可以选择不同输入:
#### Pulse Audio 音频服务器
Linux 使用<ruby> 高级 Linux 声音架构 <rt> Advanced Linux Sound Architecture </rt></ruby>(ALSA)作为其声音的后端,而 macOS 和 Windows 则使用自己的封闭框架。在 Linux 上,你可以将 Pulse Audio 音频服务器设置为你的输入源,将 Audacity 导向 *一个* 虚拟接口(Pulse),因此你可以从系统设置中选择声音输入。这是我的首选方法,因为它将所有控制集中在一个方便的控制面板上。在一个应用程序中选择一个麦克风,却发现麦克风在其他地方被静音的日子已经一去不复返了。

#### 设备访问
如果你的发行版或操作系统没有使用 Pulse Audio 音频服务器,或者由于某种原因你喜欢直接访问声音设备,你可以从下拉菜单中选择一个设备。这需要了解你的系统是如何列出声音设备的,这有时候并不很好找。台式机可能有几个输入源,有些在机箱的后面,有些在前面的面板上。笔记本电脑通常输入方式较少,但你可能在网络摄像头附近有一个麦克风,如果你使用的是外部麦克风,可能还有一个。
### 用 Audacity 录制音频
选中你的输入后,按“<ruby> 录音 <rt> Record </rt></ruby>”按钮(有红点的按钮)。

如果你是对着麦克风录音,你所要做的就是开始说话。如果你从,比如说,[黑胶唱片机](https://opensource.com/article/18/1/audacity-digitize-records) 录制输入,那么你必须启动它。不管是什么,只要 Audacity 处于录音模式,任何发送到你选择的输入的信号都会被写入 Audacity 并在你的屏幕上呈现为波形。
**我的快捷方式:** 我使用 `R` 键来开始录音。默认情况下,按下空格键停止录音(也可以回放录音)。
### 编辑音频
录音很少完全按计划进行。也许你过早地开始录音,不得不忍受几秒钟的黑胶静音(它就像静音,但更嘈杂),或者你发现你的语气停顿都是 “呃”、“嗯”或其他声调,或者你一开始就录制错误了。Audacity 首先是一个波形编辑器,这意味着你可以在最终的录音中剪掉你不想要的声音,就像你在文字处理器中输入的文字一样容易编辑。
### 编辑过零点的声音
Audacity 的主要编辑工具是“<ruby> 选择工具 <rt> Selection Tool </rt></ruby>”。它是你在文字处理程序中看到的熟悉的“工字形”光标,它的功能在这里也是一样。你可以点击并拖动这个光标,穿过声音的一个区域,然后你可以复制、粘贴、剪切、删除或直接播放这个区域。
**我的快捷键:** 我用 `I` 键来激活“<ruby> 选择工具 <rt> Selection Tool </rt></ruby>”,因为光标看起来像字母 “I”。
在文字处理器中,你可以非常清楚地看到每个字母的结尾和开头。你不可能不小心选择和删除一个字母的一半。然而,在现代应用程序中,声音的 “分辨率”(称为 *采样率*)非常好,所以人眼很难在音频波中找到一个清晰的断点。Audacity 可以调整你的选择,使你选择的区域落在所谓的 <ruby> <a href="https://en.wikipedia.org/wiki/Zero_crossing"> 过零点 </a> <rt> zero crossing </rt></ruby>,这可以避免在你做切割的地方出现微妙但明显的突兀现象。

在你做出选择后,进入“<ruby> 选择 <rt> Select </rt></ruby>”菜单,选择 “<ruby> 在过零点 <rt> At Zero Crossings </rt></ruby>”。
**我的快捷键:** 我使用 `Z` 键来调整选区到过零点,使用 `X` 键来删除一个区域(它使我不必将手一直移到 `Del` 或 `Backspace` )。
### 腾出空间
编辑的好处是,你的最终产品不一定要与你录制的内容一致。我曾经录制过一些讲座,甚至录制过一些读物的剧本,但最终因为某种原因而偏离了方向,或者遗漏了一部分重要的信息,后来在发布前又重新编排或添加了全新的音频。
移动所选的音频与删除类似,但不是删除音频,而是复制和粘贴所选内容,就像你在文字处理器中做的那样 —— 使用标准的键盘快捷键复制或剪切,重新定位你的光标,然后粘贴。不过,为插入的内容腾出空间,需要在音频时间线上留出空位,这样你就可以录制额外的音频来填补你所创造的空白。为此,你可以使用“<ruby> 选择工具 <rt> Selection Tool </rt></ruby>”和“<ruby> 时间偏移工具 <rt> Time Shift Tool </rt></ruby>”。
要在音频中创建一个空隙,将你的“<ruby> 选择工具 <rt> Selection Tool </rt></ruby>”的光标放在你想添加空隙的地方。导航到“<ruby> 编辑 <rt> Edit </rt></ruby>”菜单,选择“<ruby> 剪辑边界 <rt> Clip Boundaries </rt></ruby>”子菜单,然后选择“<ruby> 分割 <rt> Split </rt></ruby>”。这将在你的选择点上分割你的音频。
激活顶部工具栏中的“<ruby> 时间偏移工具 <rt> Time Shift Tool </rt></ruby>”(图标是两个连接的箭头,分别指向左边和右边),点击并拖动分割后的音频的右半部分,创建一个间隙。

**我的快捷方式:** 我用 `K` 来分割,用 `T` 来激活“<ruby> 时间偏移工具 <rt> Time Shift Tool </rt></ruby>”。
### 导出音频
当你对你的音频感到满意时,你可以导出它,这样你就可以与他人分享。Audacity 可以选择它能够导出的格式,并且它能够将其输出到像 [ffmpeg](https://opensource.com/article/21/11/linux-line-commands-reclaim-space-converting-files#audio) 这样的工具,以获得比你可能永远需要的更多格式。
我更喜欢用 FLAC 格式输出音频,这种音频格式有点像 WAV,只是它是无损压缩的。它只占用一小部分空间,而没有任何质量上的损失。要尝试它,去“<ruby> 文件 <rt> File </rt></ruby>”菜单,选择“<ruby> 导出 <rt> Export </rt></ruby>”子菜单,然后选择“<ruby> 导出音频 <rt> Export Audio </rt></ruby>”。有了 FLAC 文件作为你的 [黄金镜像](https://opensource.com/article/19/7/what-golden-image),你可以用 SoundConverter 把你的文件转换成任何数量的传输目标的最佳格式 —— 用于浏览器的 Ogg Vorbis 或 Opus 或 Webm,用于苹果设备的 M4A 文件,也许还有用于传统系统的 MP3。
如果你只是想从 Audacity 快速简单地导出,简单的选择是 Ogg Vorbis。这是一种开源的文件格式,可以在大多数网页浏览器(Firefox、Chromium、Chrome、Android 和 Edge)和 [如 VLC、mpv 等媒体播放器](https://opensource.com/article/21/2/linux-media-players) 播放。
### 探索 Audacity
Audacity 是开源软件世界中的一个经典动力工具。基本的录音和编辑仅仅是个开始。你可以添加效果、[过滤掉(一些)噪音](https://opensource.com/life/14/10/how-clean-digital-recordings-using-audacity)、调整速度、改变音高等等。无论你是在学校录制讲座、混合鼓循环、为视频游戏拼接声音,还是只是在探索音频世界,都可以去启动 Audacity,发挥创意!
---
via: <https://opensource.com/article/21/12/audacity-linux-creative-app>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Audacity sound editor is one of those open source applications that filled a niche that seemingly nobody else realized existed. Initially developed at Carnegie Mellon University at a time when many people still thought computers were just for office and schoolwork, and you required special DSP peripherals for serious multimedia work. Audacity recognized that, occasionally, the average computer user needed to edit audio. The Audacity team has consistently provided an open source application for recording and cleaning up sound in the two decades since.
I use Audacity a lot, and being an editor by training, I'm used to significant and usually single-key keyboard shortcuts in my applications. By building shortcuts around single letters, you can have one hand on the mouse and one on the keyboard, so the delay between choosing a tool or an important function and clicking the mouse is mere milliseconds. Throughout this article, I'll highlight the keyboard shortcut I use in Audacity if you want to optimize your own settings.
## Install Audacity on Linux
Audacity is available on most Linux distributions from your package manager. On Fedora, Mageia, and similar distributions:
`$ sudo dnf install audacity`
On Elementary, Mint, and other Debian-based distributions:
`$ sudo apt install audacity`
However, I use Audacity as a [Flatpak](https://opensource.com/article/21/11/how-install-flatpak-linux).
On Windows or macOS, download an Audacity installer from the [Audacity website](https://www.audacityteam.org/).
A recent fork, called [Tenacity](https://github.com/tenacityteam/tenacity), aims to continue the Audacity tradition with a different team of developers. At the time of writing, the two are essentially the same application, so this article applies equally to both. Whether the two diverge in features later remains to be seen.
Once installed, launch the application from your Application or Activities menu.
## Setting inputs in Audacity
First, you must set your audio *input* so that Audacity receives the signal from the microphone or audio interface you want to use. What you choose depends on your setup and what audio peripherals you own. USB microphones usually get listed as **Microphone**, but a microphone with a 1/8" input jack likely gets labeled as **Line in**. Your different options:
### Pulse Audio
Linux uses Advanced Linux Sound Architecture (ALSA) as its backend for sound, while macOS and Windows use their own closed frameworks. On Linux, you can set Pulse Audio as your input source to direct Audacity to *one* virtual interface (Pulse), so you can route sound input from your System Settings. This is my preferred method because it centralizes all control in one convenient control panel. Gone are the days of selecting a microphone in one application only to discover that the microphone got muted elsewhere.
(Seth Kenlon, CC BY-SA 4.0)
### Device access
If your distribution or OS doesn't use Pulse Audio, or if for some reason you prefer to access sound devices directly, you can alternatively select a device from the drop-down menu. This requires some knowledge of how your system lists sound devices, which isn't always obvious. A desktop might have several inputs, some in the rear of the tower and some in a front panel. Laptops usually have fewer input options, but you probably have a microphone near your webcam and possibly an external one if you're using one.
## Recording audio with Audacity
Once your input is selected, press the **Record** button (the button with a red dot).
(Seth Kenlon, CC BY-SA 4.0)
If you're recording into a microphone, all you have to do is start talking. If you're recording input from, say, [a vinyl record player](https://opensource.com/article/18/1/audacity-digitize-records), then you must start it. Whatever it is, as long as Audacity is in Record mode, any signal sent to your selected input is written to Audacity and rendered as a waveform on your screen.
**My shortcut:** I use the **R** key to start recording. By default, **Space** stops a recording (and also plays a recording back).
## Editing audio
Recording rarely goes exactly as planned. Maybe you start recording too soon and have to sit through seconds of vinyl silence (it's like silence, but scratchier), or you discover that you fill all of your spoken silence with "uh" and "um" and other vocables, or you just have a false start. Audacity is first and foremost a waveform editor, meaning you can cut out the sounds you don't want in the final recording with the same ease that you make edits to the words you type into a word processor.
## Editing sound at zero crossings
The main editing tool in Audacity is the Selection Tool. It's the familiar "I-beam" cursor you see in word processors, and its function is the same here. You can click and drag this cursor across a region of sound, and then you can copy or paste or cut or delete or just play the region.
**My shortcut:** I use the **I** key to activate the selection tool because the cursor looks like the letter "I."
However, in a word processor, you can see the end and start of each letter very clearly. There's no chance of you accidentally selecting and deleting only half of a letter.
However, the "resolution" (called the *sample rate*) of sound in modern applications is very good, so it's difficult for the human eye to locate a clean break in an audio wave. Audacity can adjust your work so that your selected region lands on what's called a [zero crossing](https://en.wikipedia.org/wiki/Zero_crossing), which avoids subtle but noticeable glitches where you made cuts.
(Seth Kenlon, CC BY-SA 4.0)
After you make a selection, go to the **Select** menu and choose **At Zero Crossings**.
**My shortcut:** I use the **Z** key to adjust a selection to zero crossings and the **X** key to delete a region (it saves me from having to move my hand all the way up to **Del** or **Backspace**.)
## Making room for more
The beauty of editing is that your final product doesn't have to be true to what you recorded. I've recorded lectures and even scripted readings that end up getting sidetracked for one reason or another, or that omit a section of important information, only to then rearrange or add brand new audio before publishing.
Moving a selection of audio is similar to deleting, except instead of removing audio, you copy and paste the selection the same way you do in a word processor—copy or cut using standard keyboard shortcuts, reposition your cursor, and paste. Making room for insert edits, though, requires empty space on your audio timeline so you can record additional audio to fill the gap you've created. For this, you use the Selection Tool and the Time Shift Tool.
To create a gap in your audio, position your Selection Tool cursor at the point where you want to add empty space. Navigate to the **Edit** menu, select the **Clip Boundaries** submenu, and then choose **Split**. This splits your audio at the point of your Selection tool.
Activate the **Time Shift Tool** in the top toolbar (the icon is two joined arrows pointing left and right.) Click and drag the right half of your split audio to create a gap.
(Seth Kenlon, CC BY-SA 4.0)
**My shortcut:** I use **K** to split (or "kut," as a mnemonic) and **T** to activate the Time Shift Tool.
## Exporting audio
When you're happy with your audio, you can export it so you can share it with others. Audacity has a good selection of formats it can export to, and it's able to pipe its output to tools like [ffmpeg](https://opensource.com/article/21/11/linux-line-commands-reclaim-space-converting-files#audio) for more formats than you'll probably ever need.
My preference is to export audio in the FLAC format, an audio format that's a little like a WAV, except it's losslessly compressed. It takes up a fraction of the space without any loss in quality. To try it out, go to **File**, select the **Export** submenu, and then choose **Export Audio**. With a FLAC file as your [golden image](https://opensource.com/article/19/7/what-golden-image), you can use SoundConverter to convert your file into whatever format is best for any number of delivery targets—Ogg Vorbis or Opus or Webm for browsers, M4A files for Apple devices, and maybe an MP3 for a legacy system.
If you just want a quick and simple export from Audacity, the easy option is Ogg Vorbis. This is an open source file format that plays in most web browsers (Firefox, Chromium, Chrome, Android, and Edge) and [media players like VLC, mpv, and many others](https://opensource.com/article/21/2/linux-media-players).
## Explore Audacity
Audacity is a classic power tool of the open source software world. Basic recording and editing are only the beginning. You can add effects, [filter out (some) noise](https://opensource.com/life/14/10/how-clean-digital-recordings-using-audacity), adjust speed, change pitch, and much more. Whether you're recording lectures at school, mixing up drum loops, splicing together sounds for a video game, or just exploring the world of audio, go launch Audacity and get creative!
## Comments are closed. |
14,165 | 为什么你要运行自己的 DNS 服务器? | https://jvns.ca/blog/2022/01/05/why-might-you-run-your-own-dns-server-/ | 2022-01-10T11:30:00 | [
"DNS"
] | https://linux.cn/article-14165-1.html | 
使得 DNS 难以理解的事情之一是它是 **分布式的**。有成千上万(也许是几十万?我不知道!)的<ruby> 权威性域名服务器 <rt> authoritative nameserver </rt></ruby>,以及至少 [1000 万个解析器](https://www.icann.org/en/blogs/details/ten-million-dns-resolvers-on-the-internet-22-3-2012-en)。而且它们正在运行许多不同的软件!不同服务器运行着不同的软件意味着 DNS 的工作方式有很多不一致的地方,这可能导致各种令人沮丧的问题。
但是,与其谈论这些问题,我更感兴趣的是弄清楚 —— 为什么 DNS 是分布式的是一件好事?
### 为什么 DNS 是分布式的是件好事?
一个原因是 **可扩展性** —— DNS 的分布式设计使其更容易扩展,对故障的恢复能力更强。我发现,尽管 DNS 已经有近 40 年的历史,但它的扩展性仍然很好,这真是令人惊讶。这一点非常重要,但这并不是这篇文章的主题。
相反,我想说的是,它是分布式的意味着你可以 **控制** 你的 DNS 的工作方式。你可以向巨大而复杂的 DNS 服务器中添加更多的服务器!添加你控制的服务器!
昨天我 [在 Twitter 上问](https://twitter.com/b0rk/status/1478490484406468614) 为什么你要运行自己的 DNS 服务器,我得到了很多很好的答案,我想在这里总结一下。
### 你可以运行 2 种类型的 DNS 服务器
你可以运行 2 种主要类型的 DNS 服务器:
1. 如果你拥有一个域名,你可以为该域名运行一个 **权威名称服务器**
2. 如果你有一台电脑(或一个有很多电脑的公司),你可以运行一个 **解析器** 来为这些电脑解析 DNS。
### DNS 不是静态数据库
我经常看到 DNS 的 “电话簿” 比喻,域名就像人名,IP 地址就像电话号码。
这是一个不错的思维模型。但是,“电话簿” 思维模型可能会使你认为,如果你对 `google.com` 进行 DNS 查询,你将永远得到相同的结果。而这是不正确的。
你在 DNS 查询中得到的记录可能取决于:
* 你在世界的哪个地方(也许你会得到一个离你更近的服务器的 IP 地址)
* 你是否在企业网络里(你可以在其中解析内部域名)
* 该域名是否被你的 DNS 解析器认为是 “坏” 的(它可能被封锁!)
* 之前的 DNS 查询(也许 DNS 解析器正在做基于 DNS 的负载平衡,每次给你一个不同的 IP 地址)
* 你是否在使用机场 Wi-Fi 专属门户(机场 Wi-Fi 会在你登录前以不同的方式解析 DNS 记录,它会给你发送一个特殊的 IP 来重定向你)
* 随便什么
你可能想控制你自己的服务器的很多原因都与 DNS 不是一个静态数据库这一事实有关 —— 对于如何处理 DNS 查询,你可能会有不同的选择(无论是为你的域名还是为你的组织)。
### 运行权威性名称服务器的理由
这些原因并没有任何特定的顺序。
对于其中一些原因,你不一定必须要运行你自己的权威名称服务器,你只需选择提供了该功能的权威名称服务器服务就行了。
要明确的是:有很多理由 **不** 运行自己的权威名称服务器 —— 我就没有运行,我也不想说服你应该这样做。它需要时间来维护,你的服务可能不那么可靠,等等。
#### 原因:安全
[这条推文说的很好](https://twitter.com/thatcks/status/1478503078680838153):
>
> [存在] 攻击者通过你的 DNS 供应商的客户支持人员获得 DNS 变更权限的风险,客服本来只应该提供帮助。他们可以被你的 DNS 阻止(也许就是因为缺少这个)。内部可能更容易审计和验证内容。
>
>
>
### 原因:你喜欢运行 bind/nsd
有几个人提到的一个原因是:“我习惯于编写区域文件和运行 `bind` 或 `nsd` ,对我来说这样做更容易。”
如果你喜欢 bind/nsd 的方式,但又不想运维自己的服务器,有几个人提到,你也可以通过运行一个 “隐藏的主服务器” 来获得 bind 的优势,该服务器存储记录,但从一个 “辅助” 服务器提供所有的实际 DNS 查询。这里有一些我发现的关于配置辅助 DNS 的网页,以 [NS1](https://help.ns1.com/hc/en-us/articles/360017508173-Configuring-NS1-as-a-secondary-provider-a-k-a-Creating-secondary-zones-)、[cloudflare](https://blog.cloudflare.com/secondary-dns-a-faster-more-resilient-way-to-serve-your-dns-records/) 和 [Dyn](https://help.dyn.com/standard-dns/dyn-secondary-dns-information/) 作为示例。
我真的不知道什么是最佳的权威 DNS 服务器。我想我只在工作中使用过 nsd。
#### 原因:你可以使用新的记录类型
并非所有的 DNS 服务都支持某些较新的 DNS 记录类型,但如果你运行你自己的 DNS,你就可以支持任何你想要的记录类型。
#### 原因:用户界面
你可能不喜欢你正在使用的 DNS 服务的用户界面(或 API,或干脆没有 API)。这与 “你喜欢运行 BIND ”的原因差不多,也许你喜欢编写区域文件的方式。
#### 原因:你可以自己修复问题
当问题出现时,能够自己解决,有一些明显的优点和缺点(优点:你可以解决问题,缺点:你必须解决问题)。
#### 原因:做一些奇怪的、自定义的事情
你可以写一个 DNS 服务器,做任何你想做的事情,它不一定要只返回一组静态记录。
有几个例子:
* Replit 有一篇博文介绍了 [为什么他们编写自己的权威性 DNS 服务器来处理路由](https://blog.replit.com/dns)
* [nip.io](https://nip.io) 将 [10.0.0.1.nip.io](http://10.0.0.1.nip.io) 映射为 10.0.0.1
* 我为 [乱用 dns](https://jvns.ca/blog/2021/12/15/mess-with-dns/) 而写了一个自定义 DNS 服务器
#### 原因:省钱
权威名称服务器似乎一般按每百万次 DNS 查询收费。比如,似乎 Route 53 每百万次查询收费 0.5 美元,[NS1](https://ns1.com/plans) 每百万次查询收费约 8 美元。
我对一个大型网站的权威 DNS 服务器实际需要解决多少次查询没有概念(哪些类型的网站会对其权威 DNS 服务器进行 10 亿次 DNS 查询?可能是很多,但我没有这方面的经验)。但是有几个人在回复中提到成本是一个原因。
#### 原因:你可以改变你的注册商
如果你为你的域名使用一个单独的权威名称服务器,而不是你的注册商的名称服务器,那么当你转移到一个不同的注册商时,你所要做的就是把你的权威 DNS 服务器设置为正确的值,从而使你的 DNS 恢复正常。你不需要迁移你所有的 DNS 记录,那非常痛苦。
但你不需要为此而运行你自己的名字服务器。
#### 原因:地理 DNS
你可能想根据客户的位置为你的域名返回不同的 IP 地址,给他们一个离他们很近的服务器。
这是很多权威的域名服务器服务所提供的服务,你不需要为此而专门运行名字服务器。
#### 原因:避免针对他人的拒绝服务攻击
许多权威 DNS 服务器是共享的。这意味着,如果有人攻击 `google.com` 或其他的 DNS 服务器,而你恰好在使用同一个权威 DNS 服务器,你可能会受到影响,即使攻击不是针对你。例如,2016 年的这次 [对 Dyn 的 DDoS 攻击](https://en.wikipedia.org/wiki/DDoS_attack_on_Dyn)。
#### 原因:把所有的配置放在一个地方
有一个人提到,他们喜欢把所有的配置(DNS 记录、let's encrypt、nginx 等)放在一台服务器上的同一个地方。
#### 另类原因:把 DNS 当作 VPN 使用
显然,[iodine](https://github.com/yarrick/iodine) 是一个可以让你通过 DNS 隧道传输流量的权威 DNS 服务器,它可以让你像 VPN 一样与外界联系,
### 运行解析器的原因
#### 原因:隐私
如果有人能看到你所有的 DNS 查询,他们就有你(或你组织中的每个人)正在访问的所有域名的完整列表!你可能更愿意保持这种隐私。你可能更愿意保持这种隐私。
#### 原因:阻止恶意网站
如果你运行你自己的解析器,你可以(通过不返回任何结果)拒绝解析你认为 “坏” 的域名的 DNS 查询。
几个你可以自己运行(或只是使用)的解析器的例子:
* [Pi-Hole](https://pi-hole.net/) 阻止广告商
* [Quad9](https://www.quad9.net/) 阻止做恶意软件/网络钓鱼/间谍软件的域名。 Cloudflare 似乎有一个 [类似的服务](https://developers.cloudflare.com/1.1.1.1/1.1.1.1-for-families)
* 我想也有一些企业安全软件会阻止那些托管恶意软件的域名的 DNS 查询
* DNS 不是静态数据库。它是非常动态的,答案往往实时取决于查询的 IP 地址、内容服务器的当前负载等。除非你将这些记录的服务委托给做出这些决定的实体,否则很难实时实现。
* DNS 委派控制使访问控制非常简单。从区域中切下的部分都由控制委派服务器的人控制,所以对一个主机名的责任是隐含在 DNS 委派中的。
#### 原因:在 nginx 中获得动态代理
这里有一个很酷的故事,来自 [这条推文](https://twitter.com/jordanorelli/status/1478795241876504577):
>
> 我在一个应用程序中写了一个 DNS 服务器,然后把它设置为 nginx 的解析器,这样我就可以获得动态的后端代理,而不需要 nginx 运行 lua。Nginx 向应用程序发送 DNS 查询,应用程序查询 Redis 并作出相应的反应。这对我正在做的事情来说,效果非常好。
>
>
>
#### 原因:避免恶意解析器
一些 ISP 运行的 DNS 解析器会做一些不好的事情,比如把不存在的域名指向他们控制的 IP,向你显示广告或他们控制的奇怪的搜索页面。
使用你控制的解析器或你信任的另一个解析器可以帮助你避免这种情况。
#### 原因:解析内部域名
你可能有一个内部网络,其域名(比如 `blah.corp.yourcompany.com`)并不在公共互联网上。为内部网络中的机器运行你自己的解析器,就有可能访问这些域名。
无论是访问只在本地的服务,还是为公共互联网上的服务获得本地地址,你都可以在家庭网络中做同样的事情。
#### 原因:避免你的 DNS 查询被中间人劫持
有一个人 [说](https://twitter.com/passcod/status/1478806468539269120):
>
> 我在我的局域网路由器上运行了一个解析器,它的上游使用了基于 HTTPS 的 DNS(DoH),所以物联网和其他不支持 DoH 或 DoT 的设备不会在外面喷射明文 DNS 查询。
>
>
>
### 就是这样
对我来说,探索 DNS 的 “原因” 感觉很重要,因为它是一个如此复杂凌乱的系统,我认为大多数人如果不理解为什么这些复杂的东西是有用的,就很难有动力去学习这么复杂的主题。
感谢 Marie 和 Kamal 对这篇文章的讨论,也感谢 Twitter 上提供这些原因的所有人。
---
via: <https://jvns.ca/blog/2022/01/05/why-might-you-run-your-own-dns-server-/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the things that makes DNS difficult to understand is that it’s
**decentralized**. There are thousands (maybe hundreds of thousands? I don’t know!) of authoritative nameservers, and at least
[10 million resolvers](https://www.icann.org/en/blogs/details/ten-million-dns-resolvers-on-the-internet-22-3-2012-en).
And they’re running lots of different software! All these different servers
running software means that there’s a lot of inconsistency in how DNS works,
which can cause all kinds of frustrating problems.
But instead of talking about the problems, I’m interested in figuring out – why is it a good thing that DNS is decentralized?
### why is it good that DNS is decentralized?
One reason is **scalability** – the decentralized design of DNS makes it
easier to scale and more resilient to failures. I find it really amazing that
DNS is still scaling well even though it’s almost 40 years old. This is very
important but it’s not what this post is about.
Instead, I want to talk about how the fact that it’s decentralized means that
you can have **control** of how your DNS works. You can add more servers to the
giant complicated mess of DNS servers! Servers that you control!
Yesterday I [asked on Twitter](https://twitter.com/b0rk/status/1478490484406468614) why you might
want to run your own DNS servers, and I got a lot of great answers that I
wanted to summarize here.
### you can run 2 types of DNS servers
There are 2 main types of DNS servers you can run:
- if you own a domain, you can run an
**authoritative nameserver**for that domain - if you have a computer (or a company with lots of computers), you can run a
**resolver**that’s resolves DNS for those computers
### DNS isn’t a static database
I’ve seen the “phone book” metaphor for DNS a lot, where domain names are like names and IP addresses are like phone numbers.
This is an okay mental model to start with. But the “phone book” mental model
might make you think that if you make a DNS query for `google.com`
, you’ll
always get the same result. And that’s not true at all!
Which record you get in reply to a DNS query can depend on:
- where you are in the world (maybe you’ll get an IP address of a server that’s physically closer to you!)
- if you’re on a corporate network (where you might be able to resolve internal domain names)
- whether the domain name is considered “bad” by your DNS resolver (it might be blocked!)
- the previous DNS query (maybe the DNS resolver is doing DNS-based load balancing to give you a different IP address every time)
- whether you’re using an airport wifi captive portal (airport wifi will resolve DNS records differently before you log in, it’ll send you a special IP to redirect you)
- literally anything
A lot of the reasons you might want to control your own server are related to the fact that DNS isn’t a static database – there are a lot of choices you might want to make about how DNS queries are handled (either for your domain or for your organization).
### reasons to run an authoritative nameserver
These reasons aren’t in any particular order.
For some of these you don’t necessarily have to run your own authoritative nameserver, you can just choose an authoritative nameserver service that has the features you want.
To be clear: there are lots of reasons **not** to run your own authoritative
nameserver – I don’t run my own, and I’m not trying to convince you that you
should. It takes time to maintain, your service might not be as reliable, etc.
**reason: security**
[There’s a] risk of an attacker gaining DNS change access through your vendor’s customer support people, who only want to be helpful. Or getting locked out from your DNS (perhaps because of the lack of that). In-house may be easier to audit and verify the contents.
**reason: you like running bind/nsd**
One reason several people mentioned was “I’m used to writing zone files and
running `bind`
or `nsd`
, it’s easier for me to just do that”.
If you like the interface of bind/nsd but don’t want to operate your own
server, a couple of people mentioned that you can also get the advantages of
bind by running a “hidden primary” server which stores the records, but serve
all of the actual DNS queries from a “secondary” server. Here are some pages
I found about configuring secondary DNS from from [NS1](https://help.ns1.com/hc/en-us/articles/360017508173-Configuring-NS1-as-a-secondary-provider-a-k-a-Creating-secondary-zones-) and [cloudflare](https://blog.cloudflare.com/secondary-dns-a-faster-more-resilient-way-to-serve-your-dns-records/) and [Dyn](https://help.dyn.com/standard-dns/dyn-secondary-dns-information/) as an example.
I don’t really know what the best authoritative DNS server to run is. I think I’ve only used nsd at work.
**reason: you can use new record types**
Some newer DNS record types aren’t supported by all DNS services, but if you run your own you can support any record types you want.
**reason: user interface**
You might not like the user interface (or API, or lack of API) of the DNS service you’re using. This is pretty related to the “you like running BIND” reason – maybe you like the zone file interface!
**reason: you can fix problems yourself**
There are some obvious pros and cons to being able to fix problems yourself when they arise (pro: you can fix the problem, con: you have to fix the problem).
**reason: do something weird and custom**
You can write a DNS server that does anything you want, it doesn’t have to just return a static set of records.
A few examples:
- Replit has a blog post about
[why they wrote their own authoritative DNS server to handle routing](https://blog.replit.com/dns) [nip.io](https://nip.io)maps 10.0.0.1.nip.io to 10.0.0.1- I wrote a custom DNS server for
[mess with dns](https://jvns.ca/blog/2021/12/15/mess-with-dns/)
**reason: to save money**
Authoritative nameservers seem to generally charge per million DNS queries. As
an example, at a quick glance it looks like Route 53 charges about $0.50 per
million queries and [NS1](https://ns1.com/plans) charges about $8 per million queries.
I don’t have the best sense for how many queries a large website’s authoritative DNS server can expect to actually need to resolve (what kinds of sites get 1 billion DNS queries to their authoritative DNS server? Probably a lot, but I don’t have experience with that.). But a few people in the replies mentioned cost as a reason.
**reason: you can change your registrar**
If you use a separate authoritative nameserver for your domain instead of your registrar’s nameserver, then when you move to a different registrar all you have to do to get your DNS back up is to set your authoritative DNS server to the right value. You don’t need to migrate all your DNS records, which is a huge pain!
You don’t need to run your own nameserver to do this.
**reason: geo DNS**
You might want to return different IP addresses for your domain depending on where the client is, to give them a server that’s close to them.
This is a service lots of authoritative nameserver services offer, you don’t need to write your own to do this.
**reason: avoid denial of service attacks targeted at someone else**
Many authoritative DNS servers are shared. This means that if someone attacks
the DNS server for `google.com`
or something and you happen to be using the
same authoritative DNS server, you could be affected even though the attack
wasn’t aimed at you. For example, this [DDoS attack on Dyn](https://en.wikipedia.org/wiki/DDoS_attack_on_Dyn) in 2016.
**reason: keep all of your configuration in one place**
One person mentioned that they like to keep all of their configuration (DNS records, let’s encrypt, nginx, etc) in the same place on one server.
**wild reason: use DNS as a VPN**
Apparently [iodine](https://github.com/yarrick/iodine) is an authoritative DNS
server that lets you tunnel your traffic over DNS, if you’re on a network that
only allows you to contact the outside world as a VPN.
### reasons to run a resolver
**reason: privacy**
If someone can see all your DNS lookups, they have a complete list of all the domains you (or everyone from your organization) is visiting! You might prefer to keep that private.
**reason: block malicious sites**
If you run your own resolver, you can refuse to resolve DNS queries (by just not returning any results) for domains that you consider “bad”.
A few examples of resolvers that you can run yourself (or just use):
[Pi-Hole](https://pi-hole.net/)blocks advertisers[Quad9](https://www.quad9.net/)blocks domains that do malware/phishing/spyware. Cloudflare seems to have a[similar service](https://developers.cloudflare.com/1.1.1.1/1.1.1.1-for-families)- I imagine there’s also corporate security software that blocks DNS queries for domains that host malware
- DNS isn’t a static database. It’s very dynamic, and answers often depend in real time on the IP address a query came from, current load on content servers etc. That’s hard to do in real time unless you delegate serving those records to the entity making those decisions.
- DNS delegating control makes access control very simple. Everything under a zone cut is controlled by the person who controls the delegated server, so responsibility for a hostname is implicit in the DNS delegation.
**reason: get dynamic proxying in nginx**
Here’s a cool story from [this tweet](https://twitter.com/jordanorelli/status/1478795241876504577):
I wrote a DNS server into an app and then set it as nginx’s resolver so that I could get dynamic backend proxying without needing nginx to run lua. Nginx sends DNS query to app, app queries redis and responds accordingly. It worked pretty great for what I was doing.
**reason: avoid malicious resolvers**
Some ISPs run DNS resolvers that do bad things like nonexistent domains to an IP they control that shows you ads or a weird search page that they control.
Using either a resolver you control or a different resolver that you trust can help you avoid that.
**reason: resolve internal domains**
You might have an internal network with domains (like
`blah.corp.yourcompany.com`
) that aren’t on the public internet. Running your
own resolver for machines in the internal network makes it possible to access
those domains.
You can do the same thing on a home network, either to access local-only services or to just get local addresses for services that are on the public internet.
**reason: avoid your DNS queries being MITM’d**
One person [said](https://twitter.com/passcod/status/1478806468539269120):
I run a resolver on my LAN router that uses DNS over HTTPS for its upstream, so IoT and other devices that don’t support DoH or DoT don’t spray plaintext DNS outside
### that’s all for now
It feels important to me to explore the “why” of DNS, because it’s such a complicated messy system and I think most people find it hard to get motivated to learn about complex topics if they don’t understand why all this complexity is useful.
Thanks to Marie and Kamal for discussing this post, and to everyone on Twitter who provided reasons |
14,166 | 在 Linux 中像专业人士一样使用 GNOME 截图工具 | https://itsfoss.com/using-gnome-screenshot-tool/ | 2022-01-10T18:47:28 | [
"截图"
] | https://linux.cn/article-14166-1.html | 有 [几个可用于 Linux 的截图工具](https://itsfoss.com/take-screenshot-linux/),我喜欢 [使用 Flameshot 进行截图](https://itsfoss.com/flameshot/) 和 Shutter 来编辑现有的截图。
但不幸的是,Flameshot 不能在 4K 屏幕上工作。因此,我不得不使用默认的 GNOME 截图工具,它在我的带有超高清屏幕的戴尔 XPS 上工作得非常好。

这一“被迫之举”让我意识到,如果你知道如何正确使用,[GNOME 截图](https://apps.gnome.org/app/org.gnome.Screenshot/) 并不是一个糟糕的工具。
在这里,我指的是用键盘快捷键来使用它,因为这样可以节省大量的时间。
让我展示一下如何像专家一样用那些方便的键盘快捷键来使用 GNOME 截图应用。
我假定你没有改变这里的默认的截图的键盘快捷键。
### 对整个屏幕进行截图:使用 Prt Scr 键
这是最简单的操作。在你的键盘上找到 `Prt Sc`(或称 `Prt Scr`、`Prt Scn`)键并按下它。它将对整个屏幕进行截图,并将其保存在你的主目录下的图片文件夹中。

在某些发行版(或版本)中,你可能会看到是否要保存截图的选项,但大多数情况下,它会自动保存屏幕截图。
这里需要注意的另一件事是,如果你有多个屏幕连接到系统上,它会把所有的屏幕一起截图。这意味着,你会得到一个超宽的图像。
但是,如果你只想对某个应用进行截图,而不是对整个屏幕进行截图呢?
### 给一个应用程序的窗口截图:使用 Alt+Prt Scr 键
要给正在运行的图形应用截图,你需要这样做:
点击正在运行的应用,使其获得焦点。现在,按住 `Alt` 键并按 `Prt Scr` 键。
它将得到应用窗口的截图,并保存到图片目录中。

这样获取的截图也有一个阴影效果,看起来很不错。
这很好,但如果你只想给某个特定区域截图,而不是整个屏幕呢?这也有一个技巧。
### 对屏幕的选定区域进行截图:使用 Shift+Prt Scr 键
按住 `Shift` 键。然后按 `Prt Scr` 键。你会看到屏幕上出现一个选框。将鼠标移动到所需的区域,开始拖动光标。它将高亮显示该区域,并在你释放鼠标后立即进行截图。

### 复制截图到剪贴板而不是保存它们
当你在和别人聊天时,要和对方分享屏幕截图时,这非常有用。

首先截图,但没必要将保存的截图文件附在聊天工具中。相反,你可以直接将截图复制到剪贴板,然后使用 `Ctrl+V` 快捷键将图像(从剪贴板)粘贴到聊天工具。
这样,你的系统就不会保留不必要的截图,你也可以节省一些鼠标点击次数。
要把截图保存到剪贴板,以便你能把它们粘贴到聊天工具、绘图工具或文档中,你必须把 `Ctrl` 键和你在前面几节中看到的其他截图快捷键一起使用。
* `Ctrl+Prt Scr`:将整个屏幕的截图复制到剪贴板上。
* `Ctrl+Alt+Prt Scr`:将应用窗口的截图复制到剪贴板上。
* `Ctrl+Shift+Prt Scr`:将选定区域的截图复制到剪贴板上
我必须补充一点,在这种情况下,[使用像 Flameshot 这样的工具](https://itsfoss.com/flameshot/) 甚至更好一些,因为它允许你在将截图保存到剪贴板之前对其进行注释。这样,你可以很容易地高亮屏幕的重要部分。
### 在截图中添加延迟,以便对下拉菜单进行截图
到目前为止,一切都很好。你只需按下几个键,就可以随心所欲地进行截图了。
问题是,当你要对下拉菜单或右键动作等进行截图时。当你按下屏幕截图键时,想要的项目可能会消失。
为了处理这种情况,你可以对该区域或整个屏幕进行截图,但要有一个延迟。

在 GNOME 屏幕截图工具中,你可以选择添加这个延迟。例如,你添加了 6 秒的延迟。你点击截图按钮,有 6 秒时间来做/显示你想做的事情。6 秒后,它就会自动截图了。
### 你有什么技巧吗?
这就是我使用 GNOME 截图工具的所有技巧。如果你还没有广泛地使用它,你应该会发现它很有帮助。如果你已经是一个专家,也许你知道一些可以添加到本文中的东西?请在评论区与我们其他人分享吧。
---
via: <https://itsfoss.com/using-gnome-screenshot-tool/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are [several screenshot tools available for Linux](https://itsfoss.com/take-screenshot-linux/). I prefer [using Flameshot for screenshots](https://itsfoss.com/flameshot/) and Shutter for editing the existing screenshots.
But Flameshot doesn’t work with 4K screens, unfortunately. And hence I had to resort back to the default GNOME screenshot tool which works perfectly on my Dell XPS with Ultra HD screen.
This ‘forced move’ made me realize that the [GNOME screenshot](https://apps.gnome.org/app/org.gnome.Screenshot/) is not a bad utility if you know how to use it properly.
From that, I meant using it with the keyboard shortcuts because that saves a lot of time.
Let me show how to use the GNOME Screenshot application like an expert with all those handy keyboard shortcuts.
I presume that you have not changed the default keyboard shortcuts for screenshot here.
## Take screenshot of entire screen(s): Use Prt Scr key
This is the simplest of the action. Locate the Prt Sc or Prt Scr or Prt Scn key on your keyboard and press it. It will take the screenshot of the entire screen and save it to the Pictures folder under your home directory.
In some distributions (or versions), you may get the options to whether you want to save the screenshot or not but mostly, it will save the screenshot automatically.
Another thing to note here is that if you have multiple screens attached to the system, it takes screenshot of all the screens together. This means, you get an ultra wide image.
But what if you want to take the screenshot of only a certain application, not the entire screen?
## Take screenshot of an application windows: Use Alt+Prt Scr key
To take the screenshot of a running graphical application, here’s what you need to do:
Click on the running application so that it in focus. Now, press and hold the Alt key and press Prt Scr key.
It will take the screenshot of the application window and save to the Pictures directory.
The screenshots thus taken also has a shadow effect applied to them which looks good.
This is good but what if you want to take the screenshot of only a particular area, not the entire screen? There is a trick for that as well.
## Take screenshot of selected area of the screen: Use Shift+Prt Scr key
Press the Shift key and hold it. Now press the Prt Scr key. You’ll see a selector appear on the screen. Move around the mouse to the desired region and start dragging the cursor. It will highlight the region and take a screenshot as soon as you release the mouse.
## Copy the screenshots to clipboard instead of saving them
This is very useful when you are chatting someone and have to share a screenshot with the other person.
Taking the screenshot first and then attach the saved screenshot file to the messaging tool is unnecessary. Instead, you could just copy the screenshot to the clipboard and then use the Ctrl+V shortcut to paste the image (from the clipboard) into the messaging tool.
This way, your system won’t have unnecessary screenshots and you also save a few mouse clicks.
To save the screenshots to your clipboard so that you can paste them in a messaging tool, drawing tool or a document, you have to use the Ctrl key together with the other screenshots shortcuts you saw in previous sections.
- Ctrl+Prt Scr: Copies the screenshot of the entire screen(s) to the clipboard
- Ctrl+Alt+Prt Scr: Copies the screenshot of the application windows to the clipboard
- Ctrl+Shift+Prt Scr: Copies the screenshot of the selected region to the clipboard
I must add that [using a tool like Flameshot](https://itsfoss.com/flameshot/) is even better in such case because it allows you to annotate the screenshots before saving them to clipboard. This way, you can easily highlight the important part of your screen.
## Add delay to screenshot to take screenshots of dropdown menu
So far everything is good. You just press a couple of keys and take the screenshots as you like.
The problem comes when you have to take the screenshot of a dropdown menu or right click context action etc. As soon as you press the screenshot keys, the intended item may disappear.
To handle the situation, you can take the screenshot of the region or entire screen but with a delay.
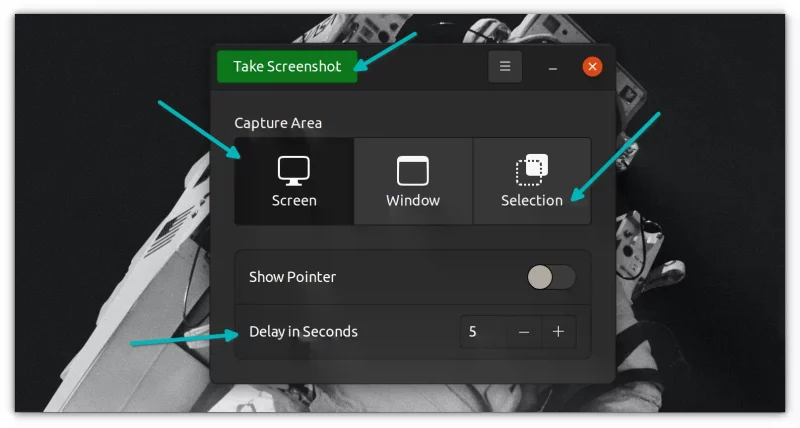
In the GNOME Screenshot tool, you get the option to add this delay. Say, you add 6 seconds of delay. You hit the take screenshot button and get 6 seconds to do/show what you intend here. After 6 seconds, it automatically takes the screenshot.
## Any tricks up your sleeve?
That’s all the tips I had on GNOME Screenshot tool. If you haven’t used it extensively, you should find it helpful. If you are already a pro, perhaps you know something that can be added to this article? Share it with the rest of us in the comment section, please. |
14,168 | 我希望在 GNOME 中看到的 5 个微小而有用的功能 | https://news.itsfoss.com/gnome-features-i-want/ | 2022-01-11T16:25:37 | [
"GNOME"
] | https://linux.cn/article-14168-1.html |
>
> 我知道对于圣诞愿望清单来说已经太晚了,但我仍然想分享我希望在 GNOME 中看到的东西。
>
>
>

GNOME 是许多 Linux 发行版的默认桌面环境。它也是我最喜欢的一个,因为它提供了一种现代的桌面体验。
但这并不意味着 GNOME 是完美的,不需要改进。事实上,这里有几个建议可以改善整个用户体验。
### 1、方便的应用程序卸载选项
桌面 Linux 是碎片化的。为了增加混乱,连软件包也是零零散散的。而最糟糕的是当你从系统中删除一个应用程序时。
举个例子,你要通过 DEB 包安装一个应用程序,并使用 GNOME 软件中心界面来安装它。
但如果你不喜欢这个应用程序,想把它删除呢?
你不会在软件中心中找到该应用程序。相反,你得必须使用命令行的方法。
这还没完。还有 Snap 和 [Flatpak](https://itsfoss.com/what-is-flatpak/) 软件包。如果你已经使用了其中之一,你必须先找出来,然后使用正确的命令才行。
GNOME 采用了类似于 Android/iOS 的方法,将应用程序显示在一个网格中,并将它们组织在文件夹中。移动操作系统为用户提供了一种方式,即按住图标并删除应用程序。如果能有一个类似的选项,右键点击应用程序图标并选择卸载,那就更好了。

这样,终端用户就不用管所安装的应用程序是 Deb 包还是 Snap 包。没有必要为此进入终端,而且它就发生在访问应用程序地方,这不是挺好吗?
Linux Mint Cinnamon 版有这样的功能,你在菜单中右键点击一个应用程序条目,选择删除它。

如果 Cinnamon 能做到,GNOME 应该也能做到,对吗?
### 2、在应用程序商店中设置默认软件源
如果一个应用程序有多种格式,GNOME 软件中心可以让你选择软件源。至少这是我在 Fedora 的 GNOME 软件中看到的,但在 Ubuntu 中没有。

假设有人在软件中心同时添加了 Flatpak 和 Snap 支持,而一个应用程序在 Flatpak、Snap 和软件包管理器(apt、DNF 等)中都可用,它可能会在搜索结果中显示多次。
如果能够设置一个默认的打包格式,使其优先于其他格式,那就更好了。如果你把 Flatpak 作为默认,它就不会显示 Snap 版本,默认只安装 Flatpak 版本。
### 3、跨系统同步安装的应用程序
这一点可能取决于发行版情况,从技术和策略的角度看都比较复杂。
安卓、iOS、macOS 和 Windows 都有这个功能,这样可以更容易开始使用新设备或重置的同一设备。你从他们的官方应用程序商店安装的应用程序与你的个人资料相关联。你重新安装/重置操作系统,或者在一个新系统上,登录应用程序商店,它就会显示你以前使用过的应用程序。
在 Linux 上,如果你由于某种原因重新安装系统,你就会失去你所安装的应用程序。当然,你可以重新安装它们,但你也必须回忆起你以前安装的应用程序。
我记得 Ubuntu 曾经有个 Ubuntu One 云,我以为他们会推出这个功能,但他们关闭了这个云服务。然而,Ubuntu One 仍然活着,并被用作 SSO 登录。事实上,你可以在 Ubuntu 软件中心看到 Ubuntu One 的登录选项,但它并没有做任何事情。

知道你之前从 GNOME 软件中心安装了哪些软件,将使电脑的格式化和在电脑之间的移动更加容易。你不觉得吗?
当然,许多 Linux 用户不一定依靠软件中心来获取应用程序,但这对一些人来说可能是一个有用的功能。
### 4、面部解锁和/或指纹登录
我喜欢用密码登录并解锁 Windows 的方式。是的,我偶尔会使用 Windows。不,不是用来玩游戏,而是用超高清观看流媒体内容。过去几周我用得比较频繁,因为我在另一个城市,我必须依靠我的笔记本电脑来观看 4K 的 Netflix,而不是使用我的电视。
输入整个 8 到 10 个字符的长密码,加上特殊字符,总觉得是件麻烦事。值得庆幸的是,我的笔记本电脑有一个指纹识别器,但不是每个人都有这种奢侈。
对于许多已经习惯于在移动设备上使用这些方法的用户来说,使用指纹或面部来解锁设备可能会很好。
已经有一些项目允许你在 Linux 上使用面部解锁,GNOME 确实可以考虑将其加入到其产品中。
### 5、带回“添加新文档”选项
几年前,GNOME 删除了从右键菜单中创建一个新文档的功能。
现在仍然可以实现这个功能。你必须先在你的主目录的 Templates 文件夹中创建一个模板文档。然后所有的模板文档都可以在右键菜单中找到。

但这本应是一个默认功能。人们不应该胡乱摆弄而试图找出“创建新文档”选项的去处。
现在是时候让 GNOME 恢复这个功能了。
### 你希望在 GNOME 中看到什么功能?
由于我主要使用 Ubuntu,它的定制 GNOME 与原生 GNOME 不同。原生 GNOME 也应该把小程序指示器带回来,这样像 Dropbox 等应用程序就可以快速访问。
GNOME 开发者不太可能关注像我们这样的普通 Linux 用户的想法,但我还是要问问你怎么看。
你希望在 GNOME 或桌面 Linux 中看到什么新功能?你也可以分享一些你最喜欢的、已经从 GNOME 中删除的,但你希望它们能重新出现的功能。
---
via: <https://news.itsfoss.com/gnome-features-i-want/>
作者:[Abhishek](https://news.itsfoss.com/author/root/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

GNOME is the default choice of desktop environment on many Linux distributions. It’s also my favorite one as it gives a modern desktop experience.
But that doesn’t mean GNOME is perfect and doesn’t need improvements. In fact, here are a few suggestions to improve the overall user experience.
## 1. Easy application uninstall option
Desktop Linux is fragmented. To add to the mess, the packaging is also fragmented. And the worst part is removing an application from the system.
Take this, for example. You install an application using the DEB package and install it using the GNOME Software Center screen.
But what if you don’t like the application and want to remove it?
You won’t find the application listed in the software center. Instead, you will have to use the command-line method.
That is not the end of the story. There are Snap and [Flatpak](https://itsfoss.com/what-is-flatpak/?ref=news.itsfoss.com) packages as well. If you have used one of them, you’ll have to figure out that first and then use the correct command for the installation.
GNOME has adopted an Android/iOS-like approach to display the applications in a grid and organize them in folders. The mobile operating systems provide an option for the users to hold the icon and remove the app. It would be nice to have a similar option to right-click on the application icon and choose to uninstall.

This way, the end-users won’t have to worry whether the installed application is Deb package or Snap. There is no need to go into the terminal for that, and it happens right where the application is accessible, makes sense?
Linux Mint Cinnamon edition has this feature where you right-click on an application entry in the menu and select remove to uninstall it.

If Cinnamon can do it, GNOME should be able to do it as well, right?
## 2. Set default software source in app store
GNOME Software center lets you choose the software source if an application is available in more than one format. At least that’s what I have seen in GNOME Software in Fedora but not in Ubuntu.
Say someone has added both Flatpak and Snap support to the software center. If an application is available in Flatpak, Snap, and the package manager (apt, DNF, etc.), it will probably be shown multiple times in the search results.
It would be good to have the ability to set a default packaging format that takes precedence over other formats. If you put Flatpak as default, it doesn’t show the Snap version, and only the Flatpak version is installed by default.
## 3. Syncing installed applications across systems
This one is probably dependent on the distributions and more complicated from both technical and policy point of view.
Android, iOS, macOS, and Windows have this feature, making it easier to start using a new device or the same device after a reset. The applications you install from their official applications stores are linked to your profile. You reinstall/reset the OS, or you get a new system, log in to the application store, and it shows the applications you had used previously.
On Linux, if you reinstall your system for some reason, you lose the applications you had installed. You can, of course, reinstall them, but you also have to recall which applications you had installed previously.
I remember Ubuntu had the Ubuntu One cloud once upon a time and I thought they would introduce this feature, but they shut down the cloud service. However, Ubuntu One is still alive and used as SSO login. In fact, you can see the sign-in option to Ubuntu One in Ubuntu Software Center, but it doesn’t do anything.

Knowing which software you previously installed from the GNOME software center will make formatting the computer and moving between computers easier. Don’t you think?
Of course, many Linux users don’t necessarily rely on the software center for getting the applications, but this could be a helpful feature for some.
## 4. Face unlock and/or pin login
I like the option to log in and unlock Windows with a pin. Yes, I use Windows occasionally. No, not for gaming, but watch streaming content in Ultra HD. I have been using it more frequently for the past couple of weeks because I am in another city, and I have to rely on my laptop to watch Netflix in 4K instead of using my TV.
Typing the entire 8/10 characters long password with special characters always feels like a chore. Thankfully, my laptop has a fingerprint reader, but not everyone has that luxury.
Using a pin or face to unlock the device could be interesting for many users who have grown accustomed to these methods on their mobile devices.
There are already a few projects that allow you to use face unlock on Linux, and GNOME could indeed consider adding it to its offering.
## 5. Bring back ‘add new document’ option
A few years ago, GNOME removed the capability to create a new document from the right-click menu.
It is still possible to achieve that. You have to create a template document first in the Templates folder of your home directory. All the templates documents are then available in the right-click context menu.

But this should have been a default feature. People should not be fiddling around, trying to figure out where the ‘create new document’ option went.
Its high time GNOME brings this feature back.
## What features do you want to see in GNOME?
Since I primarily use Ubuntu, the customized GNOME differs from the vanilla GNOME. The vanilla GNOME should also bring back the applet indicator so that applications like Dropbox etc can be quickly accessed.
It’s less likely that GNOME developers will pay attention to what ordinary Linux users like us think, but I’ll still ask your opinion.
What new feature would you like to see in GNOME or desktop Linux? You may also share some of your favorite features that have been removed from GNOME, and you would like to have them back.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,169 | 2021 总结:推进你的 Kubernetes 之旅的 15 种方法 | https://opensource.com/article/21/12/learn-kubernetes-2022 | 2022-01-11T16:52:34 | [
"Kubernetes"
] | /article-14169-1.html |
>
> 无论你是在家庭实验室里试验 Kubernetes,还是想成为一个成为 Kubernetes 的维护者,这里都有适合你的资源。
>
>
>

2021 年对于 Kubernetes 来说是令人兴奋的一年,这些文章证明了这一点。从有趣的界面到家庭实验室再到开发环境,看看我在 2021 年最喜欢的 K8s 文章。
如果你对基本原理感兴趣,这篇 [介绍 Linux 上的容器](https://opensource.com/article/21/8/container-linux-technology) 的文章从内到外阐明了 Linux 容器的工作原理。你是否想获取一些乐趣?安装 minikube 并开始使用 [DOOM 游戏作为界面](https://opensource.com/article/21/6/kube-doom) 来管理它。另一个选择是 [kubectl](https://opensource.com/article/21/7/kubectl),这是一个更传统的 Kubernetes 控制 CLI。
即使你只在你的 [Linux 家庭实验室](https://opensource.com/article/21/6/kubernetes-linux-homelab) 上运行 Kubernetes,你也可以使用 [Terraform 和 Helm](https://opensource.com/article/21/8/terraform-deploy-helm) 等工具来自动化日常操作。这创造了一个 [更好地掌握 Terraform](https://opensource.com/article/21/8/terraform-tips) 的机会。
生活中可以确定的几件事之一是,计算机会以奇怪而有趣的方式出错。[用 Prometheus 和 Grafana 监控你的 Kubernetes 集群](https://opensource.com/article/21/6/chaos-grafana-prometheus),看看它是如何出错的。[使用 Grafana Tempo 的分布式跟踪](https://opensource.com/article/21/2/tempo-distributed-tracing)来监控里面运行的应用。通过引入 [Chaos Mesh](https://opensource.com/article/21/6/chaos-mesh-kubernetes) 在 Kubernetes 中造成有意的混乱,来监控你监控的性能。
如果你正在开发在 Kubernetes 上运行的应用,[Quarkus 可以帮助你开发和测试](https://opensource.com/article/21/7/developer-productivity-linux)。使用 Java 的开发者 [可以在 Kubernetes 上使用容器运行](https://opensource.com/article/21/5/what-serverless-java) 应用。像 [Tackle-DiVA](https://opensource.com/article/21/6/tackle-diva-kubernetes) 这样的工具有助于将应用移植到容器中。
像所有成功的开源项目一样,Kubernetes 的部分价值是一个强大的 [生态系统](https://opensource.com/article/21/6/kubernetes-ebook)。比如 [KubeEdge 项目](https://opensource.com/article/21/1/kubeedge),它有助于将计算和数据更接近终端用户。在使用 Kubernetes 一段时间后,你甚至可能想 [成为 Kubernetes 维护者](https://opensource.com/article/21/2/kubernetes-maintainer)。
有这么多有趣的 Kubernetes 内容可供学习,可能很难将它们全部看完。不过,对于系统管理员和开发人员来说,优秀的 Kubernetes 资源是必须的。请阅读这些精选的内容。
---
via: <https://opensource.com/article/21/12/learn-kubernetes-2022>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
14,171 | NIST 的目标是使无线网络的频率共享更加有效 | https://www.networkworld.com/article/3561618/nist-aims-to-make-frequency-sharing-more-efficient-for-wireless-networks.html | 2022-01-12T13:09:00 | [
"5G",
"频谱"
] | https://linux.cn/article-14171-1.html |
>
> 机器学习方案将帮助不同的无线电协议,如 Wi-Fi 和 LTE,在同一的无线频谱中更有效地协同工作。
>
>
>

美国国家标准与技术研究所([NIST](https://www.nist.gov/))开发的机器学习方案有可能显著改善 [5G](https://www.networkworld.com/article/3330603/5g-versus-4g-how-speed-latency-and-application-support-differ.html) 和其他无线网络选择和共享通信频率的方式。研究人员声称,与试错法相比,NIST 的方案可以使共享通信频率的过程的效率提高多达 5000 倍。
NIST 系统的理念是,无线电设备可以从经验中学习其网络环境,而不是像现在这样,简单地根据试错法选择频率信道。
NIST 在 [其网站上的一篇文章](https://www.nist.gov/news-events/news/2020/05/nist-formula-may-help-5g-wireless-networks-efficiently-share-communications) 中说,在特定的环境条件下,“该算法可以学习哪个信道提供最好的结果”。
该团队说:“该方案可以被编程到现实世界中许多 [不同] 类型网络的发射机软件中。”
从本质上讲,这个计算机模拟的算法是一个映射环境射频条件的先前经验的公式。例如,这些条件可以包括在一个信道(一组相邻的频率)内运行的发射机的数量。
文章说:“……如果发射机选择了一个未被占用的信道,那么成功传输的概率就会上升,从而导致更高的数据速率。”同样地,当发射机选择一个没有太多干扰的信道时,信号会更强,你也会得到更好的数据速率。发射机会记住哪个信道提供了最佳结果,并学会在下次需要清晰信号时学会选择那个位置。
这与今天的工作方式不同。也就是说,无线电只是试图找到一个开放频率,然后与类似协议的无线电进行通信。在复杂的情况下,使用诸如 Wi-Fi、跳频和 [波束成形](https://www.networkworld.com/article/3445039/beamforming-explained-how-it-makes-wireless-communication-faster.html) 等技术来优化信道。
研究人员解释说,NIST 的机器学习技术的亮点在于共享频谱,比如通过授权频谱辅助接入(LAA)共享 Wi-Fi。LAA 是非授权频谱中的 LTE 频谱,称为 LTE-U,频率为 5GHz。在相同频率下的 Wi-Fi 与 LAA 的组合中,协议是不同的:无线电之间不能相互通信以协调工作,而且频带越繁忙就可能出现混乱 —— 传输会遇到其他传输。但是,如果所有的无线电接收机都能更好地选择它们的占位,通过学习哪些有效,哪些无效,那么这将会更好。
NIST 工程师 Jason Coder 在文章中说:“这可能会使非授权频段的通信更加高效。”
事实上,NIST 声称,它“可以帮助 5G 和其他无线网络选择和共享通信频率,其效率大约是试错法的 5000 倍。”
这里的关键词是“共享”,因为为了在有限的频谱内增加通信,必须进行更多的共享 —— 物联网或媒体流等用户都在争夺同样的隐喻资产。随着物联网和数字技术的不断发展,非授权和授权频段的结合,就像 LAA 中的情况一样,可能会变得更加普遍。(非授权的频段是指那些没有分配给特定用户的频段,比如移动网络运营商;授权频段是在拍卖中中标并分配的。)
在 NIST 场景中,相互竞争的发射机“各自学习在不相互通信的情况下最大化网络数据速率”。因此,多种协议和数据类型,如视频或传感器数据,或 Wi-Fi 和移动网络,可以相互协作。
NIST 的方案大大简化了为发射机分配最佳信道的过程,根据这篇文章研究发现,穷尽努力 [使用试错法] 来确定最佳解决方案需要大约 45600 次试验,而这个方案只需要尝试 10 个渠道就可以选择类似的解决方案,仅仅付出 0.02% 的努力。”
NIST 的研究人员在 IEEE 第 91 届车辆技术会议上展示了他们的研究成果。
---
via: <https://www.networkworld.com/article/3561618/nist-aims-to-make-frequency-sharing-more-efficient-for-wireless-networks.html>
作者:[Patrick Nelson](https://www.networkworld.com/author/Patrick-Nelson/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[CN-QUAN](https://github.com/CN-QUAN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
14,172 | 一些经典 Linux 命令的现代替代品 | https://itsfoss.com/legacy-linux-commands-alternatives/ | 2022-01-12T15:52:28 | [
"Linux",
"命令",
"替代品"
] | https://linux.cn/article-14172-1.html | 
当你 [开始学习 Linux](https://academy.itsfoss.com/) 时,最初学习的是一套标准的 Linux 命令,这些命令从 UNIX 时代就已经存在了。随着你作为一个 Linux 用户的年龄增长,你会不断地掌握这套标准命令。
但是,这些标准的、传统的命令是几十年前创建的,虽然它们完成了预定的工作,但是它们的功能还可以改进,结构还可以简化。
这就是为什么存在 “替代” 工具,以加强传统的 UNIX/Linux 命令。在这篇文章中,我将列出一些新的命令行工具,你可以用这些工具来代替旧式的经典 Linux 命令。
请注意,你不应该过分依赖这些替代品,特别是如果你管理(或计划管理)许多 Linux 服务器时。传统的 Linux 命令在所有的 Linux 发行版和 Linux 服务器上都可以找到。这些现代的替代方案很有可能在远程服务器上无法使用。
在你的个人能力范围内,你可以学习了解这些新的工具,以帮助你更有效率。
听起来不错?让我们看看你是否能在这里找到你下一个最喜欢的命令行工具。
### HTTPie: wget 和 curl 的替代品
[在终端下载文件](https://itsfoss.com/download-files-from-linux-terminal/) 时,`wget` 和 `curl` 是两个最常用的工具。有趣的是,并不是所有的发行版都默认安装了 `curl` 和 `wget`。
HTTPie(`http`)以一种更人性化的方式做同样的工作。你会看到彩色的、格式化的输出,这使得它更容易理解和调试。

### 蝙蝠:猫的替代品
`cat` 命令可能是你最先学会的命令之一。它可以完成查看小型文本文件内容的工作。
但 [bat 命令](https://github.com/sharkdp/bat) 更上一层楼,添加了语法高亮和 Git 集成等功能,并且还提供了分页选项。

### ncdu: du 命令的替代品
Linux 中的 [du 命令](https://linuxhandbook.com/find-directory-size-du-command/) 用来检查一个目录的大小。这不是一个非常直观的命令,当然它的默认输出也不算非常好。
与此相比,`ncdu` 要好得多,它能及时提供相关信息。

它还有其他一些功能,比如用图表显示磁盘使用情况,对显示进行排序,甚至可以交互式地删除目录。
它是基于 ncurses 的,因此 “nc” 这个前缀被加到 `du` 中。此外,还有一个类似的 CLI 工具:[gdu](https://itsfoss.com/gdu/),也是一个 `du` 的替代品,因为是使用 Go 编写的,这使得它的性能得到了提升。
### htop: top 命令的替代品
`top` 命令是 Linux 终端中的任务管理器。它是一个查看运行进程和资源消耗的好工具,但是 [理解和使用 top 命令](https://linuxhandbook.com/top-command/) 可能很复杂。
另一方面,[htop](https://htop.dev/) 有一个漂亮的彩色输出,并且界面比 `top` 命令更直观。你可以垂直和水平滚动,以图形方式配置显示的信息。你可以在 `htop` 的输出屏幕上交互式地杀死进程。

### fd:find 命令的替代品
`find` 命令是最强大和最常用的 Linux 命令之一。不能想象一个系统管理员可以不使用 `find` 命令就能生存下去。
但是,`find` 命令的结构奇怪,如果你进行大量的查找操作,它可能会很慢。
一个更好、更快的替代方案是 [fd 命令](https://github.com/sharkdp/fd)。`fd` 是用 Rust 编写的,它比其传统的竞争对手更简单、更快速。

### exa:ls 命令的替代品
[exa](https://itsfoss.com/exa/) 命令行工具不止可以列出目录内容。它的默认设置更好,使用颜色来区分文件类型和元数据。`exa` 还可以显示一个文件的扩展属性,以及标准的文件系统信息,如 inode、块数,以及文件的各种日期和时间。
你可以使用树状视图来查看目录结构。它也有内置的 Git 支持,可以看到哪些文件被修改、提交和暂存等。

### duf:df 命令的替代品
Linux 中的 [df 命令](https://linuxhandbook.com/df-command/) 用来检查磁盘空间。虽然它在大多数情况下都不错,但一个更简单、更好的替代方法是 [duf](https://itsfoss.com/duf-disk-usage/),这是一个用 Go 编写的工具。
它提供了一个所有挂载设备的概览,这很容易理解。你还可以指定一个目录/文件名并检查该挂载点的可用空间。
通过 `duf`,你可以对输出进行排序、列出 indoe 信息,甚至将输出保存为 JSON 格式。

### 太长不读:男人的替代品
我知道对于纯粹主义者来说,[Linux 中的手册页](https://itsfoss.com/linux-man-page-guide/) 是不二之选。但是,手册页有时会过于详细和复杂,难以阅读和理解。
这就是 `tldr` 登场的时机。“TLDR” 是流行的互联网行话,意思是“<ruby> 太长不读 <rt> to long didn't read </rt></ruby>”。这就是他们创建 `tldr` 的想法。如果你觉得手册页太长而不想阅读,[tldr 通过提供命令的实际例子而将其简化了](https://itsfoss.com/tldr-linux-man-pages-simplified/)。

### Neovim:Vim 的替代品
我希望我在这里没有冒犯谁,但更好的 Vim 不是 Emacs,而是 [Neovim](https://neovim.io/)。
几年前,作为对传统的 Vi 编辑器的改进,Vim 出现了。又是几年过去了,Neovim 提出了将 Vim 扩展为一个 IDE 的想法。
它增加了现代终端的功能,如光标样式、焦点事件、括号内粘贴等,并内置了一个终端模拟器。最重要的是,你不需要忘却 Vim 的习惯就可以开始使用 Neovim。
### 你的选择呢?
再次强调,这些替代命令还不能完全替代原来的命令,特别是如果你管理许多 Linux 系统的话。你可能无法在所有的系统上找到并安装它们。只有你可以完全控制你的 Linux 机器时,它们才是好东西。
除此以外,你是否在这个列表中找到了一些好的替代命令行工具?是哪一个呢?另外,你知道其他一些可以 “替代” 传统 UNIX 命令的工具吗?为什么不在评论区与我们分享呢?
---
via: <https://itsfoss.com/legacy-linux-commands-alternatives/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When you [start learning Linux](https://academy.itsfoss.com/), you begin with a standard set of Linux commands that have been in existence since the UNIX days. As you grow old as a Linux user, you keep on mastering the same set of standard commands.
But these standard, legacy commands were created several decades ago and while they do their intended jobs, their functionalities could be improved and the structure could be simplified.
This is why there exists ‘alternative’ tools that enhance the legacy UNIX/Linux commands. In this article, I am going to list some new CLI tools that you could use in place of the good old classic Linux commands.
Please note that you should not rely too much on these alternatives, specially if you manage (or plan to manage) numerous Linux servers. The legacy Linux commands are found on all Linux distributions, all Linux servers. These modern replacements are more likely to be not available on remote servers.
In your individual capacity, you can always explore these new tools that could help you in being more efficient.
Sounds all good? Let’s see if you can find your next favorite CLI tool here.
## HTTPie: Alternative to wget and curl
When it comes to [downloading files in terminal](https://itsfoss.com/download-files-from-linux-terminal/), wget and curl are the two of the most common tools. Interestingly, not all distributions have curl, wget installed by default.
HTTPie does the same job but in a more human-friendly way. You have colorized, formatted output which makes it easier to understand and debug.
## Bat: Alternative to cat
The cat command is perhaps one of the first command you learn. It does the job for viewing the contents of small text files.
But [bat command](https://github.com/sharkdp/bat) takes it to the next level by adding features like syntax highlighting and Git integration. Pagination option is also available.
## ncdu: Alternative to du command
The [du command in Linux](https://linuxhandbook.com/find-directory-size-du-command/) is used for checking the size of a directory. It’s not very straightforward command and it certainly doesn’t give a very good default output.
Compared to that, ncdu is a lot better than providing the relevant information at the first glance.
There are other features here such as showing the disk usage in graphs, sort the display and even delete directories interactively.
It is based on ncurses and hence the ‘nc’ is added to ‘du’. A similar CLI tool is [gdu](https://itsfoss.com/gdu/) which is a du replacement written in Go which gives it a performance boost.
## Htop: Alternative to top command
The top command in works as the task manager in Linux terminal. It is a good tool for looking at running processes and resource consumption but [understanding and using the top command](https://linuxhandbook.com/top-command/) could be complicated.
[Htop](https://htop.dev/) on the other hand has a pretty, colorful output and a more intuitive interface than the top command. You can scroll vertically and horizontally, configure the displayed information graphically etc. You can kill processes interactively right from the output screen of htop.
## fd: Alternative to the find command
The find command is one of the most powerful and most used Linux commands. It’s impossible to imagine that a sysadmin could survive without using the find command.
But the find command has a strange structure and it could be slow if you do a large set of find operations.
A better and faster alternative is [fd command](https://github.com/sharkdp/fd). Written in Rust, fd is simpler and faster than its legacy competitor.
## exa: Alternative to ls command
The [exa CLI tool](https://itsfoss.com/exa/) adds a few features while listing directory contents. It has better defaults and uses colors to distinguish file types and metadata. exa can also display a file’s extended attributes, as well as standard filesystem information such as the inode, the number of blocks, and a file’s various dates and times.
You can use the tree view to see directory structure. It also has built-in Git support to see what files have changed, committed and staged etc.
## Duf: Alternative to the df command
The [df command in Linux](https://linuxhandbook.com/df-command/) is used for checking disk space. While it works most of the time, an easier and better alternative is [duf](https://itsfoss.com/duf-disk-usage/), a tool written in Go.
It gives you an overview of all the devices mounted which is easy to understand. You also have the ability to specify a directory/file name and check free space for that mount point.
With duf, you can sort the output, list indoe information and even save the output in JSON format.
## Tldr: Alternative to man command
I know the purist says that there is no alternative to the [man pages in Linux](https://itsfoss.com/linux-man-page-guide/). But man pages could be too detailed and complicated at times to read and understand.
Enter tldr. TLDR is the popular Internet jargon for ‘too long didn’t read’. And that’s the idea behind the creation of tldr. If you find man pages too long to read, [tldr simplifies](https://itsfoss.com/tldr-linux-man-pages-simplified/) that by providing practical examples of the command.
## Neovim: Alternative to Vim
I hope I am not committing a blasphemy here but a better Vim is not Emacs, it’s [Neovim](https://neovim.io/).
Years ago, Vim came up as an improvement to the legacy Vi editor. A few years back, Neovim came up with the idea to extend Vim as an IDE.
It adds modern terminal features such as cursor styling, focus events, bracketed paste etc. with a built-in terminal emulator. The best thing is that you don’t need to unlearn Vim to start using Neovim.
[7 Reasons NeoVim is Better Than VimNepVim or Vim? Which one of the two similar editors is better? I think it is NeoVim and I have good reasons to support this claim.](https://linuxhandbook.com/neovim-vs-vim/)

## Your choice?
Again, these alternative commands should not be considered as a drop-in replacement, specially if you manage numerous Linux systems. You may not find and install them on all the systems. They are good only if you have full control on your Linux machine(s).
Keeping that aside, did you find some good alternative command line tools in this list? Which one is it? Also, do you know some other tools that could ‘replace’ the legacy UNIX commands? Why not share it with us in the comment section? |
14,174 | 给儿童、教师和学校的最佳 Linux 发行版 | https://itsfoss.com/educational-linux-distros/ | 2022-01-13T08:23:14 | [
"教育",
"发行版"
] | https://linux.cn/article-14174-1.html | 
孩子们可以使用 Linux 发行版吗?它又是否适合学校使用呢?
嗯,这取决于你有什么选择,以及你想选择的是什么。不管你是想给孩子还是学校老师用,都有不少选择。
因此,为了给你一个良好的开端,我们策划了一个为教育量身定做的 [最佳 Linux 发行版](https://itsfoss.com/best-linux-distributions/) 列表。
### 最适合儿童的 Linux 发行版
对于一个孩子来说,发行版必须提供一个用户友好的用户界面,而不是高级功能。
你可能会说,任何主流的、[像 Ubuntu](https://itsfoss.com/best-linux-beginners/)、Mint 或 Zorin 这样适合初学者的发行版都可以做到这一点。没错,但是如果一个发行版带有了 [基本工具](https://itsfoss.com/essential-linux-applications/) 并易于使用,孩子们会很快学会使用它并喜欢上它。
#### 1、Endless OS

[Endless OS](https://endlessos.com/home/) 是一个流行的选择,是为教育量身定做的 Linux 发行版。
它以 Debian 为基础,使用 GNOME 桌面环境。尽管它限制了一年内在超过 500 台电脑上使用其操作系统,但它是免费下载的。
它的用户界面很容易使用,看起来很有吸引力,适合安装在现代电脑上。你可以得到各种预装的应用程序。因此,这对没有互联网接入的电脑来说是很方便的。
#### 2、Ubermix

[Ubermix](https://ubermix.org/download.html) 是一个基于 Ubuntu 的 Linux 发行版,旨在通过调整用户界面,摆脱不必要的应用程序,以及增加用于教育的必要工具/应用程序来降低复杂性。
它还提供了一种方法,在出现问题的情况下可以轻松地从系统问题中恢复。在内容过滤和 [屏幕时间控制](https://itsfoss.com/activitywatch/) 方面有一个可选的家长控制功能,这确实很有用。
Ubermix 得到了积极的维护,并在其官方网站上提供了大量关于安装和故障排除的说明。
#### 3、Kano OS(用于树莓派)

[Kano OS](https://kano.me/row/downloadable) 是为 6 至 14 岁的儿童教育而量身定做的计算套件。它就像高级版的树莓派,为年轻人提供了大量的 DIY 和编码活动。
Kano OS 也有基于 Debian 的 [用于树莓派的操作系统](https://itsfoss.com/raspberry-pi-os/)。你不需要为此而购买 Kano 套件。你可以在你的树莓派上使用它。
它的目的是在与他们的计算机套件结合时,提供它所策划的教育的好处。从编码应用程序到游戏,应该有适合每个人的东西。
你还会发现有用的家长控制设置,可以为你的孩子限制/调整体验。如果需要更多的帮助,[官方帮助资源](https://help.kano.me/hc/en-us/sections/360001083699-Kano-OS) 也会派上用场。
#### 4、AcademiX GNU/Linux

[AcademiX](https://academixproject.com/en/home/) 是另一个基于 Debian 的发行版,主要用于学习。
不仅仅是初级教育,该操作系统中包含的程序对大学生也应该是有用的。它还包括虚拟互动实验室和虚拟显微镜。
**虽然它通过预装的实用程序使学习变得简单,但教师也可以用它来创建内容和发布。**
因此,它可以成为很多潜在的学习者和学校教师的一个全能选择。
#### 5、Sugar(使任何发行版都对儿童友好)

[Sugar](https://www.sugarlabs.org) 不是一个成熟的操作系统,而是一个学习平台(环境),它可以安装在任何 Linux 发行版之上,为学习而设置。
不仅仅是帮助你的孩子用一个易于使用的界面学习,它还有有助于协作、分享和学习而预装的软件工具。
它也可用于树莓派。而且提供了 [Flatpak 包](https://itsfoss.com/what-is-flatpak/),可以让你在任何 Linux 发行版中轻松安装它的一些学习活动。
#### 6、Li-f-e
Linux for education([Li-f-e](https://sourceforge.net/projects/cyberorg-home/files/Li-f-e/))最初是 OpenSUSE 的一个项目,这是它的一个延续。
尽管它现在没有 OpenSUSE 的支持(我找不到任何参考资料),但它对孩子和学校来说可能是一个有用的选择。
这款软件基于 Ubuntu MATE,按照一些教科书的说法,它提供了几个内置的应用程序。它并没有提供什么特别的东西,而更像是 Ubuntu 教育版,在写这篇文章的时候,它正在积极维护。
### 最适合学校的 Linux 发行版
到目前为止,我提到的那些都是为孩子们的教育和学习而定制的。但教育有两个部分:学生和教师。
这就是为什么这个列表分为两部分。这第二部分列出了一些可能适合学校管理者、管理层和教师的选项。
当然,如果你想利用一个稳定可靠的 Linux 桌面操作系统来管理你的学校(或)内容创作,你总是可以使用 Linux Mint、elementary OS 或 Ubuntu。然而,有一些选项是为这种目的而定制的。
#### 1、Debian Edu/Skolelinux

[Skolelinux](http://www.skolelinux.org) 是一个基于 Debian 的发行版,包含了一些适合学校师生使用的应用程序和网页服务。
它也被称为 Debian Edu。你可以通过下载所需的 ISO 或基本系统来选择离线安装,其余的可以在线安装。
尽管孩子们在安装后就可以使用它,但它需要一些学习过程来进行配置和维护。因此,这更倾向于学校管理人员或教师,而不是孩子。
#### 2、Linux Schools(Karoshi 服务器)
一个具有 Ubuntu LTS 优点的 Linux 发行版,为学校服务器而建。如果你想建立一个服务器并监视/控制一个连接的服务器网络,[Linux Schools](https://www.linuxschools.com/forum/index-main.php)(或 Karoshi 服务器)是一个很好的选择。
它可以让你使用网页界面管理一个服务器网络。你不需要 Linux 系统管理的深入知识来利用它。
#### 3、Escuelas Linux

[Escuelas Linux](https://escuelaslinux.sourceforge.io/english/index.html) 是基于 Bodhi Linux 的。它内置了几个适合教育环境的应用程序。
它有自定义的工具,可以在几秒钟内将发行版重设为安装后的状态。也有恢复用户身份的选项。除此之外,它还带有在网络中分发教育材料、屏幕广播、镜像、远程命令执行、信息发送、屏幕锁定和对学生的计算机进行静音的应用程序。
考虑到它基于 Bodhi Linux,而 Bodhi Linux 是 [最好的轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/) 之一,这对旧系统来说是个不错的选择。
如果你需要 NetBeans、Git、Android Studio 等高级工具,你还可以得到一个额外的开发者包,这是可选安装的。
除了这些选择之外,还有 [EduBOSS](https://bosslinux.in/eduboss),这是 BOSS Linux 的教育版,是为印度学校量身定做的。
### 总结
虽然有一百多个 Linux 发行版,但只有少数几个是专门为教育而设计的。
对于学生、教师和学校管理来说,有一些可行的选择是件好事。
毕竟,Linux 可以到处使用,任何人都可以使用。我说的对吗?
---
via: <https://itsfoss.com/educational-linux-distros/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Can kids use Linux distributions? And is it suitable for school use?
Well, that depends on what are your options and what you choose to go with. No matter whether you want something for a kid or the school teacher, there are options available.
Hence, to give you a head start, we have curated a list of the [best Linux distributions](https://itsfoss.com/best-linux-distributions/) tailored for education.
## Best Linux Distribution for Kids
For a kid, a distribution has to offer a user-friendly UI minus the advanced functionalities.
You may argue that it can be done with any mainstream, [beginner-friendly distro like Ubuntu](https://itsfoss.com/best-linux-beginners/), or Mint. You are right, but if a distribution comes with [essential tools](https://itsfoss.com/essential-linux-applications/) necessary for education baked in, it makes things easy and convenient.
### 1. Endless OS

Endless OS is a popular option to go for as a Linux distro tailored for education.
It is based on Debian and uses a GNOME desktop environment. Even though it restricts usage of its OS on more than five hundred computers in a year, it is free to download.
The user interface is easy to use and looks attractive for installation on a modern PC. You get a variety of applications pre-installed. Hence, this comes in handy for computers with no internet access.
### 2. Ubermix
Ubermix is an Ubuntu-based Linux distribution that aims to reduce the complexity by tweaking the user interface, getting rid of unnecessary apps, and adding essential tools/apps for education.
It also offers a way to easily recover from a system issue in case there is a problem. An optional parental control feature is present for content filtering and [screen time controls](https://itsfoss.com/activitywatch/), which is indeed useful.
Ubermix is actively maintained and provides plenty of instructions for installation and troubleshooting on its official website.
### 3. Zorin OS 16 Education
Zorin OS offers an education edition tailored for schools and universities, in some cases.
With [Zorin OS 16 Education](https://news.itsfoss.com/zorin-os-16-education-release/) (with GNOME), you get plenty of offline content, which makes educational resources accessible in areas even without a proper internet connection. It also supports sharing the resources through the network using peer-to-peer techniques.
In addition to the tech behind offline-ready content, it includes several open-source applications and offers the ability to download resources from a variety of sources like Khan Academy.
Apps like [OpenBoard](https://itsfoss.com/openboard/) and interactions through the projector or a screen. You also find apps for specific topics, like the ability to calculate things or organize them.
Zorin OS Education also provides a Lite version (based on XFCE) for systems that come with dated/low-end hardware. So, with either the full/lite edition, you can start enjoying the distro made for education.
### 4. Kano OS (for Raspberry Pi)
Kano is a computing kit tailored for educating children from 6 to 14 years. It’s like a premium version of Raspberry Pi with plenty of DIY and coding activities for the young ones.
[lasso box=”B073VTCS66″ link_id=”20955″ ref=”kano-computer-kit-a-computer-anyone-can-make” id=”101751″]
Kano also has Debian based [operating system for Raspberry Pi](https://itsfoss.com/raspberry-pi-os/). You don’t need to have a Kano kit for this purpose. You can use it on your Raspberry Pi.
It aims to provide the benefits of it—curated for education when coupled with their computer kits. Ranging from coding apps to games, there should be something for everyone.
You will also find useful parental control settings to limit/tweak the experience for your kid. For additional help, the [official help resources](https://help.kano.me/hc/en-us/sections/360001083699-Kano-OS) will come in handy as well.
### 5. AcademiX GNU/Linux

Yet another distribution based on Debian focused on learning.
Not just for primary-level education, but the programs included in the operating system should be useful for university students as well. It also includes virtual interactive labs and a virtual microscope.
**While it makes learning easy with the utilities pre-installed, teachers can also use it to create content and publish.**
So, it can be an all-in-one choice for a lot of potential learners and teachers in school.
### 6. Sugar (makes any distro kids friendly)
Sugar is not a full-fledged OS but a learning platform (environment) that can be installed on top of any Linux distro to set it up for learning.
Not just to help your kid learn with an easy-to-use interface, it also helps collaborating, sharing, and learning pre-installed software tools.
It is also available for Raspberry Pi computers. And a [Flatpak package](https://itsfoss.com/what-is-flatpak/) lets you easily install some of its activities in any Linux distribution.
### 7. Li-f-e
Linux for education (Li-f-e) was originally a project by OpenSUSE and this is a continuation of that.
Even though it is not backed by OpenSUSE now (I couldn’t find any references), it could be a useful option for kids and schools.
This is based on Ubuntu MATE and offers several built-in applications as per some of the textbooks. It does not offer anything extraordinary but more like Ubuntu for education, which is actively maintained at the time of writing this.
## Best Linux Distribution for Schools
The ones I mentioned so far were tailored to be used by children for their education and learning. But education has two parts: students and teachers.
This is why this list is divided into two parts. This second part lists some options that can be a good fit for school administrators, management, and teachers.
Of course, you can always use Linux Mint, elementary OS, or Ubuntu if you want to utilize a stable and reliable Linux desktop OS to manage your school (or) content creation. However, there are some choices that are customized for the purpose.
### 1. Debian Edu/Skolelinux

*Image Credits: Distrowatc*h
Skolelinux is a Debian-based distribution that comes packed with several applications and networking services fit for students and teachers in school.
It is also known as Debian Edu. You get the ability to opt for offline installation by downloading the required ISO or the base system with online installation for the rest.
Even though kids can use it after setup, it requires a bit of learning curve to configure and maintain. Hence, this is more inclined towards school administrators or teachers than kids.
### 2. Zorin OS 16 Education
While I mentioned it is a good fit for kids, you can also use it for schools and universities.
It gives you the ability to keep an eye on what your students are doing to make sure that they are interacting with the learning tasks assigned. Zorin OS Education utilizes [Veyon](https://veyon.io/en/) to achieve that.
Of course, it is highly unlikely that you would need that for kids. But, when it comes to schools, the ability to manage other connected computers, along with useful educational tools/resources should be a perfect choice.
### 3. Linux Schools (Karoshi Server)
A Linux distribution with the perks of Ubuntu LTS built for school servers. If you want to setup a server and monitor/control a network of connected servers, Linux Schools (or Karoshi Server) is a good fit.
It lets you administer a network of servers using a web interface. You do not need in-depth knowledge about Linux system administration to utilize it.
### 3. Escuelas Linux
[Escuelas Linux](https://itsfoss.com/escuelas-linux/) is based on Bodhi Linux. It comes baked in with several applications fit for educational environments.
It has custom tools for resetting the distro to the post-installed state in seconds. There are also options to reinstate users. Apart from that, it comes with applications for distributing educational material within the network, screen broadcasting, mirroring, remote command execution, message sending, screen locking, and muting sound to the students’ computers.
Considering it is based on Bodhi Linux, which is one of the [best lightweight Linux distros](https://itsfoss.com/lightweight-linux-beginners/), this can be a good pick for older systems.
It supports both 64-bit and 32-bit systems, so you should not have any issues installing in a variety of hardware.
You will also find a separate Developer Pack of the distribution to be able to access Android Studio, Eclipse, NetBeans, Git, SQLite, and many other development-focused applications.
In addition to these options, there is also [EduBOSS](https://bosslinux.in/eduboss), an education version of BOSS Linux which is tailored for Indian schools, if that is relevant to you.
## Wrapping Up
While there are 100s of Linux distributions, only a handful exist that are specially crafted for education.
It is a good thing that there are some viable options for students, teachers, and school administration.
After all, Linux can be used everywhere and by anyone. Am I right? |
14,175 | 2021 总结:学习 C 语言编程的 5 种方法 | https://opensource.com/article/22/1/c-programming | 2022-01-13T19:21:13 | [
"C语言"
] | https://linux.cn/article-14175-1.html |
>
> 只需掌握一点 C 语言的知识,你就可以做很多事情。
>
>
>

我精通几种编程语言,但我最喜欢的是 C 语言。C 语言开发于 20 世纪 70 年代,作为一种系统编程语言,在 2021 年仍然是最受欢迎的编程语言之一。如果你想探索 C 语言的几个特点,可以从去年的这些热门文章开始:
### 在 C 语言中使用 getopt 进行短选项解析
如果你的程序每次运行时都能对用户作出反应,你就可以使它变得更加灵活。让你的用户告诉你的程序使用什么文件或如何以不同的方式做事情。为此,你需要读取命令行。[这篇文章](https://opensource.com/article/21/8/short-option-parsing-c) 告诉你如何使用 `argv` 直接读取命令行,并使用 `getopt` 读取短命令行选项。
### 在 Linux 中用 ncurses 定位屏幕上的文本
大多数 Linux 工具只是从屏幕的底部滚动文本。但如果你想在屏幕上定位文本,比如游戏或数据显示,该怎么办?这就是 [ncurses](https://opensource.com/article/21/8/ncurses-linux) 的作用。
### 用 DOS conio 开始编程
C 语言并不只适用于 Linux。你可以在许多操作系统上找到 C,包括 DOS。许多 C 程序员控制控制台输入和输出的标准方法是使用 `conio` 库。学习如何 [使用 conio` 来更新 DOS 程序的控制台](https://opensource.com/article/21/9/programming-dos-conio),包括文本颜色和文本窗口。
### 使用位域和掩码编写国际象棋游戏
在 C 语言程序中关联信息的标准方法是使用一个结合了两个或多个相关字段的结构体。例如,你可以用一个结构体来跟踪棋盘上的棋子。但是有一种更直接的方法来跟踪同样的信息,同时使用更少的数据和内存。使用 [二进制位域和掩码](https://opensource.com/article/21/8/binary-bit-fields-masks),你可以存储一个单一的值来识别每个方格中的棋子和颜色。
### C 语言编程中的 5 个常见错误以及如何修复它们
即使是最好的程序员也会产生编程错误。根据你的程序所做的事情,这些 bug 可能会引入安全漏洞,导致程序崩溃,或产生意外的行为。但是,通过一点额外的代码,你可以避免最常见和最严重的 C 语言编程错误。这里有 [五个可能破坏你的应用的 bug 以及你如何避免它们](https://opensource.com/article/21/10/programming-bugs)。
只需一点 C 语言知识,你就可以做很多事情。探索新的方法,为你的下一个 C 语言编程项目增加功能。
---
via: <https://opensource.com/article/22/1/c-programming>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I am proficient in several programming languages, but my favorite has to be C. Developed in the 1970s as a systems programming language, C remains one of the most popular programming languages in 2021. If you'd like to explore several features of the C programming language, start with these popular articles from the last year:
[Short option parsing using getopt in C](https://opensource.com/article/21/8/short-option-parsing-c)
You can make your program much more flexible if it responds to the user every time it runs. Let your user tell your program what files to use or how to do things differently. And for that, you need to read the command line. This article shows you how to read the command line directly using `argv`
and use short command-line options using `getopt`
.
[Position text on your screen in Linux with ncurses](https://opensource.com/article/21/8/ncurses-linux)
Most Linux utilities just scroll text from the bottom of the screen. But what if you wanted to position text on the screen, such as for a game or a data display? That's where `ncurses`
comes in.
[Get started programming with DOS conio](https://opensource.com/article/21/9/programming-dos-conio)
C isn't just for Linux. You can find C on many operating systems, including DOS. The standard way for many C programmers to control console input and output was with the `conio`
library. Learn how to use `conio`
to update the console from DOS programs, including text color and text windows.
[Write a chess game using bit-fields and masks](https://opensource.com/article/21/8/binary-bit-fields-masks)
The standard way to associate information in a C program is by using a structure that combines two or more related fields. For example, you might use a structure to track chess pieces on a board. But there's a more straightforward way to track the same information while using less data and memory. Using binary bit-fields and masks, you can store a single value to identify the pieces and color in each square.
[5 common bugs in C programming and how to fix them](https://opensource.com/article/21/10/programming-bugs)
Even the best programmers can create programming bugs. Depending on what your program does, these bugs could introduce security vulnerabilities, cause the program to crash, or create unexpected behavior. But with a little extra code, you can avoid the most common and most serious C programming bugs. Here are five bugs that can break your application and how you can avoid them.
With only a little knowledge of C, you can do a lot. Explore new ways to add features to your next C programming project.
## Comments are closed. |
14,177 | 即将出现在 Ubuntu 22.04 LTS 中的新功能 | https://itsfoss.com/ubuntu-22-04-release-features/ | 2022-01-14T11:19:30 | [
"Ubuntu"
] | https://linux.cn/article-14177-1.html |
>
> 这是一篇持续更新的文章,其中列出了即将发布的 Ubuntu 22.04 LTS “Jammy Jellyfish” 中增加的所有主要功能。
>
>
>

Ubuntu 的粉丝们!现在是时候为下一个大版本,也就是 Ubuntu 22.04 LTS 感到激动了。是的。这是一个长期支持版本,它将被支持五年,直到 2027 年 4 月。
即将发布的 LTS 版本带来了一些新的功能。如果你正在使用 Ubuntu 20.04 LTS,你会注意到许多视觉上的变化。如果你正在使用 Ubuntu 21.10,你已经看到了大量的变化,但在这个即将发布的版本中仍然会有一些新的变化。
在我向你展示 22.04 中新的预期新功能之前,让我们看看它将在什么时候发布。
### Ubuntu 22.04 发布时间表
Ubuntu 22.04 的稳定版计划于 2022 年 4 月 21 日发布。开发工作已经在紧锣密鼓地进行,它将遵循如下发布时间表:
* 2022 年 2 月 24 日:功能冻结
* 2022 年 3 月 17 日:用户界面冻结
* 2022 年 3 月 31 日:测试版发布
* 2022 年 4 月 14 日:候选版本
* **2022 年 4 月 21 日:最终稳定版本**
现在你知道了重要的发布日期,是时候了解一下 Ubuntu 22.04 LTS 将带来的新功能了。
### Ubuntu 22.04 LTS “Jammy Jellyfish” 的新功能
由于开发工作仍在进行中,许多新功能会在不久的将来陆续加入。我将在它们被发现时进行更新。
现在,这里是 Ubuntu 22.04 中主要的已确认和预期的新功能。
#### GNOME 42 和随之而来的视觉变化
GNOME 42 将于 2022 年 3 月发布。它将被包含在 Ubuntu 22.04 中。
像往常一样,Ubuntu 将使用定制的 GNOME 版本,所以不是所有的 GNOME 42 的变化都会反映在这里。然而,由于使用了新的 libadwaita 和迁移到了 GTK 4,你还是应该看到一些视觉变化。

你应该看到一个界面崭新的设置程序和重新打造的屏幕截图工具。GNOME 42 还将更新一些 GNOME 应用程序,如 Boxes,并引入一个新的文本编辑器。然而,我认为 Ubuntu 会坚持使用 Gedit 作为其默认的文本编辑器。
#### Grub 2.06 和它带来的麻烦
Ubuntu 22.04 LTS 将拥有 [Grub 引导加载程序](https://itsfoss.com/what-is-grub/) 2.06 版本,但其中有一个问题,它的 os-prober 功能默认是禁用的。
这意味着,如果你在一个双启动系统上,Grub 不会探测其他操作系统,因此它不会在 Grub 中列出 Windows(或其他操作系统)。一些升级到 Ubuntu 22.04 开发版本的人已经 [开始面临这个问题](https://itsfoss.community/t/windows-10-boot-option-missing-in-grub-after-upgrading-to-ubuntu-22-04-developer-version/8306/5)。
这并不是说这个问题不能被解决,有一个变通办法。
安装 os-prober(通常已经安装),然后编辑 `/etc/default/grub` 文件,在这个文件中加入 `GRUB_DISABLE_OS_PROBER=false`。保存这个文件,[更新 Grub](https://itsfoss.com/update-grub/),Grub 现在应该可以看到其他操作系统了。
#### 新的固件更新程序
正如 [OMG! Ubuntu](https://www.omgubuntu.co.uk/2021/11/ubuntu-is-working-on-a-new-firmware-updater-app) 报道的那样,Ubuntu 22.04 可能会有一个新的固件更新程序。
通常情况下,GNOME 软件中心能够处理固件更新,即使在 Ubuntu 的 Snap 版本中。尽管如此,开发团队仍在努力开发一个专门的 GUI 工具来处理固件更新。

这个新工具基本上是 `fwupd` 的基于 Flutter 和 Dart 的 GUI 前端,`fwupd` 是一个命令行工具,用于获取 [Linux 供应商的固件](https://fwupd.org/)。
#### 新的安装程序

这个基于 Flutter 的新安装程序已经开发了很长时间。它本来应该和 Ubuntu 21.10 一起推出,但并没如期实现。有一个单独的 Ubuntu 21.10 预览版,其中有这个新的安装程序,它将成为 Ubuntu 22.04 的默认安装程序。
新的安装程序与 Ubuntu 桌面风格无缝整合,从而使 Ubuntu 22.04 从一开始就具有更现代的外观和感觉。
#### 改进对树莓派的支持
随着 20.10 版本的发布,Ubuntu 开始支持树莓派设备上运行桌面版。虽然它可以在 8GB 版本的树莓派上工作,但在 4GB 上却很吃力,在 2GB 型号上也无法工作。
随着 Ubuntu 22.04 的推出,其性能应该会得到改善,特别是它 [引入了 zswap](https://www.omgubuntu.co.uk/2022/01/ubuntu-on-raspberry-pi-4-2gb-zswap)。
#### 其他变化
在软件供应方面,你应该看到一些其他变化。大多数著名的软件应该有较新的版本。其中一些是:
* OpenSSL 3.0
* Ruby 3.0
* Python 3.10
* PHP 8.1
* GCC 11(预计)
目前还没有确认,但更有可能的是 Ubuntu 22.04 将采用 Linux 内核 5.17。
正如我之前所说,一切正在开发中,一旦有更多的新功能被披露,我将立即更新这篇文章。
### 获取 Ubuntu 22.04 LTS
**警告**:Ubuntu 22.04 仍在努力开发中,你不应该在生产机器或你的主系统上使用它。
如果你想在备用机或虚拟机上测试它,你可以从 Ubuntu 的网站上下载日常构建版。
* [下载 Ubuntu 22.04 日常构建版(不稳定)](https://cdimage.ubuntu.com/daily-live/current/)
如果你在备用机上使用 Ubuntu 20.04 LTS 或 Ubuntu 21.10,你可以强制升级到开发分支。
### 你期待 Ubuntu 22.04 的哪些功能?
很明显,GNOME 42 将是 Ubuntu 22.04 的最大亮点。你希望在这个新的 LTS 版本中看到哪些功能?
---
via: <https://itsfoss.com/ubuntu-22-04-release-features/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Ubuntu fans! It’s time to get excited about the next big release which is Ubuntu 22.04 LTS. Yes. It is a long-term support release and it will be supported for five years till April 2027.
The upcoming LTS release brings several new features. If you are using Ubuntu 20.04 LTS, you will notice numerous visual changes. If you are using Ubuntu 21.10, you already have seen plenty of changes but there will still be a few new ones in the upcoming release.
## New features in Ubuntu 22.04 LTS Jammy Jellyfish

There are several visual and under the hood changes in this release. Since it is easy to show the visual features, my focus will be on these visual changes, followed by the under-the-hood changes.
Most of the visual features come with the GNOME 3.42 version. Some are additionally added (or removed) by the Ubuntu development team.
I made a video to show some features in action:
### 1. New dock mode
Ever since Ubuntu switched to GNOME as the default desktop environment, it has featured a Unity-styled full-length launcher. However, the vanilla GNOME has a shorter launcher.
Ubuntu 22.04 has a surprise new addition where you can change the size of the dock (basically detach it from the left-side to a floating look)

It works best when combined with the auto-hide feature. You can see it when you disable the Panel mode, as shown in the image below.
### 2. Accent Color Selection
With Ubuntu 22.04, you can now [choose a different accent color](https://itsfoss.com/accent-color-ubuntu/).
If you dislike the default orange theme, the accent color choices should help you personalize the desktop experience.
The folder icons, the notification bar, buttons, and various other elements in your system will reflect the selected accent color.
### 3. New screenshot and screencast tool
Thanks to GNOME 42, Ubuntu 22.04 has a revamped screenshot tool that also includes the screencast (video recording of desktop) option.
The new UI lets you take the screenshot of the selected area, entire screen or current application window. The screenshots are copied to clipboard and saved to the Screenshots folder under Pictures directory.
The screencast option works under Wayland. That’s a good news. However, there is no configuration option on frame rate, output quality etc. The recorded videos were in poor quality in my test.
### 4. New multitasking setting
No need to use GNOME Tweaks tool to access these settings the new 22.04 LTS version. The new multitasking settings allows you to enable hot corners. With that, when you move the cursor to the top left corner, it brings the activities area. Otherwise, you have to go to the left corner and click the Activities option.
You can also disable the screen edge effect from the multitasking settings. I prefer to have this setting active because it is very helpful when you are multitasking. Keep a PDF or website open in half of the screen and keep the IDE or terminal open in the other half.
There is also option to control the number of workspaces and their behavior. If you have multi monitor setup, you can choose whether the workspaces will be displayed on all monitors or just the primary one.
### 5. Wayland is default again
With version 22.04, Ubuntu switches to the Wayland display server by default once again. However, it will be limited to systems without Nvidia graphics cards at the time of release due to some known issues.
Hopefully, the Wayland experience has improved as we get to use it. In either case, you can [switch back to the legacy X display server](https://itsfoss.com/switch-xorg-wayland/).
### 6. Grub 2.06 and the trouble that comes with it
Ubuntu 22.04 LTS will have [Grub bootloader](https://itsfoss.com/what-is-grub/) version 2.06 but there is a problem with it. It has os-prober feature disabled by default.
This means that if you are on a dual boot system, Grub won’t probe for other operating systems and thus it won’t list Windows (or other OS) in Grub. A few people, who upgraded to the development version of Ubuntu 22.04, have already [started facing this issue](https://itsfoss.community/t/windows-10-boot-option-missing-in-grub-after-upgrading-to-ubuntu-22-04-developer-version/8306/5?ref=itsfoss.com).
It’s not that the problem cannot be fixed. There is a workaround.
Install os-prober (usually installed already) and then edit the /etc/default/grub file to add GRUB_DISABLE_OS_PROBER=false to this file. Save this file, [update grub](https://itsfoss.com/update-grub/) and Grub should see other operating systems now.
### 7. New option to enable and disable animations
Ubuntu 22.04 now provides the option to toggle animations in the accessibility settings.
What does it change? By default, the animation is enabled and though you might not have noticed, when you minimize or maximize application windows, go to the activity overview area, there is a slight effect to make the UI more fluid.
Never noticed it? You can disable it to see the impact. Disabling animation could give you a tiny performance improvement. But it’s mainly for the people who have difficulties with such animation effects. Hence, it is under the accessibility settings.
### 8. Position of desktop icons
Another change is about the position of the new desktop icons. By default, it is now in the bottom right corner. If you create new folders or documents, it gets created at the position you had selected.
But when you arrange the icons, they get placed in the bottom right. Or you can change their position to top right, bottom left, or top left.
### 9. Controlling mounted drives and trash in Dock
The settings now enables you to control the behavior of mounted drives and trash icon in the dock. You can choose to show the mounted disks in the launcher or hide them as per your preference.
The same goes for the Trash icon.
### 10. Slightly revamped Software Center
Software Center is slightly revamped. The icons are bigger, licensing information is gone and Snaps still get the priority over the DEB version.
### 11. New icon for Software & Updates
This is really a tiny change but I am happy to see.
Earlier, you had too similar named applications with similar icons: Software Updater and Software & Updates.

The icon for Software & Updates is now changed so that it is easier to distinguish between the two applications.

### 12. Multimonitor settings
If you have two screens, you get the option to join displays, mirror them or use only one of them.
These settings are available for two monitor setup only. For three or more monitors, you won’t see the mirror option. However, you can still drag and arrange their alignment.
### 13. Fractional scaling up to 225%
[Fractional scaling has been available in Ubuntu](https://itsfoss.com/enable-fractional-scaling-ubuntu/) for the past several versions. But it was restricted to 200%. I noticed that in Ubuntu 22.04, the fractional scaling goes up to 225%.
### 14. Brand new logo
Ubuntu has a new logo and it is visible everywhere in Ubuntu 22.04. You’ll see it while booting into the system, on the login screen, lock screen, and even on the about page.
### 15. New wallpapers but no dark and light variants
GNOME 42 introduced the set of [dual tone wallpapers that get changed based on the dark and light system themes](https://itsfoss.com/dark-light-wallpaper-gnome/). This feature is absent from Ubuntu 22.04.
You do have a bunch of new wallpapers, though.
### 16. Improved support for Raspberry Pi
Ubuntu started supporting the desktop edition on Raspberry Pi devices with the release of version 20.10. While it could work on the 8 GB version of Raspberry Pi, it struggles on 4 GB and won’t work on 2 GB models.
The performance should improve with Ubuntu 22.04 especially with the [introduction of zswap](https://news.itsfoss.com/ubuntu-desktop-raspberry-pi-4/?ref=itsfoss.com).
### 17. Firefox as Snap
Firefox will now be included as a Snap package by default. While you can install the deb package by downloading it separately, Ubuntu recommends Snap.
This is a joint effort by Canonical and Mozilla to simplify the maintenance of Firefox across distributions, enhance security, and facilitate faster security updates.
### 18. Other changes
There are a few other changes you should see in terms of a software offering. There should be newer versions of most of the prominent software. Some of them are:
- OpenSSL 3.0
- Ruby 3.0
- Python 3.10
- PHP 8.1
- GCC 11
Ubuntu 22.04 features Linux Kernel 5.15 LTS.
As I said earlier, things are in development, and I’ll update this article as soon as more new features are revealed.
### Getting Ubuntu 22.04 LTS
Though Ubuntu 22.04 release has been announced, the ISO will take some time to arrive. Updates for existing users will be roll out in coming days. If you want, you could [force update to Ubuntu 22.04 rig](https://itsfoss.com/upgrade-ubuntu-version/)ht now from 21.10 and 20.04.
For fresh installation, get the download from this page:
## What features do you like the most in Ubuntu 22.04?
I have listed so many minor and major features in Ubuntu 22.04. Which features do you like the most? Is it missing a feature you were expecting? Share your views in the comment section. |
14,178 | 2021 总结:学习新编程语言的 5 个小知识 | https://opensource.com/article/22/1/learn-programming | 2022-01-14T15:10:38 | [
"编程"
] | https://linux.cn/article-14178-1.html |
>
> 借助开源的力量,任何人都可以编程。找到一个你想做的项目,并让它成为你进入编程的第一个项目。
>
>
>

任何人都可以开始学习编程。[我们都是从某个起点开始的](https://opensource.com/article/21/8/first-programming-language),而且你不需要有计算机科学背景就可以学习编程。这就是 Linux 和开源的力量:任何人都可以学习一点编程。
如果你想学习一种新的编程语言,我们有几篇可以让你起步的很棒的文章。下面是我们最受欢迎的几篇文章,它们可以帮助到你。
### 比较编程语言
大多数编程语言都有某些相似之处。当你知道如何用一种编程语言做一件事,学习下一种编程语言主要是弄清其语法和结构。
#### 不同的编程语言如何做同样的事情
学习一种新的编程语言的一个好方法是写一个简单的测试程序,如一个游戏,以探索该编程语言的工作原理。我经常写的一个示例程序是一个简单的“猜数字”游戏,即计算机在 1 到 100 之间挑选一个数字,让我猜出来。今年早些时候,我们发表了 [一系列文章](https://opensource.com/article/21/4/compare-programming-languages),探讨如何用几种编程语言编写猜数字游戏。了解这些不同的编程语言如何实现“猜数字”游戏的主要步骤。
#### 不同的编程语言如何读写数据
[Alan 的](https://opensource.com/users/alansmithee)文章比较了不同的编程语言如何在相同的思想下 [读写数据](https://opensource.com/article/21/7/programming-read-write)。无论这些数据是来自于配置文件还是用户创建的文件,在存储设备上处理数据对于编码者来说是很常见的。Alan 的比较文章提供了对几种流行的编程语言,如 C、Java、Groovy 和其他语言所采取的不同方法的深入了解。
### 学习一种新的编程语言
无论你是想学习一种新的编程语言,还是想探索一种现有的编程语言,请看看下面这些关于学习编程的好文章。
#### 如何用 WebAssembly 编写 “Hello World”
WebAssembly 是一种字节码格式,几乎所有的浏览器都可以将其编译为主机系统的机器代码。与 JavaScript 和 WebGL 一起,WebAssembly 满足了将应用移植到网络浏览器中独立使用的需求。[Stephan](https://opensource.com/users/hansic99) 解释了如何用 WASM-text 创建经典的 [Hello World 程序](https://opensource.com/article/21/3/hello-world-webassembly)。
#### 用 Golang 轻松实现交叉编译
[Gaurav](https://opensource.com/users/gkamathe) 写了关于通过将脚本转换为 Go 程序来学习 [Go 的交叉编译支持](https://opensource.com/article/21/1/go-cross-compiling)。你可以一次写好你的程序,并通过交叉编译为另一个环境进行编译。
#### 为什么我使用 D 编程语言来编写脚本
D 编程语言由于其静态类型和元编程能力,常常被认为是一种系统编程语言。然而,它也是一种非常高效的脚本语言。[Lawrence](https://opensource.com/users/aberba) 写了关于如何利用 D 编程语言进行 [普通的脚本编写](https://opensource.com/article/21/1/d-scripting)。
借助于开源的力量,编程可以被任何人所接受。找到一个你想做的项目,并让它成为你进入编程的第一个项目。
---
via: <https://opensource.com/article/22/1/learn-programming>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Anyone can get started in programming. [We all started somewhere](https://opensource.com/article/21/8/first-programming-language), and you don't need to have a computer science background to learn to code. That's the power of Linux and open source—anyone can learn a bit of coding.
If you want to learn a new programming language, we have several great articles to get you started. Below are a few of our most popular articles to help you.
## Comparing programming languages
Most programming languages share certain similarities. Once you know how to do a thing in one programming language, learning the next programming language is mostly a matter of figuring out its syntax and structure.
[How different programming languages do the same thing](https://opensource.com/article/21/4/compare-programming-languages)
A great way to learn a new programming language is to write a simple test program, such as a game, to explore how the programming language works. One sample program I often write is a simple "guess the number" game, where the computer picks a number between one and 100 and asks me to guess it. Earlier this year, we ran a series of articles exploring how to write the number-guessing game in several programming languages. Learn how these different programming languages implement the major steps in the "guess the number" game.
[How different programming languages read and write data](https://opensource.com/article/21/7/programming-read-write)
[Alan's](https://opensource.com/users/alansmithee) article compares how different programming languages read and write data in the same spirit. Whether that data comes from a configuration file or a file a user creates, processing data on a storage device is common for coders. Alan's comparison article provides insight into different approaches taken by several popular programming languages such as C, Java, Groovy, and others.
## Learning a new programming language
Whether you want to pick up a new programming language or want to explore an existing one, check out the great articles below about learning programming.
[How to write 'Hello World' in WebAssembly](https://opensource.com/article/21/3/hello-world-webassembly)
WebAssembly is a bytecode format that virtually every browser can compile to its host system's machine code. Alongside JavaScript and WebGL, WebAssembly fulfills the demand for porting applications for platform-independent use in the web browser. [Stephan](https://opensource.com/users/hansic99) explains how to create the classic Hello World program in WASM-text.
[Cross-compiling made easy with Golang](https://opensource.com/article/21/1/go-cross-compiling)
[Gaurav](https://opensource.com/users/gkamathe) wrote about learning Go's cross-compilation support by converting a script into a Go program. You can write your program once and compile it for another environment with cross-compilation.
[Why I use the D programming language for scripting](https://opensource.com/article/21/1/d-scripting)
The D programming language is often thought of as a system programming language due to its static typing and metaprogramming capabilities. However, it's also a very productive scripting language. [Lawrence](https://opensource.com/users/aberba) wrote about how to leverage the D programming language for common scripting.
With the power of open source, programming can be accessible to anyone. Find a project you want to work on, and let that be your first entry to programming.
## 2 Comments |
14,180 | 内容管理系统(CMS)简史 | https://opensource.com/article/20/7/history-content-management-system | 2022-01-15T00:01:00 | [
"CMS",
"JAM"
] | https://linux.cn/article-14180-1.html |
>
> 从静态页面到 JAM 栈,CMS 的历史就是开源和 Web 变迁的核心。
>
>
>

<ruby> 内容管理系统 <rt> Content Management System </rt></ruby>(CMS)是一个多产的软件类别,其涵盖了所有创建和修改数字内容的应用程序。因此,CMS 的历史可以追溯到由 [蒂姆-伯纳斯-李](https://www.w3.org/People/Berners-Lee/#:~:text=A%20graduate%20of%20Oxford%20University,refined%20as%20Web%20technology%20spread.) 在 1990 年建立的历史上的第一个网站也就不足为奇了,该网站是以基于互联网的超文本系统 HTML 为模型,只包含了文本和链接。

万维网(WWW)的雏形是静态网站,无需后端数据库即可提供内容。它们消耗的计算资源很少,所以加载速度很快 —— 因为没有数据库查询、没有模板渲染、也没有客户端-服务器请求的处理。鉴于那时很少有人经常“上网冲浪”,特别是与今天相比,Web 流量也很少。
当然,促进了这种互操作性都是开源软件。事实上,开源在 CMS 的演变中一直扮演着重要的角色。
### CMS 的崛起
快进到九十年代中期,随着万维网的普及和网站对频繁更新的需求的增加 —— 这与它最初托管手册式的静态内容有所不同。这导致了大量的 CMS 产品的出现,如 FileNet、Vignette 的StoryBuilder、Documentum 和其他许多产品。这些都是专有的闭源产品,这在那个时期并不罕见。
然而,在 21 世纪初,开源的 CMS 替代品出现了,这包括 WordPress、Drupal 和 Joomla。WordPress 包含一个可扩展的插件架构,并提供了可用于建立网站的模板,而不要求用户具备 HTML 和 CSS 知识。WordPress CMS 软件安装在 Web 服务器上,通常与 MySQL 或 MariaDB 数据库(当然,两者都是开源的)配合。CMS 是开源的这一事实在一定程度上加速了向 WordPress 的重大转变。
即使在今天,仍有大约三分之一的网站是使用这些第一代内容管理系统建立的。这些传统的 CMS 是单体系统,包括后端用户界面、插件、前端模板、层叠样式表(CSS)、Web 服务器和数据库。每当用户请求一个网站页面时,服务器首先查询数据库,然后将结果与来自页面标记和插件的数据结合起来,在浏览器中生成一个 HTML 文档。
### 趋向于 LAMP 栈
开源 CMS 的出现与建立在 LAMP(Linux、Apache、MySQL 和 PHP/Perl/Python)栈上的基础设施是一致的。这种新的结构代表了单体 Web 开发的开始,它使动态网站的创建能够使用数据库查询,为不同的终端用户提供独特的内容。在这一点上,以前放在服务器上的静态网站模式真正开始消失。(静态网站模式是指由文本和链接组成的单个文件,如 HTML、CSS、JavaScript 等,以同样的方式传递给所有的终端用户。)
### 移动 Web 改变了一切
随着我们逐渐步入 2000 年代的第一个十年,早期的移动设备如 Palm 和黑莓提供了对 Web 内容的访问,然后在 2010 年左右推出的智能手机和平板电脑让越来越多的用户可以通过移动设备访问 Web 。2016 年,天平倾斜,全球 [来自移动设备和平板电脑的 Web 访问量超过了台式机](https://techcrunch.com/2016/11/01/mobile-internet-use-passes-desktop-for-the-first-time-study-finds/)。
单体的 CMS 并不适合为这些不同类型的访问设备提供内容,这就需要不同版本的网站 —— 通常是针对移动用户的精简版网站。新的可以访问 WEB 的设备类型的出现,如智能手表、游戏机和语音助手(如 Alexa)[5](https://opensource.com/article/20/6/open-source-voice-assistant),只是加剧了这个问题,对全渠道内容交付的需求变得很明显。
### 无头 CMS 和 JAM 栈的出现
无头 CMS 将后端(用来存储所有内容、数据库和文件)与前端解耦。通常,无头 CMS 使用 API,这样就可以访问数据库(SQL 和 NoSQL)和文件的内容,以便在网站、智能手机、甚至物联网(IoT)设备上显示。此外,无头 CMS 与前端框架无关,使其与各种静态网站生成器和前端框架(如 Gatsby.js、Next.js、Nuxt.js、Angular、React 和 Vue.js)兼容,这使开发人员可以自由选择他们喜欢的工具。
无头 CMS 特别适用于 JAM(Javascript、API 和 Markup)栈的 Web 开发架构,该架构正在成为一种流行的解决方案,因为它能提供更好的 Web 性能和 SEO 排名,以及强大的安全措施。JAM 栈不依赖于 Web 服务器,当有请求时可以立即提供静态文件。不需要查询数据库,因为文件已经被编译并提供给浏览器。
向无头 CMS 的转变是由新一轮的参与者推动的,他们有的采用 SaaS 方式,如 Contentful,有的采用自托管的开源替代品,如 [Strapi](https://strapi.io/)。无头 CMS 也在颠覆电子商务行业,新的软件编辑器,如 Commerce Layer 和 [Saleor](https://saleor.io/)(也是开源的)提供了解决方案,以真正的全渠道方式管理多个 SKU、价格和库存数据。
### 总结
在 CMS 的整个演变过程中,由互联网上的信息消费方式驱动,开源软件也沿着同样的趋势发展,新技术不断出现以解决出现的需求。事实上,在内容管理系统、万维网和开源之间似乎存在着一种相互依赖的关系。管理越来越多的内容的需求不会很快消失。我们完全有理由期待在未来更广泛地采用开源软件。
---
via: <https://opensource.com/article/20/7/history-content-management-system>
作者:[Pierre Burgy](https://opensource.com/users/pierreburgy) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Content management system (CMS) is a prolific software category that covers all types of applications for the creation and modification of digital content. So it should come as no huge surprise that the history of the CMS traces back to the first website in history, by [Tim Berners-Lee](https://www.w3.org/People/Berners-Lee/#:~:text=A%20graduate%20of%20Oxford%20University,refined%20as%20Web%20technology%20spread.) in 1990, which was modeled on an internet-based hypertext system HTML, which represented just text and links.
The humble beginnings of the world wide web lay in static sites that served content without the need for a back-end database. They consumed very little computing resources, so they loaded quickly—because there were no database queries, no templates to render, and no client-server requests to process. There was also little in the way of web traffic, given that few people were regular "web surfers," especially compared to today.
And, of course, it was all open source software that facilitated this interoperability. Indeed, open source has always played an important role in the evolution of CMS.
## Rise of the CMS
Fast-forward to the mid-nineties, as the popularity of the world wide web grows and websites increase the need for frequent updates—a change from its origins hosting brochure-type static content. This led to the introduction of a plethora of CMS products from FileNet, StoryBuilder from Vignette, Documentum, and many others. These were all proprietary, closed source products, which was not unusual for that time period.
However, in the early 2000s, open source CMS alternatives emerged, including WordPress, Drupal, and Joomla. WordPress included an extensible plugin architecture and provided templates that could be used to build websites without requiring users to have knowledge of HTML and CSS. The WordPress CMS software installed on a web server and typically paired with a MySQL or MariaDB database (both open source, of course). The big shift to WordPress was, in part, accelerated by the fact that the CMS is open-source.
Even today, about one-third of websites are built using these first-generation content management systems. These traditional CMS are monolithic systems that include the back-end user interface, plugins, front-end templates, Cascading Style Sheets (CSS), a web server, and a database. With every user request for a website page, a server first queries a database, then combines the result with data from the page's markup and plugins to generate an HTML document in the browser.
## Trend to LAMPstack
The emergence of the open source CMS was consistent with infrastructure built on the LAMP (Linux, Apache, MySQL, and PHP/Perl/Python) stack. This new structure represented the start of monolithic web development that enabled the creation of dynamic websites that use database queries to deliver unique content for different end users. At this point, the previous model of static sites sitting on a server—where individual files (HTML, CSS, JavaScript) consisting of text and links are delivered the same way to all end users—really started to disappear.
## Mobile web changes everything
As we move deeper and deeper into the first decade of the 2000s, early mobile devices like Palm and Blackberry provide access to web content, then the introduction of smartphones and tablets around 2010 brings more and more users to the web via mobile devices. In 2016, the scales tip and [web access from mobile devices and tablets exceeds desktops](https://techcrunch.com/2016/11/01/mobile-internet-use-passes-desktop-for-the-first-time-study-finds/) worldwide.
The monolithic CMS wasn't suited to serving content to these different types of access devices, which necessitated different versions of websites—usually stripped-down versions of the website for mobile users. The emergence of new Web-ready device types—like smartwatches, gaming consoles, and voice assistants like [Alexa](https://opensource.com/article/20/6/open-source-voice-assistant)—only exacerbated this problem, and the need for omnichannel content delivery became clear.
## The emergence of headless CMS and JAMstack
A headless CMS decouples the backend—which stores all the content, databases, and files—from the frontend. Typically, a headless CMS uses APIs so that content from databases (SQL and NoSQL) and files can be accessed for display on websites, smartphones, and even Internet of Things (IoT) devices. Additionally, a headless CMS is front-end framework-agnostic, making it compatible with a variety of static site generators and front-end frameworks (e.g., Gatsby.js, Next.js, Nuxt.js, Angular, React, and Vue.js), which gives developers the freedom to choose their favorite tools.
Headless CMS is particularly suitable for the JAM (Javascript, API, and Markup) stack web development architecture that is emerging as a popular solution as it delivers better web performance and SEO rankings, as well as strong security considerations. JAMstack does not depend on a web server and serves static files immediately when a request is made. There is no need to query the database as the files are already compiled and served to the browser.
The shift to headless CMS is driven by a new wave of players, either with a SaaS approach such as Contentful, or self-hosted open source alternatives such as [Strapi](https://strapi.io/). Headless is also disrupting the e-commerce industry, with new software editors such as Commerce Layer and [Saleor](https://saleor.io/) (also open source) offering solutions to manage multiple SKUs, prices, and inventory data in a true omnichannel fashion.
## Conclusion
Throughout the evolution of the content management system, which has been driven by how information on the internet is consumed, open source software has progressed along the same trend lines, with new technologies emerging to solve arising requirements. Indeed, it seems there is an interdependency between CMS, the world wide web, and open source. The need to manage the growing volumes of content isn't going away anytime soon. There is every reason to expect even more widespread adoption of open source software in the coming ahead.
## 1 Comment |
14,181 | 2021 总结:必备的开源备忘单 | https://opensource.com/article/22/1/open-source-cheat-sheets | 2022-01-15T11:36:48 | [
"备忘单"
] | https://linux.cn/article-14181-1.html |
>
> 在你学习 Linux 命令行或练习新的编程语言时,请随身携带这些方便的备忘单。
>
>
>

你不可能记住每一个你需要使用的命令或快捷方式。我们都是普通人,通常情况下,我把笔记放在不同的纸片上和笔记本里。这导致我的办公桌上有些过分紊乱。到处都是一些五年前的杂乱无章的潦草文字。这这些 2021 年的备忘单将把混乱降低一个档次。从 JavaScript 到 Linux,这个列表中都有适合你的东西。
### 如何编写你的第一段 JavaScript 代码
这篇 [文章](https://opensource.com/article/21/7/javascript-cheat-sheet) 是为那些今年想尝试学习一门新语言的初来乍到者准备的。[Seth Kenlon](https://opensource.com/users/seth) 介绍了如何安装 JavaScript 和开始制作一个简单的 HTML 页面。虽然 Seth 解释说 JavaScript 并不只用于网站,但所有主要的网页浏览器都有一个运行你的代码的 JavaScript 引擎。在整个演练过程中,Seth 涵盖了语法、变量和函数,让你开始创建一个新的应用。最后,在分享 [备忘录](https://opensource.com/downloads/javascript-cheat-sheet) 之前,Seth 还介绍了用 JavaScript 进行跨平台的能力。
### Linux 软件包管理
在 [Chris Hermanse](https://opensource.com/users/clhermansen) 的 [文章](https://opensource.com/article/21/6/apt-linux) 中,在他分享他的 [备忘录](https://opensource.com/downloads/apt-cheat-sheet) 之前,我们对使用 `apt` 做了简要预览。许多人日常在家里和办公室使用基于 Debian 的 Linux。在这篇入门文章中,我们可以了解一下 `apt` 的用途,首先是用 `apt` 在软件包系统中寻找软件,也可以用另一个命令查看这些软件包的元数据。接下来,Chris 介绍了查看一个软件包是否包括安装过程中需要的文件(软件包依赖)。最后,Chris 介绍了如何用 `apt` 命令删除软件包。这份详尽的备忘录可以给你带来比 Linux 的日常软件包管理更多的东西。如果 `apt` 不适合你,你也可以看看 `dnf` [备忘录](https://opensource.com/downloads/dnf-cheat-sheet)。
### 用 DOS conio 开始编程
你是否想在明年涉足 DOS?如果是的话,你已经准备好创建令人兴奋的新应用,[Jim Hall](https://opensource.com/users/jim-hall) 为你准备了一份 [备忘录](https://opensource.com/downloads/dos-conio-cheat-sheet)。在这篇 [文章](https://opensource.com/article/21/9/programming-dos-conio) 中定义了 `conio`,在分享备忘录之前,Jim 介绍了如何制作你自己的彩色文本用户界面。Jim 解释说,你可以用你的应用做更多的事情,使其更具互动性和刺激性。现在你有了这个备忘录,你就可以用 DOS `conio` 创建你自己的应用了。
### 学习 SQLite3
与这种常见的数据库一起工作?下面是你如何通过这个 [备忘录](https://opensource.com/downloads/sqlite-cheat-sheet) 成为一个资深用户。在这个 [实践教程](https://opensource.com/article/21/2/sqlite3-cheat-sheet) 中,[Klaatu](https://opensource.com/users/klaatu) 从安装和与 SQLite3 互动开始,然后在分享备忘录之前创建了一个带表的数据库。Klaatu 还用一段很简单的文字解释了数据类型和日期时间戳功能。Klaatu 在本教程中增加了更多详细的功能,包括查看表格、改变表格等等。如果你想继续使用 SQLite3 数据库并使其变得强大,或者只是想学习如何使用它,这个备忘录就适合你。
### 更多的 Linux 备忘录
虽然我只是蜻蜓点水地提及了这些备忘单,但我想提到一些值得称赞的地方,其中包括 [Seth Kenlon](https://opensource.com/users/seth) 的 Linux 备忘单:
* Seth 对 [grep](https://opensource.com/downloads/grep-cheat-sheet) 的高级用法对各种场合都很有用。
* [find](https://opensource.com/downloads/linux-find-cheat-sheet) 命令备忘录对于我不想花大量时间在目录中徘徊的时候特别有帮助。
* [wget](https://opensource.com/downloads/linux-wget-cheat-sheet) 备忘录对于那些你需要从互联网上获取东西的时候是很方便的。
### 以回顾 2021 年开始 2022 年
2021 年是备忘录的辉煌之年,其中许多是关于 Linux 的,但也有一些备忘录甚至让你从一种全新的语言开始。我强烈建议你打印出这些备忘录,在 2022 年开始学习新东西。我们欢迎各种经验水平的作者,请通过 [给我们发送文章或备忘录](https://opensource.com/how-submit-article) 告诉我们你是如何学习新技能的。
---
via: <https://opensource.com/article/22/1/open-source-cheat-sheets>
作者:[Jessica Cherry](https://opensource.com/users/cherrybomb) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You can't remember every command or shortcut you need to use. We are all human. Usually, I keep notes on separate bits of paper and in notebooks. This has led to some serious dysfunction on my desk. There is some five years' worth of clutter in scribbled bits everywhere. 2021's cheat sheets will bring that clutter down a notch. From JavaScript to Linux, there's something in this list for you.
## How to write your first JavaScript code
This [article](https://opensource.com/article/21/7/javascript-cheat-sheet) is for those first-timers out there who want to try learning a new language this year. [Seth Kenlon](https://opensource.com/users/seth) covers installing JavaScript and getting started making a simple HTML page. While Seth explains that JavaScript isn't only for websites, all major web browsers do have a JavaScript engine to run your code. Throughout this walkthrough, Seth covers syntax, variables, and functions to get you started on your way to creating a new app. Finally, Seth covers the ability to go cross-platform with JavaScript before sharing the [cheat sheet](https://opensource.com/downloads/javascript-cheat-sheet).
## Linux Package management
In [Chris Hermansen's](https://opensource.com/users/clhermansen) [article](https://opensource.com/article/21/6/apt-linux), we get a brief preview for using `apt`
before he shares his [cheat sheet](https://opensource.com/downloads/apt-cheat-sheet). Many people use Debian-based Linux daily at home and in the office. In this starter article, we get a sneak peek at what we can use `apt`
for, starting with using `apt`
to find software within the packaging system and also look into those packages' metadata with another command. Next, Chris covers if a package includes a file or package dependencies required during the install. Finally, Chris covers how to remove packages with the `apt`
command. This thorough cheat sheet can give you more than your day-to-day package management with Linux. If `apt`
isn't for you, you can check out the `dnf`
[cheat sheet](https://opensource.com/downloads/dnf-cheat-sheet).
## Get started programming with DOS conio
Are you looking to get into DOS next year? If so, you're ready to create exciting new applications and [Jim Hall](https://opensource.com/users/jim-hall) has a [cheat sheet](https://opensource.com/downloads/dos-conio-cheat-sheet) for you. While defining `conio`
in this [article](https://opensource.com/article/21/9/programming-dos-conio), Jim covers how to make your very own colorful text-based user interface before sharing the cheat sheet. Jim explains that you can do so much more with your apps that are more interactive and exciting. Now that you have this cheat sheet, you can create your own app using DOS `conio`
.
## Learn SQLite3
Work with this common database? Here's how you can be a power user with this [cheat sheet](https://opensource.com/downloads/sqlite-cheat-sheet). In this [hands-on tutorial](https://opensource.com/article/21/2/sqlite3-cheat-sheet), [Klaatu](https://opensource.com/users/klaatu) starts with installing and interacting with SQLite3, then creates a database with a table before sharing the cheat sheet. Klaatu also explains data types and the date timestamp function in a nice simple paragraph. Klaatu adds more detailed functions to this tutorial, including viewing tables, altering tables, and so much more. If you want to go forth and be powerful with your SQLite3 database or just want to learn how to use it, this cheat sheet is for you.
## More Linux cheat sheets
While I've only scratched the surface with these cheat sheets, I would like to mention some honorable mentions that include cheat sheets for Linux by [Seth Kenlon](https://opensource.com/users/seth):
- Seth's powerful use of
[grep](https://opensource.com/downloads/grep-cheat-sheet)is useful for every occasion. - The
[find](https://opensource.com/downloads/linux-find-cheat-sheet)command cheat sheet is especially helpful for when I don't want to spend a ton of time wandering around directories. - The
[wget](https://opensource.com/downloads/linux-wget-cheat-sheet)cheat sheet is handy for those times you really need something from the internet.
## Start 2022 with a look back on 2021
2021 was a stellar year for cheat sheets, many of which were about Linux, but others have taken it so far as to start you off with a brand new language. I urge you to print out these cheat sheets and start learning something new in 2022. We welcome authors of all experience levels, so tell us how you learned your new skills by [sending us an article or cheat sheet idea](https://opensource.com/how-submit-article).
## 1 Comment |
14,183 | EndeavourOS vs. Manjaro:两个基于 Arch Linux 的最佳发行版之间的深度比较 | https://itsfoss.com/endeavouros-vs-manjaro/ | 2022-01-16T08:08:00 | [
"Manjaro",
"Arch"
] | https://linux.cn/article-14183-1.html | 如果你曾经尝试过使用 Arch Linux,你就知道如果没有适当的文档和 Linux 知识,几乎不可能安装它。而实际上,这就是 Arch Linux 的 [魅力](https://itsfoss.com/why-arch-linux/)。
但由于 Arch Linux 属于专业级的 Linux 发行版,因此有几个 [基于 Arch 的发行版,它们试图让普通人可以更轻松地使用它们](https://itsfoss.com/arch-based-linux-distros/)。
当谈到 “基于 Arch 的 Arch 替代品” 时,Manjaro 和 EndeavourOS 是两个最受欢迎的选择。
所以让我们来看看这两个的区别。为什么你要选择其中一个而不是另一个?

### 桌面变体
这两个发行版都有多种桌面风格。Manjaro 有三种官方风格:Xfce、KDE 和 GNOME。此外还有社区版:Budgie、Cinnamon、Deepin、Mate、Sway 和 i3。
Endeavour OS 官方提供了更多的变体。除了 Manjaro 所拥有的那些,它还有 LXQT、BSPWM、Openbox 和 Qtile。
由于每种风格都有不同的 [桌面环境](https://itsfoss.com/what-is-desktop-environment/)(DE)及特定于该桌面的捆绑应用程序。这就导致了没有一个“严格”的最低系统要求基线。
[根据 EndeavourOS 的网站](https://endeavouros.com/),下面是每种桌面环境对内存的系统要求清单(对 Manjaro 也应该是一样的):
* Xfce - 至少 2GB 内存,但建议 4GB。
* Mate - 至少 2GB 内存,但建议 4GB。
* Cinnamon - 需要至少 4GB 的内存
* Gnome - 至少需要 4GB 的内存(假设对 KDE 相同)
* Budgie - 至少需要 4GB 的内存
* Plasma - 至少需要 4GB 的内存
* LXQT - 至少需要 2GB 的内存,但建议 4GB
### 获取 ISO
正如我上面提到的,Manjaro 和 EndeavourOS 有各种各样的风格。这意味着,我不能给你指出一个单一的 ISO 下载链接。但是,出于本文比较操作系统的意图和目的,我选择了默认的产品 —— Xfce 风格的 ISO。
* [下载 Manjaro](https://manjaro.org/download/)
* [下载 EndeavourOS](https://endeavouros.com/latest-release/)
### 安装操作系统
EndeavourOS 和 Manjaro 都使用 Calameres 安装程序,并在其 GRUB 启动菜单中提供了一些有用的选项。
#### EndeavourOS 的安装
当你首次启动 EndeavourOS 时,它将向你展示一个 GRUB 菜单,有以下选项:
* 使用 Intel/AMD 驱动启动(**默认选项**)
* 使用专有的 NVIDIA 图形驱动启动
* 运行 [Memtest86+](https://www.memtest.org/)(内存测试)
* 运行 [HDT](https://wiki.syslinux.org/wiki/index.php?title=Hdt_(Hardware_Detection_Tool))(硬件检测工具)
EndeavourOS 启动后,它的欢迎屏幕将为你提供一些选项。
这些选项用来管理分区、安装社区版本、更新镜像和启动安装程序。

有两个选项用于安装:
* 在线 - 让你选择把你的桌面环境改成 Xfce 以外的其它桌面。
* 离线 - 给你提供带有 EndeavourOS 主题的 Xfce 桌面。
如前所述,EndeavourOS 使用开源的 Calameres 安装程序。但在此基础上,它还为你提供了一些选项,以便更好地控制用户体验和安装。
EndeavourOS 安装程序提供的可用选项列举如下:
* [LTS 内核](https://itsfoss.com/linux-kernel-release-support/)(与最新的稳定内核 *并列*)
* XFCE4
* KDE
* GNOME
* i3 WM
* Mate 桌面环境
* Cinnamon 桌面环境
* Budgie 桌面环境
* LXQT
* LXDE
EndeavourOS 安装程序中的无障碍工具列表如下:
* espeak-ng: 开源的文本朗读合成器
* mousetweaks: 指针设备的无障碍增强工具
* orca:可编写脚本的屏幕阅读器
#### Manjaro 的安装

当你第一次启动 Manjaro 时,你会看到一个 GRUB 菜单,有以下选项:
* 使用 Intel/AMD 驱动启动(**默认选项**)
* 使用专有的 NVIDIA 图形驱动启动
* 运行内存测试([不再包括 Memtest,而且在 UEFI 模式下似乎也没有了](https://forum.manjaro.org/t/memory-test-no-longer-included-on-live-isos/62074/2))
除了 Manjaro 开发人员对 Calameres 安装程序所做的品牌和操作系统特定的改变之外,原版 Calameres 安装程序和你在 Manjaro 上的没有什么区别。

>
> **Calameres 不是 Manjaro 的唯一安装程序**
>
>
> 如果你想在 Manjaro 上进行自定义安装,你可以使用 [Manjaro Architect](https://wiki.manjaro.org/index.php/Installation_with_Manjaro_Architect) ISO 来进行完全自定义的 CLI 安装。
>
>
> **请记住,在写这篇文章的时候,Manjaro 的 Architect 版本 [似乎没有被维护](https://forum.manjaro.org/t/maintainer-s-wanted/19502),有一个未解决的软件包冲突。如果你有必要的技能和时间,请帮助维护这个项目** : )
>
>
>
这可能是一件好事,也可能是一件坏事,取决于你问谁。
在我看来,如果你是第一个 Linux 发行版就使用 Manjaro 的初学者,那么你的选择最好是有限的。
这意味着更少的进入门槛,可供选择的声音服务器、显示服务器、显示管理器和/或窗口管理器太多会造成进入门槛。
一旦你对 Linux 发行版有了足够的了解,就可以对你的系统进行修补,随心所欲地添加一些东西。
如果你想定制你安装的系统,你必须在你的操作系统安装好后进行。
### 首次启动
在你安装了 Manjaro 或 EndeavourOS 之后,你会看到一个欢迎屏幕,对于一个刚接触 Linux 的人,或者刚接触 Manjaro 或 EndeavourOS 或基于 Arch 的发行版的人来说,它有一些有用的选项。
EndeavourOS 的选项包括更新镜像、更新系统、改变显示管理器(lightdm、gdm、lxdm 和 sddm)、浏览 AUR 软件包、安装 libreoffice、chromium、akm([一个内核管理器](https://discovery.endeavouros.com/endeavouros-tools/akm/2021/08/))等软件包。
在 Manjaro 方面,与 EndeavourOS 相比,我认为提供的选项是有限的,但我觉得它是“足够的有限”。
这只是你(作为初学者)开始使用 Manjaro 所需要的适当数量的东西。
Manjaro 欢迎屏幕上的几个选项是官方维基的链接、支持论坛、邮件列表、参与 Manjaro 开发、安装和/或删除应用程序等。
Manjaro 和 EndeavourOS 的欢迎屏幕上都有一个选项,如果你喜欢该项目和它的方向,你可以选择捐赠,但只有你有足够的钱才能这样做。
### 软件打包
让我们面对现实吧,操作系统的安装只是 Linux 发行版的一个部分。
软件包管理器和软件打包的方式对 Linux 发行版的稳定程度起着重要作用。
如果你在更新/安装一个软件包时,它更新了一个已经安装的库 —— 而其他软件包依赖于它,那么……这就很糟糕。它创造了所谓的“依赖性地狱”。软件包管理器应该处理这个问题。
那么,Manjaro 和 EndeavourOS 在这方面怎么比较呢?
好吧,因为 Manjaro 和 EndeavourOS 都是基于 Arch Linux 的,它们使用 Arch Linux 使用的 [pacman 软件包管理器](https://archlinux.org/pacman/pacman.8.html)。pacman 的许多功能之一是它为你处理依赖关系。
#### Manjaro
尽管 Manjaro 使用 pacman 软件包管理器,但 Manjaro 有自己的软件库。
软件包每天从 Arch Linux 中取出,并在 Manjaro Unstable 软件库中 “镜像”,然后推送到 Manjaro Testing,用于 —— 你猜对了 —— 测试。
一旦这些软件包被认为是稳定的,它们就会被推送到主软件库供其他人安装。
安全更新则是通过 Manjaro 所谓的 “快速跟踪” 直接推送到公共软件包库,以更快地解决问题。

这种测试软件包的方法可以确保不会因为某某被修改而出现意外的软件包损坏。
但是,这也意味着用户需要等待几周(通常是 2 到 4 周),才可以安装新版本的软件。
#### EndeavourOS
EndeavourOS 没有自己的软件库。他们依赖于 Arch Linux 主软件库,如果你使用 EndeavourOS,这样做你会得到最 “普通” 的体验。
如果你在同一台机器上安装 Arch Linux 和 EndeavourOS,除了桌面环境或窗口管理器和/或它们的主题以及安装体验外,几乎所有东西都应该保持不变。
### 包含的软件包
现在,你可能已经注意到 Manjaro 和 EndeavourOS 之间的差异模式了。
#### EndeavourOS
EndeavourOS 在理念上优先考虑最接近 Arch Linux。
有自定义的安装?有。
只安装必要的软件包以获得完整的桌面体验?对。
在发行库中拥有最前沿的软件包?没错。
EndeavourOS 让你有机会学习 Arch,而无需同时学习 EFI、驱动搜索和安装(看着你的 nVidia)、桌面环境/窗口管理器、显示管理器等。
它可以一次性设置好所有东西,让你有时间按照自己的节奏学习 Arch Linux 的内部工作。

#### Manjaro
而 Manjaro,在你使用它的整个过程中,它一直握着你的手(看看我做了什么?)。它处理从安装到软件包稳定性的一切,并让你可以即时获得安全更新。
它旨在用作你计算机的通用操作系统。
它默认安装了相当多的开源应用程序。这对一个新的 Linux 用户来说是非常有帮助的。
它为你安装了一些应用程序,如音频播放器、GUI 防火墙(gufw)、GIMP、HP 设备管理器、电子邮件客户端(thunderbird)、视频播放器(vlc)、办公套件(onlyoffic 桌面版)。

### 我应该使用哪个?
嗯,这是你的决定。我只能根据他们的使用情况和目标受众推荐一个或两个。
如果你自认是一个普通电脑用户,只需要办公套件([LibreOffice](https://www.libreoffice.org/)、[ONLYOFFICE](https://www.onlyoffice.com/))、媒体播放器和网页浏览器来做你的事情,我建议你试试 Manjaro,因为他们自己的仓库有 [大部分] 稳定的软件包,而且安装起来不费事。
但是,另一方面,如果你是一个以前使用过 [Ubuntu](https://ubuntu.com/)、[Pop!\_OS](https://pop.system76.com/)、[Linux Mint](https://linuxmint.com/)、[ElementaryOS](https://elementary.io/)、[Fedora](https://getfedora.org/) 等发行版的人,现在想学习如何从窗口管理器到 GRUB 菜单来安装你的 Linux 发行版(没错,[构建 GRUB 也是个事](https://www.reddit.com/r/unixporn/comments/m5522z/grub2_had_some_fun_with_grub/))。所以,如果你需要一个像 Arch 一样的基本 Linux 发行版,我会向你推荐 EndeavourOS。
现在你也可以说:*告诉 Fedora*,我使用 Arch 了。
( ͡° ͜ʖ ͡°)
---
via: <https://itsfoss.com/endeavouros-vs-manjaro/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you have ever tried using Arch Linux, you know it is almost impossible to install it without proper documentation and Linux knowledge. That’s the [charm of Arch Linux](https://itsfoss.com/why-arch-linux/), actually.
But since Arch Linux lies on the expert end of the Linux distros spectrum, there exists several [Arch-based distributions that try to make things easier for the common folks](https://itsfoss.com/arch-based-linux-distros/).
Manjaro and EndeavourOS are two of the most popular choices when it comes to an ‘Arch-based Arch alternative’.
So let’s take a look at the differences between these two. Why should you choose one Linux distribution over another?

## Desktop variants
Both of these distributions come in many flavours. Manjaro has three official flavors: Xfce, [KDE and GNOME. There is also community editions for Budgie, Cinnamon, Deepin, Mate, Sw](https://itsfoss.com/kde-vs-gnome/)ay and i3.
Endeavour OS offers a lot more variants officially. Apart from what Manjaro has, it also has LXQT, BSPWM, Openbox and Qtile.
Since each flavor has a different [Desktop Environment](https://itsfoss.com/what-is-desktop-environment/) and their own DE-specific bundled apps, this ends up in not having a “strict” baseline of a minimum of system requirements.
Here is a list of system requirements of RAM [as per EndeavourOS’ website](https://endeavouros.com/) (this should be the same for Manjaro as well) per Desktop Environment
- Xfce – A minimum of 2GB of RAM, but 4GB is recommended
- Mate – A minimum of 2GB of RAM, but 4GB is recommended
- Cinnamon – A minimum of 4GB of RAM is necessary
- Gnome – A minimum of 4GB of RAM is necessary (assume it is the same for KDE)
- Budgie – A minimum of 4GB of RAM is necessary
- Plasma – A minimum of 4GB of RAM is necessary
- LXQT – A minimum of 2GB of RAM, but 4GB is recommended
## Getting the ISO
As I mentioned above, Manjaro and EndeavourOS are available in a wide variety of flavours. I can not point you to a single ISO download link. But, for the intents and purpose of this article comparing the Operating Systems, I have gone with the default offering – the Xfce flavour ISO.
## Installing the OS
Both, EndeavourOS and Manjaro use the Calamares installer and give you a few useful options in their grub boot menus.
### EndeavourOS installation
When you first boot EndeavourOS, it will present you with a GRUB menu with the following options
- Boot using Intel/AMD drivers (
**default option**) - Boot using the proprietary NVIDIA graphics driver
- Run
[Memtest86+](https://www.memtest.org/)(RAM test) - Run
[HDT](https://wiki.syslinux.org/wiki/index.php?title=Hdt_(Hardware_Detection_Tool))(Hardware Detection Tool)
Once EndeavourOS has booted, it’s welcome screen will provide you with some options.
The options are to manage partitions, installing community editions, updating mirrors and starting the installer.
There are two options for installation
- Online – Gives you the option to change your desktop environment to something other than Xfce
- Offline – Gives you the Xfce desktop with the EndeavourOS theme
As previously mentioned, EndeavourOS uses the open source Calamares installer. But on top of that, it also offers you some options for better control over user experience and installation.
The available options provided by the EndeavourOS installer are listed below
[LTS Kernel](https://itsfoss.com/linux-kernel-release-support/)(the latest stable kernel)*alongside*- XFCE4
- KDE
- GNOME
- i3 WM
- Mate Desktop Environment
- Cinnamon Desktop Environment
- Budgie Desktop Environment
- LXQT
- LXDE
The list of accessibility tools available in the EndeavourOS installer are as following
- espeak-ng : open source text to speech synthesizer
- mousetweaks : accessibility enhancements for pointing devices
- orca : script-able screen reader
### Manjaro installation
With your first boot of Manjaro, you will see a GRUB menu with the following options
- Boot using Intel/AMD driver (
**default option**) - Boot using the proprietary NVIDIA graphics driver
- Run a RAM test (
[Memtest is no longer included and appears to be missing in UEFI mode](https://forum.manjaro.org/t/memory-test-no-longer-included-on-live-isos/62074/2))
Aside from the branding and OS-specific changes done by Manjaro devs to the Calamares installer, there isn’t much difference between the stock Calamares installer and what you get on Manjaro.
Calamares is not the only installer for Manjaro
If you want a customized install on Manjaro, you can use the [Manjaro Architect](https://wiki.manjaro.org/index.php/Installation_with_Manjaro_Architect) ISO for a fully custom CLI install.
**Keep in mind, at the time of writing this article, the Architect flavour of Manjaro appears to be unmaintained due to an un-resolved package conflict. Please help maintain the project if you have the necessary skills and time to spare** :)
Which can be a good or bad thing, based on who you ask.
In my opinion, if you are beginner starting out with your first Linux distribution as Manjaro, it is best that your options are limited.
This means less barrier of entry which would be caused by a list of alternative sound servers, display servers, display managers and/or window managers to choose from.
Once you get comfortable enough with Linux distributions to tinker with your system, you can spice things up as you like.
If you are looking to customize your installation, you will have to do that once your OS is installed.
## First boot
After you have installed Manjaro or EndeavourOS, you will get a welcome screen with a few options for someone who is new to Linux in general or new to Manjaro or EndeavourOS or Arch-based distributions.
The options available to you in EndeavourOS include things like updating mirrors, updating system, changing display manager (lightdm, gdm, lxdm and sddm), browsing AUR packages, installing packages like LibreOffice, chromium, akm ([A Kernel Manager](https://discovery.endeavouros.com/endeavouros-tools/akm/2021/08/)) and more.
On the Manjaro side, the options you are presented with are what I would consider limited when compared to EndeavourOS, but I would put it as “adequately limited”.
It is just the right amount of things you will need (as a beginner) to start with Manjaro.
A few options available in Manjaro welcome screen are a link to the official Wiki, support forums, mailing list, getting involved with Manjaro development, installing and/or removing applications, etc.
The welcome screen on both, Manjaro and EndeavourOS also have the option for you to donate if you like the project and it’s direction, but do so only you have the money to do so.
## Software packaging
Lets face it, installation of OS is only one part of a Linux distribution.
The package manager and the way software is packaged plays a major role in how stable a Linux distribution feels.
If you are updating/installing a package, and it updates an already installed library – which other packages depend on, well… that is bad. It creates what is called “dependency hell”. A package manager should take care of this.
So how do Manjaro and EndeavourOS compare in this regard?
Well, since Manjaro and EndeavourOS are based on Arch Linux, they use the [pacman package manager](https://archlinux.org/pacman/pacman.8.html) which Arch Linux uses. One of the many features of pacman is that it handles dependencies for you.
### Manjaro
Even though Manjaro uses the pacman package manager, Manjaro has their own repositories.
Packages are taken from Arch Linux on a daily basis and “mirrored” in the Manjaro Unstable package repository and then pushed to Manjaro Testing for – you guessed it – Testing.
Once the packages are found to be stable, they’re pushed to the main repositories for everyone else to install.
Security updates though, are directly pushed to the public repositories through what Manjaro calls “Fast-Tracking” for faster resolution of issues.
This method of testing packages ensures no unexpected packages breaking because “xyz” was changed.
But, this also means that users must wait a few weeks (usually 2 to 4 weeks) for the newer version of their software to be installed.
### EndeavourOS
EndeavourOS does not have their own software repositories. They depend on the main Arch Linux repositories and doing so, you get the most “vanilla” experience if you use EndeavourOS.
Suppose you were to install Arch Linux and EndeavourOS on the same machine. In that case, almost everything except the Desktop Environment or Window Manager and/or their themes and the install experience – should stay the same.
## Included packages
By now, you might be noticing a pattern in the differences between Manjaro and EndeavourOS.
### EndeavourOS
EndeavourOS prioritizes to be closest to Arch Linux in terms of philosophy.
Have a custom installation? Check.
Install only the necessary packages for a complete desktop experience? Check.
Have the most bleeding edge packages in the distribution repositories? Check.
EndeavourOS allows you to learn Arch without learning everything from EFI, driver-hunt and installation (looking at you nVidia), desktop environments/window managers, display managers, etc all at once.
It will set up everything at once and gives you the time to learn the inner working of Arch Linux yourself, at your own pace.
### Manjaro
Manjaro, on the other hand, it holds your hand (see what I did there?) the whole time you use it. It handles everything from the installation to the package stability along with giving you fairly instant access to security updates.
It is intended to be used a general purpose operating system for your computer.
It installs quite a few open source applications by default. That is extremely helpful for a new Linux user.
It has a few applications installed for you, like an audio player, GUI firewall (gufw), GIMP, HP Device Manager, e-mail client (thunderbird), video player (vlc), office suite (onlyoffice-desktopeditors).
## What should I use?
Well, that is your call. I can only recommend one or either based on their use case and target audience.
If you are someone who considers yourself as a casual computer user who only needs an Office Suite ([LibreOffice](https://www.libreoffice.org/), [ONLYOFFICE](https://www.onlyoffice.com/)), a media player and a web browser to do your stuff, I would recommend that you give Manjaro a try because of their own repo for [mostly] stable packages and a billow-free installation.
But, on the other hand, if you are someone who previously used a distribution like [Ubuntu](https://ubuntu.com/), [Pop!_OS](https://pop.system76.com/), [Linux Mint](https://linuxmint.com/), [ElementaryOS](https://elementary.io/), [Fedora](https://getfedora.org/), etc and now want to learn how to rice your Linux distro install from the WM to GRUB menu (yes, [ricing GRUB is a thing](https://www.reddit.com/r/unixporn/comments/m5522z/grub2_had_some_fun_with_grub/)). So, if you need a bare-bones Linux distribution like Arch to begin with, EndeavourOS is what I would present as my recommendation to you.
Now you too, can say: *tips fedora* I use Arch btw ( ͡° ͜ʖ ͡°) |
14,184 | 2021 总结:学习 Ansible 的 9 种方法 | https://opensource.com/article/22/1/learn-ansible | 2022-01-16T08:32:00 | [
"Ansible"
] | https://linux.cn/article-14184-1.html |
>
> Ansible 是一个开源的自动化工具,可以以多种方式使用。以下是几个去年最受欢迎的 Ansible 教程和故事。
>
>
>

自动化不断改善着 IT 团队中每个人的生活。Ansible 可以帮助任何使用 IT 自动化的人,不管是为了保持文件的有序性还是配置打印机,或者是为了任何其他可以想象和构建的东西。这些是 2021 年我们分享的一些最引人注目的使用案例和经验。
无论你是第一次听说 Ansible,还是一个经验丰富的用户,这些文章都会有你的收获。
* Ansible 的创始人 Michael DeHaan 分享了他对自己如何被引向 IT 自动化的想法。这篇访谈对 [Ansible 是如何诞生的](https://opensource.com/article/21/2/ansible-origin-story) 以及随着时间的推移而发展的信息和见解都非常好。
* 当你作为一个系统管理员可以将许多日常任务自动化时,自动化可以节省一天的时间。了解如何使用 Ansible 为 [五个日常的系统管理员任务](https://opensource.com/article/21/3/ansible-sysadmin) 实现自动化流程。
* 你的下载文件夹中充满了垃圾吗?介绍一个简单的方法,用一个简单的剧本来清理你系统上的文件。它很容易扩展,计划好后,就会按照你的要求频繁运行。了解更多关于 [用 Ansible 删除文件](https://opensource.com/article/21/9/keep-folders-tidy-ansible)。
* 如果你正在 [写 Ansible 剧本](https://opensource.com/article/21/1/improve-ansible-play),可以用四行代码改善它们。想想下一个用户,特别是当你在一个项目上合作的时候。一个小的努力可以防止大的问题。
* Ansible 社区已经采取了措施,通过审查其代码库和更新语言,使该项目更具包容性。请看 [Ansible 术语变化](https://opensource.com/article/21/5/inclusive-language-ansible) 的总结。
* 从你的 Ansible 剧本中调用 API,就像一个专业人员一样!找出每个人都应该知道的关于 [利用剧本中的 REST API](https://opensource.com/article/21/9/ansible-rest-apis)。
* 有一些应该每天、每周或每月运行的计划任务?使用 [Ansible 和 anacron](https://opensource.com/article/21/9/ansible-anacron-automation) 来设置任务,利用时间戳而不是计划时间,所以即使你的机器在计划时间关闭,它也会在重新开启时运行。
* 如果你刚刚开始使用 Ansible,也许你需要一些方向来开始。这里有 [每个人都可以使用 Ansible 的 10 种方法](https://opensource.com/article/21/1/ansible)。
* 当社区一起工作时,奇迹就会发生。这不仅仅是代码:了解 [Ansible 如何构建设计系统](https://opensource.com/article/21/4/ansible-community-logos),创建可重用的品牌资产以供社区使用。如果你是设计师或社区经理,你会特别欣赏这个故事。
---
via: <https://opensource.com/article/22/1/learn-ansible>
作者:[Sumantro Mukherjee](https://opensource.com/users/sumantro) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Automation just keeps improving the lives of everyone on the IT team. Ansible helps anyone who uses IT automation, whether for keeping files organized or configuring printers, or for anything else someone can imagine and build. These are some of the most notable use cases and experiences shared on Opensource.com in 2021.
If you are hearing about Ansible for the first time, or if you're a seasoned user, these articles will have something for you.
-
Michael DeHaan, the founder of Ansible, shares his thoughts on how he was led to IT automation. This interview has great information and insights into
[how Ansible came into existence](https://opensource.com/article/21/2/ansible-origin-story)and developed over time. -
Automation saves the day when you can automate many of your daily tasks as a sysadmin. Learn how to implement automated processes for
[five everyday sysadmin tasks](https://opensource.com/article/21/3/ansible-sysadmin)using Ansible. -
Is your Downloads folder full of junk? Introducing a simple way to clean up files on your system with a simple playbook. It scales easily, and once scheduled it will run as frequently as you ask. Learn more about
[removing files with Ansible](https://opensource.com/article/21/9/keep-folders-tidy-ansible). -
If you're
[writing Ansible playbooks](https://opensource.com/article/21/1/improve-ansible-play), four lines of code can improve them. Think about the next user, especially when you are collaborating on a project. A small effort can prevent big problems. -
The Ansible community has taken steps to make the project more inclusive by reviewing its codebase and updating its language. See a summary of the
[Ansible terminology changes](https://opensource.com/article/21/5/inclusive-language-ansible). -
Call APIs from your Ansible playbook like a pro! Find out something everyone should know about
[leveraging REST APIs from a playbook](https://opensource.com/article/21/9/ansible-rest-apis). -
Have some CronJobs that should run daily, weekly, or monthly? Use
[Ansible and anacron](https://opensource.com/article/21/9/ansible-anacron-automation)to set tasks to leverage timestamps instead of scheduled time, so even if your machine is off at the scheduled time, it will run when it's back on. -
If you are just getting started with Ansible, maybe you want some direction on where to begin. Here are
[10 ways everyone can use Ansible](https://opensource.com/article/21/1/ansible). -
Magic happens when a community works together. It's not just code: learn
[how Ansible built a design system](https://opensource.com/article/21/4/ansible-community-logos), creating reusable brand assets for community use. You'll especially appreciate this story if you are a designer or community manager.
## Comments are closed. |
14,186 | 提前了解一下 System76 新的基于 Rust 的 COSMIC 桌面 | https://news.itsfoss.com/system76-rust-cosmic-desktop/ | 2022-01-17T10:49:00 | [
"COSMIC"
] | https://linux.cn/article-14186-1.html |
>
> 提前了解一下 Pop!\_OS 即将推出的基于 Rust 的 COSMIC 桌面环境。仅供参考。
>
>
>

如果你还不知道,System76 的开发者一直在 [致力于开发一个新的桌面环境](https://news.itsfoss.com/pop-os-cosmic-rust/)(被称为 COSMIC),它是用 [Rust](https://research.mozilla.org/rust/) 编写的,Rust 是一种内存安全的超快编程语言。
从头开始创建一个桌面环境不是一件小事。这涉及到创建从合成器、面板、窗口管理器到桌面环境的 API 和其他后端任务的一切。
这不是一件容易的事,而维护它又是另一回事。
而且,看起来 System76 已经开始了这方面的工作。
在 GitHub 上,你会发现已经有一个名为 [cosmic](https://github.com/pop-os/cosmic) 的仓库,但它主要是使用 JavaScript(用于创建 GNOME shell 扩展的语言)编写的。这就是 cosmic shell 扩展仓库,也就是 Pop!\_OS 现在所搭载的。
在他们的 GitHub 中还有几个较新的仓库,这些恰好是他们即将推出的基于 Rust 的 COSMIC 桌面的元素。
所以,现在是时候构建、测试并提前了解一下了。
>
> **注:** 澄清一下,目前 Pop!\_OS 上基于 GNOME 的桌面环境叫做 COSMIC。而本文讨论的是基于 Rust 的 COSMIC 桌面环境,它是从头开始构建的,旨在取代当前的产品。
>
>
>
### 基于 Rust 的 COSMIC 桌面体验
打算成为 COSMIC 桌面环境整体一部分的三个仓库是:
* [设置应用](https://github.com/pop-os/cosmic-settings)
* [顶部面板](https://github.com/pop-os/cosmic-panel)(目前用于 X11 系统)
* [合成器](https://github.com/pop-os/cosmic-comp)(似乎支持原生的 wayland、xwayland 和 X11 系统)
#### COSMIC 设置应用

>
> **注意:** 这是一个半生不熟的早期预览,以让你有个大致印象。随着开发的继续,用户界面可能会有根本性的变化。所以,仅用于参考。
>
>
>
这是 Pop!\_OS 的新 COSMIC 桌面的设置应用。它目前还在开发当中,没有准备好使用,不过如果你想运行它并试试界面,请随意!
那么,它看起来与目前的 COSMIC 体验有什么不同呢?

在写这篇文章时,该用户界面似乎没有与任何后端 API 相连接。启用和禁用 “为工作区启用左上角热角 ”的切换并没有什么变化,其他的切换也是如此,除了设置应用的 “关于” 部分所显示的信息。
仔细看截图,放置的位置很凌乱,但作为早期预览(或原型)来说也是正常的。
看起来他们正在用圆角和更干净的外观来处理一切。
切换动画感觉快速、流畅和迅捷(即使是在虚拟机内,我等不及在裸机上尝试)。但考虑到它甚至还没有功能,谈论性能没什么意义。

就个人而言,我不喜欢他们所采用的圆角外观。在我看来,GNOME 对圆角的实现是完美的。但是,看看它的结果应该是很有趣的。
#### 顶部面板
作为 COSMIC 桌面环境的一部分,顶部面板也正在使用 Rust 语言实现。
至于这个顶部面板的外观,我不太确定如何测试它才不算对它不公平。从 GNOME 中启动它,会在 GNOME 的顶栏后面打开它。所以我想在一个单独的窗口管理器中打开它(到目前为止只用 [bspwm](https://github.com/baskerville/bspwm) 和 [i3-wm](https://github.com/i3/i3) 试过),但这导致了一些古怪的行为,比如面板像普通 GUI 软件一样占据了全部垂直空间。
#### COSMIC 合成器
COSMIC 桌面环境的合成器编译成功了,但在与 bspwm 或 i3-wm 一起使用时却无法启动。我试着在窗口管理器中启动它,因为 GNOME 不允许改变合成器。
这是由于在使用 VirtualBox 的虚拟机中,视频驱动的混乱以及 COSMIC 合成器还没有准备好。
但是,还有更多!
开发者 Eduardo Flores 也尝试了新的 COSMIC 桌面,在他的 [博客文章](https://blog.edfloreshz.dev/articles/linux/system76/rust-based-desktop-environment/) 中分享了一些应用启动器和坞站的截图。

应用程序启动器看起来很相似,但是使用 GTK 构建的。同样,你也可以期待 [Pop!\_OS 21.10](https://news.itsfoss.com/pop-os-21-10/) 引入一个类似的应用程序库,以及经典的坞站。

### 总结
当然,现在说发展的方向还为时过早。
要期待一个成熟的基于 Rust 的 COSMIC 桌面体验的测试版,应该还需要一段时间。
但是,从我们在这里看到的情况来看,我很兴奋。
你怎么看?欢迎你在下面的评论中分享你的想法!
---
via: <https://news.itsfoss.com/system76-rust-cosmic-desktop/>
作者:[Pratham Patel](https://itsfoss.com/author/pratham/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you didn’t know already, System76 developers have been [working on a new Desktop Environment](https://news.itsfoss.com/pop-os-cosmic-rust/) (dubbed COSMIC) written in [Rust](https://research.mozilla.org/rust/?ref=news.itsfoss.com): a memory-safe and superfast programming language.
Creating a desktop environment from scratch is no small feat. That involves creating everything from the compositor, panel, window manager to the APIs for your desktop environment and other back-end tasks.
It is not an easy task, and maintaining it is another story.
And, it looks like System76 has already started working on it!
Carl Richell, System76’s CEO, mentions that we can expect an alpha build this summer, and a release planned for 2023:
On GitHub, you will notice there is already a repository called [cosmic](https://github.com/pop-os/cosmic?ref=news.itsfoss.com), but it is mainly in JavaScript (the language used to create GNOME shell extensions). This is the cosmic shell extension repository, which is what Pop!_OS ships with now.
There are a couple of newer repositories on their GitHub profile, which happen to be the elements of their upcoming Rust-based COSMIC Desktop.
So, it is time to build, test, and get an early look!
**Note:** *To clarify, the current GNOME-based desktop environment on Pop!_OS is COSMIC. This article discusses the Rust-based COSMIC desktop environment, built from scratch*, *meant to replace the current offering.*
## Rust-based COSMIC Desktop Experience
The three repositories intended to be a part of the COSMIC desktop environment as a whole are
[Settings app](https://github.com/pop-os/cosmic-settings?ref=news.itsfoss.com)[Top panel](https://github.com/pop-os/cosmic-panel?ref=news.itsfoss.com)(currently for X11 systems)[Compositor](https://github.com/pop-os/cosmic-comp?ref=news.itsfoss.com)(appears to have support for native wayland, xwayland and X11 systems)
### COSMIC Settings
**Note:** This is a half-baked early preview to get an idea. The user interface can be fundamentally different as the development continues. So, hold your thoughts!
This is the settings app for Pop!_OS’s new COSMIC Desktop. It is currently WIP and not ready for use, although if you want to run it and play around with the GUI, feel free!
So, how does it look different from the current COSMIC experience?
When writing this, the GUI does not seem to be connected to any back-end APIs. Enabling and disabling “Enable top-left hot corner for Workspaces” toggle does not make a difference, nor does any other toggles, except for the information shown by the ‘About’ section of the Settings app.
Looking closer at the screenshot, the placements are messy but expected from an early preview (or prototype).
It looks like they are approaching everything with rounded corners and a cleaner look to it.
The toggle animation feels quick, smooth and snappy (even inside a virtual machine, cannot wait to try it on bare metal). Considering it’s not even functional, let’s forget about the performance.
Personally, not a fan of the rounded corner look they are going with. GNOME’s implementation of rounded corners seems perfect to me. But, it should be interesting to see how it turns out.
### Top Panel
As part of the COSMIC desktop environment, the top panel is also being implemented using Rust language.
As for the appearance of this top panel, I am not exactly sure how to test it without being unfair to it. Launching it from GNOME opens it behind the top bar that GNOME has. So I thought of opening it in a separate window manager (tried only with [bspwm](https://github.com/baskerville/bspwm?ref=news.itsfoss.com) and [i3-wm](https://github.com/i3/i3?ref=news.itsfoss.com) so far), but that resulted in some quirky behavior like the panel taking full vertical space like a normal GUI software.
### COSMIC Compositor
The compositor for COSMIC desktop environment compiled successfully but would not launch when used with bspwm or i3-wm. I tried launching it in window managers because GNOME does not allow changing compositors.
This is due to the mess of video drivers in a virtual machine using VirtualBox and the fact that the COSMIC compositor is not ready.
But, there’s more!
Developer **Eduardo Flores** also tried the new COSMIC Desktop, sharing some screenshots of the app launcher and the dock in his [blog post](https://blog.edfloreshz.dev/articles/linux/system76/rust-based-desktop-environment/?ref=news.itsfoss.com).
**Eduardo Flores**
The application launcher looks similar, but built using GTK. Similarly, you can also expect a similar-looking application library, introduced with [Pop!_OS 21.10](https://news.itsfoss.com/pop-os-21-10/), and the good-old dock.
**Eduardo Flores**
## Concluding Thoughts
Sure, it is too early to tell where the development is heading.
It should take a while to expect a beta release for a full-fledged Rust-based COSMIC Desktop experience.
But, from what we’ve seen here, I am excited!
*What do you think? You are welcome to share your thoughts in the comments down below!*
*Originally written by Pratham Patel.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,187 | QPrompt:一款为视频创作者提供的自由开源的提词器 | https://itsfoss.com/qprompt/ | 2022-01-17T12:21:03 | [
"提词器"
] | https://linux.cn/article-14187-1.html | 
这些天来,各种各样的人都在创建视频内容。从专业的 YouTubers 到学校教师,创建视频内容已经成为各种工作内容的一部分。
从屏幕记录器到视频编辑器,有各种工具可以帮助创建良好的视频。提词器也是这样的工具之一。
提词器可以提供视觉提示,甚至是完整的文本,这样演讲者就可以在讲话时接受提示。你可能已经看到新闻读者使用提词器。
有专门的提词器软件,可以在电脑或移动设备上运行。
QPrompt 就是这样一款软件,它可以在 Linux、Windows 和其他平台上免费使用。
### QPrompt:个人提词器软件

[QPrompt](https://qprompt.app/) 是一个提词器软件,适用于所有类型的视频创作者。它的主要重点是易用性和快速性能。
QPrompt 可与 Web 摄像头和手机、演播室提词器和平板提词器一起使用。它的独特能力是使其背景透明,这使得它在视频会议上表现出色。
以下是 QPrompt 的亮点功能:
* 可与演播室提词器、平板提词器、网络摄像头和电话一起使用
* 流畅移动,无抖动
* 可以在提示的同时进行即时修改
* 从其他软件中粘贴,不费力气
* 为你估算剩余时间
* 使用标记来跳到脚本的任何地方
* 向多个屏幕提示,有独立的镜像功能
* 背景透明,让你在讲话时可以看到你自己或你的听众
* 内置的计时器
* 进度指示器
* 丰富的文本格式
* 支持超过 180 种语言的书写系统
QPrompt 中的 “Q” 提示该应用是使用 Qt 框架制作的。它的用户界面使用 [Kirigami 框架](https://develop.kde.org/frameworks/kirigami/)。所有这些都使它成为 KDE 上的一个很好的选择,但在 GNOME 中也是如此。
### 安装 QPrompt

QPrompt 是一个自由开源软件,它可以用于 Linux、Windows 和 macOS。也有适用于安卓设备的 APK,但目前还不稳定。
Linux 用户可以选择 AppImage、Snap 和 Deb文件。在写这篇文章的时候,Flatpak 包正在开发中。
你可以从该项目网站的下载区获得 AppImage。
* [下载 AppImage 格式的 QPrompt](https://qprompt.app/)
其他安装选项可在其 GitHub 仓库的发布页面上找到:
* [其他下载选项](https://github.com/Cuperino/QPrompt/releases)
### 总结
我想对这个应用的功能进行评论,但由于我从未使用过提词器,我想我无法测试和“判断”其所有功能。如果你过去使用过这类软件,可以试试 QPrompt,看看它与其他同类软件的竞争情况。
---
via: <https://itsfoss.com/qprompt/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | These days, all sorts of people are creating video contents. From the professional YouTubers to school teachers, creating video content has become part of various job profiles.
From screen recorders to video editors, there are various tools that help create good videos. Teleprompter is also one such tool.
A teleprompter runs visual cues or even complete text so that a speaker can take hints while speaking. You might have seen news readers using the teleprompter.
There are dedicated teleprompter software that can be run on computer or mobile device.
One such software is QPrompt which is available for free on Linux, Windows and other platforms.
## QPrompt: Personal teleprompter software

[QPrompt](https://qprompt.app/) is a teleprompter software for all kinds of video creators. Its main focus is on ease of use, and fast performance.
QPrompt works with webcams and cellphones, studio teleprompters, and tablet teleprompters. Its unique ability is to make its background transparent and that makes it excellent for video conferencing.
Here’s the highlight of QPrompt’s features:
- Works with studio teleprompters, tablet teleprompters, webcams and phones
- Fluid motion, jitter free experience
- Make changes on the fly while prompting
- Paste from other software without hassle
- Estimates remaining time for you
- Use markers to skip to anywhere on the script
- Prompt to multiple screens, with independent mirroring
- Background transparency allows you to monitor yourself or your audience as you speak
- Built in chronometer
- Progress indicator
- Rich text formatting
- Supports writing systems of over 180 languages
The Q in QPrompt is a hint that the application is made using Qt framework. It uses [Kirigami framework](https://develop.kde.org/frameworks/kirigami/) for the user interface. All of that makes it an excellent choice for KDE but it works the same in GNOME.
## Installing QPrompt
QPrompt is a free and open source software and it is available for Linux, Windows and macOS. There is also APK available for Android devices but it’s not stable yet.
Linux users have the choice to select between AppImage, Snap and Deb file. Flatpak package is under development at the moment of writing this article.
You can get the AppImage from the download section of the project’s website:
Other installation options are available on the release page of its GitHub repository:
## Conclusion
I wanted to review this application on its functionality but since I have never used a teleprompter, I don’t think I could test and ‘judge’ all of its feature. If you have used such applications in the past, give QPrompt a try and see how it competes with other software in its category. |
14,189 | 桌面 Linux 需要什么才能在主流中获得成功? | https://news.itsfoss.com/what-desktop-linux-needs-to-succeed-in-the-mainstream/ | 2022-01-18T14:53:00 | [
"桌面",
"KDE"
] | https://linux.cn/article-14189-1.html |
>
> 这是 Linux 走向大众最重要的一件事。
>
>
>

你可能看过 [最近 Linus Tech Tips 关于切换到 Linux 的视频](/article-14053-1.html),以及 [他对 KDE 软件的一些抱怨的那个视频](https://www.youtube.com/watch?v=TtsglXhbxno&list=PL8mG-RkN2uTyhe6fxWpnsHv53Y1I-K3yu&index=3)。对于那些关注此事的人,我想让你们知道,我们(KDE)正在努力修复 Linus 提出的问题,你们可以在 [这里](https://invent.kde.org/teams/usability/issue-board/-/boards/7723) 跟踪我们的进展。值得庆幸的是,大部分的问题都相当小,应该很容易解决。
关于桌面 Linux 需要什么才能成为主流的问题。[Sway](https://swaywm.org/) 开发者 [Drew DeVault 针对该视频发表了一篇文章](https://drewdevault.com/2021/12/05/What-desktop-Linux-needs.html),而这篇博文是我的版本。Drew 强调了可访问性,我也同意,但结论略有不同。
### 桌面 Linux 需要预装在零售硬件上才能在主流市场取得成功
就是这样。
请允许我解释一下。
人们经常被功能和可用性所困扰,这些都很重要,但它们只是达到目的的手段,本身并不是目的。如果人们根本不能得到它,质量就毫无意义。而如果没有可访问的发行版,人们就无法得到它。高质量的 Linux 发行版还不够;它们需要被预装在你可以在主流零售店买到的硬件产品上。“主流人群”会购买他们可以触摸和拿起的产品;如果在主流商店找不到它,它就不存在。
想一想,**为什么普通人都使用 Windows 或 macOS**?因为他们购买的实体电脑包含了它。iOS 或 Android 呢?它被默认装在了他们的实体智能手机上。对于“主流人群”来说,不存在用一个新的操作系统替换设备的操作系统的想法。只有 [“三点”用户](https://pointieststick.com/2021/11/29/who-is-the-target-user) 才会这么做,而他们只占市场的 5% 左右。如果获得你的操作系统的唯一途径是自己安装,那么你就没有机会在主流市场取得成功。

至于功能,人们通常只使用可用功能的很小的一部分。在可用性方面,大多数用户是 [记住他们的软件如何使用而不是理解它](https://pointieststick.com/2021/11/30/more-about-those-zero-dot-users/) —— 如果你真的需要,你可以记住任何东西。一个更好的用户界面会有所帮助,但是对于那些记忆这些的人来说并不是必需的,而它主要有利于那些能够识别模式,并欣赏逻辑、一致性和良好设计的高级用户(市场上 30% 的“二点及以上”人群)。因此,这些东西本身就不够好。
但这并不意味着我们应该忘记功能和可用性!一点也不。但是如果我们的目标是“走向主流”,我们就必须了解真正的受众:**是硬件供应商,而不是终端用户**。我们的目标是让软件产品有足够的吸引力,以便在供应商选购时被他们选中,因为它基本上就是这样做的。像苹果这样为知名产品定制自上而下的硬件和软件的公司很少。大多数公司都建立在第三方软件之上,这些软件需要他们内部软件团队进行最少的整合和定制工作。如果你的软件不能胜任,他们会转向下一个选择。因此,当一些硬件供应商有需求时,你的软件最好已经准备好了!
而硬件供应商需要什么?
* **灵活性**。你的软件必须容易适应他们的任何类型的设备,而不需要大量的定制工程,他们将在产品的生命周期中负责支持。
* **能使他们的设备看起来不错的功能**。对其物理硬件特性的支持、良好的性能、令人愉快的用户界面……人们购买它的理由基本上是这些。
* **稳定性**。不能崩溃并将用户抛弃在命令行终端提示符下。必须可以实际工作。不能让人感觉像一个业余的科学展览会项目。
* **可用性要足够好,以减少支持成本**。当出现问题时,“主流人群”会联系他们的硬件供应商。可用性需要足够好,以便尽可能少地发生这种情况。
它不需要完美。它只需要做这些事情。这就是 Windows 在 90 年代征服了个人电脑市场的方式,尽管它很糟糕!而我们的东西要好得多!
我看到有证据表明 KDE 已经是这样了。Pine 在 [PinePhone](https://www.pine64.org/pinephone/) 和 [PineBook Pro](https://www.pine64.org/pinebook-pro/) 上分别为 Manjaro 提供了 Plasma 的移动版和桌面版。Valve 也为 [Steam Deck](https://www.steamdeck.com/) 选择了 Plasma 的桌面版,在他们的新版 SteamOS 中取代了 GNOME。我认为 KDE 软件定位良好,并且一直在变得更好。因此,让我们继续加倍努力提供硬件供应商销售其出色产品所需的东西。
原文由 KDE 开发者 Nate Graham 发表在他的 [博客 PointiestStick](https://pointieststick.com/2021/12/09/what-desktop-linux-needs-to-succeed-in-the-mainstream/) 中。 本文经许可后转载。所表达的观点代表作者自己,可能不能反映我们的观点。
---
via: <https://news.itsfoss.com/what-desktop-linux-needs-to-succeed-in-the-mainstream/>
作者:[Nate Graham](https://pointieststick.com/2021/12/09/what-desktop-linux-needs-to-succeed-in-the-mainstream/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You might be aware of the [recent Linus Tech Tips videos about switching to Linux](https://www.youtube.com/watch?v=0506yDSgU7M&list=PL8mG-RkN2uTyhe6fxWpnsHv53Y1I-K3yu&ref=news.itsfoss.com), including [one with some complaints about KDE software](https://www.youtube.com/watch?v=TtsglXhbxno&list=PL8mG-RkN2uTyhe6fxWpnsHv53Y1I-K3yu&index=3&ref=news.itsfoss.com). For those of you who are following along, I want to let you know that we’re (KDE) working on fixing the issues Linus brought up, and you can track our progress [here](https://invent.kde.org/teams/usability/issue-board/-/boards/7723?ref=news.itsfoss.com). Thankfully, most of the issues are fairly minor and should be easy to fix.
This blog post is my version of [Sway](https://swaywm.org/?ref=news.itsfoss.com) developer [Drew DeVault’s post](https://drewdevault.com/2021/12/05/What-desktop-Linux-needs.html?ref=news.itsfoss.com) about the videos, regarding the question of what desktop Linux needs to go mainstream. Drew emphasizes accessibility, and I agree, but with a slightly different conclusion:
## Desktop Linux needs to be pre-installed on retail hardware to succeed in the mainstream
That’s it.
Allow me to explain.
People get hung up a lot on features and usability, and these are important. But they’re means to an end and not good enough ends by themselves. Quality means nothing if people can’t get it. And people can’t get it without accessible distribution. High quality Linux distros aren’t enough; they need to be pre-installed on hardware products you can buy in mainstream retail stores! “The mainstream” buys products they can touch and hold; if you can’t find it in a mainstream store, it doesn’t exist.
Think about it: **why do normal people use Windows or macOS**? Because the physical computer they bought included it. iOS or Android? Because it was shipped by default on their physical smartphone. The notion of replacing a device’s operating system with a new one doesn’t exist to “the mainstream”. Only the [“three-dot” users](https://pointieststick.com/2021/11/29/who-is-the-target-user?ref=news.itsfoss.com) ever do that, and they’re about 5% of the market. If the only way to get your OS is to install it yourself, you have no chance of succeeding in the mainstream.
As for features, people generally use only a very small fraction of what’s available to them. When it comes to usability, most users [memorize their software rather than understanding it](https://pointieststick.com/2021/11/30/more-about-those-zero-dot-users/?ref=news.itsfoss.com)–and you can memorize anything if you really have to. A better user interface helps, but it isn’t needed for the memorizers and mostly benefits power users (the 30% of the market “two-dot and up” crowd) who recognize patterns and appreciate logic, consistency, and good design. So these are not good enough on their own.
This doesn’t mean we should forget about features and usability! Not at all! But if the goal is to “go mainstream,”we have to understand the true audience: **hardware vendors, not end users**. The goal is to have a software product appealing enough to get picked up by vendors when they go shopping for one, because that’s mostly how it works. Companies like Apple that do their own custom top-to-bottom hardware and software for big-name products are rare. Most build on top of 3rd-party software that requires the least integration and custom work from their in-house software team. If your software isn’t up to the task, they move onto the next option. So when some hardware vendor has a need, your software better be ready!
And what do hardware vendors need?
**Flexibility**. Your software has to be easily adaptable to whatever kind of device they have without tons of custom engineering they’ll be on the hook for supporting over the product’s lifecycle.**Features that make their devices look good**. Support for its physical hardware characteristics, good performance, a pleasant-looking user interface… reasons for people to buy it, basically.**Stability**. Can’t crash and dump users at a command line terminal prompt. Has to actually work. Can’t feel like a hobbyist science fair project.**Usability that’s to be good enough to minimize support costs**. When something goes wrong, “the mainstream” contacts their hardware vendor. Usability needs to be good enough so that this happens as infrequently as possible.
It doesn’t need to be perfect. It just needs to do that stuff. This is how Windows conquered the PC market in the 90s despite being terrible! And our stuff is much better!
I see evidence that this is already working for KDE. Pine ships Manjaro with Plasma Mobile and Plasma Desktop on the [PinePhone](https://www.pine64.org/pinephone/?ref=news.itsfoss.com) and [PineBook Pro](https://www.pine64.org/pinebook-pro/?ref=news.itsfoss.com), respectively. Valve also picked Plasma Desktop for the [Steam Deck](https://www.steamdeck.com/?ref=news.itsfoss.com), replacing GNOME for their new version of SteamOS. I see KDE software as well-positioned here and getting better all the time. So let’s keep doubling down on delivering what hardware vendors need to sell their awesome products.
*Originally written by KDE developer Nate Graham on his blog PointiestStick. The content has been reproduced here with his permission. The views expressed are of author’s own and it may not reflect the views of It’s FOSS.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,190 | 无需 sudo 使用 Podman 在 Linux 上运行容器 | https://opensource.com/article/22/1/run-containers-without-sudo-podman | 2022-01-18T15:31:00 | [
"Podman",
"容器"
] | https://linux.cn/article-14190-1.html |
>
> 配置你的系统使用无根容器。
>
>
>

容器是现代计算的一个重要组成部分,随着围绕容器的基础设施的发展,新的和更好的工具开始浮出水面。过去,你只需用 [LXC](https://opensource.com/article/18/11/behind-scenes-linux-containers) 就可以运行容器,然而随着 Docker 得到了普及,它开始变得越来越复杂。最终,我们在 [Podman](http://podman.io) 得到了我们所期望的容器管理系统:一个无守护进程的容器引擎,它使容器和吊舱易于构建、运行和管理。
容器直接与 Linux 内核能力(如控制组和命名空间)交互,它们在这些命名空间中产生大量的新进程。简而言之,运行一个容器实际上就是在 Linux 系统内部运行一个 Linux 系统。从操作系统的角度来看,它看起来非常像一种管理和特权活动。普通用户通常不能像容器那样自由支配系统资源,所以默认情况下,运行 Podman 需要 root 或 `sudo` 权限。然而,这只是默认设置,而且这绝不是唯一可用的设置。本文演示了如何配置你的 Linux 系统,使普通用户可以在不使用 `sudo` 的情况下(“<ruby> 无根 <rt> rootless </rt></ruby>”)运行 Podman。
### 命名空间的用户 ID
[内核命名空间](https://opensource.com/article/19/10/namespaces-and-containers-linux) 本质上是一种虚构的结构,可帮助 Linux 跟踪哪些进程属于同一类。这是 Linux 中的“队列护栏”。一个队列中的进程与另一个队列中的进程之间实际上没有区别,但可以将它们用“警戒线”彼此隔离。要声明一组进程为“容器”,而另一组进程为你的操作系统,将它们分开是关键。
Linux 通过用户 ID(UID)和组 ID(GID)来跟踪哪个用户或组拥有的进程。通常情况下,一个用户可以访问一千个左右的从属 UID,以分配给命名空间的子进程。由于 Podman 运行的是分配给启动容器的用户的整个从属操作系统,因此你需要的不仅仅是默认分配的从属 UID 和从属 GID。
你可以用 `usermod` 命令授予一个用户更多的从属 UID 和从属 GID。例如,要授予用户 `tux` 更多的从属 UID 和从属 GID,选择一个还没分配用户的适当的高 UID(如 200000),然后将其增加几千:
```
$ sudo usermod \
--add-subuids 200000-265536 \
--add-subgids 200000-265536 \
tux
```
### 命名空间访问
对命名空间数量也有限制。这通常被设置得很高。你可以用 `systctl`,即内核参数工具来验证用户的命名空间分配:
```
$ sysctl --all --pattern user_namespaces
user.max_user_namespaces = 28633
```
这是很充足的命名空间,而且可能是你的发行版默认设置的。如果你的发行版没有这个属性或者设置得很低,那么你可以在文件 `/etc/sysctl.d/userns.conf` 中输入这样的文本来创建它:
```
user.max_user_namespaces=28633
```
加载该设置:
```
$ sudo sysctl -p /etc/sysctl.d/userns.conf
```
### 在没有 root 权限的情况下运行一个容器
当你设置好你的配置,重启你的计算机,以确保你的用户和内核参数的变化被加载和激活。
重启后,试着运行一个容器镜像:
```
$ podman run -it busybox echo "hello"
hello
```
### 容器像命令一样
如果你是第一次接触容器,可能会觉得很神秘,但实际上,它们与你现有的 Linux 系统没有什么不同。它们实际上是在你的系统上运行的进程,没有仿真环境或虚拟机的成本和障碍。容器和你的操作系统之间的区别只是内核命名空间,所以它们实际上只是带有不同标签的本地进程。Podman 使这一点比以往更加明显,当你将 Podman 配置为无根命令,容器感觉更像命令而不是虚拟环境。Podman 使容器和吊舱变得简单,所以请试一试。
---
via: <https://opensource.com/article/22/1/run-containers-without-sudo-podman>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Containers are an important part of modern computing, and as the infrastructure around containers evolves, new and better tools have started to surface. It used to be that you could run containers with just [LXC](https://opensource.com/article/18/11/behind-scenes-linux-containers), and then Docker gained popularity, and things started getting more complex. Eventually, we got the container management system we all deserved with [Podman](http://podman.io), a daemonless container engine that makes containers and pods easy to build, run, and manage.
Containers interface directly with Linux kernel abilities like cgroups and namespaces, and they spawn lots of new processes within those namespaces. In short, running a container is literally running a Linux system *inside* a Linux system. From the operating system's viewpoint, it looks very much like an administrative and privileged activity. Normal users don't usually get to have free reign over system resources the way containers demand, so by default, root or `sudo`
permissions are required to run Podman. However, that's only the default setting, and it's by no means the only setting available or intended. This article demonstrates how to configure your Linux system so that a normal user can run Podman without the use of `sudo`
("rootless").
## Namespace user IDs
A [kernel namespace](https://opensource.com/article/19/10/namespaces-and-containers-linux) is essentially an imaginary construct that helps Linux keep track of what processes belong together. It's the red queue ropes of Linux. There's not actually a difference between processes in one queue and another, but it's helpful to cordon them off from one another. Keeping them separate is the key to declaring one group of processes a "container" and the other group of processes your OS.
Linux tracks what user or group owns each process by User ID (UID) and Group ID (GID). Normally, a user has access to a thousand or so subordinate UIDs to assign to child processes in a namespace. Because Podman runs an entire subordinate operating system assigned to the user who started the container, you need a lot more than the default allotment of subuids and subgids.
You can grant a user more subuids and subgids with the `usermod`
command. For example, to grant more subuids and subgids to the user `tux`
, choose a suitably high UID that has no user assigned to it (such as 200,000) and increment it by several thousand:
```
$ sudo usermod \
--add-subuids 200000-265536 \
--add-subgids 200000-265536 \
tux
```
## Namespace access
There are limits on namespaces, too. This usually gets set very high, but you can verify the user allotment of namespaces with `systctl`
, the kernel parameter tool:
```
$ sysctl --all --pattern user_namespaces
user.max_user_namespaces = 28633
```
That's plenty of namespaces, and it's probably what your distribution has set by default. If your distribution doesn't have that property or has it set very low, then you can create it by entering this text into the file `/etc/sysctl.d/userns.conf`
:
`user.max_user_namespaces=28633`
Load that setting:
`$ sudo sysctl -p /etc/sysctl.d/userns.conf`
## Run a container without root
Once you've got your configuration set, reboot your computer to ensure that the changes to your user and kernel parameters are loaded and active.
After you reboot, try running a container image:
```
$ podman run -it busybox echo "hello"
hello
```
## Containers like commands
Containers may feel mysterious if you're new to them, but actually, they're no different than your existing Linux system. They are literally processes running on your system, without the cost or barrier of an emulated environment or virtual machine. All that separates a container from your OS are kernel namespaces, so they're really just native processes with different labels on them. Podman makes this more evident than ever, and once you configure Podman to be a rootless command, containers feel more like commands than virtual environments. Podman makes containers and pods easy, so give it a try.
## Comments are closed. |
14,192 | 准备升级了!Ubuntu 21.04 将在本周达到支持终点 | https://news.itsfoss.com/ubuntu-21-04-eol/ | 2022-01-19T10:21:32 | [
"Ubuntu"
] | https://linux.cn/article-14192-1.html |
>
> 从本周 1 月 20 日起,Ubuntu 21.04 将不再收到任何更新。是时候考虑你的升级选择了!
>
>
>

[Ubuntu 21.04](https://news.itsfoss.com/ubuntu-21-04-release/) 运行良好、添加了有趣的功能,也包括一些值得注意的变化,如 [对多显示器的改进](https://news.itsfoss.com/ubuntu-21-04-multi-monitor-support/)、用户界面的改进、支持 GNOME 40 的应用程序等等。
现在,是时候升级了。
Ubuntu 21.04 的更新支持在本周,即 **1 月 20 日** 结束。
你将不再收到任何关于 Ubuntu 21.04 系统的更新。如果你一直在使用 Ubuntu 或其某种风格,如 Ubuntu MATE,你需要将你的系统升级到 Ubuntu 21.10。
顺便提一句,Ubuntu 的非 LTS 版本维护期为 9 个月。如果你是 Linux 的新手的话,我建议你了解一下 [Ubuntu 发布周期](https://itsfoss.com/end-of-life-ubuntu/)。
所以,现在你必须升级到 Ubuntu 21.10,然后再为 2022 年 7 月的另一次升级做好准备。不过,这样你的时间就充裕多了!
### 升级到 Ubuntu 21.10
除非你有一个没有连接到互联网的系统,并且你希望它继续使用 Ubuntu 21.04,否则建议你现在就升级。
在没有任何更新的情况下,你的系统将继续受到新的安全风险的影响。所以,在做决定之前要记住这一点。
[Ubuntu 21.10](https://news.itsfoss.com/ubuntu-21-10-release/) 引入了许多变化,包括 GNOME 40、[Linux 内核 5.13](https://news.itsfoss.com/linux-kernel-5-13-release/)、对高质量蓝牙音频编解码器的支持、暗色/浅色主题等等。
所以,你可能要开始考虑你的升级选择了。
你可以继续使用 Ubuntu,升级到 21.10。如果你考虑用不同的东西进行全新安装,也可以尝试像 [Pop!\_OS 21.10](https://news.itsfoss.com/pop-os-21-10/) 这样的发行版。
不要忘了,还有各种的 Ubuntu 的风格版呢。
要开始升级,你只需要搜索 “<ruby> 软件更新器 <rt> Software Updater </rt></ruby>” 并点击它,让它寻找升级并通知你。
无论你有什么发行版,软件更新器或你的软件中心应该给你提供升级选项,或者你可以在系统设置中找到它。
而且,然后按照屏幕上的指示,再点击几下就可以进行升级过程了。
重要的是,为了安全起见,在执行升级之前要备份你的必要数据。
在一些像 Ubuntu MATE 这样的版本中,你也可以选择使用终端,输入以下命令开始升级:
```
sudo do-release-upgrade
```
### 通往 Ubuntu 22.04 LTS 之路
Ubuntu 22.04 LTS 的 [预期功能列表](https://itsfoss.com/ubuntu-22-04-release-features/) 应该不会让你失望。因此,你可以在它发布时轻松地升级到它,或者留在 Ubuntu 21.10 上,等待 7 月份支持结束时升级。
你是否期待着 Ubuntu 22.04 LTS 在今年 4 月的发布?或者,你愿意坚持使用 Ubuntu 21.10 直到 2022 年 7 月?
---
via: <https://news.itsfoss.com/ubuntu-21-04-eol/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Ubuntu 21.04](https://news.itsfoss.com/ubuntu-21-04-release/) had a good run with interesting feature additions. Some notable changes included [multi-monitor improvements](https://news.itsfoss.com/ubuntu-21-04-multi-monitor-support/), UI enhancements, GNOME 40-ready applications, and more.
Now, it is time to upgrade!
The support for updates in Ubuntu 21.04 has finally come to an end today (January 20th).
You will no longer receive any updates to your Ubuntu 21.04 system. If you have been using Ubuntu or any of its flavors like Ubuntu MATE, you need to upgrade your systems to Ubuntu 21.10.
In case you did not know, Ubuntu’s non-LTS releases are maintained for nine months. I recommend you to learn about [Ubuntu release cycles](https://itsfoss.com/end-of-life-ubuntu/?ref=news.itsfoss.com), if you are new to Linux.
So, now that you have to upgrade to Ubuntu 21.10, you will have to be ready for another upgrade in July 2022. But, for that, you have plenty of time!
## Upgrading to Ubuntu 21.10
Unless you have a system that is not connected to the internet, and you want it to keep using Ubuntu 21.04, it is recommended that you upgrade now.
Your system will remain vulnerable to new security risks without any updates. So, keep that in mind before making a decision.
[Ubuntu 21.10](https://news.itsfoss.com/ubuntu-21-10-release/) introduced many changes, including GNOME 40, [Linux Kernel 5.13](https://news.itsfoss.com/linux-kernel-5-13-release/), support for high-quality Bluetooth audio codecs, dark/light theme, and more.
So, you might want to start considering your upgrade options!
You can continue with Ubuntu 21.10 upgrade. Or, you can also try distributions like [Pop!_OS 21.10](https://news.itsfoss.com/pop-os-21-10/), if you consider a fresh installation with something different.
Not to forget, there are plenty of Ubuntu flavors as well!
To start the upgrade, all you need to do is search for “**Software Updater**” and click on it to let it look for the upgrade/notify you.
No matter what distribution you have, the software updater or your software center should give you the upgrade option, or you can look for it in the system settings.
And, then follow the on-screen instructions to proceed with the upgrade process in a few more clicks.
It is important to back up your necessary data before performing the upgrade, just to be on the safe side.
On some flavors like Ubuntu MATE, you can also prefer to use the terminal and type in the following command to start the upgrade:
`sudo do-release-upgrade`
## The Road to Ubuntu 22.04 LTS
Ubuntu 22.04 LTS should not disappoint you with its [list of expected features](https://itsfoss.com/ubuntu-22-04-release-features/?ref=news.itsfoss.com). So, you can easily upgrade to it when it releases or hang on to Ubuntu 21.10 to end support in July.
*Are you looking forward to Ubuntu 22.04 LTS as soon as it releases in April this year? Or, would you prefer to stick with Ubuntu 21.10 until July 2022?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,193 | 流行的任天堂电子游戏模拟器 Cemu 计划开源并支持 Linux | https://news.itsfoss.com/cemu-nintendo-linux/ | 2022-01-19T11:11:11 | [
"任天堂",
"游戏"
] | https://linux.cn/article-14193-1.html |
>
> 这的确是个好消息!
>
>
>

如果你喜欢玩复古游戏,你可能已经接触过复古游戏机模拟器。顺便说一句,所谓“<ruby> 模拟器 <rt> Emulator </rt></ruby>”(仿真器)主要是指允许主机系统运行为另一系统设计的游戏的软件或硬件。
最近,Cemu 成功引起了开源社区的注意力。它是众多复古电子游戏模拟器之一,可以让你玩为任天堂 Wii U 定制的游戏。然而,到目前为止,它在一个主要方面与大多数模拟器不同,即它是闭源的,但这即将改变。
### Cemu 简介
[Cemu](https://cemu.info) 是一个流行的基于软件的复古电子游戏模拟器,专门模拟任天堂 Wii U 游戏,它是这类模拟器中第一个。它利用了 OpenGL 和 Vulkan 来运行游戏。
多年来,它已经有了显著的进展,现在可以 [玩整个 Wii U 库中的 51% 的游戏](https://compat.cemu.info/)。这包括《马里奥卡丁车 8》和《塞尔达传说:荒野之息》等热门游戏。
虽然它早在 2015 年就发布了,但 Cemu 只能运行在 Windows 上。不过,开发者发布的新路线图指出,Cemu 应该很快就会移植到 Linux 上了。
而且,最令人关注的是,Cemu 将走向开源!
### 通往开源和 Linux 之路
路线图总共包括了由开发人员计划的八个里程碑。其中包括计划开发一个 Linux 移植版并向社区提供代码。
谈到 Cemu 的开源问题,开发者计划在 2022 年完成这一工作。所以,你不应该对此寄予厚望。
迁移到 Linux 涉及到将源代码从 C 语言改写成 C++ 语言,并从 Visual Studio 迁移到 cmake。
以下是开发者对将 Cemu 引入 Linux 的看法:
>
> 我们最终想提供一个原生的 Linux 版本。这一直是一个正在进行的副计划,尽管由于优先级较低和依赖于其他任务而进展相对缓慢,但现在已经完成了大约 70% 的工作。
>
>
>
开发人员还提到,移植过程伴随着其他工作,如软件 H264 解码器和 cubeb 后端。由于主要的工作已经完成,可以说 Cemu 很快就会出现在 Linux 上。
### 其他计划
开发人员已经考虑将 LLVM 作为 CPU JIT 后端,用于将 PowerPC(Wii U 的主机架构)转换为 ARM 等 X86 架构。
他们还刚刚开始着手开发一个新的着色器反编译器,以减少着色器编译时间和卡顿。
你可以参考 [官方路线图](https://wiki.cemu.info/wiki/Roadmap) 了解更多细节。
### 总结
这对渴望做出贡献并使 Cemu 变得更好的复古游戏爱好者来说绝对是一份大礼。
Cemu 最终将加入许多流行的、开源的任天堂游戏机模拟器的行列,如 Citra、Dolphin 和 Yuzu。
你对 Cemu 的开源有什么看法?复古游戏模拟器应该是闭源的还是开源的?
---
via: <https://news.itsfoss.com/cemu-nintendo-linux/>
作者:[Rishabh Moharir](https://news.itsfoss.com/author/rishabh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you’re into retro gaming, you may have come across retro console emulators. For those unaware, they are basically software or hardware that allow the host system to run games designed for another system.
Lately, Cemu has managed to grab the attention of the open-source community. It is one of the many retro console emulators out there that lets you play games tailored for Nintendo Wii U. However, as of now, it distinguishes itself from most of them in one major aspect, its closed-source nature, but that’s about to change.
## What is Cemu?
[Cemu](https://cemu.info/?ref=news.itsfoss.com) is a popular software-based retro console emulator that specifically emulates Nintendo Wii U games and is the first one to do so. It makes use of both OpenGL and Vulkan to run the games.
It has improved significantly over the years and can now [play around 51% of the entire Wii U library](https://compat.cemu.info/?ref=news.itsfoss.com). This list includes popular titles like Mario Kart 8 and The Legend of Zelda: Breath of the Wild.
Although released back in 2015, Cemu is only available on Windows. But, a new roadmap published by the developers states that Cemu should arrive on Linux soon.
And, as a cherry on top, Cemu will be going open-source!
## The Way to Open-Source and Linux
The roadmap includes a total of eight milestones planned by the devs. Among them are plans to develop a Linux port and make the code available to the community.
Talking about Cemu going open-source, the devs have plans to do this by 2022. So, you should not keep your hopes high for anything to arrive soon enough.
Moving to Linux involves rewriting the source code from C to C++ and migrating from Visual Studio to cmake.
Here’s what the devs had to say about bringing Cemu to Linux:
We eventually want to offer a native Linux version. This has been an ongoing side-project, albeit progressing relatively slowly due to somewhat low-priority nature and being dependent on other tasks. About 70% of the work has been done at this point.
The devs have also mentioned that the porting process is accompanied by other duties like the software H264 decoder and cubeb backend. Since a major of work has been completed, it’s safe to say Cemu will be coming to Linux very soon.
## Other Plans
The devs have considered implementing LLVM as CPU JIT backend for translating PowerPC (Wii U’s host architecture) to x86 architectures like ARM.
They have also just begun working on a new shader decompiler to reduce shader compilation time and stuttering.
You can refer to the [official roadmap](https://wiki.cemu.info/wiki/Roadmap?ref=news.itsfoss.com) for more details.
## Wrapping Up
This is definitely a massive gift to retro gaming enthusiasts eager to contribute and make Cemu better.
Cemu will finally join the likes of many popular and open-source Nintendo console emulators like Citra, Dolphin, and Yuzu.
*What do you think of Cemu going open-source? Should retro game emulators be closed-source or open-source?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,194 | 2021 总结:提升 Git 技能的 10 篇指南 | https://opensource.com/article/22/1/git-tutorials | 2022-01-19T17:13:50 | [
"Git"
] | https://linux.cn/article-14194-1.html |
>
> 这些文章包含了黑科技、鲜为人知的事实,以及在使用 Git 时可以派上用场的技巧和窍门。
>
>
>

Git 是代码协作开发工作流程中不可或缺的一部分。无论你是初学者还是专家,第一件事就是在使用开源代码时需要学习这个功能强大的版本控制系统。对于 Git,不需要知道所有事情,但是了解一些特殊的黑科技可以让你在 GitLab 等平台上更轻松地分享代码,因此你可以与不同地方的开发人员协作。如果有什么没把握的地方,`git --help` 可以帮助你。
我每天都为了解 Git 所提供的控制能力而感到惊讶。没有哪种情况是你无法恢复到早期版本的,无论你所处的情况是多么不可能或棘手。
在 2021 年我们发布了大量 Git 的文章;我只汇总了其中前 10 篇,这些文章包含了各种黑科技、鲜为人知的事实,以及在使用 Git 时可以派上用场的技巧和窍门。
### 使用 git stash 命令的实用指南
[Ramakrishna Pattnaik](https://opensource.com/users/rkpattnaik780) 解释了 [git stash 命令](https://opensource.com/article/21/4/git-stash) 的功能。这篇文章重点介绍 `git stash` 如何帮助你列出、检查、保存和恢复更改,以确保切换分支时的无忧体验。它还可以帮助你跟踪在本地无需提交的更改,而同时保持干净的工作目录。
### 5 个让你的 Git 技能更上一层楼的 Git 命令
[Seth Kenlon](https://opensource.com/users/seth) 详细介绍了 [五个鲜为人知的 Git 命令](https://opensource.com/article/21/4/git-commands),它们可以让你的生活更轻松。开发人员可以使用 `git whatchanged`、`git stash`、`git worktree` 和 `git cherry-pick` 等命令来节省时间。
### Git cherry-pick 简介
[Rajeev Bera](https://opensource.com/users/acompiler) 教程将引导你了解 [git cherry-pick 命令](https://opensource.com/article/21/4/cherry-picking-git) 是什么,为什么和如何使用它,并列出 `git cherry-pick` 可以帮助你避免棘手的情况所有用例。
### 3 个使用 git cherry-pick 命令的原因
我分享了 [利用 git cherry-pick](https://opensource.com/article/21/3/git-cherry-pick) 如何帮助你避免冗余,一次性处理多个提交并恢复丢失的更改。
### 使用 git worktree 自由地尝试你的代码
`git stash` 命令负责将更改保存到工作目录。Seth Kenlon 向我们介绍了 `git worktree` 和几个 [git worktree 用例](https://opensource.com/article/21/4/git-worktree),它们可以帮助你将存储库恢复到已知状态。
### Git 上下文切换的 4 个技巧
[Olaf Alders](https://opensource.com/users/oalders) 的这篇文章讨论了使用 Git 时 [切换分支的四种不同方式](https://opensource.com/article/21/4/context-switching-git) 的利弊。这些选项将帮助你简化工作流程,并保持干净的工作目录,而不会丢失你的更改。
### 查找 Git 提交中的更改
Seth Kenlon 解释了如何利用如 [git log 和 git whatchanged](https://opensource.com/article/21/4/git-whatchanged) 等简单命令来提取有关 Git 提交内容中更改的特定信息。这是一个有用的快捷方式,而且名字很容易记住。
### 管理主目录的 7 个 Git 技巧
Seth Kenlon 分享了 [使用 Git 管理和组织 $HOME 变量](https://opensource.com/article/21/4/git-home) 的注意事项,并解释了它如何让他的跨设备生活更实用。更好的是,这让他可以自由地尝试新想法,因为他知道他可以轻松地将它们回滚。
### GitOps 与 DevOps:有什么区别?
[Bryant Son](https://opensource.com/users/brson) 向你介绍了 [GitOps](https://opensource.com/article/21/3/gitops),他将其描述为 DevOps 的进化版本,它使用 Git 作为单一事实来源。这篇文章还列出了其它有用资源,可用于学习 DevOps 并在开源领域找到工作。
### 开始使用 Argo CD
[Ayush Sharma](https://opensource.com/users/ayushsharma) 详细介绍了 [Argo CD](https://opensource.com/article/21/8/argo-cd) 的优势,这是一种基于拉取式的 GitOps 开发工具。Argo CD 通过在 Git 中管理 Kubernetes 清单并将它们同步到集群中,为你提供两全其美的体验。
你能想到其他让你的生活更轻松的 Git 技巧吗?请在评论中告诉我们。
---
via: <https://opensource.com/article/22/1/git-tutorials>
作者:[Manaswini Das](https://opensource.com/users/manaswinidas) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Git is an indispensable part of the code-sharing development workflow. Be you a beginner or an expert, this powerful version control system is the first thing you are expected to learn when working with open source code. You don't need to know everything under the sun when it comes to Git, but knowing specific hacks makes sharing your code a lot easier on platforms like GitLab, so you can collaborate with developers far and near. If there's something you're not sure about, `git --help`
can come to your rescue.
I'm amazed every day by the amount of control that knowing Git provides. There is not a single instance when you can't revert to an earlier version, however impossible or sticky the situation you may be in.
Opensource.com had a great set of articles regarding Git in 2021; I'm summarizing just the top 10. All the articles contain hacks, lesser-known facts, and tips and tricks that can come in handy while working with Git.
## A practical guide to using the git stash command
[Ramakrishna Pattnaik](https://opensource.com/users/rkpattnaik780) explains the functions of the [git stash command](https://opensource.com/article/21/4/git-stash). This article highlights how `git stash`
can help you list, check, save, and retrieve changes to ensure a hassle-free experience when switching branches. It can also help you track changes locally without committing and while maintaining a clean working directory.
## 5 commands to level up your Git game
[Seth Kenlon](https://opensource.com/users/seth) details [five lesser-known Git commands](https://opensource.com/article/21/4/git-commands) that can make your life easier. Developers can save time with commands like `git whatchanged, git stash, git worktree,`
and `git cherry-pick`
## What is Git cherry-picking?
This tutorial by [Rajeev Bera](https://opensource.com/users/acompiler) walks you through the what, why, and how of the [git cherry-pick command](https://opensource.com/article/21/4/cherry-picking-git) and lists all possible use cases when `git cherry-pick`
will help you escape a sticky situation.
## 3 reasons I use the git cherry-pick command
I share how [leveraging git cherry-pick](https://opensource.com/article/21/3/git-cherry-pick) can help you avoid redundancy, handle multiple commits in one go, and restore lost changes.
## Experiment on your code freely with git worktree
The `git stash`
command takes care of saving changes to a working directory. Seth Kenlon introduces us to `git worktree`
and the several [git worktree use cases](https://opensource.com/article/21/4/git-worktree) that can help you get a repository back to a known state.
## 4 tips for context switching in Git
This article by [Olaf Alders](https://opensource.com/users/oalders) discusses the pros and cons of [four different ways of switching branches](https://opensource.com/article/21/4/context-switching-git) while working with Git. These options will help you simplify your workflow and maintain a clean working directory without losing your changes.
## Find what changed in a Git commit
Seth Kenlon explains how to leverage simple commands like [git log and git whatchanged](https://opensource.com/article/21/4/git-whatchanged) to extract specific information regarding what changed in a Git commit. It's a helpful shortcut, and the name makes it easy to remember.
## 7 Git tips for managing your home directory
Seth Kenlon shares the dos and don'ts of [managing and organizing $HOME with Git](https://opensource.com/article/21/4/git-home) and explains how it made his life more convenient across devices. Even better, it's freed him to experiment with new ideas, knowing he can roll them back easily.
## GitOps vs. DevOps: What's the difference?
[Bryant Son](https://opensource.com/users/brson) introduces you to [GitOps,](https://opensource.com/article/21/3/gitops) which he describes as an evolved version of DevOps that uses Git as the single source of truth. The article also lists helpful resources available on Opensource.com for learning DevOps and landing a job in open source.
## Get started with Argo CD
[Ayush Sharma](https://opensource.com/users/ayushsharma) details the advantages of [Argo CD,](https://opensource.com/article/21/8/argo-cd) a pull-based GitOps development tool. Argo CD gives you the best of both worlds by managing Kubernetes manifests in Git and syncing them in a cluster.
Can you think of other Git hacks that make your life easier? Please let us know in the comments or [send us an article idea](https://opensource.com/how-submit-article).
## Comments are closed. |
14,196 | 将自己作为承包商而定价的基础原则 | https://theartofmachinery.com/2021/07/04/pricing_as_contractor_101.html | 2022-01-20T09:54:00 | [
"自由职业"
] | https://linux.cn/article-14196-1.html | 
我职业生涯的大部分时间都是自由职业者。有时候,我也会和一些想要辞掉全职工作去做一些承包或服务业务的人聊天。到目前为止,我们新手最常犯的错误就是为自己定价。
以 [这篇有用的博客文章为例](https://calebporzio.com/making-100k-as-an-employee-versus-being-self-employed),它分析了美国雇员与自由职业者的收入间的对比。据估计,在美国,作为一名自由职业者,你需要获得 14 万美元的收入,才能获得相当于 10 万美元的雇员薪酬。我记得当我第一次创业时,我发现这样的计算非常有用。而,有些人看到结果会想:“哎呀,如果我是自由职业者,我得赚 1.4 倍的钱。我真的能做到吗?”
不,不,不,这种想法是落后的。
### 如何给自己定价
让我们举个例子。假设你是一名全职软件工程师,年收入 10 万美元,你正考虑转成承保。
当你是自由职业者时候,你必须像做企业一样思考,因为这就是你的谋生方式。所以,你必须把所有的成本加起来,并计算出如何收回这些成本。电子表格的口碑很差(有一些很好的理由),但它们实际上非常有用,尤其是对这些东西(以及作为企业主要进行的许多其他计算)。
第一个要加入统计的成本是那 10 万美元。如果这听起来很奇怪,那就是所谓的“机会成本”。你本可以继续工作以赚到 10 万美元;而没有赚到这 10 万美元,实际上是在规划业务时的一种成本。把这一费用和其他你实际使用的任何其它就业福利一起记下来。如果你的雇主提供工作日午餐,那就加上一年中每个工作日午餐的费用。如果你的雇主为员工提供健身软件的折扣,但你却没有使用该软件,那么不要将该福利作为机会成本。
其他费用取决于你在做什么和你住在哪里。员工医疗保险在澳大利亚不像在美国那么重要。另一方面,强制性养老金支付(类似于美国的 401(K) 计划)是一个大问题。我有自己的公司,我的主要非工资成本是保险、会计/档案、法律(合同审查等)、债务催收和各种在线服务成本。如果你在计算一些耐用的东西(比如一张桌子),把成本除以你预计使用该东西的年数。
总之,到目前为止,这基本上就是 Caleb 的博客文章中的内容,所以为了简单起见,我将假设同样的 10 万美元的名义工资和 14 万美元的等效业务成本。(当然,一切都要根据自己的情况进行调整。)现在你需要想办法收回这笔成本。澳大利亚一年大约有 255 个工作日,所以如果你能把它们全部外包出去,你每天要收取 550 美元(外加销售税)。在现实中,你不可能为一整年的工作计费。我采取了一种风险更高的方法,在我目前从事自营职业的过去 6 年里,我的平均回报率约为 60%-70%。[埃森哲的年度财务报告](https://www.accenture.com/au-en/about/company/annual-report) 说他们的承包商的“利用率”大约为 90%,我想这意味着他们付费了 90% 的总工作日的费用。让我们假设你的工作适度,75% 的工作日都有付账。这意味着你可以在 255 天的 75%(即 191 天) 里收回了 14 万美元的成本,每天开出 730 美元的账单(加上销售税)。
### 误区
刚接触合同的人通常会对这样的数字做出反应,并会想,“见鬼?!这么高啊!”。这只是一个计算示例,但服务价格通常相当于你天真猜测的全职雇员工资的两倍或两倍以上。然而,这日薪是通过一个简单的计算得出的,那就是你需要收取多少钱才能获得相当于 10 万美元的工资。这是一回事。不这样想才是关键的错误。
新的承包商往往还不敢确定,他们要求那么多,听起来是不是很贪婪?如果你的客户有考虑采购你,他们也在做大致相同的计算。“我可以付给 Gentle Blog Reader 每天 730 美元,只要我愿意,我也可以花大约 14 万美元雇佣一个我甚至不是每天都真正需要的全职雇员。”从雇主的角度来看,10 万美元的薪水实际上也不是 10 万美元。把价格建立在名义基本工资的基础上是没有意义的。即使你是在销售 B2C 产品,你的潜在竞争对手也不会降价,至少不会持续降价。
### 为什么这很重要
这个具体的例子是针对承包的,但这是商业经济学的一条基本规则:除非你正在尝试一些风险极高的高收入行为(我们知道 [Pets.com](https://en.wikipedia.org/wiki/Pets.com) 的结果),否则你需要计算出你的成本,并设定足够高的价格来弥补这些成本。
一些人仍然对他们需要设定的价格感到不安,他们认为降低价格是合理的。也许他们会这样想:“我是个很好的人,如果我每天只收 400 美元,我的客户会更高兴。”问题是你得不到同样的客户。那些愿意为雇员支付 10 万美元年薪的客户,不会为承包商支付 400 美元一天来做同样的工作。相反,在实践中,你可能会得到一些好客户,他们只是没有每天 730 美元的预算,但同时你也会得到一大堆非常糟糕的客户。想想看。如果一个陌生人以 50 美元的价格卖给你一枚看起来很精美的钻戒,你会付钱吗?还是宁愿以正常价格买另一枚戒指?
我要强调的是,我只是从 Caleb 的博客文章中提取了数据,而且一切都是相对的。用你自己的数字代替吧。在世界上大多数地区,每天 400 美元可能是一个令人难以置信的价格。然而,如果你是硅谷的一名高级金融科技开发人员,每天收费 400 美元只会让你成为吸引糟糕客户的磁铁。大多数优秀的人都会知道有些事情不对劲,他们会被吓跑。
我说的糟糕客户是什么意思?浏览一下 [“来自地狱的客户”博客](https://clientsfromhell.net/) 吧。它包括很多基本的烦恼,比如客户永远不会得到满足,或者提出无理要求,或者浪费你的时间,一直到彻头彻尾的辱骂,或者让你按规格工作,然后辩称自己不应该付钱,因为“我不想要”。有些客户根本就不付钱。
如果你不够重视你自己的产品,也不要因为你的客户不够重视你的产品而感到震惊。
不过,情况会变得更糟。好客户倾向于与其他好客户合作。如果你总是按时做到,你会和那些浪费你时间的人一起工作吗?如果你尊重他人,你会和那些不讲道理、辱骂他人的人一起工作吗?一般来说,你的好客户会把你介绍给其他好客户。糟糕的客户则恰恰相反,如果他们甚至会感激地把你推荐给任何人的话。因此,如果你的价格合适,你的生意会随着你的声誉而增长。如果你收费过低,你会发现自己陷入了一个恶性循环,你不仅会赔钱,而且会发现越来越难获得适当的报酬。
这些都只是平均水平,如果你幸运的话,低收费也能吸引到好客户,如果你不幸的话,价格合理也仍然会得到坏客户。然而,如果你的收入已经很低了,那么每一个坏客户都会对你造成伤害。希望超越平均水平不是一个好计划。
### “但没人付那么多钱!”
假设你是一名经验丰富的全职工程师,你决定尝试独立工作。你可能会发现,你的计算比率似乎比你在自由职业网站上看到的要高。这是因为在自由职业网站上建立声誉很难。自由职业者网站对于那些主要想要低价的临时买家来说是最有用的。
我想,很多聪明的工程师都认为,职业社交是很难的,而且需要非常外向的性格,所以他们不得不依靠自由职业网站来工作。坏消息是,你需要建立良好的声誉才能拿到高薪。好消息是,只要他们拥有所需的技能,大多数人都可以做到。社交并不是去参加所谓的“社交活动”(实际上,这些活动对社交来说都很糟糕)。建立关系网的技巧可以写一篇全新的博客文章,但关键是在他们的日常生活中找到好客户,并做一些让他们不断回头的事情,甚至可能让你找到其他好客户。
在任何情况下,不要让自由职业网站或其他任何东西把你的价格定在你可以从全职工资中拿到的等价物以下。事实上,[你甚至可能比你现在的工资还高](https://theartofmachinery.com/2018/10/07/payrise_by_switching_jobs.html),这就是为什么这是 “定价基础原则”。收费过低会扼杀你的自主创业生涯。
---
via: <https://theartofmachinery.com/2021/07/04/pricing_as_contractor_101.html>
作者:[Simon Arneaud](https://theartofmachinery.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[CN-QUAN](https://github.com/CN-QUAN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I’ve been self-employed for most of my career. Sometimes I talk to other people who are interested in leaving a full-time job to do some kind of contracting or service business. By far, the most common newbie mistake that we all seem to make is in pricing ourselves.
Take [this useful blog post
that breaks down employee income vs freelancer income in the US](https://calebporzio.com/making-100k-as-an-employee-versus-being-self-employed). It estimates that you need $140k revenue as a
freelancer in the US to have the equivalent of $100k employee compensation. I remember finding calculations like that
really useful when I first started a business. However, some people will look at the result and think, “Gee, I have to
make 1.4x as much if I’m self employed. Can I really do that?”
No, no, no. That thinking is backwards.
## How to price yourself
Let’s make up an example. Suppose you’re a full-time-employed software engineer grossing that $100k p.a., and you’re thinking of switching to contracting.
When you’re self-employed, you have to think like a business because that’s literally how you’re making your living. So you have to add up all your costs and figure out how you’re going to recover them. Spreadsheets get a bad rap (for some good reasons), but they’re actually really useful for this stuff (and a lot of other calculations you’ll do as a business owner).
The first cost to add to the tally is that $100k. If that sounds weird, it’s what’s called “opportunity cost”. You could have made $100k by staying employed; not making that is effectively a cost you have to justify when planning your business. Mark that cost down, along with any other employment benefits you actually use. If your employer offers on-site lunches, add what it costs you to get lunch each workday of the year. If your employer offers employee discounts on its fitness software, but you don’t use that software anyway, don’t add that benefit as an opportunity cost.
Other costs depend on what you’re doing and where you live. Employee-provided health insurance isn’t as big a thing in Australia as in the US. On the other hand, compulsory superannuation payments (similar to the US 401(k)) are a big deal. I have my own company, and my major non-salary costs are insurance, accounting/filing, legal (for contract reviews, etc.), debt collection and various online service costs. If you’re counting something durable (like a desk) divide the cost by the estimated number of years you expect to use the thing.
Anyway, so far this is basically what was in Caleb’s blog post, so to keep things simple, I’ll assume the same $100k
nominal salary and $140k equivalent business cost. (Scale everything to match your own circumstances, of course.) Now
you need to figure out how to recover that cost. There are about 255 Australian working days in a year, so if you could
contract them all out, you’d charge $550 a day (plus sales tax). In reality, you won’t be able to bill the entire year.
I’ve taken a higher-risk approach and averaged about 60-70% in the past 6 years of my current stint of self employment.
[Accenture’s annual financial reports](https://www.accenture.com/au-en/about/company/annual-report) say they
get about 90% “utilization” from their contractors, which I assume means they bill 90% of the total workdays. Let’s
assume you’re moderate and bill 75% of work days. That means you recover $140k of costs in 75% of 255 days (or 191
days) by billing about $730 a day (plus sales tax).
## The mistake
People new to contracting often react to numbers like that and think, “WTF?! That’s huge!” That’s just one example calculation, but it’s normal for service prices to be around double or more what you might naïvely guess from equivalent full-time employee rates. However, that day rate came from a simple calculation of how much you need to charge to get the equivalent of a $100k salary. It’s the same thing. Thinking otherwise is the critical mistake.
New contractors are often still unsure. Won’t they sound *greedy* asking for that much? If your clients have
any clue, they’re doing pretty much the same calculation. “I could pay Gentle Blog Reader $730 a day for just as long
as I want, or I could pay ~$140k for a full-timer who I won’t even really need every day.” A $100k salary isn’t
actually $100k from the employer’s point of view, either. Basing prices on nominal base salaries just doesn’t make
sense. Even if you’re selling B2C, your cluey competitors won’t be charging less, at least not sustainably.
## Why it matters
That specific example was for contracting, but it’s a basic rule of business economics: unless you’re trying some
super-risky growth hacking (and we know how [Pets.com](https://en.wikipedia.org/wiki/Pets.com) turned out),
you need to figure out your costs and set your price high enough to cover them.
Some people still feel uncomfortable with the price they need to set, and they rationalise dropping the price.
Perhaps they think something like, “I’m a really nice person, and if I charge only $400 a day my clients will be even
happier.” The problem is that you won’t get the same clients. Cluey clients who would pay $100k a year base salary for
an employee won’t pay $400 a day for a contractor to do the same job. Instead, in practice, you might get a few good
clients who just didn’t have the budget for $730 a day, but you *will* get a whole bunch of really bad clients.
Think about it. If a stranger offered you a fancy-looking diamond ring for $50, would you pay? Or would you rather buy
another ring for a normal price?
Let me stress that I’m just taking the numbers from Caleb’s post and that everything is relative. Use your own numbers instead. In most parts of the world, $400 a day might be a fantastic rate. However, if you’re a senior fintech developer in Silicon Valley, charging $400 a day will just make you a magnet for terrible clients. Most of the good ones will know something isn’t adding up, and they’ll be scared away.
What do I mean by bad clients? Browse through [the Clients from Hell blog](https://clientsfromhell.net/)
for a bit. It ranges from a lot of basic annoyance like clients who are never satisfied, or who make unreasonable
demands, or who waste your time, all the way to clients who are outright abusive, or who get you to do work to spec
before arguing they shouldn’t have to pay because “I don’t want it”. Some clients simply don’t pay at all.
If *you* don’t value your own product enough, don’t be shocked if you have customers who don’t value it
enough, either.
It gets worse, though. Good clients tend to work with other good clients. If you’re always available when you say you will be, would you work with people who waste your time? If you treat others with respect, would you work with people who are unreasonable and abusive? On average, your good clients will tend to refer you to other good clients. The reverse is true of bad clients, if they’re even grateful enough to refer you to anyone at all. Therefore, if you charge a good price, your business will tend to grow as you build a reputation. If you undercharge, you’ll find yourself in a downward spiral where you’re not only losing money, but finding it harder and harder to get proper pay at all.
All of this is just a matter of averages, and if you’re lucky you’ll still get good clients even if you undercharge, and if you’re unlucky you’ll still get bad clients even if you charge the right price. However, if your revenue is already weak, each bad client will really hurt. Hoping to beat the averages isn’t a good plan.
## “But no one pays that much!”
Suppose you’re an experienced full-time engineer and you decide to try going independent. You’ll probably find that your calculated rate seems high compared to what you see on a freelancing website. That’s because it’s hard to build up a reputation on freelancing websites. Freelancing websites are most useful for casual buyers who primarily want a low price.
I think a lot of smart engineers assume career networking is hard and requires super high levels of extroversion, so they have to rely on freelancing websites for work. The bad news is that you need to build up a good reputation to get good pay. The good news is that most people can do it as long as they have skills that are in demand. Networking isn’t about going to so-called “networking events” (they’re actually mostly terrible for networking). Networking tips would make a whole new blog post, but the key is to find good clients in their natural habitats, and to do the things that make them keep coming back and maybe even refer you to other good clients.
In any case, don’t let freelancing websites or anything else set your price below the equivalent of what you could
get from a full-time salary. In fact, [you might even get better
than your current salary](/2018/10/07/payrise_by_switching_jobs.html), which is why this is “Pricing 101”. Undercharging, however, will kill your
self-employment career. |
14,197 | Linux Mint 全新的 Edge ISO 已经可以下载了! | https://news.itsfoss.com/linux-mint-20-3-edge-iso/ | 2022-01-20T10:55:03 | [
"LinuxMint"
] | https://linux.cn/article-14197-1.html |
>
> Linux Mint 20.3 现在为 Cinnamon 版提供了一个单独的 Edge ISO,以帮助用户使用最新一代的硬件!
>
>
>

[Linux Mint 20.3](https://news.itsfoss.com/linux-mint-20-3-una-release/) 带来了一些改进。然而,它是由 Linux 内核 5.4 LTS 驱动的。
因此,使用较新硬件的用户可能会发现启动时很麻烦,或者遇到其他与旧的 Linux 内核不兼容的问题。
幸运的是,Linux Mint 20.3 现在有一个提供了 Linux 内核 5.13.0-25 的 Edge ISO。
### 带有 Linux 内核 5.13 的 Linux Mint 20.3
[Linux 内核 5.13](https://news.itsfoss.com/linux-kernel-5-13-release/) 通过 HDMI 引入了对 AMD GPU FreeSync 的支持,以及许多其他硬件改进。
因此,举例来说,如果你有一个 AMD GPU,并且在 Linux Mint 20.3 上遇到了问题,Edge ISO 可以派上用场。
是的,如果你有较新的硬件在使用 Linux Mint 20.3 时有问题,你可以试试 Edge ISO。
然而,Linux 内核 5.13 并不完全支持所有现代硬件,如英特尔 Alder Lake 处理器。
考虑到英特尔的第 12 代产品系列已经可以供消费者使用,一个更新的 Linux 内核可能是一个更好的选择,但有总比没有好。
因此,有必要指出,使用 Edge ISO 不会神奇地解决最新一代硬件的问题。你必须了解了 [Linux 内核 5.13](https://news.itsfoss.com/linux-kernel-5-13-release/) 的详细变化/支持,然后再进行尝试。
### 下载 Linux Mint 20.3 Edge ISO
你可以选择下载单独的 Edge ISO 或从更新管理器中更新 Linux 内核。

前往 “更新管理器”,然后从“查看”菜单中导航到 Linux 内核选项。你可以注意到,你可以安装其他可用的 Linux 内核(根据你的要求),如果需要,可以删除旧的内核。
建议不要删除旧的内核,除非你确定较新的版本能按预期工作。

在进行内核升级之前,你应该备份你的重要文件,以防万一。
Edge ISO 只限于 Cinnamon 版。所以,你需要前往 Linux Mint 20.3 Cinnamon 页面下载该 ISO。
* [Linux Mint 20.3 Cinnamon(Edge)版](https://www.linuxmint.com/edition.php?id=296)
---
via: <https://news.itsfoss.com/linux-mint-20-3-edge-iso/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

[Linux Mint 20.3 release](https://news.itsfoss.com/linux-mint-20-3-una-release/) brings in several improvements. However, it is powered by Linux Kernel 5.4 LTS.
So, users with newer hardware may find it troublesome to boot or run into other incompatibility issues with an older Linux Kernel.
Fortunately, Linux Mint 20.3 now has an Edge ISO featuring Linux Kernel 5.13.0-25.
## Linux Kernel 5.13 With Linux Mint 20.3
[Linux Kernel 5.13](https://news.itsfoss.com/linux-kernel-5-13-release/) introduced support for AMD GPU FreeSync via HDMI along with many other hardware improvements.
So, for instance, if you have an AMD GPU and have issues with Linux Mint 20.3, the Edge ISO can come in handy.
Yes, if you have newer hardware having trouble with Linux Mint 20.3, you can try the Edge ISO.
However, Linux Kernel 5.13 did not fully support all the modern hardware like Intel Alder Lake processors.
Considering that Intel’s 12th Gen lineup is already available for consumers, a more recent Linux Kernel could have been a better choice, but it’s better than nothing.
So, it is essential to note that using the Edge ISO would not magically resolve issues with the latest-gen hardware. You will have to go through the detailed changes/support with [Linux Kernel 5.13](https://news.itsfoss.com/linux-kernel-5-13-release/) and then proceed to try it out.
## Download Linux Mint 20.3 Edge ISO
You can choose to download the separate Edge ISO or update the Linux Kernel from the update manager.
Head to the “**Update Manager**” and then navigate to the Linux Kernels option from the View menu. As you can notice, you can install other available Linux Kernels (as per your requirements) and remove the older ones, if needed.
It is recommended not to remove an older kernel unless you’re sure that the newer version works as expected.
Before proceeding with a kernel upgrade, you might want to back up your important files, just in case.
The Edge ISO is limited to the Cinnamon edition. So, you will need to head to Linux Mint 20.3 Cinnamon page to download the ISO.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,198 | Bash Shell 脚本新手指南(二) | https://fedoramagazine.org/bash-shell-scripting-for-beginners-part-2/ | 2022-01-20T11:41:37 | [
"Bash",
"脚本"
] | https://linux.cn/article-14198-1.html | 
欢迎来到面向初学者的 Bash Shell 脚本知识第二部分。本篇将就 Bash 脚本一些更独特的方面进行深入探讨。我们会用到一些 [上篇](/article-14131-1.html) 中已经熟悉的命令(如果遇到新命令,会给出讲解),进而涵盖一些标准输出、标准输入、标准错误、“管道”和数据重定向的相关知识。
### 使用 # 添加注释
随着脚本变得愈加复杂和实用,我们需要添加注释,以便记住程序在做什么。如果与其他人分享你的脚本,注释也将帮助他们理解思考过程,以及更好理解你的脚本实现的功能。想一想上篇文章中的数学方程,我们在新版脚本中添加了一些注释。注意,在 `learnToScript.sh` 文件(如下所示)中,注释是前面带有 `#` 号的行。当脚本运行时,这些注释行并不会出现。
```
#!/bin/bash
#Let's pick up from our last article. We
#learned how to use mathematical equations
#in bash scripting.
echo $((5+3))
echo $((5-3))
echo $((5*3))
echo $((5/3))
```
```
[zexcon ~]$ ./learnToScript.sh
8
2
15
1
```
### 管道符 |
我们将使用另一个名为 `grep` 的工具来介绍管道运算符。
>
> `grep` 可以在输入文件中搜索可以匹配指定模式的行。默认情况下,`grep` 会输出相应的匹配行。
>
>
> <https://www.gnu.org/software/grep/>
>
>
>
Paul W. Frields 在 《Fedora 杂志》上的文章很好地介绍了关于 *grep* 的知识。
>
> [命令行快速小技巧:使用 grep 进行搜索](https://fedoramagazine.org/command-line-quick-tips-searching-with-grep/)
>
>
>
管道键在键盘上位于回车键上方,可以在英文状态下按 `Shift + \` 输入。
现在你已经略微熟悉了 `grep`,接下来看一个使用管道命令的示例。在命令行输入 `ls -l | grep learn`。
```
[zexcon ~]$ ls -l | grep learn
-rwxrw-rw-. 1 zexcon zexcon 70 Sep 17 10:10 learnToScript.sh
```
通常 `ls -l` 命令会在屏幕上显示文件列表。这里 `ls -l` 命令的完整结果通过管道传送到搜索字符串 `learn` 的 `grep` 命令中。你可以将管道命令想象成一个过滤器。先运行一个命令(本例中为 `ls -l`,结果会给出目录中的文件),这些结果通过管道命令给到 `grep`,后者会在其中搜索 `learn`,并且只显示符合条件的目标行。
下面再看一个例子以巩固相关知识。`less` 命令可以让用户查看超出一个屏幕尺寸的命令结果。以下是命令手册页中关于 `less` 的简要说明。
>
> `less` 是一个类似于 `more` 的程序,但它允许在文件中向后或向前进行翻页移动。此外,`less` 不必在开始之前读取整个输入文件,因此对于大型输入文件而言,它比 `vi` 等文本编辑器启动更快。该命令较少使用 termcap(或某些系统上的 terminfo),因此可以在各种终端上运行。甚至还在一定程度上支持用于硬拷贝终端的端口。(在硬拷贝终端上,显示在屏幕顶部的行会以插入符号为前缀。)
>
>
> Fedora 34 手册页
>
>
>
下面让我们看看管道命令和 `less` 命令结合使用会是什么样子。
```
[zexcon ~]$ ls -l /etc | less
```
```
total 1504
drwxr-xr-x. 1 root root 126 Jul 7 17:46 abrt
-rw-r--r--. 1 root root 18 Jul 7 16:04 adjtime
-rw-r--r--. 1 root root 1529 Jun 23 2020 aliases
drwxr-xr-x. 1 root root 70 Jul 7 17:47 alsa
drwxr-xr-x. 1 root root 14 Apr 23 05:58 cron.d
drwxr-xr-x. 1 root root 0 Jan 25 2021 cron.daily
:
:
```
为便于阅读,此处对结果进行了修剪。用户可以使用键盘上的箭头键向上或向下滚动,进而控制显示。如果使用命令行,结果超出屏幕的话,用户可能会看不到结果的开头行。要退出 `less` 屏幕,只需点击 `q` 键。
### 标准输出(stdout)重定向 >、>>、1>、1>>
`>` 或 `>>` 符号之前的命令输出结果,会被写入到紧跟的文件名对应的文件中。`>` 和 `1>` 具有相同的效果,因为 `1` 就代表着标准输出。如果不显式指定 `1`,则默认为标准输出。`>>` 和 `1>>` 将数据附加到文件的末尾。使用 `>` 或 `>>` 时,如果文件不存在,则会创建对应文件。
例如,如果你想查看 `ping` 命令的输出,以查看它是否丢弃了数据包。与其关注控制台,不如将输出结果重定向到文件中,这样你就可以稍后再回来查看数据包是否被丢弃。下面是使用 `>` 的重定向测试。
```
[zexcon ~]$ ls -l ~ > learnToScriptOutput
```
该命令会获取本应输出到终端的结果(`~` 代表家目录),并将其重定向到 `learnToScriptOutput` 文件。注意,我们并未手动创建 `learnToScriptOutput`,系统会自动创建该文件。
```
total 128
drwxr-xr-x. 1 zexcon zexcon 268 Oct 1 16:02 Desktop
drwxr-xr-x. 1 zexcon zexcon 80 Sep 16 08:53 Documents
drwxr-xr-x. 1 zexcon zexcon 0 Oct 1 15:59 Downloads
-rw-rw-r--. 1 zexcon zexcon 685 Oct 4 16:00 learnToScriptAllOutput
-rw-rw-r--. 1 zexcon zexcon 23 Oct 4 12:42 learnToScriptInput
-rw-rw-r--. 1 zexcon zexcon 0 Oct 4 16:42 learnToScriptOutput
-rw-rw-r--. 1 zexcon zexcon 52 Oct 4 16:07 learnToScriptOutputError
-rwxrw-rw-. 1 zexcon zexcon 477 Oct 4 15:01 learnToScript.sh
drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Videos
```
### 标准错误(stderr)重定向 `2>`、`2>>`
`>` 或 `>>` 符号之前命令的错误信息输出,会被写入到紧跟的文件名对应的文件中。`2>` 和 `2>>` 具有相同的效果,但 `2>>` 是将数据追加到文件末尾。你可能会想,这有什么用?不妨假象一下用户只想捕获错误信息的场景,然后你就会意识到 `2>` 或 `2>>` 的作用。数字 `2` 表示本应输出到终端的标准错误信息输出。现在我们试着追踪一个不存在的文件,以试试这个知识点。
```
[zexcon ~]$ ls -l /etc/invalidTest 2> learnToScriptOutputError
```
这会生成错误信息,并将错误信息重定向输入到 `learnToScriptOutputError` 文件中。
```
ls: cannot access '/etc/invalidTest': No such file or directory
```
### 所有输出重定向 &>、&>>、|&
如果你不想将标准输出(`stdout`)和标准错误信息(`stderr`)写入不同的文件,那么在 Bash 5 中,你可以使用 `&>` 将标准输出和标准错误重定向到同一个文件,或者使用 `&>>` 追加到文件末尾。
```
[zexcon ~]$ ls -l ~ &>> learnToScriptAllOutput
[zexcon ~]$ ls -l /etc/invalidTest &>> learnToScriptAllOutput
```
运行这些命令后,两者的输出都会进入同一个文件中,而不会区分是错误信息还是标准输出。
```
total 128
drwxr-xr-x. 1 zexcon zexcon 268 Oct 1 16:02 Desktop
drwxr-xr-x. 1 zexcon zexcon 80 Sep 16 08:53 Documents
drwxr-xr-x. 1 zexcon zexcon 0 Oct 1 15:59 Downloads
-rw-rw-r--. 1 zexcon zexcon 685 Oct 4 16:00 learnToScriptAllOutput
-rw-rw-r--. 1 zexcon zexcon 23 Oct 4 12:42 learnToScriptInput
-rw-rw-r--. 1 zexcon zexcon 0 Oct 4 16:42 learnToScriptOutput
-rw-rw-r--. 1 zexcon zexcon 52 Oct 4 16:07 learnToScriptOutputError
-rwxrw-rw-. 1 zexcon zexcon 477 Oct 4 15:01 learnToScript.sh
drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Videos
ls: cannot access '/etc/invalidTest': No such file or directory
```
如果你直接使用命令行操作,并希望将所有结果通过管道传输到另一个命令,可以选择使用 `|&` 实现。
```
[zexcon ~]$ ls -l |& grep learn
-rw-rw-r--. 1 zexcon zexcon 1197 Oct 18 09:46 learnToScriptAllOutput
-rw-rw-r--. 1 zexcon zexcon 343 Oct 14 10:47 learnToScriptError
-rw-rw-r--. 1 zexcon zexcon 0 Oct 14 11:11 learnToScriptOut
-rw-rw-r--. 1 zexcon zexcon 348 Oct 14 10:27 learnToScriptOutError
-rwxr-x---. 1 zexcon zexcon 328 Oct 18 09:46 learnToScript.sh
[zexcon ~]$
```
### 标准输入(stdin)
在本篇和上篇文章中,我们已经多次使用过标准输入(stdin),因为在每次使用键盘输入时,我们都在使用标准输入。为了区别通常意义上的“键盘即标准输入”,这次我们尝试在脚本中使用 `read` 命令。下面的脚本中就使用了 `read` 命令,字面上就像“读取标准输入”。
```
#!/bin/bash
#Here we are asking a question to prompt the user for standard input. i.e.keyboard
echo 'Please enter your name.'
#Here we are reading the standard input and assigning it to the variable name with the read command.
read name
#We are now going back to standard output, by using echo and printing your name to the command line.
echo "With standard input you have told me your name is: $name"
```
这个示例通过标准输出给出提示,提醒用户输入信息,然后从标准输入(键盘)获取信息,使用 `read` 将其存储在 `name` 变量中,并通过标准输出显示出 `name` 中的值。
```
[zexcon@fedora ~]$ ./learnToScript.sh
Please enter your name.
zexcon
With standard input you have told me your name is: zexcon
[zexcon@fedora ~]$
```
### 在脚本中使用
现在我们把学到的东西放入脚本中,学习一下如何实际应用。下面是增加了几行后的新版本 `learnToScript.sh` 文件。它用追加的方式将标准输出、标准错误信息,以及两者混合后的信息,分别写入到三个不同文件。它将标准输出写入 `learnToScriptStandardOutput`,标准错误信息写入 `learnToScriptStandardError`,二者共同都写入 `learnToScriptAllOutput` 文件。
```
#!/bin/bash
#As we know this article is about scripting. So let's
#use what we learned in a script.
#Let's get some information from the user and add it to our scripts with stanard input and read
echo "What is your name? "
read name
#Here standard output directed to append a file to learnToScirptStandardOutput
echo "$name, this will take standard output with append >> and redirect to learnToScriptStandardOutput." 1>> learnToScriptStandardOutput
#Here we are taking the standard error and appending it to learnToScriptStandardError but to see this we need to #create an error.
eco "Standard error with append >> redirect to learnToScriptStandardError." 2>> learnToScriptStandardError
#Here we are going to create an error and a standard output and see they go to the same place.
echo "Standard output with append >> redirect to learnToScriptAllOutput." &>> learnToScriptAllOutput
eco "Standard error with append >> redirect to learnToScriptAllOutput." &>> learnToScriptAllOutput
```
脚本在同一目录中创建了三个文件。命令 `echo` 故意输入错误(LCTT 译注:缺少了字母 h)以产生错误信息。如果查看三个文件,你会在 `learnToScriptStandardOutput` 中看到一条信息,在 `learnToScriptStandardError` 中看到一条信息,在 `learnToScriptAllOutput` 中看到两条信息。另外,该脚本还会再次提示输入的 `name` 值,再将其写入 `learnToScriptStandardOutput` 中。
### 结语
至此你应该能够明确,可以在命令行中执行的操作,都可以在脚本中执行。在编写可能供他人使用的脚本时,文档非常重要。如果继续深入研究脚本,标准输出会显得更有意义,因为你将会控制它们的生成。在脚本中,你可以与命令行中操作时应用相同的内容。下一篇文章我们会讨论函数、循环,以及在此基础上进一步构建的结构。
---
via: <https://fedoramagazine.org/bash-shell-scripting-for-beginners-part-2/>
作者:[Matthew Darnell](https://fedoramagazine.org/author/zexcon/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome to part 2 of Bash Shell Scripting at a beginner level. This article will dive into some more unique aspects of bash scripting. It will continue to use familiar commands, with an explain of anything new, and cover standard output standard input, standard error, the “pipe”, and data redirection.
## Adding comments #
As your scripts get more complicated and functional you will need to add comments to remember what you were doing. If you share your scripts with others, comments will help them understand the thought process and what you intended for your script to do. From the last article recall there were mathematical equations. Some comments have been added in the new version. Notice that in the *learnToScript.sh* file (reproduced below) the comments are the lines with the hash sign before them. When the script runs these lines do not appear.
#!/bin/bash #Let's pick up from our last article. We #learned how to use mathematical equations #in bash scripting. echo $((5+3)) echo $((5-3)) echo $((5*3)) echo $((5/3))
[zexcon ~]$ ./learnToScript.sh 8 2 15 1
## Pipe Operator |
We will use another tool called *grep* to introduce the pipe operator.
Grep searches one or more input files for lines containing a match to a specified pattern. By default, Grep outputs the matching lines.
https://www.gnu.org/software/grep/
Paul W. Frields’ article in the Fedora Magazine provides a good background on *grep*.
You will find the pipe key above the Enter key. Enter it by pressing Shift + \. (English Keyboard)
Now that you are all freshened up on grep, look at an example of the use of the pipe command. At the command line type in *ls -l | grep* *learn*
```
[zexcon ~]$ ls -l | grep learn
-rwxrw-rw-. 1 zexcon zexcon 70 Sep 17 10:10 learnToScript.sh
```
Normally the *ls -l* command would provide a list of the files on your screen. Here the full results of the *ls* *-l *command are piped into the grep command which searches for the string *learn*. Think of the pipe command like a filter. A command is run, in this case *ls -l*, and the results are limited to the files inside your directory. These results are sent via the pipe command to *grep* which searches for the work *learn* and only that line appears.
Look at one more example to try and nail this home. The *less* command will allow you to see the results of a command that would extend beyond one screen size. Here is a quick description from the man pages for the *less* command.
Less is a program similar to more(1), but which allows backward movement in the file as well as
Fedora 34 Manual(man) Pages
forward movement. Also, less does not have to read the entire input file before starting, so
with large input files it starts up faster than text editors like vi(1). Less uses termcap (or
terminfo on some systems), so it can run on a variety of terminals. There is even limited sup‐
port for hardcopy terminals. (On a hardcopy terminal, lines which should be printed at the top
of the screen are prefixed with a caret.)
So let’s see what it looks like utilizing the pipe and the *less* command
[zexcon ~]$ ls -l /etc | less
total 1504 drwxr-xr-x. 1 root root 126 Jul 7 17:46 abrt -rw-r--r--. 1 root root 18 Jul 7 16:04 adjtime -rw-r--r--. 1 root root 1529 Jun 23 2020 aliases drwxr-xr-x. 1 root root 70 Jul 7 17:47 alsa drwxr-xr-x. 1 root root 14 Apr 23 05:58 cron.d drwxr-xr-x. 1 root root 0 Jan 25 2021 cron.daily : :
The results have been trimmed, here, for readability. Use the arrow keys on the keyboard to scroll up or down. Unlike the command line, where you might miss the top of the results if they scroll off screen, you can control the display. To get out of the *less* screen tap the *q* key.
## Standard Output (stdout), >, >>, 1>, and 1>>
The output of a command preceding the > or >> is sent to a file whose name follows. Keep in mind that > and 1> have the same results since the 1 stands for stdout (the standard output). Stdout is assumed if it does not appear. The >> and 1>> will append the data to the end of the file. In each case (> or >>) the file is created if it does not exist.
As an example, say you want to watch the ping command output to see if it dropped a packet. Rather than sit and watch the console, redirect the output to a file. You can come back later and see if packets were dropped. Here is a test of the redirect using *>*.
[zexcon ~]$ ls -l ~ > learnToScriptOutput
This takes the normal results you see in the terminal (recall ~ is your home directory) and redirects it to the *learnToScriptOutput* file. Did you notice that *learnToScriptOutput* was never created but now the file exists? Kind of cool.
total 128 drwxr-xr-x. 1 zexcon zexcon 268 Oct 1 16:02 Desktop drwxr-xr-x. 1 zexcon zexcon 80 Sep 16 08:53 Documents drwxr-xr-x. 1 zexcon zexcon 0 Oct 1 15:59 Downloads -rw-rw-r--. 1 zexcon zexcon 685 Oct 4 16:00 learnToScriptAllOutput -rw-rw-r--. 1 zexcon zexcon 23 Oct 4 12:42 learnToScriptInput -rw-rw-r--. 1 zexcon zexcon 0 Oct 4 16:42 learnToScriptOutput -rw-rw-r--. 1 zexcon zexcon 52 Oct 4 16:07 learnToScriptOutputError -rwxrw-rw-. 1 zexcon zexcon 477 Oct 4 15:01 learnToScript.sh drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Videos
## Standard Error (stderr), 2>, and 2>>
The error output of a command preceding the > or >> is sent to a file whose name follows. Keep in mind that 2> and 2>> have the same result but the 2>> will append the data to the end of the file. So what is the purpose of these? What if you only want to catch an error. Then the 2> or 2>> is here to help. The 2 indicates the output that would normally go to stderr (standard error). Now put this into practice by listing a non-existent file.
[zexcon ~]$ ls -l /etc/invalidTest 2> learnToScriptOutputError
This takes the error results and redirects it to the *learnToScriptOutputError* file.
ls: cannot access '/etc/invalidTest': No such file or directory
## All Output &>, &>> and |&
If you are thinking, I don’t want to write both standard output (stdout) and standard error (stderr) to different files. You are in luck. In Bash 5 the preferred way to redirect both stdout and stderr to the same file is to use &> or, as you might guess, &>> to append to a file.
[zexcon ~]$ ls -l ~ &>> learnToScriptAllOutput [zexcon ~]$ ls -l /etc/invalidTest &>> learnToScriptAllOutput
After running these commands, the output of both appear in the same file without identifying error or a standard output.
total 128 drwxr-xr-x. 1 zexcon zexcon 268 Oct 1 16:02 Desktop drwxr-xr-x. 1 zexcon zexcon 80 Sep 16 08:53 Documents drwxr-xr-x. 1 zexcon zexcon 0 Oct 1 15:59 Downloads -rw-rw-r--. 1 zexcon zexcon 685 Oct 4 16:00 learnToScriptAllOutput -rw-rw-r--. 1 zexcon zexcon 23 Oct 4 12:42 learnToScriptInput -rw-rw-r--. 1 zexcon zexcon 0 Oct 4 16:42 learnToScriptOutput -rw-rw-r--. 1 zexcon zexcon 52 Oct 4 16:07 learnToScriptOutputError -rwxrw-rw-. 1 zexcon zexcon 477 Oct 4 15:01 learnToScript.sh drwxr-xr-x. 1 zexcon zexcon 0 Jul 7 16:04 Videos ls: cannot access '/etc/invalidTest': No such file or directory
If you are working directly from the command line and looking to pipe all results to another command, you can use |& for this purpose.
[zexcon ~]$ ls -l |& grep learn -rw-rw-r--. 1 zexcon zexcon 1197 Oct 18 09:46 learnToScriptAllOutput -rw-rw-r--. 1 zexcon zexcon 343 Oct 14 10:47 learnToScriptError -rw-rw-r--. 1 zexcon zexcon 0 Oct 14 11:11 learnToScriptOut -rw-rw-r--. 1 zexcon zexcon 348 Oct 14 10:27 learnToScriptOutError -rwxr-x---. 1 zexcon zexcon 328 Oct 18 09:46 learnToScript.sh [zexcon ~]$
## Standard Input (stdin)
You have used standard input (stdin) numerous times throughout articles 1 and 2 since your keyboard uses standard input every time you type a key. To give a bit of a change to the usual “it’s your keyboard”, let’s use the *read* command in a script. The *read* command, used in the script below, does what it sounds like, reads standard input.
#!/bin/bash #Here we are asking a question to prompt the user for standard input. i.e.keyboard echo 'Please enter your name.' #Here we are reading the standard input and assigning it to the variable name with the read command. read name #We are now going back to standard output, by using echo and printing your name to the command line. echo "With standard input you have told me your name is: $name"
This example prompts for input via standard output, for information it obtains from standard input(keyboard), storing it in a variable called *name* using *read* and displays the value in *name* via standard output.
[zexcon@fedora ~]$ ./learnToScript.sh Please enter your name. zexcon With standard input you have told me your name is: zexcon [zexcon@fedora ~]$
## Into the script…
Now put what has been learned in a script to see how it can be used. The following is a new version of the previous learnToScript.sh file. There are a few added lines. It uses the append options for standard output, standard error and both into one file. It will write the standard output into learnToScriptStandardOutput, standard error into learnToScriptStandardError and both output and error into learnToScriptAllOutput
#!/bin/bash #As we know this article is about scripting. So let's #use what we learned in a script. #Let's get some information from the user and add it to our scripts with stanard input and read echo "What is your name? " read name #Here standard output directed to append a file to learnToScirptStandardOutput echo "$name, this will take standard output with append >> and redirect to learnToScriptStandardOutput." 1>> learnToScriptStandardOutput #Here we are taking the standard error and appending it to learnToScriptStandardError but to see this we need to #create an error. eco "Standard error with append >> redirect to learnToScriptStandardError." 2>> learnToScriptStandardError #Here we are going to create an error and a standard output and see they go to the same place. echo "Standard output with append >> redirect to learnToScriptAllOutput." &>> learnToScriptAllOutput eco "Standard error with append >> redirect to learnToScriptAllOutput." &>> learnToScriptAllOutput
This example creates three files in the same directory. The command *echo* is intentionally typed incorrectly to generate an error. If you check out all three files, you will see one message in learnToScriptStandardOutput, one in learnToScriptStandardError and two in learnToScriptAllOutput. Also notice the script prompts for a name which it writes to the learnToScriptStandardOutput.
# Conclusion
At this point it should start to be clear that anything you can do on the command line you can also do in a script. When writing a script that others might use, documentation is extremely important. Continuing the dive into scripting, the standard output will make more sense as you will be the one generating them. Inside a script you can use the same things used from the command line. The next article will get into functions, loops and things that will continue to build on this foundation.
## Volodymyr Lisivka
I recommend to use bash-modules library for scripting, which supports “unofficial strict mode for bash”, to convert simple bash scripts into command line utilities with proper option handling and error reporting.
See https://github.com/vlisivka/bash-modules .
## Victor R
Awesome. Thanks for sharing this.
## Matthew Darnell
Volodymyr this sounds interesting. I noticed it said it was “…developed at Fedora Linux…” so I attempted to find it in the repository but with no luck. Are you are the project owner?
## Onyeibo O
Where is the first Part please? (i.e. Part #1)
## Matthew Darnell
Onyeibo O
https://fedoramagazine.org/bash-shell-scripting-for-beginners-part-1/
## Leslie Satenstein
Typo eco for echo. (Just before the conclusion
#Here are are taking the standard error and appending it to learnToScriptStandardError but to see this we need to #create an error.
eco “Standard error with append >> redirect to
Aside from the typo, A very very well done presentation.
I learned about &> and &>>.
## Dmitry
No, this is done intentionally to generate an error to stderr, otherwise it will be empty.
But there are several typos in the article:
1) Here are are… (we are?)
2) Lets (Let’s)
3) informtion (information)
4) lack of the sign # in the beginning of each string of comments in several places
## Richard England
These were corrected
## Volodymyr Lisivka
Yes, I’m owner of bash-modules project.
## Ben
I would encourage in tutorials like this to use “set -euo pipefail” as the 2nd line of the script (perhaps this overlaps with Volodmyr’s bash-modules). In short this lets a script quit on first error, treat undefined variables are error (which they 99.999% are, see Steam’s installer script nuking home directory), and stopping a pipe chain to prevent errors/garbage being sent through them. |
14,200 | 2021 总结:Python 的 8 个令人惊讶的东西 | https://opensource.com/article/22/1/python-roundup | 2022-01-21T10:01:00 | [
"Python"
] | https://linux.cn/article-14200-1.html |
>
> 这些文章的作者们揭示了使用这一流行的编程语言的新方法。
>
>
>

长期以来,Python 一直是最受欢迎的编程语言之一,但这并不意味着没有什么新东西可学。我们关于 Python 的阅读量最大的文章列表是一个很好的开始。
* 机器学习的广泛采用已经到来,其应用仍在增长。看看使用 [朴素贝叶斯](https://opensource.com/article/21/1/machine-learning-python) 分类器并通过 Python 实现的机器学习如何解决现实生活中的问题。
* 向 Python 3 的过渡已经完成,但增强功能不断涌现。Seth Kenlon 强调了 [Python 3 中的五颗隐藏的宝石](https://opensource.com/article/21/7/python-3),它们在最近的改进中脱颖而出。
* Openshot 多年来一直是 Linux 视频编辑的最佳选择之一。这篇受欢迎的文章将告诉你,你也可以用这个 Python 应用 [在 Linux 上编辑视频](https://opensource.com/article/21/2/linux-python-video)。
* Python 最好的部分是一个程序员可以实现的无限可能。[Cython](https://opensource.com/article/21/4/cython) 是一个编译器,不仅可以帮助加快代码执行速度,还可以让用户为 Python 编写 C 语言扩展。
* Python 可以使 API 单元测试更简单。Miguel Brito 向你展示了 [用 Python 测试 API 的三种方法](https://opensource.com/article/21/9/unit-test-python)。
* 随着计算能力的提高,越来越多的程序在并发运行。这可能会使调试、日志记录和剖析出错的地方成为挑战。[VizTracer](https://opensource.com/article/21/3/python-viztracer) 正是为了解决这个问题而创建的。
* 用户的个人项目,无论大小,都很好地提醒我们开源编码可以有无穷的乐趣。这里有一个鼓舞人心的项目:Darin London 如何使用 CircuitPython [监控他的温室](https://opensource.com/article/21/5/monitor-greenhouse-open-source)。
* Linux 用户经常会遇到需要大量命令行参数的程序,这让人很不爽。这是一个 [不错的配置解析技巧](https://opensource.com/article/21/6/parse-configuration-files-python),可以让生活更轻松。
---
via: <https://opensource.com/article/22/1/python-roundup>
作者:[Sumantro Mukherjee](https://opensource.com/users/sumantro) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python has long been one of the most popular programming languages, but that doesn't mean there's nothing new to learn. This list of Opensource.com's most-read articles about Python is an excellent place to start.
-
Widespread adoption of machine learning is here, and its applications are still growing. See how machine learning, using
[Naïve Bayes](https://opensource.com/article/21/1/machine-learning-python)classifiers and implemented with Python, can solve real-life problems. -
The transition to Python 3 is complete, but enhancements keep coming. Seth Kenlon highlights
[five hidden gems in Python 3](https://opensource.com/article/21/7/python-3)that stand out among recent improvements. -
Openshot has been one of the best options for Linux video editing for years. This popular article will show you how you, too, can
[edit video on Linux](https://opensource.com/article/21/2/linux-python-video)with this Python app. -
The best part of Python is the limitless possibilities a programmer can achieve.
[Cython](https://opensource.com/article/21/4/cython)is a compiler that will not only help speed up code execution but also let users write C extensions for Python. -
Python can make API unit testing simpler. Miguel Brito shows you
[three ways to test your API](https://opensource.com/article/21/9/unit-test-python)with Python. -
As computation power increases, more and more programs run concurrently. That can make it challenging to debug, log, and profile what's going wrong.
[VizTracer](https://opensource.com/article/21/3/python-viztracer)was created to solve exactly that problem. -
Users' personal projects, big and small, are a good reminder of how much fun open source coding can be. Here's an inspirational one: how Opensource.com author Darin London
[monitors his greenhouse](https://opensource.com/article/21/5/monitor-greenhouse-open-source)using CircuitPython. -
Linux users often encounter programs requiring a lot of command-line arguments that are not pleasant to work with. This is a
[nice configuration parsing hack](https://opensource.com/article/21/6/parse-configuration-files-python)to make life easier.
## Comments are closed. |
14,201 | Linux 黑话解释:什么是 POSIX? | https://itsfoss.com/posix/ | 2022-01-21T18:30:00 | [
"POSIX"
] | https://linux.cn/article-14201-1.html | POSIX,你肯定在各种在线论坛和文章中,听到过这个缩写,或读到过关于它的信息。程序员和系统开发人员似乎最关心这个问题。它听起来很神秘,虽然有很多关于这个主题的好资料,但一些讨论区(简洁是它们的特点)并没有详细说明它是什么,这可能会让人困扰。那么,POSIX 到底是什么?

### POSIX 简介
与其说 POSIX 是一个东西,不如说是一个标签。想象一下,有一个盒子,上面贴着标签:POSIX,而盒子里是一个标准。该标准由 POSIX 所关注的规则和指令集组成。**POSIX** 是<ruby> 可移植操作系统接口 <rt> Portable Operating System Interface </rt></ruby> 的缩写。它是一个 IEEE 1003.1 标准,其定义了应用程序(以及命令行 Shell 和实用程序接口)和 UNIX 操作系统之间的语言接口。
当 UNIX 程序从一个 UNIX 平台移植到另一个平台时,遵守该标准可以确保其兼容性。POSIX 主要关注的是 AT&T 的 System V UNIX 和 BSD UNIX 的特性。
该标准必须阐明并遵循如何实现操作系统之间互操作性的目标的规则。POSIX 涵盖了以下内容:系统接口、命令和实用程序、网络文件访问,这里仅举几例(POSIX 的内容远不止这些)。
### 为什么有 POSIX?
一句话:可移植性。
60 多年前,如果程序员想让他们的软件在一个以上的系统上运行,就必须完全重写代码。由于所涉及的费用,这种情况并不经常发生,但在 1960 年代中期,可移植性成为一种特性 —— 不是通过 POSIX,而是在大型机领域。
IBM 推出了 System/360 系列的大型计算机。不同的型号有其独特的规范,但硬件使得它们可以使用同一个操作系统:OS/360。
不仅操作系统可以在不同的型号上运行,应用程序也可以在它们上面运行。这不仅降低了成本,而且创造了“计算机系统”:可以跨产品线协同工作的系统。今天,这一切都很常见,比如网络和系统,但在当时,这是一个巨大的进步!

大约在同一时间,当 UNIX 出现的时候,它也做出了承诺,它可以在不同制造商的机器上运行。然而,当 UNIX 开始衍生出不同的流派时,在这些 UNIX 变体之间移植代码变得很困难。UNIX 可移植性的承诺正在失去基础。
为了解决这个可移植性问题,在 20 世纪 80 年代形成了 POSIX 标准。这个标准是在 AT&T 的 System V UNIX 和 BSD UNIX 的基础上定义的,这是当时最大的两个 UNIX 变体。值得注意的是,POSIX 的形成并不是为了控制操作系统的构建方式,任何公司都可以自由地以他们喜欢的方式设计他们的 UNIX 变体。POSIX 只关心应用程序与操作系统的接口是怎样的。用程序员的话来说,接口是一个程序的代码与另一个程序的通信方法。接口期望程序 A 向程序 B 提供特定类型的信息。同样地,程序 A 期望程序 B 用特定类型的数据来回答。
例如,如果我想用 `cat` 命令读取一个文件,我会在命令行上输入类似这样的内容:
```
cat myfile.txt
```
我不想说很多程序员的术语,简单的来说,`cat` 命令调用操作系统来获取文件,以便 `cat` 能够读取它。`cat` 读取它,然后在屏幕上显示文件的内容。在应用程序(`cat`)和操作系统之间有很多的相互作用。这种相互作用如何工作是 POSIX 所关心的。如果这种相互作用在不同的 UNIX 变体中是相同的,那么可移植性,无论操作系统、制造商和硬件如何,就可以重新获得了。
关于如何实现这一切的具体细节,在该标准中作了规定。
### 合规是自愿的
我们所有人都至少见过这样的信息:“如需帮助,请输入:XXXX -help”。这在 Linux 中很常见,但是这不符合 POSIX 标准。POSIX 从来没有要求双破折号,他们希望用一个破折号。双破折号来自 GNU,然而,它并没有损害 Linux,而且还为其增加了一点特性。同时,Linux 大部分都是兼容 POSIX 的,特别是在涉及到系统调用接口时。这就是为什么我们能够在 Linux、Sys V UNIX 和 BSD UNIX 上运行 X、GNOME 和 KDE 应用程序。各种命令,如 `ls`、`cat`、`grep`、`find`、`awk` 等,在不同的变体中操作相同。
作为一项规则,合规是一个自愿的步骤。当代码符合要求时,移到另一个系统上就比较容易,很少有必要或根本不需要重写代码。当代码可以在不同的系统上工作时,它的使用范围就会扩大。使用其他系统的人可以从使用该程序中受益。对于初出茅庐的程序员来说,学习如何编写符合 POSIX 标准的程序,就能对他们的职业生涯有所帮助。对于那些对 Linux 领域的合规性感兴趣的读者,可以在以下网站找到很多好的信息: [Linux 基本标准(LSB)](https://refspecs.linuxfoundation.org/lsb.shtml)。
### 但我不是程序员或系统设计师...
许多从事计算机工作的人并不是程序员或操作系统设计师。他们是医院的文员,是写信件、任务清单、听写备忘录的秘书,等等。其他人则是将数字制成表格,收集和整理数据,经营网上商店,写书和文章(我们中的一些人还会阅读这些文章)。几乎在每一个工作中,附近都可能有一台计算机。
POSIX 也影响着这些用户,不管他们是否知道。用户不一定要遵守这个标准,但他们确实希望他们的计算机能够工作。当操作系统和程序符合 POSIX 标准时,他们就获得了互操作性的好处。他们将能够从一个系统转移到另一个系统,并合理地期望这些机器能够像另一个系统那样工作。他们的数据仍然可以访问,他们仍然能够对其进行修改。
POSIX,以及其他标准,都在不断发展。随着技术的发展,标准也在发展。标准实际上是人们、制造商、组织等用来以有效的方式执行任务的商定系统。一个制造商的设备能够与另一个制造商的设备一起工作。想一想吧。你的蓝牙耳机可以在苹果手机上使用,也可以在安卓手机上使用。我们的电视可以连接到不同网络的视频和节目,如 Amazon Prime、BritBox、Hulu —— 仅举几例。现在,我们甚至可以用我们的手机监测心率。所有这些在很大程度上都是通过遵守标准而实现的。
好处多多。我喜欢这样。
### 那么 “X” 是什么?
我承认,我还没说过 POSIX 中的 “X” 是什么意思。[在一篇很好的文章中](https://opensource.com/article/19/7/what-posix-richard-stallman-explains),Richard Stallman 解释了 POSIX 中的 “X” 是什么意思。用他的话来说就是这样:
>
> IEEE 已经完成了规范的制定,但没有简洁的名称。标题是 “可移植的操作系统接口”,虽然我不记得确切的字眼了。委员会把 “IEEEIX” 作为简写。我不认为这是个好的选择。它的发音很难听 —— 听起来就像恐怖的尖叫声,“Ayeee!” —— 所以我预计人们会把这个规范叫为 “Unix”。
>
>
> 由于 GNU 不是 Unix,而它的目的是取代 Unix,我不希望人们把 GNU 称为 “Unix 系统”。因此,我提出了一个人们可能真正使用的简洁的名字。在没有特别灵感的情况下,我用了一种很笨的方式取了一个名字。我取了 “可移植操作系统” 的首字母并加上 “ix”。IEEE 马上就采用了这个名字。
>
>
>
### 结论
POSIX 标准允许开发者使用大部分相同的代码在许多操作系统上创建应用程序、工具和平台。不管怎么说,按照标准写代码并不是一个要求,但当你想把你的代码移植到其他系统时,它确实有很大的帮助。
基本上,POSIX 是面向操作系统设计者和软件开发者的,但作为系统的使用者,无论我们是否意识到,我们都受到 POSIX 的影响。正是因为有了这个标准,我们才能够在一个 UNIX 或 Linux 系统上工作,并把工作带到另一个系统上,而且工作起来毫无障碍。作为用户,我们在可用性和跨系统的数据重复使用方面获得了许多好处。
---
via: <https://itsfoss.com/posix/>
作者:[Bill Dyer](https://itsfoss.com/author/bill/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You’ll hear the acronym, or read about it: POSIX, on different online boards and articles. Programmers and system developers seem to worry about it the most. It can sound mysterious and, while there are many good sources on the subject, some discussion boards (brevity is part of their nature), don’t go into detail as to what it is and this can lead to confusion. What, then, is POSIX, really?

## What is POSIX?
POSIX isn’t actually a thing. It describes a thing – much like a label. Imagine a box labeled: * POSIX*, and inside the box is a standard. A standard consists of sets of rules and instructions that POSIX is concerned with.
**POSIX**is shorthand for
*. It is an IEEE 1003.1 standard that defines the language interface between application programs (along with command line shells and utility interfaces) and the UNIX operating system.*
*Portable Operating System Interface*Compliance to the standard ensures compatibility when UNIX programs are moved from one UNIX platform to another. POSIX’s focus is primarily on features from AT&T’s System V UNIX and BSD UNIX.
A standard must be spelled out and followed by rules on how to achieve the goal of interoperability between operating systems. POSIX covers such things as: System Interfaces, and Commands and Utilities, Network File Access, just to name a few – there is much more to POSIX than this.
## Why POSIX?
In a word: portability.
Over 60 years ago, programmers had to rewrite code completely if they wanted their software to run on more than one system. This didn’t happen all that often due to the expense involved, but portability became a feature in the mid-1960s – not through POSIX – but in the mainframe arena.
IBM introduced the System/360 family of mainframe computers. Different models had their unique specializations, but the hardware was such that they could use the same operating system: OS/360.
Not only could the operating system run on different models, applications could run on them as well. Not only did this keep costs low, but it created * computer systems* – systems across a product line that could work together. It’s all common today – networks and systems, but back then, this was a huge deal!

[Image Credit: IBM](https://www.ibm.com/ibm/history/ibm100/us/en/icons/system360/impacts/)
When UNIX came about, around the same time, it also showed promise in that it could operate on machines from different manufacturers. However, when UNIX started to fork into different flavors, porting code across these UNIX variants became difficult. The promise of UNIX portability was losing ground.
To solve this portability issue POSIX was formed in the 1980s. The standard was defined based on AT&T’s System V UNIX and BSD UNIX, the two biggest variants at the time. It’s important to note that POSIX wasn’t formed to control how the operating systems were built – any company was free to design their UNIX variant any way they pleased. POSIX was only concerned with how an application interfaces with the operating system. In programmer-speak, an interface is the method one program’s code can communicate with another program. The interface expects Program A to provide a specific type of information to Program B. Likewise, Program A expects Program B to answer back with a specific type of data.
For example, if I want to read a file using the cat command, I would type something like this on the command line:
`cat myfile.txt`
Without going into a lot of programmer-speak, I’ll just say that the cat command makes a call to the operating system to fetch the file so cat can read it. cat reads it and then displays the file’s contents on the screen. There is a lot of interplay between the application (`cat`
) and the operating system. How this interplay works is what POSIX was interested in. If the interplay could be the same across the different UNIX variants, portability – regardless of operating system, manufacturer, and hardware – is regained.
The specifics as to how all of this is accomplished is defined in the standard.
## Compliance is Voluntary
All of us have at least seen a message like, “for help, type: xxxxx –help.” This is common in Linux and is not POSIX compliant. POSIX never required the double-dash, they expect one dash. The double-dash comes from GNU, yet, it doesn’t harm Linux and adds a little to its character. At the same time, Linux is mostly compliant, especially when it comes to system call interfaces. This is why we are able to run X, GNOME, and KDE applications on Linux, Sys V UNIX, and BSD UNIX. Various commands, such as ls, cat, grep, find, awk, and many more operate the same across the different variants.
As a rule, compliance is a willing step. When code is compliant, it’s easier to move to another system; very little code rewrite, if any, would be necessary. When code can work on different systems, the use of it expands. People using other systems can benefit from the use of the program. For the budding programmer, learning how to write programs that are POSIX compliant can only help their career. For those readers who are interested in the Linux sphere of compliance, much good information can be found at: [Linux Standard Base](https://refspecs.linuxfoundation.org/lsb.shtml).
## But I’m Not a Programmer or System Designer…
Many people who work on computers aren’t programmers or operating system designers. They’re the medical transcription clerks, secretaries who write out letters, task lists, dictated memos, and so on. Others tabulate numbers, gather and massage data, run online stores, write books and articles (and some of us read them). In almost every job, there’s probably a computer close by.
POSIX affects these users too, whether they know it or not. Users don’t have to comply with the standard, but they do expect their computers to work. When operating systems and programs conform to the POSIX standard, they gain the benefit of interoperability. They will be able to move from one system to another with the reasonable expectation that the machines will work much like another one does. Their data will still be accessible and they will still be able to make changes to it.
POSIX, as well as other standards, are continually evolving. As technology grows, so does the standard. Standards are actually an agreed-upon system used by people, manufacturers, organizations, etc. to perform tasks in an efficient manner. Devices from one manufacturer is able to work with another manufacturer’s device. Think about it: Your Bluetooth earpiece can be used on an Apple iPhone just as well as it can on an Android phone. Our TV can hook up to, and stream, videos and shows from different networks, such as Amazon Prime, BritBox, Hulu – just to name a few. Now, we can even monitor out heart rate with our phones. All of this is made possible, largely in part, from compliance to standards.
Benefits galore. I like that.
## So what about the X?
I admit it, I never said what the “X” was for in POSIX. [Opensource.com has an excellent article](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) where Richard Stallman explains what the “X” in POSIX means. Here it is, in his words:
The IEEE had finished developing the spec but had no concise name for it. The title said something like “portable operating system interface,” though I don’t remember the exact words. The committee put on “IEEEIX” as the concise name. I did not think that was a good choice. It is ugly to pronounce—it would sound like a scream of terror, “Ayeee!”—so I expected people would instead call the spec “Unix.”Since GNU’s Not Unix, and it was intended to replace Unix, I did not want people to call GNU a “Unix system.” I, therefore, proposed a concise name that people might actually use. Having no particular inspiration, I generated a name the unclever way: I took the initials of “portable operating system” and added “ix.” The IEEE adopted this eagerly.
## Conclusion
The POSIX standard allows developers to create applications, tools, and platforms on many operating systems using much of the same code. It isn’t a requirement, by any means, to write code according to the standard, but it does help, in a big way, when you want to port your code to other systems.
Basically, POSIX is geared toward operating system designers and software developers, but as users of a system, we are affected by POSIX whether we may realize it or not. It is because of the standard that we are able to work on one UNIX or Linux system and bring that work over to another system and work on it with no hiccups. As users, we gain numerous benefits in usability and data re-use across systems. |
14,203 | System76 的 COSMIC 桌面面板看起来很清爽! | https://news.itsfoss.com/system76-cosmic-panel/ | 2022-01-22T11:03:51 | [
"COSMIC"
] | https://linux.cn/article-14203-1.html |
>
> System76 分享了其即将推出的使用 Rust 开发的 COSMIC 桌面的顶部面板草图。看起来令人惊叹!
>
>
>

System76 令人兴奋的用 Rust 开发的 COSMIC 桌面的开发工作现在正在进行中。
虽然我们已经用早期的代码 [试过了](https://news.itsfoss.com/system76-rust-cosmic-desktop/),但我们现在可以看到更多的东西。从其 [GitHub 仓库](https://github.com/pop-os/cosmic-panel/issues) 和 [Figma 文档](https://www.figma.com/proto/ZeGTqzAM7dVZgjEW3uhxcd/Top-panel?node-id=559%3A11100&scaling=scale-down&page-id=559%3A11099&starting-point-node-id=559%3A11100&show-proto-sidebar=1) 的一些原型中,我们可以看到它的更多信息。
值得注意的是,我们可以看到顶部面板和系统托盘,正如你在 COSMIC 桌面上所期望的那样。
这仍是一项正在进行的工作,可能会有变化。
### COSMIC 桌面的顶部面板
Pop!\_OS 依赖于 GNOME 扩展来通过顶部面板或系统托盘图标提供更多的功能。
随着即将推出的使用 Rust 开发的 COSMIC 桌面,看起来他们正在创建新的小程序,与当前的外观相融合,并提供更多的功能。
开发者 Eduardo Flores [分解研究](https://blog.edfloreshz.dev/articles/linux/system76/cosmic-panel/) 了它,发现了关键的区别以及 System76 的目标是如何使其发挥作用。
而且,这也是它更有趣的地方:
>
> 看起来 System76 正在摆脱传统的“扩展”,计划为第三方小程序设计一个 API,这与 KDE、XFce 和其他公司的做法类似。
>
>
> 这是一个令人兴奋的消息,将使 COSMIC 成为一个更强大的桌面环境,使其可以扩展和定制。
>
>
>
另外,似乎这些小程序也可以和顶部面板一起放在坞站里。我们会在其未来的某个测试版中看到更多的实际情况。
在这里,让我重点介绍一下从现有的草图中观察到的基本变化:
#### 1、声音小程序

与我们现在所拥有的相比,COSMIC 的目标是增加细化的控制,如选择输入/输出设备、在顶部面板上切换媒体控制的选项、控制媒体播放,以及访问声音设置。
虽然草图没有显示专辑封面,但在发布前会包括它。
作为参考,以下是 Pop!\_OS 顶部面板选项现在的样子。

#### 2、电源小程序

很高兴看到有一个专门的电源按钮来快速访问系统设置、锁屏和注销。
另外,暂停、重启和关机的按钮应该可以提高可用性,关闭计算机不用额外的点击。
#### 3、网络小程序
虽然你可以很容易地打开或关闭有线、无线网络,但会弹出一个占据了整个屏幕的单独窗口来选择 Wi-Fi 网络并输入密码。

但是,看起来我们终于可以在这里输入密码,连接到可用的无线网络,并重试失败的连接,而不必从活动窗口分心。所有这些都发生在系统托盘上的网络小程序上,如上面的截图所示。
同样,你可以看到关于你的有线连接的更多信息,包括 IP 地址和速度。
#### 4、日期、时间和日历小程序

最重要的日历小程序看起来更加实用,信息量更大。通知区不再驻留在这里(它现在有一个单独的小程序),使它的体验更干净,可以把注意力放在你关注的东西上。
一些细微的视觉改进,比如用重点颜色来突出日历中的某一行,应该会使它更容易理解。
#### 5、通知中心

正如我前面提到的,通知现在有一个独立的空间。通知小程序会将所有的通知堆积起来,并允许你在需要时展开它们,或者将它们全部清除。
我们仍然有“请勿打扰”开关,并可以快速访问通知设置。
#### 6、图形模式小程序

这对笔记本电脑用户来说应该是非常有用的,可以在图形模式之间无缝切换,并可以看到当前使用的哪种模式。
除了所有这些,还有一个蓝牙小程序、一个电池电源模式小程序,以及一些其他的东西,比如改变输入语言或输入源的能力。


鉴于这是初次看到使用 Rust 开发 COSMIC 桌面顶部面板的外观,看来我们有很多东西要去看了。
### 总结
总的来说,System76 正准备为我们提供一个高度可定制但又简化的 COSMIC 桌面版本。
而所有这些都应该有助于形成一种独特的桌面体验。当然,明年你就得在 Pop!\_OS 中和 GNOME 说再见了。
你怎么看?请在下面的评论中告诉我你的想法!
---
via: <https://news.itsfoss.com/system76-cosmic-panel/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The development work for System76’s exciting new Rust-based COSMIC desktop is now underway.
While [we already tried it out](https://news.itsfoss.com/system76-rust-cosmic-desktop/) using the early code available, we get to see more of it now. Thanks to some prototypes available in its [GitHub repository](https://github.com/pop-os/cosmic-panel/issues?ref=news.itsfoss.com) and a [Figma document](https://www.figma.com/proto/ZeGTqzAM7dVZgjEW3uhxcd/Top-panel?node-id=559%3A11100&scaling=scale-down&page-id=559%3A11099&starting-point-node-id=559%3A11100&show-proto-sidebar=1&ref=news.itsfoss.com), we get to see more of it!
Notably, we get to see the top panel and the system tray as you would expect in the COSMIC desktop.
It is still a work in progress and is subject to change.
## Top Panel in COSMIC Desktop
Pop!_OS relies on GNOME extensions to offer more functionalities through the top panel or the system tray icons.
With the upcoming Rust-based COSMIC desktop, it looks like they’re creating new applets that blend in with the current look and offer more functionality out of the box.
Eduardo Flores, a developer, [breaks it down ](https://blog.edfloreshz.dev/articles/linux/system76/cosmic-panel/?ref=news.itsfoss.com)to learn the key differences and how System76 aims to make it work.
And, this is what makes it more interesting:
Looks like System76 is moving away from the traditional “extensions” and plans to design an API for third party applets, this is similar to what KDE, XFCE and others are doing.
This is exciting news, this will make COSMIC a much more powerful desktop environment, making it extendable and customizable.
Also, it seems that these applets can also be placed in the dock along with the top panel. We’ll have to see more of it in action in one of its future beta releases.
Here, let me highlight the fundamental changes observed from the mockups available:
### 1. Sound Applet
Compared to what we have now, COSMIC aims to add granular controls like selecting Input/Output devices, option to toggle media controls on the top panel, control playing media, and access the sound settings.
While the mockup doesn’t show album art, it will include it down the road before release.
For reference, here’s what the Pop!_OS top panel options look like now:
### 2. Power Applet
It is good to see a dedicated power button to quickly access system settings, lock screen, and log out.
Also, the buttons for suspending, restart, and shut down should improve usability, eliminating any extra clicks to shut down the computer.
### 3. Network Applet
While you can easily turn on/off the Wired/Wireless networks, a separate window pops up to select Wi-Fi network and enter the password taking up the entire screen.
But, it looks like we can finally type in the password, connect to available wireless networks, and retry the failed connection without getting distracted from the active window. All that happens from the network applet on the system tray, as shown in the screenshot above.
Similarly, you get to see more information about your wired connection, including the IP address and speed.
### 4. Date, Time, and Calendar Applet
The most important calendar applet looks much more functional and informative. The notification area no longer resides here (considering it has a separate applet now), making it a cleaner experience to focus on what you want here.
Several subtle visual enhancements like accent color to highlight a row in the calendar should make it easy to understand.
### 5. Notifications Center
As I mentioned earlier, notifications now have a separate space. The notification applet will stack up all notifications and allow you to expand them if needed or clear them all.
We still have the Do Not Disturb toggle and quick access to notification settings.
### 6. Graphics Mode Applet
This should be incredibly useful for laptop users, making it seamless to switch between graphics and keep an eye on what’s active.
In addition to all these, a Bluetooth applet, a battery power mode applet, and a few more things like the ability to change input language or input source.
Given this is the first look for the top-panel of Rust-based COSMIC desktop, it looks like we have a lot to go through!
## Closing Thoughts
Overall, System76 is gearing up to give us a highly customizable yet simplified version of the COSMIC desktop.
And all of that should contribute to a unique desktop experience. Of course, you will have to say goodbye to GNOME next year.
What do you think? Let me know your thoughts in the comments below!
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
14,204 | 2021 总结:尝试 FreeDOS | https://opensource.com/article/22/1/try-freedos | 2022-01-22T11:28:54 | [
"FreeDOS"
] | https://linux.cn/article-14204-1.html |
>
> 为这个自由操作系统的新用户和老用户提供 15 种资源。
>
>
>

在整个上世纪 80 年代和 90 年代,DOS 是桌面之王。世界各地的程序员不满足于 DOS 的专有版本,他们共同创建了一个名为 FreeDOS 的开源版本,该版本于 1994 年首次推出。[FreeDOS 项目](https://www.freedos.org/) 在 2021 年及以后还在继续发展。
我们发表了几篇关于 FreeDOS 的文章,以帮助新用户开始使用 FreeDOS 和学习新程序。以下是去年我们最受欢迎的几篇 FreeDOS 文章。
### 初学 FreeDOS
你是 FreeDOS 的新手吗?如果你想了解如何启动和运行 FreeDOS 的基本知识,请查看这些文章:
* [开始使用 FreeDOS](/article-13492-1.html):它看起来像复古计算时代,但 FreeDOS 是一个现代的操作系统,你可以用它来完成事情。
* [FreeDOS 如何启动](/article-13503-1.html):了解你的计算机是如何引导和启动 FreeDOS 的,从开机到命令行提示符。
* [用纯文本配置 FreeDOS](/article-14061-1.html):学习如何用 `fdconfig.sys` 文件来配置 FreeDOS。
* [如何用 CD 和 DIR 浏览 FreeDOS](https://opensource.com/article/21/6/navigate-freedos-cd-dir):只需掌握两个命令,`DIR` 和 `CD`,你就可以在命令行中浏览你的 FreeDOS 系统。
* [在 FreeDOS 中设置和使用环境变量](/article-13995-1.html):环境变量在几乎所有的命令行环境中都有用,包括 FreeDOS。
### Linux 用户的 FreeDOS
如果你已经熟悉了 Linux 的命令行,你可能想试试这些在 FreeDOS 上创造类似环境的命令和程序:
* [给 Linux 爱好者的 FreeDOS 命令](/article-14092-1.html):如果你已经熟悉了 Linux 的命令行,可以试试这些命令来帮助你轻松进入 FreeDOS。
* [在 FreeDOS 中像 Emacs 一样编辑文本](https://opensource.com/article/21/6/freemacs):如果你已经熟悉了 GNU Emacs,你应该在 Freemacs 中感到很自在。
* [在 Linux 和 FreeDOS 之间复制文件](/article-13548-1.html):学习如何在 FreeDOS 虚拟机和 Linux 桌面系统之间传输文件。
* [如何在 FreeDOS 上归档文件](/article-13567-1.html):这是 FreeDOS 版本的 `tar`,在 DOS 上归档的标准方法是 Zip 和 Unzip。
* [在 FreeDOS 上使用这个怀旧的文本编辑器](https://opensource.com/article/21/6/edlin-freedos):让人联想到 Linux ed(1),当你想用老式的方法编辑文本时,Edlin 是一种乐趣。
### 使用 FreeDOS
当你启动进入 FreeDOS,你可以使用这些很棒的工具和应用来完成工作或安装其他软件:
* [如何使用 FreeDOS 的文本编辑器](https://opensource.com/article/21/6/freedos-text-editor):FreeDOS 提供了一个用户友好的文本编辑器,叫做 FreeDOS Edit。
* [在 FreeDOS 上听音乐](https://opensource.com/article/21/6/listen-music-freedos):Mplayer 是一个开源的媒体播放器,通常可以在 Linux、Windows、Mac 和 DOS 上找到。
* [在 FreeDOS 上安装和删除软件包](/article-14031-1.html):了解如何使用 FDIMPLES,即 FreeDOS 包管理器,在你的 FreeDOS 系统上安装和删除软件包。
* [为什么我喜欢用 GW-BASIC 在 FreeDOS 上编程](https://opensource.com/article/21/6/freedos-gw-basic):BASIC 是我进入计算机编程的起点。我已经很多年没有写过 BASIC 代码了,但我对 BASIC 和 GW-BASIC 永远怀有好感。
* [用 Bywater BASIC 在 FreeDOS 上编程](https://opensource.com/article/21/6/freedos-bywater-basic):在你的 FreeDOS 系统上安装 Bywater BASIC,并开始尝试使用 BASIC 编程。
在其近 30 年的历程中,FreeDOS 一直试图成为一个现代 DOS。如果你想了解更多,你可以在 [FreeDOS 简史](/article-13601-1.html) 中阅读关于 FreeDOS 的起源和发展。另外,请看 Don Watkins 关于 FreeDOS 的采访:[一个大学生是如何创立一个自由和开源的操作系统](https://opensource.com/article/21/6/freedos-founder)。
如果你想尝试 FreeDOS,请下载 2021 年 12 月发布的 FreeDOS 1.3 RC5。这个版本有大量的新变化和改进,包括更新的内核和命令 shell,新的程序和游戏,更好的国际支持,以及网络支持。从 [FreeDOS 网站](https://www.freedos.org/)下载 FreeDOS 1.3 RC5。
---
via: <https://opensource.com/article/22/1/try-freedos>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Throughout the 1980s and into the 1990s, DOS was king of the desktop. Not satisfied with a proprietary version of DOS, programmers worldwide worked together to create an open source version of DOS called FreeDOS, which first became available in 1994. [The FreeDOS Project](https://www.freedos.org/) continues to grow in 2021 and beyond.
We've run several articles about FreeDOS on Opensource.com to help new users get started with FreeDOS and learn new programs. Here are a few of our most popular FreeDOS articles from the last year:
## New to FreeDOS
Are you new to FreeDOS? If you'd like to learn the basics of how to boot and run FreeDOS, check out these articles:
[Get started with FreeDOS](https://opensource.com/article/21/6/get-started-freedos): It looks like retro computing, but FreeDOS is a modern OS you can use to get things done.[How FreeDOS boots](https://opensource.com/article/21/6/freedos-boots): Learn how your computer boots up and starts FreeDOS, from power on to the command-line prompt.[Configure FreeDOS in plain text](https://opensource.com/article/21/6/freedos-fdconfigsys): Learn how to configure FreeDOS with the`fdconfig.sys`
file.[How to navigate FreeDOS with CD and DIR](https://opensource.com/article/21/6/navigate-freedos-cd-dir): Armed with just two commands,`DIR`
and`CD`
, you can navigate your FreeDOS system from the command line.[Set and use environment variables in FreeDOS](https://opensource.com/article/21/6/freedos-environment-variables): Environment variables are helpful in almost every command-line environment, including FreeDOS.
## FreeDOS for Linux users
If you're already familiar with the Linux command line, you might like to try these commands and programs that create a similar environment on FreeDOS:
[FreeDOS commands for Linux fans](https://opensource.com/article/21/6/freedos-linux-users): If you're already familiar with the Linux command line, try these commands to help ease into FreeDOS.[Edit text like Emacs in FreeDOS](https://opensource.com/article/21/6/freemacs): If you're already familiar with GNU Emacs, you should feel right at home in Freemacs.[Copy files between Linux and FreeDOS](https://opensource.com/article/21/6/copy-files-linux-freedos): Learn how to transfer files between a FreeDOS virtual machine and a Linux desktop system.[How to archive files on FreeDOS](https://opensource.com/article/21/6/archive-files-freedos): There's a version of`tar`
on FreeDOS, but the standard way to archive on DOS is Zip and Unzip.[Use this nostalgic text editor on FreeDOS](https://opensource.com/article/21/6/edlin-freedos): Reminiscent of Linux ed(1), Edlin is a joy to use when you want to edit text the old-school way.
## Using FreeDOS
Once you've booted into FreeDOS, you can use these great tools and apps to get work done or to install other software:
[How to use the FreeDOS text editor](https://opensource.com/article/21/6/freedos-text-editor): FreeDOS provides a user-friendly text editor called FreeDOS Edit.[Listen to music on FreeDOS](https://opensource.com/article/21/6/listen-music-freedos): Mplayer is an open source media player usually found on Linux, Windows, Mac, and DOS.[Install and remove software packages on FreeDOS](https://opensource.com/article/21/6/freedos-package-manager): Learn how to use FDIMPLES, the FreeDOS package manager, to install and remove packages on your FreeDOS system.[Why I love programming on FreeDOS with GW-BASIC](https://opensource.com/article/21/6/freedos-gw-basic): BASIC was my entry into computer programming. I haven't written BASIC code in years, but I'll always have a fondness for BASIC and GW-BASIC.[Program on FreeDOS with Bywater BASIC](https://opensource.com/article/21/6/freedos-bywater-basic): Install Bywater BASIC on your FreeDOS system and start experimenting with BASIC programming.
Throughout its nearly 30-year journey, FreeDOS has tried to be a modern DOS. If you'd like to learn more, you can read about the origins and development of FreeDOS in [A brief history of FreeDOS](https://opensource.com/article/21/6/history-freedos). Also, check out Don Watkins' interview about FreeDOS in [How a college student founded a free and open source operating system](https://opensource.com/article/21/6/freedos-founder).
If you'd like to try FreeDOS, download FreeDOS 1.3 RC5, released in December 2021. This version has a ton of new changes and improvements, including an updated kernel and command shell, new programs and games, better international support, and network support. Download FreeDOS 1.3 RC5 from the [FreeDOS website](https://www.freedos.org/).
## Comments are closed. |
14,206 | 现在是考虑从事开源硬件职业的好时机 | https://opensource.com/article/21/11/open-source-hardware-careers | 2022-01-23T10:22:44 | [
"开源硬件"
] | https://linux.cn/article-14206-1.html |
>
> 开源硬件现在是一个独立领域,并且正在快速的成长中。
>
>
>

在软件行业中,各种类型的程序员写代码的职业已经变得很普遍,这些代码通过开源许可证发布到公共场所。业界的猎头们通常要求查看这些代码来审查未来员工候选人。那些将自己职业生涯专注在开源项目开发的人得到了回报。从 [payscale.com](http://payscale.com) 网站得知,Linux 系统管理员的收入比 Windows 管理员要高,这表明从事开源软件领域可以获得更高的报酬和更稳定的工作机会。分享你的工作会让你感觉良好(这甚至可能是一种因果报应),你知道自己正在为整个世界创造价值。历史上,这样的机会可从来没有为我们这些从事于开源硬件领域的人存在过。
二十多年前,几乎没有人知道开源硬件是什么,更别说围绕它规划自己的职业生涯了。举例而言,在 2000 年全世界发表了超过 200 万篇学术论文,却只有 7 篇文章提到过“开源硬件”。在我第一次写《[开源实验室](https://www.appropedia.org/Open-source_Lab)》 的时候,我收集了每一个案例(其实也就几十个),并且可以轻松的跟上和阅读每一篇发布的关于开源硬件的文章,还把它们发布到维基上。我很高兴的报告大家,这种情况现在已经实际上不可能了。今年已经有超过 1500 篇文章在讨论“开源硬件”,而且我相信年底的时候还会有更多的文章发表出来。开源硬件现在已经是一个独立的领域,有一些专门报导它的杂志(比如说 《[HardwareX](https://www.hardware-x.com/)》 和 《[Journal of Open Hardware](https://openhardware.metajnl.com/)》)。在更多的领域中,数十种传统杂志现在也会定期报道最新的开源硬件的发展。

*开发智能开源硬件 3-D 打印 (Joshua Pearce, [GNU-FDL](https://www.gnu.org/licenses/fdl-1.3.en.html))*
即使是在十年前,从职业生涯的角度看,强调开源硬件开发在某种程度上也是一种冒险。我记得在我上一份工作的简历中,我淡化了和它相关的内容,更多的强调了我的传统工作。工业界和学术界的管理人员难以明白如果这些设计被送出去并在其他地方生产制造,你又怎样获得收益。这一切都在改变。和自由与开源的软件一样,开源硬件开发更快,而且我敢说,会优于专有开发模式。

*(Joshua Pearce, [GNU-FDL](https://www.gnu.org/licenses/fdl-1.3.en.html))*
每种企业都有大量成功的 [开放硬件商业模式](https://doi.org/10.5334/joh.4)。随着数字制造的兴起(主要是由于开源开发),开源软件和开源硬件之间的界限变得模糊。像 [FreeCAD](https://www.freecadweb.org/) 这样的开源软件可以制作开源设计,然后在内置 CAM 中使用,在开源激光切割机、CNC 铣床或 3D 打印机上进行制造。[OpenSCAD](https://openscad.org/) 是一个基于开源脚本的 CAD 包,尤其是它确实模糊了软件和硬件之间的界限,以至于代码和物理设计成为同义词。我们中的许多人开始公开谈论开源硬件。我把它作为我研究项目的核心主旨,首先让我自己的设备开源,然后为其他人开发开源硬件。我并不孤单。作为一个社区,我们已经获得了足够的临界质量,于 2012 年成立了 [开源硬件协会](https://www.oshwa.org/)(OSHWA)。如今,差不多十年后,开源硬件的职业前景完全不同:已经有了数百个开源硬件硬件公司,互联网上涌现出数百万(数百万!)个开源设计,学术文献中对开源硬件的兴趣也呈指数级增长。

*为太阳能光伏开发开源产品。(Joshua Pearce, [GNU-FDL](https://www.gnu.org/licenses/fdl-1.3.en.html))*
甚至有些工作的目标就是促进更快过渡到无处不在的开源硬件。例如,<ruby> 生产互联网 <rt> Internet of Production </rt></ruby>(IoP)联盟在开发<ruby> 开放数据标准 <rt> Open Data Standards </rt></ruby>和发展这些标准的用户社区方面,现在已经为运营和通信官、数据标准社区支持经理和 DevOps 工程师提供了 [职位](https://www.internetofproduction.org/hiring)。由于 **我在开源硬件上方面的工作**,我刚被聘为 [加拿大西部大学](https://www.uwo.ca/)(世界排名前 1% 的大学)的终身讲席教授。该职位是与加拿大排名第一的商学院 [毅伟商学院](https://www.ivey.uwo.ca/) 交叉任职的。我的工作是帮助大学快速发展,抓住开源技术发展机会。说到做到,我现在正 [招聘](https://www.appropedia.org/FAST_application_process) 硕士和博士水平的毕业生,包含全额奖学金和生活津贴。这些 [免费适用的可持续性技术(FAST)实验室](https://www.appropedia.org/Category:FAST) 的研究生工程职位专门用于开发开源硬件,用于太阳能光伏系统、分布式回收和紧急食品生产等一系列应用。这种工作得到了那些想要最大化 [他们的研究投资回报](https://www.academia.edu/13799962/Return_on_Investment_for_Open_Source_Hardware_Development) 的资助者的更多的资助。整个国家都在朝着这个方向前进。最近的一个好例子是法国,它刚刚发布了 [第二个开放科学计划](https://www.ouvrirlascience.fr/wp-content/uploads/2021/10/Second_French_Plan-for-Open-Science_web.pdf)。我注意到 [GrantForward](https://www.grantforward.com/index) 上列出的,用于美国开源资金的“开源”关键字资助的数量显着增加。许多基金会已经清晰明了地收到了开源备忘录 —— 因此开源研发的机会越来越多。
因此,如果你还没开始的话,也许是时候考虑将开源作为一种职业,即使你是一名喜欢开发硬件的工程师。
---
via: <https://opensource.com/article/21/11/open-source-hardware-careers>
作者:[Joshua Pearce](https://opensource.com/users/jmpearce) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zengyi1001](https://github.com/zengyi1001) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It has become commonplace in the software industry for programmers of all flavors to build careers writing code that releases to the commons with open source licenses. Industry headhunters often demand access to the code to vet future employees. Those that focus their career on open source development get rewarded. According to payscale.com, Linux sysadmins earn more than their Windows counterparts, indicating better pay and job security for jobs in open source software. There's also a good feeling (maybe even karma) that comes with sharing your work. You know you are creating value literally for the entire world. Historically, such opportunities did not exist for those of us that work in open hardware.
Twenty years or so ago, almost no one even knew what open source hardware was, let alone planned a career around it. In 2000, for example, out of the more than 2 million academic papers published that year in the entire world, only seven articles even mentioned "open source hardware" at all. When I first wrote [ Open-Source Lab](https://www.appropedia.org/Open-source_Lab), I'd collected every example (only a few dozen) and could easily keep up and read every open hardware article that got published to post them on a wiki. I am happy to report that is no longer physically possible. There have already been over 1,500 articles that discuss "open source hardware" this year, and I am sure many more will be out by year's end. Open source hardware is now a field of its own, with a few journals dedicated to it specifically (for example,
[and the](https://www.hardware-x.com/)
*HardwareX*[). In a wide range of fields, dozens of traditional journals now routinely cover the latest open hardware developments.](https://openhardware.metajnl.com/)
*Journal of Open Hardware*
Developing smart open source 3-D printing (Joshua Pearce, GNU-FDL)
Even a decade ago, stressing open source hardware development was somewhat of a risk from a career perspective. I remember downplaying it on my resume for my last job and stressing my more conventional work. Supervisors in industry and academia had difficulty figuring out how you'd capture value if designs were given away and got manufactured elsewhere. This has all been changing. Like free and open source software, open source hardware development is faster and, dare I say, superior to proprietary approaches.

(Joshua Pearce, GNU-FDL)
There are plenty of successful [open hardware business models](https://doi.org/10.5334/joh.4) for every kind of enterprise. With the rise of digital manufacturing (largely due to open source development), the lines have blurred between open source software and open source hardware. Open source software like [FreeCAD](https://www.freecadweb.org/) enables open designs to be made and then used in built-in CAM to get fabricated on open source laser cutters, CNC mills, or 3-D printers. [OpenSCAD](https://openscad.org/), an open source script-based CAD package, in particular, really blurs the lines between software and hardware so much that code and physical design become synonymous. Many of us started speaking out about open hardware openly. I made it a core thrust of my research program, first making my own equipment open source and then working on open hardware development for others. I was far from alone. As a community, we had gained enough critical mass that the [Open Source Hardware Association](https://www.oshwa.org/) (OSHWA) got founded in 2012. Today, almost a decade later, career prospects in open source hardware are totally different: Hundreds of open source hardware companies exist, the Internet is swimming with millions (millions!) of open source designs, and the interest in open source hardware in the academic literature has been rising exponentially.

(Joshua Pearce, GNU-FDL)
There are even jobs meant to push a faster transition to ubiquitous open source hardware. For example, the Internet of Production (IoP) Alliance in developing Open Data Standards and growing the community of users of these standards has [positions open now](https://www.internetofproduction.org/hiring) for Operations & Communications Officer, Data standards Community Support Manager, and DevOps engineer. I was just hired into a tenured endowed chair at [Western University in Canada,](https://www.uwo.ca/) a top 1% global university, **because** of my open source hardware work, not in spite of it. The position is cross-pointed with the [Ivey Business School,](https://www.ivey.uwo.ca/) the #1 business school in Canada. My job is to help the University rapidly evolve to take advantage of open source technology development opportunities. To put my money where my mouth is, I am [currently hiring](https://www.appropedia.org/FAST_application_process) graduate students at the masters and PhD levels, including a full-tuition scholarship and a living stipend. These [Free Appropriate Sustainability Technology (FAST) Lab](https://www.appropedia.org/Category:FAST) graduate engineering positions are specifically reserved for developing open source hardware for a range of applications covering solar photovoltaic systems, distributed recycling, and emergency food production. This type of work gets more frequently financed by funders who want to maximize [return on their investment for research](https://www.academia.edu/13799962/Return_on_Investment_for_Open_Source_Hardware_Development). Entire nations are moving in this direction. The latest good example is France, which just published its [second plan for Open Science](https://www.ouvrirlascience.fr/wp-content/uploads/2021/10/Second_French_Plan-for-Open-Science_web.pdf). I have noticed a marked uptick in the number of "open source" keyword grants listed on [GrantForward](https://www.grantforward.com/index) for open source funding in the US. Many foundations have already received the open source memo loud and clear—so there is a growing deluge of opportunities in open source R&D.
So if you have not already, maybe it is time for you to consider open source as a career, even if you are an engineer that likes to develop hardware.
## Comments are closed. |
14,207 | 2021 总结:Linux 方面的 10 篇好文章 | https://opensource.com/article/21/12/reasons-love-linux | 2022-01-23T17:17:15 | [
"Linux"
] | https://linux.cn/article-14207-1.html |
>
> 以下是 10 篇最受欢迎的 Linux 文章。
>
>
>

2021 年,我们发表了远超 [150 篇的 Linux 方面的文章](https://opensource.com/tags/linux)。从桌面 Linux 用户小工具的文章到将 Linux 作为服务器操作系统的教程,以及介乎于两者之间的各种场景,这些文章已经涵盖了 Linux 生态系统的许多方面。所有这些文章都值得你花时间去阅读,但你可以从今年发表的这十篇好文章开始阅读。
### 3 个开源工具,使 Linux 成为理想的工作站
在这篇文章中,Seth Kenlon 介绍了 LibreOffice、AbiWord、Gnumeric 和 Pandoc,涵盖了 [使 Linux 成为理想工作站的工具](/article-13133-1.html)。他解释了在使用 Linux 作为桌面操作系统时,这些应用程序如何使你的工作效率提高。文章探讨了一些高级功能,如 LibreOffice 的无头模式,并提供了如何充分利用每个应用程序的小技巧。
### 为什么我在 Linux 上使用 exa 而不是 ls
`ls` 命令是 Linux 中最常用的终端命令之一,但你知道它有一个现代的替代品,提供了许多有益的改进吗?Sudeshna Sur 的 [文章](/article-13972-1.html) 介绍了 `exa` 命令以及它相比 `ls` 的优势,讨论了 `exa` 如何跟踪添加到 Git 仓库的新文件、显示目录和文件树等等。
### 我喜欢在 Linux 上编码的 5 个原因
像许多人一样,Seth Kenlon 喜欢在 Linux 上编码。在这篇文章中,他分享了这样做的 [五个原因](https://opensource.com/article/21/2/linux-programming)。他喜欢在 Linux 上编码,因为它建立在逻辑的基础上,可以让你欣赏代码之间的关联,提供了源代码,并提供直接访问外设和抽象层的能力,使编写代码更容易。
### 在 Linux 上使用可启动的 USB 驱动器来拯救 Windows 用户
即使你喜欢 Linux,但有时你可能需要修复一台 Windows 电脑或为某人安装 Windows。在 Linux 上从 Windows ISO 创建一个可启动的 U 盘,并不像为 Linux 发行版制作一个可启动的 U 盘那样简单明了。在这个教程中,Don Watkins 演示了 [如何使用 WoeUSB](/article-13143-1.html),这个工具可以为用户处理这个过程中所有棘手的部分。
### 4 个用于运行 Linux 服务器的开源工具
当使用 Linux 作为服务器操作系统时,Seth Kenlon 推荐了这 [四个开源工具](/article-13192-1.html): Samba、Snapdrop、VLC 和 PulseAudio。正如 Seth 在他的文章中所指出的,这四个工具使得用 Linux 进行文件共享和流媒体变得很容易。
### 3 个你需要尝试的 Linux 终端
Linux 有许多不同的终端模拟器。Seth Kenlon 的这篇文章推荐了 [3 个 Linux 终端](/article-13186-1.html),值得一试:Xfce 终端、rxvt-unicode 和 Konsole。他提供了每一个的简要概述,并指出了每个终端模拟器的优势。
### 在你的 Linux 家庭实验室中运行 Kubernetes 的另外 5 个理由
在 Seth Kenlon 2020 年的文章《[在树莓派家庭实验室上运行 Kubernetes 的五个理由](https://opensource.com/article/20/8/kubernetes-raspberry-pi)》的续篇中,他给出了 [在 Linux 家庭实验室中运行 Kubernetes 的另外五个理由](https://opensource.com/article/21/6/kubernetes-linux-homelab):Kubernetes 建立在Linux 的基础上,它很灵活,学习它可以为你提供个人发展,它使容器变得有意义,而且它有利于云原生开发。他还提供了一个额外的理由:因为它很有趣。
### 6 个开源工具和技巧,为初学者保障 Linux 服务器的安全
Sahana Sreeram 提供了 [保证 Linux 服务器安全的六个优秀技巧](/article-13298-1.html)。这个教程着眼于更新软件、启用防火墙、加强密码保护、禁用非必要的服务、检查监听端口,以及扫描恶意软件。Sahana 提供的技巧可以帮助 Linux 初学者学习保持 Linux 服务器安全的基本知识。
### Linux 如何使一所学校为大流行病做好准备
Don Watkins 采访了威斯康星州莫诺纳市 [圣心玛利亚学校](https://www.ihmcatholicschool.org/) 的教师 Robert Maynord,介绍了该校 [将他们的电脑换成 Linux](https://opensource.com/article/21/5/linux-school-servers) 的情况。Maynord 分享了关于他是如何对 Linux 感兴趣的轶事,他为把学校的计算机换成 Linux 所采取的第一个步骤,Linux 如何使学校受益等等。Don 在这次采访中提出了许多很好的问题,Maynord 为有意采用 Linux 的学校提供了许多有用的信息。
### 在 Linux 上运行你喜欢的 Windows 应用程序
有时,在切换到 Linux 之后,你仍然需要那个只在 Windows 下运行的特定应用程序,或者真的想玩那个只能在 Windows 下运行的游戏。在这篇文章中,Seth Kenlon 提供了一个关于如何 [在 Linux 上运行你喜欢的 Windows 应用程序](/article-13184-1.html) 的教程。做到这一点的工具是 WINE。Seth 解释了什么是 WINE,它是如何工作的,以及如何在你的 Linux 计算机上安装它,以便你可以运行你最喜欢的 Windows 应用程序。
---
via: <https://opensource.com/article/21/12/reasons-love-linux>
作者:[Joshua Allen Holm](https://opensource.com/users/holmja) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Opensource.com published well over [150 articles about Linux in 2021](https://opensource.com/tags/linux). From articles about small utilities for desktop Linux users to tutorials about working with Linux as a server operating system and everything in between, these articles have covered many facets of the Linux ecosystem. It is well worth your time to check out all of them, but here are ten great articles published this year to get you started.
## 3 open source tools that make Linux the ideal workstation
In this article, Seth Kenlon writes about LibreOffice, AbiWord, Gnumeric, and Pandoc covering [tools that make Linux the ideal workstation](https://opensource.com/article/21/2/linux-workday). He explains how these applications can make you productive when using Linux as a desktop operating system. The article explores advanced features, like LibreOffice's headless mode, and provides tips about getting the most out of each application.
## Why I use exa instead of ls on Linux
The `ls`
command is one of the most frequently used terminal commands in Linux, but did you know there is a modern alternative with many quality of life improvements? [Why I use exa instead of ls on Linux](https://opensource.com/article/21/3/replace-ls-exa) by Sudeshna Sur describes the `exa`
command and the advantages it has over `ls`
. The article discusses how `exa`
can track new files added to a Git repository, display a directory and file tree, and more.
## 5 reasons why I love coding on Linux
Like many people, Seth Kenlon loves coding on Linux. In this article, he shares [five reasons why](https://opensource.com/article/21/2/linux-programming). He likes coding on Linux because it is built on a foundation of logic, makes you appreciate code connections, provides source code, and provides direct access to peripherals and abstractions layers that make writing code easier.
## Use this bootable USB drive on Linux to rescue Windows users
Even if you prefer Linux, there might be times where you need to fix a Windows computer or install Windows for someone. Creating a bootable USB flash drive from a Windows ISO on Linux is not as straightforward as making a bootable flash drive for a Linux distribution. In this tutorial, Don Watkins demonstrates [how to use WoeUSB](https://opensource.com/article/21/2/linux-woeusb), a utility that handles all the tricky parts of the process for the user.
## 4 open source tools for running a Linux server
When using Linux as a server operating system, Seth Kenlon recommends these [four open source tools](https://opensource.com/article/21/3/linux-server). The four tools are Samba, Snapdrop, VLC, and PulseAudio. As Seth notes in his article, these four tools make file sharing and streaming with Linux easy.
## 3 Linux terminals you need to try
There are many different terminal emulators for Linux. This article by Seth Kenlon recommends [three Linux terminals](https://opensource.com/article/21/2/linux-terminals) that are worth trying out. Seth's recommendations are Xfce terminal, rxvt-unicode, and Konsole. He provides a brief overview of each and highlights each terminal emulator's strengths.
## 5 more reasons to run Kubernetes in your Linux homelab
In the sequel to his 2020 article [five reasons to run Kubernetes on your Raspberry Pi homelab](https://opensource.com/article/20/8/kubernetes-raspberry-pi), Seth Kenlon provides [five more reasons to run Kubernetes in your Linux homelab](https://opensource.com/article/21/6/kubernetes-linux-homelab). The five more reasons are that Kubernetes is built on the foundation of Linux, it is flexible, learning it can provide you with personal development, it makes containers make sense, and it facilitates cloud-native development. He also provides a bonus reason: Because it is fun.
## 6 open source tools and tips to securing a Linux server for beginners
Sahana Sreeram provides [six excellent tips for securing a Linux server](https://opensource.com/article/21/4/securing-linux-servers). This tutorial looks at updating software, enabling a firewall, strengthening password protection, disabling nonessential services, checking for listening ports, and scanning for malware. The tips provided by Sahana will help any Linux beginner learn the basics of keeping their Linux servers secure.
## How Linux made a school pandemic-ready
Don Watkins interviews Robert Maynord, a teacher at [Immaculate Heart of Mary School](https://www.ihmcatholicschool.org/) in Monona, Wisconsin, about the school [switching their computers to Linux](https://opensource.com/article/21/5/linux-school-servers). Maynord shares anecdotes about how he became interested in Linux, the first steps he took to change the school's computers to Linux, how Linux benefits the school, and much more. Don asks many great questions in this interview, and Maynord provides a lot of useful information for schools interested in adopting Linux.
## Run your favorite Windows applications on Linux
Sometimes, after switching to Linux, you still need that one particular Windows-only application or really want to play that Windows-only game. In this article, Seth Kenlon provides a tutorial about how to [run your favorite Windows applications on Linux](https://opensource.com/article/21/2/linux-wine). The tool for doing this is WINE. Seth explains what WINE is, how it works, and how to get it installed on your Linux computer so you can run your favorite Windows applications.
## Comments are closed. |
14,209 | 用 CrowdSec 保护你的 PHP 网站不受机器人攻击 | https://opensource.com/article/22/1/php-website-bouncer-crowdsec | 2022-01-24T09:42:53 | [
"PHP",
"机器人"
] | https://linux.cn/article-14209-1.html |
>
> CrowdSec 门卫被设计成可以包含在任何 PHP 应用程序中,以帮助阻止攻击者。
>
>
>

PHP 是 Web 上广泛使用的一种编程语言,据估计有近 80% 的网站使用它。我在 [CrowdSec](https://opensource.com/article/20/10/crowdsec) 的团队决定,我们需要为服务器管理员提供一个 PHP 门卫,以帮助抵御那些可能试图与 PHP 文件互动的机器人和不良分子。
CrowdSec 门卫可以在应用栈的各个层面上进行设置:[Web 服务器、防火墙、CDN](https://hub.crowdsec.net/browse/#bouncers) 等等。本文关注的是另外一个层次:直接在应用层面设置补救措施。
由于各种原因,直接在应用程序中进行补救是有帮助的:
* 它为潜在的安全威胁提供了业务逻辑上的答案。
* 它提供了关于如何应对安全问题的自由。
虽然 CrowdSec 已经发布了一个 WordPress 门卫,但这个 PHP 库被设计成可以包含在任何 PHP 应用中(例如 Drupal)。该门卫有助于阻止攻击者,用验证码挑战他们,让人类通过,同时阻止机器人。
### 先决条件
本教程假定你在 Linux 服务器上运行 Drupal,并使用 [Apache 作为 Web 服务器](https://opensource.com/article/18/2/how-configure-apache-web-server)。
第一步是在你的服务器上 [安装 CrowdSec](https://doc.crowdsec.net/docs/getting_started/install_crowdsec)。你可以用 [官方安装脚本](https://packagecloud.io/crowdsec/crowdsec/install) 来完成。如果你使用的是 Fedora、CentOS 或类似系统,请下载 RPM 版本:
```
$ curl -s https://packagecloud.io/install/repositories/crowdsec/crowdsec/script.rpm.sh
```
在 Debian 和基于 Debian 的系统上,下载 DEB 版本:
```
$ curl -s https://packagecloud.io/install/repositories/crowdsec/crowdsec/script.deb.sh
```
这些脚本很简单,所以仔细阅读你下载的脚本,以验证它是否导入了 GPG 密钥并配置了一个新的存储库。当你清楚了它的作用后,就执行它,然后安装。
```
$ sudo dnf install crowdsec || sudo apt install crowdsec
```
CrowdSec 会自己检测到所有现有的服务,所以不需要进一步的配置就可以立即得到一个能发挥功能的设置。
### 测试初始设置
现在你已经安装了 CrowdSec,启动一个 Web 应用漏洞扫描器,比如 [Nikto](https://github.com/sullo/nikto),看看它的表现如何:
```
$ ./nikto.pl -h http://<ip_or_domain>
```

该 IP 地址已被检测到触发了各种场景,最后一个是 `crowdsecurity/http-crawl-non_statics`:

然而,CrowdSec 只检测问题,需要一个门卫来应用补救措施。这就是 PHP 门卫发挥作用的地方。
### 用 PHP 门卫进行补救
现在你可以检测到恶意行为了,你需要在网站层面上阻止 IP。在这个时候,没有用于 Drupal 的门卫可用。然而,你可以直接使用 PHP 门卫。
它是如何工作的?PHP 门卫(和其他门卫一样)对 CrowdSec 的 API 进行调用,并检查是否应该禁止进入的 IP,向他们发送验证码,或者允许他们通过。
Web 服务器是 Apache,所以你可以使用 [Apache 的安装脚本](https://github.com/crowdsecurity/cs-php-bouncer/blob/main/install.sh):
```
$ git clone https://github.com/crowdsecurity/cs-php-bouncer.git
$ cd cs-php-bouncer/
$ ./install.sh --apache
```

门卫的配置是用来保护整个网站。可以通过调整 Apache 的配置保护网站的一个特定部分。
### 尝试访问网站
PHP 门卫已经安装并配置好。由于之前的网络漏洞扫描行动,你被禁止了,你可以尝试访问该网站看看:

门卫成功阻止了你的流量。如果你在以前的 Web 漏洞扫描后没有被禁止,你可以用增加一个手动决策:
```
$ cscli decisions add -i <your_ip>
```
对于其余的测试,删除当前的决策:
```
$ cscli decisions delete -i <your_ip>
```
### 更进一步
我封锁了试图破坏 PHP 网站的 IP。这很好,但那些试图扫描、爬取或 DDoS 的 IP 怎么办?这些类型的检测可能会导致误报,那么为什么不返回一个验证码挑战来检查它是否是一个真正的用户(而不是一个机器人),而不是封锁 IP?
#### 检测爬虫和扫描器
我不喜欢爬虫和坏的用户代理,在 [Hub](https://hub.crowdsec.net/) 上有各种方案可以用来发现它们。
确保用 `cscli’ 下载了 Hub 上的`base-http-scenarios` 集合:
```
$ cscli collections list | grep base-http-scenarios
crowdsecurity/base-http-scenarios ✔️ enabled /etc/crowdsec/collections/base-http-scenarios.yaml
```
如果没有找到,请安装它,并重新加载 CrowdSec:
```
$ sudo cscli collections install crowdsecurity/base-http-scenarios
$ sudo systemctl reload crowdsec
```
#### 用验证码补救
由于检测 DDoS、爬虫或恶意的用户代理可能会导致误报,我更倾向于对任何触发这些情况的 IP 地址返回一个验证码,以避免阻止真正的用户。
为了实现这一点,请修改 `profiles.yaml` 文件。
在 `/etc/crowdsec/profiles.yaml` 中的配置文件的开头添加这个 YAML 块:
```
---
# /etc/crowdsec/profiles.yaml
name: crawler_captcha_remediation
filter: Alert.Remediation == true && Alert.GetScenario() in ["crowdsecurity/http-crawl-non_statics", "crowdsecurity/http-bad-user-agent"]
decisions:
- type: captcha
duration: 4h
on_success: break
```
有了这个配置文件,任何触发 `crowdsecurity/http-crawl-non_statics` 或 `crowdsecurity/http-bad-user-agent` 场景的 IP 地址都会被强制执行一个验证码(持续 4 小时)。
接下来,重新加载 CrowdSec:
```
$ sudo systemctl reload crowdsec
```
#### 尝试自定义的补救措施
重新启动 Web 漏洞扫描器会触发很多场景,所以你最终会再次被禁止。相反,你可以直接制作一个触发 `bad-user-agent` 场景的攻击(已知的坏用户代理列表在 [这里](https://raw.githubusercontent.com/crowdsecurity/sec-lists/master/web/bad_user_agents.txt))。请注意,你必须激活该规则两次才能被禁止。
```
$ curl --silent -I -H "User-Agent: Cocolyzebot" http://example.com > /dev/null
$ curl -I -H "User-Agent: Cocolyzebot" http://example.com
HTTP/1.1 200 OK
Date: Tue, 05 Oct 2021 09:35:43 GMT
Server: Apache/2.4.41 (Ubuntu)
Expires: Sun, 19 Nov 1978 05:00:00 GMT
Cache-Control: no-cache, must-revalidate
X-Content-Type-options: nosniff
Content-Language: en
X-Frame-Options: SAMEORIGIN
X-Generator: Drupal 7 (http://drupal.org)
Content-Type: text/html; charset=utf-8
```
当然,你可以看到,你的行为会被抓住。
```
$ sudo cscli decisions list
```

如果你试图访问该网站,不会被简单地被阻止,而是会收到一个验证码:

一旦你解决了这个验证码,你就可以重新访问网站了。
接下来,再次解禁自己:
```
$ cscli decisions delete -i <your_ip>
```
启动漏洞扫描器:
```
$ ./nikto.pl -h http://example.com
```
与上次不同的是,你现在可以看到,你已经触发了几个决策:

当试图访问网站时,禁止决策具有优先权:

### 总结
这是一个帮助阻止攻击者进入 PHP 网站和应用程序的快速方法。本文只包含一个例子。补救措施可以很容易地扩展,以适应额外的需求。要了解更多关于安装和使用 CrowdSec 代理的信息,[查看这个方法指南](https://crowdsec.net/tutorial-crowdsec-v1-1/) 来开始。
要下载 PHP 门卫,请到 [CrowdSec Hub](https://hub.crowdsec.net/author/crowdsecurity/bouncers/cs-php-bouncer) 或 [GitHub](https://github.com/crowdsecurity/cs-php-bouncer)。
---
via: <https://opensource.com/article/22/1/php-website-bouncer-crowdsec>
作者:[Philippe Humeau](https://opensource.com/users/philippe-humeau) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | PHP is a widely-used programming language on the web, and it's estimated that nearly 80% of all websites use it. My team at [CrowdSec](https://opensource.com/article/20/10/crowdsec) decided that we needed to provide server admins with a PHP bouncer to help ward away bots and bad actors who may attempt to interact with PHP files.
CrowdSec bouncers can be set up at various levels of an applicative stack: [web server, firewall, CDN](https://hub.crowdsec.net/browse/#bouncers), and so on. This article looks at one more layer: setting up remediation directly at the application level.
Remediation directly in the application can be helpful for various reasons:
- It provides a business-logic answer to potential security threats.
- It gives freedom about how to respond to security issues.
While CrowdSec already publishes a WordPress bouncer, this PHP library is designed to be included in *any* PHP application (Drupal, for example). The bouncer helps block attackers, challenging them with CAPTCHA to let humans through while blocking bots.
## Prerequisites
This tutorial assumes that you are running Drupal on a Linux server with [Apache as a web server.](https://opensource.com/article/18/2/how-configure-apache-web-server)
The first step is to [install CrowdSec](https://doc.crowdsec.net/docs/getting_started/install_crowdsec) on your server. You can do this with an [official install script](https://packagecloud.io/crowdsec/crowdsec/install). If you're on Fedora, CentOS, or similar, download the RPM version:
`$ curl -s https://packagecloud.io/install/repositories/crowdsec/crowdsec/script.rpm.sh`
On Debian and Debian-based systems, download the DEB version:
`$ curl -s https://packagecloud.io/install/repositories/crowdsec/crowdsec/script.deb.sh`
These scripts are simple, so read through the one you download to verify that it imports a GPG key and configures a new repository. Once you're comfortable with what it does, execute it and then install.
`$ sudo dnf install crowdsec || sudo apt install crowdsec`
CrowdSec detects all the existing services on its own, so there should be no further configuration to get an immediately functional setup.
## Test the initial setup
Now that you have CrowdSec installed, launch a web application vulnerability scanner, such as [Nikto](https://github.com/sullo/nikto), and see how it behaves:
`$ ./nikto.pl -h http://<ip_or_domain>`
(Philippe Humeau, CC BY-SA 4.0)
The IP address has been detected and triggers various scenarios, the last one being **crowdsecurity/http-crawl-non_statics**.

(Philippe Humeau, CC BY-SA 4.0)
However, CrowdSec only detects issues, and a bouncer is needed to apply remediation. Here comes the PHP bouncer.
## Remediate with the PHP bouncer
Now that you can detect malicious behaviors, you need to block the IP at the website level. At this time, there is no Drupal bouncer available. However, you can use the PHP bouncer directly.
How does it work? The PHP bouncer (like any other bouncer) makes an API call to the CrowdSec API and checks whether it should ban incoming IPs, send them a CAPTCHA, or allow them to pass.
The web server is Apache, so you can use the [install script for Apache](https://github.com/crowdsecurity/cs-php-bouncer/blob/main/install.sh).
```
$ git clone https://github.com/crowdsecurity/cs-php-bouncer.git
$ cd cs-php-bouncer/
$ ./install.sh --apache
```
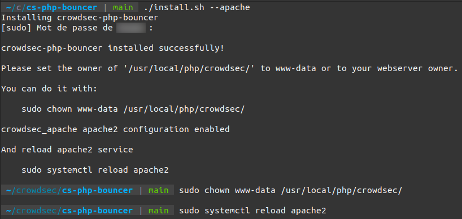
(Philippe Humeau, CC BY-SA 4.0)
The bouncer is configured to protect the whole website. Secure a specific part of the site by adapting the Apache configuration.
## Try to access the website
The PHP bouncer is installed and configured. You're banned due to the previous web vulnerability scan actions, but you can try to access the website:
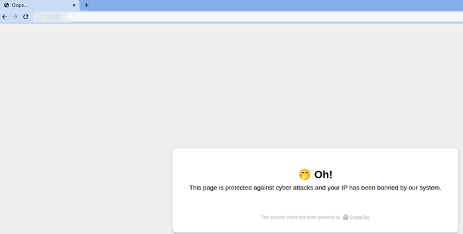
(Philippe Humeau, CC BY-SA 4.0)
The bouncer successfully blocked your traffic. If you were not banned following a previous web vulnerability scan, you could add a manual decision with:
`$ cscli decisions add -i <your_ip>`
For the remaining tests, remove the current decisions:
`$ cscli decisions delete -i <your_ip>`
## Going further
I blocked the IP trying to mess with the PHP website. It’s nice, but what about IPs trying to scan, crawl, or DDoS it? Those kinds of detections can lead to false positives, so why not return a CAPTCHA challenge to check whether it is an actual user (rather than a bot) instead of blocking the IP?
### Detect crawlers and scanners
I dislike crawlers and bad user agents and there are various scenarios available on the [Hub](https://hub.crowdsec.net/) to spot them.
Ensure the `base-http-scenarios`
collections from the Hub are downloaded with `cscli`
:
```
$ cscli collections list | grep base-http-scenarios
crowdsecurity/base-http-scenarios ✔️ enabled /etc/crowdsec/collections/base-http-scenarios.yaml
```
If it is not the case, install it, and reload CrowdSec:
```
$ sudo cscli collections install crowdsecurity/base-http-scenarios
$ sudo systemctl reload crowdsec
```
### Remedy with a CAPTCHA
Since detecting DDoS, crawlers, or malevolent user agents can lead to false positives, I prefer to return a CAPTCHA for any IP address triggering those scenarios to avoid blocking real users.
To achieve this, modify the `profiles.yaml`
file.
Add this YAML block at the beginning of your profile in `/etc/crowdsec/profiles.yaml`
:
```
---
# /etc/crowdsec/profiles.yaml
name: crawler_captcha_remediation
filter: Alert.Remediation == true && Alert.GetScenario() in ["crowdsecurity/http-crawl-non_statics", "crowdsecurity/http-bad-user-agent"]
decisions:
- type: captcha
duration: 4h
on_success: break
```
With this profile, a CAPTCHA is enforced (for four hours) on any IP address that triggers the scenarios `crowdsecurity/http-crawl-non_statics`
or `crowdsecurity/http-bad-user-agent`
.
Next, reload CrowdSec:
`$ sudo systemctl reload crowdsec`
### Try the custom remediations
Relaunching a web vulnerability scanner would trigger many scenarios, so you would ultimately be banned again. Instead, you can just craft an attack that triggers the `bad-user-agent`
scenario (the list of known bad user-agents is [here](https://raw.githubusercontent.com/crowdsecurity/sec-lists/master/web/bad_user_agents.txt)). Please note that you must activate the rule twice to get banned.
```
$ curl --silent -I -H "User-Agent: Cocolyzebot" http://example.com > /dev/null
$ curl -I -H "User-Agent: Cocolyzebot" http://example.com
HTTP/1.1 200 OK
Date: Tue, 05 Oct 2021 09:35:43 GMT
Server: Apache/2.4.41 (Ubuntu)
Expires: Sun, 19 Nov 1978 05:00:00 GMT
Cache-Control: no-cache, must-revalidate
X-Content-Type-options: nosniff
Content-Language: en
X-Frame-Options: SAMEORIGIN
X-Generator: Drupal 7 (http://drupal.org)
Content-Type: text/html; charset=utf-8
```
You can, of course, see that you get caught for your actions.
`$ sudo cscli decisions list`

(Philippe Humeau, CC BY-SA 4.0)
If you try to access the website, instead of being simply blocked, you receive a CAPTCHA:
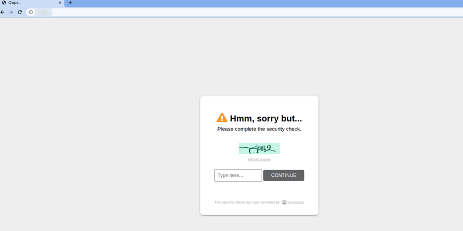
(Philippe Humeau, CC BY-SA 4.0)
Once you solve it, you can reaccess the website.
Next, unban myself again:
`$ cscli decisions delete -i <your_ip>`
Launch the vulnerability scanner:
`$ ./nikto.pl -h http://example.com`
Unlike the last time, you can now see that you've triggered several decisions:

(Philippe Humeau, CC BY-SA 4.0)
When trying to access the website, the ban decision has the priority:
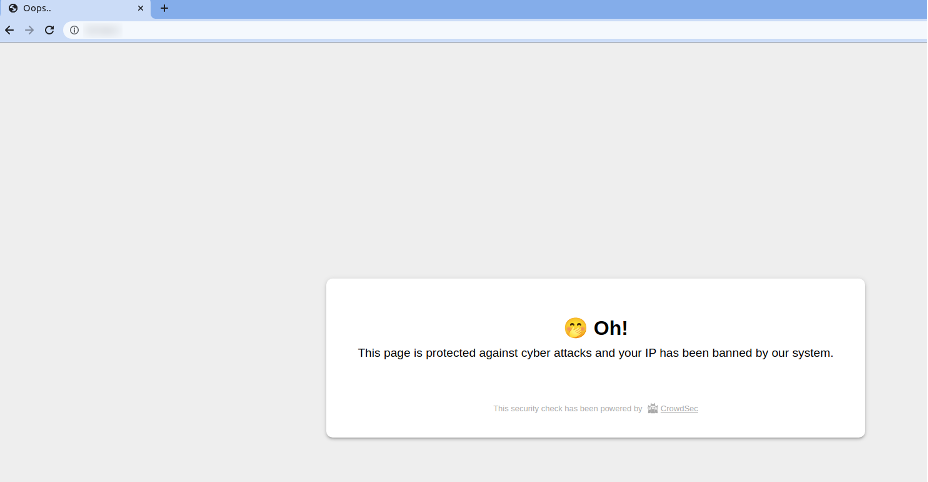
(Philippe Humeau, CC BY-SA 4.0)
## Wrap up
This is a quick way to help block attackers from PHP websites and applications. This article contains only one example. Remediations can be easily extended to fit additional needs. To find out more about installing and using the CrowdSec agent, [check this how-to guide](https://crowdsec.net/tutorial-crowdsec-v1-1/) to get started.
To download the PHP bouncer, go to [the CrowdSec Hub](https://hub.crowdsec.net/author/crowdsecurity/bouncers/cs-php-bouncer) or [GitHub](https://github.com/crowdsecurity/cs-php-bouncer).
## Comments are closed. |
14,210 | 是什么让 Linux 成为可持续的操作系统 | https://opensource.com/article/22/1/linux-sustainable-os | 2022-01-24T11:20:49 | [
"Linux"
] | https://linux.cn/article-14210-1.html |
>
> Linux 有助于弥合数字鸿沟,延长硬件的使用寿命,使得它成为操作系统的一个环保选择。
>
>
>

与大流行病作斗争,造成了生产新电脑所需的微芯片的短缺。此外,一些较新的专有操作系统提高了它们的硬件标准(LCTT 译注:Windows 11,别扭头看别人)。这个难题为我们这些在日常生活中使用 Linux 的人创造了一个机会。
### 延长硬件的生命周期
长期以来,Linux 一直以延长老旧硬件的寿命而闻名。这种能力对那些每天使用电脑的人来说是个福音。
在过去的一年里,我已经帮助许多人使用 Linux 翻新和 [改装旧电脑](https://opensource.com/article/21/4/restore-macbook-linux)。基于 Linux 的电脑耗电更少,启动速度更快。[Gnome](https://www.gnome.org/) 桌面很好,但许多旧电脑更适合 [LXDE](https://www.lxde.org/) 或 [XFCE](https://xfce.org/) 环境,它们运行需要较少的资源。
像 [FreeGeek](https://opensource.com/article/21/4/linux-free-geek) 和 [Kramden Institute](https://opensource.com/education/16/2/kramden-helps-bridge-digital-divide) 这样的组织已经把弥合数字鸿沟作为他们的核心使命,并以此为目标。这些团体对旧电脑进行了再利用,使它们不被当成垃圾填埋,而是把它们送到需要它们的用户手中。没有 Linux,就没有这些项目。
[DD-Wrt](https://dd-wrt.com/)、[OpenWrt](https://openwrt.org/) 和 [Tomato](https://www.freshtomato.org/) 都是 Linux 解决方案,使旧的网络硬件不被当成垃圾丢弃,并同时为用户的路由器提供更多的安全、隐私和性能。
借助 [GalliumOS](https://galliumos.org) 和 [Mrchromebox.tech](https://mrchromebox.tech),即使是 Chromebooks 在谷歌停止支持后也能获得新的生命。
### 新的机会
Linux 创造了一些本来不存在的机会。学生和业余爱好者都在没有投资的情况下开始了计算机科学的成功事业,这要归功于他们在旧电脑上学到的经验。这些系统运行企业级软件,如 [LAMP](https://en.wikipedia.org/wiki/LAMP_%28software_bundle%29) 栈,它促进了向 “Web 2.0” 的过渡。它是最早的 Web 开源软件栈之一。今天,它为 WordPress、Drupal 和 Joomla 系统提供了动力。事实上,Linux 为超过 96% 的世界前 100 万台 Web 服务器提供动力。Linux 还管理着 [嵌入式系统](https://opensource.com/article/20/6/open-source-rtos)、电子阅读器、智能电视、智能手表 [等等](https://opensource.com/article/19/8/everyday-tech-runs-linux)。Linux 是世界上远远 [超过 70%](https://gs.statcounter.com/os-market-share/mobile/worldwide/) 的智能手机的操作系统。甚至美国国家航空航天局(NASA)今年在火星上创造历史的 [毅力号](https://mars.nasa.gov/mars2020/spacecraft/rover/),也是由 Linux 驱动的。
为当今大多数应用提供动力的云计算,没有 Linux 就不可能存在。今天的大多数 Web 和智能手机应用都在基于 Linux 的 [容器](https://opensource.com/resources/what-are-linux-containers) 中运行。即使在微芯片短缺和专有系统成本高昂的情况下,进入云服务行业的人也有机会学习开源的操作系统和软件。
### 未来
但最恰当的是,Linux 和开源为 [联合国可持续发展目标](https://opensource.com/article/21/11/open-source-un-sustainability) 提供了动力。随着大流行的继续,Linux 仍然是一个重要的资源。
---
via: <https://opensource.com/article/22/1/linux-sustainable-os>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Battling the pandemic has created a shortage of microchips needed to produce new computers. In addition, some newer proprietary operating systems come with higher minimum standards for those systems. This conundrum has created an opportunity for those of us who use Linux in our daily lives.
## Extend the hardware lifecycle
Linux has long been noted for adding life to aging hardware. That ability has been a boon to those folks who use computers every day.
I have helped many folks refurbish and [refit older computers](https://opensource.com/article/21/4/restore-macbook-linux) using Linux in the past year. Linux-based computers consume less power and start up much quicker. The [Gnome](https://www.gnome.org/) desktop is great, but many older computers are better suited to [LXDE](https://www.lxde.org/) or [XFCE](https://xfce.org/) environments, which require fewer resources to run.
Organizations like [FreeGeek](https://opensource.com/article/21/4/linux-free-geek) and [Kramden Institute](https://opensource.com/education/16/2/kramden-helps-bridge-digital-divide) have made it their core mission to bridge the digital divide and, in so doing. These groups have repurposed older computers, keeping them out of the landfill and putting them in the hands of users who need them. Those programs don't happen without Linux.
[DD-Wrt](https://dd-wrt.com/), [OpenWrt](https://openwrt.org/), and [Tomato](https://www.freshtomato.org/) are all Linux solutions that keep older network hardware out of the landfill while providing users with added security, privacy, and performance from their routers.
With [GalliumOS](https://galliumos.org) and [Mrchromebox.tech](https://mrchromebox.tech), even Chromebooks can be given new life after Google stops supporting them.
## New opportunities
Linux has created opportunities that would not otherwise exist. Students and hobbyists alike have started successful careers in computer science with no investment, thanks to lessons learned on old computers. These systems run enterprise-grade software, such as the [LAMP](https://en.wikipedia.org/wiki/LAMP_%28software_bundle%29) stack, which facilitated the transition to "Web 2.0". It was one of the first open source software stacks for the web. Today, it powers WordPress, Drupal, and Joomla installations. In fact, Linux powers over 96% of the world's top one million web servers. Linux also manages [embedded systems](https://opensource.com/article/20/6/open-source-rtos), e-readers, smart televisions, smartwatches, [and more](https://opensource.com/article/19/8/everyday-tech-runs-linux). Linux is the OS for well [over 70%](https://gs.statcounter.com/os-market-share/mobile/worldwide/) of the world's smartphones. Even NASA's [Perseverance Rover](https://mars.nasa.gov/mars2020/spacecraft/rover/), that made history on Mars this year, is powered by Linux.
The cloud, which powers most of today's applications, could not exist without Linux. Most of today's web and smartphone applications run in Linux-based [containers](https://opensource.com/resources/what-are-linux-containers). Even with the microchip shortage and the high cost of proprietary systems, those entering the cloud services industry have the opportunity to learn on an open source operating system and software.
## The future
But most appropriately, Linux and open source power the [United Nations Sustainability Goals](https://opensource.com/article/21/11/open-source-un-sustainability). Linux continues to be a critical resource as the pandemic continues.
## Comments are closed. |
14,212 | OpenBoard:面向教育工作者的开源交互式白板 | https://itsfoss.com/openboard/ | 2022-01-25T13:46:43 | [
"白板"
] | https://linux.cn/article-14212-1.html |
>
> OpenBoard 是为中小学和大学定制的交互式开源白板。让我们来看看它提供了什么。
>
>
>

有几个可用于教育的开源工具,但是,并非所有这些面向中小学和大学的软件都能达到商业软件级的良好维护。
OpenBoard 就是这样一个不同凡响的自由开源工具,它可以不打折扣地为教育服务。它是一个交互式白板程序,具有所有基本功能,并支持各种硬件。
### OpenBoard:自由及开源的交互式白板

作为一个自由开源的程序,OpenBoard 看起来是一个令人印象深刻的选择。
瑞士日内瓦州的教育部门(DIP)与 GitHub 上的社区一起维护该工具。
通过交互式白板促进简单的数字教学不应该花费很多,这就是 OpenBoard 的优势所在。
它提供的一系列功能对大多数中小学和大学来说应该是足够的。
虽然我无法在中小学/大学环境中测试它,但我会重点介绍它提供的主要功能。
### OpenBoard 的特点

交互式白板没有众多花哨的功能,但足以使教师能够尽可能轻松地表达自己。
我注意到的一些特点包括:
* 跨平台支持
* 能够自由地写写画画
* 能够添加注释
* 能够删除注释
* 可以使用荧光笔高亮显示你的白板的部分区域
* 单独互动和移动创建/绘制的项目
* 按顺序添加多个页面,可以继续教学而不需要擦除
* 能够在页面间滚动浏览
* 绘制线条(从三种不同线宽中选择)
* 切换手写笔模式(如果你使用的是手写板或类似的东西)
* 轻松擦除在白板上创建的项目
* 可以从一组不同的背景中选择,包括把它变成黑板或带网格线的背景
* 各种必要的应用,包括计算器、地图、尺子等,都可以通过拖放使用
* 提供的一些形状,可以使绘图更容易
* 能够向你的白板添加音频/视频,并无缝播放,以获得更好的体验
* 虚拟激光笔
* 可放大和缩小
* 书写文字,调整大小,并克隆它
* 从白板中对屏幕进行截图
* 需要时可使用虚拟键盘
在我简短的测试中,用户界面和可用的选项工作得非常好,没有任何故障。

当然,你的体验将取决于设备的类型和你的设置。你可以用 Wacom 平板、双显示器设置,或者通过支持触摸的笔记本电脑使用投影仪来尝试。
### 在 Linux 中安装 OpenBoard
更好的是,它可以在多个平台上使用,包括 Windows、macOS 和 Linux。
如果你使用的是 Ubuntu,你可以到官方网站下载 DEB 文件。另外对于其他 Linux 发行版,你可以选择通过 [Flathub](https://flathub.org/apps/details/ch.openboard.OpenBoard) [安装 Flatpak 软件包](https://itsfoss.com/flatpak-guide/)。
* [OpenBoard](https://www.openboard.ch/index.en.html)
### 结语
总的来说,我发现它在使用和导航方面毫不费力。你可以在多个页面之间快速切换,无缝擦除/添加项目,同时还可以在白板上添加丰富的元素。
通过虚拟激光笔以及一些应用,使得它适合在各种中小学和大学中使用而没有任何障碍。
我不知道它是否可以被称为谷歌课堂或 Miro 白板功能的替代品,但对于更简单的使用,OpenBoard 可以胜任。
如果你还没有试过,我建议你试一试。你知道有什么比这更好的东西吗?请在下面的评论中告诉我。
---
via: <https://itsfoss.com/openboard/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief:** *OpenBoard is an interactive open-source whiteboard tailored for schools and universities. Let’s take a look at what it offers!*
There are several open-source tools available for education. But, not all of them are impressively well-maintained at the level of commercial software put forward for schools and universities.
OpenBoard is one such exceptional free and open-source tool that enables education without any compromises. It is an interactive whiteboard program that features all the essential functionalities along with support for a variety of hardware.
## OpenBoard: Free and Open Source Interactive Whiteboard
As a free and open-source program, OpenBoard seems to be an impressive option.
The Education Department (DIP) of the canton of Geneva, in Switzerland, maintains the tool along with the community on GitHub.
It shouldn’t cost a fortune just to facilitate easy digital teaching through interactive whiteboards. And, this is where OpenBoard comes in.
It offers a range of features that should be enough for most schools and universities.
While I can’t test it out in a school/university setting, I shall highlight the key features that it offers.
## Features of OpenBoard
An interactive whiteboard does not need numerous fancy features, but enough to make the experience easy for teachers to be able to express themselves as easily as possible.
Some of the features that I noticed include:
- Cross-platform support
- Ability to draw/write freely.
- The ability to add annotation.
- You get to remove annotation.
- Get the ability to highlight part of your whiteboard using highlighter.
- Individually interact and move the items created/drawn.
- Add multiple pages in an order to continue teaching without needing to erase.
- Ability to scroll through the pages.
- Draw a line (choosing from three different weights of lines)
- Toggle Stylus mode (if you are using a pen tablet or similar)
- Easy to erase the items created in the whiteboard
- Choose from a set of different backgrounds, including ones that turn it into a blackboard or with grid lines.
- A variety of essential applications including calculator, maps, ruler, and more is available to use through drag and drop.
- Limited shapes available to make drawing easier.
- Ability to add audio/video to your whiteboard and play it seamlessly for better experience.
- Virtual laser pointer.
- Option to zoom in and zoom out.
- Write text, resize it, and clone it.
- Take a screenshot of the screen from within the whiteboard.
- Virtual keyboard available when required.
In my brief testing, the user interface and the options available worked incredibly well, without any fail.
Of course, your experience will depend on the type of device and your setup. You can try it with a Wacom tablet, a dual-monitor setup, or using a projector through a touch-enabled laptop.
## Install OpenBoard in Linux
Fortunately, it is available across multiple platforms that include Windows, macOS, and Linux.
If you are using Ubuntu, you can head to its official website and download the DEB file. In either case, you can choose to [install the Flatpak package](https://itsfoss.com/flatpak-guide/) from [Flathub](https://flathub.org/apps/details/ch.openboard.OpenBoard) for any other Linux distribution.
## Closing Thoughts
Overall, I found it effortless to use and navigate. You can quickly switch between multiple pages, erase/add items seamlessly while having the ability to add rich elements to the whiteboard as well.
The presence of a virtual laser pointer, and several applications, make it suitable for use in various schools and universities without any hiccups.
I don’t know if it can be called an alternative to Google Classroom or Miro’s Whiteboard feature but for simpler usage, OpenBoard does the job.
If you haven’t tried this out, I recommend giving it a spin. Is there something better than this that you know of? Let me know in the comments down below. |
14,213 | Brave vs. Google Chrome:哪个浏览器更适合你? | https://itsfoss.com/brave-vs-chrome/ | 2022-01-25T16:32:00 | [
"Chrome",
"Brave"
] | https://linux.cn/article-14213-1.html | 
*开源朗读者 | 离漫夭*
Google Chrome 无疑是 [可用于 Linux 的最佳网页浏览器](https://itsfoss.com/best-browsers-ubuntu-linux/) 之一。无论你在什么平台上使用它,它都提供了用户体验和功能集的良好融合。
另一方面,Brave 作为跨平台可用的、以隐私为中心的开源选项而广受欢迎。
那么,你应该选择哪一个作为首选网页浏览器呢?Chrome 适合你吗?谁应该使用 Brave?
在这里,我们比较了两种浏览器的所有重要方面(包括基准测试),以帮助你做出决定。
### 用户界面

[Google Chrome](https://www.google.com/chrome/index.html) 用户界面干净、开箱即用,没有不必要的干扰。
根据我的经验,默认情况下,它与 Linux 上的(GTK)系统主题融为一体。因此,根据你的自定义设置,它可能看起来有点不同。

如果你不在 Linux 上使用它,那么除了配色方案外,其他所有界面都基本相似。
而对于 [Brave](https://brave.com),它并不能开箱即用地适应你的系统配色方案。但是,你可以在它的外观设置里启用 GTK 主题。
Brave 与 Chrome 的用户界面接近,但有一些独有的调整/选项。

就用户界面而言,两者都不错,都很容易使用。
但是,Brave 提供了一些自定义外观的附加选项,例如删除选项卡搜索按钮(左侧到最小化按钮)、显示完整的 URL 等。

如果你觉得这对你有用,Brave 就更适合你。使用 Google Chrome,你在 UI 定制方面没有太多控制权。
### 开源与专有

Brave 是一个基于 Chromium 的开源网页浏览器。顺便说一句,我们还有一份 [不基于 Chromium 的开源浏览器](https://itsfoss.com/open-source-browsers-linux/) 的列表。
Google Chrome 也基于 Chromium,但它添加了几个专有元素,使其成为一个闭源产品。
虽然你可以期待 Brave 的开源和透明度带来的好处,但考虑到 Google 有专门的安全团队,他们在修补问题时可以非常快。
对于普通用户来说,这些都是不太关注的地方。但是,如果你更在意开源和具有透明度的软件,那么 Brave 应该是首选。另一方面,如果你不在意是否是专有代码,并且信任 Google 的产品,那么 Google Chrome 是一个选择。
如果你想要一个与 Chrome 具有相似 UI 的开源浏览器,你可能想要看看我们对 [Chrome 和 Chromium](https://itsfoss.com/chrome-vs-chromium/) 的比较来选择一个。
### 功能差异
你应该会发现两个浏览器的所有基本功能都是相似的。
但是,两者之间存在一些显着差异。
如上所述,你会注意到自定义外观的能力存在差异。
在多个设备之间同步浏览器数据的能力也存在很大差异。

使用 Google Chrome,你可以快速登录你的 Google 帐户并将所有内容同步到你的手机和其他设备。
Brave 也可以让你同步,但对某些人来说可能不方便。你需要访问你已经使用 Brave 成功同步的设备之一。
你的同步数据并未存储在云中。因此,你必须使用二维码或密码授权将浏览数据传输/同步到另一台设备。

因此,你必须导出书签和其他相关数据以进行外部备份。
值得庆幸的是,如果你既想要方便的同步,也想要开源浏览器,还有另一种选择。看看我们的 [Firefox 和 Brave 比较](https://itsfoss.com/brave-vs-firefox/) 文章,了解为什么这对你来说是一个不错的选择。
除了这些差异之外,Brave 还支持 [IPFS 协议](https://ipfs.io),这是一种旨在对抗审查的点对点安全协议。
也不要忘记,Brave 默认带有 [Brave Search](https://itsfoss.com/brave-search-features/) 作为其搜索引擎。所以,如果你更喜欢它而不是将谷歌作为 [私人搜索引擎](https://itsfoss.com/privacy-search-engines/),那也是一件好事。
Brave Rewards 也是一个有趣的附加功能,你可以通过启用 Brave 的隐私友好型广告获得奖励,并将其回馈给你经常访问的网站。
如果云存储服务或任何在线平台阻止了这些,你可以将使用它的资源直接共享给接收者。
总的来说,Brave 提供了许多有趣的东西。但是,Chrome 浏览器是一个更简单的选择,对许多人来说是一个方便的选择。
### 隐私角度
Brave 的跟踪保护应该有利于注重隐私的人。你可以使用 Shield 功能阻止广告和跟踪器。除此之外,如果你想要更积极阻止广告(这可能会破坏网站显示和功能),还有几个可切换使用的过滤器。
Chrome 浏览器不提供此功能。但是,你总可以使用一些以隐私为重点的 Chrome 扩展程序,而 Google 的安全浏览功能应该可以保护你免受恶意网站的侵害。
一般来说,如果你不访问黑幕网站,应该可以使用 Chrome 浏览器。而如果你关注隐私,Brave 可能是更好的选择。
### 表现
虽然 Brave 通常被认为是最快的,但在我的基准测试中似乎并非如此。这真令人吃惊!
但是,对于大多数人来说,实际的差异应该不明显。

我使用了流行的基准测试:[JetStream 2](https://webkit.org/blog/8685/introducing-the-jetstream-2-benchmark-suite/)、[Speedometer 2.0](https://webkit.org/blog/8063/speedometer-2-0-a-benchmark-for-modern-web-app-responsiveness/) 和 [Basemark Web 3.0](https://web.basemark.com)。
请注意,我使用的 Linux 发行版是 **Pop!\_OS 21.10**,测试的浏览器版本是 **Chrome 97.0.4692.71** 和 **Brave 97.0.4692.71**。
当然,除了浏览器之外,我没有在后台运行任何东西。我的 PC 是由 **Intel i5-11600k @4.7 GHz、32 GB 3200 MHz RAM 和 1050ti Nvidia Graphics** 驱动的。
### 安装

Chrome 浏览器提供的 DEB/RPM 软件包以在 Ubuntu、Debian、Fedora 或 openSUSE 上下载和安装。
Brave 也支持相同的 Linux 发行版,但你必须使用终端,并按照下载页面中提到的命令进行安装。

你可以按照我们的安装指南 [在 Fedora 中安装 Brave](https://itsfoss.com/install-brave-browser-fedora/)。
它们都不能通过软件中心安装。此外,你也找不到任何 [Flatpak 包](https://itsfoss.com/what-is-flatpak/) 或 Snap 包。
如果你想要直接从软件中心安装,或找到一个 flatpak 包或 Snap 包,Firefox 可以满足你的需求。
### 你应该选择什么?
如果你想要更多自定义和高级功能,Brave 应该是一个令人印象深刻的选择。但是,如果你对在 Linux 发行版上使用专有浏览器没有问题,并且想要稍微更好的性能,那么 Google Chrome 是一个可行的选择。
对于注重隐私的用户来说,答案是显而易见的。但是,你必须考虑同步的便利性。因此,如果你对自己到底最在意什么感到困惑,我建议你先评估你的要求并决定你想要什么。
---
via: <https://itsfoss.com/brave-vs-chrome/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Google Chrome is undoubtedly one of the [best web browsers available for Linux](https://itsfoss.com/best-browsers-ubuntu-linux/). It offers a good blend of user experience and feature set for many, regardless of what platform you use it on.
On the other hand, Brave is popular as a privacy-focused open-source option available cross-platform.
So, what should you pick as your primary web browser? Is Chrome for you? Who should use Brave?
Here, we compare all the important aspects (including benchmarks) on both browsers to help you decide.
## User Interface
[Google Chrome](https://www.google.com/chrome/index.html) provides a clean user interface without unnecessary distractions out of the box.
By default, it blends in with the system theme on Linux (GTK), as per my experience. So, it might look a bit different as per your customizations.

If you are not using it on Linux, everything else should look similar except the color scheme.
When it comes to [Brave](https://brave.com), it does not adapt to your system color scheme out of the box. But, you can head to the Appearance settings and enable the GTK theme if you prefer.
Brave gets close to the Chrome user interface, with some unique tweaks/options to access.
You can’t go wrong with either, considering the user interface. They’re both easy to navigate.
However, Brave provides a few extra options to customize the appearance, like removing the tab search button (left to the minimize button), showing the full URL, etc.
If you find this helpful, Brave is your friend. With Google Chrome, you do not get a lot of control in terms of UI customization.
## Open Source vs. Proprietary

Brave is an open-source web browser based on Chromium. We also have a list of [open-source browsers not based on Chromium](https://itsfoss.com/open-source-browsers-linux/), if you are curious.
Google Chrome is also based on Chromium, but it adds several proprietary elements, making it a closed source offering.
While you can expect the benefits of open-source software and transparency with Brave, Google can be quite fast when patching issues considering they have a dedicated security team.
None of these should be noticeable for an average user. But, if you prefer open-source and software that believes in transparency, Brave should be the pick. In either case, if you have no issues with proprietary code and trust Google with their products, Google Chrome can be a choice.
If you want an open-source browser with a similar UI to Chrome, you may want to check our comparison between [Chrome vs Chromium](https://itsfoss.com/chrome-vs-chromium/) to pick one.
## Feature Differences
You should find all the essential functionalities on both the browsers, with similar behavior.
However, there are some notable differences between the two.
As mentioned above, you will notice differences in the ability to customize the look and feel.
There is also a big difference in the ability to sync browser data between multiple devices.
With Google Chrome, you can quickly sign in to your Google account and sync everything to your phone and other devices.
Brave also lets you sync, but it could be inconvenient for some. You will need access to one of your devices, where you use Brave to sync successfully.
Your sync data is not stored in the cloud. So, you will have to authorize using a QR code or a secret phrase to transfer/sync browsing data to another device.
Hence, you must export the bookmarks and other associated data for external backup.
Thankfully, there’s an alternative if you want the convenience of sync and an open-source browser. Head to our [Firefox vs Brave comparison ](https://itsfoss.com/brave-vs-firefox/)article to know why that can be a good pick for you.
In addition to these differences, Brave offers support [IPFS protocol](https://ipfs.io), which is a peer-to-peer secure protocol aimed to fight against censorship.
Not to forget, Brave comes with [Brave Search](https://itsfoss.com/brave-search-features/) as its search engine by default. So, if you prefer it over Google as a [private search engine](https://itsfoss.com/privacy-search-engines/), that’s a good thing as well.
Brave Rewards is also an interesting addition, where you earn rewards for enabling Brave’s privacy-friendly ads and can contribute them back to websites you frequently visit.
You can share resources using it directly to the recipient if cloud storage services or any online platform normally blocks it.
Overall, Brave offers numerous interesting things. But, Google Chrome is a simpler alternative that can be a convenient option for many.
## The Privacy Angle
The presence of tracking protection on Brave should be good for privacy enthusiasts. You can block ads and trackers using the Shield feature. In addition to that, you also get several filters available to toggle if you want aggressive blocking (which might result in broken websites).
Google Chrome does not offer this feature. But, you can always use some privacy-focused chrome extensions, and Google’s Safe Browsing feature should keep you safe from malicious websites.
Generally speaking, if you do not visit shady websites, you should be OK with Google Chrome. And, if you are a privacy enthusiast, Brave can be a better choice.
## Performance
While Brave is usually considered the fastest, it didn’t seem to be the case in my benchmark tests. That’s a surprise!
However, the real-world difference should not be noticeable for most.
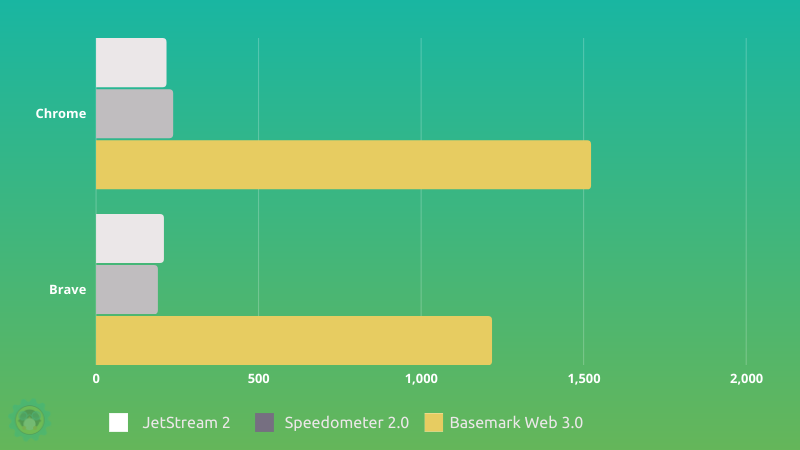
I used the popular benchmark tests: [JetStream 2](https://webkit.org/blog/8685/introducing-the-jetstream-2-benchmark-suite/), [Speedometer 2.0](https://webkit.org/blog/8063/speedometer-2-0-a-benchmark-for-modern-web-app-responsiveness/), and [Basemark Web 3.0](https://web.basemark.com).
Note that the Linux distribution used is **Pop!_OS 21.10**, and the browser versions tested were **Chrome 97.0.4692.71** and **Brave 97.0.4692.71**.
To give you an idea, I had nothing running in the background, except the browser on my PC powered by **Intel i5-11600k @4.7 GHz, 32 GB 3200 MHz RAM, and 1050ti Nvidia Graphics**.
## Installation
Google Chrome provides DEB/RPM packages to download and install on Ubuntu, Debian, Fedora, or openSUSE.
Brave also supports the same Linux distributions, but you will have to use the terminal and follow the commands mentioned in their download page to get it installed.
You can follow our installation guide to [install Brave in Fedora](https://itsfoss.com/install-brave-browser-fedora/).
None of them are available in the software center. Furthermore, you do not get any [Flatpak package](https://itsfoss.com/what-is-flatpak/). However, you will find a [Snap package](https://snapcraft.io/brave) for Brave but not for Chrome.
If you want something directly from the software center, a flatpak package, or a snap, Firefox is your friend.
## What Should You Pick?
If you want more customizations and advanced features, Brave should be an impressive choice. But, if you do not have a problem using a proprietary browser on your Linux distro and want slightly better performance, Google Chrome is a viable choice.
For privacy-focused users, the answer is obvious. But, you do have to think about the convenience of sync. So, if you are confused about your priorities, I encourage you to evaluate your requirements and decide what you want. |
14,215 | Linux 黑话解释:什么是上游和下游? | https://itsfoss.com/upstream-and-downstream-linux/ | 2022-01-26T10:47:48 | [
"上游",
"下游"
] | https://linux.cn/article-14215-1.html | 
“<ruby> 上游 <rt> upstream </rt></ruby>” 和 “<ruby> 下游 <rt> downstream </rt></ruby>”这两个术语是相当模糊的,我认为一般人并不会真正使用它们。如果你只是一个 Linux 用户,并且不编写或维护软件,那么很有可能这些术语对你来说毫无意义,但它们对 Linux 世界中各个社区之间的交流方式有益的。
这些术语被用于网络、编程、内核,甚至在非计算机领域,如供应链。当我们谈论上游和下游的时候,讨论背景是很重要的。
在其最简单的形式中,上游和下游是信息流动的方向。
由于我们都是在连接到互联网的情况下阅读这篇文章的,让我们看看适用于互联网服务提供商(ISP)的上游/下游例子。这里,ISP 关注的是流量。上游流量是指数据是从不同的 ISP 的用户处传来的。例如,如果你有一个提供订阅通讯的网站,我发送的订阅信息就是上游数据。
下游流量是指从一个用户发送到不同 ISP 的另一个用户的数据,它被认为是下游流量。使用同样的订阅例子,假设我的订阅请求被批准,我在一封邮件中收到“欢迎”说明,在又一封邮件中收到最新的新闻简报。在这种情况下,数据是顺流而下的,因为它是由你(好吧,可能是作为代表你进行操作的自动化软件)发送给我,一个来自另外 ISP 的用户。
总结:我需要或想要的东西(你的通讯)是上游的。你提供给我的东西(欢迎词和实际的通讯)是下游的。
数据是在上游还是在下游,对我们用户来说可能并不重要,但对监控带宽使用的服务器管理员,以及<ruby> 发行商 <rt> distributor </rt></ruby>(发行版的制作者)和程序员来说却很重要。
在 Linux 世界里,上游和下游有两个主要背景。一个是关于内核的,另一个是关于应用程序的。还有其他的,但我希望我可以通过这两个来表达我的想法。
### Linux 内核背景下的上游和下游
Linux *就是* 内核。在创建发行版时,Linux 发行版首先使用未经修改的内核源代码。然后添加必要的补丁,对内核进行配置。内核的配置是基于发行版想要提供的功能和选项。一旦决定了,就相应地创建了内核。
原始内核来自发行版的上游。当发行版得到源代码时,它就流向下游。一旦发行版得到了内核代码,它就会留在发行商那里,同时对它进行改造。它仍然是我们用户的上游,直到它准备好被发布。
发行版创建的内核版本将添加补丁和启用某些功能和选项。这种配置是由发行商决定的。这就是为什么有几种 Linux 流派的原因,例如,[Debian](https://www.debian.org/) 与 [Red Hat](https://www.redhat.com/)。发行商会决定向他们的用户群提供哪些选项,并相应地编译内核。
一旦这项工作完成,它就会放在一个仓库中准备发布,我们就可以获得一份副本。这个副本向下游流向我们。
同样地,如果发行商发现了内核中的一个错误,修复了它,然后将补丁发送给内核开发者,这样他们就可以为下游的每个人修补内核。这被称为对上游的贡献,因为这里的流量是向上流向原始来源的。
### 在应用程序背景下的上游和下游
同样,从技术上讲,Linux 是内核,其他都是附加软件。发行商也会在他们的项目中加入额外的软件。在这种情况下,有几个上游。一个发行版可以包含任何数量的应用程序,如 X、KDE、Gnome 等等。
让我们想象一下,你在使用 [nano](https://www.nano-editor.org/) 编辑器时发现它不能正常工作,于是你向发行版提交了一份错误报告。发行商的程序员会查看它,如果发现他们在 nano 中插入了一个错误,他们将修复它并在其仓库中发布一个新版本。如果他们发现不是他们制造了这个错误,发行商将向上游的 nano 程序员提交一份错误报告。
当涉及到像错误报告、功能请求等事情时,最好是将它们发送到上游的发行商那里,因为他们维护着你所使用的发行版的内核和附加应用程序。例如,我在几台机器上使用一个叫做 [Q4OS](https://q4os.org/) 的发行版。如果我发现一个程序中的错误,我会把它报告给 Q4OS 的人。如果你碰巧使用的是 [Mint](https://linuxmint.com/),你会把它报告给 Mint 项目。
比如说,如果你在一个普通的 Linux 论坛上发布一个问题,而你提到你在使用 Mint,你肯定会得到这样的回复。“这个问题最好在 Mint 论坛上处理”。用之前的 nano 错误的例子,有可能是 Mint 的程序员对 nano 进行了修改,使其在他们的发行版中运行得更好。如果他们确实犯了一个错误,他们会想知道这个错误,而且在犯了这个错误之后,他们会是修复它的人。
一旦修复,更新的程序就会被放入你可以使用的仓库。当你得到更新时,它就会顺流而下到你那里,像这样:
* 如果发行商进行了修复,新版本就会在发行仓库中提供。
* 如果该应用程序的程序员进行了修复,它将被发送到测试新代码的发行商那里。一旦发现它工作正常,它就会被放在仓库中,向下游流去。
### 自动流向下游
曾经有一段时间,用户得自己获取更新。用户会得到更新的源代码并编译一个新的可执行文件。随着时间的推移,像 `apt` 这样的工具被创造出来,允许用户从软件库中提取更新的二进制文件(可执行文件)。`apt` 程序是 Debian 的,但其他发行版也有他们自己的用于此用途的类似程序。
像 `apt` 这样的程序负责处理上游/下游的工作。如果你用升级选项运行 `apt`,像这样:
```
sudo apt upgrade
```
它将查看(上游)发行仓库,找到任何需要的更新包,并将它们拉到你的机器上(下游)并安装它们。
有些发行版会更进一步。发行版的程序员和维护者总是在检查他们的产品。很多时候,应用程序的程序员会对他们的程序进行改进。系统库会经常更新,安全漏洞也会被堵上,等等。这些更新会提供给发行商,然后由发行商在发行仓库中提供新的版本。
与其让你每天运行 `apt`,一些发行版会提醒你有可用的更新并询问你是否需要它们。如果你想要,只要接受,更新就会被发送到你的机器上并安装。
### 总结
上游和下游实际上只是数据流的方向。这个数据在上游或下游流动的方式取决于最终需要谁来处理它。基本上,程序员是上游,用户是下游。
同样,作为用户,我们真的不需要关心这些术语,但这些概念确实有助于软件的开发和维护。通过将工作引向适当的小组,避免了重复工作。这也确保了标准的维护。例如,Chrome 浏览器可能需要做一些细微的改变,以便在某个发行版上运行,但它的核心是 Chrome 浏览器,它的外观和行为都不会有大的变化。
如果你发现你的发行版中的任何程序有错误,只需向发行版的维护者报告,这通常是通过他们的网站进行的。你将会把它发送到上游,但你是否记得你在向上游发送报告并不重要。
---
via: <https://itsfoss.com/upstream-and-downstream-linux/>
作者:[Bill Dyer](https://itsfoss.com/author/bill/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The terms: *upstream* and *downstream* are rather ambiguous terms and, I think, not really used by the general public. If you are a Linux user and do not write or maintain software, chances are pretty good that these terms will mean nothing to you, but they can be instructive in how communication between groups within the Linux world works.
The terms are used in networking, programming, kernel, and even in non-computer areas such as supply chains. When we talk about upstream and downstream then, context is important.
In its simplest form, upstream and downstream is the direction of the flow of information.
Since we are all reading this article while we’re connected to the Internet, let’s look at an upstream/downstream example as it applies to Internet Service Providers (ISP). Here, the ISP is concerned with traffic. Upstream traffic is data is coming in from a user from a different ISP. For example, if you have a website that offers a subscription to a newsletter, the information I send, to subscribe, is upstream data.
Downstream traffic is data that is sent from a user to another user at a different ISP, then it is considered as downstream traffic. Using the same subscription example, let’s assume that my request to subscribe is approved and I get a “welcome” note in one email and the latest newsletter in another email. In this case, the data is downstream as it is sent by you (well, probably automated software operating as a representative of you) to me, a user from a different ISP.
Summing up: the thing I need or want (your newsletter) is upstream. The things you provide to me (the welcome note and actual newsletter) come to me, downstream.
Whether data is upstream or downstream is probably unimportant to us as users, but it is important to the server administrators who monitor bandwidth usage, as well as to distributors, and application programmers.
In the Linux world, upstream and downstream have two main contexts. One is concerned with the kernel and the other is concerned with applications. There are others, but I hope that I can get the idea across with these two.
## Upstream and downstream in the context of Linux kernel

Linux *is* the kernel. In creating a distribution (often called a “distro”), Linux distributions initially use the source code from an unmodified kernel. Necessary patches are added and then the kernel is configured. The kernel’s configuration is based upon what features and options the distribution wants to offer. Once decided upon, the kernel is created accordingly.
The original kernel is upstream from the distribution. When the distribution gets the source code, it flows downstream. Once the distribution has the code it stays with the makers of the distribution while work is being done on it. It is still upstream from us, as users, until it is ready for release.
The kernel version that the distribution creates will have patches added and certain features and options enabled. This configuration is determined by the distro builder. This is why there are several flavors of Linux: [Debian](https://www.debian.org/) vs. [Red Hat](https://www.redhat.com/), for example. The builder of the distro decides on the options to offer to their user base, and compiles the kernel accordingly.
Once that work is completed, it is made ready for release in a repository and we’re allowed to grab a copy. That copy flows downstream to us.
Similarly, if the distributor finds a bug in the kernel, fixes it and then sends the patch to the kernel developers so that they could patch the kernel for everyone downstream. This is called contributing to upstream because here the flow is going upwards to the original source.
## Upstream and downstream in the context of applications
Again, technically, Linux is the kernel, everything else is additional software. The distro builder also adds additional software to their project. In this case, there are several upstreams. A distro can contain any number of applications such as X, KDE, Gnome, and so on.
Let’s imagine that you are using the [nano](https://www.nano-editor.org/) editor and discover that it isn’t working right so you submit a bug report to the distributor. The programmers working on the distro will look at it and, if they find that they inserted a bug into nano, they will fix it and make a new release available in their repository. If they find that they didn’t make the bug, the distributor will submit a bug report upstream to the nano programmer.
When it comes to things like bug reports, feature requests, etc. it is always best to send them upstream to your distributor since they maintain the kernel and additional applications for the distro you’re using. For example, I use a distro called [Q4OS](https://q4os.org/) on a few machines. If I find a bug in a program, I report it to the Q4OS folks. If you happen to be using, say, [Mint](https://linuxmint.com/), you would report it to the Mint project.
If you were to post a problem on a generic Linux board, for example, and you mentioned that you were using Mint, you will surely get a reply that says something like: “This is better handled in a Mint forum.” Using the previous “nano bug” example, it’s possible that the Mint programmers made a change to nano to make it work better in their distro. If they did make a mistake, they would want to know about it and, having made the mistake, they would be the ones to fix it.
Once fixed, the updated program is put into a repository available to you. When you get the update, it comes downstream to you, like so:
- If a distributor makes the fix, the new version is made available in the distro repository
- If the programmer of the application makes the fix, it is sent downstream to the distributors who test the new code. Once it’s found to be working right, it is placed in the repository, to flow downstream to you
## Automatic flow downstream
There was a time, when users had to get their own updates. A user would get the updated source code and compile a new executable. As time went on, utilities like apt were created to allow users to pull updated binaries (executables) from the repositories. The apt program is Debian, but other distros have their own, similar program for this.
Programs like apt take care of the upstream/downstream work. If you ran apt with the upgrade option like so:
`sudo apt upgrade`
it would look (upstream) to the distro repository, find any needed updated packages and pull them (downstream) to your machine and install them.
Some distros take this further. Distro programmers and maintainers are always checking over their product. Often times, an application programmer will make improvements to their program. System libraries are updated frequently, security holes get plugged, and so on. These updates are made available to the distributors who then make the new version available in the distro’s repository.
Rather than have you run apt every day, some distros will alert you to updates that are available and ask if you want them. If you want then, just accept and the updates will be sent downstream to your machine and installed.
## Conclusion
I just remembered a bit of my history, having mentioned Red Hat. Back in 1994 or 1995, they placed a job ad and one of the cool workplace benefits listed was, “all the free peanut M&Ms you could eat and all the free Dr. Pepper you could drink.” I had no doubt that I could do the work, and I applied just for those two benefits alone. I didn’t get a call though.
Oh well. Getting back to the point…
Upstream and downstream is really just the direction of data flow. How far upstream or downstream this data flows depends on who ultimately needs to work on it. Basically, the programmers are upstream and the users are downstream.
Again, as users, we really don’t need to be worried about these terms, but the concepts do help in the development and maintenance of software. By being able to direct the work to the appropriate group, duplicate work is avoided. It also ensures that a standard is maintained. The Chrome browser, for example, might need slight changes made to it in order to work on a certain distro, but it will be Chrome at its core – it will look and act like Chrome.
If you do find a bug with any program in your distro, just report it to your distro’s maintainers, which is usually done through their website. You’ll be sending it upstream to them, but it doesn’t matter whether you remember that you’re sending the report upstream. |
14,216 | 用 Asciinema 记录你的终端会话 | https://opensource.com/article/22/1/record-terminal-session-asciinema | 2022-01-26T19:26:47 | [
"Asciinema",
"终端",
"回放"
] | https://linux.cn/article-14216-1.html |
>
> 用这个开源的终端会话记录器 Asciinema 来展示终端会话。
>
>
>

支持电话是很重要的,而且最后往往是令人满意的,但明确的沟通行为对每个参与的人来说都是艰巨的。如果你曾经参加过支持电话,你可能会花好几分钟拼出了最短的命令,并详细解释了空格和回车的位置。虽然直接拿过来用户电脑的控制权往往更容易,但这并不是真正的教育的最佳方式。你可以尝试向用户发送一个屏幕记录,而他们可以复制命令并粘贴到自己的终端。
Asciinema 是一个开源的终端会话记录器。与 `script` 和 `scriptreplay` 命令类似,Asciinema 准确记录了你的终端显示。它将你的“电影”记录保存到一个文本文件中,然后根据需要进行回放。你可以把你的电影上传到 [Asciinema.org](http://Asciinema.org),就像你在互联网上分享任何其他视频一样,你甚至可以把你的电影嵌入到网页中。
### 安装 Asciinema
在 Linux 上,你可以使用你的包管理器安装 Asciinema。
在 Fedora、CentOS、Mageia 或类似系统上:
```
$ sudo dnf install asciinema
```
在 Debian、Linux Mint 或类似系统上:
```
$ sudo apt install asciinema
```
在 macOS 上,你可以用 Homebrew 安装:
```
$ sudo brew install asciinema
```
在 BSD 和任何其它平台上使用 [Pkgsrc](https://opensource.com/article/19/11/pkgsrc-netbsd-linux):
```
$ cd /usr/pkgsrc/misc/py-asciinema
$ sudo bmake install clean
```
### 从文本中制作电影
要用 Asciinema 开始录制,你可以使用 `rec` 子命令:
```
$ asciinema rec mymovie.cast
asciinema: recording asciicast to mymovie.cast
asciinema: press <ctrl-d> or type "exit" when you're done
```
一些友好的输出信息提醒你,你正在录制,并告诉你如何停止:按 `Ctrl+D` 或直接输入 `exit`。
当 Asciinema 处于活动状态时,你在终端所做的一切都会被记录下来。这包括输入、输出、错误、尴尬的停顿、错误或成功。如果在录制时,在你的终端中查看它,它就会被剪断。
当你演示完终端如何工作时,按 `Ctrl+D` 或输入 `exit` 来停止记录。
在这个例子中,产生的文件 `mymovie.cast` 是一个时间戳和动作的集合,它用作回放所使用的脚本(像电影脚本一样)。
```
{"version": 2, "width": 139, "height": 36, "timestamp": 1641457358, "env": {"SHELL": "/bin/bash", "TERM": "xterm-256color"}}
[0.05351, "o", "\u001b]0;seth:~\u0007"]
[0.05393, "o", "\u001b[1;31m$ \u001b[00m"]
[1.380059, "o", "e"]
[1.443823, "o", "c"]
[1.514674, "o", "h"]
[1.595238, "o", "o"]
[1.789562, "o", " "]
[2.09658, "o", "\""]
[2.19683, "o", "h"]
[2.403994, "o", "e"]
[2.466784, "o", "l"]
[2.711183, "o", "lo"]
[3.120852, "o", "\""]
[3.427886, "o", "\r\nhello\r\n"]
[...]
```
如果你犯了一个错误,你可以通过删除重现错误的行来去除这个错误。如果你发现自己在录制过程中做了很多命令行修改或冗长的停顿,你可以安装并使用 [asciinema-edit](https://github.com/cirocosta/asciinema-edit) 工具,它可以通过你定义的时间戳或消除空闲时间来剪掉这些“镜头”片段。
### 播放 Asciinema 电影
你可以使用 `play` 子命令回放你的 Asciinema:
```
$ asciinema play mymovie.cast
```
这会接管你的终端会话,并使其成为最接近银幕的形式(除了那次你通过 `telnet` 观看 ASCII 格式的星球大战)。这个基于文本的电影播放,向你的用户展示了一个复杂的任务是如何完成的。当然,播放的 *实际* 命令并不真正执行。这不是一个正在运行的 shell 脚本,所以即使你在电影中创建了一个 `hello.txt` 文件,在播放后也不会有一个新的 `hello.txt`。这只是为了展示。
然而,它又不仅仅是一个展示。你可以暂停 Asciinema 电影,选择你在屏幕上看到的文本,并将其粘贴到一个活动终端以运行该命令。Asciinema 是有用的文档。它向用户展示了如何完成一项任务,并允许他们进行复制和粘贴以确保准确性。
### 上传你的 Asciinema 电影
目前还没有像大片一样的 Asciinema 电影,但你可以把你的电影上传到 [Asciinema.org](http://Asciinema.org),与全世界分享:
```
$ asciinema upload mymovie.cast
```
如果你习惯了 YouTube 上传所花费的时间,你会对 Asciinema 电影的传输速度感到惊喜。一个 `.cast` 文件通常只有几千字节,最多几兆字节,所以上传几乎是瞬间完成的。你不需要注册账户来分享你的电影,但所有无人认领的电影将在七天后会被删除。为了保存你的杰作,你可以在 Asciinema 上开设一个账户,然后坐等电影学院的电话。
### Asciinema 作为文档
Asciinema 是演示最基本概念的好方法。因为它保留了从录制中复制和粘贴代码的能力,提供了按需暂停和播放的能力,并且完全准确地描绘了它的内容,它不仅仅是屏幕录像,它要好得多。无论你是用它来向你的朋友炫耀你的终端技能,还是用它来教育同事和学生,Asciinema 都是一个无价的、社交的、可利用的工具。
---
via: <https://opensource.com/article/22/1/record-terminal-session-asciinema>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Support calls are important and often satisfying in the end, but the act of clear communication can be arduous for everyone involved. If you've ever been on a support call, you've probably spent several minutes spelling out even the shortest commands and explaining in detail where the spaces and returns fall. While it's often easier to just seize control of a user's computer, that's not really the best way to educate. What you might try instead is sending a user a screen recording, but one that they can copy commands from and paste into their own terminal.
Asciinema is an open source terminal session recorder. Similar to the `script`
and `scriptreplay`
commands, Asciinema records exactly what your terminal displays. It saves your "movie" recording to a text file and then replays it on demand. You can upload your movie to Asciinema.org and share them just as you would any other video on the internet, and you can even embed your movie into a webpage.
## Install Asciinema
On Linux, you can install Asciinema using your package manager.
On Fedora, CentOS, Mageia, or similar:
`$ sudo dnf install asciinema`
On Debian, Linux Mint, or similar:
`$ sudo apt install asciinema`
On macOS, you can install using Homebrew:
`$ sudo brew install asciinema`
On BSD and any other platform using [Pkgsrc](https://opensource.com/article/19/11/pkgsrc-netbsd-linux):
```
$ cd /usr/pkgsrc/misc/py-asciinema
$ sudo bmake install clean
```
## Making movies out of text
To start recording with Asciinema, you use the `rec`
subcommand:
```
$ asciinema rec mymovie.cast
asciinema: recording asciicast to mymovie.cast
asciinema: press <ctrl-d> or type "exit" when you're done
```
Some friendly output alerts you that you're recording, and it tells you how to stop: Press **Ctrl+D** or just type `exit`
.
Everything you do in your terminal while Asciinema is active gets recorded. This includes input, output, errors, awkward pauses, mistakes, or successes. If you see it in your terminal during recording, it makes the cut.
When you're finished demonstrating how the terminal works, press **Ctrl+D** or type `exit`
to stop the recording.
In this example, the resulting file, `mymovie.cast`
is a collection of timestamps and actions that serve as a script (in the sense of a movie script) for the playback mechanism.
```
{"version": 2, "width": 139, "height": 36, "timestamp": 1641457358, "env": {"SHELL": "/bin/bash", "TERM": "xterm-256color"}}
[0.05351, "o", "\u001b]0;seth:~\u0007"]
[0.05393, "o", "\u001b[1;31m$ \u001b[00m"]
[1.380059, "o", "e"]
[1.443823, "o", "c"]
[1.514674, "o", "h"]
[1.595238, "o", "o"]
[1.789562, "o", " "]
[2.09658, "o", "\""]
[2.19683, "o", "h"]
[2.403994, "o", "e"]
[2.466784, "o", "l"]
[2.711183, "o", "lo"]
[3.120852, "o", "\""]
[3.427886, "o", "\r\nhello\r\n"]
[...]
```
If you've made a mistake, you can cut the mistake by removing the lines recreating the error. Should you find yourself making lots of edits or belaboring long pauses during the recording, you can install and use the [asciinema-edit](https://github.com/cirocosta/asciinema-edit) utility, which can trim out blocks of "footage" by timestamps of your definition, or by eliminating idle time.
## Playing an Asciinema movie
You can playback your Asciinema using the `play`
subcommand:
`$ asciinema play mymovie.cast`
This takes over your terminal session and makes it into the nearest equivalent of the Silver Screen as it's likely ever to be (aside from that time you watched Star Wars in ASCII over `telnet`
). Your text-based movie plays—demonstrating for your users exactly how a complex task gets done. Of course, the *actual* commands getting played don't actually execute. This isn't a shell script in action, so even though you may have created a file `hello.txt`
in your movie, there won't be a new `hello.txt`
after playback. This is just for show.
And yet it's more than just a show. You can pause Asciinema movies, select the text you see on the screen and paste it into an active terminal to run the command. Asciinema is useful documentation. It shows users how to do a task, and it allows them to copy and paste to ensure accuracy.
## Upload your Asciinema movie
No Asciinema movie has yet reached a blockbuster status, but you can upload yours to Asciinema.org and share it with the world nevertheless.
`$ asciinema upload mymovie.cast`
If you're used to YouTube upload times, you'll be pleasantly surprised by how quickly Asciinema movies transfer. A `.cast`
file is usually only a few kilobytes, or at the most a few megabytes, so the upload is nearly instantaneous. You don't need an account to share your movie, but all unclaimed movies get deleted after seven days. To preserve your masterpiece, you can open an account on Asciinema and then sit back and wait for the Academy to call.
## Asciinema as documentation
Asciinema is a great way to demonstrate even the most basic of concepts. Because it retains the ability to copy and paste code from the recording, provides the ability to pause and play on-demand, and is completely accurate in what it portrays, it's not just as good as a screen recording. It's much, much better. Whether you use it to show off your terminal skills to your friends or whether you use it to educate colleagues and students, Asciinema is an invaluable, social, and accessible tool.
## 2 Comments |
14,218 | 如何建立一个开源的元宇宙 | https://opensource.com/article/22/1/open-source-metaverse | 2022-01-27T12:41:53 | [
"元宇宙"
] | https://linux.cn/article-14218-1.html |
>
> 开源世界是建立元宇宙的首选之地。
>
>
>

如果我告诉你,构建元宇宙所需要的所有内容和软件都已经有了,而且完全免费,你会去构建吗?
先别急,让我们退一步来解释一下元宇宙。
### 什么是元宇宙?
20 世纪的赛博朋克作家,如 Gibson 和 Stephenson,都曾想象过由虚拟现实支持的互联网,在 Stephenson 的小说《雪崩Snow Crash》中,他将其称之为<ruby> 元宇宙 <rt> Metaverse </rt></ruby>。随着<ruby> 虚拟现实 <rt> virtual reality </rt></ruby>(VR)设备和应用程序的日益普及,尤其是在马克•扎克伯格宣布将雇佣 1 万人来打造它,并将 Facebook 的公司名称改为 Meta 之后,元宇宙正在成为一个热门词汇。Matthew Ball 对该话题进行了 [认真分析](https://www.matthewball.vc/all/themetaverse),并以“共同构建”作为结论:“事实上,最有可能的是,元宇宙是来自不同的平台、机构和技术的网络中,它们协同配合(无论多么不情愿),并拥抱互操作性。”
互操作性,这个词本身含蓄而清楚地指出了开源和开放标准在其中的作用。
因此,简而言之,它就是支持 VR 的互联网。
### 如何建立一个开源的元宇宙?
就像互联网上的网络服务器一样,你需要 VR 服务器。不过不用担心,我写了一个,而且 [介绍它的文章](https://opensource.com/article/20/12/virtual-reality-server) 大约一年前就发表在这里了。当然,你需要支持 VR 的网络浏览器,但网络浏览器已经支持视频/音频流(WebRTC)以及 VR 和 AR(WebXR)。此外,你还需要大量 3D 内容,最好是开源标准的 glTF 格式。幸运的是,[Sketchfab](https://sketchfab.com/) 拥有 50 万个以上的免费 3D 模型,由大量的作者在<ruby> 知识共享许可 <rt> Creative Commons licenses </rt></ruby>下发布。Sketchfab 并不是唯一一家这样做的公司,但他们提供了 REST API 来搜索和下载这些模型。
### 别忘了键盘
在 VR 中已经待了一段时间了,我可以用亲身体验告诉你我最怀念的是什么:键盘!我在键盘上写代码,但当我戴上 VR 眼镜时,它就消失了。你可以想象,摘下和戴上 VR 设备是多么的混乱。不仅如此,我还需要在 VR 中看到我的代码。那么为什么要止步于此呢?为什么我在 VR 中看不到每一个应用程序呢?许多人都在使用两个或更多的显示器。在 VR 中,你可以随处布置窗口。这比多少个屏幕都要好。而一旦到了这一步,你就可以真正地谈论元宇宙了。
说实话,VR 设备仍处于起步阶段,它无疑还缺少许多功能。但是,VR 设备将得到改善,并最终包括键盘、更好的摄像头以及在现实中叠加虚拟的能力。在此期间,我们将继续戴上和摘下护目镜,以其他方式处理其他障碍。
### 那么我还等什么呢?
你不需要等待。无论是爱好者还是公司,都正在努力。而且你现在就可以开始在网络上建立你的虚拟世界。下面的视频解释了如何使用现有的免费模型来制作虚拟世界。
在底层,VRSpace 网络客户端使用一个开源的 JavaScript WebGL 库 Babylon.js 来加载 glTF 内容并使用 WebGL 渲染。它调用 Sketchfab REST API 的搜索功能(服务器所有者必须在那里有一个账户)。点击了一个模型,它就会让 VRSpace 服务器获取它。服务器下载它(仅当它之前没有下载的情况下),并将其交付给客户端。空间中发生的一切都会被广播(实际上是通过 WebSockets 进行多播)给所有连接的用户,所以他们都会看到同样的移动和物体大小的调整。当然,他们可以通过文本信息或语音进行聊天。通过点击右下角的 VR 眼镜按钮,用户可以立即进入 VR。用户还可以共享屏幕,尽管不在此空间中。
而这一切都只使用现有的标准网络技术和免费的软件和内容。它不仅适用于 PC 和 VR 设备,也适用于移动设备。然而,移动版 Chrome 浏览器并没有启用 VR 功能。它在第一次尝试进入 VR 时会提示下载谷歌 VR。
由于它是开放的,这在目前来说是可互操作的。但对于元宇宙(支持 VR 的互联网)所需的大规模来说,它的互操作性还远远不够。以头像为例。我在 LinkedIn、Facebook 以及 [Opensource.com](http://Opensource.com) 上使用相同的图片作为我的头像。我怎么能把我的 3D 头像上传到 VRSpace 或其他地方呢?
好吧,我不能。上传本身并不是一个问题。当然,文件格式(glTF)也不是问题。问题出现在头像结构上,因为它没有标准化。所以,比如说,不同的人物有不同的骨头数量。然后,本应是微不足道的必备功能,如用虚拟手拿东西,却变得极其复杂。我已经分析了 100 多个免费的角色,并将我的发现作为研究论文发表:《[迈向人形 3D 角色的自动骨架识别](https://www.researchgate.net/publication/356987355_TOWARDS_AUTOMATIC_SKELETON_RECOGNITION_OF_HUMANOID_3D_CHARACTER)》,希望它能帮助其他作者实现互操作性。
而这只是一个开始,是我们进入一个共享的虚拟世界需要做的第一件事。

### 知识产权
知识产权呢?你可能会说,这都是开源的!嗯,确实如此。作者们是如此善良,让别人使用他们的创作。用户至少可以做的是给他们点赞。知识共享许可的实际条款要求用户明确归功于作者。为此,我特别注意在搜索结果中显示作者的名字,而且作者信息被嵌入每个 glTF 文件的元数据部分。但是,即使是需要额外的工作的免费东西,我无法想象它变成专有内容会多么可怕。
### NFT和区块链
转念一想,我可以想象到。它需要 NFT、区块链,以及其他什么东西。快速搜索“元宇宙 区块链”为我提供了 *极好的购买机会*,并建议了 *最好的购买方案*。好吧,我不买。记住我的话。试图出售加密货币的人是不会建立元宇宙的。
这并不是说区块链在这里没有用,因为即使是免费的内容,你也必须对作者进行追踪。面对成千上万的免费模型,这必须以某种方式自动化,而分布式账本可能正是正确的解决方案。
话说回来,像 Sketchfab 这样的数字内容提供商并不只提供免费模型,他们还出售内容。毕竟,这就是他们谋生的方式。从技术上讲,在你的虚拟世界中使用这些专有内容,你需要做的就是把代码中的一个 `true` 改为 `false`,字面上的。但是,一旦你下载了它,没有人可以阻止你分享它。然而,在法律上,许可证禁止你这样做。NFT 可以证明所有权,可以购买,可以出售,但不能执行版权。内容提供商最终会明白这一点,但我担心的不是他们。这对普通用户有实际影响,与我反复被问到的一个具体问题有关。我可以自己制作或购买我自己的头像,而且只能是我的,不能被其他人使用吗?但技术不能阻止任何人复制它。就像我可以从 LinkedIn 复制你的头像图片,并将其作为我在 Facebook 上的图片。但你想想,为什么会有人想这么做?
有趣的是,我已经有一个 VRSpace 的商业实现。一个由自由软件驱动的 3D 多用户视频和音频流媒体网站,提供专有内容。在上锁的门后,付费进入 —— 就这么简单。而且它不妨碍建立元宇宙。然而,每个人都有自己独特的头像,永远不能被其他人使用。视频头像:

你想成为你自己,而不是其他人。只要点击视频按钮,就这么简单。当然,浏览器会提示你是否允许流式传输你的视频和音频。这个功能在日常生活中被广泛使用,以至于我们并没有把它和元宇宙联系起来,赛博朋克的作者们也没有设想到这一点。随着时间的推移,这种 *我就是我* 的方法将发展为运动跟踪和视频流映射到我们的 3D 头像上,但它仍将在昂贵的电影和视频游戏领域停留一段时间。
现在,你已经瞥见了 VRSpace 服务器的所有功能,除了 Oauth2 认证。反正你知道它是如何工作的。一个网站将你重定向到你选择的另一个网站,你在那里登录,然后被认证回来。这就是上述所有的简化图。

### 现场演示
在 [VRSpace.org](https://www.vrspace.org/) 上有一个现场演示,一直在运行最新的代码,欢迎你在任何时候尝试。它是完全匿名访问的,没有任何形式的广告和跟踪器。试着在 VRCraft 世界中建立你的世界,但要知道,一旦你断开连接,你所做的一切都会消失 —— 这是运行一个向公众开放的匿名服务的代价。主页提供了所有的相关信息,只要访问该链接即可,或者在 [GitHub](https://github.com/jalmasi/vrspace)、[YouTube](https://www.youtube.com/channel/UCLdSg22i9MZ3u7ityj_PBxw) 或[Facebook](https://www.facebook.com/vrspace.org) 上加入该项目。
非常感谢早期采用者的帮助,使项目达到这个阶段 —— 所有作者的免费模型、Sketchfab 提供的访问,以及 Babylon.js 社区,使这一切都能跨平台运作。
---
via: <https://opensource.com/article/22/1/open-source-metaverse>
作者:[Josip Almasi](https://opensource.com/users/jalmasi) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If I told you that all content and software you need to build the metaverse is already available and completely free, would you do it?
Hold that thought, and let's take a step back and explain the metaverse.
## What is the metaverse anyway?
Cyberpunk authors of the 20th century like Gibson and Stephenson imagined virtual reality-enabled internet, and in his novel *Snow Crash*, Stephenson called it Metaverse. With the growing availability of virtual reality (VR) devices and apps, Metaverse became a buzzword, especially since Mark Zuckerberg announced employing 10,000 workers to build it and changed the Facebook company name to Meta. Matthew Ball wrote a [serious analysis](https://www.matthewball.vc/all/themetaverse) of the topic that ends with the conclusion—Building together: "And in truth, it's most likely the Metaverse emerges from a network of different platforms, bodies, and technologies working together (however reluctantly) and embracing interoperability."
Interoperability. The word itself implicitly but clearly, points out how open source and open standards fit in the picture.
So, in short, it's about VR-enabled internet.
## How can an open source metaverse be built?
Like web servers on the internet, you need VR servers. But worry not, I wrote one, and [an article about it](https://opensource.com/article/20/12/virtual-reality-server) was published right here about a year ago. Then, of course, you need VR-enabled web browsers, but web browsers already do support video/audio streaming (WebRTC) and VR and AR both (WebXR). Furthermore, you need a bunch of 3D content, preferably in open source standard glTF format. And luckily, [Sketchfab](https://sketchfab.com/) hosts 500,000+ free 3D models, published under Creative Commons licenses by a huge number of authors. Sketchfab isn't the only company doing that, but they provide REST API to search and download any of these models.
## Don't forget the keyboard
Being in VR for quite a while now, I can tell you first hand what I miss the most: The keyboard! I write code on the keyboard, but it disappears when I put on my VR goggles. You can imagine how disruptive taking VR gear off and on is. And not just that, I need to see my code in VR. And then why stop there? Why wouldn't I see every application in VR? Many people are using two or more displays. In VR, arrange windows wherever you look. That's better than any number of screens. And once that happens, you'll be able to talk metaverse for real.
Truth be told, VR devices are still in their infancy, and there are undoubtedly many more functions missing. But VR devices will improve and eventually include keyboards, better cameras, and the ability to overlay virtual over real. In the meantime, we'll keep taking our goggles on and off and deal with other obstacles in other ways.
## So what am I waiting for?
You don't need to wait. People are working on it, enthusiasts and companies alike. And you can start building your virtual worlds on the web right now. The video below explains how to make virtual worlds using available free models.
Under the hood, the VRSpace web client uses Babylon.js, an open source JavaScript WebGL library to load glTF content and render with WebGL. It calls the search function of the Sketchfab REST API (server owner must have an account there). Once you click on a model, it asks the VRSpace server to fetch it. The server downloads it (only if it didn't do so earlier) and delivers it to the client. Everything that happens in the space is broadcast (multi-casted over WebSockets, actually) to all connected users, so they all see the same movement and resizing of objects. And sure, they can chat, either with text messages or voice. And by clicking on the VR goggles button in the bottom-right corner, the user instantly enters VR. Users can also share screens, though not in this space.
And this is all done using only existing standard web technologies and free software and content. It's not only available on PC and VR devices, but also on mobile devices. However, mobile Chrome doesn't come with VR functions enabled. It prompts for download of Google VR on the first attempt to enter VR.
As it's all open, this is as interoperable as it gets for the time being. But it's not nearly interoperable enough for the massive scale required for metaverse—the VR-enabled internet. Take avatars, for example. I use the same image for my avatar on LinkedIn, Facebook, as well as on Opensource.com. How can I upload my 3D avatar to VRSpace or elsewhere?
Well, I can't. Upload itself is not a problem. Of course, neither is the file format (glTF). Issues arise from the avatar structure, as it's not standardized. So, for example, different characters have a different number of bones. Then, must-have features that are supposed to be trivial, like holding something in your virtual hand, become extremely complicated. I have analyzed 100+ free characters and published my findings as a research paper: [Towards Automatic Skeleton Recognition of Humanoid 3D Character](https://www.researchgate.net/publication/356987355_TOWARDS_AUTOMATIC_SKELETON_RECOGNITION_OF_HUMANOID_3D_CHARACTER)—hopefully, it can help other authors with interoperability.
And that's just the beginning, the very first thing we need to do to enter a shared virtual world.
(Josip Almasi, CC BY-SA 4.0)
## Intellectual property
What about intellectual property? What about it, you might say, it's all open source! Well, it is. Authors are so kind to let others use their creations. The least users can do is to give them credits. The actual terms of the Creative Commons licenses require users to credit authors explicitly. To that end, I've taken special care to display the author's name in the search results, and the author information is embedded in the metadata section of each glTF file. But even with free stuff that requires additional work, I can't imagine what nightmare it turns into with proprietary content.
## Non-Fungible Tokens and Blockchain Ledgers
On second thought, I can imagine that. It requires Non-Fungible Tokens, Blockchain Ledgers, and whatnot. Quick googling *Metaverse Blockchain* offers me *excellent buy opportunities* and advises the *best buy options*. Well, I'm not buying. Mark my words: Folks trying to sell cryptos aren't going to build the metaverse.
That's not to say that blockchain can't be helpful here, as even with free content, you have to keep track of authors. With hundreds of thousands of free models, this has to be automated somehow, and distributed ledger may be just the right solution.
Then again, digital content providers like Sketchfab do not provide only free models, they sell content. That's how they make a living, after all. Technically speaking, all you need to do to use this proprietary content in your virtual worlds is change one *true* to *false* in the code—literally. But once you download it, nobody can prevent you from sharing it. Yet, legally, the license forbids you to do so. Non-Fungible Tokens can prove ownership, be bought, sold, but can't enforce copyright. Content providers will figure it out eventually, but it's not them I'm worried about. This has practical implications for ordinary users, related to one specific question I have been asked repeatedly: Can I make/buy my own avatar that will be only mine and can't get used by anybody else? Well, you can, but technology can't prevent anybody from copying it. Just like I can copy your avatar picture from, say, LinkedIn, and use it as my picture on, say, Facebook. But think of it this way: Why would anyone want to do that?
Funny though, I've had one commercial implementation of VRSpace: A 3D multi-user video and audio streaming website powered by free software, serving proprietary content. Behind the locked door, pay to enter—as simple as that. And it doesn't get in the way of building the metaverse. Yet everyone has their own unique avatars that can't be used by anybody else ever: Video avatars.
(Josip Almasi, CC BY-SA 4.0)
You want to be you and nobody else. Just click on the video button, as simple as that. Of course, the browser will prompt for your permission to stream your video and audio. This feature is so widely used in daily life that we don't really associate it with metaverse, and the cyberpunk authors did not envision it. In time, this *me being me* approach will evolve into motion tracking and video stream mapping onto our 3D avatars, but it will remain in the domain of expensive movies and video games for a while.
By now, you have glanced at all the features of the VRSpace server, except Oauth2 authentication. You know how it works anyway. A website redirects you to another one of your choosing, where you log in and then get back authenticated. This is all of the above in a simplified diagram:
(Josip Almasi, CC BY-SA 4.0)
## Live demo
A live demo is available at [VRSpace](https://www.vrspace.org/)[.org](https://www.vrspace.org/) at all times, running the latest code, and you are welcome to try it any time. It's completely anonymous, without ads and trackers of any kind. Try building your world in VRCraft world, but know that everything you do will disappear once you disconnect—the price of running an anonymous service open to the public. The home page provides all the relevant information, just follow the links, or join the project on [GitHub](https://github.com/jalmasi/vrspace), [YouTube](https://www.youtube.com/channel/UCLdSg22i9MZ3u7ityj_PBxw), or [Facebook](https://www.facebook.com/vrspace.org).
Big thanks to early adopters for their help in bringing the project to this stage—all the authors for their free models, Sketchfab for providing access, and the Babylon.js community that makes it all just work across platforms.
## 1 Comment |
14,221 | Revolt:Discord 的开源替代品 | https://itsfoss.com/revolt/ | 2022-01-28T13:21:51 | [
"Revolt",
"Discord"
] | https://linux.cn/article-14221-1.html |
>
> Revolt 是一个有前途的自由开源的 Discord 替代品。在这里,让我们看一下它所提供的东西以及它的初步印象。
>
>
>
Discord 是一个功能丰富的协作平台,主要为游戏玩家量身定做。尽管你可以在 Linux 上毫无问题地使用 Discord,但它仍然是一个专有解决方案。
你可以选择使用 [Element](https://itsfoss.com/element/) 作为一个开源的解决方案协作平台,但它不是一个替代品。
但是,Revolt 是一个令人印象深刻的 Discord 替代品,它是开源的。
>
> 注意:
>
>
> Revolt 正处于公开测试阶段,不提供任何移动应用。它可能缺乏一些你在 Discord 上找到的基本功能。
>
>
>
我会重点说一下 Revolt 的功能,以及它是否可以成为 Linux 上 Discord 的替代品。
### 一个你可以自行托管的开源 Discord 替代品

Revolt 不仅仅是一个简单的开源替代品,而且你还可以自我托管。
它确实缺少 Discord 提供的各种功能,但你可以获得许多基本功能,可以先体验一下。
即使缺乏一些功能,但它也是一个功能丰富的开源客户端。让我们来看看现有的功能。
### Revolt 的功能

它看起来和感觉已经很像 Discord,这是一些关键的亮点:
* 能够创建你自己的服务器
* 创建文字频道和语音频道
* 在服务器中分配用户角色
* 调整主题(深色/浅色)
* 改变强调色
* 从可用选项中管理字体和表情包
* 支持自定义 CSS
* 能够添加机器人
* 易于管理文本/语音频道的权限
* 向其他用户发送朋友请求
* 保存的笔记
* 能够控制通知
* 支持硬件加速
* 专门的桌面设置
* 使用 Docker 进行自我托管
* 用户状态和自定义状态支持
因此,作为处于公开测试阶段的东西,它听起来对初学者来说非常好。你已经拥有了大部分的核心功能,但你可能想等着看它成为一个成熟的 Discord 替代品。
### 使用 Revolt 的初步印象

如果你使用过 Discord,用户体验会感觉很熟悉。这是一件好事。
对于这篇快速亮点介绍,我没有比较 Discord 和 Revolt 的资源使用情况,因为它仍然处于测试阶段,不是同等级的比较。
然而,在我简短的测试中,它感觉很快速,除了第一次加载一个文本频道时。在发表这篇文章时,它没有双因素认证(2FA)功能,但应该会在他们的第一个里程碑(第一版)版本中添加。

一些功能如用户状态、权限管理和外观调整看起来很有用。但是,当涉及到语音频道时,它和 Discord 的工作方式不一样,至少现在是这样。
我不知道他们是否打算用同样的方式,但 Discord 的语音频道功能是直观的、快速的,而且有更好的控制。
不要忘了,Discord 还提供 “Discord Stage”,这是一个类似 Clubhouse 的音频聊天室功能。
其他一些我找不到的功能包括:
* 对信息作出反应的能力
* 抑制噪音的功能
* 改变服务器
* 服务器日志
* 各种有用的机器人
当然,要赶上 Discord 提供的功能还需要大量的时间,但至少我们现在有一个开源的 Discord 解决方案。
你可以了解他们的 [项目路线图/发布跟踪器](https://github.com/orgs/revoltchat/projects/2),看看你可以在其最终/未来的版本中期待什么。
### 在 Linux 中安装 Revolt
Revolt 可用于 Linux 和 Windows。你可以选择在你的网络浏览器上使用它,而不需要一个单独的应用。
但是,如果你需要在你的桌面上使用它,他们提供了一个 AppImage 文件和一个 deb 包,你可以从它的 [GitHub 发布页](https://github.com/revoltchat/desktop/releases/tag/v1.0.2) 下载。
如果你是 Linux 的新手,可以参考我们关于 [使用 AppImage 文件](https://itsfoss.com/use-appimage-linux/) 和 [安装 deb 包](https://itsfoss.com/install-deb-files-ubuntu/) 的资源来开始学习。
如果你想用你的错误报告和建议来帮助他们改进,请随时前往 [反馈页面](https://app.revolt.chat/settings/feedback)。此外,你还可以浏览他们的 [GitHub 页面](https://github.com/revoltchat) 以了解更多信息。
* [Revolt](https://revolt.chat)
你觉得 Revolt 怎么样?你认为它有可能成为 Linux 上 Discord 的一个很好的开源替代品吗?
请在下面的评论中告诉我你的想法!
---
via: <https://itsfoss.com/revolt/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief**: Revolt is a promising free and open-source choice to replace Discord. Here, we take a look at what it offers along with its initial impressions.
Discord is a feature-rich collaboration platform primarily tailored for gamers. Even though you can use Discord on Linux with no issues, it is still a proprietary solution.
You can choose to use [Element](https://itsfoss.com/element/) as an open-source solution collaboration platform, but it is not a replacement.
But, Revolt is an impressive Discord alternative that is open-source.
Note
Revolt is in the public beta testing phase and does not offer any mobile applications. It may lack some essential features that you find on Discord.
Let me highlight what you can expect with Revolt and if it can be a replacement for Discord on Linux.
## An Open Source Discord Alternative That You Can Self-Host
Revolt is not just a simple open-source replacement, but you also get the ability to self-host.
It does lack a variety of features that Discord offers, but you get a lot of basic functionalities to get a head start to start experimenting.
Even without some features, you could mention it as a feature-rich open-source client. Let us look at the features available right now.
## Features of Revolt
While it looks and feels a lot like Discord already, here are some of the key highlights:
- Ability to create your own server
- Create text channels and voice channels
- Assign user roles in a server
- Tweak the theme (dark/light)
- Change the accent color
- Manage the font and emoji packs from available options
- Custom CSS support
- Ability to add bots
- Easy to manage permissions for text/voice channels
- Send friend requests to other users
- Saved notes section
- Ability to control notifications
- Hardware acceleration support
- Dedicated desktop settings
- Self-hosting using Docker
- User status and custom status support
So, as something in the public beta testing phase, it sounds excellent for starters. You already get most of the core functionalities, but you may want to wait to see it as a full-fledged Discord replacement.
## Initial Impressions of Using Revolt
If you have used Discord, the user experience will feel familiar. And that is a good thing here.
For this quick app highlight, I did not compare the resource usage of Discord and Revolt because it is still in beta and won’t be an apples-to-apples comparison.
However, in my brief testing, it felt snappy, except the case when you load up a text channel for the first time. When publishing this, it did not have the Two-Factor Authentication (2FA) feature but was supposed to be added in their first milestone (Version 1) release.
Some features like user status, permission management, and appearance tweaks looked useful. But, when it comes to the voice channels, it is not the same way as Discord works, at least for now.
I have no idea if they plan to do it the same way, but Discord’s voice channel feature is intuitive, fast, and with better controls.
Not to forget, Discord also offers “Discord Stage,” which is a Clubhouse-like audio room feature.
Some other features that I couldn’t find included:
- Ability to react to messages
- Noise suppression feature
- Change server
- Server logs
- Variety of useful bots
Of course, it will take a significant amount of time to catch up with the features offered by Discord, but at least we now have an open-source solution to Discord.
You can explore their [project roadmap/release tracker](https://github.com/orgs/revoltchat/projects/2) to see what you can expect in its final/future releases.
## Install Revolt in Linux
Revolt is available for Linux and Windows. You can choose to use it on your web browser without needing a separate application.
But, if you need to have it on your desktop, they offer an AppImage file and a deb package that you can grab from its [GitHub releases section](https://github.com/revoltchat/desktop/releases/tag/v1.0.2).
If you’re new to Linux, refer to our resources on [using an AppImage file](https://itsfoss.com/use-appimage-linux/) and [installing deb packages](https://itsfoss.com/install-deb-files-ubuntu/) to get started.
Feel free to head to its [Feedback section](https://app.revolt.chat/settings/feedback) if you want to help them improve with your bug reports and suggestions. Also, you can explore their [GitHub page](https://github.com/revoltchat) for more information.
In a related article, you may [checkout these open source Discord bots](https://itsfoss.com/open-source-discord-bots/).
What do you think about Revolt? Do you believe that it has the potential to become a good open-source replacement to Discord on Linux?
Let me know your thoughts in the comments down below! |
14,223 | 9 个可以改善你的 Firefox 体验的插件 | https://itsfoss.com/best-firefox-add-ons/ | 2022-01-29T17:07:55 | [
"Firefox"
] | https://linux.cn/article-14223-1.html | Firefox 显然是 Linux 用户中最受欢迎的开源网络浏览器之一。
事实上,它是 [可用于 Linux 的最佳网络浏览器](https://itsfoss.com/best-browsers-ubuntu-linux/) 之一。但是,它的附加组件(或扩展组件)如何呢?
考虑到你更喜欢开源的解决方案,你是否在使用开源服务的附加组件?有哪些你可以安装的最好的开源 Mozilla Firefox 附加组件?
### 你应该尝试的开源 Firefox 扩展程序

需要注意的是,在 Firefox 中并不是每个附加组件都是开源的。
此外,有几个开源项目的 Firefox 附加组件采用了不同的许可证。
#### 1、Dark Reader

[Dark Reader](https://addons.mozilla.org/en-US/firefox/addon/darkreader/) 是一个流行的浏览器扩展,让你打开网站的深色模式。该扩展只是简单地改变背景和文本颜色,以融合深色模式主题。
在默认情况下,它与几乎所有网站都能很好地配合。然而,如果你认为深色模式无法阅读(或不好看),你也可以自定义颜色、对比度、亮度和灰度。
你也可以选择在特定的网站上启用它,而在其他网站上禁用它。在这两种情况下,你都可以创建一个网站白名单/黑名单的列表。
它是一个尊重用户隐私的开源项目。你可以在它的 [GitHub 页面](https://github.com/darkreader/darkreader) 中了解更多关于它的信息,或者安装该附加组件来尝试它。
#### 2、Bitwarden

毋庸置疑,这是现有的 [最佳密码管理器](https://itsfoss.com/password-managers-linux/) 之一。
[Bitwarden](https://addons.mozilla.org/en-US/firefox/addon/bitwarden-password-manager/) 是一个开源的密码管理器,提供各种功能。它专注于提供有竞争力的开源解决方案。
这个用于 Mozilla Firefox 的密码管理器插件并不亚于任何其他类似产品。你可以通过该扩展获得所有的基本功能,包括生成密码、管理你的保险库以及一些高级选项。
在我的使用场景中,我没有发现这个扩展有任何不足之处。如果你还没有试过,你应该尝试一下这个插件。你可以看看它的 [GitHub页面](https://github.com/bitwarden/browser) 来了解更多信息。
#### 3、Vimium-FF

这是一个受 [Vim 键盘快捷键](https://itsfoss.com/pro-vim-tips/) 启发的开源工具,最初出现在 Chrome 浏览器上,后被移植到 Firefox。
Mozilla Firefox 上的 [Vimium](https://addons.mozilla.org/en-US/firefox/addon/vimium-ff/) 附加组件还在开发中,最近没有新版本。然而,作为一个实验性的附加组件,它仍然拥有优秀的用户评价。
这个附加组件可以让你使用键盘快捷方式来改善你的浏览体验。例如,你可以设置快捷键来滚动、查看源代码、启用插入模式、浏览历史记录、检查下载等。
如果你对键盘快捷键很熟悉,这个附加组件应该是你的菜,尝试一下吧。
你可以找到它的 [GitHub 页面](https://github.com/philc/vimium),也可以试试它的几个定制版本(复刻)。
#### 4、uBlock Origin

如果你想摆脱网站中的那些动来动去的元素,以改善浏览体验,[uBlock Origin](https://addons.mozilla.org/en-US/firefox/addon/ublock-origin/) 是一个出色的内容拦截器。
首先,它能阻止各种广告、跟踪器、弹出式窗口,以使网页的加载速度更快。如果一些网页在你的浏览器中加载时出现卡顿,它应该会派上用场。
如果一个网站不能正常运行,你也可以选择选择性地阻止或允许 JavaScript。它还具有过滤列表的功能,帮助你积极地阻断或尽量减少阻断,以平衡网络浏览体验而不破坏网站。
诸如阻止恶意域名、阻止大于特定尺寸的媒体等高级功能,能帮助你保持安全并节省网络带宽。查看其 [GitHub页面](https://github.com/gorhill/uBlock#ublock-origin) 以了解更多技术细节。
#### 5、LanguageTool

**注意:** 在这个列表中,我们尽量推荐完全开源的 Firefox 附加组件。但是,这是一个例外,作为一个非 FOSS 附加组件,其服务最初是开源的,但该扩展不是。
[LanguageTool](https://languagetool.org) 是一个开源的语法和拼写检查器,它尊重你的隐私,使它成为与 Grammarly 和其他同类产品相当的替代品。它可以免费使用,但可以选择升级为高级更正功能。
对于基本的拼写检查和常见的语法错误,它应该是足够好的。在我写这篇文章的时候,我的 [LanguageTool](https://itsfoss.com/languagetool-review/) 扩展已经激活。这不仅仅是一个注重隐私的开源替代品,它的工作速度超快,不会影响你的写作体验。
服务器端是开源的,但不幸的是,该附加组件不是开源的。他们澄清了原因,因为他们不希望竞争对手使用该插件而没有任何回报(更多内容见他们的 [论坛帖子](https://forum.languagetool.org/t/about-the-browser-addon-privacy-and-open-source/7505))。
然而,Mozilla 在它每次发布时都能审查源代码,这使得它成为一个值得推荐的附加组件。你可以在其 [官方网站](https://languagetool.org) 或其 [GitHub 页面](https://github.com/languagetool-org/languagetool) 上探索关于该工具的更多信息。
#### 6、Tabby

如果你想方便地管理具有不同活动窗口的多个标签,[Tabby](https://addons.mozilla.org/en-US/firefox/addon/tabby-window-tab-manager/) 应该会派上用场。
它简化了管理一个浏览器的多个标签和窗口的方法,还可以让你保存标签/窗口以便以后使用。说到标签管理,Firefox 并不是最棒的,所以你可能想试试这个。
你可以查看它的 [GitHub 页面](https://github.com/Bill13579/tabby) 或者安装这个附加组件来了解更多。
#### 7、Emoji

在计算机上挑选或使用表情符并不容易。有了这个开源的 [扩展](https://addons.mozilla.org/en-US/firefox/addon/emoji-sav/),你就只需点击一下就可以轻松地将几个表情符复制到剪贴板。
该插件是完全开源的,并且还使用一些开源字体。
你可以在其 [GitHub 页面](https://github.com/Sav22999/emoji) 上找到更多关于它的信息。
#### 8、DownThemAll

[DownThemAll](https://addons.mozilla.org/en-US/firefox/addon/downthemall/) 是一个强大的插件,可以轻松地从一个网页上下载多个文件/媒体。你可以选择一键下载所有文件,或者自定义你想要的文件。
还有一些额外的选项可以自定义文件名、基于队列的下载和高级选择。
你可以在其 [官方网站](https://www.downthemall.org) 或 [GitHub 页面](https://github.com/downthemall/downthemall) 上了解它的更多信息。
#### 9、Tomato Clock

如果你想在你的网络浏览器中实现 Pomodoro 功能(就像 Vivaldi 开箱即用提供的功能),[Tomato Clock](https://addons.mozilla.org/en-US/firefox/addon/tomato-clock/) 是你需要的插件。
换句话说,它可以让你设置定时器,帮助你把工作分成若干个时间段,中间有短暂的休息。这应该有助于你保持生产力,而不会被工作压垮。
它使用起来很简单,还能显示一些使用统计,以了解你对它的利用情况。
你可以探索它的 [GitHub 页面](https://github.com/samueljun/tomato-clock) 了解技术信息,或者获取该扩展来开始。
### 总结
如果你是一个狂热的 Firefox 用户,我建议你看看这个 [Firefox 键盘快捷键的有用清单](https://itsfoss.com/firefox-keyboard-shortcuts/)。我们也有一个 [Firefox 罕为人知的功能](https://itsfoss.com/firefox-useful-features/) 列表。你也可以去看看。
虽然还有其他几个有用的 Firefox 附加组件,但我把这个列表限制在我自己使用的最好的那些。
你最喜欢的开源 Firefox 附加组件有哪些?请在下面的评论中告诉我。
---
via: <https://itsfoss.com/best-firefox-add-ons/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Mozilla Firefox is easily one of the most popular open-source web browsers among Linux users.
In fact, it is one of the [best web browsers available for Linux](https://itsfoss.com/best-browsers-ubuntu-linux/). But, what about its add-ons (or extensions)?
Considering that you prefer open-source solutions, are you using add-ons for open-source services? What are some of the best open-source Mozilla Firefox add-ons that you can install?
## Open-Source Mozilla Firefox Extensions You Should Try

It is important to note that just because it’s Firefox, not every add-on is open-source.
Furthermore, there are several open-source projects with a Firefox add-on, but with a different license.
### 1. Dark Reader
Dark Reader is a popular browser extension that lets you turn on the dark mode for websites. The extension simply changes the background and text color to blend in as a dark mode theme.
By default, it works well with almost every website. However, if you think that a dark mode is unreadable (or doesn’t look good), you can customize the color, contrast, brightness, and grayscale as well.
You can also choose to enable it on specific websites and have it disabled for the rest. In either case, you can create a list of sites to whitelist/blacklist.
It is an open-source project that respects users’ privacy. You can explore more about it in its [GitHub page](https://github.com/darkreader/darkreader?ref=itsfoss.com) or get the add-on to try it out.
### 2. Bitwarden
Undoubtedly, one of the [best password managers](https://itsfoss.com/password-managers-linux/) available out there.
[Bitwarden](https://itsfoss.com/bitwarden/) is an open-source password manager offering a variety of features. It focuses on providing competitive open-source solutions.
The password manager add-on available for Mozilla Firefox is no less than any other similar offerings. You get all the essential functionalities starting from generating passwords, managing your vault, along with some advanced options right through the extension.
In my use case, I don’t find the extension lacking anything at all. And, you should try the add-on if you haven’t already. You can take a look at its [GitHub page](https://github.com/bitwarden/browser?ref=itsfoss.com) to explore more.
### 3. Vimium-FF
An open-source tool inspired by [Vim keyboard shortcuts](https://itsfoss.com/pro-vim-tips/), originally popular for Chrome, ported to Firefox.
The add-on is a work in progress for Mozilla Firefox, with no recent activity. However, as an experimental add-on, it still has excellent user reviews.
This add-on lets you use keyboard shortcuts to improve your browsing experience. For instance, you can set shortcuts to scroll, view source code, enable insert mode, browse the history, check downloads, and more.
If you are comfortable with keyboard shortcuts, this add-on should be on top of your bucket lists to try if you haven’t.
You can find its [GitHub page](https://github.com/philc/vimium?ref=itsfoss.com) and explore several customized versions (forks) of it as well.
### 4. uBlock Origin
If you want to get rid of several dynamic elements in a website to improve the browsing experience, uBlock Origin is a fantastic content blocker for the job.
For starters, it blocks a wide range of ads, trackers, pop-ups, to make the web page faster to load. It should come in handy if some web pages stutter when it loads up in your browser.
You can also choose to selectively block/allow JavaScript if a website does not function as it should. It also features filter lists to help you enable aggressive blocking or minimize blocking to balance the web browsing experience without breaking websites.
Advance features like blocking malicious domains, blocking media bigger than a specific size, should help you stay secure and save internet bandwidth. Explore its [GitHub page](https://github.com/gorhill/uBlock?ref=itsfoss.com#ublock-origin) for more technical details.
### 5. LanguageTool
**Note: **For this list, we try to recommend Firefox add-ons that are totally open-source. But, this is an exception as a non-foss add-on, where the service is originally open-source, but the extension is not.
[LanguageTool](https://itsfoss.com/languagetool-review/) is an open-source grammar and spellchecker that respects your privacy, making it a decent alternative to the likes of Grammarly and others. It is free to use, with an optional premium upgrade for advanced correction features.
It should be good enough for basic spellcheck and common grammatical mistakes. As I write this, I have LanguageTool Firefox extension active. Not just a privacy-focused, open-source alternative, it works super quickly without impacting your writing experience.
The server-side is open-source but unfortunately, the add-on is not open-source. They clarified the reason as they do not want competitors to use the add-on and contribute nothing in return (more in their [forum post](https://forum.languagetool.org/t/about-the-browser-addon-privacy-and-open-source/7505?ref=itsfoss.com)).
However, Mozilla gets access to the source code to review with every release, which makes it a recommended add-on to try. You can explore more about the tool on its [official site](https://languagetool.org/?ref=itsfoss.com) or its [GitHub page](https://github.com/languagetool-org/languagetool?ref=itsfoss.com).
### 6. Tabby
If you want the convenience of managing multiple tabs with different active windows, Tabby should come in handy.
It simplifies the method of managing several tabs and windows of a browser and also lets you save tabs/windows to use later. When it comes to tab management, Firefox isn’t a champion, so you might want to try this out.
You can check out its [GitHub page](https://github.com/Bill13579/tabby?ref=itsfoss.com) to explore more, or get the add-on below.
### 7. Emoji
It isn’t easy to pick or use an emoji using the desktop. With this open-source extension, you get access to several emojis that can be easily copied to the clipboard with a single click.
The add-on is entirely open-source and also uses some open-source fonts with the add-on.
You can find more about it on its [GitHub page](https://github.com/Sav22999/emoji?ref=itsfoss.com).
### 8. DownThemAll
DownThemAll is a powerful add-on to easily download multiple files/media from a webpage. You can choose to download everything in a single click or customize the ones you want.
There are some extra options to customize the file name, queue-based downloads, and advanced selection.
You can explore more about it on its [official website](https://www.downthemall.org/?ref=itsfoss.com) or [GitHub page](https://github.com/downthemall/downthemall?ref=itsfoss.com).
### 9. Tomato Clock
If you want a Pomodoro functionality in your web browser (like Vivaldi offers out-of-the-box), Tomato Clock is the add-on you need.
In other words, it lets you set timers to help you break down your work in intervals with short breaks in between. This should help you stay productive without getting overwhelmed with work.
It is simple to use and also shows you some usage stats to see how well you make use of it.
You can explore its [GitHub page](https://github.com/samueljun/tomato-clock?ref=itsfoss.com) for technical info or get the extension to start.
## Get more out of Firefox
If you are an avid Firefox user, I advise checking out this [helpful list of Firefox keyboard shortcuts](https://itsfoss.com/firefox-keyboard-shortcuts/).
[15 Useful Firefox Keyboard Shortcuts [With Cheatsheet]Love Mozilla Firefox browser? Use it more efficiently by using these keyboard shortcuts.](https://itsfoss.com/firefox-keyboard-shortcuts/)

We also have a list of [rather unknown Firefox features](https://itsfoss.com/firefox-useful-features/). Feel free to check that as well.
[6 Awesome Firefox Features You Should Be Using Right NowLove Firefox? You’ll love it even more if you start using these awesome features in Firefox and make your browsing experience even more awesome.](https://itsfoss.com/firefox-useful-features/)

While there are several other useful Firefox add-ons available, I limited the list to the best ones I found myself using.
What are some of your favorite open-source Firefox add-ons? Let me know in the comments down below. |
14,224 | 用 Bitsy 制作电子游戏 | https://opensource.com/article/22/1/bitsy-game-design | 2022-01-29T18:02:56 | [
"游戏"
] | https://linux.cn/article-14224-1.html |
>
> Bitsy 是一个开源电子游戏设计软件。 其简约的功能使任何人都可以探索他们的创造力。
>
>
>

有许多游戏设计程序和各种游戏设计方法,但对我来说,最突出的是 Bitsy。Bitsy 由 Adam Le Doux 在 2017 年创建,在 MIT 许可下发布,用其创造者的话说,Bitsy 是:“一个用于小游戏或世界的编辑器。其目标是使制作游戏变得容易,在那里你可以四处走动,与人交谈,并到某个地方。”
### 安装 Bitsy
Bitsy 是用 JavaScript 编写的,可以制作 HTML5 游戏。你可以从 [GitHub](https://github.com/le-doux/bitsy) 或 [它的创造者的网站](https://ledoux.itch.io/bitsy) 下载它。它很小,很容易学习,有独特的位图艺术风格,有意在功能上有所欠缺,而且能做的事情有限。
尽管(也许是因为)这些限制,Bitsy 自发布以来吸引了一个充满活力的用户社区。用户对 Bitsy 采取的两个主要方法是:接受限制和寻求突破限制,看看你能走多远。
### 创意的界限
Bitsy 的局限性意味着接受这些局限性仍能制作出令人满意的游戏,这就成为一个需要创造性和创造力的挑战。你可以在 [Itch.io 网站](https://itch.io/games/tag-bitsy) 上看到和玩一些用 Bitsy 制作的令人印象深刻的游戏。同时,人们也想出了一些黑科技、调整和扩展。这些都在不牺牲 Bitsy 的本质的前提下突破了一些限制。
Bitsy 的基本元素是一个代表玩家的头像、发生游戏动作的房间、精灵(可以与之互动的非玩家角色)和物品。有一个用于创建这些元素的位图编辑器,它也支持简单的两帧动画。

在 Bitsy 中工作依赖于条件变量,而不是成熟的脚本,这使得没有编码背景的人容易学习,但有时会让那些期待更多灵活性的人感到沮丧。
如果你想了解 Bitsy 的基本情况,你可以在创作者的网站上了解,或者下载并在本地运行。

### 文档
关于 Bitsy 的文档并不是只有一个地方可以去看。如果你想看 Bitsy 的操作,可以在 YouTube 上找到各种短视频。我更喜欢基于文本的教程,我发现最有用的三个资源是:
* [Itch.io 网站上提供的官方 Bitsy 教程](https://www.shimmerwitch.space/bitsyTutorial.html),作者是 Claire Morwood
* [Bitsy workshop PDF](https://static1.squarespace.com/static/58930a6c893fc0a33ae624db/t/5bacd94ac83025ead3937071/1538054510407/BITSY-WORKSHOP.pdf), 由用户 haraiva 提供
* [Bitsy 变量](https://ayolland.itch.io/trevor/devlog/29520/bitsy-variables-a-tutorial), 教程由用户 ayolland 编写
阅读这些教程,尝试一些 Bitsy 游戏,并开始创造你自己的东西。开始时要保持简单。当你熟悉了 Bitsy,你可能想研究一下人们为它创造的一些 [工具、黑科技和扩展](https://itch.io/tools/tag-bitsy)。
它也是教育工作者的完美工具,甚至还有教育工作者 Hal Meeks 的 [Bitsy 课程](https://halmeeks.net/bitsyclass/) 可供在线学习。
你还可以在 [Itch.io 网站](https://itch.io/game-assets/tag-bitsy) 上找到人们为 Bitsy 制作的大量游戏资源。
### Twine 整合
你可能已经尝试过流行的基于浏览器的游戏开发工具 [Twine](https://opensource.com/article/18/2/twine-gaming)。你可以将 Bitsy 与 Twine 不同程度地整合。整合的范围可以从简单地将 Bitsy 游戏放在一个 iframe 中显示在你的 Twine 游戏中,到在两个引擎之间共享变量和对话命令,让你在 Bitsy 游戏中执行基本的 Twine 命令!如果你对这些感兴趣,那么请看:
* [结合 Bitsy 和 Twine 的教程](https://spdrcstl.com/blog/bitsy-twine-tutorial.html)
* [Bitsy 黑科技](https://github.com/seleb/bitsy-hacks/blob/main/dist/twine-bitsy-comms.js)
* [Freya 的 Twisty 模板](https://communistsister.itch.io/twitsy-template-1)
### 给初学者的 Bitsy
初学者很容易入门 Bitsy,无论你是编程新手还是仅仅是游戏设计的新手。有了它,你可以探索它在激发创造力、想象力和创造性方面的所有可能性。
---
via: <https://opensource.com/article/22/1/bitsy-game-design>
作者:[Peter Cheer](https://opensource.com/users/petercheer) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are many game design programs and many different possible approaches to game design, but for me, the one that stands out is Bitsy. Created by Adam Le Doux in 2017 and released under an MIT license, Bitsy is, in the words of its creator: "A little editor for little games or worlds. The goal is to make it easy to make games where you can walk around, talk to people, and be somewhere."
## Install Bitsy
Bitsy is written in JavaScript and produces HTML5 games. You can download it from [GitHub](https://github.com/le-doux/bitsy) or the [creator's website](https://ledoux.itch.io/bitsy). It's small, easy to learn, has a distinctive bit map art style, is intentionally short on features, and is limited in what it can do.
Despite (or perhaps because of) these limitations, Bitsy has attracted a vibrant user community since it was released. The two main approaches users have taken to Bitsy have been embracing the limitations and seeking to push against the limitations to see how far you can go.
## Creative bounds
The limitations of Bitsy means that accepting them and still producing a satisfying game becomes a challenge demanding inventiveness and creativity. You can see and play some of the impressive games produced with Bitsy online at the [Itch.io website](https://itch.io/games/tag-bitsy). At the same time, people have come up with hacks, tweaks, and extensions. These have pushed against some of the limitations without sacrificing the essence of Bitsy.
The basic elements in Bitsy are an avatar representing the player, rooms where the game action takes place, sprites (non-player characters that you can interact with), and items. There's a bitmap editor for creating these elements, which also allows for simple two-frame animations.
(Peter Cheer, CC BY-SA 4.0)
Working within Bitsy relies on conditional variables rather than full-fledged scripting, making it easy to learn for those without a background in coding and sometimes frustrating to those expecting more flexibility.
If you want to see the basics of Bitsy, you can do that online at the creator's website, or download it and run it locally.
(Peter Cheer, CC BY-SA 4.0)
## Documentation
There isn't just one place to go for documentation about Bitsy. Various short videos are available on YouTube if you want to see Bitsy in action. I prefer text-based tutorials, and the three resources I found most useful are:
[The official Bitsy tutorial](https://www.shimmerwitch.space/bitsyTutorial.html)made available on the Itch.io site is by Claire Morwood[Bitsy workshop PDF](https://static1.squarespace.com/static/58930a6c893fc0a33ae624db/t/5bacd94ac83025ead3937071/1538054510407/BITSY-WORKSHOP.pdf)by user haraiva[Bitsy variables](https://ayolland.itch.io/trevor/devlog/29520/bitsy-variables-a-tutorial)tutorial by user ayolland
Read through the tutorials, try out some Bitsy games, and get creating something of your own. Keep it simple to start with. Once you've become comfortable with Bitsy, you may want to investigate some of the [tools, hacks, and extensions](https://itch.io/tools/tag-bitsy) that people have created for it.
It's the perfect tool for educators, too, and there's even a [Bitsy class](https://halmeeks.net/bitsyclass/) curriculum by educator Hal Meeks available online.
You can also find heaps of game assets that people have made for Bitsy on the [Itch.io website](https://itch.io/game-assets/tag-bitsy).
## Twine integration
You may have already tried the popular browser-based game development tool [Twine](https://opensource.com/article/18/2/twine-gaming). You can integrate Bitsy with Twine by varying degrees. Integration can extend from simply placing a Bitsy game in an iframe to display inside your Twine game up to sharing variables between the two engines and dialogue commands which let you execute basic Twine commands inside a Bitsy game! If these possibilities interest you, then look at:
## Bitsy for beginners
Beginners can get started easily with Bitsy, whether you're new to programming or just to game design. With it, you can explore all its possibilities for sparking creativity, imagination, and inventiveness.
## 1 Comment |
14,226 | 我们最喜欢的好玩的 Linux 命令 | https://opensource.com/article/22/1/fun-linux-commands | 2022-01-30T10:46:00 | [
"命令行",
"有趣"
] | /article-14226-1.html |
>
> Linux 命令行以生产力强而闻名。它也是一个可以获得一些乐趣的地方!
>
>
>

去年 11 月,我们分享了一篇文章《[7 个好玩的 Linux 命令](https://opensource.com/article/21/11/fun-linux-commands)》,并请读者们告诉我们推荐的“好玩”的 Linux 命令是什么,以及为什么?
一些读者在下面分享了他们的最爱:
---
这是我的最爱:
* 当然得有 `cowsay`!
* `fortune`,我最喜欢的 “黑科技” 是让用户连接时的 `motd` 成为一个幽默的格言。
* `sl`,在你的终端上的蒸汽机车。
* `xsnow`,另一个 XWindow 黑科技,这个命令可以在你的工作区降雪,并堆积在打开的窗口上。
* GNOME 复活节彩蛋,在 GNOME 2 中,按下 `Alt+F2`(打开运行对话框)并输入 `free the fish`,就可以在你的根窗口中释放 “Wanda the Fish”。如果你点击 Wanda,它就会四处游荡,窜来窜去(一段时间)。
~[Dave Neary](https://opensource.com/users/dneary)
---
我的一天从这些开始:
`fortune`、`cowsay`、`lolcat`

紧接着是 `curl` [wttr.in](http://wttr.in/)。

现在我们可以喝咖啡了 ;-)
~[Tomasz Waraksa](https://opensource.com/user_articles/380541)
---
`cmatrix` ,因为每当这个时候,你就会觉得自己被插入了机器。
~[Gary Smith](https://opensource.com/users/greptile)
---
```
telnet towel.blinkenlights.nl
```
这并不完全是 Linux 特有的,但它还挺棒的。
~[John 'Warthog9' Hawley](https://opensource.com/users/warthog9)
---
Xroach 是 20 世纪 90 年代你的窗口管理器的一个很酷的附加功能。当时它与 Tab Window Manager (TWM)和 F Virtual Window Manager (FVWM)一起使用时非常有趣,但我已经多年没有使用它了。当你运行 Xroach 时,它添加了小蟑螂并“住”在你的窗口下。当你移动一个窗口或关闭它时,蟑螂就会窜到另一个窗口下躲起来或跑出屏幕。这只是其中一种使桌面更有趣的小方法。
看起来有一个 [Xroach 的现代移植](https://github.com/interkosmos/xroach),我得找个时间试试。
~[Jim Hall](https://opensource.com/users/jim-hall)
---
我在 90 年代末担任过计算机科学的助教,我们的计算机实验室里有 Sun Sparc 工作站。有时学生会在实验室时间里走开而不锁屏。每隔一段时间,我就会在他们不注意的时候在终端上执行 `xroach &; clear`。
XRoach 是个好东西。蟑螂躲在窗口下,在屏幕上窜来窜去,当你移动一个窗口时,又躲在另一个窗口下。
~[Ann Marie Fred](https://opensource.com/users/annmarie99)
---
我最喜欢的一个是 `hollywood`,在 [这里](https://snapcraft.io/install/hollywood/ubuntu) 了解下。
只需运行它并开始随意按键,你就会让星巴克的每个人都相信你正在摧毁美国。
~[Clint Byrum](https://opensource.com/users/spamaps)
[Jim Hall](https://opensource.com/users/jim-hall) 对此回应道:
这真是太棒了! 这让我想起了 [Hacker Typer](https://hackertyper.net/)。它是一个网站而不是一个终端程序。只要调出网站,然后敲击键盘。不管你输入什么,Hacker Typer 的输出都似乎是真正的工作。:-)
为了回应 Clint Byrum(和 Jim Hall 的回应)带来的乐趣:
这两个我都喜欢! 请欣赏这篇关于 Hollywood 黑科技的 [博文](https://www.dgregscott.com/hollywood-hacker/)。我最爱之一。
~[Greg Scott](https://opensource.com/users/greg-scott)
---
你最喜欢的“有趣的” Linux 命令是什么?请在下面的评论中分享你的。
---
via: <https://opensource.com/article/22/1/fun-linux-commands>
作者:[Opensource.com](https://opensource.com/users/admin) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
14,227 | 给开源爱好者的 10 个节日礼物创意 | https://opensource.com/article/21/11/open-source-holiday-gifts | 2022-01-30T13:39:17 | [
"节日",
"礼物"
] | https://linux.cn/article-14227-1.html |
>
> 从 DIY 项目到电脑再到书籍,这份清单提供了培养创造力、学习和探索的礼物创意。
>
>
>

你是否正在为你的节日购物清单上的人寻找很酷的礼物,或者为你自己的愿望清单寻找建议?如果是这样,请考虑以下十条建议。这些礼物建议中的每一个都以某种方式与开源精神相联系。从 DIY 项目到电脑再到书籍,这份清单提供了培养创造力、学习和探索的礼物建议。
### System76 电脑

你身边的某人需要一个新的台式机、笔记本电脑或服务器吗?[System76](https://system76.com) 应该是你首先应该寻找的地方之一。想找一些轻巧的移动设备吗?轻巧的 14 英寸 [Lemur Pro](https://system76.com/laptops/lemur) 笔记本电脑是一个很好的选择。需要一个有大量处理能力、内存和存储空间的台式机?各种 [Thelio](https://system76.com/desktops/) 台式机中就有一款是你要找的。还有很多介于两者之间的其他选择。他们的电脑配备了 Ubuntu 或 Pop!\_OS,这是该公司自己的基于 Ubuntu 的 Linux 发行版,并有终身支持。System76 也支持 [维修权法案](https://blog.system76.com/post/646726872371200000/carl-testimony-hb21-1199mp3)。虽然不是唯一一家销售安装 Linux 系统的电脑的厂商,但他们肯定是最受欢迎的厂商之一。
* **价格不一**
### 树莓派 400 个人电脑套件

树莓派几乎不需要介绍。自从 2012 年第一款树莓派风靡全球以来,树莓派一直是最受欢迎的单板计算机之一,可用于教育、业余爱好者和手工爱好者们。[树莓派 400 个人电脑套件](https://www.raspberrypi.com/products/raspberry-pi-400/) 延续了这一趋势。除了一个显示器之外,这个套件包含了人们开始使用所需的一切。花 100.00 美元,你就可以得到树莓派 400(树莓派 4 系列的一个变种,内置于一个键盘外壳中)、一只鼠标、电源、micro HDMI 转 HDMI 电缆、一张预装树莓派操作系统的 SD 卡,以及一本《树莓派初学者指南》。虽然树莓派 400 不是世界上最强大的计算机,但对于你的礼物清单上的孩子来说,树莓派 400 完全可以作为一个得当的入门计算机。
* **价格:100.00 美元**
### 树莓派 Build HAT

树莓派的诸多优势之一是它能够通过各种附加板进行扩展。最近推出的一款附加板 —— [树莓派 Build HAT](https://www.raspberrypi.com/products/build-hat/),可以用树莓派来控制多达四个乐高技术电机或 [乐高教育 SPIKE](https://education.lego.com/) 产品系列的传感器。Build HAT 适用于任何带有 40 针 GPIO 接头的树莓派。你可以使用专门开发的 Python 库对项目进行编码。Build HAT 可以使用外部 8V 直流电源(如 [官方 Built HAT 电源](https://www.raspberrypi.com/products/build-hat-power-supply/))或 7.5V 电池组为自身、树莓派板以及乐高电机和传感器供电。
* **价格:25.00 美元(加上一个项目所需的零件和配件的费用)**
### CrowPi2

[CrowPi2](https://www.crowpi.cc/) 是一个 STEM 学习项目集合,放在一个由树莓派驱动的笔记本电脑式的机箱里。CrowPi2 套件有三种尺寸:基本型、高级型和豪华型。基本型套件包括一些附件,但不包括树莓派。高级套装配备了一个拥有 4GB 内存的树莓派 4B,并有比基本套装更多的配件选择。豪华套装配备了最多的配件和一个拥有 8GB 内存的树莓派 4B。所有三个套件都有太空灰或银色可供选择。一个可选的移动电源可以在不插入电源插座时为 CrowPi2 提供电源。如果你想了解更多关于 CrowPi2 的信息,你可以阅读 Seth Kenlon 的 [对 CrowPi2 的点评](https://opensource.com/article/21/9/raspberry-pi-crowpi2)。
* **基本套件:339.99 美元**
* **高级套件:469.99 美元**
* **豪华套装:529.99 美元**
* **可选的移动电源:19.00 美元**
### Keebio Quefrency 键盘
推荐人:John Hall

[Keebio Quefrency 键盘](https://keeb.io/collections/quefrency-split-staggered-65-keyboard) 对于任何想组装自己的键盘的人来说,都是一个很好的节日礼物!它是一款 65% 键盘,这可能是大多数人愿意去做的最小的键盘,因为它有 Home、PgUp、PgDn 和方向键。它是一个分体式的人体工程学键盘,但如果你难以适应分体式的键盘,你可以将两半重新组合起来。最重要的是,最新版本的 Quefrency 有热插拔插座,所以你可以在不需要焊接任何东西的情况下组装它。
下面是一个廉价的 Quefrency 键盘组件:
* [Quefrency rev4 PCBs](https://keeb.io/collections/quefrency-split-staggered-65-keyboard/products/quefrency-rev-4-65-split-staggered-keyboard) 带有热插拔插座,加上 FR4 板(左边没有宏,右边有 65%)
+ 80 + 28 美元
* [2u 稳定器(5 个)](https://keeb.io/collections/diy-parts/products/cherry-mx-stabilizer?variant=43449871046)
+ 10 美元
* [按键开关(70 个)](https://divinikey.com/collections/linear-switches/products/gateron-milky-yellow-linear-switches?variant=32193385201729)
+ 16 美元
* [键帽](https://drop.com/buy/artifact-bloom-series-keycap-set-vintage)
+ 45 美元
* [2.25u G20 左空格键](https://pimpmykeyboard.com/g20-2-25-space-pack-of-4/) 和 [2.75u G20 右空格键](https://pimpmykeyboard.com/g20-2-75-space-pack-of-4/)
+ 8 + 8 美元
* [USB C 到 USB C 键盘连接器](https://keeb.io/products/usb-c-to-usb-c-cable?variant=32313985728606)
+ 4 美元
* **共计 199 美元**(不包括运费)
正如零件清单中指出的,Keebio Quefrency rev4 需要五个稳定器:
1. 左 Shift 键
2. 左空格键
3. 右空格键
4. 回车键
5. 退格键
Keebio Quefrency rev4 目标是构建 65% 键盘,它有一个缩短的右 Shift 键,不需要稳定器。许多键帽套装,甚至是相对便宜的套装,如 Artifact Bloom 和 Glorious GPBT,包括一个缩短的右 Shift 键,适合大多数像这样的键盘。难的是找到匹配的分体式空格键键帽。但你可以从 Pimp My Keyboard 等地方买到空格键的键帽,效果很好。不幸的是,几乎不可能从不同的制造商那里得到匹配的颜色。即使你选择白色键帽和白色空格键,其中一个也可能比另一个更灰。为什么不接受这种差异呢?试着将白色和灰色的键帽与红色或蓝色的空格键配对一下。
### Petoi Nybble 开源机器猫

[Petoi Nybble 开源机器猫](https://www.petoi.com/pages/petoi-nybble-overview) 是一个用于建造机器宠物猫的套件。该套件包含了建造该项目所需的一切,但不包括电池。Nybble 需要两块 14500 锂离子可充电 3.7V 电池,可提供约 45 分钟的游戏时间。一旦组装完成,可以使用 Arduino IDE、Python API 或 Android/iOS 应用程序对该猫进行编程/控制。查看 [Nybble 用户手册](https://nybble.petoi.com/) 了解更多细节。
* **价格:249.00 美元**
### 《苍穹浩瀚》小说系列

James S.A. Corey 的《<ruby> <a href="https://www.jamessacorey.com/writing-type/books/"> 苍穹浩瀚 </a> <rt> Expanse </rt></ruby>》系列的最后一部小说正好在假日送礼季节推出。定于 11 月 30 日发行的《<ruby> <a href="https://www.jamessacorey.com/books/leviathan-falls/"> 利维坦瀑布 </a> <rt> Leviathan Falls </rt></ruby>》将结束这个史诗般的九部科幻小说系列的主要叙事,探索人类在太空的未来。按顺序,该系列的九本书是《<ruby> 利维坦觉醒 <rt> Leviathan Wakes </rt></ruby>》、《<ruby> 卡利班之战 <rt> Caliban's War </rt></ruby>》、《<ruby> 阿巴顿之门 <rt> Abaddon's Gate </rt></ruby>》、《<ruby> 西波拉燃烧 <rt> Cibola Burn </rt></ruby>》、《<ruby> 复仇游戏 <rt> Nemesis Games </rt></ruby>》、《<ruby> 巴比伦的灰烬 <rt> Babylon's Ashes </rt></ruby>》、《<ruby> 波斯波利斯的崛起 <rt> Persepolis Rising </rt></ruby>》、《<ruby> 提亚马特之怒 <rt> Tiamat's Wrath </rt></ruby>》和《<ruby> 利维坦瀑布 <rt> Leviathan Falls </rt></ruby>》。明年还将出版一本短篇小说和长篇小说集。这些故事和长篇小说中的大部分已经有了电子书格式,但这是第一次的印刷合集。给你身边的科幻小说读者购买该系列的第一本书,让他们开始阅读,或者给他们购买整个系列。
* **第一至第六本:17.99 美元(平装本)**
* **第七本和第八本:18.99 美元(平装本)**
* **第九本:30.00 美元(精装本)**
### 书籍
如果你正在寻找书籍推荐,而《苍穹浩瀚》的推荐并不符合你的需求,可以考虑 [这份 2021 年夏季阅读清单](https://opensource.com/article/21/6/2021-opensourcecom-summer-reading-list) 中的书籍。这份清单包含八本适合各种阅读口味的书籍推荐。从《<ruby> 贝奥武夫 <rt> Beowulf </rt></ruby>》的现代翻译到关于技术的非小说类书籍,那里应该有适合你生活中的读者的东西。如果 2021 年夏季阅读清单中没有你要找的东西,这篇文章还包含了以前所有夏季阅读清单的链接,其中提供了十多份建议清单。
* **价格不一**
### 贴纸

大流行期间的虚拟会议的一个缺点是,你无法带走从各个供应商摊位上收集的贴纸。对于那些喜欢用贴纸装饰笔记本电脑的人来说,这可能意味着他们最新的笔记本电脑目前还没有通常的装饰品。如果这听起来像你生活中的某个人,考虑给他们买一个来自 Sticker Mule 的 [Unixstickers 包](https://www.stickermule.com/unixstickers)。该包有三种不同的尺寸:专业版,包含十张贴纸;精英版,包含专业版中的所有贴纸,再加十张贴纸;终极版,包含精英版中的所有内容,再加十张贴纸。这些贴纸涵盖了许多开源项目,使这些捆绑包成为参观供应商展位和亲临会议的贴纸交换台的下一个最佳选择。
* **专业包:1.00 美元**
* **精英包:19.00 美元**
* **终极包:24.00 美元**
### 向开源组织慈善捐赠
如果你购物清单上的人已经拥有了一切(或者不想要任何有形的礼物),可以考虑以他们的名义向开源项目进行慈善捐赠。这个 [开源组织](https://opensource.com/resources/organizations) 列表中有很多组织供你选择。你、以其名义捐款的人和收到你捐款的组织都会很高兴,你的礼物有助于使开源变得更好。
---
via: <https://opensource.com/article/21/11/open-source-holiday-gifts>
作者:[Joshua Allen Holm](https://opensource.com/users/holmja) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Are you looking for cool gifts for people on your holiday shopping list or ideas for your own wishlist? If so, consider one of the ten suggestions below. Each of these gift suggestions connects in some way to the open source ethos. From DIY projects to computers to books, this list provides gift suggestions that foster creativity, learning, and exploring.
## System76 computer

Does someone in your life need a new desktop, laptop, or server? [System76](https://system76.com) should be one of the first places you should look. Looking for something light and mobile? The lightweight 14-inch [Lemur Pro](https://system76.com/laptops/lemur) laptop is an excellent choice. Need a desktop with *a lot* of processing power, RAM, and storage? One of the various [Thelio](https://system76.com/desktops/) desktops is what you are looking for. And there are plenty of other options in-between. Their computers come with either Ubuntu or Pop!_OS, which is the company's own Ubuntu-based Linux distribution, and have lifetime support. System76 is also in favor of [right-to-repair legislation](https://blog.system76.com/post/646726872371200000/carl-testimony-hb21-1199mp3). While not the only vendor out there that sells Linux-powered computers, they are certainly one of the most popular.
**Prices Vary**
## Raspberry Pi 400 Personal Computer Kit

At this point, the Raspberry Pi brand needs little introduction. Since the first Raspberry Pi model took the world by storm in 2012, the Raspberry Pi has remained one of the most popular single-board computers for use in education and by hobbyists and tinkerers. The [Raspberry Pi 400 Personal Computer Kit](https://www.raspberrypi.com/products/raspberry-pi-400/) continues this trend. This kit contains everything someone needs to get started, except a monitor. For US$ 100.00, you get the Raspberry Pi 400 (a variant of the Raspberry Pi 4 series built into a keyboard casing), a mouse, power supply, micro HDMI-to-HDMI cable, an SD card preloaded with Raspberry Pi OS, and a copy of the Raspberry Pi Beginner's Guide. While not the most powerful computer in the world, the Raspberry Pi 400 is more than capable of functioning as a decent starting computer for the children on your shopping list.
**Price: US$ 100.00**
## Raspberry Pi Build HAT

One of the many benefits of the Raspberry Pi is its ability to be expanded with various add-on boards. A recently introduced add-on board, the [Raspberry Pi Build HAT](https://www.raspberrypi.com/products/build-hat/), makes it possible to use the Raspberry Pi to control up to four LEGO Technic motors or sensors from the [LEGO Education SPIKE](https://education.lego.com/) product line. The Build HAT works with any Raspberry Pi with a 40-pin GPIO header. You code projects using a specially developed Python library. The Build HAT can power itself, the Raspberry Pi board, and the LEGO motors and sensors using an external 8V DC power source (like the [official Built HAT power supply](https://www.raspberrypi.com/products/build-hat-power-supply/)) or a 7.5V battery pack.
**Price: US$ 25.00 (plus the cost of the parts and accessories needed for a project)**
## CrowPi2

The [CrowPi2](https://www.crowpi.cc/) is a collection of STEM learning projects built into a laptop-style case powered by a Raspberry Pi. The CrowPi2 kit comes in three sizes: Basic, Advanced, and Deluxe. The Basic kit comes with a few accessories but does not come with a Raspberry Pi. The Advanced kit comes with a Raspberry Pi 4B with 4GB of RAM and a larger selection of accessories than the Basic kit. The Deluxe Kit comes with the largest selection of accessories and a Raspberry Pi 4B with 8GB of RAM. All three kits are available in Space Gray or Silver. An optional power bank can provide the CrowPi2 with power when not plugged into an electrical outlet. If you want to learn more about the CrowPi2, you can read [Opensource.com's review of the CrowPi2](https://opensource.com/article/21/9/raspberry-pi-crowpi2) by Seth Kenlon.
**Basic Kit: US$ 339.99**
**Advanced Kit: US$ 469.99 **
**Deluxe Kit: US$ 529.99**
**Optional Power Bank: US$ 19.00**
## Keebio Quefrency keyboard
Recommendation by John Hall

The [Keebio Quefrency keyboard](https://keeb.io/collections/quefrency-split-staggered-65-keyboard) would make a great holiday gift for anyone who wants to build their own keyboard! It is a 65% keyboard, which is probably the smallest most people would be willing to go since it has Home, PgUp, PgDn, and arrow keys. It is a split ergonomic keyboard, but you can put the halves back together if you have difficulty adjusting to the split. Best of all, the latest revision of the Quefrency has hot-swap sockets, so you can build it without needing to solder anything.
Here is an inexpensive Quefrency keyboard build:
[Quefrency rev4 PCBs](https://keeb.io/collections/quefrency-split-staggered-65-keyboard/products/quefrency-rev-4-65-split-staggered-keyboard)with hot-swap sockets, plus FR4 Plates (left with no macros, right 65%)- $80 + $28 US
[2u stabilizers (5)](https://keeb.io/collections/diy-parts/products/cherry-mx-stabilizer?variant=43449871046)- $10 US
- $10 US
[Key switches (70)](https://divinikey.com/collections/linear-switches/products/gateron-milky-yellow-linear-switches?variant=32193385201729)- $16 US
[Keycaps](https://drop.com/buy/artifact-bloom-series-keycap-set-vintage)- $ 45 US
[2.25u G20 left spacebar](https://pimpmykeyboard.com/g20-2-25-space-pack-of-4/)and[2.75u G20 right spacebar](https://pimpmykeyboard.com/g20-2-75-space-pack-of-4/)- $8 + $8 US
[USB C to USB C keyboard connector](https://keeb.io/products/usb-c-to-usb-c-cable?variant=32313985728606)- $4 US
**Total US$ 199**(not including shipping)
As noted in the parts list, the Keebio Quefrency rev4 needs five stabilizers:
- Left Shift
- Left Space
- Right Space
- Enter
- Backspace
The Keebio Quefrency rev4 is intended to be built as a 65% keyboard, which has a shortened right shift key that does not need a stabilizer. Many keycap sets, even relatively inexpensive sets like Artifact Bloom and Glorious GPBT, include a shortened right shift key that fits most keyboards like this one. The hard part is finding matching split spacebar keycaps. But you can buy spacebar keycaps from places like Pimp My Keyboard, which work great. Unfortunately, it is nearly impossible to get matching colors from different manufacturers. Even if you pick white keycaps and white spacebars, one of them is likely to be grayer than the other. Why not celebrate the difference instead? Try pairing white and gray keycaps with red or blue spacebars.
## Petoi Nybble Open Source Robotic Cat

The [Petoi Nybble Open Source Robotic Cat](https://www.petoi.com/pages/petoi-nybble-overview) is a kit for building a robotic pet cat. The kit comes with everything needed to build the project, but batteries are not included. The Nybble requires two 14500 lithium ion rechargeable 3.7V batteries, which provide about 45 minutes of playtime. Once assembled, the cat can be programmed/controlled using the Arduino IDE, a Python API, or an Android/iOS app. Check out the [Nybble User Manual](https://nybble.petoi.com/) for more details.
**Price: US$ 249.00 USD**
## The Expanse Novel Series

The final novel in [The Expanse](https://www.jamessacorey.com/writing-type/books/) series by James S.A. Corey comes out just in time for the holiday gift-giving season. Set to release on November 30, [Leviathan Falls](https://www.jamessacorey.com/books/leviathan-falls/) will conclude the main narrative of this epic nine-book science fiction series that explorers humanity's future in space. In order, the nine books in the series are Leviathan Wakes, Caliban's War, Abaddon's Gate, Cibola Burn, Nemesis Games, Babylon's Ashes, Persepolis Rising, Tiamat's Wrath, and Leviathan Falls. There will also be a collection of short stories and novellas published next year. Most of these stories and novellas are already available in eBook format, but the collection will be the first time they are available in print. Buy the science fiction reader in your life the first book of the series to get them started, or buy them the entire series.
**Books 1 through 6: US$ 17.99 (Trade Paperback)**
**Books 7 and 8: US$ 18.99 (Trade Paperback)**
**Book 9: US$ 30.00 (Hardcover)**
## Books
If you are looking for book recommendations and the recommendation for The Expanse does not meet your needs, consider the books from [Opensource.com's 2021 Summer Reading List](https://opensource.com/article/21/6/2021-opensourcecom-summer-reading-list). This list contains eight book recommendations for a variety of reading tastes. From a modern translation of Beowulf to non-fiction books about technology, there should be something there for the reader in your life. If the 2021 Summer Reading List does not have what you are looking for, the article also contains links to all of Opensource.com's previous summer reading lists, which provides ten more lists of suggestions.
**Prices Vary**
## Stickers

(Source: Sticker Mule)
One of the drawbacks of virtual conferences during the pandemic is that you cannot walk away from the conference with a collection of stickers from various vendor booths. For those who love decorating their laptops with stickers, this could mean that their latest laptop is currently unadorned with the usual decorations. If this sounds like someone in your life, consider buying them a [Unixstickers pack](https://www.stickermule.com/unixstickers) from Sticker Mule. The packs come in three different sizes: Pro, which contains ten stickers; Elite, which contains all the stickers from the Pro pack plus ten more stickers; and Ultimate, which contains everything in the Elite pack plus an additional ten stickers. The stickers cover many open source projects making these bundles the next best thing to visiting vendor booths and the sticker swap table at an in-person conference.
**Pro pack: US$ 1.00**
**Elite pack: US$ 19.00**
**Ultimate pack: US$ 24.00**
## Charitable donation to an open source organization
If the person on your shopping list already has everything (or does not want any tangible gifts), consider making a charitable donation to an open source project in their name. Opensource.com's list of [open source organizations](https://opensource.com/resources/organizations) has plenty of organizations you can select from. You, the person whose name the donation was made in, and the organization that received your donation can all be content in knowing that your gift has helped make open source better.
## 1 Comment |
14,229 | Jrnl:你的 Linux 终端数字日记 | https://itsfoss.com/jrnl/ | 2022-01-30T23:42:16 | [
"日记",
"终端"
] | https://linux.cn/article-14229-1.html | 
想象一下:有人伤了你的心,而你想要的是心无旁骛地在日记中写下你的感受。你明白这种感受吗?没有吗?我也不知道。我没有心碎过(或者也许我心碎了,但我不想告诉你)。
但我还是想向你展示一个奇妙的极简的开源的记事应用来保存日记。
这个方便的小程序是 [Jrnl](https://jrnl.sh/en/stable/),它可以让你在终端中直接创建、搜索和查看日记条目。
用 Jrnl 创建新的笔记就像下面一样简单:
```
jrnl yesterday: I read an amazing article on It’s FOSS. I learn about a minimalist app called Jrnl, I should try it.
```
看起来很简单,不是吗?关键字 “yesterday” 在这里是一个触发器,它把你的笔记保存到昨天的日期。记住,它被称为 Jrnl(日记)是有原因的。它的主要目的是保存日记。
如果你喜欢把你的想法写成日记,或者只是想尝试一下,让我分享一下安装和使用的一些细节。
### 在你的 Linux 系统上安装和使用 Jnrl
Jrnl 可以用 pipx 或 Homebrew 包管理器安装。
我在测试中使用了 Homebrew,所以我将列出这些步骤。首先获取 Homebrew:
```
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
```

这就好了!如果你需要更多的信息,我们有一个关于 [在 Linux 上安装 Homebrew](https://itsfoss.com/homebrew-linux/) 的详细教程。
当你安装了 Homebrew 包管理器后,用它来安装 Jrnl:
```
brew install jrnl
```

安装后,只要初始化 jrnl 并开始写你的随机想法。
你还记得本文开头的第一个例子吗?让我们再来看看它吧!
```
jrnl yesterday: I read an amazing article in It’s FOSS. I learn about a minimalist app called Jrnl, I should try it.
```

在这一行中,我用命令 `jrnl` 在一个时间戳旁启动程序,在这个例子中是 `yesterday`。我写了一个冒号 `:`,表示我将开始写一些东西,在第一个句子标记 `.?!:`(在这里是句号 `.`)之前包含的所有内容将是标题。最后,这个句号旁边的所有内容将被视为文件的主体。
目前,Jnrl 有两种模式:撰写和查看;前面的步骤用于撰写条目,但如果你想查看,例如,之前写过的条目,语法也很简单,你只需输入下一行。
```
jrnl -on yesterday
```

认为有人可能会阅读你的日记和想法?你也可以对你的条目进行加密。
这就好了! 当然,Jrnl 还有很多功能,你可以通过下面这行轻松找到:
```
jrnl --help
```
你也可以参考 [其官方网站](https://jrnl.sh/en/stable/overview/) 上的文档。记住,在这样的一个开源项目中,文档是你最好的朋友。享受它吧!
### 总结
当然,Jrnl 并不适合所有人。大多数命令行工具都不适合。但如果你在终端中生活和呼吸,并喜欢记录你的想法,它就适合你。
请不要忘记在评论中与我们分享你的个人经验,或者更好的是,如果你想让更多的人了解这个项目,你可以在各个社区和论坛上分享这个帖子。
---
via: <https://itsfoss.com/jrnl/>
作者:[Marco Carmona](https://itsfoss.com/author/marco/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Imagine this: somebody has broken your heart and what you want is to write your feelings in a journal without distraction. Did you get the idea? No? Neither do I. I am not heartbroken (or maybe I am and I don’t want to tell you).
But I would still like to show you a wonderful minimalistic open-source, note-taking application to keep journal entries.
This handy little program is [Jrnl](https://jrnl.sh/en/stable/) and it lets you create, search and view journal entries right in the terminal.
Creating new notes with Jrnl is as simple as writing this:
`jrnl yesterday: I read an amazing article on It’s FOSS. I learn about a minimalist app called Jrnl, I should try it.`
Looks easy, isn’t it? The keyword yesterday is a trigger here and it saves your note to yesterday’s date. Remember that it’s called Jrnl (journal) for a reason. Its main aim is to keep journal.
If you like to keep a diary of your thoughts or simply want to try it out, let me share a few details on the installation and its usage.
## Installing and using Jnrl on your Linux system
Jrnl can be installed using pipx or Homebrew package managers.
I used Homebrew for my testing so I’ll list those steps. Get Homebrew first:
`/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"`

That’s all! If you need more information, we have a detailed tutorial on [installing Homebrew on Linux](https://itsfoss.com/homebrew-linux/).
Once you have Homebrew package manager installed, use it to install Jrnl:
`brew install jrnl`
Once you have it installed, just initialize jrnl and start writing your random thoughts.
Do you remember the first example at the beginning of this article? Let’s take a look at it again!
`jrnl yesterday: I read an amazing article in It’s FOSS. I learn about a minimalist app called Jrnl, I should try it.`
In this line, I’m starting the program with the command `jrnl`
next to a timestamp, which in this case is `yesterday`
. I write a colon `:`
to indicate that I will start writing something, and everything contained until a first sentence mark `.?!:`
(in this case a period `.`
) will be the title. Finally, everything next to this sentence mark will be considered the body of the file.
Currently, Jnrl has two modes: composing and viewing; the steps before are used to compose an entry but if what you want to view, for example, the entry that was written before, the syntax is also easy, what you only have to type is the next line.
`jrnl -on yesterday`

Think that someone may read your journal and thoughts? You can also encrypt your entries.
That’s it! Of course, Jrnl has a lot more function, which can easily be found with the next line:
`jrnl --help`
You can also refer to the documentation on [its official website](https://jrnl.sh/en/stable/overview/). Remember, the documentation is your best friend in an open-source project like this one. Enjoy it!
## Conclusion
Of course, Jrnl is not for everyone. Most command line utilities are not. But if you live and breath in the terminal and like to record your thoughts
Please don’t forget to share with us your personal experience in the comments; or even better, if you want to get this project to many more people you can share this post in various communities and forum. |
14,230 | 黑曜石:Markdown 硬核用户创建知识图谱的 Notion 替代品 | https://itsfoss.com/obsidian-markdown-editor/ | 2022-01-31T09:28:00 | [
"Markdown",
"知识图谱"
] | https://linux.cn/article-14230-1.html | 
我喜欢用 Markdown 来写文章和做笔记。我不确定我是否符合 “Markdown 硬核用户”的标准,但我觉得它对我的写作工作很方便。
我在 Linux 上试过几个 Markdown 编辑器。我最喜欢的是 [Joplin](https://itsfoss.com/joplin/),它可以用来做笔记和组织笔记,并在 Nextcloud 上保留备份。还有 [Zettlr](https://itsfoss.com/zettlr-markdown-editor/),它适合于研究人员。
最近,我遇到了另一个 Markdown 编辑器,它在文档整理方面意外的不错。你可以用它将你的文件相互连接起来,并以类似思维导图的图形方式显示出来。

这就是 <ruby> <a href="https://obsidian.md/"> 黑曜石 </a> <rt> Obsidian </rt></ruby> 的主要吸引力,你可以用图形的方式查看你的 Markdown 笔记,特别是当这些笔记需要相互连接的时候。当然,它也有其他的功能。
>
> 非 FOSS 警报!
>
>
> 最初,我以为黑曜石是一个开源软件。当我寻找他们的源代码库时(在我写完这篇文章后),我才意识到它是 [免费使用的应用程序](https://obsidian.md/eula),但不是 FOSS(自由及开源软件)。这让我觉得惭愧,因为它实在是一个好应用,好到让我继续在这里介绍它。
>
>
>
### 黑曜石 Markdown 编辑器的功能
在黑曜石里,你会发现你期望从一个标准的 Markdown 编辑器得到的所有功能。它有一个侧边栏来显示文件夹结构,还有一个主窗格来显示你的文档。你可以选择在“编辑”和“阅读”视图之间切换。

默认情况下,它只显示一个窗格,但你可以根据自己的喜好添加更多的窗格。例如,我添加了一个新的窗格来同时显示编辑和查看模式,这样就可以在同一时间编辑和预览文档。

你可以通过按 `[[` 键来创建现有笔记的内部链接。它可以打开一个文件搜索器,让你从同一项目(这里称为 “<ruby> 金库 <rt> vault </rt></ruby>”)中的现有笔记中选择。

你可以切换到“图表视图”来显示同一个“金库”(项目)中的笔记之间的联系。我快速做了几个内部链接来进行测试,你可以看到它显示了文件之间的相互联系。

你可以图形化地进行搜索和替换。对笔记进行备注、合并文件、在笔记之间移动标题等等。
它还有一个命令模式(位于编辑器的左侧侧边栏),允许你控制编辑器的各个方面。其中一些“动作”也可以用键盘快捷键来完成。

这还不是全部。黑曜石还有一个 [社区市场](https://obsidian.md/plugins),在那里你可以找到并安装插件来扩展其功能。例如,你可以下载看板插件,用黑曜石来管理项目和任务。

这里还有很多功能,我不可能把它们全部列出。即使是项目网站也没有一次性列出所有的功能,这是很无奈的。
### 安装黑曜石
黑曜石是一个跨平台的应用程序,它可用于 Linux、macOS、Windows、Android 和 iOS。
对于 Linux,你可以选择使用 AppImage、Snap 或 Flatpak。我使用 AppImage 版本进行测试。你可以在其下载页面找到相关信息和文件。
* [下载黑曜石](https://obsidian.md/download)
### 它值得使用吗?
黑曜石有一个学习曲线。你当然需要了解 [Markdown 的基础知识](https://itsfoss.com/markdown-guide/),但是除了编辑和显示 Markdown 文本之外的任何功能,你都需要在这里学习。
几乎任何应用程序都需要一些学习,但要想充分使用黑曜石,你需要付出比平常更多的努力。
但如果你是一个痴迷于 Markdown 的用户,并且有成吨的文档,这完全是值得的。这里的好处是它有 [丰富的文档](https://help.obsidian.md/Obsidian/Index) 来帮助你的学习过程。当你点击帮助按钮(显示为问号)时,这些文档也可以从应用界面中获得。

黑曜石的界面让我觉得我在使用 VS Code,这并不是一件坏事。
如果你以 Markdown 为生,并且对正确管理你的文档很着迷,你应该考虑尝试一下黑曜石。
如果你足够喜欢它并开始定期使用它,也许你可以 [考虑捐赠](https://obsidian.md/pricing) 或使用他们的高级产品以支持这个项目的发展。高级产品包括选择将你的笔记同步到他们的云端,或者将你的笔记发布到网站上。
黑曜石已经做得很专业和漂亮了。它就像 VS Code 的 Markdown 版,它有可能成为 [Notion](https://www.notion.so/) 等的真正替代品。
---
via: <https://itsfoss.com/obsidian-markdown-editor/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I like using Markdown for writing articles and taking notes. I am uncertain if I fit the criteria for a ‘hardcore Markdown user’ or not but I find it convenient for my writing works.
I have tried several markdown editors on Linux. [Joplin](https://itsfoss.com/joplin/) is my favorite for taking and organizing notes and keeping a backup on Nextcloud. There is also [Zettlr](https://itsfoss.com/zettlr-markdown-editor/) which is suitable for researchers.
Recently, I came across another Markdown editor that has a twist on document organizing. You can use it to interlink your documents and display them in a mind-map like graphical view.
That’s the main attraction of [Obsidian](https://obsidian.md/?ref=itsfoss.com) that you can get a graphical view of your Markdown notes specially when these notes have to be linked with each other. There are other features here as well.
Non-FOSS alert!
Initially, I thought that Obsidian was an open source software. It was only when I was looking for their source code repository (after I finished writing this article) that I realized it is [free-to-use application](https://obsidian.md/eula?ref=itsfoss.com) but not FOSS (free and open source software). Which is a shame because it’s a damn good application and hence I continued to feature it here.
## Features of Obsidian markdown editor
You’ll find all features you expect from a standard Markdown editor. There is a sidebar to show the folder structure and a main pane where your document lies. You can choose to switch between ‘edit’ and ‘read’ view.
By default, it displays one pane only but you can add more panes as per your liking. For example, I added a new pane to show both editing and viewing modes. This enables editing and previewing the document at the same time.
You can create internal links to existing notes by pressing [[ keys. It opens a file searcher and lets you select from the existing notes in the same project (called vaults here).
You can switch to the Graph view to display the connection between the notes in the same vault (project). I made a few quick internal links to perform a test and you can see that it shows how files are interlinked to each other.
You can perform search and replace graphically. Tag the notes, merge files, move headlines between notes and more.
It also has a command palette (located in the left sidebar of the editor) that allows you to control various aspects of the editor. Several of these ‘actions’ can be performed using keyboard shortcuts as well.
This is not it. Obsidian also has a [community marketplace](https://obsidian.md/plugins?ref=itsfoss.com) where you can find and install plugins to extend its capabilities. For example, you can download the Kanban plugin and use Obsidian to manage projects and tasks.
There are plenty more features here and I can possibly not list all of them. Even the project website doesn’t list all the features at once place which is a bummer.
## Installing Obsidian
Obsidian is a cross-platform application and it is available for Linux, macOS, Windows, Android and iOS.
For Linux, you have the option to use AppImage, Snap or Flatpak. I used the AppImage version for testing. You can find relevant information and files on its download page.
[13 Useful Tips on Organizing Notes Better With ObsidianUtilize Obsidian knowledge tool more effectively with these helpful tips and tweaks.](https://itsfoss.com/obsidian-tips/)

## Is it worth it?
Obsidian has a learning curve. You need to learn the [basics of Markdown](https://itsfoss.com/markdown-guide/) of course but even for any features besides editing and displaying Markdown text, you need to learn things here.
Almost any application requires some learning but to use Obsidian to its fullest, you need to put in more effort than usual.
But it’s entirely worth it if you are an obsessive Markdown user and with tons of documents. The good thing here is that it has [extensive documentation](https://help.obsidian.md/Obsidian/Index?ref=itsfoss.com) to help you with your learning process. This documentation is also accessible from within the application interface when you hit the Help button (displayed with a question mark).
Obsidian interface makes me feel like I am using VS Code and that’s not a negative thing.
If you live and breathe Markdown and you are also obsessed with managing your documents properly, you should consider giving Obsidian a try.
If you like it enough and start using it regularly, perhaps you may [consider a donation](https://obsidian.md/pricing?ref=itsfoss.com) or opt-in for their premium offering to support the development of this project. The premium offering includes the option to sync your notes to their cloud or publish your notes on a website.
Obsidian has been done professionally and beautifully. It’s like Visual Studio Code for Markdown and it has the potential to become a true alternative to the likes of [Notion](https://notion.grsm.io/itsfoss?ref=itsfoss.com). |
14,232 | 系统管理员排除故障的五种武器 | https://opensource.com/article/20/1/ops-hacks-sysadmins | 2022-02-01T00:56:58 | [
"排错",
"系统管理"
] | https://linux.cn/article-14232-1.html |
>
> 当你不知道从哪里开始时,这五个工具可以帮助你找到用户的 IT 问题的源头。
>
>
>

作为系统管理员,我每天都面临着需要快速解决的问题,用户和管理人员期望事情能够顺利地进行。在我管理的这样的一个大型环境中,几乎不可能从头到尾了解所有的系统和产品,所以我必须使用创造性的技术来找到问题的根源,并(希望可以)提出解决方案。
这是我 20 多年来的日常经验!每天上班时,我从不知道会发生什么。因此,我有一些快速而简陋的技巧,当一个问题落在我的身上,而我又不知道从哪里开始时,我一般就会采用这些技巧。
但等一下!在你直接打开命令行之前,请花一些时间与你的用户交谈。是的,这可能很乏味,但他们可能会有一些好的信息给你。请记住,用户可能没有你那么多的经验,你需要对他们说的东西进行一些解释。试着清楚地了解正在发生什么和应该发生什么,然后用技术语言自己描述故障。请注意,大多数用户并不阅读他们面前的屏幕上的内容;这很可悲,但却是事实。确保你和用户都阅读了所有的文字,以收集尽可能多的信息。一旦你收集到了这些信息,就打开命令行,使用这五个工具。
### Telnet
让我从一个经典开始。[Telnet](https://en.wikipedia.org/wiki/Telnet) 是 SSH 的前身,在过去,它在 Unix 系统上用来连接到远程终端,就像 SSH 一样,但它没有加密。Telnet 在诊断网络连接问题方面有一个非常巧妙和宝贵的技巧:你可以 Telnet 到不是专属于它 TCP 端口(23/TCP)。要做到这一点,可以像平时一样使用 Telnet,但在末尾加上 TCP 端口(例如 `telnet localhost 80`),以连接到一个网络服务器。这可以让你能够检查一个服务器,看看服务是否正在运行,或者防火墙是否阻挡了它。因此,在没有应用程序客户端,甚至没有登录应用程序的情况下,你可以检查 TCP 端口是否有反应。如果你知道怎么做,有时你可以通过在 Telnet 提示符手动输入并获得响应以检查。网络服务器和邮件服务器是你可以这样做的两个例子。

### Tcpdump
[tcpdump](https://www.tcpdump.org/) 工具可以让你检查网络上正在传输的数据。大多数网络协议都相当简单,如果你把 `tcpdump` 和一个像 [Wireshark](https://www.wireshark.org/) 这样的工具结合起来,你会得到一个简单而好用的方法来浏览你所捕获的流量。在如下的例子中,我在下面的窗口中检查数据包,在上面的窗口连接到 TCP 3260 端口。

这张截图显示了在现实世界中使用 Wireshark 查看 iSCSI 协议的情况;在这种情况下,我能够确定我们的 QNAP 网络附加存储的配置方式有问题。

### find
如果你不知道从哪里开始,[find](https://en.wikipedia.org/wiki/Find_%28Unix%29) 命令就是最好的工具。在其最简单的形式中,你可以用它来“寻找”文件。例如,如果我想在所有的目录中进行递归搜索,得到一个 conf 文件的列表,我可以输入:
```
find . -name '*.conf'.
```

但是,`find` 的一个隐藏的宝藏是,你可以用它对它找到的每个项目执行一个命令。例如,如果我想得到每个文件的长列表,我可以输入;
```
find . -name '*.conf' -exec ls -las {}\;
```

一旦你掌握了这种技术,你就可以用各种创造性的方法来寻找、搜索和以特定方式执行程序。
### strace
我是在 Solaris 上认识 [strace](https://strace.io/) 这个概念的,在那里它被称为 `truss`。今天,它仍然像多年前一样有用。`strace` 允许你在进程实时运行时检查它在做什么。使用它很简单,只要使用命令 `ps -ef`,找到你感兴趣的进程 ID。用 `strace -p <进程 ID>` 启动 `strace`,它会开始打印出一大堆东西,一开始看起来像垃圾信息。但如果你仔细观察,你会看到你认识的文字,如 `OPEN` 和 `CLOSE` 这样的词和文件名。如果你想弄清楚一个程序为什么不工作,这可以引导你走向正确的方向。
### grep
把最好的留到最后:[grep](https://en.wikipedia.org/wiki/Grep)。这个工具是如此有用和强大,以至于我很难想出一个简洁的方法来描述它。简单地说,它是一个搜索工具,但它的搜索方式使它如此强大。在问题分析中,我通常会用 `grep` 搜索一堆日志来寻找一些东西。一个叫 `zgrep` 的配套命令可以对压缩文件做同样的事情。在下面的例子中,我使用 `zgrep bancroft /var/log/*` 在所有的日志文件中进行 grep,以查看我在系统中的工作情况。我使用 `zgrep` 是因为该目录中有压缩文件。

使用 `grep` 的另一个好方法是将其他工具的输出通过管道输送到它里面;这样,它就可以作为一种过滤器来使用。在下面的例子中,我列出了 auth 文件,并通过使用 `cat auth.log |grep bancroft` 来搜索我的登录信息,看看我都做了什么。这也可以写成 `grep bancroft auth.log`,但我这里用管道(`|`)来证明这一点。

### 其他需要考虑的工具
你可以用这些工具做更多的事情,但我希望这个简单的介绍能给你一个窗口,让你了解如何用它们来解决你遇到的讨厌的问题。另一个值得你注意的工具是 [Nmap](https://nmap.org/),我没有包括它,因为它是如此全面,需要一整篇文章(或更多)来解释它。最后,我建议学习一些白帽和黑客技术;在试图找出问题的根源时,它们可能非常有益,因为它们可以帮助你收集对决策至关重要的信息。
---
via: <https://opensource.com/article/20/1/ops-hacks-sysadmins>
作者:[Stephen Bancroft](https://opensource.com/users/stevereaver) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As a sysadmin, every day I am faced with problems I need to solve quickly because there are users and managers who expect things to run smoothly. In a large environment like the one I manage, it's nearly impossible to know all of the systems and products from end to end, so I have to use creative techniques to find the source of the problems and (hopefully) come up with solutions.
This has been my daily experience for well over 20 years, and I love it! Coming to work each day, I never quite know what will happen. So, I have a few quick and dirty tricks that I default to when a problem lands on my lap, but I don't know where to start.
*BUT WAIT!* Before you jump straight onto the command line, spend some time talking to your users. Yes, it can be tedious, but they will have some good information for you. Keep in mind that users probably don't have as much experience as you have, and you will need to do some interpreting of whatever they say. Try to get a clear picture of what *is* happening and what *should be* happening, then describe the fault to yourself in technical language. Be aware that most users don't read what is on the screen in front of them; it's sad but true. Make sure you and the user are reading all of the text to gather as much information as possible. Once you have that together, jump onto the command line with these five tools.
## Telnet
I am starting with a classic. [Telnet](https://en.wikipedia.org/wiki/Telnet) was the predecessor to SSH, and, in the olden days, it was used on Unix systems to connect to a remote terminal just like SSH does, but it was not encrypted. Telnet has a very neat and invaluable trick for diagnosing network connectivity issues: you can Telnet into TCP ports that are not reserved for it. To do so, use Telnet like you normally would, but add the TCP port onto the end (**telnet localhost 80,** for instance) to connect to a web server. This enables you to check a server to see if a service is running or if a firewall is blocking it. So, without having the application client or even a login for the application, you can check if the TCP port is responding. If you know how, sometimes you can elicit a response from the server by manually typing into the Telnet prompt and checking the response. Web servers and mail servers are two examples where you can do this.
## Tcpdump
The [tcpdump](https://www.tcpdump.org/) tool lets you inspect what data is being transmitted on the network. Most network protocols are fairly simple and, if you combine tcpdump with a tool like [Wireshark](https://www.wireshark.org/), you will have a nice, easy way to browse the traffic that you have captured. In the example below, I am inspecting packets in the bottom window and connecting to TCP port 3260 in the top.
This screenshot shows a real-world use of Wireshark to look at the iSCSI protocol; in this case, I was able to identify that there was a problem with the way our QNAP network-attached storage was configured.
## find
The [find](https://en.wikipedia.org/wiki/Find_%28Unix%29) command is simply the best tool if you don't know where to start. In its most simple form, you can use it to "find" files. For example, if I wanted to do a recursive search through all directories and get a list of the conf files, I could enter:
`find . -name '*.conf'.`
But one of find's hidden gems is that you can use it to execute a command against each item it finds. For example, if I wanted to get a long list of each file, I could enter:
`find . -name '*.conf' -exec ls -las {} \;`
Once you know this technique, you can use it in all sorts of creative ways to find, search, and execute programs in specific ways.
## strace
I was introduced to the concept of [strace](https://strace.io/) on Solaris, where it is called truss. It is still as useful today as it was all those years ago. strace allows you to inspect what a process is doing as it runs in real time. Using it is simple; just use the command **ps -ef** and find the process ID that you are interested in. Start strace with **strace -p <pid>**; this will start printing out a whole lot of stuff, which at first looks like junk. But if you look closer, you will see text that you recognize, such as words like **OPEN** and **CLOSE** and filenames. This can lead you in the right direction if you are trying to figure out why a program is not working.
## grep
Leaving the best for last: [grep](https://en.wikipedia.org/wiki/Grep). This tool is so useful and powerful that I have trouble coming up with a succinct way to describe it. Put simply, it's a search tool, but the way it searches is what makes it so powerful. In problem analysis, I typically grep over a bunch of logs to search for something. A companion command called zgrep does the same thing with zipped files. In the following example, I used **zgrep /var/log/* bancroft** to grep across all the log files to see what I have been up to on the system. I used zgrep because there are zipped files in the directory.
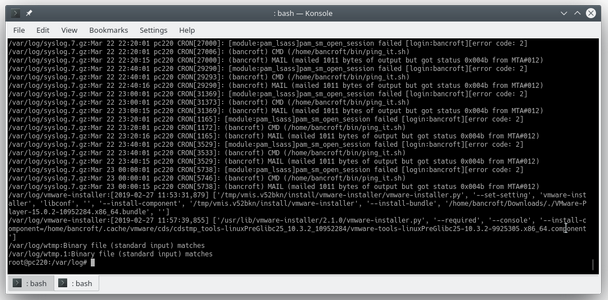
Another great way to use grep is for piping the output of other tools into it; this way, it can be used as a filter of sorts. In the following example, I listed the auth file and grepped for my login to see what I have been doing by using **cat auth.log |grep bancroft**. This can also be written as **grep bancroft auth.log**, but I used the pipe (**|**) to demonstrate the point.
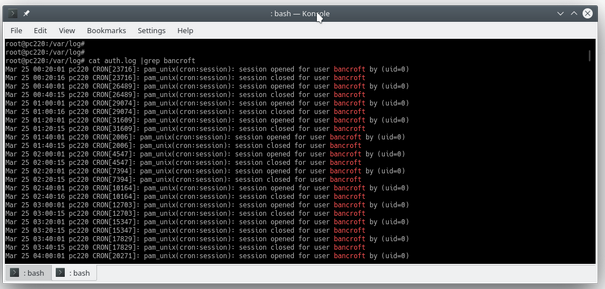
## Other tools to consider
You can do a lot more with these tools, but I hope this brief introduction gives you a window into how to use them to solve the nasty problems that come your way. Another tool worth your attention is [Nmap](https://nmap.org/), which I did not include because it is so comprehensive that it needs an entire article (or more) to explain it. Finally, I recommend learning some white hat and hacking techniques; they can be very beneficial when trying to get to the bottom of a problem because they can help you collect information that can be crucial in decision making.
## 8 Comments |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.