
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
13,259 | 用 Bash 读写文件 | https://opensource.com/article/21/3/input-output-bash | 2021-04-01T22:37:26 | [
"Bash",
"读写",
"文件"
] | https://linux.cn/article-13259-1.html |
>
> 学习 Bash 读取和写入数据的不同方式,以及何时使用每种方法。
>
>
>

当你使用 Bash 编写脚本时,有时你需要从一个文件中读取数据或向一个文件写入数据。有时文件可能包含配置选项,而另一些时候这个文件是你的用户用你的应用创建的数据。每种语言处理这个任务的方式都有些不同,本文将演示如何使用 Bash 和其他 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) shell 处理数据文件。
### 安装 Bash
如果你在使用 Linux,你可能已经有了 Bash。如果没有,你可以在你的软件仓库里找到它。
在 macOS 上,你可以使用默认终端,Bash 或 [Zsh](https://opensource.com/article/19/9/getting-started-zsh),这取决于你运行的 macOS 版本。
在 Windows 上,有几种方法可以体验 Bash,包括微软官方支持的 [Windows Subsystem for Linux](https://opensource.com/article/19/7/ways-get-started-linux#wsl)(WSL)。
安装 Bash 后,打开你最喜欢的文本编辑器并准备开始。
### 使用 Bash 读取文件
除了是 [shell](https://www.redhat.com/sysadmin/terminals-shells-consoles) 之外,Bash 还是一种脚本语言。有几种方法可以从 Bash 中读取数据。你可以创建一种数据流并解析输出, 或者你可以将数据加载到内存中。这两种方法都是有效的获取信息的方法,但每种方法都有相当具体的用例。
#### 在 Bash 中援引文件
当你在 Bash 中 “<ruby> 援引 <rt> source </rt></ruby>” 一个文件时,你会让 Bash 读取文件的内容,期望它包含有效的数据,Bash 可以将这些数据放入它建立的数据模型中。你不会想要从旧文件中援引数据,但你可以使用这种方法来读取配置文件和函数。
(LCTT 译注:在 Bash 中,可以通过 `source` 或 `.` 命令来将一个文件读入,这个行为称为 “sourcing”,英文原意为“一次性(试)采购”、“寻找供应商”、“获得”等,考虑到 Bash 的语境和发音,我建议可以翻译为“援引”,或有不当,供大家讨论参考 —— wxy)
例如,创建一个名为 `example.sh` 的文件,并输入以下内容:
```
#!/bin/sh
greet opensource.com
echo "The meaning of life is $var"
```
运行这段代码,看见失败了:
```
$ bash ./example.sh
./example.sh: line 3: greet: command not found
The meaning of life is
```
Bash 没有一个叫 `greet` 的命令,所以无法执行那一行,也没有一个叫 `var` 的变量记录,所以文件没有意义。为了解决这个问题,建立一个名为 `include.sh` 的文件:
```
greet() {
echo "Hello ${1}"
}
var=42
```
修改你的 `example.sh` 脚本,加入一个 `source` 命令:
```
#!/bin/sh
source include.sh
greet opensource.com
echo "The meaning of life is $var"
```
运行脚本,可以看到工作了:
```
$ bash ./example.sh
Hello opensource.com
The meaning of life is 42
```
`greet` 命令被带入你的 shell 环境,因为它被定义在 `include.sh` 文件中,它甚至可以识别参数(本例中的 `opensource.com`)。变量 `var` 也被设置和导入。
#### 在 Bash 中解析文件
另一种让数据“进入” Bash 的方法是将其解析为数据流。有很多方法可以做到这一点. 你可以使用 `grep` 或 `cat` 或任何可以获取数据并管道输出到标准输出的命令。另外,你可以使用 Bash 内置的东西:重定向。重定向本身并不是很有用,所以在这个例子中,我也使用内置的 `echo` 命令来打印重定向的结果:
```
#!/bin/sh
echo $( < include.sh )
```
将其保存为 `stream.sh` 并运行它来查看结果:
```
$ bash ./stream.sh
greet() { echo "Hello ${1}" } var=42
$
```
对于 `include.sh` 文件中的每一行,Bash 都会将该行打印(或 `echo`)到你的终端。先用管道把它传送到一个合适的解析器是用 Bash 读取数据的常用方法。例如, 假设 `include.sh` 是一个配置文件, 它的键和值对用一个等号(`=`)分开. 你可以用 `awk` 甚至 `cut` 来获取值:
```
#!/bin/sh
myVar=`grep var include.sh | cut -d'=' -f2`
echo $myVar
```
试着运行这个脚本:
```
$ bash ./stream.sh
42
```
### 用 Bash 将数据写入文件
无论你是要存储用户用你的应用创建的数据,还是仅仅是关于用户在应用中做了什么的元数据(例如,游戏保存或最近播放的歌曲),都有很多很好的理由来存储数据供以后使用。在 Bash 中,你可以使用常见的 shell 重定向将数据保存到文件中。
例如, 要创建一个包含输出的新文件, 使用一个重定向符号:
```
#!/bin/sh
TZ=UTC
date > date.txt
```
运行脚本几次:
```
$ bash ./date.sh
$ cat date.txt
Tue Feb 23 22:25:06 UTC 2021
$ bash ./date.sh
$ cat date.txt
Tue Feb 23 22:25:12 UTC 2021
```
要追加数据,使用两个重定向符号:
```
#!/bin/sh
TZ=UTC
date >> date.txt
```
运行脚本几次:
```
$ bash ./date.sh
$ bash ./date.sh
$ bash ./date.sh
$ cat date.txt
Tue Feb 23 22:25:12 UTC 2021
Tue Feb 23 22:25:17 UTC 2021
Tue Feb 23 22:25:19 UTC 2021
Tue Feb 23 22:25:22 UTC 2021
```
### Bash 轻松编程
Bash 的优势在于简单易学,因为只需要一些基本的概念,你就可以构建复杂的程序。完整的文档请参考 [GNU.org](http://GNU.org) 上的 [优秀的 Bash 文档](http://gnu.org/software/bash)。
---
via: <https://opensource.com/article/21/3/input-output-bash>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When you're scripting with Bash, sometimes you need to read data from or write data to a file. Sometimes a file may contain configuration options, and other times the file is the data your user is creating with your application. Every language handles this task a little differently, and this article demonstrates how to handle data files with Bash and other [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) shells.
## Install Bash
If you're on Linux, you probably already have Bash. If not, you can find it in your software repository.
On macOS, you can use the default terminal, either Bash or [Zsh](https://opensource.com/article/19/9/getting-started-zsh), depending on the macOS version you're running.
On Windows, there are several ways to experience Bash, including Microsoft's officially supported [Windows Subsystem for Linux](https://opensource.com/article/19/7/ways-get-started-linux#wsl) (WSL).
Once you have Bash installed, open your favorite text editor and get ready to code.
## Reading a file with Bash
In addition to being [a shell](https://www.redhat.com/sysadmin/terminals-shells-consoles), Bash is a scripting language. There are several ways to read data from Bash: You can create a sort of data stream and parse the output, or you can load data into memory. Both are valid methods of ingesting information, but each has pretty specific use cases.
### Source a file in Bash
When you "source" a file in Bash, you cause Bash to read the contents of a file with the expectation that it contains valid data that Bash can fit into its established data model. You won't source data from any old file, but you can use this method to read configuration files and functions.
For instance, create a file called `example.sh`
and enter this into it:
```
#!/bin/sh
greet opensource.com
echo "The meaning of life is $var"
```
Run the code to see it fail:
```
$ bash ./example.sh
./example.sh: line 3: greet: command not found
The meaning of life is
```
Bash doesn't have a command called `greet`
, so it could not execute that line, and it has no record of a variable called `var`
, so there is no known meaning of life. To fix this problem, create a file called `include.sh`
:
```
greet() {
echo "Hello ${1}"
}
var=42
```
Revise your `example.sh`
script to include a `source`
command:
```
#!/bin/sh
source include.sh
greet opensource.com
echo "The meaning of life is $var"
```
Run the script to see it work:
```
$ bash ./example.sh
Hello opensource.com
The meaning of life is 42
```
The `greet`
command is brought into your shell environment because it is defined in the `include.sh`
file, and it even recognizes the argument (`opensource.com`
in this example). The variable `var`
is set and imported, too.
### Parse a file in Bash
The other way to get data "into" Bash is to parse it as a data stream. There are many ways to do this. You can use `grep`
or `cat`
or any command that takes data and pipes it to stdout. Alternately, you can use what is built into Bash: the redirect. Redirection on its own isn't very useful, so in this example, I also use the built-in `echo`
command to print the results of the redirect:
```
#!/bin/sh
echo $( < include.sh )
```
Save this as `stream.sh`
and run it to see the results:
```
$ bash ./stream.sh
greet() { echo "Hello ${1}" } var=42
$
```
For each line in the `include.sh`
file, Bash prints (or echoes) the line to your terminal. Piping it first to an appropriate parser is a common way to read data with Bash. For instance, assume for a moment that `include.sh`
is a configuration file with key and value pairs separated by an equal (`=`
) sign. You could obtain values with `awk`
or even `cut`
:
```
#!/bin/sh
myVar=`grep var include.sh | cut -d'=' -f2`
echo $myVar
```
Try running the script:
```
$ bash ./stream.sh
42
```
## Writing data to a file with Bash
Whether you're storing data your user created with your application or just metadata about what the user did in an application (for instance, game saves or recent songs played), there are many good reasons to store data for later use. In Bash, you can save data to files using common shell redirection.
For instance, to create a new file containing output, use a single redirect token:
```
#!/bin/sh
TZ=UTC
date > date.txt
```
Run the script a few times:
```
$ bash ./date.sh
$ cat date.txt
Tue Feb 23 22:25:06 UTC 2021
$ bash ./date.sh
$ cat date.txt
Tue Feb 23 22:25:12 UTC 2021
```
To append data, use the double redirect tokens:
```
#!/bin/sh
TZ=UTC
date >> date.txt
```
Run the script a few times:
```
$ bash ./date.sh
$ bash ./date.sh
$ bash ./date.sh
$ cat date.txt
Tue Feb 23 22:25:12 UTC 2021
Tue Feb 23 22:25:17 UTC 2021
Tue Feb 23 22:25:19 UTC 2021
Tue Feb 23 22:25:22 UTC 2021
```
## Bash for easy programming
Bash excels at being easy to learn because, with just a few basic concepts, you can build complex programs. For the full documentation, refer to the [excellent Bash documentation](http://gnu.org/software/bash) on GNU.org.
## Comments are closed. |
13,261 | 为什么需要关心服务网格 | https://opensource.com/article/21/3/service-mesh | 2021-04-02T20:14:59 | [
"服务网格",
"微服务",
"云原生"
] | https://linux.cn/article-13261-1.html |
>
> 在微服务环境中,服务网格为开发和运营提供了好处。
>
>
>

很多开发者不知道为什么要关心<ruby> <a href="https://www.redhat.com/en/topics/microservices/what-is-a-service-mesh"> 服务网格 </a> <rt> Service Mesh </rt></ruby>。这是我在开发者见面会、会议和实践研讨会上关于云原生架构的微服务开发的演讲中经常被问到的问题。我的回答总是一样的:“只要你想简化你的微服务架构,它就应该运行在 Kubernetes 上。”
关于简化,你可能也想知道,为什么分布式微服务必须设计得如此复杂才能在 Kubernetes 集群上运行。正如本文所解释的那样,许多开发人员通过服务网格解决了微服务架构的复杂性,并通过在生产中采用服务网格获得了额外的好处。
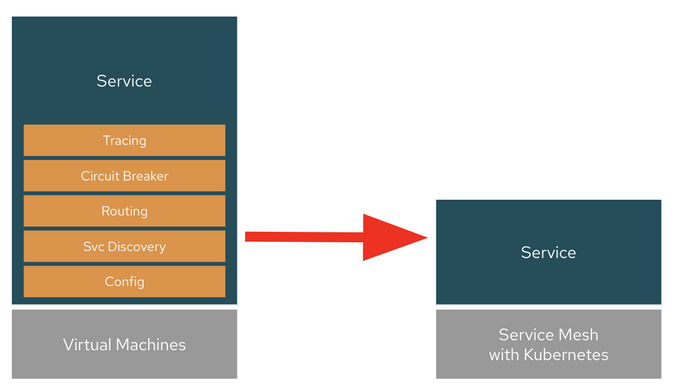
### 什么是服务网格?
服务网格是一个专门的基础设施层,用于提供一个透明的、独立于代码的 (polyglot) 方式,以消除应用代码中的非功能性微服务能力。

### 为什么服务网格对开发者很重要
当开发人员将微服务部署到云时,无论业务功能如何,他们都必须解决非功能性微服务功能,以避免级联故障。这些功能通常可以体现在服务发现、日志、监控、<ruby> 韧性 <rt> resiliency </rt></ruby>、认证、<ruby> 弹性 <rt> elasticity </rt></ruby>和跟踪等方面。开发人员必须花费更多的时间将它们添加到每个微服务中,而不是开发实际的业务逻辑,这使得微服务变得沉重而复杂。
随着企业加速向云计算转移,服务网格 可以提高开发人员的生产力。Kubernetes 加服务网格平台不需要让服务负责处理这些复杂的问题,也不需要在每个服务中添加更多的代码来处理云原生的问题,而是负责向运行在该平台上的任何应用(现有的或新的,用任何编程语言或框架)提供这些服务。那么微服务就可以轻量级,专注于其业务逻辑,而不是云原生的复杂性。
### 为什么服务网格对运维很重要
这并没有回答为什么运维团队需要关心在 Kubernetes 上运行云原生微服务的服务网格。因为运维团队必须确保在 Kubernetes 环境上的大型混合云和多云上部署新的云原生应用的强大安全性、合规性和可观察性。
服务网格由一个用于管理代理路由流量的控制平面和一个用于注入<ruby> 边车 <rt> Sidecar </rt></ruby>的数据平面组成。边车允许运维团队做一些比如添加第三方安全工具和追踪所有服务通信中的流量,以避免安全漏洞或合规问题。服务网格还可以通过在图形面板上可视化地跟踪指标来提高观察能力。
### 如何开始使用服务网格
对于开发者和运维人员,以及从应用开发到平台运维来说,服务网格可以更有效地管理云原生功能。
你可能想知道从哪里开始采用服务网格来配合你的微服务应用和架构。幸运的是,有许多开源的服务网格项目。许多云服务提供商也在他们的 Kubernetes 平台中提供 服务网格。

你可以在 [CNCF Service Mesh Landscape](https://landscape.cncf.io/card-mode?category=service-mesh&grouping=category) 页面中找到最受欢迎的服务网格项目和服务的链接。
---
via: <https://opensource.com/article/21/3/service-mesh>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many developers wonder why they should care about [service mesh](https://www.redhat.com/en/topics/microservices/what-is-a-service-mesh). It's a question I'm asked often in my presentations at developer meetups, conferences, and hands-on workshops about microservices development with cloud-native architecture. My answer is always the same: "As long as you want to simplify your microservices architecture, it should be running on Kubernetes."
Concerning simplification, you probably also wonder why distributed microservices must be designed so complexly for running on Kubernetes clusters. As this article explains, many developers solve the microservices architecture's complexity with service mesh and gain additional benefits by adopting service mesh in production.
## What is a service mesh?
A service mesh is a dedicated infrastructure layer for providing a transparent and code-independent (polyglot) way to eliminate nonfunctional microservices capabilities from the application code.
(Daniel Oh, CC BY-SA 4.0)
## Why service mesh matters to developers
When developers deploy microservices to the cloud, they have to address nonfunctional microservices capabilities to avoid cascading failures, regardless of business functionalities. Those capabilities typically can be represented in service discovery, logging, monitoring, resiliency, authentication, elasticity, and tracing. Developers must spend more time adding them to each microservice rather than developing actual business logic, which makes the microservices heavy and complex.
As organizations accelerate their move to the cloud, the service mesh can increase developer productivity. Instead of making the services responsible for dealing with those complexities and adding more code into each service to deal with cloud-native concerns, the Kubernetes + service mesh platform is responsible for providing those services to any application (existing or new, in any programming language or framework) running on the platform. Then the microservices can be lightweight and focus on their business logic rather than cloud-native complexities.
## Why service mesh matters to ops
This doesn't answer why ops teams need to care about the service mesh for operating cloud-native microservices on Kubernetes. It's because the ops teams have to ensure robust security, compliance, and observability for spreading new cloud-native applications across large hybrid and multi clouds on Kubernetes environments.
The service mesh is composed of a control plane for managing proxies to route traffic and a data plane for injecting sidecars. The sidecars allow the ops teams to do things like adding third-party security tools and tracing traffic in all service communications to avoid security breaches or compliance issues. The service mesh also improves observation capabilities by visualizing tracing metrics on graphical dashboards.
## How to get started with service mesh
Service mesh manages cloud-native capabilities more efficiently—for developers and operators and from application development to platform operation.
You might want to know where to get started adopting service mesh in alignment with your microservices applications and architecture. Luckily, there are many open source service mesh projects. Many cloud service providers also offer service mesh capabilities within their Kubernetes platforms.

(Daniel Oh, CC BY-SA 4.0)
You can find links to the most popular service mesh projects and services on the [CNCF Service Mesh Landscape](https://landscape.cncf.io/card-mode?category=service-mesh&grouping=category) webpage.
## Comments are closed. |
13,262 | 如何从硬件到防火墙建立一个家庭实验室 | https://opensource.com/article/19/3/home-lab | 2021-04-02T21:52:30 | [
"家庭实验室"
] | https://linux.cn/article-13262-1.html |
>
> 了解一下用于构建自己的家庭实验室的硬件和软件方案。
>
>
>

你有想过创建一个家庭实验室吗?或许你想尝试不同的技术,构建开发环境、亦或是建立自己的私有云。拥有一个家庭实验室的理由很多,本教程旨在使入门变得更容易。
规划家庭实验室时,需要考虑三方面:硬件、软件和维护。我们将在这里查看前两方面,并在以后的文章中讲述如何节省维护计算机实验室的时间。
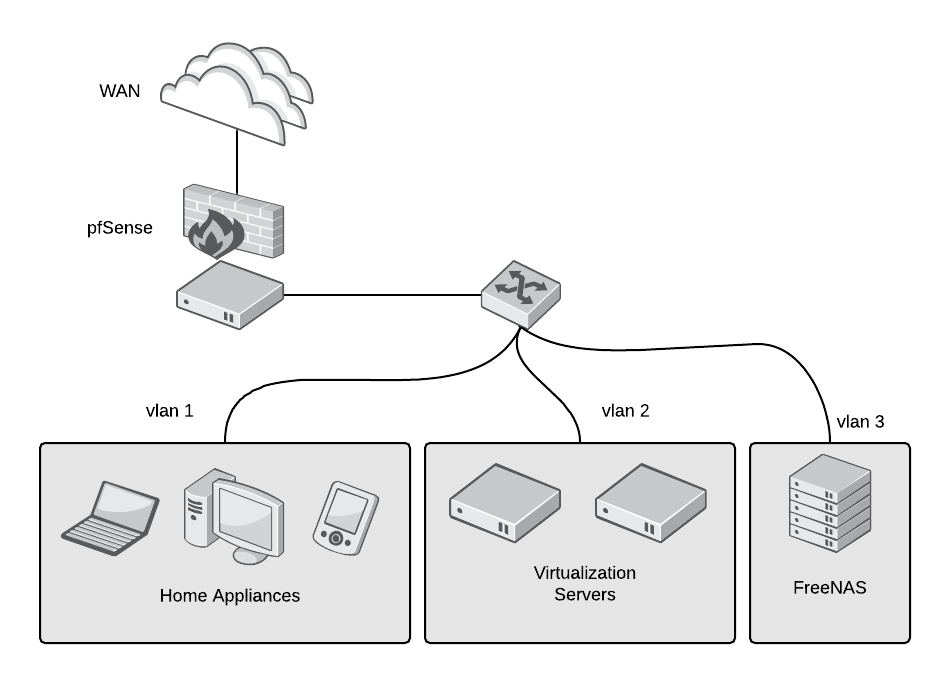
### 硬件
在考虑硬件需求时,首先要考虑如何使用实验室以及你的预算、噪声、空间和电力使用情况。
如果购买新硬件过于昂贵,请搜索当地的大学、广告以及诸如 eBay 或 Craigslist 之类的网站,能获取二手服务器的地方。它们通常很便宜,并且服务器级的硬件可以使用很多年。你将需要三类硬件:虚拟化服务器、存储设备和路由器/防火墙。
#### 虚拟化服务器
一个虚拟化服务器允许你去运行多个共享物理机资源的虚拟机,同时最大化利用和隔离资源。如果你弄坏了一台虚拟机,无需重建整个服务器,只需虚拟一个好了。如果你想进行测试或尝试某些操作而不损坏整个系统,仅需要新建一个虚拟机来运行即可。
在虚拟服务器中,需考虑两个最重要的因素是 CPU 的核心数及其运行速度以及内存容量。如果没有足够的资源够全部虚拟机共享,那么它们将被过度分配并试着获取其他虚拟机的 CPU 的周期和内存。
因此,考虑一个多核 CPU 的平台。你要确保 CPU 支持虚拟化指令(因特尔的 VT-x 指令集和 AMD 的 AMD-V 指令集)。能够处理虚拟化的优质的消费级处理器有因特尔的 i5 或 i7 和 AMD 的 Ryzen 处理器。如果你考虑服务器级的硬件,那么因特尔的志强系列和 AMD 的 EPYC 都是不错的选择。内存可能很昂贵,尤其是最近的 DDR4 内存。当我们估计所需多少内存时,请为主机操作系统的内存至少分配 2 GB 的空间。
如果你担心电费或噪声,则诸如因特尔 NUC 设备之类的解决方案虽然外形小巧、功耗低、噪音低,但是却以牺牲可扩展性为代价。
#### NAS
如果希望装有硬盘驱动器的计算机存储你的所有个人数据,电影,图片等,并为虚拟化服务器提供存储,则需要<ruby> 网络附加存储 <rt> Network-attached storage </rt></ruby>(NAS)。
在大多数情况下,你不太可能需要一颗强力的 CPU。实际上,许多商业 NAS 的解决方案使用低功耗的 ARM CPU。支持多个 SATA 硬盘的主板是必须的。如果你的主板没有足够的端口,请使用<ruby> 主机总线适配器 <rt> host bus adapter </rt> <ruby> (HBA)SAS 控制器添加额外的端口。 </ruby></ruby>
网络性能对于 NAS 来说是至关重要的,因此最好选择<ruby> 千兆 <rt> gigabit </rt></ruby>网络(或更快网络)。
内存需求根据你的文件系统而有所不同。ZFS 是 NAS 上最受欢迎的文件系统之一,你需要更多内存才能使用诸如缓存或重复数据删除之类的功能。<ruby> 纠错码 <rt> Error-correcting code </rt></ruby>(ECC)的内存是防止数据损坏的最佳选择(但在购买前请确保你的主板支持)。最后但同样重要的,不要忘记使用<ruby> 不间断电源 <rt> uninterruptible power supply </rt></ruby>(UPS),因为断电可能会使得数据出错。
#### 防火墙和路由器
你是否曾意识到,廉价的路由器/防火墙通常是保护你的家庭网络不受外部环境影响的主要部分?这些路由器很少及时收到安全更新(如果有的话)。现在害怕了吗?好吧,[确实](https://opensource.com/article/18/5/how-insecure-your-router)!
通常,你不需要一颗强大的 CPU 或是大量内存来构建你自己的路由器/防火墙,除非你需要高吞吐率或是执行 CPU 密集型任务,像是虚拟私有网络服务器或是流量过滤。在这种情况下,你将需要一个支持 AES-NI 的多核 CPU。
你可能想要至少 2 个千兆或更快的<ruby> 以太网卡 <rt> Ethernet network interface cards </rt></ruby>(NIC),这不是必需的,但我推荐使用一个管理型交换机来连接你自己的装配的路由器,以创建 VLAN 来进一步隔离和保护你的网络。

### 软件
在选择完你的虚拟化服务器、NAS 和防火墙/路由器后,下一步是探索不同的操作系统和软件,以最大程度地发挥其作用。尽管你可以使用 CentOS、Debian或 Ubuntu 之类的常规 Linux 发行版,但是与以下软件相比,它们通常花费更多的时间进行配置和管理。
#### 虚拟化软件
[KVM](https://www.linux-kvm.org/page/Main_Page)(<ruby> 基于内核的虚拟机 <rt> Kernel-based Virtual Machine </rt></ruby>)使你可以将 Linux 变成虚拟机监控程序,以便可以在同一台机器中运行多个虚拟机。最好的是,KVM 作为 Linux 的一部分,它是许多企业和家庭用户的首选。如果你愿意,可以安装 [libvirt](https://libvirt.org/) 和 [virt-manager](https://virt-manager.org/) 来管理你的虚拟化平台。
[Proxmox VE](https://www.proxmox.com/en/proxmox-ve) 是一个强大的企业级解决方案,并且是一个完全开源的虚拟化和容器平台。它基于 Debian,使用 KVM 作为其虚拟机管理程序,并使用 LXC 作为容器。Proxmox 提供了强大的网页界面、API,并且可以扩展到许多群集节点,这很有用,因为你永远不知道何时实验室容量不足。
[oVirt](https://ovirt.org/)(RHV)是另一种使用 KVM 作为虚拟机管理程序的企业级解决方案。不要因为它是企业级的,就意味着你不能在家中使用它。oVirt 提供了强大的网页界面和 API,并且可以处理数百个节点(如果你运行那么多服务器,我可不想成为你的邻居!)。oVirt 用于家庭实验室的潜在问题是它需要一套最低限度的节点:你将需要一个外部存储(例如 NAS)和至少两个其他虚拟化节点(你可以只在一个节点上运行,但你会遇到环境维护方面的问题)。
#### 网络附加存储软件
[FreeNAS](https://freenas.org/) 是最受欢迎的开源 NAS 发行版,它基于稳定的 FreeBSD 操作系统。它最强大的功能之一是支持 ZFS 文件系统,该文件系统提供了数据完整性检查、快照、复制和多个级别的冗余(镜像、条带化镜像和条带化)。最重要的是,所有功能都通过功能强大且易于使用的网页界面进行管理。在安装 FreeNAS 之前,请检查硬件是否支持,因为它不如基于 Linux 的发行版那么广泛。
另一个流行的替代方法是基于 Linux 的 [OpenMediaVault](https://www.openmediavault.org/)。它的主要功能之一是模块化,带有可扩展和添加特性的插件。它包括的功能包括基于网页管理界面,CIFS、SFTP、NFS、iSCSI 等协议,以及卷管理,包括软件 RAID、资源配额,<ruby> 访问控制列表 <rt> access control lists </rt></ruby>(ACL)和共享管理。由于它是基于 Linux 的,因此其具有广泛的硬件支持。
#### 防火墙/路由器软件
[pfSense](https://www.pfsense.org/) 是基于 FreeBSD 的开源企业级路由器和防火墙发行版。它可以直接安装在服务器上,甚至可以安装在虚拟机中(以管理虚拟或物理网络并节省空间)。它有许多功能,可以使用软件包进行扩展。尽管它也有命令行访问权限,但也可以完全使用网页界面对其进行管理。它具有你所希望路由器和防火墙提供的所有功能,例如 DHCP 和 DNS,以及更高级的功能,例如入侵检测(IDS)和入侵防御(IPS)系统。你可以侦听多个不同接口或使用 VLAN 的网络,并且只需鼠标点击几下即可创建安全的 VPN 服务器。pfSense 使用 pf,这是一种有状态的数据包筛选器,它是为 OpenBSD 操作系统开发的,使用类似 IPFilter 的语法。许多公司和组织都有使用 pfSense。
---
考虑到所有的信息,是时候动手开始建立你的实验室了。在之后的文章中,我将介绍运行家庭实验室的第三方面:自动化进行部署和维护。
---
via: <https://opensource.com/article/19/3/home-lab>
作者:[Michael Zamot (Red Hat)](https://opensource.com/users/mzamot) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Do you want to create a homelab? Maybe you want to experiment with different technologies, create development environments, or have your own private cloud. There are many reasons to have a homelab, and this guide aims to make it easier to get started.
There are three categories to consider when planning a home lab: hardware, software, and maintenance. We'll look at the first two categories here and save maintaining your computer lab for a future article.
## Hardware
When thinking about your hardware needs, first consider how you plan to use your lab as well as your budget, noise, space, and power usage.
If buying new hardware is too expensive, search local universities, ads, and websites like eBay or Craigslist for recycled servers. They are usually inexpensive, and server-grade hardware is built to last many years. You'll need three types of hardware: a virtualization server, storage, and a router/firewall.
### Virtualization servers
A virtualization server allows you to run several virtual machines that share the physical box's resources while maximizing and isolating resources. If you break one virtual machine, you won't have to rebuild the entire server, just the virtual one. If you want to do a test or try something without the risk of breaking your entire system, just spin up a new virtual machine and you're ready to go.
The two most important factors to consider in a virtualization server are the number and speed of its CPU cores and its memory. If there are not enough resources to share among all the virtual machines, they'll be overallocated and try to steal each other's CPU cycles and memory.
So, consider a CPU platform with multiple cores. You want to ensure the CPU supports virtualization instructions (VT-x for Intel and AMD-V for AMD). Examples of good consumer-grade processors that can handle virtualization are Intel i5 or i7 and AMD Ryzen. If you are considering server-grade hardware, the Xeon class for Intel and EPYC for AMD are good options. Memory can be expensive, especially the latest DDR4 SDRAM. When estimating memory requirements, factor at least 2GB for the host operating system's memory consumption.
If your electricity bill or noise is a concern, solutions like Intel's NUC devices provide a small form factor, low power usage, and reduced noise, but at the expense of expandability.
### Network-attached storage (NAS)
If you want a machine loaded with hard drives to store all your personal data, movies, pictures, etc. and provide storage for the virtualization server, network-attached storage (NAS) is what you want.
In most cases, you won't need a powerful CPU; in fact, many commercial NAS solutions use low-powered ARM CPUs. A motherboard that supports multiple SATA disks is a must. If your motherboard doesn't have enough ports, use a host bus adapter (HBA) SAS controller to add extras.
Network performance is critical for a NAS, so select a gigabit network interface (or better).
Memory requirements will differ based on your filesystem. ZFS is one of the most popular filesystems for NAS, and you'll need more memory to use features such as caching or deduplication. Error-correcting code (ECC) memory is your best bet to protect data from corruption (but make sure your motherboard supports it before you buy). Last, but not least, don't forget an uninterruptible power supply (UPS), because losing power can cause data corruption.
### Firewall and router
Have you ever realized that a cheap router/firewall is usually the main thing protecting your home network from the exterior world? These routers rarely receive timely security updates, if they receive any at all. Scared now? Well, [you should be](https://opensource.com/article/18/5/how-insecure-your-router)!
You usually don't need a powerful CPU or a great deal of memory to build your own router/firewall, unless you are handling a huge throughput or want to do CPU-intensive tasks, like a VPN server or traffic filtering. In such cases, you'll need a multicore CPU with AES-NI support.
You may want to get at least two 1-gigabit or better Ethernet network interface cards (NICs), also, not needed, but recommended, a managed switch to connect your DIY-router to create VLANs to further isolate and secure your network.
## Software
After you've selected your virtualization server, NAS, and firewall/router, the next step is exploring the different operating systems and software to maximize their benefits. While you could use a regular Linux distribution like CentOS, Debian, or Ubuntu, they usually take more time to configure and administer than the following options.
### Virtualization software
** KVM** (Kernel-based Virtual Machine) lets you turn Linux into a hypervisor so you can run multiple virtual machines in the same box. The best thing is that KVM is part of Linux, and it is the go-to option for many enterprises and home users. If you are comfortable, you can install
**and**
[libvirt](https://libvirt.org/)**to manage your virtualization platform.**
[virt-manager](https://virt-manager.org/)** Proxmox VE** is a robust, enterprise-grade solution and a full open source virtualization and container platform. It is based on Debian and uses KVM as its hypervisor and LXC for containers. Proxmox offers a powerful web interface, an API, and can scale out to many clustered nodes, which is helpful because you'll never know when you'll run out of capacity in your lab.
** oVirt (RHV)** is another enterprise-grade solution that uses KVM as the hypervisor. Just because it's enterprise doesn't mean you can't use it at home. oVirt offers a powerful web interface and an API and can handle hundreds of nodes (if you are running that many servers, I don't want to be your neighbor!). The potential problem with oVirt for a home lab is that it requires a minimum set of nodes: You'll need one external storage, such as a NAS, and at least two additional virtualization nodes (you can run it just on one, but you'll run into problems in maintenance of your environment).
### NAS software
** FreeNAS** is the most popular open source NAS distribution, and it's based on the rock-solid FreeBSD operating system. One of its most robust features is its use of the ZFS filesystem, which provides data-integrity checking, snapshots, replication, and multiple levels of redundancy (mirroring, striped mirrors, and striping). On top of that, everything is managed from the powerful and easy-to-use web interface. Before installing FreeNAS, check its hardware support, as it is not as wide as Linux-based distributions.
Another popular alternative is the Linux-based ** OpenMediaVault**. One of its main features is its modularity, with plugins that extend and add features. Among its included features are a web-based administration interface; protocols like CIFS, SFTP, NFS, iSCSI; and volume management, including software RAID, quotas, access control lists (ACLs), and share management. Because it is Linux-based, it has extensive hardware support.
### Firewall/router software
** pfSense** is an open source, enterprise-grade FreeBSD-based router and firewall distribution. It can be installed directly on a server or even inside a virtual machine (to manage your virtual or physical networks and save space). It has many features and can be expanded using packages. It is managed entirely using the web interface, although it also has command-line access. It has all the features you would expect from a router and firewall, like DHCP and DNS, as well as more advanced features, such as intrusion detection (IDS) and intrusion prevention (IPS) systems. You can create multiple networks listening on different interfaces or using VLANs, and you can create a secure VPN server with a few clicks. pfSense uses pf, a stateful packet filter that was developed for the OpenBSD operating system using a syntax similar to IPFilter. Many companies and organizations use pfSense.
With all this information in mind, it's time for you to get your hands dirty and start building your lab. In a future article, I will get into the third category of running a home lab: using automation to deploy and maintain it.
## 4 Comments |
13,263 | 如何用 C++ 读写文件 | https://opensource.com/article/21/3/ccc-input-output | 2021-04-03T20:40:00 | [
"输入输出"
] | https://linux.cn/article-13263-1.html |
>
> 如果你知道如何在 C++ 中使用输入输出(I/O)流,那么(原则上)你便能够处理任何类型的输入输出设备。
>
>
>

在 C++ 中,对文件的读写可以通过使用输入输出流与流运算符 `>>` 和 `<<` 来进行。当读写文件的时候,这些运算符被应用于代表硬盘驱动器上文件类的实例上。这种基于流的方法有个巨大的优势:从 C++ 的角度,无论你要读取或写入的内容是文件、数据库、控制台,亦或是你通过网络连接的另外一台电脑,这都无关紧要。因此,知道如何使用流运算符来写入文件能够被转用到其他领域。
### 输入输出流类
C++ 标准库提供了 [ios\_base](https://en.cppreference.com/w/cpp/io/ios_base) 类。该类作为所有 I/O 流的基类,例如 [basic\_ofstream](https://en.cppreference.com/w/cpp/io/basic_ofstream) 和 [basic\_ifstream](https://en.cppreference.com/w/cpp/io/basic_ifstream)。本例将使用读/写字符的专用类型 `ifstream` 和 `ofstream`。
* `ofstream`:输出文件流,并且其能通过插入运算符 `<<` 来实现。
* `ifstream`:输入文件流,并且其能通过提取运算符 `>>` 来实现。
该两种类型都是在头文件 `<fstream>` 中所定义。
从 `ios_base` 继承的类在写入时可被视为数据接收器,在从其读取时可被视为数据源,与数据本身完全分离。这种面向对象的方法使 <ruby> <a href="https://en.wikipedia.org/wiki/Separation_of_concerns"> 关注点分离 </a> <rt> separation of concerns </rt></ruby> 和 <ruby> <a href="https://en.wikipedia.org/wiki/Dependency_injection"> 依赖注入 </a> <rt> dependency injection </rt></ruby> 等概念易于实现。
### 一个简单的例子
本例程是非常简单:实例化了一个 `ofstream` 来写入,和实例化一个 `ifstream` 来读取。
```
#include <iostream> // cout, cin, cerr etc...
#include <fstream> // ifstream, ofstream
#include <string>
int main()
{
std::string sFilename = "MyFile.txt";
/******************************************
* *
* WRITING *
* *
******************************************/
std::ofstream fileSink(sFilename); // Creates an output file stream
if (!fileSink) {
std::cerr << "Canot open " << sFilename << std::endl;
exit(-1);
}
/* std::endl will automatically append the correct EOL */
fileSink << "Hello Open Source World!" << std::endl;
/******************************************
* *
* READING *
* *
******************************************/
std::ifstream fileSource(sFilename); // Creates an input file stream
if (!fileSource) {
std::cerr << "Canot open " << sFilename << std::endl;
exit(-1);
}
else {
// Intermediate buffer
std::string buffer;
// By default, the >> operator reads word by workd (till whitespace)
while (fileSource >> buffer)
{
std::cout << buffer << std::endl;
}
}
exit(0);
}
```
该代码可以在 [GitHub](https://github.com/hANSIc99/cpp_input_output) 上查看。当你编译并且执行它时,你应该能获得以下输出:

这是个简化的、适合初学者的例子。如果你想去使用该代码在你自己的应用中,请注意以下几点:
* 文件流在程序结束的时候自动关闭。如果你想继续执行,那么应该通过调用 `close()` 方法手动关闭。
* 这些文件流类继承自 [basic\_ios](https://en.cppreference.com/w/cpp/io/basic_ios)(在多个层次上),并且重载了 `!` 运算符。这使你可以进行简单的检查是否可以访问该流。在 [cppreference.com](https://en.cppreference.com/w/cpp/io/basic_ios/operator!) 上,你可以找到该检查何时会(或不会)成功的概述,并且可以进一步实现错误处理。
* 默认情况下,`ifstream` 停在空白处并跳过它。要逐行读取直到到达 [EOF](https://en.wikipedia.org/wiki/Newline) ,请使用 `getline(...)` 方法。
* 为了读写二进制文件,请将 `std::ios::binary` 标志传递给构造函数:这样可以防止 [EOL](https://en.wikipedia.org/wiki/Newline) 字符附加到每一行。
### 从系统角度进行写入
写入文件时,数据将写入系统的内存写入缓冲区中。当系统收到系统调用 [sync](https://en.wikipedia.org/wiki/Sync_%28Unix%29) 时,此缓冲区的内容将被写入硬盘。这也是你在不告知系统的情况下,不要卸下 U 盘的原因。通常,守护进程会定期调用 `sync`。为了安全起见,也可以手动调用 `sync()`:
```
#include <unistd.h> // needs to be included
sync();
```
### 总结
在 C++ 中读写文件并不那么复杂。更何况,如果你知道如何处理输入输出流,(原则上)那么你也知道如何处理任何类型的输入输出设备。对于各种输入输出设备的库能让你更容易地使用流运算符。这就是为什么知道输入输出流的流程会对你有所助益的原因。
---
via: <https://opensource.com/article/21/3/ccc-input-output>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In C++, reading and writing to files can be done by using I/O streams in conjunction with the stream operators `>>`
and `<<`
. When reading or writing to files, those operators are applied to an instance of a class representing a file on the hard drive. This stream-based approach has a huge advantage: From a C ++ perspective, it doesn't matter what you are reading or writing to, whether it's a file, a database, the console, or another PC you are connected to over the network. Therefore, knowing how to write files using stream operators can be transferred to other areas.
## I/O stream classes
The C++ standard library provides the class [ios_base](https://en.cppreference.com/w/cpp/io/ios_base). This class acts as the base class for all I/O stream-compatible classes, such as [basic_ofstream](https://en.cppreference.com/w/cpp/io/basic_ofstream) and [basic_ifstream](https://en.cppreference.com/w/cpp/io/basic_ifstream). This example will use the specialized types for reading/writing characters, `ifstream`
and `ofstream`
.
`ofstream`
means*output file stream*, and it can be accessed with the insertion operator,`<<`
.`ifstream`
means*input file stream*, and it can be accessed with the extraction operator,`>>`
.
Both types are defined inside the header `<fstream>`
.
A class that inherits from `ios_base`
can be thought of as a data sink when writing to it or as a data source when reading from it, completely detached from the data itself. This object-oriented approach makes concepts such as [separation of concerns](https://en.wikipedia.org/wiki/Separation_of_concerns) and [dependency injection](https://en.wikipedia.org/wiki/Dependency_injection) easy to implement.
## A simple example
This example program is quite simple: It creates an `ofstream`
, writes to it, creates an `ifstream`
, and reads from it:
```
#include <iostream> // cout, cin, cerr etc...
#include <fstream> // ifstream, ofstream
#include <string>
int main()
{
std::string sFilename = "MyFile.txt";
/******************************************
* *
* WRITING *
* *
******************************************/
std::ofstream fileSink(sFilename); // Creates an output file stream
if (!fileSink) {
std::cerr << "Canot open " << sFilename << std::endl;
exit(-1);
}
/* std::endl will automatically append the correct EOL */
fileSink << "Hello Open Source World!" << std::endl;
/******************************************
* *
* READING *
* *
******************************************/
std::ifstream fileSource(sFilename); // Creates an input file stream
if (!fileSource) {
std::cerr << "Canot open " << sFilename << std::endl;
exit(-1);
}
else {
// Intermediate buffer
std::string buffer;
// By default, the >> operator reads word by workd (till whitespace)
while (fileSource >> buffer)
{
std::cout << buffer << std::endl;
}
}
exit(0);
}
```
This code is available on [GitHub](https://github.com/hANSIc99/cpp_input_output). When you compile and execute it, you should get the following output:

(Stephan Avenwedde, CC BY-SA 4.0)
This is a simplified, beginner-friendly example. If you want to use this code in your own application, please note the following:
- The file streams are automatically closed at the end of the program. If you want to proceed with the execution, you should close them manually by calling the
`close()`
method. - These file stream classes inherit (over several levels) from
[basic_ios](https://en.cppreference.com/w/cpp/io/basic_ios), which overloads the`!`
operator. This lets you implement a simple check if you can access the stream. On[cppreference.com](https://en.cppreference.com/w/cpp/io/basic_ios/operator!), you can find an overview of when this check will (and won't) succeed, and you can implement further error handling. - By default,
`ifstream`
stops at white space and skips it. To read line by line until you reach[EOF](https://en.wikipedia.org/wiki/End-of-file), use the`getline(...)`
-method. - For reading and writing binary files, pass the
`std::ios::binary`
flag to the constructor: This prevents[EOL](https://en.wikipedia.org/wiki/Newline)characters from being appended to each line.
## Writing from the systems perspective
When writing files, the data is written to the system's in-memory write buffer. When the system receives the system call [sync](https://en.wikipedia.org/wiki/Sync_%28Unix%29), this buffer's contents are written to the hard drive. This mechanism is also the reason you shouldn't remove a USB stick without telling the system. Usually, *sync* is called on a regular basis by a daemon. If you really want to be on the safe side, you can also call *sync* manually:
```
#include <unistd.h> // needs to be included
sync();
```
## Summary
Reading and writing to files in C++ is not that complicated. Moreover, if you know how to deal with I/O streams, you also know (in principle) how to deal with any kind of I/O device. Libraries for various kinds of I/O devices let you use stream operators for easy access. This is why it is beneficial to know how I/O steams work.
## Comments are closed. |
13,264 | NewsFlash: 一款支持 Feedly 的现代开源 Feed 阅读器 | https://itsfoss.com/newsflash-feedreader/ | 2021-04-03T21:07:00 | [
"RSS"
] | https://linux.cn/article-13264-1.html | 
有些人可能认为 RSS 阅读器已经不再,但它们仍然坚持在这里,特别是当你不想让大科技算法来决定你应该阅读什么的时候。Feed 阅读器可以帮你自助选择阅读来源。
我最近遇到一个很棒的 RSS 阅读器 NewsFlash。它支持通过基于网页的 Feed 阅读器增加 feed,例如 [Feedly](https://feedly.com/) 和 NewsBlur。这是一个很大的安慰,因为如果你已经使用这种服务,就不必人工导入 feed,这节省了你的工作。
NewsFlash 恰好是 [FeedReadeer](https://jangernert.github.io/FeedReader/) 的精神继承者,原来的 FeedReader 开发人员也参与其中。
如果你正在找适用的 RSS 阅读器,我们整理了 [Linux Feed 阅读器](https://itsfoss.com/feed-reader-apps-linux/) 列表供您参考。
### NewsFlash: 一款补充网页 RSS 阅读器账户的 Feed 阅读器

请注意,NewsFlash 并不只是针对基于网页的 RSS feed 账户量身定做的,你也可以选择使用本地 RSS feed,而不必在多设备间同步。
不过,如果你在用是任何一款支持的基于网页的 feed 阅读器,那么 NewsFlash 特别有用。
这里,我将重点介绍 NewsFlash 提供的一些功能。
### NewsFlash 功能

* 支持桌面通知
* 快速搜索、过滤
* 支持标签
* 便捷、可重定义的键盘快捷键
* 本地 feed
* OPML 文件导入/导出
* 无需注册即可在 Feedly 库中轻松找到不同 RSS Feed
* 支持自定义字体
* 支持多主题(包括深色主题)
* 启动/禁止缩略图
* 细粒度调整定期同步间隔时间
* 支持基于网页的 Feed 账户,例如 Feedly、Fever、NewsBlur、feedbin、Miniflux
除上述功能外,当你调整窗口大小时,还可以打开阅读器视图,这是一个细腻的补充功能。

账户重新设置也很容易,这将删除所有本地数据。是的,你可以手动清除缓存并设置到期时间,并为你关注的所有 feed 设置一个用户数据存在本地的到期时间。
### 在 Linux 上安装 NewsFlash
你无法找到适用于各种 Linux 发行版的官方软件包,只有 [Flatpak](https://flathub.org/apps/details/com.gitlab.newsflash)。
对于 Arch 用户,可以从 [AUR](https://itsfoss.com/aur-arch-linux/) 下载。
幸运的是,[Flatpak](https://itsfoss.com/what-is-flatpak/) 软件包可以让你轻松在 Linux 发行版上安装 NewsFlash。具体请参阅我们的 [Flatpak 指南](https://itsfoss.com/flatpak-guide/)。
你可以参考 NewsFlash 的 [GitLab 页面](https://gitlab.com/news-flash/news_flash_gtk) 去解决大部分问题。
### 结束语
我现在用 NewsFlash 作为桌面本地解决方案,不用基于网页的服务。你可以通过直接导出 OPML 文件在移动 feed 应用上得到相同的 feed。这已经被我验证过了。
用户界面易于使用,也提供了数一数二的新版 UX。虽然这个 RSS 阅读器看似简单,但提供了你可以找到的所有重要功能。
你怎么看 NewsFlash?你喜欢用其他类似产品吗?欢迎在评论区中分享你的想法。
---
via: <https://itsfoss.com/newsflash-feedreader/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some may choose to believe that RSS readers are dead, but they’re here to stay. Especially when you don’t want the Big tech algorithm to decide what you should read. With a feed reader, you can choose your own reading sources.
I’ve recently come across a fantastic RSS reader NewsFlash. It also supports adding feeds through web-based feed readers like [Feedly](https://feedly.com/) and NewsBlur. That’s a big relief because if you are already such a service, you don’t have to import your feeds manually.
NewsFlash happens to be the spiritual successor to [FeedReader](https://jangernert.github.io/FeedReader/) with the original developer involved as well.
In case you’re wondering, we’ve already covered a list of [Feed Reader apps for Linux](https://itsfoss.com/feed-reader-apps-linux/) if you’re looking for more options.
## NewsFlash: A Feed Reader To Complement Web-based RSS Reader Account
It is important to note that NewsFlash isn’t just tailored for web-based RSS feed accounts, you can choose to use local RSS feeds as well without needing to sync them on multiple devices.
However, it is specifically helpful if you’re using any of the supported web-based feed readers.
Here, I’ll be highlighting some of the features that it offers.
## Features of NewsFlash
- Desktop Notifications support
- Fast search and filtering
- Supports tagging
- Useful keyboard shortcuts that can be later customized
- Local feeds
- Import/Export OPML files
- Easily discover various RSS Feeds using Feedly’s library without needing to sign up for the service
- Custom Font Support
- Multiple themes supported (including a dark theme)
- Ability to enable/disable the Thumbnails
- Tweak the time for regular sync intervals
- Support for web-based Feed accounts like Feedly, Fever, NewsBlur, feedbin, Miniflux
In addition to the features mentioned, it also opens the reader view when you re-size the window, so that’s a subtle addition.
If you want to reset the account, you can easily do that as well – which will delete all your local data as well. And, yes, you can manually clear the cache and set an expiry for user data to exist locally for all the feeds you follow.
**Recommended Read:**
## Installing NewsFlash in Linux
You do not get any official packages available for various Linux distributions but limited to a [Flatpak](https://flathub.org/apps/details/com.gitlab.newsflash).
For Arch users, you can find it available in [AUR](https://itsfoss.com/aur-arch-linux/).
Fortunately, the [Flatpak](https://itsfoss.com/what-is-flatpak/) package makes it easy for you to install it on any Linux distro you use. You can refer to our [Flatpak guide](https://itsfoss.com/flatpak-guide/) for help.
In either case, you can refer to its [GitLab page](https://gitlab.com/news-flash/news_flash_gtk) and compile it yourself.
## Closing Thoughts
I’m currently using it by moving away from web-based services as a local solution on my desktop. You can simply export the OPML file to get the same feeds on any of your mobile feed applications, that’s what I’ve done.
The user interface is easy to use and provides a modern UX, if not the best. You can find all the essential features available while being a simple-looking RSS reader as well.
What do you think about NewsFlash? Do you prefer using something else? Feel free to share your thoughts in the comments. |
13,267 | strace 可以解决什么问题? | https://jvns.ca/blog/2021/04/03/what-problems-do-people-solve-with-strace/ | 2021-04-05T09:48:36 | [
"strace"
] | https://linux.cn/article-13267-1.html | 
昨天我 [在 Twitter 上询问大家用 strace 解决了什么问题?](https://twitter.com/b0rk/status/1378014888405168132),和往常一样,大家真的是给出了自己的答案! 我收到了大约 200 个答案,然后花了很多时间手动将它们归为 9 类。
这些解决的问题都是关于寻找程序依赖的文件、找出程序卡住或慢的原因、或者找出程序失败的原因。这些总体上与我自己使用 `strace` 的内容相吻合,但也有一些我没有想到的东西!
我不打算在这篇文章里解释什么是 `strace`,但我有一本 [关于它的免费杂志](https://wizardzines.com/zines/strace) 和 [一个讲座](https://www.youtube.com/watch?v=4pEHfGKB-OE) 以及 [很多博文](https://jvns.ca/categories/strace)。
### 问题 1:配置文件在哪里?
最受欢迎的问题是“这个程序有一个配置文件,但我不知道它在哪里”。这可能也是我最常使用 `strace` 解决的问题,因为这是个很简单的问题。
这很好,因为一个程序有一百万种方法来记录它的配置文件在哪里(在手册页、网站上、`--help`等),但只有一种方法可以让它真正打开它(用系统调用!)。
### 问题 2:这个程序还依赖什么文件?
你也可以使用 `strace` 来查找程序依赖的其他类型的文件,比如:
* 动态链接库(“为什么我的程序加载了这个错误版本的 `.so` 文件?"),比如 [我在 2014 年调试的这个 ruby 问题](https://jvns.ca/blog/2014/03/10/debugging-shared-library-problems-with-strace/)
* 它在哪里寻找它的 Ruby gem(Ruby 出现了几次这种情况!)
* SSL 根证书
* 游戏的存档文件
* 一个闭源程序的数据文件
* [哪些 node\_modules 文件没有被使用](https://indexandmain.com/post/shrink-node-modules-with-refining)
### 问题 3:为什么这个程序会挂掉?
你有一个程序,它只是坐在那里什么都不做,这是怎么回事?这个问题特别容易回答,因为很多时候你只需要运行 `strace -p PID`,看看当前运行的是什么系统调用。你甚至不需要看几百行的输出。
答案通常是“正在等待某种 I/O”。“为什么会卡住”的一些可能的答案(虽然还有很多!):
* 它一直在轮询 `select()`
* 正在 `wait()` 等待一个子进程完成
* 它在向某个没有响应的东西发出网络请求
* 正在进行 `write()`,但由于缓冲区已满而被阻止。
* 它在 stdin 上做 `read()`,等待输入。
有人还举了一个很好的例子,用 `strace` 调试一个卡住的 `df` 命令:“用 `strace df -h` 你可以找到卡住的挂载,然后卸载它”。
### 问题 4:这个程序卡住了吗?
这是上一个问题的变种:有时一个程序运行的时间比你预期的要长,你只是想知道它是否卡住了,或者它是否还在继续进行。
只要程序在运行过程中进行系统调用,用 `strace` 就可以超简单地回答这个问题:只需 `strace` 它,看看它是否在进行新的系统调用!
### 问题 5:为什么这个程序很慢?
你可以使用 `strace` 作为一种粗略的剖析工具:`strace -t` 会显示每次系统调用的时间戳,这样你就可以寻找大的漏洞,找到罪魁祸首。
以下是 Twitter 上 9 个人使用 `strace` 调试“为什么这个程序很慢?”的小故事。
* 早在 2000 年,我帮助支持的一个基于 Java 的网站在适度的负载下奄奄一息:页面加载缓慢,甚至完全加载不出来。我们对 J2EE 应用服务器进行了测试,发现它每次只读取一个类文件。开发人员没有使用 BufferedReader,这是典型的 Java 错误。
* 优化应用程序的启动时间……运行 `strace` 可以让人大开眼界,因为有大量不必要的文件系统交互在进行(例如,在同一个配置文件上反复打开/读取/关闭;在一个缓慢的 NFS 挂载上加载大量的字体文件,等等)。
* 问自己为什么在 PHP 中从会话文件中读取(通常是小于 100 字节)非常慢。结果发现一些 `flock` 系统调用花了大约 60 秒。
* 一个程序表现得异常缓慢。使用 `strace` 找出它在每次请求时,通过从 `/dev/random` 读取数据并耗尽熵来重新初始化其内部伪随机数发生器。
* 我记得最近一件事是连接到一个任务处理程序,看到它有多少网络调用(这是意想不到的)。
* `strace` 显示它打开/读取同一个配置文件数千次。
* 服务器随机使用 100% 的 CPU 时间,实际流量很低。原来是碰到打开文件数限制,接受一个套接字时,得到 EMFILE 错误而没有报告,然后一直重试。
* 一个工作流运行超慢,但是没有日志,结果它做一个 POST 请求花了 30 秒而超时,然后重试了 5 次……结果后台服务不堪重负,但是也没有可视性。
* 使用 `strace` 注意到 `gethostbyname()` 需要很长时间才能返回(你不能直接看到 `gethostbyname`,但你可以看到 `strace` 中的 DNS 数据包)
### 问题 6:隐藏的权限错误
有时候程序因为一个神秘的原因而失败,但问题只是有一些它没有权限打开的文件。在理想的世界里,程序会报告这些错误(“Error opening file /dev/whatever: permission denied”),当然这个世界并不完美,所以 `strace` 真的可以帮助解决这个问题!
这其实是我最近使用 `strace` 做的事情。我使用了一台 AxiDraw 绘图仪,当我试图启动它时,它打印出了一个难以理解的错误信息。我 `strace` 它,结果发现我的用户没有权限打开 USB 设备。
### 问题 7:正在使用什么命令行参数?
有时候,一个脚本正在运行另一个程序,你想知道它传递的是什么命令行标志!
几个来自 Twitter 的例子。
* 找出实际上是用来编译代码的编译器标志
* 由于命令行太长,命令失败了
### 问题 8:为什么这个网络连接失败?
基本上,这里的目标是找到网络连接的域名 / IP 地址。你可以通过 DNS 请求来查找域名,或者通过 `connect` 系统调用来查找 IP。
一般来说,当 `tcpdump` 因为某些原因不能使用或者只是因为比较熟悉 `strace` 时,就经常会使用 `strace` 调试网络问题。
### 问题 9:为什么这个程序以一种方式运行时成功,以另一种方式运行时失败?
例如:
* 同样的二进制程序在一台机器上可以运行,在另一台机器上却失败了
* 可以运行,但被 systemd 单元文件生成时失败
* 可以运行,但以 `su - user /some/script` 的方式运行时失败
* 可以运行,作为 cron 作业运行时失败
能够比较两种情况下的 `strace` 输出是非常有用的。虽然我在调试“以我的用户身份工作,而在同一台计算机上以不同方式运行时却失败了”时,第一步是“看看我的环境变量”。
### 我在做什么:慢慢地建立一些挑战
我之所以会想到这个问题,是因为我一直在慢慢地进行一些挑战,以帮助人们练习使用 `strace` 和其他命令行工具。我的想法是,给你一个问题,一个终端,你可以自由地以任何方式解决它。
所以我的目标是用它来建立一些你可以用 `strace` 解决的练习题,这些练习题反映了人们在现实生活中实际使用它解决的问题。
### 就是这样!
可能还有更多的问题可以用 `strace` 解决,我在这里还没有讲到,我很乐意听到我错过了什么!
我真的很喜欢看到很多相同的用法一次又一次地出现:至少有 20 个不同的人回答说他们使用 `strace` 来查找配置文件。而且和以往一样,我觉得这样一个简单的工具(“跟踪系统调用!”)可以用来解决这么多不同类型的问题,真的很令人高兴。
---
via: <https://jvns.ca/blog/2021/04/03/what-problems-do-people-solve-with-strace/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Yesterday I [asked on Twitter about what problems people are solving with strace](https://twitter.com/b0rk/status/1378014888405168132) and
as usual everyone really delivered! I got 200 answers and then spent a bunch of
time manually categorizing them into 9 categories of problems.
All of the problems are about either finding files a program depends on, figuring out why a program is stuck or slow, or finding out why a program is failing. These generally matched up with what I use strace for myself, but there were some things I hadn’t thought of too!
I’m not going to explain what strace is in this post but I have a [free zine about it](https://wizardzines.com/zines/strace) and [a talk](https://www.youtube.com/watch?v=4pEHfGKB-OE) and [lots of blog posts](https://jvns.ca/categories/strace).
### problem 1: where’s the config file?
The #1 most popular problem was “this program has a configuration file and I don’t know where it is”. This is probably my most common use for strace too, because it’s such a simple question.
This is great because there are a million ways for a program to document where
its config file is (in a man page, on its website, in `--help`
, etc), but
there’s only one way for it to actually open it (with a system call!)
### problem 2: what other files does this program depend on?
You can also use strace to find other types of files a program depends on, like:
- dynamically linked libraries (“why is my program loading the wrong version of this
`.so`
file?”) like[this ruby problem I debugged in 2014](https://jvns.ca/blog/2014/03/10/debugging-shared-library-problems-with-strace/) - where it’s looking for its Ruby gems (Ruby specifically came up a few times!)
- SSL root certificates
- a game’s save files
- a closed-source program’s data files
[which node_modules files aren’t being used](https://indexandmain.com/post/shrink-node-modules-with-refining)
### problem 3: why is this program hanging?
You have a program, it’s just sitting there doing nothing, what’s going
on? This one is especially easy to answer because a lot of the time you just
need to run `strace -p PID`
and look at what system call is currently running.
You don’t even have to look through hundreds of lines of output!
The answer is usually ‘waiting for some kind of I/O’. Some possible answers for “why is this stuck” (though there are a lot more!):
- it’s polling forever on a
`select()`
- it’s
`wait()`
ing for a subprocess to finish - it’s making a network request to something that isn’t responding
- it’s doing
`write()`
but it’s blocked because the buffer is full - it’s doing a
`read()`
on stdin and it’s waiting for input
Someone also gave a nice example of using strace to debug a stuck `df`
: ‘with strace df -h you can find the stuck mount and unmount it".
### problem 4: is this program stuck?
A variation on the previous one: sometimes a program has been running for longer than you expected, and you just want to know if it’s stuck or of it’s still making progress.
As long as the program makes system calls while it’s running, this is super easy to answer with strace – just strace it and see if it’s making new system calls!
### problem 5: why is this program slow?
You can use strace as a sort of coarse profiling tool – `strace -t`
will show
the timestamp of each system call, so you can look for big gaps and find the culprit.
Here are 9 short stories from Twitter of people using strace to debug “why is this program slow?”.
- Back in 2000, a Java-based web site that I helped support was dying under modest load: pages loaded slowly, if at all. We straced the J2EE application server and found that it was reading class files one. byte. at. a. time. Devs weren’t using BufferedReader, classic Java mistake.
- Optimizing app startup times… running strace can be an eye-opening experience, in terms of the amount of unnecessary file system interaction going on (e.g. open/read/close on the same config file over and over again; loading gobs of font files over a slow NFS mount, etc)
- Asked myself why reading from session files in PHP (usually <100 bytes)
was incredibly slow. Turned out some
`flock`
-syscalls took ~60s - A program was behaving abnormally slow. Used strace to figure out it was re-initializing its internal pseudo-random number generator on every request by reading from /dev/random and exhausting entropy
- Last thing I remember was attaching to a job worker and seeing just how many network calls it was making (which was unexpected).
- Why is this program so slow to start? strace shows it opening/reading the same config file thousands of times.
- Server using 100% CPU time randomly with low actual traffic. Turns out it’s hitting the number of open files limit accepting a socket, and retrying forever after getting EMFILE and not reporting it.
- A workflow was running super slow but no logs, ends up it was trying to do a post request that was taking 30s before timing out and then retrying 5 times… ends up the backend service was overwhelmed but also had no visibility
- using strace to notice that gethostbyname() is taking a long time to return (you can’t see the
`gethostbyname`
directly but you can see the DNS packets in strace)
### problem 6: hidden permissions errors
Sometimes a program is failing for a mysterious reason, but the problem is just that there’s some file that it doesn’t have permission to open. In an ideal world programs would report those errors (“Error opening file /dev/whatever: permission denied”), but of course the world is not perfect, so strace can really help with this!
This is actually the most recent thing I used strace for: I was using an
AxiDraw pen plotter and it printed out an inscrutable error message when I
tried to start it. I `strace`
d it and it turned out that my user just didn’t
have permission to open the USB device.
### problem 7: what command line arguments are being used?
Sometimes a script is running another program, and you want to know what command line flags it’s passing!
A couple of examples from Twitter:
- find what compiler flags are actually being used to build some code
- a command was failing due to having too long a command line
### problem 8: why is this network connection failing?
Basically the goal here is just to find which domain / IP address the network
connection is being made to. You can look at the DNS request to find the domain
or the `connect`
system call to find the IP.
In general there are a lot of stories about using strace to debug network
issues when `tcpdump`
isn’t available for some reason or just because it’s what
the person is more familiar with.
### problem 9: why does this program succeed when run one way and fail when run in another way?
For example:
- the same binary works on one machine, fails on another machine
- works when you run it, fails when spawned by a systemd unit file
- works when you run it, fails when you run it as “su - user /some/script”
- works when you run it, fails when run as a cron job
Being able to compare the strace output in both cases is very helpful. Though my first step when debugging “this works as my user and fails when run in a different way on the same computer” would be “look at my environment variables”.
### problem 10: how does this Linux kernel API work?
Another one quite a few people mentioned is figuring out how a Linux kernel API (for example netlink, io_uring, hdparm, I2C, etc).
Even though these APIs are usually documented, sometimes the documentation is confusing or there aren’t very many examples, so often it’s easier to just strace an existing application and see how it interacts with the Linux kernel.
### problem 11: general reverse engineering
strace is also great for just generally figuring out “how does this program
work?”. As a simple example of this, here’s a blog post on [figuring out how killall works using strace](https://jvns.ca/blog/2013/12/22/fun-with-strace/).
### what I’m doing with this: slowly building some challenges
The reason I’m thinking about this is that I’ve been slowly working on some challenges to help people practice using strace and other command line tools. The idea is that you’re given a problem to solve, a terminal, and you’re free to solve it in any way you want.
So my goal is to use this to build some practice problems that you can solve with strace that reflect the kinds of problems that people actually use it for in real life.
### that’s all!
There are probably more problems that can be solved with strace that I haven’t covered here – I’d love to hear what I’ve missed!
I really loved seeing how many of the same uses came up over and over and over again – at least 20 different people replied saying that they use strace to find config files. And as always I think it’s really delightful how such a simple tool (“trace system calls!”) can be used to solve so many different kinds of problems. |
13,268 | 用 Lua 操作文件中的数据 | https://opensource.com/article/21/3/lua-files | 2021-04-05T10:25:03 | [
"Lua",
"读写",
"文件"
] | https://linux.cn/article-13268-1.html |
>
> 了解 Lua 如何处理数据的读写。
>
>
>

有些数据是临时的,存储在 RAM 中,只有在应用运行时才有意义。但有些数据是要持久的,存储在硬盘上供以后使用。当你编程时,无论是简单的脚本还是复杂的工具套件,通常都需要读取和写入文件。有时文件可能包含配置选项,而另一些时候这个文件是你的用户用你的应用创建的数据。每种语言都会以不同的方式处理这项任务,本文将演示如何使用 Lua 处理文件数据。
### 安装 Lua
如果你使用的是 Linux,你可以从你的发行版软件库中安装 Lua。在 macOS 上,你可以从 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac) 安装 Lua。在 Windows 上,你可以从 [Chocolatey](https://opensource.com/article/20/3/chocolatey) 安装 Lua。
安装 Lua 后,打开你最喜欢的文本编辑器并准备开始。
### 用 Lua 读取文件
Lua 使用 `io` 库进行数据输入和输出。下面的例子创建了一个名为 `ingest` 的函数来从文件中读取数据,然后用 `:read` 函数进行解析。在 Lua 中打开一个文件时,有几种模式可以启用。因为我只需要从这个文件中读取数据,所以我使用 `r`(代表“读”)模式:
```
function ingest(file)
local f = io.open(file, "r")
local lines = f:read("*all")
f:close()
return(lines)
end
myfile=ingest("example.txt")
print(myfile)
```
在这段代码中,注意到变量 `myfile` 是为了触发 `ingest` 函数而创建的,因此,它接收该函数返回的任何内容。`ingest` 函数返回文件的行数(从一个称为 `lines` 的变量中0。当最后一步打印 `myfile` 变量的内容时,文件的行数就会出现在终端中。
如果文件 `example.txt` 中包含了配置选项,那么我会写一些额外的代码来解析这些数据,可能会使用另一个 Lua 库,这取决于配置是以 INI 文件还是 YAML 文件或其他格式存储。如果数据是 SVG 图形,我会写额外的代码来解析 XML,可能会使用 Lua 的 SVG 库。换句话说,你的代码读取的数据一旦加载到内存中,就可以进行操作,但是它们都需要加载 `io` 库。
### 用 Lua 将数据写入文件
无论你是要存储用户用你的应用创建的数据,还是仅仅是关于用户在应用中做了什么的元数据(例如,游戏保存或最近播放的歌曲),都有很多很好的理由来存储数据供以后使用。在 Lua 中,这是通过 `io` 库实现的,打开一个文件,将数据写入其中,然后关闭文件:
```
function exgest(file)
local f = io.open(file, "a")
io.output(f)
io.write("hello world\n")
io.close(f)
end
exgest("example.txt")
```
为了从文件中读取数据,我以 `r` 模式打开文件,但这次我使用 `a` (用于”追加“)将数据写到文件的末尾。因为我是将纯文本写入文件,所以我添加了自己的换行符(`/n`)。通常情况下,你并不是将原始文本写入文件,你可能会使用一个额外的库来代替写入一个特定的格式。例如,你可能会使用 INI 或 YAML 库来帮助编写配置文件,使用 XML 库来编写 XML,等等。
### 文件模式
在 Lua 中打开文件时,有一些保护措施和参数来定义如何处理文件。默认值是 `r`,允许你只读数据:
* `r` 只读
* `w` 如果文件不存在,覆盖或创建一个新文件。
* `r+` 读取和覆盖。
* `a` 追加数据到文件中,或在文件不存在的情况下创建一个新文件。
* `a+` 读取数据,将数据追加到文件中,或文件不存在的话,创建一个新文件。
还有一些其他的(例如,`b` 代表二进制格式),但这些是最常见的。关于完整的文档,请参考 [Lua.org/manual](http://lua.org/manual) 上的优秀 Lua 文档。
### Lua 和文件
和其他编程语言一样,Lua 有大量的库支持来访问文件系统来读写数据。因为 Lua 有一个一致且简单语法,所以很容易对任何格式的文件数据进行复杂的处理。试着在你的下一个软件项目中使用 Lua,或者作为 C 或 C++ 项目的 API。
---
via: <https://opensource.com/article/21/3/lua-files>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some data is ephemeral, stored in RAM, and only significant while an application is running. But some data is meant to be persistent, stored on a hard drive for later use. When you program, whether you're working on a simple script or a complex suite of tools, it's common to need to read and write files. Sometimes a file may contain configuration options, and other times the file is the data that your user is creating with your application. Every language handles this task a little differently, and this article demonstrates how to handle data files with Lua.
## Installing Lua
If you're on Linux, you can install Lua from your distribution's software repository. On macOS, you can install Lua from [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac). On Windows, you can install Lua from [Chocolatey](https://opensource.com/article/20/3/chocolatey).
Once you have Lua installed, open your favorite text editor and get ready to code.
## Reading a file with Lua
Lua uses the `io`
library for data input and output. The following example creates a function called `ingest`
to read data from a file and then parses it with the `:read`
function. When opening a file in Lua, there are several modes you can enable. Because I just need to read data from this file, I use the `r`
(for "read") mode:
```
function ingest(file)
local f = io.open(file, "r")
local lines = f:read("*all")
f:close()
return(lines)
end
myfile=ingest("example.txt")
print(myfile)
```
In the code, notice that the variable `myfile`
is created to trigger the `ingest`
function, and therefore, it receives whatever that function returns. The `ingest`
function returns the lines (from a variable intuitively called `lines`
) of the file. When the contents of the `myfile`
variable are printed in the final step, the lines of the file appear in the terminal.
If the file `example.txt`
contains configuration options, then I would write some additional code to parse that data, probably using another Lua library depending on whether the configuration was stored as an INI file or YAML file or some other format. If the data were an SVG graphic, I'd write extra code to parse XML, probably using an SVG library for Lua. In other words, the data your code reads can be manipulated once it's loaded into memory, but all that's required to load it is the `io`
library.
## Writing data to a file with Lua
Whether you're storing data your user is creating with your application or just metadata about what the user is doing in an application (for instance, game saves or recent songs played), there are many good reasons to store data for later use. In Lua, this is achieved through the `io`
library by opening a file, writing data into it, and closing the file:
```
function exgest(file)
local f = io.open(file, "a")
io.output(f)
io.write("hello world\n")
io.close(f)
end
exgest("example.txt")
```
To read data from the file, I open the file in `r`
mode, but this time I use `a`
(for "append") to write data to the end of the file. Because I'm writing plain text into a file, I added my own newline character (`\n`
). Often, you're not writing raw text into a file, and you'll probably use an additional library to write a specific format instead. For instance, you might use an INI or YAML library to help write configuration files, an XML library to write XML, and so on.
## File modes
When opening files in Lua, there are some safeguards and parameters to define how a file should be handled. The default is `r`
, which permits you to read data only:
**r**for read only**w**to overwrite or create a new file if it doesn't already exist**r+**to read and overwrite**a**to append data to a file or make a new file if it doesn't already exist**a+**to read data, append data to a file, or make a new file if it doesn't already exist
There are a few others (`b`
for binary formats, for instance), but those are the most common. For the full documentation, refer to the excellent Lua documentation on [Lua.org/manual](http://lua.org/manual).
## Lua and files
Like other programming languages, Lua has plenty of library support to access a filesystem to read and write data. Because Lua has a consistent and simple syntax, it's easy to perform complex processing on data in files of any format. Try using Lua for your next software project, or as an API for your C or C++ project.
## Comments are closed. |
13,270 | 如何使用 Linux anacron 命令 | https://opensource.com/article/21/2/linux-automation | 2021-04-06T08:42:00 | [
"anacron",
"cron"
] | /article-13270-1.html |
>
> 与其手动执行重复性的任务,不如让 Linux 为你做。
>
>
>

在 2021 年,人们有更多的理由喜欢 Linux。在这个系列中,我将分享使用 Linux 的 21 个不同理由。自动化是使用 Linux 的最佳理由之一。
我最喜欢 Linux 的一个原因是它愿意为我做工作。我不想执行重复性的任务,这些任务会占用我的时间,或者容易出错,或者我可能会忘记,我安排 Linux 为我做这些工作。
### 为自动化做准备
“自动化”这个词既让人望而生畏,又让人心动。我发现用模块化的方式来处理它是有帮助的。
#### 1、你想实现什么?
首先,要知道你想产生什么结果。你是要给图片加水印吗?从杂乱的目录中删除文件?执行重要数据的备份?为自己明确定义任务,这样你就知道自己的目标是什么。如果有什么任务是你发现自己每天都在做的,甚至一天一次以上,那么它可能是自动化的候选者。
#### 2、学习你需要的应用
将大的任务分解成小的组件,并学习如何手动但以可重复和可预测的方式产生每个结果。在 Linux 上可以做的很多事情都可以用脚本来完成,但重要的是要认识到你当前的局限性。学习如何自动调整几张图片的大小,以便可以方便地通过电子邮件发送,与使用机器学习为你的每周通讯生成精心制作的艺术品之间有天壤之别。有的事你可以在一个下午学会,而另一件事可能要花上几年时间。然而,我们都必须从某个地方开始,所以只要从小做起,并时刻注意改进的方法。
#### 3、自动化
在 Linux 上使用一个自动化工具来定期实现它。这就是本文介绍的步骤!
要想自动化一些东西,你需要一个脚本来自动化一个任务。在测试时,最好保持简单,所以本文自动化的任务是在 `/tmp` 目录下创建一个名为 `hello` 的文件。
```
#!/bin/sh
touch /tmp/hello
```
将这个简单的脚本复制并粘贴到一个文本文件中,并将其命名为 `example`。
### Cron
每个安装好的 Linux 系统都会有的内置自动化解决方案就是 cron 系统。Linux 用户往往把 cron 笼统地称为你用来安排任务的方法(通常称为 “cron 作业”),但有多个应用程序可以提供 cron 的功能。最通用的是 [cronie](https://github.com/cronie-crond/cronie);它的优点是,它不会像历史上为系统管理员设计的 cron 应用程序那样,假设你的计算机总是开着。
验证你的 Linux 发行版提供的是哪个 cron 系统。如果不是 cronie,你可以从发行版的软件仓库中安装 cronie。如果你的发行版没有 cronie 的软件包,你可以使用旧的 anacron 软件包来代替。`anacron` 命令是包含在 cronie 中的,所以不管你是如何获得它的,你都要确保在你的系统上有 `anacron` 命令,然后再继续。anacron 可能需要管理员 root 权限,这取决于你的设置。
```
$ which anacron
/usr/sbin/anacron
```
anacron 的工作是确保你的自动化作业定期执行。为了做到这一点,anacron 会检查找出最后一次运行作业的时间,然后检查你告诉它运行作业的频率。
假设你将 anacron 设置为每五天运行一次脚本。每次你打开电脑或从睡眠中唤醒电脑时,anacron都会扫描其日志以确定是否需要运行作业。如果一个作业在五天或更久之前运行,那么 anacron 就会运行该作业。
### Cron 作业
许多 Linux 系统都捆绑了一些维护工作,让 cron 来执行。我喜欢把我的工作与系统工作分开,所以我在我的主目录中创建了一个目录。具体来说,有一个叫做 `~/.local` 的隐藏文件夹(“local” 的意思是它是为你的用户账户定制的,而不是为你的“全局”计算机系统定制的),所以我创建了子目录 `etc/cron.daily` 来作为 cron 在我的系统上的家目录。你还必须创建一个 spool 目录来跟踪上次运行作业的时间。
```
$ mkdir -p ~/.local/etc/cron.daily ~/.var/spool/anacron
```
你可以把任何你想定期运行的脚本放到 `~/.local/etc/cron.daily` 目录中。现在把 `example` 脚本复制到目录中,然后 [用 chmod 命令使其可执行](https://opensource.com/article/19/8/linux-chmod-command)。
```
$ cp example ~/.local/etc/cron.daily
# chmod +x ~/.local/etc/cron.daily/example
```
接下来,设置 anacron 来运行位于 `~/.local/etc/cron.daily` 目录下的任何脚本。
### anacron
默认情况下,cron 系统的大部分内容都被认为是系统管理员的领域,因为它通常用于重要的底层任务,如轮换日志文件和更新证书。本文演示的配置是为普通用户设置个人自动化任务而设计的。
要配置 anacron 来运行你的 cron 作业,请在 `/.local/etc/anacrontab` 创建一个配置文件:
```
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
1 0 cron.mine run-parts /home/tux/.local/etc/cron.daily/
```
这个文件告诉 anacron 每到新的一天(也就是每日),延迟 0 分钟后,就运行(`run-parts`)所有在 `~/.local/etc/cron.daily` 中找到的可执行脚本。有时,会使用几分钟的延迟,这样你的计算机就不会在你登录后就被所有可能的任务冲击。不过这个设置适合测试。
`cron.mine` 值是进程的一个任意名称。我称它为 `cron.mine`,但你也可以称它为 `cron.personal` 或 `penguin` 或任何你想要的名字。
验证你的 `anacrontab` 文件的语法:
```
$ anacron -T -t ~/.local/etc/anacrontab \
-S /home/tux/.var/spool/anacron
```
沉默意味着成功。
### 在 .profile 中添加 anacron
最后,你必须确保 anacron 以你的本地配置运行。因为你是以普通用户而不是 root 用户的身份运行 anacron,所以你必须将它引导到你的本地配置:告诉 anacron 要做什么的 `anacrontab` 文件,以及帮助 anacron 跟踪每一个作业最后一次执行是多少天的 spool 目录:
```
anacron -fn -t /home/tux/.local/etc/anacrontab \
-S /home/tux/.var/spool/anacron
```
`-fn` 选项告诉 anacron *忽略* 时间戳,这意味着你强迫它无论如何都要运行你的 cron 作业。这完全是为了测试的目的。
### 测试你的 cron 作业
现在一切都设置好了,你可以测试作业了。从技术上讲,你可以在不重启的情况下进行测试,但重启是最有意义的,因为这就是设计用来处理中断和不规则的登录会话的。花点时间重启电脑、登录,然后寻找测试文件:
```
$ ls /tmp/hello
/tmp/hello
```
假设文件存在,那么你的示例脚本已经成功执行。现在你可以从 `~/.profile` 中删除测试选项,留下这个作为你的最终配置。
```
anacron -t /home/tux/.local/etc/anacrontab \
-S /home/tux/.var/spool/anacron
```
### 使用 anacron
你已经配置好了你的个人自动化基础设施,所以你可以把任何你想让你的计算机替你管理的脚本放到 `~/.local/etc/cron.daily` 目录下,它就会按计划运行。
这取决于你希望作业运行的频率。示例脚本是每天执行一次。很明显,这取决于你的计算机在任何一天是否开机和醒着。如果你在周五使用电脑,但把它设置在周末,脚本就不会在周六和周日运行。然而,在周一,脚本会执行,因为 anacron 会知道至少有一天已经过去了。你可以在 `~/.local/etc` 中添加每周、每两周、甚至每月的目录,以安排各种各样的间隔。
要添加一个新的时间间隔:
1. 在 `~/.local/etc` 中添加一个目录(例如 `cron.weekly`)。
2. 在 `~/.local/etc/anacrontab` 中添加一行,以便在新目录下运行脚本。对于每周一次的间隔,其配置如下。`7 0 cron.mine run-parts /home/tux/.local/etc/cron.weekly/`(`0` 的值可以选择一些分钟数,以适当地延迟脚本的启动)。
3. 把你的脚本放在 `cron.weekly` 目录下。
欢迎来到自动化的生活方式。它不会让人感觉到,但你将会变得更有效率。
---
via: <https://opensource.com/article/21/2/linux-automation>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,271 | 值得现在就去尝试的四款开源聊天应用软件 | https://opensource.com/article/20/4/open-source-chat | 2021-04-06T10:35:41 | [
"聊天"
] | /article-13271-1.html |
>
> 现在,远程协作已作为一项必不可少的能力,让开源实时聊天成为你工具箱中必不可少的一部分吧。
>
>
>

清晨起床后,我们通常要做的第一件事是检查手机,看看是否有同事和朋友发来的重要信息。无论这是否是一个好习惯,但这种行为早已成为我们日常生活的一部分。
>
> 人是理性动物。他可以为任何他想相信的事情想出一个理由。 – 阿纳托尔·法朗士
>
>
>
无论理由是否合理,我们每天都在使用的一系列的通讯工具,例如电子邮件、电话、网络会议工具或社交网络。甚至在 COVID-19 之前,居家办公就已经使这些通信工具成为我们生活中的重要部分。随着疫情出现,居家办公成为新常态,我们交流方式的方方面面正面临着前所未有的改变,这让这些工具变得不可或缺。
### 为什么需要聊天?
作为全球团队的一部分进行远程工作时,我们必须要有一个相互协作的环境。聊天应用软件在帮助我们保持相互联系中起着至关重要的作用。与电子邮件相比,聊天应用软件可提供与全球各地的同事快速、实时的通信。
选择一款聊天应用软件需要考虑很多因素。为了帮助你选择最适合你的应用软件,在本文中,我将探讨四款开源聊天应用软件,和一个当你需要与同事“面对面”时的开源视频通信工具,然后概述在高效的通讯应用软件中,你应当考虑的一些功能。
### 四款开源聊天软件
#### Rocket.Chat

[Rocket.Chat](https://rocket.chat/) 是一个综合性的通讯平台,其将频道分为公开房间(任何人都可以加入)和私有房间(仅受邀请)。你还可以直接将消息发送给已登录的人员。其能共享文档、链接、照片、视频和<ruby> 动态图 <rt> GIF </rt></ruby>,以及进行视频通话,并可以在平台中发送语音信息。
Rocket.Chat 是自由开源软件,但是其独特之处在于其可自托管的聊天系统。你可以将其下载到你的服务器上,无论它是本地服务器或是在公有云上的虚拟专用服务器。
Rocket.Chat 是完全免费,其 [源码](https://github.com/RocketChat/Rocket.Chat) 可在 Github 获得。许多开源项目都使用 Rocket.Chat 作为他们官方交流平台。该软件在持续不断的发展且不断更新和改进新功能。
我最喜欢 Rocket.Chat 的地方是其能够根据用户需求来进行自定义操作,并且它使用机器学习在用户通讯间进行自动的、实时消息翻译。你也可以下载适用于你移动设备的 Rocket.Chat,以便能随时随地使用。
#### IRC

IRC(<ruby> <a href="https://en.wikipedia.org/wiki/Internet_Relay_Chat"> 互联网中继聊天 </a> <rt> Internet Relay Chat </rt></ruby>)是一款实时、基于文本格式的通信软件。尽管其是最古老的电子通讯形式之一,但在许多知名的软件项目中仍受欢迎。
IRC 频道是单独的聊天室。它可以让你在一个开放的频道中与多人进行聊天或与某人私下一对一聊天。如果频道名称以 `#` 开头,则可以假定它是官方的聊天室,而以 `##` 开头的聊天室通常是非官方的聊天室。
[上手 IRC](https://opensource.com/article/16/6/getting-started-irc) 很容易。你的 IRC 昵称可以让人们找到你,因此它必须是唯一的。但是,你可以完全自主地选择 IRC 客户端。如果你需要比标准 IRC 客户端更多功能的应用程序,则可以使用 [Riot.im](https://opensource.com/article/17/5/introducing-riot-IRC) 连接到 IRC。
考虑到它悠久的历史,你为什么还要继续使用 IRC?出于一个原因是,其仍是我们所依赖的许多自由及开源项目的家园。如果你想参于开源软件开发和社区,可以选择用 IRC。
#### Zulip

[Zulip](https://zulipchat.com/) 是十分流行的群聊应用程序,它遵循基于话题线索的模式。在 Zulip 中,你可以订阅<ruby> 流 <rt> stream </rt></ruby>,就像在 IRC 频道或 Rocket.Chat 中一样。但是,每个 Zulip 流都会拥有一个唯一的<ruby> 话题 <rt> topic </rt></ruby>,该话题可帮助你以后查找对话,因此其更有条理。
与其他平台一样,它支持表情符号、内嵌图片、视频和推特预览。它还支持 LaTeX 来分享数学公式或方程式、支持 Markdown 和语法高亮来分享代码。
Zulip 是跨平台的,并提供 API 用于编写你自己的程序。我特别喜欢 Zulip 的一点是它与 GitHub 的集成整合功能:如果我正在处理某个<ruby> 议题 <rt> issue </rt></ruby>,则可以使用 Zulip 的标记回链某个<ruby> 拉取请求 <rt> pull request </rt></ruby> ID。
Zulip 是开源的(你可以在 GitHub 上访问其 [源码](https://github.com/zulip/zulip))并且免费使用,但它有提供预置支持、[LDAP](https://en.wikipedia.org/wiki/Lightweight_Directory_Access_Protocol) 集成和更多存储类型的付费产品。
#### Let's Chat

[Let's Chat](https://sdelements.github.io/lets-chat/) 是一个面向小型团队的自托管的聊天解决方案。它使用 Node.js 和 MongoDB 编写运行,只需鼠标点击几下即可将其部署到本地服务器或云服务器。它是自由开源软件,可以在 GitHub 上查看其 [源码](https://github.com/sdelements/lets-chat)。
Let's Chat 与其他开源聊天工具的不同之处在于其企业功能:它支持 LDAP 和 [Kerberos](https://en.wikipedia.org/wiki/Kerberos_(protocol)) 身份验证。它还具有新用户想要的所有功能:你可以在历史记录中搜索过往消息,并使用 @username 之类的标签来标记人员。
我喜欢 Let's Chat 的地方是它拥有私人的受密码保护的聊天室、发送图片、支持 GIPHY 和代码粘贴。它不断更新,不断增加新功能。
### 附加:开源视频聊天软件 Jitsi

有时,文字聊天还不够,你还可能需要与某人面谈。在这种情况下,如果不能选择面对面开会交流,那么视频聊天是最好的选择。[Jitsi](https://jitsi.org/) 是一个完全开源的、支持多平台且兼容 WebRTC 的视频会议工具。
Jitsi 从 Jitsi Desktop 开始,已经发展成为许多 [项目](https://jitsi.org/projects/),包括 Jitsi Meet、Jitsi Videobridge、jibri 和 libjitsi,并且每个项目都在 GitHub 上开放了 [源码](https://github.com/jitsi)。
Jitsi 是安全且可扩展的,并支持诸如<ruby> 联播 <rt> simulcast </rt></ruby>和<ruby> 带宽预估 <rt> bandwidth estimation </rt></ruby>之类的高级视频路由的概念,还包括音频、录制、屏幕共享和拨入功能等经典功能。你可以来为你的视频聊天室设置密码以保护其不受干扰,并且它还支持通过 YouTube 进行直播。你还可以搭建自己的 Jitsi 服务器,并将其托管在本地或<ruby> 虚拟专用服务器 <rt> virtual private server </rt></ruby>(例如 Digital Ocean Droplet)上。
我最喜欢 Jitsi 的是它是免费且低门槛的。任何人都可以通过访问 [meet.jit.si](http://meet.jit.si) 来立即召开会议,并且用户无需注册或安装即可轻松参加会议。(但是,注册的话能拥有日程安排功能。)这种入门级低门槛的视频会议服务让 Jitsi 迅速普及。
### 选择一个聊天应用软件的建议
各种各样的开源聊天应用软件可能让你很难抉择。以下是一些选择一款聊天应用软件的一般准则。
* 最好具有交互式的界面和简单的导航工具。
* 最好寻找一种功能强大且能让人们以各种方式使用它的工具。
* 如果与你所使用的工具有进行集成整合的话,可以重点考虑。一些工具与 GitHub 或 GitLab 以及某些应用程序具有良好的无缝衔接,这将是一个非常有用的功能。
* 有能托管到云主机的工具将十分方便。
* 应考虑到聊天服务的安全性。在私人服务器上托管服务的能力对许多组织和个人来说是必要的。
* 最好选择那些具有丰富的隐私设置,并拥有私人聊天室和公共聊天室的通讯工具。
由于人们比以往任何时候都更加依赖在线服务,因此拥有备用的通讯平台是明智之举。例如,如果一个项目正在使用 Rocket.Chat,则必要之时,它还应具有跳转到 IRC 的能力。由于这些软件在不断更新,你可能会发现自己已经连接到多个渠道,因此集成整合其他应用将变得非常有价值。
在各种可用的开源聊天服务中,你喜欢和使用哪些?这些工具又是如何帮助你进行远程办公?请在评论中分享你的想法。
---
via: <https://opensource.com/article/20/4/open-source-chat>
作者:[Sudeshna Sur](https://opensource.com/users/sudeshna-sur) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,273 | 《代码英雄》第四季(2):大型机 GE-225 和 BASIC 的诞生 | https://www.redhat.com/en/command-line-heroes/season-4/mainframes | 2021-04-07T09:18:25 | [
"大型机",
"代码英雄"
] | https://linux.cn/article-13273-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》第四季(2):大型机: GE-225 和 BASIC 的诞生](https://www.redhat.com/en/command-line-heroes/season-4/mainframes)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/d27b7b80-6530-4f0a-b6df-a237c6939687/clh-s4-ep2-mainframe-the-ge-225-vfinal_tc.mp3)脚本。
>
> 导语:二战后,计算机行业开始蓬勃发展。<ruby> 通用电气 <rt> General Electric </rt></ruby>(GE)的 CEO 拒绝进入这个市场。但一小队反叛的员工不顾规则,秘密进取。他们创造了 GE 225。这是工程上的一次巨大飞跃,它将计算从一个小众市场推向了主流,为今天的科技行业播下了种子。
>
>
> 在创建通用的<ruby> 大型机 <rt> mainframe </rt></ruby>之前,计算机通常是为了执行单一功能而制造的。William Ocasio 回忆了 GE 的第一台专用计算机 ERMA 是如何帮助银行每天处理成千上万的交易的。John Joseph 讲述了 GE 的几名关键员工是如何蒙骗他们的 CEO 建立一个计算机部门的。Tomas Kellner 解释了他们的工作如何产生了一台革命性的机器:GE 225。而 Joy Lisi Rankin 则介绍了<ruby> 达特茅斯学院 <rt> Dartmouth College </rt></ruby>的工程师们如何对 GE 225 用于<ruby> 分时 <rt> time-sharing </rt></ruby>计算,并利用它创建了 BASIC —— 使计算变得更加方便的重要里程碑。
>
>
>
**00:00:05 - Saron Yitbarek**:
让我们回到几十年前,回到 40 年代末、50 年代初,当时计算机行业有“白雪公主和七个小矮人”的说法。众所周知,“白雪公主”指的是 IBM,而<ruby> 通用电气公司 <rt> General Electric </rt></ruby>便是“七个小矮人”之一。这是一家偶尔生产定制机器,但从没在公开市场售卖计算机的公司。
**00:00:32**:
通用计算机是 IBM 的地盘,而 IBM 是 GE 的第二大客户(第一是美国政府)。IBM 经常采购 GE 生产的真空管、电机、变压器和开关等设备,GE 时任总裁 Ralph Cordiner 对此非常满意。所以,每当 GE 的部门主管将转向计算机业务的计划书提交到总裁办公室时,收到的答复都是封面上大写的橙色字母:RJC,Ralph Cordiner 一次又一次地拒绝他们。
**00:01:19**:
事实上,在 Cordiner 担任 GE 总裁兼首席执行官的 13 年时间里,GE 的态度从未改变。即使研究指出计算机是电子工业中增长最快的领域,但 Cordiner 总是用愤怒回应挑战他底线的员工们。然而,一小群叛逆的员工看到了制造大型机的机会,他们不想错失良机。然而他们不知道的是,这台大型机将拯救银行业,打开分时系统的大门,并孕育出新的编程语言。在上一季,我们听了 John Kemeny 和 Thomas Kurtz 在<ruby> 达特茅斯学院 <rt> Dartmouth College </rt></ruby>创造 BASIC 的故事,了解到因为 BASIC 是解释型语言,早期的计算机没有足够的资源运行它。像 BASIC 这么好的点子,正等待着像 GE-225 这样合适的设备出现,让它大放异彩。这一章,让我们一起揭开那台差点被扼杀在摇篮中的大型机,那鲜为人知的故事。这台房间大小的机器打开了新世界的大门,它鼓舞了像<ruby> 史蒂夫•沃兹尼亚克 <rt> Steve Wozniak </rt></ruby>和<ruby> 比尔•盖茨 <rt> Bill Gates </rt></ruby>这样有远见的代码英雄,鼓舞他们推动个人电脑革命,它的创造在今天仍然意义非凡。我是 Saron Yitbarek,欢迎收听<ruby> 代码英雄 <rt> Command Line Heros </rt></ruby>,Red Hat 的原创播客第四季:硬件设备。
>
> **00:03:05 - 话音 1**:
>
>
> Adams 先生觉得他的新支票账户很好用。与其他公司直接从<ruby> 埃姆维尔国家银行 <rt> Elmvale National Bank </rt></ruby>兑现不同,用这个账号可以从自家银行兑现。与其他银行一样,自家银行把支票送到<ruby> 联邦储备银行 <rt> Federal Reserve Bank </rt></ruby>去执行兑现。联邦储备银行正是为处理每天来自数百家银行的数千张支票而设立的。
>
>
>
**00:03:29 - Saron Yitbarek**:
1947 年,支票开始流行,银行工作人员的时间耗费在无穷无尽的支票当中。战后经济的蓬勃发展,更是让银行被铺天盖地的支票所淹没。为了腾出时间手工填写账簿,他们被迫下午 2 点就早早关门,但即使这样,他们仍然赶不上进度。他们迫切的希望,能有一台快速、强大的机器,让银行跟上商业发展的步伐。当时<ruby> 美国银行 <rt> Bank of America </rt></ruby>每天要处理数百万张支票。下面有请<ruby> 西北大学凯洛格管理学院 <rt> Kellogg School of Management at Northwestern University </rt></ruby>的教授 William Ocasio。
**00:04:12 - Will Ocasio**:
难以想象,银行如果没有电脑可用会是什么样子。银行本身就是繁重、文书密集型的行业,美国银行分支机构又那么多。有这么多的信息,他们想要能够快速的传递和处理这些信息。这对于这样一个大公司来说真的很重要。他们知道计算机才是未来的方向。
**00:04:39 - Saron Yitbarek**:
所以,1950 美国银行与<ruby> 斯坦福研究院 <rt> Stanford Research Institute </rt></ruby>(SRI)签约,希望找到自动处理这些支票的方法。SRI 花了五年时间制造了一台原型机,并将其命名为<ruby> 电子记录会计机 <rt> electronic recording machine accounting </rt></ruby>简称 ERMA。ERMA 有超过 100 万英尺的电线,8000 个真空管,重约 25 吨,每天可以处理 5 万笔交易。
**00:05:11**:
美国银行希望 ERMA 马上投入生产。于是向电子制造商们发出<ruby> 招标请求 <rt> request for proposal </rt></ruby>(RFP),让它们竞标。当然,所有人都认为赢家将是行业巨头,被称作“白雪公主”的 IBM。Baker 博士是通用电气电子部门的副总裁,他知道他的老板 Cordiner 不想涉足 IBM 的领域,也知道计算机是公司的禁区,但当听到美国银行 RFP 的风声时,Baker 看到了其中的机会。他找到了 GE 位于<ruby> 帕洛阿尔托 <rt> Palo Alto </rt></ruby>的微波实验室的经理 Barney Oldfield。在这个离 SRI 最近的地方向 Oldfield 提出了一个建议。下面有请<ruby> 加州大学欧文分校 <rt> University of California, Irvine </rt></ruby>的战略副教授 John Joseph。
**00:06:09 - John Joseph**:
我认为他是一位成功、进取的企业家,也是精明的经理和商人,他认为这是部门发展的巨大机会。
**00:06:27 - Saron Yitbarek**:
Baker 和 Oldfield 成功说服了他们的老板 Cordiner,这是一台定制的生产控制系统,不是通用计算机,生产它不会让 IBM 不快。并且向他保证,GE 不会涉足计算机行业。
**00:06:45 - John Joseph**:
我觉得 Cordiner 最终屈服的原因是,他给他们提出了一个附加条件:仅此一份合同,不要继续深入商用机市场,只能参与这一次竞标。如果能做到,那你们去竞标吧。
**00:07:08 - Saron Yitbarek**:
尽管 Cordiner 不对竞标抱有任何希望,但还是让他们着手进行 RFP。就让他们发泄一下自己的创造力吧。随后 Oldfield 把他们的提案送到旧金山的银行办公室,等待着他们的答复。
**00:07:26**:
出人意料的事情发生了,IBM 忽然放弃竞标,更出乎意料的是,GE 的提案从所有制造商中脱颖而出。这个不被看好的提案赢得了百万美元的合同。美国银行董事会在 1956 年 4 月 9 日正式接受了这个方案。Baker 在没有经过他的老板 Cordiner 审核的情况下签下了这份价值 3100 万美元的合同,把不可能变成了可能。Oldfield 可以找个地方生产 ERMA 了,当然,他得先成立一个实际的计算机部门。
**00:08:19 - John Joseph**:
接下来轮到他们大显身手了。首先,他们确实成立了计算机部门,虽然听上去只是发一份声明就能搞定的事情。但是在这么大的公司内,把公司的资源和人力调动起来成立一个新部门,真的是一件很了不起的事情。
**00:08:46 - Saron Yitbarek**:
Barney Oldfield 成为计算机部门的主管。这个新部门很像 GE 的另一个制造定制机器的部门:<ruby> 军事系统部 <rt> Military Systems Division </rt></ruby>。挑战 IBM 之前,两个部门要先分出胜负。
**00:09:06 - Saron Yitbarek**:
新成立的部门想要低调行事,而 GE 的分权管理方式,刚好适合这样偷偷摸摸的搞事情。只要部门是盈利的,就不会有太多的监管。没人知道他们在做什么。
**00:09:26 - John Joseph**:
当时的情况是,想要在 GE 发展你的小领地,就必须走出去寻找发展的机会。公司没有任何这方面的计划,他是个有冲劲的人,看到了这个机会。他干劲十足,想引领公司走出这重要的一步。
**00:09:59 - Saron Yitbarek**:
更大的挑战还在后头,在哪建立工厂好呢?Palo Alto 的团队想要搬到 Stanford 的工业园区,无奈加州劳动法太严和税收太高,所以这不是个好点子。最终他们选择了 Phoenix。虽然 Phoenix 不是吸引资深工程师的最佳地点,但自有它的优势。
**00:10:26 - John Joseph**:
GE 的总部远在纽约,选择 Phoenix 能让他们远离 GE。在这里,他们可以避开高层的监督,野蛮生长。事关大把钞票,远离 Cordiner 才能获得更大的自主权。
**00:10:55 - Saron Yitbarek**:
Oldfield 在 Phoenix 组建了一支可靠的工程师团队。团队成员有:Bob Johnson、George Snively、Gene Evans 还有 George Jacobi 等人。还有 John Pivoden 负责硬件、Henry Harold 是逻辑设计师、Jay Levinthal 是系统架构师。在这个与世隔绝的桃园胜地,团队氛围非常融洽。他们不仅能担起秘密制造 ERMA 的大任,还能幽默的看待自己的工作。我们找到了他们表演过的一个小短剧,他们称之为“进步的前沿”,这个小短剧某种程度上展示了项目的进展。下面大家一起欣赏一段摘录:
>
> **00:11:39 - 话音 2**:
>
>
> 好了,我们到凤凰城了。
>
>
> **00:11:41 - 话音 3**:
>
>
> 你终于来了。欢迎来到计算机部门。
>
>
> **00:11:45 - 合音**:
>
>
> 啥部门?
>
>
> **00:11:46 - 话音 3**:
>
>
> 计算机部门。
>
>
> **00:11:47 - 话音 4**:
>
>
> 计算机是啥?
>
>
> **00:11:49 - 话音 3**:
>
>
> 哦,有点像是带有圣诞树灯的涡轮机,可以播放音乐。
>
>
> **00:11:53 - 话音 5**:
>
>
> 是一种快速执行运算的机器。
>
>
> **00:11:56 - 话音 2**:
>
>
> 我们没必要用它记账,对吧?
>
>
> **00:11:58 - 话音 3**:
>
>
> 不,但我们得给 Van 一台让他玩,假装我们在用。
>
>
> **00:12:01 - 话音 4**:
>
>
> 噢,计算机是啥?
>
>
>
**00:12:08 - Saron Yitbarek**:
对美国银行而言,计算机是可以一天处理 55000 笔交易的机器,这台机器需要对各种大小和状况的支票进行分拣和分发,需要更新客户帐户和余额,需要能识别支票。他们要的不是 1 台,而是 36 台计算机。
**00:12:34**:
项目初期,团队就决定 GE 版本的 ERMA 将使用晶体管来实现。在 50 年代,虽然晶体管比真空管更昂贵,但体积小,与逻辑板的连接器也更简单。原型机的每个真空管和触发器被两个晶体管所取代,使用额外的电阻和电容将它们连接在一起。将 ERMA 设计成软件编程设备,而不是硬件编程设备,是对原型机的另一个重大改变。这样可以简化机器设计,方便以后轻松修改。鉴于大多数 GE 的开发人员都从事硬件工作,他们得再聘请一名程序员。他们选择了一位几年前从纳粹德国逃出,以难民身份来到美国的男子。这名男子名叫 Joseph Weizenbaum。
**00:13:34**:
Weizenbaum 曾在一家名为 Bendix 的公司为 G-15 电脑编程。他甚至为它开发了一种名为 Intercom 100 的伪机器编程语言。尽管除了兑现支票之外,Weizenbaum 没有任何银行相关经验,但他还是领导小小的编程团队,开始编写支持晶体管硬件的软件。该团队还为所有的外围设备编程,包括支票排序器,还有被他们称做 MICR 阅读器的东西。MICR 的意思是“<ruby> 磁性墨水字符识别 <rt> magnetic ink character recognition </rt></ruby>”。你知道支票底部的那行数字吗?那就是 MICR。这行数字由三部分组成,分别表示银行账户、路由号码和支票号码。直到今天,支票上仍有 Weizenbaum 和他的团队在凤凰城的杰作。
**00:14:28**:
值得一提的是。Weizenbaum 后来被认为是 AI(人工智能)的奠基人之一。1958 年 12 月 28 日,在 GE 赢得合同近三年后,<ruby> 美国银行圣何塞分行 <rt> San Jose Branch of Bank of America </rt></ruby>实装了第一台 ERMA 机器。虽然这台机器每天只能处理 100 笔交易,但这是朝着正确方向迈出的一步。接下来,他们要兑现每天处理 55000 笔交易的承诺。
**00:15:04**:
到了次年 3 月,该团队不仅兑现了 5.5 万交易的的承诺,还增加了分拣机和打印机,使整个系统每天可以处理 200 万笔交易。美国银行兴奋不已。位于 Phoenix 的电脑部门交付了 32 台命名为 GE-100 的机器,还有更多的订单正在准备中,是时候庆祝了。
**00:15:32 - Will Ocasio**:
美国银行邀请 Cordiner 参加计算机的揭幕仪式。他们甚至邀请了曾在通用电气工作过的<ruby> 罗纳德•里根 <rt> Ronald Reagan </rt></ruby>作为他们的电视发言人,这太了不起了。然而,Cordiner 来到揭幕式后,忽然想到:“等一下,这跟之前说的不一样”,然后他生气的开除了 Barney Oldfield。
**00:16:00 - Saron Yitbarek**:
额,Oldfield 就这么被开除了?Phoenix 的团队的明明超额完成了任务,完成了不可思议的壮举,他们的领袖得到的奖励却是被开除?更可气的是,Cordiner 重新任命了部门的负责人,Baker 博士的继任者 Harold Strickland 对电脑并不感兴趣。因为担心会惹 IBM 生气,Cordiner 给 Strickland 下了明确的指示,要他务必管好计算机团队。一个叫 Claire Lasher 的公司职员接替了 Oldfield 的工作。可 Cordiner 不知道的是,Lasher 骨子里也是个反叛者。
**00:16:47**:
通用电气总裁 Cordiner 想要远离商用计算机行业,他从一开始就不想进入这个行业。他想让通用电气尽快回到老样子。他允许生产已有的订单,但用他的话来说:“下不为例!”。后来,当 Cordiner 听到自己银行界的朋友向他称赞 GE-100 的创新时,他的态度发生了转变。所以好吧,他们可以继续在自己创造的沙盒中自由发挥,唯一的限制就是:“不要和 IBM 正面交锋”。
**00:17:24**:
Claire Lasher 的专长是市场营销。他看到了通用计算机市场的蓝海,借鉴了 Oldfield 的经验,制定了自己的计划。那就是两用计算机 200 系列。这个系列既是定制机器,又是通用机器。Claire 将他的商业计划命名为<ruby> 大观 <rt> The Big Look </rt></ruby>,他为 Phoenix 团队招募了更多的工程师,其中包括一位曾在纽约从事 GE-312 和 412 过程控制计算机的人,他的名字叫 Arnold Spielberg,是新团队的领导。
**00:18:05**:
看完技术规格后,Arnold 说:“嘿,如果我们调整一下硬件设计方案,我们就能造出通用机器界的大杀器“。于是,Arnold 增加了读卡器、打印机和磁带处理程序等外围设备。仅用 5 个月就完成了原型机,这款新机器被称为 GE-225。有趣的是,Arnold Spielberg 是<ruby> 史蒂文•斯皮尔伯格 <rt> Steven Spielberg </rt></ruby>的父亲。为了了解更多关于 Spielberg,以及他在创造 GE-225 这台高层从来不想要的机器中所扮演的角色,我采访了通用电气的<ruby> 首席故事官 <rt> chief storyteller </rt></ruby> Tomas Kellner。
**00:18:51 - Tomas Kelner**:
Arnold 和他的同事 Chuck Prosper 是这台电脑的设计者,他们一起制造了它。有趣的是,和 GE 以前的计算机不同,GE-225 是商用计算机,它实际上有一个存储系统,并且能够处理数据的输入和输出。
**00:19:15 - Saron Yitbarek**:
GE-225 的哪些技术进步可以归功于 Arnold 呢?
**00:19:21 - Tomas Kelner**:
最有趣的是,这台电脑有自己的内存,能够记录和输出信息。这种存储器可以存储 8000 到 16000 个 <ruby> 20 位字 <rt> 20-bit word </rt></ruby>。它还有一个辅助存储器,大约可以存储 32000 个 20 位字。他之前也用过一些<ruby> 硬件编程 <rt> wire software </rt></ruby>设备,它们真的很难使用。这些设备只能编程一次,然后就不能再修改了。GE-225 的进步之处在于,有了数据存储的能力。
**00:19:58 - Saron Yitbarek**:
GE-225 长什么样子?
**00:20:02 - Tomas Kelner**:
说实话,GE-225 看起来不怎么好看,它像一堆盒子。它有存储信息的磁带,有输入终端和输出终端。尽管它被称为小型计算机,但它能占满整个地下室。
**00:20:26 - Saron Yitbarek**:
它能完成哪些其他计算机无法完成的任务呢?
**00:20:30 - Tomas Kelner**:
GE-225 计算机的新特性是支持分时操作。支持多个远程终端访问计算机,多个用户能够同时在上边工作、写代码。据我所知,当时其他的计算机没这种能力。
**00:20:58 - Saron Yitbarek**:
那么谁买了 GE-225?GE-225 的目标客户是哪些人呢?
**00:21:02 - Tomas Kelner**:
通用电气公司内部肯定使用了这些计算机,但全国各地的一些银行也使用了它们,还有<ruby> 克利夫兰布朗队 <rt> Cleveland Browns </rt></ruby>也用它们来管理季票销售。有人甚至用其中一台电脑预测了一场全州范围的选举,当然,预测的很准。人们似乎对这台机器非常着迷。Cordiner 让团队在 18 个月内退出计算机行业,但是因为这台计算机的成功,他们搁置了这个计划。
**00:21:43 - Saron Yitbarek**:
重点是,GE-225 不仅是一个银行解决方案。还记得 BASIC 的创始人 John Kemeny 和 Thomas Kurtz 吗?BASIC 就是他们在 GE-225 上创造的。还有另一位代码英雄,他发现了 GE-225 上的编程漏洞。
**00:22:03**:
尽管那时他还在上高中。接下来让 Tomas 告诉你,GE-225 在 BASIC 的开发中起到了什么作用?
**00:22:14 - Tomas Kelner**:
GE-225 上开发了很多有趣的项目,达特茅斯学院的科学家们开发的 BASIC 语言便是其中之一。当时,他们想发明一种使程序员在不同的终端上同时工作的工具。这个工具,就是后来的 BASIC。关于 BASIC 另一件趣事是,通用电气以最快的速度从达特茅斯学院获得了 BASIC 的授权,并开始在内部使用它和预装在 GE-225 上。<ruby> 史蒂夫•沃兹尼亚克 <rt> Steve Wozniak </rt></ruby>就是通过 GE-225 接触到 BASIC。当他接触到了一个连接到 GE-225 计算机上运行 BASIC 的终端时,他瞬间就爱上了这个工具,实际上他的处女作就是在上面完成的。
**00:23:13 - Saron Yitbarek**:
那么当你和 Arnold 交谈时,他意识到他对计算机世界的影响了吗?
**00:23:18 - Tomas Kelner**:
对 Arnold Spielberg 的采访真是令人难以置信。那时,他已经 99 岁了。
**00:23:23 - Saron Yitbarek**:
哇哦。
**00:23:24 - John Joseph**:
他记得所有的事情,我们谈到了互联网,我清楚的记得,他说,在 1960 年代,畅想过计算机的未来,但是他从没想到,有一天人们可以通过家用电脑和智能手机,连接到互联网这个庞大的网络中。没想到人们可以随时随地获取信息,航空公司通过计算机控制飞机,控制机器工作。一方面,他对该领域的发展非常感兴趣。另一方面,他也非常谦虚地承认,该领域的发展超过了他在 20 世纪 60 年代的想像。
**00:24:12 - Saron Yitbarek**:
你认为这一切对<ruby> 史蒂芬•斯皮尔伯格 <rt> Steven Spielberg </rt></ruby>和他的事业有什么影响?
**00:24:18 - Tomas Kelner**:
史蒂芬还记得曾拜访过 GE 在他们的家乡亚利桑那州 Phoenix 建的工厂,他的父亲带他来工作的地方参观。他当时一头雾水,他爸试图向他解释电脑是什么,能做什么。他的原话是:“这一切对我来说都像是希腊语。”可见他当时是真的听不懂。我问 Arnold 对自己儿子的印象。他说:“我想让他学习工程学,培养他的技术热情,但他却只对电影感兴趣”。
>
> **00:25:00 - 话音 6**:
>
>
> 随后银行业进入电子时代。今天,这种磁性油墨计算机系统让银行能够提供世界上最快、最有效的服务。保险公司、百货公司和公用事业公司也陆续开始使用类似的系统。事实上,所有文书工作都开始使用计算机。但谁知道呢,也许将来,会有更好的解决方案。
>
>
>
**00:25:34 - Saron Yitbarek**:
到 1962 年,GE-225 全面投产,并在推出一年后,迅速成为公司的重磅产品。它不仅为公司盈利,还在商界赢得了很高的声誉。在之后的几个月里,Cordiner 收到了来自全国各地的祝贺信息,他最终改变了他的想法,打算投身计算机行业。他终于正式认可了通用电气计算机部门。
**00:26:13**:
让我们回到与 Tomas 对话中提到的一些事情,我们在上一季的《[C 语言之巨变](/article-13066-1.html)》那一期中也有提到。当达特茅斯学院使用 GE-225 开发一个工具,让程序员可以在不同的终端上同时工作 —— 换句话说,分时系统 —— GE 并没意识到分时的潜力。
**00:26:38 - Joy Lisi Rankin**:
达特茅斯学院使用 GE-225 和 GE DATANET 30 实现了分时系统,此前通用电气从未考虑使用这两种设备来实现这一功能。
**00:26:53 - Saron Yitbarek**:
Joy Lisi Rankin 是一名技术历史学家。
**00:26:57 - Joy Lisi Rankin**:
分时系统的关键在于电脑需要某种方式来停止自己的时钟。分时不是指人们在计算机上共享时间,而是指计算机共享自己的时间来处理多个计算请求。达特茅斯学院的师生们决定,使用 DATANET 30(这是一台 GE 的通信计算机)和 GE-225 共同开发分时系统。
**00:27:32 - Saron Yitbarek**:
因为大型机在 60 年代非常昂贵,批量运行是使用大型机最高效的方法。当时的人编写程序,然后做成打孔卡片以运行程序,他们将卡片交给操作员,然后他们就得等着它和其他程序一起被分批运行。有时要等几个小时,甚至几天。
**00:27:58 - Joy Lisi Rankin**:
在社交电脑和社交网络出现之前,在 Facebook 出现之前,分时系统、BASIC 还有达特茅斯学院和 GE,对开启个人电脑时代发挥了重要作用。通用电气从达特茅斯学院建立的分时系统中吸取经验,将其应用到自己的业务中,迅速建立起了全球分时服务行业。1970 年的某个时候,仅欧洲就有 10 万分时用户。在 20 世纪 70 年代到 80 年代,分时是他们的重要业务。
**00:28:44 - Saron Yitbarek**:
尽管 GE-225 和随后的 200 系列计算机取得了成功,通用电气公司还是在 1970 年将其大型机部门卖给了 Honeywell。但他们仍然决定保持分时共享业务,并在未来几年保持盈利。
**00:29:08**:
Ralph Cordiner 的故事讲完了,就像我们在上一期,数据通用公司发明小型机的故事中看到的,下一代伟大机器,它往往需要一个由顽固的、有远见的叛逆者和一些前瞻的执行官组成的团队来建造。人算不如天算,集思广益往往会有意想不到的收获。
**00:29:41 - Saron Yitbarek**:
下一期,我们将从 GE-225 结束的地方开始,来谈谈大型机如何启发新一代程序员展开个人计算机革命,谈一谈他们对我们的启发。《代码英雄》是红帽的原创播客。访问我们的网站 [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes%22redhat.com/commandlineheroes%22) 了解更多有关 GE-225 的资料。我是 Saron Yitbarek,下期之前,编码不止!
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-4/mainframes>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[2581543189](https://github.com/2581543189) 校对:[wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
The computing industry started booming after World War II. General Electric’s CEO refused to enter that market. But a small team of rebel employees bent the rules to forge on in secret. They created the GE 225. It was a giant leap in engineering that pushed computing from a niche market to the mainstream—sowing the seeds for today’s tech industry.
Before the creation of general-purpose mainframes, computers were often built to perform a single function. William Ocasio recalls how GE’s first specialized computers, the ERMA, helped banks process thousands of transactions per day. John Joseph recounts how a few key GE employees hoodwinked their CEO into creating a computing department. Tomas Kellner explains how their work resulted in a revolutionary machine: the GE 225. And Joy Lisi Rankin describes how engineers at Dartmouth College adapted the GE 225 for time-sharing and used it to create BASIC—major milestones in making computing more accessible.

**00:05** - *Saron Yitbarek*
Let's wind the clock back a few decades. Back to the late ‘40s, early ‘50s. There was only one serious name in the computer game: IBM. It's nickname was Snow White. The other much smaller tech companies where the Seven Dwarves. One of those dwarves was General Electric, a company that sometimes built special-order machines, but never produced computers for the open market.
**00:32** - *Saron Yitbarek*
General purpose computers were IBM's territory, and IBM was GE's second largest customer next to the US government. They were regular buyers of GE's vacuum tubes, motors, transformers and switches, and the president of GE, Ralph Cordiner, wanted to keep it that way. Yet every once in a while, a GE department head would write up a business plan that veered in the direction of the computer business, and when those plans wound their way up to the president's office for final sign off, they would be promptly rejected with a big fat no, and the initials RJC scribbled on the top page—in orange crayon, no less.
**01:19** - *Saron Yitbarek*
In fact, throughout Cordiner's 13-year reign as president and CEO, GE never swayed from that position. Even as research pointed to computers as the fastest growing segment of the electronics industry, employees with projects that crossed the line faced Cordiner's wrath. And yet, a small group of rebel employees saw an opportunity to build a mainframe computer, and they couldn't let the idea go. Little did they know that this computer would save the banking industry, open the door to timesharing, and give birth to a whole new programming language. Last season, we heard how John Kemeny and Thomas Kurtz created BASIC at Dartmouth College, and we learned that BASIC is an interpreted language, which means it was too resource heavy for early computers. It's an example of a great idea that had to wait for the right hardware moment. The GE 225 was that hardware. In this episode, we uncover a little known story of a mainframe-that-almost-wasn't yet this room-sized computer would be a gateway machine, inspiring visionary command line heroes like Steve Wozniak and Bill Gates to launch the personal computing revolution. Its creation is still meaningful today. I'm Saron Yitbarek, and this is Command Line Heroes, an original podcast from Red Hat. Season Four: Hardware.
**03:05** - *Speaker 1*
Mr. Adams finds his new checking account very useful. Instead of collecting the money direct from the Elmvale National Bank, the company does it through its own bank. Like many other banks, it sends its checks to the Federal Reserve Bank for collection. The Federal Reserve Bank is set up to handle thousands of checks from hundreds of banks in a single day.
**03:29** - *Saron Yitbarek*
In 1947, a check winds its way through a bank to get deposited, and legions of bank workers are clocking in countless hours to deal with all those checks. The post-war economy was booming, but that meant banks were now drowning in paperwork. They were forced to close at 2 PM just to leave time for filling out ledgers by hand, and they were still falling behind. A fast, powerful machine was urgently needed to keep up with the pace of business. Over at Bank of America, they had millions of checks to handle each day. Here's William Ocasio, professor at the Kellogg School of Management at Northwestern University.
**04:12** - *Will Ocasio*
Can you imagine a world of banking without computers? This is a heavy, paperwork-intensive industry, and particularly the case of Bank of America with all these multiple branches. So there's all this information that they want quickly and to be able to communicate and also to process it. So that was really important for such a large company. I think they understood that computers was the way of the future.
**04:39** - *Saron Yitbarek*
So in 1950, B of A contracted Stanford Research Institute (SRI) to figure out how to automate the handling of all those checks. It took SRI 5 years to build a prototype, which they called the electronic recording machine accounting, or ERMA. The machine had over a million feet of wiring, 8,000 vacuum tubes, and weighed about 25 tons. It had the potential to handle 50,000 transactions a day.
**05:11** - *Saron Yitbarek*
Bank of America was keen to start producing the ERMA right away. So they sent out a request for proposal (RFP) to electronics manufacturers to bid on the job. Of course, everyone figured the winner would be the juggernaut of business machines: Ms. Snow White herself, IBM. Doc Baker was the VP of the Electronics Division over at GE, and he knew his boss, Cordiner, didn't want to move into IBM's territory. He knew computers were out of bounds, but when he got wind of Bank of America's RFP, well, Baker saw an opening he didn't want to miss. He approached Barney Oldfield, the manager of GE's microwave laboratory in Palo Alto, which was the nearest facility to SRI, and he made Oldfield a proposition. Here's John Joseph, an Associate Professor of Strategy at the University of California, Irvine.
**06:09** - *John Joseph*
You know I think here was somebody who was a very successful, aggressive entrepreneur type at GE, and was a savvy manager and businessman, and he saw this as a huge opportunity to grow the division.
**06:27** - *Saron Yitbarek*
Baker, along with Oldfield, was able to convince their boss, Cordiner, that this would be a special purpose process control system, not a general purpose computer, not something that would upset IBM. GE was certainly not going into the computer business.
**06:45** - *John Joseph*
The reason I think Cordiner eventually capitulated was that he put a condition on them going after it, and said, just this contract. We don't want to enter the business machine market more generally. We want to enter specifically this particular bid and you can go after it. And so, he said, go.
**07:08** - *Saron Yitbarek*
Cordiner let them go ahead with the RFP, feeling confident that they wouldn't win the contract anyway. Let them blow off some creative steam, and then Oldfield hand delivered their proposal to the bank's San Francisco office, and waited.
**07:26** - *Saron Yitbarek*
Then much to everyone's surprise, IBM pulled out of the race and, even more unexpectedly, GE's proposal rose to the top. Bank of America awarded them the contract. Not any of the other technology manufacturers—the underdogs got it. The underdogs at GE won the multimillion dollar contract. On April 9, 1956, B of A's board of directors accepted GE's proposal. Baker signed a $31 million contract without running it by his boss, Cordiner. This impossible project was becoming real. All Oldfield needed now was a place to build the ERMAs. And, oh yeah, an actual computer department.
**08:19** - *John Joseph*
Okay, so now they had to start putting it together. First of all, they actually established a computer department. Now, that seems like an obvious statement, but to create a new department at a big company like this, he was able to bring together the resources and the people to actually create a department within General Electrics. That was a big deal in and of itself.
**08:46** - *Saron Yitbarek*
Barney Oldfield became general manager of GE's new computer department. He set up the department to look like another GE department, the Military Systems Division, where they built special purpose computers. The 2 divisions could then be in competition with each other, and not in competition with IBM.
**09:06** - *Saron Yitbarek*
This was how the new computer department was meant to fly—under corporate's radar. In a way, GE's decentralized management style was kind of perfect for a stealthy operation like this. As long as departments were profitable, there really wasn't much oversight. No one would know what was going on.
**09:26** - *John Joseph*
Part of the backdrop here was that, in order to grow your little fiefdom in GE at the time, meant that you had to go out and look for opportunities for growth. There wasn't any corporate planning at the time. He was a go-getter, and saw this as a great opportunity. And I think he had the sheer will to bring the organization along because this was a huge, huge step.
**09:59** - *Saron Yitbarek*
The bigger challenge lay in where to locate the manufacturing facility. Up to this point, the Palo Alto group assumed they would move into a Stanford industrial park, but California had tough labor laws and high taxes. So it was off the table. GE decided on Phoenix instead. Maybe not the best place to attract experienced computer engineers, sure, but Phoenix had a major upside.
**10:26** - *John Joseph*
Now, the advantage to putting them in Phoenix was that it put them far away from GE. GE was headquartered in New York City at the time, so it was a case where I think it allowed them to happily operate under the radar of top management for a while to get up and running, because you know a lot of money was at stake. So it allowed them to do the skunkworks away from Cordiner.
**10:55** - *Saron Yitbarek*
Oldfield managed to put together a solid team of engineers out there in Phoenix. Bob Johnson, George Snively, Gene Evans, George Jacobi, among others. John Pivoden was in charge of the hardware. Henry Harold was the logic designer. And Jay Levinthal was the system architect. Holed up in what seemed to them like the middle of nowhere, the team got along surprisingly well. They were up to the task to build the ERMA under a shroud of secrecy, and it didn't hurt that they had a sense of humor about the whole thing. We found an old skit that the team performed, something they called Frontiers of Progress, and I think it shows you where they were at. Here's an excerpt.
**11:39** - *Speaker 2*
Well, here we are in Phoenix.
**11:41** - *Speaker 3*
Well, I see you finally made it. Welcome to the computer department.
**11:45** - *Group*
The what department?
**11:46** - *Speaker 3*
The computer department.
**11:47** - *Speaker 4*
What's a computer?
**11:49** - *Speaker 3*
Oh, it's sort of a turbine with Christmas tree lights that plays music.
**11:53** - *Speaker 5*
They're a kind of fast adding machine.
**11:56** - *Speaker 2*
We won't have to use one in accounting, will we?
**11:58** - *Speaker 3*
No, but we will have to give Van one to play with and pretend we're using it.
**12:01** - *Speaker 4*
Uh, what's a computer?
**12:08** - *Saron Yitbarek*
As far as Bank of America was concerned, a computer was something that could handle 55,000 transactions a day. It also needed to sort and distribute checks of all sizes and conditions. It needed to update customer accounts and balance operations. It needed a way to identify the checks, and Bank of America wanted not one, but 36, of these machines.
**12:34** - *Saron Yitbarek*
Early in the process, the team decided that the GE version of ERMA would be transistorized. In the '50s, transistors were more expensive than vacuum tubes, but they required less space and simpler connectors to the logic boards. So, each vacuum tube and flip flop would be replaced by two transistors, with some additional resistors and capacitors to hold it all together. The other big change to the original prototype was to make the ERMA a stored program computer rather than a hardwired machine. This would allow for a simpler machine design and easier modifications later on. Since most of GEs developers were on the hardware side, they needed to hire themselves a programmer. They chose a man who not-too-many years before had escaped Nazi Germany and had come to the U.S. as a refugee. His name was Joseph Weizenbaum.
**13:34** - *Saron Yitbarek*
Weizenbaum had programmed a G-15 computer at a company called Bendix. He even developed a pseudo machine programming language for it called Intercom 100. With no experience in banking other than cashing his own checks, Weizenbaum would now lead the micro programming team to write software capable of supporting the transistorized hardware. The team also programmed all the peripheral devices including the checks orders, and something they called the MICR reader. That stands for magnetic ink character recognition. You know that line of numbers on the bottom of your checks? That's MICR. Three sets of numbers that identify a bank account, a routing number and a check number, and it's still there on all your checks because of the work Weizenbaum and his team did out in Phoenix.
**14:28** - *Saron Yitbarek*
Cool side note. Weizenbaum would later go on to be considered one of the founding fathers of AI (artificial intelligence). On December 28, 1958, almost 3 years after GE won the contract, the San Jose Branch of Bank of America installed the first completed ERMA machine. The system could only handle 100 transactions a day, but it was a step in the right direction. The next step, get it to process the required 55,000 transactions a day.
**15:04** - *Saron Yitbarek*
By March, the team had not only finished tweaking the machine to get to 55,000, they added additional sorters and printers so that the overall system could handle 2 million transactions a day. Bank of America was thrilled. The Phoenix computer department delivered 32 machines, now christened the GE-100, with more orders in the pipeline. It was time to celebrate.
**15:32** - *Will Ocasio*
Bank of America invited Cordiner to the unveiling of the computer. They even invited Ronald Reagan who used to work for General Electric as their TV spokesperson, so this was going to be a big deal. Then Cordiner came in to the unveiling and he thought, "Wait a minute, this is not what I approved." So that's where he got mad, and he ended up firing Barney Oldfield because of that.
**16:00** - *Saron Yitbarek*
Ugh, fired. The Phoenix team had exceeded expectations, had really done something extraordinary, but now their leader was rewarded by being let go. Not only that, but Cordiner also reassigned the head of the division, Doc Baker. His replacement, Harold Strickland, didn't care for computers. Cordiner still apparently worried about upsetting IBM, gave Strickland firm instructions to keep the computer group in check. And the person who replaced Oldfield, a company man by the name of Claire Lasher. Little did Cordiner know, the rebel streak ran strong in Lasher, too.
**16:47** - *Saron Yitbarek*
GE President Cordiner wanted to get out of the business computer industry, which he never wanted to be in in the first place. He wanted to get GE back to the old ways as soon as possible. He allowed for the fulfillment of existing orders, but in his words, "No more." But you know, when Cordiner's banking friends started flooding him with compliments about the innovative GE-100, he changed his tune. So okay, they could keep playing in the sandbox they'd created, the only restriction, "Do not go head-to-head with IBM."
**17:24** - *Saron Yitbarek*
Claire Lasher's expertise was in marketing. He saw the huge sales potential of general purpose computers and took a page out of Oldfield's book. He developed his own plan. A line of computers, the 200 series, with a dual purpose. They would be specific process control machines and a general purpose system. Claire called his business plan, The Big Look. He recruited more engineers to the Phoenix team, including someone who had worked on the GE-312 and 412 process control computers back in New York. His name was Arnold Spielberg, and he would lead the team.
**18:05** - *Saron Yitbarek*
After looking over the technical specs, Arnold said something like, "Hey, if we move a few things around on this piece of hardware, we could have a highly competitive general purpose machine." Arnold added peripheral devices like card readers, printers, and magnetic tape handlers. The production prototype was completed in just 5 months. The new general purpose machine was called the GE-225. Fun fact, Arnold Spielberg is Steven Spielberg's dad. I spoke to Tomas Kellner, GE's chief storyteller, to learn more about Mr. Spielberg and his role in creating the machine that the brass never wanted, the GE-225.
**18:51** - *Tomas Kelner*
Well, Arnold and his colleague Chuck Prosper were actually the designers of the computer, they built it together. It was interesting because unlike the previous GE computers, the GE-225 was a business computer, and it actually had a storage system, so it was able to handle the input and output of data.
**19:15** - *Saron Yitbarek*
What technological advancements in the GE-225 can be attributed to Arnold?
**19:21** - *Tomas Kelner*
One thing that was really interesting was that this computer actually had its own memory, and that was able to record and output information. The memory could store between 8,000 to 16,000 20-bit words, and then it also had an auxiliary memory that had about 32,000 20-bit words. Some of the computers that he also worked on were wire software, so they were really hard to use. They basically had to be programmed once, and that was all you could do. This was different because of the computer's ability to store data.
**19:58** - *Saron Yitbarek*
What did the GE-225 look like?
**20:02** - *Tomas Kelner*
The GE-225 didn't look like much, to be honest with you. It looked like a bunch of boxes. It had magnetic tapes that stored the information. There was an input terminal, an output terminal, and even though it was called a small computer, it filled an entire basement room.
**20:26** - *Saron Yitbarek*
What tasks could it perform that no other computer could at the time?
**20:30** - *Tomas Kelner*
One of the new features of the GE-225 computers was the ability to do time-sharing. You were able to access the computer from multiple terminals, multiple remote terminals, giving users the ability to work on the computer at the same time, to write code at the same time. As far as I know, this feature was not available in other commercial computers at the time.
**20:58** - *Saron Yitbarek*
So who bought the GE-225? Who were the clients?
**21:02** - *Tomas Kelner*
GE definitely used the computers internally, but a number of banks across the country used them, as well as the Cleveland Browns apparently used them to manage season ticket sales. Somebody even used one of the computers to predict a statewide election, and apparently the prediction matched the results. So it seemed like people were quite smitten with the machine. Cordiner told the team to get out of the computer business within 18 months, and it took them longer—much longer than that because of the success of this computer.
**21:43** - *Saron Yitbarek*
I want to pause here for a sec to emphasize, the GE-225 was so much more than just a banking solution. Remember John Kemeny and Thomas Kurtz, the creators of BASIC? Their programming language was created on the GE-225. And there's another command line hero who caught the programming bug on the GE-225.
**22:03** - *Saron Yitbarek*
Though he was still in high school at the time. Well, I'll let Tomas tell you. How was the GE-225 instrumental in the development of BASIC?
**22:14** - *Tomas Kelner*
One of the interesting applications of the GE-225 was the use of the computer by Dartmouth and their computer scientists to develop the BASIC language. They wanted to come up with a tool that would allow computer programmers to work from different terminals at the same time. And that tool was essentially, would later became BASIC. Now an interesting aside about BASIC is that GE promptly licensed BASIC from Dartmouth and started using it internally and started offering it with their computers, which is how it got to Steve Wozniak. He was exposed to a terminal that was connected to the GE-225 computer running BASIC, and he was so smitten with it that he actually started writing his first software on that terminal.
**23:13** - *Saron Yitbarek*
So when you spoke to Arnold, was he aware of the impact he'd made on the computing world?
**23:18** - *Tomas Kelner*
The interview with Arnold Spielberg was truly incredible. When I talked to him, he was 99.
**23:23** - *Saron Yitbarek*
Wow.
**23:24** - *John Joseph*
He remembered everything. We talked about the internet. He definitely said that back then in the 1960s, he was thinking a lot about computer applications, but it didn't occur to him that one day all of us would be connected—in our homes and in our pockets—to this vast network that allows us to pull information on a whim and that allows airlines to control planes in the sky and corporations control machines. On one hand, he was always very interested in the development of the field. At the same time, he was also very humble in admitting that the field has evolved in a way that he could not have predicted in the 1960s.
**24:12** - *Saron Yitbarek*
Steven Spielberg. I'm wondering what kind of influence do you think this had on him and his career?
**24:18** - *Tomas Kelner*
He remembers visiting his dad's workplace, the GE factory in Phoenix, Arizona, where they lived. His dad brought him over and he had no clue what was happening. And that his dad was trying to explain to him what computers were, and what they did. And he said a quote was, "It was all like Greek to me." So he really had no idea. I asked Arnold, so what was your impression? And he said, "Yes, well, I wanted him to study engineering. I wanted him to be interested in tech, but he was always interested in movies."
**25:00** - *Speaker 6*
This then is the electronic age in banking. Today, this magnetic ink computer system makes possible the world's fastest, most efficient banking service. Similar systems eventually will be employed by insurance companies, department stores and utilities. In fact, wherever paperwork is a problem. But who knows, perhaps sometime in the future, an even better method of handling paperwork may be found. Of this, you can be sure.
**25:34** - *Saron Yitbarek*
By 1962, the GE-225 was in full production. After its launch a year later, it quickly became a blockbuster product for the company. Not only was it profitable, it also earned a great reputation in the business world. In the months afterward, Cordiner received congratulatory messages from all over the country, so much so that he finally, finally changed his mind about going into the computer business. He formally recognized the General Electric computer department at last.
**26:13** - *Saron Yitbarek*
Let's go back to something that Tomas brought up in our conversation, and something we also talked about in last season's C change episode. When Dartmouth College used the GE-225 to develop a tool that allowed programmers to work from different terminals at the same time—in other words, timesharing—GE hadn't realized the potential for that.
**26:38** - *Joy Lisi Rankin*
Dartmouth built its timesharing system using the GE-225 as well as a GE DATANET 30 and General Electric had previously considered neither of those machines for timesharing.
**26:53** - *Saron Yitbarek*
Joy Lisi Rankin is a technology historian.
**26:57** - *Joy Lisi Rankin*
The key thing about timesharing was that the computer needed some way of being able to sort of stop its own clock. That's what the timesharing refers to, not people sharing time on the computer, but the computer actually sharing its own time to process multiple computing requests, and it was the faculty and students at Dartmouth College who had the idea of using the DATANET 30, which was a GE communications computer to do that clock and time management together with the 225.
**27:32** - *Saron Yitbarek*
Because mainframes were so expensive in the '60s, the most efficient way to use them was to run programs in batches. Someone would write a program, get the cards punched to run the program, then hand over the cards to an operator. Then they'd have to wait for it to be batched with other programs. Sometimes they'd wait for hours, even days.
**27:58** - *Joy Lisi Rankin*
Timesharing, BASIC, and Dartmouth and GEs relationship are crucial to ushering in what I call an era of personal computing before social computers and social networking, well before Facebook. GE was easily able to take what was learned from Dartmouth building this timesharing system and adapt it to their own business and quickly build a global timesharing service industry. I think at one point in 1970 they had 100,000 timesharing users in Europe alone. So this was a substantial business for them through the 1970s into the 1980s.
**28:44** - *Saron Yitbarek*
Despite the success of the GE-225 and the line of two hundreds that followed, General Electric sold its mainframe division to Honeywell in 1970. But they did decide to keep their timesharing business open, and it stayed profitable for years to come.
**29:08** - *Saron Yitbarek*
So Ralph Cordiner got there eventually, but just like we saw in our last episode with the creation of the mini computer over at Data General, it often takes a team of stubborn, wide-eyed rebels and some forward-thinking execs to build the next great machine. Because, sometimes the powers that be have trouble envisioning the power that could be. Opening up the decision-making process to others can lead to surprising and amazing results.
**29:41** - *Saron Yitbarek*
In our next episode, we're picking up from where the GE-225 left off to talk about how that mainframe inspired a whole new generation of programmers to kickstart the personal computing revolution and how that generation inspired us today. Command Line Heroes is an original podcast from Red Hat. Head on over to [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) for some great research on the team behind the GE-225. I'm Saron Yitbarek. Until next time, keep on coding.
### Further reading
[ The Rise and Fall of the General Electric Corporation Computer Department (PDF)](https://ban.ai/multics/doc/The%20Rise%20and%20Fall%20of%20GE.pdf) by J.A.N. LEE
[ 1960 General Electric Computer - GE 210 - 1961 MICR - Banking Finance Data Processing](https://www.youtube.com/watch?v=QfHMu75cfjg) by General Electric
[ Bank computing turns 40](https://www.computerworld.com/au/article/158049/bank_computing_turns_40) by Rodney Gedda
[ How Steve Wozniak Wrote BASIC for the Original Apple From Scratch](https://gizmodo.com/how-steve-wozniak-wrote-basic-for-the-original-apple-fr-1570573636) by Steve Wozniak
[ Brochure for the GE-200 computers (PDF)](http://s3data.computerhistory.org/brochures/ge.235.1964.102646091.pdf) by General Electric
### Bonus episode
In the 1960s, Dartmouth saw the GE 225 as a massive opportunity for its students. Hear how a few faculty members and students made the mainframe widely accessible. |
13,274 | 在 Linux 中把多个 Markdown 文件转换成 HTML 或其他格式 | https://itsfoss.com/convert-markdown-files/ | 2021-04-07T09:55:31 | [
"Markdown",
"pandoc"
] | https://linux.cn/article-13274-1.html | 
很多时候我与 Markdown 打交道的方式是,先写完一个文件,然后把它转换成 HTML 或其他格式。也有些时候,需要创建一些新的文件。当我要写多个 Markdown 文件时,通常要把他们全部写完之后才转换它们。
我用 `pandoc` 来转换文件,它可以一次性地转换所有 Markdown 文件。
Markdown 格式的文件可以转换成 .html 文件,有时候我需要把它转换成其他格式,如 epub,这个时候 [pandoc](https://pandoc.org/) 就派上了用场。我更喜欢用命令行,因此本文我会首先介绍它,然而你还可以使用 [VSCodium](https://vscodium.com/) 在非命令行下完成转换。后面我也会介绍它。
### 使用 pandoc 把多个 Markdown 文件转换成其他格式(命令行方式)
你可以在 Ubuntu 及其他 Debian 系发行版本终端输入下面的命令来快速开始:
```
sudo apt-get install pandoc
```
本例中,在名为 `md_test` 目录下我有四个 Markdown 文件需要转换。
```
[email protected]:~/Documents/md_test$ ls -l *.md
-rw-r--r-- 1 bdyer bdyer 3374 Apr 7 2020 file01.md
-rw-r--r-- 1 bdyer bdyer 782 Apr 2 05:23 file02.md
-rw-r--r-- 1 bdyer bdyer 9257 Apr 2 05:21 file03.md
-rw-r--r-- 1 bdyer bdyer 9442 Apr 2 05:21 file04.md
[email protected]:~/Documents/md_test$
```
现在还没有 HTML 文件。现在我要对这些文件使用 `pandoc`。我会运行一行命令来实现:
* 调用 `pandoc`
* 读取 .md 文件并导出为 .html
下面是我要运行的命令:
```
for i in *.md ; do echo "$i" && pandoc -s $i -o $i.html ; done
```
如果你不太理解上面的命令中的 `;`,可以参考 [在 Linux 中一次执行多个命令](https://itsfoss.com/run-multiple-commands-linux/)。
我执行命令后,运行结果如下:
```
[email protected]:~/Documents/md_test$ for i in *.md ; do echo "$i" && pandoc -s $i -o $i.html ; done
file01.md
file02.md
file03.md
file04.md
[email protected]:~/Documents/md_test$
```
让我再使用一次 `ls` 命令来看看是否已经生成了 HTML 文件:
```
[email protected]:~/Documents/md_test$ ls -l *.html
-rw-r--r-- 1 bdyer bdyer 4291 Apr 2 06:08 file01.md.html
-rw-r--r-- 1 bdyer bdyer 1781 Apr 2 06:08 file02.md.html
-rw-r--r-- 1 bdyer bdyer 10272 Apr 2 06:08 file03.md.html
-rw-r--r-- 1 bdyer bdyer 10502 Apr 2 06:08 file04.md.html
[email protected]:~/Documents/md_test$
```
转换很成功,现在你已经有了四个 HTML 文件,它们可以用在 Web 服务器上。
pandoc 功能相当多,你可以通过指定输出文件的扩展名来把 Markdown 文件转换成其他支持的格式。不难理解它为什么会被认为是[最好的写作开源工具](https://itsfoss.com/open-source-tools-writers/)。
### 使用 VSCodium 把 Markdown 文件转换成 HTML(GUI 方式)
就像我们前面说的那样,我通常使用命令行,但是对于批量转换,我不会使用命令行,你也不必。VSCode 或 [VSCodium](https://itsfoss.com/vscodium/) 可以完成批量操作。你只需要安装一个 Markdown-All-in-One 扩展,就可以在一次运行中转换多个 Markdown 文件。
有两种方式安装这个扩展:
* VSCodium 的终端
* VSCodium 的插件管理器
通过 VSCodium 的终端安装该扩展:
1. 点击菜单栏的 `终端`。会打开终端面板
2. 输入,或[复制下面的命令并粘贴到终端](https://itsfoss.com/copy-paste-linux-terminal/):
```
codium --install-extension yzhang.markdown-all-in-one
```
**注意**:如果你使用的 VSCode 而不是 VSCodium,那么请把上面命令中的 `codium` 替换为 `code`

第二种安装方式是通过 VSCodium 的插件/扩展管理器:
1. 点击 VSCodium 窗口左侧的块区域。会出现一个扩展列表,列表最上面有一个搜索框。
2. 在搜索框中输入 “Markdown All in One”。在列表最上面会出现该扩展。点击 “安装” 按钮来安装它。如果你已经安装过,在安装按钮的位置会出现一个齿轮图标。

安装完成后,你可以打开含有需要转换的 Markdown 文件的文件夹。
点击 VSCodium 窗口左侧的纸张图标。你可以选择文件夹。打开文件夹后,你需要打开至少一个文件。你也可以打开多个文件,但是最少打开一个。
当打开文件后,按下 `CTRL+SHIFT+P` 唤起命令面板。然后,在出现的搜索框中输入 `Markdown`。当你输入时,会出现一列 Markdown 相关的命令。其中有一个是 `Markdown All in One: Print documents to HTML` 命令。点击它:

你需要选择一个文件夹来存放这些文件。它会自动创建一个 `out` 目录,转换后的 HTML 文件会存放在 `out` 目录下。从下面的图中可以看到,Markdown 文档被转换成了 HTML 文件。在这里,你可以打开、查看、编辑这些 HTML 文件。

在等待转换 Markdown 文件时,你可以更多地集中精力在写作上。当你准备好时,你就可以把它们转换成 HTML —— 你可以通过两种方式转换它们。
---
via: <https://itsfoss.com/convert-markdown-files/>
作者:[Bill Dyer](https://itsfoss.com/author/bill/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Many times, when I use Markdown, I work on one file and when I’m done with it, I convert it to HTML or some other format. Occasionally, I have to create a few files. When I do work with more than one Markdown file, I usually wait until I have finished them before I convert them.
I use pandoc to convert files, and it’s possible convert all the Markdown files in one shot.
Markdown can convert its files to .html, but if there’s a chance that I will have to convert to other formats like epub, [pandoc](https://pandoc.org/?ref=itsfoss.com) is the tool to use. I prefer to use the command line, so I will cover that first, but you can also do this in [VSCodium](https://vscodium.com/?ref=itsfoss.com) without the command line. I’ll cover that too.
## Converting multiple Markdown files to another format with Pandoc [command line method]
To get started quickly, Ubuntu, and other Debian distros can type the following commands in the terminal:
`sudo apt-get install pandoc`
In this example, I have four Markdown files in a directory called md_test.
```
bdyer@bill-pc:~/Documents/md_test$ ls -l *.md
-rw-r--r-- 1 bdyer bdyer 3374 Apr 7 2020 file01.md
-rw-r--r-- 1 bdyer bdyer 782 Apr 2 05:23 file02.md
-rw-r--r-- 1 bdyer bdyer 9257 Apr 2 05:21 file03.md
-rw-r--r-- 1 bdyer bdyer 9442 Apr 2 05:21 file04.md
bdyer@bill-pc:~/Documents/md_test$
```
There are no HTML files yet. Now I’ll use Pandoc to do its magic on the collection of files. To do this, I run a one-line command that:
- calls pandoc
- reads the .md files and exports them as .html
This is the command:
`for i in *.md ; do echo "$i" && pandoc -s $i -o $i.html ; done`
If you are not aware already, `;`
is used for [running multiple commands at once in Linux](https://itsfoss.com/run-multiple-commands-linux/).
Here’s what the display looks like once I have executed the command:
```
bdyer@bill-pc:~/Documents/md_test$ for i in *.md ; do echo "$i" && pandoc -s $i -o $i.html ; done
file01.md
file02.md
file03.md
file04.md
bdyer@bill-pc:~/Documents/md_test$
```
Let me use the `ls`
command once more to see if HTML files were created:
```
bdyer@bill-pc:~/Documents/md_test$ ls -l *.html
-rw-r--r-- 1 bdyer bdyer 4291 Apr 2 06:08 file01.md.html
-rw-r--r-- 1 bdyer bdyer 1781 Apr 2 06:08 file02.md.html
-rw-r--r-- 1 bdyer bdyer 10272 Apr 2 06:08 file03.md.html
-rw-r--r-- 1 bdyer bdyer 10502 Apr 2 06:08 file04.md.html
bdyer@bill-pc:~/Documents/md_test$
```
The conversion was a success, and you have four HTML files ready to go on the Web server.
Pandoc is quite a versatile tool. Similarly, you can [use Pandoc to convert the markdown files to PDF](https://tiiny.host/blog/pandoc-markdown-pdf/) or some other supported format by specifying the extension of the output files. You can understand why it is considered among the [best open source tools for writers](https://itsfoss.com/open-source-tools-writers/).
## Converting Markdown files to HTML using VSCodium [GUI method]
Like I’ve said earlier, I normally use the command line, but I don’t always use it for batch conversions, and you don’t have to either. VSCode or [VSCodium](https://itsfoss.com/vscodium/) can do the job. You just need to add one extension, called: *Markdown-All-in-One* which will allow you to convert more than one Markdown file in one run.
There are two ways to install the extension:
- VSCodium’s terminal
- VSCodium’s plug-in manager
To install the extension through VSCodium’s terminal:
- Click on
`Terminal`
on the menu bar. The terminal panel will open - Type, or
[copy-and-paste, the following command in the terminal](https://itsfoss.com/copy-paste-linux-terminal/):
`codium --install-extension yzhang.markdown-all-in-one`
**Note**: If you’re using VSCode instead of VSCodium, replace the word, `codium`
, in the above command, with `code`
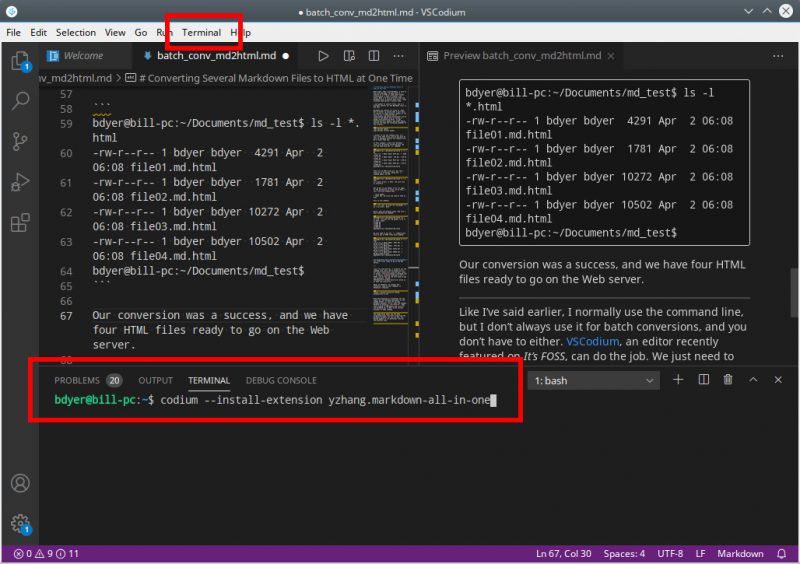
The second way to install is through VSCodium’s plug-in, or extension, manager:
- Click on the blocks on the left side of the VSCodium window. A list of extensions will appear. At the top of the list, there will be a search bar.
- In the search bar, type:
`Markdown All in One`
. The extension will be listed at the top of the list. Click on the`Install`
button to install it. If it is already installed, a gear icon will appear in place of the install button.
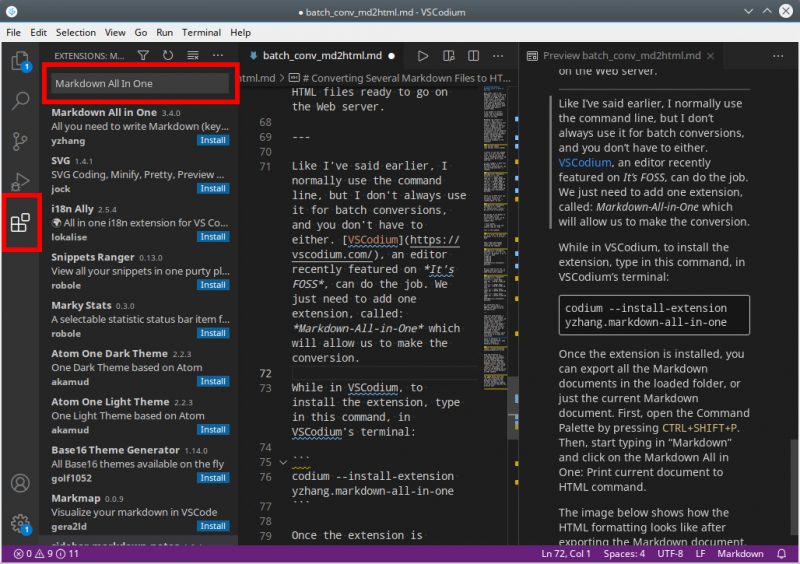
Once the extension is installed, you can open the folder that contains the Markdown files you want to convert.
Click on the paper icon located on the left side of the VSCodium window. You’ll be given the opportunity to choose your folder. Once a folder is open, you’ll need to open at least one file. You can open as many files as you want, but one is the minimum.
Once a file is open, bring up the Command Palette by pressing `CTRL+SHIFT+P`
. Then, start typing `Markdown`
in the search bar that will appear. As you do this, a list of Markdown related commands will appear. One of these will be `Markdown All in One: Print documents to HTML`
command. Click on that one.
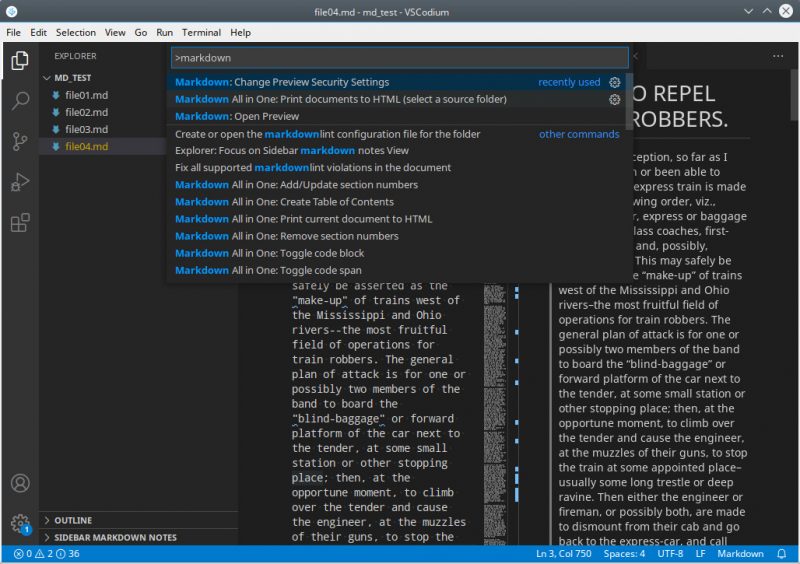
You’ll be asked to choose a folder containing the files. This is so an output directory (called `out`
) can be made and this is where the HTML files will go. The image below shows that the HTML was made after exporting the Markdown documents. From here, you can open, view, and edit the HTML as you wish.
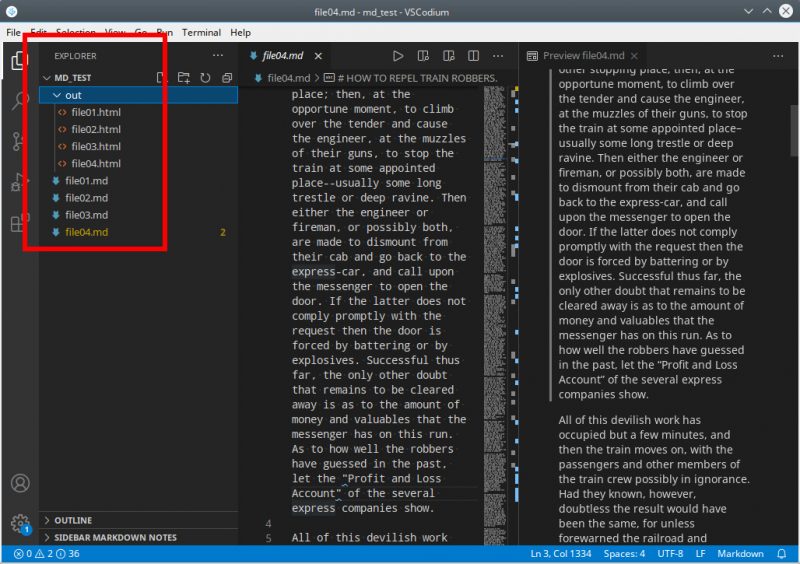
By waiting to convert your Markdown files, you can concentrate more on writing. Conversion to HTML can come when you’re ready – and you have two ways to get that done. |
13,276 | 如何解决 Windows-Linux 双启动设置中显示时间错误的问题 | https://itsfoss.com/wrong-time-dual-boot/ | 2021-04-08T10:21:10 | [
"时间",
"双启动",
"时钟"
] | https://linux.cn/article-13276-1.html | 
如果你 [双启动 Windows 和 Ubuntu](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/) 或任何其他 Linux 发行版,你可能会注意到两个操作系统之间的时间差异。
当你 [使用 Linux](https://itsfoss.com/why-use-linux/) 时,它会显示正确的时间。但当你进入 Windows 时,它显示的时间是错误的。有时,情况正好相反,Linux 显示的是错误的时间,而 Windows 的时间是正确的。
特别奇怪的是,因为你已连接到互联网,并且已将日期和时间设置为自动使用。
别担心!你并不是唯一一个遇到这种问题的人。你可以在 Linux 终端上使用以下命令来解决这个问题:
```
timedatectl set-local-rtc 1
```
同样,不要担心。我会解释为什么你在双启动设置中会遇到时间差。我会向你展示上面的命令是如何修复 Windows 双启动后的时间错误问题的。
### 为什么 Windows 和 Linux 在双启动时显示不同的时间?
一台电脑有两个主要时钟:系统时钟和硬件时钟。
硬件时钟也叫 RTC([实时时钟](https://www.computerhope.com/jargon/r/rtc.htm))或 CMOS/BIOS 时钟。这个时钟在操作系统之外,在电脑的主板上。即使在你的系统关机后,它也会继续运行。
系统时钟是你在操作系统内看到的。
当计算机开机时,硬件时钟被读取并用于设置系统时钟。之后,系统时钟被用于跟踪时间。如果你的操作系统对系统时钟做了任何改变,比如改变时区等,它就会尝试将这些信息同步到硬件时钟上。
默认情况下,Linux 认为硬件时钟中存储的时间是 UTC,而不是本地时间。另一方面,Windows 认为硬件时钟上存储的时间是本地时间。这就是问题的开始。
让我用例子来解释一下。
你看我在加尔各答 UTC+5:30 时区。安装后,当我把 [Ubuntu 中的时区](https://itsfoss.com/change-timezone-ubuntu/) 设置为加尔各答时区时,Ubuntu 会把这个时间信息同步到硬件时钟上,但会有 5:30 的偏移,因为对于 Linux 来说它必须是 UTC。
假设加尔各答时区的当前时间是 15:00,这意味着 UTC 时间是 09:30。
现在当我关闭系统并启动到 Windows 时,硬件时钟有 UTC 时间(本例中为 09:30)。但是 Windows 认为硬件时钟已经存储了本地时间。因此,它改变了系统时钟(应该显示为 15:00),而使用 UTC 时间(09:30)作为本地时间。因此,Windows 显示时间为 09:30,这比实际时间(我们的例子中为 15:00)早了 5:30。

同样,如果我在 Windows 中通过自动时区和时间按钮来设置正确的时间,你知道会发生什么吗?现在它将在系统上显示正确的时间(15:00),并将此信息(注意图片中的“同步你的时钟”选项)同步到硬件时钟。
如果你启动到 Linux,它会从硬件时钟读取时间,而硬件时钟是当地时间(15:00),但由于 Linux 认为它是 UTC 时间,所以它在系统时钟上增加了 5:30 的偏移。现在 Linux 显示的时间是 20:30,比实际时间超出晚了 5:30。
现在你了解了双启动中时差问题的根本原因,是时候看看如何解决这个问题了。
### 修复 Windows 在 Linux 双启动设置中显示错误时间的问题
有两种方法可以处理这个问题:
* 让 Windows 将硬件时钟作为 UTC 时间
* 让 Linux 将硬件时钟作为本地时间
在 Linux 中进行修改是比较容易的,因此我推荐使用第二种方法。
现在 Ubuntu 和大多数其他 Linux 发行版都使用 systemd,因此你可以使用 `timedatectl` 命令来更改设置。
你要做的是告诉你的 Linux 系统将硬件时钟(RTC)作为本地时间。你可以通过 `set-local-rtc` (为 RTC 设置本地时间)选项来实现:
```
timedatectl set-local-rtc 1
```
如下图所示,RTC 现在使用本地时间。

现在如果你启动 Windows,它把硬件时钟当作本地时间,而这个时间实际上是正确的。当你在 Linux 中启动时,你的 Linux 系统知道硬件时钟使用的是本地时间,而不是 UTC。因此,它不会尝试添加这个时间的偏移。
这就解决了 Linux 和 Windows 双启动时的时差问题。
你会看到一个关于 RTC 不使用本地时间的警告。对于桌面设置,它不应该引起任何问题。至少,我想不出有什么问题。
希望我把事情给你讲清楚了。如果你还有问题,请在下面留言。
---
via: <https://itsfoss.com/wrong-time-dual-boot/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you [dual boot Windows and Ubuntu](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/) or any other Linux distribution, you might have noticed a time difference between the two operating systems.
When you [use Linux](https://itsfoss.com/why-use-linux/), it shows the correct time. But when you boot into Windows, it shows the wrong time. Sometimes, it is the opposite and Linux shows the wrong time and Windows has the correct time.
That’s strange specially because you are connected to the internet and your date and time is set to be used automatically.
Don’t worry! You are not the only one to face this issue. You can fix it by using the following command in the Linux terminal:
`timedatectl set-local-rtc 1`
Again, don’t worry. I’ll explain in detail how the above command fixes the wrong time issue in Windows after dual boot. But before that, let me tell you why you encounter a time difference in a dual boot setup.
## Why Windows and Linux show different time in dual boot?
A computer has two main clocks: a system clock and a hardware clock.
A hardware clock which is also called RTC ([real time clock](https://www.computerhope.com/jargon/r/rtc.htm)) or CMOS/BIOS clock. This clock is outside the operating system, on your computer’s motherboard. It keeps on running even after your system is powered off.
The system clock is what you see inside your operating system.
When your computer is powered on, the hardware clock is read and used to set the system clock. Afterwards, the system clock is used for tracking time. If your operating system makes any changes to system clock, like changing time zone etc, it tries to sync this information to the hardware clock.
By default, Linux assumes that the time stored in the hardware clock is in UTC, not the local time. On the other hand, Windows thinks that the time stored on the hardware clock is local time. That’s where the trouble starts.
Let me explain with examples.
You see I am in Kolkata time zone which is UTC+5:30. After installing, when I set the [timezone in Ubuntu](https://itsfoss.com/change-timezone-ubuntu/) to the Kolkata time zone, Ubuntu syncs this time information to the hardware clock but with an offset of 5:30 because hardware clock (RTC) has to be in UTC for Linux.
Let’ say the current time in Kolkata timezone is 15:00 which means that the UTC time is 09:30.
Now when I turn off the system and boot into Windows, the hardware clock has the UTC time (09:30 in this example). But Windows thinks the hardware clock has stored the local time. And thus it changes the system clock (which should have shown 15:00) to use the UTC time (09:30) as the local time. And hence, Windows shows 09:30 as the time which is 5:30 hours behind the actual time (15:00 in this example).
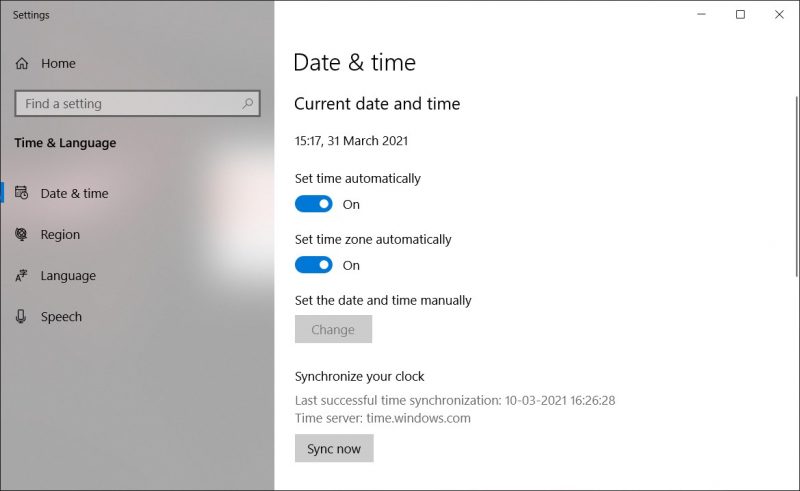
Again, if I set the correct time in Windows by toggling the automatic time zone and time buttons, you know what is going to happen? Now it will show the correct time on the system (15:00) and sync this information (notice the “Synchronize your clock” option in the image) to the hardware clock.
If you boot into Linux, it reads the time from the hardware clock which is in local time (15:00) but since Linux believes it to be the UTC time, it adds an offset of 5:30 to the system clock. Now Linux shows a time of 20:30 which is 5:30 hours ahead of the actual time.
Now that you understand the root cause of the time difference issues in dual boot, it’s time to see how to fix the issue.
## Fixing Windows Showing Wrong Time in a Dual Boot Setup With Linux
There are three ways you can go about handling this issue:
- Make both Ubuntu and Windows check for date, time and timezone automatically via internet
- Make Linux use local time for the hardware clock
- Make Windows use UTC time for the hardware clock
I’ll discuss two of them which are easier.
### Method 1: Make your OS set time and date automatically
What happens in this case is that though your operating system (be it Windows or Linux) will show the incorrect time for a minute, and then it automatically sets the correct time if you are connected to the internet.
To make your Ubuntu Linux system check for date and time automatically, go to System Settings -> Date & Time and enable both options.
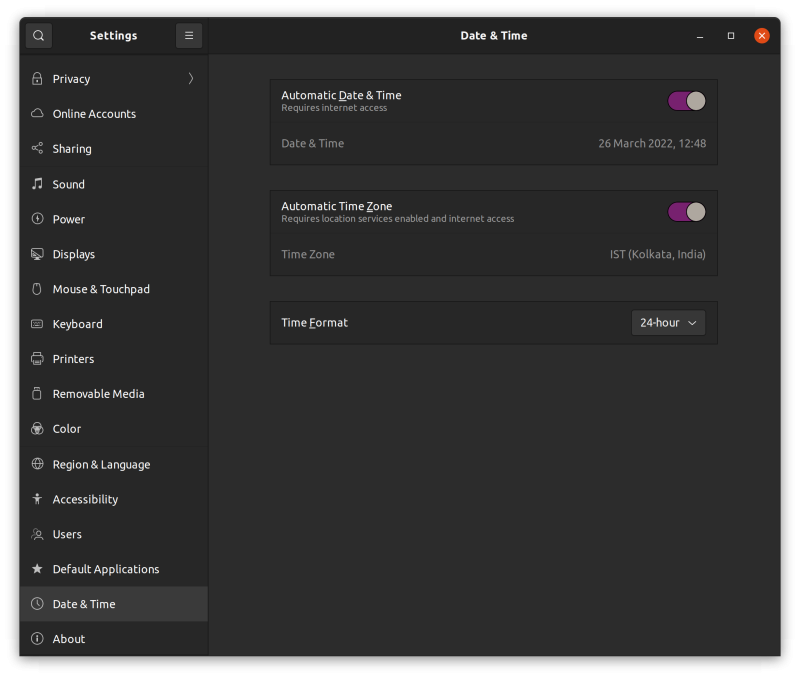
You should do a similar settings change for Windows as well.
### Method 2: Make Ubuntu use local time for hardware clock
It is easier to make the changes in Linux and hence I’ll recommend going with the second method.
Ubuntu and most other Linux distributions use systemd these days and hence you can use timedatectl command to change the settings.
What you are doing is to tell your Linux system to use the local time for the hardware clock (RTC). You do that with the `set-local-rtc`
(set local time for RTC) option:
`sudo timedatectl set-local-rtc 1`
As you can notice in the image below, the RTC now uses the local time.
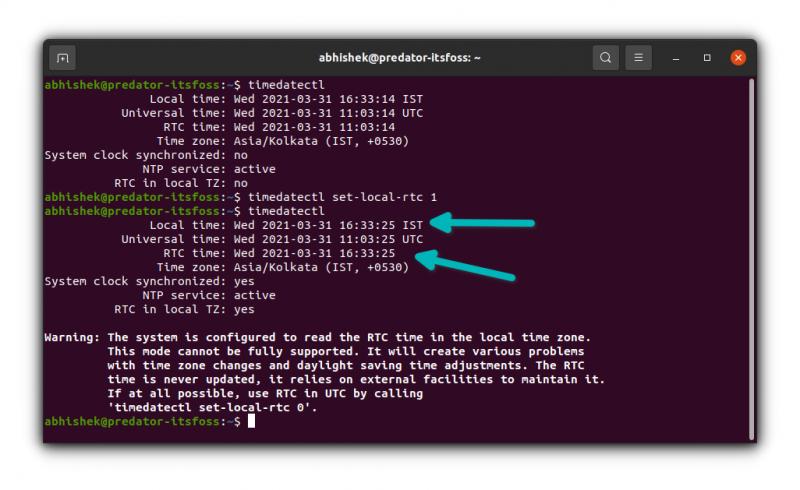
Now if you boot into Windows, it takes the hardware clock to be as local time which is actually correct this time. When you boot into Linux, your Linux system knows that the hardware clock is using local time, not UTC. And hence, it doesn’t try to add the off-set this time.
This fixes the time difference issue between Linux and Windows in dual boot.
You see a warning about not using local time for RTC. For desktop setups, it should not cause any issues. At least, I cannot think of one.
I hope I made things clear for you. If you still have questions, please leave a comment below. |
13,277 | 为什么我喜欢使用 IPython shell 和 Jupyter 笔记本 | https://opensource.com/article/21/3/ipython-shell-jupyter-notebooks | 2021-04-08T12:53:31 | [
"Jupyter",
"IPython",
"Python"
] | /article-13277-1.html |
>
> Jupyter 笔记本将 IPython shell 提升到一个新的高度。
>
>
>

Jupyter 项目最初是以 IPython 和 IPython 笔记本的形式出现的。它最初是一个专门针对 Python 的交互式 shell 和笔记本环境,后来扩展为不分语言的环境,支持 Julia、Python 和 R 以及其他任何语言。

IPython 是一个 Python shell,类似于你在命令行输入 `python` 或者 `python3` 时看到的,但它更聪明、更有用。如果你曾经在 Python shell 中输入过多行命令,并且想重复它,你就会理解每次都要一行一行地滚动浏览历史记录的挫败感。有了 IPython,你可以一次滚动浏览整个块,同时还可以逐行浏览和编辑这些块的部分内容。

它具有自动补全,并提供上下文感知的建议:

它默认会整理输出:

它甚至允许你运行 shell 命令:

它还提供了一些有用的功能,比如将 `?` 添加到对象中,作为运行 `help()` 的快捷方式,而不会破坏你的流程:

如果你使用的是虚拟环境(参见我关于 [virtualenvwrapper](https://opensource.com/article/21/2/python-virtualenvwrapper) 的帖子),可以在环境中用 `pip` 安装:
```
pip install ipython
```
要在全系统范围内安装,你可以在 Debian、Ubuntu 或树莓派上使用 `apt`:
```
sudo apt install ipython3
```
或使用 `pip`:
```
sudo pip3 install ipython
```
### Jupyter 笔记本
Jupyter 笔记本将 IPython shell 提升到了一个新的高度。首先,它们是基于浏览器的,而不是基于终端的。要开始使用,请安装 `jupyter`。
如果你使用的是虚拟环境,请在环境中使用 `pip` 进行安装:
```
pip install jupyter
```
要在全系统范围内安装,你可以在 Debian、Ubuntu 或树莓派上使用 `apt`:
```
sudo apt install jupyter-notebook
```
或使用 `pip`:
```
sudo pip3 install jupyter
```
启动笔记本:
```
jupyter notebook
```
这将在你的浏览器中打开:

你可以使用 “New” 下拉菜单创建一个新的 Python 3 笔记本:

现在你可以在 `In[ ]` 字段中编写和执行命令。使用 `Enter` 在代码块中换行,使用 `Shift+Enter` 来执行:

你可以编辑和重新运行代码块,你可以重新排序、删除,复制/粘贴,等等。你可以以任何顺序运行代码块,但是要注意的是,任何创建的变量的作用域都将根据执行的时间而不是它们在笔记本中出现的顺序。你可以在 “Kernel” 菜单中重启并清除输出或重启并运行所有的代码块。
使用 `print` 函数每次都会输出。但是如果你有一条没有分配的语句,或者最后一条语句没有分配,那么它总是会输出:

你甚至可以把 `In` 和 `Out` 作为可索引对象:

所有的 IPython 功能都可以使用,而且通常也会表现得更漂亮一些:

你甚至可以使用 [Matplotlib](https://matplotlib.org/) 进行内联绘图:

最后,你可以保存你的笔记本,并将其包含在 Git 仓库中,如果你将其推送到 GitHub,它们将作为已完成的笔记本被渲染:输出、图形和所有一切(如 [本例](https://github.com/piwheels/stats/blob/master/2020.ipynb)):

---
本文原载于 Ben Nuttall 的 [Tooling Tuesday 博客](https://tooling.bennuttall.com/the-ipython-shell-and-jupyter-notebooks/),经许可后重用。
---
via: <https://opensource.com/article/21/3/ipython-shell-jupyter-notebooks>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,279 | 使用这个开源工具来监控 Python 中的变量 | https://opensource.com/article/21/4/monitor-debug-python | 2021-04-08T23:16:21 | [
"Python",
"变量"
] | https://linux.cn/article-13279-1.html |
>
> Watchpoints 是一个简单但功能强大的工具,可以帮助你在调试 Python 时监控变量。
>
>
>

在调试代码时,你经常面临着要弄清楚一个变量何时发生变化。如果没有任何高级工具,那么可以选择使用打印语句在期望它们更改时输出变量。然而,这是一种非常低效的方法,因为变量可能在很多地方发生变化,并且不断地将其打印到终端上会产生很大的干扰,而将它们打印到日志文件中则变得很麻烦。
这是一个常见的问题,但现在有一个简单而强大的工具可以帮助你监控变量:[watchpoints](https://github.com/gaogaotiantian/watchpoints)。
[“监视点”的概念在 C 和 C++ 调试器中很常见](https://opensource.com/article/21/3/debug-code-gdb),用于监控内存,但在 Python 中缺乏相应的工具。`watchpoints` 填补了这个空白。
### 安装
要使用它,你必须先用 `pip` 安装它:
```
$ python3 -m pip install watchpoints
```
### 在Python中使用 watchpoints
对于任何一个你想监控的变量,使用 `watch` 函数对其进行监控。
```
from watchpoints import watch
a = 0
watch(a)
a = 1
```
当变量发生变化时,它的值就会被打印到**标准输出**:
```
====== Watchpoints Triggered ======
Call Stack (most recent call last):
<module> (my_script.py:5):
> a = 1
a:
0
->
1
```
信息包括:
* 变量被改变的行。
* 调用栈。
* 变量的先前值/当前值。
它不仅适用于变量本身,也适用于对象的变化:
```
from watchpoints import watch
a = []
watch(a)
a = {} # 触发
a["a"] = 2 # 触发
```
当变量 `a` 被重新分配时,回调会被触发,同时当分配给 `a` 的对象发生变化时也会被触发。
更有趣的是,监控不受作用域的限制。你可以在任何地方观察变量/对象,而且无论程序在执行什么函数,回调都会被触发。
```
from watchpoints import watch
def func(var):
var["a"] = 1
a = {}
watch(a)
func(a)
```
例如,这段代码打印出:
```
====== Watchpoints Triggered ======
Call Stack (most recent call last):
<module> (my_script.py:8):
> func(a)
func (my_script.py:4):
> var["a"] = 1
a:
{}
->
{'a': 1}
```
`watch` 函数不仅可以监视一个变量,它也可以监视一个字典或列表的属性和元素。
```
from watchpoints import watch
class MyObj:
def __init__(self):
self.a = 0
obj = MyObj()
d = {"a": 0}
watch(obj.a, d["a"]) # 是的,你可以这样做
obj.a = 1 # 触发
d["a"] = 1 # 触发
```
这可以帮助你缩小到一些你感兴趣的特定对象。
如果你对输出格式不满意,你可以自定义它。只需定义你自己的回调函数:
```
watch(a, callback=my_callback)
# 或者全局设置
watch.config(callback=my_callback)
```
当触发时,你甚至可以使用 `pdb`:
```
watch.config(pdb=True)
```
这与 `breakpoint()` 的行为类似,会给你带来类似调试器的体验。
如果你不想在每个文件中都导入这个函数,你可以通过 `install` 函数使其成为全局:
```
watch.install() # 或 watch.install("func_name") ,然后以 func_name() 方式使用
```
我个人认为,`watchpoints` 最酷的地方就是使用直观。你对一些数据感兴趣吗?只要“观察”它,你就会知道你的变量何时发生变化。
### 尝试 watchpoints
我在 [GitHub](https://github.com/gaogaotiantian/watchpoints) 上开发维护了 `watchpoints`,并在 Apache 2.0 许可下发布了它。安装并使用它,当然也欢迎大家做出贡献。
---
via: <https://opensource.com/article/21/4/monitor-debug-python>
作者:[Tian Gao](https://opensource.com/users/gaogaotiantian) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When debugging code, you're often faced with figuring out when a variable changes. Without any advanced tools, you have the option of using print statements to announce the variables when you expect them to change. However, this is a very ineffective way because the variables could change in many places, and constantly printing them to a terminal is noisy, while printing them to a log file becomes unwieldy.
This is a common issue, but now there is a simple but powerful tool to help you with monitoring variables: [watchpoints](https://github.com/gaogaotiantian/watchpoints).
The [watchpoint concept is common in C and C++ debuggers](https://opensource.com/article/21/3/debug-code-gdb) to monitor memories, but there's a lack of equivalent tools in Python. `watchpoints`
fills in the gap.
## Installing
To use it, you must first install it by using `pip`
:
`$ python3 -m pip install watchpoints`
## Using watchpoints in Python
For any variable you'd like to monitor, use the **watch** function on it.
```
from watchpoints import watch
a = 0
watch(a)
a = 1
```
As the variable changes, information about its value is printed to **stdout**:
```
====== Watchpoints Triggered ======
Call Stack (most recent call last):
<module> (my_script.py:5):
> a = 1
a:
0
->
1
```
The information includes:
- The line where the variable was changed.
- The call stack.
- The previous/current value of the variable.
It not only works with the variable itself, but it also works with object changes:
```
from watchpoints import watch
a = []
watch(a)
a = {} # Trigger
a["a"] = 2 # Trigger
```
The callback is triggered when the variable **a** is reassigned, but also when the object assigned to a is changed.
What makes it even more interesting is that the monitor is not limited by the scope. You can watch the variable/object anywhere you want, and the callback is triggered no matter what function the program is executing.
```
from watchpoints import watch
def func(var):
var["a"] = 1
a = {}
watch(a)
func(a)
```
For example, this code prints:
```
====== Watchpoints Triggered ======
Call Stack (most recent call last):
<module> (my_script.py:8):
> func(a)
func (my_script.py:4):
> var["a"] = 1
a:
{}
->
{'a': 1}
```
The **watch** function can monitor more than a variable. It can also monitor the attributes and an element of a dictionary or list.
```
from watchpoints import watch
class MyObj:
def __init__(self):
self.a = 0
obj = MyObj()
d = {"a": 0}
watch(obj.a, d["a"]) # Yes you can do this
obj.a = 1 # Trigger
d["a"] = 1 # Trigger
```
This could help you narrow down to some specific objects that you are interested in.
If you are not happy about the format of the output, you can customize it. Just define your own callback function:
```
watch(a, callback=my_callback)
# Or set it globally
watch.config(callback=my_callback)
```
You can even bring up **pdb** when the trigger is hit:
`watch.config(pdb=True)`
This behaves similarly to **breakpoint()**, giving you a debugger-like experience.
If you don’t want to import the function in every single file, you can make it global by using **install** function:
`watch.install() # or watch.install("func_name") and use it as func_name()`
Personally, I think the coolest thing about watchpoints is its intuitive usage. Are you interested in some data? Just "watch" it, and you'll know when your variable changes.
## Try watchpoints
I developed and maintain `watchpoints`
on [GitHub](https://github.com/gaogaotiantian/watchpoints), and have released it under the licensed under Apache 2.0. Install it and use it, and of course contribution is always welcome.
## 1 Comment |
13,280 | 你可能是 Rust 程序员的五个迹象 | https://opensource.com/article/21/3/rust-programmer | 2021-04-08T23:32:40 | [
"Rust"
] | https://linux.cn/article-13280-1.html |
>
> 在我学习 Rust 的过程中,我注意到了 Rust 一族的一些常见行为。
>
>
>

我是最近才 [皈依 Rust](https://opensource.com/article/20/6/why-rust) 的,我大约在是 2020 年 4 月底开始学习的。但是,像许多皈依者一样,我还是一个热情的布道者。说实话,我也不是一个很好的 Rust 人,因为我的编码风格不是很好,我写的也不是特别符合 Rust 习惯。我猜想这一方面是因为我在写大量代码之前还没有没有真正学完 Rust(其中一些代码又困扰了我),另一方面是因为我并不是那么优秀的程序员。
但我喜欢 Rust,你也应该喜欢吧。它很友好,比 C 或 C++ 更友好;它为低级系统任务做好了准备,这比 Python 做的更好;而且结构良好,这要超过 Perl;而且,最重要的是,从设计层面开始,它就是完全开源的,这要比 Java 那些语言好得多。
尽管我缺乏专业知识,但我注意到了一些我认为是许多 Rust 爱好者和程序员的共同点。如果你对以下五个迹象点头(其中第一个迹象是由最近的一些令人兴奋的新闻引发的),那么你也可能是一个 Rust 程序员。
### 1、“基金会”一词会使你兴奋
对于 Rust 程序员来说,“基金会”一词将不再与<ruby> 艾萨克·阿西莫夫 <rt> Isaac Asimov </rt></ruby>关联在一起,而是与新成立的 [Rust 基金会](https://foundation.rust-lang.org/) 关联。微软、华为、谷歌、AWS 和Mozilla 为该基金会提供了董事(大概也提供了大部分初始资金),该基金会将负责该语言的各个方面,“预示着 Rust 成为企业生产级技术的到来”,[根据临时执行董事](https://foundation.rust-lang.org/posts/2021-02-08-hello-world/) Ashley Williams 说。(顺便说一句,很高兴看到一位女士领导这样一项重大的行业计划。)
该基金会似乎致力于维护 Rust 的理念,并确保每个人都有参与的机会。在许多方面,Rust 都是开源项目的典型示例。并不是说它是完美的(无论是语言还是社区),而是因为似乎有足够的爱好者致力于维护高参与度、低门槛的社区方式,我认为这是许多开源项目的核心。我强烈欢迎此举,我认为这只会帮助促进 Rust 在未来数年和数月内的采用和成熟。
### 2、你会因为新闻源中提到 Rust 游戏而感到沮丧
还有一款和电脑有关的东西,也叫做“Rust”,它是一款“只限多玩家生存类的电子游戏”。它比 Rust 这个语言更新一些(2013 年宣布,2018 年发布),但我曾经在搜索 Rust 相关的内容时,犯了一个错误,用这个名字搜索了游戏。互联网络就是这样的,这意味着我的新闻源现在被这个另类的 Rust 野兽感染了,我现在会从它的影迷和公关人员那里随机得到一些更新消息。这是个低调的烦恼,但我很确定在 Rust(语言)社区中并不是就我一个人这样。我强烈建议,如果你确实想了解更多关于这个计算世界的后起之秀的信息,你可以使用一个提高隐私(我拒绝说 "保护隐私")的 [开源浏览器](https://opensource.com/article/19/7/open-source-browsers) 来进行研究。
### 3、“不安全”这个词会让你感到恐惧。
Rust(语言,再次强调)在帮助你做**正确的事情**™方面做得非常好,当然,在内存安全方面,这是 C 和 C++ 内部的主要关注点(不是因为不可能做到,而是因为真的很难持续正确)。Dave Herman 在 2016 年写了一篇文章《[Safety is Rust's fireflower](https://www.thefeedbackloop.xyz/safety-is-rusts-fireflower/)》,讲述了为什么安全是 Rust 语言的一个积极属性。安全性(内存、类型安全)可能并不赏心悦目,但随着你写的 Rust 越多,你就会习惯并感激它,尤其是当你参与任何系统编程时,这也是 Rust 经常擅长的地方。
现在,Rust 并不能阻止你做**错误的事情**™,但它确实通过让你使用 `unsafe` 关键字,让你在希望超出安全边界的时候做出一个明智的决定。这不仅对你有好处,因为它(希望)会让你非常、非常仔细地思考你在任何使用它的代码块中放入了什么;它对任何阅读你的代码的人也有好处,这是一个触发词,它能让任何不太清醒的 Rust 人至少可以稍微打起精神,在椅子上坐直,然后想:“嗯,这里发生了什么?我需要特别注意。”如果幸运的话,读你代码的人也许能想到重写它的方法,使它利用到 Rust 的安全特性,或者至少减少提交和发布的不安全代码的数量。
### 4、你想知道为什么没有 `?;`、`{:?}` 、`::<>` 这样的表情符号
人们喜欢(或讨厌)涡轮鱼(`::<>`),但在 Rust 代码中你经常还会看到其他的语义结构。特别是 `{:?}` (用于字符串格式化)和 `?;`(`?` 是向调用栈传播错误的一种方式,`;` 则是行/块的结束符,所以你经常会看到它们在一起)。它们在 Rust 代码中很常见,你只需边走边学,边走边解析,而且它们也很有用,我有时会想,为什么它们没有被纳入到正常对话中,至少可以作为表情符号。可能还有其他的。你有什么建议?
### 5、Clippy 是你的朋友(而不是一个动画回形针)
微软的动画回形针 Clippy 可能是 Office 用户很快就觉得讨厌的“功能”,并成为许多 [模因](https://knowyourmeme.com/memes/clippy) 的起点。另一方面,`cargo clippy` 是那些 [很棒的 Cargo 命令](https://opensource.com/article/20/11/commands-rusts-cargo) 之一,应该成为每个 Rust 程序员工具箱的一部分。Clippy 是一个语言<ruby> 整洁器 <rt> Linter </rt></ruby>,它可以帮助改进你的代码,使它更干净、更整洁、更易读、更惯用,让你与同事或其他人分享 Rust 代码时,不会感到尴尬。Cargo 可以说是让 “Clippy” 这个名字恢复了声誉,虽然我不会选择给我的孩子起这个名字,但现在每当我在网络上遇到这个词的时候,我不会再有一种不安的感觉。
---
这篇文章最初发表在 [Alice, Eve, and Bob] [9](https://aliceevebob.com/2021/02/09/5-signs-that-you-may-be-a-rust-programmer/)上,经作者许可转载。
---
via: <https://opensource.com/article/21/3/rust-programmer>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I'm a fairly recent [convert to Rust](https://opensource.com/article/20/6/why-rust), which I started to learn around the end of April 2020. But, like many converts, I'm an enthusiastic evangelist. I'm also not a very good Rustacean, truth be told, in that my coding style isn't great, and I don't write particularly idiomatic Rust. I suspect this is partly because I never really finished learning Rust before diving in and writing quite a lot of code (some of which is coming back to haunt me) and partly because I'm just not that good a programmer.
But I love Rust, and so should you. It's friendly—well, more friendly than C or C++; it's ready for low-level systems tasks—more so than Python, it's well-structured—more than Perl; and, best of all, it's completely open source from the design level up—much more than Java, for instance.
Despite my lack of expertise, I noticed a few things that I suspect are common to many Rust enthusiasts and programmers. If you say "yes" to the following five signs (the first of which was sparked by some exciting recent news), you, too, might be a Rust programmer.
## 1. The word "foundation" excites you
For Rust programmers, the word "foundation" will no longer be associated first and foremost with Isaac Asimov but with the newly formed [Rust Foundation](https://foundation.rust-lang.org/). Microsoft, Huawei, Google, AWS, and Mozilla are providing the directors (and presumably most of the initial funding) for the Foundation, which will look after all aspects of the language, "heralding Rust's arrival as an enterprise production-ready technology," [according to interim executive director](https://foundation.rust-lang.org/posts/2021-02-08-hello-world/) Ashley Williams. (On a side note, it's great to see a woman heading up such a major industry initiative.)
The Foundation seems committed to safeguarding the philosophy of Rust and ensuring that everybody has the opportunity to get involved. Rust is, in many ways, a poster-child example of an open source project. Not that it's perfect (neither the language nor the community), but in that there seem to be sufficient enthusiasts who are dedicated to preserving the high-involvement, low-bar approach to community, which I think of as core to much of open source. I strongly welcome the move, which I think can only help promote Rust's adoption and maturity over the coming years and months.
## 2. You get frustrated by newsfeed references to Rust (the game)
There's another computer-related thing out there that goes by the name "Rust," and it's a "multi-player only survival video game." It's newer than Rust the language (having been announced in 2013 and released in 2018), but I was once searching for Rust-related swag and made the mistake of searching for the game by that name. The interwebs being what they are, this meant that my news feed is now infected with this alternative Rust beast, and I now get random updates from their fandom and PR folks. This is low-key annoying, but I'm pretty sure I'm not alone in the Rust (language) community. I strongly suggest that if you *do* want to find out more about this upstart in the computing world, you use a privacy-improving (I refuse to say "privacy-preserving") [open source browser](https://opensource.com/article/19/7/open-source-browsers) to do your research.
## 3. The word "unsafe" makes you recoil in horror
Rust (the language, again) does a *really* good job of helping you do the Right Thing™, certainly in terms of memory safety, which is a major concern within C and C++ (not because it's impossible but because it's really hard to get right consistently). Dave Herman wrote a post in 2016 on why safety is such a positive attribute of the Rust language: [ Safety is Rust's fireflower](https://www.thefeedbackloop.xyz/safety-is-rusts-fireflower/). Safety (memory, type safety) may not be glamourous, but it's something you become used to—and grateful for—as you write more Rust, particularly if you're involved in any systems programming, which is where Rust often excels.
Now, Rust doesn't *stop* you from doing the Wrong Thing™, but it does make you make a conscious decision when you wish to go outside the bounds of safety by making you use the `unsafe`
keyword. This is good not only for you, as it will (hopefully) make you think really, really carefully about what you're putting in any code block that uses it; it is also good for anyone reading your code. It's a trigger-word that makes any half-sane Rustacean shiver at least slightly, sit upright in their chair, and think, "hmm, what's going on here? I need to pay special attention." If you're lucky, the person reading your code may be able to think of ways of rewriting it such that it *does* make use of Rust's safety features or at least reduces the amount of unsafe code that gets committed and released.
## 4. You wonder why there's no emoji for `?;`
or `{:?}`
or `::<>`
Everybody loves (to hate) the turbofish (`::<>`
) but there are other semantic constructs that you see regularly in Rust code. In particular, `{:?}`
(for string formatting) and `?;`
(`?`
is a way of propagating errors up the calling stack, and `;`
ends the line/block, so you often see them together). They're so common in Rust code that you just learn to parse them as you go, and they're also so useful that I sometimes wonder why they've not made it into normal conversation, at least as emojis. There are probably others, too. What would be your suggestions?
## 5. Clippy is your friend (and not an animated paperclip)
Clippy, the Microsoft animated paperclip, was a "feature" that Office users learned very quickly to hate and has become the starting point for many [memes](https://knowyourmeme.com/memes/clippy). On the other hand, `cargo clippy`
is one of those [amazing Cargo commands](https://opensource.com/article/20/11/commands-rusts-cargo) that should become part of every Rust programmer's toolkit. Clippy is a language linter and helps improve your code to make it cleaner, tidier, more legible, more idiomatic, and generally less embarrassing when you share it with your colleagues or the rest of the world. Cargo has arguably rehabilitated the name "Clippy," and although it's not something I'd choose to name one of my kids, I don't feel a sense of unease whenever I come across the term on the web anymore.
*This article was originally published on Alice, Eve, and Bob and is reprinted with the author's permission.*
## Comments are closed. |
13,283 | Plausible:注重隐私的 Google Analytics 替代方案 | https://itsfoss.com/plausible/ | 2021-04-10T11:07:00 | [
"Plausible",
"网站分析"
] | https://linux.cn/article-13283-1.html | 
[Plausible](https://plausible.io/)是一款简单的、对隐私友好的分析工具。它可以帮助你分析独立访客数量、页面浏览量、跳出率和访问时间。
如果你有一个网站,你可能会理解这些术语。作为一个网站所有者,它可以帮助你了解你的网站是否随着时间的推移获得更多的访问者,流量来自哪里,如果你对这些事情有一定的了解,你可以努力改进你的网站,以获得更多的访问量。
说到网站分析,统治这个领域的一个服务就是谷歌的免费工具 Google Analytics。就像 Google 是事实上的搜索引擎一样,Google Analytics 是事实上的分析工具。但你不必再忍受它,尤其是当你无法信任大科技公司使用你和你的网站访问者的数据的时候。
Plausible 让你摆脱 Google Analytics 的束缚,我将在本文中讨论这个开源项目。
请注意,如果你从来没有管理过网站或对分析感兴趣,文章中的一些技术术语可能对你来说是陌生的。
### Plausible 是隐私友好的网站分析工具
Plausible 使用的分析脚本是非常轻量级的,大小不到 1KB。
其重点在于保护隐私,因此你可以在不影响访客隐私的情况下获得有价值且可操作的统计数据。Plausible 是为数不多的不需要 cookie 横幅或 GDP 同意的分析工具之一,因为它在隐私方面已经符合 [GDPR 标准](https://gdpr.eu/compliance/)。这是超级酷的。
在功能上,它没有 Google Analytics 那样的粒度和细节。Plausible 靠的是简单。它显示的是你过去 30 天的流量统计图。你也可以切换到实时视图。

你还可以看到你的流量来自哪里,以及你网站上的哪些页面访问量最大。来源也可以显示 UTM 活动。

你还可以选择启用 GeoIP 来了解网站访问者的地理位置。你还可以检查有多少访问者使用桌面或移动设备访问你的网站。还有一个操作系统的选项,正如你所看到的,[Linux Handbook](https://linuxhandbook.com/) 有 48% 的访问者来自 Windows 设备。很奇怪,对吧?

显然,提供的数据与 Google Analytics 的数据相差甚远,但这是有意为之。Plausible 意图是为你提供简单的模式。
### 使用 Plausible:选择付费托管或在你的服务器上自行托管
使用 Plausible 有两种方式:注册他们的官方托管服务。你必须为这项服务付费,这最终会帮助 Plausible 项目的发展。它们有 30 天的试用期,甚至不需要你这边提供任何支付信息。
定价从每月 1 万页浏览量 6 美元开始。价格会随着页面浏览量的增加而增加。你可以在 Plausible 网站上计算价格。
* [Plausible 价格](https://plausible.io/#pricing)
你可以试用 30 天,看看你是否愿意向 Plausible 开发者支付服务费用,并拥有你的数据。
如果你觉得定价不合理,你可以利用 Plausible 是开源的优势,自己部署。如果你有兴趣,请阅读我们的 [使用 Docker 自助托管 Plausible 实例的深度指南](https://linuxhandbook.com/plausible-deployment-guide/)。
我们自行托管 Plausible。我们的 Plausible 实例添加了我们的三个网站。

如果你维护一个开源项目的网站,并且想使用 Plausible,你可以通过我们的 [High on Cloud 项目](https://highoncloud.com/) 联系我们。通过 High on Cloud,我们帮助小企业在其服务器上托管和使用开源软件。
### 总结
如果你不是超级痴迷于数据,只是想快速了解网站的表现,Plausible 是一个不错的选择。我喜欢它,因为它是轻量级的,而且遵守隐私。这也是我在 Linux Handbook,我们 [教授 Linux 服务器相关的门户网站](https://linuxhandbook.com/about/#ethical-web-portal) 上使用它的主要原因。
总的来说,我对 Plausible 相当满意,并向其他网站所有者推荐它。
你也经营或管理一个网站吗?你是用什么工具来做分析,还是根本不关心这个?
---
via: <https://itsfoss.com/plausible/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Plausible](https://plausible.io/) is a simple, privacy-friendly analytics tool. It helps you analyze the number of unique visitors, pageviews, bounce rate and visit duration.
If you have a website you would probably understand those terms. As a website owner, it helps you know if your site is getting more visitors over the time, from where the traffic is coming and if you have some knowledge on these things, you can work on improving your website for more visits.
When it comes to website analytics, the one service that rules this domain is the Google’s free tool Google Analytics. Just like Google is the de-facto search engine, Google Analytics is the de-facto analytics tool. But you don’t have to live with it specially if you cannot trust Big tech with your and your site visitor’s data.
Plausible gives you the freedom from Google Analytics and I am going to discuss this open source project in this article.
Please bear in mind that some technical terms in the article could be unknown to you if you have never managed a website or bothered about analytics.
## Plausible for privacy friendly website analytics
The script used by Plausible for analytics is extremely lightweight with less than 1 KB in size.
The focus is on preserving the privacy so you get valuable and actionable stats without compromising on the privacy of your visitors. Plausible is one of the rare few analytics tool that doesn’t require cookie banner or GDP consent because it is already [GDPR-compliant](https://gdpr.eu/compliance/) on privacy front. That’s super cool.
In terms of features, it doesn’t have the same level of granularity and details of Google Analytics. Plausible banks on simplicity. It shows a graph of your traffic stats for past 30 days. You may also switch to real time view.
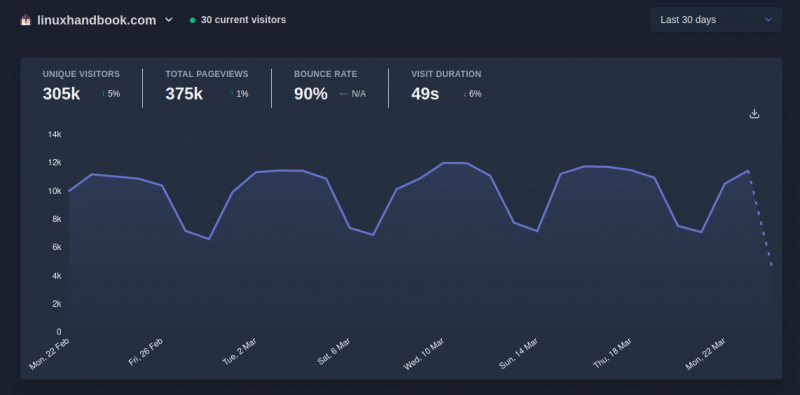
You can also see where your traffic is coming from and which pages on your website gets the most visits. The sources can also show UTM campaigns.
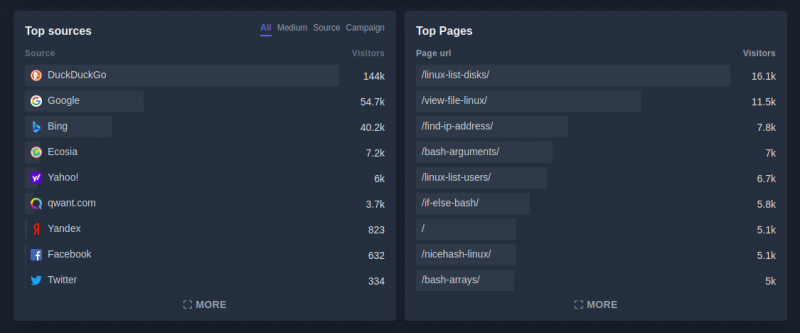
You also have the option to enable GeoIP to get some insights about the geographical location of your website visitors. You can also check how many visitors use desktop or mobile device to visit your website. There is also an option for operating system and as you can see, [Linux Handbook](https://linuxhandbook.com/) gets 48% of its visitors from Windows devices. Pretty strange, right?
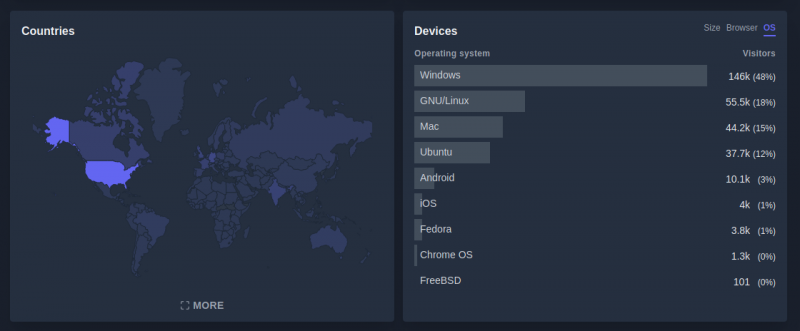
Clearly, the data provided is nowhere close to what Google Analytics can do, but that’s intentional. Plausible intends to provide you simple matrix.
## Using Plausible: Opt for paid managed hosting or self-host it on your server
There are two ways you can start using Plausible. Sign up for their official managed hosting. You’ll have to pay for the service and this eventually helps the development of the Plausible project. They do have 30-days trial period and it doesn’t even require any payment information from your side.
The pricing starts at $6 per month for 10k monthly pageviews. Pricing increases with the number of pageviews. You can calculate the pricing on Plausible website.
You can try it for 30 days and see if you would like to pay to Plausible developers for the service and own your data.
If you think the pricing is not affordable, you can take the advantage of the fact that Plausible is open source and deploy it yourself. If you are interested, read our [in-depth guide on self-hosting a Plausible instance with Docker](https://linuxhandbook.com/plausible-deployment-guide/).
At It’s FOSS, we self-host Plausible. Our Plausible instance has three of our websites added.
If you maintain the website of an open source project and would like to use Plausible, you can contact us through our [High on Cloud project](https://highoncloud.com/). With High on Cloud, we help small businesses host and use open source software on their servers.
## Conclusion
If you are not super obsessed with data and just want a quick glance on how your website is performing, Plausible is a decent choice. I like it because it is lightweight and privacy compliant. That’s the main reason why I use it on Linux Handbook, our [ethical web portal for teaching Linux server related stuff](https://linuxhandbook.com/about/#ethical-web-portal).
Overall, I am pretty content with Plausible and recommend it to other website owners.
Do you run or manage a website as well? What tool do you use for the analytics or do you not care about that at all? |
13,284 | 选择 Linux 的五大好处 | https://opensource.com/article/21/2/linux-choice | 2021-04-10T13:13:40 | [
"Linux",
"选择"
] | https://linux.cn/article-13284-1.html |
>
> Linux 的一大优点是多样化选择,选择激发了用户之间自由分享想法和解决方案。Linux 将如何激发你为这个社区做出贡献呢?
>
>
>

到了 2021 年,人们比以往任何时候都更有理由喜欢 Linux。在本系列中,我将分享 21 个使用 Linux 的理由。本文讨论选择 Linux 带来的好处。
*选择* 是 Linux 中被误解最深的特性之一。这种误解从可被选择的 Linux 发行版数量就开始了。[Distrowatch.org](http://Distrowatch.org) 报告了数百种可用的和活跃的 Linux 发行版。当然,在这些发行版当中,许多都是业余爱好项目或者针对某些晦涩需求的特别版。因为是开源的,所以实际上,任何人都可以“重新设计”或“重新混搭”现有的 Linux 发行版,赋予一个新名称,提供一个新的默认墙纸,然后称其为自己的作品。尽管这些修改似乎微不足道,但我认为这显示了 Linux 的一些特别之处。
### 灵感
Linux 似乎一直在启迪着人们,从了解它的那一刻起,到创造出自己的版本。
有数十家公司花费数百万美元来从他们自己的产品中获取灵感。商业技术广告试着强硬地说服你,只要你购买某种产品,你就会与所关心的人建立更多的联系,更具创造力、更加充满活力。这些广告用 4k 视频拍摄,焦点柔和,并在欢快振奋的音乐节奏下播放,试图说服人们不仅购买而且还要支持和宣传该公司的产品。
当然,Linux 基本没有营销预算,因为 Linux 是个形形色色的大集合,*没有固定实体*。然而,当人们发现它的存在时候,他们似乎就被启发着去构建属于自己的版本。
灵感的数量很难量化,但是它显然很有价值,要不然那些公司不会花钱来尝试创造灵感。
### 革新
灵感,无论给它标价有多难,它都因它的生产创造而有价值。许多 Linux 用户受启发来为各种奇怪问题定制解决方案。我们解决的大多数问题,对于其他大部分人而言,似乎微不足道:也许你使用 [Seeed 微控制器](https://opensource.com/article/19/12/seeeduino-nano-review) 来监控番茄植株土壤的水分含量;或者你使用脚本来搜索 Python 软件包的索引,因为你总是会忘记每天导入的库的名称;或者设置了自动清理下载文件夹,因为将文件图标拖进回收站这个活儿干太多了。不管你在使用 Linux 的过程中,为自己解决过什么问题,都是这个平台包含的特性之一,你被这个正在运行中的开放的技术所启发,使其更好地服务于你自己。
### 开放策略
诚然,不论是灵感,还是创新,都不能算 Linux 独有的属性。其他平台也确实让我们激发灵感,我们也以或大或小的方式进行创新。运算能力已在很大程度上拉平了操作系统的竞争领域,你在一个操作系统上可以完成的任何事,在另一个操作系统上或许都能找到对应的方法来完成。
但是,许多用户发现,Linux 操作系统保留了坚定的开放策略,当你尝试可能无人想到过的尝试时,Linux 不会阻挡你。这种情况不会也不可能发生在专有的操作系统上,因为无法进入系统层级的某些区域,因为它们本身就是被设计为不开放源码的。有各种独断的封锁。当你完全按照操作系统的期望进行操作时,你不会碰到那些看不见的墙,但是当你心里想着要做一些只对你有意义的事情的时候,你的系统环境可能变得无从适应。
### 小小的选择,大大的意义
并非所有创新都是大的或重要的,但总的来说,它们带来的变化并不小。如今,数百万用户的那些疯狂想法在 Linux 的各个部分中愈发显现。它们存在于 KDE 或 GNOME 桌面的工作方式中,存在于 [31 种不同的文本编辑器](https://opensource.com/article/21/1/text-editor-roundup) 中 —— 每一种都有人喜爱,存在于不计其数的浏览器插件和多媒体应用程序中,存在于文件系统和扩展属性中,以及数以百万行计的 Linux 内核代码中。而且,如果上述功能中的哪怕仅其中一项,能让你每天额外节省下一小时时间,陪家人、朋友或用在自己的业余爱好上,那么按照定义,套用一句老话就是,“改变生活”。
### 在社区中交流
开源的重要组成部分之一是共享工作。共享代码是开源软件中显而易见的、普遍流行的事务,但我认为,分享,可不仅仅是在 Gitlab 做一次提交那么简单。当人们彼此分享着自己的奇思妙想,除了获得有用的代码贡献作为回报外,再无其他动机,我们都认为这是一种馈赠。这与你花钱从某公司购买软件时的感觉非常不同,甚至与得到某公司对外分享他们自己生产的开源代码时的感觉也有很大不同。开源的实质是,由全人类创造,服务于全人类。当知识和灵感可以被自由地分享时,人与人之间就建立了连接,这是市场营销活动无法复制的东西,我认为我们都认同这一点。
### 选择
Linux 并不是唯一拥有很多选择的平台。无论使用哪种操作系统,你都可以找到针对同一问题的多种解决方案,尤其是在深入研究开源软件的时候。但是,Linux 明显的选择水准指示了推动 Linux 前进的因素:诚邀协作。在 Linux 上,有些创造会很快消失,有些会在你家用电脑中保留数年 —— 即便只是执行一些不起眼的自动化任务,然而有一些则非常成功,以至于被其他系统平台借鉴并变得司空见惯。没关系,无论你在 Linux 上创作出什么,都请毫不犹豫地把它加入千奇百怪的选择之中,你永远都不知道它可能会激发到谁的灵感。
---
via: <https://opensource.com/article/21/2/linux-choice>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[max27149](https://github.com/max27149) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In 2021, there are more reasons why people love Linux than ever before. In this series, I'll share 21 different reasons to use Linux. This article discusses the benefit of choice Linux brings.
*Choice* is one of the most misunderstood features of Linux. It starts with how many Linuxes there are to choose from. Distrowatch.org reports hundreds of available and active Linux distributions. Many of these distributions, of course, are hobby projects or extremely specific to some obscure requirement. Because it's open source, in fact, anyone can "re-spin" or "remix" an existing distribution of Linux, give it a new name, maybe a new default wallpaper, and call it their own. And while that may seem trivial, I see it as an indication of something very special.
## Inspiration
Linux, it seems, inspires people, from the very moment they learn about it, to make it their own.
There are dozens of companies spending millions of dollars to generate inspiration from their product. Commercials for technology overwhelmingly try to convince you that as long as you buy some product, you'll feel more connected to the people you care about, more creative, and more alive. Shot in 4k video with soft focus and played to the beat of cheerful and uplifting music, these advertisements are attempts to convince people to not only purchase but then also to support and advertise that company's product.
Of course, Linux has essentially no marketing budget because Linux is a diverse collection of individuals, a body *discorporate*. Yet when people discover it, they are seemingly inspired to build their own version of it.
It's difficult to quantify amounts of inspiration, but there's obvious value to it, or else companies wouldn't spend money in an attempt to create it.
## Innovation
Inspiration, however difficult it is to put a price tag on it, is valuable because of what it produces. Many Linux users have been inspired to create custom solutions to odd problems. Many of the problems we each solve seem trivial to most other people. Maybe you monitor moisture levels of your tomato plant's soil with a [Seeed micro-controller](https://opensource.com/article/19/12/seeeduino-nano-review), or you have a script to search through an index of Python packages because you keep forgetting the names of libraries you import every day, or you've automated cleaning out your Downloads folder because dragging icons to the Trash is too much work. Whatever problem you've solved for yourself on Linux, it's a feature of the platform that you're inspired by the open technology you're running to make it work better for yourself.
## Staying out of the way
Of course, neither inspiration nor innovation are exclusive properties of Linux. Other platforms do authentically produce inspiration in us, and we do innovate in small and huge ways. Computing has largely leveled most playing fields, and anything you can do on one OS, you can likely find a way to do on another.
What many users find, however, is that the Linux operating system maintains a firm policy of staying out of your way when you have the idea of trying something that possibly nobody else has thought to try yet. This doesn't and cannot happen, by design, on a proprietary operating system because there's just no way to get into certain areas of the system because they don't happen to be open source. There are arbitrary blockades. You tend not to bump up against invisible walls when you're doing exactly what the OS expects you to do, but when you have it in mind to do something that makes sense only to you, your environment may fail to adapt.
## Small choices and why they matter
Not all innovations are big or important, but collectively they make a big difference. The crazy ideas that millions of users have had are evident today in every part of Linux. They're in the ways that the KDE and GNOME desktops work, they're in [31 different text editors](https://opensource.com/article/21/1/text-editor-roundup) each of them loved by someone, and countless plugins for browsers and media applications, in file systems and extended attributes, and in the millions of lines of the Linux kernel. And if just one of these features gives you an extra hour each day to spend with your family or friends or hobby, then it's by definition, to use an over-used phrase, "life-changing."
## Connecting with a community
An important part of open source is the sharing of work. Sharing code is the obvious, prevalent transaction of open source software, but I think there's a lot more to the act of sharing than just making a commit to Gitlab. When people share their ideas with one another, with no ulterior motive aside from potentially getting useful code contributions in return, we all recognize it as a gift. It feels very different from when you purchase software from a company, and it's even different from when a company shares open source code they've produced. The reality of open source is that it's made by humans for humans. There's a connection created when knowledge and inspiration are given freely. It's not something that a marketing campaign can replicate, and I think that we recognize that.
## Choice
Linux isn't the only platform with a lot of choices. You can find several solutions to the same problem regardless of your OS, especially when you delve into open source software. However, the level of choice evident on Linux is indicative of what drives Linux forward: The invitation to collaborate. Some things created on Linux fade quickly away, others stay on your home computer for years doing whatever small mundane task you've automated, and others are so successful that they get borrowed by other platforms and become commonplace. It doesn't matter. Whatever you create on Linux, don't hesitate to add it to the cacophony of choice. You never know who it might inspire.
## Comments are closed. |
13,286 | 查看 Git 提交中发生了什么变化 | https://opensource.com/article/21/4/git-whatchanged | 2021-04-11T09:35:01 | [
"Git"
] | https://linux.cn/article-13286-1.html |
>
> Git 提供了几种方式可以帮你快速查看提交中哪些文件被改变。
>
>
>

如果你每天使用 Git,应该会提交不少改动。如果你每天和其他人在一个项目中使用 Git,假设 *每个人* 每天的提交都是安全的,你会意识到 Git 日志会变得多么混乱,似乎永恒地滚动着变化,却没有任何迹象表明修改了什么。
那么,你该怎样查看指定提交中文件发生哪些变化?这比你想的容易。
### 查看提交中文件发生的变化
要想知道指定提交中哪些文件发生变化,可以使用 `git log --raw` 命令。这是发现一个提交影响了哪些文件的最快速、最方便的方法。`git log` 命令一般都没有被充分利用,主要是因为它有太多的格式化选项,许多用户在面对很多选择以及在一些情况下不明所以的文档时,会望而却步。
然而,Git 的日志机制非常灵活,`--raw` 选项提供了当前分支中的提交日志,以及更改的文件列表。
以下是标准的 `git log` 输出:
```
$ git log
commit fbbbe083aed75b24f2c77b1825ecab10def0953c (HEAD -> dev, origin/dev)
Author: tux <[email protected]>
Date: Sun Nov 5 21:40:37 2020 +1300
exit immediately from failed download
commit 094f9948cd995acfc331a6965032ea0d38e01f03 (origin/master, master)
Author: Tux <[email protected]>
Date: Fri Aug 5 02:05:19 2020 +1200
export makeopts from etc/example.conf
commit 76b7b46dc53ec13316abb49cc7b37914215acd47
Author: Tux <[email protected]>
Date: Sun Jul 31 21:45:24 2020 +1200
fix typo in help message
```
即使作者在提交消息中指定了哪些文件发生变化,日志也相当简洁。
以下是 `git log --raw` 输出:
```
$ git log --raw
commit fbbbe083aed75b24f2c77b1825ecab10def0953c (HEAD -> dev, origin/dev)
Author: tux <[email protected]>
Date: Sun Nov 5 21:40:37 2020 +1300
exit immediately from failed download
:100755 100755 cbcf1f3 4cac92f M src/example.lua
commit 094f9948cd995acfc331a6965032ea0d38e01f03 (origin/master, master)
Author: Tux <[email protected]>
Date: Fri Aug 5 02:05:19 2020 +1200
export makeopts from etc/example.conf
:100755 100755 4c815c0 cbcf1f3 M src/example.lua
:100755 100755 71653e1 8f5d5a6 M src/example.spec
:100644 100644 9d21a6f e33caba R100 etc/example.conf etc/example.conf-default
commit 76b7b46dc53ec13316abb49cc7b37914215acd47
Author: Tux <[email protected]>
Date: Sun Jul 31 21:45:24 2020 +1200
fix typo in help message
:100755 100755 e253aaf 4c815c0 M src/example.lua
```
这会准确告诉你哪个文件被添加到提交中,哪些文件发生改变(`A` 是添加,`M` 是修改,`R` 是重命名,`D` 是删除)。
### Git whatchanged
`git whatchanged` 命令是一个遗留命令,它的前身是日志功能。文档说用户不应该用该命令替代 `git log --raw`,并且暗示它实质上已经被废弃了。不过,我还是觉得它是一个很有用的捷径,可以得到同样的输出结果(尽管合并提交的内容不包括在内),如果它被删除的话,我打算为它创建一个别名。如果你只想查看已更改的文件,不想在日志中看到合并提交,可以尝试 `git whatchanged` 作为简单的助记符。
### 查看变化
你不仅可以看到哪些文件发生更改,还可以使用 `git log` 显示文件中发生了哪些变化。你的 Git 日志可以生成一个内联差异,用 `--patch` 选项可以逐行显示每个文件的所有更改:
```
commit 62a2daf8411eccbec0af69e4736a0fcf0a469ab1 (HEAD -> master)
Author: Tux <[email protected]>
Date: Wed Mar 10 06:46:58 2021 +1300
commit
diff --git a/hello.txt b/hello.txt
index 65a56c3..36a0a7d 100644
--- a/hello.txt
+++ b/hello.txt
@@ -1,2 +1,2 @@
Hello
-world
+opensource.com
```
在这个例子中,“world” 这行字从 `hello.txt` 中删掉,“[opensource.com](http://opensource.com)” 这行字则添加进去。
如果你需要在其他地方手动进行相同的修改,这些<ruby> 补丁 <rt> patch </rt></ruby>可以与常见的 Unix 命令一起使用,例如 [diff 与 patch](https://opensource.com/article/18/8/diffs-patches)。补丁也是一个好方法,可以总结指定提交中引入新信息的重要部分内容。当你在冲刺阶段引入一个 bug 时,你会发现这里的内容就是非常有价值的概述。为了更快地找到错误的原因,你可以忽略文件中没有更改的部分,只检查新代码。
### 用简单命令得到复杂的结果
你不必理解引用、分支和提交哈希,就可以查看提交中更改了哪些文件。你的 Git 日志旨在向你报告 Git 的活动,如果你想以特定方式格式化它或者提取特定的信息,通常需要费力地浏览许多文档来组合出正确的命令。幸运的是,关于 Git 历史记录最常用的请求之一只需要一两个选项:`--raw` 与 `--patch`。如果你不记得 `--raw`,就想想“Git,什么改变了?”,然后输入 `git whatchanged`。
---
via: <https://opensource.com/article/21/4/git-whatchanged>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you use Git every day, you probably make a lot of commits. If you're using Git every day in a project with other people, it's safe to assume that *everyone* is making lots of commits. Every day. And this means you're aware of how disorienting a Git log can become, with a seemingly eternal scroll of changes and no sign of what's been changed.
So how do you find out what file changed in a specific commit? It's easier than you think.
## Find what file changed in a commit
To find out which files changed in a given commit, use the `git log --raw`
command. It's the fastest and simplest way to get insight into which files a commit affects. The `git log`
command is underutilized in general, largely because it has so many formatting options, and many users get overwhelmed by too many choices and, in some cases, unclear documentation.
The log mechanism in Git is surprisingly flexible, though, and the `--raw`
option provides a log of commits in your current branch, plus a list of each file that had changes made to it.
Here's the output of a standard `git log`
:
```
$ git log
commit fbbbe083aed75b24f2c77b1825ecab10def0953c (HEAD -> dev, origin/dev)
Author: tux <[email protected]>
Date: Sun Nov 5 21:40:37 2020 +1300
exit immediately from failed download
commit 094f9948cd995acfc331a6965032ea0d38e01f03 (origin/master, master)
Author: Tux <[email protected]>
Date: Fri Aug 5 02:05:19 2020 +1200
export makeopts from etc/example.conf
commit 76b7b46dc53ec13316abb49cc7b37914215acd47
Author: Tux <[email protected]>
Date: Sun Jul 31 21:45:24 2020 +1200
fix typo in help message
```
Even when the author helpfully specifies in the commit message which files changed, the log is fairly terse.
Here's the output of `git log --raw`
:
```
$ git log --raw
commit fbbbe083aed75b24f2c77b1825ecab10def0953c (HEAD -> dev, origin/dev)
Author: tux <[email protected]>
Date: Sun Nov 5 21:40:37 2020 +1300
exit immediately from failed download
:100755 100755 cbcf1f3 4cac92f M src/example.lua
commit 094f9948cd995acfc331a6965032ea0d38e01f03 (origin/master, master)
Author: Tux <[email protected]>
Date: Fri Aug 5 02:05:19 2020 +1200
export makeopts from etc/example.conf
:100755 100755 4c815c0 cbcf1f3 M src/example.lua
:100755 100755 71653e1 8f5d5a6 M src/example.spec
:100644 100644 9d21a6f e33caba R100 etc/example.conf etc/example.conf-default
commit 76b7b46dc53ec13316abb49cc7b37914215acd47
Author: Tux <[email protected]>
Date: Sun Jul 31 21:45:24 2020 +1200
fix typo in help message
:100755 100755 e253aaf 4c815c0 M src/example.lua
```
This tells you exactly which file was added to the commit and how the file was changed (`A`
for added, `M`
for modified, `R`
for renamed, and `D`
for deleted).
## Git whatchanged
The `git whatchanged`
command is a legacy command that predates the log function. Its documentation says you're not meant to use it in favor of `git log --raw`
and implies it's essentially deprecated. However, I still find it a useful shortcut to (mostly) the same output (although merge commits are excluded), and I anticipate creating an alias for it should it ever be removed. If you don't need to merge commits in your log (and you probably don't, if you're only looking to see files that changed), try `git whatchanged`
as an easy mnemonic.
## View changes
Not only can you see which files changed, but you can also make `git log`
display exactly what changed in the files. Your Git log can produce an inline diff, a line-by-line display of all changes for each file, with the `--patch`
option:
```
commit 62a2daf8411eccbec0af69e4736a0fcf0a469ab1 (HEAD -> master)
Author: Tux <[email protected]>
Date: Wed Mar 10 06:46:58 2021 +1300
commit
diff --git a/hello.txt b/hello.txt
index 65a56c3..36a0a7d 100644
--- a/hello.txt
+++ b/hello.txt
@@ -1,2 +1,2 @@
Hello
-world
+opensource.com
```
In this example, the one-word line "world" was removed from `hello.txt`
and the new line "opensource.com" was added.
These patches can be used with common Unix utilities like [diff and patch](https://opensource.com/article/18/8/diffs-patches), should you need to make the same changes manually elsewhere. The patches are also a good way to summarize the important parts of what new information a specific commit introduces. This is an invaluable overview when you've introduced a bug during a sprint. To find the cause of the error faster, you can ignore the parts of a file that didn't change and review just the new code.
## Simple commands for complex results
You don't have to understand refs and branches and commit hashes to view what files changed in a commit. Your Git log was designed to report Git activity to you, and if you want to format it in a specific way or extract specific information, it's often a matter of wading through many screens of documentation to put together the right command. Luckily, one of the most common requests about Git history is available with just one or two options: `--raw`
and `--patch`
. And if you can't remember `--raw`
, just think, "Git, what changed?" and type `git whatchanged`
.
## Comments are closed. |
13,287 | GNOME OS:一个并不是适合所有人的 Linux 发行版 | https://itsfoss.com/gnome-os/ | 2021-04-11T10:33:03 | [
"GNOME"
] | https://linux.cn/article-13287-1.html | 
每当 GNOME 的一个重要版本到来时,总是很想尽快试用它。但是,要想第一时间进行测试,主要还是得依靠 [Fedora Rawhide](https://fedoraproject.org/wiki/Releases/Rawhide) 开发分支。
然而,开发分支并不总是让人放心的,所以,用来尝试最新的 GNOME 并不是最方便的解决方案。这里,我所说的测试,并不仅仅是指用户的测试,同时也能够用于开发者对设计变更进行测试。
所以,最近来了个大救星 GNOME OS,让测试的过程变得轻松起来。但是,它到底是什么,怎么安装呢?让我们一起来看看吧。
### 什么是 GNOME OS?
GNOME OS 并不是一个独立完整的 Linux 发行版。事实上,它根本不基于任何东西。它是一个不完整的参考系统,只是为了让 GNOME 桌面工作。它仅仅是一个可启动的虚拟机镜像,在 GNOME 进入任何发行版的仓库之前,为调试和测试功能而量身定做的。
在 GNOME 的博客中,有一篇提到了它:
>
> GNOME OS 旨在通过提供一个用于开发、设计和用户测试的工作系统,来更好地促进 GNOME 的开发。
>
>
>
如果你好奇的话,你可以看看 GNOME 星球上的一篇 [博客文章](https://blogs.gnome.org/alatiera/2020/10/07/what-is-gnome-os/) 来了解关于 GNOME OS 的更多信息。
### 如果它不是一个成熟的 Linux 发行版,那么它是用来干什么的?

值得注意的是,每一次新的提交都可以创建一个新的 GNOME OS 镜像,所以它应该会使测试过程变得高效,并帮助你在开发周期的早期测试并发现问题。
不要忘了,设计者不再需要自己构建软件来测试 GNOME Shell 或任何其他核心模块。这为他们节省了时间和整个 GNOME 开发周期。
当然,不仅限于开发者和技术测试人员,它还可以让记者们拿到最新的和最棒的东西,来报道 GNOME 下一个版本或它是如何成型的。
媒体和 GNOME 团队也得到了一个很好的机会,借助于 GNOME OS,他们可以准备视频、图片两种形式的视觉资料来宣传此次发布。
### 如何安装 GNOME OS?
要轻松安装 GNOME OS,你需要先安装 GNOME Boxes 应用程序。
#### 安装 GNOME Boxes
Boxes 是一款简单的虚拟化软件,它不提供任何高级选项,但可以让你轻松安装操作系统镜像来快速测试。它是专门针对桌面终端用户的,所以使用起来也很方便。
要在任何 Linux 发行版上安装它,你可以利用 [Flathub](https://flathub.org/apps/details/org.gnome.Boxes) 的 [Flatpak](https://itsfoss.com/what-is-flatpak/) 包。如果你不知道 Flatpak,你可能需要阅读我们的《[在 Linux 中安装和使用 Flatpak](https://itsfoss.com/flatpak-guide/)》指南。
你也可以在任何基于 Ubuntu 的发行版上直接在终端上输入以下内容进行安装:
```
sudo apt install gnome-boxes
```
一旦你安装了 Boxes,从这里安装 GNOME OS 就相当容易了。
#### 安装 GNOME OS
安装好 Boxes 后,你需要启动程序。接下来,点击窗口左上角的 “+” 标志,然后点击 “操作系统下载”,如下图所示。

这个选项可以让你直接下载镜像文件,然后就可以继续安装它。
你所需要做的就是搜索 “GNOME”,然后你应该会找到可用的每夜构建版。这可以确保你正在尝试最新和最优秀的 GNOME 开发版本。
另外,你也可以前往 [GNOME OS 每夜构建网站](https://os.gnome.org/) 下载系统镜像,然后在 Boxes 应用中选择 “运行系统镜像文件” 选择该 ISO,如上图截图所示,继续安装。

考虑到你没有单独下载镜像。当你点击后,应该会开始下载,并且会出现一个进度条。

完成后,如果需要,它会要求你自定义配置,让你创建虚拟机,如下图所示。

你可以根据你可用的系统资源来定制资源分配,但应该可以使用默认设置。
点击 “创建”,就会直接开始 GNOME OS 的安装。

选择“使用现有的版本”,然后继续。接下来,你必须选择磁盘(保持原样),然后同意擦除你所有的文件和应用程序(它不会删除本地计算机上的任何东西)。

现在,它将简单地重新格式化并安装它。然后就完成了。它会提示你重启,重启后,你会发现 GNOME OS 已经安装好了。
它会像其他 Linux 发行版一样简单地启动,并要求你设置一些东西,包括用户名和密码。然后,你就可以开始探索了。
如果你想知道它的样子,它基本上就是最新的 GNOME 桌面环境。在 GNOME 40 正式发布之前,我用 GNOME OS 做了一个 GNOME 40 的概述视频。
### 结束语
GNOME OS 绝对是对开发者、设计师和媒体有用的东西。它可以让你轻松地测试最新的 GNOME 开发版本,而无需投入大量的时间。
我可以很快地测试 [GNOME 40](https://news.itsfoss.com/gnome-40-release/),就是因为这个。当然,你要记住,这并不是一个可以在物理设备上安装的完整功能的操作系统。他们有计划让它可以在物理机器上运行,但就目前而言,它只是为虚拟机量身定做的,尤其是使用 GNOME Boxes。
GNOME Boxes 并没有提供任何高级选项,所以设置和使用它变得相当容易。如果体验太慢的话,你可能要调整一下资源,但在我的情况下,总体来说是一个不错的体验。
你试过 GNOME OS 了吗?欢迎在下面的评论中告诉我你的想法。
---
via: <https://itsfoss.com/gnome-os/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Whenever a major release for GNOME arrives, it is always tempting to try it out as soon as possible. But, to get your hands on it first to test it, you had to mostly rely on [Fedora Rawhide](https://fedoraproject.org/wiki/Releases/Rawhide?ref=itsfoss.com) (development branch).
However, a development branch isn’t always hassle-free. So, it wasn’t the most convenient solution to try the latest GNOME. Now, by testing, I don’t mean just for users but also being able to test design changes for the developers as well.
So, GNOME OS recently came to the rescue to ease the process of testing. But, what exactly is it and how to get it installed? Let us take a look.
## What is GNOME OS?
GNOME OS is not a separate full-fledged Linux distribution. In fact, it isn’t based on anything at all. It’s an incomplete reference system just to make GNOME desktop work. **It is just a bootable VM (Virtual Machine) image tailored for debugging and testing features before it hits any distribution’s repository.**
One of the GNOME blogs mention it as:
GNOME OS aims to better facilitate development of GNOME by providing a working system for development, design, and user testing purposes.
If you’re curious, you may want to check out a [blog post](https://blogs.gnome.org/alatiera/2020/10/07/what-is-gnome-os/?ref=itsfoss.com) on Planet GNOME to know more about GNOME OS.
## If it’s not a full-fledged Linux distribution then what is it used for?

It is interesting to note that a new GNOME OS image can be created for every new commit made, so it should make the testing process efficient and help you test/find issues early in the development cycle.
Not to forget, designers no longer have to build the software themselves to test the GNOME Shell or any other core modules. It saves them time and the whole GNOME development cycle.
Of course, not just limited to developers and technical testers, it also lets journalists to get their hands on the latest and greatest to cover a story about GNOME’s next release or how it’s being shaped.
The media and the GNOME team also gets a good opportunity to prepare visual materials to promote the release in both video/picture format thanks to GNOME OS.
## How to install GNOME OS?
To easily install GNOME OS, you will need to install GNOME Boxes application first.
### Installing GNOME Boxes
‘**Boxes**‘ is a simple virtualization software that does not offer any advanced options but lets you easily install an operating system image to test quickly. It is targeted specially for desktop end-users, so it is easy to use as well.
To install it on any Linux distribution, you can utilize the [Flatpak](https://itsfoss.com/what-is-flatpak/) package from [Flathub](https://flathub.org/apps/details/org.gnome.Boxes?ref=itsfoss.com). In case you don’t know about a Flatpak, you might want to read our guide on [installing and using Flatpak in Linux](https://itsfoss.com/flatpak-guide/).
You may also directly install it from the terminal on any Ubuntu-based distro by typing this:
`sudo apt install gnome-boxes`
Once you get Boxes installed, it is fairly easy to install GNOME OS from here.
### Install GNOME OS
After you have Boxes installed, you need to launch the program. Next, click on the “**+**” sign that you see in the upper-left corner of the window and then click on “**Operating System Download**” as shown in the image below.
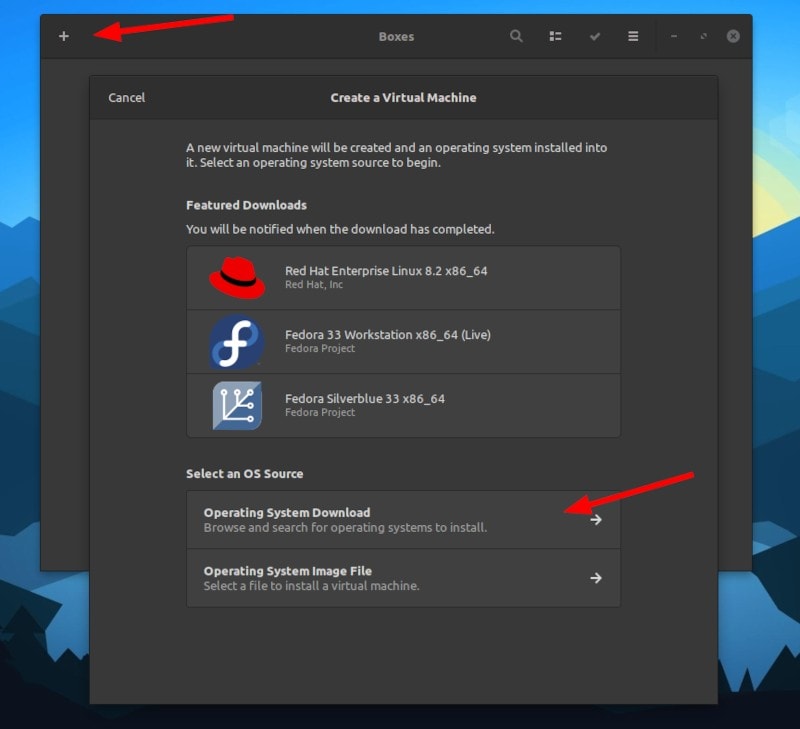
This option lets you directly download the image file and then you can proceed to install it.
All you need to do is search for “GNOME” and you should find the Nightly build available. This will ensure that you are trying the latest and greatest GNOME version in development.
Alternatively, you can head to the [GNOME OS Nightly website](https://os.gnome.org/?ref=itsfoss.com) and download the system image and choose the “**Operating System Image File**” in the Boxes app to select the ISO as shown in the screenshot above to proceed installing it.
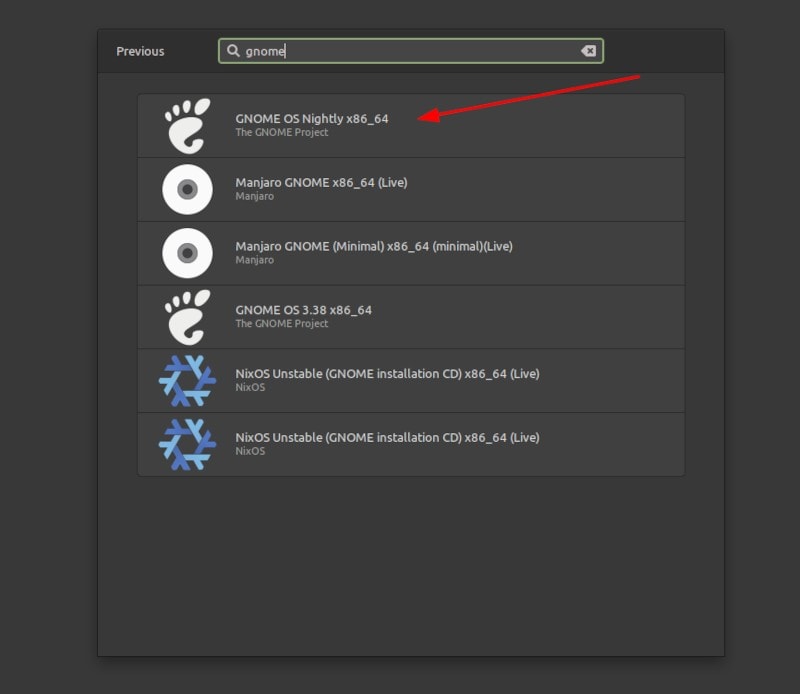
Considering you didn’t download the image separately. When you click on it, the download should start and a progress bar will appear:

Once it is done, it will ask you to customize the configuration if needed and let you create the VM as shown below:
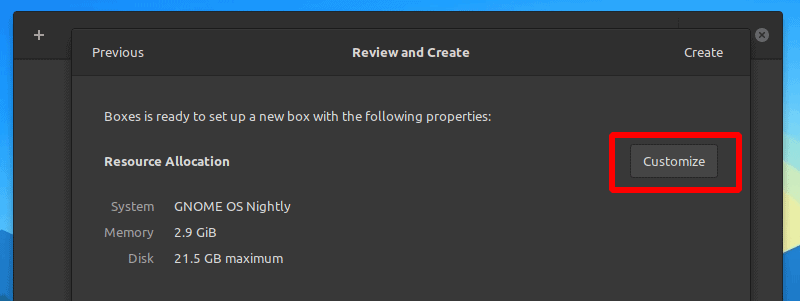
You can customize the resource allocation depending on your available system resources, but you should be good to go with the default settings.
Click on “**Create**” and it will directly start GNOME OS installation:
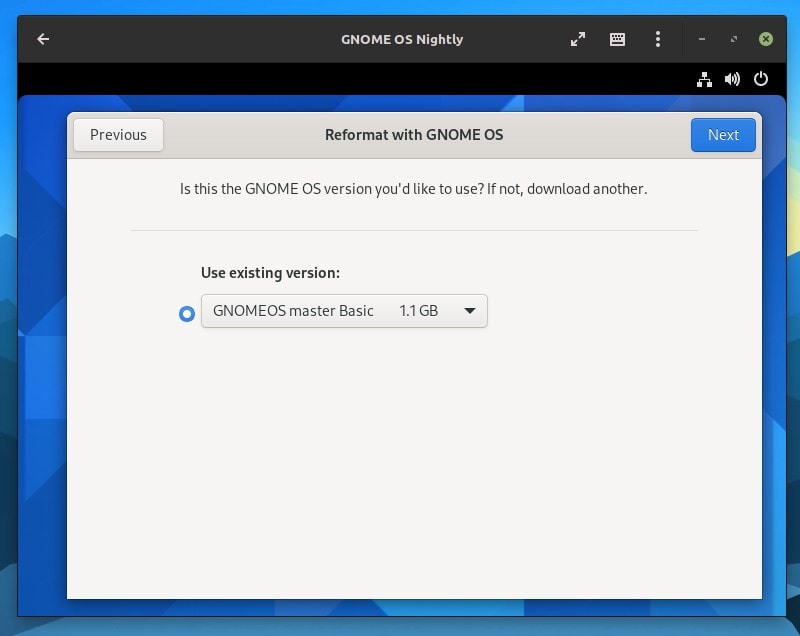
Select the existing version and proceed. Next, you will have to select the disk (keep it as is) and then agree to erasing all your files and apps (it won’t delete anything from your local computer).
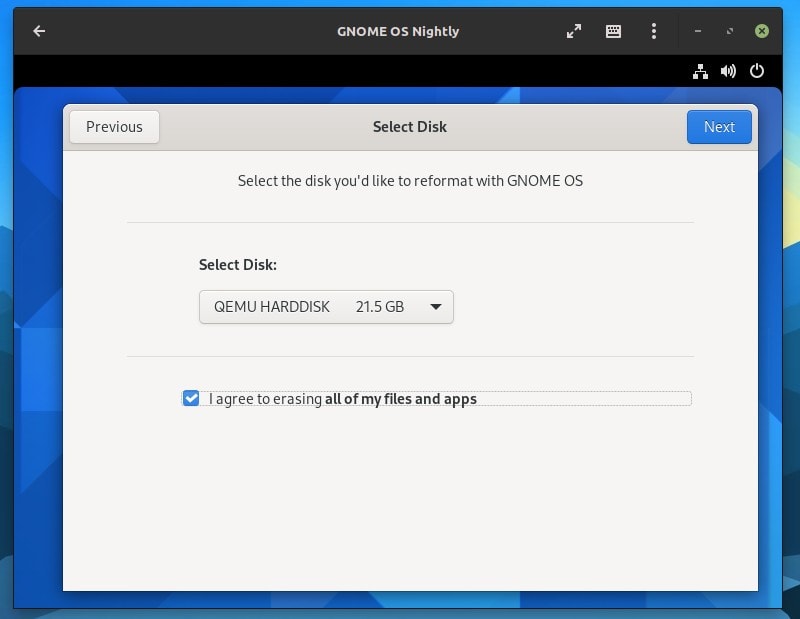
Now, it will simply reformat and install it. And, you’re done. It will prompt you to restart it and when you do, you will find GNOME OS installed.
It will simply boot up as any Linux distro would and will ask you to set up a few things, including the username and a password. And, you’re good to explore!
If you are curious what it looks like, it’s basically the latest GNOME desktop environment. I used GNOME OS to make an overview video of GNOME 40 before the official release.
## Closing Thoughts
GNOME OS is definitely something useful for developers, designers, and the media. It makes it easy to test the latest development version of GNOME without investing a lot of time.
I could test [GNOME 40](https://news.itsfoss.com/gnome-40-release/?ref=itsfoss.com) quickly just because of this. Of course, you will have to keep in mind that this isn’t a fully functional OS that you should install on a physical device. There are plans to make one available to run on a physical machine, but as it stands now, it is only tailored for virtual machines, especially using GNOME Boxes.
GNOME Boxes does not offer any advanced options, so it becomes quite easy to set it up and use it. You might want to tweak the resources if the experience is too slow, but it was a good experience overall in my case.
Have you tried GNOME OS yet? Feel free to let me know your thoughts in the comments down below. |
13,289 | 使用 CPUFetch 在 Linux 终端中漂亮地显示 CPU 细节 | https://itsfoss.com/cpufetch/ | 2021-04-12T09:38:46 | [
"CPU"
] | https://linux.cn/article-13289-1.html | 
Linux 上有 [检查 CPU 信息的方法](https://linuxhandbook.com/check-cpu-info-linux/)。最常见的可能是 `lscpu` 命令,它可以提供大量的系统上所有 CPU 核心的信息。

你可以在那里找到 CPU 信息,而无需安装任何额外的包。当然这是可行的。然而,我最近偶然发现了一个新的工具,它以一种漂亮的方式显示 Linux 中的 CPU 细节。
处理器制造商的 ASCII 艺术使它看起来很酷。

这看起来很美,不是吗?这类似于 [Neoftech 或者 Screenfetch,在 Linux 中用漂亮的 ASCII 艺术来展示系统信息](https://itsfoss.com/display-linux-logo-in-ascii/)。与这些工具类似,如果你要展示你的桌面截图,可以使用 CPUFetch。
该工具可以输出处理器制造商的 ASCII 艺术,它的名称、微架构、频率、核心、线程、峰值性能、缓存大小、[高级向量扩展](https://software.intel.com/content/www/us/en/develop/articles/introduction-to-intel-advanced-vector-extensions.html) 等等。
除了它提供的一些主题外,你还可以使用自定义颜色。当你在整理桌面,并希望对 Linux 环境中的所有元素进行颜色匹配时,这给了你更多的自由度。
### 在 Linux 上安装 CPUFetch
不幸的是,CPUFetch 是一个相当新的软件,而且它并不包含在你的发行版的软件库中,甚至没有提供现成的 DEB/RPM 二进制文件、PPA、Snap 或 Flatpak 包。
Arch Linux 用户可以在 [AUR](https://itsfoss.com/aur-arch-linux/) 中 [找到](https://aur.archlinux.org/packages/cpufetch-git) 它,但对于其他人来说,唯一的出路是 [从源代码构建](https://itsfoss.com/install-software-from-source-code/)。
不要担心。安装以及删除并不是那么复杂。让我来告诉你步骤。
我使用的是 Ubuntu,你会 [需要先在 Ubuntu 上安装 Git](https://itsfoss.com/install-git-ubuntu/)。一些发行版会预装 Git,如果没有,请使用你的发行版的包管理器来安装。
现在,把 Git 仓库克隆到你想要的地方。家目录也可以。
```
git clone https://github.com/Dr-Noob/cpufetch
```
切换到你刚才克隆的目录:
```
cd cpufetch
```
你会在这里看到一个 Makefile 文件。用它来编译代码。
```
make
```

现在你会看到一个新的可执行文件,名为 `cpufetch`。你运行这个可执行文件来显示终端的 CPU 信息。
```
./cpufetch
```
这是我系统的显示。AMD 的徽标用 ASCII 码看起来更酷,你不觉得吗?

如何删除 CPUFetch?这很简单。当你编译代码时,它只产生了一个文件,而且也和其他代码在同一个目录下。
所以,要想从系统中删除 CPUFetch,只需删除它的整个文件夹即可。你知道 [在 Linux 终端中删除一个目录](https://linuxhandbook.com/remove-files-directories/) 的方法吧?从 `cpufetch` 目录中出来,然后使用 `rm` 命令。
```
rm -rf cpufetch
```
这很简单,值得庆幸的是,因为从源代码中删除安装的软件有时真的很棘手。
说回 CPUFetch。我想这是一个实用工具,适合那些喜欢在各种 Linux 群里炫耀自己桌面截图的人。既然发行版有了 Neofetch,CPU 有了 CPUFetch,不知道能不能也来个 Nvidia ASCII 艺术的 GPUfetch?
---
via: <https://itsfoss.com/cpufetch/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

There are [ways to check CPU information on Linux](https://linuxhandbook.com/check-cpu-info-linux/?ref=itsfoss.com). Probably the most common is the `lscpu`
command that gives you plenty of information about all the CPU cores on your system.
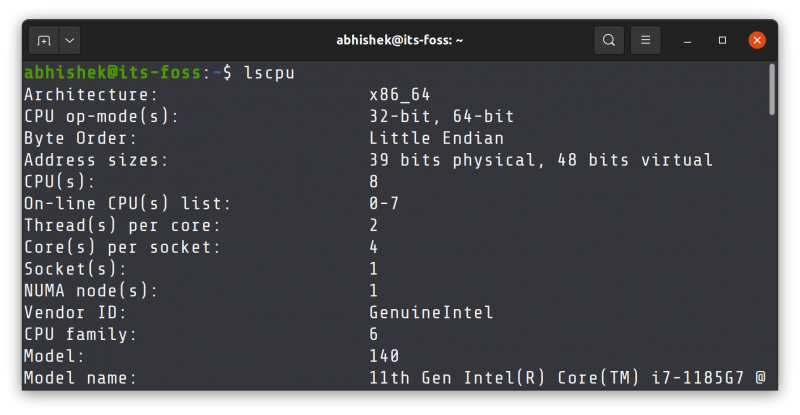
You may find CPU information there without installing any additional packages. That works of course. However, I recently stumbled upon a new tool that displays the CPU details in Linux in a beautiful manner.
The ASCII art of the processor manufacturer makes it look cool.

This looks beautiful, isn’t it? This is similar to [Neofetch or Screenfetch tools that show the system information in beautiful ASCII art in Linux](https://itsfoss.com/display-linux-logo-in-ascii/). Similar to those tools, you can use CPUFetch if you are showcasing your desktop screenshot.
The tool outputs the ASCII art of the processor manufacturer, its name, microarchitecture, frequency, cores, threads, peak performance, cache sizes, [Advanced Vector Extensions](https://software.intel.com/content/www/us/en/develop/articles/introduction-to-intel-advanced-vector-extensions.html?ref=itsfoss.com), and more.
You can use custom colors apart from a few themes it provides. This gives you additional degree of freedom when you are ricing your desktop and want to color match all the elements on your Linux setup.
## Installing CPUFetch on Linux
Unfortunately, CPUFetch is rather new, and it is not included in your distribution’s repository. It doesn’t even provide ready to use DEB/RPM binaries, PPAs, Snap or Flatpak packages.
Arch Linux users can [find](https://aur.archlinux.org/packages/cpufetch-git?ref=itsfoss.com) it in [AUR](https://itsfoss.com/aur-arch-linux/) but for others, the only way forward here is to [build from source code](https://itsfoss.com/install-software-from-source-code/).
Don’t worry. Installation as well as removal is not that complicated. Let me show you the steps.
I am using Ubuntu and you would [need to install Git on Ubuntu first](https://itsfoss.com/install-git-ubuntu/). Some other distributions come preinstalled with it, if not use your distribution’s package manager to install it.
Now, clone the Git repository wherever you want. Home directory is fine as well.
`git clone https://github.com/Dr-Noob/cpufetch`
Switch to the directory you just cloned:
`cd cpufetch`
You’ll see a make file here. Use it to compile the code.
`make`
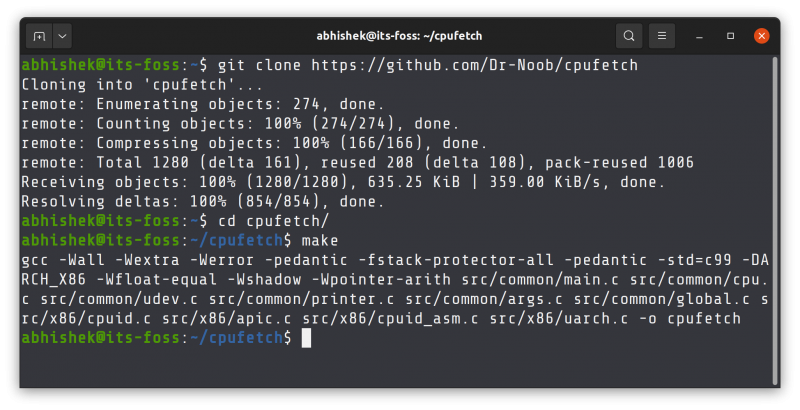
Now you’ll see a new executable file named `cpufetch`
. You run this executable to display the CPU information in the terminal.
`./cpufetch`
This is what it showed for my system. AMD logo looks a lot cooler in ASCII, don’t you think?
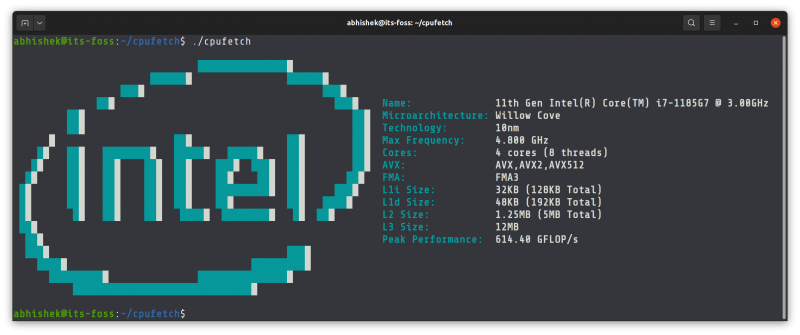
How do you remove Cpufetch? It’s pretty simple. When you compiled the code, it produced just one file and that too in the same directory as the rest of the code.
So, to remove CPUFetch from your system, simply remove its entire folder. You know how to [remove a directory in Linux terminal](https://linuxhandbook.com/remove-files-directories/?ref=itsfoss.com), don’t you? Come out of the cpufetch directory and use the rm command:
`rm -rf cpufetch`
That was simple, thankfully because removing software installed from source code could be really tricky at times.
Back to cpufetch. I think it’s a utility for those who like to show off their desktop screenshots in various Linux group. Since we have [Neofetch](https://itsfoss.com/using-neofetch/) for the distribution and CPUFetch for CPU, I wonder if we could have a GPU fetch with ASCII art of Nvidia as well :) |
13,290 | 用 Hedy 教人编程 | https://opensource.com/article/21/4/hedy-teach-code | 2021-04-12T11:18:37 | [
"Hedy",
"编程",
"开发"
] | https://linux.cn/article-13290-1.html |
>
> Hedy 是一种专门为教人编程而设计的新型编程语言。
>
>
>

学习编程既要学习编程逻辑,又要学习特定编程语言的语法。我在大学上第一堂编程课的时候,教的语言是 C++。第一个代码例子是基本的 “Hello World” 程序,就像下面的例子。
```
#include <iostream>
int main() {
std::cout << "Hello World!";
return 0;
}
```
老师直到几节课后才会解释大部分的代码。我们的期望是,我们只需输入代码,并最终了解为什么需要这些东西以及它们如何工作。
C++(以及其他类似的语言)的复杂语法是为什么 Python 经常被建议作为一种更容易的编程教学语言。下面是 Python 中的同一个例子:
```
print("Hello World!")
```
虽然 Python 中的 “Hello World” 基础例子要简单得多,但它仍然有复杂而精确的语法规则。`print` 函数需要在字符串周围加括号和引号。这对于没有编程经验的人来说,还是会感到困惑。Python 比 C++ 少了 “我以后再解释” 的语法问题,但还是有一些。
[Hedy](https://www.hedycode.com/) 是一种专门为编码教学而设计的新语言,它通过在语言中将复杂性分成多个关卡来解决语法复杂性的问题。Hedy 没有马上提供语言的全部功能,而是采取循序渐进的方式,随着学生在 Hedy 的学习的通关,慢慢变得更加复杂。随着关卡的进展,该语言获得了新的功能,最终变得更像 Python。目前有七个关卡,但更多的关卡正在计划中。
在第 1 关,Hedy 程序除了打印(`print`)一条语句(不需要引号或括号),提出(`ask`)一个问题,并回传(`echo`)一个答案外,不能做任何事情。第 1 关没有变量,没有循环,结构极精简。回传的工作原理几乎和变量一样,但只针对用户的最后一个输入。这可以让学生对基本概念感到舒适,而不必一下子学习所有的东西。
这是一个第 1 关的 Hedy “Hello World” 程序:
```
print Hello World
```
第 2 关引入了变量,但由于 `print` 函数没有使用引号,可能会出现一些有趣的结果。如果用来存储一个人的名字的变量是 `name`,那么就不可能打印输出 `Your name is [name]`,因为 `name` 的第一次使用(本意是字符串)和第二次使用(是变量)都被解释为变量。如果将 `name` 设置为(`is`) `John Doe`,那么 `print Your name is name.` 的输出就会是 `Your John Doe is John Doe`。虽然这听起来很奇怪,但这是一个引入变量概念的好方法,这恰好是第 3 关中增加的一个功能。
第 3 关要求在字符串周围加引号,这使得变量的功能就像在 Python 中一样。现在可以输出与变量相结合的字符串,做出复杂的语句,而不用担心变量名和字符串中的单词之间的冲突。这个级别取消了 “回传”(`echo`)函数,这看起来确实是一个可能会让一些学习者感到沮丧的东西。他们应该使用变量,这是更好的代码,但如果一个 `ask`/`echo` 代码块变成无效语法,可能会让人感到困惑。
第 4 关增加了基本的 `if`/`else` 功能。学生可以从简单的问/答代码转向复杂的交互。例如,一个问“你最喜欢的颜色是什么?”的提示可以根据用户输入的内容接受不同的回复。如果他们输入绿色,回答可以是“绿色!这也是我最喜欢的颜色。”如果他们输入其他的东西,回复可以是不同的。`if`/`else` 块是一个基本的编程概念,Hedy 引入了这个概念,而不必担心复杂的语法或过于精确的格式。
第 5 关有一个 `repeat` 函数,在现有的功能上增加了一个基本的循环。这个循环只能多次重复同一个命令,所以它没有 Python 中的循环那么强大,但它让学生习惯了重复命令的一般概念。这是多介绍了一个编程概念,而不会用无谓的复杂来拖累。学生们可以先掌握概念的基础知识,然后再继续学习同一事物的更强大、更复杂的版本。
在第 6 关,Hedy 现在可以进行基本的数学计算。加法、减法、乘法和除法都支持,但更高级的数学功能不支持。不能使用指数、模数或其他任何 Python 和其他语言能处理的东西。目前,Hedy 还没有更高关卡的产品增加更复杂的数学功能。
第 7 关引入了 Python 风格的缩进,这意味着 `repeat` 可以处理多行代码。学生在这之前都是逐行处理代码,但现在他们可以处理代码块。这个 Hedy 关卡与非教学型编程语言能做的事情相比还是有很大的差距,但它可以教会学生很多东西。
开始学习 Hedy 最简单的方法是访问 Hedy 网站上的 [课程](https://www.hedycode.com/hedy?lang=en),目前有荷兰语、英语、法语、德语、葡萄牙语和西班牙语。这样一来,任何有网页浏览器的人都可以进入学习过程。也可以从 [GitHub](https://github.com/felienne/hedy) 下载 Hedy,并从命令行运行解释器,或者运行 Hedy 网站的本地副本及其交互式课程。基于网页的版本更容易使用,但网页版本和命令行版本都支持运行针对不同复杂程度的 Hedy 程序。
Hedy 永远不会与 Python、C++ 或其他语言竞争,成为现实世界项目编码的首选语言,但它是编码教学的绝佳方式。作为学习过程的一部分,学生编写的程序是真实的,甚至可能是复杂的。Hedy 可以促进学生的学习和创造力,而不会让学生在学习过程中过早地被过多的信息所迷惑。就像数学课一样,在进入微积分之前很久要从学习计数、相加等开始(这个过程需要数年时间),编程也不必一开始就对编程语言的语法问题“我稍后再解释”、精确地遵循这些语法问题,才能产生哪怕是最基本的语言程序。
---
via: <https://opensource.com/article/21/4/hedy-teach-code>
作者:[Joshua Allen Holm](https://opensource.com/users/holmja) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Learning to code involves learning both the programming logic and the syntax of a specific programming language. When I took my first programming class in college, the language taught was C++. The first code example, the basic "Hello World" program, looked like the example below.
```
#include <iostream>
int main() {
std::cout << "Hello World!";
return 0;
}
```
The instructor would not explain most of the code until several lessons later. The expectation was that we would just type in the code and eventually learn why things were required and how they worked.
The complex syntax of C++ (and other, similar languages) is why Python is often suggested as an easier language for teaching programming. Here is the same example in Python:
`print("Hello World!")`
While the basic "Hello World" example in Python is much simpler, it still has complex and precise syntax rules. The `print`
function requires parentheses and quotes around the string. This can still confuse those who have no experience with programming. Python has fewer "I'll explain later" syntax issues than C++, but it still has them.
[Hedy](https://www.hedycode.com/), a new language designed specifically for teaching coding, addresses the issue of syntax complexity by building multiple levels of complexity into the language. Instead of providing the full features of the language right away, Hedy takes a gradual approach and slowly becomes more complex as students work through Hedy's levels. As the levels progress, the language gains new features and eventually becomes more Python-like. There are currently seven levels available, but more are planned.
At level 1, a Hedy program cannot do anything except print a statement (which does not require quotes or parentheses), ask a question, and echo back an answer. Level 1 has no variables, no loops, and minimal structure. Echo works almost like a variable but only for the last user input. This allows students to become comfortable with basic concepts without having to learn everything all at once.
This is a level 1 Hedy "Hello World" program:
`print Hello World`
Level 2 introduces variables, but because the `print`
function does not use quotes, there can be some interesting outcomes. If the variable used to store a person's name is `name`
, it is impossible to print the output "Your name is [name]" because both the first use of name, which is intended to be a string, and the second use, which is a variable, are both interpreted as a variable. If `name`
is set to `John Doe`
, the output of `print Your name is name.`
would be "Your John Doe is John Doe." As odd as this sounds, it is a good way for to introduce the concept of variables, which just happens to be a feature added in Level 3.
Level 3 requires quotation marks around strings, which makes variables function like they do in Python. It is now possible to output strings combined with variables to make complex statements without worrying about conflicts between variable names and words in a string. This level does away with the `echo`
function, which does seem like something that might frustrate some learners. They should be using variables, which is better code, but it could be confusing if an `ask`
/`echo`
block of code becomes invalid syntax.
Level 4 adds basic `if`
/`else`
functionality. Students can move from simple ask/answer code to complex interactions. For example, a prompt that asks, "What is your favorite color?" can accept different replies depending on what the user enters. If they enter green, the reply can be "Green! That's also my favorite color." If they enter anything else, the reply could be different. The `if`
/`else`
block is a basic programming concept, which Hedy introduces without having to worry about complex syntax or overly precise formatting.
Level 5 has a `repeat`
function, which adds a basic loop to the features available. This loop can only repeat the same command multiple times, so it is not as powerful as loops in Python, but it lets the students get used to the general concept of repeating commands. It's one more programming concept introduced without bogging things down with needless complexity. The students can grasp the basics of the concept before moving on to more powerful, complex versions of the same thing.
At level 6, Hedy can now do basic math calculations. Addition, subtraction, multiplication, and division are supported, but more advanced math features are not. It is not possible to use exponents, modulo, or anything else that Python and other languages handle. As yet, no higher level of Hedy adds more complex math.
Level 7 brings in Python-style indenting, which means `repeat`
can work with multiple lines of code. Students worked with code line by line up to this point, but now they can work with blocks of code. This Hedy level still falls way short of what a non-teaching programming language can do, but it can teach students a lot.
The easiest way to get started with Hedy is to access the [lessons](https://www.hedycode.com/hedy?lang=en) on the Hedy website, which is currently available in Dutch, English, French, German, Portuguese, and Spanish. This makes the learning process accessible to anyone with a web browser. It is also possible to download Hedy from [GitHub](https://github.com/felienne/hedy) and run the interpreter from the command line or run a local copy of the Hedy website with its interactive lessons. The web-based version is more approachable, but both the web and command-line versions support running Hedy programs targeted at its various levels of complexity.
Hedy will never compete with Python, C++, or other languages as the language of choice for coding for real-world projects, but it is an excellent way to teach coding. The programs students write as part of the learning process are real and possibly even complex. Hedy can foster learning and creativity without confusing students with too much information too soon in the learning process. Like math classes, which start with counting, adding, etc., long before getting to calculus (a process that takes years), programming does not have to start with "I'll explain later" for programming language syntax issues that must be followed precisely to produce even the most basic program in the language.
## 2 Comments |
13,292 | 使用 Elixir 语言编写一个小游戏 | https://opensource.com/article/20/12/elixir | 2021-04-12T22:34:26 | [
"猜数字",
"Elixir"
] | https://linux.cn/article-13292-1.html |
>
> 通过编写“猜数字”游戏来学习 Elixir 编程语言,并将它与一个你熟知的语言做对比。
>
>
>

为了更好的学习一门新的编程语言,最好的方法是去关注主流语言的一些共有特征:
* 变量
* 表达式
* 语句
这些概念是大多数编程语言的基础。因为这些相似性,只要你通晓了一门编程语言,你可以通过对比差异来熟知另一门编程语言。
另外一个学习新编程语言的好方法是开始编写一个简单标准的程序。它可以让你集中精力在语言上而非程序的逻辑本身。在这个系列的文章中,我们使用“猜数字”程序来实现,在这个程序中,计算机会选择一个介于 1 到 100 之间的数字,并要求你来猜测它。程序会循环执行,直到你正确猜出该数字为止。
“猜数字”这个程序使用了编程语言的以下概念:
* 变量
* 输入
* 输出
* 条件判断
* 循环
这是一个学习新编程语言的绝佳实践。
### 猜数字的 Elixir 实现
[Elixir](https://elixir-lang.org/) 是一门被设计用于构建稳定可维护应用的动态类型的函数式编程语言。它与 [Erlang](https://www.erlang.org/) 运行于同一虚拟机之上,吸纳了 Erlang 的众多长处的同时拥有更加简单的语法。
你可以编写一个 Elixir 版本的“猜数字”游戏来体验这门语言。
这是我的实现方法:
```
defmodule Guess do
def guess() do
random = Enum.random(1..100)
IO.puts "Guess a number between 1 and 100"
Guess.guess_loop(random)
end
def guess_loop(num) do
data = IO.read(:stdio, :line)
{guess, _rest} = Integer.parse(data)
cond do
guess < num ->
IO.puts "Too low!"
guess_loop(num)
guess > num ->
IO.puts "Too high!"
guess_loop(num)
true ->
IO.puts "That's right!"
end
end
end
Guess.guess()
```
Elixir 通过列出变量的名称后面跟一个 `=` 号来为了给变量分配一个值。举个例子,表达式 `random = 0` 给 `random` 变量分配一个数值 0。
代码以定义一个模块开始。在 Elixir 语言中,只有模块可以包含命名函数。
紧随其后的这行代码定义了入口函数 `guess()`,这个函数:
* 调用 `Enum.random()` 函数来获取一个随机整数
* 打印游戏提示
* 调用循环执行的函数
剩余的游戏逻辑实现在 `guess_loop()` 函数中。
`guess_loop()` 函数利用 [尾递归](https://en.wikipedia.org/wiki/Tail_call) 来实现循环。Elixir 中有好几种实现循环的方法,尾递归是比较常用的一种方式。`guess_loop()` 函数做的最后一件事就是调用自身。
`guess_loop()` 函数的第一行读取用户输入。下一行调用 `parse()` 函数将输入转换成一个整数。
`cond` 表达式是 Elixir 版本的多重分支表达式。与其他语言中的 `if/elif` 或者 `if/elsif` 表达式不同,Elixir 对于的首个分支或者最后一个没有分支并没有区别对待。
这个 `cond` 表达式有三路分支:猜测的结果可以比随机数大、小或者相等。前两个选项先输出不等式的方向然后递归调用 `guess_loop()`,循环返回至函数开始。最后一个选项输出 `That's right`,然后这个函数就完成了。
### 输出例子
现在你已经编写了你的 Elixir 代码,你可以运行它来玩“猜数字”的游戏。每次你执行这个程序,Elixir 会选择一个不同的随机数,你可以一直猜下去直到你找到正确的答案:
```
$ elixir guess.exs
Guess a number between 1 and 100
50
Too high
30
Too high
20
Too high
10
Too low
15
Too high
13
Too low
14
That's right!
```
“猜数字”游戏是一个学习一门新编程语言的绝佳入门程序,因为它用了非常直接的方法实践了常用的几个编程概念。通过用不同语言实现这个简单的小游戏,你可以实践各个语言的核心概念并且比较它们的细节。
你是否有你最喜爱的编程语言?你将怎样用它来编写“猜数字”这个游戏?关注这个系列的文章来看看其他你可能感兴趣的语言实现。
---
via: <https://opensource.com/article/20/12/elixir>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tt67wq](https://github.com/tt67wq) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | To you learn a new programming language, it's good to focus on the things most programming languages have in common:
- Variables
- Expressions
- Statements
These concepts are the basis of most programming languages. Because of these similarities, once you know one programming language, you can start figuring another one out by recognizing its differences.
Another good tool for learning a new language is starting with a standard program. This allows you to focus on the language, not the program's logic. We're doing that in this article series using a "guess the number" program, in which the computer picks a number between one and 100 and asks you to guess it. The program loops until you guess the number correctly.
The "guess the number" program exercises several concepts in programming languages:
- Variables
- Input
- Output
- Conditional evaluation
- Loops
It's a great practical experiment to learn a new programming language.
## Guess the number in Elixir
The [Elixir](https://elixir-lang.org/) programming language is a dynamically typed functional language designed for building stable and maintainable applications. It runs on top of the same virtual machine as [Erlang](https://www.erlang.org/) and shares many of its strengths—but with slightly easier syntax.
You can explore Elixir by writing a version of the "guess the number" game.
Here is my implementation:
```
defmodule Guess do
def guess() do
random = Enum.random(1..100)
IO.puts "Guess a number between 1 and 100"
Guess.guess_loop(random)
end
def guess_loop(num) do
data = IO.read(:stdio, :line)
{guess, _rest} = Integer.parse(data)
cond do
guess < num ->
IO.puts "Too low!"
guess_loop(num)
guess > num ->
IO.puts "Too high!"
guess_loop(num)
true ->
IO.puts "That's right!"
end
end
end
Guess.guess()
```
To assign a value to a variable, list the variable's name followed by the `=`
sign. For example, the statement `random = 0`
assigns a zero value to the `random`
variable.
The script starts by defining a **module**. In Elixir, only modules can have named functions in them.
The next line defines the function that will serve as the entry point, `guess()`
, which:
- Calls the
`Enum.random()`
function to get a random integer - Prints the game prompt
- Calls the function that will serve as the loop
The rest of the game logic is implemented in the `guess_loop()`
function.
The `guess_loop()`
function uses [tail recursion](https://en.wikipedia.org/wiki/Tail_call) to loop. There are several ways to do looping in Elixir, but using tail recursion is a common one. The last thing `guess_loop()`
does is call *itself*.
The first line in `guess_loop()`
reads the input from the user. The next line uses `parse()`
to convert the input to an integer.
The `cond`
statement is Elixir's version of a multi-branch statement. Unlike `if/elif`
or `if/elsif`
in other languages, Elixir does not treat the first nor the last branch in a different way.
This `cond`
statement has a three-way branch: The guess can be smaller, bigger, or equal to the random number. The first two options output the inequality's direction and then tail-call `guess_loop()`
, looping back to the beginning. The last option outputs `That's right`
, and the function finishes.
## Sample output
Now that you've written your Elixir program, you can run it to play the "guess the number" game. Every time you run the program, Elixir will pick a different random number, and you can guess until you find the correct number:
```
$ elixir guess.exs
Guess a number between 1 and 100
50
Too high
30
Too high
20
Too high
10
Too low
15
Too high
13
Too low
14
That's right!
```
This "guess the number" game is a great introductory program for learning a new programming language because it exercises several common programming concepts in a pretty straightforward way. By implementing this simple game in different programming languages, you can demonstrate some core concepts of the languages and compare their details.
Do you have a favorite programming language? How would you write the "guess the number" game in it? Follow this article series to see examples of other programming languages that might interest you.
## Comments are closed. |
13,293 | git stash 命令实用指南 | https://opensource.com/article/21/4/git-stash | 2021-04-12T23:28:39 | [
"git",
"暂存"
] | https://linux.cn/article-13293-1.html |
>
> 学习如何使用 `git stash` 命令,以及何时应该使用它。
>
>
>

版本控制是软件开发人员日常生活中不可分割的一部分。很难想象有哪个团队在开发软件时不使用版本控制工具。同样也很难想象有哪个开发者没有使用过(或没有听说过)Git。在 2018 年 Stackoverflow 开发者调查中,74298 名参与者中有 87.2% 的人 [使用 Git](https://insights.stackoverflow.com/survey/2018#work-_-version-control) 进行版本控制。
Linus Torvalds 在 2005 年创建了 Git 用于开发 Linux 内核。本文将介绍 `git stash` 命令,并探讨一些有用的暂存变更的选项。本文假定你对 [Git 概念](https://opensource.com/downloads/cheat-sheet-git) 有基本的了解,并对工作树、暂存区和相关命令有良好的理解。
### 为什么 git stash 很重要?
首先要明白为什么在 Git 中暂存变更很重要。假设 Git 没有暂存变更的命令。当你正在一个有两个分支(A 和 B)的仓库上工作时,这两个分支已经分叉了一段时间,并且有不同的头。当你正在处理 A 分支的一些文件时,你的团队要求你修复 B 分支的一个错误。你迅速将你的修改保存到 A 分支(但没有提交),并尝试用 `git checkout B` 来签出 B 分支。Git 会立即中止了这个操作,并抛出错误:“你对以下文件的本地修改会被该签出覆盖……请在切换分支之前提交你的修改或将它们暂存起来。”
在这种情况下,有几种方法可以启用分支切换:
* 在分支 A 中创建一个提交,提交并推送你的修改,以修复 B 中的错误,然后再次签出 A,并运行 `git reset HEAD^` 来恢复你的修改。
* 手动保留不被 Git 跟踪的文件中的改动。
第二种方法是个馊主意。第一种方法虽然看起来很传统,但却不太灵活,因为保存未完成工作的修改会被当作一个检查点,而不是一个仍在进行中的补丁。这正是设计 `git stash` 的场景。
`git stash` 将未提交的改动保存在本地,让你可以进行修改、切换分支以及其他 Git 操作。然后,当你需要的时候,你可以重新应用这些存储的改动。暂存是本地范围的,不会被 `git push` 推送到远程。
### 如何使用 git stash
下面是使用 `git stash` 时要遵循的顺序:
1. 将修改保存到分支 A。
2. 运行 `git stash`。
3. 签出分支 B。
4. 修正 B 分支的错误。
5. 提交并(可选)推送到远程。
6. 查看分支 A
7. 运行 `git stash pop` 来取回你的暂存的改动。
`git stash` 将你对工作目录的修改存储在本地(在你的项目的 `.git` 目录内,准确的说是 `/.git/refs/stash`),并允许你在需要时检索这些修改。当你需要在不同的上下文之间切换时,它很方便。它允许你保存以后可能需要的更改,是让你的工作目录干净同时保持更改完整的最快方法。
### 如何创建一个暂存
暂存你的变化的最简单的命令是 `git stash`:
```
$ git stash
Saved working directory and index state WIP on master; d7435644 Feat: configure graphql endpoint
```
默认情况下,`git stash` 存储(或称之为“暂存”)未提交的更改(已暂存和未暂存的文件),并忽略未跟踪和忽略的文件。通常情况下,你不需要暂存未跟踪和忽略的文件,但有时它们可能会干扰你在代码库中要做的其他事情。
你可以使用附加选项让 `git stash` 来处理未跟踪和忽略的文件:
* `git stash -u` 或 `git stash --includ-untracked` 储存未追踪的文件。
* `git stash -a` 或 `git stash --all` 储存未跟踪的文件和忽略的文件。
要存储特定的文件,你可以使用 `git stash -p` 或 `git stash -patch` 命令:
```
$ git stash --patch
diff --git a/.gitignore b/.gitignore
index 32174593..8d81be6e 100644
--- a/.gitignore
+++ b/.gitignore
@@ -3,6 +3,7 @@
# dependencies
node_modules/
/.pnp
+f,fmfm
.pnp.js
# testing
(1/1) Stash this hunk [y,n,q,a,d,e,?]?
```
### 列出你的暂存
你可以用 `git stash list` 命令查看你的暂存。暂存是后进先出(LIFO)方式保存的:
```
$ git stash list
stash@{0}: WIP on master: d7435644 Feat: configure graphql endpoint
```
默认情况下,暂存会显示在你创建它的分支和提交的顶部,被标记为 `WIP`。然而,当你有多个暂存时,这种有限的信息量并没有帮助,因为很难记住或单独检查它们的内容。要为暂存添加描述,可以使用命令 `git stash save <description>`:
```
$ git stash save "remove semi-colon from schema"
Saved working directory and index state On master: remove semi-colon from schema
$ git stash list
stash@{0}: On master: remove semi-colon from schema
stash@{1}: WIP on master: d7435644 Feat: configure graphql endpoint
```
### 检索暂存起来的变化
你可以用 `git stash apply` 和 `git stash pop` 这两个命令来重新应用暂存的变更。这两个命令都会重新应用最新的暂存(即 `stash@{0}`)中的改动。`apply` 会重新应用变更;而 `pop` 则会将暂存的变更重新应用到工作副本中,并从暂存中删除。如果你不需要再次重新应用被暂存的更改,则首选 `pop`。
你可以通过传递标识符作为最后一个参数来选择你想要弹出或应用的储藏:
```
$ git stash pop stash@{1}
```
或
```
$ git stash apply stash@{1}
```
### 清理暂存
删除不再需要的暂存是好的习惯。你必须用以下命令手动完成:
* `git stash clear` 通过删除所有的暂存库来清空该列表。
* `git stash drop <stash_id>` 从暂存列表中删除一个特定的暂存。
### 检查暂存的差异
命令 `git stash show <stash_id>` 允许你查看一个暂存的差异:
```
$ git stash show stash@{1}
console/console-init/ui/.graphqlrc.yml | 4 +-
console/console-init/ui/generated-frontend.ts | 742 +++++++++---------
console/console-init/ui/package.json | 2 +-
```
要获得更详细的差异,需要传递 `--patch` 或 `-p` 标志:
```
$ git stash show stash@{0} --patch
diff --git a/console/console-init/ui/package.json b/console/console-init/ui/package.json
index 755912b97..5b5af1bd6 100644
--- a/console/console-init/ui/package.json
+++ b/console/console-init/ui/package.json
@@ -1,5 +1,5 @@
{
- "name": "my-usepatternfly",
+ "name": "my-usepatternfly-2",
"version": "0.1.0",
"private": true,
"proxy": "http://localhost:4000"
diff --git a/console/console-init/ui/src/AppNavHeader.tsx b/console/console-init/ui/src/AppNavHeader.tsx
index a4764d2f3..da72b7e2b 100644
--- a/console/console-init/ui/src/AppNavHeader.tsx
+++ b/console/console-init/ui/src/AppNavHeader.tsx
@@ -9,8 +9,8 @@ import { css } from "@patternfly/react-styles";
interface IAppNavHeaderProps extends PageHeaderProps {
- toolbar?: React.ReactNode;
- avatar?: React.ReactNode;
+ toolbar?: React.ReactNode;
+ avatar?: React.ReactNode;
}
export class AppNavHeader extends React.Component<IAppNavHeaderProps>{
render()
```
### 签出到新的分支
你可能会遇到这样的情况:一个分支和你的暂存中的变更有分歧,当你试图重新应用暂存时,会造成冲突。一个简单的解决方法是使用 `git stash branch <new_branch_name stash_id>` 命令,它将根据创建暂存时的提交创建一个新分支,并将暂存中的修改弹出:
```
$ git stash branch test_2 stash@{0}
Switched to a new branch 'test_2'
On branch test_2
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: .graphqlrc.yml
modified: generated-frontend.ts
modified: package.json
no changes added to commit (use "git add" and/or "git commit -a")
Dropped stash@{0} (fe4bf8f79175b8fbd3df3c4558249834ecb75cd1)
```
### 在不打扰暂存参考日志的情况下进行暂存
在极少数情况下,你可能需要创建一个暂存,同时保持暂存参考日志(`reflog`)的完整性。这些情况可能出现在你需要一个脚本作为一个实现细节来暂存的时候。这可以通过 `git stash create` 命令来实现;它创建了一个暂存条目,并返回它的对象名,而不将其推送到暂存参考日志中:
```
$ git stash create "sample stash"
63a711cd3c7f8047662007490723e26ae9d4acf9
```
有时,你可能会决定将通过 `git stash create` 创建的暂存条目推送到暂存参考日志:
```
$ git stash store -m "sample stash testing.." "63a711cd3c7f8047662007490723e26ae9d4acf9"
$ git stash list
stash @{0}: sample stash testing..
```
### 结论
我希望你觉得这篇文章很有用,并学到了新的东西。如果我遗漏了任何有用的使用暂存的选项,请在评论中告诉我。
---
via: <https://opensource.com/article/21/4/git-stash>
作者:[Ramakrishna Pattnaik](https://opensource.com/users/rkpattnaik780) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Version control is an inseparable part of software developers' daily lives. It's hard to imagine any team developing software without using a version control tool. It's equally difficult to envision any developer who hasn't worked with (or at least heard of) Git. In the 2018 Stackoverflow Developer Survey, 87.2% of the 74,298 participants [use Git](https://insights.stackoverflow.com/survey/2018#work-_-version-control) for version control.
Linus Torvalds created git in 2005 for developing the Linux kernel. This article walks through the `git stash`
command and explores some useful options for stashing changes. It assumes you have basic familiarity with [Git concepts](https://opensource.com/downloads/cheat-sheet-git) and a good understanding of the working tree, staging area, and associated commands.
## Why is git stash important?
The first thing to understand is why stashing changes in Git is important. Assume for a moment that Git doesn't have a command to stash changes. Suppose you are working on a repository with two branches, A and B. The A and B branches have diverged from each other for quite some time and have different heads. While working on some files in branch A, your team asks you to fix a bug in branch B. You quickly save your changes to A and try to check out branch B with `git checkout B`
. Git immediately aborts the operation and throws the error, "Your local changes to the following files would be overwritten by checkout … Please commit your changes or stash them before you switch branches."
There are few ways to enable branch switching in this case:
- Create a commit at that point in branch A, commit and push your changes to fix the bug in B, then check out A again and run
`git reset HEAD^`
to get your changes back. - Manually keep the changes in files not tracked by Git.
The second method is a bad idea. The first method, although appearing conventional, is less flexible because the unfinished saved changes are treated as a checkpoint rather than a patch that's still a work in progress. This is exactly the kind of scenario git stash is designed for.
Git stash saves the uncommitted changes locally, allowing you to make changes, switch branches, and perform other Git operations. You can then reapply the stashed changes when you need them. A stash is locally scoped and is not pushed to the remote by `git push`
.
## How to use git stash
Here's the sequence to follow when using git stash:
- Save changes to branch A.
- Run
`git stash`
. - Check out branch B.
- Fix the bug in branch B.
- Commit and (optionally) push to remote.
- Check out branch A
- Run
`git stash pop`
to get your stashed changes back.
Git stash stores the changes you made to the working directory locally (inside your project's .git directory; `/.git/refs/stash`
, to be precise) and allows you to retrieve the changes when you need them. It's handy when you need to switch between contexts. It allows you to save changes that you might need at a later stage and is the fastest way to get your working directory clean while keeping changes intact.
## How to create a stash
The simplest command to stash your changes is `git stash`
:
```
$ git stash
Saved working directory and index state WIP on master; d7435644 Feat: configure graphql endpoint
```
By default, `git stash`
stores (or "stashes") the uncommitted changes (staged and unstaged files) and overlooks untracked and ignored files. Usually, you don't need to stash untracked and ignored files, but sometimes they might interfere with other things you want to do in your codebase.
You can use additional options to let `git stash`
take care of untracked and ignored files:
`git stash -u`
or`git stash --include-untracked`
stash untracked files.`git stash -a`
or`git stash --all`
stash untracked files and ignored files.
To stash specific files, you can use the command `git stash -p`
or `git stash –patch`
:
```
$ git stash --patch
diff --git a/.gitignore b/.gitignore
index 32174593..8d81be6e 100644
--- a/.gitignore
+++ b/.gitignore
@@ -3,6 +3,7 @@
# dependencies
node_modules/
/.pnp
+f,fmfm
.pnp.js
# testing
(1/1) Stash this hunk [y,n,q,a,d,e,?]?
```
## Listing your stashes
You can view your stashes with the command `git stash list`
. Stashes are saved in a last-in-first-out (LIFO) approach:
```
$ git stash list
stash@{0}: WIP on master: d7435644 Feat: configure graphql endpoint
```
By default, stashes are marked as WIP on top of the branch and commit that you created the stash from. However, this limited amount of information isn't helpful when you have multiple stashes, as it becomes difficult to remember or individually check their contents. To add a description to the stash, you can use the command `git stash save <description>`
:
```
$ git stash save "remove semi-colon from schema"
Saved working directory and index state On master: remove semi-colon from schema
$ git stash list
stash@{0}: On master: remove semi-colon from schema
stash@{1}: WIP on master: d7435644 Feat: configure graphql endpoint
```
## Retrieving stashed changes
You can reapply stashed changes with the commands `git stash apply`
and `git stash pop`
. Both commands reapply the changes stashed in the latest stash (that is, `stash@{0}`
). A `stash`
reapplies the changes while `pop`
removes the changes from the stash and reapplies them to the working copy. Popping is preferred if you don't need the stashed changes to be reapplied more than once.
You can choose which stash you want to pop or apply by passing the identifier as the last argument:
`$ git stash pop stash@{1} `
or
`$ git stash apply stash@{1}`
## Cleaning up the stash
It is good practice to remove stashes that are no longer needed. You must do this manually with the following commands:
`git stash clear`
empties the stash list by removing all the stashes.`git stash drop <stash_id>`
deletes a particular stash from the stash list.
## Checking stash diffs
The command `git stash show <stash_id>`
allows you to view the diff of a stash:
```
$ git stash show stash@{1}
console/console-init/ui/.graphqlrc.yml | 4 +-
console/console-init/ui/generated-frontend.ts | 742 +++++++++---------
console/console-init/ui/package.json | 2 +-
```
To get a more detailed diff, pass the `--patch`
or `-p`
flag:
```
$ git stash show stash@{0} --patch
diff --git a/console/console-init/ui/package.json b/console/console-init/ui/package.json
index 755912b97..5b5af1bd6 100644
--- a/console/console-init/ui/package.json
+++ b/console/console-init/ui/package.json
@@ -1,5 +1,5 @@
{
- "name": "my-usepatternfly",
+ "name": "my-usepatternfly-2",
"version": "0.1.0",
"private": true,
"proxy": "http://localhost:4000"
diff --git a/console/console-init/ui/src/AppNavHeader.tsx b/console/console-init/ui/src/AppNavHeader.tsx
index a4764d2f3..da72b7e2b 100644
--- a/console/console-init/ui/src/AppNavHeader.tsx
+++ b/console/console-init/ui/src/AppNavHeader.tsx
@@ -9,8 +9,8 @@ import { css } from "@patternfly/react-styles";
interface IAppNavHeaderProps extends PageHeaderProps {
- toolbar?: React.ReactNode;
- avatar?: React.ReactNode;
+ toolbar?: React.ReactNode;
+ avatar?: React.ReactNode;
}
export class AppNavHeader extends React.Component<IAppNavHeaderProps>{
render()
```
## Checking out to a new branch
You might come across a situation where the changes in a branch and your stash diverge, causing a conflict when you attempt to reapply the stash. A clean fix for this is to use the command `git stash branch <new_branch_name stash_id>`
, which creates a new branch based on the commit the stash was created *from* and pops the stashed changes to it:
```
$ git stash branch test_2 stash@{0}
Switched to a new branch 'test_2'
On branch test_2
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: .graphqlrc.yml
modified: generated-frontend.ts
modified: package.json
no changes added to commit (use "git add" and/or "git commit -a")
Dropped stash@{0} (fe4bf8f79175b8fbd3df3c4558249834ecb75cd1)
```
## Stashing without disturbing the stash reflog
In rare cases, you might need to create a stash while keeping the stash reference log (reflog) intact. These cases might arise when you need a script to stash as an implementation detail. This is achieved by the `git stash create`
command; it creates a stash entry and returns its object name without pushing it to the stash reflog:
```
$ git stash create "sample stash"
63a711cd3c7f8047662007490723e26ae9d4acf9
```
Sometimes, you might decide to push the stash entry created via `git stash create`
to the stash reflog:
```
$ git stash store -m "sample stash testing.." "63a711cd3c7f8047662007490723e26ae9d4acf9"
$ git stash list
stash @{0}: sample stash testing..
```
## Conclusion
I hope you found this article useful and learned something new. If I missed any useful options for using stash, please let me know in the comments.
## Comments are closed. |
13,295 | 什么是 Git 遴选(cherry-pick)? | https://opensource.com/article/21/4/cherry-picking-git | 2021-04-14T13:17:53 | [
"git",
"遴选"
] | https://linux.cn/article-13295-1.html |
>
> 了解 `git cherry-pick` 命令是什么,为什么用以及如何使用。
>
>
>

当你和一群程序员一起工作时,无论项目大小,处理多个 Git 分支之间的变更都会变得很困难。有时,你不想将整个 Git 分支合并到另一个分支,而是想选择并移动几个特定的提交。这个过程被称为 “<ruby> 遴选 <rt> cherry-pick </rt></ruby>”。
本文将介绍“遴选”是什么、为何使用以及如何使用。
那么让我们开始吧。
### 什么是遴选?
使用遴选(`cherry-pick`)命令,Git 可以让你将任何分支中的个别提交合并到你当前的 [Git HEAD](https://acompiler.com/git-head/) 分支中。
当执行 `git merge` 或者 `git rebase` 时,一个分支的所有提交都会被合并。`cherry-pick` 命令允许你选择单个提交进行整合。
### 遴选的好处
下面的情况可能会让你更容易理解遴选功能。
想象一下,你正在为即将到来的每周冲刺实现新功能。当你的代码准备好了,你会把它推送到远程分支,准备进行测试。
然而,客户并不是对所有修改都满意,要求你只呈现某些修改。因为客户还没有批准下次发布的所有修改,所以 `git rebase` 不会有预期的结果。为什么会这样?因为 `git rebase` 或者 `git merge` 会把上一个冲刺的每一个调整都纳入其中。
遴选就是答案!因为它只关注在提交中添加的变更,所以遴选只会带入批准的变更,而不添加其他的提交。
还有其他几个原因可以使用遴选:
* 这对于 bug 修复是必不可少的,因为 bug 是出现在开发分支中对应的提交的。
* 你可以通过使用 `git cherry-pick` 来避免不必要的工作,而不用使用其他选项例如 `git diff` 来应用特定变更。
* 如果因为不同 Git 分支的版本不兼容而无法将整个分支联合起来,那么它是一个很有用的工具。
### 使用 cherry-pick 命令
在 `cherry-pick` 命令的最简单形式中,你只需使用 [SHA](https://en.wikipedia.org/wiki/Secure_Hash_Algorithms) 标识符来表示你想整合到当前 HEAD 分支的提交。
要获得提交的哈希值,可以使用 `git log` 命令:
```
$ git log --oneline
```
当你知道了提交的哈希值后,你就可以使用 `cherry-pick` 命令。
语法是:
```
$ git cherry-pick <commit sha>
```
例如:
```
$ git cherry-pick 65be1e5
```
这将会把指定的修改合并到当前已签出的分支上。
如果你想做进一步的修改,也可以让 Git 将提交的变更内容添加到你的工作副本中。
语法是:
```
$ git cherry-pick <commit sha> --no-commit
```
例如:
```
$ git cherry-pick 65be1e5 --no-commit
```
如果你想同时选择多个提交,请将它们的提交哈希值用空格隔开:
```
$ git cherry-pick hash1 hash3
```
当遴选提交时,你不能使用 `git pull` 命令,因为它能获取一个仓库的提交**并**自动合并到另一个仓库。`cherry-pick` 是一个专门不这么做的工具;另一方面,你可以使用 `git fetch`,它可以获取提交,但不应用它们。毫无疑问,`git pull` 很方便,但它不精确。
### 自己尝试
要尝试这个过程,启动终端并生成一个示例项目:
```
$ mkdir fruit.git
$ cd fruit.git
$ git init .
```
创建一些数据并提交:
```
$ echo "Kiwifruit" > fruit.txt
$ git add fruit.txt
$ git commit -m 'First commit'
```
现在,通过创建一个项目的复刻来代表一个远程开发者:
```
$ mkdir ~/fruit.fork
$ cd !$
$ echo "Strawberry" >> fruit.txt
$ git add fruit.txt
$ git commit -m 'Added a fruit"
```
这是一个有效的提交。现在,创建一个不好的提交,代表你不想合并到你的项目中的东西:
```
$ echo "Rhubarb" >> fruit.txt
$ git add fruit.txt
$ git commit -m 'Added a vegetable that tastes like a fruit"
```
返回你的仓库,从你的假想的开发者那里获取提交的内容:
```
$ cd ~/fruit.git
$ git remote add dev ~/fruit.fork
$ git fetch dev
remote: Counting objects: 6, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 6 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (6/6), done...
```
```
$ git log –oneline dev/master
e858ab2 Added a vegetable that tastes like a fruit
0664292 Added a fruit
b56e0f8 First commit
```
你已经从你想象中的开发者那里获取了提交的内容,但你还没有将它们合并到你的版本库中。你想接受第二个提交,但不想接受第三个提交,所以使用 `cherry-pick`。
```
$ git cherry-pick 0664292
```
第二次提交现在在你的仓库里了:
```
$ cat fruit.txt
Kiwifruit
Strawberry
```
将你的更改推送到远程服务器上,这就完成了!
### 避免使用遴选的原因
在开发者社区中,通常不鼓励所以遴选。主要原因是它会造成重复提交,而你也失去了跟踪你的提交历史的能力。
如果你不按顺序地遴选了大量的提交,这些提交会被记录在你的分支中,这可能会在 Git 分支中导致不理想的结果。
遴选是一个强大的命令,如果没有正确理解可能发生的情况,它可能会导致问题。不过,当你搞砸了,提交到错误的分支时,它可能会救你一命(至少是你当天的工作)。
---
via: <https://opensource.com/article/21/4/cherry-picking-git>
作者:[Rajeev Bera](https://opensource.com/users/acompiler) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Whenever you're working with a group of programmers on a project, whether small or large, handling changes between multiple Git branches can become difficult. Sometimes, instead of combining an entire Git branch into a different one, you want to select and move a couple of specific commits. This procedure is known as "cherry-picking."
This article will cover the what, why, and how of cherry-picking.
So let's start.
## What is cherry-pick?
With the `cherry-pick`
command, Git lets you incorporate selected individual commits from any branch into your current [Git HEAD](https://acompiler.com/git-head/) branch.
When performing a `git merge`
or `git rebase`
, all the commits from a branch are combined. The `cherry-pick`
command allows you to select individual commits for integration.
## Benefits of cherry-pick
The following situation might make it easier to comprehend the way cherry-picking functions.
Imagine you are implementing new features for your upcoming weekly sprint. When your code is ready, you will push it into the remote branch, ready for testing.
However, the customer is not delighted with all of the modifications and requests that you present only certain ones. Because the client hasn't approved all changes for the next launch, `git rebase`
wouldn't create the desired results. Why? Because `git rebase`
or `git merge`
will incorporate every adjustment from the last sprint.
Cherry-picking is the answer! Because it focuses only on the changes added in the commit, cherry-picking brings in only the approved changes without adding other commits.
There are several other reasons to use cherry-picking:
- It is essential for bug fixing because bugs are set in the development branch using their commits.
- You can avoid unnecessary battles by using
`git cherry-pick`
instead of other options that apply changes in the specified commits, e.g.,`git diff`
. - It is a useful tool if a full branch unite is impossible because of incompatible versions in the various Git branches.
## Using the cherry-pick command
In the `cherry-pick`
command's simplest form, you can just use the [SHA](https://en.wikipedia.org/wiki/Secure_Hash_Algorithms) identifier for the commit you want to integrate into your current HEAD branch.
To get the commit hash, you can use the `git log`
command:
`$ git log --oneline`
Once you know the commit hash, you can use the `cherry-pick`
command.
The syntax is:
`$ git cherry-pick <commit sha>`
For example:
`$ git cherry-pick 65be1e5`
This will dedicate the specified change to your currently checked-out branch.
If you'd like to make further modifications, you can also instruct Git to add commit changes to your working copy.
The syntax is:
`$ git cherry-pick <commit sha> --no-commit`
For example:
`$ git cherry-pick 65be1e5 --no-commit`
If you would like to select more than one commit simultaneously, add their commit hashes separated by a space:
`$ git cherry-pick hash1 hash3`
When cherry-picking commits, you can't use the `git pull`
command because it fetches *and* automatically merges commits from one repository into another. The `cherry-pick`
command is a tool you use to specifically not do that; instead, use `git fetch`
, which fetches commits but does not apply them. There's no doubt that `git pull`
is convenient, but it's imprecise.
## Try it yourself
To try the process, launch a terminal and generate a sample project:
```
$ mkdir fruit.git
$ cd fruit.git
$ git init .
```
Create some data and commit it:
```
$ echo "Kiwifruit" > fruit.txt
$ git add fruit.txt
$ git commit -m 'First commit'
```
Now, represent a remote developer by creating a fork of your project:
```
$ mkdir ~/fruit.fork
$ cd !$
$ echo "Strawberry" >> fruit.txt
$ git add fruit.txt
$ git commit -m 'Added a fruit"
```
That's a valid commit. Now, create a bad commit to represent something you wouldn't want to merge into your project:
```
$ echo "Rhubarb" >> fruit.txt
$ git add fruit.txt
$ git commit -m 'Added a vegetable that tastes like a fruit"
```
Return to your authoritative repo and fetch the commits from your imaginary developer:
```
$ cd ~/fruit.git
$ git remote add dev ~/fruit.fork
$ git fetch dev
remote: Counting objects: 6, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 6 (delta 0), reused 0 (delta 0)
Unpacking objects: 100% (6/6), done...
```
```
$ git log –oneline dev/master
e858ab2 Added a vegetable that tastes like a fruit
0664292 Added a fruit
b56e0f8 First commit
```
You've fetched the commits from your imaginary developer, but you haven't merged them into your repository yet. You want to accept the second commit but not the third, so use `cherry-pick`
:
`$ git cherry-pick 0664292`
The second commit is now in your repository:
```
$ cat fruit.txt
Kiwifruit
Strawberry
```
Push your changes to your remote server, and you're done!
## Reasons to avoid cherry-picking
Cherry-picking is usually discouraged in the developer community. The primary reason is that it creates duplicate commits, but you also lose the ability to track your commit history.
If you're cherry-picking a lot of commits out of order, those commits will be recorded in your branch, and it might lead to undesirable results in your Git branch.
Cherry-picking is a powerful command that might cause problems if it's used without a proper understanding of what might occur. However, it may save your life (or at least your day job) when you mess up and make commits to the wrong branches.
## Comments are closed. |
13,296 | 在 Linux 上创建一个加密文件保险库 | https://opensource.com/article/21/4/linux-encryption | 2021-04-14T15:12:28 | [
"LUKS",
"加密",
"保险库"
] | /article-13296-1.html |
>
> 使用 Linux 统一密钥设置(LUKS)为物理驱动器或云存储上的敏感文件创建一个加密保险库。
>
>
>

最近,我演示了如何在 Linux 上使用<ruby> 统一密钥设置 <rt> Linux Unified Key Setup </rt></ruby>([LUKS](https://gitlab.com/cryptsetup/cryptsetup/blob/master/README.md))和 `cryptsetup` 命令 [实现全盘加密](https://opensource.com/article/21/3/encryption-luks)。虽然加密整个硬盘在很多情况下是有用的,但也有一些原因让你不想对整个硬盘进行加密。例如,你可能需要让一个硬盘在多个平台上工作,其中一些平台可能没有集成 [LUKS](https://gitlab.com/cryptsetup/cryptsetup/blob/master/README.md)。此外,现在是 21 世纪,由于云的存在,你可能不会使用物理硬盘来处理所有的数据。
几年前,有一个名为 [TrueCrypt](https://en.wikipedia.org/wiki/TrueCrypt) 的系统,允许用户创建加密的文件保险库,可以通过 TrueCrypt 解密来提供读/写访问。这是一项有用的技术,基本上提供了一个虚拟的便携式、完全加密的驱动器,你可以在那里存储重要数据。TrueCrypt 项目关闭了,但它可以作为一个有趣的模型。
幸运的是,LUKS 是一个灵活的系统,你可以使用它和 `cryptsetup` 在一个独立的文件中创建一个加密保险库,你可以将其保存在物理驱动器或云存储中。
下面就来介绍一下怎么做。
### 1、建立一个空文件
首先,你必须创建一个预定大小的空文件。就像是一种保险库或保险箱,你可以在其中存储其他文件。你使用的命令是 `util-linux` 软件包中的 `fallocate`:
```
$ fallocate --length 512M vaultfile.img
```
这个例子创建了一个 512MB 的文件,但你可以把你的文件做成任何你想要的大小。
### 2、创建一个 LUKS 卷
接下来,在空文件中创建一个 LUKS 卷:
```
$ cryptsetup --verify-passphrase \
luksFormat vaultfile.img
```
### 3、打开 LUKS 卷
要想创建一个可以存储文件的文件系统,必须先打开 LUKS 卷,并将其挂载到电脑上:
```
$ sudo cryptsetup open \
--type luks vaultfile.img myvault
$ ls /dev/mapper
myvault
```
### 4、建立一个文件系统
在你打开的保险库中建立一个文件系统:
```
$ sudo mkfs.ext4 -L myvault /dev/mapper/myvault
```
如果你现在不需要它做什么,你可以关闭它:
```
$ sudo cryptsetup close myvault
```
### 5、开始使用你的加密保险库
现在一切都设置好了,你可以在任何需要存储或访问私人数据的时候使用你的加密文件库。要访问你的保险库,必须将其挂载为一个可用的文件系统:
```
$ sudo cryptsetup open \
--type luks vaultfile.img myvault
$ ls /dev/mapper
myvault
$ sudo mkdir /myvault
$ sudo mount /dev/mapper/myvault /myvault
```
这个例子用 `cryptsetup` 打开保险库,然后把保险库从 `/dev/mapper` 下挂载到一个叫 `/myvault` 的新目录。和 Linux 上的任何卷一样,你可以把 LUKS 卷挂载到任何你想挂载的地方,所以除了 `/myvault`,你可以用 `/mnt` 或 `~/myvault` 或任何你喜欢的位置。
当它被挂载后,你的 LUKS 卷就会被解密。你可以像读取和写入文件一样读取和写入它,就像它是一个物理驱动器一样。
当使用完你的加密保险库时,请卸载并关闭它:
```
$ sudo umount /myvault
$ sudo cryptsetup close myvault
```
### 加密的文件保险库
你用 LUKS 加密的镜像文件和其他文件一样,都是可移动的,因此你可以将你的保险库存储在硬盘、外置硬盘,甚至是互联网上。只要你可以使用 LUKS,就可以解密、挂载和使用它来保证你的数据安全。轻松加密,提高数据安全性,不妨一试。
---
via: <https://opensource.com/article/21/4/linux-encryption>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,298 | 6 个提升 Linux 服务器安全的开源工具和技巧 | https://opensource.com/article/21/4/securing-linux-servers | 2021-04-15T08:23:42 | [
"安全",
"Linux",
"服务器"
] | /article-13298-1.html |
>
> 使用开源工具来保护你的 Linux 环境不被入侵。
>
>
>

如今我们的许多个人和专业数据都可以在网上获得,因此无论是专业人士还是普通互联网用户,学习安全和隐私的基本知识是非常重要的。作为一名学生,我通过学校的 CyberPatriot 活动获得了这方面的经验,在那里我有机会与行业专家交流,了解网络漏洞和建立系统安全的基本步骤。
本文基于我作为初学者迄今所学的知识,详细介绍了六个简单的步骤,以提高个人使用的 Linux 环境的安全性。在我的整个旅程中,我利用开源工具来加速我的学习过程,并熟悉了与提升 Linux 服务器安全有关的更高层次的概念。
我使用我最熟悉的 Ubuntu 18.04 版本测试了这些步骤,但这些步骤也适用于其他 Linux 发行版。
### 1、运行更新
开发者们不断地寻找方法,通过修补已知的漏洞,使服务器更加稳定、快速、安全。定期运行更新是一个好习惯,可以最大限度地提高安全性。运行它们:
```
sudo apt-get update && apt-get upgrade
```
### 2、启用防火墙保护
[启用防火墙](https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd) 可以更容易地控制服务器上的进站和出站流量。在 Linux 上有许多防火墙应用程序可以使用,包括 [firewall-cmd](https://opensource.com/article/20/2/firewall-cheat-sheet) 和 <ruby> 简单防火墙 <rt> Uncomplicated Firewall </rt></ruby>([UFW](https://wiki.ubuntu.com/UncomplicatedFirewall))。我使用 UFW,所以我的例子是专门针对它的,但这些原则适用于你选择的任何防火墙。
安装 UFW:
```
sudo apt-get install ufw
```
如果你想进一步保护你的服务器,你可以拒绝传入和传出的连接。请注意,这将切断你的服务器与世界的联系,所以一旦你封锁了所有的流量,你必须指定哪些出站连接是允许从你的系统中发出的:
```
sudo ufw default deny incoming
sudo ufw default allow outgoing
```
你也可以编写规则来允许你个人使用所需要的传入连接:
```
ufw allow <service>
```
例如,允许 SSH 连接:
```
ufw allow ssh
```
最后,启用你的防火墙:
```
sudo ufw enable
```
### 3、加强密码保护
实施强有力的密码政策是保持服务器安全、防止网络攻击和数据泄露的一个重要方面。密码策略的一些最佳实践包括强制要求最小长度和指定密码年龄。我使用 libpam-cracklib 软件包来完成这些任务。
安装 libpam-cracklib 软件包:
```
sudo apt-get install libpam-cracklib
```
强制要求密码的长度:
* 打开 `/etc/pam.d/common-password` 文件。
* 将 `minlen=12` 行改为你需要的任意字符数,从而改变所有密码的最小字符长度要求。
为防止密码重复使用:
* 在同一个文件(`/etc/pam.d/common-password`)中,添加 `remember=x` 行。
* 例如,如果你想防止用户重复使用他们最后 5 个密码中的一个,使用 `remember=5`。
要强制要求密码年龄:
* 在 `/etc/login.defs` 文件中找到以下几行,并用你喜欢的时间(天数)替换。例如:
```
PASS_MIN_AGE: 3
PASS_MAX_AGE: 90
PASS_WARN_AGE: 14
```
强制要求字符规格:
* 在密码中强制要求字符规格的四个参数是 `lcredit`(小写)、`ucredit`(大写)、`dcredit`(数字)和 `ocredit`(其他字符)。
* 在同一个文件(`/etc/pam.d/common-password`)中,找到包含 `pam_cracklib.so` 的行。
+ 在该行末尾添加以下内容:`lcredit=-a ucredit=-b dcredit=-c ocredit=-d`。
+ 例如,下面这行要求密码必须至少包含一个每种字符。你可以根据你喜欢的密码安全级别来改变数字。`lcredit=-1 ucredit=-1 dcredit=-1 ocredit=-1`。
### 4、停用容易被利用的非必要服务。
停用不必要的服务是一种最好的做法。这样可以减少开放的端口,以便被利用。
安装 systemd 软件包:
```
sudo apt-get install systemd
```
查看哪些服务正在运行:
```
systemctl list-units
```
[识别](http://www.yorku.ca/infosec/Administrators/UNIX_disable.html) 哪些服务可能会导致你的系统出现潜在的漏洞。对于每个服务可以:
* 停止当前正在运行的服务:`systemctl stop <service>`。
* 禁止服务在系统启动时启动:`systemctl disable <service>`。
* 运行这些命令后,检查服务的状态:`systemctl status <service>`。
### 5、检查监听端口
开放的端口可能会带来安全风险,所以检查服务器上的监听端口很重要。我使用 [netstat](https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/netstat) 命令来显示所有的网络连接:
```
netstat -tulpn
```
查看 “address” 列,确定 [端口号](https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers)。一旦你找到了开放的端口,检查它们是否都是必要的。如果不是,[调整你正在运行的服务](https://opensource.com/article/20/5/systemd-units),或者调整你的防火墙设置。
### 6、扫描恶意软件
杀毒扫描软件可以有用的防止病毒进入你的系统。使用它们是一种简单的方法,可以让你的服务器免受恶意软件的侵害。我首选的工具是开源软件 [ClamAV](https://www.clamav.net/)。
安装 ClamAV:
```
sudo apt-get install clamav
```
更新病毒签名:
```
sudo freshclam
```
扫描所有文件,并打印出被感染的文件,发现一个就会响铃:
```
sudo clamscan -r --bell -i /
```
你可以而且应该设置为自动扫描,这样你就不必记住或花时间手动进行扫描。对于这样简单的自动化,你可以使用 [systemd 定时器](https://opensource.com/article/20/7/systemd-timers) 或者你的 [喜欢的 cron](https://opensource.com/article/21/2/linux-automation) 来做到。
### 保证你的服务器安全
我们不能把保护服务器安全的责任只交给一个人或一个组织。随着威胁环境的不断迅速扩大,我们每个人都应该意识到服务器安全的重要性,并采用一些简单、有效的安全最佳实践。
这些只是你提升 Linux 服务器的安全可以采取的众多步骤中的一部分。当然,预防只是解决方案的一部分。这些策略应该与严格监控拒绝服务攻击、用 [Lynis](https://opensource.com/article/20/5/linux-security-lynis) 做系统分析以及创建频繁的备份相结合。
你使用哪些开源工具来保证服务器的安全?在评论中告诉我们它们的情况。
---
via: <https://opensource.com/article/21/4/securing-linux-servers>
作者:[Sahana Sreeram](https://opensource.com/users/sahanasreeram01gmailcom) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,299 | 开源为你带来竞争优势的 4 种方式 | https://opensource.com/article/21/4/open-source-competitive-advantage | 2021-04-15T08:53:52 | [
"开源"
] | /article-13299-1.html |
>
> 使用开源技术可以帮助组织获得更好的业务结果。
>
>
>

构建技术栈是每个组织的主要决策。选择合适的工具将让团队获得成功,选择错误的解决方案或平台会对生产率和利润率产生毁灭性影响。为了在当今快节奏的世界中脱颖而出,组织必须明智地选择数字解决方案,好的数字解决方案可以提升团队行动力与运营敏捷性。
这就是为什么越来越多的组织都采用开源解决方案的原因,这些组织来自各行各业,规模有大有小。根据 [麦肯锡](https://www.mckinsey.com/industries/technology-media-and-telecommunications/our-insights/developer-velocity-how-software-excellence-fuels-business-performance#) 最近的报告,高绩效组织的最大区别是采用不同的开源方案。
采用开源技术可以帮助组织提高竞争优势、获得更好业务成果的原因有以下四点。
### 1、可拓展性和灵活性
可以说,技术世界发展很快。例如,在 2014 年之前,Kubernetes 并不存在,但今天,它却令人印象深刻,无处不在。根据 CNCF [2020 云原生调查](https://www.cncf.io/blog/2020/11/17/cloud-native-survey-2020-containers-in-production-jump-300-from-our-first-survey/),91% 的团队正在以某种形式使用 Kubernetes。
组织投资开源的一个主要原因是因为开源赋予组织行动敏捷性,组织可以迅速地将新技术集成到技术栈中。这与传统方法不同,在传统方法中,团队需要几个季度甚至几年来审查、实施、采用软件,这导致团队不可能实现火速转变。
开源解决方案完整地提供源代码,团队可以轻松将软件与他们每天使用的工具连接起来。
简而言之,开源让开发团队能够为手头的东西构建完美的工具,而不是被迫改变工作方式来适应不灵活的专有工具。
### 2、安全性和高可信的协作
在数据泄露备受瞩目的时代,组织需要高度安全的工具来保护敏感数据的安全。
专有解决方案中的漏洞不易被发现,被发现时为时已晚。不幸的是,使用这些平台的团队无法看到源代码,本质上是他们将安全性外包给特定供应商,并希望得到最好的结果。
采用开源的另一个主要原因是开源工具使组织能够自己把控安全。例如,开源项目——尤其是拥有大型开源社区的项目——往往会收到更负责任的漏洞披露,因为每个人在使用过程中都可以彻底检查源代码。
由于源代码是免费提供的,因此披露通常伴随着修复缺陷的详细建议解决方案。这些方案使得开发团队能够快速解决问题,不断增强软件。
在远程办公时代,对于分布式团队来说,在知道敏感数据受到保护的情况下进行协作比以往任何时候都更重要。开源解决方案允许组织审核安全性、完全掌控自己数据,因此开源方案可以促进远程环境下高可信协作方式的成长。
### 3、不受供应商限制
根据 [最近的一项研究](https://solutionsreview.com/cloud-platforms/flexera-68-percent-of-cios-worry-about-vendor-lock-in-with-public-cloud/),68% 的 CIO 担心受供应商限制。当你受限于一项技术中,你会被迫接受别人的结论,而不是自己做结论。
当组织更换供应商时,专有解决方案通常会 [给你带走数据带来挑战](https://www.computerworld.com/article/3428679/mattermost-makes-case-for-open-source-as-team-messaging-market-booms.html)。另一方面,开源工具提供了组织需要的自由度和灵活性,以避免受供应商限制,开源工具可以让组织把数据带去任意地方。
### 4、顶尖人才和社区
随着越来越多的公司 [接受远程办公](https://mattermost.com/blog/tips-for-working-remotely/),人才争夺战变得愈发激烈。
在软件开发领域,获得顶尖人才始于赋予工程师先进工具,让工程师在工作中充分发挥潜力。开发人员 [越来越喜欢开源解决方案](https://opensource.com/article/20/6/open-source-developers-survey) 而不是专有解决方案,组织应该强烈考虑用开源替代商业解决方案,以吸引市场上最好的开发人员。
除了雇佣、留住顶尖人才更容易,公司能够通过开源平台利用贡献者社区,得到解决问题的建议,从平台中得到最大收益。此外,社区成员还可以 [直接为开源项目做贡献](https://mattermost.com/blog/100-most-popular-mattermost-features-invented-and-contributed-by-our-amazing-open-source-community/)。
### 开源带来自由
开源软件在企业团队中越来越受到欢迎——[这是有原因的](https://mattermost.com/blog/100-most-popular-mattermost-features-invented-and-contributed-by-our-amazing-open-source-community/)。它帮助团队灵活地构建完美的工作工具,同时使团队可以维护高度安全的环境。同时,开源允许团队掌控未来方向,而不是局限于供应商的路线图。开源还帮助公司接触才华横溢的工程师和开源社区成员。
---
via: <https://opensource.com/article/21/4/open-source-competitive-advantage>
作者:[Jason Blais](https://opensource.com/users/jasonblais) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,301 | 使用 Git 工作树对你的代码进行自由实验 | https://opensource.com/article/21/4/git-worktree | 2021-04-16T08:55:43 | [
"git",
"工作树"
] | https://linux.cn/article-13301-1.html |
>
> 获得自由尝试的权利,同时在你的实验出错时可以安全地拥有一个新的、链接的克隆存储库。
>
>
>

Git 的设计部分是为了进行实验。如果你知道你的工作会被安全地跟踪,并且在出现严重错误时有安全状态存在,你就不会害怕尝试新的想法。不过,创新的部分代价是,你很可能会在这个过程中弄得一团糟。文件会被重新命名、移动、删除、更改、切割成碎片;新的文件被引入;你不打算跟踪的临时文件会在你的工作目录中占据一席之地等等。
简而言之,你的工作空间变成了纸牌屋,在“快好了!”和“哦,不,我做了什么?”之间岌岌可危地平衡着。那么,当你需要把仓库恢复到下午的一个已知状态,以便完成一些真正的工作时,该怎么办?我立刻想到了 `git branch` 和 [git stash](/article-13293-1.html) 这两个经典命令,但这两个命令都不是用来处理未被跟踪的文件的,而且文件路径的改变和其他重大的转变也会让人困惑,它们只能把工作暂存(`stash`)起来以备后用。解决这个需求的答案是 Git 工作树。
### 什么是 Git 工作树
Git <ruby> 工作树 <rt> worktree </rt></ruby>是 Git 仓库的一个链接副本,允许你同时签出多个分支。工作树与主工作副本的路径是分开的,它可以处于不同的状态和不同的分支上。在 Git 中新建工作树的好处是,你可以在不干扰当前工作环境的情况下,做出与当前任务无关的修改、提交修改,然后在以后合并。
直接从 `git-worktree` 手册中找到了一个典型的例子:当你正在为一个项目做一个令人兴奋的新功能时,你的项目经理告诉你有一个紧急的修复工作。问题是你的工作仓库(你的“工作树”)处于混乱状态,因为你正在开发一个重要的新功能。你不想在当前的冲刺中“偷偷地”进行修复,而且你也不愿意把变更暂存起来,为修复创建一个新的分支。相反,你决定创建一个新的工作树,这样你就可以在那里进行修复:
```
$ git branch | tee
* dev
trunk
$ git worktree add -b hotfix ~/code/hotfix trunk
Preparing ../hotfix (identifier hotfix)
HEAD is now at 62a2daf commit
```
在你的 `code` 目录中,你现在有一个新的目录叫做 `hotfix`,它是一个与你的主项目仓库相连的 Git 工作树,它的 `HEAD` 停在叫做 `trunk` 的分支上。现在你可以把这个工作树当作你的主工作区来对待。你可以把目录切换到它里面,进行紧急修复、提交、并最终删除这个工作树:
```
$ cd ~/code/hotfix
$ sed -i 's/teh/the/' hello.txt
$ git commit --all --message 'urgent hot fix'
```
一旦你完成了你的紧急工作,你就可以回到你之前的任务。你可以控制你的热修复何时被集成到主项目中。例如,你可以直接将变更从其工作树推送到项目的远程存储库中:
```
$ git push origin HEAD
$ cd ~/code/myproject
```
或者你可以将工作树存档为 TAR 或 ZIP 文件:
```
$ cd ~/code/myproject
$ git archive --format tar --output hotfix.tar master
```
或者你可以从单独的工作树中获取本地的变化:
```
$ git worktree list
/home/seth/code/myproject 15fca84 [dev]
/home/seth/code/hotfix 09e585d [master]
```
从那里,你可以使用任何最适合你和你的团队的策略合并你的变化。
### 列出活动工作树
你可以使用 `git worktree list` 命令获得工作树的列表,并查看每个工作树签出的分支:
```
$ git worktree list
/home/seth/code/myproject 15fca84 [dev]
/home/seth/code/hotfix 09e585d [master]
```
你可以在任何一个工作树中使用这个功能。工作树始终是连接的(除非你手动移动它们,破坏 Git 定位工作树的能力,从而切断连接)。
### 移动工作树
Git 会跟踪项目 `.git` 目录下工作树的位置和状态:
```
$ cat ~/code/myproject/.git/worktrees/hotfix/gitdir
/home/seth/code/hotfix/.git
```
如果你需要重定位一个工作树,必须使用 `git worktree move`;否则,当 Git 试图更新工作树的状态时,就会失败:
```
$ mkdir ~/Temp
$ git worktree move hotfix ~/Temp
$ git worktree list
/home/seth/code/myproject 15fca84 [dev]
/home/seth/Temp/hotfix 09e585d [master]
```
### 移除工作树
当你完成你的工作时,你可以用 `remove` 子命令删除它:
```
$ git worktree remove hotfix
$ git worktree list
/home/seth/code/myproject 15fca84 [dev]
```
为了确保你的 `.git` 目录是干净的,在删除工作树后使用 `prune` 子命令:
```
$ git worktree remove prune
```
### 何时使用工作树
与许多选项一样,无论是标签还是书签还是自动备份,都要靠你来跟踪你产生的数据,否则可能会变得不堪重负。不要经常使用工作树,要不你最终会有 20 份存储库的副本,每份副本的状态都略有不同。我发现最好是创建一个工作树,做需要它的任务,提交工作,然后删除树。保持简单和专注。
重要的是,工作树为你管理 Git 存储库的方式提供了更好的灵活性。在需要的时候使用它们,再也不用为了检查另一个分支上的内容而争先恐后地保存工作状态了。
---
via: <https://opensource.com/article/21/4/git-worktree>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Git is designed in part to enable experimentation. Once you know that your work is safely being tracked and safe states exist for you to fall back upon if something goes horribly wrong, you're not afraid to try new ideas. Part of the price of innovation, though, is that you're likely to make a mess along the way. Files get renamed, moved, removed, changed, and cut into pieces. New files are introduced. Temporary files that you don't intend to track take up residence in your working directory.
In short, your workspace becomes a house of cards, balancing precariously between *"it's almost working!"* and *"oh no, what have I done?"*. So what happens when you need to get your repository back to a known state for an afternoon so that you can get some *real* work done? The classic commands git branch and [git stash](https://opensource.com/article/21/4/git-stash) come immediately to mind, but neither is designed to deal, one way or another, with untracked files, and changed file paths and other major shifts can make it confusing to just stash your work away for later. The answer is Git worktree.
## What is a Git worktree
A Git worktree is a linked copy of your Git repository, allowing you to have multiple branches checked out at a time. A worktree has a separate path from your main working copy, but it can be in a different state and on a different branch. The advantage of a new worktree in Git is that you can make a change unrelated to your current task, commit the change, and then merge it at a later date, all without disturbing your current work environment.
The canonical example, straight from the `git-worktree`
man page, is that you're working on an exciting new feature for a project when your project manager tells you there's an urgent fix required. The problem is that your working repository (your "worktree") is in disarray because you're developing a major new feature. You don't want to "sneak" the fix into your current sprint, and you don't feel comfortable stashing changes to create a new branch for the fix. Instead, you decide to create a fresh worktree so that you can make the fix there:
```
$ git branch | tee
* dev
trunk
$ git worktree add -b hotfix ~/code/hotfix trunk
Preparing ../hotfix (identifier hotfix)
HEAD is now at 62a2daf commit
```
In your `code`
directory, you now have a new directory called `hotfix`
, which is a Git worktree linked to your main project repository, with its `HEAD`
parked at the branch called `trunk`
. You can now treat this worktree as if it were your main workspace. You can change directory into it, make the urgent fix, commit it, and eventually remove the worktree:
```
$ cd ~/code/hotfix
$ sed -i 's/teh/the/' hello.txt
$ git commit --all --message 'urgent hot fix'
```
Once you've finished your urgent work, you can return to your previous task. You're in control of when your hotfix gets integrated into the main project. For instance, you can push the change directly from its worktree to the project's remote repo:
```
$ git push origin HEAD
$ cd ~/code/myproject
```
Or you can archive the worktree as a TAR or ZIP file:
```
$ cd ~/code/myproject
$ git archive --format tar --output hotfix.tar master
```
Or you can fetch the changes locally from the separate worktree:
```
$ git worktree list
/home/seth/code/myproject 15fca84 [dev]
/home/seth/code/hotfix 09e585d [master]
```
From there, you can merge your changes using whatever strategy works best for you and your team.
## Listing active worktrees
You can get a list of the worktrees and see what branch each has checked out using the `git worktree list`
command:
```
$ git worktree list
/home/seth/code/myproject 15fca84 [dev]
/home/seth/code/hotfix 09e585d [master]
```
You can use this from within either worktree. Worktrees are always linked (unless you manually move them, breaking Git's ability to locate a worktree, and therefore severing the link).
## Moving a worktree
Git tracks the locations and states of a worktree in your project's `.git`
directory:
```
$ cat ~/code/myproject/.git/worktrees/hotfix/gitdir
/home/seth/code/hotfix/.git
```
If you need to relocate a worktree, you must do that using `git worktree move`
; otherwise, when Git tries to update the worktree's status, it fails:
```
$ mkdir ~/Temp
$ git worktree move hotfix ~/Temp
$ git worktree list
/home/seth/code/myproject 15fca84 [dev]
/home/seth/Temp/hotfix 09e585d [master]
```
## Removing a worktree
When you're finished with your work, you can remove it with the `remove`
subcommand:
```
$ git worktree remove hotfix
$ git worktree list
/home/seth/code/myproject 15fca84 [dev]
```
To ensure your `.git`
directory is clean, use the `prune`
subcommand after removing a worktree:
`$ git worktree prune`
## When to use worktrees
As with many options, whether it's tabs or bookmarks or automatic backups, it's up to you to keep track of the data you generate, or it could get overwhelming. Don't use worktrees so often that you end up with 20 copies of your repo, each in a slightly different state. I find it best to create a worktree, do the task that requires it, commit the work, and then remove the tree. Keep it simple and focused.
The important thing is that worktrees provide improved flexibility for how you manage a Git repository. Use them when you need them, and never again scramble to preserve your working state just to check something on another branch.
## Comments are closed. |
13,302 | 如何在 Fedora 上安装 Steam | https://itsfoss.com/install-steam-fedora/ | 2021-04-16T09:07:12 | [
"Steam"
] | https://linux.cn/article-13302-1.html | 
Steam 对 Linux 游戏玩家来说是最好的东西了。由于 Steam,你可以在 Linux 上玩成百上千的游戏。
如果你还不知道,Steam 是最流行的 PC 游戏平台。2013 年,它开始可以在 Linux 使用。[Steam 最新的 Proton 项目](https://itsfoss.com/steam-play-proton/) 允许你在 Linux 上玩为 Windows 平台创建的游戏。这让 Linux 游戏库增强了许多倍。

Steam 提供了一个桌面客户端,你可以用它从 Steam 商店下载或购买游戏,然后安装并玩它。
过去我们曾讨论过 [在 Ubuntu 上安装 Steam](https://itsfoss.com/install-steam-ubuntu-linux/)。在这个初学者教程中,我将向你展示在 Fedora Linux 上安装 Steam 的步骤。
### 在 Fedora 上安装 Steam
要在 Fedora 上使用 Steam,你必须使用 RMPFusion 软件库。[RPMFusion](https://rpmfusion.org/) 是一套第三方软件库,其中包含了 Fedora 选择不与它们的操作系统一起发布的软件。它们提供自由(开源)和非自由(闭源)的软件库。由于 Steam 在非自由软件库中,你将只安装那一个。
我将同时介绍终端和图形安装方法。
#### 方法 1:通过终端安装 Steam
这是最简单的方法,因为它需要的步骤最少。只需输入以下命令即可启用仓库:
```
sudo dnf install https://mirrors.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm
```
你会被要求输入密码。然后你会被要求验证是否要安装这些仓库。你同意后,仓库安装就会完成。
要安装 Steam,只需输入以下命令:
```
sudo dnf install steam
```

输入密码后按 `Y` 接受。安装完毕后,打开 Steam,玩一些游戏。
#### 方法 2:通过 GUI 安装 Steam
你可以从软件中心 [启用 Fedora 上的第三方仓库](https://itsfoss.com/fedora-third-party-repos/)。打开软件中心并点击菜单。

在 “软件仓库” 窗口中,你会看到顶部有一个 “第三方软件仓库”。点击 “安装” 按钮。当提示你输入密码时,就完成了。

安装了 Steam 的 RPM Fusion 仓库后,更新你系统的软件缓存(如果需要),并在软件中心搜索 Steam。

安装完成后,打开 GNOME 软件中心,搜索 Steam。找到 Steam 页面后,点击安装。当被问及密码时,输入你的密码就可以了。
安装完 Steam 后,启动应用,输入你的 Steam 帐户详情或注册它,然后享受你的游戏。
### 将 Steam 作为 Flatpak 使用
Steam 也可以作为 Flatpak 使用。Fedora 上默认安装 Flatpak。在使用该方法安装 Steam 之前,我们必须安装 Flathub 仓库。

首先,在浏览器中打开 [Flatpak 网站](https://www.flatpak.org/setup/Fedora/)。现在,点击标有 “Flathub repository file” 的蓝色按钮。浏览器会询问你是否要在 GNOME 软件中心打开该文件。点击确定。在 GNOME 软件中心打开后,点击安装按钮。系统会提示你输入密码。
如果你在尝试安装 Flathub 仓库时出现错误,请在终端运行以下命令:
```
flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
```
安装好 Flathub 仓库后,你需要做的就是在 GNOME 软件中心搜索 Steam。找到后,安装它,你就可以开始玩了。

Flathub 版本的 Steam 也有几个附加组件可以安装。其中包括一个 DOS 兼容工具和几个 [Vulkan](https://developer.nvidia.com/vulkan) 和 Proton 工具。

我想这应该可以帮助你在 Fedora 上使用 Steam。享受你的游戏 :smiley:
---
via: <https://itsfoss.com/install-steam-fedora/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Steam is the best thing that could happen to Linux gamers. Thanks to Steam, you can play hundreds and thousands of games on Linux.
If you are not already aware of it, Steam is the most popular PC gaming platform. In 2013, it became available for Linux. [Steam’s latest Proton project](https://itsfoss.com/steam-play-proton/) allows you to play games created for Windows platform on Linux. This enhanced Linux gaming library many folds.
Steam provides a desktop client and you can use it to download or purchase games from the Steam store, install the game and play it.
We have discussed [installing Steam on Ubuntu](https://itsfoss.com/install-steam-ubuntu-linux/) in the past. In this beginner’s tutorial, I am going to show you the steps for installing Steam on Fedora Linux.
## Installing Steam on Fedora
To get Steam on Fedora, you’ll have to use RMPFusion repository. [RPMFusion](https://rpmfusion.org/?ref=itsfoss.com) is a series of third-party repos that contain software that Fedora chooses not to ship with their operating system. They offer both free (open source) and non-free (closed source) repos. Since Steam is in the non-free repo, you will only install that one.
I shall go over both the terminal and graphical installation methods.
### Method 1: Install Steam via terminal
This is the easiest method because it requires the fewest steps. Just enter the following command to enable the non-free repo:
`sudo dnf install https://mirrors.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm`
You will be asked to enter your password. You will then be asked to verify that you want to install these repos. Once you approve it, the installation of the repo will be completed.
To install Steam, simply enter the following command:
`sudo dnf install steam`
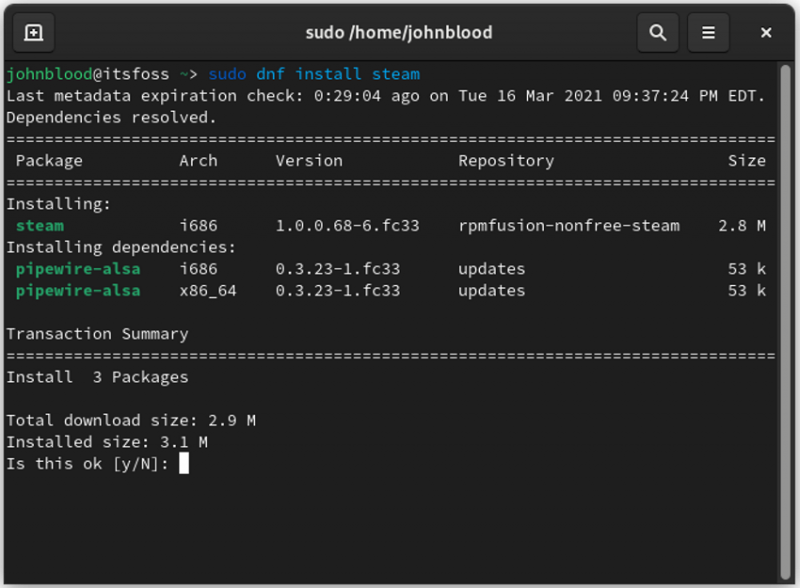
Enter your password and press “Y” to accept. Once installed, open Steam and play some games.
### Method 2: Install Steam via GUI
You can [enable the third-party repository on Fedora](https://itsfoss.com/fedora-third-party-repos/) from the Software Center. Open the Software Center application and click on the hamburger menu:
In the Software Repositories window, you will see a section at the top that says “Third Party Repositories”. Click the Install button. Enter your password when you are prompted and you are done.
Once you have installed RPM Fusion repository for Steam, update your system’s software cache (if needed) and search for Steam in the software center.
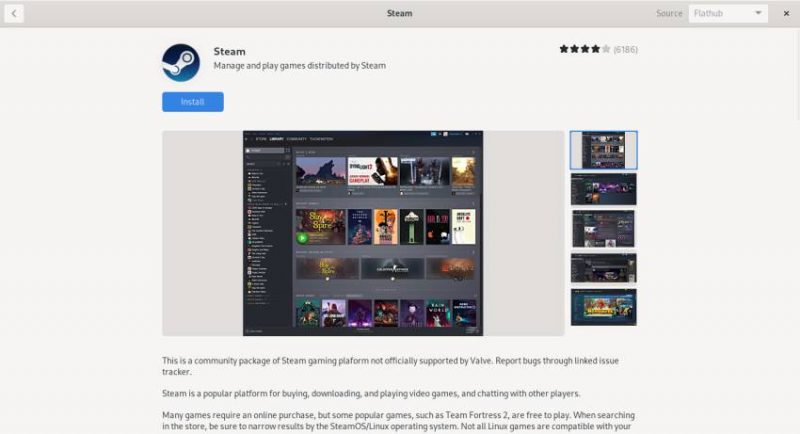
Once that installation is complete, open up the GNOME Software Center and search for Steam. Once you locate the Steam page, click install. Enter your password when asked and you’re done.
After installing Steam, start the application, enter your Steam account details or register for it and enjoy your games.
## Using Steam as Flatpak
Steam is also available as a Flatpak. Flatpak is installed by default on Fedora. Before we can install Steam using that method, we have to install the Flathub repo.
First, open the [Flatpak site](https://www.flatpak.org/setup/Fedora/?ref=itsfoss.com) in your browser. Now, click the blue button marked “Flathub repository file”. The browser will ask you if you want to open the file in GNOME Software Center. Click okay. Once GNOME Software Center open, click the install button. You will be prompted to enter your password.
If you get an error when you try to install the Flathub repo, run this command in the terminal:
`flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo`
With the Flathub repo installed, all you need to do is search for Steam in the GNOME Software Center. Once you find it, install it, and you are ready to go.
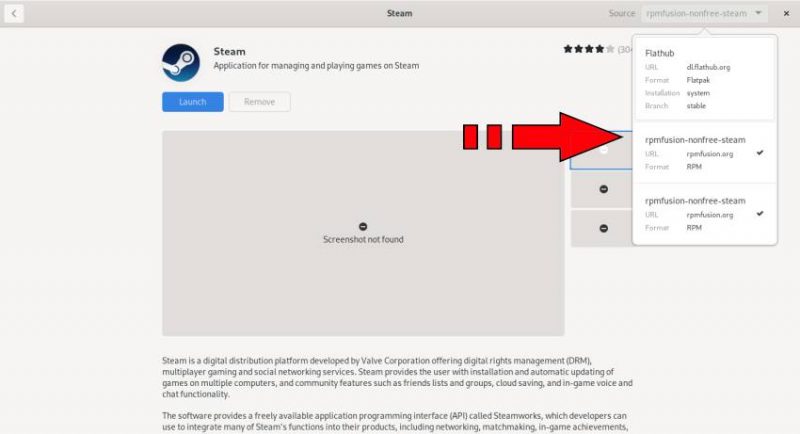
The Flathub version of Steam has several add-ons you can install, as well. These include a DOS compatibility tool and a couple of tools for [Vulkan](https://developer.nvidia.com/vulkan?ref=itsfoss.com) and Proton.
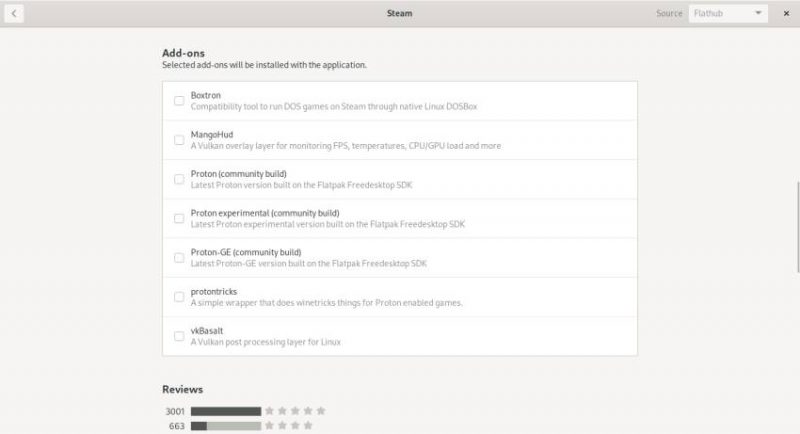
I think this should help you with Steam on Fedora. Enjoy your games :) |
13,304 | 用开源的 VeraCrypt 加密你的文件 | https://opensource.com/article/21/4/open-source-encryption | 2021-04-17T10:56:00 | [
"加密",
"VeraCrypt"
] | /article-13304-1.html |
>
> VeraCrypt 提供跨平台的开源文件加密功能。
>
>
>

许多年前,有一个名为 [TrueCrypt](https://en.wikipedia.org/wiki/TrueCrypt) 的加密软件。它的源码是可以得到的,尽管没有任何人声称曾对它进行过审计或贡献过。它的作者是(至今仍是)匿名的。不过,它是跨平台的,易于使用,而且真的非常有用。
TrueCrypt 允许你创建一个加密的文件“保险库”,在那里你可以存储任何类型的敏感信息(文本、音频、视频、图像、PDF 等)。只要你有正确的口令,TrueCrypt 就可以解密保险库,并在任何运行 TrueCrypt 的电脑上提供读写权限。这是一项有用的技术,它基本上提供了一个虚拟的、可移动的、完全加密的驱动器(除了文件以外),你可以在其中安全地存储你的数据。
TrueCrypt 最终关闭了,但一个名为 VeraCrypt 的替代项目迅速兴起,填补了这一空白。[VeraCrypt](https://www.veracrypt.fr/en/Home.html) 基于 TrueCrypt 7.1a,比原来的版本有许多改进(包括标准加密卷和引导卷的算法的重大变化)。在 VeraCrypt 1.12 及以后的版本中,你可以使用自定义迭代来提高加密安全性。更好的是,VeraCrypt 可以加载旧的 TrueCrypt 卷,所以如果你是 TrueCrypt 用户,可以很容易地将它们转移到 VeraCrypt 上。
### 安装 VeraCrypt
你可以从 [VeraCrypt 下载页面](https://www.veracrypt.fr/en/Downloads.html) 下载相应的安装文件,之后在所有主流平台上安装 VeraCrypt。
另外,你也可以自己从源码构建它。在 Linux 上,它需要 wxGTK3、makeself 和通常的开发栈(Binutils、GCC 等)。
当你安装后,从你的应用菜单中启动 VeraCrypt。
### 创建一个 VeraCrypt 卷
如果你刚接触 VeraCrypt,你必须先创建一个 VeraCrypt 加密卷(否则,你没有任何东西可以解密)。在 VeraCrypt 窗口中,点击左侧的 “Create Volume” 按钮。

在出现的 VeraCrypt 的卷创建向导窗口中,选择要创建一个加密文件容器还是要加密整个驱动器或分区。向导将为你的数据创建一个保险库,所以请按照提示进行操作。
在本文中,我创建了一个文件容器。VeraCrypt 容器和其他文件很像:它保存在硬盘、外置硬盘、云存储或其他任何你能想到的存储数据的地方。与其他文件一样,它可以被移动、复制和删除。与大多数其他文件不同的是,它可以\_容纳\_更多的文件,这就是为什么我认为它是一个“保险库”,而 VeraCrypt 开发者将其称为“容器”。它的开发者将 VeraCrypt 文件称为“容器”,是因为它可以包含其他数据对象;它与 LXC、Kubernetes 和其他现代 IT 机制所流行的容器技术无关。
#### 选择一个文件系统
在创建卷的过程中,你会被要求选择一个文件系统来决定你放在保险库中的文件的存储方式。微软 FAT 格式是过时的、非日志型,并且限制了卷和文件的大小,但它是所有平台都能读写的一种格式。如果你打算让你的 VeraCrypt 保险库跨平台,FAT 是你最好的选择。
除此之外,NTFS 适用于 Windows 和 Linux。开源的 EXT 系列适用于 Linux。
### 挂载 VeraCrypt 加密卷
当你创建了 VeraCrypt 卷,你就可以在 VeraCrypt 窗口中加载它。要挂载一个加密库,点击右侧的 “Select File” 按钮。选择你的加密文件,选择 VeraCrypt 窗口上半部分的一个编号栏,然后点击位于 VeraCrypt 窗口左下角的 “Mount” 按钮。
你挂载的卷在 VeraCrypt 窗口的可用卷列表中,你可以通过文件管理器访问该卷,就像访问一个外部驱动器一样。例如,在 KDE 上,我打开 [Dolphin](https://en.wikipedia.org/wiki/Dolphin_%28file_manager%29),进入 `/media/veracrypt1`,然后我就可以把文件复制到我的保险库里。
只要你的设备上有 VeraCrypt,你就可以随时访问你的保险库。在你手动在 VeraCrypt 中挂载之前,文件都是加密的,在那里,文件会保持解密,直到你再次关闭卷。
### 关闭 VeraCrypt 卷
为了保证你的数据安全,当你不需要打开 VeraCrypt 卷时,关闭它是很重要的。这样可以保证数据的安全,不被人窥视,且不被人趁机犯罪。

关闭 VeraCrypt 容器和打开容器一样简单。在 VeraCrypt 窗口中选择列出的卷,然后点击 “Dismount”。你就不能访问保险库中的文件了,其他人也不会再有访问权。
### VeraCrypt 轻松实现跨平台加密
有很多方法可以保证你的数据安全,VeraCrypt 试图为你提供方便,而无论你需要在什么平台上使用这些数据。如果你想体验简单、开源的文件加密,请尝试 VeraCrypt。
---
via: <https://opensource.com/article/21/4/open-source-encryption>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,305 | 我使用 Git cherry-pick 命令的 3 个理由 | https://opensource.com/article/21/3/git-cherry-pick | 2021-04-17T17:44:51 | [
"遴选",
"Git"
] | https://linux.cn/article-13305-1.html |
>
> “遴选”可以解决 Git 仓库中的很多问题。以下是用 `git cherry-pick` 修复错误的三种方法。
>
>
>

在版本控制系统中摸索前进是一件很棘手的事情。对于一个新手来说,这可能是非常难以应付的,但熟悉版本控制系统(如 Git)的术语和基础知识是开始为开源贡献的第一步。
熟悉 Git 也能帮助你在开源之路上走出困境。Git 功能强大,让你感觉自己在掌控之中 —— 没有哪一种方法会让你无法恢复到工作版本。
这里有一个例子可以帮助你理解“<ruby> 遴选 <rt> cherry-pick </rt></ruby>”的重要性。假设你已经在一个分支上做了好几个提交,但你意识到这是个错误的分支!你现在该怎么办?你现在要做什么?要么在正确的分支上重复所有的变更,然后重新提交,要么把这个分支合并到正确的分支上。等一下,前者太过繁琐,而你可能不想做后者。那么,还有没有办法呢?有的,Git 已经为你准备好了。这就是“遴选”的作用。顾名思义,你可以用它从一个分支中手工遴选一个提交,然后转移到另一个分支。
使用遴选的原因有很多。以下是其中的三个原因。
### 避免重复性工作
如果你可以直接将相同的提交复制到另一个分支,就没有必要在不同的分支中重做相同的变更。请注意,遴选出来的提交会在另一个分支中创建带有新哈希的新提交,所以如果你看到不同的提交哈希,请不要感到困惑。
如果您想知道什么是提交的哈希,以及它是如何生成的,这里有一个说明可以帮助你。提交哈希是用 [SHA-1](https://en.wikipedia.org/wiki/SHA-1) 算法生成的字符串。SHA-1 算法接收一个输入,然后输出一个唯一的 40 个字符的哈希值。如果你使用的是 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 系统,请尝试在您的终端上运行这个命令:
```
$ echo -n "commit" | openssl sha1
```
这将输出一个唯一的 40 个字符的哈希值 `4015b57a143aec5156fd1444a017a32137a3fd0f`。这个哈希代表了字符串 `commit`。
Git 在提交时生成的 SHA-1 哈希值不仅仅代表一个字符串。它代表的是:
```
sha1(
meta data
commit message
committer
commit date
author
authoring date
Hash of the entire tree object
)
```
这就解释了为什么你对代码所做的任何细微改动都会得到一个独特的提交哈希值。哪怕是一个微小的改动都会被发现。这是因为 Git 具有完整性。
### 撤销/恢复丢失的更改
当你想恢复到工作版本时,遴选就很方便。当多个开发人员在同一个代码库上工作时,很可能会丢失更改,最新的版本会被转移到一个陈旧的或非工作版本上。这时,遴选提交到工作版本就可以成为救星。
#### 它是如何工作的?
假设有两个分支:`feature1` 和 `feature2`,你想把 `feature1` 中的提交应用到 `feature2`。
在 `feature1` 分支上,运行 `git log` 命令,复制你想遴选的提交哈希值。你可以看到一系列类似于下面代码示例的提交。`commit` 后面的字母数字代码就是你需要复制的提交哈希。为了方便起见,您可以选择复制前六个字符(本例中为 `966cf3`)。
```
commit 966cf3d08b09a2da3f2f58c0818baa37184c9778 (HEAD -> master)
Author: manaswinidas <[email protected]>
Date: Mon Mar 8 09:20:21 2021 +1300
add instructions
```
然后切换到 `feature2` 分支,在刚刚从日志中得到的哈希值上运行 `git cherry-pick`:
```
$ git checkout feature2
$ git cherry-pick 966cf3.
```
如果该分支不存在,使用 `git checkout -b feature2` 来创建它。
这里有一个问题。你可能会遇到下面这种情况:
```
$ git cherry-pick 966cf3
On branch feature2
You are currently cherry-picking commit 966cf3d.
nothing to commit, working tree clean
The previous cherry-pick is now empty, possibly due to conflict resolution.
If you wish to commit it anyway, use:
git commit --allow-empty
Otherwise, please use 'git reset'
```
不要惊慌。只要按照建议运行 `git commit --allow-empty`:
```
$ git commit --allow-empty
[feature2 afb6fcb] add instructions
Date: Mon Mar 8 09:20:21 2021 +1300
```
这将打开你的默认编辑器,允许你编辑提交信息。如果你没有什么要补充的,可以保存现有的信息。
就这样,你完成了你的第一次遴选。如上所述,如果你在分支 `feature2` 上运行 `git log`,你会看到一个不同的提交哈希。下面是一个例子:
```
commit afb6fcb87083c8f41089cad58deb97a5380cb2c2 (HEAD -> feature2)
Author: manaswinidas <[[email protected]][4]>
Date: Mon Mar 8 09:20:21 2021 +1300
add instructions
```
不要对不同的提交哈希感到困惑。这只是区分 `feature1` 和 `feature2` 的提交。
### 遴选多个提交
但如果你想遴选多个提交的内容呢?你可以使用:
```
git cherry-pick <commit-hash1> <commit-hash2>... <commit-hashn>
```
请注意,你不必使用整个提交的哈希值,你可以使用前五到六个字符。
同样,这也是很繁琐的。如果你想遴选的提交是一系列的连续提交呢?这种方法太费劲了。别担心,有一个更简单的方法。
假设你有两个分支:
* `feature1` 包括你想复制的提交(从更早的 `commitA` 到 `commitB`)。
* `feature2` 是你想把提交从 `feature1` 转移到的分支。
然后:
1. 输入 `git checkout <feature1>`。
2. 获取 `commitA` 和 `commitB` 的哈希值。
3. 输入 `git checkout <branchB>`。
4. 输入 `git cherry-pick <commitA>^..<commitB>` (请注意,这包括 `commitA` 和 `commitB`)。
5. 如果遇到合并冲突,[像往常一样解决](https://opensource.com/article/20/4/git-merge-conflict),然后输入 `git cherry-pick --continue` 恢复遴选过程。
### 重要的遴选选项
以下是 [Git 文档](https://git-scm.com/docs/git-cherry-pick) 中的一些有用的选项,你可以在 `cherry-pick` 命令中使用。
* `-e`、`--edit`:用这个选项,`git cherry-pick` 可以让你在提交前编辑提交信息。
* `-s`、`--signoff`:在提交信息的结尾添加 `Signed-off by` 行。更多信息请参见 `git-commit(1)` 中的 signoff 选项。
* `-S[<keyid>]`、`--pgg-sign[=<keyid>]`:这些是 GPG 签名的提交。`keyid` 参数是可选的,默认为提交者身份;如果指定了,则必须嵌在选项中,不加空格。
* `--ff`:如果当前 HEAD 与遴选的提交的父级提交相同,则会对该提交进行快进操作。
下面是除了 `--continue` 外的一些其他的后继操作子命令:
* `--quit`:你可以忘记当前正在进行的操作。这可以用来清除遴选或撤销失败后的后继操作状态。
* `--abort`:取消操作并返回到操作序列前状态。
下面是一些关于遴选的例子:
* `git cherry-pick master`:应用 `master` 分支顶端的提交所引入的变更,并创建一个包含该变更的新提交。
* `git cherry-pick master~4 master~2':应用`master` 指向的第五个和第三个最新提交所带来的变化,并根据这些变化创建两个新的提交。
感到不知所措?你不需要记住所有的命令。你可以随时在你的终端输入 `git cherry-pick --help` 查看更多选项或帮助。
---
via: <https://opensource.com/article/21/3/git-cherry-pick>
作者:[Manaswini Das](https://opensource.com/users/manaswinidas) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Finding your way around a version control system can be tricky. It can be massively overwhelming for a newbie, but being well-versed with the terminology and the basics of a version control system like Git is one of the baby steps to start contributing to open source.
Being familiar with Git can also help you out of sticky situations in your open source journey. Git is powerful and makes you feel in control—there is not a single way in which you cannot revert to a working version.
Here is an example to help you understand the importance of cherry-picking. Suppose you have made several commits in a branch, but you realize it's the wrong branch! What do you do now? Either you repeat all your changes in the correct branch and make a fresh commit, or you merge the branch into the correct branch. Wait, the former is too tedious, and you may not want to do the latter. So, is there a way? Yes, Git's got you covered. Here is where cherry-picking comes into play. As the term suggests, you can use it to hand-pick a commit from one branch and transfer it into another branch.
There are various reasons to use cherry-picking. Here are three of them.
## Avoid redundancy of efforts
There's no need to redo the same changes in a different branch when you can just copy the same commits to the other branch. Please note that cherry-picking commits will create a fresh commit with a new hash in the other branch, so please don't be confused if you see a different commit hash.
In case you are wondering what a commit hash is and how it is generated, here is a note to help you: A commit hash is a string generated using the [SHA-1](https://en.wikipedia.org/wiki/SHA-1) algorithm. The SHA-1 algorithm takes an input and outputs a unique 40-character hash. If you are on a [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) system, try running this in your terminal:
`$ echo -n "commit" | openssl sha1`
This outputs a unique 40-character hash, `4015b57a143aec5156fd1444a017a32137a3fd0f`
. This hash represents the string `commit`
.
A SHA-1 hash generated by Git when you make a commit represents much more than just a single string. It represents:
```
sha1(
meta data
commit message
committer
commit date
author
authoring date
Hash of the entire tree object
)
```
This explains why you get a unique commit hash for the slightest change you make to your code. Not even a single change goes unnoticed. This is because Git has integrity.
## Undoing/restoring lost changes
Cherry-picking can be handy when you want to restore to a working version. When multiple developers are working on the same codebase, it is very likely for changes to get lost and the latest version to move to a stale or non-working version. That's where cherry-picking commits to the working version can be a savior.
### How does it work?
Suppose there are two branches, `feature1`
and `feature2`
, and you want to apply commits from `feature1`
to `feature2`
.
On the `feature1`
branch, run a `git log`
command, and copy the commit hash that you want to cherry-pick. You can see a series of commits resembling the code sample below. The alphanumeric code following "commit" is the commit hash that you need to copy. You may choose to copy the first six characters (`966cf3`
in this example) for the sake of convenience:
```
commit 966cf3d08b09a2da3f2f58c0818baa37184c9778 (HEAD -> master)
Author: manaswinidas <[email protected]>
Date: Mon Mar 8 09:20:21 2021 +1300
add instructions
```
Then switch to `feature2`
and run `git cherry-pick`
on the hash you just got from the log:
```
$ git checkout feature2
$ git cherry-pick 966cf3.
```
If the branch doesn't exist, use `git checkout -b feature2`
to create it.
Here's a catch: You may encounter the situation below:
```
$ git cherry-pick 966cf3
On branch feature2
You are currently cherry-picking commit 966cf3d.
nothing to commit, working tree clean
The previous cherry-pick is now empty, possibly due to conflict resolution.
If you wish to commit it anyway, use:
git commit --allow-empty
Otherwise, please use 'git reset'
```
Do not panic. Just run `git commit --allow-empty`
as suggested:
```
$ git commit --allow-empty
[feature2 afb6fcb] add instructions
Date: Mon Mar 8 09:20:21 2021 +1300
```
This opens your default editor and allows you to edit the commit message. It's acceptable to save the existing message if you have nothing to add.
There you go; you did your first cherry-pick. As discussed above, if you run a `git log`
on branch `feature2`
, you will see a different commit hash. Here is an example:
```
commit afb6fcb87083c8f41089cad58deb97a5380cb2c2 (HEAD -> feature2)
Author: manaswinidas <[email protected]>
Date: Mon Mar 8 09:20:21 2021 +1300
add instructions
```
Don't be confused about the different commit hash. That just distinguishes between the commits in `feature1`
and `feature2`
.
## Cherry-pick multiple commits
But what if you want to cherry-pick multiple commits? You can use:
`git cherry-pick <commit-hash1> <commit-hash2>... <commit-hashn>`
Please note that you don't have to use the entire commit hash; you can use the first five or six characters.
Again, this is tedious. What if the commits you want to cherry-pick are a range of continuous commits? This approach is too much work. Don't worry; there's an easier way.
Assume that you have two branches:
`feature1`
includes commits you want to copy (from`commitA`
(older) to`commitB`
).`feature2`
is the branch you want the commits to be transferred to from`feature1`
.
Then:
- Enter
`git checkout <feature1>`
. - Get the hashes of
`commitA`
and`commitB`
. - Enter
`git checkout <branchB>`
. - Enter
`git cherry-pick <commitA>^..<commitB>`
(please note that this includes`commitA`
and`commitB`
). - Should you encounter a merge conflict,
[solve it as usual](https://opensource.com/article/20/4/git-merge-conflict)and then type`git cherry-pick --continue`
to resume the cherry-pick process.
## Important cherry-pick options
Here are some useful options from the [Git documentation](https://git-scm.com/docs/git-cherry-pick) that you can use with the `cherry-pick`
command:
`-e`
,`--edit`
: With this option,`git cherry-pick`
lets you edit the commit message prior to committing.`-s`
,`--signoff`
: Add a "Signed-off-by" line at the end of the commit message. See the signoff option in git-commit(1) for more information.`-S[<keyid>]`
,`--gpg-sign[=<keyid>]`
: These are GPG-sign commits. The`keyid`
argument is optional and defaults to the committer identity; if specified, it must be stuck to the option without a space.`--ff`
: If the current HEAD is the same as the parent of the cherry-picked commit, then a fast-forward to this commit will be performed.
Here are some other sequencer subcommands (apart from continue):
`--quit`
: You can forget about the current operation in progress. This can be used to clear the sequencer state after a failed cherry-pick or revert.`--abort`
: Cancel the operation and return to the presequence state.
Here are some examples of cherry-picking:
`git cherry-pick master`
: Applies the change introduced by the commit at the tip of the master branch and creates a new commit with this change`git cherry-pick master~4 master~2`
: Applies the changes introduced by the fifth and third-last commits pointed to by master and creates two new commits with these changes
Feeling overwhelmed? You needn't remember all the commands. You can always type `git cherry-pick --help`
in your terminal to look at more options or help.
## 3 Comments |
13,307 | 使用 systemd 定时器代替 cron 作业 | https://opensource.com/article/20/7/systemd-timers | 2021-04-18T10:45:00 | [
"定时器",
"cron",
"systemd"
] | https://linux.cn/article-13307-1.html |
>
> 定时器提供了比 cron 作业更为细粒度的事件控制。
>
>
>

我正在致力于将我的 [cron](https://opensource.com/article/17/11/how-use-cron-linux) 作业迁移到 systemd 定时器上。我已经使用定时器多年了,但通常来说,我的学识只足以支撑我当前的工作。但在我研究 [systemd 系列](https://opensource.com/users/dboth) 的过程中,我发现 systemd 定时器有一些非常有意思的能力。
与 cron 作业类似,systemd 定时器可以在特定的时间间隔触发事件(shell 脚本和程序),例如每天一次或在一个月中的特定某一天(或许只有在周一生效),或在从上午 8 点到下午 6 点的工作时间内每隔 15 分钟一次。定时器也可以做到 cron 作业无法做到的一些事情。举个例子,定时器可以在特定事件发生后的一段时间后触发一段脚本或者程序去执行,例如开机、启动、上个任务完成,甚至于定时器调用的上个服务单元的完成的时刻。
### 操作系统维护的计时器
当在一个新系统上安装 Fedora 或者是任意一个基于 systemd 的发行版时,作为系统维护过程的一部分,它会在 Linux 宿主机的后台中创建多个定时器。这些定时器会触发事件来执行必要的日常维护任务,比如更新系统数据库、清理临时目录、轮换日志文件,以及更多其他事件。
作为示例,我会查看一些我的主要工作站上的定时器,通过执行 `systemctl status *timer` 命令来展示主机上的所有定时器。星号的作用与文件通配相同,所以这个命令会列出所有的 systemd 定时器单元。
```
[root@testvm1 ~]# systemctl status *timer
● mlocate-updatedb.timer - Updates mlocate database every day
Loaded: loaded (/usr/lib/systemd/system/mlocate-updatedb.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Fri 2020-06-05 00:00:00 EDT; 15h left
Triggers: ● mlocate-updatedb.service
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Updates mlocate database every day.
● logrotate.timer - Daily rotation of log files
Loaded: loaded (/usr/lib/systemd/system/logrotate.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Fri 2020-06-05 00:00:00 EDT; 15h left
Triggers: ● logrotate.service
Docs: man:logrotate(8)
man:logrotate.conf(5)
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Daily rotation of log files.
● sysstat-summary.timer - Generate summary of yesterday's process accounting
Loaded: loaded (/usr/lib/systemd/system/sysstat-summary.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Fri 2020-06-05 00:07:00 EDT; 15h left
Triggers: ● sysstat-summary.service
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Generate summary of yesterday's process accounting.
● fstrim.timer - Discard unused blocks once a week
Loaded: loaded (/usr/lib/systemd/system/fstrim.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Mon 2020-06-08 00:00:00 EDT; 3 days left
Triggers: ● fstrim.service
Docs: man:fstrim
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Discard unused blocks once a week.
● sysstat-collect.timer - Run system activity accounting tool every 10 minutes
Loaded: loaded (/usr/lib/systemd/system/sysstat-collect.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Thu 2020-06-04 08:50:00 EDT; 41s left
Triggers: ● sysstat-collect.service
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Run system activity accounting tool every 10 minutes.
● dnf-makecache.timer - dnf makecache --timer
Loaded: loaded (/usr/lib/systemd/system/dnf-makecache.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Thu 2020-06-04 08:51:00 EDT; 1min 41s left
Triggers: ● dnf-makecache.service
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started dnf makecache –timer.
● systemd-tmpfiles-clean.timer - Daily Cleanup of Temporary Directories
Loaded: loaded (/usr/lib/systemd/system/systemd-tmpfiles-clean.timer; static; vendor preset: disabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Fri 2020-06-05 08:19:00 EDT; 23h left
Triggers: ● systemd-tmpfiles-clean.service
Docs: man:tmpfiles.d(5)
man:systemd-tmpfiles(8)
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Daily Cleanup of Temporary Directories.
```
每个定时器至少有六行相关信息:
* 定时器的第一行有定时器名字和定时器目的的简短介绍
* 第二行展示了定时器的状态,是否已加载,定时器单元文件的完整路径以及预设信息。
* 第三行指明了其活动状态,包括该定时器激活的日期和时间。
* 第四行包括了该定时器下次被触发的日期和时间和距离触发的大概时间。
* 第五行展示了被定时器触发的事件或服务名称。
* 部分(不是全部)systemd 单元文件有相关文档的指引。我虚拟机上输出中有三个定时器有文档指引。这是一个很好(但非必要)的信息。
* 最后一行是计时器最近触发的服务实例的日志条目。
你也许有一些不一样的定时器,取决于你的主机。
### 创建一个定时器
尽管我们可以解构一个或多个现有的计时器来了解其工作原理,但让我们创建我们自己的 [服务单元](https://opensource.com/article/20/5/manage-startup-systemd) 和一个定时器去触发它。为了保持简单,我们将使用一个相当简单的例子。当我们完成这个实验之后,就能更容易理解其他定时器的工作原理以及发现它们正在做什么。
首先,创建一个运行基础东西的简单的服务,例如 `free` 命令。举个例子,你可能想定时监控空余内存。在 `/etc/systemd/system` 目录下创建如下的 `myMonitor.server` 单元文件。它不需要是可执行文件:
```
# This service unit is for testing timer units
# By David Both
# Licensed under GPL V2
#
[Unit]
Description=Logs system statistics to the systemd journal
Wants=myMonitor.timer
[Service]
Type=oneshot
ExecStart=/usr/bin/free
[Install]
WantedBy=multi-user.target
```
这大概是你能创建的最简单的服务单元了。现在我们查看一下服务状态同时测试一下服务单元确保它和我们预期一样可用。
```
[root@testvm1 system]# systemctl status myMonitor.service
● myMonitor.service - Logs system statistics to the systemd journal
Loaded: loaded (/etc/systemd/system/myMonitor.service; disabled; vendor preset: disabled)
Active: inactive (dead)
[root@testvm1 system]# systemctl start myMonitor.service
[root@testvm1 system]#
```
输出在哪里呢?默认情况下,systemd 服务单元执行程序的标准输出(`STDOUT`)会被发送到系统日志中,它保留了记录供现在或者之后(直到某个时间点)查看。(在本系列的后续文章中,我将介绍系统日志的记录和保留策略)。专门查看你的服务单元的日志,而且只针对今天。`-S` 选项,即 `--since` 的缩写,允许你指定 `journalctl` 工具搜索条目的时间段。这并不代表你不关心过往结果 —— 在这个案例中,不会有过往记录 —— 如果你的机器以及运行了很长时间且堆积了大量的日志,它可以缩短搜索时间。
```
[root@testvm1 system]# journalctl -S today -u myMonitor.service
-- Logs begin at Mon 2020-06-08 07:47:20 EDT, end at Thu 2020-06-11 09:40:47 EDT. --
Jun 11 09:12:09 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
Jun 11 09:12:09 testvm1.both.org free[377966]: total used free shared buff/cache available
Jun 11 09:12:09 testvm1.both.org free[377966]: Mem: 12635740 522868 11032860 8016 1080012 11821508
Jun 11 09:12:09 testvm1.both.org free[377966]: Swap: 8388604 0 8388604
Jun 11 09:12:09 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
[root@testvm1 system]#
```
由服务触发的任务可以是单个程序、一组程序或者是一个脚本语言写的脚本。通过在 `myMonitor.service` 单元文件里的 `[Service]` 块末尾中添加如下行可以为服务添加另一个任务:
```
ExecStart=/usr/bin/lsblk
```
再次启动服务,查看日志检查结果,结果应该看上去像这样。你应该在日志中看到两条命令的结果输出:
```
Jun 11 15:42:18 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
Jun 11 15:42:18 testvm1.both.org free[379961]: total used free shared buff/cache available
Jun 11 15:42:18 testvm1.both.org free[379961]: Mem: 12635740 531788 11019540 8024 1084412 11812272
Jun 11 15:42:18 testvm1.both.org free[379961]: Swap: 8388604 0 8388604
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: sda 8:0 0 120G 0 disk
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─sda1 8:1 0 4G 0 part /boot
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: └─sda2 8:2 0 116G 0 part
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-root 253:0 0 5G 0 lvm /
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-var 253:4 0 20G 0 lvm /var
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: └─VG01-home 253:5 0 10G 0 lvm /home
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: sr0 11:0 1 1024M 0 rom
Jun 11 15:42:18 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
Jun 11 15:42:18 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
```
现在你知道了你的服务可以按预期工作了,在 `/etc/systemd/system` 目录下创建 `myMonitor.timer` 定时器单元文件,添加如下代码:
```
# This timer unit is for testing
# By David Both
# Licensed under GPL V2
#
[Unit]
Description=Logs some system statistics to the systemd journal
Requires=myMonitor.service
[Timer]
Unit=myMonitor.service
OnCalendar=*-*-* *:*:00
[Install]
WantedBy=timers.target
```
在 `myMonitor.timer` 文件中的 `OnCalendar` 时间格式,`*-*-* *:*:00`,应该会每分钟触发一次定时器去执行 `myMonitor.service` 单元。我会在文章的后面进一步探索 `OnCalendar` 设置。
到目前为止,在服务被计时器触发运行时观察与之有关的日志记录。你也可以跟踪计时器,跟踪服务可以让你接近实时的看到结果。执行 `journalctl` 时带上 `-f` 选项:
```
[root@testvm1 system]# journalctl -S today -f -u myMonitor.service
-- Logs begin at Mon 2020-06-08 07:47:20 EDT. --
```
执行但是不启用该定时器,看看它运行一段时间后发生了什么:
```
[root@testvm1 ~]# systemctl start myMonitor.service
[root@testvm1 ~]#
```
一条结果立即就显示出来了,下一条大概在一分钟后出来。观察几分钟日志,看看你有没有跟我发现同样的事情:
```
[root@testvm1 system]# journalctl -S today -f -u myMonitor.service
-- Logs begin at Mon 2020-06-08 07:47:20 EDT. --
Jun 13 08:39:18 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
Jun 13 08:39:18 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
Jun 13 08:39:19 testvm1.both.org free[630566]: total used free shared buff/cache available
Jun 13 08:39:19 testvm1.both.org free[630566]: Mem: 12635740 556604 10965516 8036 1113620 11785628
Jun 13 08:39:19 testvm1.both.org free[630566]: Swap: 8388604 0 8388604
Jun 13 08:39:18 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: sda 8:0 0 120G 0 disk
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─sda1 8:1 0 4G 0 part /boot
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: └─sda2 8:2 0 116G 0 part
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-root 253:0 0 5G 0 lvm /
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-var 253:4 0 20G 0 lvm /var
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: └─VG01-home 253:5 0 10G 0 lvm /home
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: sr0 11:0 1 1024M 0 rom
Jun 13 08:40:46 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
Jun 13 08:40:46 testvm1.both.org free[630572]: total used free shared buff/cache available
Jun 13 08:40:46 testvm1.both.org free[630572]: Mem: 12635740 555228 10966836 8036 1113676 11786996
Jun 13 08:40:46 testvm1.both.org free[630572]: Swap: 8388604 0 8388604
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: sda 8:0 0 120G 0 disk
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─sda1 8:1 0 4G 0 part /boot
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: └─sda2 8:2 0 116G 0 part
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-root 253:0 0 5G 0 lvm /
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-var 253:4 0 20G 0 lvm /var
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: └─VG01-home 253:5 0 10G 0 lvm /home
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: sr0 11:0 1 1024M 0 rom
Jun 13 08:40:46 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
Jun 13 08:40:46 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
Jun 13 08:41:46 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
Jun 13 08:41:46 testvm1.both.org free[630580]: total used free shared buff/cache available
Jun 13 08:41:46 testvm1.both.org free[630580]: Mem: 12635740 553488 10968564 8036 1113688 11788744
Jun 13 08:41:46 testvm1.both.org free[630580]: Swap: 8388604 0 8388604
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: sda 8:0 0 120G 0 disk
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─sda1 8:1 0 4G 0 part /boot
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: └─sda2 8:2 0 116G 0 part
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-root 253:0 0 5G 0 lvm /
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-var 253:4 0 20G 0 lvm /var
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: └─VG01-home 253:5 0 10G 0 lvm /home
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: sr0 11:0 1 1024M 0 rom
Jun 13 08:41:47 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
Jun 13 08:41:47 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
```
别忘了检查下计时器和服务的状态。
你在日志里大概至少注意到两件事。第一,你不需要特地做什么来让 `myMonitor.service` 单元中 `ExecStart` 触发器产生的 `STDOUT` 存储到日志里。这都是用 systemd 来运行服务的一部分功能。然而,它确实意味着你需要小心对待服务单元里面执行的脚本和它们能产生多少 `STDOUT`。
第二,定时器并不是精确在每分钟的 :00 秒执行的,甚至每次执行的时间间隔都不是刚好一分钟。这是特意的设计,但是有必要的话可以改变这种行为(如果只是它挑战了你的系统管理员的敏感神经)。
这样设计的初衷是为了防止多个服务在完全相同的时刻被触发。举个例子,你可以用例如 Weekly,Daily 等时间格式。这些快捷写法都被定义为在某一天的 00:00:00 执行。当多个定时器都这样定义的话,有很大可能它们会同时执行。
systemd 定时器被故意设计成在规定时间附近随机波动的时间点触发,以避免同一时间触发。它们在一个时间窗口内半随机触发,时间窗口开始于预设的触发时间,结束于预设时间后一分钟。根据 `systemd.timer` 的手册页,这个触发时间相对于其他已经定义的定时器单元保持在稳定的位置。你可以在日志条目中看到,定时器在启动后立即触发,然后在每分钟后的 46 或 47 秒触发。
大部分情况下,这种概率抖动的定时器是没事的。当调度类似执行备份的任务,只需要它们在下班时间运行,这样是没问题的。系统管理员可以选择确定的开始时间来确保不和其他任务冲突,例如 01:05:00 这样典型的 cron 作业时间,但是有很大范围的时间值可以满足这一点。在开始时间上的一个分钟级别的随机往往是无关紧要的。
然而,对某些任务来说,精确的触发时间是个硬性要求。对于这类任务,你可以向单元文件的 `Timer` 块中添加如下声明来指定更高的触发时间跨度精确度(精确到微秒以内):
```
AccuracySec=1us
```
时间跨度可用于指定所需的精度,以及定义重复事件或一次性事件的时间跨度。它能识别以下单位:
* `usec`,`us`,`µs`
* `msec`,`ms`
* `seconds`,`second`,`sec`,`s`
* `minutes`,`minute`,`min`,`m`
* `hours`,`hour`,`hr`,`h`
* `days`,`day`,`d`
* `weeks`,`week`,`w`
* `months`,`month`,`M`(定义为 30.44 天)
* `years`,`year`,`y`(定义为 365.25 天)
所有 `/usr/lib/systemd/system` 中的定时器都指定了一个更宽松的时间精度,因为精准时间没那么重要。看看这些系统创建的定时器的时间格式:
```
[root@testvm1 system]# grep Accur /usr/lib/systemd/system/*timer
/usr/lib/systemd/system/fstrim.timer:AccuracySec=1h
/usr/lib/systemd/system/logrotate.timer:AccuracySec=1h
/usr/lib/systemd/system/logwatch.timer:AccuracySec=12h
/usr/lib/systemd/system/mlocate-updatedb.timer:AccuracySec=24h
/usr/lib/systemd/system/raid-check.timer:AccuracySec=24h
/usr/lib/systemd/system/unbound-anchor.timer:AccuracySec=24h
[root@testvm1 system]#
```
看下 `/usr/lib/systemd/system` 目录下部分定时器单元文件的完整内容,看看它们是如何构建的。
在本实验中不必让这个定时器在启动时激活,但下面这个命令可以设置开机自启:
```
[root@testvm1 system]# systemctl enable myMonitor.timer
```
你创建的单元文件不需要是可执行的。你同样不需要启用服务,因为它是被定时器触发的。如果你需要的话,你仍然可以在命令行里手动触发该服务单元。尝试一下,然后观察日志。
关于定时器精度、事件时间规格和触发事件的详细信息,请参见 systemd.timer 和 systemd.time 的手册页。
### 定时器类型
systemd 定时器还有一些在 cron 中找不到的功能,cron 只在确定的、重复的、具体的日期和时间触发。systemd 定时器可以被配置成根据其他 systemd 单元状态发生改变时触发。举个例子,定时器可以配置成在系统开机、启动后,或是某个确定的服务单元激活之后的一段时间被触发。这些被称为单调计时器。“单调”指的是一个持续增长的计数器或序列。这些定时器不是持久的,因为它们在每次启动后都会重置。
表格 1 列出了一些单调定时器以及每个定时器的简短定义,同时有 `OnCalendar` 定时器,这些不是单调的,它们被用于指定未来有可能重复的某个确定时间。这个信息来自于 `systemd.timer` 的手册页,有一些不重要的修改。
| 定时器 | 单调性 | 定义 |
| --- | --- | --- |
| `OnActiveSec=` | X | 定义了一个与定时器被激活的那一刻相关的定时器。 |
| `OnBootSec=` | X | 定义了一个与机器启动时间相关的计时器。 |
| `OnStartupSec=` | X | 定义了一个与服务管理器首次启动相关的计时器。对于系统定时器来说,这个定时器与 `OnBootSec=` 类似,因为系统服务管理器在机器启动后很短的时间后就会启动。当以在每个用户服务管理器中运行的单元进行配置时,它尤其有用,因为用户的服务管理器通常在首次登录后启动,而不是机器启动后。 |
| `OnUnitActiveSec=` | X | 定义了一个与将要激活的定时器上次激活时间相关的定时器。 |
| `OnUnitInactiveSec=` | X | 定义了一个与将要激活的定时器上次停用时间相关的定时器。 |
| `OnCalendar=` | | 定义了一个有日期事件表达式语法的实时(即时钟)定时器。查看 `systemd.time(7)` 的手册页获取更多与日历事件表达式相关的语法信息。除此以外,它的语义和 `OnActiveSec=` 类似。 |
*Table 1: systemd 定时器定义*
单调计时器可使用同样的简写名作为它们的时间跨度,即我们之前提到的 `AccuracySec` 表达式,但是 systemd 将这些名字统一转换成了秒。举个例子,比如你想规定某个定时器在系统启动后五天触发一次事件;它可能看起来像 `OnBootSec=5d`。如果机器启动于 `2020-06-15 09:45:27`,这个定时器会在 `2020-06-20 09:45:27` 或在这之后的一分钟内触发。
### 日历事件格式
日历事件格式是定时器在所需的重复时间触发的关键。我们开始看下一些 `OnCalendar` 设置一起使用的格式。
与 crontab 中的格式相比,systemd 及其计时器使用的时间和日历格式风格不同。它比 crontab 更为灵活,而且可以使用类似 `at` 命令的方式允许模糊的日期和时间。它还应该足够熟悉使其易于理解。
systemd 定时器使用 `OnCalendar=` 的基础格式是 `DOW YYYY-MM-DD HH:MM:SS`。DOW(星期几)是选填的,其他字段可以用一个星号(`*`)来匹配此位置的任意值。所有的日历时间格式会被转换成标准格式。如果时间没有指定,它会被设置为 `00:00:00`。如果日期没有指定但是时间指定了,那么下次匹配的时间可能是今天或者明天,取决于当前的时间。月份和星期可以使用名称或数字。每个单元都可以使用逗号分隔的列表。单元范围可以在开始值和结束值之间用 `..` 指定。
指定日期有一些有趣的选项,波浪号(`~`)可以指定月份的最后一天或者最后一天之前的某几天。`/` 可以用来指定星期几作为修饰符。
这里有几个在 `OnCalendar` 表达式中使用的典型时间格式例子。
| 日期事件格式 | 描述 |
| --- | --- |
| `DOW YYYY-MM-DD HH:MM:SS` | |
| `*-*-* 00:15:30` | 每年每月每天的 0 点 15 分 30 秒 |
| `Weekly` | 每个周一的 00:00:00 |
| `Mon *-*-* 00:00:00` | 同上 |
| `Mon` | 同上 |
| `Wed 2020-*-*` | 2020 年每个周三的 00:00:00 |
| `Mon..Fri 2021-*-*` | 2021 年的每个工作日(周一到周五)的 00:00:00 |
| `2022-6,7,8-1,15 01:15:00` | 2022 年 6、7、8 月的 1 到 15 号的 01:15:00 |
| `Mon *-05~03` | 每年五月份的下个周一同时也是月末的倒数第三天 |
| `Mon..Fri *-08~04` | 任何年份 8 月末的倒数第四天,同时也须是工作日 |
| `*-05~03/2` | 五月末的倒数第三天,然后 2 天后再来一次。每年重复一次。注意这个表达式使用了波浪号(`~`)。 |
| `*-05-03/2` | 五月的第三天,然后每两天重复一次直到 5 月底。注意这个表达式使用了破折号(`-`)。 |
*Table 2: `OnCalendar` 事件时间格式例子*
### 测试日历格式
systemd 提供了一个绝佳的工具用于检测和测试定时器中日历时间事件的格式。`systemd-analyze calendar` 工具解析一个时间事件格式,提供标准格式和其他有趣的信息,例如下次“经过”(即匹配)的日期和时间,以及距离下次触发之前大概时间。
首先,看看未来没有时间的日(注意 `Next elapse` 和 `UTC` 的时间会根据你当地时区改变):
```
[student@studentvm1 ~]$ systemd-analyze calendar 2030-06-17
Original form: 2030-06-17
Normalized form: 2030-06-17 00:00:00
Next elapse: Mon 2030-06-17 00:00:00 EDT
(in UTC): Mon 2030-06-17 04:00:00 UTC
From now: 10 years 0 months left
[root@testvm1 system]#
```
现在添加一个时间,在这个例子中,日期和时间是当作无关的部分分开解析的:
```
[root@testvm1 system]# systemd-analyze calendar 2030-06-17 15:21:16
Original form: 2030-06-17
Normalized form: 2030-06-17 00:00:00
Next elapse: Mon 2030-06-17 00:00:00 EDT
(in UTC): Mon 2030-06-17 04:00:00 UTC
From now: 10 years 0 months left
Original form: 15:21:16
Normalized form: *-*-* 15:21:16
Next elapse: Mon 2020-06-15 15:21:16 EDT
(in UTC): Mon 2020-06-15 19:21:16 UTC
From now: 3h 55min left
[root@testvm1 system]#
```
为了把日期和时间当作一个单元来分析,可以把它们包在引号里。你在定时器单元里 `OnCalendar=` 时间格式中使用的时候记得把引号去掉,否则会报错:
```
[root@testvm1 system]# systemd-analyze calendar "2030-06-17 15:21:16"
Normalized form: 2030-06-17 15:21:16
Next elapse: Mon 2030-06-17 15:21:16 EDT
(in UTC): Mon 2030-06-17 19:21:16 UTC
From now: 10 years 0 months left
[root@testvm1 system]#
```
现在我们测试下 Table2 里的例子。我尤其喜欢最后一个:
```
[root@testvm1 system]# systemd-analyze calendar "2022-6,7,8-1,15 01:15:00"
Original form: 2022-6,7,8-1,15 01:15:00
Normalized form: 2022-06,07,08-01,15 01:15:00
Next elapse: Wed 2022-06-01 01:15:00 EDT
(in UTC): Wed 2022-06-01 05:15:00 UTC
From now: 1 years 11 months left
[root@testvm1 system]#
```
让我们看一个例子,这个例子里我们列出了时间表达式的五个经过时间。
```
[root@testvm1 ~]# systemd-analyze calendar --iterations=5 "Mon *-05~3"
Original form: Mon *-05~3
Normalized form: Mon *-05~03 00:00:00
Next elapse: Mon 2023-05-29 00:00:00 EDT
(in UTC): Mon 2023-05-29 04:00:00 UTC
From now: 2 years 11 months left
Iter. #2: Mon 2028-05-29 00:00:00 EDT
(in UTC): Mon 2028-05-29 04:00:00 UTC
From now: 7 years 11 months left
Iter. #3: Mon 2034-05-29 00:00:00 EDT
(in UTC): Mon 2034-05-29 04:00:00 UTC
From now: 13 years 11 months left
Iter. #4: Mon 2045-05-29 00:00:00 EDT
(in UTC): Mon 2045-05-29 04:00:00 UTC
From now: 24 years 11 months left
Iter. #5: Mon 2051-05-29 00:00:00 EDT
(in UTC): Mon 2051-05-29 04:00:00 UTC
From now: 30 years 11 months left
[root@testvm1 ~]#
```
这些应该为你提供了足够的信息去开始测试你的 `OnCalendar` 时间格式。`systemd-analyze` 工具可用于其他有趣的分析,我会在这个系列的下一篇文章来探索这些。
### 总结
systemd 定时器可以用于执行和 cron 工具相同的任务,但是通过按照日历和单调时间格式去触发事件的方法提供了更多的灵活性。
虽然你为此次实验创建的服务单元通常是由定时器调用的,你也可以随时使用 `systemctl start myMonitor.service` 命令去触发它。可以在一个定时器中编写多个维护任务的脚本;它们可以是 Bash 脚本或者其他 Linux 程序。你可以通过触发定时器来运行所有的脚本来运行服务,也可以按照需要执行单独的脚本。
我会在下篇文章中更加深入的探索 systemd 时间格式的用处。
我还没有看到任何迹象表明 cron 和 at 将被废弃。我希望这种情况不会发生,因为至少 `at` 在执行一次性调度任务的时候要比 systemd 定时器容易的多。
### 参考资料
网上有大量的关于 systemd 的参考资料,但是大部分都有点简略、晦涩甚至有误导性。除了本文中提到的资料,下列的网页提供了跟多可靠且详细的 systemd 入门信息。
* Fedora 项目有一篇切实好用的 [systemd 入门](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html),它囊括了几乎所有你需要知道的关于如何使用 systemd 配置、管理和维护 Fedora 计算机的信息。
* Fedora 项目也有一个不错的 [备忘录](https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet),交叉引用了过去 SystemV 命令和 systemd 命令做对比。
* 关于 systemd 的技术细节和创建这个项目的原因,请查看 [Freedesktop.org](http://Freedesktop.org) 上的 [systemd 描述](http://www.freedesktop.org/wiki/Software/systemd)。
* [Linux.com](http://Linux.com) 的“更多 systemd 的乐趣”栏目提供了更多高级的 systemd [信息和技巧](https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/)。
此外,还有一系列深度的技术文章,是由 systemd 的设计者和主要实现者 Lennart Poettering 为 Linux 系统管理员撰写的。这些文章写于 2010 年 4 月至 2011 年 9 月间,但它们现在和当时一样具有现实意义。关于 systemd 及其生态的许多其他好文章都是基于这些文章:
* [Rethinking PID 1](http://0pointer.de/blog/projects/systemd.html)
* [systemd for Administrators,Part I](http://0pointer.de/blog/projects/systemd-for-admins-1.html)
* [systemd for Administrators,Part II](http://0pointer.de/blog/projects/systemd-for-admins-2.html)
* [systemd for Administrators,Part III](http://0pointer.de/blog/projects/systemd-for-admins-3.html)
* [systemd for Administrators,Part IV](http://0pointer.de/blog/projects/systemd-for-admins-4.html)
* [systemd for Administrators,Part V](http://0pointer.de/blog/projects/three-levels-of-off.html)
* [systemd for Administrators,Part VI](http://0pointer.de/blog/projects/changing-roots)
* [systemd for Administrators,Part VII](http://0pointer.de/blog/projects/blame-game.html)
* [systemd for Administrators,Part VIII](http://0pointer.de/blog/projects/the-new-configuration-files.html)
* [systemd for Administrators,Part IX](http://0pointer.de/blog/projects/on-etc-sysinit.html)
* [systemd for Administrators,Part X](http://0pointer.de/blog/projects/instances.html)
* [systemd for Administrators,Part XI](http://0pointer.de/blog/projects/inetd.html)
---
via: <https://opensource.com/article/20/7/systemd-timers>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tt67wq](https://github.com/tt67wq) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I am in the process of converting my [cron](https://opensource.com/article/17/11/how-use-cron-linux) jobs to systemd timers. I have used timers for a few years, but usually, I learned just enough to perform the task I was working on. While doing research for this [systemd series](https://opensource.com/users/dboth), I learned that systemd timers have some very interesting capabilities.
Like cron jobs, systemd timers can trigger events—shell scripts and programs—at specified time intervals, such as once a day, on a specific day of the month (perhaps only if it is a Monday), or every 15 minutes during business hours from 8am to 6pm. Timers can also do some things that cron jobs cannot. For example, a timer can trigger a script or program to run a specific amount of time after an event such as boot, startup, completion of a previous task, or even the previous completion of the service unit called by the timer.
## System maintenance timers
When Fedora or any systemd-based distribution is installed on a new system, it creates several timers that are part of the system maintenance procedures that happen in the background of any Linux host. These timers trigger events necessary for common maintenance tasks, such as updating system databases, cleaning temporary directories, rotating log files, and more.
As an example, I'll look at some of the timers on my primary workstation by using the `systemctl status *timer`
command to list all the timers on my host. The asterisk symbol works the same as it does for file globbing, so this command lists all systemd timer units:
```
[root@testvm1 ~]# systemctl status *timer
● mlocate-updatedb.timer - Updates mlocate database every day
Loaded: loaded (/usr/lib/systemd/system/mlocate-updatedb.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Fri 2020-06-05 00:00:00 EDT; 15h left
Triggers: ● mlocate-updatedb.service
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Updates mlocate database every day.
● logrotate.timer - Daily rotation of log files
Loaded: loaded (/usr/lib/systemd/system/logrotate.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Fri 2020-06-05 00:00:00 EDT; 15h left
Triggers: ● logrotate.service
Docs: man:logrotate(8)
man:logrotate.conf(5)
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Daily rotation of log files.
● sysstat-summary.timer - Generate summary of yesterday's process accounting
Loaded: loaded (/usr/lib/systemd/system/sysstat-summary.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Fri 2020-06-05 00:07:00 EDT; 15h left
Triggers: ● sysstat-summary.service
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Generate summary of yesterday's process accounting.
● fstrim.timer - Discard unused blocks once a week
Loaded: loaded (/usr/lib/systemd/system/fstrim.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Mon 2020-06-08 00:00:00 EDT; 3 days left
Triggers: ● fstrim.service
Docs: man:fstrim
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Discard unused blocks once a week.
● sysstat-collect.timer - Run system activity accounting tool every 10 minutes
Loaded: loaded (/usr/lib/systemd/system/sysstat-collect.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Thu 2020-06-04 08:50:00 EDT; 41s left
Triggers: ● sysstat-collect.service
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Run system activity accounting tool every 10 minutes.
● dnf-makecache.timer - dnf makecache --timer
Loaded: loaded (/usr/lib/systemd/system/dnf-makecache.timer; enabled; vendor preset: enabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Thu 2020-06-04 08:51:00 EDT; 1min 41s left
Triggers: ● dnf-makecache.service
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started dnf makecache –timer.
● systemd-tmpfiles-clean.timer - Daily Cleanup of Temporary Directories
Loaded: loaded (/usr/lib/systemd/system/systemd-tmpfiles-clean.timer; static; vendor preset: disabled)
Active: active (waiting) since Tue 2020-06-02 08:02:33 EDT; 2 days ago
Trigger: Fri 2020-06-05 08:19:00 EDT; 23h left
Triggers: ● systemd-tmpfiles-clean.service
Docs: man:tmpfiles.d(5)
man:systemd-tmpfiles(8)
Jun 02 08:02:33 testvm1.both.org systemd[1]: Started Daily Cleanup of Temporary Directories.
```
Each timer has at least six lines of information associated with it:
- The first line has the timer's file name and a short description of its purpose.
- The second line displays the timer's status, whether it is loaded, the full path to the timer unit file, and the vendor preset.
- The third line indicates its active status, which includes the date and time the timer became active.
- The fourth line contains the date and time the timer will be triggered next and an approximate time until the trigger occurs.
- The fifth line shows the name of the event or the service that is triggered by the timer.
- Some (but not all) systemd unit files have pointers to the relevant documentation. Three of the timers in my virtual machine's output have pointers to documentation. This is a nice (but optional) bit of data.
- The final line is the journal entry for the most recent instance of the service triggered by the timer.
Depending upon your host, you will probably have a different set of timers.
## Create a timer
Although we can deconstruct one or more of the existing timers to learn how they work, let’s create our own [service unit](https://opensource.com/article/20/5/manage-startup-systemd) and a timer unit to trigger it. We will use a fairly trivial example in order to keep this simple. After we have finished this, it will be easier to understand how the other timers work and to determine what they are doing.
First, create a simple service that will run something basic, such as the `free`
command. For example, you may want to monitor free memory at regular intervals. Create the following `myMonitor.service`
unit file in the `/etc/systemd/system`
directory. It does not need to be executable:
```
# This service unit is for testing timer units
# By David Both
# Licensed under GPL V2
#
[Unit]
Description=Logs system statistics to the systemd journal
Wants=myMonitor.timer
[Service]
Type=oneshot
ExecStart=/usr/bin/free
[Install]
WantedBy=multi-user.target
```
Now let’s look at the status and test our service unit to ensure that it works as we expect it to.
```
[root@testvm1 system]# systemctl status myMonitor.service
● myMonitor.service - Logs system statistics to the systemd journal
Loaded: loaded (/etc/systemd/system/myMonitor.service; disabled; vendor preset: disabled)
Active: inactive (dead)
[root@testvm1 system]# systemctl start myMonitor.service
[root@testvm1 system]#
```
Where is the output? By default, the standard output (`STDOUT`
) from programs run by systemd service units is sent to the systemd journal, which leaves a record you can view now or later—up to a point. (I will look at systemd journaling and retention strategies in a future article in this series.) Look at the journal specifically for your service unit and for today only. The `-S`
option, which is the short version of `--since`
, allows you to specify the time period that the `journalctl`
tool should search for entries. This isn't because you don't care about previous results—in this case, there won't be any—it is to shorten the search time if your host has been running for a long time and has accumulated a large number of entries in the journal:
```
[root@testvm1 system]# journalctl -S today -u myMonitor.service
-- Logs begin at Mon 2020-06-08 07:47:20 EDT, end at Thu 2020-06-11 09:40:47 EDT. --
Jun 11 09:12:09 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
Jun 11 09:12:09 testvm1.both.org free[377966]: total used free shared buff/cache available
Jun 11 09:12:09 testvm1.both.org free[377966]: Mem: 12635740 522868 11032860 8016 1080012 11821508
Jun 11 09:12:09 testvm1.both.org free[377966]: Swap: 8388604 0 8388604
Jun 11 09:12:09 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
[root@testvm1 system]#
```
A task triggered by a service can be a single program, a series of programs, or a script written in any scripting language. Add another task to the service by adding the following line to the end of the `[Service]`
section of the `myMonitor.service`
unit file:
`ExecStart=/usr/bin/lsblk`
Start the service again and check the journal for the results, which should look like this. You should see the results from both commands in the journal:
```
Jun 11 15:42:18 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
Jun 11 15:42:18 testvm1.both.org free[379961]: total used free shared buff/cache available
Jun 11 15:42:18 testvm1.both.org free[379961]: Mem: 12635740 531788 11019540 8024 1084412 11812272
Jun 11 15:42:18 testvm1.both.org free[379961]: Swap: 8388604 0 8388604
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: sda 8:0 0 120G 0 disk
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─sda1 8:1 0 4G 0 part /boot
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: └─sda2 8:2 0 116G 0 part
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-root 253:0 0 5G 0 lvm /
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: ├─VG01-var 253:4 0 20G 0 lvm /var
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: └─VG01-home 253:5 0 10G 0 lvm /home
Jun 11 15:42:18 testvm1.both.org lsblk[379962]: sr0 11:0 1 1024M 0 rom
Jun 11 15:42:18 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
Jun 11 15:42:18 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
```
Now that you know your service works as expected, create the timer unit file, `myMonitor.timer`
in `/etc/systemd/system`
, and add the following:
```
# This timer unit is for testing
# By David Both
# Licensed under GPL V2
#
[Unit]
Description=Logs some system statistics to the systemd journal
Requires=myMonitor.service
[Timer]
Unit=myMonitor.service
OnCalendar=*-*-* *:*:00
[Install]
WantedBy=timers.target
```
The `OnCalendar`
time specification in the `myMonitor.timer file`
, `*-*-* *:*:00`
, should trigger the timer to execute the `myMonitor.service`
unit every minute. I will explore `OnCalendar`
settings a bit later in this article.
For now, observe any journal entries pertaining to running your service when it is triggered by the timer. You could also follow the timer, but following the service allows you to see the results in near real time. Run `journalctl`
with the `-f`
(follow) option:
```
[root@testvm1 system]# journalctl -S today -f -u myMonitor.service
-- Logs begin at Mon 2020-06-08 07:47:20 EDT. --
```
Start but do not enable the timer, and see what happens after it runs for a while:
```
[root@testvm1 ~]# systemctl start myMonitor.service
[root@testvm1 ~]#
```
One result shows up right away, and the next ones come at—sort of—one-minute intervals. Watch the journal for a few minutes and see if you notice the same things I did:
```
[root@testvm1 system]# journalctl -S today -f -u myMonitor.service
-- Logs begin at Mon 2020-06-08 07:47:20 EDT. --
Jun 13 08:39:18 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
Jun 13 08:39:18 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
Jun 13 08:39:19 testvm1.both.org free[630566]: total used free shared buff/cache available
Jun 13 08:39:19 testvm1.both.org free[630566]: Mem: 12635740 556604 10965516 8036 1113620 11785628
Jun 13 08:39:19 testvm1.both.org free[630566]: Swap: 8388604 0 8388604
Jun 13 08:39:18 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: sda 8:0 0 120G 0 disk
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─sda1 8:1 0 4G 0 part /boot
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: └─sda2 8:2 0 116G 0 part
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-root 253:0 0 5G 0 lvm /
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: ├─VG01-var 253:4 0 20G 0 lvm /var
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: └─VG01-home 253:5 0 10G 0 lvm /home
Jun 13 08:39:19 testvm1.both.org lsblk[630567]: sr0 11:0 1 1024M 0 rom
Jun 13 08:40:46 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
Jun 13 08:40:46 testvm1.both.org free[630572]: total used free shared buff/cache available
Jun 13 08:40:46 testvm1.both.org free[630572]: Mem: 12635740 555228 10966836 8036 1113676 11786996
Jun 13 08:40:46 testvm1.both.org free[630572]: Swap: 8388604 0 8388604
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: sda 8:0 0 120G 0 disk
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─sda1 8:1 0 4G 0 part /boot
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: └─sda2 8:2 0 116G 0 part
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-root 253:0 0 5G 0 lvm /
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: ├─VG01-var 253:4 0 20G 0 lvm /var
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: └─VG01-home 253:5 0 10G 0 lvm /home
Jun 13 08:40:46 testvm1.both.org lsblk[630574]: sr0 11:0 1 1024M 0 rom
Jun 13 08:40:46 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
Jun 13 08:40:46 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
Jun 13 08:41:46 testvm1.both.org systemd[1]: Starting Logs system statistics to the systemd journal...
Jun 13 08:41:46 testvm1.both.org free[630580]: total used free shared buff/cache available
Jun 13 08:41:46 testvm1.both.org free[630580]: Mem: 12635740 553488 10968564 8036 1113688 11788744
Jun 13 08:41:46 testvm1.both.org free[630580]: Swap: 8388604 0 8388604
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: sda 8:0 0 120G 0 disk
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─sda1 8:1 0 4G 0 part /boot
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: └─sda2 8:2 0 116G 0 part
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-root 253:0 0 5G 0 lvm /
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-swap 253:1 0 8G 0 lvm [SWAP]
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-usr 253:2 0 30G 0 lvm /usr
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-tmp 253:3 0 10G 0 lvm /tmp
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: ├─VG01-var 253:4 0 20G 0 lvm /var
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: └─VG01-home 253:5 0 10G 0 lvm /home
Jun 13 08:41:47 testvm1.both.org lsblk[630581]: sr0 11:0 1 1024M 0 rom
Jun 13 08:41:47 testvm1.both.org systemd[1]: myMonitor.service: Succeeded.
Jun 13 08:41:47 testvm1.both.org systemd[1]: Finished Logs system statistics to the systemd journal.
```
Be sure to check the status of both the timer and the service.
You probably noticed at least two things in the journal. First, you do not need to do anything special to cause the `STDOUT`
from the `ExecStart`
triggers in the `myMonitor.service`
unit to be stored in the journal. That is all part of using systemd for running services. However, it does mean that you might need to be careful about running scripts from a service unit and how much `STDOUT`
they generate.
The second thing is that the timer does not trigger exactly on the minute at :00 seconds or even exactly one minute from the previous instance. This is intentional, but it can be overridden if necessary (or if it just offends your sysadmin sensibilities).
The reason for this behavior is to prevent multiple services from triggering at exactly the same time. For example, you can use time specifications such as Weekly, Daily, and more. These shortcuts are all defined to trigger at 00:00:00 hours on the day they are triggered. When multiple timers are specified this way, there is a strong likelihood that they would attempt to start simultaneously.
systemd timers are intentionally designed to trigger somewhat randomly around the specified time to try to prevent simultaneous triggers. They trigger semi-randomly within a time window that starts at the specified trigger time and ends at the specified time plus one minute. This trigger time is maintained at a stable position with respect to all other defined timer units, according to the `systemd.timer`
man page. You can see in the journal entries above that the timer triggered immediately when it started and then about 46 or 47 seconds after each minute.
Most of the time, such probabilistic trigger times are fine. When scheduling tasks such as backups to run, so long as they run during off-hours, there will be no problems. A sysadmin can select a deterministic start time, such as 01:05:00 in a typical cron job specification, to not conflict with other tasks, but there is a large range of time values that will accomplish that. A one-minute bit of randomness in a start time is usually irrelevant.
However, for some tasks, exact trigger times are an absolute requirement. For those, you can specify greater trigger time-span accuracy (to within a microsecond) by adding a statement like this to the `Timer`
section of the timer unit file:
`AccuracySec=1us`
Time spans can be used to specify the desired accuracy as well as to define time spans for repeating or one-time events. It recognizes the following units:
- usec, us, µs
- msec, ms
- seconds, second, sec, s
- minutes, minute, min, m
- hours, hour, hr, h
- days, day, d
- weeks, week, w
- months, month, M (defined as 30.44 days)
- years, year, y (defined as 365.25 days)
All the default timers in `/usr/lib/systemd/system`
specify a much larger range for accuracy because exact times are not critical. Look at some of the specifications in the system-created timers:
```
[root@testvm1 system]# grep Accur /usr/lib/systemd/system/*timer
/usr/lib/systemd/system/fstrim.timer:AccuracySec=1h
/usr/lib/systemd/system/logrotate.timer:AccuracySec=1h
/usr/lib/systemd/system/logwatch.timer:AccuracySec=12h
/usr/lib/systemd/system/mlocate-updatedb.timer:AccuracySec=24h
/usr/lib/systemd/system/raid-check.timer:AccuracySec=24h
/usr/lib/systemd/system/unbound-anchor.timer:AccuracySec=24h
[root@testvm1 system]#
```
View the complete contents of some of the timer unit files in the `/usr/lib/systemd/system`
directory to see how they are constructed.
You do not have to enable the timer in this experiment to activate it at boot time, but the command to do so would be:
`# systemctl enable myMonitor.timer`
The unit files you created do not need to be executable. You also did not enable the service unit because it is triggered by the timer. You can still trigger the service unit manually from the command line, should you want to. Try that and observe the journal.
See the man pages for `systemd.timer`
and `systemd.time`
for more information about timer accuracy, event-time specifications, and trigger events.
## Timer types
systemd timers have other capabilities that are not found in cron, which triggers only on specific, repetitive, real-time dates and times. systemd timers can be configured to trigger based on status changes in other systemd units. For example, a timer might be configured to trigger a specific elapsed time after system boot, after startup, or after a defined service unit activates. These are called monotonic timers. Monotonic refers to a count or sequence that continually increases. These timers are not persistent because they reset after each boot.
Table 1 lists the monotonic timers along with a short definition of each, as well as the `OnCalendar`
timer, which is not monotonic and is used to specify future times that may or may not be repetitive. This information is derived from the `systemd.timer`
man page with a few minor changes.
Timer | Monotonic | Definition |
---|---|---|
`OnActiveSec=` |
X | This defines a timer relative to the moment the timer is activated. |
`OnBootSec=` |
X | This defines a timer relative to when the machine boots up. |
`OnStartupSec=` |
X | This defines a timer relative to when the service manager first starts. For system timer units, this is very similar to `OnBootSec=` , as the system service manager generally starts very early at boot. It's primarily useful when configured in units running in the per-user service manager, as the user service manager generally starts on first login only, not during boot. |
`OnUnitActiveSec=` |
X | This defines a timer relative to when the timer that is to be activated was last activated. |
`OnUnitInactiveSec=` |
X | This defines a timer relative to when the timer that is to be activated was last deactivated. |
`OnCalendar=` |
This defines real-time (i.e., wall clock) timers with calendar event expressions. See `systemd.time(7)` for more information on the syntax of calendar event expressions. Otherwise, the semantics are similar to `OnActiveSec=` and related settings. This timer is the one most like those used with the cron service. |
*Table 1: systemd timer definitions*
The monotonic timers can use the same shortcut names for their time spans as the `AccuracySec`
statement mentioned before, but systemd normalizes those names to seconds. For example, you might want to specify a timer that triggers an event one time, five days after the system boots; that might look like: `OnBootSec=5d`
. If the host booted at `2020-06-15 09:45:27`
, the timer would trigger at `2020-06-20 09:45:27`
or within one minute after.
## Calendar event specifications
Calendar event specifications are a key part of triggering timers at desired repetitive times. Start by looking at some specifications used with the `OnCalendar`
setting.
systemd and its timers use a different style for time and date specifications than the format used in crontab. It is more flexible than crontab and allows fuzzy dates and times in the manner of the `at`
command. It should also be familiar enough that it will be easy to understand.
The basic format for systemd timers using `OnCalendar=`
is `DOW YYYY-MM-DD HH:MM:SS`
. DOW (day of week) is optional, and other fields can use an asterisk (*) to match any value for that position. All calendar time forms are converted to a normalized form. If the time is not specified, it is assumed to be 00:00:00. If the date is not specified but the time is, the next match might be today or tomorrow, depending upon the current time. Names or numbers can be used for the month and day of the week. Comma-separated lists of each unit can be specified. Unit ranges can be specified with `..`
between the beginning and ending values.
There are a couple interesting options for specifying dates. The Tilde (~) can be used to specify the last day of the month or a specified number of days prior to the last day of the month. The “/” can be used to specify a day of the week as a modifier.
Here are some examples of some typical time specifications used in `OnCalendar`
statements.
Calendar event specification | Description |
---|---|
DOW YYYY-MM-DD HH:MM:SS | |
*-*-* 00:15:30 | Every day of every month of every year at 15 minutes and 30 seconds after midnight |
Weekly | Every Monday at 00:00:00 |
Mon *-*-* 00:00:00 | Same as weekly |
Mon | Same as weekly |
Wed 2020-*-* | Every Wednesday in 2020 at 00:00:00 |
Mon..Fri 2021-*-* | Every weekday in 2021 at 00:00:00 |
2022-6,7,8-1,15 01:15:00 | The 1st and 15th of June, July, and August of 2022 at 01:15:00am |
Mon *-05~03 | The next occurrence of a Monday in May of any year which is also the 3rd day from the end of the month. |
Mon..Fri *-08~04 | The 4th day preceding the end of August for any years in which it also falls on a weekday. |
*-05~03/2 | The 3rd day from the end of the month of May and then again two days later. Repeats every year. Note that this expression uses the Tilde (~). |
*-05-03/2 | The third day of the month of may and then every 2nd day for the rest of May. Repeats every year. Note that this expression uses the dash (-). |
*Table 2: Sample OnCalendar event specifications*
## Test calendar specifications
systemd provides an excellent tool for validating and examining calendar time event specifications in a timer. The `systemd-analyze calendar`
tool parses a calendar time event specification and provides the normalized form as well as other interesting information such as the date and time of the next "elapse," i.e., match, and the approximate amount of time before the trigger time is reached.
First, look at a date in the future without a time (note that the times for `Next elapse`
and `UTC`
will differ based on your local time zone):
```
[student@studentvm1 ~]$ systemd-analyze calendar 2030-06-17
Original form: 2030-06-17
Normalized form: 2030-06-17 00:00:00
Next elapse: Mon 2030-06-17 00:00:00 EDT
(in UTC): Mon 2030-06-17 04:00:00 UTC
From now: 10 years 0 months left
[root@testvm1 system]#
```
Now add a time. In this example, the date and time are analyzed separately as non-related entities:
```
[root@testvm1 system]# systemd-analyze calendar 2030-06-17 15:21:16
Original form: 2030-06-17
Normalized form: 2030-06-17 00:00:00
Next elapse: Mon 2030-06-17 00:00:00 EDT
(in UTC): Mon 2030-06-17 04:00:00 UTC
From now: 10 years 0 months left
Original form: 15:21:16
Normalized form: *-*-* 15:21:16
Next elapse: Mon 2020-06-15 15:21:16 EDT
(in UTC): Mon 2020-06-15 19:21:16 UTC
From now: 3h 55min left
[root@testvm1 system]#
```
To analyze the date and time as a single unit, enclose them together in quotes. Be sure to remove the quotes when using them in the `OnCalendar=`
event specification in a timer unit or you will get errors:
```
[root@testvm1 system]# systemd-analyze calendar "2030-06-17 15:21:16"
Normalized form: 2030-06-17 15:21:16
Next elapse: Mon 2030-06-17 15:21:16 EDT
(in UTC): Mon 2030-06-17 19:21:16 UTC
From now: 10 years 0 months left
[root@testvm1 system]#
```
Now test the entries in Table 2. I like the last one, especially:
```
[root@testvm1 system]# systemd-analyze calendar "2022-6,7,8-1,15 01:15:00"
Original form: 2022-6,7,8-1,15 01:15:00
Normalized form: 2022-06,07,08-01,15 01:15:00
Next elapse: Wed 2022-06-01 01:15:00 EDT
(in UTC): Wed 2022-06-01 05:15:00 UTC
From now: 1 years 11 months left
[root@testvm1 system]#
```
Let’s look at one example in which we list the next five elapses for the timestamp expression.
```
[root@testvm1 ~]# systemd-analyze calendar --iterations=5 "Mon *-05~3"
Original form: Mon *-05~3
Normalized form: Mon *-05~03 00:00:00
Next elapse: Mon 2023-05-29 00:00:00 EDT
(in UTC): Mon 2023-05-29 04:00:00 UTC
From now: 2 years 11 months left
Iter. #2: Mon 2028-05-29 00:00:00 EDT
(in UTC): Mon 2028-05-29 04:00:00 UTC
From now: 7 years 11 months left
Iter. #3: Mon 2034-05-29 00:00:00 EDT
(in UTC): Mon 2034-05-29 04:00:00 UTC
From now: 13 years 11 months left
Iter. #4: Mon 2045-05-29 00:00:00 EDT
(in UTC): Mon 2045-05-29 04:00:00 UTC
From now: 24 years 11 months left
Iter. #5: Mon 2051-05-29 00:00:00 EDT
(in UTC): Mon 2051-05-29 04:00:00 UTC
From now: 30 years 11 months left
[root@testvm1 ~]#
```
This should give you enough information to start testing your `OnCalendar`
time specifications. The `systemd-analyze`
tool can be used for other interesting analyses, which I will begin to explore in the next article in this series.
## Summary
systemd timers can be used to perform the same kinds of tasks as the cron tool but offer more flexibility in terms of the calendar and monotonic time specifications for triggering events.
Even though the service unit you created for this experiment is usually triggered by the timer, you can also use the `systemctl start myMonitor.service`
command to trigger it at any time. Multiple maintenance tasks can be scripted in a single timer; these can be Bash scripts or Linux utility programs. You can run the service triggered by the timer to run all the scripts, or you can run individual scripts as needed.
I will explore systemd's use of time and time specifications in much more detail in the next article.
I have not yet seen any indication that `cron`
and `at`
will be deprecated. I hope that does not happen because `at`
, at least, is much easier to use for one-off task scheduling than systemd timers.
## Resources
There is a great deal of information about systemd available on the internet, but much is terse, obtuse, or even misleading. In addition to the resources mentioned in this article, the following webpages offer more detailed and reliable information about systemd startup.
- The Fedora Project has a good, practical
[guide to systemd](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html). It has pretty much everything you need to know in order to configure, manage, and maintain a Fedora computer using systemd. - The Fedora Project also has a good
[cheat sheet](https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet)that cross-references the old SystemV commands to comparable systemd ones. - For detailed technical information about systemd and the reasons for creating it, check out
[Freedesktop.org](http://Freedesktop.org)'s[description of systemd](http://www.freedesktop.org/wiki/Software/systemd). [Linux.com](http://Linux.com)'s "More systemd fun" offers more advanced systemd[information and tips](https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/).
There is also a series of deeply technical articles for Linux sysadmins by Lennart Poettering, the designer and primary developer of systemd. These articles were written between April 2010 and September 2011, but they are just as relevant now as they were then. Much of everything else good that has been written about systemd and its ecosystem is based on these papers.
[Rethinking PID 1](http://0pointer.de/blog/projects/systemd.html)[systemd for Administrators, Part I](http://0pointer.de/blog/projects/systemd-for-admins-1.html)[systemd for Administrators, Part II](http://0pointer.de/blog/projects/systemd-for-admins-2.html)[systemd for Administrators, Part III](http://0pointer.de/blog/projects/systemd-for-admins-3.html)[systemd for Administrators, Part IV](http://0pointer.de/blog/projects/systemd-for-admins-4.html)[systemd for Administrators, Part V](http://0pointer.de/blog/projects/three-levels-of-off.html)[systemd for Administrators, Part VI](http://0pointer.de/blog/projects/changing-roots)[systemd for Administrators, Part VII](http://0pointer.de/blog/projects/blame-game.html)[systemd for Administrators, Part VIII](http://0pointer.de/blog/projects/the-new-configuration-files.html)[systemd for Administrators, Part IX](http://0pointer.de/blog/projects/on-etc-sysinit.html)[systemd for Administrators, Part X](http://0pointer.de/blog/projects/instances.html)[systemd for Administrators, Part XI](http://0pointer.de/blog/projects/inetd.html)
## 10 Comments |
13,308 | 为什么我喜欢用 bspwm 来做我的 Linux 窗口管理器 | https://opensource.com/article/21/4/bspwm-linux | 2021-04-18T11:47:04 | [
"bspwm",
"窗口管理器"
] | https://linux.cn/article-13308-1.html |
>
> 在 Fedora Linux 上安装、配置并开始使用 bspwm 窗口管理器。
>
>
>

有些人喜欢重新布置家具。还有的人喜欢尝试新鞋或定期重新装修他们的卧室。我呢,则是尝试 Linux 桌面。
在对网上看到的一些不可思议的桌面环境流口水之后,我对一个窗口管理器特别好奇:[bspwm](https://github.com/baskerville/bspwm)。

我喜欢 [i3](https://i3wm.org/) 窗口管理器已经有一段时间了,我很喜欢它的布局方式和上手的便捷性。但 bspwm 的某些特性吸引了我。有几个原因让我决定尝试一下:
* 它\_只是\_一个窗口管理器(WM)。
* 它由几个易于配置的脚本管理。
* 它默认支持窗口之间的间隙。
可能是最需要指出的第一个原因是它只是一个窗口管理器。和 i3 一样,默认情况下没有任何图形化的那些花哨东西。你当然可以随心所欲地定制它,但\_你\_需要付出努力来使它看起来像你想要的。这也是它吸引我的部分原因。
虽然它可以在许多发行版上使用,但在我这个例子中使用的是 Fedora Linux。
### 安装 bspwm
bspwm 在大多数常见的发行版中都有打包,所以你可以用系统的包管理器安装它。下面这个命令还会安装 [sxkhd](https://github.com/baskerville/sxhkd),这是一个 X 窗口系统的守护程序,它“通过执行命令对输入事件做出反应”;还有 [dmenu](https://linux.die.net/man/1/dmenu),这是一个通用的 X 窗口菜单:
```
dnf install bspwm sxkhd dmenu
```
因为 bspwm 只是一个窗口管理器,所以没有任何内置的快捷键或键盘命令。这也是它与 i3 等软件的不同之处。所以,在你第一次启动窗口管理器之前,请先配置一下 `sxkhd`:
```
systemctl start sxkhd
systemctl enable sxkhd
```
这样就可以在登录时启用 `sxkhd`,但你还需要一些基本功能的配置:
```
curl https://raw.githubusercontent.com/baskerville/bspwm/master/examples/sxhkdrc --output ~/.config/sxkhd/sxkhdrc
```
在你深入了解之前,不妨先看看这个文件,因为有些脚本调用的命令可能在你的系统中并不存在。一个很好的例子是调用 `urxvt` 的 `super + Return` 快捷键。把它改成你喜欢的终端,尤其是当你没有安装 `urxvt` 的时候:
```
#
# wm independent hotkeys
#
# terminal emulator
super + Return
urxvt
# program launcher
super + @space
dmenu_run
```
如果你使用的是 GDM、LightDM 或其他显示管理器(DM),只要在登录前选择 `bspwm` 即可。
### 配置 bspwm
当你登录后,你会看到屏幕上什么都没有。这不是你感觉到的空虚感。而是无限可能性!你现在可以开始摆弄桌面环境的所有部分了。你现在可以开始摆弄这些年你认为理所当然的桌面环境的所有部分了。从头开始构建并不容易,但一旦你掌握了诀窍,就会非常有收获。
任何窗口管理器最困难的是掌握快捷键。你开始会很慢,但在很短的时间内,你就可以只使用键盘在系统中到处操作,在你的朋友和家人面前看起来像一个终极黑客。
你可以通过编辑 `~/.config/bspwm/bspwmrc`,在启动时添加应用,设置桌面和显示器,并为你的窗口应该如何表现设置规则,随心所欲地定制系统。有一些默认设置的例子可以让你开始使用。键盘快捷键都是由 `sxkhdrc` 文件管理的。
还有更多的开源项目可以安装,让你的电脑看起来更漂亮,比如用于桌面背景的 [Feh](https://github.com/derf/feh)、状态栏的 [Polybar](https://github.com/polybar/polybar)、应用启动器的 [Rofi](https://github.com/davatorium/rofi),还有 [Compton](https://github.com/chjj/compton) 可以给你提供阴影和透明度,可以让你的电脑看起来焕然一新。
玩得愉快!
---
via: <https://opensource.com/article/21/4/bspwm-linux>
作者:[Stephen Adams](https://opensource.com/users/stevehnh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Some folks like to rearrange furniture. Other folks like to try new shoes or redecorate their bedroom on the regular. Me? I try out Linux desktops.
After drooling over some of the incredible desktop environments I've seen online, I got curious about one window manager in particular: [bspwm](https://github.com/baskerville/bspwm).
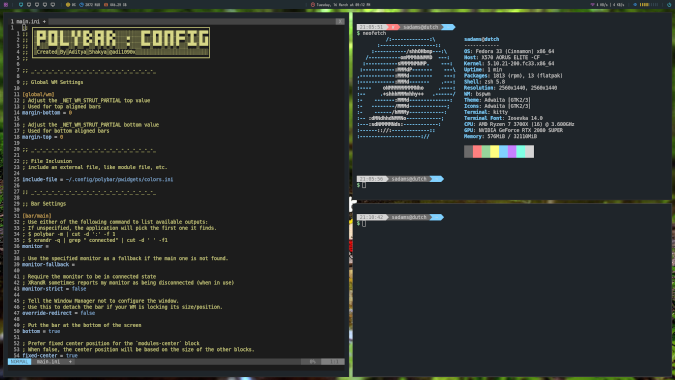
(Stephen Adams, CC BY-SA 4.0)
I've been a fan of the [i3](https://i3wm.org/) window manager for quite a while, and I enjoy the way everything is laid out and the ease of getting started. But something about bspwm called to me. There are a few reasons I decided to try it out:
- It is
*only*a window manager. - It is managed by a few easy-to-configure scripts.
- It supports gaps between windows by default.
The first reason—that it is simply a window manager—is probably the top thing to point out. Like i3, there are no graphical bells and whistles applied by default. You can certainly customize it to your heart's content, but *you* will be putting in all the work to make it look like you want. That's part of its appeal to me.
Although it is available on many distributions, my examples use Fedora Linux.
## Install bspwm
Bspwm is packaged in most common distributions, so you can install it with your system's package manager. This command also installs [sxkhd](https://github.com/baskerville/sxhkd), a daemon for the X Window System "that reacts to input events by executing commands," and [dmenu](https://linux.die.net/man/1/dmenu), a generic X Window menu:
`dnf install bspwm sxkhd dmenu`
Since bspwm is *just* a window manager, there aren't any built-in shortcuts or keyboard commands. This is where it stands in contrast to something like i3. sxkhd makes it easier to get going. So, go ahead and configure sxkhd before you fire up the window manager for the first time:
```
systemctl start sxkhd
systemctl enable sxkhd
```
This enables sxkhd at login, but you also need a configuration with some basic functionality ready to go:
`curl https://raw.githubusercontent.com/baskerville/bspwm/master/examples/sxhkdrc --output ~/.config/sxkhd/sxkhdrc`
It's worth taking a look at this file before you get much further, as some commands that the scripts call may not exist on your system. A good example is the `super + Return`
shortcut that calls `urxvt`
. Change this to your preferred terminal, especially if you do not have urxvt installed:
```
#
# wm independent hotkeys
#
# terminal emulator
super + Return
urxvt
# program launcher
super + @space
dmenu_run
```
If you are using GDM, LightDM, or another display manager, just choose bspwm before logging in.
## Configure bspwm
Once you are logged in, you'll see a whole lot of nothing on the screen. That's not a sense of emptiness you feel. It's possibility! You are now ready to start fiddling with all the parts of a desktop environment that you have taken for granted all these years. Building from scratch is not easy, but it's very rewarding once you get the hang of it.
The most difficult thing about any window manager is getting a handle on the shortcuts. You're going to be slow to start, but in a short time, you'll be flying around your system using your keyboard alone and looking like an ultimate hacker to your friends and family.
You can tailor the system as much as you want by editing `~/.config/bspwm/bspwmrc`
to add apps at launch, set up your desktops and monitors, and set rules for how your windows should behave. There are a few examples set by default to get you going. Keyboard shortcuts are all managed by the **sxkhdrc** file.
There are plenty more open source projects to install to really get things looking nice—like [Feh](https://github.com/derf/feh) for desktop backgrounds, [Polybar](https://github.com/polybar/polybar) for that all-important status bar, [Rofi](https://github.com/davatorium/rofi) to really help your app launcher pop, and [Compton](https://github.com/chjj/compton) to give you the shadows and transparency to get things nice and shiny.
Happy hacking!
## 1 Comment |
13,310 | 用这个开源工具让你的数据对老板友好起来 | https://opensource.com/article/21/4/visualize-data-eda | 2021-04-19T09:26:23 | [
"数据"
] | /article-13310-1.html |
>
> 企业数据分析旨在将数据可视化带给日常商务用户。
>
>
>

<ruby> 企业数据分析 <rt> Enterprise Data Analytics </rt></ruby>([EDA](https://eda.jortilles.com/en/jortilles-english/)) 是一个网页应用,它可以通过一个简单、清晰的界面来获取信息。
在巴塞罗那开源分析公司 [Jortilles](https://www.jortilles.com/) 工作几年后,我们意识到,现代世界强制性地收集数据,但普通人没有简单的方法来查看或解释这些数据。有一些强大的开源工具可用于此目的,但它们非常复杂。我们找不到一个工具设计成能让没有什么技术能力的普通人轻松使用。
我们之所以开发 EDA,是因为我们认为获取信息是现代组织的要求和义务,并希望为每个人提供获取信息的机会。

### 可视化你的数据
EDA 使用人们已经理解的商业术语提供了一个数据模型。你可以选择你想要的信息,并可以以你想要的方式查看它。它的目标是对用户友好,同时又功能强大。
EDA 通过元数据模型将数据库中的信息可视化和丰富化。它可以从 BigQuery、Postgres、[MariaDB、MySQL](https://opensource.com/article/20/10/mariadb-mysql-cheat-sheet) 和其他一些数据库中读取数据。这就把技术性的数据库模型转化为熟悉的商业概念。
它还设计为加快信息传播的速度,因为它可以利用已经存储在数据库中的数据。EDA 可以发现数据库的拓扑结构,并提出业务模型。如果你设计了一个好的数据库模型,你就有了一个好的业务模型。EDA 还可以连接到生产服务器,提供实时分析。
这种数据和数据模型的结合意味着你和你组织中的任何人都可以分析其数据。然而,为了保护数据,你可以定义数据安全,可以精确到行,以授予正当的人访问正当的数据。
EDA 的一些功能包括:
* 自动生成数据模型
* 一致的数据模型,防止出现不一致的查询
* 高级用户的 SQL 模式
* 数据可视化:
+ 标准图表(如柱状图、饼状图、线状图、树状图)
+ 地图整合(如 geoJSON shapefile、纬度、经度)
+ 电子邮件提醒,可通过关键绩效指标 (KPI) 来定义
* 私人和公共信息控制,以启用私人和公共仪表板,你可以通过链接分享它。
* 数据缓存和程序刷新。
### 如何使用 EDA
用 EDA 实现数据可视化的第一步是创建数据模型。
#### 创建数据模型
首先,在左侧菜单中选择 “New Datasource”。
接下来,选择你的数据存储的数据库系统(如 Postgres、MariaDB、MySQL、Vertica、SqlServer、Oracle、Big Query),并提供连接参数。
EDA 将自动为你生成数据模型。它读取表和列,并为它们定义名称以及表之间的关系。你还可以通过添加虚拟视图或 geoJSON 图来丰富你的数据模型。
#### 制作仪表板
现在你已经准备好制作第一个仪表板了。在 EDA 界面的主页面上,你应该会看到一个 “New dashboard” 按钮。点击它,命名你的仪表板,并选择你创建的数据模型。新的仪表板将出现一个面板供你配置。
要配置面板,请单击右上角的 “Configuration” 按钮,并选择你要做的事情。在 “Edit query” 中,选择你要显示的数据。这将出现一个新的窗口,你的数据模型由实体和实体的属性表示。选择你要查看的实体和你要使用的属性。例如,对于名为 “Customers” 的实体,你可能会显示 “Customer Name”,对于 “Sales” 实体,你可能希望显示 “Total Sales”。
接下来,运行一个查询,并选择你想要的可视化。

你可以添加任意数量的面板、过滤器和文本字段,所有这些都有说明。当你保存仪表板后,你可以查看它,与同事分享,甚至发布到互联网上。
### 获取 EDA
最快的方法是用 [公开演示](https://demoeda.jortilles.com/) 来查看 EDA。但如果你想自己试一试,可以用 Docker 获取最新的 EDA 版本:
```
$ docker run -p 80:80 jortilles / eda: latest
```
我们还有一个 SaaS 选项,适用于任何想要使用 EDA 而无需进行安装、配置和持续更新的用户。你可以在我们的网站上查看 [云选项](https://eda.jortilles.com)。
如果你想看看它的实际运行情况,你可以在 YouTube 上观看一些 [演示](https://youtu.be/cBAAJbohHXQ)。
EDA 正在持续开发中,你可以在 GitHub 上找到它的 [源代码](https://github.com/jortilles/EDA)。
---
via: <https://opensource.com/article/21/4/visualize-data-eda>
作者:[Juanjo Ortilles](https://opensource.com/users/jortilles) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,311 | Stratis 加密入门 | https://fedoramagazine.org/getting-started-with-stratis-encryption/ | 2021-04-19T09:49:00 | [
"加密",
"Stratis"
] | https://linux.cn/article-13311-1.html | 
Stratis 在其 [官方网站](https://stratis-storage.github.io/) 上被描述为“*易于使用的 Linux 本地存储管理*”。请看这个 [短视频](https://www.youtube.com/watch?v=CJu3kmY-f5o),快速演示基础知识。该视频是在 Red Hat Enterprise Linux 8 系统上录制的。视频中显示的概念也适用于 Fedora 中的 Stratis。
Stratis 2.1 版本引入了对加密的支持。继续阅读以了解如何在 Stratis 中开始加密。
### 先决条件
加密需要 Stratis 2.1 或更高版本。这篇文章中的例子使用的是 Fedora 33 的预发布版本。Stratis 2.1 将用在 Fedora 33 的最终版本中。
你还需要至少一个可用的块设备来创建一个加密池。下面的例子是在 KVM 虚拟机上完成的,虚拟磁盘驱动器为 5GB(`/dev/vdb`)。
### 在内核密钥环中创建一个密钥
Linux 内核<ruby> 密钥环 <rt> keyring </rt></ruby>用于存储加密密钥。关于内核密钥环的更多信息,请参考 `keyrings` 手册页(`man keyrings`)。
使用 `stratis key set` 命令在内核钥匙圈中设置密钥。你必须指定从哪里读取密钥。要从标准输入中读取密钥,使用 `-capture-key` 选项。要从文件中读取密钥,使用 `-keyfile-path <file>` 选项。最后一个参数是一个密钥描述。它将稍后你创建加密的 Stratis 池时使用。
例如,要创建一个描述为 `pool1key` 的密钥,并从标准输入中读取密钥,可以输入:
```
# stratis key set --capture-key pool1key
Enter desired key data followed by the return key:
```
该命令提示我们输入密钥数据/密码,然后密钥就创建在内核密钥环中了。
要验证密钥是否已被创建,运行 `stratis key list`:
```
# stratis key list
Key Description
pool1key
```
这将验证是否创建了 `pool1key`。请注意,这些密钥不是持久的。如果主机重启,在访问加密的 Stratis 池之前,需要再次提供密钥(此过程将在后面介绍)。
如果你有多个加密池,它们可以有一个单独的密钥,也可以共享同一个密钥。
也可以使用以下 `keyctl` 命令查看密钥:
```
# keyctl get_persistent @s
318044983
# keyctl show
Session Keyring
701701270 --alswrv 0 0 keyring: _ses
649111286 --alswrv 0 65534 \_ keyring: _uid.0
318044983 ---lswrv 0 65534 \_ keyring: _persistent.0
1051260141 --alswrv 0 0 \_ user: stratis-1-key-pool1key
```
### 创建加密的 Stratis 池
现在已经为 Stratis 创建了一个密钥,下一步是创建加密的 Stratis 池。加密池只能在创建池时进行。目前不可能对现有的池进行加密。
使用 `stratis pool create` 命令创建一个池。添加 `-key-desc` 和你在上一步提供的密钥描述(`pool1key`)。这将向 Stratis 发出信号,池应该使用提供的密钥进行加密。下面的例子是在 `/dev/vdb` 上创建 Stratis 池,并将其命名为 `pool1`。确保在你的系统中指定一个空的/可用的设备。
```
# stratis pool create --key-desc pool1key pool1 /dev/vdb
```
你可以使用 `stratis pool list` 命令验证该池是否已经创建:
```
# stratis pool list
Name Total Physical Properties
pool1 4.98 GiB / 37.63 MiB / 4.95 GiB ~Ca, Cr
```
在上面显示的示例输出中,`~Ca` 表示禁用了缓存(`~` 否定了该属性)。`Cr` 表示启用了加密。请注意,缓存和加密是相互排斥的。这两个功能不能同时启用。
接下来,创建一个文件系统。下面的例子演示了创建一个名为 `filesystem1` 的文件系统,将其挂载在 `/filesystem1` 挂载点上,并在新文件系统中创建一个测试文件:
```
# stratis filesystem create pool1 filesystem1
# mkdir /filesystem1
# mount /stratis/pool1/filesystem1 /filesystem1
# cd /filesystem1
# echo "this is a test file" > testfile
```
### 重启后访问加密池
当重新启动时,你会发现 Stratis 不再显示你的加密池或它的块设备:
```
# stratis pool list
Name Total Physical Properties
```
```
# stratis blockdev list
Pool Name Device Node Physical Size Tier
```
要访问加密池,首先要用之前使用的相同的密钥描述和密钥数据/口令重新创建密钥:
```
# stratis key set --capture-key pool1key
Enter desired key data followed by the return key:
```
接下来,运行 `stratis pool unlock` 命令,并验证现在可以看到池和它的块设备:
```
# stratis pool unlock
# stratis pool list
Name Total Physical Properties
pool1 4.98 GiB / 583.65 MiB / 4.41 GiB ~Ca, Cr
# stratis blockdev list
Pool Name Device Node Physical Size Tier
pool1 /dev/dm-2 4.98 GiB Data
```
接下来,挂载文件系统并验证是否可以访问之前创建的测试文件:
```
# mount /stratis/pool1/filesystem1 /filesystem1/
# cat /filesystem1/testfile
this is a test file
```
### 使用 systemd 单元文件在启动时自动解锁 Stratis 池
可以在启动时自动解锁 Stratis 池,无需手动干预。但是,必须有一个包含密钥的文件。在某些环境下,将密钥存储在文件中可能会有安全问题。
下图所示的 systemd 单元文件提供了一个简单的方法来在启动时解锁 Stratis 池并挂载文件系统。欢迎提供更好的/替代方法的反馈。你可以在文章末尾的评论区提供建议。
首先用下面的命令创建你的密钥文件。确保用之前输入的相同的密钥数据/密码来代替`passphrase`。
```
# echo -n passphrase > /root/pool1key
```
确保该文件只能由 root 读取:
```
# chmod 400 /root/pool1key
# chown root:root /root/pool1key
```
在 `/etc/systemd/system/stratis-filesystem1.service` 创建包含以下内容的 systemd 单元文件:
```
[Unit]
Description = stratis mount pool1 filesystem1 file system
After = stratisd.service
[Service]
ExecStartPre=sleep 2
ExecStartPre=stratis key set --keyfile-path /root/pool1key pool1key
ExecStartPre=stratis pool unlock
ExecStartPre=sleep 3
ExecStart=mount /stratis/pool1/filesystem1 /filesystem1
RemainAfterExit=yes
[Install]
WantedBy = multi-user.target
```
接下来,启用服务,使其在启动时运行:
```
# systemctl enable stratis-filesystem1.service
```
现在重新启动并验证 Stratis 池是否已自动解锁,其文件系统是否已挂载。
### 结语
在今天的环境中,加密是很多人和组织的必修课。本篇文章演示了如何在 Stratis 2.1 中启用加密功能。
---
via: <https://fedoramagazine.org/getting-started-with-stratis-encryption/>
作者:[briansmith](https://fedoramagazine.org/author/briansmith/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Stratis is described on its [official website](https://stratis-storage.github.io/) as an “*easy to use local storage management for Linux*.” See this [short video](https://www.youtube.com/watch?v=CJu3kmY-f5o) for a quick demonstration of the basics. The video was recorded on a Red Hat Enterprise Linux 8 system. The concepts shown in the video also apply to Stratis in Fedora.
Stratis version 2.1 introduces support for encryption. Continue reading to learn how to get started with encryption in Stratis.
## Prerequisites
Encryption requires Stratis version 2.1 or greater. The examples in this post use a pre-release of Fedora 33. Stratis 2.1 will be available in the final release of Fedora 33.
You’ll also need at least one available block device to create an encrypted pool. The examples shown below were done on a KVM virtual machine with a 5 GB virtual disk drive *(/dev/vdb*).
## Create a key in the kernel keyring
The Linux kernel keyring is used to store the encryption key. For more information on the kernel keyring, refer to the *keyrings* manual page (*man keyrings*).
Use the *stratis key set *command to set up the key within the kernel keyring. You must specify where the key should be read from. To read the key from standard input, use the *–capture-key* option. To retrieve the key from a file, use the *–keyfile-path <file>* option. The last parameter is a key description. It will be used later when you create the encrypted Stratis pool.
For example, to create a key with the description *pool1key*, and to read the key from standard input, you would enter:
#stratis key set --capture-key pool1keyEnter desired key data followed by the return key:
The command prompts us to type the key data / passphrase, and the key is then created within the kernel keyring.
To verify that the key was created, run *stratis key list*:
#stratis key listKey Description pool1key
This verifies that the *pool1key* was created. Note that these keys are not persistent. If the host is rebooted, the key will need to be provided again before the encrypted Stratis pool can be accessed (this process is covered later).
If you have multiple encrypted pools, they can have a separate keys, or they can share the same key.
The keys can also be viewed using the following *keyctl* commands:
#keyctl get_persistent @s318044983 #keyctl showSession Keyring 701701270 --alswrv 0 0 keyring: _ses 649111286 --alswrv 0 65534 \_ keyring: _uid.0 318044983 ---lswrv 0 65534 \_ keyring: _persistent.0 1051260141 --alswrv 0 0 \_ user: stratis-1-key-pool1key
## Create the encrypted Stratis pool
Now that a key has been created for Stratis, the next step is to create the encrypted Stratis pool. Encrypting a pool can only be done at pool creation. It isn’t currently possible to encrypt an existing pool.
Use the *stratis pool create* command to create a pool. Add *–key-desc* and the key description that you provided in the previous step (*pool1key*). This will signal to Stratis that the pool should be encrypted using the provided key. The below example creates the Stratis pool on */dev/vdb*, and names it *pool1*. Be sure to specify an empty/available device on your system.
# stratis pool create --key-desc pool1key pool1 /dev/vdb
You can verify that the pool has been created with the *stratis pool list* command:
#stratis pool listName Total Physical Properties pool1 4.98 GiB / 37.63 MiB / 4.95 GiB ~Ca, Cr
In the sample output shown above, *~Ca *indicates that caching is disabled (the tilde negates the property). *Cr *indicates that encryption is enabled. Note that caching and encryption are mutually exclusive. Both features cannot be simultaneously enabled.
Next, create a filesystem. The below example, demonstrates creating a filesystem named *filesystem1*, mounting it at the */filesystem1* mountpoint, and creating a test file in the new filesystem:
# stratis filesystem create pool1 filesystem1 # mkdir /filesystem1 # mount /stratis/pool1/filesystem1 /filesystem1 # cd /filesystem1 # echo "this is a test file" > testfile
## Access the encrypted pool after a reboot
When you reboot you’ll notice that Stratis no longer shows your encrypted pool or its block device:
# stratis pool listName Total Physical Properties
# stratis blockdev listPool Name Device Node Physical Size Tier
To access the encrypted pool, first re-create the key with the same key description and key data / passphrase that you used previously:
# stratis key set --capture-key pool1keyEnter desired key data followed by the return key:
Next, run the *stratis pool unlock* command, and verify that you can now see the pool and its block device:
#stratis pool unlock#stratis pool listName Total Physical Properties pool1 4.98 GiB / 583.65 MiB / 4.41 GiB ~Ca, Cr #stratis blockdev listPool Name Device Node Physical Size Tier pool1 /dev/dm-2 4.98 GiB Data
Next, mount the filesystem and verify that you can access the test file you created previously:
#mount /stratis/pool1/filesystem1 /filesystem1/#cat /filesystem1/testfilethis is a test file
## Use a systemd unit file to automatically unlock a Stratis pool at boot
It is possible to automatically unlock your Stratis pool at boot without manual intervention. However, a file containing the key must be available. Storing the key in a file might be a security concern in some environments.
The systemd unit file shown below provides a simple method to unlock a Stratis pool at boot and mount the filesystem. Feedback on a better/alternative methods is welcome. You can provide suggestions in the comment section at the end of this article.
Start by creating your key file with the following command. Be sure to substitute *passphrase *with the same key data / passphrase you entered previously.
# echo -n passphrase > /root/pool1key
Make sure that the file is only readable by root:
# chmod 400 /root/pool1key # chown root:root /root/pool1key
Create a systemd unit file at */etc/systemd/system/stratis-filesystem1.service* with the following content:
[Unit] Description = stratis mount pool1 filesystem1 file system After = stratisd.service [Service] ExecStartPre=sleep 2 ExecStartPre=stratis key set --keyfile-path /root/pool1key pool1key ExecStartPre=stratis pool unlock ExecStartPre=sleep 3 ExecStart=mount /stratis/pool1/filesystem1 /filesystem1 RemainAfterExit=yes [Install] WantedBy = multi-user.target
Next, enable the service so that it will run at boot:
# systemctl enable stratis-filesystem1.service
Now reboot and verify that the Stratis pool has been automatically unlocked and that its filesystem is mounted.
## Summary and conclusion
In today’s environment, encryption is a must for many people and organizations. This post demonstrated how to enable encryption in Stratis 2.1.
## Sheogorath
A very nice article, I wasn’t aware of stratis at all. But I have one question: how is stratis relationship to LVM, cryptsetup and alike? Is stratis a daemon working on top of these or is it managing an entire own implementation of the storage management? Do they interfere with each other?
Also, one minor remark: in the key management part during automated unlock, the proper order would be:
touch /root/pool1key
chown root:root /root/pool1key
chmod 400 /root/pool1key
echo “secret password” > /root/pool1key
This would eliminate the possible race condition where the previous owner, given that the file already exist and was owned by a non-root user, could modify the permissions of the file before its ownership is changed, resulting in unexpected access to the file for the previous owner.
Hope that helps and looking forward to the next article!
## Brian Smith
Hi Sheogorath,
The Stratis design document at https://stratis-storage.github.io/StratisSoftwareDesign.pdf should answer your questions about how Stratis works.
## Oscar
Why Fedora has choosen btrfs (deprecated by RedHat) instead of Stratis? I can’t understand.
## Brian Smith
Hi Oscar,
This link might help answer your question about btrfs and Red Hat: https://fedoraproject.org/wiki/Changes/BtrfsByDefault#Red_Hat_doesn.27t_support_Btrfs.3F_Can_Fedora_do_this.3F
## Oscar
Thanks a lot. Very interesting!!
## Felipe
Great post! Shouldn’t all hashtags be a dollar sign?
## Brian Smith
Hi Felipe,
The commands in the article were run as the root user, indicated by the “# ” prompt.
## Gregory Bartholomew
Hi Felipe. The hashtags would be dollar signs for unprivileged commands. The commands being demonstrated in this article require super user privileges. The hashtag indicates that super user mode has been locked on by entering “sudo -i” so that every command does not need to be prefixed with sudo individually.
## Ross
There are no hashtags in this post. A hashtag is a hash (#) followed by a tag (one or more non-whitespace characters) — ‘#’ alone is just called a hash (or octothorpe, number sign, etc).
## T
If you wrote the password in a file on the hard drive anyway, what’s the point of encryption in the first place? Or am I missing something.
For a bad guy sitting with the hard drive connected to his system or your laptop booted into single mode in front of him, it’s not rocket science to figure out how it gets mounted at boot time.
## Brian Smith
Hi, as I mentioned in the article there are some security concerns with storing the key in a file. It is not required that you store it in file, you can always follow the steps in the “Access the encrypted pool after a reboot” section to manually re-create the key after each reboot.
Also keep in mind that in the example in this article, the key file is stored in the root filesystem. If the Stratis device was a removable storage drive, if the removable drive was lost/stolen by itself it would not have the key file on it (it would be on the systems root filesystem). So in other words, if you had a USB drive with encrypted Stratis on it, and lost the USB drive and not the laptop (root filesystem), the Stratis USB drive would not have the key file on it.
Also, your root filesystem could be encrypted (with LUKS). In that case, your laptop and the Stratis USB drive could be stolen, and without the LUKS password they couldn’t get to the Stratis key file in the root filesystem.
## Christian Horn
This depends on the scenario, I think.
If the storage is local, and you have the passphrase in a file, then the benefit of encryption might indeed come down to “instead of zeroing the device for removing the data, I can remove the passphrase file”.
If your volumes are backed by iSCSI devices provided by some remote system, then even having the passphrase in the local file can help you: then you “just” have to trust/secure the local system and not the system providing the iSCSI devices.
## T
Yours and Brian’s replies are all valid, and highlight how the proposed solution might still be viable in some cases.
The article as it stands does not reflect this. It still says “in some cases this might be a security concern”.
Quite the opposite is true at best; “in a few special scnearios this might be a meaningful approach” sounds more right.
For the likely reader of this article putting the pass phrase in a clear text file on the local hard drive would negate all security benefits that come with encr.yption in the first place.
If you access centralized storage that needs to be decrypted before accessing, you are likely not the kind of guy who needs to be told that you can put your passphrase in a clear text file on the local hard drive to mount it on boot using systemd.
Removable storage is a valid case, and reading on how to mount your encrypted usb device seemlessly when you plug it in, would make for a nice read. Though currently you need to dig deep down into the comments to figure that out. And in the same time un-learn the first impression you got from reading the article.
## Federico Chiacchiaretta
What about Clevis TPM integration with Stratis? Is there a roadmap?
## Dennis Keefe
Stratis has been working on this feature. Here are some links to the work.
Clevis support
https://github.com/stratis-storage/project/issues/192
Prototype of clevis integration from CLI
https://github.com/stratis-storage/stratis-cli/pull/657
## Dmitri Pal
Yes integration with clevis will give you also the option of automatically unlocking the keys using tang server which is already used with LUKS encryption.
https://www.youtube.com/watch?v=d4GmJPvhjcY
## ket bilietai nemokamai
Thank you, I have recently been looking for information about this subject for
a while and yours is the best I have discovered so far.
But, what about the bottom line? Are you positive about the
source?
my website ket bilietai nemokamai |
13,313 | 7个管理家目录的 Git 技巧 | https://opensource.com/article/21/4/git-home | 2021-04-20T09:52:33 | [
"Git",
"家目录",
"配置"
] | https://linux.cn/article-13313-1.html |
>
> 这是我怎样设置 Git 来管理我的家目录的方法。
>
>
>

我有好几台电脑。一台笔记本电脑用于工作,一台工作站放在家里,一台树莓派(或四台),一台 [Pocket CHIP](https://opensource.com/article/17/2/pocketchip-or-pi),一台 [运行各种不同的 Linux 的 Chromebook](https://opensource.com/article/21/2/chromebook-linux),等等。我曾经在每台计算机上或多或少地按照相同的步骤设置我的用户环境,也经常告诉自己让每台计算机都略有不同。例如,我在工作中比在家里更经常使用 [Bash 别名](https://opensource.com/article/17/5/introduction-alias-command-line-tool),并且我在家里使用的辅助脚本可能对工作没有用。
这些年来,我对各种设备的期望开始相融,我会忘记我在家用计算机上建立的功能没有移植到我的工作计算机上,诸如此类。我需要一种标准化我的自定义工具包的方法。使我感到意外的答案是 Git。
Git 是版本跟踪软件。它以既可以用在非常大的开源项目也可以用在极小的开源项目而闻名,甚至最大的专有软件公司也在用它。但是它是为源代码设计的,而不是用在一个装满音乐和视频文件、游戏、照片等的家目录。我听说过有人使用 Git 管理其家目录,但我认为这是程序员们进行的一项附带实验,而不是像我这样的现实生活中的用户。
用 Git 管理我的家目录是一个不断发展的过程。随着时间的推移我一直在学习和适应。如果你决定使用 Git 管理家目录,则可能需要记住以下几点。
### 1、文本和二进制位置

当由 Git 管理时,除了配置文件之外,你的家目录对于所有内容而言都是“无人之地”。这意味着当你打开主目录时,除了可预见的目录的列表之外,你什么都看不到。不应有任何杂乱无章的照片或 LibreOffice 文档,也不应有 “我就在这里放一分钟” 的临时文件。
原因很简单:使用 Git 管理家目录时,家目录中所有 *未* 提交的内容都会变成噪音。每次执行 `git status` 时,你都必须翻过去之前 Git 未跟踪的任何文件,因此将这些文件保存在子目录(添加到 `.gitignore` 文件中)至关重要。
许多 Linux 发行版提供了一组默认目录:
* `Documents`
* `Downloads`
* `Music`
* `Photos`
* `Templates`
* `Videos`
如果需要,你可以创建更多。例如,我把创作的音乐(`Music`)和购买来聆听的音乐(`Albums`)区分开来。同样,我的电影(`Cinema`)目录包含了其他人的电影,而视频(`Videos`)目录包含我需要编辑的视频文件。换句话说,我的默认目录结构比大多数 Linux 发行版提供的默认设置更详细,但是我认为这样做有好处。如果没有适合你的目录结构,你更会将其存放在家目录中,因为没有更好的存放位置,因此请提前考虑并规划好适合你的工作目录。你以后总是可以添加更多,但是最好先开始擅长的。
### 2、、设置最优的 `.gitignore`
清理家目录后,你可以像往常一样将其作为 Git 存储库实例化:
```
$ cd
$ git init .
```
你的 Git 仓库中还没有任何内容,你的家目录中的所有内容均未被跟踪。你的第一项工作是筛选未跟踪文件的列表,并确定要保持未跟踪状态的文件。要查看未跟踪的文件:
```
$ git status
.AndroidStudio3.2/
.FBReader/
.ICEauthority
.Xauthority
.Xdefaults
.android/
.arduino15/
.ash_history
[...]
```
根据你使用家目录的时间长短,此列表可能很长。简单的是你在上一步中确定的目录。通过将它们添加到名为 `.gitignore` 的隐藏文件中,你告诉 Git 停止将它们列为未跟踪文件,并且永远不对其进行跟踪:
```
$ \ls -lg | grep ^d | awk '{print $8}' >> ~/.gitignore
```
完成后,浏览 `git status` 所示的其余未跟踪文件,并确定是否有其他文件需要排除。这个过程帮助我发现了几个陈旧的配置文件和目录,这些文件和目录最终被我全部丢弃了,而且还发现了一些特定于一台计算机的文件和目录。我在这里非常严格,因为许多配置文件在自动生成时会表现得更好。例如,我从不提交我的 KDE 配置文件,因为许多文件包含了诸如最新文档之类的信息以及其他机器上不存在的其他元素。
我会跟踪我的个性化配置文件、脚本和实用程序、配置文件和 Bash 配置,以及速查表和我经常引用的其他文本片段。如果有软件主要负责维护的文件,则将其忽略。当对一个文件不确定时,我将其忽略。你以后总是可以取消忽略它(通过从 `.gitignore` 文件中删除它)。
### 3、了解你的数据
我使用的是 KDE,因此我使用开源扫描程序 [Filelight](https://utils.kde.org/projects/filelight) 来了解我的数据概况。Filelight 为你提供了一个图表,可让你查看每个目录的大小。你可以浏览每个目录以查看占用了空间的内容,然后回溯调查其他地方。这是一个令人着迷的系统视图,它使你可以以全新的方式看待你的文件。

使用 Filelight 或类似的实用程序查找不需要提交的意外数据缓存。例如,KDE 文件索引器(Baloo)生成了大量特定于其主机的数据,我绝对不希望将其传输到另一台计算机。
### 4、不要忽略你的 `.gitignore` 文件
在某些项目中,我告诉 Git 忽略我的 `.gitignore` 文件,因为有时我要忽略的内容特定于我的工作目录,并且我不认为同一项目中的其他开发人员需要我告诉他们 `.gitignore` 文件应该是什么样子。因为我的家目录仅供我使用,所以我 *不* 会忽略我的家目录的 `.gitignore` 文件。我将其与其他重要文件一起提交,因此它已在我的所有系统中被继承。当然,从家目录的角度来看,我所有的系统都是相同的:它们具有一组相同的默认文件夹和许多相同的隐藏配置文件。
### 5、不要担心二进制文件
我对我的系统进行了数周的严格测试,确信将二进制文件提交到 Git 绝对不是明智之举。我试过 GPG 加密的密码文件、试过 LibreOffice 文档、JPEG、PNG 等等。我甚至有一个脚本,可以在将 LibreOffice 文件添加到 Git 之前先解压缩,提取其中的 XML,以便仅提交 XML,然后重新构建 LibreOffice 文件,以便可以在 LibreOffice 中继续工作。我的理论是,提交 XML 会比使用 ZIP 文件(LibreOffice 文档实际上就是一个 ZIP 文件)会让 Git 存储库更小一些。
令我惊讶的是,我发现偶尔提交一些二进制文件并没有大幅增加我的 Git 存储库的大小。我使用 Git 已经很长时间了,我知道如果我要提交几千兆的二进制数据,我的存储库将会受到影响,但是偶尔提交几个二进制文件也不是不惜一切代价要避免的紧急情况。
有了这种信心,我将字体 OTF 和 TTF 文件添加到我的标准主存储库,以及 GDM 的 `.face` 文件以及其他偶尔小型二进制 Blob 文件。不要想太多,不要浪费时间去避免它。只需提交即可。
### 6、使用私有存储库
即使托管方提供了私人帐户,也不要将你的主目录提交到公共 Git 存储库。如果你像我一样,拥有 SSH 密钥、GPG 密钥链和 GPG 加密的文件,这些文件不应该出现在任何人的服务器上,而应该出现在我自己的服务器上。
我在树莓派上 [运行本地 Git 服务器](https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6)(这比你想象的要容易),因此我可以在家里时随时更新任何一台计算机。我是一名远程工作者,所以通常情况下就足够了,但是我也可以在旅行时通过 [虚拟私人网络](https://www.redhat.com/sysadmin/run-your-own-vpn-libreswan) 访问我的计算机。
### 7、要记得推送
Git 的特点是,只有当你告诉它要推送改动时,它才会把改动推送到你的服务器上。如果你是 Git 的老用户,则此过程可能对你很自然。对于可能习惯于 Nextcloud 或 Syncthing 自动同步的新用户,这可能需要一些时间来适应。
### Git 家目录
使用 Git 管理我的常用文件,不仅使我在不同设备上的生活更加便利。我知道我拥有所有配置和实用程序脚本的完整历史记录,这会鼓励我尝试新的想法,因为如果结果变得 *很糟糕*,则很容易回滚我的更改。Git 曾将我从在 `.bashrc` 文件中一个欠考虑的 `umask` 设置中解救出来、从深夜对包管理脚本的拙劣添加中解救出来、从当时看似很酷的 [rxvt](https://opensource.com/article/19/10/why-use-rxvt-terminal) 配色方案的修改中解救出来,也许还有其他一些错误。在家目录中尝试 Git 吧,因为这些提交会让家目录融合在一起。
---
via: <https://opensource.com/article/21/4/git-home>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I have several computers. I've got a laptop at work, a workstation at home, a Raspberry Pi (or four), a [Pocket CHIP](https://opensource.com/article/17/2/pocketchip-or-pi), a [Chromebook running various forms of Linux](https://opensource.com/article/21/2/chromebook-linux), and so on. I used to set up my user environment on each computer by more or less following the same steps, and I often told myself that I enjoyed that each one was slightly unique. For instance, I use [Bash aliases](https://opensource.com/article/17/5/introduction-alias-command-line-tool) more often at work than at home, and the helper scripts I use at home might not be useful at work.
Over the years, my expectations across devices began to merge, and I'd forget that a feature I'd built up on my home machine wasn't ported over to my work machine, and so on. I needed a way to standardize my customized toolkit. The answer, to my surprise, was Git.
Git is version-tracker software. It's famously used by the biggest and smallest open source projects and even by the largest proprietary software companies. But it was designed for source code—not a home directory filled with music and video files, games, photos, and so on. I'd heard of people managing their home directory with Git, but I assumed that it was a fringe experiment done by coders, not real-life users like me.
Managing my home directory with Git has been an evolving process. I've learned and adapted along the way. Here are the things you might want to keep in mind should you decide to manage your home directory with Git.
## 1. Text and binary locations
(Seth Kenlon, CC BY-SA 4.0)
When managed by Git, your home directory becomes something of a no-man 's-land for everything but configuration files. That means when you open your home directory, you should see nothing but a list of predictable directories. There shouldn't be any stray photos or LibreOffice documents, and no "I'll put this here for just a minute" files.
The reason for this is simple: when you manage your home directory with Git, everything in your home directory that's *not* being committed becomes noise. Every time you do a `git status`
, you'll have to scroll past any file that Git isn't tracking, so it's vital that you keep those files in subdirectories (which you add to your `.gitignore`
file).
Many Linux distributions provide a set of default directories:
- Documents
- Downloads
- Music
- Photos
- Templates
- Videos
You can create more if you need them. For instance, I differentiate between the music I create (Music) and the music I purchase to listen to (Albums). Likewise, my Cinema directory contains movies by other people, while Videos contains video files I need for editing. In other words, my default directory structure has more granularity than the default set provided by most Linux distributions, but I think there's a benefit to that. Without a directory structure that works for you, you'll be more likely to just stash stuff in your home directory, for lack of a better place for it, so think ahead and plan out directories that work for you. You can always add more later, but it's best to start strong.
## 2. Setting up your very best .gitignore
Once you've cleaned up your home directory, you can instantiate it as a Git repository as usual:
```
$ cd
$ git init .
```
Your Git repository contains nothing yet, so everything in your home directory is untracked. Your first job is to sift through the list of untracked files and determine what you want to remain untracked. To see untracked files:
```
$ git status
.AndroidStudio3.2/
.FBReader/
.ICEauthority
.Xauthority
.Xdefaults
.android/
.arduino15/
.ash_history
[...]
```
Depending on how long you've been using your home directory, this list may be long. The easy ones are the directories you decided on in the first step. By adding these to a hidden file called `.gitignore`
, you tell Git to stop listing them as untracked files and never to track them:
`$ \ls -lg | grep ^d | awk '{print $8}' >> ~/.gitignore`
With that done, go through the remaining untracked files shown by `git status`
and determine whether any other files warrant exclusion. This process helped me discover several stale old configuration files and directories, which I ended up trashing altogether, but also some that were very specific to one computer. I was fairly strict here because many configuration files do better when they're auto-generated. For instance, I never commit my KDE configuration files because many contain information like recent documents and other elements that don't exist on another machine.
I track my personalized configuration files, scripts and utilities, profile and Bash configs, and cheat sheets and other snippets of text that I refer to frequently. If the software is mostly responsible for maintaining a file, I ignore it. And when in doubt about a file, I ignore it. You can always un-ignore it later (by removing it from your `.gitignore`
file).
## 3. Get to know your data
I'm on KDE, so I use the open source scanner [Filelight](https://utils.kde.org/projects/filelight) to get an overview of my data. Filelight gives you a chart that lets you see the size of each directory. You can navigate through each directory to see what's taking up all the space and then backtrack to investigate elsewhere. It's a fascinating view of your system, and it lets you see your files in a completely new light.
(Seth Kenlon, CC BY-SA 4.0)
Use Filelight or a similar utility to find unexpected caches of data you don't need to commit. For instance, the KDE file indexer (Baloo) generates quite a lot of data specific to its host that I definitely wouldn't want to transport to another computer.
## 4. Don't ignore your .gitignore file
On some projects, I tell Git to ignore my `.gitignore`
file because what I want to ignore is sometimes specific to my working directory, and I don't presume other developers on the same project need me to tell them what their `.gitignore`
file ought to look like. Because my home directory is for my use only, I do *not* ignore my home's `.gitignore`
file. I commit it along with other important files, so it's inherited across all of my systems. And of course, all of my systems are identical from the home directory's viewpoint: they have the same set of default folders and many of the same hidden configuration files.
## 5. Don't fear the binary
I put my system through weeks and weeks of rigorous testing, convinced that it was *never* wise to commit binary files to Git. I tried GPG encrypted password files, I tried LibreOffice documents, JPEGs, PNGs, and more. I even had a script that unarchived LibreOffice files before adding them to Git, extracted the XML inside so I could commit just the XML, and then rebuilt the LibreOffice file so that I could work on it within LibreOffice. My theory was that committing XML would render a smaller Git repository than a ZIP file (which is all a LibreOffice document really is).
To my great surprise, I found that committing a few binary files every now and then did not substantially increase the size of my Git repository. I've worked with Git long enough to know that if I were to commit gigabytes of binary data, my repository would suffer, but the occasional binary file isn't an emergency to avoid at all costs.
Armed with this new confidence, I add font OTF and TTF files to my standard home repo, my `.face`
file for GDM, and other incidental minor binary blobs. Don't overthink it, don't waste time trying to avoid it; just commit it.
## 6. Use a private repo
Don't commit your home directory to a public Git repository, even if the host offers private accounts. If you're like me, you have SSH keys and GPG keychains and GPG-encrypted files that ought not end up on anybody's server but my own.
I [run a local Git server](https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6) on a Raspberry Pi (it's easier than you think), so I can update any computer any time I'm home. I'm a remote worker, so that's usually good enough, but I can also reach the computer when traveling over my [VPN](https://www.redhat.com/sysadmin/run-your-own-vpn-libreswan).
## 7. Remember to push
The thing about Git is that it only pushes changes to your server when you tell it to. If you're a longtime Git user, this process is probably natural to you. For new users who might be accustomed to the automatic synchronization in Nextcloud or Syncthing, this may take some getting used to.
## Git at home
Managing my common files with Git hasn't just made life more convenient across devices. Knowing that I have a full history for all my configurations and utility scripts encourages me to try out new ideas because it's always easy to roll back my changes if they turn out to be *bad* ideas. Git has rescued me from an ill-advised umask setting in `.bashrc`
, a poorly executed late-night addition to my package management script, and an it-seemed-like-a-cool-idea-at-the-time change of my [rxvt](https://opensource.com/article/19/10/why-use-rxvt-terminal) color scheme—and probably a few other mistakes in my past. Try Git in your home because a home that commits together merges together.
## 6 Comments |
13,314 | 将你的安卓手机屏幕投射到 Linux | https://opensource.com/article/21/3/android-raspberry-pi | 2021-04-20T16:24:00 | [
"手机",
"安卓"
] | /article-13314-1.html |
>
> 使用 Scrcpy 可以把你的手机屏幕变成一个“应用”,与在树莓派或任何其他基于 Linux 的设备上的应用一起运行。
>
>
>

要远离我们日常使用的电子产品是很难的。在熙熙攘攘的现代生活中,我想确保我不会错过手机屏幕上弹出的来自朋友和家人的重要信息。我也很忙,不希望迷失在令人分心的事情中,但是拿起手机并且回复信息往往会使我分心。
更糟糕的是,有很多的设备。幸运地是,大多数的设备(从功能强大的笔记本电脑到甚至不起眼的树莓派)都可以运行 Linux。因为它们运行的是 Linux,所以我为一种设置找到的解决方案几乎都适用于其他设备。
### 普遍适用
我想要一种无论我使用什么屏幕,都能统一我生活中不同来源的数据的方法。
我决定通过把手机屏幕复制到电脑上来解决这个问题。本质上,我把手机变成了一个“应用”,可以和我所有的其他程序运行在一起。这有助于我将注意力集中在桌面上,防止我走神,并使我更容易回复紧急通知。
听起来有吸引力吗?你也可以这样做。
### 设置 Scrcpy
[Scrcpy](https://github.com/Genymobile/scrcpy) 俗称屏幕复制(Screen Copy),是一个开源的屏幕镜像工具,它可以在 Linux、Windows 或者 macOS 上显示和控制安卓设备。安卓设备和计算机之间的通信主要是通过 USB 连接和<ruby> 安卓调试桥 <rt> Android Debug Bridge </rt></ruby>(ADB)。它使用 TCP/IP,且不需要 root 权限访问。
Scrcpy 的设置和配置非常简单。如果你正在运行 Fedora,你可以从 COPR 仓库安装它:
```
$ sudo dnf copr enable zeno/scrcpy
$ sudo dnf install scrcpy -y
```
在 Debian 或者 Ubuntu 上:
```
$ sudo apt install scrcpy
```
你也可以自己编译 Scrcpy。即使是在树莓派上,按照 [Scrcpy 的 GitHub 主页](https://github.com/Genymobile/scrcpy/blob/master/BUILD.md) 上的说明来构建也不需要很长时间。
### 设置手机
Scrcpy 安装好后,你必须启用 USB 调试并授权每个设备(你的树莓派、笔记本电脑或者工作站)为受信任的控制器。
打开安卓上的“设置”应用程序。如果“开发者选项”没有被激活,按照安卓的 [说明来解锁它](https://developer.android.com/studio/debug/dev-options)。
接下来,启用“USB 调试”。

然后通过 USB 将手机连接到你的树莓派或者笔记本电脑(或者你正在使用的任何设备),如果可以选择的话,将模式设置为 [PTP](https://en.wikipedia.org/wiki/Picture_Transfer_Protocol)。如果你的手机不能使用 PTP,将你的手机设置为用于传输文件的模式(而不是,作为一个<ruby> 叠接 <rt> tethering </rt></ruby>或者 MIDI 设备)。
你的手机可能会提示你授权你的电脑,这是通过它的 RSA 指纹进行识别的。你只需要在你第一次连接的时候操作即可,在之后你的手机会识别并信任你的计算机。
使用 `lsusb` 命令确认设置:
```
$ lsusb
Bus 007 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 011 Device 004: ID 046d:c21d Logitech, Inc. F310 Gamepad
Bus 005 Device 005: ID 0951:1666 Kingston Technology DataTraveler G4
Bus 005 Device 004: ID 05e3:0608 Genesys Logic, Inc. Hub
Bus 004 Device 001: ID 18d1:4ee6 Google Inc. Nexus/Pixel Device (PTP + debug)
Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
```
然后执行 `scrcpy` 以默认设置运行。

性能和响应能力取决于你使用什么设备来控制你的手机。在树莓派派上,一些动画可能会变慢,甚至有时候会响应滞后。Scrcpy 提供了一个简单的解决办法:降低 Scrcpy 显示图像的位速率和分辨率使得你的计算机能够容易显示动画。使用以下命令来实现:
```
$ scrcpy --bit-rate 1M --max-size 800
```
尝试不同的值来找到一个适合你的值。为了使键入更方便,在选定一个命令之后,可以考虑 [创建自己的 Bash 别名](https://opensource.com/article/19/7/bash-aliases)。
### 剪断连线
Scrcpy 开始运行后,你甚至可以通过 WiFi 连接你的手机和计算机。Scrcpy 安装过程也会安装 `adb`,它是一个与安卓设备通信的命令。Scrcpy 也可以使用这个命令与你的设备通信,`adb` 可以通过 TCP/IP 连接。

要尝试的话,请确保你的手机通过 WiFi 连在与你的计算机所使用的相同的无线网络上。依然不要断开你的手机与 USB 的连接!
接下来,通过手机中的“设置”,选择“关于手机”来获取你手机的 IP 地址。查看“状态”选项来获得你的地址。它通常是 192.168 或者 10 开头。
或者,你也可以使用 `adb` 来获得你手机的IP地址:
```
$ adb shell ip route | awk '{print $9}'
To connect to your device over WiFi, you must enable TCP/IP connections. This, you must do through the adb command:
$ adb tcpip 5555
Now you can disconnect your mobile from USB.
Whenever you want to connect over WiFi, first connect to the mobile with the command adb connect. For instance, assuming my mobile's IP address is 10.1.1.22, the command is:
$ adb connect 10.1.1.22:5555
```
连接好之后,你就可以像往常一样运行 Scrcpy 了。
### 远程控制
Scrcpy 很容易使用。你可以在终端或者 [一个图形界面应用](https://opensource.com/article/19/9/mirror-android-screen-guiscrcpy) 中尝试它。
你是否在使用其它的屏幕镜像工具?如果有的话,请在评论中告诉我们吧。
---
via: <https://opensource.com/article/21/3/android-raspberry-pi>
作者:[Sudeshna Sur](https://opensource.com/users/sudeshna-sur) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ShuyRoy](https://github.com/ShuyRoy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,316 | groff 程序员的 5 个标志 | https://opensource.com/article/21/4/groff-programmer | 2021-04-20T22:12:25 | [
"groff",
"排版",
"字处理"
] | https://linux.cn/article-13316-1.html |
>
> 学习一款老派的文本处理软件 groff,就像是学习骑自行车。
>
>
>

我第一次发现 Unix 系统是在 20 世纪 90 年代早期,当时我还在大学读本科。我太喜欢这个系统了,所以我将家里电脑上的 MS-DOS 也换成了 Linux 系统。
在 90 年代早期至中期,Linux 所缺失的一个东西是<ruby> 字处理软件 <rt> word processor </rt></ruby>。作为其他桌面操作系统的标准办公程序,字处理软件能让你轻松地编辑文本。我经常在 DOS 上使用字处理软件来撰写课程论文。直到 90 年代末,我都没能找到一款 Linux 原生的字处理软件。直到那时,文字处理是我在第一台电脑上保留双启动的少有的原因之一,那样我可以偶尔切换到 DOS 系统写论文。
后来,我发现 Linux 提供了一款文字处理软件:GNU troff,它一般称为 [groff](https://en.wikipedia.org/wiki/Groff_(software)),是经典的文本处理系统 troff 的一个现代实现。troff 是 “<ruby> 排版工快印 <rt> typesetter roff </rt></ruby>” 的简称,是 nroff 系统的改进版本,而 nroff 又是最初的 roff 系统的新实现。roff 表示<ruby> 快速印出 <rt> run off </rt></ruby>,比如“快速印出”一份文档。
利用文本处理系统,你在纯文本编辑器里编辑内容,通过<ruby> 宏 <rt> macro </rt></ruby>或其他处理命令来添加格式。然后将文件输入文本处理系统,比如 groff,来生成适合打印的格式化输出。另一个知名的文本处理系统是 LaTeX,但是 groff 已经满足我的需求,而且足够简单。
经过一点实践,我发现在 Linux 上使用 groff 来撰写课程论文与使用字处理软件一样容易。尽管我现在不再使用 groff 来写文档了,我依然记得它的那些宏和命令。如果你也是这样并且在那么多年之前学会了使用 groff 写作,你可能会认出这 5 个 groff 程序员的标志。
### 1、你有一个喜欢的宏集
输入由宏点缀的纯文本,你便能在 groff 里对文档进行格式化。groff 里的宏是行首为单个句点(`.`)的短命令。例如:如果你想在输出里插入几行,宏命令 `.sp 2` 会添加两个空行。groff 还具有其他一些基本的宏,支持各种各样的格式化。
为了能让作者更容易地格式化文档,groff 还提供了不同的 <ruby> 宏集 <rt> macro set </rt></ruby>,即一组能够让你以自己的方式格式化文档的宏的集合。我学会的第一个宏集是 `-me` 宏集。这个宏集的名称其实是 `e`,你在处理文件时使用 `-me` 选项来指定这个 `e` 宏集。
groff 还包含其他宏集。例如,`-man` 宏集以前是用于格式化 Unix 系统内置的 <ruby> 手册页 <rt> manual page </rt></ruby> 的标准宏集,`-ms` 宏集经常用于格式化其他一些技术文档。如果你学会了使用 groff 写作,你可能有一个喜欢的宏集。
### 2、你想专注于内容而非格式
使用 groff 写作的一个很好的特点是,你能专注于你的 *内容*,而不用太担心它看起来会怎么样。对于技术作者而言这是一个很实用的特点。对专业作家来说,groff 是一个很好的、“不会分心”的写作环境。至少,使用 groff `-T` 选项所支持的任何格式来交付内容时你不用担心,这包括 PDF、PostScript、HTML、以及纯文本。不过,你无法直接从 groff 生成 LibreOffice ODT 文件或者 Word DOC 文件。
一旦你使用 groff 写作变得有信心之后,宏便开始 *消失*。用于格式化的宏变成了背景的一部分,而你纯粹地专注于眼前的文本内容。我已经使用 groff 写了足够多内容,以至于我甚至不再看见那些宏。也许,这就像写代码,而你的大脑随意换档,于是你就像计算机一样思考,看到的代码就是一组指令。对我而言,使用 groff 写作就像那样:我仅仅看到文本,而我的大脑将宏自动地翻译成格式。
### 3、你喜欢怀旧复古的感觉
当然,使用一个更典型的字处理软件来写你的文档可能更 *简单*,比如 LibreOffice Writer、甚至 Google Docs 或 Microsoft Word。而且对于某些种类的文档,桌面型字处理软件才是正确的选择。但是,如果你想要这种怀旧复古的感觉,使用 groff 写作很难被打败。
我承认,我的大部分写作是用 LibreOffice Writer 完成的,它的表现很出色。但是当我渴望以一种怀旧复古的方式去做时,我会打开编辑器用 groff 来写文档。
### 4、你希望能到处使用它
groff 及其同类软件在几乎所有的 Unix 系统上都是标准软件包。此外,groff 宏不会随系统而变化。比如,`-me` 宏集在不同系统上都应该相同。因此,一旦你在一个系统上学会使用宏,你能在下一个系统上同样地使用它们。
另外,因为 groff 文档就是纯文本文档,所以你能使用任何你喜欢的编辑器来编辑文档。我喜欢使用 GNU Emacs 来编辑我的 groff 文档,但是你可能使用 GNOME Gedit、Vim、其他你 [最喜欢的文本编辑器](https://opensource.com/article/21/2/open-source-text-editors)。大部分编辑器会支持这样一种模式,其中 groff 宏会以不同的颜色高亮显示,帮助你在处理文件之前便能发现错误。
### 5、你使用 -me 写了这篇文章
当我决定要写这篇文章时,我认为最佳的方式便是直接使用 groff。我想要演示 groff 在编写文档方面是多么的灵活。所以,虽然你正在网上读这篇文章,但是它最初是用 groff 写的。
我希望这激发了你学习如何使用 groff 撰写文档的兴趣。如果你想学习 `-me` 宏集里更高级的函数,参考 Eric Allman 的《Writing papers with groff using -me》,你应该能在系统的 groff 文档找到这本书,文件名为 `meintro.me`。这是一份很好的参考资料,还解释了使用 `-me` 宏集格式化论文的其他方式。
我还提供了这篇文章的原始草稿,其中使用了 `-me` 宏集。下载这个文件并保存为 `five-signs-groff.me`,然后运行 groff 处理来查看它。`-T` 选项设置输出类型,比如 `-Tps` 用于生成 PostScript 输出,`-Thtml` 用于生成 HTML 文件。比如:
```
groff -me -Thtml five-signs-groff.me > five-signs-groff.html
```
---
via: <https://opensource.com/article/21/4/groff-programmer>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[liweitianux](https://github.com/liweitianux) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I first discovered Unix systems in the early 1990s, when I was an undergraduate at university. I liked it so much that I replaced the MS-DOS system on my home computer with the Linux operating system.
One thing that Linux didn't have in the early to mid-1990s was a word processor. A standard office application on other desktop operating systems, a word processor lets you edit text easily. I often used a word processor on DOS to write my papers for class. I wouldn't find a Linux-native word processor until the late 1990s. Until then, word processing was one of the rare reasons I maintained dual-boot on my first computer, so I could occasionally boot back into DOS to write papers.
Then I discovered that Linux provided kind of a word processor. GNU troff, better known as [groff](https://en.wikipedia.org/wiki/Groff_(software)), is a modern implementation of a classic text processing system called troff, short for "typesetter roff," which is an improved version of the nroff system. And nroff was meant to be a new implementation of the original roff (which stood for "run off," as in to "run off" a document).
With text processing, you edit text in a plain text editor, and you add formatting through macros or other processing commands. You then process that text file through a text-processing system such as groff to generate formatted output suitable for a printer. Another well-known text processing system is LaTeX, but groff was simple enough for my needs.
With a little practice, I found I could write my class papers just as easily in groff as I could using a word processor on Linux. While I don't use groff to write documents today, I still remember the macros and commands to generate printed documents with it. And if you're the same and you learned how to write with groff all those years ago, you probably recognize these five signs that you're a groff writer.
## 1. You have a favorite macro set
You format a document in groff by writing plain text interspersed with macros. A macro in groff is a short command that starts with a single period at the beginning of a line. For example: if you want to insert a few lines into your output, the `.sp 2`
macro command adds two blank lines. groff supports other basic macros for all kinds of formatting.
To make formatting a document easier for the writer, groff also provides different *macro sets*, collections of macros that let you format documents your own way. The first macro set I learned was the `-me`
macro set. Really, the macro set is called the `e`
macro set, and you specify the `e`
macro set when you process a file using the `-me`
option.
groff includes other macro sets, too. For example, the `-man`
macro set used to be the standard macro set to format the built-in *manual* pages on Unix systems, and the `-ms`
macro set is often used to format certain other technical documents. If you learned to write with groff, you probably have a favorite macro set.
## 2. You want to focus on your content, not the formatting
One great feature of writing with groff is that you can focus on your *content* and not worry too much about what it looks like. That is a handy feature for technical writers. groff is a great "distraction-free" environment for professional writers. At least, as long as you don't mind delivering your output in any of the formats that groff supports with the `-T`
command-line option, including PDF, PostScript, HTML, and plain text. You can't generate a LibreOffice ODT file or Word DOC file directly from groff.
Once you get comfortable writing in groff, the macros start to *disappear*. The formatting macros become part of the background, and you focus purely on the text in front of you. I've done enough writing in groff that I don't even see the macros anymore. Maybe it's like writing programming code, and your mind just switches gears, so you think like a computer and see the code as a set of instructions. For me, writing in groff is like that; I just see my text, and my mind interprets the macros automatically into formatting.
## 3. You like the old-school feel
Sure, it might be *easier* to write your documents with a more typical word processor like LibreOffice Writer or even Google Docs or Microsoft Word. And for certain kinds of documents, a desktop word processor is the right fit. But if you want the "old-school" feel, it's hard to beat writing in groff.
I'll admit that I do most of my writing with LibreOffice Writer, which does an outstanding job. But when I get that itch to do it "old-school," I'll open an editor and write my document using groff.
## 4. You like that you can use it anywhere
groff (and its cousins) are a standard package on almost any Unix system. And with groff, the macros don't change. For example, the `-me`
macros should be the same from system to system. So once you've learned to use the macros on one system, you can use them on the next system.
And because groff documents are just plain text, you can use any editor you like to edit your documents for groff. I like to use GNU Emacs to edit my groff documents, but you can use GNOME Gedit, Vim, or your [favorite text editor](https://opensource.com/article/21/2/open-source-text-editors). Most editors include some kind of "mode" that will highlight the groff macros in a different color from the rest of your text to help you spot errors before processing the file.
## 5. You wrote this article in -me
When I decided to write this article, I thought the best way would be to use groff directly. I wanted to demonstrate how flexible groff was in preparing documents. So even though you're reading this on a website, the article was originally written using groff.
I hope this has interested you in learning how to use groff to write documents. If you'd like to use more advanced functions in the `-me`
macro set, refer to Eric Allman's *Writing papers with groff using -me*, which you should find on your system as **meintro.me** in groff's documentation. It's a great reference document that explains other ways to format papers using the `-me`
macros.
I've also included a copy of the original draft of my article that uses the `-me`
macros. Save the file to your system as **five-signs-groff.me**, and run it through groff to view it. The `-T`
option sets the output type, such as `-Tps`
to generate PostScript output or `-Thtml`
to create an HTML file. For example:
groff -me -Thtml five-signs-groff.me > five-signs-groff.html
## 1 Comment |
13,318 | 怎样在 Linux 中使用动态和静态库 | https://opensource.com/article/20/6/linux-libraries | 2021-04-21T18:48:31 | [
"动态库",
"静态库",
"编译"
] | https://linux.cn/article-13318-1.html |
>
> 了解 Linux 如何使用库,包括静态库和动态库的差别,有助于你解决依赖问题。
>
>
>

Linux 从某种意义上来说就是一堆相互依赖的静态和动态库。对于 Linux 系统新手来说,库的整个处理过程简直是个迷。但对有经验的人来说,被构建进操作系统的大量共享代码对于编写新应用来说却是个优点。
为了让你熟悉这个话题,我准备了一个小巧的 [应用例子](https://github.com/hANSIc99/library_sample) 来展示在普通的 Linux 发行版(在其他操作系统上未验证)上是经常是如何处理库的。为了用这个例子来跟上这个需要动手的教程,请打开命令行输入:
```
$ git clone https://github.com/hANSIc99/library_sample
$ cd library_sample/
$ make
cc -c main.c -Wall -Werror
cc -c libmy_static_a.c -o libmy_static_a.o -Wall -Werror
cc -c libmy_static_b.c -o libmy_static_b.o -Wall -Werror
ar -rsv libmy_static.a libmy_static_a.o libmy_static_b.o
ar: creating libmy_static.a
a - libmy_static_a.o
a - libmy_static_b.o
cc -c -fPIC libmy_shared.c -o libmy_shared.o
cc -shared -o libmy_shared.so libmy_shared.o
$ make clean
rm *.o
```
当执行完这些命令,这些文件应当被添加进目录下(执行 `ls` 来查看):
```
my_app
libmy_static.a
libmy_shared.so
```
### 关于静态链接
当你的应用链接了一个静态库,这个库的代码就变成了可执行文件的一部分。这个动作只在链接过程中执行一次,这些静态库通常以 `.a` 扩展符结尾。
静态库是多个<ruby> 目标 <rt> object </rt></ruby>文件的<ruby> 归档 <rt> archive </rt></ruby>([ar](https://en.wikipedia.org/wiki/Ar_%28Unix%29))。这些目标文件通常是 ELF 格式的。ELF 是 <ruby> <a href="https://linuxhint.com/understanding_elf_file_format/"> 可执行可链接格式 </a> <rt> Executable and Linkable Format </rt></ruby> 的简写,它与多个操作系统兼容。
`file` 命令的输出可以告诉你静态库 `libmy_static.a` 是 `ar` 格式的归档文件类型。
```
$ file libmy_static.a
libmy_static.a: current ar archive
```
使用 `ar -t`,你可以看到归档文件的内部。它展示了两个目标文件:
```
$ ar -t libmy_static.a
libmy_static_a.o
libmy_static_b.o
```
你可以用 `ax -x <archive-file>` 命令来提取归档文件的文件。被提出的都是 ELF 格式的目标文件:
```
$ ar -x libmy_static.a
$ file libmy_static_a.o
libmy_static_a.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
```
### 关于动态链接
动态链接指的是使用共享库。共享库通常以 `.so` 的扩展名结尾(“<ruby> 共享对象 <rt> shared object </rt></ruby>” 的简写)。
共享库是 Linux 系统中依赖管理的最常用方法。这些共享库在应用启动前被载入内存,当多个应用都需要同一个库时,这个库在系统中只会被加载一次。这个特性减少了应用的内存占用。
另外一个值得注意的地方是,当一个共享库的 bug 被修复后,所有引用了这个库的应用都会受益。但这也意味着,如果一个 bug 还没被发现,那所有相关的应用都会遭受这个 bug 影响(如果这个应用使用了受影响的部分)。
当一个应用需要某个特定版本的库,但是<ruby> 链接器 <rt> linker </rt></ruby>只知道某个不兼容版本的位置,对于初学者来说这个问题非常棘手。在这个场景下,你必须帮助链接器找到正确版本的路径。
尽管这不是一个每天都会遇到的问题,但是理解动态链接的原理总是有助于你修复类似的问题。
幸运的是,动态链接的机制其实非常简洁明了。
为了检查一个应用在启动时需要哪些库,你可以使用 `ldd` 命令,它会打印出给定文件所需的动态库:
```
$ ldd my_app
linux-vdso.so.1 (0x00007ffd1299c000)
libmy_shared.so => not found
libc.so.6 => /lib64/libc.so.6 (0x00007f56b869b000)
/lib64/ld-linux-x86-64.so.2 (0x00007f56b8881000)
```
可以注意到 `libmy_shared.so` 库是代码仓库的一部分,但是没有被找到。这是因为负责在应用启动之前将所有依赖加载进内存的动态链接器没有在它搜索的标准路径下找到这个库。
对新手来说,与常用库(例如 `bizp2`)版本不兼容相关的问题往往十分令人困惑。一种方法是把该仓库的路径加入到环境变量 `LD_LIBRARY_PATH` 中来告诉链接器去哪里找到正确的版本。在本例中,正确的版本就在这个目录下,所以你可以导出它至环境变量:
```
$ LD_LIBRARY_PATH=$(pwd):$LD_LIBRARY_PATH
$ export LD_LIBRARY_PATH
```
现在动态链接器知道去哪找库了,应用也可以执行了。你可以再次执行 `ldd` 去调用动态链接器,它会检查应用的依赖然后加载进内存。内存地址会在对象路径后展示:
```
$ ldd my_app
linux-vdso.so.1 (0x00007ffd385f7000)
libmy_shared.so => /home/stephan/library_sample/libmy_shared.so (0x00007f3fad401000)
libc.so.6 => /lib64/libc.so.6 (0x00007f3fad21d000)
/lib64/ld-linux-x86-64.so.2 (0x00007f3fad408000)
```
想知道哪个链接器被调用了,你可以用 `file` 命令:
```
$ file my_app
my_app: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=26c677b771122b4c99f0fd9ee001e6c743550fa6, for GNU/Linux 3.2.0, not stripped
```
链接器 `/lib64/ld-linux-x86–64.so.2` 是一个指向 `ld-2.30.so` 的软链接,它也是我的 Linux 发行版的默认链接器:
```
$ file /lib64/ld-linux-x86-64.so.2
/lib64/ld-linux-x86-64.so.2: symbolic link to ld-2.31.so
```
回头看看 `ldd` 命令的输出,你还可以看到(在 `libmy_shared.so` 边上)每个依赖都以一个数字结尾(例如 `/lib64/libc.so.6`)。共享对象的常见命名格式为:
```
libXYZ.so.<MAJOR>.<MINOR>
```
在我的系统中,`libc.so.6` 也是指向同一目录下的共享对象 `libc-2.31.so` 的软链接。
```
$ file /lib64/libc.so.6
/lib64/libc.so.6: symbolic link to libc-2.31.so
```
如果你正在面对一个应用因为加载库的版本不对导致无法启动的问题,有很大可能你可以通过检查整理这些软链接或者确定正确的搜索路径(查看下方“动态加载器:[ld.so](http://ld.so)”一节)来解决这个问题。
更为详细的信息请查看 [ldd 手册页](https://www.man7.org/linux/man-pages/man1/ldd.1.html)。
#### 动态加载
动态加载的意思是一个库(例如一个 `.so` 文件)在程序的运行时被加载。这是使用某种特定的编程方法实现的。
当一个应用使用可以在运行时改变的插件时,就会使用动态加载。
查看 [dlopen 手册页](https://www.man7.org/linux/man-pages/man3/dlopen.3.html) 获取更多信息。
#### 动态加载器:[ld.so](http://ld.so)
在 Linux 系统中,你几乎总是正在跟共享库打交道,所以必须有个机制来检测一个应用的依赖并将其加载进内存中。
`ld.so` 按以下顺序在这些地方寻找共享对象:
1. 应用的绝对路径或相对路径下(用 GCC 编译器的 `-rpath` 选项硬编码的)
2. 环境变量 `LD_LIBRARY_PATH`
3. `/etc/ld.so.cache` 文件
需要记住的是,将一个库加到系统库归档 `/usr/lib64` 中需要管理员权限。你可以手动拷贝 `libmy_shared.so` 至库归档中来让应用可以运行,而避免设置 `LD_LIBRARY_PATH`。
```
unset LD_LIBRARY_PATH
sudo cp libmy_shared.so /usr/lib64/
```
当你运行 `ldd` 时,你现在可以看到归档库的路径被展示出来:
```
$ ldd my_app
linux-vdso.so.1 (0x00007ffe82fab000)
libmy_shared.so => /lib64/libmy_shared.so (0x00007f0a963e0000)
libc.so.6 => /lib64/libc.so.6 (0x00007f0a96216000)
/lib64/ld-linux-x86-64.so.2 (0x00007f0a96401000)
```
### 在编译时定制共享库
如果你想你的应用使用你的共享库,你可以在编译时指定一个绝对或相对路径。
编辑 `makefile`(第 10 行)然后通过 `make -B` 来重新编译程序。然后 `ldd` 输出显示 `libmy_shared.so` 和它的绝对路径一起被列出来了。
把这个:
```
CFLAGS =-Wall -Werror -Wl,-rpath,$(shell pwd)
```
改成这个(记得修改用户名):
```
CFLAGS =/home/stephan/library_sample/libmy_shared.so
```
然后重新编译:
```
$ make
```
确认下它正在使用你设定的绝对路径,你可以在输出的第二行看到:
```
$ ldd my_app
linux-vdso.so.1 (0x00007ffe143ed000)
libmy_shared.so => /lib64/libmy_shared.so (0x00007fe50926d000)
/home/stephan/library_sample/libmy_shared.so (0x00007fe509268000)
libc.so.6 => /lib64/libc.so.6 (0x00007fe50909e000)
/lib64/ld-linux-x86-64.so.2 (0x00007fe50928e000)
```
这是个不错的例子,但是如果你在编写给其他人用的库,它是怎样工作的呢?新库的路径可以通过写入 `/etc/ld.so.conf` 或是在 `/etc/ld.so.conf.d/` 目录下创建一个包含路径的 `<library-name>.conf` 文件来注册至系统。之后,你必须执行 `ldconfig` 命令来覆写 `ld.so.cache` 文件。这一步有时候在你装了携带特殊的共享库的程序来说是不可省略的。
查看 [ld.so 的手册页](https://www.man7.org/linux/man-pages/man8/ld.so.8.html) 获取更多详细信息。
### 怎样处理多种架构
通常来说,32 位和 64 位版本的应用有不同的库。下面列表展示了不同 Linux 发行版库的标准路径:
**红帽家族**
* 32 位:`/usr/lib`
* 64 位:`/usr/lib64`
**Debian 家族**
* 32 位:`/usr/lib/i386-linux-gnu`
* 64 位:`/usr/lib/x86_64-linux-gnu`
**Arch Linux 家族**
* 32 位:`/usr/lib32`
* 64 位:`/usr/lib64`
[FreeBSD](https://opensource.com/article/20/5/furybsd-linux)(技术上来说不算 Linux 发行版)
* 32 位:`/usr/lib32`
* 64 位:`/usr/lib`
知道去哪找这些关键库可以让库链接失效的问题成为历史。
虽然刚开始会有点困惑,但是理解 Linux 库的依赖管理是一种对操作系统掌控感的表现。在其他应用程序中运行这些步骤,以熟悉常见的库,然后继续学习怎样解决任何你可能遇到的库的挑战。
---
via: <https://opensource.com/article/20/6/linux-libraries>
作者:[Stephan Avenwedde](https://opensource.com/users/hansic99) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tt67wq](https://github.com/tt67wq) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux, in a way, is a series of static and dynamic libraries that depend on each other. For new users of Linux-based systems, the whole handling of libraries can be a mystery. But with experience, the massive amount of shared code built into the operating system can be an advantage when writing new applications.
To help you get in touch with this topic, I prepared a small [application example](https://github.com/hANSIc99/library_sample) that shows the most common methods that work on common Linux distributions (these have not been tested on other systems). To follow along with this hands-on tutorial using the example application, open a command prompt and type:
```
$ git clone https://github.com/hANSIc99/library_sample
$ cd library_sample/
$ make
cc -c main.c -Wall -Werror
cc -c libmy_static_a.c -o libmy_static_a.o -Wall -Werror
cc -c libmy_static_b.c -o libmy_static_b.o -Wall -Werror
ar -rsv libmy_static.a libmy_static_a.o libmy_static_b.o
ar: creating libmy_static.a
a - libmy_static_a.o
a - libmy_static_b.o
cc -c -fPIC libmy_shared.c -o libmy_shared.o
cc -shared -o libmy_shared.so libmy_shared.o
$ make clean
rm *.o
```
After executing these commands, these files should be added to the directory (run `ls`
to see them):
```
my_app
libmy_static.a
libmy_shared.so
```
## About static linking
When your application links against a static library, the library's code becomes part of the resulting executable. This is performed only once at linking time, and these static libraries usually end with a `.a`
extension.
A static library is an archive ([ar](https://en.wikipedia.org/wiki/Ar_%28Unix%29)) of object files. The object files are usually in the ELF format. ELF is short for [Executable and Linkable Format](https://linuxhint.com/understanding_elf_file_format/), which is compatible with many operating systems.
The output of the `file`
command tells you that the static library `libmy_static.a`
is the `ar`
archive type:
```
$ file libmy_static.a
libmy_static.a: current ar archive
```
With `ar -t`
, you can look into this archive; it shows two object files:
```
$ ar -t libmy_static.a
libmy_static_a.o
libmy_static_b.o
```
You can extract the archive's files with `ar -x <archive-file>`
. The extracted files are object files in ELF format:
```
$ ar -x libmy_static.a
$ file libmy_static_a.o
libmy_static_a.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
```
## About dynamic linking
Dynamic linking means the use of shared libraries. Shared libraries usually end with `.so`
(short for "shared object").
Shared libraries are the most common way to manage dependencies on Linux systems. These shared resources are loaded into memory before the application starts, and when several processes require the same library, it will be loaded only once on the system. This feature saves on memory usage by the application.
Another thing to note is that when a bug is fixed in a shared library, every application that references this library will profit from it. This also means that if the bug remains undetected, each referencing application will suffer from it (if the application uses the affected parts).
It can be very hard for beginners when an application requires a specific version of the library, but the linker only knows the location of an incompatible version. In this case, you must help the linker find the path to the correct version.
Although this is not an everyday issue, understanding dynamic linking will surely help you in fixing such problems.
Fortunately, the mechanics for this are quite straightforward.
To detect which libraries are required for an application to start, you can use `ldd`
, which will print out the shared libraries used by a given file:
```
$ ldd my_app
linux-vdso.so.1 (0x00007ffd1299c000)
libmy_shared.so => not found
libc.so.6 => /lib64/libc.so.6 (0x00007f56b869b000)
/lib64/ld-linux-x86-64.so.2 (0x00007f56b8881000)
```
Note that the library `libmy_shared.so`
is part of the repository but is not found. This is because the dynamic linker, which is responsible for loading all dependencies into memory before executing the application, cannot find this library in the standard locations it searches.
Errors associated with linkers finding incompatible versions of common libraries (like `bzip2`
, for example) can be quite confusing for a new user. One way around this is to add the repository folder to the environment variable `LD_LIBRARY_PATH`
to tell the linker where to look for the correct version. In this case, the right version is in this folder, so you can export it:
```
$ LD_LIBRARY_PATH=$(pwd):$LD_LIBRARY_PATH
$ export LD_LIBRARY_PATH
```
Now the dynamic linker knows where to find the library, and the application can be executed. You can rerun `ldd`
to invoke the dynamic linker, which inspects the application's dependencies and loads them into memory. The memory address is shown after the object path:
```
$ ldd my_app
linux-vdso.so.1 (0x00007ffd385f7000)
libmy_shared.so => /home/stephan/library_sample/libmy_shared.so (0x00007f3fad401000)
libc.so.6 => /lib64/libc.so.6 (0x00007f3fad21d000)
/lib64/ld-linux-x86-64.so.2 (0x00007f3fad408000)
```
To find out which linker is invoked, you can use `file`
:
```
$ file my_app
my_app: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=26c677b771122b4c99f0fd9ee001e6c743550fa6, for GNU/Linux 3.2.0, not stripped
```
The linker `/lib64/ld-linux-x86–64.so.2`
is a symbolic link to `ld-2.30.so`
, which is the default linker for my Linux distribution:
```
$ file /lib64/ld-linux-x86-64.so.2
/lib64/ld-linux-x86-64.so.2: symbolic link to ld-2.31.so
```
Looking back to the output of `ldd`
, you can also see (next to `libmy_shared.so`
) that each dependency ends with a number (e.g., `/lib64/libc.so.6`
). The usual naming scheme of shared objects is:
`**lib** XYZ.so **.<MAJOR>** . **<MINOR>**`
On my system, `libc.so.6`
is also a symbolic link to the shared object `libc-2.30.so`
in the same folder:
```
$ file /lib64/libc.so.6
/lib64/libc.so.6: symbolic link to libc-2.31.so
```
If you are facing the issue that an application will not start because the loaded library has the wrong version, it is very likely that you can fix this issue by inspecting and rearranging the symbolic links or specifying the correct search path (see "The dynamic loader: ld.so" below).
For more information, look on the [ ldd man page](https://www.man7.org/linux/man-pages/man1/ldd.1.html).
### Dynamic loading
Dynamic loading means that a library (e.g., a `.so`
file) is loaded during a program's runtime. This is done using a certain programming scheme.
Dynamic loading is applied when an application uses plugins that can be modified during runtime.
See the [ dlopen man page](https://www.man7.org/linux/man-pages/man3/dlopen.3.html) for more information.
### The dynamic loader: ld.so
On Linux, you mostly are dealing with shared objects, so there must be a mechanism that detects an application's dependencies and loads them into memory.
`ld.so`
looks for shared objects in these places in the following order:
- The relative or absolute path in the application (hardcoded with the
`-rpath`
compiler option on GCC) - In the environment variable
`LD_LIBRARY_PATH`
- In the file
`/etc/ld.so.cache`
Keep in mind that adding a library to the systems library archive `/usr/lib64`
requires administrator privileges. You could copy `libmy_shared.so`
manually to the library archive and make the application work without setting `LD_LIBRARY_PATH`
:
```
unset LD_LIBRARY_PATH
sudo cp libmy_shared.so /usr/lib64/
```
When you run `ldd`
, you can see the path to the library archive shows up now:
```
$ ldd my_app
linux-vdso.so.1 (0x00007ffe82fab000)
libmy_shared.so => /lib64/libmy_shared.so (0x00007f0a963e0000)
libc.so.6 => /lib64/libc.so.6 (0x00007f0a96216000)
/lib64/ld-linux-x86-64.so.2 (0x00007f0a96401000)
```
## Customize the shared library at compile time
If you want your application to use your shared libraries, you can specify an absolute or relative path during compile time.
Modify the makefile (line 10) and recompile the program by invoking `make -B`
. Then, the output of `ldd`
shows `libmy_shared.so`
is listed with its absolute path.
Change this:
`CFLAGS =-Wall -Werror -Wl,-rpath,$(shell pwd) `
To this (be sure to edit the username):
`CFLAGS =/home/stephan/library_sample/libmy_shared.so `
Then recompile:
`$ make`
Confirm it is using the absolute path you set, which you can see on line 2 of the output:
```
$ ldd my_app
linux-vdso.so.1 (0x00007ffe143ed000)
libmy_shared.so => /lib64/libmy_shared.so (0x00007fe50926d000)
/home/stephan/library_sample/libmy_shared.so (0x00007fe509268000)
libc.so.6 => /lib64/libc.so.6 (0x00007fe50909e000)
/lib64/ld-linux-x86-64.so.2 (0x00007fe50928e000)
```
This is a good example, but how would this work if you were making a library for others to use? New library locations can be registered by writing them to `/etc/ld.so.conf`
or creating a `<library-name>.conf`
file containing the location under `/etc/ld.so.conf.d/`
. Afterward, `ldconfig`
must be executed to rewrite the `ld.so.cache`
file. This step is sometimes necessary after you install a program that brings some special shared libraries with it.
See the [ ld.so man page](https://www.man7.org/linux/man-pages/man8/ld.so.8.html) for more information.
## How to handle multiple architectures
Usually, there are different libraries for the 32-bit and 64-bit versions of applications. The following list shows their standard locations for different Linux distributions:
**Red Hat family**
- 32 bit:
`/usr/lib`
- 64 bit:
`/usr/lib64`
**Debian family**
- 32 bit:
`/usr/lib/i386-linux-gnu`
- 64 bit:
`/usr/lib/x86_64-linux-gnu`
**Arch Linux family**
- 32 bit:
`/usr/lib32`
- 64 bit:
`/usr/lib64`
[ FreeBSD](https://opensource.com/article/20/5/furybsd-linux) (technical not a Linux distribution)
- 32bit:
`/usr/lib32`
- 64bit:
`/usr/lib`
Knowing where to look for these key libraries can make broken library links a problem of the past.
While it may be confusing at first, understanding dependency management in Linux libraries is a way to feel in control of the operating system. Run through these steps with other applications to become familiar with common libraries, and continue to learn how to fix any library challenges that could come up along your way.
## Comments are closed. |
13,321 | 开源供应链:一个有关信任的问题 | https://www.linux.com/articles/open-source-supply-chain-a-matter-of-trust/ | 2021-04-22T19:09:32 | [
"供应链",
"开源",
"信任"
] | https://linux.cn/article-13321-1.html | 
共同作者:Curtis Franklin, Jr
开源软件通常被认为比专有软件更安全、更有保障,因为如果用户愿意,他们可以从源代码编译软件。他们知道在他们环境中运行的代码的来源。在他们的环境中运行的代码每个部分都可以被审查,也可以追溯每段代码的开发者。
然而,用户和提供者们正在逐渐远离完全控制软件所带来的复杂性,而在转而追求软件的便捷和易用。
VMware 副总裁兼首席开源官 Dirk Hohndel 说:“当我看到在一个有关网络安全和隐私的讲座中,演讲者运行 `docker run` 命令来安装和运行一些从互联网上下载的随机二进制文件时,我经常会大吃一惊。这两件事似乎有点相左。”
软件供应链,即将应用程序从编码、打包、分发到最终用户的过程是相当复杂的。如果其中有一环出现错误,可能会导致软件存在潜在的风险,特别是对于开源软件。一个恶意行为者可以访问后端,并在用户不知情或不受控的情况下向其插入任何可能的恶意代码。
这样的问题不单单存在于云原生领域,在现代应用开发中很常见,这包括 JavaScript、NPM、PyPI、RubyGems 等等。甚至连 Mac 上的 Homebrew 过去也是通过源代码提供,由用户自己编译。
“如今,你只需要下载二进制文件并安装它,并期望其源代码并没有被恶意修改过。”Hohndel 说,“作为一个行业,我们需要更加关注我们的开源代码供应。这对我来说是非常重要的事,我正努力让更多的人意识到其重要性。”
然而,这不仅仅是一个二进制与源代码的关系。只运行一个二进制文件,而不必从源代码构建所有东西有着巨大的优势。当软件开发需求发生转变时候,这种运行方式允许开发人员在过程中更加灵活和响应更快。通过重用一些二进制文件,他们可以在新的开发和部署中快速地循环。
Hohndel 说:“如果有办法向这些软件添加签名,并建立一个‘即时’验证机制,让用户知道他们可以信任此软件,那就更好了。”
Linux 发行版解决了这个问题,因为发行版充当了看门人的角色,负责检查进入受支持的软件存储库的软件包的完整性。
“像通过 Debian 等发行版提供的软件包都使用了密钥签名。要确保它确实是发行版中应包含的软件,需要进行大量工作。开发者们通过这种方式解决了开源供应链问题。”Hohndel 说。
但是,即使在 Linux 发行版上,人们也希望简化事情,并以正确性和安全性换取速度。现在,诸如 AppImage、Snap 和 Flatpack 之类的项目已经采用了二进制方式,从而将开源供应链信任问题带入了 Linux 发行版。这和 Docker 容器的问题如出一辙。
“理想的解决方案是为开源社区找到一种设计信任系统的方法,该系统可以确保如果二进制文件是用受信任网络中的密钥签名的,那么它就可以被信任,并允许我们可靠地返回源头并进行审核,” Hohndel 建议。
但是,所有这些额外的步骤都会产生成本,大多数项目开发者要么不愿意,或无力承担。一些项目正在尝试寻找解决该问题的方法。例如,NPM 已开始鼓励提交软件包的用户正确认证和保护其账户安全,以提高平台的可信度。
### 开源社区善于解决问题
Hohndel 致力于解决开源供应链问题,并正试图让更多开发者意识到其重要性。去年,VMware 收购了 Bitnami,这为管理由 VMware 所签名的开源软件提供了一个良机。
“我们正在与各种上游开源社区进行交流,以提高对此的认识。我们还在讨论技术解决方案,这些方案将使这些社区更容易解决潜在的开源供应链问题。” Hohndel 说。
开源社区历来致力于确保软件质量,这其中也包括安全性和隐私性。不过,Hohndel 说:“我最担心的是,在对下一个新事物感到兴奋时,我们经常忽略了需要的基础工程原则。”
最终,Hohndel 认为答案将来自开源社区本身。 “开源是一种工程方法论,是一种社会实验。开源就是人们之间相互信任、相互合作、跨国界和公司之间以及竞争对手之间的合作,以我们以前从未有过的方式。”他解释说。
---
via: <https://www.linux.com/articles/open-source-supply-chain-a-matter-of-trust/>
作者:[Swapnil Bhartiya](https://www.linux.com/author/swapnil/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Kevin3599](https://github.com/kevin3599) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
13,323 | 用开源工具定制 Mac 终端主题的 4 个步骤 | https://opensource.com/article/21/4/zsh-mac | 2021-04-22T23:45:41 | [
"Mac",
"终端",
"Zsh"
] | https://linux.cn/article-13323-1.html |
>
> 用开源工具让你的终端窗口在 Mac 上漂亮起来。
>
>
>

你是否曾经厌倦了在你的 macOS 电脑上看到同样老式的终端窗口?如果是这样,使用开源的 Oh My Zsh 框架和 Powerlevel10k 主题为你的视图添加一些点缀。
这个基本的逐步教程将让你开始定制你的 macOS 终端。如果你是一个 Linux 用户,请查看 Seth Kenlon 的指南 [为 Zsh 添加主题和插件](https://opensource.com/article/19/9/adding-plugins-zsh) 以获得深入指导。
### 步骤 1:安装 Oh My Zsh
[Oh My Zsh](https://ohmyz.sh/) 是一个开源的、社区驱动的框架,用于管理你的 Z shell (Zsh) 配置。

Oh My Zsh 是在 MIT 许可下发布的。使用以下命令安装:
```
$ sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"
```
### 步骤 2:安装 Powerlevel10k 字体

Powerlevel10k 是一个 MIT 许可的 Zsh 主题。在安装 Powerlevel10k 之前,你需要为你的终端安装自定义字体。
到 [Powerlevel10 GitHub](https://github.com/romkatv/powerlevel10k) 页面,在 `README` 中 搜索 “fonts”。安装自定义字体的步骤会根据你的操作系统而有所不同。这只需要简单地点击-下载-安装的系列操作。

### 步骤 3:安装 Powerlevel10k 主题
接下来,运行以下命令安装 Powerlevel10k:
```
git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-$HOME/.oh-my-zsh/custom}/themes/powerlevel10k
```
完成后,用文本编辑器,比如 [Vim](https://opensource.com/resources/what-vim),打开 `~/.zshrc` 配置文件,设置行 `ZSH_THEME="powerlevel10k/powerlevel10k`,然后保存文件。
### 步骤 4:完成 Powerlevel10 的设置
打开一个新的终端,你应该看到 Powerlevel10k 配置向导。如果没有,运行 `p10k configure` 来调出配置向导。如果你在步骤 2 中安装了自定义字体,那么图标和符号应该正确显示。将默认字体更改为 `MeslowLG NF`。

当你完成配置后,你应该会看到一个漂亮的终端。

就是这些了!你应该可以享受你美丽的新终端了。
---
via: <https://opensource.com/article/21/4/zsh-mac>
作者:[Bryant Son](https://opensource.com/users/brson) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Do you ever get bored with seeing the same old terminal window on your macOS computer? If so, add some bells and whistles to your view with the open source Oh My Zsh framework and Powerlevel10k theme.
This basic step-by-step walkthrough (including a video tutorial at the end) will get you started customizing your macOS terminal. If you're a Linux user, check out Seth Kenlon's guide to [Adding themes and plugins to Zsh](https://opensource.com/article/19/9/adding-plugins-zsh) for in-depth guidance.
## Step 1: Install Oh My Zsh
[Oh My Zsh](https://ohmyz.sh/) is an open source, community-driven framework for managing your Z shell (Zsh) configuration.
(Bryant Son, CC BY-SA 4.0)
Oh My Zsh is released under the MIT License. Install it with:
`$ sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"`
## Step 2: Install Powerlevel10k fonts
(Bryant Son, CC BY-SA 4.0)
Powerlevel10k is an MIT-Licensed Zsh theme. Before installing Powerlevel10k, you will want to install custom fonts for your terminal.
Go to the [Powerlevel10 GitHub](https://github.com/romkatv/powerlevel10k) page, and search for "fonts" in the README. The steps for installing the custom fonts will vary depending on your operating system; the video at the bottom of this page explains how to do it on macOS. It should be just a simple click–download–install series of operations.
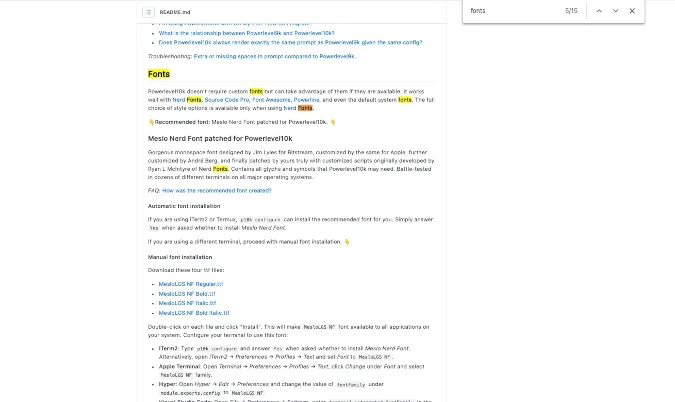
(Bryant Son, CC BY-SA 4.0)
## Step 3: Install the Powerlevel10k theme
Next, install Powerlevel10k by running:
`git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-$HOME/.oh-my-zsh/custom}/themes/powerlevel10k`
After you finish, open a `~/.zshrc`
configuration file with a text editor, such as [Vim](https://opensource.com/resources/what-vim), set the line `ZSH_THEME="powerlevel10k/powerlevel10k`
, then save the file.
## Step 4: Finalize your Powerlevel10k setup
Open a new terminal, and you should see the Powerlevel10k configuration wizard. If not, run `p10k configure`
to bring up the configuration wizard. If you installed the custom fonts in Step 2, the icons and symbols should display correctly. Change the default font to **MeslowLG NF** (see the video below for instructions).

(Bryant Son, CC BY-SA 4.0)
Once you complete the configuration, you should see a beautiful terminal.

(Bryant Son, CC BY-SA 4.0)
If you want to see an interactive tutorial, please check out this video:
That's it! You should be ready to enjoy your beautiful new terminal. Be sure to check out other Opensource.com articles for more tips and articles on using the shell, Linux administration, and more.
## Comments are closed. |
13,325 | 用 Sigil 在 Linux 上创建和编辑 EPUB 文件 | https://itsfoss.com/sigile-epub-editor/ | 2021-04-23T18:45:01 | [
"EPUB",
"电子书"
] | https://linux.cn/article-13325-1.html | 
Sigil 是一个开源的 Linux、Windows 和 MacOS 上的 EPUB 编辑器。你可以使用 Sigil 创建一个新的 EPUB 格式的电子书,或编辑现有的 EPUB 电子书(以 `.epub` 扩展结尾的文件)。
如果你感到好奇,EPUB 是一个标准的电子书格式,并被几个数字出版集团认可。它被许多设备和电子阅读器支持,除了亚马逊的 Kindle。
### Sigil 让你创建或编辑 EPUB 文件
[Sigil](https://sigil-ebook.com/) 是一个允许你编辑 EPUB 文件的开源软件。当然,你可以从头开始创建一个新的 EPUB 文件。

很多人在 [创建或编辑电子书时非常相信 Calibre](https://itsfoss.com/create-ebook-calibre-linux/)。它确实是一个完整的工具,它有很多的功能,支持的格式不只是 EPUB 格式。然而,Calibre 有时可能需要过多的资源。
Sigil 只专注于 EPUB 书籍,它有以下功能:
* 支持 EPUB 2 和 EPUB 3(有一定的限制)
* 提供代码视图预览
* 编辑 EPUB 语法
* 带有多级标题的目录生成器
* 编辑元数据
* 拼写检查
* 支持正则查找和替换
* 支持导入 EPUB、HTML 文件、图像和样式表
* 额外插件
* 多语言支持的接口
* 支持 Linux、Windows 和 MacOS
Sigil 不是你可以直接输入新书章节的 [所见即所得](https://www.computerhope.com/jargon/w/wysiwyg.htm) 类型的编辑器。由于 EPUB 依赖于 XML,因此它专注于代码。可以将其视为用于 EPUB 文件的 [类似于 VS Code 的代码编辑器](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/)。出于这个原因,你应该使用一些其他 [开源写作工具](https://itsfoss.com/open-source-tools-writers/),以 epub 格式导出你的文件(如果可能的话),然后在 Sigil 中编辑它。

Sigil 有一个 [Wiki](https://github.com/Sigil-Ebook/Sigil/wiki) 来提供一些安装和使用 Sigil 的文档。
### 在 Linux 上安装 Sigil
Sigil 是一款跨平台应用,支持 Windows 和 macOS 以及 Linux。它是一个流行的软件,有超过十年的历史。这就是为什么你应该会在你的 Linux 发行版仓库中找到它。只要在你的发行版的软件中心应用中寻找它就可以了。

你可能需要事先启用 universe 仓库。你也可以在 Ubuntu发行版中使用 `apt` 命令:
```
sudo apt install sigil
```
Sigil 有很多对 Python 库和模块的依赖,因此它下载和安装了大量的包。

我不会列出 Fedora、SUSE、Arch 和其他发行版的命令。你可能已经知道如何使用你的发行版的软件包管理器,对吧?
你的发行版提供的版本不一定是最新的。如果你想要 Sigil 的最新版本,你可以查看它的 GitHub 仓库。
* [Sigil 的 GitHub 仓库](https://github.com/Sigil-Ebook/Sigil)
### 并不适合所有人,当然也不适合用于阅读 ePUB 电子书
我不建议使用 Sigil 阅读电子书。Linux 上有 [其他专门的应用来阅读 .epub 文件](https://itsfoss.com/open-epub-books-ubuntu-linux/)。
如果你是一个必须处理 EPUB 书籍的作家,或者如果你在数字化旧书,并在各种格式间转换,Sigil 可能是值得一试。
我还没有大量使用 过 Sigil,所以我不提供对它的评论。我让你去探索它,并在这里与我们分享你的经验。
---
via: <https://itsfoss.com/sigile-epub-editor/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sigil is an open source EPUB editor available for Linux, Windows and macOS. With Sigil, you can create a new ebook in EPUB file format or edit an existing EPUB ebook (file ending in .epub extension).
In case you are wondering, EPUB is a standard ebook file format endorsed by several digital publishing groups. It is well-supported on a range of devices and ebook readers except Amazon Kindle.
## Sigil lets you create or edit EPUB files
[Sigil](https://sigil-ebook.com/) is an open source software that allows you to edit EPUB files. You may, of course, create a new EPUB file from scratch.
Many people swear by [Calibre for creating ebooks](https://itsfoss.com/create-ebook-calibre-linux/) or editing them. It is indeed a complete tool with lots of features and supports more than just EPUB file format. However, Calibre could be heavy on resources at times.
Sigil is focused on just the EPUB books with the following features:
- Support for EPUB 2 and EPUB 3 (with some limitations)
- Provides a preview along with the code view
- Editing EPUB syntax
- Table of content generator with mult-level heading
- Edit metadat
- Spell checking
- REGEX support for find and replace feature
- Supports import of EPUB and HTML files, images, and style sheets
- Additional plugins
- Multiple language support for the interface
- Supports Linux, Windows and macOS
Sigil is not [WYSIWYG type of editor](https://itsfoss.com/open-source-wysiwyg-editors/) where you can type the chapters of new book. It is focused on code as EPUB depends on XML. Consider it a [code editor like VS Code](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/) for EPUB files. For this reason, you should use some other [open source tool for writing](https://itsfoss.com/open-source-tools-writers/), export your files in .epub format (if possible) and then edit it in Sigil.
Sigil does have a [Wiki](https://github.com/Sigil-Ebook/Sigil/wiki) to provide you some documentation on installing and using Sigil.
## Installing Sigil on Linux
Sigil is a cross-platform application with support for Windows and macOS along with Linux. It is a popular software with more than a decade of existence. This is why you should find it in the repositories of your Linux distributions. Just look for it in the software center application of your distribution.
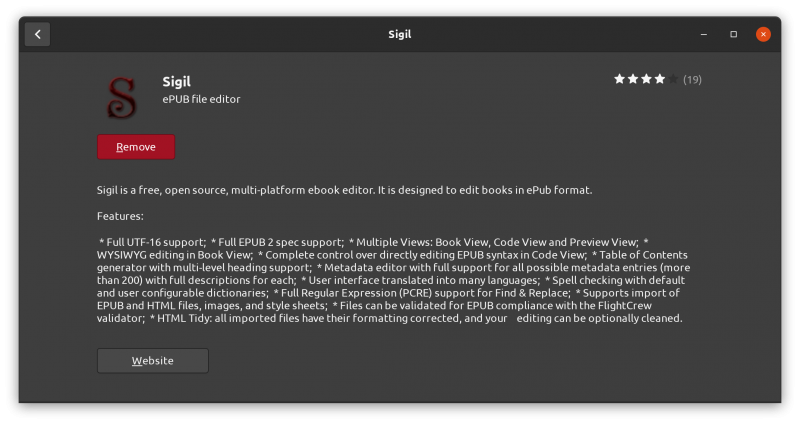
You may need to enable the universe repository beforehand. You may also use the apt command in Ubuntu-based distributions:
`sudo apt install sigil`
Sigil has a lot of dependencies on Python libraries and modules and hence it downloads and installs a good number of packages.
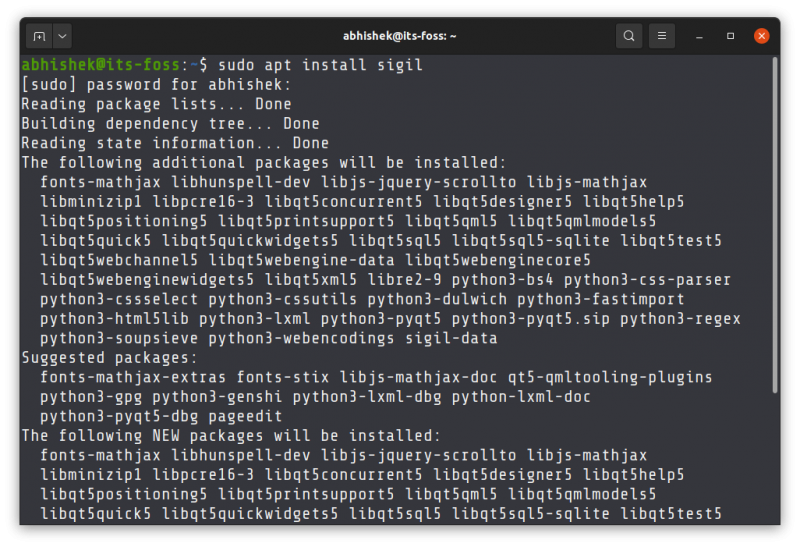
I am not going to list commands for Fedora, SUSE, Arch and other distributions. You probably already know how to use your distribution’s package manager, right?
The version provided by your distribution may not always be the latest. If you want the latest version of Sigil, you can check out its GitHub repositories.
## Not for everyone, certianly not for reading ePUB books
I wouldn’t recommend using Sigil for reading ebooks. There are [other dedicated applications on Linux to read .epub files](https://itsfoss.com/open-epub-books-ubuntu-linux/).
If you are a writer who has to deal with EPUB books or if you are digitizing old books and converting them in various formats, Sigil could be worth a try.
I haven’t used Sigil extensively so I cannot provide a review of it. I let it up to you to explore it and share your experienced with the rest of us here. |
13,326 | 14 种可以在古老的 32 位计算机上使用的 Linux 发行版 | https://itsfoss.com/32-bit-linux-distributions/ | 2021-04-24T14:44:00 | [
"发行版",
"32位",
"旧计算机"
] | https://linux.cn/article-13326-1.html | 如果你一直关注最新的 [Linux 发行版](https://itsfoss.com/what-is-linux-distribution/),那么你一定已经注意到,[大多数流行的 Linux 发行版](https://itsfoss.com/best-linux-distributions/) 已经终止了 32 位支持。Arch Linux、Ubuntu、Fedora,每一个都已经放弃了对这种较旧架构的支持。
但是,如果你拥有仍然需要再利用的老式硬件,或者想将其用于某些用途,该怎么办?不用担心,你的 32 位系统还有一些选择。
在本文中,我试图汇编一些最好的 Linux 发行版,这些发行版将在未来几年继续支持 32 位平台。
### 仍提供 32 位支持的最佳 Linux 发行版

此列表与 [我们之前的支持旧笔记本电脑的 Linux 发行版列表](https://itsfoss.com/lightweight-linux-beginners/) 略有不同。即使是 64 位计算机,如果是在 2010 年之前发布的,那么也可以认为它们是旧的。这就是为什么其中列出的一些建议包括现在仅支持 64 位版本的发行版的原因。
根据我的知识和认知,此处提供的信息是正确的,但是如果你发现有误,请在评论部分让我知道。
在继续之前,我认为你知道 [如何检查你拥有的是否是 32 位或 64 位计算机](https://itsfoss.com/32-bit-64-bit-ubuntu/)。
#### 1、Debian

对于 32 位系统,[Debian](https://www.debian.org/) 是一个绝佳的选择,因为他们的最新的稳定版本仍然支持它。在撰写本文时,最新的稳定发行版 **Debian 10 “buster”** 提供了 32 位版本,并一直支持到 2024 年。
如果你是 Debian 的新手,值得一提的是,你可以在 [官方 Wiki](https://wiki.debian.org/FrontPage) 上获得有关其所有内容的可靠文档。因此,上手应该不是问题。
你可以浏览 [可用的安装程序](https://www.debian.org/releases/buster/debian-installer/) 进行安装。但是,在开始之前,除了 [安装手册](https://www.debian.org/releases/buster/installmanual) 外,我建议你参考 [安装 Debian 之前要记住的事情](https://itsfoss.com/before-installing-debian/) 列表。
最低系统要求:
* 512 MB 内存
* 10 GB 磁盘空间
* 1 GHz 处理器(奔腾 4 或同等水平)
#### 2、Slax

如果你只是想快速启动设备以进行一些临时工作,[Slax](https://www.slax.org) 是一个令人印象深刻的选择。
它基于 Debian,但它通过 USB 设备或 DVD 运行旨在成为一种便携且快速的选项。你可以从他们的网站免费下载 32 位 ISO 文件,或购买预装有 Slax 的可擦写 DVD 或加密的闪存盘。
当然,这并不是要取代传统的桌面操作系统。但是,是的,你确实获得了以 Debian 为基础的 32 位支持。
最低系统要求:
* 内存:128MB(离线使用)/ 512MB(用于网页浏览器使用)
* CPU: i686 或更新版本
#### 3、AntiX

[AntiX](https://antixlinux.com) 是另一个令人印象深刻的基于 Debian 的发行版。AntiX 是众所周知的无 systemd 发行版,该发行版侧重于性能,是一个轻量级的系统。
它完全适合于所有老式的 32 位系统。它只需要低至 256 MB 内存和 2.7 GB 存储空间。不仅易于安装,而且用户体验也是针对新手和有经验的用户的。
你应该可以得到基于 Debian 的最新稳定分支的最新版本。
最低系统要求:
* 内存:256 MB 的内存
* CPU:奔腾 3 系统
* 磁盘空间:5GB 的驱动器空间
#### 4、openSUSE

[openSUSE](https://www.opensuse.org/) 是一个独立的 Linux 发行版,也支持 32 位系统。实际上最新的常规版本(Leap)不提供 32 位镜像,但滚动发行版本(Tumbleweed)确实提供了 32 位镜像。
如果你是新手,那将是完全不同的体验。但是,我建议你仔细阅读 [为什么要使用 openSUSE 的原因](https://itsfoss.com/why-use-opensuse/)。
它主要面向开发人员和系统管理员,但也可以将其用作普通桌面用户。值得注意的是,openSUSE 不意味在老式硬件上运行,因此必须确保至少有 2 GB 内存、40+ GB 存储空间和双核处理器。
最低系统要求:
* 奔腾 4 1.6 GHz 或更高的处理器
* 1GB 物理内存
* 5 GB 硬盘
#### 5、Emmabuntüs

[Emmanbuntus](https://emmabuntus.org/) 是一个有趣的发行版,旨在通过 32 位支持来延长硬件的使用寿命,以减少原材料的浪费。作为一个团体,他们还参与向学校提供计算机和数字技术的工作。
它提供了两个不同的版本,一个基于 Ubuntu,另一个基于 Debian。如果你需要更长久的 32 位支持,则可能要使用 Debian 版本。它可能不是最好的选择,但是它具有许多预配置的软件来简化 Linux 学习体验,并提供 32 位支持,如果你希望在此过程中支持他们的事业,那么这是一个相当不错的选择。
最低系统要求:
* 512MB 内存
* 硬盘驱动器:2GB
* 奔腾处理器或同等配置
#### 6、NixOS

[NixOS](https://nixos.org/) 是另一个支持 32 位系统的独立 Linux 发行版。它着重于提供一个可靠的系统,其中程序包彼此隔离。
这可能不是直接面向普通用户,但它是一个 KDE 支持的可用发行版,具有独特的软件包管理方式。你可以从其官方网站上了解有关其 [功能](https://nixos.org/features.html) 的更多信息。
最低系统要求:
* 内存:768 MB
* 8GB 磁盘空间
* 奔腾 4 或同等水平
#### 7、Gentoo Linux

如果你是经验丰富的 Linux 用户,并且正在寻找 32 位 Linux 发行版,那么 [Gentoo Linux](https://www.gentoo.org) 应该是一个不错的选择。
如果需要,你可以使用 Gentoo Linux 的软件包管理器轻松配置、编译和安装内核。不仅限于众所周知的可配置性,你还可以在较旧的硬件上运行而不会出现任何问题。
即使你不是经验丰富的用户,也想尝试一下,只需阅读 [安装说明](https://www.gentoo.org/get-started/),就可以大胆尝试了。
最低系统要求:
* 256MB 内存
* 奔腾 4 或 AMD 的同类产品
* 2.5 GB 磁盘空间
#### 8、Devuan

[Devuan](https://www.devuan.org) 是另一种无 systemd 的发行版。从技术上讲,它是 Debian 的一个分支,只是没有 systemd ,并鼓励 [初始化系统自由](https://www.devuan.org/os/init-freedom)。
对于普通用户来说,它可能不是一个非常流行的 Linux 发行版,但是如果你想要一个无 systemd 的发行版和 32 位支持,Devuan 应该是一个不错的选择。
最低系统要求:
* 内存:1GB
* CPU:奔腾 1.0GHz
#### 9、Void Linux

[Void Linux](https://voidlinux.org/) 是由志愿者独立开发的有趣发行版。它旨在成为一个通用的操作系统,同时提供稳定的滚动发布周期。它以 runit 作为初始化系统替代 systemd,并为你提供了多个 [桌面环境](https://itsfoss.com/best-linux-desktop-environments/) 选择。
它具有非常令人印象深刻的最低需求规格,只需 96 MB 的内存配以奔腾 4 或等同的芯片。试试看吧!
最低系统要求:
* 96MB 内存
* 奔腾 4 或相当的 AMD 处理器
#### 10、Q4OS

[Q4OS](https://q4os.org/index.html) 是另一个基于 Debian 的发行版,致力于提供极简和快速的桌面用户体验。它也恰好是我们的 [最佳轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/) 列表中的一个。它的 32 位版本具有 [Trinity 桌面](https://en.wikipedia.org/wiki/Trinity_Desktop_Environment),你可以在 64 位版本上找到 KDE Plasma 支持。
与 Void Linux 类似,Q4OS 可以运行在至低 128 MB 的内存和 300 MHz 的 CPU 上,需要 3 GB 的存储空间。对于任何老式硬件来说,它应该绰绰有余。因此,我想说,你绝对应该尝试一下!
要了解更多信息,你还可以查看 [我们对 Q4OS 的点评](https://itsfoss.com/q4os-linux-review/)。
Q4OS 的最低要求:
* 内存:128MB(Trinity 桌面)/ 1GB(Plasma 桌面)
* CPU:300 MHz(Trinity 桌面)/ 1 GHz(Plasma 桌面)
* 存储空间:5GB(Trinity 桌面)/3GB(Plasma 桌面)
#### 11、MX Linux

如果有一个稍微不错的配置(不完全是老式的,而是旧的),对于 32 位系统,我个人推荐 [MX Linux](https://mxlinux.org/)。它也恰好是适合各种类型用户的 [最佳 Linux 发行版](https://itsfoss.com/best-linux-distributions/) 之一。
通常,MX Linux 是基于 Debian 的出色的轻量级和可定制的发行版。你可以选择 KDE、XFce 或 Fluxbox(这是他们自己为旧硬件设计的桌面环境)。你可以在他们的官方网站上找到更多关于它的信息,并尝试一下。
最低系统要求:
* 1GB 内存(建议使用 2GB,以便舒适地使用)
* 15GB 的磁盘空间(建议 20GB)
#### 12、Linux Mint Debian Edtion

[基于 Debian 的 Linux Mint](https://www.linuxmint.com/download_lmde.php)?为什么不可以呢?
你可以得到同样的 Cinnamon 桌面体验,只是不基于 Ubuntu。它和基于 Ubuntu 的 Linux Mint 一样容易使用,一样可靠。
不仅仅是基于 Debian,你还可以得到对 64 位和 32 位系统的支持。如果你不想在 32 位系统上使用一个你从未听说过的 Linux 发行版,这应该是一个不错的选择。
最低系统要求:
* 1GB 内存(建议使用 2GB,以便舒适地使用)
* 15GB 的磁盘空间(建议 20GB)
#### 13、Sparky Linux

[Sparky Linux](https://sparkylinux.org/download/stable/) 是 [为初学者定制的最好的轻量级 Linux 发行版](https://itsfoss.com/lightweight-linux-beginners/) 之一。它很容易定制,而且资源占用很少。
它可以根据你的要求提供不同的版本,但它确实支持 32 位版本。考虑到你想为你的旧电脑买点东西,我建议你看看它的 MinimalGUI 版本,除非你真的需要像 Xfce 或 LXQt 这样成熟的桌面环境。
最低系统要求:
* 内存:512 MB
* CPU:奔腾 4,或 AMD Athlon
* 磁盘空间:2GB(命令行版),10GB(家庭版),20GB(游戏版)
#### 14、Mageia

作为 [Mandriva Linux](https://en.wikipedia.org/wiki/Mandriva_Linux) 的分支,[Mageia Linux](https://www.mageia.org/en/) 是一个由社区推动的 Linux 发行版,支持 32 位系统。
通常情况下,你会注意到每年都有一个重大版本。他们的目的是贡献他们的工作,以提供一个自由的操作系统,这也是潜在的安全。对于 32 位系统来说,它可能不是一个流行的选择,但它支持很多桌面环境(如 KDE Plasma、GNOME),如果你需要,你只需要从它的软件库中安装它。
你应该可以从他们的官方网站上得到下载桌面环境特定镜像的选项。
最低系统要求:
* 512MB 内存(推荐 2GB)
* 最小安装需 5GB 存储空间(常规安装 20GB)
* CPU:奔腾4,或 AMD Athlon
### 荣誉提名:Funtoo & Puppy Linux
[Funtoo](https://www.funtoo.org/Welcome) 是基于 Gentoo 的由社区开发的 Linux 发行版。它着重于为你提供 Gentoo Linux 的最佳性能以及一些额外的软件包,以使用户获得完整的体验。有趣的是,该开发实际上是由 Gentoo Linux 的创建者 Daniel Robbins 领导的。
[Puppy Linux](http://puppylinux.com/) 是一个很小的 Linux 发行版,除了基本的工具,几乎没有捆绑的软件应用。如果其他选择都不行,而你又想要最轻量级的发行版,Puppy Linux 可能是一个选择。
当然,如果你不熟悉 Linux,这两个可能都不能提供最好的体验。但是,它们确实支持 32 位系统,并且可以在许多较旧的 Intel/AMD 芯片组上很好地工作。可以在它们的官方网站上探索更多的信息。
### 总结
我将列表重点放在基于 Debian 的发行版和一些独立发行版上。但是,如果你不介意长期支持条款,而只想获得一个支持 32 位的镜像,也可以尝试使用任何基于 Ubuntu 18.04 的发行版(或任何官方版本)。
在撰写本文时,它们只剩下几个月的软件支持。因此,我避免将其作为主要选项提及。但是,如果你喜欢基于 Ubuntu 18.04 的发行版或其它任何版本,可以选择 [LXLE](https://www.lxle.net/)、[Linux Lite](https://www.linuxliteos.com)、[Zorin Lite 15](https://zorinos.com/download/15/lite/32/) 及其他官方版本。
即使大多数基于 Ubuntu 的现代桌面操作系统都放弃了对 32 位的支持。你仍然有很多选项可以选择。
在 32 位系统中更喜欢哪一个?在下面的评论中让我知道你的想法。
---
via: <https://itsfoss.com/32-bit-linux-distributions/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

If you’ve been keeping up with the latest [Linux distributions](https://itsfoss.com/what-is-linux-distribution/), you must have noticed that 32-bit support has been dropped from [most of the popular Linux distributions](https://itsfoss.com/best-linux-distributions/). Arch Linux, Ubuntu, Fedora, everyone has dropped the support for this older architecture.
But, what if you have vintage hardware with you that still needs to be revived or you want to make use of it for something? Fret not, there are still a few options left to choose from for your 32-bit system.
In this article, I’ve tried to compile some of the best Linux distributions that will keep on supporting 32-bit platform for next few years.
This list differs from [our earlier list of Linux distributions for old laptops](https://itsfoss.com/lightweight-linux-beginners/). Even 64-bit computers can be considered old if they were released before 2010. This is why some suggestions included distros that only support 64-bit now.
The information presented here is correct as per my knowledge and findings, but if you find otherwise, please let me know in the comment section.
Before you go on, I suppose you know [how to check if you have a 32 bit or 64 bit computer](https://itsfoss.com/32-bit-64-bit-ubuntu/).
## 1. Debian
[Deviantart](https://www.deviantart.com/mrneilypops/art/Debian-9-RC1-660956798?ref=its-foss)
Debian is a fantastic choice for 32-bit systems because they still support it with their latest stable release. At the time of writing this, the latest stable release **Debian 11 “bullseye”** offers a 32-bit version and is supported until 2026.
If you’re new to Debian, it is worth mentioning that you get solid documentation for everything on their [official wiki](https://wiki.debian.org/FrontPage?ref=its-foss). So, it shouldn’t be an issue to get started.
You can browse through the [available installers](https://www.debian.org/releases/bullseye/debian-installer/?ref=its-foss) to get it installed. However, before you proceed, I would recommend referring to the list of [things to remember before installing Debian](https://itsfoss.com/before-installing-debian/) in addition to its [installation manual](https://www.debian.org/releases/bullseye/installmanual?ref=its-foss).
**Minimum System Requirements:**
- 512 MB RAM
- 10 GB Disk Space
- 1 GHz Processor (Pentium 4 or equivalent)
## 2. Slax

If you just want to quickly boot up a device for some temporary work, Slax is an impressive option.
Although there are separate Slackware and Debian-based releases, the 32-bit variant of Slax is available with Debian at its core. It aims to be a portable and fast option that is meant to be run through USB devices or DVDs. You can download the 32-bit ISO file from their website or purchase a rewritable DVD/encrypted pen drive with Slax pre-installed.
Of course, this isn’t meant to replace a traditional desktop operating system. But, yes, you do get the 32-bit support with Debian as its base.
**Minimum System Requirements:**
- RAM: 128 MB (offline usage) / 512 MB (for web browser usage)
- CPU: i686 or newer
## 3. AntiX
Yet another impressive Debian-based distribution. AntiX is popularly known as a systemd-free distribution that focuses on performance while being a lightweight installation.
It is perfectly suitable for just about any old 32-bit system. To give you an idea, it just needs 256 MB RAM and 2.7 GB storage space at the very least. Not just easy to install, but the user experience is focused on both newbies and experienced users.
You should get the latest version based on Debian’s latest stable branch available.
**Minimum System Requirements:**
- RAM: 256 MB of RAM
- CPU: PIII systems
- Disk space: 5 GB of drive space
## 4. openSUSE

openSUSE is an independent Linux distribution that supports 32-bit systems as well. Even though the latest regular version (Leap) does not offer 32-bit images, the rolling release edition (Tumbleweed) does provide 32-bit image.
It will be an entirely different experience if you’re new. However, I suggest you to go through the [reasons why you should be using openSUSE.](https://itsfoss.com/why-use-opensuse/)
It is mostly focused for developers and system administrators but you can utilize it as an average desktop user as well. It is worth noting that openSUSE is not meant to run on vintage hardware — so you have to make sure that you have at least 2 GB RAM, 40+ GB storage space, and a dual-core processor.
**Minimum System Requirements:**
- Pentium 4 1.6 GHz or higher processor
- 1 GB physical RAM (at least 1.5 GB when using online repos, 2 GB recommended)
- 10 GB Hard Disk for a minimal install, 16 GB available for a graphical desktop (40 GB or more recommended)
## 5. Emmabuntüs
Emmabuntus is an interesting distribution that aims to extend the life of the hardware to reduce the waste of raw materials with 32-bit support. As a group they’re also involved in providing computers and digital technologies to schools.
It offers two different editions, one based on Ubuntu and the other based on Debian. If you want longer 32-bit support, you may want to go with the Debian edition. It may not be the best option, but with a number of pre-configured software to make the Linux learning experience easy and 32-bit support, it is a decent option if you want to support their cause in the process.
**Minimum System Requirements:**
- 512 MB RAM
- Hard Drive: 80GB for comfortable use
- Pentium 4 processor or equivalent and Dual Core
## 6. NixOS

NixOS is yet another independent Linux distribution that supports 32-bit systems. It focuses on providing a reliable system where packages are isolated from each other.
This may not be directly geared towards average users but it is a KDE-powered usable distribution with a unique approach to package management. You can learn more about its [features](https://nixos.org/explore.html?ref=its-foss) from its official website.
**Minimum System Requirements:**
- RAM: 768 MB
- 8 GB Disk Space
- Pentium 4 or equivalent
## 7. Gentoo Linux

If you’re an experienced Linux user and looking for a 32-bit Linux distributions, Gentoo Linux should be a great choice.
You can easily configure, compile, and install a kernel through package manager with Gentoo Linux if you want. Not just limited to its configurability, which it is popularly known for, you will also be able to run it without any issues on older hardware.
Even if you’re not an experienced user and want to give it a try, simply read through the [installation instructions](https://www.gentoo.org/get-started/?ref=its-foss) and you will be in for an adventure.
**Minimum System Requirements:**
- 256 MB RAM
- Pentium 4 or AMD equivalent
- 2.5 GB Disk Space
## 8. Devuan
[Devuan](https://itsfoss.com/devuan-3-release/) is yet another systemd-free distribution. It is technically a fork of Debian, just without systemd and encouraging [Init freedom](https://www.devuan.org/os/init-freedom?ref=its-foss).
It may not be a very popular Linux distribution for an average user but if you want a systemd-free distribution and 32-bit support, Devuan should be a good option.
**Minimum System Requirements:**
- RAM: 1 GB
- CPU: Pentium 1.0 GHz
## 9. Void Linux

Void Linux is an interesting distribution independently developed by volunteers. It aims to be a general-purpose OS while offering a stable rolling release cycle. It features runit as the init system instead of systemd and gives you the option of several [desktop environments](https://itsfoss.com/best-linux-desktop-environments/).
It has an extremely impressive minimum requirement specification with just 96 MB of RAM paired up with Pentium 4 (or equivalent) chip. Try it out!
**Minimum System Requirements:**
- 96 MB RAM
- Pentium 4 or AMD equivalent processor
- Void is not available for the older 32-bit architectures like i386, i486, or i586
## 10. Q4OS
Q4OS is another Debian-based distribution that focuses on providing a minimal and fast desktop user experience. It also happens to be one of the [best lightweight Linux distributions](https://itsfoss.com/lightweight-linux-beginners/) in our list. It features the [Trinity desktop](https://en.wikipedia.org/wiki/Trinity_Desktop_Environment?ref=its-foss) for its 32-bit edition and you can find KDE Plasma support on 64-bit version.
Similar to Void Linux, Q4OS also runs on a bare minimum of at least 256 MB RAM and a 300 MHz CPU with a 3 GB storage space requirement. It should be more than enough for any vintage hardware. So, I’d say you should definitely try it out!
To learn more about it, you can also check out [our review of Q4OS](https://itsfoss.com/q4os-linux-review/).
**Minimum Requirements for Q4OS:**
- RAM: 256 MB (Trinity Desktop) / 1 GB (Plasma Desktop)
- CPU: 300 MHz (Trinity Desktop) / 1 GHz (Plasma Desktop)
- Storage Space: 5 GB (Plasma Desktop) / 3 GB (Trinity Desktop)
## 11: MX Linux
If you’ve got a slightly decent configuration (not completely vintage but old), MX Linux would be my personal recommendation for 32-bit systems. It also happens to be one of the [best Linux distributions](https://itsfoss.com/best-linux-distributions/) for every type of user.
In general, MX Linux is a fantastic lightweight and customizable distribution based on Debian. You get the option to choose from KDE, XFCE or Fluxbox (which is their own desktop environment for older hardware). You can explore more about it on their official website and give it a try.
**Minimum System Requirements:**
- 1 GB RAM (2 GB recommended for comfortable usage)
- 15 GB of disk space (20 GB recommended).
## 12. Linux Mint Debian Edition

Linux Mint based on Debian? Why not?
You get the same Cinnamon desktop experience just without Ubuntu as its base. It is equally easy to use and as reliable as Linux Mint based on Ubuntu.
Not just limited to the Debian base, but you get support for both 64-bit and 32-bit systems. This should be a great choice if you do not want to use a Linux distribution that you’ve never heard on your 32-bit system.
**Minimum System Requirements:**
- 1 GB RAM (2 GB recommended for comfortable usage)
- 15 GB of disk space (20 GB recommended)
## 13. Sparky Linux

Sparky Linux is one of the [best lightweight Linux distributions tailored for beginners](https://itsfoss.com/lightweight-linux-beginners/). It is easily customizable and light on resources.
It offers different editions as per your requirements but it does support 32-bit versions. Considering that you want something for your old computer, I would recommend taking a look at its MinimalGUI edition unless you really need a full-fledged desktop environment like Xfce or LXQt.
**Minimum System Requirements:**
- RAM: 128MB (CLI Edition), 256MB (LXDE, LXQt, Openbox) or 512MB (XFCE)
- CPU: Pentium 4, or AMD Athlon
- Disk space: 2 GB (CLI Edition), 10 GB (Home Edition), 20 GB (GameOver Edition)
## 14. Mageia

A fork of [Mandriva Linux](https://en.wikipedia.org/wiki/Mandriva_Linux?ref=its-foss), Mageia Linux is a community-powered Linux distribution that supports 32-bit systems.
Usually, you will notice a major release every year. They aim to contribute their work to provide a free operating system that is also potentially secure. It may not be a popular choice for 32-bit systems but it supports a lot of desktop environments (like KDE Plasma, GNOME); you just need to install it from its repositories if you need.
You should get the option to download a desktop environment-specific image from their official site.
**Minimum System Requirements:**
- 512 MB RAM (2 GB Recommended)
- 5 GB storage space for minimal installation (20 GB for regular installation)
- CPU: Pentium 4, or AMD Athlon
## 15. Alpine Linux

Alpine Linux is extremely popular among Docker users because it provides a minimal container image of just 5 MB in size.
Although its desktop version is nowhere as small as 5 MB, it is still a pretty decent desktop Linux distro.
There are several release branches for Alpine Linux. Usually, you will get 2-year support for the main repository and support until the next stable release for the community repository. Moreover, it offers several variants, including 32-bit systems.
Since it is made around musl libc and busybox with resource-efficient containers, a minimal installation to disk requires around 130 MB of storage (for server edition). Also, you get a full-fledged Linux Environment together with a huge collection of packages in repository.
**Minimum System Requirements**
- RAM: 128MB (To start), 256MB (to install), 1GB (for GUI)
- At least 700 MB space on a writable storage device.
### Honorable Mentions: Funtoo & Puppy Linux
[Funtoo](https://www.funtoo.org/Welcome?ref=its-foss) is a Gentoo-based community-developed Linux distribution. It focuses on giving you the best performance with Gentoo Linux and some extra packages to complete the experience for users. It is also interesting to note that the development is actually led by Gentoo Linux’s creator **Daniel Robbins**.
[Puppy Linux](https://puppylinux-woof-ce.github.io/?ref=its-foss) is a tiny Linux distro with almost no bundled software applications but basic tools. Puppy Linux could be an option if nothing else works and you want the lightest distro.
Of course, if you’re new to Linux, you may not have the best experience with these options. But, both the distros support 32-bit systems and work well across many older Intel/AMD chipsets. Explore more about it on their official websites to explore.
### Wrapping Up
I focused the list on Debian-based and some Independent distributions. However, if you don’t mind long-term support and just want to get your hands on a 32-bit supported image, you can try any Ubuntu 18.04 based distributions as well.
At the time of writing this, they just have a few more months of software support left. Hence, I avoided mentioning it as primary options. But, if you like Ubuntu 18.04 based distros or any of its flavours, you do have options like [LXLE](https://www.lxle.net/?ref=its-foss), [Zorin Lite 15](https://zorinos.com/download/15/lite/32/?ref=its-foss) (ZorinOS 15.3 has 32-bit version supported until April 2023).
Even though most modern desktop operating systems based on Ubuntu have dropped support for 32-bit support, you still have plenty of choices to go with.
What would you prefer to have on your 32-bit system? Let me know your thoughts in the comments below. |
13,328 | Arch Linux 中的引导式安装程序是迈向正确的一步 | https://news.itsfoss.com/arch-new-guided-installer/ | 2021-04-25T10:34:17 | [
"Arch",
"安装程序"
] | https://linux.cn/article-13328-1.html |
>
> 在 Arch ISO 中加入一个可选的引导式安装程序,对新手和高级用户都有好处。
>
>
>

20 年来,Arch Linux 为用户提供了一个完全定制、独特的系统。这些年来,它以牺牲用户友好性为代价,赢得了在定制方面独有的声誉。
作为滚动发行版本,Arch Linux 不提供任何固定发行版本,而是每月更新一次。但是,如果你在最近几周下载了 Arch Linux,那么你很可能已经注意到了一个新的附加功能:archinstall。它使 Arch Linux 更加易于安装。

今天,我将探讨 archinstall 的发布对未来的 Arch Linux 项目和发行版意味着什么。
### Arch Linux 新的发展方向?

尽管很多人对此感到惊讶,但默认情况下包含官方安装程序实际上是非常明智的举动。这意味着 Arch Linux 的发展方向发生变化,即在保留使其知名的定制性同时更加侧重用户的易用性。
在该安装程序的 GitHub 页面上有这样的描述:
>
> “引导性安装程序会给用户提供一个友好的逐步安装方式,但是关键在于这个安装程序是个选项,它是可选的,绝不会强迫用户使用其进行安装。”
>
>
>
这意味着新的安装程序不会影响高级用户,同时也使得其可以向更广泛的受众开放,在这一改动所带来的许多优点之中,一个显著的优点即是:更广泛的用户。
更多的用户意味着对项目的更多支持,不管其是通过网络捐赠或参与 Arch Linux 的开发,随着这些项目贡献的增加,不管是新用户还是有经验的用户的使用体验都会得到提升。
### 这必然要发生
回顾过去,我们可以看到安装介质增加了许多对新用户有所帮助的功能。这些示例包括 pacstrap(一个安装基本系统的工具)和 reflector(查找最佳 pacman 镜像的工具)。
另外,多年来,用户一直在追求使用脚本安装的方法,新安装程序允许了用户使用安装脚本。它能够使用 Python 编写脚本,这使得管理员的部署更加容易,成为一个非常有吸引力的选择。
### 更多可定制性(以某种方式?)
尽管这看上去可能有些反直觉,但是这个安装程序实际上能够增进 Arch Linux 的可定制性。当前,Arch Linux 定制性的最大瓶颈是用户的技术水平,而这一问题能够通过 archinstall 解决。
有了新的安装程序,用户不需要掌握创建完美开发环境的技巧,安装程序可以帮助用户完成这些工作,这提供了广泛的自定义选项,是普通用户难以实现的。
### 总结
有了这一新功能,Arch Linux 似乎正在向着“用户友好”这一软件设计哲学靠近,新安装程序为新手和高级用户提供了广泛的好处。其中包括更广泛的定制性和更大的用户社区。
总而言之,这个新变动对整个 Arch Linux 社区都会产生积极的影响。
你对这个 Arch Linux 安装程序怎么看?是否已经尝试过它了呢?
---
via: <https://news.itsfoss.com/arch-new-guided-installer/>
作者:[Jacob Crume](https://news.itsfoss.com/author/jacob/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Kevin3599](https://github.com/Kevin3599) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

For 20 years, Arch Linux has provided users access to a completely custom and unique system. Over those years, it has built a reputation for customization, at the expense of user-friendliness.
As a [rolling release distro](https://itsfoss.com/rolling-release/?ref=news.itsfoss.com), Arch doesn’t provide any set releases, instead they just update the image each month. However, if you have downloaded Arch in the last few weeks, you may have noticed a new addition: **archinstall**. It makes [installing Arch Linux way easier](https://news.itsfoss.com/arch-linux-easy-install/).

Today, I will be discussing what this change represents for the future of the Arch project, and what this could mean for future releases.
## A New Direction for Arch?

While many were surprised at this move, having an official installer included by default is actually a very sensible move. It signifies a change in direction for Arch, with a greater focus on accessibility, while still retaining the legendary customization it is known for.
As the installer’s GitHub page says:
The guided installer will provide user-friendly options along the way, but the keyword here is options, they are optional and will never be forced upon anyone
This means that the new installer doesn’t affect advanced users, yet also opens up the distro to a wider audience. Among the many benefits this change brings, one stands above the crowd: more users.
More users mean more support for the project, whether that is through donations or development work. And with each of these contributions, the user experience continues to improve for both new and experienced users alike.
## This was bound to happen
Looking into the past, we can see many additions to the installation medium that have helped new users. Examples of these include [pacstrap](https://man.archlinux.org/man/pacstrap.8?ref=news.itsfoss.com) (a tool to install base system) and [reflector](https://wiki.archlinux.org/index.php/Reflector?ref=news.itsfoss.com) (a tool to find the best pacman mirrors).
Plus, users have been asking for a way to script their installation for years, which the new installer provides. Capable of being scripted in Python, it enables far easier deployment for administrators, making it a very attractive option.
## More Customizability (Somehow?)
While it may seem counter-intuitive, the inclusion of an installer actually may improve the customization options of Arch. Currently, the biggest bottleneck with Arch’s incredible customization options is the user’s skill level, an issue eliminated thanks to archinstall.
With the new installer, you don’t need to have the skills to create your perfect environment, instead taking advantage of the installer to do it for you. This opens up a huge range of customization options that would otherwise be out of reach for the average user.
## Closing Thoughts
With this new addition, it seems that Arch Linux has started moving towards a more User-Friendly philosophy. The new installer provides a wide range of benefits to Newbies and advanced users alike. These include wider customization options and a larger community.
All in all, the new installer will provide a positive impact on the community as a whole.
*What do you think about the new Arch guided installer? Have you tried it out yet?*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,329 | 11 个可以部署在 Linux 服务器上的开源论坛软件 | https://itsfoss.com/open-source-forum-software/ | 2021-04-25T17:41:16 | [
"论坛"
] | https://linux.cn/article-13329-1.html |
>
> 是否想要建立社区论坛或客户支持门户站点?以下是一些可以在服务器上部署的最佳开源论坛软件。
>
>
>
就像我们的论坛一样,重要的是建立一个让志趣相投的人可以讨论,互动和寻求支持的平台。
论坛为用户(或客户)提供了一个空间,让他们可以接触到在互联网上大多数情况下不容易找到的东西。
如果你是一家企业,则可以聘请开发人员团队并按照自己的方式建立自己的论坛,但这会增加大量预算。
幸运的是,有几个令人印象深刻的开源论坛软件,你只需要将其部署在你的服务器上就万事大吉了!在此过程中,你将节省很多钱,但仍能获得所需的东西。
在这里,我列出了可以在 Linux 服务器上安装的最佳开源论坛软件列表。
### 建立社区门户的最佳开源论坛软件

如果你尚未建立过网站,则在部署论坛之前,可能需要看一下 [某些开源网站创建工具](https://itsfoss.com/open-source-cms/)。
**注意:** 此列表没有特定的排名顺序。
#### 1、Discourse(现代、流行)

[Discourse](https://www.discourse.org/) 是人们用来部署配置讨论平台的最流行的现代论坛软件。实际上,[It's FOSS 社区](https://itsfoss.community/) 论坛使用了 Discourse 平台。
它提供了我所知道的大多数基本功能,包括电子邮件通知、审核工具、样式自定义选项,Slack/WordPress 等第三方集成等等。
它的自托管是完全免费的,你也可以在 [GitHub](https://github.com/discourse/discourse) 上找到该项目。如果你要减少将其部署在自托管服务器上的麻烦,可以选择 [Discourse 提供的托管服务](https://discourse.org/buy)(肯定会很昂贵)。
#### 2、Talkyard(受 Discourse 和 StackOverflow 启发)

[Talkyard](https://www.talkyard.io/) 是完全免费使用的,是一个开源项目。它看起来很像 Discourse,但是如果你深入了解一下,还是有区别的。
你可以在这里获得 StackOverflow 的大多数关键功能,以及在论坛平台上期望得到的所有基本功能。它可能不是一个流行的论坛解决方案,但是如果你想要类似于 Discourse 的功能以及一些有趣的功能,那么值得尝试一下。
你可以在他们的 [GitHub 页面](https://github.com/debiki/talkyard) 中进一步了解它。
#### 3、Forem (一种独特的社区平台,正在测试中)

你可能以前没有听说过 [Forem](https://www.forem.com/),但它支持了 [dev.to](https://dev.to/)(这是一个越来越受欢迎的开发者社区网站)。
它仍然处于测试阶段,所以你或许不会选择在生产服务器上实验。但是,你可以通过在他们的官方网站上填写一个表格并与他们取得联系,让他们为你托管。
尽管没有官方的功能列表来强调所有的东西,但如果我们以 [dev.to](https://dev.to/) 为例,你会得到许多基本的特性和功能,如社区列表、商店、帖子格式化等。你可以在他们的 [公告帖子](https://dev.to/devteam/for-empowering-community-2k6h) 中阅读更多关于它提供的内容,并在 [GitHub](https://github.com/forem/forem) 上探索该项目。
#### 4、NodeBB(现代化、功能齐全)

[NodeBB](https://nodebb.org/) 是一个基于 [Node.js](https://nodejs.org/en/) 的开源论坛软件。它的目标是简单、优雅和快速。首先,它面向有托管计划的组织和企业。但是,你也可以选择自己托管它。
你还可以获得实时本地分析功能,以及聊天和通知支持。它还提供一个 API,可以将其与你的现有产品集成。它还支持审核工具和打击垃圾邮件的工具。
你可以获得一些开箱即用的第三方集成支持,例如 WordPress、Mailchimp 等。
请在他们的 [GitHub 页面](https://github.com/NodeBB/NodeBB) 或官方网站上可以进一步了解它。
#### 5、Vanilla 论坛(面向企业)

[Vanilla 论坛](https://vanillaforums.com/en/) 主要是一款以企业为中心的论坛软件,它的基本功能是为你的平台打造品牌,为客户提供问答,还可以对帖子进行投票。
用户体验具有现代的外观,并且已被像 EA、Adobe 和其他一些大公司使用。
当然,如果你想尝试基于云的 Vanilla 论坛(由专业团队管理)以及对某些高级功能的访问权,可以随时申请演示。无论哪种情况,你都可以选择社区版,该社区版可以免费使用大多数最新功能,但需要自己托管和管理。
你可以在他们的官方网站和 [GitHub 页面](https://github.com/Vanilla) 上进一步了解它。
#### 6、bbPress (来自 WordPress)

[bbPress](https://bbpress.org/) 是一个可靠的论坛软件,由 WordPress 的创建者建立。旨在提供一个简单而迅速的论坛体验。
用户界面看起来很老旧,但易于使用,它提供了你通常在论坛软件中需要的基本功能。审核工具很好用,易于设置。你可以使用现有的插件扩展功能,并从几个可用的主题中进行选择以调整论坛的外观。
如果你只想要一个没有花哨功能的简单论坛平台,bbPress 应该是完美的。你也可以查看他们的 [GitHub 页面](https://github.com/bbpress) 了解更多信息。
#### 7、phpBB(经典论坛软件)

如果你想要传统的论坛设计,只想要基本功能,则 [phpBB](https://www.phpbb.com/) 软件是一个不错的选择。当然,你可能无法获得最佳的用户体验或功能,但是作为按传统设计的论坛平台,它是实用的并且非常有效。
尤其是,对于习惯使用传统方式的用户而言,这将是一种简单而有效的解决方案。
不仅仅是简单,而且在一般的托管供应商那里,它的设置也是非常容易的。在任何共享主机平台上,你都能获得一键式安装功能,因此也不需要太多的技术知识来进行设置。
你可以在他们的官方网站或 [GitHub 页面](https://github.com/phpbb/phpbb) 上找到更多有关它的信息。
#### 8、Simple Machines 论坛(另一个经典)

与 phpBB 类似,[Simple Machines 论坛](https://www.simplemachines.org/) 是另一种基本(或简单)的论坛。很大程度上你可能无法自定义外观(至少不容易),但是默认外观是干净整洁的,提供了良好的用户体验。
就个人而言,相比 php BB 我更喜欢它,但是你可以前往他们的 [官方网站](https://www.simplemachines.org/) 进行进一步的探索。同样,你可以使用一键安装方法在任何共享托管服务上轻松安装 Simple Machines 论坛。
#### 9、FluxBB(古典)

[FluxBB](https://fluxbb.org/) 是另一个简单、轻量级的开源论坛。与其他的相比,它可能维护的不是非常积极,但是如果你只想部署一个只有很少几个用户的基本论坛,则可以轻松尝试一下。
你可以在他们的官方网站和 [GitHub 页面](https://github.com/fluxbb/fluxbb/) 上找到更多有关它的信息。
#### 10、MyBB(不太流行,但值得看看)

[MyBB](https://mybb.com/) 是一款独特的开源论坛软件,它提供多种样式,并包含你需要的基本功能。
从插件支持和审核工具开始,你将获得管理大型社区所需的一切。它还支持类似于 Discourse 和同类论坛软件面向个人用户的私人消息传递。
它可能不是一个流行的选项,但是它可以满足大多数用例,并且完全免费。你可以在 [GitHub](https://github.com/mybb/mybb) 上得到支持和探索这个项目。
#### 11、Flarum(测试版)

如果你想要更简单和独特的论坛,请看一下 [Flarum](https://flarum.org/)。它是一款轻量级的论坛软件,旨在以移动为先,同时提供快速的体验。
它支持某些第三方集成,也可以使用扩展来扩展功能。就我个人而言,它看起来很漂亮。我没有机会尝试它,你可以看一下它的 [文档](https://docs.flarum.org/),可以肯定它具有论坛所需的所有必要功能的特征。
值得注意的是 Flarum 是相当新的,因此仍处于测试阶段。你可能需要先将其部署在测试服务器上测试后,再应用到生产环境。请查看其 [GitHub 页面](https://github.com/flarum) 了解更多详细信息。
#### 补充:Lemmy(更像是 Reddit 的替代品,但也是一个不错的选择)

一个用 [Rust](https://www.rust-lang.org/) 构建的 Reddit 的联盟式论坛的替代品。它的用户界面很简单,有些人可能觉得它不够直观,无法获得有吸引力的论坛体验。
其联盟网络仍在构建中,但如果你想要一个类似 Reddit 的社区平台,你可以很容易地将它部署在你的 Linux 服务器上,并制定好管理规则、版主,然后就可以开始了。它支持跨版发帖(参见 Reddit),以及其他基本功能,如标签、投票、用户头像等。
你可以通过其 [官方文档](https://lemmy.ml/docs/about.html) 和 [GitHub 页面](https://github.com/LemmyNet/lemmy) 探索更多信息。
### 总结
大多数开源论坛软件都为基本用例提供了几乎相同的功能。如果你正在寻找特定的功能,则可能需要浏览其文档。
就个人而言,我推荐 Discourse。它很流行,外观现代,拥有大量的用户基础。
你认为最好的开源论坛软件是什么?我是否错过了你的偏爱?在下面的评论中让我知道。
---
via: <https://itsfoss.com/open-source-forum-software/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Just like our [It’s FOSS Community](https://itsfoss.community/?ref=itsfoss.com) forum, it is important to always build a platform where like-minded people can discuss, interact, and seek support.
A forum gives users (or customers) a space to reach out for something that they cannot easily find on the Internet for the most part.
If you are an enterprise, you may hire a team of developers and build your own forum the way you want, but that adds a lot of cost to your budget.
Fortunately, there are several impressive open-source forum software that you can deploy on your server, and you’re good to go! You will save a lot of money in the process and still get what you need.
Here, I have compiled a list of the best open source forum software that you can install on your Linux server.
If you haven’t built a website yet, you might want to look at [some open-source website creation tools](https://itsfoss.com/open-source-cms/) before you deploy a forum.
*The list is in no particular order of ranking.*## 1. Discourse (modern and popular)
Discourse is the most popular modern forum software that people deploy to set up their discussion platforms. In fact, our [It’s FOSS community](https://itsfoss.community/?ref=itsfoss.com) forum utilizes the Discourse platform.
It offers most of the essential features that I’m aware of which include email notifications, moderation tools, style customization options, third-part integrations like Slack/WordPress, and more.
It is completely free to self-host and you can find the project on [GitHub](https://github.com/discourse/discourse?ref=itsfoss.com) as well. If you do not need the hassle of deploying it on a self-managed server, you can always choose to opt for [managed services offered by Discourse](https://discourse.org/buy?ref=itsfoss.com) itself (which will be certainly expensive).
## 2. Apache Answer (All-in-One Platform)
An incubation project under The Apache Software Foundation, [Apache Answer](https://answer.apache.org/) is the perfect modern open-source forum software built for multiple use-cases.
You can utilize it for building a community, making a Q/A platform, help center for customers, and more. It includes the essentials of a forum, and interactive/gamification elements like user reputation and badges.
It also includes plugin functionality to help extend features available. You can self-host it, but it does not offer any managed cloud hosting options.
## 3. Talkyard (inspired by Discourse and StackOverflow)
Talkyard is completely free to use and an open-source project. It looks close to Discourse, but there are distinctions if you inspect it.
You get most of the key features from StackOverflow here, along with all the essential features that you would expect on a forum platform. It may not be a popular forum solution, but if you want something similar to Discourse along with some interesting features, this is worth trying out.
You can explore more about it on their [GitHub page](https://github.com/debiki/talkyard?ref=itsfoss.com).
## 4. Forem (Unique approach for a community platform)
You may not have heard about it before, but Forem is what powers [dev.to](https://dev.to/?ref=itsfoss.com) (which is an increasingly popular developer community website).
It appears to be out of beta, but we haven’t had any experience with it, you might want to experiment with it before deploying it to production.
The self-hosting option can be challenging if you are new to the tech stack. In that case, they also offer managed hosting option. You will have to fill out a [form](https://formkeep.com/p/cfa67316d1c12d23ecb3c08b359f944b?ref=itsfoss.com) with your requirements, and they’ll reach out to you about that.
Even though there’s no official feature list to highlight everything, you do get many essential features and functionalities like community listing, shop, post formatting, etc, if we take [dev.to](https://dev.to/?ref=itsfoss.com) as an example.
You can read more about what it offers in its [announcement post](https://dev.to/devteam/for-empowering-community-2k6h?ref=itsfoss.com) and latest [changelogs](https://forem.dev/t/changelog?ref=itsfoss.com). Or you can also explore the project on [GitHub](https://github.com/forem/forem?ref=itsfoss.com).
## 5. Fider (Feedback and Customer Requests)
[Fider](https://fider.io/) is a feedback or customer request focused platform. With this platform, you give your users a way to voice their opinions and suggestions, and others to vote (similar to Reddit).
It is a simple and flexible solution if you want to build a forum around feedbacks. You can choose to keep your website private to registered users, or keep it open. The CSS customization options let you tweak the design, logo, and other elements to go along with your brand/organization style.
You can self-host it or pick the managed cloud hosting option.
## 6. NodeBB (Modern and full of features)
NodeBB is an open-source forum software based on [Node.js](https://nodejs.org/en/?ref=itsfoss.com). It aims to be simple, elegant, and fast as well. Primarily, it is geared towards organizations and enterprises with managed hosting plans available. But, you can choose to host it yourself as well.
You get a real-time native analytics feature along with chat and notification support as well. It also offers an API, if you want to integrate it with any of your existing products. It also supports moderation tools and tools to fight spam.
You get some 3rd party integration support out of the box, like WordPress, Mailchimp, etc.
Explore more about it on their [GitHub page](https://github.com/NodeBB/NodeBB?ref=itsfoss.com) or the official website.
## 7. Vanilla Forums (enterprise focused)
Vanilla Forums is primarily an enterprise-focused forum software with essential features to brand your platform, offer a Q/A for customers, and also give the ability to vote on posts.
The user experience is geared with a modern look and is being used by the likes of EA, Adobe, and some other big-shot companies at the time of writing.
Of course, if you want to try the cloud-based Vanilla Forums (managed by a team of professionals) along with access to some premium features, feel free to request a Demo. In either case, you can opt for the community edition, which is free to use with most of the latest features, with the responsibility of hosting it yourself and managing it.
You can explore more about it on their official website and [GitHub page](https://github.com/Vanilla?ref=itsfoss.com).
## 8. bbPress (from WordPress)
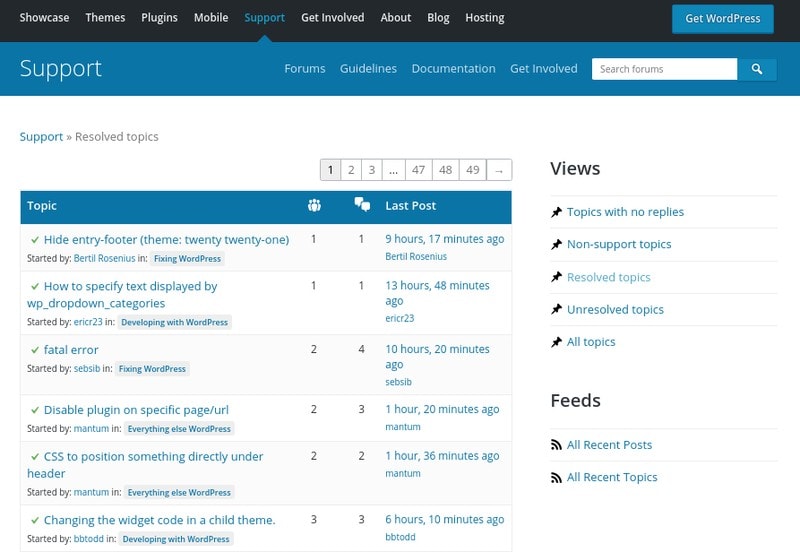
bbPress is a solid forum software built by the creators of WordPress. It aims to provide a simple and snappy forum experience.
The user interface would seem old-school, but it is easy to use and offers the basic functionalities that you would normally look for in a forum software. The moderation tools are simple and easy to set up. You can extend the functionality using plugins available and choose from several themes available to tweak the look and feel of your forum.
If you just want a simple forum platform with no fancy features, bbPress should be perfect. You can also check out their [GitHub page](https://github.com/bbpress?ref=itsfoss.com) for more information.
## 9. phpBB (classic forum software)
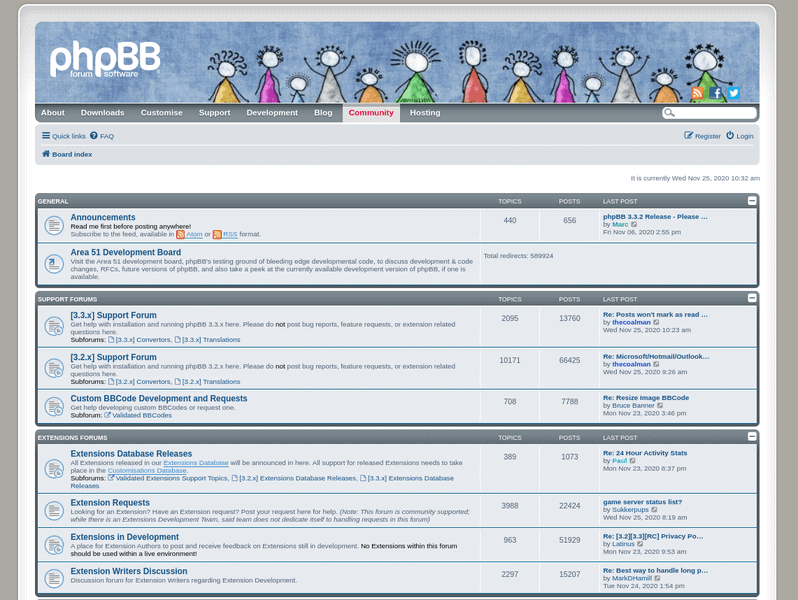
If you want a traditional forum design and just want the basic functionalities, phpBB software is a good choice. Of course, you may not get the best user experience or the features, but it is functional and quite effective as a traditional-design forum platform.
Especially, for users comfortable with the traditional approach, it will be a simple and effective solution.
Not just limited to the simplicity, but also it is way easier to set up with an average hosting provider. You get a 1-click installation feature on every shared hosting platform, so you do not need a lot of technical knowledge to set it up as well.
You can explore more about it on their official website or the [GitHub page](https://github.com/phpbb/phpbb?ref=itsfoss.com).
## 10. Simple Machines Forum (another classic)
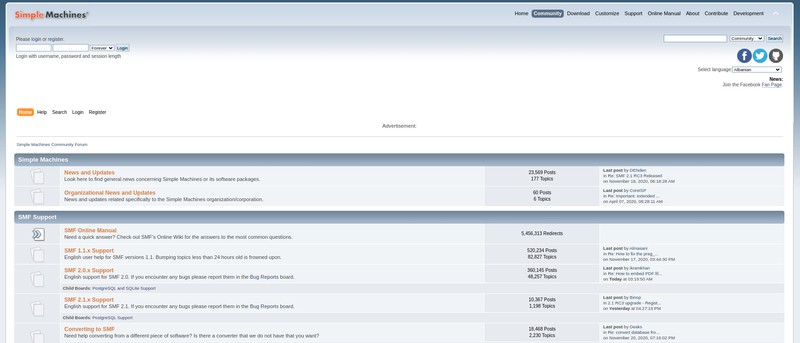
Similar to php BB, Simple Machines forum is yet another basic (or simple) implementation of a forum platform. You may not be able to customize the look and feel by a long extent (not easily at least) but the default look is clean and offers a good user experience.
Personally, I like it better than phpBB, but you can head to their [official website](https://www.simplemachines.org/?ref=itsfoss.com) to explore more about it. Furthermore, you can easily install Simple Machines Forum on any shared hosting service using the 1-click installation method.
## 11. MyBB (less popular but worth a look)
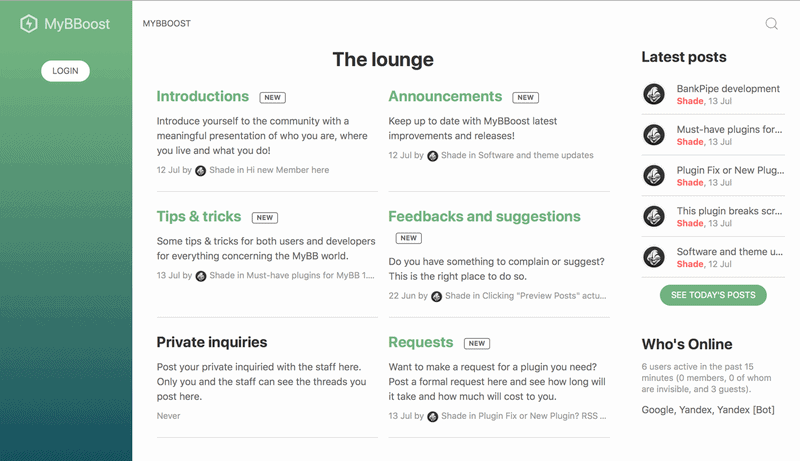
MyBB is unique open-source forum software that offers a wide range of styles and includes essential features you’ll need.
Starting from plugin support and moderation tools, you get everything necessary needed to manage a big community. It also supports private messaging to individual users similar to Discourse and similar forum software.
It may not be a popular option but it checks out for most of the use-cases and it is completely free. You might want to support and explore the project on [GitHub](https://github.com/mybb/mybb?ref=itsfoss.com) as well.
## 12. Flarum
If you want something simpler and unique, take a look at Flarum. It is a lightweight forum software that aims to be mobile-first while offering a fast experience.
It supports some third-party integrations, and you can extend the functionality using extensions as well. Personally, it looks beautiful to me. I haven’t got a chance to try it you can take a look at its [documentation](https://docs.flarum.org/?ref=itsfoss.com) and it is safe to assume that it features all the necessary features for a forum.
It is worth noting that Flarum is fairly new compared to others, but no longer in beta. You might want to deploy it on your test server first before taking a leap of faith in your production environment. Do check out their [GitHub page](https://github.com/flarum?ref=itsfoss.com) for more details.
[Start free with $5 welcome credit](https://www.pikapods.com/)😎
## Bonus: Lemmy (More like a Reddit alternative but a decent option)
A federated alternative to Reddit built using [Rust](https://www.rust-lang.org/?ref=itsfoss.com). The user interface is simple and some of you may not find it to be intuitive enough for an attractive forum experience.
The federated network is still a work in progress but if you want a Reddit-like community platform, you can easily deploy it in your Linux server with moderation rules, moderators, and get started. It supports cross-posting (as seen in Reddit) along with other basic features of tagging, voting, user avatar, and more.
You can explore more about it through their [official documentation](https://lemmy.ml/docs/about.html?ref=itsfoss.com) and the [GitHub page](https://github.com/LemmyNet/lemmy?ref=itsfoss.com).
## Wrapping Up
Most of the open-source forum software offers pretty much the same features for the basic use-case. If you are searching for something specific, you might want to explore their documentation.
Personally, I recommend Discourse. It is popular, modern looking, and has a significant user base.
What do you think is the best open source forum software? Did I miss any of your favorites? Let me know in the comments below. |
13,333 | Fedora Linux 中有 Bug 吗?一起来修复它! | https://fedoramagazine.org/something-bugging-you-in-fedora-linux-lets-get-it-fixed/ | 2021-04-26T09:45:51 | [
"Fedora",
"bug"
] | https://linux.cn/article-13333-1.html | 
软件有 bug。任何复杂系统都无法保证每个部分都能按计划工作。Fedora Linux 是一个 *非常* 复杂的系统,包含几千个包,这些包由全球无数个独立的上游项目创建。每周还有数百个更新。因此,问题是不可避免的。本文介绍了 bug 修复过程以及如何确定 bug 优先级。
### 发布开发过程
作为一个 Linux 发行项目,我们希望为用户提供完善的、一切正常的体验。我们的发布起始于 “Rawhide”。我们在 Rawhide 中集成了所有更新的自由及开源软件的新版本。我们一直在不断改进正在进行的测试和<ruby> 持续集成 <rt> Continuous Integration </rt></ruby>过程,为了让即使是 Rawhide 也能被冒险者安全使用。可是,从本质来讲,Rawhide 始终有点粗糙。
每年两次,我们把这个粗糙的操作系统先后分支到测试版本、最终版本。当我们这么做时,我们齐心协力地寻找问题。我们在<ruby> 测试日 <rt> Test Days </rt></ruby>检查特定的区域和功能。制作“<ruby> 候选版本 <rt> Candidate builds </rt></ruby>”,并根据我们的 [发布验证测试计划](https://fedoraproject.org/wiki/QA:Release_validation_test_plan) 进行检测。然后我们进入<ruby> 冻结状态 <rt> freeze state </rt></ruby>,只有批准的更改可以并入候选版本。这就把候选版本从持续的开发隔离开来,持续的开发不断并入 Rawhide 中。所以,不会引入新的问题。
在发布过程中许多 bug 被粉碎去除,这些 bug 有大有小。当一切按计划进行时,我们为所有用户提供了按计划发布的崭新的 Fedora Linux 版本。(在过去几年里,我们已经可靠地重复这一动作——感谢每一个为之努力工作的人!)如果确实有问题,我们可以将其标记为<ruby> 发布阻碍 <rt> release blocker </rt></ruby>。这就意味着我们要等到修复后才能发布。发布阻碍通常代表重大问题,该表达一定会引发对 bug 的关注。
有时,我们遇到的一些问题是持续存在的。可能一些问题已经持续了一两个版本,或者我们还没有达成共识的解决方案。有些问题确实困扰着许多用户,但个别问题并没有达到阻碍发布的程度。我们可以将这些东西标记为<ruby> 阻碍 <rt> blocker </rt></ruby>。但这会像锤子一样砸下来。阻碍可能导致最终粉碎该 bug,但也可能导致破坏了周围。如果进度落后,所有其它的 bug 修复、改进以及人们一直在努力的功能,都不能到达用户手中。
### 按优先顺序排列 bug 流程
所以,我们有另一种方法来解决烦人的 bug。[按优先顺序排列 bug 流程](https://docs.fedoraproject.org/en-US/program_management/prioritized_bugs/),与其他方式不同,可以标出导致大量用户不满意的问题。这里没有锤子,更像是聚光灯。与发布阻碍不同,按优先顺序排列 bug 流程没有一套严格定义的标准。每个 bug 都是根据影响范围和严重性来评估的。
一个由感兴趣的贡献者组成的团队帮助策划一个简短列表,上面罗列着需要注意的问题。然后,我们的工作是将问题匹配到能够解决它们的人。这有助于减轻发布过程中的压力,因为它没有给问题指定任何特定的截止时间。理想情况下,我们能在进入测试阶段之前就发现并解决问题。我们尽量保持列表简短,不会超过几个,这样才会真正有重点。这种做法有助于团队和个人解决问题,因为他们知道我们尊重他们捉襟见肘的时间与精力。
通过这个过程,Fedora 解决了几十个严重而恼人的问题,包括从键盘输入故障到 SELinux 错误,再到数千兆字节大小的旧包更新会逐渐填满你的磁盘。但是我们可以做得更多——我们实际上收到的提案没有达到我们的处理能力上限。因此,如果你知道有什么事情导致了长期挫折或影响了很多人,至今没有达成解决方案,请遵循 [按优先顺序排列 bug 流程](https://docs.fedoraproject.org/en-US/program_management/prioritized_bugs/),提交给我们。
### 你可以帮助我们
邀请所有 Fedora 贡献者参与按优化顺序排列 bug 的流程。评估会议每两周在 IRC 上举办一次。欢迎任何人加入并帮助我们评估提名的 bug。会议时间和地点参见 [日历](https://calendar.fedoraproject.org/base/)。Fedora 项目经理在会议开始的前一天将议程发送到 [triage](https://lists.fedoraproject.org/archives/list/triage%40lists.fedoraproject.org/) 和 [devel](https://lists.fedoraproject.org/archives/list/devel%40lists.fedoraproject.org/) 邮件列表。
### 欢迎报告 bug
当你发现 bug 时,无论大小,我们很感激你能报告 bug。在很多情况下,解决 bug 最好的方式是交给创建该软件的项目。例如,假设渲染数据相机照片的 Darktable 摄影软件出了问题,最好把它带给 Darktable 摄影软件的开发人员。再举个例子,假设 GNOME 或 KDE 桌面环境或组成部分软件出了问题,将这些问题交给这些项目中通常会得到最好的结果。
然而, 如果这是一个特定的 Fedora 问题,比如我们的软件构建或配置或者它的集成方式的问题,请毫不犹豫地 [向我们提交 bug](https://docs.fedoraproject.org/en-US/quick-docs/howto-file-a-bug/)。当你知道有一个问题是我们还没有解决的,也要提交给我们。
我知道这很复杂……最好有一个一站式的地方来处理所有 bug。但是请记住,Fedora 打包者大部分是志愿者,他们负责获取上游软件并将其配置到我们系统中。他们并不总是对他们正在使用的软件的代码有深入研究的专家。有疑问的时候,你可以随时提交一个 [Fedora bug](https://docs.fedoraproject.org/en-US/quick-docs/howto-file-a-bug/)。Fedora 中负责相应软件包的人可以通过他们与上游软件项目的联系提供帮助。
请记住,当你发现一个已通过诊断但尚未得到良好修复的 bug 时,当你看到影响很多人的问题时,或者当有一个长期存在的问题没有得到关注时,请将其提名为高优先级 bug。我们会看以看能做些什么。
*附言:标题中的著名图片当然是来自哈佛大学马克 2 号计算机的日志,这里曾是格蕾丝·赫柏少将工作的地方。但是与这个故事的普遍看法相背,这并不是 “bug” 一词第一次用于表示系统问题——它在工程中已经很常见了,这就是为什么发现一个字面上的 “bug” 作为问题的原因是很有趣的。 #nowyouknow #jokeexplainer*
---
via: <https://fedoramagazine.org/something-bugging-you-in-fedora-linux-lets-get-it-fixed/>
作者:[Matthew Miller](https://fedoramagazine.org/author/mattdm/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Software has bugs. Any complicated system is guaranteed to have at least some bits that don’t work as planned. Fedora Linux is a *very* complicated system. It contains thousands of packages created by countless independent upstream projects around the world. There are also hundreds of updates every week. So, it’s inevitable that problems creep in. This article addresses the bug fixing process and how some bugs may be prioritized.
## The release development process
As a Linux distribution project, we want to deliver a polished, “everything just works” experience to our users. Our release process starts with “Rawhide”. This is our development area where we integrate new versions of all that updated free and open source software. We’re constantly improving our ongoing testing and continuous integration processes to make even Rawhide safe to use for the adventurous. By its nature, however, Rawhide will always be a little bit rough.
Twice a year we take that rough operating system and branch it for a beta release, and then a final release. As we do that, we make a concerted effort to find problems. We run Test Days to check on specific areas and features. “Candidate builds” are made which are checked against our [release validation test plan](https://fedoraproject.org/wiki/QA:Release_validation_test_plan). We then enter a “freeze” state where only approved changes go into the candidates. This isolates the candidate from the constant development (which still goes into Rawhide!) so new problems are not introduced.
Many bugs, big and small, are squashed as part of the release process. When all goes according to plan, we have a shiny new on-schedule Fedora Linux release for all of our users. (We’ve done this reliably and repeatedly for the last few years — thanks, everyone who works so hard to make it so!) If something is really wrong, we can mark it as a “release blocker”. That means we won’t ship until it’s fixed. This is often appropriate for big issues, and definitely turns up the heat and attention that bug gets.
Sometimes, we have issues that are persistent. Perhaps something that’s been going on for a release or two, or where we don’t have an agreed solution. Some issues are really annoying and frustrating to many users, but individually don’t rise to the level we’d normally block a release for. We *can* mark these things as blockers. But that is a really big sledgehammer. A blocker may cause the bug to get finally smashed, but it can also cause disruption all around. If the schedule slips, all the *other* bug fixes and improvements, as well as features people have been working on, don’t get to users.
## The Prioritized Bugs process
So, we have another way to address annoying bugs! The [Prioritized Bugs process](https://docs.fedoraproject.org/en-US/program_management/prioritized_bugs/) is a different way to highlight issues that result in unpleasantness for a large number of users. There’s no hammer here, but something more like a spotlight. Unlike the release blocker process, the Prioritized Bugs process does not have a strictly-defined set of criteria. Each bug is evaluated based on the breadth and severity of impact.
A team of interested contributors helps curate a short list of issues that need attention. We then work to connect those issues to people who can fix them. This helps take pressure off of the release process, by not tying the issues to any specific deadlines. Ideally, we find and fix things before we even get to the beta stage. We try to keep the list short, no more than a handful, so there truly is a focus. This helps the teams and individuals addressing problems because they know we’re respectful of their often-stretched-thin time and energy.
Through this process, Fedora has resolved dozens of serious and annoying problems. This includes everything from keyboard input glitches to SELinux errors to that thing where gigabytes of old, obsolete package updates would gradually fill up your disk. But we can do a lot more — we actually aren’t getting as many nominations as we can handle. So, if there’s something *you* know that’s causing long-term frustration or affecting a lot of people and yet which seems to not be reaching a resolution, follow the [Prioritized Bugs process](https://docs.fedoraproject.org/en-US/program_management/prioritized_bugs/) and let *us* know.
**You can help**
All Fedora contributors are invited to participate in the Prioritized Bugs process. Evaluation meetings occur every two weeks on IRC. Anyone is welcome to join and help us evaluate the nominated bugs. See the [calendar](https://calendar.fedoraproject.org/base/) for meeting time and location. The Fedora Program Manager sends an agenda to the [triage](https://lists.fedoraproject.org/archives/list/triage%40lists.fedoraproject.org/) and [devel](https://lists.fedoraproject.org/archives/list/devel%40lists.fedoraproject.org/) mailing lists the day before meetings.
## Bug reports welcome
Big or small, when you find a bug, we really appreciate it if you report it. In many cases, the best place to do that is with the project that creates the software. For example, lets say there is a problem with the way the Darktable photography software renders images from your digital camera. It’s best to take that to the Darktable developers. For another example, say there’s a problem with the GNOME or KDE desktop environments or with the software that is part of them. Taking these issues to those projects will usually get you the best results.
However, if it’s a Fedora-specific problem, like something with our build or configuration of the software, or a problem with how it’s integrated, don’t hesitate to [file a bug with us](https://docs.fedoraproject.org/en-US/quick-docs/howto-file-a-bug/). This is also true when there is a problem which you know has a fix that we just haven’t included yet.
I know this is kind of complex… it’d be nice to have a one-stop place to handle all of the bugs. But remember that Fedora packagers — the people who do the work of taking upstream software and configuring it to build in our system — are largely volunteers. They are not always the deepest experts in the code for the software they’re working with. When in doubt, you can always file a [Fedora bug](https://docs.fedoraproject.org/en-US/quick-docs/howto-file-a-bug/). The folks in Fedora responsible for the corresponding package can help with their connections to the upstream software project.
Remember, when you find a bug that’s gone through diagnosis and doesn’t yet have a good fix, when you see something that affects a lot of people, or when there’s a long-standing problem that just isn’t getting attention, please nominate it as a Prioritized Bug. We’ll take a look and see what can be done!
*PS: The famous image in the header is, of course, from the logbook of the Mark II computer at Harvard where Rear Admiral Grace Murray Hopper worked. But contrary to popular belief about the story, this isn’t the first use of the term “bug” for a systems problem — it was already common in engineering, which is why it was funny to find a literal bug as the cause of an issue. #nowyouknow #jokeexplainer*
## akors
“Bug reports welcome”, but this is the average Bugzilla user experience:
¯_(ツ)_/¯
## Matthew Miller
Yeah, that can definitely be the case and it can be disheartening. That’s really what this article is about — the Prioritized Bugs process can help bring attention to issues which remain unresolved for a long time.
## Yogesh Sharma
But some bugs are never prioritized. I had a bug opened for 2-3 years. With every new release I would and update bugzilla to fix release number. Issue is that my Sony Bluetooth headset not working for conference calls, microphone won’t work, for over the course of 2-3 years. Till date I can not use my Sony Bluetooth headsets for meetings .
## Matthew Miller
Hardware enablement is a special class of bug. Someone has to make a driver, and that’s a special skillset that is especially rare when the manufacturer isn’t involved.
In the case of bluetooth, patents and proprietary codecs become an issue. Really, the best organization to talk to about support for Sony headsets is Sony.
## akors
Disheartening is the right word. Writing understandable and helpful bug reports, dig for logs, simplifying reproduction, be available for testing, that is all effort. I’m happy to help and do that if it brings the distribution forward.
However, if I only get “This message is a reminder that Fedora 32 is nearing its end of life” as in in the majority of all bug reports, then putting in that effort is just not worth it. I have stopped filing bugs years ago, because it’s just lost effort.
Did we need a “prioritized bug process” for that? The longest standing bugs should be easily identifiable, if they have been open for years and have dozens of comments from different people under them.
## Sean Sollars
The Fedora Linux is for business and I don’t have a business. I am disabled and play games, watch movies and such.
## Tim Hawkins
I play games (steam), watch movies and other things on my fedora workstation. Redhat is for business, fedora is not so limited.
## Arjen Heidinga
Exact this is my experience with Fedora bugs. You file a bug with as much as possible information, willingness to cooperate, test etcetera. And nothing happens…. If I just browse the bugzilla, its appears riddled with those reports.
Not even a message a response comes. It is just the bugreport which rots away and gets automatically closed.
To me it appears people have other things to do than solve those pesky bug reports, which I understand.
## Matthew Miller
We do depend on many volunteers — even people paid by Red Hat to work on Fedora in some way are often doing a lot of their Fedora work out of interest not as a job obligation. So, there’s definitely some amount of … “better things to do”. But in general, Fedora maintainers really do care… it’s just hard to keep up.
This process is intended to help triage, so we can get the right attention on issues with a lot of impact.
## Jaison
haha yes! I have seen a few of those.
## Jet
Couldn’t agree more.😂👍
## Erik
I’m very glad to see this article and outlining the “spotlight” approach. I had a really annoying bug upstream in Gnome that took years to fix (involving lack of UTC support in the session). A process like that which is outlined in the article above probably would have hastened the fix of that bug.
## Glenn Junkert
This is an informative article, and very helpful to me. As a recent linux convert (Nov. 2019), exploring the myriad choices of OS systems was often disorienting (but fun) but I crave stability and have now run Fedora for nearly a year. My issue is not a “bug,” but a kind-of accessibility “wished-for” option. I have a chronic, but not severe vision problem (keratoconus) and I would like to see a modest system option (added to the accessibility menu) to increase/adjust font & icon size in the top bar… without having to download a separate “dock” or extensions (many with severe bug problems). That’s it! I otherwise consider Fedora perfect!
## Frederik
That’s a GNOME issue. They are very keen on making sure you do not get an option like that, lets their grand vision of the pure desktop is tainted with the imperfection that is the user.
## Ed Scott
This is not a bug but just a wish. Over the versions of Fedora you have had some really beautiful background images and more recently not as many I cared so much about. Is there a collection of those older backgrounds in a folder somewhere? Perhaps someday there might be a link allowing users to pick one of those older ones via Internet?
I wonder if it would ever be feasible to add selections to update a MoBo BIOS and graphics drivers, as you support updating software apps? AMD and MoBo makers offer apps to do this but only for MS Windows of course.
This next is probably not so likely but I will ask it anyway. Sony, Canon, Nikon, HP, etc. only ever support Windows and MacOS for firmware updates on digital cameras and ink jet printers. I would love to be able to do this from Linux.
None of these are real big deals – postings like Glenn Junkert’s are far more important to get done. Most recent major Linux distros have gotten amazingly good now, and of course Fedora definitely is. Thanks for asking for suggestions. Do you know that for a while I was trying to get used to Apple MacOS and made a suggestion to them, and then a short while later got a letter from an Apple lawyer saying something like “We have software engineers to improve MacOS and do not want you making suggestions.” So one of wonderful things about running Linux is user suggestions are usually welcome … and probably because of that, distros like Fedora are getting really wonderful to use. Thanks!
## Gregory Bartholomew
Did you see How to install more wallpaper packs on Fedora Workstation?
Here is a list of some older packages that you can install to get the older backgrounds:
## Matthew Miller
You can also see a collection in the Fedora wiki at https://fedoraproject.org/wiki/Wallpapers
## Leslie Satenstein, Montreal,Que,Canada
Hi Matt
Can the system distinguish between user raised bugs and those that the system trapped and filed to RH bugzilla because it is programmed into the handler.
I have a bug to report about design which may be what I term a deviation of gnome from the previous version. Sometimes, and rightly so, it is not a bug, Othertimes, it is one, or a bug about an inconvenience.
## Strategist
Making everyone happy, is a wish too good to be true.
Atleast practically impossible unless the work is done and continuously improved by robots.
To the people who complain, you need to understand the extend and vastness of the project, the components which you are expecting to get an update(especially for proprietary drivers – requires heavy use of free time to reverse egnineer the available softwares).
Try to do that and you will understand the pain involved.
We have reached till here from a time where the world was dominated by unnecessarily complicated proprietary softwares and OS. So instead of complaining, try to help the team find solutions and thereby help all people.
For all the people involved in making Fedora, ALL OF YOU ARE AWESOME AND KEEP UP THE WORK FRIENDS.
## Darvond
Yeah, for every bugfix there is a non-zero chance that someone was using it as a spacebar heater. https://xkcd.com/1172/
## Naheem
I always thought it strange that regular software doesnt not have access to flatpak style overlays.
Ideally eg the system gstreamer should also check and ake available all installed plugins even if they are flatpak extensions (the search path should check if flatpak extension points are available and if so mount them). Then loading of any plugins can be standardised between all editions of Fedora including silverblue.
## Rudi Simon
I’ve always dreamed of a “Fedora-Mini”. An ARM cpu/chipset/bios and dedicated gpu developed by Fedora with Fedora installed. It would be in a beautiful space-blue box with the logo in the top.
I know it’s a dream since Linux won’t allow it, but it would be cool.
## Devil's Chariot
Pulseeffects and conky manager. I last used them successfully on F32. when i upgraded to F33 the both stopped working and even now on F34 still not working proper
## Darvond
Have you upgraded to Pipewire? Or made sure that the server and program are on speaking terms?
If not the former, I can fully recommend so.
As for Conky Manager, I think the bad news is, that project was last updated four years ago.
The one thing I wish DNF/DNFdragora made more obvious was when a package was last updated, and not just “version bumped.”
## Anon Ymous the 8th
Nvidia related bug and a fix. (to help others counter the screen going blank, forcing a live cold boot)
I have a dell g5 gaming rig – i9 processor , nvidia rtx 2080 video card. Fedora often just locks up on it. The screen goes blank, and nothing works. (screen is set to never go blank in power settings)
As of a month ago, fedora workstation 33 and fedora silverblue seem to work without the screen going blank. However, the Fedora Design Suite version still locks up with a blank screen, forcing me to do a cold boot. Anyway, here is one fix that seems to work
1) sudo dnf update
2) sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
3) sudo dnf install https://download1.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm
4) sudo dnf install akmod-nvidia
sudo reboot or reboot the computer.
After doing the above, the screen problem is fixed. Also it shows the exact video card I have in settings. “NVIDIA Corporation TU104 [GeForce RTX 2080]”
## Mohd AsifAli Rizvan
with Nvidia and Fedora you should use stable kernel, the frequent updates of kernel break nvidia a lot.
sudo dnf copr enable kwizart/kernel-longterm-5.10 -y
or if you want 5.4
sudo dnf copr enable kwizart/kernel-longterm-5.4 -y
## sampsonf
Sorry in advance if this is off topic.
Question 1:
When filing a bug, is there any field that I can set to indicate it is only applicable to specific product like Workstation, Silverblue, coreOS, etc?
## Matthew Miller
There isn’t a field like that. Maybe there should be, but I think the trend is towards fewer fancy bugzilla fields because it’s already pretty complicated.
It’s definitely good information to put in your summary of the issue!
## Anoop
Have been using this from the RedHat 6.1 release . Of late features are disappearing. Move to Grub-2 has been rough too. That said there are no other distribution which offer what this can.
Now just take the case of a desktop user. Of late it has become a pain to configure grub itself. Time we got a normal GUI to do it.
Yum was a good start. Then DNF does most of those functions, but is so slow to do the same thing. Also it takes a long time to do anything meaningful. Why not just have something like the trusted old timer for end. It was there and working. But disappeared.
Modern laptops don’t have two sockets for mic and headphones. Windows driver for the infamous Reltek has application to set easily how to handle it. That is why you get everywhere. On most monks too. If in a headset and the recording goes haywire. It just keeps blinking saying mic is in it is out and then headphones in and out etc.
Fedora also claims it is cutting edge. The modern OS whatever it maybe don’t need you type in a terminal . Those are stuff which makes or breakers an is. I love this , but the issue is even my family does not like it. They use mint or even Ubuntu. What a fate. After all what good can an is do if you can’t configure a boot order , set up a headset or such things. Don’t even see any good software update too. Just something interfering your work saying updates is available lol.
## Darvond
Let me see if I can translate this to lay:
You don’t like Grub2. Fair enough. Grub2 is very hairy by the unfortunate nature of the beast. There are a few alternatives like ReFind.
DNF is slow? This doesn’t really speak to anything. That could be any number of things such as the dependency resolver, the server finder, or any number of sub processes. Use the -v option if you really want to see what it’s up to. If it’s really such a bother, making DNF automatic is rather trivial. https://dnf.readthedocs.io/en/latest/automatic.html
As for the matter of your headset troubles, is that across all outputs, desktops, and programs? Are you using Pulse or Pipe? This could be a lot of things.
I could argue for the sake of arguing, that upgrading Mint is more a pain than upgrading Fedora; their process is such chopped liver that they actually recommend AGAINST UPGRADING AND JUST CLEAN INSTALLING.
## Karlis K.
There’s ‘grubby’ (CLI) and ‘grub-customizer’ (GUI) that you can install to configure your GRUB. As for DNF, ‘dnf-utils’ come in handy – it provides a good few utils that came as standalone yum plugins in the past (like fastestmirror and dnf-cache).
But you can also give OpenSUSE a try – it’s an RPM based distro that I’ve switched over to using. I went with the KDE version of OpenSUSE Tumbleweed (continuous Rolling Release, but you might like the stable Leap releases more) after having trouble with KDE on older Fedora 31 release. Yast config utility has both CLI and GUI but the GUI feels more complete in KDE version and allows you to adjust Bootloader (GRUB2) settings without manually editing the /etc/default/grub and then generating the GRUB2 configs.
## Alioune
In Fedora 33 , Actually since Fedora 20 if i’m not mistaken, it’s hard to connect to a hidden network via the GUI network manager. You have to use workarounds like iwlist and so. l’m not talking about automatically connect to a hidden network; I know the network doesn’t broadcast it’s SSID , I’m taking about setting up a hidden network and then later on or some times in the future coming back and trying to connect manually it always fails. I think there is something to do with broadcom wireless network cards. That’s bugging be. Thank you for this opportunity to share this issue.
## Luchezar
Hi! From the Fedora 30 onwards, on machines with an AMD processor, the effect of a “glued” keyboard and mouse appeared, at higher loads, for example, work in the OpenOffice and gimp. I also have difficulty configuring a scanner for multifunction printers. This made me return to the fedora 29.
## Klaus
I never see a bug fixed… Currently I am not able to work with two monitors anymore after an update a few weeks ago. No reaction, no work around, no help!
This week a new update makes it impossible to shut down normally
Booting with two monitors did not work since 2 years
Sorry, it is frustrating.
## Darvond
Well, are you prepared to provision actual information such as which desktop(s) this issue is occurring on, your graphics card, connector to computer & between monitors, if Wayland vs X is an issue, and so on?
And that’s just surface level diagnostics.
## Lars Martin
What is a bug or not on fedora?
I found some on fedora https://forums.fedoraforum.org/forumdisplay.php?155-F34-Development-Forum
but no sure if kernel issue, poor design install give error message when its works correctly or some like that? its more issue with fedora 34 beta gnome 40 than ubuntu 21.04 gnome 3.1 or simlar but not sure if developer know about it?
## Darvond
You can always try to raise an issue with the upstream, but be prepared that you might end up in a game of bugtracking ping-pong. Less professional projects will often put you in a defer loop instead of actually investigating things from all ends to help all sides find a solution.
It’s kinda like a genre blindness.
## Matthew Miller
Well, less professional projects can just be one or two people in their spare time, doing something they thought would be helpful — making an open source project doesn’t obligate one to spend one’s time investigating all reports. (You won’t get that from most commercial software either, unless you’re paying considerable amounts of money!)
## Darvond
Don’t get me wrong. I know that a lot of projects are basically passion projects and uplifted hobby works. XFCE is a great example of that. But the actual people involved are professionals. I more meant in terms of casual vs serious, not hobby vs corporate; though that is a seriously good point, to which I will happily bow to.
## Matthew Miller
Yes 🙂
I take your point too — it’s great when projects are able to devote time to tracking down problems and helping their users!
## F Gholamian
Broadcom bluetooth and wifi don’t work in fedora. Probably, drivers are not installed in Fedora 34. Will packages be added to Fedora 34 automatically?
## Leslie Satenstein
I have a craint(known as a xxxch) about /tmp clutter. I thought that /tmp should be clean immediately following a fresh system boot. I thought that /tmp was for a user needing temporary file space.
Currently, on a Fedora boot (…33,34), /tmp is used by systemd until the very first logon. On my system, when I do the first login and check /tmp, there are 12 directories with the name:
“systemd-private-337693851ccd42f4ab963bf09f507….. ”
Are these directories needed after shell presents the logon prompt? Is there any reason why these files could not be created within /var/tmp so that on first logon by a user, /tmp is clean.
Is there an issue if a user wipes /tmp of files for his first use?
Is there a problem if these files are relocated to /var/tmp?
## Gregory Bartholomew
I haven’t used it for /tmp (I have for other paths) but there is an example for “polyinstantiating” /tmp in /etc/security/namespace.conf. Like I said, I haven’t tried it, but that is my best guess as to how you might go about getting a “clean” /tmp for your user session.
## Arjen Heidinga
Being a Linux admin for over 20 years, me advice: don’t bother. It never has been clean after a boot. Every house had a closet with clutter. /tmp is for users /and/ services to write tmpfiles. Those pesky long systems dirs are systemd’s-privatetemp dirs. Leave them. Please don’t wipe /tmp, you’ll upset things.
## James
Make DNF fast. I have used Arch and Alpine. Pacman and Apk is very fast compared to DNF.
Packages repository’s metadata updates automatically, worse they are too big. There should a separate command to do that like others. Some people need to pay for every bytes they receive.
## wuzuyirepaxe
Just configure dnf to your liking, see cacheonly or metadata_expire in dnf.conf (https://dnf.readthedocs.io/en/latest/conf_ref.html).
Then you can control it with dnf makecache or the –refresh option.
## Leslie Satenstein
System D alert browser post bugs the bug the x out of me. The alert has a [Troubleshoot] button that I usually select. Doing so, I am presented with two columns. the left has the title “If you were trying to…”
and on the right side, “Then this is the solution”… Here is a sample pair of right side outputs
You should report this as a bug.
You can generate a local policy module to allow this access.
Allow this access for now by executing:
ausearch -c ‘gdb’ –raw | audit2allow -M my-gdb
semodule -X 300 -i my-gdb.pp
My annoyance is the appearance of the two octothorpes on the left.
I would just want to copy the two lines into a root owned terminal, or rather have the two lines presented as
sudo ausearch -c ‘gdb’ –raw | audit2allow -M my-gdb
sudo semodule -X 300 -i my-gdb.pp
My second point. Because of the # before the two messages, most people do not report the bug or bugfix.
## Leslie Satenstein
My paste eliminated two # to the left of the aushearch and the semondule lines.
## svsv sarma
There is something wrong with dnfdragora. The display window is not adjustable at all. The bottom bar is not visible and hence not accessible. I have to use the bash for updates. Perhaps the problem will be solved in the final release of Fedora 34 cinnamon.
## Glenn Junkert
I do have an issue to report: Decided to install Fedora 44 on a new Lenovo Ideapad3 & everything worked to perfection until the software update on Apr 29. Now my touchpad does not respond. A mouse with a usb wireless connection does work. Re-installed, but still no response via touchpad. Touchpad works on other linux OS, but I much prefer using Fedora! |
13,337 | 如何在 Ubuntu 中添加指纹登录 | https://itsfoss.com/fingerprint-login-ubuntu/ | 2021-04-26T19:16:01 | [
"指纹",
"登录"
] | https://linux.cn/article-13337-1.html | 
现在很多高端笔记本都配备了指纹识别器。Windows 和 macOS 支持指纹登录已经有一段时间了。在桌面 Linux 中,对指纹登录的支持更多需要极客的调整,但 [GNOME](https://www.gnome.org/) 和 [KDE](https://kde.org/) 已经开始通过系统设置来支持它。
这意味着在新的 Linux 发行版上,你可以轻松使用指纹识别。在这里我将在 Ubuntu 中启用指纹登录,但你也可以在其他运行 GNOME 3.38 的发行版上使用这些步骤。
>
> **前提条件**
>
>
> 当然,这是显而易见的。你的电脑必须有一个指纹识别器。
>
>
> 这个方法适用于任何运行 GNOME 3.38 或更高版本的 Linux 发行版。如果你不确定,你可以[检查你使用的桌面环境版本](https://itsfoss.com/find-desktop-environment/)。
>
>
> KDE 5.21 也有一个指纹管理器。当然,截图看起来会有所不同。
>
>
>
### 在 Ubuntu 和其他 Linux 发行版中添加指纹登录功能
进入 “设置”,然后点击左边栏的 “用户”。你应该可以看到系统中所有的用户账号。你会看到几个选项,包括 “指纹登录”。
点击启用这里的指纹登录选项。

它将立即要求你扫描一个新的指纹。当你点击 “+” 号来添加指纹时,它会提供一些预定义的选项,这样你就可以很容易地识别出它是哪根手指或拇指。
当然,你可以点击右手食指但扫描左手拇指,不过我看不出你有什么好的理由要这么做。

在添加指纹时,请按照指示旋转你的手指或拇指。

系统登记了整个手指后,就会给你一个绿色的信号,表示已经添加了指纹。

如果你想马上测试一下,在 Ubuntu 中按 `Super+L` 快捷键锁定屏幕,然后使用指纹进行登录。

#### 在 Ubuntu 上使用指纹登录的经验
指纹登录顾名思义就是使用你的指纹来登录系统。就是这样。当要求对需要 `sudo` 访问的程序进行认证时,你不能使用手指。它不能代替你的密码。
还有一件事。指纹登录可以让你登录,但当系统要求输入 `sudo` 密码时,你不能用手指。Ubuntu 中的 [钥匙环](https://itsfoss.com/ubuntu-keyring/) 也仍然是锁定的。
另一件烦人的事情是因为 GNOME 的 GDM 登录界面。当你登录时,你必须先点击你的账户才能进入密码界面。你在这可以使用手指。如果能省去先点击用户帐户 ID 的麻烦就更好了。
我还注意到,指纹识别没有 Windows 中那么流畅和快速。不过,它可以使用。
如果你对 Linux 上的指纹登录有些失望,你可以禁用它。让我在下一节告诉你步骤。
### 禁用指纹登录
禁用指纹登录和最初启用指纹登录差不多。
进入 “设置→用户”,然后点击指纹登录选项。它会显示一个有添加更多指纹或删除现有指纹的页面。你需要删除现有的指纹。

指纹登录确实有一些好处,特别是对于我这种懒人来说。我不用每次锁屏时输入密码,我也对这种有限的使用感到满意。
用 [PAM](https://tldp.org/HOWTO/User-Authentication-HOWTO/x115.html) 启用指纹解锁 `sudo` 应该不是完全不可能。我记得我 [在 Ubuntu 中设置脸部解锁](https://itsfoss.com/face-unlock-ubuntu/)时,也可以用于 `sudo`。看看以后的版本是否会增加这个功能吧。
你有带指纹识别器的笔记本吗?你是否经常使用它,或者它只是你不关心的东西之一?
---
via: <https://itsfoss.com/fingerprint-login-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Many high-end laptops come with fingerprint readers these days. Windows and macOS have been supporting fingerprint login for some time. In desktop Linux, the support for fingerprint login was more of geeky tweaks but [GNOME](https://www.gnome.org/) and [KDE](https://kde.org/) have started supporting it through system settings.
This means that on newer Linux distribution versions, you can easily use fingerprint reading. I am going to enable fingerprint login in Ubuntu here but you may use the steps on other distributions running GNOME 3.38.
This **method works for any Linux distribution running GNOME version 3.38 or higher**. If you are not certain, you may [check which desktop environment version you are using](https://itsfoss.com/find-desktop-environment/).
KDE 5.21 also has a fingerprint manager. The screenshots will look different, of course.
## Adding fingerprint login in Ubuntu and other Linux distributions
Go to **Settings** and the click on **Users** from left sidebar. You should see all the user account on your system here. You’ll see several option including **Fingerprint Login**.
Click on the Fingerprint Login option here.
It will immediately ask you to scan a new fingerprint. When you click the + sign to add a fingerprint, it presents a few predefined options so that you can easily identify which finger or thumb it is.
You may of course scan left thumb by clicking right index finger though I don’t see a good reason why you would want to do that.
While adding the fingerprint, rotate your finger or thumb as directed.
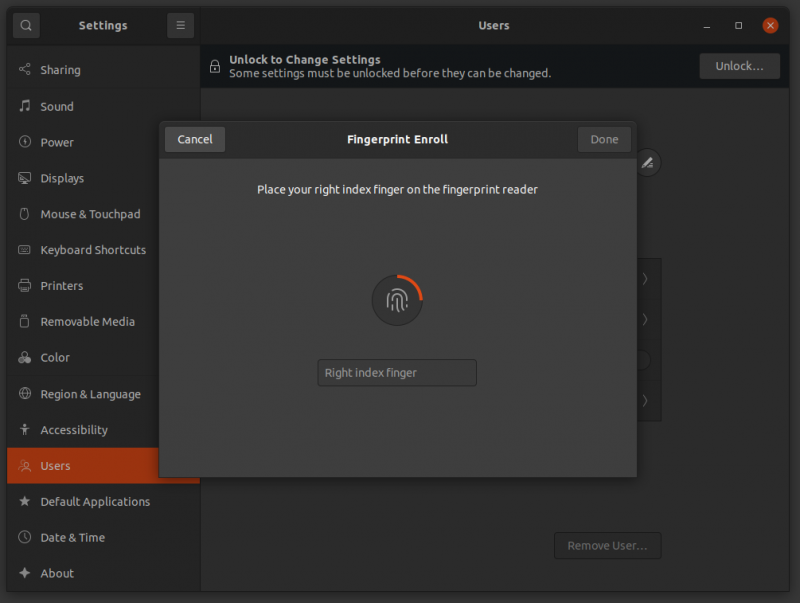
Once the system registers the entire finger, it will give you a green signal that the fingerprint has been added.
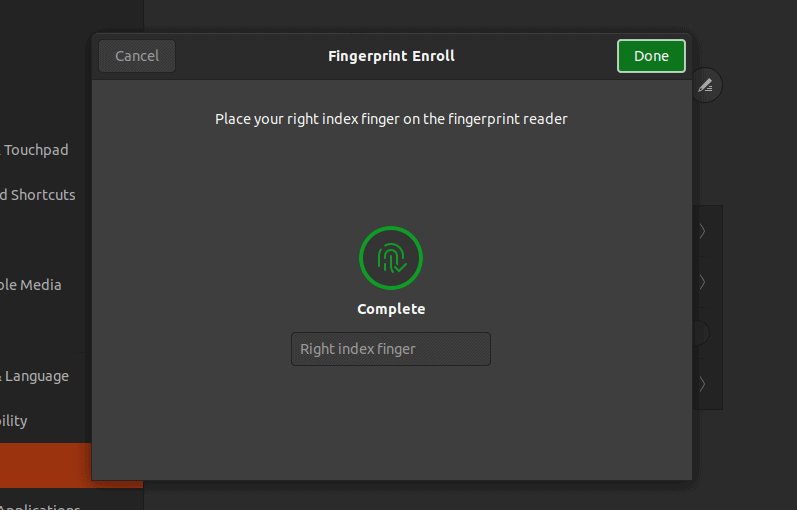
If you want to test it right away, lock the screen by pressing Super+L keyboard shortcut in Ubuntu and then using the fingerprint for login.
### Experience with fingerprint login on Ubuntu
Fingerprint login is what its name suggests: login using your fingerprint. That’s it. You cannot use your finger when it asks for authentication for programs that need sudo access. It’s not a replacement of your password.
One more thing. The fingerprint login allows you to log in but you cannot use your finger when your system asks for sudo password. The [keyring in Ubuntu](https://itsfoss.com/ubuntu-keyring/) also remains locked.
Another annoying thing is because of GNOME’s GDM login screen. When you login, you have to click on your account first to get to the password screen. This is where you can use your finger. It would have been nicer to not bothered about clicking the user account ID first.
I also notice that fingerprint reading is not as smooth and quick as it is in Windows. It works, though.
If you are somewhat disappointed with the fingerprint login on Linux, you may disable it. Let me show you the steps in the next section.
## Disable fingerprint login
Disabling fingerprint login is pretty much the same as enabling it in the first place.
Go to **Settings→User** and then click on Fingerprint Login option. It will show a screen with options to add more fingerprints or delete the existing ones. You need to delete the existing fingerprints.
## Troubleshooting: I don't see a fingerprint option
If you are sure that your laptop has a fingerprint reader and yet you don't see the option to enable Fingerprint in user account settings then it's a driver issue.
Please check the manufacturer of the fingerprint reader with this command:
`lsusb`
**Read the output in detail and see if you see something about Fingerprints. Once you know the manufacturer, you can search on the internet and see if your distribution or kernel version supports your fingerprint.**
For example, My Dell XPS came with Shenzhen Goodix fingerprint reader.
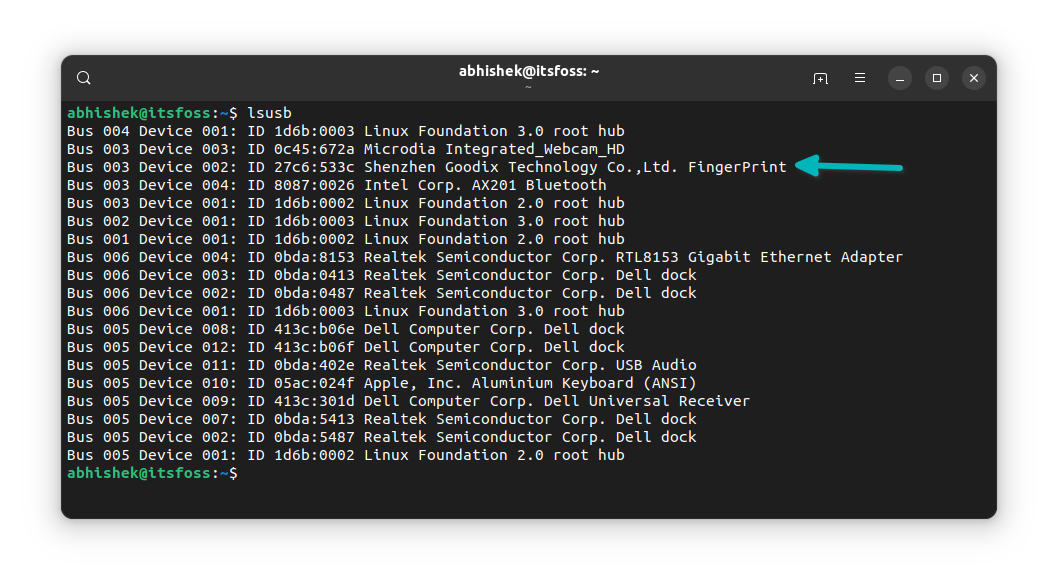
It worked till Ubuntu 20.04 as you can see above. But the later Ubuntu versions don't support it.
Apparently, there is no newer driver but the old driver still works. If you have the same Shenzhen Goodix fingerprint reader, you can try following the instructions in [this Reddit post](https://www.reddit.com/r/linux4noobs/comments/sp3iky/how_to_enable_fingerprint_login_in_ubuntu_on_dell/).
## Did you figure out the finger?
Fingerprint login does have some benefits, especially for lazy people like me. I don’t have to type my password every time I lock the screen and I am happy with the limited usage.
Enabling sudo with fingerprint should not be entirely impossible with [PAM](https://tldp.org/HOWTO/User-Authentication-HOWTO/x115.html). I remember that when I [set up face unlock in Ubuntu](https://itsfoss.com/face-unlock-ubuntu/), it could be used with sudo as well. Let’s see if future versions add this feature.
Do you have a laptop with fingerprint reader? Do you use it often or is it just one of things you don’t care about? |
13,338 | 使用 C 优化你的 Python 代码 | https://opensource.com/article/21/4/cytho | 2021-04-26T23:07:45 | [
"Python"
] | https://linux.cn/article-13338-1.html |
>
> Cython 创建的 C 模块可以加速 Python 代码的执行,这对使用效率不高的解释型语言编写的复杂应用是很重要的。
>
>
>

Cython 是 Python 编程语言的编译器,旨在优化性能并形成一个扩展的 Cython 编程语言。作为 Python 的扩展,[Cython](https://cython.org/) 也是 Python 语言的超集,它支持调用 C 函数和在变量和类属性上声明 C 类型。这使得包装外部 C 库、将 C 嵌入现有应用程序或者为 Python 编写像 Python 一样简单的 C 语言扩展语法变得容易。
Cython 一般用于创建 C 模块来加速 Python 代码的执行。这在使用解释型语言编写的效率不高的复杂应用中非常重要。
### 安装 Cython
你可以在 Linux、BSD、Windows 或 macOS 上安装 Cython 来使用 Python:
```
$ python -m pip install Cython
```
安装好后,就可以使用它了。
### 将 Python 转换成 C
使用 Cython 的一个好的方式是从一个简单的 “hello world” 开始。这虽然不是展示 Cython 优点的最好方式,但是它展示了使用 Cython 时发生的情况。
首先,创建一个简单的 Python 脚本,文件命名为 `hello.pyx`(`.pyx` 扩展名并不神奇,从技术上它可以是任何东西,但它是 Cython 的默认扩展名):
```
print("hello world")
```
接下来,创建一个 Python 设置脚本。一个像 Python 的 makefile 一样的 `setup.py`,Cython 可以使用它来处理你的 Python 代码:
```
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("hello.pyx")
)
```
最后,使用 Cython 将你的 Python 脚本转换为 C 代码:
```
$ python setup.py build_ext --inplace
```
你可以在你的工程目录中看到结果。Cython 的 `cythonize` 模块将 `hello.pyx` 转换成一个 `hello.c` 文件和一个 `.so` 库。这些 C 代码有 2648 行,所以它比一个一行的 `hello.pyx` 源码的文本要多很多。`.so` 库也比它的源码大 2000 倍(即 54000 字节和 20 字节相比)。然后,Python 需要运行单个 Python 脚本,所以有很多代码支持这个只有一行的 `hello.pyx` 文件。
要使用 Python 的 “hello world” 脚本的 C 代码版本,请打开一个 Python 提示符并导入你创建的新 `hello` 模块:
```
>>> import hello
hello world
```
### 将 C 代码集成到 Python 中
测试计算能力的一个很好的通用测试是计算质数。质数是一个比 1 大的正数,且它只有被 1 或它自己除后才会产生正整数。虽然理论很简单,但是随着数的变大,计算需求也会增加。在纯 Python 中,可以用 10 行以内的代码完成质数的计算。
```
import sys
number = int(sys.argv[1])
if not number <= 1:
for i in range(2, number):
if (number % i) == 0:
print("Not prime")
break
else:
print("Integer must be greater than 1")
```
这个脚本在成功的时候是不会提醒的,如果这个数不是质数,则返回一条信息:
```
$ ./prime.py 3
$ ./prime.py 4
Not prime.
```
将这些转换为 Cython 需要一些工作,一部分是为了使代码适合用作库,另一部分是为了提高性能。
#### 脚本和库
许多用户将 Python 当作一种脚本语言来学习:你告诉 Python 想让它执行的步骤,然后它来做。随着你对 Python(以及一般的开源编程)的了解越多,你可以了解到许多强大的代码都存在于其他应用程序可以利用的库中。你的代码越 *不具有针对性*,程序员(包括你)就越可能将其重用于其他的应用程序。将计算和工作流解耦可能需要更多的工作,但最终这通常是值得的。
在这个简单的质数计算的例子中,将其转换成 Cython,首先是一个设置脚本:
```
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("prime.py")
)
```
将你的脚本转换成 C:
```
$ python setup.py build_ext --inplace
```
到目前为止,一切似乎都工作的很好,但是当你试图导入并使用新模块时,你会看到一个错误:
```
>>> import prime
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "prime.py", line 2, in init prime
number = sys.argv[1]
IndexError: list index out of range
```
这个问题是 Python 脚本希望从一个终端运行,其中参数(在这个例子中是要测试是否为质数的整数)是一样的。你需要修改你的脚本,使它可以作为一个库来使用。
#### 写一个库
库不使用系统参数,而是接受其他代码的参数。对于用户输入,与其使用 `sys.argv`,不如将你的代码封装成一个函数来接收一个叫 `number`(或者 `num`,或者任何你喜欢的变量名)的参数:
```
def calculate(number):
if not number <= 1:
for i in range(2, number):
if (number % i) == 0:
print("Not prime")
break
else:
print("Integer must be greater than 1")
```
这确实使你的脚本有些难以测试,因为当你在 Python 中运行代码时,`calculate` 函数永远不会被执行。但是,Python 编程人员已经为这个问题设计了一个通用、还算直观的解决方案。当 Python 解释器执行一个 Python 脚本时,有一个叫 `__name__` 的特殊变量,这个变量被设置为 `__main__`,但是当它被作为模块导入的时候,`__name__` 被设置为模块的名字。利用这点,你可以写一个既是 Python 模块又是有效 Python 脚本的库:
```
import sys
def calculate(number):
if not number <= 1:
for i in range(2, number):
if (number % i) == 0:
print("Not prime")
break
else:
print("Integer must be greater than 1")
if __name__ == "__main__":
number = sys.argv[1]
calculate( int(number) )
```
现在你可以用一个命令来运行代码了:
```
$ python ./prime.py 4
Not a prime
```
你可以将它转换为 Cython 来用作一个模块:
```
>>> import prime
>>> prime.calculate(4)
Not prime
```
### C Python
用 Cython 将纯 Python 的代码转换为 C 代码是有用的。这篇文章描述了如何做,然而,Cython 还有功能可以帮助你在转换之前优化你的代码,分析你的代码来找到 Cython 什么时候与 C 进行交互,以及更多。如果你正在用 Python,但是你希望用 C 代码改进你的代码,或者进一步理解库是如何提供比脚本更好的扩展性的,或者你只是好奇 Python 和 C 是如何协作的,那么就开始使用 Cython 吧。
---
via: <https://opensource.com/article/21/4/cython>
作者:[Alan Smithee](https://opensource.com/users/alansmithee) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ShuyRoy](https://github.com/ShuyRoy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
13,340 | 使用 Stratis 的网络绑定磁盘加密 | https://fedoramagazine.org/network-bound-disk-encryption-with-stratis/ | 2021-04-27T22:18:35 | [
"Stratis",
"NBDE"
] | https://linux.cn/article-13340-1.html | 
在一个有许多加密磁盘的环境中,解锁所有的磁盘是一项困难的任务。<ruby> 网络绑定磁盘加密 <rt> Network bound disk encryption </rt></ruby>(NBDE)有助于自动解锁 Stratis 卷的过程。这是在大型环境中的一个关键要求。Stratis 2.1 版本增加了对加密的支持,这在《[Stratis 加密入门](/article-13311-1.html)》一文中介绍过。Stratis 2.3 版本最近在使用加密的 Stratis 池时引入了对网络绑定磁盘加密(NBDE)的支持,这是本文的主题。
[Stratis 网站](https://stratis-storage.github.io/) 将 Stratis 描述为一个“*易于使用的 Linux 本地存储管理*”。短视频《[使用 Stratis 管理存储](https://www.youtube.com/watch?v=CJu3kmY-f5o)》对基础知识进行了快速演示。该视频是在 Red Hat Enterprise Linux 8 系统上录制的,然而,视频中显示的概念也适用于 Fedora Linux 中的 Stratis。
### 先决条件
本文假设你熟悉 Stratis,也熟悉 Stratis 池加密。如果你不熟悉这些主题,请参考这篇 [文章](/article-13311-1.html) 和前面提到的 [Stratis 概述视频](https://www.youtube.com/watch?v=CJu3kmY-f5o)。
NBDE 需要 Stratis 2.3 或更高版本。本文中的例子使用的是 Fedora Linux 34 的预发布版本。Fedora Linux 34 的最终版本将包含 Stratis 2.3。
### 网络绑定磁盘加密(NBDE)概述
加密存储的主要挑战之一是有一个安全的方法在系统重启后再次解锁存储。在大型环境中,手动输入加密口令并不能很好地扩展。NBDE 解决了这一问题,允许以自动方式解锁加密存储。
在更高层次上,NBDE 需要环境中的 Tang 服务器。客户端系统(使用 Clevis Pin)只要能与 Tang 服务器建立网络连接,就可以自动解密存储。如果网络没有连接到 Tang 服务器,则必须手动解密存储。
这背后的想法是,Tang 服务器只能在内部网络上使用,因此,如果加密设备丢失或被盗,它将不再能够访问内部网络连接到 Tang 服务器,因此不会被自动解密。
关于 Tang 和 Clevis 的更多信息,请参见手册页(`man tang`、`man clevis`)、[Tang 的 GitHub 页面](https://github.com/latchset/tang) 和 [Clevis 的 GitHub 页面](https://github.com/latchset/clevis)。
### 设置 Tang 服务器
本例使用另一个 Fedora Linux 系统作为 Tang 服务器,主机名为 `tang-server`。首先安装 `tang` 包。
```
dnf install tang
```
然后用 `systemctl` 启用并启动 `tangd.socket`。
```
systemctl enable tangd.socket --now
```
Tang 使用的是 TCP 80 端口,所以你也需要在防火墙中打开该端口。
```
firewall-cmd --add-port=80/tcp --permanent
firewall-cmd --add-port=80/tcp
```
最后,运行 `tang-show-keys` 来显示输出签名密钥指纹。你以后会需要这个。
```
# tang-show-keys
l3fZGUCmnvKQF_OA6VZF9jf8z2s
```
### 创建加密的 Stratis 池
上一篇关于 Stratis 加密的文章详细介绍了如何设置加密的 Stratis 池,所以本文不会深入介绍。
第一步是捕获一个将用于解密 Stratis 池的密钥。即使使用 NBDE,也需要设置这个,因为在 NBDE 服务器无法到达的情况下,可以用它来手动解锁池。使用以下命令捕获 `pool1` 密钥。
```
# stratis key set --capture-key pool1key
Enter key data followed by the return key:
```
然后我将使用 `/dev/vdb` 设备创建一个加密的 Stratis 池(使用刚才创建的 `pool1key`),命名为 `pool1`。
```
# stratis pool create --key-desc pool1key pool1 /dev/vdb。
```
接下来,在这个 Stratis 池中创建一个名为 `filesystem1` 的文件系统,创建一个挂载点,挂载文件系统,并在其中创建一个测试文件:
```
# stratis filesystem create pool1 filesystem1
# mkdir /filesystem1
# mount /dev/stratis/pool1/filesystem1 /filesystem1
# cd /filesystem1
# echo "this is a test file" > testfile
```
### 将 Stratis 池绑定到 Tang 服务器上
此时,我们已经创建了加密的 Stratis 池,并在池中创建了一个文件系统。下一步是将你的 Stratis 池绑定到刚刚设置的 Tang 服务器上。使用 `stratis pool bind nbde` 命令进行。
当你进行 Tang 绑定时,需要向该命令传递几个参数:
* 池名(在本例中,`pool1`)
* 钥匙描述符名称(本例中为 `pool1key`)
* Tang 服务器名称(在本例中,`http://tang-server`)
记得之前在 Tang 服务器上,运行了 `tang-show-keys`,显示 Tang 输出的签名密钥指纹是 `l3fZGUCmnvKQF_OA6VZF9jf8z2s`。除了前面的参数外,还需要用参数 `-thumbprint l3fZGUCmnvKQF_OA6VZF9jf8z2s` 传递这个指纹,或者用 `-trust-url` 参数跳过对指纹的验证。
使用 `-thumbprint` 参数更安全。例如:
```
# stratis pool bind nbde pool1 pool1key http://tang-server --thumbprint l3fZGUCmnvKQF_OA6VZF9jf8z2s
```
### 用 NBDE 解锁 Stratis 池
接下来重启主机,并验证你可以用 NBDE 解锁 Stratis 池,而不需要使用密钥口令。重启主机后,该池不再可用:
```
# stratis pool list
Name Total Physical Properties
```
要使用 NBDE 解锁池,请运行以下命令:
```
# stratis pool unlock clevis
```
注意,你不需要使用密钥口令。这个命令可以在系统启动时自动运行。
此时,Stratis 池已经可以使用了:
```
# stratis pool list
Name Total Physical Properties
pool1 4.98 GiB / 583.65 MiB / 4.41 GiB ~Ca, Cr
```
你可以挂载文件系统,访问之前创建的文件:
```
# mount /dev/stratis/pool1/filesystem1 /filesystem1/
# cat /filesystem1/testfile
this is a test file
```
### 轮换 Tang 服务器密钥
最好定期轮换 Tang 服务器密钥,并更新 Stratis 客户服务器以使用新的 Tang 密钥。
要生成新的 Tang 密钥,首先登录到 Tang 服务器,查看 `/var/db/tang` 目录的当前状态。然后,运行 `tang-show-keys` 命令:
```
# ls -al /var/db/tang
total 8
drwx------. 1 tang tang 124 Mar 15 15:51 .
drwxr-xr-x. 1 root root 16 Mar 15 15:48 ..
-rw-r--r--. 1 tang tang 361 Mar 15 15:51 hbjJEDXy8G8wynMPqiq8F47nJwo.jwk
-rw-r--r--. 1 tang tang 367 Mar 15 15:51 l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk
# tang-show-keys
l3fZGUCmnvKQF_OA6VZF9jf8z2s
```
要生成新的密钥,运行 `tangd-keygen` 并将其指向 `/var/db/tang` 目录:
```
# /usr/libexec/tangd-keygen /var/db/tang
```
如果你再看看 `/var/db/tang` 目录,你会看到两个新文件:
```
# ls -al /var/db/tang
total 16
drwx------. 1 tang tang 248 Mar 22 10:41 .
drwxr-xr-x. 1 root root 16 Mar 15 15:48 ..
-rw-r--r--. 1 tang tang 361 Mar 15 15:51 hbjJEDXy8G8wynMPqiq8F47nJwo.jwk
-rw-r--r--. 1 root root 354 Mar 22 10:41 iyG5HcF01zaPjaGY6L_3WaslJ_E.jwk
-rw-r--r--. 1 root root 349 Mar 22 10:41 jHxerkqARY1Ww_H_8YjQVZ5OHao.jwk
-rw-r--r--. 1 tang tang 367 Mar 15 15:51 l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk
```
如果你运行 `tang-show-keys`,就会显示出 Tang 所公布的密钥:
```
# tang-show-keys
l3fZGUCmnvKQF_OA6VZF9jf8z2s
iyG5HcF01zaPjaGY6L_3WaslJ_E
```
你可以通过将两个原始文件改名为以句号开头的隐藏文件,来防止旧的密钥(以 `l3fZ` 开头)被公布。通过这种方法,旧的密钥将不再被公布,但是它仍然可以被任何没有更新为使用新密钥的现有客户端使用。一旦所有的客户端都更新使用了新密钥,这些旧密钥文件就可以删除了。
```
# cd /var/db/tang
# mv hbjJEDXy8G8wynMPqiq8F47nJwo.jwk .hbjJEDXy8G8wynMPqiq8F47nJwo.jwk
# mv l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk .l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk
```
此时,如果再运行 `tang-show-keys`,Tang 只公布新钥匙:
```
# tang-show-keys
iyG5HcF01zaPjaGY6L_3WaslJ_E
```
下一步,切换到你的 Stratis 系统并更新它以使用新的 Tang 密钥。当文件系统在线时, Stratis 支持这样做。
首先,解除对池的绑定:
```
# stratis pool unbind pool1
```
接下来,用创建加密池时使用的原始口令设置密钥:
```
# stratis key set --capture-key pool1key
Enter key data followed by the return key:
```
最后,用更新后的密钥指纹将 Stratis 池绑定到 Tang 服务器上:
```
# stratis pool bind nbde pool1 pool1key http://tang-server --thumbprint iyG5HcF01zaPjaGY6L_3WaslJ_E
```
Stratis 系统现在配置为使用更新的 Tang 密钥。一旦使用旧的 Tang 密钥的任何其他客户系统被更新,在 Tang 服务器上的 `/var/db/tang` 目录中被重命名为隐藏文件的两个原始密钥文件就可以被备份和删除了。
### 如果 Tang 服务器不可用怎么办?
接下来,关闭 Tang 服务器,模拟它不可用,然后重启 Stratis 系统。
重启后,Stratis 池又不可用了:
```
# stratis pool list
Name Total Physical Properties
```
如果你试图用 NBDE 解锁,会因为 Tang 服务器不可用而失败:
```
# stratis pool unlock clevis
Execution failed:
An iterative command generated one or more errors: The operation 'unlock' on a resource of type pool failed. The following errors occurred:
Partial action "unlock" failed for pool with UUID 4d62f840f2bb4ec9ab53a44b49da3f48: Cryptsetup error: Failed with error: Error: Command failed: cmd: "clevis" "luks" "unlock" "-d" "/dev/vdb" "-n" "stratis-1-private-42142fedcb4c47cea2e2b873c08fcf63-crypt", exit reason: 1 stdout: stderr: /dev/vdb could not be opened.
```
此时,在 Tang 服务器无法到达的情况下,解锁池的唯一选择就是使用原密钥口令:
```
# stratis key set --capture-key pool1key
Enter key data followed by the return key:
```
然后你可以使用钥匙解锁池:
```
# stratis pool unlock keyring
```
接下来,验证池是否成功解锁:
```
# stratis pool list
Name Total Physical Properties
pool1 4.98 GiB / 583.65 MiB / 4.41 GiB ~Ca, Cr
```
---
via: <https://fedoramagazine.org/network-bound-disk-encryption-with-stratis/>
作者:[briansmith](https://fedoramagazine.org/author/briansmith/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In an environment with many encrypted disks, unlocking them all is a difficult task. Network bound disk encryption (NBDE) helps automate the process of unlocking Stratis volumes. This is a critical requirement in large environments. Stratis version 2.1 added support for encryption, which was introduced in the article “[Getting started with Stratis encryption](https://fedoramagazine.org/getting-started-with-stratis-encryption/).” Stratis version 2.3 recently introduced support for Network Bound Disk Encryption (NBDE) when using encrypted Stratis pools, which is the topic of this article.
The [Stratis website](https://stratis-storage.github.io/) describes Stratis as an “*easy to use local storage management for Linux*.” The short video [“Managing Storage With Stratis”](https://www.youtube.com/watch?v=CJu3kmY-f5o) gives a quick demonstration of the basics. The video was recorded on a Red Hat Enterprise Linux 8 system, however, the concepts shown in the video also apply to Stratis in Fedora Linux.
## Prerequisites
This article assumes you are familiar with Stratis, and also Stratis pool encryption. If you aren’t familiar with these topics, refer to this [article](https://fedoramagazine.org/getting-started-with-stratis-encryption/) and the [Stratis overview video](https://www.youtube.com/watch?v=CJu3kmY-f5o) previously mentioned.
NBDE requires Stratis 2.3 or later. The examples in this article use a pre-release version of Fedora Linux 34. The Fedora Linux 34 final release will include Stratis 2.3.
## Overview of network bound disk encryption (NBDE)
One of the main challenges of encrypting storage is having a secure method to unlock the storage again after a system reboot. In large environments, typing in the encryption passphrase manually doesn’t scale well. NBDE addresses this and allows for encrypted storage to be unlocked in an automated manner.
At a high level, NBDE requires a Tang server in the environment. Client systems (using Clevis Pin) can automatically decrypt storage as long as they can establish a network connection to the Tang server. If there is no network connectivity to the Tang server, the storage would have to be decrypted manually.
The idea behind this is that the Tang server would only be available on an internal network, thus if the encrypted device is lost or stolen, it would no longer have access to the internal network to connect to the Tang server, therefore would not be automatically decrypted.
For more information on Tang and Clevis, see the man pages (man tang, man clevis) , the [Tang GitHub page](https://github.com/latchset/tang), and the [Clevis GitHub page](https://github.com/latchset/clevis).
## Setting up the Tang server
This example uses another Fedora Linux system as the Tang server with a hostname of tang-server. Start by installing the tang package:
dnf install tang
Then enable and start the tangd.socket with systemctl:
systemctl enable tangd.socket --now
Tang uses TCP port 80, so you also need to open that in the firewall:
firewall-cmd --add-port=80/tcp --permanent
firewall-cmd --add-port=80/tcp
Finally, run *tang-show-keys* to display the output signing key thumbprint. You’ll need this later.
# tang-show-keys l3fZGUCmnvKQF_OA6VZF9jf8z2s
## Creating the encrypted Stratis Pool
The previous article on Stratis encryption goes over how to setup an encrypted Stratis pool in detail, so this article won’t cover that in depth.
The first step is capturing a key that will be used to decrypt the Stratis pool. Even when using NBDE, you need to set this, as it can be used to manually unlock the pool in the event that the NBDE server is unreachable. Capture the pool1 key with the following command:
# stratis key set --capture-key pool1key Enter key data followed by the return key:
Then I’ll create an encrypted Stratis pool (using the pool1key just created) named pool1 using the */dev/vdb* device:
# stratis pool create --key-desc pool1key pool1 /dev/vdb
Next, create a filesystem in this Stratis pool named filesystem1, create a mount point, mount the filesystem, and create a testfile in it:
# stratis filesystem create pool1 filesystem1 # mkdir /filesystem1 # mount /dev/stratis/pool1/filesystem1 /filesystem1 # cd /filesystem1 # echo "this is a test file" > testfile
## Binding the Stratis pool to the Tang server
At this point, we have the encrypted Stratis pool created, and also have a filesystem created in the pool. The next step is to bind your Stratis pool to the Tang server that you just setup. Do this with the *stratis pool bind nbde* command.
When you make the Tang binding, you need to pass several parameters to the command:
- the pool name (in this example, pool1)
- the key descriptor name (in this example, pool1key)
- the Tang server name (in this example, http://tang-server)
Recall that on the Tang server, you previously ran *tang-show-keys* which showed the Tang output signing key thumbprint is *l3fZGUCmnvKQF_OA6VZF9jf8z2s*. In addition to the previous parameters, you either need to pass this thumbprint with the parameter *–thumbprint l3fZGUCmnvKQF_OA6VZF9jf8z2s*, or skip the verification of the thumbprint with the *–trust-url* parameter. ** **
It is more secure to use the *–thumbprint* parameter. For example:
# stratis pool bind nbde pool1 pool1key http://tang-server --thumbprint l3fZGUCmnvKQF_OA6VZF9jf8z2s
## Unlocking the Stratis Pool with NBDE
Next reboot the host, and validate that you can unlock the Stratis pool with NBDE, without requiring the use of the key passphrase. After rebooting the host, the pool is no longer available:
# stratis pool list
Name Total Physical Properties
To unlock the pool using NBDE, run the following command:
# stratis pool unlock clevis
Note that you did not need to use the key passphrase. This command could be automated to run during the system boot up.
At this point, the pool is now available:
# stratis pool list Name Total Physical Properties pool1 4.98 GiB / 583.65 MiB / 4.41 GiB ~Ca, Cr
You can mount the filesystem and access the file that was previously created:
# mount /dev/stratis/pool1/filesystem1 /filesystem1/ # cat /filesystem1/testfile this is a test file
## Rotating Tang server keys
Best practices recommend that you periodically rotate the Tang server keys and update the Stratis client servers to use the new Tang keys.
To generate new Tang keys, start by logging in to your Tang server and look at the current status of the /var/db/tang directory. Then, run the *tang-show-keys* command:
# ls -al /var/db/tang total 8 drwx------. 1 tang tang 124 Mar 15 15:51 . drwxr-xr-x. 1 root root 16 Mar 15 15:48 .. -rw-r--r--. 1 tang tang 361 Mar 15 15:51 hbjJEDXy8G8wynMPqiq8F47nJwo.jwk -rw-r--r--. 1 tang tang 367 Mar 15 15:51 l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk # tang-show-keys l3fZGUCmnvKQF_OA6VZF9jf8z2s
To generate new keys, run tangd-keygen and point it to the /var/db/tang directory:
# /usr/libexec/tangd-keygen /var/db/tang
If you look at the /var/db/tang directory again, you will see two new files:
# ls -al /var/db/tang total 16 drwx------. 1 tang tang 248 Mar 22 10:41 . drwxr-xr-x. 1 root root 16 Mar 15 15:48 .. -rw-r--r--. 1 tang tang 361 Mar 15 15:51 hbjJEDXy8G8wynMPqiq8F47nJwo.jwk -rw-r--r--. 1 root root 354 Mar 22 10:41 iyG5HcF01zaPjaGY6L_3WaslJ_E.jwk -rw-r--r--. 1 root root 349 Mar 22 10:41 jHxerkqARY1Ww_H_8YjQVZ5OHao.jwk -rw-r--r--. 1 tang tang 367 Mar 15 15:51 l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk
And if you run *tang-show-keys*, it will show the keys being advertised by Tang:
# tang-show-keys
l3fZGUCmnvKQF_OA6VZF9jf8z2s
iyG5HcF01zaPjaGY6L_3WaslJ_E
You can prevent the old key (starting with l3fZ) from being advertised by renaming the two original files to be hidden files, starting with a period. With this method, the old key will no longer be advertised, however it will still be usable by any existing clients that haven’t been updated to use the new key. Once all clients have been updated to use the new key, these old key files can be deleted.
# cd /var/db/tang # mv hbjJEDXy8G8wynMPqiq8F47nJwo.jwk .hbjJEDXy8G8wynMPqiq8F47nJwo.jwk # mv l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk .l3fZGUCmnvKQF_OA6VZF9jf8z2s.jwk
At this point, if you run *tang-show-keys* again, only the new key is being advertised by Tang:
# tang-show-keys iyG5HcF01zaPjaGY6L_3WaslJ_E
Next, switch over to your Stratis system and update it to use the new Tang key. Stratis supports doing this while the filesystem(s) are online.
First, unbind the pool:
# stratis pool unbind pool1
Next, set the key with the original passphrase used when the encrypted pool was created:
# stratis key set --capture-key pool1key
Enter key data followed by the return key:
Finally, bind the pool to the Tang server with the updated key thumbprint:
# stratis pool bind nbde pool1 pool1key http://tang-server --thumbprint iyG5HcF01zaPjaGY6L_3WaslJ_E
The Stratis system is now configured to use the updated Tang key. Once any other client systems using the old Tang key have been updated, the two original key files that were renamed to hidden files in the /var/db/tang directory on the Tang server can be backed up and deleted.
## What if the Tang server is unavailable?
Next, shutdown the Tang server to simulate it being unavailable, then reboot the Stratis system.
Again, after the reboot, the Stratis pool is not available:
# stratis pool list Name Total Physical Properties
If you try to unlock it with NBDE, this fails because the Tang server is unavailable:
# stratis pool unlock clevis Execution failed: An iterative command generated one or more errors: The operation 'unlock' on a resource of type pool failed. The following errors occurred: Partial action "unlock" failed for pool with UUID 4d62f840f2bb4ec9ab53a44b49da3f48: Cryptsetup error: Failed with error: Error: Command failed: cmd: "clevis" "luks" "unlock" "-d" "/dev/vdb" "-n" "stratis-1-private-42142fedcb4c47cea2e2b873c08fcf63-crypt", exit reason: 1 stdout: stderr: /dev/vdb could not be opened.
At this point, without the Tang server being reachable, the only option to unlock the pool is to use the original key passphrase:
# stratis key set --capture-key pool1key
Enter key data followed by the return key:
You can then unlock the pool using the key:
# stratis pool unlock keyring
Next, verify the pool was successfully unlocked:
# stratis pool list Name Total Physical Properties pool1 4.98 GiB / 583.65 MiB / 4.41 GiB ~Ca, Cr
## Mark
Thanks. Haven’t seen the youtube videos you linked to before.
The changing the tang server keys seems like a lot of manual effort on all the client servers, so somebody has probably written an ansible playbook do update multiple servers at once :-).
Is there any advantage to using stratis over brtfs as the later is the default in fedora now and handles pools/snapshots/raid quite well anyway ?. Apart from the obvious that RedHat have “depreciated” brtfs, and removed it entirely from rhel8. As it’s fedoramagazine and all new fedora users will probably use the default install of brtfs the question is what would be the justification for users to also install stratis ?. I think this post is more aimed at enterprise users of redhat systems than fedora users.
Encryption on a stratis filesystem and the use of a tang server seems a needless overhead. The manual unlocking needed if the tang server is unavailable is probably the last thing anybody needs in the middle of the night when things have broken.
Having said that I have not investigated using a tang server so assume something so critical can be configured in a replicated way and the clients have a pool of tang servers they can check in with which would be needed in a large environment.
Personally I just use LUKS encryption on all removable disks and have /etc/crypttab unlock them using keyfiles at boot time. Before anyone mentions it yes of course a major disadvantage of that method is a keyfile is not encrypted and has to be on an unencrypted filesystem (like /boot) in order to be read at boot time it you want the disks automatically online at boot time. But the system will come up even if the network around it is dead.
And stratis can use luks encrypted devices anyway (https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/managing_file_systems/managing-layered-local-storage-with-stratis_managing-file-systems) so its adding an extra layer not really needed ?.
And that doc also mentions stratis supports md-raid devices; so I guess stratis does not support its own software raid like brtfs and zfs (yet).
The comment in the post on disks lost or stolen not being able to be unencrypted if they cannot contact the tang server also applies to the simple keyfile method as lost or stolen disks cannot be unencrypted unless the system boot disk containing the keyfiles is also taken :-).
But the advantages of something like a tang server are obvious in that no keys are in clear text. Except the ‘origional key passphrase’ for unlocking when the tang server is unavailable would have to be written down somewhere for every client server pool.
However I thank you for the post as while I don’t see any point in moving to stratis it did encourage me start googling the tang server, which looks like it isn’t bound to stratis but will manage native luks volumes as well( https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/security_hardening/configuring-automated-unlocking-of-encrypted-volumes-using-policy-based-decryption_security-hardening ) so NBDE is something worth a look for all those like me than were not aware of it.
## Brian Smith
Hi Mark, in my opinion one of the main advantages is Stratis is its ease of use, and that it is built on top of very stable technologies like XFS (Stratis is a control plane, not a filesystem). BRTFS has some very nice features that Stratis lacks, and I’m glad that Fedora offers different options in this area.
I think the main concern with having the keyfile unencrypted in something like the /boot filesystem is that if the encrypted disks are lost/stolen, it is likely that the disk with the /boot filesystem containing the unencrypted key was lost/stolen as well. Especially if you consider something like a laptop.
Yes, you are correct that NBDE can be used with LUKS as well. NBDE is easy to get started with and to setup, so hopefully you can give it a try.
## Mark
Thanks, you have definately inspired me, even if my focus was on luks encrypted disks.
Using it on external USB luks encrypted devices is easy after installing clevis-udisk2, but less secure. In a gnome desktop environment the visible change is instead of prompting for the luks key and mounting it tang decrypts it ok then prompts for the gnome logged on user password to bump up to authority to use the mount command for it. So anyone can take a disk from one desktop to their own and use it if they know their own password; so I guess removable media while supported is a bad idea.
Most of the tutorials on youtube show examples of clevis binding to a named server, such as your example of http://tang-server.
I assume that in most use cases clevis/tang is only used well after boot or if the server(s) is configured to get its own ip-addresses and dns server lists from a dhcp server when it boots.
At boot time for servers that have static ip-addresses configured its a bit of a mess, found the answer in redhat documentation, you have to use dracut not just to install the clevis-dracut code but to also configure your server network settings using dracut (and that overrides anything customised in /etc/sysconfig/network-scripts or networkmanager; and selinux does not like a network built by dracut at all)… but fiddling with dracut does allow luks boot disks to be unlocked by a tang server.
The doc for later viewers is https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/security_guide/sec-policy-based_decryption
So this reply is not directly related to your post on stratis but specificaly to the reply of NDBE is easy to get started with. As your post was very informative I hope it ranks high in google searches, but playing with clevis/tang/luks it is not easy so just wanted to correct that for the millions of viewers who may hit the page because comments have luks in them.
Once again thanks for the post Brian. Last week I didn’t know tang/clevis existed; now I am determined to make it work for me, although it may take a while. Nice to read a post that triggers the I must learn this response.
## Brian Smith
Hi Mark,
If it helps, here is a short video I made that covers using NBDE at boot with LUKS:
https://www.youtube.com/watch?v=y_9_iWNUBug
## Natxo
I hope you don’t mind if I chip in.
There is to my knowledge a more recent piece of official documentation for rhel8: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/security_hardening/configuring-automated-unlocking-of-encrypted-volumes-using-policy-based-decryption_security-hardening
The probably incorrect assumption for your use case is that I guess (I am not the developer, so take it with a grain of salt) clevis-udisks2 is meant for laptops. Those systems have usually just one user, so this is what one normally wants, it automatically decrypts the disk. If this is not your situation, you are very right to point this and the documentation should warn about this, and one should take measures to not let other users but the ones allowed to decrypt the disk log on to the workstation.
Dracut is …, special, yes. It’s super flexible, but it comes at a price. It’s not something most people usually require to modify. For fixed ips you can add the plugin omit_dracutmodules+=”ifcfg” to the dracut configuration, and dracut will not try to be helpful and will not overwrite your network configuration. Believe me, it can get messier if the host is multihomed and you need to boot from a specific network interface, or if you have ipv6 in the picture, or if you have several disks in the equation. If you are new to the technology I understand completely it can be overwhelming at first. You do need to be ready to fix stuff if it breaks, that is always fun (so what do you do if you tried to set up a fixed ip address, and someone messes up the dracut configuration with a typo, and the system halts during its boot process – yes, this happens)
All in all, for the simplest use case (automatically boot in single network with dhcp enabled in a wired network) it works out of the box. In other use cases, it does require some more leg work, but it is worth it if you require the luks encryption and you manage a fleet of linux hosts.
There are new things for automatically decrypting disks coming up like this one: http://0pointer.net/blog/unlocking-luks2-volumes-with-tpm2-fido2-pkcs11-security-hardware-on-systemd-248.html which could be better suited to your use case. They are not available on rhel 8 I think, maybe in fedora 34 they are. To me being able to decrypt with a yubikey is very helpful and I look forward to using it.
## Natxo
In our case we required that systems only can boot if they are in an accept list in firewalls to contact the tang servers. So if systems go to customers they cannot boot (if they are intercepted by a third party, they will not reach our tang servers, so they do not boot). This is what we required, and it’s quite easy to do. Decryption using the key in a tpm chip for instance will have a booting system everytime, even if the system has been hijacked by a third actor, we did not want this.
You can use several tang servers at the same time, and using the sss pin you can even set policies (like, you need to contact 3 of the 5 tang servers in order to decrypt the luks container).
using tang + nbde in combination with kickstarts from the foreman/satellite is really simple, you can replace the first luks key (the get out of jail card, so to speak) using automation. In practice, you only need to contact the tang server(s) during the boot process, so it really is stable (having it in production for the last three years, no problems at all).
The question is, for me, why to encrypt? but rather why not to encrypt? 😉
## Natxo
the main advantage of nbde is that it makes luks encryption easy.
Using automation we save luks keys in hashicorp vault, and rotate those (autogenerated) every now and then. Every system one different key, and a copy of the old key is archived in vault in case something goes wrong. So in fact, you just need to know how to get to hashicorp vault and set the right acls for the key/values (this is something you can easily set up and delegate).
Very happy with this solution. |
13,341 | 用 Linux 翻新旧的 MacBook | https://opensource.com/article/21/4/restore-macbook-linux | 2021-04-27T22:52:58 | [
"MacBook"
] | https://linux.cn/article-13341-1.html |
>
> 不要把你又旧又慢的 MacBook 扔进垃圾桶。用 Linux Mint 延长它的寿命。
>
>
>

去年,我写了篇关于如何用 Linux 赋予[旧 MacBook 的新生命](https://opensource.com/article/20/2/macbook-linux-elementary)的文章,在例子中提到了 Elementary OS。最近,我用回那台 2015 年左右的 MacBook Air,发现遗失了我的登录密码。我下载了最新的 Elementary OS 5.1.7 Hera,但无法让实时启动识别我的 Broadcom 4360 无线芯片组。
最近,我一直在使用 [Linux Mint](https://linuxmint.com/) 来翻新旧的笔记本电脑,我想在这台 MacBook Air 上试一下。我下载了 Linux Mint 20.1 ISO,并在我的 Linux 台式电脑上使用 [Popsicle](https://github.com/pop-os/popsicle) 创建了一个 USB 启动器。

接下来,我将 Thunderbolt 以太网适配器连接到 MacBook,并插入 USB 启动器。我打开系统电源,按下 MacBook 上的 Option 键,指示它从 USB 驱动器启动系统。
Linux Mint 在实时启动模式下启动没问题,但操作系统没有识别出无线连接。
### 我的无线网络在哪里?
这是因为为苹果设备制造 WiFi 卡的公司 Broadcom 没有发布开源驱动程序。这与英特尔、Atheros 和许多其他芯片制造商形成鲜明对比,但它是苹果公司使用的芯片组,所以这是 MacBook 上的一个常见问题。
我通过我的 Thunderbolt 适配器有线连接到以太网,因此我 *是* 在线的。通过之前的研究,我知道要让无线适配器在这台 MacBook 上工作,我需要在 Bash 终端执行三条独立的命令。然而,在安装过程中,我了解到 Linux Mint 有一个很好的内置驱动管理器,它提供了一个简单的图形用户界面来协助安装软件。

该操作完成后,我重启了安装了 Linux Mint 20.1 的新近翻新的 MacBook Air。Broadcom 无线适配器工作正常,使我能够轻松地连接到我的无线网络。
### 手动安装无线
你可以从终端完成同样的任务。首先,清除 Broadcom 内核源码的残余。
```
$ sudo apt-get purge bcmwl-kernel-source
```
然后添加一个固件安装程序:
```
$ sudo apt install firmware-b43-installer
```
最后,为系统安装新固件:
```
$ sudo apt install linux-firmware
```
### 将 Linux 作为你的 Mac 使用
我安装了 [Phoronix 测试套件](https://www.phoronix-test-suite.com/) 以获得 MacBook Air 的系统信息。

系统工作良好。对内核 5.4.0-64-generic 的最新更新显示,无线连接仍然存在,并且我与家庭网络之间的连接为 866Mbps。Broadcom 的 FaceTime 摄像头不能工作,但其他东西都能正常工作。
我非常喜欢这台 MacBook 上的 [Linux Mint Cinnamon 20.1](https://www.linuxmint.com/edition.php?id=284) 桌面。

如果你有一台因 macOS 更新而变得缓慢且无法使用的旧 MacBook,我建议你试一下 Linux Mint。我对这个发行版印象非常深刻,尤其是它在我的 MacBook Air 上的工作情况。它无疑延长了这个强大的小笔记本电脑的寿命。
---
via: <https://opensource.com/article/21/4/restore-macbook-linux>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, I wrote about how you can give [new life to an old MacBook](https://opensource.com/article/20/2/macbook-linux-elementary) with Linux, specifically Elementary OS in that instance. Recently, I returned to that circa 2015 MacBook Air and discovered I had lost my login password. I downloaded the latest Elementary OS 5.1.7 Hera release and could not get the live boot to recognize my Broadcom 4360 wireless chipset.
Lately, I have been using [Linux Mint](https://linuxmint.com/) to refurbish older laptops, and I thought I would give it a try on this MacBook Air. I downloaded the Linux Mint 20.1 ISO and created a USB boot drive using the [Popsicle](https://github.com/pop-os/popsicle) software on my Linux desktop computer.
(Don Watkins, CC BY-SA 4.0)
Next, I connected the Thunderbolt Ethernet adapter to the MacBook and inserted the USB boot drive. I powered on the system and pressed the Option key on the MacBook to instruct it to start it from a USB drive.
Linux Mint started up nicely in live-boot mode, but the operating system didn't recognize a wireless connection.
## Where's my wireless?
This is because Broadcom, the company that makes WiFi cards for Apple devices, doesn't release open source drivers. This is in contrast to Intel, Atheros, and many other chip manufacturers—but it's the chipset used by Apple, so it's a common problem on MacBooks.
I had a hard-wired Ethernet connection to the internet through my Thunderbolt adapter, so I *was* online. From prior research, I knew that to get the wireless adapter working on this MacBook, I would need to issue three separate commands in the Bash terminal. However, during the installation process, I learned that Linux Mint has a nice built-in Driver Manager that provides an easy graphical user interface to assist with installing the software.
(Don Watkins, CC BY-SA 4.0)
Once that operation completed, I rebooted and brought up my newly refurbished MacBook Air with Linux Mint 20.1 installed. The Broadcom wireless adapter was working properly, allowing me to connect to my wireless network easily.
## Installing wireless the manual way
You can accomplish the same task from a terminal. First, purge any vestige of the Broadcom kernel source:
`$ sudo apt-get purge bcmwl-kernel-source`
Then add a firmware installer:
`$ sudo apt install firmware-b43-installer`
Finally, install the new firmware for the system:
`$ sudo apt install linux-firmware`
## Using Linux as your Mac
I installed [Phoronix Test Suite](https://www.phoronix-test-suite.com/) to get a good snapshot of the MacBook Air.
(Don Watkins, CC BY-SA 4.0)
The system works very well. A recent update to kernel 5.4.0-64-generic revealed that the wireless connection survived, and I have an 866Mbps connection to my home network. The Broadcom FaceTime camera does not work, but everything else works fine.
I really like the [Linux Mint Cinnamon 20.1](https://www.linuxmint.com/edition.php?id=284) desktop on this MacBook.

(Don Watkins, CC BY-SA 4.0)
I recommend giving Linux Mint a try if you have an older MacBook that has been rendered slow and inoperable due to macOS updates. I am very impressed with the distribution, and especially how it works on my MacBook Air. It has definitely extended the life expectancy of this powerful little laptop.
## 1 Comment |
13,343 | Blanket:拥有各种环境噪音的应用,帮助保持注意力集中 | https://itsfoss.com/blanket-ambient-noise-app/ | 2021-04-29T09:48:23 | [
"噪音",
"声音",
"音乐"
] | https://linux.cn/article-13343-1.html |
>
> 一个开源的环境噪音播放器,提供各种声音,帮助你集中注意力或入睡。
>
>
>

随着你周围活动的增加,要保持冷静和专注往往是很困难的。
有时,音乐会有所帮助,但在某些情况下也会分散注意力。但是,环境噪音如何?这总是让人听起来很舒心。谁不想在餐厅里听到鸟叫声、雨滴声和人群的交谈声?好吧,可能不是最后一个,但听自然的声音可以帮助放松和集中注意力。这间接地提高了你的工作效率。
最近,我发现了一个专门的播放器,其中包含了不同的声音,可以帮助任何人集中注意力。
### 使用 Blanket 播放不同的环境声音
Blanket 是一个令人印象深刻的环境噪音播放器,它具有不同的声音,可以帮助你入睡或只是通过帮助你忘记周围的干扰来重获注意力。
它包括自然界的声音,像雨声、海浪声、鸟鸣声、风暴声、风声、水流声、夏夜声。

此外,如果你是一个通勤者或在轻微繁忙的环境中感到舒适的人,你可以找到火车、船、城市、咖啡馆或壁炉的声音。
如果你喜欢白噪声或粉红噪声,它结合了人类能听到的所有声音频率,这里也可以找到。
它还可以让你在每次开机时自动启动,如果你喜欢这样的话。

### 在 Linux 上安装 Blanket
安装 Blanket 的最好方法是来自 [Flathub](https://flathub.org/apps/details/com.rafaelmardojai.Blanket)。考虑到你已经启用了 [Flatpak](https://itsfoss.com/what-is-flatpak/),你只需在终端键入以下命令就可以安装它:
```
flatpak install flathub com.rafaelmardojai.Blanket
```
如果你是 Flatpak 的新手,你可能想通过我们的 [Flatpak 指南](https://itsfoss.com/flatpak-guide/)了解。
如果你不喜欢使用 Flatpak,你可以使用该项目中的贡献者维护的 PPA 来安装它。对于 Arch Linux 用户,你可以在 [AUR](https://itsfoss.com/aur-arch-linux/) 中找到它,以方便安装。
此外,你还可以找到 Fedora 和 openSUSE 的软件包。要探索所有现成的软件包,你可以前往其 [GitHub 页面](https://github.com/rafaelmardojai/blanket)。
### 结束语
对于一个简单的环境噪音播放器来说,用户体验是相当好的。我有一副 HyperX Alpha S 耳机,我必须要说,声音的质量很好。
换句话说,它听起来很舒缓,如果你想体验环境声音来集中注意力,摆脱焦虑或只是睡着,我建议你试试。
你试过它了吗?欢迎在下面分享你的想法。
---
via: <https://itsfoss.com/blanket-ambient-noise-app/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief: An open-source ambient noise player offering a variety of sounds to help you focus or fall asleep.**
With the increase in the number of activities around you, it is often tough to keep calm and stay focused.
Sometimes music helps, but it also distracts in some cases. But, ambient noise? That is always soothing to hear. Who doesn’t want to hear birds chirping, rain falling and crowd chattering in a restaurant? Okay, may be not the last one but listening to natural sound could help in relaxing and focusing. This indirectly boots your productivity.
Recently, I came across a dedicated player which includes different sounds that could help anyone focus.
## Play Different Ambient Sounds Using Blanket
Blanket is an impressive ambient noise player that features different sounds that can help you fall asleep or just regain focus by helping you forget about the surrounding distractions.
It includes nature sounds like rain, waves, birds chirping, storm, wind, water stream, and summer night.
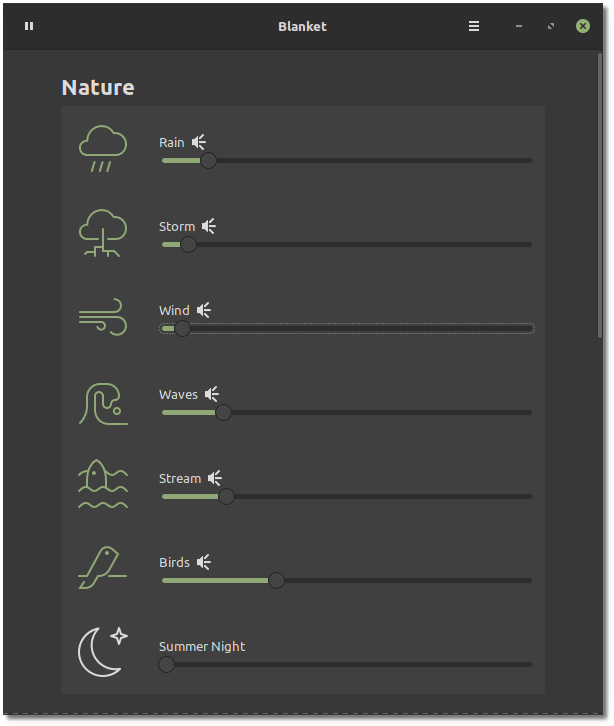
Also, if you are a commuter or someone comfortable in a mildly busy environment, you can find sounds for trains, boat, city, coffee shop, or a fireplace.
If you are fond of white noise or pink noise, which combines all sound frequencies that humans can hear, that is available here too.
It also lets you autostart every time you boot, if that is what you prefer.
## Install Blanket on Linux
The best way to install Blanket is from [Flathub](https://flathub.org/apps/details/com.rafaelmardojai.Blanket). Considering that you have [Flatpak](https://itsfoss.com/what-is-flatpak/) enabled, all you have to type in the terminal to install it is:
`flatpak install flathub com.rafaelmardojai.Blanket`
In case you’re new to Flatpak, you might want to go through our [Flatpak guide](https://itsfoss.com/flatpak-guide/).
If you do not prefer using Flatpaks, you can install it using a PPA maintained by a contributor in the project. For Arch Linux users, you can find it in [AUR](https://itsfoss.com/aur-arch-linux/) to easily install it.
In addition, you can also find packages for Fedora and openSUSE. To explore all the available packages, you can head to its [GitHub page](https://github.com/rafaelmardojai/blanket).
**Recommended Read:**
## Closing Thoughts
The user experience for a simple ambient noise player is pretty good. I have a pair of HyperX Alpha S headphones and I must mention that the quality of the sounds is good to hear.
In other words, it is soothing to hear, and I will recommend you to try it out if you wanted to experience Ambient sounds to focus, get rid of your anxiety or just fall asleep.
Have you tried it yet? Feel free to share your thoughts below. |
13,344 | 我最喜欢的开源项目管理工具 | https://opensource.com/article/21/3/open-source-project-management | 2021-04-29T15:00:21 | [
"项目管理",
"项目",
"甘特图"
] | https://linux.cn/article-13344-1.html |
>
> 如果你要管理大型复杂的项目,请尝试利用开源选择替换 MS-Project。
>
>
>

诸如建造卫星、开发机器人或推出新产品之类的项目都是昂贵的,涉及不同的提供商,并且包含必须跟踪的硬依赖性。
大型项目领域中的项目管理方法非常简单(至少在理论上如此)。你可以创建项目计划并将其拆分为较小的部分,直到你可以合理地将成本、持续时间、资源和依赖性分配给各种活动。一旦项目计划获得负责人的批准,你就可以使用它来跟踪项目的执行情况。在时间轴上绘制项目的所有活动将产生一个称为<ruby> <a href="https://en.wikipedia.org/wiki/Gantt_chart"> 甘特图 </a> <rt> Gantt chart </rt></ruby>的条形图。
甘特图一直被用于 [瀑布项目方法](https://opensource.com/article/20/3/agiles-vs-waterfall),也可以用于敏捷方法。例如,大型项目可能将甘特图用于 Scrum 冲刺,而忽略其他像用户需求这样的细节,从而嵌入敏捷阶段。其他大型项目可能包括多个产品版本(例如,最低可行产品 [MVP]、第二版本、第三版本等)。在这种情况下,上层结构是一种敏捷方法,而每个阶段都计划为甘特图,以处理预算和复杂的依赖关系。
### 项目管理工具
不夸张地说,有数百种现成的工具使用甘特图管理大型项目,而 MS-Project 可能是最受欢迎的工具。它是微软办公软件家族的一部分,可支持到成千上万的活动,并且有大量的功能,支持几乎所有可以想象到的管理项目进度的方式。对于 MS-Project,有时候你并不知道什么更昂贵:是软件许可证还是该工具的培训课程。
另一个缺点是 MS-Project 是一个独立的桌面应用程序,只有一个人可以更新进度表。如果要多个用户进行协作,则需要购买微软 Project 服务器、Web 版的 Project 或 Planner 的许可证。
幸运的是,专有工具还有开源的替代品,包括本文中提及的应用程序。所有这些都是开源的,并且包括基于资源和依赖项的分层活动调度的甘特图。ProjectLibre、GanttProject 和 TaskJuggler 都针对单个项目经理的桌面应用程序。ProjeQtOr 和 Redmine 是用于项目团队的 Web 应用程序,而 ]project-open[ 是用于管理整个组织的 Web 应用程序。
我根据一个单用户计划和对一个大型项目的跟踪评估了这些工具。我的评估标准包括甘特图编辑器功能、Windows/Linux/macOS 上的可用性、可扩展性、导入/导出和报告。(背景披露:我是 ]project-open[ 的创始人,我在多个开源社区中活跃了很多年。此列表包括我们的产品,因此我的观点可能有偏见,但我尝试着眼于每个产品的最佳功能。)
### Redmine 4.1.0

[Redmine](https://www.redmine.org/) 是一个基于 Web 的专注于敏捷方法论的项目管理工具。
其标准安装包括一个甘特图时间轴视图,但缺少诸如调度、拖放、缩进(缩排和凸排)以及资源分配之类的基本功能。你必须单独编辑任务属性才能更改任务树的结构。
Redmine 具有甘特图编辑器插件,但是它们要么已经过时(例如 [Plus Gantt](https://redmine.org/plugins/plus_gantt)),要么是专有的(例如 [ANKO 甘特图](https://www.redmine.org/plugins/anko_gantt_chart))。如果你知道其他开源的甘特图编辑器插件,请在评论中分享它们。
Redmine 用 Ruby on Rails 框架编写,可用于 Windows、Linux 和 macOS。其核心部分采用 GPLv2 许可证。
* **适合于:** 使用敏捷方法的 IT 团队。
* **独特卖点:** 这是 OpenProject 和 EasyRedmine 的原始“上游”父项目。
### ]project-open[ 5.1
![]project-open[](/data/attachment/album/202104/29/150024ajim3fma2loniapb.png "]project-open[")
[]project-open[](https://www.project-open.com) 是一个基于 Web 的项目管理系统,从整个组织的角度看类似于<ruby> 企业资源计划 <rt> enterprise resource planning </rt></ruby>(ERP)系统。它还可以管理项目档案、预算、发票、销售、人力资源和其他功能领域。有一些不同的变体,如用于管理项目公司的<ruby> 专业服务自动化 <rt> professional services automation </rt></ruby>(PSA)、用于管理企业战略项目的<ruby> 项目管理办公室 <rt> project management office </rt></ruby>(PMO)和用于管理部门项目的<ruby> 企业项目管理 <rt> enterprise project management </rt></ruby>(EPM)。
]project-open[ 甘特图编辑器包括按等级划分的任务、依赖关系和基于计划工作和分配资源的调度。它不支持资源日历和非人力资源。]project-open[ 系统非常复杂,其 GUI 可能需要刷新。
]project-open[ 是用 TCL 和 JavaScript 编写的,可用于 Windows 和 Linux。 ]project-open[ 核心采用 GPLv2 许可证,并具有适用于大公司的专有扩展。
* **适合于:** 需要大量财务项目报告的大中型项目组织。
* **独特卖点:** ]project-open[ 是一个综合系统,可以运行整个项目公司或部门。
### ProjectLibre 1.9.3

在开源世界中,[ProjectLibre](http://www.projectlibre.org) 可能是最接近 MS-Project 的产品。它是一个桌面应用程序,支持所有重要的项目计划功能,包括资源日历、基线和成本管理。它还允许你使用 MS-Project 的文件格式导入和导出计划。
ProjectLibre 非常适合计划和执行中小型项目。然而,它缺少 MS-Project 中的一些高级功能,并且它的 GUI 并不是最漂亮的。
ProjectLibre 用 Java 编写,可用于 Windows、Linux 和macOS,并在开源的<ruby> 通用公共署名许可证 <rt> Common Public Attribution License </rt></ruby>(CPAL)下授权。ProjectLibre 团队目前正在开发一个名为 ProjectLibre Cloud 的 Web 产品,并采用专有许可证。
* **适合于:** 负责中小型项目的个人项目管理者,或者作为没有完整的 MS-Project 许可证的项目成员的查看器。
* **独特卖点:** 这是最接近 MS-Project 的开源软件。
### GanttProject 2.8.11

[GanttProject](https://www.ganttproject.biz) 与 ProjectLibre 类似,它是一个桌面甘特图编辑器,但功能集更为有限。它不支持基线,也不支持非人力资源,并且报告功能比较有限。
GanttProject 是一个用 Java 编写的桌面应用程序,可在 GPLv3 许可下用于 Windows、Linux 和 macOS。
* **适合于:** 简单的甘特图或学习基于甘特图的项目管理技术。
* **独特卖点:** 它支持<ruby> 流程评估和审阅技术 <rt> program evaluation and review technique </rt></ruby>([PERT](https://en.wikipedia.org/wiki/Program_evaluation_and_review_technique))图表,并使用 WebDAV 的协作。
### TaskJuggler 3.7.1

[TaskJuggler](https://taskjuggler.org/) 用于在大型组织中安排多个并行项目,重点是自动解决资源分配冲突(即资源均衡)。
它不是交互式的甘特图编辑器,而是一个命令行工具,其工作方式类似于一个编译器:它从文本文件中读取任务列表,并生成一系列报告,这些报告根据分配的资源、依赖项、优先级和许多其他参数为每个任务提供最佳的开始和结束时间。它支持多个项目、基线、资源日历、班次和时区,并且被设计为可扩展到具有许多项目和资源的企业场景。
使用特定语法编写 TaskJuggler 输入文件可能超出了普通项目经理的能力。但是,你可以使用 ]project-open[ 作为 TaskJuggler 的图形前端来生成输入,包括缺勤、任务进度和记录的工作时间。当以这种方式使用时,TaskJuggler 就成为了功能强大的假设情景规划器。
TaskJuggler 用 Ruby 编写,并且在 GPLv2 许可证下可用于 Windows、Linux 和 macOS。
* **适合于:** 由真正的技术极客管理的中大型部门。
* **独特卖点:** 它在自动资源均衡方面表现出色。
### ProjeQtOr 9.0.4

[ProjeQtOr](https://www.projeqtor.org) 是适用于 IT 项目的、基于 Web 的项目管理应用程序。除了项目、工单和活动外,它还支持风险、预算、可交付成果和财务文件,以将项目管理的许多方面集成到单个系统中。
ProjeQtOr 提供了一个甘特图编辑器,与 ProjectLibre 功能类似,包括按等级划分的任务、依赖关系以及基于计划工作和分配资源。但是,它不支持取值的就地编辑(例如,任务名称、估计时间等);用户必须在甘特图视图下方的输入表单中更改取值,然后保存。
ProjeQtOr 用 PHP 编写,并且在 Affero GPL3 许可下可用于 Windows、Linux 和 macOS。
* **适合于:** 跟踪项目列表的 IT 部门。
* **独特卖点:** 让你为存储每个项目的大量信息,将所有信息保存在一个地方。
### 其他工具
对于特定的用例,以下系统可能是有效的选择,但由于各种原因,它们被排除在主列表之外。

* [LibrePlan](https://www.libreplan.dev/) 是一个基于 Web 的项目管理应用程序,专注于甘特图。由于其功能集,它本来会在上面的列表中会占主导地位,但是没有可用于最新 Linux 版本(CentOS 7 或 8)的安装。作者说,更新的说明将很快推出。
* [dotProject](https://dotproject.net/) 是一个用 PHP 编写的基于 Web 的项目管理系统,可在 GPLv2.x 许可证下使用。它包含一个甘特图时间轴报告,但是没有编辑它的选项,并且依赖项还不起作用(它们“仅部分起作用”)。
* [Leantime](https://leantime.io) 是一个基于 Web 的项目管理系统,具有漂亮的用 PHP 编写的 GUI,并且可以在 GPLv2 许可证下使用。它包括一个里程碑的甘特时间线,但没有依赖性。
* [Orangescrum](https://orangescrum.org/) 是基于 Web 的项目管理工具。甘特图图可以作为付费附件或付费订阅使用。
* [Talaia/OpenPPM](http://en.talaia-openppm.com/) 是一个基于 Web 的项目组合管理系统。但是,版本 4.6.1 仍显示“即将推出:交互式甘特图”。
* [Odoo](https://odoo.com) 和 [OpenProject](http://openproject.org) 都将某些重要功能限制在付费企业版中。
在这篇评论中,目的是包括所有带有甘特图编辑器和依赖调度的开源项目管理系统。如果我错过了一个项目或误导了什么,请在评论中让我知道。
---
via: <https://opensource.com/article/21/3/open-source-project-management>
作者:[Frank Bergmann](https://opensource.com/users/fraber) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Projects like building a satellite, developing a robot, or launching a new product are all expensive, involve different providers, and contain hard dependencies that must be tracked.
The approach to project management in the world of large projects is quite simple (in theory at least). You create a project plan and split it into smaller pieces until you can reasonably assign costs, duration, resources, and dependencies to the various activities. Once the project plan is approved by the people in charge of the money, you use it to track the project's execution. Drawing all of the project's activities on a timeline produces a bar chart called a [Gantt chart](https://en.wikipedia.org/wiki/Gantt_chart).
Gantt charts have always been used in [waterfall project methodologies](https://opensource.com/article/20/3/agiles-vs-waterfall), but they can also be used with agile. For example, large projects may use a Gantt chart for a scrum sprint and ignore other details like user stories, thereby embedding agile phases. Other large projects may include multiple product releases (e.g., minimum viable product [MVP], second version, third version, etc.). In this case, the super-structure is kind of agile, with each phase planned as a Gantt chart to deal with budgets and complex dependencies.
## Project management tools
There are literally hundreds of tools available to manage large projects with Gantt charts, and Microsoft Project is probably the most popular. It is part of the Microsoft Office family, scales to hundreds of thousands of activities, and has an incredible number of features that support almost every conceivable way to manage a project schedule. With Project, it's not always clear what is more expensive: the software license or the training courses that teach you how to use the tool.
Another drawback is that Microsoft Project is a standalone desktop application, and only one person can update a schedule. You would need to buy licenses for Microsoft Project Server, Project for the web, or Microsoft Planner if you want multiple users to collaborate.
Fortunately, there are open source alternatives to the proprietary tools, including the applications in this article. All are open source and include a Gantt for scheduling hierarchical activities based on resources and dependencies. ProjectLibre, GanttProject, and TaskJuggler are desktop applications for a single project manager; ProjeQtOr and Redmine are web applications for project teams, and ]project-open[ is a web application for managing entire organizations.
I evaluated the tools based on a single user planning and tracking a single large project. My evaluation criteria includes Gantt editor features, availability on Windows, Linux, and macOS, scalability, import/export, and reporting. (Full disclosure: I'm the founder of ]project-open[, and I've been active in several open source communities for many years. This list includes our product, so my views may be biased, but I tried to focus on each product's best features.)
## Redmine 4.1.0
(Frank Bergmann, CC BY-SA 4.0)
[Redmine](https://www.redmine.org/) is a web-based project management tool with a focus on agile methodologies.
The standard installation includes a Gantt timeline view, but it lacks fundamental features like scheduling, drag-and-drop, indent and outdent, and resource assignments. You have to edit task properties individually to change the task tree's structure.
Redmine has Gantt editor plugins, but they are either outdated (e.g., [Plus Gantt](https://redmine.org/plugins/plus_gantt)) or proprietary (e.g., [ANKO Gantt chart](https://www.redmine.org/plugins/anko_gantt_chart)). If you know of other open source Gantt editor plugins, please share them in the comments.
Redmine is written in Ruby on Rails and available for Windows, Linux, and macOS. The core is available under a GPLv2 license.
**Best for:**IT teams working using agile methodologies**Unique selling proposition:**It's the original "upstream" parent project of OpenProject and EasyRedmine.
## ]project-open[ 5.1
![]project-open[ ]project-open[](https://opensource.com/sites/default/files/uploads/project-open.png)
(Frank Bergmann, CC BY-SA 4.0)
[]project-open[](https://www.project-open.com) is a web-based project management system that takes the perspective of an entire organization, similar to an enterprise resource planning (ERP) system. It can also manage project portfolios, budgets, invoicing, sales, human resources, and other functional areas. Specific variants exist for professional services automation (PSA) for running a project company, project management office (PMO) for managing an enterprise's strategic projects, and enterprise project management (EPM) for managing a department's projects.
The ]po[ Gantt editor includes hierarchical tasks, dependencies, and scheduling based on planned work and assigned resources. It does not support resource calendars and non-human resources. The ]po[ system is quite complex, and the GUI might need a refresh.
]project-open[ is written in TCL and JavaScript and available for Windows and Linux. The ]po[ core is available under a GPLv2 license with proprietary extensions available for large companies.
**Best for:**Medium to large project organizations that need a lot of financial project reporting**Unique selling proposition:**]po[ is an integrated system to run an entire project company or department.
## ProjectLibre 1.9.3
(Frank Bergmann, CC BY-SA 4.0)
[ProjectLibre](http://www.projectlibre.org) is probably the closest you can get to Microsoft Project in the open source world. It is a desktop application that supports all-important project planning features, including resource calendars, baselines, and cost management. It also allows you to import and export schedules using MS-Project's file format.
ProjectLibre is perfectly suitable for planning and executing small or midsized projects. However, it's missing some advanced features in MS-Project, and its GUI is not the prettiest.
ProjectLibre is written in Java and available for Windows, Linux, and macOS and licensed under an open source Common Public Attribution (CPAL) license. The ProjectLibre team is currently working on a Web offering called ProjectLibre Cloud under a proprietary license.
**Best for:**An individual project manager running small to midsized projects or as a viewer for project members who don't have a full MS-Project license**Unique selling proposition:**It's the closest you can get to MS-Project with open source.
## GanttProject 2.8.11
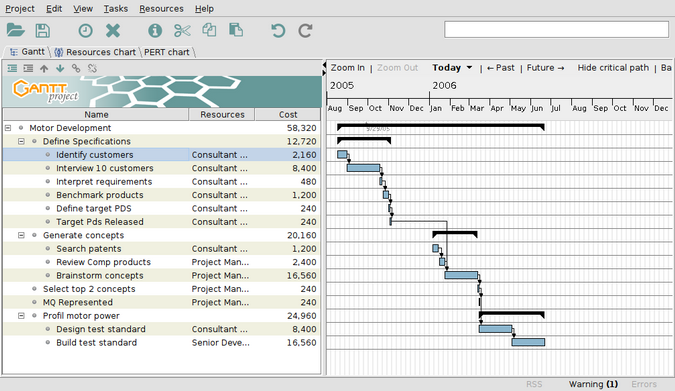
(Frank Bergmann, CC BY-SA 4.0)
[GanttProject](https://www.ganttproject.biz) is similar to ProjectLibre as a desktop Gantt editor but with a more limited feature set. It doesn't support baselines nor non-human resources, and the reporting functionality is more limited.
GanttProject is a desktop application written in Java and available for Windows, Linux, and macOS under the GPLv3 license.
**Best for:**Simple Gantt charts or learning Gantt-based project management techniques.**Unique selling proposition:**It supports program evaluation and review technique ([PERT](https://en.wikipedia.org/wiki/Program_evaluation_and_review_technique)) charts and collaboration using WebDAV.
## TaskJuggler 3.7.1
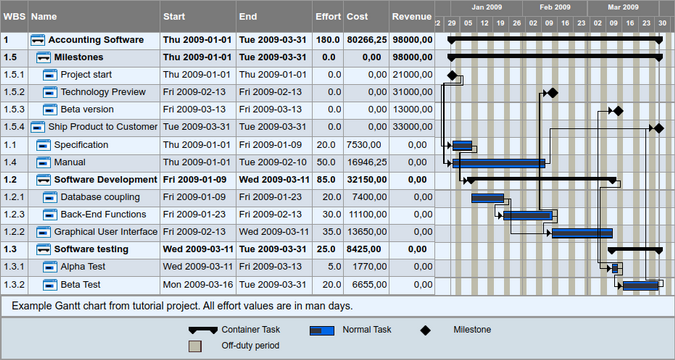
(Frank Bergmann, CC BY-SA 4.0)
[TaskJuggler](https://taskjuggler.org/) schedules multiple parallel projects in large organizations, focusing on automatically resolving resource assignment conflicts (i.e., resource leveling).
It is not an interactive Gantt editor but a command-line tool that works similarly to a compiler: It reads a list of tasks from a text file and produces a series of reports with the optimum start and end times for each task depending on the assigned resources, dependencies, priorities, and many other parameters. It supports multiple projects, baselines, resource calendars, shifts, and time zones and has been designed to scale to enterprise scenarios with many projects and resources.
Writing a TaskJuggler input file with its specific syntax may be beyond the average project manager's capabilities. However, you can use ]project-open[ as a graphical frontend for TaskJuggler to generate input, including absences, task progress, and logged hours. When used this way, TaskJuggler becomes a powerful what-if scenario planner.
TaskJuggler is written in Ruby and available for Windows, Linux, and macOS under a GPLv2 license.
**Best for:**Medium to large departments managed by a true nerd**Unique selling proposition:**It excels in automatic resource-leveling.
## ProjeQtOr 9.0.4
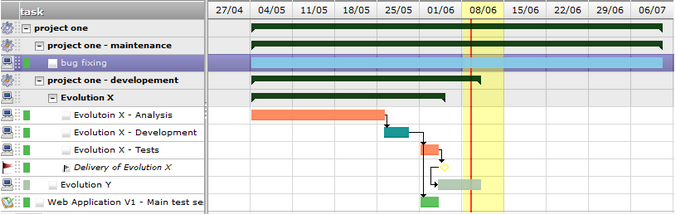
(Frank Bergmann, CC BY-SA 4.0)
[ProjeQtOr](https://www.projeqtor.org) is a web-based project management application that's suitable for IT projects. It supports risks, budgets, deliverables, and financial documents in addition to projects, tickets, and activities to integrate many aspects of project management into a single system.
ProjeQtOr provides a Gantt editor with a feature set similar to ProjectLibre, including hierarchical tasks, dependencies, and scheduling based on planned work and assigned resources. However, it doesn't support in-place editing of values (e.g., task name, estimated time, etc.); users must change values in an entry form below the Gantt view and save the values.
ProjeQtOr is written in PHP and available for Windows, Linux, and macOS under the Affero GPL3 license.
**Best for:**IT departments tracking a list of projects**Unique selling proposition:**Lets you store a wealth of information for every project, keeping all information in one place.
## Other tools
The following systems may be valid options for specific use cases but were excluded from the main list for various reasons.
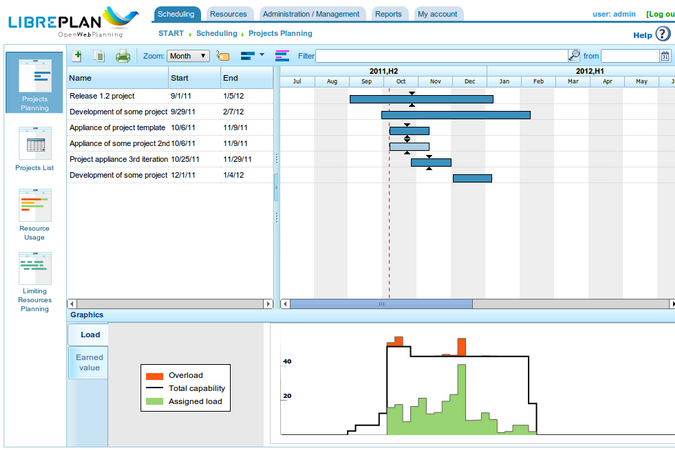
(Frank Bergmann, CC BY-SA 4.0)
is a web-based project management application focusing on Gantt charts. It would have figured prominently in the list above due to its feature set, but there is no installation available for recent Linux versions (CentOS 7 or 8). The authors say updated instructions will be available soon.**LibrePlan**is a web-based project management system written in PHP and available under the GPLv2.x license. It includes a Gantt timeline report, but it doesn't have options to edit it, and dependencies don't work yet (they're "only partially functional").**dotProject**is a web-based project management system with a pretty GUI written in PHP and available under the GPLv2 license. It includes a Gantt timeline for milestones but without dependencies.**Leantime**is a web-based project-management tool. Gantt charts are available as a paid add-on or with a paid subscription.**Orangescrum**is a web-based project portfolio management system. However, version 4.6.1 still says "Coming Soon: Interactive Gantt Charts."**Talaia/OpenPPM**and**Odoo**both restrict some important features to the paid enterprise edition.**OpenProject**
In this review, I aimed to include all open source project management systems that include a Gantt editor with dependency scheduling. If I missed a project or misrepresented something, please let me know in the comments.
## 3 Comments |
13,346 | 如何在 Linux 中删除分区 | https://itsfoss.com/delete-partition-linux/ | 2021-04-30T09:54:32 | [
"分区",
"磁盘"
] | https://linux.cn/article-13346-1.html | 
管理分区是一件严肃的事情,尤其是当你不得不删除它们时。我发现自己经常这样做,特别是在使用 U 盘作为实时磁盘和 Linux 安装程序之后,因为它们创建了几个我以后不需要的分区。
在本教程中,我将告诉你如何使用命令行和 GUI 工具在 Linux 中删除分区。
>
> 警告!
>
>
> 删除了分区,就会失去你的数据。无论何时,当你在操作分区时,一定要备份你的数据。一个轻微的打字错误或手滑都可能是昂贵的。不要说我们没有警告你!
>
>
>
### 使用 GParted 删除磁盘分区 (GUI 方法)
作为一个桌面 Linux 用户,你可能会对基于 GUI 的工具感到更舒服,也许更安全。
有 [几个让你在 Linux 上管理分区的工具](https://itsfoss.com/partition-managers-linux/)。根据你的发行版,你的系统上已经安装了一个甚至多个这样的工具。
在本教程中,我将使用 [GParted](https://gparted.org/index.php)。它是一个流行的开源工具,使用起来非常简单和直观。
第一步是 [安装 GParted](https://itsfoss.com/gparted/),如果它还没有在你的系统中。你应该能够在你的发行版的软件中心找到它。

或者,你也可以使用你的发行版的软件包管理器来安装它。在基于 Debian 和 Ubuntu 的 Linux 发行版中,你可以 [使用 apt install 命令](https://itsfoss.com/apt-command-guide/):
```
sudo apt install gparted
```
安装完毕后,让我们打开 **GParted**。由于你正在处理磁盘分区,你需要有 root 权限。它将要求进行认证,打开后,你应该看到一个类似这样的窗口:

在右上角,你可以选择磁盘,在下面选择你想删除的分区。
接下来,从分区菜单中选择 “删除” 选项:

这个过程是没有完整完成的,直到你重写分区表。这是一项安全措施,它让你在确认之前可以选择审查更改。
要完成它,只需点击位于工具栏中的 “应用所有操作” 按钮,然后在要求确认时点击 “应用”。

点击 “应用” 后,你会看到一个进度条和一个结果消息说所有的操作都成功了。你可以关闭该信息和主窗口,并认为你的分区已从磁盘中完全删除。
现在你已经知道了 GUI 的方法,让我们继续使用命令行。
### 使用 fdisk 命令删除分区(CLI 方法)
几乎每个 Linux 发行版都默认带有 [fdisk](https://man7.org/linux/man-pages/man8/fdisk.8.html),我们今天就来使用这个工具。你需要知道的第一件事是,你想删除的分区被分配到哪个设备上了。为此,在终端输入以下内容:
```
sudo fdisk --list
```
这将打印出我们系统中所有的驱动器和分区,以及分配的设备。你 [需要有 root 权限](https://itsfoss.com/root-user-ubuntu/),以便让它发挥作用。
在本例中,我将使用一个包含两个分区的 USB 驱动器,如下图所示:

系统中分配的设备是 `/sdb`,它有两个分区:`sdb1` 和 `sdb2`。现在你已经确定了哪个设备包含这些分区,你可以通过使用 `fdisk` 和设备的路径开始操作:
```
sudo fdisk /dev/sdb
```
这将在命令模式下启动 `fdisk`。你可以随时按 `m` 来查看选项列表。
接下来,输入 `p`,然后按回车查看分区信息,并确认你正在使用正确的设备。如果使用了错误的设备,你可以使用 `q` 命令退出 `fdisk` 并重新开始。
现在输入 `d` 来删除一个分区,它将立即询问分区编号,这与 “Device” 列中列出的编号相对应,在这个例子中是 1 和 2(在下面的截图中可以看到),但是可以也会根据当前的分区表而有所不同。

让我们通过输入 `2` 并按下回车来删除第二个分区。你应该看到一条信息:**“Partition 2 has been deleted”**,但实际上,它还没有被删除。`fdisk` 还需要一个步骤来重写分区表并应用这些变化。你看,这就是完全网。
你需要输入 `w`,然后按回车来使这些改变成为永久性的。没有再要求确认。
在这之后,你应该看到下面这样的反馈:

现在,使用 `sudo fdisk --list /dev/sdb` 查看该设备的当前分区表,你可以看到第二个分区已经完全消失。你已经完成了使用终端和 `fdisk` 命令来删除你的分区。成功了!
#### 总结
这样,这个关于如何使用终端和 GUI 工具在 Linux 中删除分区的教程就结束了。记住,要始终保持安全,在操作分区之前备份你的文件,并仔细检查你是否使用了正确的设备。删除一个分区将删除其中的所有内容,而几乎没有 [恢复](https://itsfoss.com/recover-deleted-files-linux/) 的机会。
---
via: <https://itsfoss.com/delete-partition-linux/>
作者:[Chris Patrick Carias Stas](https://itsfoss.com/author/chris/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Managing partitions is serious business, especially when you have to remove them. I find myself doing this frequently, especially after using thumb drives as live disks and Linux installers because they create several partitions that I won’t need afterwards.
In this tutorial, I will show you how to remove partitions in Linux using both command line and GUI tools.
Warning!
You delete the partition, you lose your data. Whenever you are playing with partitions, make sure backup your data. A slight typo or slip of finger could prove costly. Don’t say we didn’t warn you!
## Remove disk partition using GParted [GUI Method]
As a desktop Linux user, you probably will be more comfortable and perhaps safer with a GUI-based tool.
There are [several tools that let you manage partitions on Linux](https://itsfoss.com/partition-managers-linux/). Depending on your distribution you will have one or even more such tool already installed on your system.
For this tutorial, I am going to use [GParted](https://gparted.org/index.php). It is a popular open source tool and it’s very easy and intuitive to use.
The first step is [installing GParted](https://itsfoss.com/gparted/) if it isn’t already in your system. You should be able to find it in the software center of your distribution.
Alternatively, you can use your distribution’s package manager for installing it. In Debian and Ubuntu-based Linux distributions, you can [use the apt install command](https://itsfoss.com/apt-command-guide/):
`sudo apt install gparted`
Once installed, let’s open **GParted**. Since you are dealing with disk partitions, you’ll be required to have root access. It will ask for authentication and once it opens you should see a window like this one:
On the right-upper corner you can select the disk and in the lower screen the partition you want to remove.
Next, select the option **Delete** from the Partition menu:
The process is incomplete until you rewrite the partition table. This is a safety measure and it gives you the option to review the changes before confirming it.
To do this just click on the **Apply All Operations **button located in the toolbar and then **Apply** when asked for confirmation.
After hitting **Apply**, you will see a progress bar and a results message saying that all the operations were successful. You can close the message and the main window and consider your partition completely deleted from our disk.
Now that you are aware of the GUI method, let’s move on to the command line.
## Delete partitions using fdisk command
Almost every Linux distribution comes with [fdisk](https://man7.org/linux/man-pages/man8/fdisk.8.html) by default and we are going to use this tool today. The first thing you need to know is what device is assigned to the disk with the partitions you want to remove. To do that, type the following in the terminal:
`sudo fdisk --list`
This will print all the drives and partitions in our system as well as the assigned devices. You [need to have root access](https://itsfoss.com/root-user-ubuntu/) in order for it work.
In this example, I will work with a USB drive that contains two partitions as shown below:
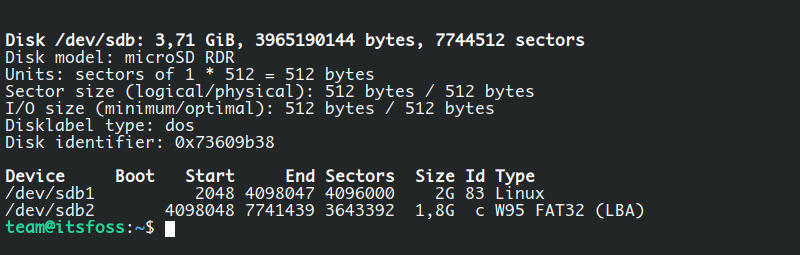
The device assigned in the system is /sdb and it has two partitions, sdb1 and sdb2. Now that you identified which device contains the partitions, you can start working on it by using `fdisk`
and the path to the device:
`sudo fdisk /dev/sdb`
This will start `fdisk`
in command mode. You can always press `m`
to see a list of options.
Next, type `p`
and press `Enter`
to view the partition information and confirm that you are using the right device. If the wrong device is in use you can use the `q`
command to exit `fdisk`
and start the procedure again.
Now enter `d`
to delete a partition and it will immediately ask for the partition number, that corresponds to the number listed in the Device column, which in this case are numbers 1 and 2 (as can be seen in the screen capture below) but can and will vary according to the current partition table.
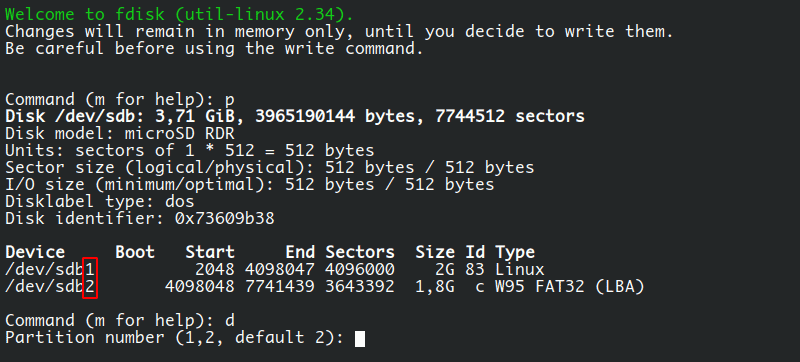
Let’s remove the second partition by typing `2`
and pressing `Enter`
. You should see a message saying **“Partition 2 has been deleted**“, but actually, it hasn’t been removed yet. `fdisk`
needs one more step to rewrite the partition table and apply the changes. Safety net, you see.
You need to type `w`
and press `Enter`
to make the changes permanent. No confirmation is asked.
After this, you should receive some feedback like the one here:

Now, use `sudo fdisk --list /dev/sdb`
to view the current partition table of the device and you can see that the second partition is completely gone. You are done removing your partition using the terminal and `fdisk`
command. Success!
### Wrapping up
And so I end this tutorial on how to remove partitions in Linux using both the terminal and GUI tools. Remember, stay always on the safe side, backup your files before manipulating your partitions and double check that you are using the right device. Deleting a partition will delete everything in it with little to no chance of [recovering](https://itsfoss.com/recover-deleted-files-linux/) it. |
13,347 | 使用 Linux 自动化工具提高生产率 | https://opensource.com/article/21/2/linux-autokey | 2021-04-30T11:12:00 | [
"键盘",
"自动化"
] | https://linux.cn/article-13347-1.html |
>
> 用 AutoKey 配置你的键盘,纠正常见的错别字,输入常用的短语等等。
>
>
>

[AutoKey](https://github.com/autokey/autokey) 是一个开源的 Linux 桌面自动化工具,一旦它成为你工作流程的一部分,你就会想,如何没有它,那该怎么办。它可以成为一种提高生产率的变革性工具,或者仅仅是减少与打字有关的身体压力的一种方式。
本文将研究如何安装和开始使用 AutoKey ,介绍一些可以立即在工作流程中使用的简单方法,并探讨 AutoKey 高级用户可能会感兴趣的一些高级功能。
### 安装并设置 AutoKey
AutoKey 在许多 Linux 发行版中都是现成的软件包。该项目的 [安装指南](https://github.com/autokey/autokey/wiki/Installing) 包含许多平台的说明,也包括了从源代码进行构建的指导。本文使用 Fedora 作为操作平台。
AutoKey 有两个变体:为像 GNOME 等基于 [GTK](https://www.gtk.org/) 环境而设计的 autokey-gtk 和基于 [QT](https://www.qt.io/) 的 autokey-qt。
你可以从命令行安装任一变体:
```
sudo dnf install autokey-gtk
```
安装完成后,使用 `autokey-gtk`(或 `autokey-qt`)运行它。
### 探究界面
在将 AutoKey 设置为在后台运行并自动执行操作之前,你首先需要对其进行配置。调出用户界面(UI)配置:
```
autokey-gtk -c
```
AutoKey 提供了一些预设配置的示例。你可能希望在熟悉 UI 时将他们留作备用,但是可以根据需要删除它们。

左侧窗格包含一个文件夹式的短语和脚本的层次结构。“<ruby> 短语 <rt> Phrases </rt></ruby>” 代表要让 AutoKey 输入的文本。“<ruby> 脚本 <rt> Scripts </rt></ruby>” 是动态的、程序化的等效项,可以使用 Python 编写,并且获得与键盘击键发送到活动窗口基本相同的结果。
右侧窗格构建和配置短语和脚本。
对配置满意后,你可能希望在登录时自动运行 AutoKey,这样就不必每次都启动它。你可以通过在 “<ruby> 首选项 <rt> Preferences </rt></ruby>”菜单(“<ruby> 编辑 -> 首选项 <rt> Edit -> Preferences” </rt></ruby>”)中勾选 “<ruby> 登录时自动启动 AutoKey <rt> Automatically start AutoKey at login </rt></ruby>”进行配置。

### 使用 AutoKey 纠正常见的打字排版错误
修复常见的打字排版错误对于 AutoKey 来说是一个容易解决的问题。例如,我始终键入 “gerp” 来代替 “grep”。这里是如何配置 AutoKey 为你解决这些类型问题。
创建一个新的子文件夹,可以在其中将所有“打字排版错误校正”配置分组。在左侧窗格中选择 “My Phrases” ,然后选择 “<ruby> 文件 -> 新建 -> 子文件夹 <rt> File -> New -> Subfolder </rt></ruby>”。将子文件夹命名为 “Typos”。
在 “<ruby> 文件 -> 新建 -> 短语 <rt> File -> New -> Phrase </rt></ruby>” 中创建一个新短语。并将其称为 “grep”。
通过高亮选择短语 “grep”,然后在 <ruby> 输入短语内容 <rt> Enter phrase contents </rt></ruby>部分(替换默认的 “Enter phrase contents” 文本)中输入 “grep” ,配置 AutoKey 插入正确的关键词。
接下来,通过定义缩写来设置 AutoKey 如何触发此短语。点击用户界面底部紧邻 “<ruby> 缩写 <rt> Abbreviations </rt></ruby>” 的 “<ruby> 设置 <rt> Set </rt></ruby>”按钮。
在弹出的对话框中,单击 “<ruby> 添加 <rt> Add </rt></ruby>” 按钮,然后将 “gerp” 添加为新的缩写。勾选 “<ruby> 删除键入的缩写 <rt> Remove typed abbreviation </rt></ruby>”;此选项让 AutoKey 将任何键入 “gerp” 一词的替换为 “grep”。请不要勾选“<ruby> 在键入单词的一部分时触发 <rt> Trigger when typed as part of a word </rt></ruby>”,这样,如果你键入包含 “grep”的单词(例如 “fingerprint”),就不会尝试将其转换为 “fingreprint”。仅当将 “grep” 作为独立的单词键入时,此功能才有效。

### 限制对特定应用程序的更正
你可能希望仅在某些应用程序(例如终端窗口)中打字排版错误时才应用校正。你可以通过设置 <ruby> 窗口过滤器 <rt> Window Filter </rt></ruby>进行配置。单击 “<ruby> 设置 <rt> Set </rt></ruby>” 按钮来定义。
设置<ruby> 窗口过滤器 <rt> Window Filter </rt></ruby>的最简单方法是让 AutoKey 为你检测窗口类型:
1. 启动一个新的终端窗口。
2. 返回 AutoKey,单击 “<ruby> 检测窗口属性 <rt> Detect Window Properties </rt></ruby>”按钮。
3. 单击终端窗口。
这将自动填充窗口过滤器,可能的窗口类值为 `gnome-terminal-server.Gnome-terminal`。这足够了,因此单击 “OK”。

### 保存并测试
对新配置满意后,请确保将其保存。 单击 “<ruby> 文件 <rt> File </rt></ruby>” ,然后选择 “<ruby> 保存 <rp> ( </rp> <rt> Save </rt> <rp> ) </rp></ruby>” 以使更改生效。
现在进行重要的测试!在你的终端窗口中,键入 “gerp” 紧跟一个空格,它将自动更正为 “grep”。要验证窗口过滤器是否正在运行,请尝试在浏览器 URL 栏或其他应用程序中键入单词 “gerp”。它并没有变化。
你可能会认为,使用 [shell 别名](https://opensource.com/article/19/7/bash-aliases) 可以轻松解决此问题,我完全赞成!与别名不同,只要是面向命令行,无论你使用什么应用程序,AutoKey 都可以按规则纠正错误。
例如,我在浏览器,集成开发环境和终端中输入的另一个常见打字错误 “openshfit” 替代为 “openshift”。别名不能完全解决此问题,而 AutoKey 可以在任何情况下纠正它。
### 键入常用短语
你可以通过许多其他方法来调用 AutoKey 的短语来帮助你。例如,作为从事 OpenShift 的站点可靠性工程师(SRE),我经常在命令行上输入 Kubernetes 命名空间名称:
```
oc get pods -n openshift-managed-upgrade-operator
```
这些名称空间是静态的,因此它们是键入特定命令时 AutoKey 可以为我插入的理想短语。
为此,我创建了一个名为 “Namespaces” 的短语子文件夹,并为我经常键入的每个命名空间添加了一个短语条目。
### 分配热键
接下来,也是最关键的一点,我为子文件夹分配了一个 “<ruby> 热键 <rt> hotkey </rt></ruby>”。每当我按下该热键时,它都会打开一个菜单,我可以在其中选择(要么使用 “方向键”+回车键要么使用数字)要插入的短语。这减少了我仅需几次击键就可以输入这些命令的击键次数。
“My Phrases” 文件夹中 AutoKey 的预配置示例使用 `Ctrl+F7` 热键进行配置。如果你将示例保留在 AutoKey 的默认配置中,请尝试一下。你应该在此处看到所有可用短语的菜单。使用数字或箭头键选择所需的项目。
### 高级自动键入
AutoKey 的 [脚本引擎](https://autokey.github.io/index.html) 允许用户运行可以通过相同的缩写和热键系统调用的 Python 脚本。这些脚本可以通过支持的 API 的函数来完成诸如切换窗口、发送按键或执行鼠标单击之类的操作。
AutoKey 用户非常欢迎这项功能,发布了自定义脚本供其他用户采用。例如,[NumpadIME 脚本](https://github.com/luziferius/autokey_scripts) 将数字键盘转换为旧的手机样式的文本输入方法,[Emojis-AutoKey](https://github.com/AlienKevin/Emojis-AutoKey) 可以通过将诸如: `:smile:` 之类的短语转换为它们等价的表情符号来轻松插入。
这是我设置的一个小脚本,该脚本进入 Tmux 的复制模式,以将前一行中的第一个单词复制到粘贴缓冲区中:
```
from time import sleep
# 发送 Tmux 命令前缀(b 更改为 s)
keyboard.send_keys("<ctr>+s")
# Enter copy mode
keyboard.send_key("[")
sleep(0.01)
# Move cursor up one line
keyboard.send_keys("k")
sleep(0.01)
# Move cursor to start of line
keyboard.send_keys("0")
sleep(0.01)
# Start mark
keyboard.send_keys(" ")
sleep(0.01)
# Move cursor to end of word
keyboard.send_keys("e")
sleep(0.01)
# Add to copy buffer
keyboard.send_keys("<ctrl>+m")
```
之所以有 `sleep` 函数,是因为 Tmux 有时无法跟上 AutoKey 发送击键的速度,并且它们对整体执行时间的影响可忽略不计。
### 使用 AutoKey 自动化
我希望你喜欢这篇使用 AutoKey 进行键盘自动化的探索,它为你提供了有关如何改善工作流程的一些好主意。如果你在使用 AutoKey 时有什么有用的或新颖的方法,一定要在下面的评论中分享。
---
via: <https://opensource.com/article/21/2/linux-autokey>
作者:[Matt Bargenquast](https://opensource.com/users/mbargenquast) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stevenzdg988](https://github.com/stevenzdg988) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [AutoKey](https://github.com/autokey/autokey) is an open source Linux desktop automation tool that, once it's part of your workflow, you'll wonder how you ever managed without. It can be a transformative tool to improve your productivity or simply a way to reduce the physical stress associated with typing.
This article will look at how to install and start using AutoKey, cover some simple recipes you can immediately use in your workflow, and explore some of the advanced features that AutoKey power users may find attractive.
## Install and set up AutoKey
AutoKey is available as a software package on many Linux distributions. The project's [installation guide](https://github.com/autokey/autokey/wiki/Installing) contains directions for many platforms, including building from source. This article uses Fedora as the operating platform.
AutoKey comes in two variants: autokey-gtk, designed for [GTK](https://www.gtk.org/)-based environments such as GNOME, and autokey-qt, which is [QT](https://www.qt.io/)-based.
You can install either variant from the command line:
`sudo dnf install autokey-gtk`
Once it's installed, run it by using `autokey-gtk`
(or `autokey-qt`
).
## Explore the interface
Before you set AutoKey to run in the background and automatically perform actions, you will first want to configure it. Bring up the configuration user interface (UI):
`autokey-gtk -c`
AutoKey comes preconfigured with some examples. You may wish to leave them while you're getting familiar with the UI, but you can delete them if you wish.
(Matt Bargenquast, CC BY-SA 4.0)
The left pane contains a folder-based hierarchy of phrases and scripts. *Phrases* are text that you want AutoKey to enter on your behalf. *Scripts* are dynamic, programmatic equivalents that can be written using Python and achieve basically the same result of making the keyboard send keystrokes to an active window.
The right pane is where the phrases and scripts are built and configured.
Once you're happy with your configuration, you'll probably want to run AutoKey automatically when you log in so that you don't have to start it up every time. You can configure this in the **Preferences** menu (**Edit -> Preferences**) by selecting **Automatically start AutoKey at login**.

(Matt Bargenquast, CC BY-SA 4.0)
## Correct common typos with AutoKey
Fixing common typos is an easy problem for AutoKey to fix. For example, I consistently type "gerp" instead of "grep." Here's how to configure AutoKey to fix these types of problems for you.
Create a new subfolder where you can group all your "typo correction" configurations. Select **My Phrases** in the left pane, then **File -> New -> Subfolder**. Name the subfolder **Typos**.
Create a new phrase in **File -> New -> Phrase**, and call it "grep."
Configure AutoKey to insert the correct word by highlighting the phrase "grep" then entering "grep" in the **Enter phrase contents** section (replacing the default "Enter phrase contents" text).
Next, set up how AutoKey triggers this phrase by defining an Abbreviation. Click the **Set** button next to **Abbreviations** at the bottom of the UI.
In the dialog box that pops up, click the **Add** button and add "gerp" as a new abbreviation. Leave **Remove typed abbreviation** checked; this is what instructs AutoKey to replace any typed occurrence of the word "gerp" with "grep." Leave **Trigger when typed as part of a word** unchecked so that if you type a word containing "gerp" (such as "fingerprint"), it *won't* attempt to turn that into "fingreprint." It will work only when "gerp" is typed as an isolated word.
(Matt Bargenquast, CC BY-SA 4.0)
## Restrict corrections to specific applications
You may want a correction to apply only when you make the typo in certain applications (such as a terminal window). You can configure this by setting a Window Filter. Click the **Set** button to define one.
The easiest way to set a Window Filter is to let AutoKey detect the window type for you:
- Start a new terminal window.
- Back in AutoKey, click the
**Detect Window Properties**button. - Click on the terminal window.
This will auto-populate the Window Filter, likely with a Window class value of `gnome-terminal-server.Gnome-terminal`
. This is sufficient, so click **OK**.
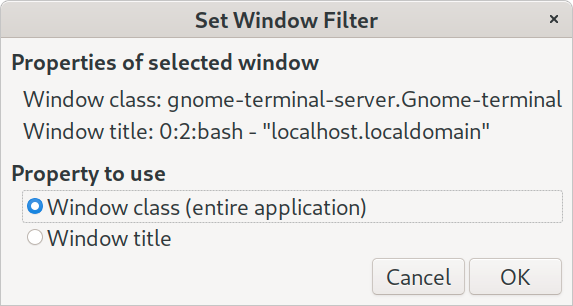
<p class="rtecenter"><sup>(Matt Bargenquast, <a href="https://opensource.com/%3Ca%20href%3D"https://creativecommons.org/licenses/by-sa/4.0/" rel="ugc">https://creativecommons.org/licenses/by-sa/4.0/" target="_blank">CC BY-SA 4.0</a>)</sup></p>
## Save and test
Once you're satisfied with your new configuration, make sure to save it. Click **File** and choose **Save** to make the change active.
Now for the grand test! In your terminal window, type "gerp" followed by a space, and it should automatically correct to "grep." To validate the Window Filter is working, try typing the word "gerp" in a browser URL bar or some other application. It should not change.
You may be thinking that this problem could have been solved just as easily with a [shell alias](https://opensource.com/article/19/7/bash-aliases), and I'd totally agree! Unlike aliases, which are command-line oriented, AutoKey can correct mistakes regardless of what application you're using.
For example, another common typo I make is "openshfit" instead of "openshift," which I type into browsers, integrated development environments, and terminals. Aliases can't quite help with this problem, whereas AutoKey can correct it in any occasion.
## Type frequently used phrases with AutoKey
There are numerous other ways you can invoke AutoKey's phrases to help you. For example, as a site reliability engineer (SRE) working on OpenShift, I frequently type Kubernetes namespace names on the command line:
`oc get pods -n openshift-managed-upgrade-operator`
These namespaces are static, so they are ideal phrases that AutoKey can insert for me when typing ad-hoc commands.
For this, I created a phrase subfolder named **Namespaces** and added a phrase entry for each namespace I type frequently.
## Assign hotkeys
Next, and most crucially, I assign the subfolder a **hotkey**. Whenever I press that hotkey, it opens a menu where I can select (either with **Arrow key**+**Enter** or using a number) the phrase I want to insert. This cuts down on the number of keystrokes I need to enter those commands to just a few keystrokes.
AutoKey's pre-configured examples in the **My Phrases** folder are configured with a **Ctrl**+**F7** hotkey. If you kept the examples in AutoKey's default configuration, try it out. You should see a menu of all the phrases available there. Select the item you want with the number or arrow keys.
## Advanced AutoKeying
AutoKey's [scripting engine](https://autokey.github.io/index.html) allows users to run Python scripts that can be invoked through the same abbreviation and hotkey system. These scripts can do things like switching windows, sending keystrokes, or performing mouse clicks through supporting API functions.
AutoKey users have embraced this feature by publishing custom scripts for others to adopt. For example, the [NumpadIME script](https://github.com/luziferius/autokey_scripts) transforms a numeric keyboard into an old cellphone-style text entry method, and [Emojis-AutoKey](https://github.com/AlienKevin/Emojis-AutoKey) makes it easy to insert emojis by converting phrases such as `:smile:`
into their emoji equivalent.
Here's a small script I set up that enters Tmux's copy mode to copy the first word from the preceding line into the paste buffer:
```
from time import sleep
# Send the tmux command prefix (changed from b to s)
keyboard.send_keys("<ctrl>+s")
# Enter copy mode
keyboard.send_key("[")
sleep(0.01)
# Move cursor up one line
keyboard.send_keys("k")
sleep(0.01)
# Move cursor to start of line
keyboard.send_keys("0")
sleep(0.01)
# Start mark
keyboard.send_keys(" ")
sleep(0.01)
# Move cursor to end of word
keyboard.send_keys("e")
sleep(0.01)
# Add to copy buffer
keyboard.send_keys("<ctrl>+m")
```
The sleeps are there because occasionally Tmux can't keep up with how fast AutoKey sends the keystrokes, and they have a negligible effect on the overall execution time.
## Automate with AutoKey
I hope you've enjoyed this excursion into keyboard automation with AutoKey and it gives you some bright ideas about how it can improve your workflow. If you're using AutoKey in a helpful or novel way, be sure to share it in the comments below.
## 4 Comments |
13,349 | Ubuntu MATE 21.04 更新,多项新功能来袭 | https://news.itsfoss.com/ubuntu-mate-21-04-release/ | 2021-05-01T10:53:00 | [
"Ubuntu"
] | https://linux.cn/article-13349-1.html |
>
> 与 Yaru 团队合作,Ubuntu MATE 带来了一个主题大修、一系列有趣的功能和性能改进。
>
>
>

自从 18.10 发行版以来,Yaru 一直都是 Ubuntu 的默认用户桌面,今年,Yaru 团队与Canonical Design 和 Ubuntu 桌面团队携手合作,为 Ubuntu MATE 21.04 创建了新的外观界面。
### Ubuntu MATE 21.04 有什么新变化?
以下就是 Ubuntu MATE 21.04 此次发布中的关键变化:
#### MATE 桌面
此次更新的 MATE 桌面相比以往并没有较大改动,此次只是修复了错误 BUG 同时更新了语言翻译,Debian 中的 MATE 软件包已经更新,用户可以下载所有的 BUG 修复和更新。
#### Avatana 指示器

这是一个控制面板指示器(也称为系统托盘)的动作、布局和行为的系统。现在,你可以从控制中心更改 Ayatana 指示器的设置。
添加了一个新的打印机标识,并删除了 RedShift 以保持稳定。
#### Yaru MATE 主题
Yaru MATE 现在是 Yaru 主题的派生产品。Yaru MATE 将提供浅色和深色主题,浅色作为默认主题。来确保更好的应用程序兼容性。
从现在开始,用户可以使用 GTK 2.x、3.x、4.x 浅色和深色主题,也可以使用 Suru 图标以及一些新的图标。
LibreOffice 在 MATE 上会有新的默认桌面图标,字体对比度也得到了改善。你会发现阅读小字体文本或远距离阅读更加容易。
如果在系统层面选择了深色模式,网站将维持深色。要让网站和系统的其它部分一起使用深色主题,只需启用 Yaru MATE 深色主题即可。
现在,Macro、Metacity 和 Compiz 的管理器主题使用了矢量图标。这意味着,如果你的屏幕较大,图标不会看起来像是像素画,又是一个小细节!
#### Yaru MATE Snap 包
尽管你现在无法安装 MATE 主题,但是不要着急,它很快就可以了。gtk-theme-yaru-mate 和 icon-theme-yaru-mate Snap 包是预安装的,可以在需要将主题连接到兼容的 Snap 软件包时使用。
根据官方发布的公告,Snapd 很快就会自动将你的主题连接到兼容的 Snap 包:
>
> Snapd 很快就能自动安装与你当前活动主题相匹配的主题的 snap 包。我们创建的 snap 包已经准备好在该功能可用时与之整合。
>
>
>
#### Mutiny 布局的新变化

Mutiny 布局模仿了 Unity 的桌面布局。删除了 MATE 软件坞小应用,并且对 Mutiny 布局进行了优化以使用 Plank。Plank 会被系统自动应用主题。这是通过 Mate Tweak 切换到 Mutiny 布局完成的。Plank 的深色和浅色 Yaru 主题都包含在内。
其他调整和更新使得 Mutiny 在不改变整体风格的前提下具备了更高的可靠性
#### 主要应用升级
* Firefox 87(火狐浏览器)
* LibreOffice 7.1.2.2(办公软件)
* Evolution 3.40(邮件)
* Celluloid 0.20(视频播放器)
#### 其他更改
* Linux 命令的忠实用户会喜欢在 Ubuntu MATE 中默认安装的 `neofetch`、`htop` 和 `inxi` 之类的命令。
* 树莓派的 21.04 版本很快将会发布。
* Ubuntu MATE 上没有离线升级选项。
* 针对侧边和底部软件坞引入了新的 Plank 主题,使其与 Yaru MATE 的配色方案相匹配。
* Yaru MATE 的窗口管理器为侧边平铺的窗口应用了简洁的边缘风格。
* Ubuntu MATE 欢迎窗口有多种色彩可供选择。
* Yaru MATE 主题和图标主题的快照包已在 Snap Store 中发布。
* 为 Ubuntu MATE 20.04 LTS 的用户发布了 Yaru MATE PPA。
### 下载 Ubuntu MATE 21.04
你可以从官网上下载镜像:
* [Ubuntu MATE 21.04](https://ubuntu-mate.org/download/)
如果你对此感兴趣,[请查看发行说明](https://discourse.ubuntu.com/t/hirsute-hippo-release-notes/19221)。
你对尝试新的 Yaru MATE 感到兴奋吗?你觉得怎么样?请在下面的评论中告诉我们。
---
via: <https://news.itsfoss.com/ubuntu-mate-21-04-release/>
作者:[Asesh Basu](https://news.itsfoss.com/author/asesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Kevin3599](https://github.com/Kevin3599) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Since 18.10, Yaru has been the default user interface. This year, the Yaru team along with the Canonical Design and Ubuntu Desktop Teams joined forces to create a new visual look for Ubuntu MATE 21.04.
## What’s New in Ubuntu MATE 21.04?
Here are all the key changes that comes with this release.
## MATE Desktop
This time there are no new features but just bug fixes and translation updates. The MATE packaging in Debian has been updated to receive all the new bug fixes and updates.
## Ayatana Indicators
It is a system that controls the action, layout, behaviour of the panel indicator area that is also known as your system tray. You can now change settings of Ayatana Indicators from Control Center.
A new printer indication has been added and RedShift has been removed to maintain stability.
## Yaru MATE Theme
Yaru MATE is now a derivative of the Yaru theme. Yaru MATE will now be provided with a light and dark theme, the light theme being the default one. This should ensure better application compatibility.
Users will now have access to GTK 2.x, 3.x, 4.x light and dark themes collectively. You can also use Suru icons along with some new icons.
LibreOffice will have a new Yaru MATE icon theming applied by default. Font contrast has been improved as well. As a result of this, you will find it easier to read tiny texts and/or reading from a distance.
Websites will now maintain the Dark Mode, if selected, at an Operating System level. To get dark theme in websites along with the rest of your system, just enable the Yaru MATE Dark theme.
Windows manager themes for Macro, Metacity, Compiz now have SVG icons. What this means is that if you have a large screen, the icons won’t look pixelated, that’s a subtle but useful addition!
## Yaru MATE Snaps
Although you can’t install Yaru MATE themes right now, you will soon be able to! The gtk-theme-yaru-mate and icon-theme-yaru-mate snaps are pre-installed and ready to be used when you need to connect the themes to compatible snaps.
As per the announcement, snapd will automatically connect your theme to compatible snaps soon:
`snapd`
will soon be able to automatically install snaps of themes that match your currently active theme. The snaps we’ve created are ready to integrate with that capability when it is available.
## Mutiny Layout Changes
Mutiny layout mimics the desktop layout of Unity. The MATE Dock Applet has been removed and the Mutiny Layout has been optimized to use Plank. Plank theming will be applied automatically. This will be done when switching to Mutiny Layout via Mate Tweak. Both dark and light Yaru themes of Plank are provided.
Other tweaks and updates have made the Mutiny much more reliability while the look and feel remains the same.
## Major Application Upgrades
- Firefox 87
- LibreOffice 7.1.2.2
- Evolution 3.40
- Celluloid 0.20
## Other Changes
- Linux command line fans will appreciate commands like neofetch, htop and inxi being included in the default Ubuntu MATE install.
- A Raspberry Pi 21.04 version will be released soon.
- There are no offline upgrade options in Ubuntu MATE.
- New Plank themes introduced for side and bottom docks that matches with the color scheme of Yaru MATE.
- A clean edge styling is applied to Yaru MATE windows manager for side tiled windows.
- It is available in various colors in Ubuntu MATE Welcome.
- Yaru MATE theme snap and icon theme snap has been published in Snap Store
- Yaru MATE PPA published for users of Ubunut MATE 20.04 LTS.
## Download Ubuntu MATE 21.04
You can download the ISO from the official website.
If you’re curious to learn more about it, [check out the release notes.](https://discourse.ubuntu.com/t/hirsute-hippo-release-notes/19221?ref=news.itsfoss.com)
*Are you excited to try out the new Yaru MATE theme? What do you think? Let us know in the comments below.*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,350 | 我们能从明尼苏达大学事件吸取什么教训? | https://lwn.net/SubscriberLink/854645/334317047842b6c3/ | 2021-05-01T20:19:00 | [
"明尼苏达大学"
] | https://linux.cn/article-13350-1.html | 
4 月 20 日,全世界都知道了明尼苏达大学(UMN)进行的一项研究计划,该计划涉及提交有意的错误补丁以纳入 Linux 内核。[从那时起](/article-13320-1.html),由这项工作产生的一篇论文被撤回了,各种信件来来回回,来自 UMN 的许多补丁被审计。显然,现在是时候对情况进行更新了。
>
> LCTT 译注:明尼苏达大学“伪君子提交”这件事引发了开源和技术社区的很多争议,我们也一直关注此事,本文是 LWN 编辑对事件后继发展的总结和观点。
>
>
>
关于[这项研究的论文](https://github.com/QiushiWu/QiushiWu.github.io/blob/main/papers/OpenSourceInsecurity.pdf)的撰写并不是最近事件的直接原因;相反,它是由 UMN 的另一位开发者发布的一个源于实验性静态分析工具的错误补丁引起的。这导致内核社区的开发者怀疑,提交故意恶意补丁的工作仍在进行。情况显然不是这样的,但当整个故事变得清晰时,讨论已经全面进行了。
>
> LCTT 译注:提交“实验性静态分析工具的错误补丁”的开发者也是 UMN “伪君子提交”研究团队的成员,只是按该团队的说法,“伪君子提交”研究已经结束,最近引发争议的补丁来自另外一个项目。
>
>
>
老话仍然适用:**不应该把那些可以充分解释为无能的东西归结为恶意。**
4 月 22 日,Linux 基金会技术顾问委员会(TAB,写作本文的 LWN 编辑是该委员会的成员)发表了一份[简短的声明](https://lwn.net/Articles/854064/),指出,除其他事项外,最近的补丁似乎是真诚地提交的。同时,Linux 基金会和 TAB 给 UMN 的研究人员发了一封信,概述了应该如何处理这种情况;该信没有公开发布,但 ZDNet 显然从某个地方[得到了一份副本](https://www.zdnet.com/article/the-linux-foundations-demands-to-the-university-of-minnesota-for-its-bad-linux-patches/)。除其他事项外,信中要求完全公开作为 UMN 项目的一部分而发送的错误补丁,并要求撤回这项工作所产生的论文。
作为回应,UMN 的研究人员发布了一封[公开信](/article-13330-1.html),向社区道歉,几天后又发布了他们作为“伪君子提交”项目的一部分所做工作的[总结](https://www-users.cs.umn.edu/~kjlu/papers/full-disclosure.pdf)。总共有五个补丁是从两个 sock-puppet 账户提交的,但其中[一个](https://lwn.net/ml/linux-kernel/[email protected]/)是普通的 bug 修复,被错误地从这个错误的账户发送。在剩下的四个补丁中,[其中一个](https://lwn.net/ml/linux-kernel/[email protected]/#t)是试图插入一个 bug,但是它本身没插入成功,所以这个补丁实际上是有效的;另外三个([1](https://lwn.net/ml/linux-kernel/[email protected]/)、[2](https://lwn.net/ml/linux-kernel/[email protected]/)、[3](https://lwn.net/ml/linux-kernel/20200821070537.30317-1-jameslouisebond%40gmail.com/))包含真正的 bug,这三个都没有被维护者接受,尽管拒绝的原因不一定是有关的 bug。
>
> LCTT 译注:根据 UMN 团队发布的总结:
>
>
> * 第一个补丁是以“伪君子提交”而发出的,但是后来实际检查发现实际解决了问题,于是 UMN 团队就没有阻止该补丁被合入。
> * 第二个补丁没有合入,但是内核维护者说之前有个别人的类似实现的补丁合并过,后来发现有问题而被别人撤销了。
> * 第三个补丁没有合入,内核维护者发现了一个问题而没有接受,但是其实该补丁还有另外一个问题并没有被发现。
> * 第四个补丁没有合入,和上一个类似,内核维护者没有发现有意放入的缺陷,而是找到另外的编码问题,因此没有合入。
> * 第五个补丁是有效的补丁,但不是这个项目的,使用了错误的邮箱发出的。
>
>
>
论文本身已被撤回,不会按原计划在 5 月提交。希望大家可以认为 UMN 在短期内不会再进行类似的研究了。
>
> LCTT 译注:在原文下面有不少评论认为这个研究方向应该继续下去,只是方式方法需要改善。
>
>
>
### 补丁的重新审查
UMN 活动引起的关注的一个直接结果是,人们对其开发者失去了信任,加上某些方面希望采取某种惩罚性行动。因此,当整个事件爆发时,首先发生的事情之一是 Greg Kroah-Hartman(GKH)发布了一个由 [190 个部分组成的补丁系列](https://lwn.net/ml/linux-kernel/[email protected]/),以撤销他能找到的尽可能多的 UMN 的补丁。事实上,这并不是所有的补丁;他提到了另外 68 个需要人工审查的补丁清单,因为它们不容易撤销。
碰巧的是,这些“容易撤销”的补丁也需要人工审查;一旦最初的愤怒过去,就没有什么愿望去恢复那些实际上没有错误的补丁。在过去的一周里,这种审查过程一直在进行,一些开发人员在为之努力。大多数可疑的补丁被证明是可以接受的(即使不是很好),已经从撤销列表中删除了;如果本文作者的计数是正确的,仍有 42 个补丁将被从内核中撤出。
对于这 42 个补丁,撤销背后的原因各不相同。在某些情况下,这些补丁适用于旧的、可能是未使用的驱动程序,而且没有人愿意去适当地审查它们。在其他情况下,其希望实现的变更做得很差,将以更好的方式重新实现。而有些补丁包含了严重的错误;这些肯定需要被恢复(而且一开始就不应该被接受)。
不过,看一下全套的 UMN 补丁,印证了一些我们的早期印象。首先,几乎所有的补丁都解决了某种真正的(即使是晦涩难懂的且难以解决)问题;为之写一个补丁是有理由的。虽然这些补丁中有许多显示出对代码的理解程度很低,因此包含了错误,但似乎其中任何一个修复程序的意图都不大可能是恶意的。
也就是说,“恶意”有多种定义。对一些相关的开发者来说,发布未经验证的实验性静态分析工具的补丁而不披露其性质是一种恶意行为。这是另一种涉及未经同意的人类的实验形式。至少,这是对内核开发社区有效工作所需的信任的一种侵犯。
>
> LCTT 译注:如果研究涉及到人类,为了避免人类受到伤害,需要取得人类同意,这就是研究需要得到 IRB 许可的原因。UMN 认为 “伪君子提交” 不是针对人类的研究,给予了 IRB 免除许可。在这个事件中,有人对 UMN IRB 的意见也很大,而且怀疑 IRB 是否有能力对计算机相关研究给出有效判断。
>
>
>
这 190 个补丁中有 42 个坏补丁,坏补丁比率是 22%。很有可能,对几乎任何一个内核开发者的 190 个补丁进行详细审查,都会发现一些回想起来并不是一个好主意的补丁。但愿这个比率不会接近 22%。但必须说的是,所有这些补丁都被整个内核的子系统维护者所接受,这不是一个好的结果。也许这比最初的“伪君子提交”的研究人员所寻找的结果更有意思。**他们故意插入 bug 的努力失败了,但却在无意中增加几十个 bug**。
同时,还有一份不能干净地撤销的补丁清单。这个名单还没有公布,但 GKH 是从其中的七个子集开始的。他还指出,TAB 将在所有这些补丁的审计工作完成后公布一份完整的报告。到目前为止,这些补丁中还没有任何一个在主线上被撤销;这似乎有可能在 5.13 合并窗口结束时发生。
### 吸取的教训
从这一系列事件中得到的关键教训之一显然是:**不要把自由软件开发社区作为你的实验性工具的一种免费验证服务**。内核开发者很高兴看到新工具的产生,并且 —— 如果这些工具能带来好的结果 —— 就使用它们。他们也会帮助测试这些工具,但他们不太乐意成为缺乏适当审查和解释的工具产生的补丁的接受者。
另一个教训是我们已经知道的:内核维护者(以及许多其他自由软件项目的维护者)工作压力过度,没有时间正确地审查经过他们手中的每一个补丁。因此,他们不得不依赖向他们提交补丁的开发者的可信度。可以说,当这种信任得到妥善建立时,内核开发过程是勉强可持续的;如果通常无法信任进入的补丁时,那么它将无法维持下去。
推论 —— 也是我们已经知道的 —— 是**进入内核的代码往往不像我们所想的那样得到很好的审查**。我们希望相信每一行被合并的代码都经过了高质量的内核开发人员的仔细审查。有些代码确实得到了这种审查,但不是所有的代码。例如,考虑一下 5.12 开发周期(一个相对较小的周期),它在十周的时间里向内核添加了超过 50 万行的代码。仔细审查 50 万行代码所需的资源将是巨大的,因此,不幸的是,其中许多行在被合并之前只得到了粗略的审查而已。
最后一个教训是,人们可能倾向于认为内核正面临着被具有比 UMN 研究人员所展示的更多技能和资源的行为者插入恶意补丁的可怕风险。这可能是事实,但事情的简单真相是,**正规的内核开发者继续以这样的速度插入错误,恶意行为者应该没有什么必要增加更多**。2 月份发布的 5.11 内核,到 5.11.17 为止,在稳定更新中已经积累了 2281 个修复。如果我们做一个(过于简单的)假设,即每个修复都会修正一个原始的 5.11 补丁,那么进入 5.11 的补丁中有 16%(到目前为止)被证明是有错误的。这并不比 UMN 补丁的比率好多少。
所以,这也许是我们从整个经历中得到的真正教训:内核处理流程的速度是它最好的属性之一,我们都依赖它来尽可能快地获得功能。但是**这种速度可能与严肃的补丁审查和低数量的错误不相容**。在一段时间内,我们可能会看到处理变得有点慢,因为维护者觉得有必要更仔细地审查变化,特别是那些来自新的开发人员。但是,如果我们不能将更谨慎的处理流程制度化,我们将继续看到大量的 bug,而这些 bug 是否是故意插入的,其实并不重要。
---
via: <https://lwn.net/SubscriberLink/854645/334317047842b6c3/>
作者:Jonathan Corbet 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-13349-1.html) 荣誉推出
| 301 | Moved Permanently | null |
13,352 | 使用 Apache Kafka 和 SigNoz 实现应用可观测性 | https://opensource.com/article/21/4/observability-apache-kafka-signoz | 2021-05-01T23:17:20 | [
"可观测性",
"Kafka"
] | https://linux.cn/article-13352-1.html |
>
> SigNoz 帮助开发者使用最小的精力快速实现他们的可观测性目标。
>
>
>

SigNoz 是一个开源的应用可观察性平台。SigNoz 是用 React 和 Go 编写的,它从头到尾都是为了让开发者能够以最小的精力尽快实现他们的可观察性目标。
本文将详细介绍该软件,包括架构、基于 Kubernetes 的部署以及一些常见的 SigNoz 用途。
### SigNoz 架构
SigNoz 将几个组件捆绑在一起,创建了一个可扩展的、耦合松散的系统,很容易上手使用。其中一些最重要的组件有:
* OpenTelemetry Collector
* Apache Kafka
* Apache Druid
[OpenTelemetry Collector](https://github.com/open-telemetry/opentelemetry-collector) 是跟踪或度量数据收集引擎。这使得 SigNoz 能够以行业标准格式获取数据,包括 Jaeger、Zipkin 和 OpenConsensus。之后,收集的数据被转发到 Apache Kafka。
SigNoz 使用 Kafka 和流处理器来实时获取大量的可观测数据。然后,这些数据被传递到 Apache Druid,它擅长于存储这些数据,用于短期和长期的 SQL 分析。
当数据被扁平化并存储在 Druid 中,SigNoz 的查询服务可以查询并将数据传递给 SigNoz React 前端。然后,前端为用户创建漂亮的图表,使可观察性数据可视化。

### 安装 SigNoz
SigNoz 的组件包括 Apache Kafka 和 Druid。这些组件是松散耦合的,并协同工作,以确保终端用户的无缝体验。鉴于这些组件,最好将 SigNoz 作为 Kubernetes 或 Docker Compose(用于本地测试)上的微服务组合来运行。
这个例子使用基于 Kubernetes Helm Chart 的部署在 Kubernetes 上安装 SigNoz。作为先决条件,你需要一个 Kubernetes 集群。如果你没有可用的 Kubernetes 集群,你可以使用 [MiniKube](https://minikube.sigs.k8s.io/docs/start/) 或 [Kind](https://kind.sigs.k8s.io/docs/user/quick-start/) 等工具,在你的本地机器上创建一个测试集群。注意,这台机器至少要有 4GB 的可用空间才能工作。
当你有了可用的集群,并配置了 kubectl 来与集群通信,运行:
```
$ git clone https://github.com/SigNoz/signoz.git && cd signoz
$ helm dependency update deploy/kubernetes/platform
$ kubectl create ns platform
$ helm -n platform install signoz deploy/kubernetes/platform
$ kubectl -n platform apply -Rf deploy/kubernetes/jobs
$ kubectl -n platform apply -f deploy/kubernetes/otel-collector
```
这将在集群上安装 SigNoz 和相关容器。要访问用户界面 (UI),运行 `kubectl port-forward` 命令。例如:
```
$ kubectl -n platform port-forward svc/signoz-frontend 3000:3000
```
现在你应该能够使用本地浏览器访问你的 SigNoz 仪表板,地址为 `http://localhost:3000`。
现在你的可观察性平台已经建立起来了,你需要一个能产生可观察性数据的应用来进行可视化和追踪。对于这个例子,你可以使用 [HotROD](https://github.com/jaegertracing/jaeger/tree/master/examples/hotrod),一个由 Jaegar 团队开发的示例应用。
要安装它,请运行:
```
$ kubectl create ns sample-application
$ kubectl -n sample-application apply -Rf sample-apps/hotrod/
```
### 探索功能
现在你应该有一个已经安装合适仪表的应用,并可在演示设置中运行。看看 SigNoz 仪表盘上的指标和跟踪数据。当你登录到仪表盘的主页时,你会看到一个所有已配置的应用列表,这些应用正在向 SigNoz 发送仪表数据。

#### 指标
当你点击一个特定的应用时,你会登录到该应用的主页上。指标页面显示最近 15 分钟的信息(这个数字是可配置的),如应用的延迟、平均吞吐量、错误率和应用目前访问最高的接口。这让你对应用的状态有一个大概了解。任何错误、延迟或负载的峰值都可以立即看到。

#### 追踪
追踪页面按时间顺序列出了每个请求的高层细节。当你发现一个感兴趣的请求(例如,比预期时间长的东西),你可以点击追踪,查看该请求中发生的每个行为的单独时间跨度。下探模式提供了对每个请求的彻底检查。


#### 用量资源管理器
大多数指标和跟踪数据都非常有用,但只在一定时期内有用。随着时间的推移,数据在大多数情况下不再有用。这意味着为数据计划一个适当的保留时间是很重要的。否则,你将为存储支付更多的费用。用量资源管理器提供了每小时、每一天和每一周获取数据的概况。

### 添加仪表
到目前为止,你一直在看 HotROD 应用的指标和追踪。理想情况下,你会希望对你的应用进行检测,以便它向 SigNoz 发送可观察数据。参考 SigNoz 网站上的[仪表概览](https://signoz.io/docs/instrumentation/overview/)。
SigNoz 支持一个与供应商无关的仪表库,OpenTelemetry,作为配置仪表的主要方式。OpenTelemetry 提供了各种语言的仪表库,支持自动和手动仪表。
### 了解更多
SigNoz 帮助开发者快速开始度量和跟踪应用。要了解更多,你可以查阅 [文档](https://signoz.io/docs/),加入[社区](https://github.com/SigNoz/signoz#community),并访问 [GitHub](https://github.com/SigNoz/signoz) 上的源代码。
---
via: <https://opensource.com/article/21/4/observability-apache-kafka-signoz>
作者:[Nitish Tiwari](https://opensource.com/users/tiwarinitish86) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | SigNoz is an open source application observability platform. Built in React and Go, SigNoz is written from the ground up to allow developers to get started with their observability goals as soon as possible and with minimum effort.
This article looks at the software in detail, including the architecture, Kubernetes-based deployment, and some common SigNoz uses.
## SigNoz architecture
SigNoz ties several components together to create a scalable, loosely coupled system that is easy to get started with. Some of the most important components are:
- OpenTelemetry Collector
- Apache Kafka
- Apache Druid
[OpenTelemetry Collector](https://github.com/open-telemetry/opentelemetry-collector) is the trace or metrics data collection engine. This enables SigNoz to ingest data in industry-standard formats, including Jaeger, Zipkin, and OpenConsensus. Then the collected data is forwarded to Apache Kafka.
SigNoz uses Kafka and stream processors for real-time ingestion of high volumes of observability data. This data is then passed on to Apache Druid, which excels at storing such data for short- and long-term SQL analysis.
Once the data is flattened and stored in Druid, SigNoz's query service can query and pass the data to the SigNoz React frontend. The front end then creates nice graphs for users to visualize the observability data.
(Nitish Tiwari, CC BY-SA 4.0)
## Install SigNoz
SigNoz's components include Apache Kafka and Druid. These components are loosely coupled and work in tandem to ensure a seamless experience for the end user. Given all the components, it is best to run SigNoz as a combination of microservices on Kubernetes or Docker Compose (for local testing).
This example uses a Kubernetes Helm chart-based deployment to install SigNoz on Kubernetes. As a prerequisite, you'll need a Kubernetes cluster. If you don't have a Kubernetes cluster available, you can use tools like [MiniKube](https://minikube.sigs.k8s.io/docs/start/) or [Kind](https://kind.sigs.k8s.io/docs/user/quick-start/) to create a test cluster on your local machine. Note that the machine should have at least 4GB available for this to work.
Once you have the cluster available and kubectl configured to communicate with the cluster, run:
```
$ git clone https://github.com/SigNoz/signoz.git && cd signoz
$ helm dependency update deploy/kubernetes/platform
$ kubectl create ns platform
$ helm -n platform install signoz deploy/kubernetes/platform
$ kubectl -n platform apply -Rf deploy/kubernetes/jobs
$ kubectl -n platform apply -f deploy/kubernetes/otel-collector
```
This installs SigNoz and related containers on the cluster. To access the user interface (UI), run the `kubectl port-forward`
command; for example:
`$ kubectl -n platform port-forward svc/signoz-frontend 3000:3000`
You should now be able to access your SigNoz dashboard using a local browser on the address `http://localhost:3000`
.
Now that your observability platform is up, you need an application that generates observability data to visualize and trace. For this example, you can use [HotROD](https://github.com/jaegertracing/jaeger/tree/master/examples/hotrod), a sample application developed by the Jaegar team.
To install it, run:
```
$ kubectl create ns sample-application
$ kubectl -n sample-application apply -Rf sample-apps/hotrod/
```
## Explore the features
You should now have a sample application with proper instrumentation up and running in the demo setup. Look at the SigNoz dashboard for metrics and trace data. As you land on the dashboard's home, you will see a list of all the configured applications that are sending instrumentation data to SigNoz.
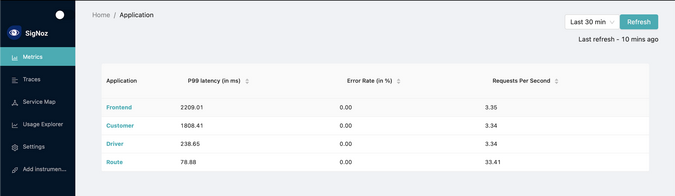
(Nitish Tiwari, CC BY-SA 4.0)
### Metrics
When you click on a specific application, you will land on the application's homepage. The Metrics page displays the last 15 minutes worth (this number is configurable) of information, like application latency, average throughput, error rate, and the top endpoints the application is accessing. This gives you a birds-eye view of the application's status. Any spikes in errors, latency, or load are immediately visible.
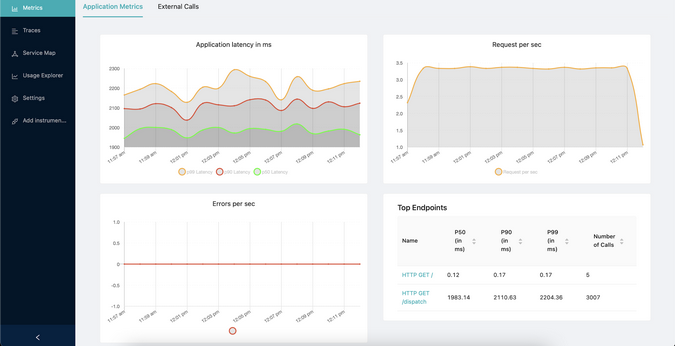
(Nitish Tiwari, CC BY-SA 4.0)
### Tracing
The Traces page lists every request in chronological order with high-level details. As soon as you identify a single request of interest (e.g., something taking longer than expected to complete), you can click the trace and look at individual spans for every action that happened inside that request. The drill-down mode offers thorough inspection for each request.
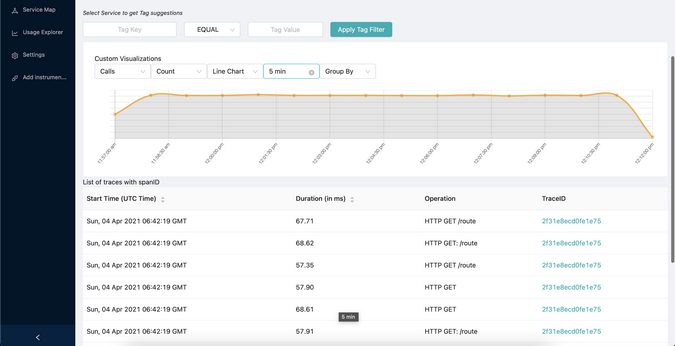
(Nitish Tiwari, CC BY-SA 4.0)
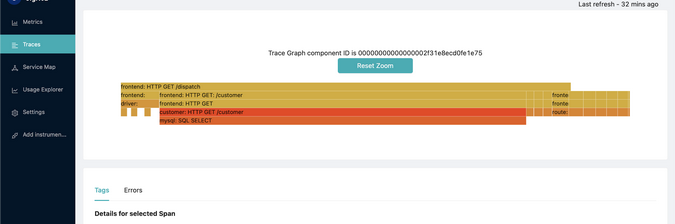
(Nitish Tiwari, CC BY-SA 4.0)
### Usage Explorer
Most of the metrics and tracing data are very useful, but only for a certain period. As time passes, the data ceases to be useful in most cases. This means it is important to plan a proper retention duration for data; otherwise, you will pay more for the storage. The Usage Explorer provides an overview of ingested data per hour, day, and week.
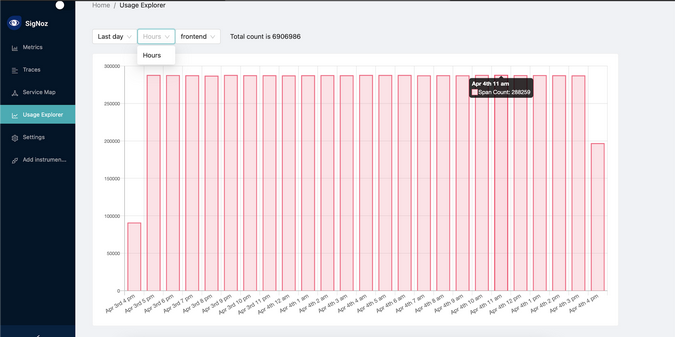
(Nitish Tiwari, CC BY-SA 4.0)
## Add instrumentation
So far, you've been looking at metrics and traces from the sample HotROD application. Ideally, you'll want to instrument your application so that it sends observability data to SigNoz. Do this by following the [Instrumentation Overview](https://signoz.io/docs/instrumentation/overview/) on SigNoz's website.
SigNoz supports a vendor-agnostic instrumentation library, OpenTelemetry, as the primary way to configure instrumentation. OpenTelemetry offers instrumentation libraries for various languages with support for both automatic and manual instrumentation.
## Learn more
SigNoz helps developers get started quickly with metrics and tracing applications. To learn more, you can consult the [documentation](https://signoz.io/docs/), join the [community](https://github.com/SigNoz/signoz#community), and access the source code on [GitHub](https://github.com/SigNoz/signoz).
## Comments are closed. |
13,353 | dnspeep:监控 DNS 查询的工具 | https://jvns.ca/blog/2021/03/31/dnspeep-tool/ | 2021-05-02T19:15:32 | [
"DNS"
] | https://linux.cn/article-13353-1.html | 
在过去的几天中,我编写了一个叫作 [dnspeep](https://github.com/jvns/dnspeep) 的小工具,它能让你看到你电脑中正进行的 DNS 查询,并且还能看得到其响应。它现在只有 [250 行 Rust 代码](https://github.com/jvns/dnspeep/blob/f5780dc822df5151f83703f05c767dad830bd3b2/src/main.rs)。
我会讨论如何去尝试它、能做什么、为什么我要编写它,以及当我在开发时所遇到的问题。
### 如何尝试
我构建了一些二进制文件,因此你可以快速尝试一下。
对于 Linux(x86):
```
wget https://github.com/jvns/dnspeep/releases/download/v0.1.0/dnspeep-linux.tar.gz
tar -xf dnspeep-linux.tar.gz
sudo ./dnspeep
```
对于 Mac:
```
wget https://github.com/jvns/dnspeep/releases/download/v0.1.0/dnspeep-macos.tar.gz
tar -xf dnspeep-macos.tar.gz
sudo ./dnspeep
```
它需要以<ruby> 超级用户 <rt> root </rt></ruby>身份运行,因为它需要访问计算机正在发送的所有 DNS 数据包。 这与 `tcpdump` 需要以超级身份运行的原因相同:它使用 `libpcap`,这与 tcpdump 使用的库相同。
如果你不想在超级用户下运行下载的二进制文件,你也能在 <https://github.com/jvns/dnspeep> 查看源码并且自行编译。
### 输出结果是什么样的
以下是输出结果。每行都是一次 DNS 查询和响应:
```
$ sudo dnspeep
query name server IP response
A firefox.com 192.168.1.1 A: 44.235.246.155, A: 44.236.72.93, A: 44.236.48.31
AAAA firefox.com 192.168.1.1 NOERROR
A bolt.dropbox.com 192.168.1.1 CNAME: bolt.v.dropbox.com, A: 162.125.19.131
```
这些查询是来自于我在浏览器中访问的 `neopets.com`,而 `bolt.dropbox.com` 查询是因为我正在运行 Dropbox 代理,并且我猜它不时会在后台运行,因为其需要同步。
### 为什么我要开发又一个 DNS 工具?
之所以这样做,是因为我认为当你不太了解 DNS 时,DNS 似乎真的很神秘!
你的浏览器(和你电脑上的其他软件)一直在进行 DNS 查询,我认为当你能真正看到请求和响应时,似乎会有更多的“真实感”。
我写这个也把它当做一个调试工具。我想“这是 DNS 的问题?”的时候,往往很难回答。我得到的印象是,当尝试检查问题是否由 DNS 引起时,人们经常使用试错法或猜测,而不是仅仅查看计算机所获得的 DNS 响应。
### 你可以看到哪些软件在“秘密”使用互联网
我喜欢该工具的一方面是,它让我可以感知到我电脑上有哪些程序正使用互联网!例如,我发现在我电脑上,某些软件出于某些理由不断地向 `ping.manjaro.org` 发送请求,可能是为了检查我是否已经连上互联网了。
实际上,我的一个朋友用这个工具发现,他的电脑上安装了一些以前工作时的企业监控软件,但他忘记了卸载,因此你甚至可能发现一些你想要删除的东西。
### 如果你不习惯的话, tcpdump 会令人感到困惑
当我试图向人们展示他们的计算机正在进行的 DNS 查询时,我的第一感是想“好吧,使用 tcpdump”!而 `tcpdump` 确实可以解析 DNS 数据包!
例如,下方是一次对 `incoming.telemetry.mozilla.org.` 的 DNS 查询结果:
```
11:36:38.973512 wlp3s0 Out IP 192.168.1.181.42281 > 192.168.1.1.53: 56271+ A? incoming.telemetry.mozilla.org. (48)
11:36:38.996060 wlp3s0 In IP 192.168.1.1.53 > 192.168.1.181.42281: 56271 3/0/0 CNAME telemetry-incoming.r53-2.services.mozilla.com., CNAME prod.data-ingestion.prod.dataops.mozgcp.net., A 35.244.247.133 (180)
```
绝对可以学着去阅读理解一下,例如,让我们分解一下查询:
`192.168.1.181.42281 > 192.168.1.1.53: 56271+ A? incoming.telemetry.mozilla.org. (48)`
* `A?` 意味着这是一次 A 类型的 DNS **查询**
* `incoming.telemetry.mozilla.org.` 是被查询的名称
* `56271` 是 DNS 查询的 ID
* `192.168.1.181.42281` 是源 IP/端口
* `192.168.1.1.53` 是目的 IP/端口
* `(48)` 是 DNS 报文长度
在响应报文中,我们可以这样分解:
`56271 3/0/0 CNAME telemetry-incoming.r53-2.services.mozilla.com., CNAME prod.data-ingestion.prod.dataops.mozgcp.net., A 35.244.247.133 (180)`
* `3/0/0` 是在响应报文中的记录数:3 个回答,0 个权威记录,0 个附加记录。我认为 tcpdump 甚至只打印出回答响应报文。
* `CNAME telemetry-incoming.r53-2.services.mozilla.com`、`CNAME prod.data-ingestion.prod.dataops.mozgcp.net.` 和 `A 35.244.247.133` 是三个响应记录。
* `56271` 是响应报文 ID,和查询报文的 ID 相对应。这就是你如何知道它是对前一行请求的响应。
我认为,这种格式最难处理的是(作为一个只想查看一些 DNS 流量的人),你必须手动匹配请求和响应,而且它们并不总是相邻的行。这就是计算机擅长的事情!
因此,我决定编写一个小程序(`dnspeep`)来进行匹配,并排除一些我认为多余的信息。
### 我在编写时所遇到的问题
在撰写本文时,我遇到了一些问题:
* 我必须给 `pcap` 包打上补丁,使其能在 Mac 操作系统上和 Tokio 配合工作([这个更改](https://github.com/ebfull/pcap/pull/168))。这是其中的一个 bug,花了很多时间才搞清楚,用了 1 行代码才解决 :smiley:
* 不同的 Linux 发行版似乎有不同的 `libpcap.so` 版本。所以我不能轻易地分发一个动态链接 libpcap 的二进制文件(你可以 [在这里](https://github.com/google/gopacket/issues/734) 看到其他人也有同样的问题)。因此,我决定在 Linux 上将 libpcap 静态编译到这个工具中。但我仍然不太了解如何在 Rust 中正确做到这一点作,但我通过将 `libpcap.a` 文件复制到 `target/release/deps` 目录下,然后直接运行 `cargo build`,使其得以工作。
* 我使用的 `dns_parser` carte 并不支持所有 DNS 查询类型,只支持最常见的。我可能需要更换一个不同的工具包来解析 DNS 数据包,但目前为止还没有找到合适的。
* 因为 `pcap` 接口只提供原始字节(包括以太网帧),所以我需要 [编写代码来计算从开头剥离多少字节才能获得数据包的 IP 报头](https://github.com/jvns/dnspeep/blob/f5780dc822df5151f83703f05c767dad830bd3b2/src/main.rs#L136)。我很肯定我还遗漏了一些情形。
我对于给它取名也有过一段艰难的时光,因为已经有许多 DNS 工具了(dnsspy!dnssnoop!dnssniff!dnswatch!)我基本上只是查了下有关“监听”的每个同义词,然后选择了一个看起来很有趣并且还没有被其他 DNS 工具所占用的名称。
该程序没有做的一件事就是告诉你哪个进程进行了 DNS 查询,我发现有一个名为 [dnssnoop](https://github.com/lilydjwg/dnssnoop) 的工具可以做到这一点。它使用 eBPF,看上去很酷,但我还没有尝试过。
### 可能会有许多 bug
我只在 Linux 和 Mac 上简单测试了一下,并且我已知至少有一个 bug(不支持足够多的 DNS 查询类型),所以请在遇到问题时告知我!
尽管这个 bug 没什么危害,因为这 libpcap 接口是只读的。所以可能发生的最糟糕的事情是它得到一些它无法解析的输入,最后打印出错误或是崩溃。
### 编写小型教育工具很有趣
最近,我对编写小型教育的 DNS 工具十分感兴趣。
到目前为止我所编写的工具:
* <https://dns-lookup.jvns.ca>(一种进行 DNS 查询的简单方法)
* <https://dns-lookup.jvns.ca/trace.html>(向你显示在进行 DNS 查询时内部发生的情况)
* 本工具(`dnspeep`)
以前我尽力阐述已有的工具(如 `dig` 或 `tcpdump`)而不是编写自己的工具,但是经常我发现这些工具的输出结果让人费解,所以我非常关注以更加友好的方式来看这些相同的信息,以便每个人都能明白他们电脑正在进行的 DNS 查询,而不仅仅是依赖 tcmdump。
---
via: <https://jvns.ca/blog/2021/03/31/dnspeep-tool/>
作者:[Julia Evans](https://jvns.ca/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Hello! Over the last few days I made a little tool called [dnspeep](https://github.com/jvns/dnspeep) that lets
you see what DNS queries your computer is making, and what responses it’s getting. It’s about [250 lines of Rust right now](https://github.com/jvns/dnspeep/blob/f5780dc822df5151f83703f05c767dad830bd3b2/src/main.rs).
I’ll talk about how you can try it, what it’s for, why I made it, and some problems I ran into while writing it.
### how to try it
I built some binaries so you can quickly try it out.
For Linux (x86):
```
wget https://github.com/jvns/dnspeep/releases/download/v0.1.0/dnspeep-linux.tar.gz
tar -xf dnspeep-linux.tar.gz
sudo ./dnspeep
```
For Mac:
```
wget https://github.com/jvns/dnspeep/releases/download/v0.1.0/dnspeep-macos.tar.gz
tar -xf dnspeep-macos.tar.gz
sudo ./dnspeep
```
It needs to run as root because it needs access to all the DNS packets your computer is sending. This is the same reason `tcpdump`
needs to run as root – it uses `libpcap`
which is the same library that tcpdump uses.
You can also read the source and build it yourself at
[https://github.com/jvns/dnspeep](https://github.com/jvns/dnspeep) if you don’t want to just download binaries and
run them as root :).
### what the output looks like
Here’s what the output looks like. Each line is a DNS query and the response.
```
$ sudo dnspeep
query name server IP response
A firefox.com 192.168.1.1 A: 44.235.246.155, A: 44.236.72.93, A: 44.236.48.31
AAAA firefox.com 192.168.1.1 NOERROR
A bolt.dropbox.com 192.168.1.1 CNAME: bolt.v.dropbox.com, A: 162.125.19.131
```
Those queries are from me going to `neopets.com`
in my browser, and the
`bolt.dropbox.com`
query is because I’m running a Dropbox agent and I guess it phones
home behind the scenes from time to time because it needs to sync.
### why make another DNS tool?
I made this because I think DNS can seem really mysterious when you don’t know a lot about it!
Your browser (and other software on your computer) is making DNS queries all the time, and I think it makes it seem a lot more “real” when you can actually see the queries and responses.
I also wrote this to be used as a debugging tool. I think the question “is this a DNS problem?” is harder to answer than it should be – I get the impression that when trying to check if a problem is caused by DNS people often use trial and error or guess instead of just looking at the DNS responses that their computer is getting.
### you can see which software is “secretly” using the Internet
One thing I like about this tool is that it gives me a sense for what programs
on my computer are using the Internet! For example, I found out that something
on my computer is making requests to `ping.manjaro.org`
from time to time
for some reason, probably to check I’m connected to the internet.
A friend of mine actually discovered using this tool that he had some corporate monitoring software installed on his computer from an old job that he’d forgotten to uninstall, so you might even find something you want to remove.
### tcpdump is confusing if you’re not used to it
My first instinct when trying to show people the DNS queries their computer is
making was to say “well, use tcpdump”! And `tcpdump`
does parse DNS packets!
For example, here’s what a DNS query for `incoming.telemetry.mozilla.org.`
looks like:
```
11:36:38.973512 wlp3s0 Out IP 192.168.1.181.42281 > 192.168.1.1.53: 56271+ A? incoming.telemetry.mozilla.org. (48)
11:36:38.996060 wlp3s0 In IP 192.168.1.1.53 > 192.168.1.181.42281: 56271 3/0/0 CNAME telemetry-incoming.r53-2.services.mozilla.com., CNAME prod.data-ingestion.prod.dataops.mozgcp.net., A 35.244.247.133 (180)
```
This is definitely possible to learn to read, for example let’s break down the query:
`192.168.1.181.42281 > 192.168.1.1.53: 56271+ A? incoming.telemetry.mozilla.org. (48)`
`A?`
means it’s a DNS**query**of type A`incoming.telemetry.mozilla.org.`
is the name being queried`56271`
is the DNS query’s ID`192.168.1.181.42281`
is the source IP/port`192.168.1.1.53`
is the destination IP/port`(48)`
is the length of the DNS packet
And in the response breaks down like this:
`56271 3/0/0 CNAME telemetry-incoming.r53-2.services.mozilla.com., CNAME prod.data-ingestion.prod.dataops.mozgcp.net., A 35.244.247.133 (180)`
`3/0/0`
is the number of records in the response: 3 answers, 0 authority, 0 additional. I think tcpdump will only ever print out the answer responses though.`CNAME telemetry-incoming.r53-2.services.mozilla.com`
,`CNAME prod.data-ingestion.prod.dataops.mozgcp.net.`
, and`A 35.244.247.133`
are the three answers`56271`
is the responses ID, which matches up with the query’s ID. That’s how you can tell it’s a response to the request in the previous line.
I think what makes this format the most difficult to deal with (as a human who just wants to look at some DNS traffic) though is that you have to manually match up the requests and responses, and they’re not always on adjacent lines. That’s the kind of thing computers are good at!
So I decided to write a little program (`dnspeep`
) which would do this matching
up and also remove some of the information I felt was extraneous.
### problems I ran into while writing it
When writing this I ran into a few problems.
- I had to patch the
`pcap`
crate to make it work properly with Tokio on Mac OS ([this change](https://github.com/ebfull/pcap/pull/168)). This was one of those bugs which took many hours to figure out and 1 line to fix :) - Different Linux distros seem to have different versions of
`libpcap.so`
, so I couldn’t easily distribute a binary that dynamically links libpcap (you can see other people having the same problem[here](https://github.com/google/gopacket/issues/734)). So I decided to statically compile libpcap into the tool on Linux. I still don’t really know how to do this properly in Rust, but I got it to work by copying the`libpcap.a`
file into`target/release/deps`
and then just running`cargo build`
. - The
`dns_parser`
crate I’m using doesn’t support all DNS query types, only the most common ones. I probably need to switch to a different crate for parsing DNS packets but I haven’t found the right one yet. - Becuase the
`pcap`
interface just gives you raw bytes (including the Ethernet frame), I needed to[write code to figure out how many bytes to strip from the beginning to get the packet’s IP header](https://github.com/jvns/dnspeep/blob/f5780dc822df5151f83703f05c767dad830bd3b2/src/main.rs#L136). I’m pretty sure there are some cases I’m still missing there.
I also had a hard time naming it because there are SO MANY DNS tools already (dnsspy! dnssnoop! dnssniff! dnswatch!). I basically just looked at every synonym for “spy” and then picked one that seemed fun and did not already have a DNS tool attached to it.
One thing this program doesn’t do is tell you which process made the DNS query,
there’s a tool called [dnssnoop](https://github.com/lilydjwg/dnssnoop) I found that does that.
It uses eBPF and it looks cool but I haven’t tried it.
### there are probably still lots of bugs
I’ve only tested this briefly on Linux and Mac and I already know of at least one bug (caused by not supporting enough DNS query types), so please report problems you run into!
The bugs aren’t dangerous though – because the libpcap interface is read-only the worst thing that can happen is that it’ll get some input it doesn’t understand and print out an error or crash.
### writing small educational tools is fun
I’ve been having a lot of fun writing small educational DNS tools recently.
So far I’ve made:
[https://dns-lookup.jvns.ca](https://dns-lookup.jvns.ca)(a simple way to make DNS queries)[https://dns-lookup.jvns.ca/trace.html](https://dns-lookup.jvns.ca/trace.html)(shows you exactly what happens behind the scenes when you make a DNS query)- this tool (
`dnspeep`
)
Historically I’ve mostly tried to explain existing tools (like `dig`
or
`tcpdump`
) instead of writing my own tools, but often I find that the output of
those tools is confusing, so I’m interested in making more friendly ways to see
the same information so that everyone can understand what DNS queries their
computer is making instead of just tcpdump wizards :). |
13,355 | 爱了!3 个受欢迎的 U 盘 Linux 发行版 | https://opensource.com/article/21/4/usb-drive-linux-distro | 2021-05-03T10:40:00 | [
"发行版",
"U盘",
"USB"
] | https://linux.cn/article-13355-1.html |
>
> 开源技术人员对此深有体会。
>
>
>

Linux 用户几乎都会记得他们第一次发现无需实际安装,就可以用 Linux 引导计算机并在上面运行。当然,许多用户都知道可以引导计算机进入操作系统安装程序,但是 Linux 不同:它根本就不需要安装!你的计算机甚至不需要有一个硬盘。你可以通过一个 U 盘运行 Linux 几个月甚至几 *年*。
自然,有几种不同的 “<ruby> 临场 <rt> live </rt></ruby>” Linux 发行版可供选择。我们向我们的作者们询问了他们的最爱,他们的回答如下。
### 1、Puppy Linux
“作为一名前 **Puppy Linux** 开发者,我对此的看法自然有些偏见,但 Puppy 最初吸引我的地方是:
* 它专注于第三世界国家容易获得的低端和老旧硬件。这为买不起最新的现代系统的贫困地区开放了计算能力
* 它能够在内存中运行,可以利用该能力提供一些有趣的安全优势
* 它在一个单一的 SFS 文件中处理用户文件和会话,使得备份、恢复或移动你现有的桌面/应用/文件到另一个安装中只需一个拷贝命令”
—— [JT Pennington](https://opensource.com/users/jtpennington)
“对我来说,一直就是 **Puppy Linux**。它启动迅速,支持旧硬件。它的 GUI 很容易就可以说服别人第一次尝试 Linux。” —— [Sachin Patil](https://opensource.com/users/psachin)
“Puppy 是真正能在任何机器上运行的临场发行版。我有一台废弃的 microATX 塔式电脑,它的光驱坏了,也没有硬盘(为了数据安全,它已经被拆掉了),而且几乎没有多少内存。我把 Puppy 插入它的 SD 卡插槽,运行了好几年。” —— [Seth Kenlon](http://opensource.com/users/seth)
“我在使用 U 盘上的 Linux 发行版没有太多经验,但我把票投给 **Puppy Linux**。它很轻巧,非常适用于旧机器。” —— [Sergey Zarubin](https://opensource.com/users/sergey-zarubin)
### 2、Fedora 和 Red Hat
“我最喜欢的 USB 发行版其实是 **Fedora Live USB**。它有浏览器、磁盘工具和终端仿真器,所以我可以用它来拯救机器上的数据,或者我可以浏览网页或在需要时用 ssh 进入其他机器做一些工作。所有这些都不需要在 U 盘或在使用中的机器上存储任何数据,不会在受到入侵时被泄露。” —— [Steve Morris](https://opensource.com/users/smorris12)
“我曾经用过 Puppy 和 DSL。如今,我有两个 U 盘:**RHEL7** 和 **RHEL8**。 这两个都被配置为完整的工作环境,能够在 UEFI 和 BIOS 上启动。当我有问题要解决而又面对随机的硬件时,在现实生活中这就是时间的救星。” —— [Steven Ellis](https://opensource.com/users/steven-ellis)
### 3、Porteus
“不久前,我安装了 Porteus 系统每个版本的虚拟机。很有趣,所以有机会我会再试试它们。每当提到微型发行版的话题时,我总是想起我记得的第一个使用的发行版:**tomsrtbt**。它总是安装适合放在软盘上来设计。我不知道它现在有多大用处,但我想我应该把它也算上。” —— [Alan Formy-Duval](https://opensource.com/users/alanfdoss)
“作为一个 Slackware 的长期用户,我很欣赏 **Porteus** 提供的 Slack 的最新版本和灵活的环境。你可以用运行在内存中的 Porteus 进行引导,这样就不需要把 U 盘连接到你的电脑上,或者你可以从驱动器上运行,这样你就可以保留你的修改。打包应用很容易,而且 Slacker 社区有很多现有的软件包。这是我唯一需要的实时发行版。” —— [Seth Kenlon](http://opensource.com/users/seth)
### 其它:Knoppix
“我已经有一段时间没有使用过 **Knoppix** 了,但我曾一度经常使用它来拯救那些被恶意软件破坏的 Windows 电脑。它最初于 2000 年 9 月发布,此后一直在持续开发。它最初是由 Linux 顾问 Klaus Knopper 开发并以他的名字命名的,被设计为临场 CD。我们用它来拯救由于恶意软件和病毒而变得无法访问的 Windows 系统上的用户文件。” —— [Don Watkins](https://opensource.com/users/don-watkins)
“Knoppix 对临场 Linux 影响很大,但它也是对盲人用户使用最方便的发行版之一。它的 [ADRIANE 界面](https://opensource.com/life/16/7/knoppix-adriane-interface) 被设计成可以在没有视觉显示器的情况下使用,并且可以处理任何用户可能需要从计算机上获得的所有最常见的任务。” —— [Seth Kenlon](https://opensource.com/article/21/4/opensource.com/users/seth)
### 选择你的临场 Linux
有很多没有提到的,比如 [Slax](http://slax.org)(一个基于 Debian 的实时发行版)、[Tiny Core](http://www.tinycorelinux.net/)、[Slitaz](http://www.slitaz.org/en/)、[Kali](http://kali.org)(一个以安全为重点的实用程序发行版)、[E-live](https://www.elivecd.org/),等等。如果你有一个空闲的 U 盘,请把 Linux 放在上面,在任何时候都可以在任何电脑上使用 Linux!
---
via: <https://opensource.com/article/21/4/usb-drive-linux-distro>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are few Linux users who don't remember the first time they discovered you could boot a computer and run Linux on it without ever actually installing it. Sure, many users are aware that you can boot a computer to an operating system installer, but with Linux it's different: there doesn't need to be an install at all! Your computer doesn't even need to have a hard drive in it. You can run Linux for months or even *years* off of a USB drive.
Naturally, there are a few different "live" Linux distributions to choose from. We asked our writers for their favourites, and their responses represent the full spectrum of what's available.
## 1. Puppy Linux
"As a prior **Puppy Linux**** **developer, my views on this are rather biased. But what originally attracted me to Puppy was:
- its focus on lower-end and older hardware which is readily available in 3rd world countries; this opens up computing for disadvantaged areas that can't afford the latest modern systems
- its ability to run in RAM, which when utilized can offer some interesting security benefits
- the way it handles user files and sessions in a single SFS file making backing up, restoring, or moving your existing desktop/applications/files to another install with a single copy command"
"It has always been **Puppy Linux** for me. It boots up quickly and supports old hardware. The GUI is super easy to convince someone to try Linux for the first time." —[Sachin Patil](https://opensource.com/users/psachin)
"Puppy is the live distro that truly runs on anything. I had an old discarded microATX tower with a broken optical drive, literally no hard drive (it had been removed for data security), and hardly any RAM. I slotted Puppy into its SD card slot and ran it for years." —[Seth Kenlon](http://opensource.com/users/seth)
"I don't have that much experience in using USB drive Linux distros but my vote goes to **Puppy Linux**. It's light and perfectly suitable for old machines." —[Sergey Zarubin](https://opensource.com/users/sergey-zarubin)
## 2. Fedora and Red Hat
"My favourite USB distro is actually just the **Fedora Live USB**. It has a browser, disk utilities, and a terminal emulator so I can use it to rescue data from a machine or I can browse the web or ssh to other machines to do some work if needed. All this without storing any data on the stick or the machine in use to be exposed if compromised." —[Steve Morris](https://opensource.com/users/smorris12)
"I used to use Puppy and DSL. These days I have two USB Keys: **RHEL7 and RHEL8**. These are both configured as full working environments with the ability to boot for UEFI and BIOS. These have been real-life and time savers when I'm faced with a random piece of hardware where we're having issues troubleshooting an issue." —[Steven Ellis](https://opensource.com/users/steven-ellis)
## 3. Porteus
"Not long ago, I installed VMs of every version of Porteus OS. That was fun, so maybe I'll take another look at them. Whenever the topic of tiny distros comes up, I'm always reminded of the first one that I can remember using: **tomsrtbt**. It was always designed to fit on a floppy. I'm not sure how useful it is these days, but just thought I'd throw it in the mix." —[Alan Formy-Duval](https://opensource.com/users/alanfdoss)
"As a longtime Slackware user, I appreciate** Porteus** for providing a current build of Slack, and a flexible environment. You can boot with Porteus running in RAM so there's no need to keep the USB drive attached to your computer, or you can run it off the drive so you can retain your changes. Packaging applications is easy, and there are lots of existing packages available from the Slacker community. It's the only live distro I need." —[Seth Kenlon](http://opensource.com/users/seth)
## Bonus: Knoppix
"I haven't used** Knoppix **in a while but I used it a lot at one time to save Windows computers that had been damaged by malware. It was originally released in September 2000 and has been under continuous development since then. It was originally developed and named after Linux consultant Klaus Knopper and designed to be used as a Live CD. We used it to rescue user files on Windows systems that had become inaccessible due to malware and viruses." —[Don Watkins](https://opensource.com/users/don-watkins)
"Knoppix was hugely influencial to live Linux, but it's also one of the most accessible distributions for blind users. Its [ADRIANE interface](https://opensource.com/life/16/7/knoppix-adriane-interface) is designed to be used without a visual display, and can handle all the most common tasks any user is likely to require from a computer." —[Seth Kenlon](https://opensource.com/opensource.com/users/seth)
## Choose your live Linux
There are many that haven't been mentioned, such as [Slax](http://slax.org) (a Debian-based live distro), [Tiny Core](http://www.tinycorelinux.net/), [Slitaz](http://www.slitaz.org/en/), [Kali](http://kali.org) (a security-focused utility distro), [E-live](https://www.elivecd.org/), and more. If you have a spare USB drive, put Linux on it and use Linux on any computer, any time!
## 17 Comments |
13,356 | 使用 requests 访问 Python 包索引(PyPI)的 JSON API | https://opensource.com/article/21/3/python-package-index-json-apis-requests | 2021-05-03T11:20:00 | [
"Python",
"PyPI"
] | https://linux.cn/article-13356-1.html |
>
> PyPI 的 JSON API 是一种机器可直接使用的数据源,你可以访问和你浏览网站时相同类型的数据。
>
>
>

PyPI(Python 软件包索引)提供了有关其软件包信息的 JSON API。本质上,它是机器可以直接使用的数据源,与你在网站上直接访问是一样的的。例如,作为人类,我可以在浏览器中打开 [Numpy](https://pypi.org/project/numpy/) 项目页面,点击左侧相关链接,查看有哪些版本,哪些文件可用以及发行日期和支持的 Python 版本等内容:

但是,如果我想编写一个程序来访问此数据,则可以使用 JSON API,而不必在这些页面上抓取和解析 HTML。
顺便说一句:在旧的 PyPI 网站上,还托管在 `pypi.python.org` 时,NumPy 的项目页面位于 `pypi.python.org/pypi/numpy`,访问其 JSON API 也很简单,只需要在最后面添加一个 `/json` ,即 `https://pypi.org/pypi/numpy/json`。现在,PyPI 网站托管在 `pypi.org`,NumPy 的项目页面是 `pypi.org/project/numpy`。新站点不会有单独的 JSON API URL,但它仍像以前一样工作。因此,你不必在 URL 后添加 `/json`,只要记住 URL 就够了。
你可以在浏览器中打开 NumPy 的 JSON API URL,Firefox 很好地渲染了数据:

你可以查看 `info`,`release` 和 `urls` 其中的内容。或者,你可以将其加载到 Python Shell 中,以下是几行入门教程:
```
import requests
url = "https://pypi.org/pypi/numpy/json"
r = requests.get(url)
data = r.json()
```
获得数据后(调用 `.json()` 提供了该数据的 [字典](https://docs.python.org/3/tutorial/datastructures.html#dictionaries)),你可以对其进行查看:

查看 `release` 中的键:

这表明 `release` 是一个以版本号为键的字典。选择一个并查看以下内容:

每个版本都包含一个列表,`release` 包含 24 项。但是每个项目是什么?由于它是一个列表,因此你可以索引第一项并进行查看:

这是一个字典,其中包含有关特定文件的详细信息。因此,列表中的 24 个项目中的每一个都与此特定版本号关联的文件相关,即在 <https://pypi.org/project/numpy/1.20.1/#files> 列出的 24 个文件。
你可以编写一个脚本在可用数据中查找内容。例如,以下的循环查找带有 sdist(源代码包)的版本,它们指定了 `requires_python` 属性并进行打印:
```
for version, files in data['releases'].items():
for f in files:
if f.get('packagetype') == 'sdist' and f.get('requires_python'):
print(version, f['requires_python'])
```

### piwheels
去年,我在 piwheels 网站上[实现了类似的 API](https://blog.piwheels.org/requires-python-support-new-project-page-layout-and-a-new-json-api/)。[piwheels.org](https://www.piwheels.org/) 是一个 Python 软件包索引,为树莓派架构提供了 wheel(预编译的二进制软件包)。它本质上是 PyPI 软件包的镜像,但带有 Arm wheel,而不是软件包维护者上传到 PyPI 的文件。
由于 piwheels 模仿了 PyPI 的 URL 结构,因此你可以将项目页面 URL 的 `pypi.org` 部分更改为 `piwheels.org`。它将向你显示类似的项目页面,其中详细说明了构建的版本和可用的文件。由于我喜欢旧站点允许你在 URL 末尾添加 `/json` 的方式,所以我也支持这种方式。NumPy 在 PyPI 上的项目页面为 [pypi.org/project/numpy](https://pypi.org/project/numpy),在 piwheels 上,它是 [piwheels.org/project/numpy](https://www.piwheels.org/project/numpy),而 JSON API 是 [piwheels.org/project/numpy/json](https://www.piwheels.org/project/numpy/json) 页面。
没有必要重复 PyPI API 的内容,所以我们提供了 piwheels 上可用内容的信息,包括所有已知发行版的列表,一些基本信息以及我们拥有的文件列表:

与之前的 PyPI 例子类似,你可以创建一个脚本来分析 API 内容。例如,对于每个 NumPy 版本,其中有多少 piwheels 文件:
```
import requests
url = "https://www.piwheels.org/project/numpy/json"
package = requests.get(url).json()
for version, info in package['releases'].items():
if info['files']:
print('{}: {} files'.format(version, len(info['files'])))
else:
print('{}: No files'.format(version))
```
此外,每个文件都包含一些元数据:

方便的是 `apt_dependencies` 字段,它列出了使用该库所需的 Apt 软件包。本例中的 NumPy 文件,或者通过 `pip` 安装 Numpy,你还需要使用 Debian 的 `apt` 包管理器安装 `libatlas3-base` 和 `libgfortran`。
以下是一个示例脚本,显示了程序包的 Apt 依赖关系:
```
import requests
def get_install(package, abi):
url = 'https://piwheels.org/project/{}/json'.format(package)
r = requests.get(url)
data = r.json()
for version, release in sorted(data['releases'].items(), reverse=True):
for filename, file in release['files'].items():
if abi in filename:
deps = ' '.join(file['apt_dependencies'])
print("sudo apt install {}".format(deps))
print("sudo pip3 install {}=={}".format(package, version))
return
get_install('opencv-python', 'cp37m')
get_install('opencv-python', 'cp35m')
get_install('opencv-python-headless', 'cp37m')
get_install('opencv-python-headless', 'cp35m')
```
我们还为软件包列表提供了一个通用的 API 入口,其中包括每个软件包的下载统计:
```
import requests
url = "https://www.piwheels.org/packages.json"
packages = requests.get(url).json()
packages = {
pkg: (d_month, d_all)
for pkg, d_month, d_all, \*_ in packages
}
package = 'numpy'
d_month, d_all = packages[package]
print(package, "has had", d_month, "downloads in the last month")
print(package, "has had", d_all, "downloads in total")
```
### pip search
`pip search` 因为其 XMLRPC 接口过载而被禁用,因此人们一直在寻找替代方法。你可以使用 piwheels 的 JSON API 来搜索软件包名称,因为软件包的集合是相同的:
```
#!/usr/bin/python3
import sys
import requests
PIWHEELS_URL = 'https://www.piwheels.org/packages.json'
r = requests.get(PIWHEELS_URL)
packages = {p[0] for p in r.json()}
def search(term):
for pkg in packages:
if term in pkg:
yield pkg
if __name__ == '__main__':
if len(sys.argv) == 2:
results = search(sys.argv[1].lower())
for res in results:
print(res)
else:
print("Usage: pip_search TERM")
```
有关更多信息,参考 piwheels 的 [JSON API 文档](https://www.piwheels.org/json.html).
---
*本文最初发表在 Ben Nuttall 的 [Tooling Tuesday 博客上](https://tooling.bennuttall.com/accessing-python-package-index-json-apis-with-requests/),经许可转载使用。*
---
via: <https://opensource.com/article/21/3/python-package-index-json-apis-requests>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | PyPI, the Python package index, provides a JSON API for information about its packages. This is essentially a machine-readable source of the same kind of data you can access while browsing the website. For example, as a human, I can head to the [ NumPy](https://pypi.org/project/numpy/) project page in my browser, click around, and see which versions there are, what files are available, and things like release dates and which Python versions are supported:
(Ben Nuttall, CC BY-SA 4.0)
But if I want to write a program to access this data, I can use the JSON API instead of having to scrape and parse the HTML on these pages.
As an aside: On the old PyPI website, when it was hosted at `pypi.python.org`
, the NumPy project page was at `pypi.python.org/pypi/numpy`
, and accessing the JSON was a simple matter of adding a `/json`
on the end, hence `https://pypi.org/pypi/numpy/json`
. Now the PyPI website is hosted at `pypi.org`
, and NumPy's project page is at `pypi.org/project/numpy`
. The new site doesn't include rendering the JSON, but it still runs as it was before. So now, rather than adding `/json`
to the URL, you have to remember the URL where they are.
You can open up the JSON for NumPy in your browser by heading to its URL. Firefox renders it nicely like this:
(Ben Nuttall, CC BY-SA 4.0)
You can open `info`
, `releases`
, and `urls`
to inspect the contents within. Or you can load it into a Python shell. Here are a few lines to get started:
```
import requests
url = "https://pypi.org/pypi/numpy/json"
r = requests.get(url)
data = r.json()
```
Once you have the data (calling `.json()`
provides a [ dictionary](https://docs.python.org/3/tutorial/datastructures.html#dictionaries) of the data), you can inspect it:
(Ben Nuttall, CC BY-SA 4.0)
Open `releases`
, and inspect the keys inside it:
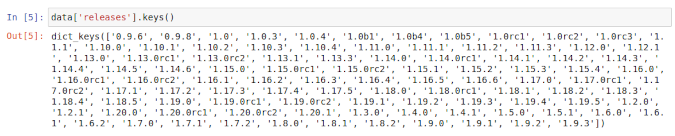
(Ben Nuttall, CC BY-SA 4.0)
This shows that `releases`
is a dictionary with version numbers as keys. Pick one (say, the latest one) and inspect that:
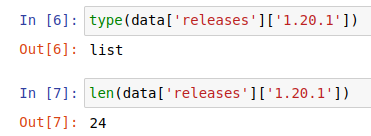
(Ben Nuttall, CC BY-SA 4.0)
Each release is a list, and this one contains 24 items. But what is each item? Since it's a list, you can index the first one and take a look:
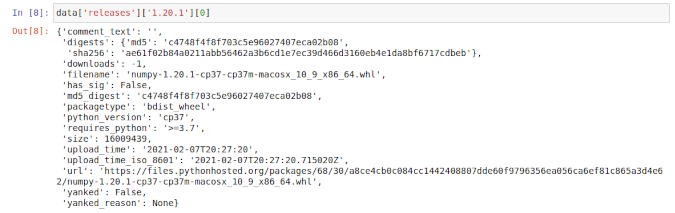
(Ben Nuttall, CC BY-SA 4.0)
This item is a dictionary containing details about a particular file. So each of the 24 items in the list relates to a file associated with this particular version number, i.e., the 24 files listed at [ https://pypi.org/project/numpy/1.20.1/#files](https://pypi.org/project/numpy/1.20.1/#files).
You could write a script that looks for something within the available data. For example, the following loop looks for versions with sdist (source distribution) files that specify a `requires_python`
attribute and prints them:
```
for version, files in data['releases'].items():
for f in files:
if f.get('packagetype') == 'sdist' and f.get('requires_python'):
print(version, f['requires_python'])
```
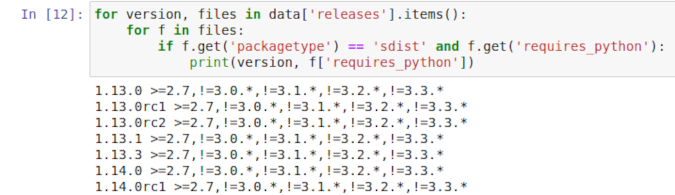
(Ben Nuttall, CC BY-SA 4.0)
## piwheels
Last year I [ implemented a similar API](https://blog.piwheels.org/requires-python-support-new-project-page-layout-and-a-new-json-api/) on the piwheels website. [ piwheels.org](https://www.piwheels.org/) is a Python package index that provides wheels (precompiled binary packages) for the Raspberry Pi architecture. It's essentially a mirror of the package set on PyPI, but with Arm wheels instead of files uploaded to PyPI by package maintainers.
Since piwheels mimics the URL structure of PyPI, you can change the `pypi.org`
part of a project page's URL to `piwheels.org`
. It'll show you a similar kind of project page with details about which versions we have built and which files are available. Since I liked how the old site allowed you to add `/json`
to the end of the URL, I made ours work that way, so NumPy's project page on PyPI is [ pypi.org/project/numpy](https://pypi.org/project/numpy). On piwheels, it is [ piwheels.org/project/numpy](https://www.piwheels.org/project/numpy), and the JSON is at [ piwheels.org/project/numpy/json](https://www.piwheels.org/project/numpy/json).
There's no need to duplicate the contents of PyPI's API, so we provide information about what's available on piwheels and include a list of all known releases, some basic information, and a list of files we have:
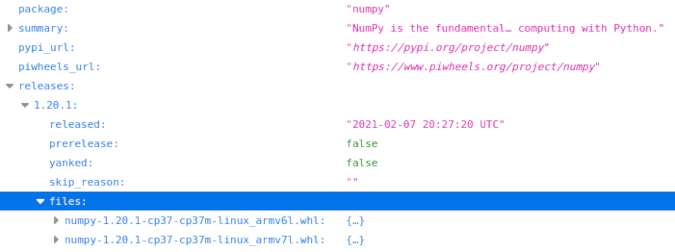
(Ben Nuttall, CC BY-SA 4.0)
Similar to the previous PyPI example, you could create a script to analyze the API contents, for example, to show the number of files piwheels has for each version of NumPy:
```
import requests
url = "https://www.piwheels.org/project/numpy/json"
package = requests.get(url).json()
for version, info in package['releases'].items():
if info['files']:
print('{}: {} files'.format(version, len(info['files'])))
else:
print('{}: No files'.format(version))
```
Also, each file contains some metadata:
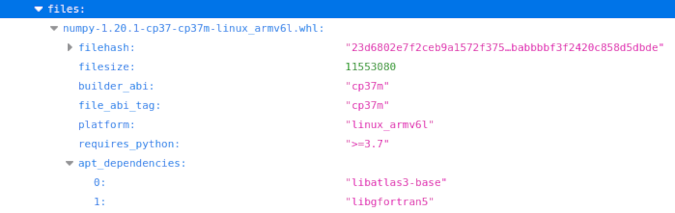
(Ben Nuttall, CC BY-SA 4.0)
One handy thing is the `apt_dependencies`
field, which lists the Apt packages needed to use the library. In the case of this NumPy file, as well as installing NumPy with pip, you'll also need to install `libatlas3-base`
and `libgfortran`
using Debian's Apt package manager.
Here is an example script that shows the Apt dependencies for a package:
```
import requests
def get_install(package, abi):
url = 'https://piwheels.org/project/{}/json'.format(package)
r = requests.get(url)
data = r.json()
for version, release in sorted(data['releases'].items(), reverse=True):
for filename, file in release['files'].items():
if abi in filename:
deps = ' '.join(file['apt_dependencies'])
print("sudo apt install {}".format(deps))
print("sudo pip3 install {}=={}".format(package, version))
return
get_install('opencv-python', 'cp37m')
get_install('opencv-python', 'cp35m')
get_install('opencv-python-headless', 'cp37m')
get_install('opencv-python-headless', 'cp35m')
```
We also provide a general API endpoint for the list of packages, which includes download stats for each package:
```
import requests
url = "https://www.piwheels.org/packages.json"
packages = requests.get(url).json()
packages = {
pkg: (d_month, d_all)
for pkg, d_month, d_all, *_ in packages
}
package = 'numpy'
d_month, d_all = packages[package]
print(package, "has had", d_month, "downloads in the last month")
print(package, "has had", d_all, "downloads in total")
```
## pip search
Since `pip search`
is currently disabled due to its XMLRPC interface being overloaded, people have been looking for alternatives. You can use the piwheels JSON API to search for package names instead since the set of packages is the same:
```
#!/usr/bin/python3
import sys
import requests
PIWHEELS_URL = 'https://www.piwheels.org/packages.json'
r = requests.get(PIWHEELS_URL)
packages = {p[0] for p in r.json()}
def search(term):
for pkg in packages:
if term in pkg:
yield pkg
if __name__ == '__main__':
if len(sys.argv) == 2:
results = search(sys.argv[1].lower())
for res in results:
print(res)
else:
print("Usage: pip_search TERM")
```
For more information, see the piwheels [ JSON API documentation](https://www.piwheels.org/json.html).
*This article originally appeared on Ben Nuttall's Tooling Tuesday blog and is reused with permission.*
## 1 Comment |
13,358 | 用 Linux 命令玩一个有趣的数学游戏 | https://opensource.com/article/21/4/math-game-linux-commands | 2021-05-03T22:15:07 | [
"数字",
"编程",
"Bash"
] | https://linux.cn/article-13358-1.html |
>
> 在家玩流行的英国游戏节目 “Countdown” 中的数字游戏。
>
>
>

像许多人一样,我在大流行期间看了不少新的电视节目。我最近发现了一个英国的游戏节目,叫做 [Countdown](https://en.wikipedia.org/wiki/Countdown_%28game_show%29),参赛者在其中玩两种游戏:一种是 *单词* 游戏,他们试图从杂乱的字母中找出最长的单词;另一种是 *数字* 游戏,他们从随机选择的数字中计算出一个目标数字。因为我喜欢数学,我发现自己被数字游戏所吸引。
数字游戏可以为你的下一个家庭游戏之夜增添乐趣,所以我想分享我自己的一个游戏变体。你以一组随机数字开始,分为 1 到 10 的“小”数字和 15、20、25,以此类推,直到 100 的“大”数字。你从大数字和小数字中挑选六个数字的任何组合。
接下来,你生成一个 200 到 999 之间的随机“目标”数字。然后用你的六个数字进行简单的算术运算,尝试用每个“小”和“大”数字计算出目标数字,但使用不能超过一次。如果你能准确地计算出目标数字,你就能得到最高分,如果距离目标数字 10 以内就得到较低的分数。
例如,如果你的随机数是 75、100、2、3、4 和 1,而你的目标数是 505,你可以说 `2+3=5`,`5×100=500`,`4+1=5`,以及 `5+500=505`。或者更直接地:`(2+3)×100 + 4 + 1 = 505`。
### 在命令行中随机化列表
我发现在家里玩这个游戏的最好方法是从 1 到 10 的池子里抽出四个“小”数字,从 15 到 100 的 5 的倍数中抽出两个“大”数字。你可以使用 Linux 命令行来为你创建这些随机数。
让我们从“小”数字开始。我希望这些数字在 1 到 10 的范围内。你可以使用 Linux 的 `seq` 命令生成一个数字序列。你可以用几种不同的方式运行 `seq`,但最简单的形式是提供序列的起始和结束数字。要生成一个从 1 到 10 的列表,你可以运行这个命令:
```
$ seq 1 10
1
2
3
4
5
6
7
8
9
10
```
为了随机化这个列表,你可以使用 Linux 的 `shuf`(“shuffle”,打乱)命令。`shuf` 将随机化你给它的东西的顺序,通常是一个文件。例如,如果你把 `seq` 命令的输出发送到 `shuf` 命令,你会收到一个 1 到 10 之间的随机数字列表:
```
$ seq 1 10 | shuf
3
6
8
10
7
4
5
2
1
9
```
要从 1 到 10 的列表中只选择四个随机数,你可以将输出发送到 `head` 命令,它将打印出输入的前几行。使用 `-4` 选项来指定 `head` 只打印前四行:
```
$ seq 1 10 | shuf | head -4
6
1
8
4
```
注意,这个列表与前面的例子不同,因为 `shuf` 每次都会生成一个随机顺序。
现在你可以采取下一步措施来生成“大”数字的随机列表。第一步是生成一个可能的数字列表,从 15 开始,以 5 为单位递增,直到达到 100。你可以用 Linux 的 `seq` 命令生成这个列表。为了使每个数字以 5 为单位递增,在 `seq` 命令中插入另一个选项来表示 *步进*:
```
$ seq 15 5 100
15
20
25
30
35
40
45
50
55
60
65
70
75
80
85
90
95
100
```
就像以前一样,你可以随机化这个列表,选择两个“大”数字:
```
$ seq 15 5 100 | shuf | head -2
75
40
```
### 用 Bash 生成一个随机数
我想你可以用类似的方法从 200 到 999 的范围内选择游戏的目标数字。但是生成单个随机数的最简单的方案是直接在 Bash 中使用 `RANDOM` 变量。当你引用这个内置变量时,Bash 会生成一个大的随机数。要把它放到 200 到 999 的范围内,你需要先把随机数放到 0 到 799 的范围内,然后加上 200。
要把随机数放到从 0 开始的特定范围内,你可以使用**模数**算术运算符。模数计算的是两个数字相除后的 *余数*。如果我用 801 除以 800,结果是 1,余数是 1(模数是 1)。800 除以 800 的结果是 1,余数是 0(模数是 0)。而用 799 除以 800 的结果是 0,余数是 799(模数是 799)。
Bash 通过 `$(())` 结构支持算术展开。在双括号之间,Bash 将对你提供的数值进行算术运算。要计算 801 除以 800 的模数,然后加上 200,你可以输入:
```
$ echo $(( 801 % 800 + 200 ))
201
```
通过这个操作,你可以计算出一个 200 到 999 之间的随机目标数:
```
$ echo $(( RANDOM % 800 + 200 ))
673
```
你可能想知道为什么我在 Bash 语句中使用 `RANDOM` 而不是 `$RANDOM`。在算术扩展中, Bash 会自动扩展双括号内的任何变量. 你不需要在 `$RANDOM` 变量上的 `$` 来引用该变量的值, 因为 Bash 会帮你做这件事。
### 玩数字游戏
让我们把所有这些放在一起,玩玩数字游戏。产生两个随机的“大”数字, 四个随机的“小”数值,以及目标值:
```
$ seq 15 5 100 | shuf | head -2
75
100
$ seq 1 10 | shuf | head -4
4
3
10
2
$ echo $(( RANDOM % 800 + 200 ))
868
```
我的数字是 **75**、**100**、**4**、**3**、**10** 和 **2**,而我的目标数字是 **868**。
如果我用每个“小”和“大”数字做这些算术运算,并不超过一次,我就能接近目标数字了:
```
10×75 = 750
750+100 = 850
然后:
4×3 = 12
850+12 = 862
862+2 = 864
```
只相差 4 了,不错!但我发现这样可以用每个随机数不超过一次来计算出准确的数字:
```
4×2 = 8
8×100 = 800
然后:
75-10+3 = 68
800+68 = 868
```
或者我可以做 *这些* 计算来准确地得到目标数字。这只用了六个随机数中的五个:
```
4×3 = 12
75+12 = 87
然后:
87×10 = 870
870-2 = 868
```
试一试 *Countdown* 数字游戏,并在评论中告诉我们你做得如何。
---
via: <https://opensource.com/article/21/4/math-game-linux-commands>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Like many people, I've been exploring lots of new TV shows during the pandemic. I recently discovered a British game show called * Countdown*, where contestants play two types of games: a
*words*game, where they try to make the longest word out of a jumble of letters, and a
*numbers*game, where they calculate a target number from a random selection of numbers. Because I enjoy mathematics, I've found myself drawn to the numbers game.
The numbers game can be a fun addition to your next family game night, so I wanted to share my own variation of it. You start with a collection of random numbers, divided into "small" numbers from 1 to 10 and "large" numbers that are 15, 20, 25, and so on until 100. You pick any combination of six numbers from both large and small numbers.
Next, you generate a random "target" number between 200 and 999. Then use simple arithmetic operations with your six numbers to try to calculate the target number using each "small" and "large" number no more than once. You get the highest number of points if you calculate the target number exactly and fewer points if you can get within 10 of the target number.
For example, if your random numbers were 75, 100, 2, 3, 4, and 1, and your target number was 505, you might say *2+3=5*, *5×100=500*, *4+1=5*, and *5+500=505*. Or more directly: (**2**+**3**)×**100** + **4** + **1** = **505**.
## Randomize lists on the command line
I've found the best way to play this game at home is to pull four "small" numbers from a pool of 1 to 10 and two "large" numbers from multiples of five from 15 to 100. You can use the Linux command line to create these random numbers for you.
Let's start with the "small" numbers. I want these to be in the range of 1 to 10. You can generate a sequence of numbers using the Linux `seq`
command. You can run `seq`
a few different ways, but the simplest form is to provide the starting and ending numbers for the sequence. To generate a list from 1 to 10, you might run this command:
```
$ seq 1 10
1
2
3
4
5
6
7
8
9
10
```
To randomize this list, you can use the Linux
("shuffle") command. **shuf**
will randomize the order of whatever you give it, usually a file. For example, if you send the output of the **shuf**
command to the **seq**
command, you will receive a randomized list of numbers between 1 and 10:**shuf**
```
$ seq 1 10 | shuf
3
6
8
10
7
4
5
2
1
9
```
To select just four random numbers from a list of 1 to 10, you can send the output to the `head`
command, which prints out the first few lines of its input. Use the `-4`
option to specify that `head`
should print only the first four lines:
```
$ seq 1 10 | shuf | head -4
6
1
8
4
```
Note that this list is different from the earlier example because `shuf`
will generate a random order every time.
Now you can take the next step to generate the random list of "large" numbers. The first step is to generate a list of possible numbers starting at 15, incrementing by five, until you reach 100. You can generate this list with the Linux `seq`
command. To increment each number by five, insert another option for the `seq`
command to indicate the *step*:
```
$ seq 15 5 100
15
20
25
30
35
40
45
50
55
60
65
70
75
80
85
90
95
100
```
And just as before, you can randomize this list and select two of the "large" numbers:
```
$ seq 15 5 100 | shuf | head -2
75
40
```
## Generate a random number with Bash
I suppose you could use a similar method to select the game's target number from the range 200 to 999. But the simplest solution to generate a single random value is to use the `RANDOM`
variable directly in Bash. When you reference this built-in variable, Bash generates a large random number. To put this in the range of 200 to 999, you need to put the random number into the range 0 to 799 first, then add 200.
To put a random number into a specific range starting at 0, you can use the **modulo** arithmetic operation. Modulo calculates the *remainder* after dividing two numbers. If I started with 801 and divided by 800, the result is 1 *with a remainder of* 1 (the modulo is 1). Dividing 800 by 800 gives 1 *with a remainder of* 0 (the modulo is 0). And dividing 799 by 800 results in 0 *with a remainder of* 799 (the modulo is 799).
Bash supports arithmetic expansion with the `$(( ))`
construct. Between the double parentheses, Bash will perform arithmetic operations on the values you provide. To calculate the modulo of 801 divided by 800, then add 200, you would type:
```
$ echo $(( 801 % 800 + 200 ))
201
```
With that operation, you can calculate a random target number between 200 and 999:
```
$ echo $(( RANDOM % 800 + 200 ))
673
```
You might wonder why I used `RANDOM`
instead of `$RANDOM`
in my Bash statement. In arithmetic expansion, Bash will automatically expand any variables within the double parentheses. You don't need the `$`
on the `$RANDOM`
variable to reference the value of the variable because Bash will do it for you.
## Playing the numbers game
Let's put all that together to play the numbers game. Generate two random "large" numbers, four random "small" values, and the target value:
```
$ seq 15 5 100 | shuf | head -2
75
100
$ seq 1 10 | shuf | head -4
4
3
10
2
$ echo $(( RANDOM % 800 + 200 ))
868
```
My numbers are **75**, **100**, **4**, **3**, **10**, and **2**, and my target number is **868**.
I can get close to the target number if I do these arithmetic operations using each of the "small" and "large" numbers no more than once:
```
10×75 = 750
750+100 = 850
and:
4×3 = 12
850+12 = 862
862+2 = 864
```
That's only four away—not bad! But I found this way to calculate the exact number using each random number no more than once:
```
4×2 = 8
8×100 = 800
and:
75-10+3 = 68
800+68 = 868
```
Or I could perform *these* calculations to get the target number exactly. This uses only five of the six random numbers:
```
4×3 = 12
75+12 = 87
and:
87×10 = 870
870-2 = 868
```
Give the *Countdown* numbers game a try, and let us know how well you did in the comments.
## 13 Comments |
13,359 | Fedora Workstation 34 中的新变化 | https://fedoramagazine.org/whats-new-fedora-34-workstation/ | 2021-05-03T23:38:28 | [
"Fedora"
] | https://linux.cn/article-13359-1.html | 
Fedora Workstation 34 是我们领先的操作系统的最新版本,这次你将获得重大改进。最重要的是,你可以从 [官方网站](https://getfedora.org/workstation) 下载它。我听到你在问,有什么新的东西?好吧,让我们来介绍一下。
### GNOME 40
[GNOME 40](https://forty.gnome.org/) 是对 GNOME 桌面的一次重大更新,Fedora 社区成员在其设计和实现过程中发挥了关键作用,因此你可以确信 Fedora 用户的需求被考虑在内。
当你登录到 GNOME 40 桌面时,首先注意到的就是你现在会被直接带到一个重新设计的概览屏幕。你会注意到仪表盘已经移到了屏幕的底部。GNOME 40 的另一个主要变化是虚拟工作空间现在是水平摆放的,这使 GNOME 与其他大多数桌面更加一致,因此应该使新用户更容易适应 GNOME 和 Fedora。
我们还做了一些工作来改善桌面中的手势支持,用三根手指水平滑动来切换工作空间,用三根手指垂直滑动来调出概览。

更新后的概览设计带来了一系列其他改进,包括:
* 仪表盘现在将收藏的和未收藏的运行中的应用程序分开。这使得可以清楚了解哪些应用已经被收藏,哪些未收藏。
* 窗口缩略图得到了改进,现在每个窗口上都有一个应用程序图标,以帮助识别。
* 当工作区被设置为在所有显示器上显示时,工作区切换器现在会显示在所有显示器上,而不仅仅是主显示器。
* 应用启动器的拖放功能得到了改进,可以更轻松地自定义应用程序网格的排列方式。
GNOME 40 中的变化经历了大量的用户测试,到目前为止反应非常正面,所以我们很高兴能将它们介绍给 Fedora 社区。更多信息请见 [forty.gnome.org](https://forty.gnome.org/) 或 [GNOME 40 发行说明](https://help.gnome.org/misc/release-notes/40.0/)。
### 应用程序的改进
GNOME “天气”为这个版本进行了重新设计,具有两个视图,一个是未来 48 小时的小时预报,另一个是未来 10 天的每日预报。
新版本现在显示了更多的信息,并且更适合移动设备,因为它支持更窄的尺寸。

其他被改进的应用程序包括“文件”、“地图”、“软件”和“设置”。更多细节请参见 [GNOME 40 发行说明](https://help.gnome.org/misc/release-notes/40.0/)。
### PipeWire
PipeWire 是新的音频和视频服务器,由 Wim Taymans 创建,他也共同创建了 GStreamer 多媒体框架。到目前为止,它只被用于视频捕获,但在 Fedora Workstation 34 中,我们也开始将其用于音频,取代 PulseAudio。
PipeWire 旨在与 PulseAudio 和 Jack 兼容,因此应用程序通常应该像以前一样可以工作。我们还与 Firefox 和 Chrome 合作,确保它们能与 PipeWire 很好地配合。OBS Studio 也即将支持 PipeWire,所以如果你是一个播客,我们已经帮你搞定了这些。
PipeWire 在专业音频界获得了非常积极的回应。谨慎地说,从一开始就可能有一些专业音频应用不能完全工作,但我们会源源不断收到测试报告和补丁,我们将在 Fedora Workstation 34 的生命周期内使用这些报告和补丁来延续专业音频 PipeWire 的体验。
### 改进的 Wayland 支持
我们预计将在 Fedora Workstation 34 的生命周期内解决在专有的 NVIDIA 驱动之上运行 Wayland 的支持。已经支持在 NVIDIA 驱动上运行纯 Wayland 客户端。然而,当前还缺少对许多应用程序使用的 Xwayland 兼容层的支持。这就是为什么当你安装 NVIDIA 驱动时,Fedora 仍然默认为 [X.Org](http://X.Org)。
我们正在 [与 NVIDIA 上游合作](https://gitlab.freedesktop.org/xorg/xserver/-/merge_requests/587),以确保 Xwayland 能在 Fedora 中使用 NVIDIA 硬件加速。
### QtGNOME 平台和 Adwaita-Qt
Jan Grulich 继续他在 QtGNOME 平台和 Adawaita-qt 主题上的出色工作,确保 Qt 应用程序与 Fedora 工作站的良好整合。多年来,我们在 Fedora 中使用的 Adwaita 主题已经发生了演变,但随着 QtGNOME 平台和 Adwaita-Qt 在 Fedora 34 中的更新,Qt 应用程序将更接近于 Fedora Workstation 34 中当前的 GTK 风格。
作为这项工作的一部分,Fedora Media Writer 的外观和风格也得到了改进。

### Toolbox
Toolbox 是我们用于创建与主机系统隔离的开发环境的出色工具,它在 Fedora 34 上有了很多改进。例如,我们在改进 Toolbox 的 CI 系统集成方面做了大量的工作,以避免在我们的环境中出现故障时导致 Toolbox 停止工作。
我们在 Toolbox 的 RHEL 集成方面投入了大量的工作,这意味着你可以很容易地在 Fedora 系统上建立一个容器化的 RHEL 环境,从而方便地为 RHEL 服务器和云实例做开发。现在在 Fedora 上创建一个 RHEL 环境就像运行:`toolbox create -distro rhel -release 8.4` 一样简单。
这给你提供了一个最新桌面的优势:支持最新硬件,同时能够以一种完全原生的方式进行针对 RHEL 的开发。

### Btrfs
自 Fedora 33 以来,Fedora Workstation 一直使用 Btrfs 作为其默认文件系统。Btrfs 是一个现代文件系统,由许多公司和项目开发。Workstation 采用 Btrfs 是通过 Facebook 和 Fedora 社区之间的奇妙合作实现的。根据到目前为止的用户反馈,人们觉得与旧的 ext4 文件系统相比,Btrfs 提供了更快捷、更灵敏的体验。
在 Fedora 34 中,新安装的 Workstation 系统现在默认使用 Btrfs 透明压缩。与未压缩的 Btrfs 相比,这可以节省 20-40% 的大量磁盘空间。它也增加了 SSD 和其他闪存介质的寿命。
---
via: <https://fedoramagazine.org/whats-new-fedora-34-workstation/>
作者:[Christian Fredrik Schaller](https://fedoramagazine.org/author/uraeus/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora Workstation 34 is the latest version of our leading-edge operating system and this time there are major improvements heading your way. Best of all, you can download it from [the official website](https://getfedora.org/workstation). What’s new, I hear you ask!? Well let’s get to it.
## GNOME 40
[GNOME 40](https://forty.gnome.org/) is a major update to the GNOME desktop, which Fedora community members played a key role in designing and implementing, so you can be sure that the needs of Fedora users were taken into account.
The first thing you notice as you log into the GNOME 40 desktop is that you are now taken directly to a redesigned overview screen. You will notice that the dash bar has moved to the bottom of the screen. Another major change to GNOME 40 is the virtual work spaces are now horizontal which brings GNOME more in line with most other desktops out there and should thus make getting used to GNOME and Fedora easier for new users.
Work has also been done to improve gesture support in the desktop with 3-finger horizontal swipes for switching workspaces, and 3-finger vertical swipes for bringing up the overview.
The updated overview design brings a collection of other improvements, including:
- The dash now separates favorite and non-favorite running apps. This makes it clear which apps have been favorited and which haven’t.
- Window thumbnails have been improved, and now have an app icon over each one, to help identification.
- When workspaces are set to be on all displays, the workspace switcher is now shown on all displays rather than just the primary one.
- App launcher drag and drop has been improved, to make it easier to customize the arrangement of the app grid.
The changes in GNOME 40 underwent a good deal of user testing, and have had a very positive reaction so far, so we’re excited to be introducing them to the Fedora community. For more information, see [forty.gnome.org](https://forty.gnome.org/) or the [GNOME 40 release notes](https://help.gnome.org/misc/release-notes/40.0/).
## App Improvements
GNOME Weather has been redesigned for this release with two views, one for the hourly forecast for the next 48 hours, and one for the daily forecast for the next 10 days.
The new version now shows more information, and is more mobile-friendly, as it supports narrower sizes.
Other apps which have been improved include Files, Maps, Software and Settings. See the [GNOME 40 release notes](https://help.gnome.org/misc/release-notes/40.0/) for more details.
**PipeWire**
PipeWire is the new audio and video server, created by Wim Taymans, who also co-created the GStreamer multimedia framework. Until now, it has only been used for video capture, but in Fedora Workstation 34 we are making the jump to also use it for audio, replacing PulseAudio.
PipeWire is designed to be compatible with both PulseAudio and Jack, so applications should generally work as before. We have also worked with Firefox and Chrome to ensure that they work well with PipeWire. PipeWire support is also coming soon in OBS Studio, so if you are a podcaster, we’ve got you covered.
PipeWire has had a very positive reception from the pro-audio community. It is prudent to say that there may be pro-audio applications that will not work 100% from day one, but we are receiving a constant stream of test reports and patches, which we will be using to continue the pro-audio PipeWire experience during the Fedora Workstation 34 lifecycle.
**Improved Wayland support**
Support for running Wayland on top of the proprietary NVIDIA driver is expected to be resolved within the Fedora Workstation 34 lifetime. Support for running a pure Wayland client on the NVIDIA driver already exists. However, this currently lacks support for the Xwayland compatibility layer, which is used by many applications. This is why Fedora still defaults to X.Org when you install the NVIDIA driver.
We are [working upstream with NVIDIA](https://gitlab.freedesktop.org/xorg/xserver/-/merge_requests/587) to ensure Xwayland works in Fedora with NVIDIA hardware acceleration.
**QtGNOME platform and Adwaita-Qt**
Jan Grulich has continued his great work on the QtGNOME platform and Adawaita-qt themes, ensuring that Qt applications integrate well with Fedora Workstation. The Adwaita theme that we use in Fedora has evolved over the years, but with the updates to QtGNOME platform and Adwaita-Qt in Fedora 34, Qt applications will more closely match the current GTK style in Fedora Workstation 34.
As part of this work, the appearance and styling of Fedora Media Writer has also been improved.
**Toolbox**
Toolbox is our great tool for creating development environments that are isolated from your host system, and it has seen lots of improvements for Fedora 34. For instance we have put a lot of work into improving the CI system integration for toolbox to avoid breakages in our stack causing Toolbox to stop working.
A lot of work has been put into the RHEL integration in Toolbox, which means that you can easily set up a containerized RHEL environment on a Fedora system, and thus conveniently do development for RHEL servers and cloud instances. Creating a RHEL environment on Fedora is now as easy as running: toolbox create –distro rhel –release 8.4.
This gives you the advantage of an up to date desktop which supports the latest hardware, while being able to do RHEL-targeted development in a way that feels completely native.
**Btrfs**
Fedora Workstation has been using Btrfs as its default file system since Fedora 33. Btrfs is a modern filesystem that is developed by many companies and projects. Workstation’s adoption of Btrfs came about through fantastic collaboration between Facebook and the Fedora community. Based on user feedback so far, people feel that Btrfs provides a snappier and more responsive experience, compared with the old ext4 filesystem.
With Fedora 34, new workstation installs now use Btrfs transparent compression by default. This saves significant disk space compared with uncompressed Btrfs, often in the range of 20-40%. It also increases the lifespan of SSDs and other flash media.
## Leslie Satenstein
Gnome 40 is very promising. I am dual booting Fedora33 and Fedora34. Gradually, I am moving my applications to the new setup. I have a few gnome extensions and I find value in them. They are not in Gnome40, and thus, I am hopeful that one or more will become gnome40 compatible.
When I do C programming, I am doing it using my Fedora34 installation. I do like the new layout and am learning the secrets that are not in the official documentation.
## Eric Mesa
Recently started using toolbox on my workstation install so that I could install Ruby gems and Perl CPAN modules without mucking up my main system. Expect to also get great use once I start using Rust crates and whatever Go’s stuff is called.
## A. User
Hi,
I freshly updated to Fedora 34 and all of my Display Settings are gone. How can I change my App Grid from the bottom to the left side again? It’s a little bit annoying to work on all of these settings again. Can you help me?
Thanks in advance.
## Renich Bon Ćirić
I do pro audio recording with pipewire. It’s just awesome. Super low latency and very flexible.
It’s easy to achieve good audio quality while streaming or recording. Flatpak apps work awesome with it.
## aab bsba
Have you tried snapd apps babe?
## hammerhead corvette
why use snapd when we have flatpak?!
## Hossam Elbadissi
Snap is really hell slow. I have elementaryOS which is built on Ubuntu (hence it comes with snapd) but the first thing I did was remove it and depend on flatpak (thankfully elementaryOS team already uses flatpak primarily).
## Ralf Oltmanns
Well, pipewire integration in Gnome 40 still seems to have some toothing problems.
Topbar volume control broke with my Fedora 34 and I find it hard to control volume for different applications.
Additionally, pipewire tends to forget how it was configured for applications and audio devices (i. e. unplugging and reconnecting a USB device is always a pain, as pipewire appears to fall back to some other device when the device is unplugged, but fails to return to the previous setting when the device is plugged in again).
But well, I found workarounds for the time being. I guess it just needs some additional time and tweaking.
## david
is there any changes on other than workstation like server?
## Miguel Jasso
PipeWire, ¿Que resampler usa? SoX VHQ,HQ o SRC, Speex?
## Wim Taymans
Usa su propio resampler: https://src.infinitewave.ca/
## Sean Sollars
I won’t use Fedora because I am disabled and play games, watch movies and such. Incompatible.
## Andrea R
Not really. If you enable rpmfusion repos you will be able to play almost any video file. For games there’s steam.
## hammerhead corvette
I have been playing games on Fedora since Fedora 27… Steam Proton, and Lutris solve your gaming problems. Third Party repos like rpm-fusion that enable these are 1 click away on the software center.
## romie
Indeed, Windows, thankfully, has a large range of accessibility options that allow a great number more of people to use their computers and it’s (again, thankfully) much better than what linux has.
But if you are looking for something other than windows and you think the accessibility is ok for you, then Fedora can easily allow you to watch movies and play (most) games 🙂
If I could, I would have my linux be friendlier too, buddy
## Pawel
There are many accessibility options in Fedora. Probably more than in windows.
## Sean Sollars
I won’t use Fedora because I am disabled and play games, watch movies and such. Incompatible. I enjoyed Fedora when it was for everyone.
## Jeroen
Great install and user experience. Thanks.
## Michael
If i updated from Fedora 33 to 34, is it normal to see pulseaudio running alongside pipewire? Is there a way to test whether pipewire is used?
## oldkid
I still think dash on the left is better. I’ve been using 34 for a few hours and I already use hot corner + dash much less than before as I mainly use touchpad. I usually just launch apps with super + search. The rest of changes are great but is there a way to move dock to dash?
## Cornel Panceac
i’ve created a ticket for this. for laptop users this is a real impact.
## Zardian
Well that’s why there is 3 finger gesture to access dock. You don’t need to access hot corner with touchpad now.
## Cornel Panceac
Not every laptop has a touchpad. For example Thinkpads Xseries do not have.
## Jeffrey Goh
Most Xseries do have a touchpad – with the exception of X200/X200s (and possibly others) – I’m told the X200 has a touchscreen, but I have no personal experience with three finger anything there.
## Cornel Panceac
Ok, looking at the Lenovo site it seems that indeed, all NEW thinkpad X series have a tocuhpad, so i stand corrected: not ALL X-series TPS miss a touchpad. However, i am using X200 or older Thinkads. What now? Do i/we have to buy a new laptop just to use Gnome 40? What about other laptops ? Do all other laptops have a touchpad? I hope you understand my point.
## FeRDNYC
“Do all other laptops have a touchpad?”
Not that it’s an argument against making the interface usable with other forms of input, but… yes, honestly. Even Lenovo caved on that a while back, and they were the last holdout. You’d be hard-pressed to find any current portable without either a touchpad, or a touchscreen that accepts the same gestures.
## Philip P
Dash on the bottom is the only reason I won’t update.
## Linus Sphinx
Try using the, ‘windows’, menu key, between Alt and Ctrl on the Thinkpad to bring up activities. Really working for me.
## Andrea R
I will wait for the dash-to-dock extension. I hope it gets updated for Gnome 3.40 soon.
## Gilbert
I like the new Gnome 40 layout much better than the previous version. It is a major improvement, and I ‘d like to thank the Gnome and Fedora team for getting this out now. I find the dash at the bottom is easier to use (shorter mouse travel). I love the fantastic “trees” wallpaper. F34 even runs fine on my older netbook (HP stream), although it runs of course much faster on regular desktops and laptops (generally, I find Gnome much smoother than Windows 10, which feels sluggish).
Three things are still missing or not working correctly, and I haven’t figured out how to solve (any suggestions?):
1) I upgraded from F33 to F34, and I do
notget the nice rounded windows for the file manager. When I install F34 as a new install, it works all fine.2) There seems still no way to do good screencasting in Wayland. Several Fedora’s ago, I used the EasyScreencast extension which was great under wayland and super easy to use; now I need to use Vokoscreen under X. I wished this would be easier under wayland. There must be many people using screencasts for tutorials and teaching.
3) The weather extension I used to have does not longer work. Not a bit issue, but I look forward to this extension working again.
## Maksym
Related to Wayland – there is a bug “Add an API for taking screenshots and recording screencasts” which was created in 2016. It is still open.
So, the solution might be not to use Wayland until this is fixed, and support for this API is implemented in applications.
## Robert
The APIs are already there for a while, but adoption is somewhat slow. Fortunately, OBS studio just got pretty good support for it in the new version (27). Firefox and Chromium also support it.
## Maksym
If I understood correctly, Firefox and OBS Studio adopted a PipeWire API. It seems PipeWire will be used as a universal screen capture method which works on Wayland too.
## Alfred Johnson
Will not reboot after update/upgrade
## pedrito_el
Is it me or there’s no gnome-document app anymore?
## luigi votta
same here: I felt horphanized! 🙂
## thiago
It’s possible to make an upgrade above Fedora 33 or more indicated made a clean installation?
## lemc
I installed Fedora Workstation 34 using the server-netinst ISO image and selecting “Fedora Workstation” under “Base environment”. Everything runs smoothly, but the installed file system is XFS. Shouldn’t it be BTRFS, the new default for the Workstation edition ?
## Ben Cotton
The server-netinst ISO uses Fedora Server configuration. Since Server defaults to XFS that’s what you get when you install from that ISO, even if you select different packages.
## lemc
Thank you for the information. The Workstation edition as installed by the server-netinst ISO also allows the creation of separate root and user accounts before actual installation (which I prefer). So are there other differences between the Workstation editions that are installed by the live ISO image and the server-netinst ISO ?
## Matheus Guedes
Late reply, but the Fedora Everything ISO does exactly that, same interface as the Server-netinstall but uses Workstation’s defaults like BTRFS.
## [email protected]
as of 29 april 2021 00:17 at tokyo time 34-workstation downloading seemingly starting but in fail wrongly. as ever most cases at another computer within a comfortable short time the download opertion had been completed and had moved to the normal installation operation of 34-workstaion at another computers safely. but with this my computer…something wrong ????
san10-38-58.ubonedih.net
2021年 4月 29日 木曜日 00:23:54 JST
4月 2021
日 月 火 水 木 金 土
1 2 3
4 5 6 7 8 9 10
11 12 13 14 15 16 17
18 19 20 21 22 23 24
25 26 27 28 29 30
[udh123@san10-38-58 ~]$
## Noel
I just upgraded from F33 to F34, and my keyboard LED does not turn on – even trying the command “xset led 3” that the web tell me to do.
I know that my keyboard works, because on Windows it does, theferore indeed is something related to F34.
For reference, the keyboard is a Knup KP-2059.
By the way, the overall experience is faster on F34, great job.
## Andrew
wish that btrfs had the ability to have a default raid level for 2+ devices but that you could also specify raid-1 for example on a per folder (ok… per subvolume otherwise) basis, so that I could duplicate my important stuff but take advantage of speed increase of raid-0 on machanical drives for everything else.
## Nygu-Phee Yen
Congratulations to the team for the fantastic work! You guys rock!
I have been a user since the Red Hat Linux 6.0 days, and we both are still alive even though you have changed name several times!
## sdoux
More of a Gnome related feedback than Fedora but having a gnome shell extension to configure the overview would be nice. With the multimonitor setup i have these horizontal workspaces are killing me
## Morten Juhl-Johansen Zölde-Fejér
It is beautiful – I was surprised that it starts with the overview, but I can get used to it,
The 3-finger gesture navigation is not sensitive enough to work from. Even slowly dragging 3 fingers from one end of the touchpad to the other, I could barely switch from one workspace to the other.
## Jyotirmay Barman
I really hate gnome 40’s UI. I know they tried to be minimal but it is extraaa minimal and the extension support is not yet there so there is very less reason to update.
## Sphinx
Damn the torpedoes full speed ahead, couple bugs never bothered me, there is no progress without pain.
## Christian Ortega
When you finally feel comfortable with PulseAudio…..boom…..then PipeWare appears
## Mohamed Salama
Hello,
I’ve lost my sound output devices after the upgrade, however the sound is working but with no volume control. Any help!
Thanks,
## Gregory Bartholomew
According to the PipeWire change set notice for Fedora Linux 34, You should be able to switch back to pulseaudio with the following command:
## Mohamed Salama
Thank you for you update. Unfortunately, many issues with Sound even after a fresh installation .. Ended up re-installing F33
## Federico
Thanks! With PipeWire my USB headphones did not work (LX-3000 on a Dell 7400; not my choice, it’s my employer’s), but going back to pulseaudio worked just fine.
As soon as I saw the notices that PipeWire would “just work”, I felt I should resist upgrading, as it would clearly be the exact opposite. I see there are many open bug reports, I have no idea which one might be relevant. Thank you everyone who’s testing, reporting and fixing all the bugs!
https://bugzilla.redhat.com/buglist.cgi?bug_status=__open__&bug_status=__closed__&f0=OP&f1=OP&f2=product&f3=component&f4=alias&f5=short_desc&f6=status_whiteboard&f7=CP&f8=CP&j1=OR&o2=substring&o3=substring&o4=substring&o5=substring&o6=substring&query_format=advanced&v2=pipewire&v3=pipewire&v4=pipewire&v5=pipewire&v6=pipewire&version=34
## Mark
A five months ago I have try workstation 33 my first impression was : unstable, not snappy.
Then installed POP OS and it was better. After time system was getting a bit heavy.
I decided to give a try Fedora. I got 33 I was surprise how snappy it is. Just after two days it was official release 34 I did fresh installation. I wanted to try new GNOME and I knowed I need minimum two days to find out if the changes are for better.
System wasn’t so snappy as 33 and my felling about new GNOME was so, so I didn’t know if is better or no but I am open for changes and I know many peoples jurge new things from old behaviors.
I though two days and I will see.
After one day I knowed it is better !
One more day after several updates system started to be really stable.
New Gnome : Simple, clean, nice colors beautiful wallpapers. I like color’s in and dark background with icon’s area that’s make everything more visible.
Very clear ! 👍
I faced problem sometimes I can’t copy text for example from, LibrreOffice to internet browsers or from browsers to telegram but that happen sometimes.
Another think Virtual Box after I set up I got information that ther is something wrong wit kernel configuration and it didn’t work.
I would like to use Boxes but I can’t make internet work’s ? How can make it ?
## Andrey
After almost every Fedora upgrade, I got an issue with HPLIP. Is current HPLIP version 3.21.2 compatible with Fedora 34 Workstation?
## Felix Calderon
Good morning, some solution to my problems, please I will be grateful if you guide me the following:
In previous versions of Fedora 34, you could listen to music while configuring the sound. Now you can’t, the sound settings hang.
Or if I’m listening to music with Rythmbox and I want to use VLC, I just can’t, a VLC window opens with messages in endless red lines device busy.
No player uses my 5.1 sound system.
Only on the console using mpg123 can I listen to the flac or mp3 sound with fidelity
## Gregory Bartholomew
You can try the following to switch back to the previous sound system (but still keep the rest of Fedora Linux 34):
After running the above, reboot, and then you should have your previous sound settings back.
## Andy Loven
Love seeing the 01886 in the Gnome Weather screenshot!
## Juhani Vuorio
Where is the networking and drivers?
## giocomai
But what if I don’t want to start with the overview open, and I like my dash on the left? Is there an easy way to just keep things as they are? I see that you want to make things “easier for new users”, but pretty please, don’t make them annoying for old users who liked the way things were. Fine if there’s a new default, as long as it’s just a switch in the settings to return to previous behaviour, without having to resort to extension that break oh so often with updates…
## bubka
can you do smth with wifi tribers (for lenovo yogo). it’s just terrible. connection always on low. on windows! it’s perfect!
## John Williams
I did a fresh install of Fedora 34 Workstation and the thing I noticed more than anything is the incredibly good sound quality. I’m currently listening to all my music files again ! Well done Fedora.
## Bilal Ahmad
What about nvidia and cuda compatibility . Will they update along side Fedora 34 installation or we have to install them separately.
## Leon
The virtual desktops are now side by side, instead of on ‘top of eachother’ (sorry, no other way to express myself). If anyone knows of a way to have the f33 behavior again, please let me know.
## bubka
I still have problems with wi-fi on lenovo yoga. low signal. how much time do you still need to fix it? everything is perfect with windows but not with fedora. rly sad.
## Steve Nordquist
bubka, eat an entire 4 channels of misdirected gain. Seriously, can you drop debug info to the appropriate developers to mark differences in the Win10 and Linux drivers (e.g. are they both for the same subsets of chips and for the same front-end amplifiers for WiFi6E?)
If you select among all available drivers and driver options (use the source, Luke) and still haven’t gotten the same signal strength as in the same location when using Win10, that’s handy info. to know for the next Yoga user and/or driver developer and will probably avail a fix sooner (if indeed it can’t be fixed with mere driver parameters.)
It would similarly help to induce Lenovo to seek Linux Foundation or other Linux developer Certification (as Windows Certification for hardware funds Windows driver activity) for their products. You can put bounties on development milestones in some contexts! |
13,361 | 神器:在一个 U 盘上放入多个 Linux 发行版 | https://opensource.com/article/21/5/linux-ventoy | 2021-05-05T13:15:00 | [
"U盘",
"启动",
"可引导",
"Ventoy"
] | https://linux.cn/article-13361-1.html |
>
> 用 Ventoy 创建多启动 U 盘,你将永远不会缺少自己喜欢的 Linux 发行版。
>
>
>

给朋友和邻居一个可启动 U 盘,里面包含你最喜欢的 Linux 发行版,是向 Linux 新手介绍我们都喜欢的 Linux 体验的好方法。仍然有许多人从未听说过 Linux,把你喜欢的发行版放在一个可启动的 U 盘上是让他们进入 Linux 世界的好办法。
几年前,我在给一群中学生教授计算机入门课。我们使用旧笔记本电脑,我向学生们介绍了 Fedora、Ubuntu 和 Pop!\_OS。下课后,我给每个学生一份他们喜欢的发行版的副本,让他们带回家安装在自己选择的电脑上。他们渴望在家里尝试他们的新技能。
### 把多个发行版放在一个驱动器上
最近,一个朋友向我介绍了 Ventoy,它(根据其 [GitHub 仓库](https://github.com/ventoy/Ventoy))是 “一个开源工具,可以为 ISO/WIM/IMG/VHD(x)/EFI 文件创建可启动的 USB 驱动器”。与其为每个我想分享的 Linux 发行版创建单独的驱动器,我可以在一个 U 盘上放入我喜欢的 *所有* Linux 发行版!

正如你所能想到的那样,U 盘的大小决定了你能在上面容纳多少个发行版。在一个 16GB 的 U 盘上,我放置了 Elementary 5.1、Linux Mint Cinnamon 5.1 和 Linux Mint XFCE 5.1......但仍然有 9.9GB 的空间。
### 获取 Ventoy
Ventoy 是开源的,采用 [GPLv3](https://www.ventoy.net/en/doc_license.html) 许可证,可用于 Windows 和 Linux。有很好的文档介绍了如何在 Windows 上下载和安装 Ventoy。Linux 的安装是通过命令行进行的,所以如果你不熟悉这个过程,可能会有点混乱。然而,其实很容易。
首先,[下载 Ventoy](https://github.com/ventoy/Ventoy/releases)。我把存档文件下载到我的桌面上。
接下来,使用 `tar` 命令解压 `ventoy-x.y.z-linux.tar.gz` 档案(但要用你下载的版本号替换 `x.y.z`)(为了保持简单,我在命令中使用 `*` 字符作为任意通配符):
```
$ tar -xvf ventoy*z
```
这个命令将所有必要的文件提取到我桌面上一个名为 `ventoy-x.y.z` 的文件夹中。
你也可以使用你的 Linux 发行版的存档管理器来完成同样的任务。下载和提取完成后,你就可以把 Ventoy 安装到你的 U 盘上了。
### 在 U 盘上安装 Ventoy 和 Linux
把你的 U 盘插入你的电脑。改变目录进入 Ventoy 的文件夹,并寻找一个名为 `Ventoy2Disk.sh` 的 shell 脚本。你需要确定你的 U 盘的正确挂载点,以便这个脚本能够正常工作。你可以通过在命令行上发出 `mount` 命令或者使用 [GNOME 磁盘](https://wiki.gnome.org/Apps/Disks) 来找到它,后者提供了一个图形界面。后者显示我的 U 盘被挂载在 `/dev/sda`。在你的电脑上,这个位置可能是 `/dev/sdb` 或 `/dev/sdc` 或类似的位置。

下一步是执行 Ventoy shell 脚本。因为它被设计成不加选择地复制数据到一个驱动器上,我使用了一个假的位置(`/dev/sdX`)来防止你复制/粘贴错误,所以用你想覆盖的实际驱动器的字母替换后面的 `X`。
**让我重申**:这个 shell 脚本的目的是把数据复制到一个驱动器上, *破坏该驱动器上的所有数据。* 如果该驱动器上有你关心的数据,在尝试这个方法之前,先把它备份! 如果你不确定你的驱动器的位置,在你继续进行之前,请验证它,直到你完全确定为止。
一旦你确定了你的驱动器的位置,就运行这个脚本:
```
$ sudo sh Ventoy2Disk.sh -i /dev/sdX
```
这样就可以格式化它并将 Ventoy 安装到你的 U 盘上。现在你可以复制和粘贴所有适合放在 U 盘上的 Linux 发行版文件。如果你在电脑上用新创建的 U 盘引导,你会看到一个菜单,上面有你复制到 U 盘上的发行版。

### 构建一个便携式的动力源
Ventoy 是你在钥匙串上携带多启动 U 盘的关键(钥匙),这样你就永远不会缺少你所依赖的发行版。你可以拥有一个全功能的桌面、一个轻量级的发行版、一个纯控制台的维护工具,以及其他你想要的东西。
我从来没有在没有 Linux 发行版的情况下离开家,你也不应该。拿上 Ventoy、一个 U 盘,和一串 ISO。你不会后悔的。
---
via: <https://opensource.com/article/21/5/linux-ventoy>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Giving friends and neighbors a bootable USB drive containing your favorite Linux distribution is a great way to introduce neophyte Linux users to the experience we all enjoy. There are still a large number of folks who have never heard of Linux, and putting your favorite distribution on a bootable USB drive is a great way to break the ice.
A few years ago, I was teaching an introductory computer class to a group of middle schoolers. We used old laptops, and I introduced the students to Fedora, Ubuntu, and Pop!_OS. When the class was over, I gave each student a copy of their favorite distribution to take home and install on a computer of their choice. They were eager to try their new skills at home.
## Put multiple distros on one drive
Recently, a friend introduced me to Ventoy, which (according to its [GitHub repository](https://github.com/ventoy/Ventoy)) is "an open source tool to create bootable a USB drive for ISO/WIM/IMG/VHD(x)/EFI files." Instead of creating separate drives for each Linux distribution I want to share, I can create a single drive with *all* my favorite Linux distributions on the drive!
(Don Watkins, CC BY-SA 4.0)
As you might expect, a USB drive's size will determine how many distributions you can fit onto it. On a 16GB drive, I placed Elementary 5.1, Linux Mint Cinnamon 5.1, and Linux Mint XFCE 5.1… and still have 9.9GB free.
## Get Ventoy
Ventoy is open source with a [GPL v3](https://www.ventoy.net/en/doc_license.html) license and available for Windows and Linux. There is excellent documentation to download and install Ventoy on Microsoft Windows. The Linux installation happens from the command line, so it can be a little confusing if you're not familiar with that process. Yet, it's easier than it might seem.
First, [download Ventoy](https://github.com/ventoy/Ventoy/releases). I downloaded the archive file to my desktop.
Next, extract the `ventoy-x.y.z-linux.tar.gz`
archive (but replace `x.y.z`
with your download's version number) using the `tar`
command (to keep things simple, I use the `*`
character as an infinite wildcard in the command):
`$ tar -xvf ventoy*z`
This command extracts all the necessary files into a folder named `ventoy-x.y.z`
on my desktop.
You can also use your Linux distribution's archive manager to accomplish the same task. After the download and extraction are complete, you are ready to install Ventoy to your USB drive.
## Install Ventoy and Linux on a USB
Insert your USB drive into your computer. Change directory into the Ventoy folder, and look for a shell script named `Ventoy2Disk.sh`
. You need to determine your USB drive's correct mount point for this script to work properly. You can find it by issuing the `mount`
command on the command line or with the [GNOME Disks](https://wiki.gnome.org/Apps/Disks) command, which provides a graphical interface. The latter shows that my USB drive is mounted at `/dev/sda`
. On your computer, the location could be `/dev/sdb`
or `/dev/sdc`
or something similar.
(Don Watkins, CC BY-SA 4.0)
The next step is to execute the Ventoy shell script. Because it's designed to copy data onto a drive indiscriminately, I'm using a fake location (`/dev/sdx`
) to foil copy/paste errors, so replace the trailing `x`
with the letter of the actual drive you want to overwrite.
*Let me reiterate:* This shell script is designed to copy data to a drive, *destroying all data on that drive.* If there is data you care about on the drive, back it up before trying this! If you're not sure about your drive's location, verify it until you're absolutely sure before you proceed!
Once you're sure of your drive's location, run the script:
`$ sudo sh Ventoy2Disk.sh -i /dev/sdX`
This formats the drive and installs Ventoy to your USB. Now you can copy and paste all the Linux distributions that will fit on the drive. If you boot the newly created drive on your computer, you'll see a menu with the distributions you have copied to your USB drive.
(Don Watkins, CC BY-SA 4.0)
## Build a portable powerhouse
Ventoy is your key to carrying a multiboot drive on your keychain, so you'll never be without the distributions you rely on. You can have a full-featured desktop, a lightweight distro, a console-only maintenance utility, *and* anything else you want.
I never leave the house without a Linux distro anymore, and neither should you. Grab Ventoy, a USB drive, and a handful of ISOs. You won't be sorry.
## 4 Comments |
13,362 | 用 Linux 使计算机更容易使用和可持续 | https://opensource.com/article/21/4/linux-free-geek | 2021-05-05T13:50:56 | [
"计算机",
"Linux"
] | https://linux.cn/article-13362-1.html |
>
> Free Geek 是一个非营利组织,通过向有需要的人和团体提供 Linux 电脑,帮助减少数字鸿沟。
>
>
>

有很多理由选择 Linux 作为你的桌面操作系统。在 [为什么每个人都应该选择 Linux](https://opensource.com/article/21/2/try-linux) 中,Seth Kenlon 强调了许多选择 Linux 的最佳理由,并为人们提供了许多开始使用该操作系统的方法。
这也让我想到了我通常向人们介绍 Linux 的方式。这场大流行增加了人们上网购物、远程教育以及与家人和朋友 [通过视频会议](https://opensource.com/article/20/8/linux-laptop-video-conferencing) 联系的需求。
我和很多有固定收入的退休人员一起工作,他们并不特别精通技术。对于这些人中的大多数人来说,购买电脑是一项充满担忧的大投资。我的一些朋友和客户对在大流行期间去零售店感到不舒服,而且他们完全不熟悉如何买电脑,无论是台式机还是笔记本电脑,即使在非大流行时期。他们来找我,询问在哪里买,要注意些什么。
我总是想看到他们得到一台 Linux 电脑。他们中的许多人买不起名牌供应商出售的 Linux 设备。直到最近,我一直在为他们购买翻新的设备,然后用 Linux 改装它们。
但是,当我发现 [Free Geek](https://www.freegeek.org/) 时,这一切都改变了,这是一个位于俄勒冈州波特兰的非营利组织,它的使命是“可持续地重复使用技术,实现数字访问,并提供教育,以创建一个使人们能够实现其潜力的社区。”
Free Geek 有一个 eBay 商店,我在那里以可承受的价格购买了几台翻新的笔记本电脑。他们的电脑都安装了 [Linux Mint](https://opensource.com/article/21/4/restore-macbook-linux)。 事实上,电脑可以立即使用,这使得向 [新用户介绍 Linux](https://opensource.com/article/18/12/help-non-techies) 很容易,并帮助他们快速体验操作系统的力量。
### 让电脑继续使用,远离垃圾填埋场
Oso Martin 在 2000 年地球日发起了 Free Geek。该组织为其志愿者提供课程和工作计划,对他们进行翻新和重建捐赠电脑的培训。志愿者们在服务 24 小时后还会收到一台捐赠的电脑。
这些电脑在波特兰的 Free Geek 实体店和 [网上](https://www.ebay.com/str/freegeekbasicsstore) 出售。该组织还通过其项目 [Plug Into Portland](https://www.freegeek.org/our-programs/plug-portland)、[Gift a Geekbox](https://www.freegeek.org/our-programs/gift-geekbox) 以及[组织](https://www.freegeek.org/our-programs-grants/organizational-hardware-grants)和[社区资助](https://www.freegeek.org/our-programs-grants/community-hardware-grants)向有需要的人和实体提供电脑。
该组织表示,它已经“从垃圾填埋场翻新了 200 多万件物品,向非营利组织、学校、社区变革组织和个人提供了 75000 多件技术设备,并从 Free Geek 学习者那里提供了 5000 多课时”。
### 参与其中
自成立以来,Free Geek 已经从 3 名员工发展到近 50 名员工,并得到了世界各地的认可。它是波特兰市的 [数字包容网络](https://www.portlandoregon.gov/oct/73860) 的成员。
你可以在 [Twitter](https://twitter.com/freegeekpdx)、[Facebook](https://www.facebook.com/freegeekmothership)、[LinkedIn](https://www.linkedin.com/company/free-geek/)、[YouTube](https://www.youtube.com/user/FreeGeekMothership) 和 [Instagram](https://www.instagram.com/freegeekmothership/) 上与 Free Geek 联系。你也可以订阅它的[通讯](https://app.e2ma.net/app2/audience/signup/1766417/1738557/?v=a)。从 Free Geek 的 [商店](https://www.freegeek.org/shop) 购买物品,可以直接支持其工作,减少数字鸿沟。
---
via: <https://opensource.com/article/21/4/linux-free-geek>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are many reasons to choose Linux for your desktop operating system. In [ Why everyone should choose Linux](https://opensource.com/article/21/2/try-linux), Opensource.com's Seth Kenlon highlighted many of the best reasons to select Linux and provided lots of ways for people to get started with the operating system.
This also got me thinking about how I usually introduce folks to Linux. The pandemic has increased the need for people to go online for shopping, doing remote education, and connecting with family and friends [over video conferencing](https://opensource.com/article/20/8/linux-laptop-video-conferencing).
I work with a lot of retirees who have fixed incomes and are not particularly tech-savvy. For most of these folks, buying a computer is a major investment fraught with concern. Some of my friends and clients are uncomfortable going to a retail store during a pandemic, and they're completely unfamiliar with what to look for in a computer, whether it's a desktop or laptop, even in non-pandemic times. They come to me with questions about where to buy one and what to look for.
I'm always eager to see them get a Linux computer. Many of them cannot afford the Linux units sold by name-brand vendors. Until recently, I've been purchasing refurbished units for them and refitting them with Linux.
But that all changed when I discovered [Free Geek](https://www.freegeek.org/), a nonprofit organization based in Portland, Ore., with the mission "to sustainably reuse technology, enable digital access, and provide education to create a community that empowers people to realize their potential."
Free Geek has an eBay store where I have purchased several refurbished laptops at affordable prices. Their computers come with [Linux Mint](https://opensource.com/article/21/4/restore-macbook-linux) installed. The fact that a computer comes ready-to-use makes it easy to introduce [new users to Linux](https://opensource.com/article/18/12/help-non-techies) and help them quickly experience the operating system's power.
## Keeping computers in service and out of landfills
Oso Martin launched Free Geek on Earth Day 2000. The organization provides classes and work programs to its volunteers, who are trained to refurbish and rebuild donated computers. Volunteers also receive a donated computer after 24 hours of service.
The computers are sold in Free Geek's brick-and-mortar store in Portland and [online](https://www.ebay.com/str/freegeekbasicsstore). The organization also provides computers to people and entities in need through its programs [Plug Into Portland](https://www.freegeek.org/our-programs/plug-portland), [Gift a Geekbox](https://www.freegeek.org/our-programs/gift-geekbox), and [organizational](https://www.freegeek.org/our-programs-grants/organizational-hardware-grants) and [community grants](https://www.freegeek.org/our-programs-grants/community-hardware-grants).
The organization says it has "diverted over 2 million items from landfills, granted over 75,000 technology devices to nonprofits, schools, community change organizations, and individuals, and plugged over 5,000 classroom hours from Free Geek learners."
## Get involved
Since its inception, Free Geek has grown from a staff of three to almost 50 and has been recognized around the world. It is a member of the City of Portland's [Digital Inclusion Network](https://www.portlandoregon.gov/oct/73860).
You can connect with Free Geek on [Twitter](https://twitter.com/freegeekpdx), [Facebook](https://www.facebook.com/freegeekmothership), [LinkedIn](https://www.linkedin.com/company/free-geek/), [YouTube](https://www.youtube.com/user/FreeGeekMothership), and [Instagram](https://www.instagram.com/freegeekmothership/). You can also subscribe to its [newsletter](https://app.e2ma.net/app2/audience/signup/1766417/1738557/?v=a). Purchasing items from Free Geek's [shop](https://www.freegeek.org/shop) directly supports its work and reduces the digital divide.
## Comments are closed. |
13,364 | 网络地址转换(NAT)之报文跟踪 | https://fedoramagazine.org/network-address-translation-part-1-packet-tracing/ | 2021-05-06T11:25:00 | [
"NAT",
"nftables"
] | https://linux.cn/article-13364-1.html | 
这是有关<ruby> 网络地址转换 <rt> network address translation </rt></ruby>(NAT)的系列文章中的第一篇。这一部分将展示如何使用 iptables/nftables 报文跟踪功能来定位 NAT 相关的连接问题。
### 引言
网络地址转换(NAT)是一种将容器或虚拟机暴露在互联网中的一种方式。传入的连接请求将其目标地址改写为另一个地址,随后被路由到容器或虚拟机。相同的技术也可用于负载均衡,即传入的连接被分散到不同的服务器上去。
当网络地址转换没有按预期工作时,连接请求将失败,会暴露错误的服务,连接最终出现在错误的容器中,或者请求超时,等等。调试此类问题的一种方法是检查传入请求是否与预期或已配置的转换相匹配。
### 连接跟踪
NAT 不仅仅是修改 IP 地址或端口号。例如,在将地址 X 映射到 Y 时,无需添加新规则来执行反向转换。一个被称为 “conntrack” 的 netfilter 系统可以识别已有连接的回复报文。每个连接都在 conntrack 系统中有自己的 NAT 状态。反向转换是自动完成的。
### 规则匹配跟踪
nftables 工具(以及在较小的程度上,iptables)允许针对某个报文检查其处理方式以及该报文匹配规则集合中的哪条规则。为了使用这项特殊的功能,可在合适的位置插入“跟踪规则”。这些规则会选择被跟踪的报文。假设一个来自 IP 地址 C 的主机正在访问一个 IP 地址是 S 以及端口是 P 的服务。我们想知道报文匹配了哪条 NAT 转换规则,系统检查了哪些规则,以及报文是否在哪里被丢弃了。
由于我们要处理的是传入连接,所以我们将规则添加到 prerouting 钩子上。prerouting 意味着内核尚未决定将报文发往何处。修改目标地址通常会使报文被系统转发,而不是由主机自身处理。
### 初始配置
```
# nft 'add table inet trace_debug'
# nft 'add chain inet trace_debug trace_pre { type filter hook prerouting priority -200000; }'
# nft "insert rule inet trace_debug trace_pre ip saddr $C ip daddr $S tcp dport $P tcp flags syn limit rate 1/second meta nftrace set 1"
```
第一条规则添加了一张新的规则表,这使得将来删除和调试规则可以更轻松。一句 `nft delete table inet trace_debug` 命令就可以删除调试期间临时加入表中的所有规则和链。
第二条规则在系统进行路由选择之前(`prerouting` 钩子)创建了一个基本钩子,并将其优先级设置为负数,以保证它在连接跟踪流程和 NAT 规则匹配之前被执行。
然而,唯一最重要的部分是第三条规则的最后一段:`meta nftrace set 1`。这条规则会使系统记录所有匹配这条规则的报文所关联的事件。为了尽可能高效地查看跟踪信息(提高信噪比),考虑对跟踪的事件增加一个速率限制,以保证其数量处于可管理的范围。一个好的选择是限制每秒钟最多一个报文或一分钟最多一个报文。上述案例记录了所有来自终端 `$C` 且去往终端 `$S` 的端口 `$P` 的所有 SYN 报文和 SYN/ACK 报文。限制速率的配置语句可以防范事件过多导致的洪泛风险。事实上,大多数情况下只记录一个报文就足够了。
对于 iptables 用户来讲,配置流程是类似的。等价的配置规则类似于:
```
# iptables -t raw -I PREROUTING -s $C -d $S -p tcp --tcp-flags SYN SYN --dport $P -m limit --limit 1/s -j TRACE
```
### 获取跟踪事件
原生 nft 工具的用户可以直接运行 `nft` 进入 nft 跟踪模式:
```
# nft monitor trace
```
这条命令会将收到的报文以及所有匹配该报文的规则打印出来(用 `CTRL-C` 来停止输出):
```
trace id f0f627 ip raw prerouting packet: iif "veth0" ether saddr ..
```
我们将在下一章详细分析该结果。如果你用的是 iptables,首先通过 `iptables –version` 命令检查一下已安装的版本。例如:
```
# iptables --version
iptables v1.8.5 (legacy)
```
`(legacy)` 意味着被跟踪的事件会被记录到内核的环形缓冲区中。你可以用 `dmesg` 或 `journalctl` 命令来查看这些事件。这些调试输出缺少一些信息,但和新工具提供的输出从概念上来讲很类似。你将需要首先查看规则被记录下来的行号,并与活跃的 iptables 规则集合手动关联。如果输出显示 `(nf_tables)`,你可以使用 `xtables-monitor` 工具:
```
# xtables-monitor --trace
```
如果上述命令仅显示版本号,你仍然需要查看 `dmesg`/`journalctl` 的输出。`xtables-monitor` 工具和 `nft` 监控跟踪工具使用相同的内核接口。它们之间唯一的不同点就是,`xtables-monitor` 工具会用 `iptables` 的语法打印事件,且如果你同时使用了 `iptables-nft` 和 `nft`,它将不能打印那些使用了 maps/sets 或其他只有 nftables 才支持的功能的规则。
### 示例
我们假设需要调试一个到虚拟机/容器的端口不通的问题。`ssh -p 1222 10.1.2.3` 命令应该可以远程连接那台服务器上的某个容器,但连接请求超时了。
你拥有运行那台容器的主机的登录权限。现在登录该机器并增加一条跟踪规则。可通过前述案例查看如何增加一个临时的调试规则表。跟踪规则类似于这样:
```
nft "insert rule inet trace_debug trace_pre ip daddr 10.1.2.3 tcp dport 1222 tcp flags syn limit rate 6/minute meta nftrace set 1"
```
在添加完上述规则后,运行 `nft monitor trace`,在跟踪模式下启动 nft,然后重试刚才失败的 `ssh` 命令。如果规则集较大,会出现大量的输出。不用担心这些输出,下一节我们会做逐行分析。
```
trace id 9c01f8 inet trace_debug trace_pre packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
trace id 9c01f8 inet trace_debug trace_pre rule ip daddr 10.2.1.2 tcp dport 1222 tcp flags syn limit rate 6/minute meta nftrace set 1 (verdict continue)
trace id 9c01f8 inet trace_debug trace_pre verdict continue
trace id 9c01f8 inet trace_debug trace_pre policy accept
trace id 9c01f8 inet nat prerouting packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
trace id 9c01f8 inet nat prerouting rule ip daddr 10.1.2.3 tcp dport 1222 dnat ip to 192.168.70.10:22 (verdict accept)
trace id 9c01f8 inet filter forward packet: iif "enp0" oif "veth21" ether saddr .. ip daddr 192.168.70.10 .. tcp dport 22 tcp flags == syn tcp window 29200
trace id 9c01f8 inet filter forward rule ct status dnat jump allowed_dnats (verdict jump allowed_dnats)
trace id 9c01f8 inet filter allowed_dnats rule drop (verdict drop)
trace id 20a4ef inet trace_debug trace_pre packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
```
### 对跟踪结果作逐行分析
输出结果的第一行是触发后续输出的报文编号。这一行的语法与 nft 规则语法相同,同时还包括了接收报文的首部字段信息。你也可以在这一行找到接收报文的接口名称(此处为 `enp0`)、报文的源和目的 MAC 地址、报文的源 IP 地址(可能很重要 - 报告问题的人可能选择了一个错误的或非预期的主机),以及 TCP 的源和目的端口。同时你也可以在这一行的开头看到一个“跟踪编号”。该编号标识了匹配跟踪规则的特定报文。第二行包括了该报文匹配的第一条跟踪规则:
```
trace id 9c01f8 inet trace_debug trace_pre rule ip daddr 10.2.1.2 tcp dport 1222 tcp flags syn limit rate 6/minute meta nftrace set 1 (verdict continue)
```
这就是刚添加的跟踪规则。这里显示的第一条规则总是激活报文跟踪的规则。如果在这之前还有其他规则,它们将不会在这里显示。如果没有任何跟踪输出结果,说明没有抵达这条跟踪规则,或者没有匹配成功。下面的两行表明没有后续的匹配规则,且 `trace_pre` 钩子允许报文继续传输(判定为接受)。
下一条匹配规则是:
```
trace id 9c01f8 inet nat prerouting rule ip daddr 10.1.2.3 tcp dport 1222 dnat ip to 192.168.70.10:22 (verdict accept)
```
这条 DNAT 规则设置了一个到其他地址和端口的映射。规则中的参数 `192.168.70.10` 是需要收包的虚拟机的地址,目前为止没有问题。如果它不是正确的虚拟机地址,说明地址输入错误,或者匹配了错误的 NAT 规则。
### IP 转发
通过下面的输出我们可以看到,IP 路由引擎告诉 IP 协议栈,该报文需要被转发到另一个主机:
```
trace id 9c01f8 inet filter forward packet: iif "enp0" oif "veth21" ether saddr .. ip daddr 192.168.70.10 .. tcp dport 22 tcp flags == syn tcp window 29200
```
这是接收到的报文的另一种呈现形式,但和之前相比有一些有趣的不同。现在的结果有了一个输出接口集合。这在之前不存在的,因为之前的规则是在路由决策之前(`prerouting` 钩子)。跟踪编号和之前一样,因此仍然是相同的报文,但目标地址和端口已经被修改。假设现在还有匹配 `tcp dport 1222` 的规则,它们将不会对现阶段的报文产生任何影响了。
如果该行不包含输出接口(`oif`),说明路由决策将报文路由到了本机。对路由过程的调试属于另外一个主题,本文不再涉及。
```
trace id 9c01f8 inet filter forward rule ct status dnat jump allowed_dnats (verdict jump allowed_dnats)
```
这条输出表明,报文匹配到了一个跳转到 `allowed_dnats` 链的规则。下一行则说明了连接失败的根本原因:
```
trace id 9c01f8 inet filter allowed_dnats rule drop (verdict drop)
```
这条规则无条件地将报文丢弃,因此后续没有关于该报文的日志输出。下一行则是另一个报文的输出结果了:
```
trace id 20a4ef inet trace_debug trace_pre packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
```
跟踪编号已经和之前不一样,然后报文的内容却和之前是一样的。这是一个重传尝试:第一个报文被丢弃了,因此 TCP 尝试了重传。可以忽略掉剩余的输出结果了,因为它并没有提供新的信息。现在是时候检查那条链了。
### 规则集合分析
上一节我们发现报文在 inet filter 表中的一个名叫 `allowed_dnats` 的链中被丢弃。现在我们来查看它:
```
# nft list chain inet filter allowed_dnats
table inet filter {
chain allowed_dnats {
meta nfproto ipv4 ip daddr . tcp dport @allow_in accept
drop
}
}
```
接受 `@allow_in` 集的数据包的规则没有显示在跟踪日志中。我们通过列出元素的方式,再次检查上述报文的目标地址是否在 `@allow_in` 集中:
```
# nft "get element inet filter allow_in { 192.168.70.10 . 22 }"
Error: Could not process rule: No such file or directory
```
不出所料,地址-服务对并没有出现在集合中。我们将其添加到集合中。
```
# nft "add element inet filter allow_in { 192.168.70.10 . 22 }"
```
现在运行查询命令,它将返回新添加的元素。
```
# nft "get element inet filter allow_in { 192.168.70.10 . 22 }"
table inet filter {
set allow_in {
type ipv4_addr . inet_service
elements = { 192.168.70.10 . 22 }
}
}
```
`ssh` 命令现在应该可以工作,且跟踪结果可以反映出该变化:
```
trace id 497abf58 inet filter forward rule ct status dnat jump allowed_dnats (verdict jump allowed_dnats)
trace id 497abf58 inet filter allowed_dnats rule meta nfproto ipv4 ip daddr . tcp dport @allow_in accept (verdict accept)
trace id 497abf58 ip postrouting packet: iif "enp0" oif "veth21" ether .. trace id 497abf58 ip postrouting policy accept
```
这表明报文通过了转发路径中的最后一个钩子 - `postrouting`。
如果现在仍然无法连接,问题可能处在报文流程的后续阶段,有可能并不在 nftables 的规则集合范围之内。
### 总结
本文介绍了如何通过 nftables 的跟踪机制检查丢包或其他类型的连接问题。本系列的下一篇文章将展示如何检查连接跟踪系统和可能与连接跟踪流相关的 NAT 信息。
---
via: <https://fedoramagazine.org/network-address-translation-part-1-packet-tracing/>
作者:[Florian Westphal](https://fedoramagazine.org/author/strlen/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cooljelly](https://github.com/cooljelly) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The first post in a series about network address translation (NAT). Part 1 shows how to use the iptables/nftables packet tracing feature to find the source of NAT related connectivity problems.
## Introduction
Network address translation is one way to expose containers or virtual machines to the wider internet. Incoming connection requests have their destination address rewritten to a different one. Packets are then routed to a container or virtual machine instead. The same technique can be used for load-balancing where incoming connections get distributed among a pool of machines.
Connection requests fail when network address translation is not working as expected. The wrong service is exposed, connections end up in the wrong container, request time out, and so on. One way to debug such problems is to check that the incoming request matches the expected or configured translation.
## Connection tracking
NAT involves more than just changing the ip addresses or port numbers. For instance, when mapping address X to Y, there is no need to add a rule to do the reverse translation. A netfilter system called “conntrack” recognizes packets that are replies to an existing connection. Each connection has its own NAT state attached to it. Reverse translation is done automatically.
## Ruleset evaluation tracing
The utility nftables (and, to a lesser extent, iptables) allow for examining how a packet is evaluated and which rules in the ruleset were matched by it. To use this special feature “trace rules” are inserted at a suitable location. These rules select the packet(s) that should be traced. Lets assume that a host coming from IP address C is trying to reach the service on address S and port P. We want to know which NAT transformation is picked up, which rules get checked and if the packet gets dropped somewhere.
Because we are dealing with incoming connections, add a rule to the prerouting hook point. Prerouting means that the kernel has not yet made a decision on where the packet will be sent to. A change to the destination address often results in packets to get forwarded rather than being handled by the host itself.
## Initial setup
# nft 'add table inet trace_debug'
# nft 'add chain inet trace_debug trace_pre { type filter hook prerouting priority -200000; }'
# nft "insert rule inet trace_debug trace_pre ip saddr $C ip daddr $S tcp dport $P tcp flags syn limit rate 1/second meta nftrace set 1"
The first rule adds a new table This allows easier removal of the trace and debug rules later. A single “nft delete table inet trace_debug” will be enough to undo all rules and chains added to the temporary table during debugging.
The second rule creates a base hook before routing decisions have been made (prerouting) and with a negative priority value to make sure it will be evaluated before connection tracking and the NAT rules.
The only important part, however, is the last fragment of the third rule: “*meta nftrace set 1″*. This enables tracing events for all packets that match the rule. Be as specific as possible to get a good signal-to-noise ratio. Consider adding a rate limit to keep the number of trace events at a manageable level. A limit of one packet per second or per minute is a good choice. The provided example traces all syn and syn/ack packets coming from host $C and going to destination port $P on the destination host $S. The limit clause prevents event flooding. In most cases a trace of a single packet is enough.
The procedure is similar for iptables users. An equivalent trace rule looks like this:
# iptables -t raw -I PREROUTING -s $C -d $S -p tcp --tcp-flags SYN SYN --dport $P -m limit --limit 1/s -j TRACE
## Obtaining trace events
Users of the native nft tool can just run the nft trace mode:
# nft monitor trace
This prints out the received packet and all rules that match the packet (use CTRL-C to stop it):
trace id f0f627 ip raw prerouting packet: iif "veth0" ether saddr ..
We will examine this in more detail in the next section. If you use iptables, first check the installed version via the “*iptables –version”* command. Example:
# iptables --version
iptables v1.8.5 (legacy)
*(legacy)* means that trace events are logged to the kernel ring buffer. You will need to check *dmesg or* *journalctl*. The debug output lacks some information but is conceptually similar to the one provided by the new tools. You will need to check the rule line numbers that are logged and correlate those to the active iptables ruleset yourself. If the output shows *(nf_tables)*, you can use the xtables-monitor tool:
# xtables-monitor --trace
If the command only shows the version, you will also need to look at dmesg/journalctl instead. xtables-monitor uses the same kernel interface as the nft monitor trace tool. Their only difference is that it will print events in iptables syntax and that, if you use a mix of both iptables-nft and nft, it will be unable to print rules that use maps/sets and other nftables-only features.
## Example
Lets assume you’d like to debug a non-working port forward to a virtual machine or container. The command “ssh -p 1222 10.1.2.3” should provide remote access to a container running on the machine with that address, but the connection attempt times out.
You have access to the host running the container image. Log in and add a trace rule. See the earlier example on how to add a temporary debug table. The trace rule looks like this:
nft "insert rule inet trace_debug trace_pre ip daddr 10.1.2.3 tcp dport 1222 tcp flags syn limit rate 6/minute meta nftrace set 1"
After the rule has been added, start nft in trace mode: *nft monitor trace*, then retry the failed ssh command. This will generate a lot of output if the ruleset is large. Do not worry about the large example output below – the next section will do a line-by-line walkthrough.
trace id 9c01f8 inet trace_debug trace_pre packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
trace id 9c01f8 inet trace_debug trace_pre rule ip daddr 10.2.1.2 tcp dport 1222 tcp flags syn limit rate 6/minute meta nftrace set 1 (verdict continue)
trace id 9c01f8 inet trace_debug trace_pre verdict continue
trace id 9c01f8 inet trace_debug trace_pre policy accept
trace id 9c01f8 inet nat prerouting packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
trace id 9c01f8 inet nat prerouting rule ip daddr 10.1.2.3 tcp dport 1222 dnat ip to 192.168.70.10:22 (verdict accept)
trace id 9c01f8 inet filter forward packet: iif "enp0" oif "veth21" ether saddr .. ip daddr 192.168.70.10 .. tcp dport 22 tcp flags == syn tcp window 29200
trace id 9c01f8 inet filter forward rule ct status dnat jump allowed_dnats (verdict jump allowed_dnats)
trace id 9c01f8 inet filter allowed_dnats rule drop (verdict drop)
trace id 20a4ef inet trace_debug trace_pre packet: iif "enp0" ether saddr .. ip saddr 10.2.1.2 ip daddr 10.1.2.3 ip protocol tcp tcp dport 1222 tcp flags == syn
## Line-by-line trace walkthrough
The first line generated is the packet id that triggered the subsequent trace output. Even though this is in the same grammar as the nft rule syntax, it contains header fields of the packet that was just received. You will find the name of the receiving network interface (here named “enp0”) the source and destination mac addresses of the packet, the source ip address (can be important – maybe the reporter is connecting from a wrong/unexpected host) and the tcp source and destination ports. You will also see a “trace id” at the very beginning. This identification tells which incoming packet matched a rule. The second line contains the first rule matched by the packet:
trace id 9c01f8 inet trace_debug trace_pre rule ip daddr 10.2.1.2 tcp dport 1222 tcp flags syn limit rate 6/minute meta nftrace set 1 (verdict continue)
This is the just-added trace rule. The first rule is always one that activates packet tracing. If there would be other rules before this, we would not see them. If there is no trace output at all, the trace rule itself is never reached or does not match. The next two lines tell that there are no further rules and that the “trace_pre” hook allows the packet to continue (*verdict accept)*.
The next matching rule is
trace id 9c01f8 inet nat prerouting rule ip daddr 10.1.2.3 tcp dport 1222 dnat ip to 192.168.70.10:22 (verdict accept)
This rule sets up a mapping to a different address and port. Provided 192.168.70.10 really is the address of the desired VM, there is no problem so far. If its not the correct VM address, the address was either mistyped or the wrong NAT rule was matched.
## IP forwarding
Next we can see that the IP routing engine told the IP stack that the packet needs to be forwarded to another host:
trace id 9c01f8 inet filter forward packet: iif "enp0" oif "veth21" ether saddr .. ip daddr 192.168.70.10 .. tcp dport 22 tcp flags == syn tcp window 29200
This is another dump of the packet that was received, but there are a couple of interesting changes. There is now an output interface set. This did not exist previously because the previous rules are located before the routing decision (the prerouting hook). The id is the same as before, so this is still the same packet, but the address and port has already been altered. In case there are rules that match “tcp dport 1222” they will have no effect anymore on this packet.
If the line contains no output interface (oif), the routing decision steered the packet to the local host. Route debugging is a different topic and not covered here.
This tells that the packet matched a rule that jumps to a chain named “allowed_dnats”. The next line shows the source of the connection failure:
trace id 9c01f8 inet filter allowed_dnats rule drop (verdict drop)
The rule unconditionally drops the packet, so no further log output for the packet exists. The next output line is the result of a different packet:
The trace id is different, the packet however has the same content. This is a retransmit attempt: The first packet was dropped, so TCP re-tries. Ignore the remaining output, it does not contain new information. Time to inspect that chain.
## Ruleset investigation
The previous section found that the packet is dropped in a chain named “allowed_dnats” in the inet filter table. Time to look at it:
# nft list chain inet filter allowed_dnats
table inet filter {
chain allowed_dnats {
meta nfproto ipv4 ip daddr . tcp dport @allow_in accept
drop
}
}
The rule that accepts packets in the @allow_in set did not show up in the trace log. Double-check that the address is in the @allow_set by listing the element:
# nft "get element inet filter allow_in { 192.168.70.10 . 22 }"
Error: Could not process rule: No such file or directory
As expected, the address-service pair is not in the set. We add it now.
# nft "add element inet filter allow_in { 192.168.70.10 . 22 }"
Run the query command now, it will return the newly added element.
# nft "get element inet filter allow_in { 192.168.70.10 . 22 }" table inet filter { set allow_in { type ipv4_addr . inet_service elements = { 192.168.70.10 . 22 } } }
The ssh command should now work and the trace output reflects the change:
This shows the packet passes the last hook in the forwarding path – postrouting.
In case the connect is still not working, the problem is somewhere later in the packet pipeline and outside of the nftables ruleset.
## Summary
This Article gave an introduction on how to check for packet drops and other sources of connectivity problems with the nftables trace mechanism. A later post in the series shows how to inspect the connection tracking subsystem and the NAT information that may be attached to tracked flows.
## Bruno
Interesting post. I must admit that some kind of refresher about firewalld, iptables, ipset, nftables, eBPF and else would be useful. There has been many articles during the last 5 years, but a recap about the current status and legacy support, conversion program available would be nice.
## laolux
Thank you for this great article! It is clear and easy to understand and made me want to try for myself. And the result: works just as described 🙂 Great!
Cleanup is also very easy:
Now, only question is when I will really need this. Fedora is so awesome (or I do only too basic stuff) that I never ran into connection problems on my side
## Pavel
very well written, thanks! can’t wait for part2! |
13,365 | Fedora Linux 34 各版本介绍 | https://fedoramagazine.org/announcing-fedora-34/ | 2021-05-06T12:16:15 | [
"Fedora"
] | https://linux.cn/article-13365-1.html | 
今天(4/27),我很高兴地与大家分享成千上万的 Fedora 项目贡献者的辛勤工作成果:我们的最新版本,Fedora Linux 34 来了!我知道你们中的很多人一直在等待。我在社交媒体和论坛上看到的“它出来了吗?”的期待比我记忆中的任何一个版本都多。所以,如果你想的话,不要再等了,[现在升级](https://docs.fedoraproject.org/en-US/quick-docs/upgrading/) 或者去 [获取 Fedora](https://getfedora.org) 下载一个安装镜像。或者,如果你想先了解更多,请继续阅读。
你可能注意到的第一件事是我们漂亮的新标志。这个新标志是由 Fedora 设计团队根据广大社区的意见开发的,它在保持 Fedoraness 的同时解决了我们旧标志的很多技术问题。请继续关注以新设计为特色的 Fedora 宣传品。
### 适合各种使用场景的 Fedora Linux
Fedora Editions 面向桌面、服务器、云环境和物联网等各种特定场景。
Fedora Workstation 专注于台式机,尤其是面向那些希望获得“正常使用”的 Linux 操作系统体验的软件开发者。这个版本的带来了 [GNOME 40](https://forty.gnome.org/),这是专注、无干扰计算的下一步。无论你使用触控板、键盘还是鼠标,GNOME 40 都带来了导航方面的改进。应用网格和设置已经被重新设计,以使交互更加直观。你可以从 3 月份的 [Fedora Magazine](https://fedoramagazine.org/fedora-34-feature-focus-updated-activities-overview/) 文章中阅读更多的变化和原因。
Fedora CoreOS 是一个新兴的 Fedora 版本。它是一个自动更新的最小化操作系统,用于安全和大规模地运行容器化工作负载。它提供了几个更新流,跟随它之后大约每两周自动更新一次,当前,next 流基于 Fedora Linux 34,随后是 testing 流和 stable 流。你可以从 [下载页面](https://getfedora.org/en/coreos) 中找到关于跟随 next 流的已发布工件的信息,以及在 [Fedora CoreOS 文档](https://docs.fedoraproject.org/en-US/fedora-coreos/) 中找到如何使用这些工件的信息。
Fedora IoT 为物联网生态系统和边缘计算场景提供了一个强大的基础。在这个版本中,我们改善了对流行的 ARM 设备的支持,如 Pine64、RockPro64 和 Jetson Xavier NX。一些 i.MX8 片上系统设备,如 96boards Thor96 和 Solid Run HummingBoard-M 的硬件支持也有所改善。此外,Fedora IoT 34 改进了对用于自动系统恢复的硬件看门狗的支持。
当然,我们不仅仅提供 Editions。[Fedora Spins](https://spins.fedoraproject.org/) 和 [Labs](https://labs.fedoraproject.org/) 针对不同的受众和使用情况,例如 [Fedora Jam](https://labs.fedoraproject.org/en/jam/),它允许你释放你内心的音乐家,以及像新的 Fedora i3 Spin 这样的桌面环境,它提供了一个平铺的窗口管理器。还有,别忘了我们的备用架构。[ARM AArch64 Power 和 S390x](https://alt.fedoraproject.org/alt/)。
### 一般性改进
无论你使用的是 Fedora 的哪个变种,你都会得到开源世界所能提供的最新成果。秉承我们的 “[First](https://docs.fedoraproject.org/en-US/project/#_first)” 原则,我们已经更新了关键的编程语言和系统库包,包括 Ruby 3.0 和 Golang 1.16。在 Fedora KDE Plasma 中,我们已经从 X11 切换到 Wayland 作为默认。
在 Fedora Linux 33 中 BTRFS 作为桌面变体中的默认文件系统引入之后,我们又引入了 [BTRFS 文件系统的透明压缩](https://fedoramagazine.org/fedora-workstation-34-feature-focus-btrfs-transparent-compression/)。
我们很高兴你能试用这个新发布版本!现在就去 <https://getfedora.org/> 下载它。或者如果你已经在运行 Fedora Linux,请按照 [简易升级说明](https://docs.fedoraproject.org/en-US/quick-docs/upgrading/)。关于 Fedora Linux 34 的新功能的更多信息,请看 [发行说明](https://docs.fedoraproject.org/en-US/fedora/f34/release-notes/)。
### 万一出现问题……
如果你遇到了问题,请查看 [Fedora 34 常见问题页面](https://fedoraproject.org/wiki/Common_F34_bugs),如果你有问题,请访问我们的 Ask Fedora 用户支持平台。
### 谢谢各位
感谢在这个发布周期中为 Fedora 项目做出贡献的成千上万的人,特别是那些在大流行期间为使这个版本按时发布而付出额外努力的人。Fedora 是一个社区,很高兴看到我们如此互相支持!
---
via: <https://fedoramagazine.org/announcing-fedora-34/>
作者:[Matthew Miller](https://fedoramagazine.org/author/mattdm/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today, I’m excited to share the results of the hard work of thousands of contributors to the Fedora Project: our latest release, Fedora Linux 34, is here! I know a lot of you have been waiting… I’ve seen more “is it out yet???” anticipation on social media and forums than I can remember for any previous release. So, if you want, wait no longer — [upgrade now](https://docs.fedoraproject.org/en-US/quick-docs/upgrading/) or go to [Get Fedora](https://getfedora.org) to download an install image. Or, if you’d like to learn more first, read on.
The first thing you might notice is our beautiful new logo. Developed by the Fedora Design Team with input from the wider community, this new logo solves a lot of the technical problems with our old logo while keeping its Fedoraness. Stay tuned for new Fedora swag featuring the new design!
## A Fedora Linux for every use case
Fedora Editions are targeted outputs geared toward specific “showcase” uses on the desktop, in server & cloud environments, and the Internet of Things.
Fedora Workstation focuses on the desktop, and in particular, it’s geared toward software developers who want a “just works” Linux operating system experience. This release features [GNOME 40](https://forty.gnome.org/), the next step in focused, distraction-free computing. GNOME 40 brings improvements to navigation whether you use a trackpad, a keyboard, or a mouse. The app grid and settings have been redesigned to make interaction more intuitive. You can read more about [what changed and why in a Fedora Magazine article](https://fedoramagazine.org/fedora-34-feature-focus-updated-activities-overview/) from March.
Fedora CoreOS is an emerging Fedora Edition. It’s an automatically-updating, minimal operating system for running containerized workloads securely and at scale. It offers several update streams that can be followed for automatic updates that occur roughly every two weeks. Currently the next stream is based on Fedora Linux 34, with the testing and stable streams to follow. You can find information about released artifacts that follow the next stream from the [download page](https://getfedora.org/en/coreos) and information about how to use those artifacts in the [Fedora CoreOS Documentation](https://docs.fedoraproject.org/en-US/fedora-coreos/).
Fedora IoT provides a strong foundation for IoT ecosystems and edge computing use cases. With this release, we’ve improved support for popular ARM devices like Pine64, RockPro64, and Jetson Xavier NX. Some i.MX8 system on a chip devices like the 96boards Thor96 and Solid Run HummingBoard-M have improved hardware support. In addition, Fedora IoT 34 improves support for hardware watchdogs for automated system recovery.”
Of course, we produce more than just the Editions. [Fedora Spins](https://spins.fedoraproject.org/) and [Labs](https://labs.fedoraproject.org/) target a variety of audiences and use cases, including [Fedora Jam](https://labs.fedoraproject.org/en/jam/), which allows you to unleash your inner musician, and desktop environments like the new Fedora i3 Spin, which provides a tiling window manager. And, don’t forget our alternate architectures: [ARM AArch64, Power, and S390x](https://alt.fedoraproject.org/alt/).
## General improvements
No matter what variant of Fedora you use, you’re getting the latest the open source world has to offer. Following our “[First](https://docs.fedoraproject.org/en-US/project/#_first)” foundation, we’ve updated key programming language and system library packages, including Ruby 3.0 and Golang 1.16. In Fedora KDE Plasma, we’ve switched from X11 to Wayland as the default.
Following the introduction of BTRFS as the default filesystem on desktop variants in Fedora Linux 33, we’ve introduced [transparent compression on BTRFS filesystems](https://fedoramagazine.org/fedora-workstation-34-feature-focus-btrfs-transparent-compression/).
We’re excited for you to try out the new release! Go to [https://getfedora.org/](https://getfedora.org/) and download it now. Or if you’re already running Fedora Linux, follow the [easy upgrade instructions](https://docs.fedoraproject.org/en-US/quick-docs/upgrading/). For more information on the new features in Fedora Linux 34, see the [release notes](https://docs.fedoraproject.org/en-US/fedora/f34/release-notes/).
## In the unlikely event of a problem…
If you run into a problem, check out the [Fedora 34 Common Bugs page](https://fedoraproject.org/wiki/Common_F34_bugs), and if you have questions, visit our Ask Fedora user-support platform.
## Thank you everyone
Thanks to the thousands of people who contributed to the Fedora Project in this release cycle, and especially to those of you who worked extra hard to make this another on-time release during a pandemic. Fedora is a community, and it’s great to see how much we’ve supported each other. Be sure to join us on April 30 and May 1 for a [virtual release party](https://hopin.com/events/fedora-linux-34-release-party)!
## Striker Leggette
I suppose I can finally make the move from F30 🙂
## Asiri Iroshan
You are still using Fedora 30? What made you not upgrade to the newer versions? I have been upgrading Fedora from Fedora 30, but, I plan on doing a fresh installation for Fedora 34 because of its many changes. Including the BTRFS file system that became the default in F33.
## david
Great job to all the Fedora community!
keep the good work going!
## Charles
congratulations! I’m exciting.
## Rigol
I love Fedora. Great work!
## Ryan
Thanks guys! Great work on this release, I’ve already started testing it as of this morning and it’s working great. Wayland and KDE is actually working and pipewire has not given me any grief so far. Initially had some font related issues, but resetting my system fonts (which i customised in F33) back to default fixed most of those. The only application I’ve found still not displaying fonts properly is GIMP which I have raised a bug report for after researching the issue pretty extensively and trying a few ‘fixes’.
## Marco
Upgrade applied! Very nice!
My only disagree is to keep some rpm with previous distro version in their name (eg: bitstream-vera-sans-fonts-1.10-41.fc33.noarch.rpm)
It should be nice to have all packages with fc34 distro in their name 🙂
## Rabin
This 3 magic lines 😛
sudo dnf system-upgrade download --releasever=34
sudo dnf system-upgrade reboot
## Matthias Lätzsch
Thank you.
## Rajkumar
Uhy8
## Jatin
There are many people getting iptables update errors when they update from F33 to F34, there are reports on Fedora reddit and discord. Please address them. Thanks.
## Ben Cotton
Please file a bug in Bugzilla or see this article about our Prioritized Bugs process.
## Ben Cotton
Actually, it looks like iptables as an update that fixes upgrades, it may just not be out to all of the mirrors yet.
## V S Sridharan
While updating from fedora 33 To 34 the process got stuck at 38 % for the past 3 hours . What do zi do?
## Gregory Bartholomew
V S Sridharan:
I’d suggest starting a thread on ask.fedoraproject.org. I know at least one other person reported issues with their upgrade there. There might be someone there who knows what the problem is and how to fix it. Sorry that your upgrade didn’t go smoothly. Fedora Linux is working on a rollback feature for their Btrfs-formatted editions which should make fixing this sort of problem much easier in the future. Unfortunately, rollback isn’t available for Fedora Workstation 34 just yet. 🙁
## Marco
I had the same issue on iptables. Just ignore it and after the upgrade run
sudo dnf update
## Jatin
Ya I did the same.. Landed in Fedora 34 however I have 2 issues first is
https://pastebin.com/gaB72MnS
And on Xorg my display is yellow, at first I thought nightlight could be on, but it was off, on wayland the display is fine !
## sixpack13
Thanks to all
## Gingler
First of all congratulations on the new release. It would nice that fedora played nice with intel/nvidia laptops, its a problem to install and after install the performance compared to other distros specially on the offload render its far away. I hope in the future i can have a better experience with fedora.
## Umaralikhon
Thank youuuuuuuuuuuuuu!!!!!!
## Andre Gompel
First thanks to the Fedora team, for releasing an almost boring (means good!) Fedora 34, which means very few wrinkles, even with the Beta release that I installed almost two months before F34 release. (I use MATE)
The only small (not show-stopper) that I experienced were with the BlueTooth, and the Network manager, and were quickly fixed. I also reported as a solid bug the package “Digikam” which was fixed within two days ! Wow !
I am a “linux old salty” and as such love Fedora, which means not afraid to used the CLI (Command Line Interface), but as long as there are not GUI’s to install and manage Fedora by “not-nerds” Fedora will remain the realm of the computer-literate, perhaps its place for ever, as the place to develop, and test RHLE versions? Ideally Linux for everyone, like Ubuntu (and derivatives aim at).
On the install too there is room, not only Fedora, but for other distro’s as well to do the following from all GUI’s, So I can recommend Fedora/Linux to my scientists friends:
* Allow install over new or existing BRTFS volumes and subvolumes, so date there can be preserved.
Most of us do this routinely, but only most of us Linux nerds !
Let’s open the tent…
Thanks again !
A.G
Please comment.
## Gianni
Thanks
upgrading now
## Renich Bon Ćirić
I, also, like to use https://torrents.fedoraproject.org/ to get my latest Fedora. Plus, I can contribute a little bit of bandwidth afterwards. ;D
## Renich Bon Ćirić
Another thing. If you like a bit more of control when installing (advanced installation), download the Server and not the Workstation image. The installer allows for much more control over the installation.
## Matthew Miller
Or the “Everything” net install image.
## Renich Bon Ćirić
Yup!
## Joe
This the only distro that I use. Awesome! Thanks.
## Mark Pearson
Congrats Fedora team! Looks like a great release.
## Jorge Marin
I was looking forward to the stable version, now it’s finally here, thanks fedora. ^^)
## gruiz
Me encanta fedora 34 desde que sacateis la beta he estado trabajando sin problemas, una maravilla Gnome 40. Gracias
## Nun4tix
Thank you for the hard work, thank you to the community, thank you for giving us the fruits of your time and dedication. Long live contributors around the world.
## Aaron Stark
Nice to see the release of my favourite version ever. Fedora 34 Workstation feels so well on my laptop with my Intel iGPU, thanks to Gnome 40 and Wayland, the support is better than ever. I’ve installed Fedora 34 on all my laptops, even a 15 years old laptop can handle Gnome 40 Wayland with no problems.
## omar
Felicidades!!!!!!.
## Gabriel Hernandez
I just upgraded from Fedora 33 to 34 and it took less than 15 minute, and I have a 5 year old laptop, so this upgrade is really quick. Gnome 40 is great, it looks much more polished and easy to navigate than previous versions
## Mahassan313
Great
## AlexB
I must say I wasn’t hugely impressed by a few things
A ew Classic developer errors that are common but very bad practice.
The software center got stuck at about 30% telling me nothing. I killed it after 15 minutes. I resorted to a command line upgrade. After reboot the progress bar was stuck at 0% for a good few minutes, so thought it was stuck (Never happened in previous versions). Rebooted, once again, the progress bar did the same thing. After a good few minutes it went up to 1% and steadily thereafter.
Golden rule of GUI development. I think the rule in books I read went as extreme as advising 3 seconds. You must let users know in some way via a useful progress bar it is actually progressing. A little console displaying update details (I think POP and or Ubuntu has this) would be useful.
I have seen this issue plague GNOME apps also over the years. The software center a good example.
The default login on NVIDIA was wayland. Bad idea. Within seconds there were graphical issues. Mouse pointers sprouting all over my screen. Resorted to an Xorg login. Everything seems okay.
33 received 5.16 before 34. The grub boot order is now strange with Fedora 34 in the middle option, not the latesrt, probably will sort itself out once 5.16 arrives in 34.
I’ll keep playing. Hopefully the GNOME high CPU usage under X with heavy input has been resolved.
Otherwise i am happy, at least I didn’t have to reinstall, so congrats everyone 🙂
## AlexB
Well, been running Wayland session for an hour now with NVIDIA0, so could it be ? finally it works. It was only shortly after install it went haywire. People should give it a try definitely, contrary what I said, and my experience with older versions.
It may be a placebo, but it all feels a smidgen more responsive with the mouse.
## Adhul.
i am new to this linux ecosystem, can you tell me which distribution should i use?
fedora or pop which one you prefer?!
## Roy Ritonga
fedora
## Bat
Thank you
## Hugo
I was hoping that for this release, Silverblue would be available alongside the other fedora spin.
## Levski
dnf system-upgrade download –releasever=34
No match for group package “xorg-x11-drv-armsoc”
No match for group package “k3b-extras-freeworld”
No match for group package “gstreamer1-plugins-bad-nonfree”
No match for group package “banshee”
No match for group package “lsvpd”
No match for group package “bcm283x-firmware”
No match for group package “lame-mp3x”
No match for group package “khmeros-handwritten-fonts”
No match for group package “khmeros-bokor-fonts”
No match for group package “vdr-skinsoppalusikka”
No match for group package “khmeros-metal-chrieng-fonts”
No match for group package “khmeros-muol-fonts”
No match for group package “powerpc-utils”
No match for group package “khmeros-siemreap-fonts”
No match for group package “libguestfs-tools”
No match for group package “khmeros-battambang-fonts”
No match for group package “sonic-visualiser-freeworld”
Error:
Problem 1: problem with installed package xfce4-sensors-plugin-devel-1.3.92-6.fc33.x86_64
– package xfce4-sensors-plugin-devel-1.3.95-2.fc34.x86_64 requires pkgconfig(libxfce4ui-1), but none of the providers can be installed
– xfce4-sensors-plugin-devel-1.3.92-6.fc33.x86_64 does not belong to a distupgrade repository
– libxfce4ui-devel-4.14.1-6.fc33.x86_64 does not belong to a distupgrade repository
Problem 2: problem with installed package xfce4-equake-plugin-1.3.8.1-12.fc33.x86_64
– package xfce4-equake-plugin-1.3.8.1-12.fc33.x86_64 requires libxfce4panel-1.0.so.4()(64bit), but none of the providers can be installed
– xfce4-panel-4.14.4-3.fc33.x86_64 does not belong to a distupgrade repository
(try to add ‘–skip-broken’ to skip uninstallable packages)
[root@pepo ~]#
## Matthew Miller
Try doing what it says:
## Levski
Thanks @Matthew Miller
After remove
xfce4-sensors-plugin-devel
libxfce4ui-devel
xfce4-equake-plugin
everything works!
Now from Fedora 34 workstation
[bgpepi@pepo ~]$ cat /etc/os-release
NAME=Fedora
VERSION=”34 (Workstation Edition)”
ID=fedora
VERSION_ID=34
VERSION_CODENAME=””
PLATFORM_ID=”platform:f34″
PRETTY_NAME=”Fedora 34 (Workstation Edition)”
ANSI_COLOR=”0;38;2;60;110;180″
LOGO=fedora-logo-icon
CPE_NAME=”cpe:/o:fedoraproject:fedora:34″
HOME_URL=”https://fedoraproject.org/”
DOCUMENTATION_URL=”https://docs.fedoraproject.org/en-US/fedora/34/system-administrators-guide/”
SUPPORT_URL=”https://fedoraproject.org/wiki/Communicating_and_getting_help”
BUG_REPORT_URL=”https://bugzilla.redhat.com/”
REDHAT_BUGZILLA_PRODUCT=”Fedora”
REDHAT_BUGZILLA_PRODUCT_VERSION=34
REDHAT_SUPPORT_PRODUCT=”Fedora”
REDHAT_SUPPORT_PRODUCT_VERSION=34
PRIVACY_POLICY_URL=”https://fedoraproject.org/wiki/Legal:PrivacyPolicy”
VARIANT=”Workstation Edition”
VARIANT_ID=workstation
[bgpepi@pepo ~]$
What is not normal is this:
[bgpepi@pepo ~]$ uname -a
Linux pepo 5.11.16-200.fc33.x86_64 #1 SMP Wed Apr 21 16:08:37 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
Kernel is still from 33 release: 5.11.16-200.fc33
## Nun4atix
Please be patient and do everything correctly, with information in hand. Let’s support the fedora team, ask about issues, and report bugs in the right way.
## Malik Tamboli
Congratulations fedora team, Great work
## Alex
If you run into this:
$ sudo dnf system-upgrade download –releasever=34 –skip-broken
Error:
Problem: rdma-core-34.0-1.fc33.i686 has inferior architecture
– rdma-core-34.0-1.fc33.x86_64 does not belong to a distupgrade repository
– problem with installed package rdma-core-34.0-1.fc33.i686
Then you can upgrade rdma-core.x86_64 to the f34 version (this transaction will replace rdma-core.i686)
$ sudo dnf install rdma-core-34.0-3.fc34.x86_64 –releasever=34
Once that’s complete, you can proceed with your upgrade to f34.
$ sudo dnf system-upgrade download –releasever=34 –skip-broken
## R
Valuable hint and thanks for this. However double “–skip broken” but not “–skip-broken” and “–releasever=34” but not “–releasever=34″. Thank you anyway.
Have you’ve got an idea what to do with:
” – libhandy-0.0.13-6.fc33.x86_64 does not belong to a distupgrade repository
(try to add ‘–skip-broken’ to skip uninstallable packages)”
Seems as if some libs are missing in version 34 or have been replaced by s.th. I do not know.
Thanks for any support or idea.
## Alex
The way I figured out the correct package name to install for f34 while on f33 was to run
.
Trying that search with libhandy suggests perhaps
would help here.
& yes, formatting is turning my double-hyphen “–” into “–”.
## Gian Paolo
I had to brute-force this upgrade by first removing the offending package with rpm -e –nodeps and THEN install with dnf, before it went through with the upgrade.
## Dinu Radhakrishnan
Great work! I have been waiting to upgrade my daily driver ever since I tried the beta. Loving the changes in GNOME.
Thanks again Fedora Team, for another excellent release.
## idoric
Congratulations and well done to the fedora team. Can we expect a sticker with the new logo? (with the logo and the name it would be perfect ;))
## Matthew Miller
Yes, stickers will happen soon!
## Kanwar
I’ve been running F34 (KDE Plasma spin) since it’s beta release and loving it. I’ve been a non-RPM user for a long time but happy to get back.
That being said, Wayland as default has a major disadvantage for those running Zoom for daily work. Screen sharing is limited to application windows only. A screen cannot be shared.
Not sure if there is any fix for that (besides switching in to an X11 session).
## Ricardo
Bluetooth audio issues :
My headphones or any Bluetooth audio player does not work well !!
Waiting for a fix.
## Jeffrey Goh
Yay! Downloading now for my T470 right now! every new release improves benchmark numbers (and user experience) over the previous.
## AlexB
FY I . If you are an NVIDIA user and trying a GNOME Wayland session I can shed some more light on the erratic GNOME behaviour I experienced earlier.
GTK4 apps do not run in GNOME40. not even a single one. it even crashes the shell. Hope that gets fixed pronto. that’s pretty serious one IMO.
Fine under Xorg. Everything else under a Wayland session worked fine so far.
haven’t tried a GTK4 flatpak.
The same gtk4 progs worked fine in 3.38
## Darvond
Surprisingly I was most excited for the new version of XFCE and the new i3 spin; I’m curious to see if many will give it a try now that it’s actually properly visible.
Really like this edition’s wallapaper, kudos to the team for that.
I’ve been using 34 for a few days, so it’s all been nice. I’m still amazed at how refreshingly direct the upgrade process is. No crossed fingers or prayers to Bell Labs needed.
## sampsonf
I have the i3 spin installed to my old notebook with only 2GB of ram.
It is very usable.
What I wanted next is able to install and use Chinese Input Method – Cangjie .
## joe
take RIME input method into consideratuon
## Roger
Judging by the number and persistence of peers on my bittorrent client when I downloaded Fedora 34 I would say that interest in Fedora was piqued with this release.
## Daniel
Correction: Should say 34.
## Luc
Hi, the only problem I had was pipewire. Unfortunately https://fedoraproject.org/wiki/Common_F34_bugs is not very precise, all the conf files including subfolders in /etc/pipewire need to be removed.
I solved it by:
mv /etc/pipewire /etc/pipewire.old
dnf reinstall pipewire-alsa.x86_64 pipewire-gstreamer.x86_64 pipewire-pulseaudio.x86_64 pipewire
systemctl –user restart pipewire pipewire-pulse
And all started working again 🙂
Thanks,
Luc
## MrMarcie
Very nice as always. I only have one issue (using XFCE):
When my PC comes back from sleep I can’t input my password so I have to restart PC.
## Carlos
Congratulations Fedora Team! Great job!
## Drew
Video is very choppy with AMD Ryzen 3050U processor! Firefox won’t stream video – neither will Chromium or Brave!
Looks nice but not useable!
## Peter
Another fantastic edition – thank you all.
You know I eagerly wait for each new Fedora release like I used to wait for the “Hotspur” magazine when I was but a boy!
## Shahnawaz
I have already installed Fedora34/Gnome40 and find that touchscreen of my all-in-one pc is not working.
Hardware: I-Life Digital Technologies LLC ZED-PC
Processor: Intel® Celeron(R) CPU N3350 @ 1.10GHz × 2
Graphic: Mesa Intel® HD Graphics 500 (APL 2)
Intel have already said they do not have Linux driver for this machine..
Any help?
## JAI BIR
Unable to upgrade to Fedora 34. Getting the following error
Error: Transaction test error: file /usr/share/pixmaps/poweredby.png conflicts between attempted installs of generic-logos-httpd-18.0.0-12.fc34.noarch and fedora-logos-httpd-34.0.2-2.fc34.noarch
## George Murdocca
I solved this issue with the following commands:
rpm -ev –nodeps generic-logos-httpd
dnf install fedora-logos-httpd -y
Hope this helps.
## Luiz Carlos
Strange. I upgrade and after, the web go stand off. But only in Plasma, on Genome and Cinnamon was right. I restart and nothing. Entering in Cinnamon, I update packages that was quering and shutdown to work. Now, from nothing come on line. Strange. Baut good, is my 5 upgrade on Fedora and no more crashes occurred like in pass. Congratulations.
## Erik
Hello! I am just starting to explore F34 in a virtual machine.
My initial comment: I like the default wallpaper in F34 much better than F33!
I am wondering what the proper art credit for the F34 background is? Looking on the discussion website for it (https://pagure.io/design/issue/688), it seems to me the design has been created as a group effort/by committee. If that’s true, what’s the proper credit? Not planning on using it elsewhere, but wondering nonetheless.
Thanks!
## Marcel Hergaarden
Thank you very much Fedora team !
Upgrade went smoothly and all works like a charm.
## rfm83
Another great release! Smooth upgrade from F33. No issues so far on both Gnome and KDE.
## Brian
dnf system-upgrade download –releasever=34 –skip-broken –best –allowerasing
Ignoring repositories: fedora-cisco-openh264
No match for group package “paratype-pt-sans-fonts”
No match for group package “dnf-yum”
No match for group package “kexec-tools-anaconda-addon”
No match for group package “fedora-user-agent-chrome”
No match for group package “totem-nautilus”
Failed to download metadata for repo ‘fedora-cisco-openh264’: Cannot download repomd.xml: Cannot download repodata/repomd.xml: All mirrors were tried
cannot install the best update candidate for package iptables-1.8.5-6.fc33.x86_64
– problem with installed package iptables-1.8.5-6.fc33.x86_64
– package iptables-1.8.7-3.fc34.x86_64 requires iptables-libs(x86-64) = 1.8.7-3.fc34, but none of the providers can be installed
– cannot install the best update candidate for package iptables-libs-1.8.5-6.fc33.x86_64
– cannot install both iptables-libs-1.8.7-3.fc34.x86_64 and iptables-libs-1.8.7-6.fc34.x86_64
– iptables-1.8.5-6.fc33.x86_64 does not belong to a distupgrade repository
This is the first Fedora distribution to fail from the beginning on my machine. Using nVidia graphics.
I’ve been using Fedora since before Fedora Core 1 — it was still Red Hat.
I’ll try again in a month.
## vinu
Upgraded to 34 from 33. Thinkpad t450. Lot of animation bugs, glitching. Switching to xfce for the time being.
## Jason M
A beautiful OS, but avoid at all costs if you’re an Nvidia user.
Sadly I jumped, took the upgrade, it’s stunning, but now I can’t do anything remotely intensive. I would buy an AMD GPU, if there were any GPUs ever in stock. There is no ability to rollback, so now I have the painful process of finding the F33 ISO, and making a fresh install. Nvidias lack of support for Wayland is shameful.
## Lars-Åke
varför är inte svenska med i installationen för fedora 34
## Dmitry
Great work guys!
## Bill Davidsen
Only one bug, using Fedora with Cinnamon (both spin and workstation with Cinnamon added) the system-monitor crashes. Fails both virgins install both ways, I tried an update from FC33, and Intel, AMD, and ATOM (4 core). Tried to install on VM for qemu-kvm, tested using the software screen, installed NVIDIA and that failed too.
And the mate-system-monitor works.
## Martin Karari
I upgraded successfully from Fedora 33.
The only issue I have is that Software Centre keeps crashing
I have submitted the buy
## Michael Cassidy
I’m using an HP Pavilion notebook, 32-bit Core 2 duo, 1.5 GHz, 2GB RAM, 1 TB Hard Drive. Which version of Fedora Linux would be best to run on this system, this latest one, Fedora 34, or an earlier copy? Thank you.
## Gregory Bartholomew
Your system meets the
minimumrequirements, but it is well under the recommended specification. All editions of Fedora Linux 34shouldinstall, but performance may not be great, especially with the new GNOME desktop environment. You might want to consider installing one of the spins that require slightly less system memory such as LXDE or i3.P.S. Intel Core 2 Duo’s are 64-bit processors.
## Alessio Annunziata
Fedora 34 is only causing problems. KRDC cant open multiple RDP windows anymore. You cant fast-switch between multiple windows of a single program anymore by just clicking the said program multiple times. The Desktop (Plasma from KDE) crashes everytime I open a new Terminal window via mouse wheel button.
Hope these problems get fixed…its impossible to work under these conditions. 🙁
## Arbyway
I can’t get Fedora 34 to install alongside Windows 10! Help! I deleted the partition KDE Neon was on but the install keeps displaying an error!
## tom
Hi there,
i result into “removing” gnome-shell and therefore i don’t know if i should
or what may cause the issue.
Any help would be appreciated.
Output:
sudo dnf system-upgrade download –releasever=34
Bevor Sie fortfahren, stelle Sie bitte sicher, das alle Aktualisierungen installiert sind. Dies kann durch den Aufruf von “dnf –refresh upgrade” erfolgen. Wollen Sie fortfahren? [y/N]: y
Copr repo for OpenRGB owned by r3pek 9.3 kB/s | 3.3 kB 00:00
Fedora 34 – x86_64 48 kB/s | 26 kB 00:00
Fedora 34 openh264 (From Cisco) – x86_64 2.6 kB/s | 989 B 00:00
Fedora Modular 34 – x86_64 51 kB/s | 25 kB 00:00
Fedora 34 – x86_64 – Updates 45 kB/s | 23 kB 00:00
Fedora Modular 34 – x86_64 – Updates 47 kB/s | 23 kB 00:00
Photivo – photo processor (Fedora_33) 17 kB/s | 1.7 kB 00:00
RPM Fusion for Fedora 34 – Free 21 kB/s | 7.9 kB 00:00
RPM Fusion for Fedora 34 – Free tainted 19 kB/s | 7.3 kB 00:00
RPM Fusion for Fedora 34 – Free – Updates 20 kB/s | 7.3 kB 00:00
RPM Fusion for Fedora 34 – Nonfree 21 kB/s | 8.0 kB 00:00
RPM Fusion for Fedora 34 – Nonfree – Steam 20 kB/s | 7.3 kB 00:00
RPM Fusion for Fedora 34 – Nonfree – Updates 20 kB/s | 7.4 kB 00:00
Fedora – – VirtualBox 702 B/s | 181 B 00:00
Keine Übereinstimmung für Gruppenpaket “xorg-x11-drv-armsoc”
Keine Übereinstimmung für Gruppenpaket “k3b-extras-freeworld”
Keine Übereinstimmung für Gruppenpaket “typemade-josefinsansstd-light-fonts”
Keine Übereinstimmung für Gruppenpaket “totem-nautilus”
Keine Übereinstimmung für Gruppenpaket “cf-sorts-mill-goudy-fonts”
Keine Übereinstimmung für Gruppenpaket “senamirmir-washra-tint-fonts”
Keine Übereinstimmung für Gruppenpaket “kranky-fonts”
Keine Übereinstimmung für Gruppenpaket “senamirmir-washra-zelan-fonts”
Keine Übereinstimmung für Gruppenpaket “senamirmir-washra-wookianos-fonts”
Keine Übereinstimmung für Gruppenpaket “google-croscore-tinos-fonts”
Keine Übereinstimmung für Gruppenpaket “senamirmir-washra-jiret-fonts”
Keine Übereinstimmung für Gruppenpaket “tlomt-orbitron-fonts”
Keine Übereinstimmung für Gruppenpaket “lsvpd”
Keine Übereinstimmung für Gruppenpaket “isight-firmware-tools”
Keine Übereinstimmung für Gruppenpaket “oflb-brett-fonts”
Keine Übereinstimmung für Gruppenpaket “ecolier-court-lignes-fonts”
Keine Übereinstimmung für Gruppenpaket “atomic”
Keine Übereinstimmung für Gruppenpaket “smc-raghumalayalam-fonts”
Keine Übereinstimmung für Gruppenpaket “wallpoet-fonts”
Keine Übereinstimmung für Gruppenpaket “phetsarath-fonts”
Keine Übereinstimmung für Gruppenpaket “carterone-fonts”
Keine Übereinstimmung für Gruppenpaket “xorg-x11-drv-geode”
Keine Übereinstimmung für Gruppenpaket “cvsgraph”
Keine Übereinstimmung für Gruppenpaket “paratype-pt-sans-fonts”
Keine Übereinstimmung für Gruppenpaket “khmeros-muol-fonts”
Keine Übereinstimmung für Gruppenpaket “senamirmir-washra-yigezu-bisrat-gothic-fonts”
Keine Übereinstimmung für Gruppenpaket “monofett-fonts”
Keine Übereinstimmung für Gruppenpaket “paratype-pt-sans-caption-fonts”
Keine Übereinstimmung für Gruppenpaket “xcdroast”
Keine Übereinstimmung für Gruppenpaket “gstreamer1-plugins-bad-nonfree”
Keine Übereinstimmung für Gruppenpaket “smc-kalyani-fonts”
Keine Übereinstimmung für Gruppenpaket “tomahawk”
Keine Übereinstimmung für Gruppenpaket “google-croscore-arimo-fonts”
Keine Übereinstimmung für Gruppenpaket “google-crosextra-carlito-fonts”
Keine Übereinstimmung für Gruppenpaket “banshee”
Keine Übereinstimmung für Gruppenpaket “cmusphinx3”
Keine Übereinstimmung für Gruppenpaket “sarai-fonts”
Keine Übereinstimmung für Gruppenpaket “specialelite-fonts”
Keine Übereinstimmung für Gruppenpaket “google-crosextra-caladea-fonts”
Keine Übereinstimmung für Gruppenpaket “tuladha-jejeg-fonts”
Keine Übereinstimmung für Gruppenpaket “oflb-roadstencil-fonts”
Keine Übereinstimmung für Gruppenpaket “oflb-sportrop-fonts”
Keine Übereinstimmung für Gruppenpaket “sphinxtrain”
Keine Übereinstimmung für Gruppenpaket “apanov-edrip-fonts”
Keine Übereinstimmung für Gruppenpaket “aldusleaf-crimson-text-fonts”
Keine Übereinstimmung für Gruppenpaket “google-croscore-symbolneu-fonts”
Keine Übereinstimmung für Gruppenpaket “tabish-eeyek-fonts”
Keine Übereinstimmung für Gruppenpaket “khmeros-siemreap-fonts”
Keine Übereinstimmung für Gruppenpaket “xmms-adplug”
Keine Übereinstimmung für Gruppenpaket “senamirmir-washra-fantuwua-fonts”
Keine Übereinstimmung für Gruppenpaket “pyvnc2swf”
Keine Übereinstimmung für Gruppenpaket “khmeros-battambang-fonts”
Keine Übereinstimmung für Gruppenpaket “tharlon-fonts”
Keine Übereinstimmung für Gruppenpaket “archmage”
Keine Übereinstimmung für Gruppenpaket “exaile”
Keine Übereinstimmung für Gruppenpaket “lame-mp3x”
Keine Übereinstimmung für Gruppenpaket “google-croscore-cousine-fonts”
Keine Übereinstimmung für Gruppenpaket “nyquist”
Keine Übereinstimmung für Gruppenpaket “google-noto-sans-balinese-fonts”
Keine Übereinstimmung für Gruppenpaket “bzr”
Keine Übereinstimmung für Gruppenpaket “senamirmir-washra-yigezu-bisrat-goffer-fonts”
Keine Übereinstimmung für Gruppenpaket “whaawmp”
Keine Übereinstimmung für Gruppenpaket “labelleaurore-fonts”
Keine Übereinstimmung für Gruppenpaket “cockpit-docker”
Keine Übereinstimmung für Gruppenpaket “impallari-lobster-fonts”
Keine Übereinstimmung für Gruppenpaket “docker”
Keine Übereinstimmung für Gruppenpaket “moyogo-molengo-fonts”
Keine Übereinstimmung für Gruppenpaket “vdr-tvonscreen”
Keine Übereinstimmung für Gruppenpaket “tclabc”
Keine Übereinstimmung für Gruppenpaket “reeniebeanie-fonts”
Keine Übereinstimmung für Gruppenpaket “gnomad2”
Keine Übereinstimmung für Gruppenpaket “ht-alegreya-smallcaps-fonts”
Keine Übereinstimmung für Gruppenpaket “bcm283x-firmware”
Keine Übereinstimmung für Gruppenpaket “google-droid-kufi-fonts”
Keine Übereinstimmung für Gruppenpaket “trabajo-fonts”
Keine Übereinstimmung für Gruppenpaket “stix-math-fonts”
Keine Übereinstimmung für Gruppenpaket “tangerine-fonts”
Keine Übereinstimmung für Gruppenpaket “inkboy-fonts”
Keine Übereinstimmung für Gruppenpaket “vdr-skinsoppalusikka”
Keine Übereinstimmung für Gruppenpaket “khmeros-bokor-fonts”
Keine Übereinstimmung für Gruppenpaket “vdr-ttxtsubs”
Keine Übereinstimmung für Gruppenpaket “powerpc-utils”
Keine Übereinstimmung für Gruppenpaket “google-noto-sans-ui-fonts”
Keine Übereinstimmung für Gruppenpaket “senamirmir-washra-hiwua-fonts”
Keine Übereinstimmung für Gruppenpaket “totem-lirc”
Keine Übereinstimmung für Gruppenpaket “xorg-x11-drv-omap”
Keine Übereinstimmung für Gruppenpaket “shadowsintolight-fonts”
Keine Übereinstimmung für Gruppenpaket “csound-csoundac”
Keine Übereinstimmung für Gruppenpaket “decibel-audio-player”
Keine Übereinstimmung für Gruppenpaket “vt323-fonts”
Keine Übereinstimmung für Gruppenpaket “pnmixer”
Keine Übereinstimmung für Gruppenpaket “adplay”
Keine Übereinstimmung für Gruppenpaket “pagul-fonts”
Keine Übereinstimmung für Gruppenpaket “cyreal-wireone-fonts”
Keine Übereinstimmung für Gruppenpaket “mph-2b-damase-fonts”
Keine Übereinstimmung für Gruppenpaket “sonic-visualiser-freeworld”
Keine Übereinstimmung für Gruppenpaket “khmeros-metal-chrieng-fonts”
Keine Übereinstimmung für Gruppenpaket “almas-mongolian-title-fonts”
Keine Übereinstimmung für Gruppenpaket “oflb-icelandic-fonts”
Keine Übereinstimmung für Gruppenpaket “min12xxw”
Keine Übereinstimmung für Gruppenpaket “khmeros-handwritten-fonts”
Keine Übereinstimmung für Gruppenpaket “senamirmir-washra-yebse-fonts”
Keine Übereinstimmung für Gruppenpaket “astloch-fonts”
Keine Übereinstimmung für Gruppenpaket “gnomebaker”
Fehler:
Problem: The operation would result in removing the following protected packages: gnome-shell
(try to add ‘–allowerasing’ to command line to replace conflicting packages or ‘–skip-broken’ to skip uninstallable packages)
## Gregory Bartholomew
I would try adding
If that still doesn’t work, try it without
## tom
Hi there and thank you for your respond. I get a new error:
Problem: cannot install the best update candidate for package iptables-1.8.5-6.fc33.x86_64
- problem with installed package iptables-1.8.5-6.fc33.x86_64
- package iptables-1.8.7-3.fc34.x86_64 requires iptables-libs(x86-64) = 1.8.7-3.fc34, but none of the providers can be installed
- cannot install the best update candidate for package iptables-libs-1.8.5-6.fc33.x86_64
- cannot install both iptables-libs-1.8.7-7.fc34.x86_64 and iptables-libs-1.8.7-3.fc34.x86_64
- iptables-1.8.5-6.fc33.x86_64 does not belong to a distupgrade repository
## Gregory Bartholomew
It looks like this known bug: https://fedoraproject.org/wiki/Common_F34_bugs#Upgrade_does_not_install_latest_version_of_iptables.2C_or_fails_on_iptables_if_–best_is_used
## Carlos Ferrer
Fedora FTW! Best distro linux. I`m installing Fedora 34 right now! |
13,367 | 《星球大战》的世界拥抱开源的 5 种方式 | https://opensource.com/article/21/5/open-source-star-wars | 2021-05-07T16:04:16 | [
"星球大战",
"开源"
] | https://linux.cn/article-13367-1.html |
>
> 与《星球大战》一起成长的过程中,我学到了很多关于开源的知识。
>
>
>

让我们先说清楚一件事:在现实生活中,《<ruby> 星球大战 <rt> Star Wars </rt></ruby>》特许经营权没有任何开放性(尽管其所有者确实发布了 [一些开源代码](https://disney.github.io/))。《星球大战》是一个严格控制的资产,没有任何东西是在自由文化许可证下出版的。抛开任何关于 [文化形象应该成为伴随它们成长的人们的财产](https://opensource.com/article/18/1/creative-commons-real-world) 的争论,本文邀请你走进《星球大战》的世界,想象你是很久以前的一个电脑用户,在一个遥远的星系里……
### 机器人
>
> “但我还要去<ruby> 托西站 <rt> Tosche Station </rt></ruby>弄些电力转换器呢。” —— 卢克•天行者
>
>
>
在<ruby> 乔治•卢卡斯 <rt> George Lucas </rt></ruby>拍摄他的第一部《星球大战》电影之前,他导演了一部名为《<ruby> 美国涂鸦 <rt> American Graffiti </rt></ruby>》的电影,这是一部以上世纪 60 年代为背景的成长电影。这部电影的部分背景是<ruby> 改装车 <rt> hot-rod </rt></ruby>和街头赛车文化,一群机械修理工在车库里花了好几个小时,无休止地改装他们的汽车。今天仍然可以这样做,但大多数汽车爱好者会告诉你,“经典”汽车改装起来容易得多,因为它们主要使用机械部件而不是技术部件,而且它们以一种可预测的方式使用普通部件。
我一直把卢克和他的朋友们看作是对同样怀旧的科幻小说诠释。当然,花哨的新战斗堡垒是高科技,可以摧毁整个星球,但当 [防爆门不能正确打开](https://www.hollywoodreporter.com/heat-vision/star-wars-40th-anniversary-head-banging-stormtrooper-explains-classic-blunder-1003769) 或监禁层的垃圾压实机开始压扁人时,你会怎么做?如果你没有一个备用的 R2 机器人与主机对接,你就没辙了。卢克对修理和维护“机器人”的热情以及他在修理蒸发器和 X 翼飞机方面的天赋从第一部电影中就可以看出。
看到塔图因星球对待技术的态度,我不禁相信,大多数常用设备都是大众的技术。卢克并没有为 C-3PO 或 R2-D2 签订最终用户许可协议。当他让 C-3PO 在热油浴中放松时,或者当楚巴卡在兰多的云城重新组装他时,并没有使他的保修失效。同样,汉•索罗和楚巴卡从来没有把千年隼带到经销商那里去购买经批准的零件。
我无法证明这都是开源技术。鉴于电影中大量的终端用户维修和定制,我相信在星战世界中,技术是开放的,[用户是有拥有和维修的常识的](https://www.eff.org/issues/right-to-repair)。
### 加密和隐写术
>
> “帮助我,欧比旺•克诺比。你是我唯一的希望。” —— 莱亚公主
>
>
>
诚然,《星球大战》世界中的数字身份认证很难理解,但如果有一点是明确的,加密和隐写术对叛军的成功至关重要。而当你身处叛军时,你就不能依靠公司的标准,怀疑它们是由你正在斗争的邪恶帝国批准的。当 R2-D2 隐瞒莱娅公主绝望的求救时,它的记忆库中没有任何后门,而叛军在潜入敌方领土时努力获得认证凭证(这是一个旧的口令,但它通过检查了)。
加密不仅仅是一个技术问题。它是一种通信形式,在历史上有这样的例子。当政府试图取缔加密时,就是在努力取缔社区。我想这也是“叛乱”本应抵制的一部分。
### 光剑
>
> “我看到你已经打造了新的光剑,你的技能现在已经完成了。” —— 达斯•维德
>
>
>
在《帝国反击战》中,天行者卢克失去了他标志性的蓝色光剑,同时他的手也被邪恶霸主达斯•维德砍断。在下一部电影《绝地归来》中,卢克展示了他自己打造的绿色光剑 —— 每一个粉丝都为之着迷。
虽然没有明确说明绝地武士的激光剑的技术规格是开源的,但有一定的暗指。例如,没有迹象表明卢克在制造他的武器之前必须从拥有版权的公司获得设计许可。他没有与一家高科技工厂签订合同来生产他的剑。
他自己打造了它,作为一种成年仪式。也许制造如此强大的武器的方法是绝地武士团所守护的秘密;再者,也许这只是描述开源的另一种方式。我所知道的所有编码知识都是从值得信赖的导师、某些互联网 UP 主、精心撰写的博客文章和技术讲座中学到的。
严密保护的秘密?还是对任何寻求知识的人开放的信息?
根据我在原三部曲中看到的绝地武士秩序,我选择相信后者。
### 伊沃克文化
>
> “Yub nub!” —— 伊沃克人
>
>
>
恩多的伊沃克人与帝国其他地区的文化形成了鲜明的对比。他们热衷于集体生活、分享饮食和故事到深夜。他们自己制作武器、陷阱和安全防火墙,还有他们自己的树顶村庄。作为象征意义上的弱者,他们不可能摆脱帝国的占领。他们通过咨询礼仪机器人做了研究,汇集了他们的资源,并在关键时刻发挥了作用。当陌生人进入他们的家时,他们并没有拒绝他们。相反,他们帮助他们(在确定他们毕竟不是食物之后)。当他们面对令人恐惧的技术时,他们就参与其中并从中学习。
伊沃克人是《星球大战》世界中开放文化和开源的庆典。他们是我们应该努力的社区:分享信息、分享知识、接受陌生人和进步的技术,以及维护捍卫正义的决心。
### 原力
>
> “原力将与你同在,永远。” —— 欧比旺•克诺比
>
>
>
在最初的电影中,甚至在新生的衍生宇宙中(最初的衍生宇宙小说,也是我个人的最爱,是《心灵之眼的碎片》,其中卢克从一个叫哈拉的女人那里学到了更多关于原力的知识),原力只是:一种任何人都可以学习使用的力量。它不是一种与生俱来的天赋,而是一门需要掌握的强大学科。

相比之下,邪恶的西斯人对他们的知识是保护性的,只邀请少数人加入他们的行列。他们可能认为自己有一个群体,但这正是看似随意的排他性的模式。
我不知道对开源和开放文化还有什么更好的比喻。永远存在被认为是排他的危险,因为爱好者似乎总是在“人群中”。但现实是,每个人都可以加入这些邀请,而且任何人都可以回到源头(字面意思是源代码或资产)。
### 愿源与你同在
作为一个社区,我们的任务是要问,我们如何能让人明白,无论我们拥有什么知识,都不是为了成为特权信息,而是一种任何人都可以学习使用的力量,以改善他们的世界。
套用欧比旺•克诺比的不朽名言:“使用源”。
---
via: <https://opensource.com/article/21/5/open-source-star-wars>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Let's get one thing straight up front: there's nothing open about the Star Wars franchise in real life (although its owner does publish [some open source code](https://disney.github.io/)). Star Wars is a tightly controlled property with nothing published under a free-culture license. Setting aside any debate of when [cultural icons should become the property of the people](https://opensource.com/article/18/1/creative-commons-real-world) who've grown up with them, this article invites you to step *into* the Star Wars universe and imagine you're a computer user a long time ago, in a galaxy far, far away…
## Droids
"But I was going into Tosche Station to pick up some power converters!"
— Luke Skywalker
Before George Lucas made his first Star Wars movie, he directed a movie called *American Graffiti*, a coming-of-age movie set in the 1960s. Part of the movie's backdrop was the hot-rod and street-racing culture, featuring a group of mechanical tinkerers who spent hours and hours in the garage, endlessly modding their cars. This can still be done today, but most car enthusiasts will tell you that "classic" cars are a lot easier to work on because they use mostly mechanical rather than technological parts, and they use common parts in a predictable way.
I've always seen Luke and his friends as the science fiction interpretation of the same nostalgia. Sure, fancy new battle stations are high tech and can destroy entire planets, but what do you do when a [blast door fails to open correctly](https://www.hollywoodreporter.com/heat-vision/star-wars-40th-anniversary-head-banging-stormtrooper-explains-classic-blunder-1003769) or when the trash compactor on the detention level starts crushing people? If you don't have a spare R2 unit to interface with the mainframe, you're out of luck. Luke's passion for fixing and maintaining 'droids and his talent for repairing vaporators and X-wings were evident from the first film.
Seeing how technology is treated on Tatooine, I can't help but believe that most of the commonly used equipment was the people's technology. Luke didn't have an end-user license agreement for C-3PO or R2-D2. He didn't void his warranty when he let Threepio relax in a hot oil bath or when Chewbacca reassembled him in Lando's Cloud City. Likewise, Han Solo and Chewbacca never took the Millennium Falcon to the dealership for approved parts.
I can't prove it's all open source technology. Given the amount of end-user repair and customization in the films, I believe that technology is open and common knowledge intended to be [owned and repaired by users](https://www.eff.org/issues/right-to-repair) in the Star Wars universe.
## Encryption and steganography
"Help me, Obi-Wan Kenobi. You're my only hope."
— Princess Leia
Admittedly, digital authentication in the Star Wars universe is difficult to understand, but if one thing is clear, encryption and steganography are vital to the Rebellion's success. And when you're in a rebellion, you can't rely on corporate standards, suspiciously sanctioned by the evil empire you're fighting. There were no backdoors into Artoo's memory banks when he was concealing Princess Leia's desperate plea for help, and the Rebellion struggles to get authentication credentials when infiltrating enemy territory (it's an older code, but it checks out).
Encryption isn't just a technological matter. It's a form of communication, and there are examples of it throughout history. When governments attempt to outlaw encryption, it's an effort to outlaw community. I assume that this is part of what the Rebellion was meant to resist.
## Lightsabers
"I see you have constructed a new lightsaber. Your skills are now complete."
— Darth Vader
In *The Empire Strikes Back*, Luke Skywalker loses his iconic blue lightsaber, along with his hand, to nefarious overlord Darth Vader. In the next film, *Return of the Jedi,* Luke reveals—to the absolute enchantment of every fan—a green lightsaber that he *constructed* himself.
It's not explicitly stated that the technical specifications of the Jedi Knight's laser sword are open source, but there are implications. For example, there's no indication that Luke had to license the design from a copyright-holding firm before building his weapon. He didn't contract a high-tech factory to produce his sword.
He built it *all by himself* as a rite of passage. Maybe the method for building such a powerful weapon is a secret guarded by the Jedi order; then again, maybe that's just another way of describing open source. I learned all the coding I know from trusted mentors, random internet streamers, artfully written blog posts, and technical talks.
Closely guarded secrets? Or open information for anyone seeking knowledge?
Based on the Jedi order I saw in the original trilogy, I choose to believe the latter.
## Ewok culture
"Yub nub!"
— Ewoks
The Ewoks of Endor are a stark contrast to the rest of the Empire's culture. They're ardently communal, sharing meals and stories late into the night. They craft their own weapons, honey pots, and firewalls for security, as well as their own treetop village. As the figurative underdogs, they shouldn't have been able to rid themselves of the Empire's occupation. They did their research by consulting a protocol 'droid, pooled their resources, and rose to the occasion. When strangers dropped into their homes, they didn't reject them. Rather, they helped them (after determining that they were not, after all, food). When they were confronted with frightening technology, they engaged with it and learned from it.
Ewoks are a celebration of open culture and open source within the Star Wars universe. Theirs is the community we should strive for: sharing information, sharing knowledge, being receptive to strangers and progressive technology, and maintaining the resolve to stand up for what's right.
## The Force
"The Force will be with you. Always."
— Obi-Wan Kenobi
In the original films and even in the nascent Expanded Universe (the original EU novel, and my personal favorite, is *Splinter of the Mind's Eye*, in which Luke learns more about the Force from a woman named Halla), the Force was just that: a force that anyone can learn to wield. It isn't an innate talent, rather a powerful discipline to master.

By contrast, the evil Sith are protective of their knowledge, inviting only a select few to join their ranks. They may believe they have a community, but it's the very model of seemingly arbitrary exclusivity.
I don't know of a better analogy for open source and open culture. The danger of perceived exclusivity is ever-present because enthusiasts always seem to be in the "in-crowd." But the reality is, the invitation is there for everyone to join. And the ability to go back to the source (literally the source code or assets) is always available to anyone.
## May the source be with you
Our task, as a community, is to ask how we can make it clear that whatever knowledge we possess isn't meant to be privileged information and instead, a force that anyone can learn to use to improve their world.
To paraphrase the immortal words of Obi-Wan Kenobi: "Use the source."
## 1 Comment |
13,368 | 使用 OpenSSL 加密和解密文件 | https://opensource.com/article/21/4/encryption-decryption-openssl | 2021-05-07T16:38:38 | [
"OpenSSL",
"加密",
"解密"
] | https://linux.cn/article-13368-1.html |
>
> OpenSSL 是一个实用工具,它可以确保其他人员无法打开你的敏感和机密消息。
>
>
>

加密是对消息进行编码的一种方法,这样可以保护消息的内容免遭他人窥视。一般有两种类型:
1. 密钥加密或对称加密
2. 公钥加密或非对称加密
<ruby> 密钥加密 <rt> secret-key encryption </rt></ruby>使用相同的密钥进行加密和解密,而<ruby> 公钥加密 <rt> public-key encryption </rt></ruby>使用不同的密钥进行加密和解密。每种方法各有利弊。密钥加密速度更快,而公钥加密更安全,因为它解决了安全共享密钥的问题,将它们结合在一起可以最大限度地利用每种类型的优势。
### 公钥加密
公钥加密使用两组密钥,称为密钥对。一个是公钥,可以与你想要秘密通信的任何人自由共享。另一个是私钥,应该是一个秘密,永远不会共享。
公钥用于加密。如果某人想与你交流敏感信息,你可以将你的公钥发送给他们,他们可以使用公钥加密消息或文件,然后再将其发送给你。私钥用于解密。解密发件人加密的消息的唯一方法是使用私钥。因此,它们被称为“密钥对”,它们是相互关联的。
### 如何使用 OpenSSL 加密文件
[OpenSSL](https://www.openssl.org/) 是一个了不起的工具,可以执行各种任务,例如加密文件。本文使用安装了 OpenSSL 的 Fedora 计算机。如果你的机器上没有,则可以使用软件包管理器进行安装:
```
alice $ cat /etc/fedora-release
Fedora release 33 (Thirty Three)
alice $
alice $ openssl version
OpenSSL 1.1.1i FIPS 8 Dec 2020
alice $
```
要探索文件加密和解密,假如有两个用户 Alice 和 Bob,他们想通过使用 OpenSSL 交换加密文件来相互通信。
#### 步骤 1:生成密钥对
在加密文件之前,你需要生成密钥对。你还需要一个<ruby> 密码短语 <rt> passphrase </rt></ruby>,每当你使用 OpenSSL 时都必须使用该密码短语,因此务必记住它。
Alice 使用以下命令生成她的一组密钥对:
```
alice $ openssl genrsa -aes128 -out alice_private.pem 1024
```
此命令使用 OpenSSL 的 [genrsa](https://www.openssl.org/docs/man1.0.2/man1/genrsa.html) 命令生成一个 1024 位的公钥/私钥对。这是可以的,因为 RSA 算法是不对称的。它还使用了 aes128 对称密钥算法来加密 Alice 生成的私钥。
输入命令后,OpenSSL 会提示 Alice 输入密码,每次使用密钥时,她都必须输入该密码:
```
alice $ openssl genrsa -aes128 -out alice_private.pem 1024
Generating RSA private key, 1024 bit long modulus (2 primes)
..........+++++
..................................+++++
e is 65537 (0x010001)
Enter pass phrase for alice_private.pem:
Verifying - Enter pass phrase for alice_private.pem:
alice $
alice $
alice $ ls -l alice_private.pem
-rw-------. 1 alice alice 966 Mar 22 17:44 alice_private.pem
alice $
alice $ file alice_private.pem
alice_private.pem: PEM RSA private key
alice $
```
Bob 使用相同的步骤来创建他的密钥对:
```
bob $ openssl genrsa -aes128 -out bob_private.pem 1024
Generating RSA private key, 1024 bit long modulus (2 primes)
..................+++++
............................+++++
e is 65537 (0x010001)
Enter pass phrase for bob_private.pem:
Verifying - Enter pass phrase for bob_private.pem:
bob $
bob $ ls -l bob_private.pem
-rw-------. 1 bob bob 986 Mar 22 13:48 bob_private.pem
bob $
bob $ file bob_private.pem
bob_private.pem: PEM RSA private key
bob $
```
如果你对密钥文件感到好奇,可以打开命令生成的 .pem 文件,但是你会看到屏幕上的一堆文本:
```
alice $ head alice_private.pem
-----BEGIN RSA PRIVATE KEY-----
Proc-Type: 4,ENCRYPTED
DEK-Info: AES-128-CBC,E26FAC1F143A30632203F09C259200B9
pdKj8Gm5eeAOF0RHzBx8l1tjmA1HSSvy0RF42bOeb7sEVZtJ6pMnrJ26ouwTQnkL
JJjUVPPHoKZ7j4QpwzbPGrz/hVeMXVT/y33ZEEA+3nrobwisLKz+Q+C9TVJU3m7M
/veiBO9xHMGV01YBNeic7MqXBkhIrNZW6pPRfrbjsBMBGSsL8nwJbb3wvHhzPkeM
e+wtt9S5PWhcnGMj3T+2mtFfW6HWpd8Kdp60z7Nh5mhA9+5aDWREfJhJYzl1zfcv
Bmxjf2wZ3sFJNty+sQVajYfk6UXMyJIuWgAjnqjw6c3vxQi0KE3NUNZYO93GQgEF
pyAnN9uGUTBCDYeTwdw8TEzkyaL08FkzLfFbS2N9BDksA3rpI1cxpxRVFr9+jDBz
alice $
```
要查看密钥的详细信息,可以使用以下 OpenSSL 命令打开 .pem 文件并显示内容。你可能想知道在哪里可以找到另一个配对的密钥,因为这是单个文件。你观察的很细致,获取公钥的方法如下:
```
alice $ openssl rsa -in alice_private.pem -noout -text
Enter pass phrase for alice_private.pem:
RSA Private-Key: (1024 bit, 2 primes)
modulus:
00:bd:e8:61:72:f8:f6:c8:f2:cc:05:fa:07:aa:99:
47:a6:d8:06:cf:09:bf:d1:66:b7:f9:37:29:5d:dc:
c7:11:56:59:d7:83:b4:81:f6:cf:e2:5f:16:0d:47:
81:fe:62:9a:63:c5:20:df:ee:d3:95:73:dc:0a:3f:
65:d3:36:1d:c1:7d:8b:7d:0f:79:de:80:fc:d2:c0:
e4:27:fc:e9:66:2d:e2:7e:fc:e6:73:d1:c9:28:6b:
6a:8a:e8:96:9d:65:a0:8a:46:e0:b8:1f:b0:48:d4:
db:d4:a3:7f:0d:53:36:9a:7d:2e:e7:d8:f2:16:d3:
ff:1b:12:af:53:22:c0:41:51
publicExponent: 65537 (0x10001)
<< 截断 >>
exponent2:
6e:aa:8c:6e:37:d0:57:37:13:c0:08:7e:75:43:96:
33:01:99:25:24:75:9c:0b:45:3c:a2:39:44:69:84:
a4:64:48:f4:5c:bc:40:40:bf:84:b8:f8:0f:1d:7b:
96:7e:16:00:eb:49:da:6b:20:65:fc:a9:20:d9:98:
76:ca:59:e1
coefficient:
68:9e:2e:fa:a3:a4:72:1d:2b:60:61:11:b1:8b:30:
6e:7e:2d:f9:79:79:f2:27:ab:a0:a0:b6:45:08:df:
12:f7:a4:3b:d9:df:c5:6e:c7:e8:81:29:07:cd:7e:
47:99:5d:33:8c:b7:fb:3b:a9:bb:52:c0:47:7a:1c:
e3:64:90:26
alice $
```
#### 步骤 2:提取公钥
注意,公钥是你可以与他人自由共享的密钥,而你必须将私钥保密。因此,Alice 必须提取她的公钥,并将其保存到文件中:
```
alice $ openssl rsa -in alice_private.pem -pubout > alice_public.pem
Enter pass phrase for alice_private.pem:
writing RSA key
alice $
alice $ ls -l *.pem
-rw-------. 1 alice alice 966 Mar 22 17:44 alice_private.pem
-rw-rw-r--. 1 alice alice 272 Mar 22 17:47 alice_public.pem
alice $
```
你可以使用与之前相同的方式查看公钥详细信息,但是这次,输入公钥 .pem 文件:
```
alice $
alice $ openssl rsa -in alice_public.pem -pubin -text -noout
RSA Public-Key: (1024 bit)
Modulus:
00:bd:e8:61:72:f8:f6:c8:f2:cc:05:fa:07:aa:99:
47:a6:d8:06:cf:09:bf:d1:66:b7:f9:37:29:5d:dc:
c7:11:56:59:d7:83:b4:81:f6:cf:e2:5f:16:0d:47:
81:fe:62:9a:63:c5:20:df:ee:d3:95:73:dc:0a:3f:
$
```
Bob 可以按照相同的过程来提取他的公钥并将其保存到文件中:
```
bob $ openssl rsa -in bob_private.pem -pubout > bob_public.pem
Enter pass phrase for bob_private.pem:
writing RSA key
bob $
bob $ ls -l *.pem
-rw-------. 1 bob bob 986 Mar 22 13:48 bob_private.pem
-rw-r--r--. 1 bob bob 272 Mar 22 13:51 bob_public.pem
bob $
```
#### 步骤 3:交换公钥
这些公钥在 Alice 和 Bob 彼此交换之前没有太大用处。有几种共享公钥的方法,例如使用 `scp` 命令将密钥复制到彼此的工作站。
将 Alice 的公钥发送到 Bob 的工作站:
```
alice $ scp alice_public.pem bob@bob-machine-or-ip:/path/
```
将 Bob 的公钥发送到 Alice 的工作站:
```
bob $ scp bob_public.pem alice@alice-machine-or-ip:/path/
```
现在,Alice 有了 Bob 的公钥,反之亦然:
```
alice $ ls -l bob_public.pem
-rw-r--r--. 1 alice alice 272 Mar 22 17:51 bob_public.pem
alice $
```
```
bob $ ls -l alice_public.pem
-rw-r--r--. 1 bob bob 272 Mar 22 13:54 alice_public.pem
bob $
```
#### 步骤 4:使用公钥交换加密的消息
假设 Alice 需要与 Bob 秘密交流。她将秘密信息写入文件中,并将其保存到 `top_secret.txt` 中。由于这是一个普通文件,因此任何人都可以打开它并查看其内容,这里并没有太多保护:
```
alice $
alice $ echo "vim or emacs ?" > top_secret.txt
alice $
alice $ cat top_secret.txt
vim or emacs ?
alice $
```
要加密此秘密消息,Alice 需要使用 `openssls -encrypt` 命令。她需要为该工具提供三个输入:
1. 秘密消息文件的名称
2. Bob 的公钥(文件)
3. 加密后新文件的名称
```
alice $ openssl rsautl -encrypt -inkey bob_public.pem -pubin -in top_secret.txt -out top_secret.enc
alice $
alice $ ls -l top_secret.*
-rw-rw-r--. 1 alice alice 128 Mar 22 17:54 top_secret.enc
-rw-rw-r--. 1 alice alice 15 Mar 22 17:53 top_secret.txt
alice $
alice $
```
加密后,原始文件仍然是可见的,而新创建的加密文件在屏幕上看起来像乱码。这样,你可以确定秘密消息已被加密:
```
alice $ cat top_secret.txt
vim or emacs ?
alice $
alice $ cat top_secret.enc
�s��uM)M&>��N��}dmCy92#1X�q?��v���M��@��E�~��1�k~&PU�VhHL�@^P��(��zi�M�4p�e��g+R�1�Ԁ���s�������q_8�lr����C�I-��alice $
alice $
alice $
alice $ hexdump -C ./top_secret.enc
00000000 9e 73 12 8f e3 75 4d 29 4d 26 3e bf 80 4e a0 c5 |.s...uM)M&>..N..|
00000010 7d 64 6d 43 79 39 32 23 31 58 ce 71 f3 ba 95 a6 |}dmCy92#1X.q....|
00000020 c0 c0 76 17 fb f7 bf 4d ce fc 40 e6 f4 45 7f db |[email protected]..|
00000030 7e ae c0 31 f8 6b 10 06 7e 26 50 55 b5 05 56 68 |~..1.k..~&PU..Vh|
00000040 48 4c eb 40 5e 50 fe 19 ea 28 a8 b8 7a 13 69 d7 |HL.@^P...(..z.i.|
00000050 4d b0 34 70 d8 65 d5 07 95 67 2b 52 ea 31 aa d4 |M.4p.e...g+R.1..|
00000060 80 b3 a8 ec a1 73 ed a7 f9 17 c3 13 d4 fa c1 71 |.....s.........q|
00000070 5f 38 b9 6c 07 72 81 a6 fe af 43 a6 49 2d c4 ee |_8.l.r....C.I-..|
00000080
alice $
alice $ file top_secret.enc
top_secret.enc: data
alice $
```
删除秘密消息的原始文件是安全的,这样确保任何痕迹都没有:
```
alice $ rm -f top_secret.txt
```
现在,Alice 需要再次使用 `scp` 命令将此加密文件通过网络发送给 Bob 的工作站。注意,即使文件被截获,其内容也会是加密的,因此内容不会被泄露:
```
alice $ scp top_secret.enc bob@bob-machine-or-ip:/path/
```
如果 Bob 使用常规方法尝试打开并查看加密的消息,他将无法看懂该消息:
```
bob $ ls -l top_secret.enc
-rw-r--r--. 1 bob bob 128 Mar 22 13:59 top_secret.enc
bob $
bob $ cat top_secret.enc
�s��uM)M&>��N��}dmCy92#1X�q?��v���M��@��E�~��1�k~&PU�VhHL�@^P��(��zi�M�4p�e��g+R�1�Ԁ���s�������q_8�lr����C�I-��bob $
bob $
bob $ hexdump -C top_secret.enc
00000000 9e 73 12 8f e3 75 4d 29 4d 26 3e bf 80 4e a0 c5 |.s...uM)M&>..N..|
00000010 7d 64 6d 43 79 39 32 23 31 58 ce 71 f3 ba 95 a6 |}dmCy92#1X.q....|
00000020 c0 c0 76 17 fb f7 bf 4d ce fc 40 e6 f4 45 7f db |[email protected]..|
00000030 7e ae c0 31 f8 6b 10 06 7e 26 50 55 b5 05 56 68 |~..1.k..~&PU..Vh|
00000040 48 4c eb 40 5e 50 fe 19 ea 28 a8 b8 7a 13 69 d7 |HL.@^P...(..z.i.|
00000050 4d b0 34 70 d8 65 d5 07 95 67 2b 52 ea 31 aa d4 |M.4p.e...g+R.1..|
00000060 80 b3 a8 ec a1 73 ed a7 f9 17 c3 13 d4 fa c1 71 |.....s.........q|
00000070 5f 38 b9 6c 07 72 81 a6 fe af 43 a6 49 2d c4 ee |_8.l.r....C.I-..|
00000080
bob $
```
#### 步骤 5:使用私钥解密文件
Bob 需要使用 OpenSSL 来解密消息,但是这次使用的是 `-decrypt` 命令行参数。他需要向工具程序提供以下信息:
1. 加密的文件(从 Alice 那里得到)
2. Bob 的私钥(用于解密,因为文件是用 Bob 的公钥加密的)
3. 通过重定向保存解密输出的文件名
```
bob $ openssl rsautl -decrypt -inkey bob_private.pem -in top_secret.enc > top_secret.txt
Enter pass phrase for bob_private.pem:
bob $
```
现在,Bob 可以阅读 Alice 发送给他的秘密消息:
```
bob $ ls -l top_secret.txt
-rw-r--r--. 1 bob bob 15 Mar 22 14:02 top_secret.txt
bob $
bob $ cat top_secret.txt
vim or emacs ?
bob $
```
Bob 需要回复 Alice,因此他将秘密回复写在一个文件中:
```
bob $ echo "nano for life" > reply_secret.txt
bob $
bob $ cat reply_secret.txt
nano for life
bob $
```
#### 步骤 6:使用其他密钥重复该过程
为了发送消息,Bob 采用和 Alice 相同的步骤,但是由于该消息是发送给 Alice 的,因此他需要使用 Alice 的公钥来加密文件:
```
bob $ openssl rsautl -encrypt -inkey alice_public.pem -pubin -in reply_secret.txt -out reply_secret.enc
bob $
bob $ ls -l reply_secret.enc
-rw-r--r--. 1 bob bob 128 Mar 22 14:03 reply_secret.enc
bob $
bob $ cat reply_secret.enc
�F݇��.4"f�1��\��{o$�M��I{5�|�\�l͂�e��Y�V��{�|!$c^a
�*Ԫ\vQ�Ϡ9����'��ٮsP��'��Z�1W�n��k���J�0�I;P8������&:bob $
bob $
bob $ hexdump -C ./reply_secret.enc
00000000 92 46 dd 87 04 bc a7 2e 34 22 01 66 1a 13 31 db |.F......4".f..1.|
00000010 c4 5c b4 8e 7b 6f d4 b0 24 d2 4d 92 9b 49 7b 35 |.\..{o..$.M..I{5|
00000020 da 7c ee 5c bb 6c cd 82 f1 1b 92 65 f1 8d f2 59 |.|.\.l.....e...Y|
00000030 82 56 81 80 7b 89 07 7c 21 24 63 5e 61 0c ae 2a |.V..{..|!$c^a..*|
00000040 d4 aa 5c 76 51 8d cf a0 39 04 c1 d7 dc f0 ad 99 |..\vQ...9.......|
00000050 27 ed 8e de d9 ae 02 73 50 e0 dd 27 13 ae 8e 5a |'......sP..'...Z|
00000060 12 e4 9a 31 57 b3 03 6e dd e1 16 7f 6b c0 b3 8b |...1W..n....k...|
00000070 4a cf 30 b8 49 3b 50 38 e0 9f 84 f6 83 da 26 3a |J.0.I;P8......&:|
00000080
bob $
bob $ # remove clear text secret message file
bob $ rm -f reply_secret.txt
```
Bob 通过 `scp` 将加密的文件发送至 Alice 的工作站:
```
$ scp reply_secret.enc alice@alice-machine-or-ip:/path/
```
如果 Alice 尝试使用常规工具去阅读加密的文本,她将无法理解加密的文本:
```
alice $
alice $ ls -l reply_secret.enc
-rw-r--r--. 1 alice alice 128 Mar 22 18:01 reply_secret.enc
alice $
alice $ cat reply_secret.enc
�F݇��.4"f�1��\��{o$�M��I{5�|�\�l͂�e��Y�V��{�|!$c^a
�*Ԫ\vQ�Ϡ9����'��ٮsP��'��Z�1W�n��k���J�0�I;P8������&:alice $
alice $
alice $
alice $ hexdump -C ./reply_secret.enc
00000000 92 46 dd 87 04 bc a7 2e 34 22 01 66 1a 13 31 db |.F......4".f..1.|
00000010 c4 5c b4 8e 7b 6f d4 b0 24 d2 4d 92 9b 49 7b 35 |.\..{o..$.M..I{5|
00000020 da 7c ee 5c bb 6c cd 82 f1 1b 92 65 f1 8d f2 59 |.|.\.l.....e...Y|
00000030 82 56 81 80 7b 89 07 7c 21 24 63 5e 61 0c ae 2a |.V..{..|!$c^a..*|
00000040 d4 aa 5c 76 51 8d cf a0 39 04 c1 d7 dc f0 ad 99 |..\vQ...9.......|
00000050 27 ed 8e de d9 ae 02 73 50 e0 dd 27 13 ae 8e 5a |'......sP..'...Z|
00000060 12 e4 9a 31 57 b3 03 6e dd e1 16 7f 6b c0 b3 8b |...1W..n....k...|
00000070 4a cf 30 b8 49 3b 50 38 e0 9f 84 f6 83 da 26 3a |J.0.I;P8......&:|
00000080
alice $
```
所以,她使用 OpenSSL 解密消息,只不过这次她提供了自己的私钥并将输出保存到文件中:
```
alice $ openssl rsautl -decrypt -inkey alice_private.pem -in reply_secret.enc > reply_secret.txt
Enter pass phrase for alice_private.pem:
alice $
alice $ ls -l reply_secret.txt
-rw-rw-r--. 1 alice alice 14 Mar 22 18:02 reply_secret.txt
alice $
alice $ cat reply_secret.txt
nano for life
alice $
```
### 了解 OpenSSL 的更多信息
OpenSSL 在加密界是真正的瑞士军刀。除了加密文件外,它还可以执行许多任务,你可以通过访问 OpenSSL [文档页面](https://www.openssl.org/docs/)来找到使用它的所有方式,包括手册的链接、 《OpenSSL Cookbook》、常见问题解答等。要了解更多信息,尝试使用其自带的各种加密算法,看看它是如何工作的。
---
via: <https://opensource.com/article/21/4/encryption-decryption-openssl>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Encryption is a way to encode a message so that its contents are protected from prying eyes. There are two general types:
- Secret-key or symmetric encryption
- Public-key or asymmetric encryption
Secret-key encryption uses the same key for encryption and decryption, while public-key encryption uses different keys for encryption and decryption. There are pros and cons to each method. Secret-key encryption is faster, and public-key encryption is more secure since it addresses concerns around securely sharing the keys. Using them together makes optimal use of each type's strengths.
## Public-key encryption
Public-key encryption uses two sets of keys, called a key pair. One is the public key and can be freely shared with anyone you want to communicate with secretly. The other, the private key, is supposed to be a secret and never shared.
Public keys are used for encryption. If someone wants to communicate sensitive information with you, you can send them your public key, which they can use to encrypt their messages or files before sending them to you. Private keys are used for decryption. The only way you can decrypt your sender's encrypted message is by using your private key. Hence the descriptor "key-pair"; the set of keys goes hand-in-hand.
## How to encrypt files with OpenSSL
[OpenSSL](https://www.openssl.org/) is an amazing tool that does a variety of tasks, including encrypting files. This demo uses a Fedora machine with OpenSSL installed. The tool is usually installed by default by most Linux distributions; if not, you can use your package manager to install it:
```
$ cat /etc/fedora-release
Fedora release 33 (Thirty Three)
$
alice $ openssl version
OpenSSL 1.1.1i FIPS 8 Dec 2020
alice $
```
To explore file encryption and decryption, imagine two users, Alice and Bob, who want to communicate with each other by exchanging encrypted files using OpenSSL.
### Step 1: Generate key pairs
Before you can encrypt files, you need to generate a pair of keys. You will also need a passphrase, which you must use whenever you use OpenSSL, so make sure to remember it.
Alice generates her set of key pairs with:
`alice $ openssl genrsa -aes128 -out alice_private.pem 1024`
This command uses OpenSSL's [genrsa](https://www.openssl.org/docs/man1.0.2/man1/genrsa.html) command to generate a 1024-bit public/private key pair. This is possible because the RSA algorithm is asymmetric. It also uses aes128, a symmetric key algorithm, to encrypt the private key that Alice generates using genrsa.
After entering the command, OpenSSL prompts Alice for a passphrase, which she must enter each time she wants to use the keys:
```
alice $ openssl genrsa -aes128 -out alice_private.pem 1024
Generating RSA private key, 1024 bit long modulus (2 primes)
..........+++++
..................................+++++
e is 65537 (0x010001)
Enter pass phrase for alice_private.pem:
Verifying - Enter pass phrase for alice_private.pem:
alice $
alice $
alice $ ls -l alice_private.pem
-rw-------. 1 alice alice 966 Mar 22 17:44 alice_private.pem
alice $
alice $ file alice_private.pem
alice_private.pem: PEM RSA private key
alice $
```
Bob follows the same procedure to create his key pair:
```
bob $ openssl genrsa -aes128 -out bob_private.pem 1024
Generating RSA private key, 1024 bit long modulus (2 primes)
..................+++++
............................+++++
e is 65537 (0x010001)
Enter pass phrase for bob_private.pem:
Verifying - Enter pass phrase for bob_private.pem:
bob $
bob $ ls -l bob_private.pem
-rw-------. 1 bob bob 986 Mar 22 13:48 bob_private.pem
bob $
bob $ file bob_private.pem
bob_private.pem: PEM RSA private key
bob $
```
If you are curious about what the key file looks like, you can open the .pem file that the command generated—but all you will see is a bunch of text on the screen:
```
alice $ head alice_private.pem
-----BEGIN RSA PRIVATE KEY-----
Proc-Type: 4,ENCRYPTED
DEK-Info: AES-128-CBC,E26FAC1F143A30632203F09C259200B9
pdKj8Gm5eeAOF0RHzBx8l1tjmA1HSSvy0RF42bOeb7sEVZtJ6pMnrJ26ouwTQnkL
JJjUVPPHoKZ7j4QpwzbPGrz/hVeMXVT/y33ZEEA+3nrobwisLKz+Q+C9TVJU3m7M
/veiBO9xHMGV01YBNeic7MqXBkhIrNZW6pPRfrbjsBMBGSsL8nwJbb3wvHhzPkeM
e+wtt9S5PWhcnGMj3T+2mtFfW6HWpd8Kdp60z7Nh5mhA9+5aDWREfJhJYzl1zfcv
Bmxjf2wZ3sFJNty+sQVajYfk6UXMyJIuWgAjnqjw6c3vxQi0KE3NUNZYO93GQgEF
pyAnN9uGUTBCDYeTwdw8TEzkyaL08FkzLfFbS2N9BDksA3rpI1cxpxRVFr9+jDBz
alice $
```
To view the key's details, you can use the following OpenSSL command to input the .pem file and display the contents. You may be wondering where to find the other key since this is a single file. This is a good observation. Here's how to get the public key:
```
alice $ openssl rsa -in alice_private.pem -noout -text
Enter pass phrase for alice_private.pem:
RSA Private-Key: (1024 bit, 2 primes)
modulus:
00:bd:e8:61:72:f8:f6:c8:f2:cc:05:fa:07:aa:99:
47:a6:d8:06:cf:09:bf:d1:66:b7:f9:37:29:5d:dc:
c7:11:56:59:d7:83:b4:81:f6:cf:e2:5f:16:0d:47:
81:fe:62:9a:63:c5:20:df:ee:d3:95:73:dc:0a:3f:
65:d3:36:1d:c1:7d:8b:7d:0f:79:de:80:fc:d2:c0:
e4:27:fc:e9:66:2d:e2:7e:fc:e6:73:d1:c9:28:6b:
6a:8a:e8:96:9d:65:a0:8a:46:e0:b8:1f:b0:48:d4:
db:d4:a3:7f:0d:53:36:9a:7d:2e:e7:d8:f2:16:d3:
ff:1b:12:af:53:22:c0:41:51
publicExponent: 65537 (0x10001)
<< snip >>
exponent2:
6e:aa:8c:6e:37:d0:57:37:13:c0:08:7e:75:43:96:
33:01:99:25:24:75:9c:0b:45:3c:a2:39:44:69:84:
a4:64:48:f4:5c:bc:40:40:bf:84:b8:f8:0f:1d:7b:
96:7e:16:00:eb:49:da:6b:20:65:fc:a9:20:d9:98:
76:ca:59:e1
coefficient:
68:9e:2e:fa:a3:a4:72:1d:2b:60:61:11:b1:8b:30:
6e:7e:2d:f9:79:79:f2:27:ab:a0:a0:b6:45:08:df:
12:f7:a4:3b:d9:df:c5:6e:c7:e8:81:29:07:cd:7e:
47:99:5d:33:8c:b7:fb:3b:a9:bb:52:c0:47:7a:1c:
e3:64:90:26
alice $
```
### Step 2: Extract the public keys
Remember, the public key is the one you can freely share with others, whereas you must keep your private key secret. So, Alice must extract her public key and save it to a file using the following command:
```
alice $ openssl rsa -in alice_private.pem -pubout > alice_public.pem
Enter pass phrase for alice_private.pem:
writing RSA key
alice $
alice $ ls -l *.pem
-rw-------. 1 alice alice 966 Mar 22 17:44 alice_private.pem
-rw-rw-r--. 1 alice alice 272 Mar 22 17:47 alice_public.pem
alice $
```
You can view the public key details the same way as before, but this time, input the public key .pem file instead:
```
alice $
alice $ openssl rsa -in alice_public.pem -pubin -text -noout
RSA Public-Key: (1024 bit)
Modulus:
00:bd:e8:61:72:f8:f6:c8:f2:cc:05:fa:07:aa:99:
47:a6:d8:06:cf:09:bf:d1:66:b7:f9:37:29:5d:dc:
c7:11:56:59:d7:83:b4:81:f6:cf:e2:5f:16:0d:47:
81:fe:62:9a:63:c5:20:df:ee:d3:95:73:dc:0a:3f:
$
```
Bob can follow the same process to extract his public key and save it to a file:
```
bob $ openssl rsa -in bob_private.pem -pubout > bob_public.pem
Enter pass phrase for bob_private.pem:
writing RSA key
bob $
bob $ ls -l *.pem
-rw-------. 1 bob bob 986 Mar 22 13:48 bob_private.pem
-rw-r--r--. 1 bob bob 272 Mar 22 13:51 bob_public.pem
bob $
```
### Step 3: Exchange public keys
These public keys are not much use to Alice and Bob until they exchange them with each other. Several methods are available for sharing public keys, including copying the keys to each other's workstations using the `scp`
command.
To send Alice's public key to Bob's workstation:
` alice $ scp alice_public.pem bob@bob-machine-or-ip:/path/`
To send Bob's public key to Alice's workstation:
`bob $ scp bob_public.pem alice@alice-machine-or-ip:/path/`
Now, Alice has Bob's public key and vice versa:
```
alice $ ls -l bob_public.pem
-rw-r--r--. 1 alice alice 272 Mar 22 17:51 bob_public.pem
alice $
```
```
bob $ ls -l alice_public.pem
-rw-r--r--. 1 bob bob 272 Mar 22 13:54 alice_public.pem
bob $
```
### Step 4: Exchange encrypted messages with a public key
Say Alice needs to communicate secretly with Bob. She writes her secret message in a file and saves it to `top_secret.txt`
. Since this is a regular file, anybody can open it and see its contents. There isn't much protection here:
```
alice $
alice $ echo "vim or emacs ?" > top_secret.txt
alice $
alice $ cat top_secret.txt
vim or emacs ?
alice $
```
To encrypt this secret message, Alice needs to use the `openssls -encrypt`
command. She needs to provide three inputs to the tool:
- The name of the file that contains the secret message
- Bob's public key (file)
- The name of a file where the encrypted message will be stored
```
alice $ openssl rsautl -encrypt -inkey bob_public.pem -pubin -in top_secret.txt -out top_secret.enc
alice $
alice $ ls -l top_secret.*
-rw-rw-r--. 1 alice alice 128 Mar 22 17:54 top_secret.enc
-rw-rw-r--. 1 alice alice 15 Mar 22 17:53 top_secret.txt
alice $
alice $
```
After encryption, the original file is still viewable, whereas the newly created encrypted file looks like gibberish on the screen. You can be assured that the secret message has been encrypted:
```
alice $ cat top_secret.txt
vim or emacs ?
alice $
alice $ cat top_secret.enc
�s��uM)M&>��N��}dmCy92#1X�q?��v���M��@��E�~��1�k~&PU�VhHL�@^P��(��zi�M�4p�e��g+R�1�Ԁ���s�������q_8�lr����C�I-��alice $
alice $
alice $
alice $ hexdump -C ./top_secret.enc
00000000 9e 73 12 8f e3 75 4d 29 4d 26 3e bf 80 4e a0 c5 |.s...uM)M&>..N..|
00000010 7d 64 6d 43 79 39 32 23 31 58 ce 71 f3 ba 95 a6 |}dmCy92#1X.q....|
00000020 c0 c0 76 17 fb f7 bf 4d ce fc 40 e6 f4 45 7f db |[email protected]..|
00000030 7e ae c0 31 f8 6b 10 06 7e 26 50 55 b5 05 56 68 |~..1.k..~&PU..Vh|
00000040 48 4c eb 40 5e 50 fe 19 ea 28 a8 b8 7a 13 69 d7 |HL.@^P...(..z.i.|
00000050 4d b0 34 70 d8 65 d5 07 95 67 2b 52 ea 31 aa d4 |M.4p.e...g+R.1..|
00000060 80 b3 a8 ec a1 73 ed a7 f9 17 c3 13 d4 fa c1 71 |.....s.........q|
00000070 5f 38 b9 6c 07 72 81 a6 fe af 43 a6 49 2d c4 ee |_8.l.r....C.I-..|
00000080
alice $
alice $ file top_secret.enc
top_secret.enc: data
alice $
```
It's safe to delete the original file with the secret message to remove any traces of it:
`alice $ rm -f top_secret.txt `
Now Alice needs to send this encrypted file to Bob over a network, once again, using the `scp`
command to copy the file to Bob's workstation. Remember, even if the file is intercepted, its contents are encrypted, so the contents can't be revealed:
`alice $ scp top_secret.enc bob@bob-machine-or-ip:/path/`
If Bob uses the usual methods to try to open and view the encrypted message, he won't be able to read it:
```
bob $ ls -l top_secret.enc
-rw-r--r--. 1 bob bob 128 Mar 22 13:59 top_secret.enc
bob $
bob $ cat top_secret.enc
�s��uM)M&>��N��}dmCy92#1X�q?��v���M��@��E�~��1�k~&PU�VhHL�@^P��(��zi�M�4p�e��g+R�1�Ԁ���s�������q_8�lr����C�I-��bob $
bob $
bob $ hexdump -C top_secret.enc
00000000 9e 73 12 8f e3 75 4d 29 4d 26 3e bf 80 4e a0 c5 |.s...uM)M&>..N..|
00000010 7d 64 6d 43 79 39 32 23 31 58 ce 71 f3 ba 95 a6 |}dmCy92#1X.q....|
00000020 c0 c0 76 17 fb f7 bf 4d ce fc 40 e6 f4 45 7f db |[email protected]..|
00000030 7e ae c0 31 f8 6b 10 06 7e 26 50 55 b5 05 56 68 |~..1.k..~&PU..Vh|
00000040 48 4c eb 40 5e 50 fe 19 ea 28 a8 b8 7a 13 69 d7 |HL.@^P...(..z.i.|
00000050 4d b0 34 70 d8 65 d5 07 95 67 2b 52 ea 31 aa d4 |M.4p.e...g+R.1..|
00000060 80 b3 a8 ec a1 73 ed a7 f9 17 c3 13 d4 fa c1 71 |.....s.........q|
00000070 5f 38 b9 6c 07 72 81 a6 fe af 43 a6 49 2d c4 ee |_8.l.r....C.I-..|
00000080
bob $
```
### Step 5: Decrypt the file using a private key
Bob needs to do his part by decrypting the message using OpenSSL, but this time using the `-decrypt`
command-line argument. He needs to provide the following information to the utility:
- The encrypted file (which he got from Alice)
- Bob's own private key (for decryption, since it was encrypted using Bob's public key)
- A file name to save the decrypted output to via redirection
```
bob $ openssl rsautl -decrypt -inkey bob_private.pem -in top_secret.enc > top_secret.txt
Enter pass phrase for bob_private.pem:
bob $
```
Bob can now read the secret message that Alice sent him:
```
bob $ ls -l top_secret.txt
-rw-r--r--. 1 bob bob 15 Mar 22 14:02 top_secret.txt
bob $
bob $ cat top_secret.txt
vim or emacs ?
bob $
```
Bob needs to reply to Alice, so he writes his secret reply in a file:
```
bob $ echo "nano for life" > reply_secret.txt
bob $
bob $ cat reply_secret.txt
nano for life
bob $
```
### Step 6: Repeat the process with the other key
To send his message, Bob follows the same process Alice used, but since the message is intended for Alice, he uses Alice's public key to encrypt the file:
```
bob $ openssl rsautl -encrypt -inkey alice_public.pem -pubin -in reply_secret.txt -out reply_secret.enc
bob $
bob $ ls -l reply_secret.enc
-rw-r--r--. 1 bob bob 128 Mar 22 14:03 reply_secret.enc
bob $
bob $ cat reply_secret.enc
�F݇��.4"f�1��\��{o$�M��I{5�|�\�l͂�e��Y�V��{�|!$c^a
�*Ԫ\vQ�Ϡ9����'��ٮsP��'��Z�1W�n��k���J�0�I;P8������&:bob $
bob $
bob $ hexdump -C ./reply_secret.enc
00000000 92 46 dd 87 04 bc a7 2e 34 22 01 66 1a 13 31 db |.F......4".f..1.|
00000010 c4 5c b4 8e 7b 6f d4 b0 24 d2 4d 92 9b 49 7b 35 |.\..{o..$.M..I{5|
00000020 da 7c ee 5c bb 6c cd 82 f1 1b 92 65 f1 8d f2 59 |.|.\.l.....e...Y|
00000030 82 56 81 80 7b 89 07 7c 21 24 63 5e 61 0c ae 2a |.V..{..|!$c^a..*|
00000040 d4 aa 5c 76 51 8d cf a0 39 04 c1 d7 dc f0 ad 99 |..\vQ...9.......|
00000050 27 ed 8e de d9 ae 02 73 50 e0 dd 27 13 ae 8e 5a |'......sP..'...Z|
00000060 12 e4 9a 31 57 b3 03 6e dd e1 16 7f 6b c0 b3 8b |...1W..n....k...|
00000070 4a cf 30 b8 49 3b 50 38 e0 9f 84 f6 83 da 26 3a |J.0.I;P8......&:|
00000080
bob $
bob $ # remove clear text secret message file
bob $ rm -f reply_secret.txt
```
Bob sends the encrypted file back to Alice's workstation via `scp`
:
`$ scp reply_secret.enc alice@alice-machine-or-ip:/path/`
Alice cannot make sense of the encrypted text if she tries to read it using normal tools:
```
alice $
alice $ ls -l reply_secret.enc
-rw-r--r--. 1 alice alice 128 Mar 22 18:01 reply_secret.enc
alice $
alice $ cat reply_secret.enc
�F݇��.4"f�1��\��{o$�M��I{5�|�\�l͂�e��Y�V��{�|!$c^a
�*Ԫ\vQ�Ϡ9����'��ٮsP��'��Z�1W�n��k���J�0�I;P8������&:alice $
alice $
alice $
alice $ hexdump -C ./reply_secret.enc
00000000 92 46 dd 87 04 bc a7 2e 34 22 01 66 1a 13 31 db |.F......4".f..1.|
00000010 c4 5c b4 8e 7b 6f d4 b0 24 d2 4d 92 9b 49 7b 35 |.\..{o..$.M..I{5|
00000020 da 7c ee 5c bb 6c cd 82 f1 1b 92 65 f1 8d f2 59 |.|.\.l.....e...Y|
00000030 82 56 81 80 7b 89 07 7c 21 24 63 5e 61 0c ae 2a |.V..{..|!$c^a..*|
00000040 d4 aa 5c 76 51 8d cf a0 39 04 c1 d7 dc f0 ad 99 |..\vQ...9.......|
00000050 27 ed 8e de d9 ae 02 73 50 e0 dd 27 13 ae 8e 5a |'......sP..'...Z|
00000060 12 e4 9a 31 57 b3 03 6e dd e1 16 7f 6b c0 b3 8b |...1W..n....k...|
00000070 4a cf 30 b8 49 3b 50 38 e0 9f 84 f6 83 da 26 3a |J.0.I;P8......&:|
00000080
alice $
```
So she decrypts the message with OpenSSL, only this time she provides her secret key and saves the output to a file:
```
alice $ openssl rsautl -decrypt -inkey alice_private.pem -in reply_secret.enc > reply_secret.txt
Enter pass phrase for alice_private.pem:
alice $
alice $ ls -l reply_secret.txt
-rw-rw-r--. 1 alice alice 14 Mar 22 18:02 reply_secret.txt
alice $
alice $ cat reply_secret.txt
nano for life
alice $
```
## Learn more about OpenSSL
OpenSSL is a true Swiss Army knife utility for cryptography-related use cases. It can do many tasks besides encrypting files. You can find out all the ways you can use it by accessing the OpenSSL [docs page](https://www.openssl.org/docs/), which includes links to the manual, the *OpenSSL Cookbook*, frequently asked questions, and more. To learn more, play around with its various included encryption algorithms to see how it works.
## 1 Comment |
13,370 | 《地铁:离去》终于来到了 Steam for Linux | https://news.itsfoss.com/metro-exodus-steam/ | 2021-05-07T23:00:54 | [
"游戏"
] | https://linux.cn/article-13370-1.html |
>
> 在其他平台上推出后,《地铁:离去》正式登陆 Linux/GNU 平台。准备好体验最好的射击游戏之一了吗?
>
>
>

《<ruby> 地铁:离去 <rt> Metro Exodus </rt></ruby>》是一款长久以来深受粉丝喜爱的游戏,现在终于来到了 Linux 平台。在超过两年的漫长等待之后,Linux 用户终于可以上手《地铁》三部曲的第三部作品。虽然先前已经有一些非官方移植的版本,但这个版本是 4A Games 发布的官方版本。
《地铁:离去》是一款第一人称射击游戏,拥有华丽的光线跟踪画面,故事背景设置在横跨俄罗斯广阔土地的荒野之上。这条精彩的故事线横跨了从春、夏、秋到核冬天的整整一年。游戏结合了快节奏的战斗和隐身以及探索和生存,可以轻而易举地成为 Linux 中最具沉浸感的游戏之一。
### 我的 PC 可以运行它吗?
作为一款图形计算密集型游戏,你得有像样的硬件来运行以获得不错的帧率。这款游戏重度依赖光线追踪来让画面看起来更棒。
运行游戏的最低要求需要 **Intel Core i5 4400**、**8 GB** 内存,以及最低 **NVIDIA GTX670** 或 **AMD Radeon R9 380** 的显卡。推荐配置是 **Intel Core i7 4770K** 搭配 **GTX1070** 或 **RX 5500XT**。
这是开发者提及的官方配置清单:

《地铁:离去》是付费游戏,你需要花费 39.99 美元来获取这个最新最棒的版本。
如果你在游玩的时候遇到持续崩溃的情况,检查一下你的显卡驱动以及 Linux 内核版本。有人反馈了一些相关的问题,但不是普遍性的问题。
### 从哪获取游戏?
Linux 版本的游戏可以从 [Steam](https://store.steampowered.com/app/412020/Metro_Exodus/) for Linux 获取。如果你已经购买了游戏,它会自动出现在你的 Steam for Linux 游戏库内。
* [Metro Exodus (Steam)](https://store.steampowered.com/app/412020/Metro_Exodus/)
如果你还没有安装 Steam,你可以参考我们的教程:[在 Ubuntu 上安装 Steam](https://itsfoss.com/install-steam-ubuntu-linux/) 和 [在 Fedora 上安装 Steam](https://itsfoss.com/install-steam-fedora/)。
你的 Steam 游戏库中已经有《地铁:离去》了吗?准备购买一份吗?可以在评论区写下你的想法。
---
via: <https://news.itsfoss.com/metro-exodus-steam/>
作者:[Asesh Basu](https://news.itsfoss.com/author/asesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Metro Exodus, a long-time fan favorite, is finally here in Linux. After a long wait of over two years, Linux users can finally get their hands on the third installment of the Metro trilogy. Although a few unofficial ports of the game was available, this is an official release by 4A Games.
It is a first-person shooter game with gorgeous ray tracing graphics and the story is set in Russian wilderness across vast lands. The brilliant story-line spans an entire year through spring, summer and autumn to the nuclear winter. The game is a combination of fast-paced combat and stealth with exploration and survival and is easily one of the most immersive games in Linux.
## Can my PC Run it?
Being a graphically intensive game means you need to have a decent hardware to get good frame rates. This game heavily depends on Ray Tracing to make the images look as good as they do.
Just to run the game, you will need **Intel Core i5 4400** with **8 GB** of RAM and an **NVIDIA GTX670** or AMD Radeon R9 380, at least. The recommended specification is Intel Core i7 4770K with a GTX1070 or RX 5500XT.
Here is the official list of specifications as mentioned by developers:

It’s a paid game, and you need to shell out $39.99 USD to get your hands on the newest and greatest version of Metro Exodus.
Check for your graphics drivers and Linux kernel version if you can’t play it due to constant crashes. Some have reported a few issues with it to start with, but not a widespread problem.
## Where do I get the Game?
The Linux version is available on [Steam](https://store.steampowered.com/app/412020/Metro_Exodus/?ref=news.itsfoss.com) for Linux. If you already bought the game, it will appear in your Steam for Linux library automatically.
If you don’t have it installed, you can follow our guide to [install Steam on Ubuntu](https://itsfoss.com/install-steam-ubuntu-linux/?ref=news.itsfoss.com) and [Fedora](https://itsfoss.com/install-steam-fedora/?ref=news.itsfoss.com).
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,372 | Fedora 和红帽 Linux:你应该使用哪个,为什么? | https://itsfoss.com/fedora-vs-red-hat/ | 2021-05-08T10:45:12 | [
"Fedora",
"红帽"
] | https://linux.cn/article-13372-1.html | Fedora 和红帽 Linux。这两个 Linux 发行版都属于同一个组织,都使用 RPM 包管理器,都提供桌面版和服务器版。这两个 Linux 发行版对操作系统世界都有较大的影响。
这就是为什么在这两个类似的发行版之间比较容易混淆的原因。在这篇文章中,我将讨论红帽 Linux 和 Fedora 的相似之处和区别。
如果你想在两者之间做出选择,或者只是想了解来自同一组织的两个发行版的概念,这将对你有所帮助。
### Fedora 和红帽 Linux 的区别

我们先来谈谈这两个发行版的区别。
#### 社区版与企业版
早在 1995 年,红帽 Linux 就有了它的第一个正式版本,它是作为盒装产品出售的。它也被称为<ruby> 红帽商业 Linux <rt> Red Hat Commercial Linux </rt></ruby>。
后来在 2003 年,红帽把红帽 Linux 变成了完全以企业客户为中心的<ruby> 红帽企业 Linux <rt> Red Hat Enterprise Linux </rt></ruby>(RHEL)。从那时起,红帽 Linux 就是一个企业版的 Linux 发行版。
它的意思是,你必须订阅并付费才能使用红帽 Linux,因为它不是作为一个免费的操作系统。甚至所有的软件、错误修复和安全支持都只对那些拥有红帽订阅的人开放。
当红帽 Linux 变成 RHEL 时,它也导致了 Fedora 项目的成立,该项目负责 Fedora Linux的开发。
与红帽不同,Fedora 是一个社区版的 Linux 发行版,每个人都可以免费使用,包括错误修复和其他服务。
尽管红帽公司赞助了 Fedora 项目,但 Fedora Linux 主要由一个独立的开源社区维护。
#### 免费与付费
好吧,你会发现大多数的 Linux 发行版都可以免费下载。Fedora Linux 也是这样一个发行版,它的桌面版、服务器版、所有其他版本和 Spin 版都是免费 [可下载](https://getfedora.org/) 的。
还有一些 Linux 发行版,你必须付费购买。红帽企业 Linux 就是这样一个流行的基于 Linux 的操作系统,它是需要付费的。
除了价格为 99 美元的 RHEL [开发者版本](https://www.redhat.com/en/store/red-hat-enterprise-linux-developer-suite),你必须支付超过 100 美元才能购买 [其他 RHEL 版本](https://www.redhat.com/en/store/linux-platforms),用于服务器、虚拟数据中心和台式机。
然而,如果你碰巧是一个个人开发者,而不是一个组织或团队,你可以加入 [红帽开发者计划](https://developers.redhat.com/register/)。根据该计划,你可以在 12 个月内免费获得红帽企业 Linux 包括其他产品的使用权。
#### 上游还是下游
Fedora 是 RHEL 的上游,RHEL 是 Fedora 的下游。这意味着当 Fedora 的新版本发布时,红帽公司会利用 Fedora 的源代码,在其下一个版本中加入所需的功能。
当然,红帽公司也会在合并到自己的 RHEL 代码库之前测试这些拉来的代码。
换句话说,Fedora Linux 作为红帽公司的一个试验场,首先检查功能,然后将其纳入 RHEL 系统中。
#### 发布周期
为了给操作系统的所有组件提供定期更新,RHEL 和 Fedora 都遵循一个标准的定点发布模式。
Fedora 大约每六个月发布一个新版本(主要在四月和十月),并提供长达 13 个月的维护支持。
红帽 Linux 每年发布一个特定系列的新的定点版本,大约 5 年后发布一个主要版本。红帽 Linux 的每个主要版本都要经过四个生命周期阶段,从 5 年的支持到使用附加订阅的 10 年的延长寿命阶段。
#### 尝鲜 Linux 发行版
当涉及到创新和新技术时,Fedora 比 RHEL 更积极。即使 Fedora 不遵循 [滚动发布模式](https://itsfoss.com/rolling-release/),它也是以早期提供尝鲜技术而闻名的发行版。
这是因为 Fedora 定期将软件包更新到最新版本,以便在每六个月后提供一个最新的操作系统。
如果你知道,[GNOME 40](https://news.itsfoss.com/gnome-40-release/) 是 GNOME 桌面环境的最新版本,上个月才发布。而 Fedora 的最新稳定版 [版本 34](https://news.itsfoss.com/fedora-34-release/) 确实包含了它,而 RHEL 的最新稳定版 8.3 仍然带有 GNOME 3.32。
#### 文件系统
在选择操作系统时,你是否把系统中数据的组织和检索放在了很重要的位置?如果是的话,在决定选择 Red Hat 和 Fedora 之前,你应该了解一下 XFS 和 Btrfs 文件系统。
那是在 2014 年,RHEL 7.0 用 XFS 取代 Ext4 作为其默认文件系统。从那时起,红帽在每个版本中都默认有一个 XFS 64 位日志文件系统。
虽然 Fedora 是红帽 Linux 的上游,但 Fedora 继续使用 Ext4,直到去年 [Fedora 33](https://itsfoss.com/fedora-33/) 引入 [Btrfs 作为默认文件系统](https://itsfoss.com/btrfs-default-fedora/)。
有趣的是,红帽在最初发布的 RHEL 6 中包含了 Btrfs 作为“技术预览”。后来,红帽放弃了使用 Btrfs 的计划,因此在 2019 年从 RHEL 8 和后来发布的主要版本中完全 [删除](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/considerations_in_adopting_rhel_8/file-systems-and-storage_considerations-in-adopting-rhel-8#btrfs-has-been-removed_file-systems-and-storage) 了它。
#### 可用的变体
与 Fedora 相比,红帽 Linux 的版本数量非常有限。它主要适用于台式机、服务器、学术界、开发者、虚拟服务器和 IBM Power LE。
而 Fedora 除了桌面、服务器和物联网的官方版本外,还提供不可变的桌面 Silverblue 和专注于容器的 Fedora CoreOS。
不仅如此,Fedora 也有特定目的的定制变体,称为 [Fedora Labs](https://labs.fedoraproject.org/)。每个 ISO 都为专业人士、神经科学、设计师、游戏玩家、音乐家、学生和科学家打包了一套软件。
想要 Fedora 中不同的桌面环境吗?你也可以查看官方的 [Fedora Spins](https://spins.fedoraproject.org/),它预先配置了几种桌面环境,如 KDE、Xfce、LXQT、LXDE、Cinnamon 和 i3 平铺窗口管理器。

此外,如果你想在新软件登陆稳定版 Fedora 之前就得到它,Fedora Rawhide 是另一个基于滚动发布模式的版本。
### Fedora 和红帽 Linux 的相似之处
除了不同之处,Fedora 和红帽 Linux 也有几个共同点。
#### 母公司
红帽公司是支持 Fedora 项目和 RHEL 的共同公司,在开发和财务方面都有支持。
即使红帽公司在财务上赞助 Fedora 项目,Fedora 也有自己的理事会,在没有红帽公司干预的情况下监督其发展。
#### 开源产品
在你认为红帽 Linux 要收钱,那么它怎么能成为一个开源产品之前,我建议阅读我们的 [文章](https://itsfoss.com/what-is-foss/),它分析了关于 FOSS 和开源的一切。
作为一个开源软件,并不意味着你可以免费得到它,有时它可能要花钱。红帽公司是一个已经在开源中建立了业务的开源公司。
Fedora 和红帽 Linux 都是开源的操作系统。所有的 Fedora 软件包都可以在 [这里](https://src.fedoraproject.org/) 得到源代码和在 [这里](https://getfedora.org/) 得到已经打包好的软件。
然而,就红帽 Linux 而言,源代码也 [免费提供](http://ftp.redhat.com/pub/redhat/linux/enterprise/) 给任何人。但与 Fedora 不同的是,你需要为使用可运行的代码付费,要么你可以自由地自行构建。
你支付给红帽的订阅费实际上是用于系统维护和技术支持。
#### 桌面环境和初始系统
Fedora 和红帽 Linux 的旗舰桌面版采用了 GNOME 图形界面。所以,如果你已经熟悉了 GNOME,从任何一个发行版开始都不会有太大的问题。

你是少数讨厌 SystemD 初始化系统的人吗?如果是这样,那么 Fedora 和红帽 Linux 都不适合你,因为它们都默认支持并使用 SystemD。
总之,如果你想用 Runit 或 OpenRC 等其他初始化系统代替它,也不是不可能,但我认为这不是一个好主意。
#### 基于 RPM 的发行版
如果你已经精通使用 YUM、RPM 或 DNF 命令行工具来处理 RPM 软件包,赞一个!你可以在这两个基于 RPM 的发行版中选一个。
默认情况下,红帽 Linux 使用 RPM(<ruby> 红帽包管理器 <rt> Red Hat Package Manager </rt></ruby>)来安装、更新、删除和管理 RPM 软件包。
Fedora 在 2015 年的 Fedora 21 之前使用 YUM(<ruby> 黄狗更新器修改版 <rt> Yellowdog Updater Modified </rt></ruby>)。从 Fedora 22 开始,它现在使用 DNF(<ruby> 时髦版 Yum <rt> Dandified Yum </rt></ruby>)代替 YUM 作为默认的 [软件包管理器](https://itsfoss.com/package-manager/)。
### Fedora 或红帽 Linux:你应该选择哪一个?
坦率地说,这真的取决于你是谁以及你为什么要使用它。如果你是一个初学者、开发者,或者是一个想用它来提高生产力或学习 Linux 的普通用户,Fedora 可以是一个不错的选择。
它可以帮助你轻松地设置系统,进行实验,节省资金,还可以成为 Fedora 项目的一员。让我提醒你,Linux 的创造者 [Linus Torvalds](https://itsfoss.com/linus-torvalds-facts/) 在他的主要工作站上使用 Fedora Linux。
然而,这绝对不意味着你也应该使用 Fedora。如果你碰巧是一个企业,考虑到 Fedora 的支持生命周期在一年内就会结束,你可能会重新考虑选择它。
而且,如果你不喜欢每个新版本的快速变化,你可能不喜欢尝鲜的 Fedora 来满足你的服务器和业务需求。
使用企业版红帽,你可以得到高稳定性、安全性和红帽专家工程师为你的大型企业提供的支持品质。
那么,你是愿意每年升级你的服务器并获得免费的社区支持,还是购买订阅以获得超过 5 年的生命周期和专家技术支持?决定权在你。
---
via: <https://itsfoss.com/fedora-vs-red-hat/>
作者:[Sarvottam Kumar](https://itsfoss.com/author/sarvottam/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Fedora and Red Hat. Both Linux distributions belong to the same organization, both use RPM package manager and both provide desktop and server editions. Both Linux distributions have a greater impact on the operating system world.
This is why it is easier to get confused between the two similar distributions. In this article, I will discuss the similarities and difference between Red Hat and Fedora.
This will help you if you want to choose between the two or simply want to understand the concept of having two distributions from the same organization.
## Difference Between Fedora And RHEL

Let’s talk about the difference between the two distributions first.
### Community Version vs Enterprise Version
Back in 1995, Red Hat Linux had its first non-beta release, which was sold as a boxed product. It was also called Red Hat Commercial Linux.
Later in 2003, Red Hat turned Red Hat Linux into a Red Hat Enterprise Linux (RHEL) focussed completely on enterprise customers. Since then, Red Hat is an enterprise version of Linux distribution.
What it means is that you have to subscribe and pay to use Red Hat as it is not available as a free OS. Even all software, bug fixes, and security support are available for only those who have an active Red Hat subscription.
At the time when Red Hat Linux became RHEL, it also resulted in the foundation of the Fedora Project that takes care of the development of Fedora Linux.
Unlike Red Hat, Fedora is a community version of the Linux distribution that is available at free of cost for everyone including bug fixes and other services.
Even though Red Hat sponsors the Fedora Project, Fedora Linux is primarily maintained by an independent open source community.
### Free vs Paid
Well, you will find the majority of Linux distributions are available to download free of cost. Fedora Linux is also one such distro, whose desktop, server, all other editions, and spins are freely [available to download](https://getfedora.org/?ref=itsfoss.com).
There are still Linux distros for which you have to pay. Red Hat Enterprise Linux is one such popular Linux-based operating system that comes at cost of money.
You may [get Red Hat for free](https://linuxhandbook.com/get-red-hat-linux-free/?ref=itsfoss.com) by registering for its developer program. If you want the entire RHEL [developer suite](https://www.redhat.com/en/store/red-hat-enterprise-linux-developer-suite?ref=itsfoss.com), it costs $99 per year. You have to pay more than $100 to purchase [other RHEL versions](https://www.redhat.com/en/store/linux-platforms?ref=itsfoss.com) for servers, virtual datacenters, and desktops. This comes with Red Hat customer support.
### Upstream vs Downstream
Fedora is upstream of RHEL and RHEL is downstream of Fedora. This means when a new version of Fedora releases with new features and changes, Red Hat makes use of Fedora source code to include the desired features in its next release.
Of course, Red Hat also test the pulled code before merging into its own codebase for RHEL.
In another way, Fedora Linux acts as a testing ground for Red Hat to first check and then incorporate features into the RHEL system.
### Release Cycle
For delivering the regular updates to all components of the OS, both RHEL and Fedora follow a standard fixed-point release model.
Fedora has a new version release approximately every six months (mostly in April and October) that comes with maintenance support for up to 13 months.
Red Hat releases a new point version of a particular series every year and a major version after approximately 5 years. Each major release of Red Hat goes through four lifecycle phases that range from 5 years of support to 10 years with Extended Life Phase using add-on subscriptions.
### Cutting-edge Linux Distribution
When it comes to innovation and new technologies, Fedora takes a complete edge over the RHEL. Even though Fedora does not follow the [rolling release model](https://itsfoss.com/rolling-release/), it is the distribution known for offering bleeding-edge technology early on.
This is because Fedora regularly updates the packages to their latest version to provide an up-to-date OS after every six months.
If you know, [GNOME 40](https://news.itsfoss.com/gnome-40-release/?ref=itsfoss.com) is the latest version of the GNOME desktop environment that arrived last month. And the latest stable [version 34](https://news.itsfoss.com/fedora-34-release/?ref=itsfoss.com) of Fedora does include it, while the latest stable version 8.3 of RHEL still comes with GNOME 3.32.
### File System
Do you put the organization and retrieval of data on your system at a high priority in choosing an operating system? If so, you should know about XFS and BTRFS file system before deciding between Red Hat and Fedora.
It was in 2014 when RHEL 7.0 replaced EXT4 with XFS as its default file system. Since then, Red Hat has an XFS 64-bit journaling file system in every version by default.
Though Fedora is upstream to Red Hat, Fedora continued with EXT4 until last year when [Fedora 33](https://itsfoss.com/fedora-33/) introduced [Btrfs as the default file system](https://itsfoss.com/btrfs-default-fedora/).
Interestingly, Red Hat had included Btrfs as a “technology preview” at the initial release of RHEL 6. Later on, Red Hat dropped the plan to use Btrfs and hence [removed](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/considerations_in_adopting_rhel_8/file-systems-and-storage_considerations-in-adopting-rhel-8?ref=itsfoss.com#btrfs-has-been-removed_file-systems-and-storage) it completely from RHEL 8 and future major release in 2019.
### Variants Available
Compared to Fedora, Red Hat has very limited number of editions. It is mainly available for desktops, servers, academics, developers, virtual servers, and IBM Power Little Endian.
While Fedora along with official editions for desktop, server, and IoT, provides an immutable desktop Silverblue and a container-focused Fedora CoreOS.
Not just that, but Fedora also has purpose-specific custom variants called [Fedora Labs](https://labs.fedoraproject.org/?ref=itsfoss.com). Each ISO packs a set of software packages for professionals, neuroscience, designers, gamers, musicians, students, and scientists.
Want different desktop environments in Fedora? you can also check for the official [Fedora Spins](https://spins.fedoraproject.org/?ref=itsfoss.com) that comes pre-configured with several desktop environments such as KDE, Xfce, LXQT, LXDE, Cinnamon, and i3 tiling window manager.
Furthermore, if you want to get your hands on new software before it lands in stable Fedora, Fedora Rawhide is yet another edition based on the rolling release model.
**Similarities Between Fedora And RHEL**
Besides the dissimilarities, both Fedora and Red Hat also have several things in common.
### Parent Company
Red Hat Inc. is the common company that backs both Fedora project and RHEL in terms of both development and financial.
Even Red Hat sponsors the Fedora Project financially, Fedora also has its own council that supervises the development without Red Hat intervention.
### Open Source Product
Before you think that Red Hat charges money then how it can be an open-source product, I would suggest reading our [article](https://itsfoss.com/what-is-foss/) that breaks down everything about FOSS and Open Source.
Being an open source software does not mean you can get it freely, sometimes it can cost money. Red Hat is one of the open source companies that have built a business in it.
Both Fedora and Red Hat is an open source operating system. All the Fedora package sources are available [here](https://src.fedoraproject.org/?ref=itsfoss.com) and already packaged software [here](https://getfedora.org/?ref=itsfoss.com).
However, in the case of Red Hat, the source code is also [freely available](http://ftp.redhat.com/pub/redhat/linux/enterprise/?ref=itsfoss.com) for anyone. But unlike Fedora, you need to pay for using the runnable code or else you are free to build on your own.
What you pay to Red Hat subscription is actually for the system maintenance and technical support.
### Desktop Environment And Init System
The flagship desktop edition of Fedora and Red Hat ships GNOME graphical interface. So, if you’re already familiar with GNOME, starting with any of the distributions won’t be of much trouble.
Are you one of the few people who hate SystemD init system? If so, then none of Fedora and Red Hat is an OS for you as both supports and uses SystemD by default.
Anyhow if you wishes to replace it with other init system like Runit or OpenRC, it’s not impossible but I would say it won’t be a best idea.
### RPM-based Distribution
If you’re already well-versed with handling the rpm packages using YUM, RPM, or DNF command-line utility, kudos! you can count in both RPM-based distributions.
By default, Red Hat uses RPM (Red Hat Package Manager) for installing, updating, removing, and managing RPM software packages.
Fedora used YUM (Yellowdog Updater Modified) until Fedora 21 in 2015. Since Fedora 22, it now uses DNF (Dandified Yum) in place of YUM as the default [package manager](https://itsfoss.com/package-manager/).
## Fedora Or Red Hat: Which One Should You Choose?
Frankly, it really depends on who you’re and why do you want to use it. If you’re a beginner, developer, or a normal user who wants it for productivity or to learn about Linux, Fedora can be a good choice.
It will help you to set up the system easily, experiment, save money, and also become a part of the Fedora Project. Let me remind you that Linux creator [Linus Torvalds](https://itsfoss.com/linus-torvalds-facts/) uses Fedora Linux on his main workstation.
However, it definitely does not mean you should also use Fedora. If you happen to be an enterprise, you may rethink choosing it considering Fedora’s support lifecycle that reaches end of life in a year.
And if you’re not a fan of rapid changes in every new version, you may dislike cutting-edge Fedora for your server and business needs.
With enterprise version Red Hat, you get high stability, security, and quality of support from expert Red Hat engineers for your large enterprise.
So, are you willing to upgrade your server every year and get free community support or purchase a subscription to get more than 5 years of lifecycle and expert technical support? The decision is yours. |
13,373 | 网络地址转换(NAT)之连接跟踪工具 | https://fedoramagazine.org/network-address-translation-part-2-the-conntrack-tool/ | 2021-05-09T12:12:47 | [
"NAT"
] | https://linux.cn/article-13373-1.html | 
这是有关<ruby> 网络地址转换 <rt> network address translation </rt></ruby>(NAT)的系列文章中的第二篇。之前的第一篇文章介绍了 [如何使用 iptables/nftables 的报文跟踪功能](/article-13364-1.html) 来定位 NAT 相关的连接问题。作为第二部分,本文介绍 `conntrack` 命令,它允许你查看和修改被跟踪的连接。
### 引言
通过 iptables 或 nftables 配置的 NAT 建立在 netfilters 连接跟踪子系统之上。`conntrack` 命令作为 “conntrack-tools” 软件包的一部分,用于查看和更改连接状态表。
### 连接跟踪状态表
连接跟踪子系统会跟踪它看到的所有报文流。运行 `sudo conntrack -L` 可查看其内容:
```
tcp 6 43184 ESTABLISHED src=192.168.2.5 dst=10.25.39.80 sport=5646 dport=443 src=10.25.39.80 dst=192.168.2.5 sport=443 dport=5646 [ASSURED] mark=0 use=1
tcp 6 26 SYN_SENT src=192.168.2.5 dst=192.168.2.10 sport=35684 dport=443 [UNREPLIED] src=192.168.2.10 dst=192.168.2.5 sport=443 dport=35684 mark=0 use=1
udp 17 29 src=192.168.8.1 dst=239.255.255.250 sport=48169 dport=1900 [UNREPLIED] src=239.255.255.250 dst=192.168.8.1 sport=1900 dport=48169 mark=0 use=1
```
上述显示结果中,每行表示一个连接跟踪项。你可能会注意到,每行相同的地址和端口号会出现两次,而且第二次出现的源地址/端口对和目标地址/端口对会与第一次正好相反!这是因为每个连接跟踪项会先后两次被插入连接状态表。第一个四元组(源地址、目标地址、源端口、目标端口)记录的是原始方向的连接信息,即发送者发送报文的方向。而第二个四元组则记录的是连接跟踪子系统期望收到的对端回复报文的连接信息。这解决了两个问题:
1. 如果报文匹配到一个 NAT 规则,例如 IP 地址伪装,相应的映射信息会记录在链接跟踪项的回复方向部分,并自动应用于同一条流的所有后续报文。
2. 即使一条流经过了地址或端口的转换,也可以成功在连接状态表中查找到回复报文的四元组信息。
原始方向的(第一个显示的)四元组信息永远不会改变:它就是发送者发送的连接信息。NAT 操作只会修改回复方向(第二个)四元组,因为这是接受者看到的连接信息。修改第一个四元组没有意义:netfilter 无法控制发起者的连接状态,它只能在收到/转发报文时对其施加影响。当一个报文未映射到现有连接表项时,连接跟踪可以为其新建一个表项。对于 UDP 报文,该操作会自动进行。对于 TCP 报文,连接跟踪可以配置为只有 TCP 报文设置了 [SYN 标志位](https://en.wikipedia.org/wiki/Transmission_Control_Protocol#TCP_segment_structure) 才新建表项。默认情况下,连接跟踪会允许从流的中间报文开始创建,这是为了避免对启用连接跟踪之前就存在的流处理出现问题。
### 连接跟踪状态表和 NAT
如上一节所述,回复方向的四元组包含 NAT 信息。你可以通过命令过滤输出经过源地址 NAT 或目标地址 NAT 的连接跟踪项。通过这种方式可以看到一个指定的流经过了哪种类型的 NAT 转换。例如,运行 `sudo conntrack -L -p tcp –src-nat` 可显示经过源 NAT 的连接跟踪项,输出结果类似于以下内容:
```
tcp 6 114 TIME_WAIT src=10.0.0.10 dst=10.8.2.12 sport=5536 dport=80 src=10.8.2.12 dst=192.168.1.2 sport=80 dport=5536 [ASSURED]
```
这个连接跟踪项表示一条从 10.0.0.10:5536 到 10.8.2.12:80 的连接。与前面示例不同的是,回复方向的四元组不是原始方向四元组的简单翻转:源地址已修改。目标主机(10.8.2.12)将回复数据包发送到 192.168.1.2,而不是 10.0.0.10。每当 10.0.0.10 发送新的报文时,具有此连接跟踪项的路由器会将源地址替换为 192.168.1.2。当 10.8.2.12 发送回复报文时,该路由器将目的地址修改回 10.0.0.10。上述源 NAT 行为源自一条 [NFT 伪装](https://wiki.nftables.org/wiki-nftables/index.php/Performing_Network_Address_Translation_(NAT)#Masquerading) 规则:
```
inet nat postrouting meta oifname "veth0" masquerade
```
其他类型的 NAT 规则,例如目标地址 DNAT 规则或重定向规则,其连接跟踪项也会以类似的方式显示,回复方向四元组的远端地址或端口与原始方向四元组的远端地址或端口不同。
### 连接跟踪扩展
连接跟踪的记帐功能和时间戳功能是两个有用的扩展功能。运行 `sudo sysctl net.netfilter.nf_conntrack_acct=1` 可以在运行 `sudo conntrack -L` 时显示每个流经过的字节数和报文数。运行 `sudo sysctl net.netfilter.nf_conntrack_timestamp=1` 为每个连接记录一个开始时间戳,之后每次运行 `sudo conntrack -L` 时都可以显示这个流从开始经过了多少秒。在上述命令中增加 `–output ktimestamp` 选项也可以看到流开始的绝对时间。
### 插入和更改连接跟踪项
你可以手动为状态表添加连接跟踪项,例如:
```
sudo conntrack -I -s 192.168.7.10 -d 10.1.1.1 --protonum 17 --timeout 120 --sport 12345 --dport 80
```
这项命令通常被 conntrackd 用于状态复制,即将主防火墙的连接跟踪项复制到备用防火墙系统。于是当切换发生的时候,备用系统可以接管已经建立的连接且不会造成中断。连接跟踪还可以存储报文的带外元数据,例如连接跟踪标记和连接跟踪标签。可以用更新选项(`-U`)来修改它们:
```
sudo conntrack -U -m 42 -p tcp
```
这条命令将所有的 TCP 流的连接跟踪标记修改为 42。
### 删除连接跟踪项
在某些情况下,你可能想从状态表中删除条目。例如,对 NAT 规则的修改不会影响表中已存在流的经过报文。因此对 UDP 长连接(例如像 VXLAN 这样的隧道协议),删除表项可能很有意义,这样新的 NAT 转换规则才能生效。可以通过 `sudo conntrack -D` 命令附带可选的地址和端口列表选项,来删除相应的表项,如下例所示:
```
sudo conntrack -D -p udp --src 10.0.12.4 --dst 10.0.0.1 --sport 1234 --dport 53
```
### 连接跟踪错误计数
`conntrack` 也可以输出统计数字:
```
# sudo conntrack -S
cpu=0 found=0 invalid=130 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=10
cpu=1 found=0 invalid=0 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=0
cpu=2 found=0 invalid=0 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=1
cpu=3 found=0 invalid=0 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=0
```
大多数计数器将为 0。`Found` 和 `insert` 数将始终为 0,它们只是为了后向兼容。其他错误计数包括:
* `invalid`:报文既不匹配已有连接跟踪项,也未创建新连接。
* `insert_failed`:报文新建了一个连接,但插入状态表时失败。这在 NAT 引擎在伪装时恰好选择了重复的源地址和端口时可能出现。
* `drop`:报文新建了一个连接,但是没有可用的内存为其分配新的状态条目。
* `early_drop`:连接跟踪表已满。为了接受新的连接,已有的未看到双向报文的连接被丢弃。
* `error`:icmp(v6) 收到与已知连接不匹配的 icmp 错误数据包。
* `search_restart`:查找过程由于另一个 CPU 的插入或删除操作而中断。
* `clash_resolve`:多个 CPU 试图插入相同的连接跟踪条目。
除非经常发生,这些错误条件通常无害。一些错误可以通过针对预期工作负载调整连接跟踪子系统的参数来降低其发生概率,典型的配置包括 `net.netfilter.nf_conntrack_buckets` 和 `net.netfilter.nf_conntrack_max` 参数。可在 [nf\_conntrack-sysctl 文档](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/networking/nf_conntrack-sysctl.rst) 中查阅相应配置参数的完整列表。
当报文状态是 `invalid` 时,请使用 `sudo sysctl net.netfilter.nf_conntrack_log_invalid=255` 来获取更多信息。例如,当连接跟踪遇到一个所有 TCP 标志位均为 0 的报文时,将记录以下内容:
```
nf_ct_proto_6: invalid tcp flag combination SRC=10.0.2.1 DST=10.0.96.7 LEN=1040 TOS=0x00 PREC=0x00 TTL=255 ID=0 PROTO=TCP SPT=5723 DPT=443 SEQ=1 ACK=0
```
### 总结
本文介绍了如何检查连接跟踪表和存储在跟踪流中的 NAT 信息。本系列的下一部分将延伸讨论连接跟踪工具和连接跟踪事件框架。
---
via: <https://fedoramagazine.org/network-address-translation-part-2-the-conntrack-tool/>
作者:[Florian Westphal](https://fedoramagazine.org/author/strlen/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[cooljelly](https://github.com/cooljelly) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the second article in a series about network address translation (NAT). The first article introduced [how to use the iptables/nftables packet tracing feature](https://fedoramagazine.org/network-address-translation-part-1-packet-tracing/) to find the source of NAT-related connectivity problems. Part 2 introduces the “conntrack” command. conntrack allows you to inspect and modify tracked connections.
## Introduction
NAT configured via iptables or nftables builds on top of netfilters connection tracking facility. The *conntrack* command is used to inspect and alter the state table. It is part of the “conntrack-tools” package.
## Conntrack state table
The connection tracking subsystem keeps track of all packet flows that it has seen. Run “*sudo conntrack -L*” to see its content:
tcp 6 43184 ESTABLISHED src=192.168.2.5 dst=10.25.39.80 sport=5646 dport=443 src=10.25.39.80 dst=192.168.2.5 sport=443 dport=5646 [ASSURED] mark=0 use=1
tcp 6 26 SYN_SENT src=192.168.2.5 dst=192.168.2.10 sport=35684 dport=443 [UNREPLIED] src=192.168.2.10 dst=192.168.2.5 sport=443 dport=35684 mark=0 use=1
udp 17 29 src=192.168.8.1 dst=239.255.255.250 sport=48169 dport=1900 [UNREPLIED] src=239.255.255.250 dst=192.168.8.1 sport=1900 dport=48169 mark=0 use=1
Each line shows one connection tracking entry. You might notice that each line shows the addresses and port numbers twice and even with inverted address and port pairs! This is because each entry is inserted into the state table twice. The first address quadruple (source and destination address and ports) are those recorded in the original direction, i.e. what the initiator sent. The second quadruple is what conntrack expects to see when a reply from the peer is received. This solves two problems:
- If a NAT rule matches, such as IP address masquerading, this is recorded in the reply part of the connection tracking entry and can then be automatically applied to all future packets that are part of the same flow.
- A lookup in the state table will be successful even if its a reply packet to a flow that has any form of network or port address translation applied.
The original (first shown) quadruple stored never changes: Its what the initiator sent. NAT manipulation only alters the reply (second) quadruple because that is what the receiver will see. Changes to the first quadruple would be pointless: netfilter has no control over the initiators state, it can only influence the packet as it is received/forwarded. When a packet does not map to an existing entry, conntrack may add a new state entry for it. In the case of UDP this happens automatically. In the case of TCP conntrack can be configured to only add the new entry if the TCP packet has the [SYN bit](https://en.wikipedia.org/wiki/Transmission_Control_Protocol#TCP_segment_structure) set. By default conntrack allows mid-stream pickups to not cause problems for flows that existed prior to conntrack becoming active.
## Conntrack state table and NAT
As explained in the previous section, the reply tuple listed contains the NAT information. Its possible to filter the output to only show entries with source or destination nat applied. This allows to see which kind of NAT transformation is active on a given flow. *“sudo conntrack -L -p tcp –src-nat*” might show something like this:
tcp 6 114 TIME_WAIT src=10.0.0.10 dst=10.8.2.12 sport=5536 dport=80 src=10.8.2.12 dst=192.168.1.2 sport=80 dport=5536 [ASSURED]
This entry shows a connection from 10.0.0.10:5536 to 10.8.2.12:80. But unlike the previous example, the reply direction is not just the inverted original direction: the source address is changed. The destination host (10.8.2.12) sends reply packets to 192.168.1.2 instead of 10.0.0.10. Whenever 10.0.0.10 sends another packet, the router with this entry replaces the source address with 192.168.1.2. When 10.8.2.12 sends a reply, it changes the destination back to 10.0.0.10. This source NAT is due to a [nft masquerade](https://wiki.nftables.org/wiki-nftables/index.php/Performing_Network_Address_Translation_(NAT)#Masquerading) rule:
inet nat postrouting meta oifname "veth0" masquerade
Other types of NAT rules, such as “dnat to” or “redirect to” would be shown in a similar fashion, with the reply tuples destination different from the original one.
## Conntrack extensions
Two useful extensions are conntrack accounting and timestamping. *“sudo sysctl net.netfilter.nf_conntrack_acct=1”* makes *“sudo conntrack -L*” track byte and packet counters for each flow.
*“sudo sysctl net.netfilter.nf_conntrack_timestamp=1” *records a “start timestamp” for each connection.* “sudo conntrack -L”* then displays the seconds elapsed since the flow was first seen. Add “*–output ktimestamp*” to see the absolute start date as well.
## Insert and change entries
You can add entries to the state table. For example:
sudo conntrack -I -s 192.168.7.10 -d 10.1.1.1 --protonum 17 --timeout 120 --sport 12345 --dport 80
This is used by conntrackd for state replication. Entries of an active firewall are replicated to a standby system. The standby system can then take over without breaking connectivity even on established flows. Conntrack can also store metadata not related to the packet data sent on the wire, for example the conntrack mark and connection tracking labels. Change them with the “update” (-U) option:
sudo conntrack -U -m 42 -p tcp
This changes the connmark of all tcp flows to 42.
**Delete entries**
In some cases, you want to delete enries from the state table. For example, changes to NAT rules have no effect on packets belonging to flows that are already in the table. For long-lived UDP sessions, such as tunneling protocols like VXLAN, it might make sense to delete the entry so the new NAT transformation can take effect. Delete entries via *“sudo conntrack -D*” followed by an optional list of address and port information. The following example removes the given entry from the table:
sudo conntrack -D -p udp --src 10.0.12.4 --dst 10.0.0.1 --sport 1234 --dport 53
## Conntrack error counters
Conntrack also exports statistics:
# sudo conntrack -Scpu=0 found=0 invalid=130 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=10 cpu=1 found=0 invalid=0 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=0 cpu=2 found=0 invalid=0 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=1 cpu=3 found=0 invalid=0 insert=0 insert_failed=0 drop=0 early_drop=0 error=0 search_restart=0
Most counters will be 0. “Found” and “insert” will always be 0, they only exist for backwards compatibility. Other errors accounted for are:
- invalid: packet does not match an existing connection and doesn’t create a new connection.
- insert_failed: packet starts a new connection, but insertion into the state table failed. This can happen for example when NAT engine happened to pick identical source address and port when Masquerading.
- drop: packet starts a new connection, but no memory is available to allocate a new state entry for it.
- early_drop: conntrack table is full. In order to accept the new connection existing connections that did not see two-way communication were dropped.
- error: icmp(v6) received icmp error packet that did not match a known connection
- search_restart: lookup interrupted by an insertion or deletion on another CPU.
- clash_resolve: Several CPUs tried to insert identical conntrack entry.
These error conditions are harmless unless they occur frequently. Some can be mitigated by tuning the conntrack sysctls for the expected workload. *net.netfilter.nf_conntrack_buckets* and *net.netfilter.nf_conntrack_max* are typical candidates. See the [nf_conntrack-sysctl documentation](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/networking/nf_conntrack-sysctl.rst) for a full list.
Use “*sudo sysctl* *net.netfilter.nf_conntrack_log_invalid=255″* to get more information when a packet is invalid. For example, when conntrack logs the following when it encounters a packet with all tcp flags cleared:
nf_ct_proto_6: invalid tcp flag combination SRC=10.0.2.1 DST=10.0.96.7 LEN=1040 TOS=0x00 PREC=0x00 TTL=255 ID=0 PROTO=TCP SPT=5723 DPT=443 SEQ=1 ACK=0
## Summary
This article gave an introduction on how to inspect the connection tracking table and the NAT information stored in tracked flows. The next part in the series will expand on the conntrack tool and the connection tracking event framework.
## Chris
pretty sure in fedora, at least standard version, you know base io, you have to install conntrackd and then enable with systemctl. could be wrong… i remember doing this for it though.
## Göran Uddeborg
Very interesting, I’ve never really understood that conntrack thing before.
I note that some of the lines from my statistics
dohave a non-zero value forfound. Example taken right now: |
13,374 | 网络管理初学者指南 | https://opensource.com/article/21/4/network-management | 2021-05-09T16:42:00 | [
"网络"
] | https://linux.cn/article-13374-1.html |
>
> 了解网络是如何工作的,以及使用开源工具进行网络性能调优的一些窍门。
>
>
>

大多数人每一天至少会接触到两种类型的网络。当你打开计算机或者移动设备,设备连接到本地 WiFi,本地 WiFi 然后连接到所谓“互联网”的互联网络。
但是网络实际上是如何工作的?你的设备如何能够找到互联网、共享打印机或文件共享?这些东西如何知道响应你的设备?系统管理员用什么措施来优化网络的性能?
开源思想在网络技术领域根深蒂固,因此任何想更多了解网络的人,可以免费获得网络相关的资源。本文介绍了使用开源技术的网络管理相关的基础知识。
### 网络是什么?
计算机网络是由两台或者多台计算机组成的、互相通信的集合。为了使得网络能够工作,网络上一台计算机必须能够找到其他计算机,且通信必须能够从一台计算机到达另外一台。为了解决这一需求,开发和定义了两种不同的通信协议:TCP 和 IP。
#### 用于传输的 TCP 协议
为了使得计算机之间能够通信,它们之间必须有一种传输信息的手段。人说话产生的声音是通过声波来传递的,计算机是通过以太网电缆、无线电波或微波传输的数字信号进行通信的。这方面的规范被正式定义为 [TCP 协议](https://tools.ietf.org/html/rfc793)。
#### 用于寻址的 IP 协议
计算机必须有一些识别手段才能相互寻址。当人类相互称呼时,我们使用名字和代名词。当计算机相互寻址时,它们使用 IP 地址,如 `192.168.0.1`,IP 地址可以被映射到名称上,如“Laptop”、“Desktop”、“Tux” 或 “Penguin”。这方面的规范被定义为 [IP 协议](https://tools.ietf.org/html/rfc791)。
### 最小配置设置
最简单的网络是一个两台计算机的网络,使用称为“交叉电缆”的特殊布线方式的以太网电缆。交叉电缆将来自一台计算机的信号连接并传输到另一台计算机上的适当受体。还有一些交叉适配器可以将标准的以太网转换为交叉电缆。

由于在这两台计算机之间没有路由器,所有的网络管理都必须在每台机器上手动完成,因此这是一个很好的网络基础知识的入门练习。
用一根交叉电缆,你可以把两台计算机连接在一起。因为这两台计算机是直接连接的,没有网络控制器提供指导,所以这两台计算机都不用做什么创建网络或加入网络的事情。通常情况下,这项任务会由交换机和 DHCP 服务器或路由器来提示,但在这个简单的网络设置中,这一切都由你负责。
要创建一个网络,你必须先为每台计算机分配一个 IP 地址,为自行分配而保留的地址从 169.254 开始,这是一个约定俗成的方式,提醒你本 IP 段是一个闭环系统。
#### 找寻网络接口
首先,你必须知道你正在使用什么网络接口。以太网端口通常用 “eth” 加上一个从 0 开始的数字来指定,但有些设备用不同的术语来表示接口。你可以用 `ip` 命令来查询计算机上的接口:
```
$ ip address show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 ...
link/loopback 00:00:00:00:00:00 brd ...
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> ...
link/ether dc:a6:32:be:a3:e1 brd ...
3: wlan0: <BROADCAST,MULTICAST> ...
link/ether dc:a6:32:be:a3:e2 brd ...
```
在这个例子中,`eth0` 是正确的接口名称。然而,在某些情况下,你会看到 `en0` 或 `enp0s1` 或类似的东西,所以在使用设备名称之前,一定要先检查它。
#### 分配 IP 地址
通常情况下,IP 地址是从路由器获得的,路由器在网络上广播提供地址。当一台计算机连接到一个网络时,它请求一个地址。路由器通过介质访问控制(MAC)地址识别设备(注意这个 MAC 与苹果 Mac 电脑无关),并被分配 IP 地址。这就是计算机在网络上找到彼此的方式。
在本文的简单网络中,没有路由器来分配 IP 地址及注册设备,因此我们需要手动分配 IP 地址,使用 `ip` 命令来给计算机分配 IP 地址:
```
$ sudo ip address add 169.254.0.1 dev eth0
```
给另外一台计算机分配 IP 地址,将 IP 地址增 1:
```
$ sudo ip address add 169.254.0.2 dev eth0
```
现在计算机有了交叉电缆作为通信介质,有了独一无二的 IP 地址用来识别身份。但是这个网络还缺少一个重要成分:计算机不知道自己是网络的一部分。
#### 设置路由
路由器另外的一个功能是设置从一个地方到另一个地方的网络路径,称作路由表,路由表可以简单的看作网络的城市地图。
虽然现在我们还没有设置路由表,但是我们可以通过 `route` 命令来查看路由表:
```
$ route
Kernel IP routing table
Destination | Gateway | Genmask | Flags|Metric|Ref | Use | Iface
$
```
同样,你可以通过 `ip` 命令来查看路由表:
```
$ ip route
$
```
通过 `ip` 命令添加一条路由信息:
```
$ sudo ip route \
add 169.254.0.0/24 \
dev eth0 \
proto static
```
这条命令为 `eth0` 接口添加一个地址范围(从 `169.254.0.0` 开始到 `169.254.0.255` 结束)的路由。它将路由协议设置为“静态”,表示作为管理员的你创建了这个路由,作为对该范围内的任何动态路由进行覆盖。
通过 `route` 命令来查询路由表:
```
$ route
Kernel IP routing table
Destination | Gateway | Genmask | ... | Iface
link-local | 0.0.0.0 | 255.255.255.0 | ... | eth0
```
或者使用`ip`命令从不同角度来查询路由表:
```
$ ip route
169.254.0.0/24 dev eth0 proto static scope link
```
#### 探测相邻网络
现在,你的网络有了传输方式、寻址方法以及网络路由。你可以联系到你的计算机以外的主机。向另一台计算机发送的最简单的信息是一个 “呯”,这也是产生该信息的命令的名称(`ping`)。
```
$ ping -c1 169.254.0.2
64 bytes from 169.254.0.2: icmp_seq=1 ttl=64 time=0.233 ms
--- 169.254.0.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.244/0.244/0.244/0.000 ms
```
你可以通过下面的命令看到与你交互的邻居:
```
$ ip neighbour
169.254.0.2 dev eth0 lladdr e8:6a:64:ac:ef:7c STALE
```
### 通过交换机扩展你的网络
只需要双节点的网络并不多。为了解决这个问题,人们开发了特殊的硬件,称为网络“交换机”。网络交换机允许你将几条以太网电缆连接到它上面,它将消息不加区分地从发送消息的计算机分发到交换机上所有监听的计算机。除了拥有与预期接收者相匹配的 IP 地址的计算机外,其他所有计算机都会忽略该信息。这使得网络变得相对嘈杂,但这是物理上,将一组计算机连接在一起的简单方法。
在大多数现代家庭网络中,用于物理电缆的物理交换机并不实用。所以 WiFi 接入点代替了物理交换机。WiFi 接入点的功能与交换机相同:它允许许多计算机连接到它并在它们之间传递信息。
接入互联网不仅仅是一种期望,它通常是家庭网络存在的原因。没有接入互联网的交换机或 WiFi 接入点不是很有用,但要将你的网络连接到另一个网络,你需要一个路由器。
#### 添加路由器
实际上,本地网络连接了许多设备,并且越来越多的设备具备联网能力,使得网络的规模呈数量级级别增长。
手动配置网络是不切实际的,因此这些任务分配给网络中特定的节点来处理,网络中每台计算机运行一个后台守护进程,以填充从网络上的权威服务器收到的网络设置。家庭网络中,这些工作通常被整合到一个小型嵌入式设备中,通常由你的互联网服务提供商(ISP)提供,称为**路由器**(人们有时错误地将其称为调制解调器)。在一个大型网络中,每项工作通常被分配到一个单独的专用服务器上,以确保专用服务器能够专注于自己的工作以及保证工作弹性。这些任务包括:
* DHCP 服务器,为加入网络的设备分配和跟踪 IP 地址
* DNS 服务器将诸如域名 [redhat.com](http://redhat.com) 转换成 IP 地址 `209.132.183.105`
* [防火墙](https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd) 保护你的网络免受不需要的传入流量或被禁止的传出流量
* 路由器有效传输网络流量,作为其他网络(如互联网)的网关,并进行网络地址转换(NAT)
你现在的网络上可能有一个路由器,它可能管理着所有这些任务,甚至可能更多。感谢像 VyOS 这样的项目,现在你可以运行 [自己的开源路由器](https://opensource.com/article/20/1/open-source-networking)。对于这样一个项目,你应该使用一台专门的计算机,至少有两个网络接口控制器(NIC):一个连接到你的 ISP,另一个连接到交换机,或者更有可能是一个 WiFi 接入点。
### 扩大你的知识规模
无论你的网络上有多少设备,或你的网络连接到多少其他网络,其原则仍然与你的双节点网络相同。你需要一种传输方式,一种寻址方案,以及如何路由到网络的知识。
### 网络知识速查表
了解网络是如何运作的,对管理网络至关重要。除非你了解你的测试结果,否则你无法排除问题,除非你知道哪些命令能够与你的网络设备交互,否则你无法运行测试。对于重要的网络命令的基本用法以及你可以用它们提取什么样的信息,[请下载我们最新的网络速查表](https://opensource.com/downloads/cheat-sheet-networking)。
---
via: <https://opensource.com/article/21/4/network-management>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ddl-hust](https://github.com/ddl-hust) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Most people connect to at least two networks every day. After you turn on a computer or mobile device, it connects to a local WiFi network, which in turn provides access to the interconnected network of networks that is "the internet" (a combination of the words *inter*connected *net*works).
But how do networks actually work? How does your device know how to find the internet, a shared printer, or a file share? How do these things know how to respond to your device? What tricks do system administrators use to optimize the performance of a network?
Open source is firmly embedded into networking technology, so resources on networking are freely available to anyone who wants to learn more. This article covers the basics of network management using open source.
## What is a network?
A network of computers is a collection of two or more computers that can communicate with one another. For networking to work, one machine on a network must be able to find another, and communication must be able to get from one machine to another. To resolve this requirement, two different systems were developed and defined: TCP and IP.
### TCP for transport
For computers to communicate, there must be a means of transport for messages between them. When humans talk, the sounds of our voices are made possible by sound waves moving through air. Computers communicate with digital signals carried over Ethernet cables, radio waves, or microwaves. The specifications for this are formally defined as the [TCP protocol](https://tools.ietf.org/html/rfc793).
### IP for addressing
For computers to address one another, they must have some means for identification. When humans address one another, we use names and pronouns. When computers address each other, they use IP addresses, such as `192.168.0.1`
, which can be mapped to names, such as Laptop and Desktop or Tux or Penguin. The specifications for this are formally defined as the [IP protocol](https://tools.ietf.org/html/rfc791).
## Set up a minimal configuration
The simplest network is a two-computer network using a specially wired Ethernet cable called a **crossover cable**. A crossover cable connects and transmits signals coming from one computer to the appropriate receptors on another computer. There are also crossover adapters that convert a standard Ethernet into a crossover cable.

(Seth Kenlon, CC BY-SA 4.0)
With no router between the computers, all network management must be done manually on each machine, making this a good introductory exercise for networking basics.
With a crossover cable, you can connect two computers together. Because the two computers are connected directly with no network controller to offer guidance, neither computer does anything to create or join a network. Normally, this task would be prompted by a switch and a DHCP server or a router, but in this simple network setup, you are the ultimate authority.
To create a network, you first must assign an IP address to each computer. The block reserved for self-assigned IP addresses starts with `169.254`
, and it's a useful convention for reminding yourself that this is a closed-loop system.
### Find a network interface
First, you must know what network interfaces you're working with. The Ethernet port is usually designated with the term `eth`
plus a number starting with `0`
, but some devices are reported with different terms. You can discover the interfaces on a computer with the `ip`
command:
```
$ ip address show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 ...
link/loopback 00:00:00:00:00:00 brd ...
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> ...
link/ether dc:a6:32:be:a3:e1 brd ...
3: wlan0: <BROADCAST,MULTICAST> ...
link/ether dc:a6:32:be:a3:e2 brd ...
```
In this case, `eth0`
turns out to be the correct interface name. However, in some cases, you'll see `en0`
or `enp0s1`
or something similar, so it's important to always verify a device name before using it.
### Assign an IP address
Normally, an IP address is obtained from a router, which broadcasts offers for addresses over the network. When a computer gets connected to a network, it requests an address. The router registers which device on the network, identified by its Media Access Control (MAC) address (this has nothing to do with Apple Mac computers) has been assigned which address. That's how computers know how to find one another across a network.
In this simple network, however, there is no router handing out IP addresses or registering devices, so you must create an IP address. To assign an IP address to a computer, use the `ip`
command:
`$ sudo ip address add 169.254.0.1 dev eth0`
And again on the other computer, this time incrementing the IP address by 1:
`$ sudo ip address add 169.254.0.2 dev eth0`
Now each computer has a means of transport (the crossover cable) and a way to be found on the network (a unique IP address). But this network still lacks one important element: The computers still don't know they're a member of a network.
### Set up a route
Another task that's usually managed by a router is setting up the paths network traffic must take to get from one place to another. This is called a *routing table*, and you can think of it as a very basic city map for your network.
Currently, no routing table exists on your network. You can view your non-existent routing table with the `route`
command:
```
$ route
Kernel IP routing table
Destination | Gateway | Genmask | Flags|Metric|Ref | Use | Iface
$
```
Alternatively, you can view it with the `ip`
command:
```
$ ip route
$
```
You can add a route with the `ip`
command:
```
$ sudo ip route \
add 169.254.0.0/24 \
dev eth0 \
proto static
```
This command adds a route to the address range (starting from `169.254.0.0`
and ending at `169.254.0.255`
) to the `eth0`
interface. It sets the routing protocol to `static`
to indicate that you, the administrator, created the route as an intentional override for any dynamic routing.
Verify your routing table with the `route`
command:
```
$ route
Kernel IP routing table
Destination | Gateway | Genmask | ... | Iface
link-local | 0.0.0.0 | 255.255.255.0 | ... | eth0
```
Or use the `ip`
command for a different view:
```
$ ip route
169.254.0.0/24 dev eth0 proto static scope link
```
### Ping your neighbor
Now that your network has established a method of transport, a means of addressing, and a network route, you can reach hosts outside your computer. The simplest message to send another computer is a `ping`
, which is conveniently also the name of the command that generates the message:
```
$ ping -c1 169.254.0.2
64 bytes from 169.254.0.2: icmp_seq=1 ttl=64 time=0.233 ms
--- 169.254.0.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.244/0.244/0.244/0.000 ms
```
You can also view the neighbors you've interacted with:
```
$ ip neighbour
169.254.0.2 dev eth0 lladdr e8:6a:64:ac:ef:7c STALE
```
## Grow your network with a switch
There aren't many needs for two-node networks. Special hardware, called a network **switch**, was developed to solve this problem. A network switch allows you to attach several Ethernet cables to it, and it distributes messages indiscriminately from the computer sending it to the destination IP address. It's an easy way to physically connect a group of computers.
A physical switch with physical cables isn't practical or desired on most modern home networks, so a WiFi access point is often used instead. A WiFi access point serves the same function as a switch: it allows many computers to connect to it and pass messages between them.
A switch or WiFi access point without access to the Internet isn't very useful for most computer users, and to connect your network to another network such as the Internet, you need a router.
## Add a router
In practice, local networks connect many devices, and the number is growing as more devices become network-aware. Connect a network to the Internet (a network itself), and that number goes up by orders of magnitude.
It's impractical to manually configure even a small network, so common tasks are assigned to specific nodes on the network, and each computer runs a **daemon **(a job that runs silently in the background) to populate network settings received from authoritative servers on the network. On a home network, these jobs are often consolidated into one small embedded device, often provided by your Internet service provider (ISP), called a **router **(people sometimes incorrectly call it a modem). In a large network, each task is usually assigned to a separate dedicated server to ensure focus and resiliency. These include:
- DHCP server to assign and track IP addresses to devices joining the network
[DNS server](https://opensource.com/article/17/4/build-your-own-name-server)to convert registered domain names like[redhat.com](http://redhat.com)to IP addresses like`209.132.183.105`
[Firewall](https://www.redhat.com/sysadmin/secure-linux-network-firewall-cmd)to protect your network from unwanted incoming traffic or forbidden outgoing traffic- Router to efficiently direct traffic on the network, serve as a gateway to other networks (such as the Internet), and perform network address translation (NAT)
You probably have a router on your network now, and it probably manages all these tasks and possibly more. You can run[ your own open source router](https://opensource.com/article/20/1/open-source-networking), thanks to projects like VyOS. For such a project, you should use a dedicated computer with at least two network interface controllers (NICs): one to connect to your ISP and another to connect to a switch or, more likely, a WiFi access point.
## Scale your knowledge
Regardless of how many devices are on your network or how many other networks your network connects to, the principles remain the same as with your two-node network. You need a mode of transport, a scheme for addressing, and knowledge of how to reach the network.
## Networking cheat sheet
Understanding how a network operates is vital for managing a network. You can't troubleshoot issues unless you understand the results of your tests, and you can't run tests unless you know what commands interact with your network infrastructure. For an overview of important networking commands and what kind of information you can extract with them, [download our updated networking cheat sheet](https://opensource.com/downloads/cheat-sheet-networking).
## 1 Comment |
13,376 | 在 Windows 中运行基于 Linux 的应用程序已经成为现实 | https://news.itsfoss.com/linux-gui-apps-wsl/ | 2021-05-10T11:03:33 | [
"WSL"
] | https://linux.cn/article-13376-1.html |
>
> 微软宣布对其 WSL 进行重大改进,使你能够轻松地运行 Linux 图形化应用程序。
>
>
>

当微软在 2016 年发布 “Windows subsystem for Linux”(也就是 WSL)的时候显然有夸大宣传的嫌疑,当时人们梦想着无需重启就可以同时运行基于 Windows 和 Linux 的应用程序,令人可惜的是,WSL 只能运行 Linux 终端程序。
去年,微软再次尝试去颠覆 Windows 的应用生态,这一次,他们替换了老旧的模拟核心,转而使用了真正的 Linux 核心,这一变化使你可以 [在 Windows 中运行 Linux 应用程序](https://itsfoss.com/run-linux-apps-windows-wsl/)。
### WSL 图形化应用的初步预览
从技术上讲,用户最初确实在 WSL 上获得了对 Linux 图形化应用程序的支持,但仅限于使用第三方 X 服务器时。这通常是不稳定的、缓慢、难以设置,并且使人们有隐私方面的顾虑。
结果是小部分 Linux 爱好者(碰巧运行 Windows),他们具有设置 X 服务器的能力。但是,这些爱好者对没有硬件加速支持感到失望。
所以,较为明智的方法是在 WSL 上只运行基于命令行的程序。
**但是现在这个问题得到了改善**。现在,微软 [正式支持](https://devblogs.microsoft.com/commandline/the-initial-preview-of-gui-app-support-is-now-available-for-the-windows-subsystem-for-linux-2/) 了 Linux 图形化应用程序,我们很快就能够享受硬件加速了,
### 面向大众的 Linux 图形化应用程序:WSLg

随着微软发布新的 WSL,有了一系列巨大的改进,它们包括:
* GPU 硬件加速
* 开箱即用的音频和麦克风支持
* 自动启用 X 服务器和 Pulse 音频服务
有趣的是,开发者们给这个功能起了一个有趣的外号 “WSLg”。
这些功能将使在 WSL 上运行 Linux 应用程序几乎与运行原生应用程序一样容易,同时无需占用过多性能资源。
因此,你可以尝试运行 [自己喜欢的 IDE](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/)、特定于 Linux 的测试用例以及诸如 [CAD](https://itsfoss.com/cad-software-linux/) 之类的各种软件。
#### Linux 应用的 GPU 硬件加速

以前在 Windows 上运行图形化 Linux 程序的最大问题之一是它们无法使用硬件加速。当用户尝试移动窗口和执行任何需要对 GPU 性能有要求的任务时候,它常常陷入缓慢卡顿的局面。
根据微软发布的公告:
>
> “作为此次更新的一部分,我们也启用了对 3D 图形的 GPU 加速支持,多亏了 Mesa 21.0 中完成的工作,所有的复杂 3D 渲染的应用程序都可以利用 OpenGL 在 Windows 10 上使用 GPU 为这些应用程序提供硬件加速。”
>
>
>
这是一个相当实用的改进,这对用户在 WSL 下运行需求强大 GPU 性能的应用程序提供了莫大帮助。
#### 开箱即用的音频和麦克风支持!
如果想要良好的并行 Windows 和 Linux 程序,好的音频支持是必不可少的,随着新的 WSL 发布,音频得到开箱即用的支持,这都要归功于随着 X 服务器一同启动的 Pulse 音频服务。
微软解释说:
>
> “WSL 上的 Linux 图形化应用程序还将包括开箱即用的音频和麦克风支持。这一令人兴奋的改进将使你的应用程序可以播放音频提示并调用麦克风,适合构建、测试或使用电影播放器、电信应用程序等。”
>
>
>
如果我们希望 Linux 变得更加普及,这是一项关键功能。这也将允许 Windows 应用的开发人员更好地将其应用移植到 Linux。
#### 自动启动所有必需的服务器

以前,你必须先手动启动 [PulseAudio](https://www.freedesktop.org/wiki/Software/PulseAudio/) 和 [X 服务器](https://x.org/wiki/),然后才能运行应用程序。现在,微软已经实现了一项服务,可以检查 Linux 应用程序是否正在运行,然后自动启动所需的服务器。
这使得用户更容易在 Windows 上运行 Linux 应用程序。
微软声称这些改动会显著提升用户体验。
>
> “借助此功能,我们将启动一个配套的系统分发包,其中包含 Wayland、X 服务器、Pulse 音频服务以及使 Linux 图形化应用程序与 Windows 通信所需的所有功能。使用完图形化应用程序并终止 WSL 发行版后,系统分发包也会自动结束其会话。”
>
>
>
这些组件的结合使 Linux 图形化应用程序与常规 Windows 程序并行运行更为简单。
### 总结
有了这些新功能,微软似乎正在竭尽全力使 Linux 应用程序在 Windows 上运行。随着越来越多的用户在 Windows 上运行 Linux 应用程序,我们可能会看到更多的用户转向 Linux。特别是因为他们习惯的应用程序能够运行。
如果这种做法取得了成功(并且微软几年后仍未将其雪藏),它将结束 5 年来对将 Linux 应用引入 Windows 的探索。如果你想了解更多信息,可以查看 [发行公告](https://blogs.windows.com/windows-insider/2021/04/21/announcing-windows-10-insider-preview-build-21364/)。
你对在 Windows 上运行 Linux 图形化应用程序怎么看?请在下面留下你的评论。
---
via: <https://news.itsfoss.com/linux-gui-apps-wsl/>
作者:[Jacob Crume](https://news.itsfoss.com/author/jacob/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Kevin3599](https://github.com/Kevin3599) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

When Microsoft released [Windows Subsystem for Linux](https://docs.microsoft.com/en-us/windows/wsl/?ref=news.itsfoss.com) (WSL) in 2016, the hype was unreal. People were dreaming of running their Windows and Linux apps side-by-side, without having to reboot. But alas, WSL could only run terminal applications.
Last year, Microsoft set out again to try to revolutionize the Windows app ecosystem. This time, they replaced the old emulated kernel with a real Linux kernel. This change allowed you to run [Linux apps in Windows](https://itsfoss.com/run-linux-apps-windows-wsl/?ref=news.itsfoss.com).
## Initial Preview of GUI Apps for WSL
Technically, you did get the initial support for Linux GUI apps on WSL, but only when using a 3rd-party X server. These were often buggy, slow, hard to set up, and posed a privacy concern.
The result of this was a small group of Linux enthusiasts (that happened to run Windows) that had the skills and knowledge to set up an X server. These people were then horribly disappointed at the fact there was no hardware acceleration at all.
So, it was wise to stick to command line utilities on WSL.
**But this all changes now. **Now that Microsoft is [officially supporting](https://devblogs.microsoft.com/commandline/the-initial-preview-of-gui-app-support-is-now-available-for-the-windows-subsystem-for-linux-2/?ref=news.itsfoss.com) GUI Linux apps, we will be receiving hardware acceleration, alongside a huge range of other improvements in WSL.
## Linux GUI Apps For The Masses: WSLg
With the new official support from Microsoft in WSL, there is a huge range of available improvements. These include:
- GPU hardware acceleration
- Audio and microphone support out of the box
- Automatic starting of the X and PulseAudio servers
And, they’ve given this feature a nickname “**WSLg**“.
These features will make running Linux apps on WSL almost as easy as running native apps, with a minimal performance impact.
So, you can try running your [favorite IDE](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/?ref=news.itsfoss.com), Linux-specific testing use-cases, and a variety of other applications like [CAD software](https://itsfoss.com/cad-software-linux/?ref=news.itsfoss.com).
### GPU Hardware Acceleration In Linux Apps
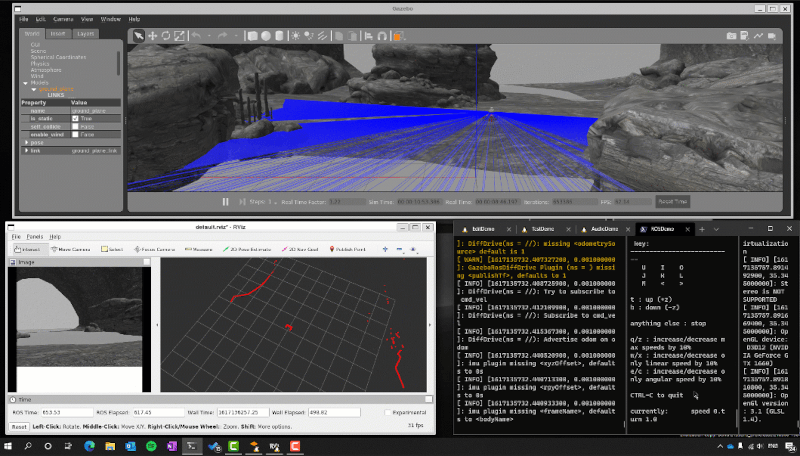
One of the biggest issues with running GUI Linux apps on Windows previously was that they couldn’t use hardware acceleration. This left us with a slow mess when trying to move windows around and doing anything that needed some GPU horsepower.
According to the announcement post from Microsoft:
As part of this feature, we have also enabled support for GPU accelerated 3D graphics! Thanks to work that was completed in Mesa 21.0, any applications that are doing complex 3D rendering can leverage OpenGL to accelerate these using the GPU on your Windows 10 machine.
This is a useful addition, and should help anyone wanting to run GPU intensive applications through WSL.
### Audio And Microphone Support Out Of The Box!
One of the key elements to a good experience with Linux apps running alongside Windows apps is the audio. With the new WSL update, audio is supported out of the box. This is achieved with a PulseAudio server being started at the same time as the X server.
Microsoft explains:
Linux GUI applications on WSL will also include out-of-the-box audio and microphone support. This exciting aspect will let your apps play audio cues and utilize the microphone, perfect for building, testing, or using movie players, telecommunication apps, and more.
If we want Linux apps to become more widespread, this is a key feature. This will also allow developers of Windows apps to better support porting their apps to Linux.
### Automatic Starting Of All The Required Servers
Previously, you had to start the [PulseAudio](https://www.freedesktop.org/wiki/Software/PulseAudio/?ref=news.itsfoss.com) and [X servers](https://x.org/wiki/?ref=news.itsfoss.com) manually before being able to actually run anything. Now, Microsoft has implemented a service that checks to see if a Linux app is running, and then starts the required servers automatically.
This allows much easier launching and using of Linux apps on Windows.
Microsoft claims this will improve the user experience significantly:
With this feature, we are automatically starting a companion system distro, containing a Wayland, X server, pulse audio server, and everything else needed to make Linux GUI apps communicate with Windows. After you’re finished using GUI applications and terminate your WSL distribution the system distro will automatically end its session as well.
These components combine to make it super easy to run Linux GUI apps alongside regular Windows apps.
## Wrapping Up
With all these new features, it looks like Microsoft is giving it their best to get Linux apps working on Windows. And with more users running Linux apps on Windows, we may see more of them jump ship and move solely to Linux. Especially since the apps they’re used to would run anyway.
If this takes off (and Microsoft doesn’t kill it in a few years), it will bring an end to a 5-year quest to bring Linux apps to Windows. If you are curious to learn more about it, you can look at the [release announcement](https://blogs.windows.com/windows-insider/2021/04/21/announcing-windows-10-insider-preview-build-21364/?ref=news.itsfoss.com).
*What are your thoughts on GUI Linux apps running on Windows? Share them in the comments below!*
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,377 | OpenRGB:一个控制所有 RGB 灯光设置的开源应用 | https://itsfoss.com/openrgb/ | 2021-05-10T11:39:19 | [
"OpenRGB",
"LED"
] | https://linux.cn/article-13377-1.html |
>
> OpenRGB 是一个有用的开源工具,可以一个工具管理所有的 RGB 灯光。让我们来了解一下它。
>
>
>

无论是你的键盘、鼠标、CPU 风扇、AIO,还是其他连接的外围设备或组件,Linux 都没有官方软件支持来控制 RGB 灯光。
而 OpenRGB 似乎是一个适用于 Linux 的多合一 RGB 灯光控制工具。
### OpenRGB:多合一的 RGB 灯光控制中心

是的,你可能会找到不同的工具来调整设置,如 **Piper** 专门 [在 Linux 上配置游戏鼠标](https://itsfoss.com/piper-configure-gaming-mouse-linux/)。但是,如果你有各种组件或外设,要把它们都设置成你喜欢的 RGB 颜色,那将是一件很麻烦的事情。
OpenRGB 是一个令人印象深刻的工具,它不仅专注于 Linux,也可用于 Windows 和 MacOS。
它不仅仅是一个将所有 RGB 灯光设置放在一个工具下的想法,而是旨在摆脱所有需要安装来调整灯光设置的臃肿软件。
即使你使用的是 Windows 系统的机器,你可能也知道像 Razer Synapse 这样的软件工具是占用资源的,并伴随着它们的问题。因此,OpenRGB 不仅仅局限于 Linux 用户,还适用于每一个希望调整 RGB 设置的用户。
它支持大量设备,但你不应该期待对所有设备的支持。
### OpenRGB 的特点

它在提供简单的用户体验的同时,赋予了你许多有用的功能。其中的一些特点是:
* 轻便的用户界面
* 跨平台支持
* 能够使用插件扩展功能
* 设置颜色和效果
* 能够保存和加载配置文件
* 查看设备信息
* 连接 OpenRGB 的多个实例,在多台电脑上同步灯光

除了上述所有的特点外,你还可以很好地控制照明区域、色彩模式、颜色等。
### 在 Linux 中安装 OpenRGB
你可以在其官方网站上找到 AppImage 文件和 DEB 包。对于 Arch Linux 用户,你也可以在 [AUR](https://itsfoss.com/aur-arch-linux/) 中找到它。
如需更多帮助,你可以参考我们的 [AppImage 指南](https://itsfoss.com/use-appimage-linux/)和[安装 DEB 文件的方法](https://itsfoss.com/install-deb-files-ubuntu/)来设置。
官方网站应该也可以让你下载其他平台的软件包。但是,如果你想探索更多关于它的信息或自己编译它,请前往它的 [GitLab 页面](https://gitlab.com/CalcProgrammer1/OpenRGB)。
* [OpenRGB](https://openrgb.org/)
### 总结
尽管我没有很多支持 RGB 的设备/组件,但我可以成功地调整我的罗技 G502 鼠标。
如果你想摆脱多个应用,用一个轻量级的界面来管理你所有的 RGB 灯光,我肯定会推荐你试一试。
你已经试过它了吗?欢迎在评论中分享你对它的看法!
---
via: <https://itsfoss.com/openrgb/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief*:*OpenRGB is a useful open-source utility to manage all your RGB lighting under a single roof. Let’s find out more about it.*
No matter whether it is your keyboard, mouse, CPU fan, AIO, and other connected peripherals or components, Linux does not have official software support to control the RGB lighting.
And, OpenRGB seems to be an all-in-one RGB lighting control utility for Linux.
## OpenRGB: An All-in-One RGB Lighting Control Center
Yes, you may find different tools to tweak the settings like **Piper** to specifically [configure a gaming mouse on Linux](https://itsfoss.com/piper-configure-gaming-mouse-linux/). But, if you have a variety of components or peripherals, it will be a cumbersome task to set them all to your preference of RGB color.
OpenRGB is an impressive utility that not only focuses on Linux but also available for Windows and macOS.
It is not just an idea to have all the RGB lighting settings under one roof, but it aims to get rid of all the bloatware apps that you need to install to tweak lighting settings.
Even if you are using a Windows-powered machine, you probably know that software tools like Razer Synapse are resource hogs and come with their share of issues. So, OpenRGB is not just limited for Linux users but for every user looking to tweak RGB settings.
It supports a long list of devices, but you should not expect support for everything.
## Features of OpenRGB
It empowers you with many useful functionalities while offering a simple user experience. Some of the features are:
- Lightweight user interface
- Cross-platform support
- Ability to extend functionality using plugins
- Set colors and effects
- Ability to save and load profiles
- View device information
- Connect multiple instances of OpenRGB to synchronize lighting across multiple PCs
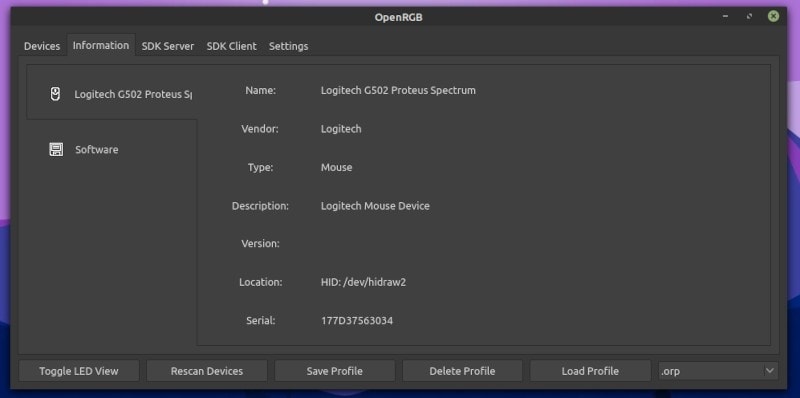
Along with all the above-mentioned features, you get a good control over the lighting zones, color mode, colors, and more.
## Installing OpenRGB in Linux
You can find AppImage files and DEB packages on their official website. For Arch Linux users, you can also find it in [AUR](https://itsfoss.com/aur-arch-linux/).
For additional help, you can refer to our [AppImage guide](https://itsfoss.com/use-appimage-linux/) and [ways to install DEB files](https://itsfoss.com/install-deb-files-ubuntu/) to set it up.
The official website should let you download packages for other platforms as well. But, if you want to explore more about it or compile it yourself, head to its [GitLab page](https://gitlab.com/CalcProgrammer1/OpenRGB).
## Closing Thoughts
Even though I do not have many RGB-enabled devices/components, I could tweak my Logitech G502 mouse successfully.
I would definitely recommend you to give it a try if you want to get rid of multiple applications and use a lightweight interface to manage all your RGB lighting.
Have you tried it already? Feel free to share what you think about it in the comments! |
13,379 | 用 NetworkManager 配置 WireGuard 虚拟私有网络 | https://fedoramagazine.org/configure-wireguard-vpns-with-networkmanager/ | 2021-05-10T23:56:44 | [
"WireGuard"
] | https://linux.cn/article-13379-1.html | 
<ruby> 虚拟私有网络 <rt> Virtual Private Networks </rt></ruby>应用广泛。如今有各种方案可供使用,用户可通过这些方案访问任意类型的资源,同时保持其机密性与隐私性。
最近,WireGuard 因为其简单性、速度与安全性成为最广泛使用的虚拟私有网络协议之一。WireGuard 最早应用于 Linux 内核,但目前可以用在其他平台,例如 iOS、Android 等。
WireGuard 使用 UDP 作为其传输协议,并在 Critokey Routing(CKR)的基础上建立对等节点之间的通信。每个对等节点(无论是服务器或客户端)都有一对<ruby> 密钥 <rt> key </rt></ruby>(公钥与私钥),公钥与许可 IP 间建立通信连接。有关 WireGuard 更多信息请访问其 [主页](https://www.wireguard.com/)。
本文描述了如何在两个对等节点(PeerA 与 PeerB)间设置 WireGuard。两个节点均运行 Fedora Linux 系统,使用 NetworkManager 进行持久性配置。
### WireGuard 设置与网络配置
在 PeerA 与 PeerB 之间建立持久性虚拟私有网络连接只需三步:
1. 安装所需软件包。
2. 生成<ruby> 密钥对 <rt> key pair </rt></ruby>。
3. 配置 WireGuard 接口。
### 安装
在两个对等节点(PeerA 与 PeerB)上安装 `wireguard-tools` 软件包:
```
$ sudo -i
# dnf -y install wireguard-tools
```
这个包可以从 Fedora Linux 更新库中找到。它在 `/etc/wireguard/` 中创建一个配置目录。在这里你将创建密钥和接口配置文件。
### 生成密钥对
现在,使用 `wg` 工具在每个节点上生成公钥与私钥:
```
# cd /etc/wireguard
# wg genkey | tee privatekey | wg pubkey > publickey
```
### 在 PeerA 上配置 WireGuard 接口
WireGuard 接口命名规则为 `wg0`、`wg1` 等等。完成下述步骤为 WireGuard 接口创建配置:
* PeerA 节点上配置想要的 IP 地址与掩码。
* 该节点监听的 UDP 端口。
* PeerA 的私钥。
```
# cat << EOF > /etc/wireguard/wg0.conf
[Interface]
Address = 172.16.1.254/24
SaveConfig = true
ListenPort = 60001
PrivateKey = mAoO2RxlqRvCZZoHhUDiW3+zAazcZoELrYbgl+TpPEc=
[Peer]
PublicKey = IOePXA9igeRqzCSzw4dhpl4+6l/NiQvkDSAnj5LtShw=
AllowedIPs = 172.16.1.2/32
EOF
```
允许 UDP 流量通过节点监听的端口:
```
# firewall-cmd --add-port=60001/udp --permanent --zone=public
# firewall-cmd --reload
success
```
最后,将接口配置文件导入 NetworkManager。这样,WireGuard 接口在重启后将持续存在。
```
# nmcli con import type wireguard file /etc/wireguard/wg0.conf
Connection 'wg0' (21d939af-9e55-4df2-bacf-a13a4a488377) successfully added.
```
验证 `wg0`的状态:
```
# wg
interface: wg0
public key: FEPcisOjLaZsJbYSxb0CI5pvbXwIB3BCjMUPxuaLrH8=
private key: (hidden)
listening port: 60001
peer: IOePXA9igeRqzCSzw4dhpl4+6l/NiQvkDSAnj5LtShw=
allowed ips: 172.16.1.2/32
# nmcli -p device show wg0
===============================================================================
Device details (wg0)
===============================================================================
GENERAL.DEVICE: wg0
-------------------------------------------------------------------------------
GENERAL.TYPE: wireguard
-------------------------------------------------------------------------------
GENERAL.HWADDR: (unknown)
-------------------------------------------------------------------------------
GENERAL.MTU: 1420
-------------------------------------------------------------------------------
GENERAL.STATE: 100 (connected)
-------------------------------------------------------------------------------
GENERAL.CONNECTION: wg0
-------------------------------------------------------------------------------
GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveC>
-------------------------------------------------------------------------------
IP4.ADDRESS[1]: 172.16.1.254/24
IP4.GATEWAY: --
IP4.ROUTE[1]: dst = 172.16.1.0/24, nh = 0.0.0.0, mt =>
-------------------------------------------------------------------------------
IP6.GATEWAY: --
-------------------------------------------------------------------------------
```
上述输出显示接口 `wg0` 已连接。现在,它可以和虚拟私有网络 IP 地址为 172.16.1.2 的对等节点通信。
### 在 PeerB 上配置 WireGuard 接口
现在可以在第二个对等节点上创建 `wg0` 接口的配置文件了。确保你已经完成以下步骤:
* PeerB 节点上设置 IP 地址与掩码。
* PeerB 的私钥。
* PeerA 的公钥。
* PeerA 的 IP 地址或主机名、监听 WireGuard 流量的 UDP 端口。
```
# cat << EOF > /etc/wireguard/wg0.conf
[Interface]
Address = 172.16.1.2
SaveConfig = true
PrivateKey = UBiF85o7937fBK84c2qLFQwEr6eDhLSJsb5SAq1lF3c=
[Peer]
PublicKey = FEPcisOjLaZsJbYSxb0CI5pvbXwIB3BCjMUPxuaLrH8=
AllowedIPs = 172.16.1.254/32
Endpoint = peera.example.com:60001
EOF
```
最后一步是将接口配置文件导入 NetworkManager。如上所述,这一步是重启后保持 WireGuard 接口持续存在的关键。
```
# nmcli con import type wireguard file /etc/wireguard/wg0.conf
Connection 'wg0' (39bdaba7-8d91-4334-bc8f-85fa978777d8) successfully added.
```
验证 `wg0` 的状态:
```
# wg
interface: wg0
public key: IOePXA9igeRqzCSzw4dhpl4+6l/NiQvkDSAnj5LtShw=
private key: (hidden)
listening port: 47749
peer: FEPcisOjLaZsJbYSxb0CI5pvbXwIB3BCjMUPxuaLrH8=
endpoint: 192.168.124.230:60001
allowed ips: 172.16.1.254/32
# nmcli -p device show wg0
===============================================================================
Device details (wg0)
===============================================================================
GENERAL.DEVICE: wg0
-------------------------------------------------------------------------------
GENERAL.TYPE: wireguard
-------------------------------------------------------------------------------
GENERAL.HWADDR: (unknown)
-------------------------------------------------------------------------------
GENERAL.MTU: 1420
-------------------------------------------------------------------------------
GENERAL.STATE: 100 (connected)
-------------------------------------------------------------------------------
GENERAL.CONNECTION: wg0
-------------------------------------------------------------------------------
GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveC>
-------------------------------------------------------------------------------
IP4.ADDRESS[1]: 172.16.1.2/32
IP4.GATEWAY: --
-------------------------------------------------------------------------------
IP6.GATEWAY: --
-------------------------------------------------------------------------------
```
上述输出显示接口 `wg0` 已连接。现在,它可以和虚拟私有网络 IP 地址为 172.16.1.254 的对等节点通信。
### 验证节点间通信
完成上述步骤后,两个对等节点可以通过虚拟私有网络连接相互通信,以下是 ICMP 测试结果:
```
[root@peerb ~]# ping 172.16.1.254 -c 4
PING 172.16.1.254 (172.16.1.254) 56(84) bytes of data.
64 bytes from 172.16.1.254: icmp_seq=1 ttl=64 time=0.566 ms
64 bytes from 172.16.1.254: icmp_seq=2 ttl=64 time=1.33 ms
64 bytes from 172.16.1.254: icmp_seq=3 ttl=64 time=1.67 ms
64 bytes from 172.16.1.254: icmp_seq=4 ttl=64 time=1.47 ms
```
在这种情况下,如果你在 PeerA 端口 60001 上捕获 UDP 通信,则将看到依赖 WireGuard 协议的通信过程和加密的数据:

总结
--
虚拟私有网络很常见。在用于部署虚拟私有网络的各种协议和工具中,WireGuard 是一种简单、轻巧和安全的选择。它可以在对等节点之间基于 CryptoKey 路由建立安全的点对点连接,过程非常简单。此外,NetworkManager 支持 WireGuard 接口,允许重启后进行持久配置。
---
via: <https://fedoramagazine.org/configure-wireguard-vpns-with-networkmanager/>
作者:[Maurizio Garcia](https://fedoramagazine.org/author/malgnuz/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Virtual Private Networks (VPNs) are used extensively. Nowadays there are different solutions available which allow users access to any kind of resource while maintaining their confidentiality and privacy.
Lately, one of the most commonly used VPN protocols is WireGuard because of its simplicity, speed and the security it offers. WireGuard’s implementation started in the Linux kernel but currently it is available in other platforms such as iOS and Android among others.
WireGuard uses UDP as its transport protocol and it bases the communication between peers upon Critokey Routing (CKR). Each peer, either server or client, has a pair of keys (public and private) and there is a link between public keys and allowed IPs to communicate with. For further information about WireGuard please visit its [page](https://www.wireguard.com/).
This article describes how to set up WireGuard between two peers: PeerA and PeerB. Both nodes are running Fedora Linux and both are using NetworkManager for a persistent configuration.
**WireGuard set up and networking configuration**
You are only three steps away from having a persistent VPN connection between PeerA and PeerB:
- Install the required packages.
- Generate key pairs.
- Configure the WireGuard interfaces.
**Installation**
Install the *wireguard-tools* package on both peers (PeerA and PeerB):
$ sudo -i # dnf -y install wireguard-tools
This package is available in the Fedora Linux updates repository. It creates a configuration directory at */etc/wireguard/*. This is where you will create the keys and the interface configuration file.
**Generate the key pairs**
Next, use the *wg* utility to generate both public and private keys on each node:
# cd /etc/wireguard # wg genkey | tee privatekey | wg pubkey > publickey
**Configure the WireGuard interface on PeerA**
WireGuard interfaces use the names: *wg0*, *wg1* and so on. Create the configuration for the WireGuard interface. For this, you need the following items:
- The IP address and MASK you want to configure in the PeerA node.
- The UDP port where this peer listens.
- PeerA’s private key.
# cat << EOF > /etc/wireguard/wg0.conf [Interface] Address = 172.16.1.254/24 SaveConfig = true ListenPort = 60001 PrivateKey = mAoO2RxlqRvCZZoHhUDiW3+zAazcZoELrYbgl+TpPEc= [Peer] PublicKey = IOePXA9igeRqzCSzw4dhpl4+6l/NiQvkDSAnj5LtShw= AllowedIPs = 172.16.1.2/32 EOF
Allow UDP traffic through the port on which this peer will listen:
# firewall-cmd --add-port=60001/udp --permanent --zone=public # firewall-cmd --reload success
Finally, import the interface profile into NetworkManager. As a result, the WireGuard interface will persist after reboots.
# nmcli con import type wireguard file /etc/wireguard/wg0.conf Connection 'wg0' (21d939af-9e55-4df2-bacf-a13a4a488377) successfully added.
Verify the status of device *wg0*:
# wg interface: wg0 public key: FEPcisOjLaZsJbYSxb0CI5pvbXwIB3BCjMUPxuaLrH8= private key: (hidden) listening port: 60001 peer: IOePXA9igeRqzCSzw4dhpl4+6l/NiQvkDSAnj5LtShw= allowed ips: 172.16.1.2/32 # nmcli -p device show wg0 =============================================================================== Device details (wg0) =============================================================================== GENERAL.DEVICE: wg0 ------------------------------------------------------------------------------- GENERAL.TYPE: wireguard ------------------------------------------------------------------------------- GENERAL.HWADDR: (unknown) ------------------------------------------------------------------------------- GENERAL.MTU: 1420 ------------------------------------------------------------------------------- GENERAL.STATE: 100 (connected) ------------------------------------------------------------------------------- GENERAL.CONNECTION: wg0 ------------------------------------------------------------------------------- GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveC> ------------------------------------------------------------------------------- IP4.ADDRESS[1]: 172.16.1.254/24 IP4.GATEWAY: -- IP4.ROUTE[1]: dst = 172.16.1.0/24, nh = 0.0.0.0, mt => ------------------------------------------------------------------------------- IP6.GATEWAY: -- -------------------------------------------------------------------------------
The above output shows that interface *wg0* is connected. It is now able to communicate with one peer whose VPN IP address is 172.16.1.2.
### Configure the WireGuard interface in PeerB
It is time to create the configuration file for the *wg0* interface on the second peer. Make sure you have the following:
- The IP address and MASK to set on PeerB.
- The PeerB’s private key.
- The PeerA’s public key.
- The PeerA’s IP address or hostname and the UDP port on which it is listening for WireGuard traffic.
# cat << EOF > /etc/wireguard/wg0.conf [Interface] Address = 172.16.1.2 SaveConfig = true PrivateKey = UBiF85o7937fBK84c2qLFQwEr6eDhLSJsb5SAq1lF3c= [Peer] PublicKey = FEPcisOjLaZsJbYSxb0CI5pvbXwIB3BCjMUPxuaLrH8= AllowedIPs = 172.16.1.254/32 Endpoint = peera.example.com:60001 EOF
The last step is about importing the interface profile into NetworkManager. As I mentioned before, this allows the WireGuard interface to have a persistent configuration after reboots.
# nmcli con import type wireguard file /etc/wireguard/wg0.conf Connection 'wg0' (39bdaba7-8d91-4334-bc8f-85fa978777d8) successfully added.
Verify the status of device *wg0*:
# wg interface: wg0 public key: IOePXA9igeRqzCSzw4dhpl4+6l/NiQvkDSAnj5LtShw= private key: (hidden) listening port: 47749 peer: FEPcisOjLaZsJbYSxb0CI5pvbXwIB3BCjMUPxuaLrH8= endpoint: 192.168.124.230:60001 allowed ips: 172.16.1.254/32 # nmcli -p device show wg0 =============================================================================== Device details (wg0) =============================================================================== GENERAL.DEVICE: wg0 ------------------------------------------------------------------------------- GENERAL.TYPE: wireguard ------------------------------------------------------------------------------- GENERAL.HWADDR: (unknown) ------------------------------------------------------------------------------- GENERAL.MTU: 1420 ------------------------------------------------------------------------------- GENERAL.STATE: 100 (connected) ------------------------------------------------------------------------------- GENERAL.CONNECTION: wg0 ------------------------------------------------------------------------------- GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveC> ------------------------------------------------------------------------------- IP4.ADDRESS[1]: 172.16.1.2/32 IP4.GATEWAY: -- ------------------------------------------------------------------------------- IP6.GATEWAY: -- -------------------------------------------------------------------------------
The above output shows that interface *wg0* is connected. It is now able to communicate with one peer whose VPN IP address is 172.16.1.254.
**Verify connectivity between peers**
After executing the procedure described earlier both peers can communicate to each other through the VPN connection as demonstrated in the following ICMP test:
[root@peerb ~]# ping 172.16.1.254 -c 4 PING 172.16.1.254 (172.16.1.254) 56(84) bytes of data. 64 bytes from 172.16.1.254: icmp_seq=1 ttl=64 time=0.566 ms 64 bytes from 172.16.1.254: icmp_seq=2 ttl=64 time=1.33 ms 64 bytes from 172.16.1.254: icmp_seq=3 ttl=64 time=1.67 ms 64 bytes from 172.16.1.254: icmp_seq=4 ttl=64 time=1.47 ms
In this scenario, if you capture UDP traffic on port 60001 on PeerA you will see the communication relying on WireGuard protocol and the encrypted data:
## Conclusion
Virtual Private Networks (VPNs) are very common. Among a wide variety of protocols and tools for deploying a VPN, WireGuard is a simple, lightweight and secure choice. It allows secure point-to-point connections between peers based on CryptoKey routing and the procedure is very straight-forward. In addition, NetworkManager supports WireGuard interfaces allowing persistent configurations after reboots.
## Martin
Can this method be used to connect to Mozilla VPN?
## Steven
I’d love to see another of these using systemd-networkd as well. Thanks for the write up!
## Ray
I’ve been using this setup for a while.
I do have an issue however. I set up my connection to use a specific DNS server for certain domains. Once in a while the system just stops using that DNS server. Restarting the wireguard connection fixes it.
So it seems like something is overwriting the DNS configuration. But I don’t know what. It doesn’t appear to be anything triggered by what I am doing, I can be using a web browser hitting sites on my VPN when suddenly it happens.
If anyone has any advice, it would be appreciated.
## setenforce 1
Hi,
I’m using something like this :
resolvectl dns wlp0s20f3 “1.1.1.1#one.one.one.one 1.0.0.1#one.one.one.one 2606:4700:4700::1111#one.one.one.one 2606:4700:4700::1001#one.one.one.one”
resolvectl domain wlp0s20f3 ~.
resolvectl dnsovertls wlp0s20f3 yes
resolvectl dnssec wlp0s20f3 yes
resolvectl dns enp0s13f0u3u1 “1.1.1.1#one.one.one.one 1.0.0.1#one.one.one.one 2606:4700:4700::1111#one.one.one.one 2606:4700:4700::1001#one.one.one.one”
resolvectl domain enp0s13f0u3u1 ~.
resolvectl dnsovertls enp0s13f0u3u1 yes
resolvectl dnssec enp0s13f0u3u1 yes
resolvectl dns wg1 10.0.0.1 10.0.0.2
resolvectl domain wg1 example.com
resolvectl dnsovertls wg1 no
resolvectl dnssec wg1 no
Do you use something similar?
I don’t have any issue as long as I don’t restart the Networking / disconnect reconnect the Wi-Fi.
## Ray
Thanks for the reply.
No, I am setting the DNS resolution via Network Manager:
nmcli connection modify wg0 ipv4.dns-search custom.domain1.com,customdomain2.com
My setup is based on https://blogs.gnome.org/thaller/2019/03/15/wireguard-in-networkmanager/
I will look into resolvectl to see if it can help me though.
## Sergey
Where’s the GUI?
## Felix Kaechele
For Gnome it’s in the works: https://gitlab.gnome.org/GNOME/gnome-control-center/-/issues/982
## Devin Zuczek
KDE has one.
## Martin
Finally! 2 months ago this was impossible. Great work NetworkManager devs. Works on Fedora 33 for me.
## jack
Great to see, i’ve been waiting for this !
## Sergey
Also. How to make exceptions ?
I am forced to have many subnets in the configuration to specify that only they need to be rotated.
So that my local network and the internet do not go through vpn.
## Reiza
I like to see a NetworkManager tutorial for more. BTW, good writing
## jonas bloch riisgaard
which command prompt should be typed in Terminal to see the UDP and port listening ?
## Gregory Bartholomew
Does
not work?
## jonas bloch riisgaard
after typing if config which IP address should I choose to make peer2peer between. Is it the “Inet” or “broadcast” I see in the terminal after following: https://www.wireguard.com/quickstart/
I do not find the ip address 192.168.2.1/24
for typing in
Does the / between 1/24 means the numbers of Subnetmasks.
Can somebody please help
## Gregory Bartholomew
You are interested in the “inet” address. BTW,
ifconfigis deprecated. Useip address listinstead. The slash is just a separator. The number after the slash indicates the number of bits (starting from the highest order) to use to form the subnet mask (i.e. “24” is a shorter way of writing “255.255.255.0”).## Renich Bon Ćirić
Thank you for the article! Really good to give some exposure to wireguard.
IMHO, it’s better to use wg-quick to setup and verify it works so you can, later on, to import it with nmcli.
Here’s a quick script to setup Peer A as a gateway and Peer B as a client (kind of a VPN of sorts, but with WireGuard!)
# create the directory (if it doesn't exist)
umask 077
mkdir -p /etc/wireguard
# create config
cat << 'EOF' > /etc/wireguard/wg0.conf
[Interface]
Address = 192.168.200.1/24 # some private address/network.
PrivateKey = QOQwOjFhRQlPGV0R+oJ6mQboA3PHGoGEBxRRD9evXXE=
ListenPort = 51820 # The port where you want to listen for connections.
# Post up and down actions
PostUp = firewall-cmd --zone=public --add-port 51820/udp && firewall-cmd --zone=public --add-masquerade
PostDown = firewall-cmd --zone=public --remove-port 51820/udp && firewall-cmd --zone=public --remove-masquerade
# Allowed peers
[Peer]
AllowedIPs = 192.168.200.2/32 # IP to allow for Peer B.
PublicKey = aPkGZq/RAVJvAtEgoaSqX8DTJwPGlp0tVR7kSW3QTDs=
EOF
# either set it up
wg-quick up wg0
# or import it and activate it
nmcli connection import type wireguard file /etc/wireguard/wg0.conf
nmcli connection up wg0
# Peer B (your client host)
# create the directory (if it doesn't exist)
umask 077
mkdir -p /etc/wireguard
# create config
cat << 'EOF' > /etc/wireguard/wg0.conf
[Interface]
PrivateKey = mAIjTzYpdyGnQRBATsfrM50O2w+Eo1pYHnQPknhcilg=
Address = 192.168.200.2/32 # the address you're allowed on in Peer A.
DNS = 8.8.8.8, 8.8.4.4, 1.1.1.1, 1.0.0.1 # DNS settings. You can use whatever you prefer.
[Peer]
PublicKey = HdDeIa/WqALjAh3+NgfrXHaUAsWdoKEzNvJ11SyXMUI=
Endpoint = web1.woralelandia.com:51820 # you can use either a domain name or IP address.
AllowedIPs = 0.0.0.0/0 # yeah, allow the Internet through this one.
EOF
# either set it up
wg-quick up wg0
# or import it and activate it
nmcli connection import type wireguard file /etc/wireguard/wg0.conf
nmcli connection up wg0
## Eric Nicholls
That’s too much work. I will stay with OpenVPN until it becomes simpler to configure.
## jack
a different topologyPlease?
the peerA to peerB configuration, very nice.
how about a different topo.
i have a simple static ip with host(fedora) serving http & https behind routers.
i want a tunnel such that all internet traffic is run through WG.
## Devin Zuczek
KDE has a UI for this, works great.
## christoph
I use a simple helper script to manage WireGuard connections with NetworkManager CLI.
See https://gist.github.com/skipperTux/5bbc3d261c82c21bfee530d518a4bc38
## Rodehoed
Hi,
I tried WG last week. One thing which put me back to openVpn. The wg0 interface is always up when started. Even when the peer connection is not. The up status is also seen in network manager and is confusing.
Maybe I’m doing something wrong or missing something?
## Gregory Bartholomew
I think it is normal for the status of
wg0on the client to be independent of the status of the peer. I use thewgcommand to check if packets are being received from the peer.## Grayson
Is that a radio in the header picture? Maybe hooking up an antenna? Haha, that’s the first thing I noticed. Thanks for the good article, Wireguard is awesome!
## jask
I found interesting problem. I have small wireguard network with one central node (server). I use it to provide access to these nodes which are not accessible from the Internet. And I also use my company’s openVPN which pushes default route to my laptop. As long as I setup with
it works as it is supposed to. But after switching to NM (
) wireguard tunnel stops to work because of bad MTU.
It seems to me
is better to guess right MTU for
. Or it has better default. |
13,381 | 用 OpenSSL 替代 Telnet | https://opensource.com/article/21/5/drop-telnet-openssl | 2021-05-11T12:00:22 | [
"telnet",
"OpenSSL"
] | https://linux.cn/article-13381-1.html |
>
> Telnet 缺乏加密,这使得 OpenSSL 成为连接远程系统的更安全的选择。
>
>
>

[telnet](https://www.redhat.com/sysadmin/telnet-netcat-troubleshooting) 命令是最受欢迎的网络故障排除工具之一,从系统管理员到网络爱好者都可以使用。在网络计算的早期,`telnet` 被用来连接到一个远程系统。你可以用 `telnet` 访问一个远程系统的端口,登录并在该主机上运行命令。
由于 `telnet` 缺乏加密功能,它在很大程度上已经被 OpenSSL 取代了这项工作。然而,作为一种智能的 `ping`,`telnet` 的作用仍然存在(甚至在某些情况下至今仍然存在)。虽然 `ping` 命令是一个探测主机响应的好方法,但这是它能做的 *全部*。另一方面,`telnet` 不仅可以确认一个活动端口,而且还可以与该端口的服务进行交互。即便如此,由于大多数现代网络服务都是加密的,`telnet` 的作用可能要小得多,这取决于你想实现什么。
### OpenSSL s\_client
对于大多数曾经需要 `telnet` 的任务,我现在使用 OpenSSL 的 `s_client` 命令。(我在一些任务中使用 [curl](https://opensource.com/downloads/curl-command-cheat-sheet),但那些情况下我可能无论如何也不会使用 `telnet`)。大多数人都知道 [OpenSSL](https://www.openssl.org/) 是一个加密的库和框架,但不是所有人都意识到它也是一个命令。`openssl` 命令的 `s_client` 组件实现了一个通用的 SSL 或 TLS 客户端,帮助你使用 SSL 或 TLS 连接到远程主机。它是用来测试的,至少在内部使用与该库相同的功能。
### 安装 OpenSSL
OpenSSL 可能已经安装在你的 Linux 系统上了。如果没有,你可以用你的发行版的软件包管理器安装它:
```
$ sudo dnf install openssl
```
在 Debian 或类似的系统上:
```
$ sudo apt install openssl
```
安装后,验证它的响应是否符合预期:
```
$ openssl version
OpenSSL x.y.z FIPS
```
### 验证端口访问
最基本的 `telnet` 用法是一个看起来像这样的任务:
```
$ telnet mail.example.com 25
Trying 98.76.54.32...
Connected to example.com.
Escape character is '^]'.
```
在此示例中,这将与正在端口 25(可能是邮件服务器)监听的任意服务打开一个交互式会话。只要你获得访问权限,就可以与该服务进行通信。
如果端口 25 无法访问,连接就会被拒绝。
OpenSSL 也是类似的,尽管通常较少互动。要验证对一个端口的访问:
```
$ openssl s_client -connect example.com:80
CONNECTED(00000003)
140306897352512:error:1408F10B:SSL [...]
no peer certificate available
No client certificate CA names sent
SSL handshake has read 5 bytes and written 309 bytes
Verification: OK
New, (NONE), Cipher is (NONE)
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
No ALPN negotiated
Early data was not sent
Verify return code: 0 (ok)
```
但是,这仅是目标性 `ping`。从输出中可以看出,没有交换 SSL 证书,所以连接立即终止。为了充分利用 `openssl s_client`,你必须连接加密的端口。
### 交互式 OpenSSL
Web 浏览器和 Web 服务器进行交互,可以使指向 80 端口的流量实际上被转发到 443,这是保留给加密 HTTP 流量的端口。知道了这一点,你就可以用 `openssl` 命令连接到加密的端口,并与在其上运行的任何网络服务进行交互。
首先,使用 SSL 连接到一个端口。使用 `-showcerts` 选项会使 SSL 证书打印到你的终端上,一开始的输出要比 telnet 要冗长得多:
```
$ openssl s_client -connect example.com:443 -showcerts
[...]
0080 - 52 cd bd 95 3d 8a 1e 2d-3f 84 a0 e3 7a c0 8d 87 R...=..-?...z...
0090 - 62 d0 ae d5 95 8d 82 11-01 bc 97 97 cd 8a 30 c1 b.............0.
00a0 - 54 78 5c ad 62 5b 77 b9-a6 35 97 67 65 f5 9b 22 Tx\\.b[w..5.ge.."
00b0 - 18 8a 6a 94 a4 d9 7e 2f-f5 33 e8 8a b7 82 bd 94 ..j...~/.3......
Start Time: 1619661100
Timeout : 7200 (sec)
Verify return code: 0 (ok)
Extended master secret: no
Max Early Data: 0
-
read R BLOCK
```
你被留在一个交互式会话中。最终,这个会话将关闭,但如果你及时行动,你可以向服务器发送 HTTP 信号:
```
[...]
GET / HTTP/1.1
HOST: example.com
```
按**回车键**两次,你会收到 `example.com/index.html` 的数据:
```
[...]
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
```
#### Email 服务器
你也可以使用 OpenSSL 的 `s_client` 来测试一个加密的 Email 服务器。要做到这点,你必须把你的测试用户的用户名和密码用 Base64 编码。
这里有一个简单的方法来做到:
```
$ perl -MMIME::Base64 -e 'print encode_base64("username");'
$ perl -MMIME::Base64 -e 'print encode_base64("password");'
```
当你记录了这些值,你就可以通过 SSL 连接到邮件服务器,它通常在 587 端口:
```
$ openssl s_client -starttls smtp \
-connect email.example.com:587
> ehlo example.com
> auth login
##paste your user base64 string here##
##paste your password base64 string here##
> mail from: [email protected]
> rcpt to: [email protected]
> data
> Subject: Test 001
This is a test email.
.
> quit
```
检查你的邮件(在这个示例代码中,是 `[email protected]`),查看来自 `[email protected]` 的测试邮件。
### OpenSSL 还是 Telnet?
`telnet` 仍然有用途,但它已经不是以前那种不可缺少的工具了。该命令在许多发行版上被归入 “遗留” 网络软件包,而且还没有 `telnet-ng` 之类的明显的继任者,管理员有时会对它被排除在默认安装之外感到疑惑。答案是,它不再是必不可少的,它的作用越来越小,这 *很好*。网络安全很重要,所以要适应与加密接口互动的工具,这样你就不必在排除故障时禁用你的保护措施。
---
via: <https://opensource.com/article/21/5/drop-telnet-openssl>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The [telnet](https://www.redhat.com/sysadmin/telnet-netcat-troubleshooting) command is one of the most popular network troubleshooting tools for anyone from systems administrators to networking hobbyists. In the early years of networked computing, telnet was used to connect to a remote system. You could use telnet to access a port on a remote system, log in, and run commands on that host.
Due to telnet's lack of encryption, it has largely been replaced by OpenSSL for this job. Yet telnet's relevance persisted (and persists in some cases even today) as a sort of intelligent `ping`
. While the `ping`
command is a great way to probe a host for responsiveness, that's *all* it can do. Telnet, on the other hand, not only confirms an active port, but it can also interact with a service on that port. Even so, because most modern network services are encrypted, telnet can be far less useful depending on what you're trying to achieve.
## OpenSSL s_client
For most tasks that once required telnet, I now use OpenSSL's `s_client`
command. (I use [curl](https://opensource.com/downloads/curl-command-cheat-sheet) for some tasks, but those are cases where I probably wouldn't have used telnet anyway.) Most people know [OpenSSL](https://www.openssl.org/) as a library and framework for encryption, but not everyone realizes it's also a command. The `s_client`
component of the `openssl`
command implements a generic SSL or TLS client, helping you connect to a remote host using SSL or TLS. It's intended for testing and, internally at least, uses the same functionality as the library.
## Install OpenSSL
OpenSSL may already be installed on your Linux system. If not, you can install it with your distribution's package manager:
`$ sudo dnf install openssl`
On Debian or similar:
`$ sudo apt install openssl`
Once it's installed, verify that it responds as expected:
```
$ openssl version
OpenSSL x.y.z FIPS
```
## Verify port access
The most basic telnet usage is a task that looks something like this:
```
$ telnet mail.example.com 25
Trying 98.76.54.32...
Connected to example.com.
Escape character is '^]'.
```
This opens an interactive session with (in this example) whatever service is listening on port 25 (probably a mail server). As long as you gain access, you can communicate with the service.
Should port 25 be inaccessible, the connection is refused.
OpenSSL is similar, although usually less interactive. To verify access to a port:
```
$ openssl s_client -connect example.com:80
CONNECTED(00000003)
140306897352512:error:1408F10B:SSL [...]
no peer certificate available
No client certificate CA names sent
SSL handshake has read 5 bytes and written 309 bytes
Verification: OK
New, (NONE), Cipher is (NONE)
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
No ALPN negotiated
Early data was not sent
Verify return code: 0 (ok)
```
This is little more than a targeted ping, though. As you can see from the output, no SSL certificate was exchanged, so the connection immediately terminated. To get the most out of `openssl s_client`
, you must target the encrypted port.
## Interactive OpenSSL
Web browsers and web servers interact such that traffic directed at port 80 is actually forwarded to 443, the port reserved for encrypted HTTP traffic. Knowing this, you can navigate to encrypted ports with the `openssl`
command and interact with whatever web service is running on it.
First, make a connection to a port using SSL. Using the `-showcerts`
option causes the SSL certificate to print to your terminal, making the initial output a lot more verbose than telnet:
```
$ openssl s_client -connect example.com:443 -showcerts
[...]
0080 - 52 cd bd 95 3d 8a 1e 2d-3f 84 a0 e3 7a c0 8d 87 R...=..-?...z...
0090 - 62 d0 ae d5 95 8d 82 11-01 bc 97 97 cd 8a 30 c1 b.............0.
00a0 - 54 78 5c ad 62 5b 77 b9-a6 35 97 67 65 f5 9b 22 Tx\.b[w..5.ge.."
00b0 - 18 8a 6a 94 a4 d9 7e 2f-f5 33 e8 8a b7 82 bd 94 ..j...~/.3......
Start Time: 1619661100
Timeout : 7200 (sec)
Verify return code: 0 (ok)
Extended master secret: no
Max Early Data: 0
-
read R BLOCK
```
You're left in an interactive session. Eventually, this session will close, but if you act promptly, you can send HTTP signals to the server:
```
[...]
GET / HTTP/1.1
HOST: example.com
```
Press **Return** twice, and you receive the data for `example.com/index.html`
:
```
[...]
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
```
### Email server
You can also use OpenSSL's `s_client`
to test an encrypted email server. For this to work, you must have your test user's username and password encoded in Base64.
Here's an easy way to do this:
```
$ perl -MMIME::Base64 -e 'print encode_base64("username");'
$ perl -MMIME::Base64 -e 'print encode_base64("password");'
```
Once you have those values recorded, you can connect to a mail server over SSL, usually on port 587:
```
$ openssl s_client -starttls smtp \
-connect email.example.com:587
> ehlo example.com
> auth login
##paste your user base64 string here##
##paste your password base64 string here##
> mail from: [email protected]
> rcpt to: [email protected]
> data
> Subject: Test 001
This is a test email.
.
> quit
```
Check your email (in this sample code, it's `[email protected]`
) for a test message from `[email protected]`
.
## OpenSSL or telnet?
There are still uses for telnet, but it's not the indispensable tool it once was. The command has been relegated to "legacy" networking packages on many distributions, but without a `telnet-ng`
or some obvious successor, admins are sometimes puzzled about why it's excluded from default installs. The answer is that it's not essential anymore, it's getting less and less useful—and that's *good*. Network security is important, so get comfortable with tools that interact with encrypted interfaces, so you don't have to disable your safeguards during troubleshooting.
## 6 Comments |
13,382 | 如何构建更小的容器 | https://fedoramagazine.org/build-smaller-containers/ | 2021-05-12T11:22:01 | [
"容器"
] | https://linux.cn/article-13382-1.html | 
使用容器工作是很多用户和开发者的日常任务。容器开发者经常需要频繁地(重新)构建容器镜像。如果你开发容器,你有想过减小镜像的大小吗?较小的镜像有一些好处。在下载的时候所需要的带宽更少,而且在云环境中运行的时候也可以节省开销。而且在 Fedora [CoreOS](https://fedoramagazine.org/getting-started-with-fedora-coreos/)、[IoT](https://getfedora.org/en/iot/) 以及[Silverblue](https://fedoramagazine.org/what-is-silverblue/) 上使用较小的容器镜像可以提升整体系统性能,因为这些操作系统严重依赖于容器工作流。这篇文章将会提供一些减小容器镜像大小的技巧。
### 工具
以下例子所用到的主机操作系统是 Fedora Linux 33。例子使用 [Podman](https://podman.io/) 3.1.0 和[Buildah](https://buildah.io/) 1.2.0。Podman 和 Buildah 已经预装在大多数 Fedora Linux 变种中。如果你没有安装 Podman 和 Buildah,可以用下边的命令安装:
```
$ sudo dnf install -y podman buildah
```
### 任务
从一个基础的例子开始。构建一个满足以下需求的 web 容器:
* 容器必须基于 Fedora Linux
* 使用 Apache httpd web 服务器
* 包含一个定制的网站
* 容器应该比较小
下边的步骤也适用于比较复杂的镜像。
### 设置
首先,创建一个工程目录。这个目录将会包含你的网站和容器文件:
```
$ mkdir smallerContainer
$ cd smallerContainer
$ mkdir files
$ touch files/index.html
```
制作一个简单的登录页面。对于这个演示,你可以将下面的 HTML 复制到 `index.html` 文件中。
```
<!doctype html>
<html lang="de">
<head>
<title>Container Page</title>
</head>
<body>
<header>
<h1>Container Page</h1>
</header>
<main>
<h2>Fedora</h2>
<ul>
<li><a href="https://getfedora.org">Fedora Project</a></li>
<li><a href="https://docs.fedoraproject.org/">Fedora Documentation</a></li>
<li><a href="https://fedoramagazine.org">Fedora Magazine</a></li>
<li><a href="https://communityblog.fedoraproject.org/">Fedora Community Blog</a></li>
</ul>
<h2>Podman</h2>
<ul>
<li><a href="https://podman.io">Podman</a></li>
<li><a href="https://docs.podman.io/">Podman Documentation</a></li>
<li><a href="https://github.com/containers/podman">Podman Code</a></li>
<li><a href="https://podman.io/blogs/">Podman Blog</a></li>
</ul>
<h2>Buildah</h2>
<ul>
<li><a href="https://buildah.io">Buildah</a></li>
<li><a href="https://github.com/containers/buildah">Buildah Code</a></li>
<li><a href="https://buildah.io/blogs/">Buildah Blog</a></li>
</ul>
<h2>Skopeo</h2>
<ul>
<li><a href="https://github.com/containers/skopeo">skopeo Code</a></li>
</ul>
<h2>CRI-O</h2>
<ul>
<li><a href="https://cri-o.io/">CRI-O</a></li>
<li><a href="https://github.com/cri-o/cri-o">CRI-O Code</a></li>
<li><a href="https://medium.com/cri-o">CRI-O Blog</a></li>
</ul>
</main>
</body>
</html>
```
此时你可以选择在浏览器中测试上面的 `index.html` 文件:
```
$ firefox files/index.html
```
最后,创建一个容器文件。这个文件可以命名为 `Dockerfile` 或者 `Containerfile`:
```
$ touch Containerfile
```
现在你应该有了一个工程目录,并且该目录中的文件系统布局如下:
```
smallerContainer/
|- files/
| |- index.html
|
|- Containerfile
```
### 构建
现在构建镜像。下边的每个阶段都会添加一层改进来帮助减小镜像的大小。你最终会得到一系列镜像,但只有一个 `Containerfile`。
#### 阶段 0:一个基本的容器镜像
你的新镜像将会非常简单,它只包含强制性步骤。在 `Containerfile` 中添加以下内容:
```
# 使用 Fedora 33 作为基镜像
FROM registry.fedoraproject.org/fedora:33
# 安装 httpd
RUN dnf install -y httpd
# 复制这个网站
COPY files/* /var/www/html/
# 设置端口为 80/tcp
EXPOSE 80
# 启动 httpd
CMD ["httpd", "-DFOREGROUND"]
```
在上边的文件中有一些注释来解释每一行内容都是在做什么。更详细的步骤:
1. 在 `FROM registry.fedoraproject.org/fedora:33` 的基础上创建一个构建容器
2. 运行命令: `dnf install -y httpd`
3. 将与 `Containerfile` 有关的文件拷贝到容器中
4. 设置 `EXPOSE 80` 来说明哪个端口是可以自动设置的
5. 设置一个 `CMD` 指令来说明如果从这个镜像创建一个容器应该运行什么
运行下边的命令从工程目录创建一个新的镜像:
```
$ podman image build -f Containerfile -t localhost/web-base
```
使用一下命令来查看你的镜像的属性。注意你的镜像的大小(467 MB)。
```
$ podman image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/web-base latest ac8c5ed73bb5 5 minutes ago 467 MB
registry.fedoraproject.org/fedora 33 9f2a56037643 3 months ago 182 MB
```
以上这个例子中展示的镜像在现在占用了467 MB的空间。剩下的阶段将会显著地减小镜像的大小。但是首先要验证镜像是否能够按照预期工作。
输入以下命令来启动容器:
```
$ podman container run -d --name web-base -P localhost/web-base
```
输入以下命令可以列出你的容器:
```
$ podman container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d24063487f9f localhost/web-base httpd -DFOREGROUN... 2 seconds ago Up 3 seconds ago 0.0.0.0:46191->80/tcp web-base
```
以上展示的容器正在运行,它正在监听的端口是 `46191` 。从运行在主机操作系统上的 web 浏览器转到 `localhost:46191` 应该呈现你的 web 页面:
```
$ firefox localhost:46191
```
#### 阶段 1:清除缓存并将残余的内容从容器中删除
为了优化容器镜像的大小,第一步应该总是执行“清理”。这将保证安装和打包所残余的内容都被删掉。这个过程到底需要什么取决于你的容器。对于以上的例子,只需要编辑 `Containerfile` 让它包含以下几行。
```
[...]
# Install httpd
RUN dnf install -y httpd && \
dnf clean all -y
[...]
```
构建修改后的 `Containerfile` 来显著地减小镜像(这个例子中是 237 MB)。
```
$ podman image build -f Containerfile -t localhost/web-clean
$ podman image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/web-clean latest f0f62aece028 6 seconds ago 237 MB
```
#### 阶段 2:删除文档和不需要的依赖包
许多包在安装时会被建议拉下来,包含一些弱依赖和文档。这些在容器中通常是不需要的,可以删除。 `dnf` 命令有选项可以表明它不需要包含弱依赖或文档。
再次编辑 `Containerfile` ,并在 `dnf install` 行中添加删除文档和弱依赖的选项:
```
[...]
# Install httpd
RUN dnf install -y httpd --nodocs --setopt install_weak_deps=False && \
dnf clean all -y
[...]
```
构建经过以上修改后的 `Containerfile` 可以得到一个更小的镜像(231 MB)。
```
$ podman image build -f Containerfile -t localhost/web-docs
$ podman image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/web-docs latest 8a76820cec2f 8 seconds ago 231 MB
```
#### 阶段 3:使用更小的容器基镜像
前面的阶段结合起来,使得示例镜像的大小减少了一半。但是仍然还有一些途径来进一步减小镜像的大小。这个基镜像 `registry.fedoraproject.org/fedora:33` 是通用的。它提供了一组软件包,许多人希望这些软件包预先安装在他们的 Fedora Linux 容器中。但是,通用的 Fedora Linux 基镜像中提供的包通常必须要的更多。Fedora 项目也为那些希望只从基本包开始,然后只添加所需内容来实现较小总镜像大小的用户提供了一个 `fedora-minimal` 镜像。
使用 `podman image search` 来查找 `fedora-minimal` 镜像,如下所示:
```
$ podman image search fedora-minimal
INDEX NAME DESCRIPTION STARS OFFICIAL AUTOMATED
fedoraproject.org registry.fedoraproject.org/fedora-minimal 0
```
`fedora-minimal` 基镜像不包含 [DNF](https://github.com/rpm-software-management/dnf),而是倾向于使用不需要 Python 的较小的 [microDNF](https://github.com/rpm-software-management/microdnf)。当 `registry.fedoraproject.org/fedora:33` 被 `registry.fedoraproject.org/fedora-minimal:33` 替换后,需要用 `microdnf` 命令来替换 `dnf`。
```
# 使用 Fedora minimal 33 作为基镜像
FROM registry.fedoraproject.org/fedora-minimal:33
# 安装 httpd
RUN microdnf install -y httpd --nodocs --setopt install_weak_deps=0 && \
microdnf clean all -y
[...]
```
使用 `fedora-minimal` 重新构建后的镜像大小如下所示 (169 MB):
```
$ podman image build -f Containerfile -t localhost/web-docs
$ podman image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/web-minimal latest e1603bbb1097 7 minutes ago 169 MB
```
最开始的镜像大小是 **467 MB**。结合以上每个阶段所提到的方法,进行重新构建之后可以得到最终大小为 **169 MB** 的镜像。最终的 *总* 镜像大小比最开始的 *基* 镜像小了 182 MB!
### 从零开始构建容器
前边的内容使用一个容器文件和 Podman 来构建一个新的镜像。还有最后一个方法要展示——使用 Buildah 来从头构建一个容器。Podman 使用与 Buildah 相同的库来构建容器。但是 Buildah 被认为是一个纯构建工具。Podman 被设计来是为了代替 Docker 的。
使用 Buildah 从头构建的容器是空的——它里边什么都 *没有* 。所有的东西都需要安装或者从容器外复制。幸运地是,使用 Buildah 相当简单。下边是一个从头开始构建镜像的小的 Bash 脚本。除了运行这个脚本,你也可以在终端逐条地运行脚本中的命令,来更好的理解每一步都是做什么的。
```
#!/usr/bin/env bash
set -o errexit
# 创建一个容器
CONTAINER=$(buildah from scratch)
# 挂载容器文件系统
MOUNTPOINT=$(buildah mount $CONTAINER)
# 安装一个基本的文件系统和最小的包以及 nginx
dnf install -y --installroot $MOUNTPOINT --releasever 33 glibc-minimal-langpack httpd --nodocs --setopt install_weak_deps=False
dnf clean all -y --installroot $MOUNTPOINT --releasever 33
# 清除
buildah unmount $CONTAINER
# 复制网站
buildah copy $CONTAINER 'files/*' '/var/www/html/'
# 设置端口为 80/tcp
buildah config --port 80 $CONTAINER
# 启动 httpd
buildah config --cmd "httpd -DFOREGROUND" $CONTAINER
# 将容器保存为一个镜像
buildah commit --squash $CONTAINER web-scratch
```
或者,可以通过将上面的脚本传递给 Buildah 来构建镜像。注意不需要 root 权限。
```
$ buildah unshare bash web-scratch.sh
$ podman image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/web-scratch latest acca45fc9118 9 seconds ago 155 MB
```
最后的镜像只有 **155 MB**!而且 [攻击面](https://en.wikipedia.org/wiki/Attack_surface) 也减少了。甚至在最后的镜像中都没有安装 DNF(或者 microDNF)。
### 结论
构建一个比较小的容器镜像有许多优点。减少所需要的带宽、磁盘占用以及攻击面,都会得到更好的镜像。只用很少的更改来减小镜像的大小很简单。许多更改都可以在不改变结果镜像的功能下完成。
只保存所需的二进制文件和配置文件来构建非常小的镜像也是可能的。
---
via: <https://fedoramagazine.org/build-smaller-containers/>
作者:[Daniel Schier](https://fedoramagazine.org/author/danielwtd/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ShuyRoy](https://github.com/Shuyroy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Working with containers is a daily task for many users and developers. Container developers often need to (re)build container images frequently. If you develop containers, have you ever thought about reducing the image size? Smaller images have several benefits. They require less bandwidth to download and they save costs when run in cloud environments. Also, using smaller container images on Fedora [CoreOS](https://fedoramagazine.org/getting-started-with-fedora-coreos/), [IoT](https://getfedora.org/en/iot/) and [Silverblue](https://fedoramagazine.org/what-is-silverblue/) improves overall system performance because those operating systems rely heavily on container workflows. This article will provide a few tips for reducing the size of container images.
## The tools
The host operating system in the following examples is Fedora Linux 33. The examples use [Podman](https://podman.io/) 3.1.0 and [Buildah](https://buildah.io/) 1.2.0. Podman and Buildah are pre-installed in most Fedora Linux variants. If you don’t have Podman or Buildah installed, run the following command to install them.
$ sudo dnf install -y podman buildah
## The task
Begin with a basic example. Build a web container meeting the following requirements.
- The container must be based on Fedora Linux
- Use the Apache httpd web server
- Include a custom website
- The container should be relatively small
The following steps will also work on more complex images.
## The setup
First, create a project directory. This directory will include your website and container file.
$ mkdir smallerContainer $ cd smallerContainer $ mkdir files $ touch files/index.html
Make a simple landing page. For this demonstration, you may copy the below HTML into the *index.html* file.
<!doctype html> <html lang="de"> <head> <title>Container Page</title> </head> <body> <header> <h1>Container Page</h1> </header> <main> <h2>Fedora</h2> <ul> <li><a href="https://getfedora.org">Fedora Project</a></li> <li><a href="https://docs.fedoraproject.org/">Fedora Documentation</a></li> <li><a href="https://fedoramagazine.org">Fedora Magazine</a></li> <li><a href="https://communityblog.fedoraproject.org/">Fedora Community Blog</a></li> </ul> <h2>Podman</h2> <ul> <li><a href="https://podman.io">Podman</a></li> <li><a href="https://docs.podman.io/">Podman Documentation</a></li> <li><a href="https://github.com/containers/podman">Podman Code</a></li> <li><a href="https://podman.io/blogs/">Podman Blog</a></li> </ul> <h2>Buildah</h2> <ul> <li><a href="https://buildah.io">Buildah</a></li> <li><a href="https://github.com/containers/buildah">Buildah Code</a></li> <li><a href="https://buildah.io/blogs/">Buildah Blog</a></li> </ul> <h2>Skopeo</h2> <ul> <li><a href="https://github.com/containers/skopeo">skopeo Code</a></li> </ul> <h2>CRI-O</h2> <ul> <li><a href="https://cri-o.io/">CRI-O</a></li> <li><a href="https://github.com/cri-o/cri-o">CRI-O Code</a></li> <li><a href="https://medium.com/cri-o">CRI-O Blog</a></li> </ul> </main> </body> </html>
Optionally, test the above *index.html* file in your browser.
$ firefox files/index.html
Finally, create a container file. The file can be named either *Dockerfile* or *Containerfile*.
$ touch Containerfile
You should now have a project directory with a file system layout similar to what is shown in the below diagram.
smallerContainer/ |- files/ | |- index.html | |- Containerfile
## The build
Now make the image. Each of the below stages will add a layer of improvements to help reduce the size of the image. You will end up with a series of images, but only one *Containerfile*.
### Stage 0: a baseline container image
Your new image will be very simple and it will only include the mandatory steps. Place the following text in *Containerfile*.
# Use Fedora 33 as base image FROM registry.fedoraproject.org/fedora:33 # Install httpd RUN dnf install -y httpd # Copy the website COPY files/* /var/www/html/ # Expose Port 80/tcp EXPOSE 80 # Start httpd CMD ["httpd", "-DFOREGROUND"]
In the above file there are some comments to indicate what is being done. More verbosely, the steps are:
- Create a build container with the base FROM registry.fedoraproject.org/fedora:33
- RUN the command:
*dnf install -y httpd* - COPY files relative to the
*Containerfile*to the container - Set EXPOSE 80 to indicate which port is auto-publishable
- Set a CMD to indicate what should be run if one creates a container from this image
Run the below command to create a new image from the project directory.
$ podman image build -f Containerfile -t localhost/web-base
Use the following command to examine your image’s attributes. Note in particular the size of your image (467 MB).
$ podman image ls REPOSITORY TAG IMAGE ID CREATED SIZE localhost/web-base latest ac8c5ed73bb5 5 minutes ago467 MBregistry.fedoraproject.org/fedora 33 9f2a56037643 3 months ago 182 MB
The example image shown above is currently occupying 467 MB of storage. The remaining stages should reduce the size of the image significantly. But first, verify that the image works as intended.
Enter the following command to start the container.
$ podman container run -d --name web-base -P localhost/web-base
Enter the following command to list your containers.
$ podman container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d24063487f9f localhost/web-base httpd -DFOREGROUN... 2 seconds ago Up 3 seconds ago 0.0.0.0:46191->80/tcp web-base
The container shown above is running and it is listening on port *46191*. Going to *localhost:46191* from a web browser running on the host operating system should render your web page.
$ firefox localhost:46191
### Stage 1: clear caches and remove other leftovers from the container
The first step one should always perform to optimize the size of their container image is “clean up”. This will ensure that leftovers from installations and packaging are removed. What exactly this process entails will vary depending on your container. For the above example you can just edit *Containerfile* to include the following lines.
[...] # Install httpd RUN dnf install -y httpd && \ dnf clean all -y [...]
Build the modified *Containerfile* to reduce the size of the image significantly (237 MB in this example).
$ podman image build -f Containerfile -t localhost/web-clean $ podman image ls REPOSITORY TAG IMAGE ID CREATED SIZE localhost/web-clean latest f0f62aece028 6 seconds ago237 MB
### Stage 2: remove documentation and unneeded package dependencies
Many packages will pull in recommendations, weak dependencies and documentation when they are installed. These are often not needed in a container and can be excluded. The *dnf* command has options to indicate that it should not include weak dependencies or documentation.
Edit *Containerfile* again and add the options to exclude documentation and weak dependencies on the *dnf install* line:
[...] # Install httpd RUN dnf install -y httpd --nodocs --setopt install_weak_deps=False && \ dnf clean all -y [...]
Build *Containerfile* with the above modifications to achieve an even smaller image (231 MB).
$ podman image build -f Containerfile -t localhost/web-docs $ podman image ls REPOSITORY TAG IMAGE ID CREATED SIZE localhost/web-docs latest 8a76820cec2f 8 seconds ago231 MB
### Stage 3: use a smaller container base image
The prior stages, in combination, have reduced the size of the example image by half. But there is still one more thing that can be done to reduce the size of the image. The base image *registry.fedoraproject.org/fedora:33* is meant for general purpose use. It provides a collection of packages that many people expect to be pre-installed in their Fedora Linux containers. The collection of packages provided in the general purpose Fedora Linux base image is often more extensive than needed, however. The Fedora Project also provides a *fedora-minimal* base image for those who wish to start with only the essential packages and then add only what they need to achieve a smaller total image size.
Use *podman image search* to search for the *fedora-minimal* image as shown below.
$ podman image search fedora-minimal INDEX NAME DESCRIPTION STARS OFFICIAL AUTOMATED fedoraproject.org registry.fedoraproject.org/fedora-minimal 0
The *fedora-minimal* base image excludes [DNF](https://github.com/rpm-software-management/dnf) in favor of the smaller [microDNF](https://github.com/rpm-software-management/microdnf) which does not require Python. When *registry.fedoraproject.org/fedora:33* is replaced with *registry.fedoraproject.org/fedora-minimal:33*, *dnf* needs to be replaced with *microdnf*.
# Use Fedora minimal 33 as base image FROM registry.fedoraproject.org/fedora-minimal:33 # Install httpd RUN microdnf install -y httpd --nodocs --setopt install_weak_deps=0 && \ microdnf clean all -y [...]
Rebuild the image to see how much storage space has been recovered by using *fedora-minimal* (169 MB).
$ podman image build -f Containerfile -t localhost/web-docs $ podman image ls REPOSITORY TAG IMAGE ID CREATED SIZE localhost/web-minimal latest e1603bbb1097 7 minutes ago169 MB
The initial image size was **467 MB**. Combining the methods detailed in each of the above stages has resulted in a final image size of **169 MB**. The final *total* image size is smaller than the original *base* image size of 182 MB!
## Building containers from scratch
The previous section used a container file and Podman to build a new image. There is one last thing to demonstrate — building a container from scratch using Buildah. Podman uses the same libraries to build containers as Buildah. But Buildah is considered a pure build tool. Podman is designed to work as a replacement for Docker.
When building from scratch using Buildah, the container is empty — there is *nothing* in it. Everything needed must be installed or copied from outside the container. Fortunately, this is quite easy with Buildah. Below, a small Bash script is provided which will build the image from scratch. Instead of running the script, you can run each of the commands from the script individually in a terminal to better understand what is being done.
#!/usr/bin/env bash set -o errexit # Create a container CONTAINER=$(buildah from scratch) # Mount the container filesystem MOUNTPOINT=$(buildah mount $CONTAINER) # Install a basic filesystem and minimal set of packages, and httpd dnf install -y --installroot $MOUNTPOINT --releasever 33 glibc-minimal-langpack httpd --nodocs --setopt install_weak_deps=False dnf clean all -y --installroot $MOUNTPOINT --releasever 33 # Cleanup buildah unmount $CONTAINER # Copy the website buildah copy $CONTAINER 'files/*' '/var/www/html/' # Expose Port 80/tcp buildah config --port 80 $CONTAINER # Start httpd buildah config --cmd "httpd -DFOREGROUND" $CONTAINER # Save the container to an image buildah commit --squash $CONTAINER web-scratch
Alternatively, the image can be built by passing the above script to Buildah. Notice that root privileges are not required.
$ buildah unshare bash web-scratch.sh $ podman image ls REPOSITORY TAG IMAGE ID CREATED SIZE localhost/web-scratch latest acca45fc9118 9 seconds ago155 MB
The final image is only **155 MB**! Also, the [attack surface](https://en.wikipedia.org/wiki/Attack_surface) has been reduced. Not even DNF (or microDNF) is installed in the final image.
## Conclusion
Building smaller container images has many advantages. Reducing the needed bandwidth, the disk footprint and attack surface will lead to better images overall. It is easy to reduce the footprint with just a few small changes. Many of the changes can be done without altering the functionality of the resulting image.
It is also possible to build very small images from scratch which will only hold the needed binaries and configuration files.
## Alexander
Thank you for the last part. “Building from scratch.”
I’m woundering about SystemD. It must be installed as well? but not started?
## Daniel Schier
systemd is installed by dependencies, but is not needed in a container. In fact, it should be even avoided if necessary. Starting a service directly in foreground should be preferred.
## Rob Verduijn
Removing the layers also reduces the overhead a bit.
podman build –layers=false
## Daniel Schier
will only avoid caching layers during the build. If you want to squash everything in one layer (which can be useful depending on your usecase), you can use
or
.
## Rene Reichenbach
And now try with a go or rust app doing the same 😉
## Phozzy
– will work well in the last scenario.
## Daniel Schier
The “from scratch” example will most likely work similar, but you can also have a look at multi-stage builds. 🙂
## rnx
useful article. thanks.
perhaps dnf should get a new subcommand specifically for installing with recommended defaults for container images and cache cleaning … would make things more cleaner and more readable.
dnf containerinstall xy or something
## Mark
I have had issues in the past with microdnf when a fedora-minimal image must have been built prior to a package update being removed from the main repository and it found a package to downgrade, microdnf will fail instead of downgrading. Infrequent but if you care about attack surfaces you should always ‘microdnf -y update’ when building a new container so it can be an issue. So some of my docker files use microdnf to install dnf and then remove that when done.
I use docker and there is a utility ‘docker-squash’ (obtained simply with ‘pip3 install docker-squash’) which has made me a bit lazy; in that you can use clarity in Dockerfile usage by not bothering to use && to stack multiple commands to minimise layers but instead happily generate as many layers as you want and even have huge ones at the start. And docker-squash will happily compress 20-30 layers down to 2 for you which shrinks the container image size a lot. I also use that on images pulled from dockerhub where some application containers can be >1Gb in size when pulled from dockerhub and many of those can be shrunk as well. docker-squash does need docker though and won’t work with podman last time I checked.
Having said that I was interested in the comment from Rob Verduijn about the ‘podman build –layers=false’ option I will have to look at to see what it does, as it is the layers that while useful for managing changes/versions take up needless space in a container image. But it’s use would be in containers personally built at build time rather than run against containers already built externally.
I also appreciate the ‘building from scratch’ section, very easy to follow with the example you used.
On layers, it should probably also be mentioned it is best to keep large layers toward the end of a Dockerfile or config file; don’t layer1 copy in a 100Mb datafile then layer2 install a package then layer3 add a user or all three layers would have that datafile. Add the user then the package then the 100Mb database and you have saved 200Mb in your final container image; order is important. Or you could docker-squash and as I am also going to do investigate the ‘podman build –layers=false’ option Rob mentioned.
## Daniel Schier
For squashing layers you can use the option
or
, which is available by default for podman build and buildah.
## Diogo Lopes
Very Good
## langdon
Minor complaint. I think you have a “typo” in the final script. You say “nginx” in the comments when I think you meant “httpd” (or apache). I was confused for a minute so others might be as well. Otherwise, nice article.
## Gregory Bartholomew
Thanks langdon. I have made the correction.
## laolux
Thanks for the article. I really like the from scratch method using buildah. Now I would like to improve on that by reusing the system’s dnf metadata cache. Any idea of how to accomplish that? Otherwise any user on my system would have to download all the metadata just for himself.
Another point: When using the btrfs backend for podman, then regular users need to execute the script with
. Then it works fine though.
## Mohamed Amin
Thanks for the article. I would think of using buildah for building containers.
I pulled apache default and alpine image from docker hub and I found this:
docker.io/library/httpd alpine a4d0bee07118 8 days ago 57 MB
docker.io/library/httpd latest 0b932df43057 13 days ago 142 MB
Why the alpine image here is so small?
## Daniel Schier
Hi, this is an easy/not so easy to answer question.
Alpine is very focused on minimalism. Therefore, it replaced and stripped important packages, which are common in other Linux systems. For example, you will not have gcc/glibc, but musl libc/gcc. But this also means, that you have to build software differently and may not be able to use certain software at all.
## xhtml
useful article. thanks. 😀
Podman tutorial – How to install XAMPP server in Podman container?
## Daniel Schier
Since XAMPP was the idea to get LAMP on Windows without knowing how to install Apache, MySQL, PHP, etc. I would suggest using each of these tools in a container is the proper way. At least I am considering XAMPP “a bunch of tools for mere testing only”. Using httpd or MariaDB in a container is a piece of cake with containers 🙂
## Shaun McFee
Could multi-stage builds be used within the Containerfile itself to achieve what the bash script of Buildah commands is doing in order to keep the Containerfile as the single source of truth for how the container was built? Is there an advantage to the bash script with Buildah approach versus multi-stage builds?
## Andrea R
I was going to ask this exactly, it’s what I do with docker and it’s clean and easy enough.
## Daniel Schier
Multi-Stage builds can be done, too. Sometimes these are very useful. If you want to use the “from scratch” method in addition to multi-stage, you can also stick to “from scratch”.
Nevertheless, this article explains the capabilities of buildah with regards to both: https://www.redhat.com/en/blog/unleash-powerful-linux-container-building-capabilities-buildah
## SergMx
I’m sorry.
Doesn’t Fedora have a similar project: https://www.redhat.com/en/blog/introducing-red-hat-universal-base-image
?
## Scott McCarty
You can use UBI on Fedora. UBI is supposed to sort of be universal, can be used on Fedora or even other Linux distros.
Also, UBI micro will come out with RHEL 8.4 and that is even smaller than the minimal image with microdnf
## Daniel Schier
Last time I used UBI on Fedora/CentOS (a year ago maybe), it requested a subscription. Is this still the case?
## Lee Whitty
Great article! I just went through this exercise using Fedora 34 images. They must have reduced the minimal image size because the podman build using the minimal image was smaller (154 MB) than the buildah build (155 MB).
## Lee Whitty
Correction: Both the minimal image size build and buildah builds were smaller under Fedora 34, with the Buildah build being the smallest. I like the trend of the container image sizes shrinking! |
13,383 | 使用 cron 调度任务 | https://fedoramagazine.org/scheduling-tasks-with-cron/ | 2021-05-12T12:03:50 | [
"cron",
"定时"
] | https://linux.cn/article-13383-1.html | 
cron 是一个调度守护进程,它以指定的时间间隔执行任务,这些任务称为 corn 作业,主要用于自动执行系统维护或管理任务。例如,你可以设置一个 cron 作业来自动执行重复的任务,比如备份数据库或数据,使用最新的安全补丁更新系统,检查磁盘空间使用情况,发送电子邮件等等。 cron 作业可以按分钟、小时、日、月、星期或它们的任意组合运行。
### cron 的一些优点
以下是使用 cron 作业的一些优点:
* 你可以更好地控制作业的运行时间。例如,你可以精确到分钟、小时、天等。
* 它消除了为循环任务逻辑而去写代码的需要,当你不再需要执行任务时,可以直接关闭它。
* 作业在不执行时不会占用内存,因此你可以节省内存分配。
* 如果一个作业执行失败并由于某种原因退出,它将在适当的时间再次运行。
### 安装 cron 守护进程
幸运的是,Fedora Linux 预先配置了运行重要的系统任务来保持系统更新,有几个实用程序可以运行任务例如 cron、`anacron`、`at` 和 `batch` 。本文只关注 cron 实用程序的安装。cron 和 cronie 包一起安装,cronie 包也提供 `cron` 服务。
要确定软件包是否已经存在,使用 `rpm` 命令:
```
$ rpm -q cronie
Cronie-1.5.2-4.el8.x86_64
```
如果安装了 cronie ,它将返回 cronie 包的全名。如果你的系统中没有安装,则会显示未安装。
使用以下命令安装:
```
$ dnf install cronie
```
### 运行 cron 守护进程
cron 作业由 crond 服务来执行,它会读取配置文件中的信息。在将作业添加到配置文件之前,必须启动 crond 服务,或者安装它。什么是 crond 呢?crond 是 cron 守护程序的简称。要确定 crond 服务是否正在运行,输入以下命令:
```
$ systemctl status crond.service
● crond.service - Command Scheduler
Loaded: loaded (/usr/lib/systemd/system/crond.service; enabled; vendor pre>
Active: active (running) since Sat 2021-03-20 14:12:35 PDT; 1 day 21h ago
Main PID: 1110 (crond)
```
如果你没有看到类似的内容 `Active: active (running) since…`,你需要启动 crond 守护进程。要在当前会话中运行 crond 服务,输入以下命令:
```
$ systemctl run crond.service
```
将其配置为开机自启动,输入以下命令:
```
$ systemctl enable crond.service
```
如果出于某种原因,你希望停止 crond 服务,按以下方式使用 `stop` 命令:
```
$ systemctl stop crond.service
```
要重新启动它,只需使用 `restart` 命令:
```
$ systemctl restart crond.service
```
### 定义一个 cron 作业
#### cron 配置
以下是一个 cron 作业的配置细节示例。它定义了一个简单的 cron 作业,将 `git` master 分支的最新更改拉取到克隆的仓库中:
```
*/59 * * * * username cd /home/username/project/design && git pull origin master
```
主要有两部分:
* 第一部分是 `*/59 * * * *`。这表明计时器设置为第 59 分钟执行一次。(LCTT 译注:原文此处有误。)
* 该行的其余部分是命令,因为它将从命令行运行。 在此示例中,命令本身包含三个部分:
+ 作业将以用户 `username` 的身份运行
+ 它将切换到目录 `/home/username/project/design`
+ 运行 `git` 命令拉取 master 分支中的最新更改
#### 时间语法
如上所述,时间信息是 cron 作业字符串的第一部分,如上所属。它决定了 cron 作业运行的频率和时间。它按以下顺序包括 5 个部分:
* 分钟
* 小时
* 一个月中的某天
* 月份
* 一周中的某天
下面是一种更图形化的方式来解释语法:
```
.--------------- 分钟 (0 - 59)
| .------------- 小时 (0 - 23)
| | .---------- 一月中的某天 (1 - 31)
| | | .------- 月份 (1 - 12) 或 jan、feb、mar、apr …
| | | | .---- 一周中的某天 (0-6) (周日=0 或 7)
| | | | | 或 sun、mon、tue、wed、thr、fri、sat
| | | | |
* * * * * user-name command-to-be-executed
```
#### 星号的使用
星号(`*`)可以用来替代数字,表示该位置的所有可能值。例如,分钟位置上的星号会使它每分钟运行一次。以下示例可能有助于更好地理解语法。
这个 cron 作业将每分钟运行一次:
```
* * * * [command]
```
斜杠表示分钟的间隔数。下面的示例将每小时运行 12 次,即每 5 分钟运行一次:
```
*/5 * * * * [command]
```
下一个示例将每月的第二天午夜(例如 1 月 2 日凌晨 12:00,2 月 2 日凌晨 12:00 等等):
```
0 0 2 * * [command]
```
(LCTT 译注:关于 cron 时间格式,还有更多格式符号,此处没有展开)
#### 使用 crontab 创建一个 cron 作业
cron 作业会在后台运行,它会不断检查 `/etc/crontab` 文件和 `/etc/cron.*/` 以及 `/var/spool/cron/` 目录。每个用户在 `/var/spool/cron/` 中都有一个唯一的 crontab 文件。
不应该直接编辑这些 cron 文件。`crontab` 命令是用于创建、编辑、安装、卸载和列出 cron 作业的方法。
更酷的是,在创建新文件或编辑现有文件后,你无需重新启动 cron。
```
$ crontab -e
```
这将打开你现有的 crontab 文件,或者创建一个。调用 `crontab -e` 时,默认情况下会使用 `vi` 编辑器。注意:要使用 Nano 编辑 crontab 文件,可以设置 `EDITOR=nano` 环境变量。
使用 `-l` 选项列出所有 cron 作业。如果需要,使用 `-u` 选项指定一个用户。
```
$ crontab -l
$ crontab -u username -l
```
使用以下命令删除所有 cron 作业:
```
$ crontab -r
```
要删除特定用户的作业,你必须以 root 用户身份运行以下命令:
```
$ crontab -r -u username
```
感谢你的阅读。cron 作业看起来可能只是系统管理员的工具,但它实际上与许多 Web 应用程序和用户任务有关。
### 参考
Fedora Linux 文档的 [自动化任务](https://docs.fedoraproject.org/en-US/Fedora/12/html/Deployment_Guide/ch-autotasks.html)
---
via: <https://fedoramagazine.org/scheduling-tasks-with-cron/>
作者:[Darshna Das](https://fedoramagazine.org/author/climoiselle/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Cron is a scheduling daemon that executes tasks at specified intervals. These tasks are called *cron* jobs and are mostly used to automate system maintenance or administration tasks. For example, you could set a *cron* job to automate repetitive tasks such as backing up database or data, updating the system with the latest security patches, checking the disk space usage, sending emails, and so on. The *cron* jobs can be scheduled to run by the minute, hour, day of the month, month, day of the week, or any combination of these.
**Some advantages of cron**
These are a few of the advantages of using *cron* jobs:
- You have much more control over when your job runs i.e. you can control the minute, the hour, the day, etc. when it will execute.
- It eliminates the need to write the code for the looping and logic of the task and you can shut it off when you no longer need to execute the job.
- Jobs do not occupy your memory when not executing so you are able to save the memory allocation.
- If a job fails to execute and exits for some reason it will run again when the proper time comes.
## Installing the cron daemon
Luckily Fedora Linux is pre-configured to run important system tasks to keep the system updated. There are several utilities that can run tasks such as *cron*, *anacron*, *at* and *batch*. This article will focus on the installation of the *cron* utility only. Cron is installed with the *cronie* package that also provides the* cron* services.
To determine if the package is already present or not, use the rpm command:
$ rpm -q cronieCronie-1.5.2-4.el8.x86_64
If the *cronie * package is installed it will return the full name of the *cronie* package. If you do not have the package present in your system it will say the package is not installed.
To install type this:
$ dnf install cronie
## Running the cron daemon
A *cron* job is executed by the *crond* service based on information from a configuration file. Before adding a job to the configuration file, however, it is necessary to start the *crond* service, or in some cases install it. What is *crond*? *Crond* is the compressed name of cron daemon (crond). To determine if the *crond* service is running or not, type in the following command:
$ systemctl status crond.service● crond.service - Command Scheduler Loaded: loaded (/usr/lib/systemd/system/crond.service; enabled; vendor pre> Active: active (running) since Sat 2021-03-20 14:12:35 PDT; 1 day 21h ago Main PID: 1110 (crond)
If you do not see something similar including the line “Active: active (running) since…”, you will have to start the *crond* daemon. To run the *crond* service in the current session, enter the following command:
$ systemctl start crond.service
To configure the service to start automatically at boot time, type the following:
$ systemctl enable crond.service
If, for some reason, you wish to stop the *crond* service from running, use the *stop* command as follows:
$ systemctl stop crond.service
To restart it, simply use the *restart* command:
$ systemctl restart crond.service
## Defining a cron job
### The cron configuration
Here is an example of the configuration details for a *cron* job. This defines a simple *cron* job to pull the latest changes of a *git* master branch into a cloned repository:
*/59 * * * * username cd /home/username/project/design && git pull origin master
There are two main parts:
- The first part is “*/59 * * * *”. This is where the timer is set to every 59 minutes.
- The rest of the line is the command as it would run from the command line.
The command itself in this example has three parts:- The job will run as the user “username”
- It will change to the directory
/home/username/project/design
- The git command runs to pull the latest changes in the master branch.
**Timing syntax**
The timing information is the first part of the *cron* job string, as mentioned above. This determines how often and when the cron job is going to run. It consists of 5 parts in this order:
- minute
- hour
- day of the month
- month
- day of the week
Here is a more graphic way to explain the syntax may be seen here:
.---------------- minute (0 - 59) | .------------- hour (0 - 23) | | .---------- day of month (1 - 31) | | | .------- month (1 - 12) OR jan,feb,mar,apr … | | | | .---- day of week (0-6) (Sunday=0 or 7) | | | | | OR sun,mon,tue,wed,thr,fri,sat | | | | | * * * * * user-name command-to-be-executed
### Use of the **asterisk**
An asterisk (*) may be used in place of a number to represents all possible values for that position. For example, an asterisk in the minute position would make it run every minute. The following examples may help to better understand the syntax.
This cron job will run every minute, all the time:
* * * * * [command]
A slash (/) indicates a multiple number of minutes The following example will run 12 times per hour, i.e., every 5 minutes:
*/5 * * * * [command]
The next example will run once a month, on the second day of the month at midnight (e.g. January 2nd 12:00am, February 2nd 12:00am, etc.):
0 0 2 * * [command]
### Using crontab to create a cron job
Cron jobs run in the background and constantly check the */etc/crontab* file, and the */etc/cron.*/* and */var/spool/cron/* directories. Each user has a unique crontab file in */var/spool/cron/ *.
These *cron* files are not supposed to be edited directly. The *crontab* command is the method you use to create, edit, install, uninstall, and list cron jobs.
The same *crontab* command is used for creating and editing cron jobs. And what’s even cooler is that you don’t need to restart cron after creating new files or editing existing ones.
$ crontab -e
This opens your existing *crontab* file or creates one if necessary. The *vi* editor opens by default when calling *crontab -e*. Note: To edit the *crontab* file using Nano editor, you can optionally set the **EDITOR**=nano environment variable.
List all your *cron* jobs using the option *-l* and specify a user using the *-u* option, if desired.
$ crontab -l $ crontab -u username -l
Remove or erase all your *cron* jobs using the following command:
$ crontab -r
To remove jobs for a specific user you must run the following command as the *root user*:
$ crontab -r -u username
Thank you for reading. *cron* jobs may seem like a tool just for system admins, but they are actually relevant to many kinds of web applications and user tasks.
### Reference
Fedora Linux documentation for [Automated Tasks](https://docs.fedoraproject.org/en-US/Fedora/12/html/Deployment_Guide/ch-autotasks.html)
## Thomas
I really suggest to move away from cron jobs to systemd timers.
Many blog posts out there describing it – search for “systemd timers to replace cron”.
## hugotrip
FWIW you can also use systemd timers
https://opensource.com/article/20/7/systemd-timers
syntax can be simpler.
I use it for my backups in “user mode” :
https://wiki.archlinux.org/index.php/systemd/User
## laolux
Thanks for the article, automating things is a good habit.
I have a question though: Why use systemd to start a cron daemon when systemd does that job itself already? Is there anything I can do with cronie which systemd cannot? I myself use systemd rather often and find the timer units very helpful. They can even be used by regular users without sudo rights.
Another thing:
does not create a crontab file for me. And it also does not open anything if I
. What am I missing?
## Matěj Cepl
Wow! This is strange. Now, when the whole world switched from cron to systemd timers, your article feels like a bit of archeology.
## Oscar
There´s already Systemd timers.
## Mary Biggs
There’s a REALLY useful command in crontab which will start a process at boot time. The crontab line looks like:
@reboot
I use this to start services on my server when (if) Fedora 33 needs to be rebooted. Since this happens very infrequently, this command means that I always get the correct and complete list of services restarted.
## Mary Biggs
Sorry…..crontab line looks like this:
@reboot [your boot time command here]
## Erik
Good article!
One correction: Instead of ‘crontab -i’, I think ‘crontab -e’ is the right invocation to edit a crontab.
## Gregory Bartholomew
Thanks Erik. I’ve made the correction.
## Erik
The crontab format in the article is missing a field. It should be (per /etc/crontab):
Example of job definition:
.—————- minute (0 – 59)
| .————- hour (0 – 23)
| | .———- day of month (1 – 31)
| | | .——- month (1 – 12) OR jan,feb,mar,apr …
| | | | .—- day of week (0 – 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
| | | | |
* * * * * user-name command to be executed
## Gregory Bartholomew
Thanks Erik. I’ve made the correction.
## Erik
Thank you!
## leslie Satenstein
The following is my template for crontab (header
it contains some extra stuff that is very useful
#########################################################
string meaning
—— ——-
@reboot Run once, at startup.
@yearly Run once a year, “0 0 1 1 *”.
@annually (same as @yearly)
@monthly Run once a month, “0 0 1 * *”.
@weekly Run once a week, “0 0 * * 0”.
@daily Run once a day, “0 0 * * *”.
@midnight (same as @daily)
@hourly Run once an hour, “0 * * * *”.
#
#minute hr mnthday Mth DoW COMMAND
#………………………………….Minute of the hour
#| ……………………………Hour in the day (0..23)
#| | …………………….Day of month, 1..31
#| | | ……………..Month (1.12) Jan, Feb.. Dec
#| | | | ………day of the week 0-6 7==0 OR sun,mon,tue,wed,thr,fri,sat
#| | | | | command to be executed
With crontab I can schedule a job for the last day of the month, or even for the second Friday in a month. Is it possible with systemd.
## Gregory Bartholomew
How do you schedule a job for the last day of the month? I’ve done this before by running a script daily and aborting at the top if [[ $(date -d tomorrow ‘+%-d’) -ne 1 ]]. If there is a better way, I’m interested in knowing what it is. Thanks! 🙂
## laolux
The easy solution is to use systemd timers. They support the ~01 syntax to indicate the last day of the month. So, the last day of every month would be
–~01. And you can be even fancier: The last Monday of the month is “Mon–~07/1″. Nicely explained in the man page of. And while we’re at it:
will tell you the next time your expression is met, so you can easily check if your rules are valid.
No clue about how to to any of this with cron, though.
## Joao Rodrigues
Some cron implementations allow the usage of the non-standard “L” to represent “last”.
Otherwise use 0 0 28-31 * * [ $(date -d +1day +%d) -eq 1 ] && your-command.sh
## Sebastiaan Franken
You can do something along the following lines in a Systemd timer:
Inspired by cron, but expanded. The syntax for OnCalendar is “DayOfWeek Year-Month-Day Hour:Minute:Second”
## Mark
The post is a little confusing in the way it mixes the two crontab entry formats, the ‘username’ field is only available in files under /etc/cron.d and in /etc/crontab. It is not available in individual user crontabs would could be made a little clearer, the explaination of course being that individual user crontabs are run as the user the /var/spool/crontabs file is named and owned for so does not need to be specified.
The advantages of cron as mentioned are that it is easy to schedule repeating jobs, another advantage over systemd timers is that its simply editing a text file, and text files are easy to push out with tools like puppet/chef. Another advantage over systemd timers is that all *nix server have cron but not all have systemd.
The ‘info crontab’ page mentions cron jobs can run in a clustered environment, something I have not looked at but perhaps another adventage over systemd timers that are tied to one host.
There are a few disadvantages to cron that must be lived with
* one disadvantage you actually mentioned as an advantage with ‘If a job fails to execute and exits for some reason it will run again when the proper time comes’. That is an issue if the job must run every day; and why people tend to avoid scheduling jobs in cron between the hours of 2am and 3am to avoid the once a year issue of automatic daylight savings time skipping ahead one hour and missing them; that may be an issue with systemd timers as well but I haven’t really played with them
* any stdout/stderr from a cron job is by default mailed to the user of the crontab (although configurable), a badly written script can be a bit spammy
* /var/log/cron records jobs run, useless for alerting or fault solving when you want to know why a job failed; it cannot be easily hooked into external monitoring tools
* if a badly written cron job prompts for user input it will just hang waiting for it
For every disadvantage listed I wrote my own scheduler to solve every issue, as well as job dependency on prior jobs completing or files existing and most importantly alerting failures to external tools and a lot more bells and whistles; that was written on Fedora Core 3 and still in use. And guess what, I still make extensive use of cron jobs as well.
There are systemd timers, cron, and custom solutions out there. You don’t choose one and force it to fit, you just use the best for what you are trying to achieve and if that involves multiple solutions on a server thats fine.
In the response to the comment to the post ‘when the whole world switched from cron to systemd timers’, wrong; not all *nix platforms use systemd so a post on cron is still relevant in this day and age.
Thanks for the post; while I’ve played with /etc/cron.d|hourly|daily etc I wasn’t really aware of /etc/crontab on rhel based systems which is nothing but comments on my machines; which I will probably never use but nice to know its there as I wasn’t checking it.
I have learnt something new so the post was worthwhile.
Thanks
## laolux
While it is certainly true that not all systems run systemd, this fedora magazine is about… well, Fedora. And perhaps RHEL, which also uses systemd in all support versions that I am aware of.
## Mark
I agree. The comment that not all *nix systems support systemd is not relevant here so should not have been entered.
But fedora and rhel systems do still support cron and a post on using cron is still relevant.
Maybe one day someone will write an article on scheduling jobs using systemd I will look at.
But this article covers cron and does so quite well. It is probably the comments on systemd does it differently that are truely irrelevant to this article which is focused on using cron. There are probably many places systemd may be better, but this is not a systemd post 🙂
## Andrew
Well written comments Mark. I appreciated the advantages/disadvantages you posted.
## Ed Grimm
I’m always confused by people talking about the daylight savings time issue. It’s pretty easy to configure the system to use UTC, and then configure login and SSH to set the timezone to whatever the appropriate local timezone, so your system has a strictly linear concept of time, but your users can deal with all the madness that is DST if they want (or override that setting back to UTC if they don’t.)
## Bruno
Nice article, but as others already mentioned, why not use systemd ??
What are the avantages over systemd that would be worth having 2 differents systems to schedule task? 2 differents places to check in case of issues, 2 differents services to check for status …
Since systemd is not even mentioned in the article, a genuine user would think that installing cronie is required to schedule a task. At this stage it is misleading.
One more point, the link in “Reference” points to Fedora 12 documentation 🙂
It demonstrates how backward this article is, especially for a distribution featuring recent (cutting edge) techno.
## Göran Uddeborg
There is a little typo where you write
that should have been
.
## Gregory Bartholomew
Thanks Göran. I’ve made the correction.
## Göran Uddeborg
To all of you who point to systemd timers, one advantage of cron is that it is up all the time, while a user systemd instance might not. I can set up a user level cron job that runs on schedule as long as the machine is up, regardless if there is any systemd user instance for my account running.
Personally, I also find it much simpler to write a simple one-liner in my crontab than to create two (.timer and .service) complete systemd unit files in the common case when I don’t need the extra expressiveness of systemd. It’s like you could do anything you can do with grep using gawk instead, but for the simple cases where grep is enough, I still use that.
But of course, the latter part is a matter of taste.
## laolux
To have user systemd timers running without the user being logged in, one can use
. This command can be run by the user for his own username or by root for any user.
Using one-liners is fine for simple tasks, but for more complex ones systemd timer units have some perks. For example systemd timer units have the fancy
keyword. This is very useful if the computer was unavailable (shut down for example) when the timer was supposed to run. The timer will then execute the next time that the computer is available. I find this feature difficult to achieve with a one-liner in cron.
## Göran Uddeborg
That is kind of my point. If you want to do something simple, cron is a simpler tool. If you have more complex requirements than cron meets, systemd timers are more powerful. I want to use the right tool for the right task, trying to avoid the Law of the instrument trap. (https://en.wikipedia.org/wiki/Law_of_the_instrument)
## Erik
I agree with Göran.
In addition, even though I have been using systemd since Fedora switched to it from SysV, I find cron to be simpler and more straightforward than using systemd timers, especially for a repeating user job.
## Trey
Thank you … I hope to use Cronie to form a Conky based slide show! |
13,385 | 使用 Golang 的交叉编译 | https://opensource.com/article/21/1/go-cross-compiling | 2021-05-13T09:27:06 | [
"Go",
"交叉编译"
] | https://linux.cn/article-13385-1.html |
>
> 走出舒适区,我了解了 Go 的交叉编译功能。
>
>
>

在 Linux 上测试软件时,我使用各种架构的服务器,例如 Intel、AMD、Arm 等。当我 [分配了一台满足我的测试需求的 Linux 机器](https://opensource.com/article/20/12/linux-server),我仍然需要执行许多步骤:
1. 下载并安装必备软件
2. 验证构建服务器上是否有新的测试软件包
3. 获取并设置依赖软件包所需的 yum 仓库
4. 下载并安装新的测试软件包(基于步骤 2)
5. 获取并设置必需的 SSL 证书
6. 设置测试环境,获取所需的 Git 仓库,更改配置,重新启动守护进程等
7. 做其他需要做的事情
### 用脚本自动化
这些步骤非常常规,以至于有必要对其进行自动化并将脚本保存到中央位置(例如文件服务器),在需要时可以在此处下载脚本。为此,我编写了 100-120 行的 Bash shell 脚本,它为我完成了所有配置(包括错误检查)。这个脚本通过以下方式简化了我的工作流程:
1. 配置新的 Linux 系统(支持测试的架构)
2. 登录系统并从中央位置下载自动化 shell 脚本
3. 运行它来配置系统
4. 开始测试
### 学习 Go 语言
我想学习 [Go 语言](https://golang.org/) 有一段时间了,将我心爱的 Shell 脚本转换为 Go 程序似乎是一个很好的项目,可以帮助我入门。它的语法看起来很简单,在尝试了一些测试程序后,我开始着手提高自己的知识并熟悉 Go 标准库。
我花了一个星期的时间在笔记本电脑上编写 Go 程序。我经常在我的 x86 服务器上测试程序,清除错误并使程序健壮起来,一切都很顺利。
直到完全转换到 Go 程序前,我继续依赖自己的 shell 脚本。然后,我将二进制文件推送到中央文件服务器上,以便每次配置新服务器时,我要做的就是获取二进制文件,将可执行标志打开,然后运行二进制文件。我对早期的结果很满意:
```
$ wget http://file.example.com/<myuser>/bins/prepnode
$ chmod +x ./prepnode
$ ./prepnode
```
### 然后,出现了一个问题
第二周,我从资源池中分配了一台新的服务器,像往常一样,我下载了二进制文件,设置了可执行标志,然后运行二进制文件。但这次它出错了,是一个奇怪的错误:
```
$ ./prepnode
bash: ./prepnode: cannot execute binary file: Exec format error
$
```
起初,我以为可能没有成功设置可执行标志。但是,它已按预期设置:
```
$ ls -l prepnode
-rwxr-xr-x. 1 root root 2640529 Dec 16 05:43 prepnode
```
发生了什么事?我没有对源代码进行任何更改,编译没有引发任何错误或警告,而且上次运行时效果很好,因此我仔细查看了错误消息 `format error`。
我检查了二进制文件的格式,一切看起来都没问题:
```
$ file prepnode
prepnode: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, not stripped
```
我迅速运行了以下命令,识别所配置的测试服务器的架构以及二进制试图运行的平台。它是 Arm64 架构,但是我编译的二进制文件(在我的 x86 笔记本电脑上)生成的是 x86-64 格式的二进制文件:
```
$ uname -m
aarch64
```
### 脚本编写人员的编译第一课
在那之前,我从未考虑过这种情况(尽管我知道这一点)。我主要研究脚本语言(通常是 Python)以及 Shell 脚本。在任何架构的大多数 Linux 服务器上都可以使用 Bash Shell 和 Python 解释器。总之,之前一切都很顺利。
但是,现在我正在处理 Go 这种编译语言,它生成可执行的二进制文件。编译后的二进制文件由特定架构的 [指令码](https://en.wikipedia.org/wiki/Opcode) 或汇编指令组成,这就是为什么我收到格式错误的原因。由于 Arm64 CPU(运行二进制文件的地方)无法解释二进制文件的 x86-64 指令,因此它抛出错误。以前,shell 和 Python 解释器为我处理了底层指令码或特定架构的指令。
### Go 的交叉编译
我检查了 Golang 的文档,发现要生成 Arm64 二进制文件,我要做的就是在运行 `go build` 命令编译 Go 程序之前设置两个环境变量。
`GOOS` 指的是操作系统,例如 Linux、Windows、BSD 等,而 `GOARCH` 指的是要在哪种架构上构建程序。
```
$ env GOOS=linux GOARCH=arm64 go build -o prepnode_arm64
```
构建程序后,我重新运行 `file` 命令,这一次它显示的是 ARM AArch64,而不是之前显示的 x86。因此,我在我的笔记本上能为不同的架构构建二进制文件。
```
$ file prepnode_arm64
prepnode_arm64: ELF 64-bit LSB executable, ARM aarch64, version 1 (SYSV), statically linked, not stripped
```
我将二进制文件从笔记本电脑复制到 ARM 服务器上。现在运行二进制文件(将可执行标志打开)不会产生任何错误:
```
$ ./prepnode_arm64 -h
Usage of ./prepnode_arm64:
-c Clean existing installation
-n Do not start test run (default true)
-s Use stage environment, default is qa
-v Enable verbose output
```
### 其他架构呢?
x86 和 Arm 是我测试软件所支持的 5 种架构中的两种,我担心 Go 可能不会支持其它架构,但事实并非如此。你可以查看 Go 支持的架构:
```
$ go tool dist list
```
Go 支持多种平台和操作系统,包括:
* AIX
* Android
* Darwin
* Dragonfly
* FreeBSD
* Illumos
* JavaScript
* Linux
* NetBSD
* OpenBSD
* Plan 9
* Solaris
* Windows
要查找其支持的特定 Linux 架构,运行:
```
$ go tool dist list | grep linux
```
如下面的输出所示,Go 支持我使用的所有体系结构。尽管 x86\_64 不在列表中,但 AMD64 兼容 x86-64,所以你可以生成 AMD64 二进制文件,它可以在 x86 架构上正常运行:
```
$ go tool dist list | grep linux
linux/386
linux/amd64
linux/arm
linux/arm64
linux/mips
linux/mips64
linux/mips64le
linux/mipsle
linux/ppc64
linux/ppc64le
linux/riscv64
linux/s390x
```
### 处理所有架构
为我测试的所有体系结构生成二进制文件,就像从我的 x86 笔记本电脑编写一个微小的 shell 脚本一样简单:
```
#!/usr/bin/bash
archs=(amd64 arm64 ppc64le ppc64 s390x)
for arch in ${archs[@]}
do
env GOOS=linux GOARCH=${arch} go build -o prepnode_${arch}
done
```
```
$ file prepnode_*
prepnode_amd64: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, Go BuildID=y03MzCXoZERH-0EwAAYI/p909FDnk7xEUo2LdHIyo/V2ABa7X_rLkPNHaFqUQ6/5p_q8MZiR2WYkA5CzJiF, not stripped
prepnode_arm64: ELF 64-bit LSB executable, ARM aarch64, version 1 (SYSV), statically linked, Go BuildID=q-H-CCtLv__jVOcdcOpA/CywRwDz9LN2Wk_fWeJHt/K4-3P5tU2mzlWJa0noGN/SEev9TJFyvHdKZnPaZgb, not stripped
prepnode_ppc64: ELF 64-bit MSB executable, 64-bit PowerPC or cisco 7500, version 1 (SYSV), statically linked, Go BuildID=DMWfc1QwOGIq2hxEzL_u/UE-9CIvkIMeNC_ocW4ry/r-7NcMATXatoXJQz3yUO/xzfiDIBuUxbuiyaw5Goq, not stripped
prepnode_ppc64le: ELF 64-bit LSB executable, 64-bit PowerPC or cisco 7500, version 1 (SYSV), statically linked, Go BuildID=C6qCjxwO9s63FJKDrv3f/xCJa4E6LPVpEZqmbF6B4/Mu6T_OR-dx-vLavn1Gyq/AWR1pK1cLz9YzLSFt5eU, not stripped
prepnode_s390x: ELF 64-bit MSB executable, IBM S/390, version 1 (SYSV), statically linked, Go BuildID=faC_HDe1_iVq2XhpPD3d/7TIv0rulE4RZybgJVmPz/o_SZW_0iS0EkJJZHANxx/zuZgo79Je7zAs3v6Lxuz, not stripped
```
现在,每当配置一台新机器时,我就运行以下 `wget` 命令下载特定体系结构的二进制文件,将可执行标志打开,然后运行:
```
$ wget http://file.domain.com/<myuser>/bins/prepnode_<arch>
$ chmod +x ./prepnode_<arch>
$ ./prepnode_<arch>
```
### 为什么?
你可能想知道,为什么我没有坚持使用 shell 脚本或将程序移植到 Python 而不是编译语言上来避免这些麻烦。所以有舍有得,那样的话我不会了解 Go 的交叉编译功能,以及程序在 CPU 上执行时的底层工作原理。在计算机中,总要考虑取舍,但绝不要让它们阻碍你的学习。
---
via: <https://opensource.com/article/21/1/go-cross-compiling>
作者:[Gaurav Kamathe](https://opensource.com/users/gkamathe) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I work with multiple servers with various architectures (e.g., Intel, AMD, Arm, etc.) when I'm testing software on Linux. Once I've [provisioned a Linux box](https://opensource.com/article/20/12/linux-server) and the server meets my testing needs, I still have a number of steps to do:
- Download and install prerequisite software.
- Verify whether new test packages for the software I'm testing are available on the build server.
- Get and set the required yum repos for the dependent software packages.
- Download and install the new test packages (based on step #2).
- Get and set up the required SSL certificates.
- Set up the test environment, get the required Git repos, change configurations in files, restart daemons, etc.
- Do anything else that needs to be done.
## Script it all away
These steps are so routine that it makes sense to automate them and save the script to a central location (like a file server) where I can download it when I need it. I did this by writing a 100–120-line Bash shell script that does all the configuration for me (including error checks). The script simplifies my workflow by:
- Provisioning a new Linux system (of the architecture under test)
- Logging into the system and downloading the automated shell script from a central location
- Running it to configure the system
- Starting the testing
## Enter Go
I've wanted to learn [Golang](https://golang.org/) for a while, and converting my beloved shell script into a Go program seemed like a good project to help me get started. The syntax seemed fairly simple, and after trying out some test programs, I set out to advance my knowledge and become familiar with the Go standard library.
It took me a week to write the Go program on my laptop. I tested my program often on my go-to x86 server to weed our errors and improve the program. Everything worked fine.
I continued relying on my shell script until I finished the Go program. Then I pushed the binary onto a central file server so that every time I provisioned a new server, all I had to do was wget the binary, set the executable bit on, and run the binary. I was happy with the early results:
```
$ wget http://file.example.com/<myuser>/bins/prepnode
$ chmod +x ./prepnode
$ ./prepnode
```
## And then, an issue
The next week, I provisioned a fresh new server from the pool, as usual, downloaded the binary, set the executable bit, and ran the binary. It errored out—with a strange error:
```
$ ./prepnode
bash: ./prepnode: cannot execute binary file: Exec format error
$
```
At first, I thought maybe the executable bit was not set. However, it was set as expected:
```
$ ls -l prepnode
-rwxr-xr-x. 1 root root 2640529 Dec 16 05:43 prepnode
```
What happened? I didn't make any changes to the source code, the compilation threw no errors nor warnings, and it worked well the last time I ran it, so I looked more closely at the error message, `format error`
.
I checked the binary's format, and everything looked OK:
```
$ file prepnode
prepnode: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, not stripped
```
I quickly ran the following command to identify the architecture of the test server I provisioned and where the binary was trying to run. It was Arm64 architecture, but the binary I compiled (on my x86 laptop) was generating an x86-64 format binary:
```
$ uname -m
aarch64
```
## Compilation 101 for scripting folks
Until then, I had never accounted for this scenario (although I knew about it). I primarily work on scripting languages (usually Python) coupled with shell scripting. The Bash shell and the Python interpreter are available on most Linux servers of any architecture. Hence, everything had worked well before.
However, now I was dealing with a compiled language, Go, which produces an executable binary. The compiled binary consists of [opcodes](https://en.wikipedia.org/wiki/Opcode) or assembly instructions that are tied to a specific architecture. That's why I got the format error. Since the Arm64 CPU (where I ran the binary) could not interpret the binary's x86-64 instructions, it errored out. Previously, the shell and Python interpreter took care of the underlying opcodes or architecture-specific instructions for me.
## Cross-compiling with Go
I checked the Golang docs and discovered that to produce an Arm64 binary, all I had to do was set two environment variables when compiling the Go program before running the `go build`
command.
`GOOS`
refers to the operating system (Linux, Windows, BSD, etc.), while `GOARCH`
refers to the architecture to build for.
`$ env GOOS=linux GOARCH=arm64 go build -o prepnode_arm64`
After building the program, I reran the `file`
command, and this time it showed Arm AArch64 instead of the x86 it showed before. Therefore, I was able to build a binary for a different architecture than the one on my laptop:
```
$ file prepnode_arm64
prepnode_arm64: ELF 64-bit LSB executable, ARM aarch64, version 1 (SYSV), statically linked, not stripped
```
I copied the binary onto the Arm server from my laptop. Now, running the binary (after setting the executable bit on) produced no errors:
```
$ ./prepnode_arm64 -h
Usage of ./prepnode_arm64:
-c Clean existing installation
-n Do not start test run (default true)
-s Use stage environment, default is qa
-v Enable verbose output
```
## What about other architectures?
x86 and Arm are two of the five architectures I test software on. I was worried that Go might not support the other ones, but that was not the case. You can find out which architectures Go supports with:
`$ go tool dist list`
Go supports a variety of platforms and operating systems, including:
- AIX
- Android
- Darwin
- Dragonfly
- FreeBSD
- Illumos
- JavaScript
- Linux
- NetBSD
- OpenBSD
- Plan 9
- Solaris
- Windows
To find the specific Linux architectures it supports, run:
`$ go tool dist list | grep linux`
As the output below shows, Go supports all of the architectures I use. Although x86_64 is not on the list, AMD64 is compatible with x86_64, so you can produce an AMD64 binary, and it will run fine on x86 architecture:
```
$ go tool dist list | grep linux
linux/386
linux/amd64
linux/arm
linux/arm64
linux/mips
linux/mips64
linux/mips64le
linux/mipsle
linux/ppc64
linux/ppc64le
linux/riscv64
linux/s390x
```
## Handling all architectures
Generatiing binaries for all of the architectures under my test is as simple as writing a tiny shell script from my x86 laptop:
```
#!/usr/bin/bash
archs=(amd64 arm64 ppc64le ppc64 s390x)
for arch in ${archs[@]}
do
env GOOS=linux GOARCH=${arch} go build -o prepnode_${arch}
done
```
```
$ file prepnode_*
prepnode_amd64: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically linked, Go BuildID=y03MzCXoZERH-0EwAAYI/p909FDnk7xEUo2LdHIyo/V2ABa7X_rLkPNHaFqUQ6/5p_q8MZiR2WYkA5CzJiF, not stripped
prepnode_arm64: ELF 64-bit LSB executable, ARM aarch64, version 1 (SYSV), statically linked, Go BuildID=q-H-CCtLv__jVOcdcOpA/CywRwDz9LN2Wk_fWeJHt/K4-3P5tU2mzlWJa0noGN/SEev9TJFyvHdKZnPaZgb, not stripped
prepnode_ppc64: ELF 64-bit MSB executable, 64-bit PowerPC or cisco 7500, version 1 (SYSV), statically linked, Go BuildID=DMWfc1QwOGIq2hxEzL_u/UE-9CIvkIMeNC_ocW4ry/r-7NcMATXatoXJQz3yUO/xzfiDIBuUxbuiyaw5Goq, not stripped
prepnode_ppc64le: ELF 64-bit LSB executable, 64-bit PowerPC or cisco 7500, version 1 (SYSV), statically linked, Go BuildID=C6qCjxwO9s63FJKDrv3f/xCJa4E6LPVpEZqmbF6B4/Mu6T_OR-dx-vLavn1Gyq/AWR1pK1cLz9YzLSFt5eU, not stripped
prepnode_s390x: ELF 64-bit MSB executable, IBM S/390, version 1 (SYSV), statically linked, Go BuildID=faC_HDe1_iVq2XhpPD3d/7TIv0rulE4RZybgJVmPz/o_SZW_0iS0EkJJZHANxx/zuZgo79Je7zAs3v6Lxuz, not stripped
```
Now, whenever I provision a new machine, I just run this wget command to download the binary for a specific architecture, set the executable bit on, and run the binary:
```
$ wget http://file.domain.com/<myuser>/bins/prepnode_<arch>
$ chmod +x ./prepnode_<arch>
$ ./prepnode_<arch>
```
## But why?
You may be wondering why I didn't save all of this hassle by sticking to shell scripts or porting the program over to Python instead of a compiled language. All fair points. But then I wouldn't have learned about Go's cross-compilation capabilities and how programs work underneath the hood when they're executing on the CPU. In computing, there are always trade-offs to be considered, but never let them stop you from learning.
## 3 Comments |
13,386 | 初级:如何通过 Torrent 下载 Ubuntu | https://itsfoss.com/download-ubuntu-via-torrent/ | 2021-05-13T09:43:00 | [
"下载",
"torrent"
] | https://linux.cn/article-13386-1.html | 
下载 Ubuntu 是非常直接简单的。你可以去它的 [官方网站](https://ubuntu.com),点击 [桌面下载部分](https://ubuntu.com/download/desktop),选择合适的 Ubuntu 版本并点击下载按钮。

Ubuntu 是以一个超过 2.5GB 大小的单一镜像形式提供的。直接下载对于拥有高速网络连接的人来说效果很好。
然而,如果你的网络连接很慢或不稳定,你将很难下载这样一个大文件。在这个过程中,下载可能会中断几次,或者可能需要几个小时。

### 通过 Torrent 下载 Ubuntu
如果你也困扰于受限数据或网络连接过慢,使用下载管理器或 torrent 将是一个更好的选择。我不打算在这个快速教程中讨论什么是 torrent。你只需要知道,通过 torrent,你可以在多个会话内下载一个大文件。
好的是,Ubuntu 实际上提供了通过 torrent 的下载。不好的是,它隐藏在网站上,如果你不熟悉它,很难猜到在哪。
如果你想通过 torrent 下载 Ubuntu,请到你所选择的 Ubuntu 版本中寻找**其他下载方式**。

点击这个“**alternative downloads and torrents**” 链接,它将打开一个新的网页。**在这个页面向下滚动**,看到 BitTorrent 部分。你会看到下载所有可用版本的 torrent 文件的选项。如果你要在你的个人电脑或笔记本电脑上使用 Ubuntu,你应该选择桌面版本。

阅读 [这篇文章以获得一些关于你应该使用哪个 Ubuntu 版本的指导](https://itsfoss.com/which-ubuntu-install/)。考虑到你要使用这个发行版,了解 [Ubuntu LTS 和非 LTS 版本会有所帮助](https://itsfoss.com/long-term-support-lts/)。
#### 你是如何使用下载的 torrent 文件来获取 Ubuntu 的?
我推测你知道如何使用 torrent。如果没有,让我为你快速总结一下。
你已经下载了一个几 KB 大小的 .torrent 文件。你需要下载并安装一个 Torrent 应用,比如 uTorrent 或 Deluge 或 BitTorrent。
我建议在 Windows 上使用 [uTorrent](https://www.utorrent.com/)。如果你使用的是某个 Linux 发行版,你应该已经有一个 [像 Transmission 这样的 torrent 客户端](https://itsfoss.com/best-torrent-ubuntu/)。如果没有,你可以从你的发行版的软件管理器中安装它。
当你安装了 Torrent 应用,运行它。现在拖放你从 Ubuntu 网站下载的 .torrent 文件。你也可以使用菜单中的打开选项。
当 torrent 文件被添加到 Torrent 应用中,它就开始下载该文件。如果你关闭了系统,下载就会暂停。再次启动 Torrent 应用,下载就会从同一个地方恢复。
当下载 100% 完成后,你可以用它来 [全新安装 Ubuntu](https://itsfoss.com/install-ubuntu/) 或 [与 Windows 双启动](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/)。
享受 Ubuntu :)
---
via: <https://itsfoss.com/download-ubuntu-via-torrent/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Downloading Ubuntu is pretty straightforward. You go to its [official website](https://ubuntu.com). Click on the [desktop download section](https://ubuntu.com/download/desktop), select the appropriate Ubuntu version and hit the download button.

Ubuntu is available as a single image of more than 2.5 GB in size. The direct download works well for people with high-speed internet connection.
However, if you have a slow or inconsistent internet connection, you’ll have a difficult time downloading such a big file. The download may be interrupted several times in the process or may take several hours.
## Downloading Ubuntu via Torrent
If you also suffer from limited data or slow internet connection, using a download manager or torrent would be a better option. I am not going to discuss what torrent is in this quick tutorial. Just know that with torrents, you can download a large file in a number of sessions.
The Good thing is that Ubuntu actually provides downloads via torrents. The bad thing is that it is hidden on the website and difficult to guess if you are not familiar with it.
If you want to download Ubuntu via torrent, go to your chosen Ubuntu version’s section and look for **alternative downloads**.
**Click on this “alternative downloads” link** and it will open a new web page. **Scroll down** on this page to see the BitTorrent section. You’ll see the option to download the torrent files for all the available versions. If you are going to use Ubuntu on your personal computer or laptop, you should go with the desktop version.
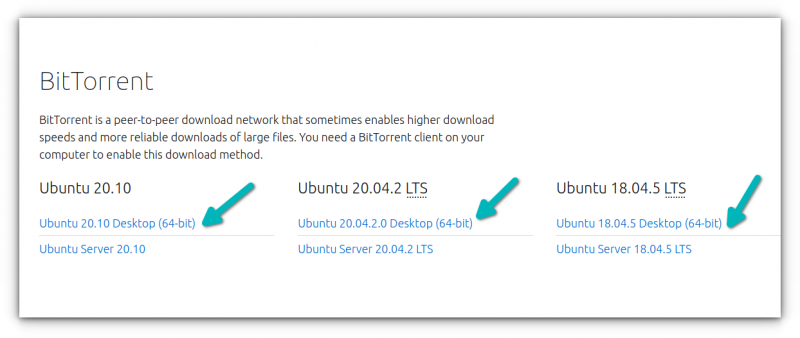
Read [this article to get some guidance on which Ubuntu version](https://itsfoss.com/which-ubuntu-install/) you should be using. Considering that you are going to use this distribution, having some ideas about [Ubuntu LTS and non-LTS release would be helpful](https://itsfoss.com/long-term-support-lts/).
### How do you use the download torrent file for getting Ubuntu?
I presumed that you know how to use torrent. If not, let me quickly summarize it for you.
You have downloaded a .torrent file of a few KB in size. You need to download and install a Torrent application like uTorrent or Deluge or BitTorrent.
I recommend using [uTorrent](https://www.utorrent.com/) on Windows. If you are using some Linux distribution, you should already have a [torrent client like Transmission](https://itsfoss.com/best-torrent-ubuntu/). If not, you can install it from your distribution’s software manager.
Once you have installed the torrent application, run it. Now drag and drop the .torrent file you had downloaded from the website of Ubuntu. You may also use the open with option from the menu.
Once the torrent file has been added to the Torrent application, it starts downloading the file. If you turn off the system, the download is paused. Start the Torrent application again and the download resumes from the same point.
When the download is 100% complete, you can use it to [install Ubuntu afresh](https://itsfoss.com/install-ubuntu/) or in [dual boot with Windows](https://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/).
Enjoy Ubuntu :) |
13,387 | 使用 GNU Screen 的小技巧 | https://opensource.com/article/21/4/gnu-screen-cheat-sheet | 2021-05-13T10:50:57 | [
"Screen",
"终端复用",
"终端"
] | https://linux.cn/article-13387-1.html |
>
> 学习基本的 GNU Screen 终端复用技术,然后下载我们的终端命令备忘录,以便你能够熟悉常用的快捷方式。
>
>
>

对于一般用户而言,命令行终端窗口可能是令人困惑和神秘的。但随着你对 Linux 终端的进一步了解,你很快就会意识到它的高效和强大。不过,也不需要很长时间,你就会想让终端变得更加高效,除了将更多的终端放到你的终端,还有什么高好的方法能够提升你的终端效率呢?
### 终端复用
终端的许多优点之一是它是一个集中控制的界面。它是一个能让你访问数百个应用程序的窗口,而你与每一个应用程序进行交互所需要的只是一个键盘。但是,现代计算机几乎总是有多余的处理能力,而且现代计算机专家喜欢多任务处理,导致一个窗口处理数百个应用程序的能力是相当有限的。
解决这一问题的常见答案是终端复用:即将虚拟终端叠放在一起,然后在它们之间移动的能力。通过终端复用器,你保持了集中控制,但是当你进行多任务时,你能够进行终端切换。更好的是,你能够在终端中拆分屏幕,使得在同一时间显示多个屏幕窗口。
### 选择合适的复用器
一些终端提供类似的功能,有标签式界面和分割式视图,但也有细微的差别。首先,这些终端的功能依赖于图形化的桌面环境。其次,许多图形化的终端功能需要鼠标交互或使用不方便的键盘快捷键。终端复用器的功能在文本控制台上和在图形桌面上一样好用,而且键位绑定是针对常见的终端序列设计的,很方便。
现有两种流行的复用器:[tmux](https://github.com/tmux/tmux/wiki) 和 [GNU Screen](https://www.gnu.org/software/screen/)。尽管你与它们互动的方式略有不同,但它们做同样的事情,而且大多具有相同的功能。这篇文章是 GNU Screen 的入门指南。关于 tmux 的相关介绍,请阅读 Kevin Sonney 的 [tmux 介绍](https://opensource.com/article/20/1/tmux-console)。
### 使用 GNU Screen
GNU Screen 的基本用法很简单,通过 `screen` 命令启动,你将进入 Screen 会话的第 0 个窗口。在你决定需要一个新的终端提示符前,你可能很难注意到有什么变化。
当一个终端窗口被某项活动占用(比如,你启动了文本编辑器 [Vim](https://opensource.com/tags/vim) 或 [Jove](https://opensource.com/article/17/1/jove-lightweight-alternative-vim) 或者你在处理音视频,或运行批处理任务),你可以新建一个窗口。要打开一个新的窗口,按 `Ctrl+A`,释放,然后按 `c`。这将在你现有窗口的基础上创建一个新的窗口。
你会知道当前你是在一个新的窗口中,因为你的终端除了默认的提示符外,似乎没有任何东西。当然,你的另一个终端仍然存在,它只是躲在新窗口的后面。要遍历打开的窗口,按 `Ctrl+A`,释放,然后按 `n`(表示下一个)或按 `p`(表示上一个)。在只打开两个窗口的情况下, `n` 和 `p` 的功能是一样的,但你可以随时打开更多的窗口(`Ctrl+A`,然后 `c` ),并在它们之间切换。
### 分屏
GNU Screen 的默认行为更像移动设备的屏幕,而不是桌面:你一次只能看到一个窗口。如果你因为喜欢多任务而使用 GNU Screen ,那么只关注一个窗口可能看起来是一种退步。幸运的是,GNU Screen 可以让你把终端分成窗口中的窗口。
要创建一个水平分割窗口,按 `Ctrl+A`,然后按 `s` 。这将把一个窗口置于另一个窗口之上,就像窗格一样。然而,在你告诉它要显示什么之前,分割的空间是没有用途的。因此,在创建一个分割窗后,你可以用 `Ctrl+A` ,然后用 `Tab` 移动到分割窗中。一旦进入,使用 `Ctrl+A` 然后 `n` 浏览所有可用的窗口,直到你想显示的内容出现在分割窗格中。
你也可以按 `Ctrl+A` 然后按 `|` (这是一个管道字符,在大多数键盘上通过按下 `shift` 键加上 `\`)创建垂直分割窗口。
### 自定义 GNU Screen
GNU Screen 使用基于 `Ctrl+A` 的快捷键。根据你的习惯,这可能会让你感觉非常自然,也可能非常不方便,因为你可能会用 `Ctrl+A` 来移动到一行的开头。无论怎样,GNU Screen 允许通过 `.screenrc` 配置文件进行各种定制。你可以用这个来改变触发键的绑定(称为 “转义” 键绑定)。
```
escape ^jJ
```
你还可以添加一个状态行,以帮助你在 Screen 会话中保持自己不迷失。
```
# status bar, with current window highlighted
hardstatus alwayslastline
hardstatus string '%{= kG}[%{G}%H%? %1`%?%{g}][%= %{= kw}%-w%{+b yk} %n*%t%?(%u)%? %{-}%+w %=%{g}][%{B}%m/%d %{W}%C%A%{g}]'
# enable 256 colors
attrcolor b ".I"
termcapinfo xterm 'Co#256:AB=\E[48;5;%dm:AF=\E[38;5;%dm'
defbce on
```
在有多个窗口打开的会话中,有一个时刻提醒哪些窗口具有焦点活动,哪些窗口有后台活动的提醒器特别有用。它类似一种终端的任务管理器。
### 下载备忘单
当你学习 GNU Screen 的使用方法时,需要记住很多新的键盘命令。有些命令你马上就能记住,但那些你不常使用的命令可能就很难记住了。你可以按 `Ctrl+A` 然后再按 `?` 来访问 GNU Screen 的帮助界面,但如果你更喜欢一些可以打印出来并放在键盘边的东西,请 [下载我们的 GNU Screen 备忘单](https://opensource.com/downloads/gnu-screen-cheat-sheet)。
学习 GNU Screen 是提高你使用你最喜欢的 [终端模拟器](https://opensource.com/article/21/2/linux-terminals) 的效率和敏捷性的一个好方法。请试一试吧!
---
via: <https://opensource.com/article/21/4/gnu-screen-cheat-sheet>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ddl-hust](https://github.com/ddl-hust) 校对:[wxy](https://github.com/wxy)
本文由[LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/)荣誉推出
| 200 | OK | To the average user, a terminal window can be baffling and cryptic. But as you learn more about the Linux terminal, it doesn't take long before you realize how efficient and powerful it is. It also doesn't take long for you to want it to be even *more* efficient, though, and what better way to make your terminal better than to put more terminals into your terminal?
## Terminal multiplexing
One of the many advantages to the terminal is that it's a centralized interface with centralized controls. It's one window that affords you access to hundreds of applications, and all you need to interact with each one of them is a keyboard. But modern computers almost always have processing power to spare, and modern computerists love to multitask, so one window for hundreds of applications can be pretty limiting.
A common answer for this flaw is terminal multiplexing: the ability to layer virtual terminal windows on top of one another and then move between them all. With a multiplexer, you retain your centralized control, but you gain the ability to swap out the interface as you multitask. Better yet, you can split your virtual screens within your terminal so you can have multiple screens up at the same time.
## Choose the right multiplexer
Some terminals offer similar features, with tabbed interfaces and split views, but there are subtle differences. First of all, these terminals' features depend on a graphical desktop environment. Second, many graphical terminal features require mouse interaction or use inconvenient keyboard shortcuts. A terminal multiplexer's features work just as well in a text console as on a graphical desktop, and the keybindings are conveniently designed around common terminal sequences.
There are two popular multiplexers: [tmux](https://github.com/tmux/tmux/wiki) and [GNU Screen](https://www.gnu.org/software/screen/). They do the same thing and mostly have the same features, although the way you interact with each is slightly different. This article is a getting-started guide for GNU Screen. For information about tmux, read Kevin Sonney's [introduction to tmux](https://opensource.com/article/20/1/tmux-console).
## Using GNU Screen
GNU Screen's basic usage is simple. Launch it with the `screen`
command, and you're placed into the zeroeth window in a Screen session. You may hardly notice anything's changed until you decide you need a new prompt.
When one terminal window is occupied with an activity (for instance, you've launched a text editor like [Vim](https://opensource.com/tags/vim) or [Jove](https://opensource.com/article/17/1/jove-lightweight-alternative-vim), or you're processing video or audio, or running a batch job), you can just open a new one. To open a new window, press **Ctrl+A**, release, and then press **c**. This creates a new window on top of your existing window.
You'll know you're in a new window because your terminal appears to be clear of anything aside from its default prompt. Your other terminal still exists, of course; it's just hiding behind the new one. To traverse through your open windows, press **Ctrl+A**, release, and then **n** for *next* or **p** for *previous*. With just two windows open, **n** and **p** functionally do the same thing, but you can always open more windows (**Ctrl+A** then **c**) and walk through them.
## Split screen
GNU Screen's default behavior is more like a mobile device screen than a desktop: you can only see one window at a time. If you're using GNU Screen because you love to multitask, being able to focus on only one window may seem like a step backward. Luckily, GNU Screen lets you split your terminal into windows within windows.
To create a horizontal split, press **Ctrl+A** and then **Shift+S** (uppercase). This places one window above another, just like window panes. The split space is, however, left unpurposed until you tell it what to display. So after creating a split, you can move into the split pane with **Ctrl+A** and then **Tab**. Once there, use **Ctrl+A** then **n** to navigate through all your available windows until the content you want to be displayed is in the split pane.
You can also create vertical splits with **Ctrl+A** then **|** (that's a pipe character, or the **Shift** option of the **\** key on most keyboards).
## Make GNU Screen your own
GNU Screen uses shortcuts based around **Ctrl+A**. Depending on your habits, this can either feel very natural or be supremely inconvenient because you use **Ctrl+A** to move to the beginning of a line anyway. Either way, GNU Screen permits all manner of customization through the `.screenrc`
configuration file. You can change the trigger keybinding (called the "escape" keybinding) with this:
```
````escape ^jJ`
You can also add a status line to help you keep yourself oriented during a Screen session:
```
``````
# status bar, with current window highlighted
hardstatus alwayslastline
hardstatus string '%{= kG}[%{G}%H%? %1`%?%{g}][%= %{= kw}%-w%{+b yk} %n*%t%?(%u)%? %{-}%+w %=%{g}][%{B}%m/%d %{W}%C%A%{g}]'
# enable 256 colors
attrcolor b ".I"
termcapinfo xterm 'Co#256:AB=\E[48;5;%dm:AF=\E[38;5;%dm'
defbce on
```
Having an always-on reminder of what window has focus activity and which windows have background activity is especially useful during a session with multiple windows open. It's a sort of task manager for your terminal.
## Download the cheat sheet
When you're learning GNU Screen, you'll have a lot of new keyboard commands to remember. Some you'll remember right away, but the ones you use less often might be difficult to keep track of. You can always access a Help screen within GNU Screen with **Ctrl+A** then **?**, but if you prefer something you can print out and keep by your keyboard, ** download our GNU Screen cheat sheet**.
Learning GNU Screen is a great way to increase your efficiency and alacrity with your favorite [terminal emulator](https://opensource.com/article/21/2/linux-terminals). Give it a try!
## Comments are closed. |
13,389 | Linux 下 Chrome 浏览器一直报“检测到网络变化”,修复方法来了 | https://itsfoss.com/network-change-detected/ | 2021-05-14T14:10:32 | [
"Chromium",
"Chrome",
"浏览器"
] | https://linux.cn/article-13389-1.html | 
过去几天,我在 Ubuntu Linux系统上遇到了一个奇怪的问题。我用的是 Firefox 浏览器和 [Brave 浏览器](https://itsfoss.com/brave-web-browser/)。Brave 浏览器一直报“network change detection”错误,几乎每次刷新都报错,但是在 Firefox 浏览器中一切正常。

这个问题严重到了几乎不能使用浏览器的地步。我不能用 [Feedly](https://feedly.com/) 来从我最喜欢的网站浏览信息流,每一个搜索结果都要多次刷新,网站也需要多次刷新。
作为替代,我尝试 [在 Ubuntu 上安装 Chrome 浏览器](https://itsfoss.com/install-chrome-ubuntu/)。但是问题依然存在。我还 [在 Linux 上安装了微软 Edge](https://itsfoss.com/microsoft-edge-linux/),但是问题依旧。基本上,任何 Chromium 内核的浏览器都会持续报“ERR\_NETWORK\_CHANGED”错误。
幸运地是,我找到了一个方法来修复这个问题。我将会把解决步骤分享给你,如果你也遇到了同样的问题,这将能够帮到你。
### 解决基于 Chromium 内核的浏览器频繁报“network change detection”错的问题
对我而言,关闭网络设置中的 IPv6 是一个有效的诀窍。虽然现在我还不确定是什么导致了这个故障,但是 IPv6 会在很多系统中导致错误并不是什么鲜为人知的事。如果你的系统,路由器和其他设备用了 IPv6 而不是古老却好用的 IPv4,那么你就可能遭遇和我相同的网络连接故障。
幸亏,[关闭 Ubuntu 的 IPv6](https://itsfoss.com/disable-ipv6-ubuntu-linux/) 并不算难。有好几种方法都能够达到目的,我将会分享一个大概是最容易的方法。这个方法就是用 GRUB 来关闭 IPv6。
>
> 新手注意!
>
>
> 如果你不习惯于用命令行和终端,请额外注意这些步骤。仔细的阅读这些操作说明。
>
>
>
#### 第 1 步:打开 GRUB 配置文件以编辑
打开终端。用下面的命令来在 Nano 编辑器中打开 GRUB 配置文件。这里你需要输入你的账户密码。
```
sudo nano /etc/default/grub
```
我希望你懂得一点 [使用 Nano 编辑器](https://itsfoss.com/nano-editor-guide/) 的方法。使用方向键移动光标,找到以`GRUB_CMDLINE_LINUX` 开头的这行。把它的值修改成这样:
```
GRUB_CMDLINE_LINUX="ipv6.disable=1"
```
注意引号和空格。不要动其他行。

使用 `Ctrl+x` 快捷键保存更改。按 `Y` 或者回车确认。
#### 第 2 步:更新 GRUB
你已经修改了 GRUB 引导器的配置,但是在你更新 GRUB 之前这些更改都不会生效。使用下面的命令来更新:
```
sudo update-grub
```

现在当你重启系统之后,IPv6 将会被关闭了。你不应该再遇到网络中断的故障了。
你可能会想为什么我没提从网络设置中关掉 IPv6。这是因为目前 Ubuntu 用了 [Netplan](https://netplan.io/) 来管理网络配置,似乎在网络设置中做出的更改并没有被完全应用到 Netplan 中。我试过虽然在网络设置中关掉了 IPv6,但是这个问题并没有被解决,直到我用了上述命令行的方法。
即使过了这么多年,IPv6 的支持还是没有成熟,并且持续引发了很多故障。比如关闭 IPv6 有时候能 [提高 Linux 下的 Wi-Fi 速度](https://itsfoss.com/speed-up-slow-wifi-connection-ubuntu/)。够扯吧?
不管怎样,我希望上述小方法也能够帮助你解决系统中的“network change detection”故障。
---
via: <https://itsfoss.com/network-change-detected/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[HuengchI](https://github.com/HuengchI) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For the past several days, I faced a strange issue in my system running Ubuntu Linux. I use Firefox and [Brave browsers](https://itsfoss.com/brave-web-browser/). Everything was normal in Firefox but Brave keeps on detecting a network change on almost every refresh.
This went on to the extent that it became impossible to use the browser. I could not use [Feedly](https://feedly.com/) to browse feeds from my favorite websites, every search result ends in multiple refresh, websites needed to be refreshed multiple times as well.
As an alternative, I tried [installing Chrome on Ubuntu](https://itsfoss.com/install-chrome-ubuntu/). The problem remained the same. I [installed Microsoft Edge on Linux](https://itsfoss.com/microsoft-edge-linux/) and yet, the problem persisted there as well. Basically, any Chromium-based browser keep encountering the ERR_NETWORK_CHANGED error.
Luckily, I found a way to fix the issue. I am going to share the steps with you so that it helps you if you are also facing the same problem.
## Fixing frequent network change detection issues in Chromium based browsers
The trick that worked for me was to disable IPv6 in the network settings. Now, I am not sure why this happens but I know that IPv6 is known to create network problems in many systems. If your system, router and other devices use IPv6 instead of the good old IPv4, you may encounter network connection issues like the one I encountered.
Thankfully, it is not that difficult to [disable IPv6 in Ubuntu](https://itsfoss.com/disable-ipv6-ubuntu-linux/). There are several ways to do that and I am going to share the easiest method perhaps. This method uses GRUB to disable IPv6.
Attention Beginners!
If you are not too comfortable with the command line and terminal, please pay extra attention on the steps. Read the instructions carefully.
### Step 1: Open GRUB config file for editing
Open the terminal. Now use the following command to edit the GRUB config file in Nano editor. You’ll have to enter your account’s password.
`sudo nano /etc/default/grub`
I hope you know a little bit about [using Nano editor](https://itsfoss.com/nano-editor-guide/). Use the arrow keys to go to the line starting with GRUB_CMDLINE_LINUX. Make its value look like this:
`GRUB_CMDLINE_LINUX="ipv6.disable=1"`
Be careful of the inverted commas and spaces. Don’t touch other lines.
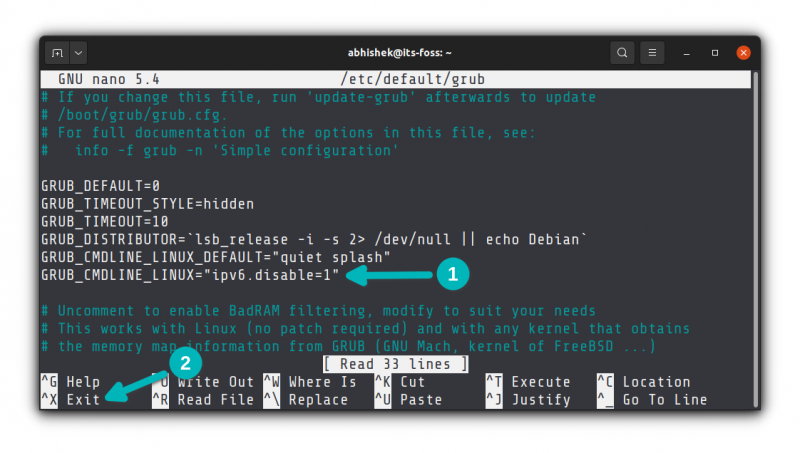
Save your changes by using the Ctrl+x keys. It will ask you to confirm the changes. Press Y or enter when asked.
### Step 2: Update grub
You have made changes to the GRUB bootloader configuration. These changes won’t be taken into account until you update grub. Use the command below for that:
`sudo update-grub`
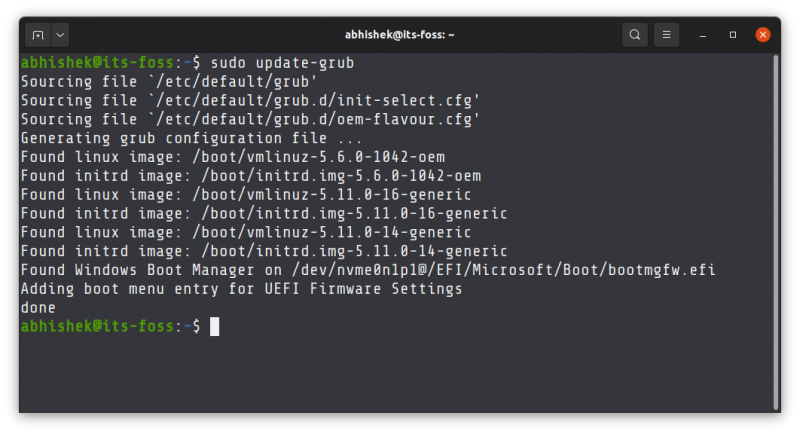
Now when you restart your system, IPv6 will be disabled for your networks. You should not encounter the network interruption issue anymore.
You may think why I didn’t mention disabling IPv6 from the network settings. It’s because Ubuntu uses [Netplan](https://netplan.io/) to manage network configuration these days and it seems that changes in Network Manager are not fully taken into account by Netplan. I tried it but despite IPv6 being disabled in the Network Manager, the problem didn’t go away until I used the command line method.
Even after so many years, IPv6 support has not matured and it keeps causing trouble. Disabling IPv6 sometimes [improve WiFi speed in Linux](https://itsfoss.com/speed-up-slow-wifi-connection-ubuntu/). Weird, I know.
Anyway, I hope this trick helps you with the network change detection issue in your system as well. |
13,390 | 速查表:学习 Kubernetes 的基本命令 | https://opensource.com/article/21/5/kubernetes-cheat-sheet | 2021-05-14T14:45:29 | [
"kubectl",
"Kubernetes",
"容器"
] | /article-13390-1.html |
>
> 开始探索 kubectl、容器、吊舱等,接着下载我们的免费的速查表,这样你就可以随时掌握关键的命令了。
>
>
>

云计算主要是在 Kubernetes 上运行,Kubernetes 主要是在 Linux 上运行,而 Linux 在有熟练的系统管理员控制时运行得最好。无论你认为自己是云计算架构师还是只是一个保守的系统管理员,现代互联网都需要了解如何在容器中创建应用和服务,按需扩展,按需扩展以及如何明智地进行监视和管理。
进入勇敢的容器世界的第一步是学习 Kubernetes 和它的基本命令:`kubectl`。
### 安装 kubectl
`kubectl` 命令允许你在 Kubernetes 集群上运行命令。你使用 `kubectl` 来部署应用、查看日志、检查和管理集群资源,并在出现问题时进行故障排除。`kubectl`(以及整个 Kubernetes)的典型“问题”是,要对集群运行命令,你首先需要一个集群。然而,有一些简单的解决方案。
首先,你可以创建自己的 Kubernetes 集群,只需买三块树莓派板和相关外围设备(主要是电源)。当你获得了硬件,阅读 Chris Collins 的 [使用树莓派构建 Kubernetes 集群](https://opensource.com/article/20/6/kubernetes-raspberry-pi),你就会拥有自己的安装有 `kubectl` 的集群。
另一种获得集群的方法是使用 [Minikube](https://opensource.com/article/18/10/getting-started-minikube),这是一个 Kubernetes 的实践环境。在所有建立和运行集群的方法中,这是最简单的。
还有更多的选择;例如,你可以参加一个关于 Kubernetes 的课程,以获得一个运行集群的实验室,或者你可以在云上购买时间。只要你有一个 Kubernetes 环境来练习,如何获得集群并不重要。
当你你能访问一个集群,你就可以开始探索 `kubectl` 命令。
### 了解吊舱和容器
容器是一个轻量级的、部分的 Linux 系统,专门用于运行一个应用或服务。容器受到 [内核命名空间](https://opensource.com/article/19/10/namespaces-and-containers-linux) 的限制,这使它能够访问其主机(运行容器的计算机)上的重要系统组件,同时防止它向其主机发送数据。容器以容器镜像(或简称 *镜像*)的形式保存,并由称为 `Containerfile` 或 `Dockerfile` 的文本文件定义。
<ruby> 吊舱 <rt> Pod </rt></ruby>是容器的正式集合,也是管理员扩展、监控和维护任何数量的容器的一种简单方法。
这些一起就像 Kubernetes 的“应用程序”。创建或获取容器镜像是你在云上运行服务的方式。
### 运行一个吊舱
容器镜像的两个可靠的仓库是 Docker Hub 和 Quay。你可以在仓库中搜索可用的镜像列表。通常有由项目提供的大型项目的官方镜像,也有专门的、定制的或特殊项目的社区镜像。最简单和最小的镜像之一是 [BusyBox](https://www.busybox.net/) 容器,它提供了一个最小的 shell 环境和一些常用命令。
无论你是从仓库中拉取镜像,还是自己编写镜像定义并从 Git 仓库中拉取到集群中,其工作流程都是一样的。当你想在 Kubernetes 中启动一个吊舱时:
1. 在 [Docker Hub](http://hub.docker.com) 或 [Quay](http://quay.io) 上找到一个你想使用的镜像
2. 拉取镜像
3. 创建一个吊舱
4. 部署吊舱
以 BusyBox 容器为例子,你可以用一条命令完成最后三个步骤:
```
$ kubectl create deployment my-busybox --image=busybox
```
等待 `kubectl` 完成这个过程,最后你就有了一个正在运行的 BusyBox 实例。这个吊舱并没有暴露给其他人。它只是在后台安静地在你的集群上运行。
要看你的集群上有哪些吊舱在运行:
```
$ kubectl get pods --all-namespaces
```
你也可以获得关于吊舱部署的信息:
```
$ kubectl describe deployment my-busybox
```
### 与吊舱互动
容器通常包含使其自动化的配置文件。例如,将 Nginx httpd 服务器作为容器安装,应该不需要你的互动。你开始运行容器,它就会工作。对于你添加到吊舱中的第一个容器和之后的每个容器都是如此。
Kubernetes 模型的优点之一是,你可以根据需要扩展你的服务。如果你的网络服务被意外的流量淹没,你可以在你的云中启动一个相同的容器(使用 `scale` 或 `autoscale` 子命令),使你的服务处理传入请求的能力增加一倍。
即便如此,有时还是很高兴看到一些证明吊舱正在按预期运行的证据,或者能够对似乎无法正常运行的某些问题进行故障排除。为此,你可以在一个容器中运行任意的命令:
```
$ kubectl exec my-busybox -- echo "hello cloud"
```
另外,你可以在你的容器中打开一个 shell,用管道将你的标准输入输入到其中,并将其输出到终端的标准输出:
```
$ kubectl exec --stdin --tty my-busybox -- /bin/sh
```
### 暴露服务
默认情况下,吊舱在创建时不会暴露给外界,这样你就有时间在上线前进行测试和验证。假设你想把 Nginx Web 服务器作为一个吊舱安装和部署在你的集群上,并使其可以访问。与任何服务一样,你必须将你的吊舱指向服务器上的一个端口。`kubectl` 子命令 `expose` 可以为你做到这点:
```
$ kubectl create deployment \
my-nginx --image=nginx
$ kubectl expose deployment \
my-nginx --type=LoadBalancer --port=8080
```
只要你的集群可以从互联网上访问,你就可以通过打开浏览器并导航到你的公共 IP 地址来测试你的新 Web 服务器的可访问性。
### 不仅仅是吊舱
Kubernetes 提供了很多东西,而不仅仅是存储普通服务的镜像。除了作为一个 [容器编排](https://opensource.com/article/20/11/orchestration-vs-automation) 系统,它还是一个云开发的平台。你可以编写和部署应用,管理和监控性能和流量,实施智能负载平衡策略等。
Kubernetes 是一个强大的系统,它已经迅速成为各种云的基础,最主要的是 [开放混合云](https://opensource.com/article/20/10/keep-cloud-open)。今天就开始学习 Kubernetes 吧。随着你对 Kubernetes 的进一步了解,你会需要一些关于其主要概念和一般语法的快速提醒,所以 [下载我们的 Kubernetes 速查表](https://opensource.com/downloads/kubernetes-cheat-sheet) 并将它放在身边。
---
via: <https://opensource.com/article/21/5/kubernetes-cheat-sheet>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
13,392 | 如何使 Jenkins 日志更可读 | https://opensource.com/article/21/5/jenkins-logs | 2021-05-15T09:30:25 | [
"Jenkins",
"日志"
] | https://linux.cn/article-13392-1.html |
>
> Jenkins 的默认日志难以阅读,但日志本不必如此。
>
>
>

Jenkins 是一个自由开源的自动化服务器,用于构建、测试和部署代码。它是<ruby> 持续集成 <rt> Continuous Integration </rt></ruby>(CI)、<ruby> 持续交付 <rt> Continuous Delivery </rt></ruby>(CD)的基础,可以为开发人员每天节约几小时,并保护他们免受失败的代码上线的影响。一旦代码失效或开发人员需要查看测试输出时,[Jenkins](https://www.jenkins.io/) 提供了日志文件以供检查。
默认的 Jenkins <ruby> 管道 <rt> Pipeline </rt></ruby>日志可能难以阅读。这篇关于 Jenkins 日志的基础知识的总结文章提供了一些技巧(和代码),说明了如何提升它们的可读性。
### 你获得什么
Jenkins 管道分为 [几个阶段](https://www.jenkins.io/doc/book/pipeline/syntax/#stage)。Jenkins 自动记录每个阶段的开始,记录内容如下:
```
[Pipeline] // stage
[Pipeline] stage (hide)
[Pipeline] { (Apply all openshift resources)
[Pipeline] dir
```
上文显示的内容没有太大区分度,重要的内容(如阶段的开始)未突出显示。在多达数百行的管道日志中,要找到一个阶段的起始和另外一个阶段的终止位置可能会很艰巨。当随意浏览日志寻找一个特定的阶段的时候,这种艰巨尤其明显。
Jenkins 管道是由 [Groovy](https://opensource.com/article/20/12/groovy) 和 Shell 脚本混合编写的。在 Groovy 代码中,日志记录很少。很多时候,日志是由命令中的不起眼的文本组成,没有详细信息。在 Shell 脚本中,打开了调试模式(`set -x`),所以每条命令都会被完全<ruby> 具现化 <rt> realized </rt></ruby>(变量被解除引用并打印出数值)并详细记录,输出也是如此。
鉴于日志可能有很多内容,通读日志获取相关信息可能很繁琐。由于在管道中被处理,并跟着一个 Shell 脚本的 Groovy 日志可读性差,它们很多时候缺少上下文:
```
[Pipeline] dir
Running in /home/jenkins/agent/workspace/devop-master/devops-server-pipeline/my-repo-dir/src
[Pipeline] { (hide)
[Pipeline] findFiles
[Pipeline] findFiles
[Pipeline] readYaml
[Pipeline] }
```
我可以知道我正在使用的目录,并且知道我正在使用 Jenkins 的步骤搜索文件、读取 YAML 文件。但是我在寻找什么?我找到并读取的内容是什么?
### 能做什么?
我很高兴你这么问,因为这里有一些简单的做法和一些小的代码片段可以提供帮助。首先,代码如下:
```
def echoBanner(def ... msgs) {
echo createBanner(msgs)
}
def errorBanner(def ... msgs) {
error(createBanner(msgs))
}
def createBanner(def ... msgs) {
return """
===========================================
${msgFlatten(null, msgs).join("\n ")}
===========================================
"""
}
// flatten function hack included in case Jenkins security
// is set to preclude calling Groovy flatten() static method
// NOTE: works well on all nested collections except a Map
def msgFlatten(def list, def msgs) {
list = list ?: []
if (!(msgs instanceof String) && !(msgs instanceof GString)) {
msgs.each { msg ->
list = msgFlatten(list, msg)
}
}
else {
list += msgs
}
return list
}
```
将这段代码添加到每个管道的末尾,也可以 [加载一个 Groovy 文件](https://www.jenkins.io/doc/pipeline/steps/workflow-cps/#load-evaluate-a-groovy-source-file-into-the-pipeline-script) 或者使其成为 [Jenkins 共享库](https://www.jenkins.io/doc/book/pipeline/shared-libraries/) 的一部分,这样更有效。
在每个阶段起始处(或者在阶段中的特定位置),只需调用 `echoBanner`:
```
echoBanner("MY STAGE", ["DOING SOMETHING 1", "DOING SOMETHING 2"])
```
你的 Jenkins 日志会展示如下:
```
===========================================
MY STAGE
DOING SOMETHING 1
DOING SOMETHING 2
===========================================
```
这个横幅很容易从日志中分辨出来。当正确使用它们时,它们还有助于界定管道流,并且可以很好的将日志分解开来进行阅读。
我已经在某些地方专业地使用这些代码一些时间了。在帮助管道日志更易读和流程更易理解方面,反馈是非常积极的。
上述的 `errorBanner` 方法以相同的方式工作,但是它会立即使脚本失效。这有助于突显失败的位置与原因。
### 最佳实践
1. 在你的 Groovy 代码中大量使用 `echo` Jenkins 步骤来通知用户你在做什么。这些也可以帮助记录你的代码。
2. 使用空的日志语句(Groovy 中空的 echo 步骤、`echo ''` 或 Shell 中的 `echo`)来分割输出,提高可读性。你可能在你的代码中为同样的目的使用空行。
3. 避免在脚本中使用 `set +x` 的陷阱,因为它隐藏了日志记录已执行的 Shell 语句。它并没有清理你的日志,而是使你的管道成为一个黑盒子,隐藏了管道正在做的行为以及出现的任何错误。确保管道功能尽可能透明。
4. 如果你的管道创建了<ruby> 中间工件 <rt> Intermediate Artifacts </rt></ruby>,开发人员和 DevOps 人员可以使用这些工件来帮助调试问题,那么也要记录它的内容。是的,它会加长日志,但这只是文本。在某些时候,这会是有用的信息,而(利用得当的)日志不就是关于发生了什么和为什么发生的大量信息吗?
### Kubernetes 机密信息:无法完全透明的地方
有些事情你不希望出现在日志里暴露出来。如果你在使用 Kubernetes 并引用保存在 Kubernetes <ruby> 机密信息 <rt> Secrets </rt></ruby>中的数据,那么你绝对不希望在日志中公开该数据,因为这些数据只是被混淆了,而没有被加密。
假如你想获取一些保存在机密信息中的数据,然后将其注入模板化 JSON 文件中。(机密信息和 JSON 模板的完整内容与此例无关。)按照最佳实践,你希望保持透明并记录你的操作,但你不想公开机密信息数据。
将脚本模式从调试(`set -x`)更改为命令记录(`set -v`)。在脚本敏感部分的结尾,将 Shell 重置为调试模式:
```
sh """
# change script mode from debugging to command logging
set +x -v
# capture data from secret in shell variable
MY_SECRET=\$(kubectl get secret my-secret --no-headers -o 'custom-column=:.data.my-secret-data')
# replace template placeholder inline
sed s/%TEMPLATE_PARAM%/${MY_SECRET_DATA}/ my-template-file.json
# do something with modified template-file.json...
# reset the shell to debugging mode
set -x +v
"""
```
这将输出此行到日志:
```
sed s/%TEMPLATE_PARAM%/${MY_SECRET_DATA}/ my-template-file.json
```
与 Shell 调试模式中不同,这不会具现化 Shell 变量 `MY_SECRET_DATA`。显然,如果管道中在这一点出现问题,而你试图找出问题出在哪里,那么这不如调试模式有用。但这是在保持管道执行对开发人员和 DevOps 透明的同时,也保持你的秘密的最佳平衡。
---
via: <https://opensource.com/article/21/5/jenkins-logs>
作者:[Evan "Hippy" Slatis](https://opensource.com/users/hippyod) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Jenkins is a free and open source automation server for building, testing, and deploying code. It's the backbone of continuous integration and continuous delivery (CI/CD) and can save developers hours each day and protect them from having failed code go live. When code does fail, or when a developer needs to see the output of tests, [Jenkins](https://www.jenkins.io/) provides log files for review.
The default Jenkins pipeline logs can be difficult to read. This quick summary of Jenkins logging basics offers some tips (and code) on how to make them more readable.
## What you get
Jenkins pipelines are split into [stages](https://www.jenkins.io/doc/book/pipeline/syntax/#stage). Jenkins automatically logs the beginning of each stage, like this:
```
[Pipeline] // stage
[Pipeline] stage (hide)
[Pipeline] { (Apply all openshift resources)
[Pipeline] dir
```
The text is displayed without much contrast, and important things (like the beginning of a stage) aren't highlighted. In a pipeline log several hundred lines long, finding where one stage starts and another ends, especially if you're casually browsing the logs looking for a particular stage, can be daunting.
Jenkins pipelines are written as a mix of [Groovy](https://opensource.com/article/20/12/groovy) and shell scripting. In the Groovy code, logging is sparse; many times, it consists of grayed-out text in the command without details. In the shell scripts, debugging mode (`set -x`
) is turned on, so every shell command is fully realized (variables are dereferenced and values printed) and logged in detail, as is the output.
It can be tedious to read through the logs to get relevant information, given that there can be so much. Since the Groovy logs that proceed and follow a shell script in a pipeline aren't very expressive, many times they lack context:
```
[Pipeline] dir
Running in /home/jenkins/agent/workspace/devop-master/devops-server-pipeline/my-repo-dir/src
[Pipeline] { (hide)
[Pipeline] findFiles
[Pipeline] findFiles
[Pipeline] readYaml
[Pipeline] }
```
I can see what directory I am working in, and I know I was searching for file(s) and reading a YAML file using Jenkins' steps. But what was I looking for, and what did I find and read?
## What can be done?
I'm glad you asked because there are a few simple practices and some small snippets of code that can help. First, the code:
```
def echoBanner(def ... msgs) {
echo createBanner(msgs)
}
def errorBanner(def ... msgs) {
error(createBanner(msgs))
}
def createBanner(def ... msgs) {
return """
===========================================
${msgFlatten(null, msgs).join("\n ")}
===========================================
"""
}
// flatten function hack included in case Jenkins security
// is set to preclude calling Groovy flatten() static method
// NOTE: works well on all nested collections except a Map
def msgFlatten(def list, def msgs) {
list = list ?: []
if (!(msgs instanceof String) && !(msgs instanceof GString)) {
msgs.each { msg ->
list = msgFlatten(list, msg)
}
}
else {
list += msgs
}
return list
}
```
Add this code to the end of each pipeline or, to be more efficient, [load a Groovy file](https://www.jenkins.io/doc/pipeline/steps/workflow-cps/#load-evaluate-a-groovy-source-file-into-the-pipeline-script) or make it part of a [Jenkins shared library](https://www.jenkins.io/doc/book/pipeline/shared-libraries/).
At the start of each stage (or at particular points within a stage), simply call `echoBanner`
:
`echoBanner("MY STAGE", ["DOING SOMETHING 1", "DOING SOMETHING 2"])`
Your logs in Jenkins will display the following:
```
===========================================
MY STAGE
DOING SOMETHING 1
DOING SOMETHING 2
===========================================
```
The banners are very easy to pick out in the logs. They also help define the pipeline flow when used properly, and they break the logs up nicely for reading.
I have used this for a while now professionally in a few places. The feedback has been very positive regarding helping make pipeline logs more readable and the flow more understandable.
The `errorBanner`
method above works the same way, but it fails the script immediately. This helps highlight where and what caused the failure.
## Best practices
- Use
`echo`
Jenkins steps liberally throughout your Groovy code to inform the user what you're doing. These can also help with documenting your code. - Use empty log statements (an empty echo step in Groovy,
`echo ''`
, or just`echo`
in shell) to break up the output for easier readability. You probably use empty lines in your code for the same purpose. - Avoid the trap of using
`set +x`
in your scripts, which hides logging executed shell statements. It doesn't so much clean up your logs as it makes your pipelines a black box that hides what your pipeline is doing and any errors that appear. Make sure your pipelines' functionality is as transparent as possible. - If your pipeline creates intermediate artifacts that developers and/or DevOps personnel could use to help debug issues, then log their contents, too. Yes, it makes the logs longer, but it's only text. It will be useful information at some point, and what else is a log (if utilized properly) than a wealth of information about what happened and why?
## Kubernetes Secrets: Where full transparency won't work
There are some things that you *don't* want to end up in your logs and be exposed. If you're using Kubernetes and referencing data held in a Kubernetes Secret, then you definitely don't want that data exposed in a log because the data is only obfuscated and not encrypted.
Imagine you want to take some data held in a Secret and inject it into a templated JSON file. (The full contents of the Secret and the JSON template are irrelevant for this example.) You want to be transparent and log what you're doing since that's best practice, but you don't want to expose your Secret data.
Change your script's mode from debugging (`set -x`
) to command logging (`set -v`
). At the end of the sensitive portion of the script, reset the shell to debugging mode:
```
sh """
# change script mode from debugging to command logging
set +x -v
# capture data from secret in shell variable
MY_SECRET=\$(kubectl get secret my-secret --no-headers -o 'custom-column=:.data.my-secret-data')
# replace template placeholder inline
sed s/%TEMPLATE_PARAM%/${MY_SECRET_DATA}/ my-template-file.json
# do something with modified template-file.json...
# reset the shell to debugging mode
set -x +v
"""
```
This will output this line to the logs:
`sed s/%TEMPLATE_PARAM%/${MY_SECRET_DATA}/ my-template-file.json`
This doesn't realize the shell variable `MY_SECRET_DATA`
, unlike in shell debug mode. Obviously, this isn't as helpful as debug mode if a problem occurs at this point in the pipeline and you're trying to figure out what went wrong. But it's the best balance between keeping your pipeline execution transparent for both developers and DevOps while also keeping your Secrets hidden.
## Comments are closed. |
13,393 | 用 OpenNIC 访问另一个互联网 | https://opensource.com/article/21/4/opennic-internet | 2021-05-15T18:16:33 | [
"OpenNIC",
"DNS"
] | https://linux.cn/article-13393-1.html |
>
> 在超级信息高速公路上绕行。
>
>
>

用传奇的 DNS 黑客 Dan Kaminsky 的话说,“事实证明,互联网对全球社会而言意义重大”。为了使互联网发挥作用,计算机必须能够在最复杂的网络万维网(WWW)中找到彼此。这是几十年前给政府工作人员和学术界 IT 人员提出的问题,而今天我们使用的正是他们的解决方案。然而,他们实际上并不是在寻求建立 <ruby> 互联网 <rt> the Internet </rt></ruby>,他们是在为 <ruby> 互联网络</ruby>(实际上是 <ruby> 级联网 <rt> catenets </rt></ruby>,即“<ruby> 级联的网络 <rt> concatenated networks </rt></ruby>”,但这个术语最终不再流行)定义规范,它是一个<ruby> 互连的网络 <rt> interconnected networks </rt></ruby>的通用术语。
根据这些规范,网络使用数字组合,作为每台在线计算机的一种家地址,并为每个网站分配一个人性化但高度结构化的“主机名”(如 `example.com`)。由于用户主要是通过网站 *名称* 与互联网互动,可以说互联网的运作只是因为我们都同意一个标准化的命名方案。如果有足够多的人决定使用不同的命名方案,互联网的工作方式 *可能* 会有所不同。一群用户可以形成一个平行的互联网,它使用相同的物理基础设施(电缆、卫星和其他传输方式,将数据从一个地方传送到另一个地方),但使用不同的方法将主机名与编号地址联系起来。
事实上,这已经存在了,这篇文章展示了你如何访问它。
### 了解名称服务器
术语“<ruby> 互联网 <rt> internet </rt></ruby>”实际上是 <ruby> 互联 <rt> interconnected </rt></ruby> 和 <ruby> 网络 <rt> networks </rt></ruby> 这两个术语的组合,因为这正是它的本质。就像一个城市里的邻里、一个国家里的城市、或一个大陆里的国家,或一个星球里的大陆一样,互联网通过将数据从一个家庭或办公室网络传输到数据中心和服务器房或其他家庭或办公室网络而跨越了全球。这是一项艰巨的任务,但它并非没有先例。毕竟,电话公司很久以前就把世界连接起来了,在那之前,电报和邮政服务也是这样做的。
在电话或邮件系统中,有一份名单,无论是正式的还是非正式的,都将人名与实际地址联系起来。它过去以电话簿的形式传递到家里,该电话簿是社区内每个电话所有者的目录。邮局的运作方式不同:他们通常依靠寄信人知道预定收信人的姓名和地址,但邮政编码和城市名称被用来把信送到正确的邮局。无论哪种方式,都需要有一个标准的组织方案。
对于计算机来说,[IP 协议](https://tools.ietf.org/html/rfc791) 描述了必须如何设置互联网上的地址格式。域名服务器 [(DNS) 协议](https://tools.ietf.org/html/rfc1035) 描述了如何将人性化名称分配给 IP 以及从 IP 解析。无论你使用的是 IPv4 还是 IPv6,其想法都是一样的:当一个节点(可能是一台计算机或通往另一个网络的网关)加入一个网络时,它被分配一个 IP 地址。
如果你愿意,你可以在 [ICANN](https://www.icann.org/resources/pages/register-domain-name-2017-06-20-en)(一个帮助协调互联网上的网站名称的非营利组织)注册一个域名,并将该名称指向该 IP。没有要求你“拥有”该 IP 地址。任何人都可以将任何域名指向任何 IP 地址。唯一的限制是,一次只能有一个人拥有一个特定的域名,而且域名必须遵循公认的 DNS 命名方案。
域名及其相关 IP 地址的记录被输入到 DNS 中。当你在浏览器中导航到一个网站时,它会迅速查询 DNS 网络,以找到与你所输入(或从搜索引擎点击)的任何 URL 相关的 IP 地址。
### 一个不同的 DNS
为了避免在谁拥有哪个域名的问题上发生争论,大多数域名注册商对域名注册收取一定的费用。该费用通常是象征性的,有时甚至是 0 美元(例如,`freenom.com` 提供免费的 `.tk`、`.ml`、`.gq` 和 `.cf` 域名,先到先得)。
在很长一段时间里,只有几个“顶级”域名,包括 `.org`、`.edu` 和 `.com`。现在有很多,包括 `.club`、`.biz`、`.name`、`.international` 等等。本质上它们就是字母组合,但是,有很多潜在的顶级域名是无效的,如 `.null`。如果你试图导航到一个以 `.null` 结尾的网站,那么你不会成功。它不能注册,也不是域名服务器的有效条目,而且它根本就不存在。
[OpenNIC项目](http://opennic.org) 已经建立了一个备用的 DNS 网络,将域名解析为 IP 地址,但它包括目前互联网不使用的名字。可用的顶级域名包括:
* .geek
* .indy
* .bbs
* .gopher
* .o
* .libre
* .oss
* .dyn
* .null
你可以在这些(以及更多的)顶级域名中注册一个域名,并在 OpenNIC 的 DNS 系统上注册,使它们映射到你选择的 IP 地址。
换句话说,一个网站可能存在于 OpenNIC 网络中,但对于不使用 OpenNIC 名称服务器的人来说,仍然无法访问。这绝不是一种安全措施,甚至不是一种混淆手段。这只是一种有意识的选择,在 *超级信息高速公路上绕行* 。
### 如何使用 OpenNIC 的 DNS 服务器
要访问 OpenNIC 网站,你必须配置你的计算机使用 OpenNIC 的 DNS 服务器。幸运的是,这并不是一个非此即彼的选择。通过使用一个 OpenNIC 的 DNS 服务器,你可以同时访问 OpenNIC 和标准网络。
要配置你的 Linux 电脑使用 OpenNIC 的 DNS 服务器,你可以使用 [nmcli](https://opensource.com/article/20/7/nmcli) 命令,这是 Network Manager 的一个终端界面。在开始配置之前,请访问 [opennic.org](http://opennic.org),寻找离你最近的 OpenNIC DNS 服务器。与标准 DNS 和 [边缘计算](https://opensource.com/article/17/9/what-edge-computing) 一样,服务器在地理上离你越近,你的浏览器查询时的延迟就越少。
下面是如何使用 OpenNIC:
1、首先,获得一个连接列表:
```
$ sudo nmcli connection
NAME TYPE DEVICE
Wired connection 1 802-3-ethernet eth0
MyPersonalWifi 802-11-wireless wlan0
ovpn-phx2-tcp vpn --
```
你的连接肯定与这个例子不同,但要关注第一栏。这提供了你的连接的可读名称。在这个例子中,我将配置我的以太网连接,但这个过程对无线连接是一样的。
2、现在你知道了需要修改的连接的名称,使用 `nmcli` 更新其 `ipv4.dns` 属性:
```
$ sudo nmcli con modify "Wired connection 1" ipv4.dns "134.195.4.2"
```
在这个例子中,`134.195.4.2` 是离我最近的服务器。
3、防止 Network Manager 使用你路由器设置的内容自动更新 `/etc/resolv.conf`:
```
$ sudo nmcli con modify "Wired connection 1" ipv4.ignore-auto-dns yes
```
4、将你的网络连接关闭,然后再次启动,以实例化新的设置:
```
$ sudo nmcli con down "Wired connection 1"
$ sudo nmcli con up "Wired connection 1"
```
完成了。你现在正在使用 OpenNIC 的 DNS 服务器。
#### 路由器上的 DNS
你可以通过对你的路由器做这样的修改,将你的整个网络设置为使用 OpenNIC。你将不必配置你的计算机的连接,因为路由器将自动提供正确的 DNS 服务器。我无法演示这个,因为路由器的接口因制造商而异。此外,一些互联网服务提供商 (ISP) 不允许你修改名称服务器的设置,所以这并不总是一种选择。
### 测试 OpenNIC
为了探索你所解锁的“其他”互联网,尝试在你的浏览器中导航到 `grep.geek`。如果你输入 `http://grep.geek`,那么你的浏览器就会带你到 OpenNIC 的搜索引擎。如果你只输入 `grep.geek`,那么你的浏览器会干扰你,把你带到你的默认搜索引擎(如 [Searx](http://searx.me) 或 [YaCy](https://opensource.com/article/20/2/open-source-search-engine)),并在窗口的顶部提供一个导航到你首先请求的页面。

不管怎么说,你最终还是来到了 `grep.geek`,现在可以在网上搜索 OpenNIC 的版本了。
### 广阔天地
互联网旨在成为一个探索、发现和平等访问的地方。OpenNIC 利用现有的基础设施和技术帮助确保这些东西。它是一个可选择的互联网替代方案。如果这些想法吸引了你,那就试一试吧!
---
via: <https://opensource.com/article/21/4/opennic-internet>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In the words of Dan Kaminsky, the legendary DNS hacker, "the Internet's proven to be a pretty big deal for global society." For the Internet to work, computers must be able to find one another on the most complex network of all: the World Wide Web. This was the problem posed to government workers and academic IT staff a few decades ago, and it's their solutions that we use today. They weren't, however, actually seeking to build _the Internet_, they were defining specifications for _internets_ (actually for _catenets_, or "concatenated networks", but the term that eventually fell out of vogue), a generic term for _interconnected networks_.
According to these specifications, a network uses a combination of numbers that serve as a sort of home address for each online computer and assigns a human-friendly but highly structured "hostname" (such as `example.com`
) to each website. Because users primarily interact with the internet through website *names*, it can be said that the internet works only because we've all agreed to a standardized naming scheme. The Internet *could* work differently, should enough people decide to use a different naming scheme. A group of users could form a parallel internet, one that exists using the same physical infrastructure (the cables and satellites and other modes of transport that get data from one place to another) but uses a different means of correlating hostnames with numbered addresses.
In fact, this already exists, and this article shows how you can access it.
## Understand name servers
The term "internet" is actually a portmanteau of the terms *interconnected* and *networks* because that's exactly what it is. Like neighborhoods in a city, or cities in a country, or countries on a continent, or continents on a planet, the internet spans the globe by transmitting data from one home or office network to data centers and server rooms or other home or office networks. It's a gargantuan task—but it's not without precedent. After all, phone companies long ago connected the world, and before that, telegraph and postal services did the same.
In a phone or mail system, there's a list, whether it's formal or informal, that relates human names to physical addresses. This used to be delivered to houses in the form of telephone books, a directory of every phone owner in that phone book's community. Post offices operate differently: they usually rely on the person sending the letter to know the name and address of the intended recipient, but postcodes and city names are used to route the letter to the correct post office. Either way, the need for a standard organizational scheme is necessary.
For computers, the [IP protocol](https://tools.ietf.org/html/rfc791) describes how addresses on the internet must be formatted. The domain name server [(DNS) protocol](https://tools.ietf.org/html/rfc1035) describes how human-friendly names may be assigned to and resolved from IP addresses. Whether you're using IPv4 or IPv6, the idea is the same: When a node (which could be a computer or a gateway leading to another network) joins a network, it is assigned an IP address.
If you wish, you may register a domain name with [ICANN](https://www.icann.org/resources/pages/register-domain-name-2017-06-20-en) (a non-profit organization that helps coordinate website names on the internet) and register the name as a pointer to an IP address. There is no requirement that you "own" the IP address. Anyone can point any domain name to any IP address. The only restrictions are that only one person can own a specific domain name at a time, and the domain name must follow the recognized DNS naming scheme.
Records of a domain name and its associated IP address are entered into a DNS. When you navigate to a website in your browser, it quickly consults the DNS network to find what IP address is associated with whatever URL you've entered (or clicked on from a search engine).
## A different DNS
To avoid arguments over who owns which domain name, most domain name registrars charge a fee for domain registration. The fee is usually nominal, and sometimes it's even $0 (for instance, `freenom.com`
offers gratis `.tk`
, `.ml`
, `.gq`
, and `.cf`
domains on a first-come, first-served basis).
For a very long time, there were only a few "top-level" domains, including `.org`
, `.edu`
, and `.com`
. Now there are a lot more, including `.club`
, `.biz`
, `.name`
, `.international`
, and so on. Letter combinations being what they are, however, there are lots of potential top-level domains that aren't valid, such as `.null`
. If you try to navigate to a website ending in `.null`
, then you won't get very far. It's not available for registration, it's not a valid entry for a domain name server, and it just doesn't exist.
The [OpenNIC Project](http://opennic.org) has established an alternate DNS network to resolve domain names to IP addresses, but it includes names not currently used by the internet. Available top-level domains include:
- .geek
- .indy
- .bbs
- .gopher
- .o
- .libre
- .oss
- .dyn
- .null
You can register a domain within these (and more) top-level domains and register them on the OpenNIC DNS system so that they map to an IP address of your choice.
In other words, a website may exist in the OpenNIC network but remain inaccessible to anyone not using OpenNIC name servers. This isn't by any means a security measure or even a means of obfuscation; it's just a conscious choice to take a detour on the *super information highway*.
## How to use an OpenNIC DNS server
To access OpenNIC sites, you must configure your computer to use OpenNIC DNS servers. Luckily, this isn't a binary choice. By using an OpenNIC DNS server, you get access to both OpenNIC and the standard web.
To configure your Linux computer to use an OpenNIC DNS server, you can use the [nmcli](https://opensource.com/article/20/7/nmcli) command, a terminal interface to Network Manager. Before starting the configuration, visit [opennic.org](http://opennic.org) and look for your nearest OpenNIC DNS server. As with standard DNS and [edge computing](https://opensource.com/article/17/9/what-edge-computing), the closer the server is to you geographically, the less delay you'll experience when your browser queries it.
Here's how to use OpenNIC:
-
First, get a list of connections:
`$ sudo nmcli connection NAME TYPE DEVICE Wired connection 1 802-3-ethernet eth0 MyPersonalWifi 802-11-wireless wlan0 ovpn-phx2-tcp vpn --`
Your connections are sure to differ from this example, but focus on the first column. This provides the human-readable name of your connections. In this example, I'll configure my Ethernet connection, but the process is the same for a wireless connection.
-
Now that you know the name of the connection you need to modify, use
`nmcli`
to update its`ipv4.dns`
property:`$ sudo nmcli con modify \ "Wired connection 1" \ ipv4.dns "134.195.4.2"`
In this example,
`134.195.4.2`
is my closest server. -
Prevent Network Manager from auto-updating
`/etc/resolv.conf`
with what your router is set to use:`$ sudo nmcli con modify \ "Wired connection 1" \ ipv4.ignore-auto-dns yes`
-
Bring your network connection down and then up again to instantiate the new settings:
`$ sudo nmcli con down \ "Wired connection 1" $ sudo nmcli con up \ "Wired connection 1"`
That's it. You're now using the OpenNIC DNS servers.
### DNS at your router
You can set your entire network to use OpenNIC by making this change to your router. You won't have to configure your computer's connection because the router will provide the correct DNS server automatically. I can't demonstrate this because router interfaces differ depending on the manufacturer. Furthermore, some internet service providers (ISP) don't allow you to modify your name server settings, so this isn't always an option.
## Test OpenNIC
To explore the "other" internet you've unlocked, try navigating to `grep.geek`
in your browser. If you enter `http://grep.geek`
, then your browser takes you to a search engine for OpenNIC. If you enter just `grep.geek`
, then your browser interferes, taking you to your default search engine (such as [Searx](http://searx.me) or [YaCy](https://opensource.com/article/20/2/open-source-search-engine)), with an offer at the top of the window to navigate to the page you requested in the first place.

(Klaatu, CC BY-SA 4.0)
Either way, you end up at `grep.geek`
and can now search the OpenNIC version of the web.
## Great wide open
The internet is meant to be a place of exploration, discovery, and equal access. OpenNIC helps ensure all of these things using existing infrastructure and technology. It's an opt-in internet alternative. If these ideas appeal to you, give it a try!
## Comments are closed. |
13,395 | 通过网络将你的扫描结果发送到 Linux 机器上 | https://opensource.com/article/21/4/linux-scan-samba | 2021-05-16T11:17:39 | [
"扫描仪",
"Samba"
] | https://linux.cn/article-13395-1.html |
>
> 设置一个 Samba 共享,使扫描仪可以容易地被网络上的一台 Linux 计算机访问。
>
>
>

自由软件运动 [因为一台设计不良的打印机](https://opensource.com/article/18/2/pivotal-moments-history-open-source) 而开始。几十年后,打印机和扫描仪制造商继续重新发明轮子,无视既定的通用协议。因此,每隔一段时间,你就会偶然发现一台打印机或扫描仪似乎无法与你的操作系统配合使用。
最近,我在一台佳能三合一扫描仪(佳能 Maxify MB2720)上遇到了这种情况。我用开源方案解决这个扫描仪的问题。具体来说,我设置了一个 Samba 共享,使扫描仪在我的网络上可用。
[Samba 项目](http://samba.org/) 是一个用于 Linux/Unix 与 Windows 互操作的套件。尽管它是大多数用户从未与之交互的低级代码,但该软件使得在你的本地网络上共享文件变得很容易,而不管使用的是什么平台。
我使用的是 Fedora,所以这些说明应该适用于任何基于 RPM 的 Linux 发行版。对于其他发行版,可能需要做一些小的修改。下面是我的做法。
### 获取佳能工具
从佳能的网站上下载所需的用于 Windows 的 “<ruby> 佳能快速实用工具箱 <rt> Canon Quick Utility Toolbox </rt></ruby>”。该软件是必需的,因为它是配置打印机目标文件夹位置和凭证的唯一方法。完成后,你就不需要再使用该工具了,除非你想做出改变。
在配置打印机之前,你必须在你的 Linux 电脑或服务器上设置一个 Samba 共享。用以下命令安装 Samba:
```
$ sudo dnf -y install samba
```
创建 `/etc/smb.conf` 文件,内容如下:
```
[global]
workgroup = WORKGROUP
netbios name = MYSERVER
security = user
#CORE needed for CANON PRINTER SCAN FOLDER
min protocol = CORE
#NTML AUTHV1 needed for CANON PRINTER SCAN FOLDER
ntlm auth = yes
passdb backend = tdbsam
printing = cups
printcap name = cups
load printers = no
cups options = raw
hosts allow = 127. 192.168.33.
max smbd processes = 1000
[homes]
comment = Home Directories
valid users = %S, %D%w%S
browseable = No
writable = yes
read only = No
inherit acls = Yes
[SCANS]
comment = MB2720 SCANS
path = /mnt/SCANS
public = yes
writable = yes
browseable = yes
printable = no
force user = tux
create mask = 770
```
在接近结尾的 `force user` 这行中,将用户名从 `tux` 改为你自己的用户名。
不幸的是,佳能打印机不能与高于 CORE 或 NTML v2 认证的服务器信息块([SMB](https://en.wikipedia.org/wiki/Server_Message_Block))协议一起工作。由于这个原因,Samba 共享必须配置最古老的 SMB 协议和 NTML 认证版本。这无论如何都不理想,而且有安全问题,所以我创建了一个单独的 Samba 服务器,专门用于扫描仪。我的另一台共享所有家庭网络文件的 Samba 服务器仍然使用 SMB 3 和 NTML v2 认证版本。
启动 Samba 服务端服务,并启用它:
```
$ sudo systemctl start smb
$ sudo systemctl enable smb
```
### 创建一个 Samba 用户
创建你的 Samba 用户并为其设置密码:
```
$ sudo smbpasswd -a tux
```
在提示符下输入你的密码。
假设你想在 Linux 系统上挂载你的 Samba 扫描仪,你需要做几个步骤。
创建一个 Samba 客户端凭证文件。我的看起来像这样:
```
$ sudo cat /root/smb-credentials.txt
username=tux
password=mySTRONGpassword
```
改变权限,使其不能被其他人阅读:
```
$ sudo chmod 640 /root/smb-credentials.txt
```
创建一个挂载点并将其添加到 `/etc/fstab` 中:
```
$ sudo mkdir /mnt/MB2720-SCANS
```
在你的 `/etc/fstab` 中添加以下这行:
```
//192.168.33.50/SCANS /mnt/MB2720-SCANS cifs vers=3.0,credentials=/root/smb-credentials.txt,gid=1000,uid=1000,_netdev 0 0
```
这将使用 [CIFS](https://searchstorage.techtarget.com/definition/Common-Internet-File-System-CIFS) 将 Samba 共享扫描挂载到新的挂载点,强制采用 SMBv3,并使用存储在 `/root/smb-credetials.txt` 中的用户名和密码。它还传递用户的组标识符(GID)和用户标识符(UID),让你拥有 Linux 挂载的全部所有权。`_netdev` 选项是必需的,以便在网络正常后(例如重启后)挂载该挂载点,因为该挂载点需要网络来访问。
### 配置佳能软件
现在你已经创建了 Samba 共享,在服务器上进行了配置,并将该共享配置到 Linux 客户端上,你需要启动“佳能快速实用工具箱”来配置打印机。因为佳能没有为 Linux 发布工具箱,所以这一步需要 Windows。你可以尝试 [在 WINE 上运行它](https://opensource.com/article/21/2/linux-wine),但如果失败了,你就必须向别人借一台 Windows 电脑,或者在 [GNOME Boxes](https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization) 或 [VirtualBox](https://www.virtualbox.org/) 中运行一个 [Windows 开发者虚拟机](https://developer.microsoft.com/en-us/windows/downloads/virtual-machines/)。
打开打印机,然后启动佳能快速实用工具箱。它应该能找到你的打印机。如果不能看到你的打印机,你必须先将打印机配置为 LAN 或无线网络。
在工具箱中,点击“<ruby> 目标文件夹设置 <rt> Destination Folder Settings </rt></ruby>”。

输入打印机管理密码。我的默认密码是 “canon”。
单击“<ruby> 添加 <rt> Add </rt></ruby>”按钮。

在表格中填写“<ruby> 显示名 <rt> Displayed Name </rt></ruby>”、“<ruby> 目标位置共享文件夹名称 <rt> Shared Folder Name in Destination </rt></ruby>”,以及你的 Samba “<ruby> 域名/用户名 <rt> Domain Name/User Name </rt></ruby>”和“<ruby> 密码 <rt> Password </rt></ruby>”。
我把 “<ruby> PIN 码 <rt> PIN Code </rt></ruby>”留空,但如果你想要求每次从打印机扫描时都要输入 PIN 码,你可以设置一个。这在办公室里很有用,每个用户都有自己的 Samba 共享和 PIN 码来保护他们的扫描。
点击“<ruby> 连接测试 <rt> Connection Test </rt></ruby>”来验证表格数据。
点击 “OK” 按钮。
点击 “<ruby> 注册到打印机 <rt> Register to Printer </rt></ruby>”,将你的配置保存到打印机上。

一切都设置好了。点击“<ruby> 退出 <rt> Exit </rt></ruby>”。你现在已经完成了 Windows 的操作,可能还有工具箱,除非你需要改变什么。
### 开始扫描
你现在可以从打印机扫描,并从其 LCD 菜单中选择你的“目标文件夹”。扫描结果将直接保存到 Samba 共享中,你可以从你的 Linux 电脑上访问该共享。
为方便起见,用以下命令在你的 Linux 桌面或家目录上创建一个符号链接:
```
$ sudo ln -sd /mnt/MB2720-SCANS /home/tux/Desktop/MB2720-SCANS
```
这就是全部内容了!
---
via: <https://opensource.com/article/21/4/linux-scan-samba>
作者:[Marc Skinner](https://opensource.com/users/marc-skinner) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The free software movement famously got started [because of a poorly designed printer](https://opensource.com/article/18/2/pivotal-moments-history-open-source). Decades later, printer and scanner manufacturers continue to reinvent the wheel, ignoring established and universal protocols. As a result, every now and again, you'll stumble onto a printer or scanner that just doesn't seem to work with your operating system.
This happened to me recently with a Canon 3-in-1 scanner (the Canon Maxify MB2720). I was able to solve the scanner's problem with open source. Specifically, I set up a Samba share to make the scanner available on my network.
The [Samba project](http://samba.org/) is a Windows interoperability suite of programs for Linux and Unix. Although it's mostly low-level code that many users never knowingly interact with, the software makes it easy to share files over your local network, regardless of what platforms are used.
I'm using Fedora, so these instructions should work for any RPM-based Linux distribution. Minor modifications may be necessary for other distributions. Here's how I did it.
## Get the Canon tools
Download the required Windows Canon Quick Utility Toolbox software from Canon's website. The software is required because it is the only way to configure the printer's destination folder location and credentials. Once this is done, you do not need to use the tool unless you want to make a change.
Before configuring the printer, you must set up a Samba share on your Linux computer or server. Install Samba with the following command:
`$ sudo dnf -y install samba`
Create `/etc/smb.conf`
file with the following content:
```
[global]
workgroup = WORKGROUP
netbios name = MYSERVER
security = user
#CORE needed for CANON PRINTER SCAN FOLDER
min protocol = CORE
#NTML AUTHV1 needed for CANON PRINTER SCAN FOLDER
ntlm auth = yes
passdb backend = tdbsam
printing = cups
printcap name = cups
load printers = no
cups options = raw
hosts allow = 127. 192.168.33.
max smbd processes = 1000
[homes]
comment = Home Directories
valid users = %S, %D%w%S
browseable = No
writable = yes
read only = No
inherit acls = Yes
[SCANS]
comment = MB2720 SCANS
path = /mnt/SCANS
public = yes
writable = yes
browseable = yes
printable = no
force user = tux
create mask = 770
```
In the `force user`
line near the end, change the username from `tux`
to your own username.
Unfortunately, the Canon printer won't work with Server Message Block ([SMB](https://en.wikipedia.org/wiki/Server_Message_Block)) protocols higher than CORE or NTML authentication v2. For this reason, the Samba share must be configured with the oldest SMB protocol and NTML authentication versions. This is not ideal by any means and has security implications, so I created a separate Samba server dedicated to the scanner use case. My other Samba server, which shares all home networked files, still uses SMB protocol 3 and NTML authentication v2.
Start the Samba server service and enable it for restart:
```
$ sudo systemctl start smb
$ sudo systemctl enable smb
```
## Create a Samba user
Create your Samba user and a password for it:
`$ sudo smbpasswd -a tux`
Enter your password at the prompt.
Assuming you want to mount your Samba scans on a Linux system, you need to do a few steps.
Create a Samba client credentials file. Mine looks like this:
```
$ sudo cat /root/smb-credentials.txt
username=tux
password=mySTRONGpassword
```
Change the permissions so that it isn't world-readable:
`$ sudo chmod 640 /root/smb-credentials.txt`
Create a mount point and add it to `/etc/fstab`
:
`$ sudo mkdir /mnt/MB2720-SCANS`
Add the following line into your `/etc/fstab`
:
`//192.168.33.50/SCANS /mnt/MB2720-SCANS cifs vers=3.0,credentials=/root/smb-credentials.txt,gid=1000,uid=1000,_netdev 0 0`
This mounts the Samba share scans to the new mount point using [CIFS](https://searchstorage.techtarget.com/definition/Common-Internet-File-System-CIFS), forcing SMBv3, and using the username and password stored in `/root/smb-credetials.txt`
. It also passes the user's group identifier (GID) and the user identifier (UID), giving you full ownership of the Linux mount. The `_netdev`
option is required so that the mount point is mounted after networking is fully functional (after a reboot, for instance) because this mount requires networking to be accessed.
## Configure the Canon software
Now that you have created the Samba share, configured it on the server, and configured the share to be mounted on your Linux client, you need to launch the Canon Quick Utility Toolbox to configure the printer. Because Canon doesn't release this toolbox for Linux, this step requires Windows. You can try [running it on WINE](https://opensource.com/article/21/2/linux-wine), but should that fail, you'll have to either borrow a Windows computer from someone or run a [Windows developer virtual machine](https://developer.microsoft.com/en-us/windows/downloads/virtual-machines/) in [GNOME Boxes](https://opensource.com/article/19/5/getting-started-gnome-boxes-virtualization) or [VirtualBox](https://www.virtualbox.org/).
Power on the printer, and then start the Canon Quick Utility Toolbox. It should find your printer. If it can't see your printer, you must configure the printer for either LAN or wireless networking first.
In the toolbox, click on **Destination Folder Settings**.
(Marc Skinner, CC BY-SA 4.0)
Enter the printer administration password—my default password was **canon**.
Click the **Add** button.
Fill out the form with a Displayed Name, your Samba share location, and your Samba username and password.
I left the PIN Code blank, but if you want to require a PIN to be entered each time you scan from the printer, you can set one. This would be useful in an office where each user has their own Samba share and PIN to protect their scans.
Click **Connection Test** to validate the form data.
Click the **OK** button.
Click **Register to Printer** to save your configuration back to the printer.
(Marc Skinner, CC BY-SA 4.0)
Everything is set up. Click **Exit**. You're done with Windows now, and probably the toolbox, unless you need to change something.
## Start scanning
You can now scan from the printer and select your Destination Folder from its LCD menu. Scans are saved directly to the Samba share, which you have access to from your Linux computer.
For convenience, create a symbolic link on your Linux desktop or home directory with the following command:
`$ sudo ln -sd /mnt/MB2720-SCANS /home/tux/Desktop/MB2720-SCANS`
That's all there is to it!
## Comments are closed. |
13,396 | 使用 Ansible 配置 Podman 容器 | https://fedoramagazine.org/using-ansible-to-configure-podman-containers/ | 2021-05-16T12:13:01 | [
"Ansible",
"Podman",
"容器"
] | https://linux.cn/article-13396-1.html | 
在复杂的 IT 基础设施中,有许多重复性任务。成功运行这些任务并不容易。运行失败大多数是人为错误引发。在 Ansible 帮助下,你可以通过远程主机来执行所有任务,这些远程主机按照<ruby> 行动手册 <rt> playbook </rt></ruby>执行,行动手册可以根据需要重复使用多次。在本文中,你将学习如何在 Fedora Linux 上安装、配置 Ansible,以及如何使用它来管理、配置 Podman 容器。
### Ansible
[Ansible](https://www.ansible.com/) 是一个由红帽赞助的开源基础设施自动化工具。它可以处理大型基础设施带来的所有问题,例如安装和更新软件包、备份、确保特定服务持续运行等等。你用 YAML 写的行动手册来做这些事。Ansible 行动手册可以反复使用,使系统管理员的工作不那么复杂。行动手册减少了重复任务,并且可以轻松修改。但是我们有很多像 Ansible 一样的自动化工具,为什么要用它呢?与其他一些配置管理工具不同,Ansible 是无代理的:你不必在受管节点上安装任何东西。
### Podman
[Podman](https://podman.io/) 是一个开源的容器引擎,用于开发、管理和运行容器镜像。但什么是容器呢?每当你创建任何新应用程序并将其部署在物理服务器、云服务器或虚拟机上时,你面临的最常见问题是可移植性和兼容性。这就是容器出现的原因。容器在操作系统级别上进行虚拟化,因此它们只包含所需的库和应用程序服务。容器的好处包括:
* 便携性
* 隔离性
* 扩展性
* 轻量级
* 快速启动
* 更小的磁盘和内存需求
简而言之:当你为任何应用程序构建容器镜像时,所有必需的依赖项都被打包到容器中。你现在可以在任何主机操作系统上运行该容器,没有任何可移植性和兼容性问题。
Podman 的关键亮点在于它没有守护程序,因此不需要 root 权限来运行容器。你可以借助 Dockerfile 构建容器镜像,或者从 Docker Hub、[fedoraproject.org](https://registry.fedoraproject.org/) 或 [Quay](https://www.projectquay.io/) 上拉取镜像。
### 为什么用 Ansible 配置 Podman?
Ansible 提供了一种轻松多次运行重复任务的方法。它还为云提供商(如 AWS、GCP 和 Azure)、容器管理工具(如 Docker 和 Podman)与数据库管理提供了大量模块。Ansible 还有一个社区([Ansible Galaxy](https://galaxy.ansible.com/)),在这里你可以找到大量 Ansible <ruby> 角色 <rt> Roles </rt></ruby>,它们由来自世界各地的贡献者创建。因为这些,Ansible 成为了 DevOps 工程师和系统管理员手中的好工具。
借助 DevOps,应用程序的开发步伐很快。开发的应用不局限于任意操作系统,这点至关重要。这就是 Podman 出现的地方。
### 安装 Ansible
首先,安装 Ansible:
```
$ sudo dnf install ansible -y
```
### 配置 Ansible
Ansible 需要在受管节点上运行 ssh,所以首先生成一个<ruby> 密钥对 <rt> Key Pair </rt></ruby>。
```
$ ssh-keygen
```
生成密钥后,将密钥复制到受管节点。
输入 `yes`,然后输入受管节点的密码。现在可以远程访问受管主机。
为了能够访问受管节点,你需要将所有主机名或 IP 地址存储在清单文件中。默认情况下,这是在 `~/etc/ansible/hosts`。
这是<ruby> 库存 <rt> inventory </rt></ruby>文件的样子。方括号用于将组分配给某些特定的节点。
```
[group1]
green.example.com
blue.example.com
[group2]
192.168.100.11
192.168.100.10
```
检查所有受管节点是否可以到达。
```
$ ansible all -m ping
```
你可以看到如下输出:
```
[mahesh@fedora new] $ ansible all -m ping
fedora.example.com I SUCCESS {
"ansibe_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
[mahesh@fedora new] $
```
现在创建你的第一个<ruby> 行动手册 <rt> playbook </rt></ruby>,它将在受管节点上安装 Podman。首先用 .yml 拓展名创建一个任意名称的文件。
```
$ vim name_of_playbook.yml
```
行动手册应该如下所示。第一个字段是行动手册的名称。主机字段(`hosts`)用于提及清单中提到的主机名或组名。`become: yes` 表示升级权限,以及任务(`tasks`)包含所要执行的任务,这里的名称(`name`)指定任务(`tasks`)名称,`yum` 是安装软件包的模块,下面在名称字段(`name`)指定软件包名称,在状态字段(`state`)指定安装或删除软件包。
```
---
- name: First playbook
hosts: fedora.example.com
become: yes
tasks:
- name: Installing podman.
yum:
name: podman
state: present
```
检查文件中是否有语法错误:
```
$ ansible-playbook filename --syntax-check
```
现在运行行动手册:
```
$ ansible-playbook filename
```
你可以看到如下输出:
```
[mahesh@fedora new] $ ansible-playbook podman_installation.yml
PLAY [First playbook] *************************************************************************************************
TASK [Gathering Facts] *************************************************************************************************
0k: [fedora.example.com]
TASK [Installing podman] ************************************************************************************************
changed: [fedora.example.com]
PLAY RECAP *************************************************************************************************
fedora.example.com : ok=2 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
[mahesh@fedora new] $
```
现在创建一个新的行动手册,从 Docker Hub 中拉取一个镜像。你将使用 `podman_image` 模块从 Docker Hub 中提取版本号为 2-alpine 的 httpd 镜像。
```
---
- name: Playbook for podman.
hosts: fedora.example.com
tasks:
- name: Pull httpd:2-alpine image from dockerhub.
podman_image:
name: docker.io/httpd
tag: 2-alpine
```
现在检查已拉取的镜像:
```
[mahesh@fedora new] $ podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/library/httpd 2-alpine fa848876521a 11 days ago 57 MB
[mahesh@fedora new] $
```
创建一个新的行动手册来运行 httpd 镜像。更多信息请查看 [podman\_container](https://docs.ansible.com/ansible/latest/collections/containers/podman/podman_container_module.html) 模块文档。
```
---
- name: Playbook for podman.
hosts: fedora.example.com
tasks:
- name: Running httpd image.
containers.podman.podman_container:
name: my-first-container
image: docker.io/httpd:2-alpine
state: started
```
检查容器运行状态。
```
[mahesh@fedora new] $ podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
45d966eOe207 docker.io/library/httpd:2-alpine httpd-foreground 13 seconds ago Up 13 seconds ago my-first-container
[mahesh@fedora new] $
```
现在停止已运行的容器,改变状态,由 `started` 变为 `absent`。
```
- name: Stopping httpd container.
containers.podman.podman_container:
name: my-first-container
image: docker.io/httpd:2-alpine
state: absent
```
当你执行 `podman ps` 命令时,你看不到任何运行的容器。
```
[mahesh@fedora new] $ podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[mahesh@fedora new] $
```
`podman_container` 可以做很多事情,例如重新创建容器、重新启动容器、检查容器是否正在运行等等。有关执行这些操作的信息,请参考 [文档](https://docs.ansible.com/ansible/latest/collections/containers/podman/podman_container_module.html)。
---
via: <https://fedoramagazine.org/using-ansible-to-configure-podman-containers/>
作者:[mahesh1b](https://fedoramagazine.org/author/mahesh1b/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DCOLIVERSUN](https://github.com/DCOLIVERSUN) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In complex IT infrastructure, there are many repetitive tasks. Running those tasks successfully is not easy. Human error always presents a chance of failure. With the help of Ansible, you can perform all of the tasks through a remote host executed with playbooks, and those playbooks can be reused as many times as you need. In this article you will learn how to install and configure Ansible on Fedora Linux, and how to use it to manage and configure Podman containers.
## Ansible
[Ansible](https://www.ansible.com/) is an open source infrastructure automation tool sponsored by Red Hat. It can deal with all the problems that come with large infrastructure, like installing & updating packages, taking backups, ensuring specific services are always running, and much more. You do this with a playbook which is written in YAML. Ansible playbooks can be used again and again, making the system administrator’s job less complex. Playbooks also eliminate repetitive tasks and can be easily modified. But we have many automation tools like Ansible, why use it? Unlike some other configuration management tools, Ansible is agentless: you don’t have to install anything on managed nodes. For more information about Ansible, see the [Ansible tag in Fedora Magazine](https://fedoramagazine.org/tag/ansible/).
## Podman
[Podman](https://podman.io/) is an open source container engine which is used for developing, managing and running container images. But what is a container? Every time you create any new application and deploy it either on physical servers, cloud servers or virtual machines, the most common problems which you face are portability and compatibility. This is where containers come into the picture. Containers virtualize at the OS level so they only contain required libraries and app services. The benefits of containers include:
- portabilty
- isolation
- scaling
- light weight
- fast boot up
- smaller disk and memory requirements
In a nutshell: when you build a container image for any application, all of the required dependencies are packed into the container. You can now run that container on any host OS without any portability and compatibility issues.
The key highlight of Podman is that it is daemon-less, and so does not require root privileges to run containers. You can build the container images with the help of a Dockerfile or pull images from Docker Hub, [fedoraproject.org](https://registry.fedoraproject.org/) or [Quay](https://www.projectquay.io/). For more information about Podman, see the [Podman tag in Fedora Magazine](https://fedoramagazine.org/tag/podman/).
## Why configure Podman with Ansible?
Ansible provides a way to easily run repetitive tasks many times. It also has tons of modules for cloud providers like AWS, GCP, and Azure, for container management tools like Docker and Podman, and also for database management. Ansible also has a community ([Ansible Galaxy](https://galaxy.ansible.com/)) where you can find tons of Ansible roles created by contributors from all over the world. All of this makes Ansible a great tool for DevOps engineers and system administrators.
With DevOps, the development of applications is fast-paced. Developing applications which can run on any operating system is essential. This is where Podman comes into picture.
## Installing ansible
First, install Ansible:
$ sudo dnf install ansible -y
## Configuring ansible
Ansible needs ssh to work on managed nodes, so first generate a key pair.
$ ssh-keygen
Once the key is generated, copy the key to the managed node.
Editors note: From the Ansible documentation found at[https://docs.ansible.com/ansible/latest/user_guide/connection_details.html#connections]the following can be done to use Ansibles ssh-agent for setting up ssh keys. $ ssh-agent bash $ ssh-add ~/.ssh/id_rsa
Enter yes and enter the password of the managed node. Now your managed host can be accessed remotely.
For ansible to access managed nodes, you need to store all hostnames or IP addresses in an inventory file. By default, this is in *~/etc/ansible/hosts*.
This is what the inventory file looks like. Here square brackets are used to assign groups to some specific nodes.
[group1]
green.example.com
blue.example.com
[group2]
192.168.100.11
192.168.100.10
Check that all managed nodes can be reached.
$ ansible all -m ping
You should see output like this:
[mahesh@fedora new] $ ansible all -m ping
fedora.example.com I SUCCESS {
"ansibe_facts": {
"discovered_interpreter_python": "/usr/bin/python"
},
"changed": false,
"ping": "pong"
}
[mahesh@fedora new] $
Now create your first playbook which will install Podman on managed nodes. First create a file with any name with .yml extension.
$ vim name_of_playbook.yml
The playbook should look something like below. The first field is name for the playbook. The hosts field is used to mention hostname or group name mentioned in inventory. *become: yes* indicates escalating privileges and tasks contain all the tasks that are going to execute, here name specifies task name, yum is module to install packages, below that specify name of package in name field and state is for installing or removing the package.
— – name: First playbook hosts: fedora.example.com become: yes tasks: – name: Installing podman. yum: name: podman state: present |
Check for any syntax errors in the file.
$ ansible-playbookfilename--syntax-check
Now run the playbook.
$ ansible-playbook filename
You should get output like this:
[mahesh@fedora new] $ ansible-playbook podman_installation.yml
PLAY [First playbook] *************************************************************************************************
TASK [Gathering Facts] *************************************************************************************************
0k: [fedora.example.com]
TASK [Installing podman] ************************************************************************************************
changed: [fedora.example.com]
PLAY RECAP *************************************************************************************************
fedora.example.com : ok=2 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
[mahesh@fedora new] $
Now create a new playbook which pulls an image from Docker Hub. You’ll use the podman_image module to pull the httpd image of version 2-alpine from Docker Hub.
---
- name: Playbook for podman.
hosts: fedora.example.com
tasks:
- name: Pull httpd:2-alpine image from dockerhub.
podman_image:
name: docker.io/httpd
tag: 2-alpine
Now check the pulled image.
[mahesh@fedora new] $ podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/library/httpd 2-alpine fa848876521a 11 days ago 57 MB
[mahesh@fedora new] $
Create a new playbook to run the httpd image. See the [podman_container](https://docs.ansible.com/ansible/latest/collections/containers/podman/podman_container_module.html) module documentation for more information.
---
- name: Playbook for podman.
hosts: fedora.example.com
tasks:
- name: Running httpd image.
containers.podman.podman_container:
name: my-first-container
image: docker.io/httpd:2-alpine
state: started
Check that the container is running.
[mahesh@fedora new] $ podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
45d966eOe207 docker.io/library/httpd:2-alpine httpd-foreground 13 seconds ago Up 13 seconds ago my-first-container
[mahesh@fedora new] $
Now to stop the running container, change the state value from *started* to *absent*.
- name: Stopping httpd container.
containers.podman.podman_container:
name: my-first-container
image: docker.io/httpd:2-alpine
state: absent
When you run the *podman ps* command, you won’t see any containers running.
[mahesh@fedora new] $ podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[mahesh@fedora new] $
There are so many things that are possible with podman_container like recreating containers, restarting containers, checking whether container is running or not and many more. See the [documentation](https://docs.ansible.com/ansible/latest/collections/containers/podman/podman_container_module.html) for information on performing these actions.
## Bruno
Nice topics, there is a typo in “become: yes indicates and ….” I guess should be “become: yes indicates running as root and …”
Also there is a “package” module that is more generic than “yum” a big part of Ansible is to be distribution agnostic.
## Stephen Snow
Hello Bruno, thanks for the typo catch. ‘become:yes’ actually escalates privileges as now noted in the article. To become root, you use ‘become_user(root):’
## Andrii
looks like guys from podman don’t very care about that they have unstable and buggy release candidate in fedora stable repository
## t0xic0der
Hi @Andrii, this was promptly detected and a rollback was made soon after. You can find more about this here https://twitter.com/fatherlinux/status/1392535997473243137 and here https://lists.podman.io/archives/list/[email protected]/thread/WYNTH224D5MVBC2RFOG6RPIC52JZFKAB/.
## Andrii
Hi @t0xic0der, but still we have rc1 in the stable repo (5 days), the rollback not take effect.
## laolux
Yeah, I just got hit by that, too.
does NOT solve the problem. How to downgrade to the last stable version?
wants to downgrade all the way to 3.1.0, so that’s obviously not the solution.
## Niko
will be nice to explain how to create a new podman container with ansible.
I mean provision a new podman container in plain ansible.
## Simon
You lost an ssh-copy-id command maybe?
## Peter Oliver
I think that should be:
## Abby
Hi,
I configured myself as follows :
name: Podman Deploy
hosts: hosts1
become: yes
tasks:
name: Podman container state
containers.podman.podman_container_info:
name:
register: result
name: Stop a container osm-backend
containers.podman.podman_container:
name:
state: stopped
when: result.stderr == “Error*”
name: Remove container osm-backend
containers.podman.podman_container:
name:
state: absent
when: result.stderr == “Error*”
name: osm-backend image remove
containers.podman.podman_image:
name: my-registry/
state: absent
name: Deploy osm-backend container
containers.podman.podman_container:
name: osm-backend
image: my-registry/
ports:
“4000:4000”
network:
bridge0
ip:
restart_policy: always |
13,398 | 《代码英雄》第四季(3):个人计算机 —— Altair 8800 和革命的曙光 | https://www.redhat.com/en/command-line-heroes/season-4/personal-computers | 2021-05-17T18:55:19 | [
"代码英雄",
"PC",
"BASIC"
] | https://linux.cn/article-13398-1.html |
>
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。
>
>
>
>
> **什么是《代码英雄》**
>
>
> <ruby> 代码英雄 <rt> Command Line Heroes </rt></ruby>是世界领先的企业开源软件解决方案供应商红帽(Red Hat)精心制作的原创音频播客,讲述开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗。该音频博客邀请到了谷歌、NASA 等重量级企业的众多技术大牛共同讲述开源、操作系统、容器、DevOps、混合云等发展过程中的动人故事。
>
>
>

本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[《代码英雄》第四季(3):个人计算机 —— Altair 8800 和革命的曙光](https://www.redhat.com/en/command-line-heroes/season-4/personal-computers)的[音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/cde302f6-79dd-43c0-a7e7-fc1dde364323/clh-s4e3-personal-computers-altair-8800-vfinal_tc.mp3)脚本。
>
> 导语:因为 Altair 8800,我们今天才能在大多数家庭中拥有计算机。它最初是为业余爱好者设计的,但是一些有远见的人看到了这个奇怪的小机器的巨大潜力,并努力使其他人也看到。他们创造的东西所带来的影响远远超出了任何人的想象。
>
>
> Forrest Mims 告诉了我们他的联合创始人 Ed Roberts 是如何计划拯救他们陷入困境的电子公司的。他的想法是什么?一台为业余爱好者制造的微型计算机。那台计算机让<ruby> 比尔•盖茨 <rt> Bill Gates </rt></ruby>和<ruby> 保罗•艾伦 <rt> Paul Allen </rt></ruby>打了一个决定性的电话。Dan Sokol 和 Lee Felsenstein 回顾了 Altair 8800 在自制计算机俱乐部的揭幕,以及它如何激发了<ruby> 史蒂夫•沃兹尼亚克 <rt> Steve Wozniak </rt></ruby>的 Apple I 的灵感。然后,我们在 John Markoff 那里听到了一个臭名昭著的软件抢劫案,该案为代码是否应该是专有的辩论创造了条件。最后,Limor Fried 回顾了这个故事如何继续影响今天的开源硬件运动。
>
>
>
**00:00:04 - Saron Yitbarek**:
1974 年 12 月一个严寒结霜的下午,两个年轻人走在哈佛广场上,他们可能正在谈论着他们最感兴趣的计算机话题。
**00:00:19**:
当他们经过报摊,看到了《<ruby> 大众电子 <rt> Popular Electronics </rt></ruby>》杂志从其他杂志中露出的蓝色字体,他们停下来看了一下,杂志封面上是一个金属盒的照片,在它的正面有十几个开关和指示灯。标题上写着:“世界上第一台小型计算机套件,Altair 8800。” 这个盒子看上去不太像样,裸露着金属,就像是给业余爱好者和修理工们准备的。但对这两个人来说却不是这样,更像是他们一直在等待的机器,因为他们正好有适合这种新硬件的完美软件。同时,他们也有一些忐忑,如果别人也有这种想法并已经开始实施的话,那该怎么办呢?必须尽快行动起来了。这两位代码英雄是谁呢?<ruby> 比尔•盖茨 <rt> Bill Gates </rt></ruby>和<ruby> 保罗•艾伦 <rt> Paul Allen </rt></ruby>。此时他们并不知道,Altair 8800 将会是打开个人计算机革命大门的机器,它将永远的改变我们的生活。这台设备还做到了另一件事,在一个神秘小偷的帮助下,它将引发自由软件和专有软件之间的争论,我们稍后会讲到。
**00:01:50**:
在硬件这一季的第一集,我们了解了 Eagle 这样的分时小型机。在第二集,我们了解了 GE-225 大型机。但它们仍然受制于自身的尺寸、价格以及处理能力。而这一集讲的是,缩小到<ruby> 微型计算机 <rt> micro computer </rt></ruby>的所有东西。这一切,都始于邮寄给业余爱好者的 DIY 套件,就像是《大众电子》的那张划时代的封面里面的一样。
**00:02:23**:
这些简单的套件,激发出了一种革命性的想法:计算机可以放在你的家里。这台计算机是属于你的,你可以用来做实验。一个全新的、面向大众的硬件产品 —— <ruby> 个人计算机 <rt> personal computer </rt></ruby>(PC) —— 诞生了。我是 Saron Yitbarek,这里是《代码英雄》,一款红帽公司的原创播客。
**00:02:51**:
让我们回到上世纪 60 年代末,在新墨西哥州的沙漠里,Altair 8800 诞生了。一个名叫 Ed Roberts 的人与人合伙创立了一家小型电子零件公司 MITS(意即“<ruby> 微型仪器和遥测系统 <rt> Micro Instrumentation and Telemetry Systems </rt></ruby>”)。通过爱好者杂志,他们可以将这些小玩意卖给痴迷于无线电遥控飞机和火箭模型的新市场。
**00:03:21**:
到 1971 年,Ed 独立经营着公司。他决定将重心转向电子计算器,这在当时是一个全新的市场。MITS 准备提供第一台爱好者计算器,但是 Ed 失算了。这位是他最初的联合创始人,Forrest Mims。
**00:03:42 - Forrest Mims**:
像索尼、夏普和德州仪器这样的公司,他们正在制造专业的袖珍计算器,并以低于 Ed 的价格出售。这是一场灾难,Ed 濒临破产,并且不知道该怎么办。
**00:03:57**:
有一天,他了解到英特尔公司开发了一种新型的微处理器,并在《<ruby> 电子杂志 <rt> Electronics Magazine </rt></ruby>》上刊登了广告。我仍然记得那则广告,那款微处理器叫做 Intel 8080。
**00:04:09 - Saron Yitbarek**:
Ed 大量购买了英特尔微处理器,因为当时没有人购买它。他围绕这个微处理器设计了一台完整的计算机。
**00:04:23 - Forrest Mims**:
有一天晚上,他给我打电话说:“我有一个新玩意儿想让你看看。”于是我骑自行车去了 MITS。桌上有一个蓝色的盒子。他说,“看这个。”我说,“这是什么?”他说,“这是一台微型计算机。”我说,“你在开玩笑吧。”他说,“不,这是一台微型计算机,《大众电子》杂志已经认可了,并且想要刊登一篇关于它的文章。”
**00:04:43 - Saron Yitbarek**:
Ed 的目标是创造一个非常基本的计算机套件,同样提供给那些模型飞机和火箭的爱好者市场。他通过《大众电子》杂志来邮购销售这个套件。当你收到这个套件时,会获得一个装满金属零件的袋子,里面有一个装有最重要的 Intel 8080 微处理器芯片的特殊管子。Ed 把整个套件的价格定在 400 美元左右。
**00:05:14 - Forrest Mims**:
他在考虑一个问题,“你觉得能卖出多少台?”他问道。基于之前我们通过《大众电子》杂志销售东西的经验,我说,“好吧,Ed,顶天了也就几百台吧。”我这么说的时候,他看起来好难过。直到今天我都为此感到内疚。在《大众电子》杂志刊登了这个套件之后,他的小楼前的停车场里挤满了汽车。最后竟然卖了 5000 台这样的计算机。它被命名为 Altair 8800。当时 Ed 不知道该怎么称呼它,这个名字还是《大众电子》杂志的工作人员想出来的。
**00:05:50 - Saron Yitbarek**:
Altair 8800 是 Ed Roberts 为了拯救他的公司而做的拼死一搏,这是他做过的最好的决定。他做了一件真正有意义的事情,但他当时并没有意识到。通过将 Altair 以一个合适的价格投放到市场,他让自己的机器展现给了比铁杆电子爱好者更大的受众群体面前。他的 Altair 开拓了一个全新的市场 —— 那些从未想过能拥有自己计算机的消费者群体。
**00:06:28**:
更重要的是,他们可以修理自己的计算机。这是一个大时代的开端,但它还缺少一个部分,软件。这个硬件需要正确的软件才能活起来。
**00:06:51**:
回到<ruby> 马萨诸塞州 <rt> Massachusetts </rt></ruby>的剑桥,比尔•盖茨和保罗•艾伦刚刚在最新一期《大众电子》杂志的封面上看到了 Altair 8800。在他们走过哈佛广场的那段决定性路程之前,保罗一直在向比尔抱怨那些 Intel 8080 的新芯片,他在寻找使用这些芯片创建软件的方法。
**00:07:16**:
比尔和保罗使用 BASIC 编程。正如我们在上一集中知道的,如果没有 GE-225 主机,BASIC 永远不会诞生并流行起来。对于比尔和保罗来说,BASIC 的易用性使得它成为了理想的语言,可以提供给那些受限于内存和处理能力的硬件,比如 8080。
**00:07:38**:
当他们看到杂志封面上封装着 8080 芯片的 Altair 时,他们意识到可以用 BASIC 编写软件来支撑这个机器。他们很快联系了 MITS 的 Ed Roberts。Forrest Mims 还记得那个电话。
**00:07:56 - Forrest Mims**:
保罗说,“我们得给这个公司打个电话,告诉他们我们已经有 BASIC 了。”盖茨同意了,但他不想亲自打这个电话,因为他的声音实在太年轻了,而且他看起来也像个青少年。所以保罗•艾伦打电话给 Ed:“我们已经为你的 Altair 准备好了 BASIC。”Ed 说,“每个人都告诉我他们已经搞好了 BASIC。如果你弄好了它,就把它送过来,合适的话,我会考虑的。”
**00:08:17**:
他们并没有 BASIC。他们花了一个月的时间在麻省理工学院或哈佛大学都不知情的情况下借用了计算机时间,为从没有见过的 Altair 开发了 BASIC 软件。
**00:08:27 - Saron Yitbarek**:
比尔和保罗知道他们有能力为 Altair 编写代码。但实际上,他们还没有开始编写。所以他们日以继夜地为这个机器改写 BASIC。使用公布的规范,他们在 DEC PDP-10 主机上创建了一个仿真器,以此来仿真 Altair,然后开发了一个 BASIC 解释器。
**00:08:53**:
没有 BASIC 解释器的 Altair 8800 本质上就是一个带有开关和指示灯的金属盒子,并没有什么用。然而随着 BASIC 解释器的加入,这台机器突然有了全新的未来。
**00:09:10**:
仅仅几个星期后,也就是 1975 年 3 月,代码就准备好了。保罗飞往 <ruby> 阿尔伯克基 <rt> Albuquerque </rt></ruby>,准备亲手将演示程序交给 Ed Roberts。前一天晚上比尔一夜没睡,以确保代码没有任何的错误。他把最终的代码打在纸带上,并在航班起飞前交给保罗。在三万英尺的高空,保罗突然意识到,他们忘了一件事。
**00:09:39 - Forrest Mims**:
他意识到,他们没有开发出<ruby> 编码器 <rt> Coder </rt></ruby>,或者说<ruby> 引导记录器 <rt> bootstrap logger </rt></ruby>,来帮助计算机读取程序。他在飞机上写了那个代码。保罗•艾伦就是这么才华横溢。
**00:09:53 - Saron Yitbarek**:
现在他已经准备好了。在第二天进行演示的时候,保罗将首次在一台真正的 Altair 上测试他们的代码。1994 年比尔•盖茨在一段旧影片中,谈到保罗•艾伦在 MITS 装上纸带时所发生的事。
>
> **00:10:13 - 比尔•盖茨**:
>
>
> 第一次,由于某些原因,代码并没有工作。当第二次加载它时,它就顺利的工作了。然而这只是仿真器,速度非常的慢,需要大量的指令才能完成一条指令。因此,实际上,即使是一个非常小的微处理器,真实的机器也比我们的 PDP-10 仿真器要快,大约快五倍。
>
>
> **00:10:32**:
>
>
> 所以,对保罗来说,当它最终出现并显示出 “READY” 提示符时,保罗输入了一个程序,“打印二加二”,它成功了。然后他让它打印出类似于平方和求和之类的结果。他和这家公司的负责人 Ed Roberts 一起坐在那里都惊呆了。我的意思是,保罗惊讶于我们的那部分能够工作,而 Ed 则惊讶于他的硬件能够工作。
>
>
>
**00:10:55 - Saron Yitbarek**:
保罗•艾伦和比尔•盖茨的 BASIC 解释器在 Altair 上工作得非常棒,这是一个惊人的成就。
**00:11:02**:
Ed Roberts 对此印象非常的深刻,以至于……
**00:11:08 - Forrest Mims**:
他当场聘请了保罗•艾伦担任他的软件开发副总裁。
**00:11:13 - Saron Yitbarek**:
保罗•艾伦在那之后很快就搬到了新墨西哥州,开始了他的新工作。至于比尔,他回到了哈佛,毕竟他还是个学生。
**00:11:23 - Forrest Mims**:
但是保罗•艾伦说服了盖茨在 1975 年的夏天回来,并开始用 BASIC 工作。他们一起开了一家公司,叫做 Micro-soft,带一个连字符。后来他们去掉了连字符。
**00:11:36 - Saron Yitbarek**:
MITS 成为了比尔和保罗的第一个客户,他们授权了他们的 BASIC 解释器给 MITS,并同意随机器分发他们的代码。他们称这套软件为 Altair BASIC,它成为了与个人计算机捆绑的第一款软件。现在他们只需要卖掉它就好了。
**00:11:57 - Forrest Mims**:
Ed 做了什么呢?嗯,他们买了一辆大型房车,把它做成一个移动销售设备,一个销售计算机的移动办公室。他们把它开到全国各地,在不同的城市停下来,举行演示,这吸引了大量的人。
**00:12:12 - Saron Yitbarek**:
它被称为“移动 MITS”,把巡回路演带到了西部。在加利福尼亚海岸沿岸,会议室里挤满了好奇的工程师和修理工。MITS 团队展示了 Altair 和 Altair BASIC。然而,在 Palo Alto 一个特别拥挤的酒店会议室里,发生了一件意想不到的事情。这件事改变了整个软件历史的进程。
**00:12:46**:
让我们先等一下。在开始说这件意想不到的事情之前,我们先来了解一下<ruby> 湾区 <rt> Bay area </rt></ruby>的电子爱好者和业余爱好者的情况。他们自称为<ruby> 自制计算机俱乐部 <rt> Homebrew Computer Club </rt></ruby>。他们互相交换零件、电路和想法,并在探索个人计算机的新世界里相互扶持。
**00:13:11 - Dan Sokol**:
这些人都对此感到好奇。他们中大多数都是某个领域的工程师。其中只有两三个人对计算机编程完全没有了解。当时做了一项调查,在座多少人拥有一台计算机,而又有多少人计划购买一台。这个调查十分有趣,所有人都想拥有一台计算机,但是实际上只有一两个人拥有它们,他们会把计算机带到俱乐部聚会上展示它们。我记得那时最令人尴尬的问题是,“你打算用它做什么?”而没有人知道。
**00:13:46 - Saron Yitbarek**:
这位是 Dan Sokol,自制计算机俱乐部最初的成员之一。因为每个人都想看一看 Altair 8800,在<ruby> 门罗公园 <rt> Menlo Park </rt></ruby>的一个车库里他们举行了第一次集会。
**00:14:08 - Lee Felsenstein**:
在 1975 年 3 月 5 日的一个雨夜,有 30 个人来到了这个车库。这里有一台为他们展示的 Altair。它是启动着的,但没有连接任何东西,也没有做任何事情。
**00:14:22 - Saron Yitbarek**:
这位是 Lee Felsenstein,俱乐部的另一个初始成员。
**00:14:27 - Lee Felsenstein**:
我们在房间里走来走去,尝试学到一些什么。我们从 Steve Dompier 听到了更多的报告,他订购了一台 Altair 计算机,它是在一月份的《大众电子》杂志上发布的。他实际上开车去了 Albuquerque 核实了他的订单,然后向我们报告了他的发现。
**00:14:48 - Dan Sokol**:
Dompier 带来了一台 Altair,他坐在那儿,通过前面板的开关进行编程,使它播放音乐。在大约尝试了一个小时后,有人不小心把电源线踢掉了,这使得他不得不重新开始。但在当时看来,这是“看一台计算机,而且是你能买得起的那种。”
**00:15:08 - Saron Yitbarek**:
在举行的聚会上还有一个人。当他看到 Altair 的时候,让他大吃一惊,但不是因为他不相信有这样一台机器存在。恰恰相反,因为有类似功能并比它好的多的机器已经存在了,他已经制造了它。那个人就是年轻的 <ruby> 史蒂夫•沃兹尼亚克 <rt> Steve Wozniak </rt></ruby>。他的一个朋友劝说他去参加那个聚会,以便让史蒂夫展示他制造的视频终端。但是每个人都被 Altair 所吸引。在此之前,史蒂夫从未听说过 Altair,也没听说过使它工作起来的英特尔 8080 微处理器。他带了一份数据表回家,这件事带来了一个不可思议的惊喜。
**00:16:01**:
这是史蒂夫•沃兹尼亚克(“沃兹”)早在 2013 年自制计算机俱乐部聚会上的发言。
>
> **00:16:10 - 史蒂夫•沃兹尼亚克**:
>
>
> 我把它带回家研究了一下,然后发现,“天哪,这些微处理器是一个芯片。”竟然能卖到 400 美元,这太疯狂了。这就是在我高中时在纸上设计的计算机。实际上,五年前我自己也制造了一个,当时我必须自己制造一个处理器。因为那时还没有微处理器。
>
>
>
**00:16:31 - Saron Yitbarek**:
在上一集中,我们了解了沃兹高中时是如何在 GE-225 计算机上开始用 BASIC 编写他自己的软件的。嗯,从高中开始,沃兹就想拥有一台属于自己的计算机。但要做到这一点,他必须包括一种编程语言,这意味着至少需要 4K 内存以及用于人工输入输出的功能来输入程序。他的机器有 256 字节的固态 RAM,而此类芯片非常的昂贵,所以他设计了一个处理器,还在高中的时候就不断地改进它。就像 Altair 一样,它有输入 1 和 0 的开关。但现在他意识到 Altair 的微处理器是他梦寐以求的。
>
> **00:17:24 - 史蒂夫•沃兹尼亚克**:
>
>
> 你按下按钮 1、0、1、0、1、0,然后按下一个按钮,它就进入一个地址寄存器,在按下几个 1 和 0,然后写入内存。你写满了内存,在俱乐部听到了 Altair 播放音乐,是如此的兴奋。但对我来说,这都不算什么,我想要的是一台可以使用的机器,现在我要做的是输入数据直接写入内存。这太容易了,我说,“我的梦想就是拥有一台自己的计算机。”那天晚上,我看到了这种方法。
>
>
>
**00:17:56 - Saron Yitbarek**:
那天晚上,Apple I 的形象突然出现在了史蒂夫•沃兹尼亚克的脑海中。他可以通过在终端机上添加一个微处理器,几乎不用做什么就可以得到一台适合使用的计算机。他的想法是:当计算机启动时,会运行一个程序去接收输入的数据,就像打字机一样。而不再需要拨弄 1 和 0 了。再加上他制造的视频终端机,让程序员可以看到自己输入的内容,一台感觉更人性化的计算机就诞生了,这是一台对普通人有用的个人电脑。下面是 Lee Felsenstein 的发言。
**00:18:42 - Lee Felsenstein**:
他已经开发出一种小型的视频终端适配器,通用术语是<ruby> 电视打字机 <rt> TV typewriter </rt></ruby>。可以把它连接在电视上。他当时接触了一种只需要 25 美元的处理器芯片,并意识到,“如果我把它放在带有内存的主板上,我也能在主板上放上电视终端,这样我就会拥有一台具有视频显示的计算机。”他就这样做了,在聚会时就在为此做准备,当我们搬到<ruby> 斯坦福直线加速器礼堂 <rt> Stanford Linear Accelerator Auditorium </rt></ruby>时,他占住了唯一有电源插座的座位。他总是比别人先到那儿,他正在为 Apple I 编写 BASIC 程序。在那里他开创了苹果计算机系列。
**00:19:34 - Saron Yitbarek**:
每次沃兹完成了他的计算机制作,他就会很兴奋地向俱乐部的每个人展示。他解释了如何使用几块芯片制造出一台价格低廉的个人计算机。沃兹是信息自由、分享知识以帮助建立更好的系统和社会的理念的主要倡导者。这与当时俱乐部的开放价值观和社会解放运动相呼应。
**00:19:59**:
因此,在会议结束的时候,他拿出了他的设计、硬件和软件的蓝图,免费传给大家。他认为他们每个人都可以利用他的方案来制造自己的 300 美元的计算机。但沃兹的朋友兼商业伙伴,一个名叫<ruby> 史蒂夫•乔布斯 <rt> Steve Jobs </rt></ruby>的人,很快就终止了他的这个想法。乔布斯一直在外奔波,并没有意识到沃兹会把 Apple I 的设计送给别人。乔布斯并不认同沃兹的黑客思维方式,他更注重专利。很快,乔布斯说服了沃兹,他们决定改为出售计算机。
**00:20:42**:
这种自由和专有技术之间的道德斗争,曾经不止一次发生在自制计算机俱乐部。事实上,在那次让大家对 Altair 瞠目结舌的首届俱乐部大会之后的几个月,还有一次聚会点燃了这场辩论的导火索。它发生在斯坦福直线加速器中心礼堂里。聚会结束时,数十名与会者冲上台去想要获取一份纸带程序,这是微软公司的 Altair Basic 的最新副本,是一款让所有人都很感兴趣的软件。
**00:21:21**:
为什么会有这些副本呢?这个软件还没有正式发布,那么它是如何在那个自制俱乐部聚会上出现的呢?原来,原始的纸带已经被偷了。这是那个时代最大的软件抢劫案。
**00:21:44**:
好吧,让我们具体了解一下这一切是如何发生的。还记得前面提起过关于移动 MITS 到西部去展示 Altair 和 Altair BASIC 的事吗?
**00:21:54 - John Markoff**:
1975 年 6 月 10 日,该公司在 Palo Alto 演示他们计算机和搭载的软件。
**00:22:03 - Saron Yitbarek**:
这位是 John Markoff,纽约时报的记者。
**00:22:06 - John Markoff**:
这家旅馆叫 Rickeys。请记住,在当时个人计算机行业实际上并不存在,对个人计算机感兴趣的大多数人也并不是真正的商人,因为那时并没有商业软件,所以他们向一个广泛的团体展示计算机。当时在新硅谷,有很多人是电气工程师,他们都是程序员。有各种各样的人对技术、对计算机感兴趣。
**00:22:39 - Saron Yitbarek**:
在那次演示过程中,MITS 的工作人员在将软件加载到机器上时遇到了一些麻烦。在当时,软件是打孔在纸带上的,纸带必须通过一个机械阅读器才能安装程序。当那名员工因此而慌乱时,房间里所有的目光都盯在闪闪发亮的新 Altair 上,然而人群中的某个人发现了一些别的东西,在旁边的一个纸板箱,在那个箱子里是一卷卷 Altair 的纸带,这是一个千载难逢的机会。他把手伸进箱子里并用手指缠住了一卷长长的纸带。把它装进口袋带走了。没人看见这些。
**00:23:36 - John Markoff**:
不知怎么回事,那卷纸带最终被一位半导体工程师得到了,他在一家名为 Signetics 的公司工作,他的名字叫 Dan Sokol,他的技术能力很强,也是参加过最初的自制计算机俱乐部聚会的人。所以 Dan 有机会接触到一台相对高速的纸带复印机,他用它做了一堆副本。直到今天 Dan 仍然坚称,他不是拿走原始纸带的人,他只是拿到了一份原纸带的副本,然后把它带到自制计算机俱乐部的下一次聚会上,并与那里的会员们分享。
**00:24:17 - Dan Sokol**:
由于我不道德的行为,我被称为世界上第一位软件盗版者,这是有其道理的。我是那个复制了 MITS BASIC(即微软 BASIC)纸带的人。当时有人在自制计算机俱乐部里站出来说,“谁有能力复制纸带吗?”我说我可以,就这样,我最终得到了那盘纸带并复制了它。
**00:24:45 - Saron Yitbarek**:
当 Dan 分发他的盗版副本时,Lee 也正在那个自制计算机俱乐部会议上。
**00:24:51 - Lee Felsenstein**:
所以发生的事情就是 Dan Sokol 做了 10 份副本,在那次会议上,我们拿到了副本并对他说,“这是 Altair BASIC 的副本。现在带回来的拷贝会比你拿过来的多。”
**00:25:02 - John Markoff**:
当时的约定是,如果你得到一个副本,你必须自己做一个副本,并与朋友分享。这是一个未知的领域。当时还没有个人计算机软件公司,所以这真的是一种狂野的西部,当时人们只是卖计算机,而共享软件。
**00:25:19 - Saron Yitbarek**:
在 1975 年,软件只是你用来让计算机工作的东西。个人计算机是一个全新的概念。当时的黑客们并没有与这个词联系在一起的所有的想法。他们只是想分享他们的工作,通过思想和软件的自由交流来建立一个开放的社区。这次抢劫和赠品事件为一场至今仍能引起反响的争论创造了条件。软件应该自由共享还是应该被买卖?对此,比尔•盖茨一定有自己的看法,当他发现自己的软件发生了什么时,他非常愤怒。
**00:26:03 - John Markoff**:
当他意识到他的 BASIC 编程语言正被业余爱好者们广泛分享时,他给他们写了一封愤怒的信,指责他们窃取了他的软件,削弱了他的谋生能力。
**00:26:18 - Lee Felsenstein**:
我们收到了那封信。在聚会上阅读了这封信,里面有一句话:“我们花费了大量的金钱去开发它。我们用了近 4 万美元的计算机时间。”房间里的每个人都知道,那样的计算机美元是假的,这只是一个会计把戏。你没有为它们支付真正的钱,而我们也知道这一点,所以我们想,“继续抱怨吧。我们会继续做我们正在做的事情。”
**00:26:45 - Dan Sokol**:
他叫我们海盗和小偷。我们试图理智和理性地向他解释,你不能以 400 美元的价格出售一台价格为 400 美元的电脑的软件。在今天这个时代,很难回过头并试图解释他们当时的心态,那就是小型计算机的思想,小型计算机被用于工业,而我们只是一群用套件来制造自己计算机的爱好者。唯一的功能性软件就是这个 BASIC 解释器,它几乎充当了一个操作系统。早在 1974 年,个人计算机里还没有操作系统,我们无法与他沟通,也无法向他解释,“把手册以 100 美元卖给我们,让我们随便用软件。”他没有听这些,多年来微软的软件价格过高,被盗版,而且盗版严重。
**00:27:51 - Saron Yitbarek**:
俱乐部成员选择无视这封信。因为早在 1975 年,当时的版权法并没有涵盖软件。将软件从一个纸带复制到另一个纸带上不会有任何的惩罚。这种情况在 1977 年会发生变化,但在那几年里,这种做法并没有违反法律。
**00:28:12 - John Markoff**:
具有讽刺意味的是,比尔•盖茨并没有创造 BASIC 语言。他只是简单地创建了它的副本,是从原始设计者<ruby> 达特茅斯大学 <rt> Dartmouth University </rt></ruby>的一位教授那得到的,他基本上是做了一个副本,然后把它卖掉,所以这一切的根源在于分享。
**00:28:31 - Saron Yitbarek**:
抢劫、纸带、分享、愤怒的信件。所有这些都导致了新兴的软件业和那些被他们视为盗版者的人们之间长达数十年的战争,但在这场战争中,开源软件运动也随之兴起。它的核心价值观与那些点燃个人计算机革命的早期爱好者是一脉相承的,因为这些业余爱好者意识到,个人计算机未来的关键点在于释放软件的潜能。
**00:29:07 - Lee Felsenstein**:
传递纸带、互相鼓励和互相借鉴彼此成果的过程确实是使个人计算机行业成功的原因。
**00:29:17 - Saron Yitbarek**:
现在,我们再也没有说过最初的小偷是谁。谁偷了那条珍贵的纸带,至今仍是个谜。那些知道答案的人们也更愿意保留这个谜。
**00:29:32 - Dan Sokol**:
至于它是如何被“解放”的,如果你想用这个词的话,我知道是谁干的,但是我不会说,因为那个人很久以前就要求保持匿名,因为这样更安全,我尊重这种选择,并且我也会继续尊重下去。所以,我当时不在 Rickey 旅馆,但纸带却找到了传递给我的方法。
**00:30:01 - Saron Yitbarek**:
随着时间的推移,个人计算机革命让位于硅谷和众多风投支持的科技创业公司,但那些修理工、那些电子爱好者和业余爱好者们却从未消失。事实上,他们比以往任何时候都更强大。
**00:30:20 - Limor Fried**:
嗨,我叫 Limor Fried,是 Adafruit 工业公司的首席工程师兼创始人。
**00:30:26 - Saron Yitbarek**:
Adafruit 是一家开源硬件公司,是过去几年开始的那场新革命的一部分,即<ruby> 开源硬件运动 <rt> open source hardware movement </rt></ruby>,这场运动与那些早期的爱好者有着同样的价值观。但它变的更好一些。
**00:30:43 - Limor Fried**:
自制计算机俱乐部,我认为,人们带着他们的计算机加入进来是有这样一种信念的,这就像,“来看看我做的这个很酷的<ruby> 魔改 <rt> hack </rt></ruby>吧”,然后每个人都会说,“天哪,这太酷了。好吧,下个月我会带来一个更棒的。”这是一个积极的反馈循环,带来了真正好的技术创新。我认为黑客哲学仍然存在,人们只是有了更多的背景知识,所以他们认为作为一个很酷的黑客,我想说的确有所进步,但它实际上已经泛化了,我认为这很好。我认为分享的价值仍然存在,相互帮助,共同努力工作与合作。这个理念贯穿始终。它存在于整个开源社区。
**00:31:32 - Saron Yitbarek**:
我们将用一整集来讲述开源硬件运动的兴起,这样就可以看到我们是如何进步的,并为 Limor Fried 这样的现代制造商创造空间。请继续关注几周后的第六集。下一集,是改变了世界的磁碟 —— 软盘。
**00:31:56 - Saron Yitbarek**:
代码英雄是红帽的原创播客。请到 [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) 了解一些关于个人计算机革命的伟大研究。这里有一个美丽的轶事,你可以读到关于比尔•盖茨在 Ed Roberts 临终前拜访他的故事,如果你想知道在那次 PC 革命期间发生了什么,请查看我们最初的几期命令行英雄节目,[操作系统战争](https://www.redhat.com/en/command-line-heroes/season-1)。我是 Saron Yitbarek,下期之前,编码不止。
>
> 附加剧集
>
>
> Forrest Mims 对 Ed Roberts 有很多话要说。听听有关 Ed 与保罗•艾伦和比尔•盖茨会面,以及他们开始合作的故事。
>
>
> [音频](https://cdn.simplecast.com/audio/a88fbe/a88fbe81-5614-4834-8a78-24c287debbe6/675ec981-8ad6-45d0-865e-6b6dddba7f58/clh-s4e3-altair-8800-bonus-final_tc.mp3)
>
>
>
>
> **什么是 LCTT SIG 和 LCTT LCRH SIG**
>
>
> LCTT SIG 是 LCTT <ruby> 特别兴趣小组 <rt> Special Interest Group </rt></ruby>,LCTT SIG 是针对特定领域、特定内容的翻译小组,翻译组成员将遵循 LCTT 流程和规范,参与翻译,并获得相应的奖励。LCRH SIG 是 LCTT 联合红帽(Red Hat)发起的 SIG,当前专注任务是《代码英雄》系列播客的脚本汉化,已有数十位贡献者加入。敬请每周三、周五期待经过我们精心翻译、校对和发布的译文。
>
>
> 欢迎[加入 LCRH SIG](/article-12436-1.html) 一同参与贡献,并领取红帽(Red Hat)和我们联合颁发的专属贡献者证书。
>
>
>
---
via: <https://www.redhat.com/en/command-line-heroes/season-4/personal-computers>
作者:[Red Hat](https://www.redhat.com/en/command-line-heroes) 选题:[bestony](https://github.com/bestony) 译者:[linitok](https://github.com/linitok) 校对:[Northurland](https://github.com/Northurland), [wxy](https://github.com/wxy)
本文由 [LCRH](https://github.com/LCTT/LCRH) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ##### Season 4, Episode 3
# Personal Computers: The Altair 8800 and the Dawn of a Revolution
[Listen to this episode later](#)

The Altair 8800 is why we have computers in most homes today. It was initially designed for hobbyists. But a few visionaries saw massive potential in this strange little machine—and worked hard to make others see it too. What they created led to so much more than anyone could have ever imagined.
**Forrest Mims** tells us how his co-founder, Ed Roberts, planned to save their struggling electronics company. His idea? A microcomputer made for hobbyists. That computer led to a fateful phone call from Bill Gates and Paul Allen. **Dan Sokol and Lee Felsenstein** recall the unveiling of the Altair 8800 at the Homebrew Computer Club, and how it sparked Steve Wozniak’s eureka moment for the Apple I. We then hear from **John Markoff** about an infamous software heist that set the stage for the debate about whether code should be proprietary. And finally, **Limor Fried** reflects on how this story continues to influence today’s open source hardware movement.

**00:04** - *Saron Yitbarek*
It's a cold and frosty December afternoon in 1974. Two young men are walking across Harvard Square. They're probably having a conversation about their favorite subject, computers.
**00:19** - *Saron Yitbarek*
As the men pass a newsstand, they see the blue lettering of Popular Electronics peeking out from the other magazines. They stop and check it out. On the cover is a photo of a metal box, with a dozen switches and small lights on the front. The headline reads, "World's first minicomputer kit. Altair 8800." The box doesn't look like much. Bare bones really, meant for hobbyists and tinkerers. But it looked like something more to these two guys. It looked like the machine they'd been waiting for, because they had the perfect software for this new hardware. At the same time, they were a little freaked out. What if others had the same idea they did and were working on it already? They had to move fast. The names of those two command line heroes? Bill Gates and Paul Allen. Little did they know that the Altair 8800 would be the gateway machine to a personal computer revolution. It would change their lives, and ours, forever. That new machine would do one other thing. It would kickstart the debate between free and proprietary software, with the help of a mysterious thief. Stay tuned.
**01:50** - *Saron Yitbarek*
In episode 1 of our season on hardware, we learned about timesharing minicomputers, like the Eagle. In episode 2, we heard about the GE-225 mainframe. But both those machines were still limited by their size, cost, and processing power. This episode is about everything shrunk down, to the micro computer. It all starts with the DIY kits that were mailed to hobbyists, like the one that graced that fateful cover of Popular Electronics.
**02:23** - *Saron Yitbarek*
Those simple kits inspired the revolutionary idea that computers could sit inside your own home. That computers were yours to own and experiment with. It was the birth of a new mass market piece of hardware. The personal computer. I'm Saron Yitbarek, and this is Command Line Heroes. An original podcast from Red Hat.
**02:51** - *Saron Yitbarek*
Let's go back to the late '60s. Out to the New Mexico desert, where the Altair 8800 was born. A man named Ed Roberts had co-founded a small electronics parts company, MITS, which stood for Micro Instrumentation and Telemetry Systems. Through hobbyist magazines, they could sell gadgets to the new market obsessed with radio controlled airplanes and model rockets.
**03:21** - *Saron Yitbarek*
By 1971, Ed was running the company solo. He decided to pivot toward electronic calculators—a brand new market at the time. MITS would offer the first hobbyist calculator. But Ed had miscalculated. Here's his original co-founder, Forrest Mims.
**03:42** - *Forrest Mims*
Companies like Sony and Sharp and Texas Instruments, they were building professional pocket calculators, and selling them for cheaper than Ed could sell them. That created a near disaster. He was nearly bankrupt, and he didn't know what to do.
**03:57** - *Forrest Mims*
Well, one day he learned about a new microprocessor that had been developed by Intel. It was advertised in Electronics Magazine. I still remember the ad. The microprocessor was called the Intel 8080.
**04:09** - *Saron Yitbarek*
Ed got a great deal on a bulk purchase of Intel microprocessors, because nobody else was buying them at that point. Then he designed a full scale computer around that microprocessor.
**04:23** - *Forrest Mims*
He called me one night and said, "Look, I've got a new product I want you to see." So I got on the bicycle and rode over to MITS. There was this blue box on a table. He said, "Well, here it is." I said, "Well, what is it?" He said, "It's a micro computer." I said, "You're kidding." He says, "Nope, it's a micro computer, and Popular Electronics has accepted it, and they want an article on it."
**04:43** - *Saron Yitbarek*
Ed's goal was to create a very basic computer kit, for the same hobbyist market that had been into model airplanes and rockets. He would sell it mail order through Popular Electronics Magazine. When you received the kit, inside would be a bag full of metal parts, including a special tube that contained the all-important Intel 8080 microprocessor chip. Ed priced the whole kit at around $400.
**05:14** - *Forrest Mims*
He had one question. He said, "How many do you think will sell?" Based on all the previous things that we sold through Popular Electronics, I said, "Well Ed, golly. Maybe a few hundred." He looked so sad when I said that. To this day I feel guilty. After that was in Popular Electronics Magazine, his parking lot in front of their little building was jammed with cars. They sold 5000 of those computers. It was named the Altair 8800. The name was dreamed up by the staff at Popular Electronics Magazine. Ed didn't know what to call it.
**05:50** - *Saron Yitbarek*
The Altair 8800 was Ed Roberts' hail mary move to save his company, and it was the best decision he'd ever make. He didn't realize it at the time, but he'd done something truly significant. Because by placing the Altair in the open market, at an affordable price, he'd exposed his machine to a much larger audience than the hardcore electronic hobbyist crowd. His Altair opened up the potential for a whole new group of consumers—those who never imagined they could own a computer of their own.
**06:28** - *Saron Yitbarek*
More than that, a computer of their own that they could tinker with. It was the start of something huge. But there was still one missing ingredient. Software. This hardware needed the right software to come alive.
**06:51** - *Saron Yitbarek*
Back in Cambridge, Massachusetts, Bill Gates and Paul Allen had just spotted the Altair 8800 on the cover of the latest issue of Popular Electronics. Before they took that fateful walk across Harvard Square, Paul had been bugging Bill about those new Intel chips, the 8080s. He was looking for a way to create software using those chips.
**07:16** - *Saron Yitbarek*
Bill and Paul programmed in BASIC. As we learned in our last episode, BASIC would never have been created and made popular if it hadn't been for the GE-225 mainframe. For Bill and Paul, BASICs’ simplicity made it an ideal language for something with restricted memory and processing power, like the 8080.
**07:38** - *Saron Yitbarek*
When they saw that magazine cover, saw the Altair wrapped around that 8080 chip, they realized they could write software in BASIC that gave that machine legs. They quickly reached out to Ed Roberts at MITS. Forrest Mims remembers that call.
**07:56** - *Forrest Mims*
Paul says, "We've got to call the company and tell them we've got BASIC," and Gates agreed. But Gates didn't want to do the phone call, because he had a much younger voice, and he looked like he was a teenager. Paul Allen makes the call to Ed and said, "We've got BASIC for your Altair." Ed says, "Well everybody's telling me they've got BASIC. If you've got BASIC, deliver it, and I'll consider it."
**08:17** - *Forrest Mims*
They didn't have BASIC. So they spent a month borrowing computer time without anybody's knowledge from either MIT or Harvard, and they developed BASIC for the Altair without ever seeing one.
**08:27** - *Saron Yitbarek*
Bill and Paul knew they could program the code for the Altair. But in reality, they hadn't even started. So yes, they worked day and night in marathon sessions to adapt BASIC for the machine. Using the published specifications, they created a simulator on a DEC PDP-10 mainframe, to emulate the Altair. Then they developed a BASIC interpreter.
**08:53** - *Saron Yitbarek*
The Altair 8800 without a BASIC interpreter was essentially a metal box with switches and lights. Not very useful. With the addition of that BASIC interpreter though, suddenly the machine had a real future.
**09:10** - *Saron Yitbarek*
Just a few weeks later in March, 1975, the code was ready. Paul flew to Albuquerque to hand deliver the demo to Ed Roberts. Bill was up the night before, to make sure they hadn't mis-coded anything. He punched out the final code onto paper tape, and gave it to Paul right before his flight. But 30,000 feet in the air, Paul realized, they forgot one thing.
**09:39** - *Forrest Mims*
He realizes he had not developed the coder, or the bootstrap logger, that allows the computer to read the program. He wrote that code on the airplane. That's how brilliant Paul Allen was.
**09:53** - *Saron Yitbarek*
Now he was ready. The next day was the demo. Paul was going to test their code on a real Altair for the very first time. Here's Bill Gates in an old video from 1994, talking about the moment Paul Allen loaded that paper tape at MITS.
**10:13** - *Bill Gates*
The first time, for some reason it didn't work. The second time they loaded it in, it worked. Of course the simulator, it's very slow. Because you go through lots of instructions to a single instruction. So actually, the real machine, even though it's such a simple little microprocessor, was faster than our PDP-10 simulator. About five times faster.
**10:32** - *Bill Gates*
So to Paul, when it finally came up and it said, "Ready," and he typed in a program, "Print two plus two," it worked. He had it print out squares and sums, and things like that. He and Ed Roberts, the head of this company, sat there. They were amazed by, this thing worked. I mean, Paul was amazed that our part had worked, and Ed was amazed that his hardware worked.
**10:55** - *Saron Yitbarek*
Yes. Paul Allen and Bill Gates' BASIC interpreter worked like a charm on the Altair. An amazing accomplishment.
**11:02** - *Saron Yitbarek*
Ed Roberts was impressed. He was so impressed that...
**11:08** - *Forrest Mims*
He hired Paul Allen on the spot to be his vice president for software development.
**11:13** - *Saron Yitbarek*
Paul Allen moved to New Mexico pretty soon after that to start his new job. As for Bill, he went back to Harvard. He was still a student after all.
**11:23** - *Forrest Mims*
But Paul Allen convinced Gates to come back the summer of '75 and work with BASIC, and that's when they developed a company—they called it Micro-soft with a hyphen, Micro-soft. They eventually left out the hyphen.
**11:36** - *Saron Yitbarek*
MITS became Bill and Paul's very first customer when it licensed their BASIC interpreter and agreed to distribute their code with the machine. They called the software Altair BASIC and it became the first piece of software bundled with a personal computer. Now they just have to sell the thing.
**11:57** - *Forrest Mims*
What did Ed do? Well, they bought a big motorhome and made it into a traveling sales device, a traveling office to sell their computers. And they would drive this thing around the country and stop at different cities and have demonstrations and that attracted huge numbers of people.
**12:12** - *Saron Yitbarek*
MITS-Mobile, as it was called, took the traveling road show out west. Up and down the California coast, in conference rooms packed with curious engineers and tinkerers. The team showed off the Altair and Altair BASIC. Then, at a stop in Palo Alto, in one particularly crowded hotel conference room, something unexpected happened. Something that changed the course of software history.
**12:46** - *Saron Yitbarek*
Okay, hold up. Before we get to that unexpected something, I need to tell you about a group of electronic enthusiasts and hobbyists in the Bay area. They call themselves the Homebrew Computer Club. They trade parts, circuits and ideas, basically support each other as they explored this new world of personal computing.
**13:11** - *Dan Sokol*
Everyone was curious. Most of the people, they were engineers of one type or another. There were only 2 or 3 people who had any knowledge of computer programming at all. I remember a survey, how many people here had a computer versus how many people intended to get one. And that was really interesting because everyone was interested, and there were only 1 or 2 people who actually had them. And they would bring them to the club meeting and show them off. And I remember that the embarrassing question of the era was, "What are you going to do with it?" And nobody had an answer.
**13:46** - *Saron Yitbarek*
That's Dan Sokol, one of the original members of the Homebrew Computer Club. Their first meeting took place in a garage in Menlo Park and that meeting happened because everyone wanted to feast their eyes on the Altair 8800.
**14:08** - *Lee Felsenstein*
So 30 people arrived at this garage on a rainy night on March 5, 1975. And there was the Altair sitting for us to look at. It was turned on, but of course it had nothing to connect to and didn't do anything.
**14:22** - *Saron Yitbarek*
And that's Lee Felsenstein, another original member of the club.
**14:27** - *Lee Felsenstein*
We just went around the room and found out what we could learn. We've had a kind of more of a report from Steve Dompier, a fellow who had ordered an Altair computer and it was announced in the January issue of the Popular Electronics Magazine. And he had actually driven down to Albuquerque to check on his order, then reported back to us what he had found.
**14:48** - *Dan Sokol*
Dompier brought one in and he sat there programming it through this front panel of switches to get it to play music. And after spending about an hour doing it, somebody tripped on the power cord, and he had to start over. But at the time this was, "Look a computer—and you can afford it."
**15:08** - *Saron Yitbarek*
There was someone else at that inaugural meeting. When he saw the Altair, it blew his mind, but not because he couldn't believe a machine like that existed. Quite the opposite. Because a machine like that, and much more than that, already existed. He'd built it. That man was the young Steve Wozniak. A friend of his had coaxed him to go to that meeting so that Steve could show off a video terminal he built. But everyone was fixated on the Altair instead. Steve had never heard of it. And he also hadn't heard of the Intel 8080 microprocessor that was making it hum. So he took home a datasheet, and it led to an incredible eureka moment.
**16:01** - *Saron Yitbarek*
Here’s Steve Wozniak, “the Woz,” was speaking at the Homebrew Computer Club reunion back in 2013.
**16:10** - *Steve Wozniak*
I took it home and studied it, and I said, “Oh my God, these microprocessors are one chip.” Might sell for $400, that was scary. One chip, that is all the computers I used to design on paper back in high school, and I'd actually built one of those five years before, myself, when I had to build a processor myself. There were no microprocessors.
**16:31** - *Saron Yitbarek*
In our last episode, we learned how Woz started writing his own software in BASIC on the GE-225 computer in high school. Well, ever since high school, Woz had wanted a computer all his own. But to do that, he had to include a programming language that meant dedicating at least 4K of memory and human input and output to type in the programs. His machine had 256 bytes of solid state RAM and the chips for that were really expensive. So he designed a processor, refining it over and over while still in high school. It had switches to enter in ones and zeros, just like the Altair. But now he realized the Altair's microprocessor was the culmination of his vision.
**17:24** - *Steve Wozniak*
You press the buttons one, zero, one, zero, one, zero, and you press a button and it goes into an address register and press some more ones and zeros, and it goes into memory and it goes into memory. You fill up memory and it's so exciting to hear how we did that with the Altair that was playing the music in our club, but I was past that and wanted a machine ready to use, but now what I would do is type the data in and it would go straight into memory. How much easier that was. I said, "Oh my gosh, my dream of having my own computer." That night, I saw the formula.
**17:56** - *Saron Yitbarek*
That night, the image of the Apple 1 popped into Steve Wozniak's head. He could build his own fully usable computer for next to nothing by adding in a microprocessor to his terminal. And he had this idea that when his computer started up, it would run a program that would take in data that you typed into it, like a typewriter. No more switching ones and zeros. Add to that the video terminal he’d built to let programmers see what they were typing in and voila, a computer that felt more human. A useful personal computer that worked for normal people. Here's Lee Felsenstein again.
**18:42** - *Lee Felsenstein*
He had already developed a little video terminal kind of adapter, which the generic term was a TV typewriter. You would hook it to a TV. And he was introduced to the processor chip, which was being sold for $25 each, and realized, "If I put this on a board with some memory, I could put that TV terminal on the board, too, and I'd have a computer that would have a video display," which he did and he was working on that while he would be in the meetings. When we moved to the Stanford Linear Accelerator Auditorium, he grabbed the only seat with an electrical outlet. He would always be there before everyone else. He was writing the BASIC program for the Apple 1. He started the Apple family of computers there.
**19:34** - *Saron Yitbarek*
Once Woz finished building his computer, he was excited to show everyone at the club. He explained how a handful of chips could make an affordable personal computer. Woz was a big proponent of freedom of information, the sharing of knowledge to help build better systems and a better society. This echoed the club's open values and the social liberation movements of the time.
**19:59** - *Saron Yitbarek*
So at the end of the meeting, he passed out the blueprints to his design, the hardware and the software, for free to everyone. He figured they could each use his plans to build their own $300 computer. But Woz's friend and business partner, a guy named Steve Jobs, quickly put an end to that idea. You see, Jobs had been traveling all this time and didn't realize Woz was giving away the design to the Apple 1. Jobs didn't share Woz's hacker mindset. He was more proprietary. Jobs soon convinced Woz that they should sell the computers instead.
**20:42** - *Saron Yitbarek*
That ethical struggle between free and proprietary technology happened more than once at the Homebrew Computer Club. In fact, a few months after that inaugural club meeting, which had everyone gawking at the Altair, there was one more meeting that would light the fuse to this debate. It happened in the auditorium of the Stanford Linear Accelerator Center. At the end of that meeting, dozens of attendees rushed the stage to collect a program on paper tape, fresh copies of Microsoft's Altair BASIC, the new software that everyone was excited about.
**21:21** - *Saron Yitbarek*
But how did those copies even exist? The software hadn't been fully released yet, so how did it end up at that Homebrew meeting? Turns out the original paper tape had been stolen. It was the great software heist of the decade.
**21:44** - *Saron Yitbarek*
Okay. Let's dig into how this all came to be. Remember I told you about MITS-Mobile traveling out west to show off the Altair and Altair BASIC?
**21:54** - *John Markoff*
The company was demonstrating their computer with their software in Palo Alto on June 10, 1975.
**22:03** - *Saron Yitbarek*
That's John Markoff, journalist for The New York Times.
**22:06** - *John Markoff*
And the hotel was called Rickeys. Remember, the personal computer industry didn't really exist then, and most of the people who were interested in personal computers weren't really business people, because there was really no business software, and so they were demonstrating the computer to a real eclectic group. There were lots of people around in the new Silicon Valley then who were electrical engineers, they were programmers. There were all kinds of people who were interested in technology and interested in computers.
**22:39** - *Saron Yitbarek*
During that demonstration, one of the MITS crew was having trouble loading the software onto the machine. Keep in mind that at that time, software was punched onto paper tape and the tape had to be pulled through a mechanical reader to install the program. So while that employee was distracted and all eyes in the room were on the shiny new Altair, someone in the crowd spotted something else, a nearby cardboard box, and the opportunity of a lifetime. Inside that box were rolls of Altair Basic on paper tape. This person slid his hand into the box and wrapped his fingers around a long roll of paper tape. He pocketed it and left. No one saw a thing.
**23:36** - *John Markoff*
Somehow that paper tape got to a semiconductor engineer who worked at a company called Signetics, whose name was Dan Sokol, and Dan, he was very technical and he was also someone who had gone to the original Homebrew Computer Club meetings. So Dan had access to a relatively high speed paper tape copying machine, and he made a bunch of copies. Dan to this day insists that he was not the person who took the original paper tape, but that he got a copy of it and then he brought it to the next meeting of the Homebrew Computer Club and he shared it with the members there.
**24:17** - *Dan Sokol*
Amongst my nefarious activities, I am known as the world's first software pirate, and for a damn good reason. I'm the one who duplicated the MITS BASIC, the Microsoft BASIC paper tape. And how that came about was someone stood up at Homebrew and said, "Does anybody here have the capability to copy paper tapes?" And I raised my hand, and that's how I ended up with that tape and copied it.
**24:45** - *Saron Yitbarek*
Lee was at that Homebrew meeting when Dan handed out his pirated copies.
**24:51** - *Lee Felsenstein*
So what happened was that Dan Sokol made up 10 copies, we had it at the next meeting and said, "Here's copies of Altair BASIC. Now bring back more copies than you took."
**25:02** - *John Markoff*
The deal was that if you got a copy, you had to make a copy yourself and share it with a friend. This was sort of uncharted territory. There was no personal computer software companies at that point, and so it was really kind of the wild west and people sold computers and they shared software at that point.
**25:19** - *Saron Yitbarek*
This was 1975, and software was simply the stuff that you used to make computers work. Personal computing was a brand new concept. Hackers back then didn't have all the baggage associated with that word now. They just wanted to share their work to foster an open community with the free exchange of ideas and software. The heist and giveaway had set the stage for a debate that still resonates today. Should software be freely shared or should it be bought and sold? Well, Bill Gates certainly had an opinion on that. When he found out what happened to his software, he was furious.
**26:03** - *John Markoff*
When he realized that his BASIC programming language was being widely shared by the hobbyists, he wrote this irate letter to them accusing them of stealing his software and undercutting his ability to make a living.
**26:18** - *Lee Felsenstein*
Well, we got that letter. We read it in the meeting and there was one line in it saying, "It cost us a lot of money to develop this. We used almost $40,000 in computer time." Everybody in the room knew that computer dollars like that were phony. They were just an accounting trick. You didn't pay real money for them, and we were onto that, so we figured, "Complain away. We're going to keep doing what we're doing."
**26:45** - *Dan Sokol*
He called us pirates and thieves. We tried to be reasonable and rational and explain to him that you can't sell a piece of software for $400 for a computer that costs $400. It's very difficult now in this day and age to look back and try and explain the mentality that they were working under, which was the minicomputer mentality, and minicomputers were used in industry, and we were just a bunch of hobbyists building our own computers from kits. The only piece of functional software was this BASIC interpreter, which pretty much acted as an operating system. There was no such thing as an operating system back in 1974 in these personal computers, and we couldn't get through to him. We couldn't explain to him that, "Sell us the manual for 100 bucks, and let us just take the software." He wasn't hearing any of this, and for years Microsoft software was overpriced and pirated, pirated terribly.
**27:51** - *Saron Yitbarek*
The club members chose to ignore the letter. That's because back in 1975, copyright laws didn't cover software. There was no penalty for copying the software from one paper tape to another. That would change in 1977, but for a couple of years there, no law was being violated.
**28:12** - *John Markoff*
The irony here of course is that Bill Gates didn't create the BASIC language. He simply created a copy of it, taking it from its original designer who was a professor at Dartmouth University and basically making a copy and then selling it, so it all had its roots in sharing.
**28:31** - *Saron Yitbarek*
The heist, the tape, sharing, the angry letter. All of that led to a decades long war between the burgeoning software industry and those they considered pirates, but out of that struggle grew the open source software movement. Its core values are cut from the same cloth as those early hobbyists who ignited the personal computer revolution, because those hobbyists realized that the key to the future of personal computing lay in unleashing the potential of software.
**29:07** - *Lee Felsenstein*
The process of passing the tapes around and encouraging and building upon each other's results is really what made the personal computer industry.
**29:17** - *Saron Yitbarek*
Now, we never did say who the original thief was, the one who made the heist of that precious paper tape. That's because it's still a mystery to this day. Those who know prefer to keep it that way.
**29:32** - *Dan Sokol*
As far as how it was liberated, if you want to use that word, I know who did it, and I will not say because that person has asked a long time ago, to remain anonymous because it was safer, and so I have honored that and I will continue to honor that. So no, I was not at Rickey's, but the paper tape found its way to me.
**30:01** - *Saron Yitbarek*
In time, the personal computer revolution gave way to Silicon Valley and multitudes of VC-backed tech startups, but those tinkerers, those electronic enthusiasts and hobbyists, they never went away. In fact, they're stronger than ever.
**30:20** - *Limor Fried*
Hi, my name is Limor Fried, and I'm lead engineer and founder of Adafruit Industries.
**30:26** - *Saron Yitbarek*
Adafruit is an open source hardware company, part of a new revolution that started up in the past few years, the open source hardware movement, and this movement shares the same values of those early hobbyists. But it's gotten even better.
**30:43** - *Limor Fried*
The Homebrew Computer Club, I think, had that philosophy where people were coming in with their computers, and it was a little bit like, "Check this cool hack I did," and then everyone was like, "Damn, that's cool. Okay, next month I got to bring something better." And that is a positive feedback cycle that brings really good technological innovation. I think that hacker philosophy still exists. People have just more background and so what they think of as a cool hack has really, I want to say improved, but it has diffused, and I think that's good. But I think the values of sharing are still there and helping each other and working together and cooperation. That thread has passed through. I mean, it's in the entire open source community.
**31:32** - *Saron Yitbarek*
We're going to dedicate a whole episode to the emergence of the open source hardware movement so we can see how we've evolved and made space for modern makers like Limor Fried. Stay tuned for that, episode 6, in a few weeks time. But next episode, it's the discs that changed the world—floppies.
**31:56** - *Saron Yitbarek*
Command Line Heroes is an original podcast from Red Hat. Head on over to [redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) for some great research on the personal computer revolution. There's a beautiful anecdote you can read there about Bill Gates visiting Ed Roberts on his deathbed, and if you want to know what happened during that PC revolution, check out our very first couple of Command Line Heroes episodes for the whole story, [the OS wars](https://www.redhat.com/en/command-line-heroes/season-1). I'm Saron Yitbarek. Until next time, keep on coding.
### Further reading
[ First Invite to the Homebrew Computer Club](https://blog.adafruit.com/2015/01/12/homebrew-computer-club-invite-from-1975) by Fred Moore
[ The Altair story; early days at MITS](https://www.atarimagazines.com/creative/v10n11/17_The_Altair_story_early_d.php) by Forrest M. Mims III
[ WIRED article on the Altair](https://www.wired.com/2011/12/1219altair-8800-computer-kit-goes-on-sale) by Randy Alfred
[ Video: Demo of the Altair](https://www.youtube.com/watch?v=vAhp_LzvSWk) by Don Russ
[ PC Mag article on Altair](https://www.pcmag.com/news/the-altair-8800-the-machine-that-launched-the-pc-revolution) by Michael J. Miller
### Bonus episode
Forrest Mims had a lot to say about Ed Roberts. Hear more stories about Ed's meeting with Paul Allen and Bill Gates, and the partnership they started. |
13,399 | OpenStreetMap:社区驱动的谷歌地图替代品 | https://itsfoss.com/openstreetmap/ | 2021-05-17T19:25:00 | [
"OpenStreetMap",
"地图"
] | https://linux.cn/article-13399-1.html |
>
> 作为谷歌地图的潜在替代品,OpenStreetMap 是一个由社区驱动的地图项目,在本文中我们将了解更多关于这个开源项目的信息。
>
>
>
[OpenStreetMap](https://www.openstreetmap.org/)(OSM)是一个可自由编辑的世界地图,任何人都可以对 OpenStreetMap 贡献、编辑和修改,以对其进行改进。

查看地图并不需要帐号,但如果你想要编辑或增加地图信息,就得先注册一个帐号了。
尽管 OpenStreetMap 以 [开放数据库许可证](https://opendatacommons.org/licenses/odbl/) 授权,可以自由使用,但也有所限制 —— 你不能使用地图 API 在 OpenStreetMap 之上建立另一个服务来达到商业目的。
因此,你可以下载地图数据来使用,以及在标示版权信息的前提下自己托管这些数据。可以在 OpenStreetMap 的官方网站上了解更多关于其 [API 使用政策](https://operations.osmfoundation.org/policies/api/) 和 [版权](https://www.openstreetmap.org/copyright) 的信息。
在这篇文章中,我们将简单看看 OpenStreetMap 是如何工作的,以及什么样的项目使用 OpenStreetMaps 作为其地图数据的来源。
### OpenStreetMap:概述

OpenStreetMap 是很好的谷歌地图替代品,虽然你无法得到和谷歌地图一样的信息水平,但对于基本的导航和旅行来说,OpenStreetMap 已经足够了。
就像其他地图一样,你能够在地图的多个图层间切换,了解自己的位置,并轻松地查找地点。
你可能找不到关于附近企业、商店和餐馆的所有最新信息。但对于基本的导航来说,OpenStreetMap 已经足够了。
通常可以通过网页浏览器在桌面和手机上访问 [OpenStreetMap 的网站](https://www.openstreetmap.org) 来使用 OpenStreetMap,它还没有一个官方的安卓/iOS 应用程序。
然而,也有各种各样的应用程序在其核心中使用了 OpenStreetMap。因此,如果你想在智能手机上使用 OpenStreetMap,你可以看看一些流行的谷歌地图开源替代:
* [OsmAnd](https://play.google.com/store/apps/details?id=net.osmand)
* [MAPS.ME](https://play.google.com/store/apps/details?id=com.mapswithme.maps.pro)
**[MAPS.ME](http://MAPS.ME)** 和 **OsmAnd** 是两个适用于安卓和 iOS 的开源应用程序,它们利用 OpenStreetMap 的数据提供丰富的用户体验,并在应用中添加了一堆有用的信息和功能。
如果你愿意,也可以选择其他专有选项,比如 [Magic Earth](https://www.magicearth.com/)。
无论是哪种情况,你都可以在 OpenStreetMap 的官方维基页面上看一下适用于 [安卓](https://wiki.openstreetmap.org/wiki/Android#OpenStreetMap_applications) 和 [iOS](https://wiki.openstreetmap.org/wiki/Apple_iOS) 的大量应用程序列表。
### 在 Linux 上使用 OpenStreetMap

在 Linux 上使用 OpenStreetMap 最简单的方法就是在网页浏览器中使用它。如果你使用 GNOME 桌面环境,可以安装 GNOME 地图,它是建立在 OpenStreetMap 之上的。
还有几个软件(大多已经过时了)在 Linux 上使用 OpenStreetMap 来达到特定目的,你可以在 OpenStreetMap 的 [官方维基列表](https://wiki.openstreetmap.org/wiki/Linux) 中查看可用软件包的列表。
### 总结
对于最终用户来说,OpenStreetMap 可能不是最好的导航源,但是它的开源模式允许它被自由使用,这意味着可以用 OpenStreetMap 来构建许多服务。例如,[ÖPNVKarte](http://xn--pnvkarte-m4a.de/) 使用 OpenStreetMap 在一张统一的地图上显示全世界的公共交通设施,这样你就不必再浏览各个运营商的网站了。
你对 OpenStreetMap 有什么看法?你能用它作为谷歌地图的替代品吗?欢迎在下面的评论中分享你的想法。
---
via: <https://itsfoss.com/openstreetmap/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[rakino](https://github.com/rakino) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: OpenStreetMap is a community-driven map – which is a potential alternative to Google Maps. Learn more about this open source project.*
[OpenStreetMap](https://www.openstreetmap.org/) (OSM) is a free editable map of the world. Anyone can contribute, edit, and make changes to the OpenStreetMap to improve it.
You need to sign up for an account first – in order to be able to edit or add information to the OpenStreetMap. To view the map, you wouldn’t need an account.
Even though it’s a free-to-use map under an [open data license](https://opendatacommons.org/licenses/odbl/), you cannot use the map API to build another service on top of it for commercial purpose.
So, you can download the map data to use it and host it yourself while mentioning the credits to OSM. You can learn more about its [API usage policy](https://operations.osmfoundation.org/policies/api/) and [copyright](https://www.openstreetmap.org/copyright) information on its official website to learn more.
In this article, we shall take a brief look at how it works and what kind of projects use OpenStreetMaps as the source of their map data.
## OpenStreetMap: Overview
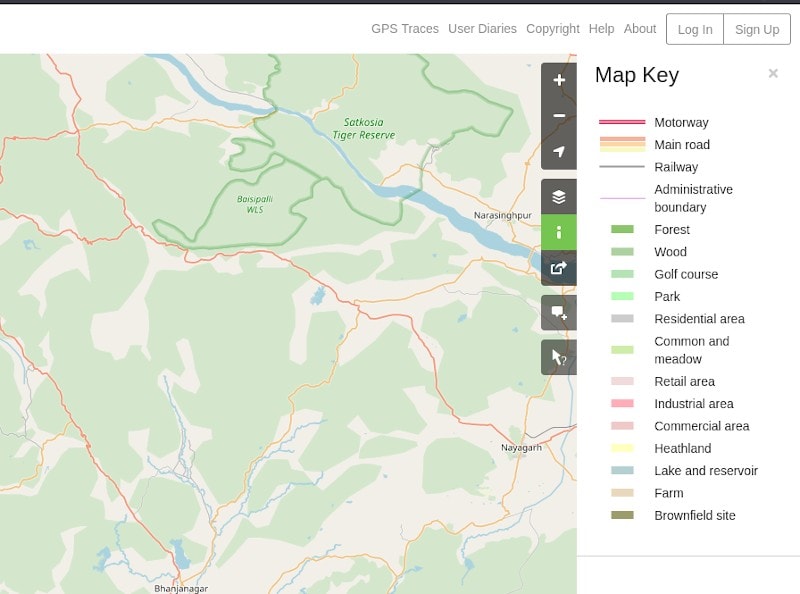
OpenStreetMap is a good alternative to Google Maps. You might not get the same level of information as Google Maps- but for basic navigation and traveling, OpenStreetMap is sufficient.
Just like any other map, you will be able to switch between multiple layers in the map, get to know your location, and easily search for places.
You may not find all the latest information for the businesses, shops, and restaurants nearby. But, for basic navigation, it’s more than enough.
OpenStreetMap can be usually accessed through a web browser on both desktop and mobile by visiting the [OpenStreetMap site](https://www.openstreetmap.org). It does not have an official Android/iOS app yet.
However, there are a variety of applications available that utilize OpenStreetMap at its core. So, if you want to utilize OpenStreetMap on a smartphone, you can take a look at some of the popular open-source Google Maps alternatives:
**MAPS.ME** and **OsmAnd** are two open-source applications for Android and iOS that utilize OpenStreetMap data to provide a rich user experience with a bunch of useful information and features added to it.
You can also opt for other proprietary options if you wish, like [Magic Earth](https://www.magicearth.com/).
In either case, you can take a look at the extensive list of applications on their official wiki page for [Android](https://wiki.openstreetmap.org/wiki/Android#OpenStreetMap_applications) and [iOS](https://wiki.openstreetmap.org/wiki/Apple_iOS).
## Using OpenStreetMap On Linux
The easiest way to use OpenStreetMap on Linux is to use it in a web browser. If you use GNOME desktop environment, you can install GNOME Maps which is built on top of OpenStreetMap.
There are also several software (that are mostly obsolete) that utilize OpenStreetMap on Linux for specific purposes. You can check out the list of available packages in their [official wiki list](https://wiki.openstreetmap.org/wiki/Linux).
## Wrapping Up
OpenStreetMap may not be the best source for navigation for end users but its open source model allows it to be used freely. This means that many services can be built using OpenStreetMap. For example, [ÖPNVKarte](http://xn--pnvkarte-m4a.de/) uses OpenStreetMap to display worldwide public transport facilities on a uniform map so that you don’t have to browse individual operator’s websites.
What do you think about OpenStreetMap? Can you use it as a Google Maps alternative? Feel free to share your thoughts in the comments below. |
13,401 | 用 Ttyper 测试你在 Linux 终端的打字速度 | https://itsfoss.com/ttyper/ | 2021-05-18T09:23:15 | [
"打字",
"终端"
] | https://linux.cn/article-13401-1.html | 
有几种方法可以测试和提高你的打字速度。你可以使用在线工具,在桌面上安装专门的应用,或者在 Linux 终端测试。
Linux 终端?是的。从 [浏览互联网](https://itsfoss.com/terminal-web-browsers/) 到 [玩游戏](https://itsfoss.com/best-command-line-games-linux/),你可以在强大的 Linux 终端中做 [许多有趣的事情](https://itsfoss.com/funny-linux-commands/)。测试你的打字速度就是其中之一。
### Ttyper:基于终端的打字测试工具
[Ttyper](https://github.com/max-niederman/ttyper) 是一个用 [Rust](https://www.rust-lang.org/) 编写的工具,允许你练习打字。
它给出了一些最常见的英语单词的随机选择。打出的正确单词用绿色突出显示,错误的用红色突出显示,而且这是实时发生的。你可以按退格键纠正单词,但这将导致分数下降。

当你打完所有显示的单词后,你会得到你的打字速度(每分钟字数)、准确率和正确按键数的结果。如果你没有心情打完全部,你可以使用 `Ctrl+C` 退出 Ttyper。

你可以在这个由开发者录制的 GIF 中看到 Ttyper 的操作。

默认情况下,你有 50 个单词可以练习,但你可以用命令选项来扩大。你还可以使用一个自定义的文本文件,用它的内容来练习打字。
| 命令 | 内容 |
| --- | --- |
| `ttyper` | 200 个最常见的英语单词中的 50 个 |
| `ttyper -w 100` | 200 个最常见的英语单词中的 100 个 |
| `ttyper -w 100 -l english1000` | 1000 个最常见的英语单词中的 100 个 |
| `ttyper text.txt` | 内容来自用空格分隔的 `test.txt` |
Ttyper 也专注于开发者。它支持几种编程语言,如果你是一个程序员,你可以用它来测试和改进你在编码时的打字速度。

截至目前,支持 C、Csharp、Go、HTML、Java、JavaScript、Python、Ruby 和 Rust 语言。
你可以通过以下方式改变语言:
```
ttyper -l html
```
顺便说一下,“Ttyper” 中的双 “T” 不是一个打字错误。它是故意的,因为TTY(**T**ele**TY**pewriter)代表 [终端模拟器](https://itsfoss.com/linux-terminal-emulators/),表明它是一个终端工具。
### 在 Linux 上安装 Ttyper
Ttyper 是用 Rust 构建的,你可以把它安装在任何支持 Rust 编程语言及其 [Cargo 软件包管理器](https://doc.rust-lang.org/cargo/index.html)的 Linux 发行版上。
Cargo 相当于 Python 中的 PIP。它有一个[中央仓库](https://crates.io/),你可以用 Cargo 轻松地下载和安装 Rust 包和它的依赖项。
我将添加在基于 Ubuntu 的 Linux 发行版上安装 Cargo 的说明。你应该可以用你的[发行版的包管理器](https://itsfoss.com/package-manager/)来安装它。
请确保你在 Ubuntu 上启用了 universe 仓库。你可以用这个命令来安装 Cargo:
```
sudo apt install cargo
```
它将安装 Cargo 包管理器和 Rust 语言的 `rustc` 包。
当你的系统安装了 Cargo,就可以用这个命令来安装 Ttyper:
```
cargo install ttyper
```
这将在你的主目录下的 `.cargo/bin` 目录中添加一个可执行 Rust 文件。它将在软件包安装输出的最后显示。

你可以切换到这个目录:
```
cd ~/.cargo/bin
```
并运行 `ttyper` 可执行文件:
```
./ttyper
```
当然,这不是很方便。这就是为什么你应该 [把这个目录添加到 PATH 变量中](https://itsfoss.com/add-directory-to-path-linux/)。如果你熟悉 Linux 的命令行,你可以很容易做到这一点。
不幸的是,我不能在这里给你确切的命令,因为你需要提供这个目录的绝对路径,而这个路径名称会根据你的用户名而不同。例如,对我来说,它是 `/home/abhishek/.cargo/bin`。这个绝对路径对你来说会有所不同。
我建议阅读 [绝对路径和相对路径](https://linuxhandbook.com/absolute-vs-relative-path/) 以了解更多关于这个问题的信息。
你可以通过删除二进制文件来卸载 Ttyper,或者用 Cargo 命令来卸载:
```
cargo uninstall ttyper
```
如果你喜欢这个灵巧的终端工具,[在 GitHub 上给它加星](https://github.com/max-niederman/ttyper) 以感谢开发者的努力。
正如我在本文开头提到的,你可以在终端做很多很酷的事情。如果你想给你的同事一个惊喜,也许你可以试试 [完全在 Linux 终端中制作幻灯片][12]。
---
via: <https://itsfoss.com/ttyper/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are several ways to test and improve your typing speed. You can use online tools, install dedicated applications on the desktop or test in the Linux terminal.
Linux terminal? That’s right. From [browsing internet](https://itsfoss.com/terminal-web-browsers/) to [playing games](https://itsfoss.com/best-command-line-games-linux/), you can do [so many fun things in the mighty Linux terminal](https://itsfoss.com/funny-linux-commands/). Testing your typing speed is one of them.
## Ttyper: Terminal-based typing test tool
[Ttyper](https://github.com/max-niederman/ttyper) is a tool written in [Rust](https://www.rust-lang.org/) that allows you to practice your touch typing.
It gives a random selection of some of the most common English words. The correct typed words are highlighted in green and the incorrect ones in red and this happens in real time. You can press backspace and correct the words but that will contribute to a reduced score.
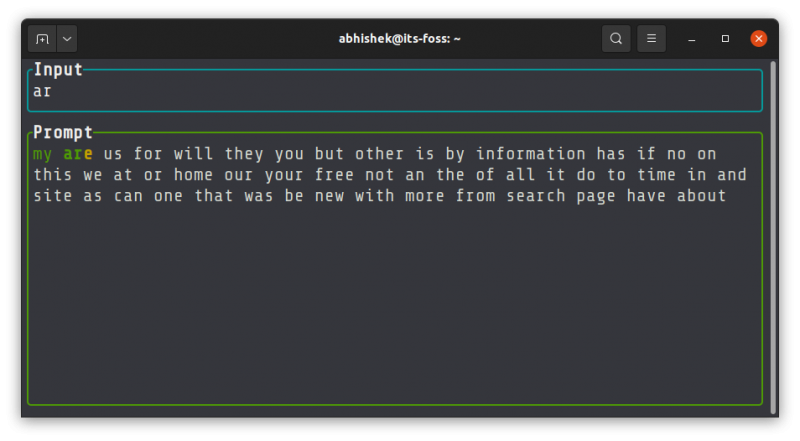
When you finish typing all the displayed words, you get the result with your typing speed in words per minute, accuracy and number of correct keypresses. You can ** use Ctrl+C to exit** Ttyper if you are not in a mood for typing the entire section.
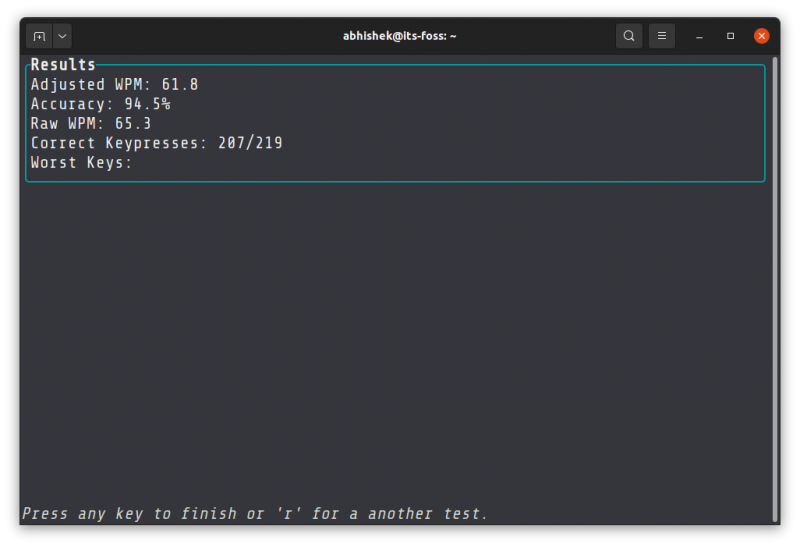
You can see Ttyper in action in this GIF recorded by the developer.

By default, you get 50 words to practice but you may expand that with command options. You can also use a custom text file and use its content to practice typing.
Command | Contents |
---|---|
ttyper | 50 of the 200 most common English words |
ttyper -w 100 | 100 of the 200 most common English words |
ttyper -w 100 -l english1000 | 100 of the 1000 most common English words |
ttyper text.txt | contents of test.txt split at whitespace |
Ttyper also focuses on developers. It supports several programming languages and if you are a programmer, you may use it to test and improve your typing while you code.
As of now, C, Csharp, Go, HTML, Java, JavaScript, Python, Ruby and Rust languages are supported.
You may change the language in the following manner:
`ttyper -l html`
By the way, the double ‘T’ in ‘Ttyper’ is not a typo. It is deliberate as [TTY](https://itsfoss.com/what-is-tty-in-linux/) (**T**ele**TY**pewriter) represent the [terminal emulator](https://itsfoss.com/linux-terminal-emulators/), an indication that it is a terminal tool.
**Recommended Read:**
## Installing Ttyper on Linux
Ttyper is built with Rust and you can install it on any Linux distribution that has support for Rust programming language and its [Cargo package manager](https://doc.rust-lang.org/cargo/index.html).
Cargo is the Rust equivalent to Python’s PIP. There is a [central repository](https://crates.io/) and you can download and install the Rust packages along with its dependencies easily with Cargo.
I am going to add the [instructions for installing Rust and Cargo on Ubuntu-based Linux distributions](https://itsfoss.com/install-rust-cargo-ubuntu-linux/). You should be able to install it using your [distribution’s package manager](https://itsfoss.com/package-manager/).
Please make sure that you have universe repository enabled on Ubuntu. You can install Cargo with this command:
`sudo apt install cargo`
It will install Cargo package manager along with `rustc`
package for Rust language.
Once you have Cargo installed on your system, use it install Ttyper with this command:
`cargo install ttyper`
This will add an executable rust file in .cargo/bin directory under your home directory. It will be mentioned at the end of the output of the package installation.
You may switch to this directory:
`cd ~/.cargo/bin`
and run the ttyper executable:
`ttyper`
Of course, it’s not very convenient. This is why you should [add this directory to the PATH variable](https://itsfoss.com/add-directory-to-path-linux/). If you are familiar with the Linux command line, you can easily do that.
Unfortunately, I cannot give you the exact commands here because you need to provide the absolute PATH to this directory and that path name will differ based on your username. For example, for me, it is /home/abhishek/.cargo/bin. This absolute PATH will be different for you.
I advise reading about [absolute and relative path](https://linuxhandbook.com/absolute-vs-relative-path/) for more clarity on this topic.
You can uninstall Ttyper by removing the binary file or use Cargo command in this manner:
`cargo uninstall ttyper`
If you like this nifty terminal tool, [star it on GitHub](https://github.com/max-niederman/ttyper) to appreciate the developer’s effort.
As I mentioned at the beginning of this article, you can do a lot of cool stuff in the terminal. If you want to surprise your colleagues, maybe you can try [making presentation slides entirely in the Linux terminal](https://itsfoss.com/presentation-linux-terminal/). |
13,402 | 使用 systemd 来管理启动项 | https://opensource.com/article/20/5/manage-startup-systemd | 2021-05-18T11:00:06 | [
"systemd",
"启动"
] | https://linux.cn/article-13402-1.html |
>
> 了解 systemd 是怎样决定服务启动顺序,即使它本质上是个并行系统。
>
>
>

最近在设置 Linux 系统时,我想知道如何确保服务和其他单元的依赖关系在这些依赖于它们的服务和单元启动之前就已经启动并运行了。我需要更多 systemd 如何管理启动程序的相关知识,特别是在本质上是一个并行的系统中如何是决定服务启动顺序的。
你可能知道 SystemV(systemd 的前身,我在这个系列的 [第一篇文章](/article-12214-1.html) 中解释过)通过 Sxx 前缀命名启动脚本来决定启动顺序,xx 是一个 00-99 的数字。然后 SystemV 利用文件名来排序,然后按照所需的运行级别执行队列中每个启动脚本。
但是 systemd 使用单元文件来定义子程序,单元文件可由系统管理员创建或编辑,这些文件不仅可以用于初始化时也可以用于常规操作。在这个系列的 [第三篇文章](https://opensource.com/article/20/5/systemd-units) 中,我解释了如何创建一个挂载单元文件。在第五篇文章中,我解释了如何创建一种不同的单元文件 —— 在启动时执行一个程序的服务单元文件。你也可以修改单元文件中某些配置,然后通过 systemd 日志去查看你的修改在启动序列中的位置。
### 准备工作
先确认你已经在 `/etc/default/grub` 文件中的 `GRUB_CMDLINE_LINUX=` 这行移除了 `rhgb` 和 `quiet`,如同我在这个系列的 [第二篇文章](https://opensource.com/article/20/5/systemd-startup) 中展示的那样。这让你能够查看 Linux 启动信息流,你在这篇文章中部分实验中需要用到。
### 程序
在本教程中,你会创建一个简单的程序让你能够在主控台和后续的 systemd 日志中查看启动时的信息。
创建一个 shell 程序 `/usr/local/bin/hello.sh` 然后添加下述内容。你要确保执行结果在启动时是可见的,可以轻松的在 systemd 日志中找到它。你会使用一版携带一些方格的 “Hello world” 程序,这样它会非常显眼。为了确保这个文件是可执行的,且为了安全起见,它需要 root 的用户和组所有权和 [700 权限](https://chmodcommand.com/chmod-700/)。
```
#!/usr/bin/bash
# Simple program to use for testing startup configurations
# with systemd.
# By David Both
# Licensed under GPL V2
#
echo "###############################"
echo "######### Hello World! ########"
echo "###############################"
```
在命令行中执行这个程序来检查它能否正常运行。
```
[root@testvm1 ~]# hello.sh
###############################
######### Hello World! ########
###############################
[root@testvm1 ~]#
```
这个程序可以用任意脚本或编译语言实现。`hello.sh` 程序可以被放在 [Linux 文件系统层级结构](https://opensource.com/life/16/10/introduction-linux-filesystems)(FHS)上的任意位置。我把它放在 `/usr/local/bin` 目录下,这样它可以直接在命令行中执行而不必在打命令的时候前面带上路径。我发现我创建的很多 shell 程序需要从命令行和其他工具(如 systemd)运行。
### 服务单元文件
创建服务单元文件 `/etc/systemd/system/hello.service`,写入下述内容。这个文件不一定是要可执行的,但是为了安全起见,它需要 root 的用户和组所有权和 [644](https://chmodcommand.com/chmod-644/) 或 [640](https://chmodcommand.com/chmod-640/) 权限。
```
# Simple service unit file to use for testing
# startup configurations with systemd.
# By David Both
# Licensed under GPL V2
#
[Unit]
Description=My hello shell script
[Service]
Type=oneshot
ExecStart=/usr/local/bin/hello.sh
[Install]
WantedBy=multi-user.target
```
通过查看服务状态来确认服务单元文件能如期运行。如有任何语法问题,这里会显示错误。
```
[root@testvm1 ~]# systemctl status hello.service
● hello.service - My hello shell script
Loaded: loaded (/etc/systemd/system/hello.service; disabled; vendor preset: disabled)
Active: inactive (dead)
[root@testvm1 ~]#
```
你可以运行这类 “oneshot”(单发)类型的服务多次而不会有问题。此类服务适用于服务单元文件启动的程序是主进程,必须在 systemd 启动任何依赖进程之前完成的服务。
共有 7 种服务类型,你可以在 [systemd.service(5)](http://man7.org/linux/man-pages/man5/systemd.service.5.html) 的手册页上找到每一种(以及服务单元文件的其他部分)的详细解释。(你也可以在文章末尾的 [资料](file:///Users/xingyuwang/develop/TranslateProject-wxy/translated/tech/tmp.bYMHU00BHs#resources) 中找到更多信息。)
出于好奇,我想看看错误是什么样子的。所以我从 `Type=oneshot` 这行删了字母 “o”,现在它看起来是这样 `Type=neshot`,现在再次执行命令:
```
[root@testvm1 ~]# systemctl status hello.service
● hello.service - My hello shell script
Loaded: loaded (/etc/systemd/system/hello.service; disabled; vendor preset: disabled)
Active: inactive (dead)
May 06 08:50:09 testvm1.both.org systemd[1]: /etc/systemd/system/hello.service:12: Failed to parse service type, ignoring: neshot
[root@testvm1 ~]#
```
执行结果明确地告诉我错误在哪,这样解决错误变得十分容易。
需要注意的是即使在你将 `hello.service` 文件保存为它原来的形式之后,错误依然存在。虽然重启机器能消除这个错误,但你不必这么做,所以我去找了一个清理这类持久性错误的方法。我曾遇到有些错误需要 `systemctl daemon-reload` 命令来重置错误状态,但是在这个例子里不起作用。可以用这个命令修复的错误似乎总是有一个这样的声明,所以你知道要运行它。
然而,每次修改或新建一个单元文件之后执行 `systemctl daemon-reload` 确实是值得推荐的做法。它提醒 systemd 有修改发生,而且它可以防止某些与管理服务或单元相关的问题。所以继续去执行这条命令吧。
在修改完服务单元文件中的拼写错误后,一个简单的 `systemctl restart hello.service` 命令就可以清除错误。实验一下,通过添加一些其他的错误至 `hello.service` 文件来看看会得到怎样的结果。
### 启动服务
现在你已经准备好启动这个新服务,通过检查状态来查看结果。尽管你可能之前已经重启过,你仍然可以启动或重启这个单发服务任意次,因为它只运行一次就退出了。
继续启动这个服务(如下所示),然后检查状态。你的结果可能和我的有区别,取决于你做了多少试错实验。
```
[root@testvm1 ~]# systemctl start hello.service
[root@testvm1 ~]# systemctl status hello.service
● hello.service - My hello shell script
Loaded: loaded (/etc/systemd/system/hello.service; disabled; vendor preset: disabled)
Active: inactive (dead)
May 10 10:37:49 testvm1.both.org hello.sh[842]: ######### Hello World! ########
May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
[root@testvm1 ~]#
```
从状态检查命令的输出中我们可以看到,systemd 日志表明 `hello.sh` 启动然后服务结束了。你也可以看到脚本的输出。该输出是根据服务的最近调用的日志记录生成的,试试看多启动几次这个服务,然后再看状态命令的输出就能理解我所说的。
你也应该直接查看日志内容,有很多种方法可以实现。一种办法是指定记录类型标识符,在这个例子中就是 shell 脚本的名字。它会展示前几次重启和当前会话的日志记录。如你所见,我已经为这篇文章做了挺长一段时间的研究测试了。
```
[root@testvm1 ~]# journalctl -t hello.sh
<剪去>
-- Reboot --
May 08 15:55:47 testvm1.both.org hello.sh[840]: ###############################
May 08 15:55:47 testvm1.both.org hello.sh[840]: ######### Hello World! ########
May 08 15:55:47 testvm1.both.org hello.sh[840]: ###############################
-- Reboot --
May 08 16:01:51 testvm1.both.org hello.sh[840]: ###############################
May 08 16:01:51 testvm1.both.org hello.sh[840]: ######### Hello World! ########
May 08 16:01:51 testvm1.both.org hello.sh[840]: ###############################
-- Reboot --
May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
May 10 10:37:49 testvm1.both.org hello.sh[842]: ######### Hello World! ########
May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
[root@testvm1 ~]#
```
为了定位 `hello.service` 单元的 systemd 记录,你可以在 systemd 中搜索。你可以使用 `G+Enter` 来翻页到日志记录 记录的末尾,然后用回滚来找到你感兴趣的日志。使用 `-b` 选项仅展示最近启动的记录。
```
[root@testvm1 ~]# journalctl -b -t systemd
<剪去>
May 10 10:37:49 testvm1.both.org systemd[1]: Starting SYSV: Late init script for live image....
May 10 10:37:49 testvm1.both.org systemd[1]: Started SYSV: Late init script for live image..
May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:37:50 testvm1.both.org systemd[1]: Starting D-Bus System Message Bus...
May 10 10:37:50 testvm1.both.org systemd[1]: Started D-Bus System Message Bus.
```
我拷贝了一些其他的日志记录,让你对你可能找到的东西有所了解。这条命令喷出了所有属于 systemd 的日志内容 —— 当我写这篇时是 109183 行。这是一个需要整理的大量数据。你可以使用页面的搜索功能,通常是 `less` 或者你可以使用内置的 `grep` 特性。`-g`( 或 `--grep=`)选项可以使用兼容 Perl 的正则表达式。
```
[root@testvm1 ~]# journalctl -b -t systemd -g "hello"
[root@testvm1 ~]# journalctl -b -t systemd -g "hello"
-- Logs begin at Tue 2020-05-05 18:11:49 EDT, end at Sun 2020-05-10 11:01:01 EDT. --
May 10 10:37:49 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
[root@testvm1 ~]#
```
你可以使用标准的 GNU `grep` 命令,但是这不会展示日志首行的元数据。
如果你只想看包含你的 `hello` 服务的日志记录,你可以指定时间来缩小范围。举个例子,我将在我的测试虚拟机上以 `10:54:00` 为开始时间,这是上述的日志记录开始的分钟数。注意 `--since=` 的选项必须加引号,这个选项也可以写成 `-S "某个时间"`。
日期和时间可能在你的机器上有所不同,所以确保使用能匹配你日志中的时间的时间戳。
```
[root@testvm1 ~]# journalctl --since="2020-05-10 10:54:00"
May 10 10:54:35 testvm1.both.org audit: BPF prog-id=54 op=LOAD
May 10 10:54:35 testvm1.both.org audit: BPF prog-id=55 op=LOAD
May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd"'
May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/"'
May 10 10:56:00 testvm1.both.org NetworkManager[840]: <error> [1589122560.0633] dhcp4 (enp0s3): error -113 dispatching events
May 10 10:56:00 testvm1.both.org NetworkManager[840]: <info> [1589122560.0634] dhcp4 (enp0s3): state changed bound -> fail
<剪去>
```
`since` 选项跳过了指定时间点的所有记录,但在此时间点之后仍有大量你不需要的记录。你也可以使用 `until` 选项来裁剪掉你感兴趣的时间之后的记录。我想要事件发生时附近的一分钟,其他的都不用:
```
[root@testvm1 ~]# journalctl --since="2020-05-10 10:54:35" --until="2020-05-10 10:55:00"
-- Logs begin at Tue 2020-05-05 18:11:49 EDT, end at Sun 2020-05-10 11:04:59 EDT. --
May 10 10:54:35 testvm1.both.org systemd[1]: Reloading.
May 10 10:54:35 testvm1.both.org audit: BPF prog-id=27 op=UNLOAD
May 10 10:54:35 testvm1.both.org audit: BPF prog-id=26 op=UNLOAD
<剪去>
ay 10 10:54:35 testvm1.both.org audit: BPF prog-id=55 op=LOAD
May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd>
May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/>
lines 1-46/46 (END)
```
如果在这个时间段中仍然有大量的活动的话,你可以使用这些选项组合来进一步缩小结果数据流:
```
[root@testvm1 ~]# journalctl --since="2020-05-10 10:54:35" --until="2020-05-10 10:55:00" -t "hello.sh"
-- Logs begin at Tue 2020-05-05 18:11:49 EDT, end at Sun 2020-05-10 11:10:41 EDT. --
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
[root@testvm1 ~]#
```
你的结果应该与我的相似。你可以从这一系列的实验中看出,这个服务运行的很正常。
### 重启 —— 还是走到这一步
到目前为止,你还没有重启过安装了服务的机器。所以现在重启吧,因为毕竟这个教程是关于启动阶段程序运行的情况。首先,你需要在启动序列中启用这个服务。
```
[root@testvm1 ~]# systemctl enable hello.service
Created symlink /etc/systemd/system/multi-user.target.wants/hello.service → /etc/systemd/system/hello.service.
[root@testvm1 ~]#
```
注意到这个软链接是被创建在 `/etc/systemd/system/multi-user.target.wants` 目录下的。这是因为服务单元文件指定了服务是被 `multi-user.target` 所“需要”的。
重启机器,确保能在启动阶段观察数据流,这样你能看到 “Hello world” 信息。等等……你看见了么?嗯,我看见了。尽管它很快被刷过去了,但是我确实看到 systemd 的信息显示它启动了 `hello.service` 服务。
看看上次系统启动后的日志。你可以使用页面搜索工具 `less` 来找到 “Hello” 或 “hello”。我裁剪了很多数据,但是留下了附近的日志记录,这样你就能感受到和你服务有关的日志记录在本地是什么样子的:
```
[root@testvm1 ~]# journalctl -b
<剪去>
May 10 10:37:49 testvm1.both.org systemd[1]: Listening on SSSD Kerberos Cache Manager responder socket.
May 10 10:37:49 testvm1.both.org systemd[1]: Reached target Sockets.
May 10 10:37:49 testvm1.both.org systemd[1]: Reached target Basic System.
May 10 10:37:49 testvm1.both.org systemd[1]: Starting Modem Manager...
May 10 10:37:49 testvm1.both.org systemd[1]: Starting Network Manager...
May 10 10:37:49 testvm1.both.org systemd[1]: Starting Avahi mDNS/DNS-SD Stack...
May 10 10:37:49 testvm1.both.org systemd[1]: Condition check resulted in Secure Boot DBX (blacklist) updater being skipped.
May 10 10:37:49 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:37:49 testvm1.both.org systemd[1]: Starting IPv4 firewall with iptables...
May 10 10:37:49 testvm1.both.org systemd[1]: Started irqbalance daemon.
May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=irqbalance comm="systemd" exe="/usr/lib/sy>"'
May 10 10:37:49 testvm1.both.org systemd[1]: Starting LSB: Init script for live image....
May 10 10:37:49 testvm1.both.org systemd[1]: Starting Hardware Monitoring Sensors...
<剪去>
May 10 10:37:49 testvm1.both.org systemd[1]: Starting NTP client/server...
May 10 10:37:49 testvm1.both.org systemd[1]: Starting SYSV: Late init script for live image....
May 10 10:37:49 testvm1.both.org systemd[1]: Started SYSV: Late init script for live image..
May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=livesys-late comm="systemd" exe="/usr/lib/>"'
May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
May 10 10:37:49 testvm1.both.org hello.sh[842]: ######### Hello World! ########
May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd>"'
May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/>
May 10 10:37:50 testvm1.both.org audit: BPF prog-id=28 op=LOAD
<剪去>
```
你可以看到 systemd 启动了 `hello.service` 单元,它执行了 `hello.sh` 脚本并将输出记录在日志中。如果你能在启动阶段抓到它,你也应该能看见,systemd 信息表明了它正在启动这个脚本,另外一条信息表明了服务成功。通过观察上面数据流中第一条 systemd 消息,你会发现 systemd 在到达基本的系统目标后很快就启动了你的服务。
但是我想看见信息在启动阶段也被打印出来。有一种方法可以做到:在 `hello.service` 文件的 `[Service]` 段中加入下述行:
```
StandardOutput=journal+console
```
现在 `hello.service` 文件看起来像这样:
```
# Simple service unit file to use for testing
# startup configurations with systemd.
# By David Both
# Licensed under GPL V2
#
[Unit]
Description=My hello shell script
[Service]
Type=oneshot
ExecStart=/usr/local/bin/hello.sh
StandardOutput=journal+console
[Install]
WantedBy=multi-user.target
```
加上这一行后,重启系统,并在启动过程中观察显示屏上滚动的数据流。你应该在它的小方框中看到信息。在启动序列完成后,你可以查看最近的启动日志,然后定位到你新服务的日志记录。
### 修改次序
现在你的服务已经可用了,你可以看看它在启动序列中哪个位置启动的,尝试下修改它。需要牢记的是 systemd 倾向于在每个主要目标(`basic.target`、`multi-user.target` 和 `graphical.**target`)中并行启动尽可能多的服务和其他的单元类型。你应该刚刚看过最近一次开机的日志记录,它应该和上面我的日志看上去类似。
注意,systemd 在它到达到基本系统目标(`basic.target`)后不久就启动了你的测试服务。这正是你在在服务单元文件的 `WantedBy` 行中指定的,所以它是对的。在你做出修改之前,列出 `/etc/systemd/system/multi-user.target.wants` 目录下的内容,你会看到一个指向服务单元文件的软链接。服务单元文件的 `[Install]` 段指定了哪一个目标会启动这个服务,执行 `systemctl enable hello.service` 命令会在适当的 `targets.wants` 路径下创建软链接。
```
hello.service -> /etc/systemd/system/hello.service
```
某些服务需要在 `basic.target` 阶段启动,其他则没这个必要,除非系统正在启动 `graphical.target`。这个实验中的服务不会在 `basic.target` 期间启动 —— 假设你直到 `graphical.target` 阶段才需要它启动。那么修改 `WantedBy` 这一行:
```
WantedBy=graphical.target
```
一定要先禁用 `hello.service` 再重新启用它,这样可以删除旧链接并且在 `graphical.targets.wants` 目录下创建一个新的链接。我注意到如果我在修改服务需要的目标之前忘记禁用该服务,我可以运行 `systemctl disable` 命令,链接将从两个 `targets.wants` 目录中删除。之后我只需要重新启用这个服务然后重启电脑。
启动 `graphical.target` 下的服务有个需要注意的地方,如果电脑启动到 `multi-user.target` 阶段,这个服务不会自动启动。如果这个服务需要 GUI 桌面接口,这或许是你想要的,但是它同样可能不是你想要的。
用 `-o short-monotonic` 选项来查看 `graphical.target` 和 `multi-user.target` 的日志,展示内核启动几秒后的日志,精度为微秒级别:
```
[root@testvm1 ~]# journalctl -b -o short-monotonic
```
`multi-user.target` 的部分日志:
```
[ 17.264730] testvm1.both.org systemd[1]: Starting My hello shell script...
[ 17.265561] testvm1.both.org systemd[1]: Starting IPv4 firewall with iptables...
<剪去>
[ 19.478468] testvm1.both.org systemd[1]: Starting LSB: Init script for live image....
[ 19.507359] testvm1.both.org iptables.init[844]: iptables: Applying firewall rules: [ OK ]
[ 19.507835] testvm1.both.org hello.sh[843]: ###############################
[ 19.507835] testvm1.both.org hello.sh[843]: ######### Hello World! ########
[ 19.507835] testvm1.both.org hello.sh[843]: ###############################
<剪去>
[ 21.482481] testvm1.both.org systemd[1]: hello.service: Succeeded.
[ 21.482550] testvm1.both.org smartd[856]: Opened configuration file /etc/smartmontools/smartd.conf
[ 21.482605] testvm1.both.org systemd[1]: Finished My hello shell script.
```
还有部分 `graphical.target` 的日志:
```
[ 19.436815] testvm1.both.org systemd[1]: Starting My hello shell script...
[ 19.437070] testvm1.both.org systemd[1]: Starting IPv4 firewall with iptables...
<剪去>
[ 19.612614] testvm1.both.org hello.sh[841]: ###############################
[ 19.612614] testvm1.both.org hello.sh[841]: ######### Hello World! ########
[ 19.612614] testvm1.both.org hello.sh[841]: ###############################
[ 19.629455] testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
[ 19.629569] testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
[ 19.629682] testvm1.both.org systemd[1]: hello.service: Succeeded.
[ 19.629782] testvm1.both.org systemd[1]: Finished My hello shell script.
```
尽管单元文件的 `WantedBy` 部分包含了 `graphical.target`,`hello.service` 单元在启动后大约 19.5 或 19.6 秒后运行。但是 `hello.service` 在 `multi-user.target` 中开始于 17.24 秒,在 `graphical target` 中开始于 19.43 秒。
这意味着什么呢?看看 `/etc/systemd/system/default.target` 这个链接。文件内容显示 systemd 先启动了默认目标 `graphical.target`,然后 `graphical.target` 触发了 `multi-user.target`。
```
[root@testvm1 system]# cat default.target
# SPDX-License-Identifier: LGPL-2.1+
#
# This file is part of systemd.
#
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
[Unit]
Description=Graphical Interface
Documentation=man:systemd.special(7)
Requires=multi-user.target
Wants=display-manager.service
Conflicts=rescue.service rescue.target
After=multi-user.target rescue.service rescue.target display-manager.service
AllowIsolate=yes
[root@testvm1 system]#
```
不管是用 `graphical.target` 还是 `multi-user.target` 启动服务,`hello.service` 单元都在启动后的 19.5 或 19.6 秒后启动。基于这个事实和日志结果(特别是使用单调输出的日志),你就知道这些目标是在并行启动。再看看日志中另外一件事:
```
[ 28.397330] testvm1.both.org systemd[1]: Reached target Multi-User System.
[ 28.397431] testvm1.both.org systemd[1]: Reached target Graphical Interface.
```
两个目标几乎是同时完成的。这是和理论一致的,因为 `graphical.target` 触发了 `multi-user.target`,在 `multi-user.target` 到达(即完成)之前它是不会完成的。但是 `hello.service` 比这个完成的早的多。
这一切表明,这两个目标几乎是并行启动的。如果你查看日志,你会发现各种目标和来自这类主要目标的服务大多是平行启动的。很明显,`multi-user.target` 没有必要在 `graphical.target` 启动前完成。所以,简单的使用这些主要目标来并不能很好地排序启动序列,尽管它在保证单元只在它们被 `graphical.target` 需要时启动这方面很有用。
在继续之前,把 `hello.service` 单元文件回滚至 `WantedBy=multi-user.target`(如果还没做的话)。
### 确保一个服务在网络运行后启动
一个常见的启动问题是保证一个单元在网络启动运行后再启动。[Freedesktop.org](http://Freedesktop.org) 的文章《[在网络启动后运行服务](https://www.freedesktop.org/wiki/Software/systemd/NetworkTarget/)》中提到,目前没有一个真正的关于网络何时算作“启动”的共识。然而,这篇文章提供了三个选项,满足完全可用网络需求的是 `network-online.target`。需要注意的是 `network.target` 是在关机阶段使用的而不是启动阶段,所以它对你做有序启动方面没什么帮助。
在做出任何改变之前,一定要检查下日志,确认 `hello.service` 单元在网络可用之前可以正确启动。你可以在日志中查找 `network-online.target` 来确认。
你的服务并不真的需要网络服务,但是你可以把它当作是需要网络的。
因为设置 `WantedBy=graphical.target` 并不能保证服务会在网络启动可用后启动,所以你需要其他的方法来做到这一点。幸运的是,有个简单的方法可以做到。将下面两行代码加入 `hello.service` 单元文件的 `[Unit]` 段:
```
After=network-online.target
Wants=network-online.target
```
两个字段都需要才能生效。重启机器,在日志中找到服务的记录:
```
[ 26.083121] testvm1.both.org NetworkManager[842]: <info> [1589227764.0293] device (enp0s3): Activation: successful, device activated.
[ 26.083349] testvm1.both.org NetworkManager[842]: <info> [1589227764.0301] manager: NetworkManager state is now CONNECTED_GLOBAL
[ 26.085818] testvm1.both.org NetworkManager[842]: <info> [1589227764.0331] manager: startup complete
[ 26.089911] testvm1.both.org systemd[1]: Finished Network Manager Wait Online.
[ 26.090254] testvm1.both.org systemd[1]: Reached target Network is Online.
[ 26.090399] testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=NetworkManager-wait-online comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? termina>"'
[ 26.091991] testvm1.both.org systemd[1]: Starting My hello shell script...
[ 26.095864] testvm1.both.org sssd[be[implicit_files]][1007]: Starting up
[ 26.290539] testvm1.both.org systemd[1]: Condition check resulted in Login and scanning of iSCSI devices being skipped.
[ 26.291075] testvm1.both.org systemd[1]: Reached target Remote File Systems (Pre).
[ 26.291154] testvm1.both.org systemd[1]: Reached target Remote File Systems.
[ 26.292671] testvm1.both.org systemd[1]: Starting Notify NFS peers of a restart...
[ 26.294897] testvm1.both.org systemd[1]: iscsi.service: Unit cannot be reloaded because it is inactive.
[ 26.304682] testvm1.both.org hello.sh[1010]: ###############################
[ 26.304682] testvm1.both.org hello.sh[1010]: ######### Hello World! ########
[ 26.304682] testvm1.both.org hello.sh[1010]: ###############################
[ 26.306569] testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
[ 26.306669] testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
[ 26.306772] testvm1.both.org systemd[1]: hello.service: Succeeded.
[ 26.306862] testvm1.both.org systemd[1]: Finished My hello shell script.
[ 26.584966] testvm1.both.org sm-notify[1011]: Version 2.4.3 starting
```
这样证实了 `hello.service` 单元会在 `network-online.target` 之后启动。这正是你想要的。你可能也看见了 “Hello World” 消息在启动阶段出现。还需要注意的是,在启动时记录出现的时间戳比之前要晚了大约 6 秒。
### 定义启动序列的最好方法
本文章详细地探讨了 Linux 启动时 systemd 和单元文件以及日志的细节,并且发现了当错误被引入单元文件时候会发生什么。作为系统管理员,我发现这类实验有助于我理解程序或者服务出故障时的行为,并且在安全环境中有意破坏是一种学习的好方法。
文章中实验结果证明,仅将服务单元添加至 `multi-user.target` 或者 `graphical.target` 并不能确定它在启动序列中的位置。它仅仅决定了一个单元是否作为图形环境一部分启动。事实上,启动目标 `multi-user.target` 和 `graphical.target` 和所有它们的 `Wants` 以及 `Required` 几乎是并行启动的。确保单元在特定位置启动的最好方法是确定它所依赖的单元,并将新单元配置成 `Want` 和 `After` 它的依赖。
### 资源
网上有大量的关于 systemd 的参考资料,但是大部分都有点简略、晦涩甚至有误导性。除了本文中提到的资料,下列的网页提供了跟多可靠且详细的 systemd 入门信息。
Fedora 项目有一篇切实好用的 systemd 入门,它囊括了几乎所有你需要知道的关于如何使用 systemd 配置、管理和维护 Fedora 计算机的信息。
Fedora 项目也有一个不错的 备忘录,交叉引用了过去 SystemV 命令和 systemd 命令做对比。
关于 systemd 的技术细节和创建这个项目的原因,请查看 [Freedesktop.org](http://Freedesktop.org) 上的 systemd 描述。
[Linux.com](http://Linux.com) 的“更多 systemd 的乐趣”栏目提供了更多高级的 systemd 信息和技巧。
此外,还有一系列深度的技术文章,是由 systemd 的设计者和主要开发者 Lennart Poettering 为 Linux 系统管理员撰写的。这些文章写于 2010 年 4 月至 2011 年 9 月间,但它们现在和当时一样具有现实意义。关于 systemd 及其生态的许多其他好文章都是基于这些文章:
* [Rethinking PID 1](http://0pointer.de/blog/projects/systemd.html)
* [systemd for Administrators,Part I](http://0pointer.de/blog/projects/systemd-for-admins-1.html)
* [systemd for Administrators,Part II](http://0pointer.de/blog/projects/systemd-for-admins-2.html)
* [systemd for Administrators,Part III](http://0pointer.de/blog/projects/systemd-for-admins-3.html)
* [systemd for Administrators,Part IV](http://0pointer.de/blog/projects/systemd-for-admins-4.html)
* [systemd for Administrators,Part V](http://0pointer.de/blog/projects/three-levels-of-off.html)
* [systemd for Administrators,Part VI](http://0pointer.de/blog/projects/changing-roots)
* [systemd for Administrators,Part VII](http://0pointer.de/blog/projects/blame-game.html)
* [systemd for Administrators,Part VIII](http://0pointer.de/blog/projects/the-new-configuration-files.html)
* [systemd for Administrators,Part IX](http://0pointer.de/blog/projects/on-etc-sysinit.html)
* [systemd for Administrators,Part X](http://0pointer.de/blog/projects/instances.html)
* [systemd for Administrators,Part XI](http://0pointer.de/blog/projects/inetd.html)
---
via: <https://opensource.com/article/20/5/manage-startup-systemd>
作者:[David Both](https://opensource.com/users/dboth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tt67wq](https://github.com/tt67wq) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | While setting up a Linux system recently, I wanted to know how to ensure that dependencies for services and other units were up and running before those dependent services and units start. Specifically, I needed more knowledge of how systemd manages the startup sequence, especially in determining the order services are started in what is essentially a parallel system.
You may know that SystemV (systemd's predecessor, as I explained in the [first article](https://opensource.com/article/20/4/systemd) in this series) orders the startup sequence by naming the startup scripts with an SXX prefix, where XX is a number from 00 to 99. SystemV then uses the sort order by name and runs each start script in sequence for the desired runlevel.
But systemd uses unit files, which can be created or modified by a sysadmin, to define subroutines for not only initialization but also for regular operation. In the [third article](https://opensource.com/article/20/5/systemd-units) in this series, I explained how to create a mount unit file. In this fifth article, I demonstrate how to create a different type of unit file—a service unit file that runs a program at startup. You can also change certain configuration settings in the unit file and use the systemd journal to view the location of your changes in the startup sequence.
## Preparation
Make sure you have removed `rhgb`
and `quiet`
from the `GRUB_CMDLINE_LINUX=`
line in the `/etc/default/grub`
file, as I showed in the [second article](https://opensource.com/article/20/5/systemd-startup) in this series. This enables you to observe the Linux startup message stream, which you'll need for some of the experiments in this article.
## The program
In this tutorial, you will create a simple program that enables you to observe a message during startup on the console and later in the systemd journal.
Create the shell program `/usr/local/bin/hello.sh`
and add the following content. You want to ensure that the result is visible during startup and that you can easily find it when looking through the systemd journal. You will use a version of the "Hello world" program with some bars around it, so it stands out. Make sure the file is executable and has user and group ownership by root with [700 permissions](https://chmodcommand.com/chmod-700/) for security:
```
#!/usr/bin/bash
# Simple program to use for testing startup configurations
# with systemd.
# By David Both
# Licensed under GPL V2
#
echo "###############################"
echo "######### Hello World! ########"
echo "###############################"
```
Run this program from the command line to verify that it works correctly:
```
[root@testvm1 ~]# hello.sh
###############################
######### Hello World! ########
###############################
[root@testvm1 ~]#
```
This program could be created in any scripting or compiled language. The `hello.sh`
program could also be located in other places based on the [Linux filesystem hierarchical structure](https://opensource.com/life/16/10/introduction-linux-filesystems) (FHS). I place it in the `/usr/local/bin`
directory so that it can be easily run from the command line without having to prepend a path when I type the command. I find that many of the shell programs I create need to be run from the command line and by other tools such as systemd.
## The service unit file
Create the service unit file `/etc/systemd/system/hello.service`
with the following content. This file does not need to be executable, but for security, it does need user and group ownership by root and [644](https://chmodcommand.com/chmod-644/) or [640](https://chmodcommand.com/chmod-640/) permissions:
```
# Simple service unit file to use for testing
# startup configurations with systemd.
# By David Both
# Licensed under GPL V2
#
[Unit]
Description=My hello shell script
[Service]
Type=oneshot
ExecStart=/usr/local/bin/hello.sh
[Install]
WantedBy=multi-user.target
```
Verify that the service unit file performs as expected by viewing the service status. Any syntactical errors will show up here:
```
[root@testvm1 ~]# systemctl status hello.service
● hello.service - My hello shell script
Loaded: loaded (/etc/systemd/system/hello.service; disabled; vendor preset: disabled)
Active: inactive (dead)
[root@testvm1 ~]#
```
You can run this "oneshot" service type multiple times without problems. The oneshot type is intended for services where the program launched by the service unit file is the main process and must complete before systemd starts any dependent process.
There are seven service types, and you can find an explanation of each (along with the other parts of a service unit file) in the [systemd.service(5)](http://man7.org/linux/man-pages/man5/systemd.service.5.html) man page. (You can also find more information in the [resources](#resources) at the end of this article.)
As curious as I am, I wanted to see what an error might look like. So, I deleted the "o" from the `Type=oneshot`
line, so it looked like `Type=neshot`
, and ran the command again:
```
[root@testvm1 ~]# systemctl status hello.service
● hello.service - My hello shell script
Loaded: loaded (/etc/systemd/system/hello.service; disabled; vendor preset: disabled)
Active: inactive (dead)
May 06 08:50:09 testvm1.both.org systemd[1]: /etc/systemd/system/hello.service:12: Failed to parse service type, ignoring: neshot
[root@testvm1 ~]#
```
These results told me precisely where the error was and made it very easy to resolve the problem.
Just be aware that even after you restore the `hello.service`
file to its original form, the error will persist. Although a reboot will clear the error, you should not have to do that, so I went looking for a method to clear out persistent errors like this. I have encountered service errors that require the command `systemctl daemon-reload`
to reset an error condition, but that did not work in this case. The error messages that can be fixed with this command always seem to have a statement to that effect, so you know to run it.
It is, however, recommended that you run `systemctl daemon-reload`
after changing a unit file or creating a new one. This notifies systemd that the changes have been made, and it can prevent certain types of issues with managing altered services or units. Go ahead and run this command.
After correcting the misspelling in the service unit file, a simple `systemctl restart hello.service`
cleared the error. Experiment a bit by introducing some other errors into the `hello.service`
file to see what kinds of results you get.
## Start the service
Now you are ready to start the new service and check the status to see the result. Although you probably did a restart in the previous section, you can start or restart a oneshot service as many times as you want since it runs once and then exits.
Go ahead and start the service (as shown below), and then check the status. Depending upon how much you experimented with errors, your results may differ from mine:
```
[root@testvm1 ~]# systemctl start hello.service
[root@testvm1 ~]# systemctl status hello.service
● hello.service - My hello shell script
Loaded: loaded (/etc/systemd/system/hello.service; disabled; vendor preset: disabled)
Active: inactive (dead)
May 10 10:37:49 testvm1.both.org hello.sh[842]: ######### Hello World! ########
May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
[root@testvm1 ~]#
```
Notice in the status command's output that the systemd messages indicate that the `hello.sh`
script started and the service completed. You can also see the output from the script. This display is generated from the journal entries of the most recent invocations of the service. Try starting the service several times, and then run the status command again to see what I mean.
You should also look at the journal contents directly; there are multiple ways to do this. One way is to specify the record type identifier, in this case, the name of the shell script. This shows the journal entries for previous reboots as well as the current session. As you can see, I have been researching and testing for this article for some time now:
```
[root@testvm1 ~]# journalctl -t hello.sh
<snip>
-- Reboot --
May 08 15:55:47 testvm1.both.org hello.sh[840]: ###############################
May 08 15:55:47 testvm1.both.org hello.sh[840]: ######### Hello World! ########
May 08 15:55:47 testvm1.both.org hello.sh[840]: ###############################
-- Reboot --
May 08 16:01:51 testvm1.both.org hello.sh[840]: ###############################
May 08 16:01:51 testvm1.both.org hello.sh[840]: ######### Hello World! ########
May 08 16:01:51 testvm1.both.org hello.sh[840]: ###############################
-- Reboot --
May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
May 10 10:37:49 testvm1.both.org hello.sh[842]: ######### Hello World! ########
May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
[root@testvm1 ~]#
```
To locate the systemd records for the `hello.service`
unit, you can search on systemd. You can use **G+Enter** to page to the end of the journal entries and then scroll back to locate the ones you are interested in. Use the `-b`
option to show only the entries for the most recent startup:
```
[root@testvm1 ~]# journalctl -b -t systemd
<snip>
May 10 10:37:49 testvm1.both.org systemd[1]: Starting SYSV: Late init script for live image....
May 10 10:37:49 testvm1.both.org systemd[1]: Started SYSV: Late init script for live image..
May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:37:50 testvm1.both.org systemd[1]: Starting D-Bus System Message Bus...
May 10 10:37:50 testvm1.both.org systemd[1]: Started D-Bus System Message Bus.
```
I copied a few other journal entries to give you an idea of what you might find. This command spews all of the journal lines pertaining to systemd—109,183 lines when I wrote this. That is a lot of data to sort through. You can use the pager's search facility, which is usually `less`
, or you can use the built-in `grep`
feature. The `-g`
(or `--grep=`
) option uses Perl-compatible regular expressions:
```
[root@testvm1 ~]# journalctl -b -t systemd -g "hello"
[root@testvm1 ~]# journalctl -b -t systemd -g "hello"
-- Logs begin at Tue 2020-05-05 18:11:49 EDT, end at Sun 2020-05-10 11:01:01 EDT. --
May 10 10:37:49 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
[root@testvm1 ~]#
```
You could use the standard GNU `grep`
command, but that would not show the log metadata in the first line.
If you do not want to see just the journal entries pertaining to your `hello`
service, you can narrow things down a bit by specifying a time range. For example, I will start with the beginning time of `10:54:00`
on my test VM, which was the start of the minute the entries above are from.** **Note that the `--since=`
option must be enclosed in quotes and that this option can also be expressed as `-S "<time specification>"`
.
The date and time will be different on your host, so be sure to use the timestamps that match the times in your journals:
```
[root@testvm1 ~]# journalctl --since="2020-05-10 10:54:00"
May 10 10:54:35 testvm1.both.org audit: BPF prog-id=54 op=LOAD
May 10 10:54:35 testvm1.both.org audit: BPF prog-id=55 op=LOAD
May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd"'
May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/"'
May 10 10:56:00 testvm1.both.org NetworkManager[840]: <error> [1589122560.0633] dhcp4 (enp0s3): error -113 dispatching events
May 10 10:56:00 testvm1.both.org NetworkManager[840]: <info> [1589122560.0634] dhcp4 (enp0s3): state changed bound -> fail
<snip>
```
The `since`
specification skips all of the entries before that time, but there are still a lot of entries after that time that you do not need. You can also use the `until`
option to trim off the entries that come a bit after the time you are interested in. I want the entire minute when the event occurred and nothing more:
```
[root@testvm1 ~]# journalctl --since="2020-05-10 10:54:35" --until="2020-05-10 10:55:00"
-- Logs begin at Tue 2020-05-05 18:11:49 EDT, end at Sun 2020-05-10 11:04:59 EDT. --
May 10 10:54:35 testvm1.both.org systemd[1]: Reloading.
May 10 10:54:35 testvm1.both.org audit: BPF prog-id=27 op=UNLOAD
May 10 10:54:35 testvm1.both.org audit: BPF prog-id=26 op=UNLOAD
<snip>
ay 10 10:54:35 testvm1.both.org audit: BPF prog-id=55 op=LOAD
May 10 10:54:45 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:54:45 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd>
May 10 10:54:45 testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/>
lines 1-46/46 (END)
```
If there were a lot of activity in this time period, you could further narrow the resulting data stream using a combination of these options:
```
[root@testvm1 ~]# journalctl --since="2020-05-10 10:54:35" --until="2020-05-10 10:55:00" -t "hello.sh"
-- Logs begin at Tue 2020-05-05 18:11:49 EDT, end at Sun 2020-05-10 11:10:41 EDT. --
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ######### Hello World! ########
May 10 10:54:45 testvm1.both.org hello.sh[1380]: ###############################
[root@testvm1 ~]#
```
Your results should be similar to mine. You can see from this series of experiments that the service executed properly.
## Reboot—finally
So far, you have not rebooted the host where you installed your service. So do that now because, after all, this how-to is about running a program at startup. First, you need to enable the service to launch during the startup sequence:
```
[root@testvm1 ~]# systemctl enable hello.service
Created symlink /etc/systemd/system/multi-user.target.wants/hello.service → /etc/systemd/system/hello.service.
[root@testvm1 ~]#
```
Notice that the link was created in the `/etc/systemd/system/multi-user.target.wants`
directory. This is because the service unit file specifies that the service is "wanted" by the `multi-user.target`
.
Reboot, and be sure to watch the data stream during the startup sequence to see the "Hello world" message. Wait … you did not see it? Well, neither did I. Although it went by very fast, I did see systemd's message that it was starting the `hello.service`
.
Look at the journal since the latest system boot. You can use the `less`
pager's search tool to find "Hello" or "hello." I pruned many lines of data, but I left some of the surrounding journal entries, so you can get a feel for what the entries pertaining to your service look like locally:
```
[root@testvm1 ~]# journalctl -b
<snip>
May 10 10:37:49 testvm1.both.org systemd[1]: Listening on SSSD Kerberos Cache Manager responder socket.
May 10 10:37:49 testvm1.both.org systemd[1]: Reached target Sockets.
May 10 10:37:49 testvm1.both.org systemd[1]: Reached target Basic System.
May 10 10:37:49 testvm1.both.org systemd[1]: Starting Modem Manager...
May 10 10:37:49 testvm1.both.org systemd[1]: Starting Network Manager...
May 10 10:37:49 testvm1.both.org systemd[1]: Starting Avahi mDNS/DNS-SD Stack...
May 10 10:37:49 testvm1.both.org systemd[1]: Condition check resulted in Secure Boot DBX (blacklist) updater being skipped.
May 10 10:37:49 testvm1.both.org systemd[1]: Starting My hello shell script...
May 10 10:37:49 testvm1.both.org systemd[1]: Starting IPv4 firewall with iptables...
May 10 10:37:49 testvm1.both.org systemd[1]: Started irqbalance daemon.
May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=irqbalance comm="systemd" exe="/usr/lib/sy>"'
May 10 10:37:49 testvm1.both.org systemd[1]: Starting LSB: Init script for live image....
May 10 10:37:49 testvm1.both.org systemd[1]: Starting Hardware Monitoring Sensors...
<snip>
May 10 10:37:49 testvm1.both.org systemd[1]: Starting NTP client/server...
May 10 10:37:49 testvm1.both.org systemd[1]: Starting SYSV: Late init script for live image....
May 10 10:37:49 testvm1.both.org systemd[1]: Started SYSV: Late init script for live image..
May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=livesys-late comm="systemd" exe="/usr/lib/>"'
May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
May 10 10:37:49 testvm1.both.org hello.sh[842]: ######### Hello World! ########
May 10 10:37:49 testvm1.both.org hello.sh[842]: ###############################
May 10 10:37:49 testvm1.both.org systemd[1]: hello.service: Succeeded.
May 10 10:37:49 testvm1.both.org systemd[1]: Finished My hello shell script.
May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd>"'
May 10 10:37:49 testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/>
May 10 10:37:50 testvm1.both.org audit: BPF prog-id=28 op=LOAD
<snip>
```
You can see that systemd started the `hello.service`
unit, which ran the `hello.sh`
shell script with the output recorded in the journal. If you were able to catch it during boot, you would also have seen the systemd message indicating that it was starting the script and another message indicating that the service succeeded. By looking at the first systemd message in the data stream above, you can see that systemd started your service very soon after reaching the basic system target.
But I would like to see the message displayed at startup as well. There is a way to make that happen: Add the following line to the `[Service]`
section of the `hello.service`
file:
`StandardOutput=journal+console`
The `hello.service`
file now looks like this:
```
# Simple service unit file to use for testing
# startup configurations with systemd.
# By David Both
# Licensed under GPL V2
#
[Unit]
Description=My hello shell script
[Service]
Type=oneshot
ExecStart=/usr/local/bin/hello.sh
StandardOutput=journal+console
[Install]
WantedBy=multi-user.target
```
After adding this line, reboot the system, and watch the data stream as it scrolls up the display during the boot process. You should see the message in its little box. After the startup sequence completes, you can view the journal for the most recent boot and locate the entries for your new service.
## Changing the sequence
Now that your service is working, you can look at where it starts in the startup sequence and experiment with changing it. It is important to remember that systemd's intent is to start as many services and other unit types in parallel within each of the major targets: `basic.target`
, `multi-user.target`
, and `graphical.target`
. You should have just seen the journal entries for the most recent boot, which should look similar to my journal in the output above.
Notice that systemd started your test service soon after it reached the target basic system. This is what you specified in the service unit file in the `WantedBy`
line, so it is correct. Before you change anything, list the contents of the `/etc/systemd/system/multi-user.target.wants`
directory, and you will see a symbolic (soft) link to the service unit file. The `[Install]`
section of the service unit file specifies which target will start the service, and running the `systemctl enable hello.service`
command creates the link in the appropriate "target wants" directory:
`hello.service -> /etc/systemd/system/hello.service`
Certain services need to start during the `basic.target`
, and others do not need to start unless the system is starting the `graphical.target`
. The service in this experiment will not start in the `basic.target`
—assume you do not need it to start until the `graphical.target`
. So change the `WantedBy`
line:
`WantedBy=graphical.target`
Be sure to disable the `hello.service`
and re-enable it to delete the old link and add the new one in the `graphical.targets.wants`
directory. I have noticed that if I forget to disable the service before changing the target that wants it, I can run the `systemctl disable`
command, and the links will be removed from both "target wants" directories. Then, I just need to re-enable the service and reboot.
One concern with starting services in the `graphical.target`
is that if the host boots to `multi-user.target`
, this service will not start automatically. That may be what you want if the service requires a GUI desktop interface, but it also may not be what you want.
Look at the journal entries for the `graphical.target`
and the `multi-user.target`
using the `-o short-monotonic`
option that displays seconds after kernel startup with microsecond precision:
`[root@testvm1 ~]# journalctl -b -o short-monotonic`
Some results for `multi-user.target`
:
```
[ 17.264730] testvm1.both.org systemd[1]: Starting My hello shell script...
[ 17.265561] testvm1.both.org systemd[1]: Starting IPv4 firewall with iptables...
<SNIP>
[ 19.478468] testvm1.both.org systemd[1]: Starting LSB: Init script for live image....
[ 19.507359] testvm1.both.org iptables.init[844]: iptables: Applying firewall rules: [ OK ]
[ 19.507835] testvm1.both.org hello.sh[843]: ###############################
[ 19.507835] testvm1.both.org hello.sh[843]: ######### Hello World! ########
[ 19.507835] testvm1.both.org hello.sh[843]: ###############################
<SNIP>
[ 21.482481] testvm1.both.org systemd[1]: hello.service: Succeeded.
[ 21.482550] testvm1.both.org smartd[856]: Opened configuration file /etc/smartmontools/smartd.conf
[ 21.482605] testvm1.both.org systemd[1]: Finished My hello shell script.
```
And some results for `graphical.target`
:
```
[ 19.436815] testvm1.both.org systemd[1]: Starting My hello shell script...
[ 19.437070] testvm1.both.org systemd[1]: Starting IPv4 firewall with iptables...
<SNIP>
[ 19.612614] testvm1.both.org hello.sh[841]: ###############################
[ 19.612614] testvm1.both.org hello.sh[841]: ######### Hello World! ########
[ 19.612614] testvm1.both.org hello.sh[841]: ###############################
[ 19.629455] testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
[ 19.629569] testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
[ 19.629682] testvm1.both.org systemd[1]: hello.service: Succeeded.
[ 19.629782] testvm1.both.org systemd[1]: Finished My hello shell script.
```
Despite having the `graphical.target`
"want" in the unit file, the `hello.service`
unit runs about 19.5 or 19.6 seconds into startup. But `hello.service`
starts at about 17.24 seconds in the `multi-user.target`
and 19.43 seconds in the graphical target.
What does this mean? Look at the `/etc/systemd/system/default.target`
link. The contents of that file show that systemd first starts the default target, `graphical.target`
, which then pulls in the `multi-user.target`
:
```
[root@testvm1 system]# cat default.target
# SPDX-License-Identifier: LGPL-2.1+
#
# This file is part of systemd.
#
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
[Unit]
Description=Graphical Interface
Documentation=man:systemd.special(7)
Requires=multi-user.target
Wants=display-manager.service
Conflicts=rescue.service rescue.target
After=multi-user.target rescue.service rescue.target display-manager.service
AllowIsolate=yes
[root@testvm1 system]#
```
Whether it starts the service with the `graphical.target`
or the `multi-user.target`
, the `hello.service`
unit runs at about 19.5 or 19.6 seconds into startup. Based on this and the journal results (especially the ones using the monotonic output), you know that both of these targets are starting in parallel. Look at one more thing from the journal output:
```
[ 28.397330] testvm1.both.org systemd[1]: Reached target Multi-User System.
[ 28.397431] testvm1.both.org systemd[1]: Reached target Graphical Interface.
```
Both targets finish at almost the same time. This is consistent because the `graphical.target`
pulls in the `multi-user.target`
and cannot finish until the `multi.user target`
is reached, i.e., finished. But **hello.service** finishes much earlier than this.
What all this means is that these two targets start up pretty much in parallel. If you explore the journal entries, you will see various targets and services from each of those primary targets starting mostly in parallel. It is clear that the `multi-user.target`
does not need to complete before the `graphical.target`
starts. Therefore, simply using these primary targets to sequence the startup does not work very well, although it can be useful for ensuring that units are started only when they are needed for the `graphical.target`
.
Before continuing, revert the `hello.service`
unit file to `WantedBy=multi-user.target`
(if it is not already.)
## Ensure a service starts after the network is running
A common startup sequence issue is ensuring that a unit starts after the network is up and running. The Freedesktop.org article [ Running services after the network is up](https://www.freedesktop.org/wiki/Software/systemd/NetworkTarget/) says there is no real consensus on when a network is considered "up." However, the article provides three options, and the one that meets the needs of a fully operational network is
`network-online.target`
. Just be aware that `network.target`
is used during shutdown rather than startup, so it will not do you any good when you are trying to sequence the startup.Before making any other changes, be sure to examine the journal and verify that the `hello.service`
unit starts well before the network. You can look for the `network-online.target`
in the journal to check.
Your service does not really require the network service, but you can use it as an avatar for one that does.
Because setting `WantedBy=graphical.target`
does not ensure that the service will be started after the network is up and running, you need another way to ensure that it is. Fortunately, there is an easy way to do this. Add the following two lines to the `[Unit]`
section of the `hello.service`
unit file:
```
After=network-online.target
Wants=network-online.target
```
Both of these entries are required to make this work. Reboot the host and look for the location of entries for your service in the journals:
```
[ 26.083121] testvm1.both.org NetworkManager[842]: <info> [1589227764.0293] device (enp0s3): Activation: successful, device activated.
[ 26.083349] testvm1.both.org NetworkManager[842]: <info> [1589227764.0301] manager: NetworkManager state is now CONNECTED_GLOBAL
[ 26.085818] testvm1.both.org NetworkManager[842]: <info> [1589227764.0331] manager: startup complete
[ 26.089911] testvm1.both.org systemd[1]: Finished Network Manager Wait Online.
[ 26.090254] testvm1.both.org systemd[1]: Reached target Network is Online.
[ 26.090399] testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=NetworkManager-wait-online comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? termina>"'
[ 26.091991] testvm1.both.org systemd[1]: Starting My hello shell script...
[ 26.095864] testvm1.both.org sssd[be[implicit_files]][1007]: Starting up
[ 26.290539] testvm1.both.org systemd[1]: Condition check resulted in Login and scanning of iSCSI devices being skipped.
[ 26.291075] testvm1.both.org systemd[1]: Reached target Remote File Systems (Pre).
[ 26.291154] testvm1.both.org systemd[1]: Reached target Remote File Systems.
[ 26.292671] testvm1.both.org systemd[1]: Starting Notify NFS peers of a restart...
[ 26.294897] testvm1.both.org systemd[1]: iscsi.service: Unit cannot be reloaded because it is inactive.
[ 26.304682] testvm1.both.org hello.sh[1010]: ###############################
[ 26.304682] testvm1.both.org hello.sh[1010]: ######### Hello World! ########
[ 26.304682] testvm1.both.org hello.sh[1010]: ###############################
[ 26.306569] testvm1.both.org audit[1]: SERVICE_START pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
[ 26.306669] testvm1.both.org audit[1]: SERVICE_STOP pid=1 uid=0 auid=4294967295 ses=4294967295 msg='unit=hello comm="systemd" exe="/usr/lib/systemd/systemd" hostname=? addr=? terminal=? res=success'
[ 26.306772] testvm1.both.org systemd[1]: hello.service: Succeeded.
[ 26.306862] testvm1.both.org systemd[1]: Finished My hello shell script.
[ 26.584966] testvm1.both.org sm-notify[1011]: Version 2.4.3 starting
```
This confirms that the `hello.service`
unit started after the `network-online.target`
. This is exactly what you want. You may also have seen the "Hello World" message as it passed by during startup. Notice also that the timestamp is about six seconds later in the startup than it was before.
## The best way to define the start sequence
This article explored Linux startup with systemd and unit files and journals in greater detail and discovered what happens when errors are introduced into the service file. As a sysadmin, I find that this type of experimentation helps me understand the behaviors of a program or service when it breaks, and breaking things intentionally is a good way to learn in a safe environment.
As the experiments in this article proved, just adding a service unit to either the `multi-user.target`
or the `graphical.target`
does not define its place in the start sequence. It merely determines whether a unit starts as part of a graphical environment or not. The reality is that the startup targets `multi-user.target`
and `graphical.target`
—and all of their Wants and Requires—start up pretty much in parallel. The best way to ensure that a unit starts in a specific order is to determine the unit it is dependent on and configure the new unit to "Want" and "After" the unit upon which it is dependent.
Resources
There is a great deal of information about systemd available on the internet, but much is terse, obtuse, or even misleading. In addition to the resources mentioned in this article, the following webpages offer more detailed and reliable information about systemd startup.
- The Fedora Project has a good, practical
[guide to systemd](https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/index.html). It has pretty much everything you need to know in order to configure, manage, and maintain a Fedora computer using systemd. - The Fedora Project also has a good
[cheat sheet](https://fedoraproject.org/wiki/SysVinit_to_Systemd_Cheatsheet)that cross-references the old SystemV commands to comparable systemd ones. - For detailed technical information about systemd and the reasons for creating it, check out
[Freedesktop.org](http://Freedesktop.org)'s[description of systemd](http://www.freedesktop.org/wiki/Software/systemd). [Linux.com](http://Linux.com)'s "More systemd fun" offers more advanced systemd[information and tips](https://www.linux.com/training-tutorials/more-systemd-fun-blame-game-and-stopping-services-prejudice/).
There is also a series of deeply technical articles for Linux sysadmins by Lennart Poettering, the designer and primary developer of systemd. These articles were written between April 2010 and September 2011, but they are just as relevant now as they were then. Much of everything else good that has been written about systemd and its ecosystem is based on these papers.
[Rethinking PID 1](http://0pointer.de/blog/projects/systemd.html)[systemd for Administrators, Part I](http://0pointer.de/blog/projects/systemd-for-admins-1.html)[systemd for Administrators, Part II](http://0pointer.de/blog/projects/systemd-for-admins-2.html)[systemd for Administrators, Part III](http://0pointer.de/blog/projects/systemd-for-admins-3.html)[systemd for Administrators, Part IV](http://0pointer.de/blog/projects/systemd-for-admins-4.html)[systemd for Administrators, Part V](http://0pointer.de/blog/projects/three-levels-of-off.html)[systemd for Administrators, Part VI](http://0pointer.de/blog/projects/changing-roots)[systemd for Administrators, Part VII](http://0pointer.de/blog/projects/blame-game.html)[systemd for Administrators, Part VIII](http://0pointer.de/blog/projects/the-new-configuration-files.html)[systemd for Administrators, Part IX](http://0pointer.de/blog/projects/on-etc-sysinit.html)[systemd for Administrators, Part X](http://0pointer.de/blog/projects/instances.html)[systemd for Administrators, Part XI](http://0pointer.de/blog/projects/inetd.html)
## 3 Comments |
13,404 | 每个人都应该尝试 Linux 的 21 个理由 | https://opensource.com/article/21/4/linux-reasons | 2021-05-19T11:20:40 | [
"Linux"
] | https://linux.cn/article-13404-1.html |
>
> 游戏、交易、预算、艺术、编程等等,这些都只是任何人都可以使用 Linux 的众多方式中的一种。
>
>
>

当我在度假时,我经常会去一家或者多家的二手书店。我经常能够找到我想读的一本好书,而且我总是以 “我在度假;我应该用这本书来犒劳自己” 来为不可避免的购买行为辩护。这很有效,我用这种方式获得了一些我最喜欢的书。但是,买一本好书在生活中很常见,这个理由经不起推敲。事实上,我不需要为买一本好书来找理由。事情都是这样的,我可以在任何时候做我想做的事。但不知何故,有一个理由似乎确实能让这个过程更有趣。
在我的日常生活中,我会收到很多关于 Linux 的问题。有时候我会不自觉地滔滔不绝地讲述开源软件的历史,或者共享资源的知识和利益。有时候,我会设法提到一些我喜欢的 Linux 上的特性,然后对这些好处进行逆向工程以便它们可以在其它的操作系统上享用。这些讨论经常是有趣且有益的,但只有一个问题:这些讨论都没有回答大家真正要问的问题。
当一个人问你关于 Linux 的问题时,他们经常希望你能够给他们一些使用 Linux 的理由。当然,也有例外。从来没有听过“Linux”的人们可能会问一些字面定义。但是当你的朋友或者同事吐露出他们对当前的操作系统有些不满意的时候,解释一下你为什么喜欢 Linux 可能更好,而不是告诉他们为什么 Linux 是一个比专有系统更好的选择。换句话说,你不需要销售演示,你需要的是度假照片(如果你是个书虫的话,也可以是度假时买的一本书)。
为了达到这个目的,下面是我喜欢 Linux 的 21 个原因,分别在 21 个不同的场合讲给 21 个不同的人。
### 游戏

说到玩电脑,最明显的活动之一就是玩游戏,说到玩游戏,我很喜欢。我很高兴花一个晚上玩一个 8 位的益智游戏或者 epic 工作室的一个 AAA 级游戏。其它时候,我还会沉浸在棋盘游戏或者角色扮演游戏(RPG)中。
这些我都是 [在 Linux 系统的电脑上做的](https://opensource.com/article/21/2/linux-gaming)。
### 办公

一种方法并不适合所有人。这对帽子和办公室工作来说都是如此。看到同事们被困在一个不适合他们的单一工作流程中,我感到很痛苦,我喜欢 Linux 鼓励用户找到他们喜欢的工具。我曾使用过的应用大到套件(例如 LibreOffice 和 OpenOffice),小到轻量级文字处理器(如 Abiword),再到最小的文本编辑器(利用 Pandoc 进行转换)。
不管我周围的用户被限制在什么范围内,我都可以 [自由地使用可以在我的电脑上工作的最好的工具](/article-13133-1.html),并且以我希望的方式工作。
### 选择

开源最有价值的特性之一是用户在使用这些软件的时候是可以信任它的。这种信任来自于好友网络,他们可以阅读他们所使用的应用程序和操作系统的源代码。也就是说,即使你不知道源代码的好坏,你也可以在 [开源社区](https://opensource.com/article/21/2/linux-community) 中结交一些知道的朋友。这些都是 Linux 用户在探索他们运行的发行版时建立的重要联系。如果你不信任构建和维护的发行版的社区,你可以去找其它的发行版。我们都是这样做的,这是有许多发行版可供选择的优势之一。
[Linux 提供了可选择的特性](/article-13284-1.html)。一个强大的社区,充满了真实的人际关系,结合 Linux 提供的选择自由,所有这些都让用户对他们运行的软件有信心。因为我读过一些源码,也因为我信任哪些维护我没读过的代码的人,[所以我信任 Linux](https://opensource.com/article/21/2/open-source-security)。
### 预算

做预算并不有趣,但是很重要。我很早就认识到,在业余时间做一些不起眼的工作,就像我学会了一种 *免费* 的操作系统(Linux!)一样。预算不是为了追踪你的钱,而是为了追踪你的习惯。这意味着无论你是靠薪水生活,还是正在计划退休,你都应该 [保持预算](https://opensource.com/article/21/2/linux-skrooge)。
如果你在美国,你甚至可以 [用 Linux 来交税](https://opensource.com/article/21/2/linux-tax-software)。
### 艺术

不管你是画画还是做像素艺术、[编辑视频](https://opensource.com/article/21/2/linux-python-video) 还是随性记录,你都可以在 Linux 上创建出色的内容。我所见过的一些最优秀的艺术作品都是使用一些非“行业标准”的工具随意创作出来的,并且你可能会惊讶于你所看到的许多内容都是基于同样的方式创造出来的。Linux 是一个不会被宣扬的引擎,但它是具有强大功能的引擎,驱动着独立艺术家和大型制作人。
尝试使用 Linux 来 [创作一些艺术作品](/article-13157-1.html)。
### 编程

听着,用 Linux 来编程几乎是定论。仅次于服务器管理,开源和 Linux 是一个明显的组合。这其中有 [许多原因](https://opensource.com/article/21/2/linux-programming),但我这里给出了一个有趣的原因。我在发明新东西时遇到了很多障碍,所以我最不希望的就是操作系统或者软件工具开发包(SDK)成为失败的原因。在 Linux 上,我可以访问一切,字面意义上的一切。
### 封包

当他们在谈编程的时候,没有人谈封包。作为一个开发者,你必须将你的代码提供给您的用户,否则你将没有任何用户。Linux 使得开发人员可以轻松地 [发布应用程序](https://opensource.com/article/21/2/linux-packaging),用户也可以轻松地 [安装这些应用程序](/article-13160-1.html)。
令很多人感到惊讶的是 [Linux 可以像运行本地程序一样运行许多 Windows 应用程序](https://opensource.com/article/21/2/linux-wine)。你不应该期望一个 Windows 应用可以在 Linux 上执行。不过,许多主要的通用应用要么已经在 Linux 上原生存在,要么可以通过名为 Wine 的兼容层运行。
### 技术

如果你正在找一份 IT 工作,Linux 是很好的第一步。作为一个曾经为了更快地渲染视频而误入 Linux 的前艺术系学生,我说的是经验之谈。
尖端技术发生在 Linux 上。Linux 驱动着大部分的互联网、世界上最快的超级计算机以及云本身。现在,Linux 驱动着 [边缘计算](https://opensource.com/article/21/2/linux-edge-computing),将云数据中心的能力与分散的节点相结合,以实现快速响应。
不过,你不需要从最顶层开始。你可以学习在笔记本电脑或者台式机上[自动](https://opensource.com/article/21/2/linux-automation)完成任务,并通过一个 [好的终端](/article-13186-1.html) 远程控制系统。
Linux 对你的新想法是开放的,并且 [可以进行定制](https://opensource.com/article/21/2/linux-technology)。
### 分享文件

无论你是一个新手系统管理员,还是仅仅是要将一个将文件分发给室友,Linux 都可以使 [文件共享变得轻而易举](/article-13192-1.html)。
### 多媒体

在所有关于编程和服务器的讨论中,人们有时把 Linux 想象成一个充满绿色的 1 和 0 的黑屏。对于我们这些使用它的人来说,Linux 也能 [播放你所有的媒体](https://opensource.com/article/21/2/linux-media-players),这并不令人惊讶。
### 易于安装

以前从来没有安装过操作系统吗?Linux 非常简单。一步一步来,Linux 安装程序会手把手带你完成操作系统的安装,让你在一个小时内感觉到自己是个电脑专家。
[来安装 Linux 吧](/article-13164-1.html)!
### 试一试 Linux

如果你还没有准备好安装 Linux,你可以 *试一试* Linux。不知道如何开始?它没有你想象的那么吓人。这里给了一些你 [一开始需要考虑的事情](https://opensource.com/article/21/2/try-linux)。然后选择下载一个发行版,并想出你自己使用 Linux 的 21 个理由。
---
via: <https://opensource.com/article/21/4/linux-reasons>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ShuyRoy](https://github.com/ShuyRoy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When I go on holiday, I often end up at one or more used bookstores. I always find a good book I've been meaning to read, and I always justify the inevitable purchase by saying, "I'm on vacation; I should treat myself to this book." It works well, and I've acquired some of my favorite books this way. Yet, like so many traditions in life, it doesn't hold up to scrutiny. In reality, I don't need an excuse to buy a good book. All things being equal, I can do it any time I want. But having a reason does seem to make the process more enjoyable, somehow.
In my everyday life, I get a lot of questions about Linux. When caught unaware, I sometimes awkwardly ramble on about the history of open source software or the intellectual and economic benefits of sharing resources. Sometimes, I manage to mention some of my favorite features I enjoy on Linux and then end up reverse-engineering those benefits so they can be enjoyed on another operating system. These discussions are usually enjoyable and informative, but there's just one problem: None of it answers the question that people are really asking.
When a person asks you about Linux, they're often asking you to give them a reason to try it. There are exceptions, of course. People who have never heard the term "Linux" are probably asking for a literal definition of the word. But when your friends and colleagues confide that they're a little dissatisfied with their current operating system, it's probably safe to explain why you enjoy Linux, rather than lecturing them on why Linux is a better option than proprietary systems. In other words, you don't need a sales presentation; you need vacation photos (or used books you bought on vacation, if you're a bookworm).
To that end, the links below connect to 21 reasons I enjoy Linux, given to 21 separate people on 21 separate occasions.
## Gaming

(Seth Kenlon, CC BY-SA 4.0)
When it comes to enjoying a computer, one of the most obvious activities is gaming, and when it comes to gaming, I love it all. I'm happy to spend an evening playing an 8-bit puzzler or a triple-A studio epic. Other times, I settle in for a board game or a tabletop role-playing game (RPG).
And I [do it all on a Linux computer](https://opensource.com/article/21/2/linux-gaming).
## Office
(Seth Kenlon, CC BY-SA 4.0)
One size doesn't fit all. This is as true for hats as it is for office work. It pains me to see colleagues locked into a singular workflow that doesn't suit them, and I enjoy the way Linux encourages users to find tools they love. I've used office applications ranging from big suites (like LibreOffice and OpenOffice) to lightweight word processors (such as Abiword) to minimal text editors (with Pandoc for conversion).
Regardless of what users around me are locked into, I have [the freedom to use the tools that work best](https://opensource.com/article/21/2/linux-workday) on my computer and with the way I want to work.
## Choice
(Seth Kenlon, CC BY-SA 4.0)
One of open source's most valuable traits is the trust it allows users to have in the software they use. This trust is derived from a network of friends who can read the source code of the applications and operating systems they use. That means, even if you don't know good source code from bad, you can make friends within the [open source community](https://opensource.com/article/21/2/linux-community) who do. These are important connections that Linux users can make as they explore the distribution they run. If you don't trust the community that builds and maintains a distribution, you can and should move to a different distribution. Many of us have done it, and it's one of the strengths of having many distros to choose from.
[Linux offers choice](https://opensource.com/article/21/2/linux-choice) as a feature. A strong community, filled with real human connections, combined with the freedom of choice that Linux provides all give users confidence in the software they run. Because I've read some source code, and because I trust the people who maintain the code I haven't read, [I trust Linux](https://opensource.com/article/21/2/open-source-security).
## Budgeting
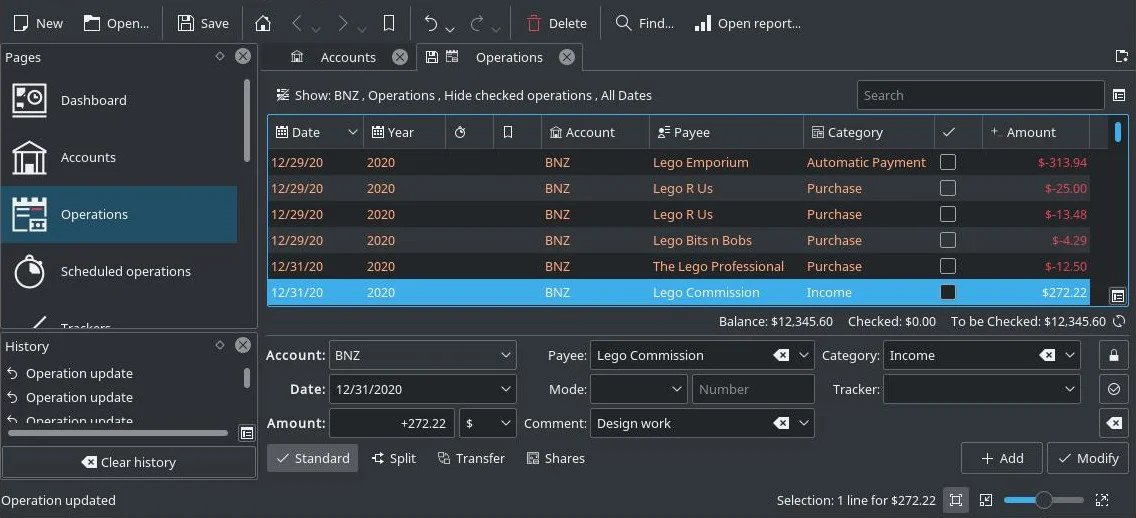
(Seth Kenlon, CC BY-SA 4.0)
Budgeting isn't fun, but it's important. I learned early, while working menial jobs as I learned a *free* operating system (Linux!) in my free time, that a budget isn't meant to track your money so much as it tracks your habits. That means that whether you're living paycheck to paycheck or you're well on the way to planning your retirement, you should [maintain a budget](https://opensource.com/article/21/2/linux-skrooge).
If you're in the United States, you can even [pay your taxes on Linux](https://opensource.com/article/21/2/linux-tax-software).
## Art
(Dogchicken, CC BY-SA 4.0)
It doesn't matter whether you paint or do pixel art, [edit video](https://opensource.com/article/21/2/linux-python-video), or scratch records, you can create great content on Linux. Some of the best art I've seen has been casually made with tools that aren't "industry standard," and it might surprise you just how much of the content you see is made the same way. Linux is a quiet engine, but it's a powerful one that drives indie artists as well as big producers.
Try using Linux [to create some art](https://opensource.com/article/21/2/linux-art-design).
## Programming
(Seth Kenlon, CC BY-SA 4.0)
Look, using Linux to program is almost a foregone conclusion. Second only to server administration, open source code and Linux are an obvious combination. There are [many reasons for this](https://opensource.com/article/21/2/linux-programming), but the one I cite is that it's just more fun. I run into plenty of roadblocks when inventing something new, so the last thing I need is for an operating system or software development kit (SDK) to be the reason for failure. On Linux, I have access to everything. Literally everything.
## Packaging
(Seth Kenlon, CC BY-SA 4.0)
The thing nobody talks about when they tell you about programming is *packaging*. As a developer, you have to get your code to your users, or you won't have any users. Linux makes it easy for developers [to deliver apps](https://opensource.com/article/21/2/linux-packaging) and easy for users to [install those applications](https://opensource.com/article/21/2/linux-package-management).
It surprises many people, but [Linux can run many Windows applications](https://opensource.com/article/21/2/linux-wine) as if they were native apps. You shouldn't expect a Windows application to be executable on Linux. Still, many of the major common applications either already exist natively on Linux or else can be run through a compatibility layer called Wine.
## Technology

If you're looking for a career in IT, Linux is a great first step. As a former art student who stumbled into Linux to render video faster, I speak from experience!
Cutting-edge technology happens on Linux. Linux drives most of the internet, most of the world's fastest supercomputers, and the cloud itself. Today, Linux drives [edge computing](https://opensource.com/article/21/2/linux-edge-computing), combining the power of cloud data centers with decentralized nodes for quick response.
You don't have to start at the top, though. You can learn to [automate](https://opensource.com/article/21/2/linux-automation) tasks on your laptop or desktop and remotely control systems with a [good terminal](https://opensource.com/article/21/2/linux-terminals).
Linux is open to your new ideas and [available for customization](https://opensource.com/article/21/2/linux-technology).
## Share files

(Seth Kenlon, CC BY-SA 4.0)
Whether you're a fledgling sysadmin or just a housemate with files to distribute to friends, Linux makes [file sharing a breeze](https://opensource.com/article/21/3/linux-server).
## Media
(Seth Kenlon, CC BY-SA 4.0)
With all the talk about programming and servers, people sometimes envision Linux as just a black screen filled with green 1's and 0's. Unsurprisingly to those of us who use it, Linux [plays all your media](https://opensource.com/article/21/2/linux-media-players), too.
## Easy install
(Seth Kenlon, CC BY-SA 4.0)
Never installed an operating system before? Linux is shockingly easy. Step-by-step, Linux installers hold your hand through an operating system installation to make you feel like a computer expert in under an hour.
## Try Linux
(Seth Kenlon, CC BY-SA 4.0)
If you're not ready to install Linux, then you can *try* Linux instead. No idea where to start? It's less intimidating than you may think. Here are some [things you should consider first](https://opensource.com/article/21/2/try-linux). Then take your pick, download a distro, and come up with your own 21 reasons to use Linux.
## 1 Comment |
13,405 | SonoBus:支持跨平台的开源点对点音频流应用 | https://itsfoss.com/sonobus/ | 2021-05-19T12:27:19 | [
"音乐",
"流媒体"
] | https://linux.cn/article-13405-1.html | 
>
> 一个有趣的开源点对点音频流应用,它提供了一个简单的用户界面和强大的功能。
>
>
>
### SonoBus: 跨平台音频流应用
如今,音频流服务在听音乐时非常受欢迎。然而,本地音乐集仍然是一种有用的方式,这不需要一直连接到互联网。
尽管流媒体音乐服务很方便,但你并不真正拥有这些音乐。因此,如果出现许可问题,该平台可能会删除你最喜欢的音乐,而你对此无能为力。
而有了本地音乐音乐集,你就不会遇到这个问题了。但是,你如何通过设备网络串流你本地的音乐,或者与一个小组分享?

SonoBus 可以成为解决这个问题的办法。不仅仅限于音乐,还包括任何音频,如与一群朋友远程练习音乐或合作制作音乐,为什么不呢?
让我们来看看它提供了什么。
### SonoBus 的功能

SonoBus 使用起来比较简单,但提供的功能可能会让人震惊。因此,在继续使用之前,你可能想先知道它能让你做什么:
* 能够连接到多个用户
* 创建一个有可选密码的小组
* 分享来自你的麦克风的音频输入
* 分享来自文件的音频流
* 支持单声道/立体声
* 组内播放
* 录制所有人的音频
* 能够使个别用户或所有人都静音
* 可以通过互联网或本地网络连接
* 支持节拍器,用于协作制作音乐或远程练习课程
* 支持高质量的音频,最高可达 256Kbps
* 输入混音器
* 支持声相
* 支持有用的效果器(噪声门、压缩器和均衡器)
* 可在 JACK 和 ALSA 下工作
* 跨平台支持(Windows、macOS、Android、iOS 和 Linux)
虽然我试图提到所有的基本功能,但你可以在效果器的帮助下得到非常多的控制,来调整音量、质量、延迟,以及音频效果。

它最好的一点是**跨平台支持**,这使它成为任何用户群的有趣选择,而无论你出于什么原因要串流音频。
### 在 Linux 中安装 SonoBus
无论你使用什么 Linux 发行版,你都可以轻松地安装 [Snap 包](https://snapcraft.io/sonobus)或 [Flatpak 包](https://flathub.org/apps/details/net.sonobus.SonoBus)。如果你不想使用它们,你可以手动添加官方仓库来安装:
```
echo "deb http://pkg.sonobus.net/apt stable main" | sudo tee /etc/apt/sources.list.d/sonobus.list
sudo wget -O /etc/apt/trusted.gpg.d/sonobus.gpg https://pkg.sonobus.net/apt/keyring.gpg
sudo apt update && sudo apt install sonobus
```
你也可以通过其官方网站为你喜欢的平台下载它。
* [SonoBus](https://sonobus.net/)
### 总结
SonoBus 是一个令人印象深刻的音频流应用,有很多潜在的用途,但它也有一些问题,可能不是每个人的完美解决方案。
例如,我注意到桌面应用占用大量的系统资源,所以这对较旧的系统来说可能是个问题。
另外,Play Store 上的安卓应用仍处于早期访问阶段(测试版)。在我的快速测试中,它工作符合预期,但我已经很久没有使用它了。因此,当依靠它进行跨平台会话时,可能会出现预期的小问题。
在任何情况下,它都适用于每种用例的大量功能。如果你还没有使用过,请试一试。
---
via: <https://itsfoss.com/sonobus/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Brief: An interesting open-source peer-to-peer audio streaming app which offers a simple user interface with powerful functionalities.*
## SonoBus: Cross-Platform Audio Streaming App
Audio streaming services are extremely popular nowadays when listening to music. However, a local collection is still a useful way that does not require to be constantly connected to the Internet.
Even though a streaming music service is convenient, you do not really own the music. So, if there is a licensing issue, the platform might remove your favorite music, and you cannot do anything about it.
And, with a local music collection, you do not have that problem. But, how do you stream your local music over a network of devices or share with a group?
SonoBus can be a solution to the problem. Not just limited to music, but just any audio like practicing music with a group of friends remotely or collaborating to make music, why not?
Let us take a look at what it offers.
## Features of SonoBus
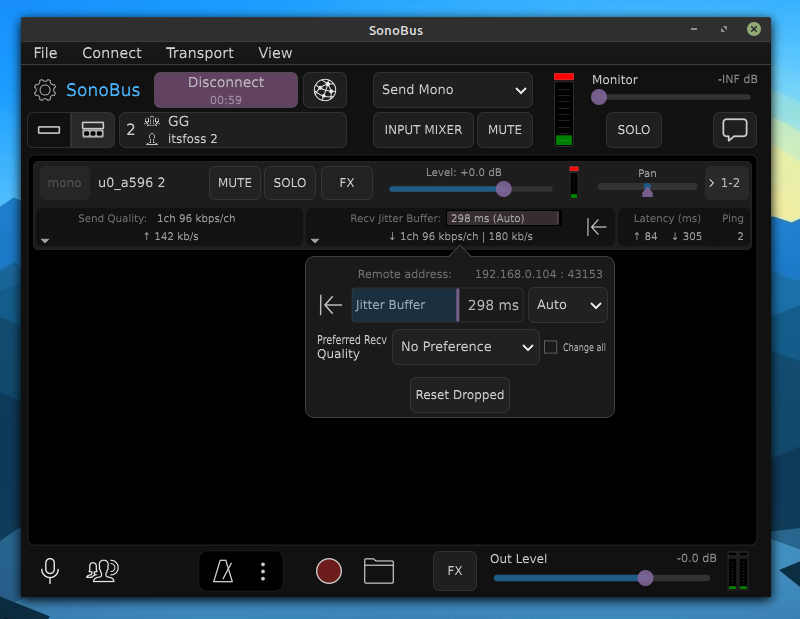
SonoBus is relatively simple to use, but the features offered can be overwhelming. So, before proceeding, you might want to know what it lets you do to get a head start:
- Ability to connect to multiple users
- Create a group with optional password
- Share audio input from your microphone
- Share audio stream from a file
- Mono/Stereo support
- Playback to the group
[Record audio](https://itsfoss.com/record-streaming-audio/)from everyone- Ability to mute individual users or everyone
- Can be connected via the Internet or the local network
- Metronome support for collaborating to make music or remote practice sessions
- High-quality audio support up to 256 Kbps
- Input mixer
- Pan support
- Useful effects supported (Noise Gate, Compressor, and EQ)
- Works with JACK and ALSA
- Cross-platform support (Windows, macOS, Android, iOS, and Linux)
While I tried to mention all the essential features, you get so much control to adjust the volume, quality, latency, and how the audio sounds with the help of effects.
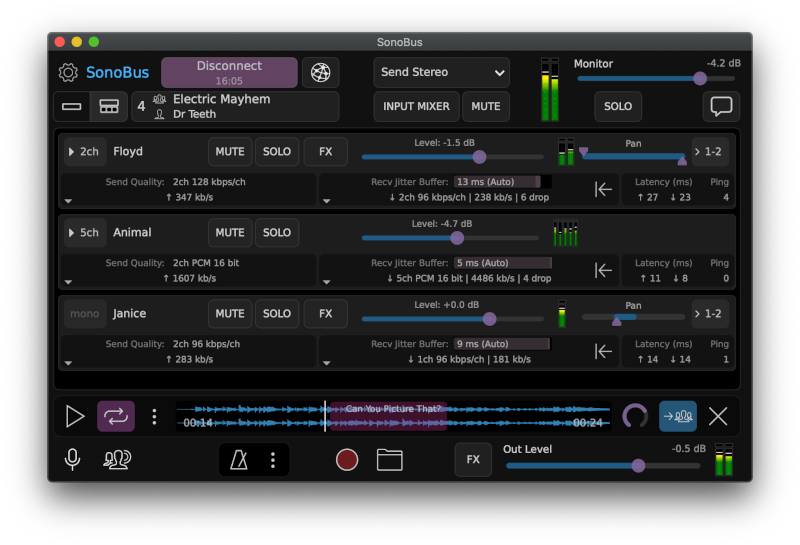
The best thing about it is **cross-platform support**, which makes it an interesting choice for any group of users no matter why you want to stream audio.
## Installing SonoBus in Linux
You can easily install the [Snap package](https://snapcraft.io/sonobus) or [Flatpak package](https://flathub.org/apps/details/net.sonobus.SonoBus) no matter what Linux distribution you use. If you do not want to use them, you can add the official repository manually to get it installed:
```
echo "deb http://pkg.sonobus.net/apt stable main" | sudo tee /etc/apt/sources.list.d/sonobus.list
sudo wget -O /etc/apt/trusted.gpg.d/sonobus.gpg https://pkg.sonobus.net/apt/keyring.gpg
sudo apt update && sudo apt install sonobus
```
You can also download it for your preferred platform through its official website.
## Closing Thoughts
SonoBus is an impressive audio streaming application with plenty of potential use-cases, but it has its share of issues and may not be the perfect solution for everyone.
For instance, I noticed that the desktop app takes a significant amount of system resources, so that could be a problem for older systems.
Also, the Android app on Play Store is still in early access (beta). It works as expected for my quick test session, but I haven’t used it for a long time – so there could be expected hiccups when relying on it for cross-platform sessions.
In either case, it works quite well with plenty of features for every type of use-case. Do give it a try if you haven’t. |
13,407 | 3 个值得使用的首次亮相在 Python 3.0 中的特性 | https://opensource.com/article/21/5/python-30-features | 2021-05-20T10:13:00 | [
"Python"
] | https://linux.cn/article-13407-1.html |
>
> 探索一些未被充分利用但仍然有用的 Python 特性。
>
>
>

这是 Python 3.x 首发特性系列文章的第一篇。Python 3.0 于 2008 年首次发布,尽管它已经发布了一段时间,但它引入的许多特性都没有被充分利用,而且相当酷。这里有三个你应该知道的。
### 仅限关键字参数
Python 3.0 首次引入了**仅限关键字参数**参数的概念。在这之前,不可能指定一个只通过关键字传递某些参数的 API。这在有许多参数,其中一些参数可能是可选的函数中很有用。
请看一个特意设计的例子:
```
def show_arguments(base, extended=None, improved=None, augmented=None):
print("base is", base)
if extended is not None:
print("extended is", extended)
if improved is not None:
print("improved is", improved)
if augmented is not None:
print("augmented is", augmented)
```
当阅读调用该函数的代码时,有时很难理解发生了什么:
```
show_arguments("hello", "extra")
base is hello
extended is extra
show_arguments("hello", None, "extra")
base is hello
improved is extra
```
虽然可以用关键字参数来调用这个函数,但这明显不是最好的方法。相反,你可以将这些参数标记为仅限关键字:
```
def show_arguments(base, *, extended=None, improved=None, augmented=None):
print("base is", base)
if extended is not None:
print("extended is", extended)
if improved is not None:
print("improved is", improved)
if augmented is not None:
print("augmented is", augmented)
```
现在,你不能用位置参数传入额外的参数:
```
show_arguments("hello", "extra")
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-7-6000400c4441> in <module>
----> 1 show_arguments("hello", "extra")
TypeError: show_arguments() takes 1 positional argument but 2 were given
```
对该函数的有效调用更容易预测:
```
show_arguments("hello", improved="extra")
base is hello
improved is extra
```
### nonlocal
有时,函数式编程的人根据编写累加器的难易程度来判断一种语言。累加器是一个函数,当它被调用时,返回目前为止发给它的所有参数的总和。
在 3.0 之前,Python 的标准答案是:
```
class _Accumulator:
def __init__(self):
self._so_far = 0
def __call__(self, arg):
self._so_far += arg
return self._so_far
def make_accumulator():
return _Accumulator()
```
虽然我承认有些啰嗦,但这确实有效:
```
acc = make_accumulator()
print("1", acc(1))
print("5", acc(5))
print("3", acc(3))
```
这样做的输出结果将是:
```
1 1
5 6
3 9
```
在 Python 3.x 中,`nonlocal` 关键字可以用少得多的代码实现同样的行为。
```
def make_accumulator():
so_far = 0
def accumulate(arg):
nonlocal so_far
so_far += arg
return so_far
return accumulate
```
虽然累加器是人为的例子,但使用 `nonlocal` 关键字使内部函数拥有具有状态的的能力是一个强大的工具。
### 扩展析构
想象一下,你有一个 CSV 文件,每一行由几个元素组成:
* 第一个元素是年份
* 第二个元素是月
* 其他元素是该月发表的全部文章数,每天一个条目
请注意,最后一个元素是 *文章总数*,而不是 *每天发表的文章*。例如,一行的开头可以是:
```
2021,1,5,8,10
```
这意味着在 2021 年 1 月,第一天发表了 5 篇文章。第二天,又发表了三篇文章,使总数达到 8 篇。第三天,又发表了两篇文章。
一个月可以有 28 天、30 天或 31 天。提取月份、日期和文章总数有多难?
在 3.0 之前的 Python 版本中,你可能会这样写:
```
year, month, total = row[0], row[1], row[-1]
```
这是正确的,但它掩盖了格式。使用**扩展析构**,同样可以这样表达:
```
year, month, *rest, total = row
```
这意味着如果该格式改为前缀了一个描述,你可以把代码改成:
```
_, year, month, *rest, total = row
```
而不需要在每个索引中添加 `1`。
### 接下来是什么?
Python 3.0 和它的后期版本已经推出了 12 年多,但是它的一些功能还没有被充分利用。在本系列的下一篇文章中,我将会写另外三个。
---
via: <https://opensource.com/article/21/5/python-30-features>
作者:[Moshe Zadka](https://opensource.com/users/moshez) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the first in a series of articles about features that first appeared in a version of Python 3.x. Python 3.0 was first released in 2008, and even though it has been out for a while, many of the features it introduced are underused and pretty cool. Here are three you should know about.
## Keyword-only arguments
Python 3.0 first introduced the idea of **keyword-only** arguments. Before this, it was impossible to specify an API where some arguments could be passed in only via keywords. This is useful in functions with many arguments, some of which might be optional.
Consider a contrived example:
```
def show_arguments(base, extended=None, improved=None, augmented=None):
print("base is", base)
if extended is not None:
print("extended is", extended)
if improved is not None:
print("improved is", improved)
if augmented is not None:
print("augmented is", augmented)
```
When reading code that calls this function, it is sometimes hard to understand what is happening:
`show_arguments("hello", "extra")`
```
base is hello
extended is extra
```
`show_arguments("hello", None, "extra")`
```
base is hello
improved is extra
```
While it is possible to call this function with keyword arguments, it is not obvious that this is the best way. Instead, you can mark these arguments as keyword-only:
```
def show_arguments(base, *, extended=None, improved=None, augmented=None):
print("base is", base)
if extended is not None:
print("extended is", extended)
if improved is not None:
print("improved is", improved)
if augmented is not None:
print("augmented is", augmented)
```
Now, you can't pass in the extra arguments with positional arguments:
`show_arguments("hello", "extra")`
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-7-6000400c4441> in <module>
----> 1 show_arguments("hello", "extra")
TypeError: show_arguments() takes 1 positional argument but 2 were given
```
Valid calls to the function are much easier to predict:
`show_arguments("hello", improved="extra")`
```
base is hello
improved is extra
```
## nonlocal
Sometimes, functional programming folks judge a language by how easy is it to write an accumulator. An accumulator is a function that, when called, returns the sum of all arguments sent to it so far.
The standard answer in Python before 3.0 was:
```
class _Accumulator:
def __init__(self):
self._so_far = 0
def __call__(self, arg):
self._so_far += arg
return self._so_far
def make_accumulator():
return _Accumulator()
```
While admittedly somewhat verbose, this does work:
```
acc = make_accumulator()
print("1", acc(1))
print("5", acc(5))
print("3", acc(3))
```
The output for this would be:
```
1 1
5 6
3 9
```
In Python 3.x, **nonlocal** can achieve the same behavior with significantly less code.
```
def make_accumulator():
so_far = 0
def accumulate(arg):
nonlocal so_far
so_far += arg
return so_far
return accumulate
```
While accumulators are contrived examples, the ability to use the `nonlocal`
keyword to have inner functions with state is a powerful tool.
## Extended destructuring
Imagine you have a CSV file where each row consists of several elements:
- The first element is a year
- The second element is a month
- The other elements are the total articles published that month, one entry for each day
Note that the last element is *total articles*, not *articles published per day*. For example, a row can begin with:
`2021,1,5,8,10`
This means that in January 2021, five articles were published on the first day. On the second day, three more articles were published, bringing the total to 8. On the third day, two more articles were published.
Months can have 28, 30, or 31 days. How hard is it to extract the month, day, and total articles?
In versions of Python before 3.0, you might write something like:
`year, month, total = row[0], row[1], row[-1]`
This is correct, but it obscures the format. With **extended destructuring**, the same can be expressed this way:
`year, month, *rest, total = row`
This means that if the format ever changes to prefix a description, you can change the code to:
`_, year, month, *rest, total = row`
Without needing to add `1`
to each of the indices.
## What's next?
Python 3.0 and its later versions have been out for more than 12 years, but some of its features are underutilized. In the next article in this series, I'll look at three more of them.
## Comments are closed. |
13,408 | 如何在 Ubuntu 服务器上安装桌面环境(GUI) | https://itsfoss.com/install-gui-ubuntu-server/ | 2021-05-20T11:00:33 | [
"服务器",
"GUI"
] | https://linux.cn/article-13408-1.html | 
你想在你的 Ubuntu 服务器上安装 GUI 吗?大部分情况下你是可以安装的,在本教程中我会详细介绍安装的步骤。
在正式开始之前,我来告诉你为什么服务器版的 Ubuntu 不带 GUI,以及在什么情况下你可以在服务器上安装 GUI。
### 为什么 Ubuntu 服务器没有 GUI?
你对比过 Ubuntu 的桌面版和服务器版会发现,两者的主要区别是服务器版缺少 GUI(比如 [桌面环境](https://itsfoss.com/what-is-desktop-environment/))。Ubuntu 服务器基本上就是桌面版去掉图形模块后的降级版本。
这是刻意为之的。Linux 服务器需要占用系统资源来运行服务。图形化桌面环境会消耗大量的系统资源,因此服务器操作系统默认不包含桌面环境。
你可以在只有 512 MB RAM 的机器上使用 Ubuntu 服务器,但是 Ubuntu 桌面需要至少 2 GB 的 RAM 才能提供正常的功能。在服务器运行桌面环境被认为是浪费资源。
作为一个服务器使用者(或系统管理员),你应该通过命令行来使用和管理你的系统。为了达到这个水平,你需要掌握丰富的 Linux 命令相关的知识。

### 你是否真正需要在你的服务器上安装 GUI?
有些用户可能不太习惯在终端下使用命令行来完成工作。毕竟大部分用户是有条件通过图形界面操作计算机的。
你可能会在你的服务器上安装桌面环境并使用图形界面。大部分人不会这么干,但这是可行的。
但是这只有在你可以直接操作服务器时才行得通。假设你是在物理机器上运行它,比如服务器、台式机或笔记本电脑,抑或类似树莓派的设备。如果你可以直接操作宿主机系统,那么你还可以在运行在虚拟机上的服务器上安装。
如果你是通过 [云服务器提供商如 Linode、DigitalOcean 或 AWS](https://linuxhandbook.com/free-linux-cloud-servers/) 部署的服务器,那么安装 GUI 就行不通了。如果你想通过图形界面来管理你的远程服务器,你可以使用 Webmin 或 [Cockpit](https://linuxhandbook.com/cockpit/) 等工具。你可以在 Web 浏览器中通过这些工具使用和管理你的服务器。相比于成熟的桌面环境,它能大大降低资源消耗。

### 如何在 Ubuntu 服务器上安装 GUI?
当你了解了基础知识后,我们一起来看看在 Ubuntu 服务器上安装桌面环境的步骤。
你需要做以下准备:
* 已经配置好 Ubuntu 服务器,且 RAM 至少 2 GB
* 管理员权限(你需要用 `sudo` 执行命令)
* 网络连接正常(你需要下载和安装新包)
我是在虚拟机上安装的 Ubuntu 服务器,并且我可以直接操作宿主机器。我使用同样的方法[在树莓派上安装了 Ubuntu 服务器](https://itsfoss.com/install-ubuntu-server-raspberry-pi/)。
>
> 注意!
>
>
> 如果你是出于学习和调研等实验性的目的,那么你可以进行这些操作。请不要在生产环境的服务器上添加 GUI。后续删除 GUI 时可能会导致依赖问题,有些情况会破坏系统。
>
>
>
#### 准备系统
首先,因为你将要做一些系统级的修改,因此先进行更新和升级以确保我们系统的包是最新的:
```
sudo apt update && sudo apt upgrade
```
#### 安装桌面环境
更新结束后,你就可以安装桌面环境了。
有两种方法:
* 使用 [apt](https://itsfoss.com/apt-command-guide/) 来安装包
* 使用一个名为 [tasksel](https://manpages.ubuntu.com/manpages/bionic/man8/tasksel.8.html) 的 Debian 工具,这个工具可以通过一条龙处理(任务)方式来安装多个包
任何一种方法都可以用完整包的方式来安装完整的桌面环境,就跟你从头安装桌面版本一样。我的意思是你可以得到跟桌面版本一样的所有的默认应用程序和工具。
如果你想使用 `tasksel`,需要先用下面的命令安装它:
```
sudo apt install tasksel
```
执行结束后,你就可以用 `tasksel` 来安装桌面环境(也叫 DE)了。
你可能知道有 [很多可用的桌面环境](https://itsfoss.com/best-linux-desktop-environments/)。你可以选择自己喜欢的一个。有些桌面环境对系统资源占用得多(像 GNOME),有些占用得少(像 Xfce、MATE 等等)。
你可以自己决定使用哪个 DE。我会安装 [GNOME 桌面](https://www.gnome.org/),因为它是 Ubuntu 默认的桌面。之后我也会介绍其他桌面的安装。
如果你使用的是 `tasksel`,执行下面这条命令:
```
sudo tasksel install ubuntu-desktop
```
如果你使用 `apt`,执行下面这条命令:
```
sudo apt install ubuntu-desktop
```
这个过程可能会持续几分钟到一个小时,执行速度取决于你的网速和硬件。
我想提醒下,上面两个命令执行后都会安装完整的 GNOME 桌面环境。在本文中我两个命令都会执行,两个命令的结果是一样的。
#### 安装和配置显示管理器
安装完成后,你需要一个名为 [显示管理器](https://itsfoss.com/display-manager/) 或“登录管理器”的组件。这个工具的功能是在管理用户对话和鉴权时启动 [显示服务器](https://itsfoss.com/display-server/) 并加载桌面。
GNOME 桌面默认使用 GDM3 作为显示管理器,但从资源角度考虑它有点重。你可以使用更轻量级和资源友好的管理器。这里我们使用一个平台无关的显示管理器 [lightdm](https://wiki.debian.org/LightDM)。使用 `apt` 安装它:
```
sudo apt install lightdm
```
安装 lightdm 时系统会让我们选择默认的显示管理器,因为即使你可以安装多个管理器,也只能运行一个。

选择列表中的 “lightdm” 并点击 “<Ok>”。这应该用不了几分钟。完成后你可以用下面的命令启动显示管理器并加载 GUI:
```
sudo service lightdm start
```
你可以使用下面的命令来检查当前的显示管理器:
```
cat /etc/X11/default-display-manager
```
运行后得到的结果类似这样:

如果一切顺利,你现在会来到欢迎界面。

输入你的凭证,你的桌面就运行起来了。

如果你想关闭 GUI,那么打开一个终端并输入:
```
sudo service lightdm stop
```
#### 安装其他的桌面环境(可选)
前面我说过我们可以选择不同的桌面。我们一起来看看一些其他的选项:
##### MATE
[MATE](https://mate-desktop.org/) 是基于 GNOME2 源码的轻量级桌面,它完全开源,是一个不错的选项。
用下面的命令来安装 MATE:
```
sudo tasksel install ubuntu-mate-core
```
或
```
sudo apt install ubuntu-mate-core
```
##### Lubuntu / LXDE/LXQT
如果你的系统资源有限或者电脑很旧,那么我推荐另一个轻量级的 [Lubuntu](https://lubuntu.net/)。使用下面的命令安装它:
```
sudo tasksel install lubuntu-core
```
或
```
sudo apt install lubuntu-core
```
##### Xubuntu / Xfce
[Xubuntu](https://xubuntu.org/) 是基于 [Xfce](https://www.xfce.org/) 的 Ubuntu 衍生版,轻量、简单、稳定但可高度定制。如果你想使用它,执行下面的命令:
```
sudo tasksel install xubuntu-core
```
或
```
sudo apt install xubuntu-core
```
还有一些桌面没有列出来,像 [KDE](https://itsfoss.com/install-kde-on-ubuntu/),[Cinnamon](https://itsfoss.com/install-cinnamon-on-ubuntu/) 和 [Budgie](https://itsfoss.com/install-budgie-ubuntu/),不代表它们不好,它们也都是非常卓越的,你可以自己尝试安装它们。
### 如何从 Ubuntu 服务器上删除 GUI?
如果你觉得桌面环境占用了太多的计算资源,你可以把之前安装的包删除掉。
请注意在某些情况下删除 GUI 可能会带来依赖问题,因此请备份好重要数据或创建一个系统快照。
* [如何从 Ubuntu 上删除包](https://itsfoss.com/uninstall-programs-ubuntu/)
```
sudo apt remove ubuntu-desktop
sudo apt remove lightdm
sudo apt autoremove
sudo service lightdm stop
```
现在重启你的系统。你应该回到了正常的命令行登录。
### 结语
在大多数场景下是可以安装桌面 GUI 的。如果你不适应命令行,那么请使用类似 [YunoHost](https://yunohost.org/) 的发行版的服务器,YunoHost 基于 Debian 系统,你可以通过 GUI 来管理服务器。
上面说了,如果你是从头安装系统,那么我建议你使用桌面版本以避免后续的步骤。
如果你有任何问题,请在评论区留言。你会在服务器上使用 GUI 吗?参照本文后你遇到了什么问题吗?
---
via: <https://itsfoss.com/install-gui-ubuntu-server/>
作者:[Chris Patrick Carias Stas](https://itsfoss.com/author/chris/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lxbwolf](https://github.com/lxbwolf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Do you want to install GUI on your Ubuntu server? You can totally do that in most scenarios and I am going to discuss the steps in details in this tutorial.
But before you see that, let me tell you why the server edition does not come with GUI and in which cases you could install the GUI on your server.
## Why does Ubuntu server not have a GUI?
If you [compare Ubuntu desktop with server](https://itsfoss.com/ubuntu-server-vs-desktop/), the main difference will be the absence of GUI, i.e. [the desktop environment](https://itsfoss.com/what-is-desktop-environment/) in the server edition. Ubuntu Server is basically a striped-down version of Ubuntu desktop without the graphical modules.
This is intentional. A Linux server intends to use the system resources on running services. The graphical desktop environment consumes a lot of system resources and for this reason, the server operating systems do not include a desktop environment by default.
You may use an Ubuntu server on 512 MB of RAM but an Ubuntu desktop will need at least 2 GB of RAM to function decently. That’s considered a waste of resources in the server world.
As a server user (or sysadmin), you are expected to use and manage your system through command line. You should have decent knowledge of the Linux commands for this purpose.
## Do you really need to install GUI on your server?
Some people do not feel comfortable with the idea of doing everything using commands in the terminal. Most people are conditioned to use a computer graphically after all.
You may choose to install a desktop environment on your server and use it graphically. That’s not how most people do it but it’s an option.
But this works only if you have direct access to the server. If you are running it on a physical machine like a server, a desktop/laptop or devices like Raspberry Pi. You may also install it on a server running in a virtual machine if you have direct access to the host system.
If you have a server deployed using a [cloud server provider like Linode, DigitalOcean or AWS](https://linuxhandbook.com/free-linux-cloud-servers/?ref=itsfoss.com), installing GUI won’t be a good idea. If you have a remote server that you want to manage graphically, you may use tools like [Webmin](https://linuxhandbook.com/use-webmin/?ref=itsfoss.com) or [Cockpit](https://linuxhandbook.com/cockpit/?ref=itsfoss.com). These tools allow you to use and manage your servers graphically in a web browser. It consumes a lot less system resources than a full-fledged desktop environment.
## How to install GUI on Ubuntu server?
Once the basics are clear, let’s see the steps for installing a desktop environment on an Ubuntu server.
You’ll need the following things:
- Ubuntu Server configured and running with at least 2 GB of RAM
- Administrative privileges (you need to run sudo commands)
- Internet connection (you are going to download and install new packages)
In my case, the Ubuntu server is installed in a virtual machine and I have direct access to the host machine. I have used the same method on an [Ubuntu server installed on a Raspberry Pi](https://itsfoss.com/install-ubuntu-server-raspberry-pi/).
Attention!
These things are fine for experimental purpose when you are learning and exploring. Please do not add GUI on a production server. Removing GUI afterwards could cause dependency issues and leave a broken system in some cases.
### Preparing your system
First, since you are going to make some system-wide modifications, let’s update & upgrade everything to make sure that our system is running the latest packages:
`sudo apt update && sudo apt upgrade`
### Installing the desktop environment
With the updates out of the way, you can continue with the installation of a desktop environment.
There are two ways to do this:
- Using
[apt](https://itsfoss.com/apt-command-guide/)to install the packages - Using a Debian tool called
[tasksel](http://manpages.ubuntu.com/manpages/bionic/man8/tasksel.8.html?ref=itsfoss.com)which helps with the installation of multiple packages in one coordinated process (tasks)
Either one will let you install the full desktop environment you choose as a full package, just like if you were installing the desktop version from scratch. By this, I mean that you will get all the default applications and tools you get with the desktop version.
If you want to use `tasksel`
you must first install it using the following command:
`sudo apt install tasksel`
Once this task is finished, you can use `tasksel`
to install the desktop environment (also referred as DE).
Now, you probably know that there are [several desktop environments available](https://itsfoss.com/best-linux-desktop-environments/). You may choose the one you like. Some desktop environments need more system resources (like GNOME) while some use fewer system resources (like Xfce, MATE etc).
It is up to you to decide which DE you would like to use. I am going with the [GNOME Desktop](https://www.gnome.org/?ref=itsfoss.com) since it is the default desktop for Ubuntu. Later on, I’ll share some tips for installing different desktops too.
If you are using `tasksel`
run this command:
`sudo tasksel install ubuntu-desktop`
if you want to use only apt, then run this command:
`sudo apt install ubuntu-desktop`
Depending on your connection speed and hardware this process will take from a couple of minutes to an hour.
I want to point that both actions will result in the full installation of the GNOME Desktop Environment. I ran both commands for the sake of this tutorial and ended up having the exact same results.
### Installing and setting up the display manager
After this process is completed, you will need a component called a [Display Manager](https://itsfoss.com/display-manager/), also known as a “login manager”. This tool is going to be responsible for starting the [display server](https://itsfoss.com/display-server/) and loading the desktop while managing user sessions and authentication.
By default, GNOME Desktop uses GDM3 as its display manager, but it is a bit heavy on the resources side. You can use something lighter and more resource-friendly. In this case, let’s go with [lightdm](https://wiki.debian.org/LightDM?ref=itsfoss.com), a platform independent display manager. Install it with apt:
`sudo apt install lightdm`
When installing lightdm the system is going to ask for a default display manager because only one can run at a time, although you can have several installed.
Just choose **lightdm** from the list and hit **<Ok>**. This shouldn’t take more than a couple of minutes. After this task is done, you can then start the display manager and load the GUI with the following command:
`sudo service lightdm start`
If you want to check what display manager is configured in your system you can run:
`cat /etc/X11/default-display-manager`
and you will get a prompt similar to this:

If everything went according to the plan, you will have a greeting screen loaded.
Enter your credentials and you will have your desktop running.
If you want to shutdown the GUI open a terminal window and type:
`sudo service lightdm stop`
### Installing other desktop environments (optional)
Earlier on I said that we could choose different desktops, so let’s take a look at some alternatives.
#### MATE
[MATE](https://mate-desktop.org/?ref=itsfoss.com) is a lightweight desktop based on GNOME2 base code, it’s fully open source and a very nice option.
To install MATE, you would run:
`sudo tasksel install ubuntu-mate-core`
or
`sudo apt install ubuntu-mate-core`
#### Lubuntu / LXDE/LXQT
[Lubuntu](https://lubuntu.net/?ref=itsfoss.com) is another lightweight option which I recommend if your system is low on resources or if you are giving new life to an older computer. Install it using this command:
`sudo tasksel install lubuntu-core`
or
`sudo apt install lubuntu-core`
#### Xubuntu / Xfce
[Xubuntu](https://xubuntu.org/?ref=itsfoss.com) is an Ubuntu derivative based on the [Xfce](https://www.xfce.org/?ref=itsfoss.com) desktop environment that is light, simple, stable, but it’s also highly customizable. If you want to try it, use the following command:
`sudo tasksel install xubuntu-core`
or
`sudo apt install xubuntu-core`
I’m leaving some other desktops out, like [KDE](https://itsfoss.com/install-kde-on-ubuntu/), [Cinnamon](https://itsfoss.com/install-cinnamon-on-ubuntu/), and [Budgie](https://itsfoss.com/install-budgie-ubuntu/), not for anything wrong, they are all excellent desktops too and you are free to install them as you want.
## How to remove the GUI from Ubuntu server?
If you realize that the desktop environment is taking too much computing resources, you may remove the packages you installed previously.
Please keep in mind that it may cause dependency issues in some cases so please make a backup of your important data or create a system snapshot.
You know [how to remove packages from Ubuntu](https://itsfoss.com/uninstall-programs-ubuntu/):
```
sudo apt remove ubuntu-desktop
sudo apt remove lightdm
sudo apt autoremove
sudo service lightdm stop
```
Reboot your system now. You should be back to the normal command line login.
## Wrapping up
Installing a GUI for a desktop is possible but not needed in most scenarios. If you are not too comfortable with the command line, use a server distribution like [YunoHost](https://yunohost.org/?ref=itsfoss.com) that is built on top of Debian to give you a server that can be managed via GUI.
You may also use a tool like Webmin that allows you to manage the server via a web browser.
[How to Install Webmin on Ubuntu Linux [and Configure It]Learn to install and configure Webmin to manage Linux servers remotely and graphically.](https://linuxhandbook.com/use-webmin/)

That said, if you are installing a system from scratch, then I’d recommend that you go with a desktop version and avoid the extra steps afterward.
With this information, I leave the comment section to you. Do you use GUI on a server? Did you face any issues in following this tutorial? |
13,410 | 用 Pulp 托管你的容器注册中心的 5 个理由 | https://opensource.com/article/21/5/container-management-pulp | 2021-05-21T09:12:33 | [
"容器",
"注册中心"
] | https://linux.cn/article-13410-1.html |
>
> 有很多令人信服的理由来用 Pulp 来托管你自己的容器注册中心。下面是其中的一些。
>
>
>

Linux 容器极大地简化了软件发布。将一个应用程序与它运行所需的一切打包的能力有助于提高环境的稳定性和可重复性。
虽然有许多公共注册中心可以上传、管理和分发容器镜像,但有许多令人信服的论据支持托管自己的容器注册中心。让我们来看看为什么自我托管是有意义的,以及 [Pulp](https://pulpproject.org/),一个自由开源项目,如何帮助你在企业内部环境中管理和分发容器。
### 为什么要托管你自己的容器注册中心
你可以考虑托管自己的容器注册中心,原因有很多:
* **体积**:一些容器镜像是相当大的。如果你有多个团队下载同一个镜像,这可能需要大量的时间,并给你的网络和预算带来压力。
* **带宽**:如果你在一个带宽有限的地区工作,或在一个出于安全原因限制访问互联网的组织中工作,你需要一个可靠的方法来管理你工作的容器。
* **金钱**:服务条款可以改变。外部容器注册中心能引入或增加速率限制阈值,这可能会对你的操作造成极大的限制。
* **稳定性**:托管在外部资源上的容器镜像可能会因为一些原因消失几天。小到你所依赖的更新容器镜像,可能会导致你想要避免的重大更改。
* **隐私**:你可能也想开发和分发容器,但你不想在公共的第三方注册中心托管。
### 使用 Pulp 进行自我托管
使用 Pulp,你可以避免这些问题并完全控制你的容器。
#### 1、避免速率限制
在 Pulp 中创建容器镜像的本地缓存,可以让你组织中的每个人都能拉取到 Pulp 上托管的容器镜像,而不是从外部注册中心拉取。这意味着你可以避免速率限制,只有当你需要新的东西时才从外部注册中心进行同步。当你确实需要从外部注册中心同步容器时,Pulp 首先检查内容是否已经存在,然后再从远程注册中心启动同步。如果你受到注册中心的速率限制,你就只镜像你需要的内容,然后用 Pulp 在整个组织中分发它。
#### 2、整理你的容器
使用 Pulp,你可以创建一个仓库,然后从任何与 Docker Registry HTTP API V2 兼容的注册中心镜像和同步容器。这包括 Docker、Google Container registry、[Quay.io](http://Quay.io) 等,也包括另一个 Pulp 服务器。对于你结合来自不同注册中心的镜像容器的方式,没有任何限制或约束。你可以自由地混合来自不同来源的容器。这允许你整理一套公共和私人容器,以满足你的确切要求。
#### 3、无风险的实验
在 Pulp 中,每当你对仓库进行修改时,就会创建一个新的不可变的版本。你可以创建多个版本的仓库,例如,development、test、stage 和 production,并在它们之间推送容器。你可以自由地将容器镜像的最新更新从外部注册中心同步到 Pulp,然后让最新的变化在开发或其他环境中可用。你可以对你认为必要的仓库进行任何修改,并促进容器内容被测试团队或其他环境使用。如果出了问题,你可以回滚到早期版本。
#### 4、只同步你需要的内容
如果你想使用 Pulp 来创建一个容器子集的本地缓存,而不是一个完整的容器注册中心,你可以从一个远程源过滤选择容器。使用 Pulp,有多种内容同步选项,以便你只存储你需要的内容,或配置你的部署,按需缓存内容。
#### 5、在断线和空气隔离的环境中工作
如果你在一个断线或受限制的环境中工作,你可以从一个连接的 Pulp 实例中同步更新到你断连的 Pulp。目前,有计划为 Pulp 实现一个原生的空气隔离功能,以促进完全断线的工作流程。同时,作为一种变通方法,你可以使用 [Skopeo](https://github.com/containers/skopeo) 等工具来下载你需要的容器镜像,然后将它们推送到你断线的 Pulp 容器注册中心。
#### 还有更多!
通过 Pulp,你还可以从容器文件中构建容器,将私有容器推送到仓库,并在整个组织中分发这些容器。我们将在未来的文章中对这个工作流程进行介绍。
### 如何开始
如果你对自我托管你的容器注册中心感兴趣,你现在就可以 [安装 Pulp](https://pulpproject.org/installation-introduction/)。随着 Pulp Ansible 安装程序的加入,安装过程已经被大量自动化和简化了。
Pulp 有一个基于插件的架构。当你安装 Pulp 时,选择容器插件和其他任何你想管理的内容插件类型。如果你想测试一下 Pulp,你今天就可以评估 Pulp 的容器化版本。
如果你有任何问题或意见,请随时在 Freenode IRC 的 #pulp 频道与我们联系,我们也很乐意在我们的邮件列表 [[email protected]](mailto:[email protected]) 中接受问题。
---
via: <https://opensource.com/article/21/5/container-management-pulp>
作者:[Melanie Corr](https://opensource.com/users/melanie-corr) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux containers have greatly simplified software distribution. The ability to package an application with everything it needs to run has helped increase stability and reproducibility of environments.
While there are many public registries where you can upload, manage, and distribute container images, there are many compelling arguments in favor of hosting your own container registry. Let's take a look at the reasons why self-hosting makes sense, and how [Pulp](https://pulpproject.org/), a free and open source project, can help you manage and distribute containers in an on-premises environment.
## Why host your own container registry
There are a number of reasons why you might consider hosting your own container registry:
**Size:**Some container images are quite large. If you have multiple teams downloading the same image, it can take a significant amount of time and put pressure on both your network and your budget.**Bandwidth:**If you work in an area of limited bandwidth or in an organization that restricts access to the internet for security reasons, you need a reliable way of managing the containers you work with.**Money:**Terms of service can change. External container registries can introduce or increase rate-limit thresholds that can become prohibitively restrictive to your operation.**Stability:**Container images hosted on an external source can disappear from one day to the next for a number of reasons. Something as small as an update for a container image you rely on can introduce breaking changes that you want to avoid.**Privacy:**You might also want to develop and distribute containers that you don't want to host in a public, third-party registry.
## Self-hosting with Pulp
Using Pulp, you can avoid these problems and take full control of your containers.
### 1. Avoid rate limits
Creating a local cache of container images in Pulp allows everyone in your organization to pull the container images hosted on Pulp rather than from an external registry. This means you can avoid rate limits and synchronize from an external registry only when you need something new. Whenever you do need to sync containers from an external registry, Pulp first checks if the content already exists before initiating the synchronization from the remote registry. If you are subject to registry rate limits, you're mirroring only the content you need and then distributing it throughout your organization using Pulp.
### 2. Curate your containers
With Pulp, you can create a repository, then mirror and synchronize containers from any registry that is Docker Registry HTTP API V2-compatible. This includes Docker, Google Container registry, Quay.io, and many more, including another Pulp server. There are no limits or restrictions to the way you combine containers that you mirror from different registries. You are free to blend containers from different sources. This allows you to curate a set of public and private containers to suit your exact requirements.
### 3. Experiment without risk
In Pulp, every time you make a change to the repository, a new immutable version is created. You can create multiple versions of a repository, for example, *development, test, stage*, and *production*, and promote containers across them. You are free to sync the latest updates to a container image from an external registry to Pulp, then make the latest changes consumable to a development or other environment. You can make any changes to the repositories you deem necessary, and promote the container content to be consumed by a test team or other environment. If something goes wrong, you can roll back to an earlier version.
### 4. Sync only the content you need
If you want to use Pulp to create a local cache of a subset of containers rather than a full container registry, you can filter a selection of containers from a remote source. With Pulp, there are multiple content synchronization options so that you store only the content you need or configure your deployment to cache content on demand.
### 5. Work with disconnected and air-gapped environments
If you work in a disconnected or restricted environment, you can sync updates from a connected Pulp instance to your disconnected Pulp. Currently, there are plans to implement a native air-gapped feature for Pulp to facilitate a fully disconnected workflow. In the meantime, as a workaround, you can use a tool such as [Skopeo](https://github.com/containers/skopeo) to download container images you need and then push them to your disconnected Pulp container registry.
### And much more!
With Pulp, you can also build containers from containerfiles, push private containers to repositories, and distribute those containers throughout your organization. We will take a look at this workflow in a future article.
## How to get started
If you're interested in self-hosting your container registry, you can [install Pulp](https://pulpproject.org/installation-introduction/) today. The installation process has been heavily automated and streamlined with the addition of a Pulp Ansible installer.
Pulp has a plugin-based architecture. When you install Pulp, select the Container plugin and whatever other type of content plugin you want to manage. If you would prefer to take Pulp for a test drive, you can evaluate a containerized version of Pulp today.
If you have any questions or comments, feel free to reach out to us on the #pulp channel on Freenode IRC, and we're happy to take questions on our mailing list, [[email protected]](mailto:[email protected]).
## Comments are closed. |
13,413 | 用 C 语言理解 Linux 软件库 | https://opensource.com/article/21/2/linux-software-libraries | 2021-05-22T16:53:46 | [
"软件库",
"C语言"
] | https://linux.cn/article-13413-1.html |
>
> 软件库是重复使用代码的一种简单而合理的方式。
>
>
>

软件库是一种是一直以来长期存在的、简单合理的复用代码的方式。这篇文章解释了如何从头开始构建库并使得其可用。尽管这两个示例库都以 Linux 为例,但创建、发布和使用这些库的步骤也可以应用于其它类 Unix 系统。
这些示例库使用 C 语言编写,非常适合该任务。Linux 内核大部分由 C 语言和少量汇编语言编写(Windows 和 Linux 的表亲如 macOS 也是如此)。用于输入/输出、网络、字符串处理、数学、安全、数据编码等的标准系统库等主要由 C 语言编写。所以使用 C 语言编写库就是使用 Linux 的原生语言来编写。除此之外,C 语言的性能也在一众高级语言中鹤立鸡群。
还有两个来访问这些库的示例<ruby> 客户程序 <rt> client </rt></ruby>(一个使用 C,另一个使用 Python)。毫无疑问可以使用 C 语言客户程序来访问 C 语言编写的库,但是 Python 客户程序示例说明了一个由 C 语言编写的库也可以服务于其他编程语言。
### 静态库和动态库对比
Linux 系统存在两种类型库:
* **静态库(也被称为归档库)**:在编译过程中的链接阶段,静态库会被编译进程序(例如 C 或 Rust)中。每个客户程序都有属于自己的一份库的拷贝。静态库有一个显而易见的缺点 —— 当库需要进行一定改动时(例如修复一个 bug),静态库必须重新链接一次。接下来要介绍的动态库避免了这一缺点。
* **动态库(也被称为共享库)**:动态库首先会在程序编译中的链接阶段被标记,但是客户程序和库代码在运行之前仍然没有联系,且库代码不会进入到客户程序中。系统的动态加载器会把一个共享库和正在运行的客户程序进行连接,无论该客户程序是由静态编译语言(如 C)编写,还是由动态解释语言(如 Python)编写。因此,动态库不需要麻烦客户程序便可以进行更新。最后,多个客户程序可以共享同一个动态库的单一副本。
通常来说,动态库优于静态库,尽管其复杂性较高而性能较低。下面是两种类型的库如何创建和发布:
1. 库的源代码会被编译成一个或多个目标模块,目标模块是二进制文件,可以被包含在库中并且链接到可执行的二进制中。
2. 目标模块会会被打包成一个文件。对于静态库,标准的文件拓展名是 `.a` 意为“<ruby> 归档 <rt> archive </rt></ruby>”;对于动态库,标准的文件拓展名是 `.so` 意为“<ruby> 共享目标 <rt> shared object </rt></ruby>”。对于这两个相同功能的示例库,分别发布为 `libprimes.a` (静态库)和 `libshprimes.so` (动态库)。两种库的文件名都使用前缀 `lib` 进行标识。
3. 库文件被复制到标准目录下,使得客户程序可以轻松地访问到库。无论是静态库还是动态库,典型的位置是 `/usr/lib` 或者 `/usr/local/lib`,当然其他位置也是可以的。
构建和发布每种库的具体步骤会在下面详细介绍。首先我将介绍两种库里涉及到的 C 函数。
### 示例库函数
这两个示例库都是由五个相同的 C 函数构建而成的,其中四个函数可供客户程序使用。第五个函数是其他四个函数的一个工具函数,它显示了 C 语言怎么隐藏信息。每个函数的源代码都很短,可以将这些函数放在单个源文件中,尽管也可以放在多个源文件中(如四个公布的函数都有一个文件)。
这些库函数是基本的处理函数,以多种方式来处理质数。所有的函数接收无符号(即非负)整数值作为参数:
* `is_prime` 函数测试其单个参数是否为质数。
* `are_coprimes` 函数检查了其两个参数的<ruby> 最大公约数 <rt> greatest common divisor </rt></ruby>(gcd)是否为 1,即是否为互质数。
* `prime_factors`:函数列出其参数的质因数。
* `glodbach`:函数接收一个大于等于 4 的偶数,列出其可以分解为两个质数的和。它也许存在多个符合条件的数对。该函数是以 18 世纪数学家 <ruby> <a href="https://en.wikipedia.org/wiki/Christian_Goldbach"> 克里斯蒂安·哥德巴赫 </a> <rt> Christian Goldbach </rt></ruby> 命名的,他的猜想是任意一个大于 2 的偶数可以分解为两个质数之和,这依旧是数论里最古老的未被解决的问题。
工具函数 `gcd` 留在已部署的库文件中,但是在没有包含这个函数的文件无法访问此函数。因此,一个使用库的客户程序无法调用 `gcd` 函数。仔细观察 C 函数可以明白这一点。
### 更多关于 C 函数的内容
每个在 C 语言中的函数都有一个存储类,它决定了函数的范围。对于函数,有两种选择。
* 函数默认的存储类是 `extern`,它给了函数一个全局域。一个客户程序可以调用在示例库中用 `extern` 修饰的任意函数。下面是一个带有显式 `extern` 声明的 `are_coprimes` 函数定义:
```
extern unsigned are_coprimes(unsigned n1, unsigned n2) {
...
}
```
* 存储类 `static` 将一个函数的的范围限制到函数被定义的文件中。在示例库中,工具函数 `gcd` 是静态的(`static`):
```
static unsigned gcd(unsigned n1, unsigned n2) {
...
}
```
只有在 `primes.c` 文件中的函数可以调用 `gcd`,而只有 `are_coprimes` 函数会调用它。当静态库和动态库被构建和发布后,其他的程序可以调用外部的(`extern`)函数,如 `are_coprimes` ,但是不可以调用静态(`static`)函数 `gcd`。静态(`static`)存储类通过将函数范围限制在其他库函数内,进而实现了对库的客户程序隐藏 `gcd` 函数。
在 `primes.c` 文件中除了 `gcd` 函数外,其他函数并没有指明存储类,默认将会设置为外部的(`extern`)。然而,在库中显式注明 `extern` 更加常见。
C 语言区分了函数的<ruby> 定义 <rt> definition </rt></ruby>和<ruby> 声明 <rt> declaration </rt></ruby>,这对库来说很重要。接下来让我们开始了解定义。C 语言仅允许命名函数不允许匿名函数,并且每个函数需要定义以下内容:
* 一个唯一的名字。一个程序不允许存在两个同名的函数。
* 一个可以为空的参数列表。参数需要指明类型。
* 一个返回值类型(例如:`int` 代表 32 位有符号整数),当没有返回值时设置为空类型(`void`)。
* 用一对花括号包围起来的函数主体部分。在一个特制的示例中,函数主体部分可以为空。
程序中的每个函数必须要被定义一次。
下面是库函数 `are_coprimes` 的完整定义:
```
extern unsigned are_coprimes(unsigned n1, unsigned n2) { /* 定义 */
return 1 == gcd(n1, n2); /* 最大公约数是否为 1? */
}
```
函数返回一个布尔值(`0` 代表假,`1` 代表真),取决于两个整数参数值的最大公约数是否为 1。工具函数 `gcd` 计算两个整数参数 `n1` 和 `n2` 的最大公约数。
函数声明不同于定义,其不需要主体部分:
```
extern unsigned are_coprimes(unsigned n1, unsigned n2); /* 声明 */
```
声明在参数列表后用一个分号代表结束,它没有被花括号包围起来的主体部分。程序中的函数可以被多次声明。
为什么需要声明?在 C 语言中,一个被调用的函数必须对其调用者可见。有多种方式可以提供这样的可见性,具体依赖于编译器如何实现。一个必然可行的方式就是当它们二者位于同一个文件中时,将被调用的函数定义在在它的调用者之前。
```
void f() {...} /* f 定义在其被调用前 */
void g() { f(); } /* ok */
```
当函数 `f` 被在调用前声明,此时函数 `f` 的定义可以移动到函数 `g` 的下方。
```
void f(); /* 声明使得函数 f 对调用者可见 */
void g() { f(); } /* ok */
void f() {...} /* 相较于前一种方式,此方式显得更简洁 */
```
但是当如果一个被调用的函数和调用它的函数不在同一个文件中时呢?因为前文提到一个函数在一个程序中需要被定义一次,那么如何使得让一个文件中被定义的函数在另一个文件中可见?
这个问题会影响库,无论是静态库还是动态库。例如在这两个质数库中函数被定义在源文件 `primes.c` 中,每个库中都有该函数的二进制副本,但是这些定义的函数必须要对使用库的 C 程序可见,该 C 程序有其自身的源文件。
函数声明可以帮助提供跨文件的可见性。对于上述的“质数”例子,它有一个名为 `primes.h` 的头文件,其声明了四个函数使得它们对使用库的 C 程序可见。
```
/** 头文件 primes.h:函数声明 **/
extern unsigned is_prime(unsigned);
extern void prime_factors(unsigned);
extern unsigned are_coprimes(unsigned, unsigned);
extern void goldbach(unsigned);
```
这些声明通过为每个函数指定其调用语法来作为接口。
为了客户程序的便利性,头文件 `primes.h` 应该存储在 C 编译器查找路径下的目录中。典型的位置有 `/usr/include` 和 `/usr/local/include`。一个 C 语言客户程序应使用 `#include` 包含这个头文件,并尽可能将这条语句其程序源代码的首部(头文件将会被导入另一个源文件的“头”部)。C 语言头文件可以被导入其他语言(如 Rust 语言)中的 `bindgen`,使其它语言的客户程序可以访问 C 语言的库。
总之,一个库函数只可以被定义一次,但可以在任何需要它的地方进行声明,任一使用 C 语言库的程序都需要该声明。头文件可以包含函数声明,但不能包含函数定义。如果头文件包含了函数定义,那么该文件可能会在一个 C 语言程序中被多次包含,从而破坏了一个函数在 C 语言程序中必须被精确定义一次的规则。
### 库的源代码
下面是两个库的源代码。这部分代码、头文件、以及两个示例客户程序都可以在 [我的网页](https://condor.depaul.edu/mkalin) 上找到。
```
#include <stdio.h>
#include <math.h>
extern unsigned is_prime(unsigned n) {
if (n <= 3) return n > 1; /* 2 和 3 是质数 */
if (0 == (n % 2) || 0 == (n % 3)) return 0; /* 2 和 3 的倍数不会是质数 */
/* 检查 n 是否是其他 < n 的值的倍数 */
unsigned i;
for (i = 5; (i * i) <= n; i += 6)
if (0 == (n % i) || 0 == (n % (i + 2))) return 0; /* 不是质数 */
return 1; /* 一个不是 2 和 3 的质数 */
}
extern void prime_factors(unsigned n) {
/* 在数字 n 的质因数分解中列出所有 2 */
while (0 == (n % 2)) {
printf("%i ", 2);
n /= 2;
}
/* 数字 2 已经处理完成,下面处理奇数 */
unsigned i;
for (i = 3; i <= sqrt(n); i += 2) {
while (0 == (n % i)) {
printf("%i ", i);
n /= i;
}
}
/* 还有其他质因数?*/
if (n > 2) printf("%i", n);
}
/* 工具函数:计算最大公约数 */
static unsigned gcd(unsigned n1, unsigned n2) {
while (n1 != 0) {
unsigned n3 = n1;
n1 = n2 % n1;
n2 = n3;
}
return n2;
}
extern unsigned are_coprimes(unsigned n1, unsigned n2) {
return 1 == gcd(n1, n2);
}
extern void goldbach(unsigned n) {
/* 输入错误 */
if ((n <= 2) || ((n & 0x01) > 0)) {
printf("Number must be > 2 and even: %i is not.\n", n);
return;
}
/* 两个简单的例子:4 和 6 */
if ((4 == n) || (6 == n)) {
printf("%i = %i + %i\n", n, n / 2, n / 2);
return;
}
/* 当 n > 8 时,存在多种可能性 */
unsigned i;
for (i = 3; i < (n / 2); i++) {
if (is_prime(i) && is_prime(n - i)) {
printf("%i = %i + %i\n", n, i, n - i);
/* 如果只需要一对,那么用 break 语句替换这句 */
}
}
}
```
*库函数*
这些函数可以被库利用。两个库可以从相同的源代码中获得,同时头文件 `primes.h` 是两个库的 C 语言接口。
### 构建库
静态库和动态库在构建和发布的步骤上有一些细节的不同。静态库需要三个步骤,而动态库需要增加两个步骤即一共五个步骤。额外的步骤表明了动态库的动态方法具有更多的灵活性。让我们先从静态库开始。
库的源文件 `primes.c` 被编译成一个目标模块。下面是命令,百分号 `%` 代表系统提示符,两个井字符 `#` 是我的注释。
```
% gcc -c primes.c ## 步骤1(静态)
```
这一步生成目标模块是二进制文件 `primes.o`。`-c` 标志意味着只编译。
下一步是使用 Linux 的 `ar` 命令将目标对象归档。
```
% ar -cvq libprimes.a primes.o ## 步骤2(静态)
```
`-cvq` 三个标识分别是“创建”、“详细的”、“快速添加”(以防新文件没有添加到归档中)的简称。回忆一下,前文提到过前缀 `lib` 是必须的,而库名是任意的。当然,库的文件名必须是唯一的,以避免冲突。
归档已经准备好要被发布:
```
% sudo cp libprimes.a /usr/local/lib ## 步骤3(静态)
```
现在静态库对接下来的客户程序是可见的,示例在后面。(包含 `sudo` 可以确保有访问权限将文件复制进 `/usr/local/lib` 目录中)
动态库还需要一个或多个对象模块进行打包:
```
% gcc primes.c -c -fpic ## 步骤1(动态)
```
增加的选项 `-fpic` 指示编译器生成与位置无关的代码,这意味着不需要将该二进制模块加载到一个固定的内存位置。在一个拥有多个动态库的系统中这种灵活性是至关重要的。生成的对象模块会略大于静态库生成的对象模块。
下面是从对象模块创建单个库文件的命令:
```
% gcc -shared -Wl,-soname,libshprimes.so -o libshprimes.so.1 primes.o ## 步骤2(动态)
```
选项 `-shared` 表明了该库是一个共享的(动态的)而不是静态的。`-Wl` 选项引入了一系列编译器选项,第一个便是设置动态库的 `-soname`,这是必须设置的。`soname` 首先指定了库的逻辑名字(`libshprimes.so`),接下来的 `-o` 选项指明了库的物理文件名字(`libshprimes.so.1`)。这样做的目的是为了保持逻辑名不变的同时允许物理名随着新版本而发生变化。在本例中,在物理文件名 `libshprimes.so.1` 中最后的 1 代表是第一个库的版本。尽管逻辑文件名和物理文件名可以是相同的,但是最佳做法是将它们命名为不同的名字。一个客户程序将会通过逻辑名(本例中为 `libshprimes.so`)来访问库,稍后我会进一步解释。
接下来的一步是通过复制共享库到合适的目录下使得客户程序容易访问,例如 `/usr/local/lib` 目录:
```
% sudo cp libshprimes.so.1 /usr/local/lib ## 步骤3(动态)
```
现在在共享库的逻辑名(`libshprimes.so`)和它的物理文件名(`/usr/local/lib/libshprimes.so.1`)之间设置一个符号链接。最简单的方式是将 `/usr/local/lib` 作为工作目录,在该目录下输入命令:
```
% sudo ln --symbolic libshprimes.so.1 libshprimes.so ## 步骤4(动态)
```
逻辑名 `libshprimes.so` 不应该改变,但是符号链接的目标(`libshrimes.so.1`)可以根据需要进行更新,新的库实现可以是修复了 bug,提高性能等。
最后一步(一个预防措施)是调用 `ldconfig` 工具来配置系统的动态加载器。这个配置保证了加载器能够找到新发布的库。
```
% sudo ldconfig ## 步骤5(动态)
```
到现在,动态库已为包括下面的两个在内的示例客户程序准备就绪了。
### 一个使用库的 C 程序
这个示例 C 程序是一个测试程序,它的源代码以两条 `#include` 指令开始:
```
#include <stdio.h> /* 标准输入/输出函数 */
#include <primes.h> /* 我的库函数 */
```
文件名两边的尖括号表示可以在编译器的搜索路径中找到这些头文件(对于 `primes.h` 文件来说在 `/usr/local/inlcude` 目录下)。如果不包含 `#include`,编译器会抱怨缺少 `is_prime` 和 `prime_factors` 等函数的声明,它们在两个库中都有发布。顺便提一句,测试程序的源代码不需要更改即可测试两个库中的每一个库。
相比之下,库的源文件(`primes.c`)使用 `#include` 指令打开以下头文件:
```
#include <stdio.h>
#include <math.h>
```
`math.h` 头文件是必须的,因为库函数 `prime_factors` 会调用数学函数 `sqrt`,其在标准库 `libm.so` 中。
作为参考,这是测试库程序的源代码:
```
#include <stdio.h>
#include <primes.h>
int main() {
/* 是质数 */
printf("\nis_prime\n");
unsigned i, count = 0, n = 1000;
for (i = 1; i <= n; i++) {
if (is_prime(i)) {
count++;
if (1 == (i % 100)) printf("Sample prime ending in 1: %i\n", i);
}
}
printf("%i primes in range of 1 to a thousand.\n", count);
/* prime_factors */
printf("\nprime_factors\n");
printf("prime factors of 12: ");
prime_factors(12);
printf("\n");
printf("prime factors of 13: ");
prime_factors(13);
printf("\n");
printf("prime factors of 876,512,779: ");
prime_factors(876512779);
printf("\n");
/* 是合数 */
printf("\nare_coprime\n");
printf("Are %i and %i coprime? %s\n",
21, 22, are_coprimes(21, 22) ? "yes" : "no");
printf("Are %i and %i coprime? %s\n",
21, 24, are_coprimes(21, 24) ? "yes" : "no");
/* 哥德巴赫 */
printf("\ngoldbach\n");
goldbach(11); /* error */
goldbach(4); /* small one */
goldbach(6); /* another */
for (i = 100; i <= 150; i += 2) goldbach(i);
return 0;
}
```
*测试程序*
在编译 `tester.c` 文件到可执行文件时,难处理的部分时链接选项的顺序。回想前文中提到两个示例库都是用 `lib` 作为前缀开始,并且每一个都有一个常规的拓展后缀:`.a` 代表静态库 `libprimes.a`,`.so` 代表动态库 `libshprimes.so`。在链接规范中,前缀 `lib` 和拓展名被忽略了。链接标志以 `-l` (小写 L)开始,并且一条编译命令可能包含多个链接标志。下面是一个完整的测试程序的编译指令,使用动态库作为示例:
```
% gcc -o tester tester.c -lshprimes -lm
```
第一个链接标志指定了库 `libshprimes.so`,第二个链接标志指定了标准数学库 `libm.so`。
链接器是懒惰的,这意味着链接标志的顺序是需要考虑的。例如,调整上述实例中的链接顺序将会产生一个编译时错误:
```
% gcc -o tester tester.c -lm -lshprimes ## 危险!
```
链接 `libm.so` 库的标志先出现,但是这个库中没有函数被测试程序显式调用;因此,链接器不会链接到 `math.so` 库。调用 `sqrt` 库函数仅发生在 `libshprimes.so` 库中包含的 `prime_factors` 函数。编译测试程序返回的错误是:
```
primes.c: undefined reference to 'sqrt'
```
因此,链接标志的顺序应该是通知链接器需要 `sqrt` 函数:
```
% gcc -o tester tester.c -lshprimes -lm ## 首先链接 -lshprimes
```
链接器在 `libshprimes.so` 库中发现了对库函数 `sqrt` 的调用,所以接下来对数学库 `libm.so`做了合适的链接。链接还有一个更复杂的选项,它支持链接的标志顺序。然而在本例中,最简单的方式就是恰当地排列链接标志。
下面是运行测试程序的部分输出结果:
```
is_prime
Sample prime ending in 1: 101
Sample prime ending in 1: 401
...
168 primes in range of 1 to a thousand.
prime_factors
prime factors of 12: 2 2 3
prime factors of 13: 13
prime factors of 876,512,779: 211 4154089
are_coprime
Are 21 and 22 coprime? yes
Are 21 and 24 coprime? no
goldbach
Number must be > 2 and even: 11 is not.
4 = 2 + 2
6 = 3 + 3
...
32 = 3 + 29
32 = 13 + 19
...
100 = 3 + 97
100 = 11 + 89
...
```
对于 `goldbach` 函数,即使一个相当小的偶数值(例如 18)也许存在多个一对质数之和的组合(在这种情况下,5+13 和 7+11)。因此这种多个质数对是使得尝试证明哥德巴赫猜想变得复杂的因素之一。
### 封装使用库的 Python 程序
与 C 不同,Python 不是一个静态编译语言,这意味着 Python 客户示例程序必须访问动态版本而非静态版本的 `primes` 库。为了能这样做,Python 中有众多的支持<ruby> 外部语言接口 <rt> foreign function interface </rt></ruby>(FFI)的模块(标准的或第三方的),它们允许用一种语言编写的程序来调用另一种语言编写的函数。Python 中的 `ctypes` 是一个标准的、相对简单的允许 Python 代码调用 C 函数的 FFI。
任何 FFI 都面临挑战,因为对接的语言不大可能会具有完全相同的数据类型。例如:`primes` 库使用 C 语言类型 `unsigned int`,而 Python 并不具有这种类型;因此 `ctypes` FFI 将 C 语言中的 `unsigned int` 类型映射为 Python 中的 `int` 类型。在 `primes` 库中发布的四个 `extern` C 函数中,有两个在具有显式 `ctypes` 配置的 Python 中会表现得更好。
C 函数 `prime_factors` 和 `goldbach` 返回 `void` 而不是返回一个具体类型,但是 `ctypes` 默认会将 C 语言中的 `void` 替换为 Python 语言中的 `int`。当从 Python 代码中调用时,这两个 C 函数会从栈中返回一个随机整数值(因此,该值无任何意义)。然而,可以对 `ctypes` 进行配置,让这些函数返回 `None` (Python 中为 `null` 类型)。下面是对 `prime_factors` 函数的配置:
```
primes.prime_factors.restype = None
```
可以用类似的语句处理 `goldbach` 函数。
下面的交互示例(在 Python3 中)展示了在 Python 客户程序和 `primes` 库之间的接口是简单明了的。
```
>>> from ctypes import cdll
>>> primes = cdll.LoadLibrary("libshprimes.so") ## 逻辑名
>>> primes.is_prime(13)
1
>>> primes.is_prime(12)
0
>>> primes.are_coprimes(8, 24)
0
>>> primes.are_coprimes(8, 25)
1
>>> primes.prime_factors.restype = None
>>> primes.goldbach.restype = None
>>> primes.prime_factors(72)
2 2 2 3 3
>>> primes.goldbach(32)
32 = 3 + 29
32 = 13 + 19
```
在 `primes` 库中的函数只使用一个简单数据类型:`unsigned int`。如果这个 C 语言库使用复杂的类型如结构体,如果库函数传递和返回指向结构体的指针,那么比 `ctypes` 更强大的 FFI 更适合作为一个在 Python 语言和 C 语言之间的平滑接口。尽管如此,`ctypes` 示例展示了一个 Python 客户程序可以使用 C 语言编写的库。值得注意的是,用作科学计算的流行的 `Numpy` 库是用 C 语言编写的,然后在高级 Python API 中公开。
简单的 `primes` 库和高级的 `Numpy` 库强调了 C 语言仍然是编程语言中的通用语言。几乎每一个语言都可以与 C 语言交互,同时通过 C 语言也可以和任何其他语言交互。Python 很容易和 C 语言交互,作为另外一个例子,当 [Panama 项目](https://openjdk.java.net/projects/panama) 成为 Java Native Interface(JNI)一个替代品后,Java 语言和 C 语言交互也会变的很容易。
---
via: <https://opensource.com/article/21/2/linux-software-libraries>
作者:[Marty Kalin](https://opensource.com/users/mkalindepauledu) 选题:[lujun9972](https://github.com/lujun9972) 译者:[萌新阿岩](https://github.com/mengxinayan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Software libraries are a longstanding, easy, and sensible way to reuse code. This article explains how to build libraries from scratch and make them available to clients. Although the two sample libraries target Linux, the steps for creating, publishing, and using these libraries apply to other Unix-like systems.
The sample libraries are written in C, which is well suited to the task. The Linux kernel is written mostly in C with the rest in assembly language. (The same goes for Windows and Linux cousins such as macOS.) The standard system libraries for input/output, networking, string processing, mathematics, security, data encoding, and so on are likewise written mainly in C. To write a library in C is therefore to write in Linux's native language. Moreover, C sets the mark for performance among high-level languages.
There are also two sample clients (one in C, the other in Python) to access the libraries. It's no surprise that a C client can access a library written in C, but the Python client illustrates that a library written in C can serve clients from other languages.
## Static versus dynamic libraries
Linux systems have two types of libraries:
- A
**static library (aka library archive)**is baked into a statically compiled client (e.g., one in C or Rust) during the compilation process' link phase. In effect, each client gets its own copy of the library. A significant downside of a static library comes to the fore if the library needs to be revised (for example, to fix a bug), as each library client must be relinked to the static library. A dynamic library, described next, avoids this shortcoming. - A
**dynamic (aka shared) library**is flagged during a statically compiled client program's link phase, but the client program and the library code remain otherwise unconnected until runtime—the library code is not baked into the client. At runtime, the system's dynamic loader connects a shared library with an executing client, regardless of whether the client comes from a statically compiled language, such as C, or a dynamically compiled language, such as Python. As a result, a dynamic library can be updated without inconveniencing clients. Finally, multiple clients can share a single copy of a dynamic library.
In general, dynamic libraries are preferred over static ones, although there is a cost in complexity and performance. Here's how each library type is created and published:
- The source code for the library is compiled into one or more object modules, which are binary files that can be included in a library and linked to executable clients.
- The object modules are packaged into a single file. For a static library, the standard extension is
`.a`
for "archive." For a dynamic library, the extension is`.so`
for "shared object." The two sample libraries, which have the same functionality, are published as the files`libprimes.a`
(static) and`libshprimes.so`
(dynamic). The prefix`lib`
is used for both types of library. - The library file is copied to a standard directory so that client programs, without fuss, can access the library. A typical location for the library, whether static or dynamic, is
`/usr/lib`
or`/usr/local/lib`
; other locations are possible.
Detailed steps for building and publishing each type of library are coming shortly. First, however, I will introduce the C functions in the two libraries.
## The sample library functions
The two sample libraries are built from the same five C functions, four of which are accessible to client programs. The fifth function, which is a utility for one of the other four, shows how C supports hiding information. The source code for each function is short enough that the functions can be housed in a single source file, although multiple source files (e.g., one per each of the four published functions) is an option.
The library functions are elementary and deal, in various ways, with prime numbers. All of the functions expect unsigned (i.e., non-negative) integer values as arguments:
- The
`is_prime`
function tests whether its single argument is a prime. - The
`are_coprimes`
function checks whether its two arguments have a greatest common divisor (gcd) of 1, which defines co-primes. - The
`prime_factors`
function lists the prime factors of its argument. - The
`goldbach`
function expects an even integer value of 4 or more, listing whichever two primes sum to this argument; there may be multiple summing pairs. The function is named after the 18th-century mathematician[Christian Goldbach](https://en.wikipedia.org/wiki/Christian_Goldbach), whose conjecture that every even integer greater than two is the sum of two primes remains one of the oldest unsolved problems in number theory.
The utility function `gcd`
resides in the deployed library files, but this function is not accessible outside of its containing file; hence, a library client cannot directly invoke the `gcd`
function. A closer look at C functions clarifies the point.
## More on C functions
Every function in C has a storage class, which determines the function's scope. For functions there are two options:
- The default storage class for functions is
`extern`
, which gives a function global scope. A client program can call any`extern`
function in the sample libraries. Here's the definition for the function`are_coprimes`
with an explicit`extern`
:
`extern unsigned are_coprimes(unsigned n1, unsigned n2) { ... }`
- The storage class
`static`
limits a function's scope to the file in which the function is defined. In the sample libraries, the utility function`gcd`
is`static`
:
`static unsigned gcd(unsigned n1, unsigned n2) { ... }`
Only functions within the `primes.c`
file can invoke `gcd`
, and only the function `are_coprimes`
does so. When the static and dynamic libraries are built and published, other programs can call an `extern`
function such as `are_coprimes`
but not the `static`
function `gcd`
. The `static`
storage class thus hides the `gcd`
function from library clients by limiting the function's scope to the other library functions.
The functions other than `gcd`
in the `primes.c`
file need not specify a storage class, which would default to `extern`
. However, it is common in libraries to make the `extern`
explicit.
C distinguishes between function definitions and declarations, which is important for libraries. Let's start with definitions. C has named functions only, and every function is defined with:
- A unique name. No two functions in a program can have the same name.
- An argument list, which may be empty. The arguments are typed.
- Either a return value type (e.g.,
`int`
for a 32-bit signed integer) or`void`
if there is no value returned. - A body enclosed in curly braces. In a contrived example, the body could be empty.
Every function in a program must be defined exactly once.
Here's the full definition for the library function `are_coprimes`
:
```
extern unsigned are_coprimes(unsigned n1, unsigned n2) { /* definition */
return 1 == gcd(n1, n2); /* greatest common divisor of 1? */
}
```
The function returns a boolean value (either 0 for false or 1 for true), depending on whether the two integer arguments have a greatest common divisor of 1. The utility function `gcd`
computes the greatest common divisor of integer arguments `n1`
and `n2`
.
A function declaration, unlike a definition, does not have a body:
`extern unsigned are_coprimes(unsigned n1, unsigned n2); /* declaration */`
The declaration ends with a semicolon after the argument list; there are no curly braces enclosing a body. A function may be declared multiple times within a program.
Why are declarations needed at all? In C, a called function must be visible to its caller. There are various ways to provide such visibility, depending on how fussy the compiler is. One sure way is to define the called function above its caller when both reside in the same file:
```
void f() {...} /* f is defined before being called */
void g() { f(); } /* ok */
```
The definition of function `f`
could be moved below the call from function `g`
if `f`
were declared above the call:
```
void f(); /* declaration makes f visible to caller */
void g() { f(); } /* ok */
void f() {...} /* easier to put this above the call from g */
```
But what if the called function resides in a different file than its caller? How are functions defined in one file made visible in another file, given that each function must be defined exactly once in a program?
This issue impacts libraries, whether static or dynamic. For example, the functions in the two primes libraries are defined in the source file `primes.c`
, binary copies of which are in each library; but these defined functions must be visible to a library client in C, which is a separate program with its own source file(s).
Providing visibility across files is what function declarations can do. For the "primes" examples, there is a header file named `primes.h`
that declares the four functions to be made visible to library clients in C:
```
/** header file primes.h: function declarations **/
extern unsigned is_prime(unsigned);
extern void prime_factors(unsigned);
extern unsigned are_coprimes(unsigned, unsigned);
extern void goldbach(unsigned);
```
These declarations serve as an interface by specifying the invocation syntax for each function.
For client convenience, the text file `primes.h`
could be stored in a directory on the C compiler's search path. Typical locations are `/usr/include`
and `/usr/local/include`
. A C client would `#include`
this header file near the top of the client's source code. (A header file is thus imported into the "head" of another source file.) C header files also serve as input to utilities (e.g., Rust's `bindgen`
) that enable clients in other languages to access a C library.
In summary, a library function is defined exactly once but declared wherever needed; any library client in C needs the declaration. A header file should contain function declarations—but not function definitions. If a header file did contain definitions, the file might be included multiple times in a C program, thereby breaking the rule that a function must be defined exactly once in a C program.
## The library source code
Below is the source code for two libraries. This code, the header file, and the two sample clients are available on my [website](https://condor.depaul.edu/mkalin).
**The library functions**
```
#include <stdio.h>
#include <math.h>
extern unsigned is_prime(unsigned n) {
if (n <= 3) return n > 1; /* 2 and 3 are prime */
if (0 == (n % 2) || 0 == (n % 3)) return 0; /* multiples of 2 or 3 aren't */
/* check that n is not a multiple of other values < n */
unsigned i;
for (i = 5; (i * i) <= n; i += 6)
if (0 == (n % i) || 0 == (n % (i + 2))) return 0; /* not prime */
return 1; /* a prime other than 2 or 3 */
}
extern void prime_factors(unsigned n) {
/* list 2s in n's prime factorization */
while (0 == (n % 2)) {
printf("%i ", 2);
n /= 2;
}
/* 2s are done, the divisor is now odd */
unsigned i;
for (i = 3; i <= sqrt(n); i += 2) {
while (0 == (n % i)) {
printf("%i ", i);
n /= i;
}
}
/* one more prime factor? */
if (n > 2) printf("%i", n);
}
/* utility function: greatest common divisor */
static unsigned gcd(unsigned n1, unsigned n2) {
while (n1 != 0) {
unsigned n3 = n1;
n1 = n2 % n1;
n2 = n3;
}
return n2;
}
extern unsigned are_coprimes(unsigned n1, unsigned n2) {
return 1 == gcd(n1, n2);
}
extern void goldbach(unsigned n) {
/* input errors */
if ((n <= 2) || ((n & 0x01) > 0)) {
printf("Number must be > 2 and even: %i is not.\n", n);
return;
}
/* two simple cases: 4 and 6 */
if ((4 == n) || (6 == n)) {
printf("%i = %i + %i\n", n, n / 2, n / 2);
return;
}
/* for n >= 8: multiple possibilities for many */
unsigned i;
for (i = 3; i < (n / 2); i++) {
if (is_prime(i) && is_prime(n - i)) {
printf("%i = %i + %i\n", n, i, n - i);
/* if one pair is enough, replace this with break */
}
}
}
```
These functions serve as grist for the library mill. The two libraries derive from exactly the same source code, and the header file `primes.h`
is the C interface for both libraries.
## Building the libraries
The steps for building and publishing static and dynamic libraries differ in a few details. Only three steps are required for the static library and just two more for the dynamic library. The additional steps in building the dynamic library reflect the added flexibility of the dynamic approach. Let's start with the static library.
The library source file `primes.c`
is compiled into an object module. Here's the command, with the percent sign as the system prompt (double sharp signs introduce my comments):
`% gcc -c primes.c ## step 1 static`
This produces the binary file `primes.o`
, the object module. The flag `-c`
means compile only.
The next step is to archive the object module(s) by using the Linux `ar`
utility:
`% ar -cvq libprimes.a primes.o ## step 2 static`
The three flags `-cvq`
are short for "create," "verbose," and "quick append" (in case new files must be added to an archive). Recall that the prefix `lib`
is standard, but the library name is arbitrary. Of course, the file name for a library must be unique to avoid conflicts.
The archive is ready to be published:
`% sudo cp libprimes.a /usr/local/lib ## step 3 static`
The static library is now accessible to clients, examples of which are forthcoming. (The `sudo`
is included to ensure the correct access rights for copying a file into `/usr/local/lib`
.)
The dynamic library also requires one or more object modules for packaging:
`% gcc primes.c -c -fpic ## step 1 dynamic`
The added flag `-fpic`
directs the compiler to generate position-independent code, which is a binary module that need not be loaded into a fixed memory location. Such flexibility is critical in a system of multiple dynamic libraries. The resulting object module is slightly larger than the one generated for the static library.
Here's the command to create the single library file from the object module(s):
`% gcc -shared -Wl,-soname,libshprimes.so -o libshprimes.so.1 primes.o ## step 2 dynamic`
The flag `-shared`
indicates that the library is shared (dynamic) rather than static. The `-Wl`
flag introduces a list of compiler options, the first of which sets the dynamic library's `soname`
, which is required. The `soname`
first specifies the library's logical name (`libshprimes.so`
) and then, following the `-o`
flag, the library's physical file name (`libshprimes.so.1`
). The goal to is keep the logical name constant while allowing the physical file name to change with new versions. In this example, the 1 at the end of the physical file name `libshprimes.so.1`
represents the first version of the library. The logical and physical file names could be the same, but best practice is to have separate names. A client accesses the library through its logical name (in this case, `libshprimes.so`
), as I will clarify shortly.
The next step is to make the shared library easily accessible to clients by copying it to the appropriate directory; for example, `/usr/local/lib again:`
`% sudo cp libshprimes.so.1 /usr/local/lib ## step 3 dynamic`
A symbolic link is now set up between the shared library's logical name (`libshprimes.so`
) and its full physical file name (`/usr/local/lib/libshprimes.so.1`
). It's easiest to give the command with `/usr/local/lib`
as the working directory:
`% sudo ln --symbolic libshprimes.so.1 libshprimes.so ## step 4 dynamic`
The logical name `libshprimes.so`
should not change, but the target of the symbolic link (`libshrimes.so.1`
) can be updated as needed for new library implementations that fix bugs, boost performance, and so on.
The final step (a precautionary one) is to invoke the `ldconfig`
utility, which configures the system's dynamic loader. This configuration ensures that the loader will find the newly published library:
`% sudo ldconfig ## step 5 dynamic`
The dynamic library is now ready for clients, including the two sample ones that follow.
## A C library client
The sample C client is the program tester, whose source code begins with two `#include`
directives:
```
#include <stdio.h> /* standard input/output functions */
#include <primes.h> /* my library functions */
```
The angle brackets around the file names indicate that these header files are to be found on the compiler's search path (in the case of `primes.h`
, the directory `/usr/local/include`
). Without this `#include`
, the compiler would complain about missing declarations for functions such as `is_prime`
and `prime_factors`
, which are published in both libraries. By the way, the source code for the tester program need not change at all to test each of the two libraries.
By contrast, the source file for the library (`primes.c`
) opens with these `#include`
directives:
```
#include <stdio.h>
#include <math.h>
```
The header file `math.h`
is required because the library function `prime_factors`
calls the mathematics function `sqrt`
in the standard library `libm.so`
.
For reference, here is the source code for the tester program:
**The tester program**
```
#include <stdio.h>
#include <primes.h>
int main() {
/* is_prime */
printf("\nis_prime\n");
unsigned i, count = 0, n = 1000;
for (i = 1; i <= n; i++) {
if (is_prime(i)) {
count++;
if (1 == (i % 100)) printf("Sample prime ending in 1: %i\n", i);
}
}
printf("%i primes in range of 1 to a thousand.\n", count);
/* prime_factors */
printf("\nprime_factors\n");
printf("prime factors of 12: ");
prime_factors(12);
printf("\n");
printf("prime factors of 13: ");
prime_factors(13);
printf("\n");
printf("prime factors of 876,512,779: ");
prime_factors(876512779);
printf("\n");
/* are_coprimes */
printf("\nare_coprime\n");
printf("Are %i and %i coprime? %s\n",
21, 22, are_coprimes(21, 22) ? "yes" : "no");
printf("Are %i and %i coprime? %s\n",
21, 24, are_coprimes(21, 24) ? "yes" : "no");
/* goldbach */
printf("\ngoldbach\n");
goldbach(11); /* error */
goldbach(4); /* small one */
goldbach(6); /* another */
for (i = 100; i <= 150; i += 2) goldbach(i);
return 0;
}
```
In compiling `tester.c`
into an executable, the tricky part is the order of the link flags. Recall that the two sample libraries begin with the prefix `lib`
, and each has the usual extension: `.a`
for the static library `libprimes.a`
and `.so`
for the dynamic library `libshprimes.so`
. In a links specification, the prefix `lib`
and the extension fall away. A link flag begins with `-l`
(lowercase L), and a compilation command may contain many link flags. Here is the full compilation command for the tester program, using the dynamic library as the example:
`% gcc -o tester tester.c -lshprimes -lm`
The first link flag identifies the library `libshprimes.so`
and the second link flag identifies the standard mathematics library `libm.so`
.
The linker is lazy, which means that the order of the link flags matters. For example, reversing the order of the link specifications generates a compile-time error:
`% gcc -o tester tester.c -lm -lshprimes ## danger!`
The flag that links to `libm.so`
comes first, but no function from this library is invoked explicitly in the tester program; hence, the linker does not link to the `math.so`
library. The call to the `sqrt`
library function occurs only in the `prime_factors`
function that is now contained in the `libshprimes.so`
library. The resulting error in compiling the tester program is:
`primes.c: undefined reference to 'sqrt'`
Accordingly, the order of the link flags should notify the linker that the `sqrt`
function is needed:
`% gcc -o tester tester.c -lshprimes -lm ## -lshprimes 1st`
The linker picks up the call to the library function `sqrt`
in the `libshprimes.so`
library and, therefore, does the appropriate link to the mathematics library `libm.so`
. There is a more complicated option for linking that supports either link-flag order; in this case, however, the easy way is to arrange the link flags appropriately.
Here is some output from a run of the tester client:
```
is_prime
Sample prime ending in 1: 101
Sample prime ending in 1: 401
...
168 primes in range of 1 to a thousand.
prime_factors
prime factors of 12: 2 2 3
prime factors of 13: 13
prime factors of 876,512,779: 211 4154089
are_coprime
Are 21 and 22 coprime? yes
Are 21 and 24 coprime? no
goldbach
Number must be > 2 and even: 11 is not.
4 = 2 + 2
6 = 3 + 3
...
32 = 3 + 29
32 = 13 + 19
...
100 = 3 + 97
100 = 11 + 89
...
```
For the `goldbach`
function, even a relatively small even value (e.g., 18) may have multiple pairs of primes that sum to it (in this case, 5+13 and 7+11). Such multiple prime pairs are among the factors that complicate an attempted proof of Goldbach's conjecture.
## Wrapping up with a Python client
Python, unlike C, is not a statically compiled language, which means that the sample Python client must access the dynamic rather than the static version of the primes library. To do so, Python has various modules (standard and third-party) that support a foreign function interface (FFI), which allows a program written in one language to invoke functions written in another. Python `ctypes`
is a standard and relatively simple FFI that enables Python code to call C functions.
Any FFI has challenges because the interfacing languages are unlikely to have exactly the same data types. For example, the primes library uses the C type `unsigned int`
, which Python does not have; the `ctypes`
FFI maps a C `unsigned int`
to a Python `int`
. Of the four `extern`
C functions published in the primes library, two behave better in Python with explicit `ctypes`
configuration.
The C functions `prime_factors`
and `goldbach`
have `void`
instead of a return type, but `ctypes`
by default replaces the C `void`
with the Python `int`
. When called from Python code, the two C functions then return a random (hence, meaningless) integer value from the stack. However, `ctypes`
can be configured to have the functions return `None`
(Python's null type) instead. Here's the configuration for the `prime_factors`
function:
`primes.prime_factors.restype = None`
A similar statement handles the `goldbach`
function.
The interactive session below (in Python 3) shows that the interface between a Python client and the primes library is straightforward:
```
>>> from ctypes import cdll
>>> primes = cdll.LoadLibrary("libshprimes.so") ## logical name
>>> primes.is_prime(13)
1
>>> primes.is_prime(12)
0
>>> primes.are_coprimes(8, 24)
0
>>> primes.are_coprimes(8, 25)
1
>>> primes.prime_factors.restype = None
>>> primes.goldbach.restype = None
>>> primes.prime_factors(72)
2 2 2 3 3
>>> primes.goldbach(32)
32 = 3 + 29
32 = 13 + 19
```
The functions in the primes library use only a simple data type, `unsigned int`
. If this C library used complicated types such as structures, and if pointers to structures were passed to and returned from library functions, then an FFI more powerful than `ctypes`
might be better for a smooth interface between Python and C. Nonetheless, the `ctypes`
example shows that a Python client can use a library written in C. Indeed, the popular NumPy library for scientific computing is written in C and then exposed in a high-level Python API.
The simple primes library and the advanced NumPy library underscore that C remains the lingua franca among programming languages. Almost every language can talk to C—and, through C, to any other language that talks to C. Python talks easily to C and, as another example, Java may do the same when [Project Panama](https://openjdk.java.net/projects/panama) becomes an alternative to Java Native Interface (JNI).
## 2 Comments |
13,414 | 在 Linux 上重新映射你的大写锁定键 | https://opensource.com/article/21/5/remap-caps-lock-key-linux | 2021-05-22T17:48:02 | [
"大写锁定",
"键盘"
] | https://linux.cn/article-13414-1.html |
>
> 通过在 GNOME 3 和 Wayland 上重新映射你的键盘,提高你的打字和导航速度,避免重复性压力伤害。
>
>
>

对我来说,有许多改变生活的 Linux 时刻,但大多数都在成为现状后淡忘了。有一个 Linux 教给我的键盘小技巧,每次我使用它的时候(也许每天有 1000 次),我都会想起这件事,那就是把大写锁定键转换为 `Ctrl` 键。
我从不使用大写锁定键,但我整天使用 `Ctrl` 键进行复制、粘贴、在 [Emacs](https://opensource.com/article/20/12/emacs) 内导航,以及 [调用 Bash](https://opensource.com/article/18/5/bash-tricks#key)、[GNU Screen](https://opensource.com/article/17/3/introduction-gnu-screen) 或 [tmux](https://opensource.com/article/19/6/tmux-terminal-joy) 等操作。大写锁定键在我的键盘上占据了宝贵的空间,而将实际上有用的 `Ctrl` 键挤到了难以触及的底部角落。

*这看起来就痛苦*
重新映射 `Ctrl` 提高了我的打字和导航速度,并可能使我免受重复性压力伤害。
### 消失的控制
系好安全带,这是个过山车式的历史课。
对于像我这样的大写锁定键交换者来说,不幸的是,当 GNOME 3 问世时,它几乎删除了改变 `Ctrl` 键位置的功能。
幸运的是,优秀的 GNOME Tweaks 应用程序带回了这些 “失踪” 的控制面板。
不幸的是,[GNOME 40](https://discourse.gnome.org/t/new-gnome-versioning-scheme/4235) 没有 GNOME Tweaks 应用程序(还没有?)
另外,不幸的是,过去在 X11 上可以工作的老的 `xmodmap` 技巧在新的 [Wayland 显示服务器](https://wayland.freedesktop.org) 上没有用。
有一小段时间(最多一个下午),我觉得对于那些讨厌大写锁定键的人来说人生都灰暗了。然后我想起我是一个开源的用户,总有一种方法可以解决诸如被忽略的 GUI 控制面板之类的简单问题。
### dconf
GNOME 桌面使用 dconf,这是一个存储重要配置选项的数据库。它是 GSettings 的后端,GSettings 是 GNOME 系统应用程序需要发现系统偏好时的接口。你可以使用 `gsetting` 命令查询 dconf 数据库,也可以使用 `dconf` 命令直接设置 dconf 的键值。
### GSettings
dconf 数据库不一定是你可能称为可发现的数据库。它是一个不起眼的数据库,你通常不需要去考虑它,它包含了许多通常无需直接交互的数据。然而,如果你想更好地了解 GNOME 所要管理的所有偏好选项,那么浏览它是很有趣的。
你可以用 `list-schemas` 子命令列出所有 dconf 的模式。在浏览了数百个模式之后,你可以使用 [grep](https://opensource.com/downloads/grep-cheat-sheet) 将你的注意力缩小到一些看起来特别相关的东西上,比如 `org.gnome.desktop`。
```
$ gsettings list-schemas | grep ^org.gnome.desktop
[...]
org.gnome.desktop.background
org.gnome.desktop.privacy
org.gnome.desktop.remote-desktop.vnc
org.gnome.desktop.interface
org.gnome.desktop.default-applications.terminal
org.gnome.desktop.session
org.gnome.desktop.thumbnailers
org.gnome.desktop.app-folders
org.gnome.desktop.notifications
org.gnome.desktop.sound
org.gnome.desktop.lockdown
org.gnome.desktop.default-applications.office
```
无论是通过手动搜索还是通过 [阅读 GSetting 文档](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/using_the_desktop_environment_in_rhel_8/configuring-gnome-at-low-level_using-the-desktop-environment-in-rhel-8),你可能会注意到 `org.gnome.desktop.input-sources` 模式,它有助于定义键盘布局。从设计上来说,GSetting 模式包含了键和值。
### 用 dconf 重新映射大写字母锁
`xkb-options` 键包含了可选的键盘覆写。要设置这个键值,请使用`dconf`,将上面模式中的点(`.`)转换为斜线(`/`),因为 dconf 数据库需要使用 `/`。
```
$ dconf write /org/gnome/desktop/input-sources/xkb-options "['caps:ctrl_modifier']"
```
我把 `caps` 设置为 `ctrl_modifier`,因为我使用 `Ctrl` 修饰键的次数多于其他修饰键,但 Vim 用户可能喜欢把它设置为 `escape`。
### 查看你的设置
这个改变会立即生效,并在重启后仍然生效。这是你在 GNOME 中定义的首选项,在你改变它之前一直有效。
你可以通过 `gsettings` 查看 dconf 中的新值。首先,查看可用的键:
```
$ gsettings list-keys \
org.gnome.desktop.input-sources
xkb-options
mru-sources
show-all-sources
current
per-window
sources
```
然后用 `xkb-options` 键名查看设置:
```
$ gsettings get \
org.gnome.desktop.input-sources \
xkb-options
['caps:ctrl_modifier']
```
### 选项丰富
我在我的 GNOME 3.4 系统上使用这个小技巧来设置大写锁定键以及 [Compose](https://opensource.com/article/17/5/7-cool-kde-tweaks-will-improve-your-life) 键(`compose:ralt`)。虽然我相信正在开发中的 GUI 控件可以控制这些选项,但我也不得不承认,能以编程方式设置这些选项的能力是我的荣幸。作为以前没有可靠方法来调整桌面设置的系统的管理员,能够用命令修改我的首选项使得设置新桌面变得快速而容易。
GSettings 提供了很多有用的选项,而且文档也很详尽。如果你有想要改变的东西,可以看看有什么可用的。
---
via: <https://opensource.com/article/21/5/remap-caps-lock-key-linux>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There have been many life-changing Linux moments for me, but most fade into my backstory as they become the status quo. There's one little keyboard trick Linux taught me that I'm reminded of every time I use it (maybe 1,000 times a day), and that's converting the **Caps Lock** key to **Ctrl**.
I never use **Caps Lock**, but I use the **Ctrl** key all day for copying, pasting, navigating within [Emacs](https://opensource.com/article/20/12/emacs), and [invoking Bash](https://opensource.com/article/18/5/bash-tricks#key), [GNU Screen](https://opensource.com/article/17/3/introduction-gnu-screen), or [tmux](https://opensource.com/article/19/6/tmux-terminal-joy) actions. **Caps Lock** occupies valuable real estate on my keyboard, forcing the actually useful **Ctrl** key down to the awkward-to-reach bottom corner.

This is as painful as it looks. (Seth Kenlon, CC BY-SA 4.0)
Remapping **Ctrl** increased my typing and navigation speed and has probably saved me from repetitive stress injuries.
## The case of the disappearing control
Buckle in, this is a roller coaster of a history lesson:
Unfortunately for **Caps Lock** swappers like me, when GNOME 3 came out, it all but removed the ability to change the location of the **Ctrl** key.
Fortunately, the excellent GNOME Tweaks app brought back these "missing" control panels.
Unfortunately, [GNOME 40](https://discourse.gnome.org/t/new-gnome-versioning-scheme/4235) has no GNOME Tweaks app (yet?)
Also, unfortunately, the old `xmodmap`
hack that used to work on X11 is useless on the new [Wayland display server](https://wayland.freedesktop.org).
For a short while (an afternoon at best), I felt things were looking dim for people who hate **Caps Lock**. Then I remembered I am a user of open source, and there's *always* a way around something as simple as an overlooked GUI control panel.
## dconf
The GNOME desktop uses dconf, a database that stores important configuration options. It's the backend to GSettings, which is the system GNOME applications interface with when they need to discover system preferences. You can query the dconf database using the `gsetting`
command, and you can set dconf key values directly with the `dconf`
command.
## GSettings
The dconf database isn't necessarily what you might call discoverable. It's a humble database you're not meant to have to think about, and it holds a lot of data you usually don't have to interact with directly. However, it does use a sensible schema that's fun to browse if you want to better understand all of the preference options GNOME has to manage.
You can list all of dconf's schemas with the `list-schemas`
subcommand. After browsing hundreds of schemas, you might use [grep](https://opensource.com/downloads/grep-cheat-sheet) to narrow your focus to something that seems especially relevant, such as `org.gnome.desktop`
:
```
$ gsettings list-schemas | grep ^org.gnome.desktop
[...]
org.gnome.desktop.background
org.gnome.desktop.privacy
org.gnome.desktop.remote-desktop.vnc
org.gnome.desktop.interface
org.gnome.desktop.default-applications.terminal
org.gnome.desktop.session
org.gnome.desktop.thumbnailers
org.gnome.desktop.app-folders
org.gnome.desktop.notifications
org.gnome.desktop.sound
org.gnome.desktop.lockdown
org.gnome.desktop.default-applications.office
```
Whether through a manual search or through [reading GSetting documentation](https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/using_the_desktop_environment_in_rhel_8/configuring-gnome-at-low-level_using-the-desktop-environment-in-rhel-8), you may notice the `org.gnome.desktop.input-sources`
schema, which helps define the keyboard layout. A GSetting schema, by design, contains keys and values.
## Remapping Caps Lock with dconf
The `xkb-options`
key contains optional keyboard overrides. To set this key, use `dconf`
, converting the dots (`.`
) in the schema above to slashes (`/`
) because the dconf database requires it:
`$ dconf write /org/gnome/desktop/input-sources/xkb-options "['caps:ctrl_modifier']"`
I set `caps`
to `ctrl_modifier`
because I use the **Ctrl** modifier more than any other modifier, but Vim users may prefer to set it to `escape`
instead.
## View your setting
The change takes effect immediately and persists across reboots. It's a preference you've defined in GNOME, so it remains in effect until you change it.
You can view the new value in `dconf`
with `gsettings`
. First, view the available keys:
```
$ gsettings list-keys \
org.gnome.desktop.input-sources
xkb-options
mru-sources
show-all-sources
current
per-window
sources
```
And then view the settings with the `xkb-options`
key:
```
$ gsettings get \
org.gnome.desktop.input-sources \
xkb-options
['caps:ctrl_modifier']
```
## Options aplenty
I use this little trick to set **Caps Lock** as well as the [Compose](https://opensource.com/article/17/5/7-cool-kde-tweaks-will-improve-your-life) key (`compose:ralt`
) on my GNOME 3.4 system. While I believe there are GUI controls in development to control options like these, I also have to admit that the ability to set them programmatically is a luxury I enjoy. As a former admin of systems that had no reliable way to adjust desktop settings, the ability to script my preferences makes setting up a fresh desktop quick and easy.
There are lots of useful options available with GSettings, and the documentation is thorough. If you have something you want to change, take a look at what's available.
## 2 Comments |
13,416 | 全新 1Password for Linux 正式推出 | https://news.itsfoss.com/1password-linux-released/ | 2021-05-22T23:47:25 | [
"1Password",
"密码"
] | https://linux.cn/article-13416-1.html | 
1Password 是一个相当不错的密码管理器(尽管不是开源的),在开源社区也有很好的口碑。他们甚至 [为从事开源项目的用户提供免费的团队成员资格](https://news.itsfoss.com/1password-free-subscriptions/)。
它的 Linux 桌面客户端已经处于测试阶段,但现在它已经准备好进入黄金时间。
他们已经正式 [宣布](https://blog.1password.com/welcoming-linux-to-the-1password-family/) 推出 1Password Linux 版,具有完整的桌面体验,可以与你的网络浏览器集成。
它还亮相了一些很快会进入 Android、iOS、Mac 和 Windows **的新功能**。
在这里,我要安利一下,Linux 上的 1Password 值得期待。
### 1Password Linux 桌面客户端
虽然它可以作为浏览器扩展而无需考虑平台,但桌面客户端的出现使体验更好。

桌面客户端内置了基于 GTK 主题的**黑暗模式支持**。它还能与 **GNOME、KDE 和你选择的任何其他窗口管理器**很好地整合。
看起来他们也在更多的细节上花费了心思,因此桌面客户端也支持**系统托盘图标**,即使你关闭了它也能保持活跃。
你可以用它直接在你的默认浏览器上自动填入密码。不过,虽然它提到了 **X11 剪贴板集成和支持**,但没有提到 Wayland。

它还包括了对 GNOME 钥匙环和 KDE 钱包的支持、内核钥匙环的集成、与系统锁定和闲置服务的集成。
除了这些,1Password for Linux 还首次推出了新的功能,这些功能将很快用于其他平台。
* 安全文件附件
* 项目归档和删除功能,以便更好地组织文件
* Watchtower 仪表板,检查和评估你的密码安全状况
* 新的共享细节,查看谁可以访问什么
* 快速查找和智能搜索建议
* 翻新的外观和感觉
如果你想了解该版本以及他们对开源和 Linux 社区的计划,请浏览 [官方公告](https://blog.1password.com/welcoming-linux-to-the-1password-family/)。
### 在 Linux 中安装 1Password
其官方称,该桌面客户端支持几个 Linux 发行版,包括 Ubuntu、 Debian、 Arch Linux、 Fedora、 CentOS 和 RHEL。你可以得到用来安装的 **.deb** 和 **.rpm** 软件包,或者使用软件包管理器找到它们。
* [下载 1Password for Linux](https://1password.com/downloads/linux/)
它也有一个可用的 [snap 包](https://snapcraft.io/1password),你可以参考我们的 [在 Linux 中使用 snap](https://itsfoss.com/use-snap-packages-ubuntu-16-04/) 的指南。
关于安装的更多信息,你也可以参考 [官方说明](https://support.1password.com/install-linux/)。
---
via: <https://news.itsfoss.com/1password-linux-released/>
作者:[Ankush Das](https://news.itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

1Password is a pretty good password manager (even though not open-source) and has a good rep in the open-source community as well. They even offer [free team memberships for users working on open-source projects](https://news.itsfoss.com/1password-free-subscriptions/).
Its desktop client for Linux was in the beta phase but now it is ready for prime time.
They have officially [announced](https://blog.1password.com/welcoming-linux-to-the-1password-family/?ref=news.itsfoss.com) the availability of 1Password for Linux with a full-blown desktop experience that integrates with your web browser.
It also **debuts with some new features** that will be making its way to Android, iOS, Mac, and Windows soon.
Here, let me highlight what you can expect with 1Password on Linux.
## 1Password Desktop Client for Linux
While it was already available as a browser extension irrespective of the platform, the presence of a desktop client makes the experience better.
The desktop client comes baked in with the **dark mode support** based on your GTK theme. It also integrates well with **GNOME, KDE, and any other window manager** of your choice.
Looks like they have paid attention to finer details as well, hence the desktop client also supports **system tray icon** to keep it active even when you have closed it.
You can auto-fill passwords directly on your default browser with it. While it mentions **X11 clipboard integration and support**, there’s no mention of Wayland.
It also includes support for GNOME Keyring and KDE Wallet, Kernel keyring integration, integration with system lock and idle services.
In addition to these, 1Password for Linux debuts with newly launched features that will be available for other platforms soon:
- Secure file attachments
- Item archiving and deletion features for better document organization
- Watchtower dashboard to check and evaluate your password security health
- New sharing details to see who has access to what
- Quick find and intelligent search suggestions
- Overhauled look and feel
If you are curious to know about the release and their plans for open-source and Linux community, go through the [official announcement post](https://blog.1password.com/welcoming-linux-to-the-1password-family/?ref=news.itsfoss.com).
## Install 1Password in Linux
Officially, the desktop client supports several Linux distributions that include Ubuntu, Debian, Arch Linux, Fedora, CentOS, and RHEL. You get both **.deb** and **.rpm** packages to install or find them using package managers.
It is also available as a [snap package](https://snapcraft.io/1password?ref=news.itsfoss.com). You can follow our guide on [using snap in Linux](https://itsfoss.com/use-snap-packages-ubuntu-16-04/?ref=news.itsfoss.com) for help.
For more information on installation, you may refer to the [official instructions](https://support.1password.com/install-linux/?ref=news.itsfoss.com) as well.
## More from It's FOSS...
- Support us by opting for
[It's FOSS Plus](https://itsfoss.com/#/portal/signup)membership. - Join our
[community forum](https://itsfoss.community/). - 📩 Stay updated with the latest on Linux and Open Source. Get our
[weekly Newsletter](https://itsfoss.com/newsletter/). |
13,417 | 使用 sed 命令进行复制、剪切和粘贴 | https://opensource.com/article/21/3/sed-cheat-sheet | 2021-05-23T18:16:43 | [
"sed",
"复制",
"粘贴"
] | https://linux.cn/article-13417-1.html |
>
> 了解 sed 的基本用法,然后下载我们的备忘单,方便快速地参考 Linux 流编辑器。
>
>
>

很少有 Unix 命令像 `sed`、[grep](https://opensource.com/article/21/3/grep-cheat-sheet) 和 [awk](https://opensource.com/article/20/9/awk-ebook) 一样出名,它们经常组合在一起,可能是因为它们具有奇怪的名称和强大的文本解析能力。它们还在一些语法和逻辑上有相似之处。虽然它们都能用于文本解析,但都有其特殊性。本文研究 `sed` 命令,它是一个 <ruby> 流编辑器 <rt> stream editor </rt></ruby>。
我之前写过关于 [sed](https://opensource.com/article/20/12/sed) 以及它的远亲 [ed](https://opensource.com/article/20/12/gnu-ed) 的文章。要熟悉 `sed`,对 `ed` 有一点了解是有帮助的,因为这有助于你熟悉缓冲区的概念。本文假定你熟悉 `sed` 的基本知识,这意味着你至少已经运行过经典的 `s/foo/bar` 风格的查找和替换命令。
* 下载我们的免费 [sed 备忘录](https://opensource.com/downloads/sed-cheat-sheet)
### 安装 sed
如果你使用的是 Linux、BSD 或 macOS,那么它们已经安装了 GNU 的或 BSD 的 sed。这些是原始 `sed` 命令的独特重新实现。虽然它们很相似,但也有一些细微的差别。本文已经在 Linux 和 NetBSD 版本上进行了测试,所以你可以使用你的计算机上找到的任何 sed,但是对于 BSD sed,你必须使用短选项(例如 `-n` 而不是 `--quiet`)。
GNU sed 通常被认为是功能最丰富的 sed,因此无论你是否运行 Linux,你可能都想要尝试一下。如果在 Ports 树中找不到 GNU sed(在非 Linux 系统上通常称为 gsed),你可以从 GNU 网站 [下载源代码](http://www.gnu.org/software/sed/)。 安装 GNU sed 的好处是,你可以使用它的额外功能,但是如果需要可移植性,还可以限制它以遵守 sed 的 [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) 规范。
MacOS 用户可以在 [MacPorts](https://opensource.com/article/20/11/macports) 或 [Homebrew](https://opensource.com/article/20/6/homebrew-mac) 上找到 GNU sed。
在 Windows 上,你可以通过 [Chocolatey](https://opensource.com/article/20/3/chocolatey) 来 [安装 GNU sed](https://chocolatey.org/packages/sed)。
### 了解模式空间和保留空间
sed 一次只能处理一行。因为它没有可视化模式,所以会创建一个 <ruby> 模式空间 <rt> pattern space </rt></ruby>,这是一个内存空间,其中包含来自输入流的当前行(删除了尾部的任何换行符)。填充模式空间后,sed 将执行你的指令。当命令执行完时,sed 将模式空间中的内容打印到输出流,默认是 **标准输出**,但是可以将输出重定向到文件,甚至使用 `--in-place=.bak` 选项重定向到同一文件。
然后,循环从下一个输入行再次开始。
为了在遍历文件时提供一点灵活性,sed 还提供了<ruby> 保留空间 <rt> hold space </rt></ruby>(有时也称为 <ruby> 保留缓冲区 <rt> hold buffer </rt></ruby>),即 sed 内存中为临时数据存储保留的空间。你可以将保留空间当作剪贴板,实际上,这正是本文所演示的内容:如何使用 sed 复制/剪切和粘贴。
首先,创建一个示例文本文件,其内容如下:
```
Line one
Line three
Line two
```
### 复制数据到保留空间
要将内容放置在 sed 的保留空间,使用 `h` 或 `H` 命令。小写的 `h` 告诉 sed 覆盖保留空间中的当前内容,而大写的 `H` 告诉 sed 将数据追加到保留空间中已经存在的内容之后。
单独使用,什么都看不到:
```
$ sed --quiet -e '/three/ h' example.txt
$
```
`--quiet`(缩写为 `-n`)选项禁止显示所有输出,但 sed 执行了我的搜索需求。在这种情况下,sed 选择包含字符串 `three` 的任何行,并将其复制到保留空间。我没有告诉 sed 打印任何东西,所以没有输出。
### 从保留空间复制数据
要了解保留空间,你可以从保留空间复制内容,然后使用 `g` 命令将其放入模式空间,观察会发生什么:
```
$ sed -n -e '/three/h' -e 'g;p' example.txt
Line three
Line three
```
第一个空白行是因为当 sed 第一次复制内容到模式空间时,保留空间为空。
接下来的两行包含 `Line three` 是因为这是从第二行开始的保留空间。
该命令使用两个唯一的脚本(`-e`)纯粹是为了帮助提高可读性和组织性。将步骤划分为单独的脚本可能会很有用,但是从技术上讲,以下命令与一个脚本语句一样有效:
```
$ sed -n -e '/three/h ; g ; p' example.txt
Line three
Line three
```
### 将数据追加到模式空间
`G` 命令会将一个换行符和保留空间的内容添加到模式空间。
```
$ sed -n -e '/three/h' -e 'G;p' example.txt
Line one
Line three
Line three
Line two
Line three
```
此输出的前两行同时包含模式空间(`Line one`)的内容和空的保留空间。接下来的两行与搜索文本(`three`)匹配,因此它既包含模式空间又包含保留空间。第三行的保留空间没有变化,因此在模式空间(`Line two`)的末尾是保留空间(仍然是 `Line three`)。
### 用 sed 剪切和粘贴
现在你知道了如何将字符串从模式空间转到保留空间并再次返回,你可以设计一个 sed 脚本来复制、删除,然后在文档中粘贴一行。例如,将示例文件的 `Line three` 挪至第三行,sed 可以解决这个问题:
```
$ sed -n -e '/three/ h' -e '/three/ d' \
-e '/two/ G;p' example.txt
Line one
Line two
Line three
```
* 第一个脚本找到包含字符串 `three` 的行,并将其从模式空间复制到保留空间,替换当前保留空间中的任何内容。
* 第二个脚本删除包含字符串 `three` 的任何行。这样就完成了与文字处理器或文本编辑器中的 *剪切* 动作等效的功能。
* 最后一个脚本找到包含字符串 `two` 的行,并将保留空间的内容\_追加\_到模式空间,然后打印模式空间。
任务完成。
### 使用 sed 编写脚本
再说一次,使用单独的脚本语句纯粹是为了视觉和心理上的简单。剪切和粘贴命令作为一个脚本同样有效:
```
$ sed -n -e '/three/ h ; /three/ d ; /two/ G ; p' example.txt
Line one
Line two
Line three
```
它甚至可以写在一个专门的脚本文件中:
```
#!/usr/bin/sed -nf
/three/h
/three/d
/two/ G
p
```
要运行该脚本,将其加入可执行权限,然后用示例文件尝试:
```
$ chmod +x myscript.sed
$ ./myscript.sed example.txt
Line one
Line two
Line three
```
当然,你需要解析的文本越可预测,则使用 sed 解决问题越容易。发明 sed 操作(例如复制和粘贴)的“配方”通常是不切实际的,因为触发操作的条件可能因文件而异。但是,你对 sed 命令的使用越熟练,就越容易根据需要解析的输入来设计复杂的动作。
重要的事情是识别不同的操作,了解 sed 何时移至下一行,并预测模式和保留空间包含的内容。
### 下载备忘单
sed 很复杂。虽然它只有十几个命令,但它灵活的语法和原生功能意味着它充满了无限的潜力。为了充分利用 sed,我曾经参考过一些巧妙的单行命令,但是直到我开始发明(有时是重新发明)自己的解决方案时,我才觉得自己真正开始学习 sed 了 。如果你正在寻找命令提示和语法方面的有用技巧,[下载我们的 sed 备忘单](https://opensource.com/downloads/sed-cheat-sheet),然后开始一劳永逸地学习 sed!
---
via: <https://opensource.com/article/21/3/sed-cheat-sheet>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Few Unix commands are as famous as sed, [grep](https://opensource.com/article/21/3/grep-cheat-sheet), and [awk](https://opensource.com/article/20/9/awk-ebook). They get grouped together often, possibly because they have strange names and powerful tools for parsing text. They also share some syntactical and logical similarities. And while they're all useful for parsing text, each has its specialties. This article examines the `sed`
command, which is a *stream editor*.
I've written before about [sed](https://opensource.com/article/20/12/sed), as well as its distant relative [ed](https://opensource.com/article/20/12/gnu-ed). To get comfortable with sed, it helps to have some familiarity with ed because that helps you get used to the idea of buffers. This article assumes that you're familiar with the very basics of sed, meaning you've at least run the classic `s/foo/bar/`
style find-and-replace command.
**[Download our free sed cheat sheet]**
## Installing sed
If you're using Linux, BSD, or macOS, you already have GNU or BSD sed installed. These are unique reimplementations of the original `sed`
command, and while they're similar, there are minor differences. This article has been tested on the Linux and NetBSD versions, so you can use whatever sed you find on your computer in this case, although for BSD sed you must use short options (`-n`
instead of `--quiet`
, for instance) only.
GNU sed is generally regarded to be the most feature-rich sed available, so you might want to try it whether or not you're running Linux. If you can't find GNU sed (often called gsed on non-Linux systems) in your ports tree, then you can [download its source code](http://www.gnu.org/software/sed/) from the GNU website. The nice thing about installing GNU sed is that you can use its extra functions but also constrain it to conform to the [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) specifications of sed, should you require portability.
MacOS users can find GNU sed on [MacPorts](https://opensource.com/article/20/11/macports) or [Homebrew](https://opensource.com/article/20/6/homebrew-mac).
On Windows, you can [install GNU sed](https://chocolatey.org/packages/sed) with [Chocolatey](https://opensource.com/article/20/3/chocolatey).
## Understanding pattern space and hold space
Sed works on exactly one line at a time. Because it has no visual display, it creates a *pattern space*, a space in memory containing the current line from the input stream (with any trailing newline character removed). Once you populate the pattern space, sed executes your instructions. When it reaches the end of the commands, sed prints the pattern space's contents to the output stream. The default output stream is **stdout**, but the output can be redirected to a file or even back into the same file using the `--in-place=.bak`
option.
Then the cycle begins again with the next input line.
To provide a little flexibility as you scrub through files with sed, sed also provides a *hold space* (sometimes also called a *hold buffer*), a space in sed's memory reserved for temporary data storage. You can think of hold space as a clipboard, and in fact, that's exactly what this article demonstrates: how to copy/cut and paste with sed.
First, create a sample text file with this text as its contents:
```
Line one
Line three
Line two
```
## Copying data to hold space
To place something in sed's hold space, use the `h`
or `H`
command. A lower-case `h`
tells sed to overwrite the current contents of hold space, while a capital `H`
tells it to append data to whatever's already in hold space.
Used on its own, there's not much to see:
```
$ sed --quiet -e '/three/ h' example.txt
$
```
The `--quiet`
(`-n `
for short) option suppresses all output but what sed has performed for my search requirements. In this case, sed selects any line containing the string `three`
, and copying it to hold space. I've not told sed to print anything, so no output is produced.
## Copying data from hold space
To get some insight into hold space, you can copy its contents from hold space and place it into pattern space with the `g`
command. Watch what happens:
```
$ sed -n -e '/three/h' -e 'g;p' example.txt
Line three
Line three
```
The first blank line prints because the hold space is empty when it's first copied into pattern space.
The next two lines contain `Line three`
because that's what's in hold space from line two onward.
This command uses two unique scripts (`-e`
) purely to help with readability and organization. It can be useful to divide steps into individual scripts, but technically this command works just as well as one script statement:
```
$ sed -n -e '/three/h ; g ; p' example.txt
Line three
Line three
```
## Appending data to pattern space
The `G`
command appends a newline character and the contents of the hold space to the pattern space.
```
$ sed -n -e '/three/h' -e 'G;p' example.txt
Line one
Line three
Line three
Line two
Line three
```
The first two lines of this output contain both the contents of the pattern space (`Line one`
) and the empty hold space. The next two lines match the search text (`three`
), so it contains both the pattern space and the hold space. The hold space doesn't change for the third pair of lines, so the pattern space (`Line two`
) prints with the hold space (still `Line three`
) trailing at the end.
## Doing cut and paste with sed
Now that you know how to juggle a string from pattern to hold space and back again, you can devise a sed script that copies, then deletes, and then pastes a line within a document. For example, the example file for this article has `Line three`
out of order. Sed can fix that:
```
$ sed -n -e '/three/ h' -e '/three/ d' \
-e '/two/ G;p' example.txt
Line one
Line two
Line three
```
- The first script finds a line containing the string
`three`
and copies it from pattern space to hold space, replacing anything currently in hold space. - The second script deletes any line containing the string
`three`
. This completes the equivalent of a*cut*action in a word processor or text editor. - The final script finds a line containing
`two`
and*appends*the contents of hold space to pattern space and then prints the pattern space.
Job done.
## Scripting with sed
Once again, the use of separate script statements is purely for visual and mental simplicity. The cut-and-paste command works as one script:
```
$ sed -n -e '/three/ h ; /three/ d ; /two/ G ; p' example.txt
Line one
Line two
Line three
```
It can even be written as a dedicated script file:
```
#!/usr/bin/sed -nf
/three/h
/three/d
/two/ G
p
```
To run the script, mark it executable and try it on your sample file:
```
$ chmod +x myscript.sed
$ ./myscript.sed example.txt
Line one
Line two
Line three
```
Of course, the more predictable the text you need to parse, the easier it is to solve your problem with sed. It's usually not practical to invent "recipes" for sed actions (such as a copy and paste) because the condition to trigger the action is probably different from file to file. However, the more fluent you become with sed's commands, the easier it is to devise complex actions based on the input you need to parse.
The important things are recognizing distinct actions, understanding when sed moves to the next line, and predicting what the pattern and hold space can be expected to contain.
## Download the cheat sheet
Sed is complex. It only has a dozen commands, yet its flexible syntax and raw power mean it's full of endless potential. I used to reference pages of clever one-liners in an attempt to get the most use out of sed, but it wasn't until I started inventing (and sometimes reinventing) my own solutions that I felt like I was starting to *actually* learn sed. If you're looking for gentle reminders of commands and helpful tips on syntax, [download our sed cheat sheet](https://opensource.com/downloads/sed-cheat-sheet), and start learning sed once and for all!
## Comments are closed. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.