
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
13,592 | 在 Linux 上用密码加密和解密文件 | https://opensource.com/article/21/7/linux-age | 2021-07-18T10:26:11 | [
"加密",
"解密"
] | https://linux.cn/article-13592-1.html |
>
> age 是一个简单的、易于使用的工具,允许你用一个密码来加密和解密文件。
>
>
>

文件的保护和敏感文档的安全加密是用户长期以来关心的问题。即使越来越多的数据被存放在网站和云服务上,并由具有越来越安全和高强度密码的用户账户来保护,但我们能够在自己的文件系统中存储敏感数据仍有很大的价值,特别是我们能够快速和容易地加密这些数据时。
[age](https://github.com/FiloSottile/age) 能帮你这样做。它是一个小型且易于使用的工具,允许你用一个密码加密一个文件,并根据需要解密。
### 安装 age
`age` 可以从众多 Linux 软件库中 [安装](https://github.com/FiloSottile/age#installation)。
在 Fedora 上安装它:
```
$ sudo dnf install age -y
```
在 macOS 上,使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac) 来安装。在 Windows 上,使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey) 来安装。
### 用 age 加密和解密文件
`age` 可以用公钥或用户自定义密码来加密和解密文件。
#### 在 age 中使用公钥
首先,生成一个公钥并写入 `key.txt` 文件:
```
$ age-keygen -o key.txt
Public key: age16frc22wz6z206hslrjzuv2tnsuw32rk80pnrku07fh7hrmxhudawase896m9
```
### 使用公钥加密
要用你的公钥加密一个文件:
```
$ touch mypasswds.txt | age -r \
ageage16frc22wz6z206hslrjzuv2tnsuw32rk80pnrku07fh7hrmxhudawase896m9 \
> mypass.tar.gz.age
```
在这个例子中,我使用生成的公钥加密文件 `mypasswds.txt`,保存在名为 `mypass.tar.gz.age` 的加密文件中。
### 用公钥解密
如需解密加密文件,使用 `age` 命令和 `--decrypt` 选项:
```
$ age --decrypt -i key.txt -o mypass.tar.gz mypass.tar.gz.age
```
在这个例子中,`age` 使用存储在 `key.text` 中的密钥,并解密了我在上一步创建的加密文件。
### 使用密码加密
不使用公钥的情况下对文件进行加密被称为对称加密。它允许用户设置密码来加密和解密一个文件。要做到这一点:
```
$ age --passphrase --output mypasswd-encrypted.txt mypasswd.txt
Enter passphrase (leave empty to autogenerate a secure one):
Confirm passphrase:
```
在这个例子中,`age` 提示你输入一个密码,它将通过这个密码对输入文件 `mypasswd.txt` 进行加密,并生成加密文件 `mypasswd-encrypted.txt`。
### 使用密码解密
如需将用密码加密的文件解密,可以使用 `age` 命令和 `--decrypt` 选项:
```
$ age --decrypt --output passwd-decrypt.txt mypasswd-encrypted.txt
```
在这个例子中,`age` 提示你输入密码,只要你提供的密码与加密时设置的密码一致,`age` 随后将 `mypasswd-encrypted.txt` 加密文件的内容解密为 `passwd-decrypt.txt`。
### 不要丢失你的密钥
无论你是使用密码加密还是公钥加密,你都\_不能\_丢失加密数据的凭证。根据设计,如果没有用于加密的密钥,通过 `age` 加密的文件是不能被解密的。所以,请备份你的公钥,并记住这些密码!
### 轻松实现加密
`age` 是一个真正强大的工具。我喜欢把我的敏感文件,特别是税务记录和其他档案数据,加密到 `.tz` 文件中,以便以后访问。`age` 是用户友好的,使其非常容易随时加密。
---
via: <https://opensource.com/article/21/7/linux-age>
作者:[Sumantro Mukherjee](https://opensource.com/users/sumantro) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Encryption and security for protecting files and sensitive documents have long been a concern for users. Even as more and more of our data is housed on websites and cloud services, protected by user accounts with ever-more secure and challenging passwords, there's still great value in being able to store sensitive data on our own filesystems, especially when we can encrypt that data quickly and easily.
[Age](https://github.com/FiloSottile/age) allows you to do this. It is a small, easy-to-use tool that allows you to encrypt a file with a single passphrase and decrypt it as required.
## Install age
Age is available to [install](https://github.com/FiloSottile/age#installation) from most Linux repositories.
To install it on Fedora:
`$ sudo dnf install age -y`
On macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac). On Windows, use [Chocolatey](https://opensource.com/article/20/3/chocolatey).
## Encrypting and decrypting files with age
Age can encrypt and decrypt files with either a public key or a passphrase set by the user.
### Using age with a public key
First, generate a public key and write the output to a `key.txt`
file:
```
$ age-keygen -o key.txt
Public key: age16frc22wz6z206hslrjzuv2tnsuw32rk80pnrku07fh7hrmxhudawase896m9
```
## Encrypt with a public key
To encrypt a file with your public key:
`$ touch mypasswds.txt | age -r ageage16frc22wz6z206hslrjzuv2tnsuw32rk80pnrku07fh7hrmxhudawase896m9 > mypass.tar.gz.age`
In this example, the file `mypasswds.txt`
is encrypted with the public key I generated and put inside an encrypted file called `mypass.tar.gz.age`
.
## Decrypt with a public key
To decrypt the information you've protected, use the `age`
command and the `--decrypt`
option:
`$ age --decrypt -i key.txt -o mypass.tar.gz mypass.tar.gz.age`
In this example, age uses the key stored in `key.text`
and decrypts the file I created in the previous step.
## Encrypt with a passphrase
Encrypting a file without a public key is known as symmetrical encryption. It allows a user to set the passphrase to encrypt and decrypt a file. To do so:
```
$ age --passphrase --output mypasswd-encrypted.txt mypasswd.txt
Enter passphrase (leave empty to autogenerate a secure one):
Confirm passphrase:
```
In this example, age prompts you for a passphrase, which it uses to encrypt the input file `mypasswd.txt`
and render the file `mypasswd-encrypted.txt`
in return.
## Decrypt with a passphrase
To decrypt a file encrypted with a passphrase, use the `age`
command with the `--decrypt`
option:
`$ age --decrypt --output passwd-decrypt.txt mypasswd-encrypted.txt `
In this example, age prompts you for the passphrase, then decrypts the contents of the `mypasswd-encrypted.txt`
file into `passwd-decrypt.txt`
, as long as you provide the passphrase that matches the one set during encryption.
## Don't lose your keys
Whether you're using passphrase encryption or public-key encryption, you *must not* lose the credentials for your encrypted data. By design, a file encrypted with age cannot be decrypted without the key used to encrypt it. So back up your public key, and remember those passphrases!
## Easy encryption at last
Age is a really robust tool. I like to encrypt my sensitive files, especially tax records and other archival data, into a `.tz`
file for later access. Age is user-friendly and makes it very easy to get started with encryption on the go.
## 1 Comment |
13,594 | 用于 Web 前端开发的 9 个 JavaScript 开源框架 | https://opensource.com/article/20/5/open-source-javascript-frameworks | 2021-07-18T20:53:03 | [
"JavaScript",
"前端"
] | https://linux.cn/article-13594-1.html |
>
> 根据 JavaScript 框架的优点和主要特点对许多 JavaScript 框架进行细分。
>
>
>

大约十年前,JavaScript 社区开始见证一场 JavaScript 框架的激战。在本文中,我将介绍其中最著名的一些框架。值得注意的是,这些都是开源的 JavaScript 项目,这意味着你可以在 [开源许可证](https://opensource.com/article/17/9/open-source-licensing) 下自由地使用它们,甚至为它们的源代码和社区做出贡献。
不过,在开始之前,了解一些 JavaScript 开发者谈论框架时常用的术语,将对后续的内容大有裨益。
| 术语 | 释义 |
| --- | --- |
| [文档对象模型(DOM)](https://www.w3schools.com/js/js_htmldom.asp) | 网站的树形结构表示,每一个节点都是代表网页一部分的对象。万维网联盟(W3C),是万维网的国际标准组织,维护着 DOM 的定义。 |
| [虚拟 DOM](https://reactjs.org/docs/faq-internals.html) | 用户界面(UI)以“虚拟”或“理想”的方式保存在内存中,并通过 [ReactDOM](https://reactjs.org/docs/react-dom.html) 等一些库与“真实” DOM 同步。要进一步探索,请阅读 ReactJS 的虚拟 DOM 和内部文档。 |
| [数据绑定](https://en.wikipedia.org/wiki/Data_binding) | 一个编程概念,为访问网站上的数据提供一致的接口。Web 元素与 DOM 维护的元素的<ruby> 属性 <rt> property </rt></ruby> 或 <ruby> 特性 <rt> attribute </rt></ruby> 相关联(LCTT 译注:根据 MDN 的解释,Javascript 的<ruby> 属性 <rt> property </rt></ruby>是对象的特征,通常描述与数据结构相关的特征;<ruby> 特性 <rt> attribute </rt></ruby> 是指元素所有属性节点的一个实时集合)。例如,当需要在网页表单中填写密码时,数据绑定机制可以用密码验证逻辑检验,确保密码格式有效。 |
我们已经清楚了常用的术语,下面我们来探索一下开源的 JavaScript 框架有哪些。
| 框架 | 简介 | 许可证 | 发布日期 |
| --- | --- | --- | --- |
| [ReactJS](https://github.com/facebook/react) | 目前最流行的 JavaScript 框架,由 Facebook 创建 | MIT 许可证 | 2013-5-24 |
| [Angular](https://github.com/angular/angular) | Google 创建的流行的 JavaScript 框架 | MIT 许可证 | 2010-1-5 |
| [VueJS](https://github.com/vuejs/vue) | 快速增长的 JavaScript 框架 | MIT 许可证 | 2013-7-28 |
| [MeteorJS](https://github.com/meteor/meteor) | 超乎于 JavaScript 框架的强大框架 | MIT 许可证 | 2012-1-18 |
| [KnockoutJS](https://github.com/knockout/knockout) | 开源的 MVVM(<ruby> 模型-视图-视图模型 <rt> Model-View-ViewModel </rt></ruby>) 框架 | MIT 许可证 | 2010-7-5 |
| [EmberJS](https://github.com/emberjs/ember.js) | 另一个开源的 MVVM 框架 | MIT 许可证 | 2011-12-8 |
| [BackboneJS](https://github.com/jashkenas/backbone) | 带有 RESTful JSON 和<ruby> 模型-视图-主持人 <rt> Model-View-Presenter </rt></ruby>模式的 JavaScript 框架 | MIT 许可证 | 2010-9-30 |
| [Svelte](https://github.com/sveltejs/svelte) | 不使用虚拟 DOM 的 JavaScript 开源框架 | MIT 许可证 | 2016-11-20 |
| [AureliaJS](https://github.com/aurelia/framework) | 现代 JavaScript 模块的集合 | MIT 许可证 | 2018-2-14 |
为了说明情况,下面是每个框架的 NPM 包下载量的公开数据,感谢 [npm trends](https://www.npmtrends.com/angular-vs-react-vs-vue-vs-meteor-vs-backbone)。

### ReactJS

[ReactJS](https://reactjs.org) 是由 Facebook 研发的,它虽然在 Angular 之后发布,但明显是当今 JavaScript 框架的领导者。React 引入了一个虚拟 DOM 的概念,这是一个抽象副本,开发者能在框架内仅使用他们想要的 ReactJS 功能,而无需重写整个项目。此外,React 项目活跃的开源社区无疑成为增长背后的主力军。下面是一些 React 的主要优势:
* 合理的学习曲线 —— React 开发者可以轻松地创建 React 组件,而不需要重写整个 JavaScript 的代码。在 ReactJS 的 [首页](https://reactjs.org/) 查看它的优点以及它如何使编程更容易。
* 高度优化的性能 —— React 的虚拟 DOM 的实现和其他功能提升了应用程序的渲染性能。请查看 ReactJS 的关于如何对其性能进行基准测试,并对应用性能进行衡量的相关 [描述](https://reactjs.org/docs/perf.html)。
* 优秀的支持工具 —— [Redux](https://redux.js.org/)、[Thunk](https://github.com/reduxjs/redux-thunk) 和 [Reselect](https://github.com/reduxjs/reselect) 是构建良好、可调式代码的最佳工具。
* 单向数据绑定 —— 模型使用 Reach 流,只从所有者流向子模块,这使得在代码中追踪因果关系更加简单。请在 ReactJS 的 [数据绑定页](https://reactjs.org/docs/two-way-binding-helpers.html) 阅读更多相关资料。
谁在使用 ReactJS?Facebook 自从发明它,就大量使用 React 构建公司首页,据说 [Instagram](https://instagram-engineering.com/react-native-at-instagram-dd828a9a90c7) 完全基于 ReactJS 库。你可能会惊讶地发现,其他知名公司如 [纽约时报](https://open.nytimes.com/introducing-react-tracking-declarative-tracking-for-react-apps-2c76706bb79a)、[Netflix](https://medium.com/dev-channel/a-netflix-web-performance-case-study-c0bcde26a9d9) 和 [可汗学院](https://khan.github.io/react-components/) 也在他们的技术栈中使用了 ReactJS。
更令人惊讶的是 ReactJS 开发者的工作机会,正如在下面 Stackoverflow 所做的研究中看到的,嘿,你可以从事开源项目并获得报酬。这很酷!

*Stackoverflow 的研究显示了对 ReactJS 开发者的巨大需求——[来源:2017 年开发者招聘趋势——Stackoverflow 博客](https://stackoverflow.blog/2017/03/09/developer-hiring-trends-2017)*
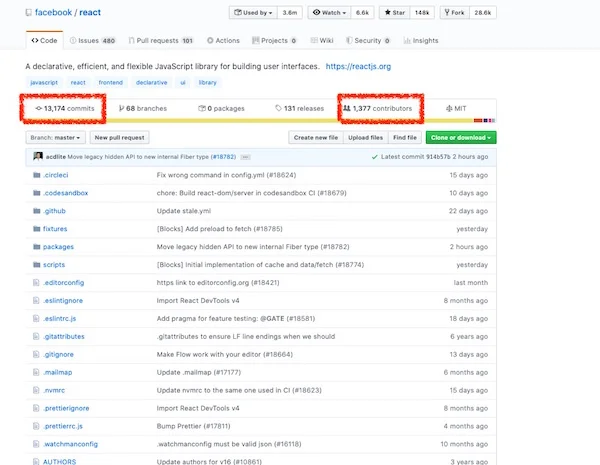
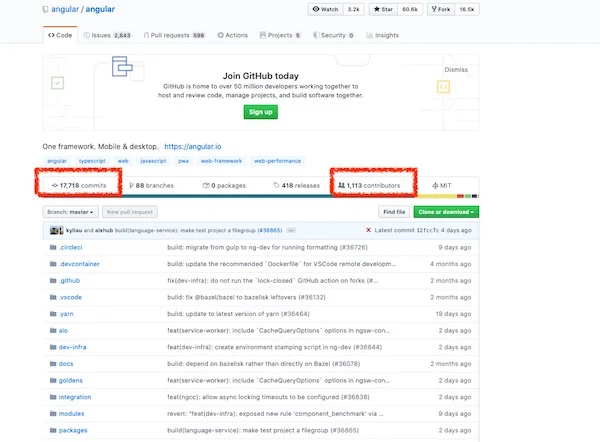
[ReactJS 的 GitHub](https://github.com/facebook/react) 目前显示超过 13,000 次提交和 1,377 位贡献者。它是一个在 MIT 许可证下的开源项目。

### Angular

就开发者数量来说,也许 React 是现在最领先的 JavaScript 框架,但是 [Angular](https://angular.io) 紧随其后。事实上,开源开发者和初创公司更乐于选择 React,而较大的公司往往更喜欢 Angular(下面列出了一些例子)。主要原因是,虽然 Angular 可能更复杂,但它的统一性和一致性适用于大型项目。例如,在我整个职业生涯中一直研究 Angular 和 React,我观察到大公司通常认为 Angular 严格的结构是一种优势。下面是 Angular 的另外一些关键优势:
* 精心设计的命令行工具 —— Angular 有一个优秀的命令行工具(CLI),可以轻松起步和使用 Angular 进行开发。ReactJS 提供命令行工具和其他工具,同时 Angular 有广泛的支持和出色的文档,你可以参见 [这个页面](https://cli.angular.io/)。
* 单向数据绑定 —— 和 React 类似,单向数据绑定模型使框架受更少的不必要的副作用的影响。
* 更好的 TypeScript 支持 —— Angular 与 [TypeScript](https://www.typescriptlang.org/) 有很好的一致性,它其实是 JavaScript 强制类型的拓展。它还可以转译为 JavaScript,强制类型是减少错误代码的绝佳选择。
像 YouTube、[Netflix](https://netflixtechblog.com/netflix-likes-react-509675426db)、[IBM](https://developer.ibm.com/technologies/javascript/tutorials/wa-react-intro/) 和 [Walmart](https://medium.com/walmartlabs/tagged/react) 等知名网站,都已在其应用程序中采用了 Angular。我通过自学使用 Angular 来开始学习前端 JavaScript 开发。我参与了许多涉及 Angular 的个人和专业项目,但那是当时被称为 AngularJS 的 Angular 1.x。当 Google 决定将版本升级到 2.0 时,他们对框架进行了彻底的改造,然后变成了 Angular。新的 Angular 是对之前的 AngularJS 的彻底改造,这一举动带来了一部分新开发者也驱逐了一部分原有的开发者。
截止到撰写本文,[Angular 的 GitHub](https://github.com/angular/angular) 页面显示 17,781 次提交和 1,133 位贡献者。它也是一个遵循 MIT 许可证的开源项目,因此你可以自由地在你的项目或贡献中使用。

### VueJS

[VueJS](https://vuejs.org) 是一个非常有趣的框架。它是 JavaScript 框架领域的新来者,但是在过去几年里它的受欢迎程度显著增加。VueJS 由 [尤雨溪](https://www.freecodecamp.org/news/between-the-wires-an-interview-with-vue-js-creator-evan-you-e383cbf57cc4/) 创建,他是曾参与过 Angular 项目的谷歌工程师。该框架现在变得如此受欢迎,以至于许多前端工程师更喜欢 VueJS 而不是其他 JavaScript 框架。下图描述了该框架随着时间的推移获得关注的速度。

这里有一些 VueJS 的主要优点:
* 更容易地学习曲线 —— 与 Angular 或 React 相比,许多前端开发者都认为 VueJS 有更平滑的学习曲线。
* 小体积 —— 与 Angular 或 React 相比,VueJS 相对轻巧。在 [官方文档](https://vuejs.org/v2/guide/comparison.html#Size) 中,它的大小据说只有约 30 KB;而 Angular 生成的项目超过 65 KB。
* 简明的文档 —— VueJS 有全面清晰的文档。请自行查看它的 [官方文档](https://vuejs.org/v2/guide/)。
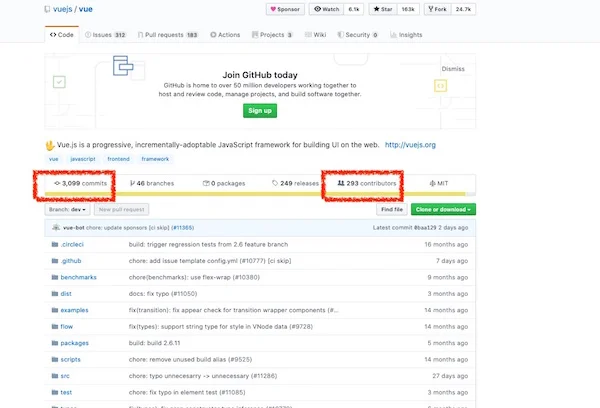
[VueJS 的 GitHub](https://github.com/vuejs/vue) 显示该项目有 3,099 次提交和 239 位贡献者。

### MeteorJS

[MeteorJS](https://www.meteor.com) 是一个自由开源的 [同构框架](https://en.wikipedia.org/wiki/Isomorphic_JavaScript),这意味着它和 NodeJS 一样,同时运行客户端和服务器的 JavaScript。Meteor 能够和任何其他流行的前端框架一起使用,如 Angular、React、Vue、Svelte 等。
Meteor 被高通、马自达和宜家等多家公司以及如 Dispatch 和 Rocket.Chat 等多个应用程序使用。[您可以其在官方网站上查看更多案例](https://www.meteor.com/showcase)。

Meteor 的一些主要功能包括:
* 在线数据 —— 服务器发送数据而不是 HTML,并由客户端渲染。在线数据主要是指 Meteor 在页面加载时通过一个 WebSocket 连接服务器,然后通过该链接传输所需要的数据。
* 用 JavaScript 开发一切 —— 客户端、应用服务、网页和移动界面都可以用 JavaScript 设计。
* 支持大多数主流框架 —— Angular、React 和 Vue 都可以与 Meteor 结合。因此,你仍然可以使用最喜欢的框架如 React 或 Angular,这并不防碍 Meteor 为你提供一些优秀的功能。
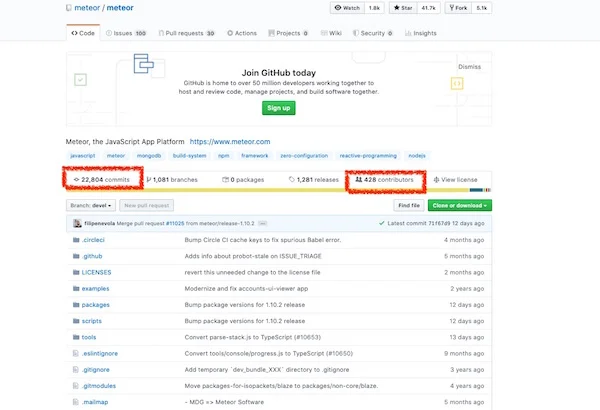
截止到目前,[Meteor 的 GitHub](https://github.com/meteor/meteor) 显示 22,804 次提交和 428 位贡献者。这对于开源项目来说相当多了。

### EmberJS

[EmberJS](https://emberjs.com) 是一个基于 [模型-视图-视图模型(MVVM)](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel) 模式的开源 JavaScript 框架。如果你从来没有听说过 EmberJS,你肯定会惊讶于有多少公司在使用它。Apple Music、Square、Discourse、Groupon、LinkedIn、Twitch、Nordstorm 和 Chipotle 都将 EmberJS 作为公司的技术栈之一。你可以通过查询 [EmberJS 的官方页面](https://emberjs.com/ember-users) 来发掘所有使用 EmberJS 的应用和客户。
Ember 虽然和我们讨论过的其他框架有类似的好处,但这里有些独特的区别:
* 约定优于配置 —— Ember 将命名约定标准化并自动生成结果代码。这种方法学习曲线有些陡峭,但可以确保程序员遵循最佳实践。
* 成熟的模板机制 —— Ember 依赖于直接文本操作,直接构建 HTML 文档,而并不关心 DOM。
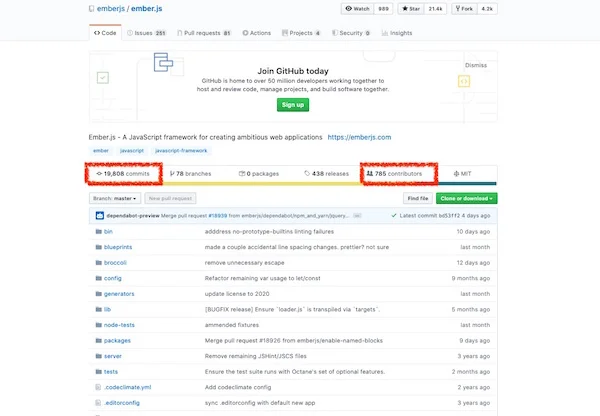
正如所期待的那样,作为一个被许多应用程序使用的框架,[Ember 的 GitHub](https://github.com/emberjs) 页面显示该项目拥有 19,808 次提交和 785 位贡献者。这是一个巨大的数字!

### KnockoutJS

[KnockoutJS](https://knockoutjs.com) 是一个独立开源的 JavaScript 框架,采用 [模板-视图-视图模型(MVVM)](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel) 模式与模板。尽管与 Angular、React 或 Vue 相比,听说过这个框架的人可能比较少,这个项目在开发者社区仍然相当活跃,并且有以下功能:
* 声明式绑定 —— Knockout 的声明式绑定系统提供了一种简洁而强大的方式来将数据链接到 UI。绑定简单的数据属性或使用单向绑定很简单。请在 [KnockoutJS 的官方文档页面](https://knockoutjs.com/documentation/binding-syntax.html) 阅读更多相关信息。
* 自动 UI 刷新。
* 依赖跟踪模板。
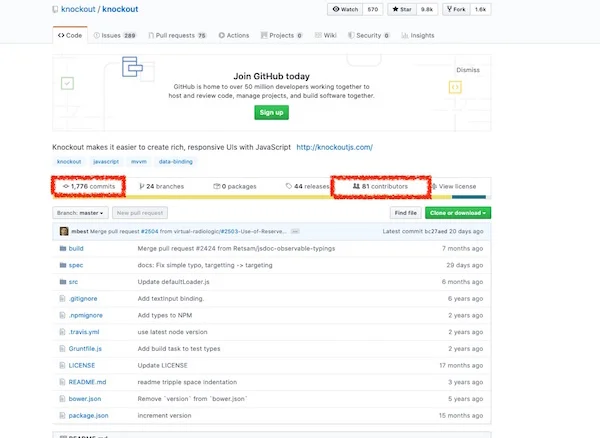
[Knockout 的 GitHub](https://github.com/knockout/knockout) 页面显示约有 1,766 次提交和 81 位贡献者。与其他框架相比,这些数据并不重要,但是该项目仍然在积极维护中。

### BackboneJS

[BackboneJS](https://backbonejs.org) 是一个具有 RESTful JSON 接口,基于<ruby> 模型-视图-主持人 <rt> Model-View-Presenter </rt></ruby>(MVP)设计范式的轻量级 JavaScript 框架。
这个框架据说已经被 [Airbnb](https://medium.com/airbnb-engineering/our-first-node-js-app-backbone-on-the-client-and-server-c659abb0e2b4)、Hulu、SoundCloud 和 Trello 使用。你可以在 [Backbone 的页面](https://sites.google.com/site/backbonejsja/examples) 找到上面所有这些案例来研究。
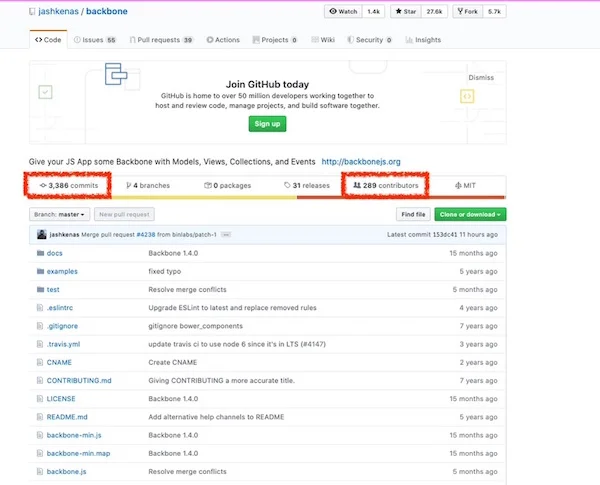
[BackboneJS 的 GitHub](https://github.com/jashkenas/backbone) 页面显示有 3,386 次提交和 289 位贡献者。

### Svelte

[Svelte](https://svelte.dev) 是一个开源的 JavaScript 框架,它生成操作 DOM 的代码,而不是包含框架引用。在构建时而非运行时将应用程序转换为 JavaScript 的过程,在某些情况下可能会带来轻微的性能提升。
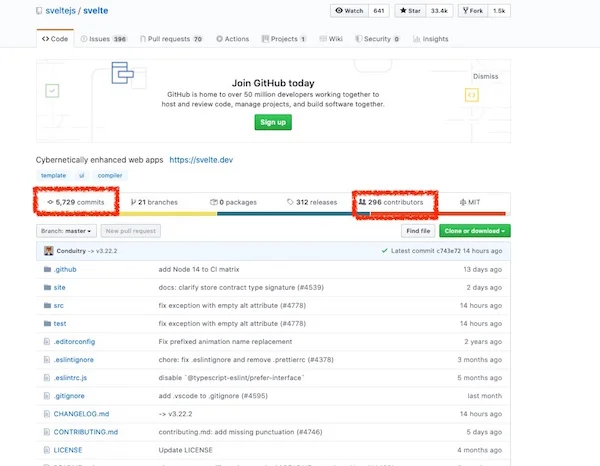
[Svelte 的 GitHub](https://github.com/sveltejs/svelte) 页面显示,截止到本文撰写为止,该项目有 5,729 次提交和 296 位贡献者。

### AureliaJS

最后我们介绍一下 [Aurelia](https://aurelia.io)。Aurelia 是一个前端 JavaScript 框架,是一个现代 JavaScript 模块的集合。Aurelia 有以下有趣的功能:
* 快速渲染 —— Aurelia 宣称比当今其他任何框架的渲染速度都快。
* 单向数据流 —— Aurelia 使用一个基于观察的绑定系统,将数据从模型推送到视图。
* 使用原生 JavaScript 架构 —— 可以用原生 JavaScript 构建网站的所有组件。
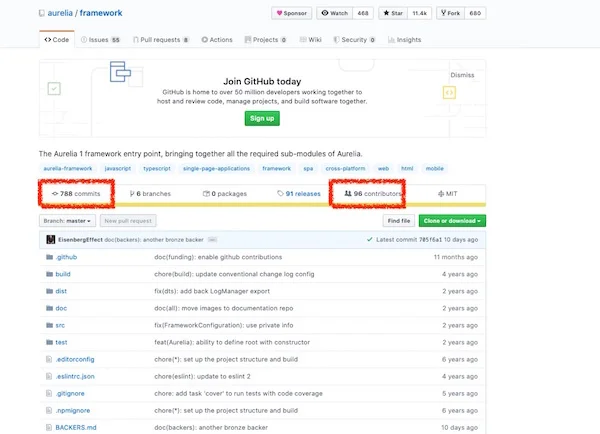
[Aurelia 的 GitHub](https://github.com/aurelia/framework) 页面显示,截止到撰写本文为止该项目有 788 次提交和 96 位贡献者。

这就是我在查看 JavaScript 框架世界时发现的新内容。我错过了其他有趣的框架吗?欢迎在评论区分享你的想法。
---
via: <https://opensource.com/article/20/5/open-source-javascript-frameworks>
作者:[Bryant Son](https://opensource.com/users/brson) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevending1st](https://github.com/stevending1st) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | About a decade ago, the JavaScript developer community began to witness fierce battles emerging among JavaScript frameworks. In this article, I will introduce some of the most well-known of these frameworks. And it's important to note that these are all open source JavaScript projects, meaning that you can freely utilize them under an [open source license](https://opensource.com/article/17/9/open-source-licensing) and even contribute to the source code and communities.
If you prefer to follow along as I explore these frameworks, you can watch my video.
Before getting started, though, it will be useful to learn some of the terminology JavaScript developers commonly use when discussing frameworks.
Term | What It Is |
---|---|
|
[Virtual DOM](https://reactjs.org/docs/faq-internals.html)[ReactDOM](https://reactjs.org/docs/react-dom.html). To explore further, please read ReactJS's virtual DOM and internals documentation.[Data Binding](https://en.wikipedia.org/wiki/Data_binding)Now that we are clear about common terms, let's explore what open source JavaScript frameworks are out there.
Framework | About | License | Release Date |
---|---|---|---|
|
[Angular](https://github.com/angular/angular)[VueJS](https://github.com/vuejs/vue)[MeteorJS](https://github.com/meteor/meteor)[KnockoutJS](https://github.com/knockout/knockout)[EmberJS](https://github.com/emberjs/ember.js)[BackboneJS](https://github.com/jashkenas/backbone)[Svelte](https://github.com/sveltejs/svelte)[AureliaJS](https://github.com/aurelia/framework)For context, here is the publicly available data on popularity based on NPM package downloads per framework, thanks to [npm trends](https://www.npmtrends.com/angular-vs-react-vs-vue-vs-meteor-vs-backbone).
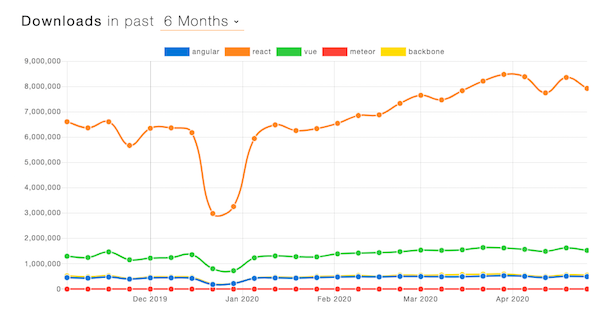
## ReactJS
[ReactJS](https://reactjs.org) was invented by Facebook, and it is the clear leader among JavaScript frameworks today, though it was invented well after Angular. React introduces a concept called a virtual DOM, an abstract copy where developers can utilize only the ReactJS features that they want, without having to rewrite the entire project to work within the framework. In addition, the active open source community with the React project has definitely been the workhorse behind the growth. Here are some of React's key strengths:
- Reasonable learning curve—React developers can easily create the React components without rewriting the entire code in JavaScript. See the benefits of ReactJS and how it makes it the programming easier on ReactJS's
[front page](https://reactjs.org/). - Highly optimized for performance—React's virtual DOM implementation and other features boost app rendering performance. See ReactJS's
[description](https://reactjs.org/docs/perf.html)of how its performance can be benchmarked and measured in terms of how the app performs. - Excellent supporting tools—
[Redux](https://redux.js.org/),[Thunk](https://github.com/reduxjs/redux-thunk), and[Reselect](https://github.com/reduxjs/reselect)are some of the best tools for building well-structured, debuggable code. - One way data binding—The model used in Reach flows from owner to child only making it simpler to trace cause and effect in code. Read more about it on ReactJS's
[page on data binding](https://reactjs.org/docs/two-way-binding-helpers.html).
Who is using ReactJS? Since Facebook invented it, the company itself heavily uses React for its frontpage, and [Instagram](https://instagram-engineering.com/react-native-at-instagram-dd828a9a90c7) is said to be completely based on the ReactJS library. You might be surprised to know that other well-known companies like [New York Times](https://open.nytimes.com/introducing-react-tracking-declarative-tracking-for-react-apps-2c76706bb79a), [Netflix](https://medium.com/dev-channel/a-netflix-web-performance-case-study-c0bcde26a9d9), and [Khan Academy](https://khan.github.io/react-components/) also implement ReactJS in their technology stacks.
What may be even more surprising is the availability of jobs for ReactJS developers, as you can see below from research done by Stackoverflow. Hey, you can work on an open source project and get paid to do it. That is pretty cool!
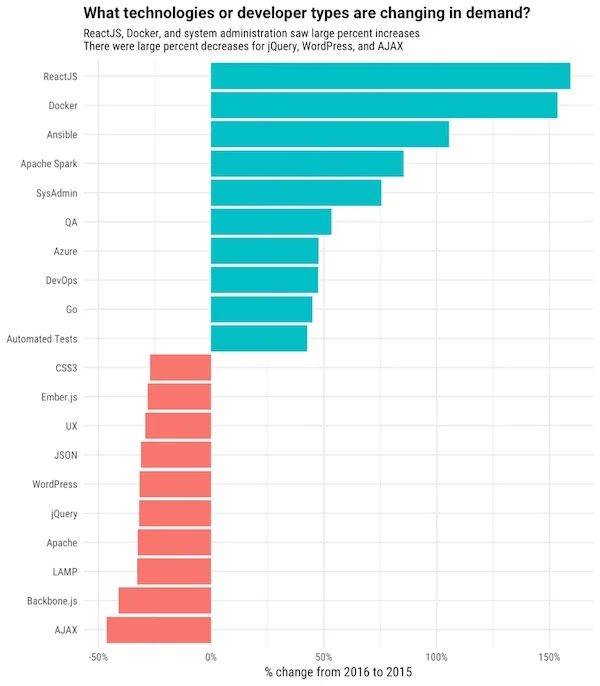
Stackoverflow shows the huge demand for ReactJS developers—[Source: Developer Hiring Trends in 2017 - Stackoverflow Blog](https://stackoverflow.blog/2017/03/09/developer-hiring-trends-2017)
[ReactJS's GitHub](https://github.com/facebook/react) currently shows over 13K commits and 1,377 contributors to the open source project. And it is an open source project under MIT License.
## Angular
React may now be the leading JavaScript framework in terms of the number of developers, but [Angular](https://angular.io) is close behind. In fact, while React is the more popular choice among open source developers and startup companies, larger corporations tend to prefer Angular (a few are listed below). The main reason is that, while Angular might be more complicated, its uniformity and consistency works well for larger projects. For example, I have worked on both Angular and React throughout my career, and I observed that the larger companies generally consider Angular's strict structure a strength. Here are some other key strengths of Angular:
- Well-designed Command Line Interface: Angular has an excellent Command Line Interface (CLI) tool to easily bootstrap and to develop with Angular. ReactJS also offers the Command Line Interface as well as other tools, but Angular has extensive support and excellent documentation, as you can see on
[this page](https://cli.angular.io/). - One way data binding—Similarly to React, the one-way data binding model makes the framework less susceptible to unwanted side effects.
- Great support for TypeScript—Angular has excellent alignment with
[TypeScript](https://www.typescriptlang.org/), which is effectively JavaScript more type enforcement. It also transcompiling to JavaScript, making it a great option to enforce types for less buggy code.
Well-known websites like YouTube, [Netflix](https://netflixtechblog.com/netflix-likes-react-509675426db), [IBM](https://developer.ibm.com/technologies/javascript/tutorials/wa-react-intro/), and [Walmart](https://medium.com/walmartlabs/tagged/react) all have implemented Angular into their applications. I personally started front-end JavaScript development with Angular by educating myself on the subject. I have worked on quite a few personal and professional projects involving Angular, but that was Angular 1.x, which was called by AngularJS at the time. When Google decided to upgrade the version to 2.0, they completely revamped the framework, and then it became Angular. The new Angular was a complete transformation of the previous AngularJS, which drove off some existing developers while bringing new developers.
[Angular's](https://github.com/angular/angular)[ GitHub](https://github.com/angular/angular) page shows 17,781 commits and 1,133 contributors at the time of this writing. It is also an open source project with an MIT License, so you can feel free to use it for your project or to contribute.
## VueJS

[VueJS](https://vuejs.org) is a very interesting framework. It is a newcomer to the JavaScript framework scene, but its popularity has increased significantly over the course of a few years. VueJS was created by [Evan Yu](https://www.freecodecamp.org/news/between-the-wires-an-interview-with-vue-js-creator-evan-you-e383cbf57cc4/), a former Google engineer who had worked on the Angular project. The framework got so popular that many front-end engineers now prefer VueJS over other JavaScript frameworks. The chart below depicts how fast the framework gained traction over time.
Here are some of the key strengths of VueJS:
- Easier learning curve—Even compared to Angular or React, many front-end developers feel that VueJS has the lowest learning curve.
- Small size—VueJS is relatively lightweight compared to Angular or React. In its
[official documentation](https://vuejs.org/v2/guide/comparison.html#Size), its size is stated to be only about 30 KB, while the project generated by Angular, for example, is over 65 KB. - Concise documentation—Vue has thorough but concise and clear documentation. See
[its official documentation](https://vuejs.org/v2/guide/)for yourself.
[VueJS's GitHub](https://github.com/vuejs/vue) shows 3,099 commits and 239 contributors.
## MeteorJS
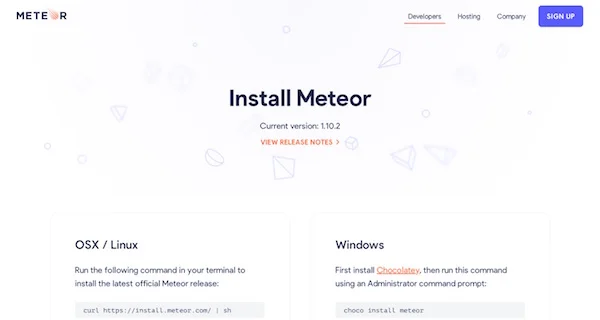
[MeteorJS](https://www.meteor.com) is a free and open source [isomorphic framework](https://en.wikipedia.org/wiki/Isomorphic_JavaScript), which means, just like NodeJS, it runs both client and server-side JavaScript. Meteor can be used in conjunction with any other popular front-end framework like Angular, React, Vue, Svelte, etc.
Meteor is used by several corporations such as Qualcomm, Mazda, and Ikea, and many applications like Dispatch and Rocket.Chat. [See the case studies on its official website.](https://www.meteor.com/showcase)
Some of the key features of Meteor include:
- Data on the wire—The server sends the data, not HTML, and the client renders it. Data on the wire refers mostly to the way that Meteor forms a WebSocket connection to the server on page load, and then transfers the data needed over that connection.
- Develop everything in JavaScript—Client-side, application server, webpage, and mobile interface can be all designed with JavaScript.
- Supports most major frameworks—Angular, React, and Vue can be all combined and used in conjunction with Meteor. Thus, you can still use your favorite framework, like React or Angular, but still leverage some of the great features that Meteor offers.
As of now, [Meteor's](https://github.com/meteor/meteor)[ GitHub](https://github.com/meteor/meteor) shows 22,804 commits and 428 contributors. That is quite a lot for open source activities!
## EmberJS
[EmberJS](https://emberjs.com) is an open source JavaScript framework based on the [Model-view-viewModel(MVVM)](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel) pattern. If you've never heard about EmberJS, you'll definitely be surprised how many companies are using it. Apple Music, Square, Discourse, Groupon, LinkedIn, Twitch, Nordstorm, and Chipotle all leverage EmberJS as one of their technology stacks. Check [EmberJS's official page](https://emberjs.com/ember-users) to discover all applications and customers that use EmberJS.
Although Ember has similar benefits to the other frameworks we've discussed, here are some of its unique differentiators:
- Convention over configuration—Ember standardizes naming conventions and automatically generates the result code. This approach has a little more of a learning curve but ensures that programmers follow best-recommended practices.
- Fully-fledged templating mechanism—Ember relies on straight text manipulation, building the HTML document dynamically while knowing nothing about DOM.
As one might expect from a framework used by many applications, [Ember's GitHub](https://github.com/emberjs) page shows 19,808 commits and 785 contributors. That is huge!
## KnockoutJS
[KnockoutJS](https://knockoutjs.com) is a standalone open source JavaScript framework adopting a [Model-View-ViewModel (MVVM)](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel) pattern with templates. Although fewer people may have heard about this framework compared to Angular, React, or Vue, the project is still quite active among the development community and leverages features such as:
- Declarative binding—Knockout's declarative binding system provides a concise and powerful way to link data to the UI. It's generally easy to bind to simple data properties or to use a single binding. Read more about it
[here at KnockoutJS's official documentation page](https://knockoutjs.com/documentation/binding-syntax.html). - Automatic UI refresh
- Dependency tracking templating
[Knockout's GitHub](https://github.com/knockout/knockout) page shows about 1,766 commits and 81 contributors. Those numbers are not as significant compared to the other frameworks, but the project is still actively maintained.
## BackboneJS

[BackboneJS](https://backbonejs.org) is a lightweight JavaScript framework with a RESTful JSON interface and is based on Model-View-Presenter (MVP) design paradigm.
The framework is said to be used by [Airbnb](https://medium.com/airbnb-engineering/our-first-node-js-app-backbone-on-the-client-and-server-c659abb0e2b4), Hulu, SoundCloud, and Trello. You can find all of these case studies on [Backbone's page](https://sites.google.com/site/backbonejsja/examples).
The [BackboneJS GitHub](https://github.com/jashkenas/backbone) page shows 3,386 commits and 289 contributors.
## Svelte
[Svelte](https://svelte.dev) is an open source JavaScript framework that generates the code to manipulate DOM instead of including framework references. This process of converting an app into JavaScript at build time rather than run time might offer a slight boost in performance in some scenarios.
[Svelte's](https://github.com/sveltejs/svelte)[ GitHub](https://github.com/sveltejs/svelte) page shows 5,729 commits and 296 contributors as of this writing.
## AureliaJS

Last on the list is [Aurelia](https://aurelia.io). Aurelia is a front-end JavaScript framework that is a collection of modern JavaScript modules. Aurelia has the following interesting features:
- Fast rendering—Aurelia claims that its framework can render faster than any other framework today.
- Uni-directional data flow—Aurelia uses an observable-based binding system that pushes the data from the model to the view.
- Build with vanilla JavaScript—You can build all of the website's components with plain JavaScript.
[Aurelia's](https://github.com/aurelia/framework)[ GitHub](https://github.com/aurelia/framework) page shows 788 commits and 96 contributors as of this writing.
So that is what I found when looking at what is new in the JavaScript framework world. Did I miss any interesting frameworks? Feel free to share your ideas in the comment section!
## 6 Comments |
13,595 | 从实际代码开始编写好的示例 | https://jvns.ca/blog/2021/07/08/writing-great-examples/ | 2021-07-18T23:16:25 | [
"代码",
"示例"
] | https://linux.cn/article-13595-1.html | 
当编写程序时,我花费了大量时间在编写好的示例上。我从未见过有人写过关于如何写出好的示例,所以我就写了一下如何写出一份好的示例。
基础思路就是从你写的真实代码开始,然后删除不相关的细节,使其成为一个独立的例子,而不是无中生有地想出一些例子。
我将会谈论两种示例:基于真实案例的示例和奇怪的示例
### 好的示例是真实的
为了说明为什么好的案例应该是真实的,我们就先讨论一个不真实的案例。假设我们在试图解释 Python 的 lambda 函数(这只是我想到的第一个概念)。你可以举一个例子,使用 `map` 和 lambda 来让一组数字变为原先的两倍。
```
numbers = [1, 2, 3, 4]
squares = map(lambda x: x * x, numbers)
```
我觉得这个示例不是真实的,有如下两方面的原因:
* 将一组数字作平方运算不是在真实的程序中完成的事,除非是欧拉项目或某种东西(更多的可能是针对列表的操作)
* `map` 在 Python 中并不常用,即便是做这个我也更愿意写 `[x*x for x in numbers]`
一个更加真实的 Python lambdas 的示例是使用 `sort` 函数,就像这样:
```
children = [{"name": "ashwin", "age": 12}, {"name": "radhika", "age": 3}]
sorted_children = sorted(children, key=lambda x: x['age'])
```
但是这个示例是被精心设计的(为什么我们需要对这些孩子按照年龄进行排序呢?)。所以我们如何来做一个真实的示例呢?
### 如何让你的示例真实起来:看你所写实际代码
我认为最简单的来生成一个例子的方法就是,不是凭空出现一个例子(就像我用那个`儿童`的例子),而只是从真正的代码开始!
举一个例子吧,如果我要用 `sort.+key` 来编写一串 Python 代码,我会发现很多我按某个标准对列表进行排序的真实例子,例如:
* `tasks.sort(key=lambda task: task['completed_time'])`
* `emails = reversed(sorted(emails, key=lambda x:x['receivedAt']))`
* `sorted_keysizes = sorted(scores.keys(), key=scores.get)`
* `shows = sorted(dates[date], key=lambda x: x['time']['performanceTime'])`
在这里很容易看到一个规律——这些基本是按时间排序的!因此,你可以明白如何将按时间排序的某些对象(电子邮件、事件等)的简单实例轻松地放在一起。
### 现实的例子有助于“布道”你试图解释的概念
当我试图去解释一个想法(就好比 Python Lambdas)的时候,我通常也会试图说服读者,说这是值得学习的想法。Python lambdas 是如此的有用!当我去试图说服某个人 lambdas 是很好用的时候,让他想象一下 lambdas 如何帮助他们完成一项他们将要去做的任务或是以及一项他们以前做过的任务,对说服他会很有帮助。
### 从真实代码中提炼出示例可能需要很长时间
我给出如何使用 `lambda` 和 `sort` 函数的解释例子是十分简单的,它并不需要花费我很长时间来想出来,但是将真实的代码提炼出为一个独立的示例则是会需要花费很长的时间!
举个例子,我想在这篇文章中融入一些奇怪的 CSS 行为的例子来说明创造一个奇怪的案例是十分有趣的。我花费了两个小时来解决我这周遇到的一个实际的问题,确保我理解 CSS 的实际情况,并将其变成一个小示例。
最后,它“仅仅”用了 [五行 HTML 和一点点的 CSS](https://codepen.io/wizardzines/pen/0eda7725a46c919dcfdd3fa80aff3d41) 来说明了这个问题,看起来并不想是我花费了好多小时写出来的。但是最初它却是几百行的 JS/CSS/JavaScript,它需要花费很长时间来将所有的代码化为核心的很少的代码。
但我认为花点时间把示例讲得非常简单明了是值得的——如果有成百上千的人在读你的示例,你就节省了他们这么多时间!
### 就这么多了!
我觉得还有更多关于示例可以去讲的——几种不同类型的有用示例,例如:
* 可以更多的改变人的思维而不是直接提供使用的惊喜读者的示例代码
* 易于复制粘贴以用作初始化的示例
也许有一天我还会再写一些呢? :smiley:
---
via: <https://jvns.ca/blog/2021/07/08/writing-great-examples/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zepoch](https://github.com/zepoch) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
13,598 | 现实中的应用程序是如何丢失数据? | https://theartofmachinery.com/2021/06/06/how_apps_lose_data.html | 2021-07-20T06:27:45 | [
"备份"
] | https://linux.cn/article-13598-1.html | 
现代应用程序开发的一大优点是,像硬件故障或如何设置 RAID 这类问题是由云提供商操心的。优秀的云供应商不太可能丢失你的应用数据,所以有时我会被询问现在为什么还要备份?下面是一些现实世界的故事。
### 故事之一
第一个故事来自一个数据科学项目:它基本上是一个从正在进行的研究中来收集数据的庞大而复杂的管道,然后用各种不同的方式处理以满足一些尖端模型的需要。这个面向用户的应用程序还没有推出,但是一个由数据科学家和开发人员组成的团队已经为建立这个模型和它的数据集工作了好几个月。
在项目中工作的人有他们自己的实验工作的开发环境。他们会在终端中做一些类似 `export ENVIRONMENT=simonsdev` 的事情,然后所有在终端上运行的软件都会在那个环境下运行,而不是在生产环境下。
该团队迫切需要推出一个面向用户的应用程序,以便那些花钱的人能够从他们几个月的投资中真正看到一些回报。在一个星期六,一位工程师试图赶工一些工作。他在晚上很晚的时候做完了一个实验,决定收拾东西回家。他启动了一个清理脚本来删除他的开发环境中的所有内容,但奇怪的是,这比平时花费了更长的时间。这时他意识到,他已经忘记了哪个终端被配置为指向哪个环境。(LCTT 译注:意即删除了生产环境。)
### 故事之二
第二个故事来自于一个商业的网页和手机应用。后端有一个由一组工程师负责的微服务体系结构。这意味着部署需要协调,但是使用正式的发布过程和自动化简化了一些。新代码在准备好后会被审查并合并到主干中,并且高层开发人员通常会为每个微服务标记版本,然后自动部署到临时环境。临时环境中的版本会被定期收集到一个元版本中,在自动部署到生产环境之前,该版本会得到各个人的签署(这是一个合规环境)。
有一天,一位开发人员正在开发一个复杂的功能,而其他开发该微服务的开发人员都同意将他们正在开发的代码提交到主干,也都知道它还不能被实际发布。长话短说,并不是团队中的每个人都收到了消息,而代码就进入了发布管道。更糟糕的是,那些实验性代码需要一种新的方式来表示用户配置文件数据,因此它有一个临时数据迁移,它在推出到生产环境时运行,损坏了所有的用户配置文件。
### 故事之三
第三个故事来自另一款网页应用。这个有一个更简单的架构:大部分代码在一个应用程序中,数据在数据库中。然而,这个应用程序也是在很大的截止日期压力下编写的。事实证明,在开发初期,当彻底更改的数据库架构很常见时,添加一项功能来检测此类更改并清理旧数据,这实际上对发布前的早期开发很有用,并且始终只是作为开发环境的临时功能。不幸的是,在匆忙构建应用的其余部分并推出时,我们忘记了这些代码。当然,直到有一天它在生产环境中被触发了。
### 事后分析
对于任何故障的事后分析,很容易忽视大局,最终将一切归咎于一些小细节。一个特例是发现某人犯了一些错误,然后责怪那个人。这些故事中的所有工程师实际上都是优秀的工程师(雇佣 SRE 顾问的公司不是那些在长期雇佣中偷工减料的公司),所以解雇他们,换掉他们并不能解决任何问题。即使你拥有 100 倍的开发人员,它仍然是有限的,所以在足够的复杂性和压力下,错误也会发生。最重要的解决方案是备份,无论你如何丢失数据(包括来自恶意软件,这是最近新闻中的一个热门话题),它都能帮助你。如果你无法容忍没有副本,就不要只有一个副本。
故事之一的结局很糟糕:没有备份。该项目的六个月的数据收集白干了。顺便说一句,有些地方只保留一个每日快照作为备份,这个故事也是一个很好的例子,说明了这也会出错:如果数据丢失发生在星期六,并且你准备在星期一尝试恢复,那么一日备份就只能得到星期日的一个空数据备份。
故事之二并不算好,但结果要好得多。备份是可用的,但数据迁移也是可逆的。不好的部分是发布是在推出前完成的,并且修复工作必须在生产站点关闭时进行编码。我讲这个故事的主要原因是为了提醒大家,备份并不仅仅是灾难性的数据丢失。部分数据损坏也会发生,而且可能会更加混乱。
故事之三还好。尽管少量数据永久丢失,但大部分数据可以从备份中恢复。团队中的每个人都对没有标记极其明显的危险代码感到非常难过。我没有参与早期的开发,但我感觉很糟糕,因为恢复数据所需的时间比正常情况要长得多。如果有一个经过良好测试的恢复过程,我认为该站点应该在总共不到 15 分钟的时间内重新上线。但是第一次恢复没有成功,我不得不调试它为什么不能成功,然后重试。当一个生产站点宕机了,需要你重新启动它,每过 10 秒钟都感觉过了一个世纪。值得庆幸的是,老板们比某些人更能理解我们。他们实际上松了一口气,因为这一场可能使公司沉没的一次性灾难只导致了几分钟的数据丢失和不到一个小时的停机时间。
在实践中,备份“成功”但恢复失败的情况极为普遍。很多时候,小型数据集上进行恢复测试是可以正常工作的,但在生产规模的大数据集上就会失败。当每个人都压力过大时,灾难最有可能发生,而生产站点的故障只会增加压力。在时间合适的时候测试和记录完整的恢复过程是一个非常好的主意。
---
via: <https://theartofmachinery.com/2021/06/06/how_apps_lose_data.html>
作者:[Simon Arneaud](https://theartofmachinery.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[PearFL](https://github.com/PearFL) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A great thing about modern app development is that there are cloud providers to worry about things like hardware
failures or how to set up RAID. Decent cloud providers are extremely unlikely to lose your app’s data, so sometimes I
get asked what backups are really for these days. Here are some real-world stories that show exactly what.
## Story #1
This first story is from a data science project: it was basically a big, complex pipeline that took data collected from ongoing research and crunched it in various ways to feed some cutting-edge model. The user-facing application hadn’t been launched yet, but a team of data scientists and developers had been working on building the model and its dataset for several months.
The people working on the project had their own development environments for experimental work. They’d do something
like `export ENVIRONMENT=simonsdev`
in a terminal, and then all
the software running in that terminal would run against that environment instead of the production environment.
The team was under a lot of pressure to get a user-facing app launched so that stakeholders could actually see some results from their several months of investment. One Saturday, an engineer tried to catch up with some work. He finished an experiment he was doing late in the evening, and decided to tidy up and go home. He fired off a cleanup script to delete everything from his development environment, but strangely it took a lot longer than usual. That’s when he realised he’d lost track of which terminal was configured to point to which environment.
## Story #2
Story #2 is from a commercial web and mobile app. The backend had a microservice architecture worked on by a team of engineers. That meant deployments required co-ordination, but things were simplified a bit using a formal release process and automation. New code would get reviewed and merged into master when ready, and every so often a senior developer would tag a release for each microservice, which would then automatically deploy to the staging environment. The releases in the staging environment would periodically get collected together into a meta-release that got signoff from various people (it was a compliance environment) before being automatically deployed to production.
One day a developer was working on a complex feature, and the other developers working on that microservice agreed that the work-in-progress code should be committed to master with the understanding that it shouldn’t be actually released yet. To cut a long story short, not everyone in the team got the message, and the code got into the release pipeline. Worse, the experimental code required a new way to represent user profile data, so it had an ad-hoc data migration that ran on launch into production and corrupted all user profiles.
## Story #3
Story #3 is from another web app. This one had a much simpler architecture: most of the code was in one app, and the data was in a database. However, this app had also been written under a lot of deadline pressure. It turned out that early on in development, when radical database schema changes were common, a feature was added to detect such changes and clean up old data. This was actually useful for early development before launch, and was always meant to be a temporary feature for development environments only. Unfortunately, the code was forgotten about in the rush to build the rest of the app and get to launch. Until, of course, one day it got triggered in the production environment.
## Postmortem
With any outage postmortem, it’s easy to lose sight of the big picture and end up blaming everything on some little detail. A special case of that is finding some mistake someone made and then blaming that person. All of the engineers in these stories were actually good engineers (companies that hire SRE consultants aren’t the ones to cut corners with their permanent hires), so firing them and replacing them wouldn’t have solved any problem. Even if you have 100x developers, that 100x is still finite, so mistakes will happen with enough complexity and pressure. The big-picture solution is back ups, which help you however you lose the data (including from malware, which is a hot topic in the news lately). If you’re not okay with having zero copies of it, don’t have one copy.
Story #1 had a bad end: there were no backups. The project was set back by nearly six months of data collection. By the way, some places only keep a single daily snapshot as a backup, and this story is a good example of how that can go wrong, too: if the data loss happened on Saturday and recovery was attempted on Monday, the one-day backup would only have an empty database from the Sunday.
Story #2 wasn’t fun, but worked out much better. Backups were available, but the data migration was reversible, too. The unfun part was that the release was done just before lunch and the fix had to be coded up while the production site was down. The main reason I’m telling this story is as a reminder that backups aren’t just about catastrophic data loss. Partial data corruption happens, too, and can be extra messy.
Story #3 was so-so. A small amount of data was lost permanently, but most was recovered from the backup. Everyone on the team felt pretty bad about not flagging the now-extremely-obviously-dangerous code. I wasn’t involved in the early development, but I felt bad because the recovery took a lot longer than it should have. With a well-tested recovery process, I think the site should have been back online in under 15mins total. But the recovery didn’t work first time, and I had to debug why not and retry. When a production site is down and it’s on you to get it up again, every 10s feels like an eternity. Thankfully, the stakeholders were much more understanding than some. They were actually relieved that a one-off disaster that could have sunk the company only resulted in minutes of lost data and under an hour of downtime.
It’s extremely common in practice for the backup to “work” but the recovery to fail. Often the recovery works when tested on small datasets, but fails on production-sized datasets. Disaster is most likely to strike when everyone is stressed out, and having the production site down only increases the pressure. It’s a really good idea to test and document the full recovery process while times are good. |
13,599 | 不同的编程语言是如何读写数据的 | https://opensource.com/article/21/7/programming-read-write | 2021-07-20T06:54:11 | [
"编程语言",
"读写"
] | https://linux.cn/article-13599-1.html |
>
> 每种编程语言都有其独特的完成任务的方式,这也说明了为什么有这么多语言可供选择。
>
>
>

在 Jim Hall 的《[不同的编程语言如何完成相同的事情](https://opensource.com/article/21/4/compare-programming-languages)》文章中,他演示了 13 种不同的语言如何使用不同的语法来完成同一个任务。经验是,编程语言往往有很多相似之处。一旦你了解了一种编程语言,你就可以通过理解它的语法和结构来学习另一种。
本着同样的精神,Jim 的文章比较了不同编程语言如何读写数据。无论数据来自配置文件还是用户创建的文件,在存储设备上处理数据都是程序员的常见任务。以这种方式涵盖所有编程语言是不切实际的,但最近的 [Opensource.com](http://Opensource.com) 系列文章提供了对这些编程语言采用的不同方法的深入了解:
* [C](https://opensource.com/article/21/3/file-io-c)
* [C++](https://opensource.com/article/21/3/ccc-input-output)
* [Java](https://opensource.com/article/21/3/io-java)
* [Groovy](https://opensource.com/article/21/4/groovy-io)
* [Lua](https://opensource.com/article/21/3/lua-files)
* [Bash](https://opensource.com/article/21/3/input-output-bash)
* [Python](https://opensource.com/article/21/6/reading-and-writing-files-python)
### 读写数据
用计算机读写数据的过程和你在现实生活中读写数据的过程类似。要访问书中的数据,你首先要打开它,然后阅读单词或将生词写入书中,然后合上书。
当程序需要从文件中读取数据时,你向程序传入一个文件位置,然后计算机将该数据读入内存中并解析它。同样,当程序需要将数据写入文件时,计算机会将新数据放入系统的内存写入缓冲区,然后将其同步到存储设备上的文件中。
下面是这些操作的一些伪代码:
1. 在内存中加载文件。
2. 读取文件内容,或将数据写入文件。
3. 关闭文件。
### 从文件中读取数据
从 [Opensource.com](http://Opensource.com) 系列文章的语言中,你可以看到读取文件的三种趋势。
#### C
在 C 语言中,打开文件可能涉及检索单个字符(直到 `EOF` 指示符,表示文件结束)或一个数据块,具体取决于你的需求和方法。根据你的目标,它可能感觉像一个主要是手工的过程,但这正是其他语言所模仿的。
```
FILE *infile;
int ch;
infile = fopen(argv[1], "r");
do {
ch = fgetc(infile);
if (ch != EOF) {
printf("%c", ch);
}
} while (ch != EOF);
fclose(infile);
```
你还可以选择将文件的某些部分加载到系统缓冲区中,然后在缓冲区外工作。
```
FILE *infile;
char buffer[300];
infile = fopen(argv[1], "r");
while (!feof(infile)) {
size_t buffer_length;
buffer_length = fread(buffer, sizeof(char), 300, infile);
}
printf("%s", buffer);
fclose(infile);
```
#### C++
C++ 简化了一些步骤,允许你将数据解析为字符串。
```
std::string sFilename = "example.txt";
std::ifstream fileSource(sFilename);
std::string buffer;
while (fileSource >> buffer) {
std::cout << buffer << std::endl;
}
```
#### Java
Java 和 Groovy 类似于 C++。它们使用名为 `Scanner` 的类来设置数据流或对象,这样就会包含你选择的文件内容。你可以通过标记(字节、行、整数等)扫描文件。
```
File myFile = new File("example.txt");
Scanner myScanner = new Scanner(myFile);
while (myScanner.hasNextLine()) {
String line = myScanner.nextLine();
System.out.println(line);
}
myScanner.close();
```
#### Groovy
```
def myFile = new File('example.txt')
def myScanner = new Scanner(myFile)
while (myScanner.hasNextLine()) {
def line = myScanner.nextLine()
println(line)
}
myScanner.close()
```
#### Lua
Lua 和 Python 进一步抽象了整个过程。你不必有意识地创建数据流,你只需给一个变量赋值为 `open` 函数的返回值,然后解析该变量的内容。这种方式快速,最简且容易。
```
myFile = io.open('example.txt', 'r')
lines = myFile:read("*all")
print(lines)
myFile:close()
```
#### Python
```
f = open('example.tmp', 'r')
for line in f:
print(line)
f.close()
```
### 向文件中写入数据
就写代码来说,写入是读取的逆过程。因此,将数据写入文件的过程与从文件中读取数据基本相同,只是使用了不同的函数。
#### C
在 C 语言中,你可以使用 `fputc` 函数将字符写入文件:
```
fputc(ch, outfile);
```
或者,你可以使用 `fwrite` 将数据写入缓冲区。
```
fwrite(buffer, sizeof(char), buffer_length, outfile);
```
#### C++
因为 C++ 使用 `ifstream` 库为数据打开缓冲区,所以你可以像 C 语言那样将数据写入缓冲区(C++ 库除外)。
```
std::cout << buffer << std::endl;
```
#### Java
在 Java 中,你可以使用 `FileWriter` 类来创建一个可以写入数据的对象。它的工作方式与 `Scanner` 类非常相似,只是方向相反。
```
FileWriter myFileWriter = new FileWriter("example.txt", true);
myFileWriter.write("Hello world\n");
myFileWriter.close();
```
#### Groovy
类似地,Groovy 使用 `FileWriter`,但使用了稍微 “groovy” 的语法。
```
new FileWriter("example.txt", true).with {
write("Hello world\n")
flush()
}
```
#### Lua
Lua 和 Python 很相似,都使用名为 `open` 的函数来加载文件,`writer` 函数来写入数据,`close` 函数用于关闭文件。
```
myFile = io.open('example.txt', 'a')
io.output(myFile)
io.write("hello world\n")
io.close(myFile)
```
#### Python
```
myFile = open('example.txt', 'w')
myFile.write('hello world')
myFile.close()
```
### File 模式
许多语言在打开文件时会指定一个“模式”。模式有很多,但这是常见的定义:
* **w** 表示写入
* **r** 表示读取
* **r+** 表示可读可写
* **a** 表示追加
某些语言,例如 Java 和 Groovy,允许你根据用于加载文件的类来确定模式。
无论编程语言以何种方式来确定文件模式,你都需要确保你是在 *追加* 数据,除非你打算用新数据覆盖文件。编程语言不像文件选择器那样,没有内置的提示来警告你防止数据丢失。
### 新语言和旧把戏
每种编程语言都有其独特完成任务的方式,这就是为什么有这么多语言可供选择。你可以而且应该选择最合适你的语言。但是,你一旦了解了编程的基本结构,你可以随意尝试其他语言,而不必担心不知道如何完成基本任务。通常情况下,实现目标的途径是相似的,所以只要你牢记基本概念,它们就很容易学习。
---
via: <https://opensource.com/article/21/7/programming-read-write>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In his article * How different programming languages do the same thing*, Jim Hall demonstrates how 13 different languages accomplish the same exact task with different syntax. The lesson is that programming languages tend to have many similarities, and once you know one programming language, you can learn another by figuring its syntax and structure.
In the same spirit, Jim's article compares how different programming languages read and write data. Whether that data comes from a configuration file or from a file a user creates, processing data on a storage device is a common task for coders. It's not practical to cover all programming languages in this way, but a recent Opensource.com series provides insight into different approaches taken by these coding languages:
## Reading and writing data
The process of reading and writing data with a computer is similar to how you read and write data in real life. To access data in a book, you first open it, then you read words or you write new words into the book, and then you close the book.
When your code needs to read data from a file, you provide your code with a file location, and then the computer brings that data into its RAM and parses it from there. Similarly, when your code needs to write data to a file, the computer places new data into the system's in-memory write buffer and synchronizes it to the file on the storage device.
Here's some pseudo-code for these operations:
- Load a file in memory.
- Read the file's contents, or write data to the file.
- Close the file.
## Reading data from a file
You can see three trends in how the languages in the Opensource.com series read files.
### C
In C, opening a file can involve retrieving a single character (up to the `EOF`
designator, signaling the end of the file) or a block of data, depending on your requirements and approach. It can feel like a mostly manual process, depending on your goal, but the general process is exactly what the other languages mimic.
```
FILE *infile;
int ch;
infile = fopen(argv[1], "r");
do {
ch = fgetc(infile);
if (ch != EOF) {
printf("%c", ch);
}
} while (ch != EOF);
fclose(infile);
```
You can also choose to load some portion of a file into the system buffer and then work out of the buffer.
```
FILE *infile;
char buffer[300];
infile = fopen(argv[1], "r");
while (!feof(infile)) {
size_t buffer_length;
buffer_length = fread(buffer, sizeof(char), 300, infile);
}
printf("%s", buffer);
fclose(infile);
```
### C++
C++ simplifies a few steps, allowing you to parse data as strings.
```
std::string sFilename = "example.txt";
std::ifstream fileSource(sFilename);
std::string buffer;
while (fileSource >> buffer) {
std::cout << buffer << std::endl;
}
```
### Java
Java and Groovy are similar to C++. They use a class called `Scanner`
to set up a data object or stream containing the contents of the file of your choice. You can "scan" through the file by tokens (byte, line, integer, and many others).
```
File myFile = new File("example.txt");
Scanner myScanner = new Scanner(myFile);
while (myScanner.hasNextLine()) {
String line = myScanner.nextLine();
System.out.println(line);
}
myScanner.close();
```
### Groovy
```
def myFile = new File('example.txt')
def myScanner = new Scanner(myFile)
while (myScanner.hasNextLine()) {
def line = myScanner.nextLine()
println(line)
}
myScanner.close()
```
### Lua
Lua and Python abstract the process further. You don't have to consciously create a data stream; you just assign a variable to the results of an `open`
function and then parse the contents of the variable. It's quick, minimal, and easy.
```
myFile = io.open('example.txt', 'r')
lines = myFile:read("*all")
print(lines)
myFile:close()
```
### Python
```
f = open('example.tmp', 'r')
for line in f:
print(line)
f.close()
```
## Writing data to a file
In terms of code, writing is the inverse of reading. As such, the process for writing data to a file is basically the same as reading data from a file, except using different functions.
### C
In C, you can write a character to a file with the `fputc`
function.
`fputc(ch, outfile);`
Alternately, you can write data to the buffer with `fwrite`
.
`fwrite(buffer, sizeof(char), buffer_length, outfile);`
### C++
Because C++ uses the `ifstream`
library to open a buffer for data, you can write data to the buffer, as with C (except with C++ libraries).
`std::cout << buffer << std::endl;`
### Java
In Java, you can use the `FileWriter`
class to create a data object that you can write data to. It works a lot like the `Scanner`
class, except going the other way.
```
FileWriter myFileWriter = new FileWriter("example.txt", true);
myFileWriter.write("Hello world\n");
myFileWriter.close();
```
### Groovy
Similarly, Groovy uses `FileWriter`
but with a slightly "groovier" syntax.
```
new FileWriter("example.txt", true).with {
write("Hello world\n")
flush()
}
```
### Lua
Lua and Python are similar, both using functions called `open`
to load a file, `write`
to put data into it, and `close`
to close the file.
```
myFile = io.open('example.txt', 'a')
io.output(myFile)
io.write("hello world\n")
io.close(myFile)
```
### Python
```
myFile = open('example.txt', 'w')
myFile.write('hello world')
myFile.close()
```
## File modes
Many languages specify a "mode" when opening files. Modes vary, but this is common notation:
**w**to write**r**to read**r+**to read and write**a**to append only
Some languages, such as Java and Groovy, let you determine the mode based on which class you use to load the file.
Whichever way your programming language determines a file's mode, it's up to you to ensure that you're *appending* data—unless you intend to overwrite a file with new data. Programming languages don't have built-in prompts to warn you against data loss, the way file choosers do.
## New language and old tricks
Every programming language has a unique way of accomplishing a task; that's why there are so many languages to choose from. You can and should choose the language that works best for you. But once you understand the basic constructs of programming, you can also feel free to try out different languages, without fear of not knowing how to accomplish basic tasks. More often than not, the pathways to a goal are similar, so they're easy to learn as long as you keep the basic concepts in mind.
## Comments are closed. |
13,601 | FreeDOS 简史 | https://opensource.com/article/21/6/history-freedos | 2021-07-21T10:49:34 | [
"FreeDOS"
] | https://linux.cn/article-13601-1.html |
>
> 经历了近 30 年的发展, FreeDOS 已经成为了世界先进的 DOS。
>
>
>

>
> 一个大师正在给他的一个弟子讲 [编程之道](https://www.mit.edu/~xela/tao.html)。 “编程之道包含在所有的软件中 —— 不管它多么微不足道,” 大师说道。
>
>
> “编程之道在手持计算器里面吗?” 弟子问道。
>
>
> “是的,” 大师回答道。
>
>
> “编程之道在电子游戏里面吗?” 弟子继续问道。
>
>
> “即便是电子游戏中,” 大师说。
>
>
> “那编程之道在个人电脑的 DOS 里面吗?”
>
>
> 大师咳嗽了一下,稍稍改变了一下姿势,说道,“今天的课就到这里吧。”
>
>
> ——《编程之道》,Geoffrey James,InfoBooks,1987
>
>
>
过去,计算仅限于昂贵的大型机和“大铁疙瘩”计算机系统,如 PDP 11。但是微处理器的出现在 20 世纪 70 年代带来了一场计算革命。你终于可以在家里有一台电脑了——“个人电脑”时代已经到了!
我记得看到的最早的个人电脑包括 Commodore、TRS-80 和 Apple。个人电脑成了一个热门话题,所以 IBM 决定进入这个市场。在经历了一个快速开发周期之后,IBM 于 1981 年 8 月发布了 IBM 5150 个人电脑(最初的“IBM PC”)。
从零开始创建一台计算机并非易事,因此 IBM 以用“现成”的硬件来构建 PC 而闻名,并从外部开发商那里获得了其他组件的授权。其中之一是微软授权的操作系统。反过来,微软从西雅图计算机产品公司获得了 86-DOS ,进行了各种更新,并将新版本作为 IBM PC-DOS 与 IBM PC 一起首次亮相。
### 早期的 DOS
运行在最多只有 640 千字节内存中的 DOS,除了管理硬件和允许用户启动应用程序之外,真的做不了什么。因此,PC-DOS 1.0 命令行非常贫乏,只包含了一些设置日期和时间、管理文件、控制终端和格式化软盘的命令。DOS 还包括一个 BASIC 语言解释器,这是那个时代所有个人计算机的一个标准功能。
直到 PC-DOS 2.0,DOS 才变得更加有趣,为命令行添加了新的命令,并包含了其他有用的工具。但对我来说,直到 1991 年的 MS-DOS 5.0 才有了“现代感”。微软在这个版本中对 DOS 进行了大修,更新了许多命令,并用一个新的全屏编辑器取代了老旧的 Edlin 编辑器,使之更方便用户使用。DOS 5 还包括我喜欢的其他特性,比如基于微软 QuickBASIC 编译器的新 BASIC 解释器,简称 QBASIC. 如果你曾经在 DOS 上玩过 Gorillas 游戏,那可能就是在 MS-DOS 5.0 中运行的。
尽管进行了这些升级,但我对 DOS 命令行并不完全满意。DOS 从来没有偏离原来的设计,有其局限性。DOS 为用户提供了一些工具,可以从命令行执行一些事情 —— 否则,你就得使用 DOS 命令行来启动应用程序。微软认为用户大部分时间都会花在几个关键的应用程序上,比如文字处理器或电子表格。
但是开发人员想要一个功能更强的 DOS,此时一个细分行业正在萌芽,以提供小巧优雅的工具和程序。有些是全屏应用程序,但也有许多是增强 DOS 命令环境的命令行实用程序。当我学会一点 C 语言编程时,我开始编写自己的实用程序,扩展或替换 DOS 命令行。尽管 MS-DOS 的基础相当有限,但我发现第三方实用程序加上我自己的工具创建了一个功能强大的 DOS 命令行。
### FreeDOS
1994 年初,我开始在科技杂志上看到很多对微软高管的采访,他们说下一个版本的 Windows 将完全取代 DOS。我以前使用过 Windows,但如果你还记得那个时代,你就知道 Windows 3.1 并不是一个很好的平台。Windows 3.1 很笨重,有很多毛病,如果一个应用程序崩溃,它可能会使整个 Windows 系统瘫痪。我也不喜欢 Windows 的图形用户界面。我更喜欢在命令行做我的工作,而不是用鼠标。
我考虑过 Windows,并决定,“如果 Windows 3.2 或 Windows 4.0 会像 Windows 3.1 一样,我就不会去使用它。” 但我有什么选择?此时,我已经尝试过 Linux,并认为 [Linux 很棒](https://opensource.com/article/17/5/how-i-got-started-linux-jim-hall-freedos),但是 Linux 没有任何应用程序。我的文字处理器、电子表格和其他程序都在 DOS 上。我需要 DOS。
然后我有了个主意!我想,“如果开发人员能够在互联网上共同编写一个完整的 Unix 操作系统,那么我们当然可以对 DOS 做同样的事情。”毕竟,与 Unix 相比,DOS 是一个相当简单的操作系统。DOS 一次运行一个任务(单任务),并且有一个更简单的内存模型。编写我们自己的 DOS 应该不难。
因此,在 1994 年 6 月 29 日,我在一个名为 Usenet 的留言板网络上向 “comp.os.msdos.apps” [发布了一个公告](https://groups.google.com/g/comp.os.msdos.apps/c/oQmT4ETcSzU/m/O1HR8PE2u-EJ):
>
> PD-DOS 项目公告:
>
>
> 几个月前,我发表了关于启动公共领域版本的 DOS 的文章。 当时大家对此的普遍支持,许多人都同意这样的说法:“开始编写吧!”所以,我就……
>
>
> 宣布首次生产 PD-DOS 的努力。我已经写了一个“清单”,描述了这样一个项目的目标和工作大纲,以及一个“任务列表”,它准确地显示了需要编写什么。我会把这些贴在这里,供大家讨论。
>
>
>
\* 关于这个名字的说明 —— 我希望这个新的 DOS 成为每个人都可以使用的东西,我天真地认为,当每个人都可以使用它时,它就是“公共领域”。我很快就意识到了这种差别,所以我们把 “PD-DOS” 改名为 “Free-DOS”,然后去掉连字符变成 “FreeDOS”。
一些开发人员联系我,提供他们为替换或增强 DOS 命令行而创建的实用程序,类似于我自己的努力。就在项目宣布几个月后,我们汇集了我们的实用程序,并创建了一个实用的系统,我们在 1994 年 9 月发布了一个 “Alpha 1” 版本。在那些日子里,发展是相当迅速的,我们在 1994 年 12 月发布了 “Alpha 2”,1995 年 1 月发布了 “Alpha 3”,1995 年 6 月发布了“Alpha 4”。
### 一个现代的 DOS
从那以后,我们一直致力于使 FreeDOS 成为 “现代” DOS。而这种现代化大部分都集中在创建一个丰富的命令行环境上。是的,DOS 仍然需要支持应用程序,但是我们相信 FreeDOS 也需要一个强大的命令行环境。这就是为什么 FreeDOS 包含了许多有用的工具,包括浏览目录、管理文件、播放音乐、连接网络的命令,……以及类似 Unix 的实用程序集合,如 `less`、`du`、`head`、`tail`、`sed` 和 `tr`。
虽然 FreeDOS 的开发已经放缓,但它并没有停止。开发人员继续为 FreeDOS 编写新程序,并向 FreeDOS 添加新功能。我对 FreeDOS 1.3 RC4 的几个重要补充感到特别兴奋,FreeDOS 1.3 RC4 是即将发布的 FreeDOS 1.3 的最新候选版本。最近的一些更新如下:
* Mateusz Viste 创建了一个新的电子书阅读器,名为 Ancient Machine Book(AMB),我们利用它作为 FreeDOS 1.3 RC4 中的新帮助系统。
* Rask Ingemann Lambertsen、Andrew Jenner、TK Chia 和其他人正在更新 GCC 的 IA-16 版本,包括一个新的libi86 库,它提供了与 Borland TurboC++ 编译器的 C 库的某种程度的兼容性。
* Jason Hood 更新了一个可卸载的 CD-ROM 重定向器,以替代微软的 MSCDEX,最多支持 10 个驱动器。
* SuperIlu 创建了 DOjS,这是一个 Javascript 开发画布,具有集成的编辑器、图形和声音输出,以及鼠标、键盘和操纵杆输入。
* Japheth 创建了一个 DOS32PAE 扩展程序,它能够通过 PAE 分页使用大量的内存。
尽管 FreeDOS 有了新的发展,我们仍然忠于我们的 DOS 根基。在我们继续朝着 FreeDOS 1.3 “最终”版本努力时,我们带着几个核心假设,包括:
* **兼容性是关键** —— 如果 FreeDOS 不能运行经典 DOS 应用程序,它就不是真正的 “DOS”。虽然我们提供了许多优秀的开源工具、应用程序和游戏,但你也可以运行你的传统的 DOS 应用程序。
* **继续在旧 PC 上运行(XT、286、386 等)** —— FreeDOS 1.3 将保持 16 位英特尔架构,但在可能的情况下将支持扩展驱动程序支持的新硬件。为此,我们继续专注于单用户命令行环境。
* **FreeDOS 是开源软件** —— 我一直说,如果人们不能访问、学习和修改源代码,FreeDOS 就不是“自由的 DOS”。FreeDOS 1.3 将包括尽可能多地包括使用公认的开源许可证的软件。但 DOS 实际上早于 GNU 通用公共许可证(1989)和开放源码定义(1998),因此一些 DOS 软件可能会使用它自己的“免费源代码”许可证,而不是标准的“开源”许可。当我们考虑将软件包纳入 FreeDOS 时,我们将继续评估任何许可证,以确保它们是合适的“开放源码”,即使它们没有得到正式承认。
我们欢迎你的帮助,使 FreeDOS 强大!请加入我们的电子邮件列表,我们欢迎所有新来者和贡献者。我们通过电子邮件列表进行交流,不过这个列表的信件量非常小,所以不太可能撑爆你的收件箱。
访问 FreeDOS 网站 [www.freedos.org](https://www.freedos.org/)。
---
via: <https://opensource.com/article/21/6/history-freedos>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zxy-wyx](https://github.com/zxy-wyx) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A master was explaining the nature of [The Tao of Programming](https://www.mit.edu/~xela/tao.html) to one of his novices. "The Tao is embodied in all software—regardless of how insignificant," said the master.
"Is Tao in a hand-held calculator?" asked the novice.
"It is," came the reply.
"Is the Tao in a video game?" continued the novice.
"It is even in a video game," said the master.
"And is the Tao in the DOS for a personal computer?"
The master coughed and shifted his position slightly. "The lesson is over for today," he said.
The Tao of Programming, Geoffrey James, InfoBooks, 1987
Computing used to be limited only to expensive mainframes and "Big Iron" computer systems like the PDP11. But the advent of the microprocessor brought about a computing revolution in the 1970s. You could finally have a computer in your home—the "personal computer" had arrived!
The earliest personal computers I remember seeing included the Commodore, TRS-80, and Apple. The personal computer became such a hot topic that IBM decided to enter the market. After a rapid development cycle, IBM released the IBM 5150 Personal Computer (the original "IBM PC") in August 1981.
Creating a computer from scratch is no easy task, so IBM famously used "off-the-shelf" hardware to build the PC, and licensed other components from outside developers. One of those was the operating system, licensed from Microsoft. In turn, Microsoft acquired 86-DOS from Seattle Computer Products, applied various updates, and debuted the new version with the IBM PC as IBM PC-DOS.
## Early DOS
Running in memory *up to* 640 kilobytes, DOS really couldn't do much more than manage the hardware and allow the user to launch applications. As a result, the PC-DOS 1.0 command line was pretty anemic, only including a few commands to set the date and time, manage files, control the terminal, and format floppy disks. DOS also included a BASIC language interpreter, which was a standard feature in all personal computers of the era.
It wasn't until PC-DOS 2.0 that DOS became more interesting, adding new commands to the command line, and including other useful tools. But for me, it wasn't until MS-DOS 5.0 in 1991 that DOS began to feel "modern." Microsoft overhauled DOS in this release, updating many of the commands and replacing the venerable Edlin editor with a new full-screen editor that was more user-friendly. DOS 5 included other features that I liked, as well, such as a new BASIC interpreter based on Microsoft QuickBASIC Compiler, simply called QBASIC. If you've ever played the Gorillas game on DOS, it was probably in MS-DOS 5.0.
Despite these upgrades, I wasn't entirely satisfied with the DOS command line. DOS never strayed far from the original design, which proved limiting. DOS gave the user a few tools to do some things from the command line—otherwise, you were meant to use the DOS command line to launch applications. Microsoft assumed the user would spend most of their time in a few key applications, such as a word processor or spreadsheet.
But developers wanted a more functional DOS, and a sub-industry sprouted to offer neat tools and programs. Some were full-screen applications, but many were command-line utilities that enhanced the DOS command environment. When I learned a bit of C programming, I started writing my own utilities that extended or replaced the DOS command line. And despite the rather limited underpinnings of MS-DOS, I found that the third-party utilities, plus my own, created a powerful DOS command line.
## FreeDOS
In early 1994, I started seeing a lot of interviews with Microsoft executives in tech magazines saying the next version of Windows would totally do away with DOS. I'd used Windows before—but if you remember the era, you know Windows 3.1 wasn't a great platform. Windows 3.1 was clunky and buggy—if an application crashed, it might take down the entire Windows system. And I didn't like the Windows graphical user interface, either. I preferred doing my work at the command line, not with a mouse.
I considered Windows and decided, If Windows 3.2 or Windows 4.0 will be anything like Windows 3.1, I want nothing to do with it.
But what were my options? I'd already experimented with Linux at this point, and thought [Linux was great](https://opensource.com/article/17/5/how-i-got-started-linux-jim-hall-freedos)—but Linux didn't have any applications. My word processor, spreadsheet, and other programs were on DOS. I needed DOS.
Then I had an idea! I thought, If developers can come together over the internet to write a complete Unix operating system, surely we can do the same thing with DOS.
After all, DOS was a fairly straightforward operating system compared to Unix. DOS ran one task at a time (single-tasking) and had a simpler memory model. It shouldn't be *that* hard to write our own DOS.
So on June 29, 1994, I [posted an announcement](https://groups.google.com/g/comp.os.msdos.apps/c/oQmT4ETcSzU/m/O1HR8PE2u-EJ) to `comp.os.msdos.apps`
, on a message board network called Usenet:
ANNOUNCEMENT OF PD-DOS PROJECT:
A few months ago, I posted articles relating to starting a public domain version of DOS. The general support for this at the time was strong, and many people agreed with the statement, "start writing!" So, I have...
Announcing the first effort to produce a PD-DOS. I have written up a "manifest" describing the goals of such a project and an outline of the work, as well as a "task list" that shows exactly what needs to be written. I'll post those here, and let discussion follow.
** A note about the name—I wanted this new DOS to be something that everyone could use, and I naively assumed that when everyone could use it, it was "public domain." I quickly realized the difference, and we renamed "PD-DOS" to "Free-DOS"—and later dropped the hyphen to become "FreeDOS."*
A few developers reached out to me, to offer utilities they had created to replace or enhance the DOS command line, similar to my own efforts. We pooled our utilities and created a useful system that we released as "Alpha 1" in September 1994, just a few months after announcing the project. Development was pretty swift in those days, and we followed up with "Alpha 2" in December 1994, "Alpha 3" in January 1995, and "Alpha 4" in June 1995.
## A modern DOS
Since then, we've always focused on making FreeDOS a "modern" DOS. And much of that modernization is centered on creating a rich command-line environment. Yes, DOS still needs to support applications, but we believe FreeDOS needs a strong command-line environment, as well. That's why FreeDOS includes dozens of useful tools, including commands to navigate directories, manage files, play music, connect to networks, ... and a collection of Unix-like utilities such as `less`
, `du`
, `head`
, `tail`
, `sed`
, and `tr`
.
While FreeDOS development has slowed, it has not stopped. Developers continue to write new programs for FreeDOS, and add new features to FreeDOS. I'm particularly excited about several great additions to FreeDOS 1.3 RC4, the latest release candidate for the forthcoming FreeDOS 1.3. A few recent updates:
- Mateusz Viste created a new ebook reader called Ancient Machine Book (AMB) that we've leveraged as the new help system in FreeDOS 1.3 RC4
- Rask Ingemann Lambertsen, Andrew Jenner, TK Chia, and others are updating the IA-16 version of GCC, including a new
*libi86*library that provides some degree of compatibility with the Borland Turbo C++ compiler's C library - Jason Hood has updated an unloadable CD-ROM redirector substitute for Microsoft's MSCDEX, supporting up to 10 drives
- SuperIlu has created DOjS, a Javascript development canvas with an integrated editor, graphics and sound output, and mouse, keyboard, and joystick input
- Japheth has created a DOS32PAE extender that is able to use huge amounts of memory through PAE paging
Despite all of the new development on FreeDOS, we remain true to our DOS roots. As we continue working toward FreeDOS 1.3 "final," we carry several core assumptions, including:
**Compatibility is key**—FreeDOS isn't really "DOS" if it can't run classic DOS applications. While we provide many great open source tools, applications, and games, you can run your legacy DOS applications, too.**Continue to run on old PCs (XT, '286, '386, etc)**—FreeDOS 1.3 will remain 16-bit Intel but will support new hardware with expanded driver support, where possible. For this reason, we continue to focus on a single-user command-line environment.**FreeDOS is open source software**—I've always said that FreeDOS isn't a "free DOS" if people can't access, study, and modify the source code. FreeDOS 1.3 will include software that uses recognized open source licenses as much as possible. But DOS actually pre-dates the GNU General Public License (1989) and the Open Source Definition (1998) so some DOS software might use its own "free with source code" license that isn't a standard "open source" license. As we consider packages to include in FreeDOS, we continue to evaluate any licenses to ensure they are suitably "open source," even if they are not officially recognized.
We welcome your help in making FreeDOS great! Please join us on our email list—we welcome all newcomers and contributors. We communicate over an email list, but the list is fairly low volume so is unlikely to fill up your Inbox.
Visit the FreeDOS website at [www.freedos.org](https://www.freedos.org/).
## 1 Comment |
13,602 | 进阶教程:用 Python 和 NLTK 进行 NLP 分析 | https://opensource.com/article/20/8/nlp-python-nltk | 2021-07-21T11:56:00 | [
"NLP",
"自然语言处理"
] | https://linux.cn/article-13602-1.html |
>
> 进一步学习自然语言处理的基本概念
>
>
>

在 [之前的文章](https://opensource.com/article/20/8/intro-python-nltk) 里,我介绍了<ruby> 自然语言处理 <rt> natural language processing </rt></ruby>(NLP)和宾夕法尼亚大学研发的<ruby> 自然语言处理工具包 <rt> Natural Language Toolkit </rt></ruby> ([NLTK](http://www.nltk.org/))。我演示了用 Python 解析文本和定义<ruby> 停顿词 <rt> stopword </rt></ruby>的方法,并介绍了<ruby> 语料库 <rt> corpus </rt></ruby>的概念。语料库是由文本构成的数据集,通过提供现成的文本数据来辅助文本处理。在这篇文章里,我将继续用各种语料库对文本进行对比和分析。
这篇文章主要包括以下部分:
* <ruby> 词网 <rt> WordNet </rt></ruby>和<ruby> 同义词集 <rt> synset </rt></ruby>
* <ruby> 相似度比较 <rt> Similarity comparison </rt></ruby>
* <ruby> 树 <rt> Tree </rt></ruby>和<ruby> 树库 <rt> treebank </rt></ruby>
* <ruby> 命名实体识别 <rt> Named entity recognition </rt></ruby>
### 词网和同义词集
<ruby> <a href="https://en.wikipedia.org/wiki/WordNet"> 词网 </a> <rt> WordNet </rt></ruby> 是 NLTK 里的一个大型词汇数据库语料库。词网包含各单词的诸多<ruby> 认知同义词 <rt> cognitive synonyms </rt></ruby>(认知同义词常被称作“<ruby> 同义词集 <rt> synset </rt></ruby>”)。在词网里,名词、动词、形容词和副词,各自被组织成一个同义词的网络。
词网是一个很有用的文本分析工具。它有面向多种语言的版本(汉语、英语、日语、俄语和西班牙语等),也使用多种许可证(从开源许可证到商业许可证都有)。初代版本的词网由普林斯顿大学研发,面向英语,使用<ruby> 类 MIT 许可证 <rt> MIT-like license </rt></ruby>。
因为一个词可能有多个意义或多个词性,所以可能与多个同义词集相关联。每个同义词集通常提供下列属性:
| **属性** | **定义** | **例子** |
| --- | --- | --- |
| <ruby> 名称 <rt> Name </rt></ruby> | 此同义词集的名称 | 单词 `code` 有 5 个同义词集,名称分别是 `code.n.01`、 `code.n.02`、 `code.n.03`、`code.v.01` 和 `code.v.02` |
| <ruby> 词性 <rt> POS </rt></ruby> | 此同义词集的词性 | 单词 `code` 有 3 个名词词性的同义词集和 2 个动词词性的同义词集 |
| <ruby> 定义 <rt> Definition </rt></ruby> | 该词作对应词性时的定义 | 动词 `code` 的一个定义是:(计算机科学)数据或计算机程序指令的<ruby> 象征性排列 <rt> symbolic arrangement </rt></ruby> |
| <ruby> 例子 <rt> Example </rt></ruby> | 使用该词的例子 | `code` 一词的例子:We should encode the message for security reasons |
| <ruby> 词元 <rt> Lemma </rt></ruby> | 与该词相关联的其他同义词集(包括那些不一定严格地是该词的同义词,但可以大体看作同义词的);词元直接与其他词元相关联,而不是直接与<ruby> 单词 <rt> word </rt></ruby>相关联 | `code.v.02` 的词元是 `code.v.02.encipher`、`code.v.02.cipher`、`code.v.02.cypher`、`code.v.02.encrypt`、`code.v.02.inscribe` 和 `code.v.02.write_in_code` |
| <ruby> 反义词 <rt> Antonym </rt></ruby> | 意思相反的词 | 词元 `encode.v.01.encode` 的反义词是 `decode.v.01.decode` |
| <ruby> 上义词 <rt> Hypernym </rt></ruby> | 该词所属的一个范畴更大的词 | `code.v.01` 的一个上义词是 `tag.v.01` |
| <ruby> 分项词 <rt> Meronym </rt></ruby> | 属于该词组成部分的词 | `computer` 的一个分项词是 `chip` |
| <ruby> 总项词 <rt> Holonym </rt></ruby> | 该词作为组成部分所属的词 | `window` 的一个总项词是 `computer screen` |
同义词集还有一些其他属性,在 `<你的 Python 安装路径>/Lib/site-packages` 下的 `nltk/corpus/reader/wordnet.py`,你可以找到它们。
下面的代码或许可以帮助理解。
这个函数:
```
from nltk.corpus import wordnet
def synset_info(synset):
print("Name", synset.name())
print("POS:", synset.pos())
print("Definition:", synset.definition())
print("Examples:", synset.examples())
print("Lemmas:", synset.lemmas())
print("Antonyms:", [lemma.antonyms() for lemma in synset.lemmas() if len(lemma.antonyms()) > 0])
print("Hypernyms:", synset.hypernyms())
print("Instance Hypernyms:", synset.instance_hypernyms())
print("Part Holonyms:", synset.part_holonyms())
print("Part Meronyms:", synset.part_meronyms())
print()
synsets = wordnet.synsets('code')
print(len(synsets), "synsets:")
for synset in synsets:
synset_info(synset)
```
将会显示:
```
5 synsets:
Name code.n.01
POS: n
Definition: a set of rules or principles or laws (especially written ones)
Examples: []
Lemmas: [Lemma('code.n.01.code'), Lemma('code.n.01.codification')]
Antonyms: []
Hypernyms: [Synset('written_communication.n.01')]
Instance Hpernyms: []
Part Holonyms: []
Part Meronyms: []
...
Name code.n.03
POS: n
Definition: (computer science) the symbolic arrangement of data or instructions in a computer program or the set of such instructions
Examples: []
Lemmas: [Lemma('code.n.03.code'), Lemma('code.n.03.computer_code')]
Antonyms: []
Hypernyms: [Synset('coding_system.n.01')]
Instance Hpernyms: []
Part Holonyms: []
Part Meronyms: []
...
Name code.v.02
POS: v
Definition: convert ordinary language into code
Examples: ['We should encode the message for security reasons']
Lemmas: [Lemma('code.v.02.code'), Lemma('code.v.02.encipher'), Lemma('code.v.02.cipher'), Lemma('code.v.02.cypher'), Lemma('code.v.02.encrypt'), Lemma('code.v.02.inscribe'), Lemma('code.v.02.write_in_code')]
Antonyms: []
Hypernyms: [Synset('encode.v.01')]
Instance Hpernyms: []
Part Holonyms: []
Part Meronyms: []
```
<ruby> 同义词集 <rt> synset </rt></ruby>和<ruby> 词元 <rt> lemma </rt></ruby>在词网里是按照树状结构组织起来的,下面的代码会给出直观的展现:
```
def hypernyms(synset):
return synset.hypernyms()
synsets = wordnet.synsets('soccer')
for synset in synsets:
print(synset.name() + " tree:")
pprint(synset.tree(rel=hypernyms))
print()
```
```
code.n.01 tree:
[Synset('code.n.01'),
[Synset('written_communication.n.01'),
...
code.n.02 tree:
[Synset('code.n.02'),
[Synset('coding_system.n.01'),
...
code.n.03 tree:
[Synset('code.n.03'),
...
code.v.01 tree:
[Synset('code.v.01'),
[Synset('tag.v.01'),
...
code.v.02 tree:
[Synset('code.v.02'),
[Synset('encode.v.01'),
...
```
词网并没有涵盖所有的单词和其信息(现今英语有约 17,0000 个单词,最新版的 词网 涵盖了约 15,5000 个),但它开了个好头。掌握了“词网”的各个概念后,如果你觉得它词汇少,不能满足你的需要,可以转而使用其他工具。或者,你也可以打造自己的“词网”!
#### 自主尝试
使用 Python 库,下载维基百科的 “[open source](https://en.wikipedia.org/wiki/Open_source)” 页面,并列出该页面所有单词的<ruby> 同义词集 <rt> synset </rt></ruby>和<ruby> 词元 <rt> lemma </rt></ruby>。
### 相似度比较
相似度比较的目的是识别出两篇文本的相似度,在搜索引擎、聊天机器人等方面有很多应用。
比如,相似度比较可以识别 `football` 和 `soccer` 是否有相似性。
```
syn1 = wordnet.synsets('football')
syn2 = wordnet.synsets('soccer')
# 一个单词可能有多个 同义词集,需要把 word1 的每个同义词集和 word2 的每个同义词集分别比较
for s1 in syn1:
for s2 in syn2:
print("Path similarity of: ")
print(s1, '(', s1.pos(), ')', '[', s1.definition(), ']')
print(s2, '(', s2.pos(), ')', '[', s2.definition(), ']')
print(" is", s1.path_similarity(s2))
print()
```
```
Path similarity of:
Synset('football.n.01') ( n ) [ any of various games played with a ball (round or oval) in which two teams try to kick or carry or propel the ball into each other's goal ]
Synset('soccer.n.01') ( n ) [ a football game in which two teams of 11 players try to kick or head a ball into the opponents' goal ]
is 0.5
Path similarity of:
Synset('football.n.02') ( n ) [ the inflated oblong ball used in playing American football ]
Synset('soccer.n.01') ( n ) [ a football game in which two teams of 11 players try to kick or head a ball into the opponents' goal ]
is 0.05
```
两个词各个同义词集之间<ruby> 路径相似度 <rt> path similarity </rt></ruby>最大的是 0.5,表明它们关联性很大([<ruby> 路径相似度 <rt> path similarity </rt></ruby>](https://www.nltk.org/howto/wordnet.html)指两个词的意义在<ruby> 上下义关系的词汇分类结构 <rt> hypernym/hypnoym taxonomy </rt></ruby>中的最短距离)。
那么 `code` 和 `bug` 呢?这两个计算机领域的词的相似度是:
```
Path similarity of:
Synset('code.n.01') ( n ) [ a set of rules or principles or laws (especially written ones) ]
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]
is 0.1111111111111111
...
Path similarity of:
Synset('code.n.02') ( n ) [ a coding system used for transmitting messages requiring brevity or secrecy ]
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]
is 0.09090909090909091
...
Path similarity of:
Synset('code.n.03') ( n ) [ (computer science) the symbolic arrangement of data or instructions in a computer program or the set of such instructions ]
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]
is 0.09090909090909091
```
这些是这两个词各同义词集之间<ruby> 路径相似度 <rt> path similarity </rt></ruby>的最大值,这些值表明两个词是有关联性的。
NLTK 提供多种<ruby> 相似度计分器 <rt> similarity scorers </rt></ruby>,比如:
* path\_similarity
* lch\_similarity
* wup\_similarity
* res\_similarity
* jcn\_similarity
* lin\_similarity
要进一步了解这些<ruby> 相似度计分器 <rt> similarity scorers </rt></ruby>,请查看 [WordNet Interface](https://www.nltk.org/howto/wordnet.html) 的 Similarity 部分。
#### 自主尝试
使用 Python 库,从维基百科的 [Category: Lists of computer terms](https://en.wikipedia.org/wiki/Category:Lists_of_computer_terms) 生成一个术语列表,然后计算各术语之间的相似度。
### 树和树库
使用 NLTK,你可以把文本表示成树状结构以便进行分析。
这里有一个例子:
这是一份简短的文本,对其做预处理和词性标注:
```
import nltk
text = "I love open source"
# Tokenize to words
words = nltk.tokenize.word_tokenize(text)
# POS tag the words
words_tagged = nltk.pos_tag(words)
```
要把文本转换成树状结构,你必须定义一个<ruby> 语法 <rt> grammar </rt></ruby>。这个例子里用的是一个基于 [Penn Treebank tags](https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html) 的简单语法。
```
# A simple grammar to create tree
grammar = "NP: {<JJ><NN>}"
```
然后用这个<ruby> 语法 <rt> grammar </rt></ruby>创建一颗<ruby> 树 <rt> tree </rt></ruby>:
```
# Create tree
parser = nltk.RegexpParser(grammar)
tree = parser.parse(words_tagged)
pprint(tree)
```
运行上面的代码,将得到:
```
Tree('S', [('I', 'PRP'), ('love', 'VBP'), Tree('NP', [('open', 'JJ'), ('source', 'NN')])])
```
你也可以图形化地显示结果。
```
tree.draw()
```

这个树状结构有助于准确解读文本的意思。比如,用它可以找到文本的 [主语](https://en.wikipedia.org/wiki/Subject_(grammar)):
```
subject_tags = ["NN", "NNS", "NP", "NNP", "NNPS", "PRP", "PRP$"]
def subject(sentence_tree):
for tagged_word in sentence_tree:
# A crude logic for this case - first word with these tags is considered subject
if tagged_word[1] in subject_tags:
return tagged_word[0]
print("Subject:", subject(tree))
```
结果显示主语是 `I`:
```
Subject: I
```
这是一个比较基础的文本分析步骤,可以用到更广泛的应用场景中。 比如,在聊天机器人方面,如果用户告诉机器人:“给我妈妈 Jane 预订一张机票,1 月 1 号伦敦飞纽约的”,机器人可以用这种分析方法解读这个指令:
**动作**: 预订
**动作的对象**: 机票
**乘客**: Jane
**出发地**: 伦敦
**目的地**: 纽约
**日期**: (明年)1 月 1 号
<ruby> 树库 <rt> treebank </rt></ruby>指由许多预先标注好的<ruby> 树 <rt> tree </rt></ruby>构成的语料库。现在已经有面向多种语言的树库,既有开源的,也有限定条件下才能免费使用的,以及商用的。其中使用最广泛的是面向英语的宾州树库。宾州树库取材于<ruby> 华尔街日报 <rt> Wall Street Journal </rt></ruby>。NLTK 也包含了宾州树库作为一个子语料库。下面是一些使用<ruby> 树库 <rt> treebank </rt></ruby>的方法:
```
words = nltk.corpus.treebank.words()
print(len(words), "words:")
print(words)
tagged_sents = nltk.corpus.treebank.tagged_sents()
print(len(tagged_sents), "sentences:")
print(tagged_sents)
```
```
100676 words:
['Pierre', 'Vinken', ',', '61', 'years', 'old', ',', ...]
3914 sentences:
[[('Pierre', 'NNP'), ('Vinken', 'NNP'), (',', ','), ('61', 'CD'), ('years', 'NNS'), ('old', 'JJ'), (',', ','), ('will', 'MD'), ('join', 'VB'), ('the', 'DT'), ('board', 'NN'), ('as', 'IN'), ('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN'), ...]
```
查看一个句子里的各个<ruby> 标签 <rt> tags </rt></ruby>:
```
sent0 = tagged_sents[0]
pprint(sent0)
```
```
[('Pierre', 'NNP'),
('Vinken', 'NNP'),
(',', ','),
('61', 'CD'),
('years', 'NNS'),
...
```
定义一个<ruby> 语法 <rt> grammar </rt></ruby>来把这个句子转换成树状结构:
```
grammar = '''
Subject: {<NNP><NNP>}
SubjectInfo: {<CD><NNS><JJ>}
Action: {<MD><VB>}
Object: {<DT><NN>}
Stopwords: {<IN><DT>}
ObjectInfo: {<JJ><NN>}
When: {<NNP><CD>}
'''
parser = nltk.RegexpParser(grammar)
tree = parser.parse(sent0)
print(tree)
```
```
(S
(Subject Pierre/NNP Vinken/NNP)
,/,
(SubjectInfo 61/CD years/NNS old/JJ)
,/,
(Action will/MD join/VB)
(Object the/DT board/NN)
as/IN
a/DT
(ObjectInfo nonexecutive/JJ director/NN)
(Subject Nov./NNP)
29/CD
./.)
```
图形化地显示:
```
tree.draw()
```

<ruby> 树 <rt> trees </rt></ruby>和<ruby> 树库 <rt> treebanks </rt></ruby>的概念是文本分析的一个强大的组成部分。
#### 自主尝试
使用 Python 库,下载维基百科的 “[open source](https://en.wikipedia.org/wiki/Open_source)” 页面,将得到的文本以图形化的树状结构展现出来。
### 命名实体识别
无论口语还是书面语都包含着重要数据。文本处理的主要目标之一,就是提取出关键数据。几乎所有应用场景所需要提取关键数据,比如航空公司的订票机器人或者问答机器人。 NLTK 为此提供了一个<ruby> 命名实体识别 <rt> named entity recognition </rt></ruby>的功能。
这里有一个代码示例:
```
sentence = 'Peterson first suggested the name "open source" at Palo Alto, California'
```
验证这个句子里的<ruby> 人名 <rt> name </rt></ruby>和<ruby> 地名 <rt> place </rt></ruby>有没有被识别出来。照例先预处理:
```
import nltk
words = nltk.word_tokenize(sentence)
pos_tagged = nltk.pos_tag(words)
```
运行<ruby> 命名实体标注器 <rt> named-entity tagger </rt></ruby>:
```
ne_tagged = nltk.ne_chunk(pos_tagged)
print("NE tagged text:")
print(ne_tagged)
print()
```
```
NE tagged text:
(S
(PERSON Peterson/NNP)
first/RB
suggested/VBD
the/DT
name/NN
``/``
open/JJ
source/NN
''/''
at/IN
(FACILITY Palo/NNP Alto/NNP)
,/,
(GPE California/NNP))
```
上面的结果里,命名实体被识别出来并做了标注;只提取这个<ruby> 树 <rt> tree </rt></ruby>里的命名实体:
```
print("Recognized named entities:")
for ne in ne_tagged:
if hasattr(ne, "label"):
print(ne.label(), ne[0:])
```
```
Recognized named entities:
PERSON [('Peterson', 'NNP')]
FACILITY [('Palo', 'NNP'), ('Alto', 'NNP')]
GPE [('California', 'NNP')]
```
图形化地显示:
```
ne_tagged.draw()
```

NLTK 内置的<ruby> 命名实体标注器 <rt> named-entity tagger </rt></ruby>,使用的是宾州法尼亚大学的 [Automatic Content Extraction](https://www.ldc.upenn.edu/collaborations/past-projects/ace)(ACE)程序。该标注器能够识别<ruby> 组织机构 <rt> ORGANIZATION </rt></ruby><ruby> 、人名 <rt> PERSON </rt></ruby><ruby> 、地名 <rt> LOCATION </rt></ruby><ruby> 、设施 <rt> FACILITY </rt></ruby>和<ruby> 地缘政治实体 <rt> geopolitical entity </rt></ruby>等常见<ruby> 实体 <rt> entites </rt></ruby>。
NLTK 也可以使用其他<ruby> 标注器 <rt> tagger </rt></ruby>,比如 [Stanford Named Entity Recognizer](https://nlp.stanford.edu/software/CRF-NER.html). 这个经过训练的标注器用 Java 写成,但 NLTK 提供了一个使用它的接口(详情请查看 [nltk.parse.stanford](https://www.nltk.org/_modules/nltk/parse/stanford.html) 或 [nltk.tag.stanford](https://www.nltk.org/_modules/nltk/tag/stanford.html))。
#### 自主尝试
使用 Python 库,下载维基百科的 “[open source](https://en.wikipedia.org/wiki/Open_source)” 页面,并识别出对<ruby> 开源 <rt> open source </rt></ruby>有影响力的人的名字,以及他们为<ruby> 开源 <rt> open source </rt></ruby>做贡献的时间和地点。
### 高级实践
如果你准备好了,尝试用这篇文章以及此前的文章介绍的知识构建一个<ruby> 超级结构 <rt> superstructure </rt></ruby>。
使用 Python 库,下载维基百科的 “[Category: Computer science page](https://en.wikipedia.org/wiki/Category:Computer_science)”,然后:
* 找出其中频率最高的<ruby> 单词 <rt> unigrams </rt></ruby><ruby> 、二元搭配 <rt> bigrams </rt></ruby>和<ruby> 三元搭配 <rt> trigrams </rt></ruby>,将它们作为一个关键词列表或者技术列表。相关领域的学生或者工程师需要了解这样一份列表里的内容。
* 图形化地显示这个领域里重要的人名、技术、日期和地点。这会是一份很棒的信息图。
* 构建一个搜索引擎。你的搜索引擎性能能够超过维基百科吗?
### 下一步?
自然语言处理是<ruby> 应用构建 <rt> application building </rt></ruby>的典型支柱。NLTK 是经典、丰富且强大的工具集,提供了为现实世界构建有吸引力、目标明确的应用的工作坊。
在这个系列的文章里,我用 NLTK 作为例子,展示了自然语言处理可以做什么。自然语言处理和 NLTK 还有太多东西值得探索,这个系列的文章只是帮助你探索它们的切入点。
如果你的需求增长到 NLTK 已经满足不了了,你可以训练新的模型或者向 NLTK 添加新的功能。基于 NLTK 构建的新的自然语言处理库正在不断涌现,机器学习也正被深度用于自然语言处理。
---
via: <https://opensource.com/article/20/8/nlp-python-nltk>
作者:[Girish Managoli](https://opensource.com/users/gammay) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tanloong](https://github.com/tanloong) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my [previous article](https://opensource.com/article/20/8/intro-python-nltk), I introduced natural language processing (NLP) and the Natural Language Toolkit ([NLTK](http://www.nltk.org/)), the NLP toolkit created at the University of Pennsylvania. I demonstrated how to parse text and define stopwords in Python and introduced the concept of a corpus, a dataset of text that aids in text processing with out-of-the-box data. In this article, I'll continue utilizing datasets to compare and analyze natural language.
The fundamental building blocks covered in this article are:
- WordNet and synsets
- Similarity comparison
- Tree and treebank
- Named entity recognition
## WordNet and synsets
[WordNet](https://en.wikipedia.org/wiki/WordNet) is a large lexical database corpus in NLTK. WordNet maintains cognitive synonyms (commonly called synsets) of words correlated by nouns, verbs, adjectives, adverbs, synonyms, antonyms, and more.
WordNet is a very useful tool for text analysis. It is available for many languages (Chinese, English, Japanese, Russian, Spanish, and more), under many licenses (ranging from open source to commercial). The first WordNet was created by Princeton University for English under an MIT-like license.
A word is typically associated with multiple synsets based on its meanings and parts of speech. Each synset usually provides these attributes:
Attribute |
Definition |
Example |
---|---|---|
Name | Name of the synset | Example: The word "code" has five synsets with names `code.n.01` , `code.n.02` , `code.n.03` , `code.v.01` , `code.v.02` |
POS | Part of speech of the word for this synset | The word "code" has three synsets in noun form and two in verb form |
Definition | Definition of the word (in POS) | One of the definitions of "code" in verb form is: "(computer science) the symbolic arrangement of data or instructions in a computer program" |
Examples | Examples of word's use | One of the examples of "code": "We should encode the message for security reasons" |
Lemmas | Other word synsets this word+POC is related to (not strictly synonyms, but can be considered so); lemmas are related to other lemmas, not to words directly | Lemmas of `code.v.02` (as in "convert ordinary language into code") are `code.v.02.encipher` , `code.v.02.cipher` , `code.v.02.cypher` , `code.v.02.encrypt` , `code.v.02.inscribe` , `code.v.02.write_in_code` |
Antonyms | Opposites | Antonym of lemma `encode.v.01.encode` is `decode.v.01.decode` |
Hypernym | A broad category that other words fall under | A hypernym of `code.v.01` (as in "Code the pieces with numbers so that you can identify them later") is `tag.v.01` |
Meronym | A word that is part of (or subordinate to) a broad category | A meronym of "computer" is "chip" |
Holonym | The relationship between a parent word and its subordinate parts | A hyponym of "window" is "computer screen" |
There are several other attributes, which you can find in the `nltk/corpus/reader/wordnet.py`
source file in `<your python install>/Lib/site-packages`
.
Some code may help this make more sense.
This helper function:
```
def synset_info(synset):
print("Name", synset.name())
print("POS:", synset.pos())
print("Definition:", synset.definition())
print("Examples:", synset.examples())
print("Lemmas:", synset.lemmas())
print("Antonyms:", [lemma.antonyms() for lemma in synset.lemmas() if len(lemma.antonyms()) > 0])
print("Hypernyms:", synset.hypernyms())
print("Instance Hypernyms:", synset.instance_hypernyms())
print("Part Holonyms:", synset.part_holonyms())
print("Part Meronyms:", synset.part_meronyms())
print()
```
`synsets = wordnet.synsets('code')`
shows this:
```
5 synsets:
Name code.n.01
POS: n
Definition: a set of rules or principles or laws (especially written ones)
Examples: []
Lemmas: [Lemma('code.n.01.code'), Lemma('code.n.01.codification')]
Antonyms: []
Hypernyms: [Synset('written_communication.n.01')]
Instance Hpernyms: []
Part Holonyms: []
Part Meronyms: []
...
Name code.n.03
POS: n
Definition: (computer science) the symbolic arrangement of data or instructions in a computer program or the set of such instructions
Examples: []
Lemmas: [Lemma('code.n.03.code'), Lemma('code.n.03.computer_code')]
Antonyms: []
Hypernyms: [Synset('coding_system.n.01')]
Instance Hpernyms: []
Part Holonyms: []
Part Meronyms: []
...
Name code.v.02
POS: v
Definition: convert ordinary language into code
Examples: ['We should encode the message for security reasons']
Lemmas: [Lemma('code.v.02.code'), Lemma('code.v.02.encipher'), Lemma('code.v.02.cipher'), Lemma('code.v.02.cypher'), Lemma('code.v.02.encrypt'), Lemma('code.v.02.inscribe'), Lemma('code.v.02.write_in_code')]
Antonyms: []
Hypernyms: [Synset('encode.v.01')]
Instance Hpernyms: []
Part Holonyms: []
Part Meronyms: []
```
Synsets and lemmas follow a tree structure you can visualize:
```
def hypernyms(synset):
return synset.hypernyms()
synsets = wordnet.synsets('soccer')
for synset in synsets:
print(synset.name() + " tree:")
pprint(synset.tree(rel=hypernyms))
print()
```
```
code.n.01 tree:
[Synset('code.n.01'),
[Synset('written_communication.n.01'),
...
code.n.02 tree:
[Synset('code.n.02'),
[Synset('coding_system.n.01'),
...
code.n.03 tree:
[Synset('code.n.03'),
...
code.v.01 tree:
[Synset('code.v.01'),
[Synset('tag.v.01'),
...
code.v.02 tree:
[Synset('code.v.02'),
[Synset('encode.v.01'),
...
```
WordNet does not cover all words and their information (there are about 170,000 words in English today and about 155,000 in the latest version of WordNet), but it's a good starting point. After you learn the concepts of this building block, if you find it inadequate for your needs, you can migrate to another. Or, you can build your own WordNet!
### Try it yourself
Using the Python libraries, download Wikipedia's page on [open source](https://en.wikipedia.org/wiki/Open_source) and list the synsets and lemmas of all the words.
## Similarity comparison
Similarity comparison is a building block that identifies similarities between two pieces of text. It has many applications in search engines, chatbots, and more.
For example, are the words "football" and "soccer" related?
```
syn1 = wordnet.synsets('football')
syn2 = wordnet.synsets('soccer')
# A word may have multiple synsets, so need to compare each synset of word1 with synset of word2
for s1 in syn1:
for s2 in syn2:
print("Path similarity of: ")
print(s1, '(', s1.pos(), ')', '[', s1.definition(), ']')
print(s2, '(', s2.pos(), ')', '[', s2.definition(), ']')
print(" is", s1.path_similarity(s2))
print()
```
```
Path similarity of:
Synset('football.n.01') ( n ) [ any of various games played with a ball (round or oval) in which two teams try to kick or carry or propel the ball into each other's goal ]
Synset('soccer.n.01') ( n ) [ a football game in which two teams of 11 players try to kick or head a ball into the opponents' goal ]
is 0.5
Path similarity of:
Synset('football.n.02') ( n ) [ the inflated oblong ball used in playing American football ]
Synset('soccer.n.01') ( n ) [ a football game in which two teams of 11 players try to kick or head a ball into the opponents' goal ]
is 0.05
```
The highest path similarity score of the words is 0.5, indicating they are closely related.
What about "code" and "bug"? Similarity scores for these words used in computer science are:
```
Path similarity of:
Synset('code.n.01') ( n ) [ a set of rules or principles or laws (especially written ones) ]
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]
is 0.1111111111111111
...
Path similarity of:
Synset('code.n.02') ( n ) [ a coding system used for transmitting messages requiring brevity or secrecy ]
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]
is 0.09090909090909091
...
Path similarity of:
Synset('code.n.03') ( n ) [ (computer science) the symbolic arrangement of data or instructions in a computer program or the set of such instructions ]
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]
is 0.09090909090909091
```
These are the highest similarity scores, which indicates they are related.
NLTK provides several similarity scorers, such as:
- path_similarity
- lch_similarity
- wup_similarity
- res_similarity
- jcn_similarity
- lin_similarity
See the Similarity section of the [WordNet Interface](https://www.nltk.org/howto/wordnet.html) page to determine the appropriate one for your application.
### Try it yourself
Using Python libraries, start from the Wikipedia [Category: Lists of computer terms](https://en.wikipedia.org/wiki/Category:Lists_of_computer_terms) page and prepare a list of terminologies, then see how the words correlate.
## Tree and treebank
With NLTK, you can represent a text's structure in tree form to help with text analysis.
Here is an example:
A simple text pre-processed and part-of-speech (POS)-tagged:
```
import nltk
text = "I love open source"
# Tokenize to words
words = nltk.tokenize.word_tokenize(text)
# POS tag the words
words_tagged = nltk.pos_tag(words)
```
You must define a grammar to convert the text to a tree structure. This example uses a simple grammar based on the [Penn Treebank tags](https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html).
```
# A simple grammar to create tree
grammar = "NP: {<JJ><NN>}"
```
Next, use the grammar to create a tree:
```
# Create tree
parser = nltk.RegexpParser(grammar)
tree = parser.parse(words_tagged)
pprint(tree)
```
This produces:
`Tree('S', [('I', 'PRP'), ('love', 'VBP'), Tree('NP', [('open', 'JJ'), ('source', 'NN')])])`
You can see it better graphically.
`tree.draw()`
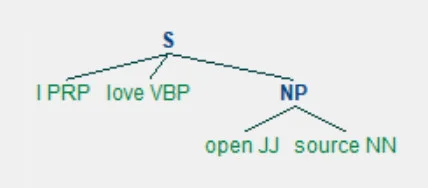
(Girish Managoli, CC BY-SA 4.0)
This structure helps explain the text's meaning correctly. As an example, identify the [subject](https://en.wikipedia.org/wiki/Subject_(grammar)) in this text:
```
subject_tags = ["NN", "NNS", "NP", "NNP", "NNPS", "PRP", "PRP$"]
def subject(sentence_tree):
for tagged_word in sentence_tree:
# A crude logic for this case - first word with these tags is considered subject
if tagged_word[1] in subject_tags:
return tagged_word[0]
print("Subject:", subject(tree))
```
It shows "I" is the subject:
`Subject: I`
This is a basic text analysis building block that is applicable to larger applications. For example, when a user says, "Book a flight for my mom, Jane, to NY from London on January 1st," a chatbot using this block can interpret the request as:
**Action**: Book
**What**: Flight
**Traveler**: Jane
**From**: London
**To**: New York
**Date**: 1 Jan (of the next year)
A treebank refers to a corpus with pre-tagged trees. Open source, conditional free-for-use, and commercial treebanks are available for many languages. The most commonly used one for English is Penn Treebank, extracted from the *Wall Street Journal*, a subset of which is included in NLTK. Some ways of using a treebank:
```
words = nltk.corpus.treebank.words()
print(len(words), "words:")
print(words)
tagged_sents = nltk.corpus.treebank.tagged_sents()
print(len(tagged_sents), "sentences:")
print(tagged_sents)
```
```
100676 words:
['Pierre', 'Vinken', ',', '61', 'years', 'old', ',', ...]
3914 sentences:
[[('Pierre', 'NNP'), ('Vinken', 'NNP'), (',', ','), ('61', 'CD'), ('years', 'NNS'), ('old', 'JJ'), (',', ','), ('will', 'MD'), ('join', 'VB'), ('the', 'DT'), ('board', 'NN'), ('as', 'IN'), ('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN'), ...]
```
See tags in a sentence:
```
sent0 = tagged_sents[0]
pprint(sent0)
```
```
[('Pierre', 'NNP'),
('Vinken', 'NNP'),
(',', ','),
('61', 'CD'),
('years', 'NNS'),
...
```
Create a grammar to convert this to a tree:
```
grammar = '''
Subject: {<NNP><NNP>}
SubjectInfo: {<CD><NNS><JJ>}
Action: {<MD><VB>}
Object: {<DT><NN>}
Stopwords: {<IN><DT>}
ObjectInfo: {<JJ><NN>}
When: {<NNP><CD>}
'''
parser = nltk.RegexpParser(grammar)
tree = parser.parse(sent0)
print(tree)
```
```
(S
(Subject Pierre/NNP Vinken/NNP)
,/,
(SubjectInfo 61/CD years/NNS old/JJ)
,/,
(Action will/MD join/VB)
(Object the/DT board/NN)
as/IN
a/DT
(ObjectInfo nonexecutive/JJ director/NN)
(Subject Nov./NNP)
29/CD
./.)
```
See it graphically:
`tree.draw()`

(Girish Managoli, CC BY-SA 4.0)
The concept of trees and treebanks is a powerful building block for text analysis.
### Try it yourself
Using the Python libraries, download Wikipedia's page on [open source](https://en.wikipedia.org/wiki/Open_source) and represent the text in a presentable view.
## Named entity recognition
Text, whether spoken or written, contains important data. One of text processing's primary goals is extracting this key data. This is needed in almost all applications, such as an airline chatbot that books tickets or a question-answering bot. NLTK provides a named entity recognition feature for this.
Here's a code example:
`sentence = 'Peterson first suggested the name "open source" at Palo Alto, California'`
See if name and place are recognized in this sentence. Pre-process as usual:
```
import nltk
words = nltk.word_tokenize(sentence)
pos_tagged = nltk.pos_tag(words)
```
Run the named-entity tagger:
```
ne_tagged = nltk.ne_chunk(pos_tagged)
print("NE tagged text:")
print(ne_tagged)
print()
```
```
NE tagged text:
(S
(PERSON Peterson/NNP)
first/RB
suggested/VBD
the/DT
name/NN
``/``
open/JJ
source/NN
''/''
at/IN
(FACILITY Palo/NNP Alto/NNP)
,/,
(GPE California/NNP))
```
Name tags were added; extract only the named entities from this tree:
```
print("Recognized named entities:")
for ne in ne_tagged:
if hasattr(ne, "label"):
print(ne.label(), ne[0:])
```
```
Recognized named entities:
PERSON [('Peterson', 'NNP')]
FACILITY [('Palo', 'NNP'), ('Alto', 'NNP')]
GPE [('California', 'NNP')]
```
See it graphically:
`ne_tagged.draw()`

(Girish Managoli, CC BY-SA 4.0)
NLTK's built-in named-entity tagger, using PENN's [Automatic Content Extraction](https://www.ldc.upenn.edu/collaborations/past-projects/ace) (ACE) program, detects common entities such as ORGANIZATION, PERSON, LOCATION, FACILITY, and GPE (geopolitical entity).
NLTK can use other taggers, such as the [Stanford Named Entity Recognizer](https://nlp.stanford.edu/software/CRF-NER.html). This trained tagger is built in Java, but NLTK provides an interface to work with it (See [nltk.parse.stanford](https://www.nltk.org/_modules/nltk/parse/stanford.html) or [nltk.tag.stanford](https://www.nltk.org/_modules/nltk/tag/stanford.html)).
### Try it yourself
Using the Python libraries, download Wikipedia's page on [open source](https://en.wikipedia.org/wiki/Open_source) and identify people who had an influence on open source and where and when they contributed.
## Advanced exercise
If you're ready for it, try building this superstructure using the building blocks discussed in these articles.
Using Python libraries, download Wikipedia's [Category: Computer science page](https://en.wikipedia.org/wiki/Category:Computer_science) and:
- Identify the most-occurring unigrams, bigrams, and trigrams and publish it as a list of keywords or technologies that students and engineers need to be aware of in this domain.
- Show the names, technologies, dates, and places that matter in this field graphically. This can be a nice infographic.
- Create a search engine. Does your search engine perform better than Wikipedia's search?
## What's next?
NLP is a quintessential pillar in application building. NLTK is a classic, rich, and powerful kit that provides the bricks and mortar to build practically appealing, purposeful applications for the real world.
In this series of articles, I explained what NLP makes possible using NLTK as an example. NLP and NLTK have a lot more to offer. This series is an inception point to help get you started.
If your needs grow beyond NLTK's capabilities, you could train new models or add capabilities to it. New NLP libraries that build on NLTK are coming up, and machine learning is being used extensively in language processing.
## Comments are closed. |
13,604 | 作为一个写作者如何使用 Git 版本控制 | https://news.itsfoss.com/version-control-writers/ | 2021-07-21T16:27:59 | [
"Git",
"写作"
] | https://linux.cn/article-13604-1.html |
>
> 我使用 Vim 和 Git 来写小说。是的,你也可以用 Git 来完成非编码任务。
>
>
>

我相信当代的写作者们应该开始思考他们的工作流程了。
在一个注意力高度分散的世界里,作为写作者,我们必须对每天执行的任务链拥有控制权。传统上,作家们会把他们的写作放在分散注意力的事较少、注意力高度集中的时间段。不幸的是,海明威、阿特伍德们的这些建议不再真正适用于我们了。我们所生活的世界联系得更紧密了,因此对作家来说就有了更多的陷阱。这首先要求我们要有足够的自制力,不要让社交媒体或小狗和小猫的可爱视频在我们写作的时候分散我们的注意力。
但是,如果你的写作需要快速地检查事实、拼写不常见和技术性的词汇等,断开与互联网连接并不是一个现实的选项 —— 这正是我写作时的场景。另一个问题是你用于写作的应用程序本身的干扰;作为一个长期使用 MS Word 的人,我发现它越来越漂亮,但速度越来越慢,也越来越让人分心。作为当初我 [迁移到 Vim 的主要原因](https://news.itsfoss.com/how-i-started-loving-vim/) 之一,我曾详细地谈到了这一点,所以我不打算再在这个问题上大谈特谈。重点是,在现代世界中,在现代设备上进行写作,可能远非理想状态。
因为我已经详细介绍过了 [我为什么转向 Vim](https://news.itsfoss.com/configuring-vim-writing/) 和开源版本控制,在这篇文章中,我更想谈谈该 **怎么做**,特别是如何使用开源的版本控制技术,比如 Git(和 GitHub)。
### 什么是版本控制?再来一次?

上图是我们如何进行传统版本控制的一个说明。这个图中假设你有一台设备,而且你只在那台设备上写作。但对我而言,我在许多机器上写作,包括我的安卓手机和一些不同年代的笔记本电脑,我会在特定的任务、特定的位置使用到它们。我在所有这些设备上进行的一个共同任务就是写作 —— 因此,我的设备必须以合理的方式捕捉变化并控制文件的版本。不要再让我将 `file1V1_device1_date.doc` 作为文件名了。
上图也没有考虑到我们用来写作的工具。像 LibreOffice Write 这样的文字处理器可以在 Linux、Mac 和 Windows 系统上使用,但在手机上使用文字处理器将会是一段不愉快的经历。我们中的一些写作者还使用其他文本工具(包括 Gmail 或我们的电子邮件客户端)来为我们的写作打草稿。但按逻辑顺序跟踪所有这些文件和电子邮件是相当折磨人的,我就用这样的流程写过一本书,相信我:我花在弄清文件名、版本变化、评论、给自己的注释以及带有附加注释的电子邮件上的时间,足以让我精神错乱。
读到这里,你们中的一些人可能会正确地指出,有云备份技术呀。虽然云存储的好处是巨大的,而且我也在继续使用它们,但其版本控制几乎不存在,或者说并不强大。
### 一个更好的工作流程
就像地球上的其它地方一样,大流行病的开始引发了一些焦虑和一些反思。我利用这段时间在 [The Odin Project](https://www.theodinproject.com/)(强烈推荐给那些想学习 html、CSS、JavaScript/Ruby 的人)上自学了网络开发。
在课程的第一个模块中,有一个关于 Git 的介绍:什么是版本控制,以及它试图解决什么问题。读了这一章后,我豁然开朗。我立即意识到,这个 *Git* 正是我作为一个写作者所要寻找的东西。
是的,更好的方法不是本地化的版本控制,而是 *分布式* 的版本控制。“分布式”描述的是设备的分布,而我在这些设备上访问文件,以及之后进行编辑修改。下图是分布式版本控制的一个直观说明。

### 我的方法
我为写作建立一个版本控制系统的目标如下:
* 使我的稿件库可以从任何地方、任何设备上访问
* 易于使用
* 减少或消除因在写作、学习和编码各工作流程之间的场景切换而产生的摩擦 —— 尽可能使用同一工具(即 Vim)。
* 可扩展性
* 易于维护
基于以上需求,下图是我进行写作的分布式版本控制系统。

如你所见,我的版本控制系统是分布式版本控制的一个简单的适配。在我的例子中,通过将 Git 版本控制应用到云存储([pCloud](https://itsfoss.com/recommends/pcloud/))的一个文件夹上,我可以同时利用这两种技术的优点。因此,我的工作流程可以用下图描述:

#### 优势
1. 我用一个写作(和编码)工具
2. 我可以对我的手稿进行版本控制,无论我是从什么设备上访问文件的
3. [超级简单,几乎没有任何不便之处](https://www.youtube.com/watch?v=NtH-HhaLw-Q)
4. 易于维护
#### 缺点
你们中的写作者一定想知道这个系统存在什么缺点。以下是我在持续使用和完善这一工作流程时预计到的几个问题。
* 对草稿的评论:文字处理器的一个更有用的功能是具有评论的功能。当我希望以后再回到文本的某一部分时,我经常在这部分为自己留下一个评论。我仍然没有想出一个解决这个问题的办法。
* 协作:文字处理程序允许写作者之间进行协作。在我以前做广告相关工作的时候,我会用 Google Docs 来写文案,然后分享链接给我的设计师,从而他可以为广告和网站对文案进行摘录。现在,我的解决方法是用 Markdown 写文案,并通过 Pandoc 将 Markdown 文件导出为 .doc 文件。更关键的是,当我的手稿完成后,我仍然需要将文件以 .doc 格式发送给我的编辑。一旦我的编辑做了一些修改并把它发回来,我再尝试用 Vim 打开它就没有意义了。在这一点上,该系统的局限性变得更加明显。
我并不是说这是最好的方法,但在我职业生涯的这个阶段,这是对我来说最好的方法。我想,随着我对我的新的 [用于写作的开源工具](https://itsfoss.com/open-source-tools-writers/) 和版本控制越来越熟悉和适应,我将进一步完善这个方法。
我希望这篇文章能为那些想使用 Git 进行文档版本控制的写作者提供一个很好的介绍。这肯定不是一篇详尽的文章,但我将分享一些有用的链接,使你的旅程更容易。
1. [The Odin Project 介绍的 Git 基础知识](https://www.theodinproject.com/paths/foundations/courses/foundations/lessons/introduction-to-git)
2. [开始使用 Git](https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control)
3. GitHub 的 Git 基础知识教程
---
via: <https://news.itsfoss.com/version-control-writers/>
作者:[Theena](https://news.itsfoss.com/author/theena/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[piaoshi](https://github.com/piaoshi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

I believe modern writers should begin thinking about their processes, or workflows.
In a highly distracted world, it is imperative to take ownership over the chain of tasks we perform every day as writers. Traditionally, writers would put their writing to the hours where the distraction is less, and the focus high. Unfortunately advice from Hemingway, Atwood, et al., isn’t really applicable to us any more. The world we live in is far more connected, and thus have far more pitfalls for writers. Part of that is being disciplined enough to not let social media or cute videos of puppies and kittens distract us at the times we are writing.
But disconnecting from the internet isn’t really an option if part of your writing requires quick fact-checks, spellings of uncommon and technical words, etc., – this is very true for me when I am writing. The other issue is the distractions that are within the writing app itself; as a life long MS Word user, I found it getting prettier, but slower and more distracting. I spoke about this at length as being among the [primary reasons for transitioning into Vim](https://news.itsfoss.com/how-i-started-loving-vim/) in the first place, so I am not going to speak extensively on this. The point being that writing in the modern world, on modern devices can be far from ideal.
Since I’ve already gone into detail on the [why I switched to Vim](https://news.itsfoss.com/configuring-vim-writing/) and open source version control, I would like to use this article to talk about the **how**, specifically how to use open source version control technology such as git (and GitHub).
## What is Version Control, again?
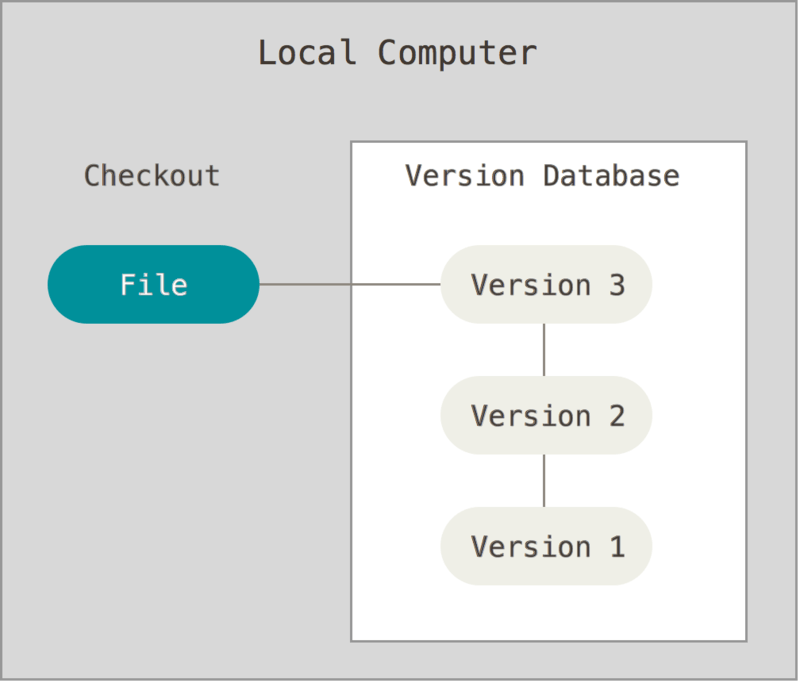
The diagram above is a illustration of how we perform traditional version control. This
diagram assumes that you have one device and that you write only in that device. In my case, I write on a number of machines, including my Android phone and a selection of laptops of varying ages that I use for specific and in specific places. The one common task that I carry out between all these devices is writing – it is imperative, therefore, that my devices capture changes and version controls my files in sane manner. No more `file1V1_device1_date.doc`
as I would name my files.
The diagram above also doesn’t take into account the tools that we use to write.A word processor such as LibreOffice Write works across Linux, Mac, and Windows machines, but using a word processor on the phone is an unpleasant experience. Some of us writers also use other text tools, including Gmail or our email clients, to write little sketches for our writing. Keeping track of all of these files and emails in a logical order is exhausting – I wrote a book using such a process, and trust me: the time I spent figuring out file names, version changes, comments, notes to self, and emails with additional notes, was enough to drive me to distraction.
Some of you reading this might rightly point out that cloud-based backup technology
exists. While the benefits of cloud-based storage are immense, and I continue using them, version control barely exists, or isn’t powerful.
## A better workflow
Like the rest of the planet, the start of the pandemic led to some anxiety and some soul
searching. I spent the time teaching myself web development on [The Odin Project](https://www.theodinproject.com/?ref=news.itsfoss.com) (highly recommended for those who are thinking of learning html, CSS, JavaScript/Ruby).
Among the first modules was an introduction to Git: what version control was, and what problems it sought to address. Reading this chapter was a revelation. I knew immediately that this *git* was exactly what I was looking for as a writer.
The better way, then, isn’t localized version control but *distributed* version control. ‘Distributed’ describes the distribution of the *devices* that I will be accessing a file from, and editing/changing thereafter. The diagram below is a visual illustration of distributed version control.
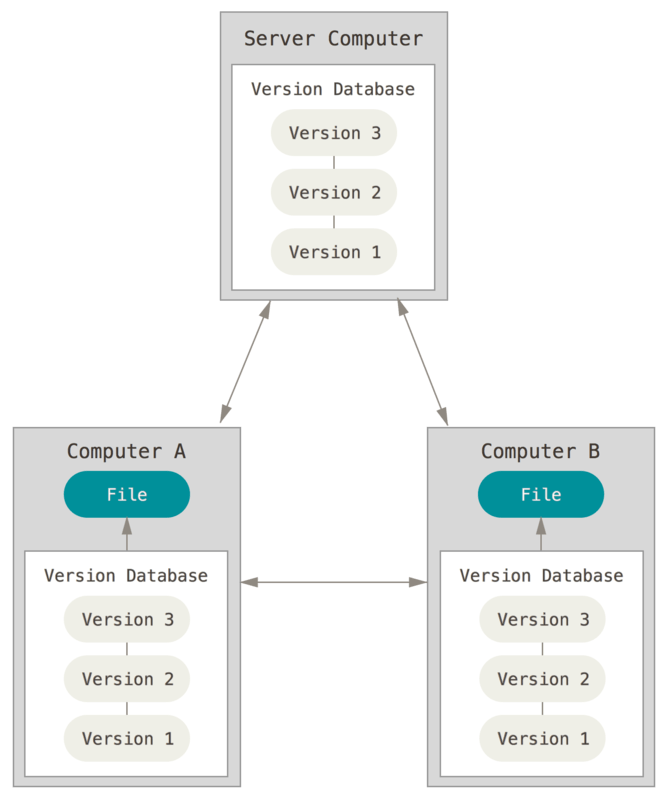
## My way
My goals in building a version control system for writing were as follows:
- Make my manuscript repository accessible from anywhere, from any device
- Ease of use
- Reduce or remove the friction that comes about from shifting context between writing, study and coding workflows – as much as possible, we will use the same tool (i.e. Vim)
- Scalable
- Easy to maintain
Based on the above needs, the diagram below is my distributed version control system for my writing.
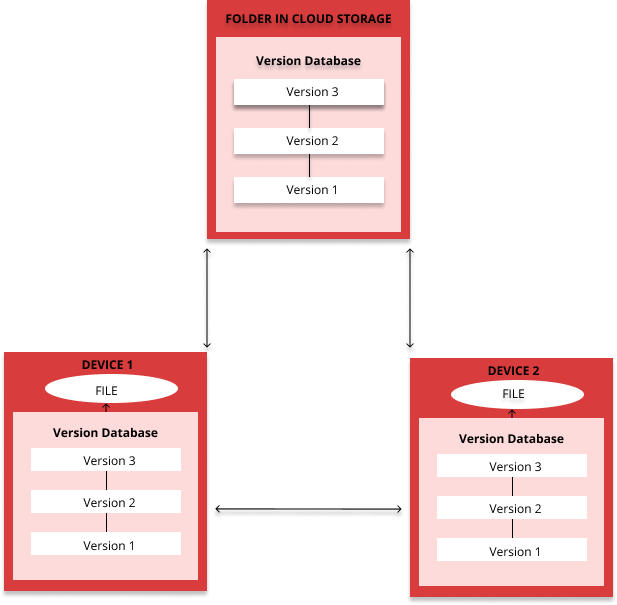
As you can see, my version control system is a simplistic adaptation of distributed version control. By adding git version control to a folder on cloud storage ([pCloud](https://itsfoss.com/recommends/pcloud/?ref=news.itsfoss.com)) in my case, I can now draw the benefits of both technologies. Thus my workflow can be visualized as follows:
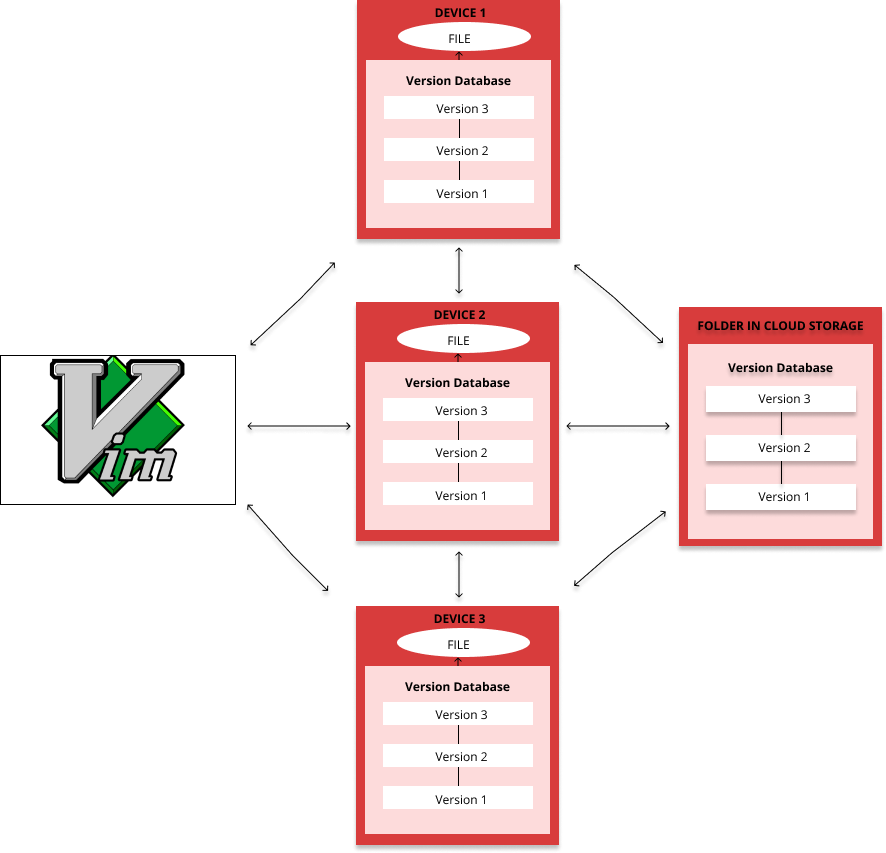
### Advantages
- I have one writing (and coding) tool
- I have version control of my manuscripts, no matter what device I access the file from
- It’s
[super easy, barely an inconvenience](https://www.youtube.com/watch?v=NtH-HhaLw-Q&ref=news.itsfoss.com) - Easy to maintain.
### Drawbacks
The writers among you must wonder what drawbacks exist in the system. Here are a few that I anticipate as I continue using and refining this workflow.
- Comments on drafts: one of the more useful features of word processors is the ability to comment. I often leave comments for myself when I want to come back to a certain portion of the text. I still haven’t figured out a workaround for this.
- Collaboration: Word processors allow for collaboration between writers. During my advertising days, I would use Google Docs to write copy and share the link with my designers to extract the copy for ads and websites. Right now, my workaround for this writing the copy in markdown, and exporting the markdown file to a .doc file via Pandoc. More critically, when my manuscripts are completed, I’d need to still send the files in .doc format for my editors. Once my editor makes
those changes and sends it back, it makes little sense for me to try opening it again in Vim. At this point, the system’s limitations will become more obvious.
In no way am I saying this is the best method, but this is the best method for *me* at this
point in my career. I imagine I will be refining this further as I get more familiar and comfortable with my new [open source tools for writing](https://itsfoss.com/open-source-tools-writers/?ref=news.itsfoss.com) and version control.
I hope this serves as a good introduction to writers wanting to use Git for their document version control. This is by no means an extensive article, but I will share some useful links to make the journey easier for you.
As a bonus, here’s a screen recording of me using Vim on my Android device to work on a poem, pushing the changes to Git.
*Contributed by Theena*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,605 | 分支与发行版有什么不同? | https://opensource.com/article/18/7/forks-vs-distributions | 2021-07-22T20:55:26 | [
"分支",
"发行版",
"fork"
] | https://linux.cn/article-13605-1.html |
>
> 开源软件的发行版和分支是不一样的。了解其中的区别和潜在的风险。
>
>
>

如果你们对开源软件有过一段时间的了解,一定曾在许多相关方面中听说过<ruby> 分支 <rt> fork </rt></ruby>和<ruby> 发行版 <rt> distribution </rt></ruby>两个词。许多人对这两个词的区别不太清楚,因此我将试着通过这篇文章为大家解答这一疑惑。
(LCTT 译注:fork 一词,按我们之前的倡议,在版本控制工作流中,为了避免和同一个仓库的 branch 一词混淆,我们建议翻译为“复刻”。但是在项目和发行版这个语境下,没有这个混淆,惯例上还是称之为“分支”。)
### 首先,一些定义
在解释分支与发行版两者的细微区别与相似之处之前,让我们先给一些相关的重要概念下定义。
**[开源软件](https://opensource.com/resources/what-open-source)** 是指具有以下特点的软件:
* 在特定的 [许可证](https://opensource.com/tags/licensing) 限制下,软件供所有人免费分发
* 在特定的许可证限制下,软件源代码可以供所有人查看与修改
开源软件可以按以下方式 **使用**:
* 以二进制或者源代码的方式下载,通常是免费的。(例如,[Eclipse 开发者环境](https://www.eclipse.org/che/getting-started/download/))
* 作为一个商业公司的产品,有时向用户提供一些服务并以此收费。(例如,[红帽产品](https://access.redhat.com/downloads))
* 嵌入在专有的软件解决方案中。(例如一些智能手机和浏览器用于显示字体的 [Freetype 软件](https://www.freetype.org/))
<ruby> 自由开源软件 <rt> free and open source software </rt></ruby>(FOSS)不一定是“零成本”的“<ruby> 免费 <rt> free </rt></ruby>”。自由开源软件仅仅意味着这个软件在遵守软件许可证的前提下可以自由地分发、修改、研究和使用。软件分发者也可能为该软件定价。例如,Linux 可以是 Fedora、Centos、Gentoo 等免费发行版,也可以是付费的发行版,如红帽企业版 Linux(RHEL)、SUSE Linux 企业版(SLES)等。
<ruby> 社区 <rt> community </rt></ruby>指的是在一个开源项目上协作的团体或个人。任何人或者团体都可以在遵守协议的前提下,通过编写或审查代码/文档/测试套件、管理会议、更新网站等方式为开源项目作出贡献。例如,在 [Openhub.net](http://openhub.net) 网站上,我们可以看见政府、非营利性机构、商业公司和教育团队等组织都在 [为一些开源项目作出贡献](https://www.openhub.net/explore/orgs)。
一个开源<ruby> 项目 <rt> project </rt></ruby>是集协作开发、文档和测试的结果。大多数项目都搭建了一个中央仓库用来存储代码、文档、测试文件和目前正在开发的文件。
<ruby> 发行版 <rt> distribution </rt></ruby>是指开源项目的一份的二进制或源代码的副本。例如,CentOS、Fedora、红帽企业版 Linux(RHEL)、SUSE Linux、Ubuntu 等都是 Linux 项目的发行版。Tectonic、谷歌的 Kubernetes 引擎(GKE)、亚马逊的容器服务和红帽的 OpenShift 都是 Kubernetes 项目的发行版。
开源项目的商业发行版经常被称作<ruby> 产品 <rt> products </rt></ruby>,因此,红帽 OpenStack 平台是红帽 OpenStack 的产品,它是 OpenStack 上游项目的一个发行版,并且是百分百开源的。
<ruby> 主干 <rt> trunk </rt></ruby>是开发开源项目的社区的主要工作流。
开源分支fork是开源项目主干的一个版本,它是分离自主干的独立工作流。
因此,**发行版并不等同于分支**。发行版是上游项目的一种包装,由厂商提供,经常作为产品进行销售。然而,发行版的核心代码和文档与上游项目的版本保持一致。分支,以及任何基于分支的的发行版,导致代码和文档的版本与上游项目不同。对上游项目进行了分支的用户必须自己来维护分支项目,这意味着他们失去了上游社区协同工作带来的好处。
为了进一步解释软件分支,让我来用动物迁徙作比喻。鲸鱼和海狮从北极迁徙到加利福尼亚和墨西哥;帝王斑蝶从阿拉斯加迁徙到墨西哥;并且北半球的燕子和许多其他鸟类飞翔南方去过冬。成功迁徙的关键因素在于,团队中的所有动物团结一致,紧跟领导者,找到食物和庇护所,并且不会迷路。
### 独立前行带来的风险
一只鸟、帝王蝶或者鲸鱼一旦掉队就失去了许多优势,例如团队带来的保护,以及知道哪儿有食物、庇护所和目的地。
相似地,从上游版本获取分支并且独立维护的用户和组织也存在以下风险:
1. **由于代码不同,分支用户不能够基于上游版本更新代码。** 这就是大家熟知的技术债,对分支的代码修改的越多,将这一分支重新归入上游项目需要花费的时间和金钱成本就越高。
2. **分支用户有可能运行不太安全的代码。** 由于代码不同的原因,当开源代码的漏洞被找到,并且被上游社区修复时,分支版本的代码可能无法从这次修复中受益。
3. **分支用户可能不会从新特性中获益。** 拥有众多组织和个人支持的上游版本,将会创建许多符合所有上游项目用户利益的新特性。如果一个组织从上游分支,由于代码不同,它们可能无法纳入新的功能。
4. **它们可能无法和其他软件包整合在一起。** 开源项目很少是作为单一实体开发的;相反地,它们经常被与其他项目打包在一起构成一套解决方案。分支代码可能无法与其他项目整合,因为分支代码的开发者没有与上游的其他参与者们合作。
5. **它们可能不会得到硬件平台认证。** 软件包通常被搭载在硬件平台上进行认证,如果有问题发生,硬件与软件工作人员可以合作找出并解决问题发生的根源。
总之,开源发行版只是一个来自上游的、多组织协同开发的、由供应商销售与支持的打包集合。分支是一个开源项目的独立开发工作流,有可能无法从上游社区协同工作的结果中受益。
---
via: <https://opensource.com/article/18/7/forks-vs-distributions>
作者:[Jonathan Gershater](https://opensource.com/users/jgershat) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Wlzzzz-del](https://github.com/Wlzzzz-del) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you've been around open source software for any length of time, you'll hear the terms fork and distribution thrown around casually in conversation. For many people, the distinction between the two isn't clear, so here I'll try to clear up the confusion.
## First, some definitions
Before explaining the nuances of a fork vs. a distribution and the pitfalls thereof, let's define key concepts.
** Open source software** is software that:
- Is freely available to distribute under certain
[license](https://opensource.com/tags/licensing)restraints - Permits its source code to be viewable and modified under certain license restraints
Open source software can be **consumed** in the following ways:
- Downloaded in binary or source code format, often at no charge (e.g., the
[Eclipse developer environment](https://www.eclipse.org/che/getting-started/download/)) - As a distribution (product) by a vendor, sometimes at a cost to the user (e.g.,
[Red Hat products](https://access.redhat.com/downloads)) - Embedded into proprietary software solutions (e.g., some smartphones and browsers display fonts using the open source
[freetype software](https://www.freetype.org/))
**Free and open source (FOSS)** is not necessarily "free" as in "zero cost." Free and open source simply means the software is free to distribute, modify, study, and use, subject to the software's licensing. The software distributor may attach a purchase price to it. For example, Linux is available at no cost as Fedora, CentOS, Gentoo, etc. or as a paid distribution as Red Hat Enterprise Linux, SUSE, etc.
**Community** refers to the organizations and individuals that collaboratively work on an open source project. Any individual or organization can contribute to the project by writing or reviewing code, documentation, test suites, managing meetings, updating websites, etc., provided they abide by the license. For example, at [Openhub.net](http://openhub.net), we see government, nonprofit, commercial, and education organizations [contributing to some open source projects](https://www.openhub.net/explore/orgs).
An open source **project** is the result of this collaborative development, documentation, and testing. Most projects have a central repository where code, documentation, testing, and so forth are developed.
A **distribution** is a copy, in binary or source code format, of an open source project. For example, CentOS, Fedora, Red Hat Enterprise Linux, SUSE, Ubuntu, and others are distributions of the Linux project. Tectonic, Google Kubernetes Engine, Amazon Container Service, and Red Hat OpenShift are distributions of the Kubernetes project.
Vendor distributions of open source projects are often called **products**, thus Red Hat OpenStack Platform is the Red Hat OpenStack product that is a distribution of the OpenStack upstream project—and it is still 100% open source.
The **trunk** is the main workstream in the community where the open source project is developed.
An open source **fork** is a version of the open source project that is developed along a separate workstream from the main trunk.
Thus, **a distribution is not the same as a fork**. A distribution is a packaging of the upstream project that is made available by vendors, often as products. However, the core code and documentation in the distribution adhere to the version in the upstream project. A fork—and any distribution based on the fork—results in a version of the code and documentation that are different from the upstream project. Users who have forked upstream open source code have to maintain it on their own, meaning they lose the benefit of the collaboration that takes place in the upstream community.
To further explain a software fork, let's use the analogy of migrating animals. Whales and sea lions migrate from the Arctic to California and Mexico; Monarch butterflies migrate from Alaska to Mexico; and (in the Northern Hemisphere) swallows and many other birds fly south for the winter. The key to a successful migration is that all animals in the group stick together, follow the leaders, find food and shelter, and don't get lost.
## Risks of going it on your own
A bird, butterfly, or whale that strays from the group loses the benefit of remaining with the group and knowing where to find food, shelter, and the desired destination.
Similarly, users or organizations that fork and modify an upstream project and maintain it on their own run the following risks:
**They cannot update their code based on the upstream because their code differs.**This is known as technical debt; the more changes made to forked code, the more it costs in time and money to rebase the fork to the upstream project.**They potentially run less secure code.**If a vulnerability is found in open source code and fixed by the community in the upstream, a forked version of the code may not benefit from this fix because it is different from the upstream.**They might not benefit from new features.**The upstream community, using input from many organizations and individuals, creates new features for the benefit of all users of the upstream project. If an organization forks the upstream, they potentially cannot incorporate the new features because their code differs.**They might not integrate with other software packages.**Open source projects are rarely developed as single entities; rather they often are packaged together with other projects to create a solution. Forked code may not be able to be integrated with other projects because the developers of the forked code are not collaborating in the upstream with other participants.**They might not certify on hardware platforms.**Software packages are often certified to run on hardware platforms so, if problems arise, the hardware and software vendors can collaborate to find the root cause or problem.
In summary, an open source distribution is simply a packaging of an upstream, multi-organizational, collaborative open source project sold and supported by a vendor. A fork is a separate development workstream of an open source project and risks not being able to benefit from the collaborative efforts of the upstream community.
## 2 Comments |
13,607 | 将 Vim 配置成一个写作工具 | https://news.itsfoss.com/configuring-vim-writing/ | 2021-07-23T10:55:00 | [
"写作",
"Vim"
] | https://linux.cn/article-13607-1.html |
>
> 我使用 Vim 来写小说。我是这样配置它的。
>
>
>

在我的第一个专栏中,我谈到了我为什么把 [我的写作工作迁移到了 Vim 上](https://news.itsfoss.com/how-i-started-loving-vim/) —— 远离了现代写作者们的标准工具,如文字处理器(MS Word 及它的开源替代方案)、文本编辑器(记事本,因为直到去年我一直是 Windows 用户)和云存储技术。如果你是一个写作者,在继续下面的内容前,我建议你先阅读一下 [那篇文章的第一部分](https://news.itsfoss.com/how-i-started-loving-vim/) 。
基本上可以说,你使用的设备越多,你需要的写作工具就越多,最终你的工作流程就越复杂。这一点对我来说是很贴切的,因为我有四台设备,包括一部安卓手机,一台日常用的运行 Linux 的主力笔记本电脑,还有两台旧的笔记本电脑,其中一台是 Mac,我去户外拍摄时会带着它。
Vim 对于我和我的工作方式来说是一个完美的解决方案;虽然我不会说我的新的工作流程是现代写作者工作的最佳方式,但我可以说的是,对于写作者来说,拥有一个能在我们所有设备上工作的工具非常重要的,并且这个工具要足够强大以满足我们写作者每天从事的不同类型的写作需求。
从这个角度来看,Vim 的主要优势是它是跨平台的 —— 无论在什么设备上,Vim 都能工作。在苹果生态系统中使用 Vim 的情况我就不细说了,但粗略地看一下 [这个应用程序](https://apps.apple.com/us/app/ivim/id1266544660) 的评论,我就会知道,总会有人在各种地方使用 Vim,不管他们使用的是什么设备。
现在我们假设你是一个想开始使用 Vim 的写作者。当你安装了它,你该从哪里开始呢?
我在这一部分给你的并不算是教程,而是一系列的建议,包含对一个用于诗歌写作的 `.vimrc` 配置文件的解读。只要有可能,我就会链接到我学习相应内容时用到的 YouTube 上的教程。
对于 Linux 用户来说,系统已经预装了 Vim —— 通过你喜欢的终端模拟器就可以启动它。对于 Windows 和 Mac 用户,你可以从 [Vim 官方网站](https://www.vim.org/) 下载它。
### 建议
**安装/启用 Vim 后**
* 通过终端打开 Vim Tutor。(Mac 用户可以用这种方式启动,而 Windows 用户也可以用这种方法启动。[LCTT 译注:原文这里本应该有链接,可能作者忘记添加了。无论如何,在终端中, Linux 中的命令是 `vimtutor`,Windows 在安装目录下找到 `vimtutor.bat` 命令并运行;Mac?应该与 Linux 一样?我没 Mac 呀!])在这个阶段,你不会使用 Vim 进行任何写作 —— 相反,你要每天花 15 分钟做 Vim 教程。不要多花一分钟或少花一分钟;看看在规定的 15 分钟内,你能在教程中取得多大的进展。你会发现,每天你都会在教程中取得更大的进步。在一个月内,你应该能够利用这些 15 分钟完成整个教程。
* 成为一个更好的打字员对 Vim 的使用来说有极大的好处。这不是必须的,但我正在重新学习打字,它的副作用是使 Vim 变得更加有用了。我每次都以花 15 分钟练习打字开始,作为进入 Vim 教程前的热身。
在每一天的开始,我分配了 30 分钟的时间做这两项练习进行热身,而每天晚上睡觉前再分配 30 分钟进行练习以让我安定下来。这样的做法帮我快速从旧的工具包过渡到了 Vim,但你的安排可能有所不同。
我再次强调,**除了 Vim Tutor 之外**,上述步骤都是可选的;这完全取决于你个人的动机水平。
现在我们来到了这篇文章的重点:如何配置 Vim ,使它对写作者友好?
### 如何配置用于写作的 .vimrc
在开始之前,我想在这里提醒各位读者,我不是一个技术人员 —— 我是一个小说家 —— 你在下面看到的任何错误都是我自己的;我希望有经验的 Vim 用户能提供反馈,告诉我如何进一步完善我的配置文件。
下面是我的 `.vimrc` 文件。你可以从我的 [GitHub](https://github.com/MiragianCycle/dotfiles) 上下载,并进一步完善它:
```
syntax on
set noerrorbells " 取消 Vim 的错误警告铃声,关闭它以免打扰到我们 "
set textwidth=100 " 确保每一行不超过 100 字符 "
set tabstop=4 softtabstop=4
set shiftwidth=4
set expandtab
set smartindent
set linebreak
set number
set showmatch
set showbreak=+++
set smartcase
set noswapfile
set undodir=~/.vim/undodir
set undofile
set incsearch
set spell
set showmatch
set confirm
set ruler
set autochdir
set autowriteall
set undolevels=1000
set backspace=indent,eol,start
" 下面的设置确保按写作者而不是程序员喜欢的方式折行 "
set wrap
nnoremap <F5> :set linebreak<CR>
nnoremap <C-F5> :set nolinebreak<CR>
call plug#begin('~/.vim/plugged')
" 这是颜色风格插件 "
Plug 'colepeters/spacemacs-theme.vim'
Plug 'sainnhe/gruvbox-material'
Plug 'phanviet/vim-monokai-pro'
Plug 'flazz/vim-colorschemes'
Plug 'chriskempson/base16-vim'
Plug 'gruvbox-community/gruvbox'
" 这是为了更容易的诗歌写作选择的一些插件 "
Plug 'dpelle/vim-LanguageTool'
Plug 'ron89/thesaurus_query.vim'
Plug 'junegunn/goyo.vim'
Plug 'junegunn/limelight.vim'
Plug 'reedes/vim-pencil'
Plug 'reedes/vim-wordy'
" 这一部分是为了更容易地与机器集成,用了 vim-airline 这类插件 "
Plug 'vim-airline/vim-airline'
" 这一部分外理工作区和会话管理 "
Plug 'thaerkh/vim-workspace'
" 与上面插件相关, 下面的代码将你的所有的会话文件保存到一个你工作区之外的目录 "
let g:workspace_session_directory = $HOME . '/.vim/sessions/'
" 与上面插件相关,这是一个 Vim 活动的跟踪器 "
Plug 'wakatime/vim-wakatime'
" 一个干扰因素:我在这里使用了一些 Emacs 的功能,特别是 org-mode "
Plug 'jceb/vim-orgmode'
" 这是文件格式相关插件 "
Plug 'plasticboy/vim-markdown'
call plug#end()
colorscheme pacific
set background=dark
if executable('rg')
let g:rg_derive_root='true'
endif
```
学习如何安装 Vim 插件时,这个[教程](https://www.youtube.com/watch?v=n9k9scbTuvQ)帮助了我。我使用 Vim Plugged 插件管理器是因为在我看来它是最简单、最优雅的。

#### 对于写作者的 .vimrc 选项的整理
* `syntax on`:这可以确保 Vim 知道我在使用什么语法。做笔记、写这种文章时我主要使用 Markdown;而在写小说的时候,纯文本是我的首选格式。
* `set noerrorbells`:为了你的精神状态,我强烈建议打开这个选项。
* `set textwidth=100`:为了便于阅读,没有人愿意横向滚动一个文本文件。
* `set spell`:如果有拼写错误的话提醒你。
* `set wrap`:确保文本以写作者而不是程序员的方式进行折行。
你会注意到,我没有花更多时间讨论其他一些基本配置选项,因为我并不觉得那些对写作者来说有多重要。因为我做一些业余的编码工作,所以我的 `.vimrc` 配置反映了这一点。如果你只想在 Vim 上写作,那么上述配置就应该能让你顺利开始。
从这点上来说,你的 `.vimrc` 是一个活的文档,它能生动地反映你想用 Vim 做什么,以及你希望 Vim 如何为你做这些事情。
#### 关于插件的说明
第 43-98 行之间是我对插件的配置。如果你已经学习了关于如何安装 Vim 插件的教程,我强烈推荐你从以下专为写作开发的 Vim 插件开始:
* `vim-LanguageTool`
* `thesaurus_query.vim`
* `vim-pencil`
* `vim-wordy`
* `vim-goyo`
* `vim-markdown`
#### 总结
在这篇文章中,我们简单地[介绍](https://youtu.be/Pq3JMp3stxQ)了写作者可以怎样开始使用 Vim,以及一个在写作工作中需要的 `.vimrc` 入门配置。除了我的 `.vimrc` 之外,我还将在这里链接到我在 GitHub 上发现的其他写作者的 `.vimrc`,它们是我自己配置时的灵感来源。

请劳记,这只是一个写作者的 `.vimrc` 的入门配置。你会发现,随着你的需求的发展,Vim 也可以随之发展。因此,投入一些时间学习配置你的 `.vimrc` 是值得的。
在下一篇文章中,我将会检视我在写作时的工作流程的具体细节,这个工作流程中我使用了 Vim 和 Git 及 GitHub。
---
via: <https://news.itsfoss.com/configuring-vim-writing/>
作者:[Theena](https://news.itsfoss.com/author/theena/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[piaoshi](https://github.com/piaoshi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

In my first column I spoke about why I moved [my writing to Vim](https://news.itsfoss.com/how-i-started-loving-vim/) – away from the standard tools of modern writers such as word processors (MS Word and their open source equivalents), text editors (Notepad since I’ve been a Windows user until last year), and cloud based storage technology. If you are a writer, I urge you to [read that part 1](https://news.itsfoss.com/how-i-started-loving-vim/) before continuing here.
Essentially, I argued that the more devices you use, the more writing tools you’ll need, the more complex the workflow eventually becomes. This is pertinent because I have four devices, including an Android phone, a main daily driver laptop running Linux, and a couple of older laptops, including a Mac, I take when I go outdoors for shoots.
Vim was the perfect solution for me, and how I work; while I won’t argue that my new workflow is the best way for writers to work in the modern world, I will argue that it is important for writers to have a tool that works across all our devices, and is powerful enough to meet the needs for the different kinds of writing that we writers engage in everyday.
Vim’s main benefit from this perspective, therefore, is that it is cross-platform – no matter what device you are on, Vim will work. I won’t speak extensively about using Vim in the Apple ecosystem, but a cursory glance at the reviews for [this app](https://apps.apple.com/us/app/ivim/id1266544660?ref=news.itsfoss.com) tells me that somewhere someone needs Vim no matter what device they are using.
Now let’s say you are a writer who wants to start using Vim. Where do you start once you’ve installed it?
This part of the article isn’t necessarily a tutorial but a series of recommendations, including an examination of a .vimrc configuration file for prose writing. Wherever possible I will link to the respective YouTube tutorial that I learnt from.
Linux users already have Vim pre-installed – launch it via the terminal emulator of choice. For Windows and Mac users, you can download it from the [official site](https://www.vim.org/?ref=news.itsfoss.com).
## Recommendations
**Post Vim Installation/Launch**
- Open Vim Tutor via terminal. (Mac users can launch it this way, while Windows users can launch it using this method. You will not be using Vim to do any writing during this phase – instead you will spend 15 minutes everyday doing the Vim Tutorial. Don’t spend a minute longer or shorter; see how much progress you can make inside the tutorial within the allotted 15 minutes. You will find that every day, you progress that much deeper into the tutorial. Inside a month, you should be able to complete the entire tutorial within those 15 minutes.
- Becoming a better typist has immense benefits for Vim usage. This is optional, but I am relearning to type from scratch and it is having the side effect of making Vim even more useful. I began spending 15 minutes everyday on this site as a warm up before I went into the Vim Tutorial.
I allocated 30 minutes at the start of every day for both these exercises to warm up, and 30 minutes every evening to cool down before I went to bed. This may have contributed to my quick transition from my old tool kit to Vim, but your mileage may vary.
Once again, let me stress that the above steps ** other than Vim Tutor** is optional; it all depends on your individual motivation levels.
We now come to the meat of this article: How do you configure Vim to be writer-friendly?
## How to configure .vimrc for writing
*Before I begin, I’d like to remind readers here that I am not a tech person – I am a novelist – and that any errors you see in the below are my own; I would love for feedback from experienced Vim users on how to refine my configuration file even further.*
Below is my .vimrc file. You can clone mine from my [GitHub](https://github.com/MiragianCycle/dotfiles?ref=news.itsfoss.com) and refine it further.
```
syntax on
set noerrorbells "This removes vim's default error bell, turning it off so that it doesn't annoy us
set textwidth=100 "Ensures that each line is not longer than 100 columns
set tabstop=4 softtabstop=4
set shiftwidth=4
set expandtab
set smartindent
set linebreak
set number
set showmatch
set showbreak=+++
set smartcase
set noswapfile
set undodir=~/.vim/undodir
set undofile
set incsearch
set spell
set showmatch
set confirm
set ruler
set autochdir
set autowriteall
set undolevels=1000
set backspace=indent,eol,start
" The next two settings ensure that line breaks and wrap work how writers, not
" coders, prefer it
set wrap
nnoremap <F5> :set linebreak<CR>
nnoremap <C-F5> :set nolinebreak<CR>
call plug#begin('~/.vim/plugged')
" This is for color themes
Plug 'colepeters/spacemacs-theme.vim'
Plug 'sainnhe/gruvbox-material'
Plug 'phanviet/vim-monokai-pro'
Plug 'flazz/vim-colorschemes'
Plug 'chriskempson/base16-vim'
Plug 'gruvbox-community/gruvbox'
" This is a selection of plugins to make prose writing easier.
Plug 'dpelle/vim-LanguageTool'
Plug 'ron89/thesaurus_query.vim'
Plug 'junegunn/goyo.vim'
Plug 'junegunn/limelight.vim'
Plug 'reedes/vim-pencil'
Plug 'reedes/vim-wordy'
" This section are nice-to-haves for easier integration with machine, using vim-airline and such.
Plug 'vim-airline/vim-airline'
"This section deals with workspace and session management
Plug 'thaerkh/vim-workspace'
"Related to above, the following code saves all session files in a single directory outside your
"workspace
let g:workspace_session_directory = $HOME . '/.vim/sessions/'
"Related to above, this is a activity tracker for vim
Plug 'wakatime/vim-wakatime'
" A disturbance in the force: we are using some emacs functionality here, org-mode specifically
Plug 'jceb/vim-orgmode'
" This is for language-specific plugins
Plug 'plasticboy/vim-markdown'
call plug#end()
colorscheme pacific
set background=dark
if executable('rg')
let g:rg_derive_root='true'
endif
```
Learn how to install Vim Plugin. This tutorial helped me. I use Vim Plugged because it was the simplest and most elegant in my view.
### .vimrc housekeeping for writers
`syntax on`
: this ensures that vim acknowledges what syntax I am using. I primarily use markdown for most note-taking and writing articles such as this one; while plain-text is my preferred method when working on my fiction.`set noerrorbells`
: for the sake of your sanity, I highly recommend turning this on`set textwidth=100`
: For ease of reading because no one wants to be horizontal scrolling a text document- `set spell“
`set wrap`
: ensures text wraps like how writers, not coders, would want it. You will notice that I haven’t spent much time discussing some of the other basic configuration, but I don’t feel those are salient for writers. I do some hobbyist coding so my .vimrc is a reflection of that. If all you want to do is to write on Vim, then the above configuration ought to get you started.
From that point, your .vimrc is a living document of what you want to do with Vim, and how you want Vim to do that for you.
### A note on plug-ins
Plug-ins are specified between lines 43-98. Assuming you’ve followed the tutorial on how to install vim plug-ins, I highly recommend the following vim writing-specific plug-ins to get started:
`vim-LanguageTool`
`thesaurus_query.vim`
`vim-pencil`
`vim-wordy`
`vim-goyo`
`vim-markdown`
### Conclusion
In this article, we gently introduced how writers can get started on vim, including a basic primer on configuring .vimrc for writing. In addition to mine, I am going to link here to the .vimrc of other writers that I found on GitHub, and have used as inspiration for my own.
Remember that this is just a starter kit of a .vimrc for writers. As your needs evolve, you will find that Vim can evolve with it. Therefore, learning to configure your .vimrc is worth investing some time in.
In the next article, I will be examining specifics of my writing workflow, using Vim and Git and GitHub.
*Contributed by Theena*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,608 | Hash Linux:预配置了四种平铺窗口管理器的 Arch Linux 衍生版 | https://itsfoss.com/hash-linux-review/ | 2021-07-23T11:25:17 | [
"Arch"
] | https://linux.cn/article-13608-1.html | 
通过一些努力,[你能安装上 Arch Linux](https://itsfoss.com/install-arch-linux/),也可以在你的 Arch 系统上安装一个你选择的桌面环境或窗口管理器。
这需要一些时间和精力,但肯定是可以实现的。但是,有一些项目可以减轻你的痛苦,为你提供一个预先配置好的桌面环境或窗口管理器的系统。[ArcoLinux](https://arcolinux.com/) 就是这样一个例子。
最近,我发现了另一个项目,它只专注于在出色的 Arch 发行版上提供完善的窗口管理器的选择。
[Hash 项目](https://hashproject.ga/) 提供了四种预配置有平铺式窗口管理器的 Arch 变体:Awesome、[Xmonad](https://xmonad.org/)、 i3 和 Bspwm。
如果你是一个刚刚接触窗口管理器的人,Hash 项目绝对是你应该马上尝试的。不用先投入时间去配置它,你就可以深入探索窗口管理器,并习惯由键盘驱动的系统。
在本文中,我将讨论我在使用 **Hash Linux Xmonad 版本** 时的部分体验,该版本采用 Linux 5.12 的内核。
### 安装 Hash Linux
Hash Linux 四个版本的 ISO 镜像均可 [下载](https://hashproject.ga/index.html#downloads) ,适用于 x86\_64 系统架构。
为了避免在实体机上安装时出现的各种意外错误,我在 GNOME Boxes 中创建了一个 Hash Linux Xmonad 版本的虚拟机。
当我启动到 Hash Linux 时,我注意到两件事。首先是一个面板,提供用于管理窗口和命令的快捷方式。我将在安装后讨论它。其次,是一个漂亮且易于使用的 GUI 安装程序。

像其他衍生版一样,图形化的安装程序使安装过程非常顺畅。在几个步骤的配置中,Hash Linux 已安装完毕,并准备重新启动。

### 第一印象

如果你曾经在你的 Linux 系统上安装过 Xmonad 窗口管理器,那么你重启后首先看到的是什么?空白的屏幕吧。
如果你是一个初学者,或者你不知道默认的按键绑定,你会被卡在一个屏幕上。因此,在使用任何窗口管理器之前,你必须先阅读其键盘快捷键。
如果你想把所有重要的快捷键提示都放在窗口上呢?一个备忘单可以为你节省很多时间。
因此,为了简化和方便初学者,Hash Linux 将重要的快捷键都钉在了桌面上。
所以,让我们先尝试其中的一些。从最重要的一个开始 `Super+Enter`,它可以打开默认的 termite 终端模拟器与 Z shell(ZSH)。
如果你多次按下它,你会发现默认情况下 Xmonad 遵循一个缩减布局,它首先将一个窗口固定在右边,然后以同样的方式将其余的全部安排在左边。

按下 `Super+Space`,你也可以将当前的布局改为标签式布局。甚至你可以按下 `Super+leftclick` 将窗口拖动。

要退出当前的窗口,你可以按下 `Super+Q`。
### Hash Linux 中的应用
默认情况下,Hash Linux 包含几个有用的命令行工具,如:NeoFetch、Htop、Vim、Pacman、Git 和 Speedtest-cli。

它还拥有大量的图形应用程序,如:Firefox 89、Gparted、Nitrogen、Conky、Flameshot、Geany 和 CPU-X。
`Super+D` 是 Hash Linux 中打开应用程序搜索菜单的默认快捷键。

### 主题美化
Hash Cyan 是 Hash Linux 的默认主题。除了它之外,Hash Linux 还提供了另外四个主题:Light Orange、Sweet Purple、Night Red 和 Arch Dark。
Hash Theme Selector 是一个自制的 Hash Linux 应用程序,你可以用它来配置窗口管理器的主题。

### 升级 Hash Linux
作为一个滚动发行版,你不需要下载一个新的 Hash Linux 的 ISO 来更新现有系统。你唯一需要的是在终端运行 `upgrade` 命令来升级你的系统。

### 结束语
如果你想使用一个窗口管理器来代替桌面环境,但又不想花很多时间来配置它,Hash 项目可以节省你的时间。
首先,它可以节省你大量的配置时间和精力,其次,它可以很轻松地让你适应使用键盘控制的系统。以后,你肯定可以学会根据自己的需要进行配置。
由于 Hash Linux 已经提供了 4 个带有不同的窗口管理器的 ISO,你可以开始使用任何一个版本,并找到你最喜欢的一个版本。总的来说,它是一个 [很好的 Arch Linux 衍生版](https://itsfoss.com/arch-based-linux-distros/)。
最后我还要提一下,目前 Hash Linux 的官方 [网站](https://hashproject.ga/) 并没有包含很多关于它的信息。

在发布信息中也提到了一个早期的 [网站](https://hashproject.org/)(我现在无法访问),在我上次访问时,其中包含了许多关于它的信息,包括配置细节等。
不想入 Arch 的教,只想用平铺式窗口管理器?可以试试 [Regolith Linux](https://itsfoss.com/regolith-linux-desktop/) 。它是预先配置了 i3wm 的 Ubuntu。棒极了,对吧?
---
via: <https://itsfoss.com/hash-linux-review/>
作者:[Sarvottam Kumar](https://itsfoss.com/author/sarvottam/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[mcfd](https://github.com/mcfd) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

With some effort, [you can install Arch Linux](https://itsfoss.com/install-arch-linux/). You may also install a desktop environment or windows manager of your choice on your Arch system.
That takes some time and effort but it is surely achievable. However, there exists projects that try to ease the pain by providing you a system preconfigured with a desktop environment or window manager of your choice. [ArcoLinux](https://arcolinux.com/?ref=itsfoss.com) is one such example.
Recently, I came across another project that has its sole focus on providing choice of window managers on top of the wonderful Arch distribution.
[Hash Project](https://hashproject.ga/?ref=itsfoss.com) offers four preconfigured Arch variants with tiling window managers: Awesome, [Xmonad](https://xmonad.org/?ref=itsfoss.com), i3, and Bspwm.
If you’re a beginner window manager hopper, the Hash project is what you should definitely try at once. Without investing time to configure it first, you can explore the potential of window managers and get used to keyboard-driven systems.
In this article, I’ll discuss my part of the experience with the **Hash Linux Xmonad edition** featuring Linux kernel 5.12.
## Installation Of Hash Linux
The ISO image of all four editions of Hash Linux is available to [download](https://hashproject.ga/index.html?ref=itsfoss.com#downloads) for x86_64 system architecture.
To avoid any unexpected error while installing it on a bare system, I created a virtual machine of Hash Linux Xmonad version in GNOME Boxes.
As I booted into Hash Linux, I noticed two things. First, a panel providing important shortcuts for managing windows and commands. I’ll discuss it later after installation. Second, a beautiful and easy-to-use GUI installer.
As usual, the graphical installer made the installation process very smooth by providing buttons to click on. Within a few steps of configuration, Hash Linux was installed and ready to reboot.
## First Impression

If you’ve ever installed Xmonad window manager on your Linux system, what is the first thing you saw after reboot? Blank screen right.
And if you’re a beginner or you don’t know the default key binding, you get stuck on the same screen. Hence, you must have to read keyboard shortcuts first before using any window manager.
What if you get all the important shortcuts right on your window? A cheat sheet can save you a lot of time.
Therefore, for the sake of simplicity and beginner-friendly, Hash Linux has pinned important keys on the desktop window.
So, let’s try some of it first. Starting with one of the most important `[Super]+Enter`
, it opens the default termite terminal emulator with Z shell (ZSH).
If you click it multiple times, you notice that by default Xmonad follows a dwindle layout where it first fixes one window on the right side and then arranges the rest of all on the left side in the same manner.
Using `[Super]+[Space]`
, you can also change the current layout to a tabbed one. Even you can use `[Super]+[left+click]`
to move a window into a float mode.
To quit the currently focussed window, you can press `[Super]+Q`
.
## Applications In Hash Linux
By default, Hash Linux contains several useful command-line tools such as NeoFetch, Htop, Vim, Pacman, Git, and Speedtest-cli.
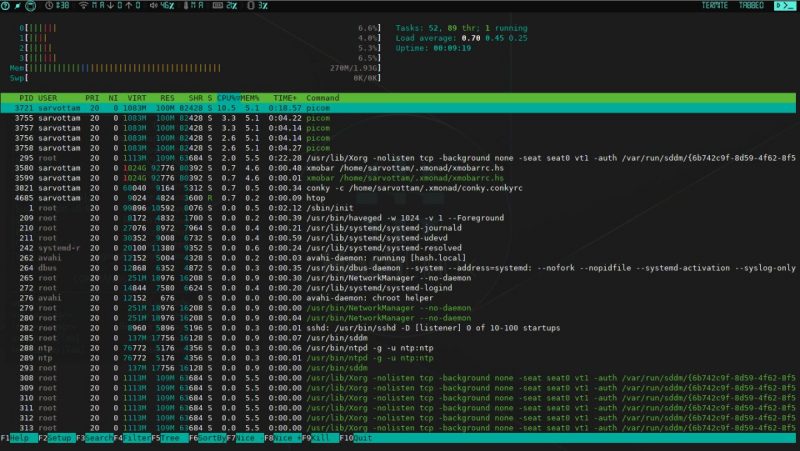
It also has a good amount of graphical applications such as Firefox 89, Gparted, Nitrogen, Conky, Flameshot, Geany, and CPU-X.
`[Super]+D`
is the default key in Hash Linux to open application search menu.
## Theming
Hash Cyan is the default theme in Hash Linux. Besides it, Hash Linux provides four more themes: Light Orange, Sweet Purple, Night Red, and Arch Dark.
Hash Theme Selector is a home-baked Hash Linux application that you can use to configure the theme for a window manager.
## Upgrading Hash Linux
Being a rolling release distribution, you don’t need to download a new ISO of Hash Linux to update the existing system. The only thing you need to upgrade your system is to run `upgrade`
command in a terminal.
## Closing Thought
If you want to use a window manager instead of the desktop environment but do not want to spend a lot of time configuring it, Hash project saves the day.
First, it will save you a lot of time and effort for configuration, and second, it will easily make you comfortable in using a keyboard-driven system. Later, you can definitely learn to configure according to your own needs.
As Hash Linux already provides four ISO with the different window managers, you can start using any version and find your favorite one. Overall, it is a [good Arch-based Linux distribution](https://itsfoss.com/arch-based-linux-distros/).
At last, I would also like to mention that the current official [site](https://hashproject.ga/?ref=itsfoss.com) of Hash Linux does not contain much information about it.
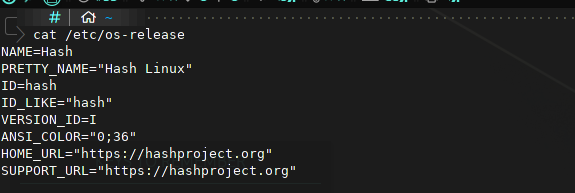
An earlier [site](https://hashproject.org/?ref=itsfoss.com) (not accessible to me now) that also mentioned in the release info, contained information about it including configuration details when I checked last time.
Don’t want to go the Arch way just for the tiling window manager? Try [Regolith Linux](https://itsfoss.com/regolith-linux-desktop/). It is Ubuntu preconfigured with i3wm. Awesome, right? |
13,610 | IT 人的 6 个晚上放松方式 | https://opensource.com/article/20/11/evening-rituals-working-tech | 2021-07-24T10:07:27 | [
"放松"
] | https://linux.cn/article-13610-1.html |
>
> 在结束了一天的远程会议、邮件往来、写代码和其他协作工作后,你在晚上如何放松自己呢?
>
>
>

这个奇怪的时代一方面给我们放慢脚步的机会,但另一方面来说,却比以前更忙了,尤其是当你除了照顾自己还要照顾家人的时候。俗话说,空杯子倒不出酒。所以,让我们看看在关上电脑或者完成最后一件工作之后,能为自己做些什么?
1、走出家门,做几次深呼吸,不要在乎是不是下雪天,让新鲜的空气从肺部充满全身。如果可以的话,在院子里走走,或者去街上逛逛。
2、如果有时间的话,给自己沏杯茶,红茶含有咖啡因,最好不要晚上喝,可以喝绿茶或者花果茶,然后在你穿上鞋(或许还有外套)时让它稍微凉一下。把茶倒在保温杯里,在小区周围散散步。不用设置目标或者目的地,就随便走走。如果你时间不充裕的话,可以定一个 15 分钟的闹钟。
3、放一首突然想到的歌,或者听之前想听但是一直没机会听的歌。
4、如果你有时间的话,别在椅子上继续坐着,可以站起来跳一段舞活动活动,或者到床上平躺着,躺着的时候什么也不要想,放空自己,让大脑休息休息。研究表明,给大脑一段空白时间后可以更好的思考。
5、打开你的 [电子书应用](https://opensource.com/article/20/2/linux-ebook-readers) 或者拿起一本纸质书,看纸质书相对来说对眼睛好点。享受轻松的阅读,如果不能长时间阅读的话,起码给自己留出能阅读一个章节的时间。
6、制做一些美食。享受把从杂货店买到的基本的食材按照菜谱做成一份美味佳肴的成就感和兴奋感。
你也可以在晚上把其中一些综合起来做,好好放松。如果你是 IT 人,那么无论是在 [早上](https://opensource.com/article/20/10/tech-morning-rituals)、中午、晚上用这些方式放松都很有效,因为现在我们都是在家工作,远程办公,没有和同事面对面交流时的闲暇。
那么,你的晚上放松方式是什么?
---
via: <https://opensource.com/article/20/11/evening-rituals-working-tech>
作者:[Jen Wike Huger](https://opensource.com/users/jen-wike) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Arzelan](https://github.com/Arzelan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This strange time has given us, on one hand, the chance to slow down, yet on the other, it's busier than ever. Especially if you have others in your life to care for in addition to yourself. But you can't give from an empty cup, so, this list of evening rituals is focused on what you can do for yourself right after you turn the computer off, shut the laptop, or say goodbye to the last virtual meeting of the day.
1. Head to the nearest door and take a big, deep belly breath in... and out. I don't care if it's snowing. Fill your lungs with fresh air. Stay for a while if you can -- take a lap around the yard, or walk down the street and back.
2. If you have some time, make a cup of tea -- black (is caffeinated, so beware), green, or herbal -- and, let it cool down while you get your shoes (and maybe a jacket) on. Pop it in a favorite thermos, and take a stroll around your neighborhood. You don't have to have a plan or a place you're walking to. Set a timer for 15 minutes if you only have a short window.
3. Turn on a song that pops into your head or the one you didn't get a chance to jam/relax to earlier today.
4. If you have some time, stand up and dance it out or lay all the way down with your feet up. No more sitting. Don't think, just listen. Research shows giving your brain blank space helps you think and deal better later.
5. Open your [reader app](https://opensource.com/article/20/2/linux-ebook-readers) or pick up a book (the latter is easier on your eyes), and fully indulge, letting the day slip away, or give yourself enough time to read at least one chapter.
6. Make food that feels good. Maybe that means a few basic ingredients and simple instructions. Maybe that means putting together that new, complex meal you've been excited about since you picked up the items at the grocery store.
Can you combine some of these to get even more out of your evening ritual time? If you're working in tech, creating rituals like this—whether they're [in the morning](https://opensource.com/article/20/10/tech-morning-rituals), middle of your day, or evening—is critical as we live out a new normal working from home, taking meetings virtually, and missing the energy of in-person connections with colleagues.
What is your evening ritual?
## 1 Comment |
13,611 | Ubuntu 20.10 到达生命终点,该升级啦! | https://news.itsfoss.com/ubuntu-20-10-end-of-life/ | 2021-07-24T20:59:49 | [
"Ubuntu"
] | https://linux.cn/article-13611-1.html |
>
> 哦!Ubuntu 20.10 将不再收到任何更新。如果你还在使用它,你的系统将面临风险,请考虑升级到 Ubuntu 21.04!
>
>
>

Ubuntu 20.10(Groovy Gorilla)2021 年 7 月 22 日停止支持啦。它是一个非长期支持发行版本,[带来了一些令人兴奋的新特性](https://itsfoss.com/ubuntu-20-10-features/)。
通常,非长期支持发行版维护 9 个月,所以生命周期结束意味着Ubuntu 20.10 用户将没有安全和维护更新。
你也会错过已安装应用的更新,[使用 apt 命令](https://itsfoss.com/apt-command-guide/) 安装新软件也会面临问题。如果不手动修改 `sources.list`(不推荐),使用软件中心也将是个问题。
支持周期的结束会影响所有的其他 Ubuntu 特色版本,像 Kubuntu、Lubuntu、MATE 等。
但是像 Linux Mint 和 elementary OS 这样的发行版不依赖于非长期支持发行版,你不必有任何担心。
使用下面的命令在终端 [检查下你安装的 Ubuntu 版本](https://itsfoss.com/how-to-know-ubuntu-unity-version/)是个好主意:
```
lsb_release -a
```
### 升级到 Ubuntu 21.04(Hirsute Hippo):正是时候!
毫无疑问,你需要升级到 Ubuntu 21.04 才能获得最新的更新和安全改进。
[Ubuntu 21.10 版本](https://news.itsfoss.com/ubuntu-21-10-release-schedule/) 将在几个月后发布,所以你也可以尝试到时升级到这个版本。
现在,你可以按照我们的 [Ubuntu 升级](https://itsfoss.com/upgrade-ubuntu-version/)教程来开始升级。
我推荐你备份一下,以防升级过程中出现问题。
如果你想重新安装,也可以。
### 还在用 Ubuntu 20.10?
从技术上来说,你可以继续使用不受支持的版本,如果你不想安全问题蔓延,建议还是升级到最新的版本,比如 Ubuntu 21.04。
Ubuntu 21.04 将会提供支持到 2022 年 1 月,升级前你可能想看下 [Ubuntu 21.04 的特性](https://news.itsfoss.com/ubuntu-21-04-features/)。
---
via: <https://news.itsfoss.com/ubuntu-20-10-end-of-life/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zd200572](https://github.com/zd200572) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Ubuntu 20.10 (Groovy Gorilla) has reached its end of life today (July 22, 2021). It was a non-LTS release that [introduced some exciting features](https://itsfoss.com/ubuntu-20-10-features/?ref=news.itsfoss.com).
Usually, non-LTS releases are maintained for up to 9 months. So, with 20.10 reaching the end of life means there will be no security and maintenance updates for Ubuntu 20.10 users.
You will also miss out on updates to installed applications, and face issues installing new applications [using the apt command](https://itsfoss.com/apt-command-guide/?ref=news.itsfoss.com). Using the Software Center is going to be a problem as well, without manually modifying sources.list (which is not recommended).
The end of life applies to all other Ubuntu flavors like Kubuntu, Lubuntu, MATE, etc.
While distributions like Linux Mint and elementary OS do not rely on non-LTS releases, you have nothing to worry about there.
It is also a good idea to [check your Ubuntu version](https://itsfoss.com/how-to-know-ubuntu-unity-version/?ref=news.itsfoss.com) installed with this command in the terminal:
`lsb_release -a`
## Upgrade to Ubuntu 21.04 (Hirsute Hippo): It’s Time!
It is a no-brainer that you need to upgrade to Ubuntu 21.04 to get the latest updates and security improvements.
[Ubuntu 21.10 release](https://news.itsfoss.com/ubuntu-21-10-release-schedule/) is only a few months later—so you can try upgrading to it when that is available as well.
For now, you can follow our [Ubuntu upgrade](https://itsfoss.com/upgrade-ubuntu-version/?ref=news.itsfoss.com) tutorial to get started.
I would recommend you to make a backup, in case things go bad with the upgrade process.
If you want to perform a fresh installation, you can do that as well.
## Still Using Ubuntu 20.10?
Technically, you can choose to keep using the unsupported version. However, if you do not want security issues to creep up, it is recommended to upgrade to the newest version available i.e Ubuntu 21.04.
Ubuntu 21.04 will be supported until January 2022. You might want to check out the [features in Ubuntu 21.04](https://news.itsfoss.com/ubuntu-21-04-features/) before making the jump.
*How was your experience so far with Ubuntu 20.10? Have you upgraded yet? Let me know in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,612 | 使用树莓派搭建下载机 | https://mp.weixin.qq.com/s/NcmKuYdPb3Q8oaSNFINj-A | 2021-07-24T21:16:00 | [
"树莓派",
"下载"
] | https://linux.cn/article-13612-1.html | 
我自己已经用树莓派几年了,从 3B+ 版本到 4B 版本,这样一个低功耗的 Linux 发行版非常适用于做下载机,来满足 PT、BT 等一些长时间挂机下载/做种的需求。它还可以搭配 SMB 分享、FTP 内网穿透实现个人 NAS 的一些功能。接下来我将介绍自己使用 Transmission 工具搭建的树莓派下载机。
### Transmission 安装
**Transmission** 是一款流行的 BT 下载软件,比其他客户端使用更少的资源,守护程序非常适合服务器,并且可以通过桌面 GUI、Web 界面和终端程序进行远程控制,支持本地对等发现、完全加密、DHT、µTP、PEX 和 Magnet Link 等。
首先,通过 `apt` 安装软件包,这里注意安装的是 `transmisson-daemon`:
```
sudo apt-get update
sudo apt-get install transmisson-daemon
```
然后在 `/etc/transmission-daemon/` 目录下修改配置文件 `settings.json`。修改设置前需要先关闭 `transmission` 服务:
```
sudo systemctl stop transmission-daemon.service
cd /etc/transmission-daemon/
sudo nano settings.json
```
`settings.json` 文件内容如下,`#` 后为我补充的需要修改字段的注释:
```
{
"alt-speed-down": 50,
"alt-speed-enabled": false,
"alt-speed-time-begin": 540,
"alt-speed-time-day": 127,
"alt-speed-time-enabled": false,
"alt-speed-time-end": 1020,
"alt-speed-up": 50,
"bind-address-ipv4": "0.0.0.0",
"bind-address-ipv6": "::",
"blocklist-enabled": false,
"blocklist-url": "http://www.example.com/blocklist",
"cache-size-mb": 4,
"dht-enabled": true,
"download-dir": "/home/pi/complete", # 下载目录
"download-limit": 100,
"download-limit-enabled": 0,
"download-queue-enabled": true,
"download-queue-size": 30,
"encryption": 1,
"idle-seeding-limit": 30,
"idle-seeding-limit-enabled": false,
"incomplete-dir": "/home/pi/incomplete", # 下载未完成文件目录
"incomplete-dir-enabled": true,
"lpd-enabled": false,
"max-peers-global": 200,
"message-level": 1,
"peer-congestion-algorithm": "",
"peer-id-ttl-hours": 6,
"peer-limit-global": 1000,
"peer-limit-per-torrent": 50,
"peer-port": 51413,
"peer-port-random-high": 65535,
"peer-port-random-low": 49152,
"peer-port-random-on-start": false,
"peer-socket-tos": "default",
"pex-enabled": true,
"port-forwarding-enabled": false,
"preallocation": 1,
"prefetch-enabled": true,
"queue-stalled-enabled": true,
"queue-stalled-minutes": 30,
"ratio-limit": 2,
"ratio-limit-enabled": false,
"rename-partial-files": true,
"rpc-authentication-required": true,
"rpc-bind-address": "0.0.0.0",
"rpc-enabled": true,
"rpc-host-whitelist": "",
"rpc-host-whitelist-enabled": true,
"rpc-password": "{525a44ba546f85ef59189a202b8d45357d17589686ReudqW", # 将双引号内修改为你要设定的密码,输入密码明文,重新启动程序后会自动加密,再打开看到的就是这样的密文了。
"rpc-port": 9091, # 默认 Web 访问端口
"rpc-url": "/transmission/",
"rpc-username": "raspberrypi", # 将双引号内修改为你要设定的用户名
"rpc-whitelist": "*.*.*.*",
"rpc-whitelist-enabled": true,
"scrape-paused-torrents-enabled": true,
"script-torrent-done-enabled": false,
"script-torrent-done-filename": "",
"seed-queue-enabled": false,
"seed-queue-size": 10,
"speed-limit-down": 2048,
"speed-limit-down-enabled": false,
"speed-limit-up": 5,
"speed-limit-up-enabled": true,
"start-added-torrents": true,
"trash-original-torrent-files": false,
"umask": 18,
"upload-limit": 100,
"upload-limit-enabled": 0,
"upload-slots-per-torrent": 14,
"utp-enabled": true # 允许 Web 登录
}
```
`settings.json` 修改完成后,保存配置文件,重启 `transmission` 服务:
```
sudo systemctl start transmission-daemon.service
```
这样在浏览器中登录树莓派 `ip:9091` 就可以访问 Transmission Web 管理界面了。

如果下载中遇到写入权限问题,需要将目录设置为权限开放:
```
sudo chmod -R a+rw /home/pi/complete
```
### 在树莓派上挂载移动硬盘
树莓派的存储设备为 SD 卡,存储容量不会很大,不适合做 BT 的存储器,最好还是外接移动硬盘。
这里要注意的是由于树莓派供电的问题。树莓派 3B 供电不能直接外接移动硬盘,需要一个可接电源的 USB HUB 对移动硬盘单独供电。树莓派 4B 可以直接外接固态硬盘。
可以先在要挂载的目录下新建一个文件夹,然后将移动硬盘挂载即可。为了能够在树莓派重启的时候自动完成挂载操作,可以将挂载设置为系统服务。
下面是我设置的移动硬盘挂载服务,请参考 `home-pi-M_disk.mount`:
```
[Unit]
Description=Auto mount USB disk
DefaultDependencies=no
ConditionPathExists=/home/pi/M_disk
Before=sysinit.target
[Mount]
What=/dev/sda1
Where=/home/pi/M_disk
Type=ntfs
[Install]
WantedBy=multi-user.target
```
上述挂载服务会在树莓派启动后自动将移动硬盘 `/dev/sda1`(设备名称可以将移动硬盘插入树莓派后通过 `sudo fdisk -l` 查看),挂载到 `/home/pi/M_disk`(此目录为新建的挂载目录)目录下。
### 结语
这样就完成了树莓派下载机的搭建,搭配之前介绍的 SMB 分享、 FTP 内网穿透,还是能够满足个人 NAS 的一些简单需求。 Enjoy!
| 200 | OK | 我自己已经用树莓派几年了,从3B+版本到4B版本,这样一个低功耗的Linux发行版非常适用于做下载机,来满足PT、BT等一些长时间挂机下载/做种的需求。还可以搭配SMB分享、FRP内网穿透实现个人NAS的一些功能。接下来我将介绍自己适用Transmission工具搭建树莓派下载机。
**Transmission**是一款流行的BT下载软件,比其他客户端使用更好的资源,守护程序非诚适合服务器,并且可以通过桌面GUI、Web和终端程序进行远程控制,支持本地对等发现、完全加密、DHT、µTP、PEX和Magnet Link等。
首先,通过apt安装软件包,这里注意安装的是`transmisson-daemon`
。
`sudo apt-get update`
sudo apt-get install transmisson-daemon
然后在`/etc/transmission-daemon/`
目录下修改配置文件`settings.json`
,修改设置前需要先关闭`transmission`
服务。
`sudo systemctl stop transmission-daemon.service`
cd /etc/transmission-daemon/
sudo nano settings.json
`settings.json`
文件内容如下,`#`
后为我补充的需要修改字段的注释:
`{`
"alt-speed-down": 50,
"alt-speed-enabled": false,
"alt-speed-time-begin": 540,
"alt-speed-time-day": 127,
"alt-speed-time-enabled": false,
"alt-speed-time-end": 1020,
"alt-speed-up": 50,
"bind-address-ipv4": "0.0.0.0",
"bind-address-ipv6": "::",
"blocklist-enabled": false,
"blocklist-url": "http://www.example.com/blocklist",
"cache-size-mb": 4,
"dht-enabled": true,
"download-dir": "/home/pi/complete",#下载目录
"download-limit": 100,
"download-limit-enabled": 0,
"download-queue-enabled": true,
"download-queue-size": 30,
"encryption": 1,
"idle-seeding-limit": 30,
"idle-seeding-limit-enabled": false,
"incomplete-dir": "/home/pi/incomplete",#下载未完成文件目录
"incomplete-dir-enabled": true,
"lpd-enabled": false,
"max-peers-global": 200,
"message-level": 1,
"peer-congestion-algorithm": "",
"peer-id-ttl-hours": 6,
"peer-limit-global": 1000,
"peer-limit-per-torrent": 50,
"peer-port": 51413,
"peer-port-random-high": 65535,
"peer-port-random-low": 49152,
"peer-port-random-on-start": false,
"peer-socket-tos": "default",
"pex-enabled": true,
"port-forwarding-enabled": false,
"preallocation": 1,
"prefetch-enabled": true,
"queue-stalled-enabled": true,
"queue-stalled-minutes": 30,
"ratio-limit": 2,
"ratio-limit-enabled": false,
"rename-partial-files": true,
"rpc-authentication-required": true,
"rpc-bind-address": "0.0.0.0",
"rpc-enabled": true,
"rpc-host-whitelist": "",
"rpc-host-whitelist-enabled": true,
"rpc-password": "{525a44ba546f85ef59189a202b8d45357d17589686ReudqW",#将双引号内修改为你要设定的密码,输入密码明文,重新启动程序后会自动加密,再打开看到的就是这样的密文了。
"rpc-port": 9091,#默认Web访问端口
"rpc-url": "/transmission/",
"rpc-username": "raspberrypi",#将双引号内修改为你要设定的用户名
"rpc-whitelist": "*.*.*.*",
"rpc-whitelist-enabled": true,
"scrape-paused-torrents-enabled": true,
"script-torrent-done-enabled": false,
"script-torrent-done-filename": "",
"seed-queue-enabled": false,
"seed-queue-size": 10,
"speed-limit-down": 2048,
"speed-limit-down-enabled": false,
"speed-limit-up": 5,
"speed-limit-up-enabled": true,
"start-added-torrents": true,
"trash-original-torrent-files": false,
"umask": 18,
"upload-limit": 100,
"upload-limit-enabled": 0,
"upload-slots-per-torrent": 14,
"utp-enabled": true #允许Web登录
}
`settings.json`
修改完成后,保存配置文件,重启`transmission`
服务。
`sudo systemctl start transmission-daemon.service`
这样在浏览器中登录`树莓派ip:9091`
就可以访问`transmission`
Web管理界面了。
如果下载中遇到写入权限问题,需要将目录设置为权限开放。
`sudo chmod -R a+rw /home/pi/complete`
树莓派的存储设备为SD卡,存储容量不会很大,不适合做BT的存储器,最好还是外接移动硬盘。这里要注意的是由于树莓派供电的问题,树莓派3B供电不能直接外接移动硬盘,需要一个可接电源的USB HUB对移动硬盘单独供电,树莓派4B可以直接外接固态硬盘。可以先在要挂载的目录下新建一个文件夹,然后将移动硬盘挂载即可,为了能够在树莓派重启的时候自动完成挂载操作,可以将挂载设置为系统服务。下面是我设置的移动硬盘挂载服务,请参考`home-pi-M_disk.mount`
:
`[Unit]`
Description=Auto mount USB disk
DefaultDependencies=no
ConditionPathExists=/home/pi/M_disk
Before=sysinit.target
[Mount]
What=/dev/sda1
Where=/home/pi/M_disk
Type=ntfs
[Install]
WantedBy=multi-user.target
上述挂载服务会在树莓派启动后自动将移动硬盘`/dev/sda1`
(设备名称可以将移动硬盘插入树莓派,通过`sudo fdisk -l`
查看),挂载到`/home/pi/M_disk`
(此目录为新建的挂载目录)目录下。
这样就完成了树莓派下载机的搭建,搭配之前介绍的SMB分享、FRP内网穿透,还是能够满足个人NAS的一些简单需求。Enjoy!
欢迎关注我的公众号,持续更新中~~~ |
13,614 | 我家的 Linux 故事 | https://opensource.com/article/21/5/my-linux-story | 2021-07-25T06:50:56 | [
"Linux",
"故事"
] | https://linux.cn/article-13614-1.html |
>
> 我们在 Linux 的第一次尝试只是一个 apt-get 的距离。
>
>
>

我在 Linux 的第一次尝试是那种“或许我应该试一试”的情况。
那是 1990 年代,我在一些软盘上找到了用某种打包方式打包的红帽发行版,我为家里的笔记本电脑买了第二个硬盘,然后开始安装它。这是一件有趣的实验,但是我记得当时家人还没有准备好在电脑上使用 Linux。转眼到了 2005 年,我最终放弃了这种做法,买了一台可爱的东芝笔记本电脑,来运行 Windows XP。在工作中,我有一台有点年头的 SUN SPARCStation 5,并且我不太喜欢当时整个 Solaris 的发展方向(基于 Motif 的桌面)。我真的想要用 GIMP 来完成一些这样或那样的项目,但是在 Solaris 上安装 GNOME 1.x(也许是 1.4?)的曲折旅程是很有挑战性的。所以,我实际上是在考虑跳槽到 Windows XP。但是在我的家用机上用了几个月之后,我发现我更不喜欢在 Solaris 上运行 GNOME,所以我安装了 Ubuntu Hoary Hedgehog 5.04,随后在我的笔记本电脑上安装了 Breezy Badger 5.10。这太棒了,那台拥有 3.2GHz 奔腾处理器、2GB 内存和 100GB 的硬盘的机器就在我的 SPARCStation 5 旁边运行。
突然之间,我不再用拼凑起来的 Solaris 安装包来试图去让东西运行起来,而只是用 apt-get 就可以了。并且这个时机也很好。我家庭和我从 2006 年 8 月到 2007 年 7 月居住在法国格勒诺布尔,当时我的妻子在休假。因为有了运行 Linux 的东芝笔记本,我可以带着我的工作一起走。那个时候我在几个大的项目上做了大量的 GIS 数据处理,我发现我可以在 PostGIS / PostgreSQL 上做同样的事情,比我们在加拿大家中使用的昂贵得多的商业 GIS 软件要快得多。大家都很开心,尤其是我。
这一路上发生的有趣的事情是,我们把另外两台电脑带到了法国 —— 我妻子的类似的东芝电脑(运行 XP,对她来说很好用)和我们孩子最近新买的东芝牌笔记本电脑,也运行 XP。也就在圣诞节过后,他们有一些朋友过来,无意中在他们的电脑上安装了一个讨厌的、无法清除的病毒。经过几个小时甚至几天后,我的一个孩子问我:“爸爸,我们就不能安装和你电脑上一样的东西吗?”然后,三个新的 Linux 用户就这样产生了。我的儿子,29 岁了,依然是一个快乐的 Linux 用户,我猜他有第四或第五台 Linux 笔记本电脑了,最后几台都是由 System 76 提供的。我的一个女儿三年前开始读法学院时被迫转换为 Windows,因为她所在的学校有一个强制性的测试框架,只能在 Windows 上运行,而且据称会检测虚拟机之类的东西(请不要让我开始骂人)。而我的另一个女儿被她的公司为她买的 Macbook Air 诱惑了。
哦,好吧,不可能全都赢了吧!
---
via: <https://opensource.com/article/21/5/my-linux-story>
作者:[Chris Hermansen](https://opensource.com/users/clhermansen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[shiboi77](https://github.com/shiboi77) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | My first attempt at Linux was one of those "maybe I should give this a try" kinds of situations.
Back in the late 1990s, I found some kind of packaged Red Hat distro on quite a few floppies, bought a second hard drive for the family laptop, and set about installing it. It was an interesting experiment, but as I recall the family wasn't quite ready to share the computer to that extent. Fast forward to 2005, I finally broke down and bought a lovely Toshiba laptop that ran Window XP. At work, I had an aging Sun SPARCStation 5, and I didn't really like the direction the whole Solaris thing was going at that point (Motif-based desktop). I really wanted GIMP for some project or the other, but the convoluted journey to installing GNOME 1.x (was it 1.4? maybe) on Solaris was challenging. So, I was actually contemplating jumping ship to Windows XP. But after living with it on my home machine for a few months, I found myself liking that even less than trying to run GNOME on Solaris, so I installed Ubuntu Hoary Hedgehog 5.04 and then Breezy Badger 5.10 on my laptop. It was wonderful. That machine with its 3.2GHz Pentium, 2GB of memory, and 100GB hard drive ran rings around my SPARCStation 5.
All of a sudden, instead of fooling around with cobbled-together Solaris packages to try to get stuff running, things were just an apt-get away. The timing was good, too. My family and I lived in Grenoble, France from August 2006 to July 2007, while my wife was on sabbatical. Because of the Linux Toshiba, I was able to take my work with me. At the time I was doing a lot of GIS data processing on a couple of big projects; I found I could do the same thing in PostGIS / PostgreSQL much more rapidly than with the incredibly expensive commercial GIS software we used back home in Canada. Everyone was happy, especially me.
The funny thing that happened along the way was that we took two other computers to France - my wife's similar Toshiba (running XP, which worked fine for her) and our kids' recently acquired new Toshiba laptop, also running XP. Just after Christmas, they had some friends over who inadvertently installed a nasty and impossible to remove virus on their computer. After several hours over a few days, one of my kids asked "Dad, can't we just install the same thing as on your computer"? And poof, three new Linux users were created. My son, at 29 years old, is still a happy Linux user, and I'm guessing on his fourth or fifth Linux laptop, the last few all supplied by System76. One of my daughters was forced to convert to Windows when she started law school three years ago as her school had a mandatory testing framework that only would run on Windows and would allegedly detect things like VMs and whatnot (please don't get me started). And, my other daughter was seduced by a Macbook Air that her company bought for her.
Oh well, can't win them all!
## 2 Comments |
13,615 | 如何在 Fedora 上使用 Podman | https://fedoramagazine.org/getting-started-with-podman-in-fedora/ | 2021-07-25T07:11:44 | [
"Podman",
"容器"
] | https://linux.cn/article-13615-1.html | 
[Podman](https://podman.io/) 是一个无守护程序的容器引擎,用于在你的 Linux 系统上开发、管理和运行 OCI 容器。在这篇文章中,我们将介绍 Podman 以及如何用 nodejs 构建一个小型应用来使用它。该应用将是非常简单和干净的。
### 安装 Podman
Podman 的命令就与 [docker](https://www.docker.com/) 相同,如果你已经安装了 Docker,只需在终端输入 `alias docker=podman`。
在 Fedora 中,Podman 是默认安装的。但是如果你因为任何原因没有安装,你可以用下面的命令安装它:
```
sudo dnf install podman
```
对于 Fedora [silverblue](https://silverblue.fedoraproject.org/) 用户,Podman 已经安装在你的操作系统中了。
安装后,运行 “hello world” 镜像,以确保一切正常:
```
podman pull hello-world
podman run hello-world
```
如果一切运行良好,你将在终端看到以下输出:
```
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1.The Docker client contacted the Docker daemon.
2.The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64)
3.The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading.
4.The Docker daemon streamed that output to the Docker client, which sent it to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
```
### 简单的 Nodejs 应用
首先,我们将创建一个文件夹 `webapp`,在终端输入以下命令:
```
mkdir webapp && cd webapp
```
现在创建文件 `package.json`,该文件包括项目运行所需的所有依赖项。在文件 `package.json` 中复制以下代码:
```
{
"dependencies": {
"express": "*"
},
"scripts": {
"start": "node index.js"
}
}
```
创建文件 `index.js`,并在其中添加以下代码:
```
const express = require('express')
const app = express();
app.get('/', (req, res)=> {
res.send("Hello World!")
});
app.listen(8081, () => {
console.log("Listing on port 8080");
});
```
你可以从 [这里](https://github.com/YazanALMonshed/webapp) 下载源代码。
### 创建 Dockerfile
首先,创建一个名为 `Dockerfile` 的文件,并确保第一个字符是大写,而不是小写,然后在那里添加以下代码:
```
FROM node:alpine
WORKDIR usr/app
COPY ./ ./
RUN npm install
CMD ["npm", "start"]
```
确保你在 `webapp` 文件夹内,然后显示镜像,然后输入以下命令:
```
podman build .
```
确保加了 `.`。镜像将在你的机器上创建,你可以用以下命令显示它:
```
podman images
```
最后一步是输入以下命令在容器中运行该镜像:
```
podman run -p 8080:8080 <image-name>
```
现在在你的浏览器中打开 `localhost:8080`,你会看到你的应用已经工作。
### 停止和删除容器
使用 `CTRL-C` 退出容器,你可以使用容器 ID 来删除容器。获取 ID 并使用这些命令停止容器:
```
podman ps -a
podman stop <container_id>
```
你可以使用以下命令从你的机器上删除镜像:
```
podman rmi <image_id>
```
在 [官方网站](https://podman.io/) 上阅读更多关于 Podman 和它如何工作的信息。
---
via: <https://fedoramagazine.org/getting-started-with-podman-in-fedora/>
作者:[Yazan Monshed](https://fedoramagazine.org/author/yazanalmonshed/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Podman](https://podman.io/) is a daemonless container engine for developing, managing, and running OCI Containers on your Linux System. In this article, we will introduce podman and how to use it with a small application build using nodejs. The app will be very simple and clean.
## Install Podman
Podman command is the same as [docker](https://www.docker.com/) just type in your terminal **alias docker=podman** if you have docker already installed
Podman is installed by default in Fedora Linux. But if you don’t have it for any reason, you can install it using the following command:
sudo dnf install podman
For fedora [silverblue](https://silverblue.fedoraproject.org/) users, podman is already installed in your OS.
After installation, run the hello world image to ensure everything is working:
podman pull hello-world podman run hello-world
If everything is working well you will see the following output in your terminal:
Hello from Docker! This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps: 1.The Docker client contacted the Docker daemon. 2.The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3.The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4.The Docker daemon streamed that output to the Docker client, which sent it to your terminal. To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/ For more examples and ideas, visit: https://docs.docker.com/get-started/
## Simple Nodejs App
First, we will create a folder **webapp** , type the following command in your terminal
mkdir webapp && cd webapp
Now create the file** ***package.json* This file includes all the dependencies that the project needs to work well. Copy the following code inside the file *package.json .*
{ "dependencies": { "express": "*" }, "scripts": { "start": "node index.js" } }
Create the file *index.js* and add the following code there:
const express = require('express') const app = express(); app.get('/', (req, res)=> { res.send("Hello World!") }); app.listen(8080, () => { console.log("Listing on port 8080"); });
You can download source code from [here](https://github.com/YazanALMonshed/webapp).
## Create Dockerfile
First of all, create a file called *Dockerfile* and make sure the first character is a capital, NOT lower case, then add the following code there:
FROM node:alpine WORKDIR usr/app COPY ./ ./ RUN npm install CMD ["npm", "start"]
Be sure you are inside the folder *webapp* then show the image and then type the following command:
podman build .
Make sure to add the **dot**. The image is created on your machine and you can show it using the following command:
podman images
The last step is to run the image inside a container by typing the following command:
podman run -p 8080:8080 <image-name>
Now open your browser in *localhost:8080 *and you will see that your app works.
## Stopping and Remove Container
To exit from the container use *CTRL-C.* You can remove the container by using the container id. Get the id and stop the container using these commands:
podman ps -a podman stop <container_id>
You can delete the images from your machine by using the following command:
podman rmi <image_id>
Read more about podman and how it works on the [official website](https://podman.io/)
## Stephen Snow
In the article you state that to run Podman as Docker do the following …
“just type in your terminal ‘alias docker=podman’ if you have docker already installed” Then you use Docker instead of Podman as can be seen by the output of the command.
## Piyush Agarwal
Exactly, from this article I didn’t get the difference between docker and podman. It seems like an alias.
## Stephen Snow
‘alias docker=podman’ Definitely is an alias. I was incorrect though, it does run Podman and not Docker, the original image pulled is from Docker and the content of the message from the container is docker oriented, so my misinterpretation.
## Edier
Thank you.
I was looking forward to install Moby (Docker) but thanks to your article I found out that Podman is lighter and more efficient. I will start my project with Podman instead. Thanks
## Stephen Snow
Good to see you are no longer considered spam!
## hammerhead corvette
Excellent article Yazan ! Can we create an image of Anaconda with the minimal Fedora install? The Docker Anaconda package is Python2.7 and has not been updated in a while, but it would be nice to have the latest Fedora supported Python and current Anaconda package instead.
## yongbin
following line looks wrong.
app.listen(8081, () => {
console.log(“Listing on port 8080”);
});
## Yazan Monshed
Thanks for the note, I’ll fix it.
## Gregory Bartholomew
Hi Yazan. You won’t be able to edit your article directly after publication, but you can reach an editor to request a correction by posting a comment on the article’s Kanban card.
Since you’ve already said that this should be corrected, I’ll go ahead and take care of this one. Thanks!
## Yazan Monshed
Great, Thanks Gregory!
## Ralf
Honestly, that’s a bit strange and an absolutely no-go for me.
You should think about whether it would make sense in your case to put the author of a text above the editors.
## Gregory Bartholomew
Well, what I said isn’t entirely accurate. If Yazan wanted to, he could become an editor for Fedora Magazine and then he would be able to edit post-publication articles. We still strive not to edit articles post-publication though. I’m not sure what the reasoning is behind that rule though. I think it might have been something to do with search engine optimization. There may have been other reasons.
## Ralf
Well then, congratulations on the promotion Yazan, and thanks for the explanation Gregory.
## Ralf Seidenschwang
I’m a bit fascinated about the whole ecosystem that has evolved over the years and that is no longer manageable from a singe person.
Virtualization is still in the enterprises, but the question is: How long? Will it vanish completely?
## Yazan Monshed
Well, good question. Virtualization does not conflict with containers, you can look to the containers as “the New way to Delivery the Software” which means the containers don’t compete with the virtualization. this is my perspective.
## Ralf
Well, I understand that they have not the same use case, but with OpenShift Virtualization for example, there is certainly some battle for customers between the Operator for the OpenShift product and Red Hat virtualization based on oVirt. Maintaining both environments would be expensive.
## Ralf
Thanks a lot. I haven’t much experience with Node.js or JavaScript, but I think you can’t remove images from the local store without first delete the container with the rm command.
I recommend the new book listed here -> https://www.keycloak.org/
Node.js examples are included. It introduces the user to some common simple programming design patterns.
Happy reading!
## Ben
Is podman compatible with Singularity (used dominantly in HPC/scientific computing over docker) ? |
13,617 | 在 Linux 上批量处理图像的 Converseen | https://itsfoss.com/converseen/ | 2021-07-25T22:00:13 | [
"图片",
"转换"
] | https://linux.cn/article-13617-1.html | 
Converseen 是一个用于批量图像转换的自由开源软件。有了这个工具,你可以一次将多张图片转换成另一种格式、调整大小、改变它们的长宽比、旋转或翻转它们。
对于像我这样的人来说,这是一个很方便的工具,我必须处理多个不同大小的截图,但在上传到网站之前必须调整它们的大小。
批量转换工具在这种情况下有很大的帮助。这可以在 Linux 命令行中用不错的 [ImageMagick](https://imagemagick.org/index.php) 来完成,但在这里使用 GUI 工具要容易得多。实际上,Converseen 在基于 Qt 的图形用户界面下使用 ImageMagick。
### 用 Converseen 批量处理图像
你可以用 [Converseen](https://converseen.fasterland.net/) 通过鼠标点击来转换、调整大小、旋转和翻转多个图像。
你有很多支持批量转换的选项。你可以在你的选择中添加更多的图片,或者删除其中的一些。你可以选择只转换你选择的几张图片。
在调整图像大小时,你可以选择保持长宽比。请记住,在宽度和高度中,你最后改变/输入的那个是控制长宽比的那个。所以,如果你想在保持长宽比的情况下调整大小,但要根据宽度来调整,不要修改高度栏。

你也可以选择将转换后的图像以不同的名称保存在同一目录或其他位置,也可以覆盖现有的图像。
你不能添加文件夹,但你可以一次选择并添加多个图像。
你可以将图像转换为多种格式,如 JPEG、JPG、TIFF、SVG 等。
在改变格式的同时,还有一个选项可以给透明背景以某种颜色。你还可以设置压缩级别的质量。

Converseen 还可以导入 PDF 文件,并将整个 PDF 或其中的一部分转换为图像。然而,在 Ubuntu 21.04 中,每次我试图转换一个 PDF 文件时,它就会崩溃。
### 在 Linux 上安装 Converseen
Converseen 是一个流行的应用。它在大多数 Linux 发行版仓库中都有。
你可以在你的发行版的软件中心搜索到它:

当然,你也可以使用你的发行版的包管理器通过命令行来安装它。
在基于 Debian 和 Ubuntu 的发行版上,使用:
```
sudo apt install converseen
```
在 Fedora 上,使用:
```
sudo dnf install converseen
```
在 Arch 和 Manjaro 上,使用:
```
sudo pacman -Sy converseen
```
Converseen 也可在 Windows 和 FreeBSD 下使用。你可以在项目网站的下载页面获得相关说明。
* [下载 Converseen](https://converseen.fasterland.net/download/)
它的源码可在 GitHub 仓库 [获取](https://github.com/Faster3ck/Converseen)。
如果你正在寻找一个更简单的方法来调整一张图片的大小,你可以使用这个巧妙的技巧,[在 Nautilus 文件管理器中用右键菜单调整图片大小和旋转图片](https://itsfoss.com/resize-images-with-right-click/)。
总的来说,Converseen 是一个有用的用于批量图像转换的 GUI 工具。它并不完美,但在大多数情况下是有用的。你曾经使用过 Converseen 或者你使用类似的工具吗?你对它的体验如何?
---
via: <https://itsfoss.com/converseen/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Converseen is a free and open source software for batch image conversion. With this tool, you can convert multiple images to another format, resize, change their aspect ratio, rotate or flip them all at once.
This is a handy tool for someone like me who has to deal with multiple screenshots of different sizes but has to resize them all before uploading to the website.
Batch conversion tools help a lot in such cases. This could be done in the Linux command line with the wonderful [ImageMagick](https://imagemagick.org/index.php) but a GUI tool is a lot easier to use here. Actually, Converseen uses [ImageMagick](https://itsfoss.com/install-imagemagick-ubuntu/) underneath the Qt-based GUI.
## Batch process images with Converseen
You can use [Converseen](https://converseen.fasterland.net/) to convert, resize, rotate and flip multiple images with a mouse click.
You have plenty of supporting options for the batch conversion. You can add additional images to your selection or remove some of them. You can choose to convert only a few of your selected images.
While resizing the images, you can choose to keep the aspect ratio. Keep in mind that out of width and height, the one you changed/typed last is the one controlling the aspect ratio. So, if you want to resize keeping the same aspect ratio but according to the width, don’t touch the height field.
You can also choose to save the converted images with different name in the same directory or some other location. You may also overwrite the existing images.
You cannot add folder but you can select and add multiple images at once.
You can convert the images to a number of formats like JPEG, JPG, TIFF, SVG and more.
There is also an option to give the transparent background a certain color while changing the format. You can also set the quality of the compression level.
Converseen says that it can also import PDF files and convert the entire PDF or part of it into images. However, it crashed in Ubuntu 21.04 each time I tried to convert a PDF file.
## Install Converseen on Linux
Converseen is a popular application. It is available in the repositories of most Linux distributions.
You can search for it in your distribution’s software center:
You may, of course, use your distribution’s package manager to install it via command line.
On Debian and Ubuntu-based distributions, use:
`sudo apt install converseen`
On Fedora, use:
`sudo dnf install converseen`
On Arch and Manjaro, use:
`sudo pacman -Sy converseen`
Converseen is also available for Windows and FreeBSD. You can get the instructions on the download page of the project website.
Its source code is [available](https://github.com/Faster3ck/Converseen) on the project’s GitHub repository.
If you are looking for an even easier way to resize a single image, you can use this nifty trick and [resize and rotate images with right click context menu in Nautilus file manager](https://itsfoss.com/resize-images-with-right-click/).
Overall, Converseen is a useful GUI tool for batch image conversion. It’s not perfect but it works for the most part. Have you ever used Converseen or do you use a similar tool? How is your experience with it? |
13,620 | Linux 包管理器比较:dnf 和 apt | https://opensource.com/article/21/7/dnf-vs-apt | 2021-07-27T08:30:10 | [
"包管理器",
"apt",
"dnf"
] | /article-13620-1.html |
>
> 包管理器提供大致相同的功能:安装、管理和移除应用,但是它们还是有一些不一样的地方。
>
>
>

[在 Linux 系统上获取一个应用](https://opensource.com/article/18/1/how-install-apps-linux) 有多种方式。例如,有新的 Flatpak 和容器方式,也有 DEB 和 RPM 这样一直以来经过考验的方式。
并没有一种通用的可以用于所有的操作系统的应用安装程序。如今,因为有无数的开发者发布软件,这导致了大部分的操作系统使用了应用商店(包括第一方和第三方)、拖放式安装,还有安装向导。不同的开发者对于他们发布的代码有不同的需求,这直接导致了他们所选择的安装方式的不同。
Linux 开创了一种通过命令行安装、管理、移除应用的包管理器的概念。`apt` 和 `dnf` 就是两种较为常见的包管理器。`apt` 命令是用来管理 DEB 格式的包,`dnf` 命令是用来管理 RPM 格式的包。这两种包管理器在理论上并不是完全互斥的,尽管在实际的实践中,Linux 发行版通常只会使用到其中的一种。理论上,这两种命令可以运行在同一个系统上,但是会造成安装包的重叠,版本控制也会更加困难,命令也会是冗余的。然而,如果你是在一个混合的 Linux 环境下工作,比如你的工作站运行的是一个发行版,同时需要与运行另外一种发行版的服务器进行交互,那么你最好同时掌握这两种包管理器。
### 搜索应用
当你通过包管理器安装一个应用时,你需要先知道包的名称。通常,应用的名称和包的名称是一样的。`dnf` 和 `apt` 验证要安装的包名的过程是完全相同的。
```
$ sudo dnf search zsh
====== Name Exactly Matched: zsh ======
zsh.x86_64 : Powerful interactive shell
[...]
```
使用 `apt`:
```
$ sudo apt search zsh
Sorting... Done
Full Text Search... Done
csh/stable 20110502-4+deb10u1 amd64
Shell with C-like syntax
ddgr/stable 1.6-1 all
DuckDuckGo from the terminal
direnv/stable 2.18.2-2 amd64
Utility to set directory specific environment variables
draai/stable 20180521-1 all
Command-line music player for MPD
[...]
```
如果想通过 `apt` 更快的获取相关的搜索结果,你可以使用 [正则表达式](https://opensource.com/article/18/5/getting-started-regular-expressions):
```
apt search ^zsh
Sorting... Done
Full Text Search... Done
zsh/stable 5.7.1-1 amd64
shell with lots of features
[...]
```
### 查找应用程序包
有一些命令是与其它命令捆绑在一起的,都在一个包中。在这种情况下,你可以通过包管理器去了解哪个包提供了你需要的命令。`dnf` 和 `apt` 命令在如何搜索这类元数据上是有区别的。
使用 `dnf`:
```
$ sudo dnf provides pgrep
procps-ng-3.3.15-6.el8.x86_64 : System and process monitoring utilities
Repo : baseos
Matched from:
Filename : /usr/bin/pgrep
```
`apt` 命令使用子命令 `apt-file`。要使用 `apt-file`,你必须先安装它,然后提示它更新缓存:
```
$ sudo apt install apt-file
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
libapt-pkg-perl libexporter-tiny-perl liblist-moreutils-perl libregexp-assemble-perl
The following NEW packages will be installed:
apt-file libapt-pkg-perl libexporter-tiny-perl liblist-moreutils-perl libregexp-assemble-perl
0 upgraded, 5 newly installed, 0 to remove and 14 not upgraded.
Need to get 297 kB of archives.
After this operation, 825 kB of additional disk space will be used.
Do you want to continue? [Y/n] y
$ sudo apt-file update
[...]
```
你可以通过 `apt-file` 搜索命令。你可以使用此命令进行广泛的全局搜索,但假如你知道命令的执行路径,它会更准确:
```
$ sudo apt-file search /usr/bin/pgrep
pgreplay: /usr/bin/pgreplay
procps: /usr/bin/pgrep
```
### 安装应用程序
使用`apt` 和 `dnf` 安装应用程序基本上是相同的:
```
$ sudo apt install zsh
```
使用 `dnf`,你可以使用同样的方式来安装一个包:
```
$ sudo dnf install zsh
```
许多基于 RPM 的发行版都具有组包安装的特性,它会将有时表面相关的应用程序收集到一个易于安装的目标中。例如,Fedora 中的 [Design Suite](https://labs.fedoraproject.org/en/design-suite/) 组包就包含流行的创意应用程序。那些想要某一个创意应用程序的艺术家可能也想要类似的应用程序,选择安装一整个组包一个简单而快速的方法,可以合理地开始建立一个数字工作室。你可以通过 `group list` 来查看可用的组包(使用 `-v` 来查看不带空格的组名):
```
$ sudo dnf group list -v
[...]
Available Groups:
Container Management (container-management)
RPM Development Tools (rpm-development-tools)
Design Suite (design-suite)
Development Tools (development)
[...]
```
使用 `group install` 子命令安装 RPM 组包:
```
$ sudo dnf group install design-suite
```
你可以使用 `@` 符号来减少输入:
```
$ sudo dnf install @design-suite
```
### 更新应用程序
使用包管理器的一个优点是,它知道所有已经安装的应用。这样你不必去寻找应用程序的更新版本。相反,你可以通过包管理器去获取更新的版本。
`dnf` 和 `apt` 使用的子命令略有不同。因为 `apt` 保存了一个需要定期更新的缓存信息,它使用 `upgrade` 子命令来更新应用程序:
```
$ sudo apt upgrade
```
相比之下,`dnf` 命令在你每次使用时都会更新元信息,所以 `update` 和 `upgrade` 子命令是可以互换的:
```
$ sudo dnf upgrade
```
这等同于:
```
$ sudo dnf update
```
### 移除应用程序
如果你曾经尝试在任何一个平台上手动删除一个应用程序,你就会知道,应用程序删除后,在硬盘上会残留各种文件,比如首选项文件、数据或图标。所以包管理器的另一个优点是,包管理器管理着包中安装的每一个文件,可以很方便的删除:
```
$ sudo dnf remove zsh
```
`remove` 子命令也适用于 `apt`:
```
$ sudo apt remove zsh
```
使用 `apt` 命令删除一个包并不会删除已修改的用户配置文件,以防你意外删除了包。如果你想通过 `apt` 命令删除一个应用及其配置文件,请在你之前删除过的应用程序上使用 `purge` 子命令:
```
$ sudo apt purge zsh
```
`apt` 和 `dnf` 都不会删除家目录中的数据和配置文件(即使使用 `purge` 子命令)。如果想要从家目录中删除数据,你必须手动操作(通常你可以在 `~/.config` 和 `~/.local` 文件中找到)。
### 了解包管理
无论你选择的发行版支持的是 `apt` 还是 `dnf`,这些命令的用途大致相同。它们可以帮助你安装、更新和移除包。这两种包管理器是目前最通用的包管理器。它们的语法元素在很大程度上是相同的,所以在两者之间切换非常容易。
`apt` 和 `dnf` 还有一些高级功能,例如仓库管理,但这些功能并不像你使用 `search` 和 `install` 那样频繁。
无论你更经常使用哪种包管理器,你都可以下载我们的 [apt 备忘单](https://opensource.com/downloads/apt-cheat-sheet) 和 [dnf 备忘单](https://opensource.com/downloads/dnf-cheat-sheet),以便你在最需要的时候可以查询使用语法。
---
via: <https://opensource.com/article/21/7/dnf-vs-apt>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,621 | 如何在 Kubuntu 21.04 中安装和升级 KDE Plasma 5.22 | https://www.debugpoint.com/2021/06/plasma-5-22-kubuntu-21-04/ | 2021-07-27T08:53:02 | [
"KDE"
] | /article-13621-1.html |
>
> KDE 团队启用了向后移植 PPA,你可以使用它在 Kubuntu 21.04 Hirsute Hippo 中安装和升级到 KDE Plasma 5.22。
>
>
>

KDE 团队最近发布了 KDE Plasma 5.22,其中有相当多的增强功能、错误修复以及更新的 KDE 框架和应用版本。这个版本带来了一些改进,如面板的自适应透明度,文件操作弹出时的用户友好通知,“发现”中的软件包类型显示,各种 Wayland 的变化等。在 [这里](https://www.debugpoint.com/2021/06/kde-plasma-5-22-release/) 查看更多关于功能细节。
如果你正在运行 Kubuntu 21.04 Hirsute Hippo,或者在 [Ubuntu 21.04 Hirsute Hippo](https://www.debugpoint.com/2021/04/ubuntu-21-04-hirsute-hippo-release/) 中安装了自定义的 KDE Plasma,你可以通过以下步骤升级到最新版本。目前的 Hirsute Hippo 系列提供了先前版本 KDE Plasma 5.21.04 与 KDE Framework 5.80。
### 在 Kubuntu 21.04 Hirsute Hippo 中安装 KDE Plasma 5.22 的步骤
按照下面的步骤进行。
如果你想使用图形方法,那么在“发现”中将 `ppa:kubuntu-ppa/backports` 添加到软件源,然后点击“更新”。
或者,使用下面的终端方法,以加快安装速度。
* **步骤 1**:打开一个终端,添加下面的 KDE Backports PPA。
```
sudo add-apt-repository ppa:kubuntu-ppa/backports
```
* **步骤 2**:然后运行以下程序来启动系统升级。这将在你的 Hirsute Hippo 系统中安装最新的 KDE Plasma 5.22。
```
sudo apt update
sudo apt full-upgrade
```

* **步骤 3**:更新后重新启动,你应该会看到一个更新的 KDE Plasma 5.22 桌面。
考虑到这是整个桌面环境的完整版本升级,安装可能需要一些时间。
### 在 Ubuntu 21.04 中安装 KDE Plasma 5.22
如果你正在运行基于 GNOME 的默认 Ubuntu 21.04 Hirsute Hippo 桌面,你可以使用这个 PPA 来安装最新的 KDE Plasma。下面是方法。
打开终端,添加 PPA(像上面的步骤那样)。
```
sudo add-apt-repository ppa:kubuntu-ppa/backports
```
然后,刷新软件包。
```
sudo apt update
```
然后运行下面的程序来安装 Kubuntu 桌面。
```
sudo apt install kubuntu-desktop
```
这将在 Ubuntu 21.04 中与 GNOME 一起安装 KDE Plasma 桌面。
### Ubuntu 20.04 LTS 中的 KDE Plasma 5.22
Ubuntu 20.04 LTS 版拥有早期的 KDE Plasma 5.18、KDE Framework 5.68、KDE Applications 19.12.3。所以,在它的整个生命周期中,它不会收到最新的 KDE 更新。所以,从技术上讲,你可以添加上述 PPA 并安装 KDE Plasma 5.22。但我不建议这样做,因为不兼容的软件包、框架可能会导致系统不稳定。
所以,建议你使用 Kubuntu 21.04 和上面的向后移植 PPA 或者使用 KDE neon 来体验最新的 Plasma 桌面。
### 卸载 KDE Plasma 5.22
如果你改变主意,想回到 KDE Plasma 的原始版本,那么安装 `ppa-purge` 并清除 PPA。这将使软件包降级,并启用仓库版本。
```
sudo apt install ppa-purge
sudo ppa-purge ppa:kubuntu-ppa/backports
sudo apt update
```
### 结束语
我希望这个快速指南能帮助你在 Kubuntu 21.04 Hirsute Hippo 中安装最新的 KDE Plasma 5.22。这可以让你体验到最新的 KDE 技术以及 KDE 框架和应用。然而,你应该知道,并不是所有的功能都应该在向后移植 PPA 中提供,它只有选定的功能和错误修复,这才能通过回归测试并安全使用。也就是说,你总是可以把 KDE Neon 安装成一个全新的系统来享受 KDE 的最新技术。
---
via: <https://www.debugpoint.com/2021/06/plasma-5-22-kubuntu-21-04/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,622 | 编程基础:Java 中的输入和输出 | https://opensource.com/article/21/3/io-java | 2021-07-27T10:19:01 | [
"Java",
"输入",
"输出"
] | /article-13622-1.html |
>
> 学习 Java 如何外理数据的读与写。
>
>
>

当你写一个程序时,你的应用程序可能需要读取和写入存储在用户计算机上的文件。这在你想加载或存储配置选项,你需要创建日志文件,或你的用户想要保存工作以待后用的情况下是很常见的。每种语言处理这项任务的方式都有所不同。本文演示了如何用 Java 处理数据文件。
### 安装 Java
不管你的计算机是什么平台,你都可以从 [AdoptOpenJDK](https://adoptopenjdk.net) 安装 Java。这个网站提供安全和开源的 Java 构建。在 Linux 上,你的软件库中也可能找到 AdoptOpenJDK 的构建。
我建议你使用最新的长期支持(LTS)版本。最新的非 LTS 版本对希望尝试最新 Java 功能的开发者来说是最好的,但它很可能超过大多数用户所安装的版本 —— 要么是系统上默认安装的,要么是以前为其他 Java 应用安装的。使用 LTS 版本可以确保你与大多数用户所安装的版本保持一致。
一旦你安装好了 Java,就可以打开你最喜欢的文本编辑器并准备开始写代码了。你可能还想要研究一下 [Java 集成开发环境](https://opensource.com/article/20/7/ide-java)。BlueJ 是新程序员的理想选择,而 Eclipse 和 Netbeans 对中级和有经验的编码者更友好。
### 利用 Java 读取文件
Java 使用 `File` 类来加载文件。
这个例子创建了一个叫 `Ingest` 的类来读取文件中数据。当你要在 Java 中打开一个文件时,你创建了一个 `Scanner` 对象,它可以逐行扫描你提供的文件。事实上,`Scanner` 与文本编辑器中的光标是相同的概念,这样你可以用 `Scanner` 的一些方法(如 `nextLine`)来控制这个“光标”以进行读写。
```
import java.io.File;
import java.util.Scanner;
import java.io.FileNotFoundException;
public class Ingest {
public static void main(String[] args) {
try {
File myFile = new File("example.txt");
Scanner myScanner = new Scanner(myFile);
while (myScanner.hasNextLine()) {
String line = myScanner.nextLine();
System.out.println(line);
}
myScanner.close();
} catch (FileNotFoundException ex) {
ex.printStackTrace();
} //try
} //main
} //class
```
这段代码首先在假设存在一个名为 `example.txt` 的文件的情况下创建了变量 `myfile`。如果该文件不存在,Java 就会“抛出一个异常”(如它所说的,这意味着它在你试图做的事情中发现了一个错误),这个异常是被非常特定的 `FileNotFoundException` 类所“捕获”。事实上,有一个专门的类来处理这个明确的错误,这说明这个错误是多么常见。
接下来,它创建了一个 `Scanner` 并将文件加载到其中。我把它叫做 `myScanner`,以区别于它的通用类模板。接着,一个 `while` 循环将 `myScanner` 逐行送入文件中,只要 *存在* 下一行。这就是 `hasNextLine` 方法的作用:它检测“光标”之后是否还有数据。你可以通过在文本编辑器中打开一个文件来模拟这个过程:你的光标从文件的第一行开始,你可以用键盘控制光标来向下扫描文件,直到你走完了所有的行。
`while` 循环创建了一个变量 `line`,并将文件当前行的数据分配给它。然后将 `line` 的内容打印出来以提供反馈。一个更有用的程序可能会解析每一行的内容,从而提取它所包含的任何重要数据。
在这个过程结束时,关闭 `myScanner` 对象。
### 运行代码
将你的代码保存到 `Ingest.java` 文件(这是一个 Java 惯例,将类名的首字母大写,并以类名来命名相应的文件)。如果你试图运行这个简单的应用程序,你可能会接收到一个错误信息,这是因为还没有 `example.txt` 文件供应用程序加载:
```
$ java ./Ingest.java
java.io.FileNotFoundException:
example.txt (No such file or directory)
```
正好可以编写一个将数据写入文件的 Java 应用程序,多么完美的时机!
### 利用 Java 将数据写入文件
无论你是存储用户使用你的应用程序创建的数据,还是仅仅存储关于用户在应用程序中做了什么的元数据(例如,游戏保存或最近播放的歌曲),有很多很好的理由来存储数据供以后使用。在 Java 中,这是通过 `FileWriter` 类实现的,这次先打开一个文件,向其中写入数据,然后关闭该文件。
```
import java.io.FileWriter;
import java.io.IOException;
public class Exgest {
public static void main(String[] args) {
try {
FileWriter myFileWriter = new FileWriter("example.txt", true);
myFileWriter.write("Hello world\n");
myFileWriter.close();
} catch (IOException ex) {
System.out.println(ex);
} // try
} // main
}
```
这个类的逻辑和流程与读取文件类似。但它不是一个 `Scanner`,而是以一个文件的名字为参数创建的一个 `FileWriter` 对象。`FileWriter` 语句末尾的 `true` 标志告诉 `FileWriter` 将文本 *追加* 到文件的末尾。要覆盖一个文件的内容,请移除 `true` 标志。
```
`FileWriter myFileWriter = new FileWriter("example.txt", true);`
```
因为我在向文件中写入纯文本,所以我在写入文件的数据(`Hello world`)的结尾处手动添加了换行符(`\n`)。
### 试试代码
将这段代码保存到 `Exgest.java` 文件,遵循 Java 的惯例,使文件名为与类名相匹配。
既然你已经掌握了用 Java 创建和读取数据的方法,你可以按相反的顺序尝试运行你的新应用程序。
```
$ java ./Exgest.java
$ java ./Ingest.java
Hello world
$
```
因为程序是把数据追加到文件末尾,所以你可以重复执行你的应用程序以多次写入数据,只要你想把更多的数据添加到你的文件中。
```
$ java ./Exgest.java
$ java ./Exgest.java
$ java ./Exgest.java
$ java ./Ingest.java
Hello world
Hello world
Hello world
$
```
### Java 和数据
你不会经常向文件中写入原始文本;事实上,你可能会使用一个其它的类库以写入特定的格式。例如,你可能使用 XML 类库来写复杂的数据,使用 INI 或 YAML 类库来写配置文件,或者使用各种专门类库来写二进制格式,如图像或音频。
更完整的信息,请参阅 [OpenJDK 文档](https://access.redhat.com/documentation/en-us/openjdk/11/)。
---
via: <https://opensource.com/article/21/3/io-java>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[piaoshi](https://github.com/piaoshi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,624 | 什么是 XML? | https://opensource.com/article/21/7/what-xml | 2021-07-28T08:26:44 | [
"XML"
] | https://linux.cn/article-13624-1.html |
>
> 了解一下 XML 吧,它是一种严格但灵活的标记语言,无论是在文档还是图像方面应用都十分广泛。
>
>
>

XML 是一种分层的标记语言。它使用打开和关闭标签来定义数据,它常用来存储和交换数据,而且由于它极大的灵活性,不论是在 [文档](https://opensource.com/article/17/9/docbook) 还是 [图像](https://opensource.com/article/17/5/coding-scalable-vector-graphics-make-steam) 中都用的非常多。
这里是一个 XML 文档的例子:
```
<xml>
<os>
<linux>
<distribution>
<name>Fedora</name>
<release>8</release>
<codename>Werewolf</codename>
</distribution>
<distribution>
<name>Slackware</name>
<release>12.1</release>
<mascot>
<official>Tux</official>
<unofficial>Bob Dobbs</unofficial>
</mascot>
</distribution>
</linux>
</os>
</xml>
```
阅读这个示例 XML,你可能会发现这个 XML 的格式具有直观的特性。 无论你是否熟悉这个文档的主题,你都可能理解本文档中的数据。 这部分原因是因为 XML 被认为是冗长的。 它使用了很多标签,标签可以有很长的描述性名称,并且数据以分层的方式排序,这有助于解释数据之间的关系。 你可能从这个示例中了解到 Fedora 发行版和 Slackware 发行版是两个不同且不相关的 Linux 发行版,因为每个实例都“包含”在自己独立的 `<distribution>` 标签中。
XML 也非常灵活。 与 HTML 不同,它没有预定义的标签列表。 你可以自由创建你需要表示任何数据结构的标签。
### XML 的组成
数据的存在为了读取,当计算机“读取”数据时,该过程称为 *解析*。 再次使用示例 XML 数据,以下是大多数 XML 解析器认为重要的术语。
* **文档**:`<xml>` 标签标记文档的开始, `</xml>` 标签标记文档的结束。
* **节点**:`<os>`、`<distribution>`、`<mascot>` 这些都是节点,在解析术语中,节点是包含其他标签的标签。
* **元素**:像 `<name>Fedora</name>` 和 `<official>Tux</official>` 这些都是元素。从第一个`<`开始,到最后一个 `>` 结束是一个元素。
* **内容**:在两个元素标签之间的数据被称之为内容,在第一个 `<name>` 标签中,`Fedora` 字符串就是一个内容。
### XML 模式
XML 文档中的标签和标签继承性称为 *模式*。
一些模式是随意组成的(例如,本文中的示例 XML 代码纯粹是即兴创作的),而其他模式则由标准组织严格定义。 例如,可缩放矢量图形(SVG)模式 [由 W3C 定义](https://www.w3.org/TR/SVG11/),而 [DocBook 模式](http://docbook.org) 由 Norman Walsh 定义。
模式强制执行一致性。 最基本的模式通常也是最严格的。 在我的示例 XML 代码中,将发行版名称放在 `<mascot>` 节点中是没有意义的,因为文档的隐含模式清楚地表明 `mascot` 必须是发行版的“子”元素。
### 数据对象模型(DOM)
如果你必须不断地描述标签和位置(例如,“系统部分中的 Linux 部分中第二个发行版标签的名称标签”),那么谈论 XML 会让人感到困惑,因此解析器使用文档对象模型(DOM)的概念来表示 XML 数据。 DOM 将 XML 数据放入一种“家谱”结构中,从根元素(在我的示例 XML 中,即 `os` 标记)开始并包括路径上的每个标记。

这种相同的 XML 数据结构可以表示为路径,就像 Linux 系统中的文件或互联网上网页的位置一样。 例如,`<mascot>` 标签的路径可以表示为 `//os/linux/distribution/slackware/mascot`。
两个 `<distribution>` 标签可以被表示为 `//os/linux/distribution` ,因为这里有两个发行版的节点,因此一个解析器可以直接将两个节点的内容载入到一个数组中,可以进行查询。
### 严格的 XML
XML 也以严格而著称。 这意味着大多数应用程序被设计为在遇到 XML 错误时就会故意失败。 这听起来可能有问题,但这是开发人员最欣赏 XML 的事情之一,因为当应用程序试图猜测如何解决错误时,可能会发生不可预测的事情。 例如,在 HTML 定义明确之前,大多数 Web 浏览器都包含“怪癖模式”,因此当人们试图查看糟糕的 HTML 代码时,Web 浏览器却可以加载作者可能想要的内容。 结果非常难以预测,尤其是当一个浏览器的猜测与另一个浏览器不同时。
XML 通过在出现故意错误时失败而不允许这样做。 这让作者可以修复错误,直到它们生成有效的 XML。 因为 XML 是良好定义的,所以有许多应用程序的验证器插件以及像 `xmllint` 和 `xmlstarlet` 这样的独立命令来帮助你及早定位错误。
### 转换 XML
因为 XML 通常用作数据交换,所以将 XML 转换为其他数据格式或其他 XML 模式是很常见的。 经典示例包括 XSLTProc、xmlto 和 [pandoc](https://opensource.com/article/20/5/pandoc-cheat-sheet),但从技术上讲,还有许多其他应用程序或者至少程序的一部分就是在转换 XML。
事实上,LibreOffice 使用 XML 来布局其文字处理器和电子表格文档,因此无论何时你导出或 [从 LibreOffice 转换文件](https://opensource.com/article/21/3/libreoffice-command-line),你都在转换 XML。
[开源 EPUB 格式的电子书](https://opensource.com/education/15/11/ebook-open-formats) 使用 XML,因此无论何时你 [将文档转换为 EPUB](https://opensource.com/life/13/8/how-create-ebook-open-source-way) 或从 EPUB 转换,你都在转换 XML。
Inkscape 是基于矢量的插图应用程序,它将其文件保存在 SVG 中,这是一种专为图形设计的 XML 模式。 任何时候你将 Inkscape 中的图像导出为 PNG 文件时,你都在转换 XML。
名单还可以一直继续下去。 XML 是一种数据存储格式,旨在确保你的数据,无论是画布上的点和线、图表上的节点,还是文档中的文字,都可以轻松准确地提取、更新和转换。
### 学习 XML
编写 XML 很像编写 HTML。 感谢 Jay Nick 的辛勤工作,[在线提供免费且有趣的 XML 课程](https://opensource.com/article/17/5/coding-scalable-vector-graphics-make-steam) 可以教你如何使用 XML 创建图形。
通常,探索 XML 所需的特殊工具很少。 由于 HTML 和 XML 之间的密切关系,你可以 [使用 Web 浏览器查看 XML](https://opensource.com/article/18/12/xml-browser)。 此外,[QXmlEdit](https://opensource.com/article/17/7/7-ways-handle-xml-qxmledit)、[NetBeans](https://opensource.com/article/20/12/netbeans) 和 [Kate](https://opensource.com/article/20/12/kate-text-editor) 等开源文本编辑器通过有用的提示、自动完成、语法验证等,使键入和阅读 XML 变得容易。
### 选择 XML
XML 起初可能看起来有很多数据,但它与 HTML 并没有太大的不同(实际上,HTML 已经 [以 XHTML 的形式重新实现为 XML](https://www.w3.org/TR/xhtml1/))。 XML 有一个独特的好处,即构成其结构的标签也恰好是元数据,提供有关其存储内容的信息。 精心设计的 XML 模式包含并描述你的数据,使用户能够一目了然并快速解析它,并使开发人员能够使用一些库 [快速解析](https://opensource.com/article/21/6/parsing-config-files-java)。
---
via: <https://opensource.com/article/21/7/what-xml>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | XML is a hierarchical markup language. It uses opening and closing tags to define data. It's used to store and exchange data, and because of its extreme flexibility, it's used for everything from [documentation](https://opensource.com/article/17/9/docbook) to [graphics](https://opensource.com/article/17/5/coding-scalable-vector-graphics-make-steam).
Here's a sample XML document:
```
<xml>
<os>
<linux>
<distribution>
<name>Fedora</name>
<release>8</release>
<codename>Werewolf</codename>
</distribution>
<distribution>
<name>Slackware</name>
<release>12.1</release>
<mascot>
<official>Tux</official>
<unofficial>Bob Dobbs</unofficial>
</mascot>
</distribution>
</linux>
</os>
</xml>
```
Reading the sample XML, you might find there's an intuitive quality to the format. You can probably understand the data in this document whether you're familiar with the subject matter or not. This is partly because XML is considered verbose. It uses lots of tags, the tags can have long and descriptive names, and the data is ordered in a hierarchical manner that helps explain the data's relationships. You probably understand from this sample that the Fedora distribution and the Slackware distribution are two different and unrelated instances of Linux because each one is "contained" inside its own independent `<distribution>`
tag.
XML is also extremely flexible. Unlike HTML, there's no predefined list of tags. You are free to create whatever data structure you need to represent.
## Components of XML
Data exists to be read, and when a computer "reads" data, the process is called *parsing*. Using the sample XML data again, here are the terms that most XML parsers consider significant.
**Document:**The`<xml>`
tag opens a*document*, and the`</xml>`
tag closes it.**Node:**The`<os>`
,`<distribution>`
, and`<mascot>`
are*nodes*. In parsing terminology, a node is a tag that contains other tags.**Element:**An entity such as`<name>Fedora</name>`
and`<official>Tux</official>`
, from the first`<`
to the last`>`
is an*element*.**Content:**The data between two element tags is considered*content*. In the first`<name>`
element, the string`Fedora`
is the content.
## XML schema
Tags and tag inheritance in an XML document are known as *schema*.
Some schemas are made up as you go (for example, the sample XML code in this article was purely improvised), while others are strictly defined by a standards group. For example, the Scalable Vector Graphics (SVG) schema is [defined by the W3C](https://www.w3.org/TR/SVG11/), while the [DocBook schema](http://docbook.org) is defined by Norman Walsh.
A schema enforces consistency. The most basic schemas are usually also the most restrictive. In my example XML code, it wouldn't make sense to place a distribution name within the `<mascot>`
node because the implied schema of the document makes it clear that a mascot must be a "child" element of a distribution.
Data object model (DOM)
Talking about XML would get confusing if you had to constantly describe tags and positions (e.g., "the name tag of the second distribution tag in the Linux part of the OS section"), so parsers use the concept of a Document Object Model (DOM) to represent XML data. The DOM places XML data into a sort of "family tree" structure, starting from the root element (in my sample XML, that's the `os`
tag) and including each tag.
(Seth Kenlon, CC BY-SA 4.0)
This same XML data structure can be expressed as paths, just like files in a Linux system or the location of web pages on the internet. For instance, the path to the `<mascot>`
tag can be represented as `//os/linux/distribution/slackware/mascot`
.
The path to *both* `<distribution>`
tags can be represented as `//os/linux/distribution`
. Because there are two distribution nodes, a parser loads both nodes (and the contents of each) into an array that can be queried.
## Strict XML
XML is also known for being strict. This means that most applications are designed to intentionally fail when they encounter errors in XML. That may sound problematic, but it's one of the things developers appreciate most about XML because unpredictable things can happen when applications try to guess how to resolve an error. For example, back before HTML was well defined, most web browsers included a "quirks mode" so that when people tried to view poor HTML code, the web browser could load what the author *probably* intended. The results were wildly unpredictable, especially when one browser guessed differently than another.
XML disallows this by intentionally failing when there's an error. This lets the author fix errors until they produce valid XML. Because XML is well-defined, there are validator plugins for many applications and standalone commands like `xmllint`
and `xmlstarlet`
to help you locate errors early.
## Transforming XML
Because XML is often used as an interchange format, it's common to transform XML into some other data format or into some other XML schema. Classic examples include XSLTProc, xmlto, and [pandoc](https://opensource.com/article/20/5/pandoc-cheat-sheet), but technically there are many other applications designed, at least in part, to convert XML.
In fact, LibreOffice uses XML to layout its word processor and spreadsheet documents, so any time you export or [convert a file from LibreOffice](https://opensource.com/article/21/3/libreoffice-command-line), you're transforming XML.
[Ebooks in the open source EPUB format](https://opensource.com/education/15/11/ebook-open-formats) use XML, so any time you [convert a document into an EPUB](https://opensource.com/life/13/8/how-create-ebook-open-source-way) or from an EPUB, you're transforming XML.
Inkscape, the vector-based illustration application, saves its files in SVG, which is an XML schema designed for graphics. Any time you export an image from Inkscape as a PNG file, you're transforming XML.
The list could go on and on. XML is a data storage format, and it's designed to ensure that your data, whether it's points and lines on a canvas, nodes on a chart, or just words in a document, can be easily and accurately extracted, updated, and converted.
## Learning XML
Writing XML is a lot like writing HTML. Thanks to the hard work of Jay Nick, [free and fun XML lessons are available online](https://opensource.com/article/17/5/coding-scalable-vector-graphics-make-steam) that teach you how to create graphics with XML.
In general, very few special tools are required to explore XML. Thanks to the close relationship between HTML and XML, you can [view XML using a web browser](https://opensource.com/article/18/12/xml-browser). In addition, open source text editors like [QXmlEdit](https://opensource.com/article/17/7/7-ways-handle-xml-qxmledit), [NetBeans](https://opensource.com/article/20/12/netbeans), and [Kate](https://opensource.com/article/20/12/kate-text-editor) make typing and reading XML easy with helpful prompts, autocompletion, syntax verification, and more.
## Choose XML
XML may look like a lot of data at first, but it's not that much different than HTML (in fact, HTML has been [reimplemented as XML in the form of XHTML](https://www.w3.org/TR/xhtml1/)). XML has the unique benefit that the components forming its structure also happen to be metadata providing information about what it's storing. A well-designed XML schema contains and describes your data, allowing a user to understand it at a glance and parse it quickly, and enabling developers to [parse it efficiently](https://opensource.com/article/21/6/parsing-config-files-java) with convenient programming libraries.
## 4 Comments |
13,625 | 满足日常需求的应用(一):Web 浏览器 | https://fedoramagazine.org/apps-for-daily-needs-part-1-web-browsers/ | 2021-07-28T08:43:56 | [
"浏览器"
] | https://linux.cn/article-13625-1.html | 
满足日常需求的重要应用之一是 Web 浏览器。这是因为上网是大多数人在电脑前进行的一项活动。本文将介绍一些你可以在 Fedora Linux 上使用的开源 Web 浏览器。你需要安装上述软件。本文提到的所有浏览器都已经在官方的 Fedora 软件库中提供。如果你不熟悉如何在 Fedora Linux 中添加软件包,请参阅我之前的文章 [安装 Fedora 34 工作站后要做的事情](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/)。
### Firefox
<ruby> 火狐 <rt> Firefox </rt></ruby>是一个快速且注重隐私的浏览器,可以在许多设备上使用。它是由 [Mozilla](https://www.mozilla.org/en-US/) 创建的,是一个具有完整功能的浏览器,提供许多扩展。你可以为你的火狐浏览器添加许多强大的功能和有用的特性。它只使用适量的内存来创造一个流畅的体验,使你的电脑保持对其他任务的响应。你可以创建一个账户,让你在多个设备上共享配置,所以你不需要在每个设备上设置火狐浏览器。

火狐浏览器提供以下功能:
* 隐私浏览模式
* 阻止广告跟踪器
* 密码管理器
* 设备之间的同步
* 画中画
关于火狐浏览器的更多信息可在此链接中找到:[https://www.mozilla.org/en-US/firefox](https://www.mozilla.org/en-US/firefox/)
### GNOME Web
GNOME Web 是 GNOME 桌面(Fedora 工作站的默认桌面环境)的一个浏览器。如果你使用 GNOME 作为默认桌面环境的 Fedora 工作站,它可能非常适合作为你的主浏览器。这个浏览器有一个简单、干净、漂亮的外观。GNOME Web 的功能比 Firefox 少,但对于普通用途来说已经足够了。

GNOME Web 提供了以下功能:
* 隐身模式
* GNOME 桌面集成
* 内置广告拦截器
* 智能跟踪预防
关于 GNOME Web 的更多信息可以在这个链接中找到:<https://wiki.gnome.org/Apps/Web>
### Chromium
Chromium 是一个来自 Chromium 项目的开源 Web 浏览器,它有一个极简的用户界面。它的外观与 Chrome 相似,因为它实际上是作为 Chrome 和其他几个浏览器的基础。许多人使用 Chromium 是因为他们已经习惯了 Chrome。

Chromium 提供以下功能:
* 隐身模式
* 扩展程序
* 密码的自动填写
关于 Chromium 浏览器的更多信息可在此链接中找到:<https://www.chromium.org/Home>
### qutebrowser
这个浏览与上面提到的稍有不同,qutebrowser 是一个以键盘为中心的浏览器,具有精简的 GUI。因此,你不会发现通常在其他浏览器中的按钮,如返回、主页、重新加载等。相反,你可以用键盘输入命令来运行 qutebrowser 中的功能。它使用 Vim 风格的键绑定,所以它适合 Vim 用户。如果你有兴趣在上网时获得不同的体验,你应该试试这个浏览器。

qutebrowser 提供以下功能:
* 广告屏蔽
* 隐私浏览模式
* 快速书签
关于 qutebrowser 浏览器的更多信息可在此链接中找到:<https://qutebrowser.org/>
### 总结
每个人在使用互联网时都有不同的需求,特别是在浏览方面。本文中提到的每个浏览器都有不同的功能。因此,请选择适合你日常需求和喜好的浏览器。如果你使用的是本文中提到的浏览器,请在评论中分享你的故事。如果你使用的是其他的浏览器,请说一下。希望这篇文章能帮助你选择在 Fedora 上满足你日常需求的浏览器。
---
via: <https://fedoramagazine.org/apps-for-daily-needs-part-1-web-browsers/>
作者:[Arman Arisman](https://fedoramagazine.org/author/armanwu/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the important apps for daily needs is a web browser. That’s because surfing the internet is an activity most people do in front of the computer. This article will introduce some of the open source web browsers that you can use on Fedora Linux. You need to install the software mentioned. All the browsers mentioned in this article are already available in the official Fedora repository. If you are unfamiliar with how to add software packages in Fedora Linux, see my earlier article [Things to do after installing Fedora 34 Workstation](https://fedoramagazine.org/things-to-do-after-installing-fedora-34-workstation/).
## Firefox
Firefox is a fast and privacy-focused browser that works across many devices. It was created by [Mozilla](https://www.mozilla.org/en-US/) and is a browser with complete features offering many extensions. You can add many powerful functions and useful features to your Firefox browser. It uses just enough memory to create a smooth experience so your computer stays responsive to other tasks. You can create an account that will allow you to share configurations on multiple devices, so you don’t need to set up Firefox on each device.
Firefox offers the following features:
- Private Browsing mode
- Ad tracker blocking
- Password manager
- Sync between devices
- Picture-in-Picture
More information about Firefox browser is available at this link: [https://www.mozilla.org/en-US/firefox](https://www.mozilla.org/en-US/firefox/)
## GNOME Web
GNOME Web is a browser for GNOME desktop which is the default desktop environment for Fedora Workstation. It may be very appropriate as your main browser if you use Fedora Workstation with GNOME as the default desktop environment. This browser has a simple, clean, and beautiful look. GNOME Web has fewer features than Firefox, but it is sufficient for common uses.
GNOME Web offers the following features:
- Incognito mode
- GNOME desktop integration
- built-in adblocker
- Intelligent tracking prevention
More information about GNOME Web is available at this link: [https://wiki.gnome.org/Apps/Web](https://wiki.gnome.org/Apps/Web)
## Chromium
Chromium is an open-source web browser from the Chromium Project and has a minimalist user interface. It has a similar appearance to Chrome, because it actually serves as the base for Chrome and several other browsers. Many people use Chromium because they are used to Chrome.
Chromium offers the following features:
- Incognito mode
- Extensions
- Autofill for passwords
More information about Chromium browser is available at this link: [https://www.chromium.org/Home](https://www.chromium.org/Home)
## qutebrowser
This browser is a little bit different than the browsers mentioned above. qutebrowser is a keyboard-focused browser with a minimal GUI. Therefore, you won’t find the buttons normally found in other browsers, like back, home, reload, etc. Instead, you can type commands with the keyboard to run functions in the qutebrowser. It uses Vim-style key bindings, so it’s suitable for Vim users. You should try this browser if you are interested in getting a different experience in surfing the internet.
qutebrowser offers the following features:
- Adblock
- Private browsing mode
- Quickmarks
More information about qutebrowser browser is available at this link: [https://qutebrowser.org/](https://qutebrowser.org/)
## Conclusion
Everyone has different needs in using the internet, especially for browsing. Each browser mentioned in this article has different features. So choose a browser that suits your daily needs and preferences. If you use the browsers mentioned in this article, share your story in the comments. And if you use a browser other than the one mentioned in this article, please mention it. Hopefully this article can help you in choosing the browser that you will use for your daily needs on Fedora.
## Lyes Saadi
Didn’t Google just announce that this wouldn’t be a thing any more? Did they change their decision?
## Arman Arisman
Hi, Lyes. Thanks for the comment. It will be revised 🙂
## Lionir
Chromium no longer offers Google sync functionality in Fedora as far as I’m aware since Google decided to make the API keys private.
## Arman Arisman
Hi, Lionir. Thanks for the correction. It will be revised 🙂
## Darvond
I use Firefox, and Lynx. I take it the web aspect of Konqueror is not suggested?
And Seamonkey, overlapping with Firefox?
And I presume Lynx is more for hobby browsing.
Note: More information about Chromium browser is available at this link: https://qutebrowser.org/
That’s probably an oops.
## Gregory Bartholomew
Thanks. The text has been corrected.
## Ralf
Qt is now in version 6.1. Interesting topic. I just ordered a new book to update my skills.
Are you familiar with Python? I would like to improve my C++ skills.
## svsv sarma
Palemoon? works without installation. What about Opera, Falkon, Vivaldi, Midori ….and etc? Is there any reason you failed to mention these also?
Firefox is the most popular. But I like Palemoon equally.
Qutebrowser I never heard of. I will try it because working with CLI is fun and professional.
By the by, which browser do you recommend and why.
Thank you Arman.
## Arman Arisman
Yes, there are actually a lot of browsers that we can use on Fedora. The browsers mentioned here are the browsers I’ve used, so I can write them well. It’s hard to make a review of an application that I have never used or just tried.
I’m currently using Firefox on Fedora Workstation and qutebrowser on Fedora i3. This is just my preference. I’m comfortable using Firefox for my work. While qutebrowser is quite compatible with the i3 workflow.
Thanks 🙂
## idoric
You put “Extensions” (more precisely WebExtensions) on the features list of Chromium, why haven’t you done the same for Firefox?
It would then be clearer to the reader that GNOME Web and qutebrowser doesn’t support webextensions. Personally, I find many qualities in Epiphany, but the absence of webextensions does not allow me to use it every day, let alone my main browser.
## Arman Arisman
Hi. Thanks for the comment. Actually I’ve written it on the explanation. But I seem to have missed it in the list. Your comments complete my article. Thanks.
## Ralf
I usually use a single very feature-rich browser and I highly recommend to explore the features your browser has in depth, including the more hidden features and the development tools. I’m hesitating in installing extensions and usually explore their functionality after the installation.
I’m not a friend of browsing on mobile devices and in my opinion, a web-browser isn’t the right place for experiments.
A problem with Linux are still the slightly different folder structures of the distributions and this sometimes makes it difficult to configure a browser uniformly and leads to more complexity than needed.
I recommend to help the browser vendors to make their product even better. The open source concept is particularly popular with the browser manufacturers – I can’t think of using closed source browsers.
Do you think the integration of a browser into the OS can be further improved?
## Arman Arisman
Your opinion is very interesting. One of the reasons I like open source applications is because everyone can contribute to developing them.
## Ralf
That’s true. Nevertheless, much research in regards to bugs is automated and done by fuzzing mechanisms, the like explained here:
https://www.chromium.org/Home/chromium-security/bugs
So possibly, inserting some random keystrokes into your browser will lead to a crash – work that’s better done by machines, saving us humans time for more important tasks.
## Ben
Thanks for the informative post. While I use Firefox most of the time, for some Chrome designed websites I find Brave an excellent alternative to Chrom{e|ium}
https://brave.com/linux/
It’s somewhat similar to having Chromium + essential plugins (adblock/https everywhere/tor …)
## Arman Arisman
Hi, Ben. Thanks for sharing !
## John
I usually read the articles and their comments. I think I understand that the idea of Fedora Magazine and therefore Fedora and other distributions is to make the transition between commercial operating systems and Linux nice, but the common thread of the vast majority of comments is opposed to this idea, why?
## Arman Arisman
Hi, John. Thanks for the opinion. I see that this magazine and all its comments are a good media for discussion. Through all the comments, we can better understand how people think about open source projects. So we can develop it better. Thanks for reading! 🙂
## svsv sarma
You are wrong john.
With everything said and done, there are still pros ands cons. Coments are for coments sake and rather a wish list. Comment does not mean opposition. No one comments unless deeply interested.
As Armon said, comments pave the way for betterment.
## Vitali Lutz
I like the GNOME Web browser. It’s easy to use, fast enough, and has all the settings I need. I would like to see the extensions feature, which would help this browser a lot to get more users, especially the professional ones.
## Arman Arisman
Hi, Vitali. Thanks for sharing! 🙂
I agree. GNOME Web browser is great. Let’s see how it develops in the future.
## VITOR GABRIEL
I really like the Brave, it’s really good. I also use sometimes Firefox and Gnome WB
## Arman Arisman
Thanks for sharing 🙂
## Richard
Hi Folks,
What about privacy-centric web browsers?
I tried to download TOR (The Onion Ring) and it did not work for me.
## Arman Arisman
I’ve never used it or installed it. But I see there is an explanation of how to install it on the official website.
## Ben
Brave has Tor support (though to be completely secure the Tor Browser is better option).
I would also recommend anti-fingerprinting plugins, you’d be surprised how much information your browser leaks (and on what sites).
I had a ‘reputable’ journal submission page trying to use audio fingerprinting, someting I would not be aware of if not for those plugins.
https://webbrowsertools.com/
## Ralf Seidenschwang
Great tools! Thanks a lot Ben.
I‘m pretty sure most readers here like Kubernetes, and I like to share the recently security report from Red Hat:
https://www.redhat.com/rhdc/managed-files/cl-state-kubernetes-security-report-ebook-f29117-202106-en_0.pdf
## Mx
Firefox threw out FTP, we need to look for a replacement.
## Arman Arisman
Any idea?
## Ralf Seidenschwang
Why they did that? Well, FTP is well known for introducing a lot of security issues into a system and most people do not use it anymore, since better alternatives are available. The FTP- support was only minimally implemented, if I remember correctly.
I would advice to implement more secure protocols.
Otherwise, there are such programs like Filezilla available.
https://pkgs.org/download/filezilla
## Ben
Wget supports FTP if you really need it
https://www.gnu.org/software/wget/manual/html_node/FTP-Options.html
or as Ralf said, FileZilla.
Tbh, if you really have no choice but to use unsecured FTP (e.g. not SFTP), then at least run it over VPN and/or SSH tunnel.
## Chris
If using qutebrowser, please be very very very careful not to install it with qt5-qtwebkit but with qt5-qtwebengine. This is very important because qt5-qtwebkit is extremely out of date and has hundreds or thousands of known dangerous security bugs.
Due to this extreme security risk, I would not recommend installing qutebrowser to non-experts.
Also, I highly recommend uninstalling the qt5-qtwebkit package and after that adding it to
in
to make sure it can never be installed again.
See also this bug report: https://bugzilla.redhat.com/show_bug.cgi?id=1872819
## Arman Arisman
Thanks for your info!
## Philip Vetter
Text mode web browsers are super fast and excellent for certain uses (slow internet connection, or browsing certain — but not all — heavy or otherwise resource-hungry webpages). If you want to see the text and pictures but not popup videos, try them.
fedora packages: links, lynx, elinks.
I install them all but mostly use, from the ‘links’ package,
links2 -g
For more information including developer websites:
dnf -C info links elinks lynx
Also, there is in emacs, a web browsing mode:
EWW, the Emacs Web Wowser
## Ralf Seidenschwang
It was a experience that was nice to take in my evening hours.
The next Nvidia vulnerability will probably come soon, so good to have something in your pocket just in the case of…
## Jorge
Opera and LibreWolf are two additional web browsers to try. Opera has an integrated Free VPN.
## Chris Cotter
I have been using Brave over Chrome lately and it is really nice. What are your thoughts on it if you have used it? |
13,627 | 在命令行中使用 XMLStarlet 来解析 XML | https://opensource.com/article/21/7/parse-xml-linux | 2021-07-29T09:13:00 | [
"XML"
] | https://linux.cn/article-13627-1.html |
>
> 借助终端上的 XML 工具包 XMLStarlet,你就是 XML 之星。
>
>
>

学习解析 XML 通常被认为是一件复杂的事情,但它不一定是这样。[XML 是高度严格结构化的](/article-13624-1.html),所以也是相对来说可预测的。也有许多其他工具可以帮助你使这项工作易于管理。
我最喜欢的 XML 实用程序之一是 [XMLStarlet](https://en.wikipedia.org/wiki/XMLStarlet),这是一个用于终端的 XML 工具包,借助这个 XML 工具包,你可以验证、解析、编辑、格式化和转换 XML 数据。XMLStarLet 是个相对较小的命令,但浏览 XML 却充满潜力,因此本文演示了如何使用它来查询 XML 数据。
### 安装
XMLStarLet 默认安装在 CentOS、Fedora,和许多其他现代 Linux 发行版上,所以你可以打开终端,输入 `xmlstarlet` 来访问它。如果 XMLStarLet 还没有被安装,你的操作系统则会为你安装它。
或者,你可以用包管理器安装 `xmlstarlet`:
```
$ sudo dnf install xmlstarlet
```
在 macOS 上,可以使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac)。在 Windows 上,可以使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey)。
如果都失败了,你可以从 [Sourceforge 上的源代码](http://xmlstar.sourceforge.net) 手动安装它。
### 用 XMLStarlet 解析 XML
有许多工具可以帮助解析和转换 XML 数据,包括允许你 [编写自己的解析器](https://opensource.com/article/21/6/parsing-config-files-java) 的软件库,和复杂的命令,如 `fop` 和 `xsltproc`。不过有时你不需要处理 XML 数据;你只需要一个方便的方法从 XML 数据中来提取、更新或验证重要数据。对于随手的 XML 交互,我使用 `xmlstarlet`,这是常见的处理 XML任务的一个典型的“瑞士军刀”式应用。通过运行 `--help` 命令,你可以看到它提供哪些选项:
```
$ xmlstarlet --help
Usage: xmlstarlet [<options>] <command> [<cmd-options>]
where <command> is one of:
ed (or edit) - Edit/Update XML document(s)
sel (or select) - Select data or query XML document(s) (XPATH, etc)
tr (or transform) - Transform XML document(s) using XSLT
val (or validate) - Validate XML document(s) (well-formed/DTD/XSD/RelaxNG)
fo (or format) - Format XML document(s)
el (or elements) - Display element structure of XML document
c14n (or canonic) - XML canonicalization
ls (or list) - List directory as XML
[...]
```
你可以通过在这些子命令的末尾附加 `-help` 来获得进一步的帮助:
```
$ xmlstarlet sel --help
-Q or --quiet - do not write anything to standard output.
-C or --comp - display generated XSLT
-R or --root - print root element <xsl-select>
-T or --text - output is text (default is XML)
-I or --indent - indent output
[...]
```
#### 用 sel 命令选择数据
可以使用 `xmlstarlet select`(简称 `sel`)命令查看 XML 格式的数据。下面是一个简单的 XML 文档:
```
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<xml>
<os>
<linux>
<distribution>
<name>Fedora</name>
<release>7</release>
<codename>Moonshine</codename>
<spins>
<name>Live</name>
<name>Fedora</name>
<name>Everything</name>
</spins>
</distribution>
<distribution>
<name>Fedora Core</name>
<release>6</release>
<codename>Zod</codename>
<spins></spins>
</distribution>
</linux>
</os>
</xml>
```
在 XML 文件中查找数据时,你的第一个任务是关注要探索的节点。如果知道节点的路径,请使用 `-value of` 选项指定完整路径。你越早浏览 [文档对象模型](https://opensource.com/article/21/6/what-xml#dom)(DOM)树,就可以看到更多信息:
```
$ xmlstarlet select --template \
--value-of /xml/os/linux/distribution \
--nl myfile.xml
Fedora
7
Moonshine
Live
Fedora
Everything
Fedora Core
6
Zod
```
`--nl` 代表“新的一行”,它插入大量的空白,以确保在输入结果后,终端在新的一行显示。我已经删除了样本输出中的一些多余空间。
通过进一步深入 DOM 树来凝聚关注点:
```
$ xmlstarlet select --template \
--value-of /xml/os/linux/distribution/name \
--nl myfile.xml
Fedora
Fedora Core
```
#### 条件选择
用于导航和解析 XML 的最强大工具之一被称为 XPath。它规范了 XML 搜索中使用的语法,并从 XML 库调用函数。XMLStarlet 能够解析 XPath 表达式,因此可以使用 XPath 函数来有条件的进行选择。XPath 具有丰富的函数,[由 W3C 提供了详细文档](https://www.w3.org/TR/1999/REC-xpath-19991116),但我觉得 [Mozilla 的 XPath 文档](https://developer.mozilla.org/en-US/docs/Web/XPath/Functions) 更简洁。
可以使用方括号作为测试函数,将元素的内容与某个值进行比较。下面是对 `<name>` 元素的值的测试,它仅返回与特定匹配相关联的版本号。
想象一下,示例 XML 文件包含以 1 开头的所有 Fedora 版本。要查看与旧名称 “Fedora Core” 关联的所有版本号(该项目从版本 7 开始删除了名称中的 “Core”),请执行以下操作:
```
$ xmlstarlet sel --template \
--value-of '/xml/os/linux/distribution[name = "Fedora Core"]/release' \
--nl myfile.xml
6
5
4
3
2
1
```
通过将路径的 `--value-of` 更改为 `/xml/os/linux/distribution[name=“Fedora Core”]/codename`,你便可以查看这些版本的所有代号。
### 匹配路径和获取目标值
将 XML 标记视为节点的一个好处是,一旦找到节点,就可以将其视为当前的数据的“目录”。它不是一个真正的目录,至少不是文件系统意义上的目录,但它是一个可以查询的数据集合。为了帮助你将目标和“里面”的数据分开,XMLStarlet 把你试图用 `--match` 选项匹配的内容和用 `--value-of` 选项匹配的数据值进行了区分。
假设你知道 `<spin>` 节点包含几个元素。这就是你的目标节点。一旦到了这里,就可以使用 `--value-of` 指定想要哪个元素的值。要查看所有元素,可以使用点(`.`)来代表当前位置:
```
$ xmlstarlet sel --template \
--match '/xml/os/linux/distribution/spin' \
--value-of '.' --nl myfile.xml \
Live
Fedora
Everything
```
与浏览 DOM 一样,可以使用 XPath 表达式来限制返回数据的范围。在本例中,我使用 `last()` 函数来检索 `spin` 节点中的最后一个元素:
```
$ xmlstarlet select --template \
--match '/xml/os/linux/distribution/spin' \
--value-of '*[last()]' --nl myfile.xml
Everything
```
在本例中,我使用 `position()` 函数选择 `spin` 节点中的特定元素:
```
$ xmlstarlet select --template \
--match '/xml/os/linux/distribution/spin' \
--value-of '*[position() = 2]' --nl myfile.xml
Fedora
```
`--match` 和 `--value` 选项可以重叠,因此如何将它们一起使用取决于你自己。对于示例 XML,这两个表达式执行的是相同的操作:
```
$ xmlstarlet select --template \
--match '/xml/os/linux/distribution/spin' \
--value-of '.' \
--nl myfile.xml
Live
Fedora
Everything
$ xmlstarlet select --template \
--match '/xml/os/linux/distribution' \
--value-of 'spin' \
--nl myfile.xml
Live
Fedora
Everything
```
### 熟悉 XML
XML 有时看起来过于冗长和笨拙,但为与之交互和构建的工具却总是让我吃惊。如果你想要好好使用 XML,那么 XMLStarlet 可能是一个很好的切入点。下次要打开 XML 文件查看其结构化数据时,请尝试使用 XMLStarlet,看看是否可以查询这些数据。当你对 XML 越熟悉时,它就越能作为一种健壮灵活的数据格式而为你服务。
---
via: <https://opensource.com/article/21/7/parse-xml-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zepoch](https://github.com/zepoch) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Learning to parse XML is often considered a complex venture, but it doesn't have to be. [XML is highly and strictly structured](https://opensource.com/article/21/6/what-xml), so it's relatively predictable. There are also lots of tools out there to help make the job manageable.
One of my favorite XML utilities is [XMLStarlet](https://en.wikipedia.org/wiki/XMLStarlet), an XML toolkit for your terminal. With XMLStarlet, you can validate, parse, edit, format, and transform XML data. XMLStarlet is a relatively minimal command, but navigating XML is full of potential, so this article demonstrates how to use it to query XML data.
## Install
XMLStarlet is installed by default on CentOS, Fedora, and many other modern Linux distributions, so just open a terminal and type `xmlstarlet`
to access it. If XMLStarlet isn't already installed, your operating system offers to install it for you.
Alternately, you can install the `xmlstarlet`
command from your package manager:
`$ sudo dnf install xmlstarlet`
On macOS, use [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac). On Windows, use [Chocolatey](https://opensource.com/article/20/3/chocolatey).
Should all else fail, you can install it manually from the [source code on Sourceforge](http://xmlstar.sourceforge.net).
## Parsing XML with XMLStarlet
There are many tools designed to help parse and transform XML data, including software libraries that let you [write your own parser](https://opensource.com/article/21/6/parsing-config-files-java) and complex commands like `fop`
and `xsltproc`
. Sometimes you don't need to process XML data, though; you just need a convenient way to extract important data from, update, or just validate it. For spontaneous XML interactions, I use `xmlstarlet`
, a classic "Swiss Army knife"-style application that does the most common XML tasks. You can see what it has to offer by running the command along with the `--help`
option:
```
$ xmlstarlet --help
Usage: xmlstarlet [<options>] <command> [<cmd-options>]
where <command> is one of:
ed (or edit) - Edit/Update XML document(s)
sel (or select) - Select data or query XML document(s) (XPATH, etc)
tr (or transform) - Transform XML document(s) using XSLT
val (or validate) - Validate XML document(s) (well-formed/DTD/XSD/RelaxNG)
fo (or format) - Format XML document(s)
el (or elements) - Display element structure of XML document
c14n (or canonic) - XML canonicalization
ls (or list) - List directory as XML
[...]
```
You can get further help by appending `--help`
to the end of any of these subcommands:
```
$ xmlstarlet sel --help
-Q or --quiet - do not write anything to standard output.
-C or --comp - display generated XSLT
-R or --root - print root element <xsl-select>
-T or --text - output is text (default is XML)
-I or --indent - indent output
[...]
```
### Selecting data with sel
You can view the data in XML with the `xmlstarlet select`
(`sel `
for short) command. Here's a simple XML document:
```
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<xml>
<os>
<linux>
<distribution>
<name>Fedora</name>
<release>7</release>
<codename>Moonshine</codename>
<spins>
<name>Live</name>
<name>Fedora</name>
<name>Everything</name>
</spins>
</distribution>
<distribution>
<name>Fedora Core</name>
<release>6</release>
<codename>Zod</codename>
<spins></spins>
</distribution>
</linux>
</os>
</xml>
```
When looking for data in an XML file, your first task is to focus on the node you want to explore. If you know the path to the node, specify the full path with the `--value-of`
option. The earlier in the [Document Object Model](https://opensource.com/article/21/6/what-xml#dom) (DOM) tree you start to explore, the more information you see:
```
$ xmlstarlet select --template \
--value-of /xml/os/linux/distribution \
--nl myfile.xml
Fedora
7
Moonshine
Live
Fedora
Everything
Fedora Core
6
Zod
```
The `--nl`
stands for "new line," and it inserts copious amounts of whitespace to ensure your terminal prompt gets a new line after your results are in. I've removed some of the excess space in the sample output.
Narrow your focus by descending further into the DOM tree:
```
$ xmlstarlet select --template \
--value-of /xml/os/linux/distribution/name \
--nl myfile.xml
Fedora
Fedora Core
```
### Conditional selects
One of the most powerful tools for navigating and parsing XML is called XPath. It governs the syntax used in XML searches and invokes functions from XML libraries. XMLStarlet understands XPath expressions, so you can make your selection conditional with an XPath function. XPath features a wealth of functions, and it's [documented in detail by W3C](https://www.w3.org/TR/1999/REC-xpath-19991116), but I find [Mozilla's XPath documentation](https://developer.mozilla.org/en-US/docs/Web/XPath/Functions) more concise.
You can use square brackets as a test function, comparing the contents of an element to some value. Here's a test for the value of the `<name>`
element, which returns the release number associated only with a specific match.
Imagine for a moment that the sample XML file contains all Fedora releases beginning with 1. To view all release numbers associated with the old name "Fedora Core" (the project dropped "Core" from the name from release 7 onward):
```
$ xmlstarlet sel --template \
--value-of '/xml/os/linux/distribution[name = "Fedora Core"]/release' \
--nl myfile.xml
6
5
4
3
2
1
```
You could view all codenames for those releases, too, by changing the `--value-of`
path to `/xml/os/linux/distribution[name = "Fedora Core"]/codename`
.
## Matching paths and getting values
An advantage of viewing XML tags as nodes is that once you find the node, you can think of it as your current "directory" of data. It's not really a directory, at least not in the filesystem sense, but it is a collection of data that you can query. To help you keep your destination and the data "inside" it separate, XMLStarlet differentiates between what you're trying to match with the `--match`
option and the value of the data you want with a `--value-of`
option.
Suppose you know that the `<spin>`
node contains several elements. That makes it your destination. Once you're there, you can use `--value-of`
to specify which element you want a value for. To look at all elements, use a dot (`.`
) to represent your current location:
```
$ xmlstarlet sel --template \
--match '/xml/os/linux/distribution/spin' \
--value-of '.' --nl myfile.xml \
Live
Fedora
Everything
```
As with navigating the DOM, you can use XPath expressions to limit the scope of what data is returned. In this example, I use the `last()`
function to retrieve just the last element in the `spin`
node:
```
$ xmlstarlet select --template \
--match '/xml/os/linux/distribution/spin' \
--value-of '*[last()]' --nl myfile.xml
Everything
```
In this example, I use the `position()`
function to select a specific element in the `spin`
node:
```
$ xmlstarlet select --template \
--match '/xml/os/linux/distribution/spin' \
--value-of '*[position() = 2]' --nl myfile.xml
Fedora
```
The `--match`
and `--value-of`
options can overlap, so it's up to you how you want to use them together. These two expressions, in the case of the sample XML, do the same thing:
```
$ xmlstarlet select --template \
--match '/xml/os/linux/distribution/spin' \
--value-of '.' \
--nl myfile.xml
Live
Fedora
Everything
$ xmlstarlet select --template \
--match '/xml/os/linux/distribution' \
--value-of 'spin' \
--nl myfile.xml
Live
Fedora
Everything
```
## Getting comfortable with XML
XML can seem over-verbose and unwieldy at times, but the tools built to interact with it consistently surprise me. If you're looking to take advantage of XML, then XMLStarlet could be a good entry point. The next time you're about to open an XML file to look at structured data, try using XMLStarlet and see if you can query that data instead. The more comfortable you get with XML, the better it can serve you as a robust and flexible data format.
## 2 Comments |
13,628 | 用 Python 轻松实现机器学习 | https://opensource.com/article/21/1/machine-learning-python | 2021-07-29T10:50:41 | [
"贝叶斯",
"机器学习"
] | https://linux.cn/article-13628-1.html |
>
> 用朴素贝叶斯分类器解决现实世界里的机器学习问题。
>
>
>

<ruby> 朴素贝叶斯 <rt> Naïve Bayes </rt></ruby>是一种分类技术,它是许多分类器建模算法的基础。基于朴素贝叶斯的分类器是简单、快速和易用的机器学习技术之一,而且在现实世界的应用中很有效。
朴素贝叶斯是从 <ruby> <a href="https://en.wikipedia.org/wiki/Bayes%27_theorem"> 贝叶斯定理 </a> <rt> Bayes' theorem </rt></ruby> 发展来的。贝叶斯定理由 18 世纪的统计学家 [托马斯·贝叶斯](https://en.wikipedia.org/wiki/Thomas_Bayes) 提出,它根据与一个事件相关联的其他条件来计算该事件发生的概率。比如,[帕金森氏病](https://en.wikipedia.org/wiki/Parkinson%27s_disease) 患者通常嗓音会发生变化,因此嗓音变化就是与预测帕金森氏病相关联的症状。贝叶斯定理提供了计算目标事件发生概率的方法,而朴素贝叶斯是对该方法的推广和简化。
### 解决一个现实世界里的问题
这篇文章展示了朴素贝叶斯分类器解决现实世界问题(相对于完整的商业级应用)的能力。我会假设你对机器学习有基本的了解,所以文章里会跳过一些与机器学习预测不大相关的步骤,比如 <ruby> 数据打乱 <rt> date shuffling </rt></ruby> 和 <ruby> 数据切片 <rt> data splitting </rt></ruby>。如果你是机器学习方面的新手或者需要一个进修课程,请查看 《[An introduction to machine learning today](https://opensource.com/article/17/9/introduction-machine-learning)》 和 《[Getting started with open source machine learning](https://opensource.com/business/15/9/getting-started-open-source-machine-learning)》。
朴素贝叶斯分类器是 <ruby> <a href="https://en.wikipedia.org/wiki/Supervised_learning"> 有监督的 </a> <rt> supervised </rt></ruby>、属于 <ruby> <a href="https://en.wikipedia.org/wiki/Generative_model"> 生成模型 </a> <rt> generative </rt></ruby> 的、非线性的、属于 <ruby> <a href="https://en.wikipedia.org/wiki/Parametric_model"> 参数模型 </a> <rt> parametric </rt></ruby> 的和 <ruby> <a href="https://en.wikipedia.org/wiki/Probabilistic_classification"> 基于概率的 </a> <rt> probabilistic </rt></ruby>。
在这篇文章里,我会演示如何用朴素贝叶斯预测帕金森氏病。需要用到的数据集来自 [UCI 机器学习库](https://archive.ics.uci.edu/ml/datasets/parkinsons)。这个数据集包含许多语音信号的指标,用于计算患帕金森氏病的可能性;在这个例子里我们将使用这些指标中的前 8 个:
* **MDVP:Fo(Hz)**:平均声带基频
* **MDVP:Fhi(Hz)**:最高声带基频
* **MDVP:Flo(Hz)**:最低声带基频
* **MDVP:Jitter(%)**、**MDVP:Jitter(Abs)**、**MDVP:RAP**、**MDVP:PPQ** 和 **Jitter:DDP**:5 个衡量声带基频变化的指标
这个例子里用到的数据集,可以在我的 [GitHub 仓库](https://github.com/gammay/Machine-learning-made-easy-Naive-Bayes/tree/main/parkinsons) 里找到。数据集已经事先做了打乱和切片。
### 用 Python 实现机器学习
接下来我会用 Python 来解决这个问题。我用的软件是:
* Python 3.8.2
* Pandas 1.1.1
* scikit-learn 0.22.2.post1
Python 有多个朴素贝叶斯分类器的实现,都是开源的,包括:
* **NLTK Naïve Bayes**:基于标准的朴素贝叶斯算法,用于文本分类
* **NLTK Positive Naïve Bayes**:NLTK Naïve Bayes 的变体,用于对只标注了一部分的训练集进行二分类
* **Scikit-learn Gaussian Naïve Bayes**:提供了部分拟合方法来支持数据流或很大的数据集(LCTT 译注:它们可能无法一次性导入内存,用部分拟合可以动态地增加数据)
* **Scikit-learn Multinomial Naïve Bayes**:针对离散型特征、实例计数、频率等作了优化
* **Scikit-learn Bernoulli Naïve Bayes**:用于各个特征都是二元变量/布尔特征的情况
在这个例子里我将使用 [sklearn Gaussian Naive Bayes](https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html)。
我的 Python 实现在 `naive_bayes_parkinsons.py` 里,如下所示:
```
import pandas as pd
# x_rows 是我们所使用的 8 个特征的列名
x_rows=['MDVP:Fo(Hz)','MDVP:Fhi(Hz)','MDVP:Flo(Hz)',
'MDVP:Jitter(%)','MDVP:Jitter(Abs)','MDVP:RAP','MDVP:PPQ','Jitter:DDP']
y_rows=['status'] # y_rows 是类别的列名,若患病,值为 1,若不患病,值为 0
# 训练
# 读取训练数据
train_data = pd.read_csv('parkinsons/Data_Parkinsons_TRAIN.csv')
train_x = train_data[x_rows]
train_y = train_data[y_rows]
print("train_x:\n", train_x)
print("train_y:\n", train_y)
# 导入 sklearn Gaussian Naive Bayes,然后进行对训练数据进行拟合
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(train_x, train_y)
# 对训练数据进行预测
predict_train = gnb.predict(train_x)
print('Prediction on train data:', predict_train)
# 在训练数据上的准确率
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(train_y, predict_train)
print('Accuray score on train data:', accuracy_train)
# 测试
# 读取测试数据
test_data = pd.read_csv('parkinsons/Data_Parkinsons_TEST.csv')
test_x = test_data[x_rows]
test_y = test_data[y_rows]
# 对测试数据进行预测
predict_test = gnb.predict(test_x)
print('Prediction on test data:', predict_test)
# 在测试数据上的准确率
accuracy_test = accuracy_score(test_y, predict_test)
print('Accuray score on test data:', accuracy_train)
```
运行这个 Python 脚本:
```
$ python naive_bayes_parkinsons.py
train_x:
MDVP:Fo(Hz) MDVP:Fhi(Hz) ... MDVP:RAP MDVP:PPQ Jitter:DDP
0 152.125 161.469 ... 0.00191 0.00226 0.00574
1 120.080 139.710 ... 0.00180 0.00220 0.00540
2 122.400 148.650 ... 0.00465 0.00696 0.01394
3 237.323 243.709 ... 0.00173 0.00159 0.00519
.. ... ... ... ... ... ...
155 138.190 203.522 ... 0.00406 0.00398 0.01218
[156 rows x 8 columns]
train_y:
status
0 1
1 1
2 1
3 0
.. ...
155 1
[156 rows x 1 columns]
Prediction on train data: [1 1 1 0 ... 1]
Accuracy score on train data: 0.6666666666666666
Prediction on test data: [1 1 1 1 ... 1
1 1]
Accuracy score on test data: 0.6666666666666666
```
在训练集和测试集上的准确率都是 67%。它的性能还可以进一步优化。你想尝试一下吗?你可以在下面的评论区给出你的方法。
### 背后原理
朴素贝叶斯分类器从贝叶斯定理发展来的。贝叶斯定理用于计算条件概率,或者说贝叶斯定理用于计算当与一个事件相关联的其他事件发生时,该事件发生的概率。简而言之,它解决了这个问题:*如果我们已经知道事件 x 发生在事件 y 之前的概率,那么当事件 x 再次发生时,事件 y 发生的概率是多少?* 贝叶斯定理用一个先验的预测值来逐渐逼近一个最终的 [后验概率](https://en.wikipedia.org/wiki/Posterior_probability)。贝叶斯定理有一个基本假设,就是所有的参数重要性相同(LCTT 译注:即相互独立)。
贝叶斯计算主要包括以下步骤:
1. 计算总的先验概率:
P(患病)P(患病) 和 P(不患病)P(不患病)
2. 计算 8 种指标各自是某个值时的后验概率 (value1,...,value8 分别是 MDVP:Fo(Hz),...,Jitter:DDP 的取值):
P(value1,\ldots,value8\ |\ 患病)P(value1,…,value8 ∣ 患病)
P(value1,\ldots,value8\ |\ 不患病)P(value1,…,value8 ∣ 不患病)
3. 将第 1 步和第 2 步的结果相乘,最终得到患病和不患病的后验概率:
P(患病\ |\ value1,\ldots,value8) \propto P(患病) \times P(value1,\ldots,value8\ |\ 患病)P(患病 ∣ value1,…,value8)∝P(患病)×P(value1,…,value8 ∣ 患病)
P(不患病\ |\ value1,\ldots,value8) \propto P(不患病) \times P(value1,\ldots,value8\ |\ 不患病)P(不患病 ∣ value1,…,value8)∝P(不患病)×P(value1,…,value8 ∣ 不患病)
上面第 2 步的计算非常复杂,朴素贝叶斯将它作了简化:
1. 计算总的先验概率:
P(患病)P(患病) 和 P(不患病)P(不患病)
2. 对 8 种指标里的每个指标,计算其取某个值时的后验概率:
P(value1\ |\ 患病),\ldots,P(value8\ |\ 患病)P(value1 ∣ 患病),…,P(value8 ∣ 患病)
P(value1\ |\ 不患病),\ldots,P(value8\ |\ 不患病)P(value1 ∣ 不患病),…,P(value8 ∣ 不患病)
3. 将第 1 步和第 2 步的结果相乘,最终得到患病和不患病的后验概率:
P(患病\ |\ value1,\ldots,value8) \propto P(患病) \times P(value1\ |\ 患病) \times \ldots \times P(value8\ |\ 患病)P(患病 ∣ value1,…,value8)∝P(患病)×P(value1 ∣ 患病)×…×P(value8 ∣ 患病)
P(不患病\ |\ value1,\ldots,value8) \propto P(不患病) \times P(value1\ |\ 不患病) \times \ldots \times P(value8\ |\ 不患病)P(不患病 ∣ value1,…,value8)∝P(不患病)×P(value1 ∣ 不患病)×…×P(value8 ∣ 不患病)
这只是一个很初步的解释,还有很多其他因素需要考虑,比如数据类型的差异,稀疏数据,数据可能有缺失值等。
### 超参数
朴素贝叶斯作为一个简单直接的算法,不需要超参数。然而,有的版本的朴素贝叶斯实现可能提供一些高级特性(比如超参数)。比如,[GaussianNB](https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html) 就有 2 个超参数:
* **priors**:先验概率,可以事先指定,这样就不必让算法从数据中计算才能得出。
* **var\_smoothing**:考虑数据的分布情况,当数据不满足标准的高斯分布时,这个超参数会发挥作用。
### 损失函数
为了坚持简单的原则,朴素贝叶斯使用 [0-1 损失函数](https://en.wikipedia.org/wiki/Loss_function#0-1_loss_function)。如果预测结果与期望的输出相匹配,损失值为 0,否则为 1。
### 优缺点
**优点**:朴素贝叶斯是最简单、最快速的算法之一。
**优点**:在数据量较少时,用朴素贝叶斯仍可作出可靠的预测。
**缺点**:朴素贝叶斯的预测只是估计值,并不准确。它胜在速度而不是准确度。
**缺点**:朴素贝叶斯有一个基本假设,就是所有特征相互独立,但现实情况并不总是如此。
从本质上说,朴素贝叶斯是贝叶斯定理的推广。它是最简单最快速的机器学习算法之一,用来进行简单和快速的训练和预测。朴素贝叶斯提供了足够好、比较准确的预测。朴素贝叶斯假设预测特征之间是相互独立的。已经有许多朴素贝叶斯的开源的实现,它们的特性甚至超过了贝叶斯算法的实现。
---
via: <https://opensource.com/article/21/1/machine-learning-python>
作者:[Girish Managoli](https://opensource.com/users/gammay) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tanloong](https://github.com/tanloong) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Naïve Bayes is a classification technique that serves as the basis for implementing several classifier modeling algorithms. Naïve Bayes-based classifiers are considered some of the simplest, fastest, and easiest-to-use machine learning techniques, yet are still effective for real-world applications.
Naïve Bayes is based on [Bayes' theorem](https://en.wikipedia.org/wiki/Bayes%27_theorem), formulated by 18th-century statistician [Thomas Bayes](https://en.wikipedia.org/wiki/Thomas_Bayes). This theorem assesses the probability that an event will occur based on conditions related to the event. For example, an individual with [Parkinson's disease](https://en.wikipedia.org/wiki/Parkinson%27s_disease) typically has voice variations; hence such symptoms are considered related to the prediction of a Parkinson's diagnosis. The original Bayes' theorem provides a method to determine the probability of a target event, and the Naïve variant extends and simplifies this method.
## Solving a real-world problem
This article demonstrates a Naïve Bayes classifier's capabilities to solve a real-world problem (as opposed to a complete business-grade application). I'll assume you have basic familiarity with machine learning (ML), so some of the steps that are not primarily related to ML prediction, such as data shuffling and splitting, are not covered here. If you are an ML beginner or need a refresher, see * An introduction to machine learning today* and
*.*
[Getting started with open source machine learning](https://opensource.com/business/15/9/getting-started-open-source-machine-learning)The Naïve Bayes classifier is [supervised](https://en.wikipedia.org/wiki/Supervised_learning), [generative](https://en.wikipedia.org/wiki/Generative_model), non-linear, [parametric](https://en.wikipedia.org/wiki/Parametric_model), and [probabilistic](https://en.wikipedia.org/wiki/Probabilistic_classification).
In this article, I'll demonstrate using Naïve Bayes with the example of predicting a Parkinson's diagnosis. The dataset for this example comes from this [UCI Machine Learning Repository](https://archive.ics.uci.edu/ml/datasets/parkinsons). This data includes several speech signal variations to assess the likelihood of the medical condition; this example will use the first eight of them:
**MDVP:Fo(Hz):**Average vocal fundamental frequency**MDVP:Fhi(Hz):**Maximum vocal fundamental frequency**MDVP:Flo(Hz):**Minimum vocal fundamental frequency**MDVP:Jitter(%)**,**MDVP:Jitter(Abs)**,**MDVP:RAP**,**MDVP:PPQ**, and**Jitter:DDP:**Five measures of variation in fundamental frequency
The dataset used in this example, shuffled and split for use, is available in my [GitHub repository](https://github.com/gammay/Machine-learning-made-easy-Naive-Bayes/tree/main/parkinsons).
## ML with Python
I'll use Python to implement the solution. The software I used for this application is:
- Python 3.8.2
- Pandas 1.1.1
- scikit-learn 0.22.2.post1
There are several open source Naïve Bayes classifier implementations available in Python, including:
**NLTK Naïve Bayes:**Based on the standard Naïve Bayes algorithm for text classification**NLTK Positive Naïve Bayes:**A variant of NLTK Naïve Bayes that performs binary classification with partially labeled training sets**Scikit-learn Gaussian Naïve Bayes:**Provides partial fit to support a data stream or very large dataset**Scikit-learn Multinomial Naïve Bayes:**Optimized for discrete data features, example counts, or frequency**Scikit-learn Bernoulli Naïve Bayes:**Designed for binary/Boolean features
I will use [sklearn Gaussian Naive Bayes](https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html) for this example.
Here is my Python implementation of `naive_bayes_parkinsons.py`
:
```
import pandas as pd
# Feature columns we use
x_rows=['MDVP:Fo(Hz)','MDVP:Fhi(Hz)','MDVP:Flo(Hz)',
'MDVP:Jitter(%)','MDVP:Jitter(Abs)','MDVP:RAP','MDVP:PPQ','Jitter:DDP']
y_rows=['status']
# Train
# Read train data
train_data = pd.read_csv('parkinsons/Data_Parkinsons_TRAIN.csv')
train_x = train_data[x_rows]
train_y = train_data[y_rows]
print("train_x:\n", train_x)
print("train_y:\n", train_y)
# Load sklearn Gaussian Naive Bayes and fit
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
gnb.fit(train_x, train_y)
# Prediction on train data
predict_train = gnb.predict(train_x)
print('Prediction on train data:', predict_train)
# Accuray score on train data
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(train_y, predict_train)
print('Accuray score on train data:', accuracy_train)
# Test
# Read test data
test_data = pd.read_csv('parkinsons/Data_Parkinsons_TEST.csv')
test_x = test_data[x_rows]
test_y = test_data[y_rows]
# Prediction on test data
predict_test = gnb.predict(test_x)
print('Prediction on test data:', predict_test)
# Accuracy Score on test data
accuracy_test = accuracy_score(test_y, predict_test)
print('Accuray score on test data:', accuracy_train)
```
Run the Python application:
```
$ python naive_bayes_parkinsons.py
train_x:
MDVP:Fo(Hz) MDVP:Fhi(Hz) ... MDVP:RAP MDVP:PPQ Jitter:DDP
0 152.125 161.469 ... 0.00191 0.00226 0.00574
1 120.080 139.710 ... 0.00180 0.00220 0.00540
2 122.400 148.650 ... 0.00465 0.00696 0.01394
3 237.323 243.709 ... 0.00173 0.00159 0.00519
.. ... ... ... ... ... ...
155 138.190 203.522 ... 0.00406 0.00398 0.01218
[156 rows x 8 columns]
train_y:
status
0 1
1 1
2 1
3 0
.. ...
155 1
[156 rows x 1 columns]
Prediction on train data: [1 1 1 0 ... 1]
Accuracy score on train data: 0.6666666666666666
Prediction on test data: [1 1 1 1 ... 1
1 1]
Accuracy score on test data: 0.6666666666666666
```
The accuracy scores on the train and test sets are 67% in this example; its performance can be optimized. Do you want to give it a try? If so, share your approach in the comments below.
## Under the hood
The Naïve Bayes classifier is based on Bayes' rule or theorem, which computes conditional probability, or the likelihood for an event to occur when another related event has occurred. Stated in simple terms, it answers the question: *If we know the probability that event x occurred before event y, then what is the probability that y will occur when x occurs again?* The rule uses a prior-prediction value that is refined gradually to arrive at a final [posterior](https://en.wikipedia.org/wiki/Posterior_probability) value. A fundamental assumption of Bayes is that all parameters are of equal importance.
At a high level, the steps involved in Bayes' computation are:
- Compute overall posterior probabilities ("Has Parkinson's" and "Doesn't have Parkinson's")
- Compute probabilities of posteriors across all values and each possible value of the event
- Compute final posterior probability by multiplying the results of #1 and #2 for desired events
Step 2 can be computationally quite arduous. Naïve Bayes simplifies it:
- Compute overall posterior probabilities ("Has Parkinson's" and "Doesn't have Parkinson's")
- Compute probabilities of posteriors for desired event values
- Compute final posterior probability by multiplying the results of #1 and #2 for desired events
This is a very basic explanation, and several other factors must be considered, such as data types, sparse data, missing data, and more.
## Hyperparameters
Naïve Bayes, being a simple and direct algorithm, does not need hyperparameters. However, specific implementations may provide advanced features. For example, [GaussianNB](https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html) has two:
**priors:**Prior probabilities can be specified instead of the algorithm taking the priors from data.**var_smoothing:**This provides the ability to consider data-curve variations, which is helpful when the data does not follow a typical Gaussian distribution.
## Loss functions
Maintaining its philosophy of simplicity, Naïve Bayes uses a [0-1 loss function](https://en.wikipedia.org/wiki/Loss_function#0-1_loss_function). If the prediction correctly matches the expected outcome, the loss is 0, and it's 1 otherwise.
## Pros and cons
**Pro:** Naïve Bayes is one of the easiest and fastest algorithms.
**Pro:** Naïve Bayes gives reasonable predictions even with less data.
**Con:** Naïve Bayes predictions are estimates, not precise. It favors speed over accuracy.
**Con:** A fundamental Naïve Bayes assumption is the independence of all features, but this may not always be true.
In essence, Naïve Bayes is an extension of Bayes' theorem. It is one of the simplest and fastest machine learning algorithms, intended for easy and quick training and prediction. Naïve Bayes provides good-enough, reasonably accurate predictions. One of its fundamental assumptions is the independence of prediction features. Several open source implementations are available with traits over and above what are available in the Bayes algorithm.
## 3 Comments |
13,629 | Linux 上的顶级安卓模拟器 | https://itsfoss.com/android-emulators-linux/ | 2021-07-29T11:15:40 | [
"安卓",
"模拟器"
] | https://linux.cn/article-13629-1.html | 
安卓系统是建立在高度定制的 Linux 内核之上的。因此,使用安卓模拟器在 Linux 上运行移动应用是有意义的。
虽然这不是在 Linux 机器上你可以做的新鲜事,但在 Windows 于 2021 年推出运行安卓应用的能力后,它是一个更需要的功能。
不仅仅限于使用应用,一些安卓模拟器也可以在开发和测试中派上用场。
因此,我总结了一份最好的模拟器清单,你可以用它来测试或在 Linux 上运行安卓应用/游戏。
### 1、Anbox
Anbox 是一个相当流行的模拟器,可以让 Linux 用户运行 Android 应用。可能深度 Linux 正是利用它使得开箱即可运行安卓应用。
它使用一个容器将安卓操作系统与主机隔离,这也让它们可以使用最新的安卓版本。
运行的安卓应用不能直接访问你的硬件,这是一个很好的安全决定。
与这里的其他一些选择不同,Anbox 在技术上不需要仿真层来使安卓系统工作。换句话说,它在你的 Linux 系统上最接近于原生的安卓体验。
由于这个原因,它可能不是最简单的选择。你不能只使用谷歌应用商店来安装应用,你需要使用安卓调试桥(ADB)。你只需要一个应用的 APK 文件就可以安装和使用它。
* [Anbox](https://anbox.io)
### 2、Genymotion

Genymotion 是一个为测试和开发量身定做的令人印象深刻的解决方案。
它不是一个自由开源的选择。它们通过云端或独立于 Android Studio 的桌面客户端,提供虚拟的安卓体验作为服务。
你可以模拟各种硬件配置和安卓版本,创建一个虚拟设备进行测试。它还让你有能力扩大规模,并有多个安卓虚拟设备运行,进行广泛的测试。
它可以帮助你测试文件上传在你的应用中如何工作,电池影响、性能、内存等等。
虽然它是一个主要针对专业人士的高级解决方案,但它确实支持最新的 Linux 发行版,包括 Ubuntu 20.04 LTS。
* [Genymotion](https://www.genymotion.com)
### 3、Android-x86

Android x86 是一个开源项目,使得安卓可以在 PC 上运行,并支持 32 位。
你可以选择在你的 Linux 系统上使用虚拟机管理器来安装它,或者直接在你的 PC 上试用它。
如果你需要安装,可以查看官方的 [安装说明](https://www.android-x86.org/installhowto.html)。
与其他一些选择不同,它是一个简单的试图在 PC 上工作的模拟器,没有花哨的功能。
* [Android x86](https://www.android-x86.org)
### 4、Android Studio (虚拟设备)

Android Studio 是一个用于开发和测试的完整工具。幸运的是,由于对 Linux 的支持,如果你需要的话,你可以用它来模拟安卓的体验进行实验。
你只需要创建一个安卓虚拟设备(AVD),你可以对其进行配置,然后作为模拟器进行模拟。
也有很大的机会能找到对一些最新的智能手机、电视和智能手表的支持。
它需要一定的学习曲线才能上手,但它是免费的,而且是完全开源的。
* [Android Studio](https://developer.android.com/studio)
### 5、ARChon

一个有趣的解决方案,这是一个你可以在 Linux 和任何其他平台上使用的安卓模拟器。
它有助于在 Chrome OS 上运行安卓应用,或者在任何操作系统上使用 Chrome 浏览器。与其他一些不同的是,你可能不会得到完整的安卓体验,而只是能够运行安卓应用。
你只需解压运行时,并将其加载到 Chrome 扩展中。接下来,下载 APK 文件到上面来添加你想使用的应用。
* [ARChon](https://archon-runtime.github.io)
### 6、Bliss OS

Bliss OS 是另一个开源项目,与 Android x86 类似,旨在使安卓在 PC 上运行。
与 Android x86 不同的是,它通过支持 32 位和 64 位架构提供了更多的兼容性选择。此外,你可以根据你的处理器下载兼容文件。
它有积极的维护,支持市场上最新的安卓版本。
* [Bliss OS](https://blissos.org)
### 总结
虽然你会能找到几个可用于 Linux 的安卓模拟器,但它们可能无法取代全面的智能手机体验。
每个模拟器都有一系列的功能和特定目的。请选择你需要的那个!
你试过安卓模拟器么?你在 Linux 中使用的最喜欢的模拟器是什么?欢迎在下面的评论中让我知道。
---
via: <https://itsfoss.com/android-emulators-linux/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Android is built on top of a heavily customized Linux kernel. So, running mobile apps on Linux makes sense using an Android emulator.
Maybe you just want to try some [open-source Android apps](https://itsfoss.com/open-source-android-apps/) because you find it more convenient on your desktop? Or, for any other fun use-cases you can think of.
Not just limited to using apps, some Android emulators can also be helpful for development and testing.
Hence, I have compiled a list of the best emulators that you can use to test or run Android applications/games on Linux.
**Non-FOSS Warning!**Some of the applications mentioned here are not open source. They have been included in the context of Linux usage.
## 1. Waydroid
Waydroid takes its inspiration from **now-defunt ****Anbox**** **(created by Canonical), which aimed to bring Android to the Linux operating system.
The only difference is, Waydroid is purely focused on supporting Wayland desktop sessions.
It uses a container-based approach to boot a full Android system on Linux, giving you full-fledged integration to use it. You can find the Android apps you need on your system.
At its core, it uses LineageOS system image based on Android 11 (at the time of updating this article). Not to forget, LineageOS is one of the best [de-googled Android-based OS](https://itsfoss.com/android-distributions-roms/) available. You can explore more about it on its [GitHub page](https://github.com/waydroid/waydroid) or visit its official website.
## 2. Genymotion

Genymotion is an impressive solution tailored for testing and development.
It is not a free and open-source option. They provide virtual Android experiences as a service through the cloud or a desktop client that is independent of Android Studio.
You can simulate a variety of hardware configurations and Android versions to create a virtual device for testing. It also gives you the ability to scale up and has multiple Android virtual devices running for extensive tests.
Genymotion solutions can help you test how file uploading works in your app, impacts battery, performance, memory, and so on.
While it is a premium option mostly for professionals, it does support the latest Linux distributions that include Ubuntu 22.04 LTS.
**Suggested Read 📖**
[5 De-Googled Android-based Operating SystemsConcerned about your privacy or want to give another life to your smartphone? You could consider these Android distributions and custom ROMs.](https://itsfoss.com/android-distributions-roms/)

## 3. Android-x86
Android x86 is an open-source project to make Android run on a PC with 32-bit support.
You can choose to install it using a virtual machine manager on your Linux system or directly try it on your PC.
Official [installation instructions](https://www.android-x86.org/installhowto.html?ref=itsfoss.com) are available if you need to go ahead.
Unlike some other options, it is a simple emulator that tries to work on a PC with no fancy features.
## 4. Android Studio (Virtual Devices)
Android Studio is a full-fledged tool for development and testing. Fortunately, with the support for Linux, you can use it to emulate the Android experience for experiments if you need to.
You just need to create an Android Virtual Device (AVD) that you can configure and then simulate as an emulator.
There are good chances to find support for some of the latest smartphones, TVs, and smartwatches as well.
It needs a certain learning curve to be able to pull it off, but it is free and completely open-source.
## 5. Bliss OS
Bliss OS is another open-source project, similar to Android x86 that aims to make Android run on PC.
Unlike Android x86, it gives more compatibility options by supporting both 32-bit and 64-bit architectures. Additionally, you get variants/editions of Bliss OS as per your personal requirements, like Stock for testing, FOSS, and Gapps.
It is actively maintained and supports the latest Android versions available in the market.
## 6. Anbox Cloud
While Anbox is no longer developed, Anbox Cloud exists for users who want to run Android in the cloud.
It supports ultra-low latency video streaming and recent Android versions. You can stream the mobile apps securely and get the best experience for your users/customers.
Anbox Cloud is a feasible solution for enterprises and businesses.
**Suggested Read 📖**
[40+ Best Open Source Android AppsThe best open source Android apps. Replace the proprietary options to enjoy a potentially better experience!](https://itsfoss.com/open-source-android-apps/)

## Wrapping Up
While you will find several Android emulator solutions available for Linux, they may not replace a full-fledged smartphone experience.
Every emulator comes with a set of features along with a specific purpose. Choose the one that you need.
💬 *Have you tried Android emulators yet? What’s your favorite emulator that you have used on Linux? You are welcome to let me know in the comments down below.* |
13,631 | pipx:在虚拟环境中运行 Python 应用 | https://opensource.com/article/21/7/python-pipx | 2021-07-29T20:52:00 | [
"Python"
] | /article-13631-1.html |
>
> 通过使用 pipx 隔离运行 Python 应用来避免版本冲突并提高安全性。
>
>
>

如果你使用 Python,你可能会安装很多 Python 应用。有些是你只想尝试的工具。还有一些是你每天都在使用的久经考验的应用,所以你把它们安装在你使用的每一台计算机上。这两种情况下,在虚拟环境中运行你的 Python 应用是非常有用的,这可以使它们以及它们的依赖关系相互分离,以避免版本冲突,并使它们与你系统的其它部分隔离,以提高安全性。
这就是 [pipx](https://pypi.org/project/pipx/) 出场的地方。
大多数 Python 应用可以使用 [pip](https://pypi.org/project/pip/) 进行安装,它只安装 Python 包。然而,`pipx` 为你的 Python 应用创建并管理一个虚拟环境,并帮助你运行它们。
### 安装 pipx
`pipx` 主要是一个 RPM 包,你可以在任何 Fedora、RHEL 或 CentOS 机器上安装它:
```
$ sudo dnf install pipx
```
### 使用 pipx
我将通过 Cowsay 以及 [Concentration](https://opensource.com/article/20/8/python-concentration) 工具演示如何使用 `pipx`。
#### 安装软件包
安装完 `pipx` 后,你可以用以下方法安装 Python 包:
```
$ pipx install <python_package>
```
要安装 Cowsay 包:
```
$ pipx install cowsay ✔ │ 20:13:41
installed package cowsay 4.0, Python 3.9.5
These apps are now globally available
- cowsay
done! ✨ ? ✨
```
现在你可以在系统的任何地方运行 Cowsay,通过终端与你对话!
```
$ cowsay "I <3 OSDC"
_________
| I <3 OSDC |
=========
\
\
^__^
(oo)\_______
(__)\ )\/\
||----w |
|| ||
```

#### 以特殊权限进行安装
不是所有的应用都像 Cowsay 一样简单。例如,Concentration 会与你系统中的许多其他组件交互,所以它需要特殊的权限。用以下方式安装它:
```
$ pipx install concentration ✔ │ 10s │ │ 20:26:12
installed package concentration 1.1.5, Python 3.9.5
These apps are now globally available
- concentration
done! ✨ ? ✨
```
Concentration 通过阻止 `distractors` 文件中列出的特定网站来帮助你集中注意力。要做到这点,它需要以 `sudo` 或 root 权限运行。你可以用 [OpenDoas](https://github.com/Duncaen/OpenDoas) 来做到这点,这是 `doas` 命令的一个版本,可以用特定的用户权限运行任何命令。要使用 `doas` 以 `sudo` 权限来运行 Concentration:
```
$ doas concentration improve ✔ │ │ 20:26:54
doas (sumantrom) password:
Concentration is now improved :D!
```
如你所见,这个独立的应用能够改变系统中的一些东西。
#### 列出已安装的应用
`pipx list` 命令显示所有用 `pipx` 安装的应用和它们的可执行路径:
```
$ pipx list
venvs are in /home/sumantrom/.local/pipx/venvs
apps are exposed on your $PATH at /home/sumantrom/.local/bin
package concentration 1.1.5, Python 3.9.5
- concentration
package cowsay 4.0, Python 3.9.5
- cowsay
```
#### 卸载应用
当你使用完毕后,知道如何卸载它们是很重要的。`pipx` 有一个非常简单的卸载命令:
```
$ pipx uninstall <package name>
```
或者你可以删除每个软件包:
```
$ pipx uninstall-all
pipx uninstall-all 2 ✘ │ 20:13:35
uninstalled cowsay! ✨ ? ✨
uninstalled concentration! ✨ ? ✨
```
### 尝试 pipx
`pipx` 是一个流行的 Python 应用的包管理器。它可以访问 [PyPi](https://pypi.org/) 上的所有东西,但它也可以从包含有效 Python 包的本地目录、Python wheel 或网络位置安装应用。
如果你安装了大量的 Python 应用,可以试试 `pipx`。
---
via: <https://opensource.com/article/21/7/python-pipx>
作者:[Sumantro Mukherjee](https://opensource.com/users/sumantro) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,632 | 在 Fedora 中用 bpftrace 追踪代码 | https://fedoramagazine.org/trace-code-in-fedora-with-bpftrace/ | 2021-07-29T22:27:17 | [
"bpftrace"
] | https://linux.cn/article-13632-1.html | 
bpftrace 是一个 [基于 eBPF 的新型追踪工具](https://github.com/iovisor/bpftrace),在 Fedora 28 第一次引入。Brendan Gregg、Alastair Robertson 和 Matheus Marchini 在网上的一个松散的黑客团队的帮助下开发了 bpftrace。它是一个允许你分析系统在幕后正在执行的操作的追踪工具,可以告诉你代码中正在被调用的函数、传递给函数的参数、函数的调用次数等。
这篇文章的内容涉及了 bpftrace 的一些基础,以及它是如何工作的,请继续阅读获取更多的信息和一些有用的实例。
### eBPF(<ruby> 扩展的伯克利数据包过滤器 <rt> extended Berkeley Packet Filter </rt></ruby>)
[eBPF](https://lwn.net/Articles/740157/) 是一个微型虚拟机,更确切的说是一个位于 Linux 内核中的虚拟 CPU。eBPF 可以在内核空间以一种安全可控的方式加载和运行小型程序,使得 eBPF 的使用更加安全,即使在生产环境系统中。eBPF 虚拟机有自己的指令集架构([ISA](https://github.com/iovisor/bpf-docs/blob/master/eBPF.md)),类似于现代处理器架构的一个子集。通过这个 ISA,可以很容易将 eBPF 程序转化为真实硬件上的代码。内核即时将程序转化为主流处理器架构上的本地代码,从而提升性能。
eBPF 虚拟机允许通过编程扩展内核,目前已经有一些内核子系统使用这一新型强大的 Linux 内核功能,比如网络、安全计算、追踪等。这些子系统的主要思想是添加 eBPF 程序到特定的代码点,从而扩展原生的内核行为。
虽然 eBPF 机器语言功能强大,由于是一种底层语言,直接用于编写代码很费力,bpftrace 就是为了解决这个问题而生的。eBPF 提供了一种编写 eBPF 追踪脚本的高级语言,然后在 clang / LLVM 库的帮助下将这些脚本转化为 eBPF,最终添加到特定的代码点。
### 安装和快速入门
在终端 [使用](https://fedoramagazine.org/howto-use-sudo/) [sudo](https://fedoramagazine.org/howto-use-sudo/) 执行下面的命令安装 bpftrace:
```
$ sudo dnf install bpftrace
```
使用“hello world”进行实验:
```
$ sudo bpftrace -e 'BEGIN { printf("hello world\n"); }'
```
注意,出于特权级的需要,你必须使用 root 运行 `bpftrace`,使用 `-e` 选项指明一个程序,构建一个所谓的“单行程序”。这个例子只会打印 “hello world”,接着等待你按下 `Ctrl+C`。
`BEGIN` 是一个特殊的探针名,只在执行一开始生效一次;每次探针命中时,大括号 `{}` 内的操作(这个例子中只是一个 `printf`)都会执行。
现在让我们转向一个更有用的例子:
```
$ sudo bpftrace -e 't:syscalls:sys_enter_execve { printf("%s called %s\n", comm, str(args->filename)); }'
```
这个例子打印了父进程的名字(`comm`)和系统中正在创建的每个新进程的名称。`t:syscalls:sys_enter_execve` 是一个内核追踪点,是 `tracepoint:syscalls:sys_enter_execve` 的简写,两种形式都可以使用。下一部分会向你展示如何列出所有可用的追踪点。
`comm` 是一个 bpftrace 内建指令,代表进程名;`filename` 是 `t:syscalls:sys_enter_execve` 追踪点的一个字段,这些字段可以通过 `args` 内建指令访问。
追踪点的所有可用字段可以通过这个命令列出:
```
bpftrace -lv "t:syscalls:sys_enter_execve"
```
### 示例用法
#### 列出探针
`bpftrace` 的一个核心概念是<ruby> 探针点 <rt> probe point </rt></ruby>,即 eBPF 程序可以连接到的(内核或用户空间的)代码中的测量点,可以分成以下几大类:
* `kprobe`——内核函数的开始处
* `kretprobe`——内核函数的返回处
* `uprobe`——用户级函数的开始处
* `uretprobe`——用户级函数的返回处
* `tracepoint`——内核静态追踪点
* `usdt`——用户级静态追踪点
* `profile`——基于时间的采样
* `interval`——基于时间的输出
* `software`——内核软件事件
* `hardware`——处理器级事件
所有可用的 `kprobe` / `kretprobe`、`tracepoints`、`software` 和 `hardware` 探针可以通过这个命令列出:
```
$ sudo bpftrace -l
```
`uprobe` / `uretprobe` 和 `usdt` 是用户空间探针,专用于某个可执行文件。要使用这些探针,通过下文中的特殊语法。
`profile` 和 `interval` 探针以固定的时间间隔触发;固定的时间间隔不在本文的范畴内。
#### 统计系统调用数
**映射** 是保存计数、统计数据和柱状图的特殊 BPF 数据类型,你可以使用映射统计每个系统调用正在被调用的次数:
```
$ sudo bpftrace -e 't:syscalls:sys_enter_* { @[probe] = count(); }'
```
一些探针类型允许使用通配符匹配多个探针,你也可以使用一个逗号隔开的列表为一个操作块指明多个连接点。上面的例子中,操作块连接到了所有名称以 `t:syscalls:sysenter_` 开头的追踪点,即所有可用的系统调用。
`bpftrace` 的内建函数 `count()` 统计系统调用被调用的次数;`@[]` 代表一个映射(一个关联数组)。该映射的键 `probe` 是另一个内建指令,代表完整的探针名。
这个例子中,相同的操作块连接到了每个系统调用,之后每次有系统调用被调用时,映射就会被更新,映射中和系统调用对应的项就会增加。程序终止时,自动打印出所有声明的映射。
下面的例子统计所有的系统调用,然后通过 `bpftrace` 过滤语法使用 PID 过滤出某个特定进程调用的系统调用:
```
$ sudo bpftrace -e 't:syscalls:sys_enter_* / pid == 1234 / { @[probe] = count(); }'
```
#### 进程写的字节数
让我们使用上面的概念分析每个进程正在写的字节数:
```
$ sudo bpftrace -e 't:syscalls:sys_exit_write /args->ret > 0/ { @[comm] = sum(args->ret); }'
```
`bpftrace` 连接操作块到写系统调用的返回探针(`t:syscalls:sys_exit_write`),然后使用过滤器丢掉代表错误代码的负值(`/arg->ret > 0/`)。
映射的键 `comm` 代表调用系统调用的进程名;内建函数 `sum()` 累计每个映射项或进程写的字节数;`args` 是一个 `bpftrace` 内建指令,用于访问追踪点的参数和返回值。如果执行成功,`write` 系统调用返回写的字节数,`arg->ret` 用于访问这个字节数。
#### 进程的读取大小分布(柱状图):
`bpftrace` 支持创建柱状图。让我们分析一个创建进程的 `read` 大小分布的柱状图的例子:
```
$ sudo bpftrace -e 't:syscalls:sys_exit_read { @[comm] = hist(args->ret); }'
```
柱状图是 BPF 映射,因此必须保存为一个映射(`@`),这个例子中映射键是 `comm`。
这个例子使 `bpftrace` 给每个调用 `read` 系统调用的进程生成一个柱状图。要生成一个全局柱状图,直接保存 `hist()` 函数到 `@`(不使用任何键)。
程序终止时,`bpftrace` 自动打印出声明的柱状图。创建柱状图的基准值是通过 *args->ret* 获取到的读取的字节数。
#### 追踪用户空间程序
你也可以通过 `uprobes` / `uretprobes` 和 USDT(用户级静态定义的追踪)追踪用户空间程序。下一个例子使用探测用户级函数结尾处的 `uretprobe` ,获取系统中运行的每个 `bash` 发出的命令行:
```
$ sudo bpftrace -e 'uretprobe:/bin/bash:readline { printf("readline: \"%s\"\n", str(retval)); }'
```
要列出可执行文件 `bash` 的所有可用 `uprobes` / `uretprobes`, 执行这个命令:
```
$ sudo bpftrace -l "uprobe:/bin/bash"
```
`uprobe` 指向用户级函数执行的开始,`uretprobe` 指向执行的结束(返回处);`readline()` 是 `/bin/bash` 的一个函数,返回键入的命令行;`retval` 是被探测的指令的返回值,只能在 `uretprobe` 访问。
使用 `uprobes` 时,你可以用 `arg0..argN` 访问参数。需要调用 `str()` 将 `char *` 指针转化成一个字符串。
### 自带脚本
`bpftrace` 软件包附带了许多有用的脚本,可以在 `/usr/share/bpftrace/tools/` 目录找到。
这些脚本中,你可以找到:
* `killsnoop.bt`——追踪 `kill()` 系统调用发出的信号
* `tcpconnect.bt`——追踪所有的 TCP 网络连接
* `pidpersec.bt`——统计每秒钟(通过 `fork`)创建的新进程
* `opensnoop.bt`——追踪 `open()` 系统调用
* `bfsstat.bt`——追踪一些 VFS 调用,按秒统计
你可以直接使用这些脚本,比如:
```
$ sudo /usr/share/bpftrace/tools/killsnoop.bt
```
你也可以在创建新的工具时参考这些脚本。
### 链接
* bpftrace 参考指南——<https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md>
* Linux 2018 `bpftrace`(DTrace 2.0)——<http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html>
* BPF:通用的内核虚拟机——<https://lwn.net/Articles/599755/>
* Linux Extended BPF(eBPF)Tracing Tools——<http://www.brendangregg.com/ebpf.html>
* 深入 BPF:一个阅读材料列表—— [https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf](https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/)
---
via: <https://fedoramagazine.org/trace-code-in-fedora-with-bpftrace/>
作者:[Augusto Caringi](https://fedoramagazine.org/author/acaringi/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[YungeG](https://github.com/YungeG) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | bpftrace is [a new eBPF-based tracing tool](https://github.com/iovisor/bpftrace) that was first included in Fedora 28. It was developed by Brendan Gregg, Alastair Robertson and Matheus Marchini with the help of a loosely-knit team of hackers across the Net. A tracing tool lets you analyze what a system is doing behind the curtain. It tells you which functions in code are being called, with which arguments, how many times, and so on.
This article covers some basics about bpftrace, and how it works. Read on for more information and some useful examples.
#### eBPF (extended Berkeley Packet Filter)
[eBPF](https://lwn.net/Articles/740157/) is a tiny virtual machine, or a virtual CPU to be more precise, in the Linux Kernel. The eBPF can load and run small programs in a safe and controlled way in kernel space. This makes it safer to use, even in production systems. This virtual machine has its own instruction set architecture ([ISA](https://github.com/iovisor/bpf-docs/blob/master/eBPF.md)) resembling a subset of modern processor architectures. The ISA makes it easy to translate those programs to the real hardware. The kernel performs just-in-time translation to native code for main architectures to improve the performance.
The eBPF virtual machine allows the kernel to be extended programmatically. Nowadays several kernel subsystems take advantage of this new powerful Linux Kernel capability. Examples include networking, seccomp, tracing, and more. The main idea is to attach eBPF programs into specific code points, and thereby extend the original kernel behavior.
eBPF machine language is very powerful. But writing code directly in it is extremely painful, because it’s a low level language. This is where bpftrace comes in. It provides a high-level language to write eBPF tracing scripts. The tool then translates these scripts to eBPF with the help of clang/LLVM libraries, and then attached to the specified code points.
## Installation and quick start
To install bpftrace, run the following command in a terminal [using ](https://fedoramagazine.org/howto-use-sudo/)* sudo*:
$ sudo dnf install bpftrace
Try it out with a “hello world” example:
$ sudo bpftrace -e 'BEGIN { printf("hello world\n"); }'
Note that you must run *bpftrace* as *root* due to the privileges required. Use the *-e* option to specify a program, and to construct the so-called “one-liners.” This example only prints *hello world*, and then waits for you to press **Ctrl+C**.
*BEGIN* is a special probe name that fires only once at the beginning of execution. Every action inside the curly braces *{ }* fires whenever the probe is hit — in this case, it’s just a *printf*.
Let’s jump now to a more useful example:
$ sudo bpftrace -e 't:syscalls:sys_enter_execve { printf("%s called %s\n", comm, str(args->filename)); }'
This example prints the parent process name *(comm)* and the name of every new process being created in the system. *t:syscalls:sys_enter_execve* is a kernel tracepoint. It’s a shorthand for *tracepoint:syscalls:sys_enter_execve*, but both forms can be used. The next section shows you how to list all available tracepoints.
*comm* is a bpftrace builtin that represents the process name. *filename* is a field of the *t:syscalls:sys_enter_execve* tracepoint. You can access these fields through the *args* builtin.
All available fields of the tracepoint can be listed with this command:
bpftrace -lv "t:syscalls:sys_enter_execve"
## Example usage
### Listing probes
A central concept for *bpftrace* are **probe points**. Probe points are instrumentation points in code (kernel or userspace) where eBPF programs can be attached. They fit into the following categories:
*kprobe*– kernel function start*kretprobe*– kernel function return*uprobe*– user-level function start*uretprobe*– user-level function return*tracepoint*– kernel static tracepoints*usdt*– user-level static tracepoints*profile*– timed sampling*interval*– timed output*software*– kernel software events*hardware*– processor-level events
All available *kprobe/kretprobe*, *tracepoints*, *software* and *hardware* probes can be listed with this command:
$ sudo bpftrace -l
The *uprobe/uretprobe* and *usdt* probes are userspace probes specific to a given executable. To use them, use the special syntax shown later in this article.
The *profile* and *interval* probes fire at fixed time intervals. Fixed time intervals are not covered in this article.
### Counting system calls
**Maps** are special BPF data types that store counts, statistics, and histograms. You can use maps to summarize how many times each syscall is being called:
$ sudo bpftrace -e 't:syscalls:sys_enter_* { @[probe] = count(); }'
Some probe types allow wildcards to match multiple probes. You can also specify multiple attach points for an action block using a comma separated list. In this example, the action block attaches to all tracepoints whose name starts with *t:syscalls:sys_enter_*, which means all available syscalls.
The bpftrace builtin function *count()* counts the number of times this function is called. *@[]* represents a map (an associative array). The key of this map is *probe*, which is another bpftrace builtin that represents the full probe name.
Here, the same action block is attached to every syscall. Then, each time a syscall is called the map will be updated, and the entry is incremented in the map relative to this same syscall. When the program terminates, it automatically prints out all declared maps.
This example counts the syscalls called globally, it’s also possible to filter for a specific process by *PID* using the bpftrace filter syntax:
$ sudo bpftrace -e 't:syscalls:sys_enter_* / pid == 1234 / { @[probe] = count(); }'
### Write bytes by process
Using these concepts, let’s analyze how many bytes each process is writing:
$ sudo bpftrace -e 't:syscalls:sys_exit_write /args->ret > 0/ { @[comm] = sum(args->ret); }'
*bpftrace* attaches the action block to the write syscall return probe (*t:syscalls:sys_exit_write*). Then, it uses a filter to discard the negative values, which are error codes *(/args->ret > 0/)*.
The map key *comm* represents the process name that called the syscall. The *sum()* builtin function accumulates the number of bytes written for each map entry or process. *args* is a bpftrace builtin to access tracepoint’s arguments and return values. Finally, if successful, the *write* syscall returns the number of written bytes. *args->ret* provides access to the bytes.
### Read size distribution by process (histogram):
*bpftrace* supports the creation of histograms. Let’s analyze one example that creates a histogram of the *read* size distribution by process:
$ sudo bpftrace -e 't:syscalls:sys_exit_read { @[comm] = hist(args->ret); }'
Histograms are BPF maps, so they must always be attributed to a map (*@*). In this example, the map key is *comm*.
The example makes *bpftrace* generate one histogram for every process that calls the *read* syscall. To generate just one global histogram, attribute the *hist()* function just to *‘@’* (without any key).
bpftrace automatically prints out declared histograms when the program terminates. The value used as base for the histogram creation is the number of read bytes, found through *args->ret*.
### Tracing userspace programs
You can also trace userspace programs with *uprobes/uretprobes* and *USDT* (User-level Statically Defined Tracing). The next example uses a *uretprobe*, which probes to the end of a user-level function. It gets the command lines issued in every *bash* running in the system:
$ sudo bpftrace -e 'uretprobe:/bin/bash:readline { printf("readline: \"%s\"\n", str(retval)); }'
To list all available *uprobes/uretprobes* of the *bash* executable, run this command:
$ sudo bpftrace -l "uprobe:/bin/bash"
*uprobe* instruments the beginning of a user-level function’s execution, and *uretprobe* instruments the end (its return). *readline()* is a function of */bin/bash*, and it returns the typed command line. *retval* is the return value for the instrumented function, and can only be accessed on *uretprobe*.
When using *uprobes*, you can access arguments with *arg0..argN*. A *str()* call is necessary to turn the *char ** pointer to a *string*.
## Shipped Scripts
There are many useful scripts shipped with bpftrace package. You can find them in the */usr/share/bpftrace/tools/* directory.
Among them, you can find:
*killsnoop.bt*– Trace signals issued by the kill() syscall.*tcpconnect.bt*– Trace all TCP network connections.*pidpersec.bt*– Count new procesess (via fork) per second.*opensnoop.bt*– Trace open() syscalls.*vfsstat.bt*– Count some VFS calls, with per-second summaries.
You can directly use the scripts. For example:
$ sudo /usr/share/bpftrace/tools/killsnoop.bt
You can also study these scripts as you create new tools.
## Links
- bpftrace reference guide –
[https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md](https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md) - bpftrace (DTrace 2.0) for Linux 2018 –
[http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html](http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html) - BPF: the universal in-kernel virtual machine –
[https://lwn.net/Articles/599755/](https://lwn.net/Articles/599755/) - Linux Extended BPF (eBPF) Tracing Tools –
[http://www.brendangregg.com/ebpf.html](http://www.brendangregg.com/ebpf.html) - Dive into BPF: a list of reading material –
[https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf](https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/)
*Photo by **Roman Romashov** on **Unsplash**.*
## child
Fantastic! And is it available in Centos 7?
## Konstantin
Great article! Wonder if bpftrace can be used inside bash scripts.
## Peter van Gemert
Yes it is possible to use bpftrace in shell scripts. bpftrace is a cli command that can be run from the prompt or from shell scripts. |
13,634 | 小说还是折磨:我如何学会克服焦虑并开始爱上 Vim | https://news.itsfoss.com/how-i-started-loving-vim/ | 2021-07-31T11:05:00 | [
"Vim"
] | https://linux.cn/article-13634-1.html |
>
> 非技术人员也可以使用 Linux 和开源软件进行非技术工作。这是我的故事。
>
>
>

(LCTT 译注:本文原文标题用 “F(r)iction” 一语双关的表示了<ruby> 小说 <rt> fiction </rt></ruby>写作过程中的<ruby> 摩擦 <rt> friction </rt></ruby>苦恼。)
时间:2009 年 12 月。我准备辞去工作。
我希望专心写我的第一本书;我的工作职责和技术环境都没办法让我完成这本书的写作。
写作是件苦差事。
在现代世界中,很少有工作像写作这样奇特或者说艰巨的追求 —— 面对一张白纸,坐下来,迫使你的大脑吐出文字,向读者传达一个想法。当然,我并不是说写作不能与他人合作完成,而只是想说明,对于作家来说,自己着手写一部新作品是多么令人生畏。小说还是非小说写作都是如此。但由于我是一名小说家,我在这篇文章中主要想关注是小说的写作。

还记得 2009 年是什么样子吗?
智能手机已经诞生 3 年了 —— 而我还在使用功能机。笔记本电脑又大又笨重。同时,基于云的生产力 Web 应用还处于起步阶段,并不那么好用。从技术上讲,像我这样的作家们正在以 Gmail 账户(和一个非常年轻的基于云的存储服务 Dropbox)作为一个始终可用的选项来处理自己的草稿,即使我的个人电脑不在身边。虽然这与作家们必须要使用打字机(或,上帝保佑,使用笔和纸)工作时相比已经是一个很好的变化了,但并没有好多少。
首先,对手稿的版本控制是一场噩梦。此外,我为简化工作流程而在工具包中添加的工具越多,我转换写作环境(无论是用户界面还是用户体验)的次数就越多。
我是在 Windows 记事本上开始写草稿的,然后把它保存在家里电脑上的 MS Word 文档中,用电子邮件发给自己一份副本,同时在 Dropbox 上保留另一份副本(因为在上班时无法访问 Dropbox),在公司时对该文件的副本进行处理,在一天结束时用电子邮件发给自己,在家里的电脑上下载它,用一个新的名字和相应的日期保存它,这样我就能认出该文件是在公司(而不是家里)进行修改的……好吧,你知道这是怎样一个画面。如果你能感受到这种涉及 Windows 记事本、MS Word、Gmail 和 Dropbox 的工作流程有多么疯狂,那么现在你就知道我为什么辞职了。
让我更清醒的是,我仍然知道一些作家,其中竟然有些还是好作家,依然在使用我 2009 年遵循的工作流程的各种变体。
在接下来的三年里,我一直在写手稿,在 2012 年完成了初稿。在这三年里,技术环境发生了很大变化。智能手机确实相当给力,我在 2009 年遇到的一些复杂情况已经消失了。我仍然可以用手机处理我在家里外理的文件(不一定是新的写作,但由于手机上的 Dropbox,编辑变得相当容易)。我的主要写作工具仍然是微软的 Windows 记事本和 Word,我就是这样完成初稿的。
小说 [《第一声》](https://www.goodreads.com/book/show/29616237-first-utterance) 于 2016 年出版,获得了评论界和商业界的好评。
结束了。
或许我是这么想的。
我一完成手稿发给了编辑,就已经开始着手第二部小说的写作。我不再为写作而辞职,而是采取了一种更务实的方法:我会在每年年底请两个星期的假,这样我就可以到山上的一个小木屋里去写作。
花了半天时间我才意识到,那些让我讨厌的 [写作工具](https://itsfoss.com/open-source-tools-writers/) 和工作流程并没有消失,而是演变成了一个更复杂的野兽。作为一个作家,我并不像我想像的那样高产或高效。
### 新冠期间的 Linux

时间:2020 年。世界正处于集体疯狂的边缘。
(为某些原因而删改的文字)一种新型病毒正在演变成 1911 年以来的第一次全球大流行疾病。3 月 20 日,斯里兰卡,跟随世界上大多数国家的脚步,封城了。
四月是斯里兰卡旱季的高峰。在像科伦坡这样的混凝土丛林中,温度可以达到三十多度,湿度高达九十多度。在最好的情况下,它也可以使大多数人精神错乱,更别说在全球大流行病正在进行的时候,被困在没有一直开着空调的家里?真是一个让人疯狂的好温床。
让我的疯狂是 Linux,或者说是“发行版跳跃”,像我们在开源社区中所说的。
我越在各种 \*nix 发行版间蹿来蹿,我就对控制的想法越迷恋。当任何事情似乎都不在我们的控制之中时 —— 即使是与另一个人握手这样的简单行为 —— 我们自然会倾向于做那些我们感觉更有控制力的事。
在我的生活中,还有什么比计算机更容易被控制的呢?自然,这也延伸到我的写作工具和工作流程。
### 通往 Vim 之路
有一个关于 [Vim](https://www.vim.org/) 的笑话完美地描述了我对它的第一次体验:人们对 Vim 难以割舍是因为他们不知道怎么关掉它。
我试图编辑一个配置文件,而 [新安装的 Ubuntu 服务器](https://itsfoss.com/install-ubuntu-server-raspberry-pi/) 只预装了 Vim 文本编辑器。第一次是恐慌 —— 以至于我重新启动了机器,以为操作系统没有识别出我的键盘。然而当它再次发生时,不可避免地,我谷歌搜索:“[我该如何关闭 Vim?](https://itsfoss.com/how-to-exit-vim/)”
*哦。这真有趣*,我想。
*但为什么呢?*
要理解我为什么会对一个复杂到无法关闭的文本编辑器有点兴趣,你必须了解我是多么崇拜 Windows 记事本。
作为一个作家,我喜欢在它的没有废话、没有按钮、白纸一样的画布上写作。它没有拼写检查。它没有格式。但这些我并不关心。
对于我这个作家来说,记事本是有史以来最好的草稿写作板。不幸的是,它并不强大 —— 所以即使我会先用记事本写草稿,一旦超过 1000 字,我就会把它移到 MS Word 上 —— 记事本不是为散文而生的,当超过这个字数限制时,这些局限就会凸显出来。
因此,当我把我所有的计算机工作从 Windows 上迁移走时,我第一个要安装的就是一个好的文本编辑器。
[Kate](https://kate-editor.org/) 是第一个让我感到比用 Windows 记事本更舒服的替代品 —— 它更强大(它有拼写检查功能!),而且,我可以在同一个环境中搞一些业余爱好式的编程。
当时它是我的爱。
但后来 Vim 出现了。
我对 Vim 了解得越多,看开发者在 Vim 上现场进行编码的次数越多,我就越发现自己在编辑文本时更想打开 Vim。我使用 Unix 传统意义上“文本编辑”这一短语:编辑配置文件中的文本块,或者有时编写基本的 Bash 脚本。
我仍然没有用 Vim 来满足我的散文写作需求。
在这方面我有 Libre Office。
算是吧。
虽然它是一个适当的 [MS Office 替代品](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/),但我发现自己没有被它打动。它的用户界面可能比 MS Word 更让人分心,而且每个发行版都有不同的 Libre Office 软件包,我发现自己使用的是一个非常零散的工具包和工作流程,更不用说用户界面在不同的发行版和桌面环境中差异是多么大。
事情变得更加复杂了,因为我也开始读我的硕士学位了。这时,我要在 Kate 上做笔记,把它们转移到 Libre Office 上,然后保存到我的 Dropbox 上。
我每天都面临着情境转换。
生产力下降,因为我不得不打开和关闭一些不相关的应用程序。我需要一个写作工具来满足我所有的需求,无论是作为一个小说家,还是一个学生、亦或是一个业余的程序员。
这时我意识到,解决我场景切换噩梦的方法也同样摆在我的面前。
这时,我已经经常使用 Vim —— 甚至在我的安卓手机上利用 Termux 使用它。这使我对要把所有东西都搬到 Vim 上的想法感到相当舒服。由于它支持 Markdown 语法,记笔记也会变得更加容易。
这仅仅是大约两个月前的事。
现在怎么样了?
时间:2021 年 4 月。
坐在出租车上,我通过 Termux(借助蓝牙键盘)[用 Vim](https://linuxhandbook.com/basic-vim-commands/) 在手机上开始写这个草稿。我把文件推送到 GitHub 上我的用于写作使用的私人仓库,我从那里把文件拉到我的电脑上,又写了几行,然后再次出门。我把新版本的文件从 GitHub 拉到我的手机上,修改、推送,如此往复,直到我把最后的草稿用电子邮件发给编辑。
现在,场景切换的情景已经不复存在。
在文字处理器中写作所带来的分心问题也没有了。
编辑工作变得无比简单,而且更快了。
我的手腕不再疼痛,因为我不再需要鼠标了。
现在是 2021 年 4 月。
我是一名小说家。
而我在 Vim 上写作。
怎么做的?我将在本专栏系列的第二部分讨论这个工作流程的具体内容,即非技术人员如何使用免费和开源技术。敬请关注。
---
via: <https://news.itsfoss.com/how-i-started-loving-vim/>
作者:[Theena](https://news.itsfoss.com/author/theena/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[piaoshi](https://github.com/piaoshi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

It is Dec 2009, and I am ready to quit my job.
I wanted to focus on writing my first book; neither my commitments at work nor the state of technology was helping.
Writing is hard work.
Few tasks in the modern world can be as singular – or as daunting – a pursuit as sitting down in front of a blank piece of paper, and asking your brain to vomit out words that communicate an idea to readers. I am not suggesting that writing can’t be collaborative of course, but merely illustrating how daunting it can be for writers to set off on a new piece by themselves. This is true for fiction
and non-fiction writing, but since I am a novelist I’d like to focus primarily on fiction in this article.
Remember what 2009 was like?
Smart phones were 3 years old – I still hadn’t gone away from feature phones. Laptops were big and bulky. Meanwhile, cloud-based web applications for productivity was in their infancy, and just not good. Technologically speaking, writers like me were using their Gmail accounts (and a very young cloud-based storage called Dropbox) as an always-available option to work on their drafts, even while away from my personal computer. While this was a nice change from what writers had to go through when working with typewriters (or god forbid, pen and paper), it wasn’t much.
For one thing, version control of manuscripts was a nightmare. Further, the more tools I added to my tool kit to simplify the workflow, the more I had to switch context – both from a UI and a UX sense.
I would start writing drafts on Windows Notepad, save it on a MS Word Document on my PC at home, email myself a copy, keep another copy on Dropbox (since Dropbox wasn’t accessible at work), work on the copy of that file at work, email it back to myself at the end of the day, download it on the home computer, saving it under a new name and the respective date so that I would recognize the changes in the file were made at work (as opposed to home)…well you get the picture. If you think this workflow involving Windows Notepad, MS Word, Gmail, and Dropbox is insane, well now you know why I quit my job.
More soberingly, I still know writers, damn good writers too, who use variations of the workflow that I followed in 2009.
Over the next three years, I worked on the manuscript, completing the first draft in 2012. During the three years much had changed with the state of technology. Smart phones were actually pretty great, and some of the complications I had in 2009 had disappeared. I could still work on the same file that I had been working from at home, on my phone (not necessarily fresh writing, but editing had become considerably easier thanks to Dropbox on the phone.) My main writing tool remained Microsoft’s Windows Notepad and Word, which is how I completed the first draft.
The novel [ First Utterance](https://www.goodreads.com/book/show/29616237-first-utterance?ref=news.itsfoss.com) was released in 2016 to critical and commercial acclaim.
The end.
Or so I thought.
As soon as I completed the manuscript and sent it to my editor, I had begun working on the second novel. I was no longer quitting my job to work on writing, but I had taken a more pragmatic approach: I’d take two weeks off at the end of ever year so that I could go to a little cabin in the mountains to write.
It took me half a day to realize that the things that annoyed me about my [writing tools](https://itsfoss.com/open-source-tools-writers/?ref=news.itsfoss.com) and workflow had not disappeared, but morphed into a more complex beast. As a writer, I wasn’t being productive or as efficient as I wanted.
## Linux in the time of Corona

It is 2020 and the world is on the verge of mass hysteria.
What had started out as an isolated novel virus in China was morphing into the first global pandemic since 1911. On March 20th, Sri Lanka followed most of the rest of the world and shutdown.
April in Sri Lanka is the height of the dry season. Temperatures in concrete jungles like Colombo can reach the mid 30s, with humidity in the high 90s. It can drive most people to distraction at the best of times, but stuck at home with no always-on air conditioning while a global pandemic is underway? That is a good recipe for madness.
My madness was Linux or, as we in the open source community call it, ‘distro-hopping’.
The more I played around with *nix distros, the more enamoured I came to be with the idea of control. When nothing seems to be within our control – not even the simple act of shaking hands with another person – then it is only natural we lean towards things where we feel more in control.
Where better to get more control in my life than with my computing? Naturally, this extended to my writing tools and workflow too.
## The path to Vim
There’s a joke about [Vim](https://www.vim.org/?ref=news.itsfoss.com) that describes perfectly my first experience with it. People are obsessive about Vim because they don’t know how to close it.
I was attempting to edit a configuration file, and the [fresh install of Ubuntu Server](https://itsfoss.com/install-ubuntu-server-raspberry-pi/?ref=news.itsfoss.com) had only Vim pre-installed. First there was panic – so much so I restarted the machine thinking the OS wasn’t picking up my keyboard. Then when it happened again, the inevitable Google search: ‘[How do I close vim?](https://itsfoss.com/how-to-exit-vim/?ref=news.itsfoss.com)‘
*Oh. That’s interesting*, I thought.
*But why?*
To understand why I was even remotely interested in a text editor that was too complex to close, you have to understand how much I adore Windows Notepad.
As a writer, I loved writing on its no-nonsense, no buttons, white-abyss like canvas. It had no spell check. It had no formatting. But I didn’t care.
For the writer in me, Notepad was the best writing scratch pad ever devised. Unfortunately, it isn’t powerful – so even if I start writing my drafts in Notepad, I would move it to MS Word once I had passed a 1000 words – Notepad wasn’t built for prose, and those limitations would be glaringly obvious when I passed that word limit.
So the first thing I installed I moved all my computing away from Windows, was a good text editor.
[Kate](https://kate-editor.org/?ref=news.itsfoss.com) was the first replacement where I felt more comfortable than I did on Windows Notepad – it was more powerful (it had spell-checker!), and hey, I could mess around with some hobbyist-type coding in the same environment.
It was love.
But then Vim happened.
The more I learnt about Vim, the more I watched developers live coding on Vim, the more I found myself opening Vim for my text editing needs. I use the phrase ‘text editing’ in the traditional Unix sense: editing blocks of text in configuration files, or sometimes writing basic Bash scripts.
I still hadn’t used Vim remotely for my prose writing needs.
For that I had LibreOffice.
Sort of.
While it is an adequate [replacement for MS Office](https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/?ref=news.itsfoss.com), I found myself underwhelmed. The UI is perhaps even more distracting than MS Word, and with each distro having different packages of LibreOffice, I found myself using a hellishly fragmented tool kit and workflow, to say nothing about how different the UI can look in various distros and desktop environments.
Things had become even more complicated because I had also started my Masters. In this scenario, I was taking notes down on Kate, transferring them to LibreOffice, and then saving it on to my Dropbox.
Context switching was staring at me in the face every day.
Productivity dropped as I had to open and close a number of unrelated applications. I needed one writing tool to meet all my needs – as a novelist, as a student, and as a hobbyist coder.
And that’s when I realized that the solution to my context switching nightmare was also staring at me in the face at the same time.
By this point, I had used Vim often enough – even used it with Termux on my Android phone – to be pretty comfortable with the idea of moving everything to Vim. Since it supported markdown syntax, note-taking would also become even easier.
This was just about two months ago.
How am I doing?
It is April 2021.
I started this draft on my phone, [using Vim](https://linuxhandbook.com/basic-vim-commands/?ref=news.itsfoss.com) via Termux (with the aid of a Bluetooth keyboard), while in a taxi. I pushed the file to a GitHub private repo for my writing, from which I pulled the file to my PC, wrote a few more lines, before heading out again. I pulled the new version of the file from GitHub to my phone, made changes, pushed it, repeat, until I emailed the final draft to the editor.
The context switching is now no more.
The distractions that come from writing in word processors is no more.
Editing is infinitely easier, and faster.
My wrists are no longer in pain because I hid my mouse from sight.
It is April 2021.
I am a novelist.
And I write on Vim.
How? I’ll discuss the specific of this workflow in the second part of this column series on how non-tech people are using free and open source technology. Stay tuned.
*Contributed by Theena*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,635 | 在 Podman 中运行一个 Linux 虚拟机 | https://opensource.com/article/21/7/linux-podman | 2021-07-31T11:40:00 | [
"容器",
"Podman"
] | https://linux.cn/article-13635-1.html |
>
> 使用 Podman Machine 创建一个基本的 Fedora CoreOS 虚拟机来使用容器和容器化工作负载。
>
>
>

Fedora CoreOS 是一个自动更新、最小化的基于 [rpm-ostree](http://coreos.github.io/rpm-ostree/) 的操作系统,用于安全地、大规模地运行容器化工作负载。
[Podman](https://github.com/containers/podman) “是一个用于管理容器和镜像、挂载到这些容器中的卷,以及由这些容器组组成的吊舱的工具。Podman 基于 libpod,它是一个容器生命周期管理库”。
当你使用 [Podman Machine](http://docs.podman.io/en/latest/markdown/podman-machine.1.html) 时,神奇的事情发生了,它可以帮助你创建一个基本的 Fedora CoreOS 虚拟机(VM)来使用容器和容器化工作负载。
### 开始使用 Podman Machine
第一步是安装 Podman。如果你已经安装了最新版本的 Podman,你可以跳过这个步骤。在我的 Fedora 34 机器上,我用以下方式安装 Podman:
```
$ sudo dnf install podman
```
我使用的是 podman-3.2.2-1.fc34.x86\_64。
### 初始化 Fedora CoreOS
Podman 安装完成后,用以下方法初始化它:
```
❯ podman machine init vm2
Downloading VM image: fedora-coreos-34.20210626.1.0-qemu.x86_64.qcow2.xz: done
Extracting compressed file
```
这个命令创建了 `vm2`,并下载了 .xz 格式的 Fedora CoreOS 的 qcow2 文件并将其解压。
### 列出你的虚拟机
了解你的虚拟机和它们的状态是很重要的,`list` 命令可以帮助你做到这一点。下面的例子显示了我所有的虚拟机的名称,它们被创建的日期,以及它们最后一次启动的时间:
```
❯ podman machine list
NAME VM TYPE CREATED LAST UP
podman-machine-default* qemu 6 days ago Currently running
vm2 qemu 11 minutes ago 11 minutes ago
```
### 启动一个虚拟机
要启动一个虚拟机,请运行:
```
❯ podman machine start
Waiting for VM ...
```
### SSH 到虚拟机
你可以使用 SSH 来访问你的虚拟机,并使用它来运行工作负载,而没有任何麻烦的设置:
```
❯ podman machine ssh
Connecting to vm podman-machine-default. To close connection, use `~.` or `exit`
Fedora CoreOS 34.20210611.1.0
Tracker: https://github.com/coreos/fedora-coreos-tracker
Discuss: https://discussion.fedoraproject.org/c/server/coreos/
Last login: Wed Jun 23 13:23:36 2021 from 10.0.2.2
[core@localhost ~]$ uname -a
Linux localhost 5.12.9-300.fc34.x86_64 #1 SMP Thu Jun 3 13:51:40 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
[core@localhost ~]$
```
目前,Podman 只支持一次运行一个虚拟机。
### 停止你的虚拟机
要停止运行中的虚拟机,请使用 `stop` 命令:
```
❯ podman machine stop
[core@localhost ~]$ Connection to localhost closed by remote host.
Connection to localhost closed.
Error: exit status 255
```
我希望这能帮助你开始使用 Podman Machine。请试一试,并在评论中告诉我们你的想法。
---
via: <https://opensource.com/article/21/7/linux-podman>
作者:[Sumantro Mukherjee](https://opensource.com/users/sumantro) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora CoreOS is an automatically updating, minimal [rpm-ostree](http://coreos.github.io/rpm-ostree/)-based operating system for running containerized workloads securely and at scale.
[Podman](https://github.com/containers/podman) "is a tool for managing containers and images, volumes mounted into those containers, and pods made from groups of containers. Podman is based on libpod, a library for container lifecycle management."
Magical things happen when you use [Podman Machine](http://docs.podman.io/en/latest/markdown/podman-machine.1.html), a feature that helps you create a basic Fedora CoreOS virtual machine (VM) to use with containers and containerized workloads.
## Getting started with Podman Machine
The first step is to install Podman. If you already have the latest version of Podman installed, you can skip the step. On my Fedora 34 machine, I installed Podman with:
`$ sudo dnf install podman`
I'm using podman-3.2.2-1.fc34.x86_64.
## Initializing a Fedora CoreOS
Once Podman is installed, initialize it with:
```
❯ podman machine init vm2
Downloading VM image: fedora-coreos-34.20210626.1.0-qemu.x86_64.qcow2.xz: done
Extracting compressed file
```
This command creates `vm2`
and downloads Fedora CoreOS's qcow2 file in .xz format and extracts it.
## Listing your VMs
It's always important to know your VMs and their status, and the `list`
command helps with that. The following example shows the names of all my VMs, the date they were created, and the last time they were up:
```
❯ podman machine list
NAME VM TYPE CREATED LAST UP
podman-machine-default* qemu 6 days ago Currently running
vm2 qemu 11 minutes ago 11 minutes ago
```
## Starting a VM
To start a VM, run:
```
❯ podman machine start
Waiting for VM …
```
## SSHing into the VM
You can use secure shell (SSH) to access your VM and use it to run workloads without any setup hassles:
```
❯ podman machine ssh
Connecting to vm podman-machine-default. To close connection, use `~.` or `exit`
Fedora CoreOS 34.20210611.1.0
Tracker: https://github.com/coreos/fedora-coreos-tracker
Discuss: https://discussion.fedoraproject.org/c/server/coreos/
Last login: Wed Jun 23 13:23:36 2021 from 10.0.2.2
[core@localhost ~]$ uname -a
Linux localhost 5.12.9-300.fc34.x86_64 #1 SMP Thu Jun 3 13:51:40 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
[core@localhost ~]$
```
Currently, Podman only supports running one VM at a time.
## Stopping your VM
To stop a running VM, use the `stop`
command:
```
❯ podman machine stop
[core@localhost ~]$ Connection to localhost closed by remote host.
Connection to localhost closed.
Error: exit status 255
```
I hope this helps you get started with Podman Machine. Give it a try, and let us know what you think in the comments.
## Comments are closed. |
13,637 | 如何在 Fedora Linux 上安装 VLC | https://itsfoss.com/install-vlc-fedora/ | 2021-07-31T21:56:00 | [
"VLC"
] | https://linux.cn/article-13637-1.html | 
如果你刚刚安装了 Fedora,现在想在上面安装你最喜欢的视频播放器 VLC,你可能不会在软件中心找到它。至少不会立即找到。
出于只有它的开发者知道的原因,Fedora 既没有安装 [VLC](https://www.videolan.org/),也不包括在 Fedora 官方仓库中。
那么,你如何在 Fedora 上安装 VLC 呢?很简单。RPM Fusion 是你的朋友。让我告诉你详细的步骤。
### 在 Fedora Linux 上安装 VLC
在这里使用命令行会更容易。你也可以使用图形化的方法。我将在后面讨论它。
打开终端,使用下面的命令来添加和启用包含 VLC 包的 RPM Fusion 仓库:
```
sudo dnf install https://mirrors.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
```
当被要求确认添加新仓库时按 `Y`。接下来,使用 DNF 命令安装 VLC:
```
sudo dnf install vlc
```
它将在 Fedora 中从 RPM Fusion 仓库中安装 VLC,并从不同的仓库中安装一些额外的依赖项。

安装后,你可以在应用程序菜单中搜索 VLC,或者在“活动区”中搜索它。

点击、启动并享受它。
#### 替代方法:从软件中心安装 VLC
当你已经启用了 RPM Fusion 仓库,你可以在软件中心显示这个仓库的应用。要做到这一点,在终端使用以下命令:
```
sudo dnf groupupdate core
```
之后,打开软件中心,搜索 VLC 并从那里安装。

如果你有添加 FlatHub 仓库,请避免安装 Flatpak 版本的 VLC,因为它的大小大约是 1GB。RPM 版本的大小要小得多。
我希望你觉得这个快速教程对在 Fedora 上安装 VLC 有帮助。享受吧。
---
via: <https://itsfoss.com/install-vlc-fedora/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you have just installed Fedora and now want to install your favorite video player VLC on it, you probably won’t find it in the software center. Not immediately, at least.
For reasons best known to their developers, Fedora neither ships with [VLC](https://www.videolan.org/?ref=itsfoss.com) nor does it include in the official Fedora repository.
So, how do you install VLC on Fedora, then? Simple. RPM Fusion is your friend here. Let me show you the steps in detail.
## Installing VLC on Fedora Linux
Using the command line will be easier here. You may use the graphical method as well. I’ll discuss it later.
Open a terminal and use the following command to add and enable RPM Fusion repository that contains the VLC package:
`sudo dnf install https://mirrors.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm `
Press Y when asked to confirm adding the new repo. Next, install VLC using DNF command:
`sudo dnf install vlc`
It will install VLC in Fedora from the RPM Fusion repository and a few additional dependencies from various repositories.
Once installed, you can search for VLC in the application menu or search for it in the “activities area”.
Click on it, start it and enjoy it.
### Alternate method: Installing VLC from software center
When you have enabled RPM Fusion repository, you can display the applications from this repo in the software center. To do that, use the following command in the terminal:
`sudo dnf groupupdate core`
After that, open software center and search for VLC and install from there.
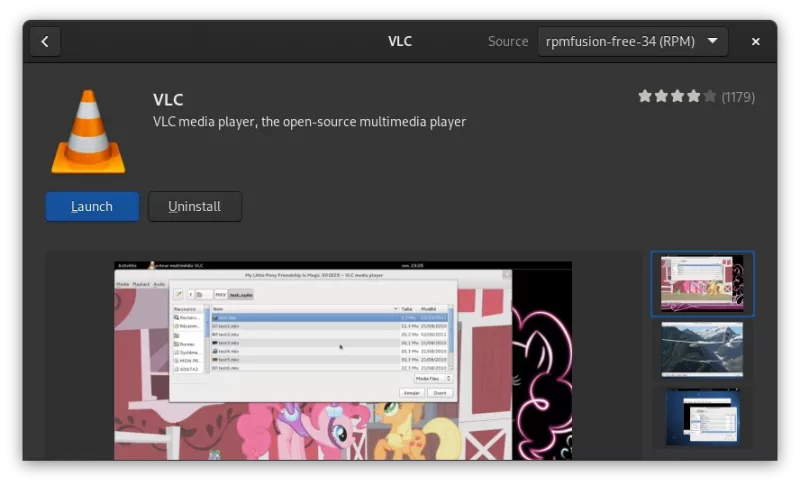
If you have added FlatHub repository, please avoid installing the Flatpak version of VLC because it is around 1 GB in size. The RPM version is a lot smaller in size.
## Do more with VLC
VLC is much more than just being an [excellent video player for Linux](https://itsfoss.com/video-players-linux/). Here are a few interesting [ways to get more out of VLC](https://itsfoss.com/simple-vlc-tips/).
[Make VLC More Awesome With These Simple TipsVLC is one of the best open source video players, if not the best. What most people don’t know about it is that it is a lot more than just a video player. You can do a lot of complex tasks like broadcasting live videos, capturing devices etc. Just](https://itsfoss.com/simple-vlc-tips/)

I hope you find this quick tutorial helpful in installing VLC on Fedora. Enjoy. |
13,638 | 认识 Clapper:一款外观时尚的 Linux 视频播放器,极简主义者适用 | https://itsfoss.com/clapper-video-player/ | 2021-07-31T22:07:00 | [
"视频播放器"
] | https://linux.cn/article-13638-1.html | 喜欢极简主义吗?你会喜欢 Clapper 的。
Clapper 是一个全新 [Linux 视频播放器](https://itsfoss.com/video-players-linux/)。实际上,它更多的是基于 GNOME 而不是 Linux。
它基于 GNOME 的 JavaScript 库和 GTK4 工具包构建,自然地融合在 GNOME 的桌面环境中。它使用 [GStreamer](https://gstreamer.freedesktop.org/) 作为媒体后端,使用 [OpenGL](https://www.opengl.org/) 进行渲染。
我喜欢极简主义的应用。虽然 VLC 是媒体播放器中的瑞士军刀,但我更喜欢 [MPV 播放器](https://itsfoss.com/mpv-video-player/),因为它的界面时尚、简约。现在我想要坚持使用 Clapper 一段时间了。
### Clapper 视频播放器

[Clapper 默认开启硬件加速](https://github.com/Rafostar/clapper/wiki/Hardware-acceleration)。它支持英特尔和 AMD 的 GPU,在 Xorg 和 Wayland 上都能工作。
[Clapper](https://github.com/Rafostar/clapper) 不使用传统的上部窗口栏。为你提供自动隐藏的偏好菜单、模式切换器和窗口控制按钮供等功能。这给了它一个时尚、简约的外观。
它有三种模式:
* 窗口模式:默认模式显示进度条和窗口控制。
* 浮动模式:隐藏进度条,播放器浮于其他应用程序的顶部,就像“[总是在顶部](https://itsfoss.com/always-on-top/)”或“画中画”模式。
* 全屏模式:播放器进入全屏,进度条变大,但它们都会自动隐藏起来

Clapper 也有一个自适应的用户界面,可基于 Linux 的智能手机和平板电脑上使用。因此,如果你有自己的 Pine Phone 或 Librem5,你可以在它上面使用 Clapper。
它支持字幕,并可选择改变字体。然而,在我的测试中,字幕并不可用。也没有可以明确地在播放的视频中添加字幕的选项。这一点必须改进。
和 VLC 一样,如果你再次打开同一个视频文件,Clapper 也可以让你选择从最后一个时间点恢复播放。这是我喜欢的 VLC 中的一个 [方便的功能](https://itsfoss.com/simple-vlc-tips/)。
如果你有 URL,Clapper 也支持从互联网上播放视频。
这里的截图中,我正在 Clapper 中播放一个 YouTube 视频。这是一首由一位美丽的歌手和演员唱的优美歌曲。你能猜到这是哪首歌或哪部电影吗?

### 在 Linux 上安装 Clapper
对 Arch 和 Manjaro 用户而言,Clapper 可在 AUR 中找到。这很稀疏平常,因为 AUR 包罗万象。
对于其他发行版,Clapper 官方提供了 [Flatpak 包](https://flathub.org/apps/details/com.github.rafostar.Clapper)。所以,请 [为你的发行版启用 Flatpak 支持](https://itsfoss.com/flatpak-guide/),然后使用下面的命令来安装它:
```
flatpak install flathub com.github.rafostar.Clapper
```
安装后,只需在应用菜单中搜索它,或右击视频文件,选择用 Clapper 打开它。
Clapper 仍不是一个完美的视频播放器。然而,它有可能成为一个流行的 Linux 应用。
如果你使用它,请分享你的经验。如果你发现问题,请[通知开发者](https://github.com/Rafostar/clapper/issues)。
---
via: <https://itsfoss.com/clapper-video-player/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Love minimalism? You’ll love Clapper.
Clapper is a new [video player for Linux](https://itsfoss.com/video-players-linux/). Actually, it’s more for GNOME than Linux.
Built on top of GNOME’s JavaScript library and GTK4 toolkit, it blends naturally in the GNOME desktop environment. It uses [GStreamer](https://gstreamer.freedesktop.org/) for media backend and [OpenGL](https://www.opengl.org/) for rendering.
I like application with minimalist approach. While VLC is the Swiss Knife of media players, I prefer [MPV player](https://itsfoss.com/mpv-video-player/) for the sleek, minimal interface. And now I think I am going to stick with Clapper for sometime.
## Clapper video player

[Clapper uses hardware acceleration](https://github.com/Rafostar/clapper/wiki/Hardware-acceleration) by default. It supports Intel and AMD GPUs and works on both Xorg and Wayland.
[Clapper](https://github.com/Rafostar/clapper) doesn’t use the traditional upper window bar. There are auto-hiding preference menu, mode changer and window control buttons for you to access a few features. This gives it a sleek, minimalist look.
It has three modes:
- Windowed mode: the default mode shows the progress bar and window control
- Floating mode: the progress bar is hidden and the player is floating on top of other applications like the ‘
[always on top](https://itsfoss.com/always-on-top/)‘ feature or ‘picture in picture’ mode - Fullscreen mode: Player goes full screen, progress bar is bigger but they all auto-hide

Clapper also has an adaptive UI which can also be used on Linux-based smartphones and tablets. So if you have got yourself a Pine Phone or Librem5, you can use Clapper on it.
There is support for subtitles with option to change the font. However, the subtitles didn’t work in my testing. There is also no option to explicitly add subtitles to a playing video. This is something that must be improved.
Like VLC, Clapper also gives you the option to resume playback from the last point if you open the same video file again. One of the [handy features I love in VLC](https://itsfoss.com/simple-vlc-tips/).
Clapper supports playing videos from the internet as well if you provide the URL.
Here, in the screenshot, I am playing a YouTube video in Clapper. It is a beautiful song sung by a beautiful singer and actress. Can you guess which song or movie it is?

## Install Clapper on Linux
Clapper is available in AUR for Arch and Manjaro users. That should not be a surprise for anyone. AUR has everything under the sun.
For other distributions, Clapper officially provides [Flatpak package](https://flathub.org/apps/details/com.github.rafostar.Clapper). So, please [enable Flatpak support for your distribution](https://itsfoss.com/flatpak-guide/) and then use the following command to install it:
`flatpak install flathub com.github.rafostar.Clapper`
Once installed, simply search for it in the application menu or right click on a video file and choose to open it with Clapper.
Clapper is far from being the perfect video player. However, it has potential to become a popular Linux application.
If you use it, please do share your experience. If you find bugs, please [notify the developer](https://github.com/Rafostar/clapper/issues). |
13,640 | Windows 11 让你的硬件过时,使用 Linux 代替吧! | https://news.itsfoss.com/windows-11-linux/ | 2021-08-01T20:48:06 | [
"Windows"
] | https://linux.cn/article-13640-1.html |
>
> 微软希望你为 Windows 11 买新的硬件。你是否应该为 Windows 11 升级你的电脑,或者只是,用 Linux 代替!?
>
>
>

Windows 11 终于来了,我们并不完全对此感到兴奋,它给许多电脑用户带来了困扰。
我甚至不是在讨论隐私方面或者它的设计选择,而是 Windows 11 要求更新的硬件才能工作,这在某种程度上让你的旧电脑变得过时,并迫使你毫无理由地升级新的硬件。
随着 Windows 11 的到来还有什么问题呢,它有什么不好的?
### 只有符合条件的设备才能获得 Windows 11 升级
首先,有意思的是,Windows 11 添加了一个最低系统需求,这表面上看起来还行:
* 1GHz 双核 64 位处理器
* 4GB 内存
* 64GB 存储空间
* 支持 UEFI 安全启动
* 受信任平台模块(TPM)版本 2.0
* DirectX 12 兼容显卡
* 720P 分辨率显示器

你可以在 [微软官方网站](https://www.microsoft.com/en-us/windows/windows-11) 下载“电脑健康状况检查”应用检查你的系统是否符合条件。
过去十年内的大多数电脑能达到这些标准 —— 但有一个陷阱。
硬件需要有一个 TPM 芯片,一些电脑和笔记本可能没有。幸运的是,你可能只需要从 BIOS 设置中启用它(包括安全引导支持),就可以使你的电脑符合条件。这里有一个 [PCGamer](https://www.pcgamer.com/Windows-11-PC-Health-Check/) 的向导可以帮你。
从技术上说,根据微软官方文档,Windows 11 不支持比 **Intel 第 8 代和 Ryzen 3000 系列**更老的处理器([AMD](https://docs.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-supported-amd-processors) | [Intel](https://docs.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-supported-intel-processors))。
可是,有相当数量的电脑不支持,你该怎么做?
很简单,在 Windows 10 不再收到更新之前,[都 2021 年了,换成 Linux 吧](https://news.itsfoss.com/switch-to-linux-in-2021/)。今年,在你的个人电脑上尝试 Linux 变得比任何时候更有意义!
### Windows 11 安装需要网络连接

虽然我们不太清楚,但根据其系统要求规范,Windows 11 安装过程中将要求用户有可连通的互联网连接。
但是,Linux 不需要这样。
这只是其中一个 [使用 Linux 而不是 Windows](https://itsfoss.com/linux-better-than-windows/) 的好处 —— 这是你可以完全掌控的操作系统。
### 没有 32 位支持

Windows 10 确实是支持 32 位系统的,但是 Windows 11 终结了相关支持。
这又是 Linux 的优势了。
尽管对 32 位支持都在逐渐减少,我们依然有一系列 [支持 32 位系统的 Linux 发行版](https://itsfoss.com/32-bit-linux-distributions/)。或许你的 32 位电脑还能与 Linux 一起工作 10 年。
### Windows 10 将在 2025 年结束支持
好吧,鉴于微软最初计划在 Windows 10 之后永远不会有升级,而是在可预见的未来一直支持它,这是个意外。
现在,Windows 10 将会在 2025 年被干掉……
那么,到时候你该怎么做呢?升级你的硬件,只因为它不支持 Windows 11?
除非有这个必要,否则 Linux 是你永远的朋友。
你可以尝试几个 [轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/),它们将使你的任何一台被微软认为过时的电脑重新焕发生机。
### 结语
尽管 Windows 11 计划在未来几年内强迫用户升级他们的硬件,但 Linux 可以让你长时间继续使用你的硬件,并有一些额外的好处。
因此,如果你对 Windows 11 的发布不满意,你可能想开始使用 Linux 代替。不要烦恼,你可以参考我们的指南,来学习开始使用 Linux 的一切知识。
---
via: <https://news.itsfoss.com/windows-11-linux/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zd200572](https://github.com/zd200572) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Windows 11 is finally here. We’re not entirely thrilled by it – but it introduces problems for many computer users.
And I’m not even talking the privacy aspect or its design choice. But it seems that Windows 11 is demanding newer hardware to work, which makes your old computer obsolete in a way and forces you to upgrade your hardware for no good reason.
What else is a problem with the arrival of Windows 11? What’s so bad about it?
## Only Eligible Devices Can Get the Windows 11 Upgrade
To start with, Windows 11 has interestingly added a minimum system requirement which looks good on paper:
- 1 GHz dual-core 64-bit processor
- 4 GB RAM
- 64 GB storage
- UEFI, Secure Boot support
- Trusted Platform Module version 2.0
- DirectX 12 compatible graphics
- 720p resolution display
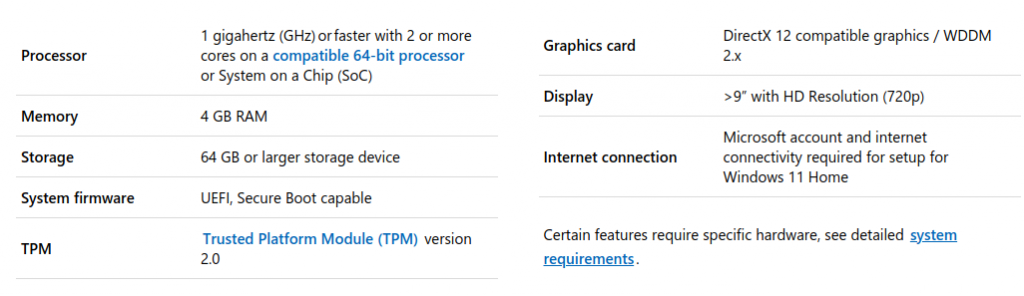
You can check if your system is eligible by downloading the **PC Health Check** app from [Microsoft’s official site](https://www.microsoft.com/en-us/windows/windows-11?ref=news.itsfoss.com).
Most of the computers from the last decade should meet these criteria – but there’s a catch.
The hardware should have a TPM chip, which may not be the case for some PC builds or laptops. Fortunately, it is not all bad, you may just need to enable it from your BIOS settings including the Secure Boot support, to make your PC eligible. There’s a guide on [PCGamer](https://www.pcgamer.com/Windows-11-PC-Health-Check/?ref=news.itsfoss.com) to help you with that.
Technically, processors older than **Intel 8th gen and Ryzen 3000 series** are not officially supported as per Microsoft’s official documentations ([AMD](https://docs.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-supported-amd-processors?ref=news.itsfoss.com) | [Intel](https://docs.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-supported-intel-processors?ref=news.itsfoss.com)).
However, there are a sound number of systems that may not have the support for it. So, what do you do?
Easy, [ switch to Linux in 2021](https://news.itsfoss.com/switch-to-linux-in-2021/) before Windows 10 no longer receives updates. This year, it makes more sense than ever for you to try Linux for your personal computer!
## Windows 11 Installation Requires Internet Connectivity

While we do not have enough clarity about this but as per its system requirement specifications, it will require users to have an active Internet connection for Windows 11 installation.
But, with Linux, you do not need that.
That’s just one of the [benefits of using Linux over Windows](https://itsfoss.com/linux-better-than-windows/?ref=news.itsfoss.com) – you get complete control of your operating system.
## No 32-Bit Support

Windows 10 did support 32-bit systems, but Windows 11 ends that.
This is where Linux shines.
Even though the 32-bit support is dwindling everywhere, we still have a bunch of [ Linux distributions that support 32-bit systems](https://itsfoss.com/32-bit-linux-distributions/?ref=news.itsfoss.com). Your 32-bit system may still live for a decade with Linux.
## Windows 10 Support Ends in 2025
Well, this was unexpected considering Microsoft initially planned to never have an upgrade after Windows 10 but support it for the foreseeable future.
Now, Windows 10 will be killed in 2025…
So, what do you do then? Upgrade your hardware just because it does not support Windows 11?
Unless there’s a necessity, Linux is your friend forever.
You can try several [ lightweight Linux distributions](https://itsfoss.com/lightweight-linux-beginners/?ref=news.itsfoss.com) that will revive any of your computers that Microsoft considers obsolete!
## Wrapping Up
While Windows 11 plans to force users to upgrade their hardware in the next few years, Linux lets you keep your hardware for a long time along with several added benefits.
So, if you are not happy with Windows 11 release, you may want to start using Linux instead. Fret not, you can refer to our guides on our main web portal [It’s FOSS](https://itsfoss.com/?ref=news.itsfoss.com) to learn everything you need to get started using Linux!
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,641 | 在 Fedora 34 及以上版本中安装 Shutter | https://www.debugpoint.com/2021/07/install-shutter-fedora/ | 2021-08-01T21:11:00 | [
"截屏",
"Shutter"
] | /article-13641-1.html | 
>
> 这个快速指南解释了在 Fedora 34 及以上版本中安装 Shutter 所需的步骤。
>
>
>
截图工具有很多替代和选择。但在我个人看来,没有一个能接近 Shutter 的灵活性。不幸的是,由于各种依赖性问题,特别是它的设计方式,多年来,Linux 发行版,如 Ubuntu、Fedora,都面临着将这个应用打包到官方仓库的问题。
主要问题是它仍然基于 GTK2 和 Perl。当大多数应用转移到 GTK3 时,它仍然是 GTK2。这就造成了一个依赖性问题,因为 Debian/Ubuntu、Fedora 删除了某些包的依赖的 GTK2 版本。
在 Fedora 34 及以上版本中安装 [Shutter](https://www.debugpoint.com/tag/shutter) 截图工具需要采用另一种方法。
现在,你只能通过个人包存档(PPA)来安装这个工具。下面是如何在 Fedora 34 及以上版本中安装它。

### 在 Fedora 34 及以上版本中安装 Shutter
在你的 Fedora 中打开一个终端,启用以下 [Shutter 的 copr 仓库](https://copr.fedorainfracloud.org/coprs/geraldosimiao/shutter/)。这个包存档为 Fedora 的 Shutter 提供了一个单独的构建,其中包含了所有未满足的依赖项。
```
sudo dnf copr enable geraldosimiao/shutter
```
完成后,你就可以通过 `dnf` 在 Fedora 34 及以上版本中简单地安装 Shutter。
```
sudo dnf install shutter
```
尽管目前最新的版本是 v0.97。遗憾的是,该仓库目前包含旧的 v0.94.x。我希望版本库的所有者尽快包括最新的版本。
安装后,你可以通过应用菜单启动它。
#### 卸载 Shutter
如果你愿意,你可以通过命令轻松地删除这个第三方仓库:
```
sudo dnf copr remove geraldosimiao/shutter
```
然后按照下面的方法,完全删除 Shutter,包括依赖关系。
```
sudo dnf autoremove shutter
```
#### 在其他 Linux 发行版中安装 Shutter
如果你想在 Debian、Ubuntu 或相关发行版中安装它,请 [查看此指南](https://www.debugpoint.com/2020/04/shutter-install-ubuntu/)。
### Shutter 的开发
最近,这个项目 [转移到了 GitHub](https://github.com/shutter-project/shutter),以便更好地协作,并且正在进行 GTK3 移植。而且它相当活跃,最近还发布了一个版本。我们希望它能尽快被移植到 GTK3 上,并在各发行版的原生仓库中可用。
如果你在安装 Shutter 时遇到任何错误,请在评论栏告诉我。
---
via: <https://www.debugpoint.com/2021/07/install-shutter-fedora/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,643 | ARPANET 协议是如何工作的 | https://twobithistory.org/2021/03/08/arpanet-protocols.html | 2021-08-03T13:02:00 | [
"ARPANET"
] | https://linux.cn/article-13643-1.html | 
ARPANET 通过证明可以使用标准化协议连接完全不同的制造商的计算机,永远改变了计算。在我的 [关于 ARPANET 的历史意义的文章](https://twobithistory.org/2021/02/07/arpanet.html) 中,我提到了其中的一些协议,但没有详细描述它们。所以我想仔细看看它们。也想看看那些早期协议的设计有多少保留到了我们今天使用的协议中。
ARPANET 协议像我们现代的互联网协议,是通过分层形式来组织的。<sup class="footnote-ref"> <a href="#fn1" id="fnref1"> [1] </a></sup> 较高层协议运行在较低层协议之上。如今的 TCP/IP 套件有 5 层(物理层、链路层、网络层、传输层以及应用层),但是这个 ARPANET 仅有 3 层,也可能是 4 层,这取决于你怎样计算它们。
我将会解释每一层是如何工作的,但首先,你需要知道是谁在 ARPANET 中构建了些什么,你需要知道这一点才能理解为什么这些层是这样划分的。
### 一些简短的历史背景
ARPANET 由美国联邦政府资助,确切的说是位于美国国防部的<ruby> 高级研究计划局 <rt> Advanced Research Projects Agency </rt></ruby>(因此被命名为 “ARPANET” )。美国政府并没有直接建设这个网络;而是,把这项工作外包给了位于波士顿的一家名为 “Bolt, Beranek, and Newman” 的咨询公司,通常更多时候被称为 BBN。
而 BBN 则承担了实现这个网络的大部分任务,但不是全部。BBN 所做的是设计和维护一种称为<ruby> 接口消息处理机 <rt> Interface Message Processor </rt></ruby>(简称为 IMP) 的机器。这个 IMP 是一种定制的<ruby> 霍尼韦尔 <rt> Honeywell </rt></ruby><ruby> 小型机 <rt> minicomputer </rt></ruby>,它们被分配给那些想要接入这个 ARPANET 的遍及全国各地的各个站点。它们充当通往 ARPANET 的网关,为每个站点提供多达四台主机的连接支持。它基本上是一台路由器。BBN 控制在 IMP 上运行的软件,把数据包从一个 IMP 转发到另一个 IMP ,但是该公司无法直接控制那些将要连接到 IMP 上并且成为 ARPANET 网络中实际主机的机器。
那些主机由网络中作为终端用户的计算机科学家们所控制。这些计算机科学家在全国各地的主机站负责编写软件,使主机之间能够相互通讯。而 IMP 赋予主机之间互相发送消息的能力,但是那并没有多大用处,除非主机之间能商定一种用于消息的格式。为了解决这个问题,一群杂七杂八的人员组成了网络工作组,其中有大部分是来自各个站点的研究生们,该组力求规定主机计算机使用的协议。
因此,如果你设想通过 ARPANET 进行一次成功的网络互动,(例如发送一封电子邮件),使这些互动成功的一些工程由一组人负责(BBN),然而其他的一些工程则由另一组人负责(网络工作组和在每个站点的工程师们)。这种组织和后勤方面的偶然性或许对推动采用分层的方法来管理 ARPANET 网络中的协议起到很大的作用,这反过来又影响了 TCP/IP 的分层方式。
### 好的,回到协议上来

*ARPANET 协议层次结构*
这些协议层被组织成一个层次结构,在最底部是 “Level 0”。<sup class="footnote-ref"> <a href="#fn2" id="fnref2"> [2] </a></sup> 这在某种意义上是不算数的,因为在 ARPANET 中这层完全由 BBN 控制,所以不需要标准协议。Level 0 的作用是管理数据在 IMP 之间如何传输。在 BBN 内部,有管理 IMP 如何做到这一点的规则;在 BBN 之外,IMP 子网是一个黑匣子,它只会传送你提供的任意数据。因此,Level 0 是一个没有真正协议的层,就公开已知和商定的规则集而言,它的存在可以被运行在 ARPANET 的主机上的软件忽略。粗略地说,它处理相当于当今使用的 TCP/IP 套件的物理层、链路层和网络层下的所有内容,甚至还包括相当多的传输层,这是我将在这篇文章的末尾回来讨论的内容。
“Level 1” 层在 ARPANET 的主机和它们所连接的 IMP 之间建立了接口。如果你愿意,可以认为它是为 BBN 构建的 “Level 0” 层的黑匣子使用的一个应用程序接口(API)。当时它也被称为 IMP-Host 协议。必须编写该协议并公布出来,因为在首次建立 ARPANET 网络时,每个主机站点都必须编写自己的软件来与 IMP 连接。除非 BBN 给他们一些指导,否则他们不会知道如何做到这一点。
BBN 在一份名为 [BBN Report 1822](https://walden-family.com/impcode/BBN1822_Jan1976.pdf) 的冗长文件中规定了 IMP-Host 协议。随着 ARPANET 的发展,该文件多次被修订;我将在这里大致描述 IMP-Host 协议最初设计时的工作方式。根据 BBN 的规则,主机可以将长度不超过 8095 位的消息传递给它们的 IMP,并且每条消息都有一个包含目标主机号和链路识别号的头部字段。<sup class="footnote-ref"> <a href="#fn3" id="fnref3"> [3] </a></sup> IMP 将检查指定的主机号,然后尽职尽责地将消息转发到网络中。当从远端主机接收到消息时,接收的 IMP 在将消息传递给本地主机之前会把目标主机号替换为源主机号。实际上在 IMP 之间传递的内容并不是消息 —— IMP 将消息分解成更小的数据包以便通过网络传输 —— 但该细节对主机来说是不可见的。

*Host-IMP 消息头部格式,截至 1969。 图表来自 [BBN Report 1763](https://walden-family.com/impcode/1969-initial-IMP-design.pdf)*
链路号的取值范围为 0 到 255 ,它有两个作用。一是更高级别的协议可以利用它在网络上的任何两台主机之间建立多个通信信道,因为可以想象得到,在任何时刻都有可能存在多个本地用户与同一个目标主机进行通信的场景(换句话说,链路号允许在主机之间进行多路通信)。二是它也被用在 “Level 1” 层去控制主机之间发送的大量流量,以防止高性能计算机压制低性能计算机的情况出现。按照最初的设计,这个 IMP-Host 协议限制每台主机在某一时刻通过某条链路仅发送一条消息。一旦某台主机沿着某条链路发送了一条消息给远端主机后,在它沿着该链路发送下一条消息之前,必须等待接收一条来自远端的 IMP 的特别类型的消息,叫做 RFNM(<ruby> 请求下一条消息 <rt> Request for Next Message </rt></ruby>)。后来为了提高性能,对该系统进行了修订,允许一台主机在给定的时刻传送多达 8 条消息给另一台主机。<sup class="footnote-ref"> <a href="#fn4" id="fnref4"> [4] </a></sup>
“Level 2” 层才是事情真正开始变得有趣的地方,因为这一层和在它上面的那一层由 BBN 和国防部全部留给学者们和网络工作组自己去研发。“Level 2” 层包括了 Host-Host 协议,这个协议最初在 RFC9 中草拟,并且在 RFC54 中首次正式规定。在 [ARPANET 协议手册](http://mercury.lcs.mit.edu/~jnc/tech/arpaprot.html) 中有更易读的 Host-Host 协议的解释。
“Host-Host 协议” 管理主机之间如何创建和管理连接。“连接”是某个主机上的写套接字和另一个主机上的读套接字之间的一个单向的数据管道。“<ruby> 套接字 <rt> socket </rt></ruby>” 的概念是在 “Level-1” 层的有限的链路设施(记住,链路号只能是那 256 个值中的一个)之上被引入的,是为了给程序提供寻址运行在远端主机上的特定进程的一种方式。“读套接字” 是用偶数表示的,而“写套接字”是用奇数表示的;套接字是 “读” 还是 “写” 被称为套接字的 “性别”。并没有类似于 TCP 协议那样的 “端口号” 机制,连接的打开、维持以及关闭操作是通过主机之间使用 “链路 0” 发送指定格式的 Host-Host 控制消息来实现的,这也是 “链路 0” 被保留的目的。一旦在 “链路 0” 上交换控制消息来建立起一个连接后,就可以使用接收端挑选的另一个链路号来发送进一步的数据消息。
Host-Host 控制消息一般通过 3 个字母的助记符来表示。当两个主机交换一条 STR(<ruby> 发送端到接收端 <rt> sender-to-receiver </rt></ruby>)消息和一条配对的 RTS(<ruby> 接收端到发送端 <rt> receiver-to-sender </rt></ruby>)消息后,就建立起了一条连接 —— 这些控制消息都被称为请求链接消息。链接能够被 CLS(<ruby> 关闭 <rt> close </rt></ruby>)控制消息关闭。还有更多的控制信息能够改变从发送端到接收端发送消息的速率。从而再次需要确保较快的主机不会压制较慢的主机。在 “Level 1” 层上的协议提供了流量控制的功能,但对 “Level 2” 层来说显然是不够的;我怀疑这是因为从远端 IMP 接收到的 RFNM 只能保证远端 IMP 已经传送该消息到目标主机,而不能保证目标主机已经全部处理了该消息。还有 INR(<ruby> 接收端中断 <rt> interrupt-by-receiver </rt></ruby>)、INS(<ruby> 发送端中断 <rt> interrupt-by-sender </rt></ruby>)控制消息,主要供更高级别的协议使用。
更高级别的协议都位于 “Level 3”,这层是 ARPANET 的应用层。Telnet 协议,它提供到另一台主机的一个虚拟电传链接,其可能是这些协议中最重要的。但在这层中也有许多其他协议,例如用于传输文件的 FTP 协议和各种用于发送 Email 的协议实验。
在这一层中有一个不同于其他的协议:<ruby> 初始链接协议 <rt> Initial Connection Protocol </rt></ruby>(ICP)。ICP 被认为是一个 “Level-3” 层协议,但实际上它是一种 “Level-2.5” 层协议,因为其他 “Level-3” 层协议都依赖它。之所以需要 ICP,是因为 “Level 2” 层的 Host-Host 协议提供的链接只是单向的,但大多数的应用需要一个双向(例如:全双工)的连接来做任何有趣的事情。要使得运行在某个主机上的客户端能够连接到另一个主机上的长期运行的服务进程,ICP 定义了两个步骤。第一步是建立一个从服务端到客户端的单向连接,通过使用服务端进程的众所周知的套接字号来实现。第二步服务端通过建立的这个连接发送一个新的套接字套接字号给客户端。到那时,那个存在的连接就会被丢弃,然后会打开另外两个新的连接,它们是基于传输的套接字号建立的“读”连接和基于传输的套接字号加 1 的“写”连接。这个小插曲是大多数事务的一个前提——比如它是建立 Telnet 链接的第一步。
以上是我们逐层攀登了 ARPANET 协议层次结构。你们可能一直期待我在某个时候提一下 “<ruby> 网络控制协议 <rt> Network Control Protocol </rt></ruby>”(NCP) 。在我坐下来为这篇文章和上一篇文章做研究之前,我肯定认为 ARPANET 运行在一个叫 “NCP” 的协议之上。这个缩写有时用来指代整个 ARPANET 协议,这可能就是我为什么有这个想法的原因。举个例子,[RFC801](https://tools.ietf.org/html/rfc801) 讨论了将 ARPANET 从 “NCP” 过渡到 “TCP” 的方式,这使 NCP 听起来像是一个相当于 TCP 的 ARPANET 协议。但是对于 ARPANET 来说,从来都没有一个叫 “网络控制协议” 的东西(即使 [大英百科全书是这样认为的](https://www.britannica.com/topic/ARPANET)),我怀疑人们错误地将 “NCP” 解释为 “<ruby> 网络控制协议 <rt> Network Control Protocol </rt></ruby>” ,而实际上它代表的是 “<ruby> 网络控制程序 <rt> Network Control Program </rt></ruby>” 。网络控制程序是一个运行在各个主机上的内核级别的程序,主要负责处理网络通信,等同于现如今操作系统中的 TCP/IP 协议栈。用在 RFC 801 的 “NCP” 是一种转喻,而不是协议。
### 与 TCP/IP 的比较
ARPANET 协议以后都会被 TCP/IP 协议替换(但 Telnet 和 FTP 协议除外,因为它们很容易就能在 TCP 上适配运行)。然而 ARPANET 协议都基于这么一个假设:就是网络是由一个单一实体(BBN)来构建和管理的。而 TCP/IP 协议套件是为网间网设计的,这是一个网络的网络,在那里一切都是不稳定的和不可靠的。这就导致了我们的现代协议套件和 ARPANET 协议有明显的不同,比如我们现在怎样区分网络层和传输层。在 ARPANET 中部分由 IMP 实现的类似传输层的功能现在完全由在网络边界的主机负责。
我发现 ARPANET 协议最有趣的事情是,现在在 TCP 中的许多传输层的功能是如何在 ARPANET 上经历了一个糟糕的青春期。我不是网络专家,因此我拿出大学时的网络课本(让我们跟着 Kurose 和 Ross 学习一下),他们对传输层通常负责什么给出了一个非常好的概述。总结一下他们的解释,一个传输层协议必须至少做到以下几点。这里的 “<ruby> 段 <rt> segment </rt></ruby>” 基本等同于 ARPANET 上的术语 “<ruby> 消息 <rt> message </rt></ruby>”:
* 提供进程之间的传送服务,而不仅仅是主机之间的(传输层多路复用和多路分解)
* 在每个段的基础上提供完整性检查(即确保传输过程中没有数据损坏)
像 TCP 那样,传输层也能够提供可靠的数据传输,这意味着:
* “段” 是按顺序被传送的
* 不会丢失任何 “段”
* “段” 的传送速度不会太快以至于被接收端丢弃(流量控制)
似乎在 ARPANET 上关于如何进行多路复用和多路分解以便进程可以通信存在一些混淆 —— BBN 在 IMP-Host 层引入了链路号来做到这一点,但结果证明在 Host-Host 层上无论如何套接字号都是必要的。然后链路号只是用于 IMP-Host 级别的流量控制,但 BBN 似乎后来放弃了它,转而支持在唯一的主机对之间进行流量控制,这意味着链路号一开始是一个超载的东西,后来基本上变成了虚设。TCP 现在使用端口号代替,分别对每一个 TCP 连接单独进行流量控制。进程间的多路复用和多路分解完全在 TCP 内部进行,不会像 ARPANET 一样泄露到较低层去。
同样有趣的是,鉴于 Kurose 和 Ross 如何开发 TCP 背后的想法,ARPANET 一开始就采用了 Kurose 和 Ross 所说的一个严谨的 “<ruby> 停止并等待 <rt> stop-and-wait </rt></ruby>” 方法,来实现 IMP-Host 层上的可靠的数据传输。这个 “停止并等待” 方法发送一个 “段” 然后就拒绝再去发送更多 “段” ,直到收到一个最近发送的 “段” 的确认为止。这是一种简单的方法,但这意味着只有一个 “段” 在整个网络中运行,从而导致协议非常缓慢 —— 这就是为什么 Kurose 和 Ross 将 “停止并等待” 仅仅作为在通往功能齐全的传输层协议的路上的垫脚石的原因。曾有一段时间 “停止并等待” 是 ARPANET 上的工作方式,因为在 IMP–Host 层,必须接收到<ruby> 请求下一条消息 <rt> Request for Next Message </rt></ruby>(RFNM)以响应每条发出的消息,然后才能发送任何进一步的消息。客观的说 ,BBN 起初认为这对于提供主机之间的流量控制是必要的,因此减速是故意的。正如我已经提到的,为了更好的性能,RFNM 的要求后来放宽松了,而且 IMP 也开始向消息中添加序列号和保持对传输中的消息的 “窗口” 的跟踪,这或多或少与如今 TCP 的实现如出一辙。<sup class="footnote-ref"> <a href="#fn5" id="fnref5"> [5] </a></sup>
因此,ARPANET 表明,如果你能让每个人都遵守一些基本规则,异构计算系统之间的通信是可能的。正如我先前所说的,这是 ARPANET 的最重要的遗产。但是,我希望对这些基线规则的仔细研究揭示了 ARPANET 协议对我们今天使用的协议有多大影响。在主机和 IMP 之间分担传输层职责的方式上肯定有很多笨拙之处,有时候是冗余的。现在回想起来真的很可笑,主机之间一开始只能通过给出的任意链路在某刻只发送一条消息。但是 ARPANET 实验是一个独特的机会,可以通过实际构建和操作网络来学习这些经验,当到了是时候升级到我们今天所知的互联网时,似乎这些经验变得很有用。
*如果你喜欢这篇贴子,更喜欢每四周发布一次的方式!那么在 Twitter 上关注 [@TwoBitHistory](https://twitter.com/TwoBitHistory) 或者订阅 [RSS 提要](https://twobithistory.org/feed.xml),以确保你知道新帖子的发布时间。*
---
1. 协议分层是网络工作组发明的。这个论点是在 [RFC 871](https://tools.ietf.org/html/rfc871) 中提出的。分层也是 BBN 如何在主机和 IMP 之间划分职责的自然延伸,因此 BBN 也值得称赞。 [↩︎](#fnref1)
2. “level” 是被网络工作组使用的术语。 详见 [RFC 100](https://www.rfc-editor.org/info/rfc100) [↩︎](#fnref2)
3. 在 IMP-Host 协议的后续版本中,扩展了头部字段,并且将链路号升级为消息 ID。但是 Host-Host 协议仅仅继续使用消息 ID 字段的高位 8 位,并将其视为链路号。请参阅 [ARPANET 协议手册](http://mercury.lcs.mit.edu/~jnc/tech/arpaprot.html) 的 “Host-Host” 协议部分。 [↩︎](#fnref3)
4. John M. McQuillan 和 David C. Walden。 “ARPA 网络设计决策”,第 284页,<https://www.walden-family.com/public/whole-paper.pdf>。 2021 年 3 月 8 日查看。 [↩︎](#fnref4)
5. 同上。 [↩︎](#fnref5)
---
via: <https://twobithistory.org/2021/03/08/arpanet-protocols.html>
作者:[Two-Bit History](https://twobithistory.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Lin-vy](https://github.com/Lin-vy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The ARPANET changed computing forever by proving that computers of wildly
different manufacture could be connected using standardized protocols. In my
[post on the historical significance of the ARPANET](/2021/02/07/arpanet.html), I mentioned a few of those protocols, but didn’t
describe them in any detail. So I wanted to take a closer look at them. I also
wanted to see how much of the design of those early protocols survives in the
protocols we use today.
The ARPANET protocols were, like our modern internet protocols, organized into
layers. 1 The protocols in the higher layers ran on top of the protocols in
the lower layers. Today the TCP/IP suite has five layers (the Physical,
Link, Network, Transport, and Application layers), but the ARPANET had only
three layers—or possibly four, depending on how you count them.
I’m going to explain how each of these layers worked, but first an aside about who built what in the ARPANET, which you need to know to understand why the layers were divided up as they were.
## Some Quick Historical Context
The ARPANET was funded by the US federal government, specifically the Advanced Research Projects Agency within the Department of Defense (hence the name “ARPANET”). The US government did not directly build the network; instead, it contracted the work out to a Boston-based consulting firm called Bolt, Beranek, and Newman, more commonly known as BBN.
BBN, in turn, handled many of the responsibilities for implementing the network but not all of them. What BBN did was design and maintain a machine known as the Interface Message Processor, or IMP. The IMP was a customized Honeywell minicomputer, one of which was delivered to each site across the country that was to be connected to the ARPANET. The IMP served as a gateway to the ARPANET for up to four hosts at each host site. It was basically a router. BBN controlled the software running on the IMPs that forwarded packets from IMP to IMP, but the firm had no direct control over the machines that would connect to the IMPs and become the actual hosts on the ARPANET.
The host machines were controlled by the computer scientists that were the end users of the network. These computer scientists, at host sites across the country, were responsible for writing the software that would allow the hosts to talk to each other. The IMPs gave hosts the ability to send messages to each other, but that was not much use unless the hosts agreed on a format to use for the messages. To solve that problem, a motley crew consisting in large part of graduate students from the various host sites formed themselves into the Network Working Group, which sought to specify protocols for the host computers to use.
So if you imagine a single successful network interaction over the ARPANET, (sending an email, say), some bits of engineering that made the interaction successful were the responsibility of one set of people (BBN), while other bits of engineering were the responsibility of another set of people (the Network Working Group and the engineers at each host site). That organizational and logistical happenstance probably played a big role in motivating the layered approach used for protocols on the ARPANET, which in turn influenced the layered approach used for TCP/IP.
## Okay, Back to the Protocols
*The ARPANET protocol hierarchy.*
The protocol layers were organized into a hierarchy. At the very bottom was
“level 0.” 2 This is the layer that in some sense doesn’t count, because on
the ARPANET this layer was controlled entirely by BBN, so there was no need
for a standard protocol. Level 0 governed how data passed between
the IMPs. Inside of BBN, there were rules governing how IMPs did this; outside
of BBN, the IMP sub-network was a black box that just passed on any data
that you gave it. So level 0 was a layer without a real protocol, in the sense
of a publicly known and agreed-upon set of rules, and its existence could be
ignored by software running on the ARPANET hosts. Loosely speaking, it handled
everything that falls under the Physical, Link, and Internet layers of the
TCP/IP suite today, and even quite a lot of the Transport layer, which is
something I’ll come back to at the end of this post.
The “level 1” layer established the interface between the ARPANET hosts and the IMPs they were connected to. It was an API, if you like, for the black box level 0 that BBN had built. It was also referred to at the time as the IMP-Host Protocol. This protocol had to be written and published because, when the ARPANET was first being set up, each host site had to write its own software to interface with the IMP. They wouldn’t have known how to do that unless BBN gave them some guidance.
The IMP-Host Protocol was specified by BBN in a lengthy document called [BBN
Report 1822](https://walden-family.com/impcode/BBN1822_Jan1976.pdf). The
document was revised many times as the ARPANET evolved; what I’m going to
describe here is roughly the way the IMP-Host protocol worked as it was
initially designed. According to BBN’s rules, hosts could pass *messages* to
their IMPs no longer than 8095 bits, and each message had a *leader* that
included the destination host number and something called a *link number*. 3
The IMP would examine the designation host number and then dutifully forward
the message into the network. When messages were received from a remote host,
the receiving IMP would replace the destination host number with the source
host number before passing it on to the local host. Messages were not actually
what passed between the IMPs themselves—the IMPs broke the messages down into
smaller
*packets*for transfer over the network—but that detail was hidden from the hosts.
*The Host-IMP message leader format, as of 1969. Diagram from BBN Report
1763.*
The link number, which could be any number from 0 to 255, served two purposes.
It was used by higher level protocols to establish more than one channel of
communication between any two hosts on the network, since it was conceivable
that there might be more than one local user talking to the same destination
host at any given time. (In other words, the link numbers allowed communication
to be multiplexed between hosts.) But it was also used at the level 1 layer to
control the amount of traffic that could be sent between hosts, which was
necessary to prevent faster computers from overwhelming slower ones. As
initially designed, the IMP-Host Protocol limited each host to sending just one
message at a time over each link. Once a given host had sent a message along a
link to a remote host, it would have to wait to receive a special kind of
message called an RFNM (Request for Next Message) from the remote IMP
before sending the next message along the same link. Later revisions to this
system, made to improve performance, allowed a host to have up to eight
messages in transit to another host at a given time.[4](#fn:4)
The “level 2” layer is where things really start to get interesting, because it
was this layer and the one above it that BBN and the Department of Defense left
entirely to the academics and the Network Working Group to invent for
themselves. The level 2 layer comprised the Host-Host Protocol, which was first
sketched in RFC 9 and first officially specified by RFC 54. A more readable
explanation of the Host-Host Protocol is given in the [ARPANET Protocol
Handbook](http://mercury.lcs.mit.edu/~jnc/tech/arpaprot.html).
The Host-Host Protocol governed how hosts created and managed *connections*
with each other. A connection was a one-way data pipeline between a *write
socket* on one host and a *read socket* on another host. The “socket” concept
was introduced on top of the limited level-1 link facility (remember that the
link number can only be one of 256 values) to give programs a way of addressing
a particular process running on a remote host. Read sockets were even-numbered
while write sockets were odd-numbered; whether a socket was a read socket or a
write socket was referred to as the socket’s gender. There were no “port
numbers” like in TCP. Connections could be opened, manipulated, and closed by
specially formatted Host-Host control messages sent between hosts using link 0,
which was reserved for that purpose. Once control messages were exchanged over
link 0 to establish a connection, further data messages could then be sent
using another link number picked by the receiver.
Host-Host control messages were identified by a three-letter mnemonic. A connection was established when two hosts exchanged a STR (sender-to-receiver) message and a matching RTS (receiver-to-sender) message—these control messages were both known as Request for Connection messages. Connections could be closed by the CLS (close) control message. There were further control messages that changed the rate at which data messages were sent from sender to receiver, which were needed to ensure again that faster hosts did not overwhelm slower hosts. The flow control already provided by the level 1 protocol was apparently not sufficient at level 2; I suspect this was because receiving an RFNM from a remote IMP was only a guarantee that the remote IMP had passed the message on to the destination host, not that the host had fully processed the message. There was also an INR (interrupt-by-receiver) control message and an INS (interrupt-by-sender) control message that were primarily for use by higher-level protocols.
The higher-level protocols all lived in “level 3”, which was the Application layer of the ARPANET. The Telnet protocol, which provided a virtual teletype connection to another host, was perhaps the most important of these protocols, but there were many others in this level too, such as FTP for transferring files and various experiments with protocols for sending email.
One protocol in this level was not like the others: the Initial Connection Protocol (ICP). ICP was considered to be a level-3 protocol, but really it was a kind of level-2.5 protocol, since other level-3 protocols depended on it. ICP was needed because the connections provided by the Host-Host Protocol at level 2 were only one-way, but most applications required a two-way (i.e. full-duplex) connection to do anything interesting. ICP specified a two-step process whereby a client running on one host could connect to a long-running server process on another host. The first step involved establishing a one-way connection from the server to the client using the server process’ well-known socket number. The server would then send a new socket number to the client over the established connection. At that point, the existing connection would be discarded and two new connections would be opened, a read connection based on the transmitted socket number and a write connection based on the transmitted socket number plus one. This little dance was a necessary prelude to most things—it was the first step in establishing a Telnet connection, for example.
That finishes our ascent of the ARPANET protocol hierarchy. You may have been
expecting me to mention a “Network Control Protocol” at some point. Before I
sat down to do research for this post and my last one, I definitely thought
that the ARPANET ran on a protocol called NCP. The acronym is occasionally used
to refer to the ARPANET protocols as a whole, which might be why I had that
idea. [RFC 801](https://tools.ietf.org/html/rfc801), for example, talks about
transitioning the ARPANET from “NCP” to “TCP” in a way that makes it sound like
NCP is an ARPANET protocol equivalent to TCP. But there has never been a
“Network Control Protocol” for the ARPANET (even if [Encyclopedia Britannica
thinks so](https://www.britannica.com/topic/ARPANET)), and I suspect people
have mistakenly unpacked “NCP” as “Network Control Protocol” when really it
stands for “Network Control Program.” The Network Control Program was the
kernel-level program running in each host responsible for handling network
communication, equivalent to the TCP/IP stack in an operating system today.
“NCP”, as it’s used in RFC 801, is a metonym, not a protocol.
## A Comparison with TCP/IP
The ARPANET protocols were all later supplanted by the TCP/IP protocols (with
the exception of Telnet and FTP, which were easily adapted to run on top of
TCP). Whereas the ARPANET protocols were all based on the assumption that the
network was built and administered by a single entity (BBN), the TCP/IP
protocol suite was designed for an *inter*-net, a network of networks where
everything would be more fluid and unreliable. That led to some of the more
immediately obvious differences between our modern protocol suite and the
ARPANET protocols, such as how we now distinguish between a Network layer and a
Transport layer. The Transport layer-like functionality that in the ARPANET was
partly implemented by the IMPs is now the sole responsibility of the hosts at
the network edge.
What I find most interesting about the ARPANET protocols though is how so much
of the transport-layer functionality now in TCP went through a janky
adolescence on the ARPANET. I’m not a networking expert, so I pulled out my
college networks textbook (Kurose and Ross, let’s go), and they give a pretty
great outline of what a transport layer is responsible for in general. To
summarize their explanation, a transport layer protocol must minimally do the
following things. Here *segment* is basically equivalent to *message* as the
term was used on the ARPANET:
- Provide a delivery service between
*processes*and not just host machines (transport layer multiplexing and demultiplexing) - Provide integrity checking on a per-segment basis (i.e. make sure there is no data corruption in transit)
A transport layer could also, like TCP does, provide *reliable data transfer*,
which means:
- Segments are delivered in order
- No segments go missing
- Segments aren’t delivered so fast that they get dropped by the receiver (flow control)
It seems like there was some confusion on the ARPANET about how to do multiplexing and demultiplexing so that processes could communicate—BBN introduced the link number to do that at the IMP-Host level, but it turned out that socket numbers were necessary at the Host-Host level on top of that anyway. Then the link number was just used for flow control at the IMP-Host level, but BBN seems to have later abandoned that in favor of doing flow control between unique pairs of hosts, meaning that the link number started out as this overloaded thing only to basically became vestigial. TCP now uses port numbers instead, doing flow control over each TCP connection separately. The process-process multiplexing and demultiplexing lives entirely inside TCP and does not leak into a lower layer like on the ARPANET.
It’s also interesting to see, in light of how Kurose and Ross develop the ideas
behind TCP, that the ARPANET started out with what Kurose and Ross would call a
strict “stop-and-wait” approach to reliable data transfer at the IMP-Host
level. The “stop-and-wait” approach is to transmit a segment and then refuse to
transmit any more segments until an acknowledgment for the most recently
transmitted segment has been received. It’s a simple approach, but it means
that only one segment is ever in flight across the network, making for a very
slow protocol—which is why Kurose and Ross present “stop-and-wait” as merely a
stepping stone on the way to a fully featured transport layer protocol. On the
ARPANET, “stop-and-wait” was how things worked for a while, since, at the
IMP-Host level, a Request for Next Message had to be received in response to
every outgoing message before any further messages could be sent. To be fair to
BBN, they at first thought this would be necessary to provide flow control
between hosts, so the slowdown was intentional. As I’ve already mentioned, the
RFNM requirement was later relaxed for the sake of better performance, and the
IMPs started attaching sequence numbers to messages and keeping track of a
“window” of messages in flight in the more or less the same way that TCP
implementations do today.[5](#fn:5)
So the ARPANET showed that communication between heterogeneous computing systems is possible if you get everyone to agree on some baseline rules. That is, as I’ve previously argued, the ARPANET’s most important legacy. But what I hope this closer look at those baseline rules has revealed is just how much the ARPANET protocols also influenced the protocols we use today. There was certainly a lot of awkwardness in the way that transport-layer responsibilities were shared between the hosts and the IMPs, sometimes redundantly. And it’s really almost funny in retrospect that hosts could at first only send each other a single message at a time over any given link. But the ARPANET experiment was a unique opportunity to learn those lessons by actually building and operating a network, and it seems those lessons were put to good use when it came time to upgrade to the internet as we know it today.
*
If you enjoyed this post, more like it come out every four weeks! Follow
@TwoBitHistory
on Twitter or subscribe to the
RSS feed
to make sure you know when a new post is out.
*
*Previously on TwoBitHistory…*
Trying to get back on this horse!
— TwoBitHistory (@TwoBitHistory)
My latest post is my take (surprising and clever, of course) on why the ARPANET was such an important breakthrough, with a fun focus on the conference where the ARPANET was shown off for the first time:[https://t.co/8SRY39c3St][February 7, 2021]
-
The protocol layering thing was invented by the Network Working Group. This argument is made in
[RFC 871](https://tools.ietf.org/html/rfc871). The layering thing was also a natural extension of how BBN divided responsibilities between hosts and IMPs, so BBN deserves some credit too.[↩](#fnref:1) -
The “level” terminology was used by the Network Working Group. See e.g.
[RFC 100](https://www.rfc-editor.org/info/rfc100).[↩](#fnref:2) -
In later revisions of the IMP-Host protocol, the leader was expanded and the link number was upgraded to a
*message ID*. But the Host-Host protocol continued to make use of only the high-order eight bits of the message ID field, treating it as a link number. See the “Host-to-Host” protocol section of the[ARPANET Protocol Handbook](http://mercury.lcs.mit.edu/~jnc/tech/arpaprot.html).[↩](#fnref:3) -
John M. McQuillan and David C. Walden. “The ARPA Network Design Decisions,” p. 284,
[https://www.walden-family.com/public/whole-paper.pdf](https://www.walden-family.com/public/whole-paper.pdf). Accessed 8 March 2021.[↩](#fnref:4) -
Ibid.
[↩](#fnref:5) |
13,644 | 如何在 Linux 上使用 cron 定时器 | https://opensource.com/article/21/7/cron-linux | 2021-08-03T13:28:29 | [
"cron",
"crontab"
] | https://linux.cn/article-13644-1.html |
>
> cron 定时器是一个可以按照计划自动运行命令的工具。
>
>
>

cron 定时器是一个可以按照计划自动运行命令的工具。定时器作业称为 cronjob,创建于 `crontab` 文件中。这是用户自动操作电脑的最简单也是最古老的方法。
### 创建一个 cronjob
要创建一个 cronjob,你可以使用 `crontab` 命令,并添加 `-e` 选项:
```
$ crontab -e
```
这将使用默认的文本编辑器打开 `crontab`。如需指定文本编辑器,请使用 `EDITOR` [环境变量](https://opensource.com/sites/default/files/styles/image-full-size/public/cron-splash.png?itok=AoBigzts "Cron expression"):
```
$ EDITOR=nano crontab -e
```
### Cron 语法
如需调度一个 cronjob,你需要提供给计算机你想要执行的命令,然后提供一个 cron 表达式。cron 表达式在命令调度时运行:
* 分钟(0 到 59)
* 小时(0 到 23, 0 代表午夜执行)
* 日期(1 到 31)
* 月份(1 到 12)
* 星期(0 到 6, 星期天是 0)
星号 (`*`) 代表的是“每一个”。例如,下面的表达式在每月每日每小时的 0 分钟运行备份脚本:
```
/opt/backup.sh 0 * * * *
```
下面的表达式在周日的凌晨 3:30 运行备份脚本:
```
/opt/backup.sh 30 3 * * 0
```
### 简写语法
现代的 cron 支持简化的宏,而不是 cron 表达式:
* `@hourly` 在每天的每小时的 0 分运行
* `@daily` 在每天的 0 时 0 分运行
* `@weekly` 在周日的 0 时 0 分运行
* `@monthly` 在每月的第一天的 0 时 0 分运行
例如,下面的 `crontab` 命令在每天的 0 时运行备份脚本:
```
/opt/backup.sh @daily
```
### 如何停止一个 cronjob
一旦你开始了一个 cronjob,它就会永远按照计划运行。想要在启动后停止 cronjob,你必须编辑 `crontab`,删除触发该作业的命令行,然后保存文件。
```
$ EDITOR=nano crontab -e
```
如需停止一个正在运行的作业,可以 [使用标准的 Linux 进程命令](https://opensource.com/article/18/5/how-kill-process-stop-program-linux) 来停止一个正在运行的进程。
### 它是自动的
一旦你编写完 `crontab`,保存了文件并且退出了编辑器。你的 cronjob 就已经被调度了,剩下的工作都交给 cron 完成。
---
via: <https://opensource.com/article/21/7/cron-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [The cron system is a method to automatically run commands on a schedule. A scheduled job is called a ]*cronjob*, and it’s created in a file called a *crontab*. It’s the easiest and oldest way for a computer user to automate their computer.
Writing a cronjob
To create a cronjob, you edit your `crontab`
using the `-e`
option:
`$ crontab -e `
This opens your crontab your default text editor. To set the text editor explicitly, use the `EDITOR`
[environment variable](https://opensource.com/article/19/8/what-are-environment-variables):
`$ EDITOR=nano crontab -e `
Cron syntax
To schedule a cronjob, you provide a cron expression followed by the command you want your computer to execute. The cron expression schedules when the command gets run:
-
minute (0 to 59)
-
hour (0 to 23, with 0 being midnight)
-
day of month (1 to 31)
-
month (1 to 12)
-
day of week (0 to 6, with Sunday being 0)
An asterisk (`*`
) in a field translates to "every." For example, this expression runs a backup script at the 0th minute of *every* hour on *every* day of *every* month:
`0 * * * * /opt/backup.sh`
This expression runs a backup script at 3:30 AM on Sunday:
`30 3 * * 0 /opt/backup.sh`
Simplified syntax
Modern cron implementations accept simplified macros instead of a cron expression:
-
`@hourly`
runs at the 0th minute of every hour of every day -
`@daily`
runs at the 0th minute of the 0th hour of every day -
`@weekly`
runs at the 0th minute of the 0th hour on Sunday -
`@monthly`
runs at the 0th minute of the 0th hour on the first day of the month
For example, this crontab line runs a backup script every day at midnight:
`/opt/backup.sh @daily`
## How to stop a cronjob
Once you've started a cronjob, it's designed to run on schedule forever. To stop a cronjob once you've started it, you must edit your crontab, remove the line that triggers the job, and then save the file.
`$ EDITOR=nano crontab -e `
To stop a job that's actively running, [use standard Linux process commands](https://opensource.com/article/18/5/how-kill-process-stop-program-linux) to stop a running process.
It’s automated
Once you’ve written your crontab, save the file and exit your editor. Your cronjob has been scheduled, so cron does the rest.
## 4 Comments |
13,646 | 使用 df 命令查看 Linux 上的可用磁盘空间 | https://opensource.com/article/21/7/check-disk-space-linux-df | 2021-08-04T11:07:51 | [
"df",
"磁盘"
] | https://linux.cn/article-13646-1.html |
>
> 利用 df 命令查看 Linux 磁盘还剩多少空间。
>
>
>

磁盘空间已经不像计算机早期那样珍贵,但无论你有多少磁盘空间,总有耗尽的可能。计算机需要一些磁盘空间才能启动运行,所以为了确保你没有在无意间用尽了所有的硬盘空间,偶尔检查一下是非常必要的。在 Linux 终端,你可以用 `df` 命令来做这件事。
`df` 命令可以显示文件系统中可用的磁盘空间。
要想使输出结果易于阅读,你可以加上 `--human-readable`(或其简写 `-h`)选项:
```
$ df --human-readable
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 1.0T 525G 500G 52% /
```
在这个例子中,计算机的磁盘已经用了 52%,还有 500 GB 可用空间。
由于 Linux 从整体上看待所有挂载设备的文件系统,`df` 命令会展示出连接到计算机上的每个存储设备的详细信息。如果你有很多磁盘,那么输出结果将会反映出来:
```
$ df --human-readable
Filesystem Size Used Avail Use% Mounted on
/dev/root 110G 45G 61G 43% /
devtmpfs 12G 0 12G 0% /dev
tmpfs 12G 848K 12G 1% /run
/dev/sda1 1.6T 1.3T 191G 87% /home
/dev/sdb1 917G 184G 687G 22% /penguin
/dev/sdc1 57G 50G 4.5G 92% /sneaker
/dev/sdd1 3.7T 2.4T 1.3T 65% /tux
```
在这个例子中,计算机的 `/home` 目录已经用了 87%,剩下 191 GB 的可用空间。
### 查看总的可用磁盘空间
如果你的文件系统确实很复杂,而你希望看到所有磁盘的总空间,可以使用 `--total` 选项:
```
$ df --human-readable --total
Filesystem Size Used Avail Use% Mounted on
/dev/root 110G 45G 61G 43% /
devtmpfs 12G 0 12G 0% /dev
tmpfs 12G 848K 12G 1% /run
/dev/sda1 1.6T 1.3T 191G 87% /home
/dev/sdb1 917G 184G 687G 22% /penguin
/dev/sdc1 57G 50G 4.5G 92% /sneaker
/dev/sdd1 3.7T 2.4T 1.3T 65% /tux
total 6.6T 4.0T 2.5T 62% -
```
输出的最后一行展示了文件系统的总空间、已用总空间、可用总空间。
### 查看磁盘空间使用情况
如果你想大概了解哪些文件占用了磁盘空间,请阅读我们关于 [du 命令](https://opensource.com/article/21/7/check-used-disk-space-linux-du) 的文章。
---
via: <https://opensource.com/article/21/7/check-disk-space-linux-df>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[piaoshi](https://github.com/piaoshi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Drive space isn't quite as precious as it was in the early days of computing, but no matter how much space you have, there's always the potential to run out. Computers need a little space just to operate, so it's important to check occasionally to ensure you haven't inadvertently used up literally *all* the space available on your drive. In the Linux terminal, you can do that with the `df`
command.
The df command displays the amount of disk space available on the file system.
To make the output easy for you to read, you can use the `--human-readable`
(or `-h`
for short) option:
```
$ df --human-readable
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 1.0T 525G 500G 52% /
```
In this example, the computer's drive is 52% full, with 500 GB free for use.
Because Linux views its file system holistically across all mounted devices, the df command provides you details for every storage device attached to your computer. If you have lots of drives, then the output reflects that:
```
$ df --human-readable
Filesystem Size Used Avail Use% Mounted on
/dev/root 110G 45G 61G 43% /
devtmpfs 12G 0 12G 0% /dev
tmpfs 12G 848K 12G 1% /run
/dev/sda1 1.6T 1.3T 191G 87% /home
/dev/sdb1 917G 184G 687G 22% /penguin
/dev/sdc1 57G 50G 4.5G 92% /sneaker
/dev/sdd1 3.7T 2.4T 1.3T 65% /tux
```
In this example, the `/home`
directory of the computer is 87% full, with 191 GB free.
## See total disk space available
If you do have a complex file system and would like to see the total space across all drives, use the `--total`
option:
```
$ df --human-readable --total
Filesystem Size Used Avail Use% Mounted on
/dev/root 110G 45G 61G 43% /
devtmpfs 12G 0 12G 0% /dev
tmpfs 12G 848K 12G 1% /run
/dev/sda1 1.6T 1.3T 191G 87% /home
/dev/sdb1 917G 184G 687G 22% /penguin
/dev/sdc1 57G 50G 4.5G 92% /sneaker
/dev/sdd1 3.7T 2.4T 1.3T 65% /tux
total 6.6T 4.0T 2.5T 62% -
```
The final line of output provides the total space of the filesystem, total space used, total space available.
## See disk space usage
To just get a summary of what's occupying the space on your drives, read our article about the [du command](https://opensource.com/article/21/7/check-used-disk-space-linux-du).
## Comments are closed. |
13,647 | 提前尝鲜,从 Debian 10 升级到 Debian 11 | https://www.debugpoint.com/2021/07/upgrade-debian-11-from-debian-10/ | 2021-08-04T11:44:34 | [
"Debian",
"升级"
] | /article-13647-1.html |
>
> 本指南解释了从 Debian 10 升级到 Debian 11 的步骤。
>
>
>

[Debian](https://www.debian.org/) 的大版本发布是很罕见的,因为它往往需要社区的多年努力。这就是为什么 Debian 是真正的通用操作系统,并且在稳定性方面坚如磐石。
代号 Bullseye 的 [Debian 11](https://www.debugpoint.com/2021/05/debian-11-features/) 即将正式发布。2021 年 7 月 15 日,Debian 11 进入完全冻结状态,这意味着发行在即。虽然官方发布日期还没有最终确定,但你现在就可以从 Debian 10 安装或升级到 Debian 11。
以下是方法。
### 前提条件
* 升级的过程非常简单明了。然而,采取某些预防措施是一个好的做法。特别是如果你正在升级一台服务器。
* 对你的系统进行备份,包括所有重要的数据和文件。
* 尝试禁用/删除你可能在一段时间内添加的任何外部仓库(PPA)。你可以在升级后逐一启用它们。
* 关闭所有正在运行的应用。
* 停止任何你可能已经启用的运行中的服务。升级完成后,你可以通过 [systemctl](https://www.debugpoint.com/2020/12/systemd-systemctl-service/) 启动它们。这包括 Web 服务器、SSH 服务器、FTP 服务器或任何其他服务器。
* 确保你有稳定的互联网连接。
* 并为你的系统留出足够的停机时间。因为根据你的系统配置,Debian 版本升级需要时间大约在 1.5 小时到 2 小时之间。
### 将 Debian 10 Buster 升级到 11 Bullseye
确保你的系统是最新的,而且你的软件包列表是最新的。
```
sudo apt update && sudo apt upgrade
```
使用下面的命令安装 `gcc-8-base` 包。这是必须的,因为在历史上曾出现过升级失败的情况,这是因为下面的软件包中包含了某些依赖。
```
sudo apt install gcc-8-base
```

打开 `/etc/apt/sources.list`,通过注释 Debian 10 buster 包,而使用 bullseye 仓库进行更新。
注释所有的 buster 仓库,在行的开头加上 `#`。

在文件的末尾添加以下几行。
```
deb http://deb.debian.org/debian bullseye main contrib non-free
deb http://deb.debian.org/debian bullseye-updates main contrib non-free
deb http://security.debian.org/debian-security bullseye-security main
deb http://ftp.debian.org/debian bullseye-backports main contrib non-free
```

按 `Ctrl + O` 保存文件,按 `Ctrl + X` 退出 `nano`。
更新一次系统仓库列表,以验证仓库的添加情况。
```
sudo apt update
```
如果上面的命令没有出现任何错误,那么你已经成功地添加了 bullseye 仓库。
现在,通过运行下面的命令开始升级过程。基本安装的下载大小约为 1.2GB。这可能会根据你的系统配置而有所不同。
```
sudo apt full-upgrade
```

这个命令需要时间。但不要让系统无人看管。因为升级过程中需要各种输入。


完成后,你可以用以下命令重启系统。
```
systemctl reboot
```
重启后,运行以下命令,以确保你的系统是最新的,并且清理了所有不再需要的不必要的软件包。
```
sudo apt --purge autoremove
```
如果一切顺利,你应该看到了 Debian 11 bullseye。你可以用下面的命令来验证版本:
```
cat /etc/os-release
```

### 结束语
我希望这个指南能帮助你将你的系统升级到 Debian 11 bullseye。如果你遇到任何问题,请在下面的评论栏告诉我。
---
via: <https://www.debugpoint.com/2021/07/upgrade-debian-11-from-debian-10/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,649 | 使用 Python 读写文件 | https://opensource.com/article/21/7/read-write-files-python | 2021-08-05T09:47:25 | [
"Python",
"读写"
] | https://linux.cn/article-13649-1.html |
>
> 每种编程语言处理文件数据的方式不尽相同,Python 是这么干的。
>
>
>

有些数据是临时的,它们在应用程序运行时存储在内存中,然后丢弃。但是有些数据是持久的。它们存储在硬盘驱动器上供以后使用,而且它们通常是用户最关心的东西。对于程序员来说,编写代码读写文件是很常见的,但每种语言处理该任务的方式都不同。本文演示了如何使用 Python 处理文件数据。
### 安装 Python
在 Linux 上,你可能已经安装了 Python。如果没有,你可以通过发行版软件仓库安装它。例如,在 CentOS 或 RHEL 上:
```
$ sudo dnf install python3
```
在 macOS 上,你可以使用 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac) 安装。在 Windows 上,你可以使用 [Chocolatey](https://opensource.com/article/20/3/chocolatey) 安装。
一旦安装了 Python,打开你最喜欢的文本编辑器,准备好写代码吧。
### 使用 Python 向文件中写入数据
如果你需要向一个文件中写入数据,记住有三个步骤:
1. 打开
2. 写入
3. 关闭
这与你在计算机上编码、编辑照片或执行其他操作时使用的步骤完全相同。首先,打开要编辑的文档,然后进行编辑,最后关闭文档。
在 Python 中,过程是这样的:
```
f = open('example.txt', 'w')
f.write('hello world')
f.close()
```
这个例子中,第一行以**写**模式打开了一个文件,然后用变量 `f` 表示,我使用了 `f` 是因为它在 Python 代码中很常见,使用其他任意有效变量名也能正常工作。
在打开文件时,有不同的模式:
* `w` 代表写入
* `r+` 代表可读可写
* `a` 表示追加
第二行表示向文件中写入数据,本例写入的是纯文本,但你可以写入任意类型的数据。
最后一行关闭了文件。
#### 使用 `with` 语法写入数据
对于快速的文件交互,常用有一种简短的方法可以写入数据。它不会使文件保持打开状态,所以你不必记得调用 `close()` 函数。相反,它使用 `with` 语法:
```
with open('example.txt', 'a') as f:
f.write('hello open source')
```
### 使用 Python 读取数据
如果你或你的用户需要通过应用程序需要向文件中写入一些数据,然后你需要使用它们,那么你就需要读取文件了。与写入类似,逻辑一样:
1. 打开
2. 读取
3. 关闭
同样的,这个逻辑反映了你一开始使用计算机就已知的内容。阅读文档,你可以打开、阅读,然后关闭。在计算机术语中,“打开”文件意味着将其加载到内存中。
实际上,一个文本文件内容肯定不止一行。例如,你需要读取一个配置文件、游戏存档或乐队下一首歌曲的歌词,正如你打开一本实体书时,你不可能立刻读完整本书,代码也只能解析已经加载到内存中的文件。因此,你可能需要遍历文件的内容。
```
f = open('example.tmp', 'r')
for line in f:
print(line)
f.close()
```
示例的第一行指明使用 **读** 模式打开一个文件,然后文件交由变量 `f` 表示,但就像你写数据一样,变量名是任意的。`f` 并没有什么特殊的,它只是单词 “file” 的最简表示,所以 Python 程序员会经常使用它。
在第二行,我们使用了 `line`,另一个任意变量名,用来表示 `f` 的每一行。这告诉 Python 逐行迭代文件的内容,并将每一行的内容打印到输出中(在本例中为终端或 [IDLE](https://opensource.com/article/17/10/python-101#idle))。
#### 使用 `with` 语法读取数据
就像写入一样,使用 `with` 语法是一种更简短的方法读取数据。即不需要调用 `close()` 方法,方便地快速交互。
```
with open('example.txt', 'r') as f:
for line in f:
print(line)
```
### 文件和 Python
使用 Python 有很多方法向文件写入数据,包括用 [JSON、YAML、TOML](https://opensource.com/article/21/6/parse-configuration-files-python) 等不同的格式写入。还有一个非常好的内置方法用于创建和维护 [SQLite](https://opensource.com/article/21/2/sqlite3-cheat-sheet) 数据库,以及许多库来处理不同的文件格式,包括 [图像](https://opensource.com/article/19/3/python-image-manipulation-tools)、音频和视频等。
---
via: <https://opensource.com/article/21/7/read-write-files-python>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some data is meant to be temporary, stored in RAM while an application is running, and then forgotten. Some data, however, is meant to be persistent. It's stored on a hard drive for later use, and it's often the stuff that a user cares about the most. For programmers, it's very common to write code to read and write files, but every language handles this task a little differently. This article demonstrates how to handle data files with Python.
## Install Python
On Linux, you probably already have Python installed. If not, you can install it from your distribution's software repository. For instance, on CentOS Stream or RHEL:
`$ sudo dnf install python3`
On macOS, you can install Python from [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac). On Windows, you can install Python from [Chocolatey](https://opensource.com/article/20/3/chocolatey).
Once you have Python installed, open your favorite text editor and get ready to code.
## Writing data to a file with Python
If you need to write data to a file, there are three steps to remember:
- Open
- Write
- Close
This is exactly the same sequence of steps you use when writing code, editing photos, or doing almost anything on a computer. First, you open the document you want to edit, then you make some edits, and then you close the document.
In Python, that translates to this process:
```
f = open('example.txt', 'w')
f.write('hello world')
f.close()
```
In this example, the first line opens a file in **write** mode. The file is represented as the variable `f`
, which is an arbitrary choice. I use `f`
because it seems to be common in Python code, but any valid variable name works just as well.
There are different modes in which you can open a file:
**w**to write**r+**to read and write**a**to append only
The second line of the example writes data to the file. The data written in this example is plain text, but you can write any kind of data.
The final line closes the file.
## Writing data using the 'with' syntax
There's a shorter way to write data into a file, and this method can be useful for quick file interactions. It doesn't leave the file open, so you don't have to remember to call the **close()** function. Instead, it uses the **with** syntax:
```
with open('example.txt', 'a') as f:
f.write('hello open source')
```
## Reading data in from a file with Python
If you (or your user, by way of your application) have placed data into a file, and your code needs to retrieve it, then you want to read a file. Similar to writing, the logic is:
- Open
- Read
- Close
Again, this logic flow mirrors what you already know from just using a computer (or a paperback book, for that matter). To read a document, you open it, read it, and then close it. In computer terms, "opening" a file means to load it into memory.
In practice, a text file contains more than one line. For example, maybe your code needs to read a configuration file, saved game data, or the lyrics to your band's next song. Just as you don't read an entire physical book the very moment you open it, your code must parse a file it has loaded into memory. So, you probably need to iterate over the file's contents.
```
f = open('example.tmp', 'r')
for line in f:
print(line)
f.close()
```
In the first line of this example code, you open a file in **read** mode. The file is represented by the variable `f`
, but just like when you open files for writing, the variable name is arbitrary. There's nothing special about `f`
; it's just the shortest possible way to represent the word "file," so it tends to be used a lot by Python programmers.
In the second line, you reserve `line`
, which is yet another arbitrary variable name, to represent each line of `f`
. This tells Python to iterate, line by line, over the file's contents and print each line to your output (in this case, the terminal or [IDLE](https://opensource.com/article/17/10/python-101#idle)).
## Reading a file using the 'with' syntax
As with writing data, there's a shorter method of reading data from files using the **with** syntax. This doesn't require you to call the **call()** function, so it can be convenient for quick interactions.
```
with open('example.txt', 'r') as f:
for line in f:
print(line)
```
## Files and Python
There are more ways to write data to files using Python, and many ways to format text you write to files using [JSON, YAML, TOML](https://opensource.com/article/21/6/parse-configuration-files-python), and more. There's also a very nice built-in method for creating and maintaining an [SQLite](https://opensource.com/article/21/2/sqlite3-cheat-sheet) database and many libraries to handle any number of file formats, including [graphics](https://opensource.com/article/19/3/python-image-manipulation-tools), audio, video, and more.
## 2 Comments |
13,650 | 使用 Linux 安全工具进行渗透测试 | https://opensource.com/article/21/5/linux-security-tools | 2021-08-05T11:11:00 | [
"安全",
"Kali"
] | /article-13650-1.html |
>
> 使用 Kali Linux 和其他开源工具来发现系统中的安全漏洞和弱点。
>
>
>

众多被广泛报道的大型消费企业入侵事件凸显了系统安全管理的重要性。幸运的是,有许多不同的应用程序可以帮助保护计算机系统。其中一个是 [Kali](https://www.kali.org/),一个为安全和渗透测试而开发的 Linux 发行版。本文演示了如何使用 Kali Linux 来审视你的系统以发现弱点。
Kali 安装了很多工具,它们都是开源的,默认情况下安装了它们会让事情变得更容易。
(LCTT 译注:Kali 及其携带工具只应该用于对自己拥有合法审查权利的系统和设备,任何未经授权的扫描、渗透和攻击均是违法的。本文作者、译者均不承担任何非授权使用的结果。)

本文使用的系统是:
1. `kali.usersts.redhat.com`:这是我将用来启动扫描和攻击的系统。它拥有 30GB 内存和 6 个虚拟 CPU(vCPU)。
2. `vulnerable.usersys.redhat.com`: 这是一个 Red Hat 企业版 Linux 8 系统,它会成为目标。它拥有 16GB 内存和 6 个 vCPU。它是一个相对较新的系统,但有些软件包可能已经过时。
3. 这个系统包括 `httpd-2.4.37-30.module+el8.3.0+7001+0766b9e7.x86_64`、 `mariadb-server-10.3.27-3.module+el8.3.0+8972+5e3224e9.x86_64`、 `tigervnc-server-1.9.0-15.el8_1.x86_64`、 `vsftpd-3.0.3-32.el8.x86_64` 和一个 5.6.1 版本的 WordPress。
我在上面列出了硬件规格,因为一些任务要求很高,尤其是在运行 WordPress 安全扫描程序([WPScan](https://wpscan.com/wordpress-security-scanner))时对目标系统 CPU 的要求。
### 探测你的系统
首先,我会在目标系统上进行基本的 Nmap 扫描(你可以阅读 [使用 Nmap 结果帮助加固 Linux 系统](https://www.redhat.com/sysadmin/using-nmap-harden-systems) 一文来更深入地了解 Nmap)。Nmap 扫描是一种快速的方法,可以大致了解被测系统中哪些端口和服务是暴露的。

默认扫描显示有几个你可能感兴趣的开放端口。实际上,任何开放端口都可能成为攻击者破坏你网络的一种方式。在本例中,端口 21、22、80 和 443 是不错的扫描对象,因为它们是常用服务的端口。在这个早期阶段,我只是在做侦察工作,尽可能多地获取有关目标系统的信息。
我想用 Nmap 侦察 80 端口,所以我使用 `-p 80` 参数来查看端口 80,`-A` 参数来获取操作系统和应用程序版本等信息。

关键信息有:
```
PORT STATE SERVICE VERSION
80/tcp open http Apache httpd 2.4.37 ((Red Hat Enterprise Linux))
|_http-generator: WordPress 5.6.1
```
现在我知道了这是一个 WordPress 服务器,我可以使用 WPScan 来获取有关潜在威胁的信息。一个很好的侦察方法是尝试找到一些用户名,使用 `--enumerate u` 告诉 WPScan 在 WordPress 实例中查找用户名。例如:
```
┌──(root?kali)-[~]
└─# wpscan --url vulnerable.usersys.redhat.com --enumerate u
_______________________________________________________________
__ _______ _____
\ \ / / __ \ / ____|
\ \ /\ / /| |__) | (___ ___ __ _ _ __ ®
\ \/ \/ / | ___/ \___ \ / __|/ _` | '_ \
\ /\ / | | ____) | (__| (_| | | | |
\/ \/ |_| |_____/ \___|\__,_|_| |_|
WordPress Security Scanner by the WPScan Team
Version 3.8.10
Sponsored by Automattic - https://automattic.com/
@_WPScan_, @ethicalhack3r, @erwan_lr, @firefart
_______________________________________________________________
[+] URL: http://vulnerable.usersys.redhat.com/ [10.19.47.242]
[+] Started: Tue Feb 16 21:38:49 2021
Interesting Finding(s):
...
[i] User(s) Identified:
[+] admin
| Found By: Author Posts - Display Name (Passive Detection)
| Confirmed By:
| Author Id Brute Forcing - Author Pattern (Aggressive Detection)
| Login Error Messages (Aggressive Detection)
[+] pgervase
| Found By: Author Posts - Display Name (Passive Detection)
| Confirmed By:
| Author Id Brute Forcing - Author Pattern (Aggressive Detection)
| Login Error Messages (Aggressive Detection)
```
这显示有两个用户:`admin` 和 `pgervase`。我将尝试使用密码字典来猜测 `admin` 的密码。密码字典是一个包含很多密码的文本文件。我使用的字典大小有 37G,有 3,543,076,137 行。
就像你可以选择不同的文本编辑器、Web 浏览器和其他应用程序 一样,也有很多工具可以启动密码攻击。下面是两个使用 Nmap 和 WPScan 的示例命令:
```
# nmap -sV --script http-wordpress-brute --script-args userdb=users.txt,passdb=/path/to/passworddb,threads=6 vulnerable.usersys.redhat.com
```
```
# wpscan --url vulnerable.usersys.redhat.com --passwords /path/to/passworddb --usernames admin --max-threads 50 | tee nmap.txt
```
这个 Nmap 脚本是我使用的许多脚本之一,使用 WPScan 扫描 URL 只是这个工具可以完成的许多任务之一。你可以用你喜欢的那一个。
WPScan 示例在文件末尾显示了密码:
```
┌──(root?kali)-[~]
└─# wpscan --url vulnerable.usersys.redhat.com --passwords passwords.txt --usernames admin
_______________________________________________________________
__ _______ _____
\ \ / / __ \ / ____|
\ \ /\ / /| |__) | (___ ___ __ _ _ __ ®
\ \/ \/ / | ___/ \___ \ / __|/ _` | '_ \
\ /\ / | | ____) | (__| (_| | | | |
\/ \/ |_| |_____/ \___|\__,_|_| |_|
WordPress Security Scanner by the WPScan Team
Version 3.8.10
Sponsored by Automattic - https://automattic.com/
@_WPScan_, @ethicalhack3r, @erwan_lr, @firefart
_______________________________________________________________
[+] URL: http://vulnerable.usersys.redhat.com/ [10.19.47.242]
[+] Started: Thu Feb 18 20:32:13 2021
Interesting Finding(s):
......
[+] Performing password attack on Wp Login against 1 user/s
Trying admin / redhat Time: 00:01:57 <==================================================================================================================> (3231 / 3231) 100.00% Time: 00:01:57
Trying admin / redhat Time: 00:01:57 <========================================================= > (3231 / 6462) 50.00% ETA: ??:??:??
[SUCCESS] - admin / redhat
[!] Valid Combinations Found:
| Username: admin, Password: redhat
[!] No WPVulnDB API Token given, as a result vulnerability data has not been output.
[!] You can get a free API token with 50 daily requests by registering at https://wpscan.com/register
[+] Finished: Thu Feb 18 20:34:15 2021
[+] Requests Done: 3255
[+] Cached Requests: 34
[+] Data Sent: 1.066 MB
[+] Data Received: 24.513 MB
[+] Memory used: 264.023 MB
[+] Elapsed time: 00:02:02
```
在末尾的“找到有效组合”部分包含了管理员用户名和密码,3231 行只用了两分钟。
我还有另一个字典文件,其中包含 3,238,659,984 行,使用它花费的时间更长并且会留下更多的证据。
使用 Nmap 可以更快地产生结果:
```
┌──(root?kali)-[~]
└─# nmap -sV --script http-wordpress-brute --script-args userdb=users.txt,passdb=password.txt,threads=6 vulnerable.usersys.redhat.com
Starting Nmap 7.91 ( https://nmap.org ) at 2021-02-18 20:48 EST
Nmap scan report for vulnerable.usersys.redhat.com (10.19.47.242)
Host is up (0.00015s latency).
Not shown: 995 closed ports
PORT STATE SERVICE VERSION
21/tcp open ftp vsftpd 3.0.3
22/tcp open ssh OpenSSH 8.0 (protocol 2.0)
80/tcp open http Apache httpd 2.4.37 ((Red Hat Enterprise Linux))
|_http-server-header: Apache/2.4.37 (Red Hat Enterprise Linux)
| http-wordpress-brute:
| Accounts:
| admin:redhat - Valid credentials <<<<<<<
| pgervase:redhat - Valid credentials <<<<<<<
|_ Statistics: Performed 6 guesses in 1 seconds, average tps: 6.0
111/tcp open rpcbind 2-4 (RPC #100000)
| rpcinfo:
| program version port/proto service
| 100000 2,3,4 111/tcp rpcbind
| 100000 2,3,4 111/udp rpcbind
| 100000 3,4 111/tcp6 rpcbind
|_ 100000 3,4 111/udp6 rpcbind
3306/tcp open mysql MySQL 5.5.5-10.3.27-MariaDB
MAC Address: 52:54:00:8C:A1:C0 (QEMU virtual NIC)
Service Info: OS: Unix
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 7.68 seconds
```
然而,运行这样的扫描可能会在目标系统上留下大量的 HTTPD 日志消息:
```
10.19.47.170 - - [18/Feb/2021:20:14:01 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
```
为了获得关于在最初的 Nmap 扫描中发现的 HTTPS 服务器的信息,我使用了 `sslscan` 命令:
```
┌──(root?kali)-[~]
└─# sslscan vulnerable.usersys.redhat.com
Version: 2.0.6-static
OpenSSL 1.1.1i-dev xx XXX xxxx
Connected to 10.19.47.242
Testing SSL server vulnerable.usersys.redhat.com on port 443 using SNI name vulnerable.usersys.redhat.com
SSL/TLS Protocols:
SSLv2 disabled
SSLv3 disabled
TLSv1.0 disabled
TLSv1.1 disabled
TLSv1.2 enabled
TLSv1.3 enabled
<snip>
```
它显示了有关启用的 SSL 协议的信息,在最下方,是关于 Heartbleed 漏洞的信息:
```
Heartbleed:
TLSv1.3 not vulnerable to heartbleed
TLSv1.2 not vulnerable to heartbleed
```
### 防御或减轻攻击的技巧
有很多方法可以保护你的系统免受大量攻击。几个关键点是:
* \*\*了解你的系统:\*\*包括了解哪些端口是开放的,哪些端口应该开放,谁应该能够看到这些开放的端口,以及使用这些端口服务的预期流量是多少。Nmap 是了解网络系统的一个绝佳工具。
* **使用当前的最佳实践:** 现在的最佳实践可能不是未来的最佳实践。作为管理员,了解信息安全领域的最新趋势非常重要。
* **知道如何使用你的产品:** 例如,与其让攻击者不断攻击你的 WordPress 系统,不如阻止他们的 IP 地址并限制尝试登录的次数。在现实世界中,阻止 IP 地址可能没有那么有用,因为攻击者可能会使用受感染的系统来发起攻击。但是,这是一个很容易启用的设置,可以阻止一些攻击。
* **维护和验证良好的备份:** 如果攻击者攻击了一个或多个系统,能从已知的良好和干净的备份中重新构建可以节省大量时间和金钱。
* **检查日志:** 如上所示,扫描和渗透命令可能会留下大量日志,这表明攻击者正在攻击系统。如果你注意到它们,可以采取先发制人的行动来降低风险。
* **更新系统、应用程序和任何额外的模块:** 正如 [NIST Special Publication 800-40r3](https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-40r3.pdf) 所解释的那样,“补丁通常是减轻软件缺陷漏洞最有效的方法,而且通常是唯一完全有效的解决方案。”
* **使用供应商提供的工具:** 供应商有不同的工具来帮助你维护他们的系统,因此一定要充分利用它们。例如,红帽企业 Linux 订阅中包含的 [Red Hat Insights](https://www.redhat.com/sysadmin/how-red-hat-insights) 可以帮助你优化系统并提醒你注意潜在的安全威胁。
### 了解更多
本文对安全工具及其使用方法的介绍只是冰山一角。深入了解的话,你可能需要查看以下资源:
* [Armitage](https://en.wikipedia.org/wiki/Armitage_(computing)),一个开源的攻击管理工具
* [Red Hat 产品安全中心](https://access.redhat.com/security)
* [Red Hat 安全频道](https://www.redhat.com/en/blog/channel/security)
* [NIST 网络安全页面](https://www.nist.gov/cybersecurity)
* [使用 Nmap 结果来帮助加固 Linux 系统](https://www.redhat.com/sysadmin/using-nmap-harden-systems)
---
via: <https://opensource.com/article/21/5/linux-security-tools>
作者:[Peter Gervase](https://opensource.com/users/pgervase) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,653 | Windows 11 的外观受到了 KDE Plasma 和 GNOME 的启发吗? | https://www.debugpoint.com/2021/06/windows-11-inspiration-linux-kde-plasma/ | 2021-08-06T10:33:00 | [
"Linux",
"Windows"
] | /article-13653-1.html |
>
> 截图显示,微软即将发布的 Windows 11 操作系统与我们所心爱的 KDE Plasma 和 GNOME 有许多相似之处。它们到底有多相似呢?我们试着比较了一下。
>
>
>

我曾记得一句俗话 —— “<ruby> 优秀者模仿,伟大者剽窃 <rp> ( </rp> <rt> Good artists copy. Great artists steal </rt> <rp> ) </rp></ruby>”。我不认识 Windows 11 背后的设计团队,但他们似乎很大程度上受到了 Linux 桌面的影响。如果你回顾近几年来的 Windows 系统外观 —— 从 Windows XP 到 7,再到 10 —— 整体视觉上都没有什么太大的变化,直到今天为止。
Windows 操作系统的新版本通常有 5 到 7 年的生命周期。如果你试着回想 Windows 提供给你的个性化选项,你会发现这些选项近几年来基本都是一致的,甚至包括开始菜单位置、宽度、颜色在内的桌面整体的体验,一切都没变过。
但随着 Windows 11 的全新外观,这一点终于改变了。让我带你看一些我之前所见过的截图,并且分析一下,它们到底和流行的 Linux [桌面环境](https://www.debugpoint.com/category/desktop-environment)(如 KDE Plasma 和 GNOME)有多相似。
### Windows 11 的外观受到了 KDE Plasma 和 GNOME 的启发?
#### 开始菜单和任务栏
传统的开始菜单和任务栏主题在 Windows 11 上有所变化。开始菜单和任务栏图标位于任务栏中央(默认视图)。Windows 也在设置中提供了将任务栏图标和开始菜单移回左侧的选项。

整体的布局方式和默认图标的色彩让我想起了 KDE Plasma 的任务栏和启动器。这些图标很精致,并且居中,给你带来一种类似 GNOME 上 Adwaita 图标的观感,而任务栏就更像是 KDE Plasma 的任务栏。
当你打开开始菜单后,它为你提供不同的图标和选项的排列方式。此外,当你开始打字时,顶部的搜索选项就会弹出。
现在,来看看全新设计的 KDE Plasma 启动器。我知道间距、图标大小和清晰度并不完全一致,但你可以看到,两者看起来有多么惊人的相似。

如果你正在使用 GNOME 或 Xfce 桌面,借助 [Arc Menu](https://gitlab.com/LinxGem33/Arc-Menu) 和一些小修改,你可以让两者看上去完全一致。

#### 窗口装饰
按照传统,GNOME 总是用圆角作为标准的窗口装饰。作为对照,Windows 则一直采用直角作为窗口装饰 —— 似乎一直都这样,直到现在为止。嗯,在 Windows 11 中,所有窗口装饰都是圆角,看起来很好。圆角的概念不是什么版权专利或者新想法,这就有一个问题了,为什么现在全都在用圆角?是有什么隐藏的目的吗?

哦,还记得 GNOME 的应用程序菜单的小指示器吗?这些小点提示着这里到底有多少页的应用程序。Windows 11 似乎也使用了这种这种思路。

#### 调色盘
Windows 多年来始终有基于“蓝色”或其他蓝色变体的主题。虽然用户可以自行更改任务栏、开始菜单背景、窗口标题栏颜色,但借助这个选项,调色板与亮暗模式结合,展示出巨大变化,给 Windows 桌面带来了更圆滑、迷人的外观。也许这个灵感源自 Ubuntu、KDE 或者其它风格的调色板。
#### 暗黑模式
Windows 11 首次官方支持了暗黑模式,或者说是暗色主题。那么,我就直接在下面放两张截图,由大家自己评判。左侧是 Windows 11 暗黑模式下的开始菜单,右侧是使用了 Breeze Dark 主题的 KDE Plasma。

#### 全新桌面小组件
灵感的启发从来不会停止。还记得 KDE Plasma 的小组件吗?其实,这也不是什么新概念,然而小组件已经出现在 Windows 11。这是全新小组件面板的截图。你可以添加、移除或者重新排序这些小组件。

这些只是吸引我眼球的冰山一角。也许 Windows 11 还有许多“灵感”来“启发”它的外观。
但问题来了 —— 为什么现在是一次推出这些功能和外观的最佳时机?
### 结束语
实话实说,当我第一次看到 Windows 11 的新外观时,我脑袋里就浮现出 Breeze Dark 主题的 KDE Plasma。借助很少量的修改,你可以让 KDE Plasma 看上去像 Windows 11。这本身就说明了它们两者是有多么地相似。
如果你看向整个桌面操作系统的市场,竞争者只有 Windows、Linux 桌面和 macOS。至今为止,它们的外观都有明显的标志性特征,例如 macOS 有自己独一无二的外观。直到现在,Windows 也有一样的蓝色主题的常规开始菜单,等等。但借助这些新变化,Windows 为用户提供了更丰富的定制选项,让它看上去更像 Linux 桌面。
在我个人看来,Windows 团队需要一种不同的标志性特征,而不是一直从我们心爱的 Linux 桌面获得“启发”。
我不知道未来会发生什么,但现在看来,“E-E-E” 还在竭尽全力运作。(LCTT 译注:“E-E-E”是微软臭名昭著的<ruby> 拥抱、扩展再消灭 <rt> Embrace, extend, and extinguish </rt></ruby>策略。)
再会。
---
via: <https://www.debugpoint.com/2021/06/windows-11-inspiration-linux-kde-plasma/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,655 | 如何在 elementary OS 中改变锁定和登录屏幕的壁纸 | https://www.debugpoint.com/2021/07/change-lock-login-screen-background-elementary-os/ | 2021-08-06T19:30:39 | [
"背景"
] | /article-13655-1.html |
>
> 本教程解释了在 elementary OS 中改变锁定和登录屏幕背景的步骤。这将取代默认的灰色背景。
>
>
>
在 elementary OS 中改变锁屏或登录屏背景的灰色默认壁纸是有点困难的。典型的用图像文件的路径改变 `greeter` 的配置是行不通的。
不幸的是,这不是一个更简单的解决方案,因为灰色背景是一个图像文件,它的数据是硬编码在 `greeter` 中的,需要用新的图像重新编译才能使其发挥作用。
下面是方法:

### 改变 elementary OS 锁定和登录屏幕背景
在 elementary OS 中打开一个终端。
为 [greeter 包](https://github.com/elementary/greeter)安装 git 和以下依赖项:
```
sudo apt install git
```
```
sudo apt install -y gnome-settings-daemon libaccountsservice-dev libgdk-pixbuf2.0-dev libgranite-dev libgtk-3-dev libhandy-1-dev liblightdm-gobject-1-dev libmutter-6-dev libwingpanel-dev libx11-dev meson valac
```
进入临时的 `/tmp` 目录,从 GitHub 克隆最新的 greeter 主分支:
```
cd /tmp
git clone https://github.com/elementary/greeter.git
```
克隆完成后,在文件管理器中打开路径 `/tmp/greeter/data`。
elementary OS 使用一个 100×100px 的 PNG 文件作为登录屏幕/锁屏的默认背景。该图像是平铺的,给人一种灰色背景的感觉。
用 `texture.png` 重命名你想要的墙纸图像,并在路径中覆盖以下文件:

```
/tmp/greeter/data/texture.png
```
在文本编辑器中打开文件 `/tmp/greeter/compositor/SystemBackground.vala`,并替换下面一行:

```
resource:///io/elementary/desktop/gala/texture.png
```
为:
```
resource:///io/elementary/greeter/texture.png
```
保存该文件。
再次打开终端,使用以下命令构建 `greeter`。
```
cd /tmp/greeter
meson _build --prefix=/usr
sudo ninja install -C _build
```

如果你遇到任何构建错误,请在下面的评论中告诉我。你应该不会看到任何错误,因为我已经测试过了。
上面的命令完成后,你可以在测试模式下运行 `lightdm` 来测试登录屏:
```
lightdm --test-mode --debug
```
如果看起来不错,重新启动系统。而你应该在 elementary OS 的登录屏上看到你的墙纸。
这个指南应该可在 [elementary OS 6 Odin](https://www.debugpoint.com/tag/elementary-os-6)、elementary OS 5 Juno 及以下版本中可用。
### 结束语
我希望本指南能帮助你在 elementary OS 中改变锁屏或登录屏的背景。老实说,在 2021 年改变登录屏的背景图像需要编译代码,这让我很吃惊。
如果你遇到错误,请在下面的评论栏里告诉我。
---
via: <https://www.debugpoint.com/2021/07/change-lock-login-screen-background-elementary-os/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,656 | 使用 du 检查 Linux 上已用的磁盘空间 | https://opensource.com/article/21/7/check-disk-space-linux-du | 2021-08-06T20:07:39 | [
"du",
"df",
"磁盘"
] | https://linux.cn/article-13656-1.html |
>
> 用 Linux 的 du 命令了解你正在使用多少磁盘空间。
>
>
>

无论你有多少存储空间,它总有可能被填满。在大多数个人设备上,磁盘被照片、视频和音乐填满,但在服务器上,由于用户账户和日志文件数据,空间减少是很正常的。无论你是负责管理一个多用户系统,还是只负责自己的笔记本电脑,你都可以用 `du` 命令检查磁盘的使用情况。
默认情况下,`du` 列出了当前目录中使用的磁盘空间,以及每个子目录的大小。
```
$ du
12 ./.backups
60 .
```
在这个例子中,当前目录总共占用了 60KB,其中 12KB 被子目录 `.backups` 占用。
如果你觉得这很混乱,并希望分别看到所有的大小,你可以使用 `--separate-dirs`(或简写 `-S`)选项:
```
$ du --separate-dirs
12 ./.backups
48 .
```
显示相同的信息(48KB 加 12KB 是 60KB),但每个目录被独立处理。
如需看到更多的细节,可以使用 `--all`(简写 `-a`)选项,它显示每个目录中以及每个文件:
```
$ du --separate-dirs --all
4 ./example.adoc
28 ./graphic.png
4 ./.backups/example.adoc~
12 ./.backups
4 ./index.html
4 ./index.adoc
48 .
```
### 查看文件的修改时间
当查看文件以找出占用空间的内容时,查看文件最后一次被修改的时间是很有用的。一年内没有使用过的文件可以考虑归档,特别是当你的空间快用完时。
通过 `du` 查看文件的修改时间,使用 `--time` 选项:
```
$ du --separate-dirs --all --time
28 2021-07-21 11:12 ./graphic.png
4 2021-07-03 10:43 ./example.adoc
4 2021-07-13 13:03 ./index.html
4 2021-07-23 14:18 ./index.adoc
48 2021-07-23 14:19 .
```
### 为文件大小设置一个阈值
当为了磁盘空间而查看文件时,你可能只关心较大的文件。你可以通过 `--threshold`(简写 `-t`)选项为文件大小设置一个阈值。例如,只查看大于 1GB 的文件:
```
$ \du --separate-dirs --all --time --threshold=1G ~/Footage/
1839008 2021-07-14 13:55 /home/tux/Footage/snowfall.mp4
1577980 2020-04-11 13:10 /home/tux/Footage/waterfall.mp4
8588936 2021-07-14 13:55 /home/tux/Footage/
```
当文件较大时,它们可能难以阅读。使用 `--human-readable`(简写 `-h`)选项可以使文件大小更容易阅读:
```
$ du --separate-dirs --all --time --threshold=1G --human-readable ~/Footage/
1.8G 2021-07-14 13:55 /home/tux/Footage/snowfall.mp4
1.6G 2020-04-11 13:10 /home/tux/Footage/waterfall.mp4
8.5G 2021-07-14 13:55 /home/tux/Footage/
```
### 查看可用磁盘空间
如需获得一个驱动器上可用磁盘空间的摘要,请阅读我们关于 [df 命令](https://opensource.com/article/21/7/use-df-check-free-disk-space-linux)的文章。
---
via: <https://opensource.com/article/21/7/check-disk-space-linux-du>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | No matter how much storage space you have, there's always the possibility for it to fill up. On most personal devices, drives get filled up with photos and videos and music, but on servers, it's not unusual for space to diminish due to data in user accounts and log files. Whether you're in charge of managing a multi-user system or just your own laptop, you can check in on disk usage with the `du`
command.
By default, `du`
provides the amount of disk space used in your current directory, as well as the size of each subdirectory:
```
$ du
12 ./.backups
60 .
```
In this example, my current directory takes up all of 60 KB, 12 KB of which is occupied by the subdirectory `.backups`
.
If you find that confusing and would prefer to see all sizes separately, you can use the `--separate-dirs`
(or `-S`
for short) option:
```
$ du --separate-dirs
12 ./.backups
48 .
```
It's the same information (48 and 12 is 60) but each directory is treated independently of one another.
To see even more detail, use the --all (or -a for short) option, which displays each file in each directory:
```
$ du --separate-dirs --all
4 ./example.adoc
28 ./graphic.png
4 ./.backups/example.adoc~
12 ./.backups
4 ./index.html
4 ./index.adoc
48 .
```
## See modification time of files
When looking through files to find out what's taking up space, it can be useful to see when a file was last modified. Something that hasn't been touched in a year is a likely candidate for archival, especially if you're running out of space.
To see modification times of files with du, use the `--time`
option:
```
$ du --separate-dirs --all --time
28 2021-07-21 11:12 ./graphic.png
4 2021-07-03 10:43 ./example.adoc
4 2021-07-13 13:03 ./index.html
4 2021-07-23 14:18 ./index.adoc
48 2021-07-23 14:19 .
```
## Set a threshold for file size
When reviewing files in the interest of disk space, you may only care about files of nontrivial size. You set a threshold for the file sizes you want to see with the `--threshold`
(or `-t`
for short) option. For instance, to view only sizes larger than 1 GB:
```
$ \du --separate-dirs --all --time --threshold=1G ~/Footage/
1839008 2021-07-14 13:55 /home/tux/Footage/snowfall.mp4
1577980 2020-04-11 13:10 /home/tux/Footage/waterfall.mp4
8588936 2021-07-14 13:55 /home/tux/Footage/
```
When file sizes get particularly large, they can be difficult to read. Make file sizes easier with the `--human-readable`
(or `-h`
for short) option:
```
$ \du --separate-dirs --all --time \
--threshold=1G --human-readable ~/Footage/
1.8G 2021-07-14 13:55 /home/tux/Footage/snowfall.mp4
1.6G 2020-04-11 13:10 /home/tux/Footage/waterfall.mp4
8.5G 2021-07-14 13:55 /home/tux/Footage/
```
## See available disk space
To just get a summary of how much disk space remains on a drive, read our article about the [df command](https://opensource.com/article/21/7/use-df-check-free-disk-space-linux).
## Comments are closed. |
13,658 | Firefox 失去了近 5000 万用户:令人担忧的原因 | https://news.itsfoss.com/firefox-decline/ | 2021-08-08T12:37:00 | [
"Firefox",
"火狐"
] | https://linux.cn/article-13658-1.html |
>
> 2018 年以来,Mozilla 的火狐浏览器正在大面积流失用户,为什么用户正在远离它?这是否值得担心?
>
>
>

Mozilla 的 Firefox 是基于 Chromium 内核的浏览器的唯一流行替代品。
它一直是 Linux 用户,以及每个平台上注重隐私的用户的默认选择。
然而,即便凭借着大量优势成为最好的 Web 浏览器之一,Firefox 近几年逐渐流失了它的影响力。
实话实说,我们都不需要借助统计数据来论证这一点,因为我们当中的许多人就已经转向其它 Chromium 内核的浏览器,或者 Chromium 本身,而不是 Firefox 和 Google Chrome。
不过,我在 Reddit 上偶然发现了由 [u/nixcraft](https://www.reddit.com/user/nixcraft/) 写的一篇帖子,这篇帖子强调了 Firefox 的用户数从 2018 年来不断下降的原因。
而令人惊讶的是,这篇帖子的原始信息来源就是 [Firefox 的公开数据报表](https://data.firefox.com/dashboard/user-activity)。

根据官方数据统计,在 2018 年底,其报告的(月度)活跃人数达到了 **2.44 亿**。
但,到了 **2021 年第二季度**,这个数字降到了 **1.98 亿**。
由此可以得出,Firefox 的用户基数下降了高达 **4600 万**。
### Firefox 的衰落确实令人担忧,但也很明显
鉴于在 2021 年以隐私为重点的工具在其用户群体中大量出现,Mozilla 的 Firefox 用户基数正面临着不断下降。
尤其是在 Firefox 设法引入一些业界首创的隐私功能之后。呵,是不是很讽刺?
如果你从来没有使用过 Firefox,或者已经迁移至其他浏览器许久,这篇 [关于 Brave 和 Firefox 浏览器的比较](https://itsfoss.com/brave-vs-firefox/) 表明,到目前为止,Firefox 其实还是一个可靠的浏览器。
所以,为什么许多用户迁移到了 Chromium 内核的浏览器,尤其是 Chrome 呢?
我这里马上就想到了这几点:
* Google Chrome 是 Android 设备上的默认浏览器
* Microsoft Edge 是 Windows 设备上的默认浏览器(因此自然就有巨大的市场份额)
* [Google.com](http://Google.com)(最大的搜索引擎)建议用户安装 Google Chrome(实际上是一种潜在的反竞争手段)
* 一些 Web 服务只兼容基于 Chromium 的浏览器
除此之外,Firefox 可能也做错了这几件事:
* 不断以大修的方式来破坏用户体验
* 近年来缺乏显著的性能改进
当然,没有哪个浏览器是完美的,但这是什么值得担心的事吗?嗯,我觉得是的。
### 为什么你应该担忧
Mozilla 的 Firefox 是基于 Chromium 的浏览器的唯一可行的竞争品。如果 Firefox 消失了,用户就会失去其它浏览器内核的选择。
我相信你会同意,纵容垄断是有害的,因此我们需要一些 Google Chromium 引擎的替代品。
实际上,相当多的网站会根据基于 Chromium 的浏览器来优化用户体验。
因此,如果用户量下降的趋势一直持续下去,**我们这样的用户可能就会被迫适应新的工作流程而改用其他浏览器**。
即使忽略掉 Google 的 Chromium 引擎在互联网的主导地位,或者认为 Chrome 之类的浏览器在技术上更好,Firefox 仍旧十分珍贵。因为它至少提供了更多的个性化功能,也不断改进隐私体验,与其他的都不一样。
换句话说,我们可能会(被迫)失去许多好的东西,而这一切仅仅是因为其他竞争对手都选择基于 Chromium 内核,或者从事反竞争活动。
也许,你现在对 Firefox 很失望而想转向其他浏览器。当然,这是你自己的选择。
**但是,待到 Firefox 因为各种使其衰落的因素而彻底消失后,你又该何去何从呢?**

因此,为了让一切保持平衡,我认为我们应该不断反抗科技巨头的反竞争行为,并且开始使用 Mozilla Firefox(不论是什么身份,甚至是作为备用浏览器)。
当然,Mozilla 也需要面对这种情况做出什么措施了。
当他们忙于添加隐私网络服务、邮件中继和其他服务集成时,Mozilla 在用户体验改善方面做的并不成功。
至少,我是这么认为的。多年来,我一直使用 Firefox 作为主力浏览器,但我最终还是会偶尔转向其他浏览器,尤其是每次 Firefox 界面进行大幅度更改后。
### 你怎么看?
我很想知道你对此有何想法,以及你认为究竟是什么因素导致了 Firefox 用户数的下降。
你更喜欢将哪款浏览器作为你的主力浏览器?在评论区中告诉我吧!
---
via: <https://news.itsfoss.com/firefox-decline/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Mozilla’s Firefox is the only popular alternative to Chromium-based browsers.
It has been the default choice for Linux users and privacy-conscious users across every platform.
However, even with all benefits as one of the best web browsers around, it is losing its grip for the past few years.
To be honest, we do not even need a stat to say that, many of us have switched over to Chromium-based browsers or Chromium itself instead of Firefox or Google Chrome.
However, I came across a Reddit thread by [u/nixcraft](https://www.reddit.com/user/nixcraft/?ref=news.itsfoss.com), which highlighted more details on the decline in the userbase of Firefox since 2018.
And surprisingly, the original source for this information is [Firefox’s Public Data Report](https://data.firefox.com/dashboard/user-activity?ref=news.itsfoss.com).
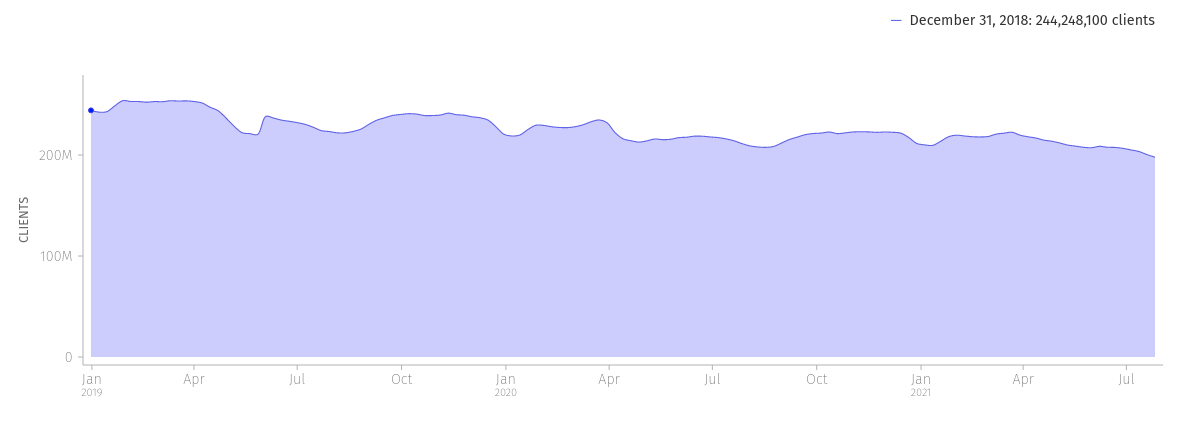
As per the official stats, the reported number of active (monthly) users was about **244 million** at the end of 2018.
And, it seems to have declined to **198 million** at the end of **Q2 2021**.
So, that makes it a whopping ~**46 million** decline in the userbase.
## Firefox’s Decline is Concerning But Obvious
Considering 2021 is the year when privacy-focused tools saw a big boost in their userbase, Mozilla’s Firefox is looking at a constant decline.
Especially when Firefox manages to introduce some industry-first privacy practices. Quite the irony, eh?
In case you have never used Firefox or have moved away for a long time, a [comparison between Brave and Firefox](https://itsfoss.com/brave-vs-firefox/?ref=news.itsfoss.com) highlights that it is still a solid web browser choice to date.
So, why are users moving away to Chromium-based web browsers or Chrome in particular?
There are a few things that I can think of right off the bat:
- Google Chrome being the default web browser on Android
- Microsoft Edge as the default web browser for Windows (which naturally has a huge marketshare)
- Google.com (the biggest search engine) recommending users to install Google Chrome (which is potentially an anti-competitive behaviour)
- Some web services are exclusive to Chrome-based browsers
In addition to that, there are also a few things that Firefox may have done wrong:
- Constantly breaking the user experience with major overhauls
- Lack of significant performance improvements in the recent years
Of course, no web browser is perfect but is this something to worry about? Well, I think, yes.
## Here’s Why You Should be Worried
Mozilla’s Firefox is the only viable competitor to Chromium-based browsers. If Firefox disappears, users won’t have a choice to select a different browser engine.
I’m sure you will agree that monopoly is bad; hence, we need something to survive as an alternative to Google’s chrome engine.
In fact, a significant number of websites optimize the user experience by keeping chrome-based browsers in mind.
So, eventually, if the declining trend continues, **users like us may just be forced to switch to other browsers by adapting to new workflows**.
Even if we ignore the dominant control of Google’s chrome engine on the web by arguing that it is technically better, Firefox is still something precious. Because it provides way more customizations and constantly improves its privacy practices unlike any other.
In other words, we will be losing out on a lot of good things (forcefully) just because all the competition prefers using Chromium as its base or engage in anti-competitive activities.
Maybe, you’re frustrated with Firefox now and move away to something else. That’s completely your choice.
**But, how would you feel if you won’t have an alternative when Firefox ceases to exist because of all the factors affecting its decline?**

Hence, to keep things balanced, I think we should constantly oppose the anti-competitive behavior by tech giants and start using Mozilla Firefox (in whatever capacity, even as a secondary browser).
Of course, Mozilla needs to give this situation some serious attention as well.
While they are busy introducing VPN services, email relays, and other service integrations, they are not succeeding with the user experience improvements.
At least, that is what I think. I’ve used Firefox as my primary browser for years now but I end up switching to other browsers once in a while, especially, after every major UI overhaul.
## What Do You Think?
I’d love to know what you think about this and what seems to be affecting Firefox’s decline in the userbase.
What do you prefer to use as your primary web browser? Let me know all of it in the comments down below!
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,659 | 初级:如何在 Linux Mint 上安装 Google Chrome | https://itsfoss.com/install-chrome-linux-mint/ | 2021-08-08T13:33:00 | [
"Chrome"
] | https://linux.cn/article-13659-1.html | 
这应该是一个非常简单的话题,但我写这个是因为我看到很多网站推荐在 Linux Mint 上安装 Google Chrome 的奇怪命令行步骤。那是可行的,但那是不必要的复杂,特别是对于不熟悉命令行的初学者。
实际上,你根本不需要走终端方式。你所要做的就是去谷歌浏览器的网站,下载 Ubuntu 的安装文件并安装。
让我详细介绍一下步骤,供你了解。
### 在 Linux Mint 上安装 Google Chrome
进入 Google Chrome 的网站。
[Google Chrome Website](https://www.google.com/chrome/index.html)
你会看到一个 “Download Chrome” 的按钮。点击它。

它将向你显示在 Linux 上下载 Chrome 的两个选项。选择 Debian/Ubuntu 选项并点击 “Accept and Install” 按钮。

在开始下载之前,Firefox 会询问你是否要用 Gdebi 打开下载的文件或保存它。你可以选择任何一个选项,因为最终你会 [使用 Gdebi 来安装 deb 文件](https://itsfoss.com/gdebi-default-ubuntu-software-center/)。然而,我更喜欢先保存文件。

等待下载完成。

下载完成后,在文件管理器中进入下载文件夹。要 [安装 deb 文件](https://itsfoss.com/install-deb-files-ubuntu/),可以双击它或者右击它并选择 “Open With GDebi Package Installer”。

等待几秒钟,它应该给你一个安装的选项。

它将要求你提供 Linux Mint 的账户密码。在 Linux 中,你需要提供你的密码来安装任何应用。

你就要完成了。它将显示哪些额外的软件包将与之一起安装(如果有的话)。点击继续按钮即可。

安装完成应该只需要几秒钟或最多一分钟。

安装完成后,你应该看到这样的屏幕。

安装完成后,你可以在应用菜单中寻找 Google Chrome 来运行它。

然后在 Linux Mint 上享受 Google Chrome。

### 如何在 Linux Mint 上更新 Google Chrome
这个方法的好处是,谷歌浏览器会随着系统的更新而更新。当你安装 deb 文件的时候,它也会在你的系统中添加一个来自谷歌的仓库。

由于这个添加的仓库,Chrome 浏览器上的更新将被添加到系统更新中。因此,当你更新 Linux Mint 时,它也会被更新(如果有可用的更新)。
### 如何从 Linux Mint 中删除 Google Chrome
不喜欢 Chrome?不用担心。你可以从 Linux Mint 中卸载谷歌浏览器。同样这次你也不需要使用终端。
点击菜单,搜索 Chrome。在 Chrome 图标上点击右键,你会看到一个 “Uninstall” 选项。选择它。

当然,你必须输入你的密码。它将显示要删除的软件包。在这里点击 OK。

你可以留下 Google Chrome 的仓库,也可以删除它。这是你的选择。
我希望你觉得这个教程对在 Linux Mint 上使用 Google Chrome 有帮助。
---
via: <https://itsfoss.com/install-chrome-linux-mint/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

This should be a really simple topic but I am writing this because I see so many websites recommending strange command line steps for installing Google Chrome on Linux Mint. That would work but that’s unnecessarily complicated, specially for beginners not familiar with the command line.
In reality, you don’t need to go the terminal way at all. All you have to do is to go to Google Chrome’s website and download the installer file for Ubuntu and install it.
Let me detail the steps for your understanding.
## Installing Google Chrome on Linux Mint
Go to the website of Google Chrome.
You’ll see a “Download Chrome” button here. Click on it.

It will show you two option for downloading Chrome on Linux. Go with the Debian/Ubuntu option and hit the “Accept and Install” button.
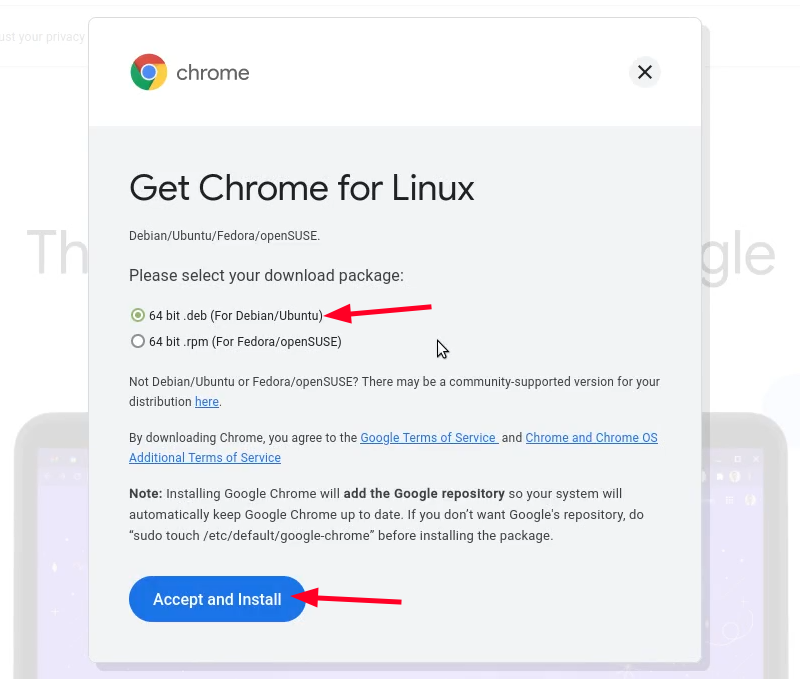
Before starting the download, Firefox asks you if you want to open the downloaded file with Gdebi or save it. You can go with either option because ultimately, you’ll be [using Gdebi for installing the deb file](https://itsfoss.com/gdebi-default-ubuntu-software-center/). However, I prefer to save the file first.
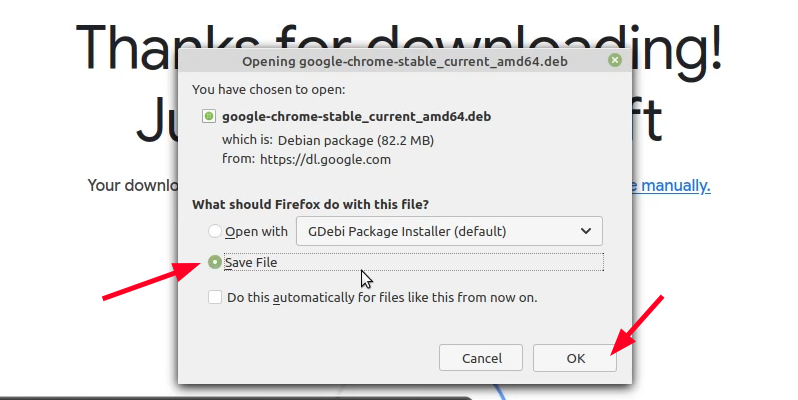
Wait for the download to finish.
Once the download finishes, go to the Downloads folder in File Explorer. To [install the deb file](https://itsfoss.com/install-deb-files-ubuntu/), either double click on it or right click on it and select ‘Open With GDebi Package Installer’.
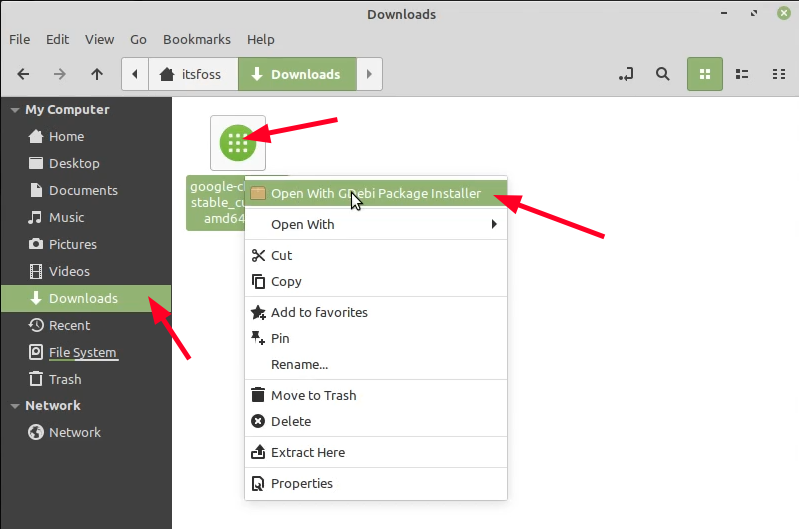
Wait for a few seconds and it should give you the option to install.
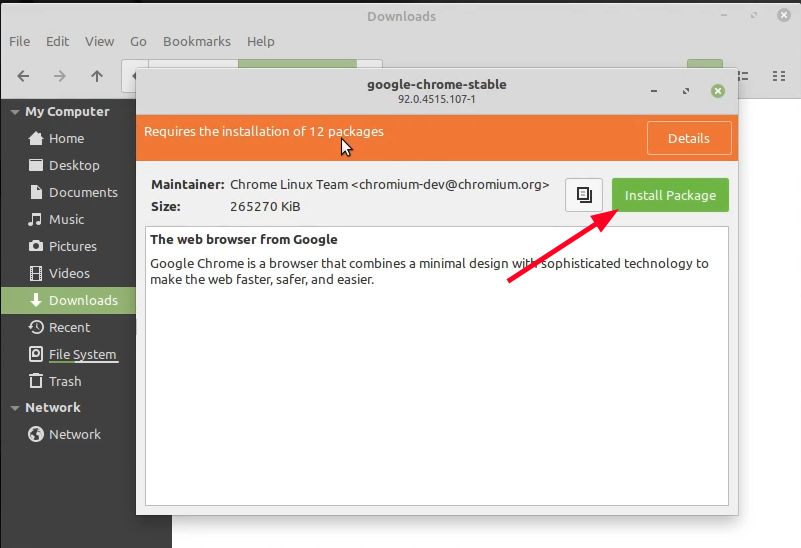
It will ask for Linux Mint account password. In Linux, you need to provide your password for installing any application.
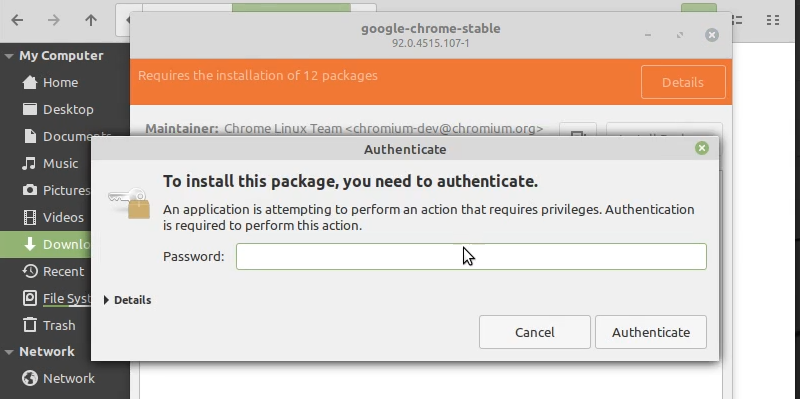
You are almost there. It will show what additional packages will be installed with it (if any). Just hit the Continue button.
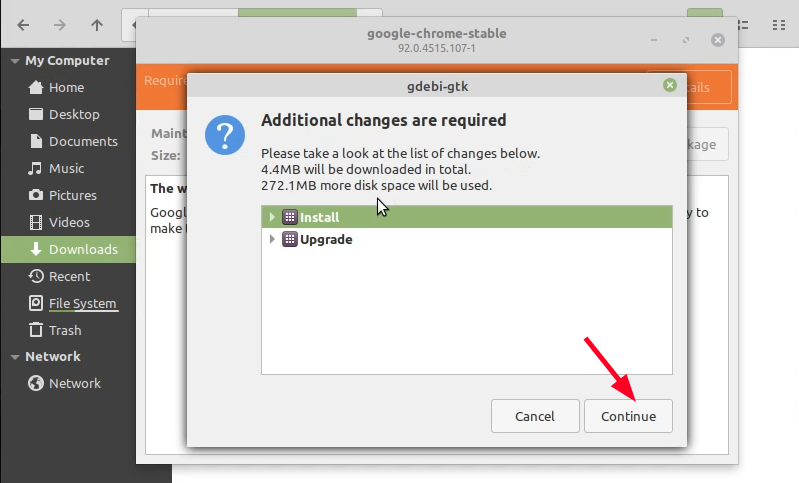
It should take a few seconds or a minute at most for installation to complete.
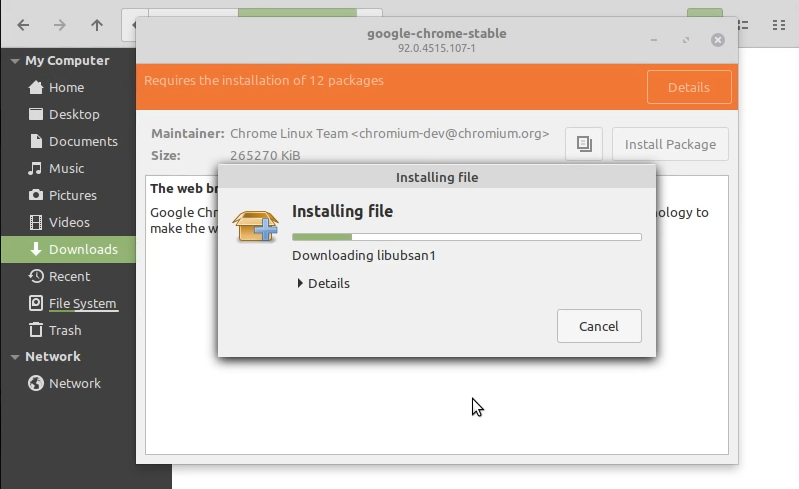
You should see a screen like this when the installation completes.
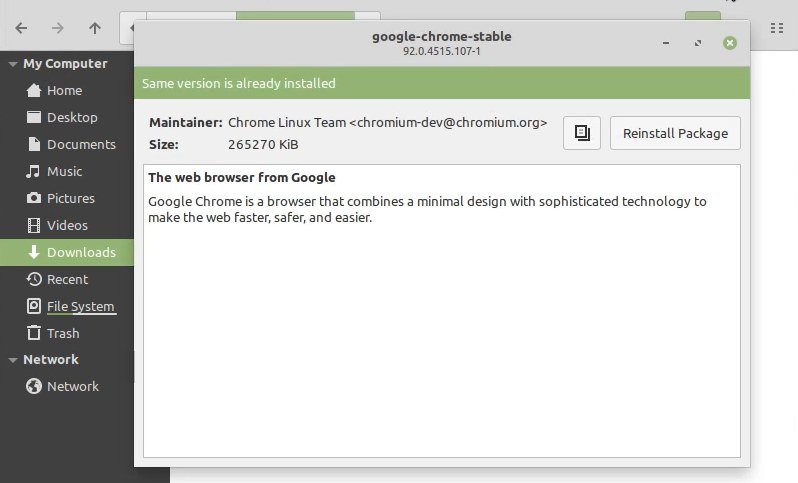
Once installed, you can run Google Chrome by looking for it in the application menu.
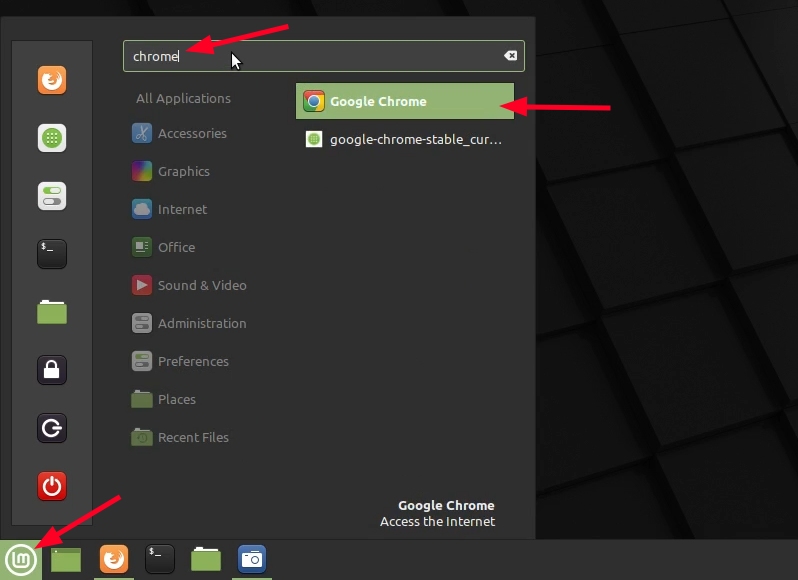
And then enjoy Google Chrome on Linux Mint.
## How to update Google Chrome on Linux Mint
The good thing about this method is that Google Chrome gets updated with system updates. When you install the deb file, it also adds a repository from Google to your system.
Thanks to this added repository, the updates on the Chrome browser will be added to the system updates. So when you update Linux Mint, it gets updated as well (if there is an update available).
## How to remove Google Chrome from Linux Mint
Don’t like Chrome? No worries. You can uninstall Google Chrome from Linux Mint. And no, you don’t need to use terminal this time as well.
Click on the menu and search for Chrome. Right click on the Chrome icon and you’ll see an ‘Uninstall’ option. Select it.
You’ll have to enter your password, of course. It will show the package to be removed. Click OK here.
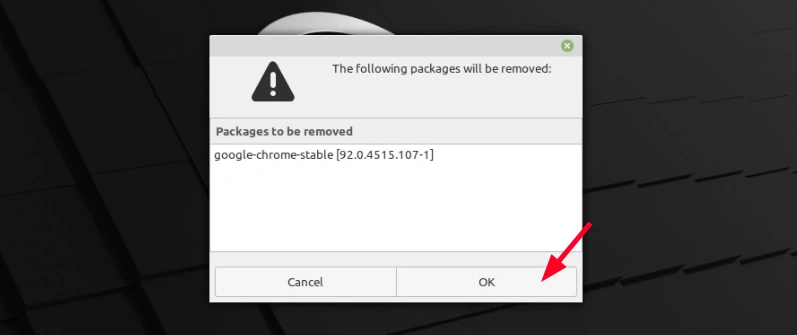
You may leave the repo from Google Chrome or remove it. It’s your choice, really.
I hope you find this tutorial helpful in using Google Chrome on Linux Mint. |
13,661 | 如何在 Linux 系统里查找并删除重复相片 | https://itsfoss.com/find-remove-duplicate-photos-linux/ | 2021-08-09T10:15:00 | [
"照片",
"重复"
] | https://linux.cn/article-13661-1.html | 
点击打开了很多相似的相片?同样的相片保存在不同文件夹里?我理解这种感受。
在相机里点击相片,通过 WhatsApp 发送。然后又备份相片,于是在 WhatsApp 和系统相册里就会存下同样的拷贝。这个很烦人,很乱而且额外占用不必要的存储空间。
我是在翻看我岳父的相片收藏时遇到这个问题的。下面是我如何找出重复相片并删除的做法。
### 使用 digiKam 来找出和删除重复相片
[digiKam](https://www.digikam.org/) 是一个 [用来管理和收集相片的自由开源应用](https://itsfoss.com/linux-photo-management-software/)。它主要是方便摄影师,但并不是说一定要专业玩相机的人才能用。
我可以演示如何使用这个工具来查找重复相片,然后根据需要删除重复内容。
#### 第一步
首先是安装 digiKam。它是一个很流行的应用程序,应该可以在软件中心里直接安装,或者通过你的发行版的包管理器安装。

#### 第二步
在第一次运行 digiKam 时,它会要求你选择相片保存的位置。然后会创建一个 SQLite 数据库并开始导入图片。



#### 第三步
在相片导入完成以后,在文件菜单里选择**工具->查找重复图片**。

#### 第四步
根据你所收集的图片数量,会需要一些时间。之后,你应该可以在左侧边栏里看到有重复的所有相片。在选中图片后,重复的相片会在右侧边栏里显示出来。

在上面的截图里,我在左侧选中的图片有四张一样的。其中有一张图片标记了“<ruby> 参考图片 <rt> Reference image </rt></ruby>”,不过还是由你来确定哪张是原始的,哪张是复制的。
重复的相片默认会按保存位置(比如文件夹)来分组。可以在文件菜单里选择**视图->分类显示**选择其他方式。
**要删除重复相片的话**,选中有侧边栏里的相片并按下删除键。
可以重复这个操作,选择左侧边栏里的图片,一个个删除重复图片。会花太长时间?有个方法可以一次删除多个重复内容。
#### 在 digiKam 里删除多个重复图片
如果想一次把所有重复相片全删掉的话,可以在左侧边栏里选中所有相片。
然后,打开**文件菜单->视图->排序**,然后选择按相似程度。

之后会在底部显示所有参考图片。然后可以在右侧边栏里选中所有没有标记重复的相片,并按下删除按钮。
#### 额外提示:可以在垃圾桶里恢复已删除的相片
意外总是有的。人们经常会不小心误删了相片。这也是为什么 digiKam 不会立刻彻底删除图片。而是选择在保存相片的文件夹下创建隐藏的 `.dtrash` 文件夹,然后将“已删除”的相片移动到里面。
在应用程序界面上,你也可以看到这个垃圾桶文件夹。在里面可以找到你“删除”的相片,然后根据需要可以选择恢复。

希望你能喜欢这个关于在 Linux 上查找和删除重复图片的简短教程。类似的,你可能会想了解 [使用 GUI 工具在 Linux 系统里搜索重复文件](https://itsfoss.com/find-duplicate-files-linux/)。
有任何问题和建议,请在下方留评。
---
via: <https://itsfoss.com/find-remove-duplicate-photos-linux/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zpl1025](https://github.com/zpl1025) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Clicked too many similar photos? Have saved the same photo in different folders? I know that feel.
You click photos on camera, send it through WhatsApp. Now you back up the images and you have two copies of the photos from the gallery and WhatsApp. It is annoying, cluttered and takes extra space unnecessarily.
I came across this issue while going through my father-in-law’s photo collection. Here’s what I did to find the duplicate photos and remove them.
## Find and remove duplicate photos with digiKam
[digiKam](https://www.digikam.org/?ref=itsfoss.com) is a free and [open source utility for managing photo collections](https://itsfoss.com/linux-photo-management-software/). It is primarily aimed at photographers but you do not need to be a professional camera person for using it.
Let me show you how you can use this tool for finding duplicate photos and if you feel like it, remove the duplicate ones.
### Step 1
First thing first, install digiKam. It is a popular application and you should be able to install it from the software center or using the package manager of your distribution.
### Step 2
When you start digiKam for the first time, it asks for the location of your image collection. Then it creates a SQLite database and then imports the images.
### Step 3
Now that you have imported your photos, go to **Tools->Find Duplicates** from the file menu.
### Step 4
It will take some time depending on the number of images you have in your collection. After that, you should see all the photos that have duplicate images in the left sidebar. It also shows the duplicate photos for the selected image in the right sidebar.
In the screenshot above, there are four copies of the same photo that I have selected in the left sidebar. You can see one of the images is labelled as ‘Reference image’. But it is up to you to believe which is original and which is duplicate.
By default, the duplicate photos are divided into sections based on their location, i.e. folders. You may change that by going to **View->Separate Items** in the file menu.
**To delete the duplicate photos**, select the image(s) in the right sidebar and then hit the delete button.
You can repeat this by selecting the image in the left sidebar and then delete the duplicates one by one. Too time taking? There is a trick to delete multiple duplicates at a time.
### Deleting multiple duplicates images in digiKam
If you want to delete duplicate photos for more than images at the same time, select all the images from the left sidebar.
Now, go to the **file menu -> View -> Sort Items** and select By Similarity.
This will put all the referenced images at the bottom. You can select all the images in the right sidebar that are NOT labelled as duplicate and press the delete button.
### Bonus Tip: There is a trash bin for restoring deleted photos
Accident happens. It is common to accidentally delete the wrong photos. This is why images are never really deleted by digiKam immediately. Instead, it creates a hidden .dtrash folder in the same folder where your photos are stored and moves the ‘deleted’ photos here.
Even on the application interface, you can see the Trash folder. You can find your ‘deleted’ photos here and restore the ones you want.
I hope you like this quick tutorial on finding and removing duplicate images in Linux. On a similar note, you may want to know about [using GUI tools for finding duplicate files in your Linux system](https://itsfoss.com/find-duplicate-files-linux/).
Have questions or suggestions? Please leave a comment below. |
13,662 | 3 个提高生产力的必备 Linux 速查表 | https://opensource.com/article/21/4/linux-cheat-sheets | 2021-08-09T12:13:00 | [
"速查表"
] | /article-13662-1.html |
>
> 下载 `sed`、`grep` 和 `parted` 的速查表来整合新的流程到你的工作中。
>
>
>

Linux 因其命令闻名,部分原因是 Linux 执行的几乎所有操作都可以从终端调用;另一部分原因是 Linux 是一个高度模块化的操作系统,它的工具被设计用于产生十分确定的结果,在非常了解一些命令后,你可以将这些命令进行奇妙的组合,产生有用的输出。Linux 的学习过程一半是学习命令,另一半是学习如何将这些命令连成有意思的组合。
然而有这么多 Linux 命令需要学习,迈出第一步似乎令人望而生畏。应该先学习哪一个命令?有那些命令需要熟练掌握,又有哪些命令只需要浅尝辄止?认真考虑过这些问题后,我个人不相信有一个通用的答案。对所有人来说,“基本”命令很可能是相同的:
* `ls`
* `cd`
* `mv`
有这些命令你就可以浏览自己的 Linux 文件系统。
但是,除了基本命令,不同行业的“默认”命令有所不同。系统管理员需要 [系统自我检查和监测](https://opensource.com/life/16/2/open-source-tools-system-monitoring) 的工具;艺术家需要 [媒体转换](https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats) 和 [图形处理](https://opensource.com/article/17/8/imagemagick) 工具;家庭用户可能想要 [PDF 处理](https://opensource.com/article/20/8/reduce-pdf)、[日历](https://opensource.com/article/19/4/calendar-git)、[文档转换](https://opensource.com/article/20/5/pandoc-cheat-sheet) 工具。这份列表无穷无尽。
然而一些 Linux 命令由于极其重要能够脱颖而出 —— 或者因为这些命令是每个人不时需要的常用的底层工具,或者因为这些命令是每个人在大多数时间都会觉得有用的万能工具。
这里有三个需要添加到你的列表中的命令。
### Sed
**用途:** `sed` 是一个任何 Linux 用户都可以从学习中获益的优良通用工具。从表面上看,它只是一个基于终端的“查找和替换”,能够简单快速地纠正多个文档。`sed` 命令为我节省了打开单个文件、寻找和替换一个单词、保存文件、关闭文件所需要的数个小时(也可能是数天)时间,仅此一条命令就证明了我在学习 Linux 终端的投入是合理的。一旦充分了解 `sed`,你很有可能发现一个使生活更加轻松的潜在编辑技巧世界。
**长处:** 命令的长处在于重复。如果你只有一个要编辑的文件,很容易在传统的 [文本编辑器](https://opensource.com/article/21/2/open-source-text-editors)打开并进行“查找和替换”。然而,如果要替换 5 或 50 个文件,恰当地使用 `sed` 命令(可能结合 [GNU Parallel](https://opensource.com/article/18/5/gnu-parallel) 进行加速)可以帮你节省数个小时。
**不足:** 你需要权衡直接更改期望所花的时间和构建正确的 `sed` 命令可能需要的时间。使用常见的 `sed 's/foo/bar/g'` 语法所做的简单编辑通常值得上输入这些命令所花的时间;但是利用保持空间和任何 `ed` 形式子命令的复杂 `sed` 命令可能需要高度集中的注意力和多次的试错。事实证明,使用 `sed` 进行编辑通常是更好的方式。
**秘技:** 下载我们的 [sed 速查表](https://opensource.com/downloads/sed-cheat-sheet) 获取命令的单字母子命令和语法概述的快速参考。
### Grep
**用途:** `grep` 一词来源于其公认的笨拙描述:全局正则表达式打印。换言之,在文件中(或者其他形式的输入中)找到的任何匹配模式,`grep` 都会打印到终端。这使得 `grep` 成为一个强大的搜索工具,尤其擅长处理大量的文本。
你可以使用 `grep` 查找 URL:
```
$ grep --only-matching \
http\:\/\/.* example.txt
```
你可以使用 `grep` 查找一个特定的配置项:
```
$ grep --line-number \
foo= example.ini
2:foo=true
```
当然,你还可以将 `grep` 和其他命令组合:
```
$ grep foo= example.ini | cut -d= -f2
true
```
**长处:** `grep` 是一个简单的搜索命令,如果你阅读了上面的例子,就已经基本有所了解。为了增强灵活性,你可以使用命令的扩展正则表达式语法。
**不足:** `grep` 的问题也是它的长处:它只有搜索功能。一旦你找到想要的内容,可能会面临一个更大的问题 —— 如何处理找到的内容。有时进行的处理可能简单如重定向输出到一个文件,作为过滤后的结果列表。但是,更复杂的使用场景可能需要对结果做进一步处理,或者使用许多类似 [awk](https://opensource.com/article/20/9/awk-ebook)、[curl](https://www.redhat.com/sysadmin/social-media-curl)(凑巧的是,我们也有 [curl 速查表](https://opensource.com/article/20/5/curl-cheat-sheet))的命令,或者使用现代计算机上你所拥有的数千个其他选项中的任何一个命令。
**秘技:** 下载我们的 [grep 速查表](https://opensource.com/downloads/grep-cheat-sheet) 获取更多命令选项和正则表达式语法的快速参考。
### Parted
**用途:** GNU `parted` 不是一个常用命令,但它是最强大的硬盘操作工具之一。关于硬盘驱动器的沮丧事实是 —— 数年来你一直忽略它们,直到需要设置一个新的硬盘时,才会想起自己对于格式化驱动器的最好方式一无所知,而此时熟悉 `parted` 会十分有用。GNU `parted` 能够创建磁盘卷标,新建、备份、恢复分区。此外,你可以通过命令获取驱动器及其布局的许多信息,并为文件系统初始化驱动器。
**长处:** 我偏爱 `parted` 而不是 `fdisk` 等类似工具的原因在于它组合了简单的交互模式和完全的非交互选项。不管你如何使用 `parted`,它的命令符合相同的语法,其编写良好的帮助菜单包含了丰富的信息。更棒的是,命令本身是 *智能* 的 —— 给一个驱动器分区时,你可以用扇区和百分比指明分区的大小,`parted` 会尽可能计算出更精细的位置存放分区表。
**不足:** 在很长一段时间内我不清楚驱动器的工作原理,因此切换到 Linux 后,我花费了很长时间学习 GNU `parted`。GNU `parted` 和大多数终端磁盘工具假定你已经知晓什么是一个分区、驱动器由扇区组成、初始时驱动器缺少文件系统,需要磁盘卷标和分区表等等知识。硬盘驱动器的基础而不是命令本身的学习曲线十分陡峭,而 GNU `parted` 并没有做太多的努力来弥补潜在的认知差距。可以说,带你完成磁盘驱动器的基础知识学习不是命令的职责,因为有类似的 [图形应用](https://opensource.com/article/18/11/partition-format-drive-linux#gui),但是一个聚焦于工作流程的选项对于 GNU `parted` 可能是一个有用的附加功能。
**秘技:** 下载我们的 [parted 速查表](https://opensource.com/downloads/parted-cheat-sheet) 获取大量子命令和选项的快速参考。
### 了解更多
这是一些我最喜欢的命令列表,但是其中的命令自然取决于我如何使用自己的计算机。我编写很多命令解释器脚本,因此频繁地使用 `grep` 查找配置选项,通过 `sed` 编辑文本。我还会用到 `parted`,因为处理多媒体项目时,通常涉及很多硬盘驱动器。你可能已经开发了,或者很快就要使用最喜欢的(至少是 *频繁使用的*)命令开发自己的工作流程。
整合新的流程到日常工作时,我会创建或者下载一个速查表(就像上面的链接),然后进行练习。我们都有自己的学习方式,找出最适合你的方式,学习一个新的必需命令。你对最常使用的命令了解越多,你就越能充分地使用它们。
---
via: <https://opensource.com/article/21/4/linux-cheat-sheets>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[YungeG](https://github.com/YungeG) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,664 | 一些命令行小技巧:wc、sort、sed 和 tr | https://fedoramagazine.org/command-line-quick-tips-wc-sort-sed-and-tr/ | 2021-08-10T08:57:26 | [
"命令行"
] | https://linux.cn/article-13664-1.html | 
Linux 发行版十分好用,而且它们有一些用户可能不知道的技巧。让我们来看看一些命令行实用工具,当你热衷于终端而不是 GUI 时,它们可能更顺手。
我们都知道在一个系统上使用终端会更高效。当你编辑和排版一个文本文件时,终端会让你确切的感受到,生活如此简单。
本文将向你介绍 `wc`、`sort`、`tr` 和 `sed` 命令。
### wc
`wc` 是一个实用工具,全称是 “word count”。顾名思义,它可以用来统计任何文件的行数、单词数和字节数。
让我们来看看它是如何工作的:
```
$ wc filename
lines words characters filename
```
输出的是文件的行数、单词数、字符数和文件名。
想获得特定的输出,我们必须使用选项:
* `-c` 打印字节总数
* `-l` 打印行数
* `-w` 打印单词总数
* `-m` 打印字符总数
#### wc 示例
让我们来看看它的运行结果。
让我们从一个文本文件 `lormipsm.txt` 开始。首先,我们通过 `cat` 查看文件内容,然后使用 `wc`:
```
$ cat loremipsm.txt
Linux is the best-known and most-used open source operating system.
As an operating system, Linux is software that sits underneath all of the other software on a computer,
receiving requests from those programs and replaying these requests to the computer's hardware.
$ wc loremipsm.txt
3 41 268 loremipsm.txt
```
假设我只想查看文件的字节数:
```
$ wc -c loremipsm.txt
268 loremipsm.txt
```
查看文件的行数:
```
$ wc -l loremipsm.txt
3 loremipsm.txt
```
查看文件的单词数:
```
$ wc -w loremipsm.txt
41 loremipsm.txt
```
现在只查看文件的字符数:
```
$ wc -m loremipsm.txt
268 loremipsm.txt
```
### sort
`sort` 命令是最有用的工具之一。它会对文件的数据进行排序。可以根据字符或数字进行升序或降序排列。它也可以用来对文件中的行进行排序和随机化。
使用 `sort` 非常简单。我们需要做的仅仅是提供一个文件名:
```
$ sort filename
```
默认的是按照字母顺序对数据进行排序。需要注意的是 `sort` 命令仅仅是对数据进行排序展示。它并不会改写文件。
使用 `sort` 命令的一些有用的选项:
* `-r` 将文件中的行按倒序进行排序
* `-R` 将文件中的行打乱为随机顺序
* `-o` 将输出保存到另一个文件中
* `-k` 按照特定列进行排序
* `-t` 使用指定的分隔符,而不使用空格
* `-n` 根据数值对数据进行排序
#### sort 示例
让我们看看 `sort` 的几个简单示例。
我们有一个 `list.txt` 的文件,包含逗号分隔的名称和数值。
首先让我们打印出文件内容并简单排序:
```
$ cat list.txt
Cieran Wilks, 9
Adelina Rowland, 4
Hayden Mcfarlnd, 1
Ananya Lamb, 5
Shyam Head, 2
Lauryn Fuents, 8
Kristian Felix, 10
Ruden Dyer, 3
Greyson Meyers, 6
Luther Cooke, 7
$ sort list.txt
Adelina Rowland, 4
Ananya Lamb, 5
Cieran Wilks, 9
Greyson Meyers, 6
Hayden Mcfarlnd, 1
Kristian Felix, 10
Lauryn Fuents, 8
Luther Cooke, 7
Ruden Dyer, 3
Shyam Head, 2
```
现在对数据进行倒序排序:
```
$ sort -r list.txt
Shyam Head, 2
Ruden Dyer, 3
Luther Cooke, 7
Lauryn Fuents, 8
Kristian Felix, 10
Hayden Mcfarlnd, 1
Greyson Meyers, 6
Cieran Wilks, 9
Ananya Lamb, 5
Adelina Rowland, 4
```
让我们打乱数据:
```
$ sort -R list.txt
Cieran Wilks, 9
Greyson Meyers, 6
Adelina Rowland, 4
Kristian Felix, 10
Luther Cooke, 7
Ruden Dyer, 3
Lauryn Fuents, 8
Hayden Mcfarlnd, 1
Ananya Lamb, 5
Shyam Head, 2
```
来看一点更复杂的。这次我们根据第二个字段,也就是数值对数据进行排序,并使用 `-o` 选项将输出保存到另一个文件中:
```
$ sort -n -k2 -t ',' -o sorted_list.txt list.txt
$ ls
sorted_list.txt list.txt
$ cat sorted_list.txt
Hayden Mcfarlnd, 1
Shyam Head, 2
Ruden Dyer, 3
Adelina Rowland, 4
Ananya Lamb, 5
Greyson Meyers, 6
Luther Cooke, 7
Lauryn Fuents, 8
Cieran Wilks, 9
Kristian Felix, 10
```
这里我们使用 `-n` 选项按数字顺序进行排序,`-k` 选项用来指定要排序的字段(在本例中为第 2 个字段),`-t` 选项指定分隔符或字段分隔符(逗号),`-o` 选项将输出保存到 `sorted_list.txt` 文件中。
### sed
`sed` 是一个流编辑器,用于过滤和转换输出中的文本。这意味着我们不需要对原文件进行修改,只需要对输出进行修改。如果需要,我们可以将更改保存到一个新的文件中。`sed` 提供了很多有用的选项用于过滤和编辑数据。
`sed` 的语法格式如下:
```
$ sed [OPTION] ‘PATTERN’ filename
```
sed 常用的一些选项:
* `-n` 取消默认输出
* `p` 打印指定的数据
* `d` 删除指定行
* `q` 退出 `sed` 脚本
#### sed 示例
我们来看看 `sed` 是如何运作的。我们从 `data` 文件开始,其中的字段表示编号、名称、年龄和操作系统。
如果行出现在特定的行范围内,该行将打印 2 次:
```
$ cat data
1 Vicky Grant 20 linux
2 Nora Burton 19 Mac
3 Willis Castillo 21 Windows
4 Gilberto Mack 30 Windows
5 Aubrey Hayes 17 windows
6 Allan Snyder 21 mac
7 Freddie Dean 25 linux
8 Ralph Martin 19 linux
9 Mindy Howard 20 Mac
$ sed '3,7 p' data
1 Vicky Grant 20 linux
2 Nora Burton 19 Mac
3 Willis Castillo 21 Windows
3 Willis Castillo 21 Windows
4 Gilberto Mack 30 Windows
4 Gilberto Mack 30 Windows
5 Aubrey Hayes 17 windows
5 Aubrey Hayes 17 windows
6 Allan Snyder 21 mac
6 Allan Snyder 21 mac
7 Freddie Dean 25 linux
7 Freddie Dean 25 linux
8 Ralph Martin 19 linux
9 Mindy Howard 20 Mac
```
这里的操作用单引号括起来,表示第 3 行和第 7 行,并且使用了 `p` 打印出符合匹配规则的数据。sed 的默认行为是在解析后打印每一行。这意味着由于使用了 `p` ,第 3 行到第 7 行打印了两次。
如何打印文件中特定的行?使用 `-n` 选项来消除在输出中不匹配的行:
```
$ sed -n '3,7 p' data
3 Willis Castillo 21 Windows
4 Gilberto Mack 30 Windows
5 Aubrey Hayes 17 windows
6 Allan Snyder 21 mac
7 Freddie Dean 25 linux
```
使用 ‘-n’ 仅仅只有第 3 行到第 7 行会被打印。
省略文件中的特定行。使用 `d` 从输出中删除行:
```
$ sed '3 d' data
1 Vicky Grant 20 linux
2 Nora Burton 19 Mac
4 Gilberto Mack 30 Windows
5 Aubrey Hayes 17 windows
6 Allan Snyder 21 mac
7 Freddie Dean 25 linux
8 Ralph Martin 19 linux
9 Mindy Howard 20 Mac
$ sed '5,9 d' data
1 Vicky Grant 20 linux
2 Nora Burton 19 Mac
3 Willis Castillo 21 Windows
4 Gilberto Mack 30 Windows
```
从文件中搜索特定的关键字:
```
$ sed -n '/linux/ p' data
7 Freddie Dean 25 linux
8 Ralph Martin 19 linux
$ sed -n '/linux/I p' data
1 Vicky Grant 20 Linux
7 Freddie Dean 25 linux
8 Ralph Martin 19 linux
```
在这些例子中,我们在 `/ /` 中使用了一个正则表达式。如果文件中有类似的单词,但大小写不一致,可以使用 `I` 使得搜索不区分大小写。回想一下,`-n` 删除了输出中不匹配的行。
替换文件中的单词:
```
$ sed 's/linux/linus/' data
1 Vicky Grant 20 Linux
2 Nora Burton 19 Mac
3 Willis Castillo 21 Windows
4 Gilberto Mack 30 Windows
5 Aubrey Hayes 17 windows
6 Allan Snyder 21 mac
7 Freddie Dean 25 linus
8 Ralph Martin 19 linus
9 Mindy Howard 20 Mac
```
这里 `s/ / /` 表示它是一个正则表达式。在两个 `/` 之间的就是定位的单词和需要替换的新单词。
### tr
`tr` 命令可以用来转换或删除字符。它可以将小写字母转换为大写字母,也可以将大写字母转换为小写字母,可以消除重复字符,也可以删除特定字符。
`tr` 的奇怪之处在于,它不同于 `wc`、`sort`、`sed` 那样接受文件作为输入。我们使用 `|` (管道符)为 `tr` 命令提供输入。
```
$ cat filename | tr [OPTION]
```
`tr` 命令使用的一些选项:
* `-d` 删除给定输入第一个集合中的指定字符,不做转换
* `-s` 将重复出现的字符替换为单个
#### tr 示例
现在让我们使用 `tr` 命令将 `letter` 文件中的所有小写字符转换为大写字符:
```
$ cat letter
Linux is too easy to learn,
And you should try it too.
$ cat letter | tr 'a-z' 'A-Z'
LINUX IS TOO EASY TO LEARN,
AND YOU SHOULD TRY IT TOO.
```
这里的 `a-z`、`A-Z` 表示我们想要将 `a` 到 `z` 范围内的小写字符转换为大写字符。
删除文件中的 `o` 字符:
```
$ cat letter | tr -d 'o'
Linux is t easy t learn,
And yu shuld try it t.
```
从文件中压缩字符 `o` 意味着如果 `o` 在文件中重复出现,那么它将会被删除并且只打印一次:
```
$ cat letter | tr -s 'o'
Linux is to easy to learn,
And you should try it to.
```
### 总结
这是使用 `wc`、`sort`、`sed`、`tr` 命令的快速演示。这些命令可以方便快捷的操作终端上的文本文件。你可以使用 `man` 命令来了解这些命令的更多信息。
---
via: <https://fedoramagazine.org/command-line-quick-tips-wc-sort-sed-and-tr/>
作者:[mahesh1b](https://fedoramagazine.org/author/mahesh1b/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux distributions are great to use and they have some tricks under their sleeves which users may not be aware of. Let’s have a look at some command line utilities which really come in handy when you’re the guy that likes to stick with the terminal rather than using a GUI.
We all know that using a terminal is more efficient to use the system. In case you are editing or playing with text files on a terminal then these tools will surely make your life easy.
For this article let’s have a look at *wc*, *sort*, *tr*, and *sed* commands.
**wc**
wc is a utility whose name stands for “word count”. As the name suggests it will count the lines, words or byte count from any file.
Let’s see how it works:
$ wcfilenamelines words characters filename
So in output we get the total number of newlines in the file, total number of words, total number of characters, and the filename.
To get some specific output we have to use options:
- -c To print the byte counts
- -l To print the newline counts
- -w To print the word counts
- -m To print the character counts
### wc demo
Let’s see it in action:
Here we start with a text file, ` loremipsm.txt`. First, we print out the file and then use
*wc*on it.
$ cat loremipsm.txtLinux is the best-known and most-used open source operating system. As an operating system, Linux is software that sits underneath all of the other software on a computer, receiving requests from those programs and replaying these requests to the computer's hardware.$ wc loremipsm.txt3 41 268 loremipsm.txt
Suppose I only want to see the byte count of the file:
$ wc -c loremipsm.txt268 loremipsm.txt
For the newline count of the file:
$ wc -l loremipsm.txt3 loremipsm.txt
To see the word count of the file:
$ wc -w loremipsm.txt41 loremipsm.txt
Now only the character count of the file:
$ wc -m loremipsm.txt268 loremipsm.txt
**sort**
The *sort* command is one of the most useful tools. It will sort the data in a file. Sorting is by either characters or numbers in ascending or descending order. It can also be used to sort or randomize the lines of files.
Using *sort* can be very simple. All we need to do is provide the name of the file.
$ sortfilename
By default it sorts the data in alphabetical order. One thing to note is that the *sort* command just displays the sorted data. It does not overwrite the file.
Some useful options for *sort*:
- -r To sort the lines in the file in reverse order
- -R To shuffle the lines in the file into random order
- -o To save the output in another file
- -k To sort as per specific column
- -t To mention the field separator
- -n To sort the data according to numerical value
### sort demo
Let’s use *sort* in some short demos:
We have a file, ` list.txt,` containing names and numeric values separated by commas.
First let’s print out the file and just do simple sorting.
$ cat list.txtCieran Wilks, 9 Adelina Rowland, 4 Hayden Mcfarlnd, 1 Ananya Lamb, 5 Shyam Head, 2 Lauryn Fuents, 8 Kristian Felix, 10 Ruden Dyer, 3 Greyson Meyers, 6 Luther Cooke, 7$ sort list.txtAdelina Rowland, 4 Ananya Lamb, 5 Cieran Wilks, 9 Greyson Meyers, 6 Hayden Mcfarlnd, 1 Kristian Felix, 10 Lauryn Fuents, 8 Luther Cooke, 7 Ruden Dyer, 3 Shyam Head, 2
Now sort the data in the reverse order.
$ sort -r list.txtShyam Head, 2 Ruden Dyer, 3 Luther Cooke, 7 Lauryn Fuents, 8 Kristian Felix, 10 Hayden Mcfarlnd, 1 Greyson Meyers, 6 Cieran Wilks, 9 Ananya Lamb, 5 Adelina Rowland, 4
Let’s shuffle the data.
$ sort -R list.txtCieran Wilks, 9 Greyson Meyers, 6 Adelina Rowland, 4 Kristian Felix, 10 Luther Cooke, 7 Ruden Dyer, 3 Lauryn Fuents, 8 Hayden Mcfarlnd, 1 Ananya Lamb, 5 Shyam Head, 2
Let’s make it more complex. This time we sort the data according to the second field, which is the numeric value, and save the output in another file using the -o option.
$ sort -n -k2 -t ',' -o sorted_list.txt list.txt$ lssorted_list.txt list.txt$ cat sorted_list.txtHayden Mcfarlnd, 1 Shyam Head, 2 Ruden Dyer, 3 Adelina Rowland, 4 Ananya Lamb, 5 Greyson Meyers, 6 Luther Cooke, 7 Lauryn Fuents, 8 Cieran Wilks, 9 Kristian Felix, 10
Here we used -n to sort in numerical order, -k to specify the field to sort (2 in this case) -t to indicate the delimiter or field-separator (a comma) and -o to save the output in the file *sorted_list.txt*.
**sed**
Sed is a stream editor that will filter and transform text in the output. This means we are not making changes in the file, only to the output. We can also save the changes in a new file if needed. Sed comes with a lot of options that are useful in filtering or editing the data.
The syntax for sed is:
$ sed[OPTION] ‘PATTERN’ filename
Some of the options used with sed:
- -n : To suppress the printing
- p: To print the current pattern
- d : To delete the pattern
- q : To quit the sed script
### sed demo
Lets see *sed* in action. We start with the file ` data` with the fields indicating number, name, age and operating system.
Printing the lines twice if they occur in a specific range of lines.
$ cat data1 Vicky Grant 20 Linux 2 Nora Burton 19 Mac 3 Willis Castillo 21 Windows 4 Gilberto Mack 30 Windows 5 Aubrey Hayes 17 windows 6 Allan Snyder 21 mac 7 Freddie Dean 25 linux 8 Ralph Martin 19 linux 9 Mindy Howard 20 Mac$ sed '3,7 p' data1 Vicky Grant 20 Linux 2 Nora Burton 19 Mac 3 Willis Castillo 21 Windows 3 Willis Castillo 21 Windows 4 Gilberto Mack 30 Windows 4 Gilberto Mack 30 Windows 5 Aubrey Hayes 17 windows 5 Aubrey Hayes 17 windows 6 Allan Snyder 21 mac 6 Allan Snyder 21 mac 7 Freddie Dean 25 linux 7 Freddie Dean 25 linux 8 Ralph Martin 19 linux 9 Mindy Howard 20 Mac
Here the operation is specified in single quotes indicating lines 3 through 7 and using ‘p’ to print the pattern found. The default behavior of sed is to print every line after parsing it. This means lines 3 through 7 appear twice because of the ‘p’ instruction.
So how can you print specific lines from the file? Use the ‘-n’ option to eliminate lines that do not match from the output.
$ sed -n '3,7 p' data3 Willis Castillo 21 Windows 4 Gilberto Mack 30 Windows 5 Aubrey Hayes 17 windows 6 Allan Snyder 21 mac 7 Freddie Dean 25 linux
Only lines 3 through 7 will appear using ‘-n’ .
Omitting specific lines from the file. This uses the ‘d’ to delete the lines from the output.
$ sed '3 d' data1 Vicky Grant 20 Linux 2 Nora Burton 19 Mac 4 Gilberto Mack 30 Windows 5 Aubrey Hayes 17 windows 6 Allan Snyder 21 mac 7 Freddie Dean 25 linux 8 Ralph Martin 19 linux 9 Mindy Howard 20 Mac$ sed '5,9 d' data1 Vicky Grant 20 Linux 2 Nora Burton 19 Mac 3 Willis Castillo 21 Windows 4 Gilberto Mack 30 Windows
Searching for a specific keyword in the file.
$ sed -n '/linux/ p' data7 Freddie Dean 25 linux 8 Ralph Martin 19 linux$ sed -n '/linux/I p' data1 Vicky Grant 20 Linux 7 Freddie Dean 25 linux 8 Ralph Martin 19 linux
In these examples we have a regular expression which appears in ‘/ /’. If we have similar words in the file but not with proper case then we use the “I” to make the search case insensitive. Recall that the -n eliminates the lines that do not match from the output.
Replacing the words in the file.
$ sed 's/linux/linus/' data1 Vicky Grant 20 Linux 2 Nora Burton 19 Mac 3 Willis Castillo 21 Windows 4 Gilberto Mack 30 Windows 5 Aubrey Hayes 17 windows 6 Allan Snyder 21 mac 7 Freddie Dean 25 linus 8 Ralph Martin 19 linus 9 Mindy Howard 20 Mac
Here ‘s/ / /’ denotes that it is a regex. The located word and then the new word to replace it appear between the two ‘/’.
**tr**
The *tr* command will translate or delete characters. It can transform the lowercase letters to uppercase or vice versa, eliminate repeating characters, and delete specific characters.
One thing weird about *tr* is that it does not take files as input like *wc*, *sort* and *sed* do. We use “|” (the pipe symbol) to provide input to the *tr* command.
$ catfilename| tr [OPTION]
Some options used with *tr*:
- -d : To delete the characters in first set of output
- -s : To replace the repeated characters with single occurrence
### tr demo
Now let’s use the *tr* command with the file ` letter` to convert all the characters from lowercase to uppercase.
$ cat letterLinux is too easy to learn, And you should try it too.$ cat letter | tr 'a-z' 'A-Z'LINUX IS TOO EASY TO LEARN, AND YOU SHOULD TRY IT TOO.
Here ‘a-z’ ‘A-Z’ denotes that we want to convert characters in the range from “a” to “z” from lowercase to uppercase.
Deleting the “o” character from the file.
$ cat letter | tr -d 'o'Linux is t easy t learn, And yu shuld try it t.
Squeezing the character “o” from the file means that if “o” is repeated in line then it will remove it and print it only once.
$ cat letter | tr -s 'o'Linux is to easy to learn, And you should try it to.
**Conclusion**
This was a quick demonstration of the *wc*, *sort*, *sed* and *tr* commands. These commands make it easy to manipulate the text files on the terminal in a quick and efficient way. You may use the *man* command to learn more about these commands.
## William gupton
This is great..quick and to the point
## James
Ooh, can I add my favourite use of sort?
sort | uniq -c | sort -n
For use on logfiles: use grep to select the lines you’re interested in, something like cut to select the resource you’re interested in (something like a user agent, a user, or a file), and then pipe that to sort | uniq -c | sort -n. Gives you a list of how often the resource turns up in the logfile, which gives you a pointer to where to start looking for further problems.
Worked example on a mail server with Exim installed:
grep -h ” <= ” /var/log/exim/main.log* | cut -d\ -f5 | cut -d@ -f2 | sort | uniq -ic | sort -n
(all one line.)
Which domains email us the most often?
## Daniel
What has happened that one needs to write a blog post to talk about basic Unix programs? Who are the targeted readers of this post?
This isn’t a good sign. If this is true that many Linux users don’t know about the shell, we are doing something wrong, the way they are introduced to the system needs to be rethinked.
## SigmaSquadron
It’s a good thing, IMO. Linux has always been behind macOS and Windows in terms of GUI usage, and if there’s a number of users who solely use the GUI as their primary method of interfacing with the system, it shows that the desktop front of Linux evolved past the need to share space with the CLI.
Besides, those users can always turn to the LFS manual to fully learn what makes Linux tick. It’s a good thing to learn new things on computing, but most of the time you just want a good GUI-only computer to get some work done.
I guess the way Linux works makes this possible. Distros like Fedora Workstation will probably never give much thought to the CLI, while distros targeted for more advanced users, like Arch, Gentoo, LFS or Slackware will pay less attention to providing a good GUI for newcomers. It’s all about different audiences and the choice to use what you want — be that a GUI-only distro, a mix of both interfaces, or a CLI-only distro.
## Darvond
Remember, not everyone is a Unix Guru or Amiga veteran. Most are probably washing ashore from the rocky shoals of MInt, Ubuntu, Pop-OS and other such things which will try their damnedest to hide the “underbelly”.
And given that most UNIX were coded with the constraints of punchcards and 300 baud terminals, there is a lot of “inside baseball”. especially given between aa and zz there are 676 potential combinations, and that’s not counting switches. Even something as simple as ls goes from -a to -z.
Is cal Calculate? Nope. It’s calendar.
Demystifying the command line is always good.
## lucky thousand
https://xkcd.com/1053/
## rex fury
Tricks UP their sleeves 🙂
## rex fury
I love Linux from the command line! Screen for multiple consoles, Midnight Commander for files, No, I really don’t use Vim that much. 🙂
## xenlo
there is a mistake in “wc demo” section, the last code box is the copy-paste of the previous one. It should be
in place of
## Gregory Bartholomew
Thanks xenlo. I’ve made the correction.
## Ron Olson
wc has another awesome benefit; because of pipes, you can pipe output to wc which works great for finding out how many items are in a directory, .e.g., “ls -l | wc -l”
## james miller
Nice introduction to some handy commands. I am fairly sure that all the commands can be used as streams, with pipes, certainly sed and wc can.
I am currently using :
ls |wc -l to list how many files are in a directory, for example.
## y0umu
isn’t it
?
## Gregory Bartholomew
Some programs vary their output depending on whether their output is connected to an interactive terminal or to a pipe. ls is one of them. Try it:
## Jasper Hartline
When doing %post processing in rpmbuild sessions to build an RPM package on Fedora I’ve used 6 command utilities in line with pipes to get what I need its so awesome the pipe is the first resort.
## You Really Don't Want to Know
perl
## Sampsonf
Thanks for sharing.
For sed, when it will modify the data file, when it will modify the output only?
## Wolfgang Marx
Great Overview! Thanks, learned something again:)
## edier88
Excellent article.
A full tutorial of awk and sed would be nice too.
Thank you!
## Jared G
I second this! Giving a “full” tutorial within a single article is surely impossible, but there are some common use cases that would be helpful to cover.
Whenever performing some rote task in my everyday administrative life, I ask myself, “Can I automate this somehow?” Often, I wind up writing a shell script to just that. In my experience, this is one of the best ways to deeply learn your way around tools like these.
## Ok5ieGh3
The tr-example makes useless use of cat, instead of cat letter | tr one should use tr < letter
## Nildo
Excelente postagem!
Thank you!
## Phoenix
When demonstrating “tr” (and “sed”), I have the feeling that “cut” should have been mentioned alongside with it as it is as easy and useful as well. As with all mentioned programs, it works tremendously well capturing (piping) the output of the previous command and further refining the output.
Example:
cut -d”:” -f1,3-4,6 /etc/passwd
“-d” uses delimiter (in this case “:”)
“-f” display only fields delimited by delimiter (here: fields 1, 3 to 4 and 6)
## Leslie Satenstein, Montreal,Que,Canada
This article is going to be my cheat sheet. In a few well designed examples, I have learned how to make better use of, or infact, consider using the above described command line tools.,
Thank You !!
## Ian
There is an error in the sed demo.
The example file (data) has ‘linux’ in the first line.
Part way through the demonstration, that line has changed to ‘Linux’ so that the use of case insensitive can be shown
## Gregory Bartholomew
Thanks Ian. I’ve attempted to correct the example file so that the first line contains ‘Linux’ from the beginning. |
13,665 | 如何安装 elementary 优化工具 | https://www.debugpoint.com/2021/07/elementary-tweaks-install/ | 2021-08-10T09:29:00 | [
"elementary"
] | /article-13665-1.html |
>
> 这篇快速教程演示了如何安装 elementary / Pantheon 优化工具。
>
>
>

<ruby> elementary 优化工具 <rt> elementary Tweaks Tool </rt></ruby>是专为 [elementary OS](https://www.debugpoint.com/tag/elementary) 设计的实用工具。它提供了一些用于修改 elementary 设置的选项。虽然 elementary 已经提供了绝大多数选项,但还有一小部分的 Pantheon 桌面优化是不能直接通过普通设置修改的,因此这个工具才得以诞生。这个工具与 GNOME 中的 [GNOME Tweaks](https://www.debugpoint.com/2018/05/customize-your-ubuntu-desktop-using-gnome-tweak/) 有些相似。
也就是说,安装这个工具其实十分简单,只是 [elementary OS 6 Odin](https://www.debugpoint.com/2020/09/elementary-os-6-odin-new-features-release-date/) 与早期版本(例如 elementary OS 5 Juno)存在一些区别。从 elementary OS 6 Odin 开始,这个工具已经重命名为 <ruby> Pantheon 优化工具 <rt> Pantheon Tweaks Tool </rt></ruby>。下面是安装步骤。
### 安装 elementary 优化工具
elementary OS 并没有内置用于添加 PPA 的 `software-properties-common` 软件包。如果你还没有安装此软件包,请使用如下命令安装:
```
sudo apt install software-properties-common
```
#### elementary OS 6 Odin
该版本的优化工具已经改名,并且独立于原版开发。它的名称是 [Pantheon Tweaks](https://github.com/pantheon-tweaks/pantheon-tweaks)。你可以使用如下命令安装它。
```
sudo add-apt-repository -y ppa:philip.scott/pantheon-tweaks
sudo apt install -y pantheon-tweaks
```
#### elementary OS 5 Juno 及更旧版本
如果你正在使用 elementary OS 5 Juno 或者更旧的版本,你可以使用同一 PPA 安装早期版本的 [elementary-tweaks](https://github.com/elementary-tweaks/elementary-tweaks)。在终端输入以下命令即可安装。
```
sudo add-apt-repository -y ppa:philip.scott/elementary-tweaks
sudo apt install -y elementary-tweaks
```
### 使用方法
安装完成后,你可以在 “应用程序菜单 > 系统设置 > 优化” 中使用此工具。

在“优化”窗口,你可以修改一些选项,配置你的 elementary 桌面。

顺便提示一下,这款工具仅仅是 elementary 桌面设置的前端。如果你知道准确的名称或属性,你可以直接在终端中修改配置。你在这款优化工具中获得的选项也可以在 `dconf` 编辑器中查找 `io.elementary` 路径以修改。
如果你在安装或使用优化工具时遇到了一些问题,你可以在评论区留言。
---
via: <https://www.debugpoint.com/2021/07/elementary-tweaks-install/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,666 | 是时候让 Ubuntu 选择混合滚动发布模式了 | https://news.itsfoss.com/ubuntu-hybrid-release-model/ | 2021-08-10T10:15:19 | [
"LTS",
"Ubuntu"
] | https://linux.cn/article-13666-1.html |
>
> 在两个 LTS 版本之间有三个短期版本。Ubuntu 应该用滚动发布模式来取代它们。
>
>
>

即使你不是 Ubuntu 的用户,你可能也知道它的发布模式。
有一个 [长期支持(LTS)版本](https://itsfoss.com/long-term-support-lts/),每两年发布一次,并有五年的支持。在这两个 LTS 版本之间,我们可以看到三个非 LTS 版本,它们的发布时间间隔为 6 个月。
LTS 版本会保持内核不会变化(除非你选择 [HWE 内核](https://itsfoss.com/ubuntu-hwe-kernel/)),它还维持了各种软件组件不变以提供稳定的生产环境。
介于两者之间的非 LTS 版 Ubuntu 具有 Ubuntu 的新功能、更新一些的内核、新的桌面环境以及 Ubuntu 软件库中的各种软件的新版本。
这些非 LTS 版本作为“试验场”,为最终在 LTS 版本中出现的功能提供测试,这已不是什么秘密。
这就是为什么我建议摆脱这些中间版本,在 LTS 版本之间选择 [滚动发布](https://itsfoss.com/rolling-release/) 模式。个中原因,请听我说。
### 在 LTS 发布之间进行滚动开发
六个月一次的发布计划给 Ubuntu 开发者制定了一个紧凑的工作时间表。这是一个好的方法,它可以使他们的目标集中在一个适当的路线图上。
但是,这也为在每个版本中提供“更多”新功能带来了额外的压力。如果时间很短,这不可能总是做到。还记得 [Ubuntu 不得不从 21.04 版本中删除 GNOME 40](https://news.itsfoss.com/no-gnome-40-in-ubuntu-21-04/) 吗?因为开发者没有足够的时间来完成它。
另外,最终用户(比如你和我)想选择留在非 LTS 版本中也是不可行的。其支持在九个月后结束,这意味着即使你没有立即升级到下一个非 LTS 的 Ubuntu 版本,最终你也不得不这样做。如果你在 6 个月内没升级,那你可能就得在 9 个月内升级。
我知道你会说,升级 Ubuntu 版本很简单。点击几下,良好的网速和一个潜在的备份就可以让你在新的 Ubuntu 版本上没有什么麻烦。
我的问题是,为什么要这么麻烦。滚动发布会更简单。让升级在 LTS 版本之间进行。
开发人员在新功能准备好的时候发布。用户随着系统更新不断得到升级,而不是每 6 个月或 9 个月做一次“重大升级”。
你看,那些选择非 LTS 版本的人是那些想要新功能的人,让他们通过滚动发布获得新功能。LTS 的发布时间表保持不变,每两年来一次。
### Bug 测试?像其他滚动发布的版本一样做个测试分支好了
当我说滚动发布时,我并不是指像 Arch Linux 那样的滚动。它应该是像 Manjaro 那样的滚动。换句话说,在测试后推出升级版,而不是直接在野外发布。
目前,新的 Ubuntu 版本有测试版,以便早期采用者可以测试它并向开发者提供反馈。这可以通过保留测试和稳定分支来实现,就像许多其他滚动发布的版本一样。
### 你对滚动发布怎么看?
我知道 Ubuntu 的铁杆用户期待着每一次的发布。代号、吉祥物、艺术品和墙纸,这些都是 Ubuntu 的传统的一部分。我们应该打破这种传统吗?
这只是我的看法,我很想听听你的看法。Ubuntu 应该选择这种混合滚动模式还是坚持目前的模式?你怎么看呢?
---
via: <https://news.itsfoss.com/ubuntu-hybrid-release-model/>
作者:[Abhishek](https://news.itsfoss.com/author/root/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Even if you are not an Ubuntu user, you probably are aware of its release model.
There is a [long term support (LTS) release](https://itsfoss.com/long-term-support-lts/?ref=news.itsfoss.com) that comes every two year and gets supported for five years. In between the two LTS releases, we see three non-LTS releases that are released at an interval of six months.
The LTS version retains the same kernel (unless you opt for [HWE kernel](https://itsfoss.com/ubuntu-hwe-kernel/?ref=news.itsfoss.com)) and it also holds on to various software components to provide a stable production environment.
The non-LTS Ubuntu releases that come in between feature new features from Ubuntu, newer kernel, new desktop environment and newer version of various software available from Ubuntu repositories.
It is no secret that these non-LTS releases work as a ‘testing ground’ for the features that would eventually land in the LTS release.
And this is why I suggest to get rid of these intermediate releases and opt for a [rolling release](https://itsfoss.com/rolling-release/?ref=news.itsfoss.com) model between the LTS releases. Here me out, please.
## Go rolling in-between the LTS releases
The six monthly release schedule gives the Ubuntu developers a tight schedule to work on. It’s good in the way that keeps their objective in focus with a proper roadmap.
But it also builds additional pressure to deliver ‘more’ new features in every release. That cannot always happen if the timeframe is short. Remember how [Ubuntu had to drop GNOME 40 from 21.04](https://news.itsfoss.com/no-gnome-40-in-ubuntu-21-04/) because the developers didn’t get enough time to work on it?
Also, it’s not that the end user (like you and me) gets a choice to stay with a non-LTS release. The support ends in nine months, which mean that even if you did not upgrade to the next non-LTS Ubuntu version immediately, you have to do it eventually. If it does not happen in six months, it has to in nine months.
I know you would say that upgrading Ubuntu version is simple. A few clicks, good internet speed and a potential backup will put you on the new Ubuntu version without much trouble.
And my questions is, why bother with that. A rolling release will be even simpler. Let the upgrades come between the LTS releases.
Developers release the new features when it is ready. Users get the upgrades with the system updates continually, instead of doing a ‘major upgrade’ every six or nine months.
See, the people who opt for non-LTS release are the ones who want new features. Let them get the new features through rolling releases. The LTS release schedule remains the same, coming every two years.
### Bug testing? Get a testing branch like other rolling releases
When I say rolling, I do not mean rolling like Arch Linux. It should be rolling like Manjaro. In other words, roll out the upgrades after testing rather than just releasing them in the wild.
At present, the new Ubuntu versions have beta releases so that early adopters can test it and provide feedback to the developers. This can be achieved by keeping testing and stable branches, like many other rolling release distributions.
## Rolling release or not? What do you think?
I know that hardcore Ubuntu users look forward to every single release. The code name, the mascot, the artwork and the wallpapers, these are all part of Ubuntu’s legacy. Should we break with this legacy?
It’s just my opinion and I am interested to hear yours. Should Ubuntu opt for this hybrid rolling model or stick with the current one? What do you think?
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,668 | 《代码英雄》第四季(6):开源硬件 —— 创客的联合 | https://www.redhat.com/en/command-line-heroes/season-4/open-source-hardware | 2021-08-11T12:34:00 | [
"开源硬件",
"代码英雄"
] | https://linux.cn/article-13668-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》:第四季(6)开源硬件 —— 创客的联合](https://www.redhat.com/en/command-line-heroes/season-4/open-source-hardware)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/84559c59-7868-461d-af3f-a002e1d0646f/s4e6-open-source-hardware-vfinal-20200306_tc.mp3)脚本。
>
> 导语:人们从未停止过改装。个人电脑成为主流后,对硬件的黑客改装并没有消失。但它确实发生了变化。新一代的艺术家、设计师和活跃分子正联合起来,用开源硬件来改变世界。
>
>
> 曾经,对硬件的黑客改装是昂贵和耗时的。更具适应性的微控制器正在使这种改装变得更加容易。但是,即使进入门槛开始下降,围绕硬件销售的做法也继续偏向于保密性。Ayah Bdeir、Alicia Gibb 和 Limor Fried 正在努力保持硬件的开放。这些领袖们分享了她们是如何帮助发起开源硬件运动的,并在激烈的分歧中穿行,使每个人都能成为工程师。
>
>
>
**00:00:00 - Saron Yitbarek**:
现在是 2010 年 9 月 22 日,明天第一届开源峰会即将在纽约开幕,现在,这次活动的两位组织者 Alicia Gibb 和 Ayah Bdeir 都有些忐忑不安。
**00:00:13 - Alicia Gibb**:

在这样的夜晚,总是会产生紧张的情绪,比如“天哪,要是没有人来参加怎么办?”
**00:00:20 - Ayah Bdeir**:

这就好比,“嗯,就像是我们有一个会议室,大概会来 30 人,嗯,我们还会提供三明治这样。”
**00:00:27 - Saron Yitbarek**:
Alicia Gibb 和 Ayah Bdeir 几个月之前才初次见面,Ayah 召集了一群人组织了一个名为<ruby> 开源硬件 <rt> Opening Hardware </rt></ruby>的研讨会,每一位与会者都以自己的方式参与到了一项新兴的、令人兴奋的新计划当中:<ruby> 开源硬件运动 <rt> open source hardware movement </rt></ruby>。但是,这个早期的社区非常分散,而且缺乏良好的组织,同时每个人对于“开源硬件”的理解都有所不同。当时,Alicia 和 Ayah 意识到她们需要将这个研讨会提升到一个新的水平。
**00:01:05 - Alicia Gibb**:
所以,她和我决定共同努力,把研讨会进一步升级为<ruby> 开源硬件峰会 <rt> Open Hardware Summit </rt></ruby>,让更多人可以参与到开源硬件中。
**00:01:12 - Saron Yitbarek**:
由于只有三个月的时间来准备这次峰会,紧迫的时间给她们带来了很大的压力。但是 Alicia Gibb 和 Ayah Bdeir 对于这次的合作感到非常兴奋。一群热烈的独立<ruby> 创客 <rt> maker </rt></ruby>的初次会面会碰撞出怎样的火花,她们对此非常好奇。距离第一次峰会的所剩时间已经不多了,在 9 月 23 日早上 6 时,也就是峰会召开当天的早上,她们收到了一封来自会场联系人的电子邮件。
**00:01:49**:
当今的开源硬件是整个开源运动中一个引人注目的分支,如同开源硬件与工程学联系在一起一样,它也同时涉及了设计和艺术领域。事实上,开源硬件运动是早期计算机爱好运动的延续。还记得第三集里提到的<ruby> 自制计算机俱乐部 <rt> Homebrew Computer Club </rt></ruby>的世界吗?在个人电脑成为主流之后,对硬件的黑客改造并没有就此销声匿迹。甚至当计算机成为一个巨大的专有业务之后,对硬件和电路的<ruby> 黑客改造 <rt> tinkering </rt></ruby>的热爱、对与同好者分享你的创作的热爱,也从未真正消失过。人们从未停止过改造,而如今开放的硬件文化与早期的改造爱好者有很多共通之处。不同的是,现在这个开源运动分支的掌舵人,比如 Alicia Gibb 和 Ayah Bdeir,是全新一代的开发者和思想家。在接下来的内容中,我还会为大家介绍这个运动的第三位领导者:Limor Fried。我是 Saron Yitbarek,这里是《代码英雄》,一档来自红帽的原创播客。
**00:03:09**:
早在 2000 年代中期,开源硬件社区还不能算是一个真正的社区。当然,有个黑客的小圈子,那里有对开源硬件充满想法的人。越来越多这样的圈子在世界各地出现,其中一个位于麻省理工学院(MIT)。
**00:03:32 - Ayah Bdeir**:
我是 Ayah Bdeir,是 littleBits 的创造者。这个团队几乎都是由一群在麻省理工媒体实验室里的怪人组成,我们之中有艺术家、有设计师,还有一些积极分子,我们想用科技对世界做出一些改变。
**00:03:54 - Saron Yitbarek**:
Ayah 是这个由新硬件赋能的下一代多学科创客之一。她是一名工程师和互动艺术家。她毕业于<ruby> 贝鲁特 <rt> Beirut </rt></ruby>,于 2004 年获得了计算机与通信工程及社会学的学位,之后于 2006 年毕业于麻省理工学院媒体实验室。
**00:04:15 - Ayah Bdeir**:
我和父母商量,在我取得了工程师的学位之后,我可以去学习我想要学的设计。这是一个约定。
**00:04:25 - Saron Yitbarek**:
工程技术开始进入世界各地的各种非工程领域。在 2008 年,Ayah 获得了 Eyebeam 艺术和科技中心的奖学金,就在这里,她创造了 littleBits。它是一种类似于乐高的、采用预制的、可以用磁性吸附的电子块,不过它们还包含了 LED 灯、声音传感器、发动机和太阳能电池板等。
**00:04:51 - Ayah Bdeir**:
所以当你拿出一个 LED 灯,装上电池,它就亮了。你可以在中间放一个光传感器,这样你就得到了一个小夜灯。你再将发动机和轮子装上,现在这是一个光动车了。如果再加上低功耗蓝牙模块,你就可以用手机来激活它。所以你并不需要是一个工程师,只需要花几秒钟就可以组装它。它们可以用磁铁扣住,就像是有魔法,而且扣住的时候声音听起来很美妙。
**00:05:22 - Saron Yitbarek**:
Ayah 有两个目标:把 littleBits 做成一个公司,并使之开源。她希望工程知识能够被每个人所接受。
**00:05:32 - Ayah Bdeir**:
现在只要是 IT 公司,它的很多工作都围绕着开源软件。有一些人感兴趣如何将开源应用于建筑、如何用于硬件、如何用于电子设备。世界上充满了这种奇思妙想,以及为此付出的努力,这很有意义。
**00:05:51**:
如果所有人都封锁他们的专利和知识产权,世界将会陷入困境。所以,对我来说,如何找到一种方法,让你可以支持自己,持续地发展,创造强大的企业,还可以分享知识,这很有趣。
**00:06:15 - Saron Yitbarek**:
但是 littleBits 也必须作为一个企业来运作,制造、分销、投资,每个部分都要花钱。Ayah Bdeir 是如何做到在商业化的同时,使她的硬件,也就是她的运营核心,成为开源的呢?为了找到这个问题的答案,她在<ruby> 知识共享 <rt> Creative Commons </rt></ruby>组织做了一项研究,把 littleBits 当作一项案例研究。这是她决定在 2010 年初举办“开源硬件”研讨会的原因。
**00:06:46 - Ayah Bdeir**:
我们做了一个研讨会,我们想,“哪些东西是关键?我们应该有一个定义吗?我们需要一个开会的地方吗?我们需要一个网站吗?什么有用,什么没用?”与此同时,Alicia Gibb 正在另一家想要做开源的创业公司 Bug Labs 做一些类似的工作。
**00:07:08 - Alicia Gibb**:
我非常赞成在开源你的硬件之前,需要做好情感上的准备,因为在某种程度上意味着,你要把自己的孩子送出去。
**00:07:17 - Saron Yitbarek**:
Alicia Gibb 当时在一家叫做 Bug Labs 的开源硬件供应商工作,担任研究员和原型设计师。她曾经是一位图书管理员。
**00:07:28 - Alicia Gibb**:
我本来是为了取得图书和信息管理硕士学位,最终却走向了这个奇怪的方向,进入了电子领域。我发现自己真的非常热爱它,我享受点亮一个 LED 灯的感觉,沉迷于自己可以让电子去实现一些事情。这种感觉有一些类似于你可以控制宇宙中的小小的一部分,这样的感觉有一种强大的力量,我喜欢这种感觉。
**00:07:51 - Saron Yitbarek**:
尽管图书管理和开源硬件似乎有很大差异,但是对于 Alicia 而言,这两者展现出了相似的精神。
**00:07:58 - Alicia Gibb**:
作为一名图书馆员,你的工作并不是看门,你在那里是为了帮助人们寻找他们想要的信息。这种本质有点为我铺平了一条通往开源的路,让它展现在了我的眼前。
**00:08:13 - Saron Yitbarek**:
就像 Alicia 任职的 Bug Labs,许多公司开始意识到开源硬件可以创造商业机会。小型公司可以通过开源接触到更广泛的创客群体(也可以说是顾客)。大型公司可以对竞争对手开放设计,并通过向他们提供相关部件而获利。
**00:08:39 - Alicia Gibb**:
我的老板最后问我,“你看,除了我们,一定有更多的人在尝试做开源硬件,你觉得自己可以找到他们并且把他们聚在一起吗?”
**00:08:49 - Saron Yitbarek**:
就是这段谈话,让开源峰会的种子在 Alicia 心中种下。为此她开始寻找其他开源硬件创客,此时 Ayah 也得到了知识共享组织的奖学金,并主持了这次研讨会。
**00:09:03 - Alicia Gibb**:
所以,这就是我第一次见到了 Ayah 本人。当时我非常激动,因为我读过她的研究报告,并且在写 Arduino 的论文时还参考了她的文章。这个领域的很多人我都见过,要么就是在电子邮件列表或其他地方见过。
**00:09:20 - Saron Yitbarek**:
Ayah 在她的研讨会上召集的人后来都成为了开源硬件运动的领导者。其中有 Arduino 的成员、SparkFun 和 MakerBot 的创办者,还有一位非常有趣,她以世界上第一位程序员的名字命名了她的公司。
**00:09:49 - Limor Fried**:

你好。
**00:09:50 - Saron Yitbarek**:
你好 Limor,最近怎么样?
**00:09:52 - Limor Fried**:
嗨,Saron,很高兴见到你。
**00:09:54 - Saron Yitbarek**:
我也很高兴见到你。我去曼哈顿中心拜访了 Limor Fried。她不仅是 Ayah 研讨会的一份子,同时在 2000 年代初,她也是 Ayah 在麻省理工的同学。
**00:10:09 - Limor Fried**:
我喜欢拆解物品。我很少有强烈的意愿做什么,就用音乐来举个例子吧,尽管我父母想让我去学习小提琴,我喜欢的却是摆弄电子产品、计算机和技术。当时我不太喜欢把它们重新组装起来。但是随着我渐渐长大,学习了解了更多工程学知识,我开始组装东西而不仅是把它们拆开。这些齿轮和发动机,都是美丽又复杂的技术之舞。
**00:10:37 - Saron Yitbarek**:
在麻省理工,Limor 学到的不仅是组装,更重要的是如何以一致而精密的方式一遍又一遍地组装。与此同时,一件很酷的事情正在发生,对硬件的黑客改造出现了。
**00:10:53 - Limor Fried**:
在过去的几十年,你可以将单个芯片连接起来,这样你可以制造出一些东西,但是它们相当巨大、昂贵,且耗费大量的时间。
**00:11:03**:
之后人们想到,“既然我们可以在电脑上写代码,为什么我们不为电子元件编写代码呢?”我开始尝试改造电子设备。就在这时,一些可重复编程的低成本 MAC 控制器出现在市场上。
**00:11:20 - Saron Yitbarek**:
改变游戏规则的是一款叫做 Arduino 板卡的微型控制器,由意大利人 Massimo Banzi 创造。他正在一款叫做 BASIC Stamp 的旧设备上探索交互设计的新方法,但是这个设备非常昂贵,而且计算能力较弱,也不兼容 MAC。所以 Banzi 和他的团队创造了一个更便宜、更强大的微控制器,还可以接入到电脑。他们基于一种叫做 Processing 的图形语言进行编程,他们还用公元十世纪的意大利统治者 Arduino 国王的名字来命名他们的新板卡。Arduino 的出现是 Limor Fried 这样的硬件黑客的灵感来源。
**00:12:07 - Limor Fried**:
Arduino 真的非常非常的强大,你可以用它创造你自己的产品,这是迄今为止没有出现过的。很多人是软件工程师,或者想成为软件或硬件工程师。他们可能对电脑技术有些熟悉,但是他们还没有意识到,哇,你实际上可以制造出物理硬件。我认为,对于那些码农们来说,让“盒子”在屏幕上移动是一件很好的事情,我自己也做过许多类似的事情,他们最终会想,“我真的厌倦了在我的屏幕上移动 CSS 盒子,我想要创造一些可以拿起来的东西,可以和朋友分享的东西。”
**00:12:43 - Saron Yitbarek**:
在当时,这种创造物理硬件的概念还很新,Limor 在麻省理工的工程课程中并没有涉及,所以她就另外自学了这方面的知识。
**00:12:53 - Limor Fried**:
我觉得我在学校课程和自学课程中都学到了很多东西,我很高兴我会傅里叶变换,但是我更高兴的是我熬夜做出了一个并行端口选择程序。这不是课程上教的东西,但现在它实际上已经在课程中了。
**00:13:07 - Saron Yitbarek**:
所以在 2005 年,Limor 在做改装而没有在寝室完成她的论文,导致她的论文延误了。她被电路板环绕,自己动手做 MP3 播放器和便携电子游戏机。每当她完成一个项目,她都在网上分享电路图。现在,她的线上教程变得非常受欢迎,甚至有其他的创客问她是否可以购买她定制的微型控制套件。起初她拒绝了。但之后她意识到这是有意义的。于是,在麻省理工的宿舍,Limor 开始向其他的爱好者出售电路板和电路图。她受到了<ruby> 自由软件基金会 <rt> Free Software Foundation </rt></ruby>和<ruby> 电子前沿基金会 <rt> Electronic Frontier Foundation </rt></ruby>的启发。
**00:13:58 - Limor Fried**:
修改的自由、重用的自由。就像是在五金商店里买的工具一样,他们不会说,“请在这里签署许可协议,你只可以用这个锤子来在墙上钉画,不可以用它们盖房子。如果你要盖房子,你需要买一把加强版锤子。”但是现在,这正是我们在软件方面所面临的情况。我们意识到,如果我们不给人们运用软件的自由,不允许他们以公共的方式运用他们自己写的或是别人写的软件,这将是我们的未来。
**00:14:26 - Saron Yitbarek**:
他们为软件做的事情,她同样也想为硬件做这些。Limor 想倡导那种你可以使用 Arduino 控制板来创造的硬件,那种你可以在自己的宿舍里制造出的硬件。但是,为了推进这一愿景,Limor 需要开放的心态,需要吸引和教导其他创客。而且,很快就需要对所有这些开源硬件进行保护。现在让我们回到对 Limor 的采访。
**00:14:56 - Limor Fried**:
我们现在位于曼哈顿中心,在我们 50,000 平方英尺的车间里,在这里我们完成了制造、生产、测试、编程、设计,还有一些命令行操作。
**00:15:09 - Saron Yitbarek**:
所以,是的,这和她在 2005 年创办公司的那个小寝室相差甚远。Limor 向业余爱好者发售工具包的业务最终大规模地发展成为了一家名为 Adafruit Industries 的公司,它是以构思了世界上第一个计算机程序的 19 世纪英国数学家 Ada Lovelace 命名的。
**00:15:31 - Limor Fried**:
我们在生产和制造包含开源的固件和软件的开源硬件。这像是开源世界里的<ruby> 威利旺卡仙境 <rt> Willy Wonka Wonderland </rt></ruby>。
**00:15:41 - Saron Yitbarek**:
这像是迪士尼乐园。
**00:15:41 - Limor Fried**:
是的,确实有人这么说过。
**00:15:42 - Saron Yitbarek**:
这是硬件的迪士尼乐园。Adafruit 的工厂在 2012 年开业。当我们参观它的时候,Limor 向我们展示了她的制版机,它可以勾勒出各个元件在版面上的位置。
**00:15:56 - Limor Fried**:
所以,你的手机、电脑、任何电子产品或者 GPS、你在假期赠送的小玩具、许许多多的产品都是由<ruby> 拾取-贴装 <rt> pick-and-place </rt></ruby>流水线制造出来的。这些流水线所做的就是拾起非常小的表面贴装部件,并且放置它们。正因为这样,它们的名字叫做“拾取-贴装”线。
**00:16:19 - Saron Yitbarek**:
它的 Pick 操作系统包含了数据库、字典、查询语言、流程语言、外设管理、多用户管理和编译的 BASIC 编程语言。
**00:16:33 - Limor Fried**:
是的,这是一块薄薄的金属,你可以看到上面的激光切割小孔。
**00:16:38 - Saron Yitbarek**:
嗯。
**00:16:39 - Limor Fried**:
他们看起来像花边一样漂亮。
**00:16:41 - Saron Yitbarek**:
这真的太美了。
**00:16:42 - Limor Fried**:
是的,你再看这里,在电路板上看到的图案与模板上的花边相匹配。所以在拾取-贴装之后,所有的元件都安置在了电路板上。它们要经过这个烤箱。
**00:16:56 - Saron Yitbarek**:
嗯。
**00:16:56 - Limor Fried**:
这基本上就像是熟食店里的那些百吉饼传送带。
**00:17:00 - Saron Yitbarek**:
这看起来像是一个微型的城市。
**00:17:01 - Limor Fried**:
是啊。
**00:17:03 - Saron Yitbarek**:
Limor 发现,总的来说硬件的生态系统在历史上是开放的。不像软件,硬件总是更为开放一些。当你购买机械产品,甚至是电子产品时,都会附赠电路图,以防万一你需要修理它们。
**00:17:20 - Limor Fried**:
那时我们并没有真正意义上的开源硬件,但是所有的东西,你只需要一个螺丝刀就可以轻轻撬开。因此,这是某种自带的文档。你不会在没有电路图的情况下修理你的 Apple II 的软盘驱动器,所以你可以深入挖掘电路图。可是如今,这不再是现实了。现在你的硬件是在一个美观光滑的玻璃柜中。由此可见,自愿分享硬件的年代已经结束了,这就是为什么我必须想出一种方法让人们分享它们。
**00:17:53 - Saron Yitbarek**:
Limor、Ayah、Alicia 和其他参加知识共享组织的研讨会的开源硬件爱好者们,在一个关键时刻走到了一起,当时,了解硬件是如何组装起来的机会正在减少。如果他们想要为开源硬件社区打造一个未来,让开源运动成为可持续的运动,而不再只是黑客爱好的聚会,他们需要一起建立一个带有规则、定义和标准的更集中的集体。
**00:18:22 - Limor Fried**:
开源社区就像是珍贵且易碎的宝石,一个小的难题都可能将它毁灭。它是由一个个人组成的,人们编写代码、支持代码、使用代码,并为它撰写文档。发布代码是一件非常私人的事情。你在向大家展示你是如何思考的、如何编写的、你的大脑是如何构思的。如果没有一个健康的良好的环境,人们就不会通过他们发布的代码来自由地表达自己。
**00:18:51 - Saron Yitbarek**:
之后发生了什么呢?当一代硬件创客离开他们的寝室和黑客圈子并彼此相遇时,所发生的事情将为一场运动奠定基础。这是 2010 年 9 月 23 日清晨,在几个小时之后,Alicia Gibb 和 Ayah Bdeir 将欢迎与会者们来到第一届开源硬件峰会。在短短三个月里,她们为全新一代的创客们成功创建并策划了一个崭新的活动。但是他们会来吗?当天早晨 6 点,她们收到了一封来自会场联系人的邮件,令她们惊讶的是,邮件中说……
**00:19:37 - Alicia Gibb**:
门外已经有一队人在等候入场了,而峰会要到 9 点或延后的某个时候才会开始,然而在 6 点就已经有人在等待了。
**00:19:48 - Saron Yitbarek**:
2010 年的首届峰会,大厅被 320 个人挤得满满当当。
**00:19:55 - Alicia Gibb**:
这个社区的规模大到完全出乎我们的意料,同时也提醒了我这是一个国际化的社区。其中令我印象深刻的一点是,有人想要从泰国给予我们捐赠,于是他们从泰国寄来了现金和一张便签。他们竟然会如此信任我们,以至于在信件里寄来现金。
**00:20:16 - Ayah Bdeir**:
我环顾四周,感到“就是这个瞬间”。我当时就感觉到,这里发生的一些事情将成为一个历史时刻。而就在这期间和之后,从想要赞助的人身上,从期待着明年发言的人身上,我们感受到了支持。
**00:20:34 - Saron Yitbarek**:
在第一届峰会之前,Alicia 和 Ayah 知道自己的主要目标是制定开源硬件的定义。
**00:20:42 - Alicia Gibb**:
我们需要一个定义,其实原因有两个:首先是为了社区里达成共识,这样人们就不会认为你可以把一些东西作为开源硬件放在那里,但又说,“哦,但你……得有一个非商业条款才行”。我们必须能够转售硬件,特别是因为硬件需要花钱才能从各种零件把它组装起来。所以对于人们是否分享布线图,还是只是电路图就足够了,或者你是否需要打开电路板文件以及诸如 “等等,这是否符合开源硬件的要求?因为我们控制着芯片,但我们不开放芯片的源代码” 之类的事情,存在着分歧。
**00:21:23**:
第二个原因很重要,这是关于硬件本身的。硬件不同于软件,你不能在创造它的那一刻拥有它的版权。硬件实际上是天生自由的,直到你申请到专利,并将专利封锁垄断,它才真正属于你。所以我们希望这里可以有一些定义,可以或多或少地提供法律保障,可以成为能够在法庭上得到支持的社区准则。
**00:21:55 - Saron Yitbarek**:
这实际上并不是开源硬件标准化的第一次尝试。在 1997 年,一个名为 Bruce Perens 的人创建了一个开源硬件的认证项目。他是一位著名的开源人物,因为他在同一时期帮助创建了最初的开源软件准则。这些被一个叫做<ruby> 开源倡议 <rt> Open Source Initiative </rt></ruby>(OSI)的组织管理着。但是在 1997 年,并没有围绕这个认证项目产生什么影响,随着新一代的创客开始出现,更新这些原则是有意义的。在开源峰会上,她们会让所有人都就开源硬件的标准化定义和最佳实践达成一致。仅仅让大家聚在一起,分享想法和项目似乎就能启动这个社区。但随后的讨论转向了定义开源硬件的含义。
**00:22:57 - Ayah Bdeir**:
有一些纯粹主义者认为,除非整个工具链都是开源的,否则不能称之为开源硬件。其他人会说,“不,这是不切实际的,因为我使用的一些电路设计工具或是 3D 打印机并不是开源的,但是它们是可以使用的,并且有免费的版本。”至少软件是这样的,因此,这就足以让你复制和修改那些发明。因此,为什么开源硬件的工具链必须全部是开源的呢?
**00:23:27**:
然后围绕归属问题进行了讨论。在许多开源软件的许可证中,<ruby> 归属权 <rt> attribution </rt></ruby>并不那么重要。但在这里,我们对此做了大量的讨论,因为硬件很昂贵。创造它的人并不只是在车库里对着电脑,他们还投入了美元,在现实世界里投入了现金到实物中,这些实物从一个国家来到另一个国家并且被制造出来,然后以某种方式被收回。
**00:23:58 - Saron Yitbarek**:
Ayah Bdeir 的老同学 Limor 是开源峰会的主讲人之一。
**00:24:04 - Limor Fried**:
所以我们的辩论之一是,CAD 文件必须是开源格式的吗?我记得当时大家围坐在一个大圆桌边,每个人都在发表自己的观点。有些人说,不。而有些人则说是。我们最终说,“我们不如说,它必须采用合理的原始格式,否则好像我们必须得想出点什么似的。”之后我们找到了比较折中的说法,“如果你可以发布你的文件,它不一定必须是公开的文件格式,但必须是一个可以被合理使用工具的人阅读的格式。”
**00:24:40 - Saron Yitbarek**:
他们甚至从知识共享组织请来了几位律师来帮助理顺问题。
**00:24:44 - Limor Fried**:
律师说,“听着,如果你要为开源硬件上法庭,那就已经输了。”所以我们说,很多被许可人和社区的裂痕是不匹配的期望或人们没有很好的沟通他们的期望。因此,这个定义所做的是,它不是一个真正的法律框架,因为实际上很多都没有法律保护,但它是一个框架,可以让人们表达他们的期望,他们想要他们的硬件、固件以及设计被他人使用。
**00:25:17**:
到目前为止,这个定义取得了良好的效果。当越多的人展示出他们希望自己的硬件被怎样使用,其他人就可以更好地使用这些硬件,因为这样就不会有类似“你说要这样做,但是按照法律来说我应该那么做。”的麻烦。
**00:25:35 - Saron Yitbarek**:
对于开源硬件定义的争论持续了一年。同时,还举行了一次竞赛,以创造一个与定义相一致的徽标。在 2011 年的第二届开源硬件峰会中,人们打算批准这个开源硬件的定义。但是也出现了一些小的问题,在竞赛中取得胜利的徽标有一个麻烦,它与<ruby> 开源倡议 <rt> Open Source Initiative </rt></ruby>(OSI)的徽标很相似。
**00:26:04 - Alicia Gibb**:
我当时还在想,“哦,就像彩虹和独角兽,每个人喜欢的都是类似的。”这就像是一个警钟,即使在开源社区,我想也会有错误发生,有分歧发生,也会有人想在法律上找你麻烦。
**00:26:22 - Saron Yitbarek**:
最终我们达成了妥协,但是这次的经历激发了新的运动。在 2012 年,Alicia、Ayah 及她们的团队创立了<ruby> 开源硬件联盟 <rt> Open Source Hardware Association </rt></ruby>(OSHWA),并且这个联盟也有了自己的定义。
**00:26:41 - Alicia Gibb**:
所以,开源硬件的定义差不多是,你同意把你的硬件以开源的方式呈现出来,允许其他人去学习、改造、然后转售你的设计和硬件。然后,你可以要求在硬件上注明归属,可以要求其他人遵循你附加在硬件上的许可证。
**00:27:11 - Saron Yitbarek**:
从最初的宿舍、车库和餐桌,从世界各地的上千名创客那里,终于出现了一个社区标准。
**00:27:22 - Limor Fried**:
无论你使用何种许可证,人们都可以对你说,“如果你把自己的东西称作‘开源硬件’,这就是它的定义,这里你可以表达你的基本期待。如果不符合这些,请别叫它‘开源硬件’。”除此之外,几年前我遇到的另一件事更具体一些,比如说,注册开源硬件的目录。当你要加入其中时,你基本上要做出一个小小的承诺,说我要发布的设计遵守这个定义。所以说定义是某种基石,这些东西是在基石上的高楼。所以当人们得到了一个小徽标和标识符,他们就可以说,“是的,这是开源硬件,开源硬件联盟是支持我的。”
**00:28:07 - Saron Yitbarek**:
今年(2020)是开源硬件峰会庆祝成立 10 周年,如今他们甚至开拓了消费者领域。
**00:28:16 - Alicia Gibb**:
因此,有一系列来自 System76 的电脑是开源硬件,像 LulzBot 这样的 3D 打印,还有其他 3D 打印机也是开源硬件。我认为现在我们正处于更多消费者产品出现的风口。
**00:28:35 - Saron Yitbarek**:
在过去的 10 年,开源硬件为科技文化的开放性和多样性设立了一个新的标准。
**00:28:43 - Alicia Gibb**:
真正让我远离开源软件的事情之一是,我去参加几个会议时被问我的男朋友在哪里,我是和谁一起来的,这样类似的问题。这是在假定,作为一位女性,我是不会自己前来的。我可以看到的是,在开源硬件社区中,大家都非常年轻,我们刚刚建立。我和 Ayah 都认为,“在开源硬件社区里,这样的事情一定不会发生。”
**00:29:11 - Saron Yitbarek**:
在第一届峰会时,有几个 10 岁的创客参加了会议。他们是峰会上的亮点。峰会的组织者是女性,而开源硬件运动的代言人就是女性。Limor Fried 在 2011 年成为了第一位登上《WIRED》杂志封面的女工程师。根据 Ayah Bdeir 的说法,开源硬件的可及性和多样性,是我们现在应该关注的问题。
**00:29:43 - Ayah Bdier**:
在我的成长过程中,技术一直在我的生活里。它曾经对我而言是一门学科。你可以说,自己不是技术人员,这不是问题。现在已经不是这样了。技术是我们做所有事情的基础。它是我们如何吃饭、喝水、交谈、旅行、预测和出版的基础。技术影响民主、心理健康、社会和环境。这个使命很重要,因为如果我们失去了科技的创造者和决策者,失去了象征着世界人口的构成的科技,这时我们所作的决定就会有所偏驳,这是不包容的、是危险的。
**00:30:39 - Saron Yitbarek**:
《代码英雄》是一档来自红帽的原创播客节目。请在 <https://www.redhat.com/commandlineheroes> 上查看我们对开源硬件的研究。如果你已经看到了,请注册订阅我们的新闻。我是 Saron Yitbarek,感谢你的收听。下期之前,编码不止。
**附加剧集**
Ayah Bdeir、Alicia Gibb 和 Limor Fried 是将多样性纳入开源硬件社区的早期支持者。听听她们是如何定下这个基调的。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-4/open-source-hardware>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[Ucoer](https://github.com/Ucoer) 校对:[Northurland](https://github.com/Northurland), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
People never stop tinkering. Hardware hacking didn’t disappear after personal computers became mainstream. But it did change. A new generation of artists, designers, and activists are banding together to change the world—with open source hardware.
Hardware hacking used to be expensive and time-consuming. Adaptable microcontrollers are making tinkering much easier. But even as the barriers to entry started falling, the practices around selling hardware have continued to veer toward secrecy. Ayah Bdeir, Alicia Gibb, and Limor Fried are working to keep hardware open. These leaders share how they helped build the open source hardware movement, and navigated fierce disagreements to make engineering accessible to all.

**00:00** - *Saron Yitbarek*
It's September 22, 2010, the night before the first ever Open Hardware Summit taking place in New York City, and the two organizers behind the event are worried.
**00:13** - *Alicia Gibb*
There's always that nightmare, the night before that's like, "Oh my God, what if nobody shows up?"
**00:20** - *Ayah Bdeir*
We were like, "Yeah, this will be like in a room. We'll have you know, maybe 30 people. We'll have, you know, sandwiches."
**00:27** - *Saron Yitbarek*
Alicia Gibb and Ayah Bdeir had only met for the first time a few months back. Ayah had gathered together a small group to a workshop called Opening Hardware. Each of the attendees were involved in their own way in a burgeoning and exciting new development, the open source hardware movement. But this early community was pretty scattered and lacked structure, and everyone had a slightly different take on what open source hardware even meant. That's when Alicia and Ayah realized they needed to take this workshop to the next level.
**01:05** - *Alicia Gibb*
So she and I decided to join forces and take it one step further to an Open Hardware Summit, and involve a lot more people.
**01:12** - *Saron Yitbarek*
With only a three-month window to prepare for the event, the pressure was on. But Ayah and Alicia, were excited to collaborate. And they wanted to see what could happen when a bunch of fiercely independent makers got together for the first time. But for the moment the clock was ticking away on the remaining hours left before that first summit. Then at 6 a.m. on September 23, the morning of the event, they received an email from someone at the venue.
**01:49** - *Saron Yitbarek*
Today's open source hardware is a fascinating branch of the larger open source movement. A branch that touches the fields of design and art, as much as it does engineering. In fact, this branch is a continuation of the early days of the hobbyist computer movement. Remember the Homebrew Computer Club world in episode 3? Hardware hacking didn't disappear after personal computing went mainstream. Even as computing became a big and a proprietary business, that love for tinkering with hardware and circuitry, that love for sharing your creations with other hobbyists, it never really went away. People never stopped tinkering, and today's open hardware culture has a lot in common with those early hobbyists. But at the helm of this particular branch of the open source movement is a whole new generation of developers and thinkers. People like Alicia Gibb and Ayah Bdeir. And a little later on, I'll introduce you to a third leader of the movement, Limor Fried. I'm Saron Yitbarek, and this is Command Line Heroes, an original podcast from Red Hat.
**03:09** - *Saron Yitbarek*
Back in the mid-2000s, the open source hardware community wasn't really much of a community. There were hackerspaces, sure. There, you could find people with a mind towards open source hardware. More and more of these spaces started to pop up all over the world, and one was located at MIT.
**03:32** - *Ayah Bdeir*
My name is Ayah Bdeir. I am the founder of littleBits. The group was really almost like a group of misfits from the Media Lab, where it was like artists and designers and activists that came together to use technology to make an impact in the world.
**03:54** - *Saron Yitbarek*
Ayah was part of this next generation of multidisciplinary makers, empowered by new hardware. Ayah is an engineer and interactive artist. She graduated in Beirut, with degrees in computer and communications engineering and sociology in 2004, and then from the MIT Media Lab in 2006.
**04:15** - *Ayah Bdeir*
I negotiated with my parents that if I had a degree in engineering, I could then do design, which is what I wanted to do. That was the deal.
**04:25** - *Saron Yitbarek*
Engineering tech was starting to make its way into non-engineering fields all over the world. In 2008, Ayah received a fellowship at Eyebeam Art and Technology Center. That's where she invented littleBits. littleBits are pre-engineered magnetic electronic bricks similar to Lego, except they contain lights, sound sensors, motors, solar panels.
**04:51** - *Ayah Bdeir*
And so you snap a light, an LED, to a battery—a light comes on. You put a light sensor in between. Now you've made a nightlight. You put a motor and two wheels on it, now you've made the light-activated car. You can put a BLE Bluetooth module on it. Now you can activate it with your phone, so you don't have to be an engineer. It takes you seconds to do it. They snap with magnets, so they're magical, and they sound beautiful when they snap.
**05:22** - *Saron Yitbarek*
Ayah had 2 goals: to make littleBits a company, and to make it open source. She wanted the engineering concepts to be accessible to everyone.
**05:32** - *Ayah Bdeir*
A lot of the work that existed at random IT was around open source software. There were a few people that were really interested in how does open source apply to architecture? How does open source apply to hardware? How does open source apply to electronics? It made sense that the world is full of these incredible ideas, incredible effort.
**05:51** - *Ayah Bdeir*
If everybody is always closing off their inventions and their IP, the world suffers. So for me, it was always interesting figuring out a way where you can be supporting yourself, and sustainable, and create strong businesses, but also be sharing knowledge.
**06:15** - *Saron Yitbarek*
But littleBits also had to function as a business. Manufacturing, distribution, investment—each area had costs associated with them. How could she combine business objectives while at the same time making her hardware, the crux of her operation, open source? To help her figure this out, Ayah did a fellowship with Creative Commons, and used littleBits as a case study. That's when she decided to hold that workshop, Opening Hardware, back in early 2010.
**06:46** - *Ayah Bdeir*
We did a workshop where we were like, "What are the things that are important? Should we have a definition? Should we have a place where we meet? Do we need a website? What works? What doesn't work?" And around the same time, Alicia had been doing similar work as part of being at Bug Labs, another startup that wanted to be open source.
**07:08** - *Alicia Gibb*
I'm a big proponent to make sure that you're emotionally prepared to open source your hardware before doing it, because it kind of means that you're giving away your baby.
**07:17** - *Saron Yitbarek*
Alicia Gibb was working at an open hardware supplier called Bug Labs, as a researcher and prototyper. She had started out as a librarian.
**07:28** - *Alicia Gibb*
Through getting my masters in library and information science, I ended up tripping down this weird path that led me to electronics. And I found that I really loved it and really enjoyed that feeling of when you light up an LED and you understand that you're making electrons do stuff. It's a little bit like you control this tiny part of the universe and it feels really powerful, and I just love that.
**07:51** - *Saron Yitbarek*
As different as library science and open hardware may be, for Alicia, they share the same ethos.
**07:58** - *Alicia Gibb*
You are not a gatekeeper as a librarian. You are there to help people find the information they need. And so those roots really kind of paved the way for open source to be just obvious to me really.
**08:13** - *Saron Yitbarek*
Companies like Alicia's employer Bug Labs, were starting to understand the business opportunities that open source hardware could offer. Smaller companies could tap into a broader group of makers, a.k.a. customers, by going open source. Larger companies could open source designs to competitors, and still profit by supplying them with related components.
**08:39** - *Alicia Gibb*
My boss ended up asking me, "Look, there's got to be more people trying to do open source hardware than us. Do you think you can find those people and get everybody together?"
**08:49** - *Saron Yitbarek*
The seed for the future summit was planted with that conversation. So as Alicia started searching for other open source hardware makers, Ayah received the Creative Commons fellowship, and hosted the workshop.
**09:03** - *Alicia Gibb*
So this was the first time that I would get to meet Ayah in person. And I was pretty excited about it, because I had read her research and used it in my research when I was doing my thesis on Arduino. A lot of the people in the field I had either met or been on email lists or whatever.
**09:20** - *Saron Yitbarek*
The people that Ayah gathered around the table at her workshop have gone on to become leaders in the open source hardware movement. Members of the Arduino team, founders of SparkFun and MakerBot, as well as one very interesting individual who named her hardware company after the world's first computer programmer.
**09:49** - *Limor Fried*
Hello, welcome.
**09:50** - *Saron Yitbarek*
Hello Limor, how's it going?
**09:52** - *Limor Fried*
Hi Saron, it's good to meet you.
**09:54** - *Saron Yitbarek*
Nice to meet you as well. I went to visit Limor Fried in downtown Manhattan. Not only was Limor part of Ayah's workshop, she and Ayah were classmates at MIT when Limor was an engineering student back in the early 2000s.
**10:09** - *Limor Fried*
I like to take things apart. I never really had an urge to, for example, play music, right? Despite what my parents wanted me to do, which was practice violin. But what I really did like to do was play with electronics and computers and technology. Not so much put them back together. But as I got older, I learned a little bit more engineering and I would put things together, and not just take them apart. There's all these gears and motors and yeah, these are very beautiful, intricate dances of technology.
**10:37** - *Saron Yitbarek*
At MIT, Limor learned not just how things are put together, but how to do it over and over again with consistency and precision. At the same time, something cool was happening. The advent of hardware hacking.
**10:53** - *Limor Fried*
In the decades before, you would take individual chips and you would wire them up, and you could build stuff, but it was extremely large, expensive and time consuming.
**11:03** - *Limor Fried*
...and then people kind of came to this idea of like, "Whoa, you can write code on a computer. Why don't we write code for electronic components?" I was starting to tinker around with electronics right at the same time when these very low-cost MAC controllers that were reprogrammable were coming into the market.
**11:20** - *Saron Yitbarek*
The game changer was a microcontroller called the Arduino board created by an Italian guy named Massimo Banzi. He was researching new approaches to interactive design on an older device called the BASIC Stamp, but it was expensive and had a relatively weak computing power. It also wasn't MAC compatible, so Banzi and his team built a cheaper, more powerful microcontroller, which you could plug into any computer. They based the programming on a graphics language called Processing and they named their new board after King Arduin, a ruler of Italy in the 1000s. The Arduino was an inspiration for hardware hackers like Limor Fried.
**12:07** - *Limor Fried*
Really, really powerful stuff because you can make your own products, which was something that was really not available. There's a lot of people out there who are software engineers, or who want to be software engineers, or want to be hardware engineers. And they may have a little bit of familiarity with computers' technology, but they don't realize, wow, you can actually make physical hardware. And I think for people who do a lot of typing in and like make boxes move on screens, which is a wonderful thing and I've done plenty of it myself, they're eventually like, "I'm really tired of just moving the CSS box on my screen. I want to make something that I can hold up, that can share it with other people."
**12:43** - *Saron Yitbarek*
At the time, this concept was so new, it wasn't being covered in Limor's engineering classes at MIT. So she taught herself on the side.
**12:53** - *Limor Fried*
I think I learned a lot from both. I'm glad I know how to take a Fourier transform, but I'm also really glad I stayed up late making a Parallel Port Pick programmer. Right? It's not something that was taught. Now it's actually in the course.
**13:07** - *Saron Yitbarek*
So in 2005, instead of working on her thesis in her dorm room, Limor procrastinated, and she did that by tinkering. She surrounded herself with circuit boards and started making DIY MP3 players and portable video game players. Each time she finished a project, she shared the schematics online. Now get this. Her online tutorials became so popular that other makers started asking her if they could buy her custom microcontroller kits. At first, she refused. But then she realized she was onto something. So from her MIT dorm room, Limor started selling her circuit boards and schematics to other hobbyists. She was inspired by the Free Software Foundation and the Electronic Frontier Foundation.
**13:58** - *Limor Fried*
Freedom to modify, freedom to reuse. Just like you can buy tools at a hardware store, they don't say, "Here, sign this license agreement. You can only use this hammer to put up a painting and you can't use it to build a house. You have to buy the pro hammer for that." But yet, that's kind of where we're at with software, that we're very aware that this was a future that was going to happen if we didn't give people freedom to use the software that they wrote and other people wrote together in a communal fashion.
**14:26** - *Saron Yitbarek*
What they were doing for software, she wanted to do for hardware. She wanted to champion the kind of hardware you could make with the Arduino board, the kind of hardware you can make in your dorm room. But to push that vision forward, Limor needed to be open, needed to attract and teach other makers. And soon, there need to be protections for all that open hardware. Back to my visit with Limor.
**14:56** - *Limor Fried*
Well, we're here in downtown Manhattan at our 50,000 square-foot facility where we do manufacturing, production, testing, programming, design, and of course, a little bit of command line as well.
**15:09** - *Saron Yitbarek*
So yeah, it's a far cry from that tiny dorm room where she started her company in 2005. Limor's business selling kits to hobbyists has grown massively into Adafruit Industries. It's named after Ada Lovelace, an English mathematician who conceptualized the world's first computer program back in the 19th century.
**15:31** - *Limor Fried*
We are producing and manufacturing open source hardware that has open source firmware and software inside of it. This is like an open source Willy Wonka Wonderland.
**15:41** - *Saron Yitbarek*
It's like a Disneyland.
**15:41** - *Limor Fried*
Yes. People say that.
**15:42** - *Saron Yitbarek*
The Disneyland for hardware. The Adafruit factory opened in 2012. As we toured it, Limor showed me her stenciling machine, which outlines where on the board the various components will go.
**15:56** - *Limor Fried*
So your cell phone, your laptop, any piece of electronic or GPS, little toys you're going to give away in the holidays, a lot of those contain electronics, and they're manufactured on a pick-and-place line. And what a pick-and-place line does is they pick up very small surface mount components and they place them. Thus, the name pick-and-place.
**16:33** - *Limor Fried*
Yeah. So this is a thin piece of metal, and you can see the little laser cut holes in it.
**16:38** - *Saron Yitbarek*
Yeah.
**16:39** - *Limor Fried*
They look quite beautiful like lace.
**16:41** - *Saron Yitbarek*
It's really pretty.
**16:42** - *Limor Fried*
Yeah. There, again, the pattern that you see here on a circuit board matches that lace on the stencil. So after the pick-and-places, all the components are placed down on the circuit board. They go through this oven.
**16:56** - *Saron Yitbarek*
Okay.
**16:56** - *Limor Fried*
Which is basically just like those bagel conveyors at the deli.
**17:00** - *Saron Yitbarek*
It's kind of like a little city, it looks like.
**17:01** - *Limor Fried*
Yes. This is...
**17:03** - *Saron Yitbarek*
Limor sees the nature of hardware as historically open in general. Unlike software, hardware has always been more open to a point. Schematics were routinely included when you bought mechanical products, even electronic products, in case you had to repair them.
**17:20** - *Limor Fried*
We didn't really have open source hardware then, but everything, you could just pop it open with a screwdriver. So in case, it was sort of self-documenting. You wouldn’t be able to fix your Apple II floppy disk drive without the schematics, so digging schematics. And nowadays, it's not true anymore. Nowadays, your hardware comes in a beautiful sleek glass rectangle. And so that's why I think we had to come up with something that allowed people to share hardware because the era of sharing hardware voluntarily was sort of ending.
**17:53** - *Saron Yitbarek*
Limor, Ayah, Alicia and the other open hardware devotees at that Creative Commons workshop came together at a crucial time when access to how hardware was put together was drying up. If they wanted to ensure the future of an open source hardware community, one that could move beyond hobby hacking to become a sustainable movement, they would need to come together as a more focused collective with rules, definitions, and standards.
**18:22** - *Limor Fried*
Open source communities are like precious delicate jewels. A little tick and they can just shatter. It's made of people, people. We write the code, we support it, we use it, we document it. Releasing code is a very personal thing. You're showing people, here's how I think, here's how I work, here's how my brain is organized. And if it's not a healthy place to do that, people aren't going to be free to express themselves through the code that they release.
**18:51** - *Saron Yitbarek*
What happened next? What happened when a generation of open hardware makers left their dorm rooms and hackerspaces and met each other would lay the groundwork for a movement. It's early morning on September 23, 2010. In a few hours, Alicia Gibb and Ayah Bdeir would welcome attendees to the first ever Open Hardware Summit. They managed to create and plan a brand new event for a whole new generation of makers in 3 short months. But would they come? At 6:00 that morning, they received an email from their contact that the venue, to their surprise it said...
**19:37** - *Alicia Gibb*
There's a line out the door already of people waiting to get in. And the event doesn't start till 9:00 or something and it was 6:00 AM and people were already there.
**19:48** - *Saron Yitbarek*
At that inaugural summit in 2010, 320 people crowded the hall.
**19:55** - *Alicia Gibb*
We were absolutely unaware of how big the community was. And it still floors me how international the community is. At one point, somebody wanted to send us a donation from Thailand. And so they sent us cash, a note from Thailand. And it's like wow, people in Thailand believe in us so much that they're going to send us cash through the mail.
**20:16** - *Ayah Bdeir*
And I kind of looked around the room and I was like, "Oh, this is a moment." There is something going on in this room that is going to be a historical moment and I felt it at the time. And just the kind of support we got during and afterwards from people that wanted to sponsor, people that wanted to speak next year.
**20:34** - *Saron Yitbarek*
Before its first year, Alicia and Ayah knew their main goal would be to develop a working definition of open hardware.
**20:42** - *Alicia Gibb*
There were really two reasons that we needed a definition. The first was to get the community on the same page so that people weren't assuming that you can put something out there as open source hardware, but then say, "Oh, but you... There's a noncommercial clause to this." You have to be able to resell the hardware, especially because hardware takes money to mine the parts out of the ground. So there were disagreements on whether or not people needed to share their routing traces, or if just the schematic was enough, or if you needed to open the board file and things like that. "Wait, does this fit with open source hardware or not? Because we control the chip, but we don't open source the chip."
**21:23** - *Alicia Gibb*
And then the second reason it was important is that with hardware, it's different than software where you don't instantly get copyright on it the second that you create it. So hardware is actually kind of born free until you patent it, until you decide to close it down with a monopoly. So we wanted there to be some kind of definition as more or less a tiny little legal hinge, that really it becomes a community norm, which can be held up in courts.
**21:55** - *Saron Yitbarek*
This wasn't actually the first attempt at a standardized notion of open hardware. In 1997, a guy named Bruce Perens created an open hardware certification program. Perens was a notable open source figure because he had helped create the original open source software guidelines around the same time. Those are administered by an organization called the Open Source Initiative, OSI. But not much happened around Perens' hardware certification program in 1997, and with a new generation of makers entering the scene, it made sense to refresh the principles. At that summit, they'd get everyone to agree on a standardized definition and best practices for open source hardware. Just getting everyone together, sharing ideas and projects seemed to kickstart the community. But then discussions turned toward defining what open source hardware meant.
**22:57** - *Ayah Bdeir*
There were the purists who believed that you couldn't call it open source hardware unless the entire toolchain was open source. Others would say, "No, that's not realistic because some of the circuit design tools or the 3D printing tools that I use are not open source, but they're accessible and there are free versions of them." Well the software at least. And so that's enough for you to replicate and modify the invention. So why does a toolchain have to be open source?
**23:27** - *Ayah Bdeir*
Then there were conversations around attribution. In many open source software licenses, attribution is not as important. In this case, there was a lot of discussion about it because hardware is expensive. So the person who's created it has not only just put in time in a garage with a laptop, they've put in dollars, actual cash into physical things that moved from country to country oftentimes, and were made, and those things need to be recouped in some way.
**23:58** - *Saron Yitbarek*
One of the summit's keynote speakers was Ayah Bdeir's old classmate, Limor Fried.
**24:04** - *Limor Fried*
So one of the debates we had was, does the CAD file have to be in an open format? I remember there was a big round table and everyone kind of had their say and some people were like, no. And some people said yes. And we eventually said, "Well, let's change it to say it has to be in the original format that's like a reasonable... Like we have to come up with something." So we kind of came up with a little bit of a middle ground saying, "If you can release the files, it doesn't have to be in an openly documented format, but has to be in a format that can be read by a person with reasonable access to tools."
**24:40** - *Saron Yitbarek*
They even brought in a few lawyers from Creative Commons to help iron things out.
**24:44** - *Limor Fried*
And they said, "Look, if you are going to court over open source hardware, it's already over." So we said that the thing that a lot of licensees and communities have that fractures them is mismatched expectations or people not communicating their expectations. So what the definition does is, it's not really a legal framework, because there's actually no legal protection for a lot of these, but it's a framework for people to express their expectations, how they want and expect their hardware and firmware and designs to be used.
**25:17** - *Limor Fried*
And so far that's actually worked out really well. The more people are open about what they want people to use their hardware for, the better off everybody else is, because there's no devolution of communication where people are like, "Well, you said this, but legally I can do that."
**25:35** - *Saron Yitbarek*
The debate over what defined open source hardware continued for a year. Meanwhile, a contest was held to create a logo to go along with the definition. In 2011 at the second Open Source Hardware Summit, the intention was to ratify the definition, but this is where things hit a bit of a snag. The winning logo raised some issues because it bore a resemblance to the Open Source Initiative’s logo.
**26:04** - *Alicia Gibb*
I was still sort of like, "Oh, everything's like rainbows and unicorns and everybody likes everybody." It was sort of a wake-up call to like, oh, even in the open source community, I guess there can be mistakes that happen and disagreements that happen and people who want to come after you legally.
**26:22** - *Saron Yitbarek*
A compromise was eventually reached, but the experience galvanized the new movement. In 2012 Alicia, Ayah, and the team founded the Open Source Hardware Association, also known as OSHWA. At long last OSHWA had its definition.
**26:41** - *Alicia Gibb*
So the open source hardware definition is more or less that you are agreeing to put your hardware out there as open source, making it available for people to study and learn from, to remix, to remake, to remanufacture and to resell your design and your hardware. And then you can ask for attribution on your hardware and you can ask people to follow a license that you attach to your hardware.
**27:11** - *Saron Yitbarek*
From all those dorm rooms and garages and dining room tables, from a thousand makers around the world, a community standard was finally emerging.
**27:22** - *Limor Fried*
No matter what license you use, people can point to and say, "If you're calling your thing open source hardware, here's the definition, here's what you're basically saying your expectations are. If that's not true, call it something else." And then on top of that, another thing that came across a few years ago was an actual, like, directory for registering open source hardware. When you go there you basically kind of check a little pledge that says, my design I'm releasing abides by this definition. So the definition kind of is the rock and this is sort of the building on top of it, so that people get a little logo and an identifier and they can say, "Yes, this is open source hardware and the Open Source Hardware Association is standing by me."
**28:07** - *Saron Yitbarek*
This year the Open Source Hardware Summit celebrates its 10th anniversary, and these days it's even creeping into consumer products.
**28:16** - *Alicia Gibb*
So there are an entire line of computers out there that are from System76 that are open source hardware, 3D printers like LulzBot, and there's other 3D printers that are also open source hardware. I think right now we're sort of on the cusp of more consumer products coming out.
**28:35** - *Saron Yitbarek*
Over the last 10 years, open hardware has set a new bar for openness and diversity in tech culture.
**28:43** - *Alicia Gibb*
One of the things that really turned me off from the open source software communities is going to a couple meetings and being asked where my boyfriend was, or who I was there with, or whatever. This assumption that, as a female, I wouldn't be there by myself. Because I could see that the open hardware community was very young and that we were just building. And so myself and Ayah were both like, "Okay, this can't happen in our community."
**29:11** - *Saron Yitbarek*
At the first summit, there were a couple of 10-year-old makers in attendance. There were people of color in the room. The organizers were women, and the face of the open hardware movement is literally female. Limor Fried was the first woman engineer to be featured on the cover of WIRED Magazine in 2011, and according to Ayah Bdeir, the accessibility and diversity that open hardware thrives in, is something we should all care about these days.
**29:43** - *Ayah Bdier*
When I was growing up, technology was a thing that existed. It was a discipline. You could live your life saying, "I'm not technical," and that would be fine. It's no longer the case. Technology is the foundation of everything that we do. It's how we eat, how we drink, how we communicate, how we travel, how we predict, how we publish. They affect democracy, they affect mental health, they affect social impact, they affect environmental impact. The mission is important because if we don't have creators of technology and decision makers and technology representing the demographic makeup of the world, then we are making decisions that are biased or discriminatory, that are non-inclusive and that are dangerous.
**30:39** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Check out our research on open source hardware at [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes). And while you're there, sign up for our newsletter. I'm Saron Yitbarek. Until next time, keep on coding.
### Further reading
[ Hackerspace Culture: An Interview with Alicia Gibb of the Blow Things Up Lab](https://manifold.umn.edu/read/hackerspace-culture/section/7d67d87e-587c-4c0c-b6f8-d9eca1aeac72) by Georgie Archibald
[ Drones, Chumbys, and big business: the Open Hardware Summit](https://arstechnica.com/gadgets/2010/09/drones-chumbys-and-big-business-too-the-open-hardware-summit/) by John Timmer
### Bonus episode
Ayah Bdeir, Alicia Gibb, and Limor Fried were early proponents of building diversity into the open source hardware community. Hear how they set the tone. |
13,669 | 使用 Linux 终端查看你的电脑上有哪些文件 | https://opensource.com/article/21/8/linux-list-files | 2021-08-11T14:24:57 | [
"ls"
] | https://linux.cn/article-13669-1.html |
>
> 通过这个 Linux 教程学习如何使用 ls 命令在终端中列出文件。
>
>
>

要在有图形界面的计算机上列出文件,你通常可以打开一个文件管理器(Linux 上的 “文件”,MacOS 上的 “访达”,Windows 上的 “文件资源管理器”)来查看文件。
要在终端中列出文件,你可以使用 `ls` 命令来列出当前目录中的所有文件。而 `pwd` 命令可以告诉你当前所在的目录:
```
$ pwd
/home/tux
$ ls
example.txt
Documents
Downloads
Music
Pictures
Templates
Videos
```
你可以通过 `--all`(简写为 `-a`) 选项看到隐藏文件:
```
$ pwd
/home/tux
$ ls --all
. Downloads
.. .local
.bashrc Music
.config Pictures
example.txt Templates
Documents Videos
```
如你所见,列出的前两项是点。单个点(`.`)实际上是一个元位置,代表 *你当前所在的文件夹* 。两个点(`..`)表示你可以从当前位置返回的上级目录。也就是说,当前目录在另一个文件夹中。当你在计算机目录间移动时,你就可以利用这些元位置为自己创建快捷方式,或者增加你的路径的独特性。
### 文件和文件夹以及如何区分它们
你可能会注意到,文件和文件夹是很难区分的。一些 Linux 发行版有一些漂亮的颜色设置,比如所有的文件夹都是蓝色的,文件是白色的,二进制文件是粉色或绿色的,等等。如果你没有看到这些颜色,你可以试试 `ls --color`。如果你有色盲症或者使用的不是彩色显示器,你可以使用 `--classify` 选项替代:
```
$ pwd
/home/tux/Downloads
$ ls --classify
android-info.txt
cheat/
test-script.sh*
```
你会发现,文件夹末尾加了一个斜杠(`/`),以表示它们是文件系统中的某一级目录。而二进制文件,如压缩文件和可执行程序,用星号(`*`)标记。
---
via: <https://opensource.com/article/21/8/linux-list-files>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[piaoshi](https://github.com/piaoshi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | To list files on a computer with a graphical interface, you usually open a file manager (**Files** on Linux, **Finder** on MacOS, **Windows Explorer** on Windows), and look at the files.
To list files in a terminal, you use the **ls** command to list all files in the current directory. The **pwd** commands tells you what directory you're currently in.
```
$ pwd
/home/tux
$ ls
example.txt
Documents
Downloads
Music
Pictures
Templates
Videos
```
You can view hidden files with the **--all** option:
```
$ pwd
/home/tux
$ ls --all
. Downloads
.. .local
.bashrc Music
.config Pictures
example.txt Templates
Documents Videos
```
As you can see, the first items listed are dots. The single dot is actually a meta location meaning *the folder you are currently in*. The two dots indicate that you can move back from this location. That is, you are in a folder in another folder. Once you start moving around within your computer, you can use that information to create shortcuts for yourself or to increase the specificity of your paths.
## Files and folders and how to tell the difference
You may notice that it's hard to tell a file from a folder. Some Linux distributions have some nice colors set up so that all folders are blue and the files are white and binary files are pink or green, and so on. If you don't see those colors, you can try **ls --color**. If you're color blind or on a display that doesn't provide colors, you can alternately use the **--classify** option:
```
$ pwd
/home/tux/Downloads
$ ls --classify
android-info.txt
cheat/
test-script.sh*
```
As you can see, folders are given a trailing slash (`/`
) to denote that they are steps within your file system. Binary entities, like zip files and executable programs, are indicated swith an asterisk (`*`
).
## Comments are closed. |
13,670 | 久等了!elementary OS 6 “Odin” 正式发布,带来令人激动的新变化 | https://news.itsfoss.com/elementary-os-6-release/ | 2021-08-11T14:42:00 | [] | https://linux.cn/article-13670-1.html |
>
> 基于 Ubuntu 20.04 LTS,备受期待的 elementary OS 6 终于可以下载了。
>
>
>

[2021 年最值得期待的 Linux 发行版](https://news.itsfoss.com/linux-distros-for-2021/) 之一,终于来了。
elementary OS 6 基于 Ubuntu 20.04 LTS,它大幅改进了用户体验和安全性。
虽然我们已经列出了 [elementary OS 6 的新功能列表](https://news.itsfoss.com/elementary-os-6-features/),但咱们还是来看看本次更新的主要亮点吧。
### 正式引入暗黑模式

elementary OS 6 加入这个功能可能为时太晚,但至少他们做了极大的努力,让整个系统拥有一致的暗黑模式体验。
你也会注意到,预装应用和应用中心里部分适配过的应用都支持暗黑模式。
暗黑模式在安装 elementary OS 6 后也可以直接在欢迎页设置。
### 通知优化

通知现在支持操作按钮和图标徽章,视觉更舒适,也更加易用。
### Flatpak 优先原则

为了加强隐私保护和安全性,elementary OS 6 提供了开箱即用的 Flatpak 应用支持。
现在,不仅仅是系统应用,在应用中心,所有应用都已经打包为 Flatpak 格式。
### 多点触控手势

对于触控板和触摸屏用户,elementary OS 6 带来了不错的手势交互,你完全可以借助手势来穿梭于系统中。
你甚至可以通过手势来忽略通知。
### 新应用,新更新
本次更新中,待办事项和固件更新正式加入预装应用。
同时,大部分系统应用(如邮件)也重构了 UI,以及获得了一些新功能。
### 其他重要改进

如果你想了解更多关于本次更新的内容,我强烈建议你试用 elementary OS 6 来自行探索。
当然,如果你现在就想速览其他重要的新功能,那么我列出几个:
* 在安装应用中心之外的第三方应用时会有警告。
* 在向终端粘贴需要 root 权限的命令时会有警告。
* 更便于区分多任务视图中活动窗口的细节变化。
* 系统设置内置了在线账户集成。
* 辅助功能优化。
* 全新壁纸。
* 改进的安装器。
### 下载 elementary OS 6
你现在可以从 elementary OS 的官网获取 elementary OS 的最新版本。如需了解详情,你也可以查阅 [官方公告](https://blog.elementary.io/elementary-os-6-odin-released/)。
* [下载 elementary OS 6](https://elementary.io)
---
via: <https://news.itsfoss.com/elementary-os-6-release/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

One of the [most anticipated Linux distros in 2021](https://news.itsfoss.com/linux-distros-for-2021/) has finally arrived.
elementary OS 6 is based on Ubuntu 20.04 LTS and it comes loaded with improvements to the user experience and security overall.
While we already have a [list of exciting features in elementary OS 6](https://news.itsfoss.com/elementary-os-6-features/), let us look at the key highlights of this release.
## Introducing Dark Mode
elementary OS 6 is probably late to the party, but it looks like they have made some significant efforts to provide a consistent system-wide dark mode.
You will notice the dark style theme preference matching the pre-loaded applications and supported applications from the AppCenter as well.
The dark style theme preference is also available in the Welcome screen right after you install elementary OS 6.
## Notification Improvements
The notifications now support action buttons and icon badges, which should make them look good and useful.
## Flatpak-First Approach
To enhance privacy and security, elementary OS 6 provides Flatpak apps out-of-the-box.
Not just limited to the pre-installed applications but you will also find all the applications listed as Flatpak packages in the AppCenter.
## Multi-Touch Gestures
For both touchpad and touch screen users, elementary OS 6 brings in some exciting gesture interactions with which you can totally navigate through the system.
You can even dismiss notifications using gestures.
## New Applications & Upgrades
Some new applications like Tasks and Firmware have been introduced with this release.
And, most of the system applications like Mail, received some level of UI redesign along with feature additions.
## Other Significant Improvements
To explore more about the latest release, I would recommend you going through the features in elementary OS 6.
However, if you want a quick summary of other important additions, here it is:
- You get warned when side loading an application outside the AppCenter.
- You get a warning if you try to paste a command that needs root access in the terminal.
- Subtle changes to distinguish active windows in the multi-tasking view.
- Online account integration support from the system settings.
- Improved accessibility
- New wallpapers
- Improved installer
## Download elementary OS 6
You can get the latest version from their website. For more details on the release, you can refer to the [official announcement](https://blog.elementary.io/elementary-os-6-odin-released/?ref=news.itsfoss.com) as well.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,672 | 2021 年可以购买的 10 大 Linux 笔记本电脑 | https://news.itsfoss.com/best-linux-laptops-2021/ | 2021-08-12T11:01:00 | [
"Linux",
"笔记本电脑"
] | https://linux.cn/article-13672-1.html |
>
> 想挑选一台安装有 Linux 的新笔记本电脑?这里有几个选项可以考虑。
>
>
>

Linux 笔记本电脑是 MacOS 和 Windows 笔记本电脑的完美替代品。
从技术上讲,你可以通过安装任何你能找到的 Linux 发行版,将你选择的任何笔记本电脑变成一台 Linux 机器。
但是,在这里,我们的重点将放在提供 Linux 开箱即用体验的笔记本电脑上,确保无论你有什么样的预算,都能获得最佳的兼容性和支持。
### 大众品牌的 Linux 笔记本电脑
对于消费者来说,选择由大众品牌制造商生产的 Linux 笔记本电脑往往是最好的选择。
你不必担心售后、延长保修期和服务维修等问题。
戴尔和联想是通常提供预装了 Linux 的笔记本电脑的厂商之一。
请注意,这会因国家/地区的情况而定。
*本文中提到的价格已转换为美元,以方便比较,不包括运费和其他额外费用。*
#### 1、联想 Thinkpad X1 Carbon (第 8 代/第 9 代)

**价格**:起价为 **$1535**
联想的整个 Thinkpad 系列是 Linux 用户的一个热门选择。它经久耐用,提供了良好的兼容性。
然而,它的价格一直偏高。
你有三种选择,这取决于你的需求。如果你定制一台第 9 代 Thinkpad 笔记本电脑,你可以选择安装 Ubuntu 20.04 和 Fedora 33。
对于第 8 代机型,似乎 Fedora 33 不在考虑之列,而是提供了 Fedora 32 和 Ubuntu 20.04。
所有的配置都采用英特尔芯片组,第 8 代采用的是 10 代芯片组,第 9 代采用 11 代芯片组。
其他的大部分规格都相似,有 14 英寸显示屏(FHD、WQHD 和 UHD 可供选择)、高达 32GB 的内存、1TB 固态硬盘、指纹识别器和 Wi-Fi 6 支持。
* [Thinkpad X1 Carbon (第 9 代)](https://www.lenovo.com/us/en/laptops/thinkpad/thinkpad-x1/X1-Carbon-G9/p/22TP2X1X1C9)
* [Thinkpad X1 Carbon (第 8 代)](https://www.lenovo.com/us/en/laptops/thinkpad/thinkpad-x1/X1-Carbon-Gen-8-/p/22TP2X1X1C8)
#### 2、戴尔 XPS 13 开发者版

**价格**:起价为 **$1059**
戴尔 XPS 系列是一个令人印象深刻的、可以考虑运行 Linux 的笔记本电脑系列。
它是为开发者运行 Linux(Ubuntu 20.04)而定制的。
你可以得到一个 13.4 英寸的显示屏(有 FHD 和 UHD 可选)、第 11 代 i5/i7 处理器、高达 32GB 的内存、2TB 固态硬盘、指纹识别器,以及 Wi-Fi 6 支持。
* [戴尔 XPS 13 开发者版](https://www.dell.com/en-us/work/shop/dell-laptops-and-notebooks/new-xps-13-developer-edition/spd/xps-13-9310-laptop/ctox139w10p2c3000u)
### 纯 Linux 制造商的笔记本电脑
如果你不想要主流的选择,而是想要一些独特的选择,那你可以选择支持纯 Linux 制造商,有几个是你可以考虑的。
#### 1、System76 Gazelle

**价格**:起价为 **$1499**
System76 的笔记本电脑将内置他们的 Pop!\_OS 操作系统,该系统基于 Ubuntu,但提供了**无忧的开箱即用体验**。
可以把 System76 视作 Linux 笔记本电脑中的苹果电脑,他们尽力为其提供的硬件优化了 Pop!\_OS。
他们可以完全控制这些软件和硬件,所以这对终端消费者来说应该是令人兴奋的产品整合。
除了 144Hz 的 16.5 英寸显示屏、第 11 代 i7 处理器、高达 8TB 的 NVMe 固态硬盘支持等令人印象深刻的基本配置外,你还会有一个 RTX 3050 GPU,应该可以让你在笔记本电脑上处理各种苛刻的任务。
虽然 System76 还有一些其他型号的笔记本电脑,但在写这篇文章时,还没有上市。因此,请随时查看官方商店页面,订购定制的配置。
* [System76 Gazelle](https://system76.com/laptops/gazelle)
#### 2、Purism 笔记本电脑

**价格**:起价为 **$1599**
如果你是一个有安全意识的用户,Purism 的笔记本电脑可以作为一个选择。
Librem 14 是他们最新的笔记本电脑之一,带有 [PureOS](https://www.pureos.net)(也是由他们制造的)。
虽然它可能没有提供最新一代的处理器,但你应该对机上的第 10 代 i7 芯片感到满意吧。
它支持高达 64GB 的内存,并具有硬件封禁开关,可以禁用网络摄像头、耳机插孔、蓝牙或无线音频。
* [Librem 14](https://puri.sm/products/librem-14/)
#### 3、TUXEDO Aura 15

**价格**:起价为 **$899**
如果你想要一台 AMD 的笔记本电脑(采用上一代处理器 Ryzen 7 4700U),TUXEDO 计算机公司的 Aura 15 是一个不错的选择。
主要规格包括全高清显示屏、高达 64GB 的内存、支持 Wi-Fi 6,以及一个 LTE 模块。
它配备了 Ubuntu 或 TUXEDO 操作系统(基于 Ubuntu Budgie),可根据你的定制要求。
* [TUXEDO Aura 15](https://www.tuxedocomputers.com/en/Linux-Hardware/Linux-Notebooks/15-16-inch/TUXEDO-Aura-15-Gen1.tuxedo)
#### 4、TUXEDO Stellaris 15

**价格**:起价为 **$2160**
如果你正在寻找最新和最强大的笔记本电脑,并希望用上 RTX 3080 显卡,这应该是一个非常好的选择。
它提供了最新的英特尔/AMD Ryzen 处理器的配置选择,并具有 165Hz 刷新率的 3K 分辨率显示屏。
它绝不是你会觉得在旅行时带着方便的东西,但如果你需要计算能力,你可以选择它。
* [TUXEDO Stellaris 15](https://www.tuxedocomputers.com/en/Linux-Hardware/Linux-Notebooks/15-16-inch/TUXEDO-Stellaris-15-Gen3.tuxedo)
#### 5、Slimbook Pro X

**价格**:起价为 **$1105**
Slimbook 专注于旅行方便携带的轻薄笔记本电脑型号。
你可以选择各种发行版,包括 Ubuntu(GNOME、KDE、MATE)、KDE Neon、Manjaro 和 Fedora。
你可以得到大部分的基本规格,包括支持高达 2TB 的固态硬盘、64GB 的内存、全高清 IPS 显示屏等等。
虽然你可以选择英特尔和 AMD Ryzen(最新一代处理器),并分别与 Nvidia 和 Vega 图形处理器相结合,但在写这篇文章时只有 Ryzen 型号有库存。
* [Slimbook Pro X](https://slimbook.es/en/store/slimbook-pro-x)
#### 6、Slimbook Essential

**价格**:起价为 **$646**
一个令人印象深刻的预算友好型 Linux 笔记本电脑的选择。
它提供了 AMD Ryzen 和英特尔的变体(最后一代)供你选择。你得到硬件规格还可以,包括高达 64GB 的内存、2TB 的 SSD 支持,但是要少一个大的屏幕和板载专用显卡。
* [Slimbook Essential](https://slimbook.es/en/essential-en)
#### 7、Jupiter 14 Pro

**价格**:起价为 **$1199**
Juno 计算机公司的 Jupiter 14 采用了第 11 代英特尔处理器,并配备了 NVIDIA GTX 1650,价格诱人。
它内置了 Ubuntu 20.04 系统,没有其他系统可供选择。
基本配置包括 16GB 内存,与其他一些产品相比,这可能更物超所值一些。
你会发现在他们的网站上可以选择你的地区(英国/欧洲或美国/加拿大),请确保利用这一点。
* [Jupiter Pro 14](https://junocomputers.com/us/product/jupiter-14-pro/)
#### 荣誉奖:PineBook Pro

PineBook Pro 是一款基于 ARM 的笔记本电脑(采用 Manjaro ARM 版),预算低廉,对于 Linux 上的很多基本任务来说,应该可以正常工作。
在写这篇文章的时候,它已经没有库存了(直到进一步通知)。然而,当你看到这篇文章时,可以自己去看看一下。
* [Pinebook Pro](https://www.pine64.org/pinebook-pro/)
### 总结
如果你不喜欢这里的选择,你可以去看看 [其他可以购买 Linux 笔记本电脑的地方](https://itsfoss.com/get-linux-laptops/)。根据你的预算,选择你觉得最适合你的东西。
毕竟,所有的东西都有 Linux 的影子。有些可以让你能够从多个发行版中选择,但大多数人都坚持使用预装的 Ubuntu。
---
via: <https://news.itsfoss.com/best-linux-laptops-2021/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Linux laptops are the perfect alternatives to macOS and Windows-powered laptops.
Technically, you can turn any laptop of your choice into a Linux machine by choosing to install any Linux distribution available.
But, here, our focus will be on the laptops that offer Linux out-of-the-box, ensuring the best compatibility and support no matter what kind of budget you have.
## Linux Laptops by Popular Brands
It is often the best choice for a consumer to opt for a Linux laptop built by a popular manufacturer.
You do not have to worry about the after-sales, warranty extensions, and service repairs.
Dell and Lenovo are usually the ones who provide laptops with Linux pre-installed.
Do note that everything is subject to availability depending on the country/region.
**Pricing mentioned in this article is converted to USD for easy comparison, excluding shipping and other extras.*
### 1. Lenovo Thinkpad X1 Carbon (Gen 8 / Gen 9)

**Pricing**: Starts at **$1535**
The entire Thinkpad series by Lenovo is a popular choice among Linux users. It is built to last and offers good compatibility
However, it stays on the expensive side.
You will have three choices to go with depending on what you go for. If you are customizing a Gen 9 Thinkpad laptop, you will have Ubuntu 20.04 and Fedora 33 as your options to have installed.
For Gen 8 models, it seems that Fedora 33 is off the table, and it is Fedora 32 instead, along with Ubuntu 20.04.
All the variants are powered by Intel chipsets, 10th gen for Gen 8 and 11th gen for Gen 9.
Most of the other specifications remain similar with a 14-inch display (FHD, WQHD, and UHD options available), up to 32 GB RAM, 1 TB SSD, fingerprint reader, and Wi-Fi 6 support.
### 2. Dell XPS 13 Developers Edition

**Pricing**: Starts at **$1059**
Dell XPS series is an impressive laptop lineup to consider running Linux.
It has been tailored to run Linux (Ubuntu 20.04) with developers in mind.
You get a 13.4-inch display (FHD and UHD options available), 11th gen i5/i7 processor, up to 32 GB RAM, 2 TB SSD, fingerprint reader, and Wi-FI 6 support.
## Laptops by Linux-only Manufacturers
If you do not want mainstream options but some unique choices to support Linux-only manufacturers in the process, there are a couple of them that you can consider.
### 1. System76 Gazelle
**Pricing**: Starts at **$1499**
System76’s laptop will come baked in with their Pop!_OS operating system which is based on Ubuntu but provides a **hassle-free out-of-the-box experience**.
It is safe to assume that System76 is like the Apple of Linux laptops who try their best to optimize Pop!_OS for their hardware offered.
They have total control over the software and hardware, so that should be some exciting product integration for end consumers.
Along with impressive essentials like 144 Hz 16.5-inch display, i7 11th gen processor, up to 8 TB NVMe SSD support—you also get an RTX 3050 GPU which should enable you to tackle a variety of demanding tasks on your laptop.
While there are some other laptops by System76, it was not available at the time of writing this. So, feel free to check out the official store page and order a customized configuration.
### 2. Purism Laptop

**Pricing**: Starts at **$1599**
A laptop by Purism can be an option if you are a security-conscious user.
Librem 14 is one of their latest laptops that comes baked in with [PureOS](https://www.pureos.net/?ref=news.itsfoss.com) (also built by them).
While it may not offer the latest generation processors, you should be fine with the i7 10th Gen chip on board.
It supports up to 64 GB of RAM and features hardware kill switches to disable the webcam, headphone jack, Bluetooth, or wireless audio
### 3. TUXEDO Aura 15

**Pricing**: Starts at **$899**
If you want an AMD-powered laptop (with its last-gen processor Ryzen 7 4700U), Aura 15 by TUXEDO Computers is a great pick.
The key specifications include a Full HD display, up to 64 GB RAM, Wi-Fi 6 support, and an LTE module.
It comes with either Ubuntu or TUXEDO OS (based on Ubuntu Budgie) as per your customization.
### 4. TUXEDO Stellaris 15

**Pricing**: Starts at **$2160**
If you are looking for the latest and greatest powerhouse with options to get RTX 3080 on board, this should be a fantastic option.
It offers the latest Intel/Ryzen processor with the configuration choices and features a 3K-res display with a 165 Hz refresh rate.
Definitely not something that you would find convenient to travel with, but if you need the computing power, you can choose to go with it.
### 5. Slimbook Pro X

**Pricing:** Starts at **$1105**
Slimbook focuses on lighter Laptop models that you can conveniently travel with.
It gives you the option to choose from a variety of distributions that include Ubuntu (*GNOME, KDE, MATE*), KDE Neon, Manjaro, and Fedora.
You get most of the essential specifications that include up to 2 TB SSD support, 64 GB of RAM, Full HD IPS display, and more.
While you get options for Intel and Ryzen (last-gen processors) coupled with Nvidia and Vega graphics respectively, only Ryzen was available in stock at the time of writing this.
### 6. Slimbook Essential

*Pric***ing:** Starts at **$646**
An impressive option for a budget-friendly Linux laptop.
It offers both Ryzen and Intel variants (last-gen) to choose from. You should get the basic specifications that include up to 64 GB RAM, 2 TB SSD support, minus a great screen and dedicated graphics onboard.
### 7. Jupiter 14 Pro by Juno Computers

**Pricing**: Starts at **$1199**
Featuring the 11th gen Intel processors, Jupiter 14 by Juno Computers is a sweet deal with NVIDIA GTX 1650 on board.
It comes baked in with Ubuntu 20.04 with no other options to choose from.
The base configuration includes 16 GB RAM, which could make the value offering slightly better compared to some others.
You will find the ability to choose your region on their website (UK/Europe or US/Canada), make sure to utilize that.
### Honorable Mention: **PineBook Pro**

PineBook Pro is an ARM-based laptop (with Manjaro ARM edition) that is budget-friendly and should work fine for a lot of basic tasks on Linux.
It is out of stock (until further notice) at the time of writing this. However, you might want to check that for yourself when you read this.
## Wrapping Up
If you do not like the choices presented here, you may check out [other places from where you can by Linux laptops](https://itsfoss.com/get-linux-laptops/?ref=news.itsfoss.com). Depending on your budget, pick what you feel is best for you.
After all, everything comes with Linux baked in. Some give you the ability to choose from multiple distros but most of them stick to Ubuntu pre-installed.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,673 | COPR 仓库中 4 个很酷的新项目(2021.07) | https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-july-2021/ | 2021-08-12T11:21:49 | [
"COPR"
] | https://linux.cn/article-13673-1.html | 
COPR 是个人软件仓库 [集合](https://copr.fedorainfracloud.org/),它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准;或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己背书的。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
本文介绍了 COPR 中一些有趣的新项目。如果你第一次使用 COPR,请参阅 [COPR 用户文档](https://docs.pagure.org/copr.copr/user_documentation.html)。
### Wike
[Wike](https://github.com/hugolabe/Wike) 是一个用于 GNOME 桌面的维基百科阅读器,在 GNOME Shell 中集成了搜索功能。它提供了对 [在线百科全书](https://en.wikipedia.org/wiki/Main_Page) 的无干扰访问。它的界面很简约,但它支持在多种语言之间切换文章、书签、文章目录、黑暗模式等。

#### 安装说明
该 [仓库](https://copr.fedorainfracloud.org/coprs/xfgusta/wike/) 目前为 Fedora 33、34 和 Fedora Rawhide 提供了 Wike。要安装它,请使用这些命令:
```
sudo dnf copr enable xfgusta/wike
sudo dnf install wike
```
### DroidCam
我们正生活在一个混乱的时代,被隔离在家中,我们与朋友和同事的大部分互动都发生在一些视频会议平台上。如果你已经有一部手机,就不要把钱浪费在价格过高的网络摄像头上。[DroidCam](https://www.dev47apps.com/) 让你将手机与电脑配对,并将其作为专用网络摄像头使用。通过 USB 线或通过 WiFi 进行连接。DroidCam 提供对摄像头的远程控制,并允许缩放、使用自动对焦、切换 LED 灯和其他便利功能。

#### 安装说明
该 [仓库](https://copr.fedorainfracloud.org/coprs/meeuw/droidcam) 目前为 Fedora 33 和 34 提供了 DroidCam。在安装之前,请更新你的系统并重新启动,或者确保你运行的是最新的内核版本,并安装了适当版本的 `kernel-headers`。
```
sudo dnf update
sudo reboot
```
Droidcam 依赖 `v4l2loopback`,必须从 [RPM Fusion 自由软件仓库](https://docs.fedoraproject.org/en-US/quick-docs/setup_rpmfusion/#proc_enabling-the-rpmfusion-repositories-using-command-line-utilities_enabling-the-rpmfusion-repositories) 手动安装。
```
sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
sudo dnf install v4l2loopback
sudo modprobe v4l2loopback
```
现在安装 `droidcam` 软件包:
```
sudo dnf copr enable meeuw/droidcam
sudo dnf install droidcam
```
### Nyxt
[Nyxt](https://nyxt.atlas.engineer/) 是一个面向键盘、可无限扩展的 Web 浏览器,专为高级用户设计。它在很大程度上受到 Emacs 的启发,因此用 Common Lisp 实现和配置,提供熟悉的按键绑定([Emacs](https://en.wikipedia.org/wiki/Emacs)、[vi](https://en.wikipedia.org/wiki/Vim_(text_editor))、[CUA](https://en.wikipedia.org/wiki/IBM_Common_User_Access))。
其他不能错过的杀手锏是一个内置的 REPL、[树形历史](https://nyxt.atlas.engineer/#tree)、[缓冲区代替标签](https://nyxt.atlas.engineer/#fuzzy),还有[更多](https://nyxt.atlas.engineer/)。
Nyxt 与网络引擎无关,所以不用担心页面会以意外的方式呈现。

#### 安装说明
该 [仓库](https://copr.fedorainfracloud.org/coprs/teervo/nyxt/) 目前为 Fedora 33、34 和 Fedora Rawhide 提供了 Nyxt。要安装它,请使用这些命令:
```
sudo dnf copr enable teervo/nyxt
sudo dnf install nyxt
```
### Bottom
[Bottom](https://github.com/ClementTsang/bottom) 是一个具有可定制界面和多种功能的系统监控器,它从 [gtop](https://github.com/aksakalli/gtop)、[gotop](https://github.com/xxxserxxx/gotop) 和 [htop](https://github.com/htop-dev/htop/) 获得了灵感。因此,它支持 [进程](https://clementtsang.github.io/bottom/nightly/usage/widgets/process/) 监控、[CPU](https://clementtsang.github.io/bottom/nightly/usage/widgets/cpu/)、[RAM](https://clementtsang.github.io/bottom/nightly/usage/widgets/memory/) 和 [网络](https://clementtsang.github.io/bottom/nightly/usage/widgets/network/) 使用监控。除了这些,它还提供了更多奇特的小部件,如 [磁盘容量](https://clementtsang.github.io/bottom/nightly/usage/widgets/disk/) 使用情况,[温度传感器](https://clementtsang.github.io/bottom/nightly/usage/widgets/temperature/),和 [电池](https://clementtsang.github.io/bottom/nightly/usage/widgets/battery/) 使用情况。
由于小部件的可自定义布局以及 [可以只关注一个小部件并最大化它](https://clementtsang.github.io/bottom/nightly/usage/general-usage/#expansion),Bottom 可以非常有效地利用屏幕空间。

#### 安装说明
该 [仓库](https://copr.fedorainfracloud.org/coprs/opuk/bottom/) 为 Fedora 33、34 和 Fedora Rawhide 提供了 Bottom。它也可用于 EPEL 7 和 8。要安装它,请使用这些命令:
```
sudo dnf copr enable opuk/bottom
sudo dnf install bottom
```
使用 `btm` 命令来运行该程序。
---
via: <https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-july-2021/>
作者:[Jakub Kadlčík](https://fedoramagazine.org/author/frostyx/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Copr is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in Fedora Linux. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora Linux standards, despite being free and open-source. Copr can offer these projects outside the Fedora Linux set of packages. Software in Copr isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
This article presents a few new and interesting projects in Copr. If you’re new to using Copr, see the [Copr User Documentation](https://docs.pagure.org/copr.copr/user_documentation.html) for how to get started.
Wike
[Wike](https://github.com/hugolabe/Wike) is a Wikipedia reader for the GNOME Desktop with search integration in the GNOME Shell. It provides distraction-free access to the [online encyclopedia](https://en.wikipedia.org/wiki/Main_Page). The interface is minimalistic but it supports switching an article between multiple languages, bookmarks, article table of contents, dark mode, and more.
Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/xfgusta/wike/) currently provides Wike for Fedora 33, 34, and Fedora Rawhide. To install it, use these commands:
sudo dnf copr enable xfgusta/wike sudo dnf install wike
DroidCam
We are living through confusing times, being isolated at our homes, and the majority of our interactions with friends and coworkers take place on some video conference platform. Don’t waste your money on an overpriced webcam if you carry one in your pocket already. [DroidCam](https://www.dev47apps.com/) lets you pair your phone with a computer and use it as a dedicated webcam. The connection made through a USB cable or over WiFi. DroidCam provides remote control of the camera and allows zooming, using autofocus, toggling the LED light, and other convenient features.
Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/meeuw/droidcam) currently provides DroidCam for Fedora 33 and 34. Before installing it, please update your system and reboot, or make sure you are running the latest kernel version and have an appropriate version of *kernel-headers* installed.
sudo dnf update sudo reboot
Droidcam depends on *v4l2loopback* which must be installed manually from the [RPM Fusion Free repository](https://docs.fedoraproject.org/en-US/quick-docs/setup_rpmfusion/#proc_enabling-the-rpmfusion-repositories-using-command-line-utilities_enabling-the-rpmfusion-repositories).
sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm sudo dnf install v4l2loopback sudo modprobe v4l2loopback
Now install the *droidcam* package:
sudo dnf copr enable meeuw/droidcam sudo dnf install droidcam
Nyxt
[Nyxt](https://nyxt.atlas.engineer/) is a keyboard-oriented, infinitely extensible web browser designed for power users. It was heavily inspired by Emacs and as such is implemented and configured in Common Lisp providing familiar key-bindings ([Emacs](https://en.wikipedia.org/wiki/Emacs), [vi](https://en.wikipedia.org/wiki/Vim_(text_editor)), [CUA](https://en.wikipedia.org/wiki/IBM_Common_User_Access)).
Other killer features that cannot be missed are a built-in REPL, [tree history](https://nyxt.atlas.engineer/#tree), [buffers instead of tabs](https://nyxt.atlas.engineer/#fuzzy), and [so much more](https://nyxt.atlas.engineer/).
Nyxt is web engine agnostic so don’t worry about pages rendering in unexpected ways.
Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/teervo/nyxt/) currently provides Nyxt for Fedora 33, 34, and Fedora Rawhide. To install it, use these commands:
sudo dnf copr enable teervo/nyxt sudo dnf install nyxt
Bottom
[Bottom](https://github.com/ClementTsang/bottom) is a system monitor with a customizable interface and multitude of features, It took inspiration from [gtop](https://github.com/aksakalli/gtop), [gotop](https://github.com/xxxserxxx/gotop), and [htop](https://github.com/htop-dev/htop/). As such, it supports [processes](https://clementtsang.github.io/bottom/nightly/usage/widgets/process/) monitoring, [CPU](https://clementtsang.github.io/bottom/nightly/usage/widgets/cpu/), [RAM](https://clementtsang.github.io/bottom/nightly/usage/widgets/memory/), and [network](https://clementtsang.github.io/bottom/nightly/usage/widgets/network/) usage monitoring. Besides those, it also provides more exotic widgets such as [disk capacity](https://clementtsang.github.io/bottom/nightly/usage/widgets/disk/) usage, [temperature sensors](https://clementtsang.github.io/bottom/nightly/usage/widgets/temperature/), and [battery](https://clementtsang.github.io/bottom/nightly/usage/widgets/battery/) usage.
Bottom utilizes the screen estate very efficiently thanks to the customizable layout of widgets as well as the [possibility to focus on just one widget and maximizing it](https://clementtsang.github.io/bottom/nightly/usage/general-usage/#expansion).
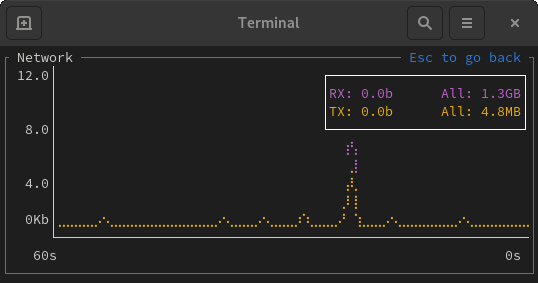
Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/opuk/bottom/) currently provides Bottom for Fedora 33, 34, and Fedora Rawhide. It is also available for EPEL 7 and 8. To install it, use these commands:
sudo dnf copr enable opuk/bottom sudo dnf install bottom
Use *btm* command to run the program.
## sefa
should/can we trust this repository?
## Darvond
Unlike PPAs or random snaps/flatpaks you find on the internet, the COPR is a centrally organized repository like the AUR.
While caution can always be advised when dealing with unfamiliar software, I think it’d be rather paranoid to not entrust the sense of trust into the article’s author and the authority of the organizers of the COPR to have vetted the software.
## Jakub Kadlčík
I like the comparison with AUR, I think it’s a good one.
It’s up to you and your own consideration. Should you install kernel from a random Copr project onto some bank servers?
Probablynot. Can you trust Copr in general, use software from it and benefit? I would say, absolutely!I would say, we need to split the topic into two separate discussions.
1) Can we trust Copr as a platform?
Copr is open source, so you can see for yourself, that we don’t do anything fishy, internally it uses all the standard tools for building packages that also Koji uses, we sign the built packages, we work closely with the Fedora infrastructure team, and what else.
If there are any worries regarding the credibility of Copr as a service/platform, please let us know, so we can address them.
2) Can we trust the software available in Copr?
We allow only people with FAS accounts to create projects and build packages in Copr. You can easily find out more information about each project owner and decide whether you find them trustworthy or not. You can also see the build details and see how exactly each build was submitted, and you can also obtain an SRPM file for each build. Therefore you can validate the sources and spec file for yourself and see there is not anything malicious.
If you are suspicious of some piece of software or just not sure about it, you can always see all the details, we don’t hide any piece of information.
To me, that makes Copr trustworthy and personally, I use multiple packages from it.
## Lyes Saadi
Congratulations to xfgusta for his first COPR repo in 4 cool projects to try in COPR 😀 ! And good luck to him in his packaging journey 🙂 !
## Jakub Kadlčík
I am also wishing the best throughout the packaging journey and success on the following steps such as adding the software into the official Fedora repositories.
Also, seems like we are going to be covering some of your new projects Lyes 😉
## Lyes Saadi
He opened some Pull Request to improve the state of some packages in src.fedoraproject.org (including on Dialect), and he seems to be packaging on COPR to gain some experience. On his wiki page he stated his willingness to enter the packaging world, so I was quite happy to see him here 😀 ! His specs are also very clean (at least, way better than what I produced when I began two years ago).
## Stephen Snow
I love these COPR articles! I’m on Fedora Linux 34 Silverblue, using nyxt from a toolbox container writing this comment now. Good write up Jakub.
## Jakub Kadlčík
I am happy to hear that Stephen, thank you. Nyxt is on my radar for maybe a year and it being packaged and available in Copr is a big deal for me. Looking forward to migrating to it soon.
## Ben
Thanks for this list Jakub, re bottom, it can be of help to share that bottom can be installed directly via Rust’s package manager:
cargo install bottom
works for me on Fedora 33 / Rust
That said I do not want to diminish the work that goes into copr making these tools available for Fedora as rpms, I prefer rpms whenever possible, just saying that if you needed the nightly/latest version then Rust’s cargo works quite well (for me).
Thanks for sharing Nyxt, really cool find.
## Jakub Kadlčík
Thank you for the feedback Ben.
I agree with you. If needed (e.g. for development purposes) installing software via third-party package managers such as cargo/pip/npm/… often works well. So if it fits you, then perfect 🙂
When I find myself wanting to use some application from such source, I usually just package it into RPM. Writing spec files for applications that are already packaged via some programming-language-specific package manager is often surprisingly easy and well documented. I encourage everyone to try if you get a chance 🙂
It is, isn’t it? I have had it on my radar for maybe a year and I am really looking forward to finding some time and migrating to it.
## Eric
PCem is available via COPR too. It is an awesome hardware-level emulator for many models of IBM PCs and compatibles.
## Jakub Kadlčík
Thank you for the suggestion. I am adding it to my list of interesting Copr projects that haven’t been written about yet 🙂
## BTWIUseFedora
Who in the world approved COPR as suitable title/abbreviation. Facepalm.
## Sebastiaan
What’s wrong with it? It’s a cheeky reference to “copper”.
## Jakub Kadlčík
In what way do you find the COPR abbreviation facepalming? Genuinely curious.
Just to throw in some info from the documentation
But I can’t remember the origin story behind inventing the name. If it is a good one, I’ll share.
## BTWIUseFedora
TBH I’m glad no one else struggling not to add O. Such nice, innocent community.
## Eric
Hi about the droidcam on fedora I was seeing
modprobe: FATAL: Module v4l2loopback not found in directory /lib/modules/5.13.5-200.fc34.x86_64
After installing
sudo dnf install v4l-utils-devel-tools
sudo modprobe v4l2loopback
without any issues now. |
13,674 | 使用 Linux 终端浏览你的计算机 | https://opensource.com/article/21/8/navigate-linux-directories | 2021-08-12T11:36:00 | [
"Linux",
"目录"
] | https://linux.cn/article-13674-1.html |
>
> 学习在 Linux 终端中从一个目录切换到另一个目录。
>
>
>

要在图形界面中浏览你的计算机上的文件夹,你可能习惯于打开一个窗口来“进入”你的计算机,然后双击一个文件夹,再双击一个子文件夹,如此反复。你也可以使用箭头按钮或按键来回溯。
而要在终端中浏览你的计算机,你可以利用 `cd` 命令。你可以使用 `cd ..` 回到 *上一级* 目录,或者使用 `cd ./另一个/文件夹的/路径` 来跳过许多文件夹进入一个特定的位置。
你在互联网上已经使用的 URL 的概念,实际上直接来自 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains)。当你浏览某个网站的一个特定页面时,比如 `http://www.example.com/tutorials/lesson2.html`,你实际上做的是进入 `/var/www/imaginarysite/tutorials/` 目录,并打开一个叫 `classic2.html` 的文件。当然,你是在 Web 浏览器中打开它的,浏览器会将所有那些看起来奇怪的 HTML 代码解释成漂亮的文本和图片。但这两者的思路是完全一样的。
如果你把你的计算机看成是互联网(或者把互联网看成是计算机会更合适),那么你就能理解如何在你的文件夹和文件中遨游了。如果从你的用户文件夹(你的家目录,或简记为 `~`)开始,那么你想切换到的文件夹都是相对于这个文件夹而言的:
```
$ cd ~/Documents
$ pwd
/home/tux/Documents
$ cd ..
$ pwd
/home/tux
```
这需要一些练习,但一段时间后,它会变得比你打开和关闭窗口、点击返回按钮和文件夹图标快得多。
### 用 Tab 键自动补全
键盘上的 `Tab` 键可以自动补全你开始输入的文件夹和文件的名字。如果你要 `cd` 到 `~/Documents` 文件夹,那么你只需要输入 `cd ~/Doc`,然后按 `Tab` 键即可。你的 Shell 会自动补全 `uments`。这不仅仅是一个令人愉快的便利工具,它也是一种防止错误的方法。如果你按下 `Tab` 键而没有任何东西自动补全,那么可能你 *认为* 存在于某个位置的文件或文件件实际上并不存在。即使有经验的 Linux 用户也会试图切换到一个当前目录下不存在的文件夹,所以你可以经常使用 `pwd` 和 `ls` 命令来确认你确实在你认为你在的目录、以及你的当前目录确实包含了你认为它包含的文件。
---
via: <https://opensource.com/article/21/8/navigate-linux-directories>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[piaoshi](https://github.com/piaoshi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | To navigate through the directories of your computer in a graphical interface, you're probably used to opening a window to get "into" your computer, and then double-clicking on a folder, and then on a subfolder, and so on. You may also use arrow buttons or keys to back track.
To navigate through your computer in the terminal, you use the **cd** command. You can use **cd ..** to move one directory *back*, or **cd ./path/to/another/folder** to jump through many folders into a specific location.
The concept of a URL, which you use on the Internet already, is actually pulled directly from [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains). When you navigate to a specific page on some website, like `http://www.example.com/tutorials/lesson2.html`
, you are actually changing directory to `/var/www/imaginarysite/tutorials/`
and opening a file called `lesson2.html`
. Of course, you open it in a web browser, which interprets all that weird-looking HTML code into pretty text and pictures. But the idea is exactly the same.
If you think of your computer as the Internet (or the Internet as a computer, more appropriately), then you can understand how to wander through your folders and files. If you start out in your user folder (your home, or `~`
for short) then everywhere you want to go is relative to that:
```
$ cd ~/Documents
$ pwd
/home/tux/Documents
$ cd ..
$ pwd
/home/tux
```
This requires some practise, but after a while it becomes far faster than opening and closing windows, clicking on back buttons and folder icons.
## Auto-completion with Tab
The **Tab** key on your keyboard auto-completes names of directories and files you're starting to type. If you're going to **cd** into `~/Documents`
, then all you need to type is `cd ~/Doc`
and then press **Tab**. Your shell auto-completes `uments`
. This isn't just a pleasant convenience, it's also a way to prevent error. If you're pressing **Tab** and nothing's being auto-completed, then probably the file or directory you *think* is in a location isn't actually there. Even experienced Linux users try to change directory to a place that doesn't exist in their current location, so use **pwd** and **ls** often to confirm you are where you think you are, and that your current directory actually contains the files you think it contains.
## 2 Comments |
13,676 | 用 kubectl 管理 Kubernetes 的 5 种有用方法 | https://opensource.com/article/21/7/kubectl | 2021-08-13T10:53:46 | [
"kubectl"
] | https://linux.cn/article-13676-1.html |
>
> 学习 kubectl,提升你与 Kubernetes 的互动方式。
>
>
>

Kubernetes 可以帮你编排运行有大量容器的软件。Kubernetes 不仅提供工具来管理(或者说 [编排](https://opensource.com/article/20/11/orchestration-vs-automation))运行的容器,还帮助这些容器根据需要进行扩展。有了 Kubernetes 作为你的中央<ruby> 控制面板 <rt> control panel </rt></ruby>(或称 <ruby> 控制平面 <rt> control plane </rt></ruby>),你需要一种方式来管理 Kubernetes,而这项工作的工具就是 kubectl。`kubectl` 命令让你控制、维护、分析和排查 Kubernetes 集群的故障。与许多使用 `ctl`(“控制”的缩写)后缀的工具一样,如 `systemctl` 和 `sysctl`,`kubectl` 拥有大量的功能和任务权限,所以如果你正在运行 Kubernetes,你肯定会经常使用它。它是一个拥有众多选项的命令,所以下面是 `kubectl` 中简单易用的五个常见任务。
### 1、列出并描述资源
按照设计,容器往往会成倍增加。在某些条件下,它们可以快速增加。如果你只能通过 `podman ps`或 `docker ps` 来查看正在运行的容器,这可能会让你不知所措。通过 `kubectl get` 和 `kubectl describe`,你可以列出正在运行的<ruby> 吊舱 <rt> pod </rt></ruby>以及它们正在处理的容器信息。更重要的是,你可以通过使用 `--namespace` 或 `name` 或 `--selector`等选项,只列出所需信息。
`get` 子命令不仅仅对吊舱和容器有用。它也有关于节点、命名空间、发布、服务和副本的信息。
### 2、创建资源
如果你只通过类似 OpenShift、OKD 或 Kubernetes 提供的 Web 用户界面(UI)创建过发布,但你想从 Linux 终端控制你的集群,那么可以使用 `kubectl create`。`kubectl create` 命令并不只是实例化一个新的应用发布。Kubernetes 中还有很多其他组件可以创建,比如服务、配额和 [计划任务](https://opensource.com/article/20/11/kubernetes-jobs-cronjobs)。
Kubernetes 中的计划任务可以创建一个临时的吊舱,用来在你选择的时间表上执行一些任务。它们并不难设置。下面是一个计划任务,让一个 BusyBox 镜像每分钟打印 “hello world”。
```
$ kubectl create cronjob \
hello-world \
--image=busybox \
--schedule="*/1 * * * *" -- echo "hello world"
```
### 3、编辑文件
Kubernetes 中的对象都有相应的配置文件,但在文件系统中查找相应的文件较为麻烦。有了 `kubectl edit`,你可以把注意力放在对象上,而不是定义文件上。你可以通过 `kubectl` 找到并打开文件(通过 `KUBE_EDITOR` 环境变量,你可以设置成你喜欢的编辑器)。
```
$ KUBE_EDITOR=emacs \
kubectl edit cronjob/hello-world
```
### 4、容器之间的传输文件
初次接触容器的人往往对无法直接访问的共享系统的概念感到困惑。他们可能会在容器引擎或 `kubectl` 中了解到 `exec` 选项,但当他们不能从容器中提取文件或将文件放入容器中时,容器仍然会显得不透明。使用 `kubectl cp` 命令,你可以把容器当做远程服务器,使主机和容器之间文件传输如 SSH 命令一样简单:
```
$ kubectl cp foo my-pod:/tmp
```
### 5、应用变更
对 Kubernetes 对象进行修改,可以通过 `kubectl apply` 命令完成。你所要做的就是将该命令指向一个配置文件:
```
$ kubectl apply -f ./mypod.json
```
类似于运行 Ansible 剧本或 Bash 脚本,`apply` 使得快速“导入”设置到运行中的 Kubernetes 实例很容易。例如,GitOps 工具 [ArgoCD](https://argoproj.github.io/argo-cd/) 由于 `apply` 子命令,安装起来出奇地简单:
```
$ kubectl create namespace argocd
$ kubectl apply -n argocd \
-f https://raw.githubusercontent.com/argoproj/argo-cd/vx.y.z/manifests/install.yaml
```
### 使用 kubectl
Kubectl 是一个强大的工具,由于它是一个终端命令,它可以写成脚本,并能实现用众多 Web UI 无法实现的功能。学习 `kubectl` 是进一步了解 Kubernetes、容器、吊舱以及围绕这些重要的云计算创新技术的一个好方法。[下载我们的 kubectl 速查表](https://opensource.com/downloads/kubectl-cheat-sheet),以获得快速参考,其中包括命令示例,以帮助你学习,并在为你提供注意细节。
---
via: <https://opensource.com/article/21/7/kubectl>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Kubernetes is software to help you run lots of containers in an organized way. Aside from providing tools to manage (or [orchestrate](https://opensource.com/article/20/11/orchestration-vs-automation)) the containers you run, Kubernetes also helps those containers scale out as needed. With Kubernetes as your central control panel (or *control plane*), you need a way to manage Kubernetes, and the tool for that job is kubectl. The `kubectl`
command lets you control, maintain, analyze, and troubleshoot Kubernetes clusters. As with many tools using the `ctl`
(short for "control") suffix, such as systemctl and sysctl, kubectl has purview over a broad array of functions and tasks, so you end up using it a lot if you're running Kubernetes. It's a big command with lots of options, so here are five common tasks that kubectl makes easy.
1. List and describe resources
Containers, by design, tend to multiply. Under certain conditions, they can multiply rapidly. This can get overwhelming if the only way you have to see running containers is `podman ps`
or `docker ps`
. With `kubectl get`
and `kubectl describe`
, you can get information about what pods are running and the containers they're handling. What's more is that you can get just the information you need by using options like `--namespace`
or `name`
or `--selector`
.
The `get`
subcommand is useful for a lot more than just pods and containers. It has information about nodes, namespaces, deployments, services, and replicas.
2. Create resources
If you've only ever created deployments through a web user interface (UI) like one provided by OpenShift, OKD, or Kubernetes, but you're looking to take control of your cluster from your Linux terminal instead, then get ready to use `kubectl create`
. The `kubectl create`
command doesn't just instantiate a new app deployment, though. There are lots of other components available in Kubernetes that you can create, such as services, quotas, and [CronJobs](https://opensource.com/article/20/11/kubernetes-jobs-cronjobs).
A CronJob in Kubernetes can create a transient pod meant to perform some task on a schedule of your choice. They're not difficult to set up. Here's a CronJob to have a BusyBox image echo "hello world" every minute:
```
$ kubectl create cronjob \
hello-world \
--image=busybox \
--schedule="*/1 * * * *" -- echo "hello world"
```
3. Edit files
You may have an understanding that objects in Kubernetes have accompanying configuration files, but rummaging through your filesystem to find the appropriate file can be troublesome. With `kubectl edit`
, you can keep your mind on the objects and not on the files that define them. You can have `kubectl`
find and open the file for you (it respects the `KUBE_EDITOR`
environment variable, so you can set your editor to whatever you prefer):
```
$ KUBE_EDITOR=emacs \
kubectl edit cronjob/hello-world
```
4. Trade files between containers
Newcomers to containers are often baffled by the concept of a shared system that they can't apparently access. They may learn about `exec`
options in their container engine or in kubectl itself, but containers still can seem impervious when they can't just grab a file from or place a file into a container. Using the `kubectl cp`
command, you can treat containers as if they were remote servers, making copying files to and from containers no more complex than an SSH command:
`$ kubectl cp foo my-pod:/tmp`
5. Apply changes
Making changes to Kubernetes objects can be done at any time with the `kubectl apply`
command. All you have to do is point the command to a configuration file:
`$ kubectl apply -f ./mypod.json`
Akin to running an Ansible playbook or a Bash script, `apply`
makes it easy to "import" settings quickly into a running Kubernetes instance. For instance, the GitOps tool [ArgoCD](https://argoproj.github.io/argo-cd/) is surprisingly simple to install thanks to the `apply` subcommand:
```
$ kubectl create namespace argocd
$ kubectl apply -n argocd \
-f https://raw.githubusercontent.com/argoproj/argo-cd/vx.y.z/manifests/install.yaml
```
Use kubectl
Kubectl is a powerful tool, and because it's a terminal command it can be scripted and used in many ways a web UI cannot. Learning kubectl is a great way to further your understanding of Kubernetes, containers, pods, and all the technologies that surround these important cloud innovations. [Download our kubectl cheat sheet](https://opensource.com/downloads/kubectl-cheat-sheet) for a quick reference, complete with sample commands, to help you as you learn and remind you of the details once you're a pro.
## Comments are closed. |
13,677 | 基础:在 Linux 终端中移动文件 | https://opensource.com/article/21/8/move-files-linux | 2021-08-13T11:22:56 | [
"mv"
] | https://linux.cn/article-13677-1.html |
>
> 使用 mv 命令将一个文件从一个位置移动到另一个位置。
>
>
>

要在有图形界面的计算机上移动一个文件,你要打开该文件当前所在的文件夹,然后打开另一个窗口导航到你想把文件移到的文件夹。最后,你把文件从一个窗口拖到另一个窗口。
要在终端中移动文件,你可以使用 `mv` 命令将文件从一个位置移动到另一个位置。
```
$ mv example.txt ~/Documents
$ ls ~/Documents
example.txt
```
在这个例子中,你已经把 `example.txt` 从当前文件夹移到了主目录下的 `Documents` 文件夹中。
只要你知道一个文件在 *哪里*,又想把它移到 *哪里* 去,你就可以把文件从任何地方移动到任何地方,而不管你在哪里。与在一系列窗口中浏览你电脑上的所有文件夹以找到一个文件,然后打开一个新窗口到你想让该文件去的地方,再拖动该文件相比,这可以大大节省时间。
默认情况下,`mv` 命令完全按照它被告知的那样做:它将一个文件从一个位置移动到另一个位置。如果在目标位置已经存在一个同名的文件,它将被覆盖。为了防止文件在没有警告的情况下被覆盖,请使用 `--interactive`(或简写 `-i`)选项。
```
$ mv -i example.txt ~/Documents
mv: overwrite '/home/tux/Documents/example.txt'?
```
---
via: <https://opensource.com/article/21/8/move-files-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | To move a file on a computer with a graphical interface, you open the folder where the file is currently located, and then open another window to the folder you want to move the file into. Finally, you drag and drop the file from one to the other.
To move a file in a terminal, you use the* * **mv **command to move a file from one location to another.
```
$ mv example.txt ~/Documents
$ ls ~/Documents
example.txt
```
In this example, you've moved **example.txt** from its current folder into the **Documents** folder.
As long as you know where you want to take a file *from* and where you want to move it *to*, you can send files from any location to any location, no matter where you are. This can be a serious time saver compared to navigating through all the folders on your computer in a series of windows just to locate a file, and then opening a new window to where you want that file to go, and then dragging that file.
The **mv** command by default does exactly as it's told: it moves a file from one location to another. Should a file with the same name already exist in the destination location, it gets overwritten. To prevent a file from being overwritten without warning, use the **--interactive **(or **-i **for short) option:
```
$ mv -i example.txt ~/Documents
mv: overwrite '/home/tux/Documents/example.txt'?
```
## 2 Comments |
13,678 | elementary OS 6 Linux 中的 11 个亮点 | https://news.itsfoss.com/elementary-os-6-features/ | 2021-08-13T14:21:48 | [] | https://linux.cn/article-13678-1.html |
>
> elementary OS 6 终于来了。让我们看一下这个主要版本中的重要亮点。
>
>
>

elementary OS 6 是其 5.x 系列经过几年更新后的一次重大升级。
虽然 5.x 系列也有许多功能更新和改进,但 [elementary OS 6](https://news.itsfoss.com/elementary-os-6-release/) 的努力成果看起来令人兴奋。
在这里,让我们来看看 elementary OS 6 引入的所有新功能和变化。
### 1、暗黑风格及强调色

[elementary OS](https://elementary.io) 暗黑风格的主题与现在主流的工作方式类似,是一种选择的偏好。你可以在安装 elementary OS 6 之后,在欢迎屏幕上选择它。
虽然增加暗黑模式听起来像是小事一桩,但他们似乎投入了大量的精力来提供一个整体一致的暗黑模式体验。
所有的第一方应用程序都无缝地支持暗黑风格和浅色主题。
elementary OS 还让应用开发者在 elementary OS 6 中遵照用户的偏好。因此,如果用户喜欢暗黑模式或浅色模式,应用程序就可以适应这种模式。
伴随着新的强调色的出现,还有一个自动的强调色偏好,可以从你当前的壁纸中挑选出强调的颜色。
### 2、改进的通知及重新设计的通知中心
通知现在支持图标徽章和行动按钮,这应该能提供更好的体验。

这可以让你快速打开链接、标记一条消息已读,以及其他几种可能的操作。
紧急通知有了新的外观和独特的声音,以帮助你识别它们。
除了通知方面的改进,通知中心也进行了改造,使其看起来更好,并可以对多个通知进行清理。
### 3、在线账户
终于,在 elementary OS 6 中,你能够从系统设置中添加在线账户了。
一旦登录,你的数据将在支持的系统应用程序(如日历、任务)中同步。
它也会显示在系统托盘通知中。
### 4、第一方 Flatpak 应用及权限查看
为了提高整个平台的隐私和安全,elementary OS 6 采用了优先选择 Flatpak 的方式。
Elementary OS 现在有自己的应用中心 Flatpak 资源库。一些默认的应用程序以 Flatpak 包的形式出现,应用中心列出的所有应用程序也都有 Flatpak。
总的来说,这意味着更好的沙盒体验,你的所有应用程序将保持相互隔离,不会访问你的敏感数据。

而且,最重要的是,elementary OS 6 增加了“门户”功能,应用程序会请求权限,以访问你的文件或启动另一个应用程序。
你还可以从系统设置中控制所有的权限。
### 5、多点触控手势

对于笔记本电脑和触摸板用户来说,新的多点触控手势将变得非常方便。
从访问多任务视图到浏览工作区,你都可以用多点触摸手势来完成。
不仅仅局限于桌面上的某些功能,你还可以与通知互动、滑过应用程序,并可以通过新的多点触控手势获得全系统的顺滑体验。
你可以自定义手势或从系统设置下的手势部分了解更多信息。
### 6、屏幕盾牌
在 elementary OS 5 中,有些人注意到当你想运行一个耗时的任务或简单地观看视频时,会出现自动锁定屏幕的问题。
然而,这种情况在 elementary OS 6 中得到了改变,它不仅解决了这个问题,还以 “屏幕盾牌” 功能的形式带来了新的实现方式。
因此,在观看视频或执行耗时的任务时,你可以轻松地保持系统的清醒,而不会突然中断。
它利用了 GNOME 的守护程序设置,与第三方应用程序有更好的兼容性。
### 7、新的任务应用

elementary OS 6 中添加了一个新的任务应用,在那里你可以管理任务、收到提醒,并在你的系统上组织任务,或与在线账户同步。
我可能还不会用它来取代 Planner,但它是一个很好的补充,因为它打造的很好。
### 8、固件更新应用程序

你可以为支持的设备获得最新的固件更新,而无需摆弄任何其他设置。
只要从菜单中寻找“固件”应用程序就可以开始了。
### 9、更新的应用程序
一些应用程序已经被更新,同时引入了新的功能。
例如,Epiphany 浏览器被重新命名为 “Web”,现在有 Flatpak 包可用,以方便快速更新。
它还包括内置的跟踪保护和广告拦截。
其他一些值得注意的变化包括:
* 相机应用获得了一个新的用户界面,可以切换相机、镜像图像等等。
* 应用中心现在不仅列出了 Flatpak 应用程序,而且还在应用程序完成安装后通知你,让你快速打开它。
* 文件应用程序也得到了改进,其形式是一个新的侧边栏和列表视图。另外,现在需要双击才能打开一个文件,而单次点击可以在文件夹中导航。
其他应用程序如邮件、日历也得到了改进,以便更好地进行在线整合。
### 10、改进的桌面工作流程及屏幕截图工具

多任务视图现在可以帮助你明确区分多个活动窗口。而热角视图可以让你将窗口移动到新的工作区,也可以将窗口最大化。

屏幕截图工具可以在窗口中移动,而不仅仅是停留在窗口的中心。你还可以从预览中拖放图片,而不需要保存。
### 11、改进的安装程序

你会注意到一些新的微妙的动画,而且还做了一些努力,以便在不重新调整窗口大小的情况下提供一个一致的安装程序布局。
这不是一次大修,但他们提到新的安装程序带有改进的磁盘检测和错误处理功能,这应该能使安装顺滑进行。
### 总结
[elementary OS 6](https://elementary.io) 是一个激动人心的版本,有多项改进。尽管外观和感觉并没有完全改变,但它已被全面精心雕琢。
我喜欢他们为提供一致和漂亮的用户体验所做的工作。另外,像全系统的 Flatpak 这样的变化应该使用户更容易和更安全。
你对这个版本有什么看法?你试过了吗?
---
via: <https://news.itsfoss.com/elementary-os-6-features/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

elementary OS 6 is a major upgrade after a few good years of updates to the 5.x series.
While the 5.x series has had numerous feature updates and improvements, [elementary OS 6](https://news.itsfoss.com/elementary-os-6-release/) looks to be an exciting endeavor.
Here, we shall take a look at all the new features and additions that have been introduced with elementary OS 6.
## 1. Dark Style & Accent Color
[elementary OS](https://elementary.io/?ref=news.itsfoss.com) approaches the dark style theme similar to how mainstream options work, as an opt-in preference. You get to choose it from the Welcome screen right after you install elementary OS 6.
While the addition of a dark mode may sound like something minor, they seem to have put a great deal of effort to provide a consistent dark mode experience overall.
All the first-party applications seamlessly support both the dark style and light theme.
elementary OS will also let the app developers respect the user’s preference in elementary OS 6. So, if the user prefers a dark mode or light mode, the app can adapt to that.
Along with new accent colors available, there is an automatic accent color preference that picks the color from your current wallpaper.
## 2. Improved Notifications & Redesigned Notification Center
The notifications now support icon badges and action buttons, which should make up for a better experience.

This could let you quickly open links, mark a message read, along with several other possibilities.
Urgent notifications have a new look and a unique sound to help you identify them.
In addition to the notification improvements, the notification center has also been revamped to look better and clean with multiple notifications.
## 3. Online Accounts
Finally, with elementary OS 6, you will be able to add online accounts from the system settings.
Once signed in, your data will sync across the system apps wherever supported (like Calendar, Tasks).
It should also show up in the system tray notifications.
## 4. First-Party Flatpak Apps & Permissions View
To improve privacy and security across the platform, elementary OS 6 chose the Flatpak-first approach.
elementary OS now has its own AppCenter Flatpak repository. Some of the default applications come baked in as Flatpak packages and all the applications listed in AppCenter are available as Flatpaks as well.
Overall, this means a better sandboxing experience where all of your applications will stay isolated from each other without accessing your sensitive data.
And, to top it all off, elementary OS 6 adds “Portals” where the applications will request permission to access your files or launch another application.
You also get to control all the permissions from the System Settings.
## 5. Multi-Touch Gestures
For Laptop and touchpad users, the new multi-touch gestures are going to come in extremely handy.
From accessing the multitasking view to navigating through the workspaces, you can do it all using multi-touch gestures.
Not just limited to certain functions on the desktop, you can interact with notifications, swipe through applications, and can have a seamless system-wide experience with the new multi-touch gestures.
You can customize the gestures or learn more about it from the Gestures section under the System Settings.
## 6. Screen Shield
With elementary OS 5, some noticed an issue with automatic screen locking when you want to run a time-consuming task or simply watch videos.
However, this changes with elementary OS 6, not only it solves the issue, it brings in a new implementation in the form of “**Screen Shield**” feature.
So, you can easily keep your system awake without sudden disruptions when watching a video or performing a time-consuming task.
It utilizes GNOME’s daemon settings to have better compatibility with third-party applications.
## 7. New Tasks App
A new tasks app has been added in elementary OS 6 where you can manage tasks, get reminded of them, and organize them on your system or synchronize it with an online account.
I may not replace it with Planner just yet, but it is a good addition to have baked in.
## 8. Firmware Updates App
You can get the latest firmware updates for supported devices without fiddling with any other settings.
Just look for the “Firmware” application from the menu to get started.
## 9. App Updates
Several applications have been updated while introducing new capabilities.
For instance, Epiphany browser was renamed to “Web” and is now available as a Flatpak to facilitate quick updates.
It also includes tracking protection and ad blocking built-in.
Some other notable changes include:
- The camera app has recieved a new UI overhaul with the ability to switch cameras, mirroring of image, and more.
- AppCenter not just lists Flatpak apps now but also notifies you when an application has completed installation to let you quickly open it.
- Files app has also received improvements in the form a new sidebar and list view. Also, a double-click is now required to open a file and a single click can navigate through folders.
Other applications like Mail, Calendar have also received improvements for better online integrations.
## 10. Improved Desktop Workflow & Screenshot Utility
The multitasking view now helps you clearly distinguish among multiple active windows. And the hot corners view lets you move the window to a new workspace and maximize the window as well.
The screenshot utility can be moved around in the window, not just stuck to the center of the window. You can also drag and drop the image from the preview without needing to save it.
## 11. Improved Installer

You will notice some new subtle animations, and some efforts have been made to provide a consistent layout of the installer without re-sizing the window.
It isn’t a major overhaul, but they mention that the new installer comes with an improved disk detection and error handling, which should make the installation seamless.
## Wrapping Up
[elementary OS 6](https://elementary.io/?ref=news.itsfoss.com) is an exciting release with several improvements. Even though the look and feel is not entirely different, it has been polished across the board.
I like what they are doing to provide a consistent and beautiful user experience. Also, changes like system-wide Flatpak should make things easier and safer for users.
What do you think about this release? Have you tried it yet?
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,680 | 如何在免费 WiFi 中保护隐私(一) | https://opensource.com/article/21/8/openvpn-server-linux | 2021-08-13T21:32:15 | [
"隐私",
"VPN"
] | https://linux.cn/article-13680-1.html |
>
> 第一步是安装一个“虚拟专用网络”服务器。
>
>
>

你是否连接到了不受信任的网络,例如酒店或咖啡馆的 WiFi,而又需要通过智能手机和笔记本电脑安全浏览互联网?通过使用虚拟专用网络,你可以匿名访问不受信任的网络,就像你在专用网络上一样安全。
“虚拟专用网络” 是保护私人数据的绝佳工具。通过使用 “虚拟专用网络”,你可以在保持匿名的同时连接到互联网上的专用网络。
可选的 “虚拟专用网络” 服务有很多,[0penVPN](https://openvpn.net/) 依然是很多人在使用不受信任的网络时保护私人数据的第一选择。
0penVPN 在两点之间创建一个加密通道,防止第三方访问你的网络流量数据。通过设置你的 “虚拟专用网络” 服务,你可以成为你自己的 “虚拟专用网络” 服务商。许多流行的 “虚拟专用网络” 服务都使用 0penVPN,所以当你可以掌控自己的网络时,为什么还要将你的网络连接绑定到特定的提供商呢?
### 搭建 Linux 服务器
首先,在备用 PC 上安装一份 Linux。本例使用 Fedora,但是不论你使用的是什么 Linux 发行版,步骤基本是相同的。
从 [Fedora 项目](http://getfedora.org) 网站下载最新的 Fedora ISO 副本。制作一个 USB 启动盘,将其插入到你的 PC 并启动,然后安装操作系统。如果你从未制作过可引导的 USB 启动盘,可以了解一下 [Fedora Media Writer](https://opensource.com/article/20/10/fedora-media-writer)。如果你从未安装过 Linux,请阅读 [三步安装 Linux](https://opensource.com/article/21/2/linux-installation)。
### 设置网络
安装完成 Fedora 操作系统后,登录到控制台或者 SSH 会话。
更新到最新并重新启动:
```
$ sudo dnf update -y && reboot
```
重新登录并关闭防火墙:
```
systemctl disable firewalld.service
systemctl stop firewalld.service
```
你可能希望在此系统上为你的内部网络添加适当的防火墙规则。如果是这样,请在关闭所有防火墙规则后完成 0penVPN 的设置和调试,然后添加本地防火墙规则。想要了解更多,请参照 [在 Linux 上设置防火墙](https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd)。
### 设置 IP 地址
你需要在你的本地网络设置一个静态 IP 地址。下面的命令假设在一个名为 `ens3` 的设备上有一个名为 `ens3` 的<ruby> 网络管理器 <rt> Network Manager </rt></ruby>连接。你的设备和连接名称可能不同,你可以通过打开 SSH 会话或从控制台输入以下命令:
```
$ sudo nmcli connection show
NAME UUID TYPE DEVICE
ens3 39ad55bd-adde-384a-bb09-7f8e83380875 ethernet ens3
```
你需要确保远程用户能够找到你的 “虚拟专用网络” 服务器。有两种方法可以做到这一点。你可以手动设置它的 IP 地址,或者将大部分工作交给你的路由器去完成。
#### 手动配置一个 IP 地址
通过以下命令来设置静态 IP 地址、前缀、网关和 DNS 解析器,用来替换掉原有的 IP 地址:
```
$ sudo nmcli connection modify ens3 ipv4.addresses 10.10.10.97/24
$ sudo nmcli connection modify ens3 ipv4.gateway 10.10.10.1
$ sudo nmcli connection modify ens3 ipv4.dns 10.10.10.10
$ sudo nmcli connection modify ens3 ipv4.method manual
$ sudo nmcli connection modify ens3 connection.autoconnect yes
```
设置主机名:
```
$ sudo hostnamectl set-hostname OVPNserver2020
```
如果你运行了一个本地的 DNS 服务,你需要设置一个 DNS 条目,将主机名指向 “虚拟专用网络” 服务器的 IP 地址。
重启并确保系统的网络运行正常。
#### 在路由器中配置 IP 地址
在你的网络当中应该有一台路由器。你可能已经购买了它,或者从互联网服务提供商(ISP)那里获得了一台。无论哪种方式,你的路由器可能都有一个内置的 DHCP 服务,可以为连接到网络上的每台设备分配一个 IP 地址。你的新 “虚拟专用网络” 服务器也是属于网络的一台设备,因此你可能已经注意到它会自动分配一个 IP 地址。
这里的潜在问题是你的路由器不能保证每台设备都能在重新连接后获取到相同的 IP 地址。路由器确实尝试保持 IP 地址一致,但这会根据当时连接的设备数量而发生变化。
但是,几乎所有的路由器都会有一个界面,允许你为特定设备调停和保留 IP 地址。

路由器没有统一的界面,因此请在你的路由器接口中搜索 “DHCP” 或 “Static IP address” 选项。为你的服务器分配自己的预留 IP 地址,使其在网络中保持 IP 不变。
### 连接到服务器
默认情况下,你的路由器可能内置了防火墙。这通常很好,因为你不希望网络之外的人能够强行进入你的任何计算机。但是,你必须允许发往 “虚拟专用网络” 服务器的流量通过防火墙,否则你的 “虚拟专用网络” 将无法访问,这种情况下你的 “虚拟专用网络” 服务器将形同虚设。
你至少需要一个来自互联网服务提供商的公共静态 IP 地址。使用其静态 IP 地址设置路由器的公共端,然后将你的 0penVPN 服务器放在专用端,在你的网络中使用专用静态 IP 地址。 0penVPN 默认使用 UDP 1194 端口。配置你的路由器,将你的公网 “虚拟专用网络” IP 地址的 UDP 1194 端口转发到 0penVPN 服务器上的 UDP 1194 端口。如果你决定使用不同的 UDP 端口,请相应地调整端口号。
### 准备好,我们开始下一步
在本文中,你在服务器上安装并配置了一个操作系统,这已经成功了一半。在下一篇文章中,你将解决安装和配置 0penVPN 本身的问题。同时,请熟悉你的路由器并确保你可以从外部访问你的服务器。但是请务必在测试后关闭端口转发,直到你的 “虚拟专用网络” 服务启动并运行。
本文的部分内容改编自 D. Greg Scott 的博客,并经许可重新发布。
---
via: <https://opensource.com/article/21/8/openvpn-server-linux>
作者:[D. Greg Scott](https://opensource.com/users/greg-scott) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Have you been connected to an untrusted network such as a hotel or café WiFi and need to securely browse the internet from your smartphone or laptop? By using a virtual private network (VPN), you can access that untrusted network anonymously and as safely as if you were on a private network.
VPN is an amazing tool for safeguarding private data. By using a VPN, you can connect to a private network on the internet while maintaining anonymity.
There are many VPN services available, and many people have found that the preferred option for securing private data when using untrusted networks is [OpenVPN](https://openvpn.net/).
OpenVPN creates an encrypted tunnel between two points, preventing a third party from accessing your network traffic data. By setting up your VPN server, you become your own VPN provider. Many popular VPN services use OpenVPN, so why tie your connection to a specific provider when you can have complete control yourself?
## Set up a Linux server
First, install a copy of Linux onto a spare PC. These examples use Fedora, but the steps are mostly the same no matter what Linux distribution you use.
Download a copy of the most recent Fedora ISO from the [Fedora project](http://getfedora.org) website. Make a bootable USB drive, plug it into and boot your PC, and install the operating system. If you've never made a bootable USB drive, read about [Fedora Media Writer](https://opensource.com/article/20/10/fedora-media-writer). If you've never installed Linux, read about [installing Linux in three steps](https://opensource.com/article/21/2/linux-installation).
## Set up networking
After installing the Fedora operating system, log into the console or SSH session.
Apply the latest updates and reboot:
`$ sudo dnf update -y && reboot`
Log in again and disable the firewall rules:
```
systemctl disable firewalld.service
systemctl stop firewalld.service
```
You may want to add appropriate firewall rules on this system for your internal network. If so, finish setting up and debugging OpenVPN with all firewall rules turned off, and then add your local firewall rules. For more information, read about [setting up firewalls on Linux](https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd).
## Set up IP addresses
You need a static IP address inside your local network. The commands below assume a Network Manager connection named `ens3`
on a device named `ens3`
. Your device and connection names might be different, so find them by opening an SSH session or the console and entering:
```
$ sudo nmcli connection show
NAME UUID TYPE DEVICE
ens3 39ad55bd-adde-384a-bb09-7f8e83380875 ethernet ens3
```
You need to ensure that your remote people can find your VPN server. There are two ways to do this. You can set its IP address manually, or you can let your router do most of the work.
### Configure an IP address manually
Set your static IP address, prefix, gateway, and DNS resolver with the following command but substituting your own IP addresses:
```
$ sudo nmcli connection modify ens3 ipv4.addresses 10.10.10.97/24
$ sudo nmcli connection modify ens3 ipv4.gateway 10.10.10.1
$ sudo nmcli connection modify ens3 ipv4.dns 10.10.10.10
$ sudo nmcli connection modify ens3 ipv4.method manual
$ sudo nmcli connection modify ens3 connection.autoconnect yes
```
Set a hostname:
`$ sudo hostnamectl set-hostname OVPNserver2020`
If you run a local DNS server, you will want to set up a DNS entry with the hostname pointing to the VPN server IP Address.
Reboot and make sure the system has the correct networking information.
### Configure an IP address in your router
You probably have a router on your network. You may have purchased it, or you may have gotten one from your internet service provider (ISP). Either way, your router probably has a built-in DHCP server that assigns an IP address to each device on your network. Your new server counts as a device on your network, so you may have noticed an IP address is assigned to it automatically.
The potential problem here is that your router doesn't guarantee that any device will ever get the same IP address after reconnecting. It does *try* to keep the IP addresses consistent, but they can change depending on how many devices are connected at the time.
However, almost all routers have an interface allowing you to intercede and reserve IP addresses for specific devices.
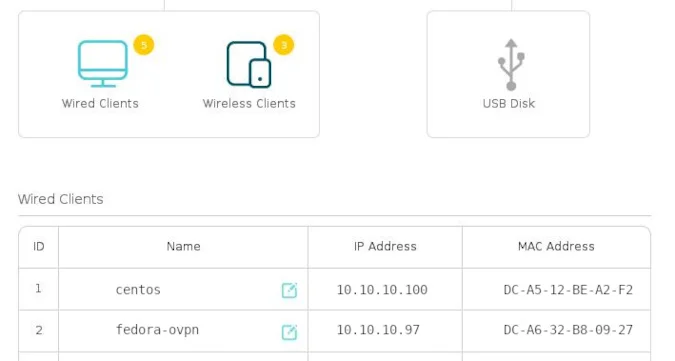
(Seth Kenlon, CC BY-SA 4.0)
There isn't a universal interface for routers, so search the interface of the router you own for **DHCP** or **Static IP address** options. Assign your server its own reserved IP address so that its network location remains the same no matter what.
## Access your server
By default, your router probably has a firewall built into it. This is normally good because you don't want someone outside your network to be able to brute force their way into any of your computers. However, you must allow traffic destined for your VPN server through your firewall, or else your VPN will be unreachable and, therefore, no use to you.
You will need at least one public static IP Address from your internet service provider. Set up the public side of your router with its static IP Address, and then put your OpenVPN server on the private side, with its own private static IP Address inside your network. OpenVPN uses UDP port 1194 by default. Configure your router to [port-forward](https://opensource.com/article/20/9/firewall) traffic for your public VPN IP Address on UDP port 1194 to UDP port 1194 on your OpenVPN server. If you decide to use a different UDP port, adjust the port number accordingly.
## Get ready for the next step
In this article, you installed and configured an operating system on your server, which is approximately half the battle. In the next article, you'll tackle installing and configuring OpenVPN itself. In the meantime, get familiar with your router and make sure you can reach your server from the outside world. But be sure to close the port forwarding after testing until your VPN is up and running.
*Parts of this article were adapted from D. Greg Scott's blog and have been republished with permission.*
## Comments are closed. |
13,681 | 用 OneDriver GUI 工具在 Linux 中挂载微软 OneDrive | https://itsfoss.com/onedriver/ | 2021-08-13T22:06:00 | [
"OneDrive"
] | https://linux.cn/article-13681-1.html | 在 Windows 上,微软提供了一个 [免费云存储服务](https://itsfoss.com/cloud-services-linux/) OneDrive。它与 Windows 集成,你可以通过你的微软账户获得 5GB 的免费存储空间。
这在 Windows 上很好用,但和谷歌一样,微软也没有在 Linux 桌面上提供 OneDrive 的本地客户端。
当然,你可以通过浏览器访问你的 OneDrive 数据。除此以外,还有一些其他的方法可以在 Linux 上访问 OneDrive。
你可以使用像 [Insync](https://itsfoss.com/use-onedrive-on-linux/) 这样的高级服务,或者选择用 [rclone 在 Linux 上使用 OneDrive](https://itsfoss.com/use-onedrive-linux-rclone/) 这种稍微复杂的命令行方式。
最近,我发现了另一个工具,它稍有不同,使用起来也更简单。不出所料,它叫 OneDriver。
### OneDriver:在你的 Linux 系统上挂载 OneDrive

[OneDriver](https://github.com/jstaf/onedriver) 是一个自由而开源的工具,允许你在 Linux 系统上挂载 OneDrive 文件。
请记住,它不会像 OneDrive 在 Windows 系统上那样同步文件。它将 OneDrive 文件挂载在本地的挂载点上。你通过网络访问这些文件。
然而,它确实提供了一种混合方法。你在挂载的 OneDrive 中打开的文件也被下载到系统中。这意味着,你也可以离线访问打开的文件。如果你没有连接到互联网,这些文件将成为只读。
如果你在本地对文件做任何修改,并且连接到互联网,它就会反映到 OneDrive 上。
我注意到,在 GNOME 上的 Nautilus 文件管理器中,它会自动下载当前文件夹中的图像。在我的印象中,它们只有在我打开它们时才会被下载。
另一件事是,Nautilus 一开始会建立缩略图缓存。OneDriver 在开始的时候可能会觉得有点慢,有点耗费资源,但最终会好起来。
哦!你也可以挂载多个 OneDrive 账户。
### 安装和使用 OneDriver
要在 Ubuntu 20.04(和 Linux Mint 20 系列)上安装 OneDriver,你可以使用 OneDriver 开发者的这个 PPA:
```
sudo add-apt-repository ppa:jstaf/onedriver
sudo apt update
sudo apt install onedriver
```
对于 Ubuntu 21.04,你可以下载 [其 PPA 中的 DEB 文件](https://launchpad.net/~jstaf/+archive/ubuntu/onedriver/+packages) 来使用它。
在 Fedora 上,你可以添加这个 COPR:
```
sudo dnf copr enable jstaf/onedriver
sudo dnf install onedriver
```
Arch 用户可以在 AUR 中找到它。
安装后,在菜单中搜索 OneDriver,然后从这里启动它。

首次运行时,它会给出一个奇怪的空界面。点击 “+” 号,选择一个文件夹或创建一个新的文件夹,OneDrive 会挂载在那里。在我的例子中,我在我的家目录下创建了一个名为 `One_drive` 的新文件夹。

当你选择了挂载点后,你会被要求输入你的微软凭证。


登录后,你可以在挂载的目录中看到 OneDrive 的文件。

完成这些后,你可以在应用界面上看到你的 OneDrive 账户。点击旁边的勾按钮,以在重启后自动挂载 OneDrive。

总的来说,OneDriver 是一个可以在 Linux 上访问 OneDrive 的不错的免费工具。它可能无法像 [高级 Insync 服务](https://itsfoss.com/recommends/insync/) 那样提供完整的同步设施,但对于有限的需求来说,它做得不错。
如果你使用这个漂亮的工具,请分享你的使用经验。如果你喜欢这个项目,也许可以给它一个 [GitHub 上的星标](https://github.com/jstaf/onedriver)。
---
via: <https://itsfoss.com/onedriver/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | On Windows, Microsoft provides a [free cloud storage service](https://itsfoss.com/cloud-services-linux/) in the form of OneDrive. It comes integrated with Windows and you get 5 GB of free storage with your Microsoft account.
This works great on Windows but like Google, Microsoft also does not provide a native client for OneDrive on Linux desktop.
You can access your OneDrive data through browser, of course. In addition to that, there are some other ways to access OneDrive on Linux.
You can use a premium service like [Insync](https://itsfoss.com/use-onedrive-on-linux/) or opt for a slightly more complicated command line approach with [rclone to use OneDrive on Linux](https://itsfoss.com/use-onedrive-linux-rclone/).
Recently, I came across another tool that is slightly different and slightly easier to use. It’s unsurprisingly called OneDriver.
## OneDriver: Mount OneDrive on your Linux system

[OneDriver](https://github.com/jstaf/onedriver) is a free and open source tool that allows you to mount your OneDrive files on your Linux system.
Please keep in mind that it does not sync files in the same way OneDrive does on the Windows system. It mounts the OneDrive files on a local mount point instead. You access the files over the network.
However, it does provide a kind of hybrid approach here. The files you open in the mounted OneDrive also get downloaded on the system. Which means that you can access the opened files offline as well. The files become read-only if you are not connected to the internet.
If you make any changes to files locally, it gets reflected on the OneDrive if you are connected to the internet.
I did notice that in Nautilus file manager on GNOME, it downloads the images present in the current folder automatically. I was under the impression that they will only be downloaded when I open them.
Another thing is that Nautilus builds thumbnail cache initially. OneDriver may feel a little bit slower and resource consuming in the beginning, but it gets better eventually.
Oh! You can also mount multiple OneDrive accounts.
## Installing and using OneDriver
To install OneDriver on Ubuntu 20.04 (and Linux Mint 20 series), you can use this PPA by the developer of OneDriver:
```
sudo add-apt-repository ppa:jstaf/onedriver
sudo apt update
sudo apt install onedriver
```
For Ubuntu 21.04, you may use it by downloading the [DEB file from its PPA](https://launchpad.net/~jstaf/+archive/ubuntu/onedriver/+packages).
On Fedora, you can add this COPR:
```
sudo dnf copr enable jstaf/onedriver
sudo dnf install onedriver
```
Arch users can find it in the AUR.
Once you install it, search for OneDriver in the menu and start it from here.
On the first run, it gives a strange looking empty interface. Click on the + sign and choose a folder or create a new one where you’ll mount the OneDrive. In my case, I created a new folder named One_drive in my home directory.
When you have selected the mount point, you will be asked to enter your Microsoft credential.
one drive login one drive permission
Once you are successfully logged in, you can see your files from OneDrive in the mounted directory.
Once you have done that, you can see your OneDrive account on the application interface. Click on the toggle button beside it to autostart OneDrive mounting after restart.
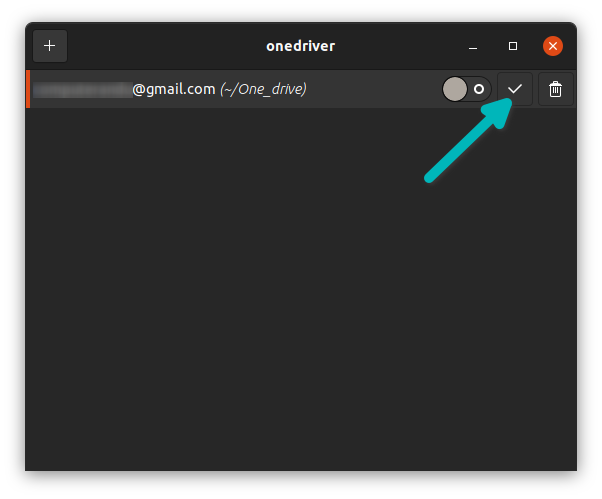
Overall, OneDriver is a nice free utility for accessing OneDrive on Linux. It may not provide the complete sync facility like the but it works fine for limited needs.
If you use this nifty tool, do share your experience with it. If you like project, maybe give it a [star on GitHub](https://github.com/jstaf/onedriver). |
13,683 | 使用 GNOME Web 的 Canary 版本测试前沿功能 | https://news.itsfoss.com/gnome-web-canary/ | 2021-08-15T09:59:07 | [
"GNOME",
"浏览器"
] | https://linux.cn/article-13683-1.html |
>
> 如果你想测试高度不稳定的 GNOME Web 浏览器的前沿功能,Canary 版本就是为了这个。
>
>
>

Epiphany(或称 [GNOME Web](https://wiki.gnome.org/Apps/Web/))是一个 Linux 发行版上精简而功能强大的浏览器,你会发现它也是 elementary OS 的默认浏览器。
随同 GNOME 40 发布的 Epiphany 浏览器有一些 [改进和新增功能](https://news.itsfoss.com/gnome-web-new-tab/)。
而在幕后,经常有许多令人兴奋的提升和新增特性。因此,你可以选择为早期测试人员量身定制的 GNOME Web 技术预览版。
现在,它发布了一个新的 Canary 版本,你可以使用它来测试甚至在技术预览版中都没有的特性。
### GNOME Web Canary 版本

GNOME Web 的 Canary 版本允许你测试甚至没有出现在最新 [WebKitGTK](https://webkitgtk.org) 版本中的特性。
注意 Canary 版本应该是极其不稳定的,甚至稳定性比开发者技术预览版更差。
可是,使用 Canary 版本,终端用户可以在开发过程中的早期进行测试,帮助开发者发现灾难性 bug。
不只是终端用户的早期测试,Canary 版本还让 GNOME Web 的开发者的工作更轻松。
他们不再需要为了实现和测试一个新特性,来单独构建 WebKitGTK。
尽管开发者有一个 Flatpak SDK 可以简化开发人员的流程,但是这仍然是一项耗时的任务。
现在,没有了这个阻碍,开发速度也有可能提升。
### 怎样获得 Canary 版本?
首先,你需要使用以下命令添加 WebKit SDK Flatpak 远端仓库:
```
flatpak --user remote-add --if-not-exists webkit https://software.igalia.com/flatpak-refs/webkit-sdk.flatpakrepo
flatpak --user install https://nightly.gnome.org/repo/appstream/org.gnome.Epiphany.Canary.flatpakref
```
完成后,你就可以使用提供的 [Flatpakref 文件](https://nightly.gnome.org/repo/appstream/org.gnome.Epiphany.Canary.flatpakref) 安装啦!
测试 Canary 版本可以让更多的用户能够在此过程中帮助 GNOME Web 的开发人员。所以,这绝对是改进 GNOME Web 浏览器开发的急需补充。
更多技术细节,你可能需要看这位开发者发布的 [公告](https://base-art.net/Articles/introducing-the-gnome-web-canary-flavor/)。
---
via: <https://news.itsfoss.com/gnome-web-canary/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zd200572](https://github.com/zd200572) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Epiphany or [GNOME Web](https://wiki.gnome.org/Apps/Web/?ref=news.itsfoss.com) is a minimal and yet capable browser for Linux distributions. You should find it as the default browser for elementary OS.
With GNOME 40, the Epiphany browser has had some [improvements and additions](https://news.itsfoss.com/gnome-web-new-tab/).
Behind the scenes, it regularly gets some exciting improvements and feature additions. And for that, you can opt for the Tech Preview version of GNOME Web tailored for early testers.
Now, a new Canary flavor has been introduced that you can use to test features that are not yet available even in the tech preview build.
## GNOME Web Canary Flavor
GNOME Web’s “Canary” builds let you test features that are not even available in the latest [WebKitGTK](https://webkitgtk.org/?ref=news.itsfoss.com) version.
Do note that the canary builds are supposed to be extremely unstable, even worse than the development builds available as a tech preview.
However, with the help of a Canary build, an end-user can test things way early in the process of development that can help find disastrous bugs.
Not just limited to end-user early testing, a canary build also makes things easier for a GNOME Web developer.
They no longer have to build WebKitGTK separately in order to implement and test a new feature.
Even though there was a Flatpak SDK available to ease the process for developers, it was still a time-consuming task.
Now, with that out of the way, the development pace can potentially improve as well.
## How to Get the Canary Build?
First, you need to add the WebKit SDK Flatpak remote using the commands below:
```
flatpak --user remote-add --if-not-exists webkit https://software.igalia.com/flatpak-refs/webkit-sdk.flatpakrepo
flatpak --user install https://nightly.gnome.org/repo/appstream/org.gnome.Epiphany.Canary.flatpakref
```
Once done, you can install the Canary by using the [Flatpakref file](https://nightly.gnome.org/repo/appstream/org.gnome.Epiphany.Canary.flatpakref?ref=news.itsfoss.com) provided.
Testing a Canary build gives more users the ability to help GNOME Web developers in the process. So, it is definitely a much-needed addition to improve the development of the GNOME Web browser.
For more technical details, you might want to take a look at the [announcement post](https://base-art.net/Articles/introducing-the-gnome-web-canary-flavor/?ref=news.itsfoss.com) by one of the developers.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,684 | 如老手一般玩转 MySQL 查询 | https://opensource.com/article/21/5/mysql-query-tuning | 2021-08-15T10:49:16 | [
"数据库",
"查询"
] | https://linux.cn/article-13684-1.html |
>
> 优化查询语句不过是一项简单的工程,而非什么高深的黑魔法。
>
>
>

许多人将数据库查询语句的调优视作哈利波特小说中某种神秘的“黑魔法”;使用错误的咒语,数据就会从宝贵的资源变成一堆糊状物。
实际上,对关系数据库系统的查询调优是一项简单的工程,其遵循的规则或启发式方法很容易理解。查询优化器会翻译你发送给 [MySQL](https://www.mysql.com/) 实例的查询指令,然后将这些启发式方法和优化器已知的数据信息结合使用,确定获取所请求数据的最佳方式。再读一下后面这半句:*“优化器已知的数据信息*。”查询优化器需要对数据所在位置的猜测越少(即已知信息越多),它就可以越好地制定交付数据的计划。
为了让优化器更好地了解数据,你可以考虑使用索引和直方图。正确使用索引和直方图可以大大提高数据库查询的速度。这就像如果你按照食谱做菜,就可以得到你喜欢吃的东西;但是假如你随意在该食谱中添加材料,最终得到的东西可能就不那么尽如人意了。
### 基于成本的优化器
大多数现代关系型数据库使用<ruby> 基于成本的优化器 <rt> cost-based optimizer </rt></ruby>来确定如何从数据库中检索数据。该成本方案是基于尽可能减少非常耗费资源的磁盘读取过程。数据库服务器内的查询优化器代码会在得到数据时对这些数据的获取进行统计,并构建一个获取数据的历史模型。
但历史数据是可能会过时的。这就好像你去商店买你最喜欢的零食,然后突然发现零食涨价或者商店关门了。服务器的优化进程可能会根据旧信息做出错误的假设,进而制定出低效的查询计划。
查询的复杂性可能会影响优化。优化器希望提供可用的最低成本查询方式。连接五个不同的表就意味着有 5 的阶乘(即 120)种可能的连接组合。代码中内置了启发式方法,以尝试对所有可能的选项进行快捷评估。MySQL 每次看到查询时都希望生成一个新的查询计划,而其他数据库(例如 Oracle)则可以锁定查询计划。这就是向优化器提供有关数据的详细信息至关重要的原因。要想获得稳定的性能,在制定查询计划时为查询优化器提供最新信息确实很有效。
此外,优化器中内置的规则可能与数据的实际情况并不相符。没有更多有效信息的情况下,查询优化器会假设列中的所有数据均匀分布在所有行中。没有其他选择依据时,它会默认选择两个可能索引中较小的一个。虽然基于成本的优化器模型可以制定出很多好的决策,但最终查询计划并不是最佳方案的情况也是有可能的。
### 查询计划是什么?
<ruby> 查询计划 <rt> query plan </rt></ruby>是指优化器基于查询语句产生的,提供给服务器执行的计划内容。查看查询计划的方法是在查询语句前加上 `EXPLAIN` 关键字。例如,以下查询要从城市表(`city`)和相应的国家表(`country`)中获得城市名称(和所属国家名称),城市表和国家表通过国家唯一代码连接。本例中仅查询了英国的字母顺序前五名的城市:
```
SELECT city.name AS 'City',
country.name AS 'Country'
FROM city
JOIN country ON (city.countrycode = country.code)
WHERE country.code = 'GBR'
LIMIT 5;
```
在查询语句前加上 `EXPLAIN` 可以看到优化器生成的查询计划。跳过除输出末尾之外的所有内容,可以看到优化后的查询:
```
SELECT `world`.`city`.`Name` AS `City`,
'United Kingdom' AS `Country`
FROM `world`.`city`
JOIN `world`.`country`
WHERE (`world`.`city`.`CountryCode` = 'GBR')
LIMIT 5;
```
看下比较大的几个变化, `country.name as 'Country'` 改成了 `'United Kingdom' AS 'Country'`,`WHERE` 子句从在国家表中查找变成了在城市表中查找。优化器认为这两个改动会提供比原始查询更快的结果。
### 索引
在 MySQL 世界中,你会听到索引或键的概念。不过,索引是由键组成的,键是一种识别记录的方式,并且大概率是唯一的。如果将列设计为键,优化器可以搜索这些键的列表以找到所需的记录,而无需读取整个表。如果没有索引,服务器必须从第一列的第一行开始读取每一行数据。如果该列是作为唯一索引创建的,则服务器可以直接读取该行数据并忽略其余数据。索引的值(也称为基数)唯一性越强越好。请记住,我们在寻找更快获取数据的方法。
MySQL 默认的 InnoDB 存储引擎希望你的表有一个主键,并按照该键将你的数据存储在 B+ 树中。“不可见列”是 MySQL 最近添加的功能,除非在查询中明确指明该不可见列,否则不会返回该列数据。例如,`SELECT * FROM foo;` 就不会返回任何不可见列。这个功能提供了一种向旧表添加主键的方法,且无需为了包含该新列而重写所有查询语句。
更复杂的是,有多种类型的索引,例如函数索引、空间索引和复合索引。甚至在某些情况下,你还可以创建这样一个索引:该索引可以为查询提供所有请求的信息,从而无需再去访问数据表。
本文不会详细讲解各种索引类型,你只需将索引看作指向要查询的数据记录的快捷方式。你可以在一个或多个列或这些列的一部分上创建索引。我的医师系统就可以通过我姓氏的前三个字母和出生日期来查找我的记录。使用多列时要注意首选唯一性最强的字段,然后是第二强的字段,依此类推。“年-月-日”的索引可用于“年-月-日”、“年-月”和“年”搜索,但不适用于“日”、“月-日”或“年-日”搜索。考虑这些因素有助于你围绕如何使用数据这一出发点来设计索引。
### 直方图
直方图就是数据的分布形式。如果你将人名按其姓氏的字母顺序排序,就可以对姓氏以字母 A 到 F 开头的人放到一个“逻辑桶”中,然后将 G 到 J 开头的放到另一个中,依此类推。优化器会假定数据在列内均匀分布,但实际使用时多数情况并不是均匀的。
MySQL 提供两种类型的直方图:所有数据在桶中平均分配的等高型,以及单个值在单个桶中的等宽型。最多可以设置 1,024 个存储桶。数据存储桶数量的选择取决于许多因素,包括去重后的数值量、数据倾斜度以及需要的结果准确度。如果桶的数量超过某个阈值,桶机制带来的收益就会开始递减。
以下命令将在表 `t` 的列 `c1` 上创建 10 个桶的直方图:
```
ANALYZE TABLE t UPDATE HISTOGRAM ON c1 WITH 10 BUCKETS;
```
想象一下你在售卖小号、中号和大号袜子,每种尺寸的袜子都放在单独的储物箱中。如果你想找某个尺寸的袜子,就可以直接去对应尺寸的箱子里找。MySQL 自从三年前发布 MySQL 8.0 以来就有了直方图功能,但该功能却并没有像索引那样广为人知。与索引不同,使用直方图插入、更新或删除记录都不会产生额外开销。而如果更新索引,就必须更新 `ANALYZE TABLE` 命令。当数据变动不大并且频繁更改数据会降低效率时,直方图是一种很好的方法。
### 选择索引还是直方图?
对需要直接访问的且具备唯一性的数据项目使用索引。虽然修改、删除和插入操作会产生额外开销,但如果数据架构正确,索引就可以方便你快速访问。对不经常更新的数据则建议使用直方图,例如过去十几年的季度结果。
### 结语
本文源于最近在 [Open Source 101 会议](https://opensource101.com/) 上的一次报告。报告的演示文稿源自 [PHP UK Conferenc](https://www.phpconference.co.uk/) 的研讨会。查询调优是一个复杂的话题,每次我就索引和直方图作报告时,我都会找到新的可改进点。但是每次报告反馈也表明很多软件界中的人并不精通索引,并且时常使用错误。我想直方图大概由于出现时间较短,还没有出现像索引这种使用错误的情况。
---
via: <https://opensource.com/article/21/5/mysql-query-tuning>
作者:[Dave Stokes](https://opensource.com/users/davidmstokes) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many people consider tuning database queries to be some mysterious "dark art" out of a Harry Potter novel; with the wrong incantation, your data turns from a valuable resource into a pile of mush.
In reality, tuning queries for a relational database system is simple engineering and follows easy-to-understand rules or heuristics. The query optimizer translates the query you send to a [MySQL](https://www.mysql.com/) instance, and then it determines the best way to get the requested data using those heuristics combined with what it knows about your data. Reread the last part of that: *"what it knows about your data*." The less the query optimizer has to guess about where your data is located, the better it can create a plan to deliver your data.
To give the optimizer better insight about the data, you can use indexes and histograms. Used properly, they can greatly increase the speed of a database query. If you follow the recipe, you will get something you will like. But if you add your own ingredients to that recipe, you may not get what you want.
## Cost-based optimizer
Most modern relational databases use a cost-based optimizer to determine how to retrieve your data out of the database. That cost is based on reducing very expensive disk reads as much as possible. The query optimizer code inside the database server keeps statistics on getting that data as it is encountered, and it builds a historical model of what it took to get the data.
But historical data can be out of date. It's like going to the store to buy your favorite snack and being shocked at a sudden price increase or that the store closed. Your server's optimization process may make a bad assumption based on old information, and that will produce a poor query plan.
A query's complexity can work against optimization. The optimizer wants to deliver the lowest-cost query of the available options. Joining five different tables means that there are five-factorial or 120 possible combinations about which to join to what. Heuristics are built into the code to try to shortcut evaluating all the possible options. MySQL wants to generate a new query plan every time it sees a query, while other databases such as Oracle can have a query plan locked down. This is why giving detailed information on your data to the optimizer is vital. For consistent performance, it really helps to have up-to-date information for the query optimizer to use when making query plans.
Also, rules are built into the optimizer with assumptions that probably do not match the reality of your data. The query optimizer will assume all the data in a column is evenly distributed among all the rows unless it has other information. And it will default to the smaller of two possible indexes if it sees no alternative. While the cost-based model for an optimizer can make a lot of good decisions, you can smack into cases where you will not get an optimal query plan.
## A query plan?
A query plan is what the optimizer will generate for the server to execute from the query. The way to see the query plan is to prepend the word `EXPLAIN`
to your query. For example, the following query asks for the name of a city from the city table and the name of the corresponding country table, and the two tables are linked by the country's unique code. This case is interested only in the top five cities alphabetically from the United Kingdom:
```
SELECT city.name as 'City',
country.name as 'Country'
FROM city
JOIN country ON (city.countrycode = country.code)
WHERE country.code = 'GBR'
LIMIT 5;
```
Prepending `EXPLAIN`
in front of this query will give the query plan generated by the optimizer. Skipping over all but the end of the output, it is easy to see the optimized query:
```
select `world`.`city`.`Name` AS `City`,
'United Kingdom' AS `Country`
from `world`.`city`
join `world`.`country`
where (`world`.`city`.`CountryCode` = 'GBR')
limit 5;
```
The big changes are that `country.name as 'Country'`
was changed to `'United Kingdom' AS 'Country'`
and the `WHERE`
clause went from looking in the country table to the city table. The optimizer determined that these two changes will provide a faster result than the original query.
## Indexes
You will hear indexes and keys used interchangeably in the MySQL-verse. However, indexes are made up of keys, and keys are a way to identify a record, hopefully uniquely. If a column is designed as a key, the optimizer can search a list of those keys to find the desired record without having to read the entire table. Without an index, the server has to start at the first row of the first column and read through every row of data. If the column was created as a unique index, then the server can go to that one row of data and ignore the rest. The more unique the value of the index (also known as its cardinality), the better. Remember, we are looking for faster ways of getting to the data.
The MySQL default InnoDB storage engine wants your table to have a primary key and will store your data in a B+ tree by that key. A recently added MySQL feature is invisible columns—columns that do not return data unless the column is explicitly named in the query. For example, `SELECT * FROM foo;`
doesn't provide any columns that are designated as hidden. This feature provides a way to add a primary key to older tables without recoding all the queries to include that new column.
To make this even more complicated, there are many types of indexes, such as functional, spatial, and composite. There are even cases where you can create an index that will provide all the requested information for a query so that there is no need to access the data table.
Describing the various indexes is beyond the scope of this article, so just think of an index as a shortcut to the record or records you desire. You can create an index on one or more columns or part of those columns. My physician's system can look up my records by the first three letters of my last name and birthdate. Using multiple columns requires using the most unique field first, then the second most unique, and so forth. An index on year-month-day works for year-month-day, year-month, and year searches, but it doesn't work for day, month-day, or year-day searches. It helps to design your indexes around how you want to use your data.
## Histograms
A histogram is a distribution of your data. If you were alphabetizing people by their last name, you could use a "logical bucket" for the folks with last names starting with the letters A to F, then another for G to J, and so forth. The optimizer assumes that the data is evenly distributed within the column, but this is rarely the case in practical use.
MySQL provides two types of histograms: equal height, where all the data is divided equally among the buckets, and singleton, where a single value is in a bucket. You can have up to 1,024 buckets. The amount of buckets to choose for your data column depends on many factors, including how many distinct values you have, how skewed your data is, and how high your accuracy really needs to be. After a certain amount of buckets, there are diminishing returns.
This command will create a histogram of 10 buckets on column c1 of table t:
`ANALYZE TABLE t UPDATE HISTOGRAM ON c1 WITH 10 BUCKETS;`
Imagine you sell small, medium, and large socks, and each size has its own bin for storage. To find the size you need, you go to the bin for that size. MySQL has had histograms since MySQL 8.0 was released three years ago, yet they are not as well-known as indexes. Unlike indexes, there is no overhead for inserting, updating, or deleting a record. To update an index, an `ANALYZE TABLE`
command must be updated. This is a good approach when the data does not churn very much and frequent changes to the data will reduce the efficiency.
## Indexes or histograms?
Use indexes for unique items where you need to access the data directly. There is overhead for updates, deletes, and inserts, but you get speedy access if your data is properly architected. Use histograms for data that does not get updated frequently, such as quarterly results for the last dozen years.
## Parting thoughts
This article grew out of a recent presentation at the [Open Source 101 conference](https://opensource101.com/). And that presentation grew out of a workshop at a [PHP UK Conference](https://www.phpconference.co.uk/). Query tuning is a complex subject, and each time I present on indexes and histograms, I find ways to refine my presentation. But each presentation also shows that many folks in the software world are not well-versed on indexes and tend to use them incorrectly. Histograms have not been around long enough (I hope) to have been misused similarly.
## Comments are closed. |
13,687 | 基础:在 Linux 终端中删除文件和文件夹 | https://opensource.com/article/21/8/remove-files-linux-terminal | 2021-08-16T11:09:56 | [
"删除"
] | https://linux.cn/article-13687-1.html |
>
> 本教程讲述了如何在 Linux 终端中安全地删除文件和文件夹。
>
>
>

要想使用图形化界面删除计算机上的文件,你可能会直接将文件或文件夹拖拽到 “垃圾箱” 或 “回收站”。或者你也可以选择要删除的文件或文件夹,右键单击并选择 **删除**。
而在终端中删除文件或文件夹时并没有垃圾箱一说(至少默认情况下没有)。在图形化桌面上,`Trash`(即垃圾箱文件夹)是一个受保护的目录,保护机制可以防止用户不小心将该目录删除,或将其从默认位置移动从而导致找不到它。Trash 本质不过是一个被高度管理的文件夹,因此你可以创建自己的 Trash 文件夹以在终端中使用。
### 为终端设置一个垃圾箱
在家目录中创建一个名为 `Trash` 的目录:
```
$ mkdir ~/Trash
```
### 删除文件
要删除文件或文件夹时,使用 `mv` 命令将文件或文件夹移至 `Trash` 中:
```
$ mv example.txt ~/Trash
```
### 永久删除文件或文件夹
当你准备从系统中永久删除某个文件或文件夹时,可以使用 `rm` 命令清除垃圾箱文件夹中的所有数据。通过将 `rm` 命令指向星号(`*`),可以删除 `Trash` 文件夹内的所有文件和文件夹,而不会删除 `Trash` 文件夹本身。因为用户可以方便且自由地创建目录,所以即使不小心删除了 `Trash` 文件夹,你也可以再次新建一个。
```
$ rm --recursive ~/Trash/*
```
### 删除空目录
删除空目录有一个专门的命令 `rmdir`,它只能用来删除空目录,从而保护你免受递归删除错误的影响。
```
$ mkdir full
$ touch full/file.txt
$ rmdir full
rmdir: failed to remove 'full/': Directory not empty
$ mkdir empty
$ rmdir empty
```
### 更好的删除方式
此外还有一些并没有默认安装在终端上的 [删除文件命令](https://www.redhat.com/sysadmin/recover-file-deletion-linux),你可以从软件库安装它们。这些命令管理和使用的 `Trash` 文件夹与你在桌面模式使用的是同一个(而非你自己单独创建的),从而使删除文件变得更加方便。
```
$ trash ~/example.txt
$ trash --list
example.txt
$ trash --empty
```
---
via: <https://opensource.com/article/21/8/remove-files-linux-terminal>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | To remove a file on a computer using a graphical interface, you usually drag a file or a folder to a "trash" or "recycle" bin. Alternately, you might be able to select the file or folder you want to remove, right-click, and select **Delete**.
When removing a file or folder in the terminal, there is no trash bin, at least by default. On a graphical desktop, the Trash is a protected directory so that users don't accidentally trash the Trash, or move it from its default location and lose track of it. The Trash is just a highly managed folder, so you can make your own Trash folder for use in your terminal.
## Setting up a trash bin for the terminal
Create a directory called **Trash** in your home directory:
`$ mkdir ~/Trash`
## Removing a file
When you want to remove a file or folder, use the **mv** command to move a file or directory to your Trash:
`$ mv example.txt ~/Trash`
## Deleting a file or folder permanently
When you're ready to remove a file or folder from your system permanently, you can use the **rm** command to erase all of the data in your Trash folder. By directing the **rm **command to an asterisk (`*`
), you delete all files and folders inside the **Trash** folder without deleting the **Trash** folder itself. If you accidentally delete the **Trash** folder, however, you can just recreate it because directories are easy and free to create.
`$ rm --recursive ~/Trash/*`
## Removing an empty directory
Deleting an empty directory has the special command **rmdir**, which only removes an empty directory, protecting you from recursive mistakes.
```
$ mkdir full
$ touch full/file.txt
$ rmdir full
rmdir: failed to remove 'full/': Directory not empty
$ mkdir empty
$ rmdir empty
```
## Better trash
There are [commands for trashing files](https://www.redhat.com/sysadmin/recover-file-deletion-linux) that aren't included by default in your terminal, but that you can install from a software repository. They make it even easier to trash files, because they manage and use the very same Trash folder you use on your desktop.
```
$ trash ~/example.txt
$ trash --list
example.txt
$ trash --empty
```
## Comments are closed. |
13,688 | SteamOS 是什么?关于这款“游戏发行版”你所要知道的事 | https://itsfoss.com/steamos/ | 2021-08-16T11:34:00 | [
"SteamOS"
] | https://linux.cn/article-13688-1.html | 
SteamOS 是一款基于 Linux 的操作系统,旨在提供来自 Steam 自己的游戏商店顺滑的游戏体验。
虽然它已经存在了许久,但有几件事你应该知道。
在这篇文章中,我们将回答许多 SteamOS 相关的常见问题。
### SteamOS 是什么?
SteamOS 是由游戏分发平台 Steam 开发的 Linux 发行版。它并是一款像 Debian、Linux Mint 或者 Ubuntu 那样的泛用型桌面操作系统,即便你确实可以使用桌面功能。默认情况下,SteamOS 的界面类似于游戏机,因为 SteamOS 旨在成为专为 Steam 游戏设备定制的操作系统,如 Steam Machine(已停产)和 Steam Deck。

你确实也可以在任何 Linux 发行版和其他平台安装 Steam 客户端,但 SteamOS 更是为了提供类似游戏机的体验,方便你玩 Steam 上的游戏。
### SteamOS 基于哪个 Linux 发行版?
作为基于 Linux 的系统,SteamOS 最初基于 Debian 8 开发。随着 Valve 的全新 [Steam Deck](https://www.steamdeck.com/en/) 掌机发布,SteamOS 的最新版本(SteamOS 3.0)将基于 Arch Linux 开发,因为 Arch 支持滚动更新。
SteamOS 的开发团队也相信,SteamOS 基于 Arch Linux 更有利于快速推送更新和优化 Steam Deck。

### SteamOS 的系统要求
理想情况下,符合以下最低要求的设备都应该可以正常运行 SteamOS:
* Intel / AMD 的 64 位 CPU
* 4GB 或更高的运行内存(RAM)
* 250GB 或更大的磁盘
* NVIDIA / Intel / AMD 的显卡
* 用于安装介质的 USB 或者 DVD
(LCTT 译注:本段内容仅针对 SteamOS 2.0。)
### SteamOS 能否在你的电脑上正常运作?
SteamOS(2.0 版本)内置了支持特定硬件的驱动程序。
理论上 SteamOS 可以在任何电脑上运行,但目前官方并没有支持最新的硬件。
### SteamOS 只是又一款 Linux 发行版吗?
SteamOS 严格来说已经是现有的 [适合游戏的 Linux 发行版](https://itsfoss.com/linux-gaming-distributions/) 之一。但与其他发行版不同的是,SteamOS 并不是为了泛用型桌面而设计的。你确实可以安装 Linux 程序,但 SteamOS 支持的软件包极为有限。
总之,它并不适合替代普通 Linux 桌面系统。
### SteamOS 现在还在积极维护中吗?
**是**,但又**不是**。
SteamOS 基于 Debian 8 许久,目前没有任何更新。
如果你正期望将 SteamOS 安装到你的个人设备上,那么目前公开发布的版本(SteamOS 2.0)已经处于不再维护的状态。
不过,Valve 目前正在为 Steam Deck 维护 SteamOS 3.0。因此,可能不久 SteamOS 就可以用于你的桌面了。
### 你是否推荐使用 SteamOS 来玩电脑游戏吗?
**不推荐**。在 Windows 和其它 Linux 发行版面前,SteamOS 并不是你应该选择的替代品。
虽然 SteamOS 主要是为游戏定制的,但在拿它玩游戏之前,你还需要了解许多注意事项。
### 所有游戏都可以在 SteamOS 上玩吗?
**不**。SteamOS 需要依赖 Proton 兼容层才能让 Windows 平台的游戏正常运行。
当然,如今借助同样的底层技术,[在 Linux 里玩游戏](https://itsfoss.com/linux-gaming-guide/) 已经成为了可能,但至少在我写这篇文章时,你并不能让 Steam 上架的所有游戏都可以在 Linux 中运行。
虽然大部分游戏都可以运行,但这并不意味着你游戏库里的所有游戏都能正常游玩。
如果你想玩 Steam 支持的游戏,以及仅限于 Linux 平台的游戏,那还是值得一试的。
### SteamOS 是否开源?
**是的**(SteamOS 2.0)。
SteamOS 操作系统是开源的,你可以在 [官方仓库](https://repo.steampowered.com/steamos/) 中找到源码。
不过,你用来玩游戏的 Steam 客户端是专有的。
值得注意的是,SteamOS 3.0 目前仍处于开发阶段,因此你无法获得它的源代码和任何公开进展。
### SteamOS 是否免费使用?
目前你暂时无法找到可供公众使用的最新版 SteamOS,但它基本上是免费的。基于 Debian 的旧版 SteamOS 可在其 [官方网站](https://store.steampowered.com/steamos/) 上获取。
### 我能找到内置 SteamOS 的游戏主机吗?

SteamOS 最初是为 Steam Machine 这款 Steam 自家的 PlayStation/Xbox 风格的游戏机定制的操作系统。2015 年 Steam Machine 发布后并没有在市场上获得成功,最终停产。
目前,唯一一款预装 SteamOS 的设备是备受瞩目的 Steam Deck。
待到 SteamOS 开放针对其它设备的下载后,你就可以看到有硬件厂商销售预装 SteamOS 的游戏设备了。
但,至少目前来看,你不应该相信任何不知名的制造商提供开箱即用的 SteamOS。
### 下一代 SteamOS 能否使 Linux 成为游戏的可行选择?
是的,绝对是的。
Linux 可能不是外界所推荐的游戏选择,但如果你乐意的话,你也可以查看 [我们所推荐的 Linux 游戏发行版](https://news.itsfoss.com/linux-for-gaming-opinion/)。最后,如果 SteamOS 下了狠心,让每款游戏都能在 Steam Deck 上运行,那么桌面 Linux 用户也将终于可以体验到所有曾经不支持的 Steam 游戏了。
---
via: <https://itsfoss.com/steamos/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

SteamOS is a Linux-based operating system that aims to provide a seamless gaming experience from Valve's game store, Steam.
While it has been around for more than a decade now, there are a few things that you should know about it.
In this article, we try to address the most common questions regarding SteamOS.
## What is SteamOS?
SteamOS is a Linux distribution from the popular game distribution platform [Steam](https://store.steampowered.com). It is not a generic desktop operating system like Debian, Linux Mint or Ubuntu, though you could use its desktop features.
By default, SteamOS gives you a console like interface because SteamOS is intended to be the operating system on Steam devices like Steam Machine (discontinued) and Steam Deck.
While you can install the Steam game client on any Linux distribution and other platforms, **SteamOS was developed to provide a console-like experience** to play games from the Steam store.
## Which Linux distribution is SteamOS based on?
SteamOS is a Linux-based operating system, **originally based on Debian 8**. With Valve’s [Steam Deck](https://www.steamdeck.com/en/?ref=itsfoss.com) handheld gaming device,** SteamOS’s latest version (SteamOS 3.0) uses Arch Linux** as its base because of its [rolling-release](https://itsfoss.com/rolling-release/) update schedule.
The developers believe that **Arch Linux as a base for SteamOS is useful to push quick updates and optimize SteamOS for Steam Deck**.

## System requirements for SteamOS
Ideally, any machine with the following minimum requirements should work:
- Intel or AMD 64-bit capable processor
- 4 GB or more memory
- 250 GB or larger disk
- NVIDIA, Intel, or AMD graphics card
- USB port or DVD drive for installation
## Will SteamOS Work on your PC?
SteamOS comes with drivers and chipsets that support a specific set of hardware.
It should theoretically work on every PC, but there’s no official support for the latest and greatest hardware — yet.
## Is SteamOS just another Linux distribution?
SteamOS is technically one of the [gaming Linux distributions](https://itsfoss.com/linux-gaming-distributions/) available. But, unlike some others, it is not meant for a full-fledged desktop experience. While you can install Linux applications, it supports a limited number of packages.
In short, it is **not suitable to replace a desktop Linux OS**.
## Is Steam OS Actively Maintained?
**Yes** and **No**.
SteamOS used to be based on Debian 8 for a long time, and with the transition to Arch Linux, the developers have been pushing constant updates to improve the overall experience.
However, if you were looking to install it on your personal machine, the version available publicly (SteamOS 2.0) is not actively maintained anymore.
With a recent preview, many improvements were shown off for SteamOS 3.0. Things such as **a fix for a black screen issue** with some games on [Steam Deck OLED](https://www.steamdeck.com/en/oled), a fix for the USB compatibility issues, and more were among the highlights of it.
We do not have a release date for SteamOS 3.0, but Valve did mention that they will be making it available for everyone eventually.
## Should You Prefer SteamOS for PC Gaming?
**No**. SteamOS is not a proper replacement for Windows or other Linux distributions. The latest version is primarily meant for the Steam Deck, and while it was tailored to play games, there are many other caveats to know before you proceed.
## Do all games work on SteamOS?
**No**. SteamOS relies on the Proton compatibility layer to make most Windows-exclusive games work.
Of course, [Gaming on Linux](https://itsfoss.com/linux-gaming-guide/) has been made possible with the same underlying tech, but at the time of writing this, you cannot make all the games available on Steam work with it.
Even though many games should work on it, that does not guarantee that all games you have in your library will work as expected.
If you are looking to play supported games and Linux-only games, you can refer to [ProtonDB](https://www.protondb.com), they list all the games on the Steam store and rank them according to the level of support for Linux.
## Is SteamOS open source?
**Yes**. (SteamOS 2.0)
The operating system is open-source, and you can find the source code in its [official repo](https://repo.steampowered.com). But, the Steam client that you will be using on it is proprietary.
It is worth noting that SteamOS 3.0 regularly receives new updates. But **you can't find the source code for it** because Valve hasn't made it public yet. We can only wait and see when they do.
However, you can get regular updates about SteamOS from its [Steam News](https://store.steampowered.com/news/app/1675200) page.
## Is SteamOS free to use?
You won’t find the latest SteamOS version available to the public yet, but it is essentially free to use.
## Can I find a gaming system with SteamOS built in?

SteamOS was originally created to be the operating system on Steam’s very own PlayStation/Xbox styled console called [Steam Machine](https://en.wikipedia.org/wiki/Steam_Machine_(computer)). Released around 2015, Steam Machine did not see much success and was eventually discontinued.
Now the only device to feature SteamOS is the Steam Deck.
If SteamOS was to be made available for other hardware, you could see popular prebuilt PC brands offering SteamOS pre-installed on their gaming products.
But, for now, you should not believe in any claims by unknown manufacturers offering SteamOS out of the box.
## Will SteamOS Make Linux a Viable Choice for Gaming?
Absolutely!
Linux may not be the recommended choice for gamers out there. But, if SteamOS continues evolving to support every game for its Steam Deck hardware, desktop Linux users could also benefit from it, finally getting to experience all unsupported Steam games.
You can also explore one of our older articles on why [we recommend Linux for gaming](https://news.itsfoss.com/linux-for-gaming-opinion/) to gain further insights. |
13,690 | 下载《Quarkus 的 Java 开发者指南》电子书 | https://opensource.com/article/21/8/java-quarkus-ebook | 2021-08-17T10:04:39 | [
"Java",
"电子书"
] | https://linux.cn/article-13690-1.html |
>
> 一本新的展示了开发者如何继续使用 Java 框架来构建新的无服务器功能的电子书。
>
>
>

[无服务器](https://opensource.com/article/21/1/devapps-strategies) 架构已经成为一种高效的解决方案,无论是物理服务器、虚拟机还是云环境,都可以根据实际工作负载调整超额配置和不足配置资源(如 CPU、内存、磁盘、网络)。然而,在选择新的编程语言来开发无服务器应用时,Java 开发者有一个担忧。对于云上的无服务器部署,尤其是 [Kubernetes](https://opensource.com/article/19/6/reasons-kubernetes),Java 框架似乎过于沉重和缓慢。
作为 Java 开发者,如果可以继续使用 Java 框架来构建传统的云原生微服务以及同时构建新的无服务器功能呢?这种方法应该是令人兴奋的,因为你不必担心新的无服务器应用框架的学习曲线会很陡峭。
此外,如果 Java 框架不仅可以为开发者提供熟悉技术的乐趣,还可以在启动时以毫秒为单位优化 Kubernetes 中的 Java 无服务器功能,并提供微小的内存足迹,又会怎样?
### 什么是 Quarkus?
[Quarkus](https://quarkus.io/) 是一个新的 Java 框架,可以为 Java 开发者、企业架构师和 DevOps 工程师提供这些功能和好处。它旨在设计无服务器应用,并编写云原生微服务,以便在云基础设施(例如 Kubernetes)上运行。
Quarkus 还支持一个名为 [Funqy](https://quarkus.io/guides/funqy) 的可移植 Java API 扩展,供开发者编写和部署无服务器功能到异构无服务器运行时。
Quarkus Funqy 使开发者能够将 [CloudEvents](https://cloudevents.io/) 与 Knative 环境中的无服务器函数绑定,以处理反应式流。这有利于开发者建立一个通用的消息传递格式来描述事件,提高多云和混合云平台之间的互操作性。
在我的新电子书 《[Java 无服务器功能指南](https://opensource.com/downloads/java-serverless-ebook)》的帮助下,开始你的 Quarkus 之旅。与他人分享你的 Quarkus 经验,让大家都能享受到用 Java 和 Quarkus 进行的无服务器开发。
---
via: <https://opensource.com/article/21/8/java-quarkus-ebook>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Serverless](https://opensource.com/article/21/1/devapps-strategies) architecture has already become an efficient solution to align overprovisioning and underprovisioning resources (e.g., CPU, memory, disk, networking) with actual workloads regardless of physical servers, virtual machines, and cloud environments. Yet, there is a concern for Java developers when choosing new programming languages to develop serverless applications. The Java framework seems too heavyweight and slow for serverless deployment on the cloud, especially [Kubernetes](https://opensource.com/article/19/6/reasons-kubernetes).
What if you, Java developer, could keep using the Java framework to build traditional cloud-native microservices as well as new serverless functions at the same time? This approach should be exciting since you don’t have to worry about a steep learning curve for new serverless application frameworks.
Furthermore, what if the Java framework could not only provide developers the joy of familiar technologies but also optimize Java serverless functions in Kubernetes by milliseconds at startup and offer tiny memory footprints?
## What is Quarkus?
[Quarkus](https://quarkus.io/) is the new Java framework that can provide these features and benefits to Java developers, enterprise architects, and DevOps engineers. It aims to design serverless applications and write cloud-native microservices for running on cloud infrastructures (for example, Kubernetes).
Quarkus also supports a portable Java API extension named [Funqy](https://quarkus.io/guides/funqy) for developers to write and deploy serverless functions to heterogeneous serverless runtimes.
Quarkus Funqy enables developers to bind [CloudEvents](https://cloudevents.io/) for handling reactive streams with serverless functions on the Knative environment. This is beneficial for developers building a common messaging format to describe events and increase interoperability among multi- and hybrid cloud platforms.
Start your journey with Quarkus with the help of my new eBook, [ A guide to Java serverless functions](https://opensource.com/downloads/java-serverless-ebook). Share your Quarkus experiences with others so everyone can enjoy serverless development with Java and Quarkus.
## Comments are closed. |
13,691 | 在 Linux 使用 systemd-udevd 管理你的接入硬件 | https://opensource.com/article/20/2/linux-systemd-udevd | 2021-08-17T10:47:02 | [
"udev",
"设备"
] | /article-13691-1.html |
>
> 使用 udev 管理你的 Linux 系统处理物理设备的方式。
>
>
>

Linux 能够出色地自动识别、加载、并公开接入的无数厂商的硬件设备。事实上,很多年以前,正是这个特性说服我,坚持让我的雇主将整个基础设施转换到 Linux。痛点在于 Redmond 的某家公司(LCTT 译注:指微软)不能在我们的 Compaq 台式机上加载集成网卡的驱动,而 Linux 可以轻松实现这一点。
从那以后的岁月里,Linux 的识别设备库随着该过程的复杂化而与日俱增,而 [udev](https://en.wikipedia.org/wiki/Udev) 就是解决这个问题的希望之星。udev 负责监听 Linux 内核发出的改变设备状态的事件。它可能是一个新 USB 设备被插入或拔出,也可能是一个无线鼠标因浸入洒出的咖啡中而脱机。
udev 负责处理所有的状态变更,比如指定访问设备使用的名称和权限。这些更改的记录可以通过 [dmesg](https://en.wikipedia.org/wiki/Dmesg) 获取。由于 dmesg 的输出通常有几千行,对结果进行过滤通常是聪明的选择。下面的例子说明了 Linux 如何识别我的 WiFi 接口。这个例子展示了我的无线设备使用的芯片组(`ath9k`)、启动过程早期阶段分配的原始名称(`wlan0`)、以及正在使用的又臭又长的永久名称(`wlxec086b1ef0b3`):
```
$ dmesg | grep wlan
[ 5.396874] ath9k_htc 1-3:1.0 wlxec086b1ef0b3: renamed from wlan0
```
在这篇文章中,我会讨论为何有人想要使用这样的名称。在这个过程中,我会探索剖析 udev 的配置文件,然后展示如何更改 udev 的设置,包括编辑系统命名设备的方式。这篇文件基于我的新课程中《[Linux 系统优化](https://pluralsight.pxf.io/RqrJb)》的一个模块。
### 理解 udev 配置系统
使用 systemd 的机器上,udev 操作由 `systemd-udevd` 守护进程管理,你可以通过常规的 systemd 方式使用 `systemctl status systemd-udevd` 检查 udev 守护进程的状态。
严格来说,udev 的工作方式是试图将它收到的每个系统事件与 `/lib/udev/rules.d/` 和 `/etc/udev/rules.d/` 目录下找到的规则集进行匹配。规则文件包括匹配键和分配键,可用的匹配键包括 `action`、`name` 和 `subsystem`。这意味着如果探测到一个属于某个子系统的、带有特定名称的设备,就会给设备指定一个预设的配置。
接着,“分配”键值对被拿来应用想要的配置。例如,你可以给设备分配一个新名称、将其关联到文件系统中的一个符号链接、或者限制为只能由特定的所有者或组访问。这是从我的工作站摘出的一条规则:
```
$ cat /lib/udev/rules.d/73-usb-net-by-mac.rules
# Use MAC based names for network interfaces which are directly or indirectly
# on USB and have an universally administered (stable) MAC address (second bit
# is 0). Don't do this when ifnames is disabled via kernel command line or
# customizing/disabling 99-default.link (or previously 80-net-setup-link.rules).
IMPORT{cmdline}="net.ifnames"
ENV{net.ifnames}=="0", GOTO="usb_net_by_mac_end"
ACTION=="add", SUBSYSTEM=="net", SUBSYSTEMS=="usb", NAME=="", \
ATTR{address}=="?[014589cd]:*", \
TEST!="/etc/udev/rules.d/80-net-setup-link.rules", \
TEST!="/etc/systemd/network/99-default.link", \
IMPORT{builtin}="net_id", NAME="$env{ID_NET_NAME_MAC}"
```
`add` 动作告诉 udev,只要新插入的设备属于网络子系统,*并且*是一个 USB 设备,就执行操作。此外,如果我理解正确的话,只有设备的 MAC 地址由特定范围内的字符组成,并且 `80-net-setup-link.rules` 和 `99-default.link` 文件*不*存在时,规则才会生效。
假定所有的条件都满足,接口 ID 会改变以匹配设备的 MAC 地址。还记得之前的 dmesg 信息显示我的接口名称从 `wlan0` 改成了讨厌的 `wlxec086b1ef0b3` 吗?那都是这条规则的功劳。我怎么知道?因为 `ec:08:6b:1e:f0:b3` 是设备的 MAC 地址(不包括冒号)。
```
$ ifconfig -a
wlxec086b1ef0b3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.103 netmask 255.255.255.0 broadcast 192.168.0.255
inet6 fe80::7484:3120:c6a3:e3d1 prefixlen 64 scopeid 0x20<link>
ether ec:08:6b:1e:f0:b3 txqueuelen 1000 (Ethernet)
RX packets 682098 bytes 714517869 (714.5 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 472448 bytes 201773965 (201.7 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
```
Linux 默认包含这条 udev 规则,我不需要自己写。但是为什么费力进行这样的命名呢——尤其是看到这样的接口命名这么难使用后?仔细看一下包含在规则中的注释:
>
> 对直接或间接插入在 USB 上的网络接口使用基于 MAC 的名称,并且用一个普遍提供的(稳定的)MAC 地址(第二位是 0)。当 ifnames 通过内核命令行或 `customizing/disabling 99-default.link`(或之前的 `80-net-setup-link.rules`)被禁用时,不要这样做。
>
>
>
注意,这个规则专为基于 USB 的网络接口设计的。和 PCI 网络接口卡(NIC)不同,USB 设备很可能时不时地被移除或者替换,这意味着无法保证它们的 ID 不变。某一天 ID 可能是 `wlan0`,第二天却变成了 `wlan3`。为了避免迷惑应用程序,指定绝对 ID 给设备——就像分配给我的 USB 接口的 ID。
### 操作 udev 的设置
下一个示例中,我将从 [VirtualBox](https://www.virtualbox.org/) 虚拟机里抓取以太网接口的 MAC 地址和当前接口 ID,然后用这些信息创建一个改变接口 ID 的 udev 新规则。为什么这么做?也许我打算从命令行操作设备,需要输入那么长的名称让人十分烦恼。下面是工作原理。
改变接口 ID 之前,我需要关闭 [Netplan](https://netplan.io/) 当前的网络配置,促使 Linux 使用新的配置。下面是 `/etc/netplan/` 目录下我的当前网络接口配置文件:
```
$ less /etc/netplan/50-cloud-init.yaml
# This file is generated from information provided by
# the datasource. Changes to it will not persist across an instance.
# To disable cloud-init's network configuration capabilities, write a file
# /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following:
# network: {config: disabled}
network:
ethernets:
enp0s3:
addresses: []
dhcp4: true
version: 2
```
`50-cloud-init.yaml` 文件包含一个非常基本的接口定义,但是注释中也包含一些禁用配置的重要信息。为此,我将移动到 `/etc/cloud/cloud.cfg.d` 目录,创建一个名为 `/etc/cloud/cloud.cfg.d` 的新文件,插入 `network: {config: disabled}` 字符串。
尽管我只在 Ubuntu 发行版上测试了这个方法,但它应该在任何一个带有 systemd 的 Linux(几乎所有的 Linux 发行版都有 systemd)上都可以工作。不管你使用哪个,都可以很好地了解编写 udev 配置文件并对其进行测试。
接下来,我需要收集一些系统信息。执行 `ip` 命令,显示我的以太网接口名为 `enp0s3`,MAC 地址是 `08:00:27:1d:28:10`。
```
$ ip a
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:1d:28:10 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.115/24 brd 192.168.0.255 scope global dynamic enp0s3
```
现在,我要在 `/etc/udev/rules.d` 目录创建一个名为 `peristent-net.rules` 的新文件。我将给文件一个以较小的数字开头的名称,比如 10:
```
$ cat /etc/udev/rules.d/10-persistent-network.rules
ACTION=="add", SUBSYSTEM=="net",ATTR{address}=="08:00:27:1d:28:10",NAME="eth3"
```
数字越小,Linux 越早执行文件,我想要这个文件早点执行。文件被添加时,包含其中的代码就会分配名称 `eth3` 给网络设备——只要设备的地址能够匹配 `08:00:27:1d:28:10`,即我的接口的 MAC 地址 。
保存文件并重启计算机后,我的新接口名应该就会生效。我可能需要直接登录虚拟机,使用 `dhclient` 手动让 Linux 为这个新命名的网络请求一个 IP 地址。在执行下列命令前,可能无法打开 SSH 会话:
```
$ sudo dhclient eth3
```
大功告成。现在你能够促使 udev 控制计算机按照你想要的方式指向一个网卡,但更重要的是,你已经有了一些工具,可以弄清楚如何管理任何不听话的设备。
---
via: <https://opensource.com/article/20/2/linux-systemd-udevd>
作者:[David Clinton](https://opensource.com/users/dbclinton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[YungeG](https://github.com/YungeG) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,694 | 如何在 Fedora Linux 上安装 Java | https://itsfoss.com/install-java-fedora/ | 2021-08-18T10:25:00 | [
"Java"
] | https://linux.cn/article-13694-1.html | 
不管是爱它还是恨它,都很难避开 Java。
Java 仍然是一种非常流行的编程语言,在学校里教,在企业里用。
如果你想使用基于 Java 的工具或用 Java 编程,你就需要在你的系统上安装 Java。
这就变得很混乱,因为围绕着 Java 有很多技术术语。
* <ruby> Java 开发工具包 <rt> Java Development Kit </rt></ruby>(JDK)用于创建 Java 程序
* <ruby> Java 运行环境 <rt> Java Runtime Environment </rt></ruby>(JRE)或 Java 虚拟机(JVM),用于运行 Java 程序。
除此之外,你还会遇到 [OpenJDK](https://openjdk.java.net/) 和 [Oracle Java SE](https://www.oracle.com/java/technologies/javase-downloads.html)。推荐使用 OpenJDK ,因为它是开源的。如果你有专门的需求,那么你应该选择 Oracle Java SE。
还有一件事。即使是 OpenJDK 也有几个版本可供选择。在写这篇文章的时候,Fedora 34 有 OpenJDK 1.8、OpenJDK 11 和 OpenJDK 16 可用。
你可以自行决定想要哪个Java版本。
### 在 Fedora Linux 上安装 Java
首先,检查是否已经安装了 Java,以及它是哪个版本。我不是在开玩笑。Fedora 通常预装了 Java。
要检查它,请使用以下命令:
```
java -version
```
正如你在下面的截图中看到的,我的 Fedora 系统上安装了 Java 11(OpenJDK 11)。

假设你想安装另一个版本的 Java。你可以用下面的命令检查可用的选项:
```
sudo dnf search openjdk
```
这里的 `sudo` 不是必须的,但它会刷新 `sudo` 用户的元数据,这在你安装另一个版本的 Java 时会有帮助。
上面的命令将显示很多输出,其中有很多看起来相似的软件包。你必须专注于最初的几个词来理解不同的版本。

例如,要安装 Java 8(OpenJDK 1.8),包的名字应该是 `java-1.8.0-openjdk.x86_64` 或者 `java-1.8.0-openjdk`。用它来安装:
```
sudo dnf install java-1.8.0-openjdk.x86_64
```

这就好了。现在你的系统上同时安装了 Java 11 和 Java 8。但你将如何使用其中一个呢?
#### 在 Fedora 上切换 Java 版本
你正在使用的 Java 版本保持不变,除非你明确改变它。使用这个命令来列出系统上安装的 Java 版本:
```
sudo alternatives --config java
```
你会注意到在 Java 版本前有一个数字。Java 版本前的 `+` 号表示当前正在使用的 Java 版本。
你可以指定这个数字来切换 Java 版本。因此,在下面的例子中,如果我输入 2,它将把系统中的 Java 版本从 Java 11 改为 Java 8。

这就是你在 Fedora 上安装 Java 所需要做的一切。
---
via: <https://itsfoss.com/install-java-fedora/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Love it or hate it, it is difficult to avoid Java.
Java is still a very popular programming language taught in the schools and used in the enterprises.
If you want to use a Java-based tool or program in Java, you’ll need to have Java on your system.
This becomes confusing because there are so many technical terms around java.
- Java Development Kit (JDK) for creating Java programs
- Java Runtime Environment (JRE) or Java Virtual Machine (JVM) for running Java programs
On top of that, you’ll come across [OpenJDK](https://openjdk.java.net/) and [Oracle Java SE](https://www.oracle.com/java/technologies/javase-downloads.html). OpenJDK is what is recommended because it is open source. If you have exclusive need then only you should go for Oracle Java SE.
There is one more thing here. Even OpenJDK has several versions available. At the time of writing this article, Fedora 34 has OpenJDK 1.8, OpenJDK 11 and OpenJDK 16 available.
It is up to you to decide which Java version you want.
## Installing Java on Fedora Linux
First thing first, check if Java is already installed and which version it is. I am not kidding. Fedora usually comes with Java preinstalled.
To check, use the following command:
`java -version`
As you can see in the screenshot below, I have Java 11 (OpenJDK 11) installed on my Fedora system.
Let’s say you want to install another version of Java. You may check the available options with the following command:
`sudo dnf search openjdk`
The sudo here is not required but it will refresh the metadata for sudo user which will eventually help when you install another version of Java.
The above command will show a huge output with plenty of similar looking packages. You have to focus on the initial few words to understand the different versions available.
For example, to install Java 8 (OpenJDK 1.8), the package name should be java-1.8.0-openjdk.x86_64 or java-1.8.0-openjdk. Use it to install it:
`sudo dnf install java-1.8.0-openjdk.x86_64`
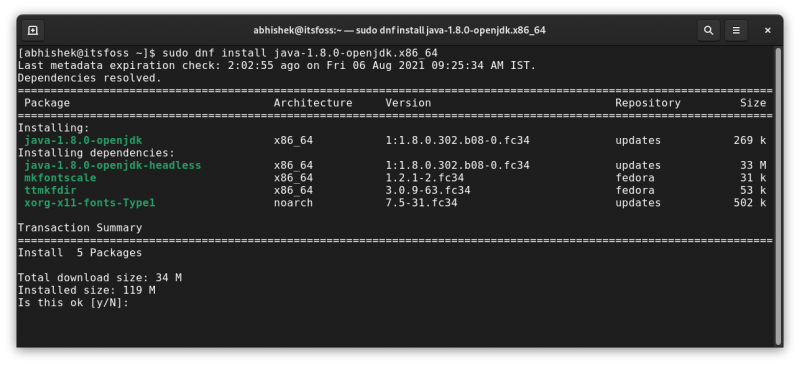
That’s good. Now you have both Java 11 and Java 8 installed on your system. But how will you use one of them?
## Switch Java version on Fedora
Your Java version in use remains the same unless you explicitly change it. Use this command to list the installed Java versions on your system:
`sudo alternatives --config java`
You’ll notice a number before the Java versions. The + sign before the Java versions indicate the current Java version in use.
You can specify the number to switch the Java version. So, in the example below, if I enter 2, it will change the Java version on the system from Java 11 to Java 8.
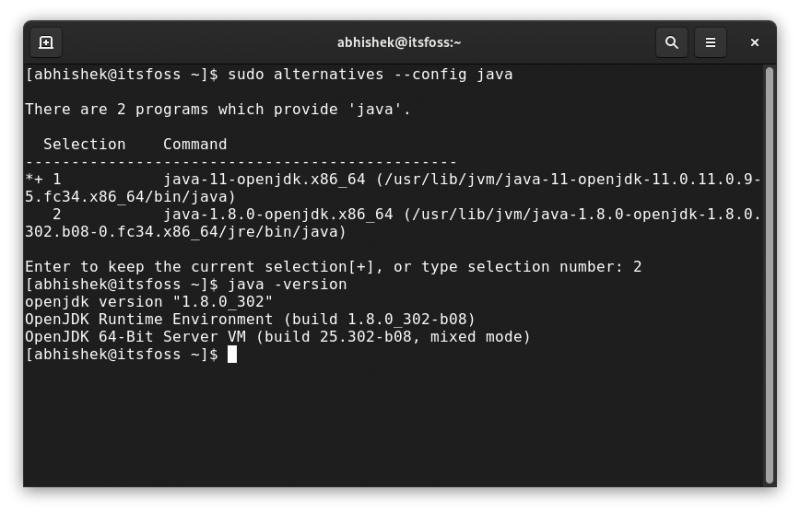
That’s all you need to do to install Java on Fedora. |
13,695 | 新发布的 Debian 11 “Bullseye” Linux 发行版的 7 大亮点 | https://news.itsfoss.com/debian-11-feature/ | 2021-08-18T13:59:35 | [
"Debian"
] | https://linux.cn/article-13695-1.html |
>
> 这个最新发布的通用操作系统已经来到。
>
>
>

期待已久的代号为 “Bullseye” 的 Debian 11 版本在经过两年的开发后终于来了。该版本将在未来五年内得到支持,就像任何其他的 Debian 稳定版版本一样。
感到兴奋吗?让我们来看看 Debian 11 的新内容。
### 1、新主题
Debian 11 带有一个新的 “Homeworld” 主题。它的灵感来自 [包豪斯运动](https://mymodernmet.com/what-is-bauhaus-art-movement/),这是一种 20 世纪初诞生于德国的艺术风格,其特点是对建筑和设计的独特处理。

在 Debian 11 中,无论是在登录界面、安装程序还是 Grub 菜单上,你都会看到这个主题。



### 2、较新版本的桌面环境
Debian 11 包含了它所提供的桌面变体的较新版本:
* GNOME 3.38
* KDE Plasma 5.20
* LXDE 11
* LXQt 0.16
* MATE 1.24
* Xfce 4.16
如果你使用 Fedora 或 Arch/Manjaro 等先锐发行版,你可能会觉得很奇怪。但就是这样。Debian 更倾向于稳定,因此桌面环境的版本不是最新的。当然,它们与之前的 Debian 稳定版相比,还是比较新的。
### 3、软件包更新
Debian 已经更新了它的软件包库。Debian 11 包括了多达 11294 个新软件包,软件包总数多达 59551 个。42821 个软件包有了新的版本。删除了 9519 个软件包。
也就是说你应该会看到像 LibreOffice、Emacs、GIMP 以及各种服务器和编程相关工具等流行应用程序的新版本。
### 4、Linux 内核 5.10 LTS
Debian 11 带有 [Linux 5.10 内核,这是一个长期支持(LTS)版本](https://news.itsfoss.com/kernel-5-10-release/)。Debian 10 Buster 在发布时使用的是 Linux 4.19 内核。
一个新的内核显然意味着对硬件有更好的支持,特别是较新的硬件以及性能的改进。
### 5、打印机和扫描器的改进
Debian 11 带来了新的软件包 ipp-usb。它使用了许多现代打印机所支持的供应商中立的 IPP-over-USB 协议。这意味着许多较新的打印机将被 Debian 11 所支持,而不需要驱动程序。
同样地,SANE 无驱动后端可以让你轻松使用扫描仪。
### 6、支持 exFAT
你不再需要使用 exfat-fuse 包来挂载 exFAT 文件系统。借助 Linux 5.10 内核,Debian 11 已经支持 exFAT 文件系统,并且默认使用它来挂载 exFAT 文件系统。
### 7、仍然支持 32 位
这算是一个功能吗?考虑到现在只有 [少数几个 Linux 发行版支持 32 位架构](https://itsfoss.com/32-bit-linux-distributions/),我觉得是。
除了 32 位和 64 位 PC,Debian 11 还支持 64 位 ARM(arm64)、ARM EABI(armel)、ARMv7(EABI hard-float ABI,armhf)、小端 MIPS(mipsel)、64 位小端 MIPS(mips64el)、64 位小端 PowerPC(ppc64el)和 IBM System z(s390x)。
现在你知道为什么它被称为“通用操作系统”了吧。 ?
### 其他变化
在这个版本中还有一些变化:
* Systemd 默认使用控制组 v2(cgroupv2)。
* 针对中文、日文、韩文和其他许多语言的新 Fcitx 5 输入法。
* Systemd 日记日志默认为持久性的。
* 一个新的打开命令,可以用某个应用程序(GUI 或 CLI)从命令行自动打开文件。
* 本地系统账户的密码散列现在默认使用 yescrypt 而不是 SHA-512 来提高安全性。
更多信息可以在 [官方发布说明](https://www.debian.org/releases/bullseye/amd64/release-notes/ch-whats-new.en.html) 中找到。
### 获取 Debian 11
Debian 11 可以从其网站下载。只要前往该网站并从那里获得 ISO。
* [下载 Debian](https://www.debian.org/)
如果你已经在使用 Debian 10,你可以 [通过改变你的源列表轻松升级到 Debian 11](https://www.debian.org/releases/bullseye/amd64/release-notes/ch-upgrading.en.html) 。
享受最新和最棒的通用操作系统吧。?
---
via: <https://news.itsfoss.com/debian-11-feature/>
作者:[Abhishek](https://news.itsfoss.com/author/root/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The much awaited release of Debian 11 codenamed Bullseye is finally here after two years of development. The release will be supported for the next five years like any other Debian stable version release.
Excited about it? Let’s see what’s new in Debian 11.
## 1. New theme
Debian 11 comes with a new ‘Homeworld’ theme. It is inspired by the [Bauhaus movement](https://mymodernmet.com/what-is-bauhaus-art-movement/?ref=news.itsfoss.com), an art style born in Germany in the early 20th century and characterized by its unique approach to architecture and design.

You’ll see this theme everywhere in Debian 11 be it on the login screen, installer or on the Grub menu.
Grub screen Installer Login screen
## 2. Newer version of desktop environments
Debian 11 consists of newer version of the desktop flavors it offers:
- GNOME 3.38
- KDE Plasma 5.20
- LXDE 11
- LXQt 0.16
- MATE 1.24
- Xfce 4.16
If you use cutting-edge distributions like Fedora or Arch/Manjaro, you may find it weird. But here’s the thing. Debian prefers stability, and hence the desktop environment versions are not the latest ones. They are newer in comparison to the previous Debian stable release.
## 3. Package updates
Debian has updates its package repositories. Debian 11 includes over 11294 new packages taking the total to over 59551 packages. Over 42821 software packages have newer versions. Over 9519 packages have been removed for the distribution.
This means that you should see newer versions of the popular applications like LibreOffice, Emacs, GIMP and various server and programming related tools.
## 4. Linux Kernel 5.10 LTS
Debian 11 features [Kernel 5.10 which is a long term support (LTS) release](https://news.itsfoss.com/kernel-5-10-release/). Debian 10 Buster used Kernel 4.19 at the time of its release.
A new kernel obviously means better support for hardware, specially the newer hardware along with performance improvements.
## 5. Printer and Scanner improvement
Debian 11 brings the new package ipp-usb. It uses the vendor-neutral IPP-over-USB protocol supported by many modern printers. This means that many newer printers will be supported by Debian 11 without needing the drivers.
Similarly, SANE driverless backend allows using scanners painlessly.
## 6. ExFAT support
You no longer need to exfat-fuse package for mounting ExFAT filesystem. Thanks to the Linux kernel 5.10, Debian 11 has support for the exFAT filesystem, and defaults to using it for mounting exFAT filesystems.
## 7. Still supports 32 bit
Is that even a feature? Considering that only a [handful of Linux distributions now support 32-bit architecture](https://itsfoss.com/32-bit-linux-distributions/?ref=news.itsfoss.com), I would say yes.
Apart from 32-bit and 64-bit PC, Debian 11 also supports 64-bit ARM (arm64), ARM EABI (armel), ARMv7 (EABI hard-float ABI, armhf), little-endian MIPS (mipsel), 64-bit little-endian MIPS (mips64el), 64-bit little-endian PowerPC (ppc64el) and IBM System z (s390x).
Now you know why is it called the ‘universal operating system’ 🙂
## Other changes
There are a few more changes in this release.
- Systemd defaults to using control groups v2 (cgroupv2).
- New Fcitx 5 is input method for Chinese, Japanese, Korean and many other languages.
- Systemd journal logs are persistent by default.
- A new open command to automatically open files from command-line with a certain app (GUI or CLI).
- Password hashing for local system accounts now uses yescrypt by default instead of SHA-512 for improved security.
More information can be found in the [official release notes](https://www.debian.org/releases/bullseye/amd64/release-notes/ch-whats-new.en.html?ref=news.itsfoss.com).
## Getting Debian 11
Debian 11 is available to download from its website. Just head over to the website and get the ISO from there and start [installing Debian](https://itsfoss.com/install-debian-easily/?ref=news.itsfoss.com).
If you are already using Debian 10, you can [easily upgrade to Debian 11 by changing your sources list. ](https://www.debian.org/releases/bullseye/amd64/release-notes/ch-upgrading.en.html?ref=news.itsfoss.com)
Enjoy the latest and greatest of the universal operating system 🙂
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,696 | [免费训练营] Shell 编程训练营,它来了 | https://developer.aliyun.com/learning/trainingcamp/linux/2?utm_content=g_1000289929 | 2021-08-18T14:16:00 | [
"Shell",
"训练营"
] | https://linux.cn/article-13696-1.html | 
Shell 作为 Linux 中的第一语言,几乎每一个使用 Linux 的人都用到或用过 Shell,但绝大多数人都并不能掌握 Shell 编程的基本能力和技巧。
但如果你的工作涉及到与 Linux 进行操作和交互,Shell 编程对于你来说,都是一个必学的选项。今天,Linux 中国将为大家带来系列公益训练营之 《**Shell 编程训练营**》,以帮助大家掌握 Shell 编程的精髓和奥义。本次训练营得到了阿里云开发者社区的大力支持。
在本次训练营当中,你将会学习到体系化的 Linux Shell 编程内容,从 0 开始,掌握 Shell 编程的各项基本信息。
本次课程将会分三天进行授课:
* DAY 1:Shell 的基本介绍、常用命令以及 Shell 的流程控制
* DAY 2:Shell 中的数组应用、参数处理和函数的应用
* DAY 3:Shell 的编码规范、调试 Debug 方案以及公共函数库
在授课过程中, 老师将以实战与理论相结合的方式,带着你学习基础知识,并掌握实战能力。
在本次训练营中,训练营导师将会带着你用三天的时间,从 Shell 的基础开始,一起开发一个 Shell 脚本,帮助你掌握 Shell 编程的精髓,提升你的 Shell 编程能力。
此外,通过 Linux 中国专属渠道报名并完成训练营学习的同学,还将获得一张由 Linux 中国颁发的训练营结业证书、全网可查询的电子证书。并有机会获得一本赠送的最新计算机书籍(共计 30 本,直播时抽取赠送)。
### 课程安排
授课时间:2021年 9 月 6 日 - 2021 年 9 月 8 日 21:00 - 22:00(为期 3 晚)
授课方式:直播授课,有回放
授课费用:免费授课,无任何费用
上课地点:报名后进入专属钉钉群
报名链接:<https://developer.aliyun.com/learning/trainingcamp/linux/2?utm_content=g_1000289929>
| 301 | Moved Permanently | null |
13,698 | 在 Fedora Linux 上使用 OpenCV(一) | https://fedoramagazine.org/use-opencv-on-fedora-linux-part-1/ | 2021-08-19T11:33:26 | [
"OpenCV"
] | https://linux.cn/article-13698-1.html | 
*封面图片选自[文森特·梵高](https://commons.wikimedia.org/wiki/File:Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg)的《星空》,公共领域,通过维基共享资源发布*
技术世界每天都在变化,对计算机视觉、人工智能和机器学习的需求也在增加。让计算机和手机能够看到周围环境的技术被称为 [计算机视觉](https://en.wikipedia.org/wiki/Computer_vision)。这个重新创造人眼的工作始于 50 年代。从那时起,计算机视觉技术有了长足的发展。计算机视觉已经通过不同的应用进入了我们的手机。这篇文章将介绍 Fedora Linux 上的 [OpenCV](https://en.wikipedia.org/wiki/OpenCV)。
### 什么是 OpenCV?
>
> OpenCV(<ruby> 开源计算机视觉库 <rt> Open Source Computer Vision Library </rt></ruby>)是一个开源的计算机视觉和机器学习软件库。OpenCV 的建立是为了给计算机视觉应用提供一个通用的基础设施,并加速机器感知在商业产品中的应用。它有超过 2500 种优化后的算法,其中包括一套全面的经典和最先进的计算机视觉和机器学习算法。这些算法可用于检测和识别人脸、识别物体、对视频中的人类行为进行分类,并建立标记,将其与增强现实叠加等等。
>
>
> [opencv.org – about](https://opencv.org/about/)
>
>
>
### 在 Fedora Linux 上安装 OpenCV
要开始使用 OpenCV,请从 Fedora Linux 仓库中安装它:
```
$ sudo dnf install opencv opencv-contrib opencv-doc python3-opencv python3-matplotlib python3-numpy
```
**注意:** 在 Fedora Silverblue 或 CoreOS 上,Python 3.9 是核心提交的一部分。用以下方法安装 OpenCV 和所需工具:
```
rpm-ostree install opencv opencv-doc python3-opencv python3-matplotlib python3-numpy
```
接下来,在终端输入以下命令,以验证 OpenCV 是否已经安装:
```
$ python
Python 3.9.6 (default, Jul 16 2021, 00:00:00)
[GCC 11.1.1 20210531 (Red Hat 11.1.1-3)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2 as cv
>>> print( cv.__version__ )
4.5.2
>>> exit()
```
当你输入 `print` 命令时,应该显示当前的 OpenCV 版本,如上图所示。这表明 OpenCV 和 Python-OpenCV 库已经成功安装。
此外,如果你想用 Jupyter Notebook 做笔记和写代码,并了解更多关于数据科学工具的信息,请查看早期的 Fedora Magazine 文章:[Fedora 中的 Jupyter 和数据科学](https://fedoramagazine.org/jupyter-and-data-science-in-fedora/)。
### 开始使用 OpenCV
安装完成后,使用 Python 和 OpenCV 库加载一个样本图像(按 `S` 键以 png 格式保存图像的副本并完成程序):
```
$ cp /usr/share/opencv4/samples/data/starry_night.jpg .
$ python starry_night.py
```
`starry_night.py` 的内容:
```
import cv2 as cv
import sys
img = cv.imread(cv.samples.findFile("starry_night.jpg"))
if img is None:
sys.exit("Could not read the image.")
cv.imshow("Display window", img)
k = cv.waitKey(0)
if k == ord("s"):
cv.imwrite("starry_night.png", img)
```

通过在 `cv.imread` 函数中添加参数 `0`,对图像进行灰度处理,如下所示。
```
img = cv.imread(cv.samples.findFile("starry_night.jpg"),0)
```

这些是一些可以用于 `cv.imread` 函数的第二个参数的替代值:
* `cv2.IMREAD_GRAYSCALE` 或 `0`:以灰度模式加载图像。
* `cv2.IMREAD_COLOR** 或`1`:以彩色模式载入图像。图像中的任何透明度将被移除。这是默认的。
* `cv2.IMREAD_UNCHANGED** 或`-1`:载入未经修改的图像。包括 alpha 通道。
#### 使用 OpenCV 显示图像属性
图像属性包括行、列和通道的数量、图像数据的类型、像素的数量等等。假设你想访问图像的形状和它的数据类型。你可以这样做:
```
import cv2 as cv
img = cv.imread(cv.samples.findFile("starry_night.jpg"))
print("Image size is", img.shape)
print("Data type of image is", img.dtype)
Image size is (600, 752, 3)
Data type of image is uint8
print(f"Image 2D numpy array \n {img}")
Image 2D numpy array
[[[0 0 0]
[0 0 0]
[0 0 0]
...
[0 0 0]
[0 0 0]
[0 0 0]]
[[0 0 0]
[0 0 0]
[0 0 0]
...
```
* `img.shape`:返回一个行数、列数和通道数的元组(如果是彩色图像)。
* `img.dtype`:返回图像的数据类型。
接下来用 Matplotlib 显示图像:
```
import cv2 as cv
import matplotlib.pyplot as plt
img = cv.imread(cv.samples.findFile("starry_night.jpg"),0)
plt.imshow(img)
plt.show()
```

#### 发生了什么?
该图像是作为灰度图像读入的,但是当使用 Matplotlib 的 `imshow` 函数时,它不一定会以灰度显示。这是因为 `imshow` 函数默认使用不同的颜色映射。要指定使用灰度颜色映射,请将 `imshow` 函数的第二个参数设置为 `cmap='gray'`,如下所示:
```
plt.imshow(img,cmap='gray')
```

这个问题在以彩色模式打开图片时也会发生,因为 Matplotlib 期望图片为 RGB(红、绿、蓝)格式,而 OpenCV 则以 BGR(蓝、绿、红)格式存储图片。为了正确显示,你需要将 BGR 图像的通道反转。
```
import cv2 as cv
import matplotlib.pyplot as plt
img = cv.imread(cv.samples.findFile("starry_night.jpg"),cv.IMREAD_COLOR)
fig, (ax1, ax2) = plt.subplots(1,2)
ax1.imshow(img)
ax1.set_title('BGR Colormap')
ax2.imshow(img[:,:,::-1])
ax2.set_title('Reversed BGR Colormap(RGB)')
plt.show()
```

#### 分割和合并颜色通道
```
import cv2 as cv
import matplotlib.pyplot as plt
img = cv.imread(cv.samples.findFile("starry_night.jpg"),cv.IMREAD_COLOR)
b,g,r = cv.split(img)
fig,ax = plt.subplots(2,2)
ax[0,0].imshow(r,cmap='gray')
ax[0,0].set_title("Red Channel");
ax[0,1].imshow(g,cmap='gray')
ax[0,1].set_title("Green Channel");
ax[1,0].imshow(b,cmap='gray')
ax[1,0].set_title("Blue Channel");
# Merge the individual channels into a BGR image
imgMerged = cv.merge((b,g,r))
# Show the merged output
ax[1,1].imshow(imgMerged[:,:,::-1])
ax[1,1].set_title("Merged Output");
plt.show()
```

* `cv2.split`:将一个多通道数组分割成几个单通道数组。
* `cv2.merge`:将几个数组合并成一个多通道数组。所有的输入矩阵必须具有相同的大小。
**注意:** 白色较多的图像具有较高的颜色密度。相反,黑色较多的图像,其颜色密度较低。在上面的例子中,红色的密度是最低的。
#### 转换到不同的色彩空间
`cv2.cvtColor` 函数将一个输入图像从一个颜色空间转换到另一个颜色空间。在 RGB 和 BGR 色彩空间之间转换时,应明确指定通道的顺序(`RGB2BGR` 或 `BGR2RGB`)。**注意,OpenCV 中的默认颜色格式通常被称为 RGB,但它实际上是 BGR(字节是相反的)。** 因此,标准(24 位)彩色图像的第一个字节将是一个 8 位蓝色分量,第二个字节是绿色,第三个字节是红色。然后第四、第五和第六个字节将是第二个像素(蓝色、然后是绿色,然后是红色),以此类推。
```
import cv2 as cv
import matplotlib.pyplot as plt
img = cv.imread(cv.samples.findFile("starry_night.jpg"),cv.IMREAD_COLOR)
img_rgb = cv.cvtColor(img, cv.COLOR_BGR2RGB)
plt.imshow(img_rgb)
plt.show()
```

### 更多信息
关于 OpenCV 的更多细节可以在[在线文档](https://docs.opencv.org/4.5.2/index.html)中找到。
感谢阅读。
---
via: <https://fedoramagazine.org/use-opencv-on-fedora-linux-part-1/>
作者:[Onuralp SEZER](https://fedoramagazine.org/author/thunderbirdtr/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The technology world changes daily and the demands for computer vision, artificial intelligence, and machine learning are increasing. The technology that allows computers and mobile phones to see their surroundings is called [computer vision](https://en.wikipedia.org/wiki/Computer_vision). Work on re-creating a human eye started in the 50s. Since then, computer vision technology has come a long way. Computer vision has already made its way to our mobile phones via different applications. This article will introduce [OpenCV](https://en.wikipedia.org/wiki/OpenCV) on Fedora Linux.
**What is OpenCV?**
OpenCV (Open Source Computer Vision Library) is an open-source computer vision and machine learning software library. OpenCV was built to provide a common infrastructure for computer vision applications and to accelerate the use of machine perception in the commercial products. It has more than 2500 optimized algorithms, which includes a comprehensive set of both classic and state-of-the-art computer vision and machine learning algorithms. These algorithms can be used to detect and recognize faces, identify objects, classify human actions in videos and establish markers to overlay it with augmented reality and much more.
[opencv.org – about]
## Install OpenCV on Fedora Linux
To get started with OpenCV, install it from the Fedora Linux repositories.
$ sudo dnf install opencv opencv-contrib opencv-doc python3-opencv python3-matplotlib python3-numpy
**Note:** On Fedora Silverblue or CoreOs, Python 3.9 is part of the core commit. Layer OpenCV and required tools with: *rpm-ostree install opencv opencv-doc python3-opencv python3-matplotlib python3-numpy*.
Next, enter the following commands in a terminal to verify that OpenCV is installed (user input shown in bold).
$pythonPython 3.9.6 (default, Jul 16 2021, 00:00:00) [GCC 11.1.1 20210531 (Red Hat 11.1.1-3)] on linux Type "help", "copyright", "credits" or "license" for more information. >>>import cv2 as cv>>>print( cv.__version__ )4.5.2 >>>exit()
The current OpenCV version should be displayed when you enter the *print* command as shown above. This indicates that OpenCV and the Python-OpenCV libraries have been installed successfully.
Additionally, if you want to take notes and write code with Jupyter Notebook and learn more about data science tools, check out the earlier Fedora Magazine article: [ Jupyter and Data Science in Fedora](https://fedoramagazine.org/jupyter-and-data-science-in-fedora/).
## Get started with OpenCV
After installation is complete, load a sample image using Python and the OpenCV libraries (press the **S** key to save a copy of the image in *png* format and finish the program):
Contents of *starry_night.py*:
import cv2 as cv import sys img = cv.imread(cv.samples.findFile("starry_night.jpg")) if img is None: sys.exit("Could not read the image.") cv.imshow("Display window", img) k = cv.waitKey(0) if k == ord("s"): cv.imwrite("starry_night.png", img)
$ python starry_night.py
Gray-scale the image by adding the parameter **0** to the *cv.imread* function as shown below.
img = cv.imread(cv.samples.findFile("starry_night.jpg"),0)
These are some alternative values that can be used for the second parameter of the *cv.imread* function.
**cv2.IMREAD_GRAYSCALE**or**0:**Load the image in grayscale mode.**cv2.IMREAD_COLOR**or**1:**Load the image in color mode. Any transparency in the image will be removed. This is the default.**cv2.IMREAD_UNCHANGED**or**-1:**Load the image unaltered; including alpha channel.
### Display image attributes using OpenCV
Image attributes include the number of rows, columns, and channels; the type of image data; the number of pixels; etc. Suppose you wanted to access the image’s shape and its datatype. This is how you would do it:
import cv2 as cv img = cv.imread(cv.samples.findFile("starry_night.jpg")) print("Image size is", img.shape) print("Data type of image is", img.dtype)
Image size is (600, 752, 3) Data type of image is uint8
print(f"Image 2D numpy array \n {img}")
Image 2D numpy array [[[0 0 0] [0 0 0] [0 0 0] ... [0 0 0] [0 0 0] [0 0 0]] [[0 0 0] [0 0 0] [0 0 0] ...
**img.shape:**return a tuple of the number of rows, columns, and channels (if it is a color image)**img.dtype:**return the datatype of the image
Next display image with Matplotlib:
import cv2 as cv import matplotlib.pyplot as plt img = cv.imread(cv.samples.findFile("starry_night.jpg"),0) plt.imshow(img) plt.show()
### What happened?
The image was read in as a gray-scale image, however it won’t necessarily display in gray-scale when using Matplotlib’s *imshow* fucntion. This is because the *imshow* function uses a different color map by default. To specify that a gray-scale color map should be used, set the second parameter of the *imshow* function to *cmap=’gray’* as shown below.
plt.imshow(img,cmap='gray')
This problem is also going to happen when opening a picture in color mode because Matplotlib expects the image in RGB (red, green, blue) format whereas OpenCV stores images in BGR (blue, green, red) format. For correct display, you need to reverse the channels of the BGR image.
import cv2 as cv import matplotlib.pyplot as plt img = cv.imread(cv.samples.findFile("starry_night.jpg"),cv.IMREAD_COLOR) fig, (ax1, ax2) = plt.subplots(1,2) ax1.imshow(img) ax1.set_title('BGR Colormap') ax2.imshow(img[:,:,::-1]) ax2.set_title('Reversed BGR Colormap(RGB)') plt.show()
### Splitting and merging color channels
import cv2 as cv import matplotlib.pyplot as plt img = cv.imread(cv.samples.findFile("starry_night.jpg"),cv.IMREAD_COLOR) b,g,r = cv.split(img) fig,ax = plt.subplots(2,2) ax[0,0].imshow(r,cmap='gray') ax[0,0].set_title("Red Channel"); ax[0,1].imshow(g,cmap='gray') ax[0,1].set_title("Green Channel"); ax[1,0].imshow(b,cmap='gray') ax[1,0].set_title("Blue Channel"); # Merge the individual channels into a BGR image imgMerged = cv.merge((b,g,r)) # Show the merged output ax[1,1].imshow(imgMerged[:,:,::-1]) ax[1,1].set_title("Merged Output"); plt.show()
**cv2.split:**Divide a multi-channel array into several single-channel arrays.**cv2.merge:**Merge several arrays to make a single multi-channel array. All the input matrices must have the same size.
**Note:** Images with more white have a higher density of color. Contrarily, images with more black have a lower density of color. In the above example the red color has the lowest density.
### Converting to different color spaces
The *cv2.cvtColor* function converts an input image from one color space to another. When transforming between the RGB and BGR color spaces, the order of the channels should be specified explicitly (*RGB2BGR* or *BGR2RGB*). **Note that the default color format in OpenCV is often referred to as RGB but it is actually BGR (the bytes are reversed).** So the first byte in a standard (24-bit) color image will be an 8-bit blue component, the second byte will be green, and the third byte will be red. The fourth, fifth, and sixth bytes would then be the second pixel (blue, then green, then red), and so on.
import cv2 as cv import matplotlib.pyplot as plt img = cv.imread(cv.samples.findFile("starry_night.jpg"),cv.IMREAD_COLOR) img_rgb = cv.cvtColor(img, cv.COLOR_BGR2RGB) plt.imshow(img_rgb) plt.show()
## Further information
More details on OpenCV are available in the [online documentation](https://docs.opencv.org/4.5.2/index.html).
Thank you.
## Samyak Jain
This is so perfectly written. It will surely help me in getting things done with OpenCV.
Waiting for part 2! 😀
Awesome work :O
## Onuralp SEZER
Thank you so much ! 🙂
## y0umu
I have always been struggling that should I build OpenCV myself, or just accept the precompiled binaries. By building it myself it is possible to have some advantages of fully exploiting CPU features, or use CUDA, or parallel traincascade (that module won’t work in multi-thread mode using precompiled binaries in most cases). On the other hand building requires too much caution between different OpenCV versions. Using precompiled binaries just help me learn the new features in new versions instantly.
## Onuralp SEZER
Our spec file already has “bcond” options such as “cuda” or “ffmpeg” etc. If you check spec file and rebuild rpm again, it will be easier to have functionality you like to have it. Also I agree since Fedora repository updates frequently it is easy to have latest version by doing “dnf update” and we have it.
## Chris
Thanks so much for sharing this astonishing guideline. Everything was working flawlessly and made starting with CV really easy.
Waiting for part 2.
## Onuralp SEZER
I’m glad It helps you a lot as well thank you 🙂
## Peter Braet
Did I miss something here?
Please explain.
## Onuralp SEZER
You forget the create “starry_night.py” and for that reason, I changed the page a little bit for avoid confusion so first please create file and write the content into it. It will work. You can see the “Contents of starry_night.py:” title and please check it out.
## ossama
Nice intro. will sure encourage me to get back to openCV.
## Karatek
Really nice article. Now I have another thing I really want to play around with when I have time for it 😂
## Kader Miyanyedi
Awesome work. Thank you.
## Kader Miyanyedi
Thank you for this article. This is perfect. |
13,699 | 使用 commons-cli 解析 Java 中的命令行选项 | https://opensource.com/article/21/8/java-commons-cli | 2021-08-19T11:59:15 | [
"Java",
"命令行"
] | /article-13699-1.html |
>
> 让用户用命令行选项调整你的 Java 应用程序运行方式。
>
>
>

通常向终端中输入命令时,无论是启动 GUI 应用程序还是仅启动终端应用程序,都可以使用 <ruby> <a href="https://opensource.com/article/21/8/linux-terminal#options"> 命令行选项 </a> <rt> options or switches or flags </rt></ruby> (**以下简称选项**)来修改应用程序的运行方式。这是 [POSIX 规范](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 设定的标准,因此能够检测和解析选项对 Java 程序员而言是很有用的技能。
Java 中有若干种解析选项的方法,其中我最喜欢用的是 [Apache Commons CLI](https://commons.apache.org/proper/commons-cli/usage.html) 库,简称 **commons-cli**。
### 安装 commons-cli
如果你使用类似 [Maven](https://maven.apache.org/) 之类的项目管理系统以及<ruby> 集成开发环境 <rt> Integrated Development Environment </rt></ruby>(简称 IDE),可以在项目属性(比如 `pom.xml` 配置文件或者 Eclipse 和 NetBeans 的配置选项卡)中安装 Apache Commons CLI 库。
而如果你采用手动方式管理库,则可以从 Apache 网站下载 [该库的最新版本](https://commons.apache.org/proper/commons-cli/download_cli.cgi)。下载到本地的是几个捆绑在一起的 JAR 文件,你只需要其中的一个文件 `commons-cli-X.Y.jar`(其中 X 和 Y 代指最新版本号)。把这个 JAR 文件或手动或使用 IDE 添加到项目,就可以在代码中使用了。
### 将库导入至 Java 代码
在使用 `commons-cli` 库之前,必须首先导入它。对于本次选项解析的简单示例而言,可以先在 `Main.java` 文件中简单写入以下标准代码:
```
package com.opensource.myoptparser;
import org.apache.commons.cli.*;
public class Main {
public static void main(String[] args) {
// code
}
}
```
至此在 Java 中解析选项的准备工作已经做好了。
### 在 Java 中定义布尔选项
要实现解析选项,首先要定义应用程序可接收的有效选项。使用 `Option`(注意是单数)类来创建选项对象,使用 `Options`(注意是复数)类来追踪项目中创建的所有选项。
首先为选项创建一个组,按照惯例命名为 `options`:
```
//code
Options options = new Options();
```
接下来,通过列出短选项(即选项名简写)、长选项(即全写)、默认布尔值(LCTT 译注:设置是否需要选项参数,指定为 `false` 时此选项不带参,即为布尔选项)和帮助信息来定义选项,然后设置该选项是否为必需项(LCTT 译注:下方创建 `alpha` 对象的代码中未手动设置此项),最后将该选项添加到包含所有选项的 `options` 组对象中。在下面几行代码中,我只创建了一个选项,命名为 `alpha`:
```
//define options
Option alpha = new Option("a", "alpha", false, "Activate feature alpha");
options.addOption(alpha);
```
### 在 Java 中定义带参选项
有时用户需要通过选项提供 `true` 或 `false` 以外的信息,比如给出配置文件、输入文件或诸如日期、颜色这样的设置项值。这种情况可以使用 `builder` 方法,根据选项名简写为其创建属性(例如,`-c` 是短选项,`--config` 是长选项)。完成定义后,再将定义好的选项添加到 `options` 组中:
```
Option config = Option.builder("c").longOpt("config")
.argName("config")
.hasArg()
.required(true)
.desc("set config file").build();
options.addOption(config);
```
`builder` 函数可以用来设置短选项、长选项、是否为必需项(本段代码中必需项设置为 `true`,也就意味着用户启动程序时必须提供此选项,否则应用程序无法运行)、帮助信息等。
### 使用 Java 解析选项
定义并添加所有可能用到的选项后,需要对用户提供的参数进行迭代处理,检测是否有参数同预设的有效短选项列表中的内容相匹配。为此要创建命令行 `CommandLine` 本身的一个实例,其中包含用户提供的所有参数(包含有效选项和无效选项)。为了处理这些参数,还要创建一个 `CommandLineParser` 对象,我在代码中将其命名为 `parser`。最后,还可以创建一个 `HelpFormatter` 对象(我将其命名为 `helper`),当参数中缺少某些必需项或者用户使用 `--help` 或 `-h` 选项时,此对象可以自动向用户提供一些有用的信息。
```
// define parser
CommandLine cmd;
CommandLineParser parser = new BasicParser();
HelpFormatter helper = new HelpFormatter();
```
最后,添加一些条件判断来分析用户提供的选项,我们假设这些选项已经作为命令行输入被获取并存储在 `cmd` 变量中。这个示例应用程序有两种不同类型的选项,但对这两种类型都可以使用 `.hasOption` 方法加上短选项名称来检测选项是否存在。检测到一个存在的选项后,就可以对数据做进一步操作了。
```
try {
cmd = parser.parse(options, args);
if(cmd.hasOption("a")) {
System.out.println("Alpha activated");
}
if (cmd.hasOption("c")) {
String opt_config = cmd.getOptionValue("config");
System.out.println("Config set to " + opt_config);
}
} catch (ParseException e) {
System.out.println(e.getMessage());
helper.printHelp("Usage:", options);
System.exit(0);
}
```
解析过程有可能会产生错误,因为有时可能缺少某些必需项如本例中的 `-c` 或 `--config` 选项。这时程序会打印一条帮助信息,并立即结束运行。考虑到此错误(Java 术语中称为异常),在 `main` 方法的开头要添加语句声明可能的异常:
```
public static void main(String[] args) throws ParseException {
```
示例程序至此就大功告成了。
### 测试代码
你可以通过调整传递给代码的默认参数来在 IDE 中测试应用程序,或者创建一个 JAR 文件并在终端运行测试。这个过程可能会因 IDE 的不同而不同。具体请参阅相应的 IDE 文档,以及我写过的关于如何创建 JAR 文件的文章,或者参考 Daniel Oh 的关于如何使用 [Maven](https://developers.redhat.com/blog/2021/04/08/build-even-faster-quarkus-applications-with-fast-jar) 执行同样操作的文章。
首先,省略必需项 `-c` 或 `--config` 选项,检测解析器的异常处理:
```
$ java -jar dist/myapp.jar
Missing required option: c
usage: Usage:
-a,--alpha Activate feature alpha
-c,--config <config> Set config file
```
然后提供输入选项再进行测试:
```
java -jar dist/myantapp.jar --config foo -a
Alpha activated
Config set to foo
```
### 选项解析
为用户提供选项功能对任何应用程序来说都是很重要的。有了 Java 和 Apache Commons,要实现这个功能并不难。
以下是完整的演示代码,供读者参考:
```
package com.opensource.myapp;
import org.apache.commons.cli.*;
public class Main {
/**
* @param args the command line arguments
* @throws org.apache.commons.cli.ParseException
*/
public static void main(String[] args) throws ParseException {
// define options
Options options = new Options();
Option alpha = new Option("a", "alpha", false, "Activate feature alpha");
options.addOption(alpha);
Option config = Option.builder("c").longOpt("config")
.argName("config")
.hasArg()
.required(true)
.desc("Set config file").build();
options.addOption(config);
// define parser
CommandLine cmd;
CommandLineParser parser = new BasicParser();
HelpFormatter helper = new HelpFormatter();
try {
cmd = parser.parse(options, args);
if(cmd.hasOption("a")) {
System.out.println("Alpha activated");
}
if (cmd.hasOption("c")) {
String opt_config = cmd.getOptionValue("config");
System.out.println("Config set to " + opt_config);
}
} catch (ParseException e) {
System.out.println(e.getMessage());
helper.printHelp("Usage:", options);
System.exit(0);
}
}
}
```
### 使用 Java 和选项
选项使用户可以调整命令的工作方式。使用 Java 时解析选项的方法有很多,其中之一的 `commons-cli` 是一个强大而灵活的开源解决方案。记得在你的下一个 Java 项目中尝试一下哦。
---
via: <https://opensource.com/article/21/8/java-commons-cli>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,701 | 如何每小时改变你的 Linux 桌面壁纸 | https://www.debugpoint.com/2021/08/change-wallpaper-every-hour/ | 2021-08-19T22:32:23 | [
"壁纸"
] | /article-13701-1.html | 
这个 shell 脚本 `styli.sh` 可以帮助你每小时自动改变你的 Linux 桌面壁纸,并且有几个选项。
用一张漂亮的壁纸来开始你的一天,你的桌面让人耳目一新。但寻找壁纸,然后保存,最终设置为壁纸,是非常麻烦的。所有这些步骤都可以通过这个叫做 [styli.sh](https://github.com/thevinter/styli.sh) 的脚本完成。
### styli.sh - 每小时改变你的 Linux 桌面壁纸
这是一个 shell 脚本,你可以从 GitHub 上下载。当运行时,它从 Reddit 的热门版块中获取壁纸并将其设置为你的壁纸。
该脚本适用于所有流行的桌面环境,如 GNOME、KDE Plasma、Xfce 和 Sway 窗口管理器。
它有很多功能,你可以通过 crontab 来运行这个脚本,并在特定的时间间隔内得到一张新的壁纸。
### 下载并安装、运行
打开一个终端,并克隆 GitHub 仓库。如果没有安装的话,你需要安装 [feh](https://feh.finalrewind.org/) 和 git。
```
git clone https://github.com/thevinter/styli.sh
cd styli.sh
```
要设置随机壁纸,根据你的桌面环境运行以下内容。

GNOME:
```
./styli.sh -g
```
Xfce:
```
./styli.sh -x
```
KDE Plasma:
```
./styli.sh -k
```
Sway:
```
./styli.sh -y
```
### 每小时改变一次
要每小时改变背景,请运行以下命令:
```
crontab -e
```
并在打开的文件中加入以下内容。不要忘记改变脚本路径。
```
@hourly script/path/styli.sh
```
### 改变版块
在源目录中,有一个名为 `subreddits` 的文件。它填满了一些标准的版块。如果你想要更多一些,只需在文件末尾添加版块名称。
### 更多配置选项
壁纸的类型、大小,也可以设置。以下是这个脚本的一些独特的配置选项。
设置一个随机的 1920×1080 背景:
```
./styli.sh
```
指定一个所需的宽度或高度:
```
./styli.sh -w 1080 -h 720
./styli.sh -w 2560
./styli.sh -h 1440
```
根据搜索词设置壁纸:
```
./styli.sh -s island
./styli.sh -s “sea sunset”
./styli.sh -s sea -w 1080
```
从设定的一个版块中获得一个随机壁纸:
注意:宽度/高度/搜索参数对 reddit 不起作用。
```
./styli.sh -l reddit
```
从一个自定义的版块获得随机壁纸:
```
./styli.sh -r
./styli.sh -r wallpaperdump
```
使用内置的 `feh -bg` 选项:
```
./styli.sh -b
./styli.sh -b bg-scale -r widescreen-wallpaper
```
添加自定义的 feh 标志:
```
./styli.sh -c
./styli.sh -c –no-xinerama -r widescreen-wallpaper
```
自动设置终端的颜色:
```
./styli.sh -p
```
使用 nitrogen 而不是 feh:
```
./styli.sh -n
```
使用 nitrogen 更新多个屏幕:
```
./styli.sh -n -m
```
从一个目录中选择一个随机的背景:
```
./styli.sh -d /path/to/dir
```
### 最后说明
这是一个独特且方便的脚本,内存占用小,可以直接在一个时间间隔内比如一个小时获取图片。让你的桌面看起来 [新鲜且高效](https://www.debugpoint.com/category/themes)。如果你不喜欢这些壁纸,你可以简单地从终端再次运行脚本来循环使用。
你喜欢这个脚本吗?或者你知道有什么像这样的壁纸切换器吗?请在下面的评论栏里告诉我。
---
via: <https://www.debugpoint.com/2021/08/change-wallpaper-every-hour/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,702 | 如何在免费 WiFi 中保护隐私(二) | https://opensource.com/article/21/7/openvpn-router | 2021-08-20T12:34:48 | [
"VPN"
] | https://linux.cn/article-13702-1.html |
>
> 安装完服务器之后,下一步就是安装和配置 0penVPN。
>
>
>

0penVPN 在两点之间创建一个加密通道,阻止第三方访问你的网络流量数据。通过设置你的 “虚拟专用网络” 服务,你可以成为你自己的 “虚拟专用网络” 服务商。许多流行的 “虚拟专用网络” 服务都使用 [0penVPN](https://openvpn.net/),所以当你可以掌控自己的网络时,为什么还要将你的网络连接绑定到特定的提供商呢?
本系列的 [第一篇文章](/article-13680-1.html) 展示了如何安装和配置一台作为你的 0penVPN 服务器的 Linux 计算机。同时也讲述了如何配置你的路由器以便你可以在外部网络连接到你的服务器。
第二篇文章将演示根据 [0penVPN wiki](https://community.openvpn.net/openvpn/wiki) 给定的步骤安装一个 0penVPN 服务软件。
### 安装 0penVPN
首先,使用包管理器安装 0penVPN 和 `easy-rsa` 应用程序(帮助你在服务器上设置身份验证)。本例使用的是 Fedora Linux,如果你选择了不同的发行版,请选用合适的命令。
```
$ sudo dnf install openvpn easy-rsa
```
此操作会创建一些空目录:
* `/etc/openvpn`
* `/etc/openvpn/client`
* `/etc/openvpn/server`
如果这些目录在安装的过程中没有创建,请手动创建它们。
### 设置身份验证
0penVPN 依赖于 `easy-rsa` 脚本,并且应该有自己的副本。复制 `easy-rsa` 脚本和文件:
```
$ sudo mkdir /etc/openvpn/easy-rsa
$ sudo cp -rai /usr/share/easy-rsa/3/* /etc/openvpn/easy-rsa/
```
身份验证很重要,0penVPN 非常重视它。身份验证的理论是,如果 Alice 需要访问 Bob 公司内部的私人信息,那么 Bob 确保 Alice 真的是 Alice 就至关重要。同样的,Alice 也必须确保 Bob 是真正的 Bob。我们称之为相互认证。
现有的最佳实践是从三个可能因素中的选择两个检查属性:
* 你拥有的
* 你知道的
* 你是谁
选择有很多。0penVPN 安装使用如下:
* **证书**:客户端和服务端都拥有的东西
* **证书口令**:某人知道的东西
Alice 和 Bob 需要帮助彼此来验证身份。由于他们都相信 Cathy,Cathy 承担了称为 <ruby> 证书颁发机构 <rt> certificate authority </rt></ruby>(CA)的角色。Cathy 证明 Alice 和 Bob 都是他们自己。因为 Alice 和 Bob 都信任 Cathy,现在他们也相互信任了。
但是是什么让 Cathy 相信 Alice 和 Bob 是真的 Alice 和 Bob?Cathy 在社区的声誉取决于如何正确处理这件事,因此如果她希望 Denielle、Evan、Fiona、Greg 和其他人也信任她,她就需要严格测试 Alice 和 Bob 的宣称内容。当 Alice 和 Bob 向 Cathy 证明了他们是真的 Alice 和 Bob 之后,Cathy 将向 Alice 和 Bob 签署证书,让他们彼此和全世界分享。
Alice 和 Bob 如何知道是 Cathy 签署了证书,而不是某个人冒充她签发了证书?他们使用一项叫做**公钥加密**的技术:
* 找到一种用一个密钥加密并用另一个密钥解密的加密算法。
* 将其中一个设为私钥,将另外一个设为公钥。
* Cathy 与全世界分享她的公钥和她的签名的明文副本。
* Cathy 用她的私钥加密她的签名,任何人都可以用她分享的公钥解密。
* 如果 Cathy 的签名解密后与明文副本匹配,Alice 和 Bob 就可以相信 Cathy 确实签署了它。
每次在线购买商品和服务时,使用的就是这种技术。
### 认证实现
0penVPN 的 [文档](https://openvpn.net/community-resources/) 建议在单独的系统上或者至少在 0penVPN 服务器的单独目录上设置 CA。该文档还建议分别从服务端和客户端生成各自的证书。因为这是一个简单的演示设置,你可以使用 0penVPN 服务器设置 CA,并将证书和密钥放入服务器上的指定目录中。
从服务端生成证书,并将证书拷贝到各个客户端,避免客户端再次设置。
此实现使用自签名证书。这是因为服务器信任自己,而客户端信任服务器。因此,服务器是签署证书的最佳 CA。
在 0penVPN 服务器上设置 CA:
```
$ sudo mkdir /etc/openvpn/ca
$ cd /etc/openvpn/ca
$ sudo /etc/openvpn/easy-rsa/easyrsa init-pki
$ sudo /etc/openvpn/easy-rsa/easyrsa build-ca
```
使用一个易记难猜的密码。
设置服务器密钥对和认证请求:
```
$ cd /etc/openvpn/server
$ sudo /etc/openvpn/easy-rsa/easyrsa init-pki
$ sudo /etc/openvpn/easy-rsa/easyrsa gen-req OVPNserver2020 nopass
```
在此例中,`OVPNServer2020` 是你在本系列第一篇文章中为 0penVPN 服务器设置的主机名。
### 生成和签署证书
现在你必须向 CA 发送服务器请求并生成和签署服务器证书。
此步骤实质上是将请求文件从 `/etc/openvpn/server/pki/reqs/OVPNserver2020.req` 复制到 `/etc/openvpn/ca/pki/reqs/OVPNserver2020.req` 以准备审查和签名:
```
$ cd /etc/openvpn/ca
$ sudo /etc/openvpn/easy-rsa/easyrsa \
import-req /etc/openvpn/server/pki/reqs/OVPNserver2020.req OVPNserver2020
```
### 审查并签署请求
你已经生成了一个请求,所以现在你必须审查并签署证书:
```
$ cd /etc/openvpn/ca
$ sudo /etc/openvpn/easy-rsa/easyrsa \
show-req OVPNserver2020
```
以服务器身份签署请求:
```
$ cd /etc/openvpn/ca
$ sudo /etc/openvpn/easy-rsa/easyrsa \
sign-req server OVPNserver2020
```
将服务器和 CA 证书的副本放在它们所属的位置,以便配置文件获取它们:
```
$ sudo cp /etc/openvpn/ca/pki/issued/OVPNserver2020.crt \
/etc/openvpn/server/pki/
$ sudo cp /etc/openvpn/ca/pki/ca.crt \
/etc/openvpn/server/pki/
```
接下来,生成 [Diffie-Hellman](https://en.wikipedia.org/wiki/Diffie%E2%80%93Hellman_key_exchange) 参数,以便客户端和服务器可以交换会话密钥:
```
$ cd /etc/openvpn/server
$ sudo /etc/openvpn/easy-rsa/easyrsa gen-dh
```
### 快完成了
本系列的下一篇文章将演示如何配置和启动你刚刚构建的 0penVPN 服务器。
本文的部分内容改编自 D. Greg Scott 的博客,并经许可重新发布。
---
via: <https://opensource.com/article/21/7/openvpn-router>
作者:[D. Greg Scott](https://opensource.com/users/greg-scott) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | OpenVPN creates an encrypted tunnel between two points, preventing a third party from accessing your network traffic. By setting up your virtual private network (VPN) server, you become your own VPN provider. Many popular VPN services already use [OpenVPN](https://openvpn.net/), so why tie your connection to a specific provider when you can have complete control?
The [first article](https://opensource.com/article/21/7/vpn-openvpn-part-1) in this series demonstrated how to set up and configure a Linux PC to serve as your OpenVPN server. It also discussed how to configure your router so that you can reach your VPN server from an outside network.
This second article demonstrates how to install the OpenVPN server software using steps customized from the [OpenVPN wiki](https://community.openvpn.net/openvpn/wiki).
## Install OpenVPN
First, install OpenVPN and the `easy-rsa`
application (to help you set up authentication on your server) using your package manager. This example uses Fedora Linux; if you've chosen something different, use the appropriate command for your distribution:
`$ sudo dnf install openvpn easy-rsa`
This creates some empty directories:
`/etc/openvpn`
`/etc/openvpn/client`
`/etc/openvpn/server`
If these aren't created during installation, create them manually.
## Set up authentication
OpenVPN depends on the `easy-rsa`
scripts and should have its own copy of them. Copy the `easy-rsa`
scripts and files:
```
$ sudo mkdir /etc/openvpn/easy-rsa
$ sudo cp -rai /usr/share/easy-rsa/3/* \
/etc/openvpn/easy-rsa/
```
Authentication is important, and OpenVPN takes it very seriously. The theory is that if Alice needs to access private information inside Bob's company, it's vital that Bob makes sure Alice really is Alice. Likewise, Alice must make sure that Bob is really Bob. We call this mutual authentication.
Today's best practice checks an attribute from two of three possible factors:
- Something you have
- Something you know
- Something you are
There are lots of choices. This OpenVPN setup uses:
**Certificates:**Something both the client and server have**Certificate password:**Something the people know
Alice and Bob need help to mutually authenticate. Since they both trust Cathy, Cathy takes on a role called **certificate authority** (CA). Cathy attests that Alice and Bob both are who they claim to be. Because Alice and Bob both trust Cathy, now they also trust each other.
But what convinces Cathy that Alice and Bob really are Alice and Bob? Cathy's reputation in the community depends on getting this right, and so if she wants Danielle, Evan, Fiona, Greg, and others to also trust her, she will rigorously test Alice and Bob's claims. After Alice and Bob convince Cathy that they really are Alice and Bob, Cathy signs certificates for them to share with each other and the world.
How do Alice and Bob know Cathy—and not somebody impersonating her—signed the certificates? They use a technology called **public key cryptography:**
- Find a cryptography algorithm that encrypts with one key and decrypts with another.
- Declare one key private and share the other key with the public.
- Cathy shares her public key and a clear-text copy of her signature with the world.
- Cathy encrypts her signature with her private key. Anyone can decrypt it with her public key.
- If Cathy's decrypted signature matches the clear-text copy, Alice and Bob can trust Cathy really did sign it.
You use this same technology every time you buy goods and services online.
## Implement authentication
OpenVPN's [documentation](https://openvpn.net/community-resources/) suggests setting up a CA on a separate system or at least a separate directory on the OpenVPN server. The documentation also suggests generating server and client certificates from the server and clients. Because this is a simple setup, you can use the OpenVPN server as its own CA and put the certificates and keys into specified directories on the server.
Generate certificates from the server and copy them to each client as part of client setup.
This implementation uses self-signed certificates. This works because the server trusts itself, and clients trust the server. Therefore, the server is the best CA to sign certificates.
From the OpenVPN server, set up the CA:
```
$ sudo mkdir /etc/openvpn/ca
$ cd /etc/openvpn/ca
$ sudo /etc/openvpn/easy-rsa/easyrsa init-pki
$ sudo /etc/openvpn/easy-rsa/easyrsa build-ca
```
Use an easy-to-remember but hard-to-guess passphrase.
Set up the server key pair and certificate request:
```
$ cd /etc/openvpn/server
$ sudo /etc/openvpn/easy-rsa/easyrsa init-pki
$ sudo /etc/openvpn/easy-rsa/easyrsa gen-req OVPNserver2020 nopass
```
In this example, `OVPNServer2020`
is whatever hostname you assigned your OpenVPN server in the first article in this series.
## Generate and sign certs
Now you must send a server request to the CA and generate and sign the server certificate.
This step essentially copies the request file from `/etc/openvpn/server/pki/reqs/OVPNserver2020.req`
to `/etc/openvpn/ca/pki/reqs/OVPNserver2020.req`
to prepare it for review and signing:
```
$ cd /etc/openvpn/ca
$ sudo /etc/openvpn/easy-rsa/easyrsa \
import-req /etc/openvpn/server/pki/reqs/OVPNserver2020.req OVPNserver2020
```
## Review and sign the request
You've generated a request, so now you must review and sign the certs:
```
$ cd /etc/openvpn/ca
$ sudo /etc/openvpn/easy-rsa/easyrsa \
show-req OVPNserver2020
```
Sign as the server:
```
$ cd /etc/openvpn/ca
$ sudo /etc/openvpn/easy-rsa/easyrsa \
sign-req server OVPNserver2020
```
Put a copy of the server and CA certificates where they belong for the config file to pick them up:
```
$ sudo cp /etc/openvpn/ca/pki/issued/OVPNserver2020.crt \
/etc/openvpn/server/pki/
$ sudo cp /etc/openvpn/ca/pki/ca.crt \
/etc/openvpn/server/pki/
```
Next, generate [Diffie-Hellman](https://en.wikipedia.org/wiki/Diffie%E2%80%93Hellman_key_exchange) parameters so that clients and the server can exchange session keys:
```
$ cd /etc/openvpn/server
$ sudo /etc/openvpn/easy-rsa/easyrsa gen-dh
```
## Almost there
The next article in this series will demonstrate how to configure and start the OpenVPN server you just built.
*This article is based on D. Greg Scott's blog and is reused with permission.*
## Comments are closed. |
13,704 | 在 LVM 上安装 Linux Mint | https://opensource.com/article/21/8/install-linux-mint-lvm | 2021-08-21T10:44:24 | [
"LVM"
] | https://linux.cn/article-13704-1.html |
>
> 一个关于让 Linux Mint 20.2 与逻辑卷管理器(LVM)一起工作的教程。
>
>
>

几周前,[Linux Mint](https://linuxmint.com/) 的人员发布了他们的开源操作系统的 20.2 版本。Live ISO 中内置的安装程序非常好,只需要点击几下就可以安装操作系统。如果你想定制你的分区,你甚至有一个内置的分区软件。
安装程序重点关注在简单的安装上:定义你的分区并安装到这些分区。对于那些想要更灵活的设置的人来说,<ruby> <a href="https://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux)"> 逻辑卷管理器 </a> <rt> logical volume manager </rt></ruby>(LVM)是个不错的选择,你可以通过设置卷组(VG)并在其中定义你的逻辑卷(LV)。
LVM 是一个硬盘管理系统,允许你在多个物理驱动器上创建存储空间。换句话说,你可以把几个小驱动器“拴”在一起,这样你的操作系统就会把它们当作一个驱动器。除此之外,它还有实时调整大小、文件系统快照和更多的优点。这篇文章并不是关于 LVM 的教程(网上已经有很多 [这方面不错的信息](https://opensource.com/business/16/9/linux-users-guide-lvm)了)。相反,我的目标是贴合这篇文章的主题,只关注让 Linux Mint 20.2 与 LVM 一起工作。
作为一个桌面操作系统,其安装程序致力于简单化,在 LVM 上安装 Linux Mint 20.2 会略微复杂一些,但不会太复杂。如果你在安装程序中选择了 LVM,你会得到一个由 Linux Mint 开发者定义的设置,而且你在安装时无法控制各个卷。
然而,有一个解决方案:在临场 ISO 中,该方案只需要在终端中使用几个命令来设置 LVM,然后你可以继续使用常规安装程序来完成工作。
我安装了 Linux Mint 20.2 和 [XFCE 桌面](https://opensource.com/article/19/12/xfce-linux-desktop),但其他 Linux Mint 桌面的过程也类似。
### 分区驱动器
在 Linux Mint 临场 ISO 中,你可以通过终端和 GUI 工具访问 Linux 命令行工具。如果你需要做任何分区工作,你可以使用命令行 `fdisk` 或 `parted` 命令,或者 GUI 应用 `gparted`。我想让这些操作简单到任何人都能遵循,所以我会在可能的情况下使用 GUI 工具,在必要时使用命令行工具。
首先,为安装创建几个分区。
使用 `gparted`(从菜单中启动),完成以下工作:
首先,创建一个 512MB 的分区,类型为 FAT32(这是用来确保系统可启动)。512MB 对大多数人来说是富余的,你可以用 256MB 甚至更少,但在今天的大容量磁盘中,即使分配 512MB 也不是什么大问题。

接下来,在磁盘的其余部分创建一个 `lvm2 pv` 类型(LVM 2 物理卷)的分区(这是你的 LVM 的位置)。

现在打开一个终端窗口,并将你的权限提升到 root:
```
$ sudo -s
# whoami
root
```
接下来,你必须找到你之前创建的 LVM 成员(那个大分区)。使用下列命令之一:`lsblk -f` 或 `pvs` 或 `pvscan`。
```
# pvs
PV VG Fmt [...]
/dev/sda2 lvm2 [...]
```
在我的例子中,该分区位于 `/dev/sda2`,但你应该用你的输出中得到的内容来替换它。
现在你知道了你的分区有哪些设备,你可以在那里创建一个 LVM 卷组(VG):
```
# vgcreate vg /dev/sda2
```
你可以使用 `vgs` 或 `vgscan` 看到你创建的卷组的细节。
创建你想在安装时使用的逻辑卷(LV)。为了简单,我分别创建了 `root` 根分区(`/`)和 `swap` 交换分区,但是你可以根据需要创建更多的分区(例如,为 `/home` 创建一个单独的分区)。
```
# lvcreate -L 80G -n root vg
# lvcreate -L 16G -n swap vg
```
我的例子中的分区大小是任意的,是基于我可用的空间。使用对你的硬盘有意义的分区大小。
你可以用 `lvs` 或 `lvdisplay` 查看逻辑卷。
终端操作到这就结束了。
### 安装 Linux
现在从桌面上的图标启动安装程序:
* 进入 “Installation type”,选择 “Something else”。
* 编辑 512Mb 的分区并将其改为 `EFI`。
* 编辑根逻辑卷,将其改为 `ext4`(或一个你选择的文件系统)。选择将其挂载为根目录(`/`),并选择将其格式化。
* 编辑 `swap` 分区并将其设置为交换分区。
* 继续正常的安装过程。Linux Mint 安装程序会将文件放在正确的位置并为你创建挂载点。
完成了。在你的 Linux Mint 安装中享受 LVM 的强大。
如果你需要调整分区大小或在系统上做任何高级工作,你会感谢选择 LVM。
---
via: <https://opensource.com/article/21/8/install-linux-mint-lvm>
作者:[Kenneth Aaron](https://opensource.com/users/flyingrhino) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A couple of weeks ago, the good folks at [Linux Mint](https://linuxmint.com/) released version 20.2 of their open source operating system. The installer built into the live ISO is excellent and only requires a few clicks to install the OS. You even have a built-in partitioner if you want to customize your partitions.
The installer is mainly focused on a simple install—define your partitions and install into them. For those wanting a more flexible setup—[logical volume manager](https://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux)) (LVM) is the way to go—you benefit from setting up volume groups and define your logical volumes within them.
LVM is a hard drive management system that allows you to create storage space across multiple physical drives. In other words, you could "tether" a few small drives together so your OS treats them as if they were one drive. Beyond that, it has the advantages of live resizing, file system snapshots, and much more. This article isn't a tutorial on LVM (the web is full of [good information on that already](https://opensource.com/business/16/9/linux-users-guide-lvm).) Instead, I aim to keep this page on topic and focus solely on getting Linux Mint 20.2 working with LVM.
As a desktop OS, the installer is kept simple, and installing LM 20.2 on LVM is slightly more involved but not too complicated. If you select LVM in the installer, you get a setup that's been defined by the Linux Mint devs, and you have no control over the individual volumes at the time of install.
However, there's a solution—right there in the live ISO—and that solution only requires a few commands in the terminal to set up the LVM, after which you resume the regular installer to complete the job.
I'm using Linux Mint 20.2 with the [XFCE desktop](https://opensource.com/article/19/12/xfce-linux-desktop) for my install, but the procedure is similar for the other LM desktops.
## Partitioning the drive
In the Linux Mint live ISO, you have access to Linux command-line tools through the terminal and GUI tools. If you need to do any partition work, you can use the command-line `fdisk`
or `parted`
commands, or the GUI application `gparted`
. I want to keep these instructions simple enough for anyone to follow, so I'll use GUI tools where possible and command-line tools where necessary.
Start by creating a couple of partitions for the install.
Using `gparted`
(launched from the menu), complete the following:
First, create a partition of 512 MB of type **FAT32** (this is used to ensure the system is bootable.) 512 MB is overkill for most, and you can get away with 256 MB or even less, but with today's big disks, allocating even 512 MB is not a significant concern.
CC BY-SA Seth Kenlon
Next, create a partition of the rest of the disk of type `lvm2 pv`
(this is where your LVM will be.)
CC BY-SA Seth Kenlon
Now open a terminal window, and escalate your privileges to root:
```
$ sudo -s
# whoami
root
```
Next, you must locate the LVM member (the big partition) you created earlier. Use one of the following commands: `lsblk -f`
or `pvs`
or `pvscan`
.
```
# pvs
PV VG Fmt [...]
/dev/sda2 lvm2 [...]
```
In my case, the partition is located at `/dev/sda2`
, but you should replace this with whatever you get in your output.
Now that you know what device designation your partition has, you can create an LVM volume group there:
`# vgcreate vg /dev/sda2`
You can see the details of the volume group you created using `vgs `
or `vgscan`
.
Create the logical volumes you want to use during install. I'm keeping it simple by creating one for the root partition (`/`
) and one for `swap`
, but you can create more as needed (for example, a separate partition for `/home`
.)
```
# lvcreate -L 80G -n root vg
# lvcreate -L 16G -n swap vg
```
The partition sizes in my examples are arbitrary and based on what I have available. Use partition sizes that make sense for your drive.
You can view the logical volumes with `lvs`
or `lvdisplay`
.
That's it for the terminal.
## Installing Linux
Now start the installer program from the desktop icon:
- Once you get to the
**Installation type**, select**Something else**. - Edit the 512 Mb partition and change it to
`EFI`
. - Edit the root LV and change it to
`ext4`
(or a file system of your choice). Select to mount it as root and select to format it. - Edit the swap partition and set it as
`swap`
. - Continue the install process normally—Linux Mint installer puts the files in the correct places and creates the mount points for you.
That's it—enjoy the power of LVM in your Linux Mint install.
If ever you need to resize partitions or do any advanced work on the system—you'll be thankful for choosing LVM.
## Comments are closed. |
13,705 | Zorin OS 16 发布:惊艳的新外观和一系列更新 | https://www.debugpoint.com/2021/08/zorin-os-16-release-announcement/ | 2021-08-21T12:18:23 | [
"Zorin"
] | /article-13705-1.html | 
Zorin 团队宣布发布了全新的 Zorin OS 16,带来了许多急需的更新和改进。 我们在这篇文章中对这个版本进行了总结。

开源而赏心悦目的 Linux 发行版 Zorin OS 发布了它的最新稳定的第 16 个版本,这个版本会在 2025 年前提供增强和更新支持。该团队在确保性能不会下降的同时,提供了一些独特和有用的特性。
Zorin OS 使用自有的软件参考,同时也可以使用 Ubuntu 的软件仓库。
让我们看下重要的新特性。
### Zorin OS 16 – 新特性
最新的 Zorin OS 16 建立在 Linux 内核 5.11(hwe 栈)的支持上,该版本基于 Ubuntu 20.04 LTS。
这个版本最主要的变化是在 Zorin 中 **默认包括了 Flathub 软件仓库**。由此,Zorin 应用商店成为了 Linux 发行版中最大的应用程序集合之一。因为它可以支持 Flathub,另外还有早前支持的 Snap 商店、Ubuntu 软件仓库、Zorin 自有仓库,和对 AppImage 的支持。
Zorin 主要因其外观而闻名,在这个版本中,有一系列改进,这是一个简要的总结:
* 新的图标和色彩方案,默认主题更加精致。
* 预装了新的设计和壁纸。
* 锁屏现在可以展示自选壁纸的模糊效果,给你一个更简洁的视觉效果。
任务栏图标启用了活动指示器,以及带有计数的通知气泡。这意味着你可以在任务栏图标中获取信息 App 的未读消息计数等信息。任务栏还有一些基本特性,比如自动隐藏、透明度和移动图标等等。

新版有许多内部提升,细节尚不清楚,但根据团队的意见,所有 Zorin 风格的整体桌面体验比其前身 [Zorin 15](https://www.debugpoint.com/2020/09/zorin-os-15-3-release/) 有了很大改进。
此版本中引入两个新应用,首次安装后可以用一个 Tour 应用概览 Zorin 桌面,另一个引入的是新的录音应用。
如果你使用笔记本,在应用和工作区间切换变得更加快捷和简便。Zorin OS 16 带来了多点触控手势,开箱即用。现在你可以通过上下滑动 4 个手指,以流畅的 1:1 动作在工作区之间切换。 用 3 个手指在触摸板撮合,可以打开活动概述,看到你工作区中运行的每个应用程序。
Zorin OS 16 现在支持高分辨率显示器的分数缩放。
安装器程序现在包含了 NVIDIA 驱动,可以在首次用临场盘启动时选择,它也支持加密。
详细的更新日志在 [这里](https://blog.zorin.com/2021/08/17/2021-08-17-zorin-os-16-is-released/)。
### Zorin OS 16 最低系统要求
Zorin OS Core、Education 和 Pro
* CPU – 1 GHz 双核处理器,Intel/AMD 64 位处理器
* RAM – 2 GB
* 存储 – 15 GB(Core & Education)或 30 GB(Pro)
* 显示器 – 800 × 600 分辨率
Zorin OS LITE
* CPU – 700 MHz 单核,Intel/AMD 64 或 32 位处理器
* RAM – 512 MB
* 存储 – 10 GB
* 显示器 – 640 × 480 分辨率
### 下载 Zorin OS 16
值得一提的是 Zorin 发布了一个 PRO 版本,售价大约 $39,有类似 Windows 11 风格等额外特性。可是,你仍然可以随时下载免费版本:Zorin OS 16 Core 和 Zorin OS 16 LITE(用于低配电脑)。你可能想看下它们的功能 [比较](https://zorin.com/os/pro/#compare)。
你可以从以下链接下载最新的 .iso 文件。然后,你可以使用 [Etcher](https://www.debugpoint.com/2021/01/etcher-bootable-usb-linux/) 或其他工具来创建临场 USB 启动盘来安装。
* [下载 zorin os 16](https://zorin.com/os/download/)
### 从 Zorin 15.x 升级
现在还没有从 Zorin OS 15 升级的路径,不过据该团队称,未来将会有升级到最新版本的简单方法。
### 结束语
Zorin 的最佳特性之一是它独特的应用生态处理方式。它可能是唯一提供开箱即用体验的 Linux 桌面发行版,可以通过它的软件商店从 Flathub、Snap 商店、AppImage、Ubuntu / 自有软件仓库来搜索和安装应用。你不需要为 Snap 或者 Flatpak 手动配置系统。也就是说,它仍然是一个带有附加项目的 GNOME 修改版。可能有些人不喜欢 Zorin,可能会因为它预装了所有这些功能而感到臃肿。从某种意义上说,它是 Linux 桌面新用户的理想发行版之一,这些用户需要拥有类似 Windows/macOS 系统感觉的现成的 Linux 功能。
---
via: <https://www.debugpoint.com/2021/08/zorin-os-16-release-announcement/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[zd200572](https://github.com/zd200572) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,707 | 如何在免费 WiFi 中保护隐私(三) | https://opensource.com/article/21/7/openvpn-firewall | 2021-08-22T08:17:16 | [
"VPN"
] | https://linux.cn/article-13707-1.html |
>
> 在你安装了 0penVPN 之后,是时候配置它了。
>
>
>

0penVPN 在两点之间建立一条加密的隧道,阻止第三方访问你的网络流量。通过设置你的 “虚拟专用网络” 服务,你就成为你自己的 “虚拟专用网络” 供应商。许多流行的 “虚拟专用网络” 服务已支持 [0penVPN](https://openvpn.net/),所以当你可以掌控自己的网络时,为什么还要将你的网络连接绑定到特定的提供商呢?
本系列中的 [第一篇](/article-13680-1.html) 展示了如何安装和配置一台作为你的 0penVPN 服务器的 Linux 计算机。,[第二篇](/article-13702-1.html) 演示了如何安装和配置 0penVPN 服务器软件。这第三篇文章演示了如何在认证成功的情况下启动 0penVPN。
要设置一个 0penVPN 服务器,你必须:
* 创建一个配置文件。
* 使用 `sysctl` 设置`net.ipv4.ip_forward = 1` 以启用路由。
* 为所有的配置和认证文件设置适当的所有权,以便使用非 root 账户运行 0penVPN 服务器守护程序。
* 设置 0penVPN 加载适当的配置文件启动。
* 配置你的防火墙。
### 配置文件
你必须在 `/etc/openvpn/server/` 中创建一个服务器配置文件。如果你想的话,你可以从头开始,0penVPN 包括了几个配置示例示例文件,可以以此作为开始。看看 `/usr/share/doc/openvpn/sample/sample-config-files/` 就知道了。
如果你想手工建立一个配置文件,可以从 `server.conf` 或 `roadwarrior-server.conf` 开始(视情况而定),并将你的配置文件放在 `/etc/openvpn/server` 中。这两个文件都有大量的注释,所以请阅读注释并根据你的情况作出决定。
你可以使用我预先建立的服务器和客户端配置文件模板和 `sysctl` 文件来打开网络路由,从而节省时间和麻烦。这个配置还包括自定义记录连接和断开的情况。它在 0penVPN 服务器的 `/etc/openvpn/server/logs` 中保存日志。
如果你使用我的模板,你需要使用你的 IP 地址和主机名编辑它们。
要使用我的预建配置模板、脚本和 `sysctl` 来打开 IP 转发,请下载我的脚本:
```
$ curl \
https://www.dgregscott.com/ovpn/OVPNdownloads.sh > \
OVPNdownloads.sh
```
阅读该脚本,了解它的工作内容。下面是它的运行概述:
* 在你的 0penVPN 服务器上创建适当的目录
* 从我的网站下载服务器和客户端的配置文件模板
* 下载我的自定义脚本,并以正确的权限把它们放到正确的目录中
* 下载 `99-ipforward.conf` 并把它放到 `/etc/sysctl.d` 中,以便在下次启动时打开 IP 转发功能
* 为 `/etc/openvpn` 中的所有内容设置了所有权
当你确定你理解了这个脚本的作用,就使它可执行并运行它:
```
$ chmod +x OVPNdownloads.sh
$ sudo ./OVPNdownloads.sh
```
下面是它复制的文件(注意文件的所有权):
```
$ ls -al -R /etc/openvpn
/etc/openvpn:
total 12
drwxr-xr-x. 4 openvpn openvpn 34 Apr 6 20:35 .
drwxr-xr-x. 139 root root 8192 Apr 6 20:35 ..
drwxr-xr-x. 2 openvpn openvpn 33 Apr 6 20:35 client
drwxr-xr-x. 4 openvpn openvpn 56 Apr 6 20:35 server
/etc/openvpn/client:
total 4
drwxr-xr-x. 2 openvpn openvpn 33 Apr 6 20:35 .
drwxr-xr-x. 4 openvpn openvpn 34 Apr 6 20:35 ..
-rw-r--r--. 1 openvpn openvpn 1764 Apr 6 20:35 OVPNclient2020.ovpn
/etc/openvpn/server:
total 4
drwxr-xr-x. 4 openvpn openvpn 56 Apr 6 20:35 .
drwxr-xr-x. 4 openvpn openvpn 34 Apr 6 20:35 ..
drwxr-xr-x. 2 openvpn openvpn 59 Apr 6 20:35 ccd
drwxr-xr-x. 2 openvpn openvpn 6 Apr 6 20:35 logs
-rw-r--r--. 1 openvpn openvpn 2588 Apr 6 20:35 OVPNserver2020.conf
/etc/openvpn/server/ccd:
total 8
drwxr-xr-x. 2 openvpn openvpn 59 Apr 6 20:35 .
drwxr-xr-x. 4 openvpn openvpn 56 Apr 6 20:35 ..
-rwxr-xr-x. 1 openvpn openvpn 917 Apr 6 20:35 client-connect.sh
-rwxr-xr-x. 1 openvpn openvpn 990 Apr 6 20:35 client-disconnect.sh
/etc/openvpn/server/logs:
total 0
drwxr-xr-x. 2 openvpn openvpn 6 Apr 6 20:35 .
drwxr-xr-x. 4 openvpn openvpn 56 Apr 6 20:35 ..
```
下面是 `99-ipforward.conf` 文件:
```
# Turn on IP forwarding. OpenVPN servers need to do routing
net.ipv4.ip_forward = 1
```
编辑 `OVPNserver2020.conf` 和 `OVPNclient2020.ovpn` 以包括你的 IP 地址。同时,编辑 `OVPNserver2020.conf` 以包括你先前的服务器证书名称。稍后,你将重新命名和编辑 `OVPNclient2020.ovpn` 的副本,以便在你的客户电脑上使用。以 `***?` 开头的块显示了你要编辑的地方。
### 文件所有权
如果你使用了我网站上的自动脚本,文件所有权就已经到位了。如果没有,你必须确保你的系统有一个叫 `openvpn` 的用户,并且是 `openvpn` 组的成员。你必须将 `/etc/openvpn` 中的所有内容的所有权设置为该用户和组。如果你不确定该用户和组是否已经存在,这样做也是安全的,因为 `useradd` 会拒绝创建一个与已经存在的用户同名的用户:
```
$ sudo useradd openvpn
$ sudo chown -R openvpn.openvpn /etc/openvpn
```
### 防火墙
如果你在步骤 1 中启用 firewalld 服务,那么你的服务器的防火墙服务可能默认不允许 “虚拟专用网络” 流量。使用 [firewall-cmd 命令](https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd),你可以启用 0penVPN 服务,它可以打开必要的端口并按需路由流量:
```
$ sudo firewall-cmd --add-service openvpn --permanent
$ sudo firewall-cmd --reload
```
没有必要在 iptables 的迷宫中迷失方向!
### 启动你的服务器
现在你可以启动 0penVPN 服务器了。为了让它在重启后自动运行,使用 `systemctl` 的 `enable` 子命令:
```
systemctl enable --now [email protected]
```
### 最后的步骤
本文的第四篇也是最后一篇文章将演示如何设置客户端,以便远程连接到你的 0penVPN。
*本文基于 D.Greg Scott 的[博客](https://www.dgregscott.com/how-to-build-a-vpn-in-four-easy-steps-without-spending-one-penny/),经许可后重新使用。*
---
via: <https://opensource.com/article/21/7/openvpn-firewall>
作者:[D. Greg Scott](https://opensource.com/users/greg-scott) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | OpenVPN creates an encrypted tunnel between two points, preventing a third party from accessing your network traffic. By setting up your virtual private network (VPN) server, you become your own VPN provider. Many popular VPN services already use [OpenVPN](https://openvpn.net/), so why tie your connection to a specific provider when you can have complete control?
The [first article](https://opensource.com/article/21/7/vpn-openvpn-part-1) in this series set up a server for your VPN, and the [second article](https://opensource.com/article/21/7/vpn-openvpn-part-2) demonstrated how to install and configure the OpenVPN server software. This third article shows how to start OpenVPN with authentication in place.
To set up an OpenVPN server, you must:
- Create a configuration file.
- Set the
`sysctl`
value`net.ipv4.ip_forward = 1`
to enable routing. - Set up appropriate ownership for all configuration and authentication files to run the OpenVPN server daemon under a non-root account.
- Set OpenVPN to start with the appropriate configuration file.
- Configure your firewall.
## Configuration file
You must create a server config file in `/etc/openvpn/server/`
. You can start from scratch if you want, and OpenVPN includes several sample configuration files to use as a starting point. Have a look in `/usr/share/doc/openvpn/sample/sample-config-files/`
to see them all.
If you want to build a config file by hand, start with either `server.conf`
or `roadwarrior-server.conf`
(as appropriate), and place your config file in `/etc/openvpn/server`
. Both files are extensively commented, so read the comments and decide which makes the most sense for your situation.
You can save time and aggravation by using my prebuilt server and client configuration file templates and `sysctl`
file to turn on network routing. This configuration also includes customization to log connects and disconnects. It keeps logs on the OpenVPN server in `/etc/openvpn/server/logs`
.
If you use my templates, you'll need to edit them to use your IP addresses and hostnames.
To use my prebuilt config templates, scripts, and `sysctl`
to turn on IP forwarding, download my script:
```
$ curl \
https://www.dgregscott.com/ovpn/OVPNdownloads.sh > \
OVPNdownloads.sh
```
Read the script to get an idea of what it does. Here's a quick overview of its actions:
- Creates the appropriate directories on your OpenVPN server
- Downloads server and client config file templates from my website
- Downloads my custom scripts and places them into the correct directory with correct permissions
- Downloads
`99-ipforward.conf`
and places it into`/etc/sysctl.d`
to turn on IP forwarding at the next boot - Sets up ownership for everything in
`/etc/openvpn`
Once you're satisfied that you understand what the script does, make it executable and run it:
```
$ chmod +x OVPNdownloads.sh
$ sudo ./OVPNdownloads.sh
```
Here are the files it copies (notice the file ownership):
```
$ ls -al -R /etc/openvpn
/etc/openvpn:
total 12
drwxr-xr-x. 4 openvpn openvpn 34 Apr 6 20:35 .
drwxr-xr-x. 139 root root 8192 Apr 6 20:35 ..
drwxr-xr-x. 2 openvpn openvpn 33 Apr 6 20:35 client
drwxr-xr-x. 4 openvpn openvpn 56 Apr 6 20:35 server
/etc/openvpn/client:
total 4
drwxr-xr-x. 2 openvpn openvpn 33 Apr 6 20:35 .
drwxr-xr-x. 4 openvpn openvpn 34 Apr 6 20:35 ..
-rw-r--r--. 1 openvpn openvpn 1764 Apr 6 20:35 OVPNclient2020.ovpn
/etc/openvpn/server:
total 4
drwxr-xr-x. 4 openvpn openvpn 56 Apr 6 20:35 .
drwxr-xr-x. 4 openvpn openvpn 34 Apr 6 20:35 ..
drwxr-xr-x. 2 openvpn openvpn 59 Apr 6 20:35 ccd
drwxr-xr-x. 2 openvpn openvpn 6 Apr 6 20:35 logs
-rw-r--r--. 1 openvpn openvpn 2588 Apr 6 20:35 OVPNserver2020.conf
/etc/openvpn/server/ccd:
total 8
drwxr-xr-x. 2 openvpn openvpn 59 Apr 6 20:35 .
drwxr-xr-x. 4 openvpn openvpn 56 Apr 6 20:35 ..
-rwxr-xr-x. 1 openvpn openvpn 917 Apr 6 20:35 client-connect.sh
-rwxr-xr-x. 1 openvpn openvpn 990 Apr 6 20:35 client-disconnect.sh
/etc/openvpn/server/logs:
total 0
drwxr-xr-x. 2 openvpn openvpn 6 Apr 6 20:35 .
drwxr-xr-x. 4 openvpn openvpn 56 Apr 6 20:35 ..
```
Here's the `99-ipforward.conf`
file:
```
# Turn on IP forwarding. OpenVPN servers need to do routing
net.ipv4.ip_forward = 1
```
Edit `OVPNserver2020.conf`
and `OVPNclient2020.ovpn`
to include your IP addresses. Also, edit `OVPNserver2020.conf`
to include your server certificate names from earlier. Later, you will rename and edit a copy of `OVPNclient2020.ovpn`
for use with your client computers. The blocks that start with `***?`
show you where to edit.
## File ownership
If you used the automated script from my website, file ownership is already in place. If not, you must ensure that your system has a user called `openvpn`
that is a member of a group named `openvpn`
. You must set the ownership of everything in `/etc/openvpn`
to that user and group. It's safe to do this if you're unsure whether the user and group already exist because `useradd`
will refuse to create a user with the same name as one that already exists:
```
$ sudo useradd openvpn
$ sudo chown -R openvpn.openvpn /etc/openvpn
```
## Firewall
If you decided not to disable the firewalld service in step 1, then your server's firewall service might not allow VPN traffic by default. Using the [ firewall-cmd command](https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd), you can enable the OpenVPN service, which opens the necessary ports and routes traffic as necessary:
```
$ sudo firewall-cmd --add-service openvpn --permanent
$ sudo firewall-cmd --reload
```
No need to get lost in a maze of iptables!
## Start your server
You can now start your OpenVPN server. So that it starts automatically after a reboot, use the `enable`
subcommand of `systemctl`
:
`systemctl enable --now [email protected]`
## Final steps
The fourth and final article in this article will demonstrate how to set up clients to connect to your OpenVPN from afar.
*This article is based on D. Greg Scott's blog and is reused with permission.*
## 1 Comment |
13,708 | 使用 VS Code 在容器中开发 | https://opensource.com/article/21/7/vs-code-remote-containers-podman | 2021-08-22T09:03:00 | [
"容器",
"VSCode"
] | https://linux.cn/article-13708-1.html |
>
> 一致性可以避免当你有多个开发人员开发同一个项目时出现问题。
>
>
>

当你有多个不同开发环境的开发人员在一个项目上工作时,编码和测试的不一致性是一种风险。[Visual Studio Code](https://code.visualstudio.com/)(VS Code)是一个集成开发环境(IDE),可以帮助减少这些问题。它可以和容器结合起来,为每个应用程序提供独立的开发环境,同时提供一个一致的开发环境。
VS Code 的 [“Remote - Containers” 扩展](https://code.visualstudio.com/docs/remote/containers) 使你能够创建一个容器定义,使用该定义来构建一个容器,并在容器内进行开发。这个容器定义可以和应用程序代码一起被签入到源代码库中,这使得所有的开发人员可以使用相同的定义在容器中进行构建和开发。
默认情况下,“Remote - Containers” 扩展使用 Docker 来构建和运行容器,但使用 [Podman](https://podman.io/) 的容器运行环境环境也很容易,它可以让你使用 [免 root 容器](https://www.redhat.com/sysadmin/rootless-podman-makes-sense)。
本文将带领你完成设置,通过 Podman 在免 root 容器内使用 VS Code 和 “Remote - Containers” 扩展进行开发。
### 初始配置
在继续之前,请确保你的红帽企业 Linux(RHEL)或 Fedora 工作站已经更新了最新的补丁,并且安装了 VS Code 和 “Remote - Containers” 扩展。(参见 [VS Code 网站](https://code.visualstudio.com/)了解更多安装信息)
接下来,用一个简单的 `dnf install` 命令来安装 Podman 和它的支持包:
```
$ sudo dnf install -y podman
```
安装完 Podman 后,配置 VS Code 以使用 Podman 的可执行文件(而不是 Docker)与容器进行交互。在 VS Code 中,导航到 “文件 > 首选项 > 设置”,点击 “扩展” 旁边的 “>” 图标。在出现的下拉菜单中,选择 “Remote - Containers”,并向下滚动找到 “Remote - Containers: Docker Path” 选项。在文本框中,用 “podman” 替换 “docker”。

现在配置已经完成,在 VS Code 中为该项目创建一个新的文件夹或打开现有的文件夹。
### 定义容器
本教程以创建 Python 3 开发的容器为例。
“Remote - Containers” 扩展可以在项目文件夹中添加必要的基本配置文件。要添加这些文件,通过在键盘上输入 `Ctrl+Shift+P` 打开命令面板,搜索 “Remote-Containers: Add Development Container Configuration Files”,并选择它。

在接下来的弹出窗口中,定义你想设置的开发环境的类型。对于这个例子的配置,搜索 “Python 3” 定义并选择它。

接下来,选择将在容器中使用的 Python 的版本。选择 “3 (default)” 选项以使用最新的版本。
 option")
Python 配置也可以安装 Node.js,但在这个例子中,取消勾选 “Install Node.js”,然后点击 “OK”。

它将创建一个 `.devcontainer` 文件夹,包含文件`devcontainer.json`和`Dockerfile`。VS Code 会自动打开`devcontainer.json` 文件,这样你就可以对它进行自定义。
### 启用免 root 容器
除了明显的安全优势外,以免 root 方式运行容器的另一个原因是,在项目文件夹中创建的所有文件将由容器外的正确用户 ID(UID)拥有。要将开发容器作为免 root 容器运行,请修改 `devcontainer.json` 文件,在它的末尾添加以下几行:
```
"workspaceMount": "source=${localWorkspaceFolder},target=/workspace,type=bind,Z",
"workspaceFolder": "/workspace",
"runArgs": ["--userns=keep-id"],
"containerUser": "vscode"
```
这些选项告诉 VS Code 用适当的 SELinux 上下文挂载工作区,创建一个用户命名空间,将你的 UID 和 GID 原样映射到容器内,并在容器内使用 `vscode` 作为你的用户名。`devcontainer.json` 文件应该是这样的(别忘了行末的逗号,如图所示):

现在你已经设置好了容器的配置,你可以构建容器并打开里面的工作空间。重新打开命令调板(用 `Ctrl+Shift+P`),并搜索 “Remote-Containers: Rebuild and Reopen in Container”。点击它,VS Code 将开始构建容器。现在是休息一下的好时机(拿上你最喜欢的饮料),因为构建容器可能需要几分钟时间:

一旦容器构建完成,项目将在容器内打开。在容器内创建或编辑的文件将反映在容器外的文件系统中,并对这些文件应用适当的用户权限。现在,你可以在容器内进行开发了。VS Code 甚至可以把你的 SSH 密钥和 Git 配置带入容器中,这样提交代码就会像在容器外编辑时那样工作。
### 接下来的步骤
现在你已经完成了基本的设置和配置,你可以进一步加强配置的实用性。比如说:
* 修改 Dockerfile 以安装额外的软件(例如,所需的 Python 模块)。
* 使用一个定制的容器镜像。例如,如果你正在进行 Ansible 开发,你可以使用 [Quay.io](http://Quay.io) 的 [Ansible Toolset](https://quay.io/repository/ansible/toolset)。(确保通过 Dockerfile 将 `vscode` 用户添加到容器镜像中)
* 将 `.devcontainer` 目录下的文件提交到源代码库,以便其他开发者可以利用容器的定义进行开发工作。
在容器内开发有助于防止不同项目之间的冲突,因为隔离了不同项目的依赖关系及代码。你可以使用 Podman 在免 root 环境下运行容器,从而提高安全性。通过结合 VS Code、“Remote - Containers” 扩展和 Podman,你可以轻松地为多个开发人员建立一个一致的环境,减少设置时间,并以安全的方式减少开发环境的差异带来的错误。
---
via: <https://opensource.com/article/21/7/vs-code-remote-containers-podman>
作者:[Brant Evans](https://opensource.com/users/branic) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Coding and testing inconsistencies are a risk when you have multiple developers with different development environments working on a project. [Visual Studio Code](https://code.visualstudio.com/) (VS Code) is an integrated development environment (IDE) that can help minimize these issues. It can be combined with containers to provide separate development environments for each application alongside a consistent development environment.
VS Code's [Remote - Containers extension](https://code.visualstudio.com/docs/remote/containers) enables you to define a container, use that definition to build a container, and develop inside the container. This container definition can be checked into the source code repository along with the application code, which allows all developers to use the same definition to build and develop within a container.
By default, the Remote - Containers extension uses Docker to build and run the container, but it is easy to use [Podman](https://podman.io/) for container runtimes, and it enables using [rootless containers](https://www.redhat.com/sysadmin/rootless-podman-makes-sense).
This article walks you through the setup to develop inside a rootless container using Podman with VS Code and the Remote - Containers extension.
## Initial configuration
Before continuing, ensure your Red Hat Enterprise Linux (RHEL) or Fedora workstation is updated with the latest errata and that VS Code and the Remote - Containers extension are installed. (See the [VS Code website](https://code.visualstudio.com/) for more information on installing.)
Next, install Podman and its supporting packages with a simple `dnf install`
command:
`$ sudo dnf install -y podman`
After you install Podman, configure VS Code to use the Podman executable (instead of Docker) for interacting with the container. Within VS Code, navigate to **File > Preferences > Settings** and click the **>** icon next to **Extensions**. In the dropdown menu that appears, select **Remote - Containers**, and scroll down to find the **Remote > Containers: Docker Path** option. In the text box, replace docker with **podman**.
(Brant Evans, CC BY-SA 4.0)
Now that the configurations are done, create and open a new folder or an existing folder for the project in VS Code.
## Define the container
This tutorial uses the example of creating a container for Python 3 development.
The Remote - Containers extension can add the necessary basic configuration files to the project folder. To add these files, open the Command Pallet by entering **Ctrl+Shift+P** on your keyboard, search for **Remote-Containers: Add Development Container Configuration Files**, and select it.

(Brant Evans, CC BY-SA 4.0)
In the next pop-up, define the type of development environment you want to set up. For this example configuration, search for the **Python 3** definition and select it.
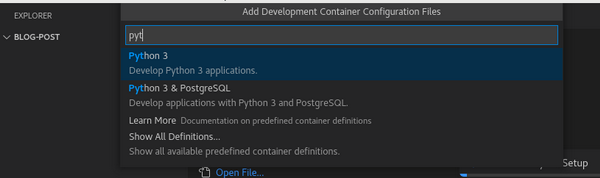
(Brant Evans, CC BY-SA 4.0)
Next, select the version of Python that will be used in the container. Select the **3 (default)** option to use the latest version.
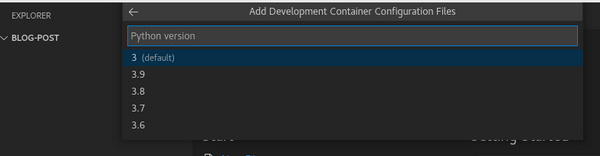
(Brant Evans, CC BY-SA 4.0)
The Python configuration can also install Node.js, but for this example, **uncheck Install Node.js** and click OK.

(Brant Evans, CC BY-SA 4.0)
It will create a `.devcontainer`
folder containing files named `devcontainer.json`
and `Dockerfile`
. VS Code automatically opens the `devcontainer.json`
file so that you can customize it.
## Enable rootless containers
In addition to the obvious security benefits, one of the other reasons to run a container as rootless is that all the files created in the project folder will be owned by the correct user ID (UID) outside the container. To run the development container as a rootless container, modify the `devcontainer.json`
file by adding the following lines to the end of it:
```
"workspaceMount": "source=${localWorkspaceFolder},target=/workspace,type=bind,Z",
"workspaceFolder": "/workspace",
"runArgs": ["--userns=keep-id"],
"containerUser": "vscode"
```
These options tell VS Code to mount the Workspace with the proper SELinux context, create a user namespace that maps your UID and GID to the same values inside the container, and use `vscode`
as your username inside the container. The `devcontainer.json`
file should look like this (don't forget the commas at the end of the lines, as indicated):
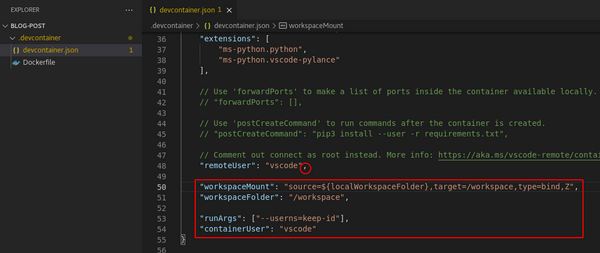
(Brant Evans, CC BY-SA 4.0)
Now that you've set up the container configuration, you can build the container and open the workspace inside it. Reopen the Command Palette (with **Ctrl+Shift+P**), and search for **Remote-Containers: Rebuild and Reopen in Container**. Click on it, and VS Code will start to build the container. Now is a great time to take a break (and get your favorite beverage), as building the container may take several minutes.

(Brant Evans, CC BY-SA 4.0)
Once the container build completes, the project will open inside the container. Files created or edited within the container will be reflected in the filesystem outside the container with the proper user permissions applied to the files. Now, you can proceed with development within the container. VS Code can even bring your SSH keys and Git configuration into the container so that committing code will work just like it does when editing outside the container.
## Next steps
Now that you've completed the basic setup and configuration, you can further enhance the configuration's usefulness. For example:
- Modify the Dockerfile to install additional software (e.g., required Python modules).
- Use a customized container image. For example, if you're doing Ansible development, you could use Quay.io's
[Ansible Toolset](https://quay.io/repository/ansible/toolset). (Be sure to add the`vscode`
user to the container image via the Dockerfile.) - Commit the files in the
`.devcontainer`
directory to the source code repository so that other developers can take advantage of the container definition for their development efforts.
Developing inside a container helps prevent conflicts between different projects by keeping the dependencies and code for each separate. You can use Podman to run containers in a rootless environment that increases security. By combining VS Code, the Remote - Containers extension, and Podman, you can easily set up a consistent environment for multiple developers, decrease setup time, and reduce bugs from differences in development environments in a secure fashion.
## Comments are closed. |
13,710 | 用 Linux 的 at 命令来安排一个任务 | https://opensource.com/article/21/8/linux-at-command | 2021-08-23T14:45:53 | [
"at"
] | /article-13710-1.html |
>
> at 命令是一种在特定时间和日期安排一次性任务的 Linux 终端方法。
>
>
>

计算机擅长 [自动化](https://opensource.com/article/20/11/orchestration-vs-automation),但不是每个人都知道如何使自动化工作。不过,能够在特定的时间为电脑安排一个任务,然后忘记它,这确实是一种享受。也许你有一个文件要在特定的时间上传或下载,或者你需要处理一批还不存在但可以保证在某个时间存在的文件,或者需要监控设置,或者你只是需要一个友好的提醒,在下班回家的路上买上面包和黄油。
这就是 `at` 命令的用处。
### 什么是 Linux at 命令?
`at` 命令是在 Linux 终端让你在特定时间和日期安排一次性工作的方法。它是一种自发的自动化,在终端上很容易实现。
### 安装 at
在 Linux 上,`at` 命令可能已经安装了。你可以使用 `at -V` 命令来验证它是否已经安装。只要返回一个版本号,就说明你已经安装了 `at`。
```
$ at -V
at version x.y.z
```
如果你试图使用 `at`,但没有找到该命令,大多数现代的 Linux 发行版会为你提供缺少的 `at` 软件包。
你可能还需要启动 `at` 守护程序,称为 `atd`。在大多数 Linux 系统中,你可以使用 `systemctl` 命令来启用该服务,并将它们设置为从现在开始自动启动:
```
$ sudo systemctl enable --now atd
```
### 用 at 交互式地安排一个作业
当你使用 `at` 命令并加上你希望任务运行的时间,会打开一个交互式 `at` 提示符。你可以输入你想在指定时间运行的命令。
做个比喻,你可以把这个过程看作是一个日历应用,就像你在你的手机上使用的那样。首先,你在某一天的某个时间创建一个事件,然后指定你想要发生什么。
例如,可以试试创建一个未来几分钟的任务,来给自己计划一个备忘录。这里运行一个简单的任务,以减少失败的可能性。要退出 `at` 提示符,请按键盘上的 `Ctrl+D`。
```
$ at 11:20 AM
warning: commands will be executed using /bin/sh
at> echo "hello world" > ~/at-test.txt
at> <EOT>
job 3 at Mon Jul 26 11:20:00 2021
```
正如你所看到的,`at` 使用直观和自然的时间定义。你不需要用 24 小时制的时钟,也不需要把时间翻译成 UTC 或特定的 ISO 格式。一般来说,你可以使用你自然想到的任何符号,如 `noon`、`1:30 PM`、`13:37` 等等,来描述你希望一个任务发生的时间。
等待几分钟,然后在你创建的文件上运行 `cat` 或者 `tac` 命令,验证你的任务是否已经运行:
```
$ cat ~/at-test.txt
hello world
```
### 用 at 安排一个任务
你不必使用 `at` 交互式提示符来安排任务。你可以使用 `echo` 或 `printf` 向它传送命令。在这个例子中,我使用了 `now` 符号,以及我希望任务从现在开始延迟多少分钟:
```
$ echo "echo 'hello again' >> ~/at-test.txt" | at now +1 minute
```
一分钟后,验证新的命令是否已被执行:
```
$ cat ~/at-test.txt
hello world
hello again
```
### 时间表达式
`at` 命令在解释时间时是非常宽容的。你可以在许多格式中选择,这取决于哪一种对你来说最方便:
* `YYMMDDhhmm[.ss]`(两位的年份、月、日、小时、分钟,及可选的秒)
* `CCYYMMDDhhmm[.ss]`(四位的年份、月、日、时、分钟,及可选的秒)
* `now`(现在)
* `midnight`(午夜 00:00)
* `noon`(中午 12:00)
* `teatime`(下午 16 点)
* `AM`(上午)
* `PM`(下午)
时间和日期可以是绝对时间,也可以加一个加号(`+`),使其与 `now` 相对。当指定相对时间时,你可以使用你可能用过的词语:
* `minutes`(分钟)
* `hours`(小时)
* `days`(天)
* `weeks`(星期)
* `months`(月)
* `years`(年)
### 时间和日期语法
`at` 命令对时间的输入相比日期不那么宽容。时间必须放在第一位,接着是日期,尽管日期默认为当前日期,并且只有在为未来某天安排任务时才需要。
这些是一些有效表达式的例子:
```
$ echo "rsync -av /home/tux me@myserver:/home/tux/" | at 3:30 AM tomorrow
$ echo "/opt/batch.sh ~/Pictures" | at 3:30 AM 08/01/2022
$ echo "echo hello" | at now + 3 days
```
### 查看你的 at 队列
当你爱上了 `at`,并且正在安排任务,而不是在桌子上的废纸上乱写乱画,你可能想查看一下你是否有任务还在队列中。
要查看你的 `at` 队列,使用 `atq` 命令:
```
$ atq
10 Thu Jul 29 12:19:00 2021 a tux
9 Tue Jul 27 03:30:00 2021 a tux
7 Tue Jul 27 00:00:00 2021 a tux
```
要从队列中删除一个任务,使用 `atrm` 命令和任务号。例如,要删除任务 7:
```
$ atrm 7
$ atq
10 Thu Jul 29 12:19:00 2021 a tux
9 Tue Jul 27 03:30:00 2021 a tux
```
要看一个计划中的任务的实际内容,你需要查看 `/var/spool/at` 下的内容。只有 root 用户可以查看该目录的内容,所以你必须使用 `sudo` 来查看或 `cat` 任何任务的内容。
### 用 Linux at 安排任务
`at` 系统是一个很好的方法,可以避免忘记在一天中晚些时候运行一个作业,或者在你离开时让你的计算机为你运行一个作业。与 `cron` 不同的是,它不像 `cron` 那样要求任务必须从现在起一直按计划运行到永远,因此它的语法比 `cron` 简单得多。
等下次你有一个希望你的计算机记住并管理它的小任务,试试 `at` 命令。
---
via: <https://opensource.com/article/21/8/linux-at-command>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,711 | 如何选择一台 Linux 手机 | https://itsfoss.com/linux-phones/ | 2021-08-23T15:53:16 | [
"Linux",
"手机"
] | https://linux.cn/article-13711-1.html | 
>
> 未来取代安卓或 iOS 的可能是 Linux 手机,但如今,有哪些选择可以尝试一下呢?
>
>
>
虽然安卓是基于 Linux 内核的,但它经过了大量修改。因此,这意味着它不是一个完全意义上的基于 Linux 的操作系统。
谷歌正在努力使安卓内核更接近主线 Linux 内核,但这仍然是一个遥远的梦想。
那么,在这种情况下,如果你正在寻找一款 Linux 手机、一款由 Linux 操作系统驱动的智能手机,有哪些可以选择呢?
这并不是一个容易做出的决定,因为你的选择非常有限。因此,我试图推荐一些最好的、不同于主流选择的 Linux 手机。
### 如今你可以使用的顶级 Linux 手机
值得注意的是,这里提到的 Linux 手机或许无法取代你的安卓或 iOS 设备。因此,在做出购买决定之前,请确保你做了一些背景研究。
**注意:** 你需要仔细检查这些 Linux 手机是否可以购买到、预期的发货日期和使用风险。它们大多数只适合于发烧友或早期试用者。
#### 1、PinePhone

[PinePhone](https://www.pine64.org/pinephone/) 是最有性价比和最受欢迎的选择之一,我觉得它是一个有前途的 Linux 手机。
它并不局限于单一的操作系统。你可以尝试使用带有 Plasma mobile OS 的 Manjaro、UBports、Sailfish OS 等系统。PinePhone 的配置不错,它包括一个四核处理器和 2G 或3G 的内存。它支持使用可启动的 microSD 卡来帮助你安装系统,还可选 16/32GB eMMC 存储。
其显示屏是一个基本的 1440×720p IPS 屏幕。你还可以得到特殊的隐私保护,如蓝牙、麦克风和摄像头的断路开关。
PinePhone 还为你提供了使用六个可用的 pogo 引脚添加自定义的硬件扩展的方式。
其基本版(2GB 内存和 16GB 存储)默认加载了 Manjaro,价格为 149 美元;而融合版(3GB 内存和 32GB 存储)价格为 199 美元。
#### 2、Fairphone

与这个清单上的其他选择相比,[Fairphone](https://shop.fairphone.com/en/) 在商业上是成功的。它不是一款 Linux 智能手机,但它具有定制版的安卓系统,即 Fairphone OS,并且可以选择 [开源安卓系统替代品](https://itsfoss.com/open-source-alternatives-android/) 之一 [/e/ OS](https://itsfoss.com/e-os-review/)。如果你想使用 Linux 操作系统,也有一些社区移植版本,但可能有点碰运气。
Fairphone 有两个不同的版本,提供了一些不错的配置规格。你会发现 Fairphone 3+ 有一个 4800 万像素的相机传感器和一个全高清显示屏。另外,你还会发现先进的高通处理器为该设备提供了动力。
他们专注于制造可持续发展的智能手机,并使用了一定量的回收塑料制造。这也为了方便维修。
因此,它不仅是一个非主流智能手机的选择,而且如果你选择了它,你也将为保护环境出了力。
### 3、Librem 5

[Librem 5](https://puri.sm/products/librem-5/) 是一款非常注重用户隐私的智能手机,同时它采用了开源的操作系统,即 PureOS,并非基于安卓。
它所提供的配置规格还不错,有 3GB 内存和四核 Cortex A53 芯片组。但是,这无法与主流选择相竞争。因此,你可能不会觉得它物美价廉。
它的目标是那些对尊重隐私的智能手机感兴趣的发烧友。
与其他产品类似,Librem 5 也专注于通过提供用户可更换的电池使手机易于维修。
在隐私方面,你会注意到有蓝牙、相机和麦克风的断路开关。他们还承诺了未来几年的安全更新。
### 4、Pro 1X

[Pro 1X](https://www.fxtec.com/pro1x) 是一款有趣的智能手机,同时支持 Ubuntu Touch、Lineage OS 和安卓。
它不仅是一款 Linux 智能手机,而且是一款带有独立 QWERTY 键盘的手机,这在现在是很罕见的。
Pro 1 X 的配置规格不错,包括了一个骁龙 662 处理器和 6GB 内存。它还带有一块不错的 AMOLED 全高清显示屏。
它的相机不是特别强大,但在大多数情况下应该是足够了。
### 5、Volla Phone

[Volla Phone](https://www.indiegogo.com/projects/volla-phone-free-your-mind-protect-your-privacy#/) 是一个有吸引力的产品,运行在 UBports 的 Ubuntu Touch。
它配备了预制的 “虚拟专用网络” ,并专注于简化用户体验。它的操作系统是定制的,因此,可以快速访问所有重要的东西,而无需自己组织。
它的配置规格令人印象深刻,包括了一个八核联发科处理器和 4700 毫安时的电池。你会得到类似于一些最新的智能手机上的设计。
### 总结
Linux 智能手机不是到处都能买到的,当然也还不适合大众使用。
因此,如果你是一个发烧友,或者想支持这种手机的发展,你可以考虑购买一台。
你已经拥有一台这种智能手机了吗?请不要犹豫,在下面的评论中分享你的经验。
---
via: <https://itsfoss.com/linux-phones/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

While Android is based on a Linux kernel, it has been heavily modified. So, that does not make it a full-fledged Linux-based operating system.
Google is trying to get the Android kernel close to the mainline Linux kernel, but that is still a distant dream.
So, in that case, what are some of the options if you are looking for a Linux phone? A smartphone powered by a Linux operating system.
It is not an easy decision to make because the options are super limited. Hence, I try to highlight some of the best Linux phones and a few different options from the mainstream choices.
## 1. PinePhone

PinePhone is one of the most affordable and popular choices to consider as a promising Linux phone.
It is not limited to a single operating system. You can try it with Manjaro with Plasma mobile OS, UBports, Sailfish OS, and others. PinePhone packs in some decent specifications that include a Quad-core processor and 2/3 Gigs of RAM. It does support a bootable microSD card to help you with installation, along with 16/32 GB eMMC storage options.
The display is a basic 1440×720p IPS screen. You also get special privacy protection tweaks like kill switches for Bluetooth, microphones, and cameras.
PinePhone also gives you an option to add custom hardware extensions using the six pogo pins available.
The base edition (2 GB RAM and 16 GB storage) comes loaded with Manjaro by default and costs $149. And, the convergence edition (3 GB RAM / 32 GB storage) costs $199.
## 2. Murena

This one is not really a Linux smartphone but it features a special customized version of Android.
What's so special about it? It's de-Googled Android. There are no traces of Google apps and services here by default.
The operating system is [/e/ OS](https://itsfoss.com/e-os-review/) and their [Murena project](https://murena.com/?sld=5) offers Fairphone and some other refurbished smartphones preloaded with /e/OS.
It's a complete ecosystem as you get private email services and cloud storage.
The Fairphone offers some decent specs, considering there are two different variants. You will find a 48 MP camera sensor for Fairphone 3+ and a full-HD display. Not to forget, you will also find decent Qualcomm processors powering the device.
They focus on making smartphones that are sustainable and have been built using some amount of recycled plastic. Fairphone is also meant to be easily repairable.
So, it is not just an option away from mainstream smartphones, but you will also be helping with protecting the environment if you opt for it.
[Murena - deGoogled and privacy by design smartphones and cloud services.Escape the digital surveillance now. We combine privacy by design smartphones smartphones with safe and transparent cloud services.](https://murena.com/?sld=5)

## 3. Librem 5

[Librem 5](https://itsfoss.com/librem-linux-phone/) is a smartphone that focuses heavily on user privacy while featuring an open-source operating system, i.e., PureOS, not based on Android.
The specifications offered are decent, with 3 Gigs of RAM and a quad-core Cortex A53 chipset. But, this is not something geared to compete with mainstream options. Hence, you may not find it as a value for money offering.
It is aimed at enthusiasts who are interested in testing privacy-respecting smartphones in the process.
Similar to others, Librem 5 also focuses on making the phone easily repairable by offering user-replaceable batteries.
For privacy, you will notice kill switches for Bluetooth, Cameras, and microphones. They also promise security updates for years to come.
## 4. Pro 1X
An interesting smartphone that supports Ubuntu Touch, Lineage OS, and Android as well.
It is not just a Linux smartphone but a mobile phone with a separate QWERTY keypad, which is rare to find these days.
The Pro 1 X features a decent specification, including a Snapdragon 662 processor coupled with 6 GB of RAM. You also get a respectable AMOLED Full HD display with the Pro 1 X.
The camera does not pack in anything crazy, but should be good enough for the most part.
## 5. Volla Phone

An attractive offering that runs on Ubuntu Touch by UBports.
It comes with a pre-built VPN and focuses on making the user experience easy. The operating system has been customized so that everything essential should be accessible quickly without organizing anything yourself.
It packs in some impressive specifications that include an Octa-core MediaTek processor along with a 4700 mAh battery. You get a notch design resembling some of the latest smartphones available.
## Wrapping Up
Linux smartphones are not readily available and certainly not yet suitable for the masses.
So, if you are an enthusiast or want to support the development of such phones, you can consider getting one of the devices.
Do you already own one of these smartphones? Please don’t hesitate to share your experiences in the comments below. |
13,713 | 在终端监控你的 Linux 系统 | https://opensource.com/article/21/8/linux-procps-ng | 2021-08-24T09:30:32 | [
"监控"
] | https://linux.cn/article-13713-1.html |
>
> 如何找到一个程序的进程 ID(PID)。最常见的 Linux 工具是由 procps-ng 包提供的,包括 `ps`、`pstree`、`pidof` 和 `pgrep` 命令。
>
>
>

在 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 术语中,<ruby> 进程 <rt> process </rt></ruby>是一个正在进行的事件,由操作系统的内核管理。当你启动一个应用时就会产生一个进程,尽管还有许多其他的进程在你的计算机后台运行,包括保持系统时间准确的程序、监测新的文件系统、索引文件,等等。
大多数操作系统都有某种类型的系统活动监视器,因此你可以了解在任何特定时刻有哪些进程在运行。Linux 有一些供你选择,包括 GNOME 系统监视器和 KSysGuard。这两个软件在桌面环境都很有用,但 Linux 也提供了在终端监控系统的能力。不管你选择哪一种,对于那些积极管理自己电脑的人来说,检查一个特定的进程是一项常见的任务。
在这篇文章中,我演示了如何找到一个程序的进程 ID(PID)。最常见的工具是由 [procps-ng](https://gitlab.com/procps-ng) 包提供的,包括 `ps`、`pstree`、`pidof` 和 `pgrep` 命令。
### 查找一个正在运行的程序的 PID
有时你想得到一个你知道正在运行的特定程序的进程 ID(PID)。`pidof` 和 `pgrep` 命令可以通过命令名称查找进程。
`pidof` 命令返回一个命令的 PID,它按名称搜索确切的命令:
```
$ pidof bash
1776 5736
```
`pgrep` 命令允许使用正则表达式:
```
$ pgrep .sh
1605
1679
1688
1776
2333
5736
$ pgrep bash
5736
```
### 通过文件查找 PID
你可以用 `fuser` 命令找到使用特定文件的进程的 PID。
```
$ fuser --user ~/example.txt
/home/tux/example.txt: 3234(tux)
```
### 通过 PID 获得进程名称
如果你有一个进程的 PID 编号,但没有生成它的命令,你可以用 `ps` 做一个“反向查找”:
```
$ ps 3234
PID TTY STAT TIME COMMAND
5736 pts/1 Ss 0:00 emacs
```
### 列出所有进程
`ps` 命令列出进程。你可以用 `-e` 选项列出你系统上的每一个进程:
```
PID TTY TIME CMD
1 ? 00:00:03 systemd
2 ? 00:00:00 kthreadd
3 ? 00:00:00 rcu_gp
4 ? 00:00:00 rcu_par_gp
6 ? 00:00:00 kworker/0:0H-events_highpri
[...]
5648 ? 00:00:00 gnome-control-c
5656 ? 00:00:00 gnome-terminal-
5736 pts/1 00:00:00 bash
5791 pts/1 00:00:00 ps
5792 pts/1 00:00:00 less
(END)
```
### 只列出你的进程
`ps -e` 的输出可能会让人不知所措,所以使用 `-U` 来查看一个用户的进程:
```
$ ps -U tux | less
PID TTY TIME CMD
3545 ? 00:00:00 systemd
3548 ? 00:00:00 (sd-pam)
3566 ? 00:00:18 pulseaudio
3570 ? 00:00:00 gnome-keyring-d
3583 ? 00:00:00 dbus-daemon
3589 tty2 00:00:00 gdm-wayland-ses
3592 tty2 00:00:00 gnome-session-b
3613 ? 00:00:00 gvfsd
3618 ? 00:00:00 gvfsd-fuse
3665 tty2 00:01:03 gnome-shell
[...]
```
这样就减少了 200 个(可能是 100 个,取决于你运行的系统)需要分类的进程。
你可以用 `pstree` 命令以不同的格式查看同样的输出:
```
$ pstree -U tux -u --show-pids
[...]
├─gvfsd-metadata(3921)─┬─{gvfsd-metadata}(3923)
│ └─{gvfsd-metadata}(3924)
├─ibus-portal(3836)─┬─{ibus-portal}(3840)
│ └─{ibus-portal}(3842)
├─obexd(5214)
├─pulseaudio(3566)─┬─{pulseaudio}(3640)
│ ├─{pulseaudio}(3649)
│ └─{pulseaudio}(5258)
├─tracker-store(4150)─┬─{tracker-store}(4153)
│ ├─{tracker-store}(4154)
│ ├─{tracker-store}(4157)
│ └─{tracker-store}(4178)
└─xdg-permission-(3847)─┬─{xdg-permission-}(3848)
└─{xdg-permission-}(3850)
```
### 列出进程的上下文
你可以用 `-u` 选项查看你拥有的所有进程的额外上下文。
```
$ ps -U tux -u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
tux 3545 0.0 0.0 89656 9708 ? Ss 13:59 0:00 /usr/lib/systemd/systemd --user
tux 3548 0.0 0.0 171416 5288 ? S 13:59 0:00 (sd-pam)
tux 3566 0.9 0.1 1722212 17352 ? S<sl 13:59 0:29 /usr/bin/pulseaudio [...]
tux 3570 0.0 0.0 664736 8036 ? SLl 13:59 0:00 /usr/bin/gnome-keyring-daemon [...]
[...]
tux 5736 0.0 0.0 235628 6036 pts/1 Ss 14:18 0:00 bash
tux 6227 0.0 0.4 2816872 74512 tty2 Sl+14:30 0:00 /opt/firefox/firefox-bin [...]
tux 6660 0.0 0.0 268524 3996 pts/1 R+ 14:50 0:00 ps -U tux -u
tux 6661 0.0 0.0 219468 2460 pts/1 S+ 14:50 0:00 less
```
### 用 PID 排除故障
如果你在某个特定的程序上有问题,或者你只是好奇某个程序在你的系统上还使用了什么资源,你可以用 `pmap` 查看运行中的进程的内存图。
```
$ pmap 1776
5736: bash
000055f9060ec000 1056K r-x-- bash
000055f9063f3000 16K r---- bash
000055f906400000 40K rw--- [ anon ]
00007faf0fa67000 9040K r--s- passwd
00007faf1033b000 40K r-x-- libnss_sss.so.2
00007faf10345000 2044K ----- libnss_sss.so.2
00007faf10545000 4K rw--- libnss_sss.so.2
00007faf10546000 212692K r---- locale-archive
00007faf1d4fb000 1776K r-x-- libc-2.28.so
00007faf1d6b7000 2044K ----- libc-2.28.so
00007faf1d8ba000 8K rw--- libc-2.28.so
[...]
```
### 处理进程 ID
procps-ng 软件包有你需要的所有命令,以调查和监控你的系统在任何时候的使用情况。无论你是对 Linux 系统中各个分散的部分如何结合在一起感到好奇,还是要对一个错误进行调查,或者你想优化你的计算机的性能,学习这些命令都会为你了解你的操作系统提供一个重要的优势。
---
via: <https://opensource.com/article/21/8/linux-procps-ng>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A process, in [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) terminology, is an ongoing event being managed by an operating system’s kernel. A process is spawned when you launch an application, although there are many other processes running in the background of your computer, including programs to keep your system time accurate, to monitor for new filesystems, to index files, and so on.
Most operating systems have a system activity monitor of some kind so you can learn what processes are running at any give moment. Linux has a few for you to choose from, including GNOME System Monitor and KSysGuard. Both are useful applications on the desktop, but Linux also provides the ability to monitor your system in your terminal. Regardless of which you choose, it’s a common task for those who take an active role in managing their computer is to examine a specific process.
In this article, I demonstrate how to find the process ID (PID) of a program. The most common tools for this are provided by the [procps-ng](https://gitlab.com/procps-ng) package, including the `ps`
and `pstree`
, `pidof`
, and `pgrep`
commands.
## Find the PID of a running program
Sometimes you want to get the process ID (PID) of a specific application you know you have running. The `pidof`
and `pgrep`
commands find processes by command name.
The `pidof`
command returns the PIDs of a command, searching for the exact command by name:
```
$ pidof bash
1776 5736
```
The `pgrep`
command allows for regular expressions (regex):
```
$ pgrep .sh
1605
1679
1688
1776
2333
5736
$ pgrep bash
5736
```
## Find a PID by file
You can find the PID of the process using a specific file with the `fuser`
command.
```
$ fuser --user ~/example.txt
/home/tux/example.txt: 3234(tux)
```
## Get a process name by PID
If you have the PID *number* of a process but not the command that spawned it, you can do a "reverse lookup" with `ps`
:
```
$ ps 3234
PID TTY STAT TIME COMMAND
5736 pts/1 Ss 0:00 emacs
```
## List all processes
The `ps`
command lists processes. You can list every process on your system with the `-e`
option:
```
$ ps -e | less
PID TTY TIME CMD
1 ? 00:00:03 systemd
2 ? 00:00:00 kthreadd
3 ? 00:00:00 rcu_gp
4 ? 00:00:00 rcu_par_gp
6 ? 00:00:00 kworker/0:0H-events_highpri
[...]
5648 ? 00:00:00 gnome-control-c
5656 ? 00:00:00 gnome-terminal-
5736 pts/1 00:00:00 bash
5791 pts/1 00:00:00 ps
5792 pts/1 00:00:00 less
(END)
```
## List just your processes
The output of `ps -e`
can be overwhelming, so use `-U`
to see the processes of just one user:
```
$ ps -U tux | less
PID TTY TIME CMD
3545 ? 00:00:00 systemd
3548 ? 00:00:00 (sd-pam)
3566 ? 00:00:18 pulseaudio
3570 ? 00:00:00 gnome-keyring-d
3583 ? 00:00:00 dbus-daemon
3589 tty2 00:00:00 gdm-wayland-ses
3592 tty2 00:00:00 gnome-session-b
3613 ? 00:00:00 gvfsd
3618 ? 00:00:00 gvfsd-fuse
3665 tty2 00:01:03 gnome-shell
[...]
```
That produces 200 fewer (give or take a hundred, depending on the system you're running it on) processes to sort through.
You can view the same output in a different format with the `pstree`
command:
```
$ pstree -U tux -u --show-pids
[...]
├─gvfsd-metadata(3921)─┬─{gvfsd-metadata}(3923)
│ └─{gvfsd-metadata}(3924)
├─ibus-portal(3836)─┬─{ibus-portal}(3840)
│ └─{ibus-portal}(3842)
├─obexd(5214)
├─pulseaudio(3566)─┬─{pulseaudio}(3640)
│ ├─{pulseaudio}(3649)
│ └─{pulseaudio}(5258)
├─tracker-store(4150)─┬─{tracker-store}(4153)
│ ├─{tracker-store}(4154)
│ ├─{tracker-store}(4157)
│ └─{tracker-store}(4178)
└─xdg-permission-(3847)─┬─{xdg-permission-}(3848)
└─{xdg-permission-}(3850)
```
## List just your processes with context
You can see extra context for all of the processes you own with the `-u`
option.
```
$ ps -U tux -u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
tux 3545 0.0 0.0 89656 9708 ? Ss 13:59 0:00 /usr/lib/systemd/systemd --user
tux 3548 0.0 0.0 171416 5288 ? S 13:59 0:00 (sd-pam)
tux 3566 0.9 0.1 1722212 17352 ? S<sl 13:59 0:29 /usr/bin/pulseaudio [...]
tux 3570 0.0 0.0 664736 8036 ? SLl 13:59 0:00 /usr/bin/gnome-keyring-daemon [...]
[...]
tux 5736 0.0 0.0 235628 6036 pts/1 Ss 14:18 0:00 bash
tux 6227 0.0 0.4 2816872 74512 tty2 Sl+14:30 0:00 /opt/firefox/firefox-bin [...]
tux 6660 0.0 0.0 268524 3996 pts/1 R+ 14:50 0:00 ps -U tux -u
tux 6661 0.0 0.0 219468 2460 pts/1 S+ 14:50 0:00 less
```
## Troubleshoot with PIDs
If you’re having trouble with a specific application, or you’re just curious about what else on your system an application uses, you can see a memory map of the running process with `pmap`
:
```
$ pmap 1776
5736: bash
000055f9060ec000 1056K r-x-- bash
000055f9063f3000 16K r---- bash
000055f906400000 40K rw--- [ anon ]
00007faf0fa67000 9040K r--s- passwd
00007faf1033b000 40K r-x-- libnss_sss.so.2
00007faf10345000 2044K ----- libnss_sss.so.2
00007faf10545000 4K rw--- libnss_sss.so.2
00007faf10546000 212692K r---- locale-archive
00007faf1d4fb000 1776K r-x-- libc-2.28.so
00007faf1d6b7000 2044K ----- libc-2.28.so
00007faf1d8ba000 8K rw--- libc-2.28.so
[...]
```
## Process IDs
The **procps-ng** package has all the commands you need to investigate and monitor what your system is using at any moment. Whether you’re just curious about how all the disparate parts of a Linux system fit together, or whether you’re investigating an error, or you’re looking to optimize how your computer is performing, learning these commands gives you a significant advantage for understanding your OS.
## 1 Comment |
13,714 | 如何在免费 WiFi 中保护隐私(四) | https://opensource.com/article/21/7/openvpn-client | 2021-08-24T10:12:23 | [
"VPN"
] | https://linux.cn/article-13714-1.html |
>
> 在 Linux 上安装好“虚拟专用网络” 之后,是时候使用它了。
>
>
>

0penVPN 在两点之间创建了一个加密通道,以阻止第三方访问你的网络流量数据。通过设置你的 “虚拟专用网络” 服务,你可以成为你自己的 “虚拟专用网络” 服务商。许多流行的 “虚拟专用网络” 服务都使用 0penVPN,所以当你可以掌控自己的网络时,为什么还要将你的网络连接绑定到特定的提供商呢?
本系列的 [第一篇文章](/article-13680-1.html) 安装了一个“虚拟专用网络” 的服务器,[第二篇文章](/article-13702-1.html) 介绍了如何安装和配置一个 0penVPN 服务软件,[第三篇文章](/article-13707-1.html) 解释了如何配置防火墙并启动你的 0penVPN 服务。第四篇也是最后一篇文章将演示如何从客户端计算机使用你的 0penVPN 服务器。这就是你做了前三篇文章中所有工作的原因!
### 创建客户端证书
请记住,0penVPN 的身份验证方法要求服务器和客户端都拥有某些东西(证书)并知道某些东西(口令)。是时候设置它了。
首先,为你的客户端计算机创建一个客户端证书和一个私钥。在你的 0penVPN 服务器上,生成证书请求。它会要求你输入密码;确保你记住它:
```
$ cd /etc/openvpn/ca
$ sudo /etc/openvpn/easy-rsa/easyrsa \
gen-req greglaptop
```
本例中,`greglaptop` 是创建证书的客户端计算机主机名。
无需将请求导入证书颁发机构(CA),因为它已经存在。审查它以确保请求存在:
```
$ cd /etc/openvpn/ca
$ /etc/openvpn/easy-rsa/easyrsa \
show-req greglaptop
```
你也可以以客户端身份签署请求:
```
$ /etc/openvpn/easy-rsa/easyrsa \
sign-req client greglaptop
```
### 安装 0penVPN 客户端软件
在 Linux 系统上,网络管理器可能已经包含了一个 0penVPN 客户端。如果没有,你可以安装插件:
```
$ sudo dnf install NetworkManager-openvpn
```
在 Windows 系统上,你必须从 0penVPN 下载网页下载和安装 0penVPN 客户端。启动安装程序并按照提示操作。
### 复制证书和私钥到客户端
现在你的客户端需要你为其生成的身份验证凭据。你在服务器上生成了这些,因此你必须将它们传输到你的客户端。我推荐使用 SSH 来完成传输。在 Linux 系统上,通过 `scp` 命令实现。在 Windows 系统上,你可以以管理员身份运行 [WinSCP](https://winscp.net/eng/index.php) 来推送证书和密钥。
假设客户端名称为 `greglaptop`,那么证书和私钥的文件名以及服务的位置如下:
```
/etc/openvpn/ca/pki/issued/greglaptop.crt
/etc/openvpn/ca/pki/private/greglaptop.key
/etc/openvpn/ca/pki/issued/ca.crt
```
在 Linux 系统上,复制这些文件到 `/etc/pki/tls/certs` 目录。在 Windows 系统上,复制它们到 `C:\Program Files\OpenVPN\config` 目录。
### 复制和自定义客户端配置文件
在 Linux 系统上,你可以复制服务器上的 `/etc/openvpn/client/OVPNclient2020.ovpn` 文件到 `/etc/NetworkManager/system-connections/` 目录,或者你也可以导航到系统设置中的网络管理器添加一个“虚拟专用网络” 连接。
连接类型选择“<ruby> 证书(TLS) <rt> Certificates(TLS) </rt></ruby>”。告知网络管理器你从服务器上复制的证书和密钥。

在 Windows 系统上,以管理员身份运行 WinSCP,将服务器上的客户端配置模板 `/etc/openvpn/client/OVPNclient2020.ovpn` 文件复制到客户端上的 `C:\Program Files\OpenVPN\config` 目录。然后:
* 重命名它以匹配上面的证书。
* 更改 CA 证书、客户端证书和密钥的名称以匹配上面从服务器复制的名称。
* 修改 IP 信息,以匹配你的网络。
你需要超级管理员权限来编辑客户端配置文件。最简单的方式就是以管理员身份启动一个 CMD 窗口,然后从管理员 CMD 窗口启动记事本来编辑此文件。
### 将你的客户端连接到服务器
在 Linux 系统上,网络管理器会显示你的 “虚拟专用网络” 连接。选择它进行连接。

在 Windows 系统上,启动 0penVPN 图形用户界面。它会在任务栏右侧的 Windows 系统托盘中生成一个图标,通常位于 Windows 桌面的右下角。右键单击图标以连接、断开连接或查看状态。
对于第一次连接,编辑客户端配置文件的 `remote` 行以使用 0penVPN 服务器的内部 IP 地址。通过右键单击 Windows 系统托盘中的 0penVPN 图标并单击“<ruby> 连接 <rt> Connect </rt></ruby>”,从办公室网络内部连接到服务器。调试此连接,这应该可以找到并解决问题,而不会出现任何防火墙问题,因为客户端和服务器都在防火墙的同一侧。
接下来,编辑客户端配置文件的 `remote` 行以使用 0penVPN 服务器的公共 IP 地址。将 Windows 客户端连接到外部网络并进行连接。调试有可能的问题。
### 安全连接
恭喜!你已经为其他客户端系统准备好了 0penVPN 网络。对其余客户端重复设置步骤。你甚至可以使用 Ansible 来分发证书和密钥并使其保持最新。
本文基于 D.Greg Scott 的 [博客](https://www.dgregscott.com/how-to-build-a-vpn-in-four-easy-steps-without-spending-one-penny/),经许可后重新使用。
---
via: <https://opensource.com/article/21/7/openvpn-client>
作者:[D. Greg Scott](https://opensource.com/users/greg-scott) 选题:[lujun9972](https://github.com/lujun9972) 译者:[perfiffer](https://github.com/perfiffer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | OpenVPN creates an encrypted tunnel between two points, preventing a third party from accessing your network traffic. By setting up your virtual private network (VPN) server, you become your own VPN provider. Many popular VPN services already use [OpenVPN](https://openvpn.net/), so why tie your connection to a specific provider when you can have complete control yourself?
The [first article](https://opensource.com/article/21/7/vpn-openvpn-part-1) in this series set up a server for your VPN, the [second article](https://opensource.com/article/21/7/vpn-openvpn-part-2) demonstrated how to install and configure the OpenVPN server software, while the [third article](https://opensource.com/article/21/7/vpn-openvpn-part-3) explained how to configure your firewall and start the OpenVPN server software. This fourth and final article demonstrates how to use your OpenVPN server from client computers. This is the reason you did all the work in the previous three articles!
## Create client certificates
Remember that the method of authentication for OpenVPN requires both the server and the client to *have* something (certificates) and to *know* something (a password). It's time to set that up.
First, create a client certificate and a private key for your client computer. On your OpenVPN server, generate a certificate request. It asks for a passphrase; make sure you remember it:
```
$ cd /etc/openvpn/ca
$ sudo /etc/openvpn/easy-rsa/easyrsa \
gen-req greglaptop
```
In this example, `greglaptop`
is the client computer for which this certificate is being created.
There's no need to import the request into the certificate authority (CA) because it's already there. Review it to make sure:
```
$ cd /etc/openvpn/ca
$ /etc/openvpn/easy-rsa/easyrsa \
show-req greglaptop
```
You can sign as the client, too:
```
$ /etc/openvpn/easy-rsa/easyrsa \
sign-req client greglaptop
```
## Install the OpenVPN client software
On Linux, Network Manager may already have an OpenVPN client included. If not, you can install the plugin:
`$ sudo dnf install NetworkManager-openvpn`
On Windows, you must download and install the OpenVPN client from the OpenVPN download site. Launch the installer and follow the prompts.
## Copy certificates and private keys to the client
Now your client needs the authentication credentials you generated for it. You generated these on the server, so you must transport them over to your client. I tend to use SSH for this. On Linux, that's the `scp`
command. On Windows, you can use [WinSCP](https://winscp.net/eng/index.php) as administrator to pull the certificates and keys.
Assuming the client is named `greglaptop`
, here are the file names and server locations:
```
/etc/openvpn/ca/pki/issued/greglaptop.crt
/etc/openvpn/ca/pki/private/greglaptop.key
/etc/openvpn/ca/pki/issued/ca.crt
```
On Linux, copy these to the `/etc/pki/tls/certs/`
directory. On Windows, copy them to the `C:\Program Files\OpenVPN\config`
directory.
## Copy and customize the client configuration file
On Linux, you can either copy the `/etc/openvpn/client/OVPNclient2020.ovpn`
file on the server to `/etc/NetworkManager/system-connections/`
, or you can navigate to Network Manager in System Settings and add a VPN connection.
For the connection type, select **Certificates**. Point Network Manager to the certificates and keys you copied from the server.
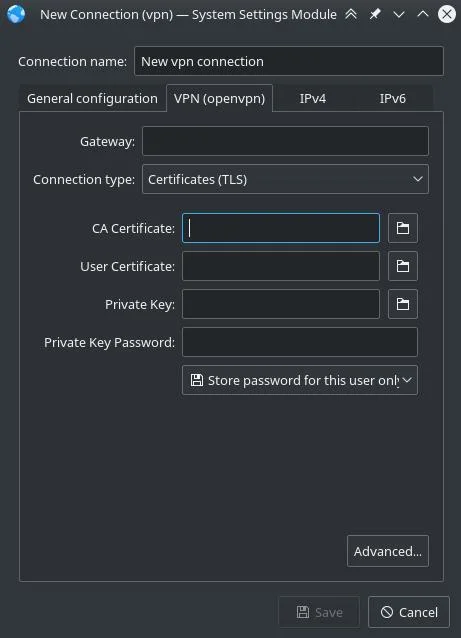
(Seth Kenlon, CC BY-SA 4.0)
On Windows, run WinSCP as administrator to copy the client configuration template `/etc/openvpn/client/OVPNclient2020.ovpn`
on the server to `C:\Program Files\OpenVPN\config`
on the client. Then:
- Rename it to match the certificate above.
- Change the names of the CA certificate, client certificate, and key to match the names copied above from the server.
- Edit the IP information to match your network.
You need super administrative permissions to edit the client config files. The easiest way to get this might be to launch a CMD window as administrator and then launch Notepad from the administrator CMD window to edit the files.
## Connect your client to the server
On Linux, Network manager displays your VPN. Select it to connect.
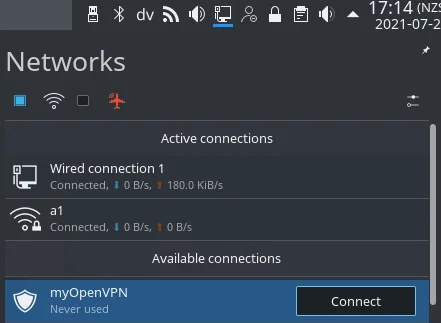
(Seth Kenlon, CC BY-SA 4.0)
On Windows, start the OpenVPN graphical user interface (GUI). It produces a graphic in the Windows System Tray on the right side of the taskbar, usually in the lower-right corner of your Windows desktop. Right-click the graphic to connect, disconnect, or view the status.
For the first connection, edit the "remote" line of your client config file to use the *inside IP address* of your OpenVPN server. Connect to the server from inside your office network by right-clicking on the OpenVPN GUI in the Windows System Tray and clicking **Connect**. Debug this connection. This should find and fix problems without any firewall issues getting in the way because both the client and server are on the same side of the firewall.
Next, edit the "remote" line of your client config file to use the *public IP address* for your OpenVPN server. Bring the Windows client to an outside network and connect. Debug any issues.
## Connect securely
Congratulations! You have an OpenVPN network ready for your other client systems. Repeat the setup steps for the rest of your clients. You might even use Ansible to distribute certs and keys and keep them up to date.
*This article is based on D. Greg Scott's blog and is reused with permission.*
## Comments are closed. |
13,716 | Linux 中 cron 系统的 4 种替代方案 | https://opensource.com/article/21/7/alternatives-cron-linux | 2021-08-25T10:40:41 | [
"定时",
"cron"
] | https://linux.cn/article-13716-1.html |
>
> 在 Linux 系统中有一些其他开源项目可以结合或者替代 cron 系统使用。
>
>
>

[Linux cron 系统](https://opensource.com/article/21/7/cron-linux) 是一项经过时间检验的成熟技术,然而在任何情况下它都是最合适的系统自动化工具吗?答案是否定的。有一些开源项目就可以用来与 cron 结合或者直接代替 cron 使用。
### at 命令
cron 适用于长期重复任务。如果你设置了一个工作任务,它会从现在开始定期运行,直到计算机报废为止。但有些情况下你可能只想设置一个一次性命令,以备不在计算机旁时该命令可以自动运行。这时你可以选择使用 `at` 命令。
`at` 的语法比 cron 语法简单和灵活得多,并且兼具交互式和非交互式调度方法。(只要你想,你甚至可以使用 `at` 作业创建一个 `at` 作业。)
```
$ echo "rsync -av /home/tux/ me@myserver:/home/tux/" | at 1:30 AM
```
该命令语法自然且易用,并且不需要用户清理旧作业,因为它们一旦运行后就完全被计算机遗忘了。
阅读有关 [at 命令](https://opensource.com/article/21/7/intro-command) 的更多信息并开始使用吧。
### systemd
除了管理计算机上的进程外,`systemd` 还可以帮你调度这些进程。与传统的 cron 作业一样,systemd 计时器可以在指定的时间间隔触发事件,例如 shell 脚本和命令。时间间隔可以是每月特定日期的一天一次(例如在星期一的时候触发),或者在 09:00 到 17:00 的工作时间内每 15 分钟一次。
此外 systemd 里的计时器还可以做一些 cron 作业不能做的事情。
例如,计时器可以在一个事件 *之后* 触发脚本或程序来运行特定时长,这个事件可以是开机,可以是前置任务的完成,甚至可以是计时器本身调用的服务单元的完成!
如果你的系统运行着 systemd 服务,那么你的机器就已经在技术层面上使用 systemd 计时器了。默认计时器会执行一些琐碎的任务,例如滚动日志文件、更新 mlocate 数据库、管理 DNF 数据库等。创建自己的计时器很容易,具体可以参阅 David Both 的文章 [使用 systemd 计时器来代替 cron](https://opensource.com/article/20/7/systemd-timers)。
### anacron 命令
cron 专门用于在特定时间运行命令,这适用于从不休眠或断电的服务器。然而对笔记本电脑和台式工作站而言,时常有意或无意地关机是很常见的。当计算机处于关机状态时,cron 不会运行,因此设定在这段时间内的一些重要工作(例如备份数据)也就会跳过执行。
anacron 系统旨在确保作业定期运行,而不是按计划时间点运行。这就意味着你可以将计算机关机几天,再次启动时仍然靠 anacron 来运行基本任务。anacron 与 cron 协同工作,因此严格来说前者不是后者的替代品,而是一种调度任务的有效可选方案。许多系统管理员配置了一个 cron 作业来在深夜备份远程工作者计算机上的数据,结果却发现该作业在过去六个月中只运行过一次。anacron 确保重要的工作在 *可执行的时候* 发生,而不是必须在安排好的 *特定时间点* 发生。
点击参阅关于 [使用 anacron 获得更好的 crontab 效果](https://opensource.com/article/21/2/linux-automation) 的更多内容。
### 自动化
计算机和技术旨在让人们的生活更美好,工作更轻松。Linux 为用户提供了许多有用的功能,以确保完成重要的操作系统任务。查看这些可用的功能,然后试着将这些功能用于你自己的工作任务吧。(LCTT 译注:作者本段有些语焉不详,读者可参阅譬如 [Ansible 自动化工具安装、配置和快速入门指南](/article-13142-1.html) 等关于 Linux 自动化的文章)
---
via: <https://opensource.com/article/21/7/alternatives-cron-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [Linux cron system](https://opensource.com/article/21/7/cron-linux) is a time-tested and proven technology. However, it's not always the right tool for system automation. There are a few other open source projects out there that can be used either in conjunction with
`cron`
or instead of `cron`
.## Linux at command
`Cron`
is intended for long-term repetition. You schedule a job, and it runs at a regular interval from now until the computer is decommissioned. Sometimes you just want to schedule a one-off command to run at a time you happen not to be at your computer. For that, you can use the `at`
command.
The syntax of `at`
is far simpler and more flexible than the `cron`
syntax, and it has both an interactive and non-interactive method for scheduling (so you could use `at`
to create an `at`
job if you really wanted to.)
`$ echo "rsync -av /home/tux/ me@myserver:/home/tux/" | at 1:30 AM`
It feels natural, it's easy to use, and you don't have to clean up old jobs because they're entirely forgotten once they've been run.
Read more about the [at command](https://opensource.com/article/21/7/intro-command) to get started.
## Systemd
In addition to managing processes on your computer, `systemd`
can also help you schedule them. Like traditional `cron`
jobs, `systemd`
timers can trigger events, such as shell scripts and commands, at specified time intervals. This can be once a day on a specific day of the month (and then, perhaps only if it's a Monday, for example), or every 15 minutes during business hours from 09:00 to 17:00.
Timers can also do some things that `cron`
jobs can't.
For example, a timer can trigger a script or program to run a specific amount of time *after* an event, such as boot, startup, completion of a previous task, or even the prior completion of the service unit called by the timer itself!
If your system runs `systemd`
, then you're technically using `systemd`
timers already. Default timers perform menial tasks like rotating log files, updating the mlocate database, manage the DNF database, and so on. Creating your own is easy, as demonstrated by David Both in his article [Use systemd timers instead of cronjobs](https://opensource.com/article/20/7/systemd-timers).
## Anacron
`Cron`
specializes in running a command at a specific time. This works well for a server that's never hibernating or powered down. Still, it's pretty common for laptops and desktop workstations to either intentionally or absent-mindedly turn the computer off from time to time. When the computer's not on, `cron`
doesn't run, so important jobs (such as backing up data) get skipped.
The `anacron`
system is designed to ensure that jobs are run periodically rather than on a schedule. This means you can leave a computer off for several days and still count on `anacron`
to run essential tasks when you boot it up again. `Anacron`
works in tandem with `cron`
, so it's not strictly an alternative to it, but it's a meaningful alternative way of scheduling tasks. Many a sysadmin has configured a `cron`
job to backup data late at night on a remote worker's computer, only to discover that the job's only been run once in the past six months.` Anacron`
ensures that important jobs happen *sometime* when they can rather than *never* when they were scheduled.
Read more about [using anacron for a better crontab](https://opensource.com/article/21/2/linux-automation).
## Automation
Computers and technology are meant to make lives better and work easier. Linux provides its users with lots of helpful features to ensure important operating system tasks get done. Take a look at what's available, and start using these features for your own tasks.
## 2 Comments |
13,717 | 改进你的脚本程序的 5 个方法 | https://opensource.com/article/20/1/improve-bash-scripts | 2021-08-25T13:13:57 | [
"Bash",
"脚本"
] | https://linux.cn/article-13717-1.html |
>
> 巧用 Bash 脚本程序能帮助你完成很多极具挑战的任务。
>
>
>

系统管理员经常写脚本程序,不论长短,这些脚本可以完成某种任务。
你是否曾经查看过某个软件发行方提供的安装用的<ruby> 脚本 <rt> script </rt></ruby>程序?为了能够适应不同用户的系统配置,顺利完成安装,这些脚本程序经常包含很多函数和逻辑分支。多年来,我积累了一些改进脚本程序的一些技巧,这里分享几个,希望能对朋友们也有用。这里列出一组短脚本示例,展示给大家做脚本样本。
### 初步尝试
我尝试写一个脚本程序时,原始程序往往就是一组命令行,通常就是调用标准命令完成诸如更新网页内容之类的工作,这样可以节省时间。其中一个类似的工作是解压文件到 Apache 网站服务器的主目录里,我的最初脚本程序大概是下面这样:
```
cp january_schedule.tar.gz /usr/apache/home/calendar/
cd /usr/apache/home/calendar/
tar zvxf january_schedule.tar.gz
```
这帮我节省了时间,也减少了键入多条命令操作。时日久了,我掌握了另外的技巧,可以用 Bash 脚本程序完成更难的一些工作,比如说创建软件安装包、安装软件、备份文件系统等工作。
### 1、条件分支结构
和众多其他编程语言一样,脚本程序的条件分支结构同样是强大的常用技能。条件分支结构赋予了计算机程序逻辑能力,我的很多实例都是基于条件逻辑分支。
基本的条件分支结构就是 `if` 条件分支结构。通过判定是否满足特定条件,可以控制程序选择执行相应的脚本命令段。比如说,想要判断系统是否安装了 Java ,可以通过判断系统有没有一个 Java 库目录;如果找到这个目录,就把这个目录路径添加到可运行程序路径,也就可以调用 Java 库应用了。
```
if [ -d "$JAVA_HOME/bin" ] ; then
PATH="$JAVA_HOME/bin:$PATH"
```
### 2、限定运行权限
你或许想只允许特定的用户才能执行某个脚本程序。除了 Linux 的权限许可管理,比如对用户和用户组设定权限、通过 SELinux 设定此类的保护权限等,你还可以在脚本里设置逻辑判断来设置执行权限。类似的情况可能是,你需要确保只有网站程序的所有者才能执行相应的网站初始化操作脚本。甚至你可以限定只有 root 用户才能执行某个脚本。这个可以通过在脚本程序里设置逻辑判断实现,Linux 提供的几个环境变量可以帮忙。其中一个是保存用户名称的变量 `$USER`, 另一个是保存用户识别码的变量 `$UID` 。在脚本程序里,执行用户的 UID 值就保存在 `$UID` 变量里。
#### 用户名判别
第一个例子里,我在一个带有几个应用服务器实例的多用户环境里指定只有用户 `jboss1` 可以执行脚本程序。条件 `if` 语句主要是判断,“要求执行这个脚本程序的用户不是 `jboss1` 吗?”当此条件为真时,就会调用第一个 `echo` 语句,接着是 `exit 1`,即退出这个脚本程序。
```
if [ "$USER" != 'jboss1' ]; then
echo "Sorry, this script must be run as JBOSS1!"
exit 1
fi
echo "continue script"
```
#### 根用户判别
接下来的例子是要求只有根用户才能执行脚本程序。根用户的用户识别码(UID)是 0,设置的条件判断采用大于操作符(`-gt`),所有 UID 值大于 0 的用户都被禁止执行该脚本程序。
```
if [ "$UID" -gt 0 ]; then
echo "Sorry, this script must be run as ROOT!"
exit 1
fi
echo "continue script"
```
### 3、带参数执行程序
可执行程序可以附带参数作为执行选项,命令行脚本程序也是一样,下面给出几个例子。在这之前,我想告诉你,能写出好的程序并不只是写出我们想要它执行什么的程序,程序还需要不执行我们不要它执行的操作。如果运行程序时没有提供参数造成程序缺少足够信息,我愿意脚本程序不要做任何破坏性的操作。因而,程序的第一步就是确认命令行是否提供了参数,判定的条件就是参数数量 `$#` 是否为 0 ,如果是(意味着没有提供参数),就直接终止脚本程序并退出操作。
```
if [ $# -eq 0 ]; then
echo "No arguments provided"
exit 1
fi
echo "arguments found: $#"
```
#### 多个运行参数
可以传递给脚本程序的参数不止一个。脚本使用内部变量指代这些参数,内部变量名用非负整数递增标识,也就是 `$1`、`$2`、`$3` 等等递增。我只是扩展前面的程序,并在下面一行输出显示用户提供的前三个参数。显然,要针对所有的每个参数有对应的响应需要更多的逻辑判断,这里的例子只是简单展示参数的使用。
```
echo $1 $2 $3
```
我们在讨论这些参数变量名,你或许有个疑问,“参数变量名怎么跳过了 `$0`,(而直接从`$1` 开始)?”
是的,是这样,这是有原因的。变量名 `$0` 确实存在,也非常有用,它储存的是被执行的脚本程序的名称。
```
echo $0
```
程序执行过程中有一个变量名指代程序名称,很重要的一个原因是,可以在生成的日志文件名称里包含程序名称,最简单的方式应该是调用一个 `echo` 语句。
```
echo test >> $0.log
```
当然,你或许要增加一些代码,确保这个日志文件存放在你希望的路径,日志名称包含你认为有用的信息。
### 4、交互输入
脚本程序的另一个好用的特性是可以在执行过程中接受输入,最简单的情况是让用户可以输入一些信息。
```
echo "enter a word please:"
read word
echo $word
```
这样也可以让用户在程序执行中作出选择。
```
read -p "Install Software ?? [Y/n]: " answ
if [ "$answ" == 'n' ]; then
exit 1
fi
echo "Installation starting..."
```
### 5、出错退出执行
几年前,我写了个脚本,想在自己的电脑上安装最新版本的 Java 开发工具包(JDK)。这个脚本把 JDK 文件解压到指定目录,创建更新一些符号链接,再做一下设置告诉系统使用这个最新的版本。如果解压过程出现错误,在执行后面的操作就会使整个系统上的 Java 破坏不能使用。因而,这种情况下需要终止程序。如果解压过程没有成功,就不应该再继续进行之后的更新操作。下面语句段可以完成这个功能。
```
tar kxzmf jdk-8u221-linux-x64.tar.gz -C /jdk --checkpoint=.500; ec=$?
if [ $ec -ne 0 ]; then
echo "Installation failed - exiting."
exit 1
fi
```
下面的单行语句可以给你快速展示一下变量 `$?` 的用法。
```
ls T; ec=$?; echo $ec
```
先用 `touch T` 命令创建一个文件名为 `T` 的文件,然后执行这个单行命令,变量 `ec` 的值会是 0。然后,用 `rm T` 命令删除文件,再执行该单行命令,变量 `ec` 的值会是 2,因为文件 `T` 不存在,命令 `ls` 找不到指定文件报错。
在逻辑条件里利用这个出错标识,参照前文我使用的条件判断,可以使脚本文件按需完成设定操作。
### 结语
要完成复杂的功能,或许我们觉得应该使用诸如 Python、C 或 Java 这类的高级编程语言,然而并不尽然,脚本编程语言也很强大,可以完成类似任务。要充分发挥脚本的作用,有很多需要学习的,希望这里的几个例子能让你意识到脚本编程的强大。
---
via: <https://opensource.com/article/20/1/improve-bash-scripts>
作者:[Alan Formy-Duval](https://opensource.com/users/alanfdoss) 选题:[lujun9972](https://github.com/lujun9972) 译者:[fisherue](https://github.com/fisherue) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A system admin often writes Bash scripts, some short and some quite lengthy, to accomplish various tasks.
Have you ever looked at an installation script provided by a software vendor? They often add a lot of functions and logic in order to ensure that the installation works properly and doesn’t result in damage to the customer’s system. Over the years, I’ve amassed a collection of various techniques for enhancing my Bash scripts, and I’d like to share some of them in hopes they can help others. Here is a collection of small scripts created to illustrate these simple examples.
## Starting out
When I was starting out, my Bash scripts were nothing more than a series of commands, usually meant to save time with standard shell operations like deploying web content. One such task was extracting static content into the home directory of an Apache web server. My script went something like this:
```
cp january_schedule.tar.gz /usr/apache/home/calendar/
cd /usr/apache/home/calendar/
tar zvxf january_schedule.tar.gz
```
While this saved me some time and typing, it certainly was not a very interesting or useful script in the long term. Over time, I learned other ways to use Bash scripts to accomplish more challenging tasks, such as creating software packages, installing software, or backing up a file server.
## 1. The conditional statement
Just as with so many other programming languages, the conditional has been a powerful and common feature. A conditional is what enables logic to be performed by a computer program. Most of my examples are based on conditional logic.
The basic conditional uses an "if" statement. This allows us to test for some condition that we can then use to manipulate how a script performs. For instance, we can check for the existence of a Java bin directory, which would indicate that Java is installed. If found, the executable path can be updated with the location to enable calls by Java applications.
```
if [ -d "$JAVA_HOME/bin" ] ; then
PATH="$JAVA_HOME/bin:$PATH"
```
## 2. Limit execution
You might want to limit a script to only be run by a specific user. Although Linux has standard permissions for users and groups, as well as SELinux for enabling this type of protection, you could choose to place logic within a script. Perhaps you want to be sure that only the owner of a particular web application can run its startup script. You could even use code to limit a script to the root user. Linux has a couple of environment variables that we can test in this logic. One is **$USER**, which provides the username. Another is **$UID**, which provides the user’s identification number (UID) and, in the case of a script, the UID of the executing user.
### User
The first example shows how I could limit a script to the user jboss1 in a multi-hosting environment with several application server instances. The conditional "if" statement essentially asks, "Is the executing user not jboss1?" When the condition is found to be true, the first echo statement is called, followed by the **exit 1,** which terminates the script.
```
if [ "$USER" != 'jboss1' ]; then
echo "Sorry, this script must be run as JBOSS1!"
exit 1
fi
echo "continue script"
```
### Root
This next example script ensures that only the root user can execute it. Because the UID for root is 0, we can use the **-gt** option in the conditional if statement to prohibit all UIDs greater than zero.
```
if [ "$UID" -gt 0 ]; then
echo "Sorry, this script must be run as ROOT!"
exit 1
fi
echo "continue script"
```
## 3. Use arguments
Just like any executable program, Bash scripts can take arguments as input. Below are a few examples. But first, you should understand that good programming means that we don’t just write applications that do what we want; we must write applications that *can’t* do what we *don’t* want. I like to ensure that a script doesn’t do anything destructive in the case where there is no argument. Therefore, this is the first check that y. The condition checks the number of arguments, **$#**, for a value of zero and terminates the script if true.
```
if [ $# -eq 0 ]; then
echo "No arguments provided"
exit 1
fi
echo "arguments found: $#"
```
### Multiple arguments
You can pass more than one argument to a script. The internal variables that the script uses to reference each argument are simply incremented, such as **$1**, **$2**, **$3**, and so on. I’ll just expand my example above with the following line to echo the first three arguments. Obviously, additional logic will be needed for proper argument handling based on the total number. This example is simple for the sake of demonstration.
`echo $1 $2 $3`
While we’re discussing these argument variables, you might have wondered, "Did he skip zero?"
Well, yes, I did, but I have a great reason! There is indeed a **$0** variable, and it is very useful. Its value is simply the name of the script being executed.
`echo $0`
An important reason to reference the name of the script during execution is to generate a log file that includes the script’s name in its own name. The simplest form might just be an echo statement.
`echo test >> $0.log`
However, you will probably want to add a bit more code to ensure that the log is written to a location with the name and information that you find helpful to your use case.
## 4. User input
Another useful feature to use in a script is its ability to accept input during execution. The simplest is to offer the user some input.
```
echo "enter a word please:"
read word
echo $word
```
This also allows you to provide choices to the user.
```
read -p "Install Software ?? [Y/n]: " answ
if [ "$answ" == 'n' ]; then
exit 1
fi
echo "Installation starting..."
```
## 5. Exit on failure
Some years ago, I wrote a script for installing the latest version of the Java Development Kit (JDK) on my computer. The script extracts the JDK archive to a specific directory, updates a symbolic link, and uses the alternatives utility to make the system aware of the new version. If the extraction of the JDK archive failed, continuing could break Java system-wide. So, I wanted the script to abort in such a situation. I don’t want the script to make the next set of system changes unless the archive was successfully extracted. The following is an excerpt from that script:
```
tar kxzmf jdk-8u221-linux-x64.tar.gz -C /jdk --checkpoint=.500; ec=$?
if [ $ec -ne 0 ]; then
echo "Installation failed - exiting."
exit 1
fi
```
A quick way for you to demonstrate the usage of the **$?** variable is with this short one-liner:
`ls T; ec=$?; echo $ec`
First, run **touch T** followed by this command. The value of **ec** will be 0. Then, delete **T**, **rm T**, and repeat the command. The value of **ec** will now be 2 because ls reports an error condition since **T** was not found.
You can take advantage of this error reporting to include logic, as I have above, to control the behavior of your scripts.
## Takeaway
We might assume that we need to employ languages, such as Python, C, or Java, for higher functionality, but that’s not necessarily true. The Bash scripting language is very powerful. There is a lot to learn to maximize its usefulness. I hope these few examples will shed some light on the potential of coding with Bash.
## 8 Comments |
13,719 | KDE Plasma 5.23 的新功能和发布日期 | https://www.debugpoint.com/2021/08/kde-plasma-5-23/ | 2021-08-25T22:29:58 | [
"KDE"
] | /article-13719-1.html |
>
> 我们在这篇文章中总结了 KDE Plasma 5.23(即将到来)的新功能,包括主要特点、下载和测试说明。
>
>
>

KDE Plasma 桌面是当今最流行、最顶级的 Linux 桌面环境,而 KDE Plasma 的热度之高主要得益于其适应能力强、迭代发展迅速,以及性能不断提高。[KDE Plasma 5.22](https://www.debugpoint.com/2021/06/kde-plasma-5-22-release/) 发布以来,KDE 团队一直忙于为即将到来的 KDE Plasma 5.23 合并更改和测试新功能。目前 KDE Plasma 5.23 仍在开发中,如下是暂定的时间表。
### KDE Plasma 5.23 发布时间表
KDE Plasma 5.23 将于 2021 年 10 月 7 日发布,以下是时间表:
* Beta 公测 – 2021 年 9 月 16 日
* 最终发布 – 2021 年 10 月 7 日
正如每个 Plasma 版本更新一样,本次更新也同样承诺对核心 Plasma Shell 和 KDE 应用进行大幅更改、代码清理、性能改进、数百个 bug 修复、Wayland 优化等。我们在本篇文章中收集了一些重要的功能,让你对即将发布的新功能有基本了解。下面就让我们看看。
### KDE Plasma 5.23 – 新功能
* 本次版本更新基于 Qt 5.15 版本,KDE 框架 5.86 版本。
#### Plasma Shell 和应用程序更新
* 本次 KDE Plasma 的 Kickoff 程序启动器将有大幅更新,包括 bug 修复、减少内存占用、视觉更新、键鼠导航优化。
* Kickoff 程序启动器菜单允许使用固定按钮固定在桌面上,保持开启状态。
* Kickoff 的标签不会在你滚动时切换(从应用标签到位置标签)。
* Kickoff 里可以使用 `CTRL+F` 快捷键直接聚焦到搜索栏。
* Kickoff 中的操作按钮(如关机等)可以设置为仅显示图标。
* 现在可以针对所有 Kickoff 项目选择使用网格或列表视图(而不仅仅局限于收藏夹)。


* 新增基于 QML 的全新概览视图(类似 GNOME 3.38 的工作区视图),用于展示所有打开的窗口(详见如下视频)。目前我找不到关于此合并请求的更多详情,而且这个新视图也很不稳定。
*视频作者:KDE 团队*
* 该概览效果将替代现有的“展现窗口”特效和“虚拟桌面平铺网格”特效(计划中)。
* 未连接触控板时将展示更易察觉的“未找到触摸板”提示。
* “电源配置方案”设置现在呈现于 Plasma UI(电池和亮度窗口)中。电源配置方案功能从 Linux 内核 5.12 版本开始已经登陆戴尔和联想的笔记本电脑了。因此,如果你拥有这些品牌的较新款笔记本电脑,你可以将电源配置方案设置为高性能或省电模式。*[注:Fedora 35(很大可能)会在 GNOME 41 中增加该功能]*

* 如果你有多屏幕设置,包括垂直和横向屏幕,那么登录屏幕现在可以正确同步和对齐。这个功能的需求度很高。
* 新的 Breeze 主题预计会有风格上的更新。
* 如前序版本一样,预计会有全新的壁纸(目前壁纸大赛仍在进行中)。
* 新增当硬件从笔记本模式切换到平板模式时是否缩放系统托盘图标的设置。
* 你可以选择在登录时的蓝牙状态:总是启用、总是禁用、记住上一次的状态。该状态在版本升级后仍可保留。
* 用户现在可以更改传感器的显示名称。
* Breeze 风格的滚动条现在比之前版本的更宽。
* Dolphin 文件管理器提供在文件夹前之前优先显示隐藏文件的新选项。
* 你现在可以使用 `DEL` 键删除剪贴板弹窗中选中的项目。
* KDE 现在允许你直接从 Plasma 桌面,向 [store.kde.org](http://store.kde.org) 提交你制作的图标和主题。
#### Wayland 更新
* 在 Wayland 会话中,运行程序时光标旁也会展示图标反馈动画。
* 现在可以从通知中复制文字。
* 中键单击粘贴功能现在可以在 Wayland 和 XWayland 应用程序中正常使用。
请务必牢记,每个版本都有数以百计的 bug 修复和改进。本文仅仅包括了我收集的表面层次的东西。因此,如果想了解应用程序和 Plasma Shell 的变更详情,请访问 GitLab 或 KDE Planet 社区。
### 不稳定版本下载
你现在可以通过下方的链接下载 KDE neon 的不稳定版本来体验上述全部功能。直接下载 .iso 文件,然后安装测试即可。请务必在发现 bug 后及时反馈。该不稳定版本不适合严肃场合及生产力设备使用。
* [下载 KDE neon 不稳定版本](https://neon.kde.org/download)
### 结束语
KDE Plasma 5.23 每次发布都在改进底层、增加新功能。虽然这个版本不是大更新,但一切优化、改进最终都将累积成稳定性、适应性和更好的用户体验。当然,还有更多的 Wayland 改进(讲真,Wayland 兼容看上去一直都处在“正在进行中”的状态 - 就像十年过去了,却还在制作那样。当然这是另一个话题了)。
再会。
---
via: <https://www.debugpoint.com/2021/08/kde-plasma-5-23/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[imgradeone](https://github.com/imgradeone) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,720 | 理解 systemd 启动时在做什么 | https://opensource.com/article/20/5/systemd-startup | 2021-08-26T11:02:00 | [
"启动",
"引导",
"systemd"
] | https://linux.cn/article-13720-1.html |
>
> systemd 启动过程提供的重要线索可以在问题出现时助你一臂之力。
>
>
>

在本系列的第一篇文章《[学着爱上 systemd](https://opensource.com/article/20/4/systemd)》,我考察了 systemd 的功能和架构,以及围绕 systemd 作为古老的 SystemV 初始化程序和启动脚本的替代品的争论。在这第二篇文章中,我将开始探索管理 Linux 启动序列的文件和工具。我会解释 systemd 启动序列、如何更改默认的启动目标(即 SystemV 术语中的运行级别)、以及在不重启的情况下如何手动切换到不同的目标。
我还将考察两个重要的 systemd 工具。第一个 `systemctl` 命令是和 systemd 交互、向其发送命令的基本方式。第二个是 `journalctl`,用于访问 systemd 日志,后者包含了大量系统历史数据,比如内核和服务的消息(包括指示性信息和错误信息)。
务必使用一个非生产系统进行本文和后续文章中的测试和实验。你的测试系统需要安装一个 GUI 桌面(比如 Xfce、LXDE、Gnome、KDE 或其他)。
上一篇文章中我写道计划在这篇文章创建一个 systemd 单元并添加到启动序列。由于这篇文章比我预期中要长,这些内容将留到本系列的下一篇文章。
### 使用 systemd 探索 Linux 的启动
在观察启动序列之前,你需要做几件事情得使引导和启动序列开放可见。正常情况下,大多数发行版使用一个开机动画或者启动画面隐藏 Linux 启动和关机过程中的显示细节,在基于 Red Hat 的发行版中称作 Plymouth 引导画面。这些隐藏的消息能够向寻找信息以排除程序故障、或者只是学习启动序列的系统管理员提供大量有关系统启动和关闭的信息。你可以通过 GRUB(<ruby> 大统一引导加载器 <rt> Grand Unified Boot Loader </rt></ruby>)配置改变这个设置。
主要的 GRUB 配置文件是 `/boot/grub2/grub.cfg` ,但是这个文件在更新内核版本时会被覆盖,你不会想修改它的。相反,应该修改用于改变 `grub.cfg` 默认设置的 `/etc/default/grub` 文件。
首先看一下当前未修改的 `/etc/default/grub` 文件的版本:
```
[root@testvm1 ~]# cd /etc/default ; cat grub
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="resume=/dev/mapper/fedora_testvm1-swap rd.lvm.
lv=fedora_testvm1/root rd.lvm.lv=fedora_testvm1/swap rd.lvm.lv=fedora_
testvm1/usr rhgb quiet"
GRUB_DISABLE_RECOVERY="true"
[root@testvm1 default]#
```
[GRUB 文档](http://www.gnu.org/software/grub/manual/grub) 的第 6 章列出了 `/etc/default/grub` 文件的所有可用项,我只关注下面的部分:
* 我将 GRUB 菜单倒计时的秒数 `GRUB_TIMEOUT`,从 5 改成 10,以便在倒计时达到 0 之前有更多的时间响应 GRUB 菜单。
* `GRUB_CMDLINE_LINUX` 列出了引导阶段传递给内核的命令行参数,我删除了其中的最后两个参数。其中的一个参数 `rhgb` 代表 “<ruby> 红帽图形化引导 <rt> Red Hat Graphical Boot </rt></ruby>”,在内核初始化阶段显示一个小小的 Fedora 图标动画,而不是显示引导阶段的信息。另一个参数 `quiet`,屏蔽显示记录了启动进度和发生错误的消息。系统管理员需要这些信息,因此我删除了 `rhgb` 和 `quiet`。如果引导阶段发生了错误,屏幕上显示的信息可以指向故障的原因。
更改之后,你的 GRUB 文件将会像下面一样:
```
[root@testvm1 default]# cat grub
GRUB_TIMEOUT=10
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="resume=/dev/mapper/fedora_testvm1-swap rd.lvm.
lv=fedora_testvm1/root rd.lvm.lv=fedora_testvm1/swap rd.lvm.lv=fedora_
testvm1/usr"
GRUB_DISABLE_RECOVERY="false"
[root@testvm1 default]#
```
`grub2-mkconfig` 程序使用 `/etc/default/grub` 文件的内容生成 `grub.cfg` 配置文件,从而改变一些默认的 GRUB 设置。`grub2-mkconfig` 输出到 `STDOUT`,你可以使用程序的 `-o` 参数指明数据流输出的文件,不过使用重定向也同样简单。执行下面的命令更新 `/boot/grub2/grub.cfg` 配置文件:
```
[root@testvm1 grub2]# grub2-mkconfig > /boot/grub2/grub.cfg
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-4.18.9-200.fc28.x86_64
Found initrd image: /boot/initramfs-4.18.9-200.fc28.x86_64.img
Found linux image: /boot/vmlinuz-4.17.14-202.fc28.x86_64
Found initrd image: /boot/initramfs-4.17.14-202.fc28.x86_64.img
Found linux image: /boot/vmlinuz-4.16.3-301.fc28.x86_64
Found initrd image: /boot/initramfs-4.16.3-301.fc28.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-7f12524278bd40e9b10a085bc82dc504
Found initrd image: /boot/initramfs-0-rescue-7f12524278bd40e9b10a085bc82dc504.img
done
[root@testvm1 grub2]#
```
重新启动你的测试系统查看本来会隐藏在 Plymouth 开机动画之下的启动信息。但是如果你没有关闭开机动画,又需要查看启动信息的话又该如何操作?或者你关闭了开机动画,而消息流过的速度太快,无法阅读怎么办?(实际情况如此。)
有两个解决方案,都涉及到日志文件和 systemd 日志 —— 两个都是你的好伙伴。你可以使用 `less` 命令查看 `/var/log/messages` 文件的内容。这个文件包含引导和启动信息,以及操作系统执行正常操作时生成的信息。你也可以使用不加任何参数的 `journalctl` 命令查看 systemd 日志,包含基本相同的信息:
```
[root@testvm1 grub2]# journalctl
-- Logs begin at Sat 2020-01-11 21:48:08 EST, end at Fri 2020-04-03 08:54:30 EDT. --
Jan 11 21:48:08 f31vm.both.org kernel: Linux version 5.3.7-301.fc31.x86_64 ([email protected]) (gcc version 9.2.1 20190827 (Red Hat 9.2.1-1) (GCC)) #1 SMP Mon Oct >
Jan 11 21:48:08 f31vm.both.org kernel: Command line: BOOT_IMAGE=(hd0,msdos1)/vmlinuz-5.3.7-301.fc31.x86_64 root=/dev/mapper/VG01-root ro resume=/dev/mapper/VG01-swap rd.lvm.lv=VG01/root rd>
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers'
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers'
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers'
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Enabled xstate features 0x7, context size is 832 bytes, using 'standard' format.
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-provided physical RAM map:
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x000000000009fc00-0x000000000009ffff] reserved
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x0000000000100000-0x00000000dffeffff] usable
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000dfff0000-0x00000000dfffffff] ACPI data
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000fec00000-0x00000000fec00fff] reserved
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000fee00000-0x00000000fee00fff] reserved
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000fffc0000-0x00000000ffffffff] reserved
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x0000000100000000-0x000000041fffffff] usable
Jan 11 21:48:08 f31vm.both.org kernel: NX (Execute Disable) protection: active
Jan 11 21:48:08 f31vm.both.org kernel: SMBIOS 2.5 present.
Jan 11 21:48:08 f31vm.both.org kernel: DMI: innotek GmbH VirtualBox/VirtualBox, BIOS VirtualBox 12/01/2006
Jan 11 21:48:08 f31vm.both.org kernel: Hypervisor detected: KVM
Jan 11 21:48:08 f31vm.both.org kernel: kvm-clock: Using msrs 4b564d01 and 4b564d00
Jan 11 21:48:08 f31vm.both.org kernel: kvm-clock: cpu 0, msr 30ae01001, primary cpu clock
Jan 11 21:48:08 f31vm.both.org kernel: kvm-clock: using sched offset of 8250734066 cycles
Jan 11 21:48:08 f31vm.both.org kernel: clocksource: kvm-clock: mask: 0xffffffffffffffff max_cycles: 0x1cd42e4dffb, max_idle_ns: 881590591483 ns
Jan 11 21:48:08 f31vm.both.org kernel: tsc: Detected 2807.992 MHz processor
Jan 11 21:48:08 f31vm.both.org kernel: e820: update [mem 0x00000000-0x00000fff] usable ==> reserved
Jan 11 21:48:08 f31vm.both.org kernel: e820: remove [mem 0x000a0000-0x000fffff] usable
<snip>
```
由于数据流可能长达几十万甚至几百万行,我在这里截断了它。(我的主要工作站上列出的日志长度是 1,188,482 行。)请确保是在你的测试系统尝试的这个命令。如果系统已经运行了一段时间 —— 即使重启过很多次 —— 还是会显示大量的数据。查看这些日志数据,因为它包含了很多信息,在进行问题判断时可能非常有用。了解这个数据文件在正常的引导和启动过程中的模样,可以帮助你在问题出现时定位问题。
我将在本系列之后的文章讨论 systemd 日志、`journalctl` 命令、以及如何整理输出的日志数据来寻找更详细的信息。
内核被 GRUB 加载到内存后,必须先将自己从压缩后的文件中解压出来,才能执行任何有意义的操作。解压自己后,内核开始运行,加载 systemd 并转交控制权。
<ruby> 引导 <rt> boot </rt></ruby>阶段到此结束,此时 Linux 内核和 systemd 正在运行,但是无法为用户执行任何生产性任务,因为其他的程序都没有执行,没有命令行解释器提供命令行,没有后台进程管理网络和其他的通信链接,也没有任何东西能够控制计算机执行生产功能。
现在 systemd 可以加载所需的功能性单元以便将系统启动到选择的目标运行状态。
### 目标
一个 systemd <ruby> 目标 <rt> target </rt></ruby>代表一个 Linux 系统当前的或期望的运行状态。与 SystemV 启动脚本十分类似,目标定义了系统运行必须存在的服务,以及处于目标状态下必须激活的服务。图表 1 展示了使用 systemd 的 Linux 系统可能的运行状态目标。就像在本系列的第一篇文章以及 systemd 启动的手册页(`man bootup`)所看到的一样,有一些开启不同必要服务的其他中间目标,包括 `swap.target`、`timers.target`、`local-fs.target` 等。一些目标(像 `basic.target`)作为检查点使用,在移动到下一个更高级的目标之前保证所有需要的服务已经启动并运行。
除非开机时在 GRUB 菜单进行更改,systemd 总是启动 `default.target`。`default.target` 文件是指向真实的目标文件的符号链接。对于桌面工作站,`default.target` 通常是 `graphical.target`,等同于 SystemV 的运行等级 5。对于服务器,默认目标多半是 `multi-user.target`,就像 SystemV 的运行等级 3。`emergency.target` 文件类似单用户模式。目标和<ruby> 服务 <rt> service </rt></ruby>都是一种 systemd 单元。
下面的图表,包含在本系列的上一篇文章中,比较了 systemd 目标和古老的 SystemV 启动运行等级。为了向后兼容,systemd 提供了 systemd 目标别名,允许脚本和系统管理员使用像 `init 3` 一样的 SystemV 命令改变运行等级。当然,SystemV 命令被转发给 systemd 进行解释和执行。
| **systemd 目标** | **SystemV 运行级别** | **目标别名** | **描述** |
| --- | --- | --- | --- |
| `default.target` | | | 这个目标通常是一个符号链接,作为 `multi-user.target` 或 `graphical.target` 的别名。systemd 总是用 `default.target` 启动系统。`default.target** 不能作为`halt.target`、`poweroff.target`和`reboot.target` 的别名。 |
| `graphical.target` | 5 | `runlevel5.target` | 带有 GUI 的 `multi-user.target` 。 |
| | 4 | `runlevel4.target` | 未使用。运行等级 4 和 SystemV 的运行等级 3 一致,可以创建这个目标并进行定制,用于启动本地服务,而不必更改默认的 `multi-user.target`。 |
| `multi-user.target` | 3 | `runlevel3.target` | 运行所有的服务,但是只有命令行界面(CLI) 。 |
| | 2 | `runlevel2.target` | 多用户,没有 NFS,但是运行其他所有的非 GUI 服务 |
| `rescue.target` | 1 | `runlevel1.target` | 一个基本的系统,包括挂载文件系统,但是只运行最基础的服务,以及一个主控制台上的用于救援的命令行解释器。 |
| `emergency.target` | S | | 单用户模式 —— 没有服务运行;文件系统没有挂载。这是最基础级的操作模式,只有一个运行在主控制台的用于紧急情况的命令行解释器,供用户和系统交互。 |
| `halt.target` | | | 不断电的情况下停止系统 |
| `reboot.target` | 6 | `runlevel6.target` | 重启 |
| `poweroff.target` | 0 | `runlevel0.target` | 停止系统并关闭电源 |
每个目标在配置文件中都描述了一组依赖关系。systemd 启动需要的依赖,即 Linux 主机运行在特定功能级别所需的服务。加载目标配置文件中列出的所有依赖并运行后,系统就运行在那个目标等级。如果愿意,你可以在本系列的第一篇文章《[学着爱上 systemd](https://opensource.com/article/20/4/systemd)》中回顾 systemd 的启动序列和运行时目标。
### 探索当前的目标
许多 Linux 发行版默认安装一个 GUI 桌面界面,以便安装的系统可以像工作站一样使用。我总是从 Fedora Live USB 引导驱动器安装 Xfce 或 LXDE 桌面。即使是安装一个服务器或者其他基础类型的主机(比如用于路由器和防火墙的主机),我也使用 GUI 桌面的安装方式。
我可以安装一个没有桌面的服务器(数据中心的典型做法),但是这样不满足我的需求。原因不是我需要 GUI 桌面本身,而是 LXDE 安装包含了许多其他默认的服务器安装没有提供的工具,这意味着初始安装之后我需要做的工作更少。
但是,仅仅因为有 GUI 桌面并不意味着我要使用它。我有一个 16 端口的 KVM,可以用于访问我的大部分 Linux 系统的 KVM 接口,但我和它们交互的大部分交互是通过从我的主要工作站建立的远程 SSH 连接。这种方式更安全,而且和 `graphical.target` 相比,运行 `multi-user.target` 使用更少的系统资源。
首先,检查默认目标,确认是 `graphical.target`:
```
[root@testvm1 ~]# systemctl get-default
graphical.target
[root@testvm1 ~]#
```
然后确认当前正在运行的目标,应该和默认目标相同。你仍可以使用老方法,输出古老的 SystemV 运行等级。注意,前一个运行等级在左边,这里是 `N`(意思是 None),表示主机启动后没有修改过运行等级。数字 5 是当前的目标,正如古老的 SystemV 术语中的定义:
```
[root@testvm1 ~]# runlevel
N 5
[root@testvm1 ~]#
```
注意,`runlevel` 的手册页指出运行等级已经被淘汰,并提供了一个转换表。
你也可以使用 systemd 方式,命令的输出有很多行,但确实用 systemd 术语提供了答案:
```
[root@testvm1 ~]# systemctl list-units --type target
UNIT LOAD ACTIVE SUB DESCRIPTION
basic.target loaded active active Basic System
cryptsetup.target loaded active active Local Encrypted Volumes
getty.target loaded active active Login Prompts
graphical.target loaded active active Graphical Interface
local-fs-pre.target loaded active active Local File Systems (Pre)
local-fs.target loaded active active Local File Systems
multi-user.target loaded active active Multi-User System
network-online.target loaded active active Network is Online
network.target loaded active active Network
nfs-client.target loaded active active NFS client services
nss-user-lookup.target loaded active active User and Group Name Lookups
paths.target loaded active active Paths
remote-fs-pre.target loaded active active Remote File Systems (Pre)
remote-fs.target loaded active active Remote File Systems
rpc_pipefs.target loaded active active rpc_pipefs.target
slices.target loaded active active Slices
sockets.target loaded active active Sockets
sshd-keygen.target loaded active active sshd-keygen.target
swap.target loaded active active Swap
sysinit.target loaded active active System Initialization
timers.target loaded active active Timers
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
21 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
```
上面列出了当前加载的和激活的目标,你也可以看到 `graphical.target` 和 `multi-user.target`。`multi-user.target` 需要在 `graphical.target` 之前加载。这个例子中,`graphical.target` 是激活的。
### 切换到不同的目标
切换到 `multi-user.target` 很简单:
```
[root@testvm1 ~]# systemctl isolate multi-user.target
```
显示器现在应该从 GUI 桌面或登录界面切换到了一个虚拟控制台。登录并列出当前激活的 systemd 单元,确认 `graphical.target` 不再运行:
```
[root@testvm1 ~]# systemctl list-units --type target
```
务必使用 `runlevel` 确认命令输出了之前的和当前的“运行等级”:
```
[root@testvm1 ~]# runlevel
5 3
```
### 更改默认目标
现在,将默认目标改为 `multi-user.target`,以便系统总是启动进入 `multi-user.target`,从而使用控制台命令行接口而不是 GUI 桌面接口。使用你的测试主机的根用户,切换到保存 systemd 配置的目录,执行一次快速列出操作:
```
[root@testvm1 ~]# cd /etc/systemd/system/ ; ll
drwxr-xr-x. 2 root root 4096 Apr 25 2018 basic.target.wants
<snip>
lrwxrwxrwx. 1 root root 36 Aug 13 16:23 default.target -> /lib/systemd/system/graphical.target
lrwxrwxrwx. 1 root root 39 Apr 25 2018 display-manager.service -> /usr/lib/systemd/system/lightdm.service
drwxr-xr-x. 2 root root 4096 Apr 25 2018 getty.target.wants
drwxr-xr-x. 2 root root 4096 Aug 18 10:16 graphical.target.wants
drwxr-xr-x. 2 root root 4096 Apr 25 2018 local-fs.target.wants
drwxr-xr-x. 2 root root 4096 Oct 30 16:54 multi-user.target.wants
<snip>
[root@testvm1 system]#
```
为了强调一些有助于解释 systemd 如何管理启动过程的重要事项,我缩短了这个列表。你应该可以在虚拟机看到完整的目录和链接列表。
`default.target` 项是指向目录 `/lib/systemd/system/graphical.target` 的符号链接(软链接),列出那个目录查看目录中的其他内容:
```
[root@testvm1 system]# ll /lib/systemd/system/ | less
```
你应该在这个列表中看到文件、目录、以及更多链接,但是专门寻找一下 `multi-user.target` 和 `graphical.target`。现在列出 `default.target`(指向 `/lib/systemd/system/graphical.target` 的链接)的内容:
```
[root@testvm1 system]# cat default.target
# SPDX-License-Identifier: LGPL-2.1+
#
# This file is part of systemd.
#
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
[Unit]
Description=Graphical Interface
Documentation=man:systemd.special(7)
Requires=multi-user.target
Wants=display-manager.service
Conflicts=rescue.service rescue.target
After=multi-user.target rescue.service rescue.target display-manager.service
AllowIsolate=yes
[root@testvm1 system]#
```
`graphical.target` 文件的这个链接描述了图形用户接口需要的所有必备条件。我会在本系列的下一篇文章至少探讨其中的一些选项。
为了使主机启动到多用户模式,你需要删除已有的链接,创建一个新链接指向正确目标。如果你的 [PWD](https://en.wikipedia.org/wiki/Pwd) 不是 `/etc/systemd/system`,切换过去:
```
[root@testvm1 system]# rm -f default.target
[root@testvm1 system]# ln -s /lib/systemd/system/multi-user.target default.target
```
列出 `default.target` 链接,确认其指向了正确的文件:
```
[root@testvm1 system]# ll default.target
lrwxrwxrwx 1 root root 37 Nov 28 16:08 default.target -> /lib/systemd/system/multi-user.target
[root@testvm1 system]#
```
如果你的链接看起来不一样,删除并重试。列出 `default.target` 链接的内容:
```
[root@testvm1 system]# cat default.target
# SPDX-License-Identifier: LGPL-2.1+
#
# This file is part of systemd.
#
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
[Unit]
Description=Multi-User System
Documentation=man:systemd.special(7)
Requires=basic.target
Conflicts=rescue.service rescue.target
After=basic.target rescue.service rescue.target
AllowIsolate=yes
[root@testvm1 system]#
```
`default.target`(这里其实是指向 `multi-user.target` 的链接)其中的 `[Unit]` 部分现在有不同的必需条件。这个目标不需要有图形显示管理器。
重启,你的虚拟机应该启动到虚拟控制台 1 的控制台登录,虚拟控制台 1 在显示器标识为 `tty1`。现在你已经知道如何修改默认的目标,使用所需的命令将默认目标改回 `graphical.target`。
首先检查当前的默认目标:
```
[root@testvm1 ~]# systemctl get-default
multi-user.target
[root@testvm1 ~]# systemctl set-default graphical.target
Removed /etc/systemd/system/default.target.
Created symlink /etc/systemd/system/default.target → /usr/lib/systemd/system/graphical.target.
[root@testvm1 ~]#
```
输入下面的命令直接切换到 `graphical.target` 和显示管理器的登录界面,不需要重启:
```
[root@testvm1 system]# systemctl isolate default.target
```
我不清楚为何 systemd 的开发者选择了术语 `isolate` 作为这个子命令。我的研究表明指的可能是运行指明的目标,但是“隔离”并终结其他所有启动该目标不需要的目标。然而,命令执行的效果是从一个运行的目标切换到另一个——在这个例子中,从多用户目标切换到图形目标。上面的命令等同于 SystemV 启动脚本和 `init` 程序中古老的 `init 5` 命令。
登录 GUI 桌面,确认能正常工作。
### 总结
本文探索了 Linux systemd 启动序列,开始探讨两个重要的 systemd 工具 `systemctl` 和 `journalctl`,还说明了如何从一个目标切换到另一个目标,以及如何修改默认目标。
本系列的下一篇文章中将会创建一个新的 systemd 单元,并配置为启动阶段运行。下一篇文章还会查看一些配置选项,可以帮助确定某个特定的单元在序列中启动的位置,比如在网络启动运行后。
### 资源
关于 systemd 网络上有大量的信息,但大部分都简短生硬、愚钝、甚至令人误解。除了本文提到的资源,下面的网页提供了关于 systemd 启动更详细可靠的信息。
* Fedora 项目有一个优质实用的 [systemd 指南](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html),几乎有你使用 systemd 配置、管理、维护一个 Fedora 计算机需要知道的一切。
* Fedora 项目还有一个好用的 [速查表](https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet),交叉引用了古老的 SystemV 命令和对应的 systemd 命令。
* 要获取 systemd 的详细技术信息和创立的原因,查看 [Freedesktop.org](http://Freedesktop.org) 的 [systemd 描述](http://www.freedesktop.org/wiki/Software/systemd)。
* [Linux.com](http://Linux.com) 上“systemd 的更多乐趣”提供了更高级的 systemd [信息和提示](https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/)。
还有一系列针对系统管理员的深层技术文章,由 systemd 的设计者和主要开发者 Lennart Poettering 所作。这些文章写于 2010 年 4 月到 2011 年 9 月之间,但在当下仍然像当时一样有价值。关于 systemd 及其生态的许多其他优秀的作品都是基于这些文章的。
* [Rethinking PID 1](http://0pointer.de/blog/projects/systemd.html)
* [systemd for Administrators, Part I](http://0pointer.de/blog/projects/systemd-for-admins-1.html)
* [systemd for Administrators, Part II](http://0pointer.de/blog/projects/systemd-for-admins-2.html)
* [systemd for Administrators, Part III](http://0pointer.de/blog/projects/systemd-for-admins-3.html)
* [systemd for Administrators, Part IV](http://0pointer.de/blog/projects/systemd-for-admins-4.html)
* [systemd for Administrators, Part V](http://0pointer.de/blog/projects/three-levels-of-off.html)
* [systemd for Administrators, Part VI](http://0pointer.de/blog/projects/changing-roots)
* [systemd for Administrators, Part VII](http://0pointer.de/blog/projects/blame-game.html)
* [systemd for Administrators, Part VIII](http://0pointer.de/blog/projects/the-new-configuration-files.html)
* [systemd for Administrators, Part IX](http://0pointer.de/blog/projects/on-etc-sysinit.html)
* [systemd for Administrators, Part X](http://0pointer.de/blog/projects/instances.html)
* [systemd for Administrators, Part XI](http://0pointer.de/blog/projects/inetd.html)
---
via: <https://opensource.com/article/20/5/systemd-startup>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[YungeG](https://github.com/YungeG) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In [ Learning to love systemd](https://opensource.com/article/20/4/systemd), the first article in this series, I looked at systemd's functions and architecture and the controversy around its role as a replacement for the old SystemV init program and startup scripts. In this second article, I'll start exploring the files and tools that manage the Linux startup sequence. I'll explain the systemd startup sequence, how to change the default startup target (runlevel in SystemV terms), and how to manually switch to a different target without going through a reboot.
I'll also look at two important systemd tools. The first is the **systemctl** command, which is the primary means of interacting with and sending commands to systemd. The second is **journalctl**, which provides access to the systemd journals that contain huge amounts of system history data such as kernel and service messages (both informational and error messages).
Be sure to use a non-production system for testing and experimentation in this and future articles. Your test system needs to have a GUI desktop (such as Xfce, LXDE, Gnome, KDE, or another) installed.
I wrote in my previous article that I planned to look at creating a systemd unit and adding it to the startup sequence in this article. Because this article became longer than I anticipated, I will hold that for the next article in this series.
## Exploring Linux startup with systemd
Before you can observe the startup sequence, you need to do a couple of things to make the boot and startup sequences open and visible. Normally, most distributions use a startup animation or splash screen to hide the detailed messages that would otherwise be displayed during a Linux host's startup and shutdown. This is called the Plymouth boot screen on Red Hat-based distros. Those hidden messages can provide a great deal of information about startup and shutdown to a sysadmin looking for information to troubleshoot a bug or to just learn about the startup sequence. You can change this using the GRUB (Grand Unified Boot Loader) configuration.
The main GRUB configuration file is **/boot/grub2/grub.cfg**, but, because this file can be overwritten when the kernel version is updated, you do not want to change it. Instead, modify the **/etc/default/grub** file, which is used to modify the default settings of **grub.cfg**.
Start by looking at the current, unmodified version of the **/etc/default/grub** file:
```
[root@testvm1 ~]# cd /etc/default ; cat grub
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="resume=/dev/mapper/fedora_testvm1-swap rd.lvm.
lv=fedora_testvm1/root rd.lvm.lv=fedora_testvm1/swap rd.lvm.lv=fedora_
testvm1/usr rhgb quiet"
GRUB_DISABLE_RECOVERY="true"
[root@testvm1 default]#
```
Chapter 6 of the [GRUB documentation](http://www.gnu.org/software/grub/manual/grub) contains a list of all the possible entries in the **/etc/default/grub** file, but I focus on the following:
- I change
**GRUB_TIMEOUT**, the number of seconds for the GRUB menu countdown, from five to 10 to give a bit more time to respond to the GRUB menu before the countdown hits zero. - I delete the last two parameters on
**GRUB_CMDLINE_LINUX**, which lists the command-line parameters that are passed to the kernel at boot time. One of these parameters,**rhgb**stands for Red Hat Graphical Boot, and it displays the little Fedora icon animation during the kernel initialization instead of showing boot-time messages. The other, the**quiet**parameter, prevents displaying the startup messages that document the progress of the startup and any errors that occur. I delete both**rhgb**and**quiet**because sysadmins need to see these messages. If something goes wrong during boot, the messages displayed on the screen can point to the cause of the problem.
After you make these changes, your GRUB file will look like:
```
[root@testvm1 default]# cat grub
GRUB_TIMEOUT=10
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="resume=/dev/mapper/fedora_testvm1-swap rd.lvm.
lv=fedora_testvm1/root rd.lvm.lv=fedora_testvm1/swap rd.lvm.lv=fedora_
testvm1/usr"
GRUB_DISABLE_RECOVERY="false"
[root@testvm1 default]#
```
The **grub2-mkconfig** program generates the **grub.cfg** configuration file using the contents of the **/etc/default/grub** file to modify some of the default GRUB settings. The **grub2-mkconfig** program sends its output to **STDOUT**. It has a **-o** option that allows you to specify a file to send the datastream to, but it is just as easy to use redirection. Run the following command to update the **/boot/grub2/grub.cfg** configuration file:
```
[root@testvm1 grub2]# grub2-mkconfig > /boot/grub2/grub.cfg
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-4.18.9-200.fc28.x86_64
Found initrd image: /boot/initramfs-4.18.9-200.fc28.x86_64.img
Found linux image: /boot/vmlinuz-4.17.14-202.fc28.x86_64
Found initrd image: /boot/initramfs-4.17.14-202.fc28.x86_64.img
Found linux image: /boot/vmlinuz-4.16.3-301.fc28.x86_64
Found initrd image: /boot/initramfs-4.16.3-301.fc28.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-7f12524278bd40e9b10a085bc82dc504
Found initrd image: /boot/initramfs-0-rescue-7f12524278bd40e9b10a085bc82dc504.img
done
[root@testvm1 grub2]#
```
Reboot your test system to view the startup messages that would otherwise be hidden behind the Plymouth boot animation. But what if you need to view the startup messages and have not disabled the Plymouth boot animation? Or you have, but the messages stream by too fast to read? (Which they do.)
There are a couple of options, and both involve log files and systemd journals—which are your friends. You can use the **less** command to view the contents of the **/var/log/messages** file. This file contains boot and startup messages as well as messages generated by the operating system during normal operation. You can also use the **journalctl** command without any options to view the systemd journal, which contains essentially the same information:
```
[root@testvm1 grub2]# journalctl
-- Logs begin at Sat 2020-01-11 21:48:08 EST, end at Fri 2020-04-03 08:54:30 EDT. --
Jan 11 21:48:08 f31vm.both.org kernel: Linux version 5.3.7-301.fc31.x86_64 ([email protected]) (gcc version 9.2.1 20190827 (Red Hat 9.2.1-1) (GCC)) #1 SMP Mon Oct >
Jan 11 21:48:08 f31vm.both.org kernel: Command line: BOOT_IMAGE=(hd0,msdos1)/vmlinuz-5.3.7-301.fc31.x86_64 root=/dev/mapper/VG01-root ro resume=/dev/mapper/VG01-swap rd.lvm.lv=VG01/root rd>
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Supporting XSAVE feature 0x001: 'x87 floating point registers'
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Supporting XSAVE feature 0x002: 'SSE registers'
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Supporting XSAVE feature 0x004: 'AVX registers'
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: xstate_offset[2]: 576, xstate_sizes[2]: 256
Jan 11 21:48:08 f31vm.both.org kernel: x86/fpu: Enabled xstate features 0x7, context size is 832 bytes, using 'standard' format.
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-provided physical RAM map:
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x0000000000000000-0x000000000009fbff] usable
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x000000000009fc00-0x000000000009ffff] reserved
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000000f0000-0x00000000000fffff] reserved
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x0000000000100000-0x00000000dffeffff] usable
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000dfff0000-0x00000000dfffffff] ACPI data
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000fec00000-0x00000000fec00fff] reserved
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000fee00000-0x00000000fee00fff] reserved
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x00000000fffc0000-0x00000000ffffffff] reserved
Jan 11 21:48:08 f31vm.both.org kernel: BIOS-e820: [mem 0x0000000100000000-0x000000041fffffff] usable
Jan 11 21:48:08 f31vm.both.org kernel: NX (Execute Disable) protection: active
Jan 11 21:48:08 f31vm.both.org kernel: SMBIOS 2.5 present.
Jan 11 21:48:08 f31vm.both.org kernel: DMI: innotek GmbH VirtualBox/VirtualBox, BIOS VirtualBox 12/01/2006
Jan 11 21:48:08 f31vm.both.org kernel: Hypervisor detected: KVM
Jan 11 21:48:08 f31vm.both.org kernel: kvm-clock: Using msrs 4b564d01 and 4b564d00
Jan 11 21:48:08 f31vm.both.org kernel: kvm-clock: cpu 0, msr 30ae01001, primary cpu clock
Jan 11 21:48:08 f31vm.both.org kernel: kvm-clock: using sched offset of 8250734066 cycles
Jan 11 21:48:08 f31vm.both.org kernel: clocksource: kvm-clock: mask: 0xffffffffffffffff max_cycles: 0x1cd42e4dffb, max_idle_ns: 881590591483 ns
Jan 11 21:48:08 f31vm.both.org kernel: tsc: Detected 2807.992 MHz processor
Jan 11 21:48:08 f31vm.both.org kernel: e820: update [mem 0x00000000-0x00000fff] usable ==> reserved
Jan 11 21:48:08 f31vm.both.org kernel: e820: remove [mem 0x000a0000-0x000fffff] usable
<snip>
```
I truncated this datastream because it can be hundreds of thousands or even millions of lines long. (The journal listing on my primary workstation is 1,188,482 lines long.) Be sure to try this on your test system. If it has been running for some time—even if it has been rebooted many times—huge amounts of data will be displayed. Explore this journal data because it contains a lot of information that can be very useful when doing problem determination. Knowing what this data looks like for a normal boot and startup can help you locate problems when they occur.
I will discuss systemd journals, the **journalctl** command, and how to sort through all of that data to find what you want in more detail in a future article in this series.
After GRUB loads the kernel into memory, it must first extract itself from the compressed version of the file before it can perform any useful work. After the kernel has extracted itself and started running, it loads systemd and turns control over to it.
This is the end of the boot process. At this point, the Linux kernel and systemd are running but unable to perform any productive tasks for the end user because nothing else is running, there's no shell to provide a command line, no background processes to manage the network or other communication links, and nothing that enables the computer to perform any productive function.
Systemd can now load the functional units required to bring the system up to a selected target run state.
## Targets
A systemd target represents a Linux system's current or desired run state. Much like SystemV start scripts, targets define the services that must be present for the system to run and be active in that state. Figure 1 shows the possible run-state targets of a Linux system using systemd. As seen in the first article of this series and in the systemd bootup man page (man bootup), there are other intermediate targets that are required to enable various necessary services. These can include **swap.target**, **timers.target**, **local-fs.target**, and more. Some targets (like **basic.target**) are used as checkpoints to ensure that all the required services are up and running before moving on to the next-higher level target.
Unless otherwise changed at boot time in the GRUB menu, systemd always starts the **default.target**. The **default.target** file is a symbolic link to the true target file. For a desktop workstation, this is typically going to be the **graphical.target**, which is equivalent to runlevel 5 in SystemV. For a server, the default is more likely to be the **multi-user.target**, which is like runlevel 3 in SystemV. The **emergency.target** file is similar to single-user mode. Targets and services are systemd units.
The following table, which I included in the previous article in this series, compares the systemd targets with the old SystemV startup runlevels. The systemd target aliases are provided by systemd for backward compatibility. The target aliases allow scripts—and sysadmins—to use SystemV commands like **init 3** to change runlevels. Of course, the SystemV commands are forwarded to systemd for interpretation and execution.
systemd targets |
SystemV runlevel |
target aliases |
Description |
default.target | This target is always aliased with a symbolic link to either multi-user.target or graphical.target. systemd always uses the default.target to start the system. The default.target should never be aliased to halt.target, poweroff.target, or reboot.target. |
||
graphical.target | 5 | runlevel5.target | Multi-user.target with a GUI |
4 | runlevel4.target | Unused. Runlevel 4 was identical to runlevel 3 in the SystemV world. This target could be created and customized to start local services without changing the default multi-user.target. |
|
multi-user.target | 3 | runlevel3.target | All services running, but command-line interface (CLI) only |
2 | runlevel2.target | Multi-user, without NFS, but all other non-GUI services running | |
rescue.target | 1 | runlevel1.target | A basic system, including mounting the filesystems with only the most basic services running and a rescue shell on the main console |
emergency.target | S | Single-user mode—no services are running; filesystems are not mounted. This is the most basic level of operation with only an emergency shell running on the main console for the user to interact with the system. | |
halt.target | Halts the system without powering it down | ||
reboot.target | 6 | runlevel6.target | Reboot |
poweroff.target | 0 | runlevel0.target | Halts the system and turns the power off |
Fig. 1: Comparison of SystemV runlevels with systemd targets and target aliases.
Each target has a set of dependencies described in its configuration file. systemd starts the required dependencies, which are the services required to run the Linux host at a specific level of functionality. When all of the dependencies listed in the target configuration files are loaded and running, the system is running at that target level. If you want, you can review the systemd startup sequence and runtime targets in the first article in this series, [ Learning to love systemd](https://opensource.com/article/20/4/systemd).
## Exploring the current target
Many Linux distributions default to installing a GUI desktop interface so that the installed systems can be used as workstations. I always install from a Fedora Live boot USB drive with an Xfce or LXDE desktop. Even when I'm installing a server or other infrastructure type of host (such as the ones I use for routers and firewalls), I use one of these installations that installs a GUI desktop.
I could install a server without a desktop (and that would be typical for data centers), but that does not meet my needs. It is not that I need the GUI desktop itself, but the LXDE installation includes many of the other tools I use that are not in a default server installation. This means less work for me after the initial installation.
But just because I have a GUI desktop does not mean it makes sense to use it. I have a 16-port KVM that I can use to access the KVM interfaces of most of my Linux systems, but the vast majority of my interaction with them is via a remote SSH connection from my primary workstation. This way is more secure and uses fewer system resources to run **multi-user.target** compared to **graphical.target.**
To begin, check the default target to verify that it is the **graphical.target**:
```
[root@testvm1 ~]# systemctl get-default
graphical.target
[root@testvm1 ~]#
```
Now verify the currently running target. It should be the same as the default target. You can still use the old method, which displays the old SystemV runlevels. Note that the previous runlevel is on the left; it is **N** (which means None), indicating that the runlevel has not changed since the host was booted. The number 5 indicates the current target, as defined in the old SystemV terminology:
```
[root@testvm1 ~]# runlevel
N 5
[root@testvm1 ~]#
```
Note that the runlevel man page indicates that runlevels are obsolete and provides a conversion table.
You can also use the systemd method. There is no one-line answer here, but it does provide the answer in systemd terms:
```
[root@testvm1 ~]# systemctl list-units --type target
UNIT LOAD ACTIVE SUB DESCRIPTION
basic.target loaded active active Basic System
cryptsetup.target loaded active active Local Encrypted Volumes
getty.target loaded active active Login Prompts
graphical.target loaded active active Graphical Interface
local-fs-pre.target loaded active active Local File Systems (Pre)
local-fs.target loaded active active Local File Systems
multi-user.target loaded active active Multi-User System
network-online.target loaded active active Network is Online
network.target loaded active active Network
nfs-client.target loaded active active NFS client services
nss-user-lookup.target loaded active active User and Group Name Lookups
paths.target loaded active active Paths
remote-fs-pre.target loaded active active Remote File Systems (Pre)
remote-fs.target loaded active active Remote File Systems
rpc_pipefs.target loaded active active rpc_pipefs.target
slices.target loaded active active Slices
sockets.target loaded active active Sockets
sshd-keygen.target loaded active active sshd-keygen.target
swap.target loaded active active Swap
sysinit.target loaded active active System Initialization
timers.target loaded active active Timers
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
21 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
```
This shows all of the currently loaded and active targets. You can also see the **graphical.target** and the **multi-user.target**. The **multi-user.target** is required before the **graphical.target** can be loaded. In this example, the **graphical.target** is active.
## Switching to a different target
Making the switch to the **multi-user.target** is easy:
`[root@testvm1 ~]# systemctl isolate multi-user.target`
The display should now change from the GUI desktop or login screen to a virtual console. Log in and list the currently active systemd units to verify that **graphical.target** is no longer running:
`[root@testvm1 ~]# systemctl list-units --type target`
Be sure to use the **runlevel** command to verify that it shows both previous and current "runlevels":
```
[root@testvm1 ~]# runlevel
5 3
```
## Changing the default target
Now, change the default target to the **multi-user.target** so that it will always boot into the **multi-user.target** for a console command-line interface rather than a GUI desktop interface. As the root user on your test host, change to the directory where the systemd configuration is maintained and do a quick listing:
```
[root@testvm1 ~]# cd /etc/systemd/system/ ; ll
drwxr-xr-x. 2 root root 4096 Apr 25 2018 basic.target.wants
<snip>
lrwxrwxrwx. 1 root root 36 Aug 13 16:23 default.target -> /lib/systemd/system/graphical.target
lrwxrwxrwx. 1 root root 39 Apr 25 2018 display-manager.service -> /usr/lib/systemd/system/lightdm.service
drwxr-xr-x. 2 root root 4096 Apr 25 2018 getty.target.wants
drwxr-xr-x. 2 root root 4096 Aug 18 10:16 graphical.target.wants
drwxr-xr-x. 2 root root 4096 Apr 25 2018 local-fs.target.wants
drwxr-xr-x. 2 root root 4096 Oct 30 16:54 multi-user.target.wants
<snip>
[root@testvm1 system]#
```
I shortened this listing to highlight a few important things that will help explain how systemd manages the boot process. You should be able to see the entire list of directories and links on your virtual machine.
The **default.target** entry is a symbolic link (symlink, soft link) to the directory **/lib/systemd/system/graphical.target**. List that directory to see what else is there:
`[root@testvm1 system]# ll /lib/systemd/system/ | less`
You should see files, directories, and more links in this listing, but look specifically for **multi-user.target** and **graphical.target**. Now display the contents of **default.target**, which is a link to **/lib/systemd/system/graphical.target**:
```
[root@testvm1 system]# cat default.target
# SPDX-License-Identifier: LGPL-2.1+
#
# This file is part of systemd.
#
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
[Unit]
Description=Graphical Interface
Documentation=man:systemd.special(7)
Requires=multi-user.target
Wants=display-manager.service
Conflicts=rescue.service rescue.target
After=multi-user.target rescue.service rescue.target display-manager.service
AllowIsolate=yes
[root@testvm1 system]#
```
This link to the **graphical.target** file describes all of the prerequisites and requirements that the graphical user interface requires. I will explore at least some of these options in the next article in this series.
To enable the host to boot to multi-user mode, you need to delete the existing link and create a new one that points to the correct target. Make the [PWD](https://en.wikipedia.org/wiki/Pwd) **/etc/systemd/system**, if it is not already:
```
[root@testvm1 system]# rm -f default.target
[root@testvm1 system]# ln -s /lib/systemd/system/multi-user.target default.target
```
List the **default.target** link to verify that it links to the correct file:
```
[root@testvm1 system]# ll default.target
lrwxrwxrwx 1 root root 37 Nov 28 16:08 default.target -> /lib/systemd/system/multi-user.target
[root@testvm1 system]#
```
If your link does not look exactly like this, delete it and try again. List the content of the **default.target** link:
```
[root@testvm1 system]# cat default.target
# SPDX-License-Identifier: LGPL-2.1+
#
# This file is part of systemd.
#
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
[Unit]
Description=Multi-User System
Documentation=man:systemd.special(7)
Requires=basic.target
Conflicts=rescue.service rescue.target
After=basic.target rescue.service rescue.target
AllowIsolate=yes
[root@testvm1 system]#
```
The **default.target**—which is really a link to the **multi-user.target** at this point—now has different requirements in the **[Unit]** section. It does not require the graphical display manager.
Reboot. Your virtual machine should boot to the console login for virtual console 1, which is identified on the display as tty1. Now that you know how to change the default target, change it back to the **graphical.target** using a command designed for the purpose.
First, check the current default target:
```
[root@testvm1 ~]# systemctl get-default
multi-user.target
[root@testvm1 ~]# systemctl set-default graphical.target
Removed /etc/systemd/system/default.target.
Created symlink /etc/systemd/system/default.target → /usr/lib/systemd/system/graphical.target.
[root@testvm1 ~]#
```
Enter the following command to go directly to the **graphical.target** and the display manager login page without having to reboot:
`[root@testvm1 system]# systemctl isolate default.target`
I do not know why the term "isolate" was chosen for this sub-command by systemd's developers. My research indicates that it may refer to running the specified target but "isolating" and terminating all other targets that are not required to support the target. However, the effect is to switch targets from one run target to another—in this case, from the multi-user target to the graphical target. The command above is equivalent to the old init 5 command in SystemV start scripts and the init program.
Log into the GUI desktop, and verify that it is working as it should.
## Summing up
This article explored the Linux systemd startup sequence and started to explore two important systemd tools, **systemctl** and **journalctl**. It also explained how to switch from one target to another and to change the default target.
The next article in this series will create a new systemd unit and configure it to run during startup. It will also look at some of the configuration options that help determine where in the sequence a particular unit will start, for example, after networking is up and running.
## Resources
There is a great deal of information about systemd available on the internet, but much is terse, obtuse, or even misleading. In addition to the resources mentioned in this article, the following webpages offer more detailed and reliable information about systemd startup.
- The Fedora Project has a good, practical
[guide](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html)[to systemd](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html). It has pretty much everything you need to know in order to configure, manage, and maintain a Fedora computer using systemd. - The Fedora Project also has a good
[cheat sheet](https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet)that cross-references the old SystemV commands to comparable systemd ones. - For detailed technical information about systemd and the reasons for creating it, check out
[Freedesktop.org](http://Freedesktop.org)'s[description of systemd](http://www.freedesktop.org/wiki/Software/systemd). [Linux.com](http://Linux.com)'s "More systemd fun" offers more advanced systemd[information and tips](https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/).
There is also a series of deeply technical articles for Linux sysadmins by Lennart Poettering, the designer and primary developer of systemd. These articles were written between April 2010 and September 2011, but they are just as relevant now as they were then. Much of everything else good that has been written about systemd and its ecosystem is based on these papers.
[Rethinking PID 1](http://0pointer.de/blog/projects/systemd.html)[systemd for Administrators, Part I](http://0pointer.de/blog/projects/systemd-for-admins-1.html)[systemd for Administrators, Part II](http://0pointer.de/blog/projects/systemd-for-admins-2.html)[systemd for Administrators, Part III](http://0pointer.de/blog/projects/systemd-for-admins-3.html)[systemd for Administrators, Part IV](http://0pointer.de/blog/projects/systemd-for-admins-4.html)[systemd for Administrators, Part V](http://0pointer.de/blog/projects/three-levels-of-off.html)[systemd for Administrators, Part VI](http://0pointer.de/blog/projects/changing-roots)[systemd for Administrators, Part VII](http://0pointer.de/blog/projects/blame-game.html)[systemd for Administrators, Part VIII](http://0pointer.de/blog/projects/the-new-configuration-files.html)[systemd for Administrators, Part IX](http://0pointer.de/blog/projects/on-etc-sysinit.html)[systemd for Administrators, Part X](http://0pointer.de/blog/projects/instances.html)[systemd for Administrators, Part XI](http://0pointer.de/blog/projects/inetd.html)
## 3 Comments |
13,722 | 使用 SubSync 自动同步视频字幕 | https://itsfoss.com/subsync/ | 2021-08-27T10:00:00 | [
"视频",
"字幕"
] | https://linux.cn/article-13722-1.html | 
让我分享一个场景:当你想要观看一部电影或视频,而又需要字幕时,在你下载字幕后,却发现字幕没有正确同步,也没有其他更好的字幕可用。现在该怎么做?
你可以 [在 VLC 中按 G 或 H 键来同步字幕](https://itsfoss.com/how-to-synchronize-subtitles-with-movie-quick-tip/)。它可以为字幕增加延迟。如果字幕在整个视频中的时间延迟相同,这可能会起作用。但如果不是这种情况,就需要 SubSync 出场了。
### SubSync: 字幕语音同步器
[SubSync](https://subsync.online/) 是一款实用的开源工具,可用于 Linux、macOS 和 Windows。
它通过监听音轨来同步字幕,这就是它的神奇之处。即使音轨和字幕使用的是不同的语言,它也能发挥作用。如果有必要,它也支持翻译,但我没有测试过这个功能。
我播放一个视频不同步的字幕进行了一个简单的测试。令我惊讶的是,它工作得很顺利,我得到了完美的同步字幕。
使用 SubSync 很简单。启动这个应用,它会让你添加字幕文件和视频文件。

你需要在界面上选择字幕和视频的语言。它可能会根据选择的语言下载额外的资源。

请记住,同步字幕需要一些时间,这取决于视频和字幕的长度。在等待过程完成时,你可以喝杯茶/咖啡或啤酒。
你可以看到正在进行同步的状态,甚至可以在完成之前保存它。

同步完成后,你就可以点击保存按钮,把修改的内容保存到原文件中,或者把它保存为新的字幕文件。

我不能保证所有情况下都能正常工作,但在我运行的样本测试中它是正常的。
### 安装 SubSync
SubSync 是一个跨平台的应用,你可以从它的 [下载页面](https://subsync.online/en/download.html) 获得 Windows 和 MacOS 的安装文件。
对于 Linux 用户,SubSync 是作为一个 Snap 包提供的。如果你的发行版已经提供了 Snap 支持,使用下面的命令来安装 SubSync:
```
sudo snap install subsync
```
请记住,下载 SubSync Snap 包将需要一些时间。所以要有一个稳定的网络连接或足够的耐心。
### 最后
就我个人而言,我很依赖字幕。即使我在 Netflix 上看英文电影,我也会把字幕打开。它有助于我清楚地理解每段对话,特别是在有强烈口音的情况下。如果没有字幕,我永远无法理解 [电影 Snatch 中 Mickey O'Neil(由 Brad Pitt 扮演)的一句话](https://www.youtube.com/watch?v=tGDO-9hfaiI)。
使用 SubSync 比 [Subtitle Editor](https://itsfoss.com/subtitld/) 同步字幕要容易得多。对于像我这样在整个互联网上搜索不同国家的冷门或推荐(神秘)电影的人来说,除了 [企鹅字幕播放器](https://itsfoss.com/penguin-subtitle-player/),这是另一个很棒的工具。
如果你是一个“字幕用户”,你会喜欢这个工具。如果你使用过它,请在评论区分享你的使用经验。
---
via: <https://itsfoss.com/subsync/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[turbokernel](https://github.com/turbokernel)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Let me share a scenario. You are trying to watch a movie or video and you need subtitles. You download the subtitle only to find that the subtitle is not properly synchronized. There are no other good subtitles available. What to do now?
You can [synchronize subtitles in VLC by pressing G or H keys](https://itsfoss.com/how-to-synchronize-subtitles-with-movie-quick-tip/). It adds a delay to the subtitles. This could work if the subtitle is out of synch by the same time interval throughout the video. But if that’s not the case, SubSync could be of great help here.
## SubSync: Subtitle Speech Synchronizer
**SubSync**** is a nifty open source utility available for Linux, macOS and Windows.**
It synchronizes the subtitles by listening to the audio track, and that’s how it works the magic. It will work even if the audio track and the subtitles are in different languages. If necessary, it could also be translated but I did not test this feature.
I made a simple test by using a subtitle which was not in synch with the video I was playing. To my surprise, it worked pretty smooth and I got perfectly synched subtitles.
Using SubSync is simple. You start the application and it asks to add the subtitle file and the video file.
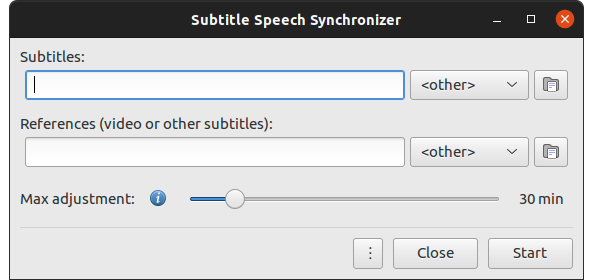
You’ll have to specif the language of the subtitle and the video on the interface. It may download additional assets based on the language in use.
Please keep in mind that it takes some time to synchronize the subtitles, depending on the length of the video and subtitle. You may grab your cup of tea/coffee or beer while you wait for the process to complete.
You can see the synchronization status in progress and even save it before it gets completed.
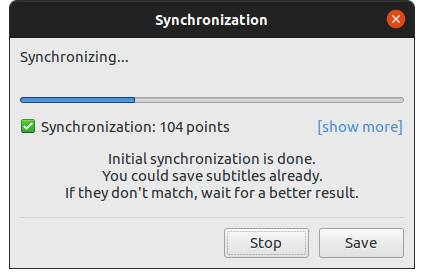
Once the synchronization completes, you hit the save button and either save the changes to the original file or save it as a new subtitle file.
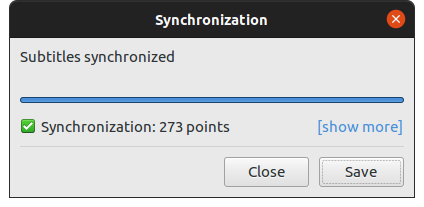
I cannot say that it will work in all the cases but it worked for the sample test I ran.
## Installing SubSync
SubSync is a cross-platform application and you can get the installer files for Windows and macOS from its [download page](https://subsync.online/en/download.html?ref=itsfoss.com).
For Linux users, SubSync is available as a Snap package. If your distribution has Snap support enabled, use the following command to install SubSync:
`sudo snap install subsync`
Please keep in mind that it will take some time to download SubSync snap package. So have a good internet connection or plenty of patience.
## In the end
Personally, I am addicted to subtitles. Even if I am watching movies in English on Netflix, I keep the subtitles on. It helps understand each dialogue clearly, specially if there is a strong accent. Without subtitles, I could never understand a [word from Mickey O’Neil (played by Brad Pitt) in the movie Snatch](https://www.youtube.com/watch?v=tGDO-9hfaiI&ref=itsfoss.com). Dags!!
Using SubSync is a lot easier than [using Subtitle Editor](https://itsfoss.com/subtitld/) for synchronizing subtitles. After [Penguin Subtitle Player](https://itsfoss.com/penguin-subtitle-player/), this is another great tool for someone like me who searches the entire internet for rare or recommended (mystery) movies from different countries.
[App Highlight: Penguin Subtitle Player for Adding Subtitles to Online VideosI must confess. I am addicted to subtitles. It helps me understand the dialogues completely, specially if some dialogues are in a different accent or in a different language. This has led to a habit of watching online videos with subtitles. While streaming services like Netflix and Amazon…](https://itsfoss.com/penguin-subtitle-player/)

If you are a ‘subtitle user’, I have a feeling you would like this tool. If you do use it, please share your experience with it in the comment section. |
13,723 | 用 fastjar 和 gjar 构建一个 JAR 文件 | https://opensource.com/article/21/8/fastjar | 2021-08-27T10:52:43 | [
"JAR",
"Java"
] | https://linux.cn/article-13723-1.html |
>
> fastjar、gjar 和 jar 等工具可以帮助你手动或以编程方式构建 JAR 文件,而其他工具链,如 Maven 和 Gradle 提供了依赖性管理的功能。
>
>
>

根据我的经验,Java 的许多优点之一是它能够以整齐方便的包(称为 JAR,或 Java 归档)来提供应用程序。JAR 文件使用户很容易下载并启动他们想尝试的应用,很容易将该应用从一台计算机转移到另一台计算机(而且 Java 是跨平台的,所以可以鼓励自由分享),而且对于新的程序员来说,查看 JAR 文件的内容,以找出使 Java 应用运行的原因是很容易理解的。
创建 JAR 文件的方法有很多,包括 Maven 和 Gradle 等工具链解决方案,以及 IDE 中的一键构建功能。然而,也有一些独立的命令,如 `jarfast`、`gjar` 和普通的 `jar`,它们对于快速和简单的构建是很有用的,并且可以演示 JAR 文件运行所需要的东西。
### 安装
在 Linux 上,你可能已经有了 `fastjar`、`gjar` 或作为 OpenJDK 包或 GCJ(GCC-Java)的一部分的 `jar` 命令。你可以通过输入不带参数的命令来测试这些命令是否已经安装:
```
$ fastjar
Try 'fastjar --help' for more information.
$ gjar
jar: must specify one of -t, -c, -u, -x, or -i
jar: Try 'jar --help' for more information
$ jar
Usage: jar [OPTION...] [ [--release VERSION] [-C dir] files] ...
Try `jar --help' for more information.
```
我安装了所有这些命令,但你只需要一个。所有这些命令都能够构建一个 JAR。
在 Fedora 等现代 Linux 系统上,输入一个缺失的命令你的操作系统提示安装它。
另外,你可以直接从 [AdoptOpenJDK.net](https://adoptopenjdk.net/) 为 Linux、MacOS 和 Windows [安装 Java](https://opensource.com/article/19/11/install-java-linux)。
### 构建 JAR
首先,你需要构建一个 Java 应用。
为了简单起见,在一个名为 `hello.java` 的文件中创建一个基本的 “hello world” 应用:
```
class Main {
public static void main(String[] args) {
System.out.println("Hello Java World");
}}
```
这是一个简单的应用,在某种程度上淡化了管理外部依赖关系在现实世界中的重要性。不过,这也足以让你开始了解创建 JAR 所需的基本概念了。
接下来,创建一个清单文件。清单文件描述了 JAR 的 Java 环境。在这个例子里,最重要的信息是识别主类,这样执行 JAR 的 Java 运行时就知道在哪里可以找到应用的入口点。
```
$ mdir META-INF
$ echo "Main-Class: Main" > META-INF/MANIFEST.MF
```
### 编译 Java 字节码
接下来,把你的 Java 文件编译成 Java 字节码。
```
$ javac hello.java
```
另外,你也可以使用 GCC 的 Java 组件来编译:
```
$ gcj -C hello.java
```
无论哪种方式,都会产生文件 `Main.class`:
```
$ file Main.class
Main.class: compiled Java class data, version XX.Y
```
### 创建 JAR
你有了所有需要的组件,这样你就可以创建 JAR 文件了。
我经常包含 Java 源码给好奇的用户参考,这只需 `META-INF` 目录和类文件即可。
`fastjar` 命令使用类似于 [tar 命令](https://opensource.com/article/17/7/how-unzip-targz-file)的语法。
```
$ fastjar cvf hello.jar META-INF Main.class
```
另外,你也可以用 `gjar`,方法大致相同,只是 `gjar` 需要你明确指定清单文件:
```
$ gjar cvf world.jar Main.class -m META-INF/MANIFEST.MF
```
或者你可以使用 `jar` 命令。注意这个命令不需要清单文件,因为它会自动为你生成一个,但为了安全起见,我明确定义了主类:
```
$ jar --create --file hello.jar --main-class=Main Main.class
```
测试你的应用:
```
$ java -jar hello.jar
Hello Java World
```
### 轻松打包
像 `fastjar`、`gjar` 和 `jar` 这样的工具可以帮助你手动或以编程方式构建 JAR 文件,而其他工具链如 Maven 和 Gradle 则提供了依赖性管理的功能。一个好的 IDE 可能会集成这些功能中的一个或多个。
无论你使用什么解决方案,Java 都为分发你的应用代码提供了一个简单而统一的目标。
---
via: <https://opensource.com/article/21/8/fastjar>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the many advantages of Java, in my experience, is its ability to deliver applications in a neat and tidy package (called a JAR, or *Java archive*.) JAR files make it easy for users to download and launch an application they want to try, easy to transfer that application from one computer to another (and Java is cross-platform, so sharing liberally can be encouraged), and easy to understand for new programmers to look inside a JAR to find out what makes a Java app run.
There are many ways to create a JAR file, including toolchain solutions such as Maven and Gradle, and one-click build features in your IDE. However, there are also stand-alone commands such as `jarfast`
, `gjar`
, and just plain old `jar`
, which are useful for quick and simple builds, and to demonstrate what a JAR file needs to run.
## Install
On Linux, you may already have the `fastjar`
, `gjar`
, or `jar`
commands as part of an OpenJDK package, or GCJ (GCC-Java.) You can test whether any of these commands are installed by typing the command with no arguments:
```
$ fastjar
Try 'fastjar --help' for more information.
$ gjar
jar: must specify one of -t, -c, -u, -x, or -i
jar: Try 'jar --help' for more information
$ jar
Usage: jar [OPTION...] [ [--release VERSION] [-C dir] files] ...
Try `jar --help' for more information.
```
I have all of them installed, but you only need one. All of these commands are capable of building a JAR.
On a modern Linux system such as Fedora, typing a missing command causes your OS to prompt you to install it for you.
Alternately, you can just [install Java](https://opensource.com/article/19/11/install-java-linux) from [AdoptOpenJDK.net](https://adoptopenjdk.net/) for Linux, MacOS, and Windows.
## Build a JAR
First, you need a Java application to build.
To keep things simple, create a basic "hello world" application in a file called hello.java:
```
class Main {
public static void main(String[] args) {
System.out.println("Hello Java World");
}}
```
It's a simple application that somewhat trivializes the real-world importance of managing external dependencies. Still, it's enough to get started with the basic concepts you need to create a JAR.
Next, create a manifest file. A manifest file describes the Java environment of the JAR. In this case, the most important information is identifying the main class, so the Java runtime executing the JAR knows where to find the application's entry point.
```
$ mdir META-INF
$ echo "Main-Class: Main" > META-INF/MANIFEST.MF
```
## Compiling Java bytecode
Next, compile your Java file into Java bytecode.
`$ javac hello.java`
Alternately, you can use the Java component of GCC to compile:
`$ gcj -C hello.java`
Either way, this produces the file `Main.class`
:
```
$ file Main.class
Main.class: compiled Java class data, version XX.Y
```
## Creating a JAR
You have all the components you need so that you can create the JAR file.
I often include the Java source code as a reference for curious users, but all that's *required* is the `META-INF`
directory and the class files.
The `fastjar`
command uses syntax similar to the [ tar command](https://opensource.com/article/17/7/how-unzip-targz-file).
`$ fastjar cvf hello.jar META-INF Main.class`
Alternately, you can use `gjar`
in much the same way, except that `gjar`
requires you to specify your manifest file explicitly:
`$ gjar cvf world.jar Main.class -m META-INF/MANIFEST.MF`
Or you can use the `jar`
command. Notice this one doesn't require a Manifest file because it auto-generates one for you, but for safety I define the main class explicitly:
`$ jar --create --file hello.jar --main-class=Main Main.class`
Test your application:
```
$ java -jar hello.jar
Hello Java World
```
## Easy packaging
Utilities like `fastjar`
, `gjar`
, and `jar `
help you manually or programmatically build JAR files, while other toolchains such as Maven and Gradle offer features for dependency management. A good IDE may integrate one or more of these features.
Whatever solution you use, Java provides an easy and unified target for distributing your application code.
## Comments are closed. |
13,724 | 关于 Linux 内核的 30 件你不知道的事 | https://opensource.com/article/21/8/linux-kernel | 2021-08-27T15:00:16 | [
"Linux",
"内核"
] | /article-13724-1.html |
>
> Linux 内核今年 30 岁了。
>
>
>

Linux 内核今年 30 岁了。这开创性的开源软件的三个十年,让用户能够运行自由软件,让他们能从运行的应用程序中学习,让他们能与朋友分享他们所学到的知识。有人认为,如果没有 Linux 内核,我们如今所享受的 [开源文化](https://opensource.com/article/18/1/creative-commons-real-world) 和自由软件的累累硕果,可能就不会应时而出现。如果没有 Linux 作为催化剂,苹果、微软和谷歌所开源的那些就不可能开源。Linux 作为一种现象,对开源文化、软件开发和用户体验的影响,是怎么强调都不为过的,但所有这一切,都滥觞于一个 Linux 内核。
Linux 内核是启动计算机、并识别和确保计算机内外所连接的所有组件之间通信的软件。这些对于大多数用户从未想过,更不用说能理解的代码,Linux 内核有很多令人惊讶的地方。以下是 Linux 内核在其三十年生命中每一年的一件事。顺序无关。
1. Linux 是第一个具有 USB 3.0 驱动的操作系统。Sarah Sharp 在 2009 年 6 月 7 日宣布她的 USB 3.0 设备的驱动程序可以使用了,她的代码被包含在内核 2.6.31 版本中。
2. 当某些事件发生时,内核会将自己标记为“受污染”,这在以后的故障排除中可能有用。运行一个“被污染”的内核并不是什么问题。但如果出现错误,首先要做的是在一个没有被污染的内核上重现该问题。
3. 你可以指定一个主机名或域名作为 `ip=` 内核命令行选项的一部分,Linux 会保留它,而不是用 DHCP 或 BOOTP 提供的主机名或域名来覆盖它。例如,`ip=::::myhostname::dhcp` 设置主机名 `myhostname`。
4. 在文本启动过程中,可以选择显示黑白的、16 色的或 224 色的 Tux 徽标之一。
5. 在娱乐业中,DRM 是一种用来防止访问媒介的技术。然而,在 Linux 内核中,DRM 指的是<ruby> 直接渲染管理器 <rt> Direct Rendering Manager </rt></ruby>,它指的是用于与对接显卡的 GPU 的库(`libdrm`)和驱动程序。
6. 能够在不重启的情况下给 Linux 内核打补丁。
7. 如果你自己编译内核,你可以将文本控制台配置为超过 80 列宽。
8. Linux 内核提供了内置的 FAT、exFAT 和 NTFS(读和写)支持。
9. Wacom 平板电脑和许多类似设备的驱动程序都内置在内核中。
10. 大多数内核高手使用 `git send-email` 来提交补丁。
11. 内核使用一个叫做 [Sphinx](https://opensource.com/article/19/11/document-python-sphinx) 的文档工具链,它是用 Python 编写的。
12. Hamlib 提供了具有标准化 API 的共享库,可以通过你的 Linux 电脑控制业余无线电设备。
13. 我们鼓励硬件制造商帮助开发 Linux 内核,以确保兼容性。这样就可以直接处理硬件,而不必从制造商那里下载驱动程序。直接成为内核一部分的驱动程序也会自动从新版本内核的性能和安全改进中受益。
14. 内核中包含了许多树莓派模块(Pi Hats)的驱动程序。
15. netcat 乐队发布了一张只能作为 [Linux 内核模块](https://github.com/usrbinnc/netcat-cpi-kernel-module) 播放的专辑。
16. 受 netcat 发布专辑的启发,人们又开发了一个 [把你的内核变成一个音乐播放器](https://github.com/FlaviaR/Netcat-Music-Kernel-Expansion) 的模块。
17. Linux 内核的功能支持许多 CPU 架构:ARM、ARM64、IA-64、 m68k、MIPS、Nios II、PA-RISC、OpenRISC、PowerPC、s390、 Sparc、x86、Xtensa 等等。
18. 2001 年,Linux 内核成为第一个 [以长模式运行的 x86-64 CPU 架构](http://www.x86-64.org/pipermail/announce/2001-June/000020.html)。
19. Linux 3.4 版引入了 x32 ABI,允许开发者编译在 64 位模式下运行的代码,而同时只使用 32 位指针和数据段。
20. 内核支持许多不同的文件系统,包括 Ext2、Ext3、Ext4、JFS、XFS、GFS2、GCFS2、BtrFS、NILFS2、NFS、Overlay FS、UDF 等等。
21. <ruby> 虚拟文件系统 <rt> Virtual File System </rt></ruby>(VFS)是 Linux 内核中的一个软件层,为用户运行的应用程序提供文件系统接口。它也是内核的一个抽象层,以便不同的文件系统实现可以共存。
22. Linux 内核包括一个实体的盲文输出设备的驱动程序。
23. 在 2.6.29 版本的内核中,启动时的 Tux 徽标被替换为 “Tuz”,以提高人们对当时影响澳大利亚的<ruby> 塔斯马尼亚魔鬼 <rt> Tasmanian Devil </rt></ruby>(即袋獾)种群的一种侵袭性癌症的认识。
24. <ruby> 控制组 <rt> Control Groups </rt></ruby>(cgroups)是容器(Docker、Podman、Kubernetes 等的基础技术)能够存在的原因。
25. 曾经花了大量的法律行动来解放 CIFS,以便将其纳入内核中,而今天,CIFS 模块已被内置于内核,以实现对 SMB 的支持。这使得 Linux 可以挂载微软的远程共享和基于云的文件共享。
26. 对于计算机来说,产生一个真正的随机数是出了名的困难(事实上,到目前为止是不可能的)。`hw_random` 框架可以利用你的 CPU 或主板上的特殊硬件功能,尽量改进随机数的生成。
27. *操作系统抖动* 是应用程序遇到的干扰,它是由后台进程的调度方式和系统处理异步事件(如中断)的方式的冲突引起的。像这些问题在内核文档中都有详细的讨论,可以帮助面向 Linux 开发的程序员写出更聪明的代码。
28. `make menuconfig` 命令可以让你在编译前使用 GUI 来配置内核。`Kconfig` 语言定义了内核配置选项。
29. 对于基本的 Linux 服务器,可以实施一个 *看门狗* 系统来监控服务器的健康状况。在健康检查间隔中,`watchdog` 守护进程将数据写入一个特殊的 `watchdog` 内核设备,以防止系统重置。如果看门狗不能成功记录,系统就会被重置。有许多看门狗硬件的实现,它们对远程任务关键型计算机(如发送到火星上的计算机)至关重要。
30. 在火星上有一个 Linux 内核的副本,虽然它是在地球上开发的。
---
via: <https://opensource.com/article/21/8/linux-kernel>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,726 | Linux 远程连接之 SSH 新手指南 | https://opensource.com/article/20/9/ssh | 2021-08-28T10:54:16 | [
"SSH"
] | https://linux.cn/article-13726-1.html |
>
> 学会使用安全外壳协议连接远程计算机。
>
>
>

使用 Linux,你只需要在键盘上输入命令,就可以巧妙地使用计算机(甚至这台计算机可以在世界上任何地方),这正是 Linux 最吸引人的特性之一。有了 OpenSSH,[POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 用户就可以在有权限连接的计算机上打开安全外壳协议,然后远程使用。这对于许多 Linux 用户来说可能不过是日常任务,但从没操作过的人可能就会感到很困惑。本文介绍了如何配置两台计算机的 <ruby> 安全外壳协议 <rt> secure shell </rt></ruby>(简称 SSH)连接,以及如何在没有密码的情况下安全地从一台计算机连接到另一台计算机。
### 相关术语
在讨论多台计算机时,如何将不同计算机彼此区分开可能会让人头疼。IT 社区拥有完善的术语来描述计算机联网的过程。
* <ruby> 服务 <rt> service </rt></ruby>: 服务是指在后台运行的软件,因此它不会局限于仅供安装它的计算机使用。例如,Web 服务器通常托管着 Web 共享 *服务*。该术语暗含(但非绝对)它是没有图形界面的软件。
* <ruby> 主机 <rt> host </rt></ruby>: 主机可以是任何计算机。在 IT 中,任何计算机都可以称为 *主机*,因为从技术上讲,任何计算机都可以<ruby> 托管 <rt> host </rt></ruby>对其他计算机有用的应用程序。你可能不会把自己的笔记本电脑视为 **主机**,但其实上面可能正运行着一些对你、你的手机或其他计算机有用的服务。
* <ruby> 本地 <rt> local </rt></ruby>: 本地计算机是指用户或某些特定软件正在使用的计算机。例如,每台计算机都会把自己称为 `localhost`。
* <ruby> 远程 <rt> remote </rt></ruby>: 远程计算机是指你既没在其面前,也没有在实际使用的计算机,是真正意义上在 *远程* 位置的计算机。
现在术语已经明确好,我们可以开始了。
### 在每台主机上激活 SSH
要通过 SSH 连接两台计算机,每个主机都必须安装 SSH。SSH 有两个组成部分:本地计算机上使用的用于启动连接的命令,以及用于接收连接请求的 *服务器*。有些计算机可能已经安装好了 SSH 的一个或两个部分。验证 SSH 是否完全安装的命令因系统而异,因此最简单的验证方法是查阅相关配置文件:
```
$ file /etc/ssh/ssh_config
/etc/ssh/ssh_config: ASCII text
```
如果返回 `No such file or directory` 错误,说明没有安装 SSH 命令。
SSH 服务的检测与此类似(注意文件名中的 `d`):
```
$ file /etc/ssh/sshd_config
/etc/ssh/sshd_config: ASCII text
```
根据缺失情况选择安装两个组件:
```
$ sudo dnf install openssh-clients openssh-server
```
在远程计算机上,使用 systemd 命令启用 SSH 服务:
```
$ sudo systemctl enable --now sshd
```
你也可以在 GNOME 上的 **系统设置** 或 macOS 上的 **系统首选项** 中启用 SSH 服务。在 GNOME 桌面上,该设置位于 **共享** 面板中:

### 开启安全外壳协议
现在你已经在远程计算机上安装并启用了 SSH,可以尝试使用密码登录作为测试。要访问远程计算机,你需要有用户帐户和密码。
远程用户不必与本地用户相同。只要拥有相应用户的密码,你就可以在远程机器上以任何用户的身份登录。例如,我在我的工作计算机上的用户是 `sethkenlon` ,但在我的个人计算机上是 `seth`。如果我正在使用我的个人计算机(即作为当前的本地计算机),并且想通过 SSH 连接到我的工作计算机,我可以通过将自己标识为 `sethkenlon` 并使用我的工作密码来实现连接。
要通过 SSH 连接到远程计算机,你必须知道其 IP 地址或可解析的主机名。在远程计算机上使用 `ip` 命令可以查看该机器的 IP 地址:
```
$ ip addr show | grep "inet "
inet 127.0.0.1/8 scope host lo
inet 10.1.1.5/27 brd 10.1.1.31 [...]
```
如果远程计算机没有 `ip` 命令,可以尝试使用 `ifconfig` 命令(甚至可以试试 Windows 上通用的 `ipconfig` 命令)。
`127.0.0.1` 是一个特殊的地址,它实际上是 `localhost` 的地址。这是一个<ruby> 环回 <rt> loopback </rt></ruby>地址,系统使用它来找到自己。这在登录远程计算机时并没有什么用,因此在此示例中,远程计算机的正确 IP 地址为 `10.1.1.5`。在现实生活中,我的本地网络正在使用 `10.1.1.0` 子网,进而可得知前述正确的 IP 地址。如果远程计算机在不同的网络上,那么 IP 地址几乎可能是任何地址(但绝不会是 `127.0.0.1`),并且可能需要一些特殊的路由才能通过各种防火墙到达远程。如果你的远程计算机在同一个网络上,但想要访问比自己的网络更远的计算机,请阅读我之前写的关于 [在防火墙中打开端口](https://opensource.com/article/20/8/open-ports-your-firewall) 的文章。
如果你能通过 IP 地址 *或* 主机名 `ping` 到远程机器,并且拥有登录帐户,那么就可以通过 SSH 接入远程机器:
```
$ ping -c1 10.1.1.5
PING 10.1.1.5 (10.1.1.5) 56(84) bytes of data.
64 bytes from 10.1.1.5: icmp_seq=1 ttl=64 time=4.66 ms
$ ping -c1 akiton.local
PING 10.1.1.5 (10.1.1.5) 56(84) bytes of data.
```
至此就成功了一小步。再试试使用 SSH 登录:
```
$ whoami
seth
$ ssh [email protected]
bash$ whoami
sethkenlon
```
测试登录有效,下一节会介绍如何激活无密码登录。
### 创建 SSH 密钥
要在没有密码的情况下安全地登录到另一台计算机,登录者必须拥有 SSH 密钥。可能你的机器上已经有一个 SSH 密钥,但再多创建一个新密钥也没有什么坏处。SSH 密钥的生命周期是在本地计算机上开始的,它由两部分组成:一个是永远不会与任何人或任何东西共享的私钥,一个是可以复制到任何你想要无密码访问的远程机器上的公钥。
有的人可能会创建一个 SSH 密钥,并将其用于从远程登录到 GitLab 身份验证的所有操作,但我会选择对不同的任务组使用不同的密钥。例如,我在家里使用一个密钥对本地机器进行身份验证,使用另一个密钥对我维护的 Web 服务器进行身份验证,再一个单独的密钥用于 Git 主机,以及又一个用于我托管的 Git 存储库,等等。在此示例中,我将只创建一个唯一密钥,以在局域网内的计算机上使用。
使用 `ssh-keygen` 命令创建新的 SSH 密钥:
```
$ ssh-keygen -t ed25519 -f ~/.ssh/lan
```
`-t` 选项代表 *类型* ,上述代码设置了一个高于默认值的密钥加密级别。`-f` 选项代表 *文件*,指定了密钥的文件名和位置。运行此命令后会生成一个名为 `lan` 的 SSH 私钥和一个名为 `lan.pub` 的 SSH 公钥。
使用 `ssh-copy-id` 命令把公钥发送到远程机器上,在此之前要先确保具有远程计算机的 SSH 访问权限。如果你无法使用密码登录远程主机,也就无法设置无密码登录:
```
$ ssh-copy-id -i ~/.ssh/lan.pub [email protected]
```
过程中系统会提示你输入远程主机上的登录密码。
操作成功后,使用 `-i` 选项将 SSH 命令指向对应的密钥(在本例中为 `lan`)再次尝试登录:
```
$ ssh -i ~/.ssh/lan [email protected]
bash$ whoami
sethkenlon
```
对局域网上的所有计算机重复此过程,你就将能够无密码访问这个局域网上的每台主机。实际上,一旦你设置了无密码认证,你就可以编辑 `/etc/ssh/sshd_config` 文件来禁止密码认证。这有助于防止其他人使用 SSH 对计算机进行身份验证,除非他们拥有你的私钥。要想达到这个效果,可以在有 `sudo` 权限的文本编辑器中打开 `/etc/ssh/sshd_config` 并搜索字符串 `PasswordAuthentication`,将默认行更改为:
```
PasswordAuthentication no
```
保存并重启 SSH 服务器:
```
$ sudo systemctl restart sshd && echo "OK"
OK
$
```
### 日常使用 SSH
OpenSSH 改变了人们对操作计算机的看法,使用户不再被束缚在面前的计算机上。使用 SSH,你可以访问家中的任何计算机,或者拥有帐户的服务器,甚至是移动和物联网设备。充分利用 SSH 也意味着解锁 Linux 终端的更多用途。如果你还没有使用过 SSH,请试一下它吧。试着适应 SSH,创建一些适当的密钥,以此更安全地使用计算机,打破必须与计算机面对面的局限性。
---
via: <https://opensource.com/article/20/9/ssh>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of Linux's most appealing features is the ability to skillfully use a computer with nothing but commands entered into the keyboard—and better yet, to be able to do that on computers anywhere in the world. Thanks to OpenSSH, [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) users can open a secure shell on any computer they have permission to access and use it from a remote location. It's a daily task for many Linux users, but it can be confusing for someone who has yet to try it. This article explains how to configure two computers for secure shell (SSH) connections, and how to securely connect from one to the other without a password.
## Terminology
When discussing more than one computer, it can be confusing to identify one from the other. The IT community has well-established terms to help clarify descriptions of the process of networking computers together.
**Service:**A service is software that runs in the background so it can be used by computers other than the one it's installed on. For instance, a web server hosts a web-sharing*service*. The term implies (but does not insist) that it's software without a graphical interface.**Host:**A host is any computer. In IT, computers are called a*host*because technically any computer can host an application that's useful to some other computer. You might not think of your laptop as a "host," but you're likely running some service that's useful to you, your mobile, or some other computer.**Local:**The local computer is the one you or some software is using. Every computer refers to itself as`localhost`
, for example.**Remote:**A remote computer is one you're not physically in front of nor physically using. It's a computer in a*remote*location.
Now that the terminology is settled, you can begin.
## Activate SSH on each host
For two computers to be connected over SSH, each host must have SSH installed. SSH has two components: the command you use on your local machine to start a connection, and a *server* to accept incoming connection requests. Some computers come with one or both parts of SSH already installed. The commands vary, depending on your system, to verify whether you have both the command and the server installed, so the easiest method is to look for the relevant configuration files:
```
$ file /etc/ssh/ssh_config
/etc/ssh/ssh_config: ASCII text
```
Should this return a `No such file or directory`
error, then you don't have the SSH command installed.
Do a similar check for the SSH service (note the `d`
in the filename):
```
$ file /etc/ssh/sshd_config
/etc/ssh/sshd_config: ASCII text
```
Install one or the other, as needed:
`$ sudo dnf install openssh-clients openssh-server`
On the remote computer, enable the SSH service with systemd:
`$ sudo systemctl enable --now sshd`
Alternately, you can enable the SSH service from within **System Settings** on GNOME or **System Preferences** on macOS. On the GNOME desktop, it's located in the **Sharing** panel:
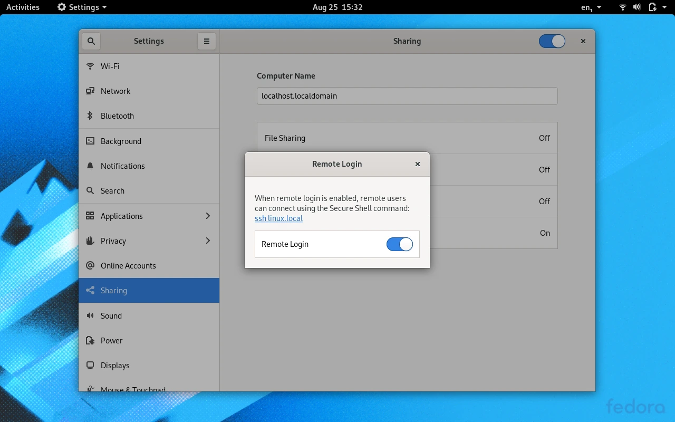
(Seth Kenlon, CC BY-SA 4.0)
## Start a secure shell
Now that you've installed and enabled SSH on the remote computer, you can try logging in with a password as a test. To access the remote computer, you must have a user account and a password.
Your remote user doesn't have to be the same as your local user. You can log in as any user on the remote machine as long as you have that user's password. For instance, I'm `sethkenlon`
on my work computer, but I'm `seth`
on my personal computer. If I'm on my personal computer (making it my current local machine) and I want to SSH into my work computer, I can do that by identifying myself as `sethkenlon`
and using my work password.
To SSH into the remote computer, you must know its internet protocol (IP) address or its resolvable hostname. To find the remote machine's IP address, use the `ip`
command (on the remote computer):
```
$ ip addr show | grep "inet "
inet 127.0.0.1/8 scope host lo
inet 10.1.1.5/27 brd 10.1.1.31 [...]
```
If the remote computer doesn't have the `ip`
command, try `ifconfig`
instead (or even `ipconfig`
on Windows).
The address 127.0.0.1 is a special one and is, in fact, the address of `localhost`
. It's a "loopback" address, which your system uses to reach itself. That's not useful when logging into a remote machine, so in this example, the remote computer's correct IP address is 10.1.1.5. In real life, I would know that because my local network uses the 10.1.1.0 subnet. If the remote computer is on a different network, then the IP address could be nearly anything (never 127.0.0.1, though), and some special routing is probably necessary to reach it through various firewalls. Assume your remote computer is on the same network, but if you're interested in reaching computers more remote than your own network, [read my article about opening ports in your firewall](https://opensource.com/article/20/8/open-ports-your-firewall).
If you can ping the remote machine by its IP address *or* its hostname, and have a login account on it, then you can SSH into it:
```
$ ping -c1 10.1.1.5
PING 10.1.1.5 (10.1.1.5) 56(84) bytes of data.
64 bytes from 10.1.1.5: icmp_seq=1 ttl=64 time=4.66 ms
$ ping -c1 akiton.local
PING 10.1.1.5 (10.1.1.5) 56(84) bytes of data.
```
That's a success. Now use SSH to log in:
```
$ whoami
seth
$ ssh [email protected]
bash$ whoami
sethkenlon
```
The test login works, so now you're ready to activate passwordless login.
## Create an SSH key
To log in securely to another computer without a password, you must have an SSH key. You may already have an SSH key, but it doesn't hurt to create a new one. An SSH key begins its life on your local machine. It consists of two components: a private key, which you never share with anyone or anything, and a public one, which you copy onto any remote machine you want to have passwordless access to.
Some people create one SSH key and use it for everything from remote logins to GitLab authentication. However, I use different keys for different groups of tasks. For instance, I use one key at home to authenticate to local machines, a different key to authenticate to web servers I maintain, a separate one for Git hosts, another for Git repositories I host, and so on. In this example, I'll create a unique key to use on computers within my local area network.
To create a new SSH key, use the `ssh-keygen`
command:
`$ ssh-keygen -t ed25519 -f ~/.ssh/lan`
The `-t`
option stands for *type* and ensures that the encryption used for the key is higher than the default. The `-f`
option stands for *file* and sets the key's file name and location. You'll be prompted to create a password for your SSH key. You should create a password for the key. This means you'll have to enter a password when using the key, but that password remains local and isn't transmitted across the network. After running this command, you're left with an SSH private key called `lan`
and an SSH public key called `lan.pub`
.
To get the public key over to your remote machine, use the `ssh-copy-id`
. For this to work, you must verify that you have SSH access to the remote machine. If you can't log into the remote host with a password, you can't set up passwordless login either:
`$ ssh-copy-id -i ~/.ssh/lan.pub [email protected]`
During this process, you'll be prompted for your login password on the remote host.
Upon success, try logging in again, but this time using the `-i`
option to point the SSH command to the appropriate key (`lan`
, in this example):
```
$ ssh -i ~/.ssh/lan [email protected]
bash$ whoami
sethkenlon
```
Repeat this process for all computers on your network, and you'll be able to wander through each host without ever thinking about passwords again. In fact, once you have passwordless authentication set up, you can edit the `/etc/ssh/sshd_config`
file to disallow password authentication. This prevents anyone from using SSH to authenticate to a computer unless they have your private key. To do this, open `/etc/ssh/sshd_config`
in a text editor with `sudo`
permissions and search for the string `PasswordAuthentication`
. Change the default line to this:
`PasswordAuthentication no`
Save it and restart the SSH server (or just reboot):
```
$ sudo systemctl restart sshd && echo "OK"
OK
$
```
## Using SSH every day
OpenSSH changes your view of computing. No longer are you bound to just the computer in front of you. With SSH, you have access to any computer in your house, or servers you have accounts on, and even mobile and Internet of Things devices. Unlocking the power of SSH also unlocks the power of the Linux terminal. If you're not using SSH every day, start now. Get comfortable with it, collect some keys, live more securely, and expand your world.
## 10 Comments |
13,727 | 如何在 Windows 和 Linux 上确定系统使用的是 MBR 还是 GPT 分区 | https://itsfoss.com/check-mbr-or-gpt/ | 2021-08-28T16:55:18 | [
"分区",
"GPT",
"MBR"
] | https://linux.cn/article-13727-1.html | 
在你安装 Linux 或任何其他系统的时候,了解你的磁盘的正确分区方案是非常关键的。
目前有两种流行的分区方案,老一点的 MBR 和新一些的 GPT。现在大多数的电脑使用 GPT。
在制作临场镜像或可启动 USB 设备时,一些工具(比如 [Rufus](https://rufus.ie/en_US/))会问你在用的磁盘分区情况。如果你在 MBR 分区的磁盘上选择 GPT 方案的话,制作出来的可启动 USB 设备可能会不起作用。
在这个教程里,我会展示若干方法,来在 Windows 和 Linux 系统上检查磁盘分区方案。
### 在 Windows 上检查系统使用的是 MBR 还是 GPT
尽管在 Windows 上包括命令行在内有不少方法可以检查磁盘分区方案,这里我还是使用图形界面的方式查看。
按下 Windows 按键然后搜索“disk”,然后点击“**创建并格式化硬盘分区**”。

在这里,**右键点击**你想要检查分区方案的磁盘。在右键菜单里**选择属性**。

在属性窗口,切换到**卷**标签页,寻找**磁盘分区形式**属性。

正如你在上面截图所看到的,磁盘正在使用 GPT 分区方案。对于一些其他系统,它可能显示的是 MBR 或 MSDOS 分区方案。
现在你知道如何在 Windows 下检查磁盘分区方案了。在下一部分,你会学到如何在 Linux 下进行检查。
### 在 Linux 上检查系统使用的是 MBR 还是 GPT
在 Linux 上也有不少方法可以检查磁盘分区方案使用的是 MBR 还是 GPT。既有命令行方法也有图形界面工具。
让我先给你演示一下命令行方法,然后再看看一些图形界面的方法。
#### 在 Linux 使用命令行检查磁盘分区方案
命令行的方法应该在所有 Linux 发行版上都有效。
打开终端并使用 `sudo` 运行下列命令:
```
sudo parted -l
```
上述命令实际上是一个基于命令行的 [Linux 分区管理器](https://itsfoss.com/partition-managers-linux/)。命令参数 `-l` 会列出系统中的所有磁盘以及它们的详情,里面包含了分区方案信息。
在命令输出中,寻找以 **Partition Table**(分区表)开头的行:

在上面的截图中,磁盘使用的是 GPT 分区方案。如果是 **MBR**,它会显示为 **msdos**。
你已经学会了命令行的方式。但如果你不习惯使用终端,你还可以使用图形界面工具。
#### 使用 GNOME Disks 工具检查磁盘信息
Ubuntu 和一些其它基于 GNOME 的发行版内置了叫做 Disks 的图形工具,你可以用它管理系统中的磁盘。
你也可以使用它来获取磁盘的分区类型。

#### 使用 Gparted 图形工具检查磁盘信息
如果你没办法使用 GNOME Disks 工具,别担心,还有其它工具可以使用。
其中一款流行的工具是 Gparted。你应该可以在大多数 Linux 发行版的软件源中找到它。如果系统中没有安装的话,使用你的发行版的软件中心或 [包管理器](https://itsfoss.com/package-manager/) 来 [安装 Gparted](https://itsfoss.com/gparted/)。
在 Gparted 中,通过菜单选择 **View->Device Information**(查看—>设备信息)。它会在左下区域显示磁盘信息,这些信息中包含分区方案信息。

看吧,也不是太复杂,对吗?现在你了解了好几种途径来确认你的系统使用的是 GPT 还是 MBR 分区方案。
同时我还要提一下,有时候磁盘还会有 [混合分区方案](https://www.rodsbooks.com/gdisk/hybrid.html)。这不是很常见,大多数时候分区不是 MBR 就是 GPT。
有任何问题或建议,请在下方留下评论。
---
via: <https://itsfoss.com/check-mbr-or-gpt/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Knowing the correct partitioning scheme of your disk could be crucial when you are installing Linux or any other operating system.
There are two popular partitioning schemes; the older MBR and the newer GPT. Most computers use GPT these days.
While creating the live or bootable USB, some tools (like [Rufus](https://rufus.ie/en_US/?ref=itsfoss.com)) ask you the type of disk partitioning in use. If you choose GPT with an MBR disk, the bootable USB might not work.
In this tutorial, I’ll show various methods to check the disk partitioning scheme on Windows and Linux systems.
## Check whether your system uses MBR or GPT on Windows systems
While there are several ways to check the disk partitioning scheme in Windows including command line ones, I’ll stick with the GUI methods.
Press the Windows button and search for ‘disk’ and then click on “**Create and format disk partitions**“.
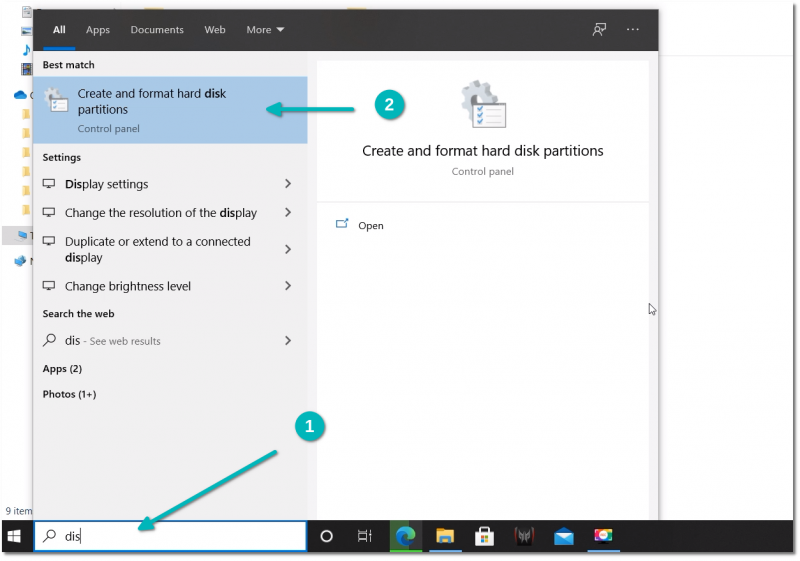
In here, **right-click on the disk** for which you want to check the partitioning scheme. In the right-click context menu, **select Properties**.
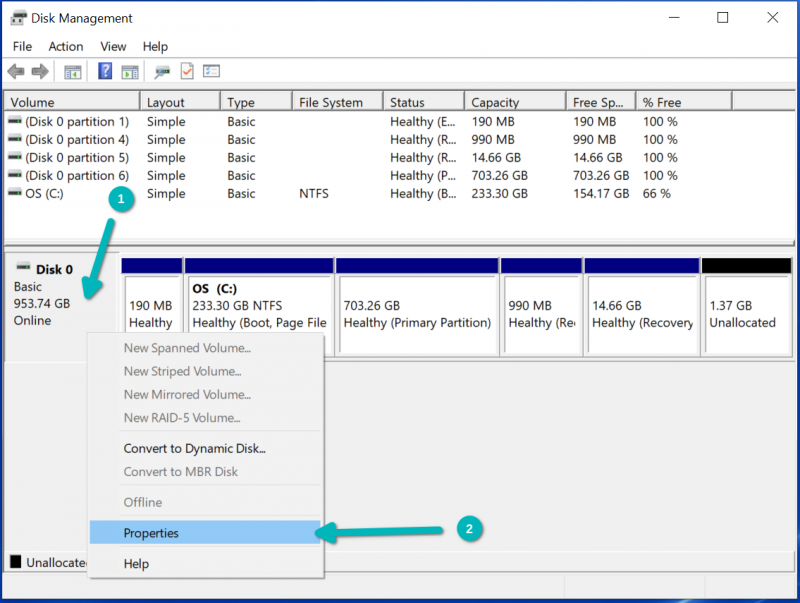
In the Properties, go to **Volumes** tab and look for **Partition style**.
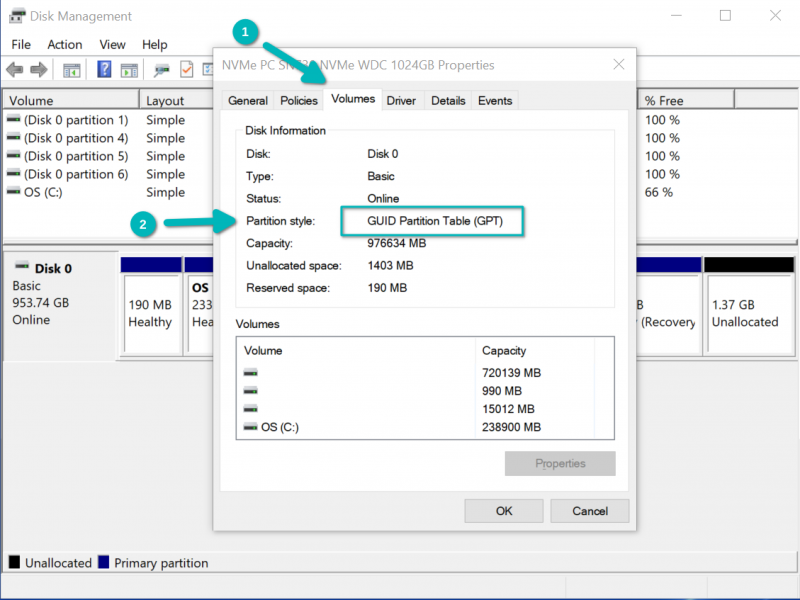
As you can see in the screenshot above, the disk is using GPT partitioning scheme. For some other systems, it could show MBR or MSDOS partitioning scheme.
Now you know how to check disk partitioning scheme in Windows. In the next section, you’ll learn to do the same in Linux.
## Check whether your system uses MBR or GPT on Linux
There are several ways to check whether a disk uses MBR or GPT partitioning scheme in Linux as well. This includes commands and GUI tools.
Let me first show the command line method and then I’ll show a couple of GUI methods.
### Check disk partitioning scheme in Linux command line
The command line method should work on all Linux distributions.
Open a terminal and use the following command with sudo:
`sudo parted -l`
The above command is actually a CLI-based [partitioning manager in Linux](https://itsfoss.com/partition-managers-linux/). With the option -l, it lists the disks on your system along with the details about those disks. It includes partitioning scheme information.
In the output, look for the line starting with **Partition Table**:
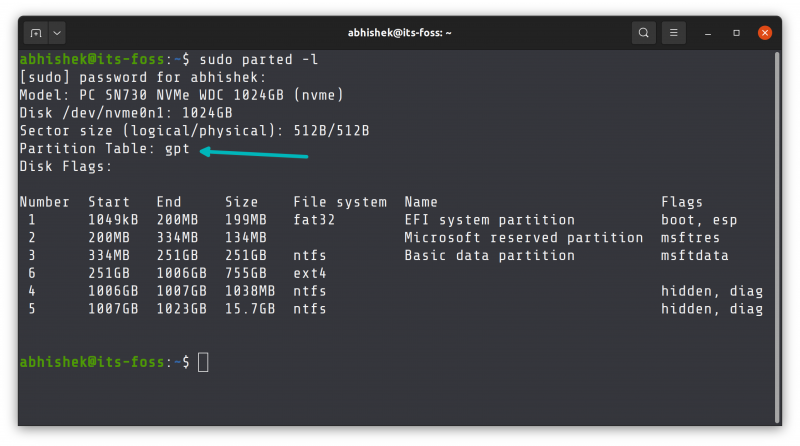
In the above screenshot, the disk has GPT partitioning scheme. For **MBR**, it would show **msdos**.
You learned the command line way. But if you are not comfortable with the terminal, you can use graphical tools as well.
### Checking disk information with GNOME Disks tool
Ubuntu and many other GNOME-based distributions have a built-in graphical tool called Disks that lets you handle the disks in your system.
You can use the same tool for getting the partition type of the disk as well.
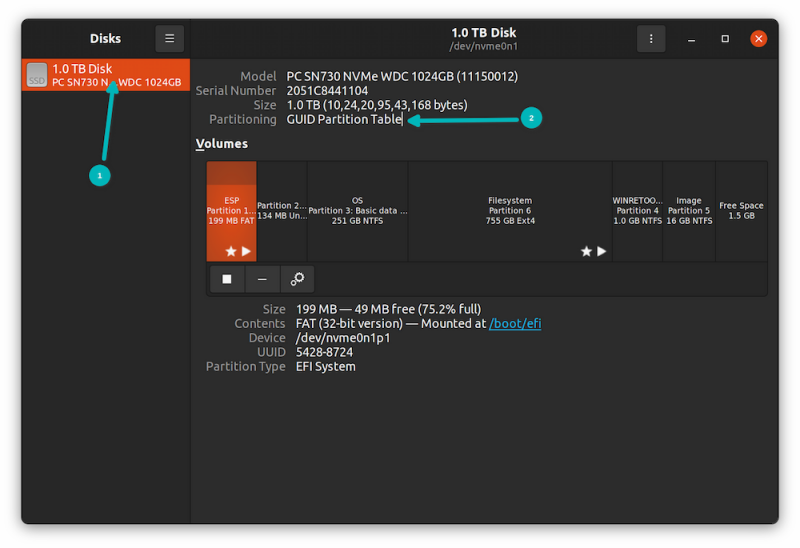
### Checking disk information with Gparted graphical tool
If you don’t have the option to use GNOME Disks tool, no worries. There are other tools available.
One such popular tool is Gparted. You should find it in the repositories of most Linux distributions. If not installed already, [install Gparted](https://itsfoss.com/gparted/) using your distribution’s software center or [package manager](https://itsfoss.com/package-manager/).
In Gparted, select the disk and from the menu select **View->Device** Information. It will start showing the disk information in the bottom-left area and this information includes the partitioning scheme.
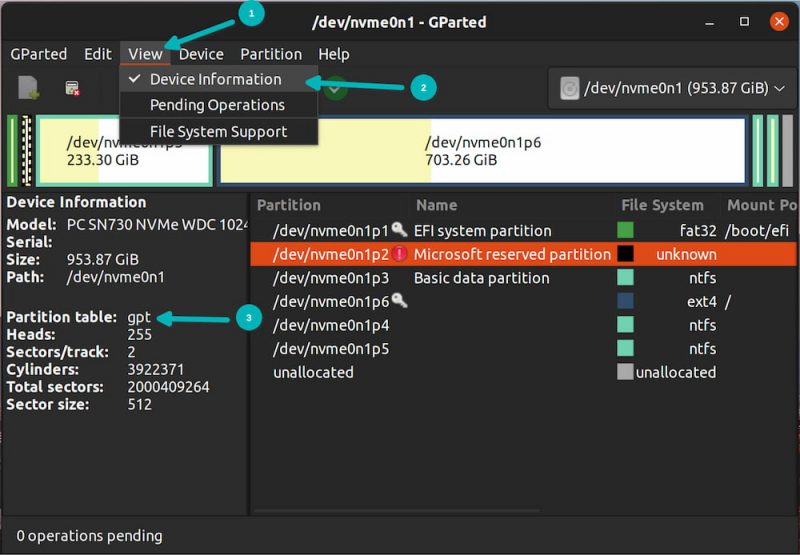
See, not too complicated, was it? Now you know multiple ways of figuring our whether the disks in your system use GPT or MBR partitioning scheme.
On the same note, I would also like to mention that sometimes disks also have a [hybrid partitioning scheme](http://www.rodsbooks.com/gdisk/hybrid.html?ref=itsfoss.com). This is not common and most of the time it is either MBR or GPT.
Questions? Suggestions? Please leave a comment below. |
13,729 | 用 ncdu 检查 Linux 中的可用磁盘空间 | https://opensource.com/article/21/8/ncdu-check-free-disk-space-linux | 2021-08-29T09:58:32 | [
"磁盘"
] | https://linux.cn/article-13729-1.html |
>
> 用 ncdu Linux 命令获得关于磁盘使用的交互式报告。
>
>
>

计算机用户多年来往往积累了大量的数据,无论是重要的个人项目、数码照片、视频、音乐还是代码库。虽然现在的硬盘往往相当大,但有时你必须退一步,评估一下你在硬盘上实际存储了什么。经典的 Linux 命令 [df](https://opensource.com/article/21/7/check-disk-space-linux-df) 和 [du](https://opensource.com/article/21/7/check-disk-space-linux-du) 是快速了解硬盘上的内容的方法,它们提供了一个可靠的报告,易于解析和处理。这对脚本和处理来说是很好的,但人的大脑对数百行的原始数据并不总是反应良好。认识到这一点,`ncdu` 命令旨在提供一份关于你在硬盘上使用的空间的交互式报告。
### 在 Linux 上安装 ncdu
在 Linux 上,你可以从你的软件仓库安装 `ncdu`。例如,在 Fedora 或 CentOS 上:
```
$ sudo dnf install ncdu
```
在 BSD 上,你可以使用 [pkgsrc](https://opensource.com/article/19/11/pkgsrc-netbsd-linux)。
在 macOS 上,你可以从 [MacPorts](https://opensource.com/article/20/11/macports) 或 [HomeBrew](https://opensource.com/article/20/6/homebrew-mac) 安装。
另外,你也可以 [从源码编译 ncdu](https://dev.yorhel.nl/ncdu)。
### 使用 ncdu
`ncdu` 界面使用 ncurses 库,它将你的终端窗口变成一个基本的图形应用,所以你可以使用方向键来浏览菜单。

这是 `ncdu` 的主要吸引力之一,也是它与最初的 `du` 命令不同的地方。
要获得一个目录的完整列表,启动 `ncdu`。它默认为当前目录。
```
$ ncdu
ncdu 1.16 ~ Use the arrow keys to navigate, press ? for help
--- /home/tux -----------------------------------------------
22.1 GiB [##################] /.var
19.0 GiB [############### ] /Iso
10.0 GiB [######## ] /.local
7.9 GiB [###### ] /.cache
3.8 GiB [### ] /Downloads
3.6 GiB [## ] /.mail
2.9 GiB [## ] /Code
2.8 GiB [## ] /Documents
2.3 GiB [# ] /Videos
[...]
```
这个列表首先显示了最大的目录(在这个例子中,那是 `~/.var` 目录,塞满了很多的 flatpak 包)。
使用键盘上的方向键,你可以浏览列表,深入到一个目录,这样你就可以更好地了解什么东西占用了最大的空间。
### 获取一个特定目录的大小
你可以在启动 `ncdu` 时提供任意一个文件夹的路径:
```
$ ncdu ~/chromiumos
```
### 排除目录
默认情况下,`ncdu` 包括一切可以包括的东西,包括符号链接和伪文件系统,如 procfs 和 sysfs。你可以用 `--exclude-kernfs` 来排除这些。
你可以使用 `--exclude` 选项排除任意文件和目录,并在后面加上一个匹配模式。
```
$ ncdu --exclude ".var"
19.0 GiB [##################] /Iso
10.0 GiB [######### ] /.local
7.9 GiB [####### ] /.cache
3.8 GiB [### ] /Downloads
[...]
```
另外,你可以在文件中列出要排除的文件和目录,并使用 `--exclude-from` 选项来引用该文件:
```
$ ncdu --exclude-from myexcludes.txt /home/tux
10.0 GiB [######### ] /.local
7.9 GiB [####### ] /.cache
3.8 GiB [### ] /Downloads
[...]
```
### 颜色方案
你可以用 `--color dark` 选项给 `ncdu` 添加一些颜色。

### 包括符号链接
`ncdu` 输出按字面意思处理符号链接,这意味着一个指向 9GB 文件的符号链接只占用 40 个字节。
```
$ ncdu ~/Iso
9.3 GiB [##################] CentOS-Stream-8-x86_64-20210427-dvd1.iso
@ 0.0 B [ ] fake.iso
```
你可以用 `--follow-symlinks` 选项强制 ncdu 跟踪符号链接:
```
$ ncdu --follow-symlinks ~/Iso
9.3 GiB [##################] fake.iso
9.3 GiB [##################] CentOS-Stream-8-x86_64-20210427-dvd1.iso
```
### 磁盘使用率
磁盘空间用完并不有趣,所以监控你的磁盘使用情况很重要。`ncdu` 命令使它变得简单和互动。下次当你对你的电脑上存储的东西感到好奇时,或者只是想以一种新的方式探索你的文件系统时,不妨试试 `ncdu`。
---
via: <https://opensource.com/article/21/8/ncdu-check-free-disk-space-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Computer users tend to amass a lot of data over the years, whether it's important personal projects, digital photos, videos, music, or code repositories. While hard drives tend to be pretty big these days, sometimes you have to step back and take stock of what you're actually storing on your drives. The classic Linux commands [ df](https://opensource.com/article/21/7/check-disk-space-linux-df) and
[are quick ways to gain insight about what's on your drive, and they provide a reliable report that's easy to parse and process. That's great for scripting and processing, but the human brain doesn't always respond well to hundreds of lines of raw data. In recognition of this, the](https://opensource.com/article/21/7/check-disk-space-linux-du)
`du`
`ncdu`
command aims to provide an interactive report about the space you're using on your hard drive.## Installing ncdu on Linux
On Linux, you can install `ncdu`
from your software repository. For instance, on Fedora or CentOS:
`$ sudo dnf install ncdu`
On BSD, you can use [pkgsrc](https://opensource.com/article/19/11/pkgsrc-netbsd-linux).
On macOS, you can install from [MacPorts](https://opensource.com/article/20/11/macports) or [HomeBrew](https://opensource.com/article/20/6/homebrew-mac).
Alternately, you can [compile ncdu from source code](https://dev.yorhel.nl/ncdu).
## Using ncdu
The interface of `ncdu`
uses the ncurses library, which turns your terminal window into a rudimentary graphical application so you can use the Arrow keys to navigate visual menus.
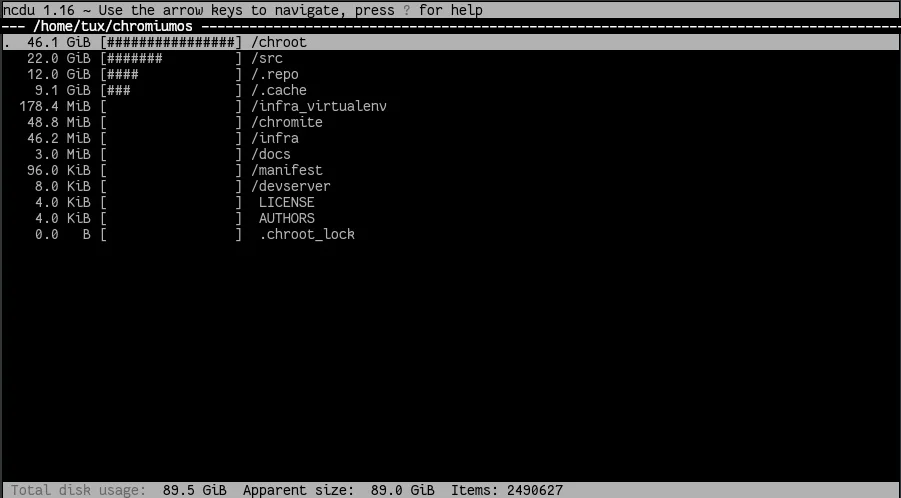
CC BY-SA Seth Kenlon
That's one of the main appeals of `ncdu`
, and what sets it apart from the original `du`
command.
To get a complete listing of a directory, launch `ncdu`
. It defaults to the current directory.
```
$ ncdu
ncdu 1.16 ~ Use the arrow keys to navigate, press ? for help
--- /home/tux -----------------------------------------------
22.1 GiB [##################] /.var
19.0 GiB [############### ] /Iso
10.0 GiB [######## ] /.local
7.9 GiB [###### ] /.cache
3.8 GiB [### ] /Downloads
3.6 GiB [## ] /.mail
2.9 GiB [## ] /Code
2.8 GiB [## ] /Documents
2.3 GiB [# ] /Videos
[...]
```
The listing shows the largest directory first (in this example, that's the `~/.var`
directory, full of many many flatpaks).
Using the Arrow keys on your keyboard, you can navigate through the listing to move deeper into a directory so you can gain better insight into what's taking up the most space.
## Get the size of a specific directory
You can run `ncdu`
on an arbitrary directory by providing the path of a folder when launching it:
`$ ncdu ~/chromiumos`
## Excluding directories
By default, `ncdu`
includes everything it can, including symbolic links and pseudo-filesystems such as procfs and sysfs. `You can`
exclude these with the `--exclude-kernfs`
.
You can exclude arbitrary files and directories using the --exclude option, followed by a pattern to match.
```
$ ncdu --exclude ".var"
19.0 GiB [##################] /Iso
10.0 GiB [######### ] /.local
7.9 GiB [####### ] /.cache
3.8 GiB [### ] /Downloads
[...]
```
Alternately, you can list files and directories to exclude in a file, and cite the file using the `--exclude-from `
option:
```
$ ncdu --exclude-from myexcludes.txt /home/tux
10.0 GiB [######### ] /.local
7.9 GiB [####### ] /.cache
3.8 GiB [### ] /Downloads
[...]
```
## Color scheme
You can add some color to ncdu with the `--color dark`
option.
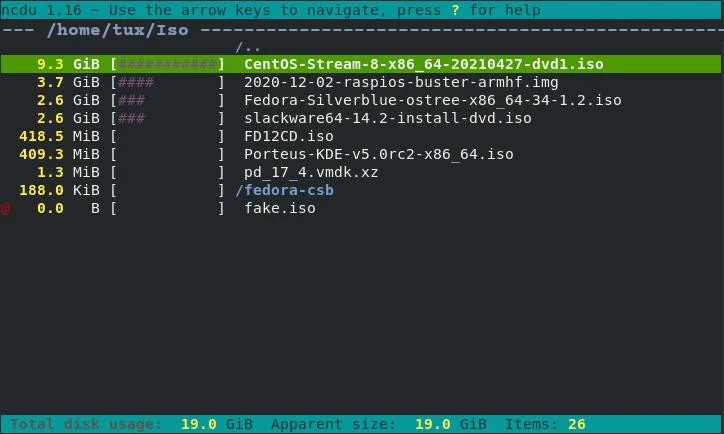
CC BY-SA Seth Kenlon
## Including symlinks
The `ncdu`
output treats symlinks literally, meaning that a symlink pointing to a 9 GB file takes up just 40 bytes.
```
$ ncdu ~/Iso
9.3 GiB [##################] CentOS-Stream-8-x86_64-20210427-dvd1.iso
@ 0.0 B [ ] fake.iso
```
You can force ncdu to follow symlinks with the `--follow-symlinks`
option:
```
$ ncdu --follow-symlinks ~/Iso
9.3 GiB [##################] fake.iso
9.3 GiB [##################] CentOS-Stream-8-x86_64-20210427-dvd1.iso
```
## Disk usage
It's not fun to run out of disk space, so monitoring your disk usage is important. The `ncdu`
command makes it easy and interactive. Try `ncdu`
the next time you're curious about what you've got stored on your PC, or just to explore your filesystem in a new way.
## 3 Comments |
13,730 | 如何在 Bash shell 脚本中解析命令行选项 | https://opensource.com/article/21/8/option-parsing-bash | 2021-08-29T11:08:59 | [
"shell",
"脚本",
"选项"
] | https://linux.cn/article-13730-1.html |
>
> 给你的 shell 脚本添加选项。
>
>
>

终端命令通常具有 [选项或开关](https://opensource.com/article/21/8/linux-terminal#options),用户可以使用它们来修改命令的执行方式。关于命令行界面的 [POSIX 规范](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 中就对选项做出了规范,这也是最早的 UNIX 应用程序建立的一个由来已久的惯例,因此你在创建自己的命令时,最好知道如何将选项包含进 [Bash 脚本](https://opensource.com/downloads/bash-scripting-ebook) 中。
与大多数语言一样,有若干种方法可以解决 Bash 中解析选项的问题。但直到今天,我最喜欢的方法仍然是我从 Patrick Volkerding 的 Slackware 构建脚本中学到的方法,当我第一次发现 Linux 并敢于冒险探索操作系统所附带的纯文本文件时,这些脚本就是我的 shell 脚本的引路人。
### Bash 中的选项解析
在 Bash 中解析选项的策略是循环遍历所有传递给 shell 脚本的参数,确定它们是否是一个选项,然后转向下一个参数。重复这个过程,直到没有选项为止。
```
#!/bin/bash
while [ True ]; do
if [ "$1" = "--alpha" -o "$1" = "-a" ]; then
ALPHA=1
shift 1
else
break
fi
done
echo $ALPHA
```
在这段代码中,我创建了一个 `while` 循环,它会一直进行循环操作,直到处理完所有参数。`if` 语句会试着将在第一个位置(`$1`)中找到的参数与 `--alpha` 或 `-a` 匹配。(此处的待匹配项是任意选项名称,并没有特殊意义。在实际的脚本中,你可以使用 `--verbose` 和 `-v` 来触发详细输出)。
`shift` 关键字会使所有参数位移一位,这样位置 2(`$2`)的参数移动到位置 1(`$1`)。处理完所有参数后会触发 `else` 语句,进而中断 `while` 循环。
在脚本的末尾,`$ALPHA` 的值会输出到终端。
测试一下这个脚本:
```
$ bash ./test.sh --alpha
1
$ bash ./test.sh
$ bash ./test.sh -a
1
```
可以看到,选项被正确地检测到了。
### 在 Bash 中检测参数
但上面的脚本还有一个问题:多余的参数被忽略了。
```
$ bash ./test.sh --alpha foo
1
$
```
要想捕获非选项名的参数,可以将剩余的参数转储到 [Bash 数组](https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays) 中。
```
#!/bin/bash
while [ True ]; do
if [ "$1" = "--alpha" -o "$1" = "-a" ]; then
ALPHA=1
shift 1
else
break
fi
done
echo $ALPHA
ARG=( "${@}" )
for i in ${ARG[@]}; do
echo $i
done
```
测试一下新版的脚本:
```
$ bash ./test.sh --alpha foo
1
foo
$ bash ./test.sh foo
foo
$ bash ./test.sh --alpha foo bar
1
foo
bar
```
### 带参选项
有一些选项需要传入参数。比如,你可能希望允许用户设置诸如颜色或图形分辨率之类的属性,或者将应用程序指向自定义配置文件。
要在 Bash 中实现这一点,你仍然可以像使用布尔开关一样使用 `shift` 关键字,但参数需要位移两位而不是一位。
```
#!/bin/bash
while [ True ]; do
if [ "$1" = "--alpha" -o "$1" = "-a" ]; then
ALPHA=1
shift 1
elif [ "$1" = "--config" -o "$1" = "-c" ]; then
CONFIG=$2
shift 2
else
break
fi
done
echo $ALPHA
echo $CONFIG
ARG=( "${@}" )
for i in ${ARG[@]}; do
echo $i
done
```
在这段代码中,我添加了一个 `elif` 子句来将每个参数与 `--config` 和 `-c` 进行比较。如果匹配,名为 `CONFIG` 的变量的值就设置为下一个参数的值(这就表示 `--config` 选项需要一个参数)。所有参数都位移两位:其中一位是跳过 `--config` 或 `-c`,另一位是跳过其参数。与上节一样,循环重复直到没有匹配的参数。
下面是新版脚本的测试:
```
$ bash ./test.sh --config my.conf foo bar
my.conf
foo
bar
$ bash ./test.sh -a --config my.conf baz
1
my.conf
baz
```
### Bash 让选项解析变得简单
还有一些其他方法也可以解析 Bash 中的选项。你可以替换使用 `case` 语句或 `getopt` 命令。无论使用什么方法,给你的用户提供选项都是应用程序的重要功能,而 Bash 让解析选项成为了一件简单的事。
---
via: <https://opensource.com/article/21/8/option-parsing-bash>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[unigeorge](https://github.com/unigeorge) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Terminal commands usually have [options or switches](https://opensource.com/article/21/8/linux-terminal#options), which you can use to modify how the command does what it does. Options are included in the [POSIX specification](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) for command-line interfaces. It's also a time-honored convention established with the earliest UNIX applications, so it's good to know how to include them in your [Bash scripts](https://opensource.com/downloads/bash-scripting-ebook) when you're creating your own commands.
As with most languages, there are several ways to solve the problem of parsing options in Bash. To this day, my favorite method remains the one I learned from Patrick Volkerding's Slackware build scripts, which served as my introduction to shell scripting back when I first discovered Linux and dared to venture into the plain text files that shipped with the OS.
## Option parsing in Bash
The strategy for parsing options in Bash is to cycle through all arguments passed to your shell script, determine whether they are an option or not, and then shift to the next argument. Repeat this process until no options remain.
Start with a simple Boolean option (sometimes called a *switch* or a *flag*):
```
#!/bin/bash
while [ True ]; do
if [ "$1" = "--alpha" -o "$1" = "-a" ]; then
ALPHA=1
shift 1
else
break
fi
done
echo $ALPHA
```
In this code, I create a `while`
loop which serves as an infinite loop until there are no further arguments to process. An `if`
statement attempts to match whatever argument is found in the first position (`$1`
) to either `--alpha`
or `-a`
. (These are arbitrary option names with no special significance. In an actual script, you might use `--verbose`
and `-v`
to trigger verbose output).
The `shift`
keyword causes all arguments to shift by 1, such that an argument in position 2 (`$2`
) is moved into position 1 (`$1`
). The `else`
statement is triggered when there are no further arguments to process, which breaks the `while`
loop.
At the end of the script, the value of `$ALPHA`
is printed to the terminal.
Test the script:
```
$ bash ./test.sh --alpha
1
$ bash ./test.sh
$ bash ./test.sh -a
1
```
The option is correctly detected.
## Detecting arguments in Bash
There is a problem, though: Extra arguments are ignored.
```
$ bash ./test.sh --alpha foo
1
$
```
To catch arguments that aren't intended as options, you can dump remaining arguments into a [Bash array](https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays).
```
#!/bin/bash
while [ True ]; do
if [ "$1" = "--alpha" -o "$1" = "-a" ]; then
ALPHA=1
shift 1
else
break
fi
done
echo $ALPHA
ARG=( "${@}" )
for i in ${ARG[@]}; do
echo $i
done
```
Test the new version of the script:
```
$ bash ./test.sh --alpha foo
1
foo
$ bash ./test.sh foo
foo
$ bash ./test.sh --alpha foo bar
1
foo
bar
```
## Options with arguments
Some options require an argument all their own. For instance, you might want to allow the user to set an attribute such as a color or the resolution of a graphic or to point your application to a custom configuration file.
To implement this in Bash, you can use the `shift`
keyword as you do with Boolean switches but shift the arguments by 2 instead of 1.
```
#!/bin/bash
while [ True ]; do
if [ "$1" = "--alpha" -o "$1" = "-a" ]; then
ALPHA=1
shift 1
elif [ "$1" = "--config" -o "$1" = "-c" ]; then
CONFIG=$2
shift 2
else
break
fi
done
echo $ALPHA
echo $CONFIG
ARG=( "${@}" )
for i in ${ARG[@]}; do
echo $i
done
```
In this code, I add an `elif`
clause to compare each argument to both `--config`
and `-c`
. In the event of a match, the value of a variable called `CONFIG`
is set to the value of whatever the second argument is (this means that the `--config`
option requires an argument). All arguments shift place by 2: 1 to shift `--config`
or `-c`
, and 1 to move its argument. As usual, the loop repeats until no matching arguments remain.
Here's a test of the new version of the script:
```
$ bash ./test.sh --config my.conf foo bar
my.conf
foo
bar
$ bash ./test.sh -a --config my.conf baz
1
my.conf
baz
```
## Option parsing made easy
There are other ways to parse options in Bash. You can alternately use a `case`
statement or the `getopt`
command. Whatever you choose to use, options for your users are important features for any application, and Bash makes it easy.
## Comments are closed. |
13,732 | 15 个被黑客利用来数百万次入侵 Linux 系统的顶级漏洞 | https://thehackernews.com/2021/08/top-15-vulnerabilities-attackers.html | 2021-08-29T22:57:22 | [
"安全",
"漏洞"
] | https://linux.cn/article-13732-1.html | 
有将近 1400 万基于 Linux 的系统直接暴露在互联网上,这使得它们成为有利可图的现实世界攻击目标,这些攻击可能会导致它们被部署恶意的 Webshell、加密货币矿工、勒索软件和其他木马。
网络安全公司 [趋势科技](https://www.trendmicro.com/vinfo/us/security/news/cybercrime-and-digital-threats/linux-threat-report-2021-1h-linux-threats-in-the-cloud-and-security-recommendations) 发布了一份对 Linux 威胁形势的深入研究,其根据从蜜罐、传感器和匿名遥测中收集的数据,详细介绍了 2021 年上半年影响 Linux 操作系统的首要威胁和漏洞。
该公司检测到近 1500 万个针对基于 Linux 的云环境的恶意软件事件,发现加密货币矿工和勒索软件占所有恶意软件的 54%,Webshell 占 29%。

此外,通过剖析同一时期 10 万台 Linux 主机报告的 5000 多万例事件,研究人员发现了 15 个顶级安全缺陷,这些缺陷已经在野外被广泛利用或有了概念证明(PoC):
* [CVE-2017-5638](https://nvd.nist.gov/vuln/detail/CVE-2017-5638)(CVSS 评分:10.0) - Apache Struts 2 远程代码执行(RCE)漏洞
* [CVE-2017-9805](https://nvd.nist.gov/vuln/detail/CVE-2017-9805)(CVSS 评分:8.1) - Apache Struts 2 REST 插件 XStream RCE 漏洞
* [CVE-2018-7600](https://nvd.nist.gov/vuln/detail/CVE-2018-7600)(CVSS 评分:9.8) - Drupal Core RCE 漏洞
* [CVE-2020-14750](https://nvd.nist.gov/vuln/detail/CVE-2020-14750)(CVSS 评分:9.8) - Oracle WebLogic Server RCE 漏洞
* [CVE-2020-25213](https://nvd.nist.gov/vuln/detail/CVE-2020-25213)(CVSS 评分:10.0) - WordPress 文件管理器(wp-file-manager)插件 RCE 漏洞
* [CVE-2020-17496](https://nvd.nist.gov/vuln/detail/CVE-2020-17496)(CVSS score: 9.8) - vBulletin subwidgetConfig 未认证 RCE 漏洞
* [CVE-2020-11651](https://nvd.nist.gov/vuln/detail/CVE-2020-11651)(CVSS 评分: 9.8) - SaltStack Salt 授权弱点漏洞
* [CVE-2017-12611](https://nvd.nist.gov/vuln/detail/CVE-2017-12611)(CVSS 评分: 9.8) - Apache Struts OGNL 表达式 RCE 漏洞
* [CVE-2017-7657](https://nvd.nist.gov/vuln/detail/CVE-2017-7657)(CVSS score: 9.8) - Eclipse Jetty 块长度解析的整数溢出漏洞
* [CVE-2021-29441](https://nvd.nist.gov/vuln/detail/CVE-2021-29441)(CVSS 评分:9.8) - 阿里巴巴 Nacos AuthFilter 认证绕过漏洞
* [CVE-2020-14179](https://nvd.nist.gov/vuln/detail/CVE-2020-14179)(CVSS 评分:5.3) - Atlassian Jira 信息泄露漏洞
* [CVE-2013-4547](https://nvd.nist.gov/vuln/detail/CVE-2013-4547)(CVSS 评分:8.0) - Nginx 制作的 URI 字符串处理访问限制绕过漏洞
* [CVE-2019-0230](https://nvd.nist.gov/vuln/detail/CVE-2019-0230)(CVSS 评分:9.8) - Apache Struts 2 RCE 漏洞
* [CVE-2018-11776](https://nvd.nist.gov/vuln/detail/CVE-2018-11776)(CVSS 评分:8.1) - Apache Struts OGNL 表达式RCE 漏洞
* [CVE-2020-7961](https://nvd.nist.gov/vuln/detail/CVE-2020-7961)(CVSS 评分:9.8) - Liferay Portal 不受信任的反序列化漏洞

更令人不安的是,官方 Docker Hub 资源库中最常用的 15 个 Docker 镜像被发现存在数百个漏洞,这涉及 python、node、wordpress、golang、nginx、postgres、influxdb、httpd、mysql、debian、memcached、redis、mongo、centos 和 rabbitmq。这表明需要在开发管道的每个阶段[保护容器](https://www.trendmicro.com/vinfo/us/security/news/security-technology/container-security-examining-potential-threats-to-the-container-environment)免受广泛的潜在威胁。
研究人员总结说:“用户和组织应始终应用安全最佳实践,其中包括利用安全设计方法,部署多层虚拟补丁或漏洞屏蔽,采用最小特权原则,并坚持共同责任模式。”
---
via: <https://thehackernews.com/2021/08/top-15-vulnerabilities-attackers.html>
作者:[Ravie Lakshmanan](https://thehackernews.com/p/authors.html) 选题:[wxy](https://github.com/wxy) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-13730-1.html) 荣誉推出
| 200 | OK | Close to 14 million Linux-based systems are directly exposed to the Internet, making them a lucrative target for an array of real-world attacks that could result in the deployment of malicious web shells, coin miners, ransomware, and other trojans.
That's according to an in-depth look at the Linux threat landscape published by U.S.-Japanese cybersecurity firm [Trend Micro](https://www.trendmicro.com/vinfo/us/security/news/cybercrime-and-digital-threats/linux-threat-report-2021-1h-linux-threats-in-the-cloud-and-security-recommendations), detailing the top threats and vulnerabilities affecting the operating system in the first half of 2021, based on data amassed from honeypots, sensors, and anonymized telemetry.
The company, which detected nearly 15 million malware events aimed at Linux-based cloud environments, found coin miners and ransomware to make up 54% of all malware, with web shells accounting for a 29% share.
In addition, by dissecting over 50 million events reported from 100,000 unique Linux hosts during the same time period, the researchers found 15 different security weaknesses that are known to be actively exploited in the wild or have a proof of concept (PoC) —
(CVSS score: 10.0) - Apache Struts 2 remote code execution (RCE) vulnerability**CVE-2017-5638**(CVSS score: 8.1) - Apache Struts 2 REST plugin XStream RCE vulnerability**CVE-2017-9805**(CVSS score: 9.8) - Drupal Core RCE vulnerability**CVE-2018-7600**(CVSS score: 9.8) - Oracle WebLogic Server RCE vulnerability**CVE-2020-14750**(CVSS score: 10.0) - WordPress File Manager (wp-file-manager) plugin RCE vulnerability**CVE-2020-25213**(CVSS score: 9.8) - vBulletin 'subwidgetConfig' unauthenticated RCE vulnerability**CVE-2020-17496**(CVSS score: 9.8) - SaltStack Salt authorization weakness vulnerability**CVE-2020-11651**(CVSS score: 9.8) - Apache Struts OGNL expression RCE vulnerability**CVE-2017-12611**(CVSS score: 9.8) - Eclipse Jetty chunk length parsing integer overflow vulnerability**CVE-2017-7657**(CVSS score: 9.8) - Alibaba Nacos AuthFilter authentication bypass vulnerability**CVE-2021-29441**(CVSS score: 5.3) - Atlassian Jira information disclosure vulnerability**CVE-2020-14179**(CVSS score: 8.0) - Nginx crafted URI string handling access restriction bypass vulnerability**CVE-2013-4547**(CVSS score: 9.8) - Apache Struts 2 RCE vulnerability**CVE-2019-0230**(CVSS score: 8.1) - Apache Struts OGNL expression RCE vulnerability**CVE-2018-11776**(CVSS score: 9.8) - Liferay Portal untrusted deserialization vulnerability**CVE-2020-7961**
Even more troublingly, the 15 most commonly used Docker images on the official Docker Hub repository has been revealed to harbor hundreds of vulnerabilities spanning across python, node, wordpress, golang, nginx, postgres, influxdb, httpd, mysql, debian, memcached, redis, mongo, centos, and rabbitmq, underscoring the need to [secure containers](https://www.trendmicro.com/vinfo/us/security/news/security-technology/container-security-examining-potential-threats-to-the-container-environment) from a wide range of potential threats at each stage of the development pipeline.
"Users and organizations should always apply security best practices, which include utilizing the security by design approach, deploying multilayered virtual patching or vulnerability shielding, employing the principle of least privilege, and adhering to the shared responsibility model," the researchers concluded. |
13,733 | 如何在 Linux 中实时监控日志文件 | https://www.debugpoint.com/2021/08/monitor-log-files-real-time/ | 2021-08-30T08:26:18 | [
"日志"
] | /article-13733-1.html |
>
> 本教程解释了如何实时监控 Linux 日志文件(桌面、服务器或应用),以进行诊断和故障排除。
>
>
>

当你在你的 Linux 桌面、服务器或任何应用中遇到问题时,你会首先查看各自的日志文件。日志文件通常是来自应用的文本和信息流,上面有一个时间戳。它可以帮助你缩小具体的实例,并帮助你找到任何问题的原因。它也可以帮助从网络上获得援助。
一般来说,所有的日志文件都位于 `/var/log` 中。这个目录包含以 `.log` 为扩展名的特定应用、服务的日志文件,它还包含单独的其他目录,这些目录包含其日志文件。

所以说,如果你想监控一堆日志文件或特定的日志文件。这里有一些你可以做到方法。
### 实时监控 Linux 日志文件
#### 使用 tail 命令
使用 `tail` 命令是实时跟踪日志文件的最基本方法。特别是,如果你所在的服务器只有一个终端,没有 GUI。这是很有帮助的。
比如:
```
tail /path/to/log/file
```

使用开关 `-f` 来跟踪日志文件,它是实时更新的。例如,如果你想跟踪 `syslog`,你可以使用以下命令:
```
tail -f /var/log/syslog
```
你可以用一个命令监控多个日志文件,使用:
```
tail -f /var/log/syslog /var/log/dmesg
```
如果你想监控 http 或 sftp 或任何服务器,你也可以在这个命令中监控它们各自的日志文件。
记住,上述命令需要管理员权限。
#### 使用 lnav(日志文件浏览器)

`lnav` 是一个很好的工具,你可以用它来通过彩色编码的信息以更有条理的方式监控日志文件。在 Linux 系统中,它不是默认安装的。你可以用下面的命令来安装它:
```
sudo apt install lnav ### Ubuntu
sudo dnf install lnav ### Fedora
```
好的是,如果你不想安装它,你可以直接下载其预编译的可执行文件,然后在任何地方运行。甚至从 U 盘上也可以。它不需要设置,而且有很多功能。使用 `lnav`,你可以通过 SQL 查询日志文件,以及其他很酷的功能,你可以在它的 [官方网站](https://lnav.org/features) 上了解。
一旦安装,你可以简单地用管理员权限从终端运行 `lnav`,它将默认显示 `/var/log` 中的所有日志并开始实时监控。
#### 关于 systemd 的 journalctl 说明
今天所有的现代 Linux 发行版大多使用 systemd。systemd 提供了运行 Linux 操作系统的基本框架和组件。systemd 通过 `journalctl` 提供日志服务,帮助管理所有 systemd 服务的日志。你还可以通过以下命令实时监控各个 systemd 服务和日志。
```
journalctl -f
```
下面是一些具体的 `journalctl` 命令,可以在一些情况下使用。你可以将这些命令与上面的 `-f` 开关结合起来,开始实时监控。
* 对紧急系统信息,使用:
```
journalctl -p 0
```
* 显示带有解释的错误:
```
journalctl -xb -p 3
```
* 使用时间控制来过滤输出:
```
journalctl --since "2020-12-04 06:00:00"
journalctl --since "2020-12-03" --until "2020-12-05 03:00:00"
journalctl --since yesterday
journalctl --since 09:00 --until "1 hour ago"
```
如果你想了解更多关于 `journalctl` 的细节,我已经写了一个 [指南](https://www.debugpoint.com/2020/12/systemd-journalctl/)。
### 结束语
我希望这些命令和技巧能帮助你找出桌面或服务器问题/错误的根本原因。对于更多的细节,你可以随时参考手册,摆弄各种开关。如果你对这篇文章有什么意见或看法,请在下面的评论栏告诉我。
加油。
---
via: <https://www.debugpoint.com/2021/08/monitor-log-files-real-time/>
作者:[Arindam](https://www.debugpoint.com/author/admin1/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response')) | null |
13,734 | 《代码英雄》第四季(7):游戏机 —— Dreamcast 的新生 | https://www.redhat.com/en/command-line-heroes/season-4/consoles | 2021-08-30T11:57:00 | [
"游戏机",
"代码英雄"
] | https://linux.cn/article-13734-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》:第四季(7):游戏机 —— Dreamcast 的新生](https://www.redhat.com/en/command-line-heroes/season-4/consoles)的[音频]( https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/0570a364-531f-472f-82f6-6b552fb07701/clh-s4e7-sega-dreamcast-vfinal-20200407_tc.mp3)脚本。
>
> 导语:游戏机是开创性的机器。Dreamcast(DC)推动了游戏机所能做到的极限。但这并不足以保证商业上的成功。但尽管它在商业上失败了,可粉丝们说,从没有其它游戏机取得过如此大的成就。
>
>
> 世嘉打造 Dreamcast 是为了恢复其辉煌时代。在令人失望的<ruby> 土星 <rt> Saturn </rt></ruby>之后,世嘉让两个团队相互竞争,以开发一个新的游戏机。Andrew Borman 将 Dreamcast 视为一个硬件上的时代性飞跃。Jeremy Parish 解释了它的生产与世嘉通常的流程的不同之处。Mineko Okamura 提供了关于开发 Dreamcast 的内幕消息。Brian Bacino 讲述了该游戏机在美国的大规模上市的情况。但是,尽管在美国的销售量创下了新高,世嘉还是不得不拔掉了 Dreamcast 的插头。不过因为它太棒了,像 Luke Benstead 这样的自制爱好者又把插头给插了回去。
>
>
>
**00:00:07 - Saron Yitbarek**:
1999 年 9 月 9 日,在日本的某个地方,一名间谍潜入了一个大型计算机的机房。她入侵并关闭了安全系统。警卫出来调查,却被她一个漂亮的踢腿打晕了。而这时,计算机系统却突然“活”了起来,所有警报都变红了,显示器上突然出现一个奇怪的漩涡图案。很明显,这个计算机系统正在运行、正在“思考”。间谍被吓跑了。而“思考”中的计算机想要阻止她,试图把她困在大楼里。最终,这名间谍撞破了一扇窗户逃跑了,不过在逃跑前她带走了一个箱子。而在这个箱子里,是一种可以改变一切的新型机器的原型机。
**00:01:06**:
我所描述的是一个名做“<ruby> 启示录 <rt> Apocalypse </rt></ruby>”的电视广告。它在宣传游戏公司<ruby> 世嘉 <rt> Sega </rt></ruby>最新的游戏机,这并非是一台普通的游戏机。这个革命性的装置被称为 Dreamcast(DC),“启示录”广告中的间谍正在偷的那个箱子里放的东西,正是那个游戏机。
**00:01:29 - Brian Bacino**:
然后这个 Dreamcast 盒子,从小偷的背上滚落下来,掉在了街上,这个神奇的盒子一直锁着的盖子突然打开了。这时,镜头放大到 Dreamcast,进入到了它的窗口之中,并下降到底部,在那里,所有的游戏角色们聚集在了一起。我们看到<ruby> 索尼克 <rt> Sonic </rt></ruby>在那里,他得意洋洋地说……
>
> **00:02:00 - 索尼克**:
>
>
> 我们拿到了!
>
>
>
**00:02:01 - Brian Bacino**:
大家全都兴奋地跳起来了,都在欢腾尖叫。
**00:02:05 - Saron Yitbarek**:
这位是 Brian Bacino,他是“启示录”广告活动的创意总监。他所指的“索尼克”就是世嘉著名的游戏角色“<ruby> 刺猬索尼克 <rt> Sonic the Hedgehog </rt></ruby>”。
**00:02:16**:
在上世纪 90 年代,世嘉是世界上最知名的电子游戏公司之一。但在那个年代结束时,竞争很激烈,所以世嘉把赌注全押在了 Dreamcast 上,它将成为公司的救星。“启示录”广告被描述为“有史以来最具史诗性的电子游戏商业广告”,似乎找不到更好的方法来展示这台有史以来最先进的游戏机了,它是如此的智能,你几乎可以说它真的在“思考”。
**00:02:49**:
唉,但是 Dreamcast 并没有改变世界。它几乎什么都没有改变。它被一些人认为是最棒的游戏机,但却从未有机会改变些什么。这是世嘉的最后一款游戏机,它几乎让该公司破产。
**00:03:11**:
这一季播客都是关于硬件改变了发展进程的,在本季的倒数第二集,让我们来看看世嘉 Dreamcast 系列的短暂历史。然而,尽管很短暂,但它仍然被许多人认为是有史以来最好的游戏机之一。在它结束后的 20 年里,它仍然以一种非常真实的方式存在着。
**00:03:40**:
我是 Saron Yitbarek,这里是《代码英雄》,一款来自红帽的原创播客。
**00:03:48**:
就像“启示录”广告里的那个思考的电脑,那低语......
>
> **00:03:52 - 配音 1**:
>
>
> 正在思考
>
>
>
**00:03:53 - Saron Yitbarek**:
成为了该公司新游戏机的新广告语。
**00:03:56 - Brian Bacino**:
所以一想到我们的配音员总是低语......
>
> **00:04:01 - 配音 1**:
>
>
> 正在思考
>
>
>
**00:04:02 - Brian Bacino**:
我们认为这是一个非常巧妙的方式,可以演变成世嘉标志性的口号。
>
> **00:04:10 - 配音 2**:
>
>
> SEGA!
>
>
>
**00:04:10 - Saron Yitbarek**:
这是一款越玩越聪明的游戏机,至少它的市场宣传是这样说的。这款游戏机为家用电子游戏市场带来了新的、大的、革命性的东西。这是一个为铁杆玩家服务而构建的系统。而在该公司内部,人们的想法是,这款游戏机将使世嘉成为电子游戏界的头牌。
**00:04:34 - Brian Bacino**:
这将改变游戏规则,改变世界。
**00:04:38 - Saron Yitbarek**:
所以,后来到底发生了什么?要想弄清楚这一切,我们需要回到过去,一直回到……
>
> **00:04:44 - 配音 3**:
>
>
> 第一关
>
>
>
**00:04:47 - Saron Yitbarek**:
在整个 90 年代早期,世嘉一直以制作超级酷的游戏而闻名,而且它的游戏比竞争对手的更成熟,尤其是相比于<ruby> 任天堂 <rt> Nintendo </rt></ruby>和它的那个拯救公主的水管工。他们用一款非常成功的游戏机<ruby> 世嘉创世记 <rt> Sega Genesis </rt></ruby>建立了这个声誉。
**00:05:05 - Alex Handy**:
世嘉决定成为真正的先锋,这些拥有过任天堂游戏机的孩子们,现在他们是青少年了,他们想要真正的体育游戏和真正的团队。他们想要血腥的格斗游戏,比如后来才出现的《<ruby> 真人快打 <rt> Mortal Kombat </rt></ruby>》。他们想要一个更成熟的、更刺激的游戏。
**00:05:22 - Saron Yitbarek**:
Alex Handy 是加州奥克兰<ruby> 艺术和数字娱乐博物馆 <rt> Museum of Art and Digital Entertainment </rt></ruby>的创始人兼负责人。他也为红帽公司工作。
**00:05:31 - Alex Handy**:
假如你回头看看这一时期的电子游戏杂志上的广告,会有点令人震惊。有些广告里会有一条血淋淋的断臂,上面有碎肉脱落,写着,“这是你对付坏人最好的武器。” 所以,世嘉在创世记游戏机上的刺猬索尼克的这种极端而刺激的成功方面做得非常非常好,与<ruby> 马里奥 <rt> Mario </rt></ruby>的 OshKosh B'gosh 工装裤的那种快乐主题正好相反。
**00:06:00 - Saron Yitbarek**:
超过 3000 万人购买了世嘉创世纪,这是一款 16 位的游戏机,可以用<ruby> 卡带 <rt> cartridge </rt></ruby>来玩游戏。全世界的玩家都喜欢它。
**00:06:11**:
随着时间的推移,世嘉努力扩大其用户群。创世纪之后,他们推出了 32 位世嘉<ruby> 土星 <rt> Saturn </rt></ruby>。比创世纪更强大的是,它可以显示二维图形和基本的三维图形。但是,土星平台从未真正兴起。它的销售很艰难。他们成功地卖出了 920 万台游戏机,只有创世纪的销量的三分之一。
**00:06:38**:
另一个严重问题是:开发者发现为土星专有的内部设计的硬件编写游戏是一个挑战。这是世嘉为未来埋下的一个隐患。再加上,任天堂 64 游戏机的推出,以及索尼的 PlayStation 的首次进入该领域,游戏业突然变得人满为患,竞争非常激烈。
**00:07:04**:
1998 年,世嘉公布亏损了 2.7 亿美元。在世嘉北美总部,电子游戏的负责人 Bernie Stolar 宣布了这样的一句话:“土星不是我们的未来”,他终止了土星的研发和销售。就这样,世嘉将重点转向打造下一代游戏机。
>
> **00:07:32 - 配音 3**:
>
>
> 第二关:打造梦想
>
>
>
**00:07:35 - Saron Yitbarek**:
世嘉土星已经严重伤害了该公司的品牌和利润。如果世嘉想要重新夺回市场份额和声誉,那么下一款游戏机需要功能更加强大、易于编写代码,并且与其他市场上其它游戏机都不一样。
**00:07:51**:
Andrew Borman 是纽约罗切斯特的<ruby> 斯特朗国家游戏博物馆 <rt> Strong National Museum of Play </rt></ruby>数字游戏馆的馆长。
**00:07:59 - Andrew Borman**:
他们想真正证明这是一个世代的飞跃。这不仅仅是世嘉土星的一个快速替代品,而是要推动图形、声音和在线技术的发展,以及 CPU 处理技术的进步,使得它比以前的游戏机更加智能化。
**00:08:22 - Saron Yitbarek**:
世嘉准备把他们的机器升级。在世嘉日本总部,他们有了一些想法。不过,他们并不是唯一有远大想法的人。
**00:08:34 - Andrew Borman**:
当时在世嘉内部也起了很多内讧。他们开始开发下一代游戏机,也就是 Dreamcast,而在美国的世嘉公司(世嘉美国)可能也有开发他们自己的下一代游戏机的想法。
**00:08:52 - Saron Yitbarek**:
因此,世嘉日本和世嘉美国同时开始开发两种不同的系统。这两个团队正在竞争谁的硬件设计会胜过对方。
**00:09:07 - Jeremy Parish**:
美国版被称为“<ruby> 黑带 <rt> Black Belt </rt></ruby>”,这是它的代号,日本版的代号是“<ruby> 杜拉尔 <rt> Dural </rt></ruby>”,以游戏《<ruby> VR 战士 <rt> Virtua Fighter </rt></ruby>》中的一个 BOSS 的名字命名。
**00:09:17 - Saron Yitbarek**:
Jeremy Parish 和人共同主持了一个名为 Retronauts 的播客。他说,日本和美国的团队都把从土星游戏机上吸取到的教训牢记在心。
**00:09:28 - Jeremy Parish**:
他们真的很想让这个系统更容易开发,这样那些创造游戏和编程游戏的人会说,“哦,你知道,这个系统有出色的性能,把游戏从其他系统移植到这里来会看起来更好。”这是他们考虑的一个关键因素。
**00:09:47 - Saron Yitbarek**:
这让他们远离了定制硅胶的设计。
**00:09:52 - Alex Handy**:
世嘉土星是从头开始建造的。我的意思是,他们设计了芯片,设计了驱动器,设计了所有部分。当到了设计 Dreamcast 的时候,世嘉只是使用了这些现成的处理器、现成的 3D 芯片,所有的东西都已经基本上设计好了,他们只是作为系统的集成商把它们整合在一起。在 90 年代的大部分时间里,它完全专注于硬件创新,这是世嘉公司迈出的重要一步。
**00:10:16 - Saron Yitbarek**:
但他们会采用哪种芯片呢?在这一点上,世嘉日本和世嘉美国意见相左。
**00:10:25 - Jeremy Parish**:
美国方面正在与 3dfx 合作,而日本方面正与 NEC 合作,共同开发基于 PowerVR 的 3D 解决方案。但由于各种政治和法律原因,世嘉最终选择了杜拉尔版本,即日本的硬件厂商。
**00:10:49 - Saron Yitbarek**:
所以,美国队的选择 3dfx 不见了。他们不得不选择了日本队的 PowerVR 芯片。这个决定给以后挖了个大坑。而后,再将其它的硬件集成在一起。DVD 技术还处于起步阶段,而且非常昂贵,因此排除了这种可能性。但是 CD-ROM 光盘,并不能容纳运行下一代游戏的图形、声音和复杂性的足够的数据。因此,世嘉用 GD-ROM(千兆光盘)光驱制造了游戏机,其本质上类似于 CD-ROM 系统,只是这些光盘能容纳千兆字节的数据。现在他们找到了这个游戏机的大脑。正如 Alex Handy 所说:
**00:11:42 - Alex Handy**:
真正重要的是,该系统确实包括了一个专用的 3D 渲染芯片。这个芯片可以做比 PlayStation 更复杂的三维渲染。Dreamcast 是我们开始获得 3D 的分界线,它在未来看起来还是相当不错的,你是知道后来的事情的。没有什么悬念。
**00:12:04 - Saron Yitbarek**:
这确实是次世代系统。Andrew Borman 表示,Dreamcast 正在成为世嘉为挑战自己而打造的革命性游戏机。
**00:12:15 - Andrew Borman**:
Dreamcast 的视频输出:它可以在四个 ADP 上输出 VGA 信号,在当时很多其他游戏机都没有这样的功能。
**00:12:23 - Saron Yitbarek**:
即使是像可拆卸存储卡、<ruby> 视觉存储单元 <rt> visual memory unit </rt></ruby>(VMU)这样简单的东西也是一种全新的设计。
**00:12:31 - Andrew Borman**:
Dreamcast 上的存储单元 VMU,真正暗示了以后的第二屏幕体验。
**00:12:39 - Saron Yitbarek**:
这些 VMU 上有小屏幕和按钮,就像一个微型游戏机。
**00:12:44 - Andrew Borman**:
你可以在里面存放你的游戏存档,它可以随身携带,可以在上面玩游戏,还可以以不同的方式、外形或形式带着你的存档,然后将其恢复到你家里的游戏机中。
**00:12:54 - Saron Yitbarek**:
但还不止这些。在 90 年代末,虽然也能将游戏机连接到互联网,但确实不常见。在线可玩性仍然只是一个概念,而不是现实。世嘉看到了这种机会。
**00:13:11 - Andrew Borman**:
每个 Dreamcast 都配有一个 56K 调制解调器,虽然现在看起来已经过时了,但当时没有其他游戏机配备了 56K 调制解调器。没有其他游戏机能够在其上安装 Web 浏览器。也没有其他游戏机可以下载内容,除非添加一些配件。而这台游戏机开箱就有这些。
**00:13:36 - Saron Yitbarek**:
这位是 Mineko Okamura,Grounding 公司的 CEO。她在 Dreamcast 时代曾是世嘉的一名助理制作人。
**00:13:50 - Mineko Okamura**:
我们当时的目标是,除了世嘉的核心粉丝,我们还想吸引新的世嘉游戏爱好者。首先,它有一个非常前沿的技术或功能,就是 Dreamcast 能够连接到互联网上,可能很多人还记得一个叫 《Seaman》的游戏,然后它引入了语音识别功能。虽然现在很普遍,但在当时,你可以通过在线下载更多的应用程序,这在当时是非常新颖的。
>
> **00:14:26 - 配音 3**:
>
>
> 第三关:梦想成真
>
>
>
**00:14:31 - Saron Yitbarek**:
继续生产新游戏主机的同时,世嘉土星也退役了。而由于世嘉的缺席,在市场上留下了一个需要填补的空白。1999 年,留给世嘉重新夺回市场份额的时间窗口很小,他们需要做的就是尽可能完美地推出新品。
**00:14:56 - Jeremy Parish**:
他们在全力以赴。Dreamcast 的发布会被广泛认为是有史以来最大的娱乐发布会。他们真的大获成功。对我来说,这是一个样板性的系统发布,就像他们应该做的那样。炒作和广告恰到好处,很引人入胜。
**00:15:16 - Saron Yitbarek**:
在发布之前,由 Brian Bacino 的“思考中”广告宣传活动所推动的炒作机器正在完美无缺地运作。下面这位是 Andrew Borman。
**00:15:26 - Andrew Borman**:
美国的 Dreamcast 在上市前就被预购了 30 万台,创下了新纪录。世嘉进入 1999 年 9 月 9 日,情况看起来非常非常好。
**00:15:40 - Saron Yitbarek**:
然后这一天到了。1999 年 9 月 9 日,Dreamcast 在美国上市,售价 199 美元。这是一个历史性的发布日。该公司在一开始的 24 小时内赚了 1 亿美元,创下了整个行业的纪录。他们把所有的游戏机都卖光了。
**00:16:11 - Andrew Borman**:
商店前台仍在不断打来电话,说,“嘿,我们需要更多的 Dreamcast 游戏机”,特别是当进入到第一个节假日的时候。
**00:16:17 - Saron Yitbarek**:
他们也确保了在发布时就有很多游戏可以玩。从格斗类到动作类再到比赛类和运动类,总共有 18 款游戏。
**00:16:26 - Andrew Borman**:
特别是在那个发布期间,我最喜欢的游戏之一是《<ruby> 索尼克大冒险 <rt> Sonic Adventure </rt></ruby>》,索尼克终于以一种非常棒的方式以 3D 形式出现了,此外还有《<ruby> 剑魂 <rt> Soulcalibur </rt></ruby>》。我是一个格斗游戏的超级粉丝,尤其是在那时,《剑魂》不仅是完美的街机游戏,而且比基于 PS1 硬件的街机版本还要好。有了 Dreamcast 和它绚丽的新图形显示,《剑魂》比我想象中的格斗游戏还要好得多。
**00:16:58 - Saron Yitbarek**:
玩家们喜欢 Dreamcast 的游戏库。它最终发展到有 600 多部作品。就连 Brian Bacino 也忍不住沉迷于其中。
**00:17:09 - Brian Bacino**:
就我个人来讲的话,我对《<ruby> 疯狂出租车 <rt> Crazy Taxi </rt></ruby>》完全着迷了。我沉迷于那个游戏,游戏中的感觉和 3D 图形是如此的有趣。
**00:17:22 - Saron Yitbarek**:
Dreamcast 显然是一款次世代游戏机,它的粉丝们都喜欢这款硬件。而且游戏本身也提供了一些不同的东西。
**00:17:31 - Jeremy Parish**:
你会体验到这么多标新立异的、富有创造性的、从未见过的游戏概念。
**00:17:38 - Saron Yitbarek**:
其中一个游戏需要一对<ruby> 沙槌 <rt> maracas </rt></ruby>来与游戏互动。还有一个游戏让你和一条长着人脸的奇怪的鱼互动。
**00:17:47 - Jeremy Parish**:
有一些控制器是非常古怪的。有一个类似传统游戏控制器的游戏控制器,但是它中间有一个完整的 ASCII 键盘,所以当你和他们在线玩的时候,你还可以打字给他们。这也适用于《<ruby> 死亡打字机 <rt> Typing of the Dead </rt></ruby>》游戏,它就像一个鬼屋射击游戏。只是你不是向僵尸射击,而是你向他们输入奇怪的、零散的短语,比如随机的英语短语。这真是一个奇怪而奇妙的系统。
**00:18:22 - Saron Yitbarek**:
世嘉在上市后的两个月内售出了第一百万台 Dreamcast。到圣诞节,它已经占据了北美市场的 31% 市场份额。他们做到了。Dreamcast 很受欢迎。但就在那次精彩的发布会后不久,Dreamcast 的梦想变成了一场噩梦。
>
> **00:18:47 - 配音 3**:
>
>
> 第四关:梦想夭折
>
>
>
**00:18:52 - Saron Yitbarek**:
尽管有着破纪录的销售和来自媒体以及铁杆玩家的赞誉,但该公司还是存在一些严重问题。首先,Dreamcast 在日本的表现并不好。他们在一年前就推出了,但销售情况不佳。这让公司损失惨重。
**00:19:10 - Jeremy Parish**:
是的,在日本的发布我觉得太早了。硬件的生产过程并没有达到所需的成熟度和可靠性。因此,出现了一些缺陷和短缺,以及供应链问题。不过,更大的问题是,在日本推出的 Dreamcast 游戏并不多。我记得只有三个游戏。
**00:19:35 - Mineko Okamura**:
[一段 00:01:37 的外语]
在 Dreamcast 真正上市的时候,我们有一个给人们留下深刻印象的广告,这是由我们的董事会成员之一 Yukawa 先生主导的。它确实卖得很好,但后来很快就卖完了,实际上我们花了很多时间重新准备库存,这很不幸,因为人们要等很长时间,然后销量开始下降。
**00:20:11 - Saron Yitbarek**:
在美国上市后,生产问题依然存在。供应不足阻碍了销售。
**00:20:17 - Andrew Borman**:
为 Dreamcast 提供动力的 PowerVR 芯片短缺,这意味着他们无法制造足够的游戏机,即便人们想买也买不到。尽管这些游戏机的销量还不错,但没有足够的游戏机可以卖。
**00:20:38 - Saron Yitbarek**:
PowerVR 芯片带来了另一个问题。它使他们失去了一些主要游戏工作室的支持,尤其是 <ruby> 电子艺界 <rt> Electronic Arts </rt></ruby>(EA)。EA 没有可以为 PowerVR 芯片编写代码的程序员团队,所以他们放弃了 Dreamcast。下面是 Jeremy Parish 的发言。
**00:20:56 - Jeremy Parish**:
我认为,最终真的对公司造成了严重伤害,因为 EA 在世嘉创世纪的成功中发挥了巨大作用,把他们的体育游戏如《<ruby> 麦登橄榄球 <rt> Madden NFL </rt></ruby>》放到任何一个平台都是对该平台的巨大推动,因为每年都有数百万人购买这些游戏。
**00:21:16 - Saron Yitbarek**:
撇开硬件问题不谈,他们已经赢得了铁杆玩家的青睐,但普通玩家还不认可。世嘉的炒作期已经结束。Dreamcast 已经上市了,但新的一轮炒作开始了。这次轮到了索尼和 PlayStation 2。以下是 Andrew Borman 的发言。
**00:21:37 - Andrew Borman**:
索尼在宣传方面做得非常非常出色。通过这个炒作机器,人们已经为 PlayStation 2 做好了准备。而不幸的是,到了 2000 年 12 月的节假日,Dreamcast 那个平台已经不怎么畅销了。
**00:21:56 - Saron Yitbarek**:
世嘉想尽一切办法提高销量,但似乎收效甚微。他们付出巨大的经济成本,大幅降低了这款游戏机 199 美元的标价。他们在 2000 年推出了一个在线游戏门户网站 SegaNet。他们提供免费订阅以吸引更多用户,但该公司一直在亏钱。2001 年 1 月,世嘉宣布将停止生产他们的次世代游戏机。在推出 16 个月后,Dreamcast 结束了。最后一批游戏机每台售价 50 美元。当这一切结束时,世嘉只卖出了 910 多万台,甚至比它所取代的失败的世嘉土星还要少。
>
> **00:22:55 - 配音 3**:
>
>
> 第五关:梦想重生
>
>
>
**00:23:00 - Jeremy Parish**:
我很失望,因为我认为,世嘉有着悠久的历史,作为游戏行业的一个重要参与者,他们总是给他们创造的游戏带来一种特殊的理念。在我看来,Dreamcast 确实是他们有史以来最富有创造力的平台。从 Dreamcast 中涌现出的大量发明和创新的游戏创意,在这之前或之后都没有人这么做过。所以,是的,当他们离场时,给人一种真正的失落感。
**00:23:31 - Saron Yitbarek**:
在 Dreamcast 之后,世嘉完全放弃了游戏机。对 Dreamcast 的技术支持一直持续到 2007 年,之后 Dreamcast 的拥有者只能靠自己了。那么,当你家里的书架上放着一台已经停产、没人支持,但深受喜爱的游戏机时,你会怎么做?好吧,对一些 Dreamcast 的超级粉丝来说,这是一个“自己动手”(DIY)复兴的开始。
**00:24:00 - Andrew Borman**:
当说到自制游戏的时候,说到在一个旧游戏机上玩真正出色的游戏的能力时,Dreamcast 社区是一个非常固执的社区。
**00:24:12 - Saron Yitbarek**:
你看,对于很多超级粉丝来说,Dreamcast 游戏机从未真正死去。他们如此热爱它,而为自己和他人留下了它。作为一个社区,他们蓬勃发展。就像我们在第三集中谈到的自制电脑俱乐部一样,他们也把自己的社区称为自制社区,因为他们也在不停的鼓捣这些。他们从其他平台移植游戏,或者从头开始构建全新的游戏。所有的一切都是为了一台注定要丢进硬件坟场的机器。
**00:24:45 - Alex Handy**:
让我看看,我找到了《<ruby> 武装七号 <rt> Armed 7 </rt></ruby>》、《<ruby> 寻找泰迪 <rt> Finding Teddy </rt></ruby>》、《Unit Yuki》、《<ruby> 魔法口袋 <rt> Magic Pockets </rt></ruby>》,还有《<ruby> 番茄超人 <rt> Captain Tomaday </rt></ruby>》,这似乎是一个会飞的西红柿的游戏。我们有横向卷轴射击游戏、点击式冒险游戏、平台式游戏。你无法真正预测或理解人们为什么要做这些东西。这是一种用爱发电,它需要付出大量的工作,人们在其中做他们想做的事情,我们称之为“自制场景”。
**00:25:17 - Andrew Borman**:
我想指出的一个例子是 Bleemcast,它是一个用于 Dreamcast 的索尼 PlayStation 模拟器。因此,PlayStation 的独占游戏《<ruby> GT 赛车 2 <rt> Gran Turismo 2 </rt></ruby>》现在也可以在 Dreamcast 上玩了。它不仅可以在 Dreamcast 上玩,而且看起来会更好。他们也为该系统开发了其他的模拟器,包括世嘉创世纪、任天堂 NES 模拟器。
**00:25:43 - Saron Yitbarek**:
之所以能做到这一点,一个重要原因是聪明的 Dreamcast 用户们早就发现该系统的反盗版保护措施非常容易绕过。当发现了这一点后,他们意识到他们可以让 Dreamcast 玩几乎任何一款经典游戏或独立游戏。
**00:26:06 - Luke Benstead**:
独立开发者甚至早在 2001 年就开始研究它,这种为它编写游戏和软件而不必越狱或做任何侵入性的事情的能力确实有帮助,因为它的门槛很低。所以,人们可以直接上网下载新的游戏和内容。
**00:26:25 - Saron Yitbarek**:
这位是 Luke Benstead。他是 Dreamcast 自制社区的一员。Luke 发现,人们正在设法将旧的 Dreamcasts 接入今天的现代互联网,这样他们就可以在线访问游戏了。
**00:26:40 - Luke Benstead**:
一直以来,人们仍然把他们的 Dreamcast 连接到互联网上,因为有一个叫做 PCDC 服务器的东西。人们曾经在他们的 Windows 个人电脑上,用 USB 调制解调器插入,也曾经把 Dreamcast 插入其中。如果他们在 Dreamcast 上拨号,在 PC 机上的适时运行合适的软件,这样就可以通过其进行路由。
**00:27:03 - Luke Benstead**:
我记得大约是在 2010 年,我上网买了一个 USB 调制解调器来试试这个。它就放在抽屉里,但我从没有真正抽出过时间去尝试。后来在 2015 年,我的第一个女儿刚刚出生,我正在休陪产假,而且我又刚刚买了一个树莓派,我突然意识到我可以把这些东西结合起来。
**00:27:28 - Saron Yitbarek**:
但在与社区分享他的树莓派解决方案之前,Luke 必须克服现代互联网的一个障碍。
**00:27:36 - Luke Benstead**:
PCDC 服务应用程序的问题是,虽然你可以让它运行起来,但很多游戏都无法运行,因为 Dreamcast 会寻找拨号音。当你在游戏中点击拨号连接时,很多游戏都希望有一个拨号音。很明显,如果你只是把它插进电脑里是没有拨号音的。所以当我开始考虑让这个树莓派运行 PCDC 服务应用程序时,我做的一件事就是下载拨号音的录音,并通过我用 Python 编写的软件把声音播放到调制解调器上。Dreamcast 会在电话那头听到这一点,并认为它是与一条真正的电话线相连的,于是它会拨号。这就是它开始的原因,DreamPi 的事情就是我在陪产假的时候摆弄了一下完成的。
**00:28:28 - Saron Yitbarek**:
一旦 Luke 解决了拨号音的问题,就面临着更多的挑战。他需要从社区里召集人手,以到达下一个关卡。
**00:28:39 - Luke Benstead**:
我开始写这个 Python 脚本,但是随着时间的推移,它变得越来越复杂,因为一个很好的例子是,如果你有美国版本的《<ruby> 雷神之锤 3 <rt> Quake III </rt></ruby>》的话,它总是可以联网的。但如果你有像英国版本一样的版本,它会在让你连接之前,对一个在线服务器进行某种身份验证。所以 DreamPi 的一个副产品是试图对这个名为 Dreamarena 的认证服务器进行逆向工程,这样在英国的《雷神之锤 3》的玩家就可以拨号了。这导致了游戏联网的连锁反应,因为它吸引了一个叫 —— 我不知道怎么读他的网名,有点像 Shuouma —— 的人。他一直负责对 Dreamcast 连接的游戏服务器进行逆向工程。因为很明显,所有的服务器都关闭了。当他看到我在 Dreamarena 做的逆向工程时,他对 Dreamarena 进行了逆向工程。Starlancer 服务器是下一个,因为尽管该服务器仍然在线,但它有很多问题。最终,他对目前在线的所有游戏都进行了逆向工程。实际上还有第三个人参与其中,他的网络账号是 PCWizard13。他在社区里的时间比我还要长。他曾经组织每周的游戏聚会。因此,我开发了 DreamPi,Shuouma 开发了服务器,加上他组织了社区,这三者的组合,让这件事像滚雪球一样不断壮大。
**00:30:12 - Saron Yitbarek**:
DreamPi 软件是开源的,与社区分享,允许任何人为 Dreamcast 制作更多游戏或重建他们最喜欢的经典作品。
**00:30:23 - Luke Benstead**:
这个网站是 dreamcast.online,如果你访问它,你可以看到谁在线或者之前在线。你可以看到他们在玩什么游戏。从理论上讲,它可以一直运行下去,所有的东西都在那里,都是开放的。
**00:30:34 - Saron Yitbarek**:
世嘉的最后一款游戏机在推出又夭折的 20 年后,一小群忠实粉丝让 Dreamcast 的梦想永存。这款游戏机可能在商业上失败了,但这台灰白色的小机器所包含的创意,盒子里的思想,已经超前了它的时代。下面是 Mineko Okamura 的发言。
**00:31:02 - Mineko Okamura**:
有趣的是,这些游戏又回来了,这让我觉得 Dreamcast 也许出现的太早了。因为现在科技更发达的今天,人们也许可以充分享受 Dreamcast 游戏的未来。
**00:31:21 - Saron Yitbarek**:
世嘉可能已经在游戏机上输给了索尼、任天堂甚至微软的 Xbox。但就在世嘉在游戏机大战中成为大赢家的那一刻,他们的硬件助推了整个行业向前发展。这至少是 Dreamcast 广告活动的幕后策划人 Brian Bacino 的看法。
**00:31:42 - Brian Bacino**:
我认为那个时候,游戏化的时代可能在不知不觉中到来了。每个人都喜欢用这种或那种的方式玩游戏。如果你能想出一个能抓住他们好奇心的东西,让他们每天都能使用这种技术,他们就会玩。我认为这可能是这种认识的开端。
**00:32:15 - Saron Yitbarek**:
在过去的几周里,我们讨论了一些令人惊叹的硬件。但是在我们完全关闭这一季的大门之前,还有一件事。两周后,我们将和一位非常特别的代码英雄交谈,讲述他对我们节目中介绍的许多机器的体验。对于所有这些机器,微型计算机、大型机、个人计算机、软盘、掌上电脑、开源硬件、游戏机等等,请访问 [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes%22redhat.com/commandlineheroes%22)。我是 Saron Yitbarek。下期之前,编码不止。
**附加剧集**
早在第二季中,我们就介绍了游戏和开源之间的联系。Warren Robinett 分享了他为<ruby> 雅达利 <rt> Atari </rt></ruby>开发《<ruby> 冒险 <rt> Adventure </rt></ruby>》。并偷偷地把第一个复活节彩蛋放了进去的经验。
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-4/consoles>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[windgeek](https://github.com/windgeek) 校对:[acyanbird](https://github.com/acyanbird), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Gaming consoles are pioneering machines. The Dreamcast pushed the limits of what even consoles could do. But that wasn’t enough to guarantee commercial success. Despite that failure, fans say no other console has accomplished so much.
The Dreamcast was meant to restore Sega to its glory days. After the disappointing Saturn, Sega pitted two teams against each other to build a new console. Andrew Borman describes the Dreamcast as a generational leap in hardware. Jeremy Parish explains how big a departure its production was from Sega’s usual processes. Mineko Okamura provides an insider’s insight on developing the Dreamcast. Brian Bacino recounts the console’s massive U.S. launch. But despite record U.S. sales, Sega had to pull the plug on the Dreamcast. Too good to let die, homebrewers like Luke Benstead plugged it back in.

**00:07** - *Saron Yitbarek*
It's September 9th, 1999, 9/9/99, and somewhere in Japan, a spy has made her way deep into a mainframe computer room. She hacks in and disables the security. A guard investigates. She knocks him out with a well-placed kick. But the computer system, it comes to life. Everything goes red. A strange swirling pattern pops up on the monitors. It's obvious that the system is thinking. The spy bolts. The thinking computer is out to stop her. It tries to lock her inside the building. The spy smashes through a window, but not before she grabs a case and runs off with it. Inside that case, a prototype for a new kind of machine that could change everything.
**01:06** - *Saron Yitbarek*
What I've been describing was a television commercial called Apocalypse. It was promoting the newest video game console from game company Sega, and no ordinary console either. This revolutionary device was called the Dreamcast, and that Apocalypse ad, what's inside the case the spy is stealing, is that very console.
**01:29** - *Brian Bacino*
Well, then the Dreamcast box, it sort of spins off of the back of the thief and lands in the street, and the lid of this magic case that kept the box plugged in the whole time pops open. Camera zooms into the Dreamcast and into the window and goes down to the bottom where it appears that all the characters from all the games are all gathered. And there, we have Sonic down there, and he triumphantly says ...
**02:00** - *Sonic*
We got it.
**02:01** - *Brian Bacino*
And the whole place erupts, and everybody is screaming.
**02:05** - *Saron Yitbarek*
That's Brian Bacino, the creative director of the Apocalypse ad campaign. And the Sonic he's referring to is Sonic the Hedgehog, Sega's famous game character.
**02:16** - *Saron Yitbarek*
In the '90s, Sega was one of the most recognized video game companies in the world. But by the end of that decade, the competition was proving to be fierce, so Sega bet the house on Dreamcast. It would be the company's savior. The Apocalypse ad was described as, "The most epic video game commercial ever created." But how else to show off the most advanced game console ever made—so smart, you could almost say it really was thinking.
**02:49** - *Saron Yitbarek*
Alas, the Dreamcast did not change the world. It barely made a dent. It's considered by some to be the greatest console that never stood a chance. It was the last console Sega would build, and it very nearly broke the company.
**03:11** - *Saron Yitbarek*
In our penultimate episode of the season, a season all about hardware that changed the course of development, we look at the short-lived history of the Sega Dreamcast. Yet, despite its short shelf life, Dreamcast is still considered by many to be one of, if not the finest gaming consoles of all time. And 20 years after its death, it manages to live on in a very real way.
**03:40** - *Saron Yitbarek*
I'm Saron Yitbarek, and this is Command Line Heroes, an original podcast from Red Hat.
**03:48** - *Saron Yitbarek*
Like the thinking computer in the Apocalypse ad, that whisper ...
**03:52** - *Speaker 1*
It's thinking.
**03:53** - *Saron Yitabrek*
... became the company's new tagline for their new console.
**03:56** - *Brian Bacino*
So the thought of having our VO always whisper ...
**04:01** - *Speaker 1*
It's thinking.
**04:02** - *Brian Bacino*
... We thought that would be a really neat way to sort of evolve that iconic Sega scream.
**04:10** - *Speaker 2*
SEGA!
**04:10** - *Saron Yitbarek*
Here was a console that got smarter as you played, at least that was the marketing pitch. A console that brought something new, something big, something revolutionary to the home video game market. A system built to serve the hard-core gamer. And inside the company, the thinking was that this console would make Sega the biggest name in video gaming.
**04:34** - *Brian Bacino*
This was going to change gaming. This was going to change the world.
**04:38** - *Saron Yitbarek*
So, what happened? To figure that out, we need to go back, all the way back to ...
**04:44** - *Speaker 3*
Level I.
**04:47** - *Saron Yitbarek*
Throughout the early '90s, Sega had a reputation for making games that were super cool and more mature than what the competition offered, particularly Nintendo and its princess-saving plumbers. They built this reputation with a very successful console, Sega Genesis.
**05:05** - *Alex Handy*
Sega decided they were going to be really cutting edge, and these kids who had the Nintendos, well, now they're teenagers, and they want real sports games with real teams. They want bloody, fighting games like Mortal Kombat, which came later on. And they wanted a more mature, in-your-face sort of system.
**05:22** - *Saron Yitbarek*
Alex Handy is the founder and director of the Museum of Art and Digital Entertainment in Oakland, California. He also works for Red Hat.
**05:31** - *Alex Handy*
If you go back and look at ads from video game magazines in this period, they're kind of shocking. There are ads where there is like a bloody, severed arm with gristle coming off of it, and it says, "This is your best weapon against the bad guy." So, Sega does really, really well with this extreme, in-your-face sort of success of the Genesis with Sonic the Hedgehog sort of impertinence as opposed to Mario's OshKosh B'gosh overalls kind of happy theme.
**06:00** - *Saron Yitbarek*
More than 30 million people bought the Sega Genesis, a 16-bit console that played games from cartridges. Gamers around the world loved it.
**06:11** - *Saron Yitbarek*
But over time, Sega struggled to grow its user base. After Genesis, they introduced the 32-bit Sega Saturn. More powerful than Genesis, it could display both 2D and basic 3D graphics. But, the Saturn platform never really took off. Sales struggled. They managed to sell 9.2 million consoles, only a third of what the Genesis sold.
**06:38** - *Saron Yitbarek*
Another sticking point: Developers found it challenging to program games for Saturn's proprietary, in-house-designed hardware. This was an issue Sega made note of for the future. Add to that, the launch of the Nintendo 64 and then Sony's first entry into the market with the PlayStation, and gaming was suddenly getting crowded and very competitive.
**07:04** - *Saron Yitbarek*
In 1998, Sega posted a loss of $270 million. At Sega's North American headquarters, video game boss Bernie Stolar announces that quote, "The Saturn is not our future." He kills the console. With that, Sega turns its focus to building the next generation of console.
**07:32** - *Speaker 3*
Level II: Building the Dream.
**07:35** - *Saron Yitbarek*
The Sega Saturn had hurt the company's brand and bottom line. If Sega was going to reclaim its market share and reputation, this next console needed to be powerful, easy to code for, and unlike anything else available.
**07:51** - *Saron Yitbarek*
Andrew Borman is the Digital Games Curator at The Strong National Museum of Play in Rochester, New York.
**07:59** - *Andrew Borman*
They wanted to really show that this was a generational leap. This wasn't just a quick replacement to move on from the Sega Saturn, but that this was going to push things forward in graphics, in sound and online technology, and in just CPU processing, allowing for better AI than had been seen on previous consoles.
**08:22** - *Saron Yitbarek*
Sega was going to level up their machine. At Sega's Japanese headquarters, they knew what they needed to do. Except, they weren't the only ones with the big ideas.
**08:34** - *Andrew Borman*
But you also had a lot of infighting at Sega at the time. As they were starting to develop what would be a next-generation console, which would result in the Dreamcast, you also had Sega in the United States, Sega of America, developing their own idea of what a next-generation console may be.
**08:52** - *Saron Yitbarek*
And so, both Sega Japan and Sega North America started developing two different systems simultaneously. Two teams were now competing for whose hardware design would win out over the other.
**09:07** - *Jeremy Parish*
The American version was called Black Belt—that was its code name—and the Japanese version was code-named Dural after one of the bosses in the game Virtua Fighter.
**09:17** - *Saron Yitbarek*
Jeremy Parish co-hosts a podcast called Retronauts. He says both the Japanese and American teams took the lessons learned from the Saturn console to heart.
**09:28** - *Jeremy Parish*
They really wanted to make the system easy to develop for so that people who created games and programmed games would say, “Oh, well, you know, it's really easy to get great performance out of this system and to port games from other systems over here and to make them look better.” That was a kind of a key consideration for them.
**09:47** - *Saron Yitbarek*
That pointed them away from designing custom silicone. Alex Handy:
**09:52** - *Alex Handy*
The Sega Saturn was built from the ground up. I mean, they designed the chips, they designed the drives, they designed everything. When it came time to do the Dreamcast, Sega just went with an off-the-shelf processor, off-the-shelf 3D chips, and everything was just basically already designed, and they just put it all together as a systems' integrator. And it was a major step for the company after being completely focused on hardware innovation for most of the ’90s.
**10:16** - *Saron Yitbarek*
But which chips would they use? On this, Sega Japan and Sega America had competing opinions.
**10:25** - *Jeremy Parish*
The U.S. side was working with 3dfx, whereas the Japanese side was working with NEC to put together a PowerVR-based 3D solution. And for various kind of political reasons and legal reasons, Sega ended up going with the Dural version, the Japanese version of the hardware.
**10:49** - *Saron Yitbarek*
So, gone was the American team's choice, the 3dfx. They went with the Japanese team's choice, the PowerVR chip. It's a decision that would come back to bite them later. From there, the rest of the hardware came together. DVD technology was still in its infancy and very expensive, so that was ruled out. But CD-ROMs, compact discs, weren't able to hold enough data to run the next gen of gaming graphics, sound, and complexity. So Sega built the console with a GD-ROM laser, essentially like CD-ROM systems, only these discs could hold a gigabyte of data. Now they had the brains of the console figured out. As Alex Handy puts it:
**11:42** - *Alex Handy*
One of the real important things, the system did include a dedicated 3D rendering chip. That chip was able to do much more complicated 3D renderings than, say, the PlayStation. The Dreamcast is the line in the sand where we start to get 3D that will in the future still look fairly OK and you know what's going on. There's no suspension of disbelief going on.
**12:04** - *Saron Yitbarek*
It truly was a next-gen system. Andrew Borman says the Dreamcast was shaping up to be the revolutionary console Sega had challenged themselves to build.
**12:15** - *Andrew Borman*
The Dreamcast video output, it output over VGA at four ADP, which a lot of other consoles did not at the time.
**12:23** - *Saron Yitbarek*
Even something as simple as detachable memory cards, visual memory units were designed in a completely new way.
**12:31** - *Andrew Borman*
The VMU, the memory unit on the Dreamcast, really hinted at some of the second-screen experiences that would come later on.
**12:39** - *Saron Yitbarek*
These VMUs had small screens on them and buttons, like a miniature Gameboy.
**12:44** - *Andrew Borman*
You could have your save file, you could take it with you, you could play games on it. You could enhance your save in some way, shape, or form, and then bring it back to your home console.
**12:54** - *Saron Yitbarek*
But that wasn't all. In the late ’90s, connecting consoles to the internet wasn't impossible, but it sure wasn't common. Online playability was still more of a concept than a reality. Sega saw an opportunity.
**13:11** - *Andrew Borman*
Every Dreamcast came with a 56K modem, which seems antiquated now, but no other consoles were shipping with a 56K modem. No other consoles were shipping with the ability to have a web browser on it. No other console would be able to download content, bar a few accessories at the time. This was stocked right out of the box—you could do all of this.
**13:36** - *Saron yitbarek*
Here's Mineko Okamura, CEO of Grounding Inc. She was an assistant producer at Sega during the Dreamcast era.
**13:50** - *Mineko Okamura*
Our goal was at the time, in addition to core Sega fans, we wanted to attract new Sega game lovers. First of all, it had a really cutting-edge technology or feature that the Dreamcast was able to connect to the internet, and probably a lot of people still can recall a game called Seaman, and then it was introduced with a voice recognition feature. Although today it's very common, but at the time it was new that you could download additional programs through online.
**14:26** - *Speaker 3*
Level III: The dream is real.
**14:31** - *Saron Yitbarek*
While production continued on the new console, the Sega Saturn got retired. But with Sega's lack of presence, it left a gap in the market that needed filling. 1999 gave Sega a narrow window to recapture their share of the market. All they needed to do was nail the launch as perfectly as possible. Jeremy Parish:
**14:56** - *Jeremy Parish*
They gave it their all. The Dreamcast launch was kind of widely regarded as the biggest entertainment launch of all time. They really hit on all the marks. To me, it was kind of a model system launch, like that is how they should be done. The hype and the advertising was on point; it was intriguing.
**15:16** - *Saron Yitbarek*
Before the launch, the hype machine driven by Brian Bacino’s, “It's thinking” ad campaign, was working flawlessly. Here's Andrew Borman:
**15:26** - *Andrew Borman*
The Dreamcast of the United States had 300,000 units pre-ordered prior to launch, so that was a new record. Things were looking really, really good for Sega going into 9/9/99.
**15:40** - *Saron Yitbarek*
And then the day arrived. September 9th, 1999. Launch day in the U.S. The Dreamcast went on sale for $199. It was a historic launch day. The company made $100 million in the first 24 hours, a record for the entire industry. They sold every console available.
**16:11** - *Andrew Borman*
Store fronts were still calling, saying, “Hey, we need more Dreamcast consoles,” especially going into that first holiday season.
**16:17** - *Saron Yitbarek*
They made sure lots of games were available at launch as well. 18 in total, from fighting to action to racing to sports.
**16:26** - *Andrew Borman*
Some of my favorite games, especially around that launch period, were Sonic Adventure, which Sonic finally in 3D in a really great way, but also Soulcalibur. I was a huge fighting game fan, especially back then, and Soulcalibur was not only arcade perfect, but it was better than the arcade version, which was based on PS1 hardware. So with the Dreamcast and its fancy new graphics, Soulcalibur was really so much better than I ever expected a fighting game could be at the time.
**16:58** - *Saron Yitbarek*
Gamers loved the Dreamcast library. It eventually grew to over 600 titles. Even Brian Bacino couldn't help but indulge in a few.
**17:09** - *Brian Bacino*
My personal thing that I got completely obsessed with was Crazy Taxi. I just could not get enough of that game, and the feeling and the 3D graphics of that game were so much fun.
**17:22** - *Saron Yitbarek*
Dreamcast was very clearly a next-gen console, and its fans loved the hardware. But the games themselves offered something different too.
**17:31** - *Jeremy Parish*
You had just so many offbeat, inventive never-before-seen game concepts.
**17:38** - *Saron Yitbarek*
One required a pair of maracas to interact with the game. Another game made you interact with a bizarre fish with a human face.
**17:47** - *Jeremy Parish*
You had controllers coming out that were just ludicrous. You had a game controller that was like a traditional game controller, but it had a full ASCII keyboard in the middle, so you could type to people when you're playing online with them. And then that would also work with the game Typing of the Dead, which was like a haunted house shooter. Except instead of shooting at the zombies, you were typing weird, fragmented phrases at them, like random English phrases. It was just such a weird and fantastic system.
**18:22** - *Saron Yitbarek*
Sega sells its millionth Dreamcast within two months of launch. By Christmas, it has 31% of the North American market. They'd done it. The Dreamcast was a hit. But not long after that tremendous launch, the Dreamcast dream turned into a nightmare.
**18:47** - *Speaker 3*
Level IV: The dream dies.
**18:52** - *Saron Yitbarek*
Despite those record-breaking sales and the accolades from press and hard-core gamers, the company had some big problems. For starters, the Dreamcast wasn't doing well in Japan. They had launched it a year earlier, and the sales were poor. It was costing the company money.
**19:10** - *Jeremy Parish*
Yeah, the Japanese launch, I think it came too early. The hardware production processes weren't as mature and reliable as they needed to be. And as a result, there were some defects and shortages and supply line issues. But also, a bigger problem is that there just weren't that many games available at launch for Dreamcast in Japan. I think there were three games.
**19:35** - *Mineko Okamura*
[Foreign language 00:01:37]
At the time when Dreamcast actually came out, we had this commercial which left a very strong impression on people which was performed by Mr. Yukawa who was one of our board members. And it was really well sold, but then it quickly became sold out, and it actually took us time to reload the stocks, which was quite unfortunate because people had to wait for a long time, and then sales start to decline.
**20:11** - *Saron Yitbarek*
Production problems continued after the U.S. launch too. A lack of supply hampered sales.
**20:17** - *Andrew Borman*
There was a shortage of the PowerVR chip that was powering the Dreamcast, which simply meant that they couldn't make enough systems to go around, even if they had people willing to buy them. Even though the systems were selling relatively OK, they just didn't have enough consoles to go around.
**20:38** - *Saron Yitbarek*
The PowerVR chip created another problem. It cost them the support of some major game studios, Electronic Arts in particular. EA didn't have a team of programmers that could code for the PowerVR chip, so they passed on Dreamcast. Here's Jeremy Parish:
**20:56** - *Jeremy Parish*
Ultimately that did really, I think, hurt the company because Electronic Arts was a huge player in the Sega Genesis' success, and putting their sports games like Madden NFL onto any system is a huge boon for that system because you have millions of people who are going to buy those games every year.
**21:16** - *Saron Yitbarek*
Hardware issues aside, they'd won over hard-core gamers, but casual gamers weren't yet convinced. The Sega hype cycle was over. Dreamcast was here, but already a new hype cycle had ramped up. This time for Sony and the PlayStation 2. Here's Andrew Borman again:
**21:37** - *Andrew Borman*
Sony did a very, very great job of hyping it up. With that hype machine, people were ready for the PlayStation 2 and unfortunately, I think by the holiday season in December 2000, the system already wasn't selling well. The system being Dreamcast.
**21:56** - *Saron Yitbarek*
Sega tried everything to push sales up, but little seemed to work. They slashed the console's 199 price tag at great financial cost. They launched an online gaming portal, SegaNet, in 2000. They offered free subscriptions to pull in more users, but the company kept bleeding cash. In January of 2001, Sega announced it would cease production of their next-gen console. Sixteen months after it launched, the Dreamcast was dead. The last batch of the consoles sold for $50 apiece. When it was all over, Sega had sold just over 9.1 million consoles, even fewer than the failed Sega Saturn it replaced.
**22:55** - *Speaker 3*
Final level: The dream reborn.
**23:00** - *Jeremy Parish*
I was disappointed because, I think, Sega has a long history behind it and as an important player in the games industry, and they always brought a special kind of point of view to the games that they created. And really the Dreamcast was, in my opinion, their most creatively fertile platform ever. Just the sheer amount of invention and off-the-wall, fresh game ideas that came out of Dreamcast, no one has done that before or since. So, yeah, there was a real sense of loss when they stepped away.
**23:31** - *Saron Yitbarek*
After Dreamcast, Sega gave up on consoles altogether. Technical support for Dreamcast continued through to 2007, after which Dreamcast owners were on their own. So, what do you do when you have a discontinued, unsupported but beloved gaming console sitting on your shelf at home? Well, for some Dreamcast super fans, it was the beginning of a do-it-yourself revival.
**24:00** - *Andrew Borman*
When you're talking about Homebrew, when you're talking about just the ability to play really great games for an older console, the Dreamcast community is a really diehard community.
**24:12** - *Saron Yitbarek*
You see, the Dreamcast console never really died for a lot of its super fans. They loved it so much that they kept it alive for themselves and others. And as a community, they thrived. Like the Homebrew computer club we talked about in episode 3, they also called their community Homebrew because they tinkered too. They ported copies of games from other platforms or built entirely new games from scratch. All for a machine that was meant for the hardware graveyard.
**24:45** - *Alex Handy*
Let's see, I've found Armed 7, Finding Teddy, Unit Yuki, Magic Pockets, and Captain Tomaday, which seems to be about a flying tomato. We've got a side-scrolling shooter. We have a point-and-click adventure. We have a platform game. You don't really get to predict or understand why people do this stuff. It is a labor of love, it takes a lot of work, and it's people do what they want to do in the Homebrew scene, as we call it.
**25:17** - *Andrew Borman*
One of the examples that I like to point to is Bleemcast, which was a Sony PlayStation emulator for the Dreamcast. So, the exclusive Gran Turismo 2 for the PlayStation could now be played on Dreamcast. Not only could it be played on Dreamcast, it would look better on Dreamcast. Other emulators were developed for the system, including a Sega Genesis, Nintendo Entertainment System emulators.
**25:43** - *Saron Yitbarek*
A big reason why this is possible is because clever Dreamcast owners long ago discovered that the system's antipiracy protections were pretty easy to work around. And once they figured that out, they realized they could make the Dreamcast play pretty much whatever classic game or indie title they could throw at it.
**26:06** - *Luke Benstead*
Indie developers started working on it even in 2001, and that ability to write games and software for it and not have to jailbreak it or do anything invasive has really helped because it's a low barrier to entry. So, people can go online and they can download new games and stuff.
**26:25** - *Saron Yitbarek*
This is Luke Benstead. He's part of the Dreamcast Homebrew community. Luke discovered that people were hacking together ways to plug old Dreamcasts into today's modern internet so they could access games online.
**26:40** - *Luke Benstead*
I'd always known that people were still connecting their Dreamcasts to the internet because there was this thing called the PCDC server. So people used to have their Windows PC, they used to plug a USB modem into it, and then they used to plug the Dreamcast into that. And if they dialed up on their Dreamcast and they ran the right bit of software at the right time on the PC, they could route it through.
**27:03** - *Luke Benstead*
And so I think about sort of 2010, I went online and I bought a USB modem to try this out. And that just sat in a drawer. I never actually got around to trying it. And then in 2015, my first daughter had just been born, I was on paternity leave, and I had just acquired a Raspberry Pi, and I suddenly realized that I could combine these things.
**27:28** - *Saron Yitbarek*
But before he could share his Raspberry Pi solution with the community, there was a hurdle to the modern internet that Luke had to overcome.
**27:36** - *Luke Benstead*
The problem with the PCDC service app is that, although you could make it work, a lot of the games didn't work because the Dreamcast would look for a dial tone. When you clicked dial connect in the game, a lot of the games would expect there to be a dial tone. And clearly there's not a dial tone if you just plug it into a computer. So when I started looking at getting this Raspberry Pi to run this PCDC service app, one of the things I did was downloaded the recording of a dial tone, and I made it so that the software that I wrote, which was written in Python, would play that sound to the modem. And the Dreamcast would hear that down the line and think that it was connected to a real phone line, and so it would dial. That's what got it started. The whole DreamPi thing was just me fiddling around on paternity leave.
**28:28** - *Saron Yitbarek*
Once Luke got past the dial tone issue, he faced more challenges. He needed to rally people from the community to get to the next level.
**28:39** - *Luke Benstead*
I started writing this Python script, and then it just got more and more complex as time went on, because a good example is Quake III has always worked online if you have the U.S. version. If you have the panel version in like the UK version, it did a kind of authentication with an online server before it would let you connect. So one of the side products from the DreamPi was trying to reverse engineer this authentication server, this Dreamarena thing, so that anyone in the UK, if they had Quake III, they could dial up. That led to a chain reaction of games coming online because it attracted a guy called—I don't know how to pronounce his internet name; it’s something like Shuouma. He has been responsible for reverse engineering the game servers that the Dreamcast connects to. Because obviously, all the servers got turned off. And when he saw what I was doing with the Dreamarena, reverse engineering, he reversed engineered the Dreamarena stuff. Starlancer server was the next one because although that server was still online, it was very buggy. And then that's led to him reverse engineering all of the games that are online at the moment. And there's actually a third person who's involved in this whose internet handle was PCWizard13. And he has been long running in the community longer than me. He used to organize weekly game meetups. So the combination of me developing the DreamPi, Shuouma developing the servers, and him organizing the community has allowed that thing to snowball.
**30:12** - *Saron Yitbarek*
The DreamPi software is open source and shared with the community, allowing anyone to build more games for the Dreamcast or rebuild their favorite classics.
**30:23** - *Luke Benstead*
So the website is dreamcast.online, and if you go there, you can see who's online or who's been online. You can see what games they're playing. And that's theoretically, it can just keep going, because everything's out there, it's all open.
**30:34** - *Saron Yitbarek*
Twenty years after the launch and then death of Sega's last gaming console, a small group of loyal fans keep the dream of Dreamcast alive. The console might have failed commercially, but the ideas this small, gray white machine contained, the thinking that went inside the box, was ahead of its time. Here's Mineko Okamura again:
**31:02** - *Mineko Okamura*
It's very interesting that these games are coming back, which kind of made me feel that maybe Dreamcast came out too early. Because now technology is more developed today, people can probably maybe fully enjoy the future of dreaming those Dreamcast games.
**31:21** - *Saron Yitbarek*
Sega may have lost the console game to Sony and Nintendo and even Microsoft's Xbox. But for a brief moment when Sega was a big winner in the console wars, their hardware helped push the entire industry forward. That's how Brian Bacino, the man behind the Dreamcast ad campaign, sees it, at least.
**31:42** - *Brian Bacino*
I think that moment in time is when gamification probably came of age without anyone knowing it. The idea that everybody likes to play games in one way or another. And if you can come up with something that catches their curiosity in a way that just falls into their daily use of technology, they're going to play. And I think that was probably the beginnings of that realization.
**32:15** - *Saron Yitbarek*
We've talked about some amazing pieces of hardware these past few weeks. But before we completely close the doors on this season, there's just one more thing. In two weeks time, we're going to be talking to a very special command line hero about his experience with many of the machines we featured on the show. And for some great research on all those machines, mini computers, mainframes, personal computers, floppies, the PalmPilot, open source hardware game consoles, and more, go to [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes). I'm Saron Yitbarek. Keep on coding.
### Further reading
[ It's Thinking Ad](https://www.youtube.com/watch?v=km5-OACKRjA) by Sega
[ The Dreamcast Died Too Soon, but Its Legacy Lives On](https://www.theringer.com/2019/9/11/20860353/sega-dreamcast-20th-anniversary) by Ben Lindbergh
[ IGN Presents the History of Dreamcast](https://www.ign.com/articles/2010/09/10/ign-presents-the-history-of-dreamcast) by Travis Fahs
__Dream on: inside the Dreamcast's homebrew scene__ by Robin Wilde
### Bonus episode
Back in Season 2, we covered the ties between gaming and open source. Warren Robinett shares his experience developing Adventure for Atari and sneaking in the very first Easter Egg. |
13,736 | Brave vs. Firefox:你的私人网络体验的终极浏览器选择 | https://itsfoss.com/brave-vs-firefox/ | 2021-08-30T22:31:44 | [
"Firefox",
"Brave",
"浏览器"
] | https://linux.cn/article-13736-1.html | 
Web 浏览器经过多年的发展,从下载文件到访问成熟的 Web 应用程序,已经有了长足的发展。
对于很多用户来说,Web 浏览器是他们如今完成工作的唯一需要。
因此,选择合适的浏览器就成为了一项重要的任务,它可以帮助改善你多年来的工作流程。
### Brave vs. Firefox
Brave 和 Mozilla Firefox 是两个最受到关注隐私的用户和开源爱好者欢迎的 Web 浏览器。
考虑到两者都非常注重隐私和安全,让我们看看它们到底能提供什么,以帮助你决定应该选择哪一个。
以下是我所使用的比较指标:
### 用户界面
用户界面是使用浏览器时的工作流程和体验的最大区别。
当然,你会有你的个人偏好,但它看起来越容易使用、越轻快、越干净,就越好。

首先,Brave 与 Chrome 和微软 Edge 有着相似的外观和感受。它提供了一种简洁的体验,具有精简的 UI 元素,所有的基本选项都可以通过浏览器菜单访问。
它也提供了一个暗色主题。恰到好处的动画使得互动成为一种愉快的体验。
要定制它,你可以选择使用 Chrome Web 商店中的主题。
说到 Mozilla Firefox,多年来它经历了几次重大的重新设计,其最新的用户界面试图提供与 Chrome 更接近的体验。

Firefox 浏览器的设计看起来令人印象深刻,并提供了干净利落的用户体验。如果需要的话,你还可以选择一个暗色主题,此外还有其它几个主题可供下载使用。
这两个 Web 浏览器都能提供良好的用户体验。
如果你想要一个熟悉的体验,但又具有一丝独特之处,Mozilla Firefox 是一个不错的选择。
但是,如果你想获得更快捷的体验、更好的动画感受,Brave 更有优势。
### 性能
实际上,我发现 Brave 加载网页的速度更快,整体的用户体验感觉很轻快。
Firefox 浏览器倒不是非常慢,但它绝对感觉比 Brave 慢。
为了给你一些参考,我还利用 [Basemark](https://web.basemark.com) 运行了一个基准测试,看看事实上是否真的如此。
你可以使用其他的浏览器基准测试工具来测试一下,但我用 Basemark 进行了各种测试,所以我们在这篇文章中会用它。


Firefox 浏览器成功获得了 **630** 的得分,而 Brave 以大约 **792** 的得分取得了更好的成绩。
请注意,这些基准测试是在没有安装任何浏览器扩展程序的情况下,以默认的浏览器设置进行的。
当然,你的分数可能会有所不同,这取决于你在后台进行的工作和你系统的硬件配置。
这是我在 **i5-7400、16GB 内存和 GTX 1050ti GPU** 配置的桌面电脑上得到的结果。
一般来说,与大多数流行的浏览器相比,Brave 浏览器是一个快速的浏览器。
这两者都占用了相当大的系统资源,而且在一定程度上随着标签数量、访问的网页类型和使用的拦截扩展的种类而变化。
例如,Brave 在默认情况下会主动阻止广告,但 Firefox 在默认情况下不会阻止显示广告。而且,这也影响了系统资源的使用。
### 浏览器引擎
Firefox 浏览器在自己的 Gecko 引擎基础上,使用来自 [servo 研究项目](https://servo.org) 的组件来进行改进。
目前,它基本上是一个改进的 Gecko 引擎,其项目名称是随着 Firefox Quantum 的发布而推出的 “Quantum”。
另一方面,Brave 使用 Chromium 的引擎。
虽然两者都有足够的能力处理现代 Web 体验,但基于 Chromium 的引擎更受欢迎,Web 开发人员通常会在基于 Chrome 的浏览器上定制他们的网站以获得最佳体验。
另外,有些服务恰好只支持基于 Chrome 的浏览器。
### 广告 & 追踪器阻止功能

正如我之前提到的,Brave 在阻止跟踪器和广告方面非常积极。默认情况下,它已经启用了屏蔽功能。
Firefox 浏览器也默认启用了增强的隐私保护功能,但并不阻止显示广告。
如果你想摆脱广告,你得选择火狐浏览器的 “严格隐私保护模式”。
也就是说,火狐浏览器执行了一些独特的跟踪保护技术,包括“全面 Cookie 保护”,可以为每个网站隔离 Cookie 并防止跨站 Cookie 跟踪。

这是在 [Firefox 86](https://news.itsfoss.com/firefox-86-release/) 中引入的技术,要使用它,你需要启用 “严格隐私保护模式”。
总的来说,Brave 可能看起来是一个更好的选择,而 Mozilla Firefox 提供了更好的隐私保护功能。
### 容器
当你访问 Facebook 时,Firefox 还提供了一种借助容器来隔离网站活动的方法。换句话说,它可以防止 Facebook 跟踪你的站外活动。
你还可以使用容器来组织你的标签,并在需要时分离会话。
Brave 没有提供任何类似的功能,但它本身可以阻止跨站追踪器和 cookie。
### 奖励

与 Firefox 不同,Brave 通过屏蔽网络上的其他广告来提供自己的广告网络。
当你选择显示 Brave 的隐私友好型广告时,你会得到可以放到加密货币钱包里的通证奖励,而你可以用这些通证来回馈你喜欢的网站。
虽然这是摆脱主流广告的一个很好的商业策略,但对于不想要任何形式的广告的用户来说,这可能没有用。
因此,Brave 以奖励的形式提供了一个替代方案,即使你屏蔽了广告,也可以帮助网站发展。如果这是你欣赏的东西,Brave 将是你的一个好选择。
### 跨平台可用性
你会发现 Brave 和 Firefox 都有 Linux、Windows 和 macOS 版本,也有用于 iOS 和 Android 的移动应用程序。
对于 Linux 用户来说,Firefox 浏览器捆绑在大多数的 Linux 发行版中。而且,你也可以在软件中心里找到它。除此之外,还有一个 [Flatpak](https://itsfoss.com/what-is-flatpak/) 包可用。
Brave 不能通过默认的软件库和软件中心获得。因此,你需要按照官方的说明来添加私有仓库,然后 [把 Brave 安装在你的 Linux 发行版中](https://itsfoss.com/brave-web-browser/)。
### 同步
通过 Mozilla Firefox,你可以创建一个 Firefox 账户来跨平台同步你的所有数据。

Brave 也可以让你跨平台同步,但你需要能访问其中一个设备才行。

因此,Firefox 的同步更方便。
另外,你可以通过 Firefox 的账户访问它的“虚拟专用网络”、数据泄露监控器、电子邮件中继,以及密码管理器。
### 服务集成
从一开始 Firefox 就提供了更多的服务集成,包括 Pocket、“虚拟私有网络”、密码管理器,还有一些新产品,如 Firefox 中继。
如果你想通过你的浏览器访问这些服务,Firefox 将是你的方便选择。
虽然 Brave 确实提供了加密货币钱包,但它并不适合所有人。

同样,如果你喜欢使用 [Brave Search](https://itsfoss.com/brave-search-features/),在使用 Brave 浏览器时,由于用户体验的原因,你可能体验会更顺滑。
### 可定制性 & 安全性
Firefox 浏览器在可定制性方面大放异彩。你可以通过众多选项来调整体验,也可以控制你的浏览器的隐私/安全。
自定义的能力使你可以让 Firefox 比 Brave 浏览器更安全。
而加固 Firefox 浏览器是一个我们将讨论的单独话题。略举一例,[Tor 浏览器](https://itsfoss.com/install-tar-browser-linux/) 只是一个定制的 Firefox 浏览器。
然而,这并不意味着 Brave 的安全性更低。总的来说,它是一个安全的浏览器,但你确实可以通过 Firefox 浏览器获得更多的选择。
### 扩展支持
毫无疑问,Chrome Web 商店提供了更多的扩展。
因此,如果你是一个使用大量扩展(或不断尝试新扩展)的人,Brave 明显比 Firefox 更有优势。
可能 Firefox 的扩展清单不是最大的,但它确实支持大多数的扩展。对于常见的使用情况,你很少能找到一个 Firefox 中没有的扩展。
### 你应该选择那个?
如果你希望尽量兼容现代的 Web 体验,并希望有更多的扩展,Brave 浏览器似乎更合适。
另一方面,Firefox 浏览器是日常浏览的绝佳选择,它具有业界首创的隐私功能,并为不懂技术的用户提供了方便的同步选项。
在选择它们中的任何一个时会有一些取舍。因此,你需要优先考虑你最想要的东西。
请在下面的评论中告诉我你的最终选择!
---
via: <https://itsfoss.com/brave-vs-firefox/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Web browsers have evolved over the years. From downloading files to accessing a full-fledged web application, we have come a long way.
For many users, the web browser is the only thing they need to get their work done these days.
Hence, choosing the right browser becomes an important task that could help improve your workflow over the years.
## Brave vs. Firefox Browser: Let's Compare!
Brave and Mozilla’s Firefox are two of the most popular web browsers for privacy-conscious users and open-source enthusiasts.
Considering that both focus heavily on privacy and security, let us look at what exactly they have to offer, to help you decide what you should go with.
## User Interface
The user interface is what makes the most significant difference with the workflow and experience when using the browser.
Of course, you can have your personal preferences, but the easier, snappier, and cleaner it looks, the better it is.
To start with, Brave shares a similar look and feel to Chrome and Microsoft Edge. It offers a clean experience with minimal UI elements and all the essential options accessible through the browser menu.
It offers a black theme as well. The subtle animations make the interaction a pleasant experience.
To customize it, you can choose to use themes available from the Chrome web store.
When it comes to Mozilla Firefox, it has had a couple of major redesigns over the years, and the latest user interface tries to offer a closer experience to Chrome.
The Firefox design looks impressive and provides a clean user experience. It also lets you opt for a dark theme if needed and there are several theme options to download/apply as well.
Both web browsers offer a good user experience.
If you want a familiar experience, but with a pinch of uniqueness, Mozilla’s Firefox can be a good pick.
But, if you want a snappier experience with a better feel for the animations, Brave gets the edge.
## Performance
Practically, I find Brave loading web pages faster. Furthermore, the overall user experience feels snappy.
Firefox is not terribly slow, but it definitely felt slower than Brave to me.
To give you some perspective, I utilized [Basemark 3.0](https://web.basemark.com/?ref=itsfoss.com), [Speedometer 2.0](https://webkit.org/blog/8063/speedometer-2-0-a-benchmark-for-modern-web-app-responsiveness/?ref=itsfoss.com), and [JetStream 2](https://webkit.org/blog/8685/introducing-the-jetstream-2-benchmark-suite/?ref=itsfoss.com) to get some synthetic benchmark numbers.
As it is clear, Firefox scored less with the benchmark scoring. However, note that the real-world experience is not that big of a difference. It comes down to user preferences.
Of course, synthetic scores may vary depending on what you have going on in the background and the hardware configuration of your system.
This is what I got with **i5-11600K, 32 GB RAM, and GTX 3060ti GPU** on my desktop.
In general, the Brave browser is a fast browser compared to most of the popular options available.
Both utilize a decent chunk of system resources and that varies to a degree with the number of tabs, types of webpages accessed, and the kind of blocking extension used.
For instance, Brave blocks aggressively by default, but Firefox does not block display advertisements by default. And, this affects the system resource usage.
## Browser Engine
Firefox utilizes its Gecko engine as the foundation and is using components on top of that from [servo research project](https://servo.org/?ref=itsfoss.com) to improve.
Currently, it is essentially an improved Gecko engine dubbed by a project name “Quantum” which was introduced with the release of Firefox Quantum.
On the other hand, Brave uses Chromium’s engine.
While both are capable enough to handle modern web experiences, the Chromium-based engine is just more popular and web developers often tailor their sites for the best experience on Chrome-based browsers
Furthermore, some services and extensions happen to support Chrome-based browsers exclusively.
## Ad & Tracker Blocking Capabilities
As I have mentioned before, Brave is aggressive in blocking trackers and advertisements. By default, it comes with the blocking feature enabled.
Firefox also enables the enhanced privacy protection by default, but does not block display advertisements.
You will have to opt for the “**Strict**” privacy protection mode with Firefox if you want to get rid of display advertisements.
With that being said, Firefox enforces some unique tracking protection technology that includes Total Cookie Protection, which isolates cookies for each site and prevents cross-site cookie tracking. Not to forget, Firefox includes some [privacy tools](https://itsfoss.com/privacy-tools/) like Firefox Relay if you sign in with its account.
This was introduced with [Firefox 86](https://news.itsfoss.com/firefox-86-release/?ref=itsfoss.com) and to use it, you need to enable a strict privacy protection mode.
Overall, Brave might look like a better option out of the box, and Mozilla Firefox offers better privacy protection features.
**Suggested Read 📖**
[12 Simple Tools to Protect Your PrivacyQuick ways to enhance online privacy? Use these simple tools to take control of your data easily.](https://itsfoss.com/privacy-tools/)

## Containers
Firefox also offers a way to isolate site activity when you use Facebook thanks to a container. In other words, it prevents Facebook from tracking your offsite activity.
You can also use containers to organize your tabs and separate sessions when needed.
Brave does not offer anything similar, but it does block cross-site trackers and cookies out-of-the-box.
## Rewards
Unlike Firefox, Brave offers its advertising network by blocking other advertisements on the web.
When you opt in to display privacy-friendly ads by Brave, you get rewarded with tokens to a crypto wallet. And you can use these tokens to give back to your favorite websites.
While this is a good business strategy to get away from mainstream advertising, for users who do not want any kind of advertisements, it may not be useful.
So, Brave offers an alternative in the form of rewards to help websites even if you block advertisements. If it is something you appreciate, Brave will be a good pick for you.
## Cross-Platform Availability
You will find both Brave and Firefox available for Linux, Windows, and macOS. Mobile apps are also available for iOS and Android.
For Linux users, Firefox comes baked in with most of the Linux distributions. And, you can also find it available in the software center. In addition to that, there is also a [Flatpak](https://itsfoss.com/what-is-flatpak/) package available.
Brave is not available through default repositories and the software center. Hence, you need to follow the official instructions to add the private repository and then [get Brave installed in your Linux distro](https://itsfoss.com/brave-web-browser/).
[Installing Brave Browser on Ubuntu & Other Linux DistrosWant to get started using Brave on Linux? This guide will help you with installation, removal and update process of the Brave browser.](https://itsfoss.com/brave-web-browser/)

## Synchronization
With Mozilla Firefox, you get to create a Firefox account to sync all your data cross-platform.

Brave also lets you sync cross-platform, but you need access to one of the devices to successfully do it.
Hence, Firefox sync is more convenient.
Furthermore, you get access to **Firefox’s VPN, data breach monitor, email relay, and password manager** with the Firefox account.
## Service Integrations
Right off the bat, Firefox offers more service integrations that include **Pocket, VPN, password manager,** and more.
If you want access to these services through your browser, Firefox will be the convenient option for you.
While Brave does offer crypto wallets, it is not for everyone.

Similarly, if you like using [Brave Search](https://itsfoss.com/brave-search-features/), you may have a seamless experience when using it with Brave browser because of the user experience.
**Suggested Read 📖**
[10 Awesome Features in Brave Search to Watch Out ForBrave Search is a privacy-friendly search engine alternative to Google by the creators of Brave Browser. What’s there to like about it? Learn more here.](https://itsfoss.com/brave-search-features/)

## Customizability & Security
Firefox shines when it comes to customizability. You get more options to tweak the experience and also take control of the privacy/security of your browser.
The ability to customize lets you make Firefox more secure than the Brave browser.
While hardening Firefox is a separate topic which we’ll talk about. To give you an example, [Tor Browser](https://itsfoss.com/install-tar-browser-linux/) is just a customized Firefox browser.
However, that does not make Brave less secure. It is a secure browser overall, but you do get more options with Firefox.
## Extension Support
There’s no doubt that the Chrome web store offers way more extensions.
So, Brave gets a clear edge over Firefox if you are someone who utilizes numerous extensions (or constantly tries new ones).
Firefox may not have the biggest catalog of extensions, it does support most of the extensions. For common use-cases, you will rarely find an extension that is not available as an [add-on for Firefox](https://itsfoss.com/best-firefox-add-ons/).
**Suggested Read 📖**
[9 Open Source Add-Ons to Improve Your Firefox ExperienceHere are the best open-source add-ons for the Firefox web browser that will help you improve your browsing experience.](https://itsfoss.com/best-firefox-add-ons/)

## What Should You Choose?
If you want the best compatibility with the **modern web experience and want access to more extensions, the Brave browser** seems to make more sense.
On the other hand, **Firefox is an excellent choice for everyday browsing** with industry-first privacy features, and a convenient sync option for non-tech savvy users.
You will have a few trade-offs when selecting either of them. So, your will have to prioritize what you want the most.
Let me know about your final choice for your use case in the comments down below! |
13,737 | 用这个开源工具在 Linux 上访问你的 iPhone | https://opensource.com/article/21/8/libimobiledevice-iphone-linux | 2021-08-31T09:29:16 | [
"iOS",
"iPhone"
] | https://linux.cn/article-13737-1.html |
>
> 通过使用 Libimobiledevice 从 Linux 与 iOS 设备进行通信。
>
>
>

iPhone 和 iPad 绝不是开源的,但它们是流行的设备。许多拥有 iOS 备的人恰好也在使用大量的开源软件,包括 Linux。Windows 和 macOS 的用户可以通过使用苹果公司提供的软件与 iOS 设备通信,但苹果公司不支持 Linux 用户。开源程序员早在 2007 年(就在 iPhone 发布一年后)就以 Libimobiledevice(当时叫 libiphone)来拯救了人们,这是一个与 iOS 通信的跨平台解决方案。它可以在 Linux、Android、Arm 系统(如树莓派)、Windows、甚至 macOS 上运行。
Libimobiledevice 是用 C 语言编写的,使用原生协议与 iOS 设备上运行的服务进行通信。它不需要苹果公司的任何库,所以它完全是自由而开源的。
Libimobiledevice 是一个面向对象的 API,它捆绑了许多便于你使用的终端工具。该库支持苹果从最早到其最新的型号的 iOS 设备。这是多年来研究和开发的结果。该项目中的应用包括 `usbmuxd`、`ideviceinstaller`、`idevicerestore`、`ifuse`、`libusbmuxd`、`libplist`、`libirecovery` 和 `libideviceactivation`。
### 在 Linux 上安装 Libimobiledevice
在 Linux 上,你可能已经默认安装了 `libimobiledevice`。你可以通过你的软件包管理器或应用商店找到,或者通过运行项目中包含的一个命令:
```
$ ifuse --help
```
你可以用你的包管理器安装 `libimobiledevice`。例如,在 Fedora 或 CentOS 上:
```
$ sudo dnf install libimobiledevice ifuse usbmuxd
```
在 Debian 和 Ubuntu 上:
```
$ sudo apt install usbmuxd libimobiledevice6 libimobiledevice-utils
```
或者,你可以从源代码 [下载](https://github.com/libimobiledevice/libimobiledevice/) 并安装 `libimobiledevice`。
### 连接你的设备
当你安装了所需的软件包,将你的 iOS 设备连接到你的电脑。
为你的 iOS 设备建立一个目录作为挂载点。
```
$ mkdir ~/iPhone
```
接下来,挂载设备:
```
$ ifuse ~/iPhone
```
你的设备提示你,是否信任你用来访问它的电脑。

*图 1:iPhone 提示你要信任该电脑。*
信任问题解决后,你会在桌面上看到新的图标。

*图 2:iPhone 的新图标出现在桌面上。*
点击 “iPhone” 图标,显示出你的 iPhone 的文件夹结构。

*图 3:显示了 iPhone 的文件夹结构。*
我通常最常访问的文件夹是 `DCIM`,那里存放着我的 iPhone 照片。有时我在写文章时使用这些照片,有时有一些照片我想用 GIMP 等开源应用来增强。可以直接访问这些图片,而不是通过电子邮件把它们发给我自己,这是使用 `libimobiledevice` 工具的好处之一。我可以把这些文件夹中的任何一个复制到我的 Linux 电脑上。我也可以在 iPhone 上创建文件夹并删除它们。
### 发现更多
[Martin Szulecki](https://github.com/FunkyM) 是该项目的首席开发者。该项目正在寻找开发者加入他们的 [社区](https://libimobiledevice.org/#community)。Libimobiledevice 可以改变你使用外设的方式,而无论你在什么平台上。这是开源的又一次胜利,这意味着它是所有人的胜利。
---
via: <https://opensource.com/article/21/8/libimobiledevice-iphone-linux>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The iPhone and iPad aren't by any means open source, but they're popular devices. Many people who own an iOS device also happen to use a lot of open source, including Linux. Users of Windows and macOS can communicate with an iOS device by using software provided by Apple, but Apple doesn't support Linux users. Open source programmers came to the rescue back in 2007 (just a year after the iPhone's release) with Libimobiledevice (then called libiphone), a cross-platform solution for communicating with iOS. It runs on Linux, Android, Arm systems such as the Raspberry Pi, Windows, and even macOS.
Libimobiledevice is written in C and uses native protocols to communicate with services running on iOS devices. It doesn't require any libraries from Apple, so it's fully free and open source.
Libimobiledevice is an object-oriented API, and there are a number of terminal utilities that come bundled with it for your convenience. The library supports Apple's earliest iOS devices all the way up to its latest models. This is the result of years of research and development. Applications in the project include **usbmuxd**, **ideviceinstaller**, **idevicerestore**, **ifuse**, **libusbmuxd**, **libplist**, **libirecovery**, and **libideviceactivation**.
## Install Libimobiledevice on Linux
On Linux, you may already have **libimobiledevice** installed by default. You can find out through your package manager or app store, or by running one of the commands included in the project:
`$ ifuse --help`
You can install **libimobiledevice** using your package manager. For instance, on Fedora or CentOS:
`$ sudo dnf install libimobiledevice ifuse usbmuxd`
On Debian and Ubuntu:
`$ sudo apt install usbmuxd libimobiledevice6 libimobiledevice-utils`
Alternatively, you can [download](https://github.com/libimobiledevice/libimobiledevice/) and install **libimobiledevice** from source code.
## Connecting your device
Once you have the required packages installed, connect your iOS device to your computer.
Make a directory as a mount point for your iOS device.
`$ mkdir ~/iPhone`
Next, mount the device:
`$ ifuse ~/iPhone`
Your device prompts you to trust the computer you're using to access it.
Figure 1: The iPhone prompts you to trust the computer.
Once the trust issue is resolved, you see new icons on your desktop.
Figure 2: New icons for the iphone appear on the desktop.
Click on the **iPhone** icon to reveal the folder structure of your iPhone.
Figure 3: The iPhone folder structure is displayed.
The folder I usually access most frequently is **DCIM**, where my iPhone photos are stored. Sometimes I use these photos in articles I write, and sometimes there are photos I want to enhance with open source applications like Gimp. Having direct access to the images instead of emailing them to myself is one of the benefits of using the Libimobiledevice utilities. I can copy any of these folders to my Linux computer. I can create folders on the iPhone and delete them too.
## Find out more
[Martin Szulecki](https://github.com/FunkyM) is the lead developer for the project. The project is looking for developers to add to their [community](https://libimobiledevice.org/#community). Libimobiledevice can change the way you use your peripherals, regardless of what platform you're on. It's another win for open source, which means it's a win for everyone.
## 5 Comments |
13,740 | 如何在 Linux 系统设置打印机 | https://opensource.com/article/21/8/add-printer-linux | 2021-09-01T10:45:49 | [
"打印机"
] | https://linux.cn/article-13740-1.html |
>
> 如果系统没有自动检测到你的打印机,这篇文章教你如何在 Linux 系统手动添加打印机。
>
>
>

即使未来已来,<ruby> 电子墨水 <rt> e-ink </rt></ruby>和 AR 技术可以现实应用,我们还是会用到打印机的。打印机制造商还不能做到让自己的专利打印机可以与各种计算机完全标准化传递信息,以至于我们需要各种打印机驱动程序,在任何操作系统上都是如此。电子电气工程师协会信息科学与技术处(IEEE-ISTO)下属的打印机工作组(PWG)和开放打印技术组织([OpenPrinting.org](http://OpenPrinting.org))长期合作致力于让人们可以(使用任何型号打印机)轻松打印。带来的便利就是,很多打印机可以不需要用户进行配置就可以自动被识别使用。
如果系统没有自动检测到你的打印机,你可以在这篇文章中找到如何在 Linux 系统手动添加打印机。文中假定你使用的是 GNOME 图形桌面系统,其设置流程同样适用于 KDE 或其他大多数桌面系统。
### 打印机驱动程序
在你尝试用打印机打印文件时,要先确认你的 Linux 系统上是不是已经安装了更新的打印机驱动程序。
可以尝试安装的打印机驱动程序有三大类:
* 作为安装包提供的,捆绑在你的 Linux 系统上的开源 [Gutenprint 驱动程序](http://gimp-print.sourceforge.net/)
* 打印机制造商提供的专用驱动程序
* 第三方开发提供的打印机驱动程序
开源打印机驱动程序库可以驱动 700 多种打印机,值得安装,这里面可能就有你的打印机的驱动,说不定可以自动设置好你的打印机(,你就可以使用它了)。
### 安装开源驱动程序包(库)
有些 Linux 发行版已经预装了开源打印机驱动程序包,如果没有,你可以用包管理器来安装。比如说,在 Fedora、CentOS、Magela 等类似发行版的 Linux 系统上,执行下面命令来安装:
```
$ sudo dnf install gutenprint
```
惠普(HP)系列的打印机,还需要安装惠普的 Linux 图形及打印系统软件包(HPLIP)。如在 Debian、Linux Mint 等类似的系统上,可以使用下面的命令:
```
$ sudo apt install hplip
```
### 安装制造商提供的驱动程序
很多时候因为打印机制造商使用了非标准的接口协议,这种情况开源打印机驱动程序就不能驱动打印机。另外的情况就是,开源驱动程序可以驱动打印机工作,但是会缺少供应商特有的某些性能。这些情况,你需要访问制造商的网站,找到适合你的打印机型号的 Linux 平台驱动。安装过程各异,仔细阅读安装指南逐步安装。
如果你的打印机根本不被厂商支持,你或许也只能尝试第三方提供的该型号打印机的驱动软件了。这类第三方驱动程序不是开源的,但大多数打印机的专用驱动程序也不是。如果你需要额外花费从供应商那里获取帮助服务才能安装好驱动并使用你的打印机,那是很心疼,或者你索性把这台打印机扔掉,至少你知道下次再也不会购买这个品牌的打印机了。
### 通用打印驱动系统(CUPS)
<ruby> 通用打印驱动系统 <rt> Common Unix Printing System </rt></ruby>(CUPS)是由 Easy Software Products 公司于 1997 年开发的,2007 年被苹果公司收购。这是 Linux 平台打印的开源基础软件包,大多数现代发行版都为它提供了一个定制化的界面。得益于 CUPS 技术,你可以发现通过 USB 接口连接到电脑的打印机,甚至连接在同一网络的共享打印机。
一旦你安装了需要的驱动程序包,你就能手工添加你的打印机了。首先,把打印机连接到运行的电脑上,并打开打印机电源。然后从“活动”屏幕或者应用列表中找到并打开“打印机”设置。

基于你已经安装的驱动包,你的 Linux 系统有可能自动检测识别到你的打印机型号,不需要额外的设置就可以使用你的打印机了。

一旦你在列表中找到你的打印机型号,设置使用这个驱动,恭喜你就可以在 Linux 系统上用它打印了。
(如果你的打印机没有被自动识别,)你需要自行添加打印机。在“打印机”设置界面,点击右上角的解锁按钮,输入管理用户密码,按钮转换成“添加打印机”按钮。
然后点击这个“添加打印机”按钮,电脑会搜索已经连接的本地打印机型号并匹配相应驱动程序。如果要添加网络共享打印机,在搜索框输入打印机或者其服务器机的 IP 地址。

选中你想添加的打印机型号,点击“添加”按钮把打印机驱动加入系统,就可以使用它了。
### 在 Linux 系统上打印
在 Linux 系统上打印很容易,不管你是在使用本地打印机还是网络打印机。如果你计划购买打印机,建议查看开放打印技术组织的(可支持打印机)数据库([OpenPrinting.org](http://www.openprinting.org/printers/)),看看你想购买的打印机是不是有相应的开源驱动程序。如果你已经拥有一台打印机,你现在也知道怎样在你的 Linux 系统上使用你的打印机了。
---
via: <https://opensource.com/article/21/8/add-printer-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[fisherue](https://github.com/fisherue) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Even though it's the future now and we're all supposed to be using e-ink and AR, there are still times when a printer is useful. Printer manufacturers have yet to standardize how their peripherals communicate with computers, so there's a necessary maze of printer drivers out there, regardless of what platform you're on. The IEEE-ISTO Printer Working Group (PWG) and the OpenPrinting.org site are working tirelessly to make printing as easy as possible, though. Today, many printers are autodetected with no interaction from the user.
In the event that your printer isn't auto-detected, this article teaches you how to add a printer on Linux manually. This article assumes you're on the GNOME desktop, but the basic workflow is the same for KDE and most other desktops.
## Printer drivers
Before attempting to interface with a printer from Linux, you should first verify that you have updated printer drivers.
There are three varieties of printer drivers:
- Open source
[Gutenprint drivers](http://gimp-print.sourceforge.net/)bundled with Linux and as an installable package - Drivers provided by the printer manufacturer
- Drivers created by a third party
It's worth installing the open source drivers because there are over 700 of them, so having them available increases the chance of attaching a printer and having it automatically configured for you.
## Installing open source drivers
Your Linux distribution probably already has these installed, but if not, you can install them with your package manager. For example, on Fedora, CentOS, Mageia, and similar:
`$ sudo dnf install gutenprint`
For HP printers, also install Hewlett-Packard's Linux Imaging and Printing (HPLIP) project. For example, on Debian, Linux Mint, and similar:
`$ sudo apt install hplip`
## Installing vendor drivers
Sometimes a printer manufacturer uses non-standard protocols, so the open source drivers don't work. Other times, the open source drivers work but may lack special vendor-only features. When that happens, you must visit the manufacturer's website and search for a Linux driver for your printer model. The install process varies, so read the install instructions carefully.
In the event that your printer isn't supported at all by the vendor, there are third-party driver authors that may support your printer. These drivers aren't open source, but neither are most vendor drivers. It's frustrating to have to spend more money to get support for a printer you've already purchased, but sometimes the alternative is to throw the printer into the rubbish, and now you know at least one brand to avoid when you purchase your next printer!
## Common Unix Printing System (CUPS)
The Common Unix Printing System (CUPS) was developed in 1997 by Easy Software Products, and purchased by Apple in 2007. It's the open source basis for printing on Linux, but most modern distributions provide a customized interface for it. Thanks to CUPS, your computer can find printers attached to it by a USB cable and even a shared printer over a network.
Once you've gotten the necessary drivers installed, you can add your printer manually. First, attach your printer to your computer and power them both on. Then open the **Printers** application from the **Activities **screen or application menu.
CC BY-SA Opensource.com
There's a possibility that your printer is autodetected by Linux, by way of the drivers you've installed, and that no further configuration is required.
CC BY-SA Opensource.com
Provided that you see your printer listed, you're all set, and you can already print from Linux!
If you see that you need to add a printer, click the **Unlock** button in the top right corner of the **Printers **window. Enter your administrative password and the button transforms into an **Add** button.
Click the **Add** button.
Your computer searches for attached printers (also called a *local* printer). To have your computer look for a shared network printer, enter the IP address of the printer or its host.

CC BY-SA Opensource.com
Select the printer you want to add to your system and click the **Add** button.
## Print from Linux
Printing from Linux is as easy as printing can be, whether you're using a local or networked printer. If you're looking for a printer to purchase, then check the [OpenPrinting.org database](http://www.openprinting.org/printers/) to confirm that a printer has an open source driver before you spend your money. If you already have a printer, you now know how to use it on your Linux computer.
## Comments are closed. |
13,743 | Ulauncher:一个超级实用的 Linux 应用启动器 | https://itsfoss.com/ulauncher/ | 2021-09-01T22:39:59 | [
"应用启动器"
] | https://linux.cn/article-13743-1.html |
>
> Ulauncher 是一个快速应用启动器,支持扩展和快捷方式,帮助你在 Linux 中快速访问应用和文件。
>
>
>
应用启动器可以让你快速访问或打开一个应用,而无需在应用菜单图标上徘徊。
在默认情况下,我发现 Pop!\_OS 的应用启动器超级方便。但是,并不是每个 Linux 发行版都提供开箱即用的应用启动器。
幸运的是,有一个你可以在大多数流行的发行版中添加应用启动器的方案。
### Ulauncher:开源应用启动器

Ulauncher 是一个使用 Python 还有 GTK+ 构建的快速应用启动器。
它提供了相当数量的自定义和控制选项来进行调整。总的来说,你可以调整它的行为和体验以适应你的喜好。
让我来说一下你可以期待它的一些功能。
### Ulauncher 功能
Ulauncher 中的选项非常非常易于访问且易于定制。一些关键的亮点包括:
* 模糊搜索算法可以让你即使拼错了,也能找到应用
* 可以记住你在同一会话中最后搜索的应用
* 显示经常使用的应用(可选)
* 自定义颜色主题
* 预设颜色主题,包括一个黑暗主题
* 召唤启动器的快捷方式可以轻松定制
* 浏览文件和目录
* 支持扩展,以获得额外的功能(表情符号、天气、速度测试、笔记、密码管理器等)
* 浏览谷歌、维基百科和 Stack Overflow 等网站的快捷方式
它几乎提供了你在一个应用启动器中所期望的所有有用的能力,甚至更好。
### 如何在 Linux 中使用 Ulauncher?
默认情况下,首次从应用菜单中打开应用启动器后,你需要按 `Ctrl + Space` 打开应用启动器。
输入以搜索一个应用。如果你正在寻找一个文件或目录,输入以 `~` 或者 `/` 开始。

有一些默认的快捷键,如 `g XYZ`,其中 “XYZ” 是你想在谷歌中搜索的搜索词。

同样,你可以通过 `wiki` 和 `so` 快捷键,直接在维基百科或 Stack Overflow 搜索。
在没有任何扩展的情况下,你也可以直接计算内容,并将结果直接复制到剪贴板。

这在快速计算时应该很方便,不需要单独启动计算器应用。
你可以前往它的 [扩展页面](https://ext.ulauncher.io),浏览有用的扩展,以及指导你如何使用它的截图。
要改变它的工作方式,启用显示经常使用的应用,并调整主题,请点击启动器右侧的齿轮图标。

你可以把它设置为自动启动。但是,如果它在你的支持 Systemd 的发行版上不工作,你可以参考它的 GitHub 页面,把它添加到服务管理器中。
这些选项是非常直观,且易于定制,如下图所示。

### 在 Linux 中安装 Ulauncher
Ulauncher 为基于 Debian 或 Ubuntu 的发行版提供了一个 deb 包。如果你是 Linux 新手,你可以了解一下 [如何安装 Deb 文件](https://itsfoss.com/install-deb-files-ubuntu/) 。
在这两种情况下,你也可以添加它的 PPA,并通过终端按照下面的命令来安装它:
```
sudo add-apt-repository ppa:agornostal/ulauncher
sudo apt update
sudo apt install ulauncher
```
你也可以在 [AUR](https://itsfoss.com/aur-arch-linux/) 中找到它,用于 Arch 和 Fedora 的默认仓库。
对于更多信息,你可以前往其官方网站或 [GitHub 页面](https://github.com/Ulauncher/Ulauncher/)。
* [Ulauncher](https://ulauncher.io)
Ulauncher 应该是任何 Linux 发行版中一个令人印象深刻的补充。特别是,如果你想要一个像 Pop!\_OS 提供的快速启动器的功能,这是一个值得考虑的奇妙选择。
你试过 Ulauncher了吗?欢迎你就如何帮助你快速完成工作分享你的想法。
---
via: <https://itsfoss.com/ulauncher/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: **Ulauncher is a fast application launcher with extension and shortcut support to help you quickly access application and files in Linux.*
An application launcher lets you quickly access or open an app without hovering over the application menu icons.
By default, I found the application launcher with Pop!_OS super handy. But, not every Linux distribution offers an application launcher out-of-the-box.
Fortunately, there is a solution with which you can add the application launcher to most of the popular distros out there.
## Ulauncher: Open Source Application Launcher
Ulauncher is a quick application launcher built using Python while utilizing GTK+.
It gives a decent amount of customization and control options to tweak. Overall, you can adjust its behavior and experience to suit your taste.
Let me highlight some of the features that you can expect with it.
## Ulauncher Features
The options that you get with Ulauncher are super accessible and easy to customize. Some key highlights include:
- Fuzzy search algorithm, which lets you find applications even if you misspell them
- Remembers your last searched application in the same session
- Frequently used apps display (optional)
- Custom color themes
- Preset color themes that include a dark theme
- Shortcut to summon the launcher can be easily customized
- Browse files and directories
- Support for extensions to get extra functionality (emoji, weather, speed test, notes, password manager, etc.)
- Shortcuts for browsing sites like Google, Wikipedia, and Stack Overflow
It provides almost every helpful ability that you may expect in an application launcher, and even better.
## How to Use Ulauncher in Linux?
By default, you need to press **Ctrl + Space** to get the application launcher after you open it from the application menu for the first time.
Start typing in to search for an application. And, if you are looking for a file or directory, start typing with “**~**” or “**/**” (ignoring the quotes).
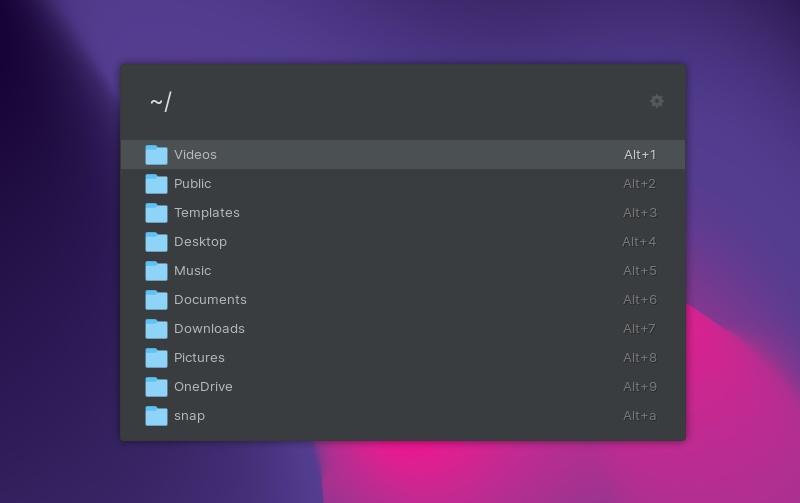
There are default shortcuts like “**g XYZ**” where XYZ is the search term you want to search for in Google.
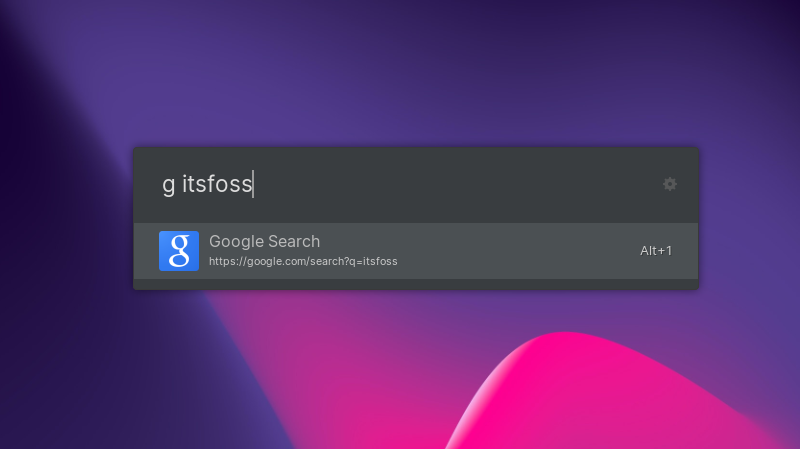
Similarly, you can search for something directly taking you to Wikipedia or Stack Overflow, with “**wiki**” and “**so**” shortcuts, respectively.
Without any extensions, you can also calculate things on the go and copy the results directly to the keyboard.
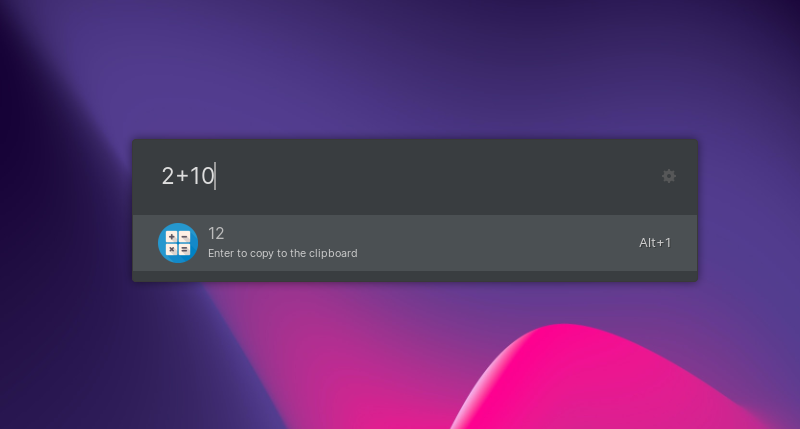
This should come in handy for quick calculations without needing to launch the calculator app separately.
You can head to its [extensions page](https://ext.ulauncher.io) and browse for useful extensions along with screenshots that should instruct you how to use it.
To change how it works, enable frequent applications display, and adjust the theme — click on the gear icon on the right side of the launcher.

You can set it to auto-start. But, if it does not work on your Systemd enabled distro, you can refer to its GitHub page to add it to the service manager.
The options are self-explanatory and are easy to customize, as shown in the screenshot below.
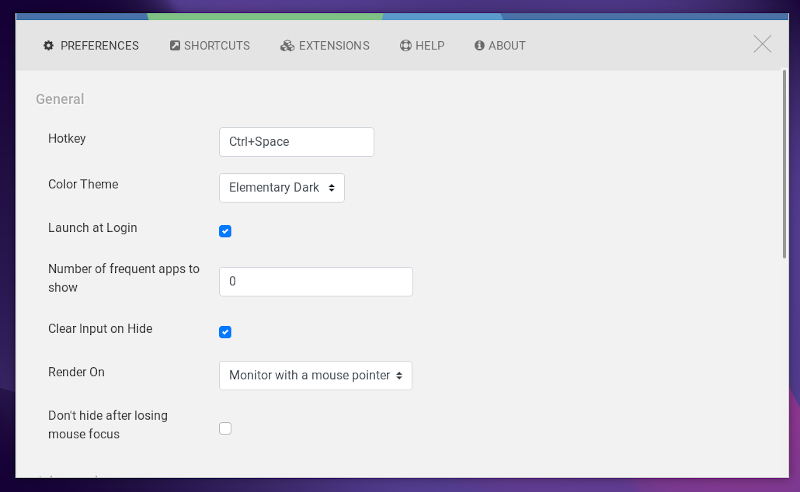
## Installing Ulauncher in Linux
Ulauncher provides a **.deb** package for Debian or Ubuntu-based distributions. You can explore [how to install Deb ](https://itsfoss.com/install-deb-files-ubuntu/)[f](https://itsfoss.com/install-deb-files-ubuntu/)[iles](https://itsfoss.com/install-deb-files-ubuntu/) if you’re new to Linux.
In either case, you can also add its PPA and install it via terminal by following the commands below:
```
sudo add-apt-repository ppa:agornostal/ulauncher
sudo apt update
sudo apt install ulauncher
```
You can also find it available in the [AUR](https://itsfoss.com/aur-arch-linux/) for Arch and Fedora’s default repositories.
For more information, you can head to its official website or the [GitHub page](https://github.com/Ulauncher/Ulauncher/).
Ulauncher should be an impressive addition to any Linux distro. Especially, if you want the functionality of a quick launcher like Pop!_OS offers, this is a fantastic option to consider.
*Have you tried Ulauncher yet? You are welcome to share your thoughts on how this might help you get things done quickly.* |
13,744 | 在 Kubernetes 上部署一个深度学习模型 | https://opensource.com/article/20/9/deep-learning-model-kubernetes | 2021-09-01T23:34:28 | [
"Kubernetes",
"深度学习"
] | https://linux.cn/article-13744-1.html |
>
> 了解如何使用 Kubermatic Kubernetes 平台来部署、扩展与管理图像识别预测的深度学习模型。
>
>
>

随着企业增加了对人工智能(AI)、机器学习(ML)与深度学习(DL)的使用,出现了一个关键问题:如何将机器学习的开发进行规模化与产业化?这些讨论经常聚焦于机器学习模型本身;然而,模型仅仅只是完整解决方案的其中一环。为了达到生产环境的应用和规模,模型的开发过程必须还包括一个可以说明开发前后关键活动以及可公用部署的可重复过程。
本文演示了如何使用 [Kubermatic Kubernetes 平台](https://www.loodse.com/products/kubermatic/) 对图像识别预测的深度学习模型进行部署、扩展与管理。
Kubermatic Kubernetes 平台是一个生产级的开源 Kubernetes 集群管理工具,提供灵活性和自动化,与机器学习/深度学习工作流程整合,具有完整的集群生命周期管理。
### 开始
这个例子部署了一个用于图像识别的深度学习模型。它使用了 [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) 数据集,包含了 60,000 张分属 10 个类别的 32x32 彩色图,同时使用了 [Apache MXNet](https://mxnet.apache.org/) 的 [Gluon](https://gluon.mxnet.io/) 与 NVIDIA GPU 进行加速计算。如果你希望使用 CIFAR-10 数据集的预训练模型,可以查阅其 [入门指南](https://gluon-cv.mxnet.io/build/examples_classification/demo_cifar10.html)。
使用训练集中的样本对模型训练 200 次,只要训练误差保持缓慢减少,就可以保证模型不会过拟合。下方图展示了训练的过程:

训练结束后,必须保存模型训练所得到的参数,以便稍后可以加载它们:
```
file_name = "net.params"
net.save_parameters(file_name)
```
一旦你的模型训练好了,就可以用 Flask 服务器来封装它。下方的程序演示了如何接收请求中的一张图片作为参数,并在响应中返回模型的预测结果:
```
from gluoncv.model_zoo import get_model
import matplotlib.pyplot as plt
from mxnet import gluon, nd, image
from mxnet.gluon.data.vision import transforms
from gluoncv import utils
from PIL import Image
import io
import flask
app = flask.Flask(__name__)
@app.route("/predict",methods=["POST"])
def predict():
if flask.request.method == "POST":
if flask.request.files.get("img"):
img = Image.open(io.BytesIO(flask.request.files["img"].read()))
transform_fn = transforms.Compose([
transforms.Resize(32),
transforms.CenterCrop(32),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
img = transform_fn(nd.array(img))
net = get_model('cifar_resnet20_v1', classes=10)
net.load_parameters('net.params')
pred = net(img.expand_dims(axis=0))
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
ind = nd.argmax(pred, axis=1).astype('int')
prediction = 'The input picture is classified as [%s], with probability %.3f.'%
(class_names[ind.asscalar()], nd.softmax(pred)[0][ind].asscalar())
return prediction
if __name__ == '__main__':
app.run(host='0.0.0.0')
```
### 容器化模型
在将模型部署到 Kubernetes 前,你需要先安装 Docker 并使用你的模型创建一个镜像。
1. 下载、安装并启动 Docker:
```
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
sudo yum-config-manager --add-repo <https://download.docker.com/linux/centos/docker-ce.repo>
sudo yum install docker-ce
sudo systemctl start docker
```
2. 创建一个你用来管理代码与依赖的文件夹:
```
mkdir kubermatic-dl
cd kubermatic-dl
```
3. 创建 `requirements.txt` 文件管理代码运行时需要的所有依赖:
```
flask
gluoncv
matplotlib
mxnet
requests
Pillow
```
4. 创建 `Dockerfile`,Docker 将根据这个文件创建镜像:
```
FROM python:3.6
WORKDIR /app
COPY requirements.txt /app
RUN pip install -r ./requirements.txt
COPY app.py /app
CMD ["python", "app.py"]
```
这个 `Dockerfile` 主要可以分为三个部分。首先,Docker 会下载 Python 的基础镜像。然后,Docker 会使用 Python 的包管理工具 `pip` 安装 `requirements.txt` 记录的包。最后,Docker 会通过执行 `python app.py` 来运行你的脚本。
5. 构建 Docker 容器:
```
sudo docker build -t kubermatic-dl:latest .
```
这条命令使用 `kubermatic-dl` 镜像为你当前工作目录的代码创建了一个容器。
6. 使用
```
sudo docker run -d -p 5000:5000 kubermatic-dl
```
命令检查你的容器可以在你的主机上正常运行。
7. 使用
```
sudo docker ps -a
```
命令查看你本地容器的运行状态:

### 将你的模型上传到 Docker Hub
在向 Kubernetes 上部署模型前,你的镜像首先需要是公开可用的。你可以通过将你的模型上传到 [Docker Hub](https://hub.docker.com/) 来将它公开。(如果你没有 Docker Hub 的账号,你需要先创建一个)
1. 在终端中登录 Docker Hub 账号:
```
sudo docker login
```
2. 给你的镜像打上标签,这样你的模型上传到 Docker Hub 后也能拥有版本信息:
```
sudo docker tag <your-image-id> <your-docker-hub-name>/<your-app-name>
sudo docker push <your-docker-hub-name>/<your-app-name>
```

3. 使用
```
sudo docker images
```
命令检查你的镜像的 ID。
### 部署你的模型到 Kubernetes 集群
1. 首先在 Kubermatic Kubernetes 平台创建一个项目, 然后根据 [快速开始](https://docs.kubermatic.com/kubermatic/v2.13/installation/install_kubermatic/_installer/) 创建一个 Kubernetes 集群。

2. 下载用于访问你的集群的 `kubeconfig`,将它放置在下载目录中,并记得设置合适的环境变量,使得你的环境能找到它:

3. 使用 `kubectl` 命令检查集群信息,例如,需要检查 `kube-system` 是否在你的集群正常启动了就可以使用命令 `kubectl cluster-info`

4. 为了在集群中运行容器,你需要创建一个部署用的配置文件(`deployment.yaml`),再运行 `apply` 命令将其应用于集群中:
```
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubermatic-dl-deployment
spec:
selector:
matchLabels:
app: kubermatic-dl
replicas: 3
template:
metadata:
labels:
app: kubermatic-dl
spec:
containers:
- name: kubermatic-dl
image: kubermatic00/kubermatic-dl:latest
imagePullPolicy: Always
ports:
- containerPort: 8080
```
```
kubectl apply -f deployment.yaml`
```
5. 为了将你的部署开放到公网环境,你需要一个能够给你的容器创建外部可达 IP 地址的服务:
```
kubectl expose deployment kubermatic-dl-deployment --type=LoadBalancer --port 80 --target-port 5000`
```
6. 就快大功告成了!首先检查你布署的服务的状态,然后通过 IP 请求的你图像识别 API:
```
kubectl get service
```

7. 最后根据你的外部 IP 使用以下两张图片对你的图像识别服务进行测试:



### 总结
在这篇教程中,你可以创建一个深度学习模型,并且使用 Flask 提供 [REST API](https://www.redhat.com/en/topics/api/what-is-a-rest-api) 服务。它介绍了如何将应用放在 Docker 容器中,如何将这个镜像上传到 Docker Hub 中,以及如何使用 Kubernetes 部署你的服务。只需几个简单的命令,你就可以使用 Kubermatic Kubernetes 平台部署该应用程序,并且开放服务给别人使用。
---
via: <https://opensource.com/article/20/9/deep-learning-model-kubernetes>
作者:[Chaimaa Zyani](https://opensource.com/users/chaimaa) 选题:[lujun9972](https://github.com/lujun9972) 译者:[chunibyo-wly](https://github.com/chunibyo-wly) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As enterprises increase their use of artificial intelligence (AI), machine learning (ML), and deep learning (DL), a critical question arises: How can they scale and industrialize ML development? These conversations often focus on the ML model; however, this is only one step along the way to a complete solution. To achieve in-production application and scale, model development must include a repeatable process that accounts for the critical activities that precede and follow development, including getting the model into a public-facing deployment.
This article demonstrates how to deploy, scale, and manage a deep learning model that serves up image recognition predictions using [Kubermatic Kubernetes Platform](https://www.loodse.com/products/kubermatic/).
Kubermatic Kubernetes Platform is a production-grade, open source Kubernetes cluster-management tool that offers flexibility and automation to integrate with ML/DL workflows with full cluster lifecycle management.
## Get started
This example deploys a deep learning model for image recognition. It uses the [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) dataset that consists of 60,000 32x32 color images in 10 classes with the [Gluon](https://gluon.mxnet.io/) library in [Apache MXNet](https://mxnet.apache.org/) and NVIDIA GPUs to accelerate the workload. If you want to use a pre-trained model on the CIFAR-10 dataset, check out the [getting started guide](https://gluon-cv.mxnet.io/build/examples_classification/demo_cifar10.html).
The model was trained over a span of 200 epochs, as long as the validation error kept decreasing slowly without causing the model to overfit. This plot shows the training process:
(Chaimaa Zyami, CC BY-SA 4.0)
After training, it's essential to save the model's parameters so they can be loaded later:
```
file_name = "net.params"
net.save_parameters(file_name)
```
Once the model is ready, wrap your prediction code in a Flask server. This allows the server to accept an image as an argument to its request and return the model's prediction in the response:
```
from gluoncv.model_zoo import get_model
import matplotlib.pyplot as plt
from mxnet import gluon, nd, image
from mxnet.gluon.data.vision import transforms
from gluoncv import utils
from PIL import Image
import io
import flask
app = flask.Flask(__name__)
@app.route("/predict",methods=["POST"])
def predict():
if flask.request.method == "POST":
if flask.request.files.get("img"):
img = Image.open(io.BytesIO(flask.request.files["img"].read()))
transform_fn = transforms.Compose([
transforms.Resize(32),
transforms.CenterCrop(32),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])])
img = transform_fn(nd.array(img))
net = get_model('cifar_resnet20_v1', classes=10)
net.load_parameters('net.params')
pred = net(img.expand_dims(axis=0))
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
ind = nd.argmax(pred, axis=1).astype('int')
prediction = 'The input picture is classified as [%s], with probability %.3f.'%
(class_names[ind.asscalar()], nd.softmax(pred)[0][ind].asscalar())
return prediction
if __name__ == '__main__':
app.run(host='0.0.0.0')
```
## Containerize the model
Before you can deploy your model to Kubernetes, you need to install Docker and create a container image with your model.
- Download, install, and start Docker:
`sudo yum install -y yum-utils device-mapper-persistent-data lvm2 sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo yum install docker-ce sudo systemctl start docker`
- Create a directory where you can organize your code and dependencies:
`mkdir kubermatic-dl cd kubermatic-dl`
- Create a
`requirements.txt`
file to contain the packages the code needs to run:
`flask gluoncv matplotlib mxnet requests Pillow`
- Create the Dockerfile that Docker will read to build and run the model:
`FROM python:3.6 WORKDIR /app COPY requirements.txt /app RUN pip install -r ./requirements.txt COPY app.py /app CMD ["python", "app.py"]~`
This Dockerfile can be broken down into three steps. First, it creates the Dockerfile and instructs Docker to download a base image of Python 3. Next, it asks Docker to use the Python package manager
`pip`
to install the packages in`requirements.txt`
. Finally, it tells Docker to run your script via`python app.py`
. - Build the Docker container:
`sudo docker build -t kubermatic-dl:latest .`
This instructs Docker to build a container for the code in your current working directory,
`kubermatic-dl`
. - Check that your container is working by running it on your local machine:
`sudo docker run -d -p 5000:5000 kubermatic-dl`
- Check the status of your container by running
`sudo docker ps -a`
:
(Chaimaa Zyami,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
## Upload the model to Docker Hub
Before you can deploy the model on Kubernetes, it must be publicly available. Do that by adding it to [Docker Hub](https://hub.docker.com/). (You will need to create a Docker Hub account if you don't have one.)
- Log into your Docker Hub account:
`sudo docker login`
- Tag the image so you can refer to it for versioning when you upload it to Docker Hub:
`sudo docker tag <your-image-id> <your-docker-hub-name>/<your-app-name> sudo docker push <your-docker-hub-name>/<your-app-name>`
(Chaimaa Zyami,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)) - Check your image ID by running
`sudo docker images`
.
## Deploy the model to a Kubernetes cluster
- Create a project on the Kubermatic Kubernetes Platform, then create a Kubernetes cluster using the
[quick start tutorial](https://docs.kubermatic.com/kubermatic/v2.13/installation/install_kubermatic/_installer/).
(Chaimaa Zyami,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)) - Download the
`kubeconfig`
used to configure access to your cluster, change it into the download directory, and export it into your environment:
(Chaimaa Zyami,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)) - Using
`kubectl`
, check the cluster information, such as the services that`kube-system`
starts on your cluster:
`kubectl cluster-info`
(Chaimaa Zyami,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)) - To run the container in the cluster, you need to create a deployment (
`deployment.yaml`
) and apply it to the cluster:
`apiVersion: apps/v1 kind: Deployment metadata: name: kubermatic-dl-deployment spec: selector: matchLabels: app: kubermatic-dl replicas: 3 template: metadata: labels: app: kubermatic-dl spec: containers: - name: kubermatic-dl image: kubermatic00/kubermatic-dl:latest imagePullPolicy: Always ports: - containerPort: 8080`
`kubectl apply -f deployment.yaml`
- To expose your deployment to the outside world, you need a service object that will create an externally reachable IP for your container:
`kubectl expose deployment kubermatic-dl-deployment --type=LoadBalancer --port 80 --target-port 5000`
- You're almost there! Check your services to determine the status of your deployment and get the IP address to call your image recognition API:
`kubectl get service`
(Chaimaa Zyami,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)) - Test your API with these two images using the external IP:
(Chaimaa Zyami,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))(Chaimaa Zyami,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))(Chaimaa Zyami,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
## Summary
In this tutorial, you created a deep learning model to be served as a [REST API](https://www.redhat.com/en/topics/api/what-is-a-rest-api) using Flask. It put the application inside a Docker container, uploaded the container to Docker Hub, and deployed it with Kubernetes. Then, with just a few commands, Kubermatic Kubernetes Platform deployed the app and exposed it to the world.
## Comments are closed. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.